

解放AI生产力——为什么要使用ComfyUI
最近状态不好,所以这几天基本没干什么,就分享一下和AI绘画有关的东西吧。
此前我都没有抱着一种教学的心态来写博客,因为我所掌握的东西实在太过简单,只要一说大家就会了,我害怕我在人群里失去自己的特征,但不得不承认,这是一种很丑陋的心态,重要的是我否定了自己所学的东西,如果不愿承认现在的软弱,我就始终看不清我走到了一个什么样的位置上。
学过3D建模的应该都知道,3D建模软件里面都有一套类似于这种的东西:
上面我所展示的,就是今天介绍的重点:AI绘画的工作流,不知道的兄弟也没关系,这东西用起来很简单。
但在介绍怎么使用它之前,我先介绍一下它相比于原来的工作优点。
各位请看,这是我原来的UI:

原来的UI用起来很简单,输入正面提示词和负面提示词后点击生成之后,就会生成图片,这也是一开始就有的生成方式。
但点击生成之后,电脑的内部并不像我们使用起来那么简单:
在加载了这个UI之后,电脑会首先读取你原先设定好的模型,就是我们左上角看见的anything,并且这个模型类型被限定,随着某个日本大神发明的简易训练模型lora诞生,越来越多的私人模型诞生,但左上角这个我试了一下,好像没办法读入私人模型,也可能是因为我的电脑没有N卡的问题,而能否使用私人模型,对于流水线式的生产图片很关键
在你点击生成之后,电脑会通过你设置的采样器进行采样,采样生成出来的图片会再次经过vae的处理,如果你的图片生成出来偏灰,可以加载一下vae试试。
这样的生产方式面临两个问题:
1.有些东西你很难用文字表达清楚,比如坐着,脚放在前面。Ai并不知道坐着是什么意思,也不知道脚放在前面是什么意思,但是它会模仿模型里它已经学习过的坐着,脚放在前面的图片来生成一个差不多的给你,问题来了,你怎么知道AI模型里它模仿的图片是什么样的?和你不一样的时候要怎么办,万一这个动作它根本没学过呢?
为了解决的这个问题,斯坦福的某个天才发明了controlnet,它可以通过不同的预处理方式,来控制图片的构成,这里贴上链接,想要细看的看官可以去看一下:https://github.com/Mikubill/sd-webui-controlnet
不想点链接的也没事,我会放出图片:
这是一张用3D建模做的图片:
利用canny预处理,这张图片可以变成这样:
在这个插件面世之前,AI生成图片从来都是随机的,比如这两张:

如果不是我人为的控制了它,这个AI可以放纵得更离谱。
通过上面两个例子的对比各位可以发现,controlnet展现了惊人的图片控制能力,而不需要人为的控制AI,限制AI发挥的强度,更厉害的是controlnet不止有canny预处理这样将图像退化为线稿再处理的预处理方式,它也可以只控制人物的姿势,而不控制图像的其他任何部分,只保留产品和建筑物的结构,对产品和建筑物进行重新装修也不再话下,配合文字,可以变成任何你想要的图片。
说了这么多,其实我想说,控制AI一直是AI绘画爱好者的心头病。
也是面临的第一个问题:AI生成出来的东西不可控,单单controlnet的发明,在AI绘画圈内就引起了巨大的轰动,但这终究只能控制图像的冰山一角,想要将AI的生产力解放出来,这还不够。
举一个很恰当的例子:我要开一个方便面厂,我生产红烧牛肉面的时候你不能给我香辣牛肉面,不然我还要人为地在生产完成后给你分出来,浪费时间浪费金钱,而且我不能只有一条流水线,我还得有另一条流水线生产香辣牛肉面,不能两种面混合着生产,不然你就要人为地调整流水线的生产,费时费力。
但是很不巧的是,这个绘画AI一开始的UI把这两个缺点全占了,我们先不从动画说起,就以游戏业内最简单的图片CG说起:
一个正常的游戏CG的人物表情是有好几种变化的,其背后的景物是不能变,为了解决这个问题,我需要让AI做到景物不变人变,但其实这很难做到。
可能有一些知道AI绘画的人会说利用图生图降低噪声强度,减少修改的范围,只修改你要修改的部分就行了,(或者使用蒙版,意思是一样的)在这里我可以和你说,在关于这个方法的视频发出来的几个月前我就试出来了这种方法,我可能也是最先放弃它的人。

