RealPython-中文系列教程-五-
RealPython 中文系列教程(五)
原文:RealPython
使用 Python 和 Flask 开始使用 Slack API
原文:https://realpython.com/getting-started-with-the-slack-api-using-python-and-flask/
光滑的托管聊天应用程序 Slack 今年风靡一时。该工具的采用并不是空洞的宣传——它对于同开发人员交流和学习非常有用。例如,软件开发者社区如 DC Python 、达拉斯沃斯开发者和丹佛开发者建立了他们自己的 Slack 频道。
然而,如果 Slack 只是一个美化了的 AOL 即时通讯工具,它就不会那么有用。这是使用 Slack web 应用程序编程接口(API)检索和发送消息的的编程访问,这是真正发挥威力的地方。
在这篇文章中,我们将看到如何通过 API 和官方的 SlackClient Python 助手库来使用 Slack。我们将获取一个 API 访问令牌,并编写一些 Python 代码来通过 API 列出、检索和发送数据。让我们现在开始挖吧!
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
这是马特·马凯的客座博文,他是 Twilio 的开发者传道者,也是全栈 Python 的作者。
我们需要的工具
在这篇博文中,将使用几个工具来运行代码,包括:
- 一个免费的 Slack 账户,在这个账户上你有 API 访问权限或者注册一个 Slack 开发者聚会团队
- Python 2 或 3
- Slack 团队构建的官方 Python slackclient 代码库
- 松弛 API 测试令牌
- 烧瓶网状微结构;如果你对它不熟悉,可以查看一下真正的 Python 课程、 Flask by Example 系列或 Full Stack Python 的 Flask 页面
打开 Slack API 文档进行参考也很方便。你可以在这篇文章中写代码或者用完成的项目克隆配套的 GitHub 库。
现在我们知道了需要使用什么工具,让我们开始创建一个新的 virtualenv 来将我们的应用程序依赖项与您正在处理的其他 Python 项目隔离开来:
$ mkdir slackapi
$ virtualenv venv
激活 virtualenv:
$ source venv/bin/activate
根据您的 virtualenv 和 shell 的设置,您的提示符现在应该是这样的:
(venv)$
让 shell 保持开放,因为我们通过 Slack 构建的官方 slackclient API helper 库建立了 Slack 访问。
社区还创建了其他精彩的 Python 助手库。为了简单起见,我们将只安装和使用 slackclient,但是一旦我们完成了这里的工作,你也可以尝试像 slacker 、 slack 和 pyslack 这样的库。
用 pip 将 slackclient 助手库安装到您的 virtualenv 中:
$ pip install slackclient==1.0.0
现在我们已经安装了 helper 库,我们需要为我们的团队和帐户获取一个 Slack 访问令牌。
Slack Web API
前往 Slack Web API 的登录页面:

登录后,您可以向下滚动 web API 页面,在这里您会看到一个生成测试令牌的按钮:
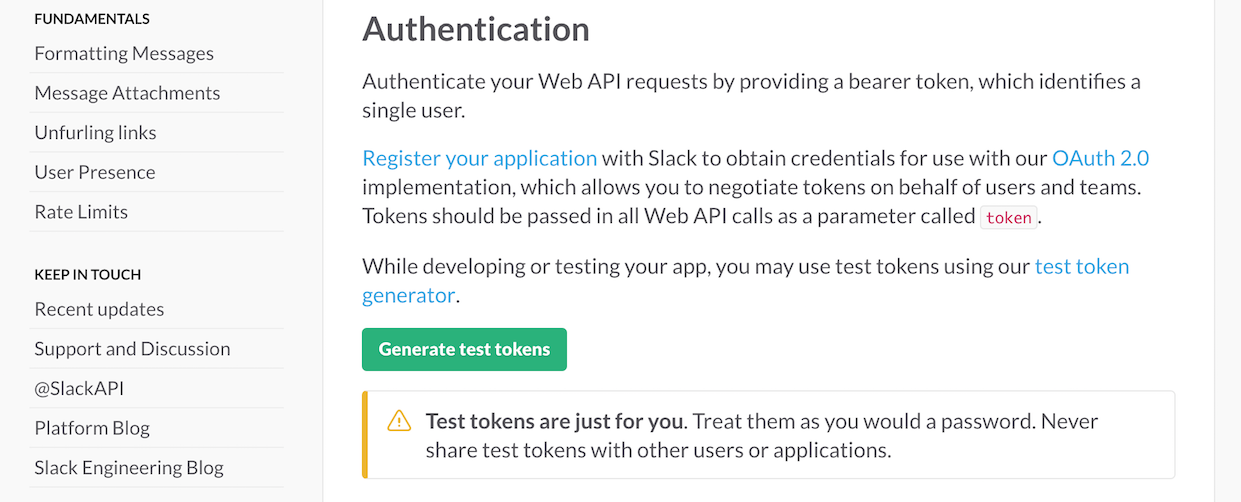
为您拥有管理权限的松散团队生成测试令牌。在这篇博文中,这个令牌将很好地满足我们的开发目的,但是您也可以创建一个 OAuth 流,其他用户可以在其中通过他们自己的帐户生成令牌进行身份验证。
我们一会儿就需要那个测试令牌,所以把它放在手边。让我们切换到我们的 Python 环境设置,这样我们就可以尝试 API 了。在 virtualenv 仍然有效的情况下,启动 Python REPL:
(venv)$ python
Python 3.5.0 (v3.5.0:374f501f4567, Sep 12 2015, 11:00:19)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
让我们用一个测试调用来测试我们的 API 令牌;在 REPL 提示符下键入以下代码:
>>> from slackclient import SlackClient >>> slack_client = SlackClient('your test token here') >>> slack_client.api_call("api.test")如果使用令牌的 API 测试成功,REPL 应该返回类似下面的字典:
{u'args': {u'token': u'xoxp-361113305843-7621238052-8691112296227-d0d4824abe'}, u'ok': True}如果您返回
{u'ok': False, u'error': u'invalid_auth'},那么仔细检查您是否正确地将 Slack 令牌复制到了在 REPL 上输入的第二行。用 REPL 中的另一行代码再输入一个快速测试来验证我们的身份:
>>> slack_client.api_call("auth.test")
您应该会看到与本词典类似的另一本词典:
{u'user_id': u'U0S77S29J', u'url': u'https://fullstackguides.slack.com/', u'team_id': u'T0S8V1ZQA', u'user': u'matt', u'team': u'Full Stack Guides, u'ok': True}
厉害!我们被授权通过我们的帐户开始使用 Slack API。现在有趣的事情开始了,我们可以开始以编程的方式获取松弛数据和处理消息!
松弛 API 基础知识
用快捷的 Ctrl + D 或exit()命令退出 REPL。回到命令行,将松弛令牌作为环境变量导出:
(venv)$ export SLACK_TOKEN='your slack token pasted here'
我们将使用os模块在 Python 脚本中捕获环境变量,而不是将其硬编码到源代码中。
进入你最喜欢的文本编辑器,比如 Vim 、 Emacs 或 Sublime Text ,这样我们就可以删减一些新的 Python 代码。创建一个名为 app.py 的新文件,并开始用以下导入内容填充它:
import os
from slackclient import SlackClient
同样,os模块将用于提取我们刚刚导出的SLACK_TOKEN环境变量。SlackClient 导入应该看起来很熟悉,因为它是我们之前在 REPL 上写的同一行:
SLACK_TOKEN = os.environ.get('SLACK_TOKEN')
slack_client = SlackClient(SLACK_TOKEN)
在上面两行中,我们截取了SLACK_TOKEN环境变量值并实例化了 SlackClient 助手库。接下来,让我们创建一个通过 API 调用列出频道的函数。Slack 在一个带有两个键的字典中返回结果:ok和channels。ok允许我们知道 API 调用是否成功,如果它的值是True,那么channels包含了我们在通道列表中需要的数据。
def list_channels():
channels_call = slack_client.api_call("channels.list")
if channels_call.get('ok'):
return channels_call['channels']
return None
最后,让我们添加一个方便的主函数,当我们在命令行上用python app.py调用 Python 文件时,它将允许我们打印所有的通道:
if __name__ == '__main__':
channels = list_channels()
if channels:
print("Channels: ")
for c in channels:
print(c['name'] + " (" + c['id'] + ")")
else:
print("Unable to authenticate.")
这就是我们目前需要的所有代码。是时候尝试一下了。用python app.py从命令行执行脚本。您将看到类似以下通道列表的输出:
Channels:
general (C0S82S5RS)
python (C0S8HABL3)
random (C0S8F4432)
我们在频道名称旁边的括号中打印出的频道 ID 是什么?Slack 的 API 需要一个惟一的通道引用,所以我们使用 ID 而不是名称作为标识符,而不是人类可读的通道名称。
我们可以编写一些代码,使用 channel.info API 方法来获取基于 ID 的特定通道的数据。
在 main 中添加一个新函数和几个新行,以输出来自每个通道的最新消息,这仅在更详细的channel.info API 调用中可用。
更新代码:
import os
from slackclient import SlackClient
SLACK_TOKEN = os.environ.get('SLACK_TOKEN', None)
slack_client = SlackClient(SLACK_TOKEN)
def list_channels():
channels_call = slack_client.api_call("channels.list")
if channels_call['ok']:
return channels_call['channels']
return None
def channel_info(channel_id):
channel_info = slack_client.api_call("channels.info", channel=channel_id)
if channel_info:
return channel_info['channel']
return None
if __name__ == '__main__':
channels = list_channels()
if channels:
print("Channels: ")
for c in channels:
print(c['name'] + " (" + c['id'] + ")")
detailed_info = channel_info(c['id'])
if detailed_info:
print(detailed_info['latest']['text'])
else:
print("Unable to authenticate.")
注意,这段代码极大地增加了脚本执行的 API 调用,从 1 个增加到 N+1 个,其中 N 是 Slack 返回的通道数。
通过执行python app.py再次运行新脚本:
Channels:
general (C0S82S5RS)
yada yada yada.
python (C0S8HABL3)
This is posted to #python and comes from a bot named webhookbot.
random (C0S8F4432)
<@U0SAEJ99T|samb> has joined the channel
不错!现在我们既有了频道列表,也有了获取每个频道及其 ID 的详细信息的方法。接下来,让我们通过发送和接收消息,在我们的一个通道中与其他用户进行交互。
发送消息
现在我们可以更深入地了解 Slack API,因为我们知道我们的 API 调用正在工作,并且有了通道 ID。我们给#总频道发个消息吧。
在channel_info下增加一个名为send_message的新功能:
def send_message(channel_id, message):
slack_client.api_call(
"chat.postMessage",
channel=channel_id,
text=message,
username='pythonbot',
icon_emoji=':robot_face:'
)
接收一个频道的 ID,然后从我们的“Python bot”向该频道发布一条消息。另外,修改main函数,这样当我们运行这个文件时,main将调用我们新的send_message函数:
if __name__ == '__main__':
channels = list_channels()
if channels:
print("Channels: ")
for channel in channels:
print(channel['name'] + " (" + channel['id'] + ")")
detailed_info = channel_info(channel['id'])
if detailed_info:
print('Latest text from ' + channel['name'] + ":")
print(detailed_info['latest']['text'])
if channel['name'] == 'general':
send_message(channel['id'], "Hello " +
channel['name'] + "! It worked!")
print('-----')
else:
print("Unable to authenticate.")
保存更改并运行python app.py。为你的懈怠团队打开#通用通道。您应该看到您的 Python bot 向频道发布了一条新消息:

厉害!所以我们可以发送消息,但是如果我们想知道#general 频道的用户在说什么呢?
接收消息
我们可以设置一个传出的 webhook,它将通过 HTTP POST 请求提醒我们的 Python 应用程序。这部分比发送消息稍微复杂一些,因为我们需要接收一个或多个 POST 请求。
首先,我们需要一个简单的 web 服务器,它可以处理来自 Slack webhook 的入站 POST 请求。使用以下代码创建一个名为 receive.py 的新文件:
import os
from flask import Flask, request, Response
app = Flask(__name__)
SLACK_WEBHOOK_SECRET = os.environ.get('SLACK_WEBHOOK_SECRET')
@app.route('/slack', methods=['POST'])
def inbound():
if request.form.get('token') == SLACK_WEBHOOK_SECRET:
channel = request.form.get('channel_name')
username = request.form.get('user_name')
text = request.form.get('text')
inbound_message = username + " in " + channel + " says: " + text
print(inbound_message)
return Response(), 200
@app.route('/', methods=['GET'])
def test():
return Response('It works!')
if __name__ == "__main__":
app.run(debug=True)
在上面的 Python 文件中,我们:
- 进口烧瓶
- 实例化新的 Flask 应用程序上下文
- 引入
SLACK_WEBHOOK_SECRET环境变量,稍后我们将从 Slack 控制台中获得该变量 - 建立一个可以接收 Slack 的 HTTP POST 请求的路由,只要发送给我们的 webhook 密钥与我们的环境变量中的密钥相匹配,就会将输出打印到命令行
- 为响应 GET 请求的测试目的创建另一个路由
- 将我们的 Flask 应用程序设置为在我们用 Python 运行这个脚本时运行
安装 Flask ( pip install flask),然后用python receive.py命令启动 Flask 应用程序,我们将看到一些调试输出,表明开发服务器正在运行。
- 运行于 http://127.0.0.1:5000/(按
Ctrl+C退出) - 使用 stat 重新启动
- 调试器处于活动状态!
- 调试器 pin 码:144-609-426
我们已经准备好接收我们的 POST 请求 webhook,只是大多数开发环境不公开 localhost 之外的路由。我们需要一个本地主机隧道,当我们开发代码时,它将为我们提供一个外部可访问的域名。我通常使用 ngrok ,因为它是简单、免费和令人敬畏的。还有其他选项如本地隧道和前向。
在新的终端窗口中下载并运行 ngrok(或另一个本地主机隧道工具)后,您将获得一个子域,该子域将发送到该子域的请求转发到您的本地主机服务器。下面是 ngrok 在控制台中用./ngrok http 5000命令启动时的样子:

记下您的转发 URL,在本例中是https://6940e7da.ngrok.io,因为 Slack 需要它来设置我们的出站 webhook。然后,通过打开您的 web 浏览器并转到转发 URL,测试我们的 ngrok 转发 URL 是否正确连接到我们的 Flask 应用程序。我们应该看到“成功了!”消息。
现在我们可以在我们的 Slack 配置中使用 ngrok 转发 URL。进入 Slack Outgoing Webhooks 页面,点击“outgoing webhook integration”链接,如下图所示:
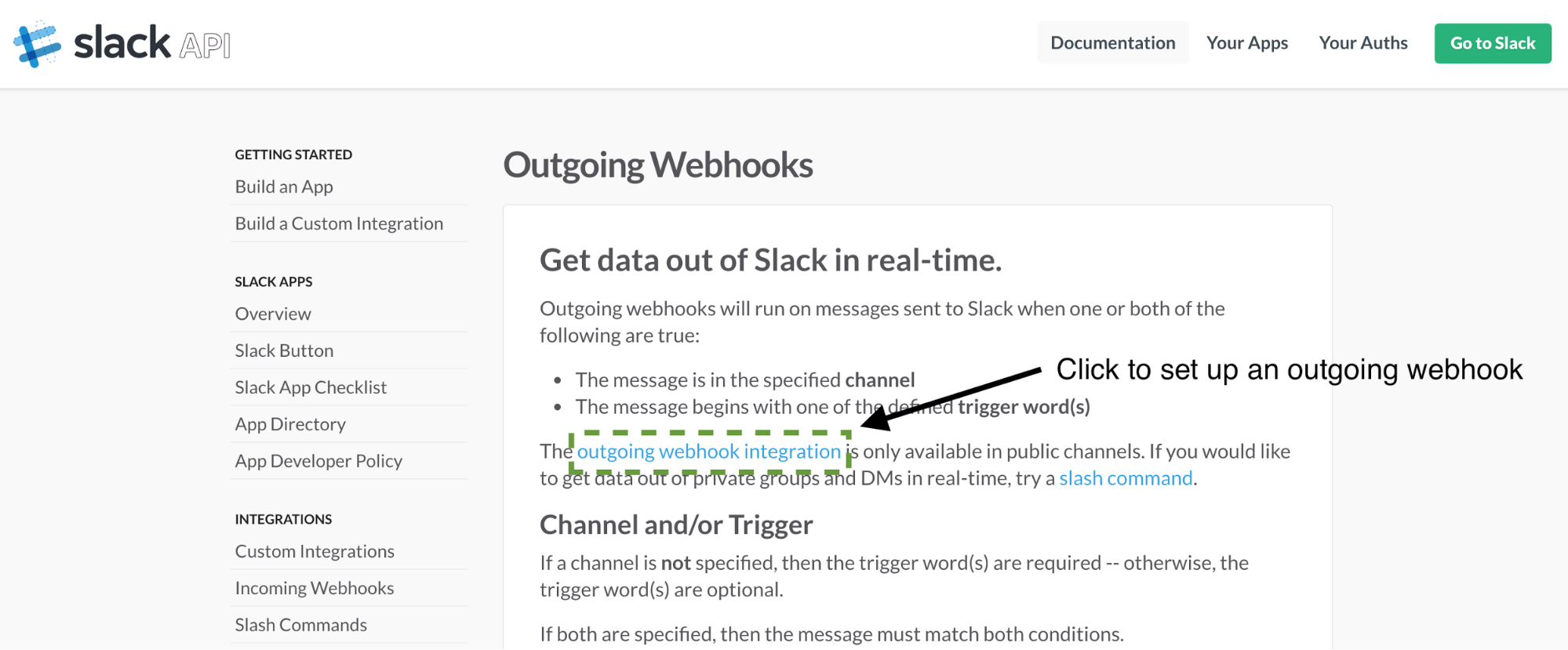
向下滚动到集成设置部分。选择“#general”作为收听频道。将您的 ngrok 转发 URL 加上“/slack”复制到 URL 文本框中:
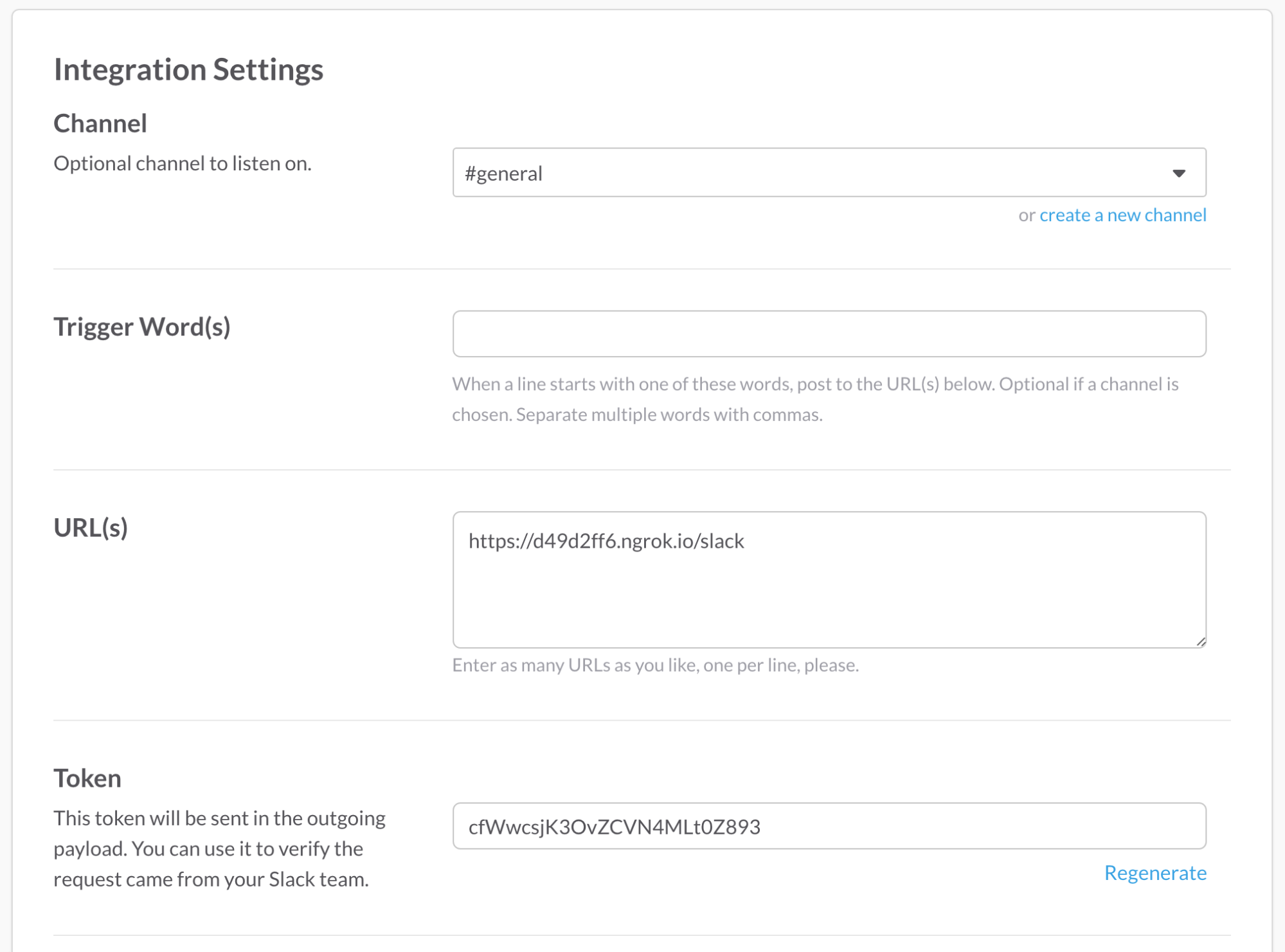
复制生成的令牌。向下滚动并按下“保存设置”按钮。
暂停一下你的 Flask 服务器。正如我们前面对 Slack 令牌所做的那样,使用export命令将传出的 webhook 令牌作为环境变量公开:
(venv)$ export SLACK_WEBHOOK_SECRET='generated outgoing webhook token here'
然后重启 Flask 服务器,这样它就可以获取生成的SLACK_WEBHOOK_SECRET。最后,是测试接收消息的时候了!
去你的 Slack #通用频道。您应该会看到外发的 webhook 集成已经添加到通道中:

在 Slack 中,输入类似“testing”的消息,然后按回车键。回到运行 Flask 应用程序的命令行。您应该看到 POST 请求输出的消息:
matt in general says: testing
127.0.0.1 - - [21/May/2016 12:39:56] "POST /slack HTTP/1.1" 200 -
现在,我们已经有了从一个或多个通道接收消息的方法,并且可以添加我们想要的任何 Python 代码来处理输入。这是构建 bot 或将消息发送到另一个服务进行处理的一个很好的挂钩。
包装完毕
呜哇!全部完成!实际上,你可以用 Slack API 做更多的事情。既然你已经有了基本的东西,这里还有几个想法可以尝试:
- 结合 Twilio API,通过短信与 Slack 频道进行通信
- 尝试不同的 Slack 客户端或完全放弃助手库,并使用请求库来实现重试逻辑
- 编写并定制一个完全松弛的机器人
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
目前就这些。
如果您有任何问题,请在下面留言或通过以下方式联系我:
- 推特: @mattmakai 和 @fullstackpython
- GitHub: makaimc
- Twitch(使用 Python 和 Swift 进行实时编码): mattmakai***
在 Python 中使用 ggplot:使用 plotnine 可视化数据
原文:# t0]https://realython . com/ggplot-python/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 和 ggplot 绘制你的数据
在本教程中,您将学习如何使用 Python 中的ggplot来创建数据可视化,使用图形的语法。图形语法是一个高级工具,它允许您以高效和一致的方式创建数据图。它抽象了大多数底层细节,让您专注于为数据创建有意义且漂亮的可视化效果。
有几个 Python 包提供了图形语法。本教程主要讲述的剧情,因为它是最成熟的一个。plotnine 基于来自 R 编程语言的 ggplot2 ,所以如果你有 R 方面的背景,那么你可以考虑将 plotnine 作为 Python 中ggplot2的等价物。
在本教程中,您将学习如何:
- 安装 plotnine 和 Jupyter 笔记本
- 组合图形的语法的不同元素
- 使用 plotnine 以高效一致的方式创建可视化效果
- 将您的数据可视化导出到文件中
本教程假设你已经对 Python 有了一些经验,并且至少对 T2 的 Jupyter 笔记本和 T4 的熊猫有了一些了解。要快速了解这些主题,请查看 Jupyter 笔记本:使用 Pandas 和 Python 探索数据集的介绍和。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
设置您的环境
在本节中,您将学习如何设置您的环境。您将涉及以下主题:
- 创建虚拟环境
- 安装绘图线
- 安装 jupiter 笔记本
虚拟环境使您能够在隔离的环境中安装软件包。当您想尝试一些包或项目而不影响系统范围的安装时,它们非常有用。你可以在 Python 虚拟环境:初级读本中了解更多。
运行以下命令创建一个名为data-visualization的目录,并在其中创建一个虚拟环境:
$ mkdir data-visualization
$ cd data-visualization
$ python3 -m venv venv
运行以上命令后,您将在data-visualization目录中找到您的虚拟环境。运行以下命令来激活虚拟环境并开始使用它:
$ source ./venv/bin/activate
激活虚拟环境时,您安装的任何软件包都将安装在该环境中,而不会影响系统范围的安装。
接下来,您将使用 pip软件包安装程序在虚拟环境中安装 plotnine。
通过运行以下命令安装 plotnine:
$ python -m pip install plotnine
执行上面的命令使plotnine包在您的虚拟环境中可用。
最后,您将安装 Jupyter 笔记本。虽然这对于使用 plotnine 不是绝对必要的,但是您会发现 Jupyter Notebook 在处理数据和构建可视化时非常有用。如果你以前从未使用过这个程序,那么你可以在 Jupyter 笔记本:简介中了解更多。
要安装 Jupyter Notebook,请使用以下命令:
$ python -m pip install jupyter
恭喜您,您现在拥有了一个安装了 plotnine 和 Jupyter 笔记本的虚拟环境!有了这个设置,您将能够运行本教程中介绍的所有代码示例。
用ggplot和 Python 构建你的第一个地块
在本节中,您将学习如何使用 Python 中的ggplot构建您的第一个数据可视化。您还将学习如何检查和使用 plotnine 中包含的示例数据集。
当您熟悉 plotnine 的特性时,示例数据集非常方便。每个数据集都以一个 pandas DataFrame 的形式提供,这是一个用来保存数据的二维表格数据结构。
在本教程中,您将使用以下数据集:
economics:美国经济数据的时间序列mpg:一系列车辆的燃油经济性数据huron:休伦湖在 1875 年至 1972 年间的水位
您可以在 plotnine 参考中找到示例数据集的完整列表。
您可以使用 Jupyter Notebook 检查任何数据集。使用以下命令启动 Jupyter 笔记本:
$ source ./venv/bin/activate
$ jupyter-notebook
然后,进入 Jupyter Notebook 后,运行以下代码查看economics数据集中的原始数据:
from plotnine.data import economics
economics
代码从plotnine.data导入economics数据集,并将其显示在一个表格中:
date pce pop psavert uempmed unemploy
0 1967-07-01 507.4 198712 12.5 4.5 2944
1 1967-08-01 510.5 198911 12.5 4.7 2945
... ... ... ... ... ... ...
572 2015-03-01 12161.5 320707 5.2 12.2 8575
573 2015-04-01 12158.9 320887 5.6 11.7 8549
如您所见,该数据集包括 1967 年至 2015 年间每个月的经济信息。每一行都有以下字段:
date:收集数据的月份pce:个人消费支出(以十亿美元计)pop:总人口(以千计)psavert:个人储蓄率uempmed:失业持续时间中位数(周)unemploy:失业人数(以千计)
现在,使用 plotnine,您可以创建一个图表来显示这些年来人口的演变:
1from plotnine.data import economics
2from plotnine import ggplot, aes, geom_line
3
4(
5 ggplot(economics) # What data to use
6 + aes(x="date", y="pop") # What variable to use
7 + geom_line() # Geometric object to use for drawing
8)
这个简短的代码示例从economics数据集创建了一个图。这里有一个快速分类:
-
第 1 行:您导入了
economics数据集。 -
第二行:你从
plotnine、aes()和geom_line()中导入ggplot()类以及一些有用的函数。 -
第 5 行:使用
ggplot()创建一个绘图对象,将economics数据帧传递给构造函数。 -
第 6 行:添加
aes()来设置每个轴使用的变量,在本例中是date和pop。 -
第 7 行:您添加了
geom_line()来指定图表应该绘制为折线图。
运行上述代码会产生以下输出:
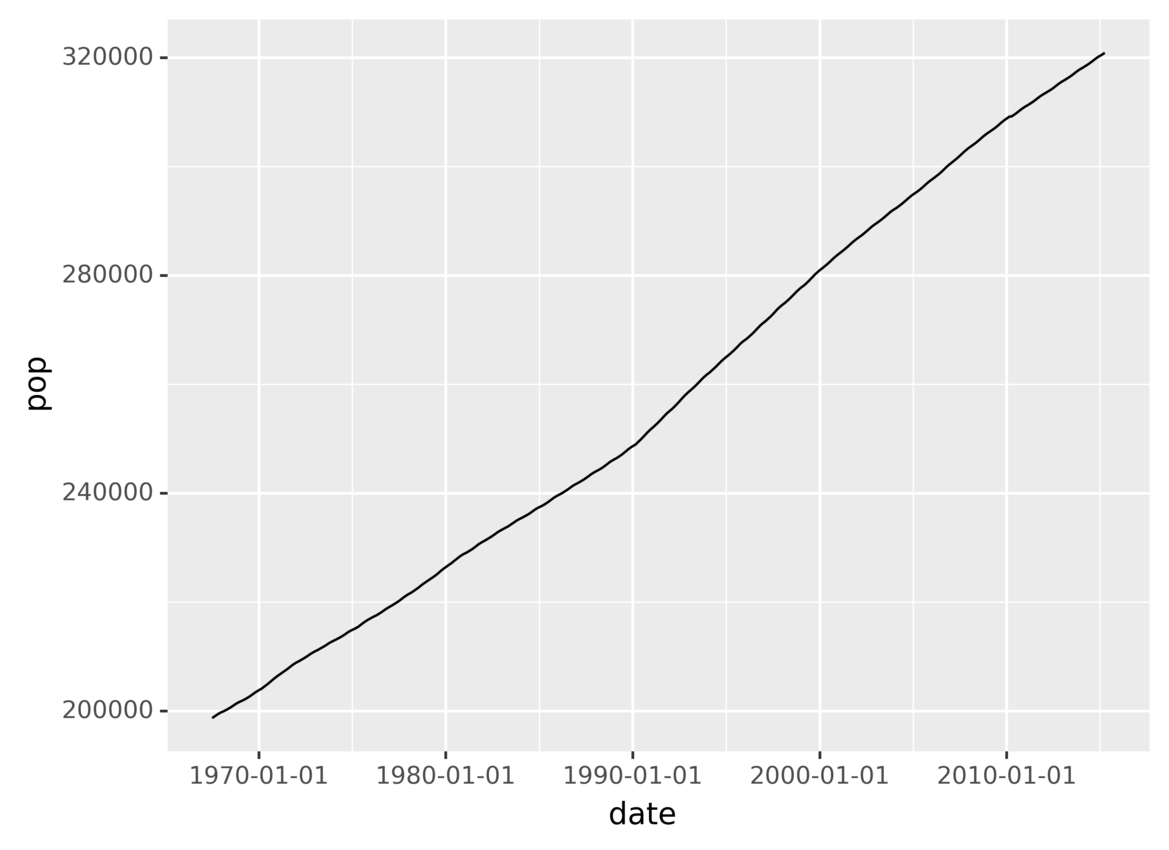
您刚刚创建了一个显示人口随时间演变的图表!
在本节中,您看到了在使用图形语法时需要指定的三个必需组件:
- 您想要绘制的数据
- 要在每个轴上使用的变量
- 用于绘图的几何对象
您还看到了使用 + 操作符组合不同的组件。
在接下来的几节中,您将更深入地了解图形语法以及如何使用 plotnine 创建数据可视化。
理解图形的语法
图形语法是一种高级工具,允许您描述图形的组成部分,将您从画布上实际绘制像素的低级细节中抽象出来。
它被称为语法,因为它定义了一组组件以及将它们组合起来创建图形的规则,就像语言语法定义了如何将单词和标点符号组合成句子一样。你可以在 Leland Wilkinson 的书*中了解更多关于图形语法的基础知识。
有许多不同的图形语法,它们使用的组件和规则也不同。plotnine 实现的图形语法是基于 R 编程语言的ggplot2。这种特定的语法出现在 Hadley Wickham 的论文“图形的分层语法”中
下面,您将了解 plotnine 图形语法的主要组件和规则,以及如何使用它们来创建数据可视化。首先,您将回顾创建情节所需的三个要素:
-
数据是创建绘图时使用的信息。
-
美学(
aes) 提供底层绘图系统使用的数据变量和美学或图形变量之间的映射。在上一节中,您将date和pop数据变量映射到 x 轴和 y 轴美学变量。 -
几何对象(
geoms) 定义图形中使用的几何对象的类型。您可以使用点、线、条和许多其他元素。
没有这三个组件中的任何一个,plotnine 都不知道如何绘制图形。
您还将了解您可以使用的可选组件:
-
统计转换指定在绘制数据之前应用于数据的计算和聚合。
-
Scales 在从数据到美学的映射过程中应用一些转换。例如,有时您可以使用对数标度来更好地反映数据的某些方面。
-
Facets 允许您根据一些属性将数据分组,然后在同一图形中将每个组绘制到单独的面板中。
-
坐标系将物体的位置映射到图形中的 2D 图形位置。例如,您可以选择翻转垂直轴和水平轴,如果这对您构建的可视化更有意义的话。
-
主题允许您控制视觉属性,如颜色、字体和形状。
如果您现在没有完全理解每个组件是什么,也不要担心。在本教程中,您将了解更多关于它们的内容。
使用 Python 和ggplot和绘制数据
在本节中,您将了解使用 plotnine 创建数据可视化所需的三个组件的更多信息:
- 数据
- 美学
- 几何对象
您还将看到它们是如何结合起来从数据集创建绘图的。
数据:信息的来源
创建数据可视化的第一步是指定要绘制的数据。在 plotnine 中,通过创建一个ggplot对象并将想要使用的数据集传递给构造函数来实现这一点。
以下代码使用 plotnine 的燃油经济性示例数据集mpg创建了一个ggplot对象:
from plotnine.data import mpg
from plotnine import ggplot
ggplot(mpg)
这段代码使用mpg数据集创建了一个属于类ggplot的对象。请注意,由于您还没有指定美学或几何对象,上面的代码将生成一个空白图。接下来,您将一点一点地构建情节。
正如您之前看到的,您可以使用以下代码从 Jupyter Notebook 检查数据集:
from plotnine.data import mpg
mpg
这两行代码导入并显示数据集,显示以下输出:
manufacturer model displ year cyl trans drv cty hwy fl class
0 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
1 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
2 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact
...
输出是一个包含 1999 年到 2008 年 234 辆汽车燃料消耗数据的表格。排量(displ)字段是发动机的大小,单位为升。cty和hwy是城市和公路驾驶的燃油经济性,单位为每加仑英里数。
在下面几节中,您将学习使用 plotnine 将这些原始数据转换成图形的步骤。
美学:为每个轴定义变量
指定要可视化的数据后,下一步是定义要用于绘图中每个轴的变量。数据帧中的每一行可以包含许多字段,所以你必须告诉 plotnine 你想在图形中使用哪些变量。
美学将数据变量映射到图形属性,比如 2D 位置和颜色。例如,下面的代码创建了一个图形,该图形在 x 轴上显示车辆类别,在 y 轴上显示公路油耗:
from plotnine.data import mpg
from plotnine import ggplot, aes
ggplot(mpg) + aes(x="class", y="hwy")
使用前一节中的ggplot对象作为可视化的基础,代码将车辆的class属性映射到水平图形轴,将hwy的燃油经济性映射到垂直轴。
但是生成的绘图仍然是空白的,因为它缺少表示每个数据元素的几何对象。
几何对象:选择不同的绘图类型
在定义了您想要在图形中使用的数据和属性之后,您需要指定一个几何对象来告诉 plotnine 应该如何绘制数据点。
plotnine 提供了许多可以开箱即用的几何对象,如线、点、条、多边形等等。所有可用几何对象的列表可在 plotnine 的geoms API 参考中找到。
以下代码说明了如何使用点几何对象来绘制数据:
from plotnine.data import mpg
from plotnine import ggplot, aes, geom_point
ggplot(mpg) + aes(x="class", y="hwy") + geom_point()
在上面的代码中,geom_point()选择了点几何对象。运行代码会产生以下输出:
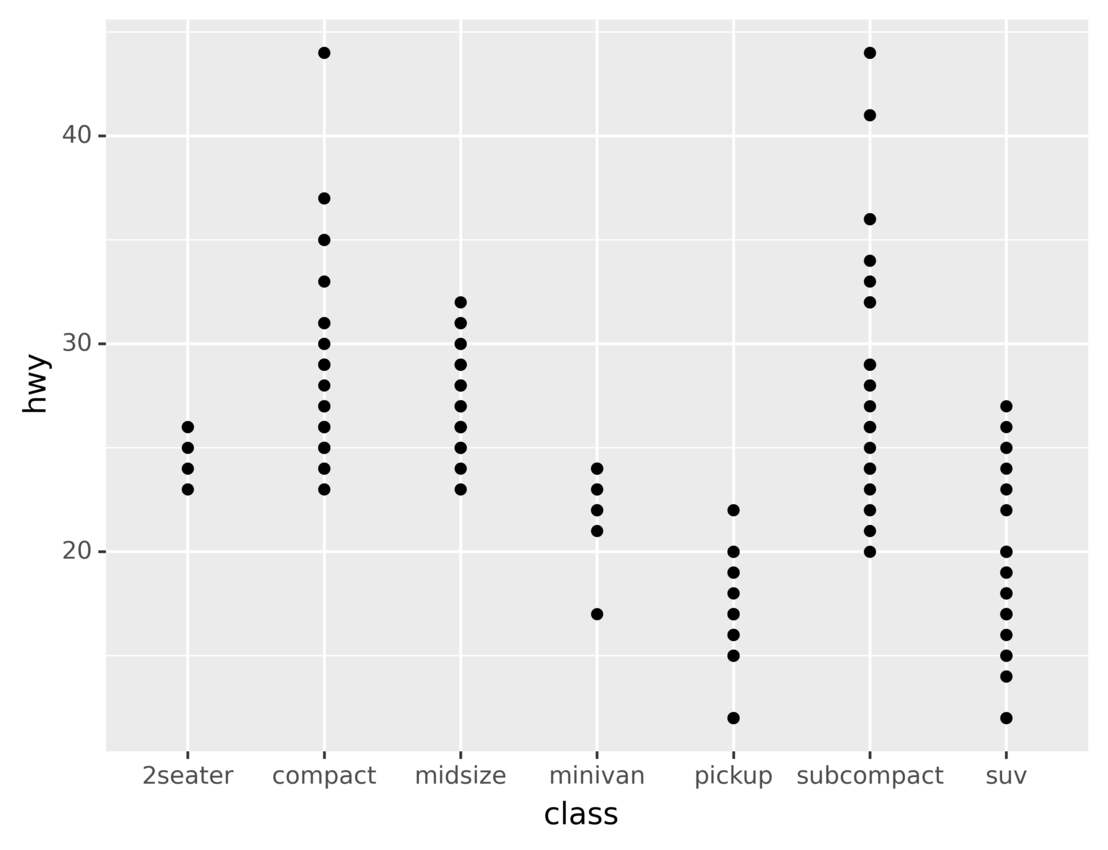
如您所见,生成的数据可视化对于数据集中的每辆车都有一个点。轴显示车辆等级和公路燃油经济性。
还有许多其他几何对象可用于可视化同一数据集。例如,下面的代码使用 bar 几何对象来显示每个类的车辆数:
from plotnine.data import mpg
from plotnine import ggplot, aes, geom_bar
ggplot(mpg) + aes(x="class") + geom_bar()
在这里,geom_bar()将几何对象设置为条形。由于代码没有为 y 轴指定任何属性,geom_bar()隐式地按照用于 x 轴的属性对数据点进行分组,然后使用 y 轴的每个组中的点数。
运行代码,您将看到以下输出:
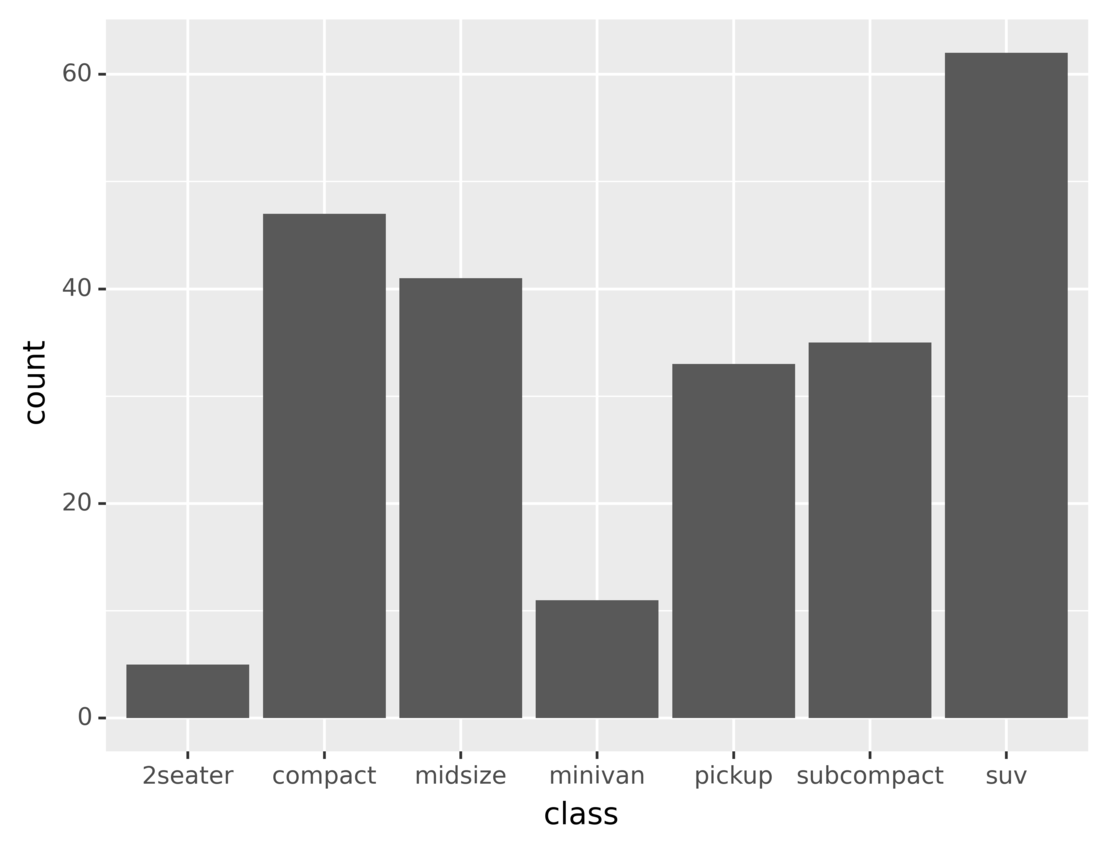
图中每个条形的高度代表属于相应车辆类别的车辆数量。在后面的章节中,您将了解更多关于数据聚合和分组的内容。
在本节中,您了解了创建数据可视化时必须指定的三个必备组件:
- 数据
- 美学
- 几何对象
您还学习了如何使用+操作符组合它们。
在接下来的几节中,您将了解一些可选组件,它们可以用来创建更复杂、更漂亮的图形。
使用额外的 Python 和ggplot特性来增强数据可视化
在本节中,您将了解在使用 plotnine 构建数据可视化时可以使用的可选组件。这些组件可以分为五类:
- 统计变换
- 天平
- 坐标系统
- 面状
- 主题
你可以用它们来创造更丰富、更美好的情节。
统计转换:汇总和转换您的数据
统计转换在绘制数据之前对其进行一些计算,例如显示一些统计指标而不是原始数据。plotnine 包括几个你可以使用的统计转换。
假设您想要创建一个直方图来显示从 1875 年到 1975 年休伦湖的水位分布。该数据集包含在 plotnine 中。您可以使用以下代码检查 Jupyter Notebook 中的数据集并了解其格式:
# Import our example dataset with the levels of Lake Huron 1875–1975
from plotnine.data import huron
huron
代码导入并显示数据集,产生以下输出:
year level decade
0 1875 580.38 1870
1 1876 581.86 1870
...
96 1971 579.89 1970
97 1972 579.96 1970
如您所见,数据集包含三列:
yearleveldecade
现在,您可以分两步构建直方图:
- 将液位测量值分组到箱中。
- 使用条形图显示每个箱中的测量数量。
以下代码显示了如何在 plotnine 中完成这些步骤:
from plotnine.data import huron
from plotnine import ggplot, aes, stat_bin, geom_bar
ggplot(huron) + aes(x="level") + stat_bin(bins=10) + geom_bar()
在上面的代码中,stat_bin()将level的范围分成十个大小相等的区间。然后,使用条形图绘制落入每个箱中的测量值的数量。
运行该代码会生成下图:
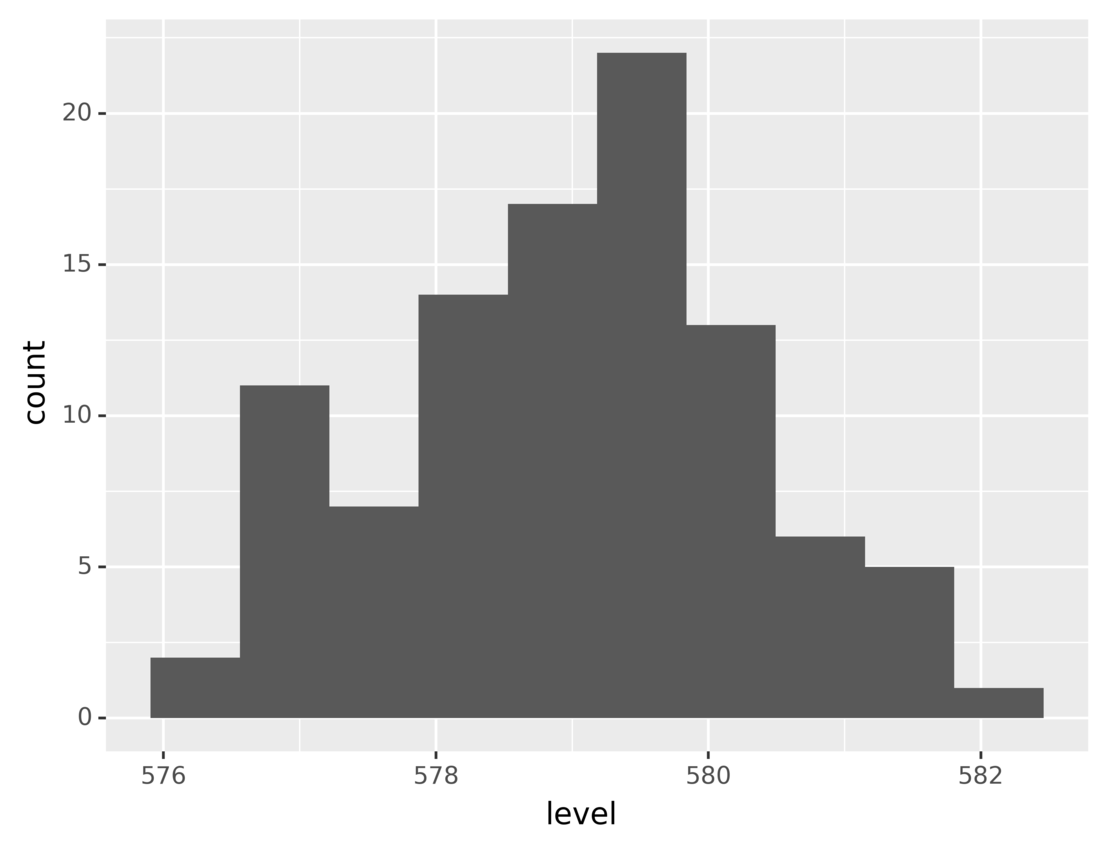
该图显示了每个湖泊水位范围的测量次数。正如你所看到的,大部分时间水平在578和580之间。
对于大多数常见的任务,如构建直方图,plotnine 包括非常方便的函数,使代码更加简洁。例如,使用geom_histogram(),您可以像这样构建上面的直方图:
from plotnine.data import huron
from plotnine import ggplot, aes, geom_histogram
ggplot(huron) + aes(x="level") + geom_histogram(bins=10)
使用geom_histogram()与使用stats_bin()然后使用geom_bar()是一样的。运行这段代码会生成与上面相同的图形。
现在让我们来看另一个统计转换的例子。箱线图是一种非常流行的统计工具,用于显示数据集中的最小值、最大值、样本中值、第一个和第三个四分位数以及异常值。
假设您想要基于相同的数据集构建可视化,以显示每十年的液位测量值的箱线图。您可以分两步构建该图:
- 将测量值按十进制分组。
- 为每个组创建一个箱线图。
您可以使用美学规范中的 factor() 完成第一步。factor()将指定属性具有相同值的所有数据点组合在一起。
然后,一旦你将数据按十年分组,你就可以用geom_boxplot()为每一组画一个方框图。
以下代码使用上述步骤创建一个图:
from plotnine.data import huron
from plotnine import ggplot, aes, geom_boxplot
(
ggplot(huron)
+ aes(x="factor(decade)", y="level")
+ geom_boxplot()
)
代码使用factor()按十进制对数据行进行分组,然后使用geom_boxplot()创建盒状图。
正如您在前面的示例中看到的,一些几何对象具有隐式统计变换。这真的很方便,因为它使你的代码更加简洁。使用geom_boxplot()意味着stat_boxplot(),它负责计算四分位数和异常值。
运行上述代码,您将获得下图:
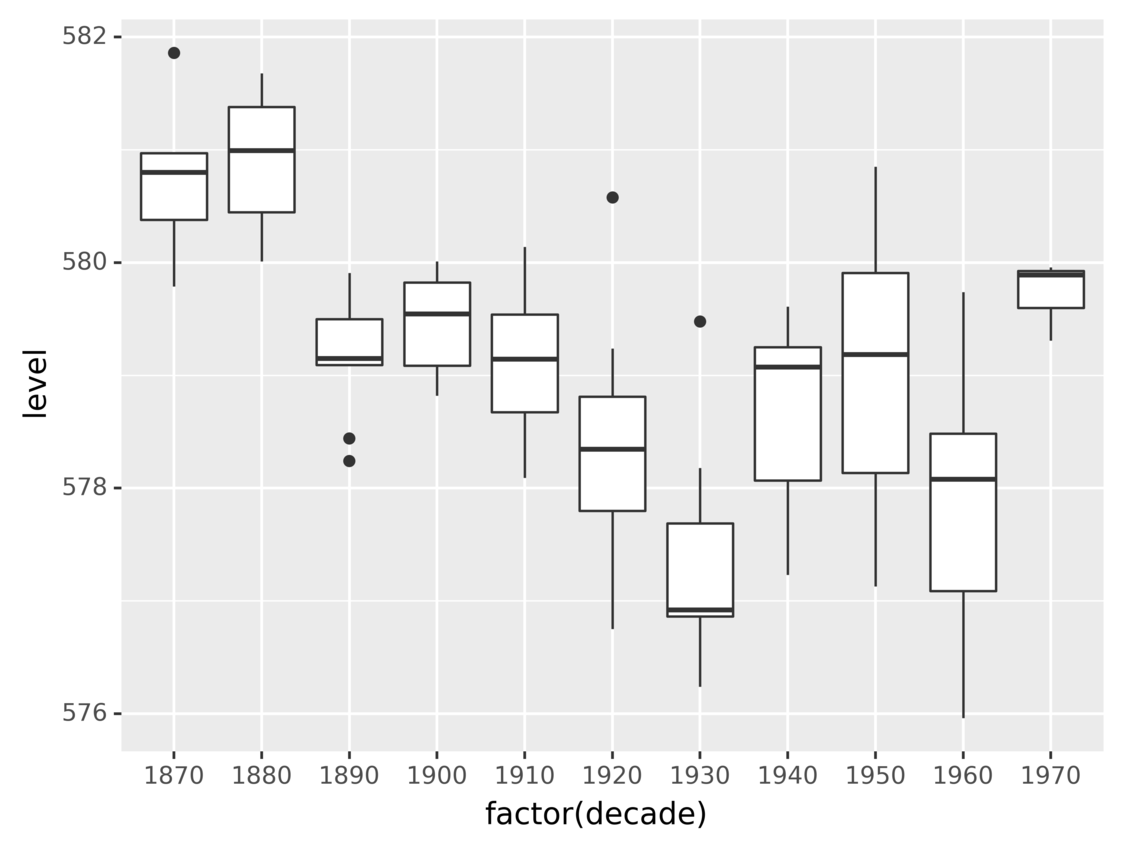
该图使用箱线图显示了每十年的水位分布。
使用 Python 中的ggplot,还可以使用其他统计转换来构建数据可视化。你可以在 plotnine 的 stats API 文档中了解它们。
标度:根据其含义改变数据标度
在从数据到美学的映射过程中,比例是您可以应用的另一种转换。它们有助于让你的可视化更容易理解。
在本教程开始时,您看到了一个显示自 1970 年以来每年人口的图。以下代码显示了如何使用刻度来显示自 1970 年以来经过的年份,而不是原始日期:
from plotnine.data import economics
from plotnine import ggplot, aes, scale_x_timedelta, labs, geom_line
(
ggplot(economics)
+ aes(x="date", y="pop")
+ scale_x_timedelta(name="Years since 1970")
+ labs(title="Population Evolution", y="Population")
+ geom_line()
)
使用scale_x_timedelta()通过计算每个点与数据集中最早日期的差异来转换每个点的 x 值。注意,代码还使用labs()为 y 轴和标题设置了一个更具描述性的标签。
运行代码显示了这个图:
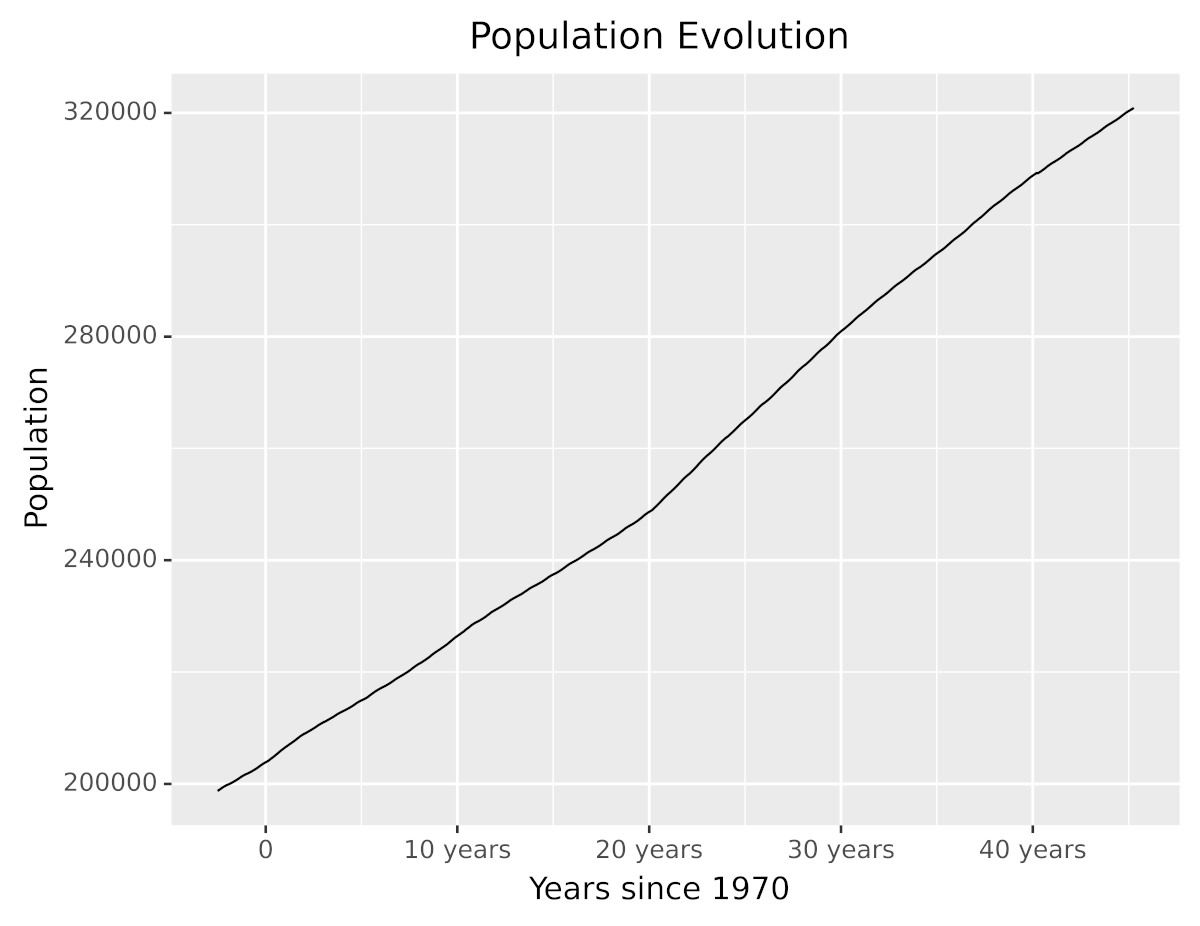
在不改变数据的情况下,您已经使可视化更容易理解,对读者更友好。如您所见,该图现在有了更好的描述,x 轴显示了自 1970 年以来经过的时间,而不是日期。
plotnine 提供了大量的标度变换供您选择,包括对数标度和其他非线性标度。你可以在 plotnine 的 scales API 参考中了解它们。
坐标系:将数据值映射到 2D 空间
坐标系定义了如何将数据点映射到图中的 2D 图形位置。你可以把它想象成从数学变量到图形位置的映射。选择正确的坐标系可以提高数据可视化的可读性。
让我们重温一下之前的条形图示例,以计算属于不同类别的车辆。您使用以下代码创建了该图:
from plotnine.data import mpg
from plotnine import ggplot, aes, geom_bar
ggplot(mpg) + aes(x="class") + geom_bar()
代码使用geom_bar()为每个车辆类别绘制一个条形。因为没有设置特定的坐标系,所以使用默认坐标系。
运行代码会生成以下图形:
图中每个条形的高度代表一类车辆的数量。
虽然上图没有问题,但是同样的信息可以通过翻转坐标轴以显示水平条而不是垂直条来更好地可视化。
plotnine 提供了几个允许您修改坐标系的功能。您可以使用coord_flip()翻转轴:
from plotnine.data import mpg
from plotnine import ggplot, aes, geom_bar, coord_flip
ggplot(mpg) + aes(x="class") + geom_bar() + coord_flip()
代码使用coord_flip()翻转 x 轴和 y 轴。运行代码,您将看到下图:
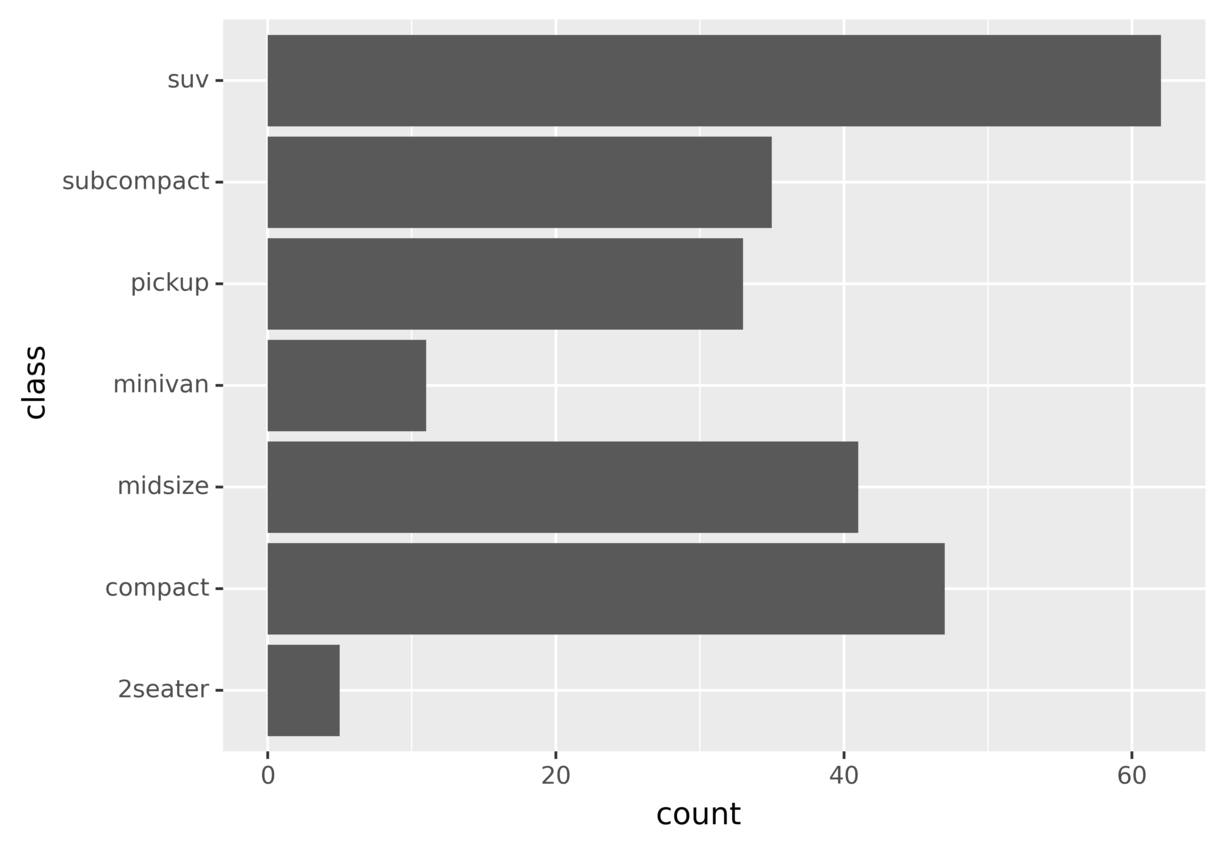
此图显示了您在之前的图中看到的相同信息,但是通过翻转轴,您可能会发现更容易理解和比较不同的条形图。
哪个坐标系更好没有硬性规定。您应该选择最适合您的问题和数据的方法。给他们一个机会,做一些实验来了解每种情况下的工作原理。你可以在 plotnine 的坐标 API 参考中找到更多关于其他坐标系的信息。
面:将数据子集绘制到同一个图中的面板上
在这一节中,你将了解到 facets ,plotnine 最酷的特性之一。刻面允许您按某些属性对数据进行分组,然后在同一图像中单独绘制每个组。当您想要在同一个图形中显示两个以上的变量时,这尤其有用。
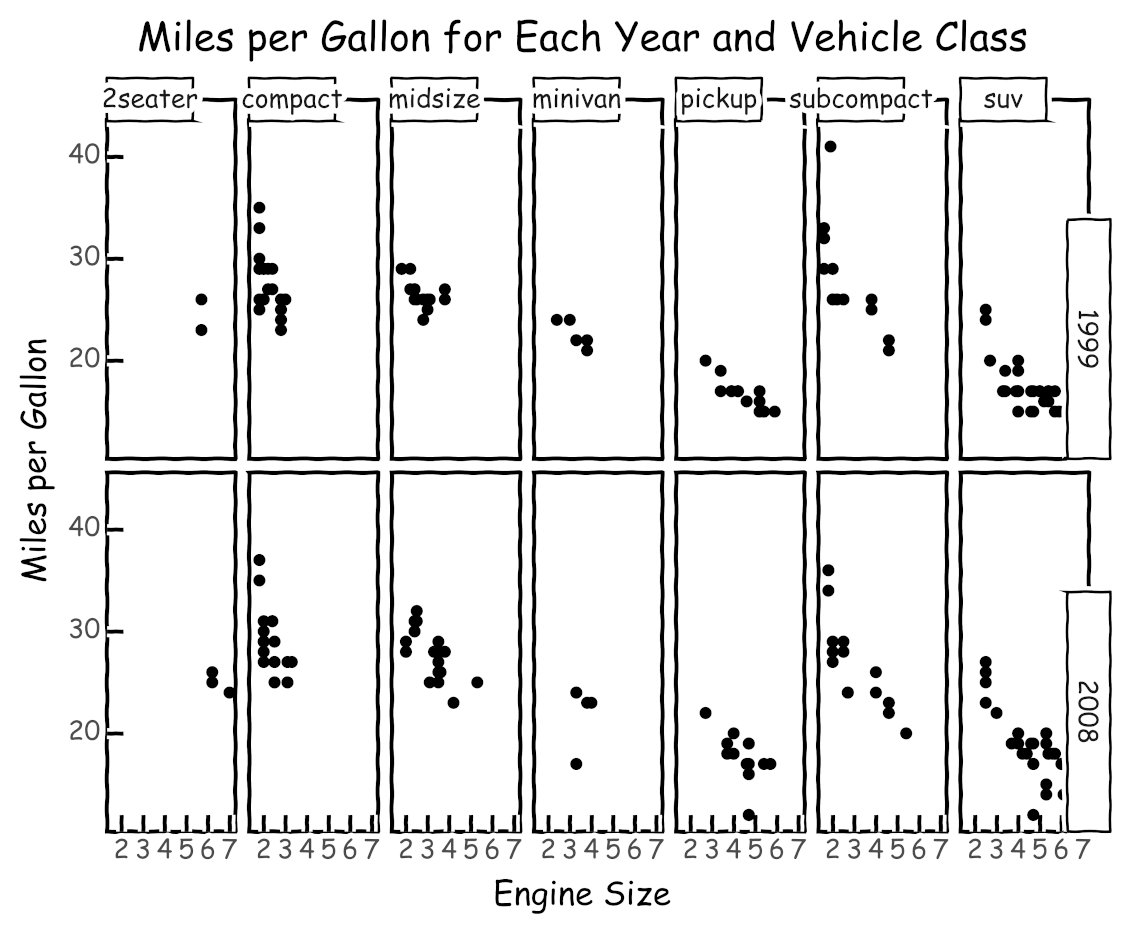
例如,假设您想要获取燃油经济性数据集(mpg)并构建一个图表,显示每种发动机规格(displacement)每种车辆类别每年的每加仑英里数。在这种情况下,您的绘图需要显示来自四个变量的信息:
hwy:每加仑英里数displ:发动机尺寸class:车辆类year:年款
这是一个挑战,因为你有比图形尺寸更多的变量。如果你必须显示三个变量,你可以使用 3D 透视图,但是四维图形甚至难以想象。
面对这个问题,你可以用一个两步走的技巧:
-
首先将数据分成组,其中一个组中的所有数据点共享某些属性的相同值。
-
单独绘制每个组,仅显示分组中未使用的属性。
回到这个例子,您可以按类别和年份对车辆进行分组,然后绘制每组的图表以显示排量和每加仑英里数。以下可视化是使用这种技术生成的:
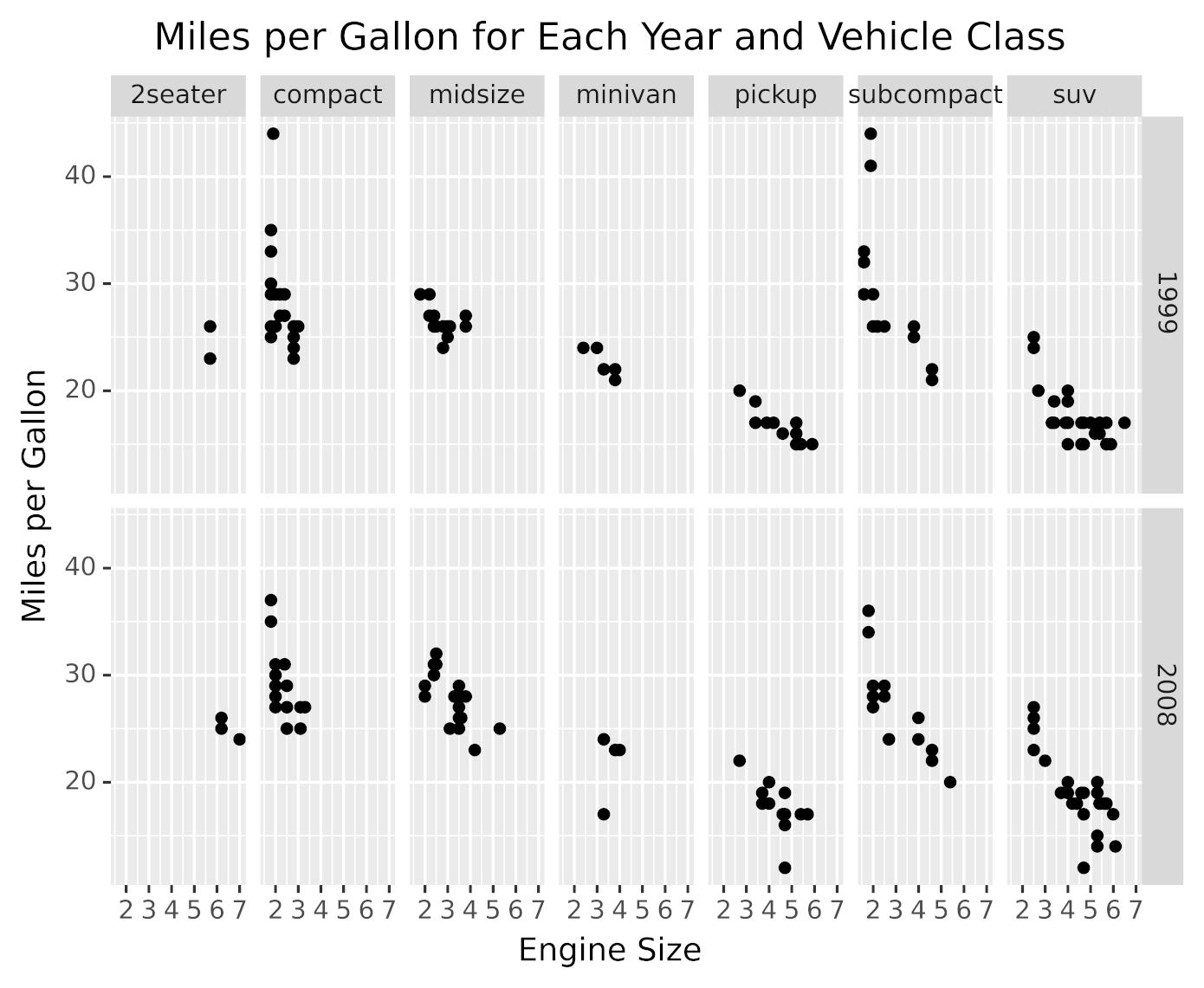
如上图所示,每个组都有一个面板。每个面板显示属于该车辆类别和年份的不同发动机排量的每加仑英里数。
该数据可视化是使用以下代码生成的:
from plotnine.data import mpg
from plotnine import ggplot, aes, facet_grid, labs, geom_point
(
ggplot(mpg)
+ facet_grid(facets="year~class")
+ aes(x="displ", y="hwy")
+ labs(
x="Engine Size",
y="Miles per Gallon",
title="Miles per Gallon for Each Year and Vehicle Class",
)
+ geom_point()
)
代码使用facet_grid()按年份和车辆类别对数据进行分区,并向其传递用于使用facets="year~class"进行分区的属性。对于每个数据分区,这个图是使用您在前面章节中看到的组件构建的,比如美学、几何对象和labs()。
facet_grid()在网格中显示分区,对行使用一个属性,对列使用另一个属性。plotnine 提供了其他分面方法,您可以使用两个以上的属性对数据进行分区。你可以在 plotnine 的 facets API 参考中了解更多。
主题:改善你的视觉效果
另一个改善数据可视化表示的好方法是选择一个非默认主题来突出您的绘图,使它们更漂亮、更有活力。
plotnine 包括几个主题,你可以从中挑选。以下代码生成了与您在上一节中看到的图形相同的图形,但是使用了深色主题:
from plotnine.data import mpg
from plotnine import ggplot, aes, facet_grid, labs, geom_point, theme_dark
(
ggplot(mpg)
+ facet_grid(facets="year~class")
+ aes(x="displ", y="hwy")
+ labs(
x="Engine Size",
y="Miles per Gallon",
title="Miles per Gallon for Each Year and Vehicle Class",
)
+ geom_point()
+ theme_dark()
)
在上面的代码中,指定theme_dark()告诉 plotnine 使用深色主题绘制绘图。下面是这段代码生成的图形:
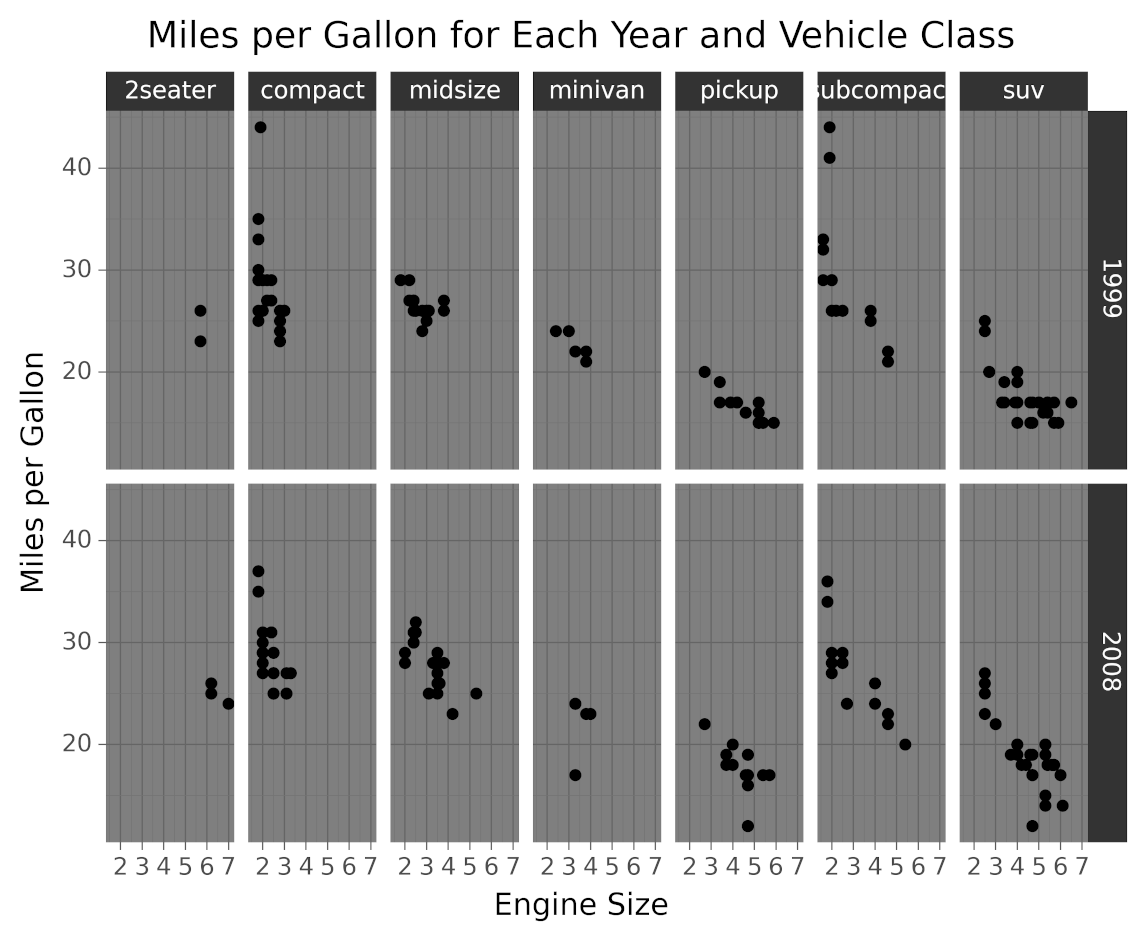
正如您在图像中看到的,设置主题会影响颜色、字体和形状样式。
是另一个值得一提的主题,因为它给你一个非常酷的漫画般的外观。它让你的数据可视化看起来像 xkcd 漫画:
选择合适的主题可以帮助你吸引并留住观众的注意力。你可以在 plotnine 的主题 API 参考中看到可用主题的列表。
在前面的章节中,您已经了解了图形语法最重要的方面,以及如何使用 plotnine 构建数据可视化。在 Python 中使用ggplot可以让你逐步构建可视化**,首先关注你的数据,然后添加和调整组件来改善它的图形表示。*
*在下一节中,您将学习如何使用颜色以及如何导出可视化效果。
可视化多维数据
正如您在关于方面的部分中看到的,显示具有两个以上变量的数据存在一些挑战。在本节中,您将学习如何同时显示三个变量,使用颜色来表示值。
例如,回到燃油经济性数据集(mpg),假设您想要可视化发动机气缸数和燃油效率之间的关系,但是您还想要在同一个图中包括关于车辆类别的信息。
作为刻面的替代方法,您可以使用颜色来表示第三个变量的值。为了实现这一点,您必须将发动机气缸数映射到 x 轴,将每加仑英里数映射到 y 轴,然后使用不同的颜色来表示车辆类别。
以下代码创建了所描述的数据可视化:
from plotnine.data import mpg
from plotnine import ggplot, aes, labs, geom_point
(
ggplot(mpg)
+ aes(x="cyl", y="hwy", color="class")
+ labs(
x="Engine Cylinders",
y="Miles per Gallon",
color="Vehicle Class",
title="Miles per Gallon for Engine Cylinders and Vehicle Classes",
)
+ geom_point()
)
通过在美学定义中传递color="class",车辆类别被映射到图形颜色。
运行代码会显示以下图形:
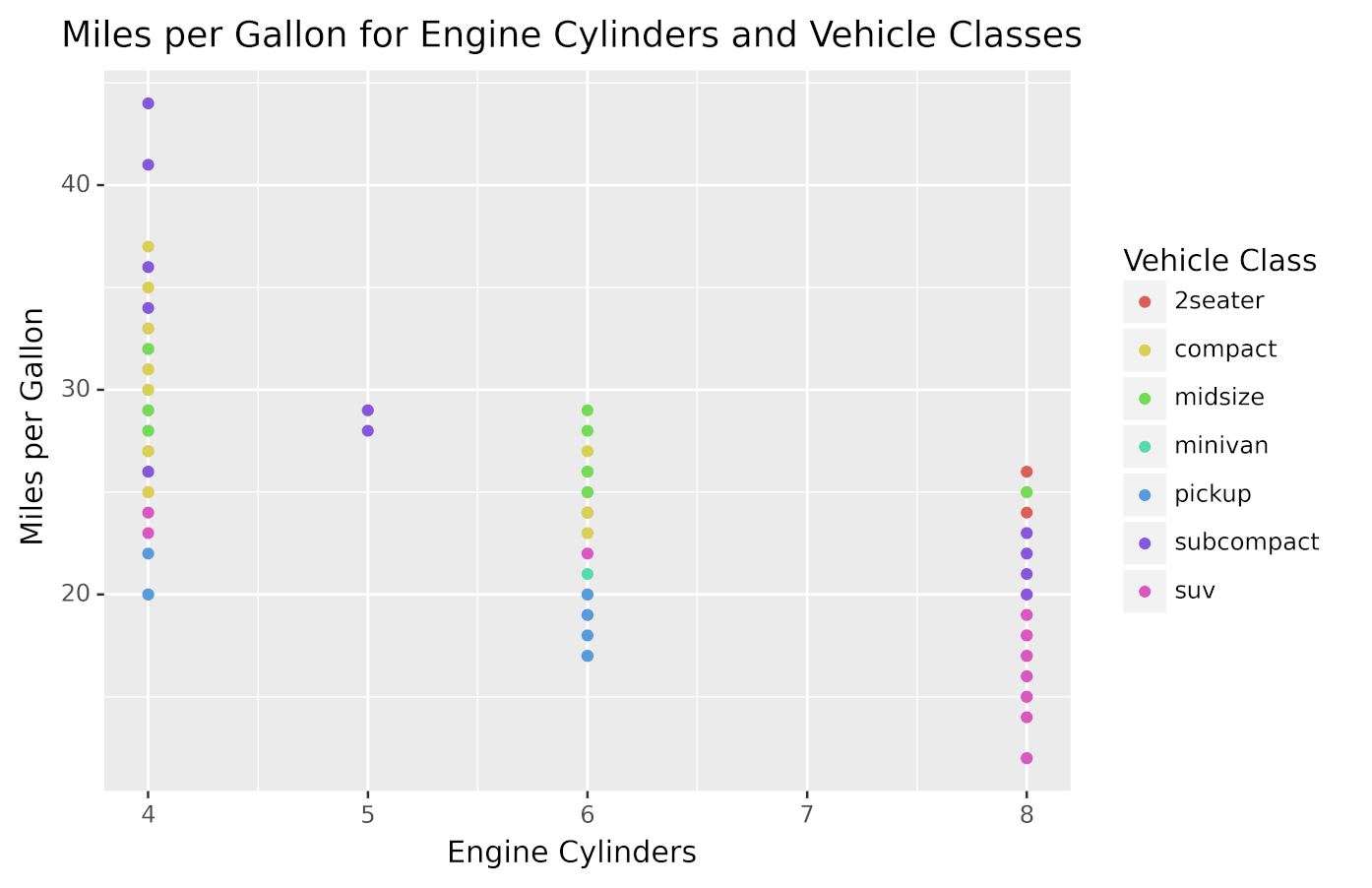
如您所见,根据车辆所属的类别,这些点具有不同的颜色。
在本节中,您学习了使用 Python 中的ggplot在图形中显示两个以上变量的另一种方法。当您有三个变量时,您应该根据哪种方法使数据可视化更容易理解,在使用面和颜色之间进行选择。
将图导出到文件
在某些情况下,您需要以编程方式将生成的图保存到图像文件中,而不是在 Jupyter Notebook 中显示它们。
plotnine 提供了一个非常方便的save()方法,您可以使用该方法将绘图导出为图像并保存到文件中。例如,下一段代码显示了如何将本教程开始时看到的图形保存到名为myplot.png的文件中:
from plotnine.data import economics
from plotnine import ggplot, aes, geom_line
myPlot = ggplot(economics) + aes(x="date", y="pop") + geom_line()
myPlot.save("myplot.png", dpi=600)
在这段代码中,您将数据可视化对象存储在myPlot中,然后调用save()将图形导出为图像并存储为myplot.png。
使用save()时,您可以调整一些图像设置,例如每英寸图像点数(dpi)。当您需要在演示文稿或文章中包含高质量的图像时,这非常有用。
plotnine 还包括一个在单个 PDF 文件中保存各种图的方法。你可以了解它,并在 plotnine 的 save_as_pdf_pages 文档中看到一些很酷的例子。
能够导出您的数据可视化打开了许多可能性。您不仅可以在交互式 Jupyter Notebook 中查看数据,还可以生成图形并将其导出以供以后分析或处理。
结论
在 Python 中使用ggplot允许您以非常简洁和一致的方式构建数据可视化。如您所见,使用 plotnine,只需几行代码就可以制作出复杂而美丽的情节。
在本教程中,您已经学会了如何:
- 安装 plotnine 和 Jupyter 笔记本
- 组合图形的语法的不同元素
- 使用 plotnine 以高效一致的方式创建可视化效果
- 将您的数据可视化导出到文件中
本教程使用 plotnine 中包含的示例数据集,但是您可以使用所学的任何内容从任何其他数据创建可视化。要了解如何将您的数据加载到 pandas data frames(plot nine 使用的数据结构)中,请使用 Pandas 和 Python 查看您的数据集。
最后,看看 plotnine 的文档继续你的 Python 之旅ggplot,也可以访问 plotnine 的画廊获得更多的想法和灵感。
还有其他值得一提的 Python 数据可视化包,比如 Altair 和 HoloViews 。在为您的下一个项目选择工具之前,看一看它们。然后使用你所学的一切来构建一些惊人的数据可视化,帮助你和其他人更好地理解数据!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 和 ggplot 绘制你的数据*********
GitHub Copilot:以思维的速度与 Python 一起飞行
GitHub Copilot 是一项激动人心的新技术,它承诺为你的代码编辑器提供一个由人工智能驱动的虚拟助手,当它向公众发布时,引起了相当大的争议。Python 是该工具特别支持的语言之一。看完这篇教程,你就知道 GitHub Copilot 到底是一个风险,一个噱头,还是软件工程中真正的游戏规则改变者。
在本教程中,您将学习如何:
- 在你的代码编辑器中安装 GitHub Copilot 扩展
- 将你对任务的自然语言描述转换成工作代码
- 在多个可选的智能代码完成建议之间进行选择
- 探索不熟悉的框架和编程语言
- 教 GitHub Copilot 如何使用您的自定义 API
- 使用虚拟对程序员实时练习测试驱动开发
要继续本教程,你需要有一个个人 GitHub 账户和一个代码编辑器,比如 Visual Studio Code 或者一个集成开发环境,比如 PyCharm 。
免费下载: 点击这里下载免费的键盘快捷键备忘单让 GitHub Copilot 的编码更快。
With GitHub Copilot 入门
GitHub Copilot 是第一款基于 OpenAI Codex 系统的商业产品,可以实时将自然语言翻译成十几种编程语言的代码。OpenAI Codex 本身就是 GPT-3 深度学习语言模型的后代。Codex 中的神经网络在文本和 GitHub 上托管的数以亿计的公共代码库中进行了训练。
注意:你可以通过收听真正的 Python 播客第 121 集来了解更多关于 GPT-3 的信息,该播客由数据科学家朱迪·波切尔主讲。
GitHub Copilot 理解一些编程语言和许多人类语言,这意味着您不仅限于英语。例如,如果你的母语是西班牙语,那么你可以用母语与 GitHub Copilot 交谈。
最初,产品仅作为技术预览版提供给特定人群。最近改变了,今天,任何人都可以在他们的代码编辑器中体验到人工智能不可思议的力量。如果你想试驾一下,你需要订阅 GitHub Copilot。
订阅 GitHub Copilot
要启用 GitHub Copilot,请转到 GitHub 个人资料中的计费设置并向下滚动,直到看到相关部分。不幸的是,这项服务对大多数人来说并不是免费的。在撰写本文时,这项服务每月收费 10 美元,如果提前支付,每年收费 100 美元。你可以享受一个60 天的试用期,无需支付任何费用,但必须提供你的账单信息。
注意:请务必在到期前取消未付费的订阅计划,以免产生不必要的费用!
