Mysql索引学习笔记
1、分类
MySQL索引分为普通索引、唯一索引、主键索引、组合索引、全文索引。索引不会包含有null值的列,索引项可以为null(唯一索引、组合索引等),但是只要列中有null值就不会被包含在索引中。
(1)普通索引:create index index_name on table(column);
或者创建表时指定,create table(..., index index_name column);
(2)唯一索引:类似普通索引,索引列的值必须唯一(可以为空,这点和主键索引不同)
create unique index index_name on table(column);或者创建表时指定unique index_name column
(3)主键索引:特殊的唯一索引,不允许为空,只能有一个,一般是在建表时指定primary key(column)
(4)组合索引:在多个字段上创建索引,遵循最左前缀原则。alter table t add index index_name(a,b,c);
最左前缀原则:https://mp.weixin.qq.com/s/RemJcqPIvLArmfWIhoaZ1g
(5)全文索引:主要用来查找文本中的关键字,不是直接与索引中的值相比较,像是一个搜索引擎,配合match against使用,现在只有char,varchar,text上可以创建全文索引。在数据量较大时,先将数据放在一张没有全文索引的表里,然后再利用create index创建全文索引,比先生成全文索引再插入数据快很多。
从另外的角度还可以分为
1、聚集索引。
表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
2、非聚集索引。
表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
2、使用
2.1、何时使用索引
MySQL每次查询只使用一个索引。与其说是“数据库查询只能用到一个索引”,倒不如说,和全表扫描比起来,去分析两个索引B+树更加耗费时间。所以where A=a and B=b这种查询使用(A,B)的组合索引最佳,B+树根据(A,B)来排序。
(1)主键,unique字段;
(2)和其他表做连接的字段需要加索引;
(3)在where里使用>,≥,=,<,≤,is null和between等字段;
(4)使用不以通配符开始的like,where A like 'China%';
(5)聚集函数MIN(),MAX()中的字段;
(6)order by和group by字段;
2.2、何时不使用索引
(1)表记录太少;
(2)数据重复且分布平均的字段(只有很少数据值的列);
(3)经常插入、删除、修改的表要减少索引;
(4)text,image等类型不应该建立索引,这些列的数据量大(假如text前10个字符唯一,也可以对text前10个字符建立索引);
(5)MySQL能估计出全表扫描比使用索引更快时,不使用索引;
2.3、索引何时失效
(1)组合索引未使用最左前缀,例如组合索引(A,B),where B=b不会使用索引;
(2)like未使用最左前缀,where A like '%China';

(3)搜索一个索引而在另一个索引上做order by,where A=a order by B,只使用A上的索引,因为查询只使用一个索引 ;
(4)or会使索引失效。如果查询字段相同,也可以使用索引。例如where A=a1 or A=a2(生效),where A=a or B=b(失效)
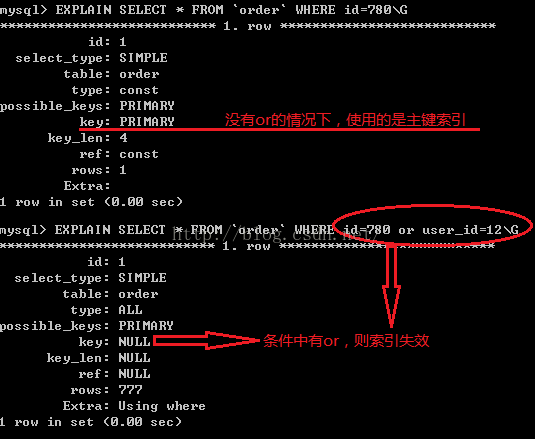
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
(5)如果列类型是字符串,要使用引号。例如where A='China',否则索引失效(会进行类型转换);

