延迟队列两种实现方式
延迟队列在我们工作中经常用到。比较常见的例子有订单发货后半个小时通知用户,用户在系统中定义了任务的执行周期,或者定时执行等场景。比较成熟的开源系统有小海豚(dolphinscheduler),目前可支持百万级的任务调度。公司级的调度或者数仓的任务调度可以在其基础上进行二次开发,而且开源给apache。
实现原理思考
针对用户设置的执行周期,我们可能想到两种实现方式。可以主动扫描或者被动通知。
主动扫描
思路:在用户定时任务表中定时超时时间,遍历 用户定时任务表,判断当前时间戳 > 任务超时时间如果满足条件,则执行任务,并更新下次执行时间。
优点:实现简单,只要创建扫描任务即可。
缺点:
- 扫描的周期不容易控制,周期太小,可能扫描一遍后,没有一个任务需要执行,周期太大,有的任务在该周期可能需要执行2次,甚至多次。为了不丢失任务,一般设置扫描周期为系统支持的最小时间粒度。
- 大量的无效IO,由于扫描周期粒度需要很小,而大部分任务可能在3,5(甚至更多)个周期后才需要执行,导致大量无效的IO。
被动通知
思路:任务到了执行时间后触发执行逻辑。
优点:不需要频繁的扫描用户定时任务表,减少了IO。
缺点:实现较主动扫描复杂,需要借助中间件实现。
延迟队列被动两种实现
本次我们介绍的是比较基础的两种实现方式,分别是基于RocketMQ和Kafka两种实现方式。
rocketMQ
rocketMQ本身提供了小时延迟的队列,我们可以利用其这一特点实现延迟队列设计。
原理
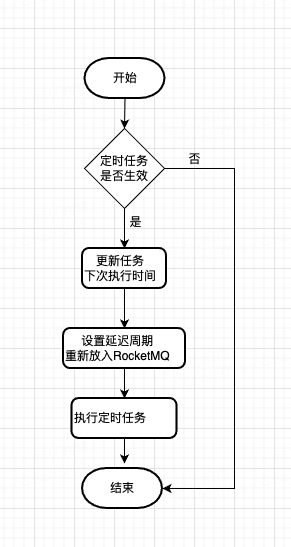
1,当用户新增定时任务时,计算其下次执行时间与当前时间的差值,将其设置为Message 的延迟时间
msg.setDelayTimeLevel(2);
其中延迟枚举:见 MessageConst.PROPERTY_DELAY_TIME_LEVEL,目前只支持固定时间粒度的延迟。
2,当用户消费消息时,首先判断定时任务是否还存在,如果存在,则将消设置延迟时长,再次放入延迟队列。待下次消费
3,执行定时任务动作。
流程图
补偿机制
RocketMQ实现机制可能会存在丢消息的可能,所以在任务执行表中添加下次执行开始时间,启动定时补偿任务,定时任务表,判断任务的下次执行时间和当前时间进行对比,如果消息gap超过1分钟,则任务消息丢失了,往消息队列中添加一条该任务的消息,不设置延迟时间。
Redis
利用Redis的ZSet实现,其内部为已score正序排列的数组。在元素小于128,且元素长度小于64byte时,为zipList,否则使用skipList+HashTable的内部结构。其实为内存级别的二级索引,一级索引为hash,二级索引为跳表。
原理
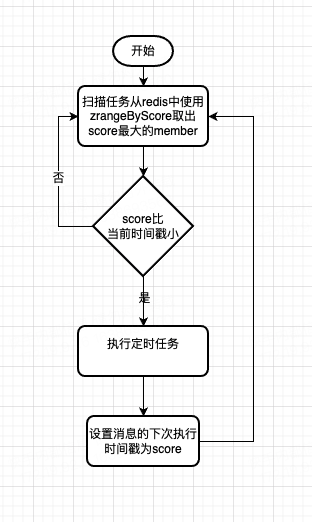
1,用户创建定时任务时,将定时任务插入到redis中,key 定时任务ID,score为下次任务执行的时间戳。
2,设置定时任务,每分钟从zset中使用zrange获取一部分key(10个)
ZRANGEBYSCORE salary -inf +inf WITHSCORES 0 10;
3,对比score和当前时间戳,如果score < 当前时间戳则开始执行定时任务,并将任务id重新放回zset,score 为下次执行的时间戳。
流程图
补偿机制
同样,redis 也可能丢失消息,补偿机制的原理为扫描定时任务表,使用zscore 查看当前任务在队列中是否存在,如果不存在,则计算下次执行时间作为score并将消息重新插入队列中。
两方案对比
RocketMQ
优点:
- 实现更简单一些,不需要写程序主动取消息,而是交给RocketMQ内部机制实现,出问题风险较小。
缺点:
- 消息堆积造成的多消费或者重复消费,在消息堆积时,会造成补偿机制的误判,从而产生重复执行,这时需要
Redis
优点:
- 基于Redis ZSet的内存结构,读写速度快,没有消息堆积的问题,补偿机制可以精准的判断消息是否在队列里,不会出现重复执行问题。
缺点:
- 会在redis服务器上生成一个大键值,再具体实现时最好使用单独的redis服务器。
- 需要实现扫描机制,实现稍微复杂一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号