「解题报告」The 1st Universal Cup. Stage 1: Shenyang
参考场上过的数量从易到难排序。
过于简单的题和我不会的(计算几何)没写。
I. Quartz Collection
有 \(n\) 个物品,每个物品有两个,价格分别为 \(a_i\) 和 \(b_i\)。只有当第一个物品被出售时,第二个物品才会被出售。
Alice 和 Bob 都需要购买这 \(n\) 个物品各 \(1\) 个。他们按照以下的顺序进行购买:
- Alice 先购买一个物品;
- Bob 购买两个物品;
- Alice 购买两个物品;
- ...(Bob 和 Alice 交替买两个物品,直到物品只剩一个)
- 最后还没有买齐 \(n\) 个物品的人购买最后剩下的一个物品、
两个人都会尽可能使得自己的花费最小,求 Alice 的最小花费。
接下来给定 \(m\) 次修改操作,每次修改一对 \((a_i, b_i)\),操作是永久的,每次求 Alice 的最小花费。\(n, m \le 10^5\)
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 400005;
struct Treap {
mt19937 rand;
Treap() : rand(time(0)) {}
int lc[MAXN], rc[MAXN], rnd[MAXN], val[MAXN], siz[MAXN], tot;
long long sum[MAXN][4];
int newNode(int x) {
rnd[++tot] = rand();
val[tot] = x;
siz[tot] = 1;
sum[tot][0] = x;
return tot;
}
void pushUp(int x) {
siz[x] = siz[lc[x]] + siz[rc[x]] + 1;
for (int i = 0; i < 4; i++) {
sum[x][i] = sum[lc[x]][i] + sum[rc[x]][((i - siz[lc[x]] - 1) % 4 + 4) % 4]
+ (siz[lc[x]] % 4 == i) * val[x];
}
}
void split(int p, int w, int &x, int &y) {
if (!p) x = y = 0;
else {
if (val[p] < w) {
x = p;
split(rc[x], w, rc[x], y);
pushUp(x);
} else {
y = p;
split(lc[y], w, x, lc[y]);
pushUp(y);
}
}
}
int merge(int x, int y) {
if (!x || !y) return x + y;
if (rnd[x] < rnd[y]) {
lc[y] = merge(x, lc[y]);
pushUp(y);
return y;
} else {
rc[x] = merge(rc[x], y);
pushUp(x);
return x;
}
}
void insert(int &p, int w) {
int x, y, z;
y = newNode(w);
split(p, w, x, z);
p = merge(merge(x, y), z);
}
void remove(int &p, int w) {
int x, y, z;
split(p, w, x, y);
split(y, w + 1, y, z);
y = merge(lc[y], rc[y]);
p = merge(x, merge(y, z));
}
} t;
int n, m;
int a[MAXN], b[MAXN];
long long sum;
int rootp, rootn;
void calc() {
long long ans = sum;
ans += t.sum[rootp][0] + t.sum[rootp][3];
if (t.siz[rootp] & 1) {
ans += t.sum[rootn][1] + t.sum[rootn][3];
} else {
ans += t.sum[rootn][0] + t.sum[rootn][2];
}
printf("%lld\n", ans);
}
void insert(int x, int y) {
sum += y;
int del = y - x;
if (del >= 0) {
t.insert(rootp, -del);
} else {
t.insert(rootn, -del);
}
}
void erase(int x, int y) {
sum -= y;
int del = y - x;
if (del >= 0) {
t.remove(rootp, -del);
} else {
t.remove(rootn, -del);
}
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) {
scanf("%d%d", &a[i], &b[i]);
insert(a[i], b[i]);
}
calc();
for (int i = 1; i <= m; i++) {
int t, x, y; scanf("%d%d%d", &t, &x, &y);
erase(a[t], b[t]);
a[t] = x, b[t] = y;
insert(a[t], b[t]);
calc();
}
return 0;
}
F. Half Mixed
你需要构造一个 \(n \times m\) 的 01 矩阵,满足所有元素相等的子矩阵数占总子矩阵数的一半。
多测,\(\sum n \times m \le 10^6\)。
总子矩阵数为 \(\dfrac{n(n+1)}{2} \times \dfrac{m(m+1)}{2}\),如果能占一半首先需要满足这个数为偶数,简单讨论一下可以发现就是 \(n,m\) 其中一个为 \(4k\) 或 \(4k-1\)。
\(n\times m\) 不好求,我们考虑 \(1 \times m\) 的方案(假设 \(m\) 为 \(4k\) 或 \(4k-1\) 的形式,否则交换 \(n,m\))。
