
【学习笔记】多项式
多项式,OI的魅力,OIer的噩梦。
多项式
这个大家应该都会。
对于式子
就是这么简单
(一般型)生成函数
注:本小节的“生成函数”都指一般型生成函数。
定义:对于序列
组合意义
举几个例子:
-
若
-
若
-
若
好了,这就是生成函数的定义。但是现在你肯定会问,这东西有啥用呢?
幼儿园我们就学过,这种有无限项相加的式子可以用“错位相减”之类的办法化成一个有限的表达方式。
那么我们就试试生成函数是否同样可以:
确实可以。即使它看起来很反常识,但这就是将一个无穷序列“浓缩”起来的表示方式。
类似地,还有
顺带一提,无限项的式子可以浓缩,有限也可以。比如可以利用等比数列求和公式把
所以到底有啥用
别急嘛,接下来看几个例题你就明白了。
例题 1:有一个多重集
,其中值为 的元素有 个。还有一个多重集 ,其中值为 的元素有 个。问:多重集 中值为 的有多少个?
显然,是
例题 2:还是刚刚的
和 ,你可以从两集合内各取一个元素,然后将和扔进 。问: 中值为 的有多少个?
你想了一下,然后还是很快反应过来了——将两多项式相乘即可。
那如果。。。我想取出
例题 3:现在有
四种水果,每种都有无限个。现在要恰好取出 个水果,但水果 必须取偶数个,水果 必须取 的倍数个,水果 最多只能取 个,水果 最多只能取 个。问:方案数是多少?
首先考虑倍数怎么办。
同理可得
此时,一条显然的规律也出来了:
然后再考虑「至多」,此时的你应该也能发现,这就是上面说的有限项数的函数。
比如,
同理,
最后总方案数的生成函数就是:
而
因此你就可以通过它的意义来还原多项式:
解释:
是不是很神奇?那么复杂的问题,它的答案就是
不信?那你可以随意拿几个数试试哦。
洛谷P2000 拯救世界
不用多说,就是刚刚那题的加强版。建议先手动推一推。
最后你会发现答案是
别急,再看看数据范围——呃?这题还卡普通高精乘,看来得用
不过你用 Ruby 写倒也不是不行
LOJ #6077. 「2017 山东一轮集训 Day7」逆序对
题解。
线性递推
定理:若对于生成函数
比较经典的一个例子是 Fibonacci 数列。其中,
可以拿 Fibonacci 数列
P4451 [国家集训队] 整数的lqp拆分
题意
序列
求
题解
一道线性递推生成函数的综合运用题。
首先,根据乘法原理,
因此,答案为下面生成函数的第
然后我们就求出了答案的递推序列!
即
矩阵快速幂即可。时间复杂度
当
拉格朗日插值法
众所周知,在平面直角坐标系中,
这时候我们看了眼数据范围:
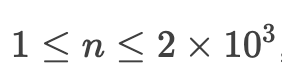
遗憾地发现高斯消元过不去了。
由于这题并不需要解出函数,只需求出
第一步,我们构造
第二步,我们计算出
聪明的你这时也一定发现了,这个思想和中国剩余定理有着异曲同工之妙:对每个条件针对性构造,且同时对于其余条件都返回单位元,最后求和(积)即可。
不过由于这题需要取模,所以需要求逆元。如果模拟上式的计算,时间复杂度是
观察上式,发现可以每轮单独记录分子之积和分母之积,因此枚举完
点击查看代码
#include <bits/stdc++.h> using namespace std; const int N = 2e3 + 5, MOD = 998244353; int n, k, x[N], y[N], ans; inline int madd(int x, int y) { return x + y >= MOD ? x + y - MOD : x + y; } inline int msub(int x, int y) { return madd(x, MOD - y); } inline int mmul(int x, int y) { return 1ll * x * y % MOD; } inline int qpow(int x, int y) { int res = 1, t = x % MOD; while (y) { if (y & 1) res = mmul(res, t); t = mmul(t, t); y >>= 1; } return res; } inline int mdiv(int x, int y) { return mmul(x, qpow(y, MOD - 2)); } int main() { cin >> n >> k; for (int i = 1; i <= n; i++) { scanf("%d%d", x + i, y + i); if (k == x[i]) { cout << y[i] << endl; return 0; } } for (int i = 1; i <= n; i++) { int bdiv = 1, div = 1; for (int j = 1; j <= n; j++) if (i != j) { bdiv = mmul(bdiv, msub(k, x[j])); div = mmul(div, msub(x[i], x[j])); } ans = madd(ans, mmul(y[i], mdiv(bdiv, div))); } cout << ans << endl; return 0; }
[省选联考 2022] 填树
一道很好的拉插优化 dp 题。
Easy version
假设树上非零最小权为
具体地,我们记
那么转移就类似求直径的方法,加入儿子时先计算对答案的贡献,然后更新 dp 数组的值。时间复杂度是
点击查看代码
int f[N], g[N], sum1, sum2; inline void add(int &to, int from) // op为1表示加,-1表示减,后面会介绍为什么有加有减 { if (op > 0) to = madd(to, from); else to = msub(to, from); } void dfs(int u, int fa) { int ln = max(L, l[u]), rn = min(R, r[u]); if (ln > rn) ln = 1, rn = 0; int x = rn - ln + 1, y = sum(ln, rn); // 本节点的可取值的个数、可取值的和 f[u] = x, g[u] = y; add(sum1, f[u]); add(sum2, g[u]); for (int v : G[u]) { if (v == fa) continue; dfs(v, u); // 统计答案 add(sum1, mmul(f[u], f[v])); add(sum2, madd(mmul(g[u], f[v]), mmul(g[v], f[u]))); // 更新dp f[u] = madd(f[u], mmul(f[v], x)); g[u] = madd(g[u], madd(mmul(y, f[v]), mmul(g[v], x))); } }
以上是对一个
于是你已经成功切掉了 Easy version。
Hard version
我们再看一下整个过程,无非就是移动一个区间,然后每次进行一回 dp。但是每次 dp 只是取值不同,过程是一样的。是不是有点浪费了呢?
