Http协议
HTTP协议
1.何为HTTP协议
HTTP协议又名超文本传输协议,是一种基于TCP/IP的传输协议,顾名思义,其传输的内容为超文本内容,在互联网早期,我们只能传输非二进制的文本,邮件间相互的来往也不能像现在一样插入文档、视频、音频等二进制内容,网页内也无法拥有现在我们可以看到的视频、图片等,于是便有了超文本传输协议,一种可以传输超越文本的内容的协议。
HTTP协议是规定浏览器与服务器之间交互的一种协议,其他常见的协议还有FTP协议,规定两台电脑间传送文件所要遵守的协议,事实上,有许许多多的人们基于TCP/IP协议发明了许多不同的协议,甚至有人已经解决TCP/IP协议的弊端,但却并没有流行起来,可见TCP/IP应用范围之广。
2.HTTP协议都包括什么
<form action="DataBase.php" method="POST">
Name:<input type="text" name="ID">
<br><br>
<input type="submit" value="submit">
</form>
上述是一个非常简单的HTML表单,通过链接同级目录下一个叫做DataBase.php的php文件将表单内容以POST方法传输到php文件中。php文件则可以利用$_POST方法进行表单内容的获取。
何为表单:
表单是收集信息的一种工具,在HTML语法中使用"form"标签来实现,举个十分简单的例子,当你在注册你的游戏账号时,你将会在指定的输入框(input)内输入符合内容的信息,并且还会有一套检测机制检测你输入的内容究竟是否符合要求(正则表达式),最终当你点击提交按钮后,会提示你账号注册成功,而你的信息就会被发送到指定的数据库,拿上述的PHP举例,信息并不是直接通过所谓“INSERT INTO”语句进行了插入,而是通过连接了一个PHP文件,PHP文件中使用不同类型的方法连接到了指定数据库,执行指定的语句,最终完成将信息插入的过程。
何为POST方法
HTTP协议是一种规定服务器与浏览器进行交互的协议,既然交互那就要有各式各样的方法,人们为HTTP协议规定有如下请求方法:
1.GET
2.POST
3.SEND
4.HEAD
5.TRACE
……
最常用的是POST、GET。
POST和GET都可以理解为想服务器发送了信息,但两种方法其实有很大不同,例如POST方法会比GET方法略微安全一些,URL中不会直接显示所提交的内容。
当你点击提交的按钮时,其实浏览器就向服务器发送了一个POST请求,服务器收到POST请求后与浏览器进行验证,通过后将你的信息录入库中,之后你在登陆账号时,就会从客户端(浏览器)向服务端(服务器)发送一个请求,服务器向数据库请求,数据库查询到你的最新密码,与你所输入的内容进行匹配,最后验证是否相同,相同则登陆成功,不相同则登陆失败。
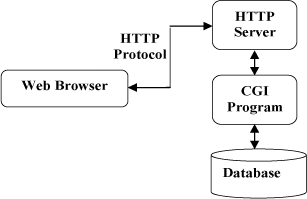
CGI是一种浏览器与你的服务器之间交互的程序,一般负责用来解释来自表单的信息,必须在网络服务器上进行运行。
HTTP状态码
当你在访问一些页面时,可能会遇到一些不知意义的数字,伴随而来的是网页的无法正常显示,最常见的应该就是404了、其次可能还有502、503、500等,这些数字其实就是人们按照一定规则所设置的HTTP状态码,用于向人们反馈到底你所请求的是个什么状态。
比如当你看到404时,后面会跟随着“Not Found”,这代表404这个状态码翻译过来就是找不到的意思,服务器无法根据你客户端的请求找到资源。一个网站的404网页是必须要创建的,这有着十分重大的意义。
502 Bad Gateway,当时体育课抢课时,报错的代码就是502和404,502则代表网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应。
又比如403 Forbidden,顾名思义,就是服务端阻止了你的请求,拒绝了你。
500 Internal Server Error 服务器内部错误,无法完成请求。
上述代码都是错误的,有问题的,肯定是人们不想看到的,那人们想看到什么样子的呢,例如200,人们就非常喜欢看到。
200代表OK,一般来说用于GET和POST请求,也就是说一切安然无恙,执行的井然有序后你就会看到200的状态码,但一般情况下你是看不到的,直接就正常浏览网页了,但是你还是要知道当你正常浏览网页时,其实状态码是200.