也就是要求一个序列 \(a_i\),满足 \(\displaystyle \sum_{\sum a_i = m} \frac{a_i(a_i + 1)}{2} = \frac{m(m+1)}{4}\)。
没啥好办法,直接暴搜吧。考虑贪心地从大往小枚举,再加上一些剪枝,跑的超级快,因为本来解数就很多。
然后我们再把这个 \(1 \times m\) 的矩阵复制 \(n\) 次即可,容易证明新矩阵仍然满足题目要求。
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 1000005;
vector<int> a;
bool dfs(int tt, long long ed) {
if (tt == ed) {
while (tt--) {
a.push_back(1);
}
return true;
}
for (int t = tt; t >= 1; t--) {
if (1ll * t * t <= ed && ed - 1ll * t * t >= tt - t &&
1ll * (tt - t) * (tt - t) >= ed - 1ll * t * t) {
a.push_back(t);
if (dfs(tt - t, ed - 1ll * t * t)) return true;
a.pop_back();
}
}
return false;
}
int T, n, m;
int b[MAXN];
int main() {
scanf("%d", &T);
while (T--) {
scanf("%d%d", &n, &m);
a.clear();
if (n % 4 == 0) {
int k = n / 4;
long long tt = 4 * k, ed = 8ll * k * k - 2 * k;
dfs(tt, ed);
int tot = 0, o = 0;
for (int i : a) {
for (int j = 1; j <= i; j++) {
b[++tot] = o;
}
o ^= 1;
}
printf("Yes\n");
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
printf("%d ", b[i]);
}
printf("\n");
}
} else if (n % 4 == 3) {
int k = (n + 1) / 4;
long long tt = 4 * k - 1, ed = 8ll * k * k - 6 * k + 1;
dfs(tt, ed);
int tot = 0, o = 0;
for (int i : a) {
for (int j = 1; j <= i; j++) {
b[++tot] = o;
}
o ^= 1;
}
printf("Yes\n");
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
printf("%d ", b[i]);
}
printf("\n");
}
} else if (m % 4 == 0) {
int k = m / 4;
long long tt = 4 * k, ed = 8ll * k * k - 2 * k;
dfs(tt, ed);
int tot = 0, o = 0;
for (int i : a) {
for (int j = 1; j <= i; j++) {
b[++tot] = o;
}
o ^= 1;
}
printf("Yes\n");
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
printf("%d ", b[j]);
}
printf("\n");
}
} else if (m % 4 == 3) {
int k = (m + 1) / 4;
long long tt = 4 * k - 1, ed = 8ll * k * k - 6 * k + 1;
dfs(tt, ed);
int tot = 0, o = 0;
for (int i : a) {
for (int j = 1; j <= i; j++) {
b[++tot] = o;
}
o ^= 1;
}
printf("Yes\n");
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
printf("%d ", b[j]);
}
printf("\n");
}
} else {
printf("No\n");
}
}
return 0;
}
A. Absolute Difference
给定两个实数集合 \(A, B\),其中 \(\displaystyle A = \bigcup_{i=1}^n [l_{i}, r_{i}],B = \bigcup_{i=1}^m [L_{i}, R_{i}]\)。保证给出的区间两两无交。若 \(l_i = r_i\)(或 \(L_i = R_i\)),则令该区间表示一个单元素集 \(\{l_i\}\)(或 \(\{L_i\}\))。
求在 \(A\) 中随机选取一个实数 \(x\),在 \(B\) 中随机选取一个实数 \(y\),\(|x-y|\) 的期望值。\(n, m \le 10^5\)
有点难写,代码咕了。
先不考虑单元素集。
考虑实数上的期望值等于 \(\dfrac{\int_L^R f(x) \mathrm{d} x}{R-L}\),那么我们可以考虑对区间两两计算 \(\int_{l_i}^{r_i} \int_{L_j}^{R_j} |x-y| \mathrm{d} x \mathrm{d} y\)。
假如两个区间不相交,绝对值很容易去掉,大力算积分可以得到等于 \(\displaystyle \frac{1}{2} (R_j^2 - L_j^2) (r_i - l_i) - \frac{1}{2} (R_j - L_j)(r_i^2 - l_i^2)\),这东西很容易前缀和优化求出。
区间相交的情况只有 \(O(n + m)\) 对,对这几对分别暴力计算即可。两个区间可以拆成不相交的几个区间和相等的两个区间,相等的区间的答案为 \(\dfrac{(r-l)^3}{3}\)。