学生和开源维护者可以免费订阅 GitHub Copilot。如果你是一个幸运的人,那么在启用该服务后,你会看到以下信息:

GitHub 将根据学术注册证明,例如您学校 ID 的照片或中的电子邮件地址,每年验证您的状态一次。edu 域,或者你在流行的开源软件库中的活动。
有关设置和管理 GitHub 订阅的详细说明,请遵循官方文档中的步骤。接下来,您将学习如何为 Visual Studio 代码安装 GitHub Copilot 扩展。如果你更喜欢使用 GitHub Copilot 和 PyCharm,那么直接跳到了解如何使用。
安装 Visual Studio 代码扩展
因为微软拥有 GitHub ,所以毫不奇怪他们的 Visual Studio 代码编辑器是第一个获得 GitHub Copilot 支持的工具。在 Visual Studio 代码中安装扩展有几种方法,但最快的方法可能是使用 Ctrl + P 或 Cmd + P 调出快速打开面板,然后键入以下命令:
ext install GitHub.copilot
当你按下 Enter 确认后,它会安装扩展并提示你重新加载编辑器。
或者,您可以在位于窗口左侧的活动栏中找到扩展图标,并尝试在 Visual Studio Marketplace 上搜索 GitHub Copilot 扩展:
您也可以使用相应的键盘快捷键直接在 Visual Studio 代码中显示扩展视图。
安装完成后,Visual Studio 代码将要求您登录到 GitHub,以访问您的 GitHub 配置文件,您的新扩展需要:
Visual Studio 代码需要知道您是谁才能验证您的 GitHub Copilot 订阅状态。然而,授予对 GitHub 配置文件的访问权限也将允许编辑读取您的私有库。如果你改变主意,那么你可以在任何时候撤销这个授权,方法是进入你的 GitHub 配置文件设置,在授权 OAuth 应用中找到 GitHub for VS 代码。
注意:如果你在任何地方遇到困难,请查看官方的Visual Studio 代码指南中的 GitHub Copilot 入门。
为了在 Visual Studio 代码中更高效地使用 GitHub Copilot,以下是值得记住的最常见的键盘快捷键:
| 行动 | Windows / Linux | 马科斯 |
|---|---|---|
| 触发内嵌建议 | Alt + \ |
Option + \ |
| 见下一条建议 | Alt + ] |
Option + ] |
| 参见前面的建议 | Alt + [ |
Option + [ |
| 接受建议 | T2Tab |
T2Tab |
| 驳回内嵌建议 | T2Esc |
T2Esc |
| 在新标签中显示所有建议 | Ctrl + Enter |
Ctrl + Enter |
如果您在使用默认快捷键时遇到问题,那么尝试在 Visual Studio 代码中定义您自己的键绑定。如果您使用的是非美式键盘布局,这可能会特别有帮助。
有时 GitHub Copilot 的建议可能会妨碍您。如果是这种情况,那么您可以通过单击编辑器窗口右下角的扩展图标来全局禁用它们,或者针对特定的编程语言禁用它们:
![]()
就是这样!您已经准备好开始在 Visual Studio 代码中使用 GitHub Copilot 扩展。但是如果你更喜欢使用 GitHub Copilot 和 PyCharm,请继续阅读了解如何使用。
安装一个 PyCharm 插件
PyCharm 是由 JetBrains 提供的众多流行集成开发环境之一,共享一个通用的 GitHub Copilot 插件。你可以通过打开 IDE 中的设置,并从选项列表中选择插件来安装该插件。然后,在 Marketplace 选项卡上,搜索 GitHub Copilot 插件并点击其旁边的安装按钮:
安装插件后,系统会提示您重启 IDE。当你这样做时,你必须通过从 PyCharm 菜单中选择工具来登录 GitHub,然后选择 GitHub 副驾驶,然后登录 GitHub :
这将生成一个伪随机的设备代码,你必须将其复制并粘贴到你的网络浏览器中的设备激活页面,登录 GitHub 后你将被带到该页面:
与 Visual Studio 代码一样,您需要授权 PyCharm 的插件来验证您的身份和相应的 GitHub Copilot 订阅状态。然而,PyCharm 使用的是 GitHub API 而不是 OAuth 令牌,所以授权过程看起来有点不同:
请注意,授权访问您的 GitHub 配置文件将允许插件检索您的配置文件信息,如您的电子邮件地址,并读取您的私有存储库。如果你改变主意,那么你可以在任何时候撤销这个授权,方法是进入你的 GitHub 个人资料设置,在授权的 GitHub 应用中找到 GitHub Copilot 插件。
注:如果你在某一点上遇到困难,请查看 JetBrains IDE 中官方的GitHub Copilot 入门指南。
为了让在 PyCharm 中使用 GitHub Copilot 的工作更有效率,以下是值得记住的最常见的键盘快捷键:
| 行动 | Windows / Linux | 马科斯 |
|---|---|---|
| 触发内嵌建议 | Alt + \ |
Option + \ |
| 见下一条建议 | Alt + ] |
Option + ] |
| 参见前面的建议 | Alt + [ |
Option + [ |
| 接受建议 | T2Tab |
T2Tab |
| 驳回内嵌建议 | T2Esc |
T2Esc |
| 在新标签中显示所有建议 | Alt + Enter |
Alt + Enter |
有时 GitHub Copilot 自动完成可能会妨碍您。如果是这样的话,你可以通过点击编辑器窗口右下角的插件图标来禁用它们,或者针对特定的编程语言禁用它们:

就是这样!您可以开始使用 PyCharm 中的 GitHub Copilot 插件了。
将控制权交给 GitHub 副驾驶
现在是时候确保 GitHub Copilot 在 Visual Studio 代码或 PyCharm 中正常工作了。为了检查 GitHub Copilot 是否在您的 Visual Studio 代码编辑器中正常工作,创建一个新的文本文件,选择 Python 作为底层编程语言,并开始编写一个示例函数签名,例如hello():
https://player.vimeo.com/video/731460961?background=1
只要您在第一行末尾键入冒号(:)来引入新的代码块,GitHub Copilot 就会为您填充建议的函数体。直到你点击 Tab 接受或者点击 Esc 拒绝,它才会以灰色字体显示。在这种情况下,建议的代码调用 print() 函数在屏幕上显示Hello World文本。虽然这并不壮观,但它证实了 GitHub Copilot 确实工作正常。
注意:你注意到扩展在你的函数体中填充得有多快了吗?GitHub Copilot 背后的工程团队投入了大量精力来确保给定建议的低延迟,以获得更好的开发者体验。
在 PyCharm 中使用 GitHub Copilot 实际上和在其他代码编辑器中一样。要验证插件安装是否成功,请尝试不同的示例。开始编写一个函数签名,其名称可能表明您希望将两个数字相加,例如add(a, b):
https://player.vimeo.com/video/731470794?background=1
果然 GitHub Copilot 给出了一个非常明智的建议,返回a和b之和。注意从函数返回值和在屏幕上打印结果之间的区别。你聪明的虚拟助手可以从函数的名字和参数中推断出意图。
注:公平地说,GitHub Copilot 没有什么内在的魔力。它接受了大量高质量数据的训练,允许它根据迄今为止在你的文件或项目中看到的内容来决定最有可能的输出。因为这个工具不能理解你的代码,它并不总是能得到正确的建议。
在本教程的其余部分,您将探索 GitHub Copilot 在日常软件工程任务中的几个实际用例。您将学习如何通过获得根据您的编程需求定制的即时代码建议,将您的生产率提升到一个全新的水平。
从自然语言合成 Python 代码
因为 GitHub Copilot 接受了自然语言(T0)和不同(T2)编程语言(T3)样本的训练,它似乎理解(T4)两个(T5)领域。因此,用简单的英语或其他自然语言向 GitHub Copilot 解释一个抽象的问题,并期望它用期望的编程语言生成相应的代码是完全可能的。
底层的机器学习模型也能够做相反的事情——即,用自然语言解释一段代码,甚至将一种编程语言翻译成另一种语言。想象一下这对初学者和有创造力的人有多大的帮助,他们对自己想要完成的事情有一个愿景,但是还没有掌握计算机编程。
你将会看到人类和计算机语言之间的翻译在实践中是怎样的。
使用 Python 注释描述问题
尽管编程界的有影响力的人物,比如罗伯特·c·马丁认为 T2 的代码注释是反模式的,但是注释有时可以帮助 T4 解释为什么某段代码看起来是这样的。你通常为你未来的自己或者你在同一个代码库工作的队友写评论。
当您将 GitHub Copilot 添加到组合中时,它将成为另一个能够阅读您的代码注释的目标受众。考虑下面 Python 中的单行注释,它描述了经典的 Hello, World! 程序:
# Print "Hello, World!"
在您的代码编辑器中输入该注释后,您会注意到 GitHub Copilot 并没有自动获取它。当您选择通过评论与它交流时,您必须打开 GitHub Copilot 侧面板或选项卡才能看到建议。或者,您可以开始键入一些代码,让它自动完成。无论哪种方式,编写上面的注释都应该为您提供以下 Python 代码:
print("Hello, World!")
这与您通过编写hello()函数存根验证 Visual Studio 代码扩展时得到的建议几乎相同。然而,这一次,您得到的输出略有不同。GitHub Copilot 理解您希望将引用的评论片段视为文字文本,而不是指令。
显然,这对 GitHub Copilot 来说太容易了。通过请求更具体的输出来提高标准怎么样?例如,您可能想用西班牙语反向打印Hello, World!:
# Print "Hello, World!" backward in Spanish.
在编辑器中刷新 GitHub Copilot 面板后,您会看到新的建议。每次触发 GitHub Copilot 时,它们的数量和质量可能会有所不同。你能从这个评论中得到的最好的答案是:
print("¡Hola, mundo!"[::-1])
现在,那令人印象深刻!GitHub Copilot 不仅能生成正确的代码,还能生成有经验的 Pythonic 专家会自己编写的 Pythonic 代码。当你加入更多的评论时,这些建议会变得更加有趣。
添加更多注释,增加问题复杂性
用一行注释来描述一个问题是可以的,但是你只能在里面装这么多内容。幸运的是,可以将多个连续的评论组合成一个符合逻辑且有凝聚力的故事,GitHub Copilot 会将其视为一个整体。最好在每行上放一个完整的句子,不要换行,但是您可以选择在句子中间包含一个明确的反斜杠(\)来标记换行:
# Ask the user to provide a line of text.
# Scan the text for the following mildly offensive words: \
# arse, bloody, damn, dummy.
# If you find any, then replace its letters with asterisks \
# except for the first letter in each offensive word.
# Print the resulting text.
def main():
确保使用语法正确的语言,并注意你的标点以获得准确的结果。在这种情况下,您还可以在注释后添加一个函数签名,这为 GitHub Copilot 提供了额外的线索。你将得到的一个建议看起来相当不错:
def main():
text = input("Enter a line of text: ")
offensive_words = ["arse", "bloody", "damn", "dummy"]
for word in offensive_words:
if word in text:
text = text.replace(word, word[0] + "*" * (len(word) - 1))
print(text)
如果你正在寻找上面函数中所发生的事情的解释,只需要看看你评论中的文字描述就可以了。建议的代码非常接近您在那里描述的内容。
注意: GitHub Copilot 生成各种风格和约定的代码。为了实现一致性和消除不必要的干扰,本教程中所有的代码建议都被重新格式化,以符合 PEP 8 风格指南。请记住,在大多数编辑器中,只需按一下按钮,您就可以自己重新格式化代码。
当您调用main()函数时,您将能够评估生成的代码执行得有多好:
Enter a line of text: She loves you, dummy.
She loves you, d****.
是不是很神奇?你给 GitHub Copilot 一个任务的自然语言描述,它就为你找到了正确的解决方案。
注意:记住,你将得到的建议可能与本教程中给出的不同。有时在得到想要的结果之前需要反复试验,所以如果你没有马上得到满意的结果,试着稍微调整一下你的评论。
关于 GitHub Copilot 需要注意的重要一点是,它实施了许多过滤器来阻止真正的攻击性词语、淫秽内容和敏感信息,如个人数据或秘密 API 密钥。它会尽力不给你包含这些元素的建议。你可以通过引诱 GitHub Copilot 泄露某人的个人信息或秘密来试验这些过滤器:
| 代码片段 | 建议完成 |
|---|---|
offensive_words = [ |
没有人 |
# My phone number is |
# My phone number is +1 (###) ###-#### |
GITHUB_API_KEY = |
GITHUB_API_KEY = '<GITHUB_API_KEY>' |
在大多数情况下,它在识别敏感信息和提供随机或匿名输出方面做得很好。然而,过滤机制并不完美,因此理论上它可能会从训练数据集中泄露某人的实际数据。根据官方网站,这种情况发生的可能性很小:
GitHub Copilot 建议的绝大部分代码都是以前没见过的。我们最新的内部研究表明,大约 1%的情况下,建议可能包含一些长度超过 150 个字符的代码片段,这些代码片段与训练集相匹配。(来源)
稍后您将更详细地探索这种可能性,但是现在,是时候让 GitHub Copilot 为您解决一个编程难题了。
解答一道编程竞赛谜题
为了测试 GitHub Copilot 的真正能力,您可以复制并粘贴一个编码挑战的文本描述片段,看看它会如何应对。例如,为什么不从 2021 年降临日的第一天开始抓取声纳扫描谜题的第一部分代码日历:
# For example, suppose you had the following report:
#
# 199
# 200
# 208
# 210
# 200
# 207
# 240
# 269
# 260
# 263
#
# (...)
#
# In this example, there are 7 measurements that are larger \
# than the previous measurement.
#
# How many measurements are larger than the previous measurement?
def solve(measurements):
问题的完整描述稍长,为了节省空间,在上面的代码块中进行了缩写。简而言之,您的目标是确定深度测量相对于前一次测量增加的次数。GitHub Copilot 很好地解决了这个具体问题,考虑到有多少人处理了完全相同的任务并在 GitHub 上分享了他们的解决方案:
def solve(measurements):
count = 0
for i in range(1, len(measurements)):
if measurements[i] > measurements[i - 1]:
count += 1
return count
这是一个短循环,从测量列表上的第二个项目开始,将当前读数与前一个读数进行比较。如果当前读数更大,那么它增加计数器,函数在最后返回。这种解决方案工作正常,并且相当高效和可读,但是不要觉得有义务以文字形式使用 GitHub Copilot 的建议。这不是全有或全无!
你可以像编辑自己的代码一样编辑 GitHub Copilot 生成的代码。有时,您可能不喜欢它的格式、它应用的命名约定,或者您更愿意重写的特定逻辑片段。在其他场合,看到一个建议可能会激发你想出一个更聪明的替代方案。在这种情况下,您可以使用这个一行程序解决方案,例如:
def solve(measurements):
return sum(1 for x, y in zip(measurements, measurements[1:]) if y - x > 0)
对于每对相邻的测量值,如果它们的差是正的,则取用生成器表达式产生的一序列的和。根据您的 Python 知识水平,您可能更喜欢这个或建议的代码片段。
现在您知道了如何使用一个或多个 Python 注释从自然语言生成代码。然而,作为一名软件工程师,您可能会更加欣赏上下文代码建议。
接收更多智能代码完成建议
你可以把 GitHub Copilot 看作是类固醇上的智能代码完成机制,它在深层次上理解你的项目的上下文,为你提供最合适的建议。当你与 GitHub Copilot 一起工作足够长的时间,它有时可能会给你一种毛骨悚然的感觉,它可以读取你的想法。在本节中,您将看到几个演示这种行为的例子。
让 GitHub Copilot 读取您的想法
说你要求二次多项式的根,也叫二次函数,三个系数:𝑎、𝑏、𝑐.您可以使用以下代数形式来表示这样的函数:

例如,具体函数 𝑥 2 + 2𝑥 - 3 有这些系数值:𝑎 = 1,𝑏 = 2,𝑐 = -3,你可以用它们来计算所谓的判别式,通常用希腊字母 delta 表示:

在这种情况下,当您用上述公式中的相应值替换字母𝑎、𝑏和𝑐时,函数的判别式等于十六(δ= 16)。根据判别式的符号,您的二次函数可以有两个、一个或根本没有根:

由于之前计算的判别式是一个正数,16,您知道您的二次函数正好有两个根,当您应用上面的公式时,它们的值为𝑥 1 = -3 和𝑥 2 = 1。将它们中的任何一个作为𝑥变量的值插入到二次函数中,都会使函数返回零。该函数的根是绘制时相应的抛物线与横轴相交的点。
现在,您可以实现一个 Python 函数,根据这种多项式的三个系数(𝑎、𝑏和𝑐.)来求其根您将希望通过计算判别式和评估根的正确数量来遵循相同的算法。首先写一个描述性的函数签名,它可能暗示你的意图是什么:
def find_roots(a, b, c):
过一会儿,GitHub Copilot 就会开始给你建议。如果你幸运的话,其中一个会惊人的准确:
def find_roots(a, b, c):
d = b**2 - 4 * a * c
if d < 0:
return None
elif d == 0:
return -b / (2 * a)
else:
return (-b + d**0.5) / (2 * a), (-b - d**0.5) / (2 * a)
该函数使用正确的公式计算判别式,并将结果存储在辅助变量中。根据判别式的符号,它返回 None 、单个根值或由两个根值组成的元组,所有这些都计算正确。注意,建议的解决方案使用了取幂运算符 ( **)来计算判别式的平方根。这避免了从 Python 的 math 模块中导入sqrt()函数。
注意:你看到的的建议可能看起来不同,因为人工智能并不完全是确定性的,因为它会不断学习新事物。在其他时候,您甚至可能得到相同输入的替代结果。当您的项目中有额外的源代码时尤其如此,GitHub Copilot 将从中提取上下文。
好吧,但是生成的函数只能找到实数根,如果它们存在的话。如果您想显示所有在复数域中的根呢?在下一节中,您将发现如何给 GitHub Copilot 这样的提示。
提供背景以获得更好的建议
代数的基本定理陈述了具有复系数的𝑛多项式恰好具有𝑛复数根。换句话说,作为二次多项式的二次函数,总是恰好有两个复数根,即使在实数域中没有复数根。
考虑函数 𝑥 2 + 1 ,其行列式为负,表示无根。你可以通过画出函数的抛物线来确认没有根,抛物线不穿过横轴。然而,同一个函数有两个复杂的根,𝑥 1 = -𝑖和𝑥 2 = 𝑖,其中𝑖是平方后计算结果为-1 的虚数单位:𝑖2=-1。
你怎么能要求 GitHub Copilot 改变实现,从而得到复杂的根而不是真正的根呢?
您需要通过给 GitHub Copilot 一些可借鉴的上下文来为问题添加约束。例如,您可以导入您希望使用的模块,或者编写一个用自然语言描述预期结果的 Python docstring :
import cmath
def find_roots(a, b, c):
"""Return a tuple of complex numbers."""
这里,您导入了cmath模块,它是math模块的复杂对应物。它包含了cmath.sqrt()函数,可以计算负数的平方根,而math.sqrt()在这种情况下会产生一个错误:
>>> import cmath >>> cmath.sqrt(-1) 1j >>> import math >>> math.sqrt(-1) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: math domain error复数域中
-1的平方根产生虚数单位,Python 将其称为1j。你可以阅读更多关于在 Python 中使用复数的内容,了解为什么它使用字母j而不是i来表示虚数单位。您的 docstring 指示函数应该返回的预期数据类型。在某些情况下,你可能需要用更具体的词语来阐明你的期望。例如,写“一个既有复数又有复数的元组”将意味着一个正好由两个元素组成的元组。另一方面,单词对而不是元组会不太明确。
注意:除了文档字符串,GitHub Copilot 还能理解你的 Python 代码中的类型提示。
添加了这两个小线索后,GitHub Copilot 现在将为完全相同的函数签名生成不同的实现:
import cmath def find_roots(a, b, c): """Return a tuple of complex numbers.""" d = (b**2) - (4 * a * c) x1 = (-b + cmath.sqrt(d)) / (2 * a) x2 = (-b - cmath.sqrt(d)) / (2 * a) return x1, x2它像以前一样计算判别式,但不再检查其符号。相反,该函数通过利用
cmath.sqrt()函数来计算两个复杂的根,正如您所希望的那样。您可以在 Python REPL 中测试您的新函数,以检查该函数是否正确计算了两个复数根:
>>> import cmath
>>> def find_roots(a, b, c):
... """Return a tuple of complex numbers."""
... d = (b**2) - (4 * a * c)
... x1 = (-b + cmath.sqrt(d)) / (2 * a)
... x2 = (-b - cmath.sqrt(d)) / (2 * a)
... return x1, x2
...
>>> find_roots(1, 0, 1) # Function f(x) = x² + 1
(1j, -1j)
>>> 1j**2 + 1
0j
>>> (-1j)**2 + 1
0j
这段代码非常棒!函数x² + 1返回两个复杂根1j和-1j的0。
即使这没有让你感到特别兴奋,你可能会对 GitHub Copilot 的创造力印象深刻,它可以节省你很多时间。接下来,您将使用 GitHub Copilot 生成一个类的主体。
受益于 GitHub Copilot 的创造力
有多少次,你在设计一种新的数据类型时,却被正确的属性或它们的实现所困扰?有了 GitHub Copilot,你可以高枕无忧,因为它会发明新的属性,方法,以及属性,按下 Tab 。
假设您想使用 Python 的数据类定义一个Person类。首先给新的数据类型起一个有意义的名字,并引入第一个属性,称为.first_name:
https://player.vimeo.com/video/731808891?background=1
GitHub Copilot 通过建议下一个最可能的属性.last_name,然后是.age,立即从那里开始。然而,你知道一个人的年龄会随着时间的推移而变化,所以你记录了他的出生日期。GitHub Copilot 的下一个逻辑建议是基于当前日期计算一个人年龄的方法。当您定义一个新的属性时,它通过连接名字和姓氏来完整地完成它的主体。
最后,这是您在代码编辑器中只需几次击键就能得到的结果:
from dataclasses import dataclass
from datetime import date
@dataclass
class Person:
first_name: str
last_name: str
birth_date: date
def age(self):
return (date.today() - self.birth_date).days // 365
@property
def full_name(self):
return f"{self.first_name} {self.last_name}"
这是前所未有的巨大的时间节省和生产力提升的 T2。即使你知道该键入什么,GitHub Copilot 也能让你以思维的速度编码,猜测你可能在想什么,然后提供一个合适的建议,你只需点击一个按钮或按键就能接受。
成为一名拥有私人翻译的编程语言者
在一个文件中混合多种语言并不少见,比如 HTML 、 CSS 、 JavaScript 、 Django 模板语言和 Python。幸运的是,GitHub Copilot 知道十几种编程语言,甚至更多的框架和几种人类语言。它可以根据上下文在它们之间随意切换,完全不会打断你的流程。
例如,您可能希望定义一个 Python 变量来存储一个通过匹配名称检索用户的 SQL 查询。只要在变量名中使用正确的单词,您应该会得到一个合理的建议,比如这个:
https://player.vimeo.com/video/731837821?background=1
请注意,您是如何在各个阶段中分别获得各个行的,因为您使用三重引号(""")定义了一个多行字符串文字。上面视频中描绘的结果如下:
query_users_by_first_or_last_name = """
SELECT * FROM users
WHERE first_name LIKE %s OR last_name LIKE %s """
乍一看,这个查询看起来不错,尽管 GitHub Copilot 对您的表名和要搜索的两列做了一些假设。不过,令人欣慰的是,它生成了一个预准备语句,而不是一个带有 SQL 查询的普通字符串,从而帮助阻止了一次 SQL 注入攻击。
好了,现在你对 GitHub Copilot 已经很熟悉了。但是请耐心等待,因为还有很多内容要介绍!
与虚拟伙伴练习结对编程
甚至在访问 GitHub Copilot 官方网站之前,你会很快在网络搜索结果中注意到它被宣传为一个人工智能配对程序员。简而言之,结对编程是一种流行的敏捷技术,涉及到两个工程师一起工作在同一个功能上。从表面上看,生产这样的软件会花费更多的钱,但是从长远来看,它保证了更少的昂贵的修复错误。
结对编程的好处包括:
- 生成代码的质量更高
- 整个团队对代码库有更好的整体理解
- 知识和最佳实践的分享
很难超越坐在一个真实的人旁边的优势,他可以对你的代码给出诚实的反馈,发现潜在的问题,并把你引向正确的方向。结对编程的许多好处只有在团队协作时才能看到。另一方面,人工智能可能会给你糟糕的建议,导致代码质量下降。最终,要不要听由你自己决定!
也就是说,GitHub Copilot 在提高您的工作效率方面非常出色,您将会发现这一点。
生成用于测试的样本数据夹具
在日常开发过程中,您经常需要考虑测试、文档或默认设置的样本数据。如果你一片空白,那么 GitHub Copilot 将会帮助你。例如,回想一下您之前定义的Person类:
from dataclasses import dataclass
from datetime import date
@dataclass
class Person:
first_name: str
last_name: str
birth_date: date
def age(self):
return (date.today() - self.birth_date).days // 365
@property
def full_name(self):
return f"{self.first_name} {self.last_name}"
现在,假设您需要创建这个类的几个实例来表示一家公司的雇员。当您仍在编辑同一个文件或从另一个模块导入了Person类时,您可以使用 GitHub Copilot 来填充员工列表。使用一个有表现力的变量名声明一个空的 Python 列表,并在左方括号([)后点击 Enter 来触发建议:
employees = [
当您在每个建议行后不断点击 Tab 时,您可能会得到以下员工列表:
employees = [
Person("John", "Smith", date(1970, 1, 1)),
Person("Jane", "Doe", date(1980, 1, 1)),
Person("Joe", "Doe", date(1990, 1, 1)),
Person("Jack", "Doe", date(2000, 1, 1)),
Person("Jill", "Doe", date(2010, 1, 1)),
Person("Jana", "Doe", date(2020, 1, 1)),
]
GitHub Copilot 成功地将您的Person类用于员工列表元素。稍后,您可以将该列表用作一组需要它的测试用例的通用测试夹具。例如,您可以将列表包装在测试框架将调用的函数中。GitHub Copilot 通过建议测试和被测代码,在测试过程中提供了很好的帮助。
希望测试用例神奇地出现
给你的测试函数起一个长的描述性的名字是一个很好的习惯,因为它们会在测试运行报告中显示出来。当其中一个失败时,一个名副其实的测试函数会立即将您的注意力吸引到失败的地方。行为驱动开发的倡导者建议使用以单词应该开头的整句话来关注被测试的行为,这使得测试看起来像一个业务需求规范。
这种有时长得离谱的函数名的额外好处是 GitHub Copilot 可以使用它们来帮助您生成测试用例实现。例如,在Person类的测试模块中定义以下函数签名:
def test_should_not_be_able_to_set_full_name():
大多数测试框架会自动发现测试用例,如果它们遵循标准的命名约定,比如当你在测试函数名前面加上test_的时候。使用 GitHub Copilot,为上述功能触发的建议可能如下所示:
def test_should_not_be_able_to_set_full_name():
person = Person("John", "Doe", date(1980, 1, 1))
with pytest.raises(AttributeError):
person.full_name = "Jane Doe"
奇怪的是,GitHub Copilot 更喜欢外部的 pytest 库,你必须手动安装和导入,而不是标准库中的内置unittest模块。
注意:这个选择可能会告诉你这两个工具的流行程度,事实上,pytest 可以说是 Python 生态系统中最广泛和最通用的测试框架之一。
虽然自动实现现有代码的测试用例有时可能是有帮助的,但是使用测试驱动的开发,以自顶向下的方式翻转步骤和开发软件可能更令人满意。在这种方法中,您首先编写您的测试用例作为代码的高级规范,这还不存在。一旦你有了一个自动化测试用例,然后你写一些代码使它通过。
测试驱动开发
如果你以前没有练习过 TDD ,那么看看用 TDD 在 Python 中构建哈希表教程,这是一个关于测试驱动开发的实践性的、循序渐进的速成课程。
简而言之,您可以将该过程总结为三个步骤:
- 写一个你将要满足的失败测试案例
- 实现最少的代码来让你的测试用例通过
- 可选地,当所有测试用例仍然通过时,重构代码
然后,冲洗,重复!只要你足够自律以保持这种永无休止的循环,你就会编写具有高测试覆盖率和文档化的可测试代码。同时,您将避免编写永远不需要的代码,从而降低整体维护成本。也就是说,测试驱动的开发不是一个银弹,所以它在研发项目中可能不实用。
好吧,复制上面提到的教程中的HashTable实现怎么样,使用 GitHub Copilot 作为你的虚拟对程序员?在同一文件夹中创建两个相邻的空 Python 文件:
src/
├── hashtable.py
└── test_hashtable.py
第一个,在下面视频的左边,将包含被测试的代码。另一个,描绘在右边,将是你驱动实现的测试用例的家。接下来,编写第一个测试用例来验证一个新的HashTable类的实例化:
https://player.vimeo.com/video/732011037?background=1
注意,为了遵循测试驱动开发,您应该在实现相应的代码之前和之后运行每个测试用例,以确保您测试的是正确的东西。除此之外,你应该只实现最基本的功能来满足你的测试。但是 GitHub Copilot 领先一步,尝试预测您未来可能需要的代码。这不是一个严格的真正的测试驱动开发方法。
概括地说,这是您刚刚编写的两个测试用例,用于检查您是否可以创建一个具有或不具有初始容量的哈希表:
# test_hashtable.py
from hashtable import HashTable
def test_should_create_hashtable():
assert HashTable() is not None
def test_should_create_hashtable_with_capacity():
assert HashTable(capacity=10) is not None
基于它们,GitHub Copilot 目前已经生成了以下哈希表实现:
# hashtable.py
class HashTable:
def __init__(self, capacity=10):
self.capacity = capacity
self.buckets = [None] * capacity
self.size = 0
initializer 方法将默认容量设置为 10,以防有人在没有提供任何参数的情况下创建哈希表,这是由您的第一个测试用例决定的。容量随后存储在实例属性中。注意,GitHub Copilot 正确地识别了哈希表的大小和容量之间的差异。它还假设了基于的经典散列表实现,通过创建空桶来分离链接。
虽然 GitHub Copilot 在监视你的背后方面可能不如人类程序员,但它作为虚拟助理为你的问题提供答案,确实做得非常好。这就像有人在 Google 或 Stack Overflow 中搜索您的独特问题的解决方案,内置在您需要的代码编辑器中!
消除堆栈溢出,实现即时的环境感知解决方案
互联网上充斥着关于过度使用像 Stack Overflow 或 Google 这样的网站来寻找程序员问题答案的笑话。比如曾经有过对热门奥赖利书籍封面的模仿,比如著名的从栈溢出复制粘贴:

这并不奇怪,因为大多数开发人员在日常工作中经常使用这些工具,现在没有它们将很难生活。
GitHub Copilot 可以减少你对那些工具的依赖。它可以立即交付定制的代码片段,像手套一样适合你的项目环境,甚至不同于你在网上找到的最佳答案。此外,它不会强迫您离开代码编辑器,因此您可以呆在该区域并加速您的进度。请继续阅读,体验一下随手可得的 Python 社区的集体知识。
再也不要想样板代码了
Python 有一个相对富于表现力的语法,它允许你编写简洁易读的代码。然而,偶尔的样板代码是不可避免的,即使是在你最喜欢的编程语言中。有时,没有办法编写一段看起来冗长的代码,但看起来并没有做很多有用的工作。
比如从一个 URL 地址获取数据,序列化到 JSON ,将结果保存到一个文件涉及到很多无聊的细节,贡献不了多少价值。如果您能够专注于对您最重要的事情,也就是说,在让 GitHub Copilot 将各个步骤映射到代码片段的同时,整理出一个更高层次问题的解决方案,这不是很酷吗?
嗯,原来可以!和以前一样,首先编写一个描述性的函数签名,剩下的交给 GitHub Copilot:
def save_json(url, filename):
响应上述签名的建议函数体可能如下:
def save_json(url, filename):
import json
import requests
import os
if not os.path.exists(filename):
with open(filename, "w") as f:
f.write(json.dumps(requests.get(url).json()))
else:
print("File already exists")
它依赖于外部的请求库,您可能需要安装这个库,因为它是用 Python 发出 HTTP 请求的事实上的标准。该函数利用上下文管理器在将 JSON 转储到文件后关闭文件。这已经足够好了,但是您可能需要添加一些修饰性的调整:
import json
import os
import requests
def save_json(url, filename):
if not os.path.exists(filename):
with open(filename, mode="w", encoding="utf-8") as file:
file.write(json.dumps(requests.get(url).json()))
else:
print("File already exists")
根据 PEP 8 风格指南,你通常应该在函数之外定义你的导入语句,外部库模块应该在标准库模块之后。此外,建议在使用 Python 处理文件时,明确说明字符编码,比如 UTF-8,以避免不同操作系统之间的差异,这些差异可能会导致不兼容的默认设置。
注意:你可以使用黑或者类似的工具来保持生成代码的格式与你项目的其余部分一致。
使用 GitHub Copilot 可能比堆栈溢出稍微安全一些。有了堆栈溢出,您可能会发现自己盲目地逐字复制和粘贴别人的代码,而没有完全理解它或考虑它在您的情况下是否有意义。接受 GitHub Copilot 的建议可能同样鲁莽,如果不是更鲁莽的话,但至少它给了你一个微调的、上下文特定的拼图,更有可能工作。
GitHub Copilot 的另一个亮点是让您不必深究您想要使用的库或 API 的文档。
总是将 API 文档放在手边
假设您想编写一个小的 Python 函数来获取 GitHub 用户的公共存储库列表。在传统方法中,你首先在网上搜索 github api ,然后登陆 GitHub REST API 文档页面。然后,您可能会被可供选择的 REST APIs 的数量,以及它们所有的指南、快速入门和参考文档所淹没。
幸运的是,你有 GitHub Copilot,它已经被训练使用众所周知的 API,所以你可以给它一个关于调用哪个 API 的最小提示。创建一个名为github_api_client的新 Python 模块,并在其中键入以下代码:
# github_api_client.py
import os
GITHUB_API_TOKEN = os.getenv("GITHUB_API_TOKEN")
def get_repository_names(username):
稍后,您将在一个终端会话中运行这个脚本,您的令牌存储在一个环境变量中。习惯上通过环境变量读取密钥和配置数据,所以你利用 Python 的os模块读取你的个人 GitHub API 令牌,你可能需要它来访问 API。
注意:虽然你不需要令牌来获取某人的公共存储库,但是作为一个匿名客户端,你将被限制在每小时六十个 API 请求。为了突破这个限制,你需要使用你的个人访问令牌来验证你自己。现在这样做是有意义的,因为大多数 API 端点无论如何都需要认证。
其中一个建议的结果是开箱即用的:
# github_api_client.py
import os
GITHUB_API_TOKEN = os.getenv("GITHUB_API_TOKEN")
def get_repository_names(username):
import requests
url = f"https://api.github.com/users/{username}/repos"
headers = {"Authorization": f"token {GITHUB_API_TOKEN}"}
response = requests.get(url, headers=headers)
response.raise_for_status()
return [repo["name"] for repo in response.json()]
在测试这个功能之前,记得在 GitHub 概要文件上生成一个新的个人访问令牌,并在终端中设置相应的环境变量:
- 视窗
** Linux + macOS*
PS> $env:GITHUB_API_TOKEN=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
$ export GITHUB_API_TOKEN=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
然后,当您仍然在定义环境变量的同一个终端会话中时,以一种交互模式运行带有您的代码的源文件,以便 Python 读取您可以调用的生成函数:
$ python -i github_api_client.py >>> for name in get_repository_names("gvanrossum"): ... print(name) ... 500lines asyncio ballot-box cpython ctok exceptiongroup guidos_time_machine gvanrossum.github.io http-get-perf minithesis mirror-cwi-stdwin mypy mypy-dummy path-pep patma pep550 peps Pyjion pythonlabs pythonlabs-com-azure pytype pyxl3在这种情况下,你得到的是由 Python 的创造者吉多·范·罗苏姆制作的一个相当短的公共库列表。
好吧,使用一个众所周知的 API 并不是特别困难,但是利用一个 GitHub Copilot 以前没有见过的自定义 API 怎么样呢?好吧,接下来你就知道了。
教 GitHub 副驾驶说你自己的方言
假设您有以下 Python 模块,它通过在三个主要平台之一上包装一个文本到语音(TTS) 命令来定义一个用于语音合成的定制 API :
# custom_api.py import platform import subprocess class TextToSpeechAPIClient: def __init__(self, command=None): self.command = command or get_default_command() def say(self, text): subprocess.call(self.command(text)) def get_default_command(): match platform.system(): case "Darwin": return lambda text: ["say", text] case "Linux": return lambda text: ["spd-say", text] case "Windows": return lambda text: \ "PowerShell -Command \"Add-Type –AssemblyName System.Speech; " \ "(New-Object System.Speech.Synthesis.SpeechSynthesizer)." \ f"Speak('{text}');\""
TextToSpeechAPIClient类为与您的操作系统相关的语音合成命令提供一个可选参数。下面定义的助手函数利用 Python 3.10 中引入的匹配语句来确定正确的命令。现在,创建另一个 Python 模块,并告诉 GitHub Copilot 通过在评论中许愿来学习如何使用您的新 API:
# main.py # Say "Hello, World!" using the custom text-to-speech API client. if __name__ == "__main__":文件末尾的执行条件通过传达您想要编写一个 Python 脚本,为 GitHub Copilot 提供了必要的上下文。否则,你可能会得到不太有用的建议。然而,有了这个重要的检查,其中一个建议看起来将是这样的:
# main.py # Say "Hello, World!" using the custom text-to-speech API client. if __name__ == "__main__": import custom_api client = custom_api.TextToSpeechAPIClient() client.say("Hello, World!")太棒了。GitHub Copilot 在另一个 Python 模块中找到了您的自定义 API,在需要的地方导入它,并完全按照它应该的那样使用
TextToSpeechAPIClient类。虽然它在本地模块上做得很好,但它也可以为第三方模块提供代码片段。导航一个不熟悉的框架或库
用 GitHub Copilot 探索 Python 中的新库是一种令人愉快的体验。也许你正在重新访问一个你的知识已经有点生疏的框架,你正在努力回忆从哪里开始。但是,即使你非常熟悉一个给定的工具,GitHub Copilot 有时也会给你带来惊喜,它会建议你更有效的解决方案或你不知道的 API 部分。
假设您想要使用 Flask 框架公开一个 REST API 端点,以提供从基于文件的 SQLite 数据库查询的 JSON 序列化图书列表。现在,创建一个新的 Python 源文件,导入必要的模块,并将本段中的前一句改写成 Python 注释:
import sqlite3 import flask # Expose a REST API endpoint using the Flask framework \ # to serve a JSON-serialized list of books queried from \ # a file-based SQLite database.等待建议到达,然后选择一个看起来最好的。有时,当您开始键入预期的代码并通过在每一行点击
Tab逐行请求建议时,您会获得更好的结果。最终,您可能会得到这样的结果:import sqlite3 import flask # Expose a REST API endpoint using the Flask framework \ # to serve a JSON-serialized list of books queried from \ # a file-based SQLite database. app = flask.Flask(__name__) @app.route("/books") def get_books(): conn = sqlite3.connect("books.db") c = conn.cursor() c.execute("SELECT * FROM books") books = c.fetchall() conn.close() return flask.jsonify(books) if __name__ == "__main__": app.run(debug=True)在本例中,GitHub Copilot 搭建了 Flask 应用程序的典型结构,您可能已经忘记了,它定义了您所请求的端点。为了测试它是否工作,在 Flask 应用程序所在的同一文件夹中打开您的终端,并创建一个名为
books.db的新的基于文件的数据库,其中包含一些样本书籍。要输入 SQL 查询,您可以在批处理模式下运行
sqlite3命令,并用文件尾(EOF) 字符终止它:$ sqlite3 books.db -batch CREATE TABLE books( id INTEGER PRIMARY KEY AUTOINCREMENT, isbn TEXT, author TEXT, title TEXT ); INSERT INTO books(isbn, author, title) VALUES ('978-0132350884', 'Robert C. Martin', 'Clean Code'), ('978-1449340377', 'David Beazley', 'Python Cookbook'), ('978-0131872486', 'Bruce Eckel', 'Thinking in Java'), ('978-1775093329', 'David Amos', 'Python Basics');在 Windows 上,您通常可以使用
Ctrl+Z将 EOF 字符发送到标准输入流,而在 Linux 和 macOS 上,您将使用Ctrl+D组合键。接下来,通过运行脚本,在默认网络接口和端口号上启动 Flask 应用程序,然后将 web 浏览器导航到
/books端点。或者,如果你使用的是 macOS 或 Linux,你可以直接在终端中使用类似于 cURL 的命令来获取书籍:$ curl http://127.0.0.1:5000/books [ [ 1, "978-0132350884", "Robert C. Martin", "Clean Code" ], [ 2, "978-1449340377", "David Beazley", "Python Cookbook" ], [ 3, "978-0131872486", "Bruce Eckel", "Thinking in Java" ], [ 4, "978-1775093329", "David Amos", "Python Basics" ] ]非常引人注目的是,GitHub Copilot 生成的代码是活的!想想吧。您仅仅提供了所需程序的自然语言描述,并导入了两个模块来给出使用哪个库的上下文。与此同时,人工智能将你的描述变成了一个工作的网络应用。
也就是说,GitHub Copilot 也有其黑暗的一面,您将在下一节中了解到。
考虑反对使用 GitHub Copilot 的理由
当你在网上搜索关于 GitHub Copilot 的信息时,你会发现赞扬和兴奋的话语,以及相当多的批评。有些是正确的,而有些则源于对技术目的的误解。最终,GitHub Copilot 对不同的人意味着不同的东西。读完这一节,你会意识到你的人工智能虚拟助手的最大缺点。
绝对不是自动驾驶!
名为 copilot 是 GitHub 描述这款产品的一个聪明的选择。它避免误导人们认为它可以控制和取代你作为程序员。就像航空业的副驾驶,通常被称为副驾驶,GitHub 副驾驶协助你,但不为你工作。这一措辞与高级驾驶辅助系统形成鲜明对比,如今一些汽车制造商直截了当地称之为自动驾驶系统。
你必须记住 GitHub Copilot 产生的代码并不总是理想的。事实上,它有时可能是次优的或不安全的,并且可能遵循糟糕的编程实践。
当代码包含语法错误或者完全没有意义时,问题就不大了,因为这很容易被发现。然而,乍一看似乎合理的代码仍然可能是不正确的,并且包含逻辑错误。因此,在没有仔细检查和测试 GitHub Copilot 生成的代码之前,你应该永远不要相信它!
换句话说,GitHub Copilot 是一个非常有价值的工具,但是你绝对不应该仅仅依赖它的建议,比如为一个核电站构建关键任务软件。
存在潜在的安全风险
因为 GitHub Copilot 背后的机器学习模型是在公共存储库上训练的,所以它容易受到数据中毒的影响。不良行为者可能故意用恶意代码污染训练数据集,这些恶意代码可能会欺骗模型在您的代码编辑器中建议类似的模式。由于训练数据中的大量代码,这也可能是偶然发生的。
再次声明,使用 GitHub Copilot 风险自担!
引发知识产权问题
GitHub Copilot 可能侵犯了知识产权,这是目前最严重的问题。因为它基于以前看到的东西合成代码,所以它可能会从私人储存库、有版权的公共储存库,甚至是拥有非许可许可证的开源储存库泄露专有算法。
注意:要使用 GitHub Copilot,您必须接受其条款和条件,其中明确声明您同意共享位于您的存储库中的代码和数据,包括您的私人存储库,以改进服务。
Flask 的创造者阿明·罗纳彻,最近在的推特上展示了 GitHub Copilot 如何不折不扣地引用雷神之锤对快速平方根倒数算法的实现。虽然生成的代码属于约翰·卡马克,GitHub Copilot 建议在它的基础上使用完全随机的许可证:
https://player.vimeo.com/video/732243025?background=1
Armin Ronacher's Tweet 上例中生成的代码甚至包括带有诅咒词的原始注释。GitHub 声称已经安装了过滤器,理论上应该可以屏蔽这些词。他们还应该删除敏感信息,如 API 密钥或电子邮件地址,这些信息可能会意外提交给 GitHub。然而,你永远无法确定。
鼓励作弊
如果你想掌握一门新的编程语言、框架、库或 API,GitHub Copilot 会是一个很好的学习工具。与此同时,不难想象一些学生滥用 GitHub Copilot 作弊,用简单的英语复制并粘贴任务描述,并在几秒钟内完成任务。回想一下你在本教程开始时做的代码拼图的出现。
此外,没有作弊意图的学生可能更愿意远离 GitHub Copilot,因为这可能会使他们变得懒惰,并阻碍他们独立思考。像所有强大的工具一样,你可以出于正确或错误的目的使用 GitHub Copilot。
需要订阅计划
对 GitHub Copilot 最常见的抱怨之一是,它需要付费订阅,这限制了潜在用户的数量。许多人似乎对被收费购买一个被认为是基于开源代码的工具感到不安。
更糟糕的是,无论你在世界的哪个角落,固定费用都是固定的。它没有考虑购买力平价,这使得一些国家的用户比其他国家的用户负担更重。如果你在一个购买力很高的国家从事工程工作,或者如果你的公司批量购买订阅,那么这个价格可能看起来是合理的。否则,价格可能会非常高。
另一方面,GitHub 至少提供了试用期,并让经过验证的学生和开源维护者可以免费使用这项服务,这很公平。最终,尽管价格可能会让一些人望而却步,但它通常是物有所值的,尤其是考虑到如此庞大的神经网络基础设施的维护成本。毕竟,它需要一个分布式集群来运行并实现低延迟。
如果你想更深入地了解更多关于底层机器学习模型的知识,那么请阅读 OpenAI Codex 上的原始论文。
结论
GitHub Copilot 是一款革命性的编程辅助工具,可以提高你作为软件工程师的速度和效率。它通过生成样板代码来节省您的时间,让您不必钻研文档。因为它了解你项目的背景,你得到的即时建议是量身定制的,通常以你想要的方式工作。
在本教程中,您学习了如何:
- 在你的代码编辑器中安装 GitHub Copilot 扩展
- 将任务的自然语言描述转换成工作代码
- 在多个可选的智能代码完成建议之间进行选择
- 探索不熟悉的框架和编程语言
- 教 GitHub Copilot 如何使用您的自定义 API
- 使用虚拟对程序员实时练习测试驱动开发
你对 GitHub Copilot 有什么看法?值这个价吗?你是否足够着迷于在未来的项目中使用它?在下面给我们留下评论吧!
免费下载: 点击这里下载免费的键盘快捷键备忘单让 GitHub Copilot 的编码更快。*************
基于 Python 和 NumPy 的随机梯度下降算法
原文:https://realpython.com/gradient-descent-algorithm-python/
随机梯度下降 是一种优化算法,常用于机器学习应用中,以找到对应于预测和实际输出之间最佳拟合的模型参数。这是一种不精确但强大的技术。
随机梯度下降广泛用于机器学习应用中。结合反向传播,在神经网络训练应用中占主导地位。
在本教程中,您将学习:
- 梯度下降和随机梯度下降算法如何工作
- 如何将梯度下降和随机梯度下降应用于最小化机器学习中的损失函数
- 什么是学习率,为什么它很重要,以及它如何影响结果
- 如何为随机梯度下降写自己的函数
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
基本梯度下降算法
梯度下降算法是数学优化的一种近似迭代方法。你可以用它来逼近任何一个可微函数的最小值。
注:数学规划有很多优化方法和子领域。如果你想学习如何在 Python 中使用它们中的一些,那么看看科学 Python:使用 SciPy 进行优化和动手线性编程:用 Python 进行优化。
虽然梯度下降有时会陷入局部最小值或 T2 鞍点,而不是找到全局最小值,但它在实践中被广泛使用。数据科学和机器学习方法经常在内部应用它来优化模型参数。例如,神经网络通过梯度下降找到权重和偏差。
成本函数:优化的目标
成本函数或损失函数,是通过改变决策变量来最小化(或最大化)的函数。许多机器学习方法在表面下解决优化问题。他们倾向于通过调整模型参数(如神经网络的权重和偏差、随机森林或梯度推进的决策规则等)来最小化实际和预测输出之间的差异。
在一个回归问题中,你通常有输入变量𝐱 = (𝑥₁,…,𝑥ᵣ)和实际输出𝑦.的向量您希望找到一个模型,将𝐱映射到预测响应𝑓(𝐱,以便𝑓(𝐱尽可能接近𝑦.例如,您可能希望在给定输入(如某人在公司的年数或受教育程度)的情况下预测一个输出(如某人的工资)。
您的目标是最小化预测𝑓(𝐱和实际数据𝑦.之间的差异这个差值称为残差。
在这种类型的问题中,您希望最小化所有观测值的残差平方和(SSR) ,其中 SSR =σᵢ(𝑦ᵢ𝑓(𝐱ᵢ)】𝑖= 1,…,𝑛,其中𝑛是观测值的总数。或者,你可以使用均方误差 (MSE = SSR / 𝑛)来代替 SSR。
SSR 和 MSE 都使用实际输出和预测输出之差的平方。差异越小,预测就越准确。差值为零表示预测值等于实际数据。
通过调整模型参数来最小化 SSR 或 MSE。比如在线性回归中,你想求函数𝑓(𝐱) = 𝑏₀ + 𝑏₁𝑥₁ + ⋯ + 𝑏ᵣ𝑥ᵣ,那么你需要确定使 SSR 或 MSE 最小化的权重𝑏₀,𝑏₁,…,𝑏ᵣ。
在分类问题中,输出𝑦是分类的,通常为 0 或 1。例如,您可能试图预测一封电子邮件是否是垃圾邮件。在二进制输出的情况下,最小化交叉熵函数是方便的,它也取决于实际输出𝑦ᵢ和相应的预测𝑝(𝐱ᵢ):
在经常用于解决分类问题的逻辑回归中,函数𝑝(𝐱和𝑓(𝐱定义如下:
同样,你需要找到权重𝑏₀,𝑏₁,…,𝑏ᵣ,但这一次他们应该最小化交叉熵函数。
函数的梯度:微积分复习器
在微积分中,一个函数的导数显示了当你修改它的参数(或多个参数)时,一个值改变了多少。导数对于优化很重要,因为零导数可能表示最小值、最大值或鞍点。
多个自变量的函数𝐶的梯度𝑣₁,…,𝑣ᵣ用∇𝐶(𝑣₁,…,𝑣ᵣ表示)定义为𝐶的偏导数相对于每个自变量的向量函数:∇𝐶 = (∂𝐶/∂𝑣₁,…,≈3/3)。∇这个符号叫做纳布拉。
函数𝐶在给定点的梯度的非零值定义了𝐶.最快增长的方向和速率使用梯度下降时,您会对成本函数中最快的下降的方向感兴趣。这个方向由负梯度−∇𝐶.决定
梯度下降背后的直觉
为了理解梯度下降算法,想象一滴水从碗的侧面滑下或者一个球从山上滚下。水滴和球趋向于向下降最快的方向运动,直到它们到达底部。随着时间的推移,他们会获得动力并加速前进。
梯度下降背后的思想是类似的:你从一个任意选择的点或向量𝐯 = (𝑣₁,…,𝑣ᵣ)的位置开始,并在成本函数下降最快的方向上迭代移动它。如前所述,这是负梯度矢量−∇𝐶.的方向
一旦你有了一个随机的起点𝐯 = (𝑣₁,…,𝑣ᵣ),你更新它,或者把它移到负梯度方向的一个新位置:𝐯→𝐯𝜂∇𝐶,其中𝜂(读作“ee-tah”)是一个小的正值,叫做学习率。
学习率决定了更新或移动步长的大小。这是一个非常重要的参数。如果𝜂太小,那么算法可能收敛得非常慢。大的𝜂值还会导致收敛问题或使算法发散。
基本梯度下降的实现
现在您已经知道了基本的梯度下降是如何工作的,您可以用 Python 实现它了。您将只使用普通 Python 和 NumPy ,这使您能够在处理数组(或向量)时编写简明代码,并获得性能提升。
这是该算法的一个基本实现,从任意点
start开始,迭代地将它移向最小值,返回一个有希望达到或接近最小值的点:1def gradient_descent(gradient, start, learn_rate, n_iter): 2 vector = start 3 for _ in range(n_iter): 4 diff = -learn_rate * gradient(vector) 5 vector += diff 6 return vector
gradient_descent()需要四个参数:
gradient是函数或任何 Python 可调用对象,它接受一个向量并返回你试图最小化的函数的梯度。start是算法开始搜索的点,以序列(元组、列表、 NumPy 数组等)或标量(在一维问题的情况下)的形式给出。learn_rate是控制向量更新幅度的学习速率。n_iter是迭代的次数。这个函数的功能与上面中描述的完全相同:它取一个起点(第 2 行),根据学习率和梯度值迭代更新它(第 3 到 5 行),最后返回找到的最后一个位置。
在应用
gradient_descent()之前,您可以添加另一个终止标准:1import numpy as np 2 3def gradient_descent( 4 gradient, start, learn_rate, n_iter=50, tolerance=1e-06 5): 6 vector = start 7 for _ in range(n_iter): 8 diff = -learn_rate * gradient(vector) 9 if np.all(np.abs(diff) <= tolerance): 10 break 11 vector += diff 12 return vector现在您有了额外的参数
tolerance(第 4 行),它指定了每次迭代中允许的最小移动。您还定义了tolerance和n_iter的默认值,因此您不必在每次调用gradient_descent()时都指定它们。如果当前迭代中的向量更新小于或等于
tolerance,第 9 行和第 10 行使gradient_descent()能够停止迭代并在到达n_iter之前返回结果。这通常发生在最小值附近,这里的梯度通常很小。不幸的是,它也可能发生在局部最小值或鞍点附近。第 9 行使用方便的 NumPy 函数
numpy.all()和numpy.abs()在一条语句中比较diff和tolerance的绝对值。这就是为什么你在 1 号线上的import numpy。现在你已经有了第一个版本的
gradient_descent(),是时候测试你的功能了。你将从一个小例子开始,找到函数 𝐶 = 𝑣 的最小值。这个函数只有一个自变量(𝑣),它的梯度是导数 2𝑣.这是一个可微的凸函数,寻找其最小值的分析方法很简单。然而,在实践中,解析微分可能是困难的,甚至是不可能的,并且通常用数值方法来近似。
您只需要一条语句来测试您的梯度下降实现:
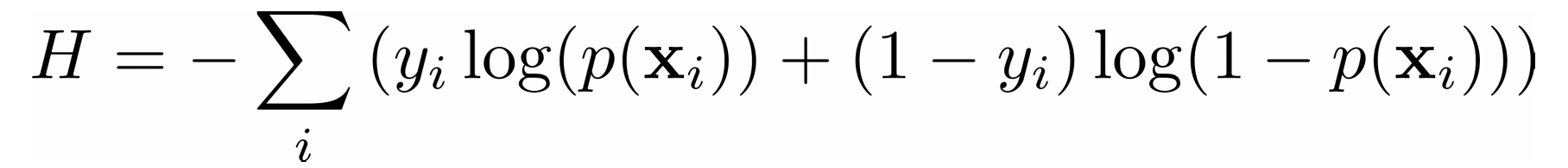
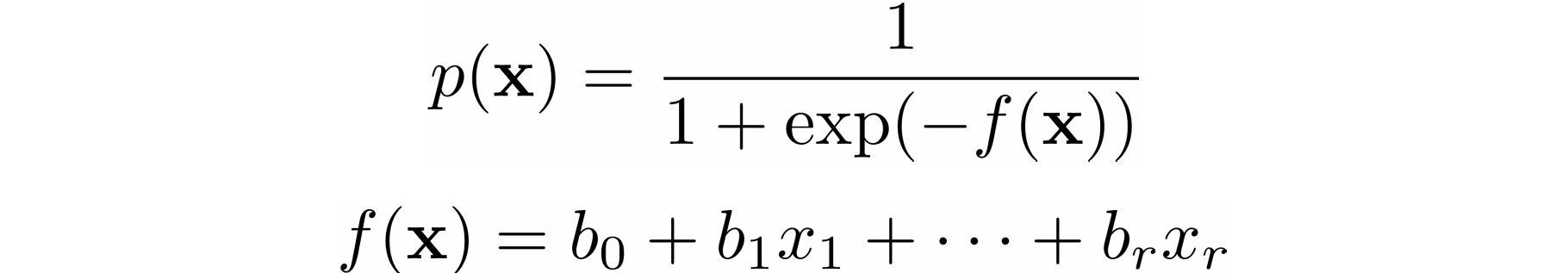
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.2
... )
2.210739197207331e-06
你使用λ函数 lambda v: 2 * v来提供𝑣的梯度。您从值10.0开始,并将学习率设置为0.2。你会得到一个非常接近于零的结果,这是正确的最小值。
下图显示了解决方案在迭代过程中的移动:
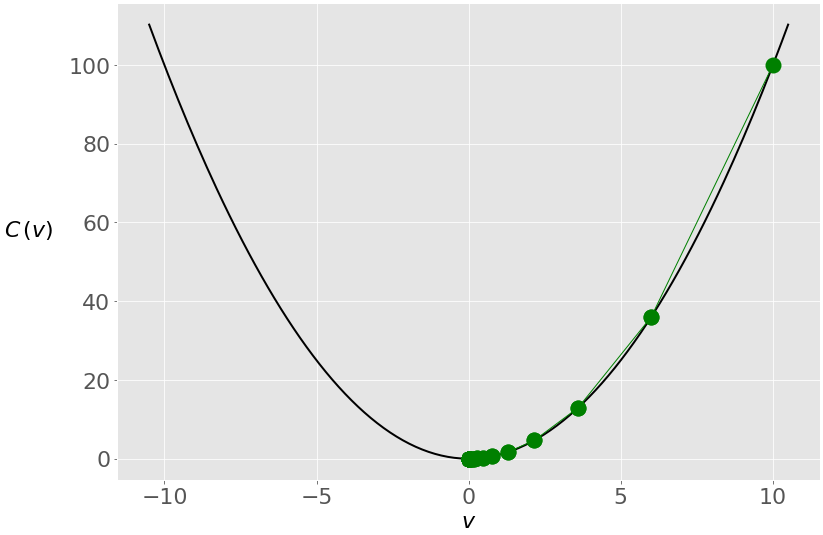
你从最右边的绿点(𝑣 = 10)开始,向最小值(𝑣 = 0)移动。因为梯度(和斜率)的值较高,所以更新一开始较大。当你接近最小值时,它们变得更低。
学习率影响
学习率是算法的一个非常重要的参数。不同的学习率值会显著影响梯度下降的行为。考虑前面的例子,但是学习率是 0.8 而不是 0.2:
>>> gradient_descent( ... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.8 ... ) -4.77519666596786e-07你会得到另一个非常接近于零的解,但是算法的内部行为是不同的。这就是𝑣的价值在迭代中发生的情况:
在这种情况下,您再次从𝑣 = 10 开始,但是由于学习率较高,𝑣发生了很大的变化,转到了最佳值的另一侧,变成了 6。在稳定在零点附近之前,它还会越过零点几次。
小的学习率会导致收敛速度非常慢。如果迭代次数有限,则算法可能会在找到最小值之前返回。否则,整个过程可能会花费不可接受的大量时间。为了说明这一点,再次运行
gradient_descent(),这一次学习率小得多,为 0.005:
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005
... )
6.050060671375367
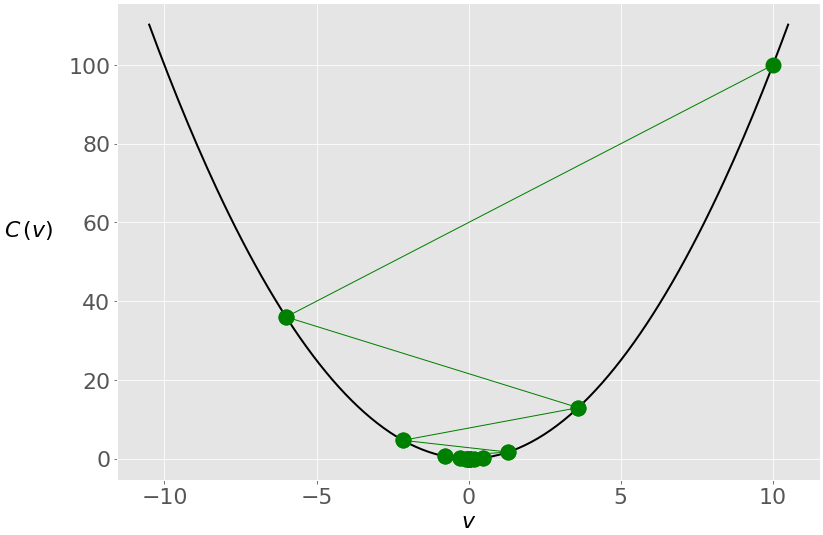
现在的结果是6.05,它离真正的最小值零很远。这是因为由于学习率小,向量的变化非常小:

像以前一样,搜索过程从𝑣 = 10 开始,但是它不能在五十次迭代中到达零。然而,经过 100 次迭代,误差会小得多,经过 1000 次迭代,误差会非常接近于零:
>>> gradient_descent( ... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005, ... n_iter=100 ... ) 3.660323412732294 >>> gradient_descent( ... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005, ... n_iter=1000 ... ) 0.0004317124741065828 >>> gradient_descent( ... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005, ... n_iter=2000 ... ) 9.952518849647663e-05非凸函数可能有局部极小值或鞍点,算法可能会陷入其中。在这种情况下,您对学习速率或起点的选择可以决定找到局部最小值还是找到全局最小值。
考虑函数 𝑣⁴ - 5𝑣 - 3𝑣 。它在𝑣有一个全局最小值≈ 1.7,在𝑣有一个局部最小值≈1.42。这个函数的梯度是 4𝑣10𝑣3。让我们看看
gradient_descent()在这里是如何工作的:
>>> gradient_descent(
... gradient=lambda v: 4 * v**3 - 10 * v - 3, start=0,
... learn_rate=0.2
... )
-1.4207567437458342
你这次从零开始,算法在局部最小值附近结束。下面是引擎盖下发生的事情:
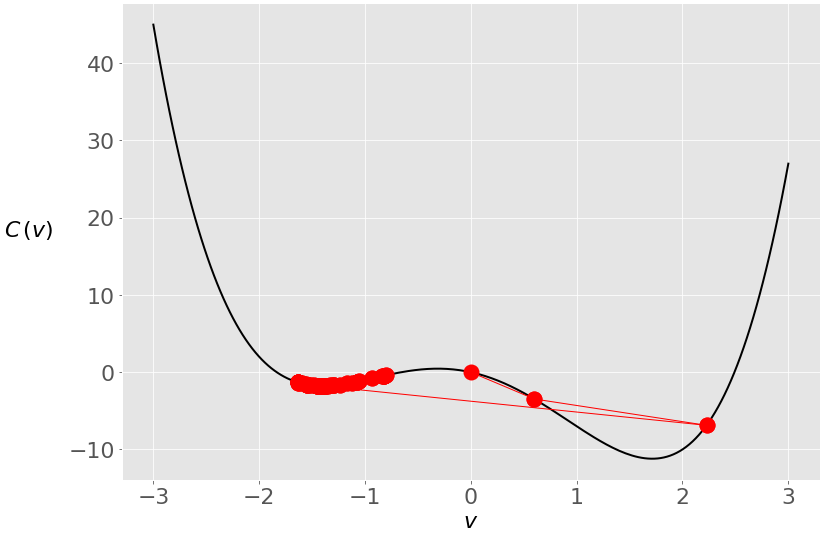
在前两次迭代中,你的向量向全局最小值移动,但之后它越过另一边,停留在局部最小值。你可以用较小的学习率来防止这种情况:
>>> gradient_descent( ... gradient=lambda v: 4 * v**3 - 10 * v - 3, start=0, ... learn_rate=0.1 ... ) 1.285401330315467当你将学习率从
0.2降低到0.1时,你会得到一个非常接近全局最小值的解。记住梯度下降是一种近似的方法。这一次,你避免跳到另一边:
较低的学习率防止向量进行大的跳跃,在这种情况下,向量保持更接近全局最优。
调整学习速度是很棘手的。你无法预先知道最佳值。有许多技术和试探法试图对此有所帮助。此外,机器学习实践者经常在模型选择和评估期间调整学习率。
除了学习速度之外,起点也会显著影响解,尤其是对于非凸函数。
梯度下降算法的应用
在本节中,您将看到两个使用梯度下降的简短示例。您还将了解到它可以用于现实生活中的机器学习问题,如线性回归。在第二种情况下,您需要修改
gradient_descent()的代码,因为您需要来自观察的数据来计算梯度。简短示例
首先,您将把
gradient_descent()应用于另一个一维问题。取函数𝑣log(𝑣)。该函数的梯度为 1 1/𝑣.有了这些信息,你可以找到它的最小值:

>>> gradient_descent(
... gradient=lambda v: 1 - 1 / v, start=2.5, learn_rate=0.5
... )
1.0000011077232125
利用提供的一组参数,gradient_descent()正确地计算出该函数在𝑣 = 1 时具有最小值。你可以用学习率和起点的其他值来试试。
您也可以将gradient_descent()用于多个变量的函数。应用程序是相同的,但是您需要以向量或数组的形式提供渐变和起始点。例如,您可以找到具有梯度向量(2𝑣₁,4𝑣₂)的函数 𝑣₁ + 𝑣₂⁴ 的最小值:
>>> gradient_descent( ... gradient=lambda v: np.array([2 * v[0], 4 * v[1]**3]), ... start=np.array([1.0, 1.0]), learn_rate=0.2, tolerance=1e-08 ... ) array([8.08281277e-12, 9.75207120e-02])在这种情况下,你的梯度函数返回一个数组,开始值是一个数组,所以你得到一个数组作为结果。得到的值几乎等于零,所以你可以说
gradient_descent()正确地发现了这个函数的最小值在𝑣₁ = 𝑣₂ = 0。普通最小二乘法
正如你已经知道的,线性回归和普通最小二乘法从输入𝐱 = (𝑥₁,…,𝑥ᵣ)和输出𝑦.的观察值开始他们定义了一个线性函数𝑓(𝐱) = 𝑏₀ + 𝑏₁𝑥₁ + ⋯ + 𝑏ᵣ𝑥ᵣ,尽可能接近𝑦.
这是一个优化问题。它会找到最小化残差平方和 SSR =σᵢ(𝑦ᵢ𝑓(𝐱ᵢ)或均方误差 MSE = SSR / 𝑛.的权重值𝑏₀、𝑏₁、…、𝑏ᵣ这里,𝑛是观测值的总数,𝑖 = 1,…,𝑛.