状态码有将近二十来种,人们是怎么记住他们的呢,实际上是有分类标准的:
状态码都是三位数字,人们按照开头的第一个数字进行划分。
例如1开头的状态码就代表信息,服务器收到请求,需要请求者继续执行一个什么操作
2开头就代表成功,也是人们最喜欢看到的一类状态码
3开头就代表重定向,比如一些网站会做一个301跳转,一些用户仍然喜欢用www加在域名前进行网站的访问,为了避免不必要的麻烦,网站所有者会为这些网址做一个重定向跳转,帮助用户跳转到正确的页面。
4开头就代表客户端错误,5开头则代表服务端错误,这些都是人们不想看到的状态码。
3.学习了HTTP协议,我能获得什么
如果我们要聊你能获得什么的话题,首先我们要分类讨论一下。
如果你比较喜欢研究算法,或者说你对计算机的了解仅仅只是算法一词,我要学一门效率极高的语言用天才程序员想出的效率极高的算法,那么我很抱歉的说一句,你学习HTTP协议可能并不能为你带来什么,而且可能你在后来学习数据结构时,也不觉得能带来什么,其实这些类比都有失妥当,比如HTTP协议其实根本就不是什么晦涩难懂的东西,他就是个协议而已,我甚至觉得学习它比你花几个小时学习一门新语言的语法还要快就可以解决,你只需要看,了解,记住。但是其实HTTP协议不能为你带来什么引起质变的东西,但我还是希望你可以试着学一学,技多不压身吗,何况连算法都不在话下,HTTP协议也不是问题了。
如果你对计算机很感兴趣,觉得方方面面都很想学习,那我觉得你学习HTTP协议应该会兴奋,我自认为HTTP协议、TCP/IP协议这些前人已经深思熟虑制定好的规则是非常值得我们学习的,就好像数据结构、计算机组成原理、操作系统这些东西一样,你学完以后真的就能写出来操作系统,真的就可以用struct实现一个媲美人家已经写好的数组的功能吗?难道灵光一闪就能够想出和雷神之锤那种平方根倒数速算法一样的上帝算法吗?这当然不能,但意义在于你终于更加明白计算机的美丽之处,以及你所日常使用的东西其实都复杂无比,充满着人类的智慧,这还不够令人兴奋吗?
4.说了很多废话,HTTP协议到底能干些什么
其实HTTP协议什么也不能干,他根本就不是个工具,他只是个协议,试问我们能让法律去判决哪个人该受什么样的刑罚吗?肯定不行。
都是法官在依据法律执行罢了,HTTP协议也是如此,你现在已经知道了一套体系的运行规则,你当然就可以利用它。
5.举例
举个例子。
当你打开一个软件,在转圈加载时,就相当于你客户端已经在向服务端开始请求了,开始拉取信息。
服务端返回后,出现了许许多多的等待你使用的功能。
比如一个下面图片里的功能,填写许多信息,聪明人都能理解到了,这不就相当于我注册游戏账号吗,我填写对方要的信息,然后我把我的信息填到一个类似于表格的地方里,最后点击提交按钮交上去,然后他就告诉我我填的是否符合要求,成功了还是失败了。

这不就是个submit吗。

好了,如果你真的读懂了,那么你现在应该就能联想到一套操作,我觉得稍微懂的都已经懂了。
