

jsoup解析html
- 介绍
jsoup 是一款 Java 的 HTML 解析器,可解析某个 URL 地址、HTML 文本内容,然后生成 Document 对象
提供了类似CSS或jQuery的语法来查找和操作元素
- 查找元素
生成Document对象
Document doc = Jsoup.connect("http://www.cnblogs.com/archie2010/")
.get();
查看本网页的源代码,找比较有特征的元素进行操作
1、查找网页的<title>元素,即网页标题
Elements title=doc.select("title");
System.out.println("title标签元素:\n"+title);
title标签元素:
<title>archie2010 - 博客园</title>
2、查找id="tagline"的无素
#id元素:
<p id="tagline">$要有勇气去开始</p>
3、查找class="postTitle"的元素
Elements elementPostTitle=doc.select(".postTitle");
4、查找class="postTitle"的元素下链接元素
Elements elementPostTitle=doc.select(".postTitle a");
System.out.println(".class元素:\n"+elementPostTitle);

选择器概述
tagname: 通过标签查找元素,比如:a
ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找 <fb:name> 元素
#id: 通过ID查找元素,比如:#logo
.class: 通过class名称查找元素,比如:.masthead
[attribute]: 利用属性查找元素,比如:[href]
[^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 Dataset属性的元素
[attr=value]: 利用属性值来查找元素,比如:[width=500]
[attr^=value], [attr$=value], [attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/]
[attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如: img[src~=(?i)\.(png|jpe?g)]
*: 这个符号将匹配所有元素
- 从元素中获取属性值,文本
直接上代码:

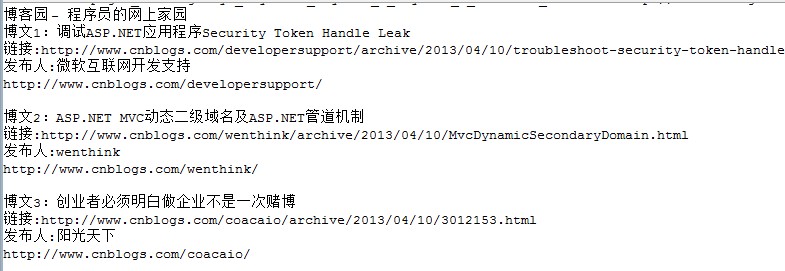
Document document= Jsoup.connect("http://www.cnblogs.com/")
.post();
//获取<title></title>标签内的文本(即此网页的标题)
System.out.println(document.select("title").text());
//获取博文链接元素
Elements postElements=document.select(".titlelnk");
Elements foot=document.select(".post_item_foot");
for (int i = 0; i < postElements.size(); i++) {
System.out.println("博文"+(i+1)+":"+postElements.get(i).text());
//获得属性href的值
System.out.println("链接:"+postElements.get(i).attr("href"));
//获得指定foot元素内的第一个a标签元素内的文本(即作者)
System.out.println("发布人:"+foot.get(i).select("a").first().text());
//href属性的值
System.out.println(foot.get(i).select("a").attr("href")+"\n");
}

posted on 2013-04-10 14:07 archie2010 阅读(1969) 评论(1) 编辑 收藏 举报

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!