证明:直接暴力算 \(\int_l^r \int_l^r |x-y| \mathrm{d} x \mathrm{d} y\) 即可。
\[\begin{aligned} & \int_l^r \int_l^r |x-y| \mathrm{d} x \mathrm{d} y\\ &= \int_0^{r-l} \int_0^{r-l} |(x + l)-(y + l)| \mathrm{d} x \mathrm{d} y\\ &= \int_0^{r-l} \left(\int_0^{x} (x - y) + \int_x^{r-l} (y - x) \right) \mathrm{d} x \mathrm{d} y\\ &= \int_0^{r-l} \left( x^2 - x(r - l) + \frac{1}{2} (r-l)^2\right) \mathrm{d} x\\ &= \frac{(r-l)^3}{3}\\ \end{aligned}\]
单元素集:如果所有集合都是单元素集,那相当于一个有限集合中随机选一个,否则可以直接把这个单元素集合删去(随机实数等于固定值的概率为 \(0\))。特判一下。
E. Graph Completing
给定一个 \(n\) 个点 \(m\) 条边的简单无向图,可以加入任意多条(包括 \(0\) 条)边,使得这张图边双联通,求加边的方案数。
边双联通的定义:任意不相等两点存在至少两条没有重复边的简单路径。\(n \le 5000, m \le 10000\)
说句闲话:边双缩点不会写调了半天,然后数组开小又调半天,最后对着真的 TLE 以为是死循环又调半天,我是傻逼。
考虑首先对原图求出所有割边,然后将分成的若干边双缩点。那么我们现在得到了一个树形结构。
我们现在的问题是加若干条边,使得这棵树变成边双联通。
考虑如何判定边双联通:就是没有割边,也就是原来的所有边都被至少有一条边连接的两个端点跨过这条边。
还是很不好求,我们考虑容斥。钦定某些边没有任何一条边被加入的边跨过,这样就能求出每条边都被加入的边跨过的方案数了。
肯定不能直接枚举钦定的边集,考虑 DP。钦定一些割边相当于将原树划分成了若干连通块,连通块内任意连边。那么我们考虑设 \(f_{u, i}\) 表示 \(u\) 子树根所在连通块大小为 \(i\) 的方案数。合并的时候,我们可能将某个子树加入,也可以钦定这条边为割边不加入。如果加入,那么系数为 \(2^{i \times j - 1}\)(\(i,j\) 为枚举的 \(f_u, f_v\) 的第二维),因为两个连通块间除了一条树边任意两点之间都没连边。如果不加入,那么系数为容斥系数 \(-1\)。
注意根节点的初值要设为 \(f_{u, siz_u} = 2^{\large \frac{siz_u(siz_u - 1)}{2} - cnt_u}\),其中 \(cnt_u\) 表示边双中的边数。
直接暴力上树形背包即可。记得写个光速幂,要不然复杂度多个 \(\log\)。
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 7005, MAXM = 40005, P = 998244353;
int qpow(int a, long long b) {
int ans = 1;
while (b) {
if (b & 1) ans = 1ll * ans * a % P;
a = 1ll * a * a % P;
b >>= 1;
}
return ans;
}
int n, m;
int u[MAXM], v[MAXM];
#define forGraph(u, v) for (int i = fst[u], v = to[i]; i; i = nxt[i], v = to[i])
int f[MAXN][MAXN], g[MAXN][MAXN];
int Pow2[MAXN], PPow2[MAXN];
int pow2(long long b) {
return 1ll * Pow2[b % n] * PPow2[b / n] % P;
}
struct Tree {
int fst[MAXN], to[MAXM << 1], nxt[MAXM << 1], tot;
int siz[MAXN], cnt[MAXN], n;
int bl[MAXN];
void add(int u, int v) {
to[++tot] = v, nxt[tot] = fst[u], fst[u] = tot;
}
void dfs(int u, int pre) {
f[u][siz[u]] = qpow(2, 1ll * siz[u] * (siz[u] - 1) / 2 - cnt[u]);
forGraph(u, v) if (v != pre) {
dfs(v, u);
for (int i = 0; i <= siz[u] + siz[v]; i++) {
g[u][i] = 0;
}
for (int i = 0; i <= siz[u]; i++) if (f[u][i]) {
for (int j = 0; j <= siz[v]; j++) if (f[v][j]) {
g[u][i + j] = (g[u][i + j] + 1ll * f[u][i] * f[v][j] % P *
// qpow(2, 1ll * i * j - 1)
pow2(1ll * i * j - 1)
) % P;
g[u][i] = (g[u][i] - 1ll * f[u][i] * f[v][j] % P + P) % P;
}
}
for (int i = 0; i <= siz[u] + siz[v]; i++) {
f[u][i] = g[u][i];
}
siz[u] += siz[v];
}
}
} t;
int test;
struct Graph {
int fst[MAXN], to[MAXM << 1], nxt[MAXM << 1], tot;
Graph() : tot(1) {}
void add(int u, int v) {
to[++tot] = v, nxt[tot] = fst[u], fst[u] = tot;
