机器学习理论知识部分--偏差方差平衡(bias-variance tradeoff)
摘要:
1.常见问题
1.1 什么是偏差与方差?
1.2 为什么会产生过拟合,有哪些方法可以预防或克服过拟合?
2.模型选择例子
3.特征选择例子
4.特征工程与数据预处理例子
内容:
1.常见问题
1.1 什么是偏差与方差?
泛化误差(general error)可以分解成偏差(bias)的平方加上方差(variance)加上噪声(noise)。
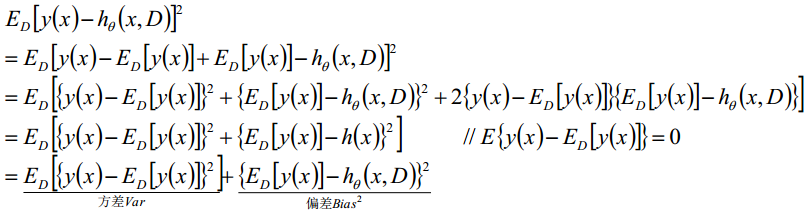
偏差度量了学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力,方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响
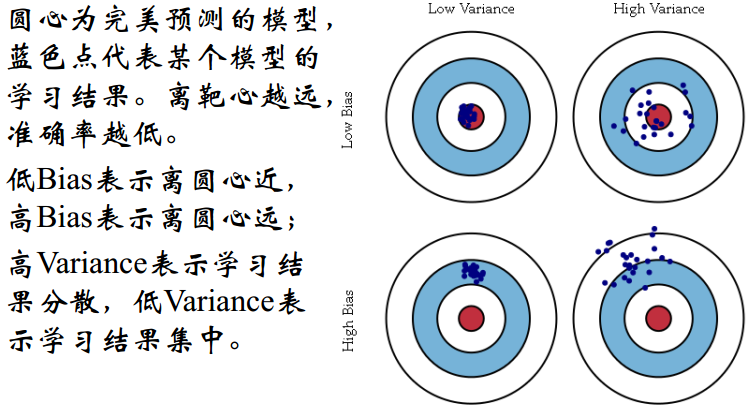
噪声表达了当前任务上任何学习算法所能达到的期望泛化误差下界,刻画了问题本身的难度。一般训练程度越强,偏差越小,方差越大,泛化误差一般在中间有一个最小值,如果偏差较大,方差较小,此时一般称为欠拟合,而偏差较小,方差较大称为过拟合。(吴恩达的讲义)
1.2 为什么会产生过拟合,有哪些方法可以预防或克服过拟合?
一般在机器学习中,将学习器在训练集上的误差称为训练误差或者经验误差,在新样本上的误差称为泛化误差。显然我们希望得到泛化误差小的学习器,但是我们事先并不知道新样本,因此实际上往往努力使经验误差最小化。然而,当学习器将训练样本学的太好的时候,往往可能把训练样本的噪声也考虑(拟合)到了。这样就会导致泛化性能下降,称之为过拟合,相反,欠拟合一般指对训练样本的一般性质尚未学习好,在训练集上仍然有较大的误差。
一般来说欠拟合更容易解决一些,例如增加模型的复杂度(增加决策树中的分支,增加神经网络中的训练次数等等),增加特征(“组合”、“泛化”、“相关性”),减少正则化系数(参考)(参考2)。
过拟合的解决方案一般有降低模型复杂度,重新清洗数据(导致过拟合的一个原因也有可能是数据不纯导致的),增加样本数量,对样本进行降维/特征选择,增加正则化系数,利用cross-validation,early stopping等等。
2.模型选择例子
交叉验证确定最佳超参数
elasticNet取L1,L2系数
模型选择的准则:
1.Bayesian Information Criterion/Schwarz criterion(贝叶斯信息准则BIC)
2.maximal information coefficient(最大信息系数MIC)
3.特征选择例子
4.特征工程与数据预处理例子

 浙公网安备 33010602011771号
浙公网安备 33010602011771号