14-2-Unsupervised Learning ----Word Embedding
Introduction
词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用
那如何用vector来表示一个word呢?
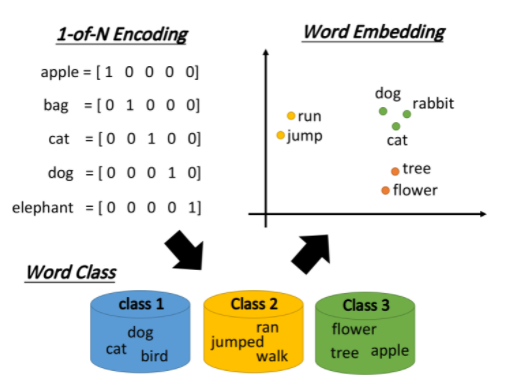
1-of-N Encoding
最传统的做法是1-of-N Encoding,假设这个vector的维数就等于世界上所有单词的数目,那么对每一个单词来说,只需要某一维为1,其余都是0即可;但这会导致任意两个vector都是不一样的,你无法建立起同类word之间的联系
Word Class
还可以把有同样性质的word进行聚类(clustering),划分成多个class,然后用word所属的class来表示这个word,但光做clustering是不够的,不同class之间关联依旧无法被有效地表达出来
Word Embedding
词嵌入(Word Embedding)把每一个word都投影到高维空间上,当然这个空间的维度要远比1-of-N Encoding的维度低,假如后者有10w维,那前者只需要50~100维就够了,这实际上也是Dimension Reduction的过程
类似语义(semantic)的词汇,在这个word embedding的投影空间上是比较接近的,而且该空间里的每一维都可能有特殊的含义
假设词嵌入的投影空间如下图所示,则横轴代表了生物与其它东西之间的区别,而纵轴则代表了会动的东西与静止的东西之间的差别
怎么做Word Embedding?
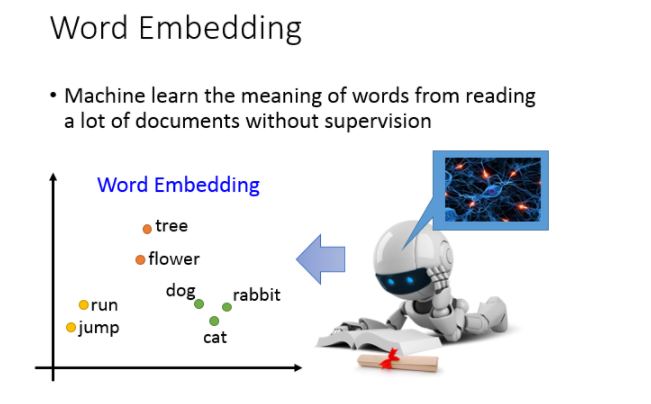
那怎么做word Embedding呢?word Embedding是Unsupervised 。我们怎么让machine知道每一个词汇的含义是什么呢,你只要透过machine阅读大量的文章,它就可以知道每一个词汇它的embeding feature vector应该长什么样子。
word embedding是一个无监督的方法(unsupervised approach),只要让机器阅读大量的文章,它就可以知道每一个词汇embedding之后的特征向量应该长什么样子。
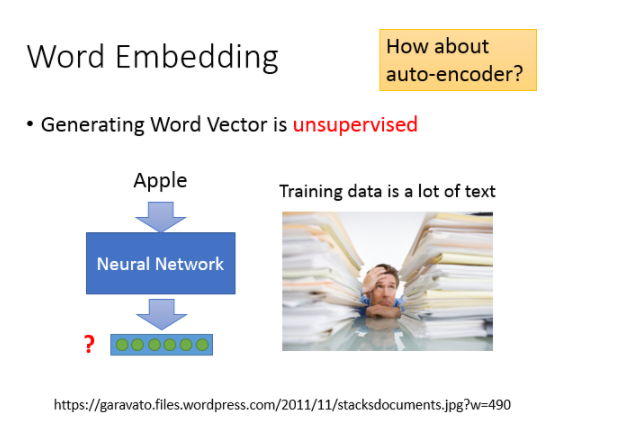
我们的任务就是训练一个neural network,input是词汇,output则是它所对应的word embedding vector,实际训练的时候我们只有data的input,该如何解这类问题呢?
之前提到过一种基于神经网络的降维方法,Auto-encoder,就是训练一个model,让它的输入等于输出,取出中间的某个隐藏层就是降维的结果,自编码的本质就是通过自我压缩和解压的过程来寻找各个维度之间的相关信息;但word embedding这个问题是不能用Auto-encoder来解的,因为输入的向量通常是1-of-N编码,各维无关,很难通过自编码的过程提取出什么有用信息。
Word Embedding
basic idea
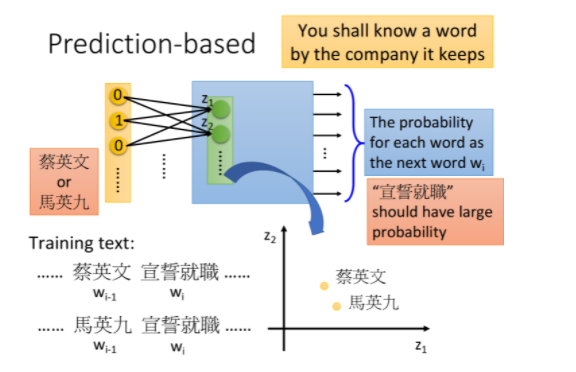
基本精神就是,每一个词汇的含义都可以根据它的上下文来得到
比如机器在两个不同的地方阅读到了“马英九520宣誓就职”、“蔡英文520宣誓就职”,它就会发现“马英九”和“蔡英文”前后都有类似的文字内容,于是机器就可以推测“马英九”和“蔡英文”这两个词汇代表了可能有同样地位的东西,即使它并不知道这两个词汇是人名

