OO第四次博客作业
OO第四次博客作业
(一)总结本单元两次作业的架构设计
第13次作业:主要是对类图进行解析
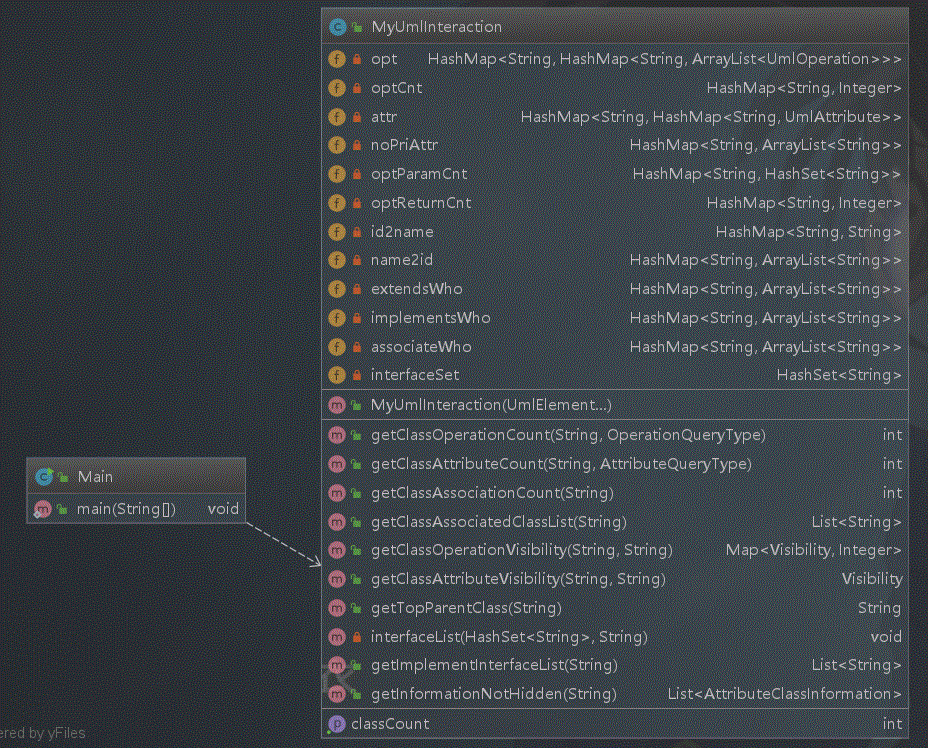
解决办法:在构造函数中,解析所有的UMLElements对象,分别针对各种需求进行存储,在指令查询函数中访问对应的数据结构求出结果即可。
主要数据结构:
//记录类的个数
private int classCount = 0;
//记录classId-><operantionId->List<UmlOperation>> 记录一个类有哪些操作,可能有同名操作
private HashMap<String,HashMap<String,ArrayList<UmlOperation>>>
opt = new HashMap<>();
//记录一个类的操作个数
private HashMap<String,Integer> optCnt = new HashMap<>();
//记录classId-><attributeName->List<UmlAttribute>> 记录一个类有哪些属性,通过属性名做索引
private HashMap<String,HashMap<String,UmlAttribute>> attr = new HashMap<>();
//记录一个类的非私有的属性
private HashMap<String,ArrayList<String>> noPriAttr = new HashMap<>();
//记录一个类的有参数的方法
private HashMap<String,HashSet<String>> optParamCnt = new HashMap<>();
//记录一个类的有返回值的方法
private HashMap<String,Integer> optReturnCnt = new HashMap<>();
//元素的id->元素的name
private HashMap<String,String> id2name = new HashMap<>();
//元素的name->List<元素的id>
private HashMap<String,ArrayList<String>> name2id = new HashMap<>();
//记录类的父类
private HashMap<String,ArrayList<String>> extendsWho = new HashMap<>();
//记录类实现的接口
private HashMap<String,ArrayList<String>> implementsWho = new HashMap<>();
//记录类的关联
private HashMap<String,ArrayList<String>> associateWho = new HashMap<>();
//记录接口的id
private HashSet<String> interfaceSet = new HashSet<>();
各类查询方法的实现(以查询类实现的接口为例)
查询自身的接口和各级父类的接口
String id = name2id.get(className).get(0); //子类id
HashSet<String> set = new HashSet<>();