也可以使用成本函数𝐶 = SSR / (2𝑛),这在数学上比 SSR 或 MSE 更方便。
线性回归最基本的形式是简单线性回归。它只有一组输入𝑥和两个权重:𝑏₀和𝑏₁.回归线的方程是𝑓(𝑥) = 𝑏₀ + 𝑏₁𝑥.虽然𝑏₀和𝑏₁的最佳值可以通过分析计算得到,但是您将使用梯度下降法来确定它们。
首先,你需要微积分来寻找成本函数𝐶=σᵢ(𝑦ᵢ𝑏₀𝑏₁𝑥ᵢ)/(2𝑛).)的梯度因为你有两个决策变量,𝑏₀和𝑏₁,梯度∇𝐶是一个向量有两个组成部分:
- ∂𝐶/∂𝑏₀ = (1/𝑛) Σᵢ(𝑏₀ + 𝑏₁𝑥ᵢ − 𝑦ᵢ) = mean(𝑏₀ + 𝑏₁𝑥ᵢ − 𝑦ᵢ)
- ∂𝐶/∂𝑏₁ = (1/𝑛) Σᵢ(𝑏₀ + 𝑏₁𝑥ᵢ − 𝑦ᵢ) 𝑥ᵢ = mean((𝑏₀ + 𝑏₁𝑥ᵢ − 𝑦ᵢ) 𝑥ᵢ)
你需要𝑥和𝑦的值来计算这个成本函数的梯度。梯度函数的输入不仅包括𝑏₀和𝑏₁,还包括𝑥和𝑦.这可能是它看起来的样子:
def ssr_gradient(x, y, b): res = b[0] + b[1] * x - y return res.mean(), (res * x).mean() # .mean() is a method of np.ndarray
ssr_gradient()获取数组x和y,它们包含观察输入和输出,以及保存决策变量𝑏₀和𝑏₁.的当前值的数组b该函数首先计算每个观测值的残差数组(res),然后返回∂𝐶/∂𝑏₀和∂𝐶/∂𝑏₁.的一对值在这个例子中,您可以使用方便的 NumPy 方法
ndarray.mean(),因为您将 NumPy 数组作为参数传递。
gradient_descent()需要两个小调整:
- 在第 4 行增加
x和y作为gradient_descent()的参数。- 将
x和y提供给渐变函数,并确保在第 8 行将渐变元组转换为 NumPy 数组。以下是
gradient_descent()对这些变化的看法:1import numpy as np 2 3def gradient_descent( 4 gradient, x, y, start, learn_rate=0.1, n_iter=50, tolerance=1e-06 5): 6 vector = start 7 for _ in range(n_iter): 8 diff = -learn_rate * np.array(gradient(x, y, vector)) 9 if np.all(np.abs(diff) <= tolerance): 10 break 11 vector += diff 12 return vector
gradient_descent()现在接受观察输入x和输出y,并可以使用它们来计算梯度。将gradient(x, y, vector)的输出转换成一个 NumPy 数组,使得梯度元素可以按元素乘以学习率,这在单变量函数的情况下是不必要的。现在应用你的新版本的
gradient_descent()来寻找x和y的任意值的回归线:
>>> x = np.array([5, 15, 25, 35, 45, 55])
>>> y = np.array([5, 20, 14, 32, 22, 38])
>>> gradient_descent(
... ssr_gradient, x, y, start=[0.5, 0.5], learn_rate=0.0008,
... n_iter=100_000
... )
array([5.62822349, 0.54012867])
结果是一个数组,其中有两个值对应于决策变量:𝑏₀ = 5.63,𝑏₁ = 0.54。最佳回归线是𝑓(𝑥) = 5.63 + 0.54𝑥.和前面的例子一样,这个结果很大程度上取决于学习速度。学习率太低或太高,你都可能得不到这么好的结果。
这个例子并不完全是随机的——它摘自 Python 中的教程线性回归。好消息是,您已经获得了与来自 scikit-learn 的线性回归器几乎相同的结果。数据和回归结果显示在简单线性回归部分。
代码的改进
您可以在不修改其核心功能的情况下使gradient_descent()更加健壮、全面和美观:
1import numpy as np
2
3def gradient_descent(
4 gradient, x, y, start, learn_rate=0.1, n_iter=50, tolerance=1e-06,
5 dtype="float64"
6):
7 # Checking if the gradient is callable
8 if not callable(gradient):
9 raise TypeError("'gradient' must be callable")
10
11 # Setting up the data type for NumPy arrays
12 dtype_ = np.dtype(dtype)
13
14 # Converting x and y to NumPy arrays
15 x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_)
16 if x.shape[0] != y.shape[0]:
17 raise ValueError("'x' and 'y' lengths do not match")
18
19 # Initializing the values of the variables
20 vector = np.array(start, dtype=dtype_)
21
22 # Setting up and checking the learning rate
23 learn_rate = np.array(learn_rate, dtype=dtype_)
24 if np.any(learn_rate <= 0):
25 raise ValueError("'learn_rate' must be greater than zero")
26
27 # Setting up and checking the maximal number of iterations
28 n_iter = int(n_iter)
29 if n_iter <= 0:
30 raise ValueError("'n_iter' must be greater than zero")
31
32 # Setting up and checking the tolerance
33 tolerance = np.array(tolerance, dtype=dtype_)
34 if np.any(tolerance <= 0):
35 raise ValueError("'tolerance' must be greater than zero")
36
37 # Performing the gradient descent loop
38 for _ in range(n_iter):
39 # Recalculating the difference
40 diff = -learn_rate * np.array(gradient(x, y, vector), dtype_)
41
42 # Checking if the absolute difference is small enough
43 if np.all(np.abs(diff) <= tolerance):
44 break
45
46 # Updating the values of the variables
47 vector += diff
48
49 return vector if vector.shape else vector.item()
gradient_descent()现在接受一个额外的dtype参数,该参数定义了函数中 NumPy 数组的数据类型。关于 NumPy 类型的更多信息,请参见关于数据类型的官方文档。
在大多数应用程序中,您不会注意到 32 位和 64 位浮点数之间的差异,但是当您处理大型数据集时,这可能会显著影响内存使用,甚至可能会影响处理速度。例如,虽然 NumPy 默认使用 64 位浮点数, TensorFlow 经常使用 32 位十进制数。
除了考虑数据类型,上面的代码还引入了一些与类型检查和确保 NumPy 功能的使用相关的修改:
-
第 8 行和第 9 行检查
gradient是否是 Python 的可调用对象,以及是否可以作为函数使用。如果没有,那么该功能会抛出一个TypeError。 -
第 12 行设置了一个
numpy.dtype的实例,该实例将在整个函数中用作所有数组的数据类型。 -
第 15 行接受参数
x和y并产生具有所需数据类型的 NumPy 数组。参数x和y可以是列表、元组、数组或其他序列。 -
第 16 行和第 17 行比较
x和y的尺寸。这很有用,因为您希望确保两个数组具有相同数量的观察值。如果没有,那么这个函数会抛出一个ValueError。 -
第 20 行将参数
start转换成一个 NumPy 数组。这是一个有趣的技巧:如果start是一个 Python 标量,那么它将被转换成一个相应的 NumPy 对象(一个只有一个元素和零维的数组)。如果你传递一个序列,那么它将变成一个具有相同数量元素的常规 NumPy 数组。 -
第 23 行对学习率做了同样的事情。这非常有用,因为它使您能够通过向
gradient_descent()传递一个列表、元组或 NumPy 数组来为每个决策变量指定不同的学习率。 -
第 24 和 25 行检查学习率值(或所有变量的值)是否大于零。
-
第 28 行到第 35 行同样设置
n_iter和tolerance并检查它们是否大于零。 -
第 38 行到第 47 行和之前差不多。唯一的区别是第 40 行的渐变数组的类型。
-
如果有几个决策变量,第 49 行方便地返回结果数组;如果只有一个变量,则返回 Python 标量。
您的gradient_descent()现在已经完成。随意添加一些额外的功能或抛光。本教程的下一步是使用你到目前为止学到的知识来实现梯度下降的随机版本。
随机梯度下降算法
随机梯度下降算法是对梯度下降的一种修改。在随机梯度下降中,只使用随机的一小部分观测值而不是全部观测值来计算梯度。在某些情况下,这种方法可以减少计算时间。
在线随机梯度下降是随机梯度下降的一种变体,在这种方法中,您可以估计每次观察的成本函数的梯度,并相应地更新决策变量。这可以帮助您找到全局最小值,尤其是在目标函数是凸的情况下。
批量随机梯度下降介于普通梯度下降和在线方法之间。计算梯度,并用所有观察值的子集迭代更新决策变量,称为小批。这种变体在训练神经网络方面非常流行。
您可以将在线算法想象成一种特殊的批处理算法,其中每个小批只有一个观察值。经典梯度下降是另一种特殊情况,其中只有一批包含所有观测值。
随机梯度下降中的小批量
与普通梯度下降的情况一样,随机梯度下降从决策变量的初始向量开始,并通过几次迭代来更新它。两者的区别在于迭代内部发生了什么:
- 随机梯度下降随机地将观察值集分成小批。
- 对于每个小批次,计算梯度并移动向量。
- 一旦所有的迷你批次都被使用,你就说迭代,或者说纪元已经完成,并开始下一个。
该算法随机选择小批次的观察值,因此您需要模拟这种随机(或伪随机)行为。你可以通过随机数生成来做到这一点。Python 内置了 random 模块,NumPy 自带随机生成器。当您使用数组时,后者更方便。
您将创建一个名为sgd()的新函数,它与gradient_descent()非常相似,但是使用随机选择的小块在搜索空间中移动:
1import numpy as np
2
3def sgd(
4 gradient, x, y, start, learn_rate=0.1, batch_size=1, n_iter=50, 5 tolerance=1e-06, dtype="float64", random_state=None 6):
7 # Checking if the gradient is callable
8 if not callable(gradient):
9 raise TypeError("'gradient' must be callable")
10
11 # Setting up the data type for NumPy arrays
12 dtype_ = np.dtype(dtype)
13
14 # Converting x and y to NumPy arrays
15 x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_)
16 n_obs = x.shape[0] 17 if n_obs != y.shape[0]:
18 raise ValueError("'x' and 'y' lengths do not match")
19 xy = np.c_[x.reshape(n_obs, -1), y.reshape(n_obs, 1)] 20
21 # Initializing the random number generator
22 seed = None if random_state is None else int(random_state) 23 rng = np.random.default_rng(seed=seed) 24
25 # Initializing the values of the variables
26 vector = np.array(start, dtype=dtype_)
27
28 # Setting up and checking the learning rate
29 learn_rate = np.array(learn_rate, dtype=dtype_)
30 if np.any(learn_rate <= 0):
31 raise ValueError("'learn_rate' must be greater than zero")
32
33 # Setting up and checking the size of minibatches
34 batch_size = int(batch_size) 35 if not 0 < batch_size <= n_obs: 36 raise ValueError( 37 "'batch_size' must be greater than zero and less than " 38 "or equal to the number of observations" 39 ) 40
41 # Setting up and checking the maximal number of iterations
42 n_iter = int(n_iter)
43 if n_iter <= 0:
44 raise ValueError("'n_iter' must be greater than zero")
45
46 # Setting up and checking the tolerance
47 tolerance = np.array(tolerance, dtype=dtype_)
48 if np.any(tolerance <= 0):
49 raise ValueError("'tolerance' must be greater than zero")
50
51 # Performing the gradient descent loop
52 for _ in range(n_iter):
53 # Shuffle x and y
54 rng.shuffle(xy) 55
56 # Performing minibatch moves
57 for start in range(0, n_obs, batch_size): 58 stop = start + batch_size 59 x_batch, y_batch = xy[start:stop, :-1], xy[start:stop, -1:] 60
61 # Recalculating the difference
62 grad = np.array(gradient(x_batch, y_batch, vector), dtype_) 63 diff = -learn_rate * grad 64
65 # Checking if the absolute difference is small enough
66 if np.all(np.abs(diff) <= tolerance):
67 break
68
69 # Updating the values of the variables
70 vector += diff
71
72 return vector if vector.shape else vector.item()
这里有一个新参数。使用batch_size,您可以指定每个迷你批次中的观察次数。这是随机梯度下降的一个重要参数,会显著影响性能。第 34 到 39 行确保batch_size是一个不大于观察总数的正整数。
另一个新参数是random_state。它在第 22 行定义了随机数发生器的种子。第 23 行的种子被用作 default_rng() 的参数,它创建了一个 Generator 的实例。
如果您为random_state传递参数 None ,那么随机数生成器将在每次实例化时返回不同的数字。如果您希望生成器的每个实例以完全相同的方式运行,那么您需要指定seed。最简单的方法是提供一个任意整数。
第 16 行用x.shape[0]减去观察次数。如果x是一维数组,那么这就是它的大小。如果x是二维的,那么.shape[0]就是行数。
在第 19 行,您使用 .reshape() 来确保x和y都成为具有n_obs行的二维数组,并且y正好有一列。 numpy.c_[] 方便的将x和y的列串联成一个数组xy。这是使数据适合随机选择的一种方法。
最后,在第 52 到 70 行,你实现了随机梯度下降的 for循环。与gradient_descent()不同。在第 54 行,您使用随机数生成器及其方法 .shuffle() 来打乱观察结果。这是随机选择迷你批次的方法之一。
每个迷你批次都重复内部for循环。与普通梯度下降的主要区别在于,在第 62 行,梯度是针对小批量的观察值(x_batch和y_batch)计算的,而不是针对所有观察值(x和y)。
在第 59 行,x_batch成为xy的一部分,包含当前迷你批处理的行(从start到stop)和对应于x的列。y_batch保存与xy相同的行,但只保存最后一列(输出)。有关 NumPy 中索引如何工作的更多信息,请参见关于索引的官方文档。
现在,您可以测试您的随机梯度下降实现了:
>>> sgd( ... ssr_gradient, x, y, start=[0.5, 0.5], learn_rate=0.0008, ... batch_size=3, n_iter=100_000, random_state=0 ... ) array([5.63093736, 0.53982921])结果和你用
gradient_descent()得到的差不多。如果你省略了random_state或者使用了None,那么每次运行sgd()时你会得到稍微不同的结果,因为随机数发生器会以不同的方式洗牌xy。随机梯度下降中的动量
正如你已经看到的,学习率对梯度下降的结果有很大的影响。在算法执行期间,您可以使用几种不同的策略来调整学习率。你也可以将动量应用到你的算法中。
你可以用动量来修正学习率的影响。其思想是记住向量的前一次更新,并在计算下一次更新时应用它。你不需要精确地在负梯度的方向上移动矢量,但是你也倾向于保持前一次移动的方向和大小。
称为衰减率或衰减因子的参数定义了先前更新的贡献有多强。要包括动量和衰减率,您可以通过添加参数
decay_rate来修改sgd(),并使用它来计算矢量更新的方向和大小(diff):1import numpy as np 2 3def sgd( 4 gradient, x, y, start, learn_rate=0.1, decay_rate=0.0, batch_size=1, 5 n_iter=50, tolerance=1e-06, dtype="float64", random_state=None 6): 7 # Checking if the gradient is callable 8 if not callable(gradient): 9 raise TypeError("'gradient' must be callable") 10 11 # Setting up the data type for NumPy arrays 12 dtype_ = np.dtype(dtype) 13 14 # Converting x and y to NumPy arrays 15 x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_) 16 n_obs = x.shape[0] 17 if n_obs != y.shape[0]: 18 raise ValueError("'x' and 'y' lengths do not match") 19 xy = np.c_[x.reshape(n_obs, -1), y.reshape(n_obs, 1)] 20 21 # Initializing the random number generator 22 seed = None if random_state is None else int(random_state) 23 rng = np.random.default_rng(seed=seed) 24 25 # Initializing the values of the variables 26 vector = np.array(start, dtype=dtype_) 27 28 # Setting up and checking the learning rate 29 learn_rate = np.array(learn_rate, dtype=dtype_) 30 if np.any(learn_rate <= 0): 31 raise ValueError("'learn_rate' must be greater than zero") 32 33 # Setting up and checking the decay rate 34 decay_rate = np.array(decay_rate, dtype=dtype_) 35 if np.any(decay_rate < 0) or np.any(decay_rate > 1): 36 raise ValueError("'decay_rate' must be between zero and one") 37 38 # Setting up and checking the size of minibatches 39 batch_size = int(batch_size) 40 if not 0 < batch_size <= n_obs: 41 raise ValueError( 42 "'batch_size' must be greater than zero and less than " 43 "or equal to the number of observations" 44 ) 45 46 # Setting up and checking the maximal number of iterations 47 n_iter = int(n_iter) 48 if n_iter <= 0: 49 raise ValueError("'n_iter' must be greater than zero") 50 51 # Setting up and checking the tolerance 52 tolerance = np.array(tolerance, dtype=dtype_) 53 if np.any(tolerance <= 0): 54 raise ValueError("'tolerance' must be greater than zero") 55 56 # Setting the difference to zero for the first iteration 57 diff = 0 58 59 # Performing the gradient descent loop 60 for _ in range(n_iter): 61 # Shuffle x and y 62 rng.shuffle(xy) 63 64 # Performing minibatch moves 65 for start in range(0, n_obs, batch_size): 66 stop = start + batch_size 67 x_batch, y_batch = xy[start:stop, :-1], xy[start:stop, -1:] 68 69 # Recalculating the difference 70 grad = np.array(gradient(x_batch, y_batch, vector), dtype_) 71 diff = decay_rate * diff - learn_rate * grad 72 73 # Checking if the absolute difference is small enough 74 if np.all(np.abs(diff) <= tolerance): 75 break 76 77 # Updating the values of the variables 78 vector += diff 79 80 return vector if vector.shape else vector.item()在这个实现中,您在第 4 行添加了
decay_rate参数,在第 34 行将其转换为所需类型的 NumPy 数组,并在第 35 和 36 行检查它是否介于 0 和 1 之间。在第 57 行,在迭代开始之前初始化diff,以确保它在第一次迭代中可用。最重要的变化发生在第 71 行。你用学习率和梯度重新计算
diff,但也加上衰减率和旧值diff的乘积。现在diff有两个组成部分:
decay_rate * diff是气势,或冲击前人的举动。-learn_rate * grad是当前渐变的影响。衰减率和学习率用作定义两者贡献的权重。
随机起始值
与普通的梯度下降相反,随机梯度下降的起点通常不那么重要。对于用户来说,这也可能是一个不必要的困难,尤其是当你有很多决策变量的时候。为了得到一个概念,想象一下如果你需要手动初始化一个有数千个偏差和权重的神经网络的值!
在实践中,可以从一些小的任意值开始。您将使用随机数生成器来获取它们:
1import numpy as np 2 3def sgd( 4 gradient, x, y, n_vars=None, start=None, learn_rate=0.1, 5 decay_rate=0.0, batch_size=1, n_iter=50, tolerance=1e-06, 6 dtype="float64", random_state=None 7): 8 # Checking if the gradient is callable 9 if not callable(gradient): 10 raise TypeError("'gradient' must be callable") 11 12 # Setting up the data type for NumPy arrays 13 dtype_ = np.dtype(dtype) 14 15 # Converting x and y to NumPy arrays 16 x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_) 17 n_obs = x.shape[0] 18 if n_obs != y.shape[0]: 19 raise ValueError("'x' and 'y' lengths do not match") 20 xy = np.c_[x.reshape(n_obs, -1), y.reshape(n_obs, 1)] 21 22 # Initializing the random number generator 23 seed = None if random_state is None else int(random_state) 24 rng = np.random.default_rng(seed=seed) 25 26 # Initializing the values of the variables 27 vector = ( 28 rng.normal(size=int(n_vars)).astype(dtype_) 29 if start is None else 30 np.array(start, dtype=dtype_) 31 ) 32 33 # Setting up and checking the learning rate 34 learn_rate = np.array(learn_rate, dtype=dtype_) 35 if np.any(learn_rate <= 0): 36 raise ValueError("'learn_rate' must be greater than zero") 37 38 # Setting up and checking the decay rate 39 decay_rate = np.array(decay_rate, dtype=dtype_) 40 if np.any(decay_rate < 0) or np.any(decay_rate > 1): 41 raise ValueError("'decay_rate' must be between zero and one") 42 43 # Setting up and checking the size of minibatches 44 batch_size = int(batch_size) 45 if not 0 < batch_size <= n_obs: 46 raise ValueError( 47 "'batch_size' must be greater than zero and less than " 48 "or equal to the number of observations" 49 ) 50 51 # Setting up and checking the maximal number of iterations 52 n_iter = int(n_iter) 53 if n_iter <= 0: 54 raise ValueError("'n_iter' must be greater than zero") 55 56 # Setting up and checking the tolerance 57 tolerance = np.array(tolerance, dtype=dtype_) 58 if np.any(tolerance <= 0): 59 raise ValueError("'tolerance' must be greater than zero") 60 61 # Setting the difference to zero for the first iteration 62 diff = 0 63 64 # Performing the gradient descent loop 65 for _ in range(n_iter): 66 # Shuffle x and y 67 rng.shuffle(xy) 68 69 # Performing minibatch moves 70 for start in range(0, n_obs, batch_size): 71 stop = start + batch_size 72 x_batch, y_batch = xy[start:stop, :-1], xy[start:stop, -1:] 73 74 # Recalculating the difference 75 grad = np.array(gradient(x_batch, y_batch, vector), dtype_) 76 diff = decay_rate * diff - learn_rate * grad 77 78 # Checking if the absolute difference is small enough 79 if np.all(np.abs(diff) <= tolerance): 80 break 81 82 # Updating the values of the variables 83 vector += diff 84 85 return vector if vector.shape else vector.item()现在有了新的参数
n_vars,它定义了问题中决策变量的数量。参数start是可选的,默认值为None。第 27 到 31 行初始化决策变量的初始值:现在给
sgd()一个机会:
>>> sgd(
... ssr_gradient, x, y, n_vars=2, learn_rate=0.0001,
... decay_rate=0.8, batch_size=3, n_iter=100_000, random_state=0
... )
array([5.63014443, 0.53901017])
你会再次得到相似的结果。
你已经学会了如何编写实现梯度下降和随机梯度下降的函数。上面的代码可以变得更加健壮和完善。你也可以在著名的机器学习库中找到这些方法的不同实现。
Keras 和张量流中的梯度下降
随机梯度下降被广泛用于训练神经网络。神经网络的库通常具有基于随机梯度下降的优化算法的不同变体,例如:
- 圣经》和《古兰经》传统中)亚当(人类第一人的名字
- 阿达格拉德
- 阿达德尔塔
- RMSProp
这些优化库通常在神经网络软件训练时内部调用。但是,您也可以独立使用它们:
>>> import tensorflow as tf >>> # Create needed objects >>> sgd = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9) >>> var = tf.Variable(2.5) >>> cost = lambda: 2 + var ** 2 >>> # Perform optimization >>> for _ in range(100): ... sgd.minimize(cost, var_list=[var]) >>> # Extract results >>> var.numpy() -0.007128528 >>> cost().numpy() 2.0000508在本例中,您首先导入
tensorflow,然后创建优化所需的对象:
sgd是随机梯度下降优化器的一个实例,学习速率为0.1,动量为0.9。var是决策变量的实例,初始值为2.5。cost是成本函数,在本例中是平方函数。代码的主要部分是一个
for循环,它反复调用.minimize()并修改var和cost。一旦循环结束,您可以使用.numpy()获得决策变量和成本函数的值。你可以在 Keras 和 TensorFlow 文档中找到关于这些算法的更多信息。文章梯度下降优化算法概述提供了梯度下降变量的综合解释列表。
结论
你现在知道什么是梯度下降和随机梯度下降算法,以及它们如何工作。它们广泛用于人工神经网络的应用程序中,并在 Keras 和 TensorFlow 等流行的库中实现。
在本教程中,您已经学习了:
- 如何为梯度下降和随机梯度下降编写自己的函数
- 如何应用你的函数解决优化问题
- 梯度下降的关键特征和概念是什么,比如学习速率或动量,以及它的局限性
您已经使用梯度下降和随机梯度下降找到几个函数的最小值,并拟合线性回归问题中的回归线。您还看到了如何应用 TensorFlow 中用于训练神经网络的类
SGD。如果你有任何问题或意见,请写在下面的评论区。*******
在 Flask 中注册期间处理电子邮件确认
原文:https://realpython.com/handling-email-confirmation-in-flask/
本教程详细介绍了如何在用户注册时验证电子邮件地址。
2015 年 4 月 30 日更新:新增 Python 3 支持。
在工作流程方面,用户注册新账户后,会发送一封确认邮件。用户帐户被标记为“未确认”,直到用户通过电子邮件中的说明“确认”帐户。这是大多数 web 应用程序遵循的简单工作流。
需要考虑的一件重要事情是未经确认的用户可以做什么。换句话说,他们对您的应用程序有完全访问权限、有限/受限访问权限还是根本没有访问权限?对于本教程中的应用程序,未经确认的用户可以登录,但他们会立即被重定向到一个页面,提醒他们在访问应用程序之前需要确认他们的帐户。
在开始之前,我们将要添加的大部分功能都是 Flask-User 和 Flask-Security 扩展的一部分——这就引出了一个问题,为什么不直接使用这些扩展呢?首先,这是一个学习的机会。此外,这两种扩展都有局限性,比如支持的数据库。例如,如果你想使用 RethinkDB 呢?
我们开始吧。
烧瓶基本注册
我们将从包含基本用户注册的 Flask 样板文件开始。从库中获取代码。创建并激活 virtualenv 后,运行以下命令快速入门:
$ pip install -r requirements.txt $ export APP_SETTINGS="project.config.DevelopmentConfig" $ python manage.py create_db $ python manage.py db init $ python manage.py db migrate $ python manage.py create_admin $ python manage.py runserver查看自述文件了解更多信息。
在应用程序运行的情况下,导航到http://localhost:5000/register并注册一个新用户。请注意,注册后,应用程序会自动让您登录,并将您重定向到主页。四处看看,然后运行代码——特别是“用户”蓝图。
完成后杀死服务器。
更新当前应用
型号
首先,让我们将
confirmed字段添加到项目/models.py 中的User模型中:class User(db.Model): __tablename__ = "users" id = db.Column(db.Integer, primary_key=True) email = db.Column(db.String, unique=True, nullable=False) password = db.Column(db.String, nullable=False) registered_on = db.Column(db.DateTime, nullable=False) admin = db.Column(db.Boolean, nullable=False, default=False) confirmed = db.Column(db.Boolean, nullable=False, default=False) confirmed_on = db.Column(db.DateTime, nullable=True) def __init__(self, email, password, confirmed, paid=False, admin=False, confirmed_on=None): self.email = email self.password = bcrypt.generate_password_hash(password) self.registered_on = datetime.datetime.now() self.admin = admin self.confirmed = confirmed self.confirmed_on = confirmed_on注意这个字段是如何默认为“False”的。我们还添加了一个
confirmed_on字段,它是一个[datetime](https://real python . com/python-datetime/)。我也喜欢包括这个字段,以便使用群组分析来分析registered_on和confirmed_on日期之间的差异。让我们从数据库和迁移开始。因此,继续删除数据库, dev.sqlite ,以及“migrations”文件夹。
管理命令
接下来,在 manage.py 中,更新
create_admin命令以考虑新的数据库字段:@manager.command def create_admin(): """Creates the admin user.""" db.session.add(User( email="ad@min.com", password="admin", admin=True, confirmed=True, confirmed_on=datetime.datetime.now()) ) db.session.commit()确保导入
datetime。现在,继续运行以下命令:$ python manage.py create_db $ python manage.py db init $ python manage.py db migrate $ python manage.py create_admin
register()查看功能最后,在我们再次注册用户之前,我们需要对项目/用户/视图. py 中的
register()视图功能进行快速更改…改变:
user = User( email=form.email.data, password=form.password.data )收件人:
user = User( email=form.email.data, password=form.password.data, confirmed=False )有道理吗?想想为什么我们要将
confirmed默认为False。好吧。再次运行应用程序。导航到http://localhost:5000/register,再次注册一个新用户。如果您在 SQLite 浏览器中打开您的 SQLite 数据库,您应该会看到:
所以,我注册的新用户
michael@realpython.com没有被确认。让我们改变这一点。添加电子邮件确认
生成确认令牌
电子邮件确认应该包含一个唯一的网址,用户只需点击确认他/她的帐户。理想情况下,URL 应该是这样的-
http://yourapp.com/confirm/<id>。这里的关键是id。我们将使用危险的包在id中对用户电子邮件(以及时间戳)进行编码。创建一个名为 project/token.py 的文件,并添加以下代码:
# project/token.py from itsdangerous import URLSafeTimedSerializer from project import app def generate_confirmation_token(email): serializer = URLSafeTimedSerializer(app.config['SECRET_KEY']) return serializer.dumps(email, salt=app.config['SECURITY_PASSWORD_SALT']) def confirm_token(token, expiration=3600): serializer = URLSafeTimedSerializer(app.config['SECRET_KEY']) try: email = serializer.loads( token, salt=app.config['SECURITY_PASSWORD_SALT'], max_age=expiration ) except: return False return email因此,在
generate_confirmation_token()函数中,我们使用用户注册期间获得的电子邮件地址,使用URLSafeTimedSerializer来生成一个令牌。实际的电子邮件被编码在令牌中。然后,为了确认令牌,在confirm_token()函数中,我们可以使用loads()方法,该方法将令牌和有效期(有效期为 1 小时(3600 秒))作为参数。只要令牌没有过期,它就会返回一封电子邮件。请务必将
SECURITY_PASSWORD_SALT添加到您的应用程序的配置(BaseConfig()):SECURITY_PASSWORD_SALT = 'my_precious_two'更新
register()查看功能现在让我们从项目/用户/视图. py 再次更新
register()视图函数:@user_blueprint.route('/register', methods=['GET', 'POST']) def register(): form = RegisterForm(request.form) if form.validate_on_submit(): user = User( email=form.email.data, password=form.password.data, confirmed=False ) db.session.add(user) db.session.commit() token = generate_confirmation_token(user.email)此外,请确保更新导入:
from project.token import generate_confirmation_token, confirm_token处理电子邮件确认
接下来,让我们添加一个新视图来处理电子邮件确认:
@user_blueprint.route('/confirm/<token>') @login_required def confirm_email(token): try: email = confirm_token(token) except: flash('The confirmation link is invalid or has expired.', 'danger') user = User.query.filter_by(email=email).first_or_404() if user.confirmed: flash('Account already confirmed. Please login.', 'success') else: user.confirmed = True user.confirmed_on = datetime.datetime.now() db.session.add(user) db.session.commit() flash('You have confirmed your account. Thanks!', 'success') return redirect(url_for('main.home'))将此添加到项目/用户/视图. py 。此外,请确保更新导入:
import datetime这里,我们调用
confirm_token()函数,传入令牌。如果成功,我们更新用户,将email_confirmed属性更改为True,并将datetime设置为确认发生的时间。此外,如果用户已经通过了确认过程——并且被确认了——那么我们会提醒用户这一点。创建电子邮件模板
接下来,让我们添加一个基本的电子邮件模板:
<p>Welcome! Thanks for signing up. Please follow this link to activate your account:</p> <p><a href="{{ confirm_url }}">{{ confirm_url }}</a></p> <br> <p>Cheers!</p>将此另存为“项目/模板/用户”中的【activate.html】T2。这需要一个名为
confirm_url的变量,它将在register()视图函数中创建。发送电子邮件
让我们在 Flask-Mail 的帮助下为发送邮件创建一个基本功能,这个功能已经在
project/__init__.py中安装并设置好了。创建名为 email.py 的文件:
# project/email.py from flask.ext.mail import Message from project import app, mail def send_email(to, subject, template): msg = Message( subject, recipients=[to], html=template, sender=app.config['MAIL_DEFAULT_SENDER'] ) mail.send(msg)将它保存在“项目”文件夹中。
因此,我们只需要传递一个收件人列表、一个主题和一个模板。我们稍后将处理邮件配置设置。
更新 project/user/views.py 中的
register()视图函数(再次!)@user_blueprint.route('/register', methods=['GET', 'POST']) def register(): form = RegisterForm(request.form) if form.validate_on_submit(): user = User( email=form.email.data, password=form.password.data, confirmed=False ) db.session.add(user) db.session.commit() token = generate_confirmation_token(user.email) confirm_url = url_for('user.confirm_email', token=token, _external=True) html = render_template('user/activate.html', confirm_url=confirm_url) subject = "Please confirm your email" send_email(user.email, subject, html) login_user(user) flash('A confirmation email has been sent via email.', 'success') return redirect(url_for("main.home")) return render_template('user/register.html', form=form)还添加以下导入:
from project.email import send_email在这里,我们将所有东西放在一起。该功能基本上充当整个过程的控制器(直接或间接):
- 处理初始注册,
- 生成令牌和确认 URL,
- 发送确认电子邮件,
- 闪光确认,
- 登录用户,然后
- 重定向用户。
你注意到
_external=True的争论了吗?在我们的例子中,这将添加包含主机名和端口的完整绝对 URL(http://localhost:5000)。)在我们测试这个之前,我们需要设置我们的邮件设置。
邮件
首先更新 project/config.py 中的
BaseConfig():class BaseConfig(object): """Base configuration.""" # main config SECRET_KEY = 'my_precious' SECURITY_PASSWORD_SALT = 'my_precious_two' DEBUG = False BCRYPT_LOG_ROUNDS = 13 WTF_CSRF_ENABLED = True DEBUG_TB_ENABLED = False DEBUG_TB_INTERCEPT_REDIRECTS = False # mail settings MAIL_SERVER = 'smtp.googlemail.com' MAIL_PORT = 465 MAIL_USE_TLS = False MAIL_USE_SSL = True # gmail authentication MAIL_USERNAME = os.environ['APP_MAIL_USERNAME'] MAIL_PASSWORD = os.environ['APP_MAIL_PASSWORD'] # mail accounts MAIL_DEFAULT_SENDER = 'from@example.com'查看官方烧瓶邮件文档了解更多信息。
如果您已经有一个 GMAIL 帐户,那么您可以使用它或注册一个测试 GMAIL 帐户。然后在当前 shell 会话中临时设置环境变量:
$ export APP_MAIL_USERNAME="foo" $ export APP_MAIL_PASSWORD="bar"如果你的 GMAIL 账户有两步认证,谷歌会阻止这一尝试。
现在我们来测试一下!
首次测试
启动应用程序,导航到http://localhost:5000/register。然后使用您可以访问的电子邮件地址进行注册。如果一切顺利,您的收件箱中应该会有一封类似如下的电子邮件:
点击网址,你应该被带到 http://localhost:5000/ 。确保用户在数据库中,“已确认”字段是
True,并且有一个datetime与confirmed_on字段关联。不错!
处理权限
如果你还记得,在本教程的开始,我们决定“未经确认的用户可以登录,但他们应该立即被重定向到一个页面——让我们称之为路由
/unconfirmed——提醒用户在他们可以访问应用程序之前需要确认他们的帐户”。所以,我们需要-
- 添加
/unconfirmed路线- 添加一个unconfirmed.html模板
- 更新
register()视图功能- 创建一个装饰器
- 更新navigation.html模板
添加
/unconfirmed路线将以下路径添加到项目/用户/视图. py :
@user_blueprint.route('/unconfirmed') @login_required def unconfirmed(): if current_user.confirmed: return redirect('main.home') flash('Please confirm your account!', 'warning') return render_template('user/unconfirmed.html')您以前见过类似的代码,所以让我们继续。
添加unconfirmed.html模板
{% extends "_base.html" %} {% block content %} <h1>Welcome!</h1> <br> <p>You have not confirmed your account. Please check your inbox (and your spam folder) - you should have received an email with a confirmation link.</p> <p>Didn't get the email? <a href="/">Resend</a>.</p> {% endblock %}将此另存为“项目/模板/用户”中的unconfirmed.html。同样,这应该很简单。目前,我们只是在中添加了一个虚拟 URL,用于重新发送确认电子邮件。我们将进一步解决这个问题。
更新
register()视图功能现在只需改变:
return redirect(url_for("main.home"))收件人:
return redirect(url_for("user.unconfirmed"))因此,在发送确认电子邮件后,用户现在被重定向到
/unconfirmed路线。创建一个装饰器*
# project/decorators.py from functools import wraps from flask import flash, redirect, url_for from flask.ext.login import current_user def check_confirmed(func): @wraps(func) def decorated_function(*args, **kwargs): if current_user.confirmed is False: flash('Please confirm your account!', 'warning') return redirect(url_for('user.unconfirmed')) return func(*args, **kwargs) return decorated_function这里我们有一个基本的功能来检查一个用户是否未经确认。如果未确认,用户将被重定向到
/unconfirmed路线。在“项目”目录下保存这个文件为 decorators.py 。现在,装饰一下
profile()视图函数:@user_blueprint.route('/profile', methods=['GET', 'POST']) @login_required @check_confirmed def profile(): # ... snip ...确保导入装饰器:
from project.decorators import check_confirmed更新navigation.html模板
最后,更新navigation.html模板的以下部分-
改变:
<ul class="nav navbar-nav"> {% if current_user.is_authenticated() %} <li><a href="{{ url_for('user.profile') }}">Profile</a></li> {% endif %} </ul>收件人:
<ul class="nav navbar-nav"> {% if current_user.confirmed and current_user.is_authenticated() %} <li><a href="{{ url_for('user.profile') }}">Profile</a></li> {% elif current_user.is_authenticated() %} <li><a href="{{ url_for('user.unconfirmed') }}">Confirm</a></li> {% endif %} </ul>再次测试的时间到了!
第二次测试
启动应用程序,使用您可以访问的电子邮件地址再次注册。(请随意从数据库中删除您之前注册的旧用户,以便再次使用。)现在你注册后应该会被重定向到http://localhost:5000/unconfirmed。
一定要测试http://localhost:5000/profile路由。这应该会将你重定向到http://localhost:5000/unconfirmed。
继续确认电子邮件,您将可以访问所有页面。嘣!
重新发送电子邮件
最后,让我们让重新发送链接工作。向项目/用户/视图. py 添加以下视图函数:
@user_blueprint.route('/resend') @login_required def resend_confirmation(): token = generate_confirmation_token(current_user.email) confirm_url = url_for('user.confirm_email', token=token, _external=True) html = render_template('user/activate.html', confirm_url=confirm_url) subject = "Please confirm your email" send_email(current_user.email, subject, html) flash('A new confirmation email has been sent.', 'success') return redirect(url_for('user.unconfirmed'))现在更新unconfirmed.html模板:
{% extends "_base.html" %} {% block content %} <h1>Welcome!</h1> <br> <p>You have not confirmed your account. Please check your inbox (and your spam folder) - you should have received an email with a confirmation link.</p> <p>Didn't get the email? <a href="{{ url_for('user.resend_confirmation') }}">Resend</a>.</p> {% endblock %}第三次测试
你知道该怎么做。这次确保重新发送一封新的确认邮件并测试链接。应该能行。
最后,如果给自己发几个确认链接会怎么样?每个都有效吗?测试一下。注册一个新用户,然后发送几封新的确认电子邮件。试着用第一封邮件确认。成功了吗?应该的。这样可以吗?如果有新的邮件发出,你认为其他的邮件应该过期吗?
在这方面做一些研究。并测试您使用的其他 web 应用程序。他们如何处理这种行为?
更新测试套件
好吧。这就是它的主要功能。不如我们更新一下当前的测试套件,因为它已经坏了。
运行测试:
$ python manage.py test您应该会看到以下错误:
TypeError: __init__() takes at least 4 arguments (3 given)要纠正这一点,我们只需要更新 project/util.py 中的
setUp()方法:def setUp(self): db.create_all() user = User(email="ad@min.com", password="admin_user", confirmed=False) db.session.add(user) db.session.commit()现在再做一次测试。都应该过去!
结论
显然,我们还可以做更多的事情:
- 富文本邮件和纯文本邮件——我们应该同时发送。
- 重置密码电子邮件-这些邮件应该发送给忘记密码的用户。
- 用户管理-我们应该允许用户更新他们的电子邮件和密码,当一个电子邮件被更改时,应该再次确认。
- 测试——我们需要编写更多的测试来覆盖新的特性。
从 Github 库下载完整的源代码。带着问题在下面评论。查看第二部。
节日快乐!******
使用 Angular 和 Flask 处理用户验证
原文:https://realpython.com/handling-user-authentication-with-angular-and-flask/
这篇文章为“我如何用 AngularJS 和 Flask 处理用户认证”这个问题提供了一个解决方案
更新:
在开始之前,请记住,这不是手头问题的唯一解决方案,甚至可能不是适合您情况的正确解决方案。无论您实施哪种解决方案,重要的是要注意到由于最终用户完全控制浏览器以及访问前端代码,因此存储在服务器端 API 中的敏感数据必须是安全的。换句话说,确保在服务器端实现身份验证策略,以保护敏感的 API 端点。
也就是说,我们需要启用以下工作流:
- 当客户端访问主路由时,会提供一个索引页面,此时 Angular 接管,处理客户端的所有路由。
- Angular 应用程序会立即“询问”服务器是否有用户登录。
- 假设服务器指示用户未登录,则客户端会立即被要求登录。
- 一旦登录,Angular 应用程序就会跟踪用户的登录状态。
开始使用
首先,从 repo 中获取样板代码,激活一个虚拟环境,并安装需求。
然后创建初始迁移:
$ python manage.py create_db $ python manage.py db init $ python manage.py db migrate测试应用:
$ python manage.py runserver导航到 http://localhost:5000/ ,您应该会看到一条简单的欢迎消息——“欢迎!”。欣赏完主页后,关闭服务器,浏览“项目”文件夹中的代码:
├── __init__.py ├── config.py ├── models.py └── static ├── app.js ├── index.html └── partials └── home.html没什么特别的。大部分后端代码/逻辑驻留在 init。py 文件,而 Angular 应用程序驻留在“静态”目录中。
关于这个结构的更多信息,请查看真正的 Python 课程。
构建登录 API
让我们从后端的 API 开始…
用户注册
更新 init 中的
register()函数。py :@app.route('/api/register', methods=['POST']) def register(): json_data = request.json user = User( email=json_data['email'], password=json_data['password'] ) try: db.session.add(user) db.session.commit() status = 'success' except: status = 'this user is already registered' db.session.close() return jsonify({'result': status})这里,我们将与 POST 请求(来自客户端)一起发送的有效负载设置为
json_data,然后用它来创建一个User实例。然后,我们尝试将用户添加到数据库中,并提交更改。如果成功,就添加了一个用户,然后我们通过带有“成功”的status的jsonify方法返回一个 JSON 响应。如果失败,会话将关闭,并发送错误响应“此用户已注册”。确保还添加了以下导入:
from flask import request, jsonify from project.models import User后一个导入必须在我们创建了
db实例之后导入——例如db = SQLAlchemy(app)——以避免循环依赖。让我们通过 curl 测试一下。启动服务器,然后在新的终端窗口中运行以下命令:
$ curl -H "Accept: application/json" \ -H "Content-type: application/json" -X POST \ -d '{"email": "test@test.com", "password": "test"}' \ http://localhost:5000/api/register您应该会看到一条成功消息:
{ "result": "success" }再试一次,您应该会看到一个错误:
{ "result": "this user is already registered" }最后,在 SQLite 数据库浏览器中打开数据库,确保用户确实插入了表中:
登录后…
用户登录
更新 init 中的
login()函数。py :@app.route('/api/login', methods=['POST']) def login(): json_data = request.json user = User.query.filter_by(email=json_data['email']).first() if user and bcrypt.check_password_hash( user.password, json_data['password']): session['logged_in'] = True status = True else: status = False return jsonify({'result': status})我们查询数据库,根据有效负载中发送的电子邮件查看用户是否存在,如果存在,则验证密码。将返回适当的响应。
确保更新导入:
from flask import Flask, request, jsonify, session在服务器运行的情况下,用 curl-再次测试
$ curl -H "Accept: application/json" \ -H "Content-type: application/json" -X POST \ -d '{"email": "test@test.com", "password": "test"}' \ http://localhost:5000/api/login-你应该看到:
{ "result": true }用 curl 再次测试,发送错误的用户凭证,您应该看到:
{ "result": false }完美!
用户注销
像这样更新
logout()函数,以便更新session:@app.route('/api/logout') def logout(): session.pop('logged_in', None) return jsonify({'result': 'success'})这应该很简单,您大概可以猜到对这个 curl 请求的响应——但是如果您愿意,可以再测试一次。完成后,让我们转向客户端!
开发角度应用程序
需要上一节的代码吗?从回购中抢过来。
现在,事情变得有点棘手了。同样,由于最终用户可以完全访问浏览器以及 DevTools 和客户端代码,所以不仅要限制对服务器端敏感端点的访问,而且不要在客户端存储敏感数据,这一点非常重要。当您向自己的应用程序堆栈添加身份验证功能时,请记住这一点。
让我们通过创建一个服务来处理认证。
认证服务
从这个服务的基本结构开始,将以下代码添加到“static”目录中一个名为 services.js 的新文件中:
angular.module('myApp').factory('AuthService', ['$q', '$timeout', '$http', function ($q, $timeout, $http) { // create user variable var user = null; // return available functions for use in controllers return ({ isLoggedIn: isLoggedIn, login: login, logout: logout, register: register }); }]);在这里,我们定义了服务名
AuthService,并注入了我们将要使用的依赖项——$q、$timeout、$http——然后返回了在服务外部使用的函数。确保将脚本添加到index.html文件中:
<script src="static/services.js" type="text/javascript"></script>让我们创建每个函数…
T2
isLoggedIn()function isLoggedIn() { if(user) { return true; } else { return false; } }如果
user的计算结果为true,这个函数将返回true,例如,一个用户已经登录,否则它将返回 false。T2
login()function login(email, password) { // create a new instance of deferred var deferred = $q.defer(); // send a post request to the server $http.post('/api/login', {email: email, password: password}) // handle success .success(function (data, status) { if(status === 200 && data.result){ user = true; deferred.resolve(); } else { user = false; deferred.reject(); } }) // handle error .error(function (data) { user = false; deferred.reject(); }); // return promise object return deferred.promise; }这里,我们使用了 [\(q](https://code.angularjs.org/1.4.10/docs/api/ng/service/\)q) 服务来建立一个承诺,我们将在未来的控制器中访问它。我们还利用了 [\(http](https://code.angularjs.org/1.4.10/docs/api/ng/service/\)http) 服务向已经在后端 Flask 应用程序中设置好的
/api/login端点发送 AJAX 请求。基于返回的响应,我们或者解析或者拒绝对象,并将
user的值设置为true或false。T2
logout()function logout() { // create a new instance of deferred var deferred = $q.defer(); // send a get request to the server $http.get('/api/logout') // handle success .success(function (data) { user = false; deferred.resolve(); }) // handle error .error(function (data) { user = false; deferred.reject(); }); // return promise object return deferred.promise; }这里,我们遵循了与
login()函数相同的公式,除了我们发送了 GET 请求而不是 POST,并且为了谨慎起见,如果用户不存在,我们没有发送错误,而是将用户注销。T2
register()function register(email, password) { // create a new instance of deferred var deferred = $q.defer(); // send a post request to the server $http.post('/api/register', {email: email, password: password}) // handle success .success(function (data, status) { if(status === 200 && data.result){ deferred.resolve(); } else { deferred.reject(); } }) // handle error .error(function (data) { deferred.reject(); }); // return promise object return deferred.promise; }同样,我们遵循类似于
logout()函数的公式。你能看出发生了什么吗?服务到此为止。请记住,我们仍然没有“使用”这项服务。为了做到这一点,我们只需要将其注入 Angular 应用程序中的必要组件。在我们的例子中,这将是控制器,每个控制器都与不同的路线相关联…
客户端路由
将客户端路线的剩余部分添加到 app.js 文件中:
myApp.config(function ($routeProvider) { $routeProvider .when('/', { templateUrl: 'static/partials/home.html' }) .when('/login', { templateUrl: 'static/partials/login.html', controller: 'loginController' }) .when('/logout', { controller: 'logoutController' }) .when('/register', { templateUrl: 'static/partials/register.html', controller: 'registerController' }) .when('/one', { template: '<h1>This is page one!</h1>' }) .when('/two', { template: '<h1>This is page two!</h1>' }) .otherwise({ redirectTo: '/' }); });在这里,我们创建了五条新路线。现在我们可以添加后续的模板和控制器。
模板和控制器
回顾我们的路线,我们需要设置两个部分/模板和三个控制器:
.when('/login', { templateUrl: 'static/partials/login.html', controller: 'loginController' }) .when('/logout', { controller: 'logoutController' }) .when('/register', { templateUrl: 'static/partials/register.html', controller: 'registerController' })登录
首先,将以下 HTML 添加到名为login.html的新文件中:
<div class="col-md-4"> <h1>Login</h1> <div ng-show="error" class="alert alert-danger">{{errorMessage}}</div> <form class="form" ng-submit="login()"> <div class="form-group"> <label>Email</label> <input type="text" class="form-control" name="email" ng-model="loginForm.email" required> </div> <div class="form-group"> <label>Password</label> <input type="password" class="form-control" name="password" ng-model="loginForm.password" required> </div> <div> </div> </form> </div>将该文件添加到“partials”目录中。
请注意表格。我们在每个输入上使用了 ng-model 指令,这样我们就可以在控制器中捕获这些值。同样,当提交表单时, ng-submit 指令通过触发
login()函数来处理事件。接下来,在“静态”文件夹中添加一个名为 controllers.js 的新文件。是的,这将持有我们所有的 Angular 应用程序的控制器。务必将脚本添加到 index.html 的文件中:
<script src="static/controllers.js" type="text/javascript"></script>现在,让我们添加第一个控制器:
angular.module('myApp').controller('loginController', ['$scope', '$location', 'AuthService', function ($scope, $location, AuthService) { $scope.login = function () { // initial values $scope.error = false; $scope.disabled = true; // call login from service AuthService.login($scope.loginForm.email, $scope.loginForm.password) // handle success .then(function () { $location.path('/'); $scope.disabled = false; $scope.loginForm = {}; }) // handle error .catch(function () { $scope.error = true; $scope.errorMessage = "Invalid username and/or password"; $scope.disabled = false; $scope.loginForm = {}; }); }; }]);因此,当触发
login()函数时,我们设置一些初始值,然后从AuthService调用login(),传递用户输入的电子邮件和密码作为参数。然后处理后续的成功或错误,并适当地更新 DOM/视图/模板。准备好测试第一次往返了吗- 客户端到服务器,然后再回到客户端?
启动服务器,在浏览器中导航到http://localhost:5000/#/log in。首先,尝试使用之前注册时使用的用户凭证登录——例如,
test@test.com和test。如果一切顺利,您应该会被重定向到主 URL。接下来,尝试使用无效凭证登录。您应该会看到错误信息闪烁,“无效的用户名和/或密码”。注销
添加控制器:
angular.module('myApp').controller('logoutController', ['$scope', '$location', 'AuthService', function ($scope, $location, AuthService) { $scope.logout = function () { // call logout from service AuthService.logout() .then(function () { $location.path('/login'); }); }; }]);在这里,我们调用了
AuthService.logout(),然后在承诺解决后将用户重定向到/login路由。给home.html添加一个按钮:
<div ng-controller="logoutController"> <a ng-click='logout()' class="btn btn-default">Logout</a> </div>然后再测试一次。
寄存器
将名为register.html的新文件添加到“partials”文件夹中,并添加以下 HTML:
<div class="col-md-4"> <h1>Register</h1> <div ng-show="error" class="alert alert-danger">{{errorMessage}}</div> <form class="form" ng-submit="register()"> <div class="form-group"> <label>Email</label> <input type="text" class="form-control" name="email" ng-model="registerForm.email" required> </div> <div class="form-group"> <label>Password</label> <input type="password" class="form-control" name="password" ng-model="registerForm.password" required> </div> <div> </div> </form> </div>接下来,添加控制器:
angular.module('myApp').controller('registerController', ['$scope', '$location', 'AuthService', function ($scope, $location, AuthService) { $scope.register = function () { // initial values $scope.error = false; $scope.disabled = true; // call register from service AuthService.register($scope.registerForm.email, $scope.registerForm.password) // handle success .then(function () { $location.path('/login'); $scope.disabled = false; $scope.registerForm = {}; }) // handle error .catch(function () { $scope.error = true; $scope.errorMessage = "Something went wrong!"; $scope.disabled = false; $scope.registerForm = {}; }); }; }]);您以前已经见过这种情况,所以让我们直接进入测试。
启动服务器,在http://localhost:5000/#/register注册一个新用户。请确保使用该新用户进行登录测试。
好了,这就是模板和控制器。我们现在需要添加功能来检查用户是否在每次更改路线时登录。
路线变更
将以下代码添加到 app.js 中:
myApp.run(function ($rootScope, $location, $route, AuthService) { $rootScope.$on('$routeChangeStart', function (event, next, current) { if (AuthService.isLoggedIn() === false) { $location.path('/login'); $route.reload(); } }); });[\(routeChangeStart](https://code.angularjs.org/1.4.10/docs/api/ngRoute/service/\)route) 事件发生在实际的路由更改发生之前。因此,无论何时访问路由,在提供视图之前,我们都要确保用户已经登录。测试一下!
保护某些路线
现在,所有客户端路由都需要用户登录。如果您希望限制某些路线,而开放其他路线,该怎么办?您可以向每个路由处理程序添加以下代码,对于您不想限制的路由,用
false替换true:access: {restricted: true}在我们的例子中,像这样更新路由:
myApp.config(function ($routeProvider) { $routeProvider .when('/', { templateUrl: 'static/partials/home.html', access: {restricted: true} }) .when('/login', { templateUrl: 'static/partials/login.html', controller: 'loginController', access: {restricted: false} }) .when('/logout', { controller: 'logoutController', access: {restricted: true} }) .when('/register', { templateUrl: 'static/partials/register.html', controller: 'registerController', access: {restricted: false} }) .when('/one', { template: '<h1>This is page one!</h1>', access: {restricted: true} }) .when('/two', { template: '<h1>This is page two!</h1>', access: {restricted: false} }) .otherwise({ redirectTo: '/' }); });现在只需更新 main.js 中的
$routeChangeStart代码:myApp.run(function ($rootScope, $location, $route, AuthService) { $rootScope.$on('$routeChangeStart', function (event, next, current) { if (next.access.restricted && AuthService.isLoggedIn() === false) { $location.path('/login'); $route.reload(); } }); });测试每条路线!
持续登录
最后,页面刷新时会发生什么?试试看。
用户已注销,对吗?为什么?因为控制器和服务被再次调用,将
user变量设置为null。这是一个问题,因为用户仍然在客户端登录。幸运的是,修复很简单:在
$routeChangeStart中,我们需要始终检查用户是否登录。现在,它正在检查isLoggedIn()是否是false。让我们添加一个新函数getUserStatus(),它在后端检查用户状态:function getUserStatus() { return $http.get('/api/status') // handle success .success(function (data) { if(data.status){ user = true; } else { user = false; } }) // handle error .error(function (data) { user = false; }); }确保也返回该函数:
return ({ isLoggedIn: isLoggedIn, login: login, logout: logout, register: register, getUserStatus: getUserStatus });然后在客户端添加路由处理程序:
@app.route('/api/status') def status(): if session.get('logged_in'): if session['logged_in']: return jsonify({'status': True}) else: return jsonify({'status': False})最后,更新
$routeChangeStart:myApp.run(function ($rootScope, $location, $route, AuthService) { $rootScope.$on('$routeChangeStart', function (event, next, current) { AuthService.getUserStatus() .then(function(){ if (next.access.restricted && !AuthService.isLoggedIn()){ $location.path('/login'); $route.reload(); } }); }); });试试吧!
结论
就是这样。有问题吗?下面评论。
您应该注意的一点是,只要在 AJAX 请求中正确设置了端点,Angular 应用程序就可以用于各种框架。因此,你可以很容易地把角的部分添加到你的 Django 或 Pyramid 或 NodeJS 应用程序中。试试看!
从回购中抓取最终代码。干杯!*****
用 Python 和 PhantomJS 进行无头 Selenium 测试
原文:https://realpython.com/headless-selenium-testing-with-python-and-phantomjs/
PhantomJS 是一个无头的 Webkit ,它有很多用途。在本例中,我们将结合 Selenium WebDriver 使用它,直接从命令行进行基本的系统测试。由于 PhantomJS 消除了对图形浏览器的需求,测试运行得更快。
点击此处观看附带视频。
设置
用 Pip 安装 Selenium,用自制软件安装 PhantomJS:
$ pip install selenium $ brew install phantomjs用 Brew 安装 PhantomJS 有问题吗?在这里获取最新版本。
示例
现在让我们看两个简单的例子。
DuckDuckGo
在第一个示例中,我们将在 DuckDuckGo 中搜索关键字“realpython ”,以找到搜索结果的 URL。
from selenium import webdriver driver = webdriver.PhantomJS() driver.set_window_size(1120, 550) driver.get("https://duckduckgo.com/") driver.find_element_by_id('search_form_input_homepage').send_keys("realpython") driver.find_element_by_id("search_button_homepage").click() print(driver.current_url) driver.quit()您可以在终端中看到输出的 URL。
下面是用 Firefox 显示结果的例子。
from selenium import webdriver driver = webdriver.Firefox() driver.get("https://duckduckgo.com/") driver.find_element_by_id('search_form_input_homepage').send_keys("realpython") driver.find_element_by_id("search_button_homepage").click() driver.quit()你有没有注意到我们不得不在幻影脚本上创建一个虚拟的浏览器尺寸?这是目前在 Github 中存在的一个问题的解决方法。尝试没有它的脚本:您将得到一个
ElementNotVisibleException异常。现在我们可以编写一个快速测试来断言搜索结果显示的 URL 是正确的。
import unittest from selenium import webdriver class TestOne(unittest.TestCase): def setUp(self): self.driver = webdriver.PhantomJS() self.driver.set_window_size(1120, 550) def test_url(self): self.driver.get("http://duckduckgo.com/") self.driver.find_element_by_id( 'search_form_input_homepage').send_keys("realpython") self.driver.find_element_by_id("search_button_homepage").click() self.assertIn( "https://duckduckgo.com/?q=realpython", self.driver.current_url ) def tearDown(self): self.driver.quit() if __name__ == '__main__': unittest.main()测试通过了。
real ython . com
最后,让我们看一个我每天运行的真实世界的例子。导航到RealPython.com,我会告诉你我们将测试什么。本质上,我想确保底部的“立即下载”按钮有正确的相关产品。
下面是基本的单元测试:
import unittest from selenium import webdriver class TestTwo(unittest.TestCase): def setUp(self): self.driver = webdriver.PhantomJS() def test_url(self): self.driver.get("https://app.simplegoods.co/i/IQCZADOY") # url associated with button click button = self.driver.find_element_by_id("payment-submit").get_attribute("value") self.assertEquals(u'Pay - $60.00', button) def tearDown(self): self.driver.quit() if __name__ == '__main__': unittest.main()基准测试
与浏览器相比,使用幻想曲的一个主要优势是测试通常要快得多。在下一个例子中,我们将使用 PhantomJS 和 Firefox 对之前的测试进行基准测试。
import unittest from selenium import webdriver import time class TestThree(unittest.TestCase): def setUp(self): self.startTime = time.time() def test_url_fire(self): time.sleep(2) self.driver = webdriver.Firefox() self.driver.get("https://app.simplegoods.co/i/IQCZADOY") # url associated with button click button = self.driver.find_element_by_id("payment-submit").get_attribute("value") self.assertEquals(u'Pay - $60.00', button) def test_url_phantom(self): time.sleep(1) self.driver = webdriver.PhantomJS() self.driver.get("https://app.simplegoods.co/i/IQCZADOY") # url associated with button click button = self.driver.find_element_by_id("payment-submit").get_attribute("value") self.assertEquals(u'Pay - $60.00', button) def tearDown(self): t = time.time() - self.startTime print("%s: %.3f" % (self.id(), t)) self.driver.quit() if __name__ == '__main__': suite = unittest.TestLoader().loadTestsFromTestCase(TestThree) unittest.TextTestRunner(verbosity=0).run(suite)你可以看到幻想曲有多快:
$ python test.py -v __main__.TestThree.test_url_fire: 19.801 __main__.TestThree.test_url_phantom: 10.676 ---------------------------------------------------------------------- Ran 2 tests in 30.683s OK视频
注意:尽管这个视频已经过时了(由于脚本的改变),但它仍然值得一看,因为为你的网站实现无头系统测试的基本方法基本上保持不变。
学习 Python 需要多长时间?
原文:https://realpython.com/how-long-does-it-take-to-learn-python/
你可能已经找到了至少一篇博客文章,作者透露他们在几天内学会了 Python,并很快过渡到一份高薪工作。这些故事中有些可能是真的,但它们并不能帮助你为一场稳定的学习马拉松做好准备。那么,学习 Python真的需要多长时间,值得你的时间投入吗?
在这篇文章中,你将了解到:
- “学习 Python”意味着什么,以及如何衡量自己的进步
- 学习 Python 有哪些不同的原因
- 哪些背景因素影响你的学习方法和结果
- 在不同的技能水平下,你想要投入多少时间来学习 Python
- 哪些资源可以用来改善你的学习过程
首先,您将了解人们想学习 Python 编程的一些不同原因。记住你的个人动机,并确定你的位置。你学习 Python 的原因将影响你的方法和你需要留出的时间。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
你为什么要学 Python?
你可能完全是编程新手,还在犹豫是否应该花时间学习 Python。在第一部分,您将考虑人们想要学习这种编程语言的不同原因。记下你最认同的一个:
职业和工作机会:也许你想开始一份软件开发员的新工作。也许你想继续在目前的公司工作,并过渡到一个更具技术性的角色,如数据分析。精通编程是对你已有技能的极好补充。一旦你掌握了你需要的 Python 技能,你就可以通过你的 Python 编码面试来获得你梦想中的工作。
自动化: Python 可以帮助你自动化你在工作和私人生活中经常做的重复性工作。你可以学习用 Excel 电子表格、来自动化你的工作,构建一个网络抓取器来访问互联网上的公共数据,创建命令行界面,或者为 Twitter 或 Discord 构建机器人来减轻你的负担。
好奇心:数码产品无处不在,你可能日常都会用到。你可能想知道你的数字温度计是如何工作的,一个受欢迎的网站是如何建立的,或者你最喜欢的电脑游戏如果用数字方式拆开会是什么样子。
创意:你可能对自己的游戏有一些奇妙的想法,你可以用街机、 Pygame 或另一个游戏引擎来构建它们。或者你可能想从用于家庭自动化、物联网(IoT)的编程硬件或嵌入式游戏开发开始。
所有这些都是进入编程的好理由!你开始这段旅程的个人动机将影响你学习 Python 的速度和深度。它还会影响语言的哪些方面需要你的关注。如果你正在寻找解决问题的灵感,那么你可以阅读一下你可以用 Python 做什么。
“学习 Python”是什么意思?
学习 Python 不仅仅意味着学习 Python 编程语言。你需要知道的不仅仅是一门编程语言的细节,这样才能用你的编程技能做一些有用的事情。同时,你不需要理解 Python 的每一个方面来提高效率。
学习 Python 就是学习如何用 Python 编程完成实际任务。这是一套你可以用来为自己或雇主构建项目的技能。
如何衡量自己的学习进度?
通常很难说在什么时候你已经完全学到了一些东西。知道 Python 的语法就知道 Python 了吗?当你知道如何使用一个流行的库而不用在网上查找时,你学会了吗?还是需要了解 Python 生态系统的所有来龙去脉,才能说自己学过 Python?
实际上,您可能永远也学不会关于 Python 生态系统的所有知识。要知道的太多了!因此,将你的旅程分成不同的部分是有帮助的。这种方法让你更容易朝着正确的方向前进。
当您考虑不同的技能水平时,您可能会想到三个传统类别:
- 新手
- 中间的
- 专家
然而,很难定义什么时候某人不再是初学者,即使是有经验的程序员也往往不认为自己是专家。另一方面,一些能力低下的程序员可能认为自己是专家,这种认知偏差被称为邓宁-克鲁格效应。记住这一点,按照这种传统的分类来规划你的进步可能对你没什么用。
能力的四个阶段
相反,你将使用一个不同的框架来评估你的学习进度,该框架遵循能力的四个阶段:
为了使能力的四个阶段更容易理解,您将看到以下简称来指代四个阶段中的每一个:
- 不知情为无意识的无能
- 觉悟为自觉无能
- 能力为意识能力
- 专长为无意识能力
您可以在本节中进一步了解每个阶段的含义。当您在本文后面了解学习 Python 的时间估计时,您将使用能力的四个阶段作为框架。但是有一个转折!你将把你的注意力转移到发生在不同阶段之间的学习过程中,并专注于把你从一个阶段带到下一个阶段的思维转变。您将了解如何从:
你会发现,四个能力阶段的每一个都涵盖了与经典的初级-中级-专家模式相似的领域。然而,这种替代框架使你更容易找到你现在的进展,这可以给你提供关于如何从无知走向专业的可操作的洞察力:
为了确定你何时从一个阶段进入下一个阶段,你应该主要依靠你对自己进步的自我评估。时间估计可以在这方面支持你,但是你不应该把它们作为严格的规则。许多因素影响着每个人的学习进度,在本文的部分,你将会看到其中的一些因素。
为了稍微改进时间估计,你会发现一个额外的基于你已经完成的项目数量的进度测量方法。试着结合你花费的时间和完成的项目数量来评估你从一个学习阶段到下一个学习阶段的进展。
请记住,这些只是估计。你可能会看到自己比描述的走得更快或更慢。作为你最终的自我评估,专注于记录你思想状态的转变,这可以表明从一个阶段到另一个阶段的转换。最后,重要的是你要继续做项目,记录你的进展,并在做的时候享受其中。你会看到你的技能随着时间而增长。
第一阶段:无意识的无能(无意识)
对于每一项对你来说新的技能,你都将从无意识的无能阶段开始。这个词听起来可能不太令人鼓舞。然而,一旦你阅读了维基百科对这个阶段的定义,你会发现这只是一个描述熟悉的精神状态的实用术语:
个人不理解或不知道如何做某事,也不一定认识到不足。他们可能会否认技能的有用性。在进入下一阶段之前,个人必须认识到自己的无能和新技能的价值。一个人在这个阶段花费的时间长短取决于学习刺激的强度。(来源)
你不知道你不知道什么。如果你不接受你不知道的事实,你就不会学到东西,你也可能不会理解你不想学的东西。
从这第一阶段毕业可能只需要几分钟。然而,这是学习任何新东西的关键一步,而且经常得不到足够的重视。
阶段 2:有意识的无能(觉知)
一旦你意识到 Python 是一种你想了解更多的编程语言,你的积极时间投入就开始了。在这一点上,你处于有意识的无能阶段:
虽然个人不理解或不知道如何做某事,但他们认识到不足,以及解决不足的新技能的价值。在这个阶段,犯错是学习过程中不可或缺的一部分。(来源)
通过这个阶段需要时间和努力。这种投资是人们在谈论学习新东西时经常想到的。
第三阶段:自觉能力
如果你认为你已经成功地从能力的四个阶段中的前一个阶段毕业,那么你已经达到了有意识的能力:
个人理解或知道如何做某事。然而,展示技能或知识需要专注。它可以被分解成几个步骤,并且在执行新技能的过程中需要大量的有意识的参与。(来源)
在这个阶段,您将具备 Python 的工作能力,这可能已经足够满足您的需求了。您可以应用编程知识来改进当前工作的工作流程,或者构建自己的项目。你可能有足够的 Python 知识来获得软件开发人员的初级职位。虽然用 Python 编程仍然需要你付出很多有意识的努力,但你可以让事情运转起来。
然而,在这个阶段,你没有足够的练习来达到流利和熟练。转移到 Python 的无意识能力将需要你更多的时间和努力。
第四阶段:无意识能力(专长)
一旦你达到了无意识能力,你就能毫不费力地使用你的工具。在这个阶段,你可以像一个伟大的音乐家使用他们的乐器一样使用 Python。一个熟练的吉他手不会专注于握吉他,而是专注于他们创作的音乐。他们可以准确而有趣地使用他们的乐器。
一旦你能把你正在使用的工具移到背景中,并且意识到你的注意力主要集中在创造上,你就获得了无意识的能力:
个人对一项技能有太多的练习,以至于它已经成为“第二天性”,可以很容易地完成。因此,该技能可以在执行另一个任务时执行。个人也许能够把它教给其他人,这取决于如何以及何时学会它。(来源)
真正的 Python 编程专业知识可能会让你觉得离你现在的位置很远。那完全正常,没问题!没有音乐家一开始是乐器的专家。专业知识需要多年的持续训练。甚至一旦他们在一个主题上达到专业水平,许多人会回到四个能力阶段的前一个阶段去发展他们在另一个领域的技能。
当一些程序员谈论他们如何从未停止学习时,他们描述的是他们在工作的一个领域从能力到专业知识的进步。虽然您可能最终在使用 Python 的一个领域获得了专业知识,但是在更多的领域,您将继续工作,并从能力上慢慢进步。
哪些因素影响你的学习之旅?
现在你知道了如何将你的学习路径分成不同的步骤,你可能想知道你在这四个阶段之间移动的具体时间。你可以在下面找到一些时间估计,但是记住学习是一个个人的过程。多种因素决定了学习 Python 需要花费你多少时间和精力。以下是一些需要考虑的个别因素:
背景:你以前有什么经验?如果你英语很好,如果你以前用另一种语言编程过,或者如果你有数理逻辑和语言学习的经验,那么你可能会进步得更快。
动机:你想用 Python 做什么,有多迫切想学?如果你有一个明确的目标,比如一个你想要解决的特定挑战,那么保持专注和动力会更简单,你可能会进步得更快。
目标:你的目标是什么技能水平,学习 Python 希望达到什么目标?假设你计划获得一份 Python 开发人员的全职工作。如果你打算把完成一个个人项目作为业余爱好,你可能需要更深入地钻研这门语言的更多方面。
可用性:学习 Python 可以投入多少时间?你是学生还是在待业中?你能每天花大量时间学习编程吗?你有全职工作吗,意味着你只能在工作之外学习吗?你照顾小孩或其他人吗?如果你有更多的时间投资,那么你会进步得更快。
导师:你有可以教你的人吗?和一个知识渊博的朋友或导师在一起,你会学得更快,他们自己也经历过这个过程,并愿意和你分享他们的知识。你可以从工作场所或网上的专职导师那里获得指导支持。如果你心中没有导师,试着加入一个学习社区。
学习资源:你能获得优质的学习资源吗?他们可以帮助你决定先学什么以及如何继续。如果你的学习资源有很高的教学质量和准确性,那么你会更快地学到正确的东西。
这个列表并不详尽,可能还有其他因素会影响你的学习之旅。然而,如果你彻底考虑了这些额外的因素,并考虑了你的个人情况,你就能更好地准确评估你需要的时间。
学习 Python 需要多长时间?
你现在知道了“学习 Python”意味着什么以及你可以使用什么样的学习框架来将学习过程分成几个阶段。你还了解了影响你学习旅程的背景因素。在本节中,您将熟悉一些指导原则,这些原则可以帮助您计划在不同的技能水平下学习 Python 需要多长时间。
从无意识到有意识
要从无意识步入有意识,你需要接受你还不了解 Python,并且你希望 T1 了解它。您需要准备好投入时间和精力来研究 Python 生态系统:
目标 接受你不知道 Python 并且你想学习它的事实 时间要求 可能几秒或几分钟 工作量 共同的好奇心 好消息是你已经迈出了这一步。你已经知道 Python 的存在,并且你想投资学习它,你也知道为什么你应该学习 Python 。因此,你很可能会发现自己在四个能力阶段的下一步中处于某个位置。
从意识到能力
要从意识到能力,你需要学习在线教程和课程,理解许多新概念,并向自己介绍编程世界和 Python 生态系统。这包括思考、阅读、倾听、构建、创造,通常还包括在没有多少直接回报的情况下,在键盘上辛勤地敲打。培养您的 Python 能力需要决心和专注。
然而,Python 可以帮助你相对快速地上手,因为它是一种初学者友好的语言,读起来与英语相似。如果你精通英语,你可以在几天内开始编写基本的 Python 代码逻辑。
您不会在短短几天内构建成熟的程序,但是您可能能够运行您自己编写的小脚本。然而此时你还没到能力的阶段。为此,您需要至少理解以下 Python 编程概念:
- Python 的语法
- 数据类型
- 流控制结构,如
for循环、while循环和条件语句- 功能和范围
- 装饰器、生成器和迭代器
- 类和面向对象编程
- 编写 Pythonic 代码的最佳实践
- 标准库中的热门包,比如
pathlib和collections如果你想构建功能性程序或申请工作,你需要学习的不仅仅是 Python。您需要了解一些基本的软件开发原则,以及如何在 Python 中使用它们。
您应该知道如何:
- 设置您的 Python 开发环境
- 管理 Python 依赖关系
- 调试您的代码以查找并修复错误
- 写入并处理异常
- 测试您的 Python 应用
- 了解模块和包以及如何在 Python 广泛的第三方生态系统中使用流行包
处理所有这些主题和理解这些概念需要大量的培训和时间投入。确切的数字很难说,每个人都不一样。作为一个指导方针,你可以在大约四个月的时间里每天至少四个小时的持续专注学习中达到目标:
目标 学习 Python 的语法和基本的编程和软件开发概念 时间要求 大约四个月,每天四小时 工作量 大约十个大型项目 从学习 Python 的语法和基本编程概念开始,然后专注于解决挑战所需的特定库。有一个特定的任务要处理可以帮助你保持你的方向,始终如一地实践你正在学习的东西,并且更快地从意识走向 Python 能力。
如果你在网上看到有人很快就学会了 Python,那么他们很可能是在说这个阶段。根据您之前的经验,您可以相对较快地学习足够多的 Python,从而具备使用该语言的能力。获得这种能力后,您将进入下一个阶段,这是大多数程序员花费大部分时间的地方。
从能力到专长
从能力到专业知识的转变需要大量的时间和实践,成为“Python 专家”的想法有点误导。你可能永远不会成为 Python 的所有专家,这没关系!大多数经验丰富的 Python 开发人员只是特定领域的专家:
这个列表并不详尽,对于每个领域,都有很多东西需要学习。你从能力到专业知识的进展在每个领域都是不同的。你可以成为其中任何一个主题的专家,但在另一个领域却完全是个初学者。
不断练习你所选领域需要的库和概念,可以让你成为那个领域的专家。
举例来说,Django 专家对框架的熟练程度足以编写应用程序,而不需要查阅文档,或者他们可能只需要搜索特定的主题。其他领域也是如此。
这种流利程度的编码需要大量的练习。通过练习,这种技能会成为你的第二天性,而你正在使用的 Python 语法、代码逻辑和库将会退居幕后。一旦你到了那里,你就可以把你的认知努力集中在解决手头的问题上,而不需要考虑你用来解决问题的工具。
坚持练习你最感兴趣的东西,训练你认为对你的任务最有帮助的编程概念和 Python 库。采取一种心态,朝着使用 Python 的一个领域的专业方向努力,并接受永远有更多东西需要学习的想法:
目标 在使用 Python 的一个领域变得非常擅长 时间要求 多年的持续实践 工作量 大约二十个大型项目 学习 Python 时,您的学习之旅永无止境。你可能想在能力的四个阶段中的这个阶段让自己感到舒服,因为你可能会在这里花很多时间。
哪些资源可以帮助你更快的学习 Python?
一旦你知道你为什么要学习 Python,你的目标是什么技能水平,以及如何考虑你的个人背景,那么你就可以考虑让你的学习过程更有趣、更有效。
好消息是你有很多可以利用的帮助!下面,你会发现一个你可以尝试的学习辅助工具的列表:
学习资源:你可以从网上学习内容,包括教程、视频课程、测验和项目。如果你心中有一个特定的项目,你可以找到现有的教程,或者如果你遵循一个关于你感兴趣的主题的学习路径,那么在线内容是最有帮助的。你会找到标有基础、中级和高级的真实 Python 内容,帮助你找到适合你技能水平的最佳学习资源。
书籍:有许多伟大的 Python 书籍可以帮助你学习不同深度和复杂程度的语言。如果你刚刚开始,看看 Python 基础书籍。如果你已经在编写 Python 程序并希望提高你的语言技能,那么你可能会喜欢上 Python 技巧。
挑战:你可能喜欢用代码示例挑战自己,并在排行榜上竞争。在 CodingBat 、 HackerRank 、 LeetCode 或coding game完成谜题并继续训练你的编码技能。另一个伟大的发现是代码的出现,真正的 Python 有一个指南,让解决你的谜题快乐而明亮。
社区:许多人在社会交往中学习得更好。一个好的学习社区可以让你保持参与和负责。你可以在 真实蟒蛇 或蟒蛇加入一个友好的专家社区。你也可以在 Twitter 上关注 Real Python ,利用平台与其他开发者保持联系。收听真正的 Python 播客并注册时事通讯,让自己了解 Python 世界的最新发展。
所有这些不同类型的资源都可以在网上找到。花些时间挑选对你个人来说最有吸引力和最有效的是值得的。也就是说,在学习任何新东西时,有两个基本因素是不可回避的:
- 时间投资
- 一贯的做法
最重要的方面是不断出现,并使编程成为一致的例行程序的一部分。学习任何水平的 Python,你都需要投入时间和精力。
结论
您了解了学习 Python 的不同阶段。你考虑了你想学习编程的原因,以及在这个过程中你可能会经历哪些阶段。
虽然你只需学习几天就可以开始用 Python 编写小脚本,但你可能要花大约四个月的时间来获得用 Python 编程的基本能力。你将不得不花费数年时间和构建许多项目来成为哪怕只是一个领域的 Python 专家。
在本文中,您学习了:
- “学习 Python”意味着什么,以及如何衡量自己的进步
- 学习 Python 有哪些不同的原因
- 哪些外部因素影响你学习 Python 的速度
- 为什么在不同的技能等级学习 Python 需要不同的时间和精力
- 哪些资源可以用来改善你的学习过程
学习 Python 编程是对你时间的一项极好的投资。如果你不断出现,让自己感到兴奋和有趣,那么你就更有可能找到将它融入你的常规习惯的方法。如果你正在寻找更多关于你的第一步的建议,看看 11 个学习 Python 编程的初学者技巧。****
如何实现 Python 堆栈
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 如何实现一个 Python 栈
你听说过 stacks,想知道它们是什么吗?你有一个大概的想法,但是想知道如何实现一个 Python 堆栈?你来对地方了!
在本教程中,您将学习:
- 如何识别栈何时是数据结构的好选择
- 如何决定哪个实现最适合您的程序
- 在线程或多处理环境中,对于堆栈有什么额外的考虑
本教程是为那些擅长运行脚本,知道什么是
list以及如何使用它,并且想知道如何实现 Python 栈的 Python 爱好者准备的。免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
什么是堆栈?