}
int dfn[MAXN], low[MAXN], dcnt;
bool vis[MAXM << 1];
void tarjan(int u, int inEdge) {
dfn[u] = low[u] = ++dcnt;
forGraph(u, v) if (!dfn[v]) {
tarjan(v, i ^ 1);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
test++;
vis[i] = vis[i ^ 1] = 1;
}
} else if (i != inEdge) {
low[u] = min(low[u], dfn[v]);
}
}
void dfs(int u, int id) {
t.bl[u] = id;
t.siz[id]++;
forGraph(u, v) if (!vis[i] && !t.bl[v]) {
dfs(v, id);
}
}
} G;
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++) {
scanf("%d%d", &u[i], &v[i]);
G.add(u[i], v[i]);
G.add(v[i], u[i]);
}
Pow2[0] = PPow2[0] = 1;
for (int i = 1; i <= n; i++) {
Pow2[i] = 2ll * Pow2[i - 1] % P;
}
for (int i = 1; i <= n; i++) {
PPow2[i] = 1ll * PPow2[i - 1] * Pow2[n] % P;
}
G.tarjan(1, 0);
for (int i = 1; i <= n; i++) if (!t.bl[i]) {
int id = ++t.n;
G.dfs(i, id);
}
for (int i = 1; i <= m; i++) {
if (t.bl[u[i]] == t.bl[v[i]]) {
t.cnt[t.bl[u[i]]]++;
} else {
t.add(t.bl[u[i]], t.bl[v[i]]);
t.add(t.bl[v[i]], t.bl[u[i]]);
}
}
t.dfs(1, 0);
int ans = 0;
for (int i = 0; i <= n; i++) {
ans = (ans + f[1][i]) % P;
}
printf("%d\n", ans);
return 0;
}
H. P-P-Palindrome
给你 \(n\) 个字符串 \(S_1, S_2, \cdots, S_n\)。求有多少种不同的字符串有序二元组 \((P, Q)\) 满足:
- \(P, Q\) 是某个 \(S_i\) 的子串;
- \(P, Q\) 均为回文串;
- \(P + Q\)(\(P\) 与 \(Q\) 拼接)为回文串。
\(n, \sum |S_i| \le 10^6\)
例如:\(P=abaabaaba, Q = abaaba\),\(P, Q, P + Q\) 都可以划分成若干个 \(A = aba\)。
这个 \(\gcd\) 的限制看起来还是很烦。假如 \(A\) 还能够被分割成若干个回文串,我们就继续划分,直到不能再划分为止。我们把这种不能再划分的回文串称作最小回文串。
那么对于每一个最小回文串 \(A\),假如在某个 \(S_i\) 中出现了连续的 \(d\) 个 \(A\),那么 \(P, Q\) 就可以是由 \(i \in [1, d]\) 个 \(A\) 组成的,那么由这个回文串 \(A\) 组成的二元组就有 \(d^2\) 个。
接下来的事情就很显然了,我们要对每个最小回文串统计在所有的 \(S_i\) 中连续出现的最多次数。
考虑对这 \(n\) 个串建出回文自动机,然后对每一个回文串进行考虑。考虑某个串 \(S\),记它的最长回文后缀的长度与 \(|S|\) 的差为 \(diff\)(即 \(diff = len_S - len_{fail_S}\)),那么我们有如下结论:如果 \(diff \mid |S|\),那么这个串可以由 \(\frac{|S|}{diff}\) 个长为 \(diff\) 的后缀拼接而成,且这个后缀为一个最小回文串;否则,这个串本身就是一个最小回文串。
这个结论很容易得到,考虑 \(|fail_i|\) 与 \(|S|\) 的关系,可以类似于 Palindrome Series 的结论推出。
直接上哈希记录即可。
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 1000005;
int n;
char s[MAXN];
const int P1 = 993244853, BASE1 = 131;
const int P2 = 1000000009, BASE2 = 13331;
int B1[MAXN], B2[MAXN];
struct Hash {
long long a1, a2;
bool operator==(const Hash &b) const {
return a1 == b.a1 && a2 == b.a2;
}
bool operator<(const Hash &b) const {
return a1 == b.a1 ? a2 < b.a2 : a1 < b.a1;
}
Hash operator+(const int b) const {
return { (a1 * BASE1 + b) % P1, (a2 * BASE2 + b) % P2 };
}
Hash operator<<(const int b) const {
return { a1 * B1[b] % P1, a2 * B2[b] % P2 };
}
Hash operator-(const Hash &b) const {
return { (a1 - b.a1 + P1) % P1, (a2 - b.a2 + P2) % P2 };
}
} h[MAXN];
Hash split(int l, int r) {
return h[r] - (h[l - 1] << (r - l + 1));
