
DGX系列服务器
部分文摘于 https://lambdalabs.com/blog/nvidia-a100-gpu-deep-learning-benchmarks-and-architectural-overview/
DGXA100架构设计上仍然沿用了上下层的设计模式。

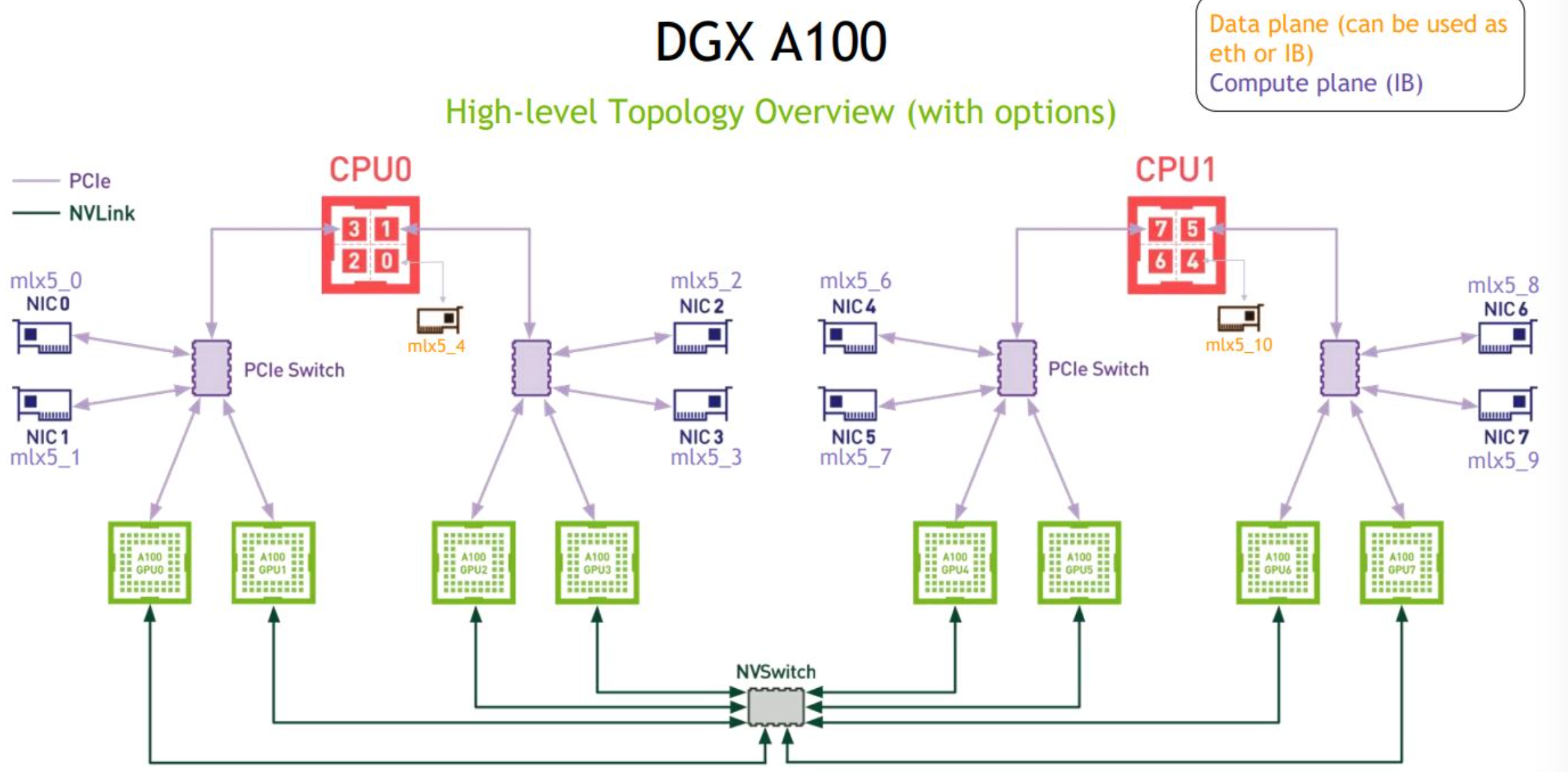
DGX-1 的拓扑:
喜欢Cube的结构拓扑图 - 简洁. 每个Tesla V100 GPU 有6个NVLink 连接点,每个节点实现网格化的连接,节点之间单向带宽可以达到25GB/s,多个NVLink链路可以实现连接聚合。
