
【学习笔记】字符串全家桶
本文正在不定期更新。
期末考试前学了下这些东西,感觉很简单,不像某 mp。
然而期末 Day1 考完就忘了,所以还是写篇笔记吧。
前置知识:字典树、自动机。
AC自动机
先来看一下洛谷上的 AC 自动机模版题。
P5357 【模板】AC 自动机
给你一个文本串
首先,AC 自动机的核心思想是:求
这句话很显然,但他就是核心思想。
然后就来看看 AC 自动机如何处理这一过程:
举个例子,文本串:
abaaaba
模式串:
aa ab aba ba
首先把模式串扔到字典树上。蓝色的加表示模式串中有“根到该节点的串”(下文称“根到一个节点的串”为该节点的串)。
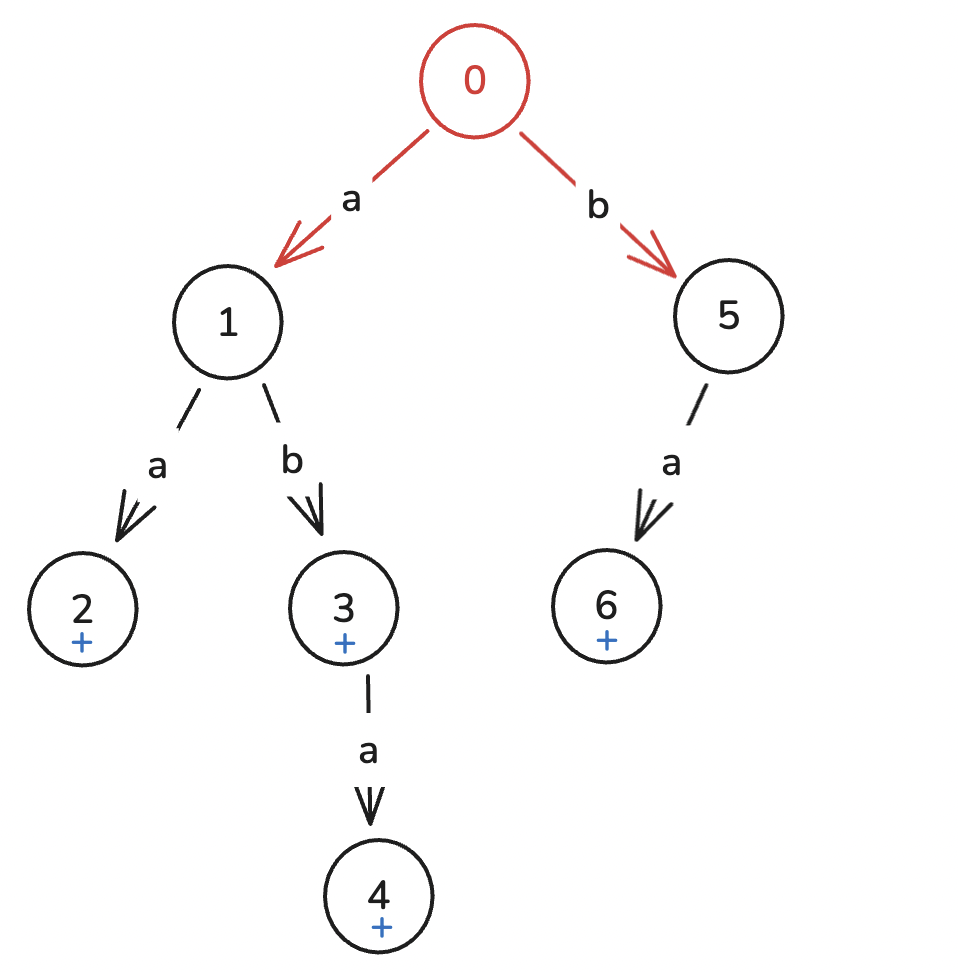
然后把
一开始在根节点(红色的)。
-
a,走到 -
b,走到ab。 -
a,走到aba,但是此时aba也行。然后我们发现他们是成一个后缀关系的!
aba ba a
现在无非就是求这个模式串有几个模式串是它的后缀。这个可以离线处理,等会儿再讲。
所以直接在当前点打个
a,由于a了,所以找其最长后缀,即ba,跳到a,跳到abaa)的最长的后缀。这个过程是 AC 自动机的精髓,请务必理解。
上面那些东西怎么实现?首先假设用来存 trie 的数组是
然后匹配的过程也差不多,可以参照步骤
处理过程太慢了!怎么优化?
优化!