}
map<Hash, int> cnt;
struct PalindromeAutomaton {
int t[MAXN][26], len[MAXN], fail[MAXN];
int lst, tot;
PalindromeAutomaton() {
len[1] = -1, fail[0] = 1;
lst = tot = 1;
}
void insert(int c, int i) {
int p = lst;
while (s[i - len[p] - 1] != s[i]) p = fail[p];
if (!t[p][c]) {
++tot;
int q = fail[p];
while (s[i - len[q] - 1] != s[i]) q = fail[q];
fail[tot] = t[q][c];
len[tot] = len[p] + 2;
t[p][c] = tot;
int diff = len[tot] - len[fail[tot]];
int l = (len[tot] % diff == 0 ? diff : len[tot]);
auto hsh = split(i - l + 1, i);
cnt[hsh] = max(cnt[hsh], len[tot] / l);
}
lst = t[p][c];
}
} pam;
int main() {
scanf("%d", &n);
B1[0] = B2[0] = 1;
for (int i = 1; i < MAXN; i++) {
B1[i] = 1ll * B1[i - 1] * BASE1 % P1;
B2[i] = 1ll * B2[i - 1] * BASE2 % P2;
}
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
int m = strlen(s + 1);
for (int j = 1; j <= m; j++) {
h[j] = h[j - 1] + (s[j] - 'a' + 1);
}
pam.lst = 0;
for (int j = 1; j <= m; j++) {
pam.insert(s[j] - 'a', j);
}
}
long long ans = 0;
for (auto p : cnt) {
ans += 1ll * p.second * p.second;
}
printf("%lld\n", ans);
return 0;
}
G. Meet in the Middle
给你两棵 \(n\) 个点的树 \(T_1, T_2\),树有边权。
记 \({\rm dis}_1(u, v)\) 为 \(T_1\) 上 \(u \to v\) 的路径长度,\({\rm dis}_2(u, v)\) 为 \(T_2\) 上 \(u \to v\) 的路径长度。
\(q\) 次询问,每次给定 \(a, b\),求 \(\displaystyle \max_{x=1}^n \{{\rm dis}_1(a, x) + {\rm dis}_2(b, x)\}\)。\(n \le 10^5, q \le 5 \times 10^5\)
确实没想到咋做,很厉害的做法。
两棵树上很难找到优秀的性质,考虑想办法将两棵树合并成一棵树。
对于某个询问 \((a, b)\),我们考虑将所有的 \({\rm dis}_2(b, x)\) 预处理出来,然后在 \(T_1\) 上的每一个点 \(x\) 下挂一个节点,边权为 \({\rm dis}_2(b, x)\),这样 \(a\) 到这个点的距离就等于 \({\rm dis}_1(a, x) + {\rm dis}_2(b, x)\)。
而考虑到距离 \(a\) 最远的点一定是一个叶子,也就是我们新挂的点,这样我们要求的最大的 \(x\) 其实就是距离 \(a\) 的最远的点。
有一个经典结论:一棵树上距离它最远的点为这棵树的直径中两个端点之一。
那么我们考虑对于第二棵树上的每个节点维护出这棵树的直径,然后再离线查询答案。
我们拿一棵线段树来维护这个东西,线段树的一个区间维护这个区间内的点形成的树的直径,合并就枚举 \(\binom{4}{2} = 6\) 种组合方式。对第二棵树 DFS 一遍,每次距离增加减少的点都是 DFN 序连续的一段区间,线段树区间修改即可。
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 200005;
int n, q;
struct Tree {
#define forGraph(u, v) for (int i = fst[u], v = to[i]; i; i = nxt[i], v = to[i])
int fst[MAXN], to[MAXN], nxt[MAXN], w[MAXN], tot;
void add(int u, int v, int ww) {
to[++tot] = v, nxt[tot] = fst[u], fst[u] = tot, w[tot] = ww;
}
};
struct Tree1 : public Tree {
int dfn[MAXN], idf[MAXN], dcnt;
int dep[MAXN];
int st[MAXN][20];
long long dis[MAXN];
void dfs(int u, int pre) {
dfn[u] = ++dcnt, idf[dcnt] = u;
dep[u] = dep[pre] + 1;
forGraph(u, v) if (v != pre) {
dis[v] = dis[u] + w[i];
dfs(v, u);
idf[++dcnt] = u;
}
}
void build() {
for (int i = 1; i <= dcnt; i++)
st[i][0] = idf[i];
for (int j = 1; j <= 18; j++) {
for (int i = 1; i + (1 << j) - 1 <= dcnt; i++) {
st[i][j] = (dep[st[i][j - 1]] < dep[st[i + (1 << (j - 1))][j - 1]]) ?