怎么用这个思想来找出word embedding的vector呢?有两种做法:
- Count based
- Prediction based
Count based

Prediction based
how to do perdition
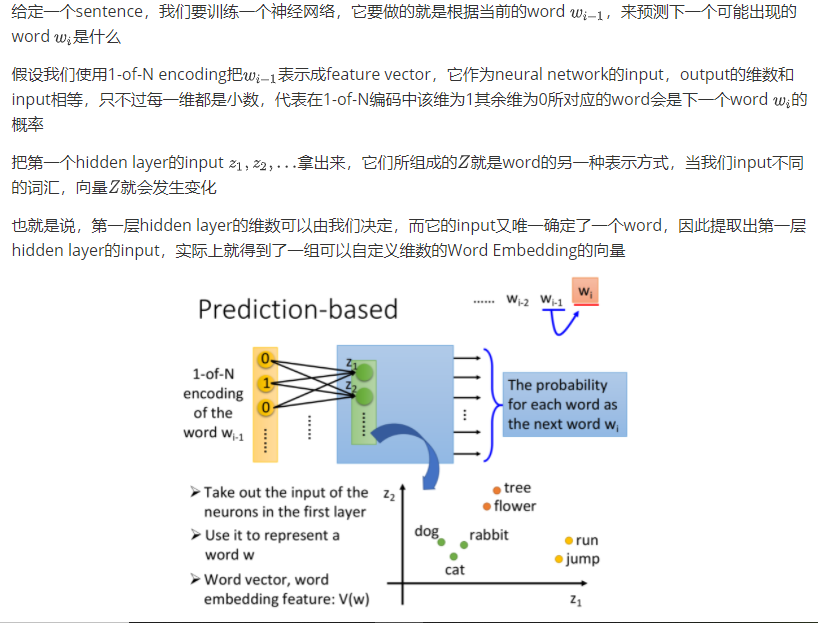
Why prediction works

Sharing Parameters

 浙公网安备 33010602011771号
浙公网安备 33010602011771号