interfaceList(set,id);
while (extendsWho.containsKey(id)) { //求父类的接口
id = extendsWho.get(id).get(0); //父类id
interfaceList(set,id);
}
求一个类实现的全部接口(接口之间可以多继承,采用bfs搜索)
private void interfaceList(HashSet<String> set,String id) {
if (implementsWho.containsKey(id)) { //直接实现的接口
for (String s : implementsWho.get(id)) { //s是接口id
LinkedList<String> queue = new LinkedList<>();
queue.addLast(s); //根节点入队
while (!queue.isEmpty()) {
String tmp = queue.removeFirst();
set.add(tmp);
if (extendsWho.containsKey(tmp)) { //邻接点
for (String t : extendsWho.get(tmp)) {
queue.addLast(t);
}
}
}
}
}
}
类图如下:
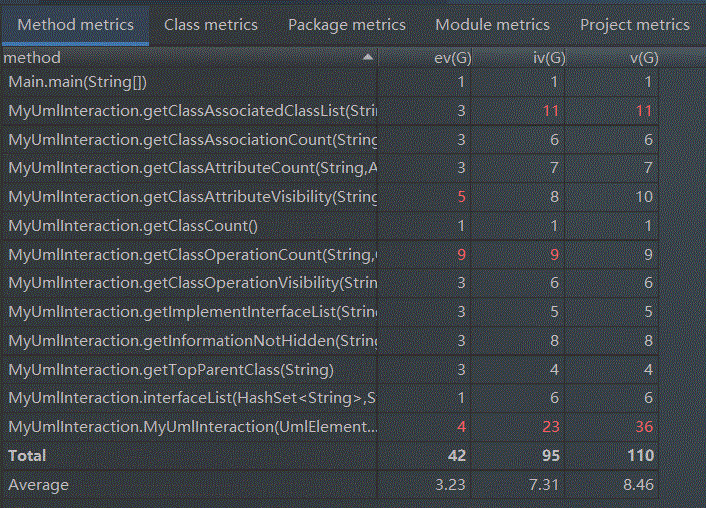
复杂度分析:
第14次作业:增加对顺序图,状态图的解析,以及三条规则验证
解决办法:在构造函数中,解析所有的UMLElements对象,分别针对各种需求进行存储,在指令查询函数中访问对应的数据结构求出结果即可。
主要数据结构:
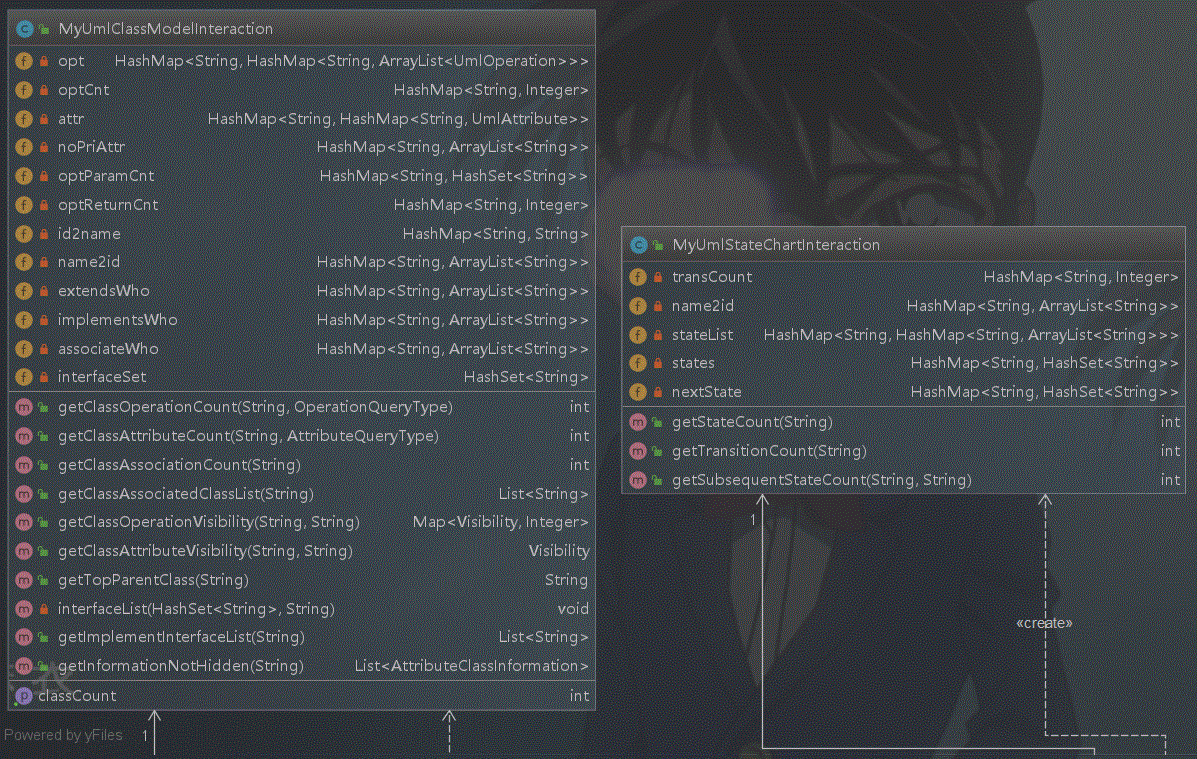
状态图:
//StateMachineID->transCnt
private HashMap<String,Integer> transCount = new HashMap<>();
//StateMachineName->List<StateMachineID>
private HashMap<String,ArrayList<String>> name2id = new HashMap<>();
//StateMachineID-><stateName->List<stateID>>
private HashMap<String,HashMap<String,ArrayList<String>>>
stateList = new HashMap<>();
//StateMachineID->List<stateID>
private HashMap<String,HashSet<String>> states = new HashMap<>();
//stateID->nextStateID 存储状态的下一个状态 构成有向图
private HashMap<String,HashSet<String>> nextState = new HashMap<>();
求后继状态:采用bfs搜索可达的状态,状态构成了有向图。注意的是,节点本身不是自己的后继,除非有自圈或者其他边成环路返回自身,所以在bfs的vis标记中,不应该标记根节点自身,以防查找后继时找不到节点本身了。
String stateId = stateList.get(id).