如果我可以有一台服务器,服务器上面可以定时部署一个任务,就类似于开游戏服务器时我写了一个sh脚本,每天凌晨都要给服务端备份,以免有一天游戏炸掉,我可以回档及时止损。但是现在不是什么备份止损,我们好像可以模拟一套HTTP请求,然后把脚本部署在服务端,实现远端执行。
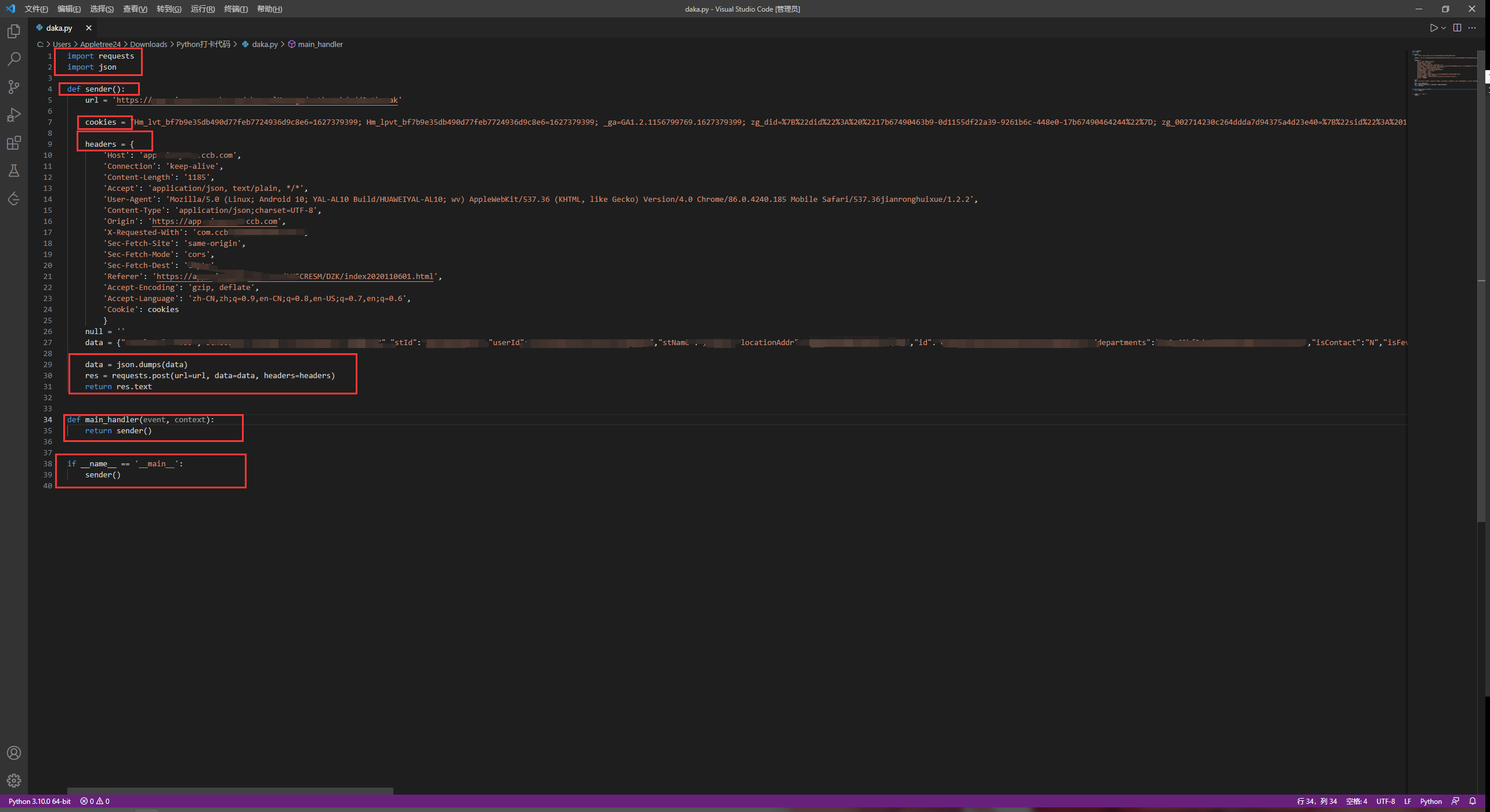
我们转换为代码其实就十分简单,短短40行就可以实现我们理想中的功能。
首先我们import进来我们需要的模块,既然要模拟一套请求,那肯定要requests来模拟一套请求流程,中间的JSON利用json来编码。
调用sender方法,我们可以轻松实现功能,把我们所需要的信息用抓包工具实现,抓包同样是一个很好玩的东西,很多网游其实都可以利用WPE抓包实现一些作弊功能,但这要说就扯得太远了,总之我们抓包是为了知道我们每次都给服务端提供了什么样的信息出去,我们既然要模拟,就要把这些东西填进去,对方才知道是我们。
url就是要向对方服务端目录下的何处进行请求。
cookies也是一个很有意思的东西,既然有很多用户都在使用一个功能,那么到底如何分辨谁是谁呢?于是乎每个用户都有一个专属于他的cookie,你的浏览器也会记录你的cookie,这就是所谓你在一些网站登陆过账号后,过几天再登陆,惊奇的发现竟然账号已经登陆了。
下面是个重头戏,关于HTTP headers。
HTTP headers是HTTP请求和响应的核心,一般来说它包含着客户端浏览器、请求页面、服务器相关的信息。
当你在浏览器中输入了一个url时,你的浏览器通常会有如下的http请求
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1
Host: net.tutsplus.comUser-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120Pragma: no-cacheCache-Control: no-cache
第一行被称作是Request Line,它描述请求的基本信息,剩下的部分就是HTTP headers了。
当请求完毕后,会有下面的内容:
HTTP/1.x 200 OK
Transfer-Encoding: chunkedDate: Sat, 28 Nov 2009 04:36:25
GMTServer: LiteSpeedConnection: closeX-Powered-By: W3 Total Cache/0.8Pragma: publicExpires: Sat, 28 Nov 2009 05:36:25 GMTEtag: "pub1259380237;gz"Cache-Control: max-age=3600, public
Content-Type: text/html; charset=UTF-8
Last-Modified: Sat, 28 Nov 2009 03:50:37
