(六)mapreduce和Hbase集成
1. mapreduce上传到hbase
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.datanucleus.transaction.jta.JOnASTransactionManagerLocator;
import breeze.linalg.mapActiveValues;
public class MapToHbase {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends TableReducer<Text,IntWritable,NullWritable> {
@SuppressWarnings("deprecation")
public void reduce(Text key, Iterable<IntWritable> values,
Context context ) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
Put put=new Put(Bytes.toBytes(key.toString()));
put.add(Bytes.toBytes("content"), Bytes.toBytes("count"), Bytes.toBytes(String.valueOf(sum)));
context.write(NullWritable.get(),put);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String tablename="maptohbase";
conf.set(TableOutputFormat.OUTPUT_TABLE,tablename);
Job job = new Job(conf, "word_count_table");
job.setJarByClass(MapToHbase.class);
job.setNumReduceTasks(3);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TableOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.19.128:9000/zinput/*"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
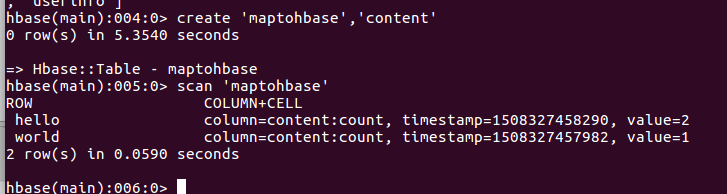
2. hbase上传到Hadoop
import java.io.IOException;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class HbaseToMap {
public static class WordCountHbaseReaderMapper extends TableMapper<Text, Text> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer("");
for (Entry<byte[], byte[]> // entry是Map中的一个实体(一个key-value对)
entry : value.getFamilyMap("tags".getBytes()).entrySet()) {
String str = new String(entry.getValue());
// 将字节数组转换为String类型
if (str != null) {
sb.append(new String(entry.getKey()));
sb.append(":");
sb.append(str);
}
context.write(new Text(key.get()), new Text(new String(sb)));
}
}
}
public static class WordCountHbaseReaderReduce extends Reducer<Text,Text,Text,Text>{
private Text result = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
for(Text val:values){
result.set(val);
context.write(key, result);
}
}
}
public static void main(String[] args) throws Exception {
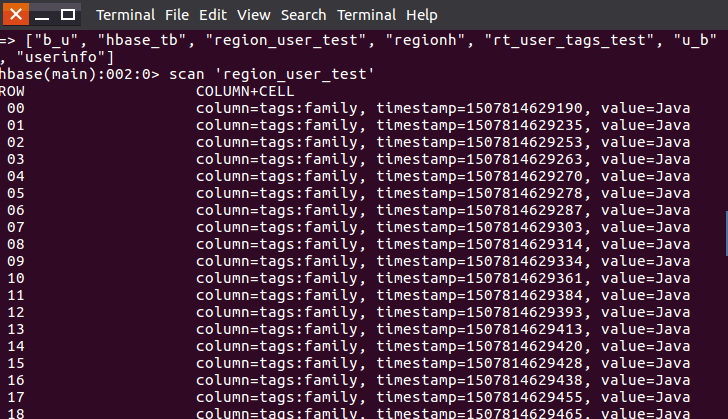
String tablename = "region_user_test";
Configuration conf = HBaseConfiguration.create();
//conf.set("hbase.zookeeper.quorum", "Master");
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 1) {
System.err.println("Usage: WordCountHbaseReader <out>");
System.exit(2);
}
Job job = new Job(conf, "WordCountHbaseReader");
job.setJarByClass(HbaseToMap.class);
//设置任务数据的输出路径;
FileOutputFormat.setOutputPath(job, new Path(otherArgs[0]));
job.setReducerClass(WordCountHbaseReaderReduce.class);
Scan scan = new Scan();
TableMapReduceUtil.initTableMapperJob(tablename,scan,WordCountHbaseReaderMapper.class, Text.class, Text.class, job);
//调用job.waitForCompletion(true) 执行任务,执行成功后退出;
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号