以下是思考过程,如果赶时间只想看结果可以跳过。
再看看这个过程:
-
找到当前点的
-
如果不能,用当前点的
是一个类似递归的过程。说的明白些:如果两个串有共同的
于是考虑记忆化!设
那直接有
然后把它记忆化一下就行。不过不用这么多数组,验证发现
新
于是最终就有了这样的形式:
本来的 trie 数组,如果不能接就是空。现在,我们修改一下它的定义:
(因此定义也可以说成是
这样以来,更新
一个显然正确的办法就是 bfs,因为跳
在上面例子中,以下是部分的新
代码实现
然后代码就是完全按照上面的过程写的:
void init_fail() { queue<int> q; q.push(root); fail[root] = root; while (!q.empty()) { int u = q.front(); q.pop(); for (int i = 0; i < 26; i++) { if (!trie[u][i]) trie[u][i] = u == root ? root : trie[fail[u]][i]; // 更新接不了的 trie(情况 2,3) else { fail[trie[u][i]] = u == root ? root : trie[fail[u]][i]; // 更新 fail,注意这里也要特判! q.push(trie[u][i]); } } } }
匹配过程的函数你也一定会写了:
void Pair() { int pos = strlen(s + 1); int u = root; for (int i = 1; i <= pos; i++) { u = trie[u][s[i] - 'a']; tag[u]++; } }
现在你已经基本掌握 AC 自动机了!让我们回到洛谷的那个经典问题。
咱们继续匹配:
-
a, -
b, -
a,走到
最后,树上的标记就是酱紫的:
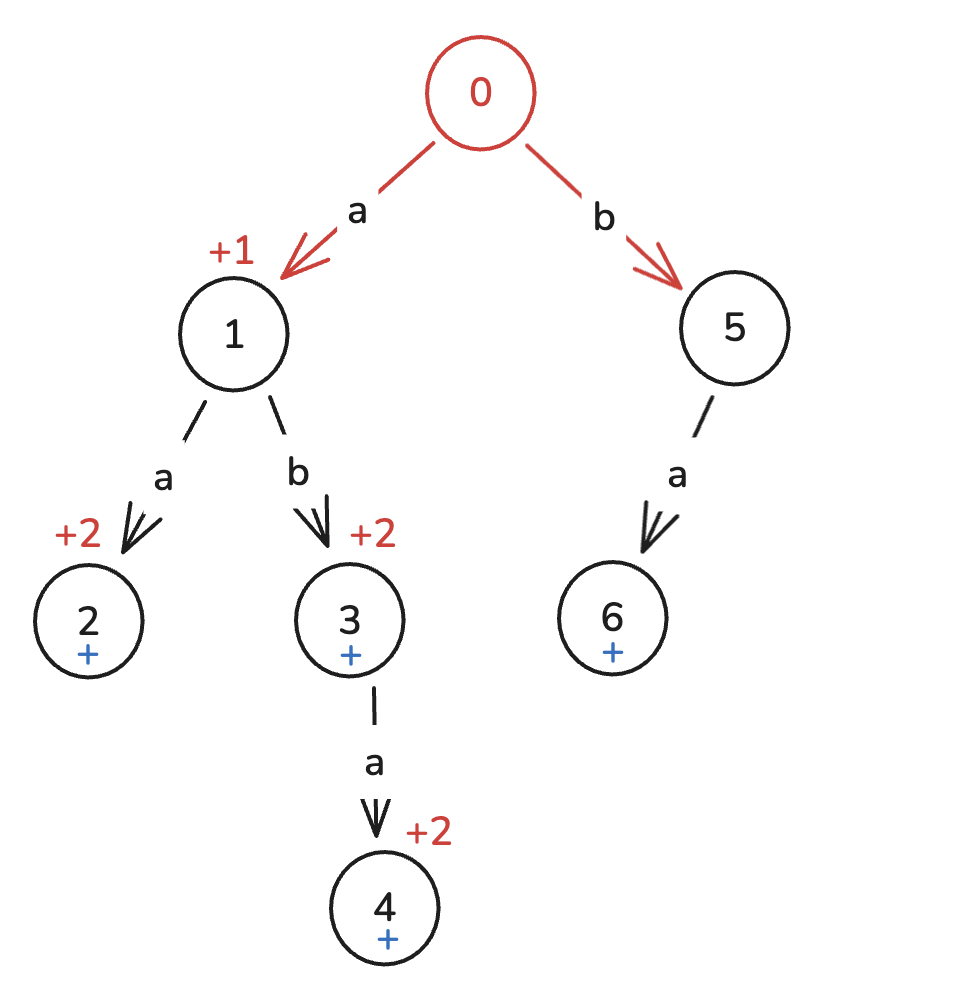
然后回到之前遗留的问题:计算模式串的出现次数。
遗留的问题
我们打上的标记,代表这个串的所有后缀都匹配上了。因此一个模式串的贡献,就是一棵 “

绿色的就是
int dfs(int u) { int res = tag[u]; for (int v : g[u]) res += dfs(v); for (int i : id[u]) ans[i] = res; return res; }
至此,原问题已经完美解决!让我们把所有元素结合在一起!
