Python基本语法学习
CSN Python学习作业
一.Python基本数据类型:列表、元组、字典 遍历输出与转换
1.写在前面
Python的变量不需要声明,但每个变量在使用前都必须赋值。在Python中,变量就是变量,它没有所谓的“类型”一说
Python允许我们同时为多个变量进行赋值,例如如下操作:
a=b=c=1 #赋值顺序为从后往前进行赋值
a,b,c=1,2,"CSN" #我们也可以为不同的变量赋予不同类型的对象
Python中有六个标准的数据类型:
1.Number(数字)
2.String(字符串)
3.List(列表)
4.Tuple(元组)
5.Set(集合)
6.Dictionary(字典)
其中Number、String、Tuple是不可变数据;List、Dictionary、Set为可变数据。
值得一提的是,Python中加入了Complex(复数)这一数值类型;在混合运算时,Python会把整型转换为浮点数;数值的除法使用/返回一个浮点数,用//返回一个整数。
在Python中,我们可以使用"变量[头下标:尾下标]"的方式对一些数据类型进行截断。
2.列表(Python中使用最为频繁的数据类型)
I>基础
Python的列表为链式存储结构,而非顺序存储。
列表被定义为写在[]之间,用逗号分隔开的元素列表。在Python中,你可以对字符串与列表进行索引和截取,这是其他语言所无法如此简单做到的。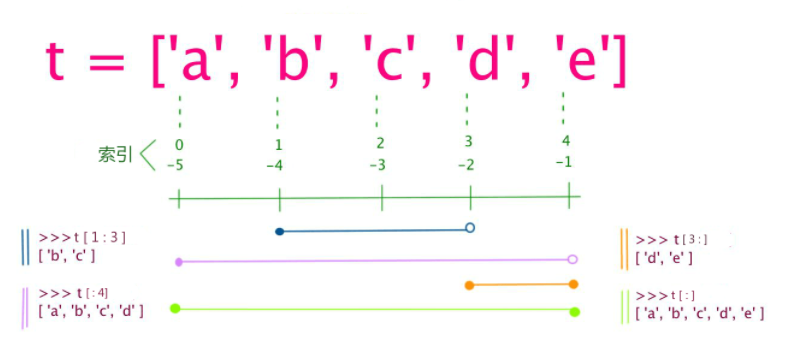
总结一下其实很简单,截断从头开始时,与C语言中的组相同,第一个元素下标为0,而最终的尾下标,截断出来的效果则是对应的位置前一个字符。
+为列表链接运算符,同java中起到链接的作用,而星号*为重复操作。
#!/usr/bin/env python3
list=['csn',123,'python',233.3]
cplist=[123,'python']
print(list)
print(list[0])
print(list[1:3])
print(list[2:])
print(cplist*2)
print(list+cplist)
上述代码的输出结果为:
['csn',123,'python',233.3]
csn
[123,'python']
['python',233.3]
[123,'python',123,'python']
['csn',123,'python',233.3,123,'python']
II>可进行的列表操作
更新列表:
#!/usr/bin/env python3
list = ['csn', 'python', 1997, 2000]
print ("第三个元素为 : ", list[2])
list[2] = 2001
print ("更新后的第三个元素为 : ", list[2])
list1 = ['csn', 'python', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
以下为输出结果:
第三个元素为 : 1997
更新后的第三个元素为 : 2001
更新后的列表 : ['csn', 'python', 'Taobao', 'Baidu']
删除列表:
#!/usr/bin/python3
list = ['csn', 'python', 1997, 2000]
print ("原始列表 : ", list)
del list[2]
print ("删除第三个元素 : ", list)
以下为输出结果:
原始列表 : ['csn', 'python', 1997, 2000]
删除第三个元素 : ['csn', 'python', 2000]
Python的列表脚本操作符:
| Python表达式 | 结果 |
|---|---|
| len([1, 2, 3]) | 3 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] |
| 3 in [1, 2, 3] | True |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 |
嵌套列表:
>>>a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0]
['a', 'b', 'c']
>>> x[0][1]
'b'
Python列表函数:
| len(list) | 列表元素个数 |
|---|---|
| max(list) | 返回列表元素的最大值 |
| min(list) | 返回列表元素的最小值 |
| list(seq) | 将元组转换为列表 |
方法:
| list.append(obj) | 在列表末尾添加新的对象 |
|---|---|
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list,index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index,obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort(key=None,reverse=False) | 对原列表进行排序 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
III>补充
间隔截取:
l = [i for i in range(0,15)]
print(l[::2])
输出结果为:
[0, 2, 4, 6, 8, 10, 12, 14]
我们可以这样来理解:
l[start:end:span] #遍历 [start,end),间隔为 span,当 span>0 时顺序遍历, 当 span<0 时,逆着遍历。
#start 不输入则默认为 0,end 不输入默认为长度。
复制列表:
先来看一个不用list方法进行复制列表的情况:
>>> a = [1, 2, 3]
>>> b = a
>>> c = []
>>> c = a
>>> d = a[:]
>>> a, b, c, d
([1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3])
>>> b[0] = 'b'
>>> a, b, c, d
(['b', 2, 3], ['b', 2, 3], ['b', 2, 3], [1, 2, 3])
>>> id(a), id(b), id(c), id(d)
(140180778120200, 140180778120200, 140180778120200, 140180778122696)
>>> c[0] = 'c'
>>> a, b, c, d
(['c', 2, 3], ['c', 2, 3], ['c', 2, 3], [1, 2, 3])
>>> id(a), id(b), id(c), id(d)
(140180778120200, 140180778120200, 140180778120200, 140180778122696)
>>> d[0] = 'd'
>>> a, b, c, d
(['c', 2, 3], ['c', 2, 3], ['c', 2, 3], ['d', 2, 3])
>>> id(a), id(b), id(c), id(d)
(140180778120200, 140180778120200, 140180778120200, 140180778122696)
可以看到a b c 三个是同一id值,当改变当中任一列表元素的值后,三者会同步改变。但d却不会改变,当d的元素值改变时,反之其他三个列表中的元素值不会改变。
另外一种复制的方法:
original_list=[0,1,2,3,4,5,6,7,8]
copy_list=original_list.copy()
copy_list=copy_list+['a','b','c']
