
Django模型层之多表操作
一 创建模型
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
在Models创建如下模型
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish_date = models.DateField(auto_now_add=True) # 注册时间,不会因为更新操作而改变
# 一对多
publish = models.ForeignKey(to='Publish')
# 多对多
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 一对一
author_detail = models.OneToOneField(to='AuthorDetail')
class AuthorDetail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=32)
# 注意:
2.x版本的django
-外键字段必须加 参数: on_delete 代表级联删除
-1.x版本不需要,默认就是级联删除
-假设
删除出版社,该出版社出版社所有图书也都删除:on_delete=models.CASCADE
删除出版社,该出版社的图书不删除,设置为空:on_delete=modeles.SET_NULL,null=True
删除出版社,该出版社出版的图书不删除,设置为默认:on_delete=models.SET_DEFAULT,default=0
# 为何取消外键约束需要在关联字段设置默认值?
如果进行了删除出版社的操作,虽然不会影响book表中相关联的数据,但是在book表中publish_id也将 随之删除,这时就需要默认值保持整条数据的完整性,所以可以设置默认为空,或设置默认值为数字因为 (publish_id是int类型)
注意:关联字段与外键约束没有必然的联系(建管理字段是为了进行查询,建约束是为了不出现脏数据)
# 关联字段
比如查询book表的内容可以通过关联字段publish_id去查询关联的publish中的其他字段记录
与外键约束没有必然关系
# 脏数据
外键约束防止出现脏数据是指,在book中建立一条数据必须在publish_id写入相关publish表中的id进行关联,不然无法插入数据。那么如果没有外键约束,就可能会出现没有publish_id字段没有对应publish表中的id的数据,那这条数据可以称之为脏数据。
# 那么是否需要建立外键约束呢?
# 引用
引言
其实这个话题是老生常谈,很多人在工作中确实也不会使用外键。包括在阿里的JAVA规范中也有下面这一条
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
但是呢,询问他们原因,大多是这么回答的
每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便。
坦白说,这么说也是对的。但是呢,不够全面,所以开一文来详细说明。
正文
首先我们明确一点,外键约束是一种约束,这个约束的存在,会保证表间数据的关系“始终完整”。因此,外键约束的存在,并非全然没有优点。
比如使用外键,可以
保证数据的完整性和一致性
级联操作方便
将数据完整性判断托付给了数据库完成,减少了程序的代码量
然而,鱼和熊掌不可兼得。外键是能够保证数据的完整性,但是会给系统带来很多缺陷。正是因为这些缺陷,才导致我们不推荐使用外键,具体如下
性能问题
假设一张表名为user_tb。那么这张表里有两个外键字段,指向两张表。那么,每次往user_tb表里插入数据,就必须往两个外键对应的表里查询是否有对应数据。如果交由程序控制,这种查询过程就可以控制在我们手里,可以省略一些不必要的查询过程。但是如果由数据库控制,则是必须要去这两张表里判断。
并发问题
在使用外键的情况下,每次修改数据都需要去另外一个表检查数据,需要获取额外的锁。若是在高并发大流量事务场景,使用外键更容易造成死锁。
扩展性问题
这里主要是分为两点
做平台迁移方便,比如你从Mysql迁移到Oracle,像触发器、外键这种东西,都可以利用框架本身的特性来实现,而不用依赖于数据库本身的特性,做迁移更加方便。
分库分表方便,在水平拆分和分库的情况下,外键是无法生效的。将数据间关系的维护,放入应用程序中,为将来的分库分表省去很多的麻烦。
技术问题
使用外键,其实将应用程序应该执行的判断逻辑转移到了数据库上。那么这意味着一点,数据库的性能开销变大了,那么这就对DBA的要求就更高了。很多中小型公司由于资金问题,并没有聘用专业的DBA,因此他们会选择不用外键,降低数据库的消耗。
相反的,如果该约束逻辑在应用程序中,发现应用服务器性能不够,可以加机器,做水平扩展。如果是在数据库服务器上,数据库服务器会成为性能瓶颈,做水平扩展比较困难。
生成的表如下:

注意事项:
- 表的名称
myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称 id字段是自动添加的- 对于外键字段,Django 会在字段名上添加
"_id"来创建数据库中的列名 - 这个例子中的
CREATE TABLESQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
二 添加表记录
一对多的
# 由于外键约束以及逻辑顺序,需要先创建好出版社再创建图书
models.Publish.objects.create(name='上海出版社', addr='上海', email='321@123')
# 方式1:
book_obj = models.Book.objects.create(title='阿刁', price=200, publish_date='1995-3-1', publish_id=2)
# 直接publish_id选定关联字段
# 方式2:
publish_obj = models.Publish.objects.get(pk=3)
book_obj = models.Book.objects.create(title='阿刁', price=200, publish_date='1995-3-1', publish_id=publish_obj.pk)