GMTX-Pingback: http://net.tutsplus.com/xmlrpc.php
Content-Encoding: gzipVary:
Accept-Encoding,
Cookie, User-Agent<!-- ... rest of the html ...
第一行就是status line,不多解释,英语通俗易懂。之外的内容就是http headers
在你的浏览器中用F12打开开发人员测试工具,点击到Network里的headers便可以从浏览器看到这些内容了。
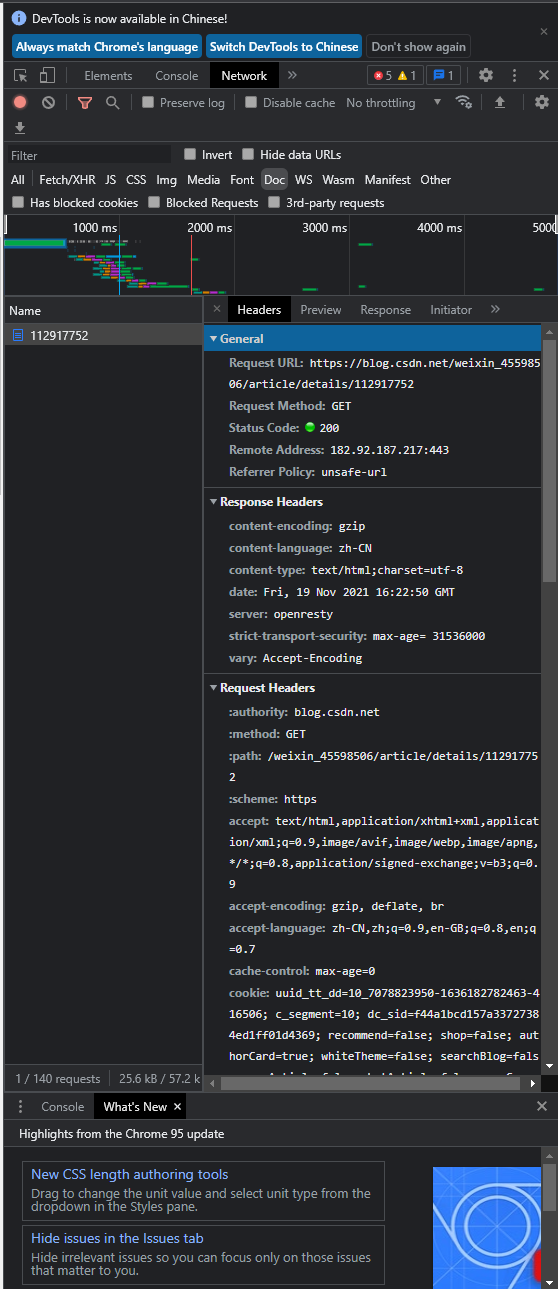
HTTP headers里有一些常用属性:
(1) Host:
请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的,例如我们在浏览器中输入:https://www.baidu.com
浏览器发送的请求消息中,就会包含Host请求报头域,如下:
Host:www.baidu.com
(此处使用缺省端口号443,若指定了端口号,则变成:Host:指定端口号)
(2)Referer
当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器该请求是从哪个页面链接过来的,服务器借此可以获得一些信息用于处理。比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。
(3)User-Agent
这个对于爬虫比较重要 因为一般都需要添加该属性,否则稍微处理过的网站,都无法爬取。
告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本。
我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从 User-Agent这个请求报头域中获取到这些信息。User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。
例如: User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
应用程序版本“Mozilla/4.0”表bai示:你使用Maxthon 2.0 浏览du器使用 IE8 内核;
版本标识“zhiMSIE 8.0”
平台自身的dao识别信息“Windows NT 5.1”表示“操作系统为zhuan Windows XP”
rident内核版本“Trident/4.0”,浏览器的一种内核,还有一种就是WebKit内核
(4)Content-type
表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。
常见的媒体格式类型如下:
text/html : HTML格式
text/plain :纯文本格式
