RealPython-中文系列教程-一-
RealPython 中文系列教程(一)
原文:RealPython
Python REST APIs 与 Flask、Connexion 和 SQLAlchemy——第 3 部分
原文:# t0]https://realython . com/flask-连接-rest API-part-3/
大多数现代网络应用程序都是由一个 REST API 驱动的。这样,开发人员可以将前端代码与后端逻辑分开,用户可以动态地与界面进行交互。在这个由三部分组成的教程系列中,您将使用 Flask web 框架构建一个 REST API。
您已经用一个基本的 Flask 项目创建了一个基础,并添加了端点,您将其连接到一个 SQLite 数据库。你也在用你一直在构建的 Swagger UI API 文档测试你的 API。
在本系列教程的第三部分,您将学习如何:
- 在数据库中使用多个表
- 在数据库中创建一对多字段
- 使用 SQLAlchemy 管理关系
- 利用棉花糖的嵌套模式
- 在前端显示相关对象
您可以通过单击下面的链接下载该项目的第三部分代码:
源代码: 点击这里下载免费的源代码,您将使用它来完成用 Flask web framework 构建 REST API。
演示
在这个由三部分组成的教程系列中,您将构建一个 REST API 来跟踪全年可能访问您的人的笔记。你会创造出像牙仙、复活节兔子和 T4 这样的人。
理想情况下,你想和他们三个都保持良好的关系。这就是为什么你要给他们寄便条,以增加从他们那里得到贵重礼物的机会。
在本教程中,您将进一步扩展您的编程工具带。您将学习如何创建由 SQLAlchemy 表示为一对多关系的分层数据结构。此外,您还将扩展已经构建的 REST API,以便为一个人创建、阅读、更新和删除笔记:
https://player.vimeo.com/video/766055660?background=1
是时候通过创建人和笔记之间的关系来完成这个由三部分组成的教程系列了!
规划第三部分
在本系列的第一部分中,您构建了您的 REST API。通过第二部分,您将 REST API 连接到数据库。这样,您的 Flask 应用程序可以对现有数据进行更改,并创建新数据,即使您重新启动应用程序服务器,这些新数据也会持续存在。
到目前为止,您已经添加了使用 SQLAlchemy 将通过 REST API 所做的更改保存到数据库中的能力,并学习了如何使用 Marshmallow 为 REST API 使用序列化该数据。
目前,people.db数据库只包含人的数据。在本系列的这一部分中,您将添加一个新表来存储笔记。为了将笔记与一个人联系起来,您将在数据库中的person表和note表的条目之间创建关系。
您将使用包含必要人员和 notes 数据的build_database.py脚本来引导people.db。以下是您将使用的数据集的摘录:
PEOPLE_NOTES = [
{
"lname": "Fairy",
"fname": "Tooth",
"notes": [
("I brush my teeth after each meal.", "2022-01-06 17:10:24"),
("The other day a friend said I have big teeth.", "2022-03-05 22:17:54"),
("Do you pay per gram?", "2022-03-05 22:18:10"),
],
},
# ...
]
您将学习如何调整 SQLite 数据库来实现关系。之后,您将能够将PEOPLE_NOTES字典翻译成符合您的数据库结构的数据。
最后,您将在应用程序的主页上显示数据库的内容,并使用 Flask REST API 添加、更新和删除您为他人编写的笔记。
开始使用
理想情况下,在继续你现在正在阅读的第三部分之前,你已经看完了这个系列教程的第一部分和第二部分的。或者,您也可以通过单击下面的链接下载第二部分的源代码:
源代码: 点击这里下载免费的源代码,您将使用它继续用 Flask web 框架构建 REST API。
如果您从上面的链接下载了源代码,那么请确保遵循所提供的README.md文件中的安装说明。
在继续学习本教程之前,请验证您的文件夹结构如下所示:
rp_flask_api/
│
├── templates/
│ └── home.html
│
├── app.py
├── config.py
├── models.py
├── people.py
└── swagger.yml
一旦有了 Flask REST API 文件夹结构,您就可以继续阅读,检查您的 Flask 项目是否按预期工作。
检查你的烧瓶项目
在你继续你的 Flask 项目之前,创建并激活一个虚拟环境是个好主意。这样,您安装的任何项目依赖项都不是系统范围的,而只是在项目的虚拟环境中。
在下面选择您的操作系统,并使用您的平台特定命令来设置虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS>
$ python -m venv venv
$ source venv/bin/activate
(venv) $
使用上面显示的命令,您可以通过使用 Python 的内置venv模块创建并激活一个名为venv的虚拟环境。提示前面的圆括号(venv)表示您已经成功激活了虚拟环境。
注意:如果您还没有完成本系列教程的第二部分,请点击下面的链接下载源代码:
源代码: 点击这里下载免费的源代码,您将使用它继续用 Flask web 框架构建 REST API。
在继续之前,按照提供的README.md文件中列出的说明安装依赖项。
现在您可以验证您的 Flask 应用程序正在运行,没有错误。在包含app.py文件的目录中执行以下命令:
(venv) $ python app.py
当您运行此应用程序时,web 服务器将在端口 8000 上启动。如果你打开浏览器并导航到http://localhost:8000,你应该会看到一个标题为 Hello,People!⒃:
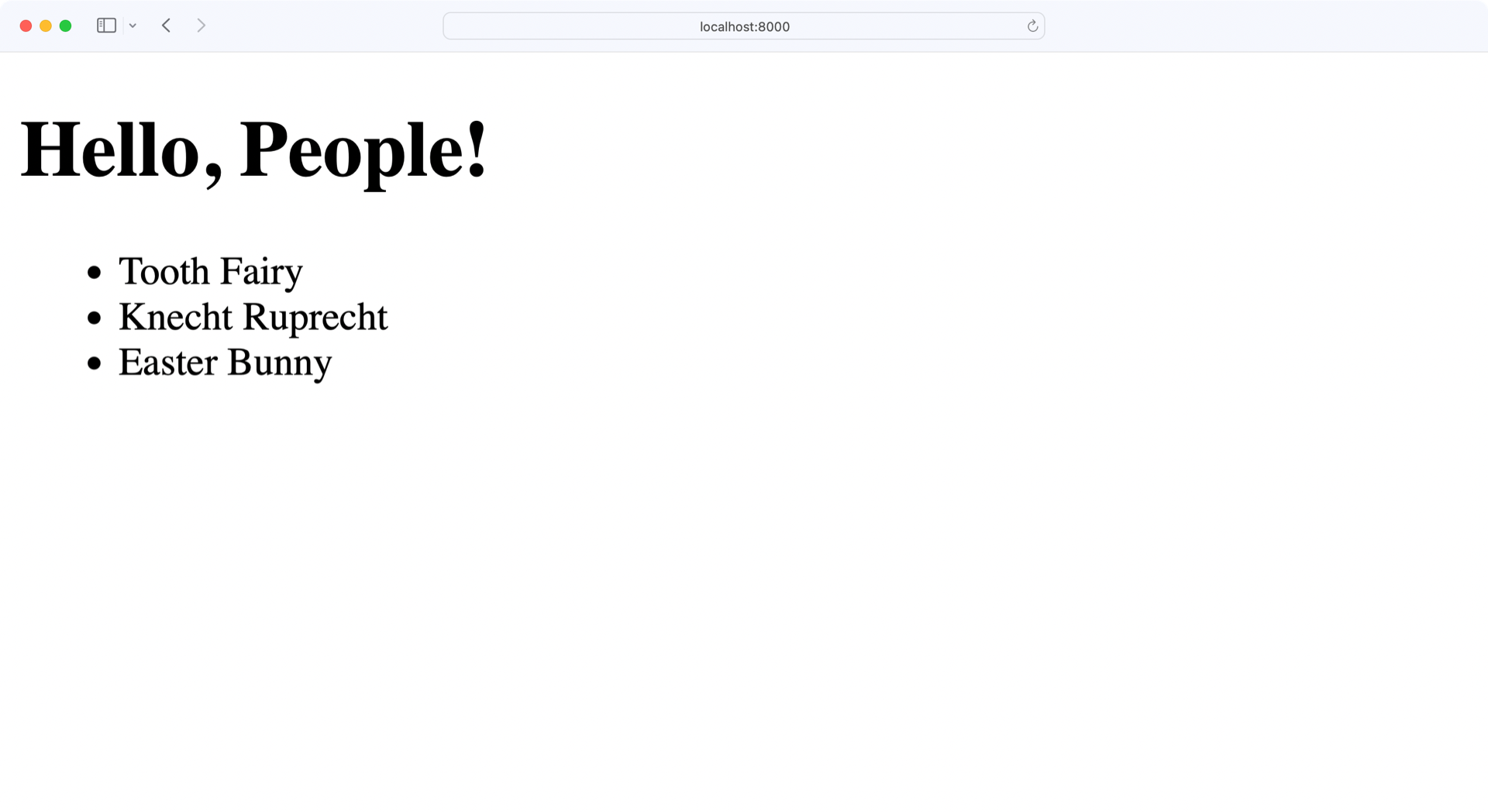
完美,你的应用程序运行完美!现在是时候考虑新的数据库结构了。
检查数据集
在开始计划如何调整数据库之前,最好先查看一下数据库当前包含的数据以及将要使用的数据集。
您的people.db数据库的person表目前如下所示:
| 身份证明(identification) | lname | fname | 时间戳 |
|---|---|---|---|
| one | 仙女 | 牙齿 | 2022-10-08 09:15:10 |
| Two | 鲁普雷希特 | 小厮 | 2022-10-08 09:15:13 |
| three | 兔子 | 复活节 | 2022-10-08 09:15:27 |
您将开始使用一个PEOPLE_NOTES列表来扩展您的数据库:
PEOPLE_NOTES = [
{
"lname": "Fairy",
"fname": "Tooth",
"notes": [
("I brush my teeth after each meal.", "2022-01-06 17:10:24"),
("The other day a friend said, I have big teeth.", "2022-03-05 22:17:54"),
("Do you pay per gram?", "2022-03-05 22:18:10"),
],
},
{
"lname": "Ruprecht",
"fname": "Knecht",
"notes": [
("I swear, I'll do better this year.", "2022-01-01 09:15:03"),
("Really! Only good deeds from now on!", "2022-02-06 13:09:21"),
],
},
{
"lname": "Bunny",
"fname": "Easter",
"notes": [
("Please keep the current inflation rate in mind!", "2022-01-07 22:47:54"),
("No need to hide the eggs this time.", "2022-04-06 13:03:17"),
],
},
]
注意,PEOPLE_NOTES中的lname值对应于people.db数据库的person表中lname列的内容。
在上面的数据集中,每个人包括一个名为notes的键,它与一个包含数据元组的列表相关联。列表中的每个元组代表一个包含内容和时间戳的单个注释。
每个单独的人与多个音符相关联,并且每个单独的音符仅与一个人相关联。这种数据层次结构称为一对多关系,其中一个父对象与许多子对象相关。在本教程的后面,您将看到如何使用 SQLAlchemy 在数据库中管理这种一对多关系。
与人建立关系
不是扩展person表并试图在单个表中表示分层数据,而是将数据分成多个表并连接它们。
对于person表,这意味着不会有变化。为了表示新的注释信息,您将创建一个名为note的新表。
note表将如下所示:
id |
person_id |
content |
timestamp |
|---|---|---|---|
| one | one | 我每顿饭后都刷牙。 | 2022-01-06 17:10:24 |
| Two | one | 有一天,一个朋友说,我的牙齿很大。 | 2022-03-05 22:17:54 |
| three | one | 你按克付费吗? | 2022-03-05 22:18:10 |
| four | Two | 我发誓,今年我会做得更好。 | 2022-01-01 09:15:03 |
| five | Two | 真的!从此只做好事! | 2022-02-06 13:09:21 |
| six | three | 请记住当前的通货膨胀率! | 2022-01-07 22:47:54 |
| seven | three | 这次不用藏蛋了。 | 2022-04-06 13:03:17 |
注意,像person表一样,note表有一个名为id的惟一标识符,它是note表的主键。person_id列创建了与person表的关系。
鉴于id是表的主键,person_id是所谓的外键。外键为note表中的每个条目提供与之相关的person记录的主键。使用这个,SQLAlchemy 可以通过将person.id主键连接到note.person_id外键来收集与每个人相关联的所有笔记,从而创建一个关系。
您构建的数据库将数据存储在表中,而表是由行和列组成的二维数组。上面的People字典可以用一个行和列的表格来表示吗?它可以通过以下方式保存在您的person数据库表中:
id |
lname |
fname |
timestamp |
content |
note_timestamp |
|---|---|---|---|---|---|
| one | 仙女 | 牙齿 | 2022-10-08 09:15:10 | 我每顿饭后都刷牙。 | 2022-01-06 17:10:24 |
| Two | 仙女 | 牙齿 | 2022-10-08 09:15:10 | 有一天,一个朋友说,我的牙齿很大。 | 2022-03-05 22:17:54 |
| three | 仙女 | 牙齿 | 2022-10-08 09:15:10 | 你按克付费吗? | 2022-03-05 22:18:10 |
| four | 鲁普雷希特 | 小厮 | 2022-10-08 09:15:13 | 我发誓,今年我会做得更好。 | 2022-01-01 09:15:03 |
| five | 鲁普雷希特 | 小厮 | 2022-10-08 09:15:13 | 真的!从此只做好事! | 2022-02-06 13:09:21 |
| six | 复活节 | 兔子 | 2022-10-08 09:15:27 | 请记住当前的通货膨胀率! | 2022-01-07 22:47:54 |
| seven | 复活节 | 兔子 | 2022-10-08 09:15:27 | 这次不用藏蛋了。 | 2022-04-06 13:03:17 |
上面的表格实际上是可行的。所有的数据都被表示出来,一个人与一组不同的笔记相关联。
从概念上讲,上面的表结构具有相对简单易懂的优点。您甚至可以将数据保存到一个 CSV 文件中,而不是数据库中。
虽然上面的表格结构可以工作,但是它有一些真正的缺点。其中包括以下内容:
- 由于冗余数据导致的维护问题
- 笨拙的列名
- 难以呈现一对多关系
为了表示笔记的集合,每个人的所有数据对于每个唯一的笔记都是重复的。因此,个人数据是多余的。这对于您的个人数据来说没什么大不了的,因为没有那么多列。但是想象一下,如果一个人有更多的列。即使使用大型磁盘驱动器,如果您要处理数百万行数据,这也会成为存储问题。
随着时间的推移,像这样的冗余数据也会导致维护问题。例如,如果复活节兔子决定改名是一个好主意呢?为了做到这一点,每个包含复活节兔子名字的记录都必须更新,以保持数据的一致性。这种针对数据库的工作会导致数据不一致,尤其是当这项工作是由手工运行 SQL 查询的人来完成时。
此外,命名列变得很笨拙。在上表中,有一个timestamp列用于跟踪表中一个人的创建和更新时间。您还希望为便笺的创建和更新时间提供类似的功能,但是因为已经使用了timestamp,所以使用了一个虚构的名称note_timestamp。
如果您想向person表添加额外的一对多关系,该怎么办?例如,您可能会决定包含一个人的孩子或电话号码。每个人可以有多个孩子和多个电话号码。使用上面的 Python People字典,您可以通过添加包含数据的新列表的children和phone_numbers键相对容易地做到这一点。
然而,在上面的person数据库表中表示这些新的一对多关系变得非常困难。每一个新的一对多关系都会显著增加子数据中每一项表示该关系所需的行数。此外,与数据冗余相关的问题变得越来越大,越来越难以处理。
注意:存储日益庞大和复杂的数据结构的需求推动了 NoSQL 数据库的流行。这些数据库系统允许开发人员有效地存储非表结构的异构数据。如果你对 NoSQL 数据库感兴趣,那就去看看 Python 和 MongoDB:连接到 NoSQL 数据库。
最后,从上面的表结构中得到的数据很难处理,因为它只是一个很大的列表。
通过将数据集分成两个表并引入外键的概念,您将使数据变得更加复杂。但是您将解决单个表表示的缺点。
关联表的最大优点是数据库中没有冗余数据。对于您希望存储在数据库中的每个人,只有一个人条目。
如果复活节兔子仍然想更改名字,那么您只需更改person表中的一行,与该行相关的任何其他内容都将立即利用这一更改。
此外,列命名更加一致和有意义。因为 person 和 note 数据存在于不同的表中,所以创建或更新时间戳可以在两个表中一致地命名,因为跨表命名没有冲突。
但是理论已经够了!在下一节中,您将创建代表您提出的数据库表关系的模型。
扩展您的数据库
在本节中,您将扩展您的数据库。您将修改models.py中的People数据结构,给每个人一个与他们相关的笔记列表。最后,您将使用一些初始数据填充数据库。
创建 SQLAlchemy 模型
要使用上面的两个表并利用它们之间的关系,您需要创建 SQLAlchemy 模型,该模型知道这两个表以及它们之间的关系。
首先更新models.py中的Person模型,以包含与notes集合的关系:
1# models.py
2
3from datetime import datetime
4from config import db, ma
5
6class Person(db.Model):
7 __tablename__ = "person"
8 person_id = db.Column(db.Integer, primary_key=True)
9 lname = db.Column(db.String(32), unique=True)
10 fname = db.Column(db.String(32))
11 timestamp = db.Column(
12 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
13 )
14 notes = db.relationship( 15 Note, 16 backref="person", 17 cascade="all, delete, delete-orphan", 18 single_parent=True, 19 order_by="desc(Note.timestamp)" 20 ) 21
22# ...
在第 14 到 20 行,您在Person类中创建了一个名为.notes的新属性。这个新的.notes属性在下面几行代码中定义:
-
第 14 行:与您对该类的其他属性所做的类似,这里您创建了一个名为
.notes的新属性,并将其设置为一个名为db.relationship的对象实例。这个对象创建了您正在添加到Person类中的关系,它是用下面几行中定义的所有参数创建的。 -
第 15 行:参数
Note定义了与Person类相关的 SQLAlchemy 类。Note类还没有被定义,所以目前它还不能工作。有时将类称为字符串可能更容易避免先定义哪个类的问题。例如,你可以用"Note"代替这里的Note。 -
第 16 行:
backref="person"参数在Note对象中创建一个向后引用。每个Note的实例将包含一个名为.person的属性。.person属性引用了一个特定的Note实例所关联的父对象。如果您的代码遍历 notes 并且必须包含关于父对象的信息,那么在子对象中引用父对象(在本例中为Person)会非常有用。 -
第 17 行:
cascade="all, delete, delete-orphan"参数决定当父Person实例发生变化时,如何处理Note实例。例如,当一个Person对象被删除时,SQLAlchemy 将创建从数据库中删除Person对象所必需的 SQL。这个参数告诉 SQLAlchemy 也删除与之相关的所有Note实例。您可以在 SQLAlchemy 文档中阅读关于这些选项的更多信息。 -
第 18 行:如果
delete-orphan是先前cascade参数的一部分,则single_parent=True参数是必需的。这告诉 SQLAlchemy 不允许孤立的Note实例——即没有父Person对象的Note—存在,因为每个Note都有一个父对象。 -
第 19 行:
order_by="desc(Note.timestamp)"参数告诉 SQLAlchemy 如何对与Person对象相关联的Note实例进行排序。当检索到一个Person对象时,默认情况下notes属性列表将包含顺序未知的Note对象。SQLAlchemydesc()函数将按照从最新到最早的降序对笔记进行排序,而不是默认的升序。
既然您的Person模型有了新的.notes属性,并且这代表了与Note对象的一对多关系,您将需要为Note对象定义一个 SQLAlchemy 模型。因为您从Person中引用了Note,所以在Person类定义之前添加新的Note类:
1# models.py
2
3from datetime import datetime
4from config import db, ma
5
6class Note(db.Model): 7 __tablename__ = "note" 8 id = db.Column(db.Integer, primary_key=True) 9 person_id = db.Column(db.Integer, db.ForeignKey("person.id")) 10 content = db.Column(db.String, nullable=False) 11 timestamp = db.Column( 12 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow 13 ) 14
15class Person(db.Model):
16 # ...
17
18# ...
正如您在上面的示例数据库表中所了解到的,Note类定义了组成一个注释的属性。使用此代码,您可以定义属性:
-
第 6 行创建了
Note类,继承自db.Model,就像你之前创建Person类一样。 -
第 7 行告诉这个类使用什么数据库表来存储
Note对象。 -
第 8 行创建了
.id属性,将其定义为一个整数值和Note对象的主键。 -
第 9 行创建了
.person_id属性并将其定义为外键,使用.person.id主键将Note类与Person类相关联。这和Person.notes属性是 SQLAlchemy 在与Person和Note对象交互时知道该做什么的方式。 -
第 10 行创建了
.content属性,它包含了注释的实际文本。nullable=False参数表示可以创建没有内容的新便笺。 -
第 11 行到第 13 行创建了
.timestamp属性,与Person类完全一样,该属性包含任何特定Note实例的创建或更新时间。
现在您已经更新了People并为Note创建了模型,接下来更新数据库。
馈入数据库
现在您已经更新了Person并创建了Note模型,您将使用它们来重建people.db数据库。为此,创建一个名为build_database.py的辅助 Python 脚本:
# build_database.py
from datetime import datetime
from config import app, db
from models import Person, Note
PEOPLE_NOTES = [
{
"lname": "Fairy",
"fname": "Tooth",
"notes": [
("I brush my teeth after each meal.", "2022-01-06 17:10:24"),
("The other day a friend said, I have big teeth.", "2022-03-05 22:17:54"),
("Do you pay per gram?", "2022-03-05 22:18:10"),
],
},
{
"lname": "Ruprecht",
"fname": "Knecht",
"notes": [
("I swear, I'll do better this year.", "2022-01-01 09:15:03"),
("Really! Only good deeds from now on!", "2022-02-06 13:09:21"),
],
},
{
"lname": "Bunny",
"fname": "Easter",
"notes": [
("Please keep the current inflation rate in mind!", "2022-01-07 22:47:54"),
("No need to hide the eggs this time.", "2022-04-06 13:03:17"),
],
},
]
with app.app_context():
db.drop_all()
db.create_all()
for data in PEOPLE_NOTES:
new_person = Person(lname=data.get("lname"), fname=data.get("fname"))
for content, timestamp in data.get("notes", []):
new_person.notes.append(
Note(
content=content,
timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
)
)
db.session.add(new_person)
db.session.commit()
在上面的代码中,您正在向项目的数据库提供PEOPLE_NOTES的内容。您从您的config模块中使用db,因此 Python 知道如何处理data并将其提交给相应的数据库表和单元格。
注意:当你执行build_database.py时,你会重新创建people.db。people.db中的任何现有数据都将丢失。
从命令行运行build_database.py程序将使用新添加的内容重新创建数据库,为 web 应用程序做好准备:
(venv) $ python build_database.py
一旦您的项目包含一个新的数据库,您可以调整您的项目以在前端显示注释。
显示人物及其注释
现在您的数据库包含了要处理的数据,您可以开始在前端和 REST API 中显示数据了。
在前端显示注释
在上一节中,您通过向Person类添加一个.notes属性,创建了一个人和他的笔记之间的关系。
更新您的templates/文件夹中的home.html以访问某人的笔记:
<!-- templates/home.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>RP Flask REST API</title>
</head>
<body>
<h1>
Hello, People!
</h1>
{% for person in people %} <h2>{{ person.fname }} {{ person.lname }}</h2> <ul> {% for note in person.notes %} <li> {{ note.content }} </li> {% endfor %} </ul> {% endfor %} </body>
</html>
在上面的代码中,您访问每个人的.notes属性。之后,您将遍历特定人的所有笔记,以访问笔记的内容。
导航到http://localhost:8000检查您的模板是否如预期呈现:
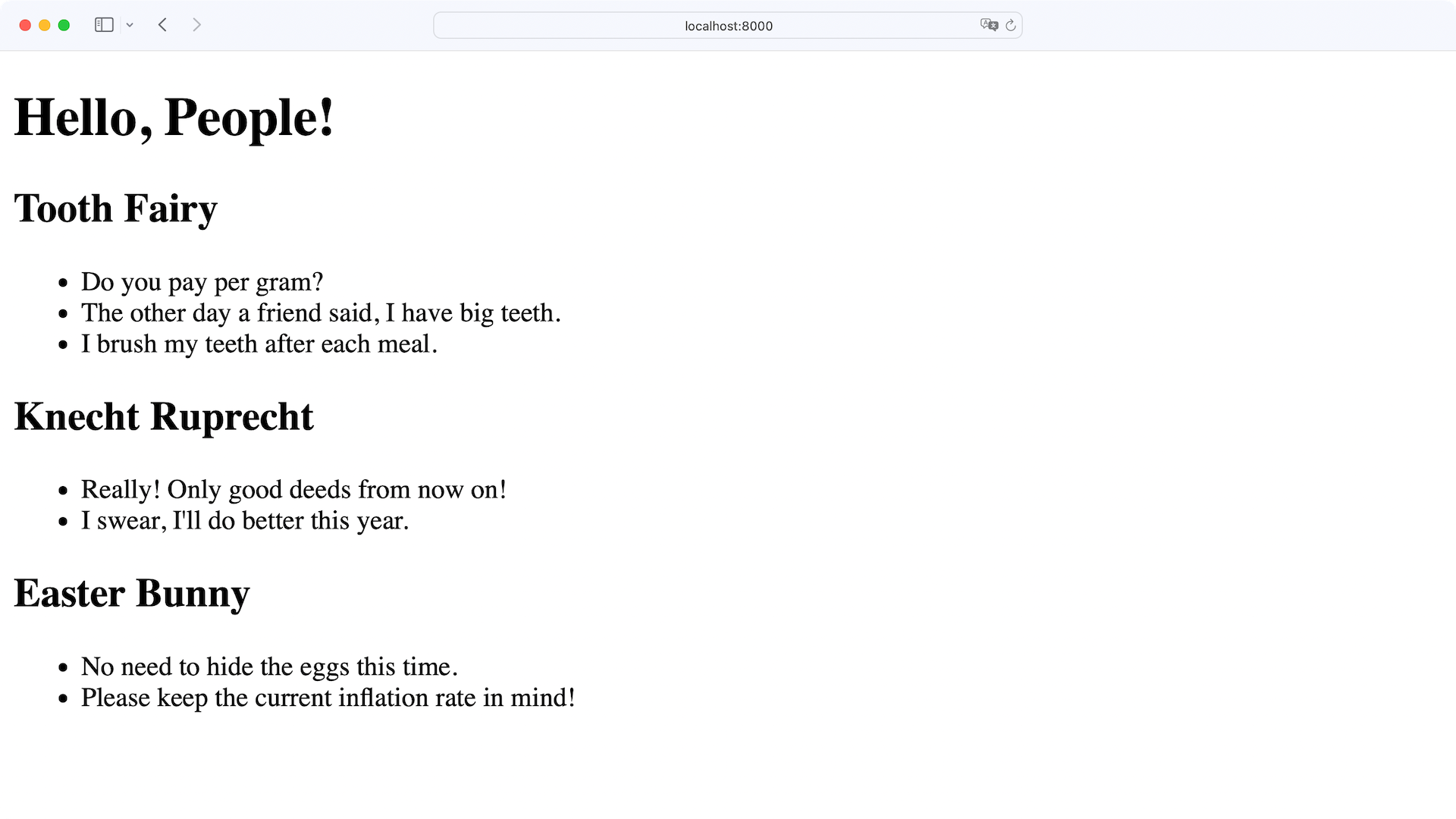
完美,你可以看到每个人的笔记列在你的前端。这意味着 Flask 成功地连接了引擎盖下的Person和Notes,并为您提供了一个可以方便使用的people对象。
用笔记回应
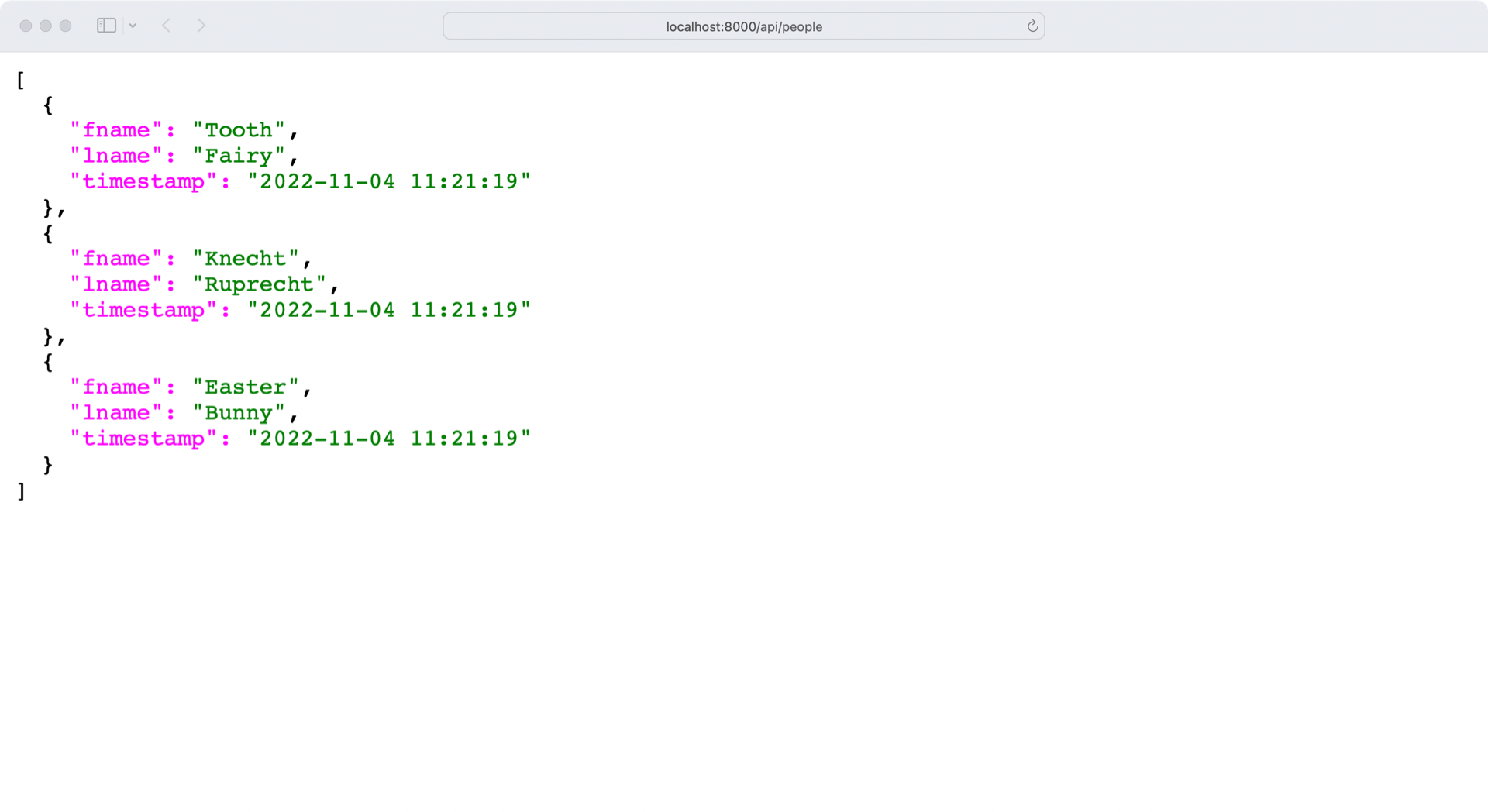
接下来,在http://localhost:8000/api/people检查 API 的/api/people端点:
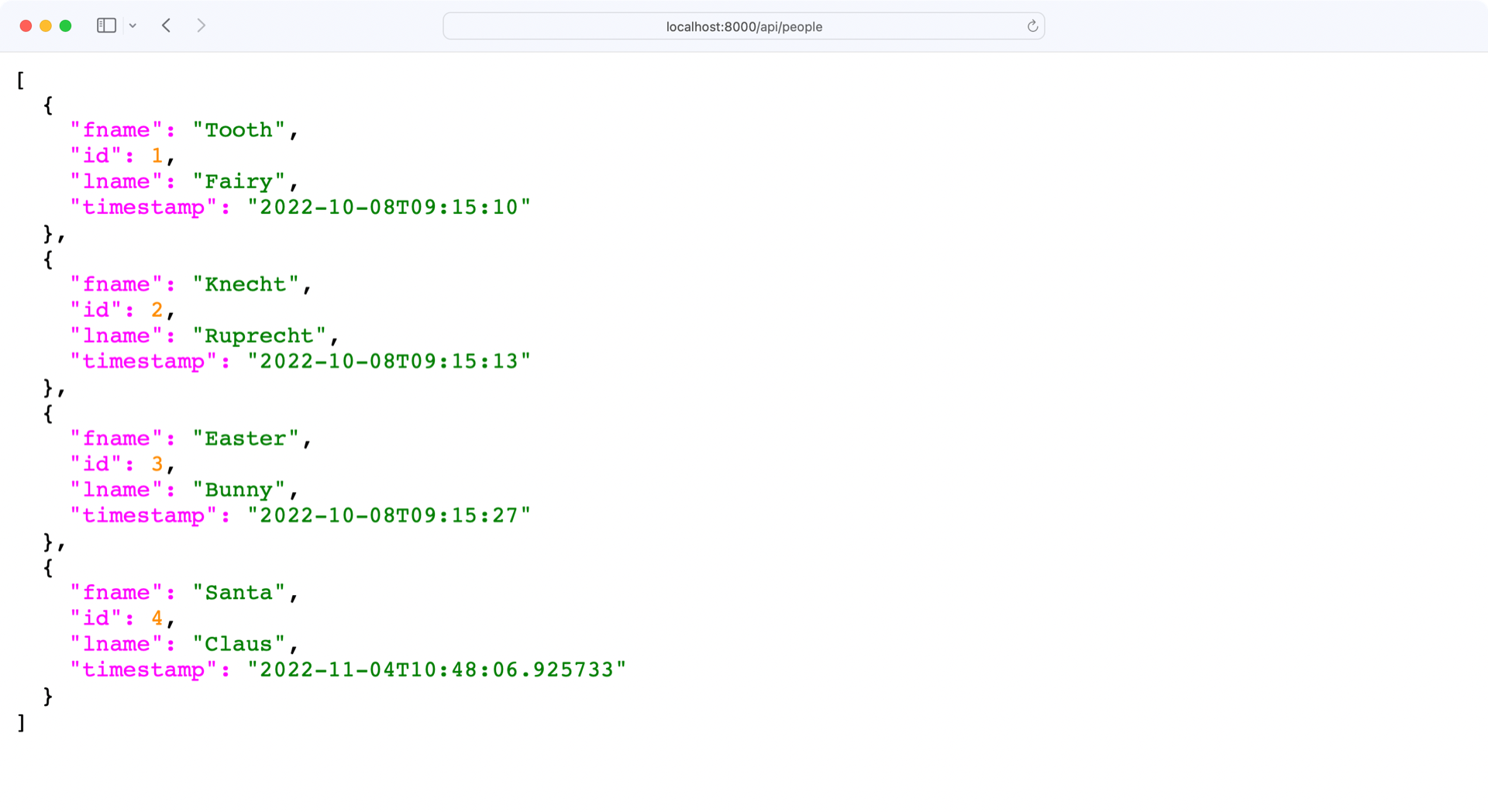
您正在接收 people 集合,没有任何错误。但是,您收到的数据中没有注释。
要调查这个问题,请看一下people.py中的read_all():
1# people.py
2
3# ...
4
5def read_all():
6 people = Person.query.all()
7 person_schema = PersonSchema(many=True)
8 return person_schema.dump(people)
9
10# ...
第 8 行中的.dump()方法处理它接收到的数据,不过滤掉任何数据。所以问题可能出在第 6 行的people或者第 7 行的person_schema的定义上。
填充people的数据库查询调用与app.py中的完全相同:
Person.query.all()
这个调用在前端成功地显示了每个人的笔记。这挑出PersonSchema作为最可能的罪犯。
默认情况下,棉花糖模式不会遍历相关的数据库对象。您必须显式地告诉模式包含关系。
打开models.py并更新PersonSchema:
# models.py
# ...
class PersonSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Person
load_instance = True
sqla_session = db.session
include_relationships = True
对于PersonSchema的Meta类中的include_relationships,您告诉 Marshmallow 将任何相关对象添加到 person 模式中。然而,结果看起来仍然不像预期的那样:
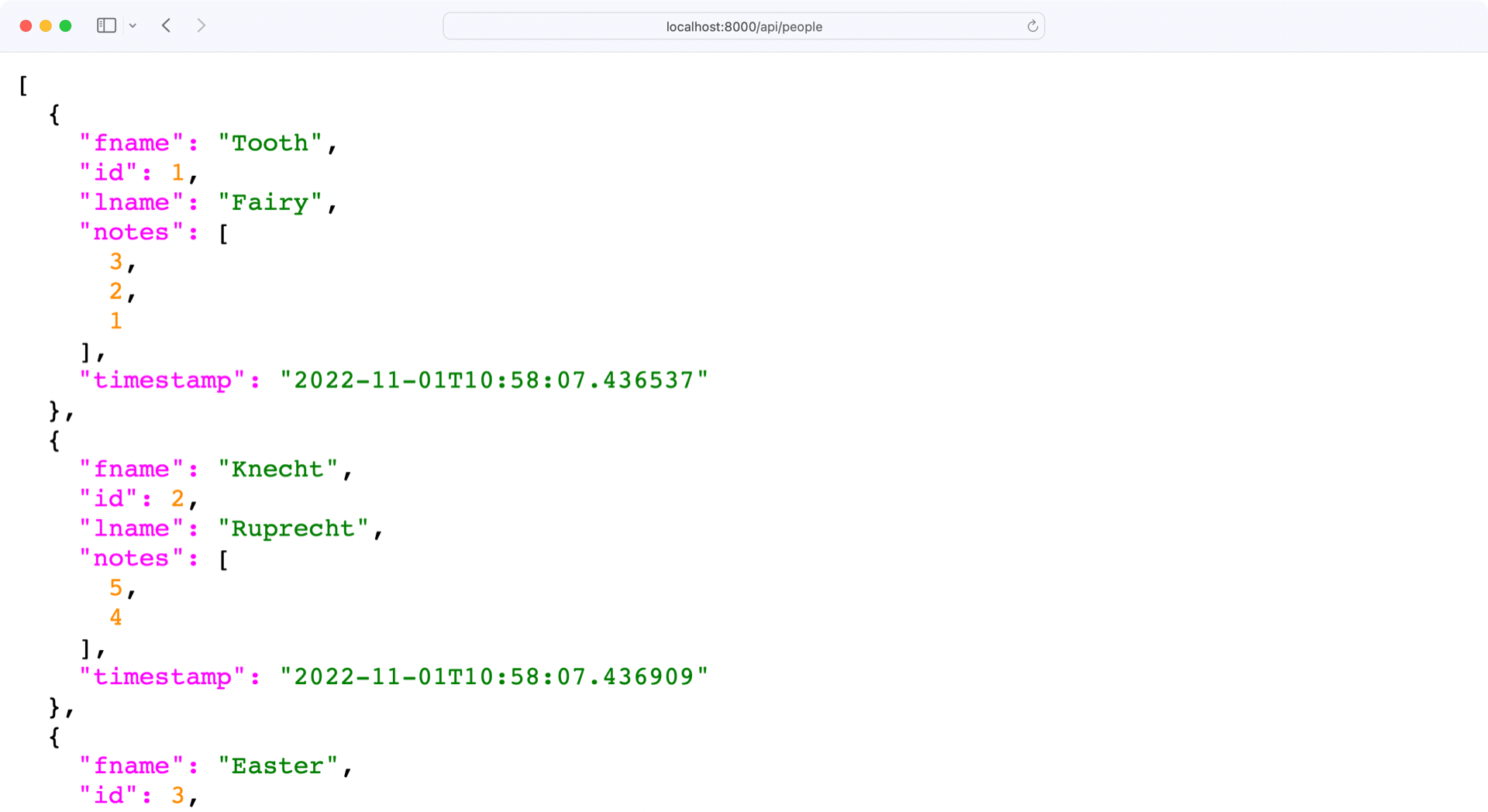
在http://localhost:8000/api/people的回复现在包含了每个人的笔记。但是,notes对象只包含一个主键列表,而不是显示一个注释包含的所有数据。
创建一个 Notes 模式
您的 API 响应只列出了每个人笔记的主键。这很公平,因为您还没有声明 Marshmallow 应该如何反序列化这些音符。
通过在Note下面的models.py和Person上面创建NoteSchema来帮助棉花糖:
# models.py
# ...
class Note(db.Model):
# ...
class NoteSchema(ma.SQLAlchemyAutoSchema):
class Meta: model = Note load_instance = True sqla_session = db.session include_fk = True
class Person(db.Model):
# ...
class PersonSchema(ma.SQLAlchemyAutoSchema):
# ...
note_schema = NoteSchema() # ...
你正在从NoteSchema中引用Note,所以你必须将NoteSchema放在你的Note类定义下面以防止错误。您还实例化了NoteSchema来创建一个稍后将引用的对象。
因为您的Note模型包含一个外键,所以您必须将include_fk设置为True。否则棉花糖不会在序列化过程中识别出person_id。
有了NoteSchema,您可以在PeopleSchema中引用它:
# models.py
from datetime import datetime
from marshmallow_sqlalchemy import fields
from config import db, ma
# ...
class PersonSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Person
load_instance = True
sqla_session = db.session
include_relationships = True
notes = fields.Nested(NoteSchema, many=True)
从marshmallow_sqlalchemy导入fields后,可以通过NoteSchema引用相关的Note对象。为了避免出错,请确认您在PeopleSchema上方定义了NoteSchema。
尽管您正在使用SQLAlchemyAutoSchema,但是您必须在PersonSchema中显式创建notes字段。否则,Marshmallow 不会收到处理Notes数据所需的所有信息。例如,它不知道你在期待一个使用many参数的对象列表。
更改完成后,在http://localhost:8000/api/people检查 API 的端点:
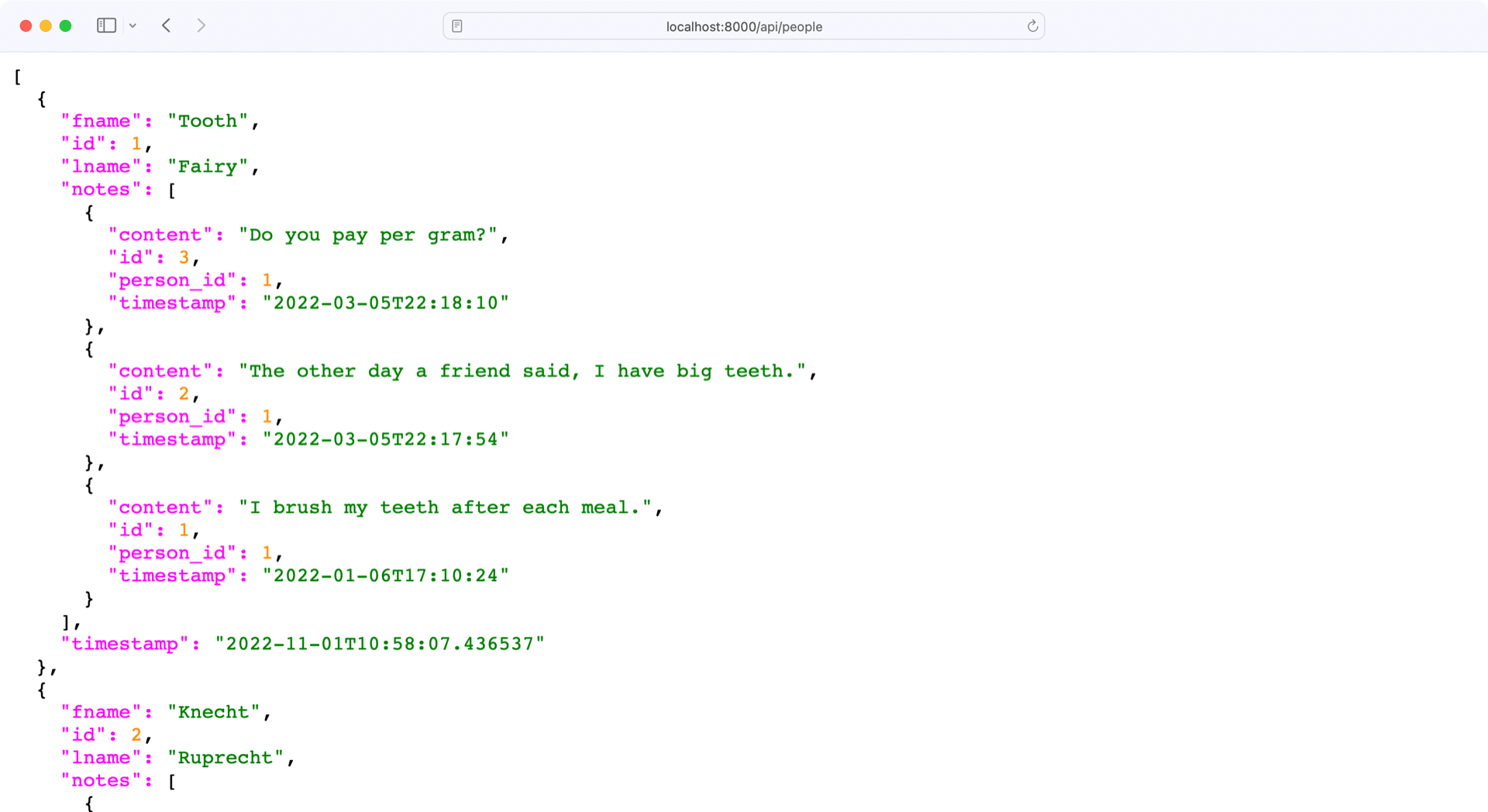
完美,你的read_all()函数不仅返回了所有的人,还返回了所有附加在每个人身上的笔记!
在下一节中,您将扩展 Flask REST API 来创建、读取、更新和删除单个注释。
用你的 REST API 处理笔记
您已经更新了 SQLAlchemy 模型,并使用它们从people.db数据库中读取数据。您的笔记可以作为嵌套模式在People中获得。当您请求一群人或某个特定的人时,您会收到笔记列表:
| 行动 | HTTP 动词 | path | 描述 |
|---|---|---|---|
| 阅读 | GET |
/api/people |
读一集人。 |
| 阅读 | GET |
/api/people/<lname> |
读一个特定的人。 |
虽然您可以通过上表中显示的端点读取注释,但是目前还没有办法只读取一个注释或者在 REST API 中管理任何注释。
注意:URL 参数是区分大小写。例如,您必须访问姓氏中有一个大写 R 的http://localhost:8000/api/people/RuprechtRUP Recht。
您可以跳到第一部分来回顾您是如何构建 REST API 的现有people端点的。在本节教程中,您将添加额外的端点来提供创建、阅读、更新和删除笔记的功能:
| 行动 | HTTP 动词 | path | 描述 |
|---|---|---|---|
| 创造 | POST |
/api/notes |
创建新便笺的 URL |
| 阅读 | GET |
/api/notes/<note_id> |
阅读单个便笺的 URL |
| 更新 | PUT |
api/notes/<note_id> |
用于更新单个注释的 URL |
| 删除 | DELETE |
api/notes/<note_id> |
删除单个便笺的 URL |
您将从添加阅读单个便笺的功能开始。为此,您将调整包含 API 定义的 Swagger 配置文件。
阅读单个笔记
目前,当你从一个特定的人那里请求数据时,你可以收到这个人的所有笔记。要获得关于一个注释的信息,您将添加另一个端点。
在添加端点之前,通过在swagger.yml文件中创建一个note_id参数组件来更新您的 Swagger 配置:
# swagger.yml # ... components: schemas: # ... parameters: lname: # ... note_id: name: "note_id" description: "ID of the note" in: path required: true schema: type: "integer" # ...
parameters中的note_id将是您的端点的一部分,用于标识您想要处理哪个音符。
继续编辑swagger.yml并添加端点数据以读取单个注释:
# swagger.yml # ... paths: /people: # ... /people/{lname}: # ... /notes/{note_id}: get: operationId: "notes.read_one" tags: - Notes summary: "Read one note" parameters: - $ref: "#/components/parameters/note_id" responses: "200": description: "Successfully read one note"
/notes/{note_id}的结构和/people/{lname}类似。您从/notes/{note_id}路径的get操作开始。{note_id}子串是一个注释 ID 的占位符,您必须将它作为一个 URL 参数传入。例如,URL http://localhost:8000/api/notes/1将为您提供带有主键1的注释的数据。
operationId指向notes.read_one。这意味着您的 API 期望在一个notes.py文件中有一个read_one()函数。继续,创建notes.py并添加read_one():
# notes.py
from flask import abort, make_response
from config import db
from models import Note, note_schema
def read_one(note_id):
note = Note.query.get(note_id)
if note is not None:
return note_schema.dump(note)
else:
abort(
404, f"Note with ID {note_id} not found"
)
虽然您还没有使用make_response()和db,但是您已经可以将它们添加到您的导入中了。当你写数据库的时候,你会用到它们。
现在,您只能从 REST URL 路径中读取带有note_id参数的数据库。您在查询的.get()方法中使用note_id来获取带有note_id整数主键的注释。
如果找到了一个注释,那么note包含一个Note对象,您返回序列化的对象。请在您的浏览器中访问http://localhost:8000/api/notes/1来试试吧:
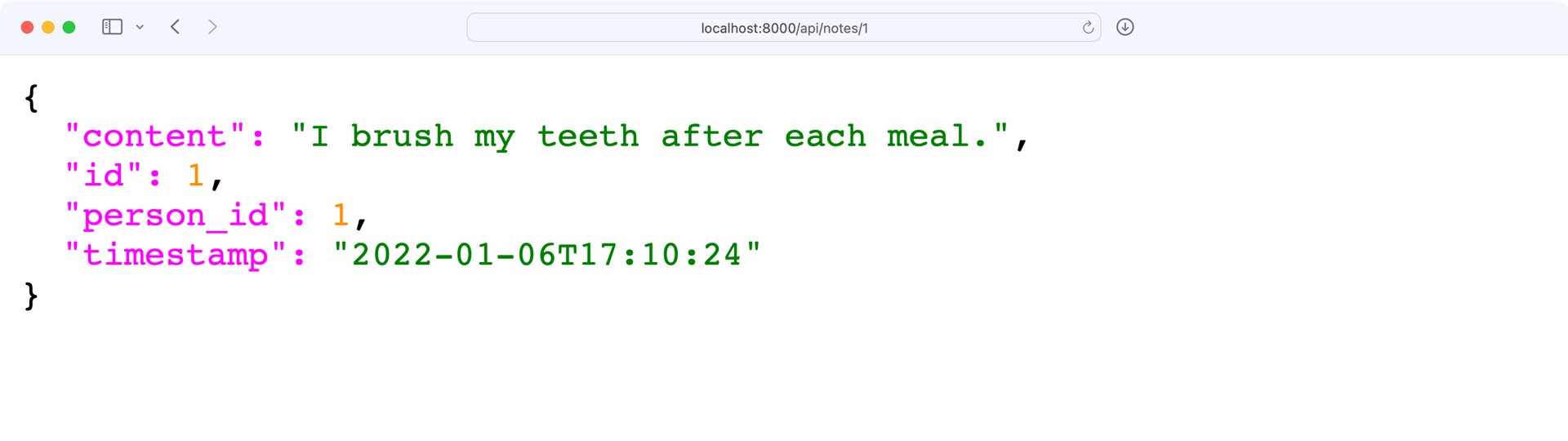
完美,带有注释数据集的 API 响应看起来和预期的一模一样!接下来,您将使用同一个端点来更新和删除一个注释。
更新和删除注释
这一次,首先在notes.py中创建函数,然后在swagger.yml中创建操作。
在notes.py中增加update()和delete():
# notes.py
# ...
def update(note_id, note):
existing_note = Note.query.get(note_id)
if existing_note:
update_note = note_schema.load(note, session=db.session)
existing_note.content = update_note.content
db.session.merge(existing_note)
db.session.commit()
return note_schema.dump(existing_note), 201
else:
abort(404, f"Note with ID {note_id} not found")
def delete(note_id):
existing_note = Note.query.get(note_id)
if existing_note:
db.session.delete(existing_note)
db.session.commit()
return make_response(f"{note_id} successfully deleted", 204)
else:
abort(404, f"Note with ID {note_id} not found")
当你比较update()和delete()时,它们有着相似的结构。这两个函数都查找现有的注释,并使用数据库会话。
为了让update()工作,您还接受一个note对象作为参数,它包含您可以更新的.content属性。
相比之下,你只需要在调用delete()的时候知道你想要去掉的音符的 ID 就可以了。
接下来,在swagger.yml中创建引用notes.update和notes.delete的两个操作:
# swagger.yml # ... paths: /people: # ... /people/{lname}: # ... /notes/{note_id}: get: # ... put: tags: - Notes operationId: "notes.update" summary: "Update a note" parameters: - $ref: "#/components/parameters/note_id" responses: "200": description: "Successfully updated note" requestBody: content: application/json: schema: x-body-name: "note" type: "object" properties: content: type: "string" delete: tags: - Notes operationId: "notes.delete" summary: "Delete a note" parameters: - $ref: "#/components/parameters/note_id" responses: "204": description: "Successfully deleted note"
同样,put和delete的结构也是类似的。主要区别在于,您需要提供一个包含注释数据的requestBody来更新数据库对象。
现在,您已经创建了使用现有笔记的端点。接下来,您将添加端点来创建注释。
为某人创建备忘录
到目前为止,您可以阅读、更新和删除单个便笺。这些是您可以在现有笔记上执行的操作。现在是时候向 REST API 添加功能来创建新的注释了。
将create()添加到notes.py:
# notes.py
from flask import make_response, abort
from config import db
from models import Note, Person, note_schema
# ...
def create(note):
person_id = note.get("person_id")
person = Person.query.get(person_id)
if person:
new_note = note_schema.load(note, session=db.session)
person.notes.append(new_note)
db.session.commit()
return note_schema.dump(new_note), 201
else:
abort(
404,
f"Person not found for ID: {person_id}"
)
一个音符总是需要一个人的归属。这就是为什么您在创建新便笺时需要使用Person模型。
首先,您通过使用person_id来寻找笔记的所有者,您通过notes参数为create()提供该笔记。如果这个人存在于数据库中,那么您继续添加新的注释到person.notes。
虽然在这种情况下您使用的是数据库表person,但是 SQLAlchemy 会注意将注释添加到表note中。
要使用您的 API 访问notes.create,请跳到swagger.yml并添加另一个端点:
# swagger.yml # ... paths: /people: # ... /people/{lname}: # ... /notes: post: operationId: "notes.create" tags: - Notes summary: "Create a note associated with a person" requestBody: description: "Note to create" required: True content: application/json: schema: x-body-name: "note" type: "object" properties: person_id: type: "integer" content: type: "string" responses: "201": description: "Successfully created a note" /notes/{note_id}: # ...
您可以在/notes/{noted_id}端点之前添加/notes端点。这样,您就可以按照从一般到特殊的顺序排列您的 notes 端点。当你的 API 变大时,这个顺序可以帮助你浏览你的swagger.yml文件。
使用schema块中的数据,您向 Marshmallow 提供了关于如何在 API 中序列化一个注释的信息。如果您将这个Note模式与models.py中的Note模型进行比较,那么您会注意到名称person_id和content是匹配的。字段的类型也是如此。
您可能还会注意到,并不是所有的注释模型字段都出现在组件模式中。这没关系,因为您将只使用这个模式来发布新的注释。对于每个音符,id和timestamp将被自动设置。
处理笔记的所有端点都准备好了,是时候看看 API 文档了。
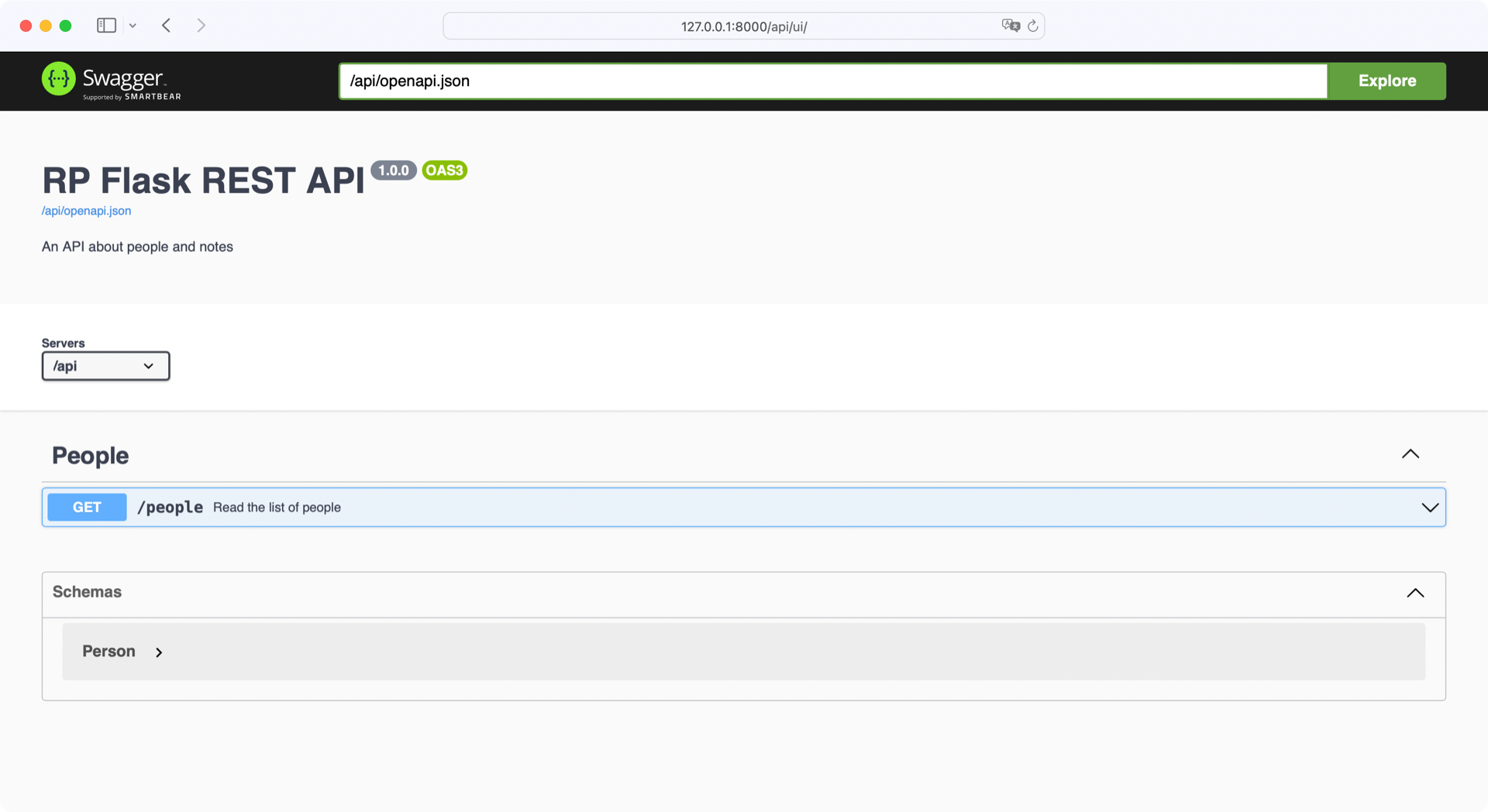
浏览您的 API 文档
完成上述更改后,您可以利用 API 来添加、更新和删除注释。在http://localhost:8000/api/ui访问您的 Swagger UI,探索您的 API 端点:
https://player.vimeo.com/video/766055660?background=1
太棒了,你的 Flask REST API 端点工作了!您对 API 执行的任何更改也会出现在您的前端。
结论
在本教程中,您调整了 SQLite 数据库来实现关系。之后,您将PEOPLE_NOTES字典翻译成符合您的数据库结构的数据,并将 Flask REST API 转换成记录笔记的 web 应用程序。
在本系列教程的第三部分中,您学习了如何:
- 在数据库中使用多个表
- 在数据库中创建一对多字段
- 使用 SQLAlchemy 管理关系
- 利用棉花糖的嵌套模式
- 在前端显示相关对象
知道如何建立和使用数据库关系为您提供了解决许多难题的强大工具。除了本教程中的一对多示例之外,还有其他关系。其他常见的有一对一、多对多、多对一。所有这些在您的工具箱中都有一席之地,SQLAlchemy 可以帮助您解决所有这些问题!
您已经成功地构建了一个 REST API 来为全年可能访问您的人跟踪笔记。你的数据库里有像牙仙、复活节兔子和 Knecht Ruprecht 这样的人。通过添加笔记,你可以记录你的善行,并有希望从他们那里收到有价值的礼物。
要查看您的代码,请单击下面的链接:
源代码: 点击这里下载免费的源代码,您将使用它来完成用 Flask web framework 构建 REST API。
你有没有在你的 Flask REST API 项目中添加一个特殊的人或者注释?在下面的评论中让真正的 Python 社区知道吧。
« Part 2: Database PersistencePart 3: Database Relationships**********
Python REST APIs 与 Flask、Connexion 和 SQLAlchemy——第 2 部分
原文:# t0]https://realython . com/flask-连接-rest API-part-2/
大多数现代网络应用程序都是由一个 REST API 驱动的。这样,开发人员可以将前端代码与后端逻辑分开,用户可以动态地与界面进行交互。在这个由三部分组成的教程系列中,您将使用 Flask web 框架构建一个 REST API。
您已经用一个基本的 Flask 项目创建了一个基础,并添加了端点,您将把端点连接到一个 SQLite 数据库。你也在用你一直在构建的 Swagger UI API 文档测试你的 API。
在本系列教程的第二部分,您将学习如何:
- 用 Python 编写 SQL 命令
- 为您的 Flask 项目配置一个 SQLite 数据库
- 使用 SQLAlchemy 将 Python 对象保存到数据库中
- 利用棉花糖库来序列化数据
- 将您的 REST API 与数据库连接起来
在完成本系列的第二部分之后,您将继续第三部分,在第三部分中,您将扩展 REST API,使其具有为某人添加注释的功能。
您可以通过单击下面的链接下载该项目的第二部分代码:
源代码: 点击这里下载免费的源代码,您将使用它继续用 Flask web 框架构建 REST API。
演示
在这个由三部分组成的教程系列中,您将构建一个 REST API 来跟踪全年可能访问您的人的笔记。你会创造出像牙仙、复活节兔子和 T4 这样的人。
理想情况下,你想和他们三个都保持良好的关系。这就是为什么你要给他们寄便条,以增加从他们那里得到贵重礼物的机会。
您可以通过利用 API 文档与您的应用程序进行交互。同时,您还构建了一个反映数据库内容的基本前端:
https://player.vimeo.com/video/766055660?background=1
在本系列的第二部分中,您将通过添加适当的数据库来增强应用程序的后端。这样,即使重新启动应用程序,您也可以保存数据:
https://player.vimeo.com/video/759061210?background=1
使用您的 Swagger UI 文档,您将能够与 REST API 进行交互,并确保一切按预期运行。
规划第二部分
在本系列教程的第一部分中,您使用了一个PEOPLE字典来存储数据。数据集看起来像这样:
PEOPLE = {
"Fairy": {
"fname": "Tooth",
"lname": "Fairy",
"timestamp": "2022-10-08 09:15:10",
},
"Ruprecht": {
"fname": "Knecht",
"lname": "Ruprecht",
"timestamp": "2022-10-08 09:15:13",
},
"Bunny": {
"fname": "Easter",
"lname": "Bunny",
"timestamp": "2022-10-08 09:15:27",
}
}
这种数据结构便于让您的项目跟上速度。然而,当您重启应用程序时,您用 REST API 添加到PEOPLE的任何数据都会丢失。
在这一部分,您将把您的PEOPLE数据结构转换成如下所示的数据库表:
| 身份证明(identification) | lname | fname | 时间戳 |
|---|---|---|---|
| one | 仙女 | 牙齿 | 2022-10-08 09:15:10 |
| Two | 鲁普雷希特 | 小厮 | 2022-10-08 09:15:13 |
| three | 兔子 | 复活节 | 2022-10-08 09:15:27 |
在本教程中,您不会对 REST API 端点进行任何更改。但是您将在后端进行的更改将是显著的,并且您将最终获得一个更加通用的代码库,以帮助您在将来扩展 Flask 项目。
开始使用
在本节中,您将签入您正在处理的 Flask REST API 项目。您需要确保为本教程系列的下一步做好准备。
为了在复杂数据类型和 Python 数据类型之间进行转换,您需要一个序列化器。在本教程中,你将使用烧瓶-棉花糖。 Flask-Marshmallow 扩展了 Marshmallow 库,并在使用 Flask 时提供额外的功能。
抓住先决条件
理想情况下,在继续阅读第二部分之前,你已经阅读了本系列教程的第一部分。或者,您也可以通过单击下面的链接从第一部分下载源代码:
源代码: 点击这里下载免费的源代码,您将使用它来构建一个带有 Flask web 框架的 REST API。
如果您从上面的链接下载了源代码,那么请确保遵循所提供的README.md文件中的安装说明。
在继续学习本教程之前,请验证您的文件夹结构如下所示:
rp_flask_api/
│
├── templates/
│ └── home.html
│
├── app.py
├── people.py
└── swagger.yml
一旦您准备好了 Flask REST API 文件夹结构,您就可以继续阅读,安装您将在本系列教程的这一部分中需要的依赖项。
添加新的依赖关系
在你继续你的 Flask 项目之前,创建并激活一个虚拟环境是个好主意。这样,您安装的任何项目依赖项都不是系统范围的,而只是在项目的虚拟环境中。
在下面选择您的操作系统,并使用您的平台特定命令来设置虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS>
$ python -m venv venv
$ source venv/bin/activate
(venv) $
使用上面显示的命令,您可以通过使用 Python 的内置venv模块创建并激活一个名为venv的虚拟环境。提示前面的圆括号(venv)表示您已经成功激活了虚拟环境。
注意:如果您还没有完成本教程系列的第一部分,请点击下面的链接下载源代码:
源代码: 点击这里下载免费的源代码,您将使用它来构建一个带有 Flask web 框架的 REST API。
在继续之前,按照提供的README.md文件中列出的说明安装依赖项。
接下来,用sqlalchemy选项安装flask-marshmallow:
(venv) $ python -m pip install "flask-marshmallow[sqlalchemy]==0.14.0"
Flask-Marshmallow 还安装了marshmallow,它提供了在 Python 对象流入流出 REST API 时序列化和反序列化 Python 对象的功能,REST API 基于 JSON 。Marshmallow 将 Python 类实例转换成可以转换成 JSON 的对象。
通过使用sqlalchemy选项,你还可以安装帮助你的 Flask 应用利用 SQLAlchemy 的能力的包。
SQLAlchemy 提供了一个对象关系模型(ORM) ,它将每个 Python 对象存储到对象数据的数据库表示中。这可以帮助您继续以 Pythonic 的方式思考,而不必关心对象数据在数据库中的表示方式。
检查你的烧瓶项目
完成上述步骤后,您可以验证您的 Flask 应用程序正在运行,没有错误。在包含app.py文件的目录中执行以下命令:
(venv) $ python app.py
当您运行这个应用程序时,web 服务器将在端口 8000 上启动,这是 Flask 使用的默认端口。如果你打开浏览器并导航到http://localhost:8000,你应该会看到 Hello,World!⒃:
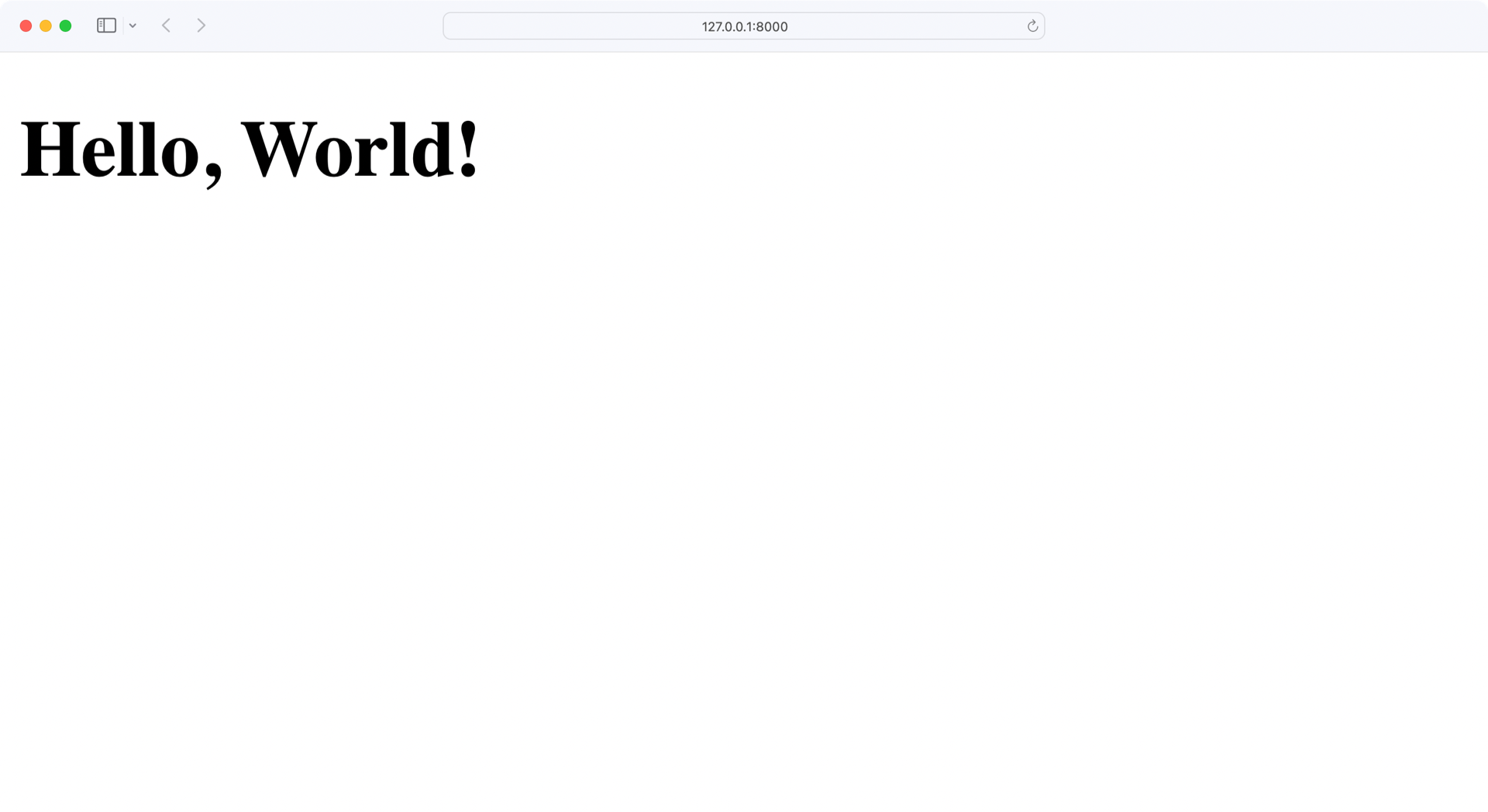
完美,你的应用程序运行完美!现在是时候进入后端并使用适当的数据库了。
初始化数据库
目前,您将 Flask 项目的数据存储在一个字典中。像这样存储数据是不持久的。这意味着当您重新启动 Flask 应用程序时,任何数据更改都会丢失。最重要的是,你的字典结构并不理想。
在本节中,您将向您的 Flask 项目添加一个适当的数据库来解决这些缺点。
检查您当前的数据结构
目前,您将数据存储在people.py的PEOPLE字典中。代码中的数据结构如下所示:
# people.py
# ...
PEOPLE = {
"Fairy": {
"fname": "Tooth",
"lname": "Fairy",
"timestamp": get_timestamp(),
},
"Ruprecht": {
"fname": "Knecht",
"lname": "Ruprecht",
"timestamp": get_timestamp(),
},
"Bunny": {
"fname": "Easter",
"lname": "Bunny",
"timestamp": get_timestamp(),
}
}
# ...
您对程序所做的修改会将所有数据移动到数据库表中。这意味着数据将被保存到您的磁盘上,并存在于app.py程序的运行之间。
概念化你的数据库表
从概念上讲,您可以将数据库表想象成一个二维的数组,其中行是记录,列是这些记录中的字段。
数据库表通常有一个自动递增的整数值作为行的查找键。这被称为主键。表中的每条记录都有一个主键,其值在整个表中是唯一的。主键独立于表中存储的数据,这使您可以自由地修改行中的任何其他字段。
您将遵循数据库惯例,将表命名为单数,因此该表将被称为person。
将上面的PEOPLE结构转换成名为person的数据库表将如下所示:
| 身份证明(identification) | lname | fname | 时间戳 |
|---|---|---|---|
| one | 仙女 | 牙齿 | 2022-10-08 09:15:10 |
| Two | 鲁普雷希特 | 小厮 | 2022-10-08 09:15:13 |
| three | 兔子 | 复活节 | 2022-10-08 09:15:27 |
表中的每列都有一个字段名,如下所示:
id: 每个人的主键字段lname: 人的姓fname: 人的名字timestamp: 最后一次更改的时间戳
有了这个数据库概念,就该构建数据库了。
构建您的数据库
您将使用 SQLite 作为数据库引擎来存储PEOPLE数据。 SQLite 是一个广泛使用的关系数据库管理系统 (RDBMS),它不需要 SQL 服务器就能工作。
与其他 SQL 数据库引擎不同,SQLite 使用一个文件来维护所有的数据库功能。因此,要使用数据库,程序只需要知道如何读写 SQLite 文件。
Python 内置的 sqlite3 模块可以让你在没有任何外部包的情况下与 SQLite 数据库进行交互。这使得 SQLite 在启动新的 Python 项目时特别有用。
启动一个新的 Python 交互 shell 来创建people.db SQLite 数据库:
>>> import sqlite3 >>> conn = sqlite3.connect("people.db") >>> columns = [ ... "id INTEGER PRIMARY KEY", ... "lname VARCHAR UNIQUE", ... "fname VARCHAR", ... "timestamp DATETIME", ... ] >>> create_table_cmd = f"CREATE TABLE person ({','.join(columns)})" >>> conn.execute(create_table_cmd) <sqlite3.Cursor object at 0x1063f4dc0>导入
sqlite3模块后,可以用.connect()创建一个新的数据库。如果您在定义了conn变量之后查看一下您的文件系统,那么您会注意到 Python 马上创建了people.db数据库文件。使用
conn.execute(),您可以运行 SQL 命令来创建一个person表,其中包含列id、lname、fname和timestamp。注意,您为
lname包含了一个UNIQUE约束。这很重要,因为您在 REST API 中使用姓氏来标识一个人。因此,您的数据库必须确保lname的唯一性,以防止您的数据不一致。现在您的数据库已经存在,您可以向其中添加数据:
>>> import sqlite3
>>> conn = sqlite3.connect("people.db")
>>> people = [
... "1, 'Fairy', 'Tooth', '2022-10-08 09:15:10'",
... "2, 'Ruprecht', 'Knecht', '2022-10-08 09:15:13'",
... "3, 'Bunny', 'Easter', '2022-10-08 09:15:27'",
... ]
>>> for person_data in people:
... insert_cmd = f"INSERT INTO person VALUES ({person_data})"
... conn.execute(insert_cmd)
...
<sqlite3.Cursor object at 0x104ac4dc0>
<sqlite3.Cursor object at 0x104ac4f40>
<sqlite3.Cursor object at 0x104ac4fc0>
>>> conn.commit()
一旦连接到people.db数据库,您就声明一个事务来将people_data插入到person表中。conn.execute()命令在内存中创建sqlite3.Cursor对象。只有当你运行conn.commit()时,你才能使交易发生。
与数据库交互
与 Python 等编程语言不同,SQL 没有定义如何获取数据。SQL 描述了什么数据是需要的,并把如何处理的任务留给了数据库引擎。
获取person表中所有数据的 SQL 查询应该是这样的:
SELECT * FROM person;
这个查询告诉数据库引擎从person表中获取所有字段。在以下 Python 代码中,使用 SQLite 运行上述查询并显示数据:
1>>> import sqlite3 2>>> conn = sqlite3.connect("people.db") 3>>> cur = conn.cursor() 4>>> cur.execute("SELECT * FROM person") 5<sqlite3.Cursor object at 0x102357a40> 6 7>>> people = cur.fetchall() 8>>> for person in people: 9... print(person) 10... 11(1, 'Fairy', 'Tooth', '2022-10-08 09:15:10') 12(2, 'Ruprecht', 'Knecht', '2022-10-08 09:15:13') 13(3, 'Bunny', 'Easter', '2022-10-08 09:15:27')上面的代码执行以下操作:
- 线 1 导入
sqlite3模块。- 第 2 行创建一个到数据库文件的连接。
- 第 3 行从连接创建一个光标。
- 第 4 行使用光标执行一个用字符串表示的
SQL查询。- 第 7 行获取
SQL查询返回的所有记录,并将它们分配给people变量。- 第 8 行和第 9 行迭代
people并打印出每个人的数据。在上面的程序中,SQL 语句是一个直接传递给数据库执行的字符串。在这种情况下,这可能不是一个大问题,因为 SQL 是一个完全受程序控制的字符串。然而,REST API 的用例将从 web 应用程序中获取用户输入,并使用它来创建 SQL 查询。这可能会使您的应用程序受到攻击。
展开以下部分,了解如何:
您可能还记得本系列教程的第一部分,REST API 端点对从
PEOPLE数据中获取单个person,如下所示:GET /api/people/{lname}这意味着您的 API 期望在 URL 端点路径中有一个变量
lname,用于查找一个人。通过修改上面的 Python SQLite 代码来实现这一点,看起来会像这样:1lname = "Fairy" 2cur.execute(f"SELECT * FROM person WHERE lname = '{lname}'")上面的代码片段执行以下操作:
- 第 1 行将
lname变量设置为'Fairy'。这将来自 REST API URL 端点路径。- 第 2 行使用 Python 字符串格式化创建一个 SQL 字符串并执行它。
为了简单起见,上面的代码将
lname变量设置为一个常量,但实际上它来自 API URL 端点路径,可以是用户提供的任何东西。字符串格式生成的 SQL 如下所示:SELECT * FROM person WHERE lname = 'Fairy'当这个 SQL 被数据库执行时,它在
person表中搜索姓氏等于'Fairy'的记录。这是我们的初衷,但是任何接受用户输入的程序也会对恶意用户开放。上面的程序中,lname变量是由用户提供的输入设置的,这让你面临所谓的 SQL 注入攻击。你可能会看到这样的攻击被称为小鲍比桌:
Image: [xkcd.com](https://xkcd.com/327/) 例如,假设一个恶意用户以这种方式调用您的 REST API:
GET /api/people/Fairy';DROP TABLE person;上面的 REST API 请求将
lname变量设置为'Fairy';DROP TABLE person;',这在上面的代码中会生成以下 SQL 语句:SELECT * FROM person WHERE lname = 'Fairy';DROP TABLE person;上面的 SQL 语句是有效的,当数据库执行该语句时,它会找到一条
lname与'Fairy'匹配的记录。然后,它会找到 SQL 语句分隔符字符;,并直接删除整个表。这实际上会破坏您的应用程序。您可以通过净化从应用程序用户处获得的所有数据来保护您的程序。在这个上下文中,净化数据意味着让程序检查用户提供的数据,以确保它不包含任何对程序有害的东西。这可能很难做到,而且在用户数据与数据库交互的任何地方都必须这样做。
如果您为
person得到的是一个 Python 对象,其中每个字段都是对象的一个属性,那会好得多。这样,您可以确保对象包含预期的值类型,而不是任何恶意命令。当您在 Python 代码中与数据库交互时,您可能会再三考虑是否要编写纯 SQL 命令。正如您在上面了解到的,编写 SQL 可能不仅感觉不方便,而且会导致安全问题。如果您不想太担心数据库交互,像 SQLAlchemy 这样的包可以帮您解决这个问题。
连接 SQLite 数据库和您的 Flask 项目
在本节中,您将利用 SQLAlchemy 帮助您与数据库通信,并将
people.db连接到 Flask 应用程序。SQLAlchemy 处理许多特定于特定数据库的交互,并让您专注于数据模型以及如何使用它们。SQLAlchemy 将在创建 SQL 语句之前为您整理用户数据。这是另一大优势,也是在处理数据库时使用 SQLAlchemy 的原因。
在本节中,您还将创建两个 Python 模块,
config.py和models.py:
config.py将需要的模块导入程序并进行配置。这包括 Flask、Connexion、SQLAlchemy 和 Marshmallow。models.py是创建 SQLAlchemy 和 Marshmallow 类定义的模块。在本节结束时,您将能够删除以前的
PEOPLE数据结构并使用连接的数据库。配置您的数据库
顾名思义,
config.py模块是创建和初始化所有配置信息的地方。在这个文件中,您将配置 Flask、Connexion、SQLAlchemy 和 Marshmallow。在您的
rp_flask_api/项目文件夹中创建config.py:1# config.py 2 3import pathlib 4import connexion 5from flask_sqlalchemy import SQLAlchemy 6from flask_marshmallow import Marshmallow 7 8basedir = pathlib.Path(__file__).parent.resolve() 9connex_app = connexion.App(__name__, specification_dir=basedir) 10 11app = connex_app.app 12app.config["SQLALCHEMY_DATABASE_URI"] = f"sqlite:///{basedir / 'people.db'}" 13app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False 14 15db = SQLAlchemy(app) 16ma = Marshmallow(app)下面是上面的代码所做的事情:
3 到 6 行导入内置
pathlib以及第三方库connexion、SQLAlchemy、Marshmallow。第 8 行创建变量
basedir,指向程序运行的目录。第 9 行使用
basedir变量创建 Connexion 应用程序实例,并给它包含您的规范文件的目录的路径。第 11 行创建一个变量
app,它是由 Connexion 初始化的 Flask 实例。第 12 行告诉 SQLAlchemy 使用 SQLite 作为数据库,并使用当前目录中一个名为
people.db的文件作为数据库文件。第 13 行关闭 SQLAlchemy 事件系统。事件系统生成在事件驱动的程序中有用的事件,但是它增加了大量的开销。因为您没有创建事件驱动的程序,所以您关闭了这个特性。
第 15 行通过将
app配置信息传递给SQLAlchemy并将结果赋给db变量来初始化 SQLAlchemy。第 16 行初始化 Marshmallow,并允许它与应用程序附带的 SQLAlchemy 组件一起工作。
如果您想了解更多关于您可以在这里实现的 SQLAlchemy 配置的信息,那么您可以查看 Flask-SQLALchemy 的配置密钥文档。
使用 SQLAlchemy 的模型数据
SQLAlchemy 是一个大项目,提供了许多使用 Python 处理数据库的功能。它提供的特性之一是对象关系映射器(ORM)。这个 ORM 使您能够通过将数据库表中的一行字段映射到一个 Python 对象,以更 Python 化的方式与
person数据库表进行交互。为
person数据库表中的数据创建一个带有 SQLAlchemy 类定义的models.py文件:1# models.py 2 3from datetime import datetime 4from config import db 5 6class Person(db.Model): 7 __tablename__ = "person" 8 id = db.Column(db.Integer, primary_key=True) 9 lname = db.Column(db.String(32), unique=True) 10 fname = db.Column(db.String(32)) 11 timestamp = db.Column( 12 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow 13 )下面是上面的代码所做的事情:
- 第 3 行从 Python 自带的模块中导入
datetime对象。这为您提供了一种在第 11 到 13 行的Person类中创建时间戳的方法。- 第 4 行导入
db,这是您在config.py模块中定义的SQLAlchemy的一个实例。这使得models.py可以访问 SQLAlchemy 属性和方法。- 第 6 行定义了
Person类。从db.Model继承给了PersonSQLAlchemy 特性来连接到数据库并访问它的表。- 第 7 行将类定义连接到
person数据库表。- 第 8 行声明了包含一个整数的
id列作为表的主键。- 第 9 行用一个字符串值定义了姓氏字段。这个字段必须是惟一的,因为您将使用
lname作为 REST API URL 中人员的标识符。- 第 10 行用一个字符串值定义名字字段。
- 第 11 到 13 行用
datetime值定义了一个timestamp字段。创建记录时,
default=datetime.utcnow参数将时间戳值默认为当前的utcnow值。当记录被更新时,onupdate=datetime.utcnow参数用当前的utcnow值更新时间戳。要了解有关 UTC 时间戳的更多信息,请展开下面的可折叠部分:您可能想知道为什么上面的类中的时间戳默认为并由
datetime.utcnow()方法更新,该方法返回一个 UTC ,或协调世界时。这是标准化时间戳来源的一种方式。源头,或零点时间,是一条从地球北极到南极穿过英国的线。这是零时区,所有其他时区都从零时区开始偏移。通过使用这个作为零时间源,你的时间戳是从这个标准参考点的偏移。
如果从不同的时区访问您的应用程序,您可以执行日期和时间计算。您所需要的只是一个 UTC 时间戳和目的地时区。
如果您使用本地时区作为时间戳源,那么在没有本地时区相对于零时的偏移信息的情况下,您无法执行日期和时间计算。没有时间戳源信息,您根本无法进行任何日期和时间比较或任何数学计算。
使用基于 UTC 的时间戳是一个很好的遵循标准。这里有一个工具包网站,可以用来更好地理解这样的时间戳。
使用 SQLAlchemy 允许您根据具有行为的对象来思考,而不是处理原始的 SQL。当您的数据库表变得更大、交互变得更复杂时,这就变得更加有益了。
用棉花糖序列化建模的数据
在程序中使用 SQLAlchemy 的建模数据非常方便。然而,REST API 处理 JSON 数据,这里您可能会遇到 SQLAlchemy 模型的问题。
因为 SQLAlchemy 将数据作为 Python 类实例返回,所以 Connexion 不能将这些类实例序列化为 JSON 格式的数据。
注意:在这个上下文中,序列化意味着将包含其他 Python 对象和复杂数据类型的 Python 对象转换为更简单的数据结构,这些数据结构可以解析为 JSON 数据类型,这里列出了:
string: 一串式number:Python 支持的数字(整数、浮点数、长整型)object: 一个 JSON 对象,大致相当于一个 Python 字典array: 大致相当于一个 Python 列表boolean: 在 JSON 中表示为true或false,但在 Python 中表示为True或Falsenull: 本质上是 Python 中的None例如,您的
Person类包含一个时间戳,这是一个 PythonDateTime类。JSON 中没有DateTime的定义,所以时间戳必须被转换成字符串才能存在于 JSON 结构中。您正在使用数据库作为持久数据存储。使用 SQLAlchemy,您可以在 Python 程序中轻松地与数据库进行通信。但是,您需要解决两个挑战:
- 您的 REST API 使用 JSON 而不是 Python 对象。
- 您必须确保添加到数据库中的数据是有效的。
这就是棉花糖模块发挥作用的地方!
Marshmallow 帮助您创建一个
PersonSchema类,它类似于您刚刚创建的 SQLAlchemyPerson类。PersonSchema类定义了如何将一个类的属性转换成 JSON 友好的格式。Marshmallow 还确保所有属性都存在,并且包含预期的数据类型。下面是您的
person表中数据的 Marshmallow 类定义:# models.py from datetime import datetime from config import db, ma class Person(db.Model): __tablename__ = "person" id = db.Column(db.Integer, primary_key=True) lname = db.Column(db.String(32), unique=True) fname = db.Column(db.String(32)) timestamp = db.Column( db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow ) class PersonSchema(ma.SQLAlchemyAutoSchema): class Meta: model = Person load_instance = True sqla_session = db.session person_schema = PersonSchema() people_schema = PersonSchema(many=True)你从
config.py中导入ma来使PersonSchema继承ma.SQLAlchemyAutoSchema。为了找到一个 SQLALchemy 模型和一个 SQLAlchemy 会话,SQLAlchemyAutoSchema寻找并使用这个内部的Meta类。对于
PersonSchema,型号为Person,sqla_session为db.session。这就是 Marshmallow 如何在Person类中找到属性并学习这些属性的类型,从而知道如何序列化和反序列化它们。使用
load_instance,您能够反序列化 JSON 数据并从中加载Person模型实例。最后,实例化两个模式,person_schema和people_schema,稍后将会用到。做一些清理工作
现在是时候摆脱旧的
PEOPLE数据结构了。这将确保您对人员数据所做的任何更改都是在数据库上执行的,而不是在过时的PEOPLE字典上。打开
people.py,去掉不再需要的导入、函数和数据结构,使用新的导入来添加db和来自models.py的数据:# people.py # Remove: from datetime import datetime from flask import make_response, abort from config import db from models import Person, people_schema, person_schema # Remove: get_timestamp(): # Remove: PEOPLE # ...您删除了
datetime导入、get_timestamp()函数和PEOPLE字典。作为交换,您添加来自config和models的对象,您将从现在开始使用这些对象。在你删除
PEOPLE字典的那一刻,你的 Python 代码编辑器可能已经抱怨了你代码中未定义的PEOPLE变量。在下一节中,您将使用数据库查询替换所有的PEOPLE引用,并让您的 Python 编辑器再次满意。用您的 API 连接数据库
您的数据库已经连接到 Flask 项目,但还没有连接到 REST API。潜在地,您可以使用 Python 交互式 shell 将更多的人添加到您的数据库中。但是增强 REST API 并利用现有的端点来添加数据会有趣得多!
在本节中,您将把 API 与数据库连接起来,这样您就可以使用现有的端点和数据库来管理人员。如果您想回顾一下您是如何构建 API 端点的,那么您可以跳到本教程系列的第一部分。
这是您的 Flask REST API 目前的样子:
行动 HTTP 动词 path 描述 阅读 GET/api/people读一集人。 创造 POST/api/people创建一个新人。 阅读 GET/api/people/<lname>读一个特定的人。 更新 PUT/api/people/<lname>更新现有人员。 删除 DELETE/api/people/<lname>删除现有人员。 接下来,您将更新连接到上面列出的端点的现有函数,以便它们可以使用
people.db数据库。从数据库中读取
首先,调整
people.py中从数据库读取数据而不向数据库写入任何内容的函数。从read_all()开始:# people.py # ... def read_all(): people = Person.query.all() return people_schema.dump(people) # ...
read_all()函数响应 REST API URL 端点GET /api/people,并返回person数据库表中的所有记录。您正在使用的是用参数
many=True创建的棉花糖PersonSchema类的实例people_schema。通过这个参数,你告诉PersonSchema期望一个交互对象被序列化。这很重要,因为people变量包含一个数据库条目列表。最后,用
.dump()序列化 Python 对象,并返回所有人的数据作为对 REST API 调用的响应。
people.py中另一个只接收数据的函数是read_one():# people.py # ... def read_one(lname): person = Person.query.filter(Person.lname == lname).one_or_none() if person is not None: return person_schema.dump(person) else: abort(404, f"Person with last name {lname} not found") # ...
read_one()函数从 REST URL 路径接收一个lname参数,表示用户正在寻找一个特定的人。您在查询的
.filter()方法中使用lname。不使用.all(),而是使用.one_or_none()方法来获得一个人,或者如果没有找到匹配,则返回None。如果找到一个人,那么
person包含一个Person对象,您返回序列化的对象。否则,您会错误地调用abort()。写入数据库
对
people.py的另一个修改是在数据库中创建一个新的人。这使您有机会使用棉花糖PersonSchema来反序列化随 HTTP 请求发送的 JSON 结构,以创建 SQLAlchemyPerson对象。下面是更新后的people.py模块的一部分,展示了 REST URL 端点POST /api/people的处理程序:# people.py # ... def create(person): lname = person.get("lname") existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person is None: new_person = person_schema.load(person, session=db.session) db.session.add(new_person) db.session.commit() return person_schema.dump(new_person), 201 else: abort(406, f"Person with last name {lname} already exists") # ...与在
read_one()中只接收姓氏不同,create()接收一个person对象。该对象必须包含lname,它必须不存在于数据库中。lname值是您个人的标识符,所以您的数据库中不能有一个人多次使用相同的姓氏。如果姓是惟一的,那么将
person对象反序列化为new_person并添加它db.session。一旦您将new_person提交给数据库,您的数据库引擎就会为该对象分配一个新的主键值和一个基于 UTC 的时间戳。稍后,您将在 API 响应中看到创建的数据集。调整
update()和delete()与您调整其他功能的方式相似:# people.py # ... def update(lname, person): existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person: update_person = person_schema.load(person, session=db.session) existing_person.fname = update_person.fname db.session.merge(existing_person) db.session.commit() return person_schema.dump(existing_person), 201 else: abort(404, f"Person with last name {lname} not found") def delete(lname): existing_person = Person.query.filter(Person.lname == lname).one_or_none() if existing_person: db.session.delete(existing_person) db.session.commit() return make_response(f"{lname} successfully deleted", 200) else: abort(404, f"Person with last name {lname} not found")完成所有这些更改后,是时候更新您的前端代码并利用 Swagger UI 来测试您的数据库是否如预期那样工作了。
在你的前端显示数据
现在,您已经添加了 SQLite 配置并定义了您的
Person模型,您的 Flask 项目包含了使用数据库的所有信息。在您可以在前端显示数据之前,您需要对app.py进行一些调整:1# app.py 2 3from flask import render_template 4# Remove: import connexion 5import config 6from models import Person 7 8app = config.connex_app 9app.add_api(config.basedir / "swagger.yml") 10 11@app.route("/") 12def home(): 13 people = Person.query.all() 14 return render_template("home.html", people=people) 15 16if __name__ == "__main__": 17 app.run(host="0.0.0.0", port=8000, debug=True)你现在与
config.py和models.py一起工作。所以您删除了第 4 行中的导入,并在第 5 行添加了config的导入,在第 6 行添加了Person的导入。
config模块为您提供了 Connexion-Flask app。因此,您不再在app.py中创建新的 Flask 应用程序,而是在第 8 行引用config.connex_app。在第 13 行中,您查询
Person模型以从person表中获取所有数据,并将其传递给第 14 行中的render_template()。为了在前端显示
people数据,需要调整home.html模板:<!-- templates/home.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>RP Flask REST API</title> </head> <body> <h1> Hello, People! </h1> <ul> {% for person in people %} <li>{{ person.fname }} {{ person.lname }}</li> {% endfor %} </ul> </body> </html>您可以在包含
app.py文件的目录中用这个命令运行您的应用程序:(venv) $ python app.py当您运行这个应用程序时,web 服务器将在端口 8000 上启动,这是您在
app.py中定义的端口。如果您打开浏览器并导航到http://localhost:8000,您将看到来自您的数据库的数据:
厉害!您的主页列出了当前数据库中的三个人。最后,您可以使用 Swagger UI 来创建、更新和删除人员,并查看主页上反映的更改。
浏览您的 API 文档
完成上述更改后,您的数据库现在可以正常工作,并且即使在您重新启动应用程序时也能持久保存数据:
https://player.vimeo.com/video/759061210?background=1
您可以利用您的 API 来添加、更新和删除人员。通过对前端的更改,您可以看到当前存储在数据库中的所有人。
当你重新启动 Flask 应用程序时,你不再重置数据。因为您现在有一个数据库附加到您的 Flask 项目,您的数据被保存。
结论
恭喜你,你已经在本教程中涵盖了很多新的内容,并且为你的武器库添加了有用的工具!
在本系列教程的第二部分中,您学习了如何:
- 用 Python 编写 SQL 命令
- 为您的 Flask 项目配置一个 SQLite 数据库
- 使用 SQLAlchemy 将 Python 对象保存到数据库中
- 利用棉花糖库来序列化数据
- 将您的 REST API 与数据库连接起来
与第一部分中的 REST API 相比,您所学到的技能在复杂性上无疑是一个进步,但是这一步为您提供了在创建更复杂的应用程序时可以使用的强大工具。使用它们将帮助您创建自己的由数据库支持的 web 应用程序。
要查看本系列教程第二部分的代码,请单击下面的链接:
源代码: 点击这里下载免费的源代码,您将使用它继续用 Flask web 框架构建 REST API。
在本系列的下一部分中,您将扩展 REST API,以便能够创建、读取、更新和删除笔记。笔记将存储在新的数据库表中。每个笔记都将与一个人相关联,因此您需要将笔记和人之间的关系添加到数据库中。
第三部分是本系列教程的最后一部分。最后,您将拥有一个成熟的 Flask REST API,后台有相关的数据库表。
« Part 1: REST APIs With Flask + ConnexionPart 2: Database PersistencePart 3: Database Relationships »**********
Python REST APIs 与 Flask、Connexion 和 SQLAlchemy——第 1 部分
原文:# t0]https://realython . com/flask-连接-rest API/
大多数现代网络应用程序都是由一个 REST API 驱动的。这样,开发人员可以将前端代码与后端逻辑分开,用户可以动态地与界面进行交互。在这个由三部分组成的教程系列中,您将使用 Flask web 框架构建一个 REST API。
您将使用一个基本的 Flask 项目创建一个基础,然后添加端点并将它们连接到一个 SQLite 数据库。您将使用 Swagger UI API 文档测试您的 API,您将在此过程中构建这些文档。
在本系列教程的第一部分,您将学习如何:
- 用一个 REST API 构建一个基础烧瓶项目
- 使用连接处理 HTTP 请求
- 使用 OpenAPI 规范定义 API 端点
- 与您的 API 交互以管理数据
- 用 Swagger UI 构建 API 文档
完成本系列的第一部分后,您将进入第二部分,在那里您将学习使用合适的数据库来永久存储您的数据,而不是依赖内存存储。
本系列教程是关于如何用 Flask 创建 REST API 并使用 CRUD 操作与之交互的实践指南。如果您想更新关于使用 API 的知识,那么您可以阅读一下 Python 和 REST APIs:与 Web 服务交互。
您可以通过单击下面的链接下载该项目的第一部分代码:
源代码: 点击这里下载免费的源代码,您将使用它来构建一个带有 Flask web 框架的 REST API。
演示
在这个由三部分组成的教程系列中,您将构建一个 REST API 来跟踪全年可能访问您的人的笔记。在本教程中,你将创建像牙仙、复活节兔子和克内赫特·鲁普雷希特这样的人。
理想情况下,你想和他们三个都保持良好的关系。这就是为什么你要给他们寄便条,以增加从他们那里得到贵重礼物的机会。
您可以通过利用 API 文档与您的应用程序进行交互。在这个过程中,您将构建一个反映数据库内容的基本前端:
https://player.vimeo.com/video/766055660?background=1
在本系列的第一部分中,您将创建一个 base Flask 项目并插入您的第一个 API 端点。在本部分结束时,您将能够在前端看到人员列表,并在后端管理每个人:
https://player.vimeo.com/video/759061156?background=1
通过利用 Swagger UI,您可以为您的 API 创建方便的文档。这样,您将有机会在本教程的每个阶段测试您的 API 如何工作,并获得所有端点的有用概述。
规划第一部分
除了构建 Flask project foundation 之外,您还将创建一个 REST API,它提供对一个人集合以及该集合中的个人的访问。下面是 people 集合的 API 设计:
行动 HTTP 动词 path 描述 阅读 GET/api/people读一集人。 创造 POST/api/people创建一个新人。 阅读 GET/api/people/<lname>读一个特定的人。 更新 PUT/api/people/<lname>更新现有人员。 删除 DELETE/api/people/<lname>删除现有人员。 您将构建的 REST API 将服务于一个简单的 people 数据结构,其中人员与姓氏相关联,任何更新都用新的时间戳标记。
您将使用的数据集如下所示:
PEOPLE = { "Fairy": { "fname": "Tooth", "lname": "Fairy", "timestamp": "2022-10-08 09:15:10", }, "Ruprecht": { "fname": "Knecht", "lname": "Ruprecht", "timestamp": "2022-10-08 09:15:13", }, "Bunny": { "fname": "Easter", "lname": "Bunny", "timestamp": "2022-10-08 09:15:27", } }API 的目的之一是将数据从使用它的应用程序中分离出来,从而隐藏数据实现的细节。在本系列教程的后面,您将把数据保存在数据库中。但是从一开始,内存中的数据结构就很好。
开始使用
在本节中,您将为 Flask REST API 项目准备开发环境。首先,您将创建一个虚拟环境并安装项目所需的所有依赖项。
创建虚拟环境
在本节中,您将构建您的项目结构。您可以随意命名项目的根文件夹。例如,您可以将其命名为
rp_flask_api/。创建文件夹并导航到其中:$ mkdir rp_flask_api $ cd rp_flask_api在这种情况下,您将项目的根文件夹命名为
rp_flask_api/。您在本系列课程中创建的文件和文件夹将位于该文件夹或其子文件夹中。导航到项目文件夹后,创建并激活一个虚拟环境是个好主意。这样,您安装的任何项目依赖项都不是系统范围的,而只是在项目的虚拟环境中。
在下面选择您的操作系统,并使用您的平台特定命令来设置虚拟环境:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> .\venv\Scripts\activate (venv) PS>$ python -m venv venv $ source venv/bin/activate (venv) $使用上面显示的命令,您可以通过使用 Python 的内置
venv模块创建并激活一个名为venv的虚拟环境。提示前面的圆括号(venv)表示您已经成功激活了虚拟环境。添加依赖关系
在你创建并激活你的虚拟环境后,是时候安装烧瓶和
pip了:(venv) $ python -m pip install Flask==2.2.2Flask micro web framework 是你的项目需要的主要依赖项。在烧瓶顶部,安装连接来处理 HTTP 请求:
(venv) $ python -m pip install "connexion[swagger-ui]==2.14.1"为了利用自动生成的 API 文档,您安装了添加了对 Swagger UI 支持的 Connexion 。在本教程的后面,您将了解更多关于您刚刚安装的 Python 包的内容。
启动你的烧瓶项目
您的 Flask 项目的主文件将是
app.py。在rp_flask_api/中创建app.py,并添加以下内容:# app.py from flask import Flask, render_template app = Flask(__name__) @app.route("/") def home(): return render_template("home.html") if __name__ == "__main__": app.run(host="0.0.0.0", port=8000, debug=True)您导入
Flask模块,让应用程序访问 Flask 功能。然后创建一个名为app的 Flask 应用程序实例。接下来,通过用@app.route("/")修饰来将 URL 路由"/"连接到home()函数。这个函数调用 Flaskrender_template()函数从模板目录中获取home.html文件,并将其返回给浏览器。简而言之,这段代码启动并运行一个基本的 web 服务器,并让它用一个
home.html模板进行响应,当导航到 URL"/"时,这个模板将被提供给浏览器。注意: Flask 的开发服务器默认为端口
5000。在较新的 macOS 版本上,此端口已经被 macOS AirPlay 接收器使用。上面,你已经用port=8000改变了 Flask 应用程序的端口。如果你愿意,你可以在 Mac 上更改 AirPlay 接收器偏好设置。Flask 期望在名为
templates/的模板目录中有home.html。创建templates/目录并添加home.html:<!-- templates/home.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>RP Flask REST API</title> </head> <body> <h1> Hello, World! </h1> </body> </html>Flask 附带了 Jinja 模板引擎,它使你能够增强你的模板。但是你的
home.html模板是一个基本的 HTML 文件,没有任何 Jinja 特性。现在没问题,因为home.html的目的是验证您的 Flask 项目是否如预期的那样响应。在 Python 虚拟环境活动的情况下,您可以在包含
app.py文件的目录中使用这个命令行运行您的应用程序:(venv) $ python app.py当您运行
app.py时,一个 web 服务器将在端口 8000 上启动。如果你打开浏览器并导航到http://localhost:8000,你应该会看到你好,世界!显示:
恭喜,您的 web 服务器正在运行!稍后您将扩展
home.html文件,以便与您正在开发的 REST API 一起工作。现在,您的 Flask 项目结构应该如下所示:
rp_flask_api/ │ ├── templates/ │ └── home.html │ └── app.py这是开始任何 Flask 项目的一个很好的结构。您可能会发现,当您从事未来的项目时,源代码会派上用场。您可以从这里下载:
源代码: 点击这里下载免费的源代码,您将使用它来构建一个带有 Flask web 框架的 REST API。
在接下来的小节中,您将扩展项目并添加您的第一个 REST API 端点。
添加您的第一个 REST API 端点
现在您已经有了一个工作的 web 服务器,您可以添加您的第一个 REST API 端点了。为此,您将使用在上一节中安装的 Connexion。
Connexion 模块允许 Python 程序通过 Swagger 使用 OpenAPI 规范。 OpenAPI 规范是 REST APIs 的 API 描述格式,提供了很多功能,包括:
- 验证 API 的输入和输出数据
- API URL 端点和预期参数的配置
当您将 OpenAPI 与 Swagger 一起使用时,您可以创建一个用户界面(UI)来浏览 API。当您创建 Flask 应用程序可以访问的配置文件时,所有这些都可能发生。
创建 API 配置文件
Swagger 配置文件是一个包含 OpenAPI 定义的 YAML 或 JSON 文件。该文件包含配置服务器以提供输入参数验证、输出响应数据验证和 URL 端点定义所需的所有信息。
创建一个名为
swagger.yml的文件,并开始向其中添加元数据:# swagger.yml openapi: 3.0.0 info: title: "RP Flask REST API" description: "An API about people and notes" version: "1.0.0"定义 API 时,必须包含 OpenAPI 定义的版本。您可以使用关键字
openapi来实现这一点。版本字符串很重要,因为 OpenAPI 结构的某些部分可能会随着时间的推移而改变。同样,就像每一个新的 Python 版本都包含了新特性一样,OpenAPI 规范中可能会添加或取消一些关键字。
info关键字开始 API 信息块的范围:
title:标题包含在 Connexion-generated UI 系统中description:对 API 提供的内容或内容的描述version:为 API 版本值接下来,添加
servers和url,它们定义了 API 的根路径:# swagger.yml # ... servers: - url: "/api"通过提供
"/api"作为url的值,您将能够访问相对于http://localhost:8000/api的所有 API 路径。您在一个
paths块中定义 API 端点:# swagger.yml # ... paths: /people: get: operationId: "people.read_all" tags: - "People" summary: "Read the list of people" responses: "200": description: "Successfully read people list"
paths块开始配置 API URL 端点路径:
/people:你的 API 端点的相对 URLget:此 URL 端点将响应的 HTTP 方法与
servers中的url定义一起,这创建了您可以在http://localhost:8000/api/people访问的GET /api/peopleURL 端点。
get块开始配置单个/api/peopleURL 端点:
operationId:响应请求的 Python 函数tags:分配给这个端点的标签,它允许你对 UI 中的操作进行分组summary: 该端点的 UI 显示文本responses: 端点响应的状态代码
operationId必须包含一个字符串。Connexion 将使用"people.read_all"在项目的people模块中找到一个名为read_all()的 Python 函数。在本教程的后面,您将创建相应的 Python 代码。
responses模块定义了可能状态代码的配置。在这里,您为状态代码"200"定义了一个成功的响应,包含一些description文本。您可以在下面的可折叠文件夹中找到
swagger.yml文件的完整内容:下面,您将找到您的 OpenAPI 定义的完整源代码:
# swagger.yml openapi: 3.0.0 info: title: "RP Flask REST API" description: "An API about people and notes" version: "1.0.0" servers: - url: "/api" paths: /people: get: operationId: "people.read_all" tags: - "People" summary: "Read the list of people" responses: "200": description: "Successfully read people list"您已经以分层的方式组织了这个文件。每个缩进级别代表一个所有权级别或范围。
例如,
paths标志着所有 API URL 端点定义的开始。下面缩进的/people值表示所有/api/peopleURL 端点将被定义的起点。缩进在/people下的get:范围保存与到/api/peopleURL 端点的 HTTP GET 请求相关的定义。这种模式适用于整个配置。
swagger.yml文件就像是你的 API 的蓝图。通过包含在swagger.yml中的规范,您定义了您的 web 服务器可以预期的数据以及您的服务器应该如何响应请求。但到目前为止,你的 Flask 项目还不知道你的swagger.yml文件。继续阅读,使用 Connexion 将您的 OpenAPI 规范与您的 Flask 应用程序连接起来。将连接添加到应用程序
使用 Connexion 向 Flask 应用程序添加 REST API URL 端点有两个步骤:
- 将 API 配置文件添加到项目中。
- 用配置文件连接您的 Flask 应用程序。
在上一节中,您已经添加了名为
swagger.yml的配置文件。要将 API 配置文件与您的 Flask 应用程序连接,您必须在您的app.py文件中引用swagger.yml:1# app.py 2 3from flask import render_template # Remove: import Flask 4import connexion 5 6app = connexion.App(__name__, specification_dir="./") 7app.add_api("swagger.yml") 8 9@app.route("/") 10def home(): 11 return render_template("home.html") 12 13if __name__ == "__main__": 14 app.run(host="0.0.0.0", port=8000, debug=True)
import connexion语句将模块添加到程序中。下一步是使用 Connexion 而不是 Flask 创建应用程序实例。在内部,仍然创建 Flask 应用程序,但是它现在添加了额外的功能。app 实例创建的一部分包括第 6 行中的参数
specification_dir。这告诉 Connexion 在哪个目录中查找其配置文件。在这种情况下,它是运行app.py的同一个目录。在第 7 行,您告诉 app 实例从规范目录中读取
swagger.yml文件,并配置系统以提供连接功能。从您的人员端点返回数据
在
swagger.yml文件中,您用operationId值"people.read_all"配置了连接。因此,当 API 获得对GET /api/people的 HTTP 请求时,您的 Flask 应用程序调用people模块中的read_all()函数。为了实现这一点,创建一个带有
read_all()函数的people.py文件:1# people.py 2 3from datetime import datetime 4 5def get_timestamp(): 6 return datetime.now().strftime(("%Y-%m-%d %H:%M:%S")) 7 8PEOPLE = { 9 "Fairy": { 10 "fname": "Tooth", 11 "lname": "Fairy", 12 "timestamp": get_timestamp(), 13 }, 14 "Ruprecht": { 15 "fname": "Knecht", 16 "lname": "Ruprecht", 17 "timestamp": get_timestamp(), 18 }, 19 "Bunny": { 20 "fname": "Easter", 21 "lname": "Bunny", 22 "timestamp": get_timestamp(), 23 } 24} 25 26def read_all(): 27 return list(PEOPLE.values())在第 5 行,您创建了一个名为
get_timestamp()的助手函数,它生成当前时间戳的字符串表示。然后在第 8 行定义
PEOPLE字典数据结构,这是您将在本系列教程的这一部分中使用的数据。字典代表一个合适的数据库。由于
PEOPLE是一个模块变量,它的状态在 REST API 调用之间保持不变。但是,当您重新启动 web 应用程序时,您更改的任何数据都将丢失。这并不理想,但目前还不错。然后在第 26 行创建
read_all()函数。当你的服务器收到一个到GET /api/people的 HTTP 请求时,它将运行read_all()。read_all()的返回值是包含一个人信息的字典列表。运行您的服务器代码并将您的浏览器导航到
http://localhost:8000/api/people将在屏幕上显示人员列表:
祝贺您,您已经创建了您的第一个 API 端点!在继续构建具有多个端点的 REST API 之前,请花点时间在下一节中更深入地研究一下这个 API。
浏览您的 API 文档
目前,您有一个 REST API 与一个 URL 端点一起运行。您的 Flask 应用程序知道基于您在
swagger.yml中的 API 规范提供什么。此外,Connexion 使用swagger.yml为您创建 API 文档。导航到
localhost:8000/api/ui查看您的 API 文档:
这是初始的 Swagger 界面。它显示了您的
http://localhost:8000/api端点支持的 URL 端点列表。Connexion 在解析swagger.yml文件时会自动构建这个文件。如果您点击界面中的
/people端点,那么界面将会展开以显示关于您的 API 的更多信息:https://player.vimeo.com/video/759061115?background=1
这将显示预期响应的结构、该响应的
content-type,以及您在swagger.yml文件中输入的关于端点的描述文本。每当配置文件改变时,Swagger UI 也会改变。您甚至可以通过点击试用按钮来试用端点。当您的 API 增长时,这个特性会非常有用。Swagger UI API 文档为您提供了一种无需编写任何代码即可探索和试验 API 的方法。
将 OpenAPI 与 Swagger UI 一起使用提供了一种创建 API URL 端点的好的、干净的方法。到目前为止,您只创建了一个端点来服务所有人。在下一节中,您将添加额外的端点来创建、更新和删除您的集合中的人。
构建完整的 API
到目前为止,您的 Flask REST API 只有一个端点。现在是时候构建一个 API 来提供对人员结构的完全 CRUD 访问了。回想一下,API 的定义如下:
行动 HTTP 动词 path 描述 阅读 GET/api/people读一集人。 创造 POST/api/people创建一个新人。 阅读 GET/api/people/<lname>读一个特定的人。 更新 PUT/api/people/<lname>更新现有人员。 删除 DELETE/api/people/<lname>删除现有人员。 为了实现这一点,您将扩展
swagger.yml和people.py文件来完全支持上面定义的 API。使用组件
在您在
swagger.yml中定义新的 API 路径之前,您将为组件添加一个新块。组件是 OpenAPI 规范中的构建块,可以从规范的其他部分引用。为单人添加一个带有
schemas的components块:# swagger.yml openapi: 3.0.0 info: title: "RP Flask REST API" description: "An API about people and notes" version: "1.0.0" servers: - url: "/api" components: schemas: Person: type: "object" required: - lname properties: fname: type: "string" lname: type: "string" # ...为了避免代码重复,您创建了一个
components块。现在,您只在schemas块中保存了Person数据模型:
type:模式的数据类型required:所需属性在
- lname前面的破折号(-)表示required可以包含一个属性列表。您定义为required的任何属性也必须存在于properties中,包括以下内容:
fname:一个人的名字lname:一个人的姓
type键定义了与其父键相关的值。对于Person,所有属性都是字符串。在本教程的后面部分,您将在 Python 代码中将该模式表示为一个字典。创建一个新的人
通过在
/people块中为post请求添加一个新块来扩展您的 API 端点:# swagger.yml # ... paths: /people: get: # ... post: operationId: "people.create" tags: - People summary: "Create a person" requestBody: description: "Person to create" required: True content: application/json: schema: x-body-name: "person" $ref: "#/components/schemas/Person" responses: "201": description: "Successfully created person"
post的结构看起来类似于现有的get模式。一个不同之处是,你还发送requestBody到服务器。毕竟,你需要告诉 Flask 它需要创建一个新人的信息。另一个区别是operationId,你设置为people.create。在
content内部,您将application/json定义为 API 的数据交换格式。您可以在 API 请求和 API 响应中提供不同的媒体类型。如今,API 通常使用 JSON 作为数据交换格式。这对 Python 开发人员来说是个好消息,因为 JSON 对象看起来非常像 Python 字典。例如:
{ "fname": "Tooth", "lname": "Fairy" }这个 JSON 对象类似于您之前在
swagger.yml中定义的Person组件,您在schema中用$ref引用了它。您还使用了 201 HTTP 状态代码,这是一个成功的响应,表示创建了一个新的资源。
注意:如果你想了解更多关于 HTTP 状态码的信息,那么你可以查看 Mozilla 关于 HTTP 响应状态码的文档。
使用
people.create,你告诉你的服务器在people模块中寻找一个create()函数。打开people.py并将create()添加到文件中:1# people.py 2 3from datetime import datetime 4from flask import abort 5 6# ... 7 8def create(person): 9 lname = person.get("lname") 10 fname = person.get("fname", "") 11 12 if lname and lname not in PEOPLE: 13 PEOPLE[lname] = { 14 "lname": lname, 15 "fname": fname, 16 "timestamp": get_timestamp(), 17 } 18 return PEOPLE[lname], 201 19 else: 20 abort( 21 406, 22 f"Person with last name {lname} already exists", 23 )在第 4 行,您导入了 Flask 的
abort()函数。使用abort()帮助您在第 20 行发送一条错误消息。当请求体不包含一个姓氏或者已经存在一个姓这个姓氏的人时,就会引发错误响应。注意:一个人的姓必须是唯一的,因为您正在使用
lname作为PEOPLE的字典键。这意味着现在你的项目中不能有两个姓氏相同的人。如果请求体中的数据有效,那么在第 13 行更新
PEOPLE,并在第 18 行用新对象和 201 HTTP 代码进行响应。处理一个人
到目前为止,您已经能够创建一个新的人,并获得一个包含所有人的列表。在本节中,您将更新
swagger.yml和people.py以使用一个新的路径来处理一个现有的人。打开
swagger.yml并添加以下代码:# swagger.yml # ... components: schemas: # ... parameters: lname: name: "lname" description: "Last name of the person to get" in: path required: True schema: type: "string" paths: /people: # ... /people/{lname}: get: operationId: "people.read_one" tags: - People summary: "Read one person" parameters: - $ref: "#/components/parameters/lname" responses: "200": description: "Successfully read person"与您的
/people路径类似,您从/people/{lname}路径的get操作开始。{lname}子字符串是姓氏的占位符,您必须将其作为 URL 参数传递。例如,URL 路径api/people/Ruprecht包含Ruprecht作为lname。注意:URL 参数是区分大小写。这意味着你必须键入一个像鲁普雷希特一样的姓,并且大写字母 r
您也将在其他操作中使用
lname参数。所以为它创建一个组件并在需要的地方引用它是有意义的。
operationId指向了people.py中的一个read_one()函数,所以再次访问那个文件并创建缺失的函数:# people.py # ... def read_one(lname): if lname in PEOPLE: return PEOPLE[lname] else: abort( 404, f"Person with last name {lname} not found" )当您的 Flask 应用程序在
PEOPLE中找到提供的姓氏时,它会返回这个特定人的数据。否则,服务器将返回 404 HTTP 错误。要更新现有人员,请使用以下代码更新
swagger.yml:# swagger.yml # ... paths: /people: # ... /people/{lname}: get: # ... put: tags: - People operationId: "people.update" summary: "Update a person" parameters: - $ref: "#/components/parameters/lname" responses: "200": description: "Successfully updated person" requestBody: content: application/json: schema: x-body-name: "person" $ref: "#/components/schemas/Person"有了这个
put操作的定义,您的服务器期望update()在people.py:# people.py # ... def update(lname, person): if lname in PEOPLE: PEOPLE[lname]["fname"] = person.get("fname", PEOPLE[lname]["fname"]) PEOPLE[lname]["timestamp"] = get_timestamp() return PEOPLE[lname] else: abort( 404, f"Person with last name {lname} not found" )
update()函数需要参数lname和person。当具有所提供姓氏的人存在时,您就用person数据更新PEOPLE中的相应值。要删除数据集中的一个人,您需要使用一个
delete操作:# swagger.yml # ... paths: /people: # ... /people/{lname}: get: # ... put: # ... delete: tags: - People operationId: "people.delete" summary: "Delete a person" parameters: - $ref: "#/components/parameters/lname" responses: "204": description: "Successfully deleted person"在
person.py上增加相应的delete()功能:# people.py from flask import abort, make_response # ... def delete(lname): if lname in PEOPLE: del PEOPLE[lname] return make_response( f"{lname} successfully deleted", 200 ) else: abort( 404, f"Person with last name {lname} not found" )如果您想要删除的人存在于您的数据集中,那么您从
PEOPLE中删除该项目。对于教程的这一部分,
people.py和swagger.yml都已完成。您可以通过单击下面的链接下载完整的文件:源代码: 点击这里下载免费的源代码,您将使用它来构建一个带有 Flask web 框架的 REST API。
管理人员的所有端点都已就绪,是时候测试您的 API 了。因为您使用了 Connexion 将 Flask 项目与 Swagger 连接起来,所以当您重新启动服务器时,您的 API 文档已经准备好了。
浏览完整的 API 文档
一旦您更新了
swagger.yml和people.py文件以完成 people API 功能,Swagger UI 系统将相应地更新,如下所示:https://player.vimeo.com/video/759061156?background=1
这个 UI 允许您查看包含在
swagger.yml文件中的所有文档,并与组成人员界面 CRUD 功能的所有 URL 端点进行交互。不幸的是,当您重新启动 Flask 应用程序时,您所做的任何更改都不会持久。这就是为什么在本系列教程的下一部分中,您将在项目中插入一个合适的数据库。
结论
在本系列教程的这一部分中,您使用 Python 的 Flask web 框架创建了一个全面的 REST API。通过 Connexion 模块和一些额外的配置工作,可以将有用的文档和交互式系统放置到位。这使得构建 REST API 成为一种非常愉快的体验。
在本系列教程的第一部分中,您学习了如何:
- 用一个 REST API 构建一个基础烧瓶项目
- 使用连接处理 HTTP 请求
- 使用 OpenAPI 规范定义 API 端点
- 与您的 API 交互以管理数据
- 用 Swagger UI 构建 API 文档
在本系列的第二部分中,您将学习如何使用合适的数据库来永久存储数据,而不是像这里一样依赖内存存储。
Part 1: REST APIs With Flask + ConnexionPart 2: Database Persistence »**********
NumPy 的 max()和 maximum():在数组中查找极值
原文:# t0]https://realython . com/num py-max/最大值]
NumPy 库支持 Python 中富有表现力的、高效的数值编程。求极值是数据分析中非常常见的要求。NumPy
max()和maximum()函数是两个例子,说明 NumPy 如何让您将 Python 提供的编码舒适性与 c 语言的运行时效率结合起来。在本教程中,您将学习如何:
- 使用 NumPy
max()功能- 使用 NumPy
maximum()函数并理解为什么与max()不同- 用这些函数解决实际问题
- 处理数据中的缺失值
- 将相同的概念应用于寻找最小值
本教程包括一个非常简短的 NumPy 介绍,所以即使你以前从未使用过 NumPy,你也应该能够直接进入。有了这里提供的背景知识,您就可以继续探索 NumPy 库中丰富的功能了。
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
NumPy:数字 Python
NumPy 是数值 Python 的简称。它是一个开源的 Python 库,通过支持对多维数字数组的快速并行计算,在科学、统计和数据分析领域实现了广泛的应用。许多最流行的数值软件包都使用 NumPy 作为它们的基本库。
介绍 NumPy
NumPy 库是围绕一个名为
np.ndarray的类和一组方法和函数构建的,这些方法和函数利用 Python 语法来定义和操作任何形状或大小的数组。NumPy 用于数组操作的核心代码是用 C 写的。你可以直接在一个
ndarray上使用函数和方法,因为 NumPy 的基于 C 的代码在后台高效地循环所有数组元素。NumPy 的高级语法意味着你可以简单优雅地表达复杂的程序,并高速执行它们。你可以用一个普通的 Python
list来表示一个数组。然而,NumPy 数组比列表有效得多,并且它们由庞大的方法和函数库支持。这些包括数学和逻辑运算、排序、傅立叶变换、线性代数、数组整形等等。今天,NumPy 广泛应用于各种领域,如天文学、量子计算、生物信息学以及各种工程。
NumPy 被用作许多其他库的数字引擎,例如 pandas 和 SciPy 。它还可以轻松地与可视化库集成,如 Matplotlib 和 seaborn 。
NumPy 很容易用你的包管理器安装,比如
pip或者conda。关于 NumPy 及其功能的详细说明和更广泛的介绍,请看一下 NumPy 教程:Python 数据科学入门或 NumPy 绝对初学者指南。在本教程中,您将学习如何迈出使用 NumPy 的第一步。然后您将探索 NumPy 的
max()和maximum()命令。创建和使用 NumPy 数组
您将从快速概述 NumPy 数组开始研究,这种灵活的数据结构赋予了 NumPy 多功能性和强大的功能。
任何 NumPy 程序的基本构件都是
ndarray。一个ndarray是一个包装数字数组的 Python 对象。原则上,它可以具有任何尺寸的任何数量的维度。有几种方法可以声明数组。最直接的方法是从常规的 Python 列表或元组开始:
>>> import numpy as np
>>> A = np.array([3, 7, 2, 4, 5])
>>> A
array([3, 7, 2, 4, 5])
>>> B = np.array(((1, 4), (1, 5), (9, 2)))
>>> B
array([[1, 4],
[1, 5],
[9, 2]])
您已经在别名np下导入了numpy。这是一个标准的、广泛的约定,所以你会在大多数教程和程序中看到它。在这个例子中,A是一个一维数组,而B是二维数组。
注意,np.array()工厂函数期望 Python 列表或元组作为它的第一个参数,因此列表或元组必须分别包装在它自己的一组括号或圆括号中。仅仅扔进一堆没有包装的数字是行不通的:
>>> np.array(3, 7, 2, 4, 5) Traceback (most recent call last): ... TypeError: array() takes from 1 to 2 positional arguments but 5 were given使用这种语法,解释器会看到五个独立的位置参数,所以很混乱。
在数组
B的构造函数中,嵌套元组参数需要一对额外的括号来标识它,作为np.array()的第一个参数。寻址数组元素很简单。像所有 Python 序列一样,NumPy 的索引从零开始。按照惯例,显示二维数组时,第一个索引指的是行,第二个索引指的是列。所以
A[0]是一维数组A的第一个元素,B[2, 1]是二维数组B第三行的第二个元素:
>>> A[0] # First element of A
3
>>> A[4] # Fifth and last element of A
5
>>> A[-1] # Last element of A, same as above
5
>>> A[5] # This won't work because A doesn't have a sixth element
Traceback (most recent call last):
...
IndexError: index 5 is out of bounds for axis 0 with size 5
>>> B[2, 1] # Second element in third row of B
2
到目前为止,您似乎只是做了一些额外的输入来创建看起来非常类似于 Python 列表的数组。但是外表是会骗人的!每个ndarray对象大约有 100 个内置属性和方法,您可以将它传递给 NumPy 库中的数百个函数。
几乎任何你能想到的对数组的操作都可以在几行代码中实现。在本教程中,您将只使用一些函数,但是您可以在 NumPy API 文档中探索数组的全部功能。
以其他方式创建数组
您已经从 Python 序列中创建了一些 NumPy 数组。但是数组可以用许多其他方式创建。最简单的一个是 np.arange() ,它的行为更像是 Python 内置的 range() 函数的增强版:
>>> np.arange(10) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> np.arange(2, 3, 0.1) array([ 2., 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9])在上面的第一个例子中,你只指定了
10的上限。NumPy 遵循范围的标准 Python 约定,并返回一个包含整数0到9的ndarray。第二个例子指定了起始值2,上限3,增量0.1。与 Python 的标准range()函数不同,np.arange()可以处理非整数增量,在这种情况下它会自动生成一个包含np.float元素的数组。NumPy 的数组也可能是从磁盘读取的、从 API返回的数据合成的,或者从缓冲区或其他数组构建的。
NumPy 数组可以包含各种类型的整数、浮点数和复数,但是数组中的所有元素必须是同一类型。
首先,您将使用内置的
ndarray属性来理解数组A和B:
>>> A.size
5
>>> A.shape
(5,)
>>> B.size
6
>>> B.shape
(3, 2)
.size属性对数组中的元素进行计数,.shape属性包含一个有序的维度元组,NumPy 称之为轴。A是一个一维数组,一行包含五个元素。因为A只有一个轴,A.shape返回一个单元素元组。
按照惯例,在二维矩阵中,0轴对应行,而1轴对应列,所以B.shape的输出告诉你B有三行两列。
Python 字符串和列表有一个非常方便的特性,叫做切片,它允许你通过指定索引或索引范围来选择字符串或列表的部分。这个想法很自然地推广到 NumPy 数组。例如,您可以从B中提取您需要的部分,而不影响原始数组:
>>> B[2, 0] 9 >>> B[1, :] array([1, 5])在上面的第一个例子中,您使用
B[2, 0]选择了行2和列0中的单个元素。第二个例子使用一个片来挑选一个子数组。这里,B[1, :]中的索引1选择B的第1行。第二个索引位置的:选择该行中的所有元素。因此,表达式B[1, :]返回一个一行两列的数组,包含来自B的行1的所有元素。如果你需要处理三维或三维以上的矩阵,NumPy 可以满足你。语法足够灵活,可以涵盖任何情况。但是,在本教程中,您将只处理一维和二维数组。
如果你在玩 NumPy 的时候有任何问题,官方 NumPy 文档是详尽且写得很好的。如果您使用 NumPy 进行严肃的开发,您会发现它们是不可或缺的。
NumPy 的
max():数组中的最大元素在本节中,您将熟悉
np.max(),这是一个在各种情况下寻找最大值的通用工具。注意: NumPy 既有一个包级函数,又有一个名为
max()的ndarray方法。它们以同样的方式工作,尽管包函数np.max()需要目标数组名作为它的第一个参数。在接下来的内容中,您将会交替使用函数和方法。Python 还有一个内置的
max()函数,可以计算 iterables 的最大值。您可以使用这个内置的max()来查找一维 NumPy 数组中的最大元素,但是它不支持更多维的数组。在处理 NumPy 数组时,应该坚持 NumPy 自己的最大值函数和方法。对于本教程的其余部分,max()将总是指 NumPy 版本。
np.max()是在一个单个数组中寻找最大值的工具。准备好试试了吗?使用
max()为了说明
max()函数,您将创建一个名为n_scores的数组,其中包含学生在牛顿教授的线性代数课上获得的测试分数。每行代表一名学生,每列包含特定考试的分数。因此列
0包含第一次测试的所有学生分数,列1包含第二次测试的分数,依此类推。这里是n_scores阵:
>>> import numpy as np
>>> n_scores = np.array([
... [63, 72, 75, 51, 83],
... [44, 53, 57, 56, 48],
... [71, 77, 82, 91, 76],
... [67, 56, 82, 33, 74],
... [64, 76, 72, 63, 76],
... [47, 56, 49, 53, 42],
... [91, 93, 90, 88, 96],
... [61, 56, 77, 74, 74],
... ])
如果您愿意,可以将这段代码复制并粘贴到 Python 控制台中。要在复制前简化格式,请单击代码块右上角的>>>。您可以对示例中的任何 Python 代码做同样的事情。一旦你这样做了,n_scores数组就在内存中了。您可以向解释器询问它的一些属性:
>>> n_scores.size 40 >>> n_scores.shape (8, 5)如上所述,
.shape和.size属性确认您有代表学生的8行和代表测试的5列,总共有40个测试分数。假设现在你想找出任何学生在任何考试中取得的最高分。在牛顿教授的线性代数课上,你可以通过检查数据很快找到最高分。但是,当您处理更大的数据集时,有一种更快的方法会显示出它的价值,这种数据集可能包含数千行和数千列。
尝试使用数组的
.max()方法:
>>> n_scores.max()
96
.max()方法已经扫描了整个数组并返回了最大的元素。使用这个方法完全等同于调用np.max(n_scores)。
但是也许你想要一些更详细的信息。每次测试的最高分是多少?这里你可以使用axis参数:
>>> n_scores.max(axis=0) array([91, 93, 90, 91, 96])新参数
axis=0告诉 NumPy 找出所有行中的最大值。由于n_scores有五个列,NumPy 独立地为每一列做这件事。这将产生五个数字,每个数字都是该列中的最大值。axis参数使用索引尺寸的标准惯例。所以axis=0指的是一个数组的行,而axis=1指的是列。每个学生的最高分也很容易找到:
>>> n_scores.max(axis=1)
array([83, 57, 91, 82, 76, 56, 96, 77])
这一次,NumPy 返回了一个包含八个元素的数组,每个学生一个元素。n_scores数组包含每个学生的一行。参数axis=1告诉 NumPy 找出每个学生跨列的最大值。因此,输出的每个元素都包含相应学生获得的最高分。
也许您想要每个学生的最高分,但是您已经决定排除第一次和最后一次测试。切片起了作用:
>>> filtered_scores = n_scores[:, 1:-1] >>> filtered_scores.shape (8, 3) >>> filtered_scores array([72, 75, 51], [53, 57, 56], [77, 82, 91], [56, 82, 33], [76, 72, 63], [56, 49, 53], [93, 90, 88], [56, 77, 74]]) >>> filtered_scores.max(axis=1) array([75, 57, 91, 82, 76, 56, 93, 77])可以这样理解切片标注
n_scores[:, 1:-1]。第一个索引范围由单个的:表示,选择切片中的所有行。逗号后面的第二个索引范围1:-1告诉 NumPy 获取列,从第1列开始,到最后一列之前的第1列结束。切片的结果存储在一个名为filtered_scores的新数组中。通过一点实践,您将学会动态地进行数组切片,因此您不需要显式地创建中间数组
filtered_scores:
>>> n_scores[:, 1:-1].max(axis=1)
array([75, 57, 91, 82, 76, 56, 93, 77])
这里,您已经在一行中执行了切片和方法调用,但是结果是相同的。NumPy 返回受限测试集的每个学生的最大值集合n_scores。
处理np.max()中的缺失值
现在你知道如何在任何完全填充的数组中找到最大值了。但是当一些数组值丢失时会发生什么呢?这在真实世界的数据中很常见。
举例来说,您将创建一个小数组,其中包含从星期一开始的一周的每日温度读数(以摄氏度为单位):
>>> temperatures_week_1 = np.array([7.1, 7.7, 8.1, 8.0, 9.2, np.nan, 8.4]) >>> temperatures_week_1.size 7看来温度计在星期六发生了故障,相应的温度值不见了,这种情况由
np.nan值表示。这是一个特殊值而不是一个数字,它通常用于在现实世界的数据应用程序中标记缺失值。到目前为止,一切顺利。但是,如果您无意中试图将
.max()应用到这个数组,就会出现一个问题:
>>> temperatures_week_1.max()
nan
由于np.nan报告了一个丢失的值,NumPy 的默认行为是通过报告最大值也是未知的来标记它。对于某些应用程序来说,这非常有意义。但是对于您的应用程序,也许您会发现忽略星期六的问题并从剩余的有效读数中获得最大值更有用。NumPy 提供了np.nanmax()函数来处理这种情况:
>>> np.nanmax(temperatures_week_1) 9.2该函数忽略任何
nan值,并返回最大数值,如预期的那样。注意,np.nanmax()是 NumPy 库中的一个函数,而不是ndarray对象的一个方法。探索相关的最大值函数
现在,您已经看到了 NumPy 的单数组最大查找能力的最常见示例。但是还有一些与最大值相关的 NumPy 函数值得了解。
例如,代替数组中的最大值,您可能想要最大值的索引。假设您想要使用您的
n_scores数组来识别在每次测试中表现最好的学生。这里的.argmax()方法是你的朋友:
>>> n_scores.argmax(axis=0)
array([6, 6, 6, 2, 6])
似乎学生6除了一次考试外,每一次考试都得了最高分。学生2在第四次考试中表现最好。
您还记得,您也可以将np.max()应用为 NumPy 包的函数,而不是 NumPy 数组的方法。在这种情况下,数组必须作为函数的第一个参数提供。由于历史原因,包级函数np.max()有一个别名np.amax(),除了名字之外,其他方面都是一样的:
>>> n_scores.max(axis=1) array([83, 57, 91, 82, 76, 56, 96, 77]) >>> np.max(n_scores, axis=1) array([83, 57, 91, 82, 76, 56, 96, 77]) >>> np.amax(n_scores, axis=1) array([83, 57, 91, 82, 76, 56, 96, 77])在上面的代码中,你已经调用了
.max()作为n_scores对象的一个方法,并且作为一个独立的库函数,将n_scores作为它的第一个参数。您也以同样的方式调用了别名np.amax()。所有三个调用产生完全相同的结果。现在,您已经看到了如何使用
np.max()、np.amax()或.max()来查找数组沿不同轴的最大值。您还使用了np.nanmax()来查找最大值,而忽略了nan值,以及np.argmax()或.argmax()来查找最大值的索引。当你得知 NumPy 有一组等价的最小函数:
np.min()、np.amin()、.min()、np.nanmin()、np.argmin()和.argmin()时,你不会感到惊讶。你不会和这里的人打交道,但是他们的行为和他们的近亲完全一样。NumPy 的
maximum():跨数组的最大元素数数据科学中的另一个常见任务是比较两个相似的数组。NumPy 的
maximum()函数是在数组中寻找最大值的首选工具。由于maximum()总是涉及到两个输入数组,所以没有相应的方法。np.maximum()函数期望输入数组作为它的前两个参数。使用
np.maximum()继续前面涉及班级分数的例子,假设牛顿教授的同事——也是主要竞争对手——莱布尼茨教授也在管理一个有八名学生的线性代数班。用 Leibniz 类的值构造一个新数组:
>>> l_scores = np.array([
... [87, 73, 71, 59, 67],
... [60, 53, 82, 80, 58],
... [92, 85, 60, 79, 77],
... [67, 79, 71, 69, 87],
... [86, 91, 92, 73, 61],
... [70, 66, 60, 79, 57],
... [83, 51, 64, 63, 58],
... [89, 51, 72, 56, 49],
... ])
>>> l_scores.shape
(8, 5)
新数组l_scores的形状与n_scores相同。
你想比较两个班级,一个学生一个学生,一个测试一个测试,找出每种情况下的高分。NumPy 有一个函数np.maximum(),专门用于以逐个元素的方式比较两个数组。查看实际情况:
>>> np.maximum(n_scores, l_scores) array([[87, 73, 75, 59, 83], [60, 53, 82, 80, 58], [92, 85, 82, 91, 77], [67, 79, 82, 69, 87], [86, 91, 92, 73, 76], [70, 66, 60, 79, 57], [91, 93, 90, 88, 96], [89, 56, 77, 74, 74]])如果你目测检查数组
n_scores和l_scores,那么你会看到np.maximum()确实为每对[行,列]索引选择了两个分数中较高的一个。如果你只想比较各个班级的最好考试成绩呢?您可以结合使用
np.max()和np.maximum()来获得这种效果:
>>> best_n = n_scores.max(axis=0)
>>> best_n
array([91, 93, 90, 91, 96])
>>> best_l = l_scores.max(axis=0)
>>> best_l
array([92, 91, 92, 80, 87])
>>> np.maximum(best_n, best_l)
array([92, 93, 92, 91, 96])
和以前一样,每次调用.max()都返回相关班级所有学生的最高分数数组,每个测试一个元素。但是这一次,您将这些返回的数组输入到maximum()函数中,该函数比较两个数组,并返回数组中每个测试的较高分数。
您可以通过去掉中间数组best_n和best_l将这些操作合并成一个操作:
>>> np.maximum(n_scores.max(axis=0), l_scores.max(axis=0)) array([91, 93, 90, 91, 96])这给出了与以前相同的结果,但是输入更少。你可以选择你喜欢的任何一种方法。
处理
np.maximum()中的缺失值还记得早先例子中的
temperatures_week_1数组吗?如果您使用第二周的温度记录和maximum()功能,您可能会发现一个熟悉的问题。首先,您将创建一个新数组来保存新的温度:
>>> temperatures_week_2 = np.array(
... [7.3, 7.9, np.nan, 8.1, np.nan, np.nan, 10.2]
... )
temperatures_week_2数据中也有缺失值。现在看看如果将np.maximum函数应用于这两个温度数组会发生什么:
>>> np.maximum(temperatures_week_1, temperatures_week_2) array([ 7.3, 7.9, nan, 8.1, nan, nan, 10.2])两个数组中的所有
nan值都在输出中作为缺失值出现。NumPy 宣传nan的方法有一个很好的理由。通常,对结果的完整性来说,重要的是跟踪缺失的值,而不是掩盖它们。但是在这里,您只想获得每周最大值的最佳视图。在这种情况下,解决方案是另一个 NumPy 包函数,np.fmax():
>>> np.fmax(temperatures_week_1, temperatures_week_2)
array([ 7.3, 7.9, 8.1, 8.1, 9.2, nan, 10.2])
现在,两个丢失的值被忽略了,该索引处剩余的浮点值被作为最大值。但是星期六的温度不能用那种方式固定,因为和两个源值都丢失了。因为这里没有合适的值可以插入,np.fmax()只是把它作为一个nan。
正如np.max()和np.nanmax()具有并行的最小值功能np.min()和np.nanmin(),所以np.maximum()和np.fmax()也具有相应的功能np.minimum()和np.fmin(),它们反映了最小值的功能。
高级用法
现在您已经看到了 NumPy 的max()和maximum()的所有基本用例的例子,以及一些相关的函数。现在,您将研究这些函数的一些更难理解的可选参数,并找出它们何时有用。
重用内存
在 Python 中调用函数时,会返回一个值或对象。您可以立即使用该结果,方法是将其打印或写入磁盘,或者作为输入参数直接输入到另一个函数中。您也可以将其保存到一个新变量中,以供将来参考。
如果你调用了 Python REPL 中的函数,但没有以其中一种方式使用它,那么 REPL 会在控制台上打印出返回值,这样你就知道有东西被返回了。所有这些都是标准的 Python 内容,并不特定于 NumPy。
NumPy 的数组函数是为处理巨大的输入而设计的,它们通常会产生巨大的输出。如果你调用这个函数成百上千次,那么你将会分配大量的内存。这可能会降低程序速度,在极端情况下,甚至可能导致内存或堆栈溢出。
这个问题可以通过使用out参数来避免,该参数对np.max()和np.maximum()以及许多其他 NumPy 函数都可用。其思想是预先分配一个合适的数组来保存函数结果,并在后续调用中重用相同的内存块。
您可以重新考虑温度问题,创建一个将out参数用于np.max()函数的示例。您还将使用dtype参数来控制返回数组的类型:
>>> temperature_buffer = np.empty(7, dtype=np.float32) >>> temperature_buffer.shape (7,) >>> np.maximum(temperatures_week_1, temperatures_week_2, out=temperature_buffer) array([ 7.3, 7.9, nan, 8.1, nan, nan, 10.2], dtype=float32)
temperature_buffer中的初始值无关紧要,因为它们会被覆盖。但是数组的形状很重要,因为它必须与输出形状相匹配。显示的结果看起来像您从最初的np.maximum()示例中收到的输出。那么有什么变化呢?不同的是,你现在有相同的数据存储在temperature_buffer:
>>> temperature_buffer
array([ 7.3, 7.9, nan, 8.1, nan, nan, 10.2], dtype=float32)
np.maximum()返回值已经存储在temperature_buffer变量中,这个变量是您之前用正确的形状创建的,用来接受返回值。由于您在声明这个缓冲区时还指定了dtype=np.float32,NumPy 会尽最大努力将输出数据转换成那个类型。
记得在下次调用这个函数时覆盖缓冲区内容之前使用它们。
过滤阵列
另一个偶尔有用的参数是where。这将对输入数组应用一个过滤器,这样只有那些where条件为True的值才会被包括在比较中。其他值将被忽略,输出数组的相应元素将保持不变。在大多数情况下,这将使他们持有任意值。
出于示例的目的,假设您出于某种原因决定忽略所有小于60的分数来计算牛顿教授班上每个学生的最大值。你的第一次尝试可能是这样的:
>>> n_scores array([[63, 72, 75, 51, 83], [44, 53, 57, 56, 48], [71, 77, 82, 91, 76], [67, 56, 82, 33, 74], [64, 76, 72, 63, 76], [47, 56, 49, 53, 42], [91, 93, 90, 88, 96], [61, 56, 77, 74, 74]]) >>> n_scores.max(axis=1, where=(n_scores >= 60)) ValueError: reduction operation 'maximum' does not have an identity, so to use a where mask one has to specify 'initial'这里的问题是,NumPy 不知道如何对待第
1排和第5排的学生,他们没有一次考试成绩达到60或更好。解决方案是提供一个initial参数:
>>> n_scores.max(axis=1, where=(n_scores >= 60), initial=60)
array([83, 60, 91, 82, 76, 60, 96, 77])
有了两个新参数where和initial , n_scores.max()只考虑大于或等于60的元素。对于没有这种元素的行,它返回60的initial值。所以指数为1和5的幸运学生通过这个操作将他们的最高分提高到了60!原来的n_scores阵原封不动。
用广播比较不同形状的阵列
您已经学习了如何使用np.maximum()来比较具有相同形状的数组。但是事实证明,这个函数,以及 NumPy 库中的许多其他函数,比这个函数更加通用。NumPy 有一个名为广播的概念,它为涉及两个数组的大多数函数的行为提供了一个非常有用的扩展,包括np.maximum()。
每当您调用对两个数组A和B进行操作的 NumPy 函数时,它都会检查它们的.shape属性,以查看它们是否兼容。如果它们有完全相同的.shape,那么 NumPy 就逐个元素地匹配数组,将A[i, j]处的元素与B[i, j]处的元素配对。np.maximum()工作原理也是这样。
广播使得 NumPy 能够在两个具有不同 T2 形状的阵列上运行,前提是仍然有一种合理的方法来匹配元素对。最简单的例子就是在整个数组中传播一个元素。您将通过继续牛顿教授和他的线性代数课的例子来探索广播。假设他要求你确保他的学生没有一个分数低于75。你可以这样做:
>>> np.maximum(n_scores, 75) array([[75, 75, 75, 75, 83], [75, 75, 75, 75, 75], [75, 77, 82, 91, 76], [75, 75, 82, 75, 75], [75, 76, 75, 75, 76], [75, 75, 75, 75, 75], [91, 93, 90, 88, 96], [75, 75, 77, 75, 75]])您已经将
np.maximum()函数应用于两个参数:n_scores,其.shape为(8,5),以及单个标量参数75。你可以把第二个参数想象成一个 1 × 1 的数组,它将在函数内部被拉伸以覆盖 8 行 5 列。然后,可以用n_scores逐个元素地比较拉伸后的数组,并且可以为结果的每个元素返回成对的最大值。结果就好像您将
n_scores与一个自身形状的数组(8,5)进行了比较,但是每个元素中的值都是75。这种拉伸只是概念性的——NumPy 足够聪明,可以在不实际创建拉伸数组的情况下完成所有这些工作。所以你可以在不影响效率的情况下得到这个例子的符号便利。你可以通过广播做更多的事情。莱布尼茨教授已经注意到了牛顿在他的
best_n_scores数组上的欺骗行为,并决定自己进行一点数据操作。莱布尼茨的计划是人为地提高所有学生的分数,使其至少等于某次考试的平均分。这将增加所有低于平均水平的分数——从而产生一些非常误导的结果!你如何帮助教授达到她有些邪恶的目的?
第一步是使用数组的
.mean()方法为每个测试创建一个一维平均值数组。然后你可以使用np.maximum()并在整个l_scores矩阵中传播这个数组:
>>> mean_l_scores = l_scores.mean(axis=0, dtype=np.integer)
>>> mean_l_scores
array([79, 68, 71, 69, 64])
>>> np.maximum(mean_l_scores, l_scores) array([[87, 73, 71, 69, 67],
[79, 68, 82, 80, 64],
[92, 85, 71, 79, 77],
[79, 79, 71, 69, 87],
[86, 91, 92, 73, 64],
[79, 68, 71, 79, 64],
[83, 68, 71, 69, 64],
[89, 68, 72, 69, 64]])
广播发生在突出显示的函数调用中。一维mean_l_scores数组在概念上被拉伸以匹配二维l_scores数组。输出数组的.shape与两个输入数组中较大的那个l_scores相同。
遵循广播规则
那么,广播有什么规则呢?许多 NumPy 函数接受两个数组参数。np.maximum()只是其中之一。可以在这样的函数中一起使用的数组被称为兼容的,它们的兼容性取决于它们的维数和大小——也就是说,取决于它们的.shape。
最简单的情况是两个数组,比如说A和B,具有相同的形状。出于函数的目的,A中的每个元素都与B中相同索引地址的元素相匹配。
当A和B具有不同的形状时,广播规则变得更加有趣。兼容数组的元素必须以某种方式明确地配对在一起,以便较大数组的每个元素都可以与较小数组的元素交互。输出数组将具有两个输入数组中较大的那个的.shape。因此,兼容阵列必须遵循以下规则:
-
如果一个数组的维数比另一个少,则只有尾随维数匹配兼容性。尾部尺寸是出现在两个数组的
.shape中的尺寸,从右边开始计数。所以如果A.shape是(99, 99, 2, 3),而B.shape是(2, 3),那么A和B是兼容的,因为(2, 3)是各自的尾部尺寸。可以完全忽略A最左边的两个维度。 -
即使尾部维度不相等,如果其中一个维度等于任一数组中的
1,数组仍然是兼容的。所以如果A.shape像以前一样是(99, 99, 2, 3),而B.shape是(1, 99, 1, 3)或(1, 3)或(1, 2, 1)或(1, 1),那么在每种情况下B仍然与A兼容。
您可以在 Python REPL 中体验一下广播规则。您将创建一些玩具数组来说明广播是如何工作的以及输出数组是如何生成的:
>>> A = np.arange(24).reshape(2, 3, 4) >>> A array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) >>> A.shape (2, 3, 4) >>> B = np.array( ... [ ... [[-7, 11, 10, 2], [-6, 7, -2, 14], [ 7, 4, 4, -1]], ... [[18, 5, 22, 7], [25, 8, 15, 24], [31, 15, 19, 24]], ... ] ... ) >>> B.shape (2, 3, 4) >>> np.maximum(A, B) array([[[ 0, 11, 10, 3], [ 4, 7, 6, 14], [ 8, 9, 10, 11]], [[18, 13, 22, 15], [25, 17, 18, 24], [31, 21, 22, 24]]])这里还没有什么新东西可看。您已经创建了两个相同的
.shape数组,并对它们应用了np.maximum()操作。注意,方便的.reshape()方法可以让你构建任何形状的数组。您可以验证结果是两个输入的逐个元素的最大值。当你实验比较两组不同形状的时,乐趣就开始了。尝试切片
B来制作一个新的数组,C:
>>> C = B[:, :1, :]
>>> C
array([[[-7, 11, 10, 2]],
[[18, 5, 22, 7]]])
>>> C.shape
(2, 1, 4)
>>> np.maximum(A, C)
array([[[ 0, 11, 10, 3], [ 4, 11, 10, 7], [ 8, 11, 10, 11]],
[[18, 13, 22, 15], [18, 17, 22, 19], [20, 21, 22, 23]]]))
两个数组A和C是兼容的,因为新数组的第二维度是1,其他维度是匹配的。注意maximum()操作结果的.shape与A.shape相同。这是因为较小的数组C正在通过A广播。阵列间广播操作的结果将总是具有比大的阵列的.shape。
现在你可以尝试对B进行更激进的分割:
>>> D = B[:, :1, :1] >>> D array([[[-7]],[[18]]]) >>> D.shape (2, 1, 1) >>> np.maximum(A, D) array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[18, 18, 18, 18], [18, 18, 18, 19], [20, 21, 22, 23]]])同样,
A和D的尾部尺寸要么都相等,要么都是1,因此数组是兼容的,广播可以工作。结果与A的.shape相同。也许最极端的广播类型发生在数组参数之一作为标量传递时:
>>> np.maximum(A, 10)
array([[[10, 10, 10, 10], [10, 10, 10, 10], [10, 10, 10, 11]],
[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]])
NumPy 自动将第二个参数10转换为带有.shapeT3 的array([10]),确定这个转换后的参数与第一个参数兼容,并适时地在整个 2 × 3 × 4 数组A上广播它。
最后,这里有一个广播失败的例子:
>>> E = B[:, 1:, :] >>> E array([[[-6, 7, -2, 14], [ 7, 4, 4, -1]], [[25, 8, 15, 24], [31, 15, 19, 24]]]) >>> E.shape (2, 2, 4) >>> np.maximum(A, E) Traceback (most recent call last): ... ValueError: operands could not be broadcast together with shapes (2,3,4) (2,2,4)如果你回头参考一下上面的广播规则,就会看到问题所在:
A和E的第二维不匹配,也不等于1,所以两个数组不兼容。你可以在 Look Ma,No For-Loops:Array Programming With NumPy中阅读更多关于广播的内容。在的数字文档中也有对规则的详细描述。
广播规则可能会令人困惑,所以最好先玩一些玩具阵列,直到你感觉到它是如何工作的!
结论
在本教程中,您已经研究了 NumPy 库的
max()和maximum()操作,以找到数组内或数组间的最大值。下面是你学到的:
- 为什么 NumPy 有自己的
max()函数,如何使用maximum()功能与max()有何不同,何时需要- 每个功能有哪些实际应用
- 你如何处理缺失数据以使你的结果有意义
- 你如何将你的知识应用于补充任务寻找最小值
在这个过程中,您已经学习或更新了 NumPy 语法的基础知识。NumPy 是一个非常受欢迎的库,因为它对数组操作有强大的支持。
现在您已经掌握了 NumPy 的
max()和maximum()的细节,您已经准备好在您的应用程序中使用它们,或者继续了解 NumPy 支持的数百个数组函数中的更多函数。免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
如果您对使用 NumPy 进行数据科学感兴趣,那么您也会想研究一下 pandas ,这是一个基于 NumPy 构建的非常流行的数据科学库。你可以在熊猫数据框架:让数据工作变得愉快中了解到这一点。如果你想从数据中产生引人注目的图像,看看用 Matplotlib (Guide) 绘制的 Python。
NumPy 的应用是无限的。无论你的 NumPy 冒险带你下一步,前进和矩阵乘法!*******
使用 Python、SQLite 和 SQLAlchemy 进行数据管理
原文:# t0]https://realython . com/python-SQLite-SQL anywhere emy/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深理解:Python 中的 SQLite 和 SQLAlchemy:将您的数据移动到平面文件之外
所有程序都以这样或那样的形式处理数据,许多程序需要能够在一次调用和下一次调用之间保存和检索数据。Python、 SQLite 和 SQLAlchemy 为您的程序提供数据库功能,允许您将数据存储在单个文件中,而不需要数据库服务器。
您可以使用任意格式的平面文件获得类似的结果,包括 CSV、JSON、XML,甚至自定义格式。平面文件通常是人类可读的文本文件,尽管它们也可以是二进制数据,其结构可以被计算机程序解析。下面,您将探索使用 SQL 数据库和平面文件进行数据存储和操作,并学习如何决定哪种方法适合您的程序。
在本教程中,你将学习如何使用:
- 平面文件用于数据存储
- SQL 改善对持久数据的访问
- SQLite 用于数据存储
- SQLAlchemy 将数据作为 Python 对象处理
通过点击下面的链接,您可以获得本教程中的所有代码和数据:
下载示例代码: 单击此处获取代码,您将使用在本教程中学习使用 SQLite 和 SQLAlchemy 进行数据管理。
使用平面文件存储数据
一个平面文件是一个包含数据的文件,没有内部层次,通常也没有对外部文件的引用。平面文件包含人类可读的字符,对于创建和读取数据非常有用。因为平面文件不需要使用固定的字段宽度,所以它们通常使用其他结构来使程序解析文本成为可能。
例如,逗号分隔值(CSV) 文件是纯文本行,其中逗号字符分隔数据元素。每行文本代表一行数据,每个逗号分隔的值是该行中的一个字段。逗号字符分隔符指示数据值之间的边界。
Python 擅长于读取和保存文件。能够使用 Python 读取数据文件允许您在以后重新运行应用程序时将它恢复到有用的状态。将数据保存在一个文件中允许你在用户和应用程序运行的站点之间共享程序的信息。
在程序能够读取数据文件之前,它必须能够理解数据。通常,这意味着数据文件需要有某种结构,应用程序可以用它来读取和解析文件中的文本。
下面是一个名为
author_book_publisher.csv的 CSV 文件,由本教程中的第一个示例程序使用:first_name,last_name,title,publisher Isaac,Asimov,Foundation,Random House Pearl,Buck,The Good Earth,Random House Pearl,Buck,The Good Earth,Simon & Schuster Tom,Clancy,The Hunt For Red October,Berkley Tom,Clancy,Patriot Games,Simon & Schuster Stephen,King,It,Random House Stephen,King,It,Penguin Random House Stephen,King,Dead Zone,Random House Stephen,King,The Shining,Penguin Random House John,Le Carre,"Tinker, Tailor, Soldier, Spy: A George Smiley Novel",Berkley Alex,Michaelides,The Silent Patient,Simon & Schuster Carol,Shaben,Into The Abyss,Simon & Schuster第一行提供了以逗号分隔的字段列表,这些字段是其余行中数据的列名。其余的行包含数据,每行代表一条记录。
注意:虽然作者、书籍和出版商都是真实的,但书籍和出版商之间的关系是虚构的,是为了本教程的目的而创建的。
接下来,您将了解使用类似上述 CSV 的平面文件处理数据的一些优点和缺点。
平面文件的优势
在平面文件中处理数据易于管理,实现起来也很简单。以人类可读的格式保存数据不仅有助于用文本编辑器创建数据文件,而且有助于检查数据并查找任何不一致或问题。
许多应用程序可以导出由文件生成的数据的平面文件版本。例如, Excel 可以在电子表格中导入或导出 CSV 文件。如果您想要共享数据,平面文件还具有自包含和可转移的优势。
几乎每种编程语言都有工具和库,使得处理 CSV 文件更加容易。Python 有内置的
csv模块和强大的熊猫模块,使得处理 CSV 文件成为一个有效的解决方案。平面文件的缺点
随着数据变大,使用平面文件的优势开始减弱。大文件仍然是人类可读的,但编辑它们以创建数据或寻找问题变得更加困难。如果您的应用程序将更改文件中的数据,那么一个解决方案是将整个文件读入内存,进行更改,并将数据写出到另一个文件。
使用平面文件的另一个问题是,您需要在文件语法中显式地创建和维护数据部分与应用程序之间的任何关系。此外,您需要在应用程序中生成代码来使用这些关系。
最后一个复杂的问题是,您希望与之共享数据文件的人还需要了解您在数据中创建的结构和关系,并对其进行操作。为了访问这些信息,这些用户不仅需要了解数据的结构,还需要了解访问数据所需的编程工具。
平面文件示例
示例程序
examples/example_1/main.py使用author_book_publisher.csv文件获取其中的数据和关系。这个 CSV 文件维护一个作者列表、他们出版的书籍以及每本书的出版商。注意:示例中使用的数据文件可以在
project/data目录中找到。在project/build_data目录中还有一个生成数据的程序文件。如果您更改了数据并希望返回到已知状态,该应用程序会很有用。要访问本节和整个教程中使用的数据文件,请单击下面的链接:
下载示例代码: 单击此处获取代码,您将使用在本教程中学习使用 SQLite 和 SQLAlchemy 进行数据管理。
上面展示的 CSV 文件是一个非常小的数据文件,只包含少数作者、书籍和出版商。您还应该注意到关于数据的一些事情:
作者斯蒂芬·金和汤姆·克兰西不止一次出现,因为他们出版的多本书都出现在数据中。
作者斯蒂芬·金和赛珍珠的同一本书由不止一家出版社出版。
这些重复的数据字段在数据的其他部分之间创建关系。一个作者可以写很多本书,一个出版商可以和多个作者合作。作者和出版商共享与单本书的关系。
author_book_publisher.csv文件中的关系由在数据文件的不同行中多次出现的字段表示。由于这种数据冗余,数据不仅仅代表一个二维表。当您使用该文件创建 SQLite 数据库文件时,您会看到更多这样的内容。示例程序
examples/example_1/main.py使用嵌入在author_book_publisher.csv文件中的关系来生成一些数据。它首先列出了作者名单和每个人写的书的数量。然后,它会显示一个出版商列表以及每个出版商出版书籍的作者数量。它还使用
treelib模块来显示作者、书籍和出版商的树状层次结构。最后,它向数据中添加一本新书,并重新显示新书所在的树层次结构。下面是这个程序的
main()入口点函数:1def main(): 2 """The main entry point of the program""" 3 # Get the resources for the program 4 with resources.path( 5 "project.data", "author_book_publisher.csv" 6 ) as filepath: 7 data = get_data(filepath) 8 9 # Get the number of books printed by each publisher 10 books_by_publisher = get_books_by_publisher(data, ascending=False) 11 for publisher, total_books in books_by_publisher.items(): 12 print(f"Publisher: {publisher}, total books: {total_books}") 13 print() 14 15 # Get the number of authors each publisher publishes 16 authors_by_publisher = get_authors_by_publisher(data, ascending=False) 17 for publisher, total_authors in authors_by_publisher.items(): 18 print(f"Publisher: {publisher}, total authors: {total_authors}") 19 print() 20 21 # Output hierarchical authors data 22 output_author_hierarchy(data) 23 24 # Add a new book to the data structure 25 data = add_new_book( 26 data, 27 author_name="Stephen King", 28 book_title="The Stand", 29 publisher_name="Random House", 30 ) 31 32 # Output the updated hierarchical authors data 33 output_author_hierarchy(data)上面的 Python 代码采取了以下步骤:
- 第 4 到 7 行将
author_book_publisher.csv文件读入熊猫数据帧。- 第 10 行到第 13 行打印每个出版商出版的书籍数量。
- 第 16 到 19 行打印与每个出版商相关的作者数量。
- 第 22 行按照作者排序的层次结构输出图书数据。
- 第 25 到 30 行向内存结构中添加一本新书。
- 第 33 行按照作者排序的层次结构输出图书数据,包括新添加的图书。
运行该程序会生成以下输出:
$ python main.py Publisher: Simon & Schuster, total books: 4 Publisher: Random House, total books: 4 Publisher: Penguin Random House, total books: 2 Publisher: Berkley, total books: 2 Publisher: Simon & Schuster, total authors: 4 Publisher: Random House, total authors: 3 Publisher: Berkley, total authors: 2 Publisher: Penguin Random House, total authors: 1 Authors ├── Alex Michaelides │ └── The Silent Patient │ └── Simon & Schuster ├── Carol Shaben │ └── Into The Abyss │ └── Simon & Schuster ├── Isaac Asimov │ └── Foundation │ └── Random House ├── John Le Carre │ └── Tinker, Tailor, Soldier, Spy: A George Smiley Novel │ └── Berkley ├── Pearl Buck │ └── The Good Earth │ ├── Random House │ └── Simon & Schuster ├── Stephen King │ ├── Dead Zone │ │ └── Random House │ ├── It │ │ ├── Penguin Random House │ │ └── Random House │ └── The Shining │ └── Penguin Random House └── Tom Clancy ├── Patriot Games │ └── Simon & Schuster └── The Hunt For Red October └── Berkley上面的作者层次在输出中出现了两次,增加了由兰登书屋出版的斯蒂芬·金的 The Stand 。上面的实际输出已经过编辑,为了节省空间,只显示了第一个层次结构输出。
调用其他函数来完成大部分工作。它调用的第一个函数是
get_data():def get_data(filepath): """Get book data from the csv file""" return pd.read_csv(filepath)这个函数接收 CSV 文件的文件路径,并使用 pandas 将它读入一个 pandas DataFrame ,然后将它传递回调用者。这个函数的返回值成为传递给组成程序的其他函数的数据结构。
get_books_by_publisher()计算每个出版商出版的图书数量。由此产生的熊猫系列使用熊猫 GroupBy 功能按出版商分组,然后基于ascending标志对排序:def get_books_by_publisher(data, ascending=True): """Return the number of books by each publisher as a pandas series""" return data.groupby("publisher").size().sort_values(ascending=ascending)
get_authors_by_publisher()基本上与前面的函数做相同的事情,但是对于作者来说:def get_authors_by_publisher(data, ascending=True): """Returns the number of authors by each publisher as a pandas series""" return ( data.assign(name=data.first_name.str.cat(data.last_name, sep=" ")) .groupby("publisher") .nunique() .loc[:, "name"] .sort_values(ascending=ascending) )在熊猫数据框架中创建一本新书。代码检查作者、书籍或出版商是否已经存在。如果没有,那么它创建一个新的书并把它附加到熊猫数据帧:
def add_new_book(data, author_name, book_title, publisher_name): """Adds a new book to the system""" # Does the book exist? first_name, _, last_name = author_name.partition(" ") if any( (data.first_name == first_name) & (data.last_name == last_name) & (data.title == book_title) & (data.publisher == publisher_name) ): return data # Add the new book return data.append( { "first_name": first_name, "last_name": last_name, "title": book_title, "publisher": publisher_name, }, ignore_index=True, )
output_author_hierarchy()使用嵌套的for循环来遍历数据结构的各个层次。然后,它使用treelib模块输出作者、他们出版的书籍以及出版这些书籍的出版商的分层列表:def output_author_hierarchy(data): """Output the data as a hierarchy list of authors""" authors = data.assign( name=data.first_name.str.cat(data.last_name, sep=" ") ) authors_tree = Tree() authors_tree.create_node("Authors", "authors") for author, books in authors.groupby("name"): authors_tree.create_node(author, author, parent="authors") for book, publishers in books.groupby("title")["publisher"]: book_id = f"{author}:{book}" authors_tree.create_node(book, book_id, parent=author) for publisher in publishers: authors_tree.create_node(publisher, parent=book_id) # Output the hierarchical authors data authors_tree.show()这个应用程序运行良好,展示了 pandas 模块的强大功能。该模块为读取 CSV 文件和与数据交互提供了出色的功能。
让我们使用 Python(作者和出版物数据的 SQLite 数据库版本)和 SQLAlchemy 来创建一个功能相同的程序,以便与这些数据进行交互。
使用 SQLite 持久化数据
正如您之前看到的,在
author_book_publisher.csv文件中有冗余数据。例如,关于赛珍珠的《大地》的所有信息被列出两次,因为两个不同的出版商出版了这本书。想象一下,如果这个数据文件包含更多相关数据,比如作者的地址和电话号码、图书的出版日期和 ISBNs,或者地址、电话号码,也许还有出版商的年收入。对于每个根数据项,比如作者、书籍或出版商,这些数据都是重复的。
以这种方式创建数据是可能的,但会异常笨拙。考虑保持该数据文件最新的问题。如果斯蒂芬·金想改名为 T1 呢?你必须更新包含他的名字的多个记录,并确保没有错别字。
比数据复制更糟糕的是向数据添加其他关系的复杂性。如果您决定为作者添加电话号码,并且他们有家庭、工作、移动电话号码,或者更多,会怎么样?您想要为任何根项添加的每个新关系都将记录数乘以新关系中的项数。
这个问题是关系存在于数据库系统中的一个原因。数据库工程中的一个重要话题是数据库规范化,即分解数据以减少冗余并增加完整性的过程。当用新类型的数据扩展数据库结构时,预先对其进行规范化可以将对现有结构的更改保持在最低限度。
SQLite 数据库在 Python 中可用,根据 SQLite 主页,它的使用量超过了所有其他数据库系统的总和。它提供了一个全功能的关系数据库管理系统(RDBMS) ,它使用一个文件来维护所有的数据库功能。
它还具有不需要单独的数据库服务器来运行的优点。数据库文件格式是跨平台的,任何支持 SQLite 的编程语言都可以访问。
所有这些都是有趣的信息,但是它与使用平面文件进行数据存储有什么关系呢?下面你就知道了!
创建数据库结构
将
author_book_publisher.csv数据放入 SQLite 数据库的强力方法是创建一个匹配 CSV 文件结构的表。这样做会忽略 SQLite 的很多功能。关系数据库提供了一种在表中存储结构化数据并在这些表之间建立关系的方法。他们通常使用结构化查询语言(SQL) 作为与数据交互的主要方式。这是对 RDBMSs 所提供内容的过度简化,但对于本教程的目的来说已经足够了。
SQLite 数据库支持使用 SQL 与数据表进行交互。SQLite 数据库文件不仅包含数据,还具有与数据交互的标准化方式。这种支持嵌入在文件中,这意味着任何可以使用 SQLite 文件的编程语言也可以使用 SQL 来处理它。
使用 SQL 与数据库交互
SQL 是一种用于创建、管理和查询数据库中包含的数据的声明性语言。陈述性语言描述了要完成什么,而不是应该如何完成。稍后在创建数据库表时,您将看到 SQL 语句的示例。
用 SQL 构建数据库
为了利用 SQL 的强大功能,您需要对
author_book_publisher.csv文件中的数据应用一些数据库规范化。为此,您需要将作者、书籍和出版商分别放在不同的数据库表中。从概念上讲,数据以二维表结构存储在数据库中。每个表由多行记录组成,每条记录由包含数据的列或字段组成。
字段中包含的数据是预定义的类型,包括文本、整数、浮点数等等。CSV 文件是不同的,因为所有的字段都是文本,并且必须由程序解析,以便为它们分配数据类型。
表中的每条记录都有一个主键,它被定义为给记录一个唯一的标识符。主键类似于 Python 字典中的键。数据库引擎本身通常会为插入到数据库表中的每条记录生成一个递增的整数值作为主键。
尽管主键通常是由数据库引擎自动生成的,但也不是必须如此。如果存储在字段中的数据在该字段的表中的所有其他数据中是唯一的,那么它可以是主键。例如,包含图书数据的表可以使用图书的 ISBN 作为主键。
使用 SQL 创建表格
下面是如何使用 SQL 语句在 CSV 文件中创建代表作者、书籍和出版商的三个表:
CREATE TABLE author ( author_id INTEGER NOT NULL PRIMARY KEY, first_name VARCHAR, last_name VARCHAR ); CREATE TABLE book ( book_id INTEGER NOT NULL PRIMARY KEY, author_id INTEGER REFERENCES author, title VARCHAR ); CREATE TABLE publisher ( publisher_id INTEGER NOT NULL PRIMARY KEY, name VARCHAR );注意,没有文件操作,没有创建变量,也没有保存变量的结构。这些语句只描述了期望的结果:创建具有特定属性的表。数据库引擎决定如何做到这一点。
一旦用来自
author_book_publisher.csv文件的作者数据创建并填充了这个表,就可以使用 SQL 语句访问它。以下语句(也称为查询)使用通配符(*)获取author表中的所有数据并输出:SELECT * FROM author;您可以使用
sqlite3命令行工具与project/data目录下的author_book_publisher.db数据库文件进行交互:$ sqlite3 author_book_publisher.db一旦 SQLite 命令行工具在数据库打开的情况下运行,您就可以输入 SQL 命令。下面是上面的 SQL 命令及其输出,后面是退出程序的
.q命令:sqlite> SELECT * FROM author; 1|Isaac|Asimov 2|Pearl|Buck 3|Tom|Clancy 4|Stephen|King 5|John|Le Carre 6|Alex|Michaelides 7|Carol|Shaben sqlite> .q请注意,每个作者在表中只出现一次。不像 CSV 文件,有些作者有多个条目,在这里,每个作者只需要一个唯一的记录。
用 SQL 维护数据库
SQL 通过插入新数据和更新或删除现有数据,提供了使用现有数据库和表的方法。下面是一个向
author表中插入新作者的 SQL 语句示例:INSERT INTO author (first_name, last_name) VALUES ('Paul', 'Mendez');该 SQL 语句将值'
Paul和'Mendez'插入到author表的相应列first_name和last_name中。注意没有指定
author_id列。因为该列是主键,所以数据库引擎生成该值并将其作为语句执行的一部分插入。更新数据库表中的记录是一个简单的过程。例如,假设斯蒂芬·金希望人们知道他的笔名理查德·巴克曼。下面是更新数据库记录的 SQL 语句:
UPDATE author SET first_name = 'Richard', last_name = 'Bachman' WHERE first_name = 'Stephen' AND last_name = 'King';SQL 语句使用条件语句
WHERE first_name = 'Stephen' AND last_name = 'King'为'Stephen King'定位单个记录,然后用新值更新first_name和last_name字段。SQL 使用等号(=)作为比较运算符和赋值运算符。您也可以从数据库中删除记录。下面是一个从
author表中删除记录的 SQL 语句示例:DELETE FROM author WHERE first_name = 'Paul' AND last_name = 'Mendez';这个 SQL 语句从
author表中删除一行,其中first_name等于'Paul',而last_name等于'Mendez'。删除记录要小心!您设置的条件必须尽可能具体。过于宽泛的条件可能会导致删除比预期更多的记录。例如,如果条件仅基于行
first_name = 'Paul',那么名字为 Paul 的所有作者都将从数据库中删除。注意:为了避免记录的意外删除,许多应用程序根本不允许删除。相反,该记录有另一列来指示它是否在使用中。该列可能被命名为
active,并包含一个评估为 True 或 False 的值,指示在查询数据库时是否应该包括该记录。例如,下面的 SQL 查询将获得
some_table中所有活动记录的所有列:SELECT * FROM some_table WHERE active = 1;SQLite 没有一个布尔数据类型,所以
active列由一个值为0或1的整数表示,以指示记录的状态。其他数据库系统可能有也可能没有本地布尔数据类型。完全有可能直接在代码中使用 SQL 语句在 Python 中构建数据库应用程序。这样做可以将数据作为列表列表或列表字典返回给应用程序。
使用原始 SQL 是处理数据库查询返回的数据的一种完全可以接受的方式。但是,与其这样做,不如直接使用 SQLAlchemy 来处理数据库。
建立关系
您可能会发现数据库系统的另一个比数据持久化和检索更强大、更有用的特性是关系。支持关系的数据库允许您将数据分解到多个表中,并在它们之间建立连接。
author_book_publisher.csv文件中的数据通过复制数据来表示数据和关系。数据库通过将数据分成三个表——author、book和publisher——并在它们之间建立关系来处理这个问题。在将所有数据放入 CSV 文件的一个位置后,为什么要将它分成多个表呢?难道不需要更多的工作去创造和重新组装吗?这在某种程度上是对的,但是使用 SQL 将数据分解并重新组合在一起的优势可能会赢得您的青睐!
一对多关系
一对多关系就像客户在网上订购商品一样。一个客户可以有许多订单,但每个订单都属于一个客户。
author_book_publisher.db数据库以作者和书籍的形式存在一对多的关系。每个作者可以写很多本书,但是每本书都是一个作者写的。正如您在上面的表创建中看到的,这些独立实体的实现是将每个实体放入一个数据库表中,一个用于作者,一个用于书籍。但是这两个表之间的一对多关系是如何实现的呢?
记住,数据库中的每个表都有一个字段被指定为该表的主键。上面的每个表都有一个主键字段,使用以下模式命名:
<table name>_id。上面显示的
book表包含一个字段author_id,它引用了author表。author_id字段在作者和书籍之间建立了一对多的关系,如下所示:
上图是一个简单的实体关系图(ERD) ,由 JetBrains DataGrip 应用程序创建,将表
author和book显示为带有各自主键和数据字段的方框。两个图形项目添加了关于关系的信息:
黄色和蓝色的小图标分别表示表的主键和外键。
连接
book和author的箭头表示基于book表中的author_id外键的表之间的关系。当您将一本新书添加到
book表中时,数据包含了一个author表中现有作者的author_id值。这样,一个作者写的所有的书都有一个追溯到那个唯一作者的查找关系。现在你有了作者和书籍的独立表格,你如何利用它们之间的关系呢?SQL 支持所谓的
JOIN操作,您可以用它来告诉数据库如何连接两个或更多的表。下面的 SQL 查询使用 SQLite 命令行应用程序将
author和book表连接在一起:sqlite> SELECT ...> a.first_name || ' ' || a.last_name AS author_name, ...> b.title AS book_title ...> FROM author a ...> JOIN book b ON b.author_id = a.author_id ...> ORDER BY a.last_name ASC; Isaac Asimov|Foundation Pearl Buck|The Good Earth Tom Clancy|The Hunt For Red October Tom Clancy|Patriot Games Stephen King|It Stephen King|Dead Zone Stephen King|The Shining John Le Carre|Tinker, Tailor, Soldier, Spy: A George Smiley Novel Alex Michaelides|The Silent Patient Carol Shaben|Into The Abyss上面的 SQL 查询通过使用 author 和 book 表之间建立的关系来连接这两个表,从而从这两个表中收集信息。SQL 字符串串联将作者的全名分配给别名
author_name。通过查询收集的数据按照last_name字段以升序排序。在 SQL 语句中有一些事情需要注意。首先,作者的全名出现在一列中,并按姓氏排序。此外,由于一对多的关系,作者在输出中出现多次。作者的名字在他们写的每本书的数据库中都是重复的。
通过为作者和书籍创建单独的表并建立它们之间的关系,可以减少数据中的冗余。现在,您只需在一个地方编辑作者的数据,这种更改就会出现在任何访问数据的 SQL 查询中。
多对多关系
多对多关系存在于
author_book_publisher.db数据库中的作者和出版商之间以及书籍和出版商之间。一个作者可以和很多出版社合作,一个出版社可以和很多作者合作。同样,一本书可以由多家出版社出版,一家出版社可以出版多本书。在数据库中处理这种情况比一对多关系更复杂,因为这种关系是双向的。多对多关系是由一个关联表创建的,它充当两个相关表之间的桥梁。
关联表包含至少两个外键字段,它们是两个关联表中每一个表的主键。该 SQL 语句创建了与
author和publisher表相关的关联表:CREATE TABLE author_publisher ( author_id INTEGER REFERENCES author, publisher_id INTEGER REFERENCES publisher );SQL 语句创建一个新的
author_publisher表,引用现有的author和publisher表的主键。author_publisher表是建立作者和出版商之间关系的关联表。因为关系是在两个主键之间,所以不需要为关联表本身创建一个主键。两个相关键的组合为一行数据创建了一个唯一的标识符。
和以前一样,您使用
JOIN关键字将两个表连接在一起。将author工作台连接到publisher工作台需要两个步骤:
JOIN``author表与author_publisher表。JOIN``author_publisher表与publisher表。
author_publisher关联表提供了JOIN连接两个表的桥梁。下面是一个 SQL 查询示例,它返回了作者和出版他们书籍的出版商的列表:1sqlite> SELECT 2 ...> a.first_name || ' ' || a.last_name AS author_name, 3 ...> p.name AS publisher_name 4 ...> FROM author a 5 ...> JOIN author_publisher ap ON ap.author_id = a.author_id 6 ...> JOIN publisher p ON p.publisher_id = ap.publisher_id 7 ...> ORDER BY a.last_name ASC; 8Isaac Asimov|Random House 9Pearl Buck|Random House 10Pearl Buck|Simon & Schuster 11Tom Clancy|Berkley 12Tom Clancy|Simon & Schuster 13Stephen King|Random House 14Stephen King|Penguin Random House 15John Le Carre|Berkley 16Alex Michaelides|Simon & Schuster 17Carol Shaben|Simon & Schuster上述语句执行以下操作:
第 1 行启动一个
SELECT语句从数据库中获取数据。第 2 行使用
author表的别名a从author表中选择名字和姓氏,并用空格字符将它们连接在一起。第 3 行选择别名为
publisher_name的出版商的名字。第 4 行使用
author表作为检索数据的第一个数据源,并将其分配给别名a。线 5 是上述将
author工作台连接到publisher工作台过程的第一步。它为author_publisher关联表使用别名ap,并执行一个JOIN操作,将ap.author_id外键引用连接到author表中的a.author_id主键。第 6 行是上面提到的两步流程中的第二步。它为
publisher表使用别名p,并执行一个JOIN操作,将ap.publisher_id外键引用与publisher表中的p.publisher_id主键相关联。第 7 行按照作者姓氏的字母升序对数据进行排序,并结束 SQL 查询。
第 8 到 17 行是 SQL 查询的输出。
注意,源
author和publisher表中的数据是标准化的,没有重复数据。然而,返回的结果在回答 SQL 查询所需的地方有重复的数据。上面的 SQL 查询演示了如何使用 SQL
JOIN关键字来利用关系,但是结果数据是对author_book_publisher.csvCSV 数据的部分重新创建。完成创建数据库来分离数据的工作有什么好处?下面的另一个 SQL 查询展示了 SQL 和数据库引擎的一点威力:
1sqlite> SELECT 2 ...> a.first_name || ' ' || a.last_name AS author_name, 3 ...> COUNT(b.title) AS total_books 4 ...> FROM author a 5 ...> JOIN book b ON b.author_id = a.author_id 6 ...> GROUP BY author_name 7 ...> ORDER BY total_books DESC, a.last_name ASC; 8Stephen King|3 9Tom Clancy|2 10Isaac Asimov|1 11Pearl Buck|1 12John Le Carre|1 13Alex Michaelides|1 14Carol Shaben|1上面的 SQL 查询返回作者列表和他们写的书的数量。列表首先按书籍数量降序排序,然后按作者姓名字母顺序排序:
第 1 行以
SELECT关键字开始 SQL 查询。第 2 行选择作者的名和姓,用空格符隔开,并创建别名
author_name。第 3 行统计每个作者写的书的数量,稍后将由
ORDER BY子句用来对列表进行排序。第 4 行选择要从中获取数据的
author表,并创建a别名。线 5 通过
JOIN到author_id连接到相关的book表,并为book表创建b别名。第 6 行使用
GROUP BY关键字生成聚合的作者和图书总数数据。GROUP BY是每个author_name的分组,并控制COUNT()为该作者记录哪些书籍。第 7 行首先按照书籍数量降序排序,然后按照作者姓氏升序排序。
第 8 到 14 行是 SQL 查询的输出。
在上面的示例中,您利用 SQL 来执行聚合计算,并将结果按有用的顺序排序。让数据库基于其内置的数据组织能力执行计算通常比在 Python 中对原始数据集执行同类计算要快。SQL 提供了使用嵌入在 RDBMS 数据库中的集合理论的优势。
实体关系图
实体关系图(ERD) 是数据库或数据库一部分的实体关系模型的可视化描述。
author_book_publisher.dbSQLite 数据库足够小,整个数据库可以通过下图可视化:
此图显示了数据库中的表结构以及它们之间的关系。每个框代表一个表,包含表中定义的字段,如果存在主键,则首先显示主键。
箭头显示了将一个表中的外键字段连接到另一个表中的字段(通常是主键)的表之间的关系。工作台
book_publisher有两个箭头,一个连接到book工作台,另一个连接到publisher工作台。箭头表示book和publisher表之间的多对多关系。author_publisher表提供了author和publisher之间的相同关系。使用 SQLAlchemy 和 Python 对象
SQLAlchemy 是一个强大的 Python 数据库访问工具包,它的对象关系映射器(ORM) 是它最著名的组件之一,也是这里讨论和使用的组件。
当你使用像 Python 这样的面向对象的语言时,从对象的角度考虑通常是有用的。可以将 SQL 查询返回的结果映射到对象,但是这样做违背了数据库的工作方式。坚持使用 SQL 提供的标量结果违背了 Python 开发人员的工作方式。这个问题被称为对象相关阻抗不匹配。
SQLAlchemy 提供的 ORM 位于 SQLite 数据库和 Python 程序之间,转换数据库引擎和 Python 对象之间的数据流。SQLAlchemy 允许您从对象的角度考虑问题,同时仍然保留数据库引擎的强大功能。
型号
将 SQLAlchemy 连接到数据库的一个基本要素是创建一个模型。该模型是一个 Python 类,定义了作为数据库查询结果返回的 Python 对象和底层数据库表之间的数据映射。
前面显示的实体关系图显示了用箭头连接的方框。这些框是用 SQL 命令构建的表,也是 Python 类将要建模的内容。箭头是表之间的关系。
模型是继承自 SQLAlchemy
Base类的 Python 类。Base类提供了模型实例和数据库表之间的接口操作。下面是创建模型来表示数据库
author_book_publisher.db的models.py文件:1from sqlalchemy import Column, Integer, String, ForeignKey, Table 2from sqlalchemy.orm import relationship, backref 3from sqlalchemy.ext.declarative import declarative_base 4 5Base = declarative_base() 6 7author_publisher = Table( 8 "author_publisher", 9 Base.metadata, 10 Column("author_id", Integer, ForeignKey("author.author_id")), 11 Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")), 12) 13 14book_publisher = Table( 15 "book_publisher", 16 Base.metadata, 17 Column("book_id", Integer, ForeignKey("book.book_id")), 18 Column("publisher_id", Integer, ForeignKey("publisher.publisher_id")), 19) 20 21class Author(Base): 22 __tablename__ = "author" 23 author_id = Column(Integer, primary_key=True) 24 first_name = Column(String) 25 last_name = Column(String) 26 books = relationship("Book", backref=backref("author")) 27 publishers = relationship( 28 "Publisher", secondary=author_publisher, back_populates="authors" 29 ) 30 31class Book(Base): 32 __tablename__ = "book" 33 book_id = Column(Integer, primary_key=True) 34 author_id = Column(Integer, ForeignKey("author.author_id")) 35 title = Column(String) 36 publishers = relationship( 37 "Publisher", secondary=book_publisher, back_populates="books" 38 ) 39 40class Publisher(Base): 41 __tablename__ = "publisher" 42 publisher_id = Column(Integer, primary_key=True) 43 name = Column(String) 44 authors = relationship( 45 "Author", secondary=author_publisher, back_populates="publishers" 46 ) 47 books = relationship( 48 "Book", secondary=book_publisher, back_populates="publishers" 49 )本模块的内容如下:
第 1 行从 SQLAlchemy 导入
Column、Integer、String、ForeignKey和Table类,用于帮助定义模型属性。第 2 行导入了
relationship()和backref对象,用于创建对象之间的关系。第 3 行导入了
declarative_base对象,它将数据库引擎连接到模型的 SQLAlchemy 功能。第 5 行创建了
Base类,这是所有模型继承的,也是它们获得 SQLAlchemy ORM 功能的方式。第 7 行到第 12 行创建
author_publisher关联表模型。第 14 到 19 行创建
book_publisher关联表模型。第 21 到 29 行定义了
author数据库表的Author类模型。第 31 到 38 行将
Book类模型定义到book数据库表中。第 40 到 49 行定义了
publisher数据库表的Publisher类模型。上面的描述显示了数据库
author_book_publisher.db中五个表的映射。但是它掩盖了一些 SQLAlchemy ORM 特性,包括Table、ForeignKey、relationship()和backref。让我们现在开始吧。
Table创建关联
author_publisher和book_publisher都是Table类的实例,它们分别创建在author和publisher表以及book和publisher表之间使用的多对多关联表。SQLAlchemy
Table类在数据库中创建一个 ORM 映射表的唯一实例。第一个参数是数据库中定义的表名,第二个是Base.metadata,它提供了 SQLAlchemy 功能和数据库引擎之间的连接。其余的参数是通过名称、类型定义表字段的
Column类的实例,在上面的例子中,是一个ForeignKey的实例。
ForeignKey创建一个连接SQLAlchemy
ForeignKey类定义了不同表中两个Column字段之间的依赖关系。一个ForeignKey就是如何让 SQLAlchemy 知道表之间的关系。例如,来自author_publisher实例创建的这一行建立了一个外键关系:Column("author_id", Integer, ForeignKey("author.author_id"))上面的语句告诉 SQLAlchemy 在
author_publisher表中有一个名为author_id的列。该列的类型是Integer,而author_id是与author表中的主键相关的外键。在
author_publisherTable实例中定义了author_id和publisher_id就创建了从author表到publisher表的连接,反之亦然,建立了多对多的关系。
relationship()建立集合拥有一个
ForeignKey定义了表之间关系的存在,而不是一个作者可以拥有的图书集合。看看Author类定义中的这一行:books = relationship("Book", backref=backref("author"))上面的代码定义了一个父子集合。属性为复数(这不是一个要求,只是一个约定)表明它是一个集合。
relationship()的第一个参数,类名Book(是而不是表名book),是与books属性相关的类。relationship通知 SQLAlchemy 在Author和Book类之间有关系。SQLAlchemy 将在Book类定义中找到关系:author_id = Column(Integer, ForeignKey("author.author_id"))SQLAlchemy 认为这是两个类之间的
ForeignKey连接点。一会儿您将会看到relationship()中的backref参数。
Author中的另一个关系是与Publisher类的关系。这是用下面的语句在Author类定义中创建的:publishers = relationship( "Publisher", secondary=author_publisher, back_populates="authors" )像
books一样,属性publishers指示与作者相关联的出版商的集合。第一个参数"Publisher"通知 SQLAlchemy 相关的类是什么。第二个和第三个参数是secondary=author_publisher和back_populates="authors":
secondary告诉 SQLAlchemy 与Publisher类的关系是通过一个二级表来实现的,这个表就是前面在models.py中创建的author_publisher关联表。secondary参数使 SQLAlchemy 找到author_publisher关联表中定义的publisher_idForeignKey。
back_populates是一个方便的配置,告诉 SQLAlchemy 在Publisher类中有一个补充集合叫做authors。
backref镜像属性
books集合relationship()的backref参数为每个Book实例创建一个author属性。该属性指的是与Book实例相关的父Author。例如,如果您执行下面的 Python 代码,那么 SQLAlchemy 查询将返回一个
Book实例。Book实例具有可用于打印出图书信息的属性:book = session.query(Book).filter_by(Book.title == "The Stand").one_or_none() print(f"Authors name: {book.author.first_name} {book.author.last_name}")上面的
Book中author属性的存在是因为backref的定义。当您需要引用父实例而您只有一个子实例时,拥有一个backref会非常方便。询问回答问题
您可以在 SQLAlchemy 中进行类似于
SELECT * FROM author;的基本查询,如下所示:results = session.query(Author).all()
session是一个 SQLAlchemy 对象,用于在 Python 示例程序中与 SQLite 通信。在这里,您告诉会话您想要针对Author模型执行一个查询并返回所有记录。此时,使用 SQLAlchemy 代替普通 SQL 的优势可能并不明显,尤其是考虑到创建表示数据库的模型所需的设置。查询返回的
results是奇迹发生的地方。您得到的不是标量数据的列表,而是属性与您定义的列名匹配的Author对象的实例列表。SQLAlchemy 维护的
books和publishers集合创建了一个层次列表,列出了作者、他们写过的书以及出版过这些书的出版商。在幕后,SQLAlchemy 将对象和方法调用转换成 SQL 语句,以针对 SQLite 数据库引擎执行。SQLAlchemy 将 SQL 查询返回的数据转换成 Python 对象。
使用 SQLAlchemy,您可以执行前面显示的更复杂的聚合查询,查询作者列表和他们写的书的数量,如下所示:
author_book_totals = ( session.query( Author.first_name, Author.last_name, func.count(Book.title).label("book_total") ) .join(Book) .group_by(Author.last_name) .order_by(desc("book_total")) .all() )上面的查询获得了作者的名和姓,以及作者写了多少本书。
group_by子句使用的聚合count基于作者的姓氏。最后,根据聚合和别名book_total对结果进行降序排序。示例程序
示例程序
examples/example_2/main.py具有与examples/example_1/main.py相同的功能,但是专门使用 SQLAlchemy 与author_book_publisher.dbSQLite 数据库接口。程序分为main()函数和它调用的函数:1def main(): 2 """Main entry point of program""" 3 # Connect to the database using SQLAlchemy 4 with resources.path( 5 "project.data", "author_book_publisher.db" 6 ) as sqlite_filepath: 7 engine = create_engine(f"sqlite:///{sqlite_filepath}") 8 Session = sessionmaker() 9 Session.configure(bind=engine) 10 session = Session() 11 12 # Get the number of books printed by each publisher 13 books_by_publisher = get_books_by_publishers(session, ascending=False) 14 for row in books_by_publisher: 15 print(f"Publisher: {row.name}, total books: {row.total_books}") 16 print() 17 18 # Get the number of authors each publisher publishes 19 authors_by_publisher = get_authors_by_publishers(session) 20 for row in authors_by_publisher: 21 print(f"Publisher: {row.name}, total authors: {row.total_authors}") 22 print() 23 24 # Output hierarchical author data 25 authors = get_authors(session) 26 output_author_hierarchy(authors) 27 28 # Add a new book 29 add_new_book( 30 session, 31 author_name="Stephen King", 32 book_title="The Stand", 33 publisher_name="Random House", 34 ) 35 # Output the updated hierarchical author data 36 authors = get_authors(session) 37 output_author_hierarchy(authors)这个程序是
examples/example_1/main.py的修改版。让我们来看看不同之处:
第 4 行到第 7 行首先初始化
sqlite_filepath变量到数据库文件路径。然后,他们创建engine变量来与 SQLite 和author_book_publisher.db数据库文件通信,这是 SQLAlchemy 对数据库的访问点。第 8 行从 SQLAlchemy 的
sessionmaker()创建了Session类。第 9 行将
Session绑定到第 8 行创建的引擎。第 10 行创建了
session实例,程序使用它与 SQLAlchemy 通信。其余函数类似,除了将
data替换为session作为main()调用的所有函数的第一个参数。
get_books_by_publisher()已经过重构,使用 SQLAlchemy 和您之前定义的模型来获取请求的数据:1def get_books_by_publishers(session, ascending=True): 2 """Get a list of publishers and the number of books they've published""" 3 if not isinstance(ascending, bool): 4 raise ValueError(f"Sorting value invalid: {ascending}") 5 6 direction = asc if ascending else desc 7 8 return ( 9 session.query( 10 Publisher.name, func.count(Book.title).label("total_books") 11 ) 12 .join(Publisher.books) 13 .group_by(Publisher.name) 14 .order_by(direction("total_books")) 15 )下面是新函数
get_books_by_publishers()正在做的事情:
第 6 行创建
direction变量,并根据ascending参数的值将其设置为等于 SQLAlchemydesc或asc函数。第 9 行到第 11 行查询
Publisher表以获得要返回的数据,在本例中是Publisher.name和与作者相关联的Book对象的聚合总数,别名为total_books。12 号线加入
Publisher.books系列。第 13 行通过
Publisher.name属性聚集图书数量。第 14 行根据
direction定义的运算符,按账面数量对输出进行排序。第 15 行关闭对象,执行查询,并将结果返回给调用者。
以上所有代码都表达了想要什么,而不是如何检索。现在,您不再使用 SQL 来描述需要什么,而是使用 Python 对象和方法。返回的是 Python 对象列表,而不是数据元组列表。
get_authors_by_publisher()也已经过修改,只适用于 SQLAlchemy。其功能与前面的功能非常相似,因此省略了功能描述:def get_authors_by_publishers(session, ascending=True): """Get a list of publishers and the number of authors they've published""" if not isinstance(ascending, bool): raise ValueError(f"Sorting value invalid: {ascending}") direction = asc if ascending else desc return ( session.query( Publisher.name, func.count(Author.first_name).label("total_authors"), ) .join(Publisher.authors) .group_by(Publisher.name) .order_by(direction("total_authors")) )添加了
get_authors()以获取按姓氏排序的作者列表。这个查询的结果是一个包含图书收藏的Author对象列表。Author对象已经包含分层数据,所以结果不必重新格式化:def get_authors(session): """Get a list of author objects sorted by last name""" return session.query(Author).order_by(Author.last_name).all()像它以前的版本一样,
add_new_book()相对复杂但易于理解。它确定数据库中是否已经存在具有相同书名、作者和出版商的书籍。如果搜索查询找到完全匹配,则函数返回。如果没有一本书符合精确的搜索条件,那么它会搜索作者是否用传入的标题写了一本书。此代码的存在是为了防止在数据库中创建重复的图书。
如果不存在匹配的书,并且作者没有写过同名的书,那么就创建一本新书。然后,该函数检索或创建作者和出版商。一旦
Book、Author和Publisher的实例存在,它们之间的关系被创建,并且结果信息被保存到数据库:1def add_new_book(session, author_name, book_title, publisher_name): 2 """Adds a new book to the system""" 3 # Get the author's first and last names 4 first_name, _, last_name = author_name.partition(" ") 5 6 # Check if book exists 7 book = ( 8 session.query(Book) 9 .join(Author) 10 .filter(Book.title == book_title) 11 .filter( 12 and_( 13 Author.first_name == first_name, Author.last_name == last_name 14 ) 15 ) 16 .filter(Book.publishers.any(Publisher.name == publisher_name)) 17 .one_or_none() 18 ) 19 # Does the book by the author and publisher already exist? 20 if book is not None: 21 return 22 23 # Get the book by the author 24 book = ( 25 session.query(Book) 26 .join(Author) 27 .filter(Book.title == book_title) 28 .filter( 29 and_( 30 Author.first_name == first_name, Author.last_name == last_name 31 ) 32 ) 33 .one_or_none() 34 ) 35 # Create the new book if needed 36 if book is None: 37 book = Book(title=book_title) 38 39 # Get the author 40 author = ( 41 session.query(Author) 42 .filter( 43 and_( 44 Author.first_name == first_name, Author.last_name == last_name 45 ) 46 ) 47 .one_or_none() 48 ) 49 # Do we need to create the author? 50 if author is None: 51 author = Author(first_name=first_name, last_name=last_name) 52 session.add(author) 53 54 # Get the publisher 55 publisher = ( 56 session.query(Publisher) 57 .filter(Publisher.name == publisher_name) 58 .one_or_none() 59 ) 60 # Do we need to create the publisher? 61 if publisher is None: 62 publisher = Publisher(name=publisher_name) 63 session.add(publisher) 64 65 # Initialize the book relationships 66 book.author = author 67 book.publishers.append(publisher) 68 session.add(book) 69 70 # Commit to the database 71 session.commit()上面的代码比较长。让我们将功能分成易于管理的几个部分:
第 7 行到第 18 行如果找到了同名、同名作者和出版商的书,则将
book变量设置为一个Book的实例。否则,他们将book设置为None。第 20 行和第 21 行确定该书是否已经存在,如果存在则返回。
第 24 行到第 37 行如果找到了同名同作者的书,将
book变量设置为一个Book的实例。否则,他们会创建一个新的Book实例。第 40 到 52 行将
author变量设置为一个现有的作者,如果找到的话,或者基于传入的作者名创建一个新的Author实例。第 55 到 63 行将
publisher变量设置为一个现有的发布者(如果找到的话),或者基于传入的发布者名称创建一个新的Publisher实例。第 66 行将
book.author实例设置为author实例。这创建了作者和书之间的关系,SQLAlchemy 将在会话提交时在数据库中创建这种关系。第 67 行将
publisher实例添加到book.publishers集合中。这在book和publisher表之间创建了多对多的关系。SQLAlchemy 将在表以及连接两者的book_publisher关联表中创建引用。第 68 行将
Book实例添加到会话中,使其成为会话工作单元的一部分。第 71 行将所有的创建和更新提交给数据库。
这里有一些事情需要注意。首先,在查询或创建和更新中没有提到
author_publisher或book_publisher关联表。由于您在models.py中设置关系的工作,SQLAlchemy 可以处理将对象连接在一起,并在创建和更新期间保持这些表同步。其次,所有的创建和更新都发生在
session对象的上下文中。这些活动都没有触及数据库。只有当session.commit()语句执行时,会话才会遍历它的工作单元,并将工作提交给数据库。例如,如果创建了一个新的
Book实例(如上面的第 37 行所示),那么除了book_id主键和author_id外键之外,book 的属性都已初始化。因为还没有发生任何数据库活动,所以book_id是未知的,并且在book的实例化中没有做任何事情来给它一个author_id。当执行
session.commit()时,它要做的事情之一是将book插入数据库,此时数据库将创建book_id主键。然后,会话将使用数据库引擎创建的主键值初始化book.book_id值。
session.commit()也知道在author.books集合中插入了Book实例。author对象的author_id主键将作为author_id外键添加到追加到author.books集合的Book实例中。为多个用户提供访问
至此,您已经看到了如何使用 pandas、SQLite 和 SQLAlchemy 以不同的方式访问相同的数据。对于作者、书籍和出版商数据这种相对简单的用例来说,是否应该使用数据库仍然是个未知数。
在选择使用平面文件还是数据库时,一个决定性因素是数据和关系的复杂性。如果每个实体的数据都很复杂,并且包含实体之间的许多关系,那么在平面文件中创建和维护它可能会变得更加困难。
另一个要考虑的因素是您是否希望在多个用户之间共享数据。这个问题的解决方案可能很简单,使用一个 sneakernet 在用户之间移动数据。以这种方式移动数据文件具有易于使用的优点,但是当进行更改时,数据会很快变得不同步。
如果用户是远程的并且想要通过网络访问数据,那么保持所有用户的数据一致的问题变得更加困难。即使当您受限于像 Python 这样的单一语言并使用 pandas 来访问数据时,网络文件锁定也不足以确保数据不会被破坏。
通过服务器应用程序和用户界面提供数据缓解了这个问题。服务器是唯一需要对数据库进行文件级访问的应用程序。通过使用数据库,无论服务器使用什么编程语言,服务器都可以利用 SQL 通过一致的接口访问数据。
最后一个示例程序通过向 Chinook sample SQLite 数据库提供 web 应用程序和用户界面来演示这一点。Peter Stark 慷慨地维护着 Chinook 数据库,作为 SQLite 教程站点的一部分。如果你想学习更多关于 SQLite 和 SQL 的知识,那么这个网站是一个很好的资源。
Chinook 数据库按照简化的 Spotify(T2)的方式提供艺术家、音乐和播放列表信息。该数据库是
project/data文件夹中示例代码项目的一部分。将 Flask 与 Python、SQLite 和 SQLAlchemy 一起使用
examples/example_3/chinook_server.py程序创建了一个烧瓶应用程序,你可以使用浏览器与之交互。该应用程序利用了以下技术:
Flask Blueprint 是 Flask 的一部分,它提供了一个遵循关注点分离设计原则的好方法,创建不同的模块来包含功能。
Flask SQLAlchemy 是 Flask 的扩展,在 web 应用程序中增加了对 SQLAlchemy 的支持。
Flask_Bootstrap4 打包 Bootstrap 前端工具包,将其与您的 Flask web 应用程序集成。
python_dotenv 是一个 python 模块,应用程序使用它从文件中读取环境变量,并在程序代码中保留敏感信息。
虽然对于这个例子来说不是必需的,但是一个
.env文件保存了应用程序的环境变量。.env文件包含密码等敏感信息,您应该将这些信息放在代码文件之外。然而,项目.env文件的内容如下所示,因为它不包含任何敏感数据:SECRET_KEY = "you-will-never-guess" SQLALCHEMY_TRACK_MODIFICATIONS = False SQLAlCHEMY_ECHO = False DEBUG = True示例应用程序相当大,其中只有一部分与本教程相关。因此,对代码的检查和学习留给了读者。也就是说,您可以看看下面应用程序的动画屏幕截图,然后是呈现主页的 HTML 和提供动态数据的 Python Flask route。
下面是应用程序的运行情况,通过各种菜单和功能进行导航:
动画屏幕截图从应用程序主页开始,使用 Bootstrap 4 进行样式化。该页面显示数据库中的艺术家,按升序排序。屏幕截图的其余部分显示了单击显示的链接或从顶层菜单浏览应用程序的结果。
下面是生成应用程序主页的 Jinja2 HTML 模板:
1{% extends "base.html" %} 2 3{% block content %} 4<div class="container-fluid"> 5 <div class="m-4"> 6 <div class="card" style="width: 18rem;"> 7 <div class="card-header">Create New Artist</div> 8 <div class="card-body"> 9 <form method="POST" action="{{url_for('artists_bp.artists')}}"> 10 {{ form.csrf_token }} 11 {{ render_field(form.name, placeholder=form.name.label.text) }} 12 13 </form> 14 </div> 15 </div> 16 <table class="table table-striped table-bordered table-hover table-sm"> 17 <caption>List of Artists</caption> 18 <thead> 19 <tr> 20 <th>Artist Name</th> 21 </tr> 22 </thead> 23 <tbody> 24 {% for artist in artists %} 25 <tr> 26 <td> 27 <a href="{{url_for('albums_bp.albums', artist_id=artist.artist_id)}}"> 28 {{ artist.name }} 29 </a> 30 </td> 31 </tr> 32 {% endfor %} 33 </tbody> 34 </table> 35 </div> 36</div> 37{% endblock %}下面是 Jinja2 模板代码中的内容:
第 1 行使用 Jinja2 模板继承从
base.html模板构建这个模板。base.html模板包含所有的 HTML5 样板代码以及在站点所有页面上一致的引导导航栏。第 3 行到第 37 行包含页面的分块内容,合并到
base.html基模板中同名的 Jinja2 宏中。第 9 行到第 13 行呈现表单以创建新的艺术家。这使用了 Flask-WTF 的特性来生成表单。
第 24 到 32 行创建了一个
for循环,呈现艺术家姓名表。第 27 行到第 29 行将艺术家的名字呈现为到艺术家专辑页面的链接,该页面显示与特定艺术家相关联的歌曲。
下面是呈现页面的 Python 路径:
1from flask import Blueprint, render_template, redirect, url_for 2from flask_wtf import FlaskForm 3from wtforms import StringField 4from wtforms.validators import InputRequired, ValidationError 5from app import db 6from app.models import Artist 7 8# Set up the blueprint 9artists_bp = Blueprint( 10 "artists_bp", __name__, template_folder="templates", static_folder="static" 11) 12 13def does_artist_exist(form, field): 14 artist = ( 15 db.session.query(Artist) 16 .filter(Artist.name == field.data) 17 .one_or_none() 18 ) 19 if artist is not None: 20 raise ValidationError("Artist already exists", field.data) 21 22class CreateArtistForm(FlaskForm): 23 name = StringField( 24 label="Artist's Name", validators=[InputRequired(), does_artist_exist] 25 ) 26 27@artists_bp.route("/") 28@artists_bp.route("/artists", methods=["GET", "POST"]) 29def artists(): 30 form = CreateArtistForm() 31 32 # Is the form valid? 33 if form.validate_on_submit(): 34 # Create new artist 35 artist = Artist(name=form.name.data) 36 db.session.add(artist) 37 db.session.commit() 38 return redirect(url_for("artists_bp.artists")) 39 40 artists = db.session.query(Artist).order_by(Artist.name).all() 41 return render_template("artists.html", artists=artists, form=form,)让我们看看上面的代码在做什么:
第 1 行到第 6 行导入所有必要的模块来呈现页面,并用数据库中的数据初始化表单。
第 9 行到第 11 行创建艺术家页面的蓝图。
第 13 行到第 20 行为 Flask-WTF 表单创建一个定制的验证函数,以确保创建新艺术家的请求不会与已经存在的艺术家冲突。
第 22 到 25 行创建表单类来处理浏览器中呈现的艺术家表单,并提供表单域输入的验证。
27 到 28 号线将两条路线连接到他们装饰的
artists()功能。第 30 行创建了一个
CreateArtistForm()类的实例。第 33 行确定页面是通过 HTTP 方法 GET 还是 POST (submit)请求的。如果是一篇文章,那么它还会验证表单的字段,并在字段无效时通知用户。
第 35 到 37 行创建一个新的 artist 对象,将其添加到 SQLAlchemy 会话中,并将 artist 对象提交到数据库中,并对其进行持久化。
第 38 行重定向回艺术家页面,该页面将用新创建的艺术家重新呈现。
第 40 行运行一个 SQLAlchemy 查询来获取数据库中的所有艺术家,并按
Artist.name对他们进行排序。如果 HTTP 请求方法是 GET,第 41 行呈现艺术家页面。
您可以看到大量的功能是由相当少量的代码创建的。
创建 REST API 服务器
您还可以创建一个提供 REST API 的 web 服务器。这种服务器提供用数据响应的 URL 端点,通常是以 JSON 格式。JavaScript 单页面 web 应用程序可以通过使用 AJAX HTTP 请求来使用提供 REST API 端点的服务器。
Flask 是创建 REST 应用程序的优秀工具。关于使用 Flask、Connexion 和 SQLAlchemy 创建 REST 应用程序的多部分系列教程,请查看使用 Flask、Connexion 和 SQLAlchemy 的Python REST API。
如果你是 Django 的粉丝,并且对创建 REST API 感兴趣,那么看看 Django Rest 框架——介绍和用 Django Tastypie 创建一个超级基本的 REST API。
注意:有理由问 SQLite 作为 web 应用程序的数据库后端是否是正确的选择。 SQLite 网站声明 SQLite 是每天提供大约 100,000 次点击的网站的一个好选择。如果你的网站获得了更多的日点击量,首先要说的是恭喜你!
除此之外,如果你已经用 SQLAlchemy 实现了你的网站,那么就有可能将数据从 SQLite 转移到另一个数据库,比如 MySQL 或者 PostgreSQL。为了比较 SQLite、MySQL 和 PostgreSQL,帮助您决定哪一个最适合您的应用程序,请查看Python SQL 库简介。
无论是什么样的 Python 应用程序,都值得考虑使用 SQLite。使用数据库为您的应用程序提供了多功能性,并且它可能会为添加额外的功能创造令人惊讶的机会。
结论
在本教程中,您已经涉及了很多关于数据库、SQLite、SQL 和 SQLAlchemy 的内容!您已经使用这些工具将平面文件中包含的数据移动到 SQLite 数据库,使用 SQL 和 SQLAlchemy 访问数据,并通过 web 服务器提供数据。
在本教程中,您已经学习了:
- 为什么一个 SQLite 数据库可以成为平面文件数据存储的一个令人信服的替代品
- 如何归一化数据减少数据冗余,增加数据完整性
- 如何使用 SQLAlchemy 以面向对象的方式处理数据库
- 如何构建一个 web 应用程序来为多个用户提供一个数据库
使用数据库是一种强大的数据处理抽象,它为 Python 程序增加了重要的功能,并允许您对数据提出有趣的问题。
您可以通过下面的链接获得本教程中的所有代码和数据:
下载示例代码: 单击此处获取代码,您将使用在本教程中学习使用 SQLite 和 SQLAlchemy 进行数据管理。
延伸阅读
本教程是对使用数据库、SQL 和 SQLAlchemy 的介绍,但是关于这些主题还有更多要学习的。这些都是强大而复杂的工具,没有一个单独的教程能够完全涵盖。以下是一些资源,可提供更多信息来拓展您的技能:
如果您的应用程序将数据库暴露给用户,那么避免 SQL 注入攻击是一项重要的技能。有关更多信息,请查看使用 Python 防止 SQL 注入攻击的。
在基于 web 的单页面应用程序中,提供对数据库的 web 访问是很常见的。要了解如何操作,请查看包含 Flask、Connexion 和 SQLAlchemy 的Python REST API–第 2 部分。
准备数据工程工作面试会给你的职业生涯助一臂之力。首先,请查看使用 Python 编写的数据工程师面试问题。
迁移数据并能够使用带有 Postgres 和 SQLAlchemy 的 Flask 回滚是软件开发生命周期(SDLC)不可或缺的一部分。您可以通过查看Flask by Example——设置 Postgres、SQLAlchemy 和 Alembic 来了解更多信息。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深理解:Python 中的 SQLite 和 SQLAlchemy:将您的数据移动到平面文件之外********
Python REST APIs 与 Flask、Connexion 和 SQLAlchemy——第 4 部分
原文:# t0]https://realython . com/flask-连接-rest API-part-4/
在本系列的第 3 部分中,您向 REST API 和支持它的数据库添加了关系。这为您提供了一个强大的工具,您可以使用它来构建有趣的程序,将持久数据以及这些数据之间的关系发送到数据库系统。有了 REST API,您就能够用 HTML、CSS 和 JavaScript 创建一个单页面应用程序(SPA) 。在您转向更强大的前端框架之前,这是一个很好的起点,比如 Angular 或 React。
注意:本教程系列目前正在更新中。在继续之前,请注意代码和对本系列中以前部分的引用可能已经过时。
本教程系列的零件一、二、三已经是最新的了。如果你还没有完成前三部分,那么先从它们开始是个好主意。
随时注册 Real Python 时事通讯以便在本教程更新时得到通知。
在这篇文章中,你将学习如何:
- 构建一个 HTML 文件,作为单页面 web 应用程序的模板
- 使用层叠样式表(CSS) 来设计应用程序的外观
- 使用本地 JavaScript 为应用程序增加交互性
- 使用 JavaScript 向您在本系列第 3 部分中开发的 REST API 发出 HTTP AJAX 请求
您可以通过下面的链接获得本教程中的所有代码:
下载代码: 单击此处下载代码,您将在本教程中使用来了解 Python REST APIs 与 Flask、Connexion 和 SQLAlchemy。
这篇文章是写给谁的
本系列的第 1 部分指导您构建 REST API,第 2 部分向您展示了如何将 REST API 连接到数据库。在第 3 部分中,您向 REST API 和支持数据库添加了关系。
本文将把 REST API 作为基于浏览器的 web 应用程序呈现给用户。这种组合让你同时拥有前端和后端能力,这是一个有用而强大的技能组合。
创建单页应用程序
在本系列的第 3 部分中,您向 REST API 和数据库添加了关系来表示与人相关联的注释。换句话说,你创造了一种迷你博客。您在第 3 部分中构建的 web 应用程序向您展示了一种呈现 REST API 并与之交互的方式。您在三个单页面应用程序(SPA) 之间导航,以访问 REST API 的不同部分。
虽然您可以将这些功能合并到一个 SPA 中,但是这种方法会使样式和交互性的概念变得更加复杂,而且没有太多的附加价值。因此,每个页面都是一个完整、独立的 SPA。
在本文中,您将重点关注 People SPA ,它显示了数据库中的人员列表,并提供了一个编辑器特性来创建新人员以及更新或删除现有人员。主页和注释页在概念上是相似的。
现有的框架有哪些?
现有的库为创建 SPA 系统提供了内置的健壮功能。例如, Bootstrap 库提供了一个流行的样式框架,用于创建一致且美观的 web 应用程序。它有 JavaScript 扩展,为样式化的 DOM 元素增加了交互性。
也有强大的 web 应用框架,像 React 和 Angular ,给你完整的 web 应用开发系统。当您想要创建大型的、多页面的 spa,而从头开始构建会很麻烦时,这些功能非常有用。
为什么要自建呢?
有了上面列出的工具,您为什么会选择从头开始创建 SPA 呢?以 Bootstrap 为例。您可以使用它来创建看起来很棒的 spa,并且您当然可以将它与您的 JavaScript 代码一起使用!
问题是 Bootstrap 有一个陡峭的学习曲线,如果你想很好地使用它,你需要爬上去。它还向 HTML 内容中定义的 DOM 元素添加了许多特定于 Bootstrap 的属性。同样,像 React 和 Angular 这样的工具也有很长的学习曲线需要你去克服。然而,不依赖这些工具的 web 应用程序仍然有一席之地。
通常,当你构建一个 web 应用程序时,你想先构建一个概念验证来看看这个应用程序是否有用。您将希望快速启动并运行它,这样您可以更快地推出自己的原型并在以后进行升级。由于您不会在原型上投入太多时间,因此重新开始并创建一个具有受支持的全功能框架的新应用程序的成本不会太高。
在这篇文章中你将要用 People 应用程序开发的东西和你用一个完整的框架可以构建的东西之间有一个差距。由您来决定是自己提供功能还是采用框架。
单页应用程序的组成部分
在传统的基于网络的系统中有几种主要的交互形式。您可以在页面之间导航,并提交包含新信息的页面。您可以填写包含输入字段、单选按钮、复选框等的表单。当您执行这些活动时,web 服务器通过向您的浏览器发送新文件来做出响应。然后,您的浏览器再次呈现内容。
单页应用程序打破了这种模式,首先加载它们需要的所有东西。然后,任何交互性或导航都由 JavaScript 或后台的服务器调用来处理。这些活动动态更新页面内容**。*
*单页应用程序有三个主要组件:
- HTML 提供了网页的内容,或者说是你的浏览器所呈现的内容。
- CSS 提供了网页的表现形式,或者说风格。它定义了页面内容在浏览器中呈现时的外观。
- JavaScript 提供网页的交互性。它还处理与后端服务器的通信。
接下来,您将进一步了解这些主要组件。
HTML
HTML 是一个发送到浏览器的文本文件,为单页应用程序提供主要的内容和结构。这个结构包括对
id和class属性的定义,CSS 使用它们来设计内容的样式,JavaScript 使用它们来与结构交互。您的浏览器解析 HTML 文件以创建文档对象模型(DOM) ,并使用它将内容呈现到显示器上。HTML 文件中的标记包括标签,如段落标签
<p>...</p>和标题标签<h1>...</h1>。当浏览器解析 HTML 并将其呈现给显示器时,这些标签成为 DOM 中的元素。HTML 文件还包含指向外部资源的链接,浏览器在解析 HTML 时会加载这些外部资源。对于您在本文中构建的 SPA,这些外部资源是 CSS 和 JavaScript 文件。CSS
层叠样式表(CSS) 是包含样式信息的文件,这些信息将应用于从 HTML 文件呈现的任何 DOM 结构。这样,网页的内容就可以从它的表现中分离出来。
在 CSS 中,DOM 结构的样式由选择器决定。选择器只是一种将样式与 DOM 中的元素相匹配的方法。例如,下面代码块中的
p选择器将样式信息应用于所有段落元素:p { font-weight: bold; background-color: cyan; }上述样式将应用于 DOM 中的所有段落元素。文本将显示为粗体,背景颜色为青色。
CSS 的层叠部分意味着稍后定义的样式,或者在一个 CSS 文件中加载的样式,将优先于任何先前定义的样式。例如,您可以在上述样式之后定义第二个段落样式:
p { font-weight: bold; background-color: cyan; } p { background-color: cornflower; }这个新的样式定义将修改现有的样式,这样 DOM 中的所有段落元素都将具有背景色
cornflower。这将覆盖先前样式的background-color,但是它将保持font-weight设置不变。您也可以在自己的 CSS 文件中定义新的段落样式。
id和class属性允许您将样式应用于 DOM 中特定的单个元素。例如,呈现新 DOM 的 HTML 可能如下所示:<p> This is some introductory text </p> <p class="panel"> This is some text contained within a panel </p>这将在 DOM 中创建两个段落元素。第一个没有
class属性,但是第二个有panel的class属性。然后,您可以像这样创建一个 CSS 样式:p { font-weight: bold; width: 80%; margin-left: auto; margin-right: auto; background-color: lightgrey; } .panel { border: 1px solid darkgrey; border-radius: 4px; padding: 10px; background-color: lightskyblue; }在这里,您为任何具有
panel属性的元素定义了一个样式。当您的浏览器呈现 DOM 时,两个段落元素应该如下所示:
两个段落元素都应用了第一个样式定义,因为
p选择器选择了它们。但是只有第二段应用了.panel样式,因为它是唯一一个具有与选择器匹配的类属性panel的元素。第二段从.panel样式中获取新的样式信息,并覆盖在p样式中定义的background-color样式。JavaScript
JavaScript 提供了 SPA 的所有交互特性,以及与服务器提供的 REST API 的动态通信。它还执行对 DOM 的所有更新,使 SPA 的行为更像一个完整的图形用户界面(GUI) 应用程序,如 Word 或 Excel。
随着 JavaScript 的发展,使用现代浏览器提供的 DOM 变得更加容易和一致。您将使用一些约定,如名称空间和关注点分离,来帮助防止您的 JavaScript 代码与您可能包含的其他库发生冲突。
注意:您将使用本地 JavaScript 创建单页面应用程序。特别是,你将使用 ES2017 版本,它可以与许多现代浏览器兼容,但如果你的目标是支持旧版本的浏览器,这可能会有问题。
模块和名称空间
您可能已经知道 Python 中的名称空间,以及它们为什么有价值。简而言之,名称空间为您提供了一种在程序中保持名称唯一以防止冲突的方法。例如,如果您想同时使用
math和cmath模块中的log(),那么您的代码可能如下所示:


>>> import math
>>> import cmath
>>> math.log(10)
2.302585092994046
>>> cmath.log(10)
(2.302585092994046+0j)
上面的 Python 代码导入了math和cmath模块,然后从每个模块调用log(10)。第一个调用返回一个实数,第二个调用返回一个复数,这是cmath的函数。每个log()实例对于它自己的名称空间(math或cmath)是唯一的,这意味着对log()的调用不会相互冲突。
现代 JavaScript 能够导入模块并为这些模块分配名称空间。如果您需要导入其他可能存在名称冲突的 JavaScript 库,这将非常有用。
如果你看一下people.js文件的结尾,你会看到:
301// Create the MVC components 302const model = new Model(); 303const view = new View(); 304const controller = new Controller(model, view); 305
306// Export the MVC components as the default 307export default { 308 model, 309 view, 310 controller 311};
上面的代码创建了 MVC 系统的三个组件,您将在本文后面看到。该模块的默认导出是一个 JavaScript 文字对象。您在people.html文件的底部导入这个模块:
50<script type="module"> 51 // Give the imported MVC components a namespace 52 import * as MVC from "/static/js/people.js"; 53
54 // Create an intentional global variable referencing the import 55 window.mvc = MVC; 56</script>
下面是这段代码的工作原理:
-
第 50 行使用
type="module"告诉系统该文件是一个模块,而不仅仅是一个 JavaScript 文件。 -
第 52 行从
people.js导入默认对象,并将其命名为MVC。这创建了一个名为MVC的名称空间。您可以为导入的对象指定任何名称,只要不与您可能无法控制的其他 JavaScript 库冲突。 -
第 55 行创建一个全局变量,这是一个方便的步骤。您可以使用 JavaScript 调试器来检查
mvc对象,并查看model、view和controller。
注意:因为MVC是导入的模块而不仅仅是包含的文件,所以 JavaScript 会默认为严格模式,这比非严格模式有一些优势。其中最大的一个就是不能使用未定义的变量。
在没有打开严格模式的情况下,这是完全合法的:
var myName = "Hello"; myNane = "Hello World";
你看到错误了吗?第一行创建了一个名为myName的变量,并将字符串"Hello"赋给它。第二行看起来像是把变量的内容改成了"Hello World",但事实并非如此!
在第二行中,"Hello World"被分配给变量名myNane,它与n拼错了。在非严格的 JavaScript 中,这会创建两个变量:
- 正确的变量
myName - 非故意的错别字版本
myNane
想象一下,如果这两行 JavaScript 代码被许多其他代码分开。这可能会产生一个难以发现的运行时错误!当您使用严格模式时,如果您的代码试图使用未声明的变量,您可以通过引发异常来消除类似这样的错误。
命名惯例
在很大程度上,您在这里使用的 JavaScript 代码是在 camel case 中。这种命名约定在 JavaScript 社区中广泛使用,因此代码示例反映了这一点。然而,您的 Python 代码将使用蛇案例,这在 Python 社区中更为常规。
在 JavaScript 代码与 Python 代码交互的地方,尤其是在共享变量进入 REST API 接口的地方,这种命名上的差异可能会令人困惑。在编写代码时,一定要记住这些差异。
关注点分离
驱动 SPA 的代码可能很复杂。您可以使用模型-视图-控制器(MVC) 架构模式,通过创建关注点分离来简化事情。Home、People 和 Notes SPAs 使用以下 MVC 模式:
-
模型提供了对服务器 REST API 的所有访问。展示的任何东西都来自模型。对数据的任何更改都会通过模型并返回到 REST API。
-
视图控制所有的显示处理和 DOM 更新。视图是 SPA 中唯一与 DOM 交互的部分,它使浏览器呈现并重新呈现对显示的任何更改。
-
控制器处理所有用户交互和任何输入的用户数据,如点击事件。因为控制器对用户输入做出反应,所以它也基于用户输入与模型和视图进行交互。
下面是在 SPA 代码中实现的 MVC 概念的可视化表示:
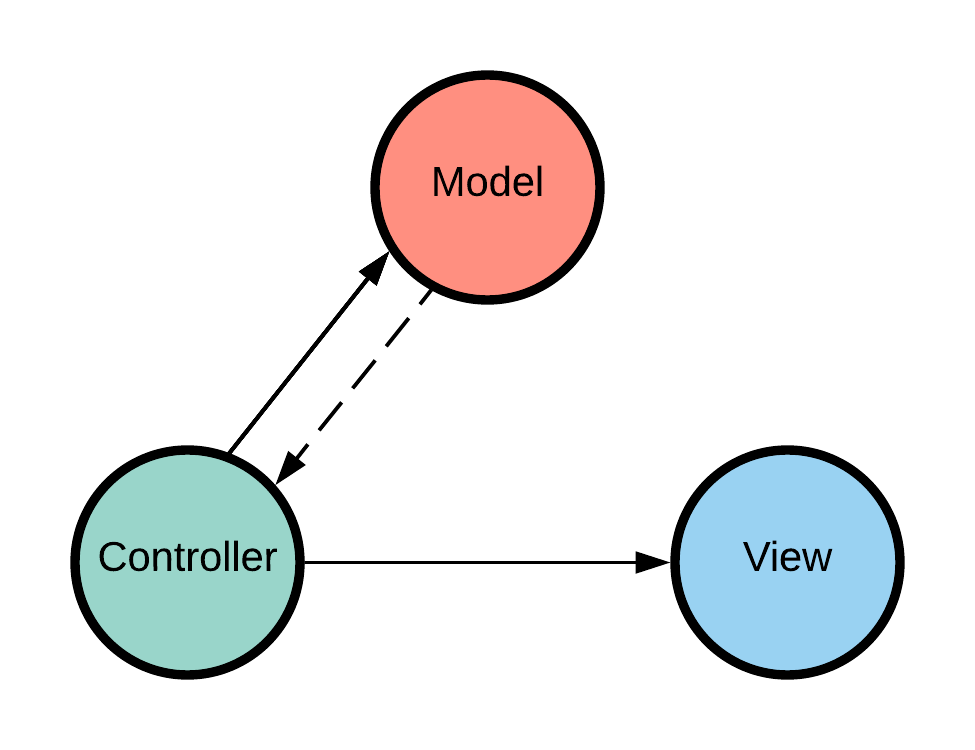
在上图中,控制器与模型和视图都有很强的联系。同样,这是因为控制器处理的任何用户交互都可能需要访问 REST API 来获取或更新数据。它甚至可能需要更新显示。
从模型到控制器的虚线表示弱连接。因为对 REST API 的调用是异步的,所以模型提供给控制器的数据会在稍后返回。
创建人民温泉
你的微型博客演示应用有主页、人物和笔记页面。这些页面中的每一个都是一个完整的、独立的 SPA。它们都使用相同的设计和结构,所以即使您在这里关注的是 People 应用程序,您也会理解如何构建它们。
人物 HTML
Python Flask web 框架提供了 Jinja2 模板引擎,您将为 People SPA 使用该引擎。SPA 的某些部分是所有三个页面共有的,因此每个页面都使用 Jinja2 模板继承特性来共享这些公共元素。
您将在两个文件中为 People SPA 提供 HTML 内容:parent.html和people.html文件。您可以通过下面的链接获得这些文件的代码:
下载代码: 单击此处下载代码,您将在本教程中使用来了解 Python REST APIs 与 Flask、Connexion 和 SQLAlchemy。
下面是您的parent.html的样子:
1<!DOCTYPE html>
2<html lang="en">
3<head>
4 <meta charset="UTF-8">
5 {% block head %}
6 <title>{% block title %}{% endblock %} Page</title>
7 {% endblock %}
8</head>
9<body>
10<div class="navigation">
11 <span class="buttons">
12 <a href="/">Home</a>
13 <a href="/people">People</a>
14 </span>
15 <span class="page_name">
16 <div></div>
17 </span>
18 <span class="spacer"></span>
19</div>
20
21{% block body %}
22{% endblock %}
23</body>
24
25{% block javascript %}
26{% endblock %}
27
28</html>
parent.html有几大要素:
- 第 1 行设置文件类型为
<!DOCTYPE html>。所有新的 HTML 页面都以这个声明开始。现代浏览器知道这意味着使用 HTML 5 标准,而旧浏览器将退回到它们所能支持的最新标准。 - 第 4 行告诉浏览器使用 UTF-8 编码。
- 第 10 到 19 行定义了导航栏。
- 第 21 行和第 22 行是 Jinja2 块标记,将被
people.html中的内容替换。 - 第 25 行和第 26 行是 Jinja2 块标记,作为 JavaScript 代码的占位符。
people.html文件将继承parent.html代码。您可以展开下面的代码块来查看整个文件:
1{% extends "parent.html" %}
2{% block title %}People{% endblock %}
3{% block head %}
4{% endblock %}
5{% block page_name %}Person Create/Update/Delete Page{% endblock %}
6
7{% block body %}
8 <div class="container">
9 <input id="url_person_id" type="hidden" value="{{ person_id }}" />
10 <div class="section editor">
11 <div>
12 <span>Person ID:</span>
13 <span id="person_id"></span>
14 </div>
15 <label for="fname">First Name
16 <input id="fname" type="text" />
17 </label>
18 <br />
19 <label for="lname">Last Name
20 <input id="lname" type="text" />
21 </label>
22 <br />
23
24
25
26
27 </div>
28 <div class="people">
29 <table>
30 <caption>People</caption>
31 <thead>
32 <tr>
33 <th>Creation/Update Timestamp</th>
34 <th>Person</th>
35 </tr>
36 </thead>
37 </table>
38 </div>
39 <div class="error">
40 </div>
41 </div>
42 <div class="error">
43 </div>
44
45{% endblock %}
只有两个主要区别:
- 第 1 行告诉 Jinja2 这个模板继承自
parent.html模板。 - 第 7 行到第 45 行创建页面的主体。这包括编辑部分和一个显示人员列表的空表。这是插入到
parent.html文件的{% block body %}{% endblock %}部分的内容。
由parent.html和people.html生成的 HTML 页面不包含样式信息。相反,页面以您用来查看它的任何浏览器的默认样式呈现。这是你的应用在 Chrome 浏览器中呈现的样子:

它看起来不太像一个单页应用程序!让我们看看你能做些什么。
人民 CSS
要对 People SPA 进行样式化,首先需要添加 normalize.css 样式表。这将确保所有浏览器一致地呈现更接近 HTML 5 标准的元素。People SPA 的特定 CSS 由两个样式表提供:
parent.css,你用parent.html拉进来people.css,你用people.html拉进来
您可以通过下面的链接获得这些样式表的代码:
下载代码: 单击此处下载代码,您将在本教程中使用来了解 Python REST APIs 与 Flask、Connexion 和 SQLAlchemy。
您将把normalize.css和parent.css都添加到parent.html的<head>...</head>部分:
1<head>
2 <meta charset="UTF-8">
3 {% block head %}
4 <title>{% block title %}{% endblock %} Page</title>
5 <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.0/normalize.min.css">
6 <link rel="stylesheet" href="/static/css/parent.css">
7 {% endblock %}
8</head>
这些新系列的作用如下:
- 5 号线从一个内容交付网络(CDN) 获取
normalize.css,不用自己下载。 - 第 6 行从你 app 的
static文件夹中获取parent.css。
在大多数情况下,parent.css为导航和错误元素设置样式。它还使用以下代码行将默认字体更改为 Google 的 Roboto 字体:
5@import url(http://fonts.googleapis.com/css?family=Roboto:400,300,500,700); 6
7body, .ui-btn { 8 font-family: Roboto; 9}
你从谷歌的 CDN 上下载 Roboto 字体。然后,您将该字体应用于 SPA 主体中也有一个类.ui-btn的所有元素。
同样,people.css包含特定于创建 People SPA 的 HTML 元素的样式信息。您将people.css添加到 Jinja2 {% block head %}部分内的people.html文件中:
3{% block head %}
4 {{ super() }}
5 <link rel="stylesheet" href="/static/css/people.css">
6{% endblock %}
该文件包含几个新行:
- 2 号线有一个对{{ super() }}的呼叫。这告诉 Jinja2 包含存在于
parent.html的{% block head %}部分中的任何内容。 - 第 3 行从你应用的静态文件夹中提取
people.css文件。
在包含样式表之后,您的 People SPA 将看起来更像这样:
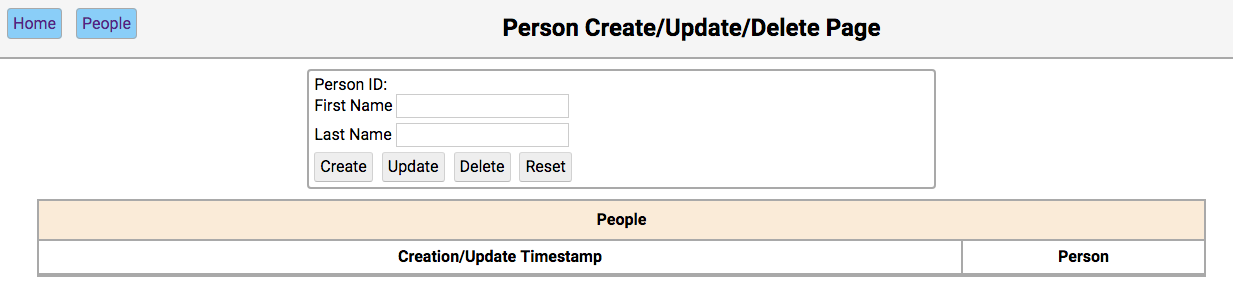
人民温泉看起来更好,但它仍然是不完整的。表中的人员数据行在哪里?编辑器部分的所有按钮都启用了,为什么它们什么都不做?在下一节中,您将使用一些 JavaScript 来解决这些问题。
人民 JavaScript
您将把 JavaScript 文件拉入 People SPA,就像您处理 CSS 文件一样。您将把以下代码添加到people.html文件的底部:
48{% block javascript %}
49{{ super() }}
50<script type="module"> 51 // Give the imported MVC components a namespace 52 import * as MVC from "/static/js/people.js"; 53
54 // Create an intentional global variable referencing the import 55 window.mvc = MVC; 56</script>
57{% endblock %}
注意第 50 行开始的<script>标签上的type="module"声明。这告诉系统这个脚本是一个 JavaScript 模块。ES6 import语法将用于将代码的导出部分拉入浏览器上下文。
人民 MVC
所有 SPA 页面都使用了一种不同的 MVC 模式。下面是一个 JavaScript 实现示例:
1// Create the MVC components 2const model = new Model(); 3const view = new View(); 4const controller = new Controller(model, view); 5
6// Export the MVC components as the default 7export default { 8 model, 9 view, 10 controller 11};
这段代码还没有做任何事情,但是您可以使用它来查看 MVC 结构和实现的以下元素:
- 第 2 行创建模型类的一个实例,并将其分配给
model。 - 第 3 行创建视图类的一个实例,并将其分配给
view。 - 第 4 行创建控制器类的一个实例,并将其分配给
controller。请注意,您将model和view都传递给了构造函数。这就是控制器如何获得到model和view实例变量的链接。 - 第 7 行到第 11 行导出一个 JavaScript 文本对象作为默认导出。
因为您在people.html的底部拉进了people.js,所以 JavaScript 在您的浏览器创建 SPA DOM 元素之后被执行。这意味着 JavaScript 可以安全地访问页面上的元素,并开始与 DOM 交互。
同样,上面的代码还没有做任何事情。为了让它工作,您需要定义您的模型、视图和控制器。
人物模型
模型负责与 Flask 服务器提供的 REST API 通信。来自数据库的任何数据,以及 SPA 更改或创建的任何数据,都必须经过模型。与 REST API 的所有通信都是通过 JavaScript 发起的 HTTP AJAX 调用来完成的。
现代 JavaScript 提供了fetch(),可以用来进行 AJAX 调用。模型类的代码实现了一个 AJAX 方法来读取 REST API URL 端点/api/people并获取数据库中的所有人:
1class Model { 2 async read() { 3 let options = { 4 method: "GET", 5 cache: "no-cache", 6 headers: { 7 "Content-Type": "application/json" 8 "accepts": "application/json" 9 } 10 }; 11 // Call the REST endpoint and wait for data 12 let response = await fetch(`/api/people`, options); 13 let data = await response.json(); 14 return data; 15 } 16}
下面是这段代码的工作原理:
-
第 1 行定义了类别
Model。这是稍后将作为mvc对象的一部分导出的内容。 -
第 2 行开始定义一个叫做
read()的异步方法。read()前面的async关键字告诉 JavaScript 这个方法执行异步工作。 -
第 3 行到第 9 行用 HTTP 调用的参数创建一个
options对象,比如方法和调用对数据的期望。 -
第 12 行使用
fetch()对服务器提供的/api/peopleURL REST 端点进行异步 HTTP 调用。fetch()前面的关键字await告诉 JavaScript 异步等待调用完成。完成后,结果被分配给response。 -
第 13 行将响应中的 JSON 字符串异步转换为 JavaScript 对象,并将其赋给
data。 -
第 14 行将数据返回给调用者。
本质上,这段代码告诉 JavaScript 向/api/people发出一个GET HTTP 请求,并且调用者正在期待一个application/json和json数据的Content-Type。回想一下,在面向 CRUD 的系统中,一个GET HTTP 调用等同于Read。
基于在swagger.yml中定义的连接配置,这个 HTTP 调用将调用def read_all()。这个函数是在people.py中定义的,它查询 SQLite 数据库来构建一个人员列表以返回给调用者。您可以通过下面的链接获得所有这些文件的代码:
下载代码: 单击此处下载代码,您将在本教程中使用来了解 Python REST APIs 与 Flask、Connexion 和 SQLAlchemy。
在浏览器中,JavaScript 在单线程中执行,旨在响应用户操作。因此,阻止等待完成的 JavaScript 执行是个坏主意,比如对服务器的 HTTP 请求。
如果请求是通过一个非常慢的网络发出的,或者服务器本身发生故障,永远不会响应,那该怎么办?如果 JavaScript 在这种情况下阻塞并等待 HTTP 请求完成,那么它可能会在几秒钟、几分钟内完成,或者根本不会完成。当 JavaScript 被阻止时,浏览器中的其他任何东西都不会对用户的动作做出反应!
为了防止这种阻塞行为,HTTP 请求被异步执行。这意味着 HTTP 请求在请求完成之前立即返回到事件循环。事件循环**存在于浏览器中运行的任何 JavaScript 应用程序中。循环不断等待事件完成,以便运行与该事件相关的代码。*
*当您将await关键字放在fetch()之前时,您告诉事件循环当 HTTP 请求完成时返回到哪里。此时,请求完成,调用返回的任何数据都被分配给response。然后,controller调用this.model.read()接收方法返回的数据。这就造成了与controller的一个薄弱环节,因为model不知道调用它的是什么,只知道它返回给调用者的是什么。
人物观点
this.view负责与 DOM 交互,由显示器显示。它可以从 DOM 中更改、添加和删除项目,然后重新呈现到显示器上。controller调用视图的方法来更新显示。View是另一个 JavaScript 类,包含控制器可以调用的方法。
下面是 People SPA 的View类的一个稍微简化的版本:
1class View { 2 constructor() { 3 this.table = document.querySelector(".people table"); 4 this.person_id = document.getElementById("person_id"); 5 this.fname = document.getElementById("fname"); 6 this.lname = document.getElementById("lname"); 7 } 8
9 reset() { 10 this.person_id.textContent = ""; 11 this.lname.value = ""; 12 this.fname.value = ""; 13 this.fname.focus(); 14 } 15
16 buildTable(people) { 17 let tbody, 18 html = ""; 19
20 // Iterate over the people and build the table 21 people.forEach((person) => { 22 html += `
23 <tr data-person_id="${person.person_id}" data-fname="${person.fname}" data-lname="${person.lname}">
24 <td class="timestamp">${person.timestamp}</td>
25 <td class="name">${person.fname} ${person.lname}</td>
26 </tr>`; 27 }); 28 // Is there currently a tbody in the table? 29 if (this.table.tBodies.length !== 0) { 30 this.table.removeChild(this.table.getElementsByTagName("tbody")[0]); 31 } 32 // Update tbody with our new content 33 tbody = this.table.createTBody(); 34 tbody.innerHTML = html; 35 } 36}
下面是这段代码的工作原理:
-
第 1 行开始类别定义。
-
第 2 行到第 7 行定义了类构造函数,很像 Python 类中的
def __init__(self):定义。构造函数从 DOM 中获取元素,并创建别名变量用于类的其他部分。那些变量名前面的this.很像 Python 中的self.。使用时,它指定该类的当前实例。 -
第 9 到 14 行定义了
reset(),您将使用它将页面设置回默认状态。 -
第 16 到 36 行定义了
buildTable(),它根据传递给它的people数据构建了人员表。
创建别名变量是为了缓存调用document.getElementByID()和document.querySelector()返回的 DOM 对象,这是相对昂贵的 JavaScript 操作。这允许在该类的其他方法中快速使用变量。
让我们仔细看看build_table(),它是View类中的第二个方法:
16buildTable(people) { 17 let tbody, 18 html = ""; 19
20 // Iterate over the people and build the table 21 people.forEach((person) => { 22 html += `
23 <tr data-person_id="${person.person_id}" data-fname="${person.fname}" data-lname="${person.lname}">
24 <td class="timestamp">${person.timestamp}</td>
25 <td class="name">${person.fname} ${person.lname}</td>
26 </tr>`; 27 }); 28 // Is there currently a tbody in the table? 29 if (this.table.tBodies.length !== 0) { 30 this.table.removeChild(this.table.getElementsByTagName("tbody")[0]); 31 } 32 // Update tbody with our new content 33 tbody = this.table.createTBody(); 34 tbody.innerHTML = html; 35}
该函数的工作原理如下:
- 第 16 行创建方法,并将
people变量作为参数传递。 - 第 21 行到第 27 行使用 JavaScript 箭头函数遍历
people数据,创建一个在html变量中构建表格行的函数。 - 第 29 到 31 行删除表格中的任何
<tbody>元素,如果它们存在的话。 - 第 33 行在表格中创建一个新的
tbody元素。 - 第 34 行将先前创建的
html字符串作为 HTML 插入到tbody元素中。
该函数根据传递给它的数据在 People SPA 中动态构建表,该表是来自于/api/people/ REST API 调用的人员列表。这些数据与 JavaScript 模板字符串一起用于生成要插入到表中的表行。
人员控制器
控制器是 MVC 实现的中心交换中心,因为它协调model和view的活动。因此,定义它的代码有点复杂。这是一个简化的版本:
1class Controller { 2 constructor(model, view) { 3 this.model = model; 4 this.view = view; 5
6 this.initialize(); 7 } 8 async initialize() { 9 await this.initializeTable(); 10 } 11 async initializeTable() { 12 try { 13 let urlPersonId = parseInt(document.getElementById("url_person_id").value), 14 people = await this.model.read(); 15
16 this.view.buildTable(people); 17
18 // Did we navigate here with a person selected? 19 if (urlPersonId) { 20 let person = await this.model.readOne(urlPersonId); 21 this.view.updateEditor(person); 22 this.view.setButtonState(this.view.EXISTING_NOTE); 23
24 // Otherwise, nope, so leave the editor blank 25 } else { 26 this.view.reset(); 27 this.view.setButtonState(this.view.NEW_NOTE); 28 } 29 this.initializeTableEvents(); 30 } catch (err) { 31 this.view.errorMessage(err); 32 } 33 } 34 initializeCreateEvent() { 35 document.getElementById("create").addEventListener("click", async (evt) => { 36 let fname = document.getElementById("fname").value, 37 lname = document.getElementById("lname").value; 38
39 evt.preventDefault(); 40 try { 41 await this.model.create({ 42 fname: fname, 43 lname: lname 44 }); 45 await this.initializeTable(); 46 } catch(err) { 47 this.view.errorMessage(err); 48 } 49 }); 50 } 51}
它是这样工作的:
-
第 1 行开始定义控制器类。
-
第 2 行到第 7 行定义了类构造函数,并用它们各自的参数创建了实例变量
this.model和this.view。它还调用this.initialize()来设置事件处理并构建初始人员表。 -
第 8 行到第 10 行定义了
initialize(),并将其标记为异步方法。它异步调用this.initializeTable()并等待它完成。这个简化版本只包含这一个调用,但是完整版本的代码包含用于其余事件处理设置的其他初始化方法。 -
第 11 行将
initializeTable()定义为异步方法。这是必要的,因为它调用model.read(),这也是异步的。 -
第 13 行用 HTML 隐藏输入
url_person_id的值声明并初始化urlPersonId变量。 -
第 14 行调用
this.model.read()并异步等待它返回人员数据。 -
第 16 行调用
this.view.buildTable(people)用人员数据填充 HTML 表。 -
第 19 到 28 行决定了如何更新页面的编辑器部分。
-
第 29 行调用
this.initializeTableEvents()为 HTML 表格安装事件处理。 -
第 31 行调用
this.view.errorMessage(err)来显示可能出现的错误。 -
第 34 到 49 行在创建按钮上安装一个点击事件处理程序。这将调用
this.model.create(...)使用 REST API 创建一个新的 person,并用新数据更新 HTML 表。
controller的大部分代码是这样的,为 People SPA 页面上所有预期的事件设置事件处理程序。控制器继续在这些事件处理程序中创建函数来编排对this.model和this.view的调用,以便它们在这些事件发生时执行正确的操作。
当您的代码完成时,您的人员 SPA 页面将如下所示:
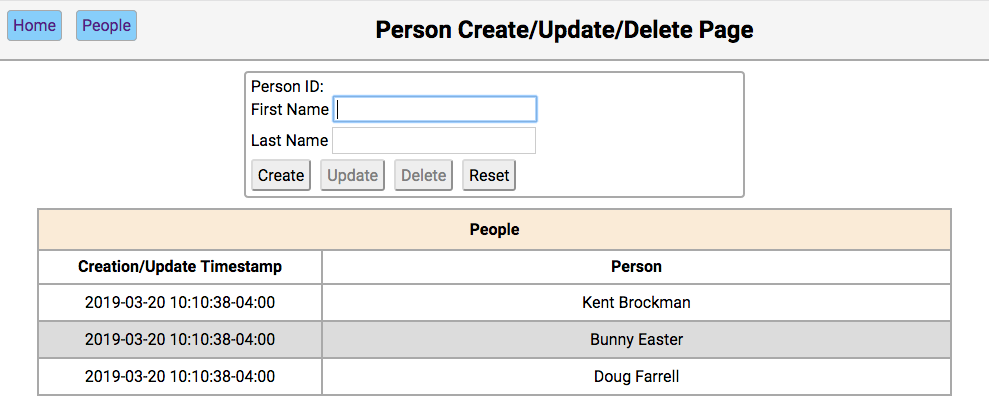
内容、样式和功能都是完整的!
结论
你已经覆盖了大量的新领域,应该为你所学到的感到自豪!为了创建一个完整的单页面应用程序,在 Python 和 JavaScript 之间来回切换可能很棘手。
如果你把你的内容 (HTML)、表示 (CSS)和交互 (JavaScript)分开,那么你可以大大降低复杂性。您还可以通过使用 MVC 模式来进一步分解用户交互的复杂性,从而使 JavaScript 编码更易于管理。
您已经看到了如何使用这些工具和思想来帮助您创建相当复杂的单页面应用程序。现在,您可以更好地决定是以这种方式构建应用程序,还是投入到更大的框架中!
您可以通过下面的链接获得本教程中的所有代码:
下载代码: 单击此处下载代码,您将在本教程中使用来了解 Python REST APIs 与 Flask、Connexion 和 SQLAlchemy。
« Part 3: Database RelationshipPart 4: Simple Web Applications**********
使用 Matplotlib 进行 Python 绘图(指南)
原文:# t0]https://realython . com/python-matplotlib 指南/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 用 Matplotlib 绘图
一张图片胜过千言万语,幸运的是,使用 Python 的 matplotlib 库,创建一张生产质量的图形只需不到一千字的代码。
然而,matplotlib 也是一个大规模的库,通常通过反复试验才能获得看起来恰到好处的图形。在 matplotlib 中使用一行程序生成基本的绘图相当简单,但是熟练地控制库的其余 98%可能会令人望而生畏。
本文是关于 matplotlib 的初级到中级的演练,将理论与示例相结合。虽然通过实例学习非常有见地,但即使只是对图书馆的内部工作和布局有一个表面的了解也是有帮助的。
以下是我们将要介绍的内容:
- Pylab 和 pyplot:哪个是哪个?
- matplotlib 设计的关键概念
- 理解
plt.subplots() - 用 matplotlib 可视化数组
- 使用 pandas + matplotlib 组合绘图
免费附赠: ,你可以以此为基础制作自己的剧情和图形。
本文假设用户知道一点点 NumPy。我们将主要使用 numpy.random 模块生成“玩具”数据,从不同的统计分布中抽取样本。
如果您还没有安装 matplotlib,请在继续之前查看这里的。
为什么 Matplotlib 可以混淆?
学习 matplotlib 有时会是一个令人沮丧的过程。问题不在于 matplotlib 的文档缺乏:文档实际上是广泛的。但是以下问题可能会带来一些挑战:
- 这个库本身非常庞大,大约有 70,000 行代码。
- Matplotlib 有几个不同的接口(构建图形的方式),能够与一些不同的后端交互。(后端处理图表实际呈现的过程,而不仅仅是内部结构化。)
- 虽然它很全面,但 matplotlib 自己的一些公开文档严重过时。该库仍在不断发展,网上流传的许多旧示例在现代版本中可能会减少 70%的代码行。
因此,在我们开始任何令人眼花缭乱的例子之前,掌握 matplotlib 设计的核心概念是有用的。
Pylab:这是什么,我应该使用它吗?
让我们从一点历史开始:神经生物学家 John D. Hunter 在 2003 年左右开始开发 matplotlib,最初的灵感来自于 Mathworks 的 MATLAB 软件。2012 年,44 岁的约翰不幸英年早逝,matplotlib 现在是一个成熟的社区项目,由许多其他人开发和维护。(约翰在 2012 年 SciPy 会议上做了一个关于 matplotlib 发展的演讲,值得一看。)
MATLAB 的一个相关特征是它的全局风格。导入的 Python 概念在 MATLAB 中并没有被大量使用,MATLAB 的大多数函数在顶层对用户来说都是现成的。
知道 matplotlib 源于 MATLAB 有助于解释 pylab 存在的原因。pylab 是 matplotlib 库中的一个模块,用于模仿 MATLAB 的全局风格。它的存在只是为了将 NumPy 和 matplotlib 中的一些函数和类引入到名称空间中,为以前不习惯使用import语句的 MATLAB 用户提供一个简单的过渡。
前 MATLAB 皈依者(他们都是好人,我保证!)喜欢这个功能,因为有了from pylab import *,他们可以简单地直接调用plot()或array(),就像在 MATLAB 中一样。
这里的问题对一些 Python 用户来说可能是显而易见的:在会话或脚本中使用from pylab import *通常是不好的做法。Matplotlib 现在在其自己的教程中直接反对这样做:
“[pylab]由于历史原因仍然存在,但强烈建议不要使用。它用会隐藏 Python 内置函数的函数污染名称空间,并可能导致难以跟踪的错误。要在没有导入的情况下集成 IPython,最好使用
%matplotlib魔法。来源
在内部,有大量潜在冲突的进口被掩盖在短皮拉布来源。事实上,使用ipython --pylab(从终端/命令行)或%pylab(从 IPython/Jupyter tools)只是简单地调用幕后的from pylab import *。
底线是 matplotlib 已经放弃了这个方便的模块,现在明确建议不要使用 pylab,使事情更符合 Python 的一个关键概念:显式比隐式好。
如果不需要 pylab,我们通常只需要一个规范的导入就可以了:
>>> import matplotlib.pyplot as plt现在,让我们也导入 NumPy,稍后我们将使用它来生成数据,并调用
np.random.seed()来使用(伪)随机数据生成可重复的示例:
>>> import numpy as np
>>> np.random.seed(444)
Matplotlib 对象层次结构
matplotlib 的一个重要概念是它的对象层次结构。
如果你读过任何介绍 matplotlib 的教程,你可能会调用类似于plt.plot([1, 2, 3])的东西。这个一行程序隐藏了一个事实,即绘图实际上是嵌套 Python 对象的层次结构。这里的“层次结构”是指每个图下面都有一个 matplotlib 对象的树状结构。
一个Figure对象是 matplotlib 图形的最外层容器,它可以包含多个Axes对象。混淆的一个来源是名称:一个Axes实际上被翻译成我们所认为的一个单独的情节或图形(而不是我们可能预期的“轴”的复数)。
您可以将Figure对象想象成一个类似盒子的容器,其中包含一个或多个Axes(实际的绘图)。在层次结构中的Axes下面是较小的对象,如刻度线、单独的线条、图例和文本框。几乎图表的每个“元素”都有自己可操作的 Python 对象,一直到刻度和标签:
下面是这种层次结构的一个实例。如果您不完全熟悉这种符号,也不要担心,我们将在后面介绍:
>>> fig, _ = plt.subplots() >>> type(fig) <class 'matplotlib.figure.Figure'>上面,我们用
plt.subplots()创建了两个变量。第一个是顶级的Figure对象。第二个是“一次性”变量,我们现在还不需要,用下划线表示。使用属性符号,很容易遍历图形层次结构,并查看第一个轴对象的 y 轴的第一个刻度:
>>> one_tick = fig.axes[0].yaxis.get_major_ticks()[0]
>>> type(one_tick)
<class 'matplotlib.axis.YTick'>
上面,fig(一个Figure类实例)有多个Axes(一个列表,我们取第一个元素)。每个Axes都有一个yaxis和xaxis,每个都有一个“主要分笔成交点”的集合,我们抓取第一个。
Matplotlib 将此呈现为图形剖析,而不是明确的层次结构:
(在真正的 matplotlib 风格中,上图是在 matplotlib 文档这里中创建的。)
有状态与无状态方法
好吧,在我们开始这个闪亮的可视化之前,我们还需要一个理论:有状态(基于状态,状态机)和无状态(面向对象,OO)接口之间的区别。
上面我们用import matplotlib.pyplot as plt从 matplotlib 导入 pyplot 模块,命名为plt。
pyplot 中的几乎所有函数,比如plt.plot(),要么隐式地引用一个现有的当前图形和当前轴,要么在不存在的情况下重新创建它们。隐藏在 matplotlib 文档中的是这个有用的片段:
[使用 pyplot],简单的函数用于添加绘图元素(线条、图像、文本等)。)到当前图中的当前轴[着重号后加]
铁杆前 MATLAB 用户可能会选择这样的措辞:“plt.plot()是一个状态机接口,它隐式地跟踪当前数字!”在英语中,这意味着:
- 有状态接口使用
plt.plot()和其他顶级 pyplot 函数进行调用。在给定的时间里,你只能操纵一个图形或轴,你不需要明确地引用它。 - 直接修改底层对象是面向对象的方法。我们通常通过调用一个
Axes对象的方法来做到这一点,这个对象代表一个绘图本身。
这个过程的流程在较高的层次上看起来是这样的:

将这些联系在一起,pyplot 中的大多数函数也作为matplotlib.axes.Axes类的方法存在。
从引擎盖下偷看更容易看到这一点。plt.plot()可以归结为五行左右的代码:
# matplotlib/pyplot.py >>> def plot(*args, **kwargs): ... """An abridged version of plt.plot().""" ... ax = plt.gca() ... return ax.plot(*args, **kwargs) >>> def gca(**kwargs): ... """Get the current Axes of the current Figure.""" ... return plt.gcf().gca(**kwargs)调用
plt.plot()只是获取当前图形的当前轴,然后调用其plot()方法的一种便捷方式。这就是断言有状态接口总是“隐式跟踪”它想要引用的图的含义。pyplot 是一批函数的所在地,这些函数实际上只是 matplotlib 面向对象接口的包装器。例如,
plt.title()在 OO 方法中有相应的 setter 和 getter 方法,ax.set_title()和ax.get_title()。(getters 和 setters 的使用在诸如 Java 之类的语言中更受欢迎,但这是 matplotlib 面向对象方法的一个关键特性。)调用
plt.title()被翻译成这一行:gca().set_title(s, *args, **kwargs)。这就是它的作用:
gca()抓取当前轴并返回。set_title()是一个 setter 方法,为 Axes 对象设置标题。这里的“方便”是我们不需要用plt.title()显式指定任何 Axes 对象。同样,如果你花点时间看看顶级函数的源代码,比如
plt.grid()plt.legend()和plt.ylabels(),你会注意到它们都遵循相同的结构,用gca()委托给当前轴,然后调用当前轴的一些方法。(这是底层的面向对象方法!)理解
plt.subplots()符号好了,理论到此为止。现在,我们准备好把所有的东西联系在一起,并做一些绘图。从现在开始,我们将主要依赖无状态(面向对象)方法,这种方法更加可定制,并且随着图形变得更加复杂而变得方便。
在面向对象方法下,用单轴创建图形的规定方法是(不太直观地)用
plt.subplots()。这确实是 OO 方法唯一一次使用pyplot来创建图形和轴:
>>> fig, ax = plt.subplots()
上面,我们利用 iterable 解包为plt.subplots()的两个结果中的每一个分配了一个单独的变量。注意,这里我们没有将参数传递给subplots()。默认呼叫是subplots(nrows=1, ncols=1)。因此,ax是一个单独的AxesSubplot对象:
>>> type(ax) <class 'matplotlib.axes._subplots.AxesSubplot'>我们可以像调用 pyplots 函数一样调用它的实例方法来操纵绘图。让我们用三个时间序列的堆积面积图来说明:
>>> rng = np.arange(50)
>>> rnd = np.random.randint(0, 10, size=(3, rng.size))
>>> yrs = 1950 + rng
>>> fig, ax = plt.subplots(figsize=(5, 3))
>>> ax.stackplot(yrs, rng + rnd, labels=['Eastasia', 'Eurasia', 'Oceania'])
>>> ax.set_title('Combined debt growth over time')
>>> ax.legend(loc='upper left')
>>> ax.set_ylabel('Total debt')
>>> ax.set_xlim(xmin=yrs[0], xmax=yrs[-1])
>>> fig.tight_layout()
上面是怎么回事:
-
在创建了三个随机时间序列之后,我们定义了一个包含一个轴的图形(
fig)(一个图,ax)。 -
我们直接调用
ax的方法来创建堆积面积图,并添加图例、标题和 y 轴标签。在面向对象的方法下,很明显所有这些都是ax的属性。 -
tight_layout()整体应用于图形对象以清除空白填充。
让我们看一个在一个图中有多个子图(轴)的例子,绘制两个从离散均匀分布中提取的相关数组:
>>> x = np.random.randint(low=1, high=11, size=50) >>> y = x + np.random.randint(1, 5, size=x.size) >>> data = np.column_stack((x, y)) >>> fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, ... figsize=(8, 4)) >>> ax1.scatter(x=x, y=y, marker='o', c='r', edgecolor='b') >>> ax1.set_title('Scatter: $x$ versus $y$') >>> ax1.set_xlabel('$x$') >>> ax1.set_ylabel('$y$') >>> ax2.hist(data, bins=np.arange(data.min(), data.max()), ... label=('x', 'y')) >>> ax2.legend(loc=(0.65, 0.8)) >>> ax2.set_title('Frequencies of $x$ and $y$') >>> ax2.yaxis.tick_right()
在这个例子中还有一点更多的内容:
因为我们正在创建一个“1x2”图形,
plt.subplots(1, 2)的返回结果现在是一个图形对象和一个轴对象的 NumPy 数组。(你可以用fig, axs = plt.subplots(1, 2)检查这个,看一看axs。)我们分别处理
ax1和ax2,用有状态的方法很难做到这一点。最后一行很好地展示了对象的层次结构,我们正在修改属于第二个轴的yaxis,将它的记号和标签放在右边。美元符号内的文本利用 TeX 标记将变量以斜体显示。
请记住,多个轴可以包含在或“属于”一个给定的图形中。在上面的例子中,
fig.axes获得了所有轴对象的列表:
>>> (fig.axes[0] is ax1, fig.axes[1] is ax2)
(True, True)
(fig.axes是小写,不是大写。不可否认,术语有点混乱。)
更进一步,我们可以创建一个图形,包含一个由Axes对象组成的 2x2 网格:
>>> fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(7, 7))现在,什么是
ax?它不再是单个的Axes,而是它们的二维 NumPy 数组:
>>> type(ax)
numpy.ndarray
>>> ax
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x1106daf98>,
<matplotlib.axes._subplots.AxesSubplot object at 0x113045c88>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x11d573cf8>,
<matplotlib.axes._subplots.AxesSubplot object at 0x1130117f0>]],
dtype=object)
>>> ax.shape
(2, 2)
docstring 重申了这一点:
"
ax可以是一个单独的matplotlib.axes.Axes对象,如果创建了一个以上的子剧情,也可以是一个Axes对象的数组。"
我们现在需要对每个Axes调用绘图方法(但不是 NumPy 数组,在本例中它只是一个容器)。解决这一问题的常见方法是在将数组展平为一维后使用可迭代解包:
>>> fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(7, 7)) >>> ax1, ax2, ax3, ax4 = ax.flatten() # flatten a 2d NumPy array to 1d我们也可以用
((ax1, ax2), (ax3, ax4)) = ax来做这件事,但是第一种方法更灵活。为了说明一些更高级的子情节特性,让我们使用 Python 标准库中的
io、tarfile和urllib从压缩的 tar 档案中提取一些宏观经济加州住房数据。
>>> from io import BytesIO
>>> import tarfile
>>> from urllib.request import urlopen
>>> url = 'http://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.tgz'
>>> b = BytesIO(urlopen(url).read())
>>> fpath = 'CaliforniaHousing/cal_housing.data'
>>> with tarfile.open(mode='r', fileobj=b) as archive:
... housing = np.loadtxt(archive.extractfile(fpath), delimiter=',')
下面的“响应”变量y,用统计学术语来说,是一个地区的平均房价。pop和age分别是该地区的人口和平均房龄:
>>> y = housing[:, -1] >>> pop, age = housing[:, [4, 7]].T接下来,让我们定义一个“辅助函数”,它将一个文本框放在一个图中,并充当“图内标题”:
>>> def add_titlebox(ax, text):
... ax.text(.55, .8, text,
... horizontalalignment='center',
... transform=ax.transAxes,
... bbox=dict(facecolor='white', alpha=0.6),
... fontsize=12.5)
... return ax
我们准备好做一些策划了。Matplotlib 的 gridspec 模块允许更多的支线剧情定制。pyplot 的subplot2grid()与这个模块很好地交互。假设我们想要创建一个这样的布局:
上面,我们实际拥有的是一个 3x2 的网格。ax1的高度和宽度是ax2 / ax3的两倍,意味着它占据了两列两行。
subplot2grid()的第二个参数是轴在网格中的(行,列)位置:
>>> gridsize = (3, 2) >>> fig = plt.figure(figsize=(12, 8)) >>> ax1 = plt.subplot2grid(gridsize, (0, 0), colspan=2, rowspan=2) >>> ax2 = plt.subplot2grid(gridsize, (2, 0)) >>> ax3 = plt.subplot2grid(gridsize, (2, 1))现在,我们可以正常进行,分别修改每个轴:
>>> ax1.set_title('Home value as a function of home age & area population',
... fontsize=14)
>>> sctr = ax1.scatter(x=age, y=pop, c=y, cmap='RdYlGn')
>>> plt.colorbar(sctr, ax=ax1, format='$%d')
>>> ax1.set_yscale('log')
>>> ax2.hist(age, bins='auto')
>>> ax3.hist(pop, bins='auto', log=True)
>>> add_titlebox(ax2, 'Histogram: home age')
>>> add_titlebox(ax3, 'Histogram: area population (log scl.)')
在上面,colorbar()(不同于之前的 ColorMap)直接在图形上调用,而不是在轴上调用。它的第一个参数使用 Matplotlib 的.scatter(),并且是ax1.scatter()的结果,后者的功能是将 y 值映射到色彩映射表。
从视觉上看,当我们沿着 y 轴上下移动时,颜色(y 变量)没有太大的差异,这表明房屋年龄似乎是房屋价值的一个更强的决定因素。
幕后的“人物”
每次您调用plt.subplots()或不常用的plt.figure()(它创建一个图形,没有轴),您都在创建一个新的图形对象,matplotlib 悄悄地将它保存在内存中。前面,我们提到了电流图和电流轴的概念。默认情况下,这些是最近创建的图形和轴,我们可以用内置函数id()来显示对象在内存中的地址:
>>> fig1, ax1 = plt.subplots() >>> id(fig1) 4525567840 >>> id(plt.gcf()) # `fig1` is the current figure. 4525567840 >>> fig2, ax2 = plt.subplots() >>> id(fig2) == id(plt.gcf()) # The current figure has changed to `fig2`. True(我们也可以在这里使用内置的
is操作符。)在上述例程之后,当前图形是最近创建的图形
fig2。然而,这两个数字仍然存在于内存中,每个数字都有一个相应的 ID 号(1-indexed,在 MATLAB 风格中):
>>> plt.get_fignums()
[1, 2]
获得所有数字本身的一个有用方法是将plt.figure()映射到这些整数中的每一个:
>>> def get_all_figures(): ... return [plt.figure(i) for i in plt.get_fignums()] >>> get_all_figures() [<matplotlib.figure.Figure at 0x10dbeaf60>, <matplotlib.figure.Figure at 0x1234cb6d8>]如果运行一个创建一组图形的脚本,请认识到这一点。为了避免出现
MemoryError,您需要在使用后显式地关闭它们。单独,plt.close()关闭当前图形,plt.close(num)关闭图形编号num,plt.close('all')关闭所有图形窗口:
>>> plt.close('all')
>>> get_all_figures()
[]
一阵变色:imshow()和matshow()
虽然ax.plot()是坐标轴上最常见的绘图方法之一,但还有许多其他方法。(上面我们用了ax.stackplot()。你可以在这里找到的完整名单。)
大量使用的方法是imshow()和matshow(),后者是前者的包装。当原始数字数组可以被可视化为彩色网格时,这些都是有用的。
首先,让我们用一些奇特的数字索引创建两个不同的网格:
>>> x = np.diag(np.arange(2, 12))[::-1] >>> x[np.diag_indices_from(x[::-1])] = np.arange(2, 12) >>> x2 = np.arange(x.size).reshape(x.shape)接下来,我们可以将这些映射到它们的图像表示。在这个具体的例子中,我们通过使用字典理解并将结果传递给
ax.tick_params()来“关闭”所有轴标签和刻度:
>>> sides = ('left', 'right', 'top', 'bottom')
>>> nolabels = {s: False for s in sides}
>>> nolabels.update({'label%s' % s: False for s in sides})
>>> print(nolabels)
{'left': False, 'right': False, 'top': False, 'bottom': False, 'labelleft': False,
'labelright': False, 'labeltop': False, 'labelbottom': False}
然后,我们可以使用上下文管理器来禁用网格,并在每个轴上调用matshow()。最后,我们需要将 colorbar 放入fig中的一个新轴中。为此,我们可以使用 matplotlib 内部的一个深奥的函数:
>>> from mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable >>> with plt.rc_context(rc={'axes.grid': False}): ... fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4)) ... ax1.matshow(x) ... img2 = ax2.matshow(x2, cmap='RdYlGn_r') ... for ax in (ax1, ax2): ... ax.tick_params(axis='both', which='both', **nolabels) ... for i, j in zip(*x.nonzero()): ... ax1.text(j, i, x[i, j], color='white', ha='center', va='center') ... ... divider = make_axes_locatable(ax2) ... cax = divider.append_axes("right", size='5%', pad=0) ... plt.colorbar(img2, cax=cax, ax=[ax1, ax2]) ... fig.suptitle('Heatmaps with `Axes.matshow`', fontsize=16)熊猫图
熊猫图书馆变得流行,不仅仅是因为它支持强大的数据分析,还因为它方便的预设绘图方法。有趣的是,熊猫绘图方法实际上只是现有 matplotlib 调用的方便包装器。
也就是说,pandas 系列的
plot()方法和数据帧是plt.plot()的包装器。例如,提供的一个便利是,如果 DataFrame 的索引由日期组成,那么 pandas 会在内部调用gcf().autofmt_xdate()来获取当前的数字,并很好地自动格式化 x 轴。反过来,记住
plt.plot()(基于状态的方法)隐含地知道当前图形和当前轴,所以 pandas 通过扩展遵循基于状态的方法。我们可以通过一点内省来证明这个函数调用“链”。首先,让我们构建一个普通的熊猫系列,假设我们正在开始一个新的解释器会话:
>>> import pandas as pd
>>> s = pd.Series(np.arange(5), index=list('abcde'))
>>> ax = s.plot()
>>> type(ax)
<matplotlib.axes._subplots.AxesSubplot at 0x121083eb8>
>>> id(plt.gca()) == id(ax)
True
当您将 pandas 绘图方法与传统的 matplotlib 调用混合使用时,这种内部架构有助于了解,这是在下面绘制一个广受关注的金融时间序列的移动平均值时完成的。ma是一个 pandas 系列,我们可以为其调用ma.plot()(pandas 方法),然后通过检索由该调用(plt.gca())创建的轴进行定制,以供 matplotlib 引用:
>>> import pandas as pd >>> import matplotlib.transforms as mtransforms >>> url = 'https://fred.stlouisfed.org/graph/fredgraph.csv?id=VIXCLS' >>> vix = pd.read_csv(url, index_col=0, parse_dates=True, na_values='.', ... infer_datetime_format=True, ... squeeze=True).dropna() >>> ma = vix.rolling('90d').mean() >>> state = pd.cut(ma, bins=[-np.inf, 14, 18, 24, np.inf], ... labels=range(4)) >>> cmap = plt.get_cmap('RdYlGn_r') >>> ma.plot(color='black', linewidth=1.5, marker='', figsize=(8, 4), ... label='VIX 90d MA') >>> ax = plt.gca() # Get the current Axes that ma.plot() references >>> ax.set_xlabel('') >>> ax.set_ylabel('90d moving average: CBOE VIX') >>> ax.set_title('Volatility Regime State') >>> ax.grid(False) >>> ax.legend(loc='upper center') >>> ax.set_xlim(xmin=ma.index[0], xmax=ma.index[-1]) >>> trans = mtransforms.blended_transform_factory(ax.transData, ax.transAxes) >>> for i, color in enumerate(cmap([0.2, 0.4, 0.6, 0.8])): ... ax.fill_between(ma.index, 0, 1, where=state==i, ... facecolor=color, transform=trans) >>> ax.axhline(vix.mean(), linestyle='dashed', color='xkcd:dark grey', ... alpha=0.6, label='Full-period mean', marker='')
上面发生了很多事情:
ma是 VIX 指数的 90 天移动平均线,衡量市场对近期股票波动的预期。state是移动平均线进入不同政权状态的宁滨。高 VIX 被视为市场恐惧程度加剧的信号。是一个 ColorMap——一个 matplotlib 对象,本质上是浮点到 RGBA 颜色的映射。任何色图都可以通过添加
'_r'来反转,所以'RdYlGn_r'就是反转的红-黄-绿色图。Matplotlib 在它的文档中维护了一个方便的视觉参考指南的彩色地图。我们这里唯一真正的熊猫叫声是
ma.plot()。这在内部调用了plt.plot(),所以为了集成面向对象的方法,我们需要用ax = plt.gca()获得对当前轴的显式引用。第二段代码创建对应于每个
state库的颜色填充块。cmap([0.2, 0.4, 0.6, 0.8])说,“给我们一个彩色图谱中第 20、40、60 和 80 个‘百分点’的颜色的 RGBA 序列。”enumerate()之所以被使用是因为我们要将每个 RGBA 颜色映射回一个州。《熊猫》还增加了少量更高级的剧情(它们自己就可以占据整个教程)。然而,所有这些都像它们更简单的对应物一样,在内部依赖于 matplotlib 机制。
总结
正如上面的一些例子所示,matplotlib 可能是一个技术性的、语法密集型的库,这是不可回避的事实。创建一个生产就绪的图表有时需要半个小时的谷歌搜索和组合大杂烩的线条,以微调一个情节。
然而,理解 matplotlib 的接口如何交互是一项投资,将来会有回报的。正如 Real Python 自己的 Dan Bader 所建议的,花时间剖析代码,而不是求助于堆栈溢出的“复制意大利面”解决方案,往往是更聪明的长期解决方案。当你想把一个简单的情节变成一件艺术作品时,坚持面向对象的方法可以节省几个小时的挫败感。
更多资源
来自 matplotlib 文档:
免费附赠: ,你可以以此为基础制作自己的剧情和图形。
第三方资源:
- DataCamp 的 matplotlib 备忘单
- PLOS 计算生物学:更好形象的十个简单规则
- Wes McKinney 的用于数据分析的 Python 的第 9 章(绘图和可视化),第 2 版。T3】
- Ted Petrou 的 熊猫食谱 的第 11 章(Matplotlib、熊猫和 Seaborn 的可视化)
- SciPy 讲义的第 1.4 节(Matplotlib:绘图)
- xkcd 调色板
- matplotlib 外部资源页面
- Matplotlib,Pylab,Pyplot 等:这些有什么区别,各自什么时候用?来自 queirozf.com
- 熊猫文档中的可视化页面
其他绘图库:
- 建立在 matplotlib 之上,为高级统计图形设计的 seaborn 库,它本身就可以占据整个教程
- Datashader ,一个专门面向大型数据集的图形库
- matplotlib 文档中的其他第三方包列表
附录 A:配置和样式
如果你一直遵循这个教程,很可能你屏幕上弹出的情节看起来与这里显示的风格不同。
Matplotlib 提供了两种跨不同地块统一配置样式的方法:
- 通过定制一个 matplotlibrc 文件
- 通过交互方式或从改变配置参数。py 脚本。
matplotlibrc 文件(上面的选项#1)基本上是一个文本文件,它指定了在 Python 会话之间记忆的用户自定义设置。在 Mac OS X 上,它通常位于 ~/。matplotlib/matplotlibrc 。
快速提示: GitHub 是保存配置文件的好地方。我把我的放在这里。只要确保它们不包含个人身份或私人信息,如密码或 SSH 私人密钥!
或者,您可以交互地更改您的配置参数(上面的选项 2)。当您
import matplotlib.pyplot as plt时,您可以访问一个类似于 Python 设置字典的rcParams对象。所有以“rc”开头的模块对象都是与打印样式和设置进行交互的一种方式:
>>> [attr for attr in dir(plt) if attr.startswith('rc')]
['rc', 'rcParams', 'rcParamsDefault', 'rc_context', 'rcdefaults']
其中:
plt.rcdefaults()从 matplotlib 的内部默认值中恢复 rc 参数,列于plt.rcParamsDefault。这将恢复(覆盖)您已经在 matplotlibrc 文件中定制的任何内容。plt.rc()用于交互设置参数。plt.rcParams是一个(可变的)类似字典的对象,可以让你直接操作设置。如果您在 matplotlibrc 文件中有自定义设置,这些设置将反映在本词典中。
对于plt.rc()和plt.rcParams,这两种语法对于调整设置是等效的:
>>> plt.rc('lines', linewidth=2, color='r') # Syntax 1 >>> plt.rcParams['lines.linewidth'] = 2 # Syntax 2 >>> plt.rcParams['lines.color'] = 'r'值得注意的是,Figure 类 then 使用这些中的一些作为它的默认参数。
与之相关的是,样式只是一组预定义的自定义设置。要查看可用的样式,请使用:
>>> plt.style.available
['seaborn-dark', 'seaborn-darkgrid', 'seaborn-ticks', 'fivethirtyeight',
'seaborn-whitegrid', 'classic', '_classic_test', 'fast', 'seaborn-talk',
'seaborn-dark-palette', 'seaborn-bright', 'seaborn-pastel', 'grayscale',
'seaborn-notebook', 'ggplot', 'seaborn-colorblind', 'seaborn-muted',
'seaborn', 'Solarize_Light2', 'seaborn-paper', 'bmh', 'seaborn-white',
'dark_background', 'seaborn-poster', 'seaborn-deep']
要设置样式,请进行以下调用:
>>> plt.style.use('fivethirtyeight')您的地块现在将呈现新的外观:
此完整示例可在此处获得。
出于灵感,matplotlib 保留了一些样式表显示作为参考。
附录 B:互动模式
在幕后,matplotlib 还与不同的后端进行交互。后端是实际呈现图表的主要部分。(例如,在流行的 Anaconda 发行版上,默认的后端是 Qt5Agg。)有些后端是交互式的,这意味着它们会动态更新,并在发生变化时“弹出”给用户。
默认情况下,交互模式是关闭的,您可以使用
plt.rcParams['interactive']或plt.isinteractive()来检查其状态,并分别使用plt.ion()和plt.ioff()来打开和关闭:
>>> plt.rcParams['interactive'] # or: plt.isinteractive()
True
>>> plt.ioff() >>> plt.rcParams['interactive'] False在一些代码示例中,您可能会注意到在一段代码的末尾出现了
plt.show()。顾名思义,plt.show()的主要目的是在关闭交互模式的情况下跑步时实际“显示”(打开)身材。换句话说:
- 如果开启了交互模式,就不需要
plt.show(),图片会自动弹出,并在你引用时更新。- 如果交互模式关闭,您将需要
plt.show()来显示一个图形,需要plt.draw()来更新一个图形。下面,我们确保交互模式是关闭的,这要求我们在构建情节本身之后调用
plt.show():
>>> plt.ioff()
>>> x = np.arange(-4, 5)
>>> y1 = x ** 2
>>> y2 = 10 / (x ** 2 + 1)
>>> fig, ax = plt.subplots()
>>> ax.plot(x, y1, 'rx', x, y2, 'b+', linestyle='solid')
>>> ax.fill_between(x, y1, y2, where=y2>y1, interpolate=True,
... color='green', alpha=0.3)
>>> lgnd = ax.legend(['y1', 'y2'], loc='upper center', shadow=True)
>>> lgnd.get_frame().set_facecolor('#ffb19a')
>>> plt.show()
值得注意的是,交互模式与您使用的 IDE 无关,也与您是否启用了类似于jupyter notebook --matplotlib inline或%matplotlib的内嵌绘图无关。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 用 Matplotlib 绘图*****
Twitter 情绪分析——Python、Docker、Elasticsearch、Kibana
原文:# t0]https://realython . com/Twitter-感情 python 坞站-弹性搜索-kibana/
在本例中,我们将连接到 Twitter 流 API,收集推文(基于关键字),计算每条推文的情绪,并使用 Elasticsearch DB 和 Kibana 构建一个实时仪表板来可视化结果。
工具: Docker v1.3.0, boot2docker v1.3.0, Tweepy v2.3.0, TextBlob v0.9.0, Elasticsearch v1.3.5, Kibana v3.1.2
Docker 环境
按照官方 Docker 文档安装 Docker 和 boot2docker。然后启动并运行 boot2docker,运行docker version来测试 docker 安装。创建一个目录来存放您的项目,从库中获取 docker 文件,并构建映像:
$ docker build -rm -t=elasticsearch-kibana .
构建完成后,运行容器:
$ docker run -d -p 8000:8000 -p 9200:9200 elasticsearch-kibana
最后,在新的终端窗口中运行下面两个命令,将 boot2docker VM 使用的 IP 地址/端口组合映射到您的本地主机:
$ boot2docker ssh -L8000:localhost:8000
$ boot2docker ssh -L9200:localhost:9200
现在你可以在 http://localhost:9200 访问 Elasticsearch,在 http://localhost:8000 访问 Kibana。
Twitter 流媒体 API
为了访问 Twitter 流媒体 API ,你需要在 http://apps.twitter.com 的注册一个应用。创建完成后,您应该会被重定向到您的应用程序页面,在那里您可以获得消费者密钥和消费者密码,并在“密钥和访问令牌”选项卡下创建访问令牌。将这些添加到一个名为 config.py 的新文件中:
consumer_key = "add_your_consumer_key"
consumer_secret = "add_your_consumer_secret"
access_token = "add_your_access_token"
access_token_secret = "add_your_access_token_secret"
注意:因为这个文件包含敏感信息,所以不要把它添加到你的 Git 库。
根据 Twitter Streaming 文档,“建立到流 API 的连接意味着发出一个非常长的 HTTP 请求,并逐步解析响应。从概念上讲,你可以把它想象成通过 HTTP 下载一个无限长的文件。”
因此,你提出一个请求,通过特定的关键词、用户和/或地理区域进行过滤,然后保持连接打开,收集尽可能多的推文。
这听起来很复杂,但是 Tweepy 让它变得简单。
十二个听众
Tweepy 使用一个“监听器”不仅获取流媒体推文,还对它们进行过滤。
代码
将以下代码另存为perspective . py:
import json
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler
from tweepy import Stream
from textblob import TextBlob
from elasticsearch import Elasticsearch
# import twitter keys and tokens
from config import *
# create instance of elasticsearch
es = Elasticsearch()
class TweetStreamListener(StreamListener):
# on success
def on_data(self, data):
# decode json
dict_data = json.loads(data)
# pass tweet into TextBlob
tweet = TextBlob(dict_data["text"])
# output sentiment polarity
print tweet.sentiment.polarity
# determine if sentiment is positive, negative, or neutral
if tweet.sentiment.polarity < 0:
sentiment = "negative"
elif tweet.sentiment.polarity == 0:
sentiment = "neutral"
else:
sentiment = "positive"
# output sentiment
print sentiment
# add text and sentiment info to elasticsearch
es.index(index="sentiment",
doc_type="test-type",
body={"author": dict_data["user"]["screen_name"],
"date": dict_data["created_at"],
"message": dict_data["text"],
"polarity": tweet.sentiment.polarity,
"subjectivity": tweet.sentiment.subjectivity,
"sentiment": sentiment})
return True
# on failure
def on_error(self, status):
print status
if __name__ == '__main__':
# create instance of the tweepy tweet stream listener
listener = TweetStreamListener()
# set twitter keys/tokens
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
# create instance of the tweepy stream
stream = Stream(auth, listener)
# search twitter for "congress" keyword
stream.filter(track=['congress'])
发生了什么事?:
- 我们连接到 Twitter 流 API
- 通过关键字
"congress"过滤数据; - 解码结果(推文);
- 通过 TextBlob 计算情感分析;
- 确定总体情绪是积极的、消极的还是中性的;而且,
- 最后,相关的情感和推文数据被添加到 Elasticsearch 数据库中。
有关更多详细信息,请查看行内注释。
TextBlob 情感基础
为了计算整体情绪,我们看一下极性得分:
- 正:从
0.01到1.0 - 中立:
0 - 负:从
-0.01到-1.0
有关 TextBlob 如何计算情感的更多信息,请参考官方文档。
弹性搜索分析
在我写这篇博客的两个多小时里,我用关键词“国会”拉了 9500 多条推文。在这一点上,继续进行你自己的搜索,搜索你感兴趣的主题。一旦你有相当数量的推文,停止脚本。现在,您可以执行一些快速搜索/分析…
使用来自perspective . py脚本的索引("sentiment",您可以使用 Elasticsearch 搜索 API 来收集一些基本的见解。
例如:
- 全文搜索“奥巴马”:http://localhost:9200/情操/_ 搜索?q =奥巴马
- 作者/Twitter 用户名搜索:http://localhost:9200/情操/_ 搜索?q =作者:allvoices
- 情感搜索:http://localhost:9200/情操/_ 搜索?q =情绪:积极
- 感悟与“奥巴马”搜索:http://localhost:9200/情操/_ 搜索?q =情绪:积极的&消息=奥巴马
除了搜索和过滤结果之外,你还可以用 Elasticsearch 做更多的事情。查看分析 API 以及弹性搜索——权威指南,了解更多关于如何分析和建模数据的想法。
基巴纳可视化工具
当您收集数据时,Kibana 可以让您实时“看到您的数据并与之互动”。因为它是用 JavaScript 编写的,所以您可以直接从浏览器访问它。查看来自官方介绍的基础知识,快速入门。
这篇文章顶部的饼状图直接来自基巴纳,它显示了每种情绪——积极的、中立的和消极的——在我提取的推文中所占的比例。这里是来自基巴纳的一些图表…
所有被“奥巴马”过滤的推文:
按推文数量排名的前几名推文用户:

请注意排名第一的作者是如何发布 76 条推文的。这绝对值得深入研究,因为在两个小时内有很多推文。无论如何,那位作者基本上发了 76 条同样的推文——所以你会想过滤掉其中的 75 条,因为总体结果目前是有偏差的。
除了这些图表之外,还有必要通过位置来可视化情绪。自己试试这个。你必须改变从每条推文中获取的数据。您可能还想尝试用直方图来可视化数据。
最后-
- 从库中获取代码。
- 在下面留下评论/问题。
干杯!**
Python 中的绝对导入与相对导入
原文:https://realpython.com/absolute-vs-relative-python-imports/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的绝对 vs 相对导入
如果您曾经处理过包含多个文件的 Python 项目,那么您很可能曾经使用过 import 语句。
即使对于拥有几个项目的 Pythonistas 来说,导入也会令人困惑!您可能正在阅读这篇文章,因为您想更深入地了解 Python 中的导入,尤其是绝对和相对导入。
在本教程中,您将了解两者之间的差异,以及它们的优缺点。让我们开始吧!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
进口快速回顾
你需要对 Python 模块和包有很好的理解,才能知道导入是如何工作的。Python 模块是一个扩展名为.py的文件,Python 包是任何包含模块的文件夹(或者,在 Python 2 中,包含__init__.py文件的文件夹)。
当一个模块中的代码需要访问另一个模块或包中的代码时会发生什么?你进口的!
进口如何运作
但是进口到底是怎么运作的呢?假设您像这样导入一个模块abc:
import abc
Python 会做的第一件事就是在 sys.modules 中查找名字abc。这是以前导入的所有模块的缓存。
如果在模块缓存中没有找到该名称,Python 将继续搜索内置模块列表。这些是 Python 预装的模块,可以在 Python 标准库中找到。如果在内置模块中仍然没有找到这个名字,Python 就会在由 sys.path 定义的目录列表中搜索它。该列表通常包括当前目录,首先搜索该目录。
当 Python 找到该模块时,它会将其绑定到本地范围内的一个名称。这意味着abc现在已经被定义,可以在当前文件中使用,而不用抛出NameError。
如果名字没有找到,你会得到一个ModuleNotFoundError。你可以在 Python 文档中找到更多关于导入的信息这里!
注意:安全问题
请注意,Python 的导入系统存在一些重大的安全风险。这很大程度上是因为它的灵活性。例如,模块缓存是可写的,并且可以使用导入系统覆盖核心 Python 功能。从第三方包导入也会使您的应用程序面临安全威胁。
以下是一些有趣的资源,可以帮助您了解更多关于这些安全问题以及如何缓解这些问题的信息:
- Anthony Shaw 的 Python 中的 10 个常见安全陷阱以及如何避免它们(第 5 点讨论了 Python 的导入系统。)
- 第 168 集:10 Python 安全漏洞和如何堵塞漏洞来自 TalkPython 播客(小组成员在大约 27:15 开始谈论进口。)
导入语句的语法
现在您已经知道了 import 语句是如何工作的,让我们来研究一下它们的语法。您可以导入包和模块。(注意,导入一个包实质上是将包的__init__.py文件作为一个模块导入。)您还可以从包或模块中导入特定的对象。
通常有两种类型的导入语法。当您使用第一个时,您直接导入资源,就像这样:
import abc
abc可以是包,也可以是模块。
当使用第二种语法时,从另一个包或模块中导入资源。这里有一个例子:
from abc import xyz
xyz可以是模块,子包,或者对象,比如类或者函数。
您还可以选择重命名导入的资源,如下所示:
import abc as other_name
这将在脚本中将导入的资源abc重命名为other_name。它现在必须被称为other_name,否则它将不会被识别。
导入报表的样式
Python 的官方风格指南 PEP 8 ,在编写导入语句时有一些提示。这里有一个总结:
-
导入应该总是写在文件的顶部,在任何模块注释和文档字符串之后。
-
进口应该根据进口的内容来划分。通常有三组:
- 标准库导入(Python 的内置模块)
- 相关的第三方导入(已安装但不属于当前应用程序的模块)
- 本地应用程序导入(属于当前应用程序的模块)
-
每组导入都应该用空格隔开。
在每个导入组中按字母顺序排列导入也是一个好主意。这使得查找特定的导入更加容易,尤其是当一个文件中有许多导入时。
以下是如何设计导入语句样式的示例:
"""Illustration of good import statement styling.
Note that the imports come after the docstring.
"""
# Standard library imports
import datetime
import os
# Third party imports
from flask import Flask
from flask_restful import Api
from flask_sqlalchemy import SQLAlchemy
# Local application imports
from local_module import local_class
from local_package import local_function
上面的导入语句分为三个不同的组,用空格隔开。它们在每个组中也是按字母顺序排列的。
绝对进口
您已经掌握了如何编写 import 语句以及如何像专家一样设计它们的风格。现在是时候多了解一点绝对进口了。
绝对导入使用项目根文件夹的完整路径指定要导入的资源。
语法和实例
假设您有以下目录结构:
└── project
├── package1
│ ├── module1.py
│ └── module2.py
└── package2
├── __init__.py
├── module3.py
├── module4.py
└── subpackage1
└── module5.py
有一个目录,project,包含两个子目录,package1和package2。package1目录下有两个文件,module1.py和module2.py。
package2目录有三个文件:两个模块module3.py和module4.py,以及一个初始化文件__init__.py。它还包含一个目录subpackage,该目录又包含一个文件module5.py。
让我们假设以下情况:
package1/module2.py包含一个函数,function1。package2/__init__.py包含一个类,class1。package2/subpackage1/module5.py包含一个函数,function2。
以下是绝对进口的实际例子:
from package1 import module1
from package1.module2 import function1
from package2 import class1
from package2.subpackage1.module5 import function2
请注意,您必须给出每个包或文件的详细路径,从顶层包文件夹开始。这有点类似于它的文件路径,但是我们用一个点(.)代替斜线(/)。
绝对进口的利弊
绝对导入是首选,因为它们非常清晰和直接。通过查看语句,很容易准确地判断导入的资源在哪里。此外,即使 import 语句的当前位置发生变化,绝对导入仍然有效。事实上,PEP 8 明确建议绝对进口。
然而,根据目录结构的复杂性,有时绝对导入会变得非常冗长。想象一下这样的陈述:
from package1.subpackage2.subpackage3.subpackage4.module5 import function6
太荒谬了,对吧?幸运的是,在这种情况下,相对进口是一个很好的选择!
相对进口
相对导入指定相对于当前位置(即导入语句所在的位置)要导入的资源。相对导入有两种类型:隐式和显式。Python 3 中不赞成隐式相对导入,所以我不会在这里讨论它们。
语法和实例
相对导入的语法取决于当前位置以及要导入的模块、包或对象的位置。以下是一些相对进口的例子:
from .some_module import some_class
from ..some_package import some_function
from . import some_class
你可以看到上面的每个 import 语句中至少有一个点。相对导入使用点符号来指定位置。
单个点意味着所引用的模块或包与当前位置在同一个目录中。两个点表示它在当前位置的父目录中,也就是上面的目录。三个点表示它在祖父母目录中,依此类推。如果您使用的是类似 Unix 的操作系统,您可能会对此很熟悉!
让我们假设您有和以前一样的目录结构:
└── project
├── package1
│ ├── module1.py
│ └── module2.py
└── package2
├── __init__.py
├── module3.py
├── module4.py
└── subpackage1
└── module5.py
回忆文件内容:
package1/module2.py包含一个函数,function1。package2/__init__.py包含一个类,class1。package2/subpackage1/module5.py包含一个函数,function2。
您可以这样将function1导入到package1/module1.py文件中:
# package1/module1.py
from .module2 import function1
这里只使用一个点,因为module2.py和当前模块module1.py在同一个目录中。
您可以这样将class1和function2导入到package2/module3.py文件中:
# package2/module3.py
from . import class1
from .subpackage1.module5 import function2
在第一个 import 语句中,单个点意味着您正在从当前包中导入class1。记住,导入一个包实际上是将包的__init__.py文件作为一个模块导入。
在第二个 import 语句中,您将再次使用一个点,因为subpackage1与当前模块module3.py在同一个目录中。
相对进口的利弊
相对导入的一个明显优势是它们非常简洁。根据当前的位置,他们可以将您之前看到的长得离谱的导入语句变成像这样简单的语句:
from ..subpackage4.module5 import function6
不幸的是,相对导入可能会很混乱,特别是对于目录结构可能会改变的共享项目。相对导入也不像绝对导入那样可读,并且不容易判断导入资源的位置。
结论
在这个绝对和相对进口的速成课程结束时做得很好!现在,您已经了解了导入是如何工作的。您已经学习了编写导入语句的最佳实践,并且知道绝对导入和相对导入之间的区别。
凭借您的新技能,您可以自信地从 Python 标准库、第三方包和您自己的本地包中导入包和模块。请记住,您通常应该选择绝对导入而不是相对导入,除非路径很复杂并且会使语句太长。
感谢阅读!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的绝对 vs 相对导入***
如何将 Python 添加到路径
如果已经安装了 Python,可能需要将 Python 添加到PATH中,但是在命令行中键入python似乎不起作用。您可能会收到一条消息,说术语python无法识别,或者您可能会运行错误版本的 Python。
解决这些问题的一个常见方法是将 Python 添加到PATH 环境变量。在本教程中,您将学习如何将 Python 添加到PATH中。您还将了解什么是PATH,以及为什么PATH对于像命令行这样的程序能够找到您的 Python 安装是至关重要的。
注意:一个路径是你硬盘上一个文件或文件夹的地址。PATH环境变量,也称为PATH或路径,是操作系统保存并用于查找可执行脚本和程序的目录的路径列表。
向PATH添加内容所需的步骤很大程度上取决于您的操作系统(OS ),所以如果您只对一个 OS 感兴趣,请务必跳到相关章节。
请注意,您可以使用以下步骤将任何程序添加到PATH,而不仅仅是 Python。
补充代码: 点击这里下载免费的补充代码,它将带你穿越操作系统的变化之路。
如何在 Windows 上给PATH添加 Python
第一步是定位目标 Python 可执行文件所在的目录。目录的路径就是您将要添加到PATH环境变量中的内容。
要找到 Python 可执行文件,您需要查找一个名为python.exe的文件。例如,Python 可执行文件可能在C:\Python\的目录中,或者在你的AppData\文件夹中。如果可执行文件在AppData\中,那么路径通常如下所示:
C:\Users\<USER>\AppData\Local\Programs\Python
在您的情况下,<USER>部分将被您当前登录的用户名替换。
找到可执行文件后,双击它并验证它是否在新窗口中启动了 Python REPL,以确保它能正常工作。
如果你正在努力寻找正确的可执行文件,你可以使用 Windows 资源管理器的搜索功能。内置搜索的问题是它非常慢。要对任何文件进行超快速的全系统搜索,一个很好的替代方法是 Everything :
那些用黄色突出显示的路径,即那些位于\WindowsApps和\Python310的路径,将是添加到PATH的理想候选路径,因为它们看起来像是安装的根级别的可执行文件。那些用红色突出显示的不适合,因为有些是虚拟环境的一部分——你可以在路径中看到venv——有些是快捷方式或内部 Windows 安装。
您还可能会遇到安装在不同程序的文件夹中的 Python 可执行文件。这是因为许多应用程序在其中捆绑了自己的 Python 版本。这些捆绑的 Python 安装也不合适。
找到 Python 可执行文件后,打开开始菜单并搜索编辑系统环境变量条目,这将打开一个系统属性窗口。在高级选项卡中,点击按钮环境变量。在那里,您将看到用户和系统变量,您可以编辑这些变量:
https://player.vimeo.com/video/729132627
在标题为用户变量的部分,双击显示路径的条目。将弹出另一个窗口,显示路径列表。点击新建按钮,将 Python 可执行文件的路径粘贴到那里。插入后,选择新添加的路径并点击上移按钮,直到它位于顶部。
就是这样!您可能需要重新启动您的计算机以使更改生效,但是您现在应该能够从命令行调用python。
要从命令行设置PATH环境变量,请查看 Windows Python 编码设置指南中关于配置环境变量的章节。您也可以在补充材料中找到说明:
补充代码: 点击这里下载免费的补充代码,它将带你穿越操作系统的变化之路。
你可能还想在你的 Linux 或 macOS 机器上设置PATH,或者你可能正在使用 Windows 子系统 for Linux (WSL) 。如果是这样,请阅读下一节,了解基于 UNIX 的系统上的过程。
如何在 Linux 和 macOS 上给PATH添加 Python
由于 Python 通常预装在基于 UNIX 的系统上,Linux 和 macOS 上最常见的问题是运行错误的python,而不是找不到任何 python。也就是说,在本节中,您将排除根本无法运行python的故障。
注意:根据您的特定系统,Python 2 可能有一个python程序,Python 3 可能有一个python3程序。在其他情况下,python和python3将指向同一个可执行文件。
第一步是定位目标 Python 可执行文件。它应该是一个可以运行的程序,首先导航到包含它的目录,然后在命令行上键入./python。
您需要使用当前文件夹(./)中的相对路径预先调用 Python 可执行文件,因为否则您将调用当前记录在您的PATH中的任何 Python。正如您之前了解到的,这可能不是您想要运行的 Python 解释器。
通常 Python 可执行文件可以在/bin/文件夹中找到。但是如果 Python 已经在/bin/文件夹中,那么它很可能已经在PATH中,因为/bin/是系统自动添加的。如果是这种情况,那么您可能想跳到关于PATH 中路径顺序的章节。
既然您在这里可能是因为您已经安装了 Python,但是当您在命令行上键入python时仍然找不到它,那么您将希望在另一个位置搜索它。
注意:快速搜索大文件夹的一个很棒的搜索工具是 fzf 。它从命令行工作,并将搜索当前工作目录中的所有文件和文件夹。例如,你可以从你的主目录中搜索python。然后 fzf 会显示包含python的路径。
也就是说,/bin/可能已经从PATH中完全删除,在这种情况下,你可以跳到关于管理PATH 的部分。
一旦你找到了你的 Python 可执行文件,并且确定它正在工作,记下路径以便以后使用。现在是时候开始将它添加到您的PATH环境变量中了。
首先,您需要导航到您的个人文件夹,查看您有哪些可用的配置脚本:
$ cd ~
$ ls -a
您应该会看到一堆以句点(.)开头的配置文件。这些文件俗称为点文件,默认情况下对ls隐藏。
每当您登录到系统时,都会执行一两个点文件,每当您启动一个新的命令行会话时,都会运行另外一两个点文件,而其他大多数点文件则由其他应用程序用于配置设置。
您正在寻找在启动系统或新的命令行会话时运行的文件。他们可能会有类似的名字:
.profile.bash_profile.bash_login.zprofile.zlogin
要查找的关键字是个人资料和登录。理论上,您应该只有其中一个,但是如果您有多个,您可能需要阅读其中的注释,以确定哪些在登录时运行。例如,Ubuntu 上的.profile文件通常会有以下注释:
# This file is not read by bash(1), if ~/.bash_profile or ~/.bash_login
# exists.
所以,如果你既有.profile又有.bash_profile,那么你会想要使用.bash_profile。
您还可以使用一个.bashrc或.zshrc文件,它们是在您启动新的命令行会话时运行的脚本。运行命令 (rc)文件是放置PATH配置的常用地方。
注意:学究气地说,rc 文件一般用于影响你的命令行提示符的外观和感觉的设置,而不是用于配置像PATH这样的环境变量。但是如果您愿意,您可以使用 rc 文件进行您的PATH配置。
要将 Python 路径添加到您的PATH环境变量的开头,您将在命令行上执行一个命令。
使用下面一行,将<PATH_TO_PYTHON>替换为 Python 可执行文件的实际路径,将.profile替换为系统的登录脚本:
$ echo export PATH="<PATH_TO_PYTHON>:$PATH" >> ~/.profile
该命令将export PATH="<PATH_TO_PYTHON>:$PATH"添加到.profile的末尾。命令export PATH="<PATH_TO_PYTHON>:$PATH"将<PATH_TO_PYTHON>添加到PATH环境变量中。它类似于 Python 中的以下操作:
>>> PATH = "/home/realpython/apps:/bin" >>> PATH = f"/home/realpython/python:{PATH}" >>> PATH '/home/realpython/python:/home/realpython/apps:/bin'因为
PATH只是一个由冒号分隔的字符串,所以在前面加上一个值需要创建一个新路径的字符串,一个冒号,然后是旧路径。使用这个字符串,您可以设置PATH的新值。要刷新您当前的命令行会话,您可以运行以下命令,用您选择的登录脚本替换
.profile:$ source ~/.profile现在,您应该能够直接从命令行调用
python。下次登录时,Python 应该会自动添加到PATH中。如果你觉得这个过程有点不透明,你并不孤单!请继续阅读,深入了解正在发生的事情。
理解什么是
PATH什么是
PATH是包含文件夹路径列表的环境变量。PATH中的每个路径由冒号或分号分隔——基于 UNIX 的系统用冒号,Windows 用分号。它就像一个 Python 变量,用一个长字符串作为它的值。不同之处在于PATH是一个几乎所有程序都可以访问的变量。像命令行这样的程序使用
PATH环境变量来查找可执行文件。例如,每当您在命令行中键入一个程序的名称时,命令行就会在各个地方搜索该程序。命令行搜索的地方之一是PATH。
PATH中的所有路径都必须是目录——它们不应该直接是文件或可执行文件。使用PATH的程序依次进入每个目录并搜索其中的所有文件。不过,PATH目录下的子目录不会被搜索。所以仅仅把你的根路径加到PATH是没有用的!同样重要的是要注意,使用
PATH的程序通常不搜索除了可执行文件之外的任何东西。所以,你不能用PATH来定义常用文件的快捷方式。理解
PATH内顺序的重要性如果在命令行中键入
python,命令行将在PATH环境变量的每个文件夹中查找一个python可执行文件。一旦它找到一个,它就会停止搜索。这就是为什么您将 Python 可执行文件的路径前置到PATH的原因。将新添加的路径放在第一个可以确保您的系统能够找到这个 Python 可执行文件。一个常见的问题是在您的
PATH上安装 Python 失败。如果损坏的可执行文件是命令行遇到的第一个文件,那么命令行将尝试运行该文件,然后中止任何进一步的搜索。对此的快速解决方法是在旧的 Python 目录之前添加新的 Python 目录,尽管您可能也想清除系统中的错误 Python 安装。在 Windows 上重新排序
PATH相对简单。打开 GUI 控制面板,使用上移和下移按钮调整顺序。但是,如果您使用的是基于 UNIX 的操作系统,那么这个过程会更加复杂。请继续阅读,了解更多信息。在基于 UNIX 的系统上管理您的
PATH通常,当你管理你的
PATH时,你的第一个任务是看看里面有什么。要查看 Linux 或 macOS 中任何环境变量的值,可以使用echo命令:$ echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/home/realpython/badpython:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games注意,
$符号是用来告诉命令行下面的标识符是一个变量。这个命令的问题是,它只是将所有路径转储到一行中,用冒号分隔。因此,您可能想利用tr命令将冒号转换成换行符:$ echo $PATH | tr ":" "\n" /usr/local/sbin /usr/local/bin /usr/sbin /home/realpython/badpython /usr/bin /sbin /bin /usr/games /usr/local/games在这个例子中,你可以看到
badpython出现在PATH中。理想的做法是执行一些PATH考古,并找出它在哪里被添加到PATH,但是现在,你只是想通过在你的登录脚本中添加一些东西来删除它。因为
PATH是一个 shell 字符串,你不能使用方便的方法来删除它的一部分,就像如果它是一个 Python 列表一样。也就是说,您可以将几个 shell 命令连接起来实现类似的功能:export PATH=`echo $PATH | tr ":" "\n" | grep -v 'badpython' | tr "\n" ":"`该命令从上一个命令中获取列表,并将其输入到
grep,它与和-v开关一起过滤掉包含子串badpython的任何行。然后,您可以将换行符翻译回冒号,这样您就有了一个新的有效的PATH字符串,您可以立即使用它来替换旧的PATH字符串。虽然这可能是一个方便的命令,但理想的解决方案是找出错误路径添加到哪里。您可以尝试查看其他登录脚本或检查
/etc/中的特定文件。例如,在 Ubuntu 中,有一个名为environment的文件,它通常定义了系统的启动路径。在 macOS 中,这可能是/etc/paths。在/etc/中也可能有profile文件和文件夹包含启动脚本。
/etc/中的配置和您的个人文件夹中的配置之间的主要区别在于,/etc/中的配置是系统范围的,而您的个人文件夹中的配置则是针对您的用户的。不过,这通常会涉及到一点考古学,来追踪你的
PATH中添加了什么东西。因此,您可能希望在您的登录或 rc 脚本中添加一行来过滤掉来自PATH的某些条目,以此作为快速解决方案。结论
在本教程中,您已经学习了如何在 Windows、Linux 和 macOS 上将 Python 或任何其他程序添加到您的
PATH环境变量中。您还了解了更多关于什么是PATH,以及为什么考虑它的内部顺序是至关重要的。最后,您还发现了如何在基于 UNIX 的系统上管理您的PATH,因为这比在 Windows 上管理您的PATH更复杂。补充代码: 点击这里下载免费的补充代码,它将带你穿越操作系统的变化之路。***
向 Django 添加社会认证
原文:https://realpython.com/adding-social-authentication-to-django/
Python Social Auth 是一个库,它提供了“一个易于设置的社交认证/注册机制,支持多个框架和认证提供者”。在本教程中,我们将详细介绍如何将这个库集成到一个 Django 项目中来提供用户认证。
我们使用的是什么:
- Django==1.7.1
- python-social-auth==0.2.1
Django 设置
如果你已经准备好了一个项目,可以跳过这一部分。
创建并激活一个 virtualenv,安装 Django,然后启动一个新的 Django 项目:
$ django-admin.py startproject django_social_project $ cd django_social_project $ python manage.py startapp django_social_app设置初始表并添加超级用户:
$ python manage.py migrate Operations to perform: Apply all migrations: admin, contenttypes, auth, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying sessions.0001_initial... OK $ python manage.py createsuperuser Username (leave blank to use 'michaelherman'): admin Email address: ad@min.com Password: Password (again): Superuser created successfully.在项目根目录下创建一个名为“templates”的新目录,然后将正确的路径添加到 settings.py 文件中:
TEMPLATE_DIRS = ( os.path.join(BASE_DIR, 'templates'), )运行开发服务器以确保一切正常,然后导航到 http://localhost:8000/ 。你应该看到“成功了!”页面。
您的项目应该如下所示:
└── django_social_project ├── db.sqlite3 ├── django_social_app │ ├── __init__.py │ ├── admin.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── django_social_project │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── templatesPython 社交认证设置
按照以下步骤和/或官方安装指南安装和设置基本配置。
安装
使用 pip 安装:
$ pip install python-social-auth==0.2.1配置
更新 settings.py 以在我们的项目中包含/注册该库:
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'django_social_project', 'social.apps.django_app.default', ) TEMPLATE_CONTEXT_PROCESSORS = ( 'django.contrib.auth.context_processors.auth', 'django.core.context_processors.debug', 'django.core.context_processors.i18n', 'django.core.context_processors.media', 'django.core.context_processors.static', 'django.core.context_processors.tz', 'django.contrib.messages.context_processors.messages', 'social.apps.django_app.context_processors.backends', 'social.apps.django_app.context_processors.login_redirect', ) AUTHENTICATION_BACKENDS = ( 'social.backends.facebook.FacebookOAuth2', 'social.backends.google.GoogleOAuth2', 'social.backends.twitter.TwitterOAuth', 'django.contrib.auth.backends.ModelBackend', )注册后,更新数据库:
$ python manage.py makemigrations Migrations for 'default': 0002_auto_20141109_1829.py: - Alter field user on usersocialauth $ python manage.py migrate Operations to perform: Apply all migrations: admin, default, contenttypes, auth, sessions Running migrations: Applying default.0001_initial... OK Applying default.0002_auto_20141109_1829... OK在 urls.py 中更新项目的
urlpatterns,以包含主要的授权 URL:urlpatterns = patterns( '', url(r'^admin/', include(admin.site.urls)), url('', include('social.apps.django_app.urls', namespace='social')), )接下来,您需要从想要包含的每个社交应用程序中获取所需的认证密钥。这个过程对于许多流行的社交网络来说是相似的——像推特、脸书和谷歌。让我们以 Twitter 为例…
Twitter 认证密钥
在https://apps.twitter.com/app/new创建一个新的应用程序,并确保使用回调 URLhttp://127 . 0 . 0 . 1:8000/complete/Twitter。
在“django_social_project”目录中,添加一个名为 config.py 的新文件。从 Twitter 的“Keys and Access Tokens”选项卡下获取
Consumer Key (API Key)和Consumer Secret (API Secret),并将其添加到配置文件中,如下所示:SOCIAL_AUTH_TWITTER_KEY = 'update me' SOCIAL_AUTH_TWITTER_SECRET = 'update me'让我们将以下 URL 添加到 config.py 中,以指定登录和重定向 URL(在用户验证之后):
SOCIAL_AUTH_LOGIN_REDIRECT_URL = '/home/' SOCIAL_AUTH_LOGIN_URL = '/'将以下导入添加到 settings.py :
from config import *确保将 config.py 添加到您的中。gitignore 文件,因为不想将此文件添加到版本控制中,因为它包含敏感信息。
欲了解更多信息,请查看官方文件。
健全性检查
让我们来测试一下。启动服务器并导航到http://127 . 0 . 0 . 1:8000/log in/Twitter,授权应用程序,如果一切正常,你应该会被重定向到http://127 . 0 . 0 . 1:8000/home/(与
SOCIAL_AUTH_LOGIN_REDIRECT_URL相关联的 URL)。您应该会看到 404 错误,因为我们还没有设置路由、视图或模板。让我们现在就开始吧…
友好的观点
现在,我们只需要两个视图——登录和主页。
URLs
更新 urls.py 中的 URL 模式:
urlpatterns = patterns( '', url(r'^admin/', include(admin.site.urls)), url('', include('social.apps.django_app.urls', namespace='social')), url(r'^$', 'django_social_app.views.login'), url(r'^home/$', 'django_social_app.views.home'), url(r'^logout/$', 'django_social_app.views.logout'), )除了
/和home/航线,我们还增加了logout/航线。视图
接下来,添加以下视图函数:
from django.shortcuts import render_to_response, redirect, render from django.contrib.auth import logout as auth_logout from django.contrib.auth.decorators import login_required # from django.template.context import RequestContext def login(request): # context = RequestContext(request, { # 'request': request, 'user': request.user}) # return render_to_response('login.html', context_instance=context) return render(request, 'login.html') @login_required(login_url='/') def home(request): return render_to_response('home.html') def logout(request): auth_logout(request) return redirect('/')在
login()函数中,我们用RequestContext获取登录的用户。作为参考,实现这一点的更明确的方法被注释掉了。模板
添加两个模板home.html和 login.htmlT2。
home.html
<h1>Welcome</h1> <p><a href="/logout">Logout</a>login.html
{% if user and not user.is_anonymous %} <a>Hello, {{ user.get_full_name }}!</a> <br> <a href="/logout">Logout</a> {% else %} <a href="{% url 'social:begin' 'twitter' %}?next={{ request.path }}">Login with Twitter</a> {% endif %}您的项目现在应该如下所示:
└── django_social_project ├── db.sqlite3 ├── django_social_app │ ├── __init__.py │ ├── admin.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── django_social_project │ ├── __init__.py │ ├── config.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── templates ├── home.html └── login.html再测试一次。启动服务器。确保首先注销,因为用户应该已经从最后一次测试中登录,然后测试登录和注销。登录后,用户应该被重定向到
/home。接下来的步骤
在这一点上,你可能想要添加更多的认证提供者——像脸书和谷歌。添加新的社交身份验证提供者的工作流程很简单:
- 在提供商的网站上创建新的应用程序。
- 设置回调 URL。
- 获取密钥/令牌并将其添加到 config.py 中。
- 将新的提供者添加到 settings.py 中的
AUTHENTICATION_BACKENDS元组中。- 通过添加新的 URL 来更新登录模板,如 so -
<a href="{% url 'social:begin' 'ADD AUTHENTICATION PROVIDER NAME' %}?next={{ request.path }}">Login with AUTHENTICATION PROVIDER NAME</a>。请查看正式文件了解更多信息。请在下面留下评论和问题。感谢阅读!
哦——一定要从回购中获取代码。***
Python 开发人员的高级 Git 技巧
如果你已经在 Git 方面做了一点工作,并且开始理解我们在 Git 简介中介绍的基础知识,但是你想学习更高效和更好的控制,那么这就是你要找的地方!
在本教程中,我们将讨论如何处理特定的提交和整个范围的提交,使用 stash 来保存临时工作,比较不同的提交,更改历史,以及如何在出现问题时清理混乱。
本文假设您已经阅读了我们的第一个 Git 教程,或者至少了解 Git 是什么以及它是如何工作的。
有很多事情要谈,所以我们开始吧。
版本选择
有几个选项可以告诉 Git 您想要使用哪个修订(或提交)。我们已经看到,我们可以使用完整的 SHA (
25b09b9ccfe9110aed2d09444f1b50fa2b4c979c)和短的 SHA (25b09b9cc)来表示修订。我们还看到了如何使用
HEAD或分支名称来指定特定的提交。然而,Git 还有其他一些技巧。相对参考
有时,能够指示相对于已知位置的修订是有用的,比如
HEAD或分支名称。Git 提供了两个操作符,虽然相似,但行为略有不同。第一个是波浪号(
~)操作符。Git 使用代字号指向提交的父级,因此HEAD~表示最后一次提交之前的修订。要进一步后退,您可以在波浪号后使用一个数字:HEAD~3带您后退三级。在我们遇到合并之前,这一切都很好。合并提交有两个父对象,所以
~只选择第一个。虽然这有时可行,但有时您希望指定第二个或更晚的父代。这就是为什么 Git 有脱字符(^)操作符。
^操作符移动到指定版本的特定父版本。你用一个数字来表示哪个父母。所以HEAD^2告诉 Git 选择最后提交的第二个父代,而不是的“祖父代”可以重复此操作以进一步后退:HEAD^2^^带您后退三级,在第一步选择第二个父级。如果不给出数字,Git 假设1。注意:使用 Windows 的用户需要使用第二个
^来转义 DOS 命令行上的^字符。我承认,为了让生活变得更有趣,可读性更差,Git 允许您组合这些方法,所以如果您使用 merges 回溯树结构,那么
25b09b9cc^2~3^3是一种有效的表示修订的方式。它会将您带到第二个父代,然后从该父代返回三个修订版本,然后到第三个父代。修订范围
有几种不同的方法来指定像
git log这样的命令的提交范围。然而,这些并不完全像 Python 中的切片那样工作,所以要小心!双点符号
用于指定范围的“双点”方法看起来像它的声音:
git log b05022238cdf08..60f89368787f0e。这很容易让人想到这是在说“显示从b05022238cdf08到60f89368787f0e的所有提交”,如果b05022238cdf08是60f89368787f0e的直接祖先,这就是它所做的。注意:在本节的剩余部分,我将用大写字母替换单个提交的 sha,因为我认为这样会使图表更容易理解。我们稍后也将使用这个“假”符号。
然而,它比那更强大一点。双点符号实际上向您显示了第二次提交中包含的所有提交,而第一次提交中不包含这些提交。让我们看几个图表来阐明:
如您所见,在我们的示例回购中有两个分支,
branch1和branch2,它们在提交A后分叉。首先,让我们看看简单的情况。我修改了日志输出,使其与图表相匹配:$ git log --oneline D..F E "Commit message for E" F "Commit message for F"
D..F给出了在提交D之后branch2的所有提交。下面是一个更有趣的例子,也是我在撰写本教程时了解到的一个例子:
$ git log --oneline C..F D "Commit message for D" E "Commit message for E" F "Commit message for F"这显示了属于提交
F的提交,而不属于提交C的提交。由于这里的结构,这些提交没有前/后关系,因为它们在不同的分支上。如果把
C和F的顺序对调,你觉得会得到什么?$ git log --oneline F..C B "Commit message for B" C "Commit message for C"三重点
你猜对了,三点符号在修订说明符之间使用了三个点。这以类似于双点符号的方式工作,除了它显示了在任一版本中的所有提交,这些提交不包括在两个版本中。对于上面的图表,使用
C...F向您展示了这一点:$ git log --oneline C...F D "Commit message for D" E "Commit message for E" F "Commit message for F" B "Commit message for B" C "Commit message for C"当您想要对一个命令使用一系列提交时,双点和三点符号可能非常强大,但是它们并不像许多人认为的那样简单。
分行对总行对 SHA
这可能是回顾 Git 中有哪些分支以及它们如何与 sha 和 HEAD 相关联的好时机。
HEAD是 Git 用来指代“你的文件系统现在指向的地方”的名字大多数情况下,这将指向一个指定的分支,但也不是必须如此。为了了解这些想法,让我们看一个例子。假设您的历史如下所示:
此时,您发现在 commit B. Rats 中意外地提交了一个 Python 日志记录语句。现在,大多数人会添加一个新的提交,
E,推送到master,然后就完成了。但是你正在学习 Git,并且想要用困难的方式来解决这个问题,并且隐藏你在历史上犯了一个错误的事实。所以你使用
git checkout B将HEAD移回B,看起来像这样:
你可以看到
master没有改变位置,但是HEAD现在指向了B。在 Git 入门教程中,我们谈到了“分离头”状态。这又是那个状态!因为您想要提交更改,所以您用
git checkout -b temp创建了一个新的分支:
现在,您可以编辑该文件并删除有问题的日志语句。一旦完成,您就可以使用
git add和git commit --amend来修改提交B:
哇哦。这里有一个名为
B'的新提交。就像B一样,它的父节点是A,而C对此一无所知。现在我们希望 master 基于这个新的 commit,B'。因为您有敏锐的记忆力,所以您记得 rebase 命令就是这样做的。因此,您可以通过键入
git checkout master返回到master分支:
一旦你上了主游戏,你可以使用
git rebase temp在B上重放C和D:
您可以看到 rebase 创建提交了
C'和D'。C'仍然有和C一样的变化,D'也有和D一样的变化,但是他们有不同的 sha,因为他们现在是基于B'而不是B。正如我前面提到的,您通常不会为了修复一个错误的日志语句而这么麻烦,但是有时候这种方法可能是有用的,并且它确实说明了
HEAD、提交和分支之间的区别。更
Git 的锦囊妙计更多,但我将在这里停下来,因为我很少看到在野外使用的其他方法。如果你想了解如何对两个以上的分支进行类似的操作,请查阅 Pro Git 书籍中关于修订选择的精彩文章。
处理中断:
git stash我经常使用并且觉得非常方便的 Git 特性之一是
stash。它提供了一种简单的机制来保存您正在处理但尚未准备好提交的文件,以便您可以切换到不同的任务。在这一节中,您将首先浏览一个简单的用例,查看每一个不同的命令和选项,然后您将总结一些其他的用例,在这些用例中git stash真正发挥了作用。
git stash save和git stash pop假设你正在处理一个讨厌的 bug。您已经在两个文件
file1和file2中获得了 Python 日志代码,以帮助您跟踪它,并且您已经添加了file3作为一个可能的解决方案。简而言之,回购的变化如下:
- 您已经编辑了
file1并完成了git add file1。- 您已经编辑了
file2但尚未添加。- 您已经创建了
file3但尚未添加。你做一个
git status来确认回购的条件:$ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: file1 Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file2 Untracked files: (use "git add <file>..." to include in what will be committed) file3现在一个同事(他们不讨厌吗?)走过来告诉你产量下降了,轮到你了。你知道你可以发挥你疯狂的技能来节省时间和扭转局面。
您还没有完成文件 1、2 和 3 的工作,所以您真的不想提交这些更改,但是您需要将它们从您的工作目录中删除,以便您可以切换到不同的分支来修复这个 bug。这是
git stash最基本的用例。您可以使用
git stash save暂时“将这些更改放在一边”,并返回到一个干净的工作目录。stash的默认选项是save,所以通常只写为git stash。当您保存一些东西到
stash时,它会为这些更改创建一个唯一的存储点,并将您的工作目录返回到上次提交的状态。它用一个神秘的信息告诉你它做了什么:$ git stash save Saved working directory and index state WIP on master: 387dcfc adding some files HEAD is now at 387dcfc adding some files在该输出中,
master是分支的名称,387dcfc是最后一次提交的 SHA,adding some files是该提交的提交消息,WIP代表“正在进行的工作”在这些细节上,你的回购协议的输出可能会有所不同。如果此时执行
status,它仍会显示file3为未跟踪文件,但file1和file2不再存在:$ git status On branch master Untracked files: (use "git add <file>..." to include in what will be committed) file3 nothing added to commit but untracked files present (use "git add" to track)在这一点上,就 Git 而言,您的工作目录是“干净的”,您可以自由地做一些事情,比如签出不同的分支、精选更改或任何您需要做的事情。
你去检查了另一个分支,修复了错误,赢得了同事的赞赏,现在准备好回到这个工作中。
你怎么把最后一批货拿回来?
git stash pop!此时使用
pop命令如下所示:$ git stash pop On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file1 modified: file2 Untracked files: (use "git add <file>..." to include in what will be committed) file3 no changes added to commit (use "git add" and/or "git commit -a") Dropped refs/stash@{0} (71d0f2469db0f1eb9ee7510a9e3e9bd3c1c4211c)现在,您可以在底部看到一条关于“丢弃的引用/存储@{0}”的消息。我们将在下面详细讨论该语法,但它基本上是说它应用了您隐藏的更改并清除了隐藏本身。在你问之前,是的,有一种方法可以使用这些藏起来的东西并且而不是处理掉它,但是我们不要想得太多。
你会注意到
file1曾经在索引中,但现在不在了。默认情况下,git stash pop不会像那样维护变更的状态。当然,有一个选项告诉它这样做。将file1添加回索引,然后重试:$ git add file1 $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: file1 Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file2 Untracked files: (use "git add <file>..." to include in what will be committed) file3 $ git stash save "another try" Saved working directory and index state On master: another try HEAD is now at 387dcfc adding some files $ git stash pop --index On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: file1 Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file2 Untracked files: (use "git add <file>..." to include in what will be committed) file3 Dropped refs/stash@{0} (aed3a02aeb876c1137dd8bab753636a294a3cc43)您可以看到,我们第二次向
git pop命令添加了--index选项,这告诉它尝试维护文件是否在索引中的状态。在前两次尝试中,你可能注意到
file3不在你的收藏中。您可能希望将file3与其他更改放在一起。幸运的是,有一个选项可以帮助你:--include-untracked。假设我们回到了上一个示例结束时的位置,我们可以重新运行命令:
$ git stash save --include-untracked "third attempt" Saved working directory and index state On master: third attempt HEAD is now at 387dcfc adding some files $ git status On branch master nothing to commit, working directory clean这就把未被跟踪的
file3和我们其他的变化放在了一起。在我们继续之前,我只想指出
save是git stash的默认选项。除非你正在指定一个消息,我们将在后面讨论,你可以简单地使用git stash,它将做一个save。
git stash list
git stash的一个强大特性是你可以拥有不止一个。Git 将数据存储在一个栈中,这意味着默认情况下,它总是使用最近保存的数据。git stash list命令将显示本地 repo 中的堆栈。让我们创建几个仓库,这样我们就可以看到它是如何工作的:$ echo "editing file1" >> file1 $ git stash save "the first save" Saved working directory and index state On master: the first save HEAD is now at b3e9b4d adding file3 $ # you can see that stash save cleaned up our working directory $ # now create a few more stashes by "editing" files and saving them $ echo "editing file2" >> file2 $ git stash save "the second save" Saved working directory and index state On master: the second save HEAD is now at b3e9b4d adding file3 $ echo "editing file3" >> file3 $ git stash save "the third save" Saved working directory and index state On master: the third save HEAD is now at b3e9b4d adding file3 $ git status On branch master nothing to commit, working directory clean你现在有三个不同的仓库保存。幸运的是,Git 有一个处理 stashes 的系统,使得这个问题很容易处理。系统的第一步是
git stash list命令:$ git stash list stash@{0}: On master: the third save stash@{1}: On master: the second save stash@{2}: On master: the first save列表显示您在此回购中的堆栈,最新的在最前面。注意每个条目开头的
stash@{n}语法吗?那是藏毒点的名字。其余的git stash子命令将使用该名称来引用一个特定的存储。一般来说,如果你不给出一个名字,它总是假设你指的是最近的藏匿,stash@{0}。稍后你会看到更多。这里我想指出的另一件事是,您可以在清单中看到我们执行
git stash save "message"命令时使用的消息。如果你藏了很多东西,这会很有帮助。如上所述,
git stash save [name]命令的save [name]部分是不需要的。你可以简单地输入git stash,它默认为一个保存命令,但是自动生成的消息不会给你太多信息:$ echo "more editing file1" >> file1 $ git stash Saved working directory and index state WIP on master: 387dcfc adding some files HEAD is now at 387dcfc adding some files $ git stash list stash@{0}: WIP on master: 387dcfc adding some files stash@{1}: On master: the third save stash@{2}: On master: the second save stash@{3}: On master: the first save默认消息是
WIP on <branch>: <SHA> <commit message>.,没告诉你多少。如果我们对前三次藏匿都这样做,他们会得到同样的信息。这就是为什么,对于这里的例子,我使用完整的git stash save <message>语法。
git stash show好了,现在你有了一堆藏物,你甚至可以用有意义的信息来描述它们,但是如果你想知道某个藏物里到底有什么呢?这就是
git stash show命令的用武之地。使用默认选项会告诉您有多少文件发生了更改,以及哪些文件发生了更改:$ git stash show stash@{2} file1 | 1 + 1 file changed, 1 insertion(+)然而,默认选项并没有告诉您发生了什么变化。幸运的是,您可以添加
-p/--patch选项,它会以“补丁”格式向您展示不同之处:$ git stash show -p stash@{2} diff --git a/file1 b/file1 index e212970..04dbd7b 100644 --- a/file1 +++ b/file1 @@ -1 +1,2 @@ file1 +editing file1这里显示行“编辑文件 1”被添加到
file1。如果您不熟悉显示差异的补丁格式,不要担心。当您到达下面的git difftool部分时,您将看到如何在一个存储上调出一个可视化的比较工具。
git stash popvsgit stash applyT2】您在前面已经看到了如何使用
git stash pop命令将最近的存储放回到您的工作目录中。您可能已经猜到,我们前面看到的 stash name 语法也适用于 pop 命令:$ git stash list stash@{0}: On master: the third save stash@{1}: On master: the second save stash@{2}: On master: the first save $ git stash pop stash@{1} On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) while read line; do echo -n "$line" | wc -c; done< modified: file2 no changes added to commit (use "git add" and/or "git commit -a") Dropped stash@{1} (84f7c9890908a1a1bf3c35acfe36a6ecd1f30a2c) $ git stash list stash@{0}: On master: the third save stash@{1}: On master: the first save您可以看到,
git stash pop stash@{1}将“第二次保存”放回到我们的工作目录中,并折叠了我们的堆栈,因此只有第一个和第三个堆栈在那里。请注意在pop之后,“第一次保存”是如何从stash@{2}变为stash@{1}的。也可以把一个存储放在你的工作目录中,但是也可以把它留在堆栈中。这是通过
git stash apply完成的:$ git stash list stash@{0}: On master: the third save stash@{1}: On master: the first save $ git stash apply stash@{1} On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file1 modified: file2 no changes added to commit (use "git add" and/or "git commit -a") $ git stash list stash@{0}: On master: the third save stash@{1}: On master: the first save如果您想要多次应用同一组更改,这可能会很方便。我最近在原型硬件上工作时使用了这个。为了让代码在我桌子上的特定硬件上工作,需要做一些修改,但其他的都不需要。每次我下载新的 master 副本时,我都会使用
git stash apply来应用这些更改。
git stash drop要查看的最后一个 stash 子命令是
drop。当您想要丢弃一个存储库并且不将它应用到您的工作目录时,这是非常有用的。看起来是这样的:$ git status On branch master nothing to commit, working directory clean $ git stash list stash@{0}: On master: the third save stash@{1}: On master: the first save $ git stash drop stash@{1} Dropped stash@{1} (9aaa9996bd6aa363e7be723b4712afaae4fc3235) $ git stash drop Dropped refs/stash@{0} (194f99db7a8fcc547fdd6d9f5fbffe8b896e2267) $ git stash list $ git status On branch master nothing to commit, working directory clean这删除了最后两个栈,Git 没有改变您的工作目录。在上面的例子中有一些事情需要注意。首先,
drop命令和大多数其他git stash命令一样,可以使用可选的stash@{n}名称。如果不提供,Git 假设stash@{0}。另一件有趣的事情是,drop 命令的输出为您提供了阿沙。像 Git 中的其他 sha 一样,您可以利用这一点。例如,如果您真的想要在上面的
stash@{1}上执行pop而不是drop,您可以使用它显示给您的那个 SHA 创建一个新的分支(9aaa9996):$ git branch tmp 9aaa9996 $ git status On branch master nothing to commit, working directory clean $ # use git log <branchname> to see commits on that branch $ git log tmp commit 9aaa9996bd6aa363e7be723b4712afaae4fc3235 Merge: b3e9b4d f2d6ecc Author: Jim Anderson <your_email_here@gmail.com> Date: Sat May 12 09:34:29 2018 -0600 On master: the first save [rest of log deleted for brevity]一旦您有了那个分支,您就可以使用
git merge或其他技术将那些变更返回到您的分支。如果您没有从git drop命令中保存 SHA,有其他方法可以尝试恢复更改,但是它们会变得复杂。你可以在这里了解更多关于的信息。
git stash举例:拉进一棵脏兮兮的树让我们通过查看它的一个最初对我来说并不明显的用途来结束这一节。通常,当你在一个共享分支上工作很长一段时间时,另一个开发人员会将变更推送到你想在本地回购中得到的分支上。您会记得我们使用了
git pull命令来做这件事。但是,如果您在文件中有本地更改,而 pull 将修改这些更改,Git 会拒绝,并显示一条错误消息,解释发生了什么错误:error: Your local changes to the following files would be overwritten by merge: <list of files that conflict> Please, commit your changes or stash them before you can merge. Aborting您可以提交它,然后执行
pull,但是这会创建一个合并节点,并且您可能还没有准备好提交这些文件。现在你知道了git stash,你可以用它来代替:$ git stash Saved working directory and index state WIP on master: b25fe34 Cleaned up when no TOKEN is present. Added ignored tasks HEAD is now at <SHA> <commit message> $ git pull Updating <SHA1>..<SHA2> Fast-forward <more info here> $ git stash pop On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: <rest of stash pop output trimmed>执行
git stash pop命令完全有可能会产生合并冲突。如果是这种情况,您需要手动编辑冲突来解决它,然后您可以继续。我们将在下面讨论解决合并冲突。比较修订:
git diff
git diff命令是一个强大的特性,您会发现自己经常使用它。我查找了它可以比较的事物列表,并对列表感到惊讶。如果你想自己看,试着输入git diff --help。我不会在这里涵盖所有这些用例,因为它们中的许多并不常见。本节有几个关于
diff命令的用例,显示在命令行上。下一节将展示如何设置 Git 来使用可视化比较工具,比如 Meld、Windiff、BeyondCompare,甚至是 IDE 中的扩展。diff和difftool的选项是相同的,所以本节中的大部分讨论也适用于此,但是在命令行版本中显示输出更容易。
git diff最常见的用途是查看您在工作目录中修改了什么:$ echo "I'm editing file3 now" >> file3 $ git diff diff --git a/file3 b/file3 index faf2282..c5dd702 100644 --- a/file3 +++ b/file3 @@ -1,3 +1,4 @@ {other contents of files3} +I'm editing file3 now如您所见,
diff在命令行上以“补丁”的格式向您展示了不同之处。一旦你完成了这个格式,你可以看到,+字符表明一行已经被添加到了文件中,正如你所期望的,行I'm editing file3 now被添加到了file3。
git diff的默认选项是向您显示您的工作目录中有哪些变化是而不是在您的索引或 HEAD 中。如果您将上述更改添加到索引中,然后执行 diff,它会显示没有差异:$ git add file3 $ git diff [no output here]我发现这让我困惑了一段时间,但我渐渐喜欢上了它。要查看索引中的更改并为下一次提交准备,请使用
--staged选项:$ git diff --staged diff --git a/file3 b/file3 index faf2282..c5dd702 100644 --- a/file3 +++ b/file3 @@ -1,3 +1,4 @@ file1 file2 file3 +I'm editing file3 now
git diff命令也可以用来比较 repo 中的任意两个提交。这可以向您展示两个 sha 之间的变化:$ git diff b3e9b4d 387dcfc diff --git a/file3 b/file3 deleted file mode 100644 index faf2282..0000000 --- a/file3 +++ /dev/null @@ -1,3 +0,0 @@ -file1 -file2 -file3您还可以使用分支名称来查看一个分支和另一个分支之间的全部更改:
$ git diff master tmp diff --git a/file1 b/file1 index e212970..04dbd7b 100644 --- a/file1 +++ b/file1 @@ -1 +1,2 @@ file1 +editing file1您甚至可以使用我们在上面看到的版本命名方法的任意组合:
$ git diff master^ master diff --git a/file3 b/file3 new file mode 100644 index 0000000..faf2282 --- /dev/null +++ b/file3 @@ -0,0 +1,3 @@ +file1 +file2 +file3当您比较两个分支时,它会显示两个分支之间的所有变化。通常,您只想查看单个文件的差异。您可以通过在一个
--(两个负号)选项后列出文件来将输出限制为一个文件:$ git diff HEAD~3 HEAD diff --git a/file1 b/file1 index e212970..04dbd7b 100644 --- a/file1 +++ b/file1 @@ -1 +1,2 @@ file1 +editing file1 diff --git a/file2 b/file2 index 89361a0..91c5d97 100644 --- a/file2 +++ b/file2 @@ -1,2 +1,3 @@ file1 file2 +editing file2 diff --git a/file3 b/file3 index faf2282..c5dd702 100644 --- a/file3 +++ b/file3 @@ -1,3 +1,4 @@ file1 file2 file3 +I'm editing file3 now $ git diff HEAD~3 HEAD -- file3 diff --git a/file3 b/file3 index faf2282..c5dd702 100644 --- a/file3 +++ b/file3 @@ -1,3 +1,4 @@ file1 file2 file3 +I'm editing file3 now
git diff有很多很多选项,我不会一一列举,但是我想探索另一个我经常使用的用例,显示在提交中被更改的文件。在您当前的回购中,
master上的最近提交向file1添加了一行文本。通过比较HEAD和HEAD^你可以看到:$ git diff HEAD^ HEAD diff --git a/file1 b/file1 index e212970..04dbd7b 100644 --- a/file1 +++ b/file1 @@ -1 +1,2 @@ file1 +editing file1对于这个小例子来说这没什么,但是提交的差异通常会有几页长,而且提取文件名会变得非常困难。当然,Git 有一个选项可以帮助解决这个问题:
$ git diff HEAD^ HEAD --name-only file1
--name-only选项将显示两次提交之间更改的文件名列表,但不显示这些文件中更改的内容。正如我上面所说的,
git diff命令覆盖了的许多选项和用例,这里你只是触及了表面。一旦你弄清楚了上面列出的命令,我鼓励你看看git diff --help,看看你还能找到什么技巧。我肯定学到了新的东西准备这个教程!
git difftoolGit 有一种机制,可以使用可视化的 diff 工具来显示差异,而不仅仅是使用我们目前看到的命令行格式。你用
git diff看到的所有选项和功能在这里仍然有效,但是它将在一个单独的窗口中显示不同之处,包括我在内的许多人都觉得这样更容易阅读。对于这个例子,我将使用meld作为 diff 工具,因为它可以在 Windows、Mac 和 Linux 上使用。如果设置得当,Difftool 更容易使用。Git 有一组配置选项来控制
difftool的默认值。您可以使用git config命令在 shell 中设置这些:$ git config --global diff.tool meld $ git config --global difftool.prompt false我认为
prompt选项很重要。如果不指定,Git 会在每次启动外部构建工具之前提示您。这可能很烦人,因为它对 diff 中的每个文件都是这样,一次一个:$ git difftool HEAD^ HEAD Viewing (1/1): 'python-git-intro/new_section.md' Launch 'meld' [Y/n]: y将
prompt设置为 false 会强制 Git 在没有询问的情况下启动该工具,从而加快您的进程并使您变得更好!在上面的
diff讨论中,您已经介绍了difftool的大部分特性,但是我想补充一点,这是我在为本文进行研究时学到的。你还记得上面你在看git stash show命令的时候吗?我提到有一种方法可以直观地看到给定的储藏中有什么,而difftool就是这种方法。我们学习的所有用于寻址堆栈的语法都适用于 difftool:$ git difftool stash@{1}与所有的
stash子命令一样,如果您只想查看最新的存储,您可以使用stash快捷键:$ git difftool stash许多 ide 和编辑器都有可以帮助查看差异的工具。在 Git 教程的介绍的最后有一个特定于编辑器的教程列表。
改变历史
Git 的一个让一些人害怕的特性是它有能力改变提交。虽然我能理解他们的担心,但这是工具的一部分,而且,像任何强大的工具一样,如果你不明智地使用它,你可能会带来麻烦。
我们将讨论修改提交的几种方法,但是在此之前,让我们讨论一下什么时候这样做是合适的。在前面几节中,您已经看到了本地回购和远程回购之间的区别。您已创建但尚未推送的提交仅位于您的本地回购中。其他开发人员已经推送但您没有拉取的提交仅在远程回购中。执行
push或pull会将这些提交放入两个回购中。你应该考虑修改提交的唯一时间是当它存在于你的本地存储库中而不是远程存储库中的时候。如果您修改已经从远程推送的提交,您很可能很难从远程推送或拉取,如果您成功了,您的同事会不高兴。
除此之外,让我们来谈谈如何修改提交和改变历史!
git commit --amend如果您刚刚提交了一个请求,但是在运行时发现
flake8有错误,您会怎么做?或者您在刚刚输入的提交消息中发现了一个打字错误?Git 将允许您“修改”提交:$ git commit -m "I am bad at spilling" [master 63f74b7] I am bad at spilling 1 file changed, 4 insertions(+) $ git commit --amend -m "I am bad at spelling" [master 951bf2f] I am bad at spelling Date: Tue May 22 20:41:27 2018 -0600 1 file changed, 4 insertions(+)现在,如果您查看修改后的日志,您会看到只有一次提交,并且它具有正确的消息:
$ git log commit 951bf2f45957079f305e8a039dea1771e14b503c Author: Jim Anderson <your_email_here@gmail.com> Date: Tue May 22 20:41:27 2018 -0600 I am bad at spelling commit c789957055bd81dd57c09f5329c448112c1398d8 Author: Jim Anderson <your_email_here@gmail.com> Date: Tue May 22 20:39:17 2018 -0600 new message [rest of log deleted]如果您在修改之前修改并添加了文件,这些文件也会包含在单次提交中。您可以看到这是一个修复错误的便捷工具。我将再次警告您,执行
commit --amend会修改提交。如果原始提交被推送到远程回购,其他人可能已经基于它进行了更改。那会很混乱,所以只对本地的提交使用它。
git rebase一个
rebase操作类似于一个合并,但是它可以产生一个更清晰的历史。当你重定基础时,Git 会在你当前的分支和指定的分支之间找到共同的祖先。然后,它将从您的分支中获取该共同祖先之后的所有更改,并在另一个分支上“重放”它们。结果看起来就像你在另一个分支之后做了所有的修改。这可能有点难以想象,所以让我们看一些实际的提交。在这个练习中,我将使用
git log命令中的--oneline选项来减少混乱。让我们从你一直在做的一个叫做my_feature_branch的特性分支开始。这是该分支的状态:$ git log --oneline 143ae7f second feature commit aef68dc first feature commit 2512d27 Common Ancestor Commit如您所料,您可以看到,
--oneline选项只显示了 SHA 和每次提交的提交消息。在标记为2512d27 Common Ancestor Commit的提交之后,您的分支有两个提交。如果你打算重定基数,你需要第二个分支,而
master似乎是个不错的选择。下面是master分支的当前状态:$ git log --oneline master 23a558c third master commit 5ec06af second master commit 190d6af first master commit 2512d27 Common Ancestor Commit在
2512d27 Common Ancestor Commit之后的master有三次提交。当您仍然签出my_feature_branch时,您可以执行rebase来将两个特性提交放在主服务器上的三个提交之后:$ git rebase master First, rewinding head to replay your work on top of it... Applying: first feature commit Applying: second feature commit $ git log --oneline cf16517 second feature commit 69f61e9 first feature commit 23a558c third master commit 5ec06af second master commit 190d6af first master commit 2512d27 Common Ancestor Commit在这个日志列表中有两件事需要注意:
1)正如所宣传的,两个特性提交在三个主提交之后。
2)这两个功能提交的 sha 已经更改。
sha 是不同的,因为回购略有不同。提交表示对文件的相同更改,但是因为它们被添加到已经在
master中的更改之上,所以回购的状态是不同的,所以它们具有不同的 sha。如果你做了一个
merge而不是一个rebase,将会有一个新的提交和消息Merge branch 'master' into my_feature_branch,并且两个特性提交的 sha 将保持不变。做一个 rebase 可以避免额外的合并提交,使你的修订历史更加清晰。
git pull -r当您与不同的开发人员一起处理一个分支时,使用 rebase 也是一个方便的工具。如果远程上有更改,并且您有对同一个分支的本地提交,那么您可以在
git pull命令上使用-r选项。当一个普通的git pull对远程分支做一个merge时,git pull -r会在远程分支上的变更的基础上重新调整你的提交。
git rebase -irebase 命令有另一种操作方法。有一个
-i标志可以添加到rebase命令中,使其进入交互模式。虽然这乍一看似乎令人困惑,但它是一个非常强大的特性,让您在将提交推送到远程之前完全控制提交列表。请记住关于不要更改已提交的提交历史的警告。这些例子展示了一个基本的交互式 rebase,但是要注意还有更多的选项和用例。
git rebase --help命令会给你一个列表,并且很好地解释了它们。对于这个例子,您将会想象您一直在使用您的 Python 库,在您实现一个解决方案、测试它、发现一个问题并修复它时,多次提交到您的本地 repo。在这个过程的最后,你有一个本地回购上的提交链,所有这些都是新特性的一部分。一旦你完成了工作,你看着你的
git log:$ git log --oneline 8bb7af8 implemented feedback from code review 504d520 added unit test to cover new bug 56d1c23 more flake8 clean up d9b1f9e restructuring to clean up 08dc922 another bug fix 7f82500 pylint cleanup a113f67 found a bug fixing 3b8a6f2 First attempt at solution af21a53 [older stuff here]这里有几个提交并没有给其他开发人员甚至是未来的你增加价值。您可以使用
rebase -i创建一个“挤压提交”,并将所有这些放入历史中的一个点。要开始这个过程,您可以运行
git rebase -i af21a53,这将显示一个编辑器,其中有一个提交列表和一些指令:pick 3b8a6f2 First attempt at solution pick a113f67 found a bug fixing pick 7f82500 pylint cleanup pick 08dc922 another bug fix pick d9b1f9e restructuring to clean up pick 56d1c23 more flake8 clean up pick 504d520 added unit test to cover new bug pick 8bb7af8 implemented feedback from code review # Rebase af21a53..8bb7af8 onto af21a53 (8 command(s)) # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # d, drop = remove commit # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. # # Note that empty commits are commented out您会注意到提交是以相反的顺序列出的,最早的放在最前面。这是 Git 在
af21a53之上重放提交的顺序。如果您只是在此时保存文件,什么都不会改变。如果删除所有文本并保存文件,也是如此。此外,有几行以
#开头,提醒您如何编辑这个文件。这些评论可以删除,但不是必须删除。但是您希望将所有这些提交压缩成一个,以便“未来的您”知道这是完全添加了该特性的提交。为此,您可以编辑该文件,如下所示:
pick 3b8a6f2 First attempt at solution squash a113f67 found a bug fixing s 7f82500 pylint cleanup s 08dc922 another bug fix s d9b1f9e restructuring to clean up s 56d1c23 more flake8 clean up s 504d520 added unit test to cover new bug s 8bb7af8 implemented feedback from code review您可以使用命令的完整单词,或者像您在前两行之后所做的那样,使用单字符版本。上面的示例选择“挑选”最早的提交,并将每个后续提交“挤压”到那个提交中。如果您保存并退出编辑器,Git 将继续将所有这些提交放入一个编辑器中,然后再次打开编辑器,列出被压缩的提交的所有提交消息:
# This is a combination of 8 commits. # The first commit's message is: Implemented feature ABC # This is the 2nd commit message: found a bug fixing # This is the 3rd commit message: pylint cleanup # This is the 4th commit message: another bug fix [the rest trimmed for brevity]默认情况下,挤压提交会有一个很长的提交消息,包含每次提交的所有消息。在你的情况下,最好改写第一条信息,删除其余的。这样做并保存文件将完成该过程,您的日志现在将只有一个针对该特性的提交:
$ git log --oneline 9a325ad Implemented feature ABC af21a53 [older stuff here]酷!你只是隐藏了任何证据,表明你不得不做一个以上的承诺来解决这个问题。干得好!请注意,决定何时进行挤压合并通常比实际过程更困难。有一篇很棒的文章很好地展示了复杂性。
正如你可能猜到的,
git rebase -i将允许你做更复杂的操作。让我们再看一个例子。在一周的时间里,你处理了三个不同的问题,在不同的时间对每个问题进行了修改。还有一个承诺,你会后悔,会假装从未发生过。这是你的起始日志:
$ git log --oneline 2f0a106 feature 3 commit 3 f0e14d2 feature 2 commit 3 b2eec2c feature 1 commit 3 d6afbee really rotten, very bad commit 6219ba3 feature 3 commit 2 70e07b8 feature 2 commit 2 c08bf37 feature 1 commit 2 c9747ae feature 3 commit 1 fdf23fc feature 2 commit 1 0f05458 feature 1 commit 1 3ca2262 older stuff here你的任务是把它分成三个干净的提交,并去掉一个坏的。您可以遵循相同的过程,
git rebase -i 3ca2262,Git 会向您显示命令文件:pick 0f05458 feature 1 commit 1 pick fdf23fc feature 2 commit 1 pick c9747ae feature 3 commit 1 pick c08bf37 feature 1 commit 2 pick 70e07b8 feature 2 commit 2 pick 6219ba3 feature 3 commit 2 pick d6afbee really rotten, very bad commit pick b2eec2c feature 1 commit 3 pick f0e14d2 feature 2 commit 3 pick 2f0a106 feature 3 commit 3交互式 rebase 不仅允许您指定每次提交要做什么,还允许您重新安排它们。因此,为了得到您的三次提交,您可以编辑该文件,如下所示:
pick 0f05458 feature 1 commit 1 s c08bf37 feature 1 commit 2 s b2eec2c feature 1 commit 3 pick fdf23fc feature 2 commit 1 s 70e07b8 feature 2 commit 2 s f0e14d2 feature 2 commit 3 pick c9747ae feature 3 commit 1 s 6219ba3 feature 3 commit 2 s 2f0a106 feature 3 commit 3 # pick d6afbee really rotten, very bad commit每个特性的提交被分组在一起,其中只有一个被“挑选”,其余的被“挤压”注释掉错误的提交将会删除它,但是您也可以很容易地从文件中删除这一行来达到相同的效果。
当您保存该文件时,您将获得一个单独的编辑器会话,为三个被压缩的提交中的每一个创建提交消息。如果您将它们称为
feature 1、feature 2和feature 3,您的日志现在将只有这三个提交,每个特性一个:$ git log --oneline f700f1f feature 3 443272f feature 2 0ff80ca feature 1 3ca2262 older stuff here就像任何重新定基或合并一样,您可能会在这个过程中遇到冲突,您需要通过编辑文件、纠正更改、
git add-ing 文件并运行git rebase --continue来解决这些冲突。我将通过指出关于 rebase 的一些事情来结束这一部分:
1)创建挤压提交是一个“很好”的特性,但是不使用它也可以成功地使用 Git。
2)大型交互式 rebases 上的合并冲突可能会令人困惑。没有一个步骤是困难的,但是可以有很多
3)我们只是简单介绍了您可以用
git rebase -i做些什么。这里有比大多数人发现的更多的功能。
git revertvsgit reset:清理不足为奇的是,Git 为你提供了几种清理混乱的方法。这些技巧取决于你的回购处于何种状态,以及混乱是发生在你的回购上还是被推到了远处。
让我们从简单的例子开始。您做出了不想要的提交,并且它还没有被推到远程。从创建提交开始,这样你就知道你在看什么了:
$ ls >> file_i_do_not_want $ git add file_i_do_not_want $ git commit -m "bad commit" [master baebe14] bad commit 2 files changed, 31 insertions(+) create mode 100644 file_i_do_not_want $ git log --oneline baebe14 bad commit 443272f feature 2 0ff80ca feature 1 3ca2262 older stuff here上面的示例创建了一个新文件
file_i_do_not_want,并将其提交给本地 repo。它尚未被推送到远程回购。本节中的其余示例将以此为起点。要管理仅在本地 repo 上的提交,可以使用
git reset命令。有两个选项可以探索:--soft和--hard。
git reset --soft <SHA>命令告诉 Git 将磁头移回指定的 SHA。它不会改变本地文件系统,也不会改变索引。我承认当我读到这个描述的时候,它对我来说没有什么意义,但是看看这个例子绝对有帮助:$ git reset --soft HEAD^ $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: file_i_do_not_want $ git log --oneline 443272f feature 2 0ff80ca feature 1 3ca2262 older stuff here在示例中,我们将
HEAD重置为HEAD^。记住^告诉 Git 退回一次提交。--soft选项告诉 Git而不是更改索引或本地文件系统,所以file_i_do_not_want仍然在索引中处于“Changes to commit:”状态。然而,git log命令显示bad commit已从历史中删除。这就是
--soft选项的作用。现在我们来看一下--hard选项。让我们回到原来的状态,让bad commit再次参与回购,并尝试--hard:$ git log --oneline 2e9d704 bad commit 443272f feature 2 0ff80ca feature 1 3ca2262 older stuff here $ git reset --hard HEAD^ HEAD is now at 443272f feature 2 $ git status On branch master nothing to commit, working directory clean $ git log --oneline 443272f feature 2 0ff80ca feature 1 3ca2262 older stuff here这里有几点需要注意。首先,
reset命令实际上在--hard选项上给了你反馈,而在--soft上却没有。老实说,我不知道这是为什么。此外,当我们之后执行git status和git log时,您会看到不仅bad commit消失了,而且提交中的更改也被清除了。--hard选项将您完全重置回您指定的 SHA。现在,如果您还记得关于在 Git 中更改历史的最后一节,您会发现对已经推送到远程的分支进行重置可能是个坏主意。它改变了历史,这真的会让你的同事感到困惑。
当然,Git 有一个解决方案。
git revert命令允许您轻松地从给定的提交中删除更改,但不会更改历史。它通过执行与您指定的提交相反的操作来实现这一点。如果您在文件中添加了一行,git revert将从文件中删除该行。它会这样做,并自动为您创建一个新的“恢复提交”。再次将回购重置回最近一次提交的时间点
bad commit。首先确认bad commit有什么变化:$ git diff HEAD^ diff --git a/file_i_do_not_want b/file_i_do_not_want new file mode 100644 index 0000000..6fe5391 --- /dev/null +++ b/file_i_do_not_want @@ -0,0 +1,6 @@ +file1 +file2 +file3 +file4 +file_i_do_not_want +growing_file您可以看到,我们只是将新的
file_i_do_not_want添加到了回购中。@@ -0,0 +1,6 @@下面的行是新文件的内容。现在,假设这次你已经把那个bad commit推到了主人面前,你不想让你的同事讨厌你,使用 revert 来修复这个错误:$ git revert HEAD [master 8a53ee4] Revert "bad commit" 1 file changed, 6 deletions(-) delete mode 100644 file_i_do_not_want当您运行该命令时,Git 将弹出一个编辑器窗口,允许您修改 revert commit 的提交消息:
Revert "bad commit" This reverts commit 1fec3f78f7aea20bf99c124e5b75f8cec319de10. # Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # On branch master # Changes to be committed: # deleted: file_i_do_not_want #与
commit不同,git revert没有在命令行上指定提交消息的选项。您可以使用-n跳过消息编辑步骤,告诉 Git 简单地使用默认消息。在我们恢复错误的提交后,我们的日志显示一个新的提交,并显示以下消息:
$ git log --oneline 8a53ee4 Revert "bad commit" 1fec3f7 bad commit 443272f feature 2 0ff80ca feature 1 3ca2262 older stuff here“错误提交”仍然存在。它需要在那里,因为你不想在这种情况下改变历史。然而,有一个新的提交,它“撤销”了该提交中的更改。
git clean我发现另一个“清理”命令很有用,但是我想提出一个警告。
注意:使用
git clean可以清除未提交给回购的文件,您将无法恢复这些文件。如你所料:它会清理你的本地工作目录。我发现当一些大的错误发生,并且我的文件系统上有几个我不想要的文件时,这非常有用。
在其简单的形式中,
git clean简单地删除不在“版本控制之下”的文件这意味着当你查看git status时,出现在Untracked files部分的文件将从工作树中移除。如果您不小心这样做了,没有办法恢复,因为那些文件不在版本控制中。这很方便,但是如果您想删除使用 Python 模块创建的所有
pyc文件,该怎么办呢?这些都在你的.gitignore文件中,所以它们不会显示为未被追踪,也不会被git clean删除。
-x选项告诉git clean删除未被跟踪和忽略的文件,所以git clean -x会处理这个问题。差不多了。Git 对
clean命令有点保守,除非你告诉它这样做,否则不会删除未被跟踪的目录。Python 3 喜欢创建__pycache__目录,清理这些目录也很好。要解决这个问题,您可以添加-d选项。git clean -xd将清理所有未被跟踪和忽略的文件和目录。现在,如果你已经测试过了,你会发现它实际上并不工作。还记得我在本节开始时给出的警告吗?Git 在删除无法恢复的文件时会尽量谨慎。因此,如果您尝试上面的命令,您会看到一条错误消息:
$ git clean -xd fatal: clean.requireForce defaults to true and neither -i, -n, nor -f given; refusing to clean虽然可以将 git 配置文件改为不需要它,但我交谈过的大多数人都习惯于将
-f选项和其他选项一起使用:$ git clean -xfd Removing file_to_delete再次警告,
git clean -xfd将删除您无法恢复的文件,因此请谨慎使用!解决合并冲突
当您刚接触 Git 时,合并冲突似乎是一件可怕的事情,但是通过一些实践和技巧,它们可以变得更容易处理。
让我们从一些可以使这变得更容易的技巧开始。第一个改变了冲突显示的格式。
diff3格式我们将通过一个简单的例子来了解 Git 在默认情况下做什么,以及我们有哪些选项可以使它变得更简单。为此,创建一个新文件
merge.py,如下所示:def display(): print("Welcome to my project!")将这个文件添加并提交到您的分支
master,这将是您的基线提交。您将创建以不同方式修改该文件的分支,然后您将看到如何解决合并冲突。您现在需要创建具有冲突变更的独立分支。您已经看到了这是如何实现的,所以我就不详细描述了:
$ git checkout -b mergebranch Switched to a new branch 'mergebranch' $ vi merge.py # edit file to change 'project' to 'program' $ git add merge.py $ git commit -m "change project to program" [mergebranch a775c38] change project to program 1 file changed, 1 insertion(+), 1 deletion(-) $ git status On branch mergebranch nothing to commit, working directory clean $ git checkout master Switched to branch 'master' $ vi merge.py # edit file to add 'very cool' before project $ git add merge.py $ git commit -m "added description of project" [master ab41ed2] added description of project 1 file changed, 1 insertion(+), 1 deletion(-) $ git show-branch master mergebranch * [master] added description of project ! [mergebranch] change project to program -- * [master] added description of project + [mergebranch] change project to program *+ [master^] baseline for merging此时,您在
mergebranch和master上有冲突的变更。使用我们在介绍教程中学到的show-branch命令,您可以在命令行上直观地看到这一点:$ git show-branch master mergebranch * [master] added description of project ! [mergebranch] change project to program -- * [master] added description of project + [mergebranch] change project to program *+ [master^] baseline for merging你在分支
master上,所以让我们试着在mergebranch中合并。既然您已经做了更改,并打算创建一个合并冲突,让我们希望这种情况发生:$ git merge mergebranch Auto-merging merge.py CONFLICT (content): Merge conflict in merge.py Automatic merge failed; fix conflicts and then commit the result.正如您所料,存在合并冲突。如果你看看状态,那里有很多有用的信息。它不仅显示您正在进行合并,
You have unmerged paths,还显示您修改了哪些文件,merge.py:$ git status On branch master You have unmerged paths. (fix conflicts and run "git commit") Unmerged paths: (use "git add <file>..." to mark resolution) both modified: merge.py no changes added to commit (use "git add" and/or "git commit -a")你已经做了所有的工作,得到了一个合并冲突的点。现在你可以开始学习如何解决它了!在第一部分中,您将使用命令行工具和编辑器。在那之后,您将会发现使用 visual diff 工具来解决这个问题。
当您在编辑器中打开
merge.py时,您可以看到 Git 产生了什么:def display(): <<<<<<< HEAD print("Welcome to my very cool project!") ======= print("Welcome to my program!") >>>>>>> mergebranchGit 使用 Linux 中的
diff语法来显示冲突。顶端部分,在<<<<<<< HEAD和=======之间,来自头部,在你的例子中是master。最下面的部分,在=======和>>>>>>> mergebranch之间,你猜对了,是来自mergebranch。现在,在这个非常简单的例子中,很容易记住哪些更改来自哪里以及我们应该如何合并它,但是有一个设置可以使这变得更容易。
diff3设置将合并冲突的输出修改为更接近三路合并,这意味着在这种情况下,它将向您显示master中的内容,然后是它在共同祖先中的样子,最后是它在mergebranch中的样子:def display(): <<<<<<< HEAD print("Welcome to my very cool project!") ||||||| merged common ancestors print("Welcome to my project!") ======= print("Welcome to my program!") >>>>>>> mergebranch现在你可以看到起点了,“欢迎来到我的项目!”,您可以确切地看到在
master上做了什么更改,在mergebranch上做了什么更改。对于这样一个简单的例子来说,这似乎没什么大不了的,但是对于大的冲突来说,尤其是在别人做了一些更改的合并中,这可能会产生巨大的影响。您可以通过发出以下命令在 Git 中全局设置该选项:
$ git config --global merge.conflictstyle diff3好了,你知道如何看待冲突了。让我们来看看如何修复它。首先编辑文件,删除 Git 添加的所有标记,并更正冲突的一行:
def display(): print("Welcome to my very cool program!")然后,将修改后的文件添加到索引中,并提交合并。这将完成合并过程并创建新节点:
$ git add merge.py $ git commit [master a56a01e] Merge branch 'mergebranch' $ git log --oneline a56a01e Merge branch 'mergebranch' ab41ed2 added description of project a775c38 change project to program f29b775 baseline for merging合并冲突也可能在你挑选的时候发生。摘樱桃的过程略有不同。不使用
git commit命令,而是使用git cherry-pick --continue命令。别担心,Git 会在状态消息中告诉你需要使用哪个命令。你可以随时回去检查,以确保这一点。
git mergetool与
git difftool类似,Git 将允许您配置一个可视化比较工具来处理三向合并。它知道不同操作系统上的几种不同的工具。您可以使用下面的命令查看它知道的您系统上的工具列表。在我的 Linux 机器上,它显示以下内容:$ git mergetool --tool-help 'git mergetool --tool=<tool>' may be set to one of the following: araxis gvimdiff gvimdiff2 gvimdiff3 meld vimdiff vimdiff2 vimdiff3 The following tools are valid, but not currently available: bc bc3 codecompare deltawalker diffmerge diffuse ecmerge emerge kdiff3 opendiff p4merge tkdiff tortoisemerge winmerge xxdiff Some of the tools listed above only work in a windowed environment. If run in a terminal-only session, they will fail.同样与
difftool类似,您可以全局配置mergetool选项以使其更易于使用:$ git config --global merge.tool meld $ git config --global mergetool.prompt false最后一个选项
mergetool.prompt,告诉 Git 不要在每次打开窗口时都提示您。这听起来可能不烦人,但是当你的合并涉及到几个文件时,它会在每个文件之间提示你。结论
您已经在这些教程中涉及了很多内容,但是还有很多内容需要学习。如果您想更深入地了解 Git,我可以推荐这些资源:
- 免费的在线工具是一个非常方便的参考。
- 对于那些喜欢在纸上阅读的人来说,有一个印刷版本的 Pro Git ,我发现奥赖利的版本控制与 Git 在我阅读时很有用。
--help对你知道的任何子命令都有用。git diff --help产生近 1000 行信息。虽然其中的一些内容非常详细,并且其中一些假设您对 Git 有很深的了解,但是阅读您经常使用的命令的帮助可以教会您如何使用它们的新技巧。*********Python 开发人员的高级 Visual Studio 代码
原文:https://realpython.com/advanced-visual-studio-code-python/
Visual Studio Code,简称 VS Code ,是微软免费开放的源代码编辑器。可以将 VS 代码作为轻量级代码编辑器进行快速修改,也可以通过使用第三方扩展将其配置为集成开发环境(IDE) 。在本教程中,您将了解如何在 Python 开发中充分利用 VS 代码。
在本教程中,您将学习如何配置、扩展和优化 VS 代码,以获得更高效的 Python 开发环境。完成本教程后,您将拥有多种工具来帮助您更高效地使用 VS 代码。它可以成为快速 Python 开发的强大工具。
在本教程中,您将学习如何:
- 定制您的用户界面
- 运行并监控 Python 测试
- 皮棉和自动格式化你的代码
- 利用类型注释和通孔以更高的准确性更快地编写代码
- 配置和利用本地和远程调试
- 设置数据科学工具
像往常一样,本教程充满了链接、提示和技巧,以帮助您上路。
如果你还没有安装 Visual Studio 代码或者 Python 扩展,那么在本教程中你需要这两个。如果你刚刚开始学习 VS 代码,在继续学习这篇之前,你可能想看看 Jon Fincher 关于用 Visual Studio 代码开发 Python 的教程。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
掌握 Visual Studio 代码用户界面
默认情况下,VS Code 的用户界面是为所有人设计的——无论你是在编写 C++,用 JavaScript 和 CSS 做前端开发,还是使用 Jupyter 笔记本这样的数据科学工具。在第一部分中,您将探索如何定制 VS 代码来支持您的工作方式。
键盘快捷键
几乎所有你在 VS 代码中做的事情,你都可以直接从键盘上完成。您可以将 VS 代码中的所有活动映射到一个键盘快捷键,无论它们是内置的还是通过扩展提供的。
一小部分内置命令已经映射在键盘快捷键中。如果你想学习这些默认快捷键,打印出适用于 Windows 、 macOS 或 Linux 的 PDF 文件,并把它钉在你的显示器旁边。
作为 Python 开发人员,您将在 Visual Studio 代码中使用的许多命令都是由扩展提供的,类似于您已经安装的 Python 扩展。这些没有默认映射的快捷键,但是你可以使用 VS Code 的键盘快捷键编辑器来配置它们。
使用键盘快捷键编辑器
在 macOS 上,进入文件→首选项→键盘快捷键或代码→首选项→键盘快捷键,打开键盘快捷键编辑器:
在此编辑器中,您可以看到所有现有快捷方式的列表及其详细信息:
- 命令:要运行的命令或动作
- 组合键:触发该命令的按键顺序,空白表示没有映射
- When :该键绑定工作需要满足的条件,减号(
-)表示没有要求- Source :这个绑定被配置的地方,要么由默认、用户定义,要么由扩展定义,最后一个表示你是通过安装一个键映射扩展提供的
要覆盖现有的绑定,右键单击现有的动作,然后单击 Change Keybinding 。要将 keybinding 分配给没有绑定的命令,请双击它。如果你按下的键序列已经被分配给其他的东西,VS Code 会警告你一个链接,看看哪些命令被映射到这个 keybinding。
例如,在顶部的搜索框中键入
python create terminal。如果没有结果,请确保安装了 Python 扩展。按Enter分配一个键位绑定,像Ctrl+Alt+T,然后再按Enter。要指定该快捷方式仅在编辑 Python 代码时工作,右键单击该快捷方式并选择当表达式改变时。输入表达式
editorLangId == 'python':
如果你需要更具体的东西,有更多的条件操作符可以选择。以下是一些帮助您入门的示例:
- 当您正在编辑的文件是
__init__.py时,使用resourceFilename == '__init__.py'- 使用 Python 时使用
editorLangId == 'python'。如果需要,您也可以用另一个语言标识符替换'python'。- 当你在编辑器里面的时候,使用
editorHasSelection。一旦你配置了这个扩展,在编辑器中打开一个 Python 文件,按下你新分配的键盘快捷键
Ctrl+Alt+T打开一个 Python 终端。从命令调板设置命令的键盘快捷键
在本教程中,你会多次引用命令面板。VS 代码中的大多数功能都可以通过 UI 从上下文菜单中访问,但是你不会在那里找到所有的东西。可以在核心编辑器中或通过扩展完成的任何事情都可以在命令面板中找到。您可以通过按以下键盘快捷键之一进入命令调板:
- macOS:
F1或Cmd+Shift+P- Windows 或 Linux:
F1或Ctrl+Shift+P要运行命令,请键入其描述性名称,如
Python: Run All Tests。命令调板打开后,您需要的命令出现在菜单顶部,单击右侧的图标以指定键盘快捷键:
一旦你开始经常使用命令面板,你会发现有五到十个命令是你经常运行的。为这些命令分配一些快捷键,这样可以节省一些额外的击键次数。
从其他编辑器安装键盘映射
如果您已经在另一个编辑器或 IDE 中工作了一段时间,您可能会将常用的键盘快捷键保存在内存中。
你会在 Vim 、 IntelliJ 和 PyCharm 、 Sublime Text 、 Notepad++ 、 Emacs 和 Atom 的扩展中找到有用的键盘映射。
如果您之前的编辑器不在此列表中,您可能会发现其他人已经为您创建了一个制图扩展。键映射是 VS 代码扩展市场上一个有用的类别。
一旦你安装了一个键映射扩展,你可能会发现除了缺省值之外,还有额外的选项来定制它。例如,您可以使用 Vim keymap 扩展来配置 Vim 特性,比如是否以插入模式启动。
定制用户界面
当你跳进汽车的驾驶座时,首先要做的是调整座椅,调整后视镜,并将转向柱调到合适的高度。代码编辑器也不例外。它们有一个默认的布局,对每个人来说都可以,但对任何人来说都不是特别好。你不想伸展身体去够踏板。让我们来设置您的 VS 代码环境以适合您,并使它看起来很棒。
首先,VS 代码左侧的活动栏是在用于查看文件的浏览器视图、源代码控制视图、搜索视图、运行和调试视图以及扩展视图之间切换的主要导航工具。你不局限于这些选项。许多扩展都带有默认隐藏的视图。右键单击活动栏来控制您可以看到哪些视图:
您也可以使用此菜单隐藏任何您从不使用的视图。请记住,您并不局限于列表中的视图。如果主视图中有一些面板——例如,您可以在浏览器视图中找到一些额外的面板——您可以将它们拖到活动栏来创建一个永久的快捷方式:
对于您一直使用的视图,请使用此功能。
使用分屏
Python 的风格指南 PEP 8 ,倾向于短线长度。对于宽屏幕,这留下了大量未使用的屏幕空间。
当您发现自己需要在两个或多个文件之间切换时,可以使用拆分面板功能一次显示多个编辑器区域。您可以使用命令
View: Split Editor通过命令面板访问该功能。或者,您可以使用相关的键盘快捷键:
- MAC OS:
Cmd+\- Windows 或者 Linux:
Ctrl+\您也可以通过进入视图→编辑器布局或右击文件标签来打开拆分编辑器功能:
这种设置在编写单元测试时非常有用,测试代码在左边,测试模块在右边。
有些文件类型,如 Markdown,有一个预览区域,您可以使用。使用
Markdown: Open Preview to the Side命令打开预览编辑器。使用禅模式专注工作
如果你需要完全专注于 VS 代码中的单个文件或任务,那么进入视图→外观→ Zen 模式使用 Zen 模式,显示一个只有编辑器的全屏窗口:
这项功能对于屏蔽嘈杂的干扰和通知特别有用,这样您就可以专注于完成当前的任务。
主题化
VS 代码在 VS 代码市场中有一个庞大的主题库。一些最受欢迎的主题有物质主题、冬天来了、吸血鬼、夜魔和 Monokai Pro 。
让我们来关注一下材质主题,因为它有一套广泛的配色方案来满足许多人的口味。你可以从扩展视图安装扩展。安装完成后,您可以通过在命令面板中运行
Preferences: Color Theme来选择颜色主题。自定义图标主题的材质主题看起来最好。图标主题是独立于颜色主题的扩展,所以你必须安装第二个扩展。在扩展视图中搜索
pkief.material-icon-theme,找到该主题最流行的材质图标包。安装后,VS 代码会提示你切换你的图标包。这是带有 Palenight 颜色主题和材料图标包的材料主题:
通过使用命令
Preferences: File Icon Theme并从列表中选择一个图标主题,您可以在命令面板中随时更改图标主题。安装更好的编程字体
编程字体是一组特殊的字体,通常具有固定宽度的字符,称为等宽。在 ProgrammingFonts.org 的有一长串可供浏览的字体:
一旦你选择了一种字体,去 Nerd Fonts 下载并在你的操作系统上安装该字体。Nerd Fonts 下载的是支持字形的等宽字体的副本,也称为图标,可以在终端提示符中使用。
安装好你选择的字体后,你需要将
editor.fontFamily设置更改为新字体的名称。你可以通过导航到代码→首选项→设置,然后在导航下拉菜单中选择文本编辑器→字体来完成。您可以通过在字体系列设置的第一个字段中添加新字体的名称来更改编辑器将使用的字体。设置您的终端
您将在 shell 终端中花费大量的 Python 开发时间。您可以使用单独的应用程序,如 iTerm2 或 Windows 终端,但 VS 代码已经有一个强大的内置终端窗口。
因为 VS 代码确实需要一点配置来使它像专用终端应用程序一样强大,所以现在您将设置它。
更改默认外壳提供者
您可以将“终端”窗口重新配置为具有多个描述文件。当您生成新的终端时,这些配置文件形成下拉列表。
VS 代码允许您配置多个终端配置文件。您不能在设置 UI 中编辑终端配置文件,因此您需要使用命令调板中的
Preferences: Open Settings (JSON)命令来打开settings.json文件。您会注意到键值对组成了设置文件。每个键代表 VS 代码或其扩展之一的配置设置。有三种终端配置文件设置,其名称如下:
操作系统 终端配置文件设置 Windows 操作系统 terminal.integrated.profiles.windowsLinux 操作系统 terminal.integrated.profiles.linux马科斯 terminal.integrated.profiles.osx输入名称后,编辑器会自动将默认概要文件填充到 JSON 文件中。
请注意,默认设置中没有 Python REPL 配置文件。您可以将带有关键字
"python3-repl"的概要文件添加到 integrated profiles JSON 文件中,这样 VS 代码就可以将它作为一个概要文件选项,并直接进入 REPL 提示符:"python3-repl": { "path": "python3", "args": ["-q"] }
-q标志是一个 Python 命令行标志,用于阻止版本头的显示。您可以向"args"添加任何额外的 Python 命令行标志。配置完成后,根据您的操作系统,您的配置文件应该如下所示:
"terminal.integrated.profiles.osx": { "bash": { "path": "bash", "icon": "terminal-bash", }, "zsh": { "path": "zsh" }, "pwsh": { "path": "pwsh", "icon": "terminal-powershell", }, "python3-repl": { "path": "python3", "args": ["-q"] } },VS 码对终端有两种发射方式:集成和外接。配置好配置文件后,您可以通过设置
"terminal.integrated.defaultProfile.osx"的值来设置集成终端的默认配置文件:"terminal.integrated.defaultProfile.osx": "zsh",如果某个东西在外部终端启动,它将使用你的操作系统的默认外壳。如果您喜欢不同的终端应用程序,如 macOS 的 iTerm 2 或 Windows 的 Windows 终端,您也可以更改默认的外部终端:
"terminal.external.osxExec": "iTerm.app",例如,对于 macOS 的这种设置,您说 VS 代码应该在每次启动外部终端窗口时调出 iTerm 应用程序。
关于 VS 代码中的终端,您甚至可以更改更多的设置。例如,当您调出一个新的终端窗口时,您可以让 VS 代码自动激活您的虚拟环境,并且您可以通过添加自定义提示来自定义您的终端的外观和感觉。在本教程中,您将探索如何做到这两点。
终端中的虚拟环境激活
虚拟环境对于管理跨 Python 项目的多种依赖关系非常重要。一旦选择了解释器,Visual Studio 代码将激活任何 Python 虚拟环境。如果您已经有了一个虚拟环境,从命令面板运行
Python: Select Interpreter来选择 Python 解释器虚拟环境。如果没有,那么在终端内部创建一个。如果虚拟环境路径被命名为
.venv/、env/或venv/,VS 代码可以自动拾取它。设置解释器后,当您在 VS 代码中启动一个新的终端窗口时,您将自动激活虚拟环境:
如果您已经打开了一个终端,您可以通过单击垃圾桶图标来销毁它。
您在终端内部运行的任何命令,如
python -m pip install,都将用于激活的虚拟环境。在上面的截图中,您可以看到一个自定义的命令提示符,它使用了 Oh My Posh prompt toolkit。在下一节中,您将安装和配置 Oh My Posh。哦,我的 Posh 是可选的,尤其是如果你已经安装了自定义命令提示符。
安装我的豪华轿车
Oh My Posh 是众多定制终端命令提示符的库之一。它可以在 Linux、macOS 和 Windows 上运行。它也适用于所有 Shell,如 Bash、Zsh、Fish 和 PowerShell。你可以安装 Oh My Posh 来增加你终端的趣味。
如果您在 macOS 上使用 Bash,运行以下命令来安装 Oh My Posh:
$ brew tap jandedobbeleer/oh-my-posh $ brew install oh-my-posh $ curl https://github.com/JanDeDobbeleer/oh-my-posh/raw/main/themes/tonybaloney.omp.json -sLo ~/.mytheme.omp.json $ echo "eval \"\$(oh-my-posh --init --shell bash --config ~/.mytheme.omp.json)\"" >> ~/.profile $ . ~/.profile如果您在 macOS 上使用 Zsh,运行以下命令来安装 Oh My Posh:
$ brew tap jandedobbeleer/oh-my-posh $ brew install oh-my-posh $ curl https://github.com/JanDeDobbeleer/oh-my-posh/raw/main/themes/tonybaloney.omp.json -sLo ~/.mytheme.omp.json $ echo "eval \"\$(oh-my-posh --init --shell bash --config ~/.mytheme.omp.json)\"" >> ~/.zprofile $ . ~/.zprofile如果您在 Windows 上使用 PowerShell,运行以下命令来安装 Oh My Posh:
PS C:\> Install-Module oh-my-posh -Scope CurrentUser PS C:\> Add-Content $PROFILE "`nSet-PoshPrompt -Theme tonybaloney"最后,如果您在 Linux 上使用 Bash,运行以下命令来安装 Oh My Posh:
$ sudo wget https://github.com/JanDeDobbeleer/oh-my-posh/releases/latest/download/posh-linux-amd64 -O /usr/local/bin/oh-my-posh $ sudo chmod +x /usr/local/bin/oh-my-posh $ curl https://github.com/JanDeDobbeleer/oh-my-posh/raw/main/themes/tonybaloney.omp.json -sLo ~/.mytheme.omp.json $ echo "eval \"\$(oh-my-posh --init --shell bash --config ~/.mytheme.omp.json)\"" >> ~/.bashrc $ . ~/.bashrc当您在 VS 代码中打开一个新的终端时,您将得到以下提示:
终端上的组件是文件夹、Git 分支和 Python 版本。查看主题列表中的其他选项。
注意:如果你正在使用定制的终端提示,如 Oh My Posh 或 Oh My Zsh ,你必须选择一个已安装的书呆子字体,以便字形在 VS 代码中正确显示。
默认情况下,终端将使用您为编辑器配置的相同字体,
editor.fontFamily。您可以通过为terminal.integrated.fontFamily标识符定义不同的字体系列来覆盖它。您还需要更新您使用的任何外部终端应用程序。团队设置 vs 个人设置
VS 代码有两个级别的设置:
- 用户设置,适用于所有项目
- 工作区设置,仅适用于该工作区
如果在两者中都声明了设置,工作区设置将覆盖用户设置。
VS 代码及其所有扩展的工作区配置位于工作区根目录下的一个
.vscode/目录中。将与项目无关的设置放在用户设置中,将特定于项目的设置放在
.vscode/中是一个好主意。通过将您的个人用户设置与您的项目设置分开,您和从事该项目的任何其他开发人员都可以更有效地工作。Python 的全局用户设置
默认情况下,Visual Studio 代码的 Python 扩展具有非常基本的配置。许多功能如林挺、格式化和安全检查被禁用,因为你需要安装第三方工具如 Black、Pylint 和 Bandit 来使用它们。
您可以安装这些工具,并通过使用
pipx或pip install --user让它们对每个虚拟环境可用。pipx比pip install --user更可取,因为它将为该包创建并维护一个虚拟环境,使您的全球站点包更小,并降低打包冲突的风险。一旦安装了
pipx,就可以安装常用工具了:$ pipx install pylint && \ pipx install black && \ pipx install poetry && \ pipx install pipenv && \ pipx install bandit && \ pipx install mypy && \ pipx install flake8或者,使用
python3 -m pip install --user安装常用工具:$ python3 -m pip install --user pylint black poetry pipenv bandit mypy flake8安装好基础工具后,用
Preferences: Open Settings (JSON)从命令面板打开用户设置。为您想要应用到所有项目的偏好设置添加设置:1"python.pipenvPath": "${env:HOME}/.local/bin/pipenv", 2"python.poetryPath": "${env:HOME}/.local/bin/poetry", 3"python.condaPath": "${env:HOME}/.local/bin/conda", 4"python.linting.enabled": true, 5"python.linting.banditPath": "${env:HOME}/.local/bin/bandit", 6"python.linting.banditEnabled": true, 7"python.linting.pylintPath": "${env:HOME}/.local/bin/pylint", 8"python.linting.mypyPath": "${env:HOME}/.local/bin/mypy", 9"python.linting.flake8Path": "${env:HOME}/.local/bin/flake8", 10"python.formatting.blackPath": "${env:HOME}/.local/bin/black",有了这些设置,您已经成功地完成了几件事,这对您跨许多项目的开发工作流很有用:
- 第 1 行到第 3 行为启用了
pipenv、poetry和conda的项目启用包发现。- 第 4 行启用 Python 林挺。
- 线 5 至线 6 使能并将路径设置为
bandit。- 第 7 到 10 行启用 Python 格式化,并设置路径到一个全局安装的
pylint、mypy、flake8和black实例。在每个绝对路径中,您可以使用宏
${env:HOME}自动替换您的主文件夹。工作区设置
在用户设置之外,您可以使用工作区内的
.vscode/目录来配置一些特定于项目的设置:
- 哪个命令运行以执行项目
- 如何测试和调试项目
- 使用哪个棉绒和格式器以及任何项目特定参数
以下文件包含 VS 代码首选项:
文件 目的 settings.jsonVS 代码设置 launch.json从运行和调试菜单执行项目的配置文件 tasks.json要执行的任何附加任务,如构建步骤 大多数 VS 代码的设置,以及您的扩展的设置,都在这三个文件中。
在工作区首选项中,支持以下预定义变量:
预定义变量 意义 ${env.VARIABLE}任何环境变量 ${workspaceFolder}在 VS 代码中打开的文件夹的路径 ${workspaceFolderBasename}在 VS 代码中打开的文件夹的名称,不带任何斜杠( /)${file}当前打开的文件 ${fileWorkspaceFolder}当前打开的文件的工作区文件夹 ${relativeFile}当前打开的文件相对于 workspaceFolder${cwd}启动时任务运行程序的当前工作目录 ${execPath}正在运行的 VS 代码可执行文件的路径 ${pathSeparator}操作系统用来分隔文件路径中各部分的字符,例如,正斜杠( /)或反斜杠(\)使用这些变量将保持项目设置与环境无关,因此您可以将它们提交到 Git 中。
作为使用这些设置的一个例子,如果您想使用 Black 作为这个项目的默认代码格式化程序,您可以用这个配置创建文件
.vscode/settings.json:{ "python.formatting.provider": "black", }任何签出这个项目的人现在将自动使用 Black 作为 Python 文件的格式化程序。在关于设置格式和 lint on save 的章节中,您将看到该设置如何影响自动套用格式选项。
使用设置同步扩展
如果您在多台计算机上使用 VS 代码,您可以启用设置、键盘快捷键、用户代码片段、扩展和 UI 状态的自动同步。如果你以前没有使用过设置同步,你需要启用它:
- 在命令面板中运行
Settings Sync: Turn On。- 按照 VS 代码提示的设置步骤进行操作。可以用 GitHub 认证。
- 一旦设置完成,从命令面板运行
Settings Sync: Configure。- 选择您想要同步的内容。
一旦在所有安装了 VS 代码的计算机上配置了设置同步,你可以通过从命令面板运行
Settings Sync: Show Synced Data来查看每个同步设置的状态,它们会显示在同步机器下:
此视图显示每个设置的上次同步时间以及哪些机器正在同步。
林挺和格式化
Visual Studio 代码中的所有语言都可以使用自动格式化程序之一进行格式化,Python 扩展也支持 linters。Linters 和 formatters 执行不同的任务:
- 一个格式化程序将改变你的代码的外观,但不会改变它的工作方式。
- 一个 linter 会警告你你的代码是否符合风格、类型坚持、安全性和一系列最佳实践的标准。
Python 扩展支持许多第三方 linters,它们经常执行不同的工作。例如, Bandit 是一个针对安全漏洞的贴体, Flake8 是一个符合风格指南的贴体。
Python 扩展还附带了语言服务器工具,它通过从您的代码和您使用的库中加载接口(方法、函数、类)来执行分析。
在写这篇教程的时候,Visual Studio 代码上最新最棒的 Python 语言服务器扩展是 Pylance 。
设置挂架
Pylance 是一个扩展,在 Visual Studio 代码中与 Python 一起工作,提供更深层次的语言支持和 Python 代码的自省。Pylance 将提供自动完成、自动化模块导入、更好的代码导航、类型检查以及更多的功能。
要获得 Pylance,进入侧边栏上的扩展菜单并搜索
Pylance(ms-python.vscode-pylance)。注意: Pylance 现在与 Python 扩展捆绑在一起,所以您可能已经安装了它。
一旦你安装了 Pylance,在你的用户设置中有两个默认的配置设置你可能想要改变,以充分利用这个扩展。
第一个要更改的设置是类型检查模式,您可以使用该模式来指定所执行的类型检查分析的级别:
"python.analysis.typeCheckingMode": "basic"默认情况下,类型检查模式设置为
"off"。其他选项是
"basic"或"strict"。使用"basic",运行与类型检查无关的规则和基本类型检查规则。如果模式设置为"strict",它将以最高的错误严重性运行所有类型检查规则。将此项设置为"basic"以在严格和禁用之间取得平衡。另一个默认设置是
python.analysis.diagnosticMode。默认情况下,Pylance 将只检查当前打开的文件。将此设置更改为workspace将检查工作区中的所有 Python 文件,在浏览器视图中给您一个错误和警告列表:
如果你有多余的内存,你应该只设置
python.analysis.diagnosticMode到"workspace",因为它会消耗更多的资源。当 Pylance 拥有关于用作方法和函数的参数的类型以及返回类型的信息时,它是最有效的。
对于外部库,Pylance 将使用typed来推断返回类型和参数类型。Pylance 还为一些最流行的数据科学库提供了类型存根和智能,如 pandas、Matplotlib、scikit-learn 和 NumPy。如果你在和熊猫一起工作,Pylance 会给你一些常见功能和模式的信息和例子:
对于在 typeshed 上没有类型存根的库,Pylance 会尽力猜测类型是什么。否则,你可以添加你自己的类型存根。
保存时设置格式和 Lint
格式化文档是一个将格式应用于 VS 代码中任何文档的动作。对于 Python 扩展,这个动作执行
"python.formatting.provider",它可以被设置为任何支持的自动格式化程序:"autopep8"、"black"或"yapf"。一旦您在
settings.json中配置了格式化程序,您可以设置格式化程序在保存文件时自动运行。在 VS 代码配置中,您可以将编辑器设置配置为只应用于某些文件类型,方法是将它们放在一个"[<file_type>]"组中:... "[python]": { "editor.formatOnSave": true, },除了执行格式化程序之外,您还可以按字母顺序组织导入语句,并通过将标准库模块、外部模块和包导入分成具有以下配置的组:
"[python]": { ... "editor.codeActionsOnSave": {"source.organizeImports": true}, },与格式化不同,林挺特定于 Python 扩展。要启用林挺,在命令面板上运行
Python: Select Linter选择一个 linter。您也可以在您的设置中启用一个或多个棉条。例如,要启用 Bandit 和 Pylint linters,请编辑您的settings.json:... "python.linting.enabled": true, "python.linting.banditEnabled": true, "python.linting.pylintEnabled": true,要在保存文件时运行启用的 linters,将以下设置添加到
settings.json:... "python.linting.lintOnSave": true,您可能会发现启用多个 linter 很有帮助。请记住,Pylance 已经提供了许多您可以从 pylint 获得的见解,因此您可能不需要同时启用 pylint 和 Pylance。相比之下,Flake8 提供了 Pylance 没有涵盖的风格反馈,因此您可以一起使用这两者。
在 Visual Studio 代码中测试您的 Python 代码
Python 提供了大量的工具来测试你的代码。VS 代码的 Python 扩展支持最流行的测试框架,
unittest和pytest。配置测试集成
要启用对 Python 的测试支持,请从命令面板运行
Python: Configure Tests命令。VS 代码将提示您从一个支持的测试框架中进行选择,并指定哪个文件夹包含您的测试。该向导将配置选项添加到
.vscode/settings.json:"python.testing.pytestEnabled": true, "python.testing.pytestArgs": [ "tests" ],您可以用您喜欢的测试框架编辑
python.testing.<framework>Args,以添加任何额外的命令行标志。上面的例子显示了 pytest 的配置选项。如果你有更复杂的 pytest 设置,把它们放在
pytest.ini而不是 VS 代码设置中。这样,您将保持配置与任何自动化测试或 CI/CD 工具一致。执行测试
一旦您为测试运行器配置了测试框架和参数,您就可以通过从命令面板运行
Python: Run All Tests命令来执行您的测试。这将使用配置的参数启动测试运行器,并将测试输出放入 Python 测试日志输出面板:
一旦测试发现完成,每个测试用例将有一个内联选项来执行或调试该用例:
失败的测试将被标记为有错误。您可以在 Python 测试日志面板中看到测试运行程序的失败,也可以将鼠标悬停在代码中失败的测试用例上:
如果您经常运行测试,您可以使用测试浏览器改善您在 VS 代码中的测试体验。
要启用测试面板,右键单击侧栏并确保选中了测试。测试面板显示 Python 扩展发现的所有测试,并为您提供许多功能:
您有一个测试套件分组以及哪些测试失败的可视化表示。您还可以使用菜单按钮来运行和调试测试。
VS Code 的测试系统很强大,但是很多功能在默认情况下是禁用的,以保持它是一个轻量级的编辑器。除了测试之外,您可能还想从 VS 代码内部定期运行其他任务。这就是任务系统的用武之地。
使用 Visual Studio 代码任务系统
Visual Studio 代码支持编译语言,如 Go、Rust 和 C++,也支持解释语言,如 Python 和 Ruby。VS Code 有一个灵活的系统来执行用户定义的配置好的任务,比如构建和编译代码。
Python 代码通常不需要提前编译,因为 Python 解释器会为你做这件事。相反,您可以使用任务系统来预配置任务,否则您将在命令行运行这些任务,例如:
- 构建一个轮或源分布
- 在像 Django 这样的框架中运行任务
- 编译 Python C 扩展
VS 代码任务是命令或可执行文件,您可以使用命令面板按需运行。有两个内置的默认任务:
- 构建任务
- 测试任务
请注意,您可以将任务用于任何原本可以通过命令行执行的事情。您并不局限于构建和测试活动。
使用任务编译车轮
如果您有一个
setup.py文件来构建一个包以便在 PyPI 上发布,那么您可以使用 tasks 系统来自动构建源代码(Python)和二进制(编译的 Python)发布包。任务在一个
.vscode/tasks.json文件中定义。为了进行试验,创建.vscode/tasks.json并复制这个配置:1{ 2 "version": "2.0.0", 3 "tasks": [ 4 { 5 "type": "shell", 6 "command": "${command:python.interpreterPath}", 7 "args": ["setup.py", "bdist_wheel", "sdist"], 8 "isBackground": true, 9 "options": {"cwd": "${workspaceFolder}"}, 10 "label": "Build Wheel", 11 "group": { 12 "kind": "build", 13 "isDefault": true 14 } 15 } 16 ] 17}在这个例子中有一些事情需要注意,所以您将逐行查看最重要的配置:
- 第 5 行:任务类型是
shell,它指定这个任务应该在您配置的 shell 下运行。- 第 6 行:命令是
${command:python.interpreterPath},这是这个环境的 Python 解释器的内置变量。这包括任何激活的虚拟环境。- 第 9 行:选项
"options": {"cwd": "${workspaceFolder}"}指定这应该在项目的根目录下运行。如果需要,您可以将其更改为子文件夹。- 第 11 行到第 13 行:
"group"设置为"build",由于你将"isDefault"设置为true,该任务将成为你的默认任务。这意味着此任务将作为默认的生成任务运行。要执行默认的构建任务,可以从命令面板运行
Tasks: Run Build Task或者使用内置的键盘快捷键Cmd+F9或者Ctrl+F9。在终端选项卡下,您可以找到在"label"中指定的构建命令的输出:
您不局限于构建脚本。对于 Django 和 Flask 的管理命令来说,任务系统是一个很好的解决方案。
使用 Django 的任务
您正在使用 Django 应用程序吗,您想从命令行自动运行
manage.py吗?您可以使用shell类型创建一个任务。这样,您就可以使用想要运行的 Django 子命令以及任何参数来执行manage.py:{ "version": "2.0.0", "tasks": [ { "type": "shell", "command": "${command:python.interpreterPath}", "args": ["manage.py", "makemigrations"], "isBackground": true, "options": {"cwd": "${workspaceFolder}"}, "label": "Make Migrations" } ] }要运行这个任务,使用命令面板中的
Tasks: Run Task命令,并从列表中选择 Make Migrations 任务。您可以复制这个代码片段,并将其粘贴到您定期运行的任何 Django 命令中,比如
collectstatic。链接任务
如果您有多个应该按顺序运行的任务或者一个任务依赖于另一个任务,您可以在
tasks.json中配置任务相关性。扩展一下的
setup.py例子,如果您想首先构建您的包的源代码发行版,您可以将下面的任务添加到tasks.json:... { "type": "shell", "command": "${command:python.interpreterPath}", "args": ["setup.py", "sdist"], "isBackground": true, "options": {"cwd": "${workspaceFolder}"}, "label": "Build Source", }在默认的构建任务中,您可以添加一个属性
dependsOn以及需要首先运行的任务标签列表:{ "version": "2.0.0", "tasks": [ { "type": "shell", "command": "${command:python.interpreterPath}", "args": ["setup.py", "bdist_wheel"], "isBackground": true, "options": {"cwd": "${workspaceFolder}"}, "label": "Build Wheel", "group": { "kind": "build", "isDefault": true }, "dependsOn": ["Build Source"] } ] }下次运行此任务时,它将首先运行所有相关任务。
如果您有该任务依赖的多个任务,并且它们可以并行运行,请将
"dependsOrder": "parallel"添加到任务配置中。使用任务运行 Tox
现在您将探索 tox ,这是一个旨在自动化和标准化 Python 测试的工具。针对 Visual Studio 代码的 Python 扩展没有与 tox 集成。相反,您可以使用 tasks 系统将 tox 设置为默认测试任务。
提示:如果你想快速上手 tox,那么安装
tox和pip并运行tox-quickstart命令:$ python -m pip install tox $ tox-quickstart这将提示您创建一个 tox 配置文件的步骤。
要使用您的 tox 配置自动运行 tox,请向
tasks.json添加以下任务:{ "type": "shell", "command": "tox", "args": [], "isBackground": false, "options": {"cwd": "${workspaceFolder}"}, "label": "Run tox", "group": { "kind": "test", "isDefault": true } }您可以使用命令面板中的
Tasks: Run Test Task来运行该任务,该任务将使用终端选项卡中的输出来执行 tox:
如果您有一些任务并且需要经常运行它们,那么是时候探索一个伟大的扩展了,它在 UI 中添加了一些快捷方式来运行配置好的任务。
使用任务浏览器扩展
任务浏览器扩展(
spmeesseman.vscode-taskexplorer) 增加了简单的 UI 控件来运行你预先配置的任务。一旦安装完毕,任务浏览器将成为浏览器视图中的一个面板。它扫描您的项目,自动发现npm、make、gulp和许多其他构建工具的任务。您可以在 vscode 组下找到您的任务:
单击任何任务旁边的箭头来执行该任务,如果更改任务的配置,则单击顶部的刷新图标。
在 Visual Studio 代码中调试 Python 脚本
Visual Studio 代码的 Python 扩展捆绑了一个强大的调试器,它支持本地和远程调试。
运行和调试一个简单的 Python 脚本最简单的方法是进入运行→开始调试菜单,并从选项中选择 Python 文件。这将使用配置的 Python 解释器执行当前文件。
您可以在代码中的任意位置设置断点,方法是单击行号左侧的空白。当代码执行过程中遇到断点时,代码将暂停并等待指令:
调试器增加了一个菜单控件:继续,跨过,步入,步出,重启,停止执行:
在左侧面板上,您可以执行常见的调试操作,例如探索局部和全局变量以及 Python 的调用堆栈。您还可以设置手表,这将在下一节中详细介绍。
设置手表
Watches 是在调试会话之间持续的表达式。当您停止执行并再次开始调试时,您将保留上次会话中的所有监视。
你可以从变量面板通过右击一个变量并选择添加到观察来添加一个变量到观察面板。
您还可以通过点击 + 图标,将任何 Python 表达式添加到观察列表中。表达式可以包含:
- 小 Python 表达式,比如
x == 3- 函数调用,如
var.upper()- 比较
每当遇到断点时,您将实时获得每个表达式的当前结果。VS 代码还会在您调试会话时更新每个观察器的值:
您可以使用左边的箭头扩展复杂类型,如字典和对象。
到目前为止,您已经看到了单个 Python 文件的调试器,但是许多 Python 应用程序都是模块,或者需要特殊的命令才能启动。
配置启动文件
VS 代码有一个用于启动概要文件的配置文件,
.vscode/launch.json。VS 代码的 Python 调试器可以启动任何启动配置,并将调试器附加到它上面。注意:要查看即将到来的配置的预期结果,您需要设置一个有效的 FastAPI 项目,并且在您正在使用的 Python 环境中安装 async web 服务器uvicon。
作为在 VS 代码中使用启动概要文件的例子,您将探索如何使用 ASGI 服务器
uvicorn来启动一个 FastAPI 应用程序。通常,您可以只使用命令行:$ python -m uvicorn example_app.main:app相反,您可以在
launch.json中设置一个等效的启动配置:{ "configurations": [ { "name": "Python: FastAPI", "type": "python", "request": "launch", "module": "uvicorn", "cwd": "${workspaceFolder}", "args": [ "example_app.main:app" ], } ] }这里,您将配置中的
"type"设置为"python",这告诉 VS 代码使用 Python 调试器。您还设置了"module"来指定要运行的 Python 模块,在本例中是"uvicorn"。您可以在"args"下提供任意数量的参数。如果您的应用程序需要环境变量,您也可以使用env参数设置这些变量。一旦您添加了这个配置,您应该会发现您的新启动配置已经准备好在运行和调试面板下启动:
当您按下
F5或从顶部菜单中选择运行→开始调试时,您配置为首次启动配置的任何内容都将运行。如果 VS 代码没有自动为您选择正确的 Python 环境,那么您也可以在您的
.vscode/launch.json文件中声明一个到适当的 Python 解释器的显式路径作为选项:1{ 2 "configurations": [ 3 { 4 "name": "Python: FastAPI", 5 "type": "python", 6 "python": "${workspaceFolder}/venv/bin/python", 7 "request": "launch", 8 "module": "uvicorn", 9 "cwd": "${workspaceFolder}", 10 "args": [ 11 "example_app.main:app" 12 ], 13 } 14 ] 15}您可以将路径作为名为
"python"的新条目添加到您的 Python 解释器中。在这个例子中,解释器位于一个名为venv的 Python 虚拟环境中,这个环境是在您的工作空间文件夹的根目录下创建的。如果您想使用不同的 Python 解释器,您可以通过编辑第 6 行所示的路径来定义它的路径,以适应您的设置。掌握远程开发
VS 代码支持三种远程开发配置文件:
- 容器
- SSH 上的远程主机
- 用于 Linux 的 Windows 子系统(WSL)
所有三个选项都由远程开发扩展包(
ms-vscode-remote.vscode-remote-extensionpack) 提供。您需要安装这个扩展包,以便在 VS 代码中显示远程调试特性。使用容器进行远程开发
您需要在您的机器上安装 Docker 运行时,以便对容器使用远程调试。如果你还没有安装 Docker,你可以从 Docker 网站下载。
Docker 运行后,转到左侧导航菜单上的远程浏览器选项卡。将远程浏览器下拉菜单更改为容器,您将看到一个带有面板的视图:
如果您有一个全新的 Docker 安装,这些面板不会被填充。
如果您已经安装并运行了 Docker 映像,则可能会填充三个面板:
- 容器:一个导航面板,显示这个工作区中的开发容器或者一些快速启动步骤的链接
- 容器的名称(如果正在运行):正在运行的容器的属性和卷装载
- DevVolumes: 您可以编辑和挂载以修改代码的开发卷列表
例如,如果您按照 VS Code 的容器教程中概述的步骤安装了试用开发容器:Python ,那么您的 VS Code 远程资源管理器选项卡将在前面提到的面板中显示运行容器的名称:
使用这些面板可以快速管理项目所依赖的任何 Docker 容器。
一般来说,运行远程容器扩展有三种主要方式:
- 附加到现有的运行容器以进行快速更改
- 创建一个
.devcontainer/devcontainer.json文件,并将工作区作为远程容器打开- 运行
Remote-Containers: Reopen in Container命令并选择 Python 3 图像创建一个
.devcontainer/devcontainer.json文件比简单地打开一个容器有更大的好处:
- 开发容器支持 GitHub 代码空间
- Dev 容器支持本教程中显示的启动概要文件和任务配置
如果你计划在容器和 VS 代码中工作很多,花费额外的时间来创建一个开发容器将会得到回报。
注意:通过通读 VS 官方代码文档,你可以更详细地了解如何创建开发容器。
开始使用 dev 容器的一个快速方法是从您当前的工作区创建它:
- 从命令面板运行
Remote-Containers: Reopen in Container命令。- 选择 Python 3,然后选择所需的 Python 版本。
- 接受 Node.js 的默认建议版本。
然后,VS 代码将移植您现有的工作空间,并基于 Python 的通用
Dockerfile创建一个.devcontainer/devcontainer.json配置。开发容器有两个必需的文件:
.devcontainer/devcontainer.json,指定所有 VS 代码需求,比如需要哪些扩展,使用什么设置Dockerfile,其中指定了哪些命令将构建环境在默认设置中,
Dockerfile位于.devcontainer/目录中。如果您的项目已经有了一个Dockerfile,您可以通过改变.devcontainer/devcontainer.json中的路径来重用它。您将使用
.devcontainer/devcontainer.json中的默认值来指定:
- 路径到
Dockerfile- 容器的名称
- 要应用的 VS 代码设置
- 任何需要安装的 VS 代码扩展
- 任何你想要运行的后期创建命令,比如
python -m pip install <package>如果您的应用程序需要来自 PyPI 的额外包,请更改
.devcontainer/devcontainer.json并取消对指定"postCreateCommand"的行的注释:{ ... // Use 'postCreateCommand' to run commands after the Container is created. "postCreateCommand": "python3 -m pip install -r requirements.txt", }如果您正在开发提供网络服务的应用程序,如 web 应用程序,您还可以添加端口转发选项。对于选项的完整列表,您可以通过
devcontainer.json参考。在对
Dockerfile或 devcontainer 规范进行更改之后,通过右键单击正在运行的容器并选择 Rebuild Container ,从远程资源管理器重新构建容器:
通过这样做,您将使用对配置和
Dockerfile的任何更改来重新构建 Docker 容器。除了远程开发扩展包的远程调试扩展功能之外,还有一个针对 VS 代码的 Docker 扩展。您将在本教程的最后讨论这个扩展,并找到更多的特性。
使用 SSH 进行远程开发
通过在命令面板中运行
Remote-SSH: Open SSH Configuration File,您可以打开本地 SSH 配置文件。这是一个标准的 SSH 配置文件,用于列出主机、端口和私有密钥的路径。IdentityFile选项默认为~/.ssh/id_rsa,因此最好的认证方式是一个私有和公共密钥对。下面是两台主机的配置示例:
Host 192.168.86.30 HostName 192.168.86.30 User development IdentityFile ~/path/to/rsa Host Test-Box HostName localhost User vagrant Port 2222一旦保存了配置文件, Remote Explorer 选项卡将在 SSH Targets 下拉选项下列出那些 SSH 主机:
要连接到该服务器,请在新窗口中点击连接到主机,该窗口是任何主机右侧的图标。这将在远程主机上打开一个新的 VS 代码窗口。
一旦连接上,点击浏览器视图下的打开文件夹。VS 代码将向您显示一个特殊的文件夹导航菜单,该菜单显示远程主机上的可用文件夹。导航到您的代码所在的文件夹,您可以在该目录下启动一个新的工作区:
在这个远程工作区中,您可以编辑和保存远程服务器上的任何文件。如果您需要运行任何额外的命令,终端选项卡会自动设置为远程主机的 SSH 终端。
使用 WSL 进行远程开发
Linux 的 Windows 子系统或 WSL 是微软 Windows 的一个组件,它使用户能够在他们的 Windows 操作系统上运行任意数量的 Linux 发行版,而不需要单独的管理程序。
VS 代码支持 WSL 作为远程目标,所以可以在 WSL 下运行 Windows 的 VS 代码,进行 Linux 的开发。
首先将 WSL 与 VS 代码一起使用需要安装 WSL。一旦安装了 WSL,您需要至少有一个可用的发行版。
在最新版本的 Windows 10 上安装 WSL 最简单的方法是打开命令提示符并运行:
C:\> wsl --install
--install命令执行以下动作:
- 启用可选的 WSL 和虚拟机平台组件
- 下载并安装最新的 Linux 内核
- 将 WSL 2 设置为默认值
- 下载并安装 Linux 发行版,可能需要重启机器
一旦你成功地在你的计算机上设置了 WSL,你还需要为 VS 代码安装 Remote - WSL (
ms-vscode-remote.remote-wsl) 扩展。之后,您就可以在 Visual Studio 代码中使用 WSL 了。如果您已经有了 WSL 中的代码,那么在 VS 代码中从命令面板运行
Remote-WSL: Open Folder in WSL。在 Linux 子系统中选择代码的目标目录。如果您的代码在 Windows 中签出,请从命令面板运行
Remote-WSL: Reopen Folder in WSL。远程浏览器将记住您配置的 WSL 目标,并让您从远程浏览器视图中的 WSL 目标下拉列表中快速重新打开它们:
如果您想要一个可再现的环境,可以考虑创建一个
Dockerfile,而不是直接在 WSL 主机上工作。使用数据科学工具
VS 代码非常适合使用 Python 进行应用程序开发和 web 开发。它还有一套强大的扩展和工具,用于处理数据科学项目。
到目前为止,您已经讨论了 VS 代码的 Python 扩展。还有 Jupyter 笔记本扩展,它将 IPython 内核和一个笔记本编辑器集成到 VS 代码中。
安装 Jupyter 笔记本扩展
要在 VS 代码上开始使用 Jupyter 笔记本,你需要 Jupyter 扩展(
ms-toolsai.jupyter) 。注意: Jupyter 笔记本支持现在与 Python 扩展捆绑在一起,所以如果您已经安装了它,请不要感到惊讶。
Jupyter 笔记本支持
pip作为包管理器,以及来自Anaconda 发行版的conda。Python 的数据科学库通常需要用 C 和 C++编写的编译模块。如果您正在使用大量第三方包,那么您应该使用
conda作为包管理器,因为 Anaconda 发行版已经代表您解决了构建依赖,使得安装包变得更加容易。VS 代码【Jupyter 笔记本入门
对于这个例子,你将打开一系列关于波变换的 Jupyter 笔记本。下载 repo 的
.zip/文件夹解压,或者克隆 GitHub repo 用 VS 代码打开。下面进一步描述的步骤也适用于包含.ipynb笔记本文件的任何其他工作区。注意:本节的其余部分使用
conda包管理器。如果您想使用本节中显示的命令,您需要安装Anaconda。在 VS 代码中,可以使用任何现有的
conda环境。您可以从终端创建一个专门针对 VS 代码的conda环境,而不是将包安装到基础环境中:$ conda create --name vscode python=3.8在创建了名为
vscode的conda环境之后,您可以在其中安装一些常见的依赖项:$ conda install -n vscode -y numpy scipy pandas matplotlib ipython ipykernel ipympl一旦安装了依赖项,从 VS 代码命令面板运行
Python: Select Interpreter命令并搜索vscode来选择新的conda环境:
这个选项将设置您的 VS 代码使用来自您的
conda环境vscode的 Python 解释器。注意:如果列表中没有
conda环境,您可能需要通过从命令面板运行Developer: Reload Window命令来重新加载窗口。选中后,在 VS 代码中打开一个笔记本,点击右边的选择内核按钮或者从命令面板中运行
Notebook: Select Notebook Kernel命令。键入vscode选择新创建的conda环境,其中安装了依赖项:
选择您的新
conda环境作为您笔记本的内核将使您的笔记本能够访问您在该环境中安装的所有依赖项。这是执行代码单元所必需的。一旦选择了内核,您就可以运行任意或所有的单元并查看显示在 VS 代码中的操作输出:
一旦笔记本被执行,Jupyter 扩展将使任何中间变量,如列表、NumPy 数组和 pandas 数据帧在 Jupyter: Variables 视图中可用:
你可以通过点击笔记本顶部的变量按钮或运行
Jupyter: Focus on Variables View命令来聚焦这个视图。对于更复杂的变量,选择图标在数据查看器中打开数据。
使用数据查看器
Jupyter 扩展附带了一个数据查看器,用于查看和过滤 2D 数组,如列表、NumPy 的
ndarray和 pandas 数据帧:
要访问数据查看器,您可以点击在数据查看器中显示变量,在变量视图中展开复杂变量。该选项由一个图标表示,该图标显示在代表复杂变量的行的左侧:
data viewer 支持对大型数据集进行在线过滤和分页。如果您在 Matplotlib 中绘制大型数据集,Jupyter 扩展支持 Matplotlib 小部件而不是 SVG 呈现。
使用 Rainbow CSV 扩展
如果您处理 CSV 或 TSV 输入数据,有一个有用的扩展叫做 Rainbow CSV (
mechatroner.rainbow-csv) ,它使您能够在 VS 代码中打开并可视化 CSV 文件:
每一列都是彩色的,让您可以快速找到遗漏的逗号。您也可以通过从命令面板运行
Rainbow CSV: Align CSV Columns命令来对齐所有列。注意:如果你正在寻找一个示例 CSV 文件来尝试这个扩展,你可以从新西兰政府的官方统计页面选择一个 CSV 文件来下载。
Rainbow CSV 扩展还附带了一个Rainbow Query Language(RBQL)查询工具,允许您对 CSV 数据编写 RBQL 查询,以创建过滤数据集:
您可以通过在命令面板中运行
Rainbow CSV: RBQL来访问 RBQL 控制台。执行查询后,您将在新的选项卡中看到作为临时 CSV 文件的结果,您可以保存该文件并将其用于进一步的数据分析工作。在本教程中,您已经为 VS 代码安装了几个有用的扩展。有许多有用的扩展可用。在本教程的最后一节,您将了解到一些到目前为止还没有涉及到的额外扩展,您可能也想尝试一下。
向 Visual Studio 代码添加额外的扩展
VS 代码市场有数千个扩展。扩展的选择涵盖了从语言支持,主题,拼写检查,甚至小游戏。
到目前为止,在本教程中,您已经介绍了许多扩展,这些扩展使 Visual Studio 代码中的 Python 开发更加强大。这最后四个扩展是可选的——但是可以让您的生活更轻松。
代码拼写检查器
代码拼写检查器(
streetsidesoftware.code-spell-checker) 是一个检查变量名、字符串中的文本和 Python 文档字符串的拼写检查器:
代码拼写检查扩展将突出任何可疑的拼写错误。您可以从字典中更正拼写,也可以将单词添加到用户或工作区字典中。
工作区字典将位于工作区文件夹中,因此您可以将其签入 Git。用户字典在所有项目中都是持久的。如果有很多经常使用的关键词和短语,您可以将它们添加到用户词典中。
码头工人
Docker 扩展(
ms-azuretools.vscode-docker) 使创建、管理和调试容器化的应用程序变得容易:
Docker 扩展超出了您之前介绍的远程容器扩展。它为您提供了一个管理映像、网络、容器注册表、卷和容器的 UI。
迅雷客户端
Thunder Client (
rangav.vscode-thunder-client) 是一个 HTTP 客户端和 VS 代码 UI,旨在帮助测试 REST APIs。如果你在像 Flask 、 FastAPI 或 Django Rest Framework 这样的框架中开发和测试 API,你可能已经使用了像 Postman 或 curl 这样的工具来测试你的应用程序。在 Thunder Client 中,您可以创建 HTTP 请求并将其发送到您的 API,操作标头,以及设置文本、XML 和 JSON 的有效负载:
Thunder Client 是 Postman 或 curl 的一个很好的替代品,因为您可以直接在 VS 代码中使用它,所以在测试和开发 REST APIs 时,您可以避免在应用程序之间切换。
VS 代码宠物
VS 代码宠物(
tonybaloney.vscode-pets) 是一个有趣的扩展,可以在你的 VS 代码窗口中放置一个或多个小宠物:
你可以定制宠物,定制它们的环境,和它们一起玩游戏。
注意:作为本教程的作者,我要说这是一个很棒的扩展——但我可能会有偏见,因为我创建了它。
这只是市场上扩展的一个快照。还有成千上万的其他语言支持、UI 改进,甚至是 Spotify 集成。
结论
Visual Studio Code 的 Python 工具正在快速发展,该团队每月都会发布错误修复和新功能的更新。确保安装任何新的更新,以保持您的环境处于最新和最佳状态。
在本教程中,您已经看到了 Visual Studio 代码中一些更高级特性的概述,Python 和 Jupyter 扩展,以及一些额外的扩展。
您学习了如何:
- 用灵活的 UI 定制和键盘绑定定制你的用户界面
- 通过将测试框架集成到 Visual Studio 代码中来运行和监控 Python 测试
- 棉绒和格式代码带挂架和外部棉绒
- 调试本地和远程环境通过 SSH 和 Docker
- 旋转数据科学工具以使用 Jupyter 笔记本
您可以利用这些知识让自己走上成为 VS Code power 用户的道路。
在下一个项目中,尝试这些扩展并测试它们。你会发现一些 VS 代码特性对你来说比其他的更有用。一旦你对一些定制和扩展有了感觉,你可能会发现自己在 VS 代码文档中寻找更多甚至是编码你自己的扩展!**********
Alexa Python 开发:构建和部署一项 Alexa 技能
智能家庭扬声器仅仅在几年前还是一个新奇的想法。今天,它们已经成为许多人的家庭和办公室的核心部分,并且它们的采用预计只会增加。这些设备中最受欢迎的是由亚马逊 Alexa 控制的设备。在本教程中,通过部署自己的 Alexa skill,你将成为一名 Alexa Python 开发人员,这是一个用户将使用语音命令与亚马逊 Alexa 设备进行交互的应用程序。
在本教程中,您将学习:
- Alexa 技能的主要组成部分是什么
- 如何设置 Alexa 技能并创造意图
- 什么是
ask_sdk_coreAlexa Python 包- 如何使用
ask_sdk_core创建你的 Alexa Python 技能的业务逻辑- 如何使用在线开发者控制台构建、部署和测试您的 Alexa Python 技能
免费奖励: 单击此处下载一个 Python 语音识别示例项目,该项目具有完整的源代码,您可以将其用作自己的语音识别应用程序的基础。
Alexa Python 开发入门
按照这个教程,你需要创建一个免费的 Alexa 开发者账户。在该页面上,您将采取以下步骤:
- 点击开始按钮。
- 点击后续页面上的注册按钮。
- 点击创建您的亚马逊账户。
- 用所需的细节填写表格。
- 点击提交完成注册过程。
你还需要熟悉一些概念,比如 Python 中的列表和字典,以及 JavaScript 对象符号(JSON)。如果你是 JSON 新手,那么看看用 Python 处理 JSON 数据的。
我们开始吧!
了解 Alexa 技能
一个 Alexa Python 开发者必须熟悉许多不同的 Alexa 技能组件,但是两个最重要的组件是接口和服务:
- 技能接口处理用户的语音输入,并将其映射到意图。
- 技能服务包含所有的业务逻辑,这些逻辑决定给定用户输入的响应,并将其作为 JSON 对象返回。
技能界面将是你 Alexa 技能的前端。在这里,您将定义执行特定功能的意图和调用短语。本质上,这是负责与用户互动的技能的一部分。
技能服务将是你的 Alexa 技能的后端。当用户触发特定意图时,它会将该信息作为请求发送给技能服务。这将包含要返回的业务逻辑以及有价值的信息,这些信息将最终传递给用户。
设置您的环境
是时候开始建立你的第一个 Alexa Python 技能了!登录 Alexa 开发者控制台,点击创造技能按钮开始。在下一页,输入技能名称,将会是笑话机器人:
这将是你技能的调用短语。这是一个用户开始使用你的 Alexa 技能时会说的短语。如果你愿意,以后你可以把这个换成别的。此外,请注意,Alexa 技能可以用多种语言进行交互,这可以从默认语言下拉菜单中看到。现在,只需将其设置为英语(美国)。
接下来,你需要选择一个模型来增加你的技能。这些模型就像是亚马逊团队根据一些常见用例预先设计的模板,帮助你开始 Alexa Python 开发。对于本教程,您应该选择定制型号。
最后,你需要选择一种方法来托管你的 Alexa 技能的后端。该服务将包含您的应用程序的业务逻辑。
注意:如果你选择提供你自己的选项,那么你将不得不为你的 Alexa Python 项目托管你自己的后端。这可以是一个在你选择的平台上构建和托管的 API 。另一个选择是创建一个单独的 AWS Lambda 函数,并将其与您的 Alexa 技能相联系。你可以在他们的定价页面上了解更多关于 AWS Lambda 定价的信息。
现在,选择 Alexa 托管(Python) 作为你的 Alexa 技能的后台。这将自动在 AWS 免费层中为您提供一个托管的后端,因此您不必预先支付任何费用或立即设置一个复杂的后端。
最后,点击创造技能按钮继续。你可能会被要求在这里填写验证码,所以也要填写完整。大约一分钟后,您应该会被重定向到开发人员控制台的构建部分。
了解 Alexa 技能模型
一旦你登录到 Alexa 开发者控制台并选择或创建了一个技能,你会看到构建部分。此部分为您提供了许多选项和控件来设置技能的交互模型。这个交互模型的组件允许您定义用户将如何与您的技能进行交互。这些属性可以通过左侧面板访问,如下所示:
作为一名 Alexa Python 开发者,你需要了解一些 Alexa 技能交互模型的组件。首先是调用。这是用户开始与你的 Alexa 技能互动时会说的话。例如,用户会说,“笑话机器人”,以调用您将在本教程中建立的 Alexa 技能。您可以在任何时候从调用部分对此进行更改。
另一个组件是 intent ,它代表了应用程序的核心功能。你的应用程序将有一套意图,代表你的技能可以执行什么样的动作。为了提供给定意图的上下文信息,您将使用一个槽,,它是话语短语中的一个变量。
考虑下面的例子。调用天气意图的示例话语可以是,“告诉我天气情况。”为了使该技能更有用,您可以将意图设置为“告诉我芝加哥的天气”,其中单词“芝加哥”将作为槽变量传递,这改善了用户体验。
最后,还有插槽类型,定义了如何处理和识别插槽中的数据。例如,亚马逊。DATE slot type 可以轻松地将表示日期的单词(如“今天”、“明天”等)转换为标准日期格式(如“2019-07-05”)。可以查看官方槽型参考页了解更多。
注意:要了解更多关于 Alexa 技能交互模型的信息,请查看官方文档。
此时,意图面板应该是打开的。如果不是,那么你可以从左边的工具条中选择意图来打开它。您会注意到默认情况下已经设置了五个意图:
意向面板包括一个hello world ent和五个内置意向。内置的意图是提醒你考虑一些对制作用户友好的机器人很重要的常见情况。这里有一个简单的概述:
- 亚马逊。cancel ent让用户取消一个事务或任务。例子包括,“没关系”,“忘记它”,“退出”和“取消”,尽管还有其他的。
- 亚马逊。HelpIntent 提供如何使用技能的帮助。这可以用来返回一句话,作为用户如何与你的技能互动的手册。
- 亚马逊。停止意图允许用户退出技能。
- 亚马逊。NavigateHomeIntent 将用户导航到设备主屏幕(如果正在使用屏幕)并结束技能课程。
默认情况下,没有指定的示例话语来触发这些意图,所以您也必须添加它们。把它当作你作为 Alexa Python 开发者培训的一部分。您可以在官方文档中了解更多关于这些内置意图的信息。
查看样本意图
在本教程的后面,你将学习如何建立一个新的意图,但是现在,看一看你创造的每个新技能中的一些现有的意图是一个好主意。首先,单击hello world ent查看其属性:
您可以看到用户为了实现这一意图而说出的示例话语。当这个意图被调用时,这个信息被发送到你的 Alexa 技能的后端服务,然后它将执行所需的业务逻辑并返回一个响应。
在此之下,您可以选择设置对话框委托策略,这允许您委托您定义的特定对话框来实现特定目的。虽然你不会在本教程中涉及这一点,但你可以在官方文档中了解更多。
接下来,您可以选择为您打算收集的一些特定数据定义槽。例如,如果您要创建一个告知给定日期天气的意图,那么您将在这里有一个日期槽,它将收集日期信息并将其发送到您的后端服务。
注意:此外,当您在一个单独的意图中从用户那里收集大量不同的数据点,并且您想在发送给用户进行进一步处理之前提示用户时,意图确认选项会很有用。
每当您对意图进行更改时,您需要点击保存模型按钮来保存它。然后,你可以点击建立模型按钮继续测试你的 Alexa Python 技能。
知道一项技能的交互模型可以完全用一种 JSON 格式来表示是很有帮助的。要查看你的 Alexa 技能的当前结构,点击控制台左侧面板的 JSON 编辑器选项:
如果您直接使用 JSON 编辑器进行更改,那么这些更改也会反映在开发人员控制台 UI 中。为了测试这种行为,添加一个新的意图并点击保存模型。
一旦你对技能的交互模型做了所有必要的修改,你就可以打开开发者控制台的测试部分来测试你的技能。测试是成为 Alexa Python 开发者的重要一环,所以一定不要跳过这一步!单击开发人员控制台顶部导航栏中的测试按钮。默认情况下,测试将被禁用。从下拉菜单中选择开发开始测试:
在这里,你有很多方法可以测试你的 Alexa Python 技能。让我们做一个快速测试,这样你就可以了解你的 Alexa 技能将如何对话语做出反应。
从左侧面板选择 Alexa 模拟器选项,然后输入短语,“嘿 Alexa,打开笑话机器人。”你可以通过在输入框中输入或者使用麦克风选项来完成。几秒钟后,会有一个响应返回给您:
除了语音响应,你还可以看到发送到你的 Alexa 技能后端服务的 JSON 输入,以及接收回控制台的 JSON 输出:
以下是目前发生的情况:
- JSON 输入对象由用户通过语音或文本输入的输入数据构建而成。
- Alexa 模拟器将输入和其他相关元数据打包,并发送到后端服务。你可以在 JSON 输入框中看到这一点。
- 后端服务接收输入的 JSON 对象,并对其进行解析以检查请求的类型。然后,它将 JSON 传递给相关的意图处理函数。
- 意图处理器函数处理输入并收集所需的响应,该响应作为 JSON 响应发送回 Alexa 模拟器。您可以在 JSON 输出框中看到这一点。
- Alexa 模拟器解析这个 JSON,把语音响应读回给你。
注:你可以在官方文档中阅读关于 Alexa 技能的 JSON 请求-响应机制。
现在你已经对 Alexa 技能的不同组成部分以及信息如何从一个部分流向另一个部分有了一个概述,是时候开始构建你的笑话机器人了!在下一节中,您将通过创建一个新的意图来测试您的 Alexa Python 开发人员技能。
创造新的意向
让我们从创建 JokeIntent 开始,它将从列表中向用户返回一个随机的笑话。打开你的 Alexa 开发者控制台的构建部分。然后,点击左侧面板中意图选项旁边的添加按钮:
选择创建自定义意图选项,将名称设置为 JokeIntent ,然后点击创建自定义意图按钮:
接下来,您需要添加示例话语,用户将说出这些话语来调用这个意图。这些短语可以是“给我讲个笑话”或“我想听个笑话”键入一个短语并单击加号(
+)将其添加为示例话语。这应该是这样的:
您可以添加更多的示例话语,但是现在,这些已经足够了。最后,点击窗口左上角的保存模型按钮保存这些更改。
请记住,在测试之前,您需要构建您的模型。点击构建模型按钮,重新构建你的 Alexa Python 技能的交互模型。您会在浏览器窗口的右下角看到一个进度通知。一旦构建过程成功,您应该会看到另一个弹出通知,指示构建过程的状态。
您可以查看 JokeIntent 是否被成功触发。点击开发者控制台右上角的评估模型按钮。一个小窗口将从侧面弹出,允许你检查给定的输入话语将触发什么意图。键入任何示例话语,以确保成功调用了 JokeIntent 。
要摆脱评估弹出窗口,再次点击评估模型按钮。
注意:这里要记住的一件关键事情是,就作为示例话语短语一部分的关键字而言,该模型非常灵活。例如,以这句话为例,“这是某种玩笑吗?”甚至这个短语也会触发的玩笑。作为一名 Alexa Python 开发者,选择在你的技能中执行其他意图的概率较低的话语是很重要的。
既然您已经成功地创建了一个意图,那么是时候编写 Python 代码来处理这个意图并返回一个笑话作为响应了。
构建技能后台
现在您已经创建了一个可以被用户触发的意图,您需要在技能后端添加功能来处理这个意图并返回有用的信息。打开 Alexa 开发者控制台的代码部分开始。
注意:由于你在设置过程中选择了 Alexa 托管的 Python 选项,你可以在开发者控制台中编写、测试、构建和部署你的 Alexa 技能的后端。
当您打开开发人员控制台的代码部分时,您可以看到一个在线代码编辑器,其中已经为您设置了一些文件。特别是,您将在 lambda 子目录中看到以下三个文件:
- lambda_function.py: 这是后端服务的主入口。来自 Alexa intent 的所有请求数据都在这里接收,并且应该只从这个文件返回。
- requirements.txt: 这个文件包含了这个项目中使用的 Python 包的列表。如果你选择建立自己的后端服务,而不是使用亚马逊提供的服务,这就特别有用。要了解更多关于需求文件的信息,请使用需求文件查看。
- utils.py: 这个文件包含一些 lambda 函数与亚马逊 S3 服务交互所需的实用函数。它包含了一些关于如何从 Amazon S3 存储桶中获取数据的示例代码,您可能会发现这在以后会很有用。目前,这个文件没有在
lambda_function.py中使用。现在,您将只对
lambda_function.py进行修改,所以让我们仔细看看文件的结构:7import logging 8import ask_sdk_core.utils as ask_utils 9 10from ask_sdk_core.skill_builder import SkillBuilder 11from ask_sdk_core.dispatch_components import AbstractRequestHandler 12from ask_sdk_core.dispatch_components import AbstractExceptionHandler 13from ask_sdk_core.handler_input import HandlerInput 14 15from ask_sdk_model import Response 16 17logger = logging.getLogger(__name__) 18logger.setLevel(logging.INFO) 19 20 21class LaunchRequestHandler(AbstractRequestHandler): 22 """Handler for Skill Launch.""" 23 def can_handle(self, handler_input): 24 # type: (HandlerInput) -> bool 25 26 return ask_utils.is_request_type("LaunchRequest")(handler_input) 27 28 def handle(self, handler_input): 29 # type: (HandlerInput) -> Response 30 speak_output = "Welcome, you can say Hello or Help. " \ 31 "Which would you like to try?" 32 33 return ( 34 handler_input.response_builder 35 .speak(speak_output) 36 .ask(speak_output) 37 .response 38 ) 39...首先,导入必要的工具,这些工具在
ask_sdk_coreAlexa Python 包中提供。然后,您需要在lambda_function.py中执行三个主要任务来处理来自 Alexa 技能前端的请求:
- 创建一个意向处理程序类,它继承自
AbstractRequestHandler类,具有函数can_handle()和handle()。在lambda_function.py中已经定义了几个处理程序类,比如LaunchRequestHandler、HelpIntentHandler等等。这些处理 Alexa 技能的基本意图。这里需要注意的重要一点是,您需要为您定义的每个意图创建一个新的意图处理程序类。- 创建一个
SkillBuilder对象,,作为你的 Alexa Python 技能的切入点。这会将所有传入的请求和响应有效负载路由到您定义的意图处理程序。- 将意图处理程序类作为参数传递给
.add_request_handler(),以便每当接收到新请求时,它们被按顺序调用。SkillBuilder是一个单例,所以只需要它的一个实例来处理所有传入请求的路由。这是你经历
lambda_function.py的好时机。你会注意到,相同的模式被一遍又一遍地遵循,以处理可能由你的 Alexa Python 技能触发的不同意图。现在,您已经大致了解了在后端处理一个意图需要做的各种事情,是时候编写代码来处理您在上一节中构建的 JokeIntent 了。
创建 JokeIntent 处理程序
因为来自
ask_sdk_coreAlexa Python 包的重要实用程序已经被导入,你不需要再次导入它们。如果你想更深入地了解这些,那么你可以查看一下官方文档。接下来,您将创建一个新的意图处理器,它将处理来自 JokeIntent 的请求。在下面的代码片段中,意图处理程序将简单地返回一个示例短语。这表明对 JokeIntent 的响应是从后端接收的。将以下代码添加到
LaunchRequestHandler()的类定义上方的lambda_function.py:20class JokeIntentHandler(AbstractRequestHandler): 21 def can_handle(self, handler_input): 22 return ask_utils.is_intent_name("JokeIntent")(handler_input) 23 24 def handle(self, handler_input): 25 speak_output = "Here's a sample joke for you." 26 27 return ( 28 handler_input.response_builder 29 .speak(speak_output) 30 .ask(speak_output) 31 .response 32 )让我们看看每个部分都做了什么。在第 20 行中,你为 JokeIntent 创建了一个新的 intent handler 类,它是
AbstractRequestHandler类的子类。当你在前端创建一个意图时,你需要在后端创建一个意图处理器类来处理来自 Alexa 的请求。您为此编写的代码需要做两件事:
JokeIntentHandler.can_handle()识别 Alexa 发送的每个传入请求。JokeIntentHandler.handle()返回一个适当的响应。在第 21 行你定义
.can_handle()。它接受handler_input作为参数,这是一个包含所有输入请求信息的dict()类型的对象。然后,它使用ask_utils.is_intent_name()或ask_utils.is_request_type()来检查它接收到的 JSON 输入是否可以被这个意图处理函数处理。您使用
.is_intent_name()并传入意图的名称。这返回一个谓词,它是一个函数对象,如果给定的handler_input来源于指定的意图,则返回True。如果这是真的,那么SkillBuilder对象将调用JokeIntentHandler.handle()。注意:如果 JokeIntent 是从 Alexa skill 前端触发的,那么它将发送一个 JSON 对象,在
request的主体中包含一个键type,表示名为JokeIntent的意图作为输入被接收。这条语句随后调用
.handle(),你在行 24 中定义。该方法接收输入请求以及可能需要的任何其他重要信息。它包含成功处理特定意图所需的业务逻辑。在 JokeIntent 的情况下,这个方法需要将包含笑话的响应发送回 Alexa 前端。
speak_ouput变量包含将由 Alexa 技能前端向用户反馈的句子。speak(speak_output)表示 Alexa 前端将向用户播放的语音内容。ask("Question to ask...")可用来问后续问题。在这个方法中,类response_builder的一个对象将响应返回给 Alexa 技能。注意:如果
.handle()不存在,将返回默认响应消息(Sorry, I had trouble doing what you asked. Please try again.)。请注意,
speak_output的值现在被设置为固定响应。稍后您将更改它,从笑话列表中返回一个随机笑话。下面是您的代码在编辑器中的样子:
一旦创建了意图处理程序类,就需要将其作为参数传递给
SkillBuilder.add_request_handler。滚动到lambda_function.py的底部,添加以下一行:sb.add_request_handler(JokeIntentHandler())这里需要注意的一点是,这一行的位置很重要,因为代码是从上到下处理的。因此,确保对自定义意图处理程序的调用在对
InstantReflectHandler()类的调用之上。它应该是这样的:171sb = SkillBuilder() 172 173sb.add_request_handler(LaunchRequestHandler()) 174sb.add_request_handler(JokeIntentHandler()) 175sb.add_request_handler(HelloWorldIntentHandler()) 176sb.add_request_handler(HelpIntentHandler()) 177sb.add_request_handler(CancelOrStopIntentHandler()) 178sb.add_request_handler(SessionEndedRequestHandler()) 179 180# Make sure IntentReflectorHandler is last so it 181# Doesn't override your custom intent handlers 182sb.add_request_handler(IntentReflectorHandler()) 183 184sb.add_exception_handler(CatchAllExceptionHandler()) 185 186...好了,是时候测试你的代码了!单击 Deploy 按钮保存更改并部署后端服务。你将从 Alexa 技能前端检查它是否会像预期的那样工作。
一旦部署过程成功,返回到开发人员控制台的测试部分并调用 JokeIntent 。请记住,输入话语短语来调用您的 Alexa Python 技能,然后输入短语来执行意图:
如果您得到类似于上图中的响应,那么这意味着您已经成功地为技能后端服务中的 JokeIntent 创建了一个意图处理程序。恭喜你!现在,剩下要做的就是将列表中的一个随机笑话返回给技能前端。
添加笑话
打开开发者控制台的代码部分。然后,在
lambda_function.py中添加jokes变量:15from ask_sdk_model import Response 16 17logger = logging.getLogger(__name__) 18logger.setLevel(logging.INFO) 19 20jokes = [ 21 "Did you hear about the semi-colon that broke the law? He was given two consecutive sentences.", 22 "I ate a clock yesterday, it was very time-consuming.", 23 "I've just written a song about tortillas; actually, it's more of a rap.", 24 "I woke up this morning and forgot which side the sun rises from, then it dawned on me.", 25 "I recently decided to sell my vacuum cleaner as all it was doing was gathering dust.", 26 "If you shouldn't eat at night, why do they put a light in the fridge?", 27 ] 28 29class JokeIntentHandler(AbstractRequestHandler): 30...这里,
jokes是一个类型为list的变量,包含一些一行笑话。确保将其添加到函数或类定义之外,以便它具有全局范围。注意:因为这个列表只会被
JokeIntentHandler()类引用,所以你是否在函数体中声明它并不重要。然而,这样做确实有助于功能体摆脱混乱。接下来,您将添加
.handle()从笑话列表中随机选择一个笑话并将其返回给用户所需的功能。用以下代码修改JokeIntentHandler.handle()的主体:29class JokeIntentHandler(AbstractRequestHandler): 30 def can_handle(self, handler_input): 31 return ask_utils.is_intent_name("JokeIntent")(handler_input) 32 33 def handle(self, handler_input): 34 speak_output = random.choice(jokes) 35 36 return ( 37 handler_input.response_builder 38 .speak(speak_output) 39 .ask(speak_output) 40 .response 41 )在
.handle()的正文中,你使用random.choice()从列表jokes中选择一个随机笑话,并将其作为对 Alexa 技能前端的响应返回。最后,通过在
lambda_function.py的顶部添加一个 import 语句来导入random包:15from ask_sdk_model import Response 16 17import random 18 19logger = logging.getLogger(__name__) 20logger.setLevel(logging.INFO) 21 22...编辑应该这样看待这一点:
测试前还有最后一个改动。你需要允许 Alexa 给出一个确认技能已经被触发。为此,在
LaunchRequestHandler.handle()中查找speak_output变量,并将其值设置为下面突出显示行中的文本:45class LaunchRequestHandler(AbstractRequestHandler): 46 """Handler for Skill Launch.""" 47 def can_handle(self, handler_input): 48 # type: (HandlerInput) -> bool 49 50 return ask_utils.is_request_type("LaunchRequest")(handler_input) 51 52 def handle(self, handler_input): 53 # type: (HandlerInput) -> Response 54 speak_output = "Hey there! I am a Joke Bot. You can ask me to tell you a random Joke that might just make your day better!" 55 56 return ( 57 handler_input.response_builder 58 .speak(speak_output) 59 .ask(speak_output) 60 .response 61 ) 62...你的笑话机器人已经准备好进行最终测试了!单击 Deploy 按钮保存更改并返回到开发人员控制台的测试部分。这一次,当你的技能第一次被调用时,你会看到一个新的问候信息。然后,当你让机器人给你讲一个笑话时,它应该每次给你讲一个不同的笑话:
就是这样!你已经成功创建了你作为 Alexa Python 开发者的第一个技能!
结论
祝贺你迈出了 Alexa Python 开发的第一步!你现在已经成功地建立了你自己的 Alexa Python 技能。您现在知道了如何创建新技能、创建意图、编写 Python 代码来处理这些意图,并将有价值的信息返回给用户。
尝试以下方法来提升你的技能:
- 增加后台笑话列表。
- 创建一个名为琐事的新意图,它将用一个有趣的琐事事实来回应。
- 向亚马逊市场发布你的技能。
可能性是无穷无尽的,所以勇往直前吧!要了解更多关于 Alexa Python 开发的信息,请查看官方文档。您还可以探索聊天机器人、 Tweepy 、 InstaPy 和 Discord 的可能性,以了解如何使用 Python 为不同平台制作机器人。*****
使用 Bootstrap 3 的有效销售页面
原文:https://realpython.com/an-effective-sales-page-with-bootstrap-3/
最初关于 Bootstrap 的两部分系列已经变成了三部分,增加了 William Ghelfi 的博客文章。你可以从这个回购中抓取最终的样式/页面。
在第一篇帖子中,我们看了一下 Bootstrap 3 的基础知识以及如何设计一个基本的网站。让我们更进一步,创建一个漂亮的销售登陆页面。
关于 Bootstrap 最常见的一个误区是,你实际上不能用它来做任何如此不同和高度专业化的事情,比如销售页面。
事实就是如此。一个神话。
让我们一起用最好的方式揭穿它:建造它。
高度专业化的页面是高度专业化的
成功的销售页面遵循精确的规则。我不认识他们所有人,我也不会告诉你我所知道的每一个人。
相反,我会试着把它们减少到你可以开始试验的小而有效的药片。
注意力吸引和第一步
抓住你注意力的最好方法是什么?
一个加粗的大问题,后面跟着一个像样的副标题。
然后,继续简要介绍您将从客户的 a 中消除的难题..从你客户的生活(!)感谢你的产品。
使用 Bootstrap,我们可以像这样构建它:
<!DOCTYPE html> <head> <meta charset="utf-8" /> <title>Bootstrap Sales Page.</title> <meta name="author" content="" /> <meta name="description" content="" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <link href="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap.min.css" rel="stylesheet" /> </head> <body> <header class="container"> <div class="row"> <div class="col-md-10 col-md-offset-1"> <h1>Have you ever seen the rain?</h1> <p class="lead">You should always open a sales page with a catchy question.</p> </div> </div> </header> <div class="container"> <div class="row"> <div class="col-xs-12 col-md-4 col-md-offset-1"> <p> Proceed then with the classic triplet: the pain, the dream, the solution. </p> <p> <strong>The pain</strong> ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.<br /><strong>The dream</strong> enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodoconsequat. Duis aute irure dolor in reprehenderit in voluptate velit essecillum dolore eu fugiat nulla pariatur. </p> <p> <strong>The solution</strong> selfies semiotics keffiyeh master cleanse Vice before they sold out. Vegan 90's tofu pork belly skateboard, Truffaut tote bag. </p> <p> <em><strong>Interested?<br /> <a href="#packages">Go straight to the packages.</a></strong></em> </p> </div> <div class="col-xs-12 col-md-6"> <figure class="text-center"> <img src="http://placehold.it/400x300" alt="The Amazing Product" class="img-thumbnail" /> </figure> </div> </div> <hr /> <div class="row"> <figure class="col-md-2 col-md-offset-1"> <img src="http://placehold.it/100x100" alt="Jonathan F. Doe" class="img-responsive img-circle pull-right" /> </figure> <blockquote class="col-md-7"> <p> Testimonials are important. Be sure to include some in your sales page. </p> <p> With Product, my sales page was <strong>online in minutes</strong>. And it rocks!. </p> <small>Jonathan F. Doe, CIO at Lorem Ipsum</small> </blockquote> </div> </div> </body> </html>
不错,但是让我们添加一些定制:
<style> @import url(http://fonts.googleapis.com/css?family=Open+Sans+Condensed:300,700|Open+Sans:400italic,700italic,400,700|Fjalla+One); body { font-size: 18px; font-family: "Open Sans", Arial, sans-serif; color: #292b33; } h1, h2 { font-family: 'Fjalla One', 'Helvetica Neue', Arial, sans-serif; font-size: 52px; font-weight: 400; text-transform: uppercase; letter-spacing: 1px; text-align: left; margin: 1em 0 0 0; } p { line-height: 1.5; margin: 0 0 20px 0; } blockquote { border-left: none; position: relative; } blockquote::before { content: '“'; position: absolute; top: 0; left: 0; font-size: 48px; font-family: "inherit"; font-weight: bold; } blockquote p { margin: 0 0 10px 20px; font-style: italic; font-family: "Georgia"; } em { font-family: Georgia, serif; font-size: 1.1em; } .lead { margin-top: 0.25em; } </style>
开始变好了!
全部在
现在是时候更好地介绍你对痛苦的解决方案了。
开始提供价值:产品的免费样品。然后列出三种不同的变型/包装,有不同的附加功能,并相应地定价。
为什么是三个?
我们只能说,在 39 美元的基本套餐和 249 美元的完整套餐之间,99 美元的中等套餐感觉既实惠又有价值。
决定顺序——从低到高,或从高到低——只是要知道你在追求什么。
如果你的目标是卖出更多的最低包装,让你的访问者在到达其他人之前到达那个包装。否则,反其道而行之。
关于这个话题的更多信息,请见 Nathan Barry 的一篇精彩的帖子。
这是代码:
... <style> ... .bg-white-dark { border-top: 1px solid #cccbd6; border-bottom: 1px solid #cccbd6; background-color: #e7e6f3; /* Older Browsers */ background-color: rgba(231, 230, 243, 0.9); } .container { padding-top: 2em; padding-bottom: 2em; } ul { list-style-type: circle; } </style> <div class="bg-white-dark" id="free-sample"> <div class="container"> <div class="row"> <div class="col-md-10 col-md-offset-1"> <h2>Get a free sample</h2> <p class="lead">A taste of what is included with the product.</p> </div> </div> <div class="row"> <div class="col-md-10 col-md-offset-1"> <div class="panel panel-default"> <div class="panel-body text-center"> <img alt="sample" src="http://placehold.it/500x250" class="img-rounded" /> <p>Describe the sample dolor sit amet and why should I want to get it adipiscint elit.</p> <p> <a href="#" class="btn btn-lg btn-default text-uppercase"> <span class="icon icon-download-alt"></span>  Download the sample </a> </p> </div> </div> </div> </div> </div> </div> <div class="container" id="packages"> <div class="row"> <div class="col-md-12"> <h2> The Complete Package <span class="pull-right"> <a class="btn btn-success btn-lg" href="#"> <span class="text-uppercase"><span class="text-white-dark">Buy now for</span> $249</span> </a> </span> </h2> <p class="lead"> Cosby sweater cray skateboard. </p> </div> </div> <div class="row"> <div class="media"> <figure class="pull-left col-xs-12 col-md-4"> <img src="http://placehold.it/300x250" alt="The Amazing Product" class="media-object img-thumbnail" /> </figure> <div class="media-body col-xs-12 col-md-7"> <h3 class="media-heading">The best package for lorem ipsumer</h3> <p> Mustache farm-to-table deep v cardigan, Banksy Godard roof party PBR&B. </p> <ul> <li>Details</li> <li>Lorem ipsum</li> <li>Nostrud exercitation</li> <li>Resources ipsum</li> <li>Adipiscit resource</li> <li>Resource numquam</li> <li>Resources ipsum</li> <li>Adipiscit resource</li> <li>Resource numquam</li> </ul> </div> </div> </div> </div> <div class="bg-white-dark"> <div class="container"> <div class="row"> <div class="col-md-12"> <h2> The Amazing Product + Resources <span class="pull-right"> <a class="btn btn-success btn-lg" href="#"> <span class="text-uppercase"><span class="text-white-dark">Buy now for</span> $99</span> </a> </span> </h2> <p class="lead"> Cosby sweater cray skateboard. </p> </div> </div> <div class="row"> <div class="media"> <figure class="pull-left col-xs-12 col-md-4"> <img src="http://placehold.it/300x250" alt="The Amazing Product" class="media-object img-thumbnail" /> </figure> <div class="media-body col-xs-12 col-md-7"> <h3 class="media-heading">Perfect for nostrud lorem</h3> <p> Mustache farm-to-table deep v cardigan, Banksy Godard roof party PBR&B. </p> <ul> <li>Details</li> <li>Lorem ipsum</li> <li>Nostrud exercitation</li> <li>Resources ipsum</li> </ul> </div> </div> </div> </div> </div> <div class="container"> <div class="row"> <div class="col-md-12"> <h2> The Amazing Product <span class="pull-right"> <a class="btn btn-success btn-lg" href="#"> <span class="text-uppercase"><span class="text-white-dark">Buy now for</span> $39</span> </a> </span> </h2> <p class="lead"> Cosby sweater cray skateboard. </p> </div> </div> <div class="row"> <div class="media"> <figure class="pull-left col-xs-12 col-md-4"> <img src="http://placehold.it/300x250" alt="The Amazing Product" class="media-object img-thumbnail" /> </figure> <div class="media-body col-xs-12 col-md-7"> <h3 class="media-heading">The budget option</h3> <p> Mustache farm-to-table deep v cardigan, Banksy Godard roof party PBR&B. </p> <p> Cliche sartorial roof party, shabby chic sustainable VHS food truck 90's four loko. Etsy hoodie distillery, organic beard DIY cliche. </p> </div> </div> </div> </div>造型更多
我们差不多完成了,但是即使我们用
.bg-white-dark添加了颜色变化——顺便说一下,它实际上是淡紫色的,因为使用像.bg-white-dark这样的名字,你可以切换到你喜欢的颜色,而不必改变类名——整体的外观&感觉还可以进一步改进,并且它可以与基本的引导更加不同。让我们添加更多的样式:
... <style> ... .text-white-dark { color: #e7e6f3; } .btn-default { font-family: "Fjalla One", sans-serif; text-shadow: 0 -1px 0 rgba(0, 0, 0, 0.2); -webkit-box-shadow: inset 0 1px 0 rgba(255, 255, 255, 0.15), 0 1px 1px rgba(0, 0, 0, 0.075); box-shadow: inset 0 1px 0 rgba(255, 255, 255, 0.15), 0 1px 1px rgba(0, 0, 0, 0.075); } .btn-default:active, .btn-default.active { -webkit-box-shadow: inset 0 3px 5px rgba(0, 0, 0, 0.125); box-shadow: inset 0 3px 5px rgba(0, 0, 0, 0.125); } .btn:active, .btn.active { background-image: none; } .btn-default { text-shadow: 0 1px 0 #fff; background-image: -webkit-gradient(linear, left 0%, left 100%, from(#ffffff), to(#e6e6e6)); background-image: -webkit-linear-gradient(top, #ffffff, 0%, #e6e6e6, 100%); background-image: -moz-linear-gradient(top, #ffffff 0%, #e6e6e6 100%); background-image: linear-gradient(to bottom, #ffffff 0%, #e6e6e6 100%); background-repeat: repeat-x; border-color: #e0e0e0; border-color: #ccc; filter: progid:DXImageTransform.Microsoft.gradient(startColorstr='#ffffffff', endColorstr='#ffe6e6e6', GradientType=0); } .btn-default:active, .btn-default.active { background-color: #e6e6e6; border-color: #e0e0e0; } .btn-success { font-family: "Fjalla One", sans-serif; } .btn-success { background: #9292c0; /* Old browsers */ background: -moz-linear-gradient(top, #9292c0 0%, #8181b7 100%); /* FF3.6+ */ background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,#9292c0), color-stop(100%,#8181b7)); /* Chrome,Safari4+ */ background: -webkit-linear-gradient(top, #9292c0 0%,#8181b7 100%); /* Chrome10+,Safari5.1+ */ background: -o-linear-gradient(top, #9292c0 0%,#8181b7 100%); /* Opera 11.10+ */ background: -ms-linear-gradient(top, #9292c0 0%,#8181b7 100%); /* IE10+ */ background: linear-gradient(to bottom, #9292c0 0%,#8181b7 100%); /* W3C */ filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#9292c0', endColorstr='#8181b7',GradientType=0 ); /* IE6-9 */ border-color: #f1ddff; } .btn-success:hover, .btn-success:focus, .btn-success:active, .btn-success.active { color: #fbfafc; background: #a3a3d1; /* Old browsers */ background: -moz-linear-gradient(top, #a3a3d1 0%, #9292c8 100%); /* FF3.6+ */ background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,#a3a3d1), color-stop(100%,#9292c8)); /* Chrome,Safari4+ */ background: -webkit-linear-gradient(top, #a3a3d1 0%,#9292c8 100%); /* Chrome10+,Safari5.1+ */ background: -o-linear-gradient(top, #a3a3d1 0%,#9292c8 100%); /* Opera 11.10+ */ background: -ms-linear-gradient(top, #a3a3d1 0%,#9292c8 100%); /* IE10+ */ background: linear-gradient(to bottom, #a3a3d1 0%,#9292c8 100%); /* W3C */ filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#a3a3d1', endColorstr='#9292c8',GradientType=0 ); /* IE6-9 */ border-color: #f1ddff; } .btn-success.disabled:hover, .btn-success[disabled]:hover, fieldset[disabled] .btn-success:hover, .btn-success.disabled:focus, .btn-success[disabled]:focus, fieldset[disabled] .btn-success:focus, .btn-success.disabled:active, .btn-success[disabled]:active, fieldset[disabled] .btn-success:active, .btn-success.disabled.active, .btn-success[disabled].active, fieldset[disabled] .btn-success.active { color: #fbfafc; background: #a3a3d1; /* Old browsers */ background: -moz-linear-gradient(top, #a3a3d1 0%, #9292c8 100%); /* FF3.6+ */ background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,#a3a3d1), color-stop(100%,#9292c8)); /* Chrome,Safari4+ */ background: -webkit-linear-gradient(top, #a3a3d1 0%,#9292c8 100%); /* Chrome10+,Safari5.1+ */ background: -o-linear-gradient(top, #a3a3d1 0%,#9292c8 100%); /* Opera 11.10+ */ background: -ms-linear-gradient(top, #a3a3d1 0%,#9292c8 100%); /* IE10+ */ background: linear-gradient(to bottom, #a3a3d1 0%,#9292c8 100%); /* W3C */ filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#a3a3d1', endColorstr='#9292c8',GradientType=0 ); /* IE6-9 */ border-color: #f1ddff; } </style> ...
结束语
就是这样。我们用 Bootstrap 构建并定制了一个最小的销售页面。该页面看起来一点也不像老一套的自举页面,最棒的是,它实际上有助于提高销售业绩!点击查看。
好了,我想现在是完全披露的时候了:我们一起构建的页面是一个真实的、经过现实生活测试的销售页面的核心。
我写了 Bootstrap In Practice ,这是一本入门电子书,目的是让他们快速生产和回到盈利,而不会陷入官方文件中,也不会因为纯粹的求知欲而进行过多/过早的深入研究。
你可以在我的网站上找到真实、完整、久经考验的销售页面,在那里我还提供了一个关于自举技巧的30 天免费课程以及电子书中的一个免费样本章节。
下一次,我们将添加 Flask,并创建一个好看的样板文件,您可以将其用于您自己的 web 应用程序。干杯!**
用 Python 分析英国的肥胖问题
原文:https://realpython.com/analyzing-obesity-in-england-with-python/
昨天在健身房看到一个牌子,上面写着“孩子每十年变胖一次”。在那个标志下面有一张图表,基本上显示了五年后英国儿童的平均体重将和拖拉机一样重。
我发现这个说法有点不可信,所以我决定调查一下…
数据
数据取自Data.gov.uk。我们将使用 2014 年的 XLS 文件。下载它,并在您选择的电子表格工具中打开它。
然后导航到表 7.2,因为它包含我们正在寻找的数据:
现在,在我们开始用 Pandas 分析数据之前,让我们后退一步,解决房间里的大象:如果您可以在 Excel 中执行分析/绘图,为什么您会使用 Python?
Python vs Excel
应该用 Python 还是 Excel?T3】
这个问题经常被刚开始做数据分析的人问到。虽然 Python 可能在编程社区中很流行,但 Excel 在更广阔的世界中更流行。大多数高级经理、销售人员、营销人员等。使用 Excel——这没什么不好。如果你知道如何很好地使用它,它是一个很棒的工具,它已经把许多非技术人员变成了专家分析师。
对于应该使用 Python 还是 Excel,这个问题并不容易回答。但是最后没有非此即彼:反而可以一起用。
Excel 非常适合查看数据、执行基本分析和绘制简单的图表,但它真的不适合清理数据(除非你愿意深入 VBA)。如果您有一个 500MB 的 Excel 文件,其中缺少数据、日期格式不同、没有标题,那么您将永远无法手工清理它。如果您的数据分散在十几个 CSV 文件中,情况也是如此,这很常见。
使用 Python 和用于数据分析的 Python 库 Pandas 来做所有这些清理工作是微不足道的。Pandas 建立在 Numpy 之上,使高级任务变得简单,你可以将你的结果写回 Excel 文件,这样你就可以继续与非程序员分享你的分析结果。
因此,虽然 Excel 不会消失,但如果您想要干净的数据并执行更高级别的数据分析,Python 是一个很好的工具。
代码
好了,让我们从代码开始——你可以从项目回购以及我上面链接的电子表格中获取,这样你就不用再下载了。
首先创建一个名为 obesity.py 的新脚本,并导入熊猫以及 matplotlib ,以便我们可以稍后绘制图形:
import pandas as pd import matplotlib.pyplot as plt确保安装了两个依赖项:
pip install pandas matplotlib接下来,让我们读入Excel 文件:
data = pd.ExcelFile("Obes-phys-acti-diet-eng-2014-tab.xls")仅此而已。在一行中,我们读入了整个 Excel 文件。
让我们把现有的打印出来:
print data.sheet_names运行脚本。
$ python obesity.py [u'Chapter 7', u'7.1', u'7.2', u'7.3', u'7.4', u'7.5', u'7.6', u'7.7', u'7.8', u'7.9', u'7.10']眼熟吗?这些是我们之前看到的床单。请记住,我们将重点关注第 7.2 页。现在,如果你在 Excel 中查看 7.2,你会看到上面的 4 行和下面的 14 行包含无用的信息。让我换个说法:它对人类有用,但对我们的脚本没用。我们只需要 5-18 排。
清理
所以当我们阅读表格时,我们需要确保任何不必要的信息都被忽略。
# Read 2nd section, by age data_age = data.parse(u'7.2', skiprows=4, skipfooter=14) print data_age再次运行。
Unnamed: 0 Total Under 16 16-24 25-34 35-44 45-54 55-64 65-74 \ 0 NaN NaN NaN NaN NaN NaN NaN NaN NaN 1 2002/03 1275 400 65 136 289 216 94 52 2 2003/04 1711 579 67 174 391 273 151 52 3 2004/05 2035 547 107 287 487 364 174 36 4 2005/06 2564 583 96 341 637 554 258 72 #...snip...#我们阅读表格,跳过最上面的 4 行和最下面的 14 行(因为它们包含对我们没有用的数据)。然后我们把现有的打印出来。(为了简单起见,我只显示了打印输出的前几行。)
第一行代表列标题。你可以马上看到熊猫很聪明,因为它正确地捡起了大多数头球。当然除了第一个——比如
Unnamed: 0。这是为什么呢?简单。在 Excel 中查看该文件,您会发现它缺少一个年份标题。另一个问题是我们在原始文件中有一个空行,它显示为
NaN(不是一个数字)。所以我们现在需要做两件事:
- 将第一个标题重命名为
Year,并且- 去掉所有的空行。
# Rename unamed to year data_age.rename(columns={u'Unnamed: 0': u'Year'}, inplace=True)在这里,我们告诉熊猫将列重命名为年份。使用内置的功能
rename()。
inplace = True修改现有对象。如果没有这个,熊猫将创建一个新的对象并返回它。接下来让我们删除填充有
NaN的空行:# Drop empties data_age.dropna(inplace=True)我们还需要做一件事,让我们的生活更轻松。如果查看 data_age 表,第一个值是一个数字。这是索引,Pandas 使用默认的 Excel 惯例,将一个数字作为索引。然而,我们想把指数改成年。这将使绘制更加容易,因为指数通常被绘制为 x 轴。
data_age.set_index('Year', inplace=True)我们将索引设置为
Year。现在打印我们清理的数据:
print "After Clean up:" print data_age并运行:
Total Under 16 16-24 25-34 35-44 45-54 55-64 65-74 \ Year 2002/03 1275 400 65 136 289 216 94 52 2003/04 1711 579 67 174 391 273 151 52 2004/05 2035 547 107 287 487 364 174 36 2005/06 2564 583 96 341 637 554 258 72 #...snip...#好多了。你可以看到索引现在是
Year,所有的NaN都不见了。图表
现在我们可以绘制我们所拥有的。
# Plot data_age.plot() plt.show()
哎呀。有一个问题:我们的原始数据包含一个总字段,它掩盖了所有其他内容。我们需要摆脱它。
# Drop the total column and plot data_age_minus_total = data_age.drop('Total', axis=1)
axis =1有点令人困惑,但它真正的意思是——丢弃列,正如从这个堆栈溢出问题中描述的那样。让我们画出我们现在拥有的。
data_age_minus_total.plot() plt.show()好多了。我们现在实际上可以看到各个年龄组。你能看出哪个年龄段的肥胖率最高吗?
回到我们最初的问题:孩子越来越胖了吗?
我们只绘制一小部分数据:16 岁以下的儿童和 35-44 岁年龄段的成年人。
plt.close() # Plot children vs adults data_age['Under 16'].plot(label="Under 16") data_age['35-44'].plot(label="35-44") plt.legend(loc="upper right") plt.show()
那么到底是谁越来越胖呢?
没错。我们看到了什么?
虽然儿童肥胖率略有下降,但他们的父母却在不断增加。所以看起来父母需要担心的是他们自己而不是他们的孩子。
但是未来呢?
图表仍然没有告诉我们未来儿童肥胖会发生什么。有很多方法可以将这样的图表外推至未来,但在我们继续之前,我必须给出一个警告:肥胖数据没有潜在的数学基础。也就是说,我们找不到一个公式来预测这些值在未来会如何变化。一切本质上都是猜测。记住这个警告,让我们看看如何推断我们的图表。
首先, Scipy 确实提供了一个用于外推的函数,但是它只对单调增加的数据有效(当我们的数据上下波动时)。
我们可以尝试曲线拟合:
我们将结合使用这两个函数来尝试预测英国儿童的未来:
kids_values = data_age['Under 16'].values x_axis = range(len(kids_values))这里,我们提取 16 岁以下儿童的值。对于 x 轴,原始图表有日期。为了简化我们的图表,我们将只使用数字 0-10。
输出:
array([ 400., 579., 547., 583., 656., 747., 775., 632., 525., 495., 556.]) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]还有一点:曲线拟合使用不同的次多项式。很简单的说,度数越高,曲线拟合会越准确,但是也有可能结果是垃圾。如果度数太高,Scipy 有时会警告你。不要担心,当我们看一些例子时,这一点会更加清楚。
poly_degree = 3 curve_fit = np.polyfit(x_axis, kids_values, poly_degree) poly_interp = np.poly1d(curve_fit)我们将多项式次数设置为 3。然后,我们使用 Numpy
polyfit()函数试图通过我们拥有的数据拟合一个图形。然后在我们生成的等式上调用poly1d()函数来创建一个函数,该函数将用于生成我们的值。这将返回一个名为poly_interp的函数,我们将在下面使用它:poly_fit_values = [] for i in range(len(x_axis)): poly_fit_values.append(poly_interp(i))我们从 0 到 10 循环,并对每个值调用
poly_interp()函数。记住,这是我们运行曲线拟合算法时生成的函数。在继续之前,让我们看看不同的多项式次数意味着什么。
我们将绘制原始数据和我们自己的数据,看看我们的方程与理想数据有多接近:
plt.plot(x_axis, poly_fit_values, "-r", label = "Fitted") plt.plot(x_axis, kids_values, "-b", label = "Orig") plt.legend(loc="upper right")原始数据将以蓝色绘制,并标记为原始,而生成的数据将以红色绘制,并标记为拟合。
多项式值为 3:
我们发现它不是很合适,所以让我们试试 5:
好多了。7 点怎么样?
现在我们得到了一个几乎完美的匹配。那么,为什么我们不总是使用更高的值呢?
因为较高的值与该图紧密相关,所以它们使预测变得无用。如果我们试图从上图中推断,我们会得到垃圾值。尝试不同的值,我发现 3 和 4 的多项式次数是唯一给出准确结果的,所以这就是我们将要使用的。
我们将重新运行我们的
poly_interp()函数,这次是从 0-15 的值,来预测未来五年。x_axis2 = range(15) poly_fit_values = [] for i in range(len(x_axis2)): poly_fit_values.append(poly_interp(i))这是和以前一样的代码。让我们再次看看多项式次数为 3 和 4 的结果。新的外推线是绿色的线,显示了我们的预测。
用 3:
在这里,肥胖率正在下降。4 点怎么样?
但是在这里,它正在迅速增长,所以孩子们最终会像拖拉机一样重!
这两幅图哪一幅是正确的?这取决于你是为政府工作还是为反对派工作。
这其实是特性,不是 bug。你一定听说过这些政治辩论,其中双方从相同的数据中得出完全相反的结论?现在你看到了通过调整小参数来得出完全不同的结论的可能性。
这就是我们在接受游说者的数字和图表时必须小心的原因,尤其是如果他们不愿意分享原始数据的话。有时候,预测最好留给占星家。
干杯!***
如何在 Python 中使用 any()
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: Python any(): Powered Up 布尔函数
作为一名 Python 程序员,你会经常处理布尔值和条件语句——有时非常复杂。在这些情况下,您可能需要依赖能够简化逻辑和整合信息的工具。好在 Python 中的
any()就是这样一个工具。它遍历 iterable 中的元素,并返回一个值,指示在布尔上下文中是否有任何元素为 true,或 truthy。在本教程中,您将学习:
- 如何使用
any()- 如何在
any()和or之间做出决定让我们开始吧!
Python 中途站:本教程是一个快速和实用的方法来找到你需要的信息,所以你会很快回到你的项目!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
如何在 Python 中使用
any()想象一下,你正在为雇主的招聘部门编写一个程序。您可能希望安排符合以下任何标准的候选人参加面试:
- 已经了解 Python 了
- 有五年或五年以上的开发经验
- 有学位
可以用来编写这个条件表达式的一个工具是
or:# recruit_developer.py def schedule_interview(applicant): print(f"Scheduled interview with {applicant['name']}") applicants = [ { "name": "Devon Smith", "programming_languages": ["c++", "ada"], "years_of_experience": 1, "has_degree": False, "email_address": "devon@email.com", }, { "name": "Susan Jones", "programming_languages": ["python", "javascript"], "years_of_experience": 2, "has_degree": False, "email_address": "susan@email.com", }, { "name": "Sam Hughes", "programming_languages": ["java"], "years_of_experience": 4, "has_degree": True, "email_address": "sam@email.com", }, ] for applicant in applicants: knows_python = "python" in applicant["programming_languages"] experienced_dev = applicant["years_of_experience"] >= 5 meets_criteria = ( knows_python or experienced_dev or applicant["has_degree"] ) if meets_criteria: schedule_interview(applicant)在上面的例子中,您检查每个申请人的证书,如果申请人符合您的三个标准中的任何一个,就安排面试。
技术细节: Python 的
any()和or并不局限于计算布尔表达式。相反,Python 对每个参数执行真值测试,评估表达式是 真值还是假值 。例如,非零整数值被认为是真的,而零被认为是假的:
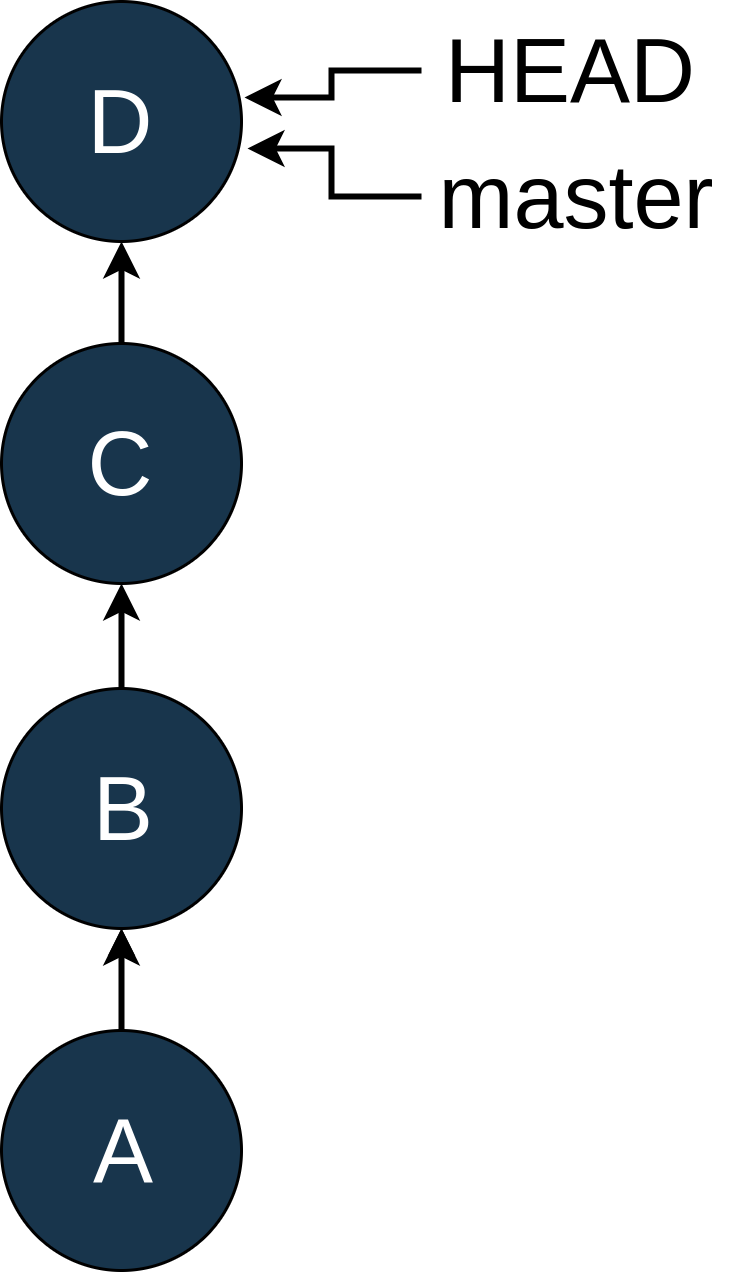

