
Hive分析函数
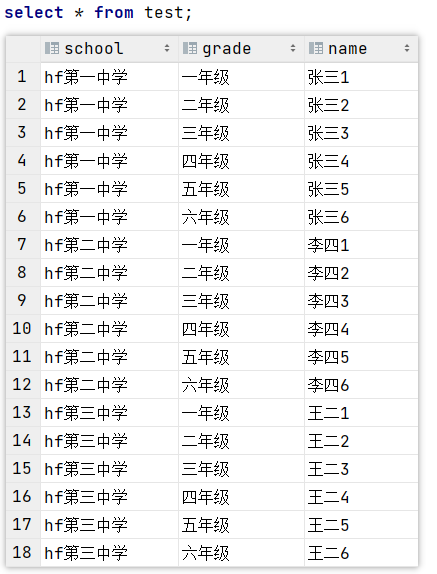
● 测试表 test
1. grouping sets
① 未使用
② 使用grouping sets (与上面等价)

【代码实例】
查看代码
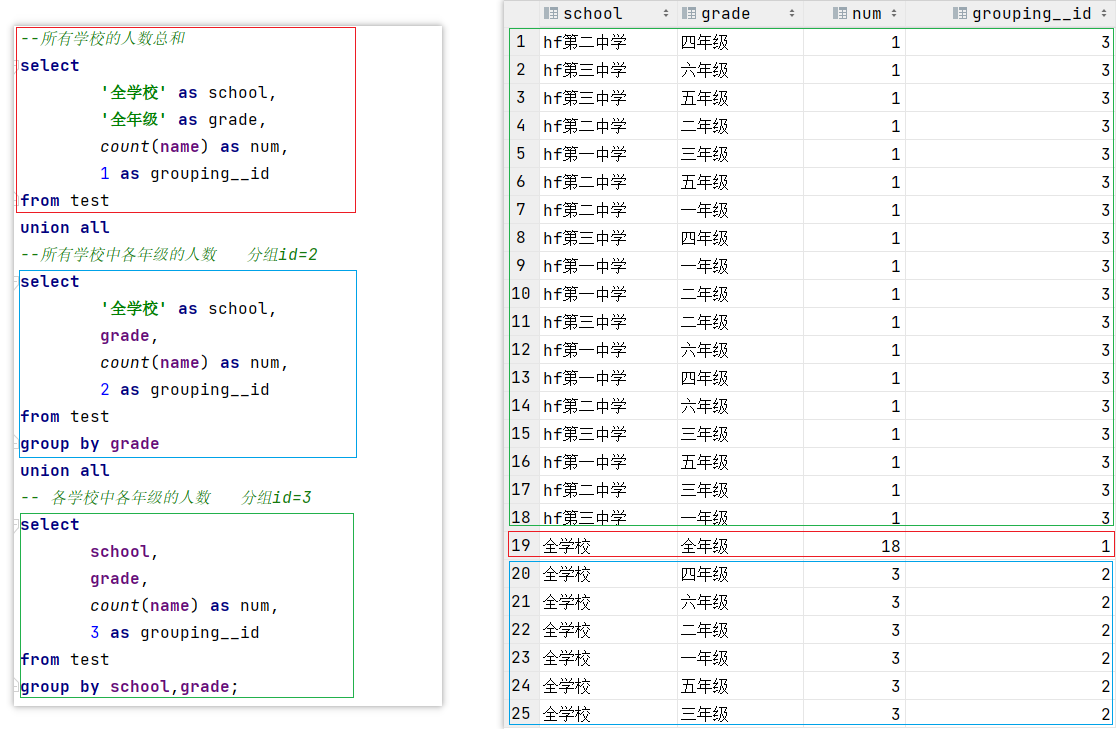
--todo 方式一
--所有学校的人数总和
select
'全学校' as school,
'全年级' as grade,
count(name) as num,
1 as grouping__id
from test
union all
--所有学校中各年级的人数 分组id=2
select
'全学校' as school,
grade,
count(name) as num,
2 as grouping__id
from test
group by grade
union all
-- 各学校中各年级的人数 分组id=3
select
school,
grade,
count(name) as num,
3 as grouping__id
from test
group by school,grade;
---------------------------------------------------------------
--todo 方式二
select
nvl(school,'全学校') as school,
nvl(grade,'全年级') as grade,
count(name) as num,
