
Object detection overview
ref:https://baijiahao.baidu.com/s?id=1644905321397514137&wfr=spider&for=pc
for most computer vision tasks, detection is necessary and important!
近年来,Object Detection 方向的很多工作已经针对检测器在准确性和速度之间的权衡进行了广泛的研究。由于许多 single-stage detector 在两者中都取得了不错的效果,two-stage 的方法逐渐失去了优势。本文首先对 single-stage 和 two-stage 的方法进行简要回顾和比较,之后介绍 anchor-free 的方法并针对以两种 CenterNet 为主的物体检测方法进行详述。
1. Single-stage and Two-stage Detector
Faster RCNN [1] 及其变体自提出以来一直是主流目标检测架构之一。由于其模型的 capacity 大,以及对 proposal 有预先处理等方面的优势,这些模型在减轻物体姿态(角度)、光照和旋转等问题方面都表现的十分出色。通过适当的 anchor 设置和训练策略,也可以有效地检测到微小和带有遮挡的物体。总体来说,这种方法有两个阶段,即 proposal 和 detection(图 1)。第二阶段筛选和校准第一阶段提出的 Region of Interests(RoIs)。proposal 阶段使用的是 region proposal network (RPN) 来尽可能多的覆盖到 True Positives(TP),detection 阶段的检测通常则是使用一些卷积和全连接层来保留第一阶段找到的 TP 同时消除第一阶段引入的 False Positives(FP)。
一方面,如果 proposal 方法不能达到高召回率(recall)或者 feature extractor 提取的特征未能提供足够有效的信息,则第二阶段的检测器的结果将很差。另一方面,由于检测是在 RoI 级别进行的,因此 convolution kernel 能够更精确地对每一个类别的物体进行区分,两阶段的结合类似于一种粗分类+细分类的结合。然而,相对较低的速度(5FPS 左右)和较大的内存占用阻碍了它在许多现实场景下的应用。
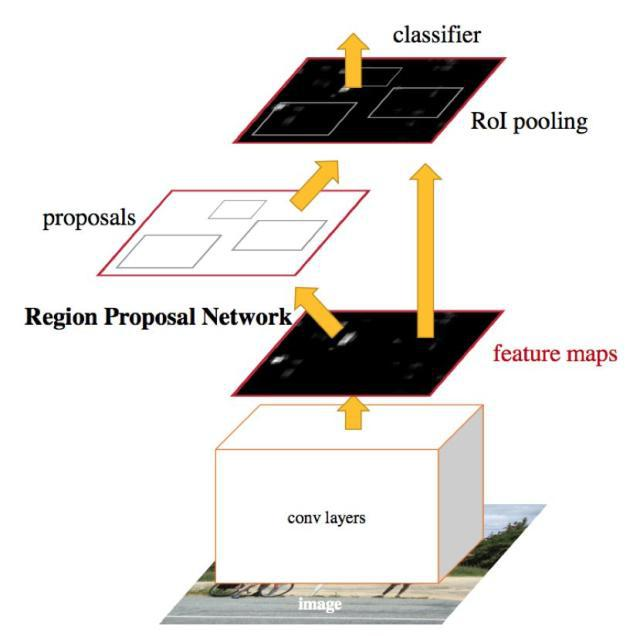
图 1. Faster RCNN 整体架构。作为 Two stage 方法的代表,其包括 proposal 和 detection 两部分。
近几年,single-stage detector 将目标检测的速度普遍提高到了 30FPS 以上,同时保持了不错的模型精度。SSD [2] 和 YOLO [3](图 2)首先提供了高精度的实时物体检测解决方案。许多基于 SSD 的变体也证明了单阶段物体检测的有效性。然而,这些方法在小物体检测上表现不佳。SSD 在很多方面类似于一个 region proposal network (RPN),但它们的目标不同。RPN 选择预测出的前 2000 个 bounding box 进行第二阶段的训练,而 SSD 只选择一小部分(保证正负样本的比例)作为训练样本。因此,在训练 one-stage detector 时,特别小的物体只能匹配到很少的 anchor(对于 20 像素及以下的物体甚至只有一个或没有)。这些 anchor 尚不足以学习小物体的统计信息。对于这种物体尺度问题,许多研究人员提出了不同的训练策略。我们也对其中一些策略进行了试验并报告了实验结果,会在后续的文章中进行总结,希望能为进一步研究提供一些见解。
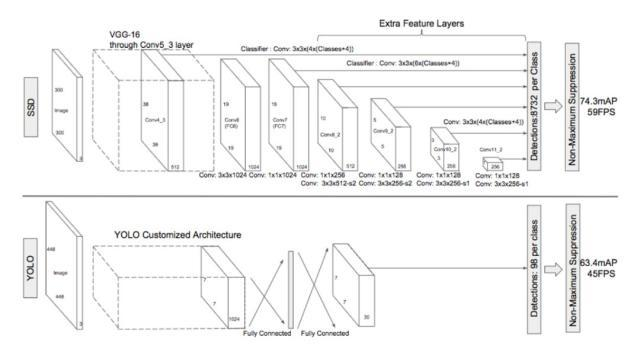
图 2. SSD 和 YOLO 作为经典的 Single stage 方法,图为其整体架构比较。
2. Anchor-based and Anchor-free Detector