text/xml : XML格式
image/gif :gif图片格式
image/jpeg :jpg图片格式
image/png:png图片格式
以application开头的媒体格式类型:
application/xhtml+xml :XHTML格式
application/xml : XML数据格式
application/atom+xml :Atom XML聚合格式
application/json : JSON数据格式
application/pdf :pdf格式(别人发的试卷、电子书籍、准考证等等)
application/msword : Word文档格式
application/octet-stream : 二进制流数据(如常见的文件下载)
application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
另外一种常见的媒体格式是上传文件之时使用的:
multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式。
(5)Accept-Language
Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,当服务器能够提供一种以上的语言版本时要用到。
(6)Cookie
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能。
依照着上述常用属性解释,不难理解headers花括号里所写的内容了。
数据都写完后,我们就需要利用json库将这些信息转换为json的格式与服务端进行交互,至于为什么要换成JSON格式,这里有一个链接可以解释:
通过jsondumps,我们将Python中的数据类型转换为JSON格式,并为这个新变量命名为Data,之后调用requests库中的post方法,填入规定的参数,发送我们的信息到指定的服务器上,之后返回res.text,这并不是代表返回了一个后缀为text的文件,而是使用了text这个方法,返回了指定网页的源代码。
之后的两部分内容其实与模拟整个流程关系不大,不过多解释。
整套脚本写好后,我们要如何部署呢,很幸运,某导论课上提到过云这一概念,懂得已经懂了,如果我们找一个云服务平台,将我们的脚本用云函数的方法放到上面,每天定时执行不就可以了吗。确实,毫无疑问是可行的。
如此看来,知识真的改变生活了。
文件:链接: https://pan.baidu.com/s/1Xq9sBvwi7ko2W4j1HFlGoQ
提取码: 7zd3
此脚本来源于互联网,本人不做任何负责,版权归作者所有,请于下载后24小时内删除。
6.声明
本文中出现的所有图片均来源于网络,侵删。
本文中出现的代码内容为网络内容,文章只负责技术层面的分析解释。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号