grouping__id
from test
group by school,grade
grouping sets( (school,grade) , grade , () );
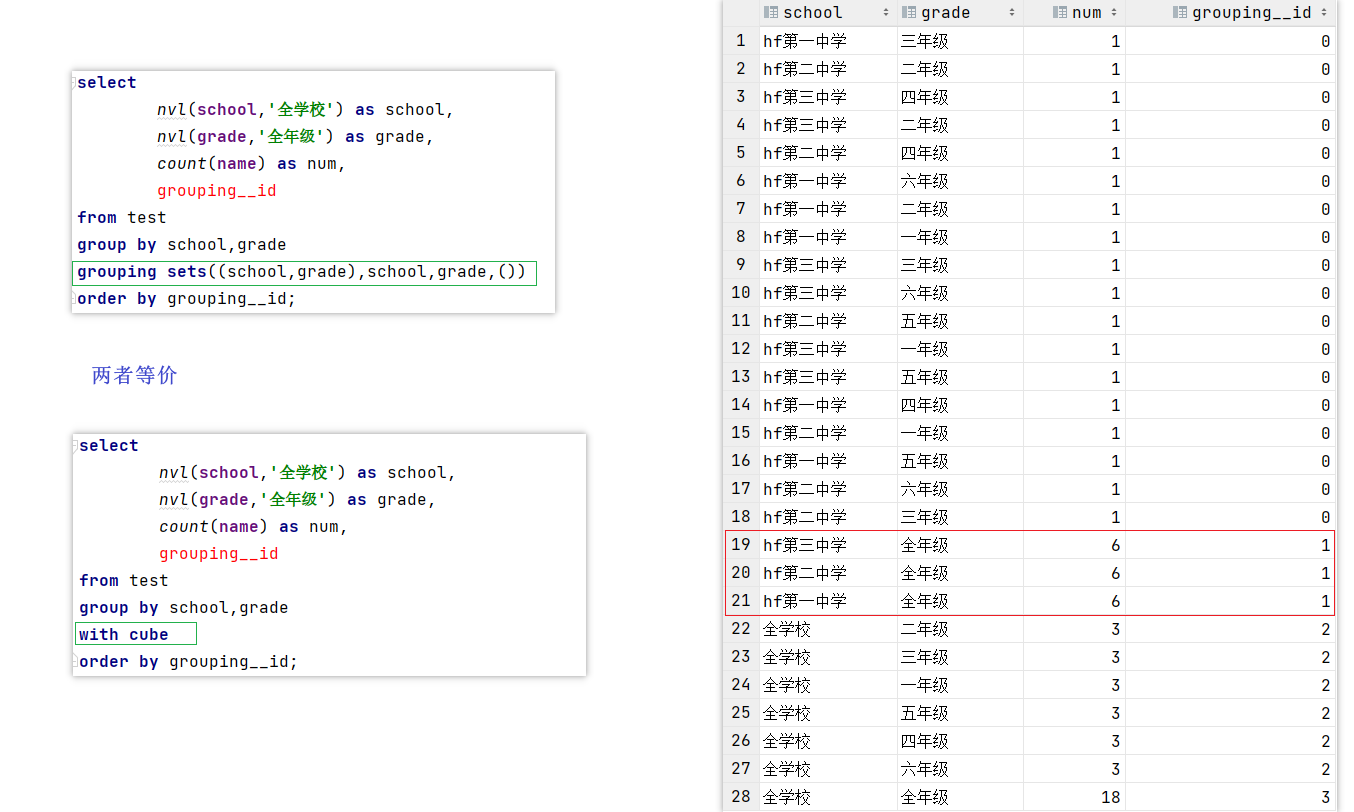
2. Cube
① cube 在一个group by 的聚合查询中,根据所有维度组合进行聚合(即是把所有的维度组合都放入grouping sets中)
【代码示例】
查看代码
--todo 方式一
select
nvl(school,'全学校') as school,
nvl(grade,'全年级') as grade,
count(name) as num,
grouping__id
from test
group by school,grade
grouping sets((school,grade),school,grade,())
order by grouping__id;
--------------------------------------------------
--todo 方式二
select
nvl(school,'全学校') as school,
nvl(grade,'全年级') as grade,
count(name) as num,
grouping__id
from test
group by school,grade
with cube
order by grouping__id;
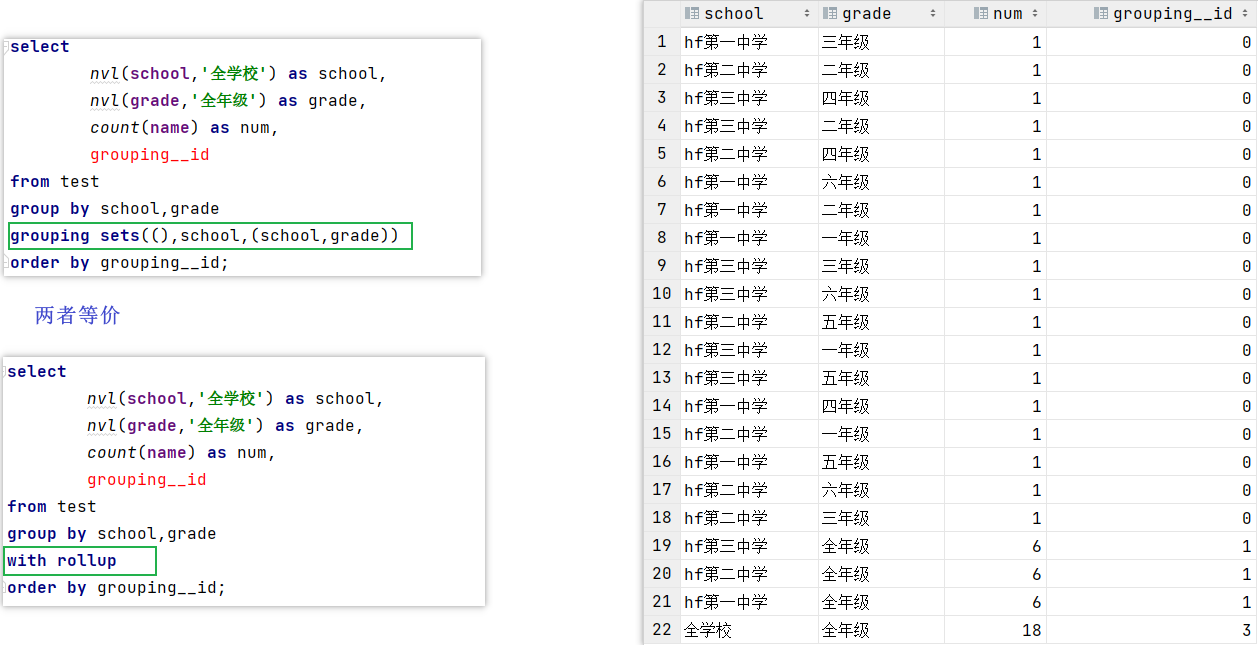
3. rollup
● rollup 是cube 的一个子集,以左边的维度为主,进行聚合
● 即是按照,汇总所有维度->汇总左侧school维度->汇总左右维度的顺序,来聚合,不会再从右到左聚合了
【代码示例】
查看代码
--todo 方式一
select
nvl(school,'全学校') as school,
nvl(grade,'全年级') as grade,
count(name) as num,
grouping__id
from test
group by school,grade
grouping sets((),school,(school,grade))
order by grouping__id;
----------------------------------------------
--todo 方式二
select
nvl(school,'全学校') as school,
nvl(grade,'全年级') as grade,
count(name) as num,
grouping__id
from test
group by school,grade
with rollup
order by grouping__id;
总结:
① grouping set是一个更加灵活的做分组维度聚合的函数,可以适应更多的场景
② cube和rollup在完全适用于场景时,有着更简单的写法和效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号