2000 年起,就已经有很多传统方法应用在了目标检测的任务上。最初的 HoG 特征,Haar 分类器等方法都是使用人工制定的规则计算特征并通过滑窗的方法来确定物体位置。RCNN 等方法的提出开始使用 Selective Search 等传统方法来生成 proposal,从而减少了计算量和运算时间。
自从 RPN 的提出以来,anchor-based 的方法便成了物体检测模型的主流。这种方法在特征图的每一个像素点预设几个不同尺度和纵横比的 bounding box,称之为 anchor。之后对每一个 anchor 进行分类,并对正类的 anchor 进行回归(位置及大小调整)。之后的 SSD,YOLO 等 single-stage 方法也是基于 anchor 进行检测。Anchor 的引入带来了很多优点:1)它很大程度上减少了计算量,并将 proposal 数量放到可控范围内以便后面的计算和筛选。2)通过调整不同的 anchor 设置可以覆盖尽可能多的物体,也可针对不同任务设置不同的 anchor 尺度范围。3)由于 anchor 的尺度是人工定义的,物体的定位是通过 anchor 的回归来实现,仅仅计算偏移量而不是物体的位置大大降低了优化难度。
然而 anchor 的设置也有着它自身的缺点。1)在 Faster RCNN 以后的很多论文中我们不难发现,单纯通过使用更多不同大小和纵横比的 anchor 以及更多的训练技巧就可以达到更好的效果,然而这种通过增加算力而改进网络的方法很难落实到实际的应用中(模型速度和大小)。2)anchor 的设定需要人为设定大量的参数,且离散的 anchor 尺度设定会导致一些物体无法很好的匹配到 anchor,从而导致遗漏。
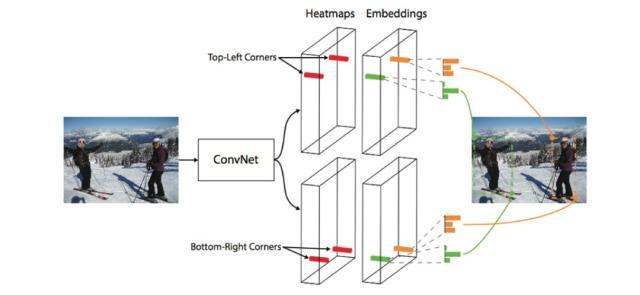
图 5. Cornernet 示意图。Cornernet 使用 key point detection+mathcing 的方法来检测物体,为 object detection 提供了一种新的解决思路。
CornerNet [4] 的提出开启了一系列 anchor-free 的方法。不同于预先设定 anchor 再预测偏移量,这一系列方法直接对物体位置进行预测。FSAF [5] 使用 anchor-free 分支直接预测物体位置并结合 anchor-based 方法进行预测,使得不同预测层可以覆盖更多的物体,从而改善了上述第二个问题。FCOS [6] 和 fovea Box [7] 等方法预测每一个正样本区域内的点距离其边框的偏移量,也避免了直接预测物体区域带来的尺度变化太大难以训练的问题(图 6)。CornerNet,CenterNet 则提供了另外一种 bottom-up 的思路-key point based object detection-将物体检测的问题转换为关键点的检测。CornerNet 直接预测每个物体左上角和右下角,并利用 embedding vector 将其进行匹配(图 5)。CenterNet 则认为 CornerNet 检测的 bounding box 的角点缺乏语义信息,并不能很好的代表一个物体,转而进行物体中心点的预测。值得一提的是,在相邻时间段有两篇不同的论文同时提出两个不同版本的 CenterNet,我们会在文章第三部分进行比较。

图 6. FCOS 示意图。FCOS 基于尺度金字塔对每个像素点预测其对应的边界框的位置。不同于 cornernet,很大一部分的 anchor free 方法还是基于 bounding box 位置的预测。
