我的面试问题记录
摘要:
记录下我的面经,尽可能给出答案,但不一定正确,如果有不同意见的小伙伴,欢迎指正和讨论
内容总结:
欧朋:
1.算法题:给一个字符串,相邻的字符去重。(我的想法是写了个循环,如果下一个和现在的不同才添加到结果字符串中,直至串尾)
2.算法题:给一个9*9的数独,判断行,列以及小九宫格不重复。(java 代码)
百度:
1.java相关:
问:垃圾回收机制
答:a、 停止—复制(stop-and-copy):先暂停程序的运行,然后将所有存活的对象从当前堆复制到另一个堆,没有复制的全部都是垃圾。当对象被复制到新堆时,它们是一个挨着一个的,紧凑的。这种方法效率很低:首先,得有两个堆空间,占用率200%;其次,垃圾较少时,复制大量的活着的对象,是很大的浪费。
b、 标记—清扫(mark-and-sweep):从对stack和静态存储区出发,遍历所有的引用,进而找出所有存活的对象,如果活着,就标记。只有全部标记完毕的时候,清理动作才开始。在清理的时候,没有标记的对象将会被释放。但是剩下的空间是不连续的,垃圾回收器要是希望得到连续空间的话,就得重新整理剩下的对象。
c、 在java虚拟机中,内存分配是以较大的块为单位的。每个块内都用相应的代数(generation count)来记录它是否还存活。代数随着引用的次数而增加。垃圾回收器将对上次回收动作之后的新分配的块进行整理。这对处理大量短命的临时对象很有帮助。垃圾回收器会定期进行完整的清理动作——大型对象仍然不会被复制(只是代数增加),内涵小型对象的那些块则被复制并整理。Java虚拟机会进行监视,如果所有对象都很稳定,垃圾回收器的效率降低的话,就切换到“标记—清扫”方式;同样,java虚拟机会追踪“标记—清扫”的效果,要是堆空间出现很多碎片,就会切换到“停止—复制”方式。这就是“自适应”技术。
总结:Java垃圾回收器是一种“自适应的、分代的、停止—复制、标记-清扫”式的垃圾回收器
问:对象是值传递还是地址传递并且对比C++
答:我还是用图表描绘比较能解释清楚:

主函数中new 了一个对象Person,实际分配了两个对象:新创建的Person类的实体对象,和指向该对象的引用变量person。
【注意:在java中,新创建的实体对象在堆内存中开辟空间,而引用变量在栈内存中开辟空间】
正如如上图所示,左侧是堆空间,用来分配内存给新创建的实体对象,红色框是新建的Person类的实体对象,000012是该实体对象的起始地址;而右侧是栈空间,用来给引用变量和一些临时变量分配内存,新实体对象的引用person就在其中,可以看到它的存储单元的内容是000012,记录的正是新建Person类实体对象的起始地址,也就是说它指向该实体对象。
调用了changeName()方法,person引用变量将自己的存储单元的内容传给了changeName()方法的p变量!也就是将实体对象的地址传给了p变量
以上答案摘自Java中只有按值传递,没有按引用传递!,另:个人意见只要把整个对象传参描述清楚即可,不必要介入到传值还是传址之争中
问:是否熟悉多线程
答:java多线程编程 ; Java多线程总结 ; 配套的代码练习
2.linux相关:给两个文件,按某列join
答:join 1 -1 2 -2 2 file1 file2 ; linux文本处理join,paste
3.scala/spark相关:写一个wordcount(sc.textFile("/tmp/log.txt").flatMap(s=>s.split(" ")).map(w=>(w,1)).reduceByKey((v1,v2) => v1+v2);spark和hadoop的区别(优缺点)
spark是把所有的数据都加载到内存吗;什么时候触发执行(action)?通过什么记录依赖关系(五大属性的dependencies和compute)
4.机器学习算法相关:监督学习和无监督学习的区别
答:1)监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人工标注的。常见的监督学习算法包括回归分析和统计分类。
2)无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类。
5.k-means的迭代停止条件
答:迭代次数,两次距离小于阀值,聚类中心两次变化小于阀值
6.k-means的K值选取
答:业务指导和机器学习的辅助手段(枚举并根据轮廓系数选择最优值)
金山云:
1.spark/hadoop相关:简述MR原理
答:Spark Shuffle原理、Shuffle操作问题解决和参数调优中第一节部分
2.spark/hadoop相关:reduceByKey与CombineByKey做对比(也可以和groupByKey,reduceByKey对比)
答:相比reduceByKey,combineByKey提供了更多的参数,可以自己定义一个combiner来实现聚合,并且支持map side combine和自定义序列化工具
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
reduceByKey与groupByKey:Spark算子选择策略中第1条
3.spark/hadoop相关:map和flatMap做对比
答:Spark算子选择策略中第8条
4.机器学习:简述朴素贝叶斯原理
答:朴素贝叶斯(NB)复习总结中算法概述
朴素贝叶斯算法是一种机器学习分类方法,其假设数据集的各特征之间相互独立,根据变量独立和朴素贝叶斯公式,得出如下模型函数:
 ,
,
也即朴素贝叶斯的分类原理是根据某观测的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该观测所属的类。
5.spark/hadoop相关:简述为什么会出现数据倾斜问题,及如何处理