print("original_list:",original_list)
print("copy_list modify:",copy_list)
运行结果:
original_list: [0, 1, 2, 3, 4, 5, 6, 7, 8]
copy_list modify: [0, 1, 2, 3, 4, 5, 6, 7, 8, 'a', 'b', 'c']
创建空列表:
>>> list_empty = [None]*10
>>> list_empty
[None, None, None, None, None, None, None, None, None, None] #None的含义即为,什么也没有
列表遍历:
# 正序遍历:
list01 = ["Googl",'Runoob',1997,2002]
for i in range(len(list01)): #用法1
print(list01[i])
for item in list01: #用法2
print(item)
# 反向遍历
for i in range(len(list01) - 1, -1, -1):
print(list01[i])
列表的排序:
利用列表中的sort方法可以快速就地进行排序,字符串按首字母进行排序:
a=[1, 51, 31, -3, 10]
a.sort()
print(a)
s=['a','ab','3e','z']
s.sort()
print(s)
输出结果为:
[-3, 1, 10, 31, 51]
['3e', 'a', 'ab', 'z']
关于列表切片:
格式:【start :end:step】
解释:start:起始索引,从0开始,-1表示结束 end:结束索引 step:步长,end-start,步长为正时,从左向右取值。步长为负时,反向取值
3.Tuple(元组)
I>基础
Python中的元组可以当成是只读的列表来看待,使用()来进行创建,在这其中添加元素,使用逗号隔开。
当创建包含单一元素的元组时,要在唯一的元素后加逗号,以免括号被识别为运算符。
>>> tup1 = (233)
>>> type(tup1) # 不加逗号,类型为整型
<class 'int'>
>>> tup1 = (233,)
>>> type(tup1) # 加上逗号,类型为元组
<class 'tuple'>
II>可进行的元组操作
元组与字符串相似,也可以进行截取与组合的操作。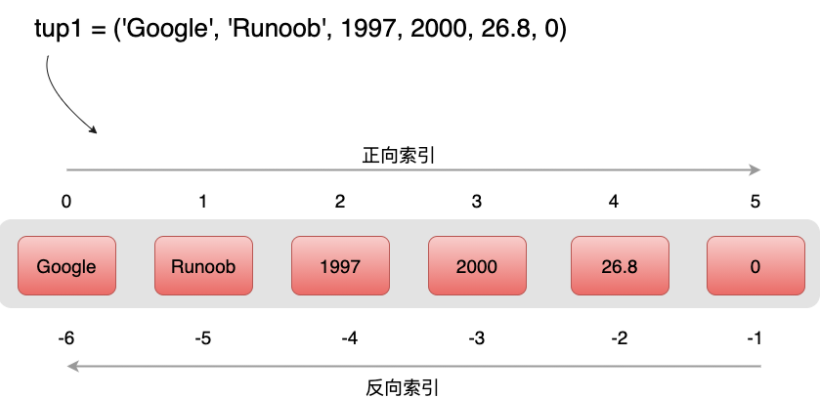
访问元组:
#!/usr/bin/env python3
tup1 = ('csn', 'python', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print ("tup1[0]: ", tup1[0])
print ("tup2[1:5]: ", tup2[1:5])
执行结果如下:
tup1[0]: csn
tup2[1:5]: (2, 3, 4, 5)
元组中的元素值是不允许修改的,但我们可以对元组进行链接和组合,与列表结果相同。
删除元组:
元组中的元素是不允许删除的,但我们可以使用del语句来删除整个元组。
del tup
元组运算符与字符串一样,拥有相同的表达式。
| Python表达式 | 结果 |
|---|---|
| len((1, 2, 3) | 3 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) |
| ('Hi!') * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') |
| 3 in (1, 2, 3) | True |
| for x in (1, 2, 3): print(x, end=" ") | 1 2 3 |
III>补充
通过间接方法进行元组的修改:
tuple1 = (1,2,4,5)
tuple2 = tuple1[:2] + (3,) + tuple1[2:]
print(tuple2)
输出结果为:
(1, 2, 3, 4, 5)
可变的Tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
其实并不是Tuple真正的变化了,而是Tuple中的元素存在可变的数据类型,只是里面的列表中的数据发生了改变,导致Tuple好像发生了改变。
元组的装包与拆包:
a=1,2,3
#它其实等价于下面的代码
a=(1,2,3)
#因为等号左边只有1个变量,而等号右边有3个值,因此自动装包成为一个元组
a,b,c=(1,2,3)
#自动拆包,得到a=1,b=2,c=3
当你返回多个变量,而外面只用一个变量去接收,会接收到一个元组;而当你用多个变量去接,就能对应的接收到每个值,这是因为自动拆包
错误示范:
a=10
b=20
a,b=b,a,1
此代码会报错为:too many values to unpack,也就是说元组中有三个值需要拆包,而你只用了2个值去接受,证明确实执元组执行时有一个拆包动作。
VI>计划
本节没有讲述关于具名元组(-- namedtuple)的使用,暂时先贴一个大概在此:
collections.namedtuple(typename, field_names, verbose=False, rename=False)
- typename:元组名称
- field_names: 元组中元素的名称
- rename: 如果元素名称中含有 python 的关键字,则必须设置为 rename=True
- verbose: 默认就好
4.Dictionary(字典)
I>基础
字典是一种可变容器模型,可存储任意类型的对象。整个字典包括在花括号{}中,用逗号进行分割。
字典中的键值对是我们需要重点了解的内容。键值对的格式为:key=>value,用冒号进行分割。
最终其形式为:
d = {key1 : value1, key2 : value2, key3 : value3 }
其中键是唯一的,但值不必,值可以取任意的数据类型,但键必须不变。
几种字典实例:
dict = {'name': 'csn', 'python': 123, 'url': 'www.csnlab.asia'}
dict1 = { 'abc': 456 }
dict2 = { 'abc': 123, 98.6: 37 }
II>可进行的字典操作
访问字典中的值:
#!/usr/bin/env python3
dict = {'name': 'csn', 'python': 123, 'url': 'www.csnlab.asia'}
print ("dict['name']: ", dict['name'])
print ("dict['Age']: ", dict['url'])
输出结果:
dict['name']: csn
dict['url']: www.csnlab.asia
修改字典:
#!/usr/bin/python3
dict = {'Name': 'csn', 'Age': 18, 'Class': 'First'}
dict['Age'] = 8 # 更新 Age
dict['School'] = "XTU" # 添加信息
print ("dict['Age']: ", dict['Age'])
print ("dict['School']: ", dict['School'])
输出结果:
dict['Age']: 8
dict['School']: XTU
删除字典中的元素:
#!/usr/bin/env python3
dict = {'Name': 'csn', 'Age':18, 'Class': 'First'}
del dict['Name'] # 删除键 'Name'
dict.clear() # 清空字典
del dict # 删除字典
字典内置函数:
| 函数 | 描述 |
|---|---|
| len(dict) | 计算字典元素个数,即键的总数。 |