P5357 自动机代码
// Author: Aquizahv #include <bits/stdc++.h> #define ll long long using namespace std; const int N = 2e5 + 5, S = 2e6 + 5; int n, ans[N]; char s[S], t[N]; struct AC_auto { int root = 1, tot = root, trie[N][30], fail[N], tag[N]; vector<int> id[N], g[N]; void insert(int cnt) { int pos = strlen(t + 1), u = root; for (int i = 1; i <= pos; i++) { int d = t[i] - 'a'; if (!trie[u][d]) trie[u][d] = ++tot; u = trie[u][d]; } id[u].push_back(cnt); } void init_fail() { queue<int> q; q.push(root); fail[root] = root; while (!q.empty()) { int u = q.front(); q.pop(); for (int i = 0; i < 26; i++) { if (!trie[u][i]) trie[u][i] = u == root ? 1 : trie[fail[u]][i]; else { fail[trie[u][i]] = u == root ? root : trie[fail[u]][i]; g[fail[trie[u][i]]].push_back(trie[u][i]); q.push(trie[u][i]); } } } } void Pair() { int pos = strlen(s + 1); int u = root; for (int i = 1; i <= pos; i++) { u = trie[u][s[i] - 'a']; tag[u]++; } } int dfs(int u) { int res = tag[u]; for (int v : g[u]) res += dfs(v); for (int i : id[u]) ans[i] = res; return res; } void debug(int u) { for (int i = 0; i < 26; i++) if (trie[u][i]) { cout << u << ' ' << char('a' + i) << ' ' << trie[u][i] << endl; debug(trie[u][i]); } } } ac; int main() { cin >> n; for (int i = 1; i <= n; i++) scanf("%s", t + 1), ac.insert(i); ac.init_fail(); scanf("%s", s + 1); ac.Pair(); ac.dfs(ac.root); for (int i = 1; i <= n; i++) printf("%d\n", ans[i]); return 0; }
P2414 [NOI2011] 阿狸的打字机
还是考虑模式串对原串的贡献。发现是对原串进行一个到根的路径加(因为是每个前缀),再对模式串的
所以考虑离线下来,再进行一次遍历统计答案。把询问挂到原串对应点上,dfs 到这个点的时候,对询问进行模式串子树查询即可(要用 dfn 把子树转成区间)。
点击查看代码
// Author: Aquizahv #include <bits/stdc++.h> #define ll long long using namespace std; const int N = 1e5 + 5; int n, m; char s[N]; vector<int> g[N]; int id[N], dfncnt, dfn[N], dfd[N]; vector<pair<int, int> > q[N]; int ans[N]; struct BIT { int t[N]; void add(int it, int x) { if (it <= 0) return; while (it <= 1e5) { t[it] += x; it += it & -it; } } int sum(int it) { int res = 0; while (it > 0) { res += t[it]; it -= it & -it; } return res; } } bit; struct Ac_auto { int root = 1, tot = 1, trie[N][30], fa[N], fail[N]; void getFail() { queue<int> q; q.push(root); while (!q.empty()) { int u = q.front(); q.pop(); for (int c = 0; c < 26; c++) { if (!trie[u][c]) trie[u][c] = u == root ? root : trie[fail[u]][c]; else { fail[trie[u][c]] = u == root ? root : trie[fail[u]][c]; g[fail[trie[u][c]]].push_back(trie[u][c]); q.push(trie[u][c]); } } } } void dfs(int u) { dfn[u] = ++dfncnt; for (int v : g[u]) dfs(v); dfd[u] = dfncnt; } void solve(int u) { bit.add(dfn[u], 1); for (auto i : q[u]) ans[i.second] = bit.sum(dfd[i.first]) - bit.sum(dfn[i.first] - 1); for (int c = 0; c < 26; c++) if (fa[trie[u][c]] == u) solve(trie[u][c]); bit.add(dfn[u], -1); } void debug(int