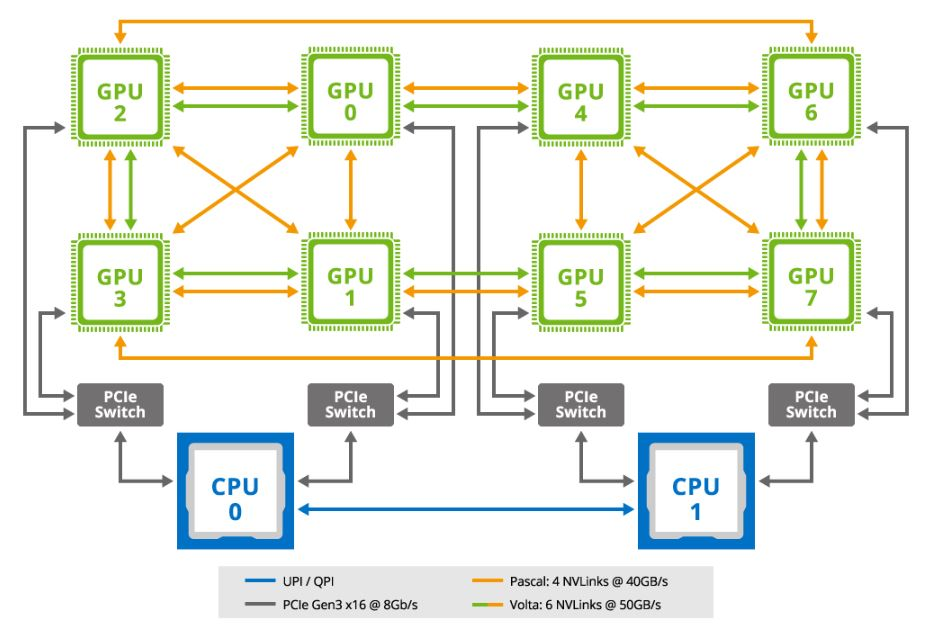
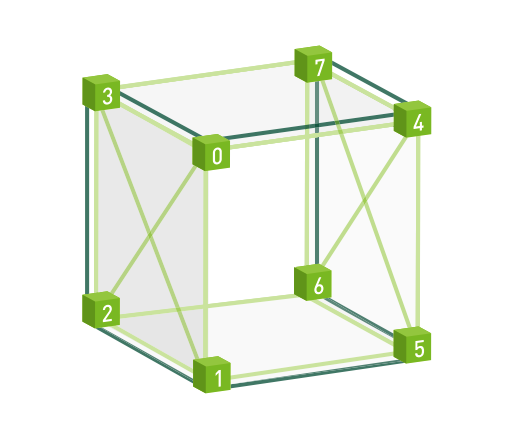
DGX1 vs. DGX-2
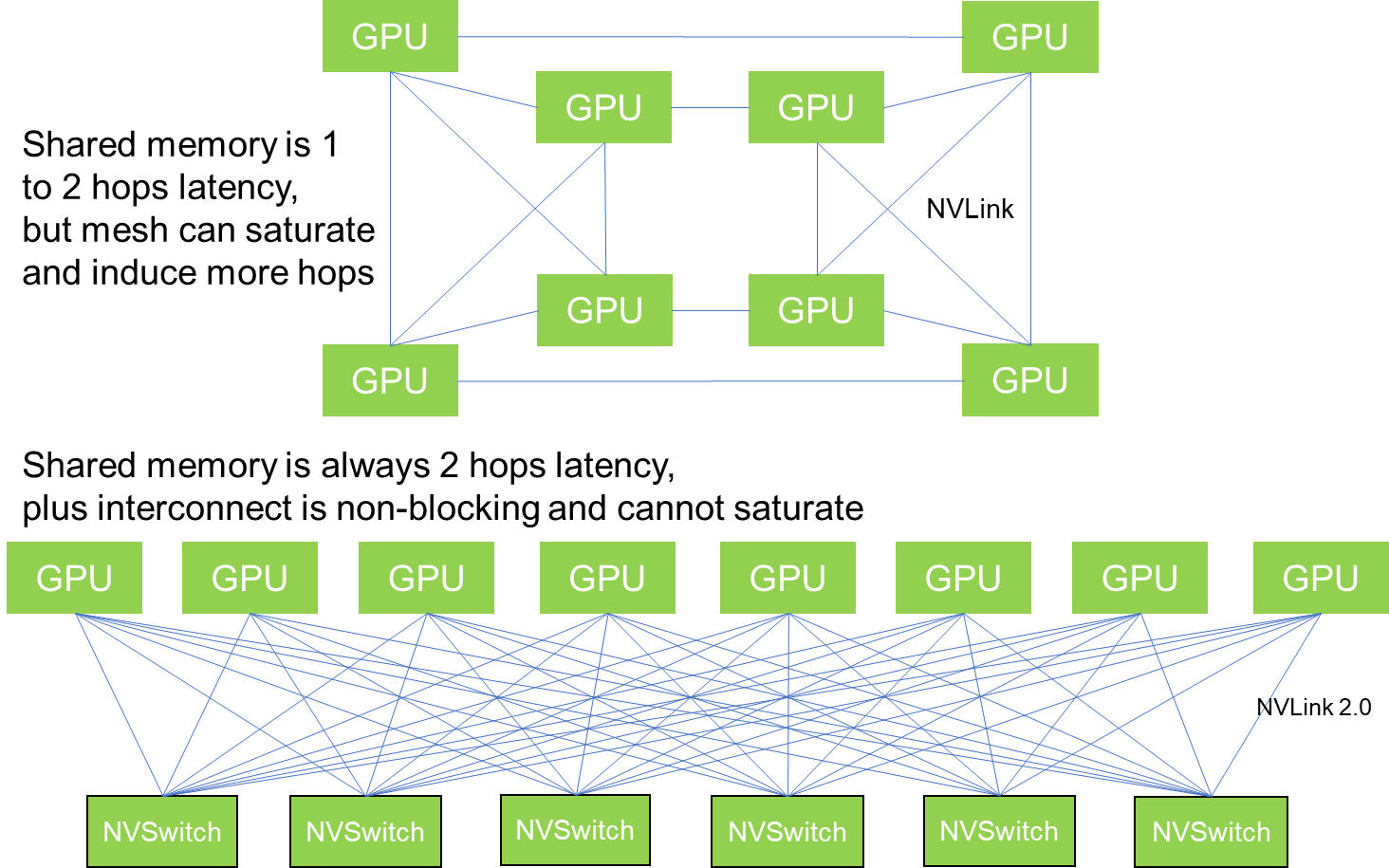
GPU + CPU 互连拓扑
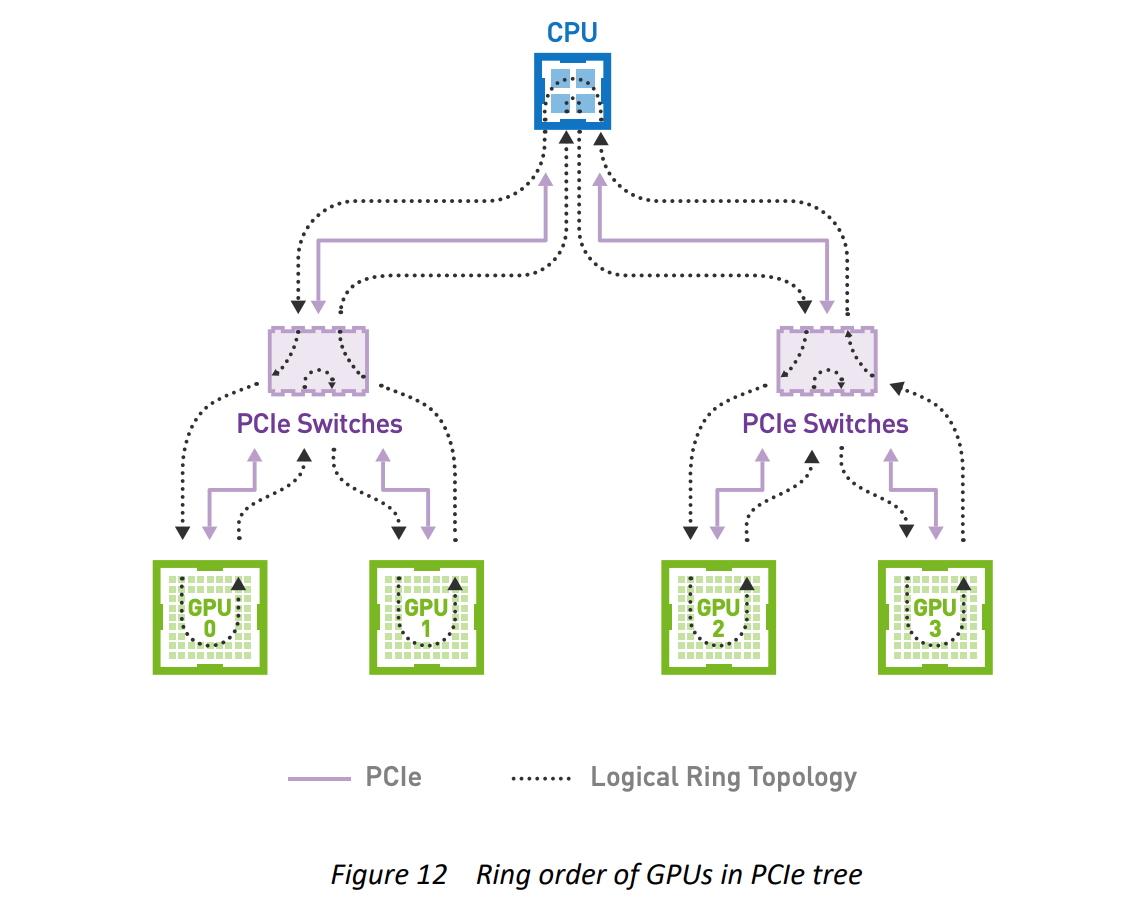
To optimize Broadcast bandwidth, an even better approach is to treat the PCIe tree topology as a ring. The broadcast is then performed by relaying small chunks of the input around the ring from GPU0 to GPU3. Interestingly, ring algorithms provide near optimal bandwidth for nearly all of the
standard collective operations, even when applied to tree-like PCIe topologies, provided that the correct ring order is selected.