这是我当时的记录,时间去年11月,这个方法第一个视频我没记错的话是1月才看见有第一个人发。
我不是说我是第一个发现它的人,而是想说,在评价这个方法的缺点的时候,我应该比你更有发言权。
这个方法属于治标不治本,本质上你还是在让AI随机抽卡,而且你修改的范围再大一点你就会发现,我靠,两个部分的色块完全不一样啊。(甚至有可能人都不一样,如果你是个小白的话)
或许也有人会说,如果AI不能生成只变化图片的部分的话,那我多生成几张CG,多良心啊。
大哥,cg的动作,场景细节,光照角度,视角都是要设计的,绘画本身是一门艺术,应该要告诉玩家某种感觉,只是排放一堆图片给观众的话,观众容易审美疲劳,谁还会注意你的音乐,图片的细节啊。像这种东西建议称为AI垃圾,和那种口水歌差不多。
这样的话就更容易出现一个问题了,如果我连场景细节,光照角度都要管,那对AI的控制不是更难了吗?
何止,你不仅要管控制,你还要管AI绘画的第二个问题:崩坏:
相信大家都或多或少听说过AI画手的问题吧?
为了避免有些人要睡着了,我先炫一下技:
这是别人的AI画手:
这是我的AI画手:
(可能有人感觉我是用momoke模型控制的,我可以保证说不是,不信你可以拿我的图片放进你的AI里读取信息)
在对SDUI的使用方面来说,我可以说我比得过一半的人,即便如此,我依然放弃了它选择了ComfyUI,为什么?
AI绘画会出现这两个问题,原因很简单,因为这个画不是我们画的,而是AI画的,画的过程我们是控制不了的,我们能做的只有点一下生成。
是的,大家应该猜到问题出在哪里了————点一下生成。
我上面说SDUI把两个缺点全占了:这里我们重点说说是哪两个缺点:
1.我们只能输入一次,虽然SDUI支持不断地生成,但除非你人为地去改,否则输入的内容都是一样的,AI根据我们的提示输出的也不会差太多,就好像我们只有一条流水线,只能生产红烧牛肉面一样,但ComfyUI可以有多条流水线。
2.SDUI里面人物和环境是一起预处理的,哪怕是controlnet也一样,这种感觉就好像你生产的一包红烧牛肉面混进了香辣牛肉面的酱包,但ComfyUI可以分开处理:
这是原图:
接着我跟我的AI强调了不需要背景,背景接着白色就可以了,但这是效果:

我连手都能控制,却不能控制背景,因为SDUI并没有给我分开处理的机会,但ComfyUI给了我这个机会,刚才的测试也成功了。

我明白要说明ComfyUI的优点应该也说明一下它的工作方式,可是已经快四千字了(好累),我就简短的说明一下,详细的下次再说或者这里有:https://github.com/comfyanonymous/ComfyUI
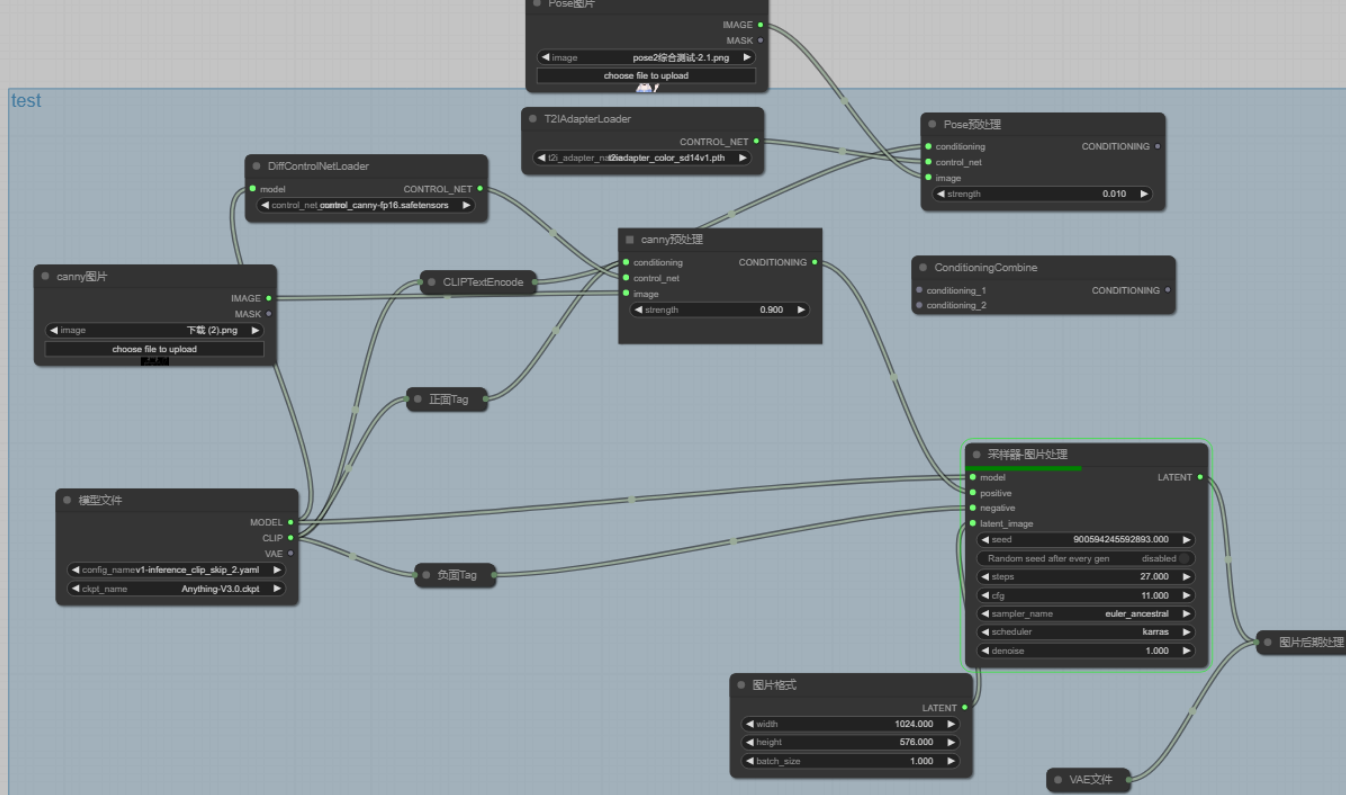
相比于SDUI,ComfyUI的生成方式并不是点一下鼠标就好了,你需要用节点的方式输入模型,插件(如果你要使用的话),正面和负面的提示词,图片格式,vae,然后用线把它们连接起来,就像这样:
在这个UI中,你每一次的生成并不只是生成一张图片,而是每一个应该输出图片的节点都会输出图片,对于同样一份输入数据,你可以用线把它连到不同的节点,用不同的插件和强度处理,然后生成图片输入下一个节点或者就这样输出,它就像有好几条流水线在同时工作,并且你可以通过许多模型控制一张图片,这在ComfyUI里面时允许,前面提到了lora,你可以使用多个自己训练的小模型来同时控制图片,增强你对AI的控制。
综上,ComfyUI相比于SDUI,它可以使用多个流水线工作,用不同的处理方式处理多个不同的图片,输出不同的图片,如果工作量很大,你只需要调整后节点然后出去玩一整天,而不用像SDUI一样坐在电脑前这张跑完了,换个输入数据换个处理方式再跑另一张。
同时,它也支持多个模型和插件(包括controlnet),输入数据同时控制一张图片,满足你对视角,动作,场景细节的要求,甚至得益于它的高效率和搞控制能力,许多AI动画爱好者狂喜,尽管这些人数量不多,因为要做到这些,需要和我差不多的对AI的控制能力,基本没人会研究的。(所以在ComfyUI面世时,很多大佬都在狂喜,但却有很多声音觉得AI退化了,不会画画,又不去学,只会让AI画,又懒得钻研........)
虽然cComfyUI很厉害,但它其实只是把AI工作的过程透明化了,它的本质还是SDAI,我也一直很感谢SDai。