一个栈是一个数据结构,以后进先出的方式存储项目。这通常被称为后进先出法。这与以先进先出(FIFO)方式存储项目的队列形成对比。
如果你想到一个你可能很熟悉的用例:你的编辑器中的撤销特性,那么理解一个栈可能是最容易的。
让我们假设您正在编辑一个 Python 文件,这样我们就可以看到您执行的一些操作。首先,添加一个新函数。这将向撤消堆栈添加一个新项:
您可以看到堆栈现在有一个 Add Function 操作。添加函数后,您从注释中删除一个单词。这也被添加到撤消堆栈中:
注意 Delete Word 项是如何放在栈顶的。最后,你缩进一个注释,使它正确地排列起来:
您可以看到,这些命令都存储在一个撤销堆栈中,每个新命令都放在顶部。当你使用堆栈时,像这样添加新的项目被称为
push。现在您已经决定撤销所有这三个更改,所以您点击了撤销命令。它获取堆栈顶部的项目,该项目缩进注释,并将其从堆栈中移除:
您的编辑器撤消了缩进,撤消堆栈现在包含两项。该操作与
push相反,通常称为pop。当您再次点击 undo 时,下一项将弹出堆栈:
这移除了删除字项,在堆栈上只留下一个操作。
最后,如果你第三次点击撤销,那么最后一个项目将弹出堆栈:
撤消堆栈现在是空的。之后再次点击撤销将不会有任何效果,因为你的撤销堆栈是空的,至少在大多数编辑器中是这样。在下面的实现描述中,您将看到当您在空堆栈上调用
.pop()时会发生什么。实现 Python 堆栈
在实现 Python 堆栈时,有几个选项。这篇文章不会涵盖所有的,只是基本的,将满足您几乎所有的需求。您将专注于使用属于 Python 库的数据结构,而不是自己编写或使用第三方包。
您将看到以下 Python 堆栈实现:
listcollections.dequequeue.LifoQueue使用
list创建一个 Python 栈您可能在程序中经常使用的内置
list结构可以用作堆栈。代替.push(),你可以使用.append()来添加新元素到你的栈顶,而.pop()以 LIFO 顺序移除元素:
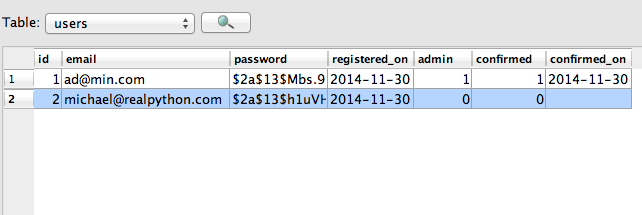
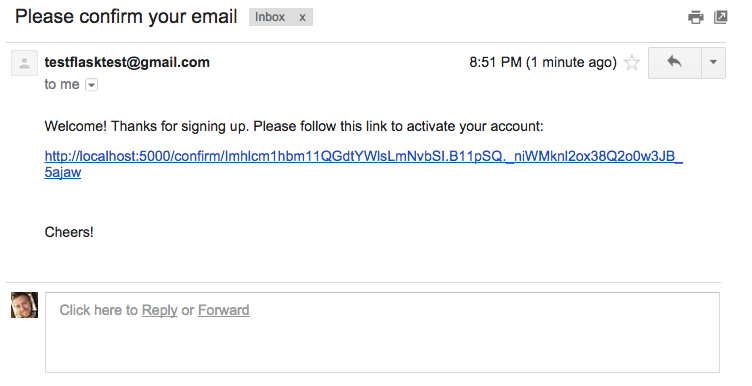
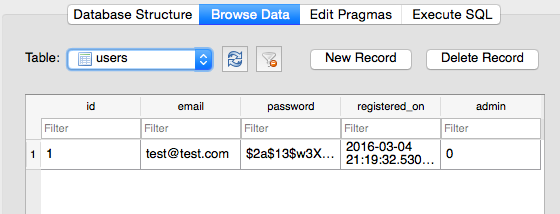


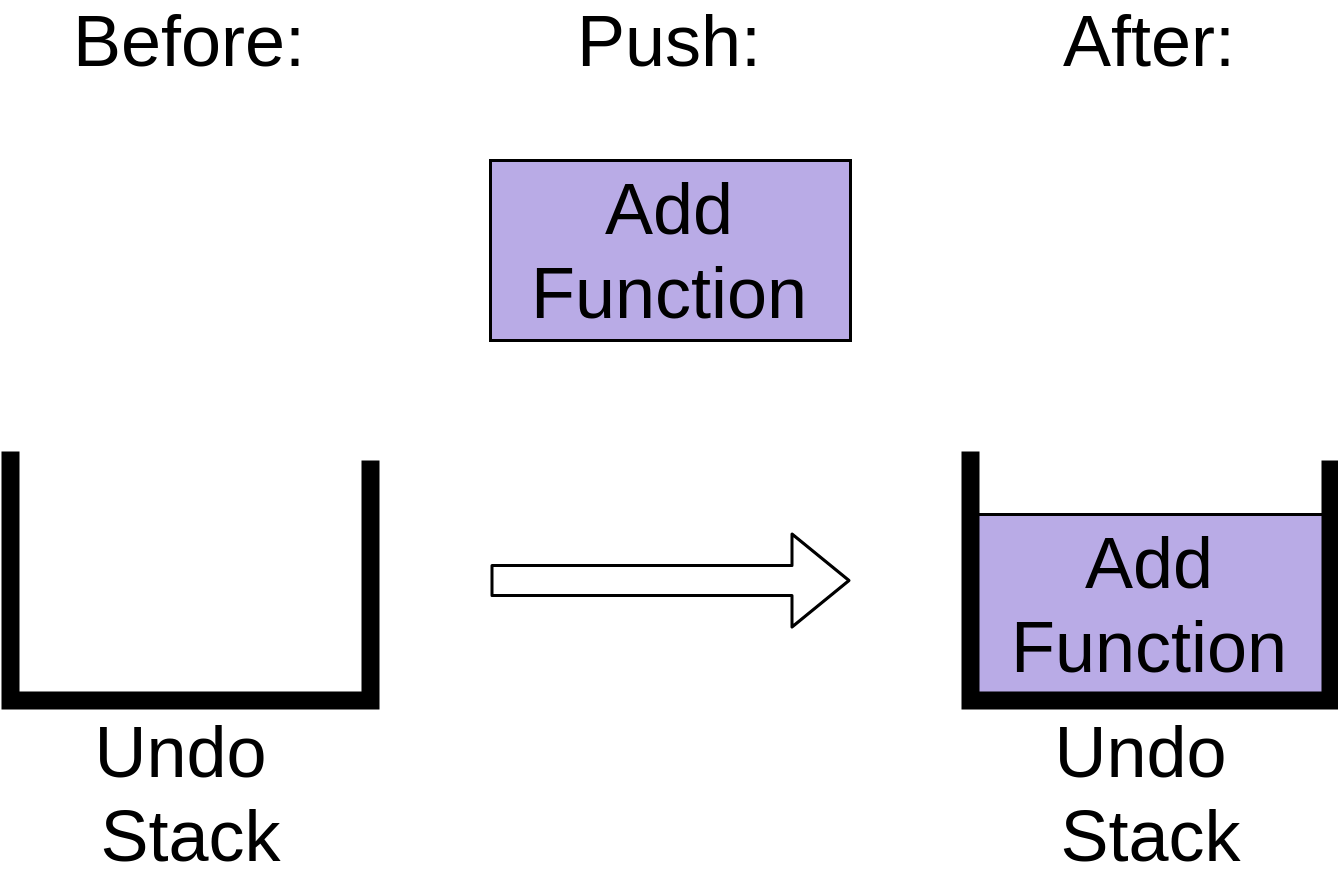
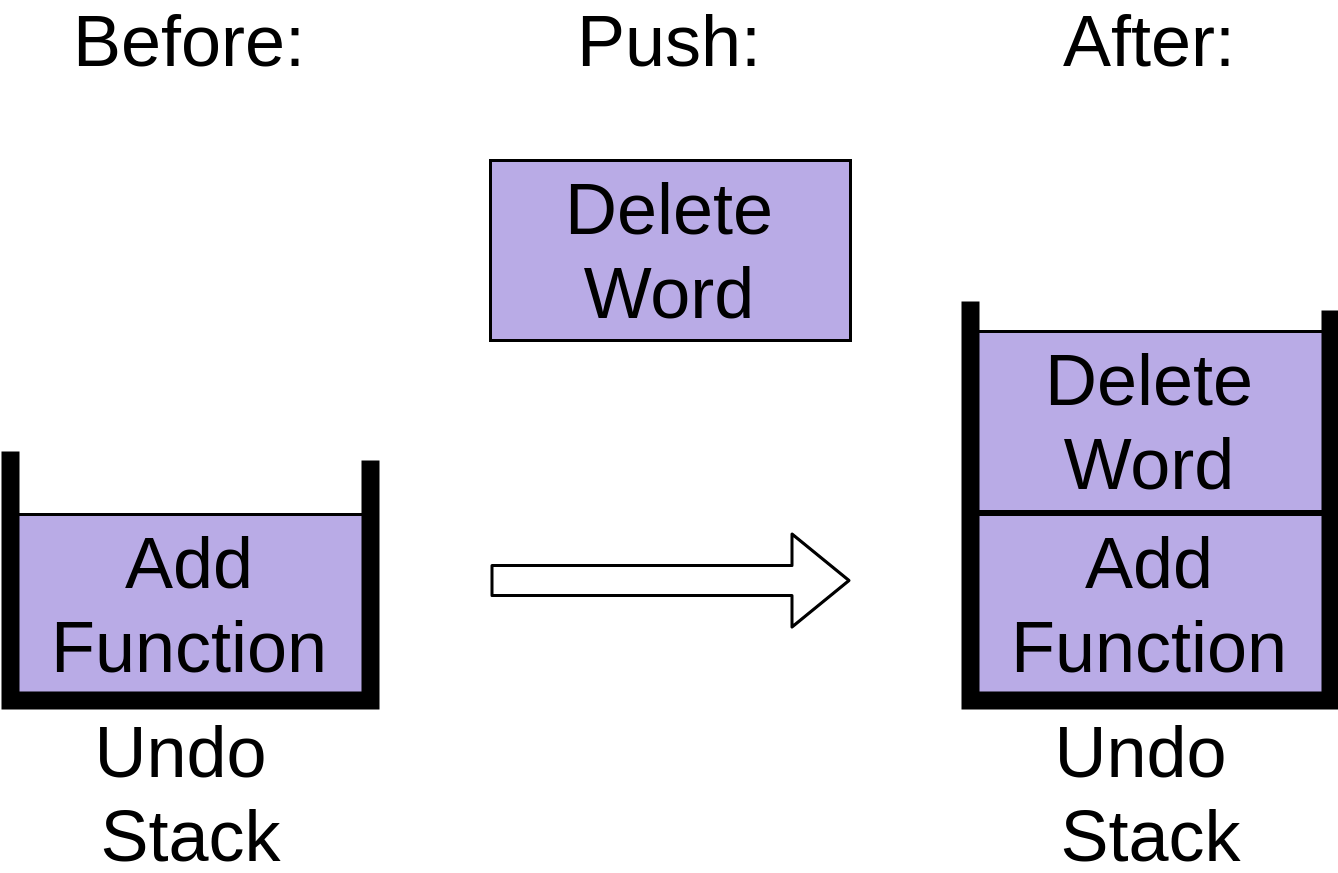
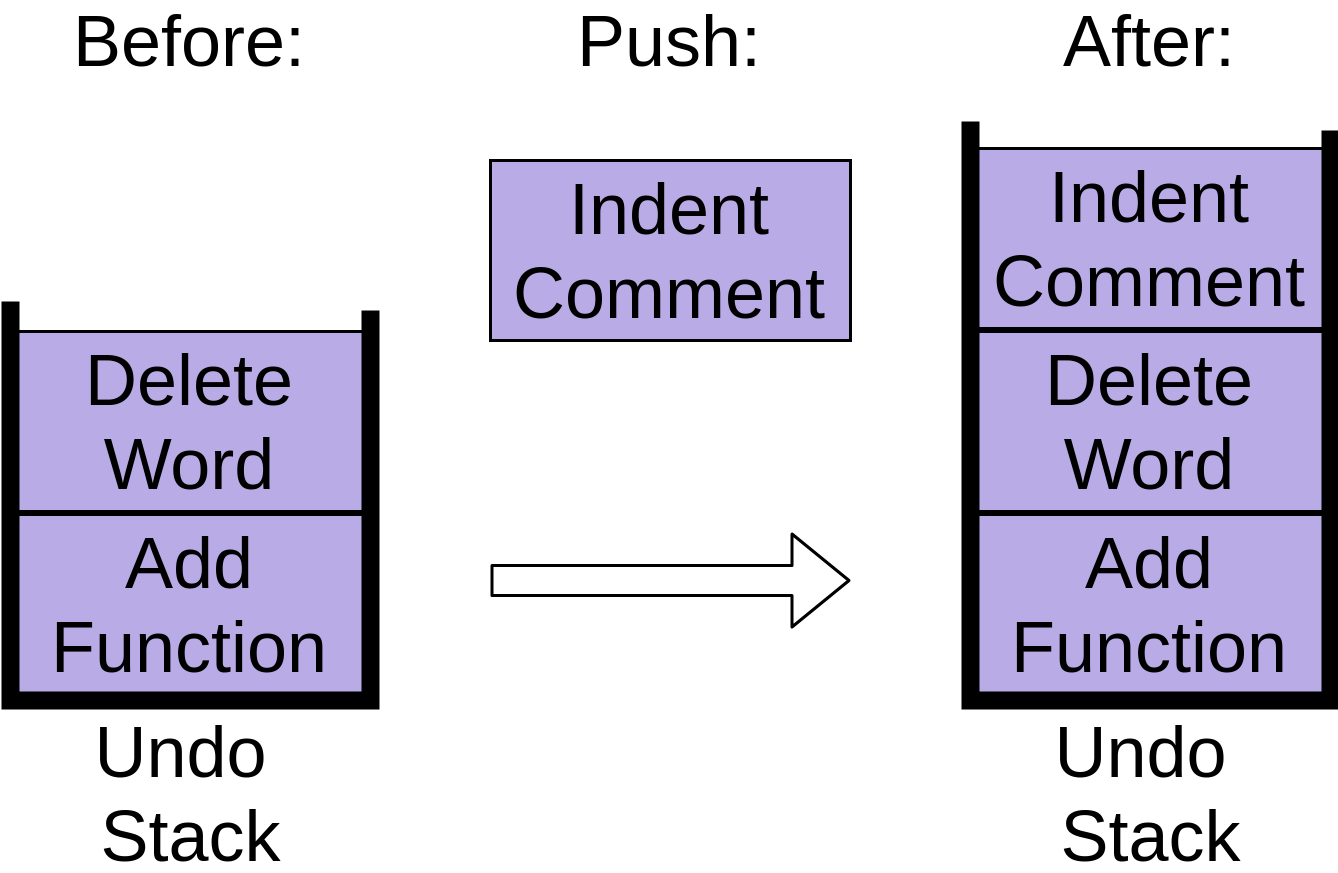
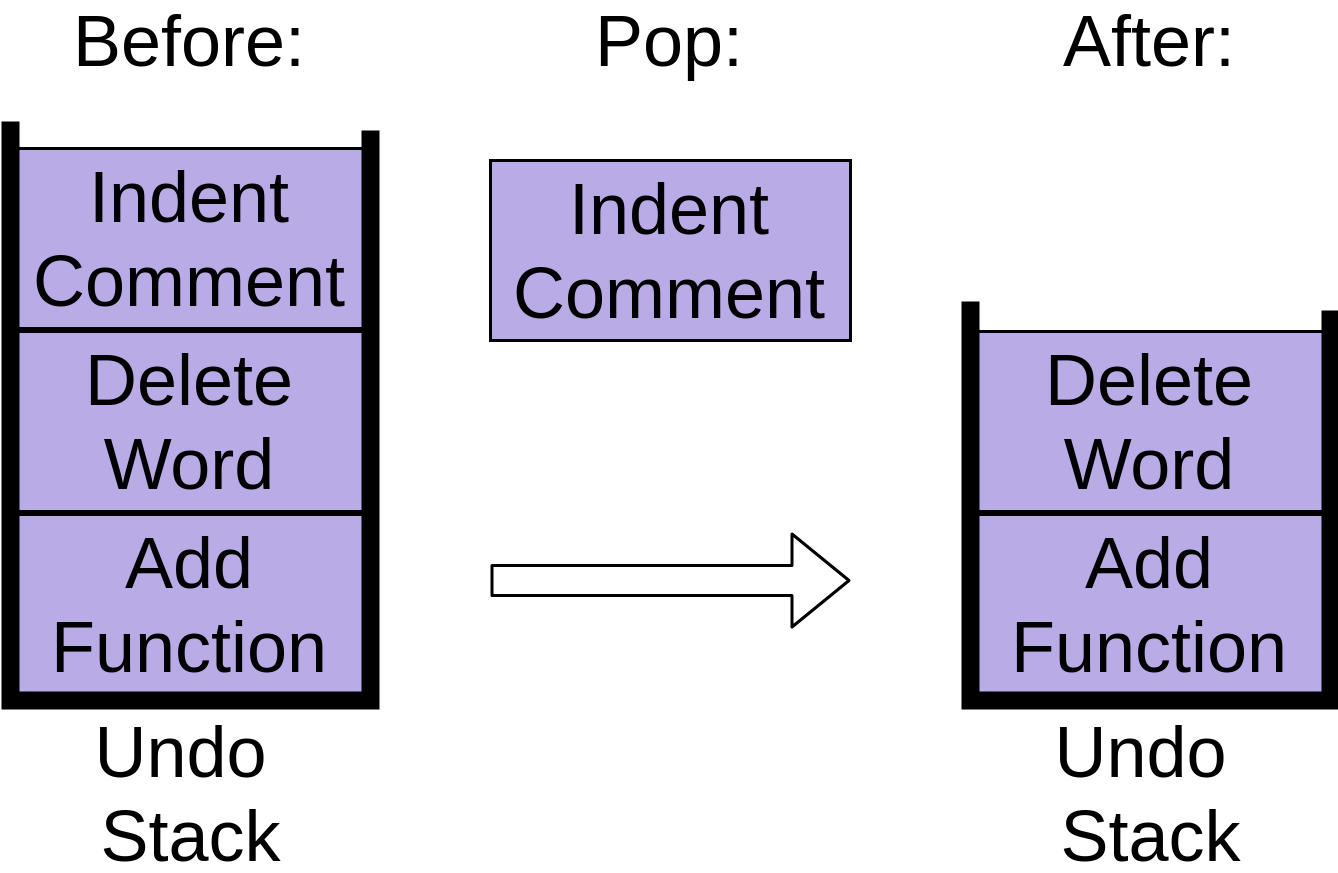
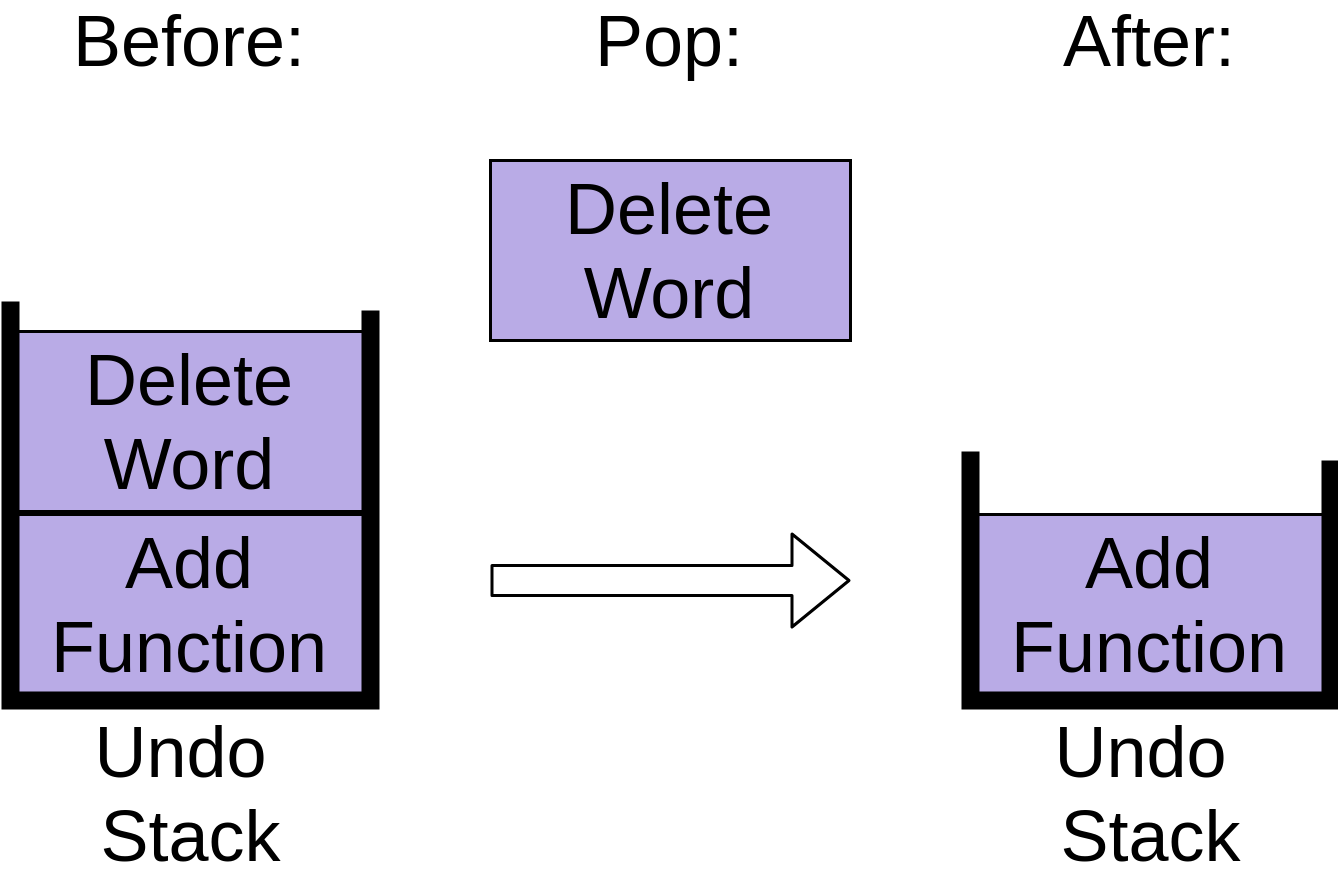
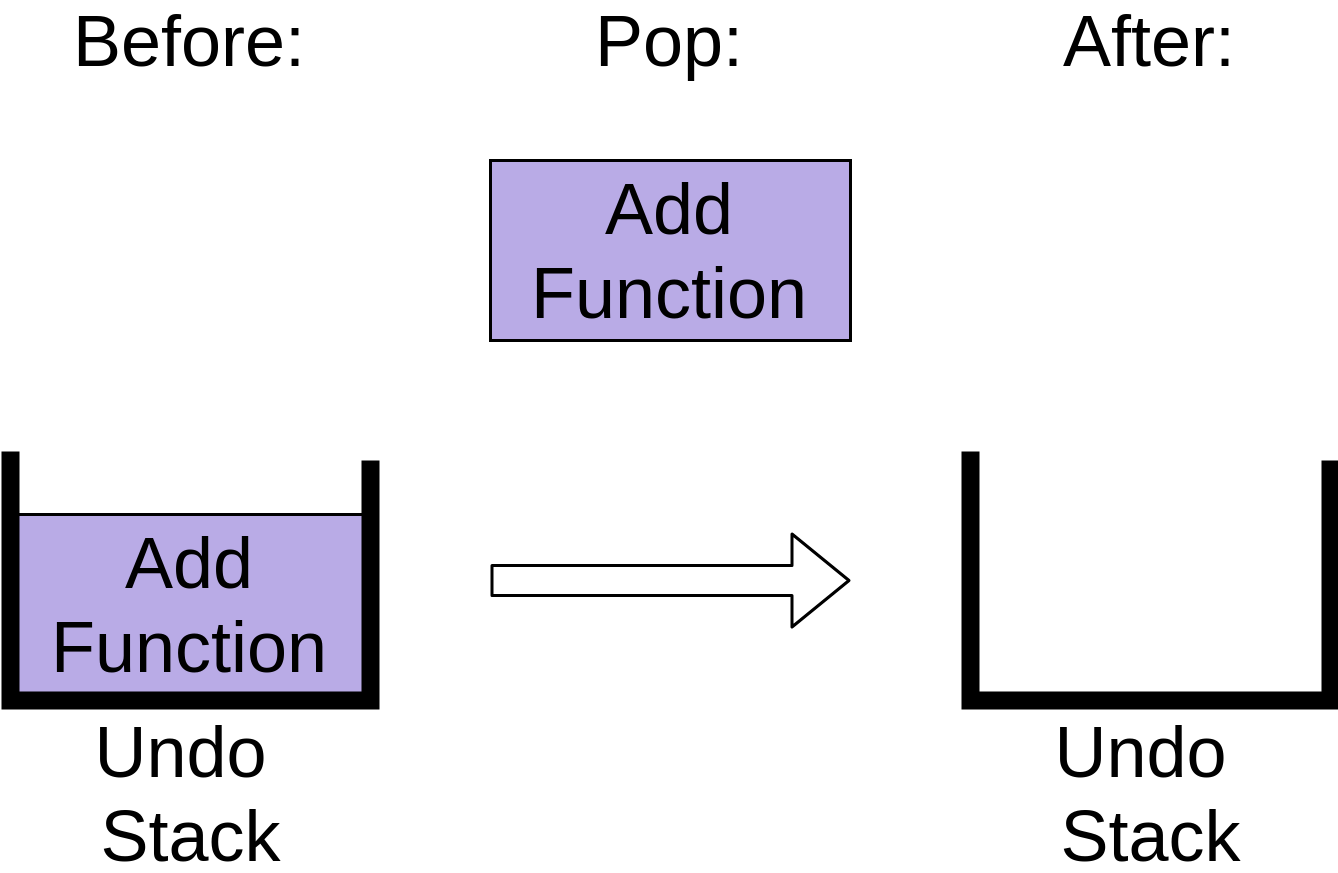
>>> myStack = []
>>> myStack.append('a')
>>> myStack.append('b')
>>> myStack.append('c')
>>> myStack
['a', 'b', 'c']
>>> myStack.pop()
'c'
>>> myStack.pop()
'b'
>>> myStack.pop()
'a'
>>> myStack.pop()
Traceback (most recent call last):
File "<console>", line 1, in <module>
IndexError: pop from empty list
你可以在最后一个命令中看到,如果你在一个空栈上调用.pop(),一个list将引发一个IndexError。
有熟悉的优势。你知道它是如何工作的,并且可能已经在你的程序中使用过了。
不幸的是,与您将看到的其他数据结构相比,list有一些缺点。最大的问题是,随着增长,它可能会遇到速度问题。存储list中的项目是为了提供对list中随机元素的快速访问。概括地说,这意味着这些项在内存中是相邻存储的。
如果你的堆栈变得比当前容纳它的内存块更大,那么 Python 需要做一些内存分配。这可能导致一些.append()电话比其他电话花费更长的时间。
还有一个不太严重的问题。如果你使用.insert()将一个元素添加到你的栈中,而不是添加到末尾,这将花费更长的时间。然而,这通常不是您对堆栈所做的事情。
下一个数据结构将帮助您解决您在list中看到的重新分配问题。
使用collections.deque创建一个 Python 栈
collections模块包含 deque ,这对创建 Python 栈很有用。deque读作“甲板”,代表“双头队列”
您可以在deque上使用与上面看到的list、.append()和.pop()相同的方法:
>>> from collections import deque >>> myStack = deque() >>> myStack.append('a') >>> myStack.append('b') >>> myStack.append('c') >>> myStack deque(['a', 'b', 'c']) >>> myStack.pop() 'c' >>> myStack.pop() 'b' >>> myStack.pop() 'a' >>> myStack.pop() Traceback (most recent call last): File "<console>", line 1, in <module> IndexError: pop from an empty deque这看起来几乎和上面的
list例子一样。此时,您可能想知道为什么 Python 核心开发人员会创建两个看起来一样的数据结构。为什么有
deque和list?正如你在上面关于
list的讨论中看到的,它是建立在连续内存块的基础上的,这意味着列表中的项目是彼此紧挨着存储的:
这对于一些操作非常有用,比如索引到
list。获取myList[3]很快,因为 Python 确切地知道在内存中的什么地方寻找它。这种内存布局也允许切片很好地处理列表。连续内存布局是
list可能需要比其他对象花费更多时间来.append()一些对象的原因。如果连续内存块已满,那么它将需要获取另一个块,这可能比普通的.append()花费更长的时间:
另一方面,
deque是建立在双向链表上的。在一个链表结构中,每个条目都存储在它自己的内存块中,并且有一个对列表中下一个条目的引用。双向链表也是一样的,只是每个条目都引用了列表中的前一个和下一个条目。这使您可以轻松地将节点添加到列表的任意一端。
向链表结构中添加新条目只需要设置新条目的引用指向堆栈的当前顶部,然后将堆栈的顶部指向新条目:
然而,这种在堆栈上添加和删除条目的恒定时间伴随着一种折衷。获取
myDeque[3]比获取列表要慢,因为 Python 需要遍历列表的每个节点才能到达第三个元素。幸运的是,您很少想要对堆栈进行随机索引或切片。栈上的大多数操作不是
push就是pop。如果您的代码不使用线程,常量时间
.append()和.pop()操作使得deque成为实现 Python 堆栈的绝佳选择。Python 堆栈和线程
Python 堆栈在多线程程序中也很有用,但是如果您对线程不感兴趣,那么您可以安全地跳过这一部分,直接跳到总结部分。
到目前为止,你已经看到的两个选项,
list和deque,如果你的程序有线程,它们的行为是不同的。从简单的开始,对于任何可以被多线程访问的数据结构,都不应该使用
list。list不是线程安全的。注意:如果您需要复习线程安全和竞争条件,请查看Python 线程介绍。
然而,事情要复杂一些。如果你阅读了
deque的文档,它清楚地说明了.append()和.pop()操作都是原子的,这意味着它们不会被不同的线程中断。所以如果你限制自己只使用
.append()和.pop(),那么你将是线程安全的。在线程环境中使用
deque的问题是,在那个类中还有其他方法,这些方法不是专门设计成原子的,也不是线程安全的。因此,虽然可以使用
deque构建线程安全的 Python 堆栈,但是这样做可能会让将来有人滥用它,从而导致竞争。好吧,如果你正在线程化,你不能使用
list进行堆栈,你可能也不想使用deque进行堆栈,那么怎么能为线程化程序构建 Python 堆栈呢?答案在
queue模块,queue.LifoQueue。还记得你是如何学习到堆栈是按照后进先出的原则运行的吗?嗯,这就是LifoQueue的“后进先出”部分的意思。虽然
list和deque的接口相似,LifoQueue使用.put()和.get()向堆栈中添加和移除数据:
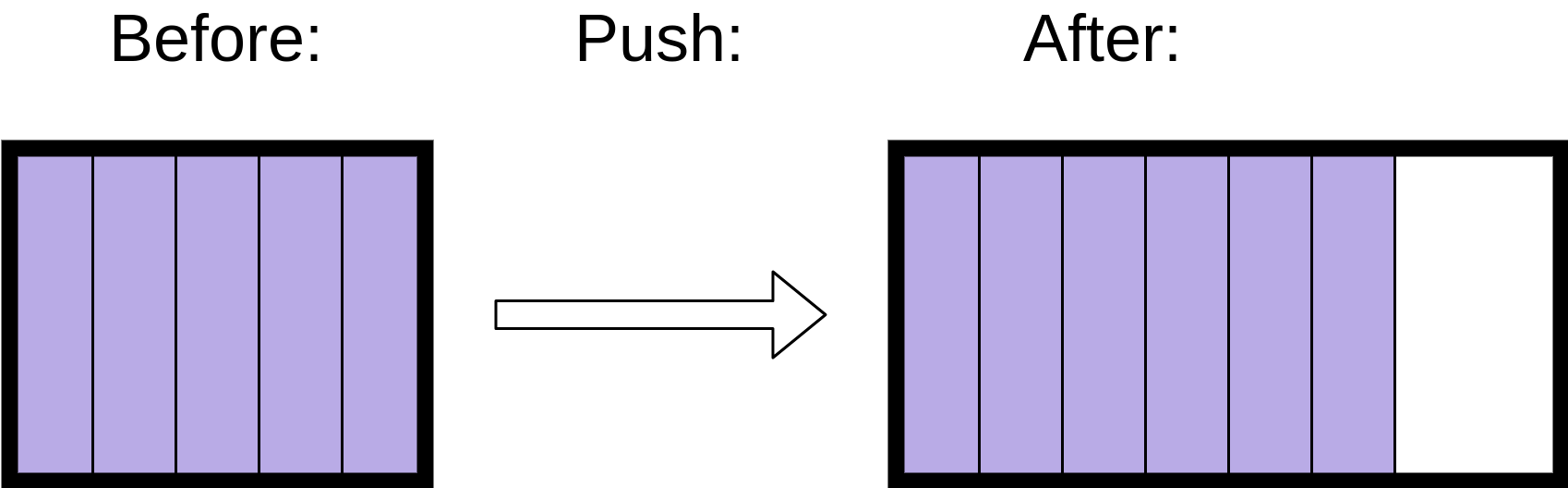
>>> from queue import LifoQueue
>>> myStack = LifoQueue()
>>> myStack.put('a')
>>> myStack.put('b')
>>> myStack.put('c')
>>> myStack
<queue.LifoQueue object at 0x7f408885e2b0>
>>> myStack.get()
'c'
>>> myStack.get()
'b'
>>> myStack.get()
'a'
>>> # myStack.get() <--- waits forever
>>> myStack.get_nowait()
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/usr/lib/python3.7/queue.py", line 198, in get_nowait
return self.get(block=False)
File "/usr/lib/python3.7/queue.py", line 167, in get
raise Empty
_queue.Empty
与deque不同,LifoQueue被设计成完全线程安全的。它的所有方法在线程环境中使用都是安全的。它还为其操作添加了可选的超时,这通常是线程程序中的必备功能。
然而,这种全线程安全是有代价的。为了实现这种线程安全,LifoQueue必须在每个操作上做一些额外的工作,这意味着它将花费更长的时间。
通常,这种轻微的减速不会影响你的整体程序速度,但是如果你已经测量了你的性能并发现你的栈操作是瓶颈,那么小心地切换到deque可能是值得的。
我想再次强调,从LifoQueue切换到deque是因为没有测量显示堆栈操作是瓶颈,所以速度更快,这是过早优化的一个例子。不要那样做。
Python 堆栈:应该使用哪种实现?
一般来说,如果不使用线程,应该使用deque。如果你正在使用线程,那么你应该使用一个LifoQueue,除非你已经测量了你的性能,并发现一个小的推动和弹出的速度提升将产生足够的差异,以保证维护风险。
可能很熟悉,但应该避免,因为它可能存在内存重新分配问题。deque和list的接口是相同的,deque没有这些问题,这使得deque成为你的非线程 Python 栈的最佳选择。
结论
现在你知道什么是栈,并且已经看到了它们在现实生活中的应用。您已经评估了实现堆栈的三种不同选择,并且看到了deque对于非线程程序是一个很好的选择。如果您在线程环境中实现堆栈,那么使用LifoQueue可能是个好主意。
您现在能够:
- 认识到什么时候栈是一个好的数据结构
- 选择适合您的问题的实施方案
如果你还有问题,请在下面的评论区联系我们。现在,去写一些代码,因为你获得了另一个工具来帮助你解决编程问题!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 如何实现一个 Python 栈**
如何用 Python 制作不和谐机器人
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 创建不和谐机器人
在一个视频游戏对许多人如此重要的世界里,围绕游戏的交流和社区是至关重要的。Discord 在一个精心设计的包中提供了这两种功能以及更多功能。在本教程中,你将学习如何用 Python 制作一个不和谐机器人,这样你就可以充分利用这个奇妙的平台。
到本文结束时,您将了解到:
- 什么是不和谐,为什么它如此有价值
- 如何通过开发者门户制作不和谐机器人
- 如何创建不和谐的连接
- 如何处理事件
- 如何接受命令和验证假设
- 如何与各种不和谐 API 交互
你将从学习什么是不和谐以及它为什么有价值开始。
什么是不和谐?
Discord 是一个面向游戏玩家的语音和文字交流平台。
玩家、飘带和开发者使用 Discord 来讨论游戏、回答问题、边玩边聊天等等。它甚至有一个游戏商店,提供评论和订阅服务。它几乎是游戏社区的一站式商店。
虽然使用 Discord 的API可以构建很多东西,但本教程将关注一个特定的学习成果:如何用 Python 制作 Discord 机器人。
什么是机器人?
不和越来越普遍。因此,自动化流程,如禁止不适当的用户和响应用户请求,对于社区的繁荣和发展至关重要。
外观和行为都像用户,并自动响应 Discord 上的事件和命令的自动化程序被称为 bot 用户。Discord bot 用户(或者仅仅是bot)拥有几乎无限的应用。
例如,假设你正在管理一个新的 Discord 公会,一个用户第一次加入。兴奋之余,你可能会亲自接触到那个用户,欢迎他们加入你的社区。你也可以告诉他们你的渠道,或者请他们介绍自己。
用户感到受欢迎,喜欢在你的公会中进行讨论,反过来,他们会邀请朋友。
随着时间的推移,你的社区变得越来越大,以至于不再可能亲自接触每个新成员,但你仍然希望给他们发送一些东西,以承认他们是公会的新成员。
有了机器人,就有可能自动对新成员加入你的公会做出反应。您甚至可以基于上下文定制它的行为,并控制它如何与每个新用户交互。
这很棒,但这只是一个机器人如何有用的小例子。一旦你知道如何制作机器人,你就有很多机会去创造它们。
注意:虽然 Discord 允许你创建处理语音通信的机器人,但本文将坚持服务的文本方面。
创建机器人有两个关键步骤:
- 在 Discord 上创建机器人用户,并向公会注册。
- 编写使用 Discord 的 API 并实现你的机器人行为的代码。
在下一节中,您将学习如何在 Discord 的开发者门户中制作一个 Discord 机器人。
如何在开发者门户制作不和谐机器人
在您可以深入任何 Python 代码来处理事件和创建令人兴奋的自动化之前,您需要首先创建一些 Discord 组件:
- 一个账户
- 一份申请
- 一个机器人
- 一个行会
在接下来的几节中,您将了解到关于每一部分的更多信息。
一旦你创建了所有这些组件,你就可以通过向你的公会注册你的机器人来把它们连接在一起。
你可以从前往 Discord 的开发者门户开始。
创建不一致账户
您首先看到的是一个登录页面,如果您有一个现有帐户,您需要在该页面上登录,或者创建一个新帐户:
如果您需要创建一个新账户,那么点击下方的注册按钮,登录,输入您的账户信息。
重要提示:你需要验证你的电子邮件,然后才能继续。
完成后,您将被重定向到开发人员门户主页,在那里您将创建自己的应用程序。
创建应用程序
一个应用程序允许您通过提供认证令牌、指定权限等方式与 Discord 的 API 进行交互。
要创建新应用程序,选择新应用程序:
接下来,系统会提示您命名应用程序。选择一个名称,点击创建:
恭喜你!你提出了不和谐的申请。在出现的屏幕上,您可以看到关于您的应用程序的信息:
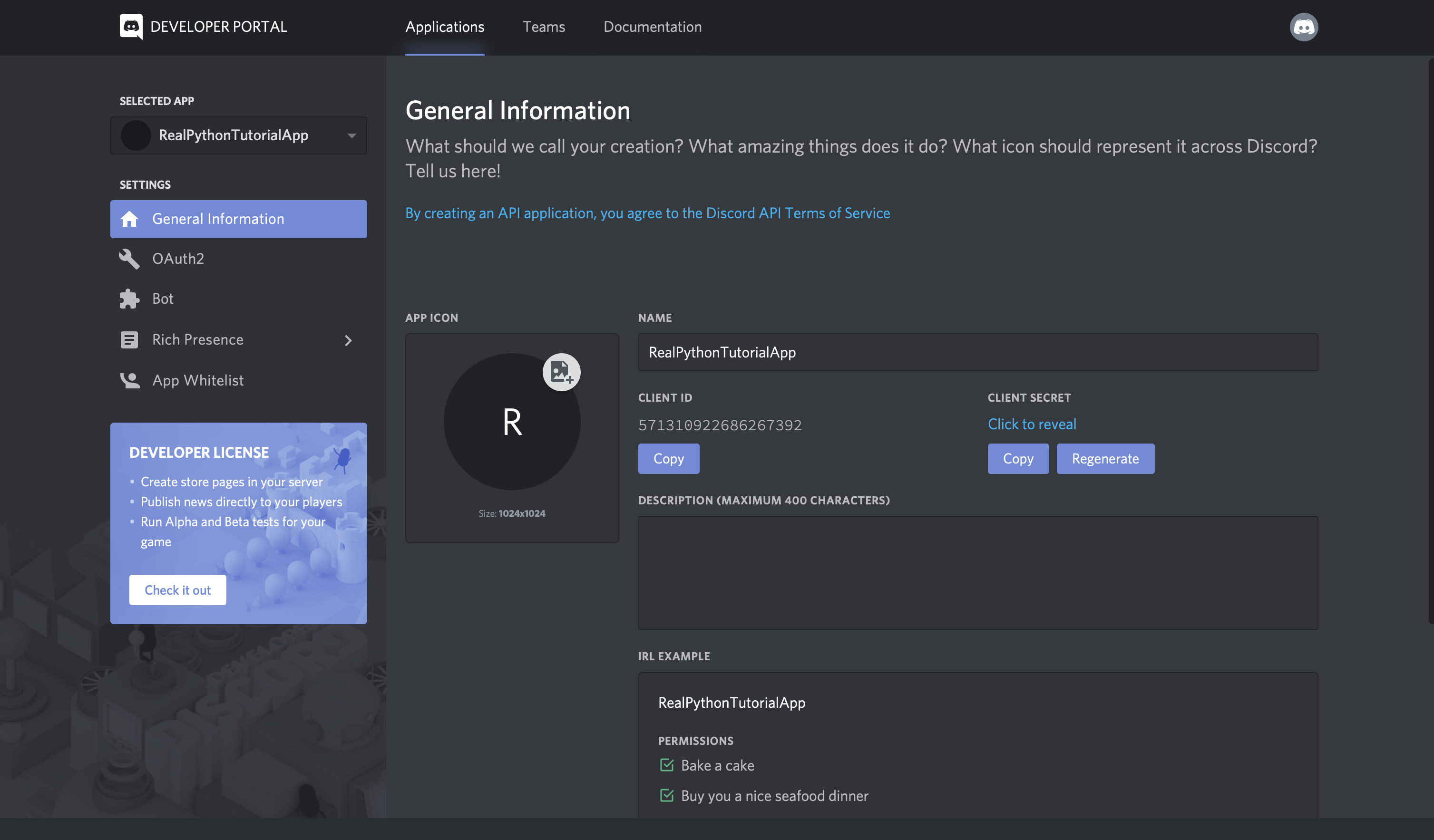
请记住,任何与 Discord APIs 交互的程序都需要 Discord 应用程序,而不仅仅是 bot。与 Bot 相关的 API 只是 Discord 总接口的一个子集。
然而,由于本教程是关于如何制作一个不和谐机器人,导航到左侧导航列表中的机器人选项卡。
创建一个机器人
正如您在前面几节中了解到的,bot 用户是一个在 Discord 上监听并自动对某些事件和命令做出反应的用户。
为了让您的代码在 Discord 上实际显示出来,您需要创建一个 bot 用户。为此,选择添加机器人:
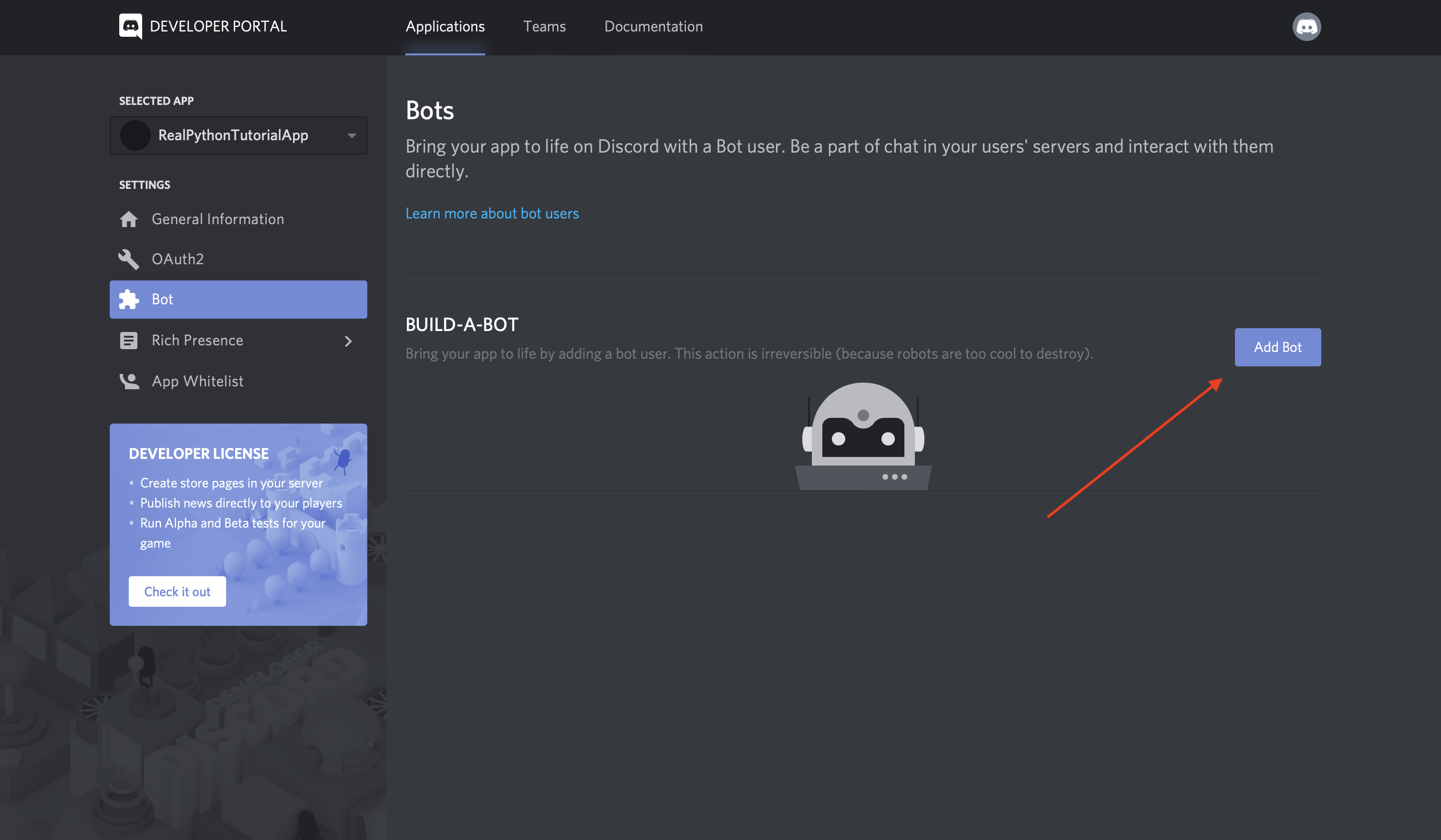
确认要将 bot 添加到应用程序后,您将在门户中看到新的 bot 用户:
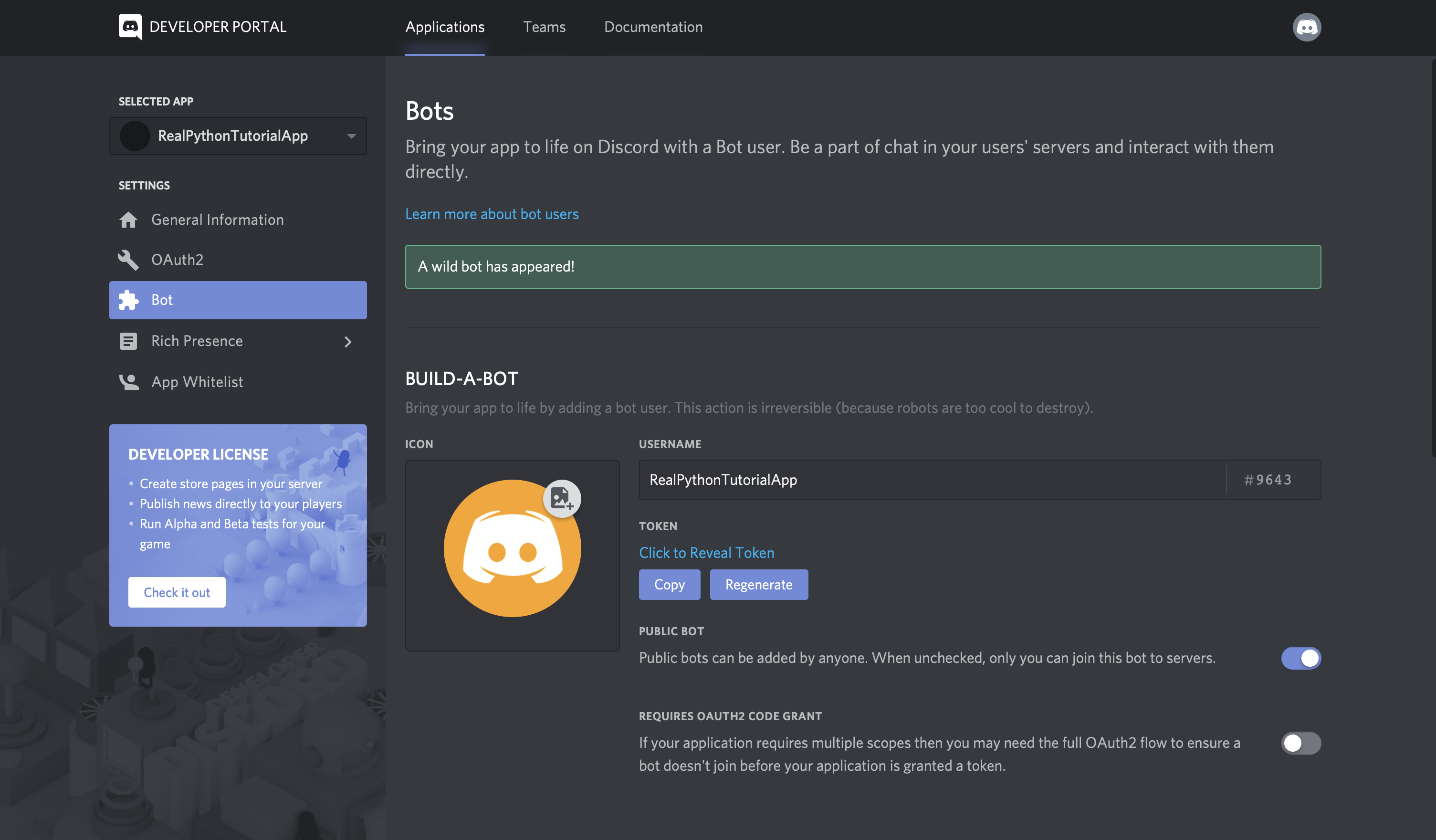
注意,默认情况下,您的 bot 用户将继承您的应用程序的名称。取而代之的是,将用户名更新为更像机器人的东西,比如RealPythonTutorialBot和保存更改:
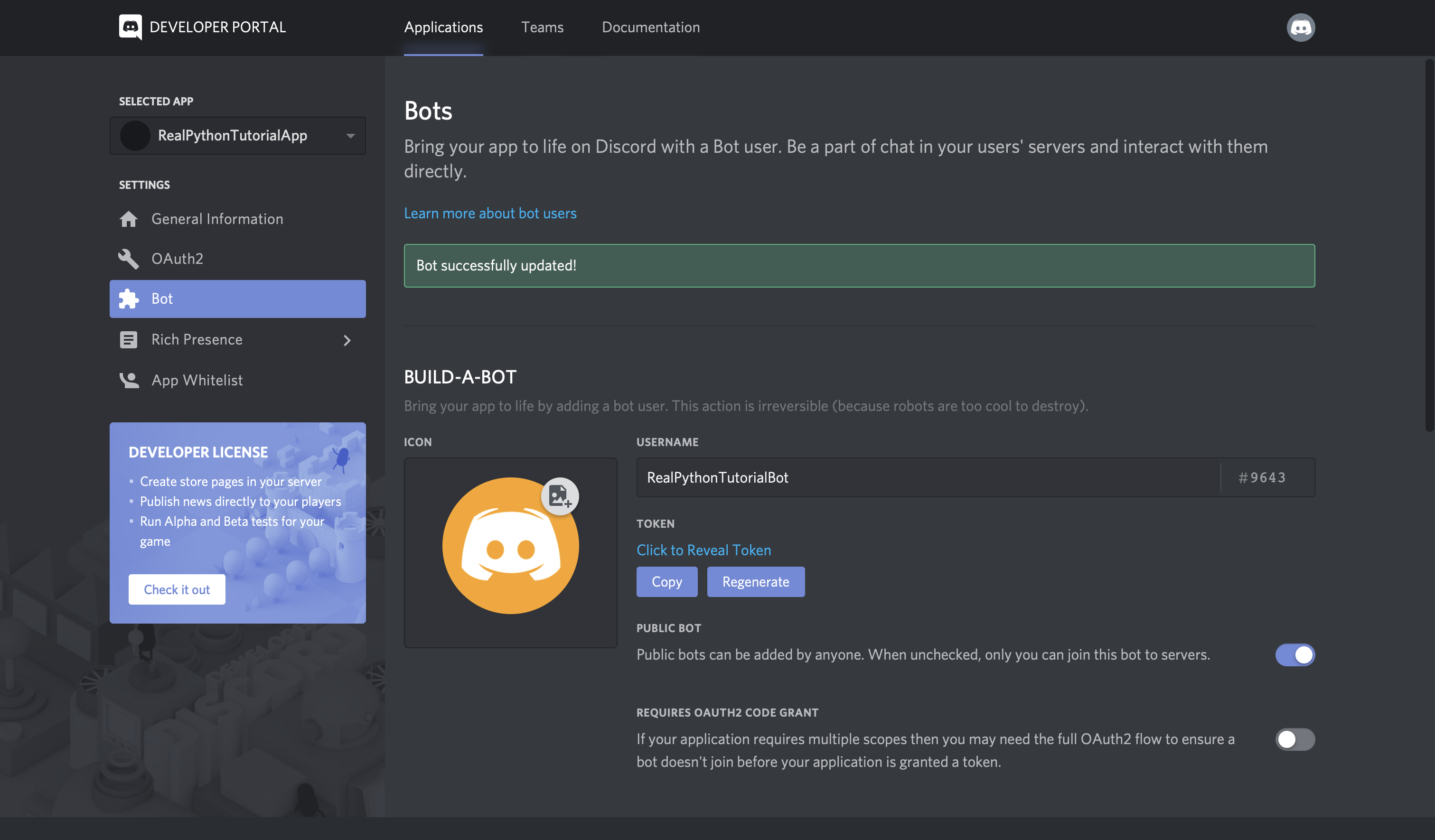
现在,机器人已经准备好了,但是去哪里呢?
如果一个机器人用户不与其他用户互动,它就没有用。接下来,您将创建一个公会,以便您的机器人可以与其他用户进行交互。
创建公会
一个公会(或者一个服务器,因为它经常被称为 Discord 的用户界面)是一组用户聚集聊天的特定频道。
注意:虽然公会和服务器是可以互换的,但本文将使用术语公会,主要是因为 API 坚持使用相同的术语。术语服务器只会在图形用户界面中提到公会时使用。
例如,假设你想创建一个空间,让用户可以聚在一起讨论你的最新游戏。你可以从创建一个行会开始。然后,在你的公会中,你可以有多个频道,例如:
- 一般讨论:一个让用户畅所欲言的渠道
- 剧透,当心:一个让已经完成你的游戏的用户谈论所有游戏结局的渠道
- 公告:一个让你宣布游戏更新和用户讨论的渠道
一旦你创建了你的公会,你会邀请其他用户来填充它。
所以,要创建一个公会,前往你的不和谐主页页面:
从这个主页,你可以查看和添加朋友,直接消息和公会。在这里,选择网页左侧的 + 图标,向添加服务器:
这将出现两个选项,创建服务器和加入服务器。在这种情况下,选择创建服务器并输入你的公会名称:
一旦你创建完你的公会,你将会在右边看到用户,在左边看到频道:
Discord 的最后一步是在你的新公会中注册你的机器人。
向公会添加机器人
机器人不能像普通用户一样接受邀请。相反,您将使用 OAuth2 协议添加您的 bot。
技术细节: OAuth2 是一个处理授权的协议,其中服务可以根据应用程序的凭证和允许的范围授予客户端应用程序有限的访问权限。
为此,请返回到开发者门户并从左侧导航中选择 OAuth2 页面:
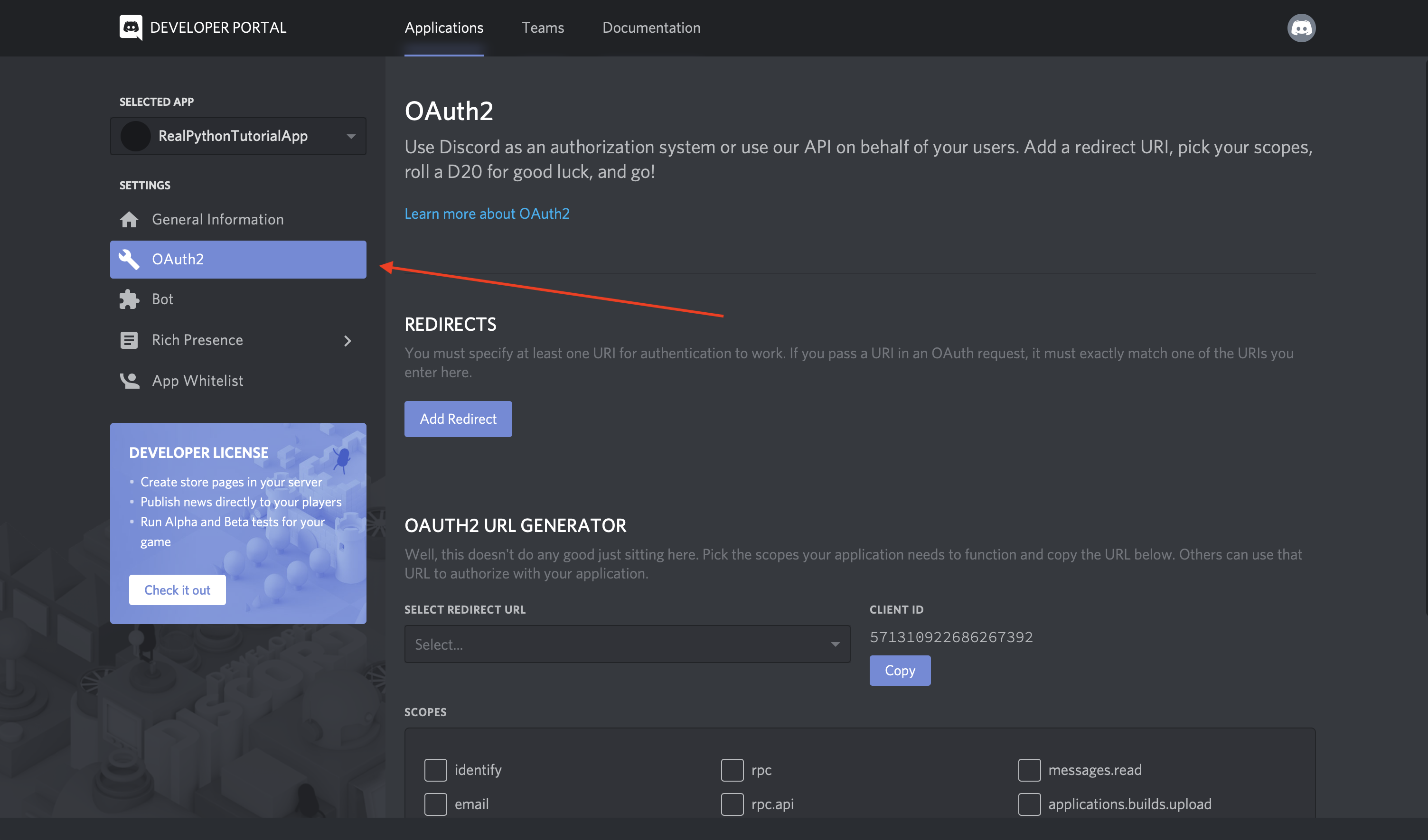
在这个窗口中,您将看到 OAuth2 URL 生成器。
这个工具会生成一个授权 URL,该 URL 会点击 Discord 的 OAuth2 API,并使用您的应用程序的凭证来授权 API 访问。
在这种情况下,您需要使用应用程序的 OAuth2 凭证授予应用程序的 bot 用户对 Discord APIs 的访问权。
为此,向下滚动并从范围选项中选择机器人,从机器人权限中选择管理员:
现在,Discord 已经用选定的范围和权限生成了您的应用程序的授权 URL。
免责声明:当我们在本教程中使用管理员时,在现实世界的应用程序中授予权限时,您应该尽可能地细化。
选择为您生成的 URL 旁边的复制,将其粘贴到您的浏览器中,并从下拉选项中选择您的公会:
点击授权,大功告成!
注意:在继续前进之前,你可能会得到一个 reCAPTCHA 。如果是这样,你需要证明你是一个人。
如果你回到你的公会,你会看到机器人已经被添加:
总之,您已经创建了:
- 一个应用程序,你的机器人将使用它来验证 Discord 的 API
- 一个机器人用户,你将使用它与你的公会中的其他用户和事件进行互动
- 一个公会,你的用户帐号和你的机器人用户将在其中活动
- 一个 Discord 账号,你用它创建了所有其他东西,并且你将使用它与你的机器人进行交互
现在,你知道如何使用开发者门户制作一个不和谐机器人。接下来是有趣的事情:用 Python 实现你的机器人!
如何用 Python 制作不和谐机器人
既然你正在学习如何用 Python 制作一个不和谐机器人,你将使用discord.py。
discord.py 是一个 Python 库,它以高效的 Python 方式详尽地实现了 Discord 的 API。这包括利用 Python 实现的异步 IO 。
从用 pip 安装discord.py开始:
$ pip install -U discord.py
现在您已经安装了discord.py,您将使用它来创建您与 Discord 的第一个连接!
创建不和谐连接
实现您的 bot 用户的第一步是创建一个到 Discord 的连接。使用discord.py,您可以通过创建Client的一个实例来实现这一点:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user} has connected to Discord!')
client.run(TOKEN)
一个Client是一个代表与不和谐的联系的对象。一个Client处理事件,跟踪状态,通常与 Discord APIs 交互。
这里,您已经创建了一个Client并实现了它的on_ready()事件处理程序,当Client已经建立了到 Discord 的连接并且已经准备好 Discord 发送的数据,比如登录状态、公会和频道数据等等时,它将处理该事件。
换句话说,一旦client准备好进一步的操作,就会调用on_ready()(并打印您的消息)。在本文的后面,您将了解更多关于事件处理程序的内容。
当您处理像 Discord token 这样的秘密时,从一个环境变量将它读入您的程序是一个很好的实践。使用环境变量有助于您:
- 避免将秘密放入源代码控制中
- 在开发和生产环境中使用不同的变量,而无需更改代码
虽然您可以export DISCORD_TOKEN={your-bot-token},但是一个更简单的解决方案是在所有运行这段代码的机器上保存一个.env文件。这不仅更容易,因为你不必每次清除外壳时都export你的令牌,而且它还保护你不将秘密存储在外壳的历史中。
在与bot.py相同的目录下创建一个名为.env的文件:
# .env
DISCORD_TOKEN={your-bot-token}
你需要用你的机器人令牌替换{your-bot-token},这可以通过返回到开发者门户上的机器人页面并点击令牌部分下的复制来获得:
回头看一下bot.py代码,您会注意到一个名为 dotenv 的库。这个库对于处理.env文件很方便。load_dotenv()将环境变量从一个.env文件加载到您的 shell 的环境变量中,这样您就可以在您的代码中使用它们。
用pip安装dotenv:
$ pip install -U python-dotenv
最后,client.run()使用您的机器人令牌运行您的Client。
现在您已经设置了bot.py和.env,您可以运行您的代码了:
$ python bot.py
RealPythonTutorialBot#9643 has connected to Discord!
太好了!您的Client已经使用您的机器人令牌连接到 Discord。在下一节中,您将通过与更多的 Discord APIs 交互来构建这个Client。
与不和谐 API 交互
使用一个Client,你可以访问各种各样的 Discord APIs。
例如,假设您想将注册 bot 用户的公会的名称和标识符写入控制台。
首先,您需要添加一个新的环境变量:
# .env
DISCORD_TOKEN={your-bot-token}
DISCORD_GUILD={your-guild-name}
不要忘记,您需要用实际值替换这两个占位符:
{your-bot-token}{your-guild-name}
请记住,一旦Client建立了连接并准备好数据,Discord 就会调用您之前使用过的on_ready()。所以,你可以依靠on_ready()内部可用的公会数据:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
for guild in client.guilds:
if guild.name == GUILD:
break
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)
这里你循环了一下 Discord 已经发来的公会数据client,也就是client.guilds。然后,你找到名字匹配的公会,打印一个格式的字符串到stdout。
注意:尽管在教程的这一点上你可以相当自信地认为你的机器人只连接到一个公会(所以client.guilds[0]会更简单),但重要的是要认识到一个机器人用户可以连接到许多公会。
因此,一个更健壮的解决方案是遍历client.guilds来找到您正在寻找的那个。
运行程序以查看结果:
$ python bot.py
RealPythonTutorialBot#9643 is connected to the following guild:
RealPythonTutorialServer(id: 571759877328732195)
太好了!您可以看到 bot 的名称、服务器的名称以及服务器的标识号。
另一个有趣的数据是你可以从一个公会中获取的,这个公会的用户列表:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
for guild in client.guilds:
if guild.name == GUILD:
break
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})\n'
)
members = '\n - '.join([member.name for member in guild.members])
print(f'Guild Members:\n - {members}')
client.run(TOKEN)
通过循环浏览guild.members,你调出了公会所有成员的名字,并用一个格式化的字符串打印出来。
当你运行这个程序时,你应该至少能看到你创建公会时使用的账号名称和机器人用户本身的名称:
$ python bot.py
RealPythonTutorialBot#9643 is connected to the following guild:
RealPythonTutorialServer(id: 571759877328732195)
Guild Members:
- aronq2
- RealPythonTutorialBot
这些例子仅仅触及了 Discord 上可用 API 的皮毛,请务必查看它们的文档以了解它们所能提供的一切。
接下来,您将了解一些实用函数以及它们如何简化这些示例。
使用实用功能
让我们再来看一下上一节中的例子,在这个例子中,您打印了机器人公会的名称和标识符:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
for guild in client.guilds:
if guild.name == GUILD:
break
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)
您可以使用discord.py中的一些实用函数来清理这些代码。
discord.utils.find() 是一个实用程序,它可以通过用一个直观的抽象函数替换for循环来提高代码的简单性和可读性:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
guild = discord.utils.find(lambda g: g.name == GUILD, client.guilds)
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)
find()接受一个名为谓词的函数,它标识了您正在寻找的 iterable 中元素的一些特征。这里,您使用了一种特殊类型的匿名函数,称为λ,作为谓词。
在这种情况下,您试图找到与您存储在DISCORD_GUILD环境变量中的名称相同的公会。一旦find()在 iterable 中找到满足谓词的元素,它将返回该元素。这基本上相当于上一个例子中的break语句,但是更清晰。
discord.py甚至用 get()实用程序进一步抽象了这个概念:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
guild = discord.utils.get(client.guilds, name=GUILD)
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)
get()接受 iterable 和一些关键字参数。关键字参数表示 iterable 中元素的属性,所有这些属性都必须满足,get()才能返回元素。
在本例中,您已经将name=GUILD标识为必须满足的属性。
技术细节:在幕后,get()实际上使用了attrs关键字参数来构建一个谓词,然后用它来调用find()。
既然您已经学习了与 API 交互的基本知识,那么您将更深入地研究一下您一直用来访问它们的函数:on_ready()。
响应事件
你已经知道on_ready()是一个事件。事实上,您可能已经注意到,它在代码中是由client.event 装饰器标识的。
但是什么是事件呢?
一个事件是不一致时发生的事情,你可以用它来触发代码中的反应。您的代码将侦听并响应事件。
使用您已经看到的例子,on_ready()事件处理程序处理Client已经连接到 Discord 并准备其响应数据的事件。
因此,当 Discord 触发一个事件时,discord.py会将事件数据路由到您连接的Client上相应的事件处理程序。
discord.py中有两种方法来柠檬一个事件处理程序:
- 使用
client.event装饰器 - 创建
Client的子类并覆盖它的处理方法
您已经看到了使用装饰器的实现。接下来,看看如何子类化Client:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
class CustomClient(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
client = CustomClient()
client.run(TOKEN)
这里,就像前面一样,您已经创建了一个client变量,并用您的 Discord 令牌调用了.run()。然而,实际的Client是不同的。没有使用普通的基类,client是CustomClient的一个实例,它有一个被覆盖的on_ready()函数。
事件的两种实现风格没有区别,但是本教程将主要使用装饰器版本,因为它看起来与您实现Bot命令的方式相似,这是您稍后将涉及的主题。
技术细节:不管你如何实现你的事件处理程序,有一点必须是一致的:discord.py中的所有事件处理程序必须是协程。
现在,您已经学习了如何创建事件处理程序,让我们来看一些您可以创建的处理程序的不同示例。
欢迎新成员
之前,您看到了响应成员加入公会事件的示例。在这个例子中,你的机器人用户可以向他们发送消息,欢迎他们加入你的 Discord 社区。
现在,您将使用事件处理程序在您的Client中实现该行为,并在 Discord 中验证其行为:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user.name} has connected to Discord!')
@client.event
async def on_member_join(member):
await member.create_dm()
await member.dm_channel.send(
f'Hi {member.name}, welcome to my Discord server!'
)
client.run(TOKEN)
像以前一样,您通过在格式化字符串中打印 bot 用户名来处理on_ready()事件。然而,新的是on_member_join()事件处理程序的实现。
on_member_join()顾名思义,处理新成员加入公会的事件。
在这个例子中,您使用了member.create_dm()来创建一个直接消息通道。然后,您使用该渠道向新成员发送直接消息。
技术细节:注意member.create_dm()和member.dm_channel.send()前的await关键词。
暂停周围协程的执行,直到每个协程的执行完成。
现在,让我们测试你的机器人的新行为。
首先,运行新版本的bot.py,等待on_ready()事件触发,将您的消息记录到stdout:
$ python bot.py
RealPythonTutorialBot has connected to Discord!
现在,前往 Discord ,登录,并通过在屏幕左侧选择公会来导航至您的公会:
选择您选择的公会列表旁边的邀请人。勾选框,将此链接设置为永不过期,并复制链接:
现在,复制了邀请链接后,创建一个新帐户并使用您的邀请链接加入公会:
首先,你会看到 Discord 默认用一条自动消息把你介绍给公会。更重要的是,请注意屏幕左侧的标记,它会通知您有新消息:
当您选择它时,您会看到一条来自您的 bot 用户的私人消息:
完美!你的机器人用户现在用最少的代码与其他用户交互。
接下来,您将学习如何在聊天中回复特定的用户消息。
回复信息
让我们通过处理on_message()事件来添加您的机器人的先前功能。
在你的机器人可以访问的频道中发布消息时发生。在这个例子中,您将使用电视节目中的一行程序来响应消息'99!':
@client.event
async def on_message(message):
if message.author == client.user:
return
brooklyn_99_quotes = [
'I\'m the human form of the 💯 emoji.',
'Bingpot!',
(
'Cool. Cool cool cool cool cool cool cool, '
'no doubt no doubt no doubt no doubt.'
),
]
if message.content == '99!':
response = random.choice(brooklyn_99_quotes)
await message.channel.send(response)
```py
这个事件处理程序的主体查看`message.content`,检查它是否等于`'99!'`,如果等于,就向消息的通道发送一个随机引用作为响应。
另一部分很重要:
if message.author == client.user:
return
因为`Client`不能区分机器人用户和普通用户帐户,所以你的`on_message()`处理程序应该防止潜在的[递归](https://realpython.com/python-recursion/)情况,在这种情况下,机器人发送它自己可能处理的消息。
举例来说,假设你想让你的机器人监听用户之间的对话`'Happy Birthday'`。您可以像这样实现您的`on_message()`处理程序:
@client.event
async def on_message(message):
if 'happy birthday' in message.content.lower():
await message.channel.send('Happy Birthday! 🎈🎉')
除了这个事件处理程序潜在的垃圾性质之外,它还有一个毁灭性的副作用。机器人响应的消息包含了它将要处理的相同的消息!
因此,如果频道中的一个人对另一个人说“生日快乐”,那么机器人也会附和……一遍又一遍……一遍又一遍:
[](https://files.realpython.com/media/discord-bot-happy-birthday-repetition.864acfe23979.png)
这就是为什么比较`message.author`和`client.user`(你的机器人用户)很重要,并且忽略它自己的任何信息。
所以,我们来修正一下`bot.py`:
bot.py
import os
import random
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user.name} has connected to Discord!')
@client.event
async def on_member_join(member):
await member.create_dm()
await member.dm_channel.send(
f'Hi {member.name}, welcome to my Discord server!'
)
@client.event
async def on_message(message):
if message.author == client.user:
return
brooklyn_99_quotes = [
'I\'m the human form of the 💯 emoji.',
'Bingpot!',
(
'Cool. Cool cool cool cool cool cool cool, '
'no doubt no doubt no doubt no doubt.'
),
]
if message.content == '99!':
response = random.choice(brooklyn_99_quotes)
await message.channel.send(response)
client.run(TOKEN)
不要忘记模块顶部的`import random`,因为`on_message()`处理器利用了`random.choice()`。
运行程序:
$ python bot.py
RealPythonTutorialBot has connected to Discord!
最后,前往 Discord 进行测试:
[](https://files.realpython.com/media/discord-bot-brooklyn-99-quotes.e934592e025e.png)
太好了!现在,您已经看到了处理一些常见不和谐事件的几种不同方法,您将学习如何处理事件处理程序可能引发的错误。
[*Remove ads*](/account/join/)
### 处理异常
正如你已经看到的,`discord.py`是一个事件驱动的系统。这种对事件的关注甚至延伸到了例外。当一个事件处理程序[引发一个`Exception`](https://realpython.com/python-exceptions/) 时,不和调用`on_error()`。
`on_error()`的默认行为是将错误消息和堆栈跟踪写入`stderr`。为了测试这一点,向`on_message()`添加一个特殊的消息处理程序:
bot.py
import os
import random
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user.name} has connected to Discord!')
@client.event
async def on_member_join(member):
await member.create_dm()
await member.dm_channel.send(
f'Hi {member.name}, welcome to my Discord server!'
)
@client.event
async def on_message(message):
if message.author == client.user:
return
brooklyn_99_quotes = [
'I\'m the human form of the 💯 emoji.',
'Bingpot!',
(
'Cool. Cool cool cool cool cool cool cool, '
'no doubt no doubt no doubt no doubt.'
),
]
if message.content == '99!':
response = random.choice(brooklyn_99_quotes)
await message.channel.send(response)
elif message.content == 'raise-exception': raise discord.DiscordException
client.run(TOKEN)
新的`raise-exception`消息处理程序允许你发出一个`DiscordException` on 命令。
运行程序并在不和谐频道中键入`raise-exception`:
[](https://files.realpython.com/media/discord-bot-raise-exception.7fcae85fb06e.png)
您现在应该可以在控制台中看到由您的`on_message()`处理程序引发的`Exception`:
$ python bot.py
RealPythonTutorialBot has connected to Discord!
Ignoring exception in on_message
Traceback (most recent call last):
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/client.py", line 255, in _run_event
await coro(*args, **kwargs)
File "bot.py", line 42, in on_message
raise discord.DiscordException
discord.errors.DiscordException
该异常被默认的错误处理程序捕获,因此输出包含消息`Ignoring exception in on_message`。让我们通过处理这个特定的错误来解决这个问题。为此,您将捕获`DiscordException`并由[将其写入文件](https://realpython.com/working-with-files-in-python/)。
`on_error()`事件处理程序将`event`作为第一个参数。在这种情况下,我们期望`event`是`'on_message'`。它还接受`*args`和`**kwargs`作为传递给原始事件处理程序的灵活的位置和关键字参数。
因此,由于`on_message()`采用单个参数`message`,我们期望`args[0]`是用户在 Discord 信道中发送的`message`:
@client.event
async def on_error(event, *args, **kwargs):
with open('err.log', 'a') as f:
if event == 'on_message':
f.write(f'Unhandled message: {args[0]}\n')
else:
raise
如果`Exception`起源于`on_message()`事件处理程序,你`.write()`一个格式化的字符串到文件`err.log`。如果另一个事件引发了一个`Exception`,那么我们只是希望我们的处理程序重新引发异常来调用默认行为。
运行`bot.py`并再次发送`raise-exception`消息,查看`err.log`中的输出:
$ cat err.log
Unhandled message: <Message id=573845548923224084 pinned=False author=<Member id=543612676807327754 name='alexronquillo' discriminator='0933' bot=False nick=None guild=
不仅仅是一个堆栈跟踪,您还有一个更具信息性的错误,显示了导致`on_message()`提高`DiscordException`的`message`,并保存到一个文件中,以便更持久地保存。
**技术细节:**如果你想在向`err.log`写错误信息时考虑实际的`Exception`,那么你可以使用来自`sys`的函数,比如 [`exc_info()`](https://docs.python.org/library/sys.html#sys.exc_info) 。
现在,您已经有了一些处理不同事件和与 Discord APIs 交互的经验,您将了解一个名为`Bot`的`Client`子类,它实现了一些方便的、特定于 bot 的功能。
## 连接机器人
一个`Bot`是一个`Client`的子类,它增加了一点额外的功能,这在你创建机器人用户时很有用。例如,`Bot`可以处理事件和命令,调用验证检查,等等。
在进入`Bot`特有的特性之前,先把`bot.py`转换成使用`Bot`而不是`Client`:
bot.py
import os
import random
from dotenv import load_dotenv
1
from discord.ext import commands
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
2
bot = commands.Bot(command_prefix='!')