DGX 集群架构:
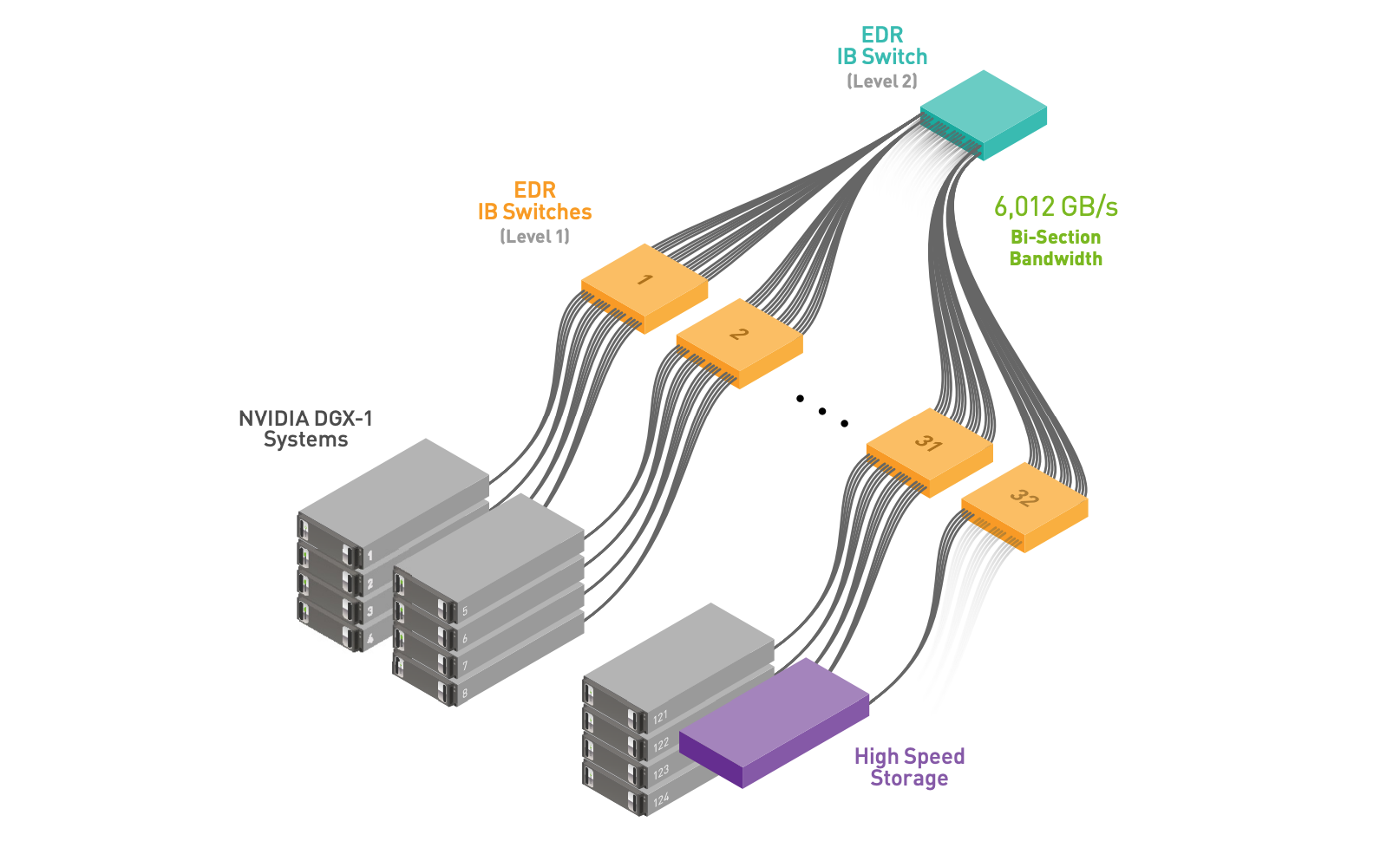
另外看见一个厂商Lambda做的分层式结构也上张图做个参考。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号