核心:book_obj.publish与book_obj.publish_id是什么
# book_obj.publish
查询book对象关联的publish对象
# book_obj.publish_id
查询book对象中的字段publish_id
多对多
# 当前生成的书籍对象
book_obj = models.Book.objects.create(title='小黑书', price=120, publish_date='2000-10-10', publish_id=1)
# 为书籍绑定作者对象
arther = models.Author.objects.filter(name='arther').first()
tank = models.Author.objects.filter(name='tank').first()
# 调用authors第三张表建立多对多关系
book_obj.authors.add(arther, tank)
# 多对多关系 写入一个书本对象对应两个作者对象 即在第三张表中写入两条数据
多对多关系的其他常用API
# 已知add是在第三张表中添加多对多的对应关系
# remove
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。
book_obj = models.Book.objects.get(pk=12)
book_obj.authors.remove(1)
book_obj.authors.remove(*[1,2]) # 相当于执行了两次删除数据的sql语句
# 删除了在第三表中book_id = 12 and author_id=1 所约束的对象
# clear
book_obj.authors.clear() #清空被关联对象集合
book_obj = models.Book.objects.get(pk=12)
book_obj.authors.clear()
# 清空了第三张表中关于该对象了对应的所有publish_id
# set
book_obj.authors.set() #先清空再设置
book_obj = models.Book.objects.get(pk=12)
book_obj.authors.set([4,])
# 先清空第三张表中对应的publish_id,然后再对应设置 publish_id = 4
# all
book_obj.authors.all()
# 直接获得该对应对应的所有publish对象的集合
核心:book_obj.authors.all()是什么?
关键点:
一 book_obj.publish=Publish.objects.filter(id=book_obj.publish_id).first()
二 book_obj.authors.all()
关键点:book.authors.all() # 与这本书关联的作者集合
1 book.id=3
2 book_authors
id book_id author_ID
3 3 1
4 3 2
3 author
id name
1 alex
2 egon
book_obj.authors.all() -------> [alex,egon]
# 所以通过book_obj.authors.all()不是表明上看的那样获得第三张表中所有相关的对象
# 而是封装成直接获得另一张表所有的相关对象
就是没有获得book_authors中 id=3和id=4的对象,
而是封装成直接获得了author表中的对应的 id=1和id=2的对象
三 基于对象的跨表查询
一对多查询(publish与book)
# 查询主键为15的图书的出版社的所在地
# 正向查询从含有关联字段的表出发(以多查少)
book_obj = models.Book.objects.get(pk=12)
publish_obj = book_obj.publish # 按对象:publish
print(publish_obj.addr)
# 查询上海出版社出版的图书
# 反向查询从没含有关联字段的表出发(以少查多)
publish_obj = models.Publish.objects.get(name='上海出版社')
book_obj = publish_obj.book_set.all() # 表名小写_set 根据出版社id找book表对应的数据
for obj in book_obj:
print(obj.title)
# 正向查询:book表内有publish字段 直接对象.字段名
多对一的方式,每本书都有自己唯一的出版社,所以可以直接publish_obj.addr
# 反向查询:publish表内没有book字段,出版社对象.Book小写_set.all()
一对多的方式,查询出来的是一个queryset对象,里面是book对象的集合因此需要
for obj in book_obj:
print(obj.title) # 分离出每一个book对象
一对一查询(author与author_detail)
# 正向查询
# 查询作者egon的居住地址
egon = models.Author.objects.get(name='egon')
addr = egon.author_detail.addr
print(addr)
# 反向查询
# 查询居住在北京的作者的名字
addr = models.AuthorDetail.objects.get(addr='北京')
author_name = addr.author.name
print(author_name)
# 为何一对一查询的反向查询不需要 表名.set
因为是一对一查询,不要像一对多查询那样需要建一个查到的对象的集合
多对多查询(book与author)
# 正向查询
# 查询书名为小黑书的作者名字以及手机号
book_obj = models.Book.objects.get(title='小黑书')
authors = book_obj.authors.all()
for author_obj in authors:
print(author_obj.name, author_obj.author_detail.phone)