(6)在索引列上的操作,函数(upper()等)、or、!=(<>)、not in等;
others
3、其他
3.1、explain语句

3.2、\g、\G
\g 的作用是分号和在sql语句中写’;’是等效的
\G 的作用是将查到的结构旋转90度变成纵向
4、例子
create table test( id1 int , id2 int, id3 int, id4 int, key index_id12(id1,id2) ); 用到索引 explain select * from test where id1 < 10; 用到索引 explain select * from test where id1 < 10 and id2 > 1; 用到索引 explain select * from test where id2 > 1 and id1 < 2; 未用到索引,组合索引要满足最左原则 explain select * from test where id2 > 1; 未用到索引 explain select * from test order by id1 desc ; 用到索引 explain select id1 from test order by id1 desc ; explain select id1,id2 from test order by id1 desc ; 未用到索引 explain select id1,id2,id3 from test order by id1 desc ;
5、常见面试问题
以下全部是基于MySQL的InnoDB引擎
5.1、什么是最左前缀原则
例如对于下面这个表
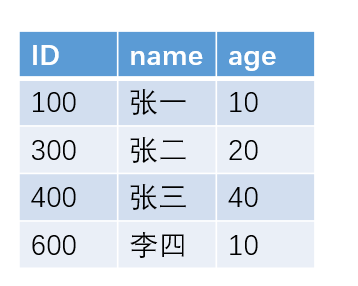
如果我们按照 name 字段来建立索引的话,采用B+树的结构,大概的索引结构如下
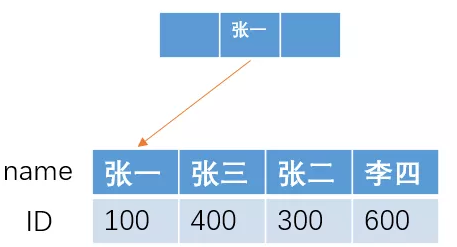
如果我们要进行模糊查找,查找name 以“张"开头的所有人的ID,即 sql 语句为
select ID from table where name like '张%'
由于在B+树结构的索引中,索引项是按照索引定义里面出现的字段顺序排序的,索引在查找的时候,可以快速定位到 ID 为 100的张一,然后直接向右遍历所有张开头的人,直到条件不满足为止。
也就是说,我们找到第一个满足条件的人之后,直接向右遍历就可以了,由于索引是有序的,所有满足条件的人都会聚集在一起。
而这种定位到最左边,然后向右遍历寻找,就是我们所说的最左前缀原则。
5.2、为什么用 B+ 树做索引而不用哈希表做索引
1、哈希表是把索引字段映射成对应的哈希码然后再存放在对应的位置,这样的话,如果我们要进行模糊查找的话,显然哈希表这种结构是不支持的,只能遍历这个表。而B+树则可以通过最左前缀原则快速找到对应的数据。
2、如果我们要进行范围查找,例如查找ID为100 ~ 400的人,哈希表同样不支持,只能遍历全表。
3、索引字段通过哈希映射成哈希码,如果很多字段都刚好映射到相同值的哈希码的话,那么形成的索引结构将会是一条很长的链表,这样的话,查找的时间就会大大增加。
5.3、主键索引和非主键索引有什么区别
例如对于下面这个表(其实就是上面的表中增加了一个k字段),且ID是主键。
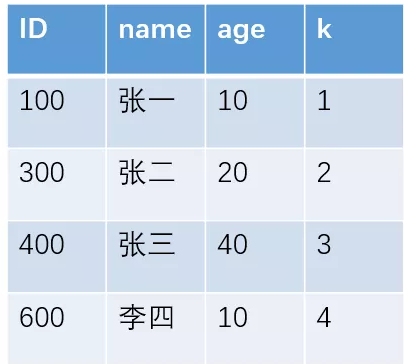
主键索引和非主键索引的示意图如下:
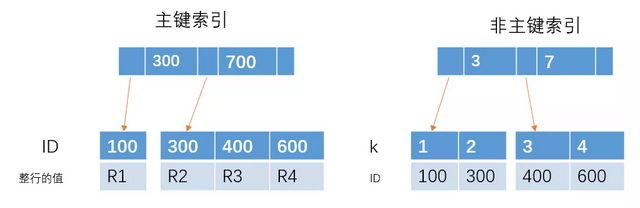
其中R代表一整行的值。
从图中不难看出,主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是主键的值,而主键索引的叶子节点存放的是整行数据,其中非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
根据这两种结构我们来进行下查询,看看他们在查询上有什么区别。