| str(dict) | 输出字典,可以打印的字符串表示 |
| type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型 |
字典内置方法:
字典的内置方法有很多,在此处不进行一一罗列,说几个初学时不能一下看出输出结果的方法:
radiansdict.fromkeys():
dict.fromkeys(seq[, value]) #seq -- 字典键值列表。 value -- 可选参数, 设置键序列(seq)对应的值,默认为 None。
实例:
#!/usr/bin/python3
seq = ('name', 'age', 'sex')
dict = dict.fromkeys(seq)
print ("新的字典为 : %s" % str(dict))
dict = dict.fromkeys(seq, 10)
print ("新的字典为 : %s" % str(dict))
#输出:
新的字典为 : {'age': None, 'name': None, 'sex': None}
新的字典为 : {'age': 10, 'name': 10, 'sex': 10}
in操作符:
key in dict
item方法:
#!/usr/bin/env python3
dict = {'Name': 'csn', 'Age': 7}
print ("Value : %s" % dict.items())
输出结果:
Value : dict_items([('Age', 7), ('Name', 'csn')])
popitm方法:
pop(key[.default]) #删除字典给定值key所对应的值,返回值可以是被删除的,但key值必须给出。
popitem():随机返回并删除字典里的最后一对键和值
III>补充
1.不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住。
#!/usr/bin/env python3 dict = {'Name': 'csn', 'Age': 7, 'Name': '小菜鸟'} print ("dict['Name']: ", dict['Name']) 输出: dict['Name']: 小菜鸟 #输出后小菜鸡替换了原本的小菜鸟
2.字典的键不能改变,所以用数字、字符串、元组充当,而用列表就不可以。
#!/usr/bin/python3
dict = {['Name']: 'Runoob', 'Age': 7} #将此处改为()即可不报错,其他两种也可
print ("dict['Name']: ", dict['Name'])
5.Set(集合)
I>基础
集合时一个无序的不重复元素序列,可以使用大括号{}或者set()函数来创建集合。
创建一个空集合必须使用set(),如果使用{}会造成歧义
集合有着去重功能,即在输出时取舍掉集合中已经出现过的元素。
test={'csn','python','csn','acm'}
print(test)
输出结果为:
{'csn','python','acm'}
II>可进行的集合操作
添加元素:
thisset = set(("Google", "csn", "Taobao"))
thisset.add("Facebook")
print(thisset)
{'Taobao', 'Facebook', 'Google', 'csn'}
输出结果如下:
{'csn', 'Google', 'Taobao', 'Facebook'}
除此之外,还有另外一种添加元素的方式,这种方式可以添加列表、元组、字典等:
# 语法格式为s.update( x )
thisset = set(("Google", "csn", "Taobao"))
thisset.update({1,3})
print(thisset)
{1, 3, 'Google', 'Taobao', 'csn'}
thisset.update([1,4],[5,6])
print(thisset)
{1, 3, 4, 5, 6, 'Google', 'Taobao', 'csn'}
相同的,有添加元素,就会有删除元素:
#语法格式为s.remove( x )
thisset = set(("Google", "csn", "Taobao"))
thisset.remove("Taobao")
print(thisset)
{'Google', 'csn'}
thisset.remove("Facebook") # 集合中本身不存在Facebook这个元素 会提示报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Facebook'
还有一个方法也是移除集合中的元素,不过如果此元素不存在,也不会报错:
#s.discard( x )
thisset = set(("Google", "csn", "Taobao"))
thisset.discard("Facebook") # 不存在不会发生错误
print(thisset)
{'csn','Taobao', 'Google'}
我们还可以使用s.pop()对集合进行元素的删除,删除的方式随着数据类型的不同而有不同,当集合是由字典和字符转换组成时,则随即删除元素;当集合是由列表和元组组成时,则从左边开始删除元素
thisset = set(("Google", "csn", "Taobao", "Facebook"))
x = thisset.pop()
print(x)
清空集合:s.clear() 判断元素时否在集合中存在: x in s
集合内置方法: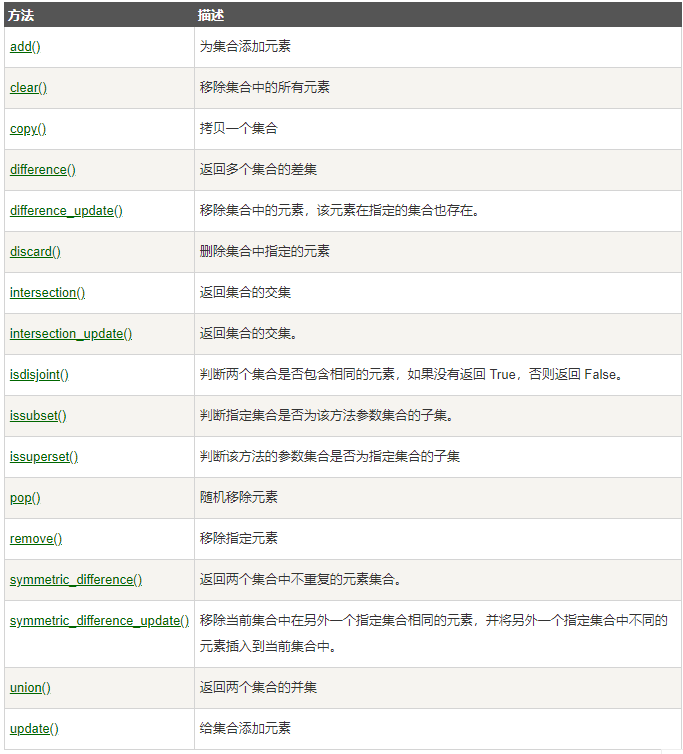
III>补充
s.update( "字符串" ) 与 s.update( {"字符串"} ) 含义不同:
thisset = set(("Google", "Runoob", "Taobao"))
print(thisset)
{'Google', 'Runoob', 'Taobao'}
thisset.update({"Facebook"})
print(thisset)
{'Google', 'Runoob', 'Taobao', 'Facebook'}
thisset.update("Yahoo")
print(thisset)
{'h', 'o', 'Facebook', 'Google', 'Y', 'Runoob', 'Taobao', 'a'}
#s.update( {"字符串"} ) 将字符串添加到集合中,有重复的会忽略。
#s.update( "字符串" ) 将字符串拆分单个字符后,然后再一个个添加到集合中,有重复的会忽略。
创建含有一个元素的集合:
my_set = set(('apple',)) #与创建一个元素的元组相同,最后要加一个逗号
my_set
{'apple'}
注意:请不要以如下的格式创建集合
my_set = set('apple') #少了一个扩起字符串的括号与逗号
my_set
{'l', 'e', 'p', 'a'}
my_set1 = set(('apple')) #少了字符串后的逗号
my_set1
{'l', 'e', 'p', 'a'}
对于Python中list、tuple类型转为集合时,其中重复的元素会被去掉,并且以升序的形式排列
list = [1,1,2,3,4,5,3,1,4,6,5]
set(list)
{1, 2, 3, 4, 5, 6}
tuple = (2,3,5,6,3,5,2,5)
set(tuple)
{2, 3, 5, 6}
6.遍历输出与转换
I>元组的遍历
元组的遍历需要借助range()函数,通过for循环进行遍历
eg:
fruits={"apple","banana","orange"}
for i in range(len(fruits)):
print(fruits[i]) #注意缩进