# 反向查询
# 查询作者egon出过的所有书的名字
author_obj = models.Author.objects.get(name='egon')
books = author_obj.book_set.all()
for book_obj in books:
print(book_obj.title)
四 基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
'''
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
'''
一对多查询
# 查询上海出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询
book = models.Book.objects
.filter(publish__name='上海出版社')
.values('title', 'price')
# 反向查询
book = models.Publish.objects
.filter(name='上海出版社')
.values('book__title', 'book__price')
# 查询的本质一样,就是select from的表不一样
多对多查询
# 查询tank出过所有书籍的名字
# 正向查询
book = models.Book.objects.filter(authors__name='egon').values('title')
# 从book表出发通过第三张表authors的关系找到对应的author表并过滤出name='egon'的对象
# 然后与之匹配出book表中的book对象后调用values('title')调出书籍的名字
# 反向查询
book = models.Author.objects.filter(name='egon').values('book__title')
# 从author表出发过滤出name = 'egon' 的对象然后通过第三张表中匹配到对应的book表中的对象
# 由于不是在自己的表操作要再通过values('book__title')调出书籍的名字
一对一查询
# 查询egon的手机号
# 正向查询
phone = models.AuthorDetail.objects.filter(author__name='egon')
.values('phone')
# 反向查询
phone = models.Author.objects.filter(name='egon')
.values('author_detail__phone')
小思绪
多对一的关系中,
如果在多的表如book表中创建完全一模一样的两条数据,那么只能根据主键去识别它们的独特性。
但是最好不要这么创建,比如创建了同样的书名name='小黄书'两条,然后分别对应不同的出版社,
就形成了阅读上与出版社多对多的关系,这时只能根据以其自增的唯一的主键id去标识这两条数据,来维持多对一的关系,如果可以在比较关键的字段如书名等建立unique的参数来确保唯一,以免造成读取数据的紊乱。
进阶联系(连续跨表)
# 查询上海出版社出版过的所有书籍的名字以及作者的名字
# 正向查询
result = models.Book.objects.filter(publish__name='上海出版社').values('title', 'authors__name')
# 反向查询
result = models.Publish.objects.filter(name='上海出版社').values('book__title', 'book__authors__name')
# 查询手机号以123开头的作者出版过的所有书籍名称以及出版社名称
# 正向查询
result = models.Book.objects
.filter(authors__author_detail__phone__startswith='123')
.values('title','publish__name')
# 反向查询
result = models.AuthorDetail.objects
.filter(phone__startswith='123')
.values('author__book__title','author__book__publish__name')
print(result)
related_name
反向查询时,如果定义了related_name ,则用related_name替换表名,例如:
# models.py
publish = ForeignKey(Blog, related_name='bookList')
# 练习: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price")
五 聚合查询与分组查询
聚合
aggregate(*args,**kwargs)
# 计算所有图书的平均价格
from django.db.models import Avg
avf_price = models.Book.objects.all().aggregate(Avg('price'))
print(avf_price)
>>>{'price__avg': 118.857143} # 返回一个字典
# 原生sql:
SELECT AVG(`app01_book`.`price`) AS `price__avg` FROM `app01_book`;
aggregate()是QuerySet的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的(字段名_聚合函数名)。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
Book.objects.aggregate(average_price=Avg('price')) # 像这样指定键名
如果希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
# 计算所有图书的平均价格
from django.db.models import Avg, Max, Min
all_price = models.Book.objects.all().aggregate(avg_price=Avg('price'), max_price=Max('price'),