考虑某一个节点,在移动
设输出的第一问的答案为
如果我们把根据个节点的「分段点」划分成若干「段」,根据 dp 的过程,对于
同理,对于
综上,对于每个「段」,对
分析时间复杂度,对于每个「段」,时间复杂度分为
代码很好写的,如果有些地方不太能理解的话建议看看代码。
点击查看代码
#include <bits/stdc++.h> using namespace std; const int N = 205, MOD = 1e9 + 7; int n, k, m; int l[N], r[N], L, R, op, pos[N << 2]; vector<int> G[N]; inline int madd(int x, int y) { return x + y >= MOD ? x + y - MOD : x + y; } inline int msub(int x, int y) { return madd(x, MOD - y); } inline int mmul(int x, int y) { return 1ll * x * y % MOD; } inline int qpow(int x, int y) { int res = 1, t = x % MOD; while (y) { if (y & 1) res = mmul(res, t); t = mmul(t, t); y >>= 1; } return res; } inline int mdiv(int x, int y) { return mmul(x, qpow(y, MOD - 2)); } int sum(int l, int r) { return 1ll * (l + r) * (r - l + 1) / 2 % MOD; } int f[N], g[N], sum1, sum2; inline void add(int &to, int from) { if (op > 0) to = madd(to, from); else to = msub(to, from); } void dfs(int u, int fa) { int ln = max(L, l[u]), rn = min(R, r[u]); if (ln > rn) ln = 1, rn = 0; int x = rn - ln + 1, y = sum(ln, rn); f[u] = x, g[u] = y; add(sum1, f[u]); add(sum2, g[u]); for (int v : G[u]) { if (v == fa) continue; dfs(v, u); add(sum1, mmul(f[u], f[v])); add(sum2, madd(mmul(g[u], f[v]), mmul(g[v], f[u]))); f[u] = madd(f[u], mmul(f[v], x)); g[u] = madd(g[u], madd(mmul(y, f[v]), mmul(g[v], x))); } } int X[N], Y[2][N]; int lag(int resx, int p, int *x, int *y) { int resy = 0; for (int i = 0; i <= p; i++) { int bd = 1, d = 1; for (int j = 0; j <= p; j++) if (i != j) { bd = mmul(bd, msub(resx, x[j])); d = mmul(d, msub(x[i], x[j])); } resy = madd(resy, mmul(y[i], mdiv(bd, d))); } return resy; } int main() { #ifdef aquazhao freopen("data.in", "r", stdin); freopen("data.out", "w", stdout); #endif cin >> n >> k; m = 1; for (int i = 1; i <= n; i++) { scanf("%d%d", l + i, r + i); // 每个区间的四个分段点 pos[++m] = max(0, l[i] - k); pos[++m] = l[i]; pos[++m] = max(0, r[i] - k); pos[++m] = r[i]; pos[1] = max(pos[1], r[i] + 1); } sort(pos + 1, pos + m + 1); m = unique(pos + 1, pos + m + 1) - pos - 1; int u, v; for (int i = 1; i < n; i++) scanf("%d%d", &u, &v), G[u].push_back(v), G[v].push_back(u); for (int i = 1; i < m; i++) { L = pos[i], R = pos[i] + k; int j; for (j = 0; pos[i] + j < pos[i + 1] && j < n + 2; j++) { op = 1; dfs(1, 0); L++; op = -1; dfs(1, 0); R++; X[j] = pos[i] + j; Y[0][j] = sum1; Y[1][j] = sum2; } if (pos[i] + j < pos[i + 1]) { sum1 = lag(pos[i + 1] - 1, j - 1, X, Y[0]); sum2 = lag(pos[i + 1] - 1, j - 1, X, Y[1]); } } R--; op = -1; dfs(1, 0); cout << sum1 << endl << sum2 << endl; return 0; }
指数型生成函数
前置知识:一般型生成函数。
先通过几个问题来引入:
问题 A:求
个相同的红球摆成一排的方案数。
