语音笔记:矢量量化
矢量量化(VQ,Vector Quantization)是一种极其重要的信号压缩方法。VQ在语音信号处理中占十分重要的地位。广泛应用于语音编码、语音识别和语音合成等领域。VQ是一种基于块编码规则的有损数据压缩方法。在 JPEG 和 MPEG-4 等多媒体压缩格式里都有 VQ的应用。它的基本思想是:将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。
一.概念
VQ实际上就是一种逼近。它的思想和”四舍五入“类似,都是用一个和一个数最接近的整数来近似表示这个数。这里借两张网上的图。

这里,小于-2的数都近似为-3,在-2和0之间的数都近似为-1 等等等 。数轴上任意的一个数都会被近似为这四个数中的一个。而我们编码这四个数只需要两个二进制位就行了。这种我们称为:1-dimensional,2-bit VQ,量化速率是2bits/dimension。
同理,在二维空间里:
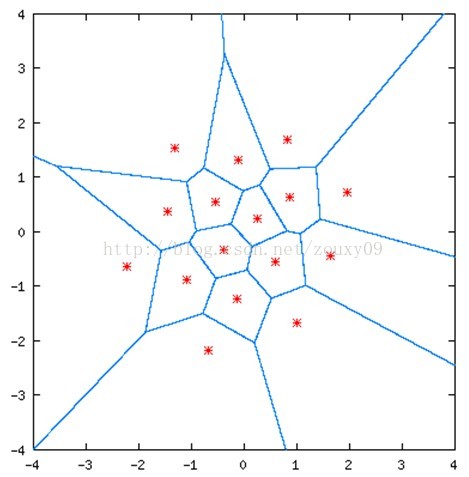
用蓝色实线将这张图划分为若干区域,落在二维空间中的任意点都可以被该区域的红星点近似表示。16个红星点可以用4位的二进制码来编码表示(2^4=16),所以这是2-dimensional, 4-bit VQ,它的速率同样是2bits/dimension。上面这些红星点就是量化矢量,表示图中的任意一个点都可以量化为这16个矢量中的其中一个。
以上的两个例子,红星被称为码矢(code vectors),蓝色边区域叫做编码区域(encoding regions)。所有码矢的集合称为码书(code book),所有编码区域的集合称为空间的划分(partition of the space)。
二.设计
我们假设M足够大(训练样本足够多),可以保证这个训练序列包含了源的所有统计特性。我们假设源矢量是k维的:
xm=(xm,1,xm,2, …, xm,k), m=1,2,…,M
假设码矢的数目是N(将矢量空间划分为N个部分,或者说是将样本量化为N种值),码书表示为:C={c1, c2,…, cN},每一个码矢是个k维向量:cn=(cn,1, cn,2, …, cn,k),n=1,2,…,N。
如果源矢量xm在S区域内,那么它的近似Q(xm)就是cn,表示为:
Q(xm)=cn 如果xm 属于Sn
平均失真度表示如下:
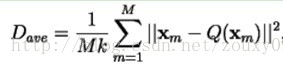
那么设计问题就可以简单的描述为:给定T(训练集)和N(码矢数目),找到能使Dave(平均失真度)最小的C(码书)和P(空间划分)。
三.优化
如果C和P是上面这个最小化问题的一个解,那么这个解需要满足以下两个条件:
1.Nearest NeighborCondition 最近邻条件:
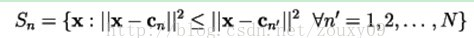
最近邻条件的意思是编码区域Sn应该包含所有与cn最接近的矢量(相比于与其他码矢的距离)。(对于在边界上面的矢量,采用某些决策方法)
2.Centroid Condition 质心条件:
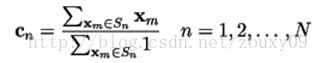
质心条件要求码矢cn是编码区域Sn内所有的训练样本向量的平均向量。现实中,需要保证每个编码区域至少要有一个训练样本向量。
四.实现
具体实现类似于K-Means聚类。
1.我们先定义一个可以接受的总失真度,设定一个初始的码矢为所有训练样本的平均值。
2.每迭代一次,使每个码矢分裂(乘以扰乱系数1+ɛ和1-ɛ)为两个,这种每一次分裂后的码矢数量就是前一次的两倍。
3.计算在现阶段的C和P基础上的总失真度,如果本次失真度相比上一次的失真度还大于可以接受的失真阈值ɛ,则继续迭代。
4.直至失真度足够低或者码矢的数目达到要求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号