答:在进行聚合操作时,由于需要将各个节点上相同的key拉取到同一个节点上的一个task来进行处理,此时如果某个key对应的数据量特别大的话,就会发生数据倾斜;通过观察stage执行情况(某个job执行时间长,输入数据量大),定位到具体的shuffle操作,然后可以添加随机数前缀或者删除异常key来解决数据倾斜。
Spark Shuffle原理、Shuffle操作问题解决和参数调优中shuffle操作问题解决
汽车之家:
1.算法题:反转单链表:github代码链接
2.算法题:给定有序数组,但未知长度,查找某一元素,返回下标:github代码部分
3.spark:介绍一下RDD
RDD,即弹性分布式数据集(Resilient distributed dataset),其内部可以抽象为partitions(分区),partitioner(分区方法),dependencies(依赖关系),compute(获取分区迭代列表),preferedLocations(优先分配节点列表) 这五大属性;其中前两个属性与任务的并行度有关,分区方式包括哈希分区和范围分区(排序类的算子);依赖关系分为宽依赖和窄依赖,窄依赖有利于任务的分布式运行,但是宽依赖就必须要顺序运行,DAGScheduler的stage之间就是根据宽依赖进行划分的;spark任务是lazy执行的,只有那些需要向driver程序返回数据或者保存操作才会触发任务的执行,把数据加载到内存,所以对于其他的转换(transformation)和创建操作只是把RDD间是如何转化的关系记录下来即可,这就是compute函数的作用(这种记录RDD间继承关系(lineage)的机制有利于容错);最后spark支持移动计算优于移动传输,所以会根据preferedLocations返回一个优先分配列表,元素下标越小,距离越近。至此说明RDD是分布式计算抽象模型。
4.spark:RDD是否可以嵌套:参考Spark RDD 核心总结的第3小节
5.推荐系统:解释协同过滤原理:
答:CF是基于这样的假设:如果两个用户共同看过某个物品,则这两个用户具有一定的关联;或者两个物品被同一个用户看过,那么这两个物品也会有一定的关联。而这个关联程度我们可以设计相似度算法进行衡量。最终我们选择出和用户(物品)最相似的k的用户(物品)进行推荐。user-based更多的考虑相同爱好的用户兴趣,推荐这些用户喜欢/访问过的item;item-based 主要考虑用户历史兴趣,推荐与用户历史喜欢item相似的item。
6.推荐系统:user-base 和 item-base的不同之处
答:一般网站的用户数大于物品数,所以user-base需要更大的内存和计算量;user-base具备热点效应,也就是推荐相似好友圈子访问最多的物品;user-base具备很强的实时性,尤其是新引入的热点,可以很快的扩散;也能解决new-item的冷启动问题。
item-base只需计算物品之间的相似关系,所以对内存和计算量的要求小了很多;user-base具有长尾问题,也就是推荐的物品很可能是历史很久的冷门物品;item-base具有很强的解释性,推荐的意义在于帮助用户找到和其兴趣相关的item;推荐item和是哪个用户关系不大,所以比较好的解决新加入用户的问题。
7.推荐系统:如果用户量和物品数量都很大,可以有什么算法计算近似的相似度吗?
答:尝试聚类或者svd对评分矩阵进行降维,然后再计算相似度矩阵;当然也可以直接用slopeone对评分进行预测;如果只考虑基于内容的相似度,也可用使用simHash这类局部哈希感知的算法
8.推荐系统: 大致了解的推荐系统类型
答:有基于规则的:比如推荐最新最热的或者基于历史pv,ctr的规则;基于内容的,比如根据文章主题(LDA)或者文章标签(用户画像)进行推荐的; 基于近邻的,比如itembase,userbase算法;基于模型的,比如ALS,深度学习在推荐上的模型(YouTube的DNN模型,网易的RNN模型);还有一些其他的策略,比如用来解决冷启动的bandit算法,考虑时间,地点,环境等因素的推荐。
9.机器学习:讲一下k-means(可以参考K-Means聚类和EM算法复习总结)
10.机器学习:欧式距离和余弦相似度有什么不同,如何选择?(参见常见的距离算法和相似度(相关系数)计算方法的第3小节)
11.机器学习:介绍下LR,以及LR的迭代公式,LR的损失函数(参见我的LR复习总结)
12.机器学习:介绍下决策树(参见决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结 )
13.机器学习:说下LR和决策树有什么不同:逻辑回归与决策树在分类上的一些区别;LR是对数损失,GBDT是指数损失
14.机器学习:如果我把数据喂给GBDT,发现过拟合,如何调整模型
答:模型方面可以调整的有最大迭代次数,学习速率,树的剪枝参数(树的深度,叶子节点最大样本树,最大特征数),数据的行采样比率,列采样比率,正则化参数,类别权重等等(参见决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结)
一下科技:
1.spark:spark算子熟悉程度foreach和foreachPartition,map和mapPartition,collect,textFile(这个不多说,熟悉说源码,不熟悉就两两比较下)
2.spark:spark streaming中的offset怎么记录的:
答: spark streaming有kafka提供的low level 和 high level两种接口形式创建Stream,其中low level的(createDirectStream方法)形式中offset是由zookeeper来维护的,可以通过set