min_price=Min('price'))
print(all_price)
分组
annotate()为调用QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
# aggregate()与annotate()区别
相同:两者都是用于聚合函数的方法
区别:前者通常用于单表查询没有values,直接返回聚合函数结果,如对全部书籍的一个平均价格
models.Book.objects.aggregate(avg_price=Avg('price'))
# 直接返回所有书籍的价钱的平均值,所以不需要values返回字段。它有自己的键值 是字典类型
'''
{'avg_price': 148.857143}
'''
后者用于多表的查询,默认以基表的主键分组,可以用values的返回字段,如每本书的平均价格
# 单表每本书查平均价格没有意义,如果是连表查每个作者下多本书的平均价格才有annotate的意义
models.Book.objects.annotate(avg_price=Avg('price'))
.values('title', 'avg_price')
# 返回结果默认对分组每本书,然后在每本书里的价格取平均价格,是QuerySet对象
'''
<QuerySet [{'title': '倚天', 'avg_price': 42.0}, {'title': '阿刁熊', 'avg_price': 230.0}, {'title': '阿刁', 'avg_price': 230.0}, {'title': '小黄书1', 'avg_price': 130.0}, {'title': '小黄书2', 'avg_price': 130.0}, {'title': '小黄书3', 'avg_price': 130.0}, {'title': '小黑书', 'avg_price': 150.0}]>
'''
前戏
# 在原生sql语句的执行顺序
1.找到表:from
2.拿到where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体做为一组
4.将分组的结果进行having过滤
5.执行select
6.去重:distinct
7.将结果按条件排序:order by
8.限制结果的显示条数:limit
'''
在聚合发生在分组之后,where后不能有聚合函数,且此次sql语句select只能找到被分组的字段,但限于单表查询,在orm框架中大多是多表查询having也是只能接被分组的字段以及聚合函数
'''
# 总结 在ORM框架中
annotate() 内写聚合函数
1.values在前表示group by字段
2.values在后表示取字段
3.filter在前表示where # 注意在orm框架不同,1要写在3的前面,但是最后出现的sql语句是遵循执行顺序
4.filter在后表示having
# 所以最后应有的顺序:1\3\4\2
# 注意:
一般分组之后只能values被分组的字段,但是如果values写入了其他字段,
基于ORM框架会自动进行join操作将表拼接然后取出字段,进行了多表查询
在单表操作时select 的字段会受到group by 字段的影响,只能select该字段以及聚合函数的字段,它的原理是比如当以publish_id分组,来封装每个出版社的图书以及每本书的属性,但是select字段的话由于只能取字段下的唯一记录,此时只有publish_id以及聚合函数出来的结果是唯一,而其他字段下可能会存在多条记录那么就不能取出。
多表操作同理,但是根据publish_id建立的连表,然后以publish_id分组后,对应的publish表每个字段下的记录是唯一由于是用其主键分组,所以publish表的其他字段的记录能取出,而被分组的基表book表的字段不能取出。
例子
# book表 # publish表
id name publish_id id name addr
1 诛仙 1 1 北京出版社 北京
2 Python 1 2 东京出版社 东京
3 霸王 2
4 hello 2
# 单表根据publish_id分组
id name publish_id
1、2 诛仙、Python 1
3、4 霸王、hello 2
# select取的字段由于严格模式只能取当下字段下唯一的记录,所以只能取publish_id以及聚合函数结果
# 多表根据publish_id进行连表以及分组
id name publish_id id name addr
1、2 诛仙、Python 1 1 北京出版社 北京
3、4 霸王、hello 2 2 东京出版社 东京
# 此时由于根据publish_id分组,publish_id唯一那么关联的publish表中的相关字段唯一
# 可以取出publish表中所有字段以及聚合函数结果
查询联系
练习:统计每一本书作者的个数
# 如果没有如果没有指定group by的字段,默认就用基表主键字段作为group by的字段
# 以Book表为基表
res = models.Book.objects.all()
.values('id')
.annotate(author_num=Count('authors__id'))
.values('title', 'author_num')
# 以Author表为基表
res = models.Author.objects.all()
.values('book__id')
.annotate(author_num=Count('id'))
.values('book__title','author_num')
# 注意:
如果不用分组的表作为基表,数据不完整可能会出现查询的问题。
如在book与author的表的第三张表中没有建立每条数据的对应关系,
那么在查询时将分组的表作为基表(BOOK)的会主动屏蔽那些没有建立对应关系的数据,不会查询出来
而没有将分组的表作为基表(AUTHOR)的会查询出来但是查询的明显就是错误数据。
# 所以:在之后练习中将分组的表作为基表来进行查询
练习:统计每一个出版社的最便宜的书
res = models.Publish.objects.annotate(min_price=Min('book__price'))
