性能测试基础理论
定义
使用测试工具模拟多种正常、峰值以及异常负载条件,观察、记录、分析系统的各项性能指标的过程。
性能测试的意义
1.有效评估系统的性能指标;
2.识别系统的性能瓶颈;
3.系统调优--重复运行测试,验证调整系统的活动得到了预期的结果,从而改进性能;
4.验证系统的稳定性和可靠性;
性能测试类型
基准测试
概念
- 每次对外发布产品版本前必须要完成的测试类型
- 执行固定的性能测试场景得到系统的性能测试报告
- 与上一版本发布时的基准测试结果进行对比
测试目的
- 获取系统性能基准作为参照物
- 识别系统或环境的配置变更对性能带来的影响
- 给系统优化前后的性能提升/下降提供参考标准
- 观察系统的整体性能趋势与性能拐点,识别系统性能风险
评估
- 同一事务的响应时间
- 系统资源的占用率
负载测试
负载测试强调的是在一定环境下系统能够达到的峰值指标,大多数的性能测试都是负载测试,这种方法的目的是找到系统处理能力的基线,通过模拟不同数量级的用户,找到如“响应时间不超过10秒”“服务器平均CPU利用率低于65%时的用户数”。
测试目的
- 持续稳定地增加系统的负载,测试系统性能的变化
- 找出指标阈值下的系统瓶颈和性能拐点
- 测试系统所能承受的最大负载量
- 找出内存管理错误,内存泄漏,缓冲区溢出的问题
- 找到处理极限,为调优提供数据
- 找出系统在稳定情况下的最大压力值
压力测试
与负载测试获得峰值性能数据不同,压力测试强调在极端情况下系统的稳定性,测试目标系统在一定饱和状态下,例如CPU、内存等在饱和状态下,系统还能稳定地提供服务。比如,在100个用户使用系统的时候,CPU使用率达到了性能测试指标的最大值,比如80%,那么101个用户就是压力值。
测试目的
- 测试系统的资源在饱和状态下的应用的处理会话能力
- 持续稳定的增加系统压力,测试系统性能的变化
- 破坏性测试,确保系统失败并能正常恢复
- 发现系统稳定性的隐患和系统在负载峰值的条件下功能隐患
- 关注大业务下系统的长时间运行状态(例如反应变慢、内存泄漏 系统崩溃、失效恢复)
- 找出系统在可控错误率下的最大压力值
稳定性/可靠性测试
通过给系统加载一定的业务压力,让系统持续运行一段时间(一般为7x24小时),检测系统是否能够稳定运行。
常用术语与性能指标
并发用户
绝对并发:即所有的用户在同一时刻做同一件事情或者操作。
相对并发:这种并发与前一种并发的区别是,尽管多个用户对系统发出了请求或者进行了操作,但是这些请求或者操作可以是相同的,也可以是不同的,对整个系统而言,仍然是有很多用户同时对系统进行操作,因此也属于并发的范畴。
并发用户数的误解:关于用户并发的数量,有2种常见的错误观点,一种错误观点是把并发用户数量理解为使用系统的全部用户的数量或者是系统的注册用户,原因是这些用户可能同时使用系统;还有一种比较接近正确的观点是把在线用户数量理解为并发用户数量,实际上在线用户也不一定会和其他用户发生并发,例如正在浏览网页的用户,对服务器没有任何影响。
计算依据
对有生产历史数据的系统,肯定是从生产历史数据来分析,进而推断业务模型;
对没有生产历史数据的,首先是根据有经验的业务人员给出来,如果没有,可以拿同行业的数据来借鉴
经典公式
平均并发用户数为 C = nL/T
并发用户数峰值 C‘ = C + 3*√𝑐
n是login session的数量,L是login session的平均长度,T是值考察的时间长度
举例 :假设系统A,该系统有3000个用户,平均每天大概有400个用户要访问该系统(可以从系统日志从获得),对于一个典型用户来说,一天之内用户从登陆到退出的平均时间为4小时,而在一天之内,用户只有在8小时之内会使用该系统。
平均并发用户数为:C = 4004/8 = 200
并发用户数峰值为:C‘ = 200 + 3√200 = 243
通用公式
对绝大多数场景,我们用(用户总量/统计时间)影响因子(一般为3)来进行估算并发量
以乘坐地铁为例子,每天乘坐人数为5万人次,每天早高峰是7到9点,晚高峰是6到7点,根据8/2原则,80%的乘客会在高峰期间乘坐地铁,则每秒到达地铁检票口的人数为5000080%/(36060)=3.7,约4人/S,考虑到安检,入口关闭等因素,实际堆积在检票口的人数肯定比这个要大,假定每个人需要3秒才能进站,那实际并发应为4人/s*3s=12,当然影响因子可以根据实际情况增大!