II>列表的遍历
列表的遍历可以直接使用for循环,也可以借助range()函数。
#直接遍历法
fruit_list=['apple','banana','orange']
for fruit in fruit_list:
print(fruit)
#借助range()函数进行遍历
fruit_list=['apple','banana','orange']
for i in range(len(furit_list)):
print(fruit_list[i])
III>字典的遍历
字典的遍历主要借助于字典中的key值。
fruit_dict={'apple':1,'banana':2,'orange':3}
for key in fruit_dict:
print(fruit_dict[key])
VI>元组、列表、字典之间的互相转换
字典因为有key的关系,其它两者不可以转换为字典。
#对元组进行转换
fruits=('apple','banana','orange')
list(fruits)
#元组转换为字符串
fruits.__str__()
#对列表进行转换
fruit_list=['apple','banana','orange']
tuple(fruit_list)
#列表转换为字符串
str(fruit_list)
#对字典进行转换
fruit_dict = {'apple':1, 'banana':2, 'orange':3}
tuple(fuit_dict)
tuple(fruit_dict.value())
#转换为列表
list(fruit_dict)
list(fruit_dict.value())
#转换为字符串
str(fruit_dict)
二.字符串(str)的常用处理方法
1.写在前面
生成字符串变量str='python String function'
方法使用样例:
print('%s lower=%s'%(a,a.title()))
2.字母处理
全部大写:str.upper() print '%s lower=%s' % (str,str.lower())
全部小写:str.lower() print '%s upper=%s' % (str,str.upper())
大小写互换:str.swapcase() print '%s swapcase=%s' % (str,str.swapcase())
首字母大写,其余小写:str.capitalize() print '%s capitalize=%s' % (str,str.capitalize())
首字母大写:str.title() print '%s title=%s' % (str,str.title())
3.格式化相关
获取固定长度,右对齐,左边不够用空格补齐:str.ljust(width) print '%s ljust=%s' % (str,str.ljust(20))
获取固定长度,左对齐,右边不够用空格补齐:str.ljust(width)
获取固定长度,中间对齐,两边不够用空格补齐:str.ljust(width)
获取固定长度,右对齐,左边不足用0补齐 str.zfill(width)
这个直接理解不太直观,贴一张效果图: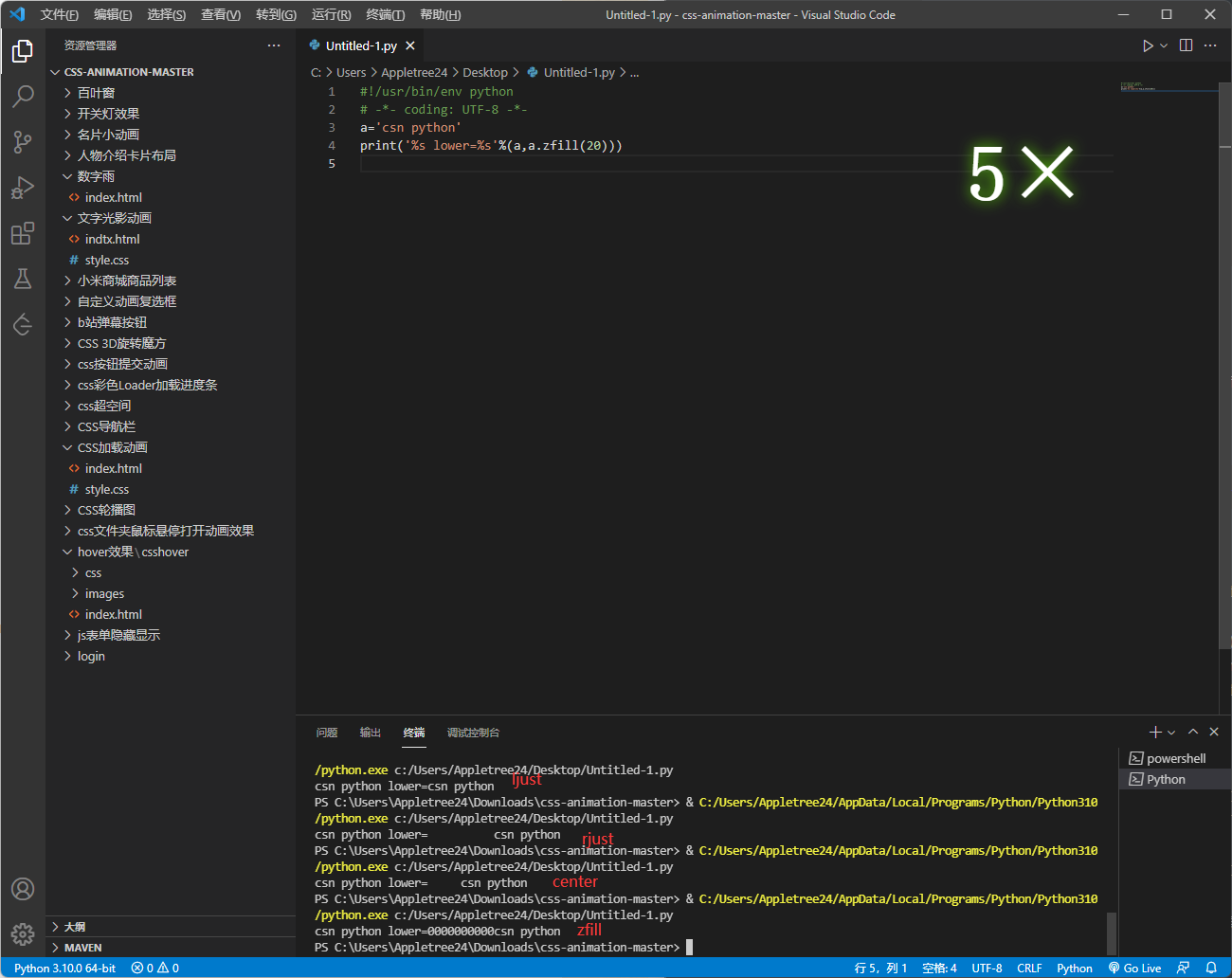
4.字符串搜索相关
搜索指定字符串,没有返回-1:str.find('t')
指定起始位置搜索:str.find('t',start)
指定起始及结束位置搜索:str.find('t',start,end)
从右边开始查找:str.rfind('t')
搜索到多少个指定字符串:str.count('t')
上面所有方法都可用index代替,不同的是使用index查找不到会抛异常,而find返回-1
此处要多加注意,如果存在你指定搜索的字符串,那么会返回0,而不是1,搜索不到时则返回-1
字符串的搜索同样也和截断相同,从0开始第一位,搜索到指定尾下标的前一位。
str.rfind('t')方法的返回值为此字符出现在字符串中的第几个位置,如果是单字符,则很好理解;如果使用的是搜索一个字符串,则返回值为这个字符串首字母所出现在的位置。经编译测试,运用rfind搜索时也是从左开始进行,目前等待解决
str.count并不会返回-1,如果指定的字符串没有出现过,那么会返回0.
5.字符串替换相关
替换old为new:str.replace('old','new')
替换指定次数的old为new:str.replace('old','new',maxReplaceTimes)
如果你不输入想要替换的次数,那么会将指定字符串中的所有符合要求的部分替换,如果你指定了替换的次数,那么Python将会从左到右依次进行替换。
6.字符串去空格及去指定字符
去两边空格:str.strip()
去左空格:str.lstrip()
去右空格:str.rstrip()
去两边字符串:str.strip('d'),相应的也有lstrip,rstrip按指定字符分割字符串为数组:str.split(' ')
上述列表中所提供的方法只能去掉左右两边的空格,并不能去掉字符串中间起到间隔作用的空格。待办
7.默认按空格分隔
str='a b c de'
print '%s strip=%s' % (str,str.split())
str='a-b-c-de'
print '%s strip=%s' % (str,str.split('-'))
正如上面所述,目前暂时掌握的一种方法是将字符串通过split方法进行空格截断为列表,然后通过对列表进行访问达到间接截断的效果。
8.字符串判断相关
是否以start开头:str.startswith('start')
是否以end结尾:str.endswith('end')
是否全为字母或数字:str.isalnum()
是否全字母:str.isalpha()
是否全数字:str.isdigit()
是否全小写:str.islower()
是否全大写:str.isupper()
上述方法返回值均为T/F,并不是数值。
三.文件读写操作
1.I/O操作概述
I/O在计算机中是指Input/Output,也就是Stream(流)的输入和输出。这里的输入和输出是相对于内存来说的,Input Stream(输入流)是指数据从外(磁盘、网络)流进内存,Output Stream是数据从内存流出到外面(磁盘、网络)。程序运行时,数据都是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方(通常是磁盘、网络操作)就需要IO接口。IO接口由操作系统来提供。
操作系统的通用目的如下:
- 硬件驱动
- 进程管理
- 内存管理
- 网络管理
- 安全管理
- I/O管理
操作系统屏蔽了底层硬件,向上提供通用接口。因此,操作I/O的能力是由操作系统的提供的,每一种编程语言都会把操作系统提供的低级C接口封装起来供开发者使用,Python也不例外。
2.文件读写实现原理&操作步骤
由于操作I/O的能力是由操作系统提供的,且现代操作系统不允许普通程序直接操作磁盘,所以读写文件时需要请求操作系统打开一个对象(通常被称为文件描述符--file descriptor, 简称fd),这就是我们在程序中要操作的文件对象。
通常高级编程语言中会提供一个内置的函数,通过接收"文件路径"以及“文件打开模式”等参数来打开一个文件对象,并返回该文件对象的文件描述符。因此通过这个函数我们就可以获取要操作的文件对象了。这个内置函数在Python中叫open(), 在PHP中叫fopen(),
不同的编程语言读写文件的操作步骤大体都是一样的,只是不同的编程语言提供的读写文件的api是不一样的,有些提供的功能比较丰富,有些比较简陋。都分为以下几个步骤:
1)打开文件,获取文件描述符
2)操作文件描述符--读/写
3)关闭文件