.values('name', 'book__title','min_price')
练习:统计每一本以小开头的书籍的作者
res = models.Book.objects.values('id').filter(title__startswith='小')
.values('title', 'authors__name')
练习:统计不止一个作者的图书:(作者数量大于一)
res=models.Book.objects.values('id').annotate(book_num=Count('authors'))
.filter(book_num__gt=1).values('id',
'authors__name', 'title', 'book_num')
练习:根据一本图书作者数量的多少对查询集 QuerySet进行排序:
res = models.Book.objects.annotate(book_num=Count('authors'))
.order_by('book_num')
.values('title', 'book_num')
练习:查询各个作者出的书的总价格:
res = models.Author.objects.annotate(all_price=Sum('book__price'))
.values('name', 'all_price')
练习:查询每个出版社的名称和书籍个数
res = models.Publish.objects.annotate(book_num=Count('book__id'))
.values('name', 'book_num')
六 F查询和Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
查询评论数大于收藏数的书籍
from django.db.models import F
res = models.Book.objects.filter(conmentNum__gt=F('keepNum')).values('title')
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
查询评论数大于收藏数2倍的书籍
res = models.Book.objects.filter(conmentNum__gt=F('keepNum')*2).values('title')
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
models.Book.objects.update(price=F('price') + 30)
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
bookList = models.Book.objects.filter(Q(authors__name="yuan") | Q(authors__name="egon")).values('authors__name')
等同于下面的SQL WHERE 子句:
WHERE name ="yuan" OR name ="egon"
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
bookList = models.Book.objects.filter(~Q(authors__name="yuan") | Q(authors__name="egon")).values('authors__name')
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017), title__icontains="python")
七 自定义中间表(中介模型)
1 多对多关系中,第三张表的建立
-默认使用ManyToMany,自动创建
-使用中介模型
-即手动创建第三张表,又要使用好用的查询
-完全自己写第三张表
# 使用中介模型
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDatail', to_field='nid', unique=True, on_delete=models.CASCADE)
class AuthorDatail(models.Model):
nid = models.AutoField(primary_key=True)
telephone = models.BigIntegerField()
birthday = models.DateField()
addr = models.CharField(max_length=64)
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField()
publish = models.ForeignKey(to='Publish', to_field='nid', on_delete=models.CASCADE)
# 当前在哪个表中,元组中的第一个参数就是 表明_id
# 为了方便查询定义一个authors字段,进行连表查询
authors=models.ManyToManyField(to='Author',through='AuthorToBook',
through_fields= ('book_id','author_id'))
def __str__(self):
return self.name
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
class AuthorToBook(models.Model):
nid = models.AutoField(primary_key=True)
# 建立多对一的外键关系
book_id = models.ForeignKey(to=Book, to_field='nid', on_delete=models.CASCADE)
author_id = models.ForeignKey(to=Author, to_field='nid', on_delete=models.CASCADE)
date=models.DecimalField()