get(stateName).get(0);
HashSet<String> vis = new HashSet<>(states.get(id));
LinkedList<String> queue = new LinkedList<>();
queue.addLast(stateId);
//vis.remove(stateId);
int cnt = 0;
while (!queue.isEmpty()) {
String tmp = queue.removeFirst();
if (nextState.containsKey(tmp)) {
for (String t : nextState.get(tmp)) {
if (vis.contains(t)) {
vis.remove(t);
queue.addLast(t);
cnt++;
}
}
}
}
return cnt;
顺序图:
//InteractionName->List<InteractionID>
private HashMap<String,ArrayList<String>> name2id = new HashMap<>();
//InteractionID-><lifelineName->List<lifelineID>>
private HashMap<String,HashMap<String,ArrayList<String>>>
lifeLineList = new HashMap<>();
//InteractionID->cnt
private HashMap<String,Integer> messageCount = new HashMap<>();
//InteractionID->cnt
private HashMap<String,Integer> lifelineCount = new HashMap<>();
//lifelineId->cnt
private HashMap<String,Integer> incomingCount = new HashMap<>();
规则检验:
//记录所有接口的id
private HashSet<String> interfaceSet = new HashSet<>();
//记录重复继承的接口id
private HashSet<String> wrongInterfaceSet = new HashSet<>();
//记录所有类的id
private HashSet<String> classSet = new HashSet<>();
//classId->UMLClass
private HashMap<String,UmlClass> idToClass = new HashMap<>();
//interfaceId->UMLInterface
private HashMap<String,UmlInterface> idToInterface = new HashMap<>();
//记录类之间,接口之间的继承关系
private HashMap<String,ArrayList<String>> extendsWho = new HashMap<>();
//记录类和接口的实现关系
private HashMap<String,ArrayList<String>> implementsWho = new HashMap<>();
//UmlRule002Exception
private HashSet<AttributeClassInformation> set002 = new HashSet<>();
//UmlRule008Exception
private HashSet<UmlClassOrInterface> set008 = new HashSet<>();
//UmlRule009Exception