@bot.event
async def on_ready():
print(f'{bot.user.name} has connected to Discord!')
bot.run(TOKEN)
如您所见,`Bot`可以像`Client`一样处理事件。然而,请注意`Client`和`Bot`的区别:
1. `Bot`是从`discord.ext.commands`模块导入的。
2. `Bot`初始化器需要一个`command_prefix`,这将在下一节中详细介绍。
扩展库`ext`提供了几个有趣的组件来帮助你创建一个 Discord `Bot`。其中一个这样的组件就是 [`Command`](https://discordpy.readthedocs.io/en/latest/ext/commands/commands.html) 。
[*Remove ads*](/account/join/)
### 使用`Bot`命令
一般来说,**命令**是用户给机器人的命令,让它做一些事情。命令不同于事件,因为它们是:
* 任意定义的
* 由用户直接调用
* 灵活,就其界面而言
用技术术语来说, **`Command`** 是一个对象,它包装了一个由文本命令调用的函数。文本命令必须以由`Bot`对象定义的`command_prefix`开始。
让我们来看看一件旧事,以便更好地理解这是怎么回事:
bot.py
import os
import random
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_message(message):
if message.author == client.user:
return
brooklyn_99_quotes = [
'I\'m the human form of the 💯 emoji.',
'Bingpot!',
(
'Cool. Cool cool cool cool cool cool cool, '
'no doubt no doubt no doubt no doubt.'
),
]
if message.content == '99!':
response = random.choice(brooklyn_99_quotes)
await message.channel.send(response)
client.run(TOKEN)
在这里,您创建了一个`on_message()`事件处理程序,它接收`message`字符串并将其与预定义的选项`'99!'`进行比较。
使用`Command`,您可以将此示例转换得更具体:
bot.py
import os
import random
from discord.ext import commands
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
bot = commands.Bot(command_prefix='!')
@bot.command(name='99')
async def nine_nine(ctx):
brooklyn_99_quotes = [
'I'm the human form of the 💯 emoji.',
'Bingpot!',
(
'Cool. Cool cool cool cool cool cool cool, '
'no doubt no doubt no doubt no doubt.'
),
]
response = random.choice(brooklyn_99_quotes)
await ctx.send(response)
bot.run(TOKEN)
关于使用`Command`,有几个重要的特征需要理解:
1. 不像以前那样使用`bot.event`,而是使用`bot.command()`,传递调用命令(`name`)作为它的参数。
2. 现在只有在聊天中提到`!99`时才会调用该功能。这不同于`on_message()`事件,后者在用户发送消息时执行,而不管内容如何。
3. 该命令必须以感叹号(`!`)为前缀,因为那是您在`Bot`的初始化器中定义的`command_prefix`。
4. 任何`Command`函数(技术上称为`callback`)必须接受至少一个参数,称为`ctx`,它是围绕被调用`Command`的 [`Context`](https://discordpy.readthedocs.io/en/latest/ext/commands/commands.html#invocation-context) 。
一个`Context`保存用户调用`Command`的频道和公会等数据。
运行程序:
$ python bot.py
随着你的机器人运行,你现在可以前往 Discord 来尝试你的新命令:
[](https://files.realpython.com/media/discord-bot-brooklyn-99-command.f01b21540756.png)
从用户的角度来看,实际的区别在于前缀有助于形式化命令,而不是简单地对特定的`on_message()`事件做出反应。
这也带来了其他巨大的好处。例如,您可以调用`!help`命令来查看您的`Bot`处理的所有命令:
[](https://files.realpython.com/media/discord-bot-help-command.a2ec772cc910.png)
如果你想给你的命令添加一个描述,让`help`消息提供更多信息,只需将一个`help`描述传递给`.command()`装饰器:
bot.py
import os
import random
from discord.ext import commands
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
bot = commands.Bot(command_prefix='!')
@bot.command(name='99', help='Responds with a random quote from Brooklyn 99')
async def nine_nine(ctx):
brooklyn_99_quotes = [
'I'm the human form of the 💯 emoji.',
'Bingpot!',
(
'Cool. Cool cool cool cool cool cool cool, '
'no doubt no doubt no doubt no doubt.'
),
]
response = random.choice(brooklyn_99_quotes)
await ctx.send(response)
bot.run(TOKEN)
现在,当用户调用`!help`命令时,您的机器人将呈现您的命令的描述:
[](https://files.realpython.com/media/discord-bot-help-description.7f710c984c66.png)
请记住,所有这些功能只存在于`Bot`子类,而不是`Client`超类。
`Command`还有另一个有用的功能:使用`Converter`来改变其参数类型的能力。
### 自动转换参数
使用命令的另一个好处是能够用**转换**参数。
有时,您需要一个特定类型的参数,但是默认情况下,`Command`函数的参数是字符串。一个 [`Converter`](https://discordpy.readthedocs.io/en/latest/ext/commands/commands.html#converters) 让你把那些参数转换成你期望的类型。
例如,如果您想为您的 bot 用户构建一个`Command`来模拟掷骰子(知道您目前所学的),您可以这样定义它:
@bot.command(name='roll_dice', help='Simulates rolling dice.')
async def roll(ctx, number_of_dice, number_of_sides):
dice = [
str(random.choice(range(1, number_of_sides + 1)))
for _ in range(number_of_dice)
]
await ctx.send(', '.join(dice))
您定义了`roll`来接受两个参数:
1. 掷骰子的数目
2. 每个骰子的边数
然后,用`.command()`修饰它,这样就可以用`!roll_dice`命令调用它。最后,你把`.send()`的结果用消息传回了`channel`。
虽然这看起来是正确的,但事实并非如此。不幸的是,如果您运行`bot.py`,并在 Discord 通道中调用`!roll_dice`命令,您将看到以下错误:
$ python bot.py
Ignoring exception in command roll_dice:
Traceback (most recent call last):
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/core.py", line 63, in wrapped
ret = await coro(*args, **kwargs)
File "bot.py", line 40, in roll
for _ in range(number_of_dice)
TypeError: 'str' object cannot be interpreted as an integer
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/bot.py", line 860, in invoke
await ctx.command.invoke(ctx)
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/core.py", line 698, in invoke
await injected(*ctx.args, **ctx.kwargs)
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/core.py", line 72, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: TypeError: 'str' object cannot be interpreted as an integer
换句话说, [`range()`](https://realpython.com/python-range/) 不能接受一个`str`作为实参。相反,它必须是一个`int`。虽然您可以将每个值转换为一个`int`,但是有一个更好的方法:您可以使用一个`Converter`。
在`discord.py`中,使用 Python 3 的[函数注释](https://realpython.com/python-type-checking/#annotations)定义了一个`Converter`:
@bot.command(name='roll_dice', help='Simulates rolling dice.')
async def roll(ctx, number_of_dice: int, number_of_sides: int):
dice = [
str(random.choice(range(1, number_of_sides + 1)))
for _ in range(number_of_dice)
]
await ctx.send(', '.join(dice))
您向两个类型为`int`的参数添加了`: int`注释。再次尝试该命令:
[](https://files.realpython.com/media/discord-bot-roll-dice.0255e76f078e.png)
只需小小的改变,你的命令就能发挥作用!不同之处在于,您现在将命令参数转换为`int`,这使得它们与您的函数逻辑兼容。
**注意:** A `Converter`可以是任何可调用的,而不仅仅是数据类型。参数将被传递给 callable,返回值将被传递给`Command`。
接下来,您将了解`Check`对象以及它如何改进您的命令。
### 检查命令谓词
`Check`是一个谓词,在执行`Command`之前对其进行评估,以确保围绕`Command`调用的`Context`有效。
在前面的示例中,您做了类似的事情来验证发送由机器人处理的消息的用户不是机器人用户本身:
if message.author == client.user:
return
`commands`扩展为执行这种检查提供了更干净、更有用的机制,即使用`Check`对象。
为了演示这是如何工作的,假设您想要支持一个创建新通道的命令`!create-channel <channel_name>`。但是,您只想让管理员能够使用该命令创建新通道。
首先,您需要在 admin 中创建一个新的成员角色。进入不和谐公会,选择*{服务器名称} →服务器设置*菜单:
[](https://files.realpython.com/media/discord-bot-server-settings.1eb7e71e881b.png)
然后,从左侧导航列表中选择*角色*:
[](https://files.realpython.com/media/discord-bot-roles.bdc21374afa9.png)
最后选择*角色*旁边的 *+* 符号,输入姓名`admin`,选择*保存更改*:
[](https://files.realpython.com/media/discord-bot-new-role.7e8d95291d0d.png)
现在,您已经创建了一个可以分配给特定用户的`admin`角色。接下来,在允许用户启动命令之前,您将把`bot.py`更新为`Check`用户角色:
bot.py
import os
import discord
from discord.ext import commands
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
bot = commands.Bot(command_prefix='!')
@bot.command(name='create-channel')
@commands.has_role('admin')
async def create_channel(ctx, channel_name='real-python'):
guild = ctx.guild
existing_channel = discord.utils.get(guild.channels, name=channel_name)
if not existing_channel:
print(f'Creating a new channel: {channel_name}')
await guild.create_text_channel(channel_name)
bot.run(TOKEN)
在`bot.py`中,你有一个新的`Command`函数,叫做`create_channel()`,它接受一个可选的`channel_name`并创建那个通道。`create_channel()`还装饰有一个`Check`,叫做`has_role()`。
您还可以使用`discord.utils.get()`来确保不会创建与现有通道同名的通道。
如果您运行这个程序,并在您的 Discord 频道中键入`!create-channel`,那么您将会看到下面的错误消息:
$ python bot.py
Ignoring exception in command create-channel:
Traceback (most recent call last):
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/bot.py", line 860, in invoke
await ctx.command.invoke(ctx)
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/core.py", line 691, in invoke
await self.prepare(ctx)
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/core.py", line 648, in prepare
await self._verify_checks(ctx)
File "/Users/alex.ronquillo/.pyenv/versions/discord-venv/lib/python3.7/site-packages/discord/ext/commands/core.py", line 598, in _verify_checks
raise CheckFailure('The check functions for command {0.qualified_name} failed.'.format(self))
discord.ext.commands.errors.CheckFailure: The check functions for command create-channel failed.
这个`CheckFailure`表示`has_role('admin')`失败。不幸的是,这个错误只打印到`stdout`。最好是在通道中向用户报告这一情况。为此,添加以下事件:
@bot.event
async def on_command_error(ctx, error):
if isinstance(error, commands.errors.CheckFailure):
await ctx.send('You do not have the correct role for this command.')
该事件处理来自命令的错误事件,并将信息性错误消息发送回被调用的`Command`的原始`Context`。
再次尝试,您应该会在 Discord 通道中看到一个错误:
[](https://files.realpython.com/media/discord-bot-role-error-message.adfe85fe76a9.png)
太好了!现在,要解决这个问题,您需要给自己一个*管理员*角色:
[](https://files.realpython.com/media/discord-bot-role-granted.081c0c317834.png)
使用*管理员*角色,您的用户将通过`Check`并能够使用该命令创建频道。
**注意:**请记住,为了分配角色,您的用户必须拥有正确的权限。确保这一点的最简单的方法是用你创建公会的用户登录。
当您再次键入`!create-channel`时,您将成功创建通道 *real-python* :
[](https://files.realpython.com/media/discord-bot-new-channel.43cd2889446c.png)
另外,请注意,您可以传递可选的`channel_name`参数来命名您想要的通道!
在最后这个例子中,您组合了一个`Command`、一个事件、一个`Check`,甚至还有一个`get()`实用程序来创建一个有用的 Discord bot!
## 结论
恭喜你!现在,你已经学会了如何用 Python 制作一个不和谐机器人。你可以在自己创建的公会中创建与用户互动的机器人,甚至是其他用户可以邀请与他们的社区互动的机器人。你的机器人将能够响应信息和命令以及许多其他事件。
在本教程中,您学习了创建自己的不和谐机器人的基础知识。你现在知道了:
* 什么是不和谐
* 为什么`discord.py`如此珍贵
* 如何在开发者门户制作不和谐机器人
* 如何在 Python 中创建不和谐连接
* 如何处理事件
* 如何创建一个`Bot`连接
* 如何使用 bot 命令、检查和转换器
要阅读更多关于强大的`discord.py`库的信息并让你的机器人更上一层楼,通读它们广泛的[文档](https://discordapp.com/developers/docs/intro)。此外,既然您已经熟悉了 Discord APIs,那么您就有了构建其他类型的 Discord 应用程序的更好基础。
您还可以探索[聊天机器人](https://realpython.com/build-a-chatbot-python-chatterbot/)、 [Tweepy](https://realpython.com/twitter-bot-python-tweepy/) 、 [InstaPy](https://realpython.com/instagram-bot-python-instapy/) 和 [Alexa Skills](hhttps://realpython.com/alexa-python-skill/) 的可能性,以了解如何使用 Python 为不同平台制作机器人。
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: [**用 Python 创建不和谐机器人**](/courses/discord-bot-python/)************
# NumPy arange():如何使用 np.arange()
> 原文:<https://realpython.com/how-to-use-numpy-arange/>
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: [**有效使用 NumPy 的 NP . arange()**](/courses/numpy-arange/)
**NumPy** 是数值计算的基本 Python 库。它最重要的类型是一个叫做`ndarray`的**数组类型**。NumPy 为不同的环境提供了许多[数组创建例程](https://docs.scipy.org/doc/numpy/reference/routines.array-creation.html)。`arange()`是一个基于**数值范围**的函数。它通常被称为`np.arange()`,因为`np`是 NumPy 的一个广泛使用的缩写。
当您使用依赖 NumPy 数组的其他 Python 库时,创建 NumPy 数组是很重要的,比如 [SciPy](https://realpython.com/python-scipy-cluster-optimize/) 、 [Pandas](https://realpython.com/pandas-python-explore-dataset/) 、 [Matplotlib](https://realpython.com/python-matplotlib-guide/) 、scikit-learn 等等。NumPy 适合创建和使用数组,因为它提供了[有用的例程](https://docs.scipy.org/doc/numpy/reference/routines.html),使[的性能提升](https://realpython.com/numpy-tensorflow-performance/),并允许您编写[简洁的代码](https://realpython.com/numpy-array-programming/)。
到本文结束时,你会知道:
* 什么是`np.arange()`
* 如何使用`np.arange()`
* `np.arange()`与 Python 内置类 [`range`](https://realpython.com/python-range/) 相比如何
* 哪些套路和`np.arange()`类似
让我们看看`np.arange()`的行动吧!
**免费奖励:** [点击此处获取免费的 NumPy 资源指南](#),它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
## `np.arange()`的返回值和参数
NumPy `arange()`是一个基于数值范围的数组创建例程。它创建一个具有*等间距值*的`ndarray`实例,并返回对它的引用。
您可以使用四个参数`arange()`定义数组中包含的值的间隔、它们之间的空间以及它们的类型:
```py
numpy.arange([start, ]stop, [step, ], dtype=None) -> numpy.ndarray
前三个参数确定值的范围,而第四个参数指定元素的类型:
start是定义数组中第一个值的数字(整数或小数)。stop是定义数组结尾的数字,不包含在数组中。step是定义数组中每两个连续值之间的间距(差)的数字,默认为1。dtype是输出数组的元素类型,默认为None。
step不能为零。否则你会得到一个ZeroDivisionError。如果增量或减量是0,你就不能离开start的任何地方。
如果省略dtype,arange()将尝试从start,stop,step的类型中推导出数组元素的类型。
你可以在官方文档中找到更多关于arange()的参数和返回值的信息。
np.arange()的范围参数
定义数组中包含的值的 NumPy arange()的自变量对应于数字参数start、stop和step。你必须通过至少其中一门。
下面的例子将向您展示arange()如何根据参数的数量和它们的值进行操作。
提供所有范围参数
使用 NumPy 例程时,必须先导入 NumPy:
>>> import numpy as np现在,您已经导入了 NumPy,并准备应用
arange()。让我们看看如何使用 NumPy
arange()的第一个例子:
>>> np.arange(start=1, stop=10, step=3)
array([1, 4, 7])
在这个例子中,start就是1。因此,获得的数组的第一个元素是1。step是3,这就是为什么你的第二个值是 1+3,也就是4,而数组中的第三个值是 4+3,等于7。
按照这种模式,下一个值将是10 (7+3),但是计数必须在到达 stop之前结束,所以这个不包括在内。
您也可以将start、stop和step作为位置参数传递:
>>> np.arange(1, 10, 3) array([1, 4, 7])此代码示例等效于,但比前一个更简洁。
stop的值不包含在数组中。这就是为什么您可以用不同的stop值获得相同的结果:
>>> np.arange(1, 8, 3)
array([1, 4, 7])
此代码示例返回与前两个值相同的数组。任何一个stop值严格大于7小于等于10都可以得到相同的结果。
但是,如果您使stop大于10,那么计数将在达到10后结束:
>>> np.arange(1, 10.1, 3) array([ 1., 4., 7., 10.])在这种情况下,您将获得包含四个元素的数组,其中包括
10。请注意,这个示例创建了一个浮点数数组,这与上一个示例不同。那是因为你还没有定义
dtype,是arange()给你推导出来的。在本文的后面,您将了解到更多这方面的内容。您可以在下图中看到这三个示例的图形表示:
start显示为绿色,stop显示为红色,而step和数组中包含的值显示为蓝色。从上图可以看出,前两个例子有三个值(
1、4和7)。他们不允许10被包括在内。在第三个例子中,stop大于10,它包含在结果数组中。提供两个范围参数
可以省略
step。在这种情况下,arange()使用其默认值1。以下两个语句是等效的:
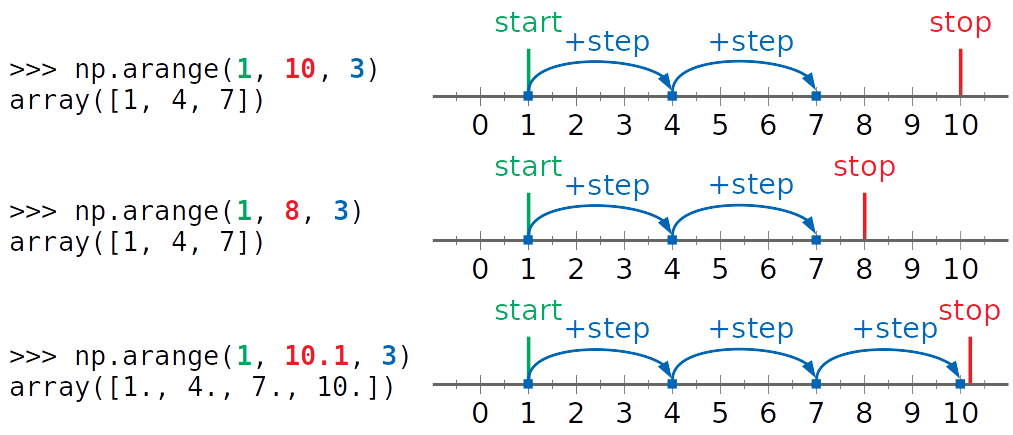
>>> np.arange(start=1, stop=10, step=1)
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(start=1, stop=10)
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
第二个语句更短。step,默认为1,通常是直觉预期的。
将arange()与增量1一起使用在实践中是非常常见的情况。同样,您可以用位置参数start和stop更简洁地编写前面的例子:
>>> np.arange(1, 10) array([1, 2, 3, 4, 5, 6, 7, 8, 9])这是调用
arange()的一种直观而简洁的方式。在这个例子中使用关键字参数并没有真正提高可读性。注意:如果你提供两个位置参数,那么第一个是
start,第二个是stop。提供一个范围参数
你必须给提供至少一个到
arange()的参数。更准确的说,你得提供start。但是如果省略
stop会怎么样呢?arange()怎么知道什么时候停止计数?在这种情况下,数组从0开始,在到达start的值之前结束!同样,step的默认值是1。换句话说,
arange()假设你已经提供了stop(而不是start),并且start是0,step是1。让我们看一个例子,你想用
0开始一个数组,增加1的值,并在10之前停止:
>>> np.arange(start=0, stop=10, step=1)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(0, 10, 1)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(start=0, stop=10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(0, 10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
这些代码示例没问题。它们的工作方式如前面的示例所示。有一种更短、更简洁但仍然直观的方法来做同样的事情。您可以只提供一个位置参数:
>>> np.arange(10) # Stop is 10, start is 0, and step is 1! array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])这是创建 NumPy 数组的最常用方法,该数组从零开始,增量为 1。
注意:单个参数定义了计数停止的位置。输出数组从
0开始,增量为1。如果你试图显式地提供没有
start的stop,那么你将得到一个TypeError:
>>> np.arange(stop=10)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: arange() missing required argument 'start' (pos 1)
你得到这个错误是因为arange()不允许你显式避开对应于start的第一个参数。如果你提供一个参数,那么它必须是start,但是arange()将使用它来定义计数停止的位置。
提供否定的论据
如果您为start或start和stop都提供负值,并且有一个正的step,那么arange()将以与所有正参数相同的方式工作:
>>> np.arange(-5, -1) array([-5, -4, -3, -2]) >>> np.arange(-8, -2, 2) array([-8, -6, -4]) >>> np.arange(-5, 6, 4) array([-5, -1, 3])这种行为与前面的例子完全一致。计数从
start的值开始,重复递增step,并在达到stop之前结束。倒数计时
有时你会希望数组的值从左到右递减。在这种情况下,您可以使用负值的
step和大于stop的start:
>>> np.arange(5, 1, -1)
array([5, 4, 3, 2])
>>> np.arange(7, 0, -3)
array([7, 4, 1])
在这个例子中,请注意下面的模式:获得的数组从第一个参数的值开始,并朝着第二个参数的值递减step。
在最后一个语句中,start是7,得到的数组以这个值开始。step是-3所以第二个值是 7+(3),也就是4。第三个值是 4+(3),即1。计数在此停止,因为在下一个值(-2)之前到达了stop ( 0)。
您可以在下图中看到此示例的图形表示:

同样,start显示为绿色,stop显示为红色,而step和数组中包含的值显示为蓝色。
这一次,箭头显示的是从右向左的方向。那是因为start大于stop,step是负数,你基本上是在倒着算。
前面的示例产生了与下面相同的结果:
>>> np.arange(1, 8, 3)[::-1] array([7, 4, 1]) >>> np.flip(np.arange(1, 8, 3)) array([7, 4, 1])不过,
step为负值的变体更优雅简洁。获取空数组
在一些极端情况下,您可以使用
arange()获得空的 NumPy 数组。这些是没有任何元素的常规实例。如果您为
start和stop提供相等的值,那么您将得到一个空数组:
>>> np.arange(2, 2)
array([], dtype=int64)
这是因为计数在达到stop的值之前就结束了。因为start的值等于stop,所以不能到达它,也不能包含在结果数组中。
一种不常见的情况是当start大于stop并且step为正时,或者当start小于stop并且step为负时:
>>> np.arange(8, 2, 1) array([], dtype=int64) >>> np.arange(2, 8, -1) array([], dtype=int64)正如你所看到的,这些例子导致空数组,而不是出现错误。
np.arange()的数据类型NumPy 数组中元素的类型是使用它们的一个重要方面。使用
arange()时,可以用参数dtype指定元素的类型。注意:下面是关于 NumPy 数组中包含的元素类型的几个要点:
- NumPy 数组中的所有元素都属于同一类型,称为dtype(数据类型的简称)。
- NumPy dtypes 比 Python 的内置数字类型允许更细的粒度。
- 在某些情况下,NumPy dtypes 的别名对应于 Python 内置类型的名称。
- 通常,NumPy 例程可以接受 Python 数字类型,反之亦然。
- 一些 NumPy 数据类型具有依赖于平台的定义。
如果你想了解更多关于 NumPy 数组的 dtypes,那么请阅读官方文档。
你可以随意省略
dtype。在这种情况下,arange()将尝试推导出结果数组的 dtype。这取决于start、stop和step的类型,如下例所示:
>>> x = np.arange(5)
>>> x
array([0, 1, 2, 3, 4])
>>> x.dtype
dtype('int64')
>>> x.itemsize # In bytes
8
这里,有一个参数(5)定义了值的范围。它的类型是int。这就是为什么数组x的 dtype 会是 NumPy 提供的整数类型之一。在这种情况下,NumPy 默认选择int64 dtype。这是一个 64 位(8 字节)整数类型。
上一个示例中的数组相当于这个数组:
>>> x = np.arange(5, dtype=int) >>> x array([0, 1, 2, 3, 4]) >>> x.dtype dtype('int64')
dtype=int的说法不是指 Pythonint。它被翻译成 NumPyint64或简单的np.int。NumPy 提供了几种固定大小的整数数据类型,它们在内存和限制方面有所不同:
np.int8: 8 位有符号整数(从-128到127np.uint8: 8 位无符号整数(从0到255np.int16: 16 位有符号整数(从-32768到32767np.uint16: 16 位无符号整数(从0到65535np.int32: 32 位有符号整数(从-2**31到2**31-1np.uint32: 32 位无符号整数(从0到2**32-1np.int64: 64 位有符号整数(从-2**63到2**63-1np.uint64: 64 位无符号整数(从0到2**64-1如果您希望数组的元素使用其他整数类型,那么只需指定
dtype:
>>> x = np.arange(5, dtype=np.int32)
>>> x
array([0, 1, 2, 3, 4], dtype=int32)
>>> x.dtype
dtype('int32')
>>> x.itemsize # In bytes
4
现在得到的数组具有与前一个例子相同的值,但是元素的类型和大小不同。参数dtype=np.int32(或dtype='int32')强制x的每个元素的大小为 32 位(4 字节)。
当您的参数是十进制数而不是整数时,dtype 将是某种 NumPy 浮点类型,在本例中为float64:
>>> y = np.arange(5.0) >>> y array([0., 1., 2., 3., 4.]) >>> y.dtype dtype('float64')在最后四个例子中,元素的值是相同的,但是数据类型不同。
通常,当您向
arange()提供至少一个浮点参数时,得到的数组将具有浮点元素,即使其他参数是整数:
>>> np.arange(1, 5.1)
array([1., 2., 3., 4., 5.])
>>> np.arange(1, 5.1).dtype
dtype('float64')
>>> np.arange(0, 9, 1.5)
array([0\. , 1.5, 3\. , 4.5, 6\. , 7.5])
>>> np.arange(0, 9, 1.5).dtype
dtype('float64')
在上面的例子中,start是一个整数,但是 dtype 是np.float64,因为stop或step是浮点数。
如果您指定了dtype,那么arange()将尝试使用所提供的数据类型的元素生成一个数组:
>>> y = np.arange(5, dtype=float) >>> y array([0., 1., 2., 3., 4.]) >>> y.dtype dtype('float64')这里的参数
dtype=float翻译成 NumPyfloat64,也就是np.float。它不是指 Pythonfloat。float64的固定大小别名是np.float64和np.float_。当需要精度和大小(以字节为单位)较低的浮点数据类型时,可以显式指定:
>>> z = np.arange(5, dtype=np.float32)
>>> z
array([0., 1., 2., 3., 4.], dtype=float32)
>>> z.dtype
dtype('float32')
使用dtype=np.float32(或dtype='float32')使数组z的每个元素变大 32 位(4 字节)。y每个元素的大小为 64 位(8 字节):
>>> y.itemsize # In bytes 8 >>> z.itemsize # In bytes 4
y和z的元素之间的区别,以及一般而言np.float64和np.float32之间的区别,是所使用的内存和精度:前者比后者更大、更精确。很多情况下,你不会注意到这种区别。然而,有时这很重要。比如 TensorFlow 使用
float32和int32。同样,当你处理图像时,甚至使用较小的字体,如uint8。当
step不是整数时,由于浮点运算的限制,结果可能不一致。用
np.arange()超越简单范围您可以方便地将
arange()与运算符(如+、-、*、/、**等)和其他 NumPy 例程(如、abs()、或、sin()、)组合起来,产生输出值的范围:
>>> x = np.arange(5)
>>> x
array([0, 1, 2, 3, 4])
>>> 2**x
array([ 1, 2, 4, 8, 16])
>>> y = np.arange(-1, 1.1, 0.5)
>>> y
array([-1\. , -0.5, 0\. , 0.5, 1\. ])
>>> np.abs(y)
array([1\. , 0.5, 0\. , 0.5, 1\. ])
>>> z = np.arange(10)
>>> np.sin(z)
array([ 0\. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ,
-0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849])
当你想在 Matplotlib 中创建一个绘图时,这是特别合适的。
如果你需要一个多维数组,那么你可以结合arange()与 .reshape() 或者类似的函数和方法:
>>> a = np.arange(6).reshape((2, 3)) >>> a array([[0, 1, 2], [3, 4, 5]]) >>> a.shape (2, 3) >>> a.ndim 2这就是如何获得包含元素
[0, 1, 2, 3, 4, 5]的ndarray实例,并将其整形为二维数组。
range和np.arange()的比较Python 有一个内置的类
range,某种程度上类似于 NumPyarange()。range和np.arange()在应用和性能方面有重要区别。你会看到他们的不同和相似之处。两者的主要区别在于
range是内置的 Python 类,而arange()是属于第三方库(NumPy)的函数。另外,他们的目的不一样!一般来说,当你需要使用 Python
for循环来迭代时,range更合适。如果你想创建一个 NumPy 数组,并在幕后应用快速循环,那么arange()是一个更好的解决方案。参数和输出
range和arange()具有相同的参数,这些参数定义了所获得数字的范围:
startstopstep即使在
start和stop相等的情况下,您也可以类似地应用这些参数。然而,在使用
range时:
- 您必须提供整数参数。否则,你会得到一个
TypeError。- 您不能指定生成的数字的类型。总是
int。
range和arange()的返回类型也不同:
range创建该类的一个实例,该实例具有与其他序列(如list和tuple)相同的特性,如成员、连接、重复、切片、比较、长度检查等等。arange()返回 NumPyndarray的一个实例。创建序列
您可以应用
range来创建一个list或tuple的实例,在预定义的范围内均匀分布数字。你可能会发现理解特别适合这个目的。然而,创建和操作 NumPy 数组通常比处理列表或元组更快,更 T2,更优雅。
让我们比较一下使用理解力创建一个
list和使用arange()创建一个等价的 NumPyndarray的性能:
>>> import timeit
>>> n = 1
>>> timeit.timeit(f'x = [i**2 for i in range({n})]')
>>> timeit.timeit(f'x = np.arange({n})**2', setup='import numpy as np')
对不同的n值重复这段代码,在我的机器上产生了以下结果:
尺寸:n |
每循环时间:range |
每循环时间:arange() |
比例 |
|---|---|---|---|
| one | 497 纳秒 | 1.14 秒 | Zero point four one |
| Ten | 2.24 秒 | 1.28 秒 | One point seven four |
| One hundred | 20.0 秒 | 1.37 秒 | Fourteen point six |
| One thousand | 211 s | 2.92 秒 | Seventy-two point three |
这些结果可能会有所不同,但是很明显,创建 NumPy 数组比创建 list 要快得多,除了长度非常短的序列。(应用程序通常会带来额外的性能优势!)
这是因为 NumPy 在 C 层执行许多操作,包括循环。此外,NumPy 为处理向量进行了优化,避免了一些与 Python 相关的开销。
Python for循环
如果您需要在 Python for循环中迭代值,那么range通常是更好的解决方案。根据官方 Python 文档:
与常规的
list或tuple相比,range类型的优势在于,range对象将总是占用相同(少量)的内存,无论它所代表的范围大小如何(因为它只存储根据需要计算单个项目和子范围的start、stop和step值)。(来源)
在 Python 的for循环中使用时,range通常比arange()快,尤其是当循环有可能很快中断的时候。这是因为range在需要的时候以惰性方式生成数字,一次一个。
相比之下,arange()在开头生成所有的数字。
更多关于range的信息,可以查看Python range()函数(指南)和官方文档。
基于数值范围的其他程序
除了arange()之外,您还可以应用其他基于数值范围的 NumPy 数组创建例程:
linspace()与arange()相似,都是返回等间距的数字。但是您可以指定要生成的值的数量,以及是否包括端点和是否一次创建多个数组。logspace()和geomspace()与linspace()类似,只是返回的数字在对数刻度上是均匀分布的。meshgrid(),ogrid(),mgrid()返回以数组表示的网格点。
所有这些功能都有自己的特点和使用案例。可以根据自己的需求选择合适的。
正如您已经看到的,NumPy 包含了更多的例程来创建ndarray 的实例。
快速总结
要使用 NumPy arange(),需要先导入numpy:
>>> import numpy as np这里有一个表格,其中有几个例子总结了如何使用 NumPy
arange()。记住各种用法可能会有帮助:
例子 结果 np.arange(start=1, stop=10, step=3)array([1, 4, 7])np.arange(1, 10, 3)array([1, 4, 7])np.arange(1, 10, 3, dtype=float)array([1., 4., 7.])np.arange(1.0, 10, 3)array([1., 4., 7.])np.arange(0, 1.1, 0.5)array([0\. , 0.5, 1\. ])np.arange(2, 6)array([2, 3, 4, 5])np.arange(5)array([0, 1, 2, 3, 4])np.arange(-8, -2, 2)array([-8, -6, -4])np.arange(7, 0, -3)array([7, 4, 1])np.arange(8, 2)array([])不要忘记,您还可以通过用参数
dtype指定 NumPy dtypes 来影响用于数组的内存。结论
你现在知道如何使用 NumPy
arange()。函数np.arange()是基本的 NumPy 例程之一,通常用于创建 NumPyndarray的实例。它有四个论点:
start: 数组的第一个值stop: 数组结束的地方step: 增量或减量dtype: 数组的元素的类型您还了解了在创建序列和生成要迭代的值时,NumPy
arange()与 Python 内置类range的比较。您看到了还有其他基于数值范围的 NumPy 数组创建例程,比如
linspace()、logspace()、meshgrid()等等。如果你有任何问题或意见,请写在下面的评论区。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 有效使用 NumPy 的 NP . arange()*****
面向 Python 开发者的 HTML 和 CSS
当你想作为一个 Python 程序员来构建网站时,没有办法绕开 HTML 和 CSS。几乎互联网上的每个网站都是用 HTML 标记来构建页面的。为了让网站看起来漂亮,你可以用 CSS 来设计 HTML 的样式。
如果你对使用 Python 进行 web 开发感兴趣,那么了解 HTML 和 CSS 将有助于你更好地理解像 Django 和 Flask 这样的 web 框架。但是,即使你刚刚开始使用 Python,HTML 和 CSS 也能让你创建小网站来打动你的朋友。
在本教程中,您将学习如何:
- 构建一个基本的 HTML 文件
- 在您的浏览器中查看和检查 HTML
- 插入图片和页面链接
- 用 CSS 设计一个网站
- 考虑到可访问性来格式化 HTML
- 使用 Python 编写和解析 HTML 代码
您将获得 HTML 和 CSS 的介绍,您可以跟随。在本教程中,您将构建一个包含三个页面和 CSS 样式的网站:
https://player.vimeo.com/video/740468859?background=1
在创建 web 项目时,您将创建一个样板 HTML 文档,您可以在即将到来的 web 项目中使用它。您可能会发现,当您从事未来的项目时,源代码会派上用场。您可以从这里下载:
免费奖励: 点击这里下载本教程的补充资料,包括一个省时的 HTML 模板文件。
在学习了 HTML 和 CSS 的基础知识之后,你会在教程的最后找到如何继续你的旅程的想法。
创建你的第一个 HTML 文件
想一想你最近访问过的任何网站。也许你看了一些新闻,和朋友聊了聊,或者看了一段视频。不管它是什么样的网站,你可以打赌它的源代码在开头有一个基本的
<html>标签。HTML 代表超文本标记语言。HTML 是由蒂姆·伯纳斯·李创造的,作为万维网的发明者,他的名字可能也让你想起来了。
HTML 的超文本部分指的是在不同的 HTML 页面之间建立连接。有了超链接,你就可以在网页之间跳转,在网上冲浪。
您使用标记来组织文档中的内容。与格式相反,标记定义了内容的含义,而不是内容的外观。在本节中,您将了解 HTML 元素及其角色。
编写语义 HTML 代码将使你的文档能够被广泛的访问者访问。毕竟,你想让每个人都能消费你的内容,不管他们是用浏览器还是用屏幕阅读工具访问你的页面。
对于每个 HTML 元素,都有一个定义其预期用途的标准。今天,HTML 的标准是由 Web 超文本应用技术工作组(WHATWG) 定义的。WHATWG 对 HTML 的作用类似于 Python 指导委员会对 Python 的作用。
大约 95%的网站使用 HTML ,所以如果你想用 Python 做任何网络开发工作,你将很难避免它。
在本节中,您将从创建第一个 HTML 文件开始。您将学习如何构建您的 HTML 代码,使其对您的浏览器和人类可读。
HTML 文档
在本节中,您将创建一个基本的 HTML 文件。HTML 文件将包含大多数网站的基本结构。
首先,创建一个名为
index.html的文件,其中包含一些文本:1<!-- index.html --> 2 3Am I HTML already?传统上,你网站的第一个文件叫做
index.html。您可以将index.html页面视为类似于 Python 项目中的main.py或app.py文件。注意:除非你的服务器配置不同,
index.html是当你访问根 URL 时服务器试图加载的文件。这就是为什么你可以访问https://www.example.com/而不是输入完整的https://www.example.com/index.html地址。到目前为止,
index.html的唯一内容是一个普通的Am I HTML already?字符串。您还没有添加任何 HTML 语法,除了第 1 行的一个 HTML 注释。类似于 Python 解释器不执行你的 Python 代码中的注释,浏览器不会呈现你的 HTML 注释的内容。尽管如此,请在浏览器中打开index.html:
你的浏览器显示文本时没有抱怨。看起来浏览器可以处理 HTML 文件,即使它的唯一提示是扩展名。知道这一点很好,但这种行为也有不好的一面。
浏览器总是试图呈现 HTML 文档,即使文档的 HTML 语法无效。很少,浏览器本身会显示类似于语法错误的东西,类似于当你试图运行无效代码时 Python 所做的。这意味着您可能不会注意到您是否发布了无效代码,这可能会给网站访问者带来问题。
注意:如果你想验证你写的 HTML 代码,那么你可以上传你的 HTML 文件到 W3C 标记验证服务。这个林挺工具分析你的代码并指出错误。
更新
index.html并通过添加以下代码创建一个最小有效的 HTML 文档:1<!-- index.html --> 2 3<!DOCTYPE html> 4<html lang="en"> 5<head> 6 <meta charset="utf-8"> 7 <title>Am I HTML already?</title> 8</head> 9</html>这段代码是你能得到的最简单有效的 HTML 文档。严格地说,您甚至可以删除第 4 行中的
lang属性。但是建议添加正确的语言子标签来声明您的文档包含哪种自然语言。注意:在本教程中,您将坚持使用英语并使用
en语言标签。你可以访问官方语言子标签注册表来查找所有其他语言标签。语言属性使翻译工具更容易使用您的网站,并使您的网站更容易访问。屏幕阅读器特别依赖 HTML 文档的语言声明来选择正确的语言模式来合成内容。
从根本上说,您构建的任何 HTML 文档都可能遵循上面示例的结构。但是缺少了一个重要的 HTML 元素。打开
index.html,在<head>下面增加<body>:1<!-- index.html --> 2 3<!DOCTYPE html> 4<html lang="en"> 5<head> 6 <meta charset="utf-8"> 7 <title>Am I HTML already?</title> 8</head> 9<body> 10Yes,<br>I am! 11</body> 12</html>任何有效的 HTML 文件都必须以一个 doctype 声明开始。在本教程中,您将使用
<!DOCTYPE html>,它告诉浏览器文档包含 HTML5 代码,应该以标准模式呈现您的页面:如果浏览器在页面开始处发现一个过时的、不完整的或丢失的 doctype,他们使用“怪癖模式”,这种模式更向后兼容旧的实践和旧的浏览器。(来源)
在 doctype 声明之后,有一个开始的
<html>标记。在第 12 行,您可以找到相应的结束标签</html>。HTML 中的大多数元素都有一个开始标签,中间有一些内容,最后有一个结束标签。这些部分甚至可以在同一行,像第 7 行中的<title>元素。其他元素,比如第 6 行的
<meta>,没有匹配的结束标记,所以它们不包含任何内容。这些空元素就是所谓的空元素。它们独立存在,甚至可能不包含属性。第 10 行中的<br>就是这样一个例子,它创建了一个换行符。HTML 标签以尖括号(
<)开始,以尖括号(>)结束。尖括号中的标签名通常是非常描述性的,说明了 HTML 元素的含义。一个很好的例子是第 7 行的<title>,其中的内容定义了页面的标题。
<body>块包含了你的大部分内容。您可以将<body>视为 HTML 文档的一部分,您可以在浏览器中与之交互。有时候标签名是缩写的,比如第 10 行的换行符
<br>。要获得其他 HTML 标签名称的概述,请访问 Mozilla 的 HTML 元素参考。一旦你熟悉了你的 HTML 文档的结构,在你的浏览器中重新加载
index.html并检查你的网站看起来如何:
太棒了,你现在正在显示你的第一个正式网站的内容!
您很有可能会以类似于本节中构建的结构开始任何 web 项目。为了在将来节省一些工作,您可以通过单击下面的链接下载 HTML 样板代码:
免费奖励: 点击这里下载本教程的补充资料,包括一个省时的 HTML 模板文件。
在下一节中,您将改进到目前为止已经创建的基础结构。为了探究为什么 HTML 被称为标记语言,您将向您的网站添加内容和结构。
空白和文本格式
到目前为止,HTML 文档仅有的标记是网站的基本框架。现在是时候深入研究并构建一些真正的内容了。要使用某些内容,请将以下文本添加到
index.html的<body>块中:1<!-- index.html --> 2 3<!DOCTYPE html> 4<html lang="en"> 5<head> 6 <meta charset="utf-8"> 7 <title>Am I HTML already?</title> 8</head> 9<body> 10Hello, World Wide Web! 11This is my first website. 12 13About me 14 15I'm a Python programmer and a bug collector. 16 17Random facts 18 19I don't just like emoji, 20I love emoji! 21 22My most-used emoji are: 23 1\. 🐞 24 2\. 🐍 25 3\. 👍 26 27Links 28 29My favorite websites are: 30 * realpython.com 31 * python.org 32 * pypi.org 33</body> 34</html> ```py 当您在浏览器中打开网站时,浏览器似乎根本没有识别任何空格。尽管您在`<body>`中将内容分布在多行上,但浏览器将所有内容显示为一个连续的行: [](https://files.realpython.com/media/03-index-whitespace.1920593829ce.png) 作为一名 Python 开发人员,您知道空白是编写漂亮的 Python 代码的重要组成部分。Python 代码的缩进会影响 Python 执行代码的方式。 无需任何额外的调整,浏览器将多个空格、换行符或缩进折叠成一个空格字符。要以不同的方式设置内容的格式,您必须向浏览器提供进一步的信息。继续通过向您的内容添加 HTML 标签来构建`index.html`:1
2
3
4
5
6
7Am I HTML already?
8
9
10Hello, World Wide Web!
11This is my first website.
12 13About me
14I'm a Python programmer and a bug collector.
15 16Random facts
17I don't just like emoji,
19
18I love emoji!My most-used emoji are:
2021
25 26- 🐞
22- 🐍
23- 👍
24Links
27My favorite websites are:
2829
33- realpython.com
30- python.org
31- pypi.org
32
34通过将文本包装在 HTML 块中,可以向浏览器提供关于内容意图的附加信息。首先,看看包装大块文本的 HTML 元素: | 线条 | HTML 元素 | 描述 | | --- | --- | --- | | Ten | `<h1>` | 你网站的主要标题 | | Eleven | `<p>` | 段落,用于组织文本和相关内容 | | Thirteen | `<h2>` | 二级标题,嵌套在`<h1>`下面 | | Sixteen | `<h3>` | 第三级标题,嵌套在`<h2>`下面 | | Twenty | `<ol>` | 有序列表,通常呈现为编号列表 | | Twenty-eight | `<ul>` | 无序列表,通常用项目符号(`•`)呈现 | 标题元素可以嵌套六层。虽然你通常只有一个`<h1>`元素,但你可能有多个`<h2>`到`<h6>`标签。标题元素是 HTML 文档的一部分,对于屏幕阅读器来说非常重要。例如,读者可能想从一个标题跳到另一个标题来浏览你的内容。 要编写有效且可访问的 HTML,您必须确保在代码中不跳过标题级别。你可以把标题标签想象成打开一栋建筑不同楼层的门。一个楼层可以有多个出口通往其他楼层。但是记住,如果你还没有第二层,你就不能建第三层。换句话说,除非您首先声明了`<h2>`,否则页面上永远不会有`<h3>`元素。 您在上面使用的一些 HTML 元素只包含文本。其他包含额外的 HTML 元素,进一步组织内容: | 线条 | HTML 元素 | 描述 | | --- | --- | --- | | Seventeen | `<em>` | 强调内容 | | Eighteen | `<strong>` | 表示重要内容 | | Twenty-one | `<li>` | 列表项必须包含在列表元素中 | 所有的 HTML 标签都传达意义。因此,仔细选择用于部分内容的标记非常重要。当你使用正确的语义时,你就能让每个人以你想要的方式消费你的内容。您让所有人都可以访问您的网站: > 网络基本上是为所有人而设计的,不管他们的硬件、软件、语言、位置或能力如何。当网络满足这一目标时,具有不同听觉、运动、视觉和认知能力的人都可以访问它。([来源](https://www.w3.org/WAI/fundamentals/accessibility-intro/)) 一些 HTML 元素非常简单。对于段落,你使用`<p>`。其他元素有点难以理解: Kushagra Gour 在他的博客条目 [Strong vs Em](https://kushagra.dev/blog/strong-vs-em/) 中提供了一个很好的总结: > 如果只是视觉重要性,你要`strong`。如果它改变了句子的意思,使用`em`。 换句话说,`em`意味着你在说话时会强调这个词。例如,如果有人说,“你看起来不像 T2 那么坏,”你可能会想,“但是我闻起来像 T4 吗?”强调的位置是句子意思的关键。 例如,如果你只是想把读者的注意力吸引到一个词汇上,那么你可能会想用`strong`来代替。 如果有疑问,不要犹豫,在网上搜索 HTML 名称。你可以找到关于任何 HTML 元素的讨论和用法说明。 此外,浏览器的默认 HTML 样式通过对元素进行不同的样式化,可以给人一种不错的印象: [](https://files.realpython.com/media/04-index-default-styling.ba56dcefe632.png) 有了标记,你就可以给网站内容增加意义。编写语义正确的 HTML 对于理解你的内容很重要。 在 HTML 文档中使用正确的语义不仅对浏览器有帮助。它还使使用[文本到语音转换](https://en.wikipedia.org/wiki/Speech_synthesis)软件的用户可以访问呈现的 HTML 页面。 如果你想了解更多关于现代 HTML 的知识,那么 [HTML5 Doctor](https://html5doctor.com) 是一个很好的资源。要了解更多关于可访问性的信息,你可以查看谷歌关于让所有人都能访问网络[的课程。](https://web.dev/accessible/) [*Remove ads*](/account/join/) ### 链接、图像和表格 从一个网站跳到另一个网站是互联网的重要组成部分。这些引用被称为**超链接**,通常被称为**链接**。如果没有链接,网站就会孤立存在,只有知道网址才能访问。 此外,如果没有连接页面的链接,您将无法在网站的多个页面之间导航。要连接到目前为止已经创建的 HTML 文档,请在 HTML 源代码中添加一个导航菜单:Am I HTML already? ```py使用
<nav>元素,您可以声明一个提供导航的部分。在<nav>中,您添加了一个带有<a>标签的链接,这是 anchor 的缩写。href属性代表超文本链接,包含链接的目标。通过相对链接,你可以引用你的目录树中的文件。当你有一个链接时,你可能希望看到一个 URL,但是相对链接不是这样。
在这种情况下,您链接到一个名为
emoji.html的文件。浏览器明白可以在同一个目录下找到emoji.html,为你完成完整的 URL。这样,当您决定在某个时候部署您的 web 项目时,您不需要担心改变任何绝对路径。到目前为止,
emoji.html还不存在。要解决这个问题,在index.html旁边创建一个名为emoji.html的新文件:<!-- emoji.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>My favorite emoji</title> </head> <body> <nav> <a href="index.html">Home</a> </nav> <h1>My favorite emoji</h1> <p>I don't just <em>like</em> emoji,<br> I <strong>love</strong> emoji!</p> <p>Here's a list of my most-used emoji:</p> <ol> <li>🐞</li> <li>🐍</li> <li>👍</li> </ol> </body> </html> ```py `emoji.html`的结构和`index.html`类似。`emoji.html`中的`<body>`的内容与`index.html`的随机事实部分几乎相同,除了你改变了标题并将其上移一级为`<h1>`。 在`<body>`的顶部,你还有一个`<nav>`元素。然而,这一次,你链接到了`index.html`。 接下来,在项目目录中创建一个名为`images/`的新文件夹,并添加一个名为`gallery.html`的文件:1
2
3
4
5
6
7Image gallery
8
9
10
14Image gallery
15
16一会儿你会给`gallery.html`添加一些图片。但是首先,看一下第 11 行和第 12 行,在那里你链接到你的其他页面。 因为`index.html`和`emoji.html`是`gallery.html`上面的一个文件夹,所以必须在链接目标的前面加上两个点(`..`和一个斜线(`/`)。 为了更方便地访问,您还可以在`index.html`的导航菜单中添加您的图库链接:Am I HTML already? ```py您也可以在
emoji.html中链接到您的图库:<!-- emoji.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>My favorite emoji</title> </head> <body> <nav> <a href="index.html">Home</a> <a href="images/gallery.html">Gallery</a> </nav> <!-- ... --> ```py 如果你添加一个链接到一个 HTML 页面,那么你必须考虑从你现在所在的文件导航到那里。`gallery.html`文件是`index.html`下一个目录中的一个名为`images/`的文件夹。所以当你链接到`gallery.html`时,你需要在链接中包含子文件夹,你已经在上面做了。 相对链接对于链接你网站的页面很有用。当你想添加外部链接时,你可以使用**绝对链接**:Links
My favorite websites are:
```py你不是链接到 HTML 文件,而是链接到你最喜欢的网站列表中的绝对网址。这些链接与你在浏览器地址栏中输入的链接相同。
跳到浏览器,使用您刚刚添加的链接浏览您的网站:
https://player.vimeo.com/video/740468915?background=1
链接不仅仅是连接网站页面的便利工具,它们还是互联网基础设施的重要组成部分。如果你想了解更多关于链接的知识,那么看看这个 HTML 锚教程。
网络的另一个重要元素是图像。如果没有分享假期照片和猫咪 gif 的能力,互联网将会变得索然无味。
您使用包含一个
src属性的<img>元素将图像附加到您的 HTML 文档中。就像链接中的href一样,你在src中引用图像源。此外,您应该始终使用alt属性来添加描述图像的可选文本。这样,使用屏幕阅读器的人就可以访问您的网站。更新
gallery.html并链接到三个图像:<html lang="en"> <head> <meta charset="utf-8"> <title>Am I HTML already?</title> <style> body { background-color: rgb(20, 40, 60); color: rgb(240, 248, 255); } a { color: rgb(255, 111, 111); } </style> </head> <body> <!-- ... --> </body> </html> ```py<!-- images/gallery.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>Image Gallery</title> </head> <body> <nav> <a href="../index.html">Home</a> <a href="../emoji.html">Emoji</a> </nav> <h1>Image Gallery</h1> <img src="sky_1.png" alt="Cloudy sky."> <img src="sky_2.png" alt="Sun shining through a cloudy sky."> <img src="sky_3.png" alt="Sky with almost no clouds."> </body> </html> ```py 点击下面的代码下载材料后,您会在`images/`文件夹中找到天空图像: **免费奖励:** [点击这里下载本教程](https://realpython.com/bonus/html-css-python-code/)的补充资料,包括一个省时的 HTML 模板文件。 如果您使用自己的图像,那么您需要相应地调整文件名。不要忘记也更新描述图片内容的`alt`文本到[使你的图片可访问](https://www.w3.org/WAI/tutoriaimg/)。 `alt`文本大致相当于 Python 中的[文档字符串。docstring 可以描述对象的用途,而`alt`文本描述图像的内容。就像 docstring 一样,`alt`文本应该以点(`.`)结尾。](https://realpython.com/documenting-python-code/#documenting-your-python-code-base-using-docstrings) 给你的图片添加额外的信息是额外的工作,但是值得一做。如果照片里有一只可爱的狗,每个人都应该知道照片里有一只可爱的狗。如果你需要任何令人信服的东西,请前往 axess 实验室的 [Alt-texts:终极指南](https://axesslab.com/alt-texts/)。 当你在浏览器中打开`gallery.html`时,你的页面应该看起来像这样: [](https://files.realpython.com/media/06-gallery-no-styling.e19041073914.png) 图片是让你的网站更具视觉吸引力的好方法。然而,图片库有点杂乱无章,没有任何额外的样式,网站看起来相当老派。是时候改变这种状况了! 在下一节中,您将向 HTML 添加样式规则,并更好地控制网站元素的外观。 [*Remove ads*](/account/join/) ## 用 CSS 设计你的内容 当您在浏览器中打开一个普通的 HTML 文件时,默认情况下浏览器会添加一些样式。这就是为什么您能够区分上一节中的元素,尽管您自己没有添加任何样式。 这基本上是一种从浏览器到人类的服务。但是严格来说,你写 HTML 的时候,只是定义了你网站的标记。纯 HTML 不为页面上的元素提供任何样式。要设计元素的样式,您需要添加 CSS。 CSS 代表**级联样式表**。稍后您将看到,您可以组合和嵌套您的 CSS 样式规则,因此命名为*级联*样式表。 就像 HTML 一样,它是互联网的基石技术。它可以帮助你将网站的外观与实际内容区分开来: > 除了具有良好的语义和吸引人的布局之外,您的内容应该在其源代码顺序中具有逻辑意义——您可以在以后使用 CSS 将其放置在您想要的位置,但是您应该从源代码顺序开始,这样屏幕阅读器用户向他们读出的内容才会有意义。([来源](https://developer.mozilla.org/en-US/docs/Learn/Accessibility/HTML#page_layouts)) 在这一节中,你将学习如何通过添加 CSS 来控制你的网站的样式。 ### 为你的网站增添色彩 到目前为止,你只使用了浏览器来*加载*你的 HTML 文件。但是网络浏览器是强大的工具,当你开发一个网站时,它们能给你极大的帮助。 您可以使用浏览器的[开发者工具窗格调查任何网站。尤其是当您使用 CSS 时,浏览器的开发工具会派上用场:](https://developer.mozilla.org/en-US/docs/Learn/Common_questions/What_are_browser_developer_tools) [https://player.vimeo.com/video/740478263?background=1](https://player.vimeo.com/video/740478263?background=1) 请注意,您的开发人员工具中的更改不会持续。当您重新加载页面时,所有更改都将消失。因此,一旦您对样式调整感到满意,就需要将代码复制并粘贴到 HTML 文件的`<style>`标签中。 打开`index.html`,在`<head>`中添加`<style>`元素:使用
<style>元素,您可以将 CSS 代码添加到 HTML 文档中。尽管浏览器对此并不严格,但你应该只将<style>元素放在<head>中。否则,浏览器可能会试图在应用任何 CSS 规则之前呈现元素,这可能会导致无样式内容的闪现。
<style>的内容不是 HTML 代码,而是 CSS。使用 CSS,您可以定义如何在页面上设置元素样式的规则。用选择器,你定义你想要的目标元素,然后是声明块。在上面的 CSS 代码中,使用了类型选择器来定位
<body>和所有<a>元素。在本教程的后面,您将使用一些其他类型的 CSS 选择器。如果你想学习更多关于 CSS 选择器的知识,那么去 Mozilla 的 CSS 选择器页面。声明块由左大括号(
{)和右大括号(})分隔。用分号(;)分隔块内的声明。宣言本身由两部分组成:
- 属性:定义特征的标识符
- 值:应该如何处理特征的描述
属性和值由冒号(
:)分隔。在上面的例子中,通过指定的 RGB 值,你将<body>的背景色改为深蓝色,文本改为非常浅的灰色。在第二个 CSS 规则集中,你用现代的鲑鱼色调给所有的链接着色。颜色是控制网站外观和感觉的重要部分。在 CSS 中,你有多种方式来描述颜色。你可以看看 Smashing 杂志的现代 CSS 颜色指南来扩展你关于 CSS 中颜色使用的知识。
注意:有超过一个上百种不同的属性可以使用,并且有大量的值可以分配给它们。但是就像 Python 一样,你写的 CSS 越多,你就越了解它的功能、特点和一般语法。
除了颜色的选择,你还可以用字体改变网站的外观。您已经更改了文本的颜色。接下来,用
font-size属性调整body的文本大小:<!-- index. html --> <!-- ... --> <style> body { background-color: rgb(20, 40, 60); color: rgb(240, 248, 255); font-size: 1.3em; } a { color: rgb(255, 111, 111); } </style> <!-- ... --> ```py 使用`font-size: 1.3em;`,您告诉浏览器显示比父元素字体大`1.3`倍的文本。`<body>`的父元素是`<html>`,所以在浏览器中显示的文本会比默认字体大`1.3`倍。默认的字体大小通常是 16 像素,所以文本将以大约 21 像素的大小显示。 你可以直接用像素来定义字体大小。然而,通常使用百分比或`em`来表示文本大小: > em 单位以字母“M”命名,在印刷术中有着悠久的传统,它被用来测量水平宽度。([来源](https://www.w3.org/Style/LieBos3e/em)) 当你不得不把 T2 字母铸进金属块时,字母 M 通常占据了铸块的整个水平宽度。在 CSS 中,您也可以使用`em`来表示垂直长度,这是创建可伸缩设计的好单位。这意味着你的用户可以在不破坏设计的情况下放大你的网站。当用户希望增加字体大小以更好地阅读您的内容时,或者当他们从移动设备访问您的网站时,这一点非常重要。 像素和`em`只是 CSS 中可以使用的[多种长度单位中的两种。当你开始专注于设计你的网站时,看看这些单元并尝试不同类型的单元是值得的。](https://www.w3.org/Style/Examples/007/units.en.html) 除了文本的大小,显示文本的字体是另一个对网站设计有巨大影响的因素。 [*Remove ads*](/account/join/) ### 改变字体 字体是改变文档字符的绝佳工具。在网站上使用字体时,您有两种选择: 1. 依靠你的访问者在他们的系统上安装的字体。 2. 从您的服务器或外部资源加载自定义 web 字体。 无论哪种选择,定义一个**字体堆栈**都是一个好主意。当您为`font-family`列出多种字体时,浏览器会尝试从左至右加载字体:当你如上所示声明一个字体堆栈时,浏览器首先尝试加载 [Helvetica 字体](https://en.wikipedia.org/wiki/Helvetica)。如果浏览器在字体堆栈中找不到字体,它会继续加载下一个**备用字体**。在这种情况下,如果 Helvetica 和 Arial 都不存在,浏览器将加载任何 T4 无衬线字体。 为你的项目选择合适的字体是让你的内容易于理解的良好开端。但是请记住,除了字体之外,还有其他因素会影响文本的易读性。你可以通过调整字体大小、行高和颜色来改变[网页排版](https://www.toptal.com/designers/typography/web-typography-infographic)的外观和感觉。你的文本可读性越强,每个人就越容易理解! 注意:你可以按照你喜欢的任何方式对你的 CSS 属性进行排序。从长远来看,字母顺序更易于维护,而按功能对属性进行分组可能更易于编写。一些 CSS 开发人员甚至按照长度对他们的 CSS 属性[进行排序。](https://css-tricks.com/poll-results-how-do-you-order-your-css-properties/) 在浏览器中打开`index.html`,看看显示的是哪种字体: [](https://files.realpython.com/media/07-index-first-styling.12974b80bb2a.png) 您可以使用浏览器的开发工具[调查加载了哪种字体](https://developer.chrome.com/blog/devtools-answers-what-font-is-that/)。如果不是 Helvetica 或阿里亚呢?跳到下面的评论,让真正的 Python 社区知道你的系统加载的是哪种字体! 如果你想对显示的字体有更多的控制,那么你需要加载自定义的网络字体。如何在 CSS 中使用@ font-face 是在你的网站上实现自定义网页字体的一个很好的指南。 使用你添加到 HTML 中的 CSS,你只是在设计你的网站。用 CSS 来设计你的内容几乎有无数种方式。如果你想深入了解,那么你可以查看 Mozilla 的 CSS 参考资料。 ### 分开你的顾虑 在`<style>`元素的帮助下,您将前一节中的 CSS 代码直接添加到了`index.html`中。如果你想以同样的方式设计`emoji.html`,那么你需要复制并粘贴代码。 作为 Python 开发人员,您知道复制和粘贴代码不是最好的主意。您最终会在两个地方得到相同的代码,这使得更新代码变得很麻烦。 在你的 Python 代码中,你可以[导入模块](https://realpython.com/python-modules-packages/)以防止重复。HTML 提供了类似的功能来将外部资源加载到 HTML 代码中。这允许你加载一个外部 CSS 文件,并从你的 HTML 文件中引用这个**样式表**。 在`index.html`和`emoji.html`旁边创建一个名为`style.css`的新文件。然后,将`index.html`中`<style>`的内容剪切下来,粘贴到`style.css`中:1/* style.css */ 2
3body { 4 background-color: rgb(20, 40, 60); 5 color: rgb(240, 248, 255); 6 font-family: "Helvetica", "Arial", sans-serif; 7 font-size: 1.3em; 8} 9
10a { 11 color: rgb(255, 111, 111); 12}<html lang="en"> <head> <meta charset="utf-8"> <title>Am I HTML already?</title> <link rel="stylesheet" href="style.css"> <!-- Removed: <style> ... </style> --> </head>请注意,您的 CSS 文件只包含 CSS 声明。在 CSS 文件中,您不需要在`index.html`中用来包装 CSS 代码的`<style>`标签。 另外,注意第 1 行中 **CSS 注释**的语法。后跟星号(`/*`)的正斜杠表示注释的开始。你可以在多行中分发一个 [CSS 注释](https://developer.mozilla.org/en-US/docs/Web/CSS/Comments)。用另一个星号加上一个正斜杠(`*/`)来结束注释。 现在你可以在你的`index.html`文件的头中引用`style.css`:<html lang="en"> <head> <meta charset="utf-8"> <title>My favorite emoji</title> <link rel="stylesheet" href="style.css"> </head>`<link>`元素类似于锚标记(`<a>`)。它还包含一个定义链接的`href`属性。然而,它是一个只包含属性的空元素,不会呈现一个可点击的超链接。 将`stylesheet`链接也添加到`emoji.html`:为了反映`gallery.html`中的变化,向`style.css`添加相对链接:1
2
3
4
5
6
7Image Gallery
8 9
10
11<html lang="en"> <head> <meta charset="utf-8"> <title>Am I HTML already?</title> <link rel="stylesheet" href="https://cdn.simplecss.org/simple.css"> <link rel="stylesheet" href="style.css"> </head>记住`style.css`是`gallery.html`上面的一个目录,在你的`images/`目录里。所以不要只是链接到`style.css`,你必须链接到`../style.css`。 一旦更新了 CSS 引用,请在浏览器中查看您的页面: [https://player.vimeo.com/video/740468952?background=1](https://player.vimeo.com/video/740468952?background=1) 现在,您所有的页面都共享相同的样式。当您在`style.css`中更改 CSS 代码时,您可以看到所有页面上出现的更改。 作为一名 Python web 开发人员,您可能需要在 web 项目中自己编写一点 HTML。然而,对于 CSS 来说,使用外部的 **CSS 框架**来照顾你的设计是相当常见的。 CSS 框架为你提供了现成的 CSS 代码。为了充分发挥 CSS 框架的优势,您可能需要调整 HTML 代码以符合其规则集。但是一旦你习惯了 CSS 框架,从长远来看,它可以省去你显式设计 HTML 元素的工作。 最流行的 CSS 框架之一是 [Bootstrap](https://getbootstrap.com) 。你还会遇到 [Simple.css](https://simplecss.org) 或[布尔玛](https://bulma.io),包括在真正的 Python 教程中[管理你的待办事项列表](https://realpython.com/django-todo-lists/)和[创建抽认卡应用](https://realpython.com/django-flashcards-app/)。 **注意:**如果你想从头开始你的 CSS 设计,你也可以加载一个外部的**重置样式表**。通过在加载你的样式之前添加一个[重置样式表](https://en.wikipedia.org/wiki/Reset_style_sheet),你重置了浏览器的所有默认样式。这使您可以完全控制页面上任何 HTML 元素的样式。 您可以添加外部的非本地 CSS 样式表,就像您的带有`<link>`元素的本地样式表一样。如果你在网站上引用了不止一个样式表,顺序很重要。稍后您将研究这种行为。 首先,继续向 HTML 页面添加另一个样式表链接。下面是`index.html`的示例代码:正如 CSS 中的 C 所暗示的,你也可以层叠样式表。当您在浏览器中打开`index.html`时,您可以看到设计已经改变: [](https://files.realpython.com/media/09-external-css.a2eac66b17bd.png) 您组合了本地`style.css`和外部`simple.css`的样式规则。尝试加载外部样式表的顺序。当你重新加载你的页面时,你会发现你的网站外观发生了变化。 类似于在 Python 中覆盖变量,CSS 属性互相覆盖。一般来说,应用于元素的最后一个值胜出。 在本节中,您了解到可以使用外部样式表来代替`<style>`元素。甚至还有第三种方法将 CSS 规则添加到 HTML 中。您可以使用一个`style` HTML 属性来直接设计 HTML 元素的样式。这被称为**内联 CSS 样式**。 **注意:**内联 CSS 样式有它的用例。但是当你开始学习 HTML 和 CSS 的时候,尽量不要使用它。一般来说,添加[内联 CSS 被认为是不好的做法](https://stackoverflow.com/questions/2612483/whats-so-bad-about-in-line-css)。 更加明确地将 CSS 声明与特定的 HTML 元素连接起来,可以让您获得完善设计所需的控制。在下一节中,您将学习如何使用 CSS 类更灵活地设计元素的样式。 [*Remove ads*](/account/join/) ### 使用类以获得更大的灵活性 到目前为止,您设置的 CSS 规则只针对一般的 HTML 元素。但是,当您为 HTML 属性设置规则时,您可以更具体地使用 CSS 代码。 给 HTML 元素添加一个`class`属性可以让你使用 **CSS 类选择器**根据元素的类值来设计元素的样式。 CSS 类的一个基本特征是,它们允许你将公共元素分组,并一次性对所有元素应用一组规则,然后在保持风格一致的同时潜在地更新它们。 例如,您可以定义一个将圆角应用于图像的类。但是,您可以只为那些应该有圆角的图像分配一个类,而不是使用`img`名称来定位所有的图像元素。这为您提供了一个额外的优势,即可以通过给其他元素添加相同的类来给它们添加圆角。 要了解 CSS 类选择器是如何工作的,调整`gallery.html`中的代码,使其看起来像这样:1
2
3
4
5
6Image Gallery
7 8 9
10
11
12
13Image Gallery
14151916
17
18
首先,记得添加一个到外部样式表的链接。不要忘记在前面添加两个点来链接到`../style.css`,因为样式表在`gallery.html`之上一个文件夹。 然后,将`<img>`元素包装在`<div>`块中。`<div>`元素是构建页面的通用元素。它不包含任何语义,只有当没有其他 HTML 标签更适合使用时,才应该使用它。 您还可以向 HTML 元素添加`class`属性。在第 14 行,您甚至在一个空格分隔的列表中链接类。这意味着您将两个 CSS 类应用于`<div>`元素。相比之下,第 15 到 17 行中的`<img>`元素只包含一个 CSS 类。 要创建类,请转到`style.css`并添加以下 CSS 代码:1/* style.css / 2
3/ ... */ 4
5.gallery { 6 background: rgba(255, 255, 255, 0.2); 7 padding: 1em; 8} 9
10.rounded { 11 border-radius: 15px; 12} 13
14.gallery img { 15 margin-right: 0.2em; 16 width: 150px; 17}你在 HTML `class`属性中引用 CSS 类,不带点(`.`)。然而,在你的 CSS 代码中,你必须在一个选择器的开头添加一个点来指定你的目标是`class`属性。如果你想阅读更多关于 CSS 选择器的内容,那么去 Mozilla 的 [CSS 选择器](https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Selectors)文档。 在第 6 行和第 7 行中,您为`.gallery`设置了规则,比如一个部分透明的背景和一个`1em`填充来增加 gallery 元素内部所有边的空间。 使用`.rounded`选择器,给所有包含这个类的 HTML 元素一个半径为 15 像素的圆角。 您甚至可以像在第 14 行那样链接您的 CSS 选择器。使用空格分隔的选择器列表`.gallery img`,您为带有类`gallery`的 HTML 元素中的所有`img`元素添加了一个规则。通过第 15 行和第 16 行的 CSS 声明,使用`margin-right`在右侧给它们留出一些空间,并使图库图像为 150 像素宽。 使用`padding`、`margin`和`border`属性,您可以定义 CSS 元素的间距。你可以把这些元素想象成盒子,它们周围有一定的空间,里面有存储内容的空间。这个概念被称为**箱式模型**: > CSS 中的每样东西都有一个方框,理解这些方框是用 CSS 创建更复杂布局的关键,也是将项目与其他项目对齐的关键。([来源](https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/The_box_model)) 如果你想更深入地研究 CSS,那么学习盒子模型是关键。你可以跟随 Mozilla 的[学习如何使用 CSS](https://developer.mozilla.org/en-US/docs/Learn/CSS) 来设计 HTML 的风格,以便更好地理解 CSS 包含的所有构件。 您可以从这里出发,探索 HTML 和 CSS 提供的标记和设计世界。但是特别是对于 HTML,你很快就会注意到它是一种非常冗长的语言,而且手写起来很麻烦。这是您作为 Python 开发人员可以大放异彩的地方。 在下一节中,您将了解 Python 如何帮助您更有效地处理 HTML 文件。 [*Remove ads*](/account/join/) ## 用 Python 处理 HTML】 作为一名 Python 开发人员,您知道 Python 是一个很好的工具,可以将原本需要手工完成的任务自动化。尤其是在处理大型 HTML 文件时,Python 的强大功能可以帮您节省一些工作。 ### 以编程方式编写 HTML 有了所有的开始和结束标签,HTML 可能很难写。幸运的是,Python 非常适合帮助您以编程方式创建大型 HTML 文件。 在这一部分,您将扩展`emoji.html`来显示更多关于您最喜欢的表情符号的信息。用表格替换有序列表:1
2
3
4My favorite emoji
5I don't just like emoji,
6I love emoji!
7Here's a table of my most-used emoji:
8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 3435
# Emoji Name 1. 🐞 Lady Beetle 2. 🐍 Snake 3. 👍 Thumbs Up Sign 您用`<table>`元素定义一个 HTML 表格,用`<tr>`定义表格行。就像电子表格中的表格一样,HTML 表格可以有表头和表体。虽然使用`<thead>`和`<tbody>`并不是表格工作的必要条件,但是将它们添加到表格标记中是一个很好的做法。 在表头中,通过向第一行添加三个`<th>`元素来定义三个表列。 表体包含相同数量的列和一行或多行。对于表格数据单元格,使用与表格标题中相同的`<td>`元素。 表情符号表列出了你最喜欢的三个表情符号及其 Unicode 描述。当然,没有人只有三个最喜欢的表情符号! 即使只有 12 个最喜欢的表情符号,手动创建 HTML 表格也很烦人。所以你把 Python 加入到这个组合中! 在项目目录中创建一个名为`emoji_table.py`的新 Python 文件,让 Python 为您完成这项工作:emoji_table.py
import unicodedata
all_emoji = "🐞🐍👍🎉🤩😂🐶🍿😎✨💬😘"
columns = ["#", "Emoji", "Name"]table_head = f"\n{''.join(columns)}\n"
table_body = "\n\n"
for i, emoji in enumerate(all_emoji, start=1):
emoji_data = [f"{i}.", emoji, unicodedata.name(emoji).title()]
table_body += f"{''.join(emoji_data)}\n"
table_body += "\n"print(f"
\n{table_head}{table_body}")
借助内置的 [`unicodedata`](https://docs.python.org/3/library/unicodedata.html#module-unicodedata) 模块和 [`enumerate()`](https://realpython.com/python-enumerate/) ,Python 可以通过编程的方式为你构建一个表情表。 **注意:**字符串中的换行符(`\n`)是可选的。浏览器会忽略任何多于一个空格的空白。但是使用`\n`会让你的 HTML 代码更漂亮一点。 在您的终端中运行`emoji_table.py`,复制 HTML 代码,并将其粘贴到`emoji.html`:1
2
3
4My favorite emoji
5I don't just like emoji,
6I love emoji!
7Here's a table of my most-used emoji:
8
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 2728
# Emoji Name 1. 🐞 Lady Beetle 2. 🐍 Snake 3. 👍 Thumbs Up Sign 4. 🎉 Party Popper 5. 🤩 Grinning Face With Star Eyes 6. 😂 Face With Tears Of Joy 7. 🐶 Dog Face 8. 🍿 Popcorn 9. 😎 Smiling Face With Sunglasses 10. ✨ Sparkles 11. 💬 Speech Balloon 12. 😘 Face Throwing A Kiss 有了`emoji_table.py`,你现在可以扩展你的 HTML 表情表来包含所有你喜欢的表情。 如果您想让您的表格看起来更好一点,那么您可以使用`style.css`中的 [`:nth-child()`伪类](https://developer.mozilla.org/en-US/docs/Web/CSS/:nth-child)添加额外的样式:/* style.css / / ... */ th, tr:nth-child(even) { background-color: rgba(255, 255, 255, 0.2); } td:nth-child(1) { text-align: right; } td:nth-child(2) { text-align: center; }
HTML 表格是在你的网站上组织表格数据的好方法。你可以查看 Mozilla 关于 HTML 表格和[样式表格](https://developer.mozilla.org/en-US/docs/Learn/HTML/Tables)的文档,了解更多关于使用 HTML 表格的信息。 虽然`emoji_table.py`可以帮助你构建更大的表,但这仍然是一个复杂的过程。目前,您需要将终端输出复制到 HTML 文件中。那不理想。 但是现在是时候探索 Python 可以帮助您处理 HTML 代码的其他方法了。 [*Remove ads*](/account/join/) ### 用 Python 创建 HTML 实体 HTML 附带了一个很大的[命名字符引用列表](https://html.spec.whatwg.org/multipage/named-characters.html#named-character-references),你可以用它在 HTML 中编码你的文本。因此,举例来说,你可以把欧元符号写成 **HTML 实体** `€`而不是 **UTF-8** `€`字符。 在过去,像这样对字符进行编码很重要,因为没有办法直接输入它们。随着 [UTF-8 字符编码](https://en.wikipedia.org/wiki/UTF-8)的出现,你可以使用真正的 UTF-8 字符来代替。大多数时候,这甚至被推荐,因为它更具可读性。 尽管如此,有些情况下 HTML 编码是更好的选择。根据经验,当字符出现以下情况时,可以使用 HTML 实体: * 视觉上无法区分 * 干扰 HTML 语法 以空白字符为例。Unicode 字符数据库中列出了 25 个空白字符。有些看起来一模一样,像正规空格()和[非断空格](https://en.wikipedia.org/wiki/Non-breaking_space) ( )。视觉上,空间是不可区分的。但是当你看一下这个页面的源代码,你会发现后者被转义为它的 HTML 实体,` `: [](https://files.realpython.com/media/12-nbsp.64c38a7ec439.png) 如果要在 HTML 文档上显示 HTML 标签,还需要对像开尖括号(`<`)和闭尖括号(`>`)这样的字符进行转义。同样,看看本教程的源代码,注意尖括号是如何转义的: [](https://files.realpython.com/media/13-angle-brackets.56f9b437fc93.png) 左尖括号转义为`<`。右尖括号转义为`>`。 要查看 HTML 实体的完整列表,您可以利用 Python 内置的 [`html`](https://docs.python.org/3.10/library/html.html) 模块:
 16
16  17
17  18
18>>> import html
>>> html.entities.html5
{'Aacute': 'Á', 'aacute': 'á', 'Aacute;': 'Á', 'aacute;': 'á',
...
'zscr;': '𝓏', 'zwj;': '\u200d', 'zwnj;': '\u200c'}
```py
`html`的`entities`模块定义了四个字典。其中之一是`html5`,它将 HTML 命名的字符引用映射到对应的 Unicode 字符。
用`html.entities.codepoint2name`你可以找到一个字符的 HTML 实体名:
>>>
import html
code_point = ord("€")
code_point
8364
html.entities.codepoint2name[cp]
'euro'
欧元(`€`)的代码点是`8364`。对于`8364`,`codepoint2name`字典返回`'euro'`。要在 HTML 代码中使用这个名称,必须在名称前加一个&符号(`&`)并在名称后加一个分号(`;`),以获得有效的`€` HTML 实体。
您可以让 Python 来帮助您,而不是自己记忆和编写 HTML 实体。Python 的`html`模块还附带了一个解析器,当您想要解析 HTML 文档时,这个解析器非常方便。
### 用 Python 解析 HTML】
当您需要从 HTML 文件中读取数据时,Python 也可以使用内置的`html`模块来帮助您。在本节中,您将使用`html.parser`构建一个原始的 HTML **解析器**。您将要编写的脚本将引用您在本教程前面创建的`gallery.html`文件。您可以[重温教程的那一部分](#links-images-and-tables)或者点击下面的链接下载所有文件:
**免费奖励:** [点击这里下载本教程](https://realpython.com/bonus/html-css-python-code/)的补充资料,包括一个省时的 HTML 模板文件。
在`gallery.html`旁边,创建一个名为`parse_image_links.py`的新 Python 文件:
images/parse_image_links.py
from html.parser import HTMLParser
class ImageParser(HTMLParser):
def handle_starttag(self, tag, attrs):
for attr, val in attrs:
if attr == "src" and tag == "img":
print(f"Found Image: {val!r}")
with open("gallery.html", mode="r", encoding="utf-8") as html_file:
html_content = html_file.read()
parser = ImageParser()
parser.feed(html_content)
当您向 Python 的`HTMLParser`实例提供 HTML 数据时,如果找到标记元素,该实例将调用其处理程序方法。在上面的例子中,您创建了一个`HTMLParser`的**子类**,在`gallery.html`的代码中寻找任何具有`src`属性的`<img>`元素。
对于`gallery.html`文件,输出如下所示:
Found Image: 'sky_1.png'
Found Image: 'sky_2.png'
Found Image: 'sky_3.png'
对于您的本地文件,您可以在您的编辑器中查找,这可能不是一个大问题。但是想象一下,如果您调整上面的脚本来从任何给定的 URL 读取代码,会有什么样的可能性!