st[i][j - 1] : st[i + (1 << (j - 1))][j - 1];
}
}
}
int lca(int u, int v) {
int l = dfn[u], r = dfn[v];
if (l > r) swap(l, r);
int len = __lg(r - l + 1);
return dep[st[l][len]] < dep[st[r - (1 << len) + 1][len]] ?
st[l][len] : st[r - (1 << len) + 1][len];
}
long long dist(int u, int v) {
return dis[u] + dis[v] - 2 * dis[lca(u, v)];
}
} t1;
struct SegmentTree {
struct Chain {
pair<int, long long> u, v;
long long dist;
inline Chain() : u(), v(), dist(0) {}
inline Chain(pair<int, long long> u, pair<int, long long> v) : u(u), v(v) {
dist = t1.dist(u.first, v.first) + u.second + v.second;
}
inline bool operator<(const Chain &b) const {
return dist < b.dist;
}
inline Chain operator+(const Chain &b) const {
Chain c = max(*this, b);
for (auto x : {u, v}) if (x.first) {
for (auto y : {b.u, b.v}) if (y.first) {
c = max(c, Chain(x, y));
}
}
return c;
}
};
struct Node {
Chain chain;
long long tag;
} t[MAXN << 2];
#define lc (i << 1)
#define rc (i << 1 | 1)
void tag(int i, long long v) {
t[i].tag += v;
t[i].chain.u.second += v;
t[i].chain.v.second += v;
if (t[i].chain.v.first) t[i].chain.dist += 2 * v;
}
void pushDown(int i) {
if (t[i].tag) {
tag(lc, t[i].tag);
tag(rc, t[i].tag);
t[i].tag = 0;
}
}
void pushUp(int i) {
t[i].chain = t[lc].chain + t[rc].chain;
}
void build(int *idf, long long *dis, int i = 1, int l = 1, int r = n) {
if (l == r) {
t[i].chain.u.first = idf[l];
t[i].chain.u.second = dis[idf[l]];
return;
}
int mid = (l + r) >> 1;
build(idf, dis, lc, l, mid);
build(idf, dis, rc, mid + 1, r);
pushUp(i);
}
void add(int a, int b, long long v, int i = 1, int l = 1, int r = n) {
if (a <= l && r <= b) {
tag(i, v);
return;
}
int mid = (l + r) >> 1;
pushDown(i);
if (a <= mid) add(a, b, v, lc, l, mid);
if (b > mid) add(a, b, v, rc, mid + 1, r);
pushUp(i);
}
} st;
long long ans[MAXN * 5];
struct Tree2 : public Tree {
long long dis[MAXN];
int dfn[MAXN], ed[MAXN], idf[MAXN], dcnt;
void dfs1(int u, int pre) {
dfn[u] = ++dcnt, idf[dcnt] = u;
forGraph(u, v) if (v != pre) {
dis[v] = dis[u] + w[i];
dfs1(v, u);
}
ed[u] = dcnt;
}
void build() {
st.build(idf, dis);
}
vector<pair<int, int>> qs[MAXN];
void dfs2(int u, int pre) {
for (auto p : qs[u]) {
ans[p.first] = max(
t1.dist(st.t[1].chain.u.first, p.second) + st.t[1].chain.u.second,
t1.dist(st.t[1].chain.v.first, p.second) + st.t[1].chain.v.second
);
}
forGraph(u, v) if (v != pre) {
st.add(1, n, w[i]);
st.add(dfn[v], ed[v], -2 * w[i]);
dfs2(v, u);
st.add(1, n, -w[i]);
