
hadoop2.7ubuntu伪分布式搭建
一.安装Java
下载java的压缩包,解压
sudo tar -zxvf 8.tar.gz配置java环境变量
sudo vim ~/.bashrcexport JAVA_HOME=/usr/local/java-8-openjdk-amd64
export JRE_HOME=/usr/local/java-8-openjdk-amd64/jre
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source ~/.bashrc二.ssh免密码登录
先判断是否安装ssh,执行ssh localhost,若需要输入密码,则已经安装
未安装,执行以下命令安装ssh
sudo apt-get install openssh-server登录ssh localhost需要输入密码
退出exit
查看/home/hadoop家目录下的/.ssh,没有就创建
ls
cd #进入用户目录
mkdir ./.ssh
cd ./.ssh
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys #将生成的公钥加入到key中
ssh -version #验证是否安装成功
ssh localhost #不需要输入密码即可登录
exit #登出
三。添加IP映射
为了方便,我们在hosts添加IP地址映射
sudo vim /etc/hosts127.0.0.1 localhost
192.168.153.133 hadoop
#IP地址 主机名四.安装hadoop
1.将压缩包放到/usr/local/目录下,解压hadoop
cd /usr/local
sudo tar -zxvf hadoop-2.7.5.tar.gz #解压
sudo mv hadoop-2.7.5 hadoop #重命名2.赋予用户权限
sudo chown -R hadoop ./hadoop3.查看hadoop版本
cd ./hadoop
./bin/hadoop version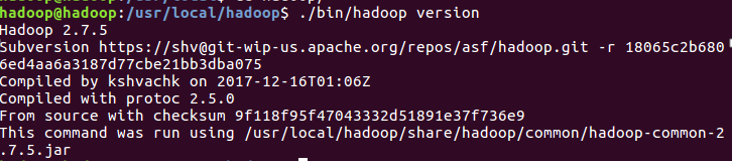
4.添加hadoop环境变量
sudo vim /etc/profileexport HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
使环境变量生效
source /etc/profile5.修改hadoop配置文件
cd /usr/local/hadoop/etc/hadoop
sudo cp mapred-site.xml.template mapred-site.xml
sudo vim core-site.xmlcore-site.xml
sudo vim core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value> <!--设置临时文件夹,只要在home下即可 -->
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value><!-- 修改为本机IP地址 -->
</property>
</configuration>
hdfs-site.xml
sudo vim hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
sudo vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
sudo vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves中添加主机名或者IP地址
sudo vim slaveshadoophadoop-env.sh 添加Javahome路径
sudo vim hadoop-env.shexport JAVA_HOME=/usr/local/java-8-openjdk-amd64
6.格式化namenode
cd /usr/lcoal/hadoop/bin
./hadoop namenode -format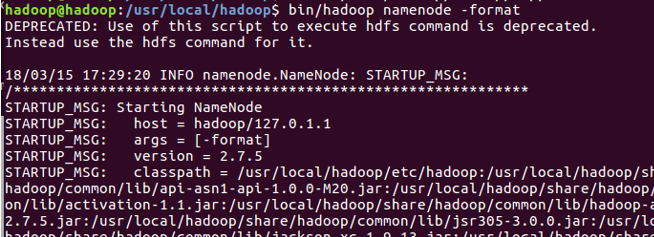
7. 启动hadoop
cd /usr/local/hadoop/sbin
./start-all.sh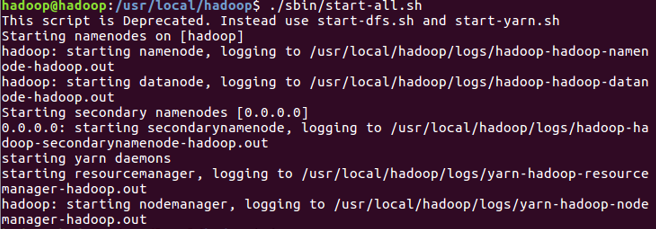
8. 查看进程jps

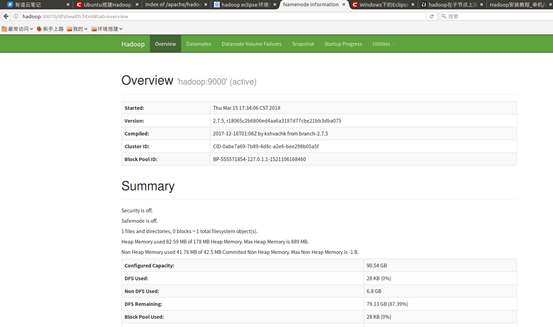
五、hadoop网址
http://hadoop:8088 8088端口查看yarn运行情况
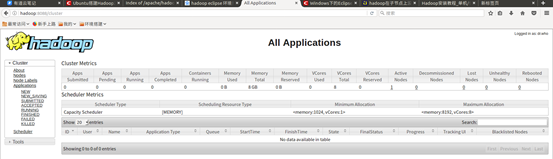
http://hadoop:50070 50070查看HDFS情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号