private HashSet<UmlClassOrInterface> set009 = new HashSet<>();
Rule002
记录类的属性名字和类的关联对端的名字,对于重复次数超过1次的名字,加入set002抛出异常即可
Rule008
从类或接口的id出发,dfs搜索查看是否能查询到自身,如果可以的话,说明这个类或者接口在某一个环中,加入set008,抛出异常即可。
private HashSet<String> vis;
private String start;
private void dfs(String id) {
vis.remove(id);
if (extendsWho.containsKey(id)) {
for (String s : extendsWho.get(id)) {
if (vis.contains(s)) {
dfs(s);
} else {
if (s.equals(start)) {
if (idToInterface.containsKey(start)) {
set008.add(idToInterface.get(start));
}
else if (idToClass.containsKey(start)) {
set008.add(idToClass.get(start));
}
}
}
}
}
}
Rule009
遍历所有的接口,利用bfs搜索所有的父接口,查看是否会出现继承重复接口,出现则加入set009。
private boolean interfaceDuplicated(String id) {
HashSet<String> set = new HashSet<>();
LinkedList<String> queue = new LinkedList<>();
queue.addLast(id);
while (!queue.isEmpty()) {
String tmp = queue.removeFirst();
if (extendsWho.containsKey(tmp)) {
for (String t : extendsWho.get(tmp)) { //t是父接口id
if (wrongInterfaceSet.contains(t)) {
return false;
}
queue.addLast(t);
if (set.contains(t)) { //重复继承
return false;
} else {
set.add(t);
}
}
}
}
return true;
}
遍历所有的类,查询自身以及各级父类所实现的接口,查看是否有重复的接口,出现则加入set009。方法跟查询类的全部接口类似。set009不为空,这抛出异常即可。
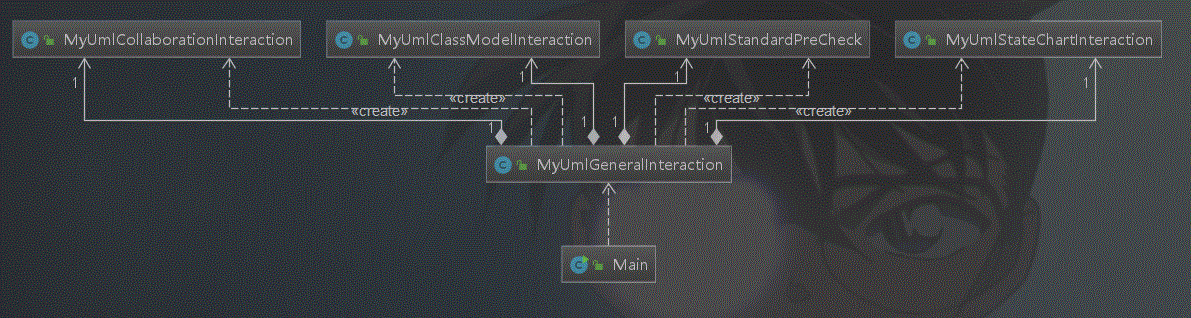
类图如下:
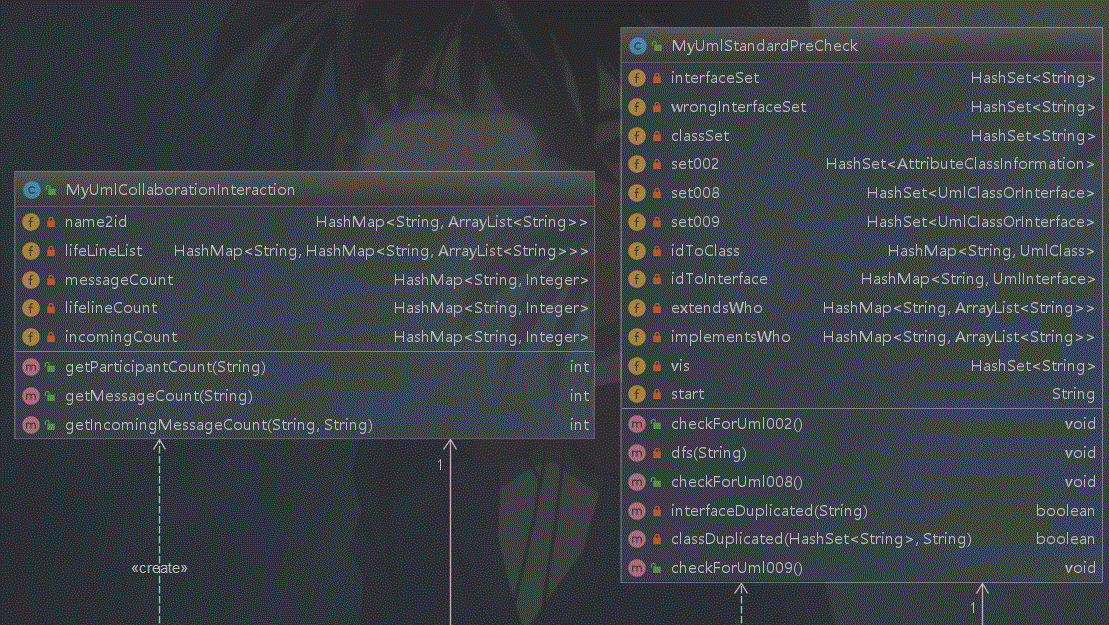

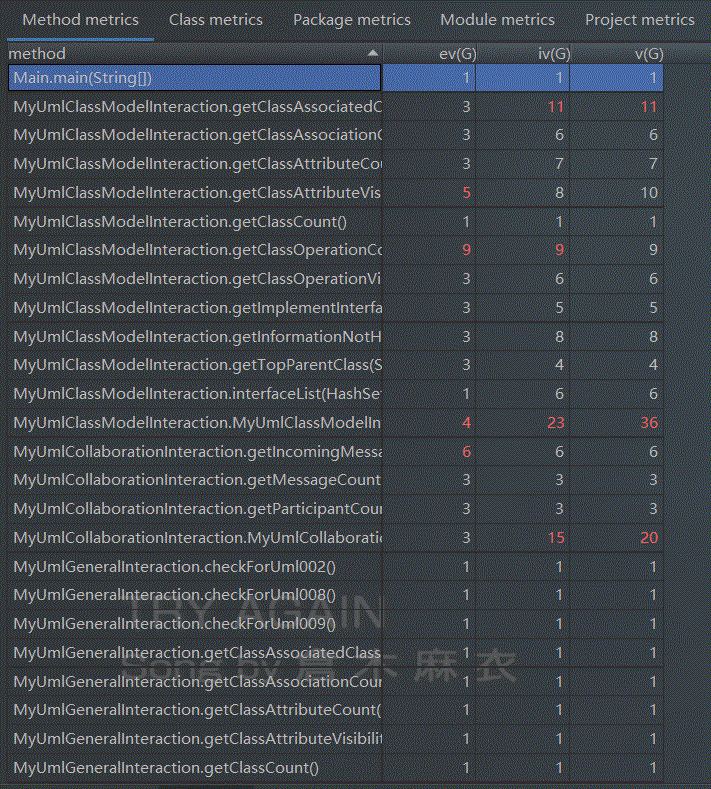
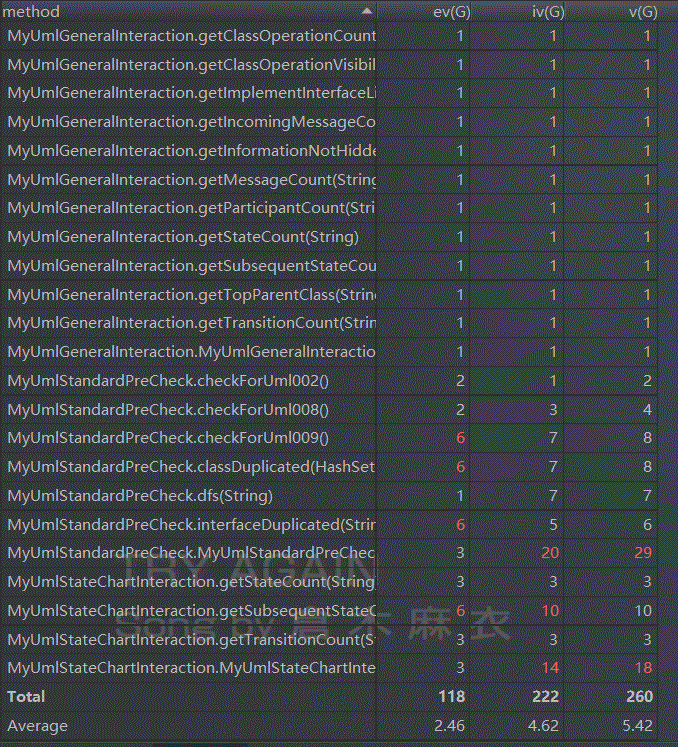
复杂度分析
(二)总结自己在四个单元中架构设计及OO方法理解的演进
有一个好的架构,才能写出一个好的代码。
第一单元
这个单元的三次作业,可以说是次次重构,这次的架构完全不能应用于下次的作业。
第1次作业简单多项式导函数的求解。解决方案:使用HashMap存储指数和系数。
第2次作业任务为包含简单幂函数和简单正余弦函数的导函数的求解。解决方案:为了处理sin(x)和cos(x)同时为了一定程度上兼容下一次作业,设计一个Func因子类,存储了内外层函数,同时表达式类Exp中使用了HashMap<HashMap<Func,BigInteger>, BigInteger> map; 这样的形式来表达了一个表达式。
