【机器学习:KNN算法/K近邻算法】
K 近邻算法
算法情况解读
KNN算法的基本思想是物以类聚,人以群分,它是一种贪心算法,可以用于做分类/回归任务。KNN算法认为,距离相近的实例(instance)总是具有类似的性质x,这意味着它们会有相似的标签y。

KNN 基于训练集划分好实例的存储范围,KNN分类的时候就直接判断新的instance所属于的存储范围的标签,如果是回归,就用内差法来输出。为了输出明确的结果,k的选择一般用奇数,采用多数投票决定的情况,避免Tie(平票)的情况,如果出现,就再丢一个铜板来决定最终新instance属于的类别。

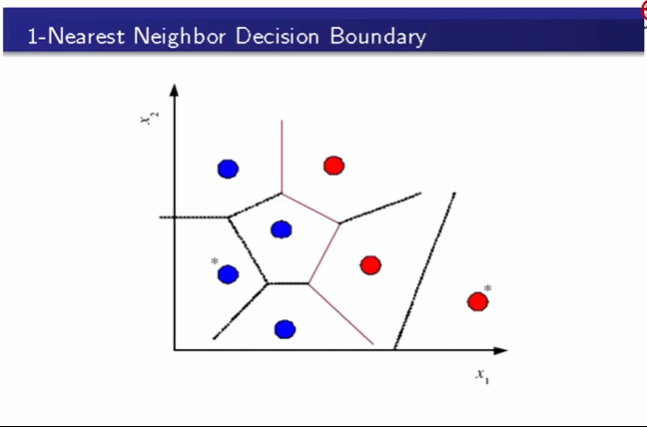
这个图是k = 1 的时候划分出的决策边界。
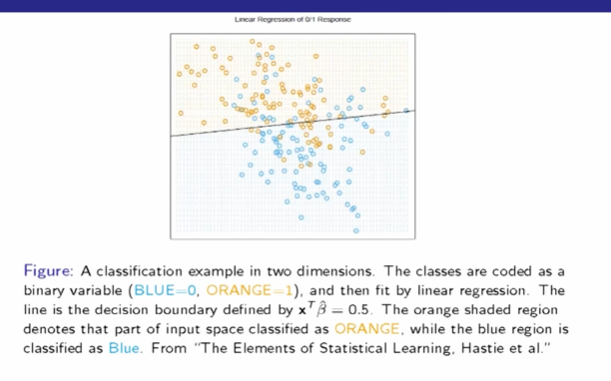
基于线性回归的决策边界
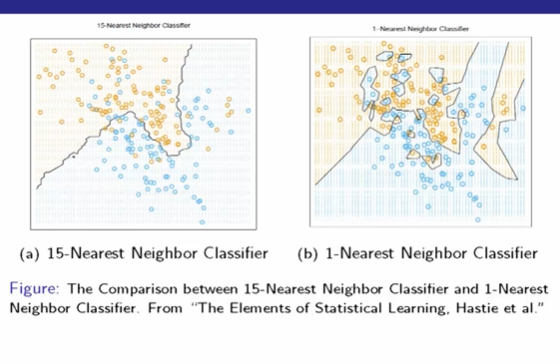
基于KNN的k = 15时划分出的决策边界

基于KNN的k = 1时划分出的决策边界,k = 1 虽然在训练集表现好,但是要注意避免过拟合现象。
优化计算
当训练集数量很大的时候,我们要基于存储范围对新instance分类,需要遍历每一个训练数据样本,计算其与instance的距离,然后取最近的作为最终结果,这种计算非常耗费资源,因此出现了一些优化方式。
思路一:取出代表性的点,在训练的时候构建 condense set,最终存储的也是condense set,只留下了最具代表性的点,算法如下:

思路二:构建KD Tree,KD树的基本形式是根据训练结果,将空间划分为多个子区域,根据子区域的特点完成标签判定。
距离度量
当属性之间的数值差异较大的时候,为了避免某一属性对距离的计算产生不符实际的过多的影响时,应当考虑对属性内的数据进行标准化。例如收入数据和支出数据,人们的收入数据差异会非常大,而支出数据往往差距较小,如果不进行标准化,收入数据将会对模型结果判断产生较多的影响,造成一定的偏差。
正态分布的标准化,结果分布在区间[-1,1]

最大最小标准化,结果分布在区间[0,1]
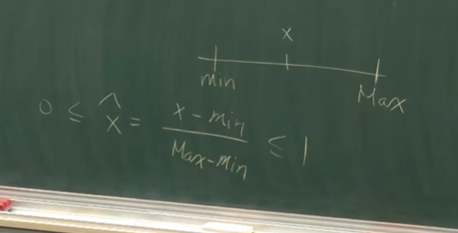
除了传统的二范数、切比雪夫等距离度量方式,也有学者提出了如下这种学习式的距离度量方法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号