st.add(dfn[v], ed[v], 2 * w[i]);
}
}
} t2;
int main() {
scanf("%d%d", &n, &q);
for (int i = 1; i < n; i++) {
int u, v, w; scanf("%d%d%d", &u, &v, &w);
t1.add(u, v, w);
t1.add(v, u, w);
}
t1.dfs(1, 0);
t1.build();
for (int i = 1; i < n; i++) {
int u, v, w; scanf("%d%d%d", &u, &v, &w);
t2.add(u, v, w);
t2.add(v, u, w);
}
t2.dfs1(1, 0);
t2.build();
for (int i = 1; i <= q; i++) {
int a, b; scanf("%d%d", &a, &b);
t2.qs[b].push_back({i, a});
}
t2.dfs2(1, 0);
for (int i = 1; i <= q; i++) {
printf("%lld\n", ans[i]);
}
return 0;
}
J. Referee Without Red
给你一个 \(n \times m\) 的矩阵,矩阵元素的大小不超过 \(3 \times 10^6\)。
有两种操作:
- 将一行中偶数位置的数放到这一行的结尾,相对位置不变;
- 将一列中偶数位置的数放到这一列的结尾,相对位置不变;
求通过这两种操作能够得到多少不同的矩阵。对 \(998244353\) 取模。
\(n \times m \le 3 \times 10^6\)
referee without red: feree
首先考虑这个操作的本质:实际上是对一行 / 一列应用了一个置换。而一个置换可以拆分成若干个环,那么我们可以先将行列置换求出来,然后找出所有的置换环。我们可以将同一个置换环的元素放到一起(交换一些行 / 列),这样我们的置换变成了将每一个连续段进行循环移位。那么实际上这些环就将原矩阵拆分成了若干个子矩阵。
那么我们问题就变成了:给你 \(n \times m\) 个矩阵,每次可以将一行矩阵的同一行同时进行循环移位,或对一列矩阵的同一列进行循环移位。
先考虑子矩阵只有一行或一列的情况:相当于有一个序列,每次循环移位,求不同的结果。显然不同的结果应当是这个排列的最小正因子周期,使用 KMP 算法容易求出这个周期。
对于这一整行的所有矩阵来说,它们的总结果数就是每个小矩阵的方案数的 \(\rm lcm\),我们直接对上述求出的所有周期取个 \(\rm lcm\) 累计到答案上即可。
由于置换的特殊性,结果的 \(\rm lcm\) 很小,可以直接暴力求,不需要担心爆 int 的问题。(我没证,但是输出出来确实是这样)
然后考虑不止一行或一列的情况:我们猜测大部分矩阵都可以通过循环移位得出,答案应该与矩阵长宽的奇偶性有关。
我们定义一个矩阵的奇偶性为:将矩阵的所有元素一行一行排成一个序列,这个序列的逆序对数的奇偶性。
众所周知,一个排列中交换两个元素会使序列的逆序对数的奇偶性改变。那么,对矩阵进行循环移位其实就是将最左边的元素交换了 \(n - 1\) 次(或最上方元素交换 \(m - 1\) 次)。也就是说,如果矩阵的 \(n, m\) 均为奇数,且矩阵中的所有数互不相等,那么整个矩阵的奇偶性是永远不会发生改变的。
那么我们猜测:在不改变其它矩阵的情况下,如果这个矩阵中包含重复元素,通过循环移位得到任意一种矩阵;否则,包含重复元素,那么可以通过循环移位得到所有奇偶性相等的矩阵。
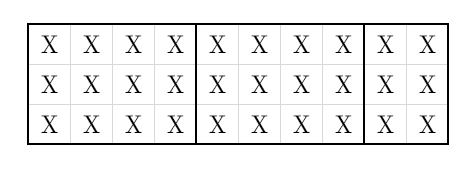
我们可以通过下图所示方法实现一个 L 形三轮换,可以发现通过这个操作就可以达到任意一种可能达到的矩阵。

那么我们可以通过可重集组合数算出一个矩阵内的方案数,如果互异则除一个 \(2\) 即可。
那么我们现在的想法就是:首先对所有矩阵进行一些操作,将所有矩阵的奇偶性固定下来;然后,再通过每个矩阵内部的三轮换操作,得到所有可能的矩阵。
但是奇偶性仍然存在着一定的限制,比如如果有一行矩阵的高为奇数,宽为偶数,且元素互异,那么对这一行进行操作,肯定会使所有矩阵的奇偶性同时改变,并不能够分别改变。
那么我们可以将这个问题抽象成一个二分图,将每个颜色互异的矩阵看做从行向列连的一条边,我们可以给行与列中的每个点选一个颜色,那么每个边的颜色就是两个端点的颜色的异或。
同时考虑到上述的奇数与偶数相连的问题,这些点只有对行操作有效,对列操作无效,那么我们新建一个虚点 \(0\),让无效的一边连向 \(0\) 即可。
考虑这个图能产生多少种不同的边的染色方案。我们给这张图跑出一个 DFS 树(森林),那么如果这个树(森林)的每条边都确定了颜色,那么其它的非树边的颜色就也能够确定了(考虑从根节点开始染色,钦定根节点颜色为白色,那么可以得到所有点的颜色,也就能确定非树边的颜色了)。
那么我们可以拿一个并查集来维护这个生成森林的边数,那么方案数就是 \(2\) 的边数次幂。
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 3000005, P = 998244353;
int T, n, m;
int a[MAXN];
vector<int> vn[MAXN], vm[MAXN];
int cn, cm;
bool vis[MAXN];
int p[MAXN], qn[MAXN], qm[MAXN];
int fa[MAXN];
int inv[MAXN];
int s[MAXN], nxt[MAXN];