第3次作业支持嵌套因子和表达式因子。解决方案:合法性判别:每次扫描表达式,将嵌套和表达式因子“抹去”,剩余的部分则变成了第2次作业的“表达式”,判断它是否合法;接着采用递归的方式去依次判别刚才“抹去”的部分是否符合表达式的定义(仍旧是递归判别)。求导:定义各种因子类和组合规则类,并且都实现了求导接口,接着对表达式求导也就是对因子和组合规则求导,主要采用了递归的方式。
第二单元
这一单元则每次作业都可以延续上一次作业的架构了,主要都是基于生产者消费者模型。
第5次作业实现了2个线程,生产者线程——Input负责读取输入请求加入请求队列,消费者线程——Elevator负责读出请求队列的请求并进行处理。采用生产者消费者模型,托盘就是请求队列类RequestQueue,采用synchronized保证读写安全,线程的run()方法采用暴力轮询。
第6次作业在作业5的基础上,利用wait()和notify()实现线程之间的通信。同时为了给作业7多电梯做准备,增加一个调度器线程Schedule,他持有Elevator类的一个对象,本次的基本模型还是生产者消费者模型,区别在于:(1)Input线程和Schedule线程是一对,Input作为生产者向缓冲区加入请求,Schedule作为消费者从缓冲区取出请求并分发给电梯,由于只有一部电梯,所以本次作业中Schedule的作用只是把请求原样取出,再原样传给电梯,(看起来有点蠢,但是这个操作确实让我的第7次作业的扩展容易许多);(2)Schedule和Elevator又是另一对,Schedule作为生产者向电梯的任务队列中加入需要电梯处理的请求,Elevator作为消费者从任务队列中取出请求并执行。也就是两对生产者和消费者。
第7次作业在作业6的基础上,要求实现3部电梯,基于作业6的结构,只需要在Schedule线程中让他持有三个电梯的对象即可。仍旧是生产者消费者模型,Input线程和Schedule线程是一对,Input作为生产者向缓冲区加入请求,Schedule作为消费者从缓冲区取出请求并分发给电梯,采用一定的分配策略,Schedule和每一个Elevator都是一对,Schedule作为生产者向电梯的任务队列中加入需要电梯处理的请求,Elevator作为消费者从任务队列中取出请求并执行。每一个Elevator线程都有自己的内外队列,即需要处理的请求队列和电梯内部人员队列。
第三单元
这一单元则每次作业都可以延续上一次作业的架构了,都是在上一次作业基础上扩充相应需求即可。
第9次作业需要完成的任务为实现两个容器器类 Path 和 PathContainer 。为了加快查找的效率,采用了双HashMap的方式,映射边和序号的关系。同时考虑到查询不同节点个数的指令条数很多,需要采用一个均摊的策略,把这个复杂度给均摊到出现次数较少的增删指令上。
第10次作业需要完成的任务为实现容器类 Path 和数据结构类 Graph。接口Graph继承自PathContainer。本次作业构成了图的结构,需求增加了判断连通性和求最短路,所以需要加入一个邻接表用于记录这个图的结构HashMap<Integer, HashMap<Integer,Integer>> lgraph,并且考虑到时间的效率,用一个数据结构对计算结果进行缓存HashMap<Integer, HashMap<Integer,Integer>> dist,当查询计算过的结果的时候可以直接返回结果,不需要重复计算,这样可以避免过多的重复计算,缩减CPU时间。其他结构则继承自上次的代码结构。