需要注意的是:文件读写操作完成后,应该及时关闭。一方面,文件对象会占用操作系统的资源;另外一方面,操作系统对同一时间能打开的文件描述符的数量是有限制的,在Linux操作系统上可以通过ulimit -n 来查看这个显示数量。如果不及时关闭文件,还可能会造成数据丢失。因为我将数据写入文件时,操作系统不会立刻把数据写入磁盘,而是先把数据放到内存缓冲区异步写入磁盘。当调用close方法时,操作系统会保证把没有写入磁盘的数据全部写到磁盘上,否则可能会丢失数据。
3.文件打开模式
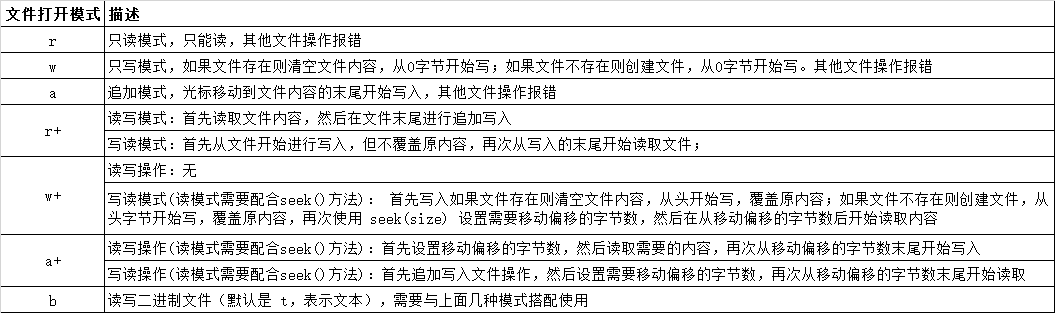
此处只给出Python3的打开文件函数定义,除C语言中使用int flags外,其他语言都具有mode参数
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
4.文件操作实例
首先要明确的是,最好将py文件与需要打开的文件放在同一目录下,或者使用绝对路径。
有很多的方式打开文件,在此处采用with语句块的打开方式。
with open('song.txt', 'r', encoding='utf-8') as f: #as f等同于f=open……
print(f.read())
print(f.closed)
with语句不仅仅可以用于文件操作,它实际上是一个很通用的结构,允许使用所谓的上下文管理器(context manager)。上下文管理器是一种支持__enter__()和__exit__()这两个方法的对象。enter()方法不带任何参数,它在进入with语句块的时候被调用,该方法的返回值会被赋值给as关键字之后的变量。exit()方法带有3个参数:type(异常类型), value(异常信息), trace(异常栈),当with语句的代码块执行完毕或执行过程中因为异常而被终止都会调用__exit__()方法。正常退出时该方法的3个参数都为None,异常退出时该方法的3个参数会被分别赋值。如果__exit__()方法返回值(真值测试结果)为True则表示异常已经被处理,命令执行结果中就不会抛出异常信息了;反之,如果__exit__()方法返回值(真值测试结果)为False,则表示异常没有被处理并且会向外抛出该异常。
5.文件读取相关
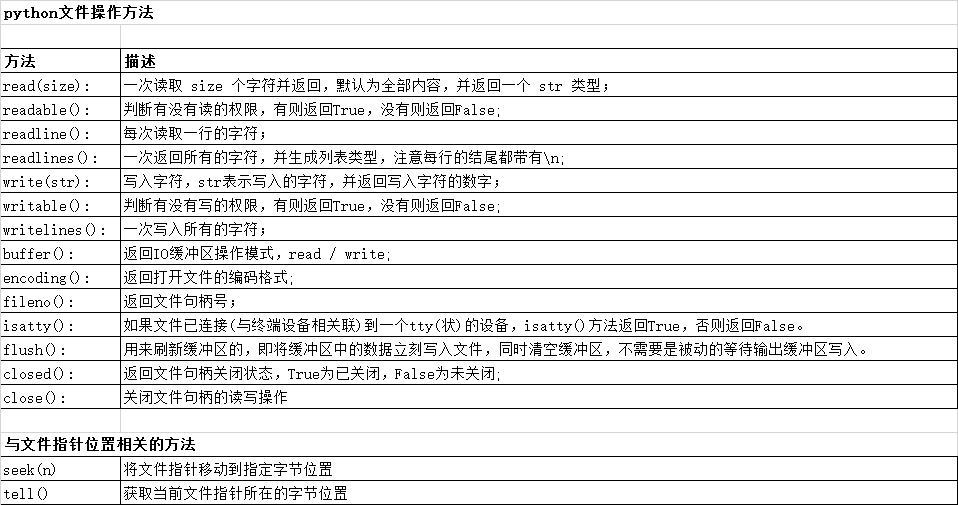
遍历打印一个文件的每一行:
#第一种方法 消耗大量的内存空间
with open('song.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
print(line)
#第二种方法 通过迭代器
with open('song.txt', 'r', encoding='utf-8', newline='') as f:
for line in f:
print(line)
以上代码的输出结果都会显示为在每行内容的之间有一行空白,这是因为文件中每行自带换行符,而print也会输出换行,所以就导致了这种情况的产生,有两种方法可以解决这样的问题。
1.使用print(line,end='')
2.使用line.rstrip()去掉字符串右边的换行符
6.文件读写与字符编码
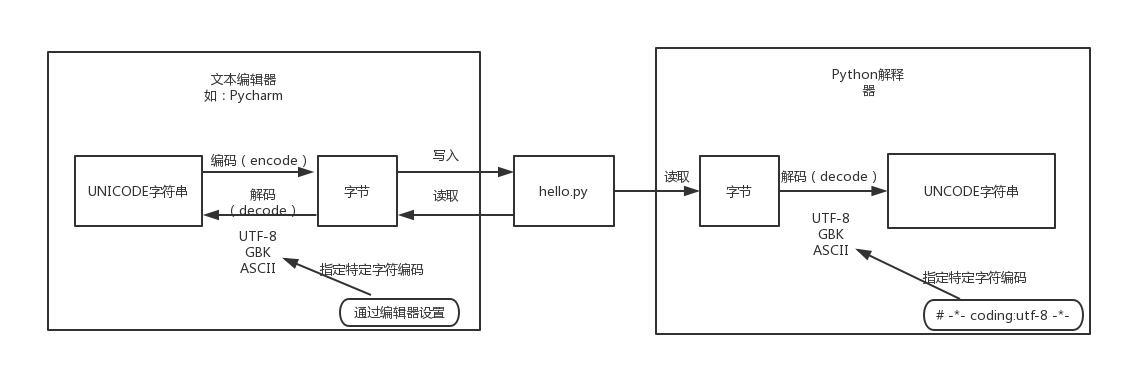
- PyCharm等IDE开发工具指定的项目工程和文件的字符编码: 它的主要作用是告诉Pycharm等IDE开发工具保存文件时应该将字符转换为怎样的字节表示形式,以及打开并展示文件内容时应该以什么字符编码将字节码转换为人类可识别的字符。
- Python源代码文件头部指定的字符编码,如
\*-\* coding:utf-8 -\*-: 它的主要作用是告诉Python解释器当前python代码文件保存时所使用的字符编码,Python解释器在执行代码之前,需要先从磁盘读取该代码文件中的字节然后通过这里指定的字符编码将其解码为unicode字符。Python解释器执行Python代码的过程与IDE开发工具是没有什么关联性的。
关于如何指定字符编码,其实上文中Open函数的定义中,encoding参数就代表这个含义。
关于文件读写时的默认编码问题:
Python中的encoding参数默认值与平台有关,Windows平台默认的字符编码为GBK,而Linux默认的字符编码为UTF-8。
三.5 Python面向对象
1.意图
这个环节本来不在PPT的流程中,要写这个环节的原因是在写with as操作时发现很多面向对象的概念理解十分混乱,所以专门开辟此环节加深巩固。
2.类的相关概念
类是一个抽象的概念,可以理解为具有相同属性的一组对象的集合,类的属性有两种
- 属性(类定义中的变量,别名:静态变量,静态属性)
- 方法(类定义中的函数,别名:动态变量,动态属性)
实例则是类的一个具体的对象,实例唯一操作就是属性引用。
类的定义:
class Csn(其它类名):
pass
其中,Csn为类名,Python中通常使用大驼峰命名法来对类进行命名,类后面的括号中也可以跟随一个类名,表示该类是从这个类继承的,所有类默认继承object类,但(object)默认不写。
每个类默认拥有__dict__方法,可以将类中的属性和方法以字典的形式展现(属性展现格式,属性名:对应的值 方法名:对应的内存地址)
一般用于查询类的所有属性和方法,如果是操作单个属性和方法使用点号,通过万能的点 可以增删改查类中的单个属性和方法
类的实例化:
类的实例化可以得到一个具体的对象。
class Csn():
pass
zzh=Csn()
在创建实例的过程中,还可以传入一些参数,以初始化实例,为此,需要添加一个__init__方法
class Csn():
def __int__(slef,name):
self.name=name
zzh=Csn('zzh')
print(zzh.name)
同时你也可以采用类自定义方法,类的自定义方法,第一个参数也必须是self(指向实例本身),类的自定义方法也可以在类定义代码块外先定义,然后在类定义代码块中引用:
def greet(self,y):
print('Hello %s, I am %s'%(y,self.name))
class Animal():
def __init__(self, name):
self.name = name
p=greet
tiger = Animal('t1')
tiger.p('bb')
对以上代码的解释:首先实例化,创建Animal这个类具体的对象,创建实例时就会调用初始化方法,self忽略,t1的值赋给了name,之后将其赋给self.name,其中animal这个类中,又有great=p。执行tiger.p这一行时,可以看作将greet替代过去,即执行great方法,还是和之前一样,self忽略,bb存在self.name。
类属性:
class Csn(object)
location='XTU'
def __init__(self,name,age):
self.name=name
self.age=age
实例对象绑定的属性只属于这个实例,绑定在一个实例上的属性不会影响其它实例;同样的,类也可以绑定属性,但是类的属性不属于任何一个对象,而是属于这个类。如果在类上绑定一个属性,则所有实例都可以访问类的属性,并且,所有实例访问的类属性都是同一个!也就是说,实例属性每个实例各自拥有,互相独立,而类属性有且只有一份。
在上面的代码中,location就是属于Csn这个class的类属性,此后,通过Csn()实例化所有的对象,都可以访问location,并且得到的是唯一的结果。
输入:
dog=Csn('zzh',18)
print(dog.location) #==>XTU
print(Csn.location) #==>XTU
上文提到的逗号进行增删改查:
Csn.localtion = 'Asia'
print(zzh.localtion) # ==>Asia
类属性和实例属性的优先级:
经过上面的学习或是稍微对实际生产环境的思考,我们其实也可以猜测出正确的结论:
属性可以分为类属性和实例属性,如果类属性和实例属性名字相同时,实例属性优先.