# s1.py
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day76.settings")
import django
django.setup()
from app01 import models
# 梅这本书是lqz和egon写的
# book=models.Book.objects.get(pk=1)
# # book.authors.add(1,2) # 用不了了
# # 只能手动写
# models.AuthorToBook.objects.create(book_id_id=1,author_id_id=1)
# models.AuthorToBook.objects.create(book_id_id=1,author_id_id=2)
# 梅这本书所有的作者
# 原生查询方式
# book = models.Book.objects.get(pk=1)
# res=models.AuthorToBook.objects.filter(book_id=book)
# print(res)
# 在Book类加了authors字段的查询方式
# book = models.Book.objects.get(pk=1)
# print(book.authors.all())
# 梅这本书是lqz和egon写的 add ,remove, clear,set
# 但是连表操作,book.authors这些都能用
book = models.Book.objects.get(pk=1)
book.authors.add(1,2) # 不能用了,在中间表中不是只有外键字段,有其他字段,所以不能用此方 式进行多对多的关联
练习:题目、ACID、事务的隔离级别、悲观锁与乐观锁
1 整理聚合查询,分组查询,F和Q查询,原生sql,defer,only,事物到博客
2 完成如下查询
1 统计每一本书作者个数
res = models.Book.objects.all()
.values('id')
.annotate(author_num=Count('authors__id'))
.values('title', 'author_num')
2 统计每一个出版社的最便宜的书
res = models.Publish.objects.values('id')
.annotate(min_price=Min('book__price'))
.values('name', 'book__title','min_price')
3 统计每一本以小开头的书籍的作者个数:
res = models.Book.objects.values('id').filter(title__startswith='小').annotate(
count_author=Count('authors')).values('title', 'count_author')
4 作者数量大于2的图书名字和价格
res = models.Book.objects.values('id').annotate(count_author=Count('authors'))
.filter(count_author__gt=2).values('title', 'price')
5 根据一本图书作者数量的多少对查询集 QuerySet进行排序:
res = models.Book.objects.values('id')
.annotate(count_author=Count('authors')).order_by("count_author")
6 查询各个作者出的书的总价格
res = models.Author.objects.values('id').
annotate(all_price=Sum('book__price')).values('name', 'all_price')
7 查询每个出版社的名称和书籍个数
res = models.Author.objects.values('id')
.annotate(all_book=Count('book__id')).values('name', 'all_book')
8 查询所有书籍的平均价格
res = models.Book.objects.aggregate(avg_price=Avg('price'))
9 统计图书平均价格和最大价格
res = models.Book.objects.aggregate(Avg('price'), Max('price'))
10 统计图书总个数和平均价格
res = models.Book.objects.aggregate(all_book=Count('id'), avg_price=Avg('price'))
11 查询评论数小于等于阅读数2倍的书籍
res = models.Book.objects.filter(conmentNum__lte=F('keepNum')*2).values('title')
12 将每一本书的价格提高30元
res = models.Book.objects.update(price=F('price')+30)
13 将id大于3的每本书价格提高5元
res = models.Book.objects.filter(id__gt=3).update(price=F('price') + 3)
14 查询名字里不包含小黄书字样,并且价格大于10的书
res = models.Book.objects.filter(~Q(title__icontains='小黄书')&Q(price__gt=10))
.values('title')
15 查询名字包含小黄书字样并且价格大于100 或者 id小于等于10的图书
res = models.Book.objects.filter(Q(title__icontains='小黄书') | Q(id__lte=10)).values('title')
16 查询名字包含小黄书字样或者出版社为上海出版社的图书
res = models.Book.objects.filter(Q(title__icontains='小黄书') | Q(publish__name='上海出版社')).values('title')
3 (拓展)事务的ACID是什么?