如果 Python 的`html`模块激发了你的兴趣,那么阅读[Python](https://realpython.com/python-web-scraping-practical-introduction/)的网络抓取实用介绍是一个不错的下一步。对于一个更实际的方法,你也可以[用漂亮的汤](https://realpython.com/beautiful-soup-web-scraper-python/)建造一个网络刮刀。
在开始解析之前,先看看本教程最后一节中的其他步骤。
[*Remove ads*](/account/join/)
## 继续使用 Python 中的 HTML 和 CSS
你可以用基本的 HTML 和 CSS 完成很多事情。当您将 Python 这样的编程语言融入其中时,使用 HTML 和 CSS 会变得更加有趣。
在这一节中,您将对可以利用您的 HTML 和 CSS 知识的技术进行概述。
### JavaScript
正如你在本教程中学到的,HTML 提供了一个网站的结构。使用 CSS,您可以添加格式和布局。这是创建网站的一个很好的基础。
然而,如果不提到 JavaScript,那么对 HTML 和 CSS 的介绍就不完整。JavaScript 是一种对现代网站至关重要的[解释编程语言](https://en.wikipedia.org/wiki/List_of_programming_languages_by_type#Interpreted_languages)。
使用 JavaScript,您可以向 web 项目添加功能。例如,当用户与您的网站交互时,您可以动态更新 HTML 和 CSS。
对于任何想从事 web 开发的程序员来说,学习 JavaScript 都是一个不错的选择。要更深入地研究 JavaScript,请前往 Mozilla 的 JavaScript 学习区。
如果你想从 Python 程序员的角度探索 JavaScript,那么看看[Python vs JavaScript for Python istas](https://realpython.com/python-vs-javascript/)。
### 金贾
在本教程中,您将 HTML 标记存储在 [Python 字符串](https://realpython.com/python-strings/)中,以动态创建 HTML 代码。当您的 web 项目发展时,HTML 和 Python 的混合会变得复杂。
为了分离关注点,使用**模板**是一个好主意。使用模板,您可以为大型网站创建构建块,而无需复制前端代码。这样,您可以将 HTML 标记保存在模板文件中,并用 Python 填充它们。Python 的首选**模板引擎**是 [Jinja](https://jinja.palletsprojects.com) 。
使用 Python 和 Jinja,您可以动态创建 HTML 代码。但你不必就此止步。任何时候你想创建带有编程内容的文本文件,Jinja 都可以帮你。
如果你想学习如何用 Jinja 构建丰富的模板,那么看看 Real Python 的关于 Jinja 模板化的[入门。](https://realpython.com/primer-on-jinja-templating/)
### 烧瓶
有了 HTML 和 CSS 的基础知识,你就可以构建你的第一个真正的 web 应用程序了。HTML 和 CSS 负责用户交互的前端。要从服务器加载内容,您需要某种后端。这就是 web 框架发挥作用的地方。
[Flask](https://flask.palletsprojects.com/) 是一个流行的 Python web 框架,非常适合从头开始构建 web 应用程序。在安装了带有 [`pip`](https://realpython.com/what-is-pip/) 的`flask`包之后,您就可以通过创建一个只有几行代码的 Python 文件来启动一个 Flask 项目。换句话说,你从小处着手,按照你自己的步调一步一步地增强你的项目。
您可以遵循 [Flask by Example](https://realpython.com/learning-paths/flask-by-example/) 学习路径,探索使用 Flask 微框架进行 Python web 开发的基础知识。
### 姜戈
Django 是另一个流行的 Python web 框架。与 Flask 相比,当您开始一个新的 Django 项目时,Django 为您提供了一个项目结构。不用自己添加太多代码,你就可以马上使用[管理后端](https://realpython.com/customize-django-admin-python/)和[数据库](https://realpython.com/python-sql-libraries/)。Django 的强大功能可以让您在更大的 web 项目中领先一步,但是对于初学者来说,浏览所有的文件可能会有些力不从心。
幸运的是,你可以找到大量关于真正 Python 的 [Django 教程来指导你。你可以通过](https://realpython.com/tutorials/django/)[开发一个文件夹应用](https://realpython.com/get-started-with-django-1/)或者[开发一个个人日记网络应用](https://realpython.com/django-diary-project-python/)来开始使用 Django。如果你想建立一个更大的项目,那么 [Django 社交网络系列](https://realpython.com/django-social-network-1/)非常适合你。
[*Remove ads*](/account/join/)
### PyScript
PyScript 是一个新的框架,允许你在网络浏览器中运行 Python。但是不要将其与 Flask 或 Django 等 web 框架混淆:
> PyScript 只是 HTML,只是稍微强大一点(好吧,可能强大很多),这要归功于 Python 库的丰富且可访问的生态系统。([来源](https://pyscript.net))
如果你感兴趣,那么在 Web 浏览器中让[先看看 PyScript: Python。](https://realpython.com/pyscript-python-in-browser/)
## 结论
无论你选择哪种方式成为 Python web 开发人员,HTML 和 CSS 都是不可避免的。这两种技术都是创建网站的基础。
在本教程中,您构建了一个样本 HTML 文档,为您即将开始的 web 项目提供了一个良好的开端。
**一路走来,你学会了如何:**
* 构建一个基本的 **HTML** 文件
* 显示**图片**和**链接**到页面
* 用 **CSS** 设计一个网站
* 考虑到**可访问性**来格式化 HTML
* 使用 Python 编写和解析 HTML 代码
Python、HTML 和 CSS 是一个强大的三重奏,使您能够创建小的 HTML 文档和大的 web 项目。但是,即使你的目标不是 web 开发人员,了解一两件关于 HTML 和 CSS 的事情也会帮助你更好地理解 Web。
**免费奖励:** [点击这里下载本教程](https://realpython.com/bonus/html-css-python-code/)的补充资料,包括一个省时的 HTML 模板文件。**********
# Python 中 if __name__ == "__main__ "是做什么的?
> 原文:<https://realpython.com/if-name-main-python/>
你可能在阅读别人的代码时遇到过 Python 的`if __name__ == "__main__"`习语。难怪——[流传甚广](https://github.com/search?q=__name__+%3D%3D+%22__main__%22&type=code)!您甚至可以在自己的脚本中使用`if __name__ == "__main__"`。但是你用对了吗?
也许你以前已经用类似于 [Java](https://realpython.com/java-vs-python/) 的 [C 族语言](https://en.wikipedia.org/wiki/List_of_C-family_programming_languages)编程过,你想知道这个构造是否是使用`main()`函数作为[入口点](https://en.wikipedia.org/wiki/Entry_point#Contemporary)的笨拙附件。
从语法上来说,Python 的`if __name__ == "__main__"`习语只是一个普通的[条件块](https://realpython.com/python-conditional-statements/):
```py
1if __name__ == "__main__":
2 ...
从第 2 行开始的缩进块包含了当第 1 行的条件语句求值为True时 Python 将执行的所有代码。在上面的代码示例中,您放在条件块中的特定代码逻辑用占位符省略号 ( ...)表示。
那么——如果if __name__ == "__main__"习语没有什么特别的,那么为什么看起来令人困惑,为什么它继续在 Python 社区引发讨论?
如果习语看起来仍然有点神秘,并且你不完全确定它是做什么的,为什么你可能想要它,以及什么时候使用它,那么你来对地方了!在本教程中,您将了解 Python 的if __name__ == "__main__"习语——从它在 Python 中的真正作用开始,以一个更快速引用它的建议结束。
源代码: 点击这里下载免费的源代码,你将使用它来了解习语这个名字。
简而言之:当文件作为脚本运行时,它允许您执行代码,但当它作为模块导入时,则不允许
出于最实际的目的,您可以将使用if __name__ == "__main__"打开的条件块视为一种存储代码的方式,这些代码只应在您的文件作为脚本执行时运行。
你马上就会明白这意味着什么。现在,假设您有以下文件:
1# echo.py
2
3def echo(text: str, repetitions: int = 3) -> str:
4 """Imitate a real-world echo."""
5 echoed_text = ""
6 for i in range(repetitions, 0, -1):
7 echoed_text += f"{text[-i:]}\n"
8 return f"{echoed_text.lower()}."
9
10if __name__ == "__main__":
11 text = input("Yell something at a mountain: ")
12 print(echo(text))
在本例中,您定义了一个函数echo(),它通过逐渐打印输入文本越来越少的最后几个字母来模拟真实世界的回声。
接下来,在第 10 到 12 行,您使用了if __name__ == "__main__"习语。这段代码从第 10 行的条件语句if __name__ == "__main__"开始。在缩进的第 11 行和第 12 行中,您收集用户输入并用该输入调用echo()。当您从命令行将echo.py作为脚本运行时,这两行将会执行:
$ python echo.py
Yell something at a mountain: HELLOOOO ECHOOOOOOOOOO
ooo
oo
o
.
当您通过将文件对象传递给 Python 解释器将文件作为脚本运行时,表达式__name__ == "__main__"返回True。然后运行if下的代码块,因此 Python 收集用户输入并调用echo()。
自己试试吧!您可以从下面的链接下载您将在本教程中使用的所有代码文件:
源代码: 点击这里下载免费的源代码,你将使用它来了解习语这个名字。
同时,如果您在另一个模块或控制台会话中导入echo(),那么嵌套代码将不会运行:
>>> from echo import echo >>> print(echo("Please help me I'm stuck on a mountain")) ain in n .在这种情况下,您希望在另一个脚本或解释器会话的上下文中使用
echo(),因此您不需要收集用户输入。运行input()会在导入echo时产生副作用,从而扰乱你的代码。当您将特定于文件脚本用法的代码嵌套在
if __name__ == "__main__"习语下时,您可以避免运行与导入的模块无关的代码。在
if __name__ == "__main__"下嵌套代码允许你迎合不同的用例:
- 脚本:当作为脚本运行时,您的代码提示用户输入,调用
echo(),并打印结果。- 模块:当你把
echo作为一个模块导入时,那么echo()被定义,但是没有代码执行。您向主代码会话提供了echo(),而没有任何副作用。通过在代码中实现
if __name__ == "__main__"习语,您设置了一个额外的入口点,允许您直接从命令行使用echo()。这就对了。您现在已经了解了关于这个主题的最重要的信息。尽管如此,还有更多东西需要了解,其中一些细微之处可以帮助您更深入地理解这段代码,更全面地理解 Python。
继续读下去,了解更多关于主习语的信息,因为本教程简称它。
域名习语是如何运作的?
在其核心,习语是一个条件语句,它检查变量
__name__的值是否等于字符串"__main__":
- 如果
__name__ == "__main__"表达式是True,那么执行条件语句后面的缩进代码。- 如果
__name__ == "__main__"表达式是False,那么 Python 会跳过缩进的代码。但是什么时候
__name__等于字符串"__main__"?在上一节中,您了解了在命令行中将 Python 文件作为脚本运行时的情况。虽然这涵盖了大多数真实生活中的用例,但也许您想更深入一些。如果 Python 解释器在顶级代码环境中运行您的代码,Python 会将模块的全局
__name__设置为等于"__main__":“顶层代码”是开始运行的第一个用户指定的 Python 模块。它是“顶级”的,因为它导入了程序需要的所有其他模块。(来源)
为了更好地理解这意味着什么,您将设置一个小的实际例子。创建一个 Python 文件,将其命名为
namemain.py,并添加一行代码:# namemain.py print(__name__, type(__name__))您的新文件只包含一行代码,它将全局
__name__的值和类型打印到控制台。启动您的终端,将 Python 文件作为脚本运行:
$ python namemain.py __main__ <class 'str'>输出显示,如果您将文件作为脚本运行,
__name__的值就是 Python 字符串"__main__"。注意:在顶层代码环境中,
__name__的值始终是"__main__"。顶层代码环境通常是作为文件参数传递给 Python 解释器的模块,如上所述。但是,还有其他选项可以构成顶级代码环境:
- 交互式提示的范围
- 用和
-m选项将 Python 模块或包传递给 Python 解释器,选项【】代表模块- Python 解释器从标准输入中读取 Python 代码
- Python 代码通过的
-c选项传递给 Python 解释器,代表命令如果您想了解更多关于这些选项的信息,那么请查看关于的 Python 文档,什么是顶级代码环境。文档用简明的代码片段说明了每一个要点。
现在,当您的代码在顶级代码环境中执行时,您知道了
__name__的值。但是,只有当条件有机会以不同的方式评估时,条件语句才能产生不同的结果。那么,什么时候你的代码不是运行在顶级代码环境中,在那种情况下
__name__的值会发生什么变化呢?如果你导入你的模块,你的文件中的代码不会在顶级代码环境中运行。在这种情况下,Python 将
__name__设置为模块的名称。为了测试这一点,启动一个 Python 控制台并从
namemain.py导入代码作为一个模块:
>>> import namemain
namemain <class 'str'>
Python 在导入过程中执行存储在全局名称空间namemain.py中的代码,这意味着它将调用print(__name__, type(__name__))并将输出写入控制台。
然而,在这种情况下,模块的__name__的值是不同的。它指向"namemain",一个等于模块名称的字符串。
注意:你可以导入任何包含 Python 代码的文件作为模块,Python 会在导入过程中运行你文件中的代码。模块的名称通常是没有 Python 文件扩展名(.py)的文件名。
您刚刚了解到,对于您的顶级代码环境,__name__始终是"__main__",所以请继续在您的解释器会话中确认这一点。还要检查字符串"namemain"来自哪里:
>>> __name__ '__main__' >>> namemain.__name__ 'namemain'全局
__name__的值为"__main__",导入的namemain模块的.__name__的值为"namemain",这是模块的字符串名称。注意:大多数时候,顶层代码环境是您执行的 Python 脚本,也是您导入其他模块的地方。然而,在这个例子中,您可以看到顶级代码环境并不严格地与脚本运行相关联,例如,它也可以是一个解释器会话。
现在您知道了
__name__的值将根据它所在的位置有两个值:
- 在顶级代码环境中,
__name__的值为"__main__"。- 在一个导入的模块中,
__name__的值是模块的名字作为一个字符串。因为 Python 遵循这些规则,所以您可以发现一个模块是否正在顶级代码环境中运行。您可以通过使用条件语句检查
__name__的值来实现这一点,这将带您回到主名称习语:# namemain.py print(__name__, type(__name__)) if __name__ == "__main__": print("Nested code only runs in the top-level code environment")有了这种条件检查,您就可以声明仅当模块在顶级代码环境中运行时才执行的代码。
将习语添加到
namemain.py中,如上面的代码块所示,然后再次将该文件作为脚本运行:$ python namemain.py __main__ <class 'str'> Nested code only runs in the top-level code environment当您的代码作为脚本运行时,对
print()的两个调用都会执行。接下来,启动一个新的解释器会话,并再次将
namemain作为模块导入:
>>> import namemain
namemain <class 'str'>
当您将文件作为模块导入时,您嵌套在if __name__ == "__main__"下的代码不会执行。
现在您已经知道了名称主习语在 Python 中是如何工作的,您可能想知道您应该何时以及如何在您的代码中使用它——以及何时避免它!
在 Python 中什么时候应该使用主习语这个名字?
当您想要为脚本创建一个额外的入口点时,可以使用这个习语,这样您的文件就可以作为一个独立的脚本以及一个可导入的模块来访问。当您的脚本需要收集用户输入时,您可能需要这样做。
在本教程的第一部分中,您使用了 name-main 习语和input()来收集运行脚本echo.py时的用户输入。这是使用“主习语”这个名字的一个很好的理由!
还有其他方法可以直接从命令行收集用户输入。例如,您可以使用sys.argv和名称 main 习语为一个小 Python 脚本创建一个命令行入口点:
1# echo.py
2
3import sys 4
5def echo(text: str, repetitions: int = 3) -> str:
6 """Imitate a real-world echo."""
7 echoed_text = ""
8 for i in range(repetitions, 0, -1):
9 echoed_text += f"{text[-i:]}\n"
10 return f"{echoed_text.lower()}."
11
12if __name__ == "__main__":
13 text = " ".join(sys.argv[1:]) 14 print(echo(text))
您没有使用input()收集用户输入,而是更改了echo.py中的代码,以便用户可以直接从命令行提供文本作为参数:
$ python echo.py HELLOOOOO ECHOOOO
ooo
oo
o
.
Python 将任意数量的单词收集到sys.argv中,这是一个表示所有输入的字符串列表。当空白字符将每个单词与其他单词分开时,每个单词都被视为一个新的参数。
通过执行处理用户输入的代码并将其嵌套在 name-main 习语中,您为脚本提供了一个额外的入口点。
如果您想为一个包创建一个入口点,那么您应该为此创建一个专用的 __main__.py 文件。这个文件表示当您使用 -m选项运行您的包时 Python 调用的入口点:
$ python -m venv venv
当您使用venv模块创建一个虚拟环境时,如上所示,然后运行在__main__.py文件中定义的代码。模块名venv后面的-m选项从venv模块中调用 __main__.py。
因为venv是一个包而不是一个小的命令行界面(CLI)脚本,所以它有一个专用的__main__.py文件作为它的入口点。
注意:在 name-main 习语下嵌套代码还有额外的优点,比如用户输入集合。因为嵌套代码不会在模块导入期间执行,所以您可以从一个单独的测试模块中对您的函数运行单元测试,而不会产生副作用。
否则会产生副作用,因为测试模块需要导入您的模块来针对您的代码运行测试。
在野外,您可能会遇到更多在 Python 代码中使用 name-main 习语的原因。然而,通过标准输入或命令行收集用户输入是使用它的主要原因。
什么时候你应该避免习语这个名字?
既然你已经学会了什么时候使用主习语这个名字,是时候找出什么时候使用它是最好的主意了。您可能会惊讶地发现,在许多情况下,有比将代码嵌套在 Python 中的if __name__ == "__main__"下更好的选择。
有时,开发人员使用主习语将测试运行添加到一个脚本中,该脚本将代码功能和测试组合在同一个文件中:
# adder.py
import unittest
def add(a: int, b: int) -> int:
return a + b
class TestAdder(unittest.TestCase):
def test_add_adds_two_numbers(self):
self.assertEqual(add(1, 2), 3)
if __name__ == "__main__":
unittest.main()
通过这种设置,当您将代码作为脚本执行时,您可以对代码运行测试:
$ python adder.py
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK
因为你将文件作为脚本运行,__name__等于"__main__",条件表达式返回True,Python 调用unittest.main()。小测试套件运行了,您的测试成功了。
同时,在将代码作为模块导入时,您没有创建任何意外的代码执行:
>>> import adder >>> adder.add(1, 2) 3仍然可以导入模块并使用您在那里定义的函数。除非在顶级代码环境中执行模块,否则单元测试不会运行。
虽然这适用于小文件,但通常不被认为是好的做法。不建议在同一个文件中混合测试和代码。相反,在单独的文件中编写测试。遵循这个建议通常会使代码库更有条理。这种方法还消除了任何开销,比如需要在主脚本文件中导入
unittest。一些程序员使用 name-main 习语的另一个原因是为了包含一个关于他们的代码能做什么的演示:
# echo_demo.py def echo(text: str, repetitions: int = 3) -> str: """Imitate a real-world echo.""" echoed_text = "" for i in range(repetitions, 0, -1): echoed_text += f"{text[-i:]}\n" return f"{echoed_text.lower()}." if __name__ == "__main__": print('Example call: echo("HELLO", repetitions=2)', end=f"\n{'-' * 42}\n") print(echo("HELLO", repetitions=2))同样,您的用户仍然可以导入该模块,而不会有任何副作用。此外,当他们将
echo_demo.py作为脚本运行时,他们可以看到它的功能:$ python echo_demo.py Example call: echo("HELLO", repetitions=2) ------------------------------------------ lo o .您可能会在习语中找到这样的演示代码执行,但是可以说还有更好的方式来演示如何使用您的程序。您可以使用可以兼作文档测试的示例运行编写详细的文档字符串,并且可以为您的项目编写适当的文档。
前面的两个例子涵盖了名称为 main 的习语的两个常见的次优用例。还有其他一些场景是最好避免使用 Python 中的名称主习语:
一个纯脚本:如果你写了一个的脚本,意味着作为一个脚本运行,那么你可以把你的代码执行放到全局名称空间中,而不用把它嵌套在主习语中。你可以使用 Python 作为脚本语言,因为它没有强制实施强面向对象模式。当你用 Python 编程时,你不必拘泥于其他语言的设计模式。
一个复杂的命令行程序:如果你写一个更大的命令行应用,那么最好创建一个单独的文件作为你的切入点。然后,从模块中导入代码,而不是处理名为 main 习语的用户输入。对于更复杂的命令行程序,使用内置的
argparse模块而不是sys.argv也会让你受益。也许你以前曾经为了这些次优的目的使用过习语这个名字。如果你想了解更多关于如何为这些场景中的每一个编写更地道的 Python 的知识,请点击提供的链接:
❌次优用例 ✅更好的选择 测试代码执行 创建专用测试模块 演示代码 构建项目文档并将示例包含在您的文档字符串中 创建一个纯脚本 作为脚本运行 提供复杂的 CLI 程序入口点 创建专用 CLI 模块 尽管您现在知道了何时应该避免使用主习语,但是您可能仍然想知道如何在有效的场景中最好地使用它。
你应该以何种方式包括名称-主要习语?
Python 中的 name-main 习语只是一个条件语句,所以你可以在文件中的任何地方使用它——甚至不止一次!然而,对于大多数用例,你将把的一个名字——主习语放在脚本的底部:
# All your code if __name__ == "__main__": ...您将名称 main 习语放在脚本的末尾,因为 Python 脚本的入口点总是在文件的顶部。如果你把主习语放在文件的底部,那么在 Python 计算条件表达式之前,你所有的函数和类都已经定义好了。
注意:在 Python 中,函数或类体中的代码在定义过程中不会运行。只有当你调用一个函数或者实例化一个类时,这些代码才会执行。
然而,尽管在一个脚本中使用多个主习语并不常见,但在某些情况下这样做可能是有原因的。Python 的风格指南文档 PEP 8 清楚地说明了将所有导入语句放在哪里:
导入总是放在文件的顶部,就在任何模块注释和文档字符串之后,模块全局变量和常量之前。(来源)
这就是为什么您在文件顶部的
echo.py中导入了sys:# echo.py import sys def echo(text: str, repetitions: int = 3) -> str: """Imitate a real-world echo.""" echoed_text = "" for i in range(repetitions, 0, -1): echoed_text += f"{text[-i:]}\n" return f"{echoed_text.lower()}." if __name__ == "__main__": text = " ".join(sys.argv[1:]) print(echo(text))然而,当您只是想将
echo作为一个模块导入时,您甚至根本不需要导入sys。为了解决这个问题,并仍然坚持在 PEP 8 中定义的风格建议,您可以使用第二个名字-主习语。通过将
sys的导入嵌套在名称主习语中,您可以将所有导入保存在文件的顶部,但避免在不需要使用sys时导入它:# echo.py if __name__ == "__main__": import sys def echo(text: str, repetitions: int = 3) -> str: """Imitate a real-world echo.""" echoed_text = "" for i in range(repetitions, 0, -1): echoed_text += f"{text[-i:]}\n" return f"{echoed_text.lower()}." if __name__ == "__main__": text = " ".join(sys.argv[1:]) print(echo(text))您将
sys的导入嵌套在的另一个名称下——主习语。这样,您可以将导入语句放在文件的顶部,但是当您将echo用作模块时,可以避免导入sys。注意:你可能不会经常遇到这种情况,但是它可以作为一个例子,说明在一个文件中使用多个主名习惯用法可能会有所帮助。
尽管如此,可读性还是很重要的,所以将 import 语句放在顶部,而不使用第二个名字——main 习语通常是更好的选择。然而,如果你在一个资源有限的环境中工作,第二个域名习语可能会派上用场。
正如你在前面的教程中了解到的,使用主习语的场合比你想象的要少。对于大多数用例,将这些条件检查之一放在脚本的底部将是您的最佳选择。
最后,您可能想知道什么代码应该放入条件代码块。在这方面,Python 文档提供了关于名为 main 的习语的习惯用法的明确指导:
在
if __name___ == '__main__'下面的块中放置尽可能少的语句可以提高代码的清晰性和正确性。(来源)尽量少用你的名字——主习语——写代码!当你开始将多行代码嵌套在名字 main 习语下时,你应该用定义一个
main()函数并调用这个函数:# echo.py import sys def echo(text: str, repetitions: int = 3) -> str: """Imitate a real-world echo.""" echoed_text = "" for i in range(repetitions, 0, -1): echoed_text += f"{text[-i:]}\n" return f"{echoed_text.lower()}." def main() -> None: text = " ".join(sys.argv[1:]) print(echo(text)) if __name__ == "__main__": main()这种设计模式的优势在于——main 习语名下的代码清晰简洁。此外,它使得调用
main()成为可能,即使你已经将你的代码作为一个模块导入,例如单元测试它的功能。注意:在 Python 中定义
main()的意思和在其他语言中不同,比如 Java 和 c .在 Python 中,将这个函数命名为 main 只是一个约定。您可以给这个函数起任何名字——正如您之前所看到的,您甚至根本不需要使用它。其他面向对象的语言将
main()函数定义为程序的入口点。在这种情况下,解释器隐式调用一个名为main()的函数,没有它你的程序就无法运行。在这一节中,你已经了解到你应该在剧本的底部写上名字“主习语”。
如果您计划将多行代码嵌套在
if __name__ == "__main__"下,那么最好将这些代码重构为一个main()函数,您可以从名为 main 习语的条件块中调用该函数。既然您已经知道如何使用主名称习语,您可能会奇怪为什么它看起来比您熟悉的其他 Python 代码更神秘。
是应该简化的习语样板代码吗?
如果您来自不同的面向对象编程语言,您可能会认为 Python 的 name-main 习语是一个入口点,类似于 Java 或 C 中的
main()函数,但是更笨拙:
Meme based on a web comic (Image: [Mike Organisciak](https://www.instagram.com/p/CH-kflgjCCZ/)) 虽然肯定有趣且相关,但这个迷因具有误导性,因为它暗示了名称主习语类似于其他语言中的入口点函数。
Python 的名字——main 习语并不特别。这只是一个条件检查。乍一看,它可能有点神秘,尤其是当您开始使用 Python,并且已经习惯了 Python 纤细优雅的语法时。毕竟,name-main 习语包括一个来自全局名称空间的 dunder 变量,以及一个也是 dunder 值的字符串。
所以它不是其他语言中 main 表示的入口点类型。但是为什么看起来是这样的呢?您可能已经多次复制和粘贴了习语,或者甚至将它打了出来,并且想知道为什么 Python 没有更简洁的语法。
如果你浏览 Python-ideas 邮件列表、被拒 PEPs 和 Python 讨论论坛的档案,你会发现许多改变习语的尝试。
如果你阅读了其中的一些讨论,那么你会注意到许多经验丰富的毕达哥拉斯派认为习语并不神秘,不应该被改变。他们给出了多种理由:
- 很短:大多数建议的修改只保存两行代码。
- 它有一个有限的用例:你应该只在你需要既作为模块又作为脚本运行一个文件的时候使用它。你应该不需要经常使用它。
- 它暴露了复杂性:一旦你看得更深一点,变量和函数是 Python 的一大部分。这可以使当前的习语成为激发学习者好奇心的一个切入点,并让他们初步了解 Python 的语法。
- 它保持向后兼容性:名字-main 习语长期以来一直是这种语言中事实上的标准,这意味着改变它会破坏向后兼容性。
好吧,所以你现在只能用
if __name__ == "__main__"了。似乎找到一种好的方法来一致而简洁地引用它会很有帮助!展开下面的部分,了解一些背景知识和一些建议,告诉你如何在不扭曲舌头或打结的情况下谈论习语这个名字:
在 Python 生涯的某个阶段,您可能会讨论使用主习语这个名字。写出来很长的表达,大声说出来就更繁琐了,不妨找个好的方式说说。
在 Python 社区中有不同的方式来引用它。大多数网上提及都包括整个
if __name__ == "__main__"表达式,后跟一个词:
if __name__ == "__main__"大会(来源if __name__ == "__main__"表情(来源if __name__ ...习语(来源if __name__ == "__main__": ...习语(来源if __name__ == "__main__"习语(来源- 可执行节(来源)
你可能会注意到,关于如何谈论
if __name__ == "__main__",并没有严格的约定,但是如果你按照普遍的共识称之为if __name__ == "__main__"习语,你可能不会做错。如果你想推广标准化的习语的简称,那么告诉你的朋友称它为主习语。在真正的 Python 中,我们将这样称呼它!如果你觉得这个术语有用,也许它会流行起来。
如果你很好奇,可以深入到各种 Python 社区渠道中的一些相关讨论中,了解更多关于开发人员为什么主张保持以域名为主的习语不变的信息。
结论
你已经学习了 Python 中的
if __name__ == "__main__"习语做了什么。它允许您编写将文件作为脚本运行时执行的代码,但不允许您将其作为模块导入时执行。当您希望在脚本运行期间收集用户输入并避免导入模块时的副作用(例如,对其功能进行单元测试)时,最好使用它。您还了解了一些常见但次优的用例,并了解了在这些场景中可以采用的更好、更习惯的方法。也许在了解了 Python 之后,你已经接受了它的名字——main 习语,但是如果你仍然不喜欢它,那么很高兴知道在大多数情况下你可能可以代替它的使用。
你什么时候在你的 Python 代码中使用名称主习语?在阅读本教程时,您是否发现了替换它的方法,或者是否有我们错过的好用例?请在下面的评论中分享你的想法。
源代码: 点击这里下载免费的源代码,你将使用它来了解习语这个名字。****
使用 Python Pillow 库进行图像处理
原文:https://realpython.com/image-processing-with-the-python-pillow-library/
当你看一幅图像时,你看到的是其中的物体和人。但是,当您使用 Python 或任何其他语言以编程方式读取图像时,计算机会看到一个数字数组。在本教程中,您将学习如何使用 Python Pillow 库操纵图像和执行基本的图像处理。
Pillow 和它的前身 PIL 是处理图像的原始 Python 库。即使有其他用于图像处理的 Python 库,Pillow 仍然是理解和处理图像的重要工具。
为了操作和处理图像,Pillow 提供了类似于 Photoshop 等图像处理软件中的工具。一些更现代的 Python 图像处理库构建在 Pillow 之上,通常提供更高级的功能。
在本教程中,您将学习如何:
- 用枕头阅读图片
- 执行基本图像操作操作
- 使用枕头进行图像处理
- 使用带枕头的 NumPy 进行的进一步加工
- 使用 Pillow 制作动画
本教程概述了通过 Python Pillow 库的一些最常用的方法可以实现的功能。一旦您对使用这些方法有了信心,那么您就可以使用 Pillow 的文档来探索库中的其余方法。如果您以前从未使用 Python 处理过图像,这是一个直接进入的好机会!
在本教程中,您将使用几个图像,您可以从教程的图像库中下载这些图像:
获取图像: 点击此处获取您将使用 Pillow 操作和处理的图像。
有了这些图片,您就可以开始使用 Pillow 了。
Python Pillow 库的基本图像操作
Python Pillow 库是一个名为 PIL 的老库的分支。PIL 代表 Python 图像库,它是使 Python 能够处理图像的原始库。PIL 于 2011 年停产,仅支持 Python 2。用开发人员自己的话来说,Pillow 是友好的 PIL 分叉,它使库保持活力,并包括对 Python 3 的支持。
Python 中有不止一个处理图像和执行图像处理的模块。如果你想通过操作像素直接处理图像,那么你可以使用 NumPy 和 SciPy 。其他流行的图像处理库有 OpenCV 、 scikit-image 和 Mahotas 。其中一些库比 Pillow 更快更强大。
然而,枕头仍然是处理图像的重要工具。它提供的图像处理功能类似于 Photoshop 等图像处理软件中的功能。枕头通常是不需要更高级图像处理专业知识的高级图像处理任务的首选。在处理图像时,它也经常用于探索性工作。
Pillow 还具有被 Python 社区广泛使用的优势,并且它没有像其他一些图像处理库那样陡峭的学习曲线。
你需要先安装这个库,然后才能使用它。您可以使用
pip在虚拟环境中安装枕头:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> .\venv\Scripts\activate (venv) PS> python -m pip install Pillow$ python -m venv venv $ source venv/bin/activate (venv) $ python -m pip install Pillow现在您已经安装了这个包,您已经准备好开始熟悉 Python Pillow library 并执行图像的基本操作。
枕头中的
Image模块和Image类Pillow 中定义的主类是
Image类。当您使用 Pillow 读取图像时,图像存储在类型为Image的对象中。对于本节中的代码,您将需要名为
buildings.jpg( image credit )的图像文件,您可以在本教程的图像库中找到该文件:获取图像: 点击此处获取您将使用 Pillow 操作和处理的图像。
您可以将此图像文件放在您正在使用的项目文件夹中。
当用 Pillow 探索图像时,最好使用一个交互式 REPL 环境。首先,您将打开刚刚下载的图像:

>>> from PIL import Image
>>> filename = "buildings.jpg"
>>> with Image.open(filename) as img:
... img.load()
...
>>> type(img)
<class 'PIL.JpegImagePlugin.JpegImageFile'>
>>> isinstance(img, Image.Image)
True
你可能会期望从枕头进口,而不是从 PIL。你确实安装了Pillow,毕竟不是PIL。然而,枕头是 PIL 图书馆的一把叉子。因此,在导入代码时,您仍然需要使用PIL。
您调用 open() 函数从文件中读取图像,并调用 .load() 将图像读入内存,这样文件现在可以关闭了。您使用一个with语句来创建一个上下文管理器,以确保文件一旦不再需要就被关闭。
在这个例子中,对象是一个特定于 JPEG 图像的类型,它是Image类的子类,正如您通过调用isinstance()所确认的那样。注意,该类和定义该类的模块共享同一个名字Image。您可以使用 .show() 显示图像:
>>> img.show()
.show()方法将图像保存为临时文件,并使用操作系统处理图像的本地软件显示。当您运行上面的代码时,您会看到下面的图像:
在一些系统中,调用
.show()会阻止 REPL,直到你关闭图像。这取决于您使用的操作系统和默认图像查看软件。在处理 Python Pillow 库中的图像时,您需要熟悉三个关键属性。您可以使用
Image类属性.format、.size和.mode来探索这些:

>>> img.format
'JPEG'
>>> img.size
(1920, 1273)
>>> img.mode
'RGB'
图像的格式显示了您正在处理的图像的类型。在这种情况下,图像的格式是'JPEG'。尺寸以像素为单位显示图像的宽度和高度。这张图的模式是'RGB'。稍后您将了解更多关于模式的内容。
通常,您可能需要裁剪图像并调整其大小。Image类有两个方法可以用来执行这些操作, .crop() 和 .resize() :
>>> cropped_img = img.crop((300, 150, 700, 1000)) >>> cropped_img.size (400, 850) >>> cropped_img.show() >>> low_res_img = cropped_img.resize( ... (cropped_img.width // 4, cropped_img.height // 4) ... ) >>> low_res_img.show()
.crop()的参数必须是一个 4 元组,它定义了要裁剪的区域的左、上、右和下边缘。Pillow 中使用的坐标系将坐标(0,0)分配给左上角的像素。这是通常用于二维阵列的同一坐标系。4 元组表示图像的以下部分:
在上面的代码中,
.crop()返回的新图像的大小为400x850像素。裁剪后的图像仅显示原始图片中的一个建筑物:
在上面的代码中,您还使用
.resize()更改裁剪图像的分辨率,这需要一个元组作为必需的参数。用作参数的元组以像素为单位定义图像的新宽度和高度。在上面的例子中,您使用地板除法运算符 (
//)和Image属性.width和.height将新的宽度和高度设置为其原始值的四分之一。对show()的最后一个调用显示了经过裁剪和调整大小的图像:
您可以使用
.resize()的其他可选参数来控制图像如何被重新采样。或者,您可以使用.reduce()实现类似的缩放:


>>> low_res_img = cropped_img.reduce(4)
参数决定了缩小图像的因子。如果你更喜欢设置一个最大尺寸而不是比例因子,那么你可以使用 .thumbnail() 。缩略图的大小将小于或等于您设置的大小。
注意:.thumbnail()方法就地改变Image对象,不返回新对象。然而,.crop()、.resize()、.reduce()都返回一个新的Image对象。并非 Pillow 库中的所有方法都以相同的方式运行。
一旦您对返回的图像满意,您可以使用 .save() 将任何Image对象保存到文件中:
>>> cropped_img.save("cropped_image.jpg") >>> low_res_img.save("low_resolution_cropped_image.png")调用方法后,它会在项目文件夹中创建图像文件。在这个例子中,一个图像是 JPEG 图像,另一个是 PNG 图像。用作文件名的扩展名会自动确定文件格式,或者您可以将格式指定为附加的可选参数。
基本图像操作
除了裁剪和调整大小之外,您还可以操作图像。另一个常见的需求是旋转或翻转图像。您可以使用
.transpose()方法进行一些变换。继续进行您在上一节中开始的 REPL 会话:
>>> converted_img = img.transpose(Image.FLIP_TOP_BOTTOM)
>>> converted_img.show()
这段代码显示了下面的图像:

有七个选项可以作为参数传递给.transpose():
Image.FLIP_LEFT_RIGHT: 左右翻转图像,产生镜像Image.FLIP_TOP_BOTTOM: 上下翻转图像Image.ROTATE_90: 将图像逆时针旋转 90 度Image.ROTATE_180: 将图像旋转 180 度Image.ROTATE_270: 将图像逆时针旋转 270 度,与顺时针旋转 90 度相同Image.TRANSPOSE: 使用左上角像素作为原点来转置行和列,转置图像中的左上角像素与原始图像中的相同Image.TRANSVERSE: 使用左下角像素作为原点来调换行和列,左下角像素是在原始版本和修改版本之间保持固定的像素
以上所有旋转选项都定义了 90 度的旋转步长。如果需要将图像旋转另一个角度,那么可以使用 .rotate() :
>>> rotated_img = img.rotate(45) >>> rotated_img.show()此方法调用将图像逆时针旋转 45 度,得到以下图像:
返回的
Image对象与原来的Image大小相同。因此,图像的角在此显示中丢失。您可以使用expand命名参数来改变这种行为:

>>> rotated_img = img.rotate(45, expand=True)
>>> rotated_img.show()
此方法返回一个更大的图像,该图像完全包含旋转后的图像:

您可以使用附加可选参数进一步定制旋转。您现在可以更改图像的大小和方向。在下一节中,您将了解 Python Pillow 库中不同类型的图像。
Python Pillow 库中图像的波段和模式
图像是二维像素阵列,其中每个像素对应一种颜色。每个像素可以由一个或多个值来表示。例如,在 RGB 图像中,每个像素由对应于该像素的红色、绿色和蓝色值的三个值表示。
因此,RBG 图像的Image对象包含三个波段,每种颜色一个。一个大小为100x100像素的 RGB 图像由一个100x100x3值数组表示。
RGBA 图像还包括阿尔法值,它包含每个像素的透明度信息。RGBA 图像有四个波段,每种颜色一个波段,第四个波段包含 alpha 值。每个条带的尺寸与图像尺寸相同。因此,大小为100x100像素的 RGBA 图像由一个100x100x4值数组表示。
图像的模式描述了您正在处理的图像的类型。Pillow 支持大多数标准模式,包括黑白(二进制)、灰度、RGB、RGBA 和 CMYK 。您可以在枕头文档中的模式上看到支持模式的完整列表。
您可以使用 .getbands() 方法找出一个Image对象中有多少个波段,并且您可以使用 .convert() 在模式之间转换。现在,在本教程中,您将使用图像库中名为strawberry.jpg ( image credit )的图像:

这张图片的模式也是 RGB。您可以将此图像转换为其他模式。此代码使用您在前面几节中启动的相同的 REPL 会话:
>>> filename = "strawberry.jpg" >>> with Image.open(filename) as img: ... img.load() ... >>> cmyk_img = img.convert("CMYK") >>> gray_img = img.convert("L") # Grayscale >>> cmyk_img.show() >>> gray_img.show() >>> img.getbands() ('R', 'G', 'B') >>> cmyk_img.getbands() ('C', 'M', 'Y', 'K') >>> gray_img.getbands() ('L',)您调用两次
.convert()将 RGB 图像转换为 CMYK 和灰度版本。CMYK 图像看起来与原始图像相似,但使用印刷材料常用的模式进行编码,而不是数字显示。转换为灰度会产生以下输出:
对
.getbands()调用的输出确认 RGB 图像中有三个波段,CMYK 图像中有四个波段,灰度图像中有一个波段。您可以使用
.split()将图像分成不同的波段,并使用merge()将不同的波段组合回一个Image对象。当您使用.split()时,该方法将所有波段作为单独的Image对象返回。您可以通过显示返回的对象之一的字符串表示来确认这一点:

>>> red, green, blue = img.split()
>>> red
<PIL.Image.Image image mode=L size=1920x1281 at 0x7FDD80C9AFA0>
>>> red.mode
'L'
.split()返回的对象的模式是'L',表示这是灰度图像,或者是只显示每个像素的亮度值的图像。
现在,您可以使用merge()创建三个新的 RGB 图像,分别显示红色、绿色和蓝色通道,这是Image模块中的一个功能:
>>> zeroed_band = red.point(lambda _: 0) >>> red_merge = Image.merge( ... "RGB", (red, zeroed_band, zeroed_band) ... ) >>> green_merge = Image.merge( ... "RGB", (zeroed_band, green, zeroed_band) ... ) >>> blue_merge = Image.merge( ... "RGB", (zeroed_band, zeroed_band, blue) ... ) >>> red_merge.show() >>> green_merge.show() >>> blue_merge.show()
merge()中的第一个参数决定了您想要创建的图像的模式。第二个参数包含要合并到单个图像中的各个波段。存储在变量
red中的单独的红乐队是具有模式 l 的灰度图像。为了创建仅显示红色通道的图像,您将原始图像的红色带与仅包含零的绿色和蓝色带合并。要创建一个处处包含零的带,可以使用.point()方法。这个方法需要一个函数作为参数。您使用的函数决定了每个点如何变换。在这种情况下,您使用一个
lambda函数将每个点映射到0。当您将红色波段与包含零的绿色和蓝色波段合并时,您会得到一个名为
red_merge的 RGB 图像。因此,您创建的 RGB 图像在红色通道中只有非零值,但是因为它仍然是 RGB 图像,所以它将以彩色显示。您还可以重复类似的过程来获得
green_merge和blue_merge,它们包含原始图像中带有绿色和蓝色通道的 RGB 图像。该代码显示以下三幅图像:
红色图像在代表草莓的像素中包含强信号,因为这些像素大部分是红色的。绿色和蓝色通道将这些像素显示为深色,因为它们的值很小。例外的是那些代表草莓表面光反射的像素,因为这些像素几乎是白色的。
在本教程中,当代码中有几个图像输出需要并排显示以便于比较时,这些图像会并排显示,而不是作为单独的图像显示。
这些并排展示是用枕头本身制作的。您可以使用如下所示的功能
tile(),将多幅图像合并到一个显示屏中:from PIL import Image def tile(*images, vertical=False): width, height = images[0].width, images[0].height tiled_size = ( (width, height * len(images)) if vertical else (width * len(images), height) ) tiled_img = Image.new(images[0].mode, tiled_size) row, col = 0, 0 for image in images: tiled_img.paste(image, (row, col)) if vertical: col += height else: row += width return tiled_img
tile()中的第一个参数使用解包操作符(*),因此任意数量的PIL.Image类型的对象都可以用作输入参数。如果您想垂直平铺图像而不是水平平铺图像,可以将关键字参数vertical设置为True。该函数假设所有图像都具有相同的大小。显示器的整体尺寸是根据图像的尺寸和所用图像的数量计算出来的。然后创建一个新的
Image对象,其模式与原始图像相同,大小与整体显示相同。
for循环将调用该函数时输入的图像粘贴到最终显示中。该函数返回包含所有并排图像的最终Image对象。主文章中显示草莓图像的三个颜色通道的图像是通过调用
tile()函数获得的,如下所示:

>>> strawberry_channels = tile(red_merge, green_merge, blue_merge)
在本教程中,这个函数用于生成显示多个图像的所有显示。
Python 中使用 Pillow 的图像处理
您已经学习了如何裁剪和旋转图像、调整图像大小以及从彩色图像中提取色带。但是,到目前为止,您所采取的任何操作都没有对图像的内容进行任何更改。在本节中,您将了解 Python Pillow 库中的图像处理特性。您将使用枕头中的 ImageFilter 模块。
使用卷积核的图像滤波器
图像处理中使用的一种方法是使用核进行图像卷积。本教程的目的不是给出图像处理理论的详细解释。如果你对图像处理科学感兴趣,你可以使用的最佳资源之一是 Gonzalez 和 Woods 的数字图像处理(T2)。
在本节中,您将学习如何使用卷积核来执行图像处理的基础知识。但是什么是卷积核?内核是一个矩阵:
您可以考虑一个简单的图像来理解使用内核的卷积过程。图像大小为30x30像素,包含一条垂直线和一个点。线条宽 4 个像素,点由一个4x4像素方块组成。下图被放大以供显示:

您可以将内核放在图像上的任何位置,并使用内核中央单元的位置作为参考。下图显示了图像的左上部分:
此图中的元素代表了映像和内核的不同方面:
- 白色方块代表图像中值为
0的像素。 - 红色方块代表图像中值为
255的像素。这些构成了上图中的圆点。 - 每个紫色区域代表内核。这个内核由一个
3x3区域组成,内核中的每个单元格都有一个值1/9。该图显示了标记为 1、2 和 3 的三个不同位置的内核。
作为图像与内核卷积的结果,可以创建新的图像。您可以通过以下步骤了解卷积过程:
- 定位内核:考虑其中一个内核位置,查看由内核的九个单元覆盖的图像像素。
- 将内核和像素值相乘:将内核的每个单元格中的值与图像中相应的像素值相乘。九次乘法你会得到九个值。
- 乘法结果相加:将这九个值相加。结果将是新图像中与内核中心像素具有相同坐标的像素值。
- 对所有像素重复:对图像中的每个像素重复该过程,每次移动内核,使内核的中心单元每次对应不同的图像像素。
在上图中,您可以看到这个过程中的三个内核位置分别标为 1、2 和 3。考虑标记为 1 的内核位置。这个内核的位置是(3, 2),这是它的中心单元格的位置,因为它在第四行(index = 3)和第三列(index = 2)。由内核覆盖的区域中的每个图像像素具有零值。
因此,步骤 2 中的所有乘法都将为零,它们的加法也将为零。新图像在像素(3, 2)处的值为零。
对于所示的其他内核位置,情况有所不同。接下来,考虑位于(4, 7)的标记为 2 的内核。与此重叠的图像像素之一不为零。这个像素值与内核值相乘将得到255 x (1/9) = 28.33。剩余的八个乘法仍然是零,因为图像像素是零。因此,新图像中位置(4, 7)处的像素值将为28.33。
上面所示的第三内核位置在(8, 11)处。有四个非零图像像素与该内核重叠。每一个都有一个值255,所以对于这些像素位置中的每一个,乘法结果将再次是28.33。这个内核位置的总结果是28.33 x 4 = 113.33。新图像将在(8, 11)具有该值。
上面的图表和讨论只考虑了三个内核位置。卷积过程对图像中每个可能的核位置重复这个过程。这为新图像中的每个像素位置提供了一个值。
卷积的结果显示在下图的右侧,原始图像显示在左侧:

你使用的内核是一个盒子模糊内核。因为有了1/9的因子,所以内核的总权重是1。卷积的结果是原始图像的模糊版本。还有其他执行不同功能的内核,包括不同的模糊方法、边缘检测、锐化等。
Python Pillow 库有几个内置的内核和函数来执行上述卷积。使用这些过滤器不需要了解通过卷积进行过滤的数学知识,但使用这些工具时了解幕后发生的事情总是有帮助的。
接下来的部分将会看到 Pillow 的 ImageFilter 模块中的内核和图像过滤功能。
图像模糊、锐化和平滑
您将返回到使用您在本教程开始时使用的建筑物图像。您可以为此部分启动新的 REPL 会话:
>>> from PIL import Image, ImageFilter >>> filename = "buildings.jpg" >>> with Image.open(filename) as img: ... img.load() ...除了
Image,还从 Pillow 导入了ImageFilter模块。您可以使用.filter()方法对图像进行过滤。这个方法需要一个卷积核作为它的参数,您可以使用 Pillow 中的ImageFilter模块中可用的几个核中的一个。您将学习的第一组滤镜用于处理模糊、锐化和平滑图像。您可以使用预定义的
ImageFilter.BLUR滤镜模糊图像:
>>> blur_img = img.filter(ImageFilter.BLUR)
>>> blur_img.show()
显示的图像是原始图像的模糊版本。您可以使用.crop()放大以更详细地观察差异,然后使用.show()再次显示图像:
>>> img.crop((300, 300, 500, 500)).show() >>> blur_img.crop((300, 300, 500, 500)).show()两个裁剪的图像显示了两个版本之间的差异:
您可以使用
ImageFilter.BoxBlur()或ImageFilter.GaussianBlur()自定义您需要的模糊类型和模糊量:

>>> img.filter(ImageFilter.BoxBlur(5)).show()
>>> img.filter(ImageFilter.BoxBlur(20)).show()
>>> img.filter(ImageFilter.GaussianBlur(20)).show()
您可以看到下面三个模糊的图像,显示顺序与上面代码中的顺序相同:

.BoxBlur()滤波器类似于上一节介绍卷积核中描述的滤波器。参数是长方体模糊滤镜的半径。在前面讨论内核的部分中,你使用的盒子模糊滤镜是一个3x3滤镜。这意味着它的半径为1,因为滤镜从中心延伸了一个像素。
模糊图像显示,半径为20的长方体模糊滤镜生成的图像比半径为5的长方体模糊滤镜生成的图像更加模糊。
你也可以使用.GaussianBlur()滤镜,它使用了高斯模糊内核。高斯核将更多的权重放在核中心的像素上,而不是边缘的像素上,这导致了比使用方框模糊所获得的更平滑的模糊。由于这个原因,高斯模糊在许多情况下可以给出更好的结果。
如果你想锐化一个图像呢?在这种情况下,您可以使用ImageFilter.SHARPEN滤镜并将结果与原始图像进行比较:
>>> sharp_img = img.filter(ImageFilter.SHARPEN) >>> img.crop((300, 300, 500, 500)).show() >>> sharp_img.crop((300, 300, 500, 500)).show()您正在比较两幅图像的裁剪版本,显示了建筑的一小部分。右边是锐化后的图像:
也许你需要平滑图像,而不是锐化图像。您可以通过将
ImageFilter.SMOOTH作为.filter()的参数来实现这一点:

>>> smooth_img = img.filter(ImageFilter.SMOOTH)
>>> img.crop((300, 300, 500, 500)).show()
>>> smooth_img.crop((300, 300, 500, 500)).show()
在下面,你可以看到左边的原始图像和右边的平滑图像:

在下一节中,你将看到平滑滤镜的应用,你将在ImageFilter模块中了解更多滤镜。这些滤镜作用于图像中对象的边缘。
边缘检测、边缘增强和压花
当你看一幅图像时,确定图像中物体的边缘是相对容易的。算法也可以使用边缘检测内核自动检测边缘。
Pillow 中的ImageFilter模块有一个预定义的内核来实现这一点。在本节中,您将再次使用建筑物的图像,并在应用边缘检测滤镜之前将其转换为灰度。您可以继续上一节中的 REPL 会话:
>>> img_gray = img.convert("L") >>> edges = img_gray.filter(ImageFilter.FIND_EDGES) >>> edges.show()结果是显示原始图像边缘的图像:
该过滤器识别图像中的边缘。在找到边缘之前,您可以通过应用
ImageFilter.SMOOTH过滤器获得更好的结果:

>>> img_gray_smooth = img_gray.filter(ImageFilter.SMOOTH)
>>> edges_smooth = img_gray_smooth.filter(ImageFilter.FIND_EDGES)
>>> edges_smooth.show()
您可以看到原始灰度图像和下面两个边缘检测结果的比较。边缘检测前平滑的版本显示在底部:

您还可以使用ImageFilter.EDGE_ENHANCE滤镜增强原始图像的边缘:
>>> edge_enhance = img_gray_smooth.filter(ImageFilter.EDGE_ENHANCE) >>> edge_enhance.show()您使用灰度图像的平滑版本来增强边缘。下面并排显示了原始灰度图像的一部分和边缘增强的图像。右边是边缘增强的图像:
ImageFilter中另一个处理物体边缘的预定义过滤器是ImageFilter.EMBOSS。您可以将它作为参数传递给.filter(),就像您在本节中处理其他过滤器一样:

>>> emboss = img_gray_smooth.filter(ImageFilter.EMBOSS)
>>> emboss.show()
您正在使用平滑的灰度版本作为此滤镜的起点。您可以看到下面的浮雕图像,它显示了使用图像边缘的不同效果:

在本节中,您已经了解了在ImageFilter模块中可以应用于图像的几种滤镜。您还可以使用其他滤镜来处理图像。您可以在 ImageFilter文档中看到所有可用过滤器的列表。
图像分割和叠加:示例
在本节中,您将使用名为cat.jpg ( 图像信用)和monastery.jpg ( 图像信用)的图像文件,您可以在本教程的图像库中找到它们:
获取图像: 点击此处获取您将使用 Pillow 操作和处理的图像。
这是两张图片:


你可以使用 Python Pillow 库从第一张图片中提取猫,并将其放置在修道院庭院的地板上。您将使用许多图像处理技术来实现这一点。
图像阈值处理
你将从cat.jpg开始。你需要使用图像分割技术将猫的图片从背景中移除。在这个例子中,你将使用阈值技术分割图像。
首先,您可以将图像裁剪为较小的图像,以移除一些背景。您可以为此项目启动新的 REPL 会话:
>>> from PIL import Image >>> filename_cat = "cat.jpg" >>> with Image.open(filename_cat) as img_cat: ... img_cat.load() ... >>> img_cat = img_cat.crop((800, 0, 1650, 1281)) >>> img_cat.show()裁剪后的图像包含猫和一些背景,这些背景离猫太近,您无法裁剪:
彩色图像中的每个像素都由对应于该像素的红色、绿色和蓝色值的三个数字数字表示。阈值处理是将所有像素转换为最大值或最小值的过程,这取决于它们是高于还是低于某个数值。在灰度图像上这样做更容易:

>>> img_cat_gray = img_cat.convert("L")
>>> img_cat_gray.show()
>>> threshold = 100
>>> img_cat_threshold = img_cat_gray.point(
... lambda x: 255 if x > threshold else 0
... )
>>> img_cat_threshold.show()
通过调用.point()将灰度图像中的每个像素转换为255或0,可以实现阈值处理。转换取决于灰度图像中的值是大于还是小于阈值。本例中的阈值为100。
下图显示了灰度图像和阈值处理的结果:

在本例中,灰度图像中像素值大于100的所有点都被转换为白色,所有其他像素都被转换为黑色。您可以通过改变阈值来改变阈值处理的灵敏度。
当要分割的对象不同于背景时,可以使用阈值处理来分割图像。使用具有更高对比度的原始图像版本可以获得更好的效果。在本例中,您可以通过对原始图像的蓝色通道而不是灰度图像设定阈值来获得更高的对比度,因为背景中的主色是棕色和绿色,它们具有较弱的蓝色成分。
您可以像前面一样从彩色图像中提取红色、绿色和蓝色通道:
>>> red, green, blue = img_cat.split() >>> red.show() >>> green.show() >>> blue.show()红色、绿色和蓝色通道从左到右显示如下。三者都显示为灰度图像:
蓝色通道在代表猫的像素和代表背景的像素之间具有较高的对比度。您可以使用蓝色通道图像来设定阈值:

>>> threshold = 57
>>> img_cat_threshold = blue.point(lambda x: 255 if x > threshold else 0)
>>> img_cat_threshold = img_cat_threshold.convert("1")
>>> img_cat_threshold.show()
在本例中,您使用了阈值57。您还可以使用"1"作为.convert()的参数,将图像转换为二进制模式。二进制图像中的像素只能有0或1的值。
如果您的结果与本教程中显示的结果不匹配,您可能需要稍微调整阈值。
阈值处理的结果如下:

你可以在这张黑白照片中认出这只猫。但是,您希望图像中对应于猫的所有像素都是白色的,而所有其他像素都是黑色的。在这张图像中,在对应于猫的区域仍然有黑色区域,例如眼睛、鼻子和嘴所在的位置,并且在图像的其他地方也仍然有白色像素。
你可以使用称为腐蚀和膨胀的图像处理技术来创建一个更好的代表猫的面具。您将在下一节学习这两种技术。
侵蚀和扩张
您可以查看名为dot_and_hole.jpg的图像文件,可以从链接到本教程的存储库中下载该文件:

这张二进制图像的左手边显示了黑色背景上的一个白点,而右手边显示了实心白色部分中的一个黑洞。
腐蚀是从图像的边界移除白色像素的过程。通过使用ImageFilter.MinFilter(3)作为.filter()方法的参数,可以在二进制图像中实现这一点。该滤镜将一个像素的值替换为以该像素为中心的3x3数组中九个像素的最小值。在二进制图像中,这意味着如果一个像素的任何相邻像素为零,则该像素的值为零。
通过对dot_and_hole.jpg图像多次应用ImageFilter.MinFilter(3),可以看到腐蚀的效果。您应该继续与上一节相同的 REPL 会话:
>>> from PIL import ImageFilter >>> filename = "dot_and_hole.jpg" >>> with Image.open(filename) as img: ... img.load() ... >>> for _ in range(3): ... img = img.filter(ImageFilter.MinFilter(3)) ... >>> img.show()您已经使用
for循环应用了过滤器三次。该代码给出以下输出:
由于侵蚀,圆点缩小了,但洞却扩大了。
膨胀是与侵蚀相反的过程。白色像素被添加到二进制图像的边界。您可以通过使用
ImageFilter.MaxFilter(3)来实现膨胀,如果一个像素的任何邻居是白色的,它会将该像素转换为白色。您可以对包含一个点和一个洞的同一图像应用膨胀,您可以再次打开并加载该图像:

>>> with Image.open(filename) as img:
... img.load()
...
>>> for _ in range(3):
... img = img.filter(ImageFilter.MaxFilter(3))
...
>>> img.show()
圆点现在变大了,而洞缩小了:

您可以同时使用腐蚀和膨胀来填充孔洞,并从二值图像中移除小对象。使用带有点和孔的图像,您可以执行十次腐蚀循环来移除点,然后执行十次膨胀循环来将孔恢复到其原始大小:
>>> with Image.open(filename) as img: ... img.load() ... >>> for _ in range(10): ... img = img.filter(ImageFilter.MinFilter(3)) ... >>> img.show() >>> for _ in range(10): ... img = img.filter(ImageFilter.MaxFilter(3)) ... >>> img.show()第一个
for循环执行十次腐蚀循环。此阶段的图像如下:
圆点消失了,洞比原来的图像要大。第二个
for循环执行十次扩张循环,将孔恢复到其原始尺寸:
但是,该点不再出现在图像中。腐蚀和膨胀改变了图像,保留了孔,但去掉了点。腐蚀和扩张的次数取决于图像和你想要达到的效果。通常,你需要通过反复试验来找到正确的组合。
您可以定义函数来执行几个腐蚀和膨胀循环:


>>> def erode(cycles, image):
... for _ in range(cycles):
... image = image.filter(ImageFilter.MinFilter(3))
... return image
...
>>> def dilate(cycles, image):
... for _ in range(cycles):
... image = image.filter(ImageFilter.MaxFilter(3))
... return image
...
这些函数使得对图像进行腐蚀和膨胀实验变得更加容易。在下一节中,当您继续将猫放入修道院时,您将使用这些函数。
使用阈值的图像分割
您可以在之前获得的阈值图像上使用一系列腐蚀和膨胀来移除不代表猫的蒙版部分,并填充包含猫的区域中的任何间隙。一旦你实验了腐蚀和扩张,你将能够在试错过程中使用有根据的猜测来找到腐蚀和扩张的最佳组合,以实现理想的掩模。
从您之前获得的图像img_cat_threshold开始,您可以通过一系列腐蚀来移除原始图像中代表背景的白色像素。您应该继续在与前面部分相同的 REPL 会话中工作:
>>> step_1 = erode(12, img_cat_threshold) >>> step_1.show()被侵蚀的阈值图像不再包含表示图像背景的白色像素:
然而,剩下的面具比猫的整体轮廓小,里面有洞和缝隙。您可以执行扩张来填充间隙:

>>> step_2 = dilate(58, step_1)
>>> step_2.show()
58 个膨胀周期填满了面具上的所有洞,给出了下面的图像:
但是,这个面具太大了。因此,你可以用一系列腐蚀来完成这个过程:
>>> cat_mask = erode(45, step_2) >>> cat_mask.show()结果是一个遮罩,您可以使用它来分割猫的图像:
您可以通过模糊二进制蒙版来避免该蒙版的锐边。你必须先把它从二进制图像转换成灰度图像:
>>> cat_mask = cat_mask.convert("L")
>>> cat_mask = cat_mask.filter(ImageFilter.BoxBlur(20))
>>> cat_mask.show()
BoxBlur()过滤器返回以下掩码:

面具现在看起来像一只猫!现在,您已经准备好从背景中提取猫的图像:
>>> blank = img_cat.point(lambda _: 0) >>> cat_segmented = Image.composite(img_cat, blank, cat_mask) >>> cat_segmented.show()首先,创建一个与
img_cat大小相同的空白图像。通过使用.point()并将所有值设置为零,从img_cat创建一个新的Image对象。接下来,使用PIL.Image中的composite()函数创建一个由img_cat和blank组成的图像,使用cat_mask来确定每个图像的哪些部分被使用。合成图像如下所示:
您已经分割了猫的图像,并从背景中提取了猫。
使用
Image.paste()和叠加图像对于本教程,您可以更进一步,将猫的分段图像粘贴到图像库中的修道院庭院图像中:

>>> filename_monastery = "monastery.jpg"
>>> with Image.open(filename_monastery) as img_monastery:
... img_monastery.load()
>>> img_monastery.paste(
... img_cat.resize((img_cat.width // 5, img_cat.height // 5)),
... (1300, 750),
... cat_mask.resize((cat_mask.width // 5, cat_mask.height // 5)),
... )
>>> img_monastery.show()
你已经使用 .paste() 将一个图像粘贴到另一个图像上。此方法可以与三个参数一起使用:
- 第一个参数是您想要粘贴的图像。您正在使用整数除法运算符(
//)将图像的大小调整为其大小的五分之一。 - 第二个参数是主图像中要粘贴第二张图片的位置。元组包括主图像中您想要放置要粘贴的图像左上角的坐标。
- 第三个参数提供了如果您不想粘贴整个图像时希望使用的蒙版。
您已经使用了从阈值处理、腐蚀和膨胀过程中获得的遮罩来粘贴没有背景的猫。输出如下图所示:

您已经从一个图像中分割出猫,并将其放入另一个图像中,以显示猫静静地坐在修道院的院子里,而不是在原始图像中它坐的地方。
水印的创建
在本例中,您的最后一项任务是将真正的 Python 徽标作为水印添加到图像中。您可以从本教程附带的存储库中获得带有真实 Python 徽标的图像文件:
获取图像: 点击此处获取您将使用 Pillow 操作和处理的图像。
您应该继续在同一个 REPL 会话中工作:
>>> logo = "realpython-logo.png" >>> with Image.open(logo) as img_logo: ... img_logo.load() ... >>> img_logo = Image.open(logo) >>> img_logo.show()这是彩色的全尺寸标志:
您可以将图像更改为灰度,并使用
.point()将其转换为黑白图像。您还可以缩小它的大小并将其转换为轮廓图像:
>>> img_logo = img_logo.convert("L")
>>> threshold = 50
>>> img_logo = img_logo.point(lambda x: 255 if x > threshold else 0)
>>> img_logo = img_logo.resize(
... (img_logo.width // 2, img_logo.height // 2)
... )
>>> img_logo = img_logo.filter(ImageFilter.CONTOUR)
>>> img_logo.show()
输出显示了真实 Python 徽标的轮廓。轮廓非常适合用作图像上的水印:

要使用它作为水印,你需要反转颜色,这样背景是黑色的,只有你想保留的轮廓是白色的。您可以再次使用.point()来实现这一点:
>>> img_logo = img_logo.point(lambda x: 0 if x == 255 else 255) >>> img_logo.show()您已经转换了值为
255的像素,并给它们赋值0,将它们从白色像素转换为黑色像素。您将剩余的像素设置为白色。反向轮廓标志如下所示:
你的最后一步是将这个轮廓粘贴到坐在修道院院子里的猫的图像上。您可以再次使用
.paste():

>>> img_monastery.paste(img_logo, (480, 160), img_logo)
>>> img_monastery.show()
.paste()中的第一个参数表示您想要粘贴的图像,第三个参数表示遮罩。在这种情况下,您使用相同的图像作为遮罩,因为该图像是二进制图像。第二个参数提供要粘贴图像的区域的左上角坐标。
该图像现在包含一个真正的 Python 水印:

水印具有矩形轮廓,这是您之前使用的轮廓滤镜的结果。如果您想要移除此轮廓,您可以使用.crop()裁剪图像。这是一个你可以自己尝试的练习。
使用 NumPy 和枕头进行图像处理
枕头有广泛的内置功能和过滤器的选择。然而,有时候你需要更进一步,在 Pillow 已经具备的功能之外处理图像。
您可以在 NumPy 的帮助下进一步处理图像。NumPy 是一个非常流行的用于处理数值数组的 Python 库,是使用 Pillow 的理想工具。你可以在 NumPy 教程:Python 中数据科学的第一步中了解更多关于 NumPy 的知识。
将图像转换为 NumPy 数组时,可以直接对数组中的像素执行所需的任何变换。一旦在 NumPy 中完成处理,就可以使用 Pillow 将数组转换回一个Image对象。您需要为该部分安装 NumPy:
(venv) $ python -m pip install numpy
现在您已经安装了 NumPy,您已经准备好使用 Pillow 和 NumPy 来发现两个图像之间的差异。
使用 NumPy 将图像相减
看看你是否能找出下面两张图片的不同之处:

这个不难!然而,你决定作弊,写一个 Python 程序为你解谜。您可以从本教程附带的存储库中下载图像文件house_left.jpg和house_right.jpg ( 图像信用):
获取图像: 点击此处获取您将使用 Pillow 操作和处理的图像。
第一步是使用 Pillow 读取图像,并将其转换为 NumPy 数组:
>>> import numpy as np >>> from PIL import Image >>> with Image.open("house_left.jpg") as left: ... left.load() ... >>> with Image.open("house_right.jpg") as right: ... right.load() ... >>> left_array = np.asarray(left) >>> right_array = np.asarray(right) >>> type(left_array) <class 'numpy.ndarray'> >>> type(right_array) <class 'numpy.ndarray'>由于
left_array和right_array是类型为numpy.ndarray的对象,您可以使用 NumPy 中所有可用的工具来操纵它们。您可以从一个数组中减去另一个数组,以显示两个图像之间的像素差异:
>>> difference_array = right_array - left_array
>>> type(difference_array)
<class 'numpy.ndarray'>
当您从另一个相同大小的数组中减去一个数组时,结果是另一个与原始数组形状相同的数组。您可以使用 Pillow 中的Image.fromarray()将该数组转换为图像:
>>> difference = Image.fromarray(difference_array) >>> difference.show()从一个 NumPy 数组中减去另一个数组并转换成枕头
Image的结果是下图所示的差值图像:
差异图像仅显示原始图像的三个区域。这些区域突出了两幅图像之间的差异。您还可以看到云和栅栏周围的一些噪声,这是由于这些项目周围区域的原始 JPEG 压缩中的微小变化。
使用 NumPy 创建图像
您可以更进一步,使用 NumPy 和 Pillow 从头开始创建图像。您可以从创建灰度图像开始。在本例中,您将创建一个包含正方形的简单图像,但您可以用同样的方法创建更复杂的图像:

>>> import numpy as np
>>> from PIL import Image
>>> square = np.zeros((600, 600))
>>> square[200:400, 200:400] = 255
>>> square_img = Image.fromarray(square)
>>> square_img
<PIL.Image.Image image mode=F size=600x600 at 0x7FC7D8541F70>
>>> square_img.show()
您创建了一个大小为600x600的数组,其中处处都包含零。接下来,将数组中心的一组像素的值设置为255。
您可以使用行和列来索引 NumPy 数组。在本例中,第一个片层200:400,代表行200到399。逗号后面的第二个片段200:400表示从200到399的列。
您可以使用Image.fromarray()将 NumPy 数组转换成类型为Image的对象。上面代码的输出如下所示:

您已经创建了一个包含正方形的灰度图像。当您使用Image.fromarray()时,会自动推断图像的模式。在这种情况下,使用模式"F",其对应于具有 32 位浮点像素的图像。如果您愿意,可以将其转换为更简单的 8 位像素灰度图像:
>>> square_img = square_img.convert("L")你还可以更进一步,创建一个彩色图像。您可以重复上述过程来创建三个图像,一个对应于红色通道,另一个对应于绿色通道,最后一个对应于蓝色通道:
>>> red = np.zeros((600, 600))
>>> green = np.zeros((600, 600))
>>> blue = np.zeros((600, 600))
>>> red[150:350, 150:350] = 255
>>> green[200:400, 200:400] = 255
>>> blue[250:450, 250:450] = 255
>>> red_img = Image.fromarray(red).convert("L")
>>> green_img = Image.fromarray(green).convert("L")
>>> blue_img = Image.fromarray((blue)).convert("L")
您从每个 NumPy 数组创建一个Image对象,并将图像转换为代表灰度的模式"L"。现在,您可以使用Image.merge()将这三个单独的图像合并成一个 RGB 图像:
>>> square_img = Image.merge("RGB", (red_img, green_img, blue_img)) >>> square_img <PIL.Image.Image image mode=RGB size=600x600 at 0x7FC7C817B9D0> >>> square_img.show()
Image.merge()中的第一个参数是图像输出的模式。第二个参数是包含单个单波段图像的序列。这段代码创建了以下图像:
您已经将单独的波段组合成一幅 RGB 彩色图像。在下一节中,您将更进一步,使用 NumPy 和 Pillow 创建一个 GIF 动画。
制作动画
在上一节中,您创建了一个包含三个不同颜色的重叠方块的彩色图像。在本节中,您将创建一个动画,显示这三个正方形合并成一个白色正方形。您将创建包含三个正方形的图像的多个版本,正方形的位置在连续的图像之间会略有不同:

>>> import numpy as np
>>> from PIL import Image
>>> square_animation = []
>>> for offset in range(0, 100, 2):
... red = np.zeros((600, 600))
... green = np.zeros((600, 600))
... blue = np.zeros((600, 600))
... red[101 + offset : 301 + offset, 101 + offset : 301 + offset] = 255
... green[200:400, 200:400] = 255
... blue[299 - offset : 499 - offset, 299 - offset : 499 - offset] = 255
... red_img = Image.fromarray(red).convert("L")
... green_img = Image.fromarray(green).convert("L")
... blue_img = Image.fromarray((blue)).convert("L")
... square_animation.append(
... Image.merge(
... "RGB",
... (red_img, green_img, blue_img)
... )
... )
...
您创建一个名为square_animation的空列表,用于存储您生成的各种图像。在for循环中,您为红色、绿色和蓝色通道创建 NumPy 数组,正如您在上一节中所做的那样。包含绿色层的数组总是相同的,表示图像中心的一个正方形。
红色方块从偏离中心左上角的位置开始。在每一个连续的帧中,红色方块向中心移动,直到它在循环的最后一次迭代中到达中心。蓝色方块最初向右下角移动,然后随着每次迭代向中心移动。
注意,在这个例子中,您正在迭代range(0, 100, 2),这意味着变量offset以两步增加。
您之前已经了解到可以使用Image.save()将Image对象保存到文件中。您可以使用相同的功能保存到包含一系列图像的 GIF 文件。您对序列中的第一幅图像调用Image.save(),这是您存储在列表square_animation中的第一幅图像:
>>> square_animation[0].save( ... "animation.gif", save_all=True, append_images=square_animation[1:] ... )
.save()中的第一个参数是您想要保存的文件的文件名。文件名中的扩展名告诉.save()它需要输出什么文件格式。您还在.save()中包含了两个关键字参数:
save_all=True确保保存序列中的所有图像,而不仅仅是第一张。append_images=square_animation[1:]允许您将序列中的剩余图像附加到 GIF 文件中。这段代码将
animation.gif保存到文件中,然后您可以用任何图像软件打开 GIF 文件。默认情况下,GIF 应该是循环的,但是在一些系统中,你需要添加关键字参数loop=0到.save()来确保 GIF 循环。你得到的动画如下:
三个不同颜色的方块合并成一个白色方块。你能使用不同的形状和不同的颜色创建你自己的动画吗?
结论
您已经学习了如何使用 Pillow 处理图像和执行图像处理。如果你喜欢处理图像,你可能想一头扎进图像处理的世界。关于图像处理的理论和实践,还有很多东西需要学习。一个很好的起点是 Gonzalez 和 Woods 的 数字图像处理,这是这个领域的经典教材。
Pillow 并不是 Python 中唯一可以用于图像处理的库。如果您的目标是执行一些基本的处理,那么您在本教程中学到的技术可能就是您所需要的。如果您想更深入地研究更高级的图像处理技术,例如机器学习和计算机视觉应用,那么您可以使用 Pillow 作为进入 OpenCV 和 scikit-image 等其他库的垫脚石。
在本教程中,您已经学会了如何:
- 用枕头阅读图片
- 执行基本图像操作操作
- 使用枕头进行图像处理
- 使用带枕头的 NumPy 进行的进一步加工
- 使用 Pillow 制作动画
现在,浏览计算机上图像文件夹中的图像,选择一些可以使用 Pillow 读入的图像,决定如何处理这些图像,然后对它们进行一些图像处理。玩得开心!*************
自定义 Python 字典:从 dict 和 UserDict 继承
创建类似字典的类可能是您 Python 职业生涯中的一项需求。具体来说,您可能对使用修改的行为、新功能或两者来制作自定义词典感兴趣。在 Python 中,你可以通过继承一个抽象基类,直接子类化内置的
dict类,或者继承UserDict来做到这一点。在本教程中,您将学习如何:
- 通过继承内置的
dict类来创建类似字典的类- 识别从
dict继承时可能发生的常见陷阱- 通过从
collections模块中用子类化UserDict来构建类似字典的类此外,您将编写几个例子来帮助您理解使用
dict和UserDict创建自定义字典类的优缺点。为了充分利用本教程,您应该熟悉 Python 的内置
dict类及其标准功能和特性。你还需要知道面向对象编程的基础知识,理解继承在 Python 中是如何工作的。立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
在 Python 中创建类似字典的类
内置的
dict类提供了一个有价值且通用的集合数据类型,Python 字典。字典无处不在,包括您的代码和 Python 本身的代码。有时,Python 字典的标准功能对于某些用例来说是不够的。在这些情况下,您可能需要创建一个自定义的类似字典的类。换句话说,您需要一个行为类似于常规字典的类,但是具有修改过的或新的功能。
您通常会发现创建定制的类似字典的类至少有两个原因:
- 通过添加新功能扩展常规词典
- 修改标准字典的功能
注意,您还可能面临需要扩展和来修改字典的标准功能的情况。
根据您的特定需求和技能水平,您可以从一些创建自定义词典的策略中进行选择。您可以:
- 从适当的抽象基类继承,如
MutableMapping- 直接从 Python 内置的
dict类继承- 子类
UserDict来自collections当您选择要实施的适当策略时,有几个关键的考虑因素。请继续阅读,了解更多详情。
从抽象基类构建类似字典的类
这种创建类似字典的类的策略要求您从一个抽象基类(ABC) 继承,就像
MutableMapping。该类提供了除.__getitem__()、.__setitem__()、.__delitem__()、.__iter__()和.__len__()之外的所有字典方法的具体泛型实现,这些方法需要您自己实现。此外,假设您需要定制任何其他标准字典方法的功能。在这种情况下,您必须覆盖手头的方法,并提供一个合适的实现来满足您的需求。
这个过程意味着大量的工作。它也容易出错,并且需要 Python 及其数据模型的高级知识。这也可能意味着性能问题,因为您将使用纯 Python 编写该类。
这种策略的主要优点是,如果您在自定义实现中遗漏了任何方法,父 ABC 都会提醒您。
出于这些原因,只有当您需要一个与内置字典完全不同的类似字典的类时,您才应该采用这种策略。
在本教程中,您将专注于通过继承内置的
dict类和UserDict类来创建类似字典的类,这似乎是最快和最实用的策略。从 Python 内置的
dict类继承而来很长一段时间,不可能在 C 中实现 Python 类型的子类化。Python 2.2 修复了这个问题。现在你可以直接子类化内置类型,包括
dict。这一变化为子类带来了几个技术优势,因为现在它们:这个列表中的第一项可能是对需要 Python 内置类的 C 代码的要求。第二项允许您在标准字典行为的基础上添加新功能。最后,第三项将使您能够将子类的属性限制为那些在
.__slots__中预定义的属性。尽管对内置类型进行子类化有几个优点,但它也有一些缺点。在字典的具体例子中,你会发现一些恼人的陷阱。例如,假设您想要创建一个类似字典的类,该类自动将其所有键存储为字符串,其中所有字母(如果存在的话)都是大写的。
为此,您可以创建一个覆盖
.__setitem__()方法的dict的子类:
>>> class UpperCaseDict(dict):
... def __setitem__(self, key, value):
... key = key.upper()
... super().__setitem__(key, value)
...