四.with as操作
1.写在前面
在了解with……as之前,我们需要先了解一下try except finally语句。
I>try……expect语句
用于处理程序执行过程中的异常情况,比如语法错误、从未定义变量上取值等等,也就是一些python程序本身引发的异常、报错。比如你在python下面输入 1 / 0:
>>> 1/0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
系统会给你一个ZeroDivisionError的报错。(Python官方提供可捕获的错误类型文档,可以查看)
Try……except的标准格式:
try:
## normal block
except A:
## exc A block
except:
## exc other block
else:
## noError block
程序执行流程是:
–>执行normal block
–>发现有A错误,执行 exc A block(即处理异常)
–>结束
如果没有A错误呢?
–>执行normal block
–>发现B错误,开始寻找匹配B的异常处理方法,发现A,跳过,发现except others(即except:),执行exc other block
–>结束
如果没有错误呢?
–>执行normal block
–>全程没有错误,跳入else 执行noError block
–>结束
异常分为两类:
- python标准异常
- 自定义异常
Python标准异常:
try:
a = 1 / 2
print(a)
print(m) # 此处抛出python标准异常
b = 1 / 0 # 此后的语句不执行
print(b)
c = 2 / 1
print(c)
except NameError:
print("Ops!!")
except ZeroDivisionError:
print("Wrong math!!")
except:
print("Error")
输出:
0.5
Ops!!
当程序执行到print(m)的时候 发现了一个NameError: name 'm' is not defined,于是控制流去寻找匹配的except异常处理语句。发现了第一条匹配,执行对应block。执行完结束。
II>try……finally语句
try:
execution block ##正常执行模块
except A:
exc A block ##发生A错误时执行
except B:
exc B block ##发生B错误时执行
except:
other block ##发生除了A,B错误以外的其他错误时执行
else:
if no exception, jump to here ##没有错误时执行
finally:
final block ##总是执行
tips: 注意顺序不能乱,否则会有语法错误。如果用else就必须有except,否则会有语法错误。
举例:
try:
a = 1 / 2
print(a)
print(m) # 抛出NameError异常
b = 1 / 0
print(b)
c = 2 / 1
print(c)
except NameError:
print("Ops!!") # 捕获到异常
except ZeroDivisionError:
print("Wrong math!!")
except:
print("Error")
else:
print("No error! yeah!")
finally: # 是否异常都执行该代码块
print("Successfully!")
输出:
0.5
Ops!!
Successfully!
2.正式开始with as
With……as结构:
with expression [as variable]:
with-block
看这个结构我们可以获取至少两点信息 1. as可以省略 2. 有一个句块要执行

With……as的执行顺序:
–>首先执行expression里面的__enter__函数,它的返回值会赋给as后面的variable,想让它返回什么就返回什么,只要你知道怎么处理就可以了,如果不写as variable,返回值会被忽略。
–>然后,开始执行with-block中的语句,不论成功失败(比如发生异常、错误,设置sys.exit()),在with-block执行完成后,会执行expression中的__exit__函数。
当with...as语句中with-block被执行或者终止后,如果这个码块执行成功,则exception_type,exception_val, trace的输入值都是null。如果码块出错了,就会变成像try/except/finally语句一样,exception_type, exception_val, trace 这三个值系统会分配值。
这个过程其实等价于:
try:
执行 __enter__的内容
执行 with_block.
finally:
执行 __exit__内容
3.例子
程序无错误:
class Sample(object): # object类是所有类最终都会继承的类
def __enter__(self): # 类中函数第一个参数始终是self,表示创建的实例本身
print("In __enter__()")
return "Foo"
def __exit__(self, type, value, trace):
print("In __exit__()")
def get_sample():
return Sample()
with get_sample() as sample:
print("sample:", sample)
print(Sample) # 这个表示类本身 <class '__main__.Sample'>
print(Sample()) # 这表示创建了一个匿名实例对象 <__main__.Sample object at 0x00000259369CF550>
输出结果:
In __enter__()
sample: Foo
In __exit__()
<class '__main__.Sample'>
<__main__.Sample object at 0x00000226EC5AF550>
步骤分析:
首先整个程序从with as开始执行,执行get_sample()函数,而上方定义的get_sample()函数中,return返回Sample类的实例。
执行Sample类中的enter方法,打印"In__enter_()"字符串,并且将"Foo"这个返回值赋给as后面的sample变量。
执行with后面的码块,即打印"sample: %s"字符串,结果为"sample: Foo"
执行with-block码块结束,返回Sample类,执行exit方法。在执行with码块时并没有错误返回,所以type,value,trace这三个arguments都没有值。直接打印"In__exit__()"
程序有错误:
class Sample:
def __enter__(self):
return self
def __exit__(self, type, value, trace):
print("type:", type)
print("value:", value)
print("trace:", trace)
def do_something(self):
bar = 1 / 0
return bar + 10
with Sample() as sample:
sample.do_something()
输出结果:
type: <class 'ZeroDivisionError'>
value: division by zero
trace: <traceback object at 0x0000019B73153848>
Traceback (most recent call last):
File "……py", line 16, in <module>
sample.do_something()
File "……py", line 11, in do_something
bar = 1 / 0
ZeroDivisionError: division by zero
步骤和上面无错的程序大致相同,唯一不同的是这次Python会帮助我们捕获错误信息并抛出。
当执行with码块时,bar的分母为0,所以Python会捕获到内置的ZeroDivisionError错误,终止With码块的执行,执行exit类方法,带入ZeroDivisionError的错误信息值,将type、value、trace打印出来。
五.正则表达式
1.简介
Regex(正则表达式)语法让新手很挠头,原因在于它其实是象征性的――只有单个字符,而不是关键字。正则表达式代码看起来某人在键盘上睡着了。如果你想一辈子不敢碰正则表达式语言,不妨看看这个极端例子:JSON解析器(http://www.perlmonks.org/?node_id=995856)。
不过,正则表达式是Linux世界的基石。旧的UNIX操作系统及Linux后续衍生版的核心原则之一就是大量使用文本。文本到处使用,用于配置、命令行上以及协议中。正则表达式帮助开发人员管理好文本。
正则表达式是用来检索信息的一种搜索模式,比起传统的搜索方式,正则表达式效率更高,可以让程序员偷懒(不是
按照刘洋学长所说的,正则表达式会在爬虫的编写中起到很大作用,但目前初步学习Python阶段,还没有真正意义上应用过正则表达式,对其语法并不熟练,计划在学习完Python后学习一下爬虫相关知识,巩固练习正则表达式。
<hr/
从此处往下内容质量参差不齐,原因为时间安排不合理,或是内容学习完毕,但认为罗列太多网上一搜就有的资料毫无效率,故仅写出易错点或是自己的思考
2.思考
正则表达式的搜索可以将目的字符串拆开,比如我要检索一个邮箱,appletree@csn.com,我可以采用下面的方式:
\b[\w.%+-]+@[\w.-]+.[a-zA-Z]{2,6}\b
我们将@号前面的字符串拆开搜索,将固定会存在的@号后面的内容进行搜索,同理再对会固定存在的.后面的内容进行检索,最后合并,一齐匹配到众多字符串中的邮箱
其中的加号并不能像Java中的理解为合并,即使不进行合并,也是表示搜索出一截一截的字符串,此处使用加号的目的是至少匹配符合前面字符集的任意一项,同样的,,要使用转义进行修饰,否则会被识别为检索除\n以外的内容。
六.Python网络请求——requests库
1.写在前面
Python官方是自带一个可以操作网页URL的库的,名字叫做urllib,顾名思义。但这个模块很麻烦,同时缺少很多高级功能,所以有人编写了requests这个库,让大家都可以Pythoner的来访问网络资源。
首先我们要安装requests库,用过Linux后这方面就很简单,要么就配源,要么你就挂梯子,命令如下
pip install requests
之后便可在IDE或是编辑器中import requests了。
值得一提的是,这个库的官方提供了中文版的官方介绍文档,所以我们可以很方便的去学习这个库的用法,link:
https://docs.python-requests.org/zh_CN/latest/user/quickstart.html#id2
2.requests内容
1.发送请求
使用 Requests 发送网络请求非常简单。
让我们来看下面这个例子:
import requests #导入模块