问题 B:求个相同的红球摆成一排的方案数。
问题 C:求相同的红球和蓝球共个摆成一排的方案数。
对于问题 A、B,三岁小孩都知道答案是
对于问题 C,幼儿园小朋友都知道答案是
但我们作为 OIer,当然要使用生成函数解决。
首先,三个问题的一般型生成函数为:
乍一看,问题 C 和问题 A、B 有某种关系,但是我们发现无法用一般型生成函数表达这种关系……
尝试将
然而实际上
即
则有
诶!那我们定义:
于是就有
根据高等数学中的泰勒展开,
于是就有
现在你已经学会指数型生成函数了,来做道题吧:
化简
答案:
同理,
[CTS2019] 珍珠
放道题,大家有兴趣可以做做,可能需要 FFT。我不会做找时间再来补()
快速傅立叶变换(FFT)
前言:虽然说在 noi 大纲里,FFT 是 10 级算法,NOI 以下都不用掌握,但是 FFT 并不难,而且也有必要掌握。我刚开始打算看 OI-wiki 学 FFT,但是他写的太深奥,压根看不懂。后来我是去了洛谷题解区才发现原来 FFT 这么简单,只需要基本的复数知识就能理解。
FFT 可以以
其思想是:
-
对两个多项式分别带入若干值,得到若干个
-
把点值们的
-
现在有一些点值,它们在最终多项式上。但是要把多项式确定出来,拉插的
一句话就是:
这个思想很重要,后面的 FWT 也是这个思想。至于 FFT 的具体操作,我推荐 attack 大佬的这篇博客,写的很好,我觉得这里没有必要再赘述了。(真不是因为懒)
学会之后可以把洛谷模版题给写了。
NTT
NTT mod table
| 3 | 1 | 1 | 2 |
| 5 | 1 | 2 | 2 |
| 17 | 1 | 4 | 3 |
| 97 | 3 | 5 | 5 |
| 193 | 3 | 6 | 5 |
| 257 | 1 | 8 | 3 |
| 7681 | 15 | 9 | 17 |
| 12289 | 3 | 12 | 11 |
| 40961 | 5 | 13 | 3 |
| 65537 | 1 | 16 | 3 |
| 786433 | 3 | 18 | 10 |
| 5767169 | 11 | 19 | 3 |
| 7340033 | 7 | 20 | 3 |
| 23068673 | 11 | 21 | 3 |
| 104857601 | 25 | 22 | 3 |
| 167772161 | 5 | 25 | 3 |
| 469762049 | 7 | 26 | 3 |
| 998244353 | 119 | 23 | 3 |
| 1004535809 | 479 | 21 | 3 |
| 2013265921 15 27 31 | |||
| 2281701377 17 27 3 | |||
| 3221225473 3 30 5 | |||
| 7516927681 35 31 3 | |||
| 77309411329 9 33 7 | |||
| 206158430209 3 36 22 | |||
| 2061584302081 15 37 7 | |||
| 2748779069441 5 39 3 | |||
| 6597069766657 3 41 5 | |||
| 39582418599937 9 42 5 | |||
| 79164837199873 9 43 5 | |||
| 263882790666241 15 4 7 | |||
| 1231453023109121 35 45 3 | |||
| 1337006139375617 19 46 3 | |||
| 3799912185593857 27 47 5 | |||
| 4222124650659841 15 48 19 | |||
| 7881299347898396 7 50 6 | |||
| 31525197391593473 7 52 3 | |||
| 180143985094819841 5 55 6 | |||
| 1945555039024054237 27 56 5 | |||
| 4179340454199820289 29 57 3 |
快速莫比乌斯变换(FMT)
FMT 用来处理高维前后缀的和/差分。然后就可以做或卷积、与卷积了。
如果对长为
那为啥它叫“高维前缀和”?这很好理解,n 维前缀和就是对于每个
以下代码可以对本身进行一次高维前缀和,时间复杂度
for (int i = 0; i < n; i++) for (int mask = 0; mask < (1 << n); mask++) if (mask & (1 << i)) f[mask] += f[mask ^ (1 << i)];
解释一下为什么可以这样:一开始,每个下标的值就是自己。当进行第一轮(
至于高维前缀差分,把加法改成减法就行。
for (int i = 0; i < n; i++) for (int mask = 0; mask < (1 << n); mask++) if (mask & (1 << i)) f[mask] += f[mask ^ (1 << i)];
你可能会问,既然是前缀和的逆运算,不应该把过程反过来吗?
确实,但是正着做也正确。理由是对于同一个
高维后缀和同理:
点击查看代码
for (int i = 0; i < n; i++) for (int mask = 0; mask < (1 << n); mask++) if (!(mask & (1 << i))) f[mask] += f[mask ^ (1 << i)];
把加改成减就是高维后缀差分。
以上应该就是 FMT(?)
快速沃尔什变换(FWT)
FFT 可以以
其中
剩下的就去看 xht 的这篇博客吧()
不过我看完之后有个问题。。【待补】
本文作者:Aquizahv's Blog
本文链接:https://www.cnblogs.com/aquizahv/p/18456034
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步