auto.offset.reset in Kafka parameters to smallest指定从最小没有被消费offset开始;如果没有指定该项则是默认的为largest,这样的话该consumer就得不到生产者先产生的消息;而high level(createStream方法)形式的接口是由kafka本身来维护offset的。
(参考自 http://spark.apache.org/docs/latest/streaming-kafka-0-8-integration.html)
3.linux:引用配置文件中的变量(source),kill 三个spark application(yarn application kill )
4.推荐系统:推荐算法
5.机器学习:GDBT介绍(见:决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结)
6.其他:redis分库/分表如何实现(见:Redis 集群的分库和分片);HBase表设计
闪银:
1.比赛相关经验/kaggle上如何和国外人员交流
这个截止到现在参加了的比赛有如下两个:
数据城堡智慧中国金融比赛:冠军分享
京东移动推荐:(类似天池的移动推荐)
2.特征工程相关/在数据挖掘的过程中的经验和教训
1.推荐系统中计算用户评分时各行为权重,通过计算信息熵确定 2.点击,浏览噪音较多,通过对数函数进行平滑
在数据清洗上:通过EDA,找到异常数据,比如销售数据中3.15日猛增;对空值的处理,如果比较重要可以使用算法进行预测填充;对数据做规整
样本缺失值个数特征的引入:样本缺失值个数的处理:在分析后,训练集和测试集中样本个数的分布一致并且样本类别和缺失值个数呈现阶梯状,利用这种阶梯状对缺失值离散化为几个分区,形成新的特征。发现去掉缺失值个数较多的样本,模型有提升
排序特征的引入:排序特征对异常数据都有较强的鲁棒性,使得模型更加稳定,降低过拟合的风险。
交叉特征的引入:交叉特征是一种很独特的方式,它将两个或更多的类别属性组合成一个。当组合的特征要比单个特征更好时,这是一项非常有用的技术。数学上来说,是对类别特征的所有可能值进行交叉相乘。
假如拥有一个特征A,A有两个可能值{A1,A2}。拥有一个特征B,存在{B1,B2}等可能值。然后,A&B之间的交叉特征如下:{(A1,B1),(A1,B2),(A2,B1),(A2,B2)},并且你可以给这些组合特征取任何名字。但是需要明白每个组合特征其实代表着A和B各自信息协同作用。
如何设计交叉特征:1种是根据实际业务涉及实际交叉特征,如果没有业务指导下,可以暴力搜索,通过计算和类别之间的皮尔逊相关系数,选择topN的交叉特征。
线性模型可以利用交叉特征增加对非线性数据的拟合
在特征挖掘上:结合业务找到各种潜在信息(比如用户的活跃度,商品的流行度等等);基本的特征类型可以有统计特征,排序特征,比率特征,时间特征,交叉/组合特征;最好可以评测出特征的重要性,做一个词云的展示
对特征的工程化管理:特征的计算,存储,监控
在模型选择上:确保正确的正负比例权重,合适的目标函数和评测函数;
融合:多个模型之间可以选择相关性比较小的做融合,随机选择参数和特征个数增加模型的差异性(模型子融合);
如果说有人问你为什么要做融合,那么你可以告诉他bagging的思想:kaggle比赛集成指南
3.(生活中)如何解决问题
4.未来规划,职业发展: 公司业务与个人学习发展的权衡,技术向:技术专家/数据科学家,未来一年找到一个公司做到骨干层或者核心开发人员,有一个机器学习的平台系统和深度学习的集群实现算法的扩展。
美图:
1.解释GBDT算法:决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
2.说说LR的损失函数:逻辑回归(LR)总结复习
3.算法题:顺时针输出方阵:
答:上右下左四个边分别变化,每遍历完一个边都要判断下是否已经遍历过
4.算法题:有一个二维数组(n*n),写程序实现从右上角到左下角沿主对角线方向打印。
测试样例:
给定一个二位数组arr及题目中的参数n,请返回结果数组。
[[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]],4
返回:
输出1:[4,3,8,2,7,12,1,6,11,16,5,10,15,9,14,13]
输出2:
4
3 8
2 7 12
1 6 11 16
5 10 15
9 14
13
侃家网
问:机器学习--解释线性可分
答:如果存在一个超平面(WX+b)可以将样本分为互不相交的两组,那么就说这些样本是线性可分的;最简单的例子就是在二维图像画上一条直线可以分割出两个平面;
如何保证建模时数据是线性可分或者接近线性可分的,工业界常用的就是核函数,这个在SVM中是最常被用到的,核函数的功能就是将特征上升到高维空间,以达到线性可分的目的。
java类加载机制
答:Java 中的类加载器大致可以分成两类,一类是系统提供的,另外一类则是由 Java 应用开发人员编写的。系统提供的类加载器主要有下面三个:
- 引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用原生代码来实现的,并不继承自
java.lang.ClassLoader。 - 扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
- 系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过
ClassLoader.getSystemClassLoader()来获取它。
一般来说,开发人员编写的类加载器的父类加载器是系统类加载器。 参考自
HBase in memory模式:提高响应
随身云
数据仓库:
现有的多维数据仓库的商业智能解决方案中,根据维度表和事实表的关系,在实施过程中,维度设计会映射到 一组关系表,可以把数据库模型分为星型模型和雪花模型
星型模型:中央表包含事实数据,多个表以中央表为中心呈放射状分布,它们通过数据库的主键和外键相互连接,是一种使用关系数据库实现多维分析空间的模式,
雪花模型:在星型模型的基础上,维度表进一步规范化为子维度表,这些子维度表没有直接与事实表连接,而是通过其他维度表连接到事实表上,看起来就像一片雪花
在大数据解决方案中hadoop提供了Hive作为数据仓库,将数据统一存储到HDFS中,并可以使用Hive SQL进行查询;相比与OLTP系统,数据仓库更关注数据的批处理能力与多维数据分析
python:python GIL
numpy使用:
问:asarray与array的区别 答: asarray是array的包装,默认原地修改; 参考自
问:reshape与resize的区别 答:reshape只是对数据进行重塑,如果重塑的m*n不等于数据的总数报错;resize不会报错,小于原长度会截断;大于原长度会复制;参考自
问:使用numpy实现softmax函数:
import numpy as np
def softmax(x):
return np.exp(x)/np.sum(np.exp(x),axis=0)
举一反三:numpy/scipy实现LR,DT,NB,感知机等算法核心 ,附:RF
def sigmoid(x):
return 1 / ( 1+np.exp(-x) )
实现GBDT的核心:参考自:机器学习:以二元决策树为基学习器实现梯度提升算法
1 ''' 2 第三步:构建模型列表,即:集合方法 3 核心思路: 4 1)初始化残差列表 5 2)在循环中 6 a)计算残差 7 b)使用残差拟合新回归树 8 c)更新残差 9 3)获得模型列表 10 ''' 11 ##初始化产生的最大二元决策树的数量 12 numTreesMax = 30 13 14 ##模型列表:二元决策树列表 15 modelList = [] 16 17 ##预测值列表 18 predList = [] 19 20 ##步长,使函数可以更快的收敛:调整eps值,使均方误差最小值在或者接近图右侧 21 eps = 0.1 22 23 #初始化残差函数:由于初始化时预测值为空,所以是实际值 24 residuals = list(yTrain) 25 ##开始生成模型列表 26 for iTrees in range(numTreesMax): 27 ##添加新二元决策树到模型列表 28 modelList.append(DecisionTreeRegressor(max_depth=treeDepth)) 29 ##通过最新的二元决策树拟合数据 30 modelList[-1].fit(numpy.array(xTrain).reshape(-1, 1), residuals) 31 ##使用最新的模型预测数据 32 latestInSamplePrediction = modelList[-1].predict(numpy.array(xTrain).reshape(-1, 1)) 33 ##更新残差 34 residuals = [residuals[i] - eps * latestInSamplePrediction[i] for i in range(len(residuals))] 35 ##在测试集上使用模型 36 latestOutSamplePrediction = modelList[-1].predict(numpy.array(xTest).reshape(-1, 1)) 37 ##加入预测值列表 38 predList.append(list(latestOutSamplePrediction))
推荐系统/广告系统:
问:推荐系统数据量大,使用SVD进行降维和ALS进行降维的区别:答:SVD是基于稠密矩阵做奇异值分解,不适用有大量的空值的矩阵;ALS(交替最小二乘) 可以预测填补空值
问:如何设计实时推荐系统 答:腾讯设计的一套基于storm的实时推荐系统
问:广告业务中的CTR预估 答:CTR的一些特征(及处理);美团应用FFM算法在DSP;
CTR在kaggle上的比赛:Display Advertising Challenge;Avito Context Ad Clicks;Click-Through Rate Prediction
新氧:
问:如何证明pageRank是收敛的?
答:我们可以把网页之间的关联关系理解为是若干张有向图,我们考虑把边权值当作网站所传递的PageRank值,则对于任意一个顶点而言,其出边的权值之和必为1。
而本质上有向图和矩阵是可以相互转化,而初始网页的权重向量经过若干次迭代,这个过程也可以理解为马尔科夫过程(中间的迭代是状态转移矩阵变换),所以说,
我们可以把PageRank收敛性问题转化为了求马尔可夫链的平稳分布的问题,
一个 Markov 过程收敛,那么它的状态转移矩阵A需要满足:
- A为随机矩阵。
- A是不可约的。
- A是非周期的。
第二点,方阵A是不可约的当且仅当与A对应的有向图是强联通的。有向图G=(V,E)是强联通的当且仅当对每一对节点对u,v∈V,存在从u到v的路径。因为我们在之前设定用户在浏览页面的时候有确定概率通过输入网址的方式访问一个随机网页,所以A矩阵同样满足不可约的要求。
第三点,若A是周期性的,那么这个Markov链的状态就是周期性变化的。因为A是素矩阵(素矩阵指自身的某个次幂为正矩阵的矩阵),所以A是非周期的。
至此,我们证明了PageRank算法的正确性。附:深入探讨PageRank(二):PageRank原理剖析;PageRank算法--从原理到实现
问:是否了解过梅西算法和科利算法?