二八原则
计算方法:二八原则
二八原则:80%的业务量在20%的时间里完成。
示例:用户登录场景
早高峰时段 8:50---9:10,5000个用户上线登陆。
业务量:5000个
时间:20x60=1200s
吞吐量=80%业务量/(20%时间)=4000/240=16.7/s
根据TPS计算
计算公式:TPS=并发数/平均响应时间
示例
业务预期的日常考勤量为 400/min,也就是 6.6/s
线程数计算: Thread = BC/(60/t) = BC(t/60)
t:单用户单次业务消耗时间,尽可能模拟用户的真实行为
单次消耗时间=打开主页(0.5s)+思考时间(3s)+输入用户名密码(1.5s)+主页响应时间 (0.5s)+考勤打卡时间(3s)=8.5s(取 90%线)
BC:业务量,本例 BC=400
单次业务消耗 8.5s
需要的线程数=400(8.5/60)=56(取整数)
注:计算的线程数即是单位时间的平均并发数。可以理解为平均每秒有 56 个用户同时 发起业务,也可以理解为平均每秒有 56 笔业务同时在处理。
根据系统用户数估算
计算公式:发用户数 = 系统最大在线用户数的8%到12%
响应时间
- 用户通过客户端向服务端发出请求的时间为:T1
- 服务端接收到请求,处理该请求的时间为:T2
- 服务端返回数据给客户端时间为:T3
- 客户端接收到响应数据,处理数据呈现给用户时间为:T4
TPS
单位时间内系统处理请求的数量。吞吐量直接体现了软件系统的业务处理能力
Rps 请求数/单位时间
Hps 点击数/单位时间
Tps 通过事物数/单位时间
Qps 查询数/单位时间
模型
随着压力不断增长,实测系统的资源会不断被消耗,TPS 值会因为这些因素而发生 变化,并且符合一定的规律
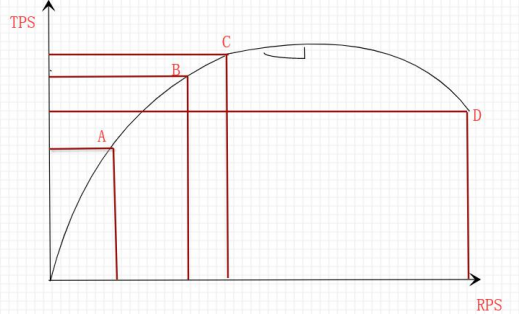
决定性因素
1 个用户在 1 秒内完成 1 笔业务,那么 TPS 就是 1 ;
1 笔业务响应时间是 1ms,如果 1 个用户在 1 秒内能完成 1000 笔,那么 TPS 就是 1000;
1 笔业务响应时间是 1s,如果 1 个用户在 1 秒内只能完成 1 笔。想达到 1000TPS 就 至少需要 1000 个用户 因此可以说 1 个用户能产生 1000TPS, 1000 个用户也可以产生 1000TPS,由响应 时间决定。
CPU使用率

%us用户空间占用cpu百分比;
%sy内核空间占用cpu百分比;
%ni用户进程空间内改变过优先级的进程占用cpu百分比;
%id空闲cpu百分比,反映一个系统cpu的闲忙程度。越大越空闲;
%wa等待输入输出(I/O)的cpu百分比;
%hi指的是cpu处理硬件中断的时间;
%si值的是cpu处理软件中断的时间;
%st当 hypervisor 服务另一个虚拟处理器的时候,虚拟 CPU 等待实际 CPU 的时间的百分比
用户态(user)是运行应用程序所占 cpu 时间百分比
用户 cpu 利用率高的原因程序运算量大。
