实验四:代码审查
一、实验题目 :代码审查
二、实验目的
1、熟悉编码风格,利用开发环境所提供的平台工具对代码进行自动格式审查;
2、根据代码规范制定代码走查表,并按所制定的审查规范互审代码。
三、实验内容
1、IDEA环境和PyCharm环境二选一;
IDEA环境
(1)预先准备在IDEA环境下实现对输入的n个整数进行排序的代码;
(2)利用Alibaba代码规约插件,对所编写代码进行自动化格式审查。
https://blog.csdn.net/larner/article/details/120894045
PyCharm环境
(1)预先准备在PyCharm环境下实现对输入的n个整数进行排序的代码;
(2)利用Code Inspections对代码进行自动格式审查。
步骤如下:
在Python中,可以使用pylint或flake8等工具来进行代码审查。
以下是一个使用flake8的例子:
首先,安装flake8:
pip install flake8
然后,在命令行中运行flake8对代码进行审查:
flake8 your_script.py
这将输出代码中潜在的问题,包括不符合PEP 8标准的代码风格和潜在的错误。
如果你使用的是IDE,比如PyCharm,可以直接在IDE中运行代码审查:
打开你的Python文件,右键点击文件名,选择"Code" -> "Run Inspection by Name..."".
输入flake8,然后按下回车键,或者选择flake8的图标。
根据需要调整flake8的规则或者添加插件来满足特定项目的代码审查需求。
这样,IDE会在下方的"Run"窗口中显示代码审查的结果。
2、2人一组根据代码规范制定代码走查表;
3、按所制定的代码走查表,小组内互相审查所编写的代码,并将审查结果填写到代码审查表中。
四、实验要求
1、预先准备的代码要求独立编写,严禁抄袭,具体排序算法可以自由选择一种;
2、利用自动化格式审查工具对代码进行格式审查,截取格式审查结果,并针对审查结果逐一进行修改;
3、制定代码走查表,提交代码格式审查表文件。
五、代码自动化格式审查结果截图

六、根据审查结果修改代码格式前后对比图(可以截取部分
前:
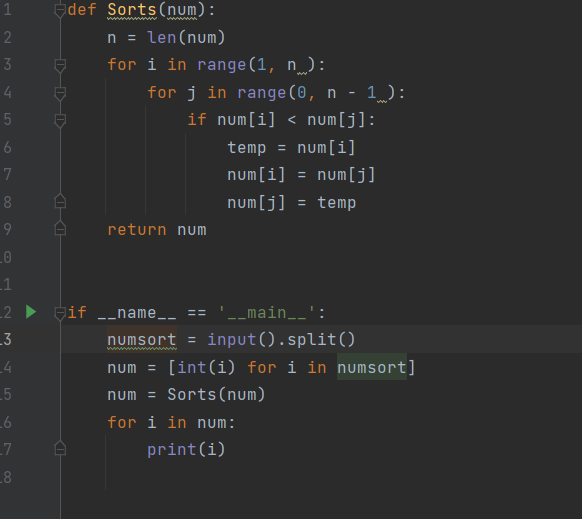
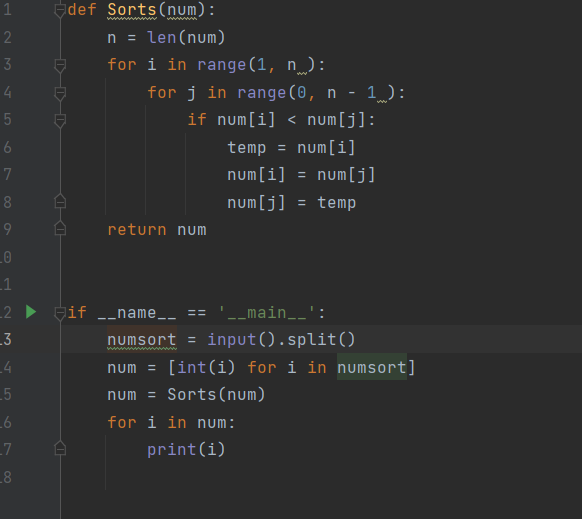
后:
七、实验中遇到的问题及解决方法
1.理解算法逻辑:
首先,审查代码之前要深入理解冒泡排序的基本原理。冒泡排序通过重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
2.代码的可读性:
审查代码时,我注意到代码的可读性非常重要。变量名应该具有描述性,注释应该清晰且准确。例如,使用i和j作为循环变量在简单循环中是可以的,但在更复杂的算法中,使用如outerLoopIndex和innerLoopIndex这样的变量名可能会更具可读性。
3.边界条件与错误处理:
在冒泡排序中,要确保所有的边界条件都被正确地处理。例如,确保循环的起始和结束索引是正确的,以及处理空数组或只有一个元素的数组时的情况。此外,虽然冒泡排序本身不会抛出异常,但在实际项目中,可能需要添加一些错误处理机制来处理不可预见的输入。
4.性能优化:
冒泡排序虽然简单,但效率并不高。在审查代码时,我思考了如何优化算法。例如,如果在某次遍历中没有发生任何交换,那么数组已经是有序的,可以提前结束排序。这种优化被称为“短路冒泡排序”。
5.测试:
审查代码时,我检查了是否有足够的测试用例来验证代码的正确性。对于冒泡排序,至少需要测试空数组、已排序数组、逆序数组和随机数组等场景。
6.代码风格与规范:
审查代码时,我也关注了代码风格和规范。例如,缩进是否一致,大括号是否成对出现,以及是否遵循了团队的编码规范。
7.可扩展性与可维护性:
虽然冒泡排序是一个简单的算法,但在审查代码时,我也思考了如何使其更具可扩展性和可维护性。例如,可以考虑将排序逻辑封装到一个单独的函数中,并为其添加文档注释。
gitee链接:https://gitee.com/aria125/myproject
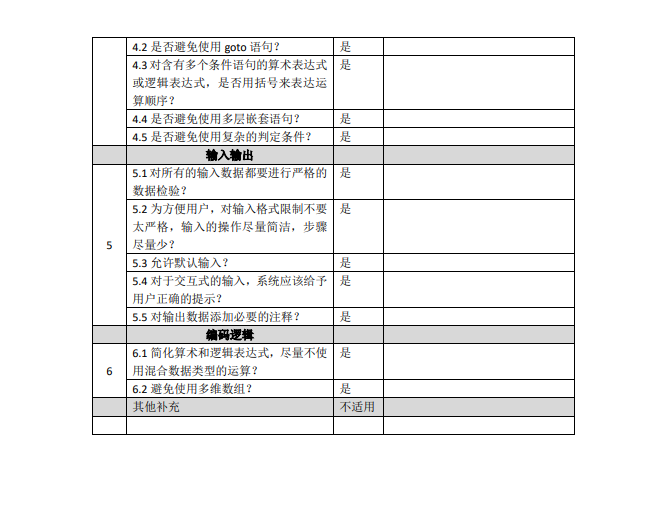
八、代码走查表



 浙公网安备 33010602011771号
浙公网安备 33010602011771号