第11次作业需要完成的任务为实现容器类 Path ,地铁系统类 RailwaySystem 。接口RailwaySystem继承自Graph。在图结构的基础上,增加了最少换乘次数,最低票价,最少不满意度,连通块个数的需求,连通块个数可以直接采用bfs进行染色的方法进行计算,对于三个“最少”的请求,实际上他们的方法是相通的,采用拆点的方式,记录了一个新的图HashMap<Pair<Integer,Integer>,HashSet<Pair<Integer,Integer>>> graph,在这个图的基础上,其实这三个需求都是基于权重的最短路,都可以采用dijkstra算法贪心求解。并且同样类似于前一次作业,采用了缓存的方式记录了结果,这里使用了三个HashMap分别缓存三种需求的计算结果(traDist,priDist,pleDist)避免了重复计算。注意dijkstra算法需要堆优化。否则O(N^2)复杂度必然超时。其他部分结构继承自前一次作业。
第四单元
这一单元则每次作业都可以延续上一次作业的架构了,都是在上一次作业基础上扩充相应需求即可。
第13次作业:主要是对类图进行解析。解决办法:在构造函数中,解析所有的UMLElements对象,分别针对各种需求进行存储,在指令查询函数中访问对应的数据结构求出结果即可。
第14次作业:增加对顺序图,状态图的解析,以及三条规则验证。解决办法:在构造函数中,解析所有的UMLElements对象,分别针对各种需求进行存储,在指令查询函数中访问对应的数据结构求出结果即可。类图部分延续上次的结构,增加顺序图,状态图对应的存储结构即可。
演进
一路走来,四个单元的架构设计,能够体会到自己的进步,尤其是在回头看第一单元的代码的时候,感觉写的是那么的垃圾。能够写出一份可维护性好,可移植性好,可扩展性好的代码,我相信这是所有人的目标,但是这样的一份好代码不是那么轻松就能写出来的,一个前提就是首先要设计一个好的代码架构。在这四个单元中,可以看到的是我逐步的可以将这次的架构应用于下一次的作业了,代码有了一定的可扩展性,也可以进行一定的代码复用。在代码实现上,也逐步的更加多的使用了组合,继承和接口,OO的代码的结构更加清晰了。预先设计一个好的架构,才能写出一个可维护性好的质量高的代码。
(三)总结自己在四个单元中测试理解与实践的演进
第一单元
程序自动基于正则表达式随机生成数据,手动构造一些WF的格式错误和一些边界数据,利用matlab和python的sympy库进行验证。(早期使用的matlab,但是发现当常数值较大时,matlab经常出现奇怪错误,后期改用python验证,速度也比matlab快了一些)这一单元的第三次作业就忘记了手动构造边界数据,出现了一个Bug,所以只靠自动生成数据是不靠谱的,因为随机产生到边界的数据是很困难的,很容易在边界上出现问题。
第二单元
大量随机化造数据进行测试,但是跟第一单元相比,第一单元的测试只需要生成数据之后运行即可,输出结果也是固定的(顶多是化简程度不同,利用matlab或者python的sympy库就可以化简),但是多线程的程序就可能涉及到不确定的因素了,而且电梯的要求比较多,所以用于验证结果是否正确的程序比较难写,正确性判断的基础主要是基于每一个乘客是否到达了目标楼层进行的。主要的难点还是如何实现定时投放,不知道如何定时投放所以难以测试,只能在同一个时刻同时输入很多组请求,测试效果比较差。(后来在hdl大佬的分享中,发布了一个可以定时投放的jar包,这样就可以实现定时投放,进行比较好的测试了)
第三单元
程序自动生成测试数据,进行大量测试,这里主要是和同学的程序运行结果进行对拍。同时由于最短换乘,最少票价等的指令的运行时间较长,可以编写投放大量这类的数据进行压力测试,有助于优化程序的运行时间。
同时这个单元,接触了Junit这个测试方式,开始尝试着对代码进行单元测试。
同时由于jml语言的特点,也可以利用jml工具进行规格与代码实现正确性的检验。
第四单元
uml这个单元的测试主要是针对各种指令,尝试着自行画一些.mdj图,考虑各种边界情形,利用官方jar包导出数据,进行边界测试。
演进
