
Spark与mysql整合
一、需求:把最终结果存储在mysql中
1、UrlGroupCount1类
import java.net.URL import java.sql.DriverManager import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 把最终结果存储在mysql中 */ object UrlGroupCount1 { def main(args: Array[String]): Unit = { //1.创建spark程序入口 val conf: SparkConf = new SparkConf().setAppName("UrlGroupCount1").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) //2.加载数据 val rdd1: RDD[String] = sc.textFile("e:/access.log") //3.将数据切分 val rdd2: RDD[(String, Int)] = rdd1.map(line => { val s: Array[String] = line.split("\t") //元组输出 (s(1), 1) }) //4.累加求和 val rdd3: RDD[(String, Int)] = rdd2.reduceByKey(_+_) //5.取出分组的学院 val rdd4: RDD[(String, Int)] = rdd3.map(x => { val url = x._1 val host: String = new URL(url).getHost.split("[.]")(0) //元组输出 (host, x._2) }) //6.根据学院分组 val rdd5: RDD[(String, List[(String, Int)])] = rdd4.groupBy(_._1).mapValues(it => { //根据访问量排序 倒序 it.toList.sortBy(_._2).reverse.take(1) }) //7.把计算结果保存到mysql中 rdd5.foreach(x => { //把数据写到mysql val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/urlcount?charactorEncoding=utf-8","root", "root") //把spark结果插入到mysql中 val sql = "INSERT INTO url_data (xueyuan,number_one) VALUES (?,?)" //执行sql val statement = conn.prepareStatement(sql) statement.setString(1, x._1) statement.setString(2, x._2.toString()) statement.executeUpdate() statement.close() conn.close() }) //8.关闭资源 sc.stop() } }
2、mysql创建数据库和表
CREATE DATABASE urlcount; USE urlcount; CREATE TABLE url_data( uid INT PRIMARY KEY AUTO_INCREMENT, xueyuan VARCHAR(50), number_one VARCHAR(200) )
3、结果

二、Spark提供的连接mysql的方式--jdbcRDD
1、JdbcRDDDemo类
import java.sql.DriverManager import org.apache.spark.rdd.JdbcRDD import org.apache.spark.{SparkConf, SparkContext} /** * spark提供的连接mysql的方式 * jdbcRDD */ object JdbcRDDDemo { def main(args: Array[String]): Unit = { //1.创建spark程序入口 val conf: SparkConf = new SparkConf().setAppName("JdbcRDDDemo").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) //匿名函数 val connection = () => { Class.forName("com.mysql.jdbc.Driver").newInstance() DriverManager.getConnection("jdbc:mysql://localhost:3306/urlcount?characterEncoding=utf-8","root", "root") } //查询数据 val jdbcRdd: JdbcRDD[(Int, String, String)] = new JdbcRDD( //指定sparkContext sc, connection, "SELECT * FROM url_data where uid >= ? AND uid <= ?", //2个任务并行 1, 4, 2, r => { val uid = r.getInt(1) val xueyuan = r.getString(2) val number_one = r.getString(3) (uid, xueyuan, number_one) } ) val result: Array[(Int, String, String)] = jdbcRdd.collect() println(result.toBuffer) sc.stop() } }
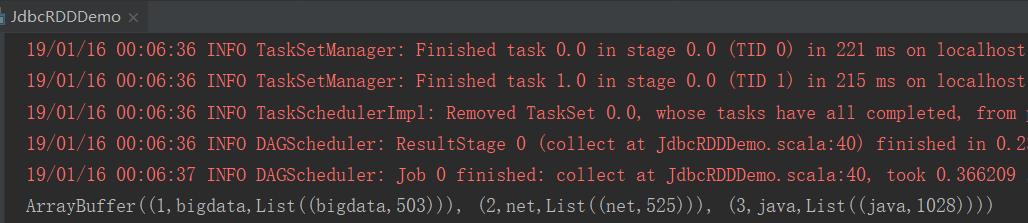
2、结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号