Anchor-free 的方法在 MSCOCO 上已经超过了 anchor-based single-stage 方法,AP 已然快和 two-stage 的方法持平。相比于 anchor-based 的方法,其亮点之一在于减少了人为设定的参数,而且不存在 anchor 与不同尺度的 ground truth 无法匹配的问题。同时,它也减少了输入图像尺度和 anchor 尺度同时变换带来的冗余计算的问题。然而,所有 Anchor-free 方法都仍然要面临的一个挑战是如何更合理的重新规划物体检测任务,从而减少图像中物体尺度差别过大导致的训练不稳定问题。除了数值上常用的 log 运算外,大部分文章仍在使用 rescale 的偏移量作为预测输出,keypoint based 方法则直接将问题进行了转换从而规避了这一风险。总体来说,anchor free 方法已成为现阶段物体检测的主流研究方向,也不断有体量更小,参数更少,精度更高的模型被提出。
3. CenterNet
2019 年 4 月,中科院联合牛津、华为在 CornerNet 的基础上提出了新的 anchor-free 物体检测方法 CenterNet,构建三元组进行物体检测(后文简称 CenteNet-Triplets)[8],并在 MSCOCO 数据集上大幅超过了所有已有 single-stage 方法。与此同时,得克萨斯奥斯汀大学和伯克利也提出了同名的 CenterNet(后文简称 CenterNet-Keypoint),取得了最佳的速度-准确性权衡。两篇文章都尝试利用物体中心点的信息进行物体检测,出发点和方式却不尽相同。

图 7. CenterNet-Triplets 整体架构图
CenterNet-Triplets 是在 CornerNet 的基础上发展而来,其架构如图 7 所示。作者发现使用 CornerNet 进行检测时会出现很多 FP,而这一问题很可能是在进行左上角和右下角的 grouping 时发生的问题。实际上,将物体框的左上角和右下角进行配对是一个比较困难的问题,因为对于大部分物体来说,这两个角点都在物体外面,两角点的 embedding vector 并不能很好的感知物体的内部信息。因此,作者提出了三种思路来解决这个问题。首先,将左上角、右下角和中心点结合成为三元组进行物体框的判断。具体来讲,CenterNet-Triplets 不仅预测角点,也预测中心点,如果角点所定义的预测框的中心区域包含中心点,则保留此预测框,否则弃掉。这样做的相当于对 CornerNet 的预测做了一次后处理的矫正,使得预测准确率更高。第二种思路是使用 Cascade Corner Pooling 替代原来的 corner Pooling,它首先提取物体边界最大值(Corner Pooling),然后在边界最大值处继续向内部提取提最大值,并与边界最大值相加,以结合更多内部信息。第三种思路是针对中心点的预测使用 Center Pooling,提取中心点水平方向和垂直方向的最大值并相加,以此给中心点提供所处位置以外的信息。这一操作使中心点有机会获得更易于区分于其他类别的语义信息。Center Pooling 可通过不同方向上的 corner pooling 的组合实现。这三种思路无一不是在尝试给 CornerNet 结合更多的物体内部信息,实验结果也表明了作者的出发点的正确性,三种思路都起到了一定效果。

图 8. CenterNet-Keypoint 示意图。
虽提出时间十分相近,但 CenterNet-Keypoint 却与 CenterNet-Triplets 思路不尽相同(图 8)[9]。本文作者仍然也指出了 CornerNet 在匹配左上角和右下角角点时会不可避免的发生一些错误,这可能会成为该模型进一步发展的 upper bound,于是作者干脆摒弃这种思路,直接将物体检测转换为关键点检测,并不需要对关键点本身做进一步的处理(比如匹配角点)。CenterNet-Keypoint 提供了一种更简洁的思路,预测每一个像素点是否为物体中心,如果是的话,针对中心点预测物体边界。这种方法和 anchor-based 的方法关系十分密切,因为 feature map 中的每一个像素点都可以看作是一个 shape-agnostic anchor,只不过这种「anchor」只和位置有关,也不需要进一步预测 offset 和使用 Non-Maximum Suppression(NMS)做后处理。CenterNet-Keypoint 也取得了目前所有 single-stage detector 在 MSCOCO 数据集上的最好成绩,比 CornerNet 提高了三个百分点。此外,值得一提的是 CenterNet-Keypoint 使用的思路十分具有普遍性,可以很容易的扩展到其他任务上。作者同时提供了该网络在 3D 物体检测和人体姿态检测任务中取得的结果,也取得了不错的成绩。
