

代码细节---Java.HashSet用法
这是我写的第一篇关于语法以及Java常用类用法的博客。
我之所以突然想写这篇博客是因为我今天看到了一道非常好的题目:
HashSet set = new HashSet(); Person p1 = new Person(1001,"AA"); Person p1 = new Person(1002,"BB"); set.add(p1); set.add(p2); p1.name = "CC"; set.remove(p1); System.out.println(set); set.add(new Person(1001,"CC")); System.out.println(set); set.add(new Person(1001,"AA")); System.out.println(set);
其中Person类重写了hashCode()和equal()方法。
问最终打印结果是什么。
这道题我可以说是涵盖了HashSet的大部分知识点,并且完全涉及到了HashSet的底层原理,是一道难度比较大的题目。
首先我们要知道HashSet的原理是什么。
这里就要用到数据结构的哈希值运算以及拉链法。
Person类重写了Object的hashCode()和equal()方法
那么每个Person对象的哈希值就确定下来了。
这里我还要讲一下HashSet的底层是怎么样的:
HashSet底层需要一个数组和链表,通过加入的对象的哈希值散射到 [ 0 , 数组长度 - 1 ] 的范围上得到一个索引值,插入到对应数组下标中,
如果那个位置有元素或者有链表了,就一一比较( 用equal() ),如果比较完了equal()返回false,说明不相同,就插入到那个位置或者插入到对应的链表位置,
如果返回true则说明这个元素和它相同,违背了Set集合的不重复性这条原则,则不插入。
我们再回到这个题目,题目中首先定义了一个HashSet集合,并且插入了两个Person对象,然后关键的一点来了:
p1.name = "CC";
set.remove(p1);
System.out.println(set);
这行代码调用之后打印啥呢?我来画一张图助于理解:
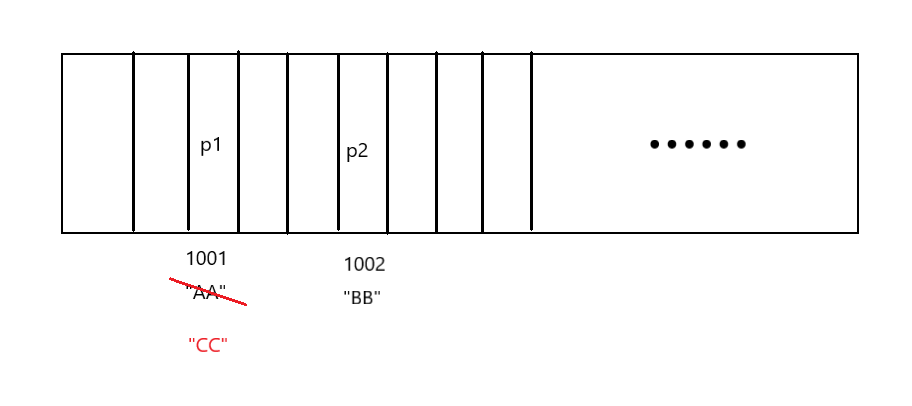
p1 p2 放置的位置都是根据这两个对象的哈希值确定的,这个时候我们把p1的name字段修改,
这个时候注意:p1本质是一个引用,p1指向的对象的name字段值改了,在set容器中存放的也是这个引用。
然后调用Collection接口中的remove方法,那么HashSet也是根据哈希值来删除这个元素的,
但是在name这个字段值修改了之后大概率找不到这个元素,因为字段修改了,哈希值也就变了,我们是根据哈希值去移除这个元素的,
现在找不到,remove就失效了,无法移除了。
所以最终打印还是p1,p2元素。
set.add(new Person(1001,"CC")); System.out.println(set);
再看这段代码,其实这和之前的道理是一样的,remove失效了,因为哈希值变了,那么现在new的这个对象哈希值的散射值在HashSet底层数组中的索引位置还是没有元素(大概率)
所以其实add成功了,所以这个时候打印了3个元素。
set.add(new Person(1001,"AA")); System.out.println(set);
这里的哈希值是存在的,就是之前的那个p1的哈希值,但是有了哈希值还要调用equal()方法,这里equal()方法返回false了,插入仍然成功,所以打印的set就有4个元素。
这道题就过了,还是一道非常好的题目,很有价值做的题目。