-
原子性:是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做;如果事务中一个sql语句执行失败,则已执行的语句也必须回滚,数据库退回到事务前的状态;实现主要基于undo log
- 事务日志:InnoDB存储引擎还提供了两种事务日志:redo log(重做日志)和undo log(回滚日志)。其中redo log用于保证事务持久性;undo log则是事务原子性和隔离性实现的基础。
- undo log:实现原子性的关键,是当事务回滚时能够撤销所有已经成功的sql语句。InnoDB实现回滚,靠的是undo log:当事务对数据库进行修改时,InnoDB会生成对应的undo log;如果事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
- undo log属于逻辑日志:它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作:对于每个insert,回滚时会执行delete;对于每个delete,回滚时会执行insert;对于每个update,回滚时会执行一个相反的update,把数据改回去。相当于会下记录相关是被执行的行,列由此精准到每个字段的记录,便于sql语句执行失败的回滚操作
-
隔离性:保证事务执行尽可能不受其他事务影响;InnoDB默认的隔离级别是RR,RR的实现主要基于锁机制、MVCC
一个事务写操作对另一个事务写操作的影响:锁机制保证隔离
事务在修改数据操作之前,要获得锁住这块数据的锁的钥匙才能进行更改,当这个事务获得钥匙进行更改时,这块数据对外是锁住的且钥匙只有一把,其他的事务没有机会进来操作。
两个锁:
- 表锁:锁住整张表,锁住的数据量较大,因此并发性较低
- 行锁:只锁住需要更改的数据比如某个字段下的记录,并发性较高推荐使用
一个事务写操作对另一个事务读操作的影响:MVCC保证隔离
并发情况下,读操作可能存在三个情况
- 脏读:事务A可以读到事务B还未提交的更改后的数据

- 不可重复读:在事务A先后两次读取数据,但是两次数据不一致。(与脏读的区别:一个是事务B提交事务之前读,一个是事务B提交事务之后读)
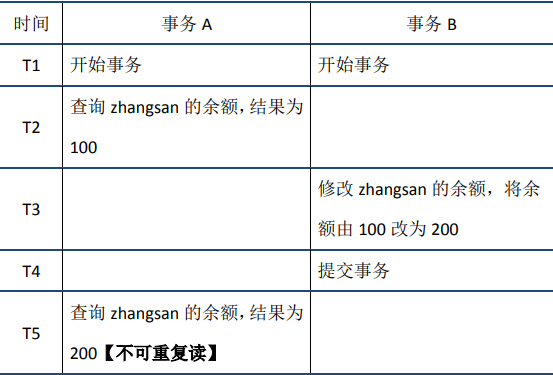
- 幻读在事务A中按照某个条件先后两次查询数据库,两次查询结果的条数不同,这种现象称为幻读。不可重复读与幻读的区别可以通俗的理解为:前者是数据变了,后者是数据的行数变了。
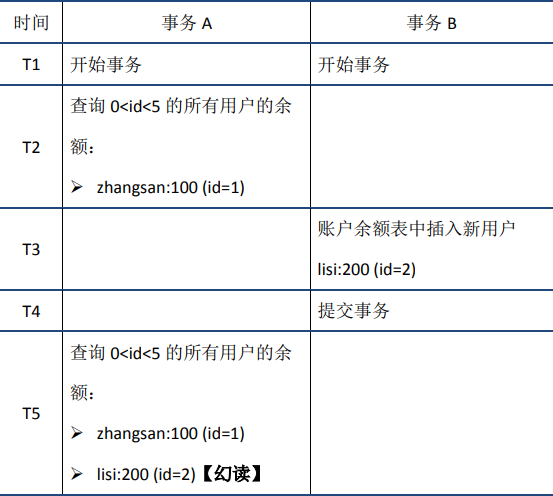
通过MVCC解决以上问题,最大优点是将最终的数据完整的保存到数据库中读不加锁,因此读写不冲突,并发性能好。InnoDB实现MVCC,多个版本的数据可以共存,主要基于以下技术及数据结构:
- 隐藏列:InnoDB中每行数据都有隐藏列,隐藏列中包含了本行数据的事务id、指向undo log的指针等
-基于undo log的版本链:前面说到每行数据的隐藏列中包含了指向undo log的指针,而每条undo log也会指向更早版本的undo log,从而形成一条版本链。