两种模型在 MSCOCO 上的物体检测结果如表 2 和表 3 所示,在输入分辨率相近的情况下,CenterNet-Triplets 表现略胜一筹。两者皆在 Single-stage 的方法中取得了最好成绩,并已经和 Two-stage 方法的准确率十分接近。作为 anchor free single stage object detector,两种模型均可达到实时的速度,但因为作者使用不同的 GPU 进行测试,结果无法进行公平的比较,感兴趣的话可以去原文一探究竟。
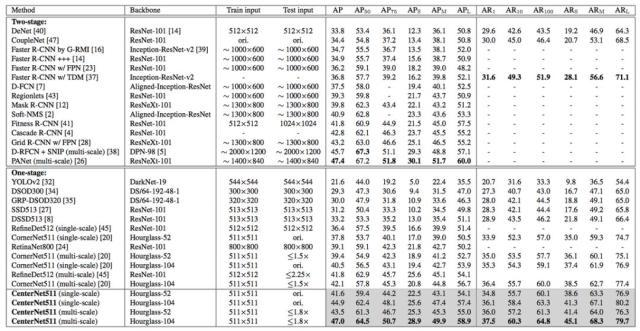
表 2. CenterNet-Triplets 在 MSCOCO 上结果比较。

表 3. CenterNet-Keypoint 在 MSCOCO 上结果比较。
总体来讲,物体检测任务一路发展过来,从人工定义特征,到 two-stage 方法,以及 single-stage 方法,再到 anchor free 方法的提出,整体架构都在不断的发生着改变,模型也正在朝着容量更小、超参数更少、速度更快、准确率更高的方向发展。近期在 arxiv 上发布的一篇文章中,Matrix Net一举打破所有记录,成为精度最高的 single-stage 实时物体检测器,并和 SOTA 的 two-stage 的方法取得了相当的成绩。目前作者尚未公开更多细节,让我们拭目以待。
[1] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
[2] Liu, Wei, et al. "Ssd: Single shot multibox detector." European conference on computer vision. Springer, Cham, 2016.
[3] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[4] Law, Hei, and Jia Deng. "Cornernet: Detecting objects as paired keypoints." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[5] Zhu, Chenchen, Yihui He, and Marios Savvides. "Feature selective anchor-free module for single-shot object detection." arXiv preprint arXiv:1903.00621 (2019).
[6] Tian, Zhi, et al. "FCOS: Fully Convolutional One-Stage Object Detection." arXiv preprint arXiv:1904.01355 (2019).
[7] Kong, Tao, et al. "FoveaBox: Beyond Anchor-based Object Detector." arXiv preprint arXiv:1904.03797 (2019).
[8] Duan, Kaiwen, et al. "CenterNet: Object Detection with Keypoint Triplets." arXiv preprint arXiv:1904.08189 (2019).
[9] Zhou, Xingyi, et al. "Objects as Points." arXiv preprint arXiv:1904.07850 (2019).