答:https://blog.csdn.net/feitongxunke/article/details/52077812
其他方面:
问:个人(价值)的定位/你目标的公司大概是一个什么样子 答:数据量大,资源整合能力强(渠道,外部数据,联盟),核心算法团队,崇尚分享与新技术
问:业余时间的一个规划 答:比赛啊,参加分享会啊,运动健身;
其他面试题:
1. 项目介绍
2. 你这个项目中间哪些地方提升,中间过程分别提升了多少CTR?
3. 你项目用的分布式LR的是用什么优化方法,参数怎么调的,mini-batch的batch是多少? parameter-server原理,如何解决数据一致性?
4. 会分布式么,hadoop,spark会么,说说hadoop的灾难处理机制
5. hadoop一个节点数据量太大拖垮reduce,怎么办,Hadoop本身的处理机制是怎么样的,手工的话可以怎么调
6. hadoop数据倾斜问题如何解决
7. L1、L2的区别,L1为什么可以保证稀疏?
8. 各种最优化方法比较 拟牛顿法和牛顿法区别,哪个收敛快?为什么?
9. 深度学习的优化方法有哪些? sgd、adam、adgrad区别? adagrad详细说一下?为什么adagrad适合处理稀疏梯度?
10. DL常用的激活函数有哪些?
11. relu和sigmoid有什么区别,优点有哪些?
12. 什么是梯度消失,标准的定义是什么?
13. DNN的初始化方法有哪些? 为什么要做初始化? kaiming初始化方法的过程是怎样的?
14. xgboost里面的lambdarank的损失函数是什么?
15. xgboost在什么地方做的剪枝,怎么做的?
16. xgboost如何分布式?特征分布式和数据分布式? 各有什么存在的问题?
17. lightgbm和xgboost有什么区别?他们的loss一样么? 算法层面有什么区别?
18 lightgbm有哪些实现,各有什么区别?
参考答案:
1.省略
2.省略
3.你项目用的分布式LR的是用什么优化方法,参数怎么调的,mini-batch的batch是多少? parameter-server原理,如何解决数据一致性?
答:spark ml中的LR默认使用的限制内存-拟牛顿迭代(L-BFGS)
LR中对结果影响比较大的参数一般有正则化系数(L1/L2),学习速率。一般使用线性搜索(固定值迭代)+交叉验证(3折或者5折);
mini-batch我一般是256-512之间,当然有时也看数据量大小,小了batch size也会相应小一点;
parameter-server原理?答:在parameter server中,每个 server 实际上都只负责分到的部分参数(servers共同维持一个全局的共享参数),而每个 work 也只分到部分数据和处理任务;
