

mapreduce 实现简单的wordcount词频统计
package com.startbigdata; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountTwo { /* * KEYIN:输入kv数据对中key的数据类型 * VALUEIN:输入kv数据对中value的数据类型 * KEYOUT:输出kv数据对中key的数据类型 * VALUEOUT:输出kv数据对中value的数据类型 */ static class WordCountMap extends Mapper<LongWritable, Text, Text,IntWritable>{ private final static IntWritable outPutValue = new IntWritable(1);//设置输出value默认为1 private Text outPutKey = new Text();//定义输出key @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将以,为分隔符的每行数据分割成数组 String[] strings = value.toString().split(","); //遍历数组,将数组里面每个字符的输出值设为1 if (strings.length>0){ for (String str:strings) { this.outPutKey.set(str);//将取得出的每个元素放到outPutKey Text对象中 context.write(outPutKey,outPutValue); //通过context对象,将map的输出逐个输出 } } } } /** * Text : Mapper输入的key * IntWritable : Mapper输入的value * Text : Reducer输出的key * IntWritable : Reducer输出的value */ static class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0;//设置输出值value默认为0 for (IntWritable value:values) {//遍历values,每出现一次字符出现的次数+1 sum+=value.get(); } context.write(key,new IntWritable(sum)); //输出字符出现的总次数 } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //实例化Configuration类,加载配置文件, 因为通过Configuration可以实现在多个mapper和多个reducer任务之间共享信息。 Configuration conf = new Configuration(); // 新建一个任务,名称为类名 Job job = Job.getInstance(conf, WordCountTwo.class.getName()); // 设置主类,打包运行时必须执行的秘密方法 job.setJarByClass(WordCountTwo.class); // 设置Mapper类 job.setMapperClass(WordCountMap.class); // 设置Map输出Key的类型 job.setMapOutputKeyClass(Text.class); // 设置Map输出Value的类型 job.setMapOutputValueClass(IntWritable.class); // 设置Reducer类 job.setReducerClass(WordCountReduce.class); // 设置Reducer输出时Key的类型 job.setOutputKeyClass(Text.class); // 设置Reducer输出时Value的类型 job.setOutputValueClass(IntWritable.class); // 设置输入文件 FileInputFormat.addInputPath(job,new Path(args[0])); //判断输出路径是否存在文件,如果存在删除该文件 FileSystem fs = FileSystem.get(conf); if (fs.exists(new Path(args[1]))){ fs.delete(new Path(args[1]),true); } // 设置输出路径 FileOutputFormat.setOutputPath(job,new Path(args[1])); // 提交任务 job.waitForCompletion(true); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
打包成jar包,记得设置主类。
执行命令:
hadoop jar /opt/modules/hadoop-2.7.3/jars/hadoopapi.jar com.startbigdata.WordCountTwo /tmp1/word.txt /tmp1/out4

原文件:

查看输出文件:
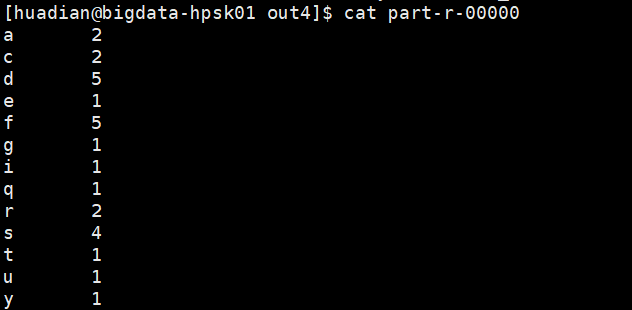
不知道有没有人遇到这种错:
20/05/21 15:31:13 INFO client.RMProxy: Connecting to ResourceManager at bigdata-hpsk01.huadian.com/192.168.235.222:8032
20/05/21 15:31:14 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
20/05/21 15:31:15 INFO input.FileInputFormat: Total input paths to process : 1
20/05/21 15:31:15 INFO mapreduce.JobSubmitter: number of splits:1
20/05/21 15:31:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1590043374409_0002
20/05/21 15:31:15 INFO impl.YarnClientImpl: Submitted application application_1590043374409_0002
20/05/21 15:31:16 INFO mapreduce.Job: The url to track the job: http://bigdata-hpsk01.huadian.com:8088/proxy/application_1590043374409_0002/
20/05/21 15:31:16 INFO mapreduce.Job: Running job: job_1590043374409_0002
20/05/21 15:31:26 INFO mapreduce.Job: Job job_1590043374409_0002 running in uber mode : false
20/05/21 15:31:26 INFO mapreduce.Job: map 0% reduce 0%
20/05/21 15:31:33 INFO mapreduce.Job: map 100% reduce 0%
20/05/21 15:31:33 INFO mapreduce.Job: Task Id : attempt_1590043374409_0002_m_000000_0, Status : FAILED
Error: java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.Text, received org.apache.hadoop.io.LongWritable
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1072)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:715)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.write(WrappedMapper.java:112)
at org.apache.hadoop.mapreduce.Mapper.map(Mapper.java:125)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Container killed by the ApplicationMaster.
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
20/05/21 15:31:34 INFO mapreduce.Job: map 0% reduce 0%
20/05/21 15:31:38 INFO mapreduce.Job: map 100% reduce 0%
20/05/21 15:31:38 INFO mapreduce.Job: Task Id : attempt_1590043374409_0002_m_000000_1, Status : FAILED
Error: java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.Text, received org.apache.hadoop.io.LongWritable
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1072)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:715)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.write(WrappedMapper.java:112)
at org.apache.hadoop.mapreduce.Mapper.map(Mapper.java:125)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Container killed by the ApplicationMaster.
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
20/05/21 15:31:39 INFO mapreduce.Job: map 0% reduce 0%
20/05/21 15:31:44 INFO mapreduce.Job: Task Id : attempt_1590043374409_0002_m_000000_2, Status : FAILED
Error: java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.Text, received org.apache.hadoop.io.LongWritable
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1072)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:715)
at org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl.write(TaskInputOutputContextImpl.java:89)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.write(WrappedMapper.java:112)
at org.apache.hadoop.mapreduce.Mapper.map(Mapper.java:125)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
20/05/21 15:31:54 INFO mapreduce.Job: map 100% reduce 100%
20/05/21 15:31:56 INFO mapreduce.Job: Job job_1590043374409_0002 failed with state FAILED due to: Task failed task_1590043374409_0002_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0
20/05/21 15:31:56 INFO mapreduce.Job: Counters: 13
Job Counters
Failed map tasks=4
Killed reduce tasks=1
Launched map tasks=4
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=20028
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=20028
Total time spent by all reduce tasks (ms)=0
Total vcore-milliseconds taken by all map tasks=20028
Total vcore-milliseconds taken by all reduce tasks=0
Total megabyte-milliseconds taken by all map tasks=20508672
Total megabyte-milliseconds taken by all reduce tasks=0
我这里的错误是因为Job建错了,写成了
Job job = new Job(conf,WordCountTest.class.getName());