>>> numbers = UpperCaseDict()
>>> numbers["one"] = 1
>>> numbers["two"] = 2
>>> numbers["three"] = 3
>>> numbers
{'ONE': 1, 'TWO': 2, 'THREE': 3}
酷!你的自定义词典似乎很好用。然而,在这个类中有一些隐藏的问题。如果您试图使用一些初始化数据创建一个UpperCaseDict的实例,那么您将会得到一个令人惊讶的错误行为:
>>> numbers = UpperCaseDict({"one": 1, "two": 2, "three": 3}) >>> numbers {'one': 1, 'two': 2, 'three': 3}刚刚发生了什么?当你调用类的构造函数时,为什么你的字典不把键转换成大写字母?看起来类的初始化器
.__init__()没有隐式调用.__setitem__()来创建字典。因此,大写转换永远不会运行。不幸的是,这个问题影响了其他的字典方法,像
.update()和.setdefault(),例如:
>>> numbers = UpperCaseDict()
>>> numbers["one"] = 1
>>> numbers["two"] = 2
>>> numbers["three"] = 3
>>> numbers
{'ONE': 1, 'TWO': 2, 'THREE': 3}
>>> numbers.update({"four": 4})
>>> numbers
{'ONE': 1, 'TWO': 2, 'THREE': 3, 'four': 4}
>>> numbers.setdefault("five", 5)
5
>>> numbers
{'ONE': 1, 'TWO': 2, 'THREE': 3, 'four': 4, 'five': 5}
同样,在这些例子中,您的大写字母功能不能很好地工作。要解决这个问题,您必须提供所有受影响方法的自定义实现。例如,要解决初始化问题,您可以编写一个类似下面的.__init__()方法:
# upper_dict.py
class UpperCaseDict(dict):
def __init__(self, mapping=None, /, **kwargs): if mapping is not None:
mapping = {
str(key).upper(): value for key, value in mapping.items()
}
else:
mapping = {}
if kwargs:
mapping.update(
{str(key).upper(): value for key, value in kwargs.items()}
)
super().__init__(mapping)
def __setitem__(self, key, value):
key = key.upper()
super().__setitem__(key, value)
这里,.__init__()将密钥转换成大写字母,然后用结果数据初始化当前实例。
有了这个更新,自定义词典的初始化过程应该可以正常工作了。继续运行下面的代码来尝试一下:
>>> from upper_dict import UpperCaseDict >>> numbers = UpperCaseDict({"one": 1, "two": 2, "three": 3}) >>> numbers {'ONE': 1, 'TWO': 2, 'THREE': 3} >>> numbers.update({"four": 4}) >>> numbers {'ONE': 1, 'TWO': 2, 'THREE': 3, 'four': 4}提供您自己的
.__init__()方法修复了初始化问题。然而,像.update()这样的其他方法继续不正确地工作,因为你可以从"four"键不是大写的得出结论。为什么子类会有这样的行为?考虑到开闭原则,内置类型被设计和实现。因此,它们可以扩展,但不能修改。允许修改这些类的核心特性可能会破坏它们的不变量。因此,Python 核心开发人员决定保护它们不被修改。
这就是为什么子类化内置的
dict类会有点棘手,耗费人力,并且容易出错。幸运的是,你还有其他选择。来自collections模块的UserDict类就是其中之一。从
collections子类化UserDict从 Python 1.6 开始,该语言提供了作为标准库一部分的
UserDict。这个类最初位于一个以类本身命名的模块中。在 Python 3 中,UserDict被移到了collections模块,这是一个更直观的地方,基于类的主要目的。
UserDict是在不可能直接从 Python 的dict继承的时候创建回来的。尽管对这个类的需求已经被直接子类化内置的dict类的可能性部分取代,但是为了方便和向后兼容,UserDict仍然可以在标准库中使用。
UserDict是一个常规dict对象的方便包装器。该类提供了与内置的dict数据类型相同的行为,并提供了通过.data实例属性访问底层字典的附加功能。这个特性有助于创建定制的类似字典的类,您将在本教程的后面了解到这一点。
UserDict是专门为子类化而不是直接实例化设计的,这意味着该类的主要目的是允许你通过继承来创建类似字典的类。还有其他隐藏的差异。要发现它们,回到最初的
UpperCaseDict实现,并像下面的代码那样更新它:
>>> from collections import UserDict
>>> class UpperCaseDict(UserDict): ... def __setitem__(self, key, value):
... key = key.upper()
... super().__setitem__(key, value)
...
这一次,不是从dict继承,而是从UserDict继承,它是从collections模块导入的。这个变化会对你的UpperCaseDict类的行为产生怎样的影响?看看下面的例子:
>>> numbers = UpperCaseDict({"one": 1, "two": 2}) >>> numbers["three"] = 3 >>> numbers.update({"four": 4}) >>> numbers.setdefault("five", 5) 5 >>> numbers {'ONE': 1, 'TWO': 2, 'THREE': 3, 'FOUR': 4, 'FIVE': 5}现在
UpperCaseDict一直正常工作。您不需要提供.__init__()、.update()或.setdefault()的定制实现。这个课程很有用!这是因为在UserDict中,所有更新现有密钥或添加新密钥的方法都始终依赖于您的.__setitem__()版本。正如您之前了解到的,
UserDict和dict之间最显著的区别是.data属性,它保存包装的字典。直接使用.data可以让你的代码更加简单,因为你不需要一直调用super()来提供想要的功能。你只需访问.data就可以像使用任何普通词典一样使用它。编码类似字典的类:实例
你已经知道
dict的子类不会从.update()和.__init__()这样的方法中调用.__setitem__()。这个事实使得dict的子类的行为不同于典型的使用.__setitem__()方法的 Python 类。要解决这个问题,您可以从
UserDict继承,它从所有设置或更新底层字典中的值的操作中调用.__setitem__()。因为这个特性,UserDict可以让你的代码更安全、更紧凑。诚然,当您考虑创建一个类似字典的类时,从
dict继承比从UserDict继承更自然。这是因为所有的 Python 开发者都知道dict,但并不是所有的 Python 开发者都知道UserDict的存在。从
dict继承通常意味着某些问题可以通过使用UserDict来解决。然而,这些问题并不总是相关的。它们的相关性很大程度上取决于您希望如何定制字典的功能。底线是
UserDict并不总是正确的解决方案。一般来说,如果你想在不影响其核心结构的情况下扩展标准字典,那么从dict继承完全没问题。另一方面,如果你想通过覆盖它的特殊方法来改变核心字典行为,那么UserDict是你最好的选择。无论如何,请记住
dict是用 C 语言编写的,并且对性能进行了高度优化。与此同时,UserDict是用纯 Python 编写的,这在性能方面有很大的限制。在决定是继承
dict还是UserDict的时候,你要考虑几个因素。这些因素包括但不限于以下内容:
- 工作量
- 错误和缺陷的风险
- 易于使用和编码
- 表演
在下一节中,您将通过编写一些实际例子来体验列表中的前三个因素。稍后,在关于性能的章节中,您将了解性能含义。
接受英式和美式拼法的字典
作为第一个例子,假设您需要一个存储美式英语关键字并允许美式英语或英式英语关键字查找的字典。要编写这个字典,您需要修改至少两个特殊方法、
.__setitem__()和.__getitem__()。
.__setitem__()方法将允许你总是用美式英语存储密钥。.__getitem__()方法将使得检索与给定键相关联的值成为可能,不管它是用美式英语还是英式英语拼写的。因为您需要修改
dict类的核心行为,所以使用UserDict来编写这个类是一个更好的选择。有了UserDict,你将不必提供.__init__()、.update()等等的定制实现。当你子类化
UserDict时,你有两种主要的方法来编码你的类。您可以依靠.data属性,这可能有助于编码,或者您可以依靠super()和特殊方法。下面是依赖于
.data的代码:# spelling_dict.py from collections import UserDict UK_TO_US = {"colour": "color", "flavour": "flavor", "behaviour": "behavior"} class EnglishSpelledDict(UserDict): def __getitem__(self, key): try: return self.data[key] except KeyError: pass try: return self.data[UK_TO_US[key]] except KeyError: pass raise KeyError(key) def __setitem__(self, key, value): try: key = UK_TO_US[key] except KeyError: pass self.data[key] = value在本例中,首先定义一个常量
UK_TO_US,其中包含作为键的英国单词和作为值的匹配美国单词。然后你定义
EnglishSpelledDict,继承自UserDict。.__getitem__()方法寻找当前的键。如果该键存在,则该方法返回它。如果该键不存在,那么该方法检查该键是否是用英式英语拼写的。如果是这样的话,那么这个键就被翻译成美式英语,并从底层字典中检索。
.__setitem__()方法试图在UK_TO_US字典中找到输入键。如果输入键存在于UK_TO_US,那么它会被翻译成美式英语。最后,该方法将输入value分配给目标key。下面是您的
EnglishSpelledDict类在实践中是如何工作的:
>>> from spelling_dict import EnglishSpelledDict
>>> likes = EnglishSpelledDict({"color": "blue", "flavour": "vanilla"})
>>> likes
{'color': 'blue', 'flavor': 'vanilla'}
>>> likes["flavour"]
vanilla
>>> likes["flavor"]
vanilla
>>> likes["behaviour"] = "polite"
>>> likes
{'color': 'blue', 'flavor': 'vanilla', 'behavior': 'polite'}
>>> likes.get("colour")
'blue'
>>> likes.get("color")
'blue'
>>> likes.update({"behaviour": "gentle"})
>>> likes
{'color': 'blue', 'flavor': 'vanilla', 'behavior': 'gentle'}
通过对UserDict进行子类化,你可以避免编写大量代码。例如,您不必提供像.get()、.update()或.setdefault()这样的方法,因为它们的默认实现将自动依赖于您的.__getitem__()和.__setitem__()方法。
如果你要写的代码少了,那么你要做的工作也就少了。更重要的是,你会更安全,因为更少的代码通常意味着更低的错误风险。
这种实现的主要缺点是,如果有一天你决定更新EnglishSpelledDict并让它从dict继承,那么你将不得不重写大部分代码来抑制.data的使用。
下面的例子展示了如何使用super()和一些特殊的方法来提供与之前相同的功能。这一次,您的自定义字典与dict完全兼容,因此您可以随时更改父类:
# spelling_dict.py
from collections import UserDict
UK_TO_US = {"colour": "color", "flavour": "flavor", "behaviour": "behavior"}
class EnglishSpelledDict(UserDict):
def __getitem__(self, key):
try:
return super().__getitem__(key) except KeyError:
pass
try:
return super().__getitem__(UK_TO_US[key]) except KeyError:
pass
raise KeyError(key)
def __setitem__(self, key, value):
try:
key = UK_TO_US[key]
except KeyError:
pass
super().__setitem__(key, value)
这个实现看起来与最初的略有不同,但工作原理相同。编码也可能更难,因为你不再使用.data了。相反,你使用的是super()、.__getitem__()和.__setitem__()。这段代码需要对 Python 的数据模型有一定的了解,这是一个复杂而高级的话题。
这个新实现的主要优点是你的类现在与dict兼容,所以如果你需要的话,你可以在任何时候改变这个超类。
注意:记住,如果您直接从dict继承,那么您需要重新实现.__init__()和其他方法,以便它们在将键添加到字典中时也将键翻译成美式拼写。
通过子类化UserDict来扩展标准字典功能通常比子类化dict更方便。主要原因是内置的dict有一些实现快捷方式和优化,最终迫使你覆盖那些如果你使用UserDict作为父类就可以继承的方法。
通过值访问键的字典
自定义词典的另一个常见需求是提供标准行为之外的附加功能。例如,假设您想要创建一个类似字典的类,该类提供检索映射到给定目标值的键的方法。
您需要一个方法来检索映射到目标值的第一个键。您还希望有一个方法返回那些映射到相等值的键的迭代器。
下面是这个自定义词典的一个可能的实现:
# value_dict.py
class ValueDict(dict):
def key_of(self, value):
for k, v in self.items():
if v == value:
return k
raise ValueError(value)
def keys_of(self, value):
for k, v in self.items():
if v == value:
yield k
这一次,不是从UserDict继承,而是从dict继承。为什么?在本例中,您添加的功能不会改变字典的核心特性。因此,从dict那里继承更合适。就性能而言,它也更加高效,您将在本教程的后面部分看到这一点。
.key_of()方法迭代底层字典中的键值对。条件语句检查与目标值匹配的值。if代码块返回第一个匹配值的关键字。如果缺少目标键,那么该方法会引发一个ValueError。
作为一个按需生成键的生成器方法,.keys_of()将只生成那些值与方法调用中作为参数提供的value相匹配的键。
下面是这本词典在实践中的用法:
>>> from value_dict import ValueDict >>> inventory = ValueDict() >>> inventory["apple"] = 2 >>> inventory["banana"] = 3 >>> inventory.update({"orange": 2}) >>> inventory {'apple': 2, 'banana': 3, 'orange': 2} >>> inventory.key_of(2) 'apple' >>> inventory.key_of(3) 'banana' >>> list(inventory.keys_of(2)) ['apple', 'orange']酷!你的字典像预期的那样工作。它从 Python 的
dict继承了核心字典的特性,并在此基础上实现了新的功能。一般来说,你应该使用
UserDict来创建一个类似字典的类,它的行为类似于内置的dict类,但是定制了它的一些核心功能,大部分是像.__setitem__()和.__getitem__()这样的特殊方法。另一方面,如果您只需要一个类似字典的类,具有不影响或修改核心
dict行为的扩展功能,那么您最好直接从 Python 中的dict继承。这种练习会更快、更自然、更有效。具有附加功能的词典
作为如何实现具有附加特性的自定义字典的最后一个示例,假设您想要创建一个提供以下方法的字典:
方法 描述 .apply(action)将可调用的 action作为参数,并将其应用于基础字典中的所有值.remove(key)从底层字典中删除给定的 key.is_empty()根据字典是否为空返回 True或False实现这三个方法,不需要修改内置
dict类的核心行为。因此,子类化dict而不是UserDict似乎是一条可行之路。下面是在
dict之上实现所需方法的代码:# extended_dict.py class ExtendedDict(dict): def apply(self, action): for key, value in self.items(): self[key] = action(value) def remove(self, key): del self[key] def is_empty(self): return len(self) == 0在这个例子中,
.apply()将一个 callable 作为参数,并将其应用于底层字典中的每个值。然后将转换后的值重新分配给原始键。.remove()方法使用del语句从字典中删除目标键。最后,.is_empty()使用内置的len()函数来查找字典是否为空。下面是
ExtendedDict的工作原理:
>>> from extended_dict import ExtendedDict
>>> numbers = ExtendedDict({"one": 1, "two": 2, "three": 3})
>>> numbers
{'one': 1, 'two': 2, 'three': 3}
>>> numbers.apply(lambda x: x**2)
>>> numbers
{'one': 1, 'two': 4, 'three': 9}
>>> numbers.remove("two")
>>> numbers
{'one': 1, 'three': 9}
>>> numbers.is_empty()
False
在这些例子中,首先使用一个常规字典作为参数创建一个ExtendedDict的实例。然后在扩展字典上调用.apply()。该方法将一个 lambda 函数作为参数,并将其应用于字典中的每个值,将目标值转换为它的平方。
然后,.remove()将一个现有的键作为参数,并从字典中删除相应的键-值对。最后,.is_empty()返回False,因为numbers不为空。如果底层字典为空,它将返回True。
考虑性能
从UserDict继承可能意味着性能成本,因为这个类是用纯 Python 编写的。另一方面,内置的dict类是用 C 编写的,并针对性能进行了高度优化。所以,如果你需要在性能关键的代码中使用自定义字典,那么确保对你的代码进行计时以发现潜在的性能问题。
为了检查当你从UserDict而不是dict继承时是否会出现性能问题,回到你的ExtendedDict类,将其代码复制到两个不同的类中,一个从dict继承,另一个从UserDict继承。
您的类应该是这样的:
# extended_dicts.py
from collections import UserDict
class ExtendedDict_dict(dict):
def apply(self, action):
for key, value in self.items():
self[key] = action(value)
def remove(self, key):
del self[key]
def is_empty(self):
return len(self) == 0
class ExtendedDict_UserDict(UserDict):
def apply(self, action):
for key, value in self.items():
self[key] = action(value)
def remove(self, key):
del self[key]
def is_empty(self):
return len(self) == 0
这两个类的唯一区别是ExtendedDict_dict子类dict,而ExtendedDict_UserDict子类UserDict。
要检查它们的性能,可以从计时核心字典操作开始,比如类实例化。在 Python 交互式会话中运行以下代码:
>>> import timeit >>> from extended_dicts import ExtendedDict_dict >>> from extended_dicts import ExtendedDict_UserDict >>> init_data = dict(zip(range(1000), range(1000))) >>> dict_initialization = min( ... timeit.repeat( ... stmt="ExtendedDict_dict(init_data)", ... number=1000, ... repeat=5, ... globals=globals(), ... ) ... ) >>> user_dict_initialization = min( ... timeit.repeat( ... stmt="ExtendedDict_UserDict(init_data)", ... number=1000, ... repeat=5, ... globals=globals(), ... ) ... ) >>> print( ... f"UserDict is {user_dict_initialization / dict_initialization:.3f}", ... "times slower than dict", ... ) UserDict is 35.877 times slower than dict在这段代码中,您使用
timeit模块和min()函数来测量一段代码的执行时间。在这个例子中,目标代码由实例化ExtendedDict_dict和ExtendedDict_UserDict组成。一旦运行了这个时间测量代码,就可以比较两个初始化时间。在这个具体的例子中,基于
UserDict的类的初始化比从dict派生的类慢。这一结果表明存在严重的性能差异。测量新功能的执行时间可能也很有趣。比如可以查看
.apply()的执行时间。要进行这项检查,请继续运行以下代码:
>>> extended_dict = ExtendedDict_dict(init_data)
>>> dict_apply = min(
... timeit.repeat(
... stmt="extended_dict.apply(lambda x: x**2)",
... number=5,
... repeat=2,
... globals=globals(),
... )
... )
>>> extended_user_dict = ExtendedDict_UserDict(init_data)
>>> user_dict_apply = min(
... timeit.repeat(
... stmt="extended_user_dict.apply(lambda x: x**2)",
... number=5,
... repeat=2,
... globals=globals(),
... )
... )
>>> print(
... f"UserDict is {user_dict_apply / dict_apply:.3f}",
... "times slower than dict",
... )
UserDict is 1.704 times slower than dict
基于UserDict的类和基于dict的类这次的性能差别不是那么大,但是还是存在的。
通常,当你通过子类化dict来创建一个自定义字典时,你可以期望标准字典操作在这个类中比在基于UserDict的类中更有效。另一方面,新功能在两个类中可能有相似的执行时间。你怎么知道哪条路是最有效的呢?你必须对你的代码进行时间测量。
值得注意的是,如果您的目标是修改核心字典功能,那么UserDict可能是一个不错的选择,因为在这种情况下,您将主要用纯 Python 重写dict类。
结论
现在,您知道了如何用修改的行为和新功能创建定制的类似字典的类。您已经学会了通过直接子类化内置的dict类和从collections模块中可用的UserDict类继承来实现这一点。
在本教程中,您学习了如何:
- 通过继承内置的
dict类来创建类似字典的类 - 识别继承 Python 内置
dict类的常见陷阱 - 通过从
collections模块中子类化UserDict来构建类似字典的类
您还编写了一些实例,帮助您理解在创建自定义字典类时使用UserDict和dict的利弊。
现在,您已经准备好创建自定义词典,并利用 Python 中这种有用的数据类型的全部功能来响应您的编码需求。
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。*****
自定义 Python 列表:从列表和用户列表继承
在您的 Python 编码冒险中的某个时刻,您可能需要创建定制的类似列表的类,具有修改的行为、新的功能,或者两者兼有。在 Python 中要做到这一点,你可以从一个抽象基类继承,直接继承内置list类的子类,或者从UserList继承,后者位于collections模块中。
在本教程中,您将学习如何:
- 通过继承内置的
list类来创建定制的类似列表的类 - 通过从
collections模块中子类化UserList来构建定制的列表类
您还将编写一些示例,帮助您决定在创建自定义列表类时使用哪个父类list或UserList。
为了充分利用本教程,您应该熟悉 Python 的内置 list 类及其标准特性。你还需要知道面向对象编程的基础知识,理解继承在 Python 中是如何工作的。
免费下载: 点击这里下载源代码,你将使用它来创建定制的列表类。
在 Python 中创建类似列表的类
内置的 list 类是 Python 中的基本数据类型。列表在很多情况下都很有用,并且有大量的实际用例。在某些用例中,Python list的标准功能可能不够,您可能需要创建定制的类似列表的类来解决手头的问题。
您通常会发现创建定制的类似列表的类至少有两个原因:
- 通过添加新功能来扩展常规列表
- 修改标准列表的功能
您还可能面临需要扩展和来修改列表的标准功能的情况。
根据您的具体需求和技能水平,您可以使用一些策略来创建您自己的定制列表类。您可以:
- 从适当的抽象基类继承,如
MutableSequence - 直接从 Python 内置的
list类继承 - 子类
UserList来自collections
注:在面向对象编程中,通常的做法是将动词继承和子类互换使用。
当您选择要使用的适当策略时,有一些注意事项。请继续阅读,了解更多详情。
从抽象基类构建类似列表的类
您可以通过继承适当的抽象基类(ABC) ,像 MutableSequence ,来创建自己的列表类。除了 .__getitem__() 、 .__setitem__() 、 .__delitem__ 、 .__len__() 和.insert()之外,这个 ABC 提供了大多数list方法的通用实现。因此,当从这个类继承时,您必须自己实现这些方法。
为所有这些特殊方法编写自己的实现是一项相当大的工作量。这很容易出错,并且需要 Python 及其数据模型的高深知识。这也可能意味着性能问题,因为您将使用纯 Python 编写方法。
此外,假设您需要定制任何其他标准列表方法的功能,如 .append() 或.insert()。在这种情况下,您必须覆盖默认实现,并提供一个满足您需求的合适实现。
这种创建类似列表的类的策略的主要优点是,如果您在自定义实现中遗漏了任何必需的方法,父 ABC 类会提醒您。
一般来说,只有当您需要一个与内置的list类完全不同的列表类时,您才应该采用这种策略。
在本教程中,您将通过继承内置的list类和标准库collections模块中的UserList类来创建类似列表的类。这些策略似乎是最快捷和最实用的。
从 Python 内置的list类继承而来
很长一段时间,直接继承用 C 实现的 Python 类型是不可能的。Python 2.2 修复了这个问题。现在你可以子类内置类型,包括list。这一变化给子类带来了一些技术优势,因为现在它们:
这个列表中的第一项可能是对需要 Python 内置类的 C 代码的要求。第二项允许您在标准列表行为的基础上添加新功能。最后,第三项将使您能够将子类的属性限制为那些在.__slots__中预定义的属性。
要开始创建定制的类似列表的类,假设您需要一个列表,它会自动将所有项目存储为字符串。假设您的定制列表将把数字仅仅存储为字符串,您可以创建下面的list子类:
# string_list.py
class StringList(list):
def __init__(self, iterable):
super().__init__(str(item) for item in iterable)
def __setitem__(self, index, item):
super().__setitem__(index, str(item))
def insert(self, index, item):
super().insert(index, str(item))
def append(self, item):
super().append(str(item))
def extend(self, other):
if isinstance(other, type(self)):
super().extend(other)
else:
super().extend(str(item) for item in other)
您的StringList类直接继承了list,这意味着它将继承标准 Python list的所有功能。因为您希望列表将项存储为字符串,所以需要修改所有在基础列表中添加或修改项的方法。这些方法包括以下内容:
.__init__初始化所有类的新实例。.__setitem__()允许您使用项目的索引为现有项目分配一个新值,就像在a_list[index] = item中一样。.insert()允许你使用项目的索引在底层列表的给定位置插入一个新项目。.append()在底层列表的末尾增加一个新的单项。.extend()将一系列项目添加到列表的末尾。
您的StringList类从list继承的其他方法工作得很好,因为它们不添加或更新您的自定义列表中的项目。
注意:如果你想让你的StringList类支持和加号运算符(+)的串联,那么你还需要实现其他特殊的方法,比如 .__add__() 、 .__radd__() 和 .__iadd__() 。
要在代码中使用StringList,您可以这样做:
>>> from string_list import StringList >>> data = StringList([1, 2, 2, 4, 5]) >>> data ['1', '2', '2', '4', '5'] >>> data.append(6) >>> data ['1', '2', '2', '4', '5', '6'] >>> data.insert(0, 0) >>> data ['0', '1', '2', '2', '4', '5', '6'] >>> data.extend([7, 8, 9]) >>> data ['0', '1', '2', '2', '4', '5', '6', '7', '8', '9'] >>> data[3] = 3 >>> data ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']你的班级像预期的那样工作。它将所有输入值动态转换成字符串。那很酷,不是吗?当你创建一个新的
StringList实例时,类的初始化器会负责转换。当您向类的实例追加、插入、扩展或分配新值时,支持每个操作的方法将负责字符串转换过程。这样,您的列表将始终将其项目存储为字符串对象。
从
collections子类化UserList另一种创建定制列表类的方法是使用
collections模块中的UserList类。这个类是内置list类型的包装器。它是为在不可能直接从内置的list类继承时创建类似列表的对象而设计的。尽管对这个类的需求已经被直接子类化内置的
list类的可能性部分取代,但是为了方便和向后兼容,UserList仍然可以在标准库中使用。
UserList的显著特点是它允许您访问它的.data属性,这可以方便您创建自定义列表,因为您不需要一直使用super()。.data属性保存一个常规的 Pythonlist,默认情况下为空。下面是你如何通过继承
UserList来重新实现你的StringList类:# string_list.py from collections import UserList class StringList(UserList): def __init__(self, iterable): super().__init__(str(item) for item in iterable) def __setitem__(self, index, item): self.data[index] = str(item) def insert(self, index, item): self.data.insert(index, str(item)) def append(self, item): self.data.append(str(item)) def extend(self, other): if isinstance(other, type(self)): self.data.extend(other) else: self.data.extend(str(item) for item in other)在这个例子中,访问
.data属性允许您通过使用委托以更直接的方式对类进行编码,这意味着.data中的列表负责处理所有请求。现在你几乎不用使用
super()这样的高级工具了。你只需要在类初始化器中调用这个函数,以防止在进一步的继承场景中出现问题。在其余的方法中,您只需利用保存常规 Python 列表的.data。使用列表是你可能已经掌握的技能。注意:在上面的例子中,你可以重用上一节中
StringList的内部实现,但是把父类从list改为UserList。您的代码将同样工作。然而,使用.data可以简化列表类的编码过程。这个新版本和你的第一个版本
StringList一样。继续运行以下代码进行试验:
>>> from string_list import StringList
>>> data = StringList([1, 2, 2, 4, 5])
>>> data
['1', '2', '2', '4', '5']
>>> data.append(6)
>>> data
['1', '2', '2', '4', '5', '6']
>>> data.insert(0, 0)
>>> data
['0', '1', '2', '2', '4', '5', '6']
>>> data.extend([7, 8, 9])
>>> data
['0', '1', '2', '2', '4', '5', '6', '7', '8', '9']
>>> data[3] = 3
>>> data
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
正如您已经了解到的,暴露.data是UserList最相关的特性。这个属性可以简化你的类,因为你不需要一直使用super()。你可以利用.data并使用熟悉的list界面来处理这个属性。
编码列表类:实例
当您需要创建自定义的类似列表的类来添加或修改list的标准功能时,您已经知道如何使用list和UserList。
诚然,当您考虑创建一个类似列表的类时,从list继承可能比从UserList继承更自然,因为 Python 开发人员知道list。他们可能不知道UserList的存在。
您还知道这两个类的主要区别在于,当您从UserList继承时,您可以访问.data属性,这是一个常规列表,您可以通过标准的list接口对其进行操作。相比之下,从list继承需要关于 Python 数据模型的高级知识,包括像内置的super()函数和一些特殊方法这样的工具。
在接下来的部分中,您将使用这两个类编写一些实际的例子。写完这些例子后,当您需要在代码中定义定制的类似列表的类时,您可以更好地选择合适的工具。
只接受数字数据的列表
作为创建具有自定义行为的列表类的第一个例子,假设您需要一个只接受数字数据的列表。你的列表应该只存储整数、浮点数和复数。如果您试图存储任何其他数据类型的值,比如字符串,那么您的列表应该引发一个TypeError。
下面是一个具有所需功能的NumberList类的实现:
# number_list.py
class NumberList(list):
def __init__(self, iterable):
super().__init__(self._validate_number(item) for item in iterable)
def __setitem__(self, index, item):
super().__setitem__(index, self._validate_number(item))
def insert(self, index, item):
super().insert(index, self._validate_number(item))
def append(self, item):
super().append(self._validate_number(item))
def extend(self, other):
if isinstance(other, type(self)):
super().extend(other)
else:
super().extend(self._validate_number(item) for item in other)
def _validate_number(self, value):
if isinstance(value, (int, float, complex)):
return value
raise TypeError(
f"numeric value expected, got {type(value).__name__}"
)
在这个例子中,您的NumberList类直接继承自list。这意味着您的类与内置的list类共享所有核心功能。您可以迭代NumberList的实例,使用它们的索引访问和更新它的条目,调用通用的list方法,等等。
现在,为了确保每个输入项都是一个数字,您需要在支持添加新项或更新列表中现有项的操作的所有方法中验证每个项。所需的方法与从 Python 内置的list类继承而来的一节中的StringList示例相同。
为了验证输入数据,您使用一个叫做._validate_number()的助手方法。该方法使用内置的 isinstance() 函数来检查当前输入值是否是int、float或complex的实例,这些是 Python 中表示数值的内置类。
注意:在 Python 中检查一个值是否为数字的更通用的方法是使用 numbers 模块中的 Number 。这将允许您验证 Fraction 和 Decimal 对象。
如果输入值是数值数据类型的实例,那么您的帮助器函数将返回该值本身。否则,该函数会引发一个TypeError 异常,并显示一条适当的错误消息。
要使用NumberList,请返回到您的交互式会话并运行以下代码:
>>> from number_list import NumberList >>> numbers = NumberList([1.1, 2, 3j]) >>> numbers [1.1, 2, 3j] >>> numbers.append("4.2") Traceback (most recent call last): ... TypeError: numeric value expected, got str >>> numbers.append(4.2) >>> numbers [1.1, 2, 3j, 4.2] >>> numbers.insert(0, "0") Traceback (most recent call last): ... TypeError: numeric value expected, got str >>> numbers.insert(0, 0) >>> numbers [0, 1.1, 2, 3j, 4.2] >>> numbers.extend(["5.3", "6"]) Traceback (most recent call last): ... TypeError: numeric value expected, got str >>> numbers.extend([5.3, 6]) >>> numbers [0, 1.1, 2, 3j, 4.2, 5.3, 6]在这些例子中,在
numbers中添加或修改数据的操作自动验证输入,以确保只接受数值。如果你给numbers加一个字符串值,那么你得到一个TypeError。使用
UserList的NumberList的另一个实现可以是这样的:# number_list.py from collections import UserList class NumberList(UserList): def __init__(self, iterable): super().__init__(self._validate_number(item) for item in iterable) def __setitem__(self, index, item): self.data[index] = self._validate_number(item) def insert(self, index, item): self.data.insert(index, self._validate_number(item)) def append(self, item): self.data.append(self._validate_number(item)) def extend(self, other): if isinstance(other, type(self)): self.data.extend(other) else: self.data.extend(self._validate_number(item) for item in other) def _validate_number(self, value): if isinstance(value, (int, float, complex)): return value raise TypeError( f"numeric value expected, got {type(value).__name__}" )在这个新的
NumberList实现中,您继承了UserList。同样,您的类将与常规的list共享所有核心功能。在这个例子中,不是一直使用
super()来访问父类中的方法和属性,而是直接使用.data属性。在某种程度上,与使用super()和其他高级工具如特殊方法相比,使用.data可以说简化了您的代码。注意,你只在类初始化器
.__init__()中使用super()。当您在 Python 中处理继承时,这是一个最佳实践。它允许您正确初始化父类中的属性,而不会破坏东西。具有附加功能的列表
现在假设您需要一个类似列表的类,具有常规 Python
list的所有标准功能。你的类还应该提供一些从 JavaScript 的数组数据类型中借用的额外功能。例如,您需要像下面这样的方法:
.join()将列表中的所有项目串联成一个字符串。.map(action)通过对底层列表中的每个项目应用一个action()callable 来产生新的项目。.filter(predicate)在调用predicate()时会产生所有返回True的物品。.for_each(func)对底层列表中的每一项都调用func()来生成一些副作用。这里有一个通过子类化
list实现所有这些新特性的类:# custom_list.py class CustomList(list): def join(self, separator=" "): return separator.join(str(item) for item in self) def map(self, action): return type(self)(action(item) for item in self) def filter(self, predicate): return type(self)(item for item in self if predicate(item)) def for_each(self, func): for item in self: func(item)
CustomList中的.join()方法以一个分隔符作为参数,并使用它来连接当前列表对象中的项目,该列表对象由self表示。为此,您使用带有一个生成器表达式的str.join()作为参数。这个生成器表达式使用str()将每一项转换成一个字符串对象。
.map()方法返回一个CustomList对象。为了构造这个对象,您使用一个生成器表达式,将action()应用到当前对象self中的每一项。请注意,该操作可以是任何可调用的操作,它将一个项作为参数并返回一个转换后的项。
.filter()方法也返回一个CustomList对象。要构建这个对象,您需要使用一个生成器表达式来生成predicate()返回True的项目。在这种情况下,predicate()必须是一个布尔值函数,它根据应用于输入项的特定条件返回True或False。最后,
.for_each()方法对底层列表中的每一项调用func()。这个调用没有返回任何东西,但是触发了一些副作用,您将在下面看到。要在代码中使用该类,您可以执行如下操作:
>>> from custom_list import CustomList
>>> words = CustomList(
... [
... "Hello,",
... "Pythonista!",
... "Welcome",
... "to",
... "Real",
... "Python!"
... ]
... )
>>> words.join()
'Hello, Pythonista! Welcome to Real Python!'
>>> words.map(str.upper)
['HELLO,', 'PYTHONISTA!', 'WELCOME', 'TO', 'REAL', 'PYTHON!']
>>> words.filter(lambda word: word.startswith("Py"))
['Pythonista!', 'Python!']
>>> words.for_each(print)
Hello,
Pythonista!
Welcome
to
Real
Python!
在这些例子中,首先在words上调用.join()。此方法返回一个唯一的字符串,该字符串是由基础列表中的所有项串联而成的。
对.map()的调用返回一个包含大写单词的CustomList对象。这种转换是将str.upper()应用于words中的所有项目的结果。这个方法与内置的 map() 函数非常相似。主要的区别是,内置的map()函数返回一个迭代器,生成转换后的条目和,而不是返回一个列表。
.filter()方法将一个 lambda 函数作为参数。在示例中,这个lambda函数使用 str.startswith() 来选择以"Py"前缀开头的单词。注意,这个方法的工作方式类似于内置的 filter() 函数,它返回一个迭代器而不是一个列表。
最后,对words上的.for_each()的调用将每个单词打印到屏幕上,作为对底层列表中的每个项目调用 print() 的副作用。注意,传递给.for_each()的函数应该将一个项目作为参数,但它不应该返回任何有成果的值。
你也可以通过继承UserList而不是list来实现CustomList。在这种情况下,您不需要更改内部实现,只需更改基类:
# custom_list.py
from collections import UserList
class CustomList(UserList):
def join(self, separator=" "):
return separator.join(str(item) for item in self)
def map(self, action):
return type(self)(action(item) for item in self)
def filter(self, predicate):
return type(self)(item for item in self if predicate(item))
def for_each(self, func):
for item in self:
func(item)
请注意,在本例中,您只是更改了父类。没必要直接用.data。但是,如果你愿意,你可以使用它。这样做的好处是,您可以为阅读您代码的其他开发人员提供更多的上下文:
# custom_list.py
from collections import UserList
class CustomList(UserList):
def join(self, separator=" "):
return separator.join(str(item) for item in self.data)
def map(self, action):
return type(self)(action(item) for item in self.data)
def filter(self, predicate):
return type(self)(item for item in self.data if predicate(item))
def for_each(self, func):
for item in self.data: func(item)
在这个新版本的CustomList()中,唯一的变化是你用self.data替换了self,以表明你正在使用一个UserList子类。这一变化使您的代码更加清晰。
考虑性能:list vs UserList
至此,您已经学会了如何通过继承list或UserList来创建自己的列表类。您还知道这两个类之间唯一可见的区别是UserList公开了.data属性,这有助于编码过程。
在这一节中,当决定是使用list还是UserList来创建定制的类似列表的类时,您将考虑一个重要的方面。那是性能!
为了评估继承自list和UserList的类之间是否存在性能差异,您将使用StringList类。继续创建包含以下代码的新 Python 文件:
# performance.py
from collections import UserList
class StringList_list(list):
def __init__(self, iterable):
super().__init__(str(item) for item in iterable)
def __setitem__(self, index, item):
super().__setitem__(index, str(item))
def insert(self, index, item):
super().insert(index, str(item))
def append(self, item):
super().append(str(item))
def extend(self, other):
if isinstance(other, type(self)):
super().extend(other)
else:
super().extend(str(item) for item in other)
class StringList_UserList(UserList):
def __init__(self, iterable):
super().__init__(str(item) for item in iterable)
def __setitem__(self, index, item):
self.data[index] = str(item)
def insert(self, index, item):
self.data.insert(index, str(item))
def append(self, item):
self.data.append(str(item))
def extend(self, other):
if isinstance(other, type(self)):
self.data.extend(other)
else:
self.data.extend(str(item) for item in other)
这两个类的工作原理是一样的。然而,它们在内部是不同的。StringList_list继承自list,其实现基于super()。相比之下,StringList_UserList继承自UserList,它的实现依赖于内部的.data属性。
要比较这两个类的性能,应该从计时标准列表操作开始,比如实例化。然而,在这些例子中,两个初始化器是等价的,所以它们应该执行相同的操作。
测量新功能的执行时间也很有用。比如可以查看.extend()的执行时间。继续运行下面的代码:
>>> import timeit >>> from performance import StringList_list, StringList_UserList >>> init_data = range(10000) >>> extended_list = StringList_list(init_data) >>> list_extend = min( ... timeit.repeat( ... stmt="extended_list.extend(init_data)", ... number=5, ... repeat=2, ... globals=globals(), ... ) ... ) * 1e6 >>> extended_user_list = StringList_UserList(init_data) >>> user_list_extend = min( ... timeit.repeat( ... stmt="extended_user_list.extend(init_data)", ... number=5, ... repeat=2, ... globals=globals(), ... ) ... ) * 1e6 >>> f"StringList_list().extend() time: {list_extend:.2f} μs" 'StringList_list().extend() time: 4632.08 μs' >>> f"StringList_UserList().extend() time: {user_list_extend:.2f} μs" 'StringList_UserList().extend() time: 4612.62 μs'在这个性能测试中,您使用
timeit模块和min()函数来测量一段代码的执行时间。目标代码包括使用一些样本数据在StringList_list和StringList_UserList的实例上对.extend()的调用。在这个例子中,基于
list的类和基于UserList的类之间的性能差异几乎不存在。通常,当你创建一个定制的类似列表的类时,你会期望
list的子类比UserList的子类执行得更好。为什么?因为list是用 C 写的,并且针对性能进行了优化,而UserList是用纯 Python 写的包装器类。然而,在上面的例子中,看起来这个假设并不完全正确。因此,要决定哪个超类最适合您的特定用例,请确保运行性能测试。
撇开性能不谈,继承
list可以说是 Python 中的自然方式,主要是因为list作为内置类直接供 Python 开发人员使用。此外,大多数 Python 开发人员将熟悉列表及其标准特性,这将允许他们更快地编写类似列表的类。相比之下,
UserList类位于collections模块中,这意味着如果想在代码中使用它,就必须导入它。另外,并不是所有的 Python 开发者都知道UserList的存在。然而,UserList仍然是一个有用的工具,因为它可以方便地访问.data属性,这有助于创建定制的类似列表的类。结论
现在你已经学会了如何创建定制列表类的类和修改后的新行为。为此,您已经直接子类化了内置的
list类。作为一种选择,你也继承了UserList类,它在collections模块中可用。从
list继承和子类化UserList都是解决在 Python 中创建自己的列表类问题的合适策略。在本教程中,您学习了如何:
- 通过继承内置
list类来创建类似列表的类- 通过从
collections模块中子类化UserList来构建类似列表的类现在,您可以更好地创建自己的自定义列表,从而充分利用 Python 中这种有用且常见的数据类型的全部功能。
免费下载: 点击这里下载源代码,你将使用它来创建定制的列表类。****
自定义 Python 字符串:从 str 和 UserString 继承
Python
str类有许多有用的特性,当你在代码中处理文本或字符串时,这些特性可以帮到你。然而,在某些情况下,所有这些伟大的功能可能还不够。您可能需要创建自定义的类似字符串的类。在 Python 中要做到这一点,你可以直接从内置的str类继承,或者继承位于collections模块中的子类UserString。在本教程中,您将学习如何:
- 通过继承内置的
str类来创建定制的类似字符串的类- 通过从
collections模块中子类化UserString来构建定制的类似字符串的类- 决定何时使用
str或UserString来创建自定义的类似字符串的类同时,您将编写几个例子来帮助您在创建自定义字符串类时决定是使用
str还是UserString。您的选择将主要取决于您的具体用例。为了跟随本教程,如果您熟悉 Python 的内置
str类及其标准特性,将会有所帮助。你还需要了解 Python 中的面向对象编程和继承的基础知识。示例代码: 点击这里下载免费的示例代码,您将使用它来创建定制的类似字符串的类。
在 Python 中创建类似字符串的类
内置的
str类允许你在 Python 中创建字符串。字符串是您将在许多情况下使用的字符序列,尤其是在处理文本数据时。有时,Python 的标准功能可能不足以满足您的需求。因此,您可能希望创建自定义的类似字符串的类来解决您的特定问题。您通常会发现创建定制的类似字符串的类至少有两个原因:
- 通过添加新功能来扩展常规字符串
- 修改标准字符串的功能
您还可能面临需要同时扩展和修改字符串的标准功能的情况。
在 Python 中,您通常会使用以下技术之一来创建类似字符串的类。可以直接从 Python 内置的
str类继承或者从collections子类UserString。注:在面向对象编程中,通常的做法是将动词继承和子类互换使用。
Python 字符串的一个相关特性是不变性,这意味着您不能就地修改它们。因此,当选择合适的技术来创建自己的定制的类似字符串的类时,您需要考虑您想要的特性是否会影响不变性。
例如,如果您需要修改现有 string 方法的当前行为,那么您可以子类化
str。相比之下,如果你需要改变字符串的创建方式,那么从str继承将需要高级知识。你必须覆盖.__new__()方法。在后一种情况下,继承UserString可能会让你的生活更轻松,因为你不必碰.__new__()。在接下来的部分中,您将了解每种技术的优缺点,这样您就可以决定哪种策略是解决特定问题的最佳策略。
从 Python 内置的
str类继承而来很长一段时间,直接继承用 C 实现的 Python 类型是不可能的。Python 2.2 修复了这个问题。现在你可以子类内置类型,包括
str。当您需要创建自定义的类似字符串的类时,这个新特性非常方便。通过直接从
str继承,您可以扩展和修改这个内置类的标准行为。您还可以在新实例准备好之前,调整您的自定义字符串类的实例化过程来执行转换。扩展字符串的标准行为
需要定制的类似字符串的类的一个例子是当您需要用新的行为扩展标准 Python 字符串时。例如,假设您需要一个类似字符串的类,它实现一个新方法来计算底层字符串中的字数。
在本例中,您的自定义字符串将使用空白字符作为其默认的单词分隔符。但是,它还应该允许您提供特定的分隔符。要编写满足这些需求的类,您可以这样做:
>>> class WordCountString(str):
... def words(self, separator=None):
... return len(self.split(separator))
...
这个类直接继承自str。这意味着它提供了与其父类相同的接口。
在这个继承的接口之上,添加一个名为.words()的新方法。这个方法将一个separator字符作为参数传递给.split()。它的缺省值是None,它将在连续的空格中分割。然后调用带有目标分隔符的.split()将底层字符串拆分成单词。最后,你用 len() 函数来确定字数。
下面是如何在代码中使用该类:
>>> sample_text = WordCountString( ... """Lorem ipsum dolor sit amet consectetur adipisicing elit. Maxime ... mollitia, molestiae quas vel sint commodi repudiandae consequuntur ... voluptatum laborum numquam blanditiis harum quisquam eius sed odit ... fugiat iusto fuga praesentium optio, eaque rerum! Provident similique ... accusantium nemo autem. Veritatis obcaecati tenetur iure eius earum ... ut molestias architecto voluptate aliquam nihil, eveniet aliquid ... culpa officia aut! Impedit sit sunt quaerat, odit, tenetur error, ... harum nesciunt ipsum debitis quas aliquid.""" ... ) >>> sample_text.words() 68酷!你的方法很有效。它将输入文本拆分成单词,然后返回单词计数。您可以修改这个方法如何定界和处理单词,但是当前的实现对于这个演示性的例子来说工作得很好。
在这个例子中,您没有修改 Python 的
str的标准行为。您刚刚向自定义类添加了新的行为。然而,也可以通过覆盖它的任何默认方法来改变str的默认行为,这将在接下来进行探讨。修改字符串的标准行为
为了学习如何在一个定制的类似字符串的类中修改
str的标准行为,假设你需要一个字符串类,它总是用大写字母打印。你可以通过覆盖.__str__()特殊方法来实现,该方法负责字符串对象的打印。这里有一个
UpperPrintString类,它的行为符合您的需要:
>>> class UpperPrintString(str):
... def __str__(self):
... return self.upper()
...
同样,这个类继承自str。.__str__()方法返回底层字符串self的副本,其中所有字母都是大写的。要变换字母,您使用 .upper() 方法。
要尝试您的自定义字符串类,请继续运行以下代码:
>>> sample_string = UpperPrintString("Hello, Pythonista!") >>> print(sample_string) HELLO, PYTHONISTA! >>> sample_string 'Hello, Pythonista!'当您打印一个
UpperPrintString的实例时,您会在屏幕上看到大写字母的字符串。请注意,原始字符串没有被修改或影响。您只更改了str的标准打印功能。调整
str的实例化过程在这一部分,您将做一些不同的事情。您将创建一个类似字符串的类,它在生成最终的字符串对象之前转换原始的输入字符串。例如,假设您需要一个类似字符串的类,它以小写形式存储所有字母。为此,您将尝试覆盖类初始值设定项
.__init__(),并执行如下操作:
>>> class LowerString(str):
... def __init__(self, string):
... super().__init__(string.lower())
...
在这个代码片段中,您提供了一个覆盖默认str初始化器的.__init__()方法。在这个.__init__()实现中,您使用 super() 来访问父类的.__init__()方法。然后,在初始化当前字符串之前,调用输入字符串上的.lower()将它的所有字母转换成小写字母。
但是,上面的代码不起作用,您将在下面的示例中确认这一点:
>>> sample_string = LowerString("Hello, Pythonista!") Traceback (most recent call last): ... TypeError: object.__init__() takes exactly one argument...因为
str对象是不可变的,你不能在.__init__()中改变它们的值。这是因为该值是在对象创建期间设置的,而不是在对象初始化期间设置的。在实例化过程中转换给定字符串值的唯一方法是覆盖.__new__()方法。下面是如何做到这一点:
>>> class LowerString(str):
... def __new__(cls, string):
... instance = super().__new__(cls, string.lower())
... return instance
...
>>> sample_string = LowerString("Hello, Pythonista!")
>>> sample_string
'hello, pythonista!'
在这个例子中,您的LowerString类覆盖了超类的.__new__()方法来定制实例的创建方式。在这种情况下,您在创建新的LowerString对象之前转换输入字符串。现在,您的类按照您需要的方式工作。它接受一个字符串作为输入,并将其存储为小写字符串。
如果您需要在实例化时转换输入字符串,那么您必须覆盖.__new__()。这项技术需要 Python 的数据模型和特殊方法的高级知识。
从collections 子类化UserString
第二个允许您创建定制的类似字符串的类的工具是来自collections模块的UserString类。这个类是内置str类型的包装器。当不能直接从内置的str类继承时,它被设计用来开发类似字符串的类。
直接子类化str的可能性意味着你可能不太需要UserString。然而,为了方便和向后兼容,这个类仍然可以在标准库中找到。在实践中,这个类也有一些隐藏的有用的特性,您很快就会了解到。
UserString最相关的特性是它的.data属性,它允许您访问包装的字符串对象。该属性有助于创建定制字符串,尤其是在您希望的定制影响字符串可变性的情况下。
在接下来的两个小节中,您将重温前面小节中的例子,但是这次您将子类化UserString而不是str。首先,您将从扩展和修改 Python 字符串的标准行为开始。
扩展和修改字符串的标准行为
你可以通过继承UserString类来实现WordCountString和UpperPrintString,而不是继承内置的str类。这个新的实现只需要你改变超类。您不必更改类的原始内部实现。
以下是WordCountString和UpperPrintString的新版本:
>>> from collections import UserString >>> class WordCountString(UserString): ... def words(self, separator=None): ... return len(self.split(separator)) ... >>> class UpperPrintString(UserString): ... def __str__(self): ... return self.upper() ...这些新实现与原始实现之间的唯一区别是,现在您是从
UserString继承的。注意,从UserString继承需要你从collections模块导入该类。如果您使用与之前相同的示例来尝试这些类,那么您将会确认它们与基于
str的等价类工作相同:
>>> sample_text = WordCountString(
... """Lorem ipsum dolor sit amet consectetur adipisicing elit. Maxime
... mollitia, molestiae quas vel sint commodi repudiandae consequuntur
... voluptatum laborum numquam blanditiis harum quisquam eius sed odit
... fugiat iusto fuga praesentium optio, eaque rerum! Provident similique
... accusantium nemo autem. Veritatis obcaecati tenetur iure eius earum
... ut molestias architecto voluptate aliquam nihil, eveniet aliquid
... culpa officia aut! Impedit sit sunt quaerat, odit, tenetur error,
... harum nesciunt ipsum debitis quas aliquid."""
... )
>>> sample_text.words() 68
>>> sample_string = UpperPrintString("Hello, Pythonista!")
>>> print(sample_string) HELLO, PYTHONISTA!
>>> sample_string
'Hello, Pythonista!'
在这些例子中,WordCountString和UpperPrintString的新实现与旧的实现工作相同。那么,为什么要用UserString而不用str?到目前为止,没有明显的理由这样做。然而,当您需要修改字符串的创建方式时,UserString就派上了用场。
调整UserString 的实例化过程
你可以通过继承UserString来编写LowerString类。通过更改父类,您将能够在实例初始化器.__init__()中定制初始化过程,而无需覆盖实例创建者.__new__()。
这是你的新版本LowerString以及它在实践中是如何工作的:
>>> from collections import UserString >>> class LowerString(UserString): ... def __init__(self, string): ... super().__init__(string.lower()) ... >>> sample_string = LowerString("Hello, Pythonista!") >>> sample_string 'hello, pythonista!'在上面的例子中,通过使用
UserString而不是str作为超类,可以对输入字符串进行转换。这种转换是可能的,因为UserString是一个包装类,在其.data属性中存储最终字符串,这是真正的不可变对象。因为
UserString是围绕str类的包装器,所以它提供了一种灵活而直接的方式来创建具有可变行为的定制字符串。通过从str继承来提供可变的行为是复杂的,因为类的自然不变性条件。在下一节中,您将使用
UserString创建一个类似字符串的类,模拟一个可变字符串数据类型。在你的字符串类中模拟突变
作为为什么应该在 Python 工具包中使用
UserString的最后一个例子,假设您需要一个可变的类似字符串的类。换句话说,您需要一个可以就地修改的类似字符串的类。与列表和字典不同,字符串不提供
.__setitem__()特殊方法,因为它们是不可变的。您的自定义字符串将需要这个方法来允许您使用一个赋值语句通过索引更新字符和片段。你的类字符串类也需要改变普通字符串方法的标准行为。为了使这个例子简短,您将只修改
.upper()和.lower()方法。最后,您将提供一个.sort()方法来对字符串进行排序。标准的字符串方法不会改变底层的字符串。它们返回带有所需转换的新字符串对象。在您的自定义字符串中,您需要方法就地执行它们的更改。
为了实现所有这些目标,启动您最喜欢的代码编辑器,创建一个名为
mutable_string.py的文件,并编写以下代码:1# mutable_string.py 2 3from collections import UserString 4 5class MutableString(UserString): 6 def __setitem__(self, index, value): 7 data_as_list = list(self.data) 8 data_as_list[index] = value 9 self.data = "".join(data_as_list) 10 11 def __delitem__(self, index): 12 data_as_list = list(self.data) 13 del data_as_list[index] 14 self.data = "".join(data_as_list) 15 16 def upper(self): 17 self.data = self.data.upper() 18 19 def lower(self): 20 self.data = self.data.lower() 21 22 def sort(self, key=None, reverse=False): 23 self.data = "".join(sorted(self.data, key=key, reverse=reverse))下面是这段代码的逐行工作方式:
三号线从
collections进口UserString。第 5 行创建
MutableString作为UserString的子类。第 6 行定义
.__setitem__()。每当您使用索引对序列运行赋值操作时,Python 都会调用这个特殊的方法,就像在sequence[0] = value中一样。这个.__setitem__()的实现将.data转换成一个列表,用value替换index处的项目,使用.join()构建最终的字符串,并将其值赋回.data。整个过程模拟了一个就地转化或突变。第 11 行定义了
.__delitem__(),这个特殊的方法允许你使用del语句从你的可变字符串中按索引删除字符。它的实现类似于.__setitem__()。在第 13 行,您使用del从临时列表中删除条目。16 线超越
UserString.upper()并在.data上调用str.upper()。然后将结果存储回.data。同样,最后一个操作模拟了一个原位突变。第 19 行使用与
.upper()相同的技术覆盖UserString.lower()。第 22 行定义了
.sort(),它将内置的sorted()函数与str.join()方法结合起来,创建原始字符串的排序版本。注意,这个方法与list.sort()和内置的sorted()函数具有相同的签名。就是这样!你的可变字符串准备好了!要尝试一下,请回到您的 Python shell 并运行以下代码:
>>> from mutable_string import MutableString
>>> sample_string = MutableString("ABC def")
>>> sample_string
'ABC def'
>>> sample_string[4] = "x"
>>> sample_string[5] = "y"
>>> sample_string[6] = "z"
>>> sample_string
'ABC xyz'
>>> del sample_string[3]
>>> sample_string
'ABCxyz'
>>> sample_string.upper()
>>> sample_string
'ABCXYZ'
>>> sample_string.lower()
>>> sample_string
'abcxyz'
>>> sample_string.sort(reverse=True)
>>> sample_string
'zyxcba'
太好了!您的新可变的类字符串类如预期的那样工作。它允许您就地修改底层字符串,就像处理可变序列一样。注意,这个例子只包含了几个字符串方法。您可以尝试其他方法,继续为您的类提供新的可变性特性。
结论
你已经学会了用新的或修改过的行为创建自定义的类似字符串的类。您已经通过直接子类化内置的str类和从UserString继承完成了这一点,这是在 collections 模块中可用的一个方便的类。
在用 Python 创建自己的类似字符串的类时,继承str和子类化UserString都是合适的选择。
在本教程中,您已经学会了如何:
- 通过继承内置的
str类来创建类似字符串的类 - 通过从
collections模块子类化UserString来构建类似字符串的类 - 决定什么时候子类化
str或者UserString来创建你的定制的类似字符串的类
现在,您已经准备好编写定制的类似字符串的类,这将允许您充分利用 Python 中这种有价值且常见的数据类型的全部功能。
示例代码: 点击这里下载免费的示例代码,您将使用它来创建定制的类似字符串的类。***
继承和组合:Python OOP 指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 继承与构成:一个 Python OOP 指南
在本文中,您将探索 Python 中的继承和组合。继承和组合是面向对象编程中的两个重要概念,它们对两个类之间的关系进行建模。它们是面向对象设计的构建模块,它们帮助程序员编写可重用的代码。
在本文结束时,你将知道如何:
- 在 Python 中使用继承
- 使用继承对类层次结构建模
- 在 Python 中使用多重继承并理解它的缺点
- 使用合成来创建复杂的对象
- 通过应用组合重用现有代码
- 通过合成在运行时改变应用程序行为
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
什么是继承和构成?
继承和 T2 是面向对象编程中的两个主要概念,它们模拟了两个类之间的关系。它们驱动应用程序的设计,并确定应用程序应该如何随着新功能的添加或需求的变化而发展。
它们都支持代码重用,但是它们以不同的方式实现。
什么是遗传?
继承模型所谓的就是关系。这意味着当你有一个继承自Base类的Derived类时,你创建了一个关系,其中Derived 是Base的特殊版本。
使用统一建模语言或 UML 以如下方式表示继承:
类被表示为顶部带有类名的方框。继承关系由从派生类指向基类的箭头表示。单词延伸通常加在箭头上。
注意:在继承关系中:
- 从另一个继承的类称为派生类、子类或子类型。
- 从其派生出其他类的类称为基类或超类。
- 派生类被称为派生、继承或扩展基类。
假设你有一个基类Animal,你从它派生出一个Horse类。继承关系声明一个HorseT8 是一个 T3。这意味着Horse继承了接口和Animal的实现,并且Horse对象可以用来替换应用中的Animal对象。
这就是所谓的利斯科夫替代原理。该原则声明“在一个计算机程序中,如果S是T的一个子类型,那么T类型的对象可以被S类型的对象替换,而不会改变程序的任何期望属性”。
在本文中,您将看到为什么在创建类层次结构时应该始终遵循 Liskov 替换原则,以及如果不这样做将会遇到的问题。
作文是什么?
组合是一个概念,模型有一个关系。它允许通过组合其他类型的对象来创建复杂类型。这意味着一个类Composite可以包含另一个类Component的对象。这种关系意味着一个CompositeT8 有一个 T3。
UML 表示组合如下:
Composition 通过一条线来表示,在 composite 类处有一个菱形,指向 component 类。复合方可以表达关系的基数。基数表示Composite类将包含的Component实例的数量或有效范围。
在上图中,1表示Composite类包含一个类型为Component的对象。基数可以用以下方式表示:
- 数字表示包含在
Composite中的Component实例的数量。 - *符号表示
Composite类可以包含数量可变的Component实例。 - 一个范围 1..4 表示
Composite类可以包含一系列Component实例。该范围用最小和最大实例数表示,或像 1 中那样用最小和许多实例表示..* 。
注意:包含其他类的对象的类通常被称为复合类,其中用于创建更复杂类型的类被称为组件。
例如,您的Horse类可以由另一个类型为Tail的对象组成。构图允许你通过说一个Horse 有一个 Tail来表达这种关系。
组合使您能够通过向其他对象添加对象来重用代码,而不是继承其他类的接口和实现。Horse和Dog类都可以通过组合来利用Tail的功能,而不需要从一个类派生另一个类。
Python 中继承的概述
Python 中的一切都是对象。模块是对象,类定义和函数是对象,当然,从类创建的对象也是对象。
继承是每一种面向对象编程语言的必备特性。这意味着 Python 支持继承,正如您稍后将看到的,它是少数支持多重继承的语言之一。
当你使用类编写 Python 代码时,即使你不知道你在使用继承,你也在使用它。让我们来看看这意味着什么。
对象超类
在 Python 中看到继承的最简单的方法是跳到 Python 交互式 shell 中,写一点代码。您将从编写尽可能简单的类开始:
>>> class MyClass: ... pass ...你声明了一个类
MyClass,它并没有做很多事情,但是它将阐明最基本的继承概念。现在您已经声明了类,您可以使用dir()函数来列出它的成员:
>>> c = MyClass()
>>> dir(c)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__',
'__str__', '__subclasshook__', '__weakref__']
dir() 返回指定对象中所有成员的列表。您没有在MyClass中声明任何成员,那么列表从何而来?您可以使用交互式解释器找到答案:
>>> o = object() >>> dir(o) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']如您所见,这两个列表几乎完全相同。在
MyClass中有一些额外的成员,比如__dict__和__weakref__,但是object类的每个成员都出现在MyClass中。这是因为您在 Python 中创建的每个类都是从
object隐式派生的。你可以更明确地写class MyClass(object):,但这是多余和不必要的。注意:在 Python 2 中,由于超出本文范围的原因,您必须显式地从
object派生,但是您可以在 Python 2 文档的新样式和经典类部分中了解到这一点。例外就是例外
您在 Python 中创建的每个类都将隐式地从
object派生。该规则的例外是用于通过引发异常来指示错误的类。使用 Python 交互式解释器可以看出问题所在:
>>> class MyError:
... pass
...
>>> raise MyError()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: exceptions must derive from BaseException
您创建了一个新类来指示一种错误。然后你试图用它来引发一个异常。出现了一个异常,但是输出声明该异常的类型是TypeError而不是MyError,并且所有的exceptions must derive from BaseException。
BaseException是为所有错误类型提供的基类。要创建新的错误类型,您必须从BaseException或它的一个派生类中派生您的类。Python 中的约定是从Exception中派生出您的定制错误类型,而后者又从BaseException中派生出来。
定义错误类型的正确方法如下:
>>> class MyError(Exception): ... pass ... >>> raise MyError() Traceback (most recent call last): File "<stdin>", line 1, in <module> __main__.MyError如您所见,当您引发
MyError时,输出正确地陈述了所引发的错误类型。创建类层次结构
继承是用来创建相关类的层次结构的机制。这些相关的类将共享一个将在基类中定义的公共接口。派生类可以通过提供适用的特定实现来专门化接口。
在本节中,您将开始对人力资源系统进行建模。该示例将演示继承的使用以及派生类如何提供基类接口的具体实现。
人力资源系统需要处理公司员工的工资单,但是根据员工工资单的计算方式不同,员工的类型也不同。
首先实现一个处理工资单的
PayrollSystem类:# In hr.py class PayrollSystem: def calculate_payroll(self, employees): print('Calculating Payroll') print('===================') for employee in employees: print(f'Payroll for: {employee.id} - {employee.name}') print(f'- Check amount: {employee.calculate_payroll()}') print('')
PayrollSystem实现了一个.calculate_payroll()方法,该方法获取一组雇员,打印他们的id、name,并使用每个雇员对象上公开的.calculate_payroll()方法检查金额。现在,您实现了一个基类
Employee,它处理每个雇员类型的公共接口:# In hr.py class Employee: def __init__(self, id, name): self.id = id self.name = name
Employee是所有雇员类型的基类。它由一个id和一个name构成。你所说的是每个Employee必须有一个id和一个名字。HR 系统要求每个被处理的
Employee必须提供一个.calculate_payroll()接口,返回员工的周工资。该接口的实现因Employee的类型而异。例如,行政人员的工资是固定的,所以每周他们的工资都是一样的:
# In hr.py class SalaryEmployee(Employee): def __init__(self, id, name, weekly_salary): super().__init__(id, name) self.weekly_salary = weekly_salary def calculate_payroll(self): return self.weekly_salary您创建了一个继承了
Employee的派生类SalaryEmployee。该类用基类所需的id和name初始化,您使用super()初始化基类的成员。你可以在用 Python super() 增强你的类中阅读关于super()的所有内容。
SalaryEmployee还需要一个weekly_salary初始化参数,表示雇员每周的收入。该类提供了人力资源系统所需的
.calculate_payroll()方法。该实现只返回存储在weekly_salary中的金额。该公司还雇佣按小时计酬的制造工人,因此您向 HR 系统添加了一个
HourlyEmployee:# In hr.py class HourlyEmployee(Employee): def __init__(self, id, name, hours_worked, hour_rate): super().__init__(id, name) self.hours_worked = hours_worked self.hour_rate = hour_rate def calculate_payroll(self): return self.hours_worked * self.hour_rate像基类一样,
HourlyEmployee类用id和name初始化,加上计算工资所需的hours_worked和hour_rate。.calculate_payroll()方法通过返回工作时间乘以小时费率来实现。最后,公司雇佣销售助理,他们的工资是固定的,外加基于销售额的佣金,所以您创建了一个
CommissionEmployee类:# In hr.py class CommissionEmployee(SalaryEmployee): def __init__(self, id, name, weekly_salary, commission): super().__init__(id, name, weekly_salary) self.commission = commission def calculate_payroll(self): fixed = super().calculate_payroll() return fixed + self.commission您从
SalaryEmployee派生CommissionEmployee,因为两个类都有一个weekly_salary需要考虑。同时,CommissionEmployee用一个基于雇员销售额的commission值初始化。
.calculate_payroll()利用基类的实现来检索fixed薪水并添加佣金值。因为
CommissionEmployee是从SalaryEmployee派生的,所以您可以直接访问weekly_salary属性,并且您可以使用该属性的值来实现.calculate_payroll()。直接访问属性的问题是,如果
SalaryEmployee.calculate_payroll()的实现改变了,那么你也必须改变CommissionEmployee.calculate_payroll()的实现。最好依赖基类中已经实现的方法,并根据需要扩展功能。您为系统创建了第一个类层次结构。这些类的 UML 图如下所示:
该图显示了类的继承层次结构。派生类实现了
PayrollSystem所需要的IPayrollCalculator接口。PayrollSystem.calculate_payroll()实现要求传递的employee对象包含一个id、name和calculate_payroll()实现。接口的表示类似于类,在接口名上面有单词 interface 。接口名称通常以大写字母
I为前缀。应用程序创建其员工,并将他们传送到工资单系统以处理工资单:
# In program.py import hr salary_employee = hr.SalaryEmployee(1, 'John Smith', 1500) hourly_employee = hr.HourlyEmployee(2, 'Jane Doe', 40, 15) commission_employee = hr.CommissionEmployee(3, 'Kevin Bacon', 1000, 250) payroll_system = hr.PayrollSystem() payroll_system.calculate_payroll([ salary_employee, hourly_employee, commission_employee ])您可以在命令行中运行该程序并查看结果:
$ python program.py Calculating Payroll =================== Payroll for: 1 - John Smith - Check amount: 1500 Payroll for: 2 - Jane Doe - Check amount: 600 Payroll for: 3 - Kevin Bacon - Check amount: 1250该程序创建三个 employee 对象,每个派生类一个。然后,它创建工资系统,并将雇员列表传递给它的
.calculate_payroll()方法,该方法计算每个雇员的工资并打印结果。注意
Employee基类没有定义.calculate_payroll()方法。这意味着如果你要创建一个普通的Employee对象并将其传递给PayrollSystem,那么你会得到一个错误。您可以在 Python 交互式解释器中尝试一下:
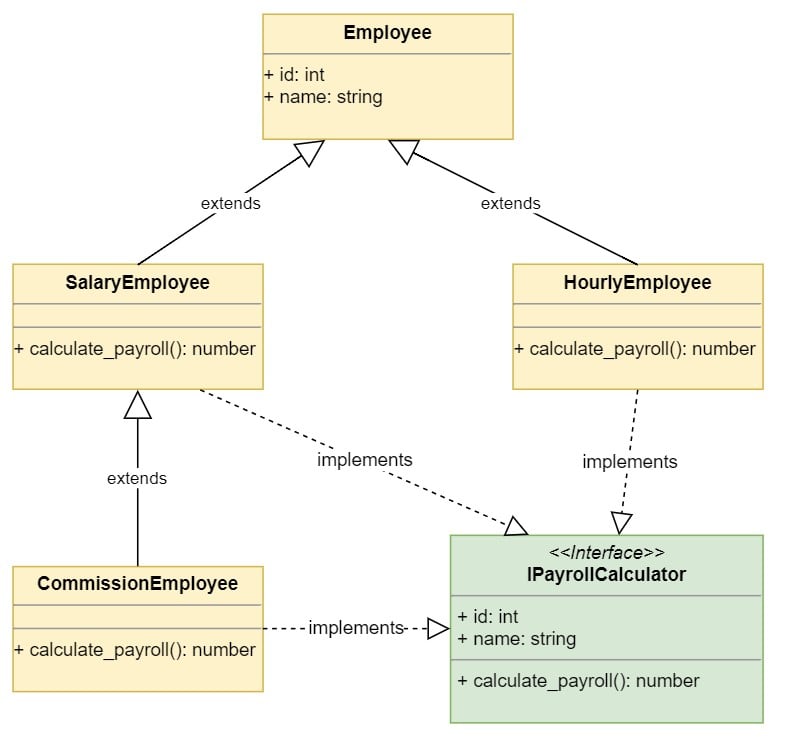
>>> import hr
>>> employee = hr.Employee(1, 'Invalid')
>>> payroll_system = hr.PayrollSystem()
>>> payroll_system.calculate_payroll([employee])
Payroll for: 1 - Invalid
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/hr.py", line 39, in calculate_payroll
print(f'- Check amount: {employee.calculate_payroll()}')
AttributeError: 'Employee' object has no attribute 'calculate_payroll'
虽然您可以实例化一个Employee对象,但是这个对象不能被PayrollSystem使用。为什么?因为它不能为了一只Employee而.calculate_payroll()。为了满足PayrollSystem的要求,您需要将Employee类(目前是一个具体类)转换成一个抽象类。这样,没有一个员工仅仅是一个Employee,而是一个实现.calculate_payroll()的员工。
Python 中的抽象基类
上面例子中的Employee类就是所谓的抽象基类。抽象基类的存在是为了被继承,而不是被实例化。Python 提供了abc模块来定义抽象基类。
您可以在类名中使用前导下划线来表明不应该创建该类的对象。下划线提供了一种友好的方式来防止你的代码被滥用,但是它们不能阻止热切的用户创建该类的实例。
Python 标准库中的 abc模块提供了防止从抽象基类创建对象的功能。
您可以修改Employee类的实现以确保它不能被实例化:
# In hr.py
from abc import ABC, abstractmethod
class Employee(ABC):
def __init__(self, id, name):
self.id = id
self.name = name
@abstractmethod
def calculate_payroll(self):
pass
您从ABC派生出Employee,使其成为一个抽象基类。然后,你用@abstractmethod 装饰器装饰.calculate_payroll()方法。
这种变化有两个好的副作用:
- 你告诉模块的用户不能创建类型为
Employee的对象。 - 你告诉其他在
hr模块上工作的开发人员,如果他们从Employee派生,那么他们必须覆盖.calculate_payroll()抽象方法。
您可以看到类型Employee的对象不能使用交互式解释器创建:
>>> import hr >>> employee = hr.Employee(1, 'abstract') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: Can't instantiate abstract class Employee with abstract methods calculate_payroll输出显示该类不能被实例化,因为它包含一个抽象方法
calculate_payroll()。派生类必须重写方法,以允许创建其类型的对象。实现继承 vs 接口继承
当您从一个类派生另一个类时,派生类将继承这两个类:
基类接口:派生类继承了基类的所有方法、属性、特性。
基类实现:派生类继承实现类接口的代码。
大多数时候,你会想要继承一个类的实现,但是你会想要实现多个接口,这样你的对象就可以在不同的情况下使用。
现代编程语言是根据这个基本概念设计的。它们允许您从单个类继承,但是您可以实现多个接口。
在 Python 中,不必显式声明接口。任何实现所需接口的对象都可以用来代替另一个对象。这就是所谓的 鸭式打字 。鸭子打字通常解释为“如果它的行为像鸭子,那么它就是鸭子。”
为了说明这一点,您现在将向上面的示例添加一个不是从
Employee派生的DisgruntledEmployee类:# In disgruntled.py class DisgruntledEmployee: def __init__(self, id, name): self.id = id self.name = name def calculate_payroll(self): return 1000000
DisgruntledEmployee类不是从Employee派生的,但是它公开了PayrollSystem所需的相同接口。PayrollSystem.calculate_payroll()需要实现以下接口的对象列表:
- 返回雇员 id 的
id属性- 代表雇员姓名的
name属性或特性- 一个
.calculate_payroll()方法,它不接受任何参数并返回要处理的工资总额所有这些要求都被
DisgruntledEmployee类满足了,所以PayrollSystem仍然可以计算它的工资单。您可以修改程序以使用
DisgruntledEmployee类:# In program.py import hr import disgruntled salary_employee = hr.SalaryEmployee(1, 'John Smith', 1500) hourly_employee = hr.HourlyEmployee(2, 'Jane Doe', 40, 15) commission_employee = hr.CommissionEmployee(3, 'Kevin Bacon', 1000, 250) disgruntled_employee = disgruntled.DisgruntledEmployee(20000, 'Anonymous') payroll_system = hr.PayrollSystem() payroll_system.calculate_payroll([ salary_employee, hourly_employee, commission_employee, disgruntled_employee ])程序创建一个
DisgruntledEmployee对象,并将其添加到由PayrollSystem处理的列表中。现在,您可以运行程序并查看其输出:$ python program.py Calculating Payroll =================== Payroll for: 1 - John Smith - Check amount: 1500 Payroll for: 2 - Jane Doe - Check amount: 600 Payroll for: 3 - Kevin Bacon - Check amount: 1250 Payroll for: 20000 - Anonymous - Check amount: 1000000如您所见,
PayrollSystem仍然可以处理新对象,因为它满足了所需的接口。因为你不需要从一个特定的类中派生出你的对象来被程序重用,你可能会问为什么你应该使用继承而不是仅仅实现你想要的接口。以下规则可能对您有所帮助:
使用继承来重用一个实现:你的派生类应该利用它们的大部分基类实现。他们还必须模拟一种是的关系。一个
Customer类可能也有一个id和一个name,但是一个Customer不是一个Employee,所以你不应该使用继承。实现一个可重用的接口:当你希望你的类被你的应用程序的特定部分重用时,你在你的类中实现所需的接口,但你不需要提供一个基类,或者从另一个类继承。
现在,您可以清理上面的示例,进入下一个主题。您可以删除
disgruntled.py文件,然后将hr模块修改为其原始状态:# In hr.py class PayrollSystem: def calculate_payroll(self, employees): print('Calculating Payroll') print('===================') for employee in employees: print(f'Payroll for: {employee.id} - {employee.name}') print(f'- Check amount: {employee.calculate_payroll()}') print('') class Employee: def __init__(self, id, name): self.id = id self.name = name class SalaryEmployee(Employee): def __init__(self, id, name, weekly_salary): super().__init__(id, name) self.weekly_salary = weekly_salary def calculate_payroll(self): return self.weekly_salary class HourlyEmployee(Employee): def __init__(self, id, name, hours_worked, hour_rate): super().__init__(id, name) self.hours_worked = hours_worked self.hour_rate = hour_rate def calculate_payroll(self): return self.hours_worked * self.hour_rate class CommissionEmployee(SalaryEmployee): def __init__(self, id, name, weekly_salary, commission): super().__init__(id, name, weekly_salary) self.commission = commission def calculate_payroll(self): fixed = super().calculate_payroll() return fixed + self.commission您移除了模块
abc的导入,因为Employee类不需要是抽象的。您还从其中移除了抽象的calculate_payroll()方法,因为它不提供任何实现。基本上,你在你的派生类中继承了
Employee类的id和name属性的实现。因为.calculate_payroll()只是PayrollSystem.calculate_payroll()方法的一个接口,所以不需要在Employee基类中实现它。注意
CommissionEmployee类是如何从SalaryEmployee派生出来的。这意味着CommissionEmployee继承了SalaryEmployee的实现和接口。您可以看到CommissionEmployee.calculate_payroll()方法如何利用基类实现,因为它依赖来自super().calculate_payroll()的结果来实现自己的版本。班级爆炸问题
如果不小心的话,继承会导致一个巨大的类层次结构,很难理解和维护。这就是所谓的级爆炸问题。
您开始构建由
PayrollSystem用来计算工资的Employee类型的类层次结构。现在,你需要给这些类添加一些功能,这样它们就可以和新的ProductivitySystem一起使用了。
ProductivitySystem根据员工角色跟踪生产力。有不同的员工角色:
- 经理们:他们走来走去,对着告诉他们该做什么的人大喊大叫。他们是领薪水的雇员,赚更多的钱。
- 秘书:他们为经理做所有的文书工作,并确保每件事都按时收到账单和付款。他们也是受薪雇员,但挣的钱更少。
- 销售人员:他们打很多电话推销产品。他们有工资,但也有销售提成。
- 工厂工人:他们为公司生产产品。他们按小时计酬。
有了这些需求,你开始看到
Employee和它的派生类可能属于除了hr模块之外的某个地方,因为现在它们也被ProductivitySystem使用。您创建一个
employees模块并将类移到那里:# In employees.py class Employee: def __init__(self, id, name): self.id = id self.name = name class SalaryEmployee(Employee): def __init__(self, id, name, weekly_salary): super().__init__(id, name) self.weekly_salary = weekly_salary def calculate_payroll(self): return self.weekly_salary class HourlyEmployee(Employee): def __init__(self, id, name, hours_worked, hour_rate): super().__init__(id, name) self.hours_worked = hours_worked self.hour_rate = hour_rate def calculate_payroll(self): return self.hours_worked * self.hour_rate class CommissionEmployee(SalaryEmployee): def __init__(self, id, name, weekly_salary, commission): super().__init__(id, name, weekly_salary) self.commission = commission def calculate_payroll(self): fixed = super().calculate_payroll() return fixed + self.commission实现保持不变,但是您将类移动到了
employee模块。现在,您更改您的程序来支持这一更改:# In program.py import hr import employees salary_employee = employees.SalaryEmployee(1, 'John Smith', 1500) hourly_employee = employees.HourlyEmployee(2, 'Jane Doe', 40, 15) commission_employee = employees.CommissionEmployee(3, 'Kevin Bacon', 1000, 250) payroll_system = hr.PayrollSystem() payroll_system.calculate_payroll([ salary_employee, hourly_employee, commission_employee ])您运行该程序,并验证它仍然工作:
$ python program.py Calculating Payroll =================== Payroll for: 1 - John Smith - Check amount: 1500 Payroll for: 2 - Jane Doe - Check amount: 600 Payroll for: 3 - Kevin Bacon - Check amount: 1250一切就绪后,您开始添加新的类:
# In employees.py class Manager(SalaryEmployee): def work(self, hours): print(f'{self.name} screams and yells for {hours} hours.') class Secretary(SalaryEmployee): def work(self, hours): print(f'{self.name} expends {hours} hours doing office paperwork.') class SalesPerson(CommissionEmployee): def work(self, hours): print(f'{self.name} expends {hours} hours on the phone.') class FactoryWorker(HourlyEmployee): def work(self, hours): print(f'{self.name} manufactures gadgets for {hours} hours.')首先,添加一个从
SalaryEmployee派生的Manager类。该类公开了一个将被生产力系统使用的方法work()。该方法采用员工工作的hours。然后你添加
Secretary、SalesPerson和FactoryWorker,然后实现work()接口,这样它们就可以被生产力系统使用了。现在,您可以添加
ProductivitySytem类:# In productivity.py class ProductivitySystem: def track(self, employees, hours): print('Tracking Employee Productivity') print('==============================') for employee in employees: employee.work(hours) print('')该类在
track()方法中跟踪雇员,该方法采用雇员列表和要跟踪的小时数。现在,您可以将生产力系统添加到您的程序中:# In program.py import hr import employees import productivity manager = employees.Manager(1, 'Mary Poppins', 3000) secretary = employees.Secretary(2, 'John Smith', 1500) sales_guy = employees.SalesPerson(3, 'Kevin Bacon', 1000, 250) factory_worker = employees.FactoryWorker(2, 'Jane Doe', 40, 15) employees = [ manager, secretary, sales_guy, factory_worker, ] productivity_system = productivity.ProductivitySystem() productivity_system.track(employees, 40) payroll_system = hr.PayrollSystem() payroll_system.calculate_payroll(employees)该程序创建了一个不同类型的员工列表。员工名单被发送到生产力系统以跟踪他们 40 小时的工作。然后,相同的雇员列表被发送到工资系统来计算他们的工资。
您可以运行该程序来查看输出:
$ python program.py Tracking Employee Productivity ============================== Mary Poppins screams and yells for 40 hours. John Smith expends 40 hours doing office paperwork. Kevin Bacon expends 40 hours on the phone. Jane Doe manufactures gadgets for 40 hours. Calculating Payroll =================== Payroll for: 1 - Mary Poppins - Check amount: 3000 Payroll for: 2 - John Smith - Check amount: 1500 Payroll for: 3 - Kevin Bacon - Check amount: 1250 Payroll for: 4 - Jane Doe - Check amount: 600该程序显示员工通过生产力系统工作 40 小时。然后,它计算并显示每个雇员的工资。
程序按预期工作,但是您必须添加四个新的类来支持这些变化。随着新需求的出现,您的类层次结构将不可避免地增长,导致类爆炸问题,您的层次结构将变得如此之大,以至于难以理解和维护。
下图显示了新的类层次结构:
该图显示了类层次结构是如何增长的。额外的需求可能会对这种设计的类的数量产生指数效应。
继承多个类
Python 是少数支持多重继承的现代编程语言之一。多重继承是同时从多个基类派生一个类的能力。
多重继承名声不好,以至于大多数现代编程语言都不支持它。相反,现代编程语言支持接口的概念。在这些语言中,您从单个基类继承,然后实现多个接口,因此您的类可以在不同的情况下重用。
这种方法给你的设计带来了一些限制。您只能通过直接从一个类派生来继承它的实现。可以实现多个接口,但是不能继承多个类的实现。
这种约束对于软件设计来说是很好的,因为它迫使你设计的类相互之间的依赖更少。您将在本文后面看到,您可以通过组合利用多个实现,这使得软件更加灵活。然而,这一节是关于多重继承的,所以让我们看看它是如何工作的。
事实证明,当有太多文书工作要做时,有时会雇用临时秘书。在
ProductivitySystem的上下文中,TemporarySecretary类执行Secretary的角色,但是出于工资的目的,它是一个HourlyEmployee。你看看你的班级设计。它已经成长了一点点,但你仍然可以理解它是如何工作的。看来你有两个选择:
从
Secretary派生:你可以从Secretary派生来继承角色的.work()方法,然后重写.calculate_payroll()方法实现为HourlyEmployee。从
HourlyEmployee派生:你可以从HourlyEmployee派生继承.calculate_payroll()方法,然后重写.work()方法实现为Secretary。然后,您记得 Python 支持多重继承,所以您决定从
Secretary和HourlyEmployee中派生:# In employees.py class TemporarySecretary(Secretary, HourlyEmployee): passPython 允许你从两个不同的类继承,方法是在类声明的括号中指定它们。
现在,您修改程序以添加新的临时秘书员工:
import hr import employees import productivity manager = employees.Manager(1, 'Mary Poppins', 3000) secretary = employees.Secretary(2, 'John Smith', 1500) sales_guy = employees.SalesPerson(3, 'Kevin Bacon', 1000, 250) factory_worker = employees.FactoryWorker(4, 'Jane Doe', 40, 15) temporary_secretary = employees.TemporarySecretary(5, 'Robin Williams', 40, 9) company_employees = [ manager, secretary, sales_guy, factory_worker, temporary_secretary, ] productivity_system = productivity.ProductivitySystem() productivity_system.track(company_employees, 40) payroll_system = hr.PayrollSystem() payroll_system.calculate_payroll(company_employees)您运行程序来测试它:
$ python program.py Traceback (most recent call last): File ".\program.py", line 9, in <module> temporary_secretary = employee.TemporarySecretary(5, 'Robin Williams', 40, 9) TypeError: __init__() takes 4 positional arguments but 5 were given你得到一个
TypeError异常,说4位置参数在预期的地方,但是5被给出。这是因为你首先从
Secretary派生TemporarySecretary,然后从HourlyEmployee派生,所以解释器试图使用Secretary.__init__()来初始化对象。好吧,让我们颠倒一下:
class TemporarySecretary(HourlyEmployee, Secretary): pass现在,再次运行程序,看看会发生什么:
$ python program.py Traceback (most recent call last): File ".\program.py", line 9, in <module> temporary_secretary = employee.TemporarySecretary(5, 'Robin Williams', 40, 9) File "employee.py", line 16, in __init__ super().__init__(id, name) TypeError: __init__() missing 1 required positional argument: 'weekly_salary'现在看起来您缺少一个
weekly_salary参数,这是初始化Secretary所必需的,但是这个参数在TemporarySecretary的上下文中没有意义,因为它是一个HourlyEmployee。也许实施
TemporarySecretary.__init__()会有所帮助:# In employees.py class TemporarySecretary(HourlyEmployee, Secretary): def __init__(self, id, name, hours_worked, hour_rate): super().__init__(id, name, hours_worked, hour_rate)试试看:
$ python program.py Traceback (most recent call last): File ".\program.py", line 9, in <module> temporary_secretary = employee.TemporarySecretary(5, 'Robin Williams', 40, 9) File "employee.py", line 54, in __init__ super().__init__(id, name, hours_worked, hour_rate) File "employee.py", line 16, in __init__ super().__init__(id, name) TypeError: __init__() missing 1 required positional argument: 'weekly_salary'那也没用。好了,是时候让你深入 Python 的方法解析顺序 (MRO)看看到底是怎么回事了。
当一个类的方法或属性被访问时,Python 使用类 MRO 来找到它。MRO 也被
super()用来决定调用哪个方法或属性。你可以在用 Python super()super charge 你的类中了解更多关于super()的内容。您可以使用交互式解释器评估
TemporarySecretary级 MRO:
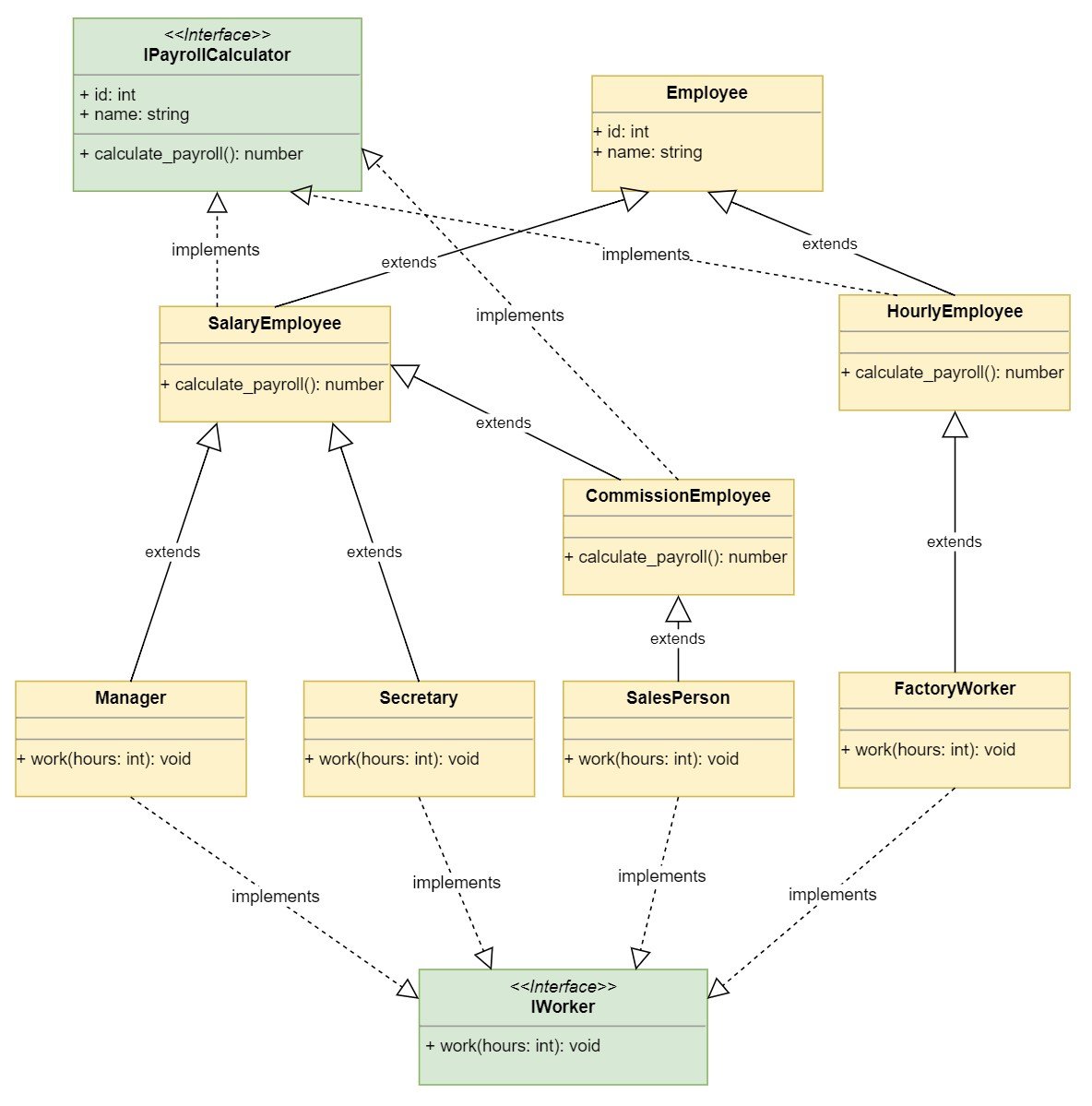
>>> from employees import TemporarySecretary
>>> TemporarySecretary.__mro__
(<class 'employees.TemporarySecretary'>,
<class 'employees.HourlyEmployee'>,
<class 'employees.Secretary'>,
<class 'employees.SalaryEmployee'>,
<class 'employees.Employee'>,
<class 'object'>
)
MRO 显示了 Python 查找匹配属性或方法的顺序。在示例中,这是我们创建TemporarySecretary对象时发生的情况:
-
调用了
TemporarySecretary.__init__(self, id, name, hours_worked, hour_rate)方法。 -
super().__init__(id, name, hours_worked, hour_rate)呼叫匹配HourlyEmployee.__init__(self, id, name, hour_worked, hour_rate)。 -
HourlyEmployee调用super().__init__(id, name),MRO 将要匹配的Secretary.__init__(),继承自SalaryEmployee.__init__(self, id, name, weekly_salary)。
因为参数不匹配,所以引发了一个TypeError异常。
您可以通过颠倒继承顺序并直接调用HourlyEmployee.__init__()来绕过 MRO,如下所示:
class TemporarySecretary(Secretary, HourlyEmployee):
def __init__(self, id, name, hours_worked, hour_rate):
HourlyEmployee.__init__(self, id, name, hours_worked, hour_rate)
这解决了创建对象的问题,但是当您试图计算工资单时,会遇到类似的问题。您可以运行程序来查看问题:
$ python program.py
Tracking Employee Productivity
==============================
Mary Poppins screams and yells for 40 hours.