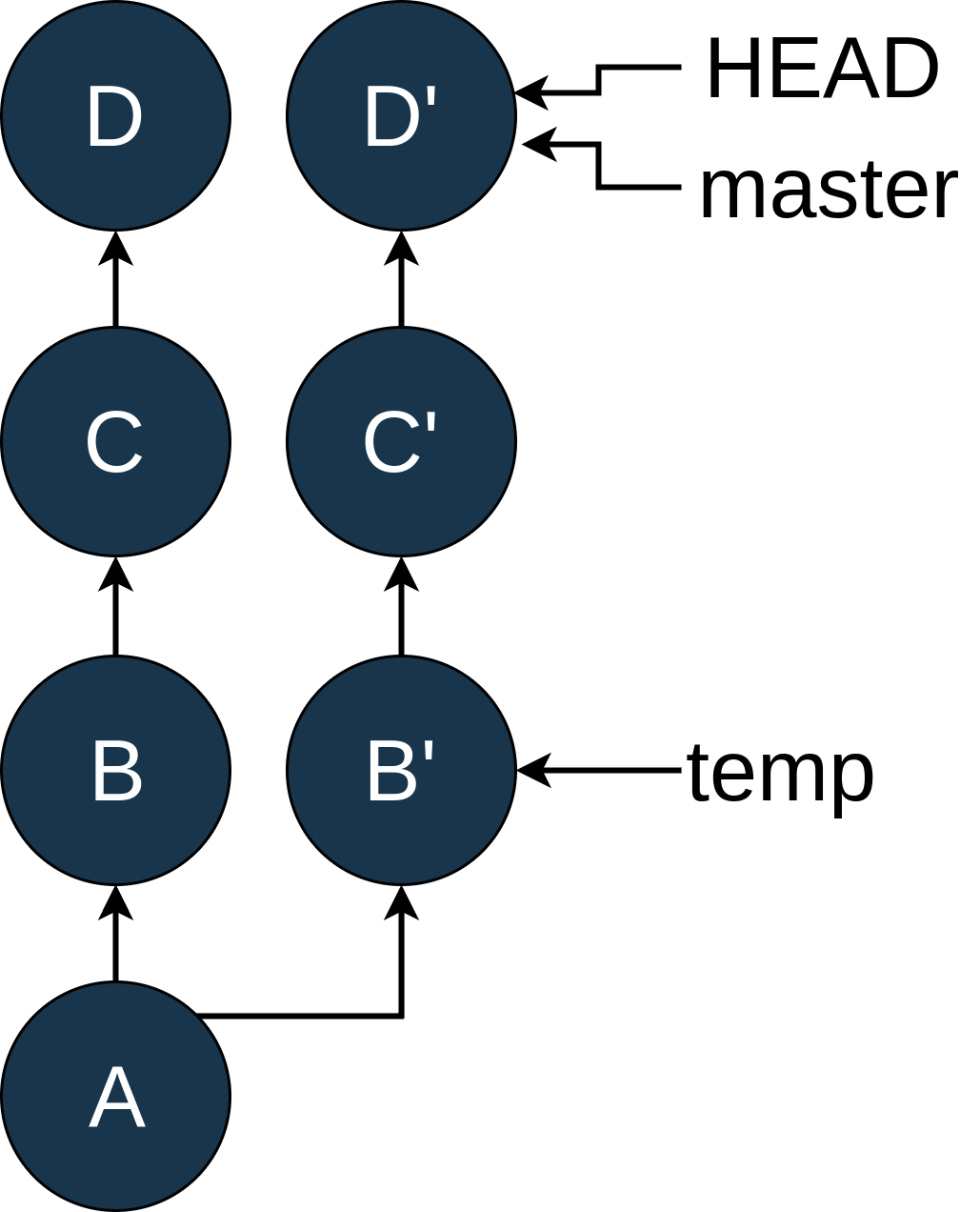

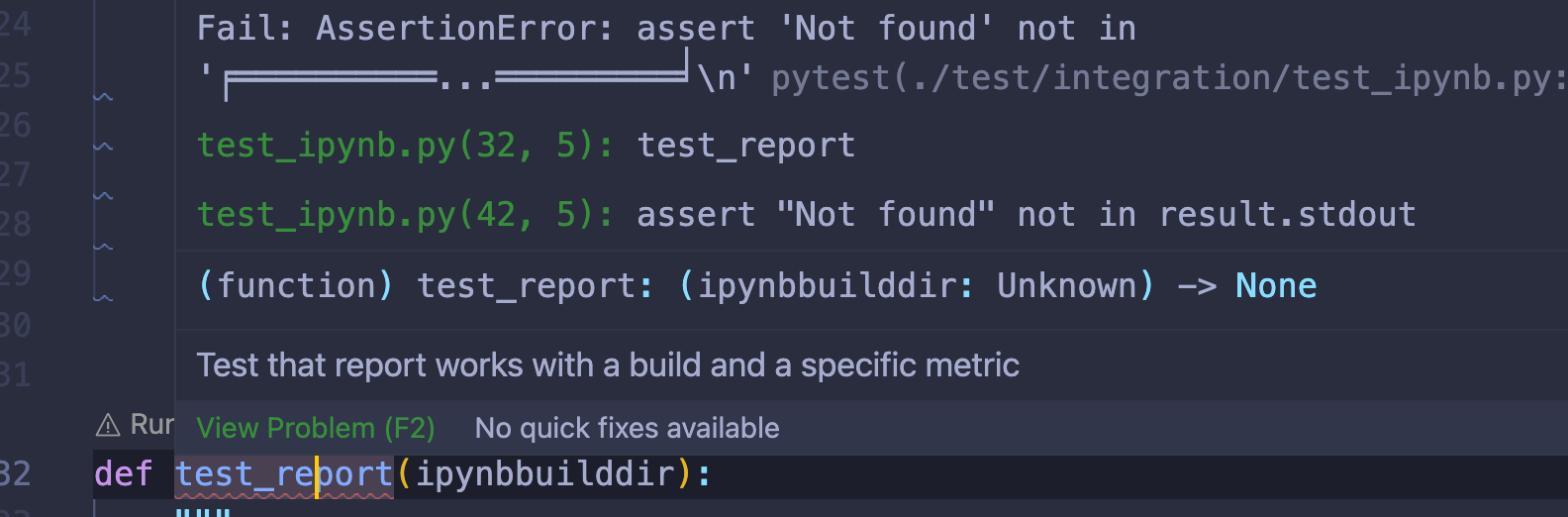


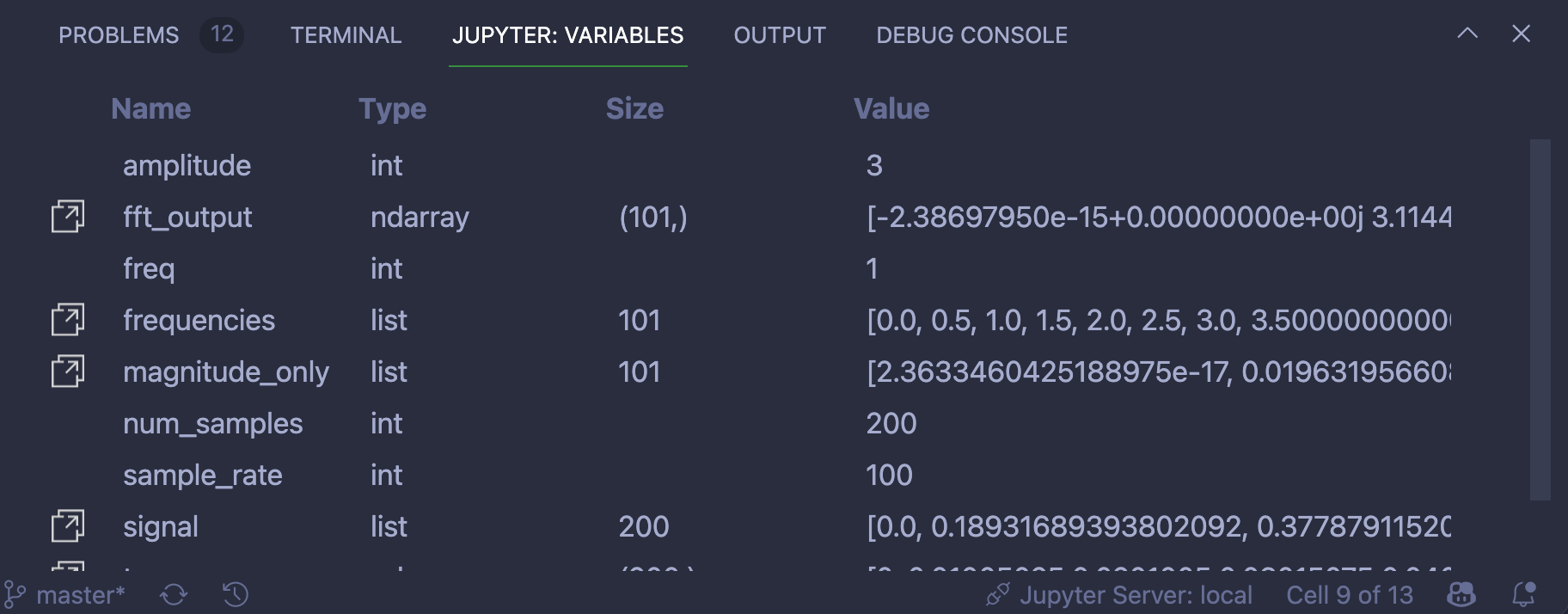
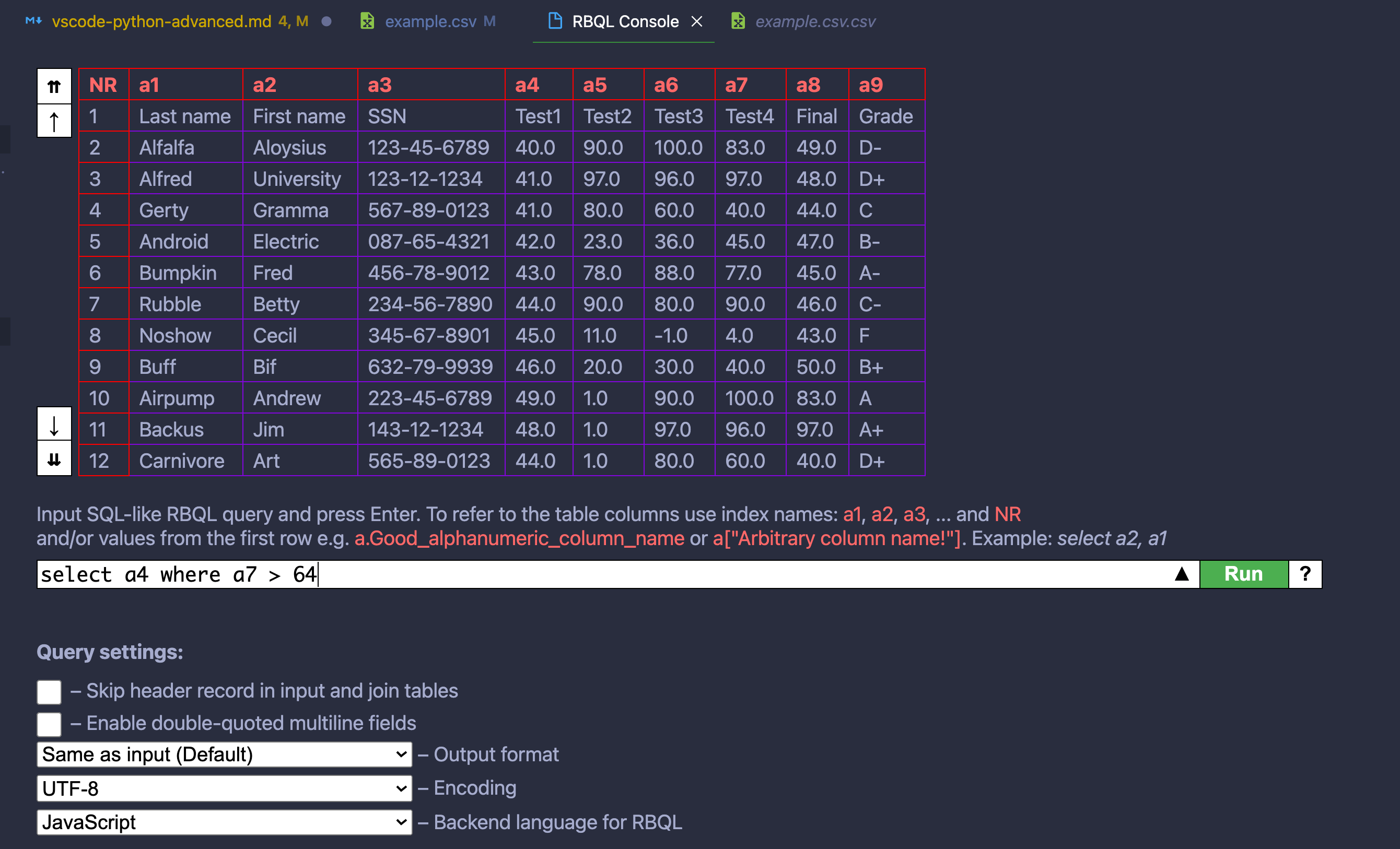




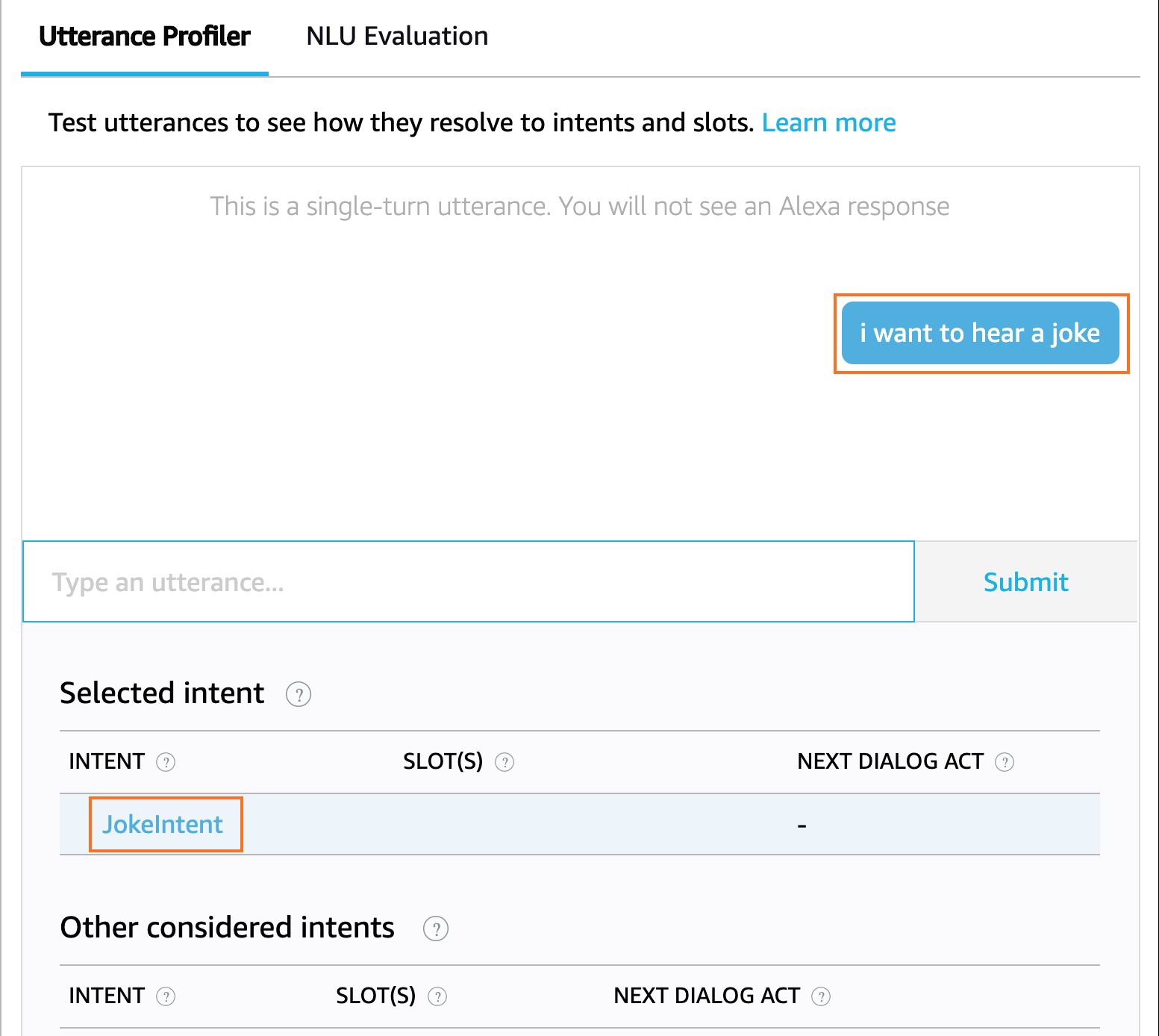
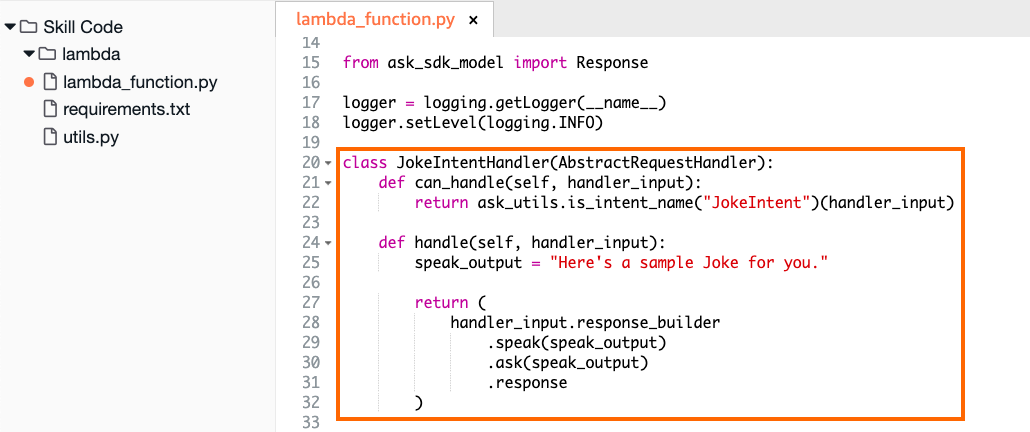
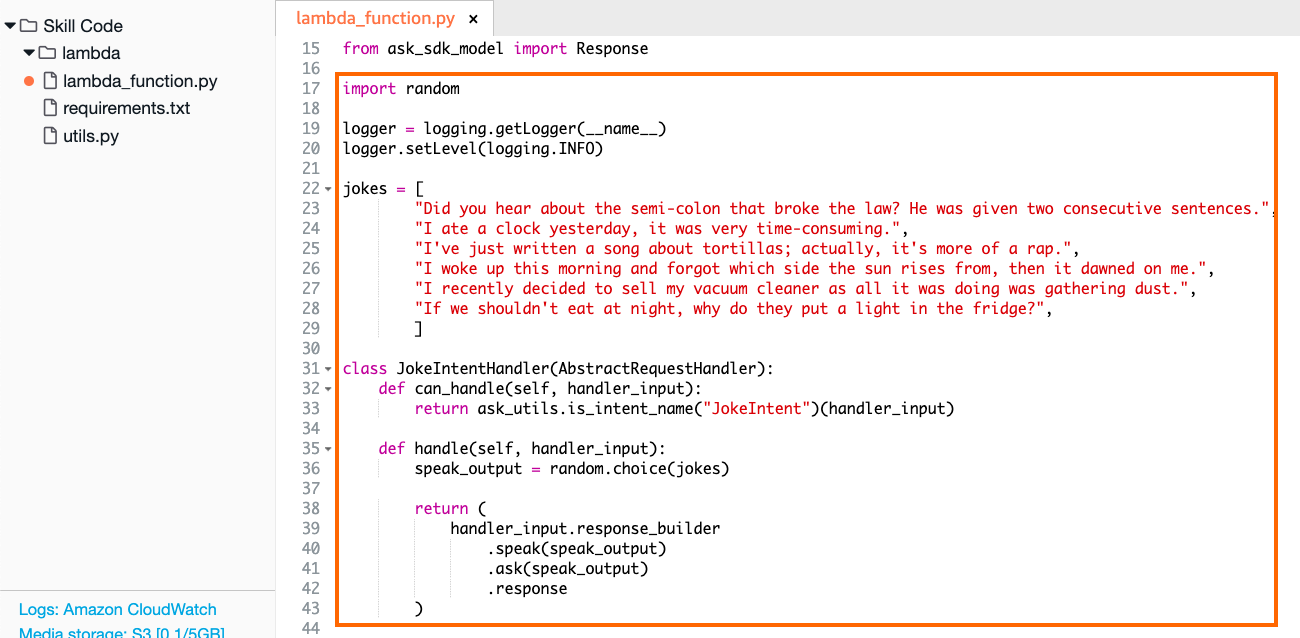