在parameter server中,每个 server 实际上都只负责分到的部分参数(servers共同维持一个全局的共享参数),而每个 work 也只分到部分数据和处理任务。
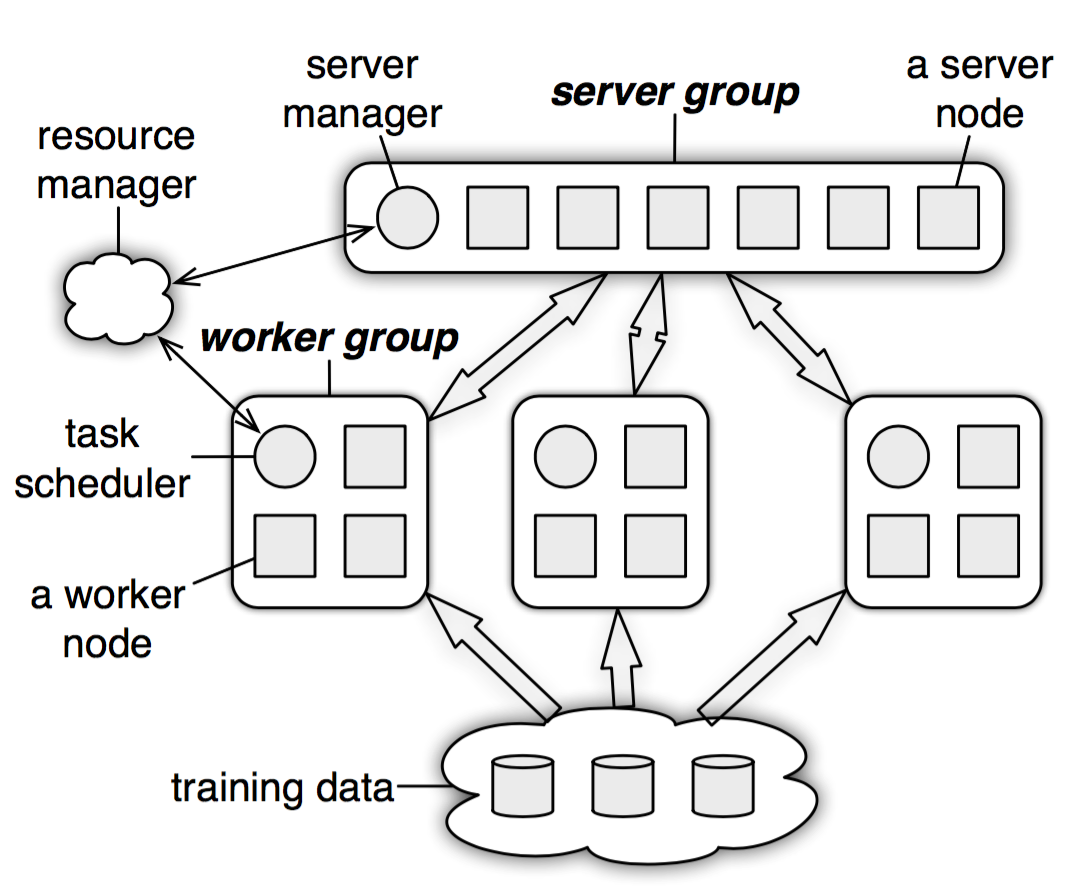
PS架构包括计算资源与机器学习算法两个部分。其中计算资源分为两个部分,参数服务器节点和工作节点:
- 参数服务器节点用来存储参数
- 工作节点部分用来做算法的训练
机器学习算法也分成两个部分,即参数和训练:
- 参数部分即模型本身,有一致性的要求,参数服务器也可以是一个集群,对于大型的算法,比如DNN,CNN,参数上亿的时候,自然需要一个集群来存储这么多的参数,因而,参数服务器也是需要调度的。
- 训练部分自然是并行的,不然无法体现分布式机器学习的优势。因为参数服务器的存在,每个计算节点在拿到新的batch数据之后,都要从参数服务器上取下最新的参数,然后计算梯度,再将梯度更新回参数服务器。
这种设计有两种好处:
- 通过将机器学习系统的共同之处模块化,算法实现代码更加简洁。
- 作为一个系统级别共享平台优化方法,PS结构能够支持很多种算法。
从而,PS架构有五个特点:
- 高效的通信:异步通信不会拖慢计算
- 弹性一致:将模型一致这个条件放宽松,允许在算法收敛速度和系统性能之间做平衡。
- 扩展性强:增加节点无需重启网络
- 错误容忍:机器错误恢复时间短,Vector Clock容许网络错误
- 易用性: 全局共享的参数使用向量和矩阵表示,而这些又可以用高性能多线程库进行优化。
Push and Pull
在parameter server中,参数都是可以被表示成(key, value)的集合,比如一个最小化损失函数的问题,key就是feature ID,而value就是它的权值。对于稀疏参数,不存在的key,就可以认为是0。
把参数表示成k-v, 形式更自然, 易于理,更易于编程解。workers跟servers之间通过push与pull来通信的。worker通过push将计算好的梯度发送到server,然后通过pull从server更新参数。为了提高计算性能和带宽效率,parameter server允许用户使用Range Push跟Range Pull 操作。
Task:Synchronous and Asynchronous
Task也分为同步和异步,区别如下图所示:

所以,系统性能跟算法收敛速率之间是存在一个平衡,你需要同时考虑:
- 算法对于参数非一致性的敏感度
- 训练数据特征之间的关联度
- 硬盘的存储容量
考虑到用户使用的时候会有不同的情况,parameter server 为用户提供了多种任务依赖方式:
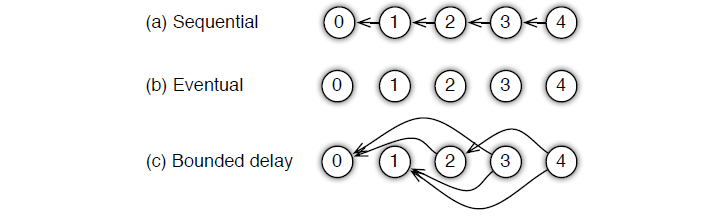
- Sequential:这里其实是 synchronous task,任务之间是有顺序的,只有上一个任务完成,才能开始下一个任务。
- Eventual: 跟sequential相反,所有任务之间没有顺序,各自独立完成自己的任务。
- Bounded Delay: 这是sequential 跟 eventual 之间的一个均衡,可以设置一个ττ作为最大的延时时间。也就是说,只有大于ττ之前的任务都被完成了,才能开始一个新的任务;极端的情况:
- τ=0τ=0,情况就是 Sequential;
- τ=∞τ=∞,情况就是 Eventual;
PS下的算法
算法1是没有经过优化的直接算法和它的流程图如下:

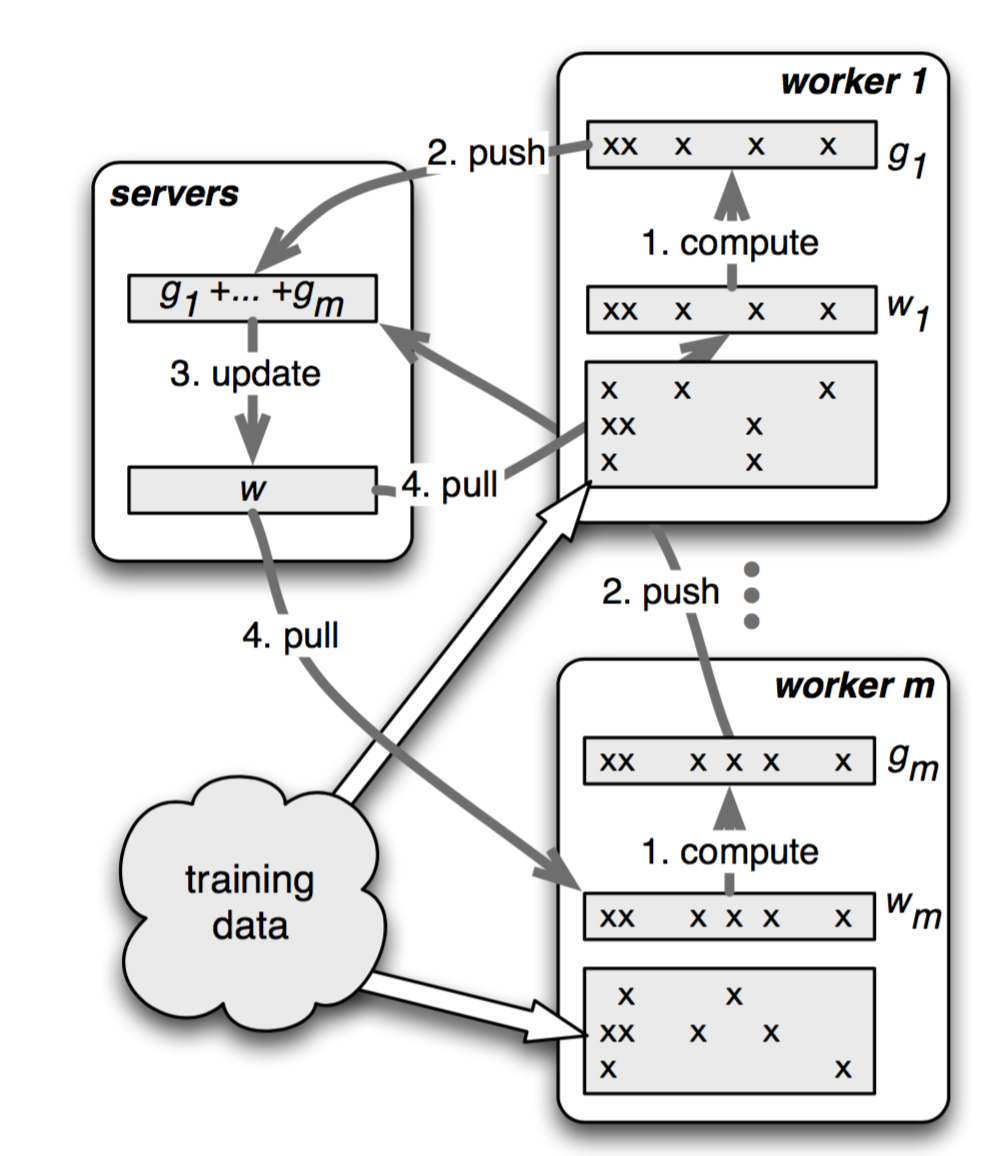

参考链接:Mu Li. Scaling Distributed Machine Learning with the Parameter Server.
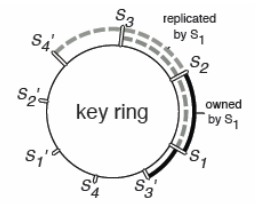
parameter-server如何解决数据一致性?答:parameter server 在数据一致性上,使用的是传统的一致性哈希算法,参数key与server node id被插入到一个hash ring中
4.说说hadoop的灾难处理机制?
答:Hadoop实现容错的主要方法就是重新执行任务,单个任务节点(TaskTracker)会不断的与系统的核心节点(JobTracker)进行通信,如果一个TaskTracker在一定时间内(默认是1分钟)无法与JobTracker进行通信,那JobTracker会假设这个TaskTracker出问题挂了;
如果作业仍然在mapping阶段,其它的TaskTracker会被要求重新执行所有的由前一个失败的TaskTracker所执行的map任务。如果作业在reduce阶段,则其它的TaskTracker会被要求重新执行所有的由前一个失败的TaskTracker所执行的reduce任务。
Reduce任务一旦完成会把数据写到HDFS。因此,如果一个TaskTracker已经完成赋予它的3个reduce任务中的2个,那只有第三个任务会被重新执行。Map任务则更复杂一点:即使一个节点已经完成了10个map任务,如果此时节点挂了,那它的mapper输出就不可访问了。所以已经完成的map任务也必须被重新执行以使它们的输出结果对剩下的reducing机器可用,所有的这些都是由Hadoop平台自动操作完成的。
5.hadoop一个节点数据量太大拖垮reduce,怎么办?Hadoop本身的处理机制是怎么样的,手工的话可以怎么调?
