语音笔记:CTC
CTC全称,Connectionist temporal classification,可以理解为基于神经网络的时序类分类。语音识别中声学模型的训练属于监督学习,需要知道每一帧对应的label才能进行有效的训练,在训练的数据准备阶段必须要对语音进行强制对齐。对于语音的一帧数据,很难给出一个label,但是几十帧数据就容易判断出对应的发音label。CTC的引入可以放宽了这种逐一对应的要求,只需要一个输入序列和一个输出序列即可以训练。CTC解决这一问题的方法是,在标注符号集中加一个空白符号blank,然后利用RNN进行标注,最后把blank符号和预测出的重复符号消除。比如有可能预测除了一个"--a-bb",就对应序列"ab",这样就让RNN可以对长度小于输入序列的标注序列进行预测了。RNN的训练需要用到前向后向算法(Forward-backward algorithm),大概思路是:对于给定预测序列,比如“ab”,在各个字符间插入空白符号,建立起篱笆网络(Trellis),然后对将所有可能映射到给定预测的序列都穷举出来求和。
CTC有两点好处:不需要对数据对齐和一一标注;CTC直接输出序列预测的概率,不需要外部的后处理。
在端到端的语音识别中有以下问题:
1).输入语音序列和标签(即文字结果)的长度不一致
2).标签和输入序列的位置是不确定的(对齐问题)
即长度问题和对齐问题,多个输入帧对应一个输出或者一个输入对多个输出。
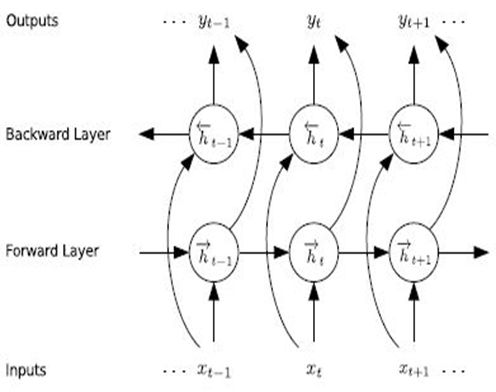
1.结构
系统可以通过双向rnn进行建模。RNN用来训练得到每个时刻不同音素的概率分布。
输入:按时序输入的每一帧的特征。
输出:每一个时刻的输出,是一个softmax,表示K+1个类别的不同概率,K表示音素的个数,1表示blank。(分类问题,是某个音素or空白)
对于给定时序长度为T的输入特征序列和任意一个输出标签序列π={π1,π2,π3,….,πT}。输出为该序列的概率为每个时刻相应标签的概率乘积:

把上式中的pr概率写成y,就变为论文中的原始公式(y表示softmax输出的概率):
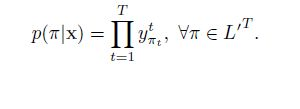
2.损失函数
因为输出序列和最后的训练标签一般不等长,我们用x表示输入序列,y表示对于的标签,a表示我们之前预测的序列:采用一个many-to-one的对应准则β(去除blank和重复),使上述的输出序列与给定的标签序列对应,比如(a,-,b,c,-,-)和(-,-,a,-,b,c)都映射成标签y(a,b,c)。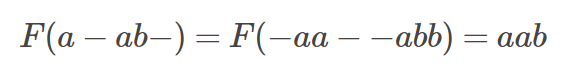
表示β的逆过程,即one-to-many,也就是把(a,b,c)映射成有重复和blank的所有可能,所以最终的标签y为给定输入序列x在LSTM模型下各个序列标签的概率之和:
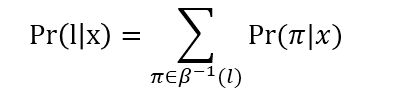
所以给定一个输入序列x和一个标注l*,上式为给定输入x,输出序列为 l 的概率。LSTM的目标函数最大化上述概率值(最小化负对数)。
CTC的损失函数定义如下所示:
![]()
其中 p(z|x)p(z|x) 代表给定输入x,输出序列 zz 的概率,S为训练集。损失函数可以解释为:给定样本后输出正确label的概率的乘积,再取负对数就是损失函数了。取负号之后我们通过最小化损失函数,就可以使输出正确的label的概率达到最大了。
由于上述定义的损失函数是可微的,因此我们可以求出它对每一个权重的导数,然后就可以使用梯度下降、Adam等优化算法来进行求解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号