>>> 1 or 0
1
在本例中,or将非零值1评估为真值,即使它不属于布尔类型。or回归1,无需评价0的真实性。在本教程的后面,您将了解更多关于or的返回值和参数求值。
如果您执行这段代码,那么您将看到 Susan 和 Sam 将获得面试机会:
$ python recruit_developer.py
Scheduled interview with Susan Jones
Scheduled interview with Sam Hughes
该计划选择与苏珊和萨姆安排面试的原因是苏珊已经知道 Python 和萨姆有学位。注意每个候选人只需要满足一个标准。
评估申请人资格的另一种方法是使用any()。当您在 Python 中使用any()时,您必须将申请人的证书作为可迭代参数传递:
for applicant in applicants:
knows_python = "python" in applicant["programming_languages"]
experienced_dev = applicant["years_of_experience"] >= 5
credentials = (
knows_python,
experienced_dev,
applicant["has_degree"],
)
if any(credentials):
schedule_interview(applicant)
当您在 Python 中使用any()时,请记住您可以将任何 iterable 作为参数传递:
>>> any([0, 0, 1, 0]) True >>> any(set((True, False, True))) True >>> any(map(str.isdigit, "hello world")) False在每个例子中,
any()循环遍历不同的 Python iterable,测试每个元素的真实性,直到找到一个真值或检查每个元素。注意:最后一个例子使用 Python 内置的
map(),返回一个迭代器,其中每个元素都是将字符串中的下一个字符传递给str.isdigit()的结果。这是使用any()进行更复杂检查的有效方法。你可能想知道
any()是否仅仅是or的装扮版。在下一节中,您将了解这些工具之间的区别。如何区分
or和any()Python 中的
or和any()有两个主要区别:
- 句法
- 返回值
首先,您将了解语法如何影响每个工具的可用性和可读性。其次,您将了解每个工具返回的值的类型。了解这些差异将有助于您决定哪种工具最适合给定的情况。
语法
or是一个操作符,所以它有两个参数,一边一个:
>>> True or False
True
另一方面,any()是一个接受一个参数的函数,一个对象的 iterable,它通过循环来评估真实性:
>>> any((False, True)) True这种语法上的差异非常显著,因为它会影响每个工具的可用性和可读性。例如,如果您有一个 iterable,那么您可以将 iterable 直接传递给
any()。要从or获得类似的行为,你需要使用一个循环或者一个类似reduce()的函数:
>>> import functools
>>> functools.reduce(lambda x, y: x or y, (True, False, False))
True
在上面的例子中,您使用了 reduce() 将一个 iterable 作为参数传递给or。用any可以更有效地做到这一点,它直接接受 iterables 作为参数。
为了说明每个工具的语法影响其可用性的另一种方式,假设您想要避免测试一个条件,如果任何前面的条件是True:
def knows_python(applicant):
print(f"Determining if {applicant['name']} knows Python...")
return "python" in applicant["programming_languages"]
def is_local(applicant):
print(f"Determine if {applicant['name']} lives near the office...")
should_interview = knows_python(applicant) or is_local(applicant)
如果is_local()执行的时间相对较长,那么当knows_python()已经返回True时,你就不要调用它了。这叫做懒评估,或者 短路评估。默认情况下,or延迟评估条件,而any不会。
在上面的例子中,程序甚至不需要确定 Susan 是否是本地人,因为它已经确认她知道 Python。这足够安排一次面试了。在这种情况下,用or延迟调用函数将是最有效的方法。
为什么不用any()来代替?您在上面了解到any()将 iterable 作为参数,Python 根据 iterable 类型评估条件。因此,如果您使用一个列表,Python 将在创建该列表期间执行knows_python()和is_local(),然后调用any():
should_interview = any([knows_python(applicant), is_local(applicant)])
在这里,Python 会为每一个申请人调用is_local(),即使是懂 Python 的人。因为is_local()将花费很长时间来执行,并且有时是不必要的,这是一个低效的逻辑实现。
在使用 iterables 时,有一些方法可以让 Python 延迟调用函数,比如用map()构建一个迭代器,或者使用生成器表达式:
any((meets_criteria(applicant) for applicant in applicants))
这个例子使用了一个生成器表达式来生成布尔值,表明申请人是否符合面试标准。一旦申请人符合标准,any()将返回True,而不检查其余的申请人。但是请记住,这些类型的解决方法也有其自身的问题,并不适合每种情况。
需要记住的最重要的事情是,any()和or之间的语法差异会影响它们的可用性。
语法并不是影响这些工具可用性的唯一差异。接下来,让我们看看any()和or的不同返回值,以及它们如何影响您决定使用哪个工具。
返回值
Python 的any()和or返回不同类型的值。any()返回一个 Boolean 值,该值指示是否在 iterable 中找到了真值:
>>> any((1, 0)) True在这个例子中,
any()找到了一个真值(整数1,所以它返回了布尔值True。另一方面,
or返回它找到的第一个真值,不一定是布尔值。如果没有真值,那么or返回最后一个值:
>>> 1 or 0
1
>>> None or 0
0
在第一个例子中,or评估了1,它是真的,并且在不评估0的情况下返回它。第二个例子中,None是 falsy,所以or接下来对0求值,也是 falsy。但是因为没有更多的表达式要检查,or返回最后一个值,0。
当您决定使用哪个工具时,考虑您是否想知道对象的实际值或者只是真值是否存在于对象集合中的某个地方是很有帮助的。
结论
恭喜你!您已经了解了在 Python 中使用any()的来龙去脉,以及any()和or之间的区别。随着对这两种工具理解的加深,您已经准备好在自己的代码中做出选择。
你现在知道了:
- 如何在 Python 中使用
any() - 为什么你会用
any()而不是or
如果您想继续学习条件表达式以及如何使用 Python 中的or和any()等工具,那么您可以查看以下资源:
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: Python any(): Powered Up 布尔函数***
Python 和 REST APIs:与 Web 服务交互
网上有数量惊人的数据。许多网络服务,如 YouTube 和 GitHub,通过应用编程接口(API) 让第三方应用程序可以访问它们的数据。构建 API 最流行的方式之一是 REST 架构风格。Python 提供了一些很棒的工具,不仅可以从 REST API 获取数据,还可以构建自己的 Python REST APIs。
在本教程中,您将学习:
- 什么是 REST 架构
- REST APIs 如何提供对 web 数据的访问
- 如何使用
requests库消费 REST APIs 中的数据 - 构建 REST API 需要采取什么步骤
- 一些流行的 Python 工具用于构建 REST APIs
通过使用 Python 和 REST APIs,您可以检索、解析、更新和操作您感兴趣的任何 web 服务提供的数据。
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
REST 架构
REST 代表representationsstatettransfer是一种软件架构风格,它定义了网络上客户机和服务器通信的模式。REST 为软件架构提供了一组约束,以提高系统的性能、可伸缩性、简单性和可靠性。
REST 定义了以下架构约束:
- 无状态:服务器不会在来自客户端的请求之间维护任何状态。
- 客户机-服务器:客户机和服务器必须相互解耦,允许各自独立开发。
- 可缓存:从服务器检索的数据应该可以被客户端或服务器缓存。
- 统一接口:服务器将提供统一的接口来访问资源,而不需要定义它们的表示。
- 分层系统:客户端可以通过代理或负载均衡器等其他层间接访问服务器上的资源。
- 按需编码(可选):服务器可能会将自己可以运行的代码转移到客户端,比如针对单页面应用的 JavaScript 。
注意,REST 不是一个规范,而是一套关于如何构建网络连接软件系统的指南。
REST APIs 和 Web 服务
REST web 服务是任何遵守 REST 架构约束的 web 服务。这些 web 服务通过 API 向外界公开它们的数据。REST APIs 通过公共 web URLs 提供对 web 服务数据的访问。
例如,下面是 GitHub 的 REST API 的 URL 之一:
https://api.github.com/users/<username>
这个 URL 允许您访问特定 GitHub 用户的信息。您通过向特定的 URL 发送一个 HTTP 请求并处理响应来访问来自 REST API 的数据。
HTTP 方法
REST APIs 监听 HTTP 方法,如GET、POST和DELETE,以了解在 web 服务的资源上执行哪些操作。资源是 web 服务中可用的任何数据,可以通过对 REST API 的 HTTP 请求来访问和操作。HTTP 方法告诉 API 在资源上执行哪个操作。
虽然有许多 HTTP 方法,但下面列出的五种方法是 REST APIs 中最常用的:
| HTTP 方法 | 描述 |
|---|---|
GET |
检索现有资源。 |
POST |
创建新资源。 |
PUT |
更新现有资源。 |
PATCH |
部分更新现有资源。 |
DELETE |
删除资源。 |
REST API 客户端应用程序可以使用这五种 HTTP 方法来管理 web 服务中资源的状态。
状态代码
一旦 REST API 接收并处理一个 HTTP 请求,它将返回一个 HTTP 响应。这个响应中包含一个 HTTP 状态代码。此代码提供了有关请求结果的信息。向 API 发送请求的应用程序可以检查状态代码,并根据结果执行操作。这些操作可能包括处理错误或向用户显示成功消息。
下面是 REST APIs 返回的最常见的状态代码列表:
| 密码 | 意义 | 描述 |
|---|---|---|
200 |
好 | 请求的操作成功。 |
201 |
创造 | 创建了新资源。 |
202 |
可接受的 | 请求已收到,但尚未进行修改。 |
204 |
没有内容 | 请求成功,但响应没有内容。 |
400 |
错误的请求 | 请求格式不正确。 |
401 |
未经授权的 | 客户端无权执行请求的操作。 |
404 |
未发现 | 找不到请求的资源。 |
415 |
不支持的媒体类型 | 服务器不支持请求数据格式。 |
422 |
不可处理实体 | 请求数据格式正确,但包含无效或丢失的数据。 |
500 |
内部服务器错误 | 处理请求时,服务器出现错误。 |
这十个状态代码仅代表可用的 HTTP 状态代码的一小部分。状态代码根据结果的类别进行编号:
| 代码范围 | 种类 |
|---|---|
2xx |
成功的手术 |
3xx |
重寄 |
4xx |
客户端错误 |
5xx |
服务器错误 |
当使用 REST APIs 时,HTTP 状态代码很方便,因为您经常需要根据请求的结果执行不同的逻辑。
API 端点
REST API 公开了一组公共 URL,客户端应用程序使用这些 URL 来访问 web 服务的资源。在 API 的上下文中,这些 URL 被称为端点。
为了帮助澄清这一点,请看下表。在这个表格中,您将看到一个假想的 CRM 系统的 API 端点。这些端点用于代表系统中潜在customers的客户资源:
| HTTP 方法 | API 端点 | 描述 |
|---|---|---|
GET |
/customers |
获取客户名单。 |
GET |
/customers/<customer_id> |
获得单个客户。 |
POST |
/customers |
创建新客户。 |
PUT |
/customers/<customer_id> |
更新客户。 |
PATCH |
/customers/<customer_id> |
部分更新客户。 |
DELETE |
/customers/<customer_id> |
删除客户。 |
上面的每个端点基于 HTTP 方法执行不同的操作。
注意:为简洁起见,省略了端点的基本 URL。实际上,您需要完整的 URL 路径来访问 API 端点:
https://api.example.com/customers
这是您用来访问此端点的完整 URL。基本 URL 是除了/customers之外的所有内容。
你会注意到一些端点的末尾有<customer_id>。这个符号意味着您需要在 URL 后面添加一个数字customer_id来告诉 REST API 您想要使用哪个customer。
上面列出的端点仅代表系统中的一种资源。生产就绪的 REST APIs 通常有数十甚至数百个不同的端点来管理 web 服务中的资源。
REST 和 Python:消费 API
为了编写与 REST APIs 交互的代码,大多数 Python 开发人员求助于 requests 来发送 HTTP 请求。这个库抽象出了进行 HTTP 请求的复杂性。这是少数几个值得作为标准库的一部分来对待的项目之一。
要开始使用requests,需要先安装。您可以使用 pip 来安装它:
$ python -m pip install requests
现在您已经安装了requests,您可以开始发送 HTTP 请求了。
获取
GET是使用 REST APIs 时最常用的 HTTP 方法之一。该方法允许您从给定的 API 中检索资源。GET是一个只读的操作,所以您不应该使用它来修改现有的资源。
为了测试本节中的GET和其他方法,您将使用一个名为 JSONPlaceholder 的服务。这个免费服务提供了虚假的 API 端点,这些端点发送回requests可以处理的响应。
为了进行测试,启动 Python REPL 并运行以下命令向 JSONPlaceholder 端点发送一个GET请求:
>>> import requests >>> api_url = "https://jsonplaceholder.typicode.com/todos/1" >>> response = requests.get(api_url) >>> response.json() {'userId': 1, 'id': 1, 'title': 'delectus aut autem', 'completed': False}这段代码调用
requests.get()向/todos/1发送一个GET请求,后者用 ID 为1的todo项进行响应。然后可以在response对象上调用.json()来查看从 API 返回的数据。响应数据被格式化为 JSON ,一个类似于 Python 字典的键值存储。这是一种非常流行的数据格式,也是大多数 REST APIs 事实上的交换格式。
除了从 API 查看 JSON 数据,您还可以查看关于
response的其他内容:
>>> response.status_code
200
>>> response.headers["Content-Type"]
'application/json; charset=utf-8'
在这里,您访问response.status_code来查看 HTTP 状态代码。您还可以使用response.headers查看响应的 HTTP 头。这个字典包含关于响应的元数据,比如响应的Content-Type。
帖子
现在,看看如何使用 REST API 的requests到POST数据来创建新资源。您将再次使用 JSONPlaceholder,但是这次您将在请求中包含 JSON 数据。这是您将发送的数据:
{ "userId": 1, "title": "Buy milk", "completed": false }
该 JSON 包含一个新的todo项目的信息。回到 Python REPL,运行下面的代码来创建新的todo:
>>> import requests >>> api_url = "https://jsonplaceholder.typicode.com/todos" >>> todo = {"userId": 1, "title": "Buy milk", "completed": False} >>> response = requests.post(api_url, json=todo) >>> response.json() {'userId': 1, 'title': 'Buy milk', 'completed': False, 'id': 201} >>> response.status_code 201这里,您调用
requests.post()在系统中创建新的todo。首先,创建一个包含您的
todo数据的字典。然后你将这个字典传递给requests.post()的json关键字参数。当您这样做时,requests.post()自动将请求的 HTTP 头Content-Type设置为application/json。它还将todo序列化为一个 JSON 字符串,并将其附加到请求体中。如果您不使用
json关键字参数来提供 JSON 数据,那么您需要相应地设置Content-Type并手动序列化 JSON。下面是前面代码的等效版本:
>>> import requests
>>> import json >>> api_url = "https://jsonplaceholder.typicode.com/todos"
>>> todo = {"userId": 1, "title": "Buy milk", "completed": False}
>>> headers = {"Content-Type":"application/json"} >>> response = requests.post(api_url, data=json.dumps(todo), headers=headers) >>> response.json()
{'userId': 1, 'title': 'Buy milk', 'completed': False, 'id': 201}
>>> response.status_code
201
在这段代码中,您添加了一个包含设置为application/json的单个标题Content-Type的headers字典。这告诉 REST API 您正在发送带有请求的 JSON 数据。
然后调用requests.post(),但不是将todo传递给json参数,而是首先调用json.dumps(todo)来序列化它。在它被序列化之后,你把它传递给data关键字参数。data参数告诉requests请求中包含什么数据。您还可以将headers字典传递给requests.post()来手动设置 HTTP 头。
当您像这样调用requests.post()时,它与前面的代码具有相同的效果,但是您可以对请求进行更多的控制。
注: json.dumps() 来自于标准库中的 json 包。这个包提供了在 Python 中使用 JSON 的有用方法。
一旦 API 响应,您就调用response.json()来查看 JSON。JSON 包括为新的todo生成的id。201状态代码告诉您一个新的资源已经创建。
放
除了GET和POST,requests还提供了对所有其他 HTTP 方法的支持,这些方法可以和 REST API 一起使用。下面的代码发送一个PUT请求,用新数据更新现有的todo。通过PUT请求发送的任何数据将完全替换todo的现有值。
您将使用与用于GET和POST相同的 JSONPlaceholder 端点,但是这次您将把10附加到 URL 的末尾。这告诉 REST API 您想要更新哪个todo:
>>> import requests >>> api_url = "https://jsonplaceholder.typicode.com/todos/10" >>> response = requests.get(api_url) >>> response.json() {'userId': 1, 'id': 10, 'title': 'illo est ... aut', 'completed': True} >>> todo = {"userId": 1, "title": "Wash car", "completed": True} >>> response = requests.put(api_url, json=todo) >>> response.json() {'userId': 1, 'title': 'Wash car', 'completed': True, 'id': 10} >>> response.status_code 200在这里,首先调用
requests.get()来查看现有todo的内容。接下来,用新的 JSON 数据调用requests.put()来替换现有的待办事项值。调用response.json()时可以看到新的值。成功的PUT请求将总是返回200而不是201,因为您不是在创建一个新的资源,而是在更新一个现有的资源。补丁
接下来,您将使用
requests.patch()来修改现有todo上特定字段的值。PATCH与PUT的不同之处在于,它不会完全取代现有的资源。它只修改与请求一起发送的 JSON 中设置的值。您将使用上一个示例中的相同的
todo来测试requests.patch()。以下是当前值:{'userId': 1, 'title': 'Wash car', 'completed': True, 'id': 10}现在您可以用新值更新
title:
>>> import requests
>>> api_url = "https://jsonplaceholder.typicode.com/todos/10"
>>> todo = {"title": "Mow lawn"} >>> response = requests.patch(api_url, json=todo) >>> response.json()
{'userId': 1, 'id': 10, 'title': 'Mow lawn', 'completed': True}
>>> response.status_code
200
当你调用response.json()时,你可以看到title被更新为Mow lawn。
删除
最后但同样重要的是,如果您想完全删除一个资源,那么您可以使用DELETE。下面是删除一个todo的代码:
>>> import requests >>> api_url = "https://jsonplaceholder.typicode.com/todos/10" >>> response = requests.delete(api_url) >>> response.json() {} >>> response.status_code 200您用一个 API URL 调用
requests.delete(),该 URL 包含您想要删除的todo的 ID。这将向 REST API 发送一个DELETE请求,然后 REST API 移除匹配的资源。删除资源后,API 发送回一个空的 JSON 对象,表明资源已经被删除。
requests库是使用 REST APIs 的一个很棒的工具,也是 Python 工具箱中不可或缺的一部分。在下一节中,您将改变思路,考虑如何构建 REST API。REST 和 Python:构建 API
REST API 设计是一个巨大的话题,有很多层。如同技术领域的大多数事情一样,对于构建 API 的最佳方法有各种各样的观点。在本节中,您将看到一些在构建 API 时推荐遵循的步骤。
身份资源
构建 REST API 的第一步是识别 API 将管理的资源。通常将这些资源描述为复数名词,如
customers、events或transactions。当您在 web 服务中识别不同的资源时,您将构建一个名词列表,描述用户可以在 API 中管理的不同数据。当您这样做时,请确保考虑任何嵌套的资源。例如,
customers可能有sales,或者events可能包含guests。当您定义 API 端点时,建立这些资源层次结构将会有所帮助。定义您的端点
一旦您确定了 web 服务中的资源,您将希望使用这些资源来定义 API 端点。下面是一些您可能在支付处理服务的 API 中找到的
transactions资源的端点示例:
HTTP 方法 API 端点 描述 GET/transactions获取交易列表。 GET/transactions/<transaction_id>获得单笔交易。 POST/transactions创建新的交易记录。 PUT/transactions/<transaction_id>更新交易记录。 PATCH/transactions/<transaction_id>部分更新交易记录。 DELETE/transactions/<transaction_id>删除交易记录。 这六个端点涵盖了您需要在 web 服务中创建、读取、更新和删除
transactions的所有操作。基于用户可以使用 API 执行的操作,web 服务中的每个资源都有一个类似的端点列表。注意:端点不应该包含动词。相反,您应该选择适当的 HTTP 方法来传达端点的操作。例如,下面的端点包含一个不需要的动词:
GET /getTransactions这里,
get在不需要的时候包含在端点中。HTTP 方法GET已经通过指示动作为端点提供了语义。您可以从端点中删除get:GET /transactions这个端点只包含一个复数名词,HTTP 方法
GET传递动作。现在来看一个嵌套资源端点的例子。在这里,您将看到嵌套在
events资源下的guests的端点:
HTTP 方法 API 端点 描述 GET/events/<event_id>/guests弄一份宾客名单。 GET/events/<event_id>/guests/<guest_id>找一个单独的客人。 POST/events/<event_id>/guests创建新客人。 PUT/events/<event_id>/guests/<guest_id>更新客人。 PATCH/events/<event_id>/guests/<guest_id>部分更新客人。 DELETE/events/<event_id>/guests/<guest_id>删除客人。 有了这些端点,您可以管理系统中特定事件的
guests。这不是为嵌套资源定义端点的唯一方式。有些人更喜欢使用查询字符串来访问嵌套资源。查询字符串允许您在 HTTP 请求中发送附加参数。在下面的端点中,您添加了一个查询字符串来获取特定
event_id的guests:GET /guests?event_id=23这个端点将过滤掉任何不引用给定
event_id的guests。与 API 设计中的许多事情一样,您需要决定哪种方法最适合您的 web 服务。注意:【REST API 不太可能在 web 服务的整个生命周期中保持不变。资源会发生变化,您需要更新您的端点来反映这些变化。这就是 API 版本的用武之地。API 版本控制允许您修改 API,而不用担心破坏现有的集成。
有很多种版本控制策略。选择正确的选项取决于 API 的需求。下面是一些最流行的 API 版本控制选项:
无论您选择什么策略,对 API 进行版本控制都是重要的一步,以确保它能够适应不断变化的需求,同时支持现有用户。
既然您已经介绍了端点,那么在下一节中,您将会看到在 REST API 中格式化数据的一些选项。
选择您的数据交换格式
格式化 web 服务数据的两个流行选项是 XML 和 JSON。传统上,XML 和SOAPAPI 非常受欢迎,但是 JSON 和 REST APIs 更受欢迎。为了比较这两者,请看一个格式化为 XML 和 JSON 的示例
book资源。这是 XML 格式的书:
<?xml version="1.0" encoding="UTF-8" ?> <book> <title>Python Basics</title> <page_count>635</page_count> <pub_date>2021-03-16</pub_date> <authors> <author> <name>David Amos</name> </author> <author> <name>Joanna Jablonski</name> </author> <author> <name>Dan Bader</name> </author> <author> <name>Fletcher Heisler</name> </author> </authors> <isbn13>978-1775093329</isbn13> <genre>Education</genre> </book>XML 使用一系列的元素来编码数据。每个元素都有一个开始和结束标记,数据在它们之间。元素可以嵌套在其他元素中。你可以在上面看到,几个
<author>标签嵌套在<authors>中。现在,看看 JSON 中的同一个
book:{ "title": "Python Basics", "page_count": 635, "pub_date": "2021-03-16", "authors": [ {"name": "David Amos"}, {"name": "Joanna Jablonski"}, {"name": "Dan Bader"}, {"name": "Fletcher Heisler"} ], "isbn13": "978-1775093329", "genre": "Education" }JSON 以类似于 Python 字典的键值对存储数据。像 XML 一样,JSON 支持任何级别的嵌套数据,因此您可以对复杂数据建模。
JSON 和 XML 本质上都没有谁更好,但是 REST API 开发人员更喜欢 JSON。当您将 REST API 与前端框架如 React 或 Vue 配对时尤其如此。
设计成功响应
一旦选择了数据格式,下一步就是决定如何响应 HTTP 请求。来自 REST API 的所有响应应该具有相似的格式,并包含正确的 HTTP 状态代码。
在这一节中,您将看到一个管理库存
cars的假想 API 的一些示例 HTTP 响应。这些例子将让你知道应该如何格式化你的 API 响应。为了清楚起见,我们将查看原始的 HTTP 请求和响应,而不是使用像requests这样的 HTTP 库。首先,看一下对
/cars的GET请求,它返回一个cars列表:GET /cars HTTP/1.1 Host: api.example.com这个 HTTP 请求由四部分组成:
GET是 HTTP 方法类型。/cars是 API 端点。HTTP/1.1是 HTTP 版本。Host: api.example.com是 API 主机。这四个部分就是你向
/cars发送一个GET请求所需要的全部。现在来看看回应。这个 API 使用 JSON 作为数据交换格式:HTTP/1.1 200 OK Content-Type: application/json ... [ { "id": 1, "make": "GMC", "model": "1500 Club Coupe", "year": 1998, "vin": "1D7RV1GTXAS806941", "color": "Red" }, { "id": 2, "make": "Lamborghini", "model":"Gallardo", "year":2006, "vin":"JN1BY1PR0FM736887", "color":"Mauve" }, { "id": 3, "make": "Chevrolet", "model":"Monte Carlo", "year":1996, "vin":"1G4HP54K714224234", "color":"Violet" } ]API 返回一个包含一列
cars的响应。您知道响应是成功的,因为有了200 OK状态代码。该响应还有一个设置为application/json的Content-Type报头。这告诉用户将响应解析为 JSON。注意:当你使用一个真正的 API 时,你会看到比这更多的 HTTP 头。这些头文件在不同的 API 之间是不同的,所以在这些例子中它们被排除了。
务必在回复中设置正确的
Content-Type标题。如果你发送 JSON,那么设置Content-Type为application/json。如果是 XML,那么将其设置为application/xml。这个头告诉用户应该如何解析数据。您还需要在回复中包含适当的状态代码。对于任何成功的
GET请求,您应该返回200 OK。这告诉用户他们的请求按预期得到了处理。看看另一个
GET请求,这次是针对一辆车:GET /cars/1 HTTP/1.1 Host: api.example.com这个 HTTP 请求查询汽车
1的 API。以下是回应:HTTP/1.1 200 OK Content-Type: application/json { "id": 1, "make": "GMC", "model": "1500 Club Coupe", "year": 1998, "vin": "1D7RV1GTXAS806941", "color": "Red" },这个响应包含一个带有汽车数据的 JSON 对象。既然是单个对象,就不需要用列表包装。与上一个响应一样,这也有一个
200 OK状态代码。注意:
GET请求不应该修改现有的资源。如果请求包含数据,那么这个数据应该被忽略,API 应该返回没有改变的资源。接下来,查看添加新车的
POST请求:POST /cars HTTP/1.1 Host: api.example.com Content-Type: application/json { "make": "Nissan", "model": "240SX", "year": 1994, "vin": "1N6AD0CU5AC961553", "color": "Violet" }这个
POST请求在请求中包含新车的 JSON。它将Content-Type头设置为application/json,这样 API 就知道请求的内容类型。API 将从 JSON 创建一辆新车。以下是回应:
HTTP/1.1 201 Created Content-Type: application/json { "id": 4, "make": "Nissan", "model": "240SX", "year": 1994, "vin": "1N6AD0CU5AC961553", "color": "Violet" }这个响应有一个
201 Created状态代码,告诉用户一个新的资源已经创建。确保对所有成功的POST请求使用201 Created而不是200 OK。这个响应还包括一个由 API 生成的带有
id的新车副本。在响应中发回一个id非常重要,这样用户就可以再次修改资源。注意:当用户用
POST创建资源或者用PUT或PATCH修改资源时,一定要发送回一份副本,这一点很重要。这样,用户可以看到他们所做的更改。现在来看看一个
PUT请求:PUT /cars/4 HTTP/1.1 Host: api.example.com Content-Type: application/json { "make": "Buick", "model": "Lucerne", "year": 2006, "vin": "4T1BF3EK8AU335094", "color":"Maroon" }这个请求使用前一个请求中的
id用所有新数据更新汽车。提醒一下,PUT用新数据更新资源上的所有域。以下是回应:HTTP/1.1 200 OK Content-Type: application/json { "id": 4, "make": "Buick", "model": "Lucerne", "year": 2006, "vin": "4T1BF3EK8AU335094", "color":"Maroon" }该响应包括带有新数据的
car的副本。同样,您总是希望为一个PUT请求发送回完整的资源。这同样适用于PATCH的请求:PATCH /cars/4 HTTP/1.1 Host: api.example.com Content-Type: application/json { "vin": "VNKKTUD32FA050307", "color": "Green" }请求只更新资源的一部分。在上面的请求中,
vin和color字段将被更新为新值。以下是回应:HTTP/1.1 200 OK Content-Type: application/json { "id": 4, "make": "Buick", "model": "Lucerne", "year": 2006, "vin": "VNKKTUD32FA050307", "color": "Green" }该响应包含
car的完整副本。如您所见,只有vin和color字段被更新。最后,看看当 REST API 收到一个
DELETE请求时应该如何响应。这里有一个删除car的DELETE请求:DELETE /cars/4 HTTP/1.1这个
DELETE请求告诉 API 移除 ID 为4的car。以下是回应:HTTP/1.1 204 No Content该响应仅包括状态代码
204 No Content。此状态代码告诉用户操作成功,但是响应中没有返回任何内容。这是有意义的,因为car已经被删除了。没有理由在响应中发送它的副本。当一切按计划进行时,上面的响应工作得很好,但是如果请求有问题会发生什么呢?在下一节中,您将看到当错误发生时,您的 REST API 应该如何响应。
设计错误响应
对 REST API 的请求总有可能失败。定义错误响应是一个好主意。这些响应应该包括发生了什么错误的描述以及相应的状态代码。在这一节中,您将看到几个例子。
首先,看一下对 API 中不存在的资源的请求:
GET /motorcycles HTTP/1.1 Host: api.example.com这里,用户向
/motorcycles发送一个GET请求,这个请求并不存在。API 发回以下响应:HTTP/1.1 404 Not Found Content-Type: application/json ... { "error": "The requested resource was not found." }该响应包括一个
404 Not Found状态代码。除此之外,响应还包含一个带有描述性错误消息的 JSON 对象。提供一个描述性的错误信息给用户更多的错误上下文。现在来看看用户发送无效请求时的错误响应:
POST /cars HTTP/1.1 Host: api.example.com Content-Type: application/json { "make": "Nissan", "year": 1994, "color": "Violet"这个
POST请求包含 JSON,但是格式不正确。它的结尾缺少了一个右花括号(})。API 将无法处理这些数据。错误响应告诉用户有关问题的信息:HTTP/1.1 400 Bad Request Content-Type: application/json { "error": "This request was not properly formatted. Please send again." }这个响应包括一个描述性的错误消息和
400 Bad Request状态代码,告诉用户他们需要修复这个请求。即使格式正确,请求也可能在其他几个方面出错。在下一个例子中,用户发送了一个
POST请求,但是包含了一个不支持的媒体类型:POST /cars HTTP/1.1 Host: api.example.com Content-Type: application/xml <?xml version="1.0" encoding="UTF-8" ?> <car> <make>Nissan</make> <model>240SX</model> <year>1994</year> <vin>1N6AD0CU5AC961553</vin> <color>Violet</color> </car>在这个请求中,用户发送 XML,但是 API 只支持 JSON。API 的响应如下:
HTTP/1.1 415 Unsupported Media Type Content-Type: application/json { "error": "The application/xml mediatype is not supported." }这个响应包含了
415 Unsupported Media Type状态代码,表明POST请求包含了 API 不支持的数据格式。这个错误代码对于格式错误的数据是有意义的,但是对于格式正确但仍然无效的数据呢?在下一个例子中,用户发送了一个
POST请求,但是包含了与其他数据的字段不匹配的car数据:POST /cars HTTP/1.1 Host: api.example.com Content-Type: application/json { "make": "Nissan", "model": "240SX", "topSpeed": 120 "warrantyLength": 10 }在这个请求中,用户向 JSON 添加了
topSpeed和warrantyLength字段。API 不支持这些字段,因此它会响应一条错误消息:HTTP/1.1 422 Unprocessable Entity Content-Type: application/json { "error": "Request had invalid or missing data." }该响应包括
422 Unprocessable Entity状态代码。此状态代码表示请求没有任何问题,但是数据无效。REST API 需要验证传入的数据。如果用户随请求发送数据,那么 API 应该验证数据并通知用户任何错误。响应请求,不管是成功的还是错误的,都是 REST API 最重要的工作之一。如果你的 API 是直观的,并提供准确的响应,那么用户围绕你的 web 服务构建应用程序就更容易了。幸运的是,一些优秀的 Python web 框架抽象出了处理 HTTP 请求和返回响应的复杂性。在下一节中,您将看到三个流行的选项。
REST 和 Python:行业工具
在这一节中,您将看到用 Python 构建 REST APIs 的三个流行框架。每个框架都有优点和缺点,所以您必须评估哪个最适合您的需求。为此,在接下来的章节中,您将会看到每个框架中的 REST API。所有的例子都是针对一个类似的管理国家集合的 API。
每个国家将有以下字段:
name是国家的名称。capital是这个国家的首都。area是以平方公里为单位的国家的面积。字段
name、capital和area存储世界上某个特定国家的数据。大多数时候,从 REST API 发送的数据来自数据库。连接数据库超出了本教程的范围。对于以下示例,您将在 Python 列表中存储数据。例外情况是 Django REST 框架示例,它运行 Django 创建的 SQLite 数据库。
注意:建议您为每个示例创建单独的文件夹,以分离源文件。您还会希望使用虚拟环境来隔离依赖性。
为了保持一致性,您将使用
countries作为所有三个框架的主要端点。您还将使用 JSON 作为所有三个框架的数据格式。现在您已经了解了 API 的背景,您可以继续下一部分,在这里您将看到 Flask 中的 REST API。
烧瓶
Flask 是用于构建 web 应用和 REST APIs 的 Python 微框架。Flask 为您的应用程序提供了坚实的基础,同时留给您许多设计选择。Flask 的主要工作是处理 HTTP 请求,并将它们路由到应用程序中适当的函数。
注意:本节中的代码使用了新的 Flask 2 语法。如果你运行的是老版本的 Flask,那么使用
@app.route("/countries")而不是@app.get("/countries")和@app.post("/countries")。为了在旧版本的 Flask 中处理
POST请求,您还需要将methods参数添加到@app.route():@app.route("/countries", methods=["POST"])这个路由处理对 Flask 1 中的
/countries的POST请求。以下是 REST API 的 Flask 应用程序示例:
# app.py from flask import Flask, request, jsonify app = Flask(__name__) countries = [ {"id": 1, "name": "Thailand", "capital": "Bangkok", "area": 513120}, {"id": 2, "name": "Australia", "capital": "Canberra", "area": 7617930}, {"id": 3, "name": "Egypt", "capital": "Cairo", "area": 1010408}, ] def _find_next_id(): return max(country["id"] for country in countries) + 1 @app.get("/countries") def get_countries(): return jsonify(countries) @app.post("/countries") def add_country(): if request.is_json: country = request.get_json() country["id"] = _find_next_id() countries.append(country) return country, 201 return {"error": "Request must be JSON"}, 415这个应用程序定义了 API 端点
/countries来管理国家列表。它处理两种不同的请求:
GET /countries返回countries的列表。POST /countries向列表中添加一个新的country。注意:这个 Flask 应用程序只包含处理两种类型的 API 端点请求的函数,
/countries。在一个完整的 REST API 中,您可能希望扩展它,以包含所有必需操作的函数。您可以通过安装带有
pip的flask来试用这个应用程序:$ python -m pip install flask一旦安装了
flask,将代码保存在一个名为app.py的文件中。要运行这个 Flask 应用程序,首先需要将一个名为FLASK_APP的环境变量设置为app.py。这告诉 Flask 哪个文件包含您的应用程序。在包含
app.py的文件夹中运行以下命令:$ export FLASK_APP=app.py这会将当前 shell 中的
FLASK_APP设置为app.py。也可以将FLASK_ENV设置为development,将 Flask 置于调试模式:$ export FLASK_ENV=development除了提供有用的错误消息,调试模式还会在所有代码更改后触发应用程序的重新加载。如果没有调试模式,您必须在每次更改后重启服务器。
注意:以上命令可以在 macOS 或 Linux 上运行。如果您在 Windows 上运行它,那么您需要在命令提示符下像这样设置
FLASK_APP和FLASK_ENV:C:\> set FLASK_APP=app.py C:\> set FLASK_ENV=development现在
FLASK_APP和FLASK_ENV被设置在 Windows 外壳内部。准备好所有的环境变量后,您现在可以通过调用
flask run来启动 Flask 开发服务器:$ flask run * Serving Flask app "app.py" (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)这将启动运行该应用程序的服务器。打开你的浏览器,进入
http://127.0.0.1:5000/countries,你会看到如下的回应:[ { "area": 513120, "capital": "Bangkok", "id": 1, "name": "Thailand" }, { "area": 7617930, "capital": "Canberra", "id": 2, "name": "Australia" }, { "area": 1010408, "capital": "Cairo", "id": 3, "name": "Egypt" } ]这个 JSON 响应包含在
app.py开头定义的三个countries。看看下面的代码,看看这是如何工作的:@app.get("/countries") def get_countries(): return jsonify(countries)这段代码使用
@app.get(),一个 Flask route decorator ,将GET请求连接到应用程序中的一个函数。当您访问/countries时,Flask 调用修饰函数来处理 HTTP 请求,然后返回一个响应。上面的代码中,
get_countries()取countries,是一个 Python 列表,用jsonify()转换成 JSON。这个 JSON 在响应中返回。注意:大多数时候,你可以直接从 Flask 函数返回一个 Python 字典。Flask 会自动将任何 Python 字典转换成 JSON。您可以通过下面的函数看到这一点:
@app.get("/country") def get_country(): return countries[1]在这段代码中,您从
countries返回第二个字典。Flask 会把这个字典转换成 JSON。当您请求/country时,您将看到以下内容:{ "area": 7617930, "capital": "Canberra", "id": 2, "name": "Australia" }这是你从
get_country()返回的字典的 JSON 版本。在
get_countries()中,您需要使用jsonify(),因为您返回的是一个字典列表,而不仅仅是一个字典。Flask 不会自动将列表转换成 JSON。现在来看看
add_country()。该函数处理对/countries的POST请求,并允许您向列表中添加一个新的国家。它使用 Flaskrequest对象来获取关于当前 HTTP 请求的信息:@app.post("/countries") def add_country(): if request.is_json: country = request.get_json() country["id"] = _find_next_id() countries.append(country) return country, 201 return {"error": "Request must be JSON"}, 415该函数执行以下操作:
- 使用
request.is_json检查请求是否为 JSON- 使用
request.get_json()创建新的country实例- 找到下一个
id并将其设置在country上- 将新的
country附加到countries- 在响应中返回
country以及201 Created状态代码- 如果请求不是 JSON,则返回错误消息和
415 Unsupported Media Type状态代码
add_country()也调用_find_next_id()来确定新country的id:def _find_next_id(): return max(country["id"] for country in countries) + 1这个辅助函数使用一个生成器表达式来选择所有的国家 id,然后对它们调用
max()来获得最大值。它将这个值递增1以获得下一个要使用的 ID。您可以使用命令行工具 curl 在 shell 中尝试这个端点,它允许您从命令行发送 HTTP 请求。在这里,您将向
countries列表中添加一个新的country:$ curl -i http://127.0.0.1:5000/countries \ -X POST \ -H 'Content-Type: application/json' \ -d '{"name":"Germany", "capital": "Berlin", "area": 357022}' HTTP/1.0 201 CREATED Content-Type: application/json ... { "area": 357022, "capital": "Berlin", "id": 4, "name": "Germany" }这个 curl 命令有一些选项,了解这些选项很有帮助:
-X为请求设置 HTTP 方法。-H给请求添加一个 HTTP 头。-d定义了请求数据。设置好这些选项后,curl 在一个
POST请求中发送 JSON 数据,其中Content-Type头设置为application/json。REST API 返回201 CREATED以及您添加的新country的 JSON。注意:在这个例子中,
add_country()不包含任何确认请求中的 JSON 与countries的格式匹配的验证。如果您想在 flask 中验证 json 的格式,请查看 flask-expects-json 。您可以使用 curl 向
/countries发送一个GET请求,以确认新的country已被添加。如果您没有在 curl 命令中使用-X,那么默认情况下它会发送一个GET请求:$ curl -i http://127.0.0.1:5000/countries HTTP/1.0 200 OK Content-Type: application/json ... [ { "area": 513120, "capital": "Bangkok", "id": 1, "name": "Thailand" }, { "area": 7617930, "capital": "Canberra", "id": 2, "name": "Australia" }, { "area": 1010408, "capital": "Cairo", "id": 3, "name": "Egypt" }, { "area": 357022, "capital": "Berlin", "id": 4, "name": "Germany" } ]这将返回系统中国家的完整列表,最新的国家在底部。
这只是 Flask 功能的一个示例。这个应用程序可以扩展到包括所有其他 HTTP 方法的端点。Flask 还有一个庞大的扩展生态系统,为 REST APIs 提供额外的功能,比如数据库集成、认证和后台处理。
Django REST 框架
构建 REST APIs 的另一个流行选项是 Django REST framework 。Django REST framework 是一个 Django 插件,它在现有 Django 项目的基础上增加了 REST API 功能。
要使用 Django REST 框架,您需要一个 Django 项目。如果您已经有了一个,那么您可以将本节中的模式应用到您的项目中。否则,继续下去,您将构建一个 Django 项目并添加到 Django REST 框架中。
首先,用
pip安装Django和djangorestframework:$ python -m pip install Django djangorestframework这将安装
Django和djangorestframework。你现在可以使用django-admin工具来创建一个新的 Django 项目。运行以下命令启动您的项目:$ django-admin startproject countryapi该命令在当前目录下创建一个名为
countryapi的新文件夹。这个文件夹中是运行 Django 项目所需的所有文件。接下来,您将在您的项目中创建一个新的 Django 应用程序。Django 将项目的功能分解成应用程序。每个应用程序管理项目的不同部分。注意:在本教程中,您将只接触到 Django 的皮毛。如果你有兴趣了解更多,请查看可用的 Django 教程。
要创建应用程序,请将目录更改为
countryapi并运行以下命令:$ python manage.py startapp countries这将在您的项目中创建一个新的
countries文件夹。这个文件夹中是这个应用程序的基本文件。既然您已经创建了一个应用程序,那么您需要将它告诉 Django。在您刚刚创建的
countries文件夹旁边是另一个名为countryapi的文件夹。此文件夹包含项目的配置和设置。注意:这个文件夹与 Django 在运行
django-admin startproject countryapi时创建的根文件夹同名。打开
countryapi文件夹中的settings.py文件。在INSTALLED_APPS中添加以下几行,告诉 Django 关于countries应用程序和 Django REST 框架的信息:# countryapi/settings.py INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", "rest_framework", "countries", ]您已经为
countries应用程序和rest_framework添加了一行。您可能想知道为什么需要将
rest_framework添加到应用程序列表中。您需要添加它,因为 Django REST 框架只是另一个 Django 应用程序。Django 插件是打包分发的 Django 应用程序,任何人都可以使用。下一步是创建 Django 模型来定义数据的字段。在
countries应用程序内部,用以下代码更新models.py:# countries/models.py from django.db import models class Country(models.Model): name = models.CharField(max_length=100) capital = models.CharField(max_length=100) area = models.IntegerField(help_text="(in square kilometers)")这段代码定义了一个
Country模型。Django 将使用这个模型为国家数据创建数据库表和列。运行以下命令,让 Django 根据这个模型更新数据库:
$ python manage.py makemigrations Migrations for 'countries': countries/migrations/0001_initial.py - Create model Country $ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, countries, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK ...这些命令使用 Django 迁移在数据库中创建一个新表。
这个表开始是空的,但是最好有一些初始数据,这样就可以测试 Django REST 框架。为此,您将使用一个 Django fixture 在数据库中加载一些数据。
将以下 JSON 数据复制并保存到一个名为
countries.json的文件中,并保存在countries目录下:[ { "model": "countries.country", "pk": 1, "fields": { "name": "Thailand", "capital": "Bangkok", "area": 513120 } }, { "model": "countries.country", "pk": 2, "fields": { "name": "Australia", "capital": "Canberra", "area": 7617930 } }, { "model": "countries.country", "pk": 3, "fields": { "name": "Egypt", "capital": "Cairo", "area": 1010408 } } ]这个 JSON 包含三个国家的数据库条目。调用以下命令将该数据加载到数据库中:
$ python manage.py loaddata countries.json Installed 3 object(s) from 1 fixture(s)这将向数据库中添加三行。
至此,您的 Django 应用程序已经设置完毕,并填充了一些数据。您现在可以开始向项目中添加 Django REST 框架了。
Django REST 框架采用现有的 Django 模型,并将其转换为 JSON 用于 REST API。它通过模型序列化器来实现这一点。模型序列化器告诉 Django REST 框架如何将模型实例转换成 JSON,以及应该包含哪些数据。
您将从上面为
Country模型创建您的序列化程序。首先在countries应用程序中创建一个名为serializers.py的文件。完成之后,将下面的代码添加到serializers.py:# countries/serializers.py from rest_framework import serializers from .models import Country class CountrySerializer(serializers.ModelSerializer): class Meta: model = Country fields = ["id", "name", "capital", "area"]这个序列化器
CountrySerializer继承了serializers.ModelSerializer,根据Country的模型字段自动生成 JSON 内容。除非指定,否则ModelSerializer子类将包含 JSON 中 Django 模型的所有字段。您可以通过将fields设置为您希望包含的数据列表来修改此行为。就像 Django 一样,Django REST 框架使用视图从数据库中查询数据并显示给用户。不用从头开始编写 REST API 视图,你可以子类化 Django REST 框架的
ModelViewSet类,该类拥有常见 REST API 操作的默认视图。注意:Django REST 框架文档将这些视图称为动作。
下面是
ModelViewSet提供的动作及其等效 HTTP 方法的列表:
HTTP 方法 行动 描述 GET.list()获取国家列表。 GET.retrieve()得到一个国家。 POST.create()创建一个新的国家。 PUT.update()更新一个国家。 PATCH.partial_update()部分更新一个国家。 DELETE.destroy()删除一个国家。 如您所见,这些动作映射到 REST API 中的标准 HTTP 方法。你可以在你的子类中覆盖这些动作或者根据你的 API 的需求添加额外的动作。
下面是名为
CountryViewSet的ModelViewSet子类的代码。这个类将生成管理Country数据所需的视图。将以下代码添加到countries应用程序内的views.py:# countries/views.py from rest_framework import viewsets from .models import Country from .serializers import CountrySerializer class CountryViewSet(viewsets.ModelViewSet): serializer_class = CountrySerializer queryset = Country.objects.all()在这个类中,
serializer_class被设置为CountrySerializer,queryset被设置为Country.objects.all()。这告诉 Django REST framework 要使用哪个序列化程序,以及如何在数据库中查询这个特定的视图集。一旦创建了视图,就需要将它们映射到适当的 URL 或端点。为此,Django REST 框架提供了一个
DefaultRouter,它将自动为一个ModelViewSet生成 URL。在
countries应用程序中创建一个urls.py文件,并将以下代码添加到该文件中:# countries/urls.py from django.urls import path, include from rest_framework.routers import DefaultRouter from .views import CountryViewSet router = DefaultRouter() router.register(r"countries", CountryViewSet) urlpatterns = [ path("", include(router.urls)) ]这段代码创建了一个
DefaultRouter,并在countriesURL 下注册了CountryViewSet。这将把CountryViewSet的所有 URL 放在/countries/下。注意: Django REST 框架自动在
DefaultRouter生成的任何端点的末尾追加一个正斜杠(/)。您可以禁用此行为,如下所示:router = DefaultRouter(trailing_slash=False)这将禁用端点末尾的正斜杠。
最后,您需要更新项目的基本
urls.py文件,以包含项目中所有的countriesURL。用下面的代码更新countryapi文件夹中的urls.py文件:# countryapi/urls.py from django.contrib import admin from django.urls import path, include urlpatterns = [ path("admin/", admin.site.urls), path("", include("countries.urls")), ]这将所有的 URL 放在
/countries/下。现在您已经准备好尝试 Django 支持的 REST API 了。在根目录countryapi中运行以下命令来启动 Django 开发服务器:$ python manage.py runserver开发服务器现在正在运行。继续向
/countries/发送GET请求,以获得 Django 项目中所有国家的列表:$ curl -i http://127.0.0.1:8000/countries/ -w '\n' HTTP/1.1 200 OK ... [ { "id": 1, "name":"Thailand", "capital":"Bangkok", "area":513120 }, { "id": 2, "name":"Australia", "capital":"Canberra", "area":7617930 }, { "id": 3, "name":"Egypt", "capital":"Cairo", "area":1010408 } ]Django REST 框架发回一个 JSON 响应,其中包含您之前添加的三个国家。上面的回答是为了可读性而格式化的,所以你的回答看起来会有所不同。
您在
countries/urls.py中创建的DefaultRouter为所有标准 API 端点的请求提供了 URL:
GET /countries/GET /countries/<country_id>/POST /countries/PUT /countries/<country_id>/PATCH /countries/<country_id>/DELETE /countries/<country_id>/您可以在下面多尝试几个端点。向
/countries/发送一个POST请求,在 Django 项目中创建一个新的Country:$ curl -i http://127.0.0.1:8000/countries/ \ -X POST \ -H 'Content-Type: application/json' \ -d '{"name":"Germany", "capital": "Berlin", "area": 357022}' \ -w '\n' HTTP/1.1 201 Created ... { "id":4, "name":"Germany", "capital":"Berlin", "area":357022 }这将使用您在请求中发送的 JSON 创建一个新的
Country。Django REST 框架返回一个201 Created状态代码和新的Country。注意:默认情况下,响应末尾不包含新行。这意味着 JSON 可能会在您的命令提示符下运行。上面的 curl 命令包含了
-w '\n'来在 JSON 后面添加一个换行符,以解决这个问题。您可以通过向已有
id的GET /countries/<country_id>/发送请求来查看已有的Country。运行以下命令获得第一个Country:$ curl -i http://127.0.0.1:8000/countries/1/ -w '\n' HTTP/1.1 200 OK ... { "id":1, "name":"Thailand", "capital":"Bangkok", "area":513120 }响应包含第一个
Country的信息。这些例子只涵盖了GET和POST请求。您可以自行尝试PUT、PATCH和DELETE请求,看看如何从 REST API 中完全管理您的模型。正如您所看到的,Django REST 框架是构建 REST APIs 的一个很好的选择,尤其是如果您已经有了一个 Django 项目,并且想要添加一个 API。
FastAPI
FastAPI 是一个针对构建 API 而优化的 Python web 框架。它使用了 Python 类型提示,并且内置了对异步操作的支持。FastAPI 构建在 Starlette 和 Pydantic 之上,性能非常好。
下面是一个用 FastAPI 构建的 REST API 的例子:
# app.py from fastapi import FastAPI from pydantic import BaseModel, Field app = FastAPI() def _find_next_id(): return max(country.country_id for country in countries) + 1 class Country(BaseModel): country_id: int = Field(default_factory=_find_next_id, alias="id") name: str capital: str area: int countries = [ Country(id=1, name="Thailand", capital="Bangkok", area=513120), Country(id=2, name="Australia", capital="Canberra", area=7617930), Country(id=3, name="Egypt", capital="Cairo", area=1010408), ] @app.get("/countries") async def get_countries(): return countries @app.post("/countries", status_code=201) async def add_country(country: Country): countries.append(country) return country这个应用程序使用 FastAPI 的特性为您在其他示例中看到的相同的
country数据构建一个 REST API。您可以通过安装带有
pip的fastapi来尝试此应用程序:$ python -m pip install fastapi您还需要安装
uvicorn[standard],一个可以运行 FastAPI 应用程序的服务器:$ python -m pip install uvicorn[standard]如果你已经安装了
fastapi和uvicorn,那么将上面的代码保存在一个名为app.py的文件中。运行以下命令启动开发服务器:$ uvicorn app:app --reload INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)服务器现在正在运行。打开浏览器,进入
http://127.0.0.1:8000/countries。您将看到 FastAPI 以如下方式响应:[ { "id": 1, "name":"Thailand", "capital":"Bangkok", "area":513120 }, { "id": 2, "name":"Australia", "capital":"Canberra", "area":7617930 }, { "id": 3, "name":"Egypt", "capital":"Cairo", "area":1010408 } ]FastAPI 用一个包含一列
countries的 JSON 数组来响应。您也可以通过向/countries发送POST请求来添加新的国家:$ curl -i http://127.0.0.1:8000/countries \ -X POST \ -H 'Content-Type: application/json' \ -d '{"name":"Germany", "capital": "Berlin", "area": 357022}' \ -w '\n' HTTP/1.1 201 Created content-type: application/json ... {"id":4,"name":"Germany","capital":"Berlin","area": 357022}您添加了一个新国家。您可以通过
GET /countries确认这一点:$ curl -i http://127.0.0.1:8000/countries -w '\n' HTTP/1.1 200 OK content-type: application/json ... [ { "id":1, "name":"Thailand", "capital":"Bangkok", "area":513120, }, { "id":2, "name":"Australia", "capital":"Canberra", "area":7617930 }, { "id":3, "name":"Egypt", "capital":"Cairo", "area":1010408 }, { "id":4, "name": "Germany", "capital": "Berlin", "area": 357022 } ]FastAPI 返回一个 JSON 列表,其中包括您刚刚添加的新国家。
您会注意到 FastAPI 应用程序看起来类似于 Flask 应用程序。像 Flask 一样,FastAPI 也有一个集中的特性集。它并不试图处理 web 应用程序开发的所有方面。它旨在构建具有现代 Python 特性的 API。
如果你靠近
app.py的顶部,你会看到一个叫做Country的类,它扩展了BaseModel。Country类描述了 REST API 中的数据结构:class Country(BaseModel): country_id: int = Field(default_factory=_find_next_id, alias="id") name: str capital: str area: int这是一个 Pydantic 模型的例子。Pydantic 模型在 FastAPI 中提供了一些有用的特性。它们使用 Python 类型注释来强制类中每个字段的数据类型。这允许 FastAPI 为 API 端点自动生成具有正确数据类型的 JSON。它还允许 FastAPI 验证传入的 JSON。
强调第一行很有帮助,因为这一行有很多内容:
country_id: int = Field(default_factory=_find_next_id, alias="id")在这一行中,您可以看到
country_id,它为Country的 ID 存储了一个整数。它使用 Pydantic 的Field函数来修改country_id的行为。在这个例子中,您将关键字参数default_factory和alias传递给Field。第一个参数
default_factory被设置为_find_next_id()。该参数指定每当创建新的Country时运行的函数。返回值将被赋给country_id。第二个参数
alias被设置为id。这告诉 FastAPI 输出键"id"而不是 JSON 中的"country_id":{ "id":1, "name":"Thailand", "capital":"Bangkok", "area":513120, },这个
alias也意味着当你创建一个新的Country时,你可以使用id。您可以在countries列表中看到:countries = [ Country(id=1, name="Thailand", capital="Bangkok", area=513120), Country(id=2, name="Australia", capital="Canberra", area=7617930), Country(id=3, name="Egypt", capital="Cairo", area=1010408), ]这个列表包含 API 中初始国家的三个
Country实例。Pydantic 模型提供了一些很棒的特性,并允许 FastAPI 轻松处理 JSON 数据。现在看看这个应用程序中的两个 API 函数。第一个函数
get_countries(),返回一个countries列表,用于对/countries的GET请求:@app.get("/countries") async def get_countries(): return countriesFastAPI 将根据 Pydantic 模型中的字段自动创建 JSON,并根据 Python 类型提示设置正确的 JSON 数据类型。
当您向
/countries发出POST请求时,Pydantic 模型也提供了一个好处。您可以在下面的第二个 API 函数中看到,参数country有一个Country注释:@app.post("/countries", status_code=201) async def add_country(country: Country): countries.append(country) return country这个类型注释告诉 FastAPI 根据
Country验证传入的 JSON。如果不匹配,那么 FastAPI 将返回一个错误。您可以通过用 JSON 发出一个与 Pydantic 模型不匹配的请求来尝试一下:$ curl -i http://127.0.0.1:8000/countries \ -X POST \ -H 'Content-Type: application/json' \ -d '{"name":"Germany", "capital": "Berlin"}' \ -w '\n' HTTP/1.1 422 Unprocessable Entity content-type: application/json ... { "detail": [ { "loc":["body","area"], "msg":"field required", "type":"value_error.missing" } ] }这个请求中的 JSON 缺少一个值
area,所以 FastAPI 返回一个响应,其中包含状态代码422 Unprocessable Entity以及关于错误的详细信息。Pydantic 模型使这种验证成为可能。这个例子只是触及了 FastAPI 的皮毛。凭借其高性能和现代化的特性,如
async函数和自动文档,FastAPI 值得考虑作为您的下一个 REST API。结论
REST APIs 无处不在。了解如何利用 Python 来消费和构建 API 可以让您处理 web 服务提供的大量数据。
在本教程中,你已经学会了如何:
- 识别 REST 架构风格
- 使用 HTTP 方法和状态代码
- 使用
requests从外部 API 获取和使用数据- 为 REST API 定义端点、数据和响应
- 开始使用 Python 工具构建一个 REST API
使用您的新 Python REST API 技能,您不仅能够与 web 服务交互,还能够为您的应用程序构建 REST API。这些工具为各种有趣的、数据驱动的应用和服务打开了大门。**********
arcade:Python 游戏框架入门
电脑游戏是向人们介绍编码和计算机科学的好方法。由于我年轻时是一名玩家,编写视频游戏的诱惑是我学习编码的原因。当然,当我学习 Python 的时候,我的第一反应是写一个 Python 游戏。
虽然 Python 让每个人都更容易学习编码,但视频游戏编写的选择可能是有限的,特别是如果你想编写具有出色图形和朗朗上口的音效的街机游戏。很多年来,Python 游戏程序员都被限制在
pygame框架内。现在,还有另一个选择。
arcade库是一个现代的 Python 框架,用于制作具有引人注目的图形和声音的游戏。arcade面向对象,为 Python 3.6 及更高版本而构建,为程序员提供了一套现代工具来打造出色的 Python 游戏体验。在本教程中,您将学习如何:
- 安装
arcade库- 在屏幕上绘制项
- 与
arcadePython 游戏循环一起工作- 管理屏幕图形元素
- 处理用户输入
- 播放音效和音乐
- 描述用
arcade编写 Python 游戏与pygame有何不同本教程假设你已经理解了如何编写 Python 程序。既然
arcade是一个面向对象的库,你也应该熟悉面向对象编程。本教程的所有代码、图像和声音都可以从下面的链接下载:下载资源: 点击这里下载你将在本教程中使用制作街机游戏的资源。
背景和设置
这个
arcade库是由美国爱荷华州辛普森学院的计算机科学教授保罗·文森特·克雷文编写的。因为它是建立在pyglet窗口和多媒体库之上的,arcade具有各种改进、现代化和超越pygame的增强功能:
- 拥有现代 OpenGL 图形
- 支持 Python 3 类型提示
- 更好地支持动画精灵
- 整合了一致的命令、函数和参数名称
- 鼓励游戏逻辑与显示代码的分离
- 需要较少的样板代码
- 维护更多的文档,包括完整的 Python 游戏示例
- 为平台游戏内置物理引擎
要安装
arcade及其依赖项,使用适当的pip命令:$ python -m pip install arcade在 Mac 上,你还需要安装
PyObjC:$ python -m pip install PyObjC arcade基于您的平台的完整安装说明可用于 Windows 、 Mac 、 Linux ,甚至树莓派。如果你愿意,你甚至可以直接从源安装
arcade。注意:
arcade的更高版本利用了数据类,这些数据类只包含在 Python 3.7 及更高版本中。然而,Python 3.6 的 PyPI 上有一个反向端口,您可以使用
pip安装它:$ python -m pip install dataclasses有关更多信息,请参见Python 3.7 数据类终极指南。
本教程假设你一直在使用
arcade2.1 和 Python 3.7。基本
arcade程序在深入研究之前,让我们先来看看一个
arcade程序,它会打开一个窗口,用白色填充,并在中间画一个蓝色的圆圈:1# Basic arcade program 2# Displays a white window with a blue circle in the middle 3 4# Imports 5import arcade 6 7# Constants 8SCREEN_WIDTH = 600 9SCREEN_HEIGHT = 800 10SCREEN_TITLE = "Welcome to Arcade" 11RADIUS = 150 12 13# Open the window 14arcade.open_window(SCREEN_WIDTH, SCREEN_HEIGHT, SCREEN_TITLE) 15 16# Set the background color 17arcade.set_background_color(arcade.color.WHITE) 18 19# Clear the screen and start drawing 20arcade.start_render() 21 22# Draw a blue circle 23arcade.draw_circle_filled( 24 SCREEN_WIDTH / 2, SCREEN_HEIGHT / 2, RADIUS, arcade.color.BLUE 25) 26 27# Finish drawing 28arcade.finish_render() 29 30# Display everything 31arcade.run()当你运行这个程序时,你会看到一个类似这样的窗口:
让我们一行一行地分析一下:
- 第 5 行导入
arcade库。没有这个,其他都不行。- 为了清楚起见,第 8 行到第 11 行定义了一些稍后会用到的常量。
- 第 14 行打开主窗口。您提供宽度、高度和标题栏文本,其余的由
arcade完成。- 第 17 行使用
arcade.color包中的常量设置背景颜色。您也可以使用列表或元组指定 RGB 颜色。- 第 20 行将
arcade设置为绘图模式。你在这条线后画的任何东西都会显示在屏幕上。- 第 23 到 25 行通过提供中心 X 和 Y 坐标、半径和使用的颜色来画圆。
- 第 28 行结束绘图模式。
- 第 31 行显示你的窗口给你看。
如果你熟悉
pygame,那么你会注意到一些不同之处:
- 没有
pygame.init()。所有初始化都在运行import arcade时处理。- 没有显式定义的显示循环。在
arcade.run()处理。- 这里也没有事件循环。同样,
arcade.run()处理事件并提供一些默认行为,比如关闭窗口的能力。- 您可以使用预定义的颜色进行绘制,而不是自己定义所有颜色。
- 您必须使用
start_render()和finish_render()在 arcade 中开始和完成绘图。让我们仔细看看该计划背后的基本概念。
arcade概念像
pygame,arcade代码运行在几乎所有支持 Python 的平台上。这要求arcade处理这些平台上各种硬件差异的抽象。理解这些概念和抽象将帮助你设计和开发你自己的游戏,同时理解arcade与pygame的不同将帮助你适应它独特的视角。初始化
由于它涉及多种平台,
arcade在使用之前必须执行初始化步骤。这一步是自动的,每当您导入arcade时都会发生,所以您不需要编写额外的代码。当您导入它时,arcade会执行以下操作:
- 验证您运行的是 Python 3.6 或更高版本。
- 导入用于声音处理的
pyglet_ffmeg2库,如果它可用的话。- 导入用于窗口和多媒体处理的
pyglet库。- 设置颜色和按键映射的常量。
- 导入剩余的
arcade库。与
pygame形成对比,它要求每个模块有一个单独的初始化步骤。窗口和坐标
arcade中的一切都发生在一个窗口中,使用open_window()创建。目前,arcade只支持单一显示窗口。您可以在打开窗口时调整其大小。
arcade使用相同的笛卡尔坐标系你可能在代数课上学过。窗口位于象限 I ,原点(0,0)位于屏幕的左下角。向右移动时,x 坐标增加,向上移动时,y 坐标增加:
需要注意的是,这种行为与
pygame和许多其他 Python 游戏框架相反。你可能需要一段时间来适应这种差异。图纸
开箱即用,
arcade具有绘制各种几何形状的功能,包括:
- 弧
- 环
- 省略
- 线
- 抛物线
- 点
- 多边形
- 长方形
- 三角形
所有绘图函数都以
draw_开头,并遵循一致的命名和参数模式。绘制填充形状和轮廓形状有不同的功能:
因为矩形很常见,所以有三个独立的函数可以用不同的方式绘制它们:
draw_rectangle()期望得到矩形中心的 x 和 y 坐标,宽度和高度。draw_lrtb_rectangle()期望左边和右边的 x 坐标,后面是顶部和底部的 y 坐标。draw_xywh_rectangle()使用左下角的 x 和 y 坐标,后跟宽度和高度。注意,每个函数需要四个参数。您还可以使用缓冲绘图功能绘制每个形状,该功能利用顶点缓冲区将所有内容直接推送到显卡,实现令人难以置信的性能提升。所有缓冲的绘图函数都以
create_开始,并遵循一致的命名和参数模式。面向对象的设计
在其核心,
arcade是一个面向对象的库。像pygame一样,你可以程序化地编写arcade代码,就像你在上面的例子中所做的那样。然而,当你创建完全面向对象的程序时,arcade的真正威力就显现出来了。当您在上面的例子中调用
arcade.open_window()时,代码在幕后创建一个arcade.Window对象来管理那个窗口。稍后,您将基于arcade.Window创建自己的类来编写一个完整的 Python 游戏。首先,看一下原始的示例代码,它现在使用面向对象的概念,以突出主要的区别:
# Basic arcade program using objects # Displays a white window with a blue circle in the middle # Imports import arcade # Constants SCREEN_WIDTH = 600 SCREEN_HEIGHT = 800 SCREEN_TITLE = "Welcome to Arcade" RADIUS = 150 # Classes class Welcome(arcade.Window): """Main welcome window """ def __init__(self): """Initialize the window """ # Call the parent class constructor super().__init__(SCREEN_WIDTH, SCREEN_HEIGHT, SCREEN_TITLE) # Set the background window arcade.set_background_color(arcade.color.WHITE) def on_draw(self): """Called whenever you need to draw your window """ # Clear the screen and start drawing arcade.start_render() # Draw a blue circle arcade.draw_circle_filled( SCREEN_WIDTH / 2, SCREEN_HEIGHT / 2, RADIUS, arcade.color.BLUE ) # Main code entry point if __name__ == "__main__": app = Welcome() arcade.run()让我们一行一行地看看这段代码:
第 1 行到第 11 行与之前的程序示例相同。
15 号线是差异开始的地方。您基于父类
arcade.Window定义了一个名为Welcome的类。这允许您根据需要重写父类中的方法。第 18 到 26 行定义了
.__init__()方法。在使用super()调用父.__init__()方法来设置窗口后,您可以像之前一样设置它的背景颜色。第 28 到 38 行定义了
.on_draw()。这是几个Window方法之一,您可以覆盖这些方法来定制您的arcade程序的行为。每次arcade想在窗口上画画的时候都会调用这个方法。它从调用arcade.start_render()开始,然后是你所有的绘图代码。然而,你不需要调用arcade.finish_render(),因为当.on_draw()结束时arcade会隐式地调用它。第 41 到 43 行是你的代码的主入口点。在你第一次创建一个名为
app的新的Welcome对象后,你调用arcade.run()来显示窗口。这个面向对象的例子是充分利用
arcade的关键。你可能已经注意到的一件事是对.on_draw()的描述。arcade每次它想在窗户上画画时都会调用这个。那么,arcade怎么知道什么时候画什么呢?让我们来看看这其中的含义。游戏循环
几乎每个游戏中的所有动作都发生在一个中央游戏循环中。你甚至可以在物理游戏中看到游戏循环的例子,如跳棋、老处女或棒球。游戏循环在游戏设置和初始化之后开始,在游戏开始时结束。在这个循环中,几件事情依次发生。一个游戏循环至少要采取以下四个动作:
- 程序判断游戏是否结束。如果是,则循环结束。
- 用户输入被处理。
- 游戏对象的状态根据用户输入或时间等因素进行更新。
- 游戏根据新的状态显示画面和播放音效。
在
pygame中,您必须明确设置和控制该循环。在arcade中,为您提供了 Python 游戏循环,封装在arcade.run()调用中。在内置的游戏循环中,
arcade调用一组Window方法来实现上面列出的所有功能。这些方法的名字都以on_开头,可以认为是任务或事件处理程序。当arcade游戏循环需要更新所有 Python 游戏对象的状态时,它调用.on_update()。当它需要检查鼠标移动时,它调用.on_mouse_motion()。默认情况下,这些方法都没有任何用处。当你基于
arcade.Window创建自己的类时,你可以根据需要覆盖它们来提供你自己的游戏功能。提供的一些方法包括:
- 键盘输入:
.on_key_press(),.on_key_release()- 鼠标输入:、
.on_mouse_press()、.on_mouse_release()、.on_mouse_motion()- 更新游戏对象:
.on_update()- 绘图:
.on_draw()您不需要覆盖所有这些方法,只需覆盖那些您想要提供不同行为的方法。你也不需要担心何时被调用,只需要在被调用时做什么。接下来,您将探索如何将所有这些概念放在一起创建一个游戏。
Python 游戏设计基础
在你开始写任何代码之前,有一个合适的设计总是一个好主意。因为您将在本教程中创建一个 Python 游戏,所以您也将为它设计一些游戏性:
- 游戏是一款水平滚动的避敌游戏。
- 玩家从屏幕左侧开始。
- 敌人每隔一段时间随机进入右边的位置。
- 敌人沿直线向左移动,直到他们离开屏幕。
- 玩家可以向左、向右、向上或向下移动来躲避敌人。
- 玩家不能离开屏幕。
- 当玩家被敌人击中,或者用户关闭窗口,游戏结束。
他在描述软件项目的时候,我的一个前同事曾经说过“你不知道你做什么,直到你知道你不做什么。”记住这一点,这里有一些你在本教程中不会涉及的内容:
- 没有多重生命
- 不计分
- 没有玩家攻击能力
- 没有升级级别
- 没有“老板”字符
您可以自由尝试将这些和其他特性添加到您自己的程序中。
导入和常量
与任何
arcade程序一样,您将从导入库开始:# Basic arcade shooter # Imports import arcade import random # Constants SCREEN_WIDTH = 800 SCREEN_HEIGHT = 600 SCREEN_TITLE = "Arcade Space Shooter" SCALING = 2.0除了
arcade,您还导入了random,因为稍后您将使用随机数。常量设置了窗口大小和标题,但是什么是SCALING?该常量用于使窗口和其中的游戏对象变大,以补偿高 DPI 屏幕。随着教程的继续,您将看到它在两个地方被使用。您可以更改该值以适合您的屏幕大小。窗口类
为了充分利用
arcadePython 游戏循环和事件处理程序,创建一个基于arcade.Window的新类:35class SpaceShooter(arcade.Window): 36 """Space Shooter side scroller game 37 Player starts on the left, enemies appear on the right 38 Player can move anywhere, but not off screen 39 Enemies fly to the left at variable speed 40 Collisions end the game 41 """ 42 43 def __init__(self, width, height, title): 44 """Initialize the game 45 """ 46 super().__init__(width, height, title) 47 48 # Set up the empty sprite lists 49 self.enemies_list = arcade.SpriteList() 50 self.clouds_list = arcade.SpriteList() 51 self.all_sprites = arcade.SpriteList()您的新类就像上面的面向对象的例子一样开始。在第 43 行,您定义了您的构造函数,它接受游戏窗口的宽度、高度和标题,并使用
super()将它们传递给父对象。然后在第 49 到 51 行初始化一些空的 sprite 列表。在下一节中,您将了解更多关于精灵和精灵列表的内容。精灵和精灵列表
您的 Python 游戏设计要求一个玩家从左边开始,并可以在窗口周围自由移动。它还要求敌人(换句话说,不止一个)随机出现在右边并移动到左边。虽然你可以使用
draw_命令来画出玩家和每个敌人,但很快就很难保持直线。相反,大多数现代游戏使用精灵来代表屏幕上的物体。从本质上来说,精灵是一个游戏对象的二维图片,具有定义的大小,绘制在屏幕上的特定位置。在
arcade中,精灵是arcade.Sprite类的物体,你可以用它们来代表你的玩家和敌人。你甚至会加入一些云彩来使背景更加有趣。管理所有这些精灵可能是一个挑战。你将创建一个单人精灵,但是你也将创建许多敌人和云精灵。跟踪他们是 T2 精灵列表的工作。如果你理解了 Python 列表是如何工作的,那么你就有了使用
arcade的精灵列表的工具。精灵列表不仅仅是保存所有的精灵。它们支持三种重要的行为:
- 你可以通过简单的调用
SpriteList.update()来更新列表中的所有精灵。- 你可以通过简单的调用
SpriteList.draw()来绘制列表中的所有精灵。- 您可以检查单个精灵是否与列表中的任何精灵冲突。
你可能想知道如果你只需要管理多个敌人和云,为什么你需要三个不同的精灵列表。原因是三个不同的精灵列表都存在,因为它们有三个不同的用途:
- 你使用
.enemies_list来更新敌人的位置并检查碰撞。- 你使用
.clouds_list来更新云位置。- 最后,你使用
.all_sprites来绘制一切。现在,列表的用处取决于它包含的数据。以下是你如何填充你的精灵列表:
53def setup(self): 54 """Get the game ready to play 55 """ 56 57 # Set the background color 58 arcade.set_background_color(arcade.color.SKY_BLUE) 59 60 # Set up the player 61 self.player = arcade.Sprite("images/jet.png", SCALING) 62 self.player.center_y = self.height / 2 63 self.player.left = 10 64 self.all_sprites.append(self.player)你定义
.setup()来初始化游戏到一个已知的起点。虽然您可以在.__init__()中这样做,但是拥有一个单独的.setup()方法是有用的。假设你希望你的 Python 游戏有多个关卡,或者你的玩家有多个生命。不是通过调用
.__init__()来重启整个游戏,而是调用.setup()来将游戏重新初始化到一个已知的起点或者设置一个新的关卡。尽管这个 Python 游戏没有这些特性,但是设置结构可以让以后添加它们变得更快。在第 58 行设置了背景颜色之后,就可以定义播放器精灵了:
第 61 行通过指定要显示的图像和缩放因子来创建一个新的
arcade.Sprite对象。将图像组织到一个子文件夹中是一个好主意,尤其是在较大的项目中。第 62 行将精灵的 y 位置设置为窗口高度的一半。
第 63 行设置精灵的 x 位置,将左边缘放在离窗口左边缘几个像素的地方。
第 64 行最后使用
.append()将精灵添加到.all_sprites列表中,您将使用该列表进行绘制。第 62 行和第 63 行显示了定位精灵的两种不同方式。让我们仔细看看所有可用的精灵定位选项。
精灵定位
arcade中的所有精灵在窗口中都有特定的大小和位置:
- 大小,由
Sprite.width和Sprite.height指定,由创建 sprite 时使用的图形决定。- 位置初始设置为子画面的中心,由
Sprite.center_x和Sprite.center_y指定,在窗口的(0,0)处。一旦知道了
.center_x和.center_y坐标,arcade就可以使用尺寸来计算Sprite.left、Sprite.right、Sprite.top和Sprite.bottom边。反之亦然。例如,如果您将
Sprite.left设置为给定值,那么arcade也会重新计算剩余的位置属性。你可以使用它们中的任何一个来定位精灵或者在窗口中移动它。这是arcade精灵极其有用和强大的特性。如果你使用它们,那么你的 Python 游戏将比pygame需要更少的代码:
既然你已经定义了玩家精灵,你就可以处理敌人精灵了。这个设计要求你让敌人的精灵以固定的间隔出现。你怎么能这样做?
调度功能
arcade.schedule()正是为此目的而设计的。它需要两个参数:
- 要调用的函数的名称
- 每次呼叫之间等待的时间间隔,以秒为单位
由于您希望敌人和云都出现在整个游戏中,您设置了一个预定功能来创建新的敌人,第二个功能来创建新的云。该代码进入
.setup()。下面是这段代码的样子:66# Spawn a new enemy every 0.25 seconds 67arcade.schedule(self.add_enemy, 0.25) 68 69# Spawn a new cloud every second 70arcade.schedule(self.add_cloud, 1.0)现在你要做的就是定义
self.add_enemy()和self.add_cloud()。添加敌人
从你的 Python 游戏设计来看,敌人有三个关键属性:
- 它们出现在窗口右侧的随机位置。
- 他们沿直线向左移动。
- 当他们离开屏幕时,他们就消失了。
创建敌人精灵的代码与创建玩家精灵的代码非常相似:
93def add_enemy(self, delta_time: float): 94 """Adds a new enemy to the screen 95 96 Arguments: 97 delta_time {float} -- How much time has passed since the last call 98 """ 99 100 # First, create the new enemy sprite 101 enemy = arcade.Sprite("images/missile.png", SCALING) 102 103 # Set its position to a random height and off screen right 104 enemy.left = random.randint(self.width, self.width + 80) 105 enemy.top = random.randint(10, self.height - 10)
.add_enemy()接受一个参数delta_time,它表示自上次调用以来已经过去了多长时间。这是arcade.schedule()所要求的,虽然您不会在这里使用它,但它对于需要高级计时的应用程序可能是有用的。与 player sprite 一样,首先创建一个新的
arcade.Sprite,带有一张图片和一个缩放因子。使用.left和.top将位置设置到屏幕右侧的任意位置:
这使得敌人可以流畅地移动到屏幕上,而不是仅仅出现在屏幕上。现在,你怎么让它动起来?
移动精灵
移动精灵需要你在游戏循环的更新阶段改变它的位置。虽然您可以自己完成这项工作,
arcade提供了一些内置功能来减少您的工作量。每个arcade.Sprite不仅有一组位置属性,还有一组运动属性。每次精灵被更新,arcade将使用运动属性来更新位置,赋予精灵相对运动。
Sprite.velocity属性是一个由 x 和 y 位置变化组成的元组。也可以直接访问Sprite.change_x和Sprite.change_y。如上所述,每次更新 sprite 时,它的.position都会根据.velocity发生变化。在.add_enemy()中,您只需设置速度:107# Set its speed to a random speed heading left 108enemy.velocity = (random.randint(-20, -5), 0) 109 110# Add it to the enemies list 111self.enemies_list.append(enemy) 112self.all_sprites.append(enemy)在第 108 行将速度设置为向左移动的随机速度后,将新的敌人添加到适当的列表中。当您稍后调用
sprite.update(),arcade将处理其余的:
在你的 Python 游戏设计中,敌人从右向左直线移动。因为你的敌人总是向左移动,一旦他们离开屏幕,他们就不会回来了。如果你能去掉一个屏幕外的敌人精灵来释放内存和加速更新就好了。幸运的是,
arcade有你罩着。移除精灵
因为你的敌人总是向左移动,他们的 x 位置总是变小,y 位置总是不变。因此,当
enemy.right小于零(窗口的左边缘)时,您可以确定敌人在屏幕外。一旦你确定敌人不在屏幕上,你调用enemy.remove_from_sprite_lists()将它从它所属的所有列表中移除,然后从内存中释放那个对象:if enemy.right < 0: enemy.remove_from_sprite_lists()但是你什么时候做这个检查呢?通常,这将发生在精灵移动之后。然而,请记住之前所说的关于
.all_enemies精灵列表的内容:你使用
.enemies_list来更新敌人的位置并检查碰撞。这意味着在
SpaceShooter.on_update()中,您将调用enemies_list.update()来自动处理敌人的移动,这实质上做了以下事情:for enemy in enemies_list: enemy.update()如果能把屏下检查直接加到
enemy.update()通话里就好了,而且可以!记住,arcade是面向对象的库。这意味着您可以基于arcade类创建自己的类,并覆盖您想要修改的方法。在这种情况下,您创建一个基于arcade.Sprite的新类,并且只覆盖.update():17class FlyingSprite(arcade.Sprite): 18 """Base class for all flying sprites 19 Flying sprites include enemies and clouds 20 """ 21 22 def update(self): 23 """Update the position of the sprite 24 When it moves off screen to the left, remove it 25 """ 26 27 # Move the sprite 28 super().update() 29 30 # Remove if off the screen 31 if self.right < 0: 32 self.remove_from_sprite_lists()你把
FlyingSprite定义为任何会在你的游戏中飞行的东西,比如敌人和云。然后你覆盖.update(),首先调用super().update()来正确处理动作。然后,您执行屏幕外检查。因为您有了一个新的类,所以您还需要对
.add_enemy()做一个小小的改变:def add_enemy(self, delta_time: float): """Adds a new enemy to the screen Arguments: delta_time {float} -- How much time as passed since the last call """ # First, create the new enemy sprite enemy = FlyingSprite("images/missile.png", SCALING)你不是创建一个新的
Sprite,而是创建一个新的FlyingSprite来利用新的.update()。添加云
为了让你的 Python 游戏在视觉上更吸引人,你可以给天空添加云彩。云飞过天空,就像你的敌人一样,所以你可以用类似的方式来创造和移动它们。
.add_cloud()遵循与.add_enemy()相同的模式,尽管随机速度较慢:def add_cloud(self, delta_time: float): """Adds a new cloud to the screen Arguments: delta_time {float} -- How much time has passed since the last call """ # First, create the new cloud sprite cloud = FlyingSprite("images/cloud.png", SCALING) # Set its position to a random height and off screen right cloud.left = random.randint(self.width, self.width + 80) cloud.top = random.randint(10, self.height - 10) # Set its speed to a random speed heading left cloud.velocity = (random.randint(-5, -2), 0) # Add it to the enemies list self.clouds_list.append(cloud) self.all_sprites.append(cloud)云比敌人移动得慢,所以你在第 129 行计算了一个较低的随机速度。
现在你的 Python 游戏看起来更加完整了:
你的敌人和云已经被创造出来了,它们现在自己移动了。是时候使用键盘让玩家移动了。
键盘输入
arcade.Window类有两个处理键盘输入的函数。每当按下一个键,你的 Python 游戏就会调用.on_key_press(),每当松开一个键,就会调用.on_key_release()。两个函数都接受两个整数参数:
symbol代表实际被按下或释放的键。modifiers表示哪些修改器被关闭。这些键包括Shift、Ctrl和Alt键。幸运的是,你不需要知道哪个整数代表哪个键。
arcade.key模块包含了您可能想要使用的所有键盘常量。传统上,用键盘移动玩家使用三组不同按键中的一组或多组:
- 这四个箭头键分别为
Up``Down``Left,Right- 按键
I、J、K、L,分别对应上、左、下、右- 对于左手控制,按键
W、A、S、D,这些按键还可以映射到上、左、下、右对于这个游戏,您将使用箭头和
I/J/K//L。每当用户按下移动键时,播放器精灵就向那个方向移动。当用户释放移动键时,精灵停止向那个方向移动。您还提供了使用Q退出游戏的方法,以及使用P暂停游戏的方法。为此,您需要响应按键和释放:
- 当按下键时,调用
.on_key_press()。在该方法中,您检查按下了哪个键:
- 如果是
Q,那你干脆退出游戏。- 如果是
P,那么你设置一个标志表示游戏暂停。- 如果是移动键,那么你相应地设置玩家的
.change_x或者.change_y。- 如果是其他键,就忽略它。
- 当释放键时,调用
.on_key_release()。再次检查哪个键被释放了:
- 如果它是一个移动键,那么你相应地设置玩家的
.change_x或.change_y为 0。- 如果是其他键,就忽略它。
代码如下所示:
134def on_key_press(self, symbol, modifiers): 135 """Handle user keyboard input 136 Q: Quit the game 137 P: Pause/Unpause the game 138 I/J/K/L: Move Up, Left, Down, Right 139 Arrows: Move Up, Left, Down, Right 140 141 Arguments: 142 symbol {int} -- Which key was pressed 143 modifiers {int} -- Which modifiers were pressed 144 """ 145 if symbol == arcade.key.Q: 146 # Quit immediately 147 arcade.close_window() 148 149 if symbol == arcade.key.P: 150 self.paused = not self.paused 151 152 if symbol == arcade.key.I or symbol == arcade.key.UP: 153 self.player.change_y = 5 154 155 if symbol == arcade.key.K or symbol == arcade.key.DOWN: 156 self.player.change_y = -5 157 158 if symbol == arcade.key.J or symbol == arcade.key.LEFT: 159 self.player.change_x = -5 160 161 if symbol == arcade.key.L or symbol == arcade.key.RIGHT: 162 self.player.change_x = 5 163 164def on_key_release(self, symbol: int, modifiers: int): 165 """Undo movement vectors when movement keys are released 166 167 Arguments: 168 symbol {int} -- Which key was pressed 169 modifiers {int} -- Which modifiers were pressed 170 """ 171 if ( 172 symbol == arcade.key.I 173 or symbol == arcade.key.K 174 or symbol == arcade.key.UP 175 or symbol == arcade.key.DOWN 176 ): 177 self.player.change_y = 0 178 179 if ( 180 symbol == arcade.key.J 181 or symbol == arcade.key.L 182 or symbol == arcade.key.LEFT 183 or symbol == arcade.key.RIGHT 184 ): 185 self.player.change_x = 0在
.on_key_release()中,你只检查会影响玩家精灵移动的按键。没有必要检查暂停或退出键是否被释放。现在你可以在屏幕上移动并立即退出游戏:
您可能想知道暂停功能是如何工作的。要了解这一点,首先需要学习更新所有 Python 游戏对象。
更新游戏对象
仅仅因为你给你所有的精灵设置了速度并不意味着他们会移动。为了让它们移动,你必须在游戏循环中一遍又一遍地更新它们。
由于
arcade控制了 Python 游戏循环,所以它也通过调用.on_update()来控制何时需要更新。您可以重写此方法,为您的游戏提供适当的行为,包括游戏移动和其他行为。对于这个游戏,您需要做一些事情来正确地更新所有内容:
- 你检查游戏是否暂停。如果是这样,那么您可以退出,这样就不会发生进一步的更新。
- 你更新你所有的精灵让他们移动。
- 你检查玩家精灵是否已经移出屏幕。如果是这样,只需将它们移回到屏幕上。
暂时就这样了。下面是这段代码的样子:
189def on_update(self, delta_time: float): 190 """Update the positions and statuses of all game objects 191 If paused, do nothing 192 193 Arguments: 194 delta_time {float} -- Time since the last update 195 """ 196 197 # If paused, don't update anything 198 if self.paused: 199 return 200 201 # Update everything 202 self.all_sprites.update() 203 204 # Keep the player on screen 205 if self.player.top > self.height: 206 self.player.top = self.height 207 if self.player.right > self.width: 208 self.player.right = self.width 209 if self.player.bottom < 0: 210 self.player.bottom = 0 211 if self.player.left < 0: 212 self.player.left = 0第 198 行是检查游戏是否暂停的地方,如果暂停就返回。跳过所有剩余的代码,所以不会有任何移动。所有子画面移动由线 202 处理。这一行行之有效有三个原因:
- 每个精灵都是
self.all_sprites列表中的一员。- 对到
self.all_sprites.update()的调用导致对列表中的每个 sprite 调用.update()。- 列表中的每一个精灵都有
.velocity(由.change_x和.change_y属性组成),当其.update()被调用时会处理自己的运动。最后,通过比较精灵的边缘和窗口的边缘,检查第 205 到 212 行的玩家精灵是否在屏幕外。例如,在第 205 行和第 206 行,如果
self.player.top超出了屏幕的顶部,那么您将self.player.top重置到屏幕的顶部。现在一切都更新了,可以画一切了。在窗户上画画
因为游戏对象的更新发生在
.on_update()中,所以绘制游戏对象应该发生在一个叫做.on_draw()的方法中。因为您已经将所有内容组织到 sprite 列表中,所以该方法的代码非常短:231def on_draw(self): 232 """Draw all game objects 233 """ 234 arcade.start_render() 235 self.all_sprites.draw()所有绘图都从调用第 234 行的
arcade.start_render()开始。就像更新一样,只需调用第 235 行的self.all_sprites.draw()就可以一次画出你所有的精灵。现在,您的 Python 游戏只剩下最后一部分要做了,这也是初始设计的最后一部分:当玩家被障碍物击中,或者用户关闭窗口时,游戏结束。
这是真正的游戏部分!现在,敌人会无所事事地飞过你的玩家精灵。让我们看看如何添加这个功能。
碰撞检测
游戏都是一种或另一种形式的碰撞,即使是非计算机游戏。如果没有真实或虚拟的碰撞,就不会有轻而易举的曲棍球进球,不会有双陆棋中的双六,也不会有国际象棋中在一个骑士叉的末端抓住对手的皇后。
计算机游戏中的 碰撞检测 要求程序员检测两个游戏对象是否部分占据屏幕上的相同空间。您使用碰撞检测来射击敌人,用墙壁和地板限制玩家的移动,并提供要避开的障碍物。根据所涉及的游戏对象和所需的行为,碰撞检测逻辑可能需要复杂的数学运算。
但是,您不必用
arcade编写自己的碰撞检测代码。您可以使用三种不同的Sprite方法之一来快速检测碰撞:
- 如果给定点
(x,y)在当前 sprite 的边界内,则Sprite.collides_with_point((x,y))返回True,否则返回False。Sprite.collides_with_sprite(Sprite)如果给定的精灵与当前精灵重叠,则返回True,否则返回False。Sprite.collides_with_list(SpriteList)返回一个列表,包含SpriteList中所有与当前精灵重叠的精灵。如果没有重叠的精灵,那么列表将是空的,这意味着它的长度为零。既然你感兴趣的是单人精灵是否与任何敌人精灵发生过碰撞,那么最后一个方法正是你所需要的。您调用
self.player.collides_with_list(self.enemies_list)并检查它返回的列表是否包含任何精灵。如果是,那么你结束游戏。你在哪里打这个电话?最好的地方是在
.on_update(),就在你更新所有东西的位置之前:189def on_update(self, delta_time: float): 190 """Update the positions and statuses of all game objects 191 If paused, do nothing 192 193 Arguments: 194 delta_time {float} -- Time since the last update 195 """ 196 197 # If paused, don't update anything 198 if self.paused: 199 return 200 201 # Did you hit anything? If so, end the game 202 if self.player.collides_with_list(self.enemies_list): 203 arcade.close_window() 204 205 # Update everything 206 self.all_sprites.update()第 202 和 203 行检查
player和.enemies_list中的任何子画面之间的冲突。如果返回的列表包含任何精灵,那么这表明发生了冲突,你可以结束游戏。现在,为什么你要在更新所有东西的位置之前检查?记住 Python 游戏循环中的动作顺序:
- 你更新游戏对象的状态。你在
.on_update()中这样做。- 你画出所有游戏物体的新位置。你在
.on_draw()中这样做。如果您在更新完
.on_update()中的所有内容后检查碰撞,那么如果检测到碰撞,将不会绘制任何新的位置。您实际上是在根据尚未显示给用户的精灵位置来检查碰撞。对玩家来说,似乎在实际碰撞发生之前游戏就已经结束了!当你先检查时,你要确保玩家看到的和你检查的游戏状态是一样的。现在你有了一个看起来不错的 Python 游戏,并提供了一个挑战!现在,您可以添加一些额外的功能来帮助您的 Python 游戏脱颖而出。
临时演员
您可以向 Python 游戏中添加更多功能,使其脱颖而出。除了游戏设计中你没有实现的功能外,你可能还想到了其他功能。这一节将介绍两个特性,它们通过添加声音效果和控制游戏速度来给你的 Python 游戏带来额外的影响。
声音
声音是任何电脑游戏的重要组成部分。从爆炸到敌人嘲讽再到背景音乐,你的 Python 游戏有点平淡没有声音。开箱即用,
arcade提供了对 WAV 文件的支持。如果 ffmpeg 库安装并可用,那么arcade也支持 Ogg 和 MP3 格式文件。您将添加三种不同的音效和一些背景音乐:
- 第一个音效随着玩家向上移动而播放。
- 第二个音效在玩家下移时播放。
- 第三种音效发生碰撞时播放。
- 背景音乐是你最后要添加的。
你将从音效开始。
音效
在你播放这些声音之前,你必须先载入它们。您在
.setup()中这样做:66# Spawn a new enemy every 0.25 seconds 67arcade.schedule(self.add_enemy, 0.25) 68 69# Spawn a new cloud every second 70arcade.schedule(self.add_cloud, 1.0) 71 72# Load your sounds 73# Sound sources: Jon Fincher 74self.collision_sound = arcade.load_sound("sounds/Collision.wav") 75self.move_up_sound = arcade.load_sound("sounds/Rising_putter.wav") 76self.move_down_sound = arcade.load_sound("sounds/Falling_putter.wav")像你的精灵图像一样,把你所有的声音放在一个子文件夹里是一个好习惯。
加载声音后,您可以在适当的时候播放它们。对于
.move_up_sound和.move_down_sound,这发生在.on_key_press()处理器:134def on_key_press(self, symbol, modifiers): 135 """Handle user keyboard input 136 Q: Quit the game 137 P: Pause the game 138 I/J/K/L: Move Up, Left, Down, Right 139 Arrows: Move Up, Left, Down, Right 140 141 Arguments: 142 symbol {int} -- Which key was pressed 143 modifiers {int} -- Which modifiers were pressed 144 """ 145 if symbol == arcade.key.Q: 146 # Quit immediately 147 arcade.close_window() 148 149 if symbol == arcade.key.P: 150 self.paused = not self.paused 151 152 if symbol == arcade.key.I or symbol == arcade.key.UP: 153 self.player.change_y = 5 154 arcade.play_sound(self.move_up_sound) 155 156 if symbol == arcade.key.K or symbol == arcade.key.DOWN: 157 self.player.change_y = -5 158 arcade.play_sound(self.move_down_sound)现在,每当玩家向上或向下移动,你的 Python 游戏就会播放声音。
每当
.on_update()检测到碰撞时,就会发出碰撞声:def on_update(self, delta_time: float): """Update the positions and statuses of all game objects If paused, do nothing Arguments: delta_time {float} -- Time since the last update """ # If paused, don't update anything if self.paused: return # Did you hit anything? If so, end the game if len(self.player.collides_with_list(self.enemies_list)) > 0: arcade.play_sound(self.collision_sound) arcade.close_window() # Update everything self.all_sprites.update()就在窗户关闭之前,会发出碰撞声。
背景音乐
添加背景音乐与添加声音效果遵循相同的模式。唯一不同的是什么时候开始播放。对于背景音乐,您通常在关卡开始时启动,因此在
.setup()中加载并启动声音:66# Spawn a new enemy every 0.25 seconds 67arcade.schedule(self.add_enemy, 0.25) 68 69# Spawn a new cloud every second 70arcade.schedule(self.add_cloud, 1.0) 71 72# Load your background music 73# Sound source: http://ccmixter.org/files/Apoxode/59262 74# License: https://creativecommons.org/licenses/by/3.0/ 75self.background_music = arcade.load_sound( 76 "sounds/Apoxode_-_Electric_1.wav" 77) 78 79# Load your sounds 80# Sound sources: Jon Fincher 81self.collision_sound = arcade.load_sound("sounds/Collision.wav") 82self.move_up_sound = arcade.load_sound("sounds/Rising_putter.wav") 83self.move_down_sound = arcade.load_sound("sounds/Falling_putter.wav") 84 85# Start the background music 86arcade.play_sound(self.background_music)现在,你不仅有音效,还有一些漂亮的背景音乐!
声音限制
arcade目前对声音的处理有一些限制:
- 任何声音都没有音量控制。
- 没有办法重复一个声音,比如循环播放背景音乐。
- 在你试图停止之前,没有办法知道一个声音是否正在播放。
- 没有
ffmpeg,你就局限于 WAV 音,可以很大。尽管有这些限制,为你的
arcadePython 游戏添加声音还是很值得的。Python 游戏速度
任何游戏的速度都是由其帧速率决定的,帧速率是屏幕上图形更新的频率。较高的帧速率通常会导致更流畅的游戏,而较低的帧速率会给你更多的时间来执行复杂的计算。
一款
arcadePython 游戏的帧率由arcade.run()中的游戏循环管理。Python 游戏循环每秒大约调用.on_update()和.on_draw()60 次。所以游戏的帧率是每秒 60 帧或者说 60 FPS 。注意上面的描述说帧速率是大约 60 FPS。这个帧速率不能保证是精确的。它可能会根据许多因素上下波动,例如机器上的负载或比正常更新时间长的时间。作为一名 Python 游戏程序员,您希望确保您的 Python 游戏行为一致,无论它是以 60 FPS、30 FPS 还是任何其他速率运行。那么你是如何做到这一点的呢?
基于时间的运动
想象一个物体在太空中以每分钟 60 公里的速度运动。您可以通过将时间乘以物体的速度来计算物体在任意时间长度内移动的距离:
物体 2 分钟移动 120 公里,半分钟移动 30 公里。
你可以使用同样的计算方法来以恒定的速度移动你的精灵,不管帧率是多少。如果你用每秒的像素数来指定精灵的速度,那么如果你知道从上一帧出现到现在过了多长时间,你就可以计算出每一帧精灵移动了多少像素。你怎麽知道?
回想一下,
.on_update()只接受一个参数,delta_time。这是从上次调用.on_update()以来经过的时间(以秒为单位)。对于一个运行速度为 60 FPS 的游戏,delta_time将是 1/60 秒或大约 0.0167 秒。如果你将经过的时间乘以精灵的移动量,那么你将确保精灵的移动是基于经过的时间而不是帧速率。更新精灵动作
只有一个问题——无论是
Sprite.on_update()还是SpriteList.on_update()都不接受delta_time参数。这意味着没有办法将它传递给你的精灵来自动处理。因此,要实现这个功能,你需要手动更新你的精灵位置。用以下代码替换对.on_update()中self.all_sprites.update()的调用:def on_update(self, delta_time: float): """Update the positions and statuses of all game objects If paused, do nothing Arguments: delta_time {float} -- Time since the last update """ # If paused, don't update anything if self.paused: return # Did you hit anything? If so, end the game if len(self.player.collides_with_list(self.enemies_list)) > 0: arcade.play_sound(self.collision_sound) arcade.close_window() # Update everything for sprite in self.all_sprites: sprite.center_x = int( sprite.center_x + sprite.change_x * delta_time ) sprite.center_y = int( sprite.center_y + sprite.change_y * delta_time )在这个新代码中,您手动修改每个精灵的位置,将
.change_x和.change_y乘以delta_time。这确保了精灵每秒移动一个恒定的距离,而不是每帧移动一个恒定的距离,这可以使游戏更加流畅。更新精灵参数
当然,这也意味着你应该重新评估和调整所有精灵的初始位置和速度。回忆位置,当你的敌人精灵被创造出来时,它们会被给予:
93def add_enemy(self, delta_time: float): 94 """Adds a new enemy to the screen 95 96 Arguments: 97 delta_time {float} -- How much time as passed since the last call 98 """ 99 100 # First, create the new enemy sprite 101 enemy = FlyingSprite("images/missile.png", SCALING) 102 103 # Set its position to a random height and off screen right 104 enemy.left = random.randint(self.width, self.width + 80) 105 enemy.top = random.randint(10, self.height - 10) 106 107 # Set its speed to a random speed heading left 108 enemy.velocity = (random.randint(-20, -5), 0)随着新的基于时间的移动计算,你的敌人现在将以每秒 20 像素的最大速度移动。这意味着在一个 800 像素宽的窗口上,最快的敌人需要四十秒才能飞过屏幕。此外,如果敌人从窗口右侧的 80 个像素开始,那么最快将需要整整 4 秒钟才能出现!
调整位置和速度是让你的 Python 游戏变得有趣和可玩的一部分。从以十为因子调整每一个开始,然后从那里重新调整。同样的重新评估和调整应该在云上进行,还有玩家的移动速度。
调整和改进
在你的 Python 游戏设计中,有几个特性你没有添加。除此之外,这里还有一些额外的增强和调整,你可能在 Python 游戏和测试中已经注意到了:
- 当游戏暂停时,敌人和云彩仍然由预定的功能生成。这意味着,当游戏未暂停时,他们中的一大群人正在等着你。你如何防止这种情况发生?
- 如上所述,由于
arcade声音引擎的一些限制,背景音乐不会重复播放。您如何解决这个问题?- 当玩家与敌人发生碰撞时,游戏会突然结束,不会播放碰撞声音。如何让游戏在关闭窗口前保持打开一两秒?
您可能还可以添加其他调整。试着把其中一些作为练习来实施,并在评论中分享你的成果!
关于来源的说明
你可能已经注意到了背景音乐加载时的一个注释,列出了音乐的来源和知识共享许可的链接。这样做是因为声音的创造者需要它。许可证要求声明,为了使用声音,必须提供正确的属性和到许可证的链接。
以下是一些音乐、声音和艺术资源,您可以从中搜索有用的内容:
- OpenGameArt.org: 声音、音效、精灵和其他作品
- Kenney.nl: 声音、音效、精灵和其他作品
- 玩家艺术 2D: 小妖精和其他艺术品
- CC Mixter: 声音和音效
- Freesound: 声音和音效
当您制作游戏并使用从其他来源下载的内容(如艺术、音乐或代码)时,请确保您遵守这些来源的许可条款。
结论
电脑游戏是对编码的很好的介绍,而
arcade库是很好的第一步。作为一个用于制作游戏的现代 Python 框架,您可以创建具有出色图形和声音的引人入胜的 Python 游戏体验。在本教程中,您学习了如何:
- 安装
arcade库- 在屏幕上绘制项目
- 使用
arcadePython 游戏循环- 管理屏幕上的图形元素
- 处理用户输入
- 播放音效和音乐
- 描述一下
arcade中的 Python 游戏编程与pygame有何不同我希望你尝试一下。如果你有,那么请在下面留下评论,祝你 python 化快乐!您可以从下面的链接下载本教程中使用的所有材料:
下载资源: 点击这里下载你将在本教程中使用制作街机游戏的资源。**********
使用 Python 的 Arduino:如何入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Arduino 搭配 Python:如何入门
微控制器已经存在很长时间了,从复杂的机械到普通的家用电器,它们都被使用。然而,与他们一起工作传统上是为那些受过正规技术培训的人保留的,比如技术员和电气工程师。T2 Arduino T3 的出现使得电子应用程序设计对所有开发者来说变得更加容易。在本教程中,您将了解如何使用 Arduino 和 Python 来开发您自己的电子项目。
您将学习 Python 与 Arduino 的基础知识,并学习如何:
- 设置电子电路
- 在 Arduino 上设置 Firmata 协议
- 用 Python 编写 Arduino 的基本应用程序
- 控制模拟和数字输入和输出
- 将 Arduino 传感器和开关与更高级别的应用程序集成
- 使用 Arduino 在电脑上触发通知并发送电子邮件
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Arduino 平台
Arduino 是一个由硬件和软件组成的开源平台,允许交互式电子项目的快速开发。Arduino 的出现吸引了许多不同行业的专业人士的注意,促成了创客运动的开始。
随着创客运动和物联网概念的日益流行,Arduino 已经成为电子原型和 MVP 开发的主要平台之一。
Arduino 使用自己的编程语言,类似于 C++ 。然而,可以将 Arduino 与 Python 或其他高级编程语言一起使用。事实上,像 Arduino 这样的平台与 Python 配合得很好,特别是对于需要与传感器和其他物理设备集成的应用程序。
总而言之,Arduino 和 Python 可以促进有效的学习环境,鼓励开发人员进入电子设计领域。如果你已经了解了 Python 的基础知识,那么你就可以通过使用 Python 来控制 Arduino。
Arduino 平台包括硬件和软件产品。在本教程中,您将使用 Arduino 硬件和 Python 软件来了解基本电路,以及数字和模拟输入和输出。
Arduino 硬件
为了运行这些例子,你需要通过连接电子元件来组装电路。您通常可以在电子元件商店或良好的 Arduino 初学者工具包中找到这些项目。你需要:
- Arduino Uno 或其他兼容的主板
- 任何颜色的标准 LED
- 按钮
- 10 千欧电位计
- 470 欧姆的电阻
- 一个 10 千欧的电阻
- 一块试验板
- 各种颜色和尺寸的跳线
让我们仔细看看其中的几个组件。
组件 1 是一个 Arduino Uno 或其他兼容板。Arduino 是一个包含许多板卡和不同用途模块的项目,Arduino Uno 是其中最基础的。它也是整个 Arduino 家族中使用最多、文档最多的电路板,因此对于刚刚开始接触电子产品的开发人员来说,它是一个非常好的选择。
注意: Arduino 是一个开放的硬件平台,因此有许多其他供应商出售可用于运行您在这里看到的示例的兼容主板。在本教程中,您将学习如何使用 Arduino Uno。
元件 5 和 6 是电阻器。根据色码,大多数电阻器由彩色条纹识别。一般来说,前三种颜色代表一个电阻的值,第四种颜色代表其容差。对于 470 欧姆的电阻,前三种颜色是黄色、紫色和棕色。对于 10 千欧的电阻,前三种颜色是棕色、黑色和橙色。
组件 7 是一个试验板,用来连接所有其他组件并组装电路。虽然试验板不是必需的,但如果您打算开始使用 Arduino,建议您购买一个。
Arduino 软件
除了这些硬件组件,你还需要安装一些软件。该平台包括 Arduino IDE ,一个用于 Arduino 设备编程的集成开发环境,以及其他在线工具。
Arduino 的设计允许你毫不费力地对电路板进行编程。一般来说,您将遵循以下步骤:
- 将主板连接到您的电脑
- 安装并打开 Arduino IDE
- 配置电路板设置
- 写代码
- 按下 IDE 上的按钮,将程序上传到板上
要在您的计算机上安装 Arduino IDE,请从 Arduino 网站下载适用于您的操作系统的版本。查看文档中的安装说明:
- 如果您使用的是 Windows ,请使用 Windows installer 确保您下载了在 Windows 上使用 Arduino 所需的驱动程序。查看 Arduino 文档了解更多详情。
- 如果您使用的是 Linux ,那么您可能需要将您的用户添加到一些组中,以便使用串行端口对 Arduino 进行编程。这个过程在Arduino Linux 安装指南中有描述。
- 如果你使用的是 macOS ,那么你可以按照OS X Arduino 安装指南来安装 Arduino IDE。
注意:在本教程中,您将使用 Arduino IDE,但是 Arduino 也提供了一个 web 编辑器,它将允许您使用浏览器对 Arduino 板进行编程。
现在您已经安装了 Arduino IDE 并收集了所有必要的组件,您已经准备好开始使用 Arduino 了!接下来,你将上传一个“你好,世界!”编程到你的板上。
“你好,世界!”带 Arduino
Arduino IDE 附带了几个示例草图,您可以使用它们来学习 Arduino 的基础知识。一个草图是一个你可以上传到板上的程序的术语。因为 Arduino Uno 没有附加的显示器,所以你需要一种方法来查看程序的物理输出。您将使用闪烁示例草图让 Arduino 板上的内置 LED 闪烁。
上传眨眼示例草图
首先,使用 USB 电缆将 Arduino 板连接到您的 PC,然后启动 Arduino IDE。要打开眨眼示例草图,进入文件菜单,选择示例,然后选择 01。基本动作,最后眨眼:
Blink 示例代码将被加载到新的 IDE 窗口中。但在将草图上传到电路板之前,您需要通过选择电路板及其连接的端口来配置 IDE。
要配置电路板,进入工具菜单,然后进入电路板。对于 Arduino Uno,您应该选择 Arduino/Genuino Uno :
选择板后,您必须设置适当的端口。再次进入工具菜单,这次选择端口:
端口的名称可能会有所不同,具体取决于您的操作系统。在 Windows 中,端口将被命名为
COM4、COM5或类似的名称。在 macOS 或 Linux 中,你可能会看到类似于/dev/ttyACM0或/dev/ttyUSB0的东西。如果您在设置端口时遇到任何问题,请查看 Arduino 故障排除页面。配置好电路板和端口后,就可以将草图上传到 Arduino 了。为此,您只需按下 IDE 工具栏中的上传按钮:
当您按下上传时,IDE 会编译草图并上传到您的主板上。如果你想检查错误,那么你可以在上传之前按验证,这样只会编译你的草图。
USB 电缆提供串行连接,用于上传程序和给 Arduino 板供电。在上传过程中,你会看到板上的 led 灯在闪烁。几秒钟后,上传的程序将运行,您将看到 LED 灯每秒闪烁一次:
上传完成后,USB 线会继续给 Arduino 板供电。该程序存储在 Arduino 微控制器的闪存中。您也可以使用电池或其他外部电源来运行应用程序,而无需 USB 电缆。
连接外部组件
在上一节中,您使用了 Arduino 板上已经存在的 LED。然而,在大多数实际项目中,您需要将外部元件连接到电路板。为了进行这些连接,Arduino 有几个不同类型的引脚:
尽管这些连接通常被称为引脚,但您可以看到它们并不完全是物理引脚。相反,引脚是插座上的孔,可以连接跳线。在上图中,您可以看到不同的引脚组:
- 橙色矩形:这是 13 个数字引脚,可以用作输入或输出。它们只能处理数字信号,数字信号有两种不同的级别:
- 电平 0: 用电压 0V 表示
- 一级:用 5V 电压表示
- 绿色矩形:这是 6 个模拟引脚,可以用作模拟输入。它们可以在 0V 到 5V 之间的任意电压下工作。
- 蓝色矩形:这是 5 个电源引脚。它们主要用于为外部组件供电。
要开始使用外部组件,您将连接一个外部 LED 来运行闪烁示例草图。内置 LED 连接到数字引脚#13 。因此,让我们将外部 LED 连接到该引脚,并检查它是否闪烁。(标准 LED 是您之前看到的中列出的组件之一。)
在将任何东西连接到 Arduino 板上之前,最好先将其从电脑上断开。拔下 USB 电缆后,您就可以将 LED 连接到您的主板上了:
请注意,图中显示的是数字引脚面向您的主板。
使用试验板
电子电路项目通常涉及测试几个想法,你添加新的元件,并进行调整。然而,直接连接元件可能很棘手,尤其是在电路很大的情况下。
为了方便原型制作,你可以使用一个 试验板 来连接组件。这是一个带有几个以特殊方式连接的孔的设备,以便您可以使用跳线轻松连接组件:
通过观察彩色线条可以看出哪些孔是相互连通的。您将使用试验板侧面的孔为电路供电:
- 将红线上的一个孔连接到电源上。
- 将蓝线上的一个孔接地。
然后,只需使用红色和蓝色线上的其他孔,您就可以轻松地将组件连接到电源或地面。试验板中间的孔按照颜色指示进行连接。你要用这些来连接电路的元件。这两个内部部分由一个小凹陷分开,在这个凹陷上可以连接集成电路(IC)。
您可以使用试验板来组装 Blink 示例草图中使用的电路:
对于这个电路,需要注意的是,LED 必须根据其极性连接,否则无法工作。LED 的正极端子称为阳极,通常较长。负极端被称为阴极并且更短。如果您使用的是回收的组件,那么您也可以通过查找 LED 本身的平面来识别端子。这将指示负极端子的位置。
当您将 LED 连接到 Arduino 引脚时,您总是需要一个电阻来限制其电流,避免过早烧坏 LED。这里,您使用一个 470 欧姆的电阻来实现这一点。您可以按照连接检查电路是否相同:
- 电阻器连接到 Arduino 板上的数字引脚 13。
- LED 阳极连接到电阻器的另一端。
- LED 阴极通过蓝线孔接地(GND)。
如需更详细的解释,请查看如何使用试验板。
完成连接后,将 Arduino 插回 PC 并重新运行 Blink sketch:
由于两个发光二极管都连接到数字引脚 13,当草图运行时,它们一起闪烁。
“你好,世界!”使用 Arduino 和 Python
在上一节中,您将眨眼草图上传到了 Arduino 板上。Arduino 草图是用类似 C++的语言编写的,当你按下上传时,它会被编译并记录在微控制器的闪存中。虽然您可以使用另一种语言直接对 Arduino 微控制器编程,但这不是一项简单的任务!
然而,你可以采取一些方法将 Arduino 与 Python 或其他语言结合使用。一种想法是在 PC 上运行主程序,并使用串行连接通过 USB 电缆与 Arduino 通信。草图将负责读取输入,将信息发送到 PC,并从 PC 获取更新以更新 Arduino 输出。
要从 PC 上控制 Arduino,你必须设计一个 PC 和 Arduino 之间的通信协议。例如,您可以考虑包含如下消息的协议:
- 引脚 13 的值为高:用于告知 PC 数字输入引脚的状态
- 设置引脚 11 为低:用于告诉 Arduino 设置输出引脚的状态
定义好协议后,您可以编写一个 Arduino 草图来向 PC 发送消息,并根据协议更新引脚的状态。在 PC 上,您可以编写一个程序,根据您设计的协议,通过串行连接来控制 Arduino。为此,您可以使用您喜欢的任何语言和库,比如 Python 和 PySerial 库。
幸运的是,有标准协议可以做到这一切! Firmata 就是其中之一。该协议建立了一种串行通信格式,允许您读取数字和模拟输入,以及向数字和模拟输出发送信息。
Arduino IDE 包括现成的草图,这些草图将使用 Firmata 协议通过 Python 驱动 Arduino。在 PC 端,有多种语言的协议实现,包括 Python。要开始使用 Firmata,让我们用它来实现一个“Hello,World!”程序。
上传 Firmata 草图
在你编写 Python 程序来驱动 Arduino 之前,你必须上传 Firmata 草图,这样你就可以使用那个协议来控制电路板。Arduino IDE 的内置示例中提供了该草图。要打开它,进入文件菜单,然后是示例,接着是固件,最后是标准固件:
草图将被加载到一个新的 IDE 窗口中。要将其上传到 Arduino,您可以按照之前相同的步骤操作:
- 将 USB 电缆插入电脑。
- 在 IDE 上选择适当的板和端口。
- 按上传。
上传完成后,您将不会注意到 Arduino 上的任何活动。要控制它,你还需要一个程序,可以通过串行连接与电路板通信。要在 Python 中使用 Firmata 协议,您需要 pyFirmata 包,您可以用
pip安装它:$ pip install pyfirmata安装完成后,您可以使用 Python 和 Firmata 运行一个等效的 Blink 应用程序:
1import pyfirmata 2import time 3 4board = pyfirmata.Arduino('/dev/ttyACM0') 5 6while True: 7 board.digital[13].write(1) 8 time.sleep(1) 9 board.digital[13].write(0) 10 time.sleep(1)下面是这个程序的工作方式。You 导入
pyfirmata并使用它与 Arduino 板建立串行连接,这由第 4 行中的board对象表示。您还可以通过向pyfirmata.Arduino()传递一个参数来配置该行中的端口。您可以使用 Arduino IDE 来查找端口。
board.digital是一个列表,其元素代表 Arduino 的数字引脚。这些元素有方法read()和write(),它们将读取和写入管脚的状态。像大多数嵌入式设备程序一样,这个程序主要由一个无限循环组成:
- 在第 7 行中,数字引脚 13 打开,这将打开 LED 一秒钟。
- 在第 9 行,此引脚关闭,关闭 LED 一秒钟。
现在你已经知道了如何用 Python 控制 Arduino 的基本知识,让我们通过一些应用程序来与它的输入和输出交互。
读取数字输入
数字输入只能有两个可能的值。在电路中,每一个值都由不同的电压表示。下表显示了标准 Arduino Uno 板的数字输入表示:
价值 水平 电压 Zero 低的 0V one 高的 5V 为了控制 LED,您将使用一个按钮向 Arduino 发送数字输入值。松开按钮时,应该向电路板发送 0V 电压,按下按钮时,应该向电路板发送 5V 电压。下图显示了如何将按钮连接到 Arduino 板:
您可能会注意到,LED 连接到 Arduino 的数字引脚 13,就像以前一样。数字引脚 10 用作数字输入。要连接按钮,您必须使用 10 千欧的电阻器,它在该电路中充当下拉。一个下拉电阻确保当按钮被释放时数字输入为 0V。
当你松开按钮时,你打开了按钮上两条电线之间的连接。因为没有电流流过电阻,所以第 10 号插脚只接地(GND)。数字输入为 0V,代表 0 (或低)状态。当您按下按钮时,向电阻和数字输入施加 5V 电压。电流流过电阻,数字输入变为 5V,代表 1 (或高)状态。
您也可以使用试验板来组装上述电路:
现在你已经组装好了电路,你必须在 PC 上运行一个程序来使用 Firmata 控制它。该程序将根据按钮的状态打开 LED:
1import pyfirmata 2import time 3 4board = pyfirmata.Arduino('/dev/ttyACM0') 5 6it = pyfirmata.util.Iterator(board) 7it.start() 8 9board.digital[10].mode = pyfirmata.INPUT 10 11while True: 12 sw = board.digital[10].read() 13 if sw is True: 14 board.digital[13].write(1) 15 else: 16 board.digital[13].write(0) 17 time.sleep(0.1)让我们浏览一下这个程序:
- 1、2 号线 导入
pyfirmata和time。- 线路 4 使用
pyfirmata.Arduino()设置与 Arduino 板的连接。- 第 6 行分配一个迭代器,用于读取电路输入的状态。
- 第 7 行启动迭代器,让一个循环与你的主代码并行运行。循环执行
board.iterate()来更新从 Arduino 板获得的输入值。- 第 9 行用
pyfirmata.INPUT将引脚 10 设置为数字输入。这是必要的,因为默认配置是使用数字引脚作为输出。- 第 11 行开始一个无限的循环。该循环读取输入引脚的状态,将其存储在
sw中,并使用该值通过改变引脚 13 的值来打开或关闭 LED。- 第 17 行在
while循环的迭代之间等待 0.1 秒。这并不是绝对必要的,但这是一个避免 CPU 过载的好办法,当循环中没有 wait 命令时,CPU 会达到 100%的负载。
pyfirmata还提供了更简洁的语法来处理输入和输出引脚。当您使用多个大头针工作时,这可能是一个不错的选择。您可以重写前面的程序,使语法更加紧凑:1import pyfirmata 2import time 3 4board = pyfirmata.Arduino('/dev/ttyACM0') 5 6it = pyfirmata.util.Iterator(board) 7it.start() 8 9digital_input = board.get_pin('d:10:i') 10led = board.get_pin('d:13:o') 11 12while True: 13 sw = digital_input.read() 14 if sw is True: 15 led.write(1) 16 else: 17 led.write(0) 18 time.sleep(0.1)在这个版本中,您使用
board.get_pin()来创建两个对象。digital_input代表数字输入状态,led代表 LED 状态。当您运行这个方法时,您必须传递一个由冒号分隔的三个元素组成的字符串参数:
- 引脚的类型(
a表示模拟,d表示数字)- pin 的编号
- 引脚的模式(
i为输入,o为输出)因为
digital_input是使用引脚 10 的数字输入,所以传递参数'd:10:i'。使用引脚 13 将 LED 状态设置为数字输出,因此led参数为'd:13:o'。当您使用
board.get_pin()时,不需要像之前使用pyfirmata.INPUT那样明确地将引脚 10 设置为输入。设置引脚后,您可以使用read()访问数字输入引脚的状态,并使用write()设置数字输出引脚的状态。数字输入广泛用于电子项目。一些传感器提供数字信号,如存在或门传感器,可用作电路的输入。然而,在某些情况下,您需要测量模拟值,例如距离或物理量。在下一节中,您将看到如何通过 Python 使用 Arduino 读取模拟输入。
读取模拟输入
与只能开或关的数字输入相反,模拟输入用于读取某个范围内的值。在 Arduino Uno 上,模拟输入的电压范围为 0V 至 5V。适当的传感器用于测量物理量,例如距离。这些传感器负责在适当的电压范围内对这些物理量进行编码,以便 Arduino 能够读取它们。
为了读取模拟电压,Arduino 使用**模数转换器(ADC),将输入电压转换为固定位数的数字。这决定了转换的分辨率。Arduino Uno 使用 10 位 ADC,可以确定 1024 种不同的电压电平。*
*模拟输入的电压范围编码为从 0 到 1023 的数字。当施加 0V 时,Arduino 将其编码为数字 0 。当施加 5V 电压时,编码数字为 1023 。所有中间电压值都按比例编码。
电位计是一个可变电阻,可以用来设置施加到 Arduino 模拟输入的电压。将它连接到模拟输入,以控制 LED 闪烁的频率:
在这个电路中,LED 的设置和以前一样。电位计的终端连接到地(GND)和 5V 引脚。通过这种方式,中央终端(光标)可以具有 0V 至 5V 范围内的任何电压,具体取决于它的位置,它连接到模拟引脚 A0 上的 Arduino。
使用试验板,可以按如下方式组装该电路:
在控制 LED 之前,您可以根据电位计的位置,使用电路检查 Arduino 读取的不同值。为此,请在您的 PC 上运行以下程序:
1import pyfirmata 2import time 3 4board = pyfirmata.Arduino('/dev/ttyACM0') 5it = pyfirmata.util.Iterator(board) 6it.start() 7 8analog_input = board.get_pin('a:0:i') 9 10while True: 11 analog_value = analog_input.read() 12 print(analog_value) 13 time.sleep(0.1)在第 8 行,您用参数
'a:0:i'将analog_input设置为模拟 A0 输入引脚。在无限的while循环内部,你读取这个值,存储在analog_value,用print()显示输出到控制台。当您在程序运行时移动电位计时,您应该输出类似如下的内容:0.0 0.0293 0.1056 0.1838 0.2717 0.3705 0.4428 0.5064 0.5797 0.6315 0.6764 0.7243 0.7859 0.8446 0.9042 0.9677 1.0 1.0打印值会发生变化,范围从电位计位置在一端时的 0 到电位计位置在另一端时的 1。请注意,这些是浮点值,可能需要根据应用进行转换。
要改变 LED 闪烁的频率,您可以使用
analog_value来控制 LED 保持亮或灭的时间:1import pyfirmata 2import time 3 4board = pyfirmata.Arduino('/dev/ttyACM0') 5it = pyfirmata.util.Iterator(board) 6it.start() 7 8analog_input = board.get_pin('a:0:i') 9led = board.get_pin('d:13:o') 10 11while True: 12 analog_value = analog_input.read() 13 if analog_value is not None: 14 delay = analog_value + 0.01 15 led.write(1) 16 time.sleep(delay) 17 led.write(0) 18 time.sleep(delay) 19 else: 20 time.sleep(0.1)这里,您将
delay计算为analog_value + 0.01,以避免delay等于零。否则,在最初的几次迭代中,得到None的analog_value是很常见的。为了避免在运行程序时出错,您在第 13 行使用一个条件来测试analog_value是否为None。然后,您可以控制 LED 闪烁的周期。尝试运行程序并改变电位计的位置。您会注意到 LED 闪烁频率的变化:
至此,您已经了解了如何在电路中使用数字输入、数字输出和模拟输入。在下一节中,您将看到如何使用模拟输出。
使用模拟输出
在某些情况下,需要一个模拟输出来驱动需要模拟信号的设备。Arduino 不包括真正的模拟输出,电压可以设置为某个范围内的任何值。然而,Arduino 确实包括几个 脉宽调制 (PWM)输出。
PWM 是一种调制技术,其中数字输出用于产生具有可变功率的信号。为此,它使用恒定频率的数字信号,其中的占空比根据所需功率而变化。占空比代表信号被设置为高电平**的时间段。*
*并非所有 Arduino 数字引脚都可以用作 PWM 输出。可以用波浪符号(
~)来标识:
一些设备被设计成由 PWM 信号驱动,包括一些电机。如果使用模拟滤波器,甚至可以从 PWM 信号中获得真实的模拟信号。在上例中,您使用数字输出来打开或关闭 LED 灯。在本节中,您将根据电位计给出的模拟输入值,使用 PWM 来控制 LED 的亮度。
当 PWM 信号施加到 LED 时,其亮度根据 PWM 信号的占空比而变化。你将使用以下电路:
该电路与上一节中用于测试模拟输入的电路相同,只有一处不同。由于不可能通过引脚 13 使用 PWM,因此用于 LED 的数字输出引脚是引脚 11。
您可以使用试验板组装电路,如下所示:
组装好电路后,您可以通过以下程序使用 PWM 控制 led:
1import pyfirmata 2import time 3 4board = pyfirmata.Arduino('/dev/ttyACM0') 5 6it = pyfirmata.util.Iterator(board) 7it.start() 8 9analog_input = board.get_pin('a:0:i') 10led = board.get_pin('d:11:p') 11 12while True: 13 analog_value = analog_input.read() 14 if analog_value is not None: 15 led.write(analog_value) 16 time.sleep(0.1)与您之前使用的程序有一些不同:
- 在第 10 行中,通过传递参数
'd:11:p'将led设置为 PWM 模式。- 在第 15 行中,你用
analog_value作为参数调用led.write()。这是一个从模拟输入读取的介于 0 和 1 之间的值。在这里,您可以看到移动电位计时 LED 的行为:
为了显示占空比的变化,将示波器插入引脚 11。当电位计处于零位时,您可以看到 LED 关闭,因为引脚 11 的输出为 0V。当您转动电位计时,LED 会随着 PWM 占空比的增加而变亮。当您将电位计转到底时,占空比达到 100%。LED 以最大亮度持续打开。
通过此示例,您已经了解了使用 Arduino 及其数字和模拟输入和输出的基础知识。在下一节中,您将看到一个使用 Arduino 和 Python 在 PC 上驱动事件的应用程序。
使用传感器触发通知
Firmata 是用 Python 开始使用 Arduino 的一个很好的方法,但是需要一台 PC 或其他设备来运行该应用程序可能会很昂贵,并且这种方法在某些情况下可能不实用。然而,当需要使用外部传感器收集数据并将其发送到 PC 时,Arduino 和 Firmata 是一个很好的组合。
在本节中,您将使用一个连接到 Arduino 的按钮来模拟一个数字传感器并在您的机器上触发一个通知。对于一个更实际的应用,你可以把按钮想象成一个门传感器,例如,它会触发一个报警通知。
为了在 PC 上显示通知,您将使用标准的 Python GUI 工具包 Tkinter 。当您按下按钮时,将显示一个消息框。要深入了解 Tkinter,请查看使用 Tkinter 的 Python GUI 编程。
您需要组装在数字输入示例中使用的相同电路:
组装电路后,使用以下程序触发通知:
1import pyfirmata 2import time 3import tkinter 4from tkinter import messagebox 5 6root = tkinter.Tk() 7root.withdraw() 8 9board = pyfirmata.Arduino('/dev/ttyACM0') 10 11it = pyfirmata.util.Iterator(board) 12it.start() 13 14digital_input = board.get_pin('d:10:i') 15led = board.get_pin('d:13:o') 16 17while True: 18 sw = digital_input.read() 19 if sw is True: 20 led.write(1) 21 messagebox.showinfo("Notification", "Button was pressed") 22 root.update() 23 led.write(0) 24 time.sleep(0.1)该程序类似于在数字输入示例中使用的程序,有一些变化:
- 第 3 行和第 4 行导入设置 Tkinter 所需的库。
- 第 6 行创建 Tkinter 的主窗口。
- 第 7 行告诉 Tkinter 不要在屏幕上显示主窗口。对于这个例子,您只需要看到消息框。
- 第 17 行开始
while循环:
- 当您按下按钮时,LED 将点亮,并且
messagebox.showinfo()显示一个消息框。- 循环暂停,直到用户按下 OK 。这样,只要信息出现在屏幕上,LED 就会一直亮着。
- 用户按下 OK 后,
root.update()从屏幕上清除消息框,LED 熄灭。为了扩展通知示例,您甚至可以使用按钮在按下时发送电子邮件:
1import pyfirmata 2import time 3import smtplib 4import ssl 5 6def send_email(): 7 port = 465 # For SSL 8 smtp_server = "smtp.gmail.com" 9 sender_email = "<your email address>" 10 receiver_email = "<destination email address>" 11 password = "<password>" 12 message = """Subject: Arduino Notification\n The switch was turned on.""" 13 14 context = ssl.create_default_context() 15 with smtplib.SMTP_SSL(smtp_server, port, context=context) as server: 16 print("Sending email") 17 server.login(sender_email, password) 18 server.sendmail(sender_email, receiver_email, message) 19 20board = pyfirmata.Arduino('/dev/ttyACM0') 21 22it = pyfirmata.util.Iterator(board) 23it.start() 24 25digital_input = board.get_pin('d:10:i') 26 27while True: 28 sw = digital_input.read() 29 if sw is True: 30 send_email() 31 time.sleep(0.1)你可以在用 Python 发送邮件的中了解更多关于
send_email()的信息。在这里,您使用电子邮件服务器凭证配置该函数,该凭证将用于发送电子邮件。注意:如果您使用 Gmail 帐户发送电子邮件,那么您需要启用允许不太安全的应用选项。关于如何做到这一点的更多信息,请查看用 Python 发送电子邮件的。
通过这些示例应用程序,您已经看到了如何使用 Firmata 与更复杂的 Python 应用程序进行交互。Firmata 允许您使用任何连接到 Arduino 的传感器为您的应用获取数据。然后,您可以在主应用程序中处理数据并做出决策。您甚至可以使用 Firmata 将数据发送到 Arduino 输出,控制开关或 PWM 设备。
如果您对使用 Firmata 与更复杂的应用程序进行交互感兴趣,请尝试以下项目:
- 当温度过高或过低时,温度监视器会发出警报
- 一种模拟光传感器,可以感知灯泡何时烧坏
- 当地面太干燥时,可以自动打开洒水器的水传感器
结论
得益于创客运动和物联网的日益流行,微控制器平台正在崛起。像 Arduino 这样的平台受到了特别的关注,因为它们允许像你这样的开发人员使用他们的技能并投入到电子项目中。
您学习了如何:
- 用 Arduino 和 Python 开发应用
- 使用 Firmata 协议
- 控制模拟和数字输入和输出
- 将传感器与高级 Python 应用程序集成
您还看到了 Firmata 如何成为需要 PC 和依赖传感器数据的项目的非常有趣的替代方案。另外,如果你已经了解 Python,这是一个开始使用 Arduino 的简单方法!
延伸阅读
现在你已经知道了用 Python 控制 Arduino 的基础,你可以开始开发更复杂的应用程序了。有几个教程可以帮助您开发集成项目。这里有一些想法:
REST API:这些被广泛用于集成不同的应用程序。您可以使用 REST 和 Arduino 构建 API,从传感器获取信息并向执行器发送命令。要了解 REST API,请查看Python REST API 与 Flask、Connexion 和 SQLAlchemy 。
在本教程中,您使用 Tkinter 构建了一个图形应用程序。然而,还有其他用于桌面应用程序的图形库。要查看替代方案,请查看如何使用 wxPython 构建 Python GUI 应用程序。
线程:你在本教程中使用的无限
while循环是 Arduino 应用程序的一个非常常见的特性。但是,使用线程运行主循环将允许您同时执行其他任务。要了解如何使用线程,请查看Python 线程介绍。人脸检测:物联网 app 整合机器学习和计算机视觉算法的情况很常见。例如,有了这些,你可以建立一个警报,当它在摄像头上检测到人脸时触发通知。要了解更多关于面部识别系统的信息,请查看使用 Python 的传统面部检测。
最后,除了 Firmata 和 Arduino,在微控制器中使用 Python 还有其他方式:
pySerial: Arduino Uno 不能直接运行 Python,但是你可以设计自己的 Arduino 草图,并使用 pySerial 来建立串行连接。然后你就可以用自己的协议用 Python 控制 Arduino 了。
如果你对直接在微控制器上运行 Python 感兴趣,那就去看看的 MicroPython 项目。它提供了在一些微控制器上执行 Python 的有效实现,如 ESP8266 和 ESP32 。
SBCs: 另一种选择是使用单板机(SBC) 比如树莓派来运行 Python。SBC 是完整的 Arduino 大小的计算机,可以运行基于 Linux 的操作系统,允许您使用普通 Python。由于大多数单板机都提供了通用输入和输出引脚,你可以用它来代替大多数应用中的 Arduino。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Arduino 搭配 Python:如何入门************
新功能:文章书签、完成状态和搜索改进
原文:https://realpython.com/article-bookmarks-search-improvements/
由于 Real Python 内容库中有近 2,000 个 Python 教程和视频课程,学习者在正确的时间找到正确的资源变得越来越困难。
为了解决这个问题,我们刚刚推出了几个新功能,帮助您轻松找到和查看您正在寻找的学习资源。
以下是最新消息:
文章完成状态和书签
就像课程和课程一样,你现在可以将编写的教程和标记为已完成来跟踪你的学习进度。
这使得保存您想要阅读的教程或保存您认为有价值的教程以供将来参考变得非常容易:
Article Bookmarks & Completion Status Tracking 例如,当我学习新的东西时,我真的喜欢沉浸在一个话题中,并在一天中使用不同的媒体。
要在真正的 Python 上实践这一点,您可以从标记一些文章和视频课程开始,并在您的手机上加载一两集相关的播客。这样,你就已经在“思维地图”的某个地方找到了这个主题的大致轮廓
接下来,您可以通过逐个完成每个书签资源来填写详细信息。这样,无论你是在平板电脑上观看课程,在电脑上完成书面教程,还是在做家务时听播客,你都可以随时掌握下一步。
在本文中尝试一下书签和文章进度跟踪——只需点击文章顶部、底部或侧边栏中的标记为已完成 / 书签按钮。
新的个性化搜索过滤器
我们的网站搜索功能也获得了新的强大选项,用于根据完成状态、书签等查找和查看内容。
例如,您现在可以运行个性化搜索查询,如:
Search Improvements & Personalized Filters 这将帮助您发现适合您的技能水平和兴趣的新内容,因此您将始终知道下一步应该关注什么,以便将您的 Python 技能提升到下一个水平。
还有更多:
希望从您离开的地方继续您的 Python 之旅吗?使用搜索功能快速找到您最近查看过但尚未完成的资源列表。
您还可以使用这些新的搜索过滤器来查看您过去发现有用的教程和课程。例如,当您想在工作面试或代码审查之前刷新您的记忆时,这是非常好的。
最后,你现在还可以搜索播客剧集。
接下来是什么
我们为给你带来这些新特性而做的数据模型的改变将会在未来给网站带来一些很酷的新改进。
比如个性化首页、个性化推荐、定制教程集,这样你就可以跟踪自己的学习进度。
文章完成状态、书签和搜索改进现在都是实时的。让他们试试这篇文章和我们的网站搜索。
快乐的蟒蛇!*
用 Python 和 Pygame 构建一个小行星游戏
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Pygame 用 Python 构建一个小行星游戏
你想创建自己的电脑游戏,但又非常喜欢 Python,以至于为了游戏开发者的职业生涯而放弃它吗?有一个解决方案!有了 Pygame 模块,你可以用你惊人的 Python 技能创造游戏,从基础到非常复杂。下面,你将通过制作小行星游戏的克隆版来学习如何使用 Pygame!
在本教程中,你将学习如何构建一个完整的游戏,包括:
- 加载图像并在屏幕上显示
- 处理用户输入以控制游戏
- 根据游戏逻辑移动物体
- 检测物体之间的碰撞
- 在屏幕上显示文本
- 播放声音
单击下面的链接下载该项目的代码,并跟随您构建游戏:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Python 和 Pygame 构建一个小行星游戏。
我们开始吧!
演示:Python 中的小行星游戏
你将要制作的游戏是经典街机游戏小行星的克隆版。在游戏中,你控制一艘宇宙飞船,拍摄小行星。如果你的宇宙飞船撞上了小行星,你就输了。如果你击落所有的小行星,你就赢了!
https://player.vimeo.com/video/511326635?background=1
项目概述
你的 Python 小行星游戏将以一艘飞船为特色。宇宙飞船可以左右旋转,也可以向前加速。当它不加速时,它会继续以原来的速度运动。宇宙飞船也能发射子弹。
游戏将使用以下按键映射:
键 行动 T2 Right向右旋转飞船 T2 Left向左旋转飞船 T2 Up加速飞船前进 T2 Space拍摄 T2 Esc退出游戏 游戏中还会出现六颗大的小行星。当一颗子弹击中一颗大的小行星时,它会分裂成两颗中等大小的小行星。当子弹击中中型小行星时,它会分裂成两个小行星。小行星不会分裂,但会被子弹摧毁。
当小行星与宇宙飞船相撞时,宇宙飞船将被摧毁,游戏将以失败告终。当所有的小行星都消失后,游戏将以胜利告终!
该项目将分为十个步骤:
- 为 Python 项目设置 Pygame
- 在游戏中处理输入
- 加载图像并在屏幕上显示
- 用图像、位置和一些逻辑创建游戏对象
- 移动宇宙飞船
- 移动小行星并探测与宇宙飞船的碰撞
- 射出子弹,摧毁小行星
- 将小行星分裂成更小的
- 播放声音
- 处理游戏的结尾
每一步都将提供所有必要资源的链接。
先决条件
要构建你的小行星游戏,你需要一些更高级的 Python 元素。您应该已经熟悉了语言本身以及类、继承和回调等概念。如果您需要更新这些主题的知识,请查看我们的 Python 3 中的面向对象编程(OOP)。
游戏还会使用向量来表示位置和方向,以及一些向量运算来移动屏幕上的元素。Pygame 会处理大部分的数学问题,所有必要的概念都会在本教程中解释。不过,如果你想知道更多,那么你可以查看一下矢量加法。
如果你想深入理解一些概念,Pygame 文档会很有用,但是你会在本教程中找到你需要知道的一切。
第一步:Pygame 设置
在这一步的最后,您将拥有一个使用 Pygame 的小 Python 项目。它将显示一个带有标题的窗口,标题用蓝色填充。这将是你的小行星游戏的第一步。你不需要任何特定的游戏开发工具。您最喜欢的文本编辑器和命令行就足够了。
Python 项目
要整理您的项目,首先要为它创建一个文件夹:
$ mkdir awesome_pygame_project $ cd awesome_pygame_project和任何 Python 项目一样,你也应该为你的小行星游戏创建一个虚拟环境。你可以在 Python 虚拟环境:初级读本中阅读更多关于虚拟环境的内容。
完成后,创建一个
requirements.txt文件并添加一个 Pygame 依赖项。对于这个项目,建议你使用最新版本,这将使你的小行星游戏在 Linux 和 macOS 上无缝运行。您的文件应该如下所示:pygame==2.0.0接下来,安装依赖项:
(venv) $ python -m pip install -r requirements.txt您可以通过运行以下命令来检查 Pygame 是否安装正确:
(venv) $ python -m pygame.examples.aliens如果一切顺利,那么你应该会看到一个显示 Pygame 外星人游戏的窗口。
Pygame Code
现在是时候开始编写自己的代码了!一般来说,Pygame 程序的结构是这样的:
1initialize_pygame() 2 3while True: 4 handle_input() 5 process_game_logic() 6 draw_game_elements()第 3 行开始一个循环,称为游戏循环。该循环的每次迭代生成游戏的单个帧,并且通常执行以下操作:
输入处理:收集并处理输入,如按下的按钮、鼠标运动和 VR 控制器位置。根据游戏的不同,它可以导致对象改变它们的位置,创建新的对象,请求游戏结束,等等。
游戏逻辑:这是大部分游戏机制实现的地方。在这里,应用物理规则,检测和处理碰撞,人工智能完成其工作,等等。这个部分还负责检查玩家是赢了游戏还是输了游戏。
绘制:如果游戏还没有结束,那么这就是屏幕上画框的地方。它将包括当前游戏中的所有物品,玩家可以看到这些物品。
Pygame 程序的一般结构并不复杂,你可以把它放在一个基本的循环中。然而,考虑到您可能会在未来扩展您的小行星游戏,将所有这些操作封装在一个 Python 类中是一个好主意。
创建一个职业意味着你需要为你的游戏取一个名字,但是“小行星”已经被取了。“太空岩石”怎么样?
创建一个
space_rocks目录,并在其中创建一个名为game.py的文件。这是你放置小行星游戏主要职业的地方:SpaceRocks。该文件应该如下所示:1import pygame 2 3class SpaceRocks: 4 def __init__(self): 5 self._init_pygame() 6 self.screen = pygame.display.set_mode((800, 600)) 7 8 def main_loop(self): 9 while True: 10 self._handle_input() 11 self._process_game_logic() 12 self._draw() 13 14 def _init_pygame(self): 15 pygame.init() 16 pygame.display.set_caption("Space Rocks") 17 18 def _handle_input(self): 19 pass 20 21 def _process_game_logic(self): 22 pass 23 24 def _draw(self): 25 self.screen.fill((0, 0, 255)) 26 pygame.display.flip()下面是代码中一步一步发生的事情:
Line 1 导入py game 模块以获得其所有令人惊叹的功能。
第 3 行创建了
SpaceRocks类。第 4 行是
SpaceRocks类的构造函数,这是放置任何初始化 Pygame 所需方法的绝佳位置。实际的 Pygame 初始化发生在_init_pygame()。一会儿你会学到更多关于这个方法的知识。第 6 行创建一个显示面。Pygame 中的图像由表面表示。这里有一些关于它们的知识:
表面可以在另一个表面上绘制,允许您从简单的图片创建复杂的场景。
每个 Pygame 项目都有一个特殊的表面。该表面代表屏幕,并且是最终将显示给玩家的表面。所有其他表面必须在某个点上画在这个表面上。否则,它们不会显示。
为了创建显示表面,您的程序使用了
pygame.display.set_mode()。传递给这个方法的唯一参数是屏幕的大小,由两个值组成的元组表示:宽度和高度。在这种情况下,Pygame 将创建一个宽度为800像素、高度为600像素的屏幕。第 8 行就是上面讨论的游戏循环。对于每个帧,它包含相同的三个步骤:
第 10 行包含输入处理。
第 11 行包含游戏逻辑。
第 12 行包含图纸。
第 14 行定义了一个叫做
_init_pygame()的方法。这是 Pygame 一次性初始化的地方。该方法做两件事:
15 号线呼叫
pygame.init()。这一行代码负责设置 Pygame 的惊人特性。每次使用 Pygame 时,都应该在程序开始时调用pygame.init(),以确保框架能够正常工作。第 16 行使用
pygame.display.set_caption()设置你的 Pygame 程序的标题。在这种情况下,标题将是你的游戏名称:Space Rocks。第 18 行和第 21 行定义
_handle_input()和_process_game_logic()。它们现在是空的,但是在接下来的部分中,你将添加一些代码来使你的游戏更有趣。第 24 行定义
_draw()。为你的游戏创建一个模板而不在屏幕上显示任何东西是没有意义的,所以这个方法已经有了一些代码。它调用每一帧来绘制屏幕内容,分两步完成:
第 25 行使用
screen.fill()用一种颜色填充屏幕。该方法采用一个具有三个值的元组,表示三种基本颜色:红色、绿色和蓝色。每个颜色值的范围在0和255之间,代表其强度。在这个例子中,( 0,0,255)的元组意味着颜色将只由蓝色组成,没有红色或绿色的痕迹。第 26 行使用
pygame.display.flip()更新屏幕内容。因为你的游戏最终会显示移动的物体,你将在每一帧调用这个方法来更新显示。因此,您需要在每一帧中用颜色填充您的屏幕,因为该方法将清除前一帧中生成的内容。这看起来像是很多额外的步骤,但是现在您的代码结构良好,并且具有带描述性名称的方法。下一次你需要改变与绘图相关的东西时,你会知道使用
_draw()。为了添加输入处理,您将修改_handle_input(),等等。注意:通常,你会在类的开始提取变量,比如屏幕尺寸和颜色。然而,在几个步骤中,您将使用图像替换颜色,并且您不会在此方法之外使用屏幕的大小。因此,您可以保留这些值。
接下来,在您的
space_rocks文件夹中创建一个__main__.py文件。这个文件将负责创建一个新的游戏实例,并通过运行main_loop()来启动它。它应该是这样的:from game import SpaceRocks if __name__ == "__main__": space_rocks = SpaceRocks() space_rocks.main_loop()项目的结构现在应该如下所示:
awesome_pygame_project/ | ├── space_rocks/ | ├── __main__.py | └── game.py | └── requirements.txt继续运行游戏:
(venv) $ python space_rocks您将看到一个蓝色背景的窗口:
恭喜你,你刚刚创建了一个 Pygame 项目!但是,此时没有退出条件,所以您仍然需要在命令行中使用
Ctrl+C来退出它。这就是为什么接下来您将学习输入处理。第二步:输入处理
至此,你已经有了游戏的主循环,准备好被逻辑填充。在这一步的最后,您还将有一个脚手架来开始插入用户控件。
Pygame 中的大多数输入处理发生在一个事件循环中。在每一帧中,您的程序可以获得自前一帧以来发生的事件的集合。这包括鼠标移动、按键等等。然后,一个接一个地处理这些事件。在 Pygame 中,获取那个集合的方法是
pygame.event.get()。你现在需要的事件是
pygame.QUIT。当有人请求程序结束时就会发生这种情况,在 Windows 和 Linux 上通过点击关闭,或者按下Alt+F4,或者在 macOS 上按下Cmd+W。通过重写SpaceRocks._handle_input()来修改space_rocks/game.py,如下所示:def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT: quit()继续测试它。运行游戏,点击角落里的小 X 或使用适当的快捷方式。正如你所料,窗户将会关闭。
但是你可以更进一步。最终,你的游戏将只能用键盘来控制,而不是鼠标。按自定义键关闭窗口怎么样?
Pygame 中还有其他类型的事件,其中之一就是按键事件。它由一个
pygame.KEYDOWN常数表示。每个这样的事件都有关于被按下的键的信息存储在event.key属性中。你可以在 Pygame 文档中查看不同按键的常量。在这个例子中,通过按下Esc来关闭游戏,你将使用pygame.K_ESCAPE。再次修改
_handle_input()方法:def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit()现在当你按下
Esc时,你的游戏也会关闭。你已经成功地显示了一个窗口并正确地关闭了它。但是窗口仍然用单一颜色填充。接下来,您将学习如何加载图像并将其显示在屏幕上。
第三步:图像
此时,你有一个游戏窗口,你可以通过按键关闭它。在这一步结束时,您将在该窗口中显示一个图像。
虽然你可以只用彩色矩形和其他简单的形状来制作一个电脑游戏,但是使用图像会使它更有吸引力。在电脑游戏开发中,图像通常被称为精灵。当然,游戏使用更多类型的资源,比如声音、字体、动画等等。这些资源统称为资产。
随着游戏的成长,保持一个合适的结构是很重要的。因此,首先创建一个名为
assets的文件夹,并在其中创建另一个名为sprites的文件夹。这是你放置游戏中所有精灵的地方。接下来,下载空间背景的图像,放入
assets/sprites文件夹。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用用 Python 和 Pygame 构建一个小行星游戏。
此外,因为图像将在程序中多次加载,所以最好将此功能提取到单独文件中的单独方法中。创建一个名为
space_rocks/utils.py的文件,保存所有可重用的方法。然后实现图像加载:1from pygame.image import load 2 3def load_sprite(name, with_alpha=True): 4 path = f"assets/sprites/{name}.png" 5 loaded_sprite = load(path) 6 7 if with_alpha: 8 return loaded_sprite.convert_alpha() 9 else: 10 return loaded_sprite.convert()事情是这样的:
第 1 行导入了一个名为
load()的方法,这个方法对于以后读取图像是必要的。第 4 行创建一个图像路径,假设它存储在
assets/sprites目录中,并且是一个 PNG 文件。这样,以后你只需要提供精灵的名字。第 5 行使用
load()加载图像。这个方法返回一个表面,这是 Pygame 用来表示图像的对象。您可以稍后在屏幕上绘制它(如果您愿意,也可以在其他表面上绘制)。第 8 行和第 10 行将图像转换成更适合屏幕的格式,以加快绘图过程。这是通过
convert_alpha()或convert()完成的,取决于你是否想要使用透明。注意:一般来说,你可以对所有类型的图像使用
convert_alpha(),因为它也可以处理没有透明像素的图像。然而,绘制透明图像比绘制不透明图像要慢一些。由于电脑游戏都是关于性能的,你将通过选择正确的图像类型和提高游戏速度来练习优化你的游戏,即使只是一点点。
现在,项目的结构如下所示:
awesome_pygame_project/ | ├── assets/ | | │ └── sprites/ │ └── space.png | ├── space_rocks/ │ ├── __main__.py │ ├── game.py │ └── utils.py | └── requirements.txt现在你的程序可以加载图像了,是时候把蓝色背景换成更有趣的东西了。编辑
space_rocks/game.py文件:import pygame from utils import load_sprite class SpaceRocks: def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) def main_loop(self): while True: self._handle_input() self._process_game_logic() self._draw() def _init_pygame(self): pygame.init() pygame.display.set_caption("Space Rocks") def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() def _process_game_logic(self): pass def _draw(self): self.screen.blit(self.background, (0, 0)) pygame.display.flip()要在 Pygame 中的另一个表面上显示一个表面,您需要在您想要绘制的表面上调用
blit()。这个方法有两个参数:
- 要绘制的表面
- 你想画它的点
请记住,在 Pygame 中,坐标系从左上角开始。x 轴从左到右,y 轴从上到下:
如你所见,
UP向量指向上方,将有一个负的 y 坐标。传递给
blit()的坐标以两个值给出:X和Y。它们表示操作后曲面左上角所在的点:
如您所见,左上角被 blit 坐标移动以计算正确的位置。
在您的例子中,新背景与屏幕大小相同(
800×600像素),所以坐标将是(0, 0),代表屏幕的左上角。这样,背景图像将覆盖整个屏幕。现在运行您的程序,您将看到一个带有背景图像的屏幕:
你的游戏现在有一个非常好的背景图像,但是还没有任何事情发生。让我们通过添加一些对象来改变这一点。
第四步:控制游戏对象
在这一点上,你的程序显示了你的小行星游戏将要发生的一小块宇宙的背景图像。它现在有点空,所以在这一部分你将把它填满。您将创建一个表示其他可绘制游戏对象的类,并使用它来显示一艘宇宙飞船和一颗小行星。
高级行为
你已经使用了表面,但是 Pygame 还提供了另一个类,
Sprite,它是可视对象的基类。它包含一些有用的方法,但是您也可能会遇到一些限制。一个限制是游戏对象不仅仅是一个精灵。它包含额外的数据,比如它的方向和速度。它还需要更高级的行为,比如发射子弹或播放声音。大多数附加信息和行为不是由
Sprite类提供的,所以您需要自己添加。另一个问题是 Pygame 从左上角开始绘制精灵。在你的游戏中,为了移动和旋转一个物体,存储它的中心位置可能更容易。在这种情况下,您必须按照 Pygame 的要求实现一种方法,将该位置转换为左上角。
最后,虽然 Pygame 已经有了检测图像重叠的方法,但它们可能不适合检测物体之间的碰撞。一艘可旋转的宇宙飞船或一颗小行星可能不会填满整个图像,而是填满图像中的圆形区域。在这种情况下,碰撞应该只考虑圆形区域,而不是精灵的整个表面。否则,您可能会得到不正确的结果:
在这个例子中,精灵会碰撞,但是游戏对象不会。
这实际上是
Sprite类可以帮忙的地方,因为您可以将它与pygame.sprite.collide_circle()一起使用。该方法使用以两个精灵的表面为中心的圆来检测它们之间的碰撞。然而,检测圆的碰撞并不是一个非常复杂的过程,您可以自己实现它。考虑到这些问题,内置的 Pygame
Sprite类应该被扩充,而不是简单地单独使用。在你的游戏中,Pygame 精灵提供了一些有用的特性。相反,为游戏对象实现一个自定义类可能是个好主意。这应该给你更多的控制,帮助你理解一些概念,因为你将自己实现它们。游戏对象类
在这一节中,您将介绍
GameObject类。它将为所有其他游戏对象封装一些通用的行为和数据。代表特定对象(如宇宙飞船)的类将继承它,并用它们自己的行为和数据扩展它。如果你想更新你的类和继承的知识,那么看看 Python 3 中的面向对象编程(OOP)。
GameObject类将存储以下数据:
position:2D 屏幕上物体中心的一点sprite: 用于显示物体的图像radius: 表示物体位置周围碰撞区域的值velocity: 用于运动的数值这是游戏对象的图形表示:
sprite将是一个加载了前面示例中的load_sprite()的曲面。radius是一个整数,表示从物体中心到碰撞区域边缘的像素数。然而,position本身和velocity将需要一个新的类型:一个向量。向量类似于元组。在 2D 世界中(就像你游戏中的一样),向量由两个值表示,分别代表 x 坐标和 y 坐标。这些坐标可以指向一个位置,但也可以表示给定方向上的运动或加速度。向量可以相加,相减,甚至相乘来快速更新精灵的位置。你可以在二维空间的矢量中阅读更多关于矢量的内容。
因为向量在游戏中非常有用,Pygame 已经为它们提供了一个类:
pygame.math模块中的Vector2。它提供了一些额外的功能,比如计算向量之间的距离和加减向量。这些特性将使你的游戏逻辑更容易实现。在
space_rocks目录中,创建一个名为models.py的新文件。目前,它将存储GameObject类,但稍后你将添加小行星、子弹和宇宙飞船类。该文件应该如下所示:1from pygame.math import Vector2 2 3class GameObject: 4 def __init__(self, position, sprite, velocity): 5 self.position = Vector2(position) 6 self.sprite = sprite 7 self.radius = sprite.get_width() / 2 8 self.velocity = Vector2(velocity) 9 10 def draw(self, surface): 11 blit_position = self.position - Vector2(self.radius) 12 surface.blit(self.sprite, blit_position) 13 14 def move(self): 15 self.position = self.position + self.velocity 16 17 def collides_with(self, other_obj): 18 distance = self.position.distance_to(other_obj.position) 19 return distance < self.radius + other_obj.radius这里有一个细目分类:
1 号线进口前面提到的
Vector2级。第 3 行创建了
GameObject类,你将使用它来表示太空岩石中的所有游戏对象。第 4 行是
GameObject类的构造器。它需要三个参数:
position: 物体的中心
sprite: 用来绘制这个对象的图像
velocity: 每帧更新物体的position第 5 行和第 8 行确保
position和velocity将始终被表示为用于未来计算的向量,即使元组被传递给构造函数。你可以通过调用Vector2()构造函数来实现。如果给它一个元组,那么它会从中创建一个新的向量。如果给它一个向量,它会创建这个向量的副本。第 7 行将
radius计算为sprite图像宽度的一半。在这个程序中,游戏对象精灵将总是带有透明背景的正方形。你也可以使用图像的高度——这没什么区别。第 10 行定义了
draw(),它将在作为参数传递的表面上绘制对象的sprite。第 11 行计算传送图像的正确位置。下面将更详细地描述该过程。请注意,
Vector2()构造函数接收的是单个数字,而不是一个元组。在这种情况下,它将对两个值都使用该数字。所以Vector2(self.radius)相当于Vector2((self.radius, self.radius))。第 12 行使用新计算的 blit 位置将你对象的精灵放到给定表面的正确位置。
第 14 行定义
move()。它将更新游戏对象的位置。第 15 行将速度加到位置上,结果得到一个更新的位置向量。Pygame 使操纵向量变得简单明了,允许你像添加数字一样添加它们。
第 17 行定义了用于检测碰撞的
collides_with()方法。第 18 行利用
Vector2.distance_to()计算两个物体之间的距离。第 19 行检查该距离是否小于物体半径之和。如果是这样,物体就会发生碰撞。
请注意,你的游戏对象有一个中心位置,但
blit()需要左上角。因此,blit 位置必须通过将对象的实际位置移动一个向量来计算:
这个过程发生在
draw()。你可以通过添加一艘飞船和一颗小行星来测试这一点。首先将飞船和小行星图像复制到
assets/sprites。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用用 Python 和 Pygame 构建一个小行星游戏。
项目的结构应该如下所示:
awesome_pygame_project/ | ├── assets/ | | │ └── sprites/ │ ├── asteroid.png │ ├── space.png │ └── spaceship.png | ├── space_rocks/ │ ├── __main__.py │ ├── game.py │ ├── models.py │ └── utils.py | └── requirements.txt现在修改
space_rocks/game.py文件:import pygame from models import GameObject from utils import load_sprite class SpaceRocks: def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.spaceship = GameObject( (400, 300), load_sprite("spaceship"), (0, 0) ) self.asteroid = GameObject( (400, 300), load_sprite("asteroid"), (1, 0) ) def main_loop(self): while True: self._handle_input() self._process_game_logic() self._draw() def _init_pygame(self): pygame.init() pygame.display.set_caption("Space Rocks") def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() def _process_game_logic(self): self.spaceship.move() self.asteroid.move() def _draw(self): self.screen.blit(self.background, (0, 0)) self.spaceship.draw(self.screen) self.asteroid.draw(self.screen) pygame.display.flip()使用坐标
(400, 300),两个对象都被放置在屏幕的中间。两个物体的位置将在每一帧使用_process_game_logic()更新,并且它们将使用_draw()绘制。运行这个程序,你会看到一颗小行星向右移动,一艘宇宙飞船停在屏幕中间:
也可以通过在
_draw()的末尾临时增加一行来测试collides_with():print("Collides:", self.spaceship.collides_with(self.asteroid))在命令行中,您会注意到该方法最初是如何打印
True的,因为小行星覆盖了飞船。后来,随着小行星进一步向右移动,它开始打印False。控制速度
既然你在屏幕上有了移动的物体,是时候考虑一下你的游戏在不同的机器上用不同的处理器会有怎样的表现了。有时它会跑得更快,有时它会跑得更慢。
正因为如此,小行星(很快子弹)将以不同的速度移动,使游戏有时更容易,有时更难。这不是你想要的。你想要的是让你的游戏以固定数量的每秒帧(FPS) 运行。
幸运的是,Pygame 可以解决这个问题。它提供了一个带有
tick()方法的pygame.time.Clock类。该方法将等待足够长的时间,以匹配作为参数传递的所需 FPS 值。继续更新
space_rocks/game.py:import pygame from models import GameObject from utils import load_sprite class SpaceRocks: def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.spaceship = GameObject( (400, 300), load_sprite("spaceship"), (0, 0) ) self.asteroid = GameObject( (400, 300), load_sprite("asteroid"), (1, 0) ) def main_loop(self): while True: self._handle_input() self._process_game_logic() self._draw() def _init_pygame(self): pygame.init() pygame.display.set_caption("Space Rocks") def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() def _process_game_logic(self): self.spaceship.move() self.asteroid.move() def _draw(self): self.screen.blit(self.background, (0, 0)) self.spaceship.draw(self.screen) self.asteroid.draw(self.screen) pygame.display.flip() self.clock.tick(60)如果你现在运行你的游戏,那么小行星可能会以不同于最初的速度移动。然而,你现在可以肯定,这个速度将保持不变,即使是在拥有超高速处理器的计算机上。那是因为你的游戏会一直以 60 FPS 的速度运行。您还可以尝试传递给
tick()的不同值,看看有什么不同。您刚刚学习了如何在屏幕上显示和移动对象。现在你可以给你的游戏添加一些更高级的逻辑。
第五步:宇宙飞船
至此,你应该有了一个通用的可绘制和可移动游戏对象的类。在这一步的最后,您将使用它来创建一个可控的宇宙飞船。
您在上一步中创建的类
GameObject,包含一些通用逻辑,可以被不同的游戏对象重用。但是,每个游戏对象也会实现自己的逻辑。例如,宇宙飞船预计会旋转和加速。它也会发射子弹,但那是以后的事了。创建一个类
飞船的图像已经在您在步骤 4 中添加的
space_rocks/assets目录中。然而,早先它被用在主游戏文件中,现在你需要在其中一个模型中加载它。要做到这一点,更新space_rocks/models.py文件中的 imports 部分:from pygame.math import Vector2 from utils import load_sprite现在,您可以在同一个文件中创建继承自
GameObject的Spaceship类:class Spaceship(GameObject): def __init__(self, position): super().__init__(position, load_sprite("spaceship"), Vector2(0))在这一点上它没有做很多事情——它只是用一个特定的图像和零速度调用了
GameObject构造函数。但是,您很快就会添加更多的功能。要使用这个新类,首先需要导入它。像这样更新
space_rocks/game.py文件中的导入:import pygame from models import Spaceship from utils import load_sprite您可能注意到了,
GameObject类的原始导入已经不存在了。那是因为GameObject是作为基类被其他类继承的。你不应该直接使用它,而是导入代表实际游戏对象的类。这意味着前一步中的小行星将停止工作,但这不是一个大问题。您将很快添加一个表示小行星的适当类。在那之前,你应该把注意力放在太空船上。
继续编辑
SpaceRocks类,如下所示:1class SpaceRocks: 2 def __init__(self): 3 self._init_pygame() 4 self.screen = pygame.display.set_mode((800, 600)) 5 self.background = load_sprite("space", False) 6 self.clock = pygame.time.Clock() 7 self.spaceship = Spaceship((400, 300)) 8 9 def main_loop(self): 10 while True: 11 self._handle_input() 12 self._process_game_logic() 13 self._draw() 14 15 def _init_pygame(self): 16 pygame.init() 17 pygame.display.set_caption("Space Rocks") 18 19 def _handle_input(self): 20 for event in pygame.event.get(): 21 if event.type == pygame.QUIT or ( 22 event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE 23 ): 24 quit() 25 26 def _process_game_logic(self): 27 self.spaceship.move() 28 29 def _draw(self): 30 self.screen.blit(self.background, (0, 0)) 31 self.spaceship.draw(self.screen) 32 pygame.display.flip() 33 self.clock.tick(60)发生了两件事:
在第 7 行,您用一个专用的
Spaceship类替换了基本的GameObject类。您删除了
__init__()、_process_game_logic()和_draw()中的所有self.asteroid引用。如果你现在运行游戏,你会在屏幕中间看到一艘宇宙飞船:
这些变化还没有添加任何新的行为,但是现在您有了一个可以扩展的类。
旋转宇宙飞船
默认情况下,飞船面朝上,朝向屏幕的顶部。你的玩家应该可以左右旋转它。幸运的是,Pygame 内置了旋转精灵的方法,但是有一个小问题。
一般来说,图像旋转是一个复杂的过程,需要重新计算新图像中的像素。在重新计算的过程中,关于原始像素的信息会丢失,图像会变形一点。随着每一次旋转,变形变得越来越明显。
因此,将原始精灵存储在
Spaceship类中并拥有另一个精灵可能是一个更好的主意,该精灵将在飞船每次旋转时更新。为了使这种方法可行,你需要知道飞船旋转的角度。这可以通过两种方式实现:
- 将角度保持为浮点值,并在旋转过程中更新它。
- 保持代表飞船朝向的向量,并使用该向量计算角度。
这两种方法都不错,但是在继续之前你需要选择一种。由于宇宙飞船的位置和速度已经是向量,所以用另一个向量来表示方向是有意义的。这将使添加向量和稍后更新位置变得更加简单。幸运的是,
Vector2类可以很轻松的旋转,结果不会变形。首先,在
space_rocks/models.py文件中创建一个名为UP的常量向量。稍后您将把它用作参考:UP = Vector2(0, -1)记住 Pygame 的 y 轴是从上到下的,所以负值实际上是向上的:
接下来,修改
Spaceship类:class Spaceship(GameObject): MANEUVERABILITY = 3
MANEUVERABILITY值决定了你的飞船能旋转多快。您之前了解到 Pygame 中的向量可以旋转,该值表示您的飞船方向可以旋转每一帧的角度,以度为单位。使用较大的数字将使飞船旋转得更快,而较小的数字将允许对旋转进行更精细的控制。接下来,通过修改构造函数向
Spaceship类添加一个方向:def __init__(self, position): # Make a copy of the original UP vector self.direction = Vector2(UP) super().__init__(position, load_sprite("spaceship"), Vector2(0))方向向量最初将与
UP向量相同。但是,它以后会被修改,所以您需要创建它的副本。接下来,您需要在
Spaceship类中创建一个名为rotate()的新方法:def rotate(self, clockwise=True): sign = 1 if clockwise else -1 angle = self.MANEUVERABILITY * sign self.direction.rotate_ip(angle)这种方法将通过顺时针或逆时针旋转来改变方向。
Vector2类的rotate_ip()方法将它旋转一定角度。在此操作过程中,向量的长度不会改变。你可以从使用旋转矩阵的旋转点中学到更多关于 2D 矢量旋转背后的高级数学知识。剩下的就是更新
Spaceship的图纸了。为此,首先需要导入rotozoom,它负责缩放和旋转图像:from pygame.math import Vector2 from pygame.transform import rotozoom from utils import load_sprite, wrap_position然后,您可以在
Spaceship类中覆盖draw()方法:1def draw(self, surface): 2 angle = self.direction.angle_to(UP) 3 rotated_surface = rotozoom(self.sprite, angle, 1.0) 4 rotated_surface_size = Vector2(rotated_surface.get_size()) 5 blit_position = self.position - rotated_surface_size * 0.5 6 surface.blit(rotated_surface, blit_position)下面是一步一步的分解:
第 2 行使用
Vector2类的angle_to()方法来计算一个向量需要旋转的角度,以便与另一个向量指向相同的方向。这使得将飞船的方向转换成以度为单位的旋转角度变得很容易。第 3 行使用
rotozoom()旋转精灵。它获取原始图像、图像应该旋转的角度以及应该应用于 sprite 的比例。在这种情况下,您不想改变大小,所以您保持比例为1.0。线 4 和线 5 使用
rotated_surface的尺寸重新计算 blit 位置。该过程描述如下。第 5 行包含了
rotated_surface_size * 0.5操作。这是 Pygame 中你可以对向量做的另一件事。当你把一个向量乘以一个数时,它的所有坐标都乘以那个数。因此,乘以0.5将返回一个长度为原来一半的向量。第 6 行使用新计算的 blit 位置将图像放在屏幕上。
注意
rotozoom()返回一个新的旋转图像表面。但是,为了保留原始精灵的所有内容,新图像可能会有不同的大小。在这种情况下,Pygame 将添加一些额外的透明背景:
新图像的大小可能与原始图像的大小有很大不同。这就是为什么
draw()重新计算rotated_surface的 blit 位置。记住blit()从左上角开始,所以为了使旋转后的图像居中,你还需要将 blit 位置移动图像大小的一半。现在您需要添加输入处理。然而,事件循环在这里并不完全有效。事件发生时会被记录下来,但您需要不断检查是否按下了某个键。毕竟飞船只要你按下
Up就要加速,按下Left或者Right就要不停旋转。您可以为每个键创建一个标志,在按下该键时设置它,并在释放时重置它。然而,有一个更好的方法。
键盘的当前状态存储在 Pygame 中,可以使用
pygame.key.get_pressed()获取。它返回一个字典,其中的键常量(如您之前使用的pygame.K_ESCAPE)是键,如果键被按下,则值为True,否则为False。了解了这一点,您就可以编辑
space_rocks/game.py文件并更新SpaceRocks类的_handle_input()方法了。箭头键需要使用的常量是pygame.K_RIGHT和pygame.K_LEFT:def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() is_key_pressed = pygame.key.get_pressed() if is_key_pressed[pygame.K_RIGHT]: self.spaceship.rotate(clockwise=True) elif is_key_pressed[pygame.K_LEFT]: self.spaceship.rotate(clockwise=False)现在,当您按下箭头键时,您的飞船将左右旋转:
如你所见,宇宙飞船正确旋转。然而,它还是不动。接下来你会解决的。
加速宇宙飞船
在本节中,您将为您的飞船添加加速度。记住,根据小行星的游戏力学,飞船只能前进。
在你的游戏中,当你按下
Up时,飞船的速度会增加。当你松开钥匙时,飞船将保持当前速度,但不再加速。所以为了让它慢下来,你必须把飞船调头,然后再次按下Up。这个过程可能看起来有点复杂,所以在你继续之前,这里有一个简短的回顾:
direction是描述飞船指向的矢量。velocity是描述飞船每帧移动到哪里的矢量。ACCELERATION是一个常数,描述飞船每一帧能加速多快。您可以通过将
direction向量乘以ACCELERATION值并将结果加到当前的velocity来计算速度的变化。这只有在引擎开启的情况下才会发生——也就是玩家按下Up的时候。飞船的新位置通过将当前速度加到飞船的当前位置来计算。无论引擎状态如何,每帧都会发生这种情况。知道了这一点,您可以将
ACCELERATION值添加到Spaceship类中:class Spaceship(GameObject): MANEUVERABILITY = 3 ACCELERATION = 0.25然后,在
Spaceship类中创建accelerate():def accelerate(self): self.velocity += self.direction * self.ACCELERATION现在您可以在
SpaceRocks中为_handle_input()添加输入处理。与旋转类似,这将检查键盘的当前状态,而不是按键事件。Up的常数为pygame.K_UP:def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() is_key_pressed = pygame.key.get_pressed() if is_key_pressed[pygame.K_RIGHT]: self.spaceship.rotate(clockwise=True) elif is_key_pressed[pygame.K_LEFT]: self.spaceship.rotate(clockwise=False) if is_key_pressed[pygame.K_UP]: self.spaceship.accelerate()继续测试这个。运行你的游戏,旋转飞船,打开引擎:
你的宇宙飞船现在可以移动和旋转了!然而,当它到达屏幕边缘时,它只是不停地移动。这是你应该解决的问题!
围绕屏幕缠绕对象
这个游戏的一个重要元素是确保游戏对象不会离开屏幕。你可以让它们从屏幕边缘反弹回来,或者让它们重新出现在屏幕的另一边。在这个项目中,您将实现后者。
首先在
space_rocks/utils.py文件中导入Vector2类:from pygame.image import load from pygame.math import Vector2接下来,在同一个文件中创建
wrap_position():1def wrap_position(position, surface): 2 x, y = position 3 w, h = surface.get_size() 4 return Vector2(x % w, y % h)通过在第 4 行使用模操作符,你可以确保这个位置不会离开给定表面的区域。在你游戏中,表面就是屏幕。
在
space_rocks/models.py中导入这个新方法:from pygame.math import Vector2 from pygame.transform import rotozoom from utils import load_sprite, wrap_position现在您可以更新
GameObject类中的move():def move(self, surface): self.position = wrap_position(self.position + self.velocity, surface)注意,使用
wrap_position()并不是这里唯一的变化。您还向该方法添加了一个新的surface参数。那是因为你需要知道这个位置应该环绕的区域。记住也要更新SpaceRocks类中的方法调用:def _process_game_logic(self): self.spaceship.move(self.screen)现在你的飞船重新出现在屏幕的另一边。
移动和旋转飞船的逻辑准备好了。但这艘船仍然孤零零地在空旷的太空中。是时候添加一些小行星了!
第六步:小行星
此时,你有了一艘可以在屏幕上移动的飞船。在这一步的最后,你的游戏还会显示一些小行星。此外,你将实现飞船和小行星之间的碰撞。
创建一个类
与
Spaceship类似,您将首先创建一个名为Asteroid的类,它继承自GameObject。像这样编辑space_rocks/models.py文件:class Asteroid(GameObject): def __init__(self, position): super().__init__(position, load_sprite("asteroid"), (0, 0))就像之前一样,首先用一个特定的图像调用
GameObject构造函数。您在前面的一个步骤中添加了图像。接下来,在
space_rocks/game.py中导入新类:import pygame from models import Asteroid, Spaceship from utils import load_sprite最后,在同一个文件中编辑
SpaceRocks类的构造函数,创建六个小行星:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.asteroids = [Asteroid((0, 0)) for _ in range(6)] self.spaceship = Spaceship((400, 300))既然您有了更多的游戏对象,那么在
SpaceRocks类中创建一个返回所有对象的 helper 方法将是一个好主意。这个方法将被绘制和移动逻辑使用。这样,您可以在以后引入新类型的游戏对象,并且只修改这一个方法,或者您可以在必要时从该组中排除一些对象。调用这个方法
_get_game_objects():def _get_game_objects(self): return [*self.asteroids, self.spaceship]现在使用它通过编辑
_process_game_logic()在单个循环中移动所有游戏对象:def _process_game_logic(self): for game_object in self._get_game_objects(): game_object.move(self.screen)同样的道理也适用于
_draw():def _draw(self): self.screen.blit(self.background, (0, 0)) for game_object in self._get_game_objects(): game_object.draw(self.screen) pygame.display.flip() self.clock.tick(60)现在运行你的游戏,你应该会看到一个小行星的屏幕:
不幸的是,所有的小行星都堆在屏幕的一角。
嗯,这是意料之中的,因为所有的小行星都是以位置
(0, 0)创建的,它代表左上角。您可以通过在屏幕上设置一个随机位置来改变这一点。随机化位置
要生成一个随机位置,你必须添加一些导入到
space_rocks/utils.py文件:import random from pygame.image import load from pygame.math import Vector2然后,在同一文件中创建一个名为
get_random_position()的方法:def get_random_position(surface): return Vector2( random.randrange(surface.get_width()), random.randrange(surface.get_height()), )这将在给定的表面上生成一组随机的坐标,并将结果作为一个
Vector2实例返回。接下来,在
space_rocks/game.py文件中导入这个方法:import pygame from models import Asteroid, Spaceship from utils import get_random_position, load_sprite现在使用
get_random_position()将所有六颗小行星放置在随机位置。修改SpaceRocks类的构造函数:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.asteroids = [ Asteroid(get_random_position(self.screen)) for _ in range(6) ] self.spaceship = Spaceship((400, 300))现在当你运行游戏时,你会在屏幕上看到一个漂亮的随机分布的小行星:
这看起来好多了,但是有一个小问题:小行星和宇宙飞船是在同一个区域产生的。添加碰撞后,这将导致玩家在开始游戏后立即失败。那太不公平了!
这个问题的一个解决方案是检查位置是否离飞船太近,如果是,生成一个新的,直到找到有效位置。
首先创建一个常数,代表一个必须保持空白的区域。
250像素的值应该足够了:class SpaceRocks: MIN_ASTEROID_DISTANCE = 250现在你可以修改
SpaceRocks类的构造函数来确保你的玩家总是有机会获胜:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.asteroids = [] self.spaceship = Spaceship((400, 300)) for _ in range(6): while True: position = get_random_position(self.screen) if ( position.distance_to(self.spaceship.position) > self.MIN_ASTEROID_DISTANCE ): break self.asteroids.append(Asteroid(position))在循环中,您的代码检查小行星的位置是否大于最小小行星距离。如果没有,则循环再次运行,直到找到这样的位置。
再次运行程序,没有一颗小行星会与飞船重叠:
你可以运行游戏几次,以确保每次飞船周围都有一些自由空间。
移动小行星
现在,你的程序显示了六颗小行星在随机的位置上,你可以通过移动它们来增加一点趣味了!与位置类似,小行星的速度也应该是随机的,不仅是方向,还有数值。
首先在
space_rocks/utils.py文件中创建一个名为get_random_velocity()的方法:def get_random_velocity(min_speed, max_speed): speed = random.randint(min_speed, max_speed) angle = random.randrange(0, 360) return Vector2(speed, 0).rotate(angle)该方法将生成一个在
min_speed和max_speed之间的随机值和一个在 0 到 360 度之间的随机角度。然后它会用那个值创建一个向量,旋转那个角度。因为小行星无论放在哪里速度都应该是随机的,所以我们直接在
Asteroid类里用这个方法吧。从更新space_rocks/models.py文件中的导入开始:from pygame.math import Vector2 from pygame.transform import rotozoom from utils import get_random_velocity, load_sprite, wrap_position注意,你在一个地方设置了随机位置,在另一个地方设置了随机速度。这是因为位置应该只对你开始的六个小行星是随机的,所以它被设置在游戏初始化的
space_rocks/game.py文件中。然而,对于每个小行星来说,速度是随机的,所以您在Asteroid类的构造函数中设置它。然后在
Asteroid类的构造函数中使用新方法:def __init__(self, position): super().__init__( position, load_sprite("asteroid"), get_random_velocity(1, 3) )注意,该方法使用了
1的最小值。这是因为小行星应该总是在移动,至少是一点点。再次运行你的游戏,看看移动的小行星:
https://player.vimeo.com/video/511327373?background=1
你也可以在屏幕上移动飞船。不幸的是,当它遇到小行星时,什么都不会发生。是时候添加一些碰撞了。
与宇宙飞船相撞
这个游戏很重要的一部分就是你的飞船有可能被小行星碰撞摧毁。您可以使用步骤 4 中介绍的
GameObject.collides_with()来检查碰撞。你只需要为每个小行星调用这个方法。像这样编辑
SpaceRocks类中的_process_game_logic()方法:def _process_game_logic(self): for game_object in self._get_game_objects(): game_object.move(self.screen) if self.spaceship: for asteroid in self.asteroids: if asteroid.collides_with(self.spaceship): self.spaceship = None break如果任何一颗小行星与宇宙飞船相撞,那么宇宙飞船就会被摧毁。在这个游戏中,你将通过设置
self.spaceship到None来表示这一点。注意,在循环的开始还有一个对
self.spaceship的检查。这是因为,当宇宙飞船被摧毁时,没有理由检查与它的任何碰撞。此外,检测与None物体的碰撞会导致错误。既然飞船有可能有一个值
None,更新SpaceRocks类中的_get_game_objects()以避免试图渲染或移动一个被摧毁的飞船是很重要的:def _get_game_objects(self): game_objects = [*self.asteroids] if self.spaceship: game_objects.append(self.spaceship) return game_objects输入处理也是如此:
def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() is_key_pressed = pygame.key.get_pressed() if self.spaceship: if is_key_pressed[pygame.K_RIGHT]: self.spaceship.rotate(clockwise=True) elif is_key_pressed[pygame.K_LEFT]: self.spaceship.rotate(clockwise=False) if is_key_pressed[pygame.K_UP]: self.spaceship.accelerate()你现在可以运行你的游戏,看到飞船在与小行星相撞后消失:
你的宇宙飞船现在可以飞来飞去,当它与小行星相撞时会被摧毁。你已经准备好让小行星也有可能被摧毁。
第七步:项目符号
在这一点上,你有一些随机放置和移动的小行星和一艘可以四处移动和避开它们的宇宙飞船。在这一步结束时,你的飞船也将能够通过发射子弹来保护自己。
创建一个类
首先给
assets/sprites添加一个子弹的图像。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用用 Python 和 Pygame 构建一个小行星游戏。
项目的结构应该如下所示:
awesome_pygame_project/ | ├── assets/ | | │ └── sprites/ │ ├── asteroid.png │ ├── bullet.png │ ├── space.png │ └── spaceship.png | ├── space_rocks/ │ ├── __main__.py │ ├── game.py │ ├── models.py │ └── utils.py | └── requirements.txt然后通过创建一个继承自
GameObject的名为Bullet的类来编辑space_rocks/models.py文件:class Bullet(GameObject): def __init__(self, position, velocity): super().__init__(position, load_sprite("bullet"), velocity)就像之前一样,这只会用一个特定的 sprite 调用
GameObject构造函数。然而,这一次速度将是一个必需的参数,因为子弹必须移动。接下来,您应该添加一种跟踪子弹的方法,就像您对小行星所做的那样。编辑
space_rocks/game.py文件中SpaceRocks类的构造函数:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.asteroids = [] self.bullets = [] self.spaceship = Spaceship((400, 300)) for _ in range(6): while True: position = get_random_position(self.screen) if ( position.distance_to(self.spaceship.position) > self.MIN_ASTEROID_DISTANCE ): break self.asteroids.append(Asteroid(position))子弹应该和其他游戏对象一样对待,所以编辑
SpaceRocks中的_get_game_object()方法:def _get_game_objects(self): game_objects = [*self.asteroids, *self.bullets] if self.spaceship: game_objects.append(self.spaceship) return game_objects项目列表在那里,但是现在是空的。你可以修好它。
射出一颗子弹
射击有个小问题。子弹存储在主游戏对象中,由
SpaceRocks类表示。不过拍摄逻辑要由飞船来决定。是宇宙飞船知道如何创造一种新的子弹,但却是游戏存储并在后来制作子弹的动画。Spaceship类需要一种方法来通知SpaceRocks类一个子弹已经被创建并且应该被跟踪。要解决这个问题,您可以向
Spaceship类添加一个回调函数。该函数将在飞船初始化时由SpaceRocks类提供。飞船每创建一个子弹,都会初始化一个Bullet对象,然后调用回调。回调会将子弹添加到游戏存储的所有子弹列表中。首先向
space_rocks/models.py文件中的Spaceship类的构造函数添加一个回调:def __init__(self, position, create_bullet_callback): self.create_bullet_callback = create_bullet_callback # Make a copy of the original UP vector self.direction = Vector2(UP) super().__init__(position, load_sprite("spaceship"), Vector2(0))你还需要子弹的速度值:
class Spaceship(GameObject): MANEUVERABILITY = 3 ACCELERATION = 0.25 BULLET_SPEED = 3接下来,在
Spaceship类中创建一个名为shoot()的方法:def shoot(self): bullet_velocity = self.direction * self.BULLET_SPEED + self.velocity bullet = Bullet(self.position, bullet_velocity) self.create_bullet_callback(bullet)你从计算子弹的速度开始。子弹总是向前射的,所以你用飞船的方向乘以子弹的速度。因为飞船不一定静止不动,你把它的速度加到子弹的速度上。这样,如果宇宙飞船移动得非常快,你就可以制造出高速子弹。
然后,使用刚刚计算的速度,在与飞船相同的位置创建一个
Bullet类的实例。最后通过使用回调方法将子弹添加到游戏中的所有子弹中。现在,在创建飞船时将回调添加到飞船中。项目符号存储在一个列表中,回调函数唯一要做的就是向列表中添加新的项目。因此,
append()方法应该可以完成这项工作。在space_rocks/game.py文件中编辑SpaceRocks类的构造函数:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.asteroids = [] self.bullets = [] self.spaceship = Spaceship((400, 300), self.bullets.append) for _ in range(6): while True: position = get_random_position(self.screen) if ( position.distance_to(self.spaceship.position) > self.MIN_ASTEROID_DISTANCE ): break self.asteroids.append(Asteroid(position))最后需要添加的是输入处理。只有当
Space被按下时,子弹才会生成,所以可以使用事件循环。Space的常数为pygame.K_SPACE。修改
SpaceRocks类中的_handle_input()方法:def _handle_input(self): for event in pygame.event.get(): if event.type == pygame.QUIT or ( event.type == pygame.KEYDOWN and event.key == pygame.K_ESCAPE ): quit() elif ( self.spaceship and event.type == pygame.KEYDOWN and event.key == pygame.K_SPACE ): self.spaceship.shoot() is_key_pressed = pygame.key.get_pressed() if self.spaceship: if is_key_pressed[pygame.K_RIGHT]: self.spaceship.rotate(clockwise=True) elif is_key_pressed[pygame.K_LEFT]: self.spaceship.rotate(clockwise=False) if is_key_pressed[pygame.K_UP]: self.spaceship.accelerate()请注意,新的输入处理还会检查飞船是否存在。否则,当试图在一个
None对象上调用shoot()时,您可能会遇到错误。现在运行您的游戏并发射一些子弹:
你的飞船终于可以发射了!然而,子弹不会离开屏幕,这可能是一个问题。
包装子弹
此刻,所有的游戏物体都缠绕在屏幕上。包括子弹。然而,由于这种环绕,屏幕很快就被飞向四面八方的子弹填满了。这可能会让游戏变得太简单了!
您可以通过仅对项目符号禁用换行来解决此问题。像这样覆盖
space_rocks/models.py文件中Bullet类中的move():def move(self, surface): self.position = self.position + self.velocity这样子弹就不会缠绕在屏幕上。然而,它们也不会被摧毁。相反,他们将继续飞向宇宙的无限深渊。很快,你的子弹列表将包含成千上万的元素,并且它们将在每一帧中被处理,导致你的游戏性能下降。
为了避免这种情况,你的游戏应该在子弹一离开屏幕就把它们移除。更新
space_rocks/game.py文件中SpaceRocks类的_process_game_logic()方法:1def _process_game_logic(self): 2 for game_object in self._get_game_objects(): 3 game_object.move(self.screen) 4 5 if self.spaceship: 6 for asteroid in self.asteroids: 7 if asteroid.collides_with(self.spaceship): 8 self.spaceship = None 9 break 10 11 for bullet in self.bullets[:]: 12 if not self.screen.get_rect().collidepoint(bullet.position): 13 self.bullets.remove(bullet)请注意,您没有使用原始列表
self.bullets,而是在第 11 行使用self.bullets[:]创建了一个副本。这是因为在遍历列表时从列表中移除元素会导致错误。Pygame 中的表面有一个
get_rect()方法,返回一个代表它们面积的矩形。这个矩形又有一个collidepoint()方法,如果矩形中包含一个点,则返回True,否则返回False。使用这两种方法,您可以检查项目符号是否已经离开屏幕,如果是,则将其从列表中删除。与小行星相撞
你的子弹仍然缺少一个关键的元素:摧毁小行星的能力!您将在本节中解决这个问题。
像这样更新
SpaceRocks类的_process_game_logic()方法:1def _process_game_logic(self): 2 for game_object in self._get_game_objects(): 3 game_object.move(self.screen) 4 5 if self.spaceship: 6 for asteroid in self.asteroids: 7 if asteroid.collides_with(self.spaceship): 8 self.spaceship = None 9 break 10 11 for bullet in self.bullets[:]: 12 for asteroid in self.asteroids[:]: 13 if asteroid.collides_with(bullet): 14 self.asteroids.remove(asteroid) 15 self.bullets.remove(bullet) 16 break 17 18 for bullet in self.bullets[:]: 19 if not self.screen.get_rect().collidepoint(bullet.position): 20 self.bullets.remove(bullet)现在,每当检测到一颗子弹和一颗小行星之间的碰撞,两者都将从游戏中删除。注意,就像前面的项目符号循环一样,这里不使用原始列表。相反,您在第 11 行和第 12 行使用
[:]创建副本。如果你现在运行你的游戏,并在射击时瞄准好,那么你应该能够摧毁一些小行星:
你的飞船终于可以保护自己了!然而,游戏中只有六个大目标。接下来,你会让它变得更有挑战性。
第八步:分裂小行星
在这一点上,你有一个宇宙飞船,小行星和子弹的游戏。在这一步结束时,你的小行星会在被子弹击中时分裂。一颗大的小行星会变成两颗中等的,一颗中等的会变成两颗小的,一颗小的会消失。
小行星的大小将由一个数字表示:
小行星大小 小行星类型 3大小行星 2中型小行星 1小行星 小行星每被撞击一次,都会产生两颗体积更小的小行星。一颗大小为 1 的小行星是个例外,因为它不会产生任何新的小行星。
小行星的大小也将决定其精灵的大小,从而决定其半径。换句话说,小行星的比例将是这样的:
小行星大小 小行星尺度 描述 three one 默认的精灵和半径 Two Zero point five 默认精灵和半径的一半 one Zero point two five 默认精灵和半径的四分之一 这可能看起来有点复杂,但是您只需要几行代码就可以做到。在
space_rocks/models.py文件中重写Asteroid类的构造函数:def __init__(self, position, size=3): self.size = size size_to_scale = { 3: 1, 2: 0.5, 1: 0.25, } scale = size_to_scale[size] sprite = rotozoom(load_sprite("asteroid"), 0, scale) super().__init__( position, sprite, get_random_velocity(1, 3) )这个方法将为一颗小行星指定一个大小,使用默认值
3,代表一颗大的小行星。它还将使用rotozoom()缩放原始精灵。你以前用过它来旋转飞船。如果角度为 0 且比例为 0 以外的任何值,此方法也可用于缩放。在本例中,size_to_scale查找表包含不同尺寸的刻度:
尺寸 刻度 three one Two Zero point five one Zero point two five 最后,将缩放后的精灵传递给
GameObject类的构造函数,它将根据新的图像大小计算半径。你的新逻辑要求一颗小行星能够创造新的小行星。情况类似于飞船和子弹,所以可以使用类似的解决方案:回调方法。
再次更新
Asteroid类的构造函数:def __init__(self, position, create_asteroid_callback, size=3): self.create_asteroid_callback = create_asteroid_callback self.size = size size_to_scale = { 3: 1, 2: 0.5, 1: 0.25, } scale = size_to_scale[size] sprite = rotozoom(load_sprite("asteroid"), 0, scale) super().__init__( position, sprite, get_random_velocity(1, 3) )现在您可以在同一个类中创建一个名为
split()的方法:def split(self): if self.size > 1: for _ in range(2): asteroid = Asteroid( self.position, self.create_asteroid_callback, self.size - 1 ) self.create_asteroid_callback(asteroid)这将在与当前小行星相同的位置创建两个新的小行星。他们每个人的尺寸都会稍微小一点。只有当前的小行星是中型或大型小行星,才会出现这种逻辑。
现在,您可以在
SpaceRocks类的构造函数中为每个新创建的小行星添加回调。就像在宇宙飞船的例子中一样,您将使用适当列表的append()方法:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.asteroids = [] self.bullets = [] self.spaceship = Spaceship((400, 300), self.bullets.append) for _ in range(6): while True: position = get_random_position(self.screen) if ( position.distance_to(self.spaceship.position) > self.MIN_ASTEROID_DISTANCE ): break self.asteroids.append(Asteroid(position, self.asteroids.append))当小行星被子弹击中时,记得打电话。更新
SpaceRocks类的_process_game_logic()方法:def _process_game_logic(self): for game_object in self._get_game_objects(): game_object.move(self.screen) if self.spaceship: for asteroid in self.asteroids: if asteroid.collides_with(self.spaceship): self.spaceship = None break for bullet in self.bullets[:]: for asteroid in self.asteroids[:]: if asteroid.collides_with(bullet): self.asteroids.remove(asteroid) self.bullets.remove(bullet) asteroid.split() break for bullet in self.bullets[:]: if not self.screen.get_rect().collidepoint(bullet.position): self.bullets.remove(bullet)如果你现在运行游戏并击落一些小行星,那么你会注意到,它们不是马上消失,而是分裂成更小的小行星:
你只是实现了游戏的整个逻辑!宇宙飞船可以移动,它在与小行星碰撞后被摧毁,它发射子弹,小行星分裂成更小的小行星。但此刻游戏是沉默的。接下来你会处理好的。
第九步:播放声音
此时,你的程序显示所有的游戏对象,并处理它们之间的交互。在这一步结束时,你的游戏也将播放声音。
在第 7 步中,飞船装备了武器。然而,这种武器是完全无声的。从物理学的角度来说,这是非常准确的,因为声音不会在真空中传播(“T2”)在太空中,没有人能听到你的尖叫(“T3”)。然而,在你的游戏中使用声音会使它更有吸引力。
首先,创建一个
assets/sounds目录,并在那里添加激光声音。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用用 Python 和 Pygame 构建一个小行星游戏。
您的项目结构应该如下所示:
awesome_pygame_project/ | ├── assets/ | | │ ├── sounds/ │ │ └── laser.wav | | │ └── sprites/ │ ├── asteroid.png │ ├── bullet.png │ ├── space.png │ └── spaceship.png | ├── space_rocks/ │ ├── __main__.py │ ├── game.py │ ├── models.py │ └── utils.py | └── requirements.txt现在您需要加载文件。在 Pygame 中,声音由来自
pygame.mixer模块的Sound类表示。虽然在这个游戏中你将只使用一种声音,但你以后可能会想添加更多的声音。这就是为什么您将创建一个加载声音的辅助方法,类似于您为精灵创建的方法。首先,在
space_rocks/utils.py文件中导入Sound类:import random from pygame.image import load from pygame.math import Vector2 from pygame.mixer import Sound接下来,在同一文件中创建一个名为
load_sound()的方法:def load_sound(name): path = f"assets/sounds/{name}.wav" return Sound(path)该方法的逻辑与
load_sprite()相似。它将假设声音总是位于assets/sounds目录中,并且是一个 WAV 文件。您现在可以在
space_rocks/models.py文件中导入这个新方法:from pygame.math import Vector2 from pygame.transform import rotozoom from utils import get_random_velocity, load_sound, load_sprite, wrap_position然后将声音加载到
Spaceship类的构造函数中:def __init__(self, position, create_bullet_callback): self.create_bullet_callback = create_bullet_callback self.laser_sound = load_sound("laser") # Make a copy of the original UP vector self.direction = Vector2(UP) super().__init__(position, load_sprite("spaceship"), Vector2(0))最后,你应该在飞船发射时播放声音。更新
shoot():def shoot(self): bullet_velocity = self.direction * self.BULLET_SPEED + self.velocity bullet = Bullet(self.position, bullet_velocity) self.create_bullet_callback(bullet) self.laser_sound.play()现在运行游戏,每次射击都会听到声音。
您刚刚学习了如何在 Pygame 中处理音频文件!剩下的就是在游戏结束时显示一条消息。
步骤 10:结束游戏
此时,您的游戏已经基本完成,包括输入处理、交互、图像,甚至声音。在这一步结束时,您还将在屏幕上显示游戏的状态。
许多游戏在游戏过程中和游戏结束后都会显示一些附加信息。这可以是剩余的生命值,盾牌等级,弹药数量,任务的总分数等等。在这个游戏中,你将显示游戏的状态。
如果飞船被小行星摧毁,那么屏幕上会出现消息
You lost!。但是如果所有的小行星都消失了,而宇宙飞船还在,那么你应该显示You won!Pygame 没有任何绘制文本的高级工具,这意味着程序员要做更多的工作。呈现的文本由具有透明背景的表面表示。你可以像操纵精灵一样操纵那个表面,例如通过使用
blit()。表面本身是使用字体创建的。在 Pygame 中处理文本的完整过程如下所示:
创建字体:字体由
pygame.font.Font类表示。您可以使用自定义字体文件,也可以使用默认字体。在这个游戏中,你会选择后者。用文本创建一个表面:使用
Font.render()完成。在本教程的后面,您将了解到更多关于该方法的内容。现在,知道它用渲染的文本和透明的背景创建一个表面就足够了。将表面 blit 到屏幕上:与 Pygame 中的任何其他表面一样,只有将它 Blit 到屏幕上或最终将显示在屏幕上的另一个表面上,文本才会可见。
您的字体将呈现一种颜色。在步骤 1 中,你用三个值创建了一种颜色:红色、绿色和蓝色。在本节中,您将使用一个
Color类来代替。首先将其导入到space_rocks/utils.py文件中:import random from pygame import Color from pygame.image import load from pygame.math import Vector2 from pygame.mixer import Sound然后,在同一文件中创建一个
print_text()方法:1def print_text(surface, text, font, color=Color("tomato")): 2 text_surface = font.render(text, True, color) 3 4 rect = text_surface.get_rect() 5 rect.center = Vector2(surface.get_size()) / 2 6 7 surface.blit(text_surface, rect)事情是这样的:
第 1 行是你方法的宣言。它需要一个表面来呈现文本、文本本身、字体和颜色。
Color类提供了许多预定义的颜色,你可以在 Pygame 库中找到。您的方法将使用名为"tomato"的默认颜色。第 2 行使用
render()创建带有文本的表面。它的第一个参数是需要呈现的文本。第二个是一个抗锯齿标志。将其设置为True将平滑渲染文本的边缘。最后一个参数是文本的颜色。第 4 行获得一个矩形,代表你的文本所在的表面区域。那个矩形是
Rect类的一个实例,可以很容易地移动和对齐。你可以在文档中了解更多关于校准的信息。第 5 行将矩形的
center属性设置为屏幕中间的一点。该点通过将屏幕尺寸除以2来计算。此操作确保您的文本将显示在屏幕中央。第 7 行在屏幕上绘制文本。注意,这一次,您传递给
blit()的是一个矩形,而不是一个点。在这种情况下,该方法将获取给定矩形的左上角,并在那里开始位块传送过程。现在您可以在
space_rocks/game.py文件中导入这个方法:import pygame from models import Asteroid, Spaceship from utils import get_random_position, load_sprite, print_text现在你需要创建一个字体。您还应该存储将要显示的消息。编辑
SpaceRocks类的构造函数:def __init__(self): self._init_pygame() self.screen = pygame.display.set_mode((800, 600)) self.background = load_sprite("space", False) self.clock = pygame.time.Clock() self.font = pygame.font.Font(None, 64) self.message = "" self.asteroids = [] self.bullets = [] self.spaceship = Spaceship((400, 300), self.bullets.append) for _ in range(6): while True: position = get_random_position(self.screen) if ( position.distance_to(self.spaceship.position) > self.MIN_ASTEROID_DISTANCE ): break self.asteroids.append(Asteroid(position, self.asteroids.append))
Font类的构造函数有两个参数:
- 字体文件的名称,其中
None表示将使用默认字体- 以像素为单位的字体大小
需要正确设置消息的内容。当飞船被摧毁后,将其设置为
"You lost!"。当所有小行星被摧毁后,将其设置为"You won!"。编辑SpaceRocks类的_process_game_logic()方法:def _process_game_logic(self): for game_object in self._get_game_objects(): game_object.move(self.screen) if self.spaceship: for asteroid in self.asteroids: if asteroid.collides_with(self.spaceship): self.spaceship = None self.message = "You lost!" break for bullet in self.bullets[:]: for asteroid in self.asteroids[:]: if asteroid.collides_with(bullet): self.asteroids.remove(asteroid) self.bullets.remove(bullet) asteroid.split() break for bullet in self.bullets[:]: if not self.screen.get_rect().collidepoint(bullet.position): self.bullets.remove(bullet) if not self.asteroids and self.spaceship: self.message = "You won!"你需要做的最后一件事就是在屏幕上显示消息。更新
SpaceRocks类的_draw()方法:def _draw(self): self.screen.blit(self.background, (0, 0)) for game_object in self._get_game_objects(): game_object.draw(self.screen) if self.message: print_text(self.screen, self.message, self.font) pygame.display.flip() self.clock.tick(60)继续测试它。开始游戏,让飞船撞上小行星:
游戏正确显示了消息
You lost!。现在再加把劲,努力摧毁所有的小行星。如果您成功做到了这一点,那么您应该会看到一个胜利屏幕:
在这一步,你已经学会了如何在屏幕上显示文本信息。这是本教程的最后一步。你的游戏现在完成了!
结论
恭喜你,你刚刚用 Python 构建了小行星游戏的克隆版!有了 Pygame,你的 Python 知识可以直接转化到游戏开发项目中。
在本教程中,您已经学会了如何:
- 加载图像并在屏幕上显示
- 将输入处理添加到游戏中
- 用 Python 实现游戏逻辑和碰撞检测
- 播放声音
- 在屏幕上显示文本
您经历了设计游戏、构建文件、导入和使用资源以及编写逻辑代码的整个过程。你可以将所有的知识用于你所有令人惊叹的未来项目!
单击下面的链接下载该项目的代码,并跟随您构建游戏:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Python 和 Pygame 构建一个小行星游戏。
接下来的步骤
你的 Python 小行星游戏已经完成了,但是你还可以添加很多特性。以下是一些让你开始的想法:
- 限制飞船的最大速度。
- 小行星被摧毁时播放声音。
- 给飞船加一个护盾,让它在一次碰撞中幸存下来。
- 记录最高分。
- 让子弹也摧毁宇宙飞船,并把它们包裹在屏幕上,让游戏变得更加困难!
你还能想出什么其他的主意来扩展这个项目?要有创意,要有乐趣!在这种情况下,正如他们所说,空间是极限😃
如果你有兴趣学习更多关于 Python 游戏开发的知识,这里有一些额外的资源:
- PyGame:Python 游戏编程入门:这篇文章更详细地解释了 py Game。
- Arcade:Python 游戏框架的初级读本:这篇文章介绍了 Arcade,这是 Python 开发者的另一个游戏框架。
- Pygame 项目列表:这个网站展示了很多可以作为灵感的 Pygame 项目。
- Pygame 文档:在这里你可以找到更多的教程和 Pygame 内部工作原理的详细解释。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Pygame 用 Python 构建一个小行星游戏*********
Python 中的异步 IO:完整演练
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 动手 Python 3 并发与 asyncio 模块
Async IO 是一种并发编程设计,在 Python 中得到了专门的支持,从 Python 3.4 到 3.7 发展迅速,可能会超过。
你可能会恐惧地想,“并发、并行、线程、多处理。已经有很多东西需要理解了。异步 IO 适用于哪里?”
本教程旨在帮助您回答这个问题,让您更牢固地掌握 Python 的异步 IO 方法。
以下是你将要报道的内容:
异步 IO (async IO) :一种与语言无关的范例(模型),在许多编程语言中都有实现
async/await:两个新的 Python 关键字,用于定义协程
asyncio:为运行和管理协程提供基础和 API 的 Python 包协同程序(专门的生成器函数)是 Python 中异步 IO 的核心,我们稍后将深入研究它们。
注意:在本文中,我使用术语异步 IO 来表示异步 IO 的语言无关设计,而
asyncio指的是 Python 包。在你开始之前,你需要确保你已经设置好使用本教程中的
asyncio和其他库。免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
设置您的环境
您需要 Python 3.7 或更高版本来完整地理解本文,以及
aiohttp和aiofiles包:$ python3.7 -m venv ./py37async $ source ./py37async/bin/activate # Windows: .\py37async\Scripts\activate.bat $ pip install --upgrade pip aiohttp aiofiles # Optional: aiodns要获得安装 Python 3.7 和设置虚拟环境的帮助,请查看 Python 3 安装&设置指南或虚拟环境入门。
就这样,让我们开始吧。
异步 IO 的 10,000 英尺视角
异步 IO 比它久经考验的表亲多处理和线程更少为人所知。这一节将让您更全面地了解什么是异步 IO,以及它如何适应周围的环境。
异步 IO 适合在哪里?
并发性和并行性是不容易深入的扩展主题。虽然本文主要关注异步 IO 及其在 Python 中的实现,但还是有必要花一点时间将异步 IO 与其同类产品进行比较,以便了解异步 IO 如何融入更大的、有时令人眼花缭乱的难题。
并行包括同时执行多个操作。多处理是一种实现并行的方法,它需要将任务分散到计算机的中央处理单元(CPU 或内核)上。多重处理非常适合 CPU 受限的任务:紧密绑定的
for循环和数学计算通常属于这一类。并发是一个比并行稍微宽泛的术语。这表明多个任务能够以重叠的方式运行。(有一种说法是并发并不意味着并行。)
线程化是一种并发执行模式,多个线程轮流执行任务。一个进程可以包含多个线程。由于其 GIL ,Python 与线程有着复杂的关系,但这超出了本文的范围。
关于线程,重要的是要知道它更适合 IO 绑定的任务。虽然 CPU 绑定的任务的特点是计算机的内核从头到尾不断努力工作,但 IO 绑定的任务主要是等待输入/输出完成。
综上所述,并发性包括多处理(适用于 CPU 受限的任务)和线程(适用于 IO 受限的任务)。多处理是并行的一种形式,并行是并发的一种特定类型(子集)。Python 标准库通过其
multiprocessing、threading和concurrent.futures包为这两个提供了长期的支持。现在是时候引入一个新成员了。在过去的几年里,一个独立的设计已经被更全面地构建到 CPython 中:异步 IO,通过标准库的
asyncio包和新的async和await语言关键字来实现。需要明确的是,异步 IO 并不是一个新发明的概念,它已经存在或者正在构建到其他语言和运行时环境中,比如 Go 、 C# 或者 Scala 。Python 文档称
asyncio包为编写并发代码的库。但是,异步 IO 不是线程化的,也不是多处理的。它不是建立在这两者之上的。事实上,async IO 是一个单线程、单进程设计:它使用协作多任务,这个术语将在本教程结束时变得更加具体。换句话说,尽管在单个进程中使用单个线程,异步 IO 给人一种并发的感觉。协同程序(异步 IO 的一个核心特性)可以被并发调度,但是它们本身并不是并发的。
重申一下,异步 IO 是并发编程的一种风格,但不是并行。与多处理相比,它与线程更紧密地结合在一起,但与这两者又有很大的不同,它是并发技术中的一个独立成员。
还剩下一个任期。什么东西异步是什么意思?这不是一个严格的定义,但是对于我们这里的目的,我可以想到两个属性:
- 异步例程能够在等待最终结果时“暂停”,同时让其他例程运行。
- 异步代码,通过上述机制,方便并发执行。换句话说,异步代码提供了并发的外观和感觉。
这里有一个图表,把所有这些放在一起。白色术语代表概念,绿色术语代表实现或影响概念的方式:
我将在这里停止并发编程模型之间的比较。本教程的重点是异步 IO 的子组件,如何使用它,以及围绕它涌现的API。要深入探究线程、多处理和异步 IO,请在这里暂停一下,看看吉姆·安德森的关于 Python 中并发性的概述。吉姆比我有趣得多,而且参加的会议也比我多。
异步 IO 解释
异步 IO 初看起来似乎违反直觉,自相矛盾。促进并发代码的东西是如何使用单线程和单 CPU 核的?我从来不擅长编造例子,所以我想借用米格尔·格林伯格 2017 年 PyCon 演讲中的一句话,它非常漂亮地解释了一切:
国际象棋大师朱迪特·波尔加主持了一场国际象棋展览,她在展览中与多名业余棋手对弈。她有两种方式进行展览:同步和异步。
假设:
- 24 名反对者
- Judit 使每一步棋在 5 秒内移动
- 每个对手需要 55 秒来移动
- 游戏平均 30 对棋(总共 60 步)
同步版 : Judit 一次玩一个游戏,从不同时玩两个,直到游戏完成。每局游戏花费 (55 + 5) * 30 == 1800 秒,即 30 分钟。整个展览需要 24 * 30 == 720 分钟,或者 12 个小时。
异步版 : Judit 从一张桌子移动到另一张桌子,每张桌子移动一次。她离开桌子,让对手在等待时间内进行下一步行动。所有 24 个游戏中的一步棋需要 Judit 24 * 5 == 120 秒,或者 2 分钟。整个展览现在被缩短到 120 * 30 == 3600 秒,或者仅仅 1 小时。(来源)
世界上只有一个朱迪特·波尔加,她只有两只手,一次只能自己做一个动作。但是异步播放将表演时间从 12 小时减少到 1 小时。因此,协作多任务是一种奇特的说法,即程序的事件循环(稍后将详细介绍)与多个任务通信,让每个任务在最佳时间轮流运行。
异步 IO 需要很长的等待时间,否则功能会被阻塞,并允许其他功能在停机期间运行。(一个有效阻塞的函数从它启动的时候到它返回的时候禁止其他函数运行。)
异步 IO 不容易
我听人说过,“能使用异步 IO 就使用异步 IO;必要时使用线程。”事实是,构建持久的多线程代码可能很难,而且容易出错。异步 IO 避免了线程设计中可能遇到的一些潜在的速度障碍。
但这并不是说 Python 中的异步 IO 很容易。注意:当你冒险深入到表面以下时,异步编程也会变得很困难!Python 的异步模型是围绕回调、事件、传输、协议和未来等概念构建的——仅仅是术语就令人生畏。事实上,它的 API 一直在不断变化,这使得它并不容易。
幸运的是,
asyncio已经发展成熟,它的大部分特性都不再是临时的,同时它的文档也有了很大的改进,一些关于这个主题的优质资源也开始出现。
asyncio包和async/await包和现在您已经有了一些异步 IO 设计的背景知识,让我们来探索 Python 的实现。Python 的
asyncio包(在 Python 3.4 中引入)和它的两个关键字async和await,服务于不同的目的,但是一起帮助你声明、构建、执行和管理异步代码。
async/await语法和本地协程一句忠告:小心你在互联网上读到的东西。Python 的异步 IO API 从 Python 3.4 到 Python 3.7 发展迅速。一些旧的模式不再被使用,一些最初被禁止的东西现在通过新的引入被允许了。
异步 IO 的核心是协程。协程是 Python 生成器函数的特殊版本。让我们从一个基线定义开始,然后在此基础上继续发展:协程是一个可以在到达
return之前暂停执行的函数,它可以在一段时间内将控制权间接传递给另一个协程。稍后,您将更深入地研究如何将传统的生成器改造成协程。目前,了解协程如何工作的最简单方法是开始制作一些。
让我们采用沉浸式方法,编写一些异步 IO 代码。这个简短的程序是异步 IO 的
Hello World,但对阐明其核心功能大有帮助:#!/usr/bin/env python3 # countasync.py import asyncio async def count(): print("One") await asyncio.sleep(1) print("Two") async def main(): await asyncio.gather(count(), count(), count()) if __name__ == "__main__": import time s = time.perf_counter() asyncio.run(main()) elapsed = time.perf_counter() - s print(f"{__file__} executed in {elapsed:0.2f} seconds.")当您执行这个文件时,请注意与仅用
def和time.sleep()来定义函数相比看起来有什么不同:$ python3 countasync.py One One One Two Two Two countasync.py executed in 1.01 seconds.该输出的顺序是异步 IO 的核心。与每个对
count()的调用对话是一个单一的事件循环,或协调器。当每个任务到达await asyncio.sleep(1)时,该函数对事件循环大喊,并把控制权交还给它,说:“我要睡一秒钟。去吧,同时让其他有意义的事情去做。”与同步版本相比:
#!/usr/bin/env python3 # countsync.py import time def count(): print("One") time.sleep(1) print("Two") def main(): for _ in range(3): count() if __name__ == "__main__": s = time.perf_counter() main() elapsed = time.perf_counter() - s print(f"{__file__} executed in {elapsed:0.2f} seconds.")执行时,顺序和执行时间会有微小但关键的变化:
$ python3 countsync.py One Two One Two One Two countsync.py executed in 3.01 seconds.虽然使用
time.sleep()和asyncio.sleep()可能看起来很老套,但它们被用作任何涉及等待时间的时间密集型流程的替身。(你能等待的最平凡的事情就是一个基本上什么也不做的sleep()电话。)也就是说,time.sleep()可以代表任何耗时的阻塞函数调用,而asyncio.sleep()则用于代表非阻塞调用(但也需要一些时间来完成)。正如您将在下一节看到的,等待某事(包括
asyncio.sleep())的好处是周围的函数可以暂时将控制权让给另一个更容易立即做某事的函数。相比之下,time.sleep()或任何其他阻塞调用都与异步 Python 代码不兼容,因为它会在休眠时间内停止其轨道上的所有东西。异步 IO 的规则
至此,
async、await的更正式定义以及它们创建的协程函数已经就绪。这一部分有点难懂,但是掌握async/await是很有用的,所以如果你需要的话可以回到这一部分:
语法
async def引入了一个本地协程或者一个异步生成器。表达式async with和async for也是有效的,稍后你会看到它们。关键字
await将函数控制传递回事件循环。(它暂停周围协程的执行。)如果 Python 在g()的范围内遇到了一个await f()表达式,这就是await告诉事件循环的方式,“暂停g()的执行,直到我所等待的东西——即f()的结果——被返回。与此同时,让其他事情去运行。”在代码中,第二个要点大致如下:
async def g(): # Pause here and come back to g() when f() is ready r = await f() return r关于何时以及如何使用
async/await,也有一套严格的规则。不管你是还在学习语法还是已经接触过使用async/await,这些都会很方便:
用
async def引入的函数是协程。它可以使用await、return或yield,但所有这些都是可选的。宣布async def noop(): pass有效:
使用
await和/或return创建一个协程函数。要调用一个协程函数,你必须await它以得到它的结果。在
async def块中使用yield不太常见(在 Python 中最近才合法)。这就创建了一个异步生成器,用async for对其进行迭代。暂时忘掉异步生成器,把注意力集中在协程函数的语法上,协程函数使用了await和/或return。任何用
async def定义的东西都不可以用yield from,这样会引出一个SyntaxError。就像在
def函数外使用yield是一个SyntaxError,在async def协程外使用await是一个SyntaxError。您只能在协程程序体中使用await。以下是一些简短的例子,旨在总结上述几条规则:
async def f(x): y = await z(x) # OK - `await` and `return` allowed in coroutines return y async def g(x): yield x # OK - this is an async generator async def m(x): yield from gen(x) # No - SyntaxError def m(x): y = await z(x) # Still no - SyntaxError (no `async def` here) return y最后,当你使用
await f()时,要求f()是一个可以被激活的对象。嗯,这不是很有帮助,是吗?现在,只需要知道一个可修改的对象要么是(1)另一个协程,要么是(2)定义一个返回迭代器的.__await__()dunder 方法的对象。如果你正在编写一个程序,对于大多数目的来说,你应该只需要担心第一种情况。这又给我们带来了一个你可能会看到的技术区别:将函数标记为协程的一个老方法是用
@asyncio.coroutine来修饰一个普通的def函数。结果是一个基于生成器的协程。自从在 Python 3.5 中使用了async/await语法以来,这种结构已经过时了。这两个协程本质上是等价的(都是可调度的),但是第一个是基于生成器的,而第二个是一个本地协程:
import asyncio @asyncio.coroutine def py34_coro(): """Generator-based coroutine, older syntax""" yield from stuff() async def py35_coro(): """Native coroutine, modern syntax""" await stuff()如果您自己编写任何代码,为了显式而不是隐式,最好使用本机协程。在 Python 3.10 中,基于生成器的协程将被移除。
在本教程的后半部分,出于解释的目的,我们将讨论基于生成器的协程。引入
async/await的原因是让协程成为 Python 的一个独立特性,可以很容易地与普通的生成器函数区分开来,从而减少模糊性。不要陷入基于生成器的协程,它们已经被
async/await故意淘汰。它们有自己的一套规则(例如,await不能用在基于生成器的协程中),如果你坚持使用async/await语法,这些规则在很大程度上是不相关的。事不宜迟,让我们看几个更复杂的例子。
这里有一个异步 IO 如何减少等待时间的例子:给定一个协程
makerandom(),它不断产生范围在[0,10]内的随机整数,直到其中一个超过一个阈值,您希望让这个协程的多个调用不需要依次等待对方完成。您可以大致遵循上面两个脚本的模式,稍作修改:#!/usr/bin/env python3 # rand.py import asyncio import random # ANSI colors c = ( "\033[0m", # End of color "\033[36m", # Cyan "\033[91m", # Red "\033[35m", # Magenta ) async def makerandom(idx: int, threshold: int = 6) -> int: print(c[idx + 1] + f"Initiated makerandom({idx}).") i = random.randint(0, 10) while i <= threshold: print(c[idx + 1] + f"makerandom({idx}) == {i} too low; retrying.") await asyncio.sleep(idx + 1) i = random.randint(0, 10) print(c[idx + 1] + f"---> Finished: makerandom({idx}) == {i}" + c[0]) return i async def main(): res = await asyncio.gather(*(makerandom(i, 10 - i - 1) for i in range(3))) return res if __name__ == "__main__": random.seed(444) r1, r2, r3 = asyncio.run(main()) print() print(f"r1: {r1}, r2: {r2}, r3: {r3}")彩色输出比我能说的多得多,并让您了解这个脚本是如何执行的:
rand.py execution 这个程序使用一个主协程
makerandom(),并在 3 个不同的输入上同时运行。大多数程序将包含小的、模块化的协程和一个包装函数,该包装函数用于将每个较小的协程链接在一起。main()然后用于通过将中央协程映射到一些可迭代的或池中来收集任务(未来)。在这个微型示例中,池是
range(3)。在后面给出的一个更完整的例子中,它是一组需要被并发请求、解析和处理的 URL,并且main()封装了每个 URL 的整个例程。虽然“生成随机整数”(这比任何事情都更受 CPU 限制)可能不是对
asyncio的最佳选择,但是示例中出现的asyncio.sleep()旨在模拟 IO 限制的进程,其中包含不确定的等待时间。例如,asyncio.sleep()调用可能代表在消息应用程序中的两个客户端之间发送和接收非随机整数。异步 IO 设计模式
Async IO 自带一套可能的脚本设计,本节将介绍这些设计。
链接协同程序
协程的一个关键特性是它们可以链接在一起。(记住,一个协程对象是可调度的,所以另一个协程可以
await它。)这允许您将程序分成更小的、可管理的、可回收的协程:#!/usr/bin/env python3 # chained.py import asyncio import random import time async def part1(n: int) -> str: i = random.randint(0, 10) print(f"part1({n}) sleeping for {i} seconds.") await asyncio.sleep(i) result = f"result{n}-1" print(f"Returning part1({n}) == {result}.") return result async def part2(n: int, arg: str) -> str: i = random.randint(0, 10) print(f"part2{n, arg} sleeping for {i} seconds.") await asyncio.sleep(i) result = f"result{n}-2 derived from {arg}" print(f"Returning part2{n, arg} == {result}.") return result async def chain(n: int) -> None: start = time.perf_counter() p1 = await part1(n) p2 = await part2(n, p1) end = time.perf_counter() - start print(f"-->Chained result{n} => {p2} (took {end:0.2f} seconds).") async def main(*args): await asyncio.gather(*(chain(n) for n in args)) if __name__ == "__main__": import sys random.seed(444) args = [1, 2, 3] if len(sys.argv) == 1 else map(int, sys.argv[1:]) start = time.perf_counter() asyncio.run(main(*args)) end = time.perf_counter() - start print(f"Program finished in {end:0.2f} seconds.")请仔细注意输出,其中
part1()休眠的时间长短不一,当结果可用时part2()开始处理这些结果:$ python3 chained.py 9 6 3 part1(9) sleeping for 4 seconds. part1(6) sleeping for 4 seconds. part1(3) sleeping for 0 seconds. Returning part1(3) == result3-1. part2(3, 'result3-1') sleeping for 4 seconds. Returning part1(9) == result9-1. part2(9, 'result9-1') sleeping for 7 seconds. Returning part1(6) == result6-1. part2(6, 'result6-1') sleeping for 4 seconds. Returning part2(3, 'result3-1') == result3-2 derived from result3-1. -->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds). Returning part2(6, 'result6-1') == result6-2 derived from result6-1. -->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds). Returning part2(9, 'result9-1') == result9-2 derived from result9-1. -->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds). Program finished in 11.01 seconds.在这个设置中,
main()的运行时间将等于它收集和调度的任务的最大运行时间。使用队列
asyncio包提供了队列类,其设计类似于queue模块的类。在我们到目前为止的例子中,我们并不真正需要队列结构。在chained.py中,每个任务(未来)由一组协同程序组成,这些协同程序显式地相互等待,并通过每个链的单个输入。还有一种替代结构也可以用于异步 IO:许多相互不关联的生产者将项目添加到队列中。每个生产者可以在交错的、随机的、未通知的时间将多个项目添加到队列中。一群消费者贪婪地从排队的队伍中拉出商品,而不等待任何其他信号。
在这种设计中,没有任何单个消费者与生产者之间的链接。消费者事先不知道生产者的数量,甚至不知道将要添加到队列中的商品的累计数量。
单个生产者或消费者分别花费不同的时间从队列中放入和取出项目。队列作为一种吞吐量,可以与生产者和消费者进行通信,而不需要他们彼此直接对话。
注意:由于
queue.Queue()的线程安全,队列经常在线程化程序中使用,但是当涉及到异步 IO 时,你不需要关心线程安全。(例外情况是当您将两者结合时,但在本教程中不会这样做。)队列的一个用例(这里就是这样)是队列充当生产者和消费者的传输器,否则生产者和消费者不会直接链接或关联。
这个程序的同步版本看起来相当糟糕:一组阻塞生产者连续地向队列中添加项目,一次一个生产者。只有在所有生产者都完成之后,队列才能被一个消费者一次一个条目地处理。这种设计中有大量的延迟。项目可能会闲置在队列中,而不是被立即拾取和处理。
下面是一个异步版本
asyncq.py。这个工作流程的挑战部分是,需要给消费者一个信号,表明生产已经完成。否则,await q.get()将无限期地挂起,因为队列将被完全处理,但是消费者不会知道生产已经完成。(非常感谢 StackOverflow 用户帮助理顺
main():关键是await q.join(),它会阻塞,直到队列中的所有项目都被接收和处理,然后取消消费者任务,否则它会挂起,并无休止地等待更多队列项目出现。)以下是完整的脚本:
#!/usr/bin/env python3 # asyncq.py import asyncio import itertools as it import os import random import time async def makeitem(size: int = 5) -> str: return os.urandom(size).hex() async def randsleep(caller=None) -> None: i = random.randint(0, 10) if caller: print(f"{caller} sleeping for {i} seconds.") await asyncio.sleep(i) async def produce(name: int, q: asyncio.Queue) -> None: n = random.randint(0, 10) for _ in it.repeat(None, n): # Synchronous loop for each single producer await randsleep(caller=f"Producer {name}") i = await makeitem() t = time.perf_counter() await q.put((i, t)) print(f"Producer {name} added <{i}> to queue.") async def consume(name: int, q: asyncio.Queue) -> None: while True: await randsleep(caller=f"Consumer {name}") i, t = await q.get() now = time.perf_counter() print(f"Consumer {name} got element <{i}>" f" in {now-t:0.5f} seconds.") q.task_done() async def main(nprod: int, ncon: int): q = asyncio.Queue() producers = [asyncio.create_task(produce(n, q)) for n in range(nprod)] consumers = [asyncio.create_task(consume(n, q)) for n in range(ncon)] await asyncio.gather(*producers) await q.join() # Implicitly awaits consumers, too for c in consumers: c.cancel() if __name__ == "__main__": import argparse random.seed(444) parser = argparse.ArgumentParser() parser.add_argument("-p", "--nprod", type=int, default=5) parser.add_argument("-c", "--ncon", type=int, default=10) ns = parser.parse_args() start = time.perf_counter() asyncio.run(main(**ns.__dict__)) elapsed = time.perf_counter() - start print(f"Program completed in {elapsed:0.5f} seconds.")前几个协程是助手函数,返回一个随机字符串、一个小数秒性能计数器和一个随机整数。生产者将 1 到 5 个项目放入队列中。每个条目是一个
(i, t)的元组,其中i是一个随机字符串,t是生产者试图将元组放入队列的时间。当消费者取出一个商品时,它只是使用商品被放入时的时间戳来计算该商品在队列中停留的时间。
请记住,
asyncio.sleep()是用来模仿其他一些更复杂的协程,如果它是一个常规的阻塞函数,那么它会耗尽时间并阻塞所有其他的执行。下面是两个生产者和五个消费者的测试运行:
$ python3 asyncq.py -p 2 -c 5 Producer 0 sleeping for 3 seconds. Producer 1 sleeping for 3 seconds. Consumer 0 sleeping for 4 seconds. Consumer 1 sleeping for 3 seconds. Consumer 2 sleeping for 3 seconds. Consumer 3 sleeping for 5 seconds. Consumer 4 sleeping for 4 seconds. Producer 0 added <377b1e8f82> to queue. Producer 0 sleeping for 5 seconds. Producer 1 added <413b8802f8> to queue. Consumer 1 got element <377b1e8f82> in 0.00013 seconds. Consumer 1 sleeping for 3 seconds. Consumer 2 got element <413b8802f8> in 0.00009 seconds. Consumer 2 sleeping for 4 seconds. Producer 0 added <06c055b3ab> to queue. Producer 0 sleeping for 1 seconds. Consumer 0 got element <06c055b3ab> in 0.00021 seconds. Consumer 0 sleeping for 4 seconds. Producer 0 added <17a8613276> to queue. Consumer 4 got element <17a8613276> in 0.00022 seconds. Consumer 4 sleeping for 5 seconds. Program completed in 9.00954 seconds.在这种情况下,项目的处理只需几分之一秒。延迟可能有两个原因:
- 标准,很大程度上不可避免的开销
- 当一个商品出现在队列中时,所有消费者都在睡觉的情况
至于第二个原因,幸运的是,扩展到成百上千的消费者是完全正常的。你用
python3 asyncq.py -p 5 -c 100应该没问题。这里的要点是,从理论上讲,您可以让不同系统上的不同用户控制生产者和消费者的管理,队列充当中心吞吐量。到目前为止,您已经看到了三个用
async和await定义的asyncio调用协程的相关例子。如果您没有完全理解或者只是想更深入地了解现代协程是如何在 Python 中出现的,那么您可以从下一节开始。异步 IO 在生成器中的根
前面,您看到了一个旧式的基于生成器的协程的例子,它已经被更显式的本机协程所淘汰。这个例子值得稍微修改一下再展示一下:
import asyncio @asyncio.coroutine def py34_coro(): """Generator-based coroutine""" # No need to build these yourself, but be aware of what they are s = yield from stuff() return s async def py35_coro(): """Native coroutine, modern syntax""" s = await stuff() return s async def stuff(): return 0x10, 0x20, 0x30作为一个实验,如果单独调用
py34_coro()或py35_coro(),而不调用await,或者不调用asyncio.run()或其他asyncio的“瓷器”函数,会发生什么?单独调用协程会返回一个协程对象:






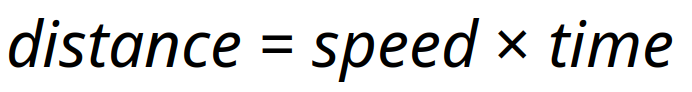







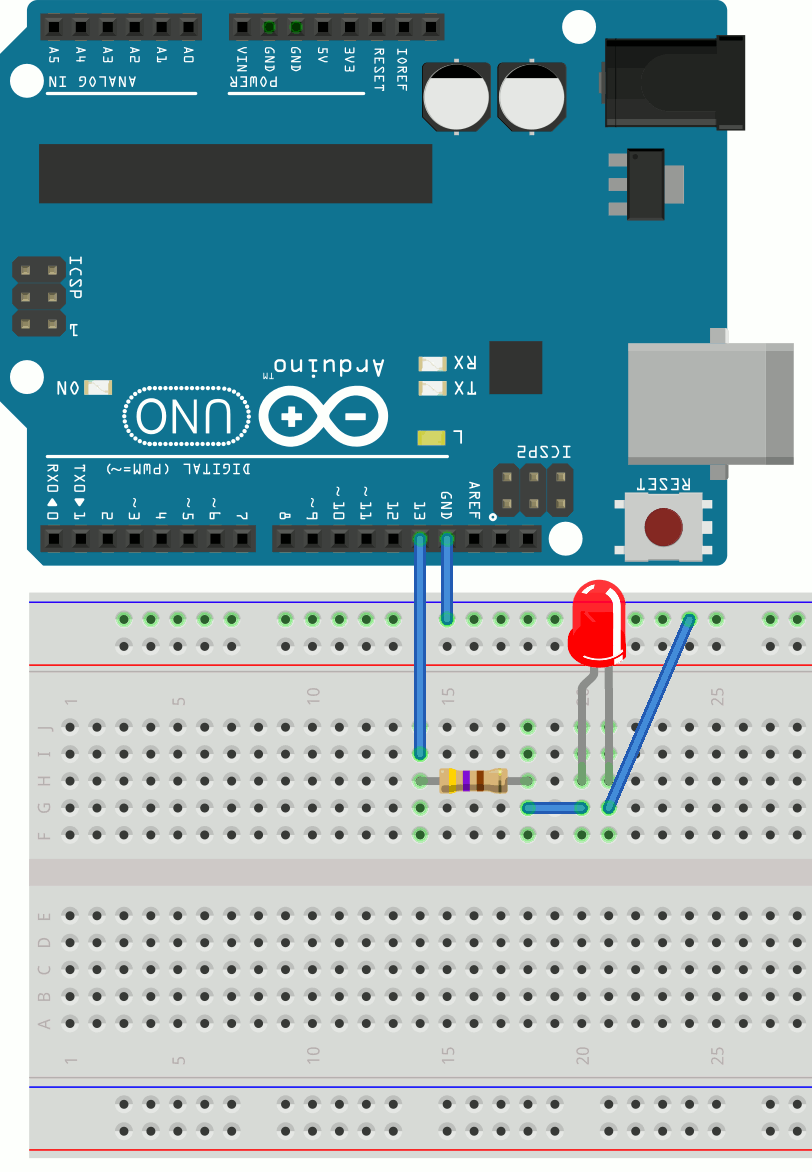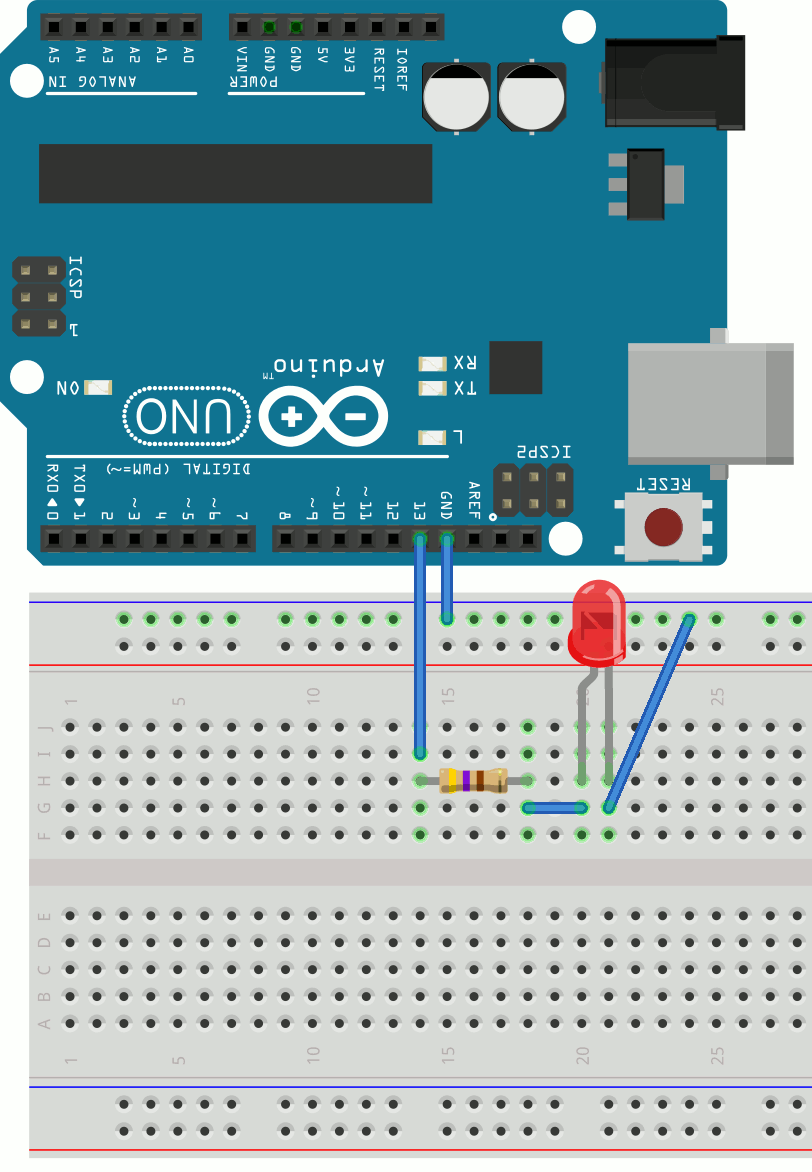







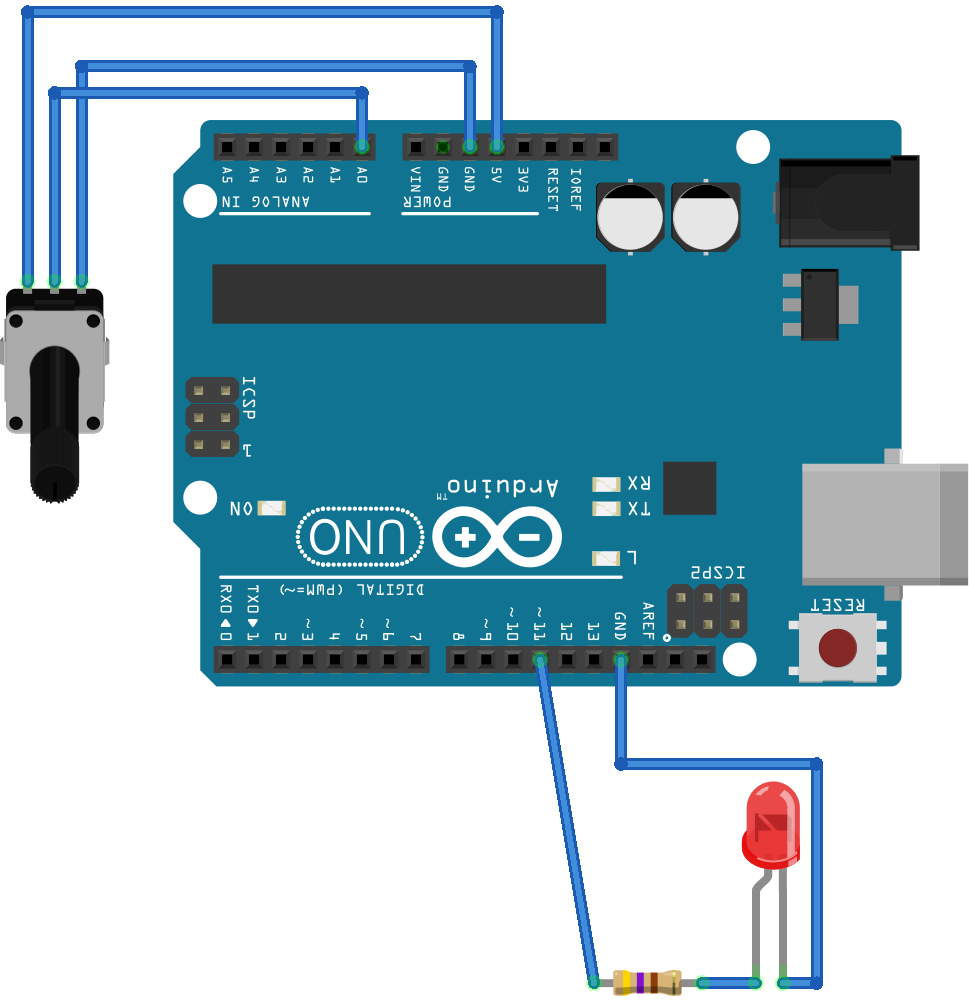


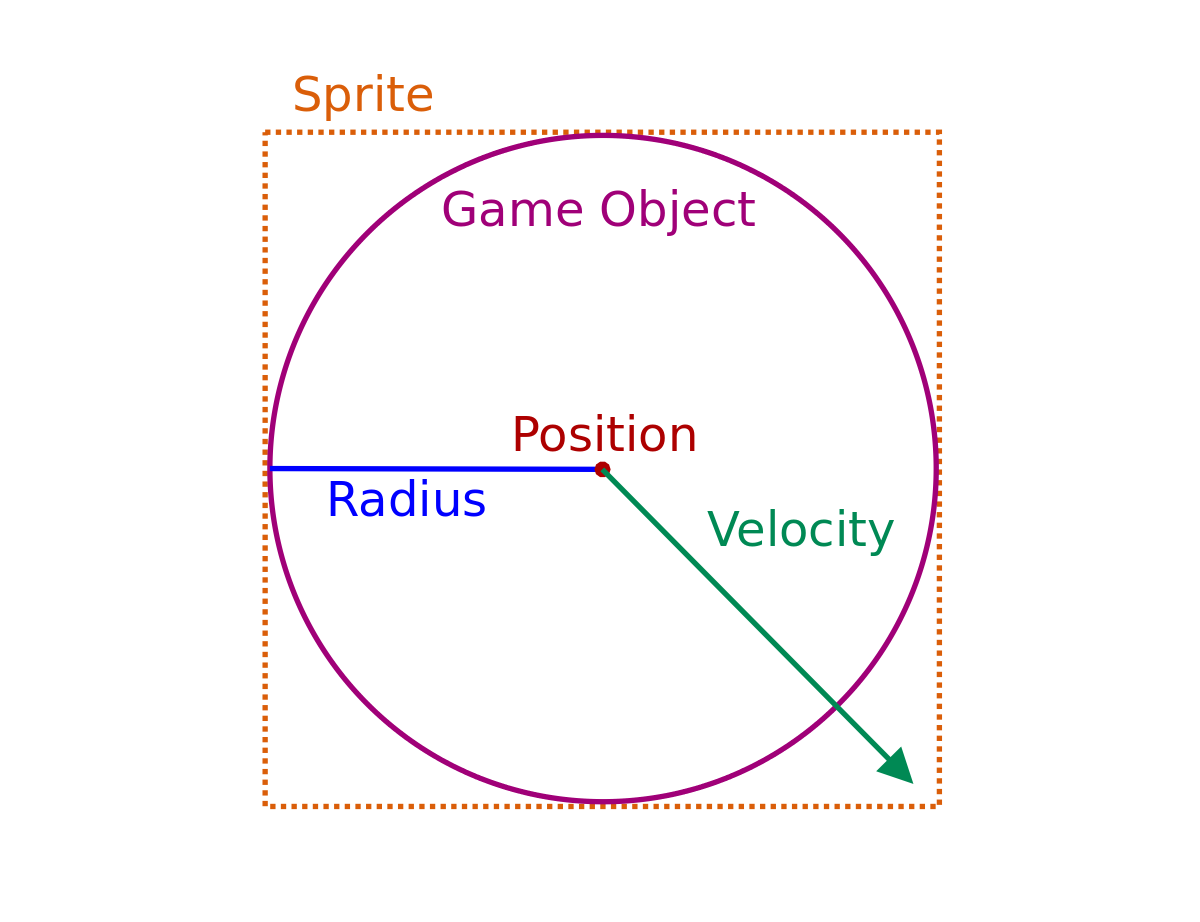

>>> py35_coro()
<coroutine object py35_coro at 0x10126dcc8>
从表面上看,这并不有趣。调用协程本身的结果是一个可唤醒的协程对象。
该做个小测验了:Python 还有什么类似的特性?(Python 的哪个特性在被单独调用时实际上并没有“做很多事情”?)
希望您正在考虑将生成器作为这个问题的答案,因为协程是幕后的增强生成器。在这方面,行为是相似的:
>>> def gen(): ... yield 0x10, 0x20, 0x30 ... >>> g = gen() >>> g # Nothing much happens - need to iterate with `.__next__()` <generator object gen at 0x1012705e8> >>> next(g) (16, 32, 48)碰巧的是,生成器函数是异步 IO 的基础(不管你是否用
async def而不是旧的@asyncio.coroutine包装器来声明协程)。从技术上来说,await更类似于yield from,而不是yield。(但是要记住yield from x()只是替换for i in x(): yield i的语法糖。)与异步 IO 相关的生成器的一个关键特性是它们可以有效地随意停止和重启。例如,您可以
break退出对一个生成器对象的迭代,然后在以后恢复对剩余值的迭代。当一个发生器函数到达yield时,它产生那个值,但之后它会一直闲置,直到被告知产生它的后续值。这可以通过一个例子来充实:
>>> from itertools import cycle
>>> def endless():
... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever"""
... yield from cycle((9, 8, 7, 6))
>>> e = endless()
>>> total = 0
>>> for i in e:
... if total < 30:
... print(i, end=" ")
... total += i
... else:
... print()
... # Pause execution. We can resume later.
... break
9 8 7 6 9 8 7 6 9 8 7 6 9 8
>>> # Resume
>>> next(e), next(e), next(e)
(6, 9, 8)
关键字await的行为类似,标记一个断点,在这个断点上协程挂起自己,让其他协程工作。“暂停”,在这种情况下,意味着协程已经暂时放弃控制,但没有完全退出或完成。请记住,yield以及延伸而来的yield from和await标志着生成器执行过程中的一个断点。
这是函数和生成器的根本区别。一个函数要么全有,要么全无。一旦开始,它就不会停止,直到碰到一个return,然后将那个值推送给调用者(调用它的函数)。另一方面,发电机每次碰到一个yield就暂停,不再前进。它不仅能把这个值推到调用栈,而且当你通过调用它的next()来恢复它时,它能保持对它的局部变量的控制。
发电机还有第二个不太为人所知的特性也很重要。您也可以通过生成器的.send()方法将值发送到生成器中。这允许生成器(和协程)在没有阻塞的情况下互相调用(await)。我不会深入研究这个特性的具体细节,因为它主要关系到后台协程的实现,但是您不应该真的需要自己直接使用它。
如果你有兴趣探索更多,你可以从正式引入协程的 PEP 342 开始。Brett Cannon 的在 Python 中 Async-Await 究竟是如何工作的也是一本好书,关于asyncio 的 PYMOTW 文章也是如此。最后,还有 David Beazley 的关于协程和并发性的好奇课程,它深入探究了协程运行的机制。
让我们试着把上面的文章浓缩成几句话:这些协程实际上是通过一种非常规的机制运行的。它们的结果是在调用它们的.send()方法时抛出的异常对象的属性。所有这些都有一些不可靠的细节,但它可能不会帮助您在实践中使用这部分语言,所以现在让我们继续。
为了把事情联系在一起,下面是关于协程作为生成器的一些要点:
-
协程是利用生成器方法特性的再利用生成器。
-
旧的基于生成器的协程使用
yield from来等待协程结果。本机协程中的现代 Python 语法只是用await代替了yield from,作为等待协程结果的方式。await类似于yield from,这样想通常会有所帮助。 -
使用
await是一个标志断点的信号。它让一个协程暂时中止执行,并允许程序稍后返回。
其他特性:async for和异步生成器+理解
除了普通的async / await,Python 还支持async for迭代异步迭代器。异步迭代器的目的是让它能够在迭代的每个阶段调用异步代码。
这个概念的自然延伸是一个异步发电机。回想一下,您可以在本机协程中使用await、return或yield。在 Python 3.6(通过 PEP 525)中,在协程中使用yield成为可能,它引入了异步生成器,目的是允许在同一个协程函数体中使用await和yield:
>>> async def mygen(u: int = 10): ... """Yield powers of 2.""" ... i = 0 ... while i < u: ... yield 2 ** i ... i += 1 ... await asyncio.sleep(0.1)最后但同样重要的是,Python 支持与
async for的异步理解。像它的同步表亲一样,这在很大程度上是语法上的糖:
>>> async def main():
... # This does *not* introduce concurrent execution
... # It is meant to show syntax only
... g = [i async for i in mygen()]
... f = [j async for j in mygen() if not (j // 3 % 5)]
... return g, f
...
>>> g, f = asyncio.run(main())
>>> g
[1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
>>> f
[1, 2, 16, 32, 256, 512]
这是一个至关重要的区别:异步生成器和理解都不会使迭代并发。它们所做的只是提供它们的同步对应物的外观和感觉,但是能够让正在讨论的循环放弃对事件循环的控制,让其他协程运行。
换句话说,异步迭代器和异步生成器并没有被设计成在一个序列或迭代器上同时映射一些函数。它们只是被设计成让封闭的协程允许其他任务轮流执行。只有在使用普通的for或with会“破坏”协程中await的性质的情况下,才需要async for和async with语句。异步和并发之间的区别是需要把握的关键。
事件循环asyncio.run()和
您可以将事件循环想象成类似于while True循环的东西,它监视协程,获取关于什么是空闲的反馈,并寻找可以同时执行的东西。当一个空闲的协程正在等待的东西变得可用时,它能够唤醒该协程。
到目前为止,事件循环的整个管理都是由一个函数调用隐式处理的:
asyncio.run(main()) # Python 3.7+
asyncio.run() ,Python 3.7 中引入,负责获取事件循环,运行任务直到它们被标记为完成,然后关闭事件循环。
使用get_event_loop()有一种更冗长的方式来管理asyncio事件循环。典型的模式如下所示:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.close()
在旧的例子中,您可能会看到loop.get_event_loop()浮动,但是除非您特别需要对事件循环管理进行微调控制,否则对于大多数程序来说,asyncio.run()应该足够了。
如果您确实需要在 Python 程序中与事件循环交互,loop是一个很好的老式 Python 对象,它支持用loop.is_running()和loop.is_closed()进行自省。如果需要更好的控制,你可以操纵它,比如在中,通过将循环作为参数传递来调度回调。
更重要的是理解事件循环背后的机制。关于事件循环,有几点值得强调。
#1: 协程在绑定到事件循环之前,不会自己做太多事情。
您之前在关于生成器的解释中已经看到了这一点,但是值得重申一下。如果您有一个等待其他人的主协程,简单地孤立地调用它没有什么效果:
>>> import asyncio >>> async def main(): ... print("Hello ...") ... await asyncio.sleep(1) ... print("World!") >>> routine = main() >>> routine <coroutine object main at 0x1027a6150>记住使用
asyncio.run()通过调度main()协程(未来对象)在事件循环上执行来实际强制执行:
>>> asyncio.run(routine)
Hello ...
World!
(其他协程可以用await执行。典型的做法是将main()包装在asyncio.run()中,从那里调用带有await的链式协同程序。)
#2: 默认情况下,异步 IO 事件循环在单个线程和单个 CPU 内核上运行。通常,在一个 CPU 内核中运行一个单线程事件循环就足够了。还可以跨多个内核运行事件循环。查看约翰·里斯在的演讲,注意你的笔记本电脑可能会自燃。
#3。事件循环是可插拔的。也就是说,如果您真的愿意,您可以编写自己的事件循环实现,并让它同样运行任务。这在 uvloop 包中得到了很好的演示,它是 Cython 中事件循环的一个实现。
这就是术语“可插拔事件循环”的含义:您可以使用事件循环的任何工作实现,与协程本身的结构无关。asyncio包本身附带了两个不同的事件循环实现,默认基于 selectors 模块。(第二个实现仅适用于 Windows。)
一个完整的程序:异步请求
你已经走到这一步了,现在是时候开始有趣和无痛的部分了。在本节中,您将使用aiohttp构建一个 web 抓取 URL 收集器areq.py,这是一个非常快速的异步 HTTP 客户端/服务器框架。(我们只需要客户端部分。)这样的工具可以用来绘制一组站点之间的连接,这些链接形成一个有向图。
注意:你可能想知道为什么 Python 的requests包与异步 IO 不兼容。requests构建在urllib3之上,后者又使用了 Python 的http和socket模块。
默认情况下,套接字操作是阻塞的。这意味着 Python 不会喜欢await requests.get(url),因为.get()不是可盈利的。相比之下,aiohttp里几乎所有的东西都是可感知的协程,比如session.request()response.text()。这是一个很棒的包,但是在异步代码中使用requests会给自己带来伤害。
高级程序结构将如下所示:
-
从本地文件中读取一系列 URL,
urls.txt。 -
发送对 URL 的 GET 请求并解码结果内容。如果失败,就在那里停下来找一个 URL。
-
在响应的 HTML 中搜索
href标签内的 URL。 -
将结果写入
foundurls.txt。 -
尽可能异步并发地完成以上所有工作。(使用
aiohttp进行请求,使用aiofiles进行文件追加。这是非常适合异步 IO 模型的两个主要 IO 示例。)
下面是urls.txt的内容。它并不大,主要包含高流量的网站:
$ cat urls.txt
https://regex101.com/
https://docs.python.org/3/this-url-will-404.html
https://www.nytimes.com/guides/
https://www.mediamatters.org/
https://1.1.1.1/
https://www.politico.com/tipsheets/morning-money
https://www.bloomberg.com/markets/economics
https://www.ietf.org/rfc/rfc2616.txt
列表中的第二个 URL 应该返回 404 响应,您需要优雅地处理它。如果你运行的是这个程序的扩展版本,你可能需要处理比这更棘手的问题,比如服务器断开和无休止的重定向。
请求本身应该使用单个会话,以利用会话内部连接池的重用。
让我们来看看完整的程序。我们将一步一步地完成以下工作:
#!/usr/bin/env python3
# areq.py
"""Asynchronously get links embedded in multiple pages' HMTL."""
import asyncio
import logging
import re
import sys
from typing import IO
import urllib.error
import urllib.parse
import aiofiles
import aiohttp
from aiohttp import ClientSession
logging.basicConfig(
format="%(asctime)s %(levelname)s:%(name)s: %(message)s",
level=logging.DEBUG,
datefmt="%H:%M:%S",
stream=sys.stderr,
)
logger = logging.getLogger("areq")
logging.getLogger("chardet.charsetprober").disabled = True
HREF_RE = re.compile(r'href="(.*?)"')
async def fetch_html(url: str, session: ClientSession, **kwargs) -> str:
"""GET request wrapper to fetch page HTML.
kwargs are passed to `session.request()`.
"""
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()
logger.info("Got response [%s] for URL: %s", resp.status, url)
html = await resp.text()
return html
async def parse(url: str, session: ClientSession, **kwargs) -> set:
"""Find HREFs in the HTML of `url`."""
found = set()
try:
html = await fetch_html(url=url, session=session, **kwargs)
except (
aiohttp.ClientError,
aiohttp.http_exceptions.HttpProcessingError,
) as e:
logger.error(
"aiohttp exception for %s [%s]: %s",
url,
getattr(e, "status", None),
getattr(e, "message", None),
)
return found
except Exception as e:
logger.exception(
"Non-aiohttp exception occured: %s", getattr(e, "__dict__", {})
)
return found
else:
for link in HREF_RE.findall(html):
try:
abslink = urllib.parse.urljoin(url, link)
except (urllib.error.URLError, ValueError):
logger.exception("Error parsing URL: %s", link)
pass
else:
found.add(abslink)
logger.info("Found %d links for %s", len(found), url)
return found
async def write_one(file: IO, url: str, **kwargs) -> None:
"""Write the found HREFs from `url` to `file`."""
res = await parse(url=url, **kwargs)
if not res:
return None
async with aiofiles.open(file, "a") as f:
for p in res:
await f.write(f"{url}\t{p}\n")
logger.info("Wrote results for source URL: %s", url)
async def bulk_crawl_and_write(file: IO, urls: set, **kwargs) -> None:
"""Crawl & write concurrently to `file` for multiple `urls`."""
async with ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
write_one(file=file, url=url, session=session, **kwargs)
)
await asyncio.gather(*tasks)
if __name__ == "__main__":
import pathlib
import sys
assert sys.version_info >= (3, 7), "Script requires Python 3.7+."
here = pathlib.Path(__file__).parent
with open(here.joinpath("urls.txt")) as infile:
urls = set(map(str.strip, infile))
outpath = here.joinpath("foundurls.txt")
with open(outpath, "w") as outfile:
outfile.write("source_url\tparsed_url\n")
asyncio.run(bulk_crawl_and_write(file=outpath, urls=urls))
这个脚本比我们最初的玩具程序要长,所以让我们来分解它。
常量HREF_RE是一个正则表达式来提取我们最终要搜索的内容,HTML 中的href标签:
>>> HREF_RE.search('Go to <a href="https://realpython.com/">Real Python</a>') <re.Match object; span=(15, 45), match='href="https://realpython.com/"'>协程
fetch_html()是一个 GET 请求的包装器,用于发出请求并解码结果页面 HTML。它发出请求,等待响应,并在非 200 状态的情况下立即引发:resp = await session.request(method="GET", url=url, **kwargs) resp.raise_for_status()如果状态正常,
fetch_html()返回页面 HTML (astr)。值得注意的是,这个函数中没有异常处理。逻辑是将该异常传播给调用者,并让它在那里得到处理:html = await resp.text()我们称之为
awaitsession.request()和resp.text()是因为它们是聪明的协程。否则,请求/响应周期将是应用程序中长尾的、占用时间的部分,但是有了异步 IO,fetch_html()让事件循环处理其他现成的工作,比如解析和写入已经获取的 URL。协程链中的下一个是
parse(),它在fetch_html()上等待一个给定的 URL,然后从该页面的 HTML 中提取所有的href标签,确保每个标签都是有效的,并将其格式化为一个绝对路径。不可否认的是,
parse()的第二部分是阻塞的,但是它包括一个快速的正则表达式匹配,并确保发现的链接成为绝对路径。在这种特定的情况下,这个同步代码应该快速且不显眼。但是请记住,给定协程中的任何一行都会阻塞其他协程,除非该行使用了
yield、await或return。如果解析是一个更密集的过程,您可能想考虑用loop.run_in_executor()在它自己的过程中运行这个部分。接下来,协程
write()获取一个文件对象和一个 URL,并等待parse()返回一个解析后的 URL 的set,通过使用aiofiles(一个用于异步文件 IO 的包)将每个 URL 与其源 URL 一起异步写入文件。最后,
bulk_crawl_and_write()作为脚本协程链的主要入口点。它使用单个会话,并为最终从urls.txt读取的每个 URL 创建一个任务。以下是值得一提的几点:
默认的
ClientSession有一个适配器,最多有 100 个开放连接。要改变这一点,可以将一个asyncio.connector.TCPConnector的实例传递给ClientSession。您还可以基于每个主机指定限制。您可以为整个会话和单个请求指定最大超时。
这个脚本还使用了
async with,它与一个异步上下文管理器一起工作。我没有用一整节的篇幅来介绍这个概念,因为从同步到异步上下文管理器的转换相当简单。后者必须定义.__aenter__()和.__aexit__(),而不是.__exit__()和.__enter__()。正如您所料,async with只能在用async def声明的协程函数中使用。如果你想了解更多,GitHub 上的本教程的伴随文件也附带了注释和文档字符串。
下面是执行的全部荣耀,因为
areq.py在不到一秒的时间内获取、解析和保存 9 个 URL 的结果:$ python3 areq.py 21:33:22 DEBUG:asyncio: Using selector: KqueueSelector 21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/ 21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/ 21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/ 21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money 21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt 21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found 21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/ 21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money 21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/ 21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt 21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/ 21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/ 21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money 21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics 21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics 21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics 21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/ 21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/ 21:33:23 INFO:areq: Found 23 links for https://regex101.com/ 21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/ 21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/那还不算太寒酸!作为健全性检查,您可以检查输出的行数。在我的例子中,它是 626,但请记住这可能会有波动:
$ wc -l foundurls.txt 626 foundurls.txt $ head -n 3 foundurls.txt source_url parsed_url https://www.bloomberg.com/markets/economics https://www.bloomberg.com/feedback https://www.bloomberg.com/markets/economics https://www.bloomberg.com/notices/tos下一步:如果你想提高赌注,让这个网络爬虫递归。您可以使用
aio-redis来跟踪树中哪些 URL 已经被抓取,以避免请求它们两次,并使用 Python 的networkx库连接链接。记得态度好一点。发送 1000 个并发请求到一个小的、没有戒心的网站是非常糟糕的。有一些方法可以限制一个批处理中并发请求的数量,比如使用
asyncio的 sempahore 对象,或者使用像这样的模式。如果您不注意这个警告,您可能会得到大量的TimeoutError异常,最终只会损害您自己的程序。上下文中的异步 IO
现在您已经看到了大量的代码,让我们退后一分钟,考虑一下什么时候异步 IO 是理想的选择,以及如何进行比较以得出结论,或者选择不同的并发模型。
何时以及为什么异步 IO 是正确的选择?
本教程不是一篇关于异步 IO、线程和多处理的长篇论文。然而,了解异步 IO 何时可能是三者中的最佳选择是很有用的。
异步 IO 与多处理之间的战争实际上根本不是一场战争。事实上,它们可以被用在演唱会上。如果你有多个相当一致的 CPU 受限任务(一个很好的例子是在库
scikit-learn或keras中的网格搜索,多处理应该是一个明显的选择。如果所有的函数都使用阻塞调用,那么简单地在每个函数前面放上
async并不是一个好主意。(这实际上会降低代码的速度。)但是如前所述,有些地方异步 IO 和多处理可以和谐共存。异步 IO 和线程之间的竞争更加直接。我在介绍中提到“线程很难。”完整的故事是,即使在线程似乎很容易实现的情况下,由于竞争条件和内存使用等原因,它仍然可能导致臭名昭著的无法跟踪的错误。
线程化的扩展性也不如异步 IO,因为线程是一种可用性有限的系统资源。创建数千个线程在很多机器上会失败,我不建议一开始就尝试。创建数千个异步 IO 任务是完全可行的。
当您有多个 IO 绑定任务时,异步 IO 会大放异彩,否则这些任务会受到阻塞 IO 绑定等待时间的支配,例如:
网络 IO,不管你的程序是服务器端还是客户端
无服务器设计,如点对点、多用户网络,如群组聊天室
在读/写操作中,您希望模仿“一劳永逸”的风格,但不太担心锁定您正在读取和写入的内容
不使用它的最大原因是
await只支持定义一组特定方法的一组特定对象。如果您想对某个 DBMS 进行异步读取操作,您不仅需要为该 DBMS 找到一个 Python 包装器,还需要找到一个支持async/await语法的包装器。包含同步调用的协同程序会阻止其他协同程序和任务运行。关于使用
async/await的库列表,请参见本教程末尾的列表。是异步 IO,但是是哪一个呢?
本教程关注异步 IO、
async/await语法,以及使用asyncio进行事件循环管理和指定任务。asyncio肯定不是唯一的异步 IO 库。Nathaniel J. Smith 的观察说明了很多问题:再过几年,
asyncio可能会发现自己沦为精明的开发人员避免使用的 stdlib 库之一,比如urllib2。…
实际上,我所争论的是
asyncio是它自身成功的受害者:当它被设计时,它使用了最好的方法;但从那以后,受asyncio启发的工作——比如增加了async/await——已经改变了局面,以便我们可以做得更好,而现在asyncio被它早先的承诺束缚住了手脚。(来源)为此,一些知名的替代产品做了
asyncio所做的事情,尽管使用不同的 API 和不同的方法,它们是curio和trio。就我个人而言,我认为如果你正在构建一个中等规模、简单明了的程序,仅仅使用asyncio就足够了,也是可以理解的,并且可以让你避免在 Python 的标准库之外添加另一个大的依赖项。但是无论如何,看看
curio和trio,你可能会发现它们以一种对用户来说更直观的方式完成了同样的事情。这里提出的许多与包无关的概念也应该渗透到可选的异步 IO 包中。零零碎碎的东西
在接下来的几个部分中,你将会涉及到
asyncio和async/await的一些杂七杂八的部分,这些部分到目前为止还没有完全融入到教程中,但是对于构建和理解一个完整的程序仍然很重要。其他顶级
asyncio功能除了
asyncio.run(),你已经看到了一些其他的包级函数,比如asyncio.create_task()和asyncio.gather()。您可以使用
create_task()来调度协程对象的执行,后面跟着asyncio.run():
>>> import asyncio
>>> async def coro(seq) -> list:
... """'IO' wait time is proportional to the max element."""
... await asyncio.sleep(max(seq))
... return list(reversed(seq))
...
>>> async def main():
... # This is a bit redundant in the case of one task
... # We could use `await coro([3, 2, 1])` on its own
... t = asyncio.create_task(coro([3, 2, 1])) # Python 3.7+
... await t
... print(f't: type {type(t)}')
... print(f't done: {t.done()}')
...
>>> t = asyncio.run(main())
t: type <class '_asyncio.Task'>
t done: True
这种模式有一个微妙之处:如果你没有在main()内await t,它可能会在main()发出完成信号之前完成。因为asyncio.run(main()) 调用loop.run_until_complete(main()) ,事件循环只关心main()是否完成(没有await t出现),而不是在main()内创建的任务是否完成。没有await t,循环的其他任务将被取消,可能在它们完成之前。如果您需要获得当前待定任务的列表,您可以使用asyncio.Task.all_tasks()。
注意 : asyncio.create_task()是 Python 3.7 中引入的。在 Python 3.6 或更低版本中,用asyncio.ensure_future()代替create_task()。
另外,还有asyncio.gather()。虽然它没有做什么特别的事情,但是gather()的目的是将一组协程(未来)整齐地放入一个单一的未来中。结果,它返回一个单一的 future 对象,并且,如果您await asyncio.gather()并指定多个任务或协程,您将等待它们全部完成。(这与我们之前的例子中的queue.join()有些相似。)结果gather()将是输入的结果列表:
>>> import time >>> async def main(): ... t = asyncio.create_task(coro([3, 2, 1])) ... t2 = asyncio.create_task(coro([10, 5, 0])) # Python 3.7+ ... print('Start:', time.strftime('%X')) ... a = await asyncio.gather(t, t2) ... print('End:', time.strftime('%X')) # Should be 10 seconds ... print(f'Both tasks done: {all((t.done(), t2.done()))}') ... return a ... >>> a = asyncio.run(main()) Start: 16:20:11 End: 16:20:21 Both tasks done: True >>> a [[1, 2, 3], [0, 5, 10]]您可能已经注意到,
gather()等待您传递的 Futures 或 coroutines 的整个结果集。或者,您可以在asyncio.as_completed()上循环,按照任务完成的顺序获取任务。该函数返回一个迭代器,在任务完成时产生任务。下面,coro([3, 2, 1])的结果将在coro([10, 5, 0])完成之前可用,而gather()的情况并非如此:
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0]))
... print('Start:', time.strftime('%X'))
... for res in asyncio.as_completed((t, t2)):
... compl = await res
... print(f'res: {compl} completed at {time.strftime("%X")}')
... print('End:', time.strftime('%X'))
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
...
>>> a = asyncio.run(main())
Start: 09:49:07
res: [1, 2, 3] completed at 09:49:10
res: [0, 5, 10] completed at 09:49:17
End: 09:49:17
Both tasks done: True
最后,你可能还会看到asyncio.ensure_future()。您应该很少需要它,因为它是一个底层的管道 API,并且大部分被稍后介绍的create_task()所取代。
await的优先顺序
虽然它们的行为有些相似,但关键字await的优先级明显高于yield。这意味着,因为它被更紧密地绑定,所以在很多情况下,在yield from语句中需要括号,而在类似的await语句中不需要。更多信息,参见 PEP 492 中await表达式的示例。
结论
你现在可以使用async / await和基于它构建的库了。以下是你所学内容的回顾:
-
异步 IO 是一种与语言无关的模型,也是一种通过让协程相互间接通信来实现并发的方式
-
Python 新的
async和await关键字的细节,用于标记和定义协程 -
asyncio,提供运行和管理协程的 API 的 Python 包
资源
Python 版本细节
Python 中的异步 IO 发展迅速,很难跟踪什么时候出现了什么。这里列出了与asyncio相关的 Python 小版本变化和介绍:
-
3.3:
yield from表达式允许发电机委托。 -
3.4:
asyncio以临时 API 状态引入 Python 标准库中。 -
3.5:
async和await成为 Python 语法的一部分,用于表示和等待协程。它们还不是保留关键字。(你仍然可以定义名为async和await的函数或变量。) -
3.6:引入了异步生成器和异步理解。
asyncio的 API 被声明为稳定的而非临时的。 -
3.7:
async和await成为保留关键字。(它们不能用作标识符。)他们打算取代asyncio.coroutine()装潢师。asyncio.run()被引入到asyncio包中,在之外还有一堆其他的特性。
如果你想要安全(并且能够使用asyncio.run()),就使用 Python 3.7 或更高版本来获得全套特性。
文章
以下是额外资源的精选列表:
- 真正的 Python: 用并发加速你的 Python 程序
- 真正的 Python: 什么是 Python 全局解释器锁?
- CPython:
asyncio包来源 - Python 文档:数据模型>协程
- talk Python:Python 中的异步技术和例子
- Brett Cannon: 在 Python 3.5 中,Async-Await 到底是如何工作的?
- PYMOTW:
asyncio - A.杰西·德维斯和吉多·范·罗苏姆:一个带有异步协同程序的网络爬虫
- 安迪·皮尔斯:Python 协程的状态:
yield from - Nathaniel J. Smith: 关于后
async/await世界中异步 API 设计的一些想法 - 阿明·罗纳彻:我不懂 Python 的 Asyncio
- 安迪·巴兰:系列上
asyncio(四贴) - 堆栈溢出:
async-await函数中的 Pythonasyncio.semaphore - 耶雷·迪亚兹:
几个 Python 新特性部分更详细地解释了语言变化背后的动机:
- Python 3.3 的新特性 (
yield from和 PEP 380) - Python 3.6 的新特性 (PEP 525 & 530)
来自大卫·比兹利:
YouTube 会谈:
- 约翰·里斯——用 AsyncIO 和多处理技术思考 GIL 之外的世界——PyCon 2018
- 主题演讲 David Beazley -感兴趣的话题(Python Asyncio)
- David Beazley - Python 从头开始并发:直播!- PyCon 2015
- Raymond Hettinger,关于并发性的主题演讲,PyBay 2017
- 思考并发性,Python 核心开发人员 Raymond Hettinger
- Miguel Grinberg 异步 Python for the Complete 初学者 PyCon 2017
- Yury Selivanov asyn cait 和 asyncio 在 Python 3 6 及以后的 PyCon 2017
- 《异步中的恐惧和等待:通往协程之梦核心的野蛮之旅》
- 什么是异步,它是如何工作的,我应该在什么时候使用它?(2014 年 APAC PyCon)
相关 pep
| 精力 | 创建日期 |
|---|---|
| PEP 342–通过增强生成器的协同程序 | 2005-05 |
| PEP 380–委托给子发电机的语法 | 2009-02 |
| PEP 3153–异步 IO 支持 | 2011-05 |
| PEP 3156–异步 io 支持重启:“异步 IO”模块 | 2012-12 |
| PEP 492–具有异步和等待语法的协同程序 | 2015-04 |
| PEP 525–异步发电机 | 2016-07 |
| PEP 530–异步理解 | 2016-09 |
与async / await 一起工作的库
从 aio-libs :
aiohttp:异步 HTTP 客户端/服务器框架aioredis:异步 IO 重定向支持aiopg:异步 IO PostgreSQL 支持aiomcache:异步 IO memcached 客户端aiokafka:异步 IO Kafka 客户端aiozmq:异步 IO ZeroMQ 支持aiojobs:管理后台任务的作业调度器async_lru:简单的 LRU 缓存用于异步 IO
从 magicstack :
从其他主机:
trio:更友好的asyncio意在展示一种彻底简单的设计aiofiles:异步文件 IOasks:异步请求——类似 http 库asyncio-redis:异步 IO 重定向支持aioprocessing:集成multiprocessing模块和asyncioumongo:异步 IO MongoDB 客户端unsync:不同步asyncioaiostream:类似itertools,但异步
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 动手 Python 3 并发与 asyncio 模块*********
Django 和 Celery 的异步任务
原文:https://realpython.com/asynchronous-tasks-with-django-and-celery/
你已经构建了一个闪亮的 Django 应用程序,并希望将其发布给公众,但你担心应用程序工作流中的时间密集型任务。你不希望你的用户在浏览你的应用时有负面体验。你可以整合芹菜来帮助解决这个问题。
Celery 是 UNIX 系统的一个分布式任务队列。它允许您从 Python 应用程序中卸载工作。一旦你将芹菜整合到你的应用程序中,你就可以将时间密集型任务发送到芹菜的任务队列中。这样,当 Celery 在后台异步完成昂贵的操作时,您的 web 应用程序可以继续快速响应用户。
在本教程中,您将学习如何:
- 识别芹菜的有效用例
- 区分芹菜工和芹菜工
- 在 Django 项目中整合芹菜和 Redis
- 设置独立于 Django 应用运行的异步任务
- 重构 Django 代码,改为用芹菜运行任务
如果你以前从未在 Django 应用程序中使用过 Celery,或者如果你偷看了 Celery 的文档却找不到路,那么你就来对地方了。您将了解使用 Django 和 Celery 开始运行异步任务所需的一切。
您将把芹菜集成到现有的 Django 应用程序中。继续下载该应用程序的代码,这样您就可以继续学习了:
源代码: 点击此处下载源代码,您将使用它将芹菜集成到您的 Django 应用程序中。
Python 芹菜基础知识
Celery 是一个分布式任务队列,它可以收集、记录、调度和执行主程序之外的任务。
注意: Celery 在版本 4 中放弃了对 Windows 的支持,所以虽然你可能仍然能够让它在 Windows 上工作,但你最好使用不同的任务队列,比如 huey 或 Dramatiq 。
在本教程中,您将专注于在 UNIX 系统上使用 Celery,所以如果您试图在 Windows 上建立一个分布式任务队列,那么本教程可能不适合您。
为了从程序接收任务并将结果发送到后端,Celery 需要一个消息代理来进行通信。 Redis 和 RabbitMQ 是开发人员经常与芹菜一起使用的两个消息代理。
在本教程中,您将使用 Redis 作为消息代理。为了挑战你自己,你可以偏离指令,使用 RabbitMQ 作为消息代理。
如果您想跟踪任务运行的结果,那么您还需要建立一个结果后端数据库。
注意:将 Celery 连接到结果后端是可选的。一旦你指示 Celery 运行一个任务,不管你是否跟踪任务结果,它都会履行它的职责。
但是,记录所有任务的结果通常是有帮助的,尤其是当您将任务分配到多个队列时。为了持久保存任务结果的信息,您需要一个数据库后端。
您可以使用许多不同的数据库来跟踪芹菜任务的结果。在本教程中,您将使用 Redis 作为消息代理和结果后端。通过使用 Redis,您可以限制需要安装的依赖项,因为它可以承担两种角色。
在本教程的范围内,您不会对记录的任务结果做任何工作。但是,下一步,您可以使用 Redis 命令行界面(CLI)检查结果,或者将信息放入 Django 项目中的专用页面。
为什么要用芹菜?
大多数开发人员想开始使用芹菜有两个主要原因:
- 将工作从你的应用卸载到可以独立于你的应用运行的分布式进程
- 调度任务在特定时间执行,有时作为重复发生的事件
芹菜是这两种用例的绝佳选择。它将自己定义为“一个专注于实时处理的任务队列,同时还支持任务调度”( Source )。
尽管这两个功能都是芹菜的一部分,但它们通常是分开处理的:
- Celery workers 是在主服务上下文之外独立运行任务的工作进程。
- Celery beat 是一个调度器,协调何时运行任务。您也可以使用它来安排定期任务。
芹菜工是芹菜的主心骨。即使你的目标是使用 Celery beat 安排周期性任务,芹菜工人也会在计划的时间收到你的指令并处理它们。芹菜节拍为芹菜工人添加了一个基于时间的调度程序。
在本教程中,您将学习如何将 Celery 与 Django 集成在一起,使用 Celery workers 从应用程序的主执行线程中异步执行操作。
在本教程中,您不会使用 Celery beat 处理任务调度,但是一旦您理解了 Celery 任务的基本知识,您将能够使用 Celery beat 设置周期性任务。
你如何为你的 Django 应用程序利用芹菜?
芹菜不仅对 web 应用程序有用,而且在这种情况下也很受欢迎。这是因为您可以通过使用分布式任务队列(如 Celery)来有效地处理 web 开发中的一些日常情况:
-
电子邮件发送:您可能想要发送电子邮件验证、密码重置电子邮件或表单提交确认。发送电子邮件可能需要一段时间,会降低应用程序的速度,尤其是当它有很多用户时。
-
图像处理:您可能想要调整用户上传的头像图像的大小,或者对用户可以在您的平台上共享的所有图像应用一些编码。图像处理通常是一项资源密集型任务,会降低您的 web 应用程序的速度,主要是在您为大型用户社区提供服务的情况下。
-
文本处理:如果你允许用户向你的应用添加数据,那么你可能需要监控他们的输入。例如,您可能希望检查评论中的亵渎内容,或者将用户提交的文本翻译成不同的语言。在 web 应用程序的上下文中处理所有这些工作会显著降低性能。
-
API 调用和其他 web 请求:如果您需要发出 web 请求来提供您的应用程序所提供的服务,那么您很快就会遇到意想不到的等待时间。对于速率受限的 API 请求和其他任务来说都是如此,比如网络抓取。将这些请求交给不同的流程通常更好。
-
数据分析:处理数据是出了名的资源密集型。如果你的 web 应用程序为你的用户分析数据,如果你在 Django 中处理所有的工作,你会很快发现你的应用程序变得没有响应。
-
机器学习模型运行:与其他数据分析一样,等待机器学习操作的结果可能需要一段时间。不要让你的用户等待计算完成,你可以把这项工作交给 Celery,这样他们就可以继续浏览你的 web 应用,直到结果出来。
-
报告生成:如果你的应用程序允许用户根据他们提供的数据生成报告,你会注意到构建 PDF 文件并不是一蹴而就的。如果你让 Celery 在后台处理这个问题,而不是冻结你的 web 应用程序,直到报告可供下载,这会是一个更好的用户体验。
所有这些不同用例的主要设置都是相似的。一旦您理解了如何将计算密集型或时间密集型流程交给分布式任务队列,您就可以解放 Django 来处理 HTTP 请求-响应周期。
在本教程中,您将处理电子邮件发送场景。您将从 Django 同步处理电子邮件发送的项目开始。您将测试如何冻结您的 Django 应用程序。然后,您将学习如何将任务交给 Celery,以便体验如何让您的 web 应用程序响应更快。
将芹菜和姜戈融合在一起
既然您已经知道了什么是 Celery 以及它如何帮助您提高 web 应用程序的性能,那么是时候集成它了,这样您就可以使用 Celery 运行异步任务了。
您将专注于将 Celery 集成到现有的 Django 项目中。您将从一个精简的 Django 应用程序开始,该应用程序有一个最小的用例:收集用户反馈并发送一封电子邮件作为回复。
设置反馈应用程序
首先下载所提供的反馈应用程序的源代码:
源代码: 点击此处下载源代码,您将使用它将芹菜集成到您的 Django 应用程序中。
解压缩下载的文件并使用您的终端导航到source_code_initial/目录,在那里您应该看到一个标准的 Django 项目文件夹结构:
source_code_initial/
│
├── django_celery/
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
│
├── feedback/
│ │
│ ├── migrations/
│ │ └── __init__.py
│ │
│ ├── templates/
│ │ │
│ │ └── feedback/
│ │ ├── base.html
│ │ ├── feedback.html
│ │ └── success.html
│ │
│ │
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── forms.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ └── views.py
│
├── .gitignore
├── manage.py
└── requirements.txt
确认你在source_code_initial/里面,然后创建并激活一个虚拟环境:
$ python -m venv venv
$ source venv/bin/activate
(venv) $
一旦您的虚拟环境被激活,您就可以安装 Django:
(venv) $ python -m pip install django
通过运行迁移并启动开发服务器,完成 Django 应用程序的本地设置:
(venv) $ python manage.py migrate
(venv) $ python manage.py runserver
现在,您可以打开浏览器,导航至该应用的主页https://localhost:8000,一个友好的反馈表格将会出现:
然而,目前只有的反馈表看起来友好。继续填写表格并提交一些反馈。想象一下,您的 web 应用程序的一个用户会遇到这样的情况:
https://player.vimeo.com/video/728157481
按下提交按钮后,应用程序会冻结。您可以在浏览器选项卡中看到旋转的小旋转符号,但是页面没有响应,您仍然可以看到您输入到表单中的所有信息。
Django 处理表单并把你重定向到成功页面花费了太长的时间!
Django 冻结是因为它需要在处理下一个任务之前同步处理电子邮件发送请求,下一个任务是将用户重定向到成功页面。
对于来说,冻结这么长时间的原因是因为.send_email()中一个偷偷摸摸的time.sleep()调用,它模拟了一个可能与电子邮件发送相关的时间或工作密集型任务。
当然,在实际应用中,你不会通过让 Django 休眠来给你的代码增加更多的时间延迟。然而,不幸的是,无论你使用什么样的电子邮件服务,都会给你带来一些延迟。尤其是一旦你的应用程序开始为许多用户服务,你很快就会遇到限制。
注意:将time.sleep()通话替换为你在网络应用中为服务用户而需要执行的任何工作密集型流程。
您的 Django 应用程序不应该同步处理长时间运行的任务,因为这样做会损害您的应用程序的用户体验和整体有用性。
相反,您将学习如何将这项任务交给芹菜工人。芹菜工人可以把计算作为后台任务来处理,让你的用户继续心满意足地浏览你时髦的网络应用。
安装芹菜作为你的任务队列
既然你设置了反馈应用并感受到了电子邮件发送带来的延迟,你开始着手改善用户体验。
将 Celery 集成到 Django 应用程序中的第一步是将 Celery 包安装到虚拟环境中:
(venv) $ python -m pip install celery
然而,仅仅安装芹菜是不够的。如果您尝试运行任务队列,您会注意到 Celery 开始时似乎运行良好,但随后显示一条错误消息,指出 Celery 找不到消息代理:
(venv) $ python -m celery worker
[ERROR/MainProcess] consumer: Cannot connect to
⮑ amqp://guest:**@127.0.0.1:5672//: [Errno 61] Connection refused.
Trying again in 2.00 seconds... (1/100)
Celery 需要一个消息代理来与向任务队列发送任务的程序通信。没有代理,Celery 无法接收指令,这就是它不断尝试重新连接的原因。
注意:您可能会注意到芹菜尝试连接的目标中类似 URL 的语法。协议名amqp,代表高级消息队列协议,是 Celery 使用的消息协议。最著名的本地实现 AMQP 的项目是 RabbitMQ,但是 Redis 也可以使用该协议进行通信。
在使用 Celery 之前,您需要安装一个消息代理,并将一个项目定义为消息生产者。在您的情况下,生产者是您的 Django 应用程序,消息代理将是 Redis。
安装 Redis 作为您的芹菜经纪人和数据库后端
您需要一个消息代理,以便芹菜可以与您的任务生产者沟通。您将使用 Redis,因为 Redis 可以同时充当消息代理和数据库后端。
回到您的终端,在您的系统上安装 Redis:
(venv) $ sudo apt update
(venv) $ sudo apt install redis
(venv) $ brew install redis
要成功运行这个命令,您需要安装的 Homebrew。
安装完成后,您可以启动 Redis 服务器来确认一切正常。打开一个新的终端窗口来启动服务器:
$ redis-server
该窗口将是 Redis 的专用终端窗口。在本教程的剩余部分保持打开状态。
注意:运行redis-server启动 Redis 服务器。您将 Redis 作为一个独立于 Python 的进程运行,因此在启动它时不需要激活您的虚拟环境。
运行redis-server后,您的终端将显示 Redis 标识为 ASCII art,以及一些启动日志消息。最新的日志消息将告诉您 Redis 已经准备好接受连接。
要测试与 Redis 服务器的通信是否正常,请在另一个新的终端窗口中启动 Redis CLI:
$ redis-cli
一旦提示发生变化,可以输入ping并按下 Enter ,然后等待 Redis 的回答:
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
在用redis-cli启动 Redis CLI 后,您将单词ping发送到 Redis 服务器,服务器用权威的PONG进行响应。如果您得到了这个响应,那么您的 Redis 安装是成功的,芹菜将能够与 Redis 通信。
在进入下一步之前,通过按 Ctrl + C 退出 Redis CLI。
接下来,您需要一个 Python 客户机来与 Redis 接口。确认您在一个终端窗口中,其中您的虚拟环境仍然是活动的,然后安装 redis-py :
(venv) $ python -m pip install redis
这个命令不会在您的系统上安装 Redis,而只是提供了一个用于连接 Redis 的 Python 接口。
注意:你需要在你的系统上安装 Redis和 redis-py 在你的 Python 虚拟环境中,这样你就可以在你的 Python 程序中使用 Redis。
完成这两个安装后,您就成功地设置了消息代理。然而,你还没有把你的生产商和芹菜联系起来。
如果您现在尝试启动 Celery 并通过传递-A选项和您的 Django 应用程序名称(django_celery)来包含生产者应用程序名称,您将遇到另一个错误:
(venv) $ python -m celery -A django_celery worker
...
Error: Invalid value for '-A' / '--app':
Unable to load celery application.
Module 'django_celery' has no attribute 'celery'
到目前为止,您的分布式任务队列不能接收来自 Django 应用程序的消息,因为在您的 Django 项目中没有设置 Celery 应用程序。
在下一节中,您将向 Django 应用程序添加必要的代码,以便它可以作为芹菜的任务生成器。
将芹菜添加到 Django 项目中
最后一个难题是将 Django 应用程序作为消息生产者连接到您的任务队列。您将从提供的项目代码开始,所以如果您还没有这样做,请继续下载它:
源代码: 点击此处下载源代码,您将使用它将芹菜集成到您的 Django 应用程序中。
一旦您的计算机上有了项目代码,导航到django_celery管理应用程序文件夹并创建一个名为celery.py的新文件:
django_celery/
├── __init__.py
├── asgi.py
├── celery.py ├── settings.py
├── urls.py
└── wsgi.py
Celery 推荐使用该模块定义 Celery 应用实例。在您最喜欢的文本编辑器或 IDE 中打开文件,并添加必要的代码:
1# django_celery/celery.py
2
3import os
4from celery import Celery
5
6os.environ.setdefault("DJANGO_SETTINGS_MODULE", "django_celery.settings")
7app = Celery("django_celery")
8app.config_from_object("django.conf:settings", namespace="CELERY")
9app.autodiscover_tasks()
您只需要将这几行代码添加到文件中。请继续阅读,了解它们各自的功能:
-
第 3 行:你导入内置的
os模块,你可能从处理文件中熟悉这个模块。您将在第 6 行使用它来设置一个环境变量。 -
第 4 行:你从
celery包中导入Celery。您将在第 7 行使用它来创建您的芹菜应用程序实例。 -
第六行:你用。setdefault() of
os.environ以确保您的 Django 项目的settings.py模块可以通过"DJANGO_SETTINGS_MODULE"键访问。 -
第 7 行:您创建了 Celery 应用程序实例,并提供了主模块的名称作为参数。在您的 Django 应用程序的上下文中,主模块是包含
celery.py的 Django 应用程序,因此您通过了"django_celery"。 -
第 8 行:您将 Django 设置文件定义为芹菜的配置文件,并提供一个名称空间
"CELERY"。您需要为每个与 Celery 相关的配置变量预定义名称空间值,后面跟一个下划线(_)。您可以定义一个不同的设置文件,但是将芹菜配置保存在 Django 的设置文件中可以让您坚持在一个中心位置进行配置。 -
第 9 行:您告诉您的 Celery 应用程序实例自动查找 Django 项目的每个应用程序中的所有任务。只要你坚持使用可重用应用的结构,并在一个专用的
tasks.py模块中为一个应用定义所有的芹菜任务,这就行得通。稍后当您重构电子邮件发送代码时,您将为您的django_celery应用程序创建并填充这个文件。
设置好celery.py并尝试从settings.py文件中获取必要的芹菜设置后,接下来您将前往settings.py将这些设置条目添加到文件的底部:
# django_celery/settings.py
# ...
# Celery settings
CELERY_BROKER_URL = "redis://localhost:6379"
CELERY_RESULT_BACKEND = "redis://localhost:6379"
这两个条目为您的 Celery 应用程序实例提供了足够的信息,以知道向哪里发送消息以及在哪里记录结果。因为您使用 Redis 作为消息代理和数据库后端,所以两个 URL 指向同一个地址。
注意:这些 URL 也可以指向不同的服务器和服务。例如,您可以使用 RabbitMQ 作为您的消息代理,使用 Redis 作为您的结果后端:
CELERY_BROKER_URL = "amqp://myuser:mypassword@localhost:5672/myvhost"
CELERY_RESULT_BACKEND = "redis://localhost:6379"
当您在生产中运行应用程序时,您将用每个服务的生产位置替换这些 URL。
请注意这些设置变量开头的CELERY_名称空间。您需要添加这个,因为您在celery.py的第 8 行传递给app.config_from_object()的namespace="CELERY"参数。
至此,您已经基本完成了将芹菜集成到您的 web 应用程序中。最后添加到您的管理应用程序的__init__.py:
django_celery/
├── __init__.py ├── asgi.py
├── celery.py
├── settings.py
├── urls.py
└── wsgi.py
在文本编辑器中打开文件。在一个默认的 Django 项目中,每个 app 文件夹都有一个__init__.py文件,这有助于将其标记为一个模块。默认情况下,该文件为空,但是您可以添加代码来影响导入行为。
为了确保在启动 Django 时加载了芹菜应用程序,您应该将它添加到 __all__ :
# django_celery/__init__.py
from .celery import app as celery_app
__all__ = ("celery_app",)
在 Django startup 上加载 Celery 应用程序可以确保@shared_task decorator 正确使用它。在下一节中,您将了解更多关于@shared_task的内容。
是时候测试您的设置了!请记住,您正在设置的流程需要至少三个服务同时运行:
- 制作人:你的 Django 应用
- 消息代理:Redis 服务器
- 消费者:你的芹菜 app
因为您正在使用 Redis,所以您将获得数据库后端作为额外的好处,而无需运行另一个服务。
打开三个独立的终端窗口,并启动所有的程序,如果他们还没有运行。
在第一个窗口中使用 Django 的开发服务器提供您的 web 应用程序:
(venv) $ python manage.py runserver
然后在第二个终端窗口中启动 Redis 服务器,以防您之前停止了它:
$ redis-server
redis-server命令是三个命令中唯一一个可以在虚拟环境之外运行的命令,所以要确保您的虚拟环境在另外两个终端窗口中是活动的。
注意:如果 Redis 服务器仍然在后台运行,您可能会收到一个错误。如果是这种情况,那么你需要在执行redis-server之前调用 SHUTDOWN 。
最后,您现在也可以正确启动 Celery,而不会遇到错误消息:
(venv) $ python -m celery -A django_celery worker
当使用这个命令启动 Celery 时,您需要将包含 Celery 应用程序实例的模块名称"django_celery"提供给-A。
注意:虽然您在安装 Redis 之前运行 Celery 时看到的错误消息已经消失,但您可能仍然会看到与 Django 的DEBUG设置相关的警告。对于这个示例应用程序,您可以忽略这个警告,但是在将站点部署到生产环境之前,您应该总是将DEBUG设置为False 。
总之,您只需要向上述三个文件添加代码,就可以将 Celery 集成到您的 Django 应用程序中,并为处理异步任务做好准备。完成这个基本设置后,您就可以编写一个任务交给 Celery 了。
在下一节中,您将重构.send_email()来调用一个异步的 Celery 任务,而不是在 Django 中处理同步发送的电子邮件。
使用芹菜异步处理工作负载
您已经成功地安排了运行 Django、Redis 和 Celery 异步任务所需的拼图。但是现在,您还没有定义任何要传递给 Celery 的任务。
集成 Celery 和 Django 并将工作卸载到 Celery 的分布式任务队列的最后一步是将电子邮件发送功能重构到 Celery 任务中。
重温同步代码
此时,您的代码在forms.py的FeedbackForm的.send_email()中定义了电子邮件发送功能:
1# feedback/forms.py
2
3from time import sleep
4from django.core.mail import send_mail
5from django import forms
6
7class FeedbackForm(forms.Form):
8 email = forms.EmailField(label="Email Address")
9 message = forms.CharField(
10 label="Message", widget=forms.Textarea(attrs={"rows": 5})
11 )
12
13 def send_email(self): 14 """Sends an email when the feedback form has been submitted."""
15 sleep(20) # Simulate expensive operation(s) that freeze Django
16 send_mail(
17 "Your Feedback",
18 f"\t{self.cleaned_data['message']}\n\nThank you!",
19 "support@example.com",
20 [self.cleaned_data["email_address"]],
21 fail_silently=False,
22 )
您在第 13 行定义了.send_email()。该方法模拟了一个昂贵的操作,通过调用第 15 行的sleep()来冻结你的应用程序 20 秒。在第 16 到 22 行,您用 Django 在第 4 行导入的便利的 send_mail() 编写您要发送的电子邮件。
您还需要在成功提交表单时调用.send_email(),您可以在views.py的 .form_valid() 中设置它:
1# feedback/views.py
2
3from feedback.forms import FeedbackForm
4from django.views.generic.edit import FormView
5from django.views.generic.base import TemplateView
6
7class FeedbackFormView(FormView):
8 template_name = "feedback/feedback.html"
9 form_class = FeedbackForm
10 success_url = "/success/"
11
12 def form_valid(self, form): 13 form.send_email() 14 return super().form_valid(form)
15
16class SuccessView(TemplateView):
17 template_name = "feedback/success.html"
第 12 行定义了.form_valid(),当表单提交成功时,FeedbackFormView会自动调用它。在第 13 行,你最后调用.send_email()。
你的设置工作正常,但是由于模拟的昂贵操作,你的应用程序再次响应并允许用户继续浏览需要很长时间。是时候改变这种情况了,让芹菜按照自己的时间表处理邮件发送!
将代码重构为芹菜任务
为了让app.autodiscover_tasks()像描述的那样工作,您需要在 Django 项目的每个应用程序中的一个单独的tasks.py模块中定义您的芹菜任务。
注意:在这个例子中,你只有一个应用程序。较大的 Django 项目可能会有更多的应用程序。如果您坚持使用标准设置,那么您将为每个应用程序创建一个tasks.py文件,并将应用程序的芹菜任务存储在该文件中。
在您的feedback/应用程序中创建一个名为tasks.py的新文件:
feedback/
│
├── migrations/
│ └── __init__.py
│
├── templates/
│ │
│ └── feedback/
│ ├── base.html
│ ├── feedback.html
│ └── success.html
│
├── __init__.py
├── admin.py
├── apps.py
├── forms.py
├── models.py
├── tasks.py ├── tests.py
├── urls.py
└── views.py
在该文件中,您定义了一个新函数来处理电子邮件发送逻辑。从forms.py中的.send_mail()获取代码,并以此为基础在tasks.py中创建send_feedback_email_task():
1# feedback/tasks.py
2
3from time import sleep
4from django.core.mail import send_mail
5
6def send_feedback_email_task(email_address, message): 7 """Sends an email when the feedback form has been submitted."""
8 sleep(20) # Simulate expensive operation(s) that freeze Django
9 send_mail(
10 "Your Feedback",
11 f"\t{message}\n\nThank you!", 12 "support@example.com",
13 [email_address], 14 fail_silently=False,
15 )
不要忘记添加必要的导入,如第 3 行和第 4 行所示。
到目前为止,你主要是把.send_mail()的代码复制到send_feedback_email_task()里。您还通过在第 6 行添加两个参数对函数定义进行了编辑。您在第 11 行和第 13 行使用这些参数来替换您之前从.send_mail()中的.cleaned_data获取的值。这种改变是必要,因为您不能访问新函数中的实例属性。
除此之外,send_feedback_email_task()看起来和.send_email()一样。芹菜都还没涉足呢!
要将这个函数转换成芹菜任务,您需要做的就是用从celery导入的 @shared_task 来修饰它:
# feedback/tasks.py
from time import sleep
from django.core.mail import send_mail
from celery import shared_task
@shared_task() def send_feedback_email_task(email_address, message):
"""Sends an email when the feedback form has been submitted."""
sleep(20) # Simulate expensive operation(s) that freeze Django
send_mail(
"Your Feedback",
f"\t{message}\n\nThank you!",
"support@example.com",
[email_address],
fail_silently=False,
)
从celery导入shared_task()并用它装饰send_feedback_email_task()之后,你就完成了这个文件中必要的代码修改。
将任务交给 Celery 围绕着 Celery 的 Task类,你可以通过在你的函数定义中添加装饰者来创建任务。
如果你的生产者是一个 Django 应用程序,那么你会希望使用@shared_task装饰器来建立一个任务,这保持了你的应用程序的可重用性。
有了这些补充,您就完成了用 Celery 设置一个异步任务。您只需要在 web 应用程序代码中重构调用它的位置和方式。
回到forms.py,在那里你得到了发送电子邮件的代码,重构.send_email(),使它调用send_feedback_email_task():
1# feedback/forms.py
2
3# Removed: from time import sleep
4# Removed: from django.core.mail import send_mail
5from django import forms
6from feedback.tasks import send_feedback_email_task 7
8class FeedbackForm(forms.Form):
9 email = forms.EmailField(label="Email Address")
10 message = forms.CharField(
11 label="Message", widget=forms.Textarea(attrs={"rows": 5})
12 )
13
14 def send_email(self):
15 send_feedback_email_task.delay( 16 self.cleaned_data["email"], self.cleaned_data["message"] 17 )
您没有在.send_email()中处理邮件发送代码逻辑,而是将它移到了tasks.py中的send_feedback_email_task()。这一更改意味着您也可以删除第 3 行和第 4 行中过时的 import 语句。
您现在从第 6 行的feedback.tasks导入send_feedback_email_task()。
在第 15 行,您调用send_feedback_email_task()上的 .delay() ,并将从.cleaned_data获取的提交的表单数据作为第 16 行的参数传递给它。
注意:调用.delay()是给芹菜发送任务消息的最快方式。这个方法是更强大的 .apply_async() 的快捷方式,它额外支持执行选项来微调你的任务消息。
使用.apply_async(),您实现上述功能的调用会稍微冗长一些:
send_feedback_email_task.apply_async(args=[
self.cleaned_data["email"], self.cleaned_data["message"]
]
)
虽然在像这样简单的任务消息中,.delay()是更好的选择,但是使用.apply_async()您将从许多执行选项中受益,比如countdown和retry。
在tasks.py和forms.py中应用这些更改后,您就完成了重构!使用 Django 和 Celery 运行异步任务的主要工作在于设置,而不是您需要编写的实际代码。
但是这有用吗?电子邮件还会发出去吗?与此同时,你的 Django 应用程序还能保持响应吗?
测试您的异步任务
当您启动一个芹菜工人,它加载您的代码到内存中。当它通过您的消息代理接收到一个任务时,它将执行该代码。因此,每次更改代码时,都需要重新启动芹菜工作器。
注意:为了避免在开发过程中每次代码变更时手动重启你的芹菜工人,你可以使用看门狗或者通过编写定制管理命令来设置自动重新加载。
您创建了一个您之前启动的 worker 不知道的任务,因此您需要重新启动 worker。打开运行芹菜工人的终端窗口,按 Ctrl + C 停止执行。
然后使用您之前使用的相同命令重新启动 worker,并添加-l info以将日志级别设置为 info:
(venv) $ python -m celery -A django_celery worker -l info
将-l选项设置为info意味着您将看到更多信息打印到您的终端上。启动时,Celery 会在[tasks]部分显示它发现的所有任务:
[tasks]
. feedback.tasks.send_feedback_email_task
这个输出确认 Celery 已经注册了send_feedback_email_task(),并准备好处理与这个任务相关的传入消息。
随着所有服务的启动和运行以及为芹菜重构的代码,您已经准备好接替您的一个用户的工作,并再次尝试重构后的工作流:
https://player.vimeo.com/video/728157432?background=1
如果你现在在应用程序的主页上提交反馈表,你会很快被重定向到成功页面。耶!没有必要等待和建立任何挫折。您甚至可以返回反馈表,立即提交另一份回复。
但是在后端会发生什么呢?在您的同步示例中,您看到电子邮件消息出现在运行 Django 开发服务器的终端窗口中。这一次,它没有出现在那里——即使二十秒过去了。
相反,您会看到电子邮件文本出现在运行 Celery 的终端窗口中,旁边是关于处理任务的其他日志:
[INFO/MainProcess] celery@Martins-MBP.home ready.
[INFO/MainProcess] Task feedback.tasks.send_feedback_email_task ⮑ [a5054d64-5592-4347-be77-cefab994c2bd] received [WARNING/ForkPoolWorker-7] Content-Type: text/plain; charset="utf-8"
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
Subject: Your Feedback
From: support@example.com
To: martin@realpython.com
Date: Tue, 12 Jul 2025 14:49:23 -0000
Message-ID: <165763736314.3405.4812564479387463177@martins-mbp.home>
Great!
Thank you!
[WARNING/ForkPoolWorker-7] -----------------------------------------
[INFO/ForkPoolWorker-7] Task feedback.tasks.send_feedback_email_task ⮑ [a5054d64-5592-4347-be77-cefab994c2bd] succeeded in 20.078754458052572s: ⮑ None
因为您运行了带有日志级别信息(-l info)的 Celery worker,所以您可以阅读关于 Celery 端发生的事情的详细描述。
首先,您可能会注意到日志通知您收到了send_feedback_email_task。如果您在提交反馈响应后立即看到这个终端窗口,那么您会看到这个日志线立即打印出来。
在那之后,芹菜进入等待阶段,这是由之前冻结你的 Django 应用的sleep()调用引起的。虽然您可以立即继续使用 Django 应用程序,但 Celery 会在后台为您执行昂贵的计算。
20 秒后,Celery 将 Django 用send_mail()构建的虚拟邮件打印到终端窗口。然后它添加另一个日志条目,告诉您send_feedback_email_task成功了,花了多长时间(20.078754458052572s,以及它的返回值是什么(None)。
注意:请记住,在这个例子中,您的 Django 应用程序不会知道芹菜任务是否成功。那意味着谢谢你!你的读者看到的信息并不一定意味着该信息对你是安全的。因为您使用 Redis 设置了一个数据库后端,所以您可以查询该后端来确定任务运行是否成功。
由于 HTTP 是如何工作的,在前端通知用户一个后台任务是否已经成功完成并不是一个简单的任务。为此,你需要通过 Django 通道设置 AJAX 轮询或 WebSockets。
那很好!您的反馈似乎很快就被提交了,而且您不必经历任何令人沮丧的等待时间。
干得好!您成功地将 Celery 集成到 Django 应用程序中,并设置它处理异步任务。芹菜现在处理你的电子邮件发送和所有的开销作为后台任务。一旦电子邮件将任务指令传递给 Celery 的分布式任务队列,它就不需要关心你的 web 应用程序了。
结论
嗖!反馈已提交!
在您集成了 Celery 并重构了 Django 代码之后,在您的应用程序中发送反馈是如此美妙的体验,以至于您不想停止发送积极的反馈信息!
使用 Celery 在后台异步处理长时间运行或计算成本高的任务,而不是让您的 web 应用程序陷入不打算处理的任务,可以为运行缓慢的应用程序注入新鲜空气。
Celery 旨在提供一个快速接口,用于向其分布式任务队列发送消息。在这个例子中,您体验到了在 Django 应用程序中使用 Celery 只需要做很少的修改。
在本教程中,您学习了如何:
- 识别芹菜的有效用例
- 区分芹菜工和芹菜工
- 在 Django 项目中整合芹菜和 Redis
- 设置独立于 Django 应用运行的异步任务
- 重构 Django 代码,改为用芹菜运行任务
不断识别 Django 不需要处理的任何任务。然后将它们卸载到您最喜欢的分布式任务队列中。
知道您可以在后台处理缓慢的任务而不影响您的用户体验也为新想法打开了大门:
- 对您提交的反馈实施自动垃圾邮件过滤,这样您就不必浪费时间筛选垃圾邮件。
- 将所有反馈提交的文本翻译成西班牙语,这样你就可以给你的抽认卡应用添加新词汇,并帮助你的语言学习。
- 确定你自己的 Django 项目中的任务,你可以将这些任务交给芹菜工人。
许多有趣而有价值的计算只需要一分钟。有了 Celery 作为盟友,您可以开始将更多这样的特性集成到您的 web 应用程序中,并让分布式任务队列在后台异步运行这些任务。********
自动缩放 Heroku Dynos
这篇文章详细介绍了如何编写一个脚本来根据一天中的时间自动缩放 Heroku dynos。我们还将了解如何添加一个防故障装置,以便我们的应用程序在完全停机或负载过重时能够自动伸缩。
让我们考虑以下假设:
| 使用 | 时间 | Web Dynos |
|---|---|---|
| 沉重的 | 早上 7 点到晚上 10 点 | three |
| 中等 | 晚上 10 点到凌晨 3 点 | Two |
| 低的 | 凌晨 3 点至 7 点 | one |
因此,我们需要在早上 7 点向外扩展,然后在晚上 10 点向内扩展,然后在凌晨 3 点再次向内扩展。重复一遍。为了简单起见,我们的大部分流量仅来自少数时区,这一点我们已经考虑在内了。我们还将基于 UTC,因为那是 Heroku 的默认时区。
如果这是针对您自己的应用程序,请确保在缩放之前给自己留有一些回旋的余地。你可能也想看看假期和周末。算算吧。算出你的成本节约。
就这样,让我们添加一些任务…
AP scheduler〔t0〕
对于本教程,让我们使用高级 Python 调度器 (APScheduler),因为它易于使用,并打算与 Heroku 平台 API 一起与其他进程一起运行。
从安装 APScheduler 开始:
$ pip install apscheduler==3.0.1
现在,创建一个名为 autoscale.py 的新文件,并添加以下代码:
from apscheduler.schedulers.blocking import BlockingScheduler
sched = BlockingScheduler()
@sched.scheduled_job('interval', minutes=1)
def job():
print 'This job is run every minute.'
sched.start()
是的,这只是每分钟运行一个任务。在继续之前,让我们测试一下,以确保它能正常工作。将该流程添加到您的 Procfile 中。假设您已经定义了一个 web 流程,该文件现在应该看起来像这样:
web: gunicorn hello:app
clock: python autoscale.py
提交您的更改,然后将它们推送到 Heroku。
运行以下命令来扩展时钟进程:
$ heroku ps:scale clock=1
然后打开 Heroku 日志查看运行中的流程:
$ heroku logs --tail
2014-11-04T14:59:22.418496+00:00 heroku[api]: Scale to clock=1, web=1 by michael@realpython.com
2014-11-04T15:00:20.357505+00:00 heroku[router]: at=info method=GET path="/" host=autoscale.herokuapp.com request_id=7537ce4a-e802-4020-9b1b-10e754263957 fwd="54.160.152.14" dyno=web.1 connect=1ms service=3ms status=200 bytes=172
2014-11-04T15:00:27.620383+00:00 app[clock.1]: This job is run every minute.
2014-11-04T15:01:27.621151+00:00 app[clock.1]: This job is run every minute.
2014-11-04T15:02:27.620780+00:00 app[clock.1]: This job is run every minute.
2014-11-04T15:03:27.621276+00:00 app[clock.1]: This job is run every minute.
简单吧?
接下来,让我们将缩放任务添加到脚本中…
自动缩放
首先从 Heroku 账户页面获取 API 密匙,并将其添加到一个名为 config.py 的新文件中。除了密钥之外,还要输入您有兴趣监控的应用程序的名称和进程。
APP = "<add your app name>"
KEY = "<add your API key>"
PROCESS = "web"
接下来,将以下函数添加到 autoscale.py :
def scale(size):
payload = {'quantity': size}
json_payload = json.dumps(payload)
url = "https://api.heroku.com/apps/" + APP + "/formation/" + PROCESS
try:
result = requests.patch(url, headers=HEADERS, data=json_payload)
except:
print "test!"
return None
if result.status_code == 200:
return "Success!"
else:
return "Failure"
更新导入并添加以下配置:
import requests
import base64
import json
from apscheduler.schedulers.blocking import BlockingScheduler
from config import APP, KEY, PROCESS
# Generate Base64 encoded API Key
BASEKEY = base64.b64encode(":" + KEY)
# Create headers for API call
HEADERS = {
"Accept": "application/vnd.heroku+json; version=3",
"Authorization": BASEKEY
}
在这里,我们通过将 API 键传递到头部来处理基本的授权,然后使用requests库,我们调用 API。关于这方面的更多信息,请查看 Heroku 官方文档。如果一切顺利,这将适当地扩展我们的应用程序。
想测试一下吗?像这样更新job()函数:
@sched.scheduled_job('interval', minutes=1)
def job():
print 'Scaling ...'
print scale(0)
提交你的代码,然后推到 Heroku。现在,如果您运行heroku logs --tail,您应该会看到:
$ heroku logs --tail
2014-11-04T20:48:12.832034+00:00 app[clock.1]: Scaling ...
2014-11-04T20:48:12.910837+00:00 heroku[api]: Scale to clock=1, web=0 by hermanmu@gmail.com
2014-11-04T20:48:12.929993+00:00 app[clock.1]: Success!
2014-11-04T20:48:51.113079+00:00 app[clock.1]: Scaling ...
2014-11-04T20:49:10.486417+00:00 heroku[web.1]: Stopping all processes with SIGTERM
2014-11-04T20:49:11.844089+00:00 heroku[web.1]: Process exited with status 0
2014-11-04T20:49:12.816363+00:00 app[clock.1]: Scaling ...
2014-11-04T20:49:12.936135+00:00 app[clock.1]: Success!
2014-11-04T20:49:12.914887+00:00 heroku[api]: Scale to clock=1, web=0 by hermanmu@gmail.com
随着脚本的运行,让我们更新 APS scheduler…
调度程序
因为我们再次希望在早上 7 点向外扩展,然后在晚上 10 点扩展,然后在凌晨 3 点再次扩展,所以按如下方式更新计划任务:
@sched.scheduled_job('cron', hour=7)
def scale_out_to_three():
print 'Scaling out ...'
print scale(3)
@sched.scheduled_job('cron', hour=22)
def scale_in_to_two():
print 'Scaling in ...'
print scale(2)
@sched.scheduled_job('cron', hour=3)
def scale_in_to_one():
print 'Scaling in ...'
print scale(1)
让它运行至少 24 小时,然后再次检查你的日志以确保它在工作。
故障安全
如果我们的应用程序出现故障,让我们确保立即向外扩展,不要问任何问题。
首先,将以下函数添加到脚本中,该函数确定有多少个 dynos 被附加到该进程:
def get_current_dyno_quantity():
url = "https://api.heroku.com/apps/" + APP + "/formation"
try:
result = requests.get(url, headers=HEADERS)
for formation in json.loads(result.text):
current_quantity = formation["quantity"]
return current_quantity
except:
return None
然后添加新任务:
@sched.scheduled_job('interval', minutes=3)
def fail_safe():
print "pinging ..."
r = requests.get('https://APPNAME.herokuapp.com/')
current_number_of_dynos = get_current_dyno_quantity()
if r.status_code < 200 or r.status_code > 299:
if current_number_of_dynos < 3:
print 'Scaling out ...'
print scale(3)
if r.elapsed.microseconds / 1000 > 5000:
if current_number_of_dynos < 3:
print 'Scaling out ...'
print scale(3)
在这里,我们向我们的应用程序发送一个 GET 请求(确保更新 URL),如果状态代码超出 200 范围或者响应时间超过 5000 毫秒,那么我们就向外扩展(只要当前的 dynos 数量不超过 3)。
想测试一下吗?手动移除应用程序中的所有 dynos,然后打开日志:
heroku ps:scale web=0
Scaling web processes... done, now running 0
$ heroku ps
=== clock: `python autoscale.py`
clock.1: up 2014/11/04 15:47:06 (~ 3m ago)
$ heroku logs --tail
2014-11-04T21:53:06.633786+00:00 app[clock.1]: pinging ...
2014-11-04T21:53:06.738860+00:00 app[clock.1]: Scaling out ...
2014-11-04T21:53:06.817780+00:00 heroku[api]: Scale to clock=1, web=3 by michael@realpython.com
2014-11-04T21:53:10.740655+00:00 heroku[web.1]: Starting process with command `gunicorn hello:app`
2014-11-04T21:53:10.634433+00:00 heroku[web.2]: Starting process with command `gunicorn hello:app`
2014-11-04T21:53:11.338596+00:00 heroku[web.3]: Starting process with command `gunicorn hello:app`
2014-11-04T21:53:11.929276+00:00 heroku[web.2]: State changed from starting to up
2014-11-04T21:53:12.731831+00:00 heroku[web.3]: State changed from starting to up
2014-11-04T21:53:12.632277+00:00 heroku[web.1]: State changed from starting to up
2014-11-04T21:56:06.611123+00:00 app[clock.1]: pinging ...
2014-11-04T21:56:06.723760+00:00 app[clock.1]: ... success!
完美!
接下来的步骤
好了,我们现在有了一个脚本(下载)来自动扩展 Heroku dynos。希望这将允许您保持您的应用程序启动和运行,同时也节省一些急需的现金。你也应该睡得更香一点,因为你知道如果有大量的流量涌入,你的应用程序会自动扩展。
下一步是什么?
- Autoscale In:当响应时间少于 1000 毫秒时,自动放大。
- 故障邮件/短信:如果任何东西坏了,发送一封邮件和/或短信。
- 图表:创建一些图表,这样你可以更好地了解你的流量/高峰期等。通过 D3。
干杯!**
使用 Fabric 和 Ansible 自动化 Django 部署
原文:https://realpython.com/automating-django-deployments-with-fabric-and-ansible/
在上一篇文章中,我们介绍了在一台服务器上成功开发和部署 Django 应用程序所需的所有步骤。在本教程中,我们将使用 Fabric (v 1.12.0 )和ansi ble(v2 . 1 . 3)来自动化部署过程,以解决这些问题:
- 扩展:当要扩展一个 web 应用程序来处理成千上万的日常请求时,依靠单个服务器并不是一个好方法。简而言之,当服务器接近最大 CPU 利用率时,它会导致缓慢的加载时间,最终导致服务器故障。为了克服这个问题,应用程序必须扩展到在多台服务器上运行,这样服务器就可以累积处理传入的并发请求。
- 冗余:手动将一个 web 应用程序部署到一个新的服务器上意味着大量的重复工作,出现人为错误的可能性更大。自动化流程是关键。
具体来说,我们将自动化:
- 添加新的非超级用户
- 配置服务器
- 从 GitHub repo 中提取 Django 应用程序代码
- 安装依赖项
- 将应用程序虚拟化
设置和配置
首先旋转一个新的数字海洋水滴,确保使用 Fedora 25 图像。不要设置预先配置的 SSH 密钥;我们将通过一个织物脚本自动完成这个过程。因为部署过程应该是可伸缩的,所以创建一个单独的存储库来存放所有的部署脚本。在本地创建一个新的项目目录,并使用 Python 2.7x 创建和激活一个 virtualenv。
为什么选择 Python 2.7?Fabric 不支持 Python 3。不要担心:当我们提供服务器时,我们将使用 Python 3.5。
$ mkdir automated-deployments
$ cd automated-deployments
$ virtualenv env
$ source env/bin/activate
织物设置
Fabric 是一个工具,用于通过 SSH 自动执行日常 shell 命令,我们将使用它来:
- 设置 SSH 密钥
- 强化用户密码
- 安装可转换的依赖项
- 升级服务器
从安装结构开始:
$ pip install fabric==1.12.0
创建一个名为“prod”的新文件夹,并向其中添加一个名为 fabfile.py 的新文件,以保存所有 Fabric 脚本:
# prod/fabfile.py
import os
from fabric.contrib.files import sed
from fabric.api import env, local, run
from fabric.api import env
# initialize the base directory
abs_dir_path = os.path.dirname(
os.path.dirname(os.path.abspath(__file__)))
# declare environment global variables
# root user
env.user = 'root'
# list of remote IP addresses
env.hosts = ['<remote-server-ip>']
# password for the remote server
env.password = '<remote-server-password>'
# full name of the user
env.full_name_user = '<your-name>'
# user group
env.user_group = 'deployers'
# user for the above group
env.user_name = 'deployer'
# ssh key path
env.ssh_keys_dir = os.path.join(abs_dir_path, 'ssh-keys')
记下行内注释。确保将您的远程服务器的 IP 地址添加到env.hosts变量中。同样更新env.full_name_user。暂缓更新env.password;我们很快就会谈到这一点。查看所有的env变量——它们完全可以根据您的系统设置进行定制。
设置 SSH 密钥
将以下代码添加到 fabfile.py :
def start_provision():
"""
Start server provisioning
"""
# Create a new directory for a new remote server
env.ssh_keys_name = os.path.join(
env.ssh_keys_dir, env.host_string + '_prod_key')
local('ssh-keygen -t rsa -b 2048 -f {0}'.format(env.ssh_keys_name))
local('cp {0} {1}/authorized_keys'.format(
env.ssh_keys_name + '.pub', env.ssh_keys_dir))
# Prevent root SSHing into the remote server
sed('/etc/ssh/sshd_config', '^UsePAM yes', 'UsePAM no')
sed('/etc/ssh/sshd_config', '^PermitRootLogin yes',
'PermitRootLogin no')
sed('/etc/ssh/sshd_config', '^#PasswordAuthentication yes',
'PasswordAuthentication no')
install_ansible_dependencies()
create_deployer_group()
create_deployer_user()
upload_keys()
set_selinux_permissive()
run('service sshd reload')
upgrade_server()
该函数充当结构脚本的入口点。除了触发一系列功能(每个功能将在后续步骤中解释)之外,它还明确地-
- 在本地系统的指定位置生成一对新的 SSH 密钥
- 将公钥的内容复制到 authorized_keys 文件中
- 对远程 sshd_config 文件进行更改,以阻止 root 登录并禁用无密码身份验证
阻止 root 用户的 SSH 访问是一个可选步骤,但建议这样做,因为它可以确保没有人拥有超级用户权限。
在项目根目录下为您的 SSH 密钥创建一个目录:
├── prod
│ └── fabfile.py
└── ssh-keys
强化用户密码
这一步包括添加三个不同的函数,每个函数依次执行以配置 SSH 密码强化…
创建部署者组
def create_deployer_group():
"""
Create a user group for all project developers
"""
run('groupadd {}'.format(env.user_group))
run('mv /etc/sudoers /etc/sudoers-backup')
run('(cat /etc/sudoers-backup; echo "%' +
env.user_group + ' ALL=(ALL) ALL") > /etc/sudoers')
run('chmod 440 /etc/sudoers')
这里,我们添加了一个名为deployers的新组,并授予它 sudo 权限,这样用户就可以使用 root 权限执行进程。
创建用户
def create_deployer_user():
"""
Create a user for the user group
"""
run('adduser -c "{}" -m -g {} {}'.format(
env.full_name_user, env.user_group, env.user_name))
run('passwd {}'.format(env.user_name))
run('usermod -a -G {} {}'.format(env.user_group, env.user_name))
run('mkdir /home/{}/.ssh'.format(env.user_name))
run('chown -R {} /home/{}/.ssh'.format(env.user_name, env.user_name))
run('chgrp -R {} /home/{}/.ssh'.format(
env.user_group, env.user_name))
这个功能-
- 向
deployers用户组添加一个新用户,这是我们在最后一个函数中定义的 - 设置保存 SSH 密钥对的 SSH 目录,并授予组和用户访问该目录的权限
上传 SSH 密钥
def upload_keys():
"""
Upload the SSH public/private keys to the remote server via scp
"""
scp_command = 'scp {} {}/authorized_keys {}@{}:~/.ssh'.format(
env.ssh_keys_name + '.pub',
env.ssh_keys_dir,
env.user_name,
env.host_string
)
local(scp_command)
在这里,我们-
- 将本地生成的 SSH 密钥上传到远程服务器,以便非根用户可以通过 SSH 登录,而无需输入密码
- 将公钥和授权密钥复制到远程服务器新创建的 ssh-keys 目录中
安装可转换的依赖关系
添加以下函数来安装 Ansible 的依赖包:
def install_ansible_dependencies():
"""
Install the python-dnf module so that Ansible
can communicate with Fedora's Package Manager
"""
run('dnf install -y python-dnf')
请记住,这是特定于 Fedora Linux 发行版的,因为我们将使用 DNF 模块来安装包,但它可能因发行版而异。
将 SELinux 设置为许可模式
下一个功能将 SELinux 设置为许可模式。这样做是为了克服任何潜在的 Nginx 502 坏网关错误。
def set_selinux_permissive():
"""
Set SELinux to Permissive/Disabled Mode
"""
# for permissive
run('sudo setenforce 0')
同样,这是特定于 Fedora Linux 发行版的。
升级服务器
最后,升级服务器:
def upgrade_server():
"""
Upgrade the server as a root user
"""
run('dnf upgrade -y')
# optional command (necessary for Fedora 25)
run('dnf install -y python')
run('reboot')
健全性检查
至此,我们完成了 Fabric 脚本。在运行它之前,确保您以 root 用户身份 SSH 到服务器,并更改密码:
$ ssh root@<server-ip-address>
You are required to change your password immediately (root enforced)
Changing password for root.
(current) UNIX password:
New password:
Retype new password:
确保用新密码更新env.password。退出服务器,返回本地终端,然后执行 Fabric:
$ fab -f ./prod/fabfile.py start_provision
如果一切顺利,将会生成新的 SSH 密钥,并且会要求您创建一个密码(一定要这样做!):
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
将运行许多任务。创建deployer用户后,系统会提示您为该用户添加密码-
[104.236.66.172] out: Changing password for user deployer.
-上传 SSH 密钥时,您必须输入:
deployer@104.236.66.172s password:
该脚本成功退出后,您将无法再以 root 用户身份登录远程服务器。相反,您将只能使用非根用户deployer。
尝试一下:
$ ssh root@<server-ip-address>
Permission denied (publickey,gssapi-keyex,gssapi-with-mic).
这是意料之中的。然后,当你跑的时候-
$ ssh -i ./ssh-keys/104.236.66.172_prod_key deployer@104.236.66.172
-您应该可以正常登录:
[deployer@fedora-512mb-nyc2-01 ~]$
易解引物
Ansible 是一个配置管理和供应工具,用于通过 SSH 自动执行部署任务。
您可以从您的 shell 远程启动针对应用服务器的单个任务,并随时执行任务。任务也可以组合成剧本——多个剧本的集合,其中每个剧本定义了部署过程中需要的某些特定任务。它们在部署过程中针对应用服务器执行。剧本是在 YAML 写成的。
剧本
行动手册由如下模块化架构组成:
- Hosts 指定所有需要协调的远程服务器的 IP 地址或域名。行动手册总是在目标主机组上运行。
- 角色分为子部分。让我们来看一些角色示例:
- 任务是需要在部署过程中执行的多个任务的集合。
- 当模块对远程服务器进行更改时,处理程序提供了一种触发一组操作的方式(最好被认为是钩子)。
- 在这种情况下,模板通常用于指定一些模块相关的配置文件——比如 nginx。
- 变量只是一个键值对列表,其中每个键(变量)都映射到一个值。这些变量可以在行动手册中作为占位符使用。
剧本样本
现在让我们来看一个单文件行动手册示例:
--- # My Ansible playbook for configuring Nginx - hosts: all vars: http_port: 80 app_name: django_bootstrap tasks: - name: Install nginx dnf: name=nginx state=latest - name: Create nginx config file template: src=django_bootstrap.conf dest=/etc/nginx/conf.d/{{ app_name }}.conf become: yes notify: - restart nginx handlers: - name: Restart nginx service: name=nginx state=restarted enabled=yes become: yes
在这里,我们定义了:
- Hosts as
hosts: all,这表示剧本将在 清单/hosts 文件中列出的所有服务器上运行 - 模板中使用的变量
http_port: 80和app_name: django_bootstrap - 任务为了安装 nginx,设置 nginx 配置(
become表示我们需要 admin 权限),并触发重启处理程序 - 处理程序来重新启动 nginx 服务
剧本设置
现在让我们为姜戈建立一个剧本。将一个 deploy.yml 文件添加到“prod”目录:
## # This playbook deploys the whole app stack ## - name: apply common configuration to server hosts: all user: deployer roles: - common
上面的代码片段将负责的主机、用户和角色结合在一起。
主机
将一个主机(纯文本格式)文件添加到“prod”目录中,并在它们各自的角色名称下列出服务器。我们在这里配置一台服务器:
[common]
<server-ip-address>
在上面的代码片段中,common指的是角色名。在角色下,我们有一个需要配置的 IP 地址列表。确保添加您的远程服务器的 IP 地址来代替<server-ip-address>。
变量
现在我们定义角色将使用的变量。在“prod”中添加一个名为“group_vars”的新文件夹,然后在该文件夹中创建一个名为 all (纯文本格式)的新文件。在这里,首先指定以下变量:
# App Name app_name: django_bootstrap # Deployer User and Groups deployer_user: deployer deployer_group: deployers # SSH Keys Directory ssh_dir: <path-to-your-ssh-keys>
确保更新<path-to-your-ssh-keys>。要获得正确的路径,请在项目根目录下运行:
$ cd ssh-keys
$ pwd
/Users/michael.herman/repos/realpython/automated-deployments/ssh-keys
有了这些文件,我们现在就可以将我们的部署过程与需要在服务器上执行的所有角色协调起来了。
剧本角色
同样,行动手册只是不同行动的集合,所有这些行动都在特定的角色下运行。在“prod”中创建一个名为“roles”的新目录。
您是否捕捉到了 deploy.yml 文件中的角色名称?
然后在“roles”目录中添加一个名为“common”的新目录——角色。角色由“任务”、“处理程序”和“模板”组成。为每个目录添加一个新目录。
完成后,您的文件结构应该如下所示:
├── prod
│ ├── deploy.yml
│ ├── fabfile.py
│ ├── group_vars
│ │ └── all
│ ├── hosts
│ └── roles
│ └── common
│ ├── handlers
│ ├── tasks
│ └── templates
└── ssh-keys
├── 104.236.66.172_prod_key
├── 104.236.66.172_prod_key.pub
└── authorized_keys
所有的剧本都定义在一个“任务”目录中,从一个 main.yml 文件开始。这个文件作为所有剧本任务的入口点。它只是需要按顺序执行的多个 YAML 文件的列表。
现在在“tasks”目录下创建该文件,然后向其中添加以下内容:
## # Configure the server for the Django app ## - include: 01_server.yml - include: 02_git.yml - include: 03_postgres.yml - include: 04_dependencies.yml - include: 05_migrations.yml - include: 06_nginx.yml - include: 07_gunicorn.yml - include: 08_systemd.yml # - include: 09_fix-502.yml
现在,让我们创建每个任务。一定要为每个任务在“tasks”目录中添加一个新文件,并为每个文件添加相应的代码。如果你迷路了,参考回购。
01_server.yml*
## # Update the DNF package cache and install packages as a root user ## - name: Install required packages dnf: name={{item}} state=latest become: yes with_items: - vim - fail2ban - python3-devel - python-virtualenv - python3-virtualenv - python-devel - gcc - libselinux-python - redhat-rpm-config - libtiff-devel - libjpeg-devel - libzip-devel - freetype-devel - lcms2-devel - libwebp-devel - tcl-devel - tk-devel - policycoreutils-devel
在这里,我们列出了所有需要安装的系统软件包。
02_git.yml*
## # Clone and pull the repo ## - name: Set up git configuration dnf: name=git state=latest become: yes - name: Clone or pull the latest code git: repo={{ code_repository_url }} dest={{ app_dir }}
将以下变量添加到 group_vars/all 文件中:
# Github Code's Repo URL code_repository_url: https://github.com/realpython/django-bootstrap # App Directory app_dir: /home/{{ deployer_user }}/{{app_name}}
确保派生然后克隆 django-bootstrap repo,然后将code_repository_url变量更新为您的派生的 URL。
03 _ posters . yml*
## # Set up and configure postgres ## - name: Install and configure db dnf: name={{item}} state=latest become: yes with_items: - postgresql-server - postgresql-contrib - postgresql-devel - python-psycopg2 - name: Run initdb command raw: postgresql-setup initdb become: yes - name: Start and enable postgres service: name=postgresql enabled=yes state=started become: yes - name: Create database postgresql_db: name={{ app_name }} become_user: postgres become: yes - name: Configure a new postgresql user postgresql_user: db={{ app_name }} name={{ db_user }} password={{ db_password }} priv=ALL role_attr_flags=NOSUPERUSER become: yes become_user: postgres notify: - restart postgres
使用行动手册所需的数据库配置更新 group_vars/all :
# DB Configuration db_url: postgresql://{{deployer_user}}:{{db_password}}@localhost/{{app_name}} db_password: thisissomeseucrepassword db_name: "{{ app_name }}" db_user: "{{ deployer_user }}"
用安全密码更新db_password变量。
您是否注意到我们在 main.yml 文件中重新启动了 postgres 服务,以便在配置数据库后应用更改?这是我们的第一个负责人。在“handlers”文件夹中创建一个名为 main.yml 的新文件,然后添加以下内容:
- name: restart postgres service: name=postgresql state=restarted become: yes
04_dependencies.yml
## # Set up all the dependencies in a virtualenv required by the Django app ## - name: Create a virtualenv directory file: path={{ venv_dir }} state=directory - name: Install dependencies pip: requirements={{ app_dir }}/requirements.txt virtualenv={{ venv_dir }} virtualenv_python=python3.5 - name: Create the .env file for running ad-hoc python commands in our virtualenv template: src=env.j2 dest={{ app_dir }}/.env become: yes
更新 group_vars/all 如下:
# Application Dependencies Setup
venv_dir: '/home/{{ deployer_user }}/envs/{{ app_name }}'
venv_python: '{{ venv_dir }}/bin/python3.5'
将名为 env.j2 的模板添加到“templates”文件夹中,并添加以下环境变量:
#!/bin/bash
export DEBUG="True"
export DATABASE_URL="postgresql://deployer:thisissomeseucrepassword@localhost/django_bootstrap"
export DJANGO_SECRET_KEY="changeme"
export DJANGO_SETTINGS_MODULE="config.settings.production"
非常小心环境变量及其在 env.j2 中的值,因为它们用于启动和运行 Django 项目。
05 _ migration . yml*
## # Run db migrations and get all static files ## - name: Make migrations shell: ". {{ app_dir }}/.env; {{ venv_python }} {{ app_dir }}/manage.py makemigrations " become: yes - name: Migrate database django_manage: app_path={{ app_dir }} command=migrate virtualenv={{ venv_dir }} - name: Get all static files django_manage: app_path={{ app_dir }} command=collectstatic virtualenv={{ venv_dir }} become: yes
06_nginx.yml*
## # Configure nginx web server ## - name: Set up nginx config dnf: name=nginx state=latest become: yes - name: Write nginx conf file template: src=django_bootstrap.conf dest=/etc/nginx/conf.d/{{ app_name }}.conf become: yes notify: - restart nginx
将以下变量添加到 group_vars/all :
# Remote Server Details server_ip: <remote-server-ip> wsgi_server_port: 8000
别忘了更新<remote-server-ip>。然后将处理程序添加到 handlers/main.yml :
- name: restart nginx service: name=nginx state=restarted enabled=yes become: yes
然后我们需要添加 django_bootstrap.conf 模板。在“templates”目录中创建该文件,然后添加代码:
upstream app_server {
server 127.0.0.1:{{ wsgi_server_port }} fail_timeout=0;
}
server {
listen 80;
server_name {{ server_ip }};
access_log /var/log/nginx/{{ app_name }}-access.log;
error_log /var/log/nginx/{{ app_name }}-error.log info;
keepalive_timeout 5;
# path for staticfiles
location /static {
autoindex on;
alias {{ app_dir }}/staticfiles/;
}
location / {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
if (!-f $request_filename) {
proxy_pass http://app_server;
break;
}
}
}
07 _ guni corn . yml*T2】
## # Set up Gunicorn and configure systemd to execute gunicorn_start script ## - name: Create a deploy directory file: path={{ deploy_dir }} state=directory become: yes - name: Create the gunicorn_start script for running our app from systemd service template: src=gunicorn_start dest={{ deploy_dir }}/gunicorn_start become: yes - name: Make the gunicorn_start script executable raw: cd {{ deploy_dir }}; chmod +x gunicorn_start become: yes
向 groups_vars/all 添加更多变量:
# Deploy Dir in App Directory deploy_dir: '{{ app_dir }}/deploy' # WSGI Vars django_wsgi_module: config.wsgi django_settings_module: config.settings.production django_secret_key: 'changeme' database_url: '{{ db_url }}'
添加 gunicorn_start 模板:
#!/bin/bash
### Define script variables
# Name of the app
NAME='{{ app_name }}'
# Path to virtualenv
VIRTUALENV='{{ venv_dir }}'
# Django Project Directory
DJANGODIR='{{ app_dir }}'
# The user to run as
USER={{ deployer_user }}
# The group to run as
GROUP={{deployer_group }}
# Number of worker processes Gunicorn should spawn
NUM_WORKERS=3
# Settings file that Gunicorn should use
DJANGO_SETTINGS_MODULE={{django_settings_module}}
# WSGI module name
DJANGO_WSGI_MODULE={{ django_wsgi_module }}
### Activate virtualenv and create environment variables
echo "Starting $NAME as `whoami`"
# Activate the virtual environment
cd $VIRTUALENV
source bin/activate
cd $DJANGODIR
# Defining the Environment Variables
export DJANGO_SECRET_KEY='{{ django_secret_key }}'
export DATABASE_URL='{{ db_url }}'
export DJANGO_SETTINGS_MODULE=$DJANGO_SETTINGS_MODULE
export PYTHONPATH=$DJANGODIR:$PYTHONPATH
### Start Gunicorn
exec gunicorn ${DJANGO_WSGI_MODULE}:application \
--name $NAME \
--workers $NUM_WORKERS \
--user=$USER --group=$GROUP \
--log-level=debug \
--bind=127.0.0.1:8000
08_systemd.yml
## # Set up systemd for executing gunicorn_start script ## - name: write a systemd service file template: src=django-bootstrap.service dest=/etc/systemd/system become: yes notify: - restart app - restart nginx
添加模板-django-bootstrap . service:
#!/bin/sh
[Unit]
Description=Django Web App
After=network.target
[Service]
PIDFile=/var/run/djangoBootstrap.pid
User={{ deployer_user }}
Group={{ deployer_group }}
ExecStart=/bin/sh {{ deploy_dir }}/gunicorn_start
Restart=on-abort
[Install]
WantedBy=multi-user.target
将以下内容添加到处理程序中:
- name: restart app service: name=django-bootstrap state=restarted enabled=yes become: yes
09 _ fix-502 . yml*T2】
## # Fix the 502 nginx error post deployment # - name: Fix nginx 502 error raw: cd ~; cat /var/log/audit/audit.log | grep nginx | grep denied | audit2allow -M mynginx; semodule -i mynginx.pp become: yes
健全性检查(最终)
激活 virtualenv 后,在本地安装 Ansible】:
$ pip install ansible==2.1.3
在项目根目录下创建一个名为 deploy_prod.sh 的新文件来运行剧本,确保更新<server-ip>:
#!/bin/bash
ansible-playbook ./prod/deploy.yml --private-key=./ssh_keys<server-ip>_prod_key -K -u deployer -i ./prod/hosts -vvv
然后运行以下命令来执行行动手册:
$ sh deploy_prod.sh
如果出现任何错误,请向终端咨询如何纠正错误的信息。修复后,再次执行部署脚本。当脚本完成后,访问服务器的 IP 地址,以验证您的 Django web 应用程序正在运行!