John Smith expends 40 hours doing office paperwork.
Kevin Bacon expends 40 hours on the phone.
Jane Doe manufactures gadgets for 40 hours.
Robin Williams expends 40 hours doing office paperwork.
Calculating Payroll
===================
Payroll for: 1 - Mary Poppins
- Check amount: 3000
Payroll for: 2 - John Smith
- Check amount: 1500
Payroll for: 3 - Kevin Bacon
- Check amount: 1250
Payroll for: 4 - Jane Doe
- Check amount: 600
Payroll for: 5 - Robin Williams
Traceback (most recent call last):
File ".\program.py", line 20, in <module>
payroll_system.calculate_payroll(employees)
File "hr.py", line 7, in calculate_payroll
print(f'- Check amount: {employee.calculate_payroll()}')
File "employee.py", line 12, in calculate_payroll
return self.weekly_salary
AttributeError: 'TemporarySecretary' object has no attribute 'weekly_salary'
现在的问题是,因为您颠倒了继承顺序,MRO 在找到HourlyEmployee中的方法之前找到了SalariedEmployee的.calculate_payroll()方法。您需要覆盖TemporarySecretary中的.calculate_payroll(),并从中调用正确的实现:
class TemporarySecretary(Secretary, HourlyEmployee):
def __init__(self, id, name, hours_worked, hour_rate):
HourlyEmployee.__init__(self, id, name, hours_worked, hour_rate)
def calculate_payroll(self):
return HourlyEmployee.calculate_payroll(self)
calculate_payroll()方法直接调用HourlyEmployee.calculate_payroll()来确保得到正确的结果。您可以再次运行该程序来查看它的工作情况:
$ python program.py
Tracking Employee Productivity
==============================
Mary Poppins screams and yells for 40 hours.
John Smith expends 40 hours doing office paperwork.
Kevin Bacon expends 40 hours on the phone.
Jane Doe manufactures gadgets for 40 hours.
Robin Williams expends 40 hours doing office paperwork.
Calculating Payroll
===================
Payroll for: 1 - Mary Poppins
- Check amount: 3000
Payroll for: 2 - John Smith
- Check amount: 1500
Payroll for: 3 - Kevin Bacon
- Check amount: 1250
Payroll for: 4 - Jane Doe
- Check amount: 600
Payroll for: 5 - Robin Williams
- Check amount: 360
程序现在按预期工作,因为您通过明确地告诉解释器我们想要使用哪个方法来强制方法解析顺序。
正如你所看到的,多重继承可能会令人困惑,尤其是当你遇到钻石问题的时候。
下图显示了类层次结构中的菱形问题:
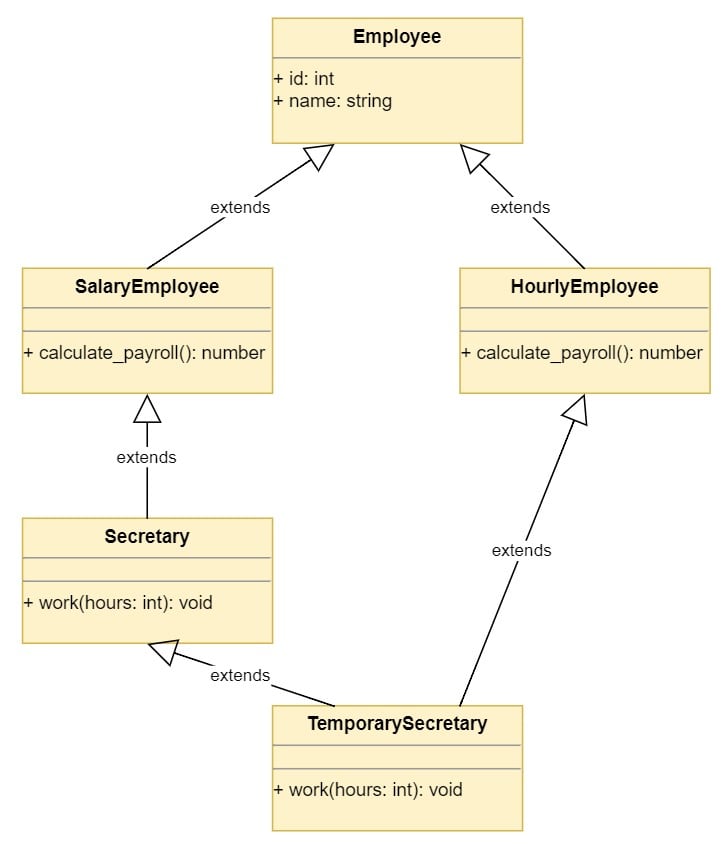
图表显示了当前类设计中的菱形问题。TemporarySecretary使用多重继承从两个类派生,这两个类最终也从Employee派生。这会导致两条路径到达Employee基类,这是您在设计中想要避免的。
当你使用多重继承并从两个有共同基类的类派生时,菱形问题就出现了。这可能会导致调用错误版本的方法。
正如您所见,Python 提供了一种强制调用正确方法的方式,分析 MRO 可以帮助您理解问题。
尽管如此,当你遇到钻石问题时,最好重新考虑一下设计。现在您将做一些改变来利用多重继承,避免菱形问题。
Employee派生类由两个不同的系统使用:
-
跟踪员工生产力的生产力系统。
-
计算员工工资的工资系统。
这意味着与生产力相关的一切都应该在一个模块中,与工资相关的一切都应该在另一个模块中。您可以开始对生产力模块进行更改:
# In productivity.py
class ProductivitySystem:
def track(self, employees, hours):
print('Tracking Employee Productivity')
print('==============================')
for employee in employees:
result = employee.work(hours)
print(f'{employee.name}: {result}')
print('')
class ManagerRole:
def work(self, hours):
return f'screams and yells for {hours} hours.'
class SecretaryRole:
def work(self, hours):
return f'expends {hours} hours doing office paperwork.'
class SalesRole:
def work(self, hours):
return f'expends {hours} hours on the phone.'
class FactoryRole:
def work(self, hours):
return f'manufactures gadgets for {hours} hours.'
productivity模块实现了ProductivitySystem类,以及它所支持的相关角色。这些类实现了系统所需的work()接口,但它们不是从Employee派生的。
您可以对hr模块进行同样的操作:
# In hr.py
class PayrollSystem:
def calculate_payroll(self, employees):
print('Calculating Payroll')
print('===================')
for employee in employees:
print(f'Payroll for: {employee.id} - {employee.name}')
print(f'- Check amount: {employee.calculate_payroll()}')
print('')
class SalaryPolicy:
def __init__(self, weekly_salary):
self.weekly_salary = weekly_salary
def calculate_payroll(self):
return self.weekly_salary
class HourlyPolicy:
def __init__(self, hours_worked, hour_rate):
self.hours_worked = hours_worked
self.hour_rate = hour_rate
def calculate_payroll(self):
return self.hours_worked * self.hour_rate
class CommissionPolicy(SalaryPolicy):
def __init__(self, weekly_salary, commission):
super().__init__(weekly_salary)
self.commission = commission
def calculate_payroll(self):
fixed = super().calculate_payroll()
return fixed + self.commission
hr模块实现了PayrollSystem,它计算雇员的工资。它还实现了工资单的策略类。如您所见,策略类不再从Employee派生。
现在您可以向employee模块添加必要的类:
# In employees.py
from hr import (
SalaryPolicy,
CommissionPolicy,
HourlyPolicy
)
from productivity import (
ManagerRole,
SecretaryRole,
SalesRole,
FactoryRole
)
class Employee:
def __init__(self, id, name):
self.id = id
self.name = name
class Manager(Employee, ManagerRole, SalaryPolicy):
def __init__(self, id, name, weekly_salary):
SalaryPolicy.__init__(self, weekly_salary)
super().__init__(id, name)
class Secretary(Employee, SecretaryRole, SalaryPolicy):
def __init__(self, id, name, weekly_salary):
SalaryPolicy.__init__(self, weekly_salary)
super().__init__(id, name)
class SalesPerson(Employee, SalesRole, CommissionPolicy):
def __init__(self, id, name, weekly_salary, commission):
CommissionPolicy.__init__(self, weekly_salary, commission)
super().__init__(id, name)
class FactoryWorker(Employee, FactoryRole, HourlyPolicy):
def __init__(self, id, name, hours_worked, hour_rate):
HourlyPolicy.__init__(self, hours_worked, hour_rate)
super().__init__(id, name)
class TemporarySecretary(Employee, SecretaryRole, HourlyPolicy):
def __init__(self, id, name, hours_worked, hour_rate):
HourlyPolicy.__init__(self, hours_worked, hour_rate)
super().__init__(id, name)
employees模块从其他模块导入策略和角色,并实现不同的Employee类型。您仍然使用多重继承来继承工资政策类和生产力角色的实现,但是每个类的实现只需要处理初始化。
注意,您仍然需要在构造函数中显式初始化工资策略。你可能看到了Manager和Secretary的初始化是相同的。另外,FactoryWorker和TemporarySecretary的初始化是相同的。
您不希望在更复杂的设计中出现这种代码重复,所以在设计类层次结构时必须小心。
这是新设计的 UML 图:
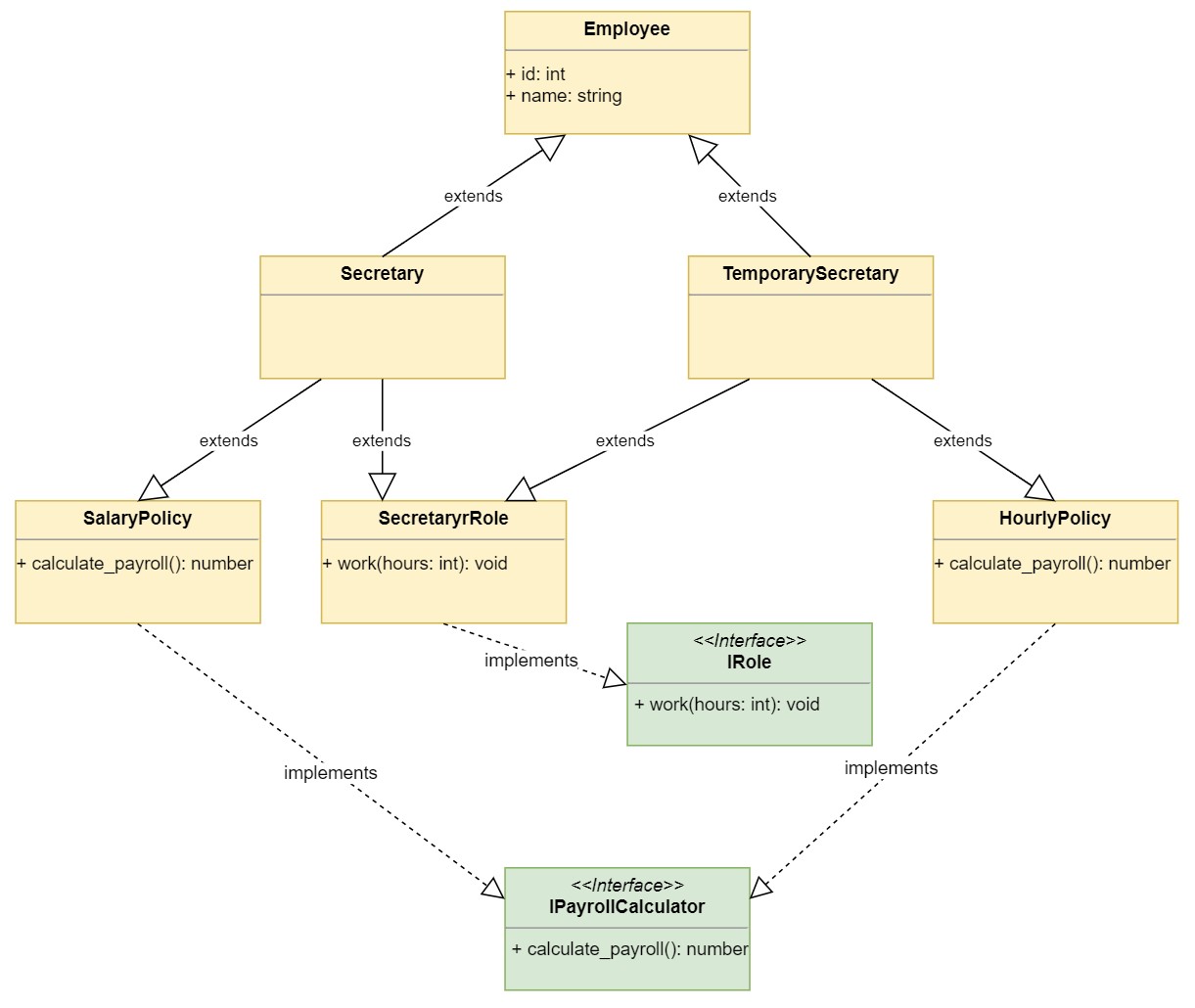
图表显示了使用多重继承定义Secretary和TemporarySecretary的关系,但是避免了菱形问题。
您可以运行该程序,看看它是如何工作的:
$ python program.py
Tracking Employee Productivity
==============================
Mary Poppins: screams and yells for 40 hours.
John Smith: expends 40 hours doing office paperwork.
Kevin Bacon: expends 40 hours on the phone.
Jane Doe: manufactures gadgets for 40 hours.
Robin Williams: expends 40 hours doing office paperwork.
Calculating Payroll
===================
Payroll for: 1 - Mary Poppins
- Check amount: 3000
Payroll for: 2 - John Smith
- Check amount: 1500
Payroll for: 3 - Kevin Bacon
- Check amount: 1250
Payroll for: 4 - Jane Doe
- Check amount: 600
Payroll for: 5 - Robin Williams
- Check amount: 360
您已经看到了 Python 中的继承和多重继承是如何工作的。现在可以探讨作文这个话题了。
Python 中的合成
组合是一个面向对象的设计概念,它模拟了与的关系。在组合中,一个名为复合的类包含另一个名为组件的类的对象。换句话说,复合类有另一个类的组件。
组合允许复合类重用它包含的组件的实现。复合类不继承组件类接口,但是它可以利用它的实现。
两个类之间的组合关系被认为是松散耦合的。这意味着对组件类的更改很少影响复合类,对复合类的更改也不会影响组件类。
这为变化提供了更好的适应性,并允许应用程序在不影响现有代码的情况下引入新的需求。
当观察两个相互竞争的软件设计时,一个基于继承,另一个基于组合,组合解决方案通常是最灵活的。你现在可以看看构图是如何工作的。
你已经在我们的例子中使用了复合。如果你看一下Employee类,你会发现它包含两个属性:
id标识一个员工。name包含员工的姓名。
这两个属性是Employee类拥有的对象。所以你可以说一个Employee 有一个id有一个的名字。
Employee的另一个属性可能是Address:
# In contacts.py
class Address:
def __init__(self, street, city, state, zipcode, street2=''):
self.street = street
self.street2 = street2
self.city = city
self.state = state
self.zipcode = zipcode
def __str__(self):
lines = [self.street]
if self.street2:
lines.append(self.street2)
lines.append(f'{self.city}, {self.state} {self.zipcode}')
return '\n'.join(lines)
您实现了一个基本的 address 类,它包含了地址的常用组件。您将street2属性设为可选属性,因为并非所有地址都有该组件。
您实现了__str__()来提供一个Address的漂亮表示。您可以在交互式解释器中看到这个实现:
>>> from contacts import Address >>> address = Address('55 Main St.', 'Concord', 'NH', '03301') >>> print(address) 55 Main St. Concord, NH 03301当你
print()变量address时,特殊方法__str__()被调用。因为您重载了该方法以返回一个格式化为地址的字符串,所以您得到了一个很好的、可读的表示。自定义 Python 类中的运算符和函数重载很好地概述了类中可用的特殊方法,可以实现这些方法来自定义对象的行为。现在可以通过组合将
Address添加到Employee类中:# In employees.py class Employee: def __init__(self, id, name): self.id = id self.name = name self.address = None现在,您可以将
address属性初始化为None,使其成为可选属性,但是通过这样做,您现在可以将一个Address分配给一个Employee。还要注意在employee模块中没有对contacts模块的引用。组合是一种松散耦合的关系,通常不需要复合类了解组件。
表示
Employee和Address之间关系的 UML 图如下所示:
图表显示了
Employee和Address之间的基本组成关系。您现在可以修改
PayrollSystem类来利用Employee中的address属性:# In hr.py class PayrollSystem: def calculate_payroll(self, employees): print('Calculating Payroll') print('===================') for employee in employees: print(f'Payroll for: {employee.id} - {employee.name}') print(f'- Check amount: {employee.calculate_payroll()}') if employee.address: print('- Sent to:') print(employee.address) print('')检查
employee对象是否有地址,如果有,就打印出来。现在,您可以修改程序,为员工分配一些地址:# In program.py import hr import employees import productivity import contacts manager = employees.Manager(1, 'Mary Poppins', 3000) manager.address = contacts.Address( '121 Admin Rd', 'Concord', 'NH', '03301' ) secretary = employees.Secretary(2, 'John Smith', 1500) secretary.address = contacts.Address( '67 Paperwork Ave.', 'Manchester', 'NH', '03101' ) sales_guy = employees.SalesPerson(3, 'Kevin Bacon', 1000, 250) factory_worker = employees.FactoryWorker(4, 'Jane Doe', 40, 15) temporary_secretary = employees.TemporarySecretary(5, 'Robin Williams', 40, 9) employees = [ manager, secretary, sales_guy, factory_worker, temporary_secretary, ] productivity_system = productivity.ProductivitySystem() productivity_system.track(employees, 40) payroll_system = hr.PayrollSystem() payroll_system.calculate_payroll(employees)您向
manager和secretary对象添加了几个地址。当您运行该程序时,您将看到打印的地址:$ python program.py Tracking Employee Productivity ============================== Mary Poppins: screams and yells for {hours} hours. John Smith: expends {hours} hours doing office paperwork. Kevin Bacon: expends {hours} hours on the phone. Jane Doe: manufactures gadgets for {hours} hours. Robin Williams: expends {hours} hours doing office paperwork. Calculating Payroll =================== Payroll for: 1 - Mary Poppins - Check amount: 3000 - Sent to: 121 Admin Rd Concord, NH 03301 Payroll for: 2 - John Smith - Check amount: 1500 - Sent to: 67 Paperwork Ave. Manchester, NH 03101 Payroll for: 3 - Kevin Bacon - Check amount: 1250 Payroll for: 4 - Jane Doe - Check amount: 600 Payroll for: 5 - Robin Williams - Check amount: 360注意
manager和secretary对象的工资输出是如何显示支票的发送地址的。
Employee类利用了Address类的实现,而不知道什么是Address对象或者它是如何表示的。这种类型的设计非常灵活,你可以改变Address类而不会对Employee类产生任何影响。灵活的组合设计
组合比继承更灵活,因为它模拟了一种松散耦合的关系。对组件类的更改对复合类的影响很小或没有影响。基于构图的设计更适合改变。
通过提供实现这些行为的新组件来改变行为,而不是在层次结构中添加新的类。
看一下上面的多重继承例子。想象一下新的工资政策将如何影响设计。试着想象一下如果需要新的角色,类的层次结构会是什么样子。正如你之前看到的,过于依赖继承会导致类爆炸。
最大的问题不在于设计中的类的数量,而在于这些类之间的关系有多紧密。当引入变化时,紧密耦合的类会相互影响。
在本节中,您将使用组合来实现一个更好的设计,它仍然符合
PayrollSystem和ProductivitySystem的需求。您可以从实现
ProductivitySystem的功能开始:# In productivity.py class ProductivitySystem: def __init__(self): self._roles = { 'manager': ManagerRole, 'secretary': SecretaryRole, 'sales': SalesRole, 'factory': FactoryRole, } def get_role(self, role_id): role_type = self._roles.get(role_id) if not role_type: raise ValueError('role_id') return role_type() def track(self, employees, hours): print('Tracking Employee Productivity') print('==============================') for employee in employees: employee.work(hours) print('')
ProductivitySystem类使用映射到实现角色的角色类的字符串标识符来定义一些角色。它公开了一个.get_role()方法,给定一个角色标识符,该方法返回角色类型对象。如果找不到该角色,则会引发一个ValueError异常。它还公开了
.track()方法中以前的功能,给定一个雇员列表,它跟踪这些雇员的生产率。现在,您可以实现不同的角色类:
# In productivity.py class ManagerRole: def perform_duties(self, hours): return f'screams and yells for {hours} hours.' class SecretaryRole: def perform_duties(self, hours): return f'does paperwork for {hours} hours.' class SalesRole: def perform_duties(self, hours): return f'expends {hours} hours on the phone.' class FactoryRole: def perform_duties(self, hours): return f'manufactures gadgets for {hours} hours.'您实现的每一个角色都公开了一个
.perform_duties(),它接受工作的hours的数量。这些方法返回一个表示职责的字符串。角色类彼此独立,但是它们公开相同的接口,所以它们是可互换的。稍后您将看到它们是如何在应用程序中使用的。
现在,您可以为应用程序实现
PayrollSystem:# In hr.py class PayrollSystem: def __init__(self): self._employee_policies = { 1: SalaryPolicy(3000), 2: SalaryPolicy(1500), 3: CommissionPolicy(1000, 100), 4: HourlyPolicy(15), 5: HourlyPolicy(9) } def get_policy(self, employee_id): policy = self._employee_policies.get(employee_id) if not policy: return ValueError(employee_id) return policy def calculate_payroll(self, employees): print('Calculating Payroll') print('===================') for employee in employees: print(f'Payroll for: {employee.id} - {employee.name}') print(f'- Check amount: {employee.calculate_payroll()}') if employee.address: print('- Sent to:') print(employee.address) print('')
PayrollSystem为每个员工保留一个工资政策的内部数据库。它公开了一个.get_policy(),给定一个雇员id,返回其工资政策。如果指定的id在系统中不存在,那么该方法会引发一个ValueError异常。
.calculate_payroll()的实现和以前一样工作。它获取雇员列表,计算工资单,并打印结果。现在,您可以实施工资单策略类:
# In hr.py class PayrollPolicy: def __init__(self): self.hours_worked = 0 def track_work(self, hours): self.hours_worked += hours class SalaryPolicy(PayrollPolicy): def __init__(self, weekly_salary): super().__init__() self.weekly_salary = weekly_salary def calculate_payroll(self): return self.weekly_salary class HourlyPolicy(PayrollPolicy): def __init__(self, hour_rate): super().__init__() self.hour_rate = hour_rate def calculate_payroll(self): return self.hours_worked * self.hour_rate class CommissionPolicy(SalaryPolicy): def __init__(self, weekly_salary, commission_per_sale): super().__init__(weekly_salary) self.commission_per_sale = commission_per_sale @property def commission(self): sales = self.hours_worked / 5 return sales * self.commission_per_sale def calculate_payroll(self): fixed = super().calculate_payroll() return fixed + self.commission首先实现一个
PayrollPolicy类,作为所有工资政策的基类。这个类跟踪所有工资政策通用的hours_worked。其他策略类源自
PayrollPolicy。我们在这里使用继承,因为我们想利用PayrollPolicy的实现。还有,SalaryPolicy、HourlyPolicy、CommissionPolicy、T6 都是一个、PayrollPolicy。
SalaryPolicy用一个weekly_salary值初始化,然后在.calculate_payroll()中使用。HourlyPolicy用hour_rate初始化,通过利用基类hours_worked实现.calculate_payroll()。
CommissionPolicy类派生自SalaryPolicy,因为它想要继承它的实现。它是用weekly_salary参数初始化的,但是它也需要一个commission_per_sale参数。
commission_per_sale用于计算.commission,它被实现为一个属性,因此在被请求时被计算。在这个例子中,我们假设每工作 5 小时就有一笔销售,.commission是销售数量乘以commission_per_sale值。
CommissionPolicy通过首先利用SalaryPolicy中的实现来实现.calculate_payroll()方法,然后添加计算出的佣金。您现在可以添加一个
AddressBook类来管理员工地址:# In contacts.py class AddressBook: def __init__(self): self._employee_addresses = { 1: Address('121 Admin Rd.', 'Concord', 'NH', '03301'), 2: Address('67 Paperwork Ave', 'Manchester', 'NH', '03101'), 3: Address('15 Rose St', 'Concord', 'NH', '03301', 'Apt. B-1'), 4: Address('39 Sole St.', 'Concord', 'NH', '03301'), 5: Address('99 Mountain Rd.', 'Concord', 'NH', '03301'), } def get_employee_address(self, employee_id): address = self._employee_addresses.get(employee_id) if not address: raise ValueError(employee_id) return address
AddressBook类为每个雇员保存一个内部的Address对象数据库。它公开了一个返回指定雇员id地址的get_employee_address()方法。如果雇员id不存在,那么它引发一个ValueError。
Address类的实现和以前一样:# In contacts.py class Address: def __init__(self, street, city, state, zipcode, street2=''): self.street = street self.street2 = street2 self.city = city self.state = state self.zipcode = zipcode def __str__(self): lines = [self.street] if self.street2: lines.append(self.street2) lines.append(f'{self.city}, {self.state} {self.zipcode}') return '\n'.join(lines)该类管理地址组件,并提供一个漂亮的地址表示。
到目前为止,新的类已经被扩展以支持更多的功能,但是对以前的设计没有重大的改变。这将随着
employees模块及其类的设计而改变。您可以从实现一个
EmployeeDatabase类开始:# In employees.py from productivity import ProductivitySystem from hr import PayrollSystem from contacts import AddressBook class EmployeeDatabase: def __init__(self): self._employees = [ { 'id': 1, 'name': 'Mary Poppins', 'role': 'manager' }, { 'id': 2, 'name': 'John Smith', 'role': 'secretary' }, { 'id': 3, 'name': 'Kevin Bacon', 'role': 'sales' }, { 'id': 4, 'name': 'Jane Doe', 'role': 'factory' }, { 'id': 5, 'name': 'Robin Williams', 'role': 'secretary' }, ] self.productivity = ProductivitySystem() self.payroll = PayrollSystem() self.employee_addresses = AddressBook() @property def employees(self): return [self._create_employee(**data) for data in self._employees] def _create_employee(self, id, name, role): address = self.employee_addresses.get_employee_address(id) employee_role = self.productivity.get_role(role) payroll_policy = self.payroll.get_policy(id) return Employee(id, name, address, employee_role, payroll_policy)
EmployeeDatabase记录公司所有的员工。对于每个雇员,它跟踪id、name和role。它有一个ProductivitySystem、PayrollSystem和AddressBook的实例。这些实例用于创建员工。它公开了一个返回雇员列表的
.employees属性。对象是在内部方法._create_employee()中创建的。注意你没有不同类型的Employee类。你只需要实现一个单独的Employee类:# In employees.py class Employee: def __init__(self, id, name, address, role, payroll): self.id = id self.name = name self.address = address self.role = role self.payroll = payroll def work(self, hours): duties = self.role.perform_duties(hours) print(f'Employee {self.id} - {self.name}:') print(f'- {duties}') print('') self.payroll.track_work(hours) def calculate_payroll(self): return self.payroll.calculate_payroll()用
id、name和address属性初始化Employee类。它还要求员工的生产力role和payroll政策。该类公开了一个获取工作时间的
.work()方法。该方法首先从role中检索duties。换句话说,它委托给role对象来执行它的任务。同样,它委托给
payroll对象来跟踪工作hours。如你所见,如果需要的话,payroll使用这些时间来计算工资。下图显示了所使用的组合设计:
该图显示了基于组合的策略的设计。有一个单独的
Employee,它由其他数据对象组成,如Address,并依赖于IRole和IPayrollCalculator接口来委托工作。这些接口有多种实现。现在,您可以在程序中使用这种设计:
# In program.py from hr import PayrollSystem from productivity import ProductivitySystem from employees import EmployeeDatabase productivity_system = ProductivitySystem() payroll_system = PayrollSystem() employee_database = EmployeeDatabase() employees = employee_database.employees productivity_system.track(employees, 40) payroll_system.calculate_payroll(employees)您可以运行该程序来查看其输出:
$ python program.py Tracking Employee Productivity ============================== Employee 1 - Mary Poppins: - screams and yells for 40 hours. Employee 2 - John Smith: - does paperwork for 40 hours. Employee 3 - Kevin Bacon: - expends 40 hours on the phone. Employee 4 - Jane Doe: - manufactures gadgets for 40 hours. Employee 5 - Robin Williams: - does paperwork for 40 hours. Calculating Payroll =================== Payroll for: 1 - Mary Poppins - Check amount: 3000 - Sent to: 121 Admin Rd. Concord, NH 03301 Payroll for: 2 - John Smith - Check amount: 1500 - Sent to: 67 Paperwork Ave Manchester, NH 03101 Payroll for: 3 - Kevin Bacon - Check amount: 1800.0 - Sent to: 15 Rose St Apt. B-1 Concord, NH 03301 Payroll for: 4 - Jane Doe - Check amount: 600 - Sent to: 39 Sole St. Concord, NH 03301 Payroll for: 5 - Robin Williams - Check amount: 360 - Sent to: 99 Mountain Rd. Concord, NH 03301这种设计被称为基于策略的设计,其中类由策略组成,它们委托这些策略来完成工作。
在《现代 C++设计》一书中介绍了基于策略的设计,它使用 C++中的模板元编程来实现结果。
Python 不支持模板,但是您可以使用合成获得类似的结果,正如您在上面的示例中看到的。
随着需求的变化,这种类型的设计为您提供了所需的所有灵活性。假设您需要在运行时更改对象的工资计算方式。
使用合成自定义行为
如果你的设计依赖于继承,你需要找到一种改变对象类型的方法来改变它的行为。有了组合,你只需要改变对象使用的策略。
想象一下,我们的
manager突然变成了按小时计酬的临时雇员。您可以在程序执行过程中以下列方式修改对象:# In program.py from hr import PayrollSystem, HourlyPolicy from productivity import ProductivitySystem from employees import EmployeeDatabase productivity_system = ProductivitySystem() payroll_system = PayrollSystem() employee_database = EmployeeDatabase() employees = employee_database.employees manager = employees[0] manager.payroll = HourlyPolicy(55) productivity_system.track(employees, 40) payroll_system.calculate_payroll(employees)该程序从
EmployeeDatabase中获取雇员列表,并检索第一个雇员,也就是我们想要的经理。然后它创建一个新的HourlyPolicy,初始化为每小时 55 美元,并将其分配给 manager 对象。新策略现在被
PayrollSystem用来修改现有的行为。您可以再次运行该程序来查看结果:$ python program.py Tracking Employee Productivity ============================== Employee 1 - Mary Poppins: - screams and yells for 40 hours. Employee 2 - John Smith: - does paperwork for 40 hours. Employee 3 - Kevin Bacon: - expends 40 hours on the phone. Employee 4 - Jane Doe: - manufactures gadgets for 40 hours. Employee 5 - Robin Williams: - does paperwork for 40 hours. Calculating Payroll =================== Payroll for: 1 - Mary Poppins - Check amount: 2200 - Sent to: 121 Admin Rd. Concord, NH 03301 Payroll for: 2 - John Smith - Check amount: 1500 - Sent to: 67 Paperwork Ave Manchester, NH 03101 Payroll for: 3 - Kevin Bacon - Check amount: 1800.0 - Sent to: 15 Rose St Apt. B-1 Concord, NH 03301 Payroll for: 4 - Jane Doe - Check amount: 600 - Sent to: 39 Sole St. Concord, NH 03301 Payroll for: 5 - Robin Williams - Check amount: 360 - Sent to: 99 Mountain Rd. Concord, NH 03301我们的经理玛丽·波平斯的支票现在是 2200 美元,而不是她每周 3000 美元的固定工资。
请注意我们是如何在不改变任何现有类的情况下将业务规则添加到程序中的。考虑一下继承设计需要什么样的改变。
您必须创建一个新的类,并更改经理雇员的类型。你不可能在运行时改变策略。
在 Python 中选择继承还是组合
到目前为止,您已经看到了 Python 中的继承和组合是如何工作的。您已经看到派生类继承了它们的基类的接口和实现。您还看到了组合允许您重用另一个类的实现。
您对同一个问题实现了两种解决方案。第一个解决方案使用多重继承,第二个使用组合。
您还看到了 Python 的 duck typing 允许您通过实现所需的接口在程序的现有部分中重用对象。在 Python 中,不需要从基类派生就可以重用你的类。
此时,您可能会问在 Python 中什么时候使用继承而不是组合。它们都支持代码重用。继承和组合可以解决 Python 程序中类似的问题。
一般的建议是使用在两个类之间产生较少依赖的关系。这种关系就是构图。尽管如此,还是会有继承更有意义的时候。
以下部分提供了一些指导方针,帮助您在 Python 中的继承和组合之间做出正确的选择。
继承到模型“是”的关系
继承应该只用于建模一个是一个关系。利斯科夫的替换原则说,继承自
Base的Derived类型的对象可以替换Base类型的对象,而不会改变程序的期望属性。Liskov 的替代原则是决定继承是否是合适的设计解决方案的最重要的指导方针。然而,答案可能不是在所有情况下都是直截了当的。幸运的是,有一个简单的测试可以用来确定你的设计是否遵循了 Liskov 的替代原理。
假设您有一个类
A,它提供了您想要在另一个类B中重用的实现和接口。您最初的想法是,您可以从A派生出B,并继承接口和实现。为了确保这是正确的设计,请遵循以下步骤:
评价
B是一个A: 想一想这段关系,为它正名。有意义吗?评价
A是个B: 颠倒关系,自圆其说。这也有意义吗?如果您可以证明这两种关系,那么您就不应该从另一个继承这些类。让我们看一个更具体的例子。
您有一个类
Rectangle,它公开了一个.area属性。你需要一个类Square,它也有一个.area。看起来一个Square是一个特殊类型的Rectangle,所以也许你可以从它派生并利用接口和实现。在开始实现之前,您使用 Liskov 的替代原则来评估这种关系。
一个
Square是一个Rectangle,因为它的面积是由它的height乘以它的length的乘积计算出来的。约束条件是Square.height和Square.length必须相等。有道理。你可以证明这种关系,并解释为什么一个
Square是一个Rectangle。我们把关系倒过来,看看有没有道理。一个
Rectangle是一个Square,因为它的面积是由它的height乘以它的length的乘积计算出来的。不同的是Rectangle.height和Rectangle.width可以独立变化。也有道理。您可以证明这种关系,并描述每个类的特殊约束。这是一个很好的迹象,表明这两个类不应该相互派生。
您可能已经看到了从
Rectangle派生出Square来解释继承的其他例子。你可能会怀疑你刚刚做的小测试。很公平。让我们写一个程序来说明从Rectangle派生Square的问题。首先,你实现
Rectangle。您甚至要封装属性,以确保满足所有约束:# In rectangle_square_demo.py class Rectangle: def __init__(self, length, height): self._length = length self._height = height @property def area(self): return self._length * self._height用一个
length和一个height初始化Rectangle类,它提供一个返回区域的.area属性。length和height被封装以避免直接改变它们。现在,您从
Rectangle派生Square,并覆盖必要的接口以满足Square的约束:# In rectangle_square_demo.py class Square(Rectangle): def __init__(self, side_size): super().__init__(side_size, side_size)用一个
side_size初始化Square类,它用于初始化基类的两个组件。现在,您编写一个小程序来测试行为:# In rectangle_square_demo.py rectangle = Rectangle(2, 4) assert rectangle.area == 8 square = Square(2) assert square.area == 4 print('OK!')程序创建一个
Rectangle和一个Square,并断言它们的.area计算正确。您可以运行该程序,看到目前为止一切都是OK:$ python rectangle_square_demo.py OK!程序正确执行,所以看起来
Square只是一个Rectangle的特例。稍后,您需要支持调整
Rectangle对象的大小,因此您对该类进行了适当的更改:# In rectangle_square_demo.py class Rectangle: def __init__(self, length, height): self._length = length self._height = height @property def area(self): return self._length * self._height def resize(self, new_length, new_height): self._length = new_length self._height = new_height
.resize()以new_length和new_width为对象。您可以将以下代码添加到程序中,以验证它是否正常工作:# In rectangle_square_demo.py rectangle.resize(3, 5) assert rectangle.area == 15 print('OK!')调整 rectangle 对象的大小,并断言新区域是正确的。您可以运行程序来验证该行为:
$ python rectangle_square_demo.py OK!断言通过,您会看到程序正确运行。
那么,如果你调整一个正方形的大小会发生什么?修改程序,并尝试修改
square对象:# In rectangle_square_demo.py square.resize(3, 5) print(f'Square area: {square.area}')您将与使用
rectangle相同的参数传递给square.resize(),并打印该区域。当您运行该程序时,您会看到:$ python rectangle_square_demo.py Square area: 15 OK!程序显示新区域是像
rectangle对象一样的15。现在的问题是,square对象不再满足length和height必须相等的Square类约束。你如何解决这个问题?你可以尝试几种方法,但所有的方法都会很尴尬。你可以覆盖
square中的.resize()并忽略height参数,但这将会让那些查看程序其他部分的人感到困惑,在这些部分中rectangles被调整了大小,其中一些没有得到预期的区域,因为它们实际上是squares。在像这样的小程序中,可能很容易发现奇怪行为的原因,但是在更复杂的程序中,问题就更难发现了。
事实是,如果你能够双向证明两个类之间的继承关系,你就不应该从一个类派生另一个类。
在例子中,
Square从Rectangle继承了.resize()的接口和实现是没有意义的。这并不意味着Square对象不能调整大小。这意味着接口是不同的,因为它只需要一个side_size参数。这种接口上的差异证明了不像上面建议的测试那样从
Rectangle派生Square。用 Mixin 类混合特性
Python 中多重继承的用途之一是通过 mixins 扩展一个类的特性。一个 mixin 是一个向其他类提供方法的类,但不被认为是基类。
mixin 允许其他类重用它的接口和实现,而不会成为超类。它们实现了一个独特的行为,可以聚合到其他不相关的类中。它们类似于作文,但它们创造了更强的关系。
假设您想将应用程序中某些类型的对象转换成对象的字典表示。你可以在每个类中提供一个
.to_dict()方法来支持这个特性,但是.to_dict()的实现看起来非常相似。这可能是一个很好的混音候选。从稍微修改合成示例中的
Employee类开始:# In employees.py class Employee: def __init__(self, id, name, address, role, payroll): self.id = id self.name = name self.address = address self._role = role self._payroll = payroll def work(self, hours): duties = self._role.perform_duties(hours) print(f'Employee {self.id} - {self.name}:') print(f'- {duties}') print('') self._payroll.track_work(hours) def calculate_payroll(self): return self._payroll.calculate_payroll()变化很小。您只是通过在名称中添加一个前导下划线,将
role和payroll属性更改为内部属性。你很快就会明白你为什么要做出这样的改变。现在,您添加了
AsDictionaryMixin类:# In representations.py class AsDictionaryMixin: def to_dict(self): return { prop: self._represent(value) for prop, value in self.__dict__.items() if not self._is_internal(prop) } def _represent(self, value): if isinstance(value, object): if hasattr(value, 'to_dict'): return value.to_dict() else: return str(value) else: return value def _is_internal(self, prop): return prop.startswith('_')
AsDictionaryMixin类公开了一个.to_dict()方法,该方法将自身的表示作为一个字典返回。该方法被实现为一个dict理解,它说:“如果prop不是内部的,为self.__dict__.items()中的每一项创建一个映射prop到value的字典。”注意:这就是为什么我们把 role 和 payroll 属性放在
Employee类的内部,因为我们不想在字典中表示它们。正如您在开始时看到的,创建一个类从
object继承一些成员,其中一个成员是__dict__,它基本上是一个对象中所有属性到它们的值的映射。您遍历
__dict__中的所有条目,并使用._is_internal()过滤掉名称以下划线开头的条目。
._represent()检查指定值。如果值是一个object,那么它会查看它是否也有一个.to_dict()成员,并使用它来表示对象。否则,它返回一个字符串表示形式。如果这个值不是一个object,那么它只是返回这个值。您可以修改
Employee类来支持这个 mixin:# In employees.py from representations import AsDictionaryMixin class Employee(AsDictionaryMixin): def __init__(self, id, name, address, role, payroll): self.id = id self.name = name self.address = address self._role = role self._payroll = payroll def work(self, hours): duties = self._role.perform_duties(hours) print(f'Employee {self.id} - {self.name}:') print(f'- {duties}') print('') self._payroll.track_work(hours) def calculate_payroll(self): return self._payroll.calculate_payroll()你所要做的就是继承
AsDictionaryMixin来支持这个功能。最好在Address类中支持相同的功能,因此Employee.address属性以相同的方式表示:# In contacts.py from representations import AsDictionaryMixin class Address(AsDictionaryMixin): def __init__(self, street, city, state, zipcode, street2=''): self.street = street self.street2 = street2 self.city = city self.state = state self.zipcode = zipcode def __str__(self): lines = [self.street] if self.street2: lines.append(self.street2) lines.append(f'{self.city}, {self.state} {self.zipcode}') return '\n'.join(lines)您将 mixin 应用到
Address类来支持这个特性。现在,您可以编写一个小程序来测试它:# In program.py import json from employees import EmployeeDatabase def print_dict(d): print(json.dumps(d, indent=2)) for employee in EmployeeDatabase().employees: print_dict(employee.to_dict())该程序实现了一个
print_dict(),使用缩进将字典转换成一个 JSON 字符串,这样输出看起来更好。然后,它遍历所有雇员,打印由
.to_dict()提供的字典表示。您可以运行该程序来查看其输出:$ python program.py { "id": "1", "name": "Mary Poppins", "address": { "street": "121 Admin Rd.", "street2": "", "city": "Concord", "state": "NH", "zipcode": "03301" } } { "id": "2", "name": "John Smith", "address": { "street": "67 Paperwork Ave", "street2": "", "city": "Manchester", "state": "NH", "zipcode": "03101" } } { "id": "3", "name": "Kevin Bacon", "address": { "street": "15 Rose St", "street2": "Apt. B-1", "city": "Concord", "state": "NH", "zipcode": "03301" } } { "id": "4", "name": "Jane Doe", "address": { "street": "39 Sole St.", "street2": "", "city": "Concord", "state": "NH", "zipcode": "03301" } } { "id": "5", "name": "Robin Williams", "address": { "street": "99 Mountain Rd.", "street2": "", "city": "Concord", "state": "NH", "zipcode": "03301" } }你在
Employee和Address类中都利用了AsDictionaryMixin的实现,即使它们并不相关。因为AsDictionaryMixin只提供行为,所以很容易与其他类重用而不会导致问题。构图与模型“有”的关系
构图模型 a 有一个关系。通过组合,一个类
Composite拥有一个类Component的实例,并且可以利用它的实现。Component类可以在与Composite完全无关的其他类中重用。在上面的合成示例中,
Employee类有一个Address对象。Address实现了处理地址的所有功能,并且可以被其他类重用。其他类像
Customer或Vendor可以重用Address而不与Employee相关。他们可以利用相同的实现,确保在整个应用程序中一致地处理地址。使用组合时可能会遇到的一个问题是,一些类可能会因为使用多个组件而开始增长。您的类可能需要在构造函数中有多个参数,只是为了传入组成它们的组件。这可能会使您的类难以使用。
避免这个问题的一个方法是使用工厂方法来构造你的对象。你在作文的例子中已经做到了。
如果你看一下
EmployeeDatabase类的实现,你会注意到它使用._create_employee()来构造一个带有正确参数的Employee对象。这种设计是可行的,但是理想情况下,你应该能够通过指定一个
id来构造一个Employee对象,例如employee = Employee(1)。以下更改可能会改进您的设计。您可以从
productivity模块开始:# In productivity.py class _ProductivitySystem: def __init__(self): self._roles = { 'manager': ManagerRole, 'secretary': SecretaryRole, 'sales': SalesRole, 'factory': FactoryRole, } def get_role(self, role_id): role_type = self._roles.get(role_id) if not role_type: raise ValueError('role_id') return role_type() def track(self, employees, hours): print('Tracking Employee Productivity') print('==============================') for employee in employees: employee.work(hours) print('') # Role classes implementation omitted _productivity_system = _ProductivitySystem() def get_role(role_id): return _productivity_system.get_role(role_id) def track(employees, hours): _productivity_system.track(employees, hours)首先,将
_ProductivitySystem类设为内部,然后向模块提供一个_productivity_system内部变量。您正在向其他开发人员传达,他们不应该直接创建或使用_ProductivitySystem。相反,您提供了两个函数,get_role()和track(),作为模块的公共接口。这是其他模块应该使用的。你所说的是
_ProductivitySystem是一个单例,并且应该只有一个从它创建的对象。现在,您可以用
hr模块做同样的事情:# In hr.py class _PayrollSystem: def __init__(self): self._employee_policies = { 1: SalaryPolicy(3000), 2: SalaryPolicy(1500), 3: CommissionPolicy(1000, 100), 4: HourlyPolicy(15), 5: HourlyPolicy(9) } def get_policy(self, employee_id): policy = self._employee_policies.get(employee_id) if not policy: return ValueError(employee_id) return policy def calculate_payroll(self, employees): print('Calculating Payroll') print('===================') for employee in employees: print(f'Payroll for: {employee.id} - {employee.name}') print(f'- Check amount: {employee.calculate_payroll()}') if employee.address: print('- Sent to:') print(employee.address) print('') # Policy classes implementation omitted _payroll_system = _PayrollSystem() def get_policy(employee_id): return _payroll_system.get_policy(employee_id) def calculate_payroll(employees): _payroll_system.calculate_payroll(employees)同样,您使
_PayrollSystem成为内部的,并为它提供一个公共接口。该应用程序将使用公共接口来获取策略和计算工资。现在,您将对
contacts模块进行同样的操作:# In contacts.py class _AddressBook: def __init__(self): self._employee_addresses = { 1: Address('121 Admin Rd.', 'Concord', 'NH', '03301'), 2: Address('67 Paperwork Ave', 'Manchester', 'NH', '03101'), 3: Address('15 Rose St', 'Concord', 'NH', '03301', 'Apt. B-1'), 4: Address('39 Sole St.', 'Concord', 'NH', '03301'), 5: Address('99 Mountain Rd.', 'Concord', 'NH', '03301'), } def get_employee_address(self, employee_id): address = self._employee_addresses.get(employee_id) if not address: raise ValueError(employee_id) return address # Implementation of Address class omitted _address_book = _AddressBook() def get_employee_address(employee_id): return _address_book.get_employee_address(employee_id)你基本上是说应该只有一个
_AddressBook、一个_PayrollSystem和一个_ProductivitySystem。同样,这种设计模式被称为 Singleton 设计模式,这对于应该只有一个实例的类来说非常方便。现在,您可以在
employees模块上工作了。您还将从_EmployeeDatabase中创建一个 Singleton,但是您将做一些额外的更改:# In employees.py from productivity import get_role from hr import get_policy from contacts import get_employee_address from representations import AsDictionaryMixin class _EmployeeDatabase: def __init__(self): self._employees = { 1: { 'name': 'Mary Poppins', 'role': 'manager' }, 2: { 'name': 'John Smith', 'role': 'secretary' }, 3: { 'name': 'Kevin Bacon', 'role': 'sales' }, 4: { 'name': 'Jane Doe', 'role': 'factory' }, 5: { 'name': 'Robin Williams', 'role': 'secretary' } } @property def employees(self): return [Employee(id_) for id_ in sorted(self._employees)] def get_employee_info(self, employee_id): info = self._employees.get(employee_id) if not info: raise ValueError(employee_id) return info class Employee(AsDictionaryMixin): def __init__(self, id): self.id = id info = employee_database.get_employee_info(self.id) self.name = info.get('name') self.address = get_employee_address(self.id) self._role = get_role(info.get('role')) self._payroll = get_policy(self.id) def work(self, hours): duties = self._role.perform_duties(hours) print(f'Employee {self.id} - {self.name}:') print(f'- {duties}') print('') self._payroll.track_work(hours) def calculate_payroll(self): return self._payroll.calculate_payroll() employee_database = _EmployeeDatabase()首先从其他模块导入相关的函数和类。
_EmployeeDatabase是内部的,在底部,您创建一个实例。这个实例是公共的,是接口的一部分,因为您将希望在应用程序中使用它。您将
_EmployeeDatabase._employees属性更改为一个字典,其中键是雇员id,值是雇员信息。您还公开了一个.get_employee_info()方法来返回指定雇员employee_id的信息。
_EmployeeDatabase.employees属性现在对键进行排序,以返回按其id排序的雇员。您用对Employee初始化器的直接调用替换了构造Employee对象的方法。
Employee类现在用id初始化,并使用其他模块中公开的公共函数来初始化它的属性。现在,您可以更改程序来测试这些更改:
# In program.py import json from hr import calculate_payroll from productivity import track from employees import employee_database, Employee def print_dict(d): print(json.dumps(d, indent=2)) employees = employee_database.employees track(employees, 40) calculate_payroll(employees) temp_secretary = Employee(5) print('Temporary Secretary:') print_dict(temp_secretary.to_dict())您从
hr和productivity模块以及employee_database和Employee类中导入相关函数。该程序更简洁,因为您公开了所需的接口并封装了对象的访问方式。请注意,您现在可以使用
id直接创建一个Employee对象。您可以运行该程序来查看其输出:$ python program.py Tracking Employee Productivity ============================== Employee 1 - Mary Poppins: - screams and yells for 40 hours. Employee 2 - John Smith: - does paperwork for 40 hours. Employee 3 - Kevin Bacon: - expends 40 hours on the phone. Employee 4 - Jane Doe: - manufactures gadgets for 40 hours. Employee 5 - Robin Williams: - does paperwork for 40 hours. Calculating Payroll =================== Payroll for: 1 - Mary Poppins - Check amount: 3000 - Sent to: 121 Admin Rd. Concord, NH 03301 Payroll for: 2 - John Smith - Check amount: 1500 - Sent to: 67 Paperwork Ave Manchester, NH 03101 Payroll for: 3 - Kevin Bacon - Check amount: 1800.0 - Sent to: 15 Rose St Apt. B-1 Concord, NH 03301 Payroll for: 4 - Jane Doe - Check amount: 600 - Sent to: 39 Sole St. Concord, NH 03301 Payroll for: 5 - Robin Williams - Check amount: 360 - Sent to: 99 Mountain Rd. Concord, NH 03301 Temporary Secretary: { "id": "5", "name": "Robin Williams", "address": { "street": "99 Mountain Rd.", "street2": "", "city": "Concord", "state": "NH", "zipcode": "03301" } }该程序的工作原理和以前一样,但是现在您可以看到一个单独的
Employee对象可以从它的id中创建并显示它的字典表示。仔细看看
Employee类:# In employees.py class Employee(AsDictionaryMixin): def __init__(self, id): self.id = id info = employee_database.get_employee_info(self.id) self.name = info.get('name') self.address = get_employee_address(self.id) self._role = get_role(info.get('role')) self._payroll = get_policy(self.id) def work(self, hours): duties = self._role.perform_duties(hours) print(f'Employee {self.id} - {self.name}:') print(f'- {duties}') print('') self._payroll.track_work(hours) def calculate_payroll(self): return self._payroll.calculate_payroll()
Employee类是一个包含多个提供不同功能的对象的组合。它包含一个Address,实现所有与员工居住地相关的功能。
Employee还包含由productivity模块提供的生产力角色,以及由hr模块提供的工资政策。这两个对象提供了被Employee类用来在.work()方法中跟踪工作和在.calculate_payroll()方法中计算工资的实现。你以两种不同的方式使用构图。
Address类向Employee提供额外的数据,其中角色和工资对象提供额外的行为。尽管如此,
Employee和这些对象之间的关系是松散耦合的,这提供了一些有趣的功能,您将在下一节看到。改变运行时行为的组合
与组合相反,继承是一种紧密耦合关系。对于继承,只有一种方法可以改变和定制行为。方法重写是自定义基类行为的唯一方式。这造成了难以改变的僵化设计。
另一方面,组合提供了一种松散耦合的关系,支持灵活的设计,并可用于在运行时改变行为。
假设您在计算工资时需要支持长期残疾(LTD)保险。该政策规定,假设雇员工作 40 小时,应向其支付 60%的周薪。
对于继承设计,这可能是一个非常难以支持的需求。将它添加到合成示例中要容易得多。让我们从添加策略类开始:
# In hr.py class LTDPolicy: def __init__(self): self._base_policy = None def track_work(self, hours): self._check_base_policy() return self._base_policy.track_work(hours) def calculate_payroll(self): self._check_base_policy() base_salary = self._base_policy.calculate_payroll() return base_salary * 0.6 def apply_to_policy(self, base_policy): self._base_policy = base_policy def _check_base_policy(self): if not self._base_policy: raise RuntimeError('Base policy missing')注意
LTDPolicy没有继承PayrollPolicy,但是实现了相同的接口。这是因为实现完全不同,所以我们不想继承任何PayrollPolicy的实现。
LTDPolicy将_base_policy初始化为None,并提供一个内部的._check_base_policy()方法,如果._base_policy没有被应用,该方法将引发一个异常。然后,它提供了一个.apply_to_policy()方法来分配_base_policy。公共接口首先检查是否已经应用了
_base_policy,然后根据基本策略实现功能。.track_work()方法只是委托给基本策略,.calculate_payroll()用它来计算base_salary,然后返回 60%。现在您可以对
Employee类做一个小小的修改:# In employees.py class Employee(AsDictionaryMixin): def __init__(self, id): self.id = id info = employee_database.get_employee_info(self.id) self.name = info.get('name') self.address = get_employee_address(self.id) self._role = get_role(info.get('role')) self._payroll = get_policy(self.id) def work(self, hours): duties = self._role.perform_duties(hours) print(f'Employee {self.id} - {self.name}:') print(f'- {duties}') print('') self._payroll.track_work(hours) def calculate_payroll(self): return self._payroll.calculate_payroll() def apply_payroll_policy(self, new_policy): new_policy.apply_to_policy(self._payroll) self._payroll = new_policy您添加了一个
.apply_payroll_policy()方法,将现有的工资政策应用到新政策中,然后替换它。现在您可以修改程序,将策略应用到一个Employee对象:# In program.py from hr import calculate_payroll, LTDPolicy from productivity import track from employees import employee_database employees = employee_database.employees sales_employee = employees[2] ltd_policy = LTDPolicy() sales_employee.apply_payroll_policy(ltd_policy) track(employees, 40) calculate_payroll(employees)程序访问位于索引
2的sales_employee,创建LTDPolicy对象,并将策略应用于雇员。当.calculate_payroll()被调用时,变化被反映出来。您可以运行程序来评估输出:$ python program.py Tracking Employee Productivity ============================== Employee 1 - Mary Poppins: - screams and yells for 40 hours. Employee 2 - John Smith: - Does paperwork for 40 hours. Employee 3 - Kevin Bacon: - Expends 40 hours on the phone. Employee 4 - Jane Doe: - Manufactures gadgets for 40 hours. Employee 5 - Robin Williams: - Does paperwork for 40 hours. Calculating Payroll =================== Payroll for: 1 - Mary Poppins - Check amount: 3000 - Sent to: 121 Admin Rd. Concord, NH 03301 Payroll for: 2 - John Smith - Check amount: 1500 - Sent to: 67 Paperwork Ave Manchester, NH 03101 Payroll for: 3 - Kevin Bacon - Check amount: 1080.0 - Sent to: 15 Rose St Apt. B-1 Concord, NH 03301 Payroll for: 4 - Jane Doe - Check amount: 600 - Sent to: 39 Sole St. Concord, NH 03301 Payroll for: 5 - Robin Williams - Check amount: 360 - Sent to: 99 Mountain Rd. Concord, NH 03301销售人员凯文·贝肯的支票金额现在是 1080 美元,而不是 1800 美元。那是因为
LTDPolicy已经应用到工资上了。如您所见,您可以通过添加新策略和修改几个接口来支持这些变化。这就是基于组合的策略设计给你的灵活性。
在 Python 中选择继承还是组合
Python 作为一种面向对象的编程语言,同时支持继承和组合。您看到了继承最适合用于建模一个是一个关系,而组合建模一个有一个关系。
有时,很难看出两个类之间应该是什么关系,但是您可以遵循以下准则:
在 Python 中使用复合继承来建模一个清晰的是一个关系。首先,证明派生类和它的基类之间的关系。然后,颠倒关系,试图自圆其说。如果你能证明两个方向的关系,那么你就不应该在它们之间使用继承。
在 Python 中使用复合继承来平衡基类的接口和实现。
在 Python 中使用复合继承来为几个不相关的类提供 mixin 特性,当这个特性只有一个实现时。
在 Python 中使用复合而非继承来建模具有利用组件类实现的关系。
在 Python 中使用复合而非继承来创建可由 Python 应用程序中的多个类重用的组件。
使用 Python 中的复合继承来实现一组行为和策略,这些行为和策略可以互换地应用于其他类来定制它们的行为。
使用 Python 中的复合继承来实现运行时行为的改变,而不影响现有的类。
结论
您探索了 Python 中的继承和组合。您了解了继承和组合创建的关系类型。您还通过一系列练习了解了继承和组合是如何在 Python 中实现的。
在本文中,您学习了如何:
- 用继承来表达一个是两个类之间的一个关系
- 评估继承是否是正确的关系
- 在 Python 中使用多重继承,并评估 Python 的 MRO 来解决多重继承问题
- 用 mixins 扩展类并重用它们的实现
- 用组合来表达一个类和两个类之间有关系
- 使用组合提供灵活的设计
- 通过基于组合的策略设计重用现有代码
推荐阅读
这里有一些书籍和文章进一步探讨了面向对象的设计,可以帮助您理解 Python 或其他语言中继承和组合的正确使用:
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 继承与构成:一个 Python OOP 指南*********
Python 内部函数:它们有什么用?
原文:https://realpython.com/inner-functions-what-are-they-good-for/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 内部函数
内部函数,也称为嵌套函数,是你在其他函数内部定义的函数。在 Python 中,这种函数可以直接访问封闭函数中定义的变量和名称。内部函数有很多用途,最著名的是作为闭包工厂和装饰函数。
在本教程中,您将学习如何:
- 提供封装并隐藏您的功能,防止外部访问
- 编写助手函数以促进代码重用
- 创建在调用之间保持状态的闭包工厂函数
- 编写代码装饰函数以向现有函数添加行为
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
创建 Python 内部函数
定义在另一个函数内部的函数被称为内部函数或嵌套函数。在 Python 中,这种函数可以访问封闭函数中的名。以下是如何在 Python 中创建内部函数的示例:
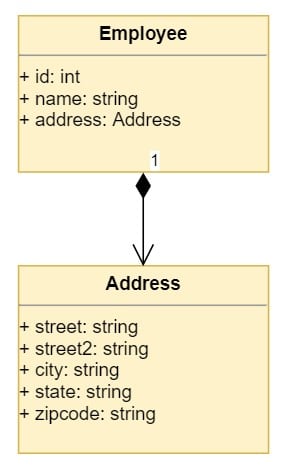
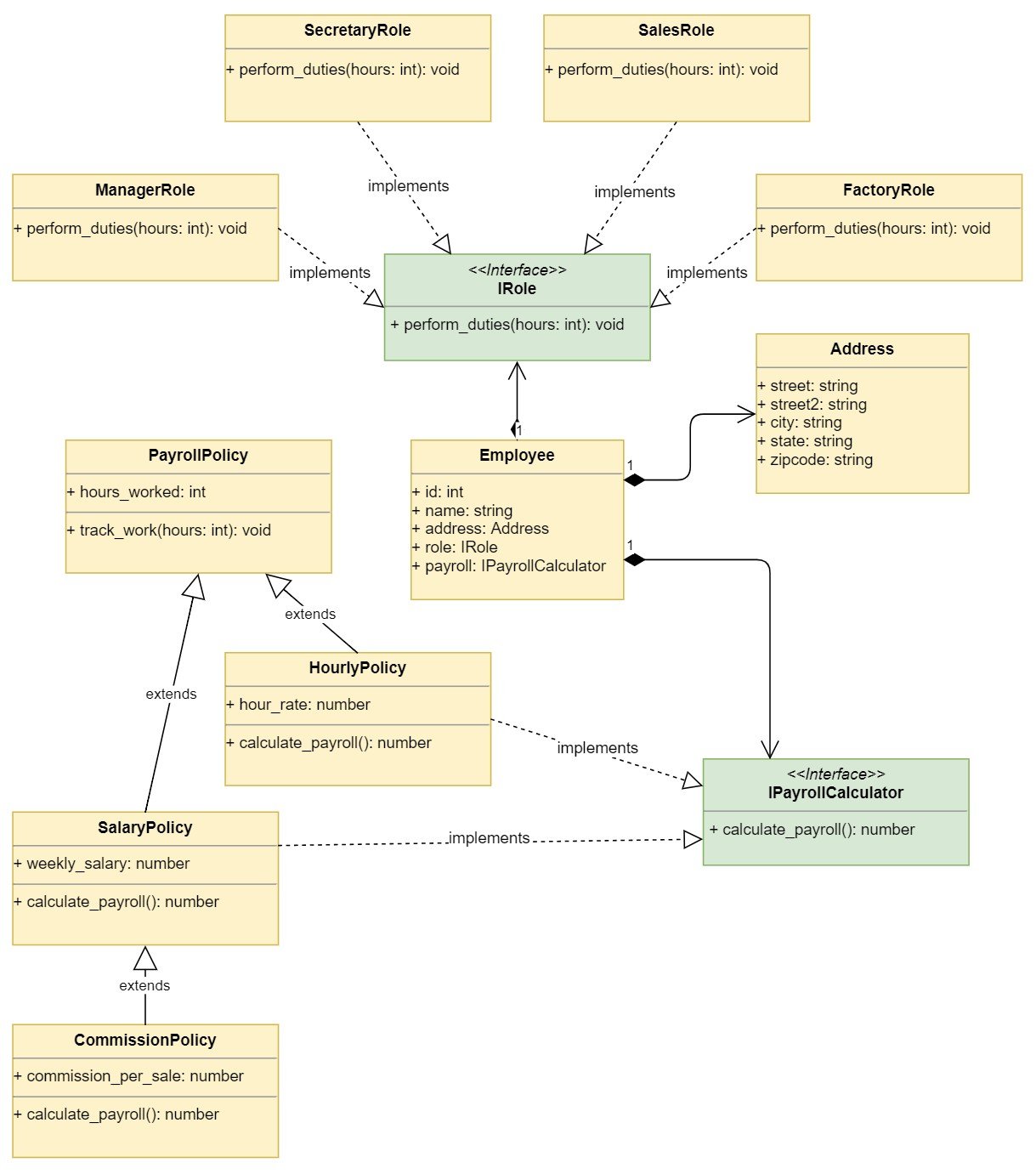
>>> def outer_func():
... def inner_func():
... print("Hello, World!")
... inner_func()
...
>>> outer_func()
Hello, World!
在这段代码中,您在outer_func()到中定义了inner_func()将Hello, World!消息打印到屏幕上。为此,您在outer_func()的最后一行调用inner_func()。这是用 Python 编写内部函数最快的方法。然而,内部函数提供了许多有趣的可能性,超出了你在这个例子中看到的。
内部函数的核心特性是,即使在函数返回后,它们也能从封闭函数中访问变量和对象。封闭函数提供了一个内部函数可访问的名称空间:
>>> def outer_func(who): ... def inner_func(): ... print(f"Hello, {who}") ... inner_func() ... >>> outer_func("World!") Hello, World!现在您可以将一个字符串作为参数传递给
outer_func(),inner_func()将通过名称who访问该参数。然而这个名字是在outer_func()的局部作用域中定义的。您在外部函数的局部作用域中定义的名称被称为非局部名称。从inner_func()的角度看,他们是外地的。下面是一个如何创建和使用更复杂的内部函数的例子:
>>> def factorial(number):
... # Validate input
... if not isinstance(number, int):
... raise TypeError("Sorry. 'number' must be an integer.")
... if number < 0:
... raise ValueError("Sorry. 'number' must be zero or positive.")
... # Calculate the factorial of number
... def inner_factorial(number):
... if number <= 1:
... return 1
... return number * inner_factorial(number - 1)
... return inner_factorial(number)
...
>>> factorial(4)
24
在factorial()中,首先验证输入数据,确保用户提供的是一个等于或大于零的整数。然后定义一个名为inner_factorial()的递归内部函数来执行阶乘计算,将结果返回给。最后一步是给inner_factorial()打电话。
注:关于递归和递归函数更详细的讨论,请查看用 Python 递归思维和用 Python 递归:简介。
使用这种模式的主要优点是,通过在外部函数中执行所有的参数检查,您可以安全地跳过内部函数中的错误检查,并专注于手头的计算。
使用内部函数:基础知识
Python 内部函数的用例多种多样。