r = requests.get('https://api.github.com/events') #要注意 在获取网页信息的同时 会返回一个response的对象
r = requests.post('http://httpbin.org/post', data = {'key':'value'})
r = requests.put('http://httpbin.org/put', data = {'key':'value'})
r = requests.delete('http://httpbin.org/delete')
r = requests.head('http://httpbin.org/get')
r = requests.options('http://httpbin.org/get')
#不难理解,上面的post、put等都是HTTP中的请求,其目的也是相同的,request就是如此的优秀
#Response对象包含服务器返回的所有信息,同时也包含向服务器请求的Request信息
2.传递URL参数
学习过JSON我们都清楚,服务端与我们之间的数据交互都是以字符串形式进行交互的,如果你想要传输一些其它类型的数据给服务端,就需要使用parse()来将数据转换为JavaScrpit对象才可以在网页上使用JSON数据。
但requests包并不需要,你只需要使用params关键字参数即可,如下:
payload = {'key1': 'value1', 'key2': 'value2'} #Dic中value为none的键都不会被添加到URL的查询字符串中
r = requests.get("http://httpbin.org/get", params=payload)
print(r.url) >>>http://httpbin.org/get?key2=value2&key1=value1
#将列表作为值传入:
payload = {'key1': 'value1', 'key2': ['value2', 'value3']}
r = requests.get('http://httpbin.org/get', params=payload)
print(r.url) >>>http://httpbin.org/get?key1=value1&key2=value2&key2=value3
3.响应内容
import requests
r=requests.get('https://api.github.com/events')
r.text >>>u'[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests会自动解码来自副武器的内容,大多数Unicode字符集都可以被直接解码。
请求发出后,Requests会在你访问文件时推测需要使用的文本编码,我们可以通过r.encoding属性查看或是改变这个编码。如果你改变了编码,那么下次你在打开文件时,会使用你指定的这个编码。
同样的,你也可以自制一个属于你的编码,并且使用这个编码来处理文件。
r.encoding >>>'utf-8'
r.encoding='ISO-8859-1'
Json响应内容:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.json()
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
requests中有一个内置的JSON解码器,如果JSON解码失败,r.json()会抛出一个异常,例如响应内容为401,那么就会为你抛出ValueError: No JSON object could be decoded异常。
成功调用r.json()并不意味着相应的成功。有的服务器会在失败的响应中包含一个JSON对象(比如HTTP500的错误细节)。这种JSON会被解码返回。要检查请求是否成功,请使用r.raise_for_status()或者检查 r.status_code 是否和你的期望相同。
4.更加复杂的POST请求
假如你现在想为服务器发送一个表单,那么你可以传递一个dic给data参数。字典会在发出请求时被自动编码为表单形式:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("http://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
你同时还可以为data参数传入一个元祖列表。在表单中多个元素使同一键值时,这种方式十分有效:
>>> payload = (('key1', 'value1'), ('key1', 'value2'))
>>> r = requests.post('http://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
正如上文所言,当你想要简单传输一个字符串时,你的数据会被直接发送出去。
在2.4.2之后的版本中,你还可以直接发送JSON数据。
5.响应状态码
在此不过多赘述HTTP协议中的常用状态码,只记录Requests模块中的用法。
我们可以使用如下代码来检测响应状态码:
>>> r = requests.get('http://httpbin.org/get')
>>> r.status_code >>>200 #(正常访问)
如果发送了一个错误请求,我们可以通过response.raise_for_status()来抛出错误信息:
>>> bad_r = requests.get('http://httpbin.org/status/404')
>>> bad_r.status_code
404
>>> bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
如果一切正常,response.raise_for_status()将抛出None
6.响应头
我们可以使用响应头来耗费较少的流量获取网页信息。这将会以字典形式呈现。
>>> r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}
这个字典比较特殊,对大小写并不敏感,我们可以使用任意大写形式来访问。
>>> r.headers['Content-Type']
'application/json'
>>> r.headers.get('content-type')
'application/json'
7.Cookie
如果某个响应中包含一些cookie,我们可以快速访问他们:
>>> url = 'http://example.com/some/cookie/setting/url'
>>> r = requests.get(url)
>>> r.cookies['example_cookie_name']
'example_cookie_value'
如果你像向服务器发送你的cookies到服务器,可以使用cookies参数:
>>> url = 'http://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = requests.get(url, cookies=cookies)
>>> r.text
'{"cookies": {"cookies_are": "working"}}'
8.超时
我们可以设定requests在经过timeout参数设定的秒数时间之后停止等待响应。建议所有的生产代码都应该使用这一参数。如果不使用,程序可能会永远失去响应:
>>> requests.get('http://github.com', timeout=0.001)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
requests.exceptions.Timeout: HTTPConnectionPool(host='github.com', port=80): Request timed out. (timeout=0.001)
timeout所设置的时间仅对连接过程有效,与响应体的下载无关。timeout其实就是你与服务器应答的时间,如果没有应答会等待响应。
9.一个爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status() #如果不是200,产生异常requests.HTTPError
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__": #关于此行解释,如果在命令行中运行此程序,会自动执行下面的内容 在其他地方则不会
url = "http://www.baidu.com"
print(getHTMLText(url))
我们来借助上面这个框架了解Requests库主要的7个方法:
| requests.request() | 构造一个请求,支撑一下各方法的基本方法 |
|---|---|
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCT |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
七.Python常用 JSON库
1.写在前面
首先和requests一样,如果我们要使用JSON函数,那么我们先要引入JSON库:
import json
json库中有两个函数:
json.dumps:将 Python 对象编码成 JSON 字符串
json.loads:将已编码的 JSON 字符串解码为 Python 对象
2.json.dumps
语法:
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
和大多数函数语法一样,参数让人眼花缭乱,但其实在实际使用过程中,大多数参数都默认即可。
举例:
#!/usr/bin/python
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
data2 = json.dumps({'a': 'csn', 'b': 7}, sort_keys=True, indent=4, separators=(',', ': '))
print(data2)
输出结果:
{
"a": "csn",
"b": 7
}
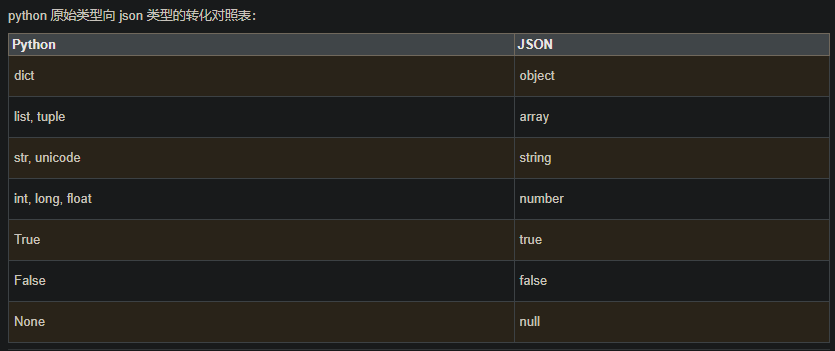
Python的原始类型向json类型转化对照表:
3.json.loads
json.loads用于解码JSON数据。该函数返回Python字段的数据类型。
举例:
#!/usr/bin/python
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print(text)
结果:
{u'a': 1, u'c': 3, u'b': 2, u'e': 5, u'd': 4}
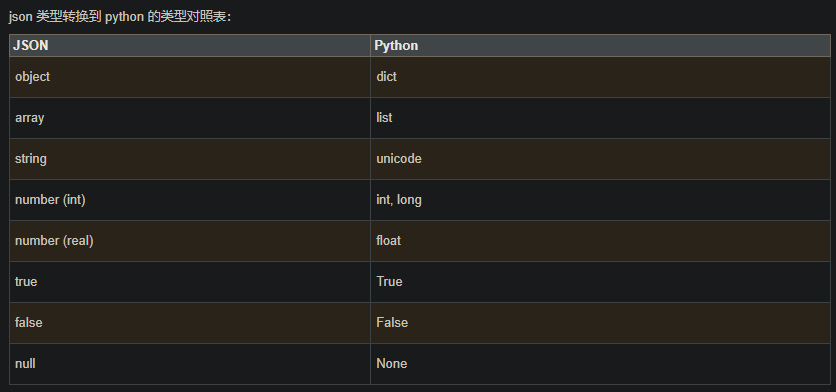
json转化到Python类型的对照表:
4.第三方JSON库
I>Demjson
Demjson是Python的第三方模块库,可用于编码和解码JSON数据,包含了JSONLint的格式化及检验功能。
有人可能会问,JSON库已经可以解码编码了,Demjson库的改进在哪里呢?