1、如果查询语句是 select * from table where ID = 100,即主键查询的方式,则只需要搜索 ID 这棵 B+树。
2、如果查询语句是 select * from table where k = 1,即非主键的查询方式,则先搜索k索引树,得到ID=100,再到ID索引树搜索一次,这个过程也被称为回表。
5.4、为什么建议使用主键自增的索引
对于这棵主键索引的树
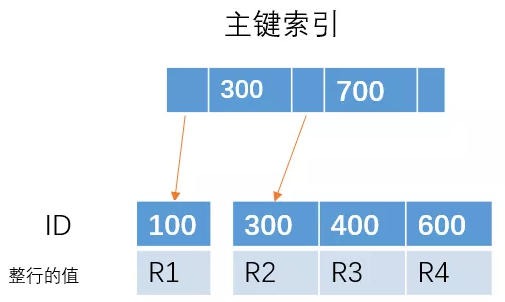
如果我们插入 ID = 650 的一行数据,那么直接在最右边插入就可以了
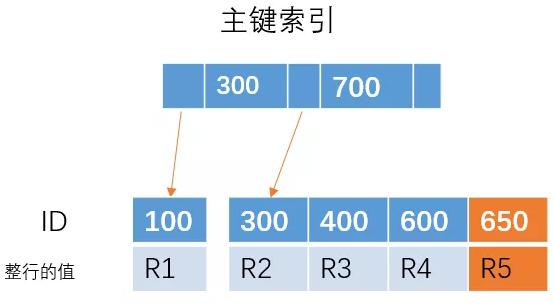
但是如果插入的是 ID = 350 的一行数据,由于 B+ 树是有序的,那么需要将下面的叶子节点进行移动,腾出位置来插入 ID = 350 的数据,这样就会比较消耗时间,如果刚好 R4 所在的数据页已经满了,需要进行页分裂操作,这样会更加糟糕。
但是,如果我们的主键是自增的,每次插入的 ID 都会比前面的大,那么我们每次只需要在后面插入就行, 不需要移动位置、分裂等操作,这样可以提高性能。也就是为什么建议使用主键自增的索引。
5.5、一条SQL语句执行得很慢的原因有哪些
一个 SQL 执行的很慢,我们要分两种情况讨论:
5.5.1、大多数情况下很正常,偶尔很慢,则有如下原因
(1)、数据库在刷新脏页,例如 redo log 写满了需要同步到磁盘。
当我们要往数据库插入一条数据、或者要更新一条数据的时候,我们知道数据库会在内存中把对应字段的数据更新了,但是更新之后,这些更新的字段并不会马上同步持久化到磁盘中去,而是把这些更新的记录写入到 redo log 日记中去,等到空闲的时候,在通过 redo log 里的日记把最新的数据同步到磁盘中去。
不过,redo log 里的容量是有限的,如果数据库一直很忙,更新又很频繁,这个时候 redo log 很快就会被写满了,这个时候就没办法等到空闲的时候再把数据同步到磁盘的,只能暂停其他操作,全身心来把数据同步到磁盘中去的,而这个时候,就会导致我们平时正常的SQL语句突然执行的很慢,所以说,数据库在在同步数据到磁盘的时候,就有可能导致我们的SQL语句执行的很慢了。
(2)、执行的时候,遇到锁,如表锁、行锁。
这个就比较容易想到了,我们要执行的这条语句,刚好这条语句涉及到的表,别人在用,并且加锁了,我们拿不到锁,只能慢慢等待别人释放锁了。或者,表没有加锁,但要使用到的某个一行被加锁了,这个时候,我也没办法啊。
如果要判断是否真的在等待锁,我们可以用 show processlist这个命令来查看当前的状态哦,这里我要提醒一下,有些命令最好记录一下。
5.5.2、这条 SQL 语句一直执行的很慢,那么sql本身的问题了,一般有如下原因。
我们先来假设我们有一个表,表里有下面两个字段,分别是主键 id,和两个普通字段 c 和 d。
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB;
(1)、没有用上索引:例如该字段没有索引;由于对字段进行运算、函数操作导致无法用索引。
没有用上索引,c 字段上没有索引,那么抱歉,只能走全表扫描了
select * from t where 100 <c and c < 100000;
字段有索引,但却没有用索引
select * from t where c - 1 = 1000;
正确的查询应该如下
select * from t where c = 1000 + 1;
函数操作导致没有用上索引
select * from t where fun(c,2) = 1000;
(2)、数据库选错了索引。
我们知道,主键索引和非主键索引是有区别的,主键索引存放的值是整行字段的数据,而非主键索引上存放的值不是整行字段的数据,而且存放主键字段的值。面试小知识:MySQL索引相关 里面有说到主键索引和非主键索引的区别.