前三个单元都会利用程序自动生成大量测试数据进行测试,只不过第一单元是正确性验证利用的是matlab和python的sympy库;第二单元的正确性验证利用的是自行编写的验证程序,验证每一个乘客是否到达了目标楼层;第三单元的正确性验证则是利用跟同学的结果对拍进行的。
一二单元是完全基于程序的自动生成数据+手动构造部分边界数据进行的测试。
第三单元除此之外,尝试了JUNIT的测试方法和利用JML工具进行验证。
而第四单元则没有利用程序造数据,只是完全依赖于自己针对每一个指令构造尽可能详细的各类数据进行的测试,类似一种手动的JUNIT方法。
总结起来,主要的测试方法如下:
**自动化随机数据测试->压力测试->边界测试->规格测试->JUNIT单元测试 **
(四)总结自己的课程收获
1. java语言
学习了java语言,继C语言之后的第二门语言,确实感受到了java语言比C语言的强大和复杂之处,各类容器使用十分方便,在作业中经常用到的比如HashMap,HashSet,ArrayList等。
2. 正则表达式相关
学习了利用正则表达式处理字符串的方法。在第一单元的三次作业中,利用正则表达式判断输入字符串的合法性,解析字符串中的各个元素,包括表达式因子,项等。这里还要了解的一点是,正则表达式有三种模式:贪婪模式、懒惰模式、独占模式。这一点可以用于处理正则的爆栈问题。
3. 多线程相关
学习了多线程相关知识,学习了生产者输入者模型的实现方式,包括
方式一:利用Java库中的阻塞队列BlockingQueue,生产者消费者两个线程分别持有同一个BlockingQueue的对象,利用put()和take()方法实现向队列中的存取。
方式二:利用普通的容器类,自行构造一个类,保证其存储和访问的线程安全性即可,也就是对对象加锁synchronized。
方式三:利用wait()和notify()实现线程之间的通信。
这里需要注意的是线程安全问题
例如对电梯作业中电梯的退出,需要对queue加锁,保证queue.isEmpty()和queue.getStop()访问是线程安全的,不会出现访问不同步。
while (true) {
synchronized (queue) {
if (queue.isEmpty() && queue.getStop() && inEle.isEmpty()) {
break;
}
}
}
4. JML相关
JML是一种为 Java量身定做的形式化的行为接口规范语言 ( BISL), 用来规范 Java程序模块 (如类和接口 )的行为及详细设计决策。它沿袭了 BISL良好定义的形式语义, 同时也继承了DBC语言较强的执行能力。使用 JML书写的形式化的接口规范可以推动程序的自动化测试, 减少单元测试的负担。
JML有两种主要的用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规
格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
通过这个单元的学习,了解规格的相关内容,学习了JML这个规格描述语言,对于面向对象程序的测试是很有帮助的。
5. UML相关
UML(统一建模语言),提供一种面向对象式的抽象又直观的描述逻辑,是语法明确、语义清晰的可视化语言,UML图包括类图,顺序图,状态图等。UML提供多种描述视角,每个视角可以通过若干UML图来描述,每个图有明确的主题,控制每个图的规模。
6. 面向对象思想
三个基本特征:
封装、继承、多态
封装,把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承,子类可以使用父类的所有功能,并且可以对这些功能进行扩展。
多态性,有两种方式,覆盖和重载。覆盖Override,是指子类重新定义父类的虚函数。重载Overload,是指允许存在多个同名函数,而这些函数的参数表不同。
五个原则:
SOLID (单一功能、开闭原则、里氏替换、接口隔离以及依赖反转)