我们来看几个例子:
import demjson
string='''
{
id: 'aaa',
columnName: 'bbb',
'columnLink': 'ccc',
time: 'ddd',
'title': 'eee',
titleLink: 'fff',
'desc': 'ggg'
}
'''
print(demjson.decode(string))
当你拿到十分不规则的JSON数据时,例如单引号的key,你便需要使用Demjson进行解码了;
import json
import demjson
data1 = {
"serviceCode":"init",
"idType":"CETP000001",
"idCardNo":"110101199011017819",
"productCode":"PDCD000012",
"customerName":"zzh",
"pid":"cW89bXXz2RVJPV9F1RLVjQ==",
"transactionId":"3746930761617",
"applyType":"1"
}
json_data = json.dumps(data1)
print(json_data)
print(type(json_data)) # str
demjson_data = demjson.encode(data1,encoding='utf-8') # 将数据转换为json 字符串,并可以指定编码格式
print(demjson_data)
print(type(demjson_data)) # bytes
print(json_data.encode('utf-8'))
同时,Demjson还可以指定编码格式,一般的Python解释器都使用Unicode,直接用json转换json数据,但是demjson可以指定编码格式,比如利用utf'-8解决中文乱码问题。
json在解析不规则的json时会出现错误,例如:# ValueError: Expecting property name: line 1 column 2 (char 1),json只能解析规则的json字符串,字典中的key要使用双引号,没有双引号或者使用单引号都不能正常解析。同时,如果你使用了Demjson进行JSON字符串的解码,在输出时,Demjson会自动为你将单引号改为双引号进行输出。
Demjson中有两个常用的方法:
| encode | 将Python对象编码成Json字符串 |
|---|---|
| decode | 将已编码的JSON字符串解码为Python对象 |
5.终极博弈:DemJSONVsSimpleJSON
在我们开始二者的较量前,我们需要先了解一下DemJSON的对手——SimpleJSON。
首先我们要明确一点,在Python下有很多优秀的Web框架,其中Django更是重量级,许多成功的网站和APP都基于这个框架,那么SimpleJSON便是这个框架中内置的一个模块。
Python-json性能不佳,2005年后再也没有更新过;demjson是个比较新的模块,simplejson是Django框架的内置模块。
了解这三者后,我们开始Demjson和Simplejson的对决。
其实总结起来也非常清晰明了:
首当其冲的是文件的大小问题,Simplejson采用包的形式,里面有5个文件,而demjson是单个文件,但这一个文件的大小却是前者五个都无法匹及的。
而在速度方面,同样也是simplejson更胜一筹。
至于SimpleJSON和Python-json的比较,在dumping方面,json要比simplejson更快,在loading方面,simplejson则优于json。
八.最后的题外话
在学习以上内容的过程中,除了要求学习的知识外,或多或少的学到了其他触类旁通的知识,特此在下面进行记录,以备以后时不时的需要:
SEO(搜索引擎优化):SEO(Search Engine Optimization):汉译为搜索引擎优化。是一种方式:利用搜索引擎的规则提高网站在有关搜索引擎内的自然排名。目的是让其在行业内占据领先地位,获得品牌收益。很大程度上是网站经营者的一种商业行为,将自己或自己公司的排名前移。link:百科
SSL证书:从前面我们可以了解到HTTPS核心的一个部分是数据传输之前的握手,握手过程中确定了数据加密的密码。在握手过程中,网站会向浏览器发送SSL证书,SSL证书和我们日常用的身份证类似,是一个支持HTTPS网站的身份证明,SSL证书里面包含了网站的域名,证书有效期,证书的颁发机构以及用于加密传输密码的公钥等信息,由于公钥加密的密码只能被在申请证书时生成的私钥解密,因此浏览器在生成密码之前需要先核对当前访问的域名与证书上绑定的域名是否一致,同时还要对证书的颁发机构进行验证,如果验证失败浏览器会给出证书错误的提示。在这一部分我将对SSL证书的验证过程以及个人用户在访问HTTPS网站时,对SSL证书的使用需要注意哪些安全方面的问题进行描述。 link:runoob
HTTP与HTTPS:超文本传输安全协议(英语:Hypertext Transfer Protocol Secure,缩写:HTTPS,常称为HTTP over TLS,HTTP over SSL或HTTP Secure)是一种网络安全传输协议。具体介绍以前先来介绍一下以前常见的HTTP,HTTP就是我们平时浏览网页时候使用的一种协议。HTTP协议传输的数据都是未加密的,也就是明文,因此使用HTTP协议传输隐私信息非常不安全。HTTP使用80端口通讯,而HTTPS占用443端口通讯。在计算机网络上,HTTPS经由超文本传输协议(HTTP)进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的,是提供对网络服务器的身份认证,保护交换数据的隐私与完整性。这个协议由网景公司(Netscape)在1994年首次提出,随后扩展到互联网上。link:runoob
接口与API:接口是一种与类相似的结构,只包含常量和抽象方法。可以把接口当作是公共场所办理业务的窗口,提供给你服务,但你并不需要了解他们是如何给你提供服务的,你只需要为你提供服务所带来的产品即可。API则是应用程序编程接口,顾名思义,就是提供应用程序与开发人员基于某软件或硬件得以访问的一组例程。
JSON的定义与语法。
Python中的迭代器与生成器;Python中一些基础报错的原因与解决方法。
开发中的前后端概念,前后端分离、服务器端渲染这两种不同的模式。
包括温习的上述学习内容中没有实际要求的Web基础、HTTP协议等。
此次Python学习时间非常短,仅仅是做完了一些个人觉得较好的资料的摘录与阅读时的理解,想要达到真正使用Python的水平还望尘莫及,所以在这篇文档封笔后,将转战至Python的语法与方法的熟练与实战,尝试使用Python编写爬虫,或是使用Python制作微信小程序,同时会学习一些开发方面的内容。专业课内知识尽快结束线性代数,抽出时间学习离散数学,补与计科专业的差距,阅读群文件中的算法笔记,达到期末考试不挂科的程度,若有时间会学习算法与数据结构方面的内容,这次学习就到此为止。
九.参考文献
https://www.runoob.com/python/python-tutorial.html
https://www.runoob.com/json/json-tutorial.html
https://www.cnblogs.com/ming-4/p/10260693.html
https://www.cnblogs.com/sunyubin/p/9753340.html
https://www.cnblogs.com/hackpig/p/8206566.html
https://www.cnblogs.com/yyds/p/6186621.html
https://blog.csdn.net/menghuanshen/article/details/79057120
https://blog.csdn.net/lidew521/article/details/86656732
https://blog.csdn.net/alicelmx/article/details/81004789
https://blog.csdn.net/qiqicos/article/details/79200089
https://www.cnblogs.com/DswCnblog/p/6126588.html
https://blog.csdn.net/kevinbai_cn/article/details/84367065
https://blog.csdn.net/qq_41187256/article/details/79687084
https://blog.csdn.net/mieleizhi0522/article/details/82142856/
https://blog.csdn.net/qiqicos/article/details/79208039
https://www.runoob.com/python/python-reg-expressions.html
https://blog.csdn.net/weixin_40431584/article/details/89031522
https://2.python-requests.org/zh_CN/latest/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号