也就是说,我们如果走 c 这个字段的索引的话,最后会查询到对应主键的值,然后,再根据主键的值走主键索引,查询到整行数据返回。
就算你在 c 字段上有索引,系统也并不一定会走 c 这个字段上的索引,而是有可能会直接扫描扫描全表,找出所有符合 100 < c and c < 100000 的数据。
为什么会这样呢?
其实是这样的,系统在执行这条语句的时候,会进行预测:究竟是走 c 索引扫描的行数少,还是直接扫描全表扫描的行数少呢?显然,扫描行数越少当然越好了,因为扫描行数越少,意味着I/O操作的次数越少。
如果是扫描全表的话,那么扫描的次数就是这个表的总行数了,假设为 n;而如果走索引 c 的话,我们通过索引 c 找到主键之后,还得再通过主键索引来找我们整行的数据,也就是说,需要走两次索引。而且,我们也不知道符合 100 c < and c < 10000 这个条件的数据有多少行,万一这个表是全部数据都符合呢?这个时候意味着,走 c 索引不仅扫描的行数是 n,同时还得每行数据走两次索引。
所以呢,系统是有可能走全表扫描而不走索引的。那系统是怎么判断呢?
判断来源于系统的预测,也就是说,如果要走 c 字段索引的话,系统会预测走 c 字段索引大概需要扫描多少行。如果预测到要扫描的行数很多,它可能就不走索引而直接扫描全表了。
那么问题来了,系统是怎么预测判断的呢?
系统是通过索引的区分度来判断的,一个索引上不同的值越多,意味着出现相同数值的索引越少,意味着索引的区分度越高。我们也把区分度称之为基数,即区分度越高,基数越大。所以呢,基数越大,意味着符合 100 < c and c < 10000 这个条件的行数越少。
所以呢,一个索引的基数越大,意味着走索引查询越有优势。
那么问题来了,怎么知道这个索引的基数呢?
系统当然是不会遍历全部来获得一个索引的基数的,代价太大了,索引系统是通过遍历部分数据,也就是通过采样的方式,来预测索引的基数的。
扯了这么多,重点的来了,居然是采样,那就有可能出现失误的情况,也就是说,c 这个索引的基数实际上是很大的,但是采样的时候,却很不幸,把这个索引的基数预测成很小。例如你采样的那一部分数据刚好基数很小,然后就误以为索引的基数很小。然后就呵呵,系统就不走 c 索引了,直接走全部扫描了。
所以呢,说了这么多,得出结论:由于统计的失误,导致系统没有走索引,而是走了全表扫描,而这,也是导致我们 SQL 语句执行的很慢的原因。
这里我声明一下,系统判断是否走索引,扫描行数的预测其实只是原因之一,这条查询语句是否需要使用使用临时表、是否需要排序等也是会影响系统的选择的。
不过呢,我们有时候也可以通过强制走索引的方式来查询,例如
select * from t force index(a) where c < 100 and c < 100000;
我们也可以通过
show index from t;
来查询索引的基数和实际是否符合,如果和实际很不符合的话,我们可以重新来统计索引的基数,可以用这条命令
analyze table t;
来重新统计分析。
既然会预测错索引的基数,这也意味着,当我们的查询语句有多个索引的时候,系统有可能也会选错索引哦,这也可能是 SQL 执行的很慢的一个原因。
5.5.3、总结
一个 SQL 执行的很慢,我们要分两种情况讨论:
1、大多数情况下很正常,偶尔很慢,则有如下原因
(1)、数据库在刷新脏页,例如 redo log 写满了需要同步到磁盘。
(2)、执行的时候,遇到锁,如表锁、行锁。
2、这条 SQL 语句一直执行的很慢,则有如下原因。
(1)、没有用上索引:例如该字段没有索引;由于对字段进行运算、函数操作导致无法用索引。
(2)、数据库选错了索引。
6、出处文章
https://blog.csdn.net/guoxingege/article/details/51034387
https://blog.csdn.net/weixin_39420024/article/details/80040549
MySQL索引相关:
https://mp.weixin.qq.com/s/RemJcqPIvLArmfWIhoaZ1g
一条SQL语句执行得很慢的原因有哪些:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号