u) { for (int i = 0; i < 26; i++) if (fa[trie[u][i]] == u) { cout << u << ' ' << char('a' + i) << ' ' << trie[u][i] << endl; debug(trie[u][i]); } } } ac; int main() { scanf("%s", s + 1); int len = strlen(s + 1); int u = ac.root, v; for (int i = 1; i <= len; i++) { if (s[i] == 'B') { u = ac.fa[u]; } else if (s[i] == 'P') id[++n] = u; else { int c = s[i] - 'a'; if (!ac.trie[u][c]) { ac.trie[u][c] = ++ac.tot; ac.fa[ac.tot] = u; } u = ac.trie[u][c]; } } ac.getFail(); ac.dfs(ac.root); cin >> m; for (int i = 1; i <= m; i++) { scanf("%d%d", &u, &v); q[id[v]].push_back({id[u], i}); } ac.solve(ac.root); for (int i = 1; i <= m; i++) printf("%d\n", ans[i]); return 0; }
Manacher
可以线性处理出一个字符串的以
这个东西其实非常简单啊,画个图就能理解了。
呃首先需要一个 trick,就是相邻的字符间插一个特殊字符,比如 |。然后开头(或结尾)也得插一个,否则开头结尾都是 0,可能会被判成回文串。
然后是 Manacher。
设
首先维护一个
假设我们已经处理了前

横线表示回文串,橙色表示相等。啊这个 K 应该改成 但是我懒。
-
如图。如果有
很有潜力!从 -
否则,说明
点击查看代码
// Author: Aquizahv #include <bits/stdc++.h> #define ll long long using namespace std; const int N = 2.2e7 + 5; int n, f[N], ans; char s[N]; int main() { s[n] = '~'; s[++n] = '|'; char c = getchar(); while ('a' <= c && c <= 'z') { s[++n] = c; s[++n] = '|'; c = getchar(); } f[1] = 1; for (int i = 2, mid = 1, r = 1; i <= n; i++) { if (i + f[2 * mid - i] - 1 >= r) { f[i] = max(r - i + 1, 0); while (s[i + f[i]] == s[i - f[i]]) f[i]++; mid = i, r = i + f[i] - 1; } else f[i] = f[2 * mid - i]; ans = max(ans, f[i] - 1); } cout << ans << endl; return 0; }
exKMP(Z函数)
以线性时间,求一个字符串
虽说这个叫做 exKMP,但它的思想是类似于 Manacher 的。
首先我们把
我们令
还是假设处理了前面的
仿照 Manacher,记录一个右端点最大的 LCP 的后缀信息,这个后缀以
设

这回横线代表公共前缀。
-
如果
-
否则这个
这辈子就只能这样了。
点击查看代码
// Author: Aquizahv #include <bits/stdc++.h> #define ll long long using namespace std; const int N = 2e7 + 5; int n, m, pos, z[N << 1]; char a[N], b[N], s[N << 1]; void exKMP() { s[pos + 1] = '~'; for (int i = 2, k = 1, r = 1; i <= pos; i++) { if (i == m + 1) // s[i] is '|' continue; if (i + z[i - k + 1] - 1 >= r) { z[i] = max(r - i + 1, 0); while (s[1 + z[i]] == s[i + z[i]]) z[i]++; k = i, r = i + z[i] - 1; } else z[i] = z[i - k + 1]; } z[1] = m; } int main() { scanf("%s%s", a + 1, b + 1); n = strlen(a + 1), m = strlen(b + 1); for (int i = 1; i <= m; i++) s[++pos] = b[i]; s[++pos] = '|'; for (int i = 1; i <= n; i++) s[++pos] = a[i]; exKMP(); ll ans1 = 0, ans2 = 0; for (int i = 1; i <= m; i++) ans1 ^= 1ll * i * (z[i] + 1); for (int i = 1; i <= n; i++) ans2 ^= 1ll * i * (z[m + 1 + i] + 1); cout << ans1 << endl << ans2 << endl; return 0; }
聪明的你一定发现了,这个代码和 Manacher 几乎一样!这不奇怪,因为它跟 Manacher 的思想是几乎一致的,只不过一个回文串、一个 LCP。它们都是用一个对应的
所以说这些字符串算法无非是从先前的信息中找到有用的信息,而不是再算一遍。
扯远了,继续讲。
回文自动机(PAM)
累死我了,下次继续补。
本文作者:Aquizahv's Blog
本文链接:https://www.cnblogs.com/aquizahv/p/18656325
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步