如果您看到 502 错误,请确保取消注释prod/roles/common/tasks/main . yml中的这一行,这表明 nginx 和 Gunicorn 之间的通信存在问题:
# - include: 09_fix-502.yml
然后再次执行剧本。
如果你多次执行剧本,确保注释掉在 03_postgres.yml 中的
Run initdb command,因为它只需要运行一次。否则,它将在尝试重新初始化数据库服务器时抛出错误。
结论
这篇文章提供了如何用 Fabric 和 Ansible 自动配置服务器的基本理解。Ansible Playbooks 特别强大,因为您可以通过 YAML 文件在服务器上自动化几乎任何任务。希望您现在可以开始编写自己的行动手册,甚至在工作场所使用它们来配置生产就绪型服务器。
请在下面添加问题和评论。完整的代码可以在自动化部署仓库中找到。*******
使用 AWS Chalice 构建无服务器 Python 应用程序
发布一个 web 应用程序通常需要在一台或多台服务器上运行您的代码。在这种模式下,您最终需要设置监控、配置和扩展服务器的流程。虽然这看起来工作得很好,但是以自动化的方式处理 web 应用程序的所有后勤工作减少了大量的人工开销。输入无服务器。
使用无服务器架构,您不需要管理服务器。相反,您只需要将代码或可执行包发送到执行它的平台。并不是真的没有服务器。服务器确实存在,但是开发者不需要担心它们。
AWS 推出了 Lambda Services ,这是一个平台,使开发人员能够简单地在特定的运行时环境中执行他们的代码。为了使平台易于使用,许多社区围绕它提出了一些非常好的框架,以使无服务器应用程序成为一个工作解决方案。
本教程结束时,你将能够:
- 讨论无服务器架构的优势
- 探索 Chalice,一个 Python 无服务器框架
- 为真实世界的使用案例构建成熟的无服务器应用
- 部署到 Amazon Web Services (AWS) Lambda
- 比较纯函数和 Lambda 函数
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
AWS 圣杯入门
Chalice ,一个由 AWS 开发的 Python 无服务器微框架,使您能够快速启动和部署一个工作的无服务器应用程序,该应用程序可以使用 AWS Lambda 根据需要自行伸缩。
为什么是圣杯?
对于习惯于 Flask web 框架的 Python 开发人员来说,在构建和发布您的第一个应用程序方面,Chalice 应该是轻而易举的事情。受到 Flask 的高度启发,Chalice 在定义服务应该是什么样的以及最终制作相同的可执行包方面保持了相当的极简主义。
理论够了!让我们从一个基本的hello-world应用开始,开始我们的无服务器之旅。
项目设置
在进入 Chalice 之前,您将在本地机器上设置一个工作环境,这将为您完成本教程的其余部分做好准备。
首先,创建并激活一个虚拟环境并安装 Chalice:
$ python3.6 -m venv env
$ source env/bin/activate
(env)$ pip install chalice
遵循我们关于 Pipenv 包装工具的全面指南。
注意: Chalice 带有一个用户友好的 CLI,可以轻松使用您的无服务器应用程序。
现在您已经在虚拟环境中安装了 Chalice,让我们使用 Chalice CLI 来生成一些样板代码:
(env)$ chalice new-project
出现提示时输入项目名称,然后按 return 键。以该名称创建一个新目录:
<project-name>/
|
├── .chalice/
│ └── config.json
|
├── .gitignore
├── app.py
└── requirements.txt
看看圣杯代码库有多简约。一个.chalice目录、app.py和requirements.txt是启动和运行一个无服务器应用程序所需要的全部。让我们在本地机器上快速运行这个应用程序。
Chalice CLI 包含非常棒的实用函数,允许您执行大量操作,从本地运行到在 Lambda 环境中部署。
在本地构建和运行
您可以通过使用 Chalice 的local实用程序在本地运行该应用程序来模拟它:
(env)$ chalice local
Serving on 127.0.0.1:8000
默认情况下,Chalice 运行在端口 8000 上。我们现在可以通过发出一个 curl 请求到http://localhost:8000/来检查索引路径:
$ curl -X GET http://localhost:8000/
{"hello": "world"}
现在,如果我们看一下app.py,我们可以体会到 Chalice 允许您构建无服务器服务的简单性。所有复杂的东西都由装饰者处理:
from chalice import Chalice
app = Chalice(app_name='serverless-sms-service')
@app.route('/')
def index():
return {'hello': 'world'}
注意:我们还没有命名我们的应用hello-world,因为我们将在同一个应用上建立我们的短信服务。
现在,让我们继续在 AWS Lambda 上部署我们的应用程序。
在 AWS Lambda 上部署
Chalice 使部署您的无服务器应用程序完全不费力。使用deploy实用程序,您可以简单地指示 Chalice 部署并创建一个 Lambda 函数,该函数可以通过 REST API 访问。
在我们开始部署之前,我们需要确保我们有 AWS 证书,通常位于~/.aws/config。该文件的内容如下所示:
[default] aws_access_key_id=<your-access-key-id> aws_secret_access_key=<your-secret-access-key> region=<your-region>
有了 AWS 凭证,让我们从一个命令开始部署过程:
(env)$ chalice deploy
Creating deployment package.
Updating policy for IAM role: hello-world-dev
Creating lambda function: hello-world-dev
Creating Rest API
Resources deployed:
- Lambda ARN: arn:aws:lambda:ap-south-1:679337104153:function:hello-world-dev
- Rest API URL: https://fqcdyzvytc.execute-api.ap-south-1.amazonaws.com/api/
注意:上面代码片段中生成的 ARN 和 API URL 会因用户而异。
哇!是的,启动和运行您的无服务器应用程序真的很容易。要进行验证,只需在生成的 Rest API URL 上发出 curl 请求:
$ curl -X GET https://fqcdyzvytc.execute-api.ap-south-1.amazonaws.com/api/
{"hello": "world"}
通常情况下,这就是你启动和运行无服务器应用程序所需的全部内容。您还可以转到 AWS 控制台,查看在 Lambda service 部分下创建的 Lambda 函数。每个 Lambda 服务都有一个惟一的 REST API 端点,可以在任何 web 应用程序中使用。
接下来,您将开始使用 Twilio 作为 SMS 服务提供商来构建您的无服务器 SMS Sender 服务。
构建无服务器手机短信服务
部署了一个基本的hello-world应用程序后,让我们继续构建一个可以与日常 web 应用程序一起使用的更真实的应用程序。在本节中,您将构建一个完全无服务器的 SMS 发送应用程序,只要输入参数正确,它可以插入任何系统并按预期工作。
为了发送短信,我们将使用 Twilio ,一个开发者友好的短信服务。在开始使用 Twilio 之前,我们需要考虑一些先决条件:
- 创建一个账户,获得
ACCOUNT_SID和AUTH_TOKEN。 - 获得一个手机号码,这是在 Twilio 免费提供的小测试的东西。
- 使用
pip install twilio在我们的虚拟环境中安装twilio包。
检查完以上所有先决条件后,您就可以开始使用 Twilio 的 Python 库构建您的 SMS 服务客户端了。让我们从克隆库并创建一个新的特性分支开始:
$ git clone <project-url>
$ cd <project-dir>
$ git checkout tags/1.0 -b twilio-support
现在对app.py做如下修改,使它从一个简单的hello-world应用程序发展到支持 Twilio 服务。
首先,让我们包括所有的导入语句:
from os import environ as env
# 3rd party imports
from chalice import Chalice, Response
from twilio.rest import Client
from twilio.base.exceptions import TwilioRestException
# Twilio Config
ACCOUNT_SID = env.get('ACCOUNT_SID')
AUTH_TOKEN = env.get('AUTH_TOKEN')
FROM_NUMBER = env.get('FROM_NUMBER')
TO_NUMBER = env.get('TO_NUMBER')
接下来,您将封装 Twilio API 并使用它来发送 SMS:
app = Chalice(app_name='sms-shooter')
# Create a Twilio client using account_sid and auth token
tw_client = Client(ACCOUNT_SID, AUTH_TOKEN)
@app.route('/service/sms/send', methods=['POST'])
def send_sms():
request_body = app.current_request.json_body
if request_body:
try:
msg = tw_client.messages.create(
from_=FROM_NUMBER,
body=request_body['msg'],
to=TO_NUMBER)
if msg.sid:
return Response(status_code=201,
headers={'Content-Type': 'application/json'},
body={'status': 'success',
'data': msg.sid,
'message': 'SMS successfully sent'})
else:
return Response(status_code=200,
headers={'Content-Type': 'application/json'},
body={'status': 'failure',
'message': 'Please try again!!!'})
except TwilioRestException as exc:
return Response(status_code=400,
headers={'Content-Type': 'application/json'},
body={'status': 'failure',
'message': exc.msg})
在上面的代码片段中,您只需使用ACCOUNT_SID和AUTH_TOKEN创建一个 Twilio 客户端对象,并使用它在send_sms视图下发送消息。send_sms是一个基本功能,使用 Twilio 客户端的 API 将 SMS 发送到指定的目的地。在继续下一步之前,让我们尝试一下并在本地机器上运行它。
在本地构建和运行
现在,您可以使用local实用程序在您的机器上运行您的应用程序,并验证一切正常:
(env)$ chalice local
现在,使用特定的有效负载向http://localhost:8000/service/sms/send发出 curl POST 请求,并在本地测试应用程序:
$ curl -H "Content-Type: application/json" -X POST -d '{"msg": "hey mate!!!"}' http://localhost:8000/service/sms/send
上述请求答复如下:
{ "status": "success", "data": "SM60f11033de4f4e39b1c193025bcd5cd8", "message": "SMS successfully sent" }
响应表明消息已成功发送。现在,让我们继续在 AWS Lambda 上部署应用程序。
在 AWS Lambda 上部署
正如在前面的部署部分中所建议的,您只需要发出以下命令:
(env)$ chalice deploy
Creating deployment package.
Updating policy for IAM role: sms-shooter-dev
Creating lambda function: sms-shooter-dev
Creating Rest API
Resources deployed:
- Lambda ARN: arn:aws:lambda:ap-south-1:679337104153:function:sms-shooter-dev
- Rest API URL: https://qtvndnjdyc.execute-api.ap-south-1.amazonaws.com/api/
注意:上面的命令成功了,您在输出中有了您的 API URL。现在在测试 URL 时,API 抛出一条错误消息。哪里出了问题?
根据 AWS Lambda 日志,没有找到或者安装twilio包,所以你需要告诉 Lambda 服务安装依赖项。为此,您需要添加twilio作为对requirements.txt的依赖:
twilio==6.18.1
其他包比如 Chalice 及其依赖项不应该包含在requirements.txt中,因为它们不是 Python 的 WSGI 运行时的一部分。相反,我们应该维护一个requirements-dev.txt,它只适用于开发环境,包含所有与 Chalice 相关的依赖项。要了解更多,请查看这期 GitHub。
一旦所有的包依赖项都被排序,您需要确保所有的环境变量都被附带,并在 Lambda 运行时被正确设置。为此,您必须以如下方式在.chalice/config.json中添加所有环境变量:
{ "version": "2.0", "app_name": "sms-shooter", "stages": { "dev": { "api_gateway_stage": "api", "environment_variables": { "ACCOUNT_SID": "<your-account-sid>", "AUTH_TOKEN": "<your-auth-token>", "FROM_NUMBER": "<source-number>", "TO_NUMBER": "<destination-number>" } } } }
现在我们可以部署了:
Creating deployment package.
Updating policy for IAM role: sms-shooter-dev
Updating lambda function: sms-shooter-dev
Updating rest API
Resources deployed:
- Lambda ARN: arn:aws:lambda:ap-south-1:679337104153:function:sms-shooter-dev
- Rest API URL: https://fqcdyzvytc.execute-api.ap-south-1.amazonaws.com/api/
通过向生成的 API 端点发出 curl 请求来进行健全性检查:
$ curl -H "Content-Type: application/json" -X POST -d '{"msg": "hey mate!!!"}' https://fqcdyzvytc.execute-api.ap-south-1.amazonaws.com/api/service/sms/send
上述请求如预期的那样响应:
{ "status": "success", "data": "SM60f11033de4f4e39b1c193025bcd5cd8", "message": "SMS successfully sent" }
现在,你有一个完全无服务器的短信发送服务启动和运行。由于该服务的前端是一个 REST API,因此它可以作为一个可伸缩、安全和可靠的即插即用特性在其他应用程序中使用。
重构
最后,我们将重构我们的 SMS 应用程序,使其不完全包含app.py中的所有业务逻辑。相反,我们将遵循圣杯规定的最佳实践,并抽象出chalicelib/目录下的业务逻辑。
让我们从创建一个新分支开始:
$ git checkout tags/2.0 -b sms-app-refactor
首先,在项目的根目录下创建一个名为chalicelib/的新目录,并创建一个名为sms.py的新文件:
(env)$ mkdir chalicelib
(env)$ touch chalicelib/sms.py
通过对app.py进行抽象,用 SMS 发送逻辑更新上面创建的chalicelib/sms.py:
from os import environ as env
from twilio.rest import Client
# Twilio Config
ACCOUNT_SID = env.get('ACCOUNT_SID')
AUTH_TOKEN = env.get('AUTH_TOKEN')
FROM_NUMBER = env.get('FROM_NUMBER')
TO_NUMBER = env.get('TO_NUMBER')
# Create a twilio client using account_sid and auth token
tw_client = Client(ACCOUNT_SID, AUTH_TOKEN)
def send(payload_params=None):
""" send sms to the specified number """
msg = tw_client.messages.create(
from_=FROM_NUMBER,
body=payload_params['msg'],
to=TO_NUMBER)
if msg.sid:
return msg
上面的代码片段只接受输入参数,并根据需要进行响应。现在,为了实现这一点,我们还需要对app.py进行修改:
# Core imports
from chalice import Chalice, Response
from twilio.base.exceptions import TwilioRestException
# App level imports
from chalicelib import sms
app = Chalice(app_name='sms-shooter')
@app.route('/')
def index():
return {'hello': 'world'}
@app.route('/service/sms/send', methods=['POST'])
def send_sms():
request_body = app.current_request.json_body
if request_body:
try:
resp = sms.send(request_body)
if resp:
return Response(status_code=201,
headers={'Content-Type': 'application/json'},
body={'status': 'success',
'data': resp.sid,
'message': 'SMS successfully sent'})
else:
return Response(status_code=200,
headers={'Content-Type': 'application/json'},
body={'status': 'failure',
'message': 'Please try again!!!'})
except TwilioRestException as exc:
return Response(status_code=400,
headers={'Content-Type': 'application/json'},
body={'status': 'failure',
'message': exc.msg})
在上面的代码片段中,所有的 SMS 发送逻辑都是从chalicelib.sms模块调用的,这使得视图层在可读性方面更加清晰。这种抽象允许您添加更复杂的业务逻辑,并根据需要定制功能。
健全性检查
重构我们的代码后,让我们确保它按预期运行。
在本地构建和运行
使用local实用程序再次运行应用程序:
(env)$ chalice local
提出 curl 请求并验证。完成后,继续部署。
在 AWS Lambda 上部署
一旦您确定一切正常,现在就可以部署您的应用了:
(env)$ chalice deploy
像往常一样,该命令成功执行,您可以验证端点。
结论
您现在知道如何执行以下操作:
- 根据最佳实践,使用 AWS Chalice 构建一个无服务器应用程序
- 在 Lambda 运行时环境中部署您的工作应用程序
底层的 Lambda 服务类似于纯函数,它在一组输入/输出上有一定的行为。开发精确的 Lambda 服务允许更好的测试、可读性和原子性。因为 Chalice 是一个极简框架,所以您可以只关注业务逻辑,剩下的工作就交给您了,从部署到 IAM 策略生成。这一切都只需要一个命令部署!
此外,Lambda 服务主要侧重于繁重的 CPU 处理,并按照单位时间内的请求数量以自我管理的方式进行扩展。使用无服务器架构允许你的代码库更像 SOA(面向服务的架构)。在 AWS 的生态系统中使用其他能够很好地插入 Lambda 功能的产品会更加强大。*****
美汤:用 Python 构建 Web 刮刀
原文:https://realpython.com/beautiful-soup-web-scraper-python/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 网刮用美汤和 Python
互联网上令人难以置信的大量数据对于任何研究领域或个人兴趣来说都是丰富的资源。为了有效地收集数据,你需要熟练掌握**。Python 库requests和 Beautiful Soup 是这项工作的强大工具。如果你喜欢通过动手的例子来学习,并且对 Python 和 HTML 有基本的了解,那么这个教程就是为你准备的。*
*在本教程中,您将学习如何:
- 解密编码在URL中的数据
- 使用
requests和美汤从网络上抓取和解析数据 - 从头到尾遍历一条网页抓取管道
- 构建一个脚本,从网络上获取工作机会,并在你的控制台上显示相关信息
通过这个项目的工作,你将获得在万维网上抓取任何静态网站所需的过程和工具的知识。您可以点击下面的链接下载项目源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程的项目和示例中使用。
我们开始吧!
什么是网页抓取?
网络搜集是从互联网上收集信息的过程。甚至复制粘贴你最喜欢的歌曲的歌词也是一种网络抓取的形式!然而,“网络搜集”这个词通常指的是一个涉及自动化的过程。一些网站不喜欢自动抓取器收集他们的数据,而另一些网站则不介意。
如果你是出于教育目的而刮一页,那么你不太可能有任何问题。尽管如此,在你开始一个大规模项目之前,自己做一些调查,确保你没有违反任何服务条款是个好主意。
抓取网页的原因
假设你在网上和现实生活中都是一名冲浪者,你正在找工作。然而,你不是在找一份简单的工作。有了冲浪者的心态,你就在等待一个绝佳的机会来冲浪!
有一个求职网站正好提供你想要的工作种类。不幸的是,一个新的职位千载难逢,而且该网站不提供电子邮件通知服务。你想每天检查一下,但这听起来并不是最有趣和最有成效的消磨时间的方式。
值得庆幸的是,世界提供了其他方式来应用冲浪者的心态!不用每天查看工作网站,你可以使用 Python 来帮助自动化你的工作搜索的重复部分。自动网页抓取可以是一个加快数据收集过程的解决方案。你写一次你的代码,它会多次从很多页面获取你想要的信息。
相比之下,当您尝试手动获取想要的信息时,您可能会花费大量时间点击、滚动和搜索,尤其是当您需要来自定期更新新内容的网站的大量数据时。手动抓取网页会花费很多时间和重复。
网络上有如此多的信息,而且新的信息还在不断增加。您可能会对至少其中一些数据感兴趣,而且其中大部分都是现成的。无论你实际上是在找工作,还是想下载你最喜欢的艺术家的所有歌词,自动网络抓取都可以帮助你实现目标。
网络抓取的挑战
网络是从许多来源有机地发展起来的。它结合了许多不同的技术、风格和个性,并且一直发展到今天。换句话说,网络是一团糟!因此,在浏览网页时,你会遇到一些挑战:
-
品种:每个网站都不一样。虽然你会遇到重复出现的一般结构,但每个网站都是独一无二的,如果你想提取相关信息,就需要进行个性化处理。
-
持久性:网站不断变化。假设你已经建立了一个闪亮的新的网页抓取工具,它可以自动从你感兴趣的资源中挑选你想要的。你第一次运行你的脚本时,它运行得完美无缺。但是当你不久之后运行同样的脚本时,你会遇到令人沮丧的冗长的回溯栈!
不稳定的脚本是一个现实的场景,因为许多网站正在积极发展。一旦站点的结构改变了,你的抓取器可能就不能正确地导航站点地图或者找到相关的信息。好消息是,网站的许多变化都是小而渐进的,所以你很可能只需做最小的调整就能更新你的 scraper。
然而,请记住,由于互联网是动态的,您将构建的抓取器可能需要不断的维护。您可以设置持续集成来定期运行抓取测试,以确保您的主脚本不会在您不知情的情况下中断。
网络抓取的替代方案:API
一些网站提供商提供应用编程接口(API),允许你以预定义的方式访问他们的数据。使用 API,您可以避免解析 HTML。相反,你可以使用像 JSON 和 XML 这样的格式直接访问数据。HTML 主要是一种向用户可视化展示内容的方式。
当您使用 API 时,这个过程通常比通过 web 抓取收集数据更稳定。这是因为开发人员创建的 API 是供程序使用的,而不是供人眼使用的。
一个网站的前端表现可能会经常改变,但是网站设计的这种改变不会影响它的 API 结构。API 的结构通常更持久,这意味着它是站点数据的更可靠来源。
然而,API也可以改变。多样性和持久性的挑战既适用于 API,也适用于网站。此外,如果所提供的文档缺乏质量,自己检查 API 的结构会困难得多。
使用 API 收集信息所需的方法和工具超出了本教程的范围。要了解更多信息,请查看 Python 中的 API 集成。
刮假 Python 作业现场
在本教程中,您将构建一个 web scraper,从假 Python Jobs 站点获取 Python 软件开发人员职位列表。这是一个有虚假招聘信息的示例网站,你可以随意抓取来训练你的技能。您的 web scraper 将解析网站上的 HTML,挑选出相关的信息,并针对特定的单词过滤内容。
注意:本教程的前一个版本侧重于抓取怪物工作板,它已经改变,不再提供静态 HTML 内容。本教程的更新版本侧重于一个自托管的静态网站,它保证保持不变,并给你一个可靠的操场来练习你需要的网络抓取技能。
你可以从网上任何一个你能看到的网站上刮下来,但是这样做的难度取决于网站。本教程向您介绍了网页抓取,以帮助您了解整个过程。然后,你可以对每个你想抓取的网站应用同样的过程。
在整个教程中,你还会遇到一些练习块。您可以单击展开它们,并通过完成其中描述的任务来挑战自己。
步骤 1:检查你的数据源
在你写任何 Python 代码之前,你需要了解你想要抓取的网站。这应该是你想要解决的任何网络抓取项目的第一步。你需要了解网站的结构来提取对你有用的信息。首先用你最喜欢的浏览器打开你想要抓取的网站。
浏览网站
就像任何一个典型的求职者一样,点击网站并与之互动。例如,您可以滚动浏览网站的主页:
可以看到很多卡片格式的招聘信息,每个都有两个按钮。如果您点击应用,那么您将看到一个新页面,其中包含所选工作的更多详细描述。您可能还会注意到,当您与网站交互时,浏览器地址栏中的 URL 会发生变化。
破译 URL 中的信息
程序员可以在一个 URL 中编码很多信息。如果你先熟悉了 URL 的工作原理以及它们是由什么组成的,你的网络抓取之旅会容易得多。例如,您可能会发现自己在具有以下 URL 的详细信息页面上:
https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html
您可以将上述 URL 分解为两个主要部分:
- 基本 URL 代表网站搜索功能的路径。在上面的例子中,基本 URL 是
https://realpython.github.io/fake-jobs/。 - 以
.html结尾的具体站点位置是工作描述唯一资源的路径。
在这个网站上发布的任何工作都将使用相同的基本 URL。但是,独特资源的位置会因您查看的具体职位而异。
URL 可以包含比文件位置更多的信息。一些网站使用查询参数对您在执行搜索时提交的值进行编码。您可以将它们视为发送到数据库以检索特定记录的查询字符串。
您将在 URL 的末尾找到查询参数。例如,如果您转到实际上是,通过搜索栏在“澳大利亚”中搜索“软件开发人员”,您会看到 URL 发生了变化,将这些值作为查询参数包括在内:
https://au.indeed.com/jobs?q=software+developer&l=Australia
这个 URL 中的查询参数是?q=software+developer&l=Australia。查询参数由三部分组成:
- Start: 查询参数的开头用问号(
?)表示。 - 信息:构成一个查询参数的信息片段被编码成键-值对,其中相关的键和值通过等号(
key=value)连接在一起。 - 分隔符:每个 URL 可以有多个查询参数,用一个&符号(
&)分隔。
有了这些信息,您可以将 URL 的查询参数分成两个键值对:
q=software+developer选择工作类型。l=Australia选择工作的地点。
尝试改变搜索参数,并观察如何影响你的网址。继续在顶部的搜索栏中输入新值:

接下来,尝试直接在 URL 中更改这些值。看看当您将以下 URL 粘贴到浏览器的地址栏时会发生什么:
https://au.indeed.com/jobs?q=developer&l=perth
如果您更改并提交网站搜索框中的值,那么它将直接反映在 URL 的查询参数中,反之亦然。如果你改变其中任何一个,那么你会在网站上看到不同的结果。
正如您所看到的,浏览网站的 URL 可以让您了解如何从网站的服务器检索数据。
回到假 Python Jobs 继续探索。这个网站是一个纯粹的静态网站,它不在数据库上运行,这就是为什么在这个抓取教程中你不必使用查询参数。
使用开发工具检查网站
接下来,您将想要了解更多关于数据是如何组织显示的信息。您需要理解页面结构,以便从 HTML 响应中选择您想要的内容,您将在接下来的步骤中收集这些响应。
开发者工具可以帮助你了解一个网站的结构。所有现代浏览器都安装了开发工具。在这一节中,你将看到如何使用 Chrome 中的开发者工具。这个过程将与其他现代浏览器非常相似。
在 macOS 上的 Chrome 中,选择视图 → 开发者 → 开发者工具,就可以通过菜单打开开发者工具。在 Windows 和 Linux 上,您可以通过单击右上角的菜单按钮(⋮)并选择更多工具 → 开发者工具来访问它们。您也可以通过右击页面并选择检查选项或使用键盘快捷键来访问您的开发人员工具:
- Mac:
Cmd+Alt+I - Windows/Linux:
Ctrl+Shift+I
开发者工具允许你交互式地探索站点的文档对象模型(DOM) 来更好地理解你的源代码。要深入你的页面的 DOM,在开发者工具中选择元素标签。您将看到一个带有可点击 HTML 元素的结构。您可以在浏览器中展开、折叠甚至编辑元素:
您可以将浏览器中显示的文本视为该页面的 HTML 结构。如果你感兴趣,那么你可以在 CSS-TRICKS 上阅读更多关于 DOM 和 HTML 的区别。
当您右键单击页面上的元素时,您可以选择 Inspect 来缩放到它们在 DOM 中的位置。您还可以将鼠标悬停在右侧的 HTML 文本上,看到页面上相应的元素亮起。
单击展开特定任务的练习模块,练习使用开发人员工具:
找到一个单一的工作发布。它被包装在什么 HTML 元素中,它还包含哪些 HTML 元素?
四处游玩,探索!你越了解你正在处理的页面,就越容易刮开它。然而,不要被那些 HTML 文本弄得不知所措。您将使用编程的力量来逐步通过这个迷宫,挑选与您相关的信息。
第二步:从页面中抓取 HTML 内容
既然您已经对正在处理的东西有了概念,那么是时候开始使用 Python 了。首先,您需要将站点的 HTML 代码放入 Python 脚本中,以便与它进行交互。对于这个任务,您将使用 Python 的 requests 库。
在安装任何外部包之前,为您的项目创建一个虚拟环境。激活新的虚拟环境,然后在终端中键入以下命令来安装外部requests库:
(venv) $ python -m pip install requests
然后在你最喜欢的文本编辑器中打开一个新文件。检索 HTML 只需要几行代码:
import requests
URL = "https://realpython.github.io/fake-jobs/"
page = requests.get(URL)
print(page.text)
这段代码向给定的 URL 发出一个 HTTP GET请求。它检索服务器发回的 HTML 数据,并将这些数据存储在一个 Python 对象中。
如果你打印page的.text属性,那么你会注意到它看起来就像你之前用浏览器的开发工具检查的 HTML。您成功地从 Internet 上获取了静态站点内容!现在,您可以从 Python 脚本中访问该站点的 HTML。
静态网站
你在本教程中抓取的网站提供静态 HTML 内容。在这种情况下,托管站点的服务器发回 HTML 文档,这些文档已经包含了用户将看到的所有数据。
当您之前使用开发人员工具检查该页面时,您发现一个职位发布由以下看起来又长又乱的 HTML 组成:
<div class="card">
<div class="card-content">
<div class="media">
<div class="media-left">
<figure class="image is-48x48">
<img
src="https://files.realpython.com/media/real-python-logo-thumbnail.7f0db70c2ed2.jpg"
alt="Real Python Logo"
/>
</figure>
</div>
<div class="media-content">
<h2 class="title is-5">Senior Python Developer</h2>
<h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3>
</div>
</div>
<div class="content">
<p class="location">Stewartbury, AA</p>
<p class="is-small has-text-grey">
<time datetime="2021-04-08">2021-04-08</time>
</p>
</div>
<footer class="card-footer">
<a
href="https://www.realpython.com"
target="_blank"
class="card-footer-item"
>Learn</a
>
<a
href="https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html"
target="_blank"
class="card-footer-item"
>Apply</a
>
</footer>
</div>
</div>
要理解一大段 HTML 代码可能很有挑战性。为了更容易阅读,你可以使用一个 HTML 格式器来自动清理它。良好的可读性有助于您更好地理解任何代码块的结构。虽然它可能有助于改进 HTML 格式,也可能没有,但总是值得一试。
注意:记住,每个网站看起来都不一样。这就是为什么在前进之前,有必要检查和理解你当前正在处理的网站的结构。
您将遇到的 HTML 有时会令人困惑。幸运的是,这个工作板的 HTML 在您感兴趣的元素上有描述性的类名:
class="title is-5"包含了职位发布的标题。class="subtitle is-6 company"包含提供职位的公司名称。class="location"包含你将要工作的地点。
如果您曾经迷失在一大堆 HTML 中,请记住,您可以随时返回到您的浏览器,并使用开发工具来进一步交互式地探索 HTML 结构。
到目前为止,您已经成功地利用了 Python 的requests库的强大功能和用户友好的设计。只用几行代码,您就成功地从 Web 上抓取了静态 HTML 内容,并使其可用于进一步处理。
然而,当你抓取网站时,你可能会遇到更具挑战性的情况。在学习如何从刚刚搜集的 HTML 中挑选相关信息之前,您将快速浏览两种更具挑战性的情况。
隐藏的网站
有些页面包含隐藏在登录名后面的信息。这意味着你需要一个账户来从页面中抓取任何内容。从 Python 脚本发出 HTTP 请求的过程不同于从浏览器访问页面的过程。仅仅因为你可以通过你的浏览器登录页面,并不意味着你可以用你的 Python 脚本抓取它。
然而,requests库自带了处理认证的内置能力。使用这些技术,您可以在从 Python 脚本发出 HTTP 请求时登录网站,然后抓取隐藏在登录后面的信息。您不需要登录就可以访问工作公告板信息,这也是本教程不讨论身份验证的原因。
动态网站
在本教程中,你将学习如何抓取一个静态网站。静态站点很容易处理,因为服务器向您发送的 HTML 页面已经包含了响应中的所有页面信息。您可以解析 HTML 响应,并立即开始挑选相关数据。
另一方面,对于一个动态网站来说,服务器可能根本不会发回任何 HTML。相反,您可以接收到作为响应的 JavaScript 代码。这段代码看起来与您用浏览器的开发工具检查页面时看到的完全不同。
注意:在本教程中,术语动态网站指的是当你在浏览器中查看页面时,不会返回相同 HTML 的网站。
许多现代 web 应用程序被设计为与客户端的浏览器协作来提供它们的功能。这些应用程序不是发送 HTML 页面,而是发送 JavaScript 代码,指示你的浏览器创建想要的 HTML。Web 应用程序以这种方式提供动态内容,将工作从服务器转移到客户端机器,同时避免页面重新加载,改善整体用户体验。
浏览器中发生的情况与脚本中发生的情况不同。您的浏览器将努力执行从服务器接收的 JavaScript 代码,并在本地为您创建 DOM 和 HTML。但是,如果您在 Python 脚本中请求一个动态网站,那么您将不会获得 HTML 页面内容。
当你使用requests时,你只接收服务器发回的内容。在动态网站的情况下,你最终会得到一些 JavaScript 代码,而不是 HTML。从你收到的 JavaScript 代码到你感兴趣的内容的唯一方法是执行代码,就像你的浏览器一样。requests库不能为您做到这一点,但是有其他解决方案可以做到。
例如, requests-html 是由requests库的作者创建的一个项目,它允许您使用类似于requests中的语法来呈现 JavaScript。它还包括通过使用漂亮的汤来解析数据的能力。
注:另一种流行的抓取动态内容的选择是硒。您可以将 Selenium 视为一个精简的浏览器,它在将呈现的 HTML 响应传递给脚本之前为您执行 JavaScript 代码。
在本教程中,您不会深入研究抓取动态生成的内容。现在,如果你需要创建一个动态的网站,记住上面提到的选项之一就足够了。
第三步:用美汤解析 HTML 代码
你已经成功地从互联网上抓取了一些 HTML,但是当你看它的时候,它看起来就像一个巨大的混乱。到处都有成吨的 HTML 元素,成千上万的属性散布在各处——难道不是也混合了一些 JavaScript 吗?现在是时候在 Python 的帮助下解析这个冗长的代码响应,使其更易于访问,并挑选出您想要的数据。
美汤是用于解析结构化数据的 Python 库。它允许您以类似于使用开发工具与网页交互的方式与 HTML 交互。该库公开了几个直观的函数,您可以使用它们来研究您收到的 HTML。首先,使用您的终端安装 Beautiful Soup:
(venv) $ python -m pip install beautifulsoup4
然后,在 Python 脚本中导入库,并创建一个漂亮的 Soup 对象:
import requests
from bs4 import BeautifulSoup
URL = "https://realpython.github.io/fake-jobs/"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
当您添加这两行突出显示的代码时,您创建了一个漂亮的 Soup 对象,它将前面抓取的 HTML 内容作为输入。
注意:为了避免字符编码的问题,你需要传递page.content而不是page.text。.content属性保存原始字节,比您之前使用.text属性打印的文本表示更容易解码。
第二个参数是"html.parser",它确保使用合适的解析器来解析 HTML 内容。
通过 ID 查找元素
在 HTML 网页中,每个元素都可以分配一个id属性。顾名思义,id属性使得元素在页面上是唯一可识别的。您可以通过按 ID 选择特定元素来开始解析页面。
切换回开发人员工具,识别包含所有职位发布的 HTML 对象。将鼠标悬停在页面的某些部分上并使用右键单击来检查来进行浏览。
注意:定期切换回您的浏览器并使用开发者工具交互式地浏览页面会有所帮助。这有助于您了解如何找到您正在寻找的确切元素。
您正在寻找的元素是一个具有值为"ResultsContainer"的id属性的<div>。它也有一些其他的属性,但是下面是你正在寻找的要点:
<div id="ResultsContainer">
<!-- all the job listings -->
</div>
Beautiful Soup 允许您通过 ID 找到特定的 HTML 元素:
results = soup.find(id="ResultsContainer")
为了便于查看,你可以在打印时美化任何漂亮的汤。如果您在上面刚刚赋值的results变量上调用.prettify(),那么您将看到包含在<div>中的所有 HTML:
print(results.prettify())
当您使用元素的 ID 时,您可以从其余的 HTML 中挑选出一个元素。现在,您可以只处理页面 HTML 的这一特定部分。看起来汤变得有点稀了!不过,还是挺密的。
通过 HTML 类名查找元素
您已经看到每个职位发布都包装在一个带有类card-content的<div>元素中。现在,您可以使用名为results的新对象,并只选择其中的招聘信息。毕竟,这些是您感兴趣的 HTML 部分!您可以在一行代码中做到这一点:
job_elements = results.find_all("div", class_="card-content")
在这里,您调用一个漂亮的 Soup 对象上的.find_all(),它返回一个可迭代的,包含该页面上显示的所有工作列表的所有 HTML。
看一看它们:
for job_element in job_elements:
print(job_element, end="\n"*2)
这已经很好了,但是仍然有很多 HTML!您在前面已经看到,您的页面在某些元素上有描述性的类名。您可以使用.find()从每个职位发布中挑选出这些子元素:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title") company_element = job_element.find("h3", class_="company") location_element = job_element.find("p", class_="location") print(title_element)
print(company_element)
print(location_element)
print()
每个job_element是另一个BeautifulSoup()对象。因此,您可以对它使用与其父元素results相同的方法。
有了这个代码片段,您就离真正感兴趣的数据越来越近了。尽管如此,所有这些 HTML 标签和属性仍然存在很多问题:
<h2 class="title is-5">Senior Python Developer</h2>
<h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3>
<p class="location">Stewartbury, AA</p>
接下来,您将学习如何缩小输出范围,只访问您感兴趣的文本内容。
从 HTML 元素中提取文本
您只想查看每个工作发布的标题、公司和地点。看哪!美味的汤已经覆盖了你。您可以将.text添加到一个漂亮的 Soup 对象中,只返回该对象包含的 HTML 元素的文本内容:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.text) print(company_element.text) print(location_element.text) print()
运行上面的代码片段,您将看到显示的每个元素的文本。然而,你也有可能得到一些额外的空白。因为你现在正在使用 Python 字符串,你可以.strip()多余的空白。您还可以应用任何其他熟悉的 Python 字符串方法来进一步清理您的文本:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.text.strip()) print(company_element.text.strip()) print(location_element.text.strip()) print()
结果看起来好得多:
Senior Python Developer
Payne, Roberts and Davis
Stewartbury, AA
Energy engineer
Vasquez-Davidson
Christopherville, AA
Legal executive
Jackson, Chambers and Levy
Port Ericaburgh, AA
这是一份可读的工作列表,其中还包括公司名称和每个工作的地点。然而,你正在寻找一个软件开发人员的职位,这些结果也包含了许多其他领域的职位信息。
通过类名和文本内容查找元素
并非所有的工作列表都是开发人员的工作。你不用把网站上列出的所有工作都打印出来,而是先用关键词筛选出来。
您知道页面中的职位保存在<h2>元素中。要仅过滤特定的作业,您可以使用 string参数:
python_jobs = results.find_all("h2", string="Python")
这段代码查找包含的字符串与"Python"完全匹配的所有<h2>元素。注意,你是在直接调用第一个results变量的方法。如果您继续将上面的代码片段输出到您的控制台,那么您可能会失望,因为它将是空的:
>>> print(python_jobs) []搜索结果中有和Python 作业,那么为什么没有显示出来呢?
当你像上面那样使用
string=时,你的程序会准确地寻找字符串*。拼写、大小写或空格方面的任何差异都将阻止元素匹配。在下一节中,您将找到一种使您的搜索字符串更加通用的方法。传递一个函数给一个漂亮的汤方法
除了字符串之外,有时还可以将函数作为参数传递给漂亮的 Soup 方法。您可以将前面的代码行改为使用函数:
python_jobs = results.find_all( "h2", string=lambda text: "python" in text.lower() )现在你将一个匿名函数传递给
string=参数。 lambda 函数查看每个<h2>元素的文本,将其转换为小写,并检查子字符串"python"是否存在。您可以使用这种方法检查是否成功识别了所有 Python 作业:
>>> print(len(python_jobs))
10
您的程序找到了标题中包含单词"python"的10匹配职位!
根据文本内容查找元素是过滤 HTML 响应中特定信息的一种有效方法。Beautiful Soup 允许您使用精确的字符串或函数作为参数来过滤 Beautiful Soup 对象中的文本。
然而,当您尝试运行 scraper 来打印出过滤后的 Python 作业的信息时,您会遇到一个错误:
AttributeError: 'NoneType' object has no attribute 'text'
这条消息是一个常见错误,当你从互联网上搜集信息时会经常遇到。检查python_jobs列表中元素的 HTML。它看起来像什么?你认为错误来自哪里?
识别错误条件
当您查看python_jobs中的单个元素时,您会看到它仅由包含职位的<h2>元素组成:
<h2 class="title is-5">Senior Python Developer</h2>
当您重新查看用于选择项目的代码时,您会发现这就是您的目标。您仅筛选了包含单词"python"的职位发布的<h2>标题元素。如您所见,这些元素不包括关于工作的其他信息。
您之前收到的错误消息与此相关:
AttributeError: 'NoneType' object has no attribute 'text'
您试图在python_jobs的每个元素中找到职位、公司名称和职位的位置,但是每个元素只包含职位文本。
你勤奋的解析库仍然会寻找其他的,并返回 None ,因为它找不到它们。然后,当您试图从这些None对象之一中提取.text属性时,print()失败并显示错误消息。
您要查找的文本嵌套在过滤器返回的<h2>元素的同级元素中。Beautiful Soup 可以帮助您选择每个 Beautiful Soup 对象的兄弟元素、子元素和父元素。
访问父元素
获取所有所需信息的一种方法是从您识别的<h2>元素开始,在 DOM 的层次结构中向上移动。再看一下一个职位发布的 HTML。找到包含职位的<h2>元素以及包含您感兴趣的所有信息的最接近的父元素:
<div class="card">
<div class="card-content"> <div class="media">
<div class="media-left">
<figure class="image is-48x48">
<img
src="https://files.realpython.com/media/real-python-logo-thumbnail.7f0db70c2ed2.jpg"
alt="Real Python Logo"
/>
</figure>
</div> <div class="media-content">
<h2 class="title is-5">Senior Python Developer</h2>
<h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3>
</div>
</div>
<div class="content">
<p class="location">Stewartbury, AA</p>
<p class="is-small has-text-grey">
<time datetime="2021-04-08">2021-04-08</time>
</p>
</div>
<footer class="card-footer">
<a
href="https://www.realpython.com"
target="_blank"
class="card-footer-item"
>Learn</a
>
<a
href="https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html"
target="_blank"
class="card-footer-item"
>Apply</a
>
</footer>
</div>
</div>
带有card-content类的<div>元素包含了您想要的所有信息。它是使用过滤器找到的<h2> title 元素的第三级父元素。
记住这些信息后,您现在可以使用python_jobs中的元素并获取它们的曾祖父元素来访问您想要的所有信息:
python_jobs = results.find_all(
"h2", string=lambda text: "python" in text.lower()
)
python_job_elements = [
h2_element.parent.parent.parent for h2_element in python_jobs
]
您添加了一个列表理解,它对通过 lambda 表达式过滤得到的python_jobs中的每个<h2>标题元素进行操作。您正在选择每个<h2>标题元素的父元素的父元素的父元素。那可是三代以上!
当您查看一个工作发布的 HTML 时,您发现这个类名为card-content的特定父元素包含了您需要的所有信息。
现在您可以修改您的 for循环中的代码来迭代父元素:
for job_element in python_job_elements:
# -- snip --
当您下次运行您的脚本时,您将看到您的代码再次可以访问所有相关信息。这是因为您现在循环的是<div class="card-content">元素,而不仅仅是<h2>标题元素。
使用每个漂亮的 Soup 对象自带的.parent属性,为您提供了一种直观的方式来遍历您的 DOM 结构并处理您需要的元素。您也可以用类似的方式访问子元素和同级元素。阅读导航树了解更多信息。
从 HTML 元素中提取属性
此时,您的 Python 脚本已经抓取了站点并过滤了相关职位发布的 HTML。干得好!但是,还缺少的是求职的环节。
当您查看页面时,您发现每张卡片底部有两个链接。如果您以处理其他元素的方式来处理 link 元素,您将无法获得感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行这个代码片段,那么您将得到链接文本Learn和Apply,而不是相关联的 URL。
这是因为.text属性只留下了 HTML 元素的可见内容。它去掉了所有的 HTML 标签,包括包含 URL 的 HTML 属性,只留下链接文本。要获取 URL,您需要提取其中一个 HTML 属性的值,而不是丢弃它。
链接元素的 URL 与href属性相关联。您正在寻找的特定 URL 是单个职位发布的 HTML 底部第二个<a>标签的href属性的值:
<!-- snip -->
<footer class="card-footer">
<a href="https://www.realpython.com" target="_blank"
class="card-footer-item">Learn</a>
<a href="https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html"
target="_blank"
class="card-footer-item">Apply</a>
</footer>
</div>
</div>
从获取工作卡中的所有<a>元素开始。然后,使用方括号符号提取它们的href属性的值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"] print(f"Apply here: {link_url}\n")
在这个代码片段中,您首先从每个经过筛选的职位发布中获取所有链接。然后使用["href"]提取包含 URL 的href属性,并将其打印到您的控制台。
在下面的练习模块中,您可以找到挑战的说明,以优化您收到的链接结果:
每个工作卡都有两个关联的链接。您只需要寻找第个第二个链接。如何编辑上面显示的代码片段,以便总是只收集第二个链接的 URL?
单击解决方案模块,阅读本练习的可能解决方案:
要获取每个工作卡的第二个链接的 URL,可以使用下面的代码片段:
for job_element in python_job_elements:
link_url = job_element.find_all("a")[1]["href"] print(f"Apply here: {link_url}\n")
您通过索引([1])从.find_all()的结果中选择了的第二个链接元素。然后使用方括号符号直接提取 URL,并处理href属性(["href"])。
您也可以使用相同的方括号符号来提取其他 HTML 属性。
继续练习
如果您已经编写了本教程旁边的代码,那么您可以直接运行您的脚本,您将会看到在您的终端上弹出的假的作业信息。你的下一步是解决一个现实生活中的工作板!要继续练习您的新技能,请使用以下任意或所有网站重新浏览网页抓取流程:
链接的网站以静态 HTML 响应的形式返回搜索结果,类似于假的 Python 求职板。因此,你可以只用requests和漂亮的汤来刮它们。
使用其他网站从头开始再次浏览本教程。你会发现每个网站的结构都是不同的,你需要以稍微不同的方式重新构建代码来获取你想要的数据。应对这个挑战是实践你刚刚学到的概念的好方法。虽然这可能会让你不时地流汗,但你的编码技能会因此变得更强!
在你的第二次尝试中,你还可以探索美丽的汤的其他特点。使用文档作为你的指南和灵感。额外的练习将帮助你更熟练地使用 Python、requests和 Beautiful Soup 进行网页抓取。
为了结束您的 web 抓取之旅,您可以对您的代码进行最后的改造,并创建一个命令行界面(CLI) 应用程序,该应用程序抓取一个工作公告板,并根据每次执行时可以输入的关键字过滤结果。您的 CLI 工具允许您搜索特定类型的作业或特定位置的作业。
如果您有兴趣了解如何将您的脚本改编为命令行界面,那么请查看如何使用 argparse 在 Python 中构建命令行界面。
结论
requests库为您提供了一种使用 Python 从互联网获取静态 HTML 的用户友好方式。然后,您可以用另一个名为 Beautiful Soup 的包解析 HTML。这两个软件包都是值得信赖的,有助于您的网络抓取冒险的伙伴。你会发现美汤会迎合你的大部分解析需求,包括导航和高级搜索。
在本教程中,您学习了如何使用 Python、requests和 Beautiful Soup 从 Web 上抓取数据。您构建了一个从互联网上获取职位发布的脚本,并从头到尾经历了完整的 web 抓取过程。
您学习了如何:
- 从头到尾遍历一条网页抓取管道
- 用你浏览器的开发者工具检查你目标网站的 HTML 结构
- 解密编码在URL中的数据
- 使用 Python 的
requests库下载页面的 HTML 内容 - 用美汤解析下载的 HTML,提取相关信息
- 构建一个脚本,从网络上获取工作机会,并在你的控制台上显示相关信息
有了这个广阔的管道和工具箱中的两个强大的库,你就可以出去看看还能找到什么网站。玩得开心,永远记得要尊重和负责任地使用你的编程技能。
您可以通过单击下面的链接下载您在本教程中构建的示例脚本的源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程的项目和示例中使用。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 网刮用美汤和 Python***************
Python 海龟入门指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 蟒龟初学
当我还是个孩子的时候,我曾经学过 Logo ,一种编程语言,里面有一只乌龟,你只需要几个命令就可以在屏幕上移动它。我记得当我控制屏幕上的这个小东西时,我感觉自己像个计算机天才,这也是我最初对编程感兴趣的原因。Python turtle库提供了类似的交互特性,让新程序员体验使用 Python 的感觉。
在本教程中,您将:
- 了解什么是 Python
turtle库 - 学习如何在电脑上设置
turtle - 用 Python
turtle库编程 - 掌握一些重要的 Python 概念和
turtle命令 - 利用你所学的知识开发一个简短但有趣的游戏
如果你是 Python 的初学者,那么本教程将帮助你在 Python 库的帮助下迈出编程世界的第一步!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
了解 Python turtle库
turtle是一个预装的 Python 库,通过为用户提供虚拟画布,用户可以创建图片和形状。你用来画画的屏幕笔被称为海龟,这就是这个图书馆的名字。简而言之,Python turtle库帮助新程序员以有趣和互动的方式体验用 Python 编程的感觉。
turtle主要用于向孩子介绍计算机的世界。这是理解 Python 概念的一种简单而通用的方式。这为的孩子们迈出 Python 编程的第一步提供了一个很好的途径。话虽如此,Python turtle库并不仅限于小家伙!事实证明,它对尝试学习 Python 的成年人非常有用,这对于 Python 初学者来说非常有用。
使用 Python turtle库,您可以绘制和创建各种类型的形状和图像。这里有一个你可以用turtle制作的绘图类型的例子:
很酷,对吧?这只是你可以使用 Python turtle库绘制的许多不同图形中的一个。大多数开发人员使用turtle来绘制形状、创建设计和制作图像。其他人使用turtle来创建迷你游戏和动画,就像你在上面看到的那样。
turtle 入门
在继续之前,您需要做两件重要的事情来充分利用本教程:
-
Python 环境:确保你熟悉你的编程环境。你可以用闲置或者 Jupyter 笔记本这样的应用来和
turtle一起编程。然而,如果你不习惯使用它们,那么你可以用 REPL 编程,你将在本教程中使用它。 -
Python 版本:确保你的电脑上有 Python 的版本 3。如果没有,那么你可以从 Python 网站下载。要帮助设置,请查看 Python 3 安装&设置指南。
turtle的好处是它是一个内置的库,所以你不需要安装任何新的包。您所需要做的就是将库导入到您的 Python 环境中,在本例中就是 REPL。打开 REPL 应用程序后,您可以通过键入以下代码行在其上运行 Python 3:
>>> python3这会将 Python 3 调用到您的 REPL 应用程序中,并为您打开环境。
在开始 Python 编程之前,您需要理解什么是库。在非计算机世界里,图书馆是存放不同类型书籍的地方。你可以随时查阅这些书,从中获取你需要的任何信息,然后把它们放回原处。
在计算机世界里,图书馆也是类似的工作方式。根据定义,库是一组重要的函数和方法,您可以通过访问它们来简化编程。Python
turtle库包含了创建图像所需的所有方法和函数。要访问一个 Python 库,您需要将它导入到您的 Python 环境中,就像这样:
>>> import turtle
现在您的 Python 环境中已经有了turtle,您可以开始用它编程了。turtle是一个图形库,这意味着你需要创建一个单独的窗口(称为屏幕)来执行每个绘图命令。你可以通过初始化一个变量来创建这个屏幕。
在 Python 中,您使用变量来存储稍后将在您的程序中使用的信息。当你给一个变量赋值的时候,你初始化了这个变量。因为变量的值不是恒定的,所以在程序执行过程中它会改变几次。
现在,要打开turtle屏幕,你用下面的方法为它初始化一个变量:
>>> s = turtle.getscreen()您应该会看到一个单独的窗口打开:
这个窗口被称为屏幕。您可以在这里查看代码的输出。屏幕中间的黑色小三角形被称为龟。
注意:记住当你给一个变量命名时,你需要选择一个看你程序的人容易理解的名字。但是,您还必须选择一个方便使用的名称,特别是因为您将在整个程序中经常调用它!
例如,选择一个像
my_turtle_screen_name这样的名字会使输入变得乏味,而像Joe或a这样的名字会显得非常随意。使用单个字母字符,如本例中的s,会更合适。那是因为它短而甜,清楚的记得字母s指的是屏。接下来,初始化变量
t,然后在整个程序中使用它来引用海龟:
>>> t = turtle.Turtle()
就像屏幕一样,你也可以给这个变量取另一个名字,比如a或者Jane甚至my_turtle,但是在这种情况下,你将坚持使用t。
你现在有了屏幕和海龟。屏幕就像一块画布,而乌龟就像一支笔。你可以设定乌龟在屏幕上移动。海龟有一些多变的特征,比如大小、颜色和速度。它总是指向一个特定的方向,并且会向那个方向移动,除非你告诉它:
- 当 up 时,表示移动时不画线。
- 当向下时,表示移动时会画一条线。
在下一节中,您将探索使用 Python turtle库编程的不同方式。
用turtle 编程
使用 Python turtle库编程时,你要学的第一件事是如何让海龟朝你想要的方向移动。接下来,你将学习如何定制你的海龟和它的环境。最后,您将学习几个额外的命令,使用它们您可以执行一些特殊的任务。
移动乌龟
乌龟可以向四个方向移动:
- 向前
- 向后的
- 左边的
- 对吧
乌龟朝它面对的方向移动.forward()或.backward()。您可以通过将.left()或.right()旋转一定角度来改变这个方向。您可以像这样尝试这些命令:
>>> t.right(90) >>> t.forward(100) >>> t.left(90) >>> t.backward(100)当你运行这些命令时,海龟将向右转 90 度,向前移动 100 个单位,向左转 90 度,向后移动 100 个单位。您可以在下图中看到这一点:
您也可以使用这些命令的缩写版本:
t.rt()而不是t.right()t.fd()而不是t.forward()t.lt()而不是t.left()t.bk()而不是t.backward()你也可以从当前位置画一条线到屏幕上的任意位置。这是在坐标的帮助下完成的:
屏幕被分成四个象限。乌龟在你程序开始时最初定位的点是
(0,0)。这就是所谓的家。要将乌龟移动到屏幕上的任何其他区域,您可以使用.goto()并像这样输入坐标:
>>> t.goto(100,100)
您的输出将如下所示:
您从当前位置到屏幕上的点(100,100)画了一条线。
要将海龟带回原位,您可以键入以下命令:
>>> t.home()这就像一个快捷命令,把乌龟送回
(0,0)点。比敲t.goto(0,0)还快。画一个形状
现在你知道了海龟的动作,你可以继续制作实际的形状了。你可以从画多边形开始,因为它们都由以一定角度连接的直线组成。这里有一个例子,你可以试试:
>>> t.fd(100)
>>> t.rt(90)
>>> t.fd(100)
>>> t.rt(90)
>>> t.fd(100)
>>> t.rt(90)
>>> t.fd(100)
您的输出将如下所示:
干得好!你刚刚画了一个正方形。这样,乌龟就可以被编程创造出不同的形状和形象。
现在,尝试绘制一个矩形,使用此代码作为模板。记住,在一个长方形里,所有的四条边都不相等。您需要相应地更改代码。一旦你这样做了,你甚至可以通过增加边数和改变角度来创建其他多边形。
绘制预设图形
假设你想画一个圆。如果你试图用画正方形的方法来画它,那将会非常乏味,你将不得不花很多时间来画这个形状。谢天谢地,Python turtle库为此提供了一个解决方案。您可以使用一个命令来绘制圆:
>>> t.circle(60)您将得到如下输出:
括号内的数字是圆的半径。您可以通过更改圆的半径值来增大或减小圆的大小。
同理,你也可以画一个点,无非就是一个填满的圆。键入以下命令:
>>> t.dot(20)
你会得到一个这样的实心圆:
括号内的数字是圆点的直径。就像圆一样,你可以通过改变它的直径值来增加或减少点的大小。
到目前为止做得很好!你已经学会了如何移动乌龟,并用它创造不同的形状。在接下来的几节中,您将看到如何根据您的需求定制您的 turtle 及其环境。
改变屏幕颜色
默认情况下,turtle总是打开一个白色背景的屏幕。但是,您可以使用以下命令随时更改屏幕的颜色:
>>> turtle.bgcolor("blue")您可以将
"blue"替换为任何其他颜色。试试"green"或者"red"。你会得到这样一个结果:
只要输入他们的十六进制代码T2 号,你就可以为你的屏幕使用多种颜色。要了解更多关于使用不同颜色的知识,请查看 Python 库
turtle文档。更改屏幕标题
有时,你可能想改变屏幕的标题。你可以让它更个性化,比如
"My Turtle Program",或者更适合你正在做的事情,比如"Drawing Shapes With Turtle"。您可以在此命令的帮助下更改屏幕标题:
>>> turtle.title("My Turtle Program")
您的标题栏现在将显示:
这样,你可以根据自己的喜好改变屏幕的标题。
改变乌龟的大小
你可以增加或减少屏幕上海龟的尺寸,使其变大或变小。这仅改变形状的大小,而不影响笔在屏幕上绘制时的输出。尝试键入以下命令:
>>> t.shapesize(1,5,10) >>> t.shapesize(10,5,1) >>> t.shapesize(1,10,5) >>> t.shapesize(10,1,5)您的输出将如下所示:
给出的数字是乌龟大小的参数:
- 拉伸长度
- 拉伸宽度
- 轮廓宽度
您可以根据自己的喜好更改这些内容。在上面给出的例子中,你可以看到乌龟外表的明显不同。关于如何改变乌龟大小的更多信息,请查看 Python 库文档。
改变笔的尺寸
前面的命令只改变了乌龟形状的大小。但是,有时,您可能需要增加或减少笔的粗细。您可以使用以下命令来完成此操作:
>>> t.pensize(5)
>>> t.forward(100)
这将导致如下结果:
如你所见,你的笔的大小现在是原来的五倍(原来是一倍)。试着多画一些不同大小的线,比较它们之间的粗细差异。
改变乌龟和钢笔的颜色
当你第一次打开一个新的屏幕时,乌龟开始是一个黑色的图形,并用黑色墨水绘制。根据您的要求,您可以做两件事:
- 改变乌龟的颜色:改变填充颜色。
- 改变笔的颜色:改变轮廓或墨水颜色。
如果你愿意,你甚至可以两者都选。在你改变颜色之前,增加你的乌龟的大小,以帮助你更清楚地看到颜色的差异。键入以下代码:
>>> t.shapesize(3,3,3)现在,要更改乌龟的颜色(或填充),您可以键入以下内容:
>>> t.fillcolor("red")
你的乌龟看起来会像这样:
要更改钢笔(或轮廓)的颜色,请键入以下内容:
>>> t.pencolor("green")你的乌龟看起来会像这样:
要更改两者的颜色,请键入以下内容:
>>> t.color("green", "red")
你的乌龟看起来会像这样:
这里,第一种颜色用于钢笔,第二种颜色用于填充。注意,改变钢笔和填充的颜色也会相应地改变屏幕上海龟的颜色。
填充图像
在图像中着色通常会使图像看起来更好,不是吗?Python turtle库为你提供了给你的绘图添加颜色的选项。尝试键入以下代码,看看会发生什么:
>>> t.begin_fill() >>> t.fd(100) >>> t.lt(120) >>> t.fd(100) >>> t.lt(120) >>> t.fd(100) >>> t.end_fill()当您执行这段代码时,您将得到一个用纯色填充的三角形,如下所示:
当你使用
.begin_fill()时,你告诉你的程序你将要画一个需要填充的闭合形状。然后,您使用.end_fill()来表示您已经完成了形状的创建,现在可以填充它了。改变乌龟的形状
乌龟的最初形状并不是真正的乌龟,而是三角形。然而,你可以改变海龟的样子,当你这么做的时候,你有几个选择。您可以通过键入以下命令来查看其中的一些:
>>> t.shape("turtle")
>>> t.shape("arrow")
>>> t.shape("circle")
乌龟的形状会相应地改变,就像这样:
您也可以尝试几个其他选项:
- 平方
- 箭
- 圆
- 龟
- 三角形
- 经典的
经典造型就是原始造型。查看 Python turtle库文档,了解更多关于你可以使用的形状类型。
改变笔速
海龟通常以适中的速度移动。如果你想降低或增加速度来让你的乌龟移动得更慢或更快,那么你可以通过键入以下命令来实现:
>>> t.speed(1) >>> t.forward(100) >>> t.speed(10) >>> t.forward(100)这段代码将首先降低速度并向前移动乌龟,然后提高速度并再次向前移动乌龟,就像这样:
速度可以是从 0(最低速度)到 10(最高速度)之间的任何数字。你可以摆弄你的代码,看看乌龟跑得有多快或多慢。
一行定制
假设你想设置你的海龟的特征如下:
- 钢笔颜色:紫色
- 填充颜色:橙色
- 笔尺寸: 10
- 笔速: 9
从您刚刚学到的内容来看,代码应该是这样的:
>>> t.pencolor("purple")
>>> t.fillcolor("orange")
>>> t.pensize(10)
>>> t.speed(9)
>>> t.begin_fill()
>>> t.circle(90)
>>> t.end_fill()
很长,但没那么糟,对吧?
现在,想象一下如果你有十只不同的海龟。改变他们所有的特征对你来说是非常令人厌倦的!好消息是,您可以通过修改单行代码中的参数来减少工作量,如下所示:
>>> t.pen(pencolor="purple", fillcolor="orange", pensize=10, speed=9) >>> t.begin_fill() >>> t.circle(90) >>> t.end_fill()这会给你一个这样的结果:
这一行代码改变了整个笔,而您不必单独改变每个特征。要了解关于这个命令的更多信息,请查看 Python
turtle库文档。干得好!现在你已经学会了定制你的乌龟和屏幕,看看用 Python
turtle库绘图时需要的其他一些重要命令。上下拿起笔
有时候,你可能想把你的乌龟移到屏幕上的另一个点,而不在屏幕上画任何东西。为此,您可以使用
.penup()。然后,当你想再次开始绘图时,你使用.pendown()。使用您之前用来绘制正方形的代码尝试一下。尝试键入以下代码:
>>> t.fd(100)
>>> t.rt(90)
>>> t.penup()
>>> t.fd(100)
>>> t.rt(90)
>>> t.pendown()
>>> t.fd(100)
>>> t.rt(90)
>>> t.penup()
>>> t.fd(100)
>>> t.pendown()
当您运行这段代码时,您的输出将如下所示:
这里,通过在原始程序之间添加一些额外的命令,您已经获得了两条平行线而不是一个正方形。
撤销更改
不管你多小心,总有出错的可能。不过,别担心!Python turtle库为您提供了撤销所做操作的选项。如果你想撤销你做的最后一件事,那么输入以下内容:
>>> t.undo()这将撤消您运行的最后一个命令。如果你想撤销你最后的三个命令,那么你可以敲三次
t.undo()。清除屏幕
现在,你可能已经在你的屏幕上看到很多了,因为你已经开始学习本教程了。要为更多内容腾出空间,只需键入以下命令:
>>> t.clear()
这将清理您的屏幕,以便您可以继续绘画。这里注意,你的变量不会改变,海龟会保持原来的位置。如果你的屏幕上除了原来的海龟之外还有其他的海龟,那么它们的图形不会被清除,除非你在代码中明确地把它们叫出来。
重置环境
您也可以选择使用重置命令重新开始。屏幕会被清空,海龟的设置会恢复到默认参数。你需要做的就是输入下面的命令:
>>> t.reset()这就清除了屏幕,把海龟带回到原来的位置。您的默认设置,如乌龟的大小、形状、颜色和其他特征,也将被恢复。
既然您已经学习了使用 Python
turtle库编程的基础知识,那么您将了解一些在编程时可能会用到的额外特性。留下印记
你可以选择在屏幕上留下你的海龟的印记,这只是海龟的印记。尝试键入以下代码,看看它是如何工作的:
>>> t.stamp()
8
>>> t.fd(100)
>>> t.stamp()
9
>>> t.fd(100)
您的输出将如下所示:
出现的数字是海龟的位置或标记 ID。现在,如果你想删除一个特定的邮票,然后只需使用以下:
>>> t.clearstamp(8)这将清除标记 ID 为
8的那个。克隆你的乌龟
有时候,你可能需要不止一只海龟出现在屏幕上。稍后在期末专题中,你会看到一个例子。现在,你可以通过把你现在的乌龟克隆到你的环境中来得到另一只乌龟。尝试运行以下代码来创建一只克隆乌龟
c,然后在屏幕上移动两只乌龟:
>>> c = t.clone()
>>> t.color("magenta")
>>> c.color("red")
>>> t.circle(100)
>>> c.circle(60)
输出将如下所示:
厉害!
现在您已经对 Python turtle库中的一些重要命令有了概念,您已经准备好继续学习一些您需要理解的概念。在用任何语言编程时,这些概念都是非常必要的。
使用循环和条件语句
当你进入高级编程时,你会发现自己经常使用循环和条件语句。这就是为什么,在这一节,你会看到几个海龟程序使用了这些类型的命令。这将为你理解这些概念提供一个实用的方法。但是,在开始之前,请记住以下三个定义:
- 循环是一组不断重复直到满足特定条件的指令。
- 条件语句根据满足的条件执行某项任务。
- 缩进用于定义代码块,尤其是在使用循环和条件语句时。一般来说,你可以通过点击键盘上的
Tab键来创建缩进。
现在,让我们继续探索这些命令吧!
for循环
你还记得你用来创建一个正方形的程序吗?你必须重复同一行代码四次,就像这样:
>>> t.fd(100) >>> t.rt(90) >>> t.fd(100) >>> t.rt(90) >>> t.fd(100) >>> t.rt(90) >>> t.fd(100) >>> t.rt(90)一个更短的方法是借助一个
for循环。尝试运行以下代码:
>>> for i in range(4):
... t.fd(100)
... t.rt(90)
在这里,i就像一个计数器,从零开始,一直递增 1。当你说in range(4)时,你是在告诉程序这个i的值应该小于 4。它会在i达到 4 之前终止程序。
以下是该程序的工作原理:
- I = 0,乌龟向前移动 100 个单位,然后向右旋转 90 度。
- 在 i = 0 + 1 = 1,乌龟向前移动 100 个单位,然后向右旋转 90 度。
- 在 i = 1 + 1 = 2,乌龟向前移动 100 个单位,然后向右旋转 90 度。
- 在 i = 2 + 1 = 3,乌龟向前移动 100 个单位,然后向右旋转 90 度。
海龟会退出循环。要检查i的值,键入i然后按下 Enter键。您将得到i的值等于 3:
>>> i 3注意,程序中第 2 行和第 3 行之前的空白是缩进。这表明这 3 行代码形成了一个单独的代码块。要了解更多关于 Python 中的
for循环,请查看Python“for”循环(有限迭代)。
while循环
while循环用于在满足某个条件时执行某个任务。如果条件不再满足,那么您的代码将终止该进程。通过输入以下代码,您可以使用while循环创建一系列圆:
>>> n=10
>>> while n <= 40:
... t.circle(n)
... n = n+10
当您运行这段代码时,您会看到圆圈一个接一个地出现,并且每个新的圆圈都比前一个大:
这里,n用作计数器。您需要指定在每个循环中您希望n的值增加多少。看一下这个迷你演示,了解该程序是如何工作的:
- n = 10,乌龟画了一个半径为 10 个单位的圆。之后,
n的值增加 10。 - n = 20,乌龟画了一个半径为 20 个单位的圆。再次将
n的值增加 10。 - n = 30,乌龟画了一个半径为 30 个单位的圆。第三次,
n的值增加 10。 - n = 40,乌龟画了一个半径为 40 个单位的圆。最后一次,
n的值增加 10。 - 在 n = 50 时,
n不再小于或等于 40。该循环被终止。
要阅读更多关于while循环的内容,请查看Python“while”循环(无限迭代)。
条件语句
您使用条件语句来检查给定的条件是否为真。如果是,则执行相应的命令。尝试在此程序中键入:
>>> u = input("Would you like me to draw a shape? Type yes or no: ") >>> if u == "yes": ... t.circle(50)
input()用于获取用户的输入。这里,它将用户的响应存储在变量u下。接下来,它会将u的值与提供的条件进行比较,并检查u的值是否为"yes"。如果是"yes",那么你的程序画一个圆。如果用户输入其他任何东西,那么程序不会做任何事情。注:比较运算符
==表示一个比较。它被用来检查一个东西的值是否等于另一个东西的值。赋值运算符=用于给某物赋值。要了解这两者之间的更多区别,请查看 Python 中的操作符和表达式。当您将一个
else子句添加到一个if语句时,您可以根据条件是真还是假来指定两个结果。让我们来看看这个程序:
>>> u = input("Would you like me to draw a shape? Type yes or no: ")
>>> if u == "yes":
... t.circle(50)
>>> else:
... print("Okay")
这里,您告诉程序显示一个特定的输出,即使用户没有说"yes"。你用 print() 在屏幕上显示一些预定义的字符。
注意,用户不需要输入"no"。他们可以键入任何其他东西,在这种情况下,结果将总是"Okay",因为你没有明确地告诉程序用户需要键入"no"。不过,不用担心,这是可以解决的。您可以添加一个elif子句,为程序提供几个条件及其各自的输出,如下所示:
>>> u = input("Would you like me to draw a shape? Type yes or no: ") >>> if u == "yes": ... t.circle(50) >>> elif u == "no": ... print("Okay") >>> else: ... print("Invalid Reply")正如您所看到的,这个程序现在有多个结果,这取决于它接收到的输入。下面是这段代码的工作原理:
- 如果你输入
"yes"、,代码会根据你的指示处理输入并画一个圆。- 如果你输入
"no",,那么代码打印出来"Okay",你的程序终止。- 如果你输入其他任何东西,比如
"Hello"或者"Sandwich",那么代码打印"Invalid Reply"并且你的程序终止。请注意,这个程序是区分大小写的,所以当您试用它时,请确保相应地将字符串置于大写或小写。
要了解更多关于条件语句的信息,请查看 Python 中的条件语句。
最终项目:巨蟒龟比赛
到目前为止,你已经学会了如何定制你的 turtle 环境,如何让 turtle 在屏幕上移动,如何使用循环和条件语句来改进你的代码。现在是您编程之旅中最重要的部分了。在本节中,您将通过创建一个可以与朋友一起玩的有趣游戏,将您所学的全部内容应用到一个程序中。
在开始之前,你需要了解这个游戏:
目标:乌龟最先到达家的玩家赢得游戏。
怎么玩:
- 每个玩家掷骰子得到一个数字。
- 然后玩家把他们的乌龟移动那么多步。
- 玩家轮流玩,直到其中一方获胜。
结构:
- 每个玩家都有一只不同颜色的乌龟。您可以有两个以上的玩家,但是在本教程中,您将创建一个双人游戏。
- 每只海龟都有它必须到达的家的位置。
- 每个玩家使用一个骰子随机选择一个数值。在您的程序中,骰子由 1 到 6 的数字列表表示。
现在你已经理解了游戏的逻辑,你可以开始创建它了!首先,您需要设置环境。
设置游戏环境
从导入 Python
turtle库开始。之后,导入内置的random库,您将使用它从列表中随机选择一个项目:
>>> import turtle
>>> import random
一旦这些库被成功地调用到您的环境中,您就可以继续您的程序的其余部分了。
建立海龟和家园
现在你必须创建两只代表玩家的乌龟。每只乌龟都有不同的颜色,对应不同的玩家。这里,一号玩家是绿色的,二号玩家是蓝色的:
**>>>
>>> player_one = turtle.Turtle()
>>> player_one.color("green")
>>> player_one.shape("turtle")
>>> player_one.penup()
>>> player_one.goto(-200,100)
>>> player_two = player_one.clone()
>>> player_two.color("blue")
>>> player_two.penup()
>>> player_two.goto(-200,-100)
一旦你创造了海龟,你把它们放在它们的起始位置,并确保这些位置是对齐的。请注意,您通过克隆一号玩家的海龟,改变其颜色,并将其放置在不同的起点,从而创建了二号玩家的海龟。
你现在需要为海龟们建立家园。这些家园将成为每只海龟的终点。每个海龟的家都用一个圆圈来代表。在这里,您需要确保两个住宅与起点的距离相等:
>>> player_one.goto(300,60) >>> player_one.pendown() >>> player_one.circle(40) >>> player_one.penup() >>> player_one.goto(-200,100) >>> player_two.goto(300,-140) >>> player_two.pendown() >>> player_two.circle(40) >>> player_two.penup() >>> player_two.goto(-200,-100)画完各自的家之后,你把海龟们送回他们的起始位置:
厉害!你的游戏的视觉方面已经完成了。现在,您可以创建将用于玩游戏的骰子。
创建模具
你可以用一个 列表 为你的游戏创建一个虚拟骰子,这是一个有序的物品序列。在现实生活中,你可能会准备购物清单和待办事项清单来帮助你保持条理。在 Python 中,列表以类似的方式工作。
在这种情况下,您将使用一个列表来创建骰子。首先,您按照从 1 到 6 的升序定义您的数字列表。您可以定义一个列表,方法是给它一个名称,然后用方括号将它的项目括起来,如下所示:
>>> die = [1,2,3,4,5,6]
这份名单现在已经变成了你的骰子。要掷骰子,你所要做的就是给你的系统编程,从中随机选择一个数字。所选的数字将被视为骰子的输出。
开发游戏
是时候为剩下的游戏开发代码了。这里将使用循环和条件语句,所以需要注意缩进和空格。首先,看看你的程序运行游戏需要采取的步骤:
- 第一步:首先,你要告诉你的程序去检查是否有一只海龟到达了它的家。
- 如果他们没有,那么你将告诉你的程序允许玩家继续尝试。
- 第三步:在每个循环中,你告诉你的程序从列表中随机选择一个数字来掷骰子。
- 第四步:然后你告诉它相应地移动相应的乌龟,移动的步数取决于随机选择的结果。
程序不断重复这个过程,一旦其中一只海龟达到目标,程序就会停止。下面是代码的样子:
1>>> for i in range(20): 2... if player_one.pos() >= (300,100): 3... print("Player One Wins!") 4... break 5... elif player_two.pos() >= (300,-100): 6... print("Player Two Wins!") 7... break 8... else: 9... player_one_turn = input("Press 'Enter' to roll the die ") 10... die_outcome = random.choice(die) 11... print("The result of the die roll is: ") 12... print(die_outcome) 13... print("The number of steps will be: ") 14... print(20*die_outcome) 15... player_one.fd(20*die_outcome) 16... player_two_turn = input("Press 'Enter' to roll the die ") 17... die_outcome = random.choice(die) 18... print("The result of the die roll is: ") 19... print(die_outcome) 20... print("The number of steps will be: ") 21... print(20*die_outcome) 22... player_two.fd(20*die_outcome)您的最终输出看起来会像这样:
简而言之,这就是代码正在做的事情:
线 1 设置一个
for循环,范围从 1 到 20。第 2 行到第 7 行检查任何一个玩家是否达到了他们的目标。如果其中一个有,那么程序打印出相应的语句,并结束循环。
如果两个玩家都没有赢,第 8 行将程序移到下一组步骤。
第 9 行打印出一条声明,要求玩家一按下
Enter键掷骰子。第 10 行从列表
die中取一个随机值,并存储在die_outcome中。第 11 行在显示掷骰子结果之前打印一份声明。
第 12 行打印骰子结果。
第 14 行将该值乘以 20,以减少完成游戏所需的总步骤数。
第 15 行将玩家一的乌龟向前移动该步数。
第 16 行到第 22 行对二号玩家重复这些步骤。
重复整个
for循环,直到玩家的一只乌龟到达最终位置。注意:在 Python 中,你用星号(
*)来表示乘法。这就是所谓的算术运算符。也可以用加号(+)做加法,减号(-)做减法,斜线(/)做除法。要了解算术运算符的更多信息,请查看 Python 中的运算符和表达式的算术运算符部分。请记住,你可以自定义游戏,所以继续玩吧!你可以添加更多的乌龟,改变颜色,改变速度,甚至制造一些障碍来挑战你的玩家。这一切都取决于你作为游戏的开发者!
结论
在本教程中,您已经学习了如何使用 Python
turtle库进行编程,并掌握了一些非常重要的编程概念。你知道如何处理变量初始化、循环、条件语句、缩进、列表和操作符。这对您来说是一个很好的开始,尤其是如果您是 Python 编程语言的新手!现在你可以:
- 建立Python
turtle库- 移动你的乌龟
- 定制你的乌龟和它的环境
- 程序你的乌龟
- 使用基本编程概念
- 创建一个可以和朋友一起玩的游戏
现在,您已经准备好开始一些更高级的 Python 编程了。为了在您的 Python 之旅中更进一步,请查看Python 简介和学习 Python 编程的 11 个初学者技巧。只要记住努力工作并不断练习,你会发现你很快就成为一名 Python 专家了!
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 蟒龟初学***************
最好的 Python 书籍
在本文中,我们通过一组书评,重点介绍了学习 Python 的最佳书籍。每一篇评论都让你领略了这本书的内容,涵盖的主题,以及用来阐述这些主题的背景。不同的书籍会引起不同人的共鸣,这取决于书籍的风格和介绍、读者的背景以及其他因素。
Python 是一种令人惊叹的编程语言。它可以应用于几乎任何编程任务,允许快速开发和调试,并带来了可以说是最受欢迎的用户社区的支持。
开始使用 Python 就像学习任何新技能一样:找到一个你能联系到的资源来指导你的学习是很重要的。幸运的是,有很多优秀的书籍可以帮助你学习编程的基本概念和 Python 编程的细节。由于资源丰富,很难确定哪本书最适合你的情况。
如果你是 Python 新手,任何一本入门书籍都会给你打下坚实的基础。
也许你想和你的孩子一起学习 Python,或者教一群孩子 Python。查看适合儿童的最佳 Python 书籍以获取针对年轻读者的资源。
随着您在 Python 之旅中的进展,您会想要更深入地挖掘以最大化代码的效率。最佳中级和高级 Python 书籍提供了帮助您提高 Python 技能的洞察力,使您能够成为 Python 专家。
读完这些评论后,如果你仍然不确定选择哪本书,出版商通常会提供一个样本章节或章节,给你一个该书提供的例子。阅读这本书的样本会让你对作者的步调、风格和期望有一个最有代表性的了解。
不管哪本书最突出,想想我们的书评人史蒂文·c·豪厄尔的轶事:
“一位喜欢的教授曾经告诉我,‘你先读哪本书并不重要。“总是第二个最有意义,”
我不能说我一直都是这种情况,但我确实发现,当第一次给我留下困惑或沮丧时,第二次推荐会有所不同。
当学习 Python 类时,我很难理解我所选的前两本书中使用的例子。直到我提到的第三本书,这些概念才开始产生共鸣。
重要的一课是,如果你陷入困境或受挫,你所拥有的资源没有帮助,那么不要放弃。看看另一本书,搜索网页,在论坛上提问,或者只是休息一下。"
注意:本文包含亚马逊等零售商的附属链接,因此您可以通过点击并购买一些链接来支持真正的 Python。从这些链接中的任何一个购买都不会增加你的额外费用。附属链接绝不会以任何方式影响我们的编辑决策。
学习 Python 的最佳书籍
如果您是 Python 的新手,您可能会遇到以下两种情况之一:
- 你是编程新手,想从学习 Python 开始。
- 你在另一种语言上有一定的编程经验,现在想学习 Python。
本节主要讨论这两种情况中的第一种,并对我们认为最适合初学编程和 Python 的读者的 Python 编程书籍进行了评述。因此,这些书不需要以前的编程经验。他们从绝对的基础开始,教授一般的编程概念以及它们如何应用于 Python。
注意:如果你正在为有经验的程序员寻找最好的 Python 书籍,请考虑以下在简介和高级部分有完整评论的书籍:
- 思 Python :这个列表最基本,思 Python 提供了全面的 Python 参考。
- 流畅的 Python:Python 的简单性让你可以快速开始编码,这本书教你如何编写地道的 Python 代码,同时深入探讨该语言的几个深层主题。
- 有效的 Python: 59 种写出更好的 Python 的方法 :这本相对较短的书是 59 篇文章的合集,与流畅的 Python 类似,专注于教你如何写出真正的 Python 代码。
- Python 食谱 :作为一本食谱,这将是一本关于如何使用 Python 来完成你用另一种语言完成的任务的好参考。
或者,你可能更喜欢直接去官方的 Python 教程,这是一个写得很好很全面的资源。
Python 速成班
埃里克·马特斯(无淀粉出版社,2016)
它按照罐头上说的做,而且做得很好。这本书从基本 Python 元素和数据结构的演练开始,通过变量、字符串、数字、列表和元组,概述了如何使用它们。
接下来,
if包括了语句和逻辑测试,接着是对字典的探究。之后,这本书涵盖了用户输入、
while循环、函数、类、文件处理,以及代码测试和调试。那只是书的前半部分!在后半部分,您将参与三个主要项目,创建一些聪明有趣的应用程序。
第一个项目是一个外星人入侵游戏,本质上是太空入侵者,使用
pygame包开发。你设计一艘船(使用类),然后编程如何驾驶它,让它发射子弹。然后,你设计几类外星人,让外星人舰队移动,让击落他们成为可能。最后,您添加一个记分牌和一个高分列表来完成游戏。在那之后,下一个项目包括使用
matplotlib的数据可视化、随机行走、掷骰子和一点点统计分析,使用pygal包创建图形和图表。您将学习如何下载各种格式的数据,将其导入 Python,并可视化结果,以及如何与 web APIs 交互,从 GitHub 和 HackerNews 中检索和可视化数据。第三个项目引导您使用 Django 创建一个完整的 web 应用程序,以建立一个学习日志来跟踪用户学习了什么。它涵盖了如何安装 Django、设置项目、设计模型、创建管理界面、设置用户帐户、基于每个用户管理访问控制、使用 Bootstrap 设计整个应用程序的样式,以及最终将其部署到 Heroku。
这本书写得很好,组织得很好。它提供了大量有用的练习以及三个具有挑战性和娱乐性的项目,构成了本书的后半部分。(由大卫·施勒辛格审核。)
Head-First Python,第二版
保罗·巴里(奥莱利,2016)
我真的很喜欢 Head-First 系列的书,尽管它们在整体内容上比本节中的许多其他推荐都要轻。代价是这种方法使这本书更加用户友好。
如果你是那种喜欢一次学习一小块相当独立的东西的人,并且你希望有大量的具体例子和相关概念的说明,那么 Head-First 系列适合你。出版商的网站对他们的方法有如下描述:
“基于认知科学和学习理论的最新研究, Head-First Python 使用视觉丰富的格式来吸引你的思维,而不是让你睡着的大量文本方法。为什么要浪费时间纠结新概念?这种多感官的学习体验是为你的大脑真正的工作方式而设计的。”(来源)
塞满了插图、例子、旁白和其他花絮, Head-First Python 始终引人入胜且易于阅读。这本书从深入列表并解释如何使用和操作它们开始了它的 Python 之旅。然后进入模块、错误和文件处理。每个主题都围绕一个统一的项目:通过公共网关接口(CGI)使用 Python 为学校体育教练构建一个动态网站。
之后,这本书会花时间教你如何使用 Android 应用程序与你创建的网站进行交互。您将学习处理用户输入、争论数据,并了解在 web 上部署和扩展 Python 应用程序所涉及的内容。
虽然这本书不如其他一些书全面,但它以一种更容易理解、更轻松、更有效的方式涵盖了大量 Python 任务。如果你一开始觉得写程序有点吓人,那就更是如此了。
这本书旨在指导你应对任何挑战。虽然内容更加集中,但这本书有足够的材料让你忙碌和学习。你不会无聊的。如果你觉得大多数编程书籍太枯燥,这可能是一本适合你开始学习 Python 的好书。(由大卫·施勒辛格和史蒂文·c·豪厄尔审核。)
用 Python 发明你自己的电脑游戏,第 4 版
阿尔·斯威加特(无淀粉,2017)
如果游戏是你的事情,或者你甚至有自己的游戏想法,这将是学习 Python 的完美书籍。在本书中,您将学习编程和 Python 的基础知识,并通过应用程序练习来构建经典游戏。
从 Python shell 和 REPL 循环的介绍开始,接下来是基本的“你好,世界!”脚本,您可以开始制作一个基本的数字猜测游戏,包括随机数、流控制、类型转换和布尔数据。之后,编写一个讲笑话的小脚本来说明打印语句、转义字符和基本字符串操作的使用。
下一个项目是一个基于文本的洞穴探索游戏,龙的领域,它向您介绍流程图和函数,指导您如何定义自己的参数和参数,并解释布尔运算符、全局和局部范围以及
sleep()函数。在简要介绍了如何调试 Python 代码之后,接下来您将使用 ASCII 作品实现 Hangman 游戏,同时学习列表、
in操作符、方法、elif语句、random模块和一些字符串方法。然后,在学习字典、键值对和多变量赋值的同时,用新特性扩展 Hangman 游戏,比如单词列表和难度级别。
你的下一个项目是一个井字游戏,它介绍了一些高级人工智能概念,向你展示了如何在条件句中短路求值,并解释了
None值以及访问列表的一些不同方式。你在这本书其余部分的旅程也是如此。您将在构建智多星风格的数字猜测游戏时学习嵌套循环,声纳狩猎游戏的笛卡尔坐标,编写凯撒密码的密码学,以及实现黑白棋(也称为奥赛罗)时的人工智能,其中计算机可以与自己对弈。
在所有这些之后,有一个在 PyGame 游戏中使用图形的潜水:你将涵盖如何动画图形,管理碰撞检测,以及使用声音,图像和精灵。为了将所有这些概念结合在一起,这本书将指导你制作一个图形化的避障游戏。
这本书做得很好,每个项目都是一个独立的单元,这一事实使它具有吸引力和可访问性。如果你喜欢边做边学,那么你会喜欢这本书的。
这本书只在需要时介绍概念的事实可能是一个缺点。虽然它更像是一个指南而不是参考,但在熟悉的游戏背景下教授的广泛内容使它成为学习 Python 的最佳书籍之一。(由大卫·施勒辛格审核。)
思考 Python:如何像计算机科学家一样思考,第二版
艾伦·b·唐尼(奥莱利,2015)
如果通过创建视频游戏来学习 Python 对你来说太无聊,可以考虑艾伦·唐尼的书 Think Python ,这本书采用了更严肃的方法。
正如标题所言,这本书的目标是教你编码人员如何思考编码,并且做得很好。与其他书籍相比,它更加枯燥,组织方式更加线性。这本书以一种非常直截了当、清晰而全面的方式,关注你需要了解的关于基本 Python 编程的一切。
与其他类似的书籍相比,它没有深入到一些更高级的领域,而是覆盖了更广泛的材料,包括其他书籍没有涉及的主题。这类主题的例子包括运算符重载、多态性、算法分析以及可变性与不可变性。
以前的版本有点轻练习,但最新版本在很大程度上纠正了这个缺点。这本书包含四个相当深入的项目,以案例研究的形式呈现,但总的来说,与许多其他书籍相比,它的直接应用练习较少。
如果你喜欢只是事实的一步一步的演示,并且你想获得专业程序员如何看待问题的一点额外的洞察力,这本书是一个很好的选择。(由大卫·施勒辛格和史蒂文·c·豪厄尔审核。)
物理学中的有效计算:Python 研究领域指南
安东尼·斯科帕茨,凯瑟琳·d·哈夫(奥莱利,2015)
这是我第一次学习 Python 时希望拥有的书。
尽管它的名字,这本书对于没有物理、研究或计算问题经验的人来说是一个极好的选择。
这确实是使用 Python 的一个领域指南。除了实际教授您 Python 之外,它还涵盖了相关主题,如命令行和版本控制,以及软件的测试和部署。
除了是一个很好的学习资源之外,这本书也将作为一个很好的 Python 参考,因为主题组织得很好,有大量穿插的例子和练习。
这本书被分为四个恰当命名的部分:开始,完成,做好,和开始。
“入门”部分包含您立即投入运行所需的一切。它从 bash 命令行基础的一章开始。(是的,你甚至可以为 Windows 安装 bash。)然后,这本书继续解释 Python 的基础,触及了所有预期的主题:操作符、字符串、变量、容器、逻辑和流控制。此外,有整整一章致力于所有不同类型的函数,另一章是关于类和面向对象编程。
在此基础上,完成部分进入了 Python 的更以数据为中心的领域。请注意,这一部分约占全书的三分之一,最适用于科学家、工程师和数据科学家。如果那是你,享受吧。如果没有,请随意跳过,挑出任何相关的部分。但是请务必阅读本节的最后一章,因为它将教您如何使用 pip、conda、虚拟机和 Docker 容器部署软件。
对于那些对处理数据感兴趣的人来说,这一节首先简要介绍了数据分析和可视化的基本库。然后有一个单独的章节专门介绍正则表达式、NumPy、数据存储(包括执行核外操作)、专用数据结构(哈希表、数据帧、D 树和 k-d 树)和并行计算。
“正确使用”一节将教您如何避免和克服许多与使用 Python 相关的常见陷阱。它首先通过教您如何使用
make构建软件管道来扩展关于部署软件的讨论。然后,您将学习如何使用 Git 和 GitHub 来跟踪、存储和组织您的代码编辑,这个过程称为版本控制。本节最后将教您如何调试和测试代码,这是两项非常有价值的技能。最后一部分,把它拿出来,集中于与你的代码的消费者有效地沟通,包括你自己。它涵盖了文档、标记语言(主要是 LaTeX)、代码协作和软件许可等主题。这一部分,也是本书,以一个按主题组织的科学 Python 项目的长列表结束。
这本书的突出之处在于,除了教授 Python 的所有基础知识之外,它还教授您 Pythonistas 使用的许多技术。这确实是学习 Python 的最佳书籍之一。
它也作为一个很好的参考,将一个完整的词汇表,书目和索引。这本书肯定有科学的含义,但是如果你没有科学背景,也不用担心。没有数学方程式,当你的同事看到你在钻研计算物理学时,你甚至会给他们留下深刻的印象!史蒂文·C·豪威尔评论。)
艰难地学习 Python 3
泽德·a·肖(艾迪森-韦斯利,2016)
艰难地学 Python经典。我非常喜欢这本书的方法。当你学会“艰难的方式”时,你必须:
- 自己输入所有代码
- 做所有的练习
- 为你遇到的问题找到自己的解决方案
这本书的伟大之处在于它的内容呈现得非常好。每一章都有清晰的呈现。代码示例都很简洁,结构良好,并且切中要点。这些练习是有益的,你遇到的任何问题都不是不可克服的。你最大的风险是印刷错误。读完这本书,你肯定不再是 Python 的初学者。
不要让标题让你分心。如果你把眼光放长远,这条“艰难的路”最终会是一条容易的路。没有人喜欢输入很多东西,但这是编程实际涉及的内容,所以从一开始就习惯它是有好处的。这本书的一个好处是,它现在已经经过了几个版本的改进,所以现在任何粗糙的边缘都变得很好很光滑。
这本书由一系列超过五十个练习组成,每一个都建立在前一个的基础上,每一个都教给你这门语言的一些新的特征。从练习 0 开始,在计算机上安装 Python,开始编写简单的程序。您将学习变量、数据类型、函数、逻辑、循环、列表、调试、字典、面向对象编程、继承和打包。你甚至可以使用游戏引擎创建一个简单的游戏。
接下来的章节涵盖了自动化测试、对用户输入进行词法扫描以解析句子,以及将你的游戏放到网上的
lpthw.web包等概念。泽德是一位迷人、耐心的作家,他从不掩饰细节。如果你以正确的方式阅读这本书——“艰难的方式”,遵循贯穿全文的学习建议以及编程练习,当你完成时,你将远远超越初级程序员阶段。(由大卫·施勒辛格审核。)
注:在本文包含的所有书籍中,这是唯一一部评论有些褒贬不一的书。堆栈溢出(SO)社区已经编制了一份包含 22 个投诉的列表,以以下声明开头:
“我们注意到一个普遍趋势,使用[艰难地学习 Python 的用户在 SO 和聊天中发布没有多大意义的问题。这要归功于书中使用的结构和技巧。”(来源)
他们提供了自己的推荐教程列表,包括以下内容:
尽管对《艰难地学习 Python》有负面的批评,大卫·施勒辛格和 T2 的亚马逊书评人同意这本书是值得的,尽管你可能想用另一本可以作为参考的 Python 书来补充你的图书馆。此外,在向 Stack Overflow 发布问题之前,一定要做好尽职调查,因为该社区有时会有些粗鲁。
真正的 Python 课程,第 1 部分
真正的 Python 团队(真正的 Python,2017)
这本电子书是真正的 Python 课程系列的 中三本书的第一本。它的目标是帮助您启动并运行,它在实现这一目标方面做得非常好。这本书是解释性散文、示例代码和复习练习的混合体。穿插的复习练习通过让你立即应用你所学的东西来巩固你的学习。
与前几本书一样,前面提供了在您的计算机上安装和运行 Python 的清晰说明。在设置部分之后,不是给出一个干巴巴的数据类型概述,真正的 Python 只是从字符串开始,实际上是相当彻底的:在你读到第 30 页之前,你就学习了字符串切片。
然后,这本书通过向您展示如何使用一些可以应用的类方法,让您很好地感受 Python 的魅力。接下来,您将学习编写函数和循环,使用条件逻辑,使用列表和字典,以及读写文件。
然后事情变得非常有趣!一旦你学会了用
pip(和从源代码)安装包,真正的 Python 涵盖了与 PDF 文件交互和操作,在 Python 内部使用 SQL,从网页抓取数据,使用numpy和matplotlib做科学计算,最后,用EasyGUI和tkinter创建图形用户界面。关于真正的 Python,我最喜欢的是,除了以全面友好的方式讲述基础知识之外,这本书还探索了 Python 的一些其他书都没有触及的更高级的用途,比如网络抓取。还有另外两卷,深入更高级的 Python 开发。(由大卫·施勒辛格审阅。)
免责声明:几年前,我第一次开始使用真正的 Python 书籍,当时它们还处于测试阶段。我当时认为——现在仍然认为——它们是学习 Python 语言及其几种用法的最佳资源之一。我在真正的 Python 网站上写文章是最近的事情,我的评论是完全独立的。—大卫
最佳儿童 Python 书籍
下面的书是针对那些对教孩子编程感兴趣的成年人的,同时也有可能让他们自己学习编程。这两本书都推荐给 9 岁或 10 岁的孩子,但它们也非常适合大一点的孩子。
重要的是要注意,这些书并不意味着只是交给一个孩子,取决于他们的年龄。对于想和孩子一起学习 Python 的父母来说,它们是理想的选择。
面向儿童的 Python:有趣的编程介绍
杰森·r·布里格斯(无淀粉,2013)
“俏皮”没错!不管书名如何,这是一本老少皆宜的有趣的书。它为 Python 编程提供了清晰易懂的介绍。它有大量的插图,例子简单明了,对于那些想有良好基础的人来说,它是一个可靠的指南。
这本书以一个优秀的、详细的指南开始,介绍如何在你的系统上安装 Python,无论是 Windows、OS X 还是 Ubuntu Linux。然后介绍 Python shell 以及如何将它用作一个简单的计算器。这是为了介绍一些基本概念,如变量和算术运算。
接下来,处理可重复项,这一章通过字符串、列表、元组和字典逐步展开。
一旦完成,Python
turtle库就被用来开始处理海龟图形,这是一个教孩子编程的流行框架。从那里,这本书通过条件语句,循环,函数和模块前进。涵盖了类和对象,接下来是关于 Python 内置函数的非常精彩的一节,然后是关于许多有用的 Python 库和模块的一节。本书更详细地回顾了海龟图形,之后介绍了用于创建用户界面、更好的图形甚至动画的
tkinter。本书的第 1 部分“学习编程”到此结束,剩下的部分集中在构建两个有趣的应用程序项目上。第一个项目是建立一个单人版本的 Pong ,名为 Bounce!这集成了函数、类和控制流的编程概念,以及使用
tkinter创建界面、向画布演示、执行几何计算和使用事件绑定创建交互性的任务。在第二个项目中,你制作一个侧滚视频游戏,斯蒂克曼先生跑向出口。这个游戏应用了很多和弹跳一样的概念和任务!但是具有更大的深度和增加的复杂性。在这个过程中,你还会接触到开源的图像处理程序 GIMP ,用来创建你的游戏资产。这本书从这两个游戏中获得了惊人的收益,让它们工作既有教育意义又很有趣。
我非常喜欢这本书。无论你是年轻的,或者只是内心年轻,如果你正在寻找一个有趣的,平易近人的,对 Python 和编程的介绍,你会喜欢这本书。(由大卫·施勒辛格和史蒂文·c·豪厄尔审核。)
教你的孩子编码:Python 编程的父母友好指南
布赖森·佩恩(无淀粉,2015)
这本书类似于面向儿童的*Python,但更像标题所暗示的那样,是面向与孩子一起学习编码的成年人的。这本书与大多数入门书籍的区别在于几乎每一页都使用了颜色和插图。这本书写得很好,把学习编码作为教孩子解决问题技能的一种方式。
通常情况下,这本书从 Python 安装指南开始。与 Python for Kids 相比,本书中的指南更加粗略,但完全足够。
第一个活动是海龟图形。这里给出了绘制旋转正方形的一些基本变化,最初没有很多基本的解释,只是为了介绍一般的概念,但在本节结束时,您将会对基础有一个相当好的理解。
接下来,解释 Python 中的计算、变量和数学。一旦字符串被涵盖,这本书将所有这些都带回海龟图形,以增强和探索之前所做的工作。到目前为止,代码解释非常清楚,有明确的逐行细节。你很难理解任何代码。
接下来探索列表,就像
eval()函数一样。引入循环,然后用它来创建越来越复杂的图形。接下来是条件表达式,还有布尔逻辑和运算符。
random图书馆引入了一个猜谜游戏和随机放置的海龟图形螺旋。你可以通过掷骰子和挑牌来进一步探索随机性,这导致你创建了游戏 Yahtzee 和 War。接下来研究功能、更高级的图形和用户交互。
这本书然后分支覆盖使用 PyGame 创建更高级的图形和动画,然后用户交互创建一个非常简单的绘图程序。
至此,您已经拥有了创建一些真正游戏的所有工具。介绍了 Pong 的全功能版本和泡泡游戏的开发。两者都提供了足够的深度来提出一些挑战和保持兴趣。
我最喜欢这本书的地方是它的大量编程挑战,以及每章结尾的精彩总结,提醒你涵盖了哪些内容。如果你和你的孩子对编程感兴趣,这本书会带你们走得更远,你们会有很多乐趣。正如作者 Bryson Payne 博士在他最近的 TEDx 演讲中所说,“走出你的舒适区,学会使用技术语言。”(大卫·施勒辛格和史蒂文·c·豪厄尔评论。)
最佳中级和高级 Python 书籍
了解 Python 是一回事。知道什么是 Pythonic 需要练习。有时 Python 的低门槛会给人一种错误的想法,认为这种语言不如其他语言,认为风格无关紧要,或者认为最佳实践只是个人偏好的问题。你见过看起来像 C 或 Fortran 的 Python 代码吗?
学习如何有效地使用 Python 需要对 Python 的本质有所了解。Python 编程利用 Python 语言的实现方式来最大化代码的效率。
幸运的是,有一些优秀的书籍,包含了专家的指导,旨在帮助你掌握你所学的知识,提高你的技能。本节中的任何一本书都会让你对 Python 编程概念有更深入的理解,并教你如何编写开发者风格的 Python 代码。注意,这些绝不是入门书籍。它们不包括入门的基础知识。如果你已经在用 Python 编程,并且想在成为一名真正的 Python 爱好者的道路上进一步磨练你的技能,这些书将会很有帮助。
Python 技巧:令人敬畏的 Python 特性自助餐
丹·巴德 (dbader.org,2017)
本书阐释了鲜为人知的宝贵 Python 特性和最佳实践,旨在帮助您更深入地了解 Python。43 个小节中的每一个都提出了一个不同的概念,称为 Python 技巧,讨论和易于理解的代码示例说明了如何利用这个概念。
本书的内容分为以下几个部分:
- 更干净 Python 的模式
- 有效功能
- 类和面向对象
- Python 中常见的数据结构
- 循环和迭代
- 字典技巧
- Pythonic 生产力技术
正如封面上所说,内容被组织成“自助餐”,每个小节都是一个独立的主题,有简短的介绍、示例、讨论和一系列关键要点。因此,你可以随意跳到最吸引人的部分。
除了这本书之外,我特别喜欢 12 个额外的视频,当你购买这本书作为电子书时可以看到。它们的平均长度为 11 分钟,非常适合在午餐时间观看。每个视频都使用清晰简洁的代码示例来说明不同的概念,这些代码示例易于复制。虽然一些视频涵盖了熟悉的概念,但它们仍然提供了有趣的见解,没有拖沓。史蒂文·c·豪厄尔评论。)
免责声明:虽然这本书是通过 Real Python 正式发行的,但我还是独立于我与 Real Python 的联系推荐它。在我有机会为真正的 Python 写作之前,我在这本书首次发行时购买了它。为了进一步证明这本书的价值,查看一下亚马逊评论 : 148,平均 4.8 分(5 颗星)。—史蒂夫
流畅的 Python:清晰、简洁、有效的编程
卢西亚诺·拉马拉(∞2014)
这本书是为希望精通 Python 3 的有经验的 Python 2 程序员编写的。因此,这本书非常适合那些有着扎实的 Python 基础(2 或 3)的人,他们希望自己的技能更上一层楼。此外,这本书也可以作为一个来自其他语言的有经验的程序员的参考,他想要查找“我如何在 Python 中做
<x>?”这本书是按主题组织的,所以每一部分都可以独立阅读。虽然本书中涉及的许多主题都可以在入门书籍中找到,但 Fluent Python 提供了更多的细节,阐明了 Python 语言的许多更微妙且被忽视的特性。
这些章节分为以下六个部分:
- 序言:介绍 Python 的面向对象特性和保持 Python 库一致性的特殊方法
- 数据结构:涵盖序列、映射、集合、
str和bytes的区别- 作为对象的函数:解释函数在 Python 语言中作为一级对象的后果
- 面向对象的习惯用法:包括引用、可变性、实例、多重继承和操作符重载
- 控制流:扩展了基本条件,涵盖了生成器、上下文管理器、协同程序、
yield from语法和使用asyncio的并发性的概念- 元编程:探索类的鲜为人知的方面,讨论动态属性和特性、属性描述符、类装饰符和元类
几乎每一页都有代码示例,并且有编号的标注将代码行链接到有用的描述,这本书非常平易近人。此外,代码示例面向交互式 Python 控制台,这是一种探索和学习所介绍概念的实用方法。
当我有一个关于 Python 的问题时,我会求助于这本书,希望得到一个比栈溢出更全面的解释。当我有一点空闲时间,只想学点新东西的时候,我也喜欢读这本书。不止一次,我发现我最近从这本书上学到的一个概念出乎意料地成为我必须解决的一个问题的完美解决方案。史蒂文·c·豪厄尔评论。)
有效的 Python:写出更好的 Python 的 59 种方法
布雷特·斯拉特金(艾迪森-韦斯利,2015 年)
这本书是 59 篇独立文章的集合,这些文章建立在对 Python 的基本理解之上,教授 Python 最佳实践、鲜为人知的功能和内置工具。这些主题的复杂性各不相同,从了解您使用的 Python 版本这一简单概念开始,到识别内存泄漏这一更复杂但通常被忽略的概念结束。
每篇文章都是示例代码、讨论和需要记住的事情列表的组合。
因为每篇文章都是独立的,所以这是一本很好的书,可以让你专注于最适用或有趣的主题。这也使得它非常适合一次阅读一篇文章。每篇文章大约两到四页长,你可以每天抽出时间读一篇文章,在两到三个月内读完这本书(取决于你是否在周末阅读)。
文章分为以下 8 章:
- Python 思维:介绍执行常见任务的最佳方式,同时利用 Python 的实现方式
- 函数:阐明 Python 函数的细微差别,并概述如何使用函数来阐明意图、促进重用和减少错误
- 类和继承:概述了使用 Python 类时的最佳实践
- 元类和属性:阐明元类这个有点神秘的话题,教你如何使用它们来创建直观的功能
- 并发和并行:解释如何用 Python 编写多线程应用
- 内置模块:引入一些 Python 鲜为人知的内置库,使您的代码更加有用和可靠
- 协作:讨论适当的文档、打包、依赖性和虚拟环境
- 生产:涵盖调试、优化、测试和内存管理等主题
如果你有一个坚实的 Python 基础,并想填补漏洞,加深理解,并学习一些不太明显的 Python 特性,这将是一本适合你的好书。史蒂文·c·豪厄尔评论。)
Python 食谱
大卫·比兹利和布莱恩·k·琼斯(奥莱利,2013 年第三版)
使这本书脱颖而出的是它的详细程度。代码烹饪书通常被设计成短小精悍的手册,用来说明做日常工作的巧妙方法。在这种情况下, Python 食谱中的每个食谱都有一个扩展的代码解决方案,以及作者对该解决方案的一些特定元素的讨论。
每个配方都以一个清晰的问题陈述开始,例如,“您想要编写一个装饰器,向包装函数的调用签名添加一个额外的参数。”然后,它跳转到一个使用现代的、惯用的 Python 3 代码、模式和数据结构的解决方案,通常花费 4 到 5 页来讨论这个解决方案。
基于它更复杂的例子,以及作者在前言中的推荐,这可能是我们列表中最高级的 Python 书籍。尽管如此,如果您认为自己是中级 Python 程序员,也不要害怕。到底是谁在评判?有句老话是这样说的:
“成为更好的篮球运动员的最好方法是输给你能找到的最好的运动员,而不是打败最差的运动员。”
你可能会看到一些你没有完全理解的代码块——过几个月再来看。在你掌握了一些额外的概念后,重读这些章节,你会突然明白。大多数章节开始时相当简单,然后逐渐变得更加激烈。
这本书的后半部分举例说明了装饰模式、闭包、访问函数和回调函数等设计。
从可靠的来源阅读总是好的,这本书的作者当然符合这一要求。大卫·比兹利是 PyCon 等活动的主题演讲人,也是 Python 基本参考 的作者。同样,Brian K. Jones 是一名首席技术官,也是一本 Python 杂志的创始人,还是普林斯顿的 Python 用户组(PUG-IP) 的创始人。
这个特别的版本是用 Python 3.3 编写和测试的。(由布拉德·所罗门审核。)
获取编码!
Python 令人惊叹的一点是,与许多其他语言相比,它的入门门槛相对较低。尽管如此,学习 Python 是一个永无止境的过程。这种语言与如此广泛的任务相关,并且发展如此之快,以至于总会有新的东西需要发现和学习。虽然您可以在一两周内学会足够多的 Python 来做一些有趣的事情,但是使用 Python 二十年的人会告诉您,他们仍然在学习使用这种灵活且不断发展的语言可以做的新事情。
要最终成为一名成功的 Python 程序员,您需要从一个坚实的基础开始,然后更深入地理解这种语言是如何工作的,以及如何最好地使用它。为了获得坚实的基础,学习 Python 的任何一本最佳书籍都不会错。如果你想和孩子一起学习 Python,或者教一群孩子,看看儿童最佳 Python 书籍列表。熟悉之后,看看一些最好的中级和高级 Python 书籍,深入挖掘那些不太明显的概念,这将提高代码的效率。
所有这些书都将教你需要知道什么才能称自己为合法的 Python 程序员。唯一缺少的成分是你。********















 浙公网安备 33010602011771号
浙公网安备 33010602011771号