[S] Single Responsibility Principle (单一功能原则)
[o] Open Close Principle (开闭原则)
[L] Liskov Substitution Principle(里氏替换原则)
[I] Interface Segregation Principle(接口隔离原则)
[D] Dependency Inversion Principle(依赖反转原则)
7.其他
早就听说过北航的OO课很难熬,不过这学期经过助教们的精心改进,整体的感受是比较舒服的,回顾整个课程的作业,只在互测出现过两次bug,一个是第一单元第三次作业,一个是第二单元第三次作业。虽然也都能够在5行之内的改动中得以修复,但是这也只能说是自己的问题,在前期的测试中准备不足,导致了虽然强测侥幸通过,但是互测却暴露了问题。11次代码作业,应该是只有第二单元电梯的第二次作业由于性能分不足,以87.9786分错失了A组线88分。
这一学期走下来,遇到过很多困难,尤其在第一单元第三次和第三单元第三次作业,这两次作业是我感觉最难熬的两次作业,第一单元的时候,由于做不出来,想不出来,就总是十分的焦虑,沮丧,虽然最后依靠自己写出了代码,但是也留下了一个小bug;到了后边第三单元的时候虽然也是历经波折,整体的架构改了多次,(由于压力测试的效果不佳,运行速度较慢)但是心中也有着一点底气,觉得自己能行。可能这就是OO课带来的历练吧,回头看自己第一单元的代码,十分陌生,有点不认识他了,看着IDEA右侧那一个个黄色的警告标志,在想“这是谁写的垃圾代码”,一学期走下来,不管是对代码架构的设计,代码测试的方法等等都有了进步和提高,甚至于看自己曾经的代码觉得是那么的不堪回首,我觉得这就是成长,从一个初识java语法的小菜鸡成长到了现在一个可以一周写出几乎上千行工程化代码的大菜鸡,从第一单元到第四单元,自己写代码的感受也在变化,越到后边就越觉得,在设计好架构之后,自己动手写代码是那么是顺畅。
总之,感谢OO的历练,它对我代码能力的提高是非常显著的。
(五)立足于自己的体会给课程提三个具体改进建议
1.研讨课的意义和形式
研讨课,名为“研讨”,现在的课,没有研,没有讨。首先这个课没有解决学生的问题,也就是没有起到他的作用,可以尝试着真的去收集学生的问题,针对问题做出解答,也不一定非得是学生上台,老师助教也可以参与;其次,现在的“讨论”是一种强制的方式,为什么学生不愿意积极参与讨论这是这个课应该考虑的地方,这种强制点名提问的方式是如何体现到“研讨”的意义所在呢?
2.实验课的安排
实验课与理论课的衔接有一定的问题,上午理论课讲的下午就做实验,或者,很久之前的理论课然后才做实验。这样不利于实验产生很好的效果。同时,前几次实验的题量很大,做的十分匆忙。再者,实验题的形式,可以加一些客观题,也可以加深对OO的理解。还有就是实验课的成绩,可以适当公布一下,现在完全不透明,也不知道正确与否,效果如何,正确答案是啥。
3.时间线问题
jml单元,uml单元的时间都没有严格遵守时间线,而且为了等理论课,拖后作业公布时间,导致大家周末和五一没事可做,尤其五一那次,整个五一闲的不行,但是五一之后那几天却非常的忙,我觉得这是没有意义的,包括uml的两次作业,第一次突然延迟了,整个时间非常充裕,然后结束之后,第二次作业迟迟不放出来,第15周的作业生生拖进了第16周,本身16周很多门考试,虽然说这次作业周期很长,但是实际上呢,大部分同学都是在周五考完离散3之后才开始写的,(相信老师从讨论区的发言也能看出来大部分人是从什么时候开始做的),而且这次采用的逐步开放的模式,这样一来就没有意义了,然后中测的时间线又一次延迟了,也没有通知。个人认为先公开指导书jar包延迟公开和留给大家看课件的时间,拖到周日晚上才放指导书的意义不是太大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号