- ReadView:通过隐藏列和版本链,MySQL可以将数据恢复到指定版本;但是具体要恢复到哪个版本,则需要根据ReadView来确定。
-
持久性:保证事务提交后不会因为宕机等原因导致数据丢失,接下来的其他操作或故障不应该对其有任何影响;实现主要基于redo log
InnoDB作为MySQL的存储引擎,数据是存放在磁盘中的,但如果每次读写数据都需要磁盘IO,效率会很低。为此,InnoDB提供了缓存(Buffer Pool);当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)。
Buffer Pool的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
这时redo log就引来解决这个问题,修改数据时,除了修改缓存Buffer Pool的数据,还会在redo log记录此次的操作;当事务提交时,会调用fsync接口对redo log进行刷盘。从缓存中将数据录到磁盘中。如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。
-
一致性:事务追求的最终目标,一致性的实现既需要数据库层面的保障,也需要应用层的保障
可以说,一致性是事务追求的最终目标:前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性。此外,除了数据库层面的保障,一致性的实现也需要应用层面进行保障。
实现的一系列措施包括:
- 保证原子性、持久性和隔离性,如果这些特性无法保证,事务的一致性也无法保证
- 数据库本身提供保障,例如不允许向整形列插入字符串值、字符串长度不能超过列的限制等
- 应用层面进行保障,例如如果转账操作只扣除转账者的余额,而没有增加接收者的余额,无论数据库实现的多么完美,也无法保证状态的一致
4 (拓展)事物的隔离级别是什么?
SQL标准中定义了四种隔离级别,并规定了每种隔离级别下上述几个问题是否存在。一般来说,隔离级别越低,系统开销越低,可支持的并发越高,但隔离性也越差。隔离级别与读问题的关系如下:

在实际应用中,读未提交在并发时会导致很多问题,而性能相对于其他隔离级别提高却很有限,因此使用较少。可串行化强制事务串行,并发效率很低,只有当对数据一致性要求极高且可以接受没有并发时使用,因此使用也较少。因此在大多数数据库系统中,默认的隔离级别是读已提交(如Oracle)或可重复读(RR)。
5 什么是乐观锁,悲观锁,mysql如何实现悲观锁和乐观锁?
悲观锁:
悲观锁是指假设并发更新冲突会发生,所以不管冲突是否真的发生,都会使用锁机制。
悲观锁会完成以下功能:锁住读取的记录,防止其它事务读取和更新这些记录。其它事务会一直阻塞,直到这个事务结束。
悲观锁是在使用了数据库的事务隔离功能的基础上,独享占用的资源,以此保证读取数据一致性,避免修改丢失。
悲观锁可以使用Repeatable Read事务,它完全满足悲观锁的要求。
乐观锁:
乐观锁不会锁住任何东西,也就是说,它不依赖数据库的事务机制,乐观锁完全是应用系统层面的东西;
乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号