聚类算法:k-means算法(一)
K-means算法思想:
对于给定的样本集,事先确定聚类簇数k,从样本集中随机选取k个样本点作为簇中心,计算所有样本与k个簇中心的距离,对于每一个样本,将其划分到和它距离最近的簇中心所在簇中,然后在各簇中再次计算新的簇中心,新的簇中心通常以该簇中所有样本的均值表示。


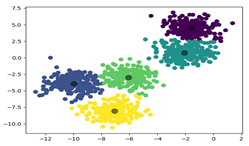
K-means算法的基本步骤:
1) 从样本集中选取k个样本点作为簇中心;
2) 计算每个样本到簇中心的距离,并通过各样本到k各簇中心的最小距离划分簇;
3) 在个簇中再次计算新的簇中心;
4) 反复迭代2,3步骤,直到达到某个终止条件。
伪代码:
function K-Means(输入数据,中心点个数K)
获取输入数据的维度Dim和个数N
随机生成K个Dim维的点
while(算法未收敛)
对N个点:计算每个点属于哪一类。
对于K个中心点:
1,找出所有属于自己这一类的所有数据点
2,把自己的坐标修改为这些数据点的中心点坐标
end
输出结果:
end
路漫漫其修远兮,吾将上下而求索

 浙公网安备 33010602011771号
浙公网安备 33010602011771号