int find(int x) {
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
bool merge(int x, int y) {
x = find(x), y = find(y);
if (x != y) {
fa[x] = y;
return true;
} else {
return false;
}
}
int lcm(int a, int b) { return a / __gcd(a, b) * b; }
int f(int x, int y) { return a[(x - 1) * m + (y - 1)]; }
int kmp(int n) {
for (int i = 2, j = 0; i <= n; i++) {
while (j && s[j + 1] != s[i]) j = nxt[j];
if (s[j + 1] == s[i]) j++;
nxt[i] = j;
}
for (int j = nxt[n]; j; j = nxt[j]) if (n % (n - j) == 0)
return n - j;
return n;
}
int cnt[MAXN];
int main() {
inv[1] = 1;
for (int i = 2; i <= 3000000; i++)
inv[i] = P - 1ll * (P / i) * inv[P % i] % P;
scanf("%d", &T);
while (T--) {
cn = cm = 0;
scanf("%d%d", &n, &m);
for (int i = 0; i < n * m; i++)
scanf("%d", &a[i]);
int o = 0; // 处理行置换
for (int i = 1; i <= n; i += 2)
p[i] = ++o, vis[i] = 0;
for (int i = 2; i <= n; i += 2)
p[i] = ++o, vis[i] = 0;
for (int i = 1; i <= n; i++) if (!vis[i]) {
vn[++cn] = { i };
for (int j = p[i]; j != i; j = p[j]) {
vn[cn].push_back(j);
vis[j] = 1;
}
}
o = 0; // 处理列置换
for (int i = 1; i <= m; i += 2)
p[i] = ++o, vis[i] = 0;
for (int i = 2; i <= m; i += 2)
p[i] = ++o, vis[i] = 0;
for (int i = 1; i <= m; i++) if (!vis[i]) {
vm[++cm] = { i };
for (int j = p[i]; j != i; j = p[j]) {
vm[cm].push_back(j);
vis[j] = 1;
}
}
int ans = 1;
// 将长 / 宽为 1 的答案用 KMP 求出
for (int i = 1; i <= cn; i++) if (vn[i].size() == 1) {
int w = 1;
for (int j = 1; j <= cm; j++) {
int len = 0;
for (int k : vm[j])
s[++len] = f(vn[i][0], k);
w = lcm(w, kmp(len));
}
ans = 1ll * ans * w % P;
}
for (int i = 1; i <= cm; i++) if (vm[i].size() == 1) {
int w = 1;
for (int j = 1; j <= cn; j++) {
int len = 0;
for (int k : vn[j])
s[++len] = f(k, vm[i][0]);
w = lcm(w, kmp(len));
}
ans = 1ll * ans * w % P;
}
for (int i = 0; i <= cn + cm; i++)
fa[i] = i;
for (int i = 1; i <= cn; i++) if (vn[i].size() != 1) {
for (int j = 1; j <= cm; j++) if (vm[j].size() != 1) {
bool diff = true;
int cc = 0;
for (int x : vn[i]) {
for (int y : vm[j]) {
cnt[f(x, y)]++;
if (cnt[f(x, y)] > 1) diff = false;
ans = 1ll * ans * (++cc) % P * inv[cnt[f(x, y)]] % P;
// 多重集组合数
}
}
if (diff) {
// 若互异,那么往二分图中加一条边
ans = 1ll * ans * ((P + 1) / 2) % P;
int u = (vn[i].size() & 1) ? 0 : cn + j;
int v = (vm[j].size() & 1) ? 0 : i;
if (merge(u, v)) ans = 2ll * ans % P;
}
for (int x : vn[i]) {
for (int y : vm[j]) {
cnt[f(x, y)]--;
}
}
}
}
printf("%d\n", ans);
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号