答:均衡各个计算节点的数据量。hadoop中有一些处理数据倾斜的参数可以调,比如hive.groupby.skewindata=true,关闭hive的map join(set hive.mapred.mode=nonstrict);手工的话要优化程序,比如修改group by为reducebykey,采样找到倾斜key后加几个随机化字符。
6.hadoop数据倾斜问题如何解决
答:同上,另外可以参考Spark Shuffle原理、Shuffle操作问题解决和参数调优
7. L1、L2的区别,L1为什么可以保证稀疏?
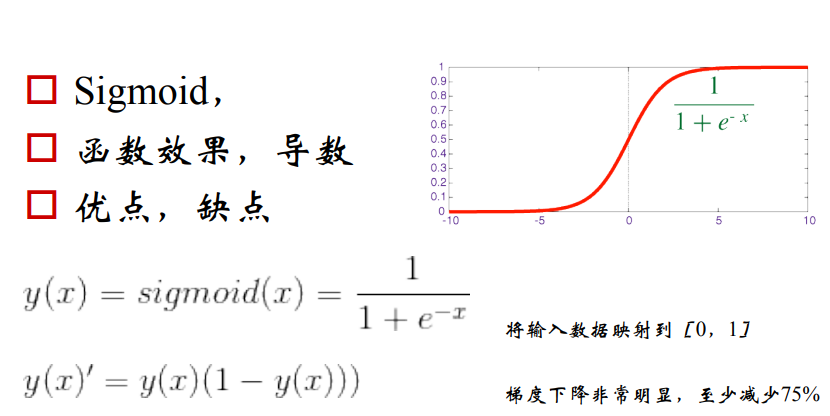
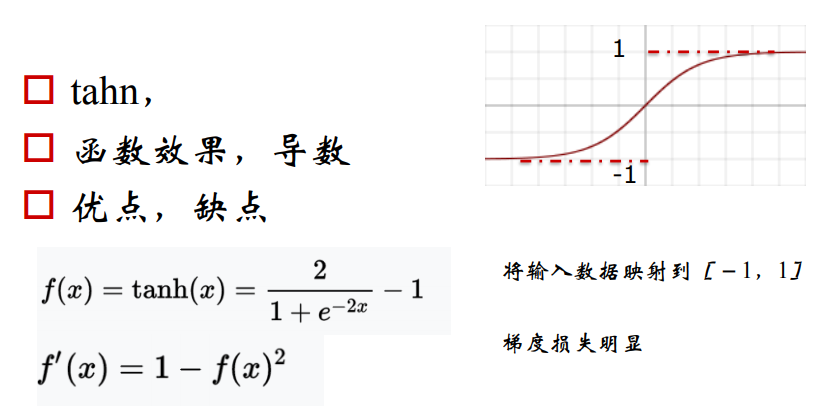

12. 什么是梯度消失,标准的定义是什么?
答:我的理解是在训练神经网络时,由于采用BP算法和链式法则对梯度进行更新,所有当隐藏层越多,梯度变化就会越小,甚至为0;
13. DNN的初始化方法有哪些? 为什么要做初始化? kaiming初始化方法的过程是怎样的?
答:深度学习中的weight initialization对模型收敛速度和模型质量有重要影响!以TF为参考,常见的初始化方法有如下几种:
- 标准高斯:tf.random_normal([2, 3], stddev=2),均值为 0,标准差为 2
- 截断正态分布:tf.truncated_normal()
- 如果随机出来(采样得到)的值偏离平均值超过 2 个标准差,该数将会舍去,重新采样获得,直到偏差不超过 2 个标准差;
- 均匀分布:tf.random_uniform()
- Gamma 分布:tf.random_gamma()
Kaiming初始化方法为:均值为0方差为(8)或者(15)的高斯分布(ReLU激活函数建议使用Kaiming初始化)。
14. xgboost里面的lambdarank的损失函数是什么?
pairwise loss:
所以我们将训练数据按Query两两组成pair,用{Ui,Uj}表示。
其中Sij取{1, 0, -1},分别对应Ui比Uj排序更高、Ui比Uj排序相同、Ui比Uj更低三种情况。

15. xgboost在什么地方做的剪枝,怎么做的?
答:XGBoost 先从顶到底建立所有可以建立的子树,再从底到顶反向进行剪枝。
16. xgboost如何分布式?特征分布式和数据分布式? 各有什么存在的问题?
答:xgboost的分布式实现是基于直方图的,利于并行;特征分块计算
17. lightgbm和xgboost有什么区别?他们的loss一样么? 算法层面有什么区别?
lightgbm:基于Histogram的决策树算法;Leaf-wise的叶子生长策略;Cache命中率优化;直接支持类别特征(categorical Feature)
xgboost:预排序;Level-wise的层级生长策略;特征对梯度的访问是一种随机访问。
18 lightgbm有哪些实现,各有什么区别?
gbdt:梯度提升决策树,串行速度慢,容易过拟合()
rf:随机森林,并行速度快
dart
goss
补充最近看到的一些面试题:
链接:
https://www.zhihu.com/question/20924039
https://leetcode.com/problems/valid-sudoku/
http://www.cnblogs.com/mfryf/p/3402200.html
http://www.cnblogs.com/dudumiaomiao/p/5839905.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号