系统态(sys)是应用程序调度所占 cpu 时间百分比
系统态是应用程序调度所占cpu时间百分比,造成系统态高的原因是程序中断切换频繁, 共享资源竞争,大量 io 交互。
CPU 利用率要低于业界警戒值范围之内,即小于或者等于 75%;
CPU Load 要小于 CPU 核数。如果该值持续超过 75%,表明 CPU 是瓶颈。
CPU 瓶颈征兆
- 响应时间很慢
- CPU 空闲百分比很小
- 过高的系统时间百分比
- 过高的用户时间百分比
- 运行队列很长
内存使用率

现代的操作系统为了最大利用内存,在内存中加了缓存,因此内存利用率 100%并不代表 内存有瓶颈,衡量系统内有有瓶颈主要看 SWAP(内存交换),swap 使用完,操作系统 会触发 OOM-Killer 机制,杀掉占用内存最大的进程。
瓶颈征兆
- 进程进入不活动状态;
- 交换区所有磁盘的活动次数很高;
- 很高的 CPU 利用率;
- 内存溢出(OOM);
IO

磁盘指标主要有每秒读写多少兆,磁盘繁忙率,磁盘队列数,平均服务时间,平均等待 时间,空间利用率。
- await-svctm 差值越大,等待时间越长,可能存在 IO 瓶颈
- %util 过大。值越高,磁盘繁忙度越大,可能存在瓶颈
错误率
指系统在负载情况下,失败交易的概率。错误率=(失败交易数/交易总数)*100%。
稳定性较好的系统,其错误率应该由超时引起,即为超时率。
不同系统对错误率的要求不同,但一般不超出千分之六,即成功率不低于99.4%。
思考时间
即请求间的停顿时间,实际中,用户在进行一个操作后往往会停顿,然后再进行下一个操作,为了模拟该用户行为,引入了该概念。
事务
在WEB性能测试中,一个事务表示一个”从用户发送请求 ->web server接收到请求,进行处理->web server向DB获取数据->生成用户的object(页面),返回给用户的过程,事务可能由一个请求,或一系列请求组成”。
事务响应时间
事务响应时间指的是从客户端发起请求开始到客户端接收到从服务器端返回的响应结果,这个过程所耗费的时间,响应时间单位一般为“秒”或者“毫秒”。一个公式可以表示:响应时间=网络响应时间+应用程序响应时间。
90%的事务响应时间
90%的响应时间,是指在一次完整的测试过程中,所有事务的响应时间,按从小到大顺序排列,90%的事务所消耗的时间范围。
在评估一次测试的结果时,仅仅有平均响应时间是不够的,平均响应时间满足了性能需求,并不能表示系统的性能已经满足了绝大多数用户的要求。所以,在评估性能测试结果时,除了要考虑事务的平均响应时间,还要考虑90%的事务响应时间。
标准可参考业界的3/5/10 、2/6/8。
在3秒之内,页面给予用户响应并有所显示,可认为是“很不错的”
在3~5秒内,页面给予用户响应并有所显示,可认为是“好的”
在5~10秒内,页面给予用户响应并有所显示,可任务是“勉强接受的”
超过10秒就让人有点不耐烦了,用户很可能不会继续等待下去2,6,8类似

 浙公网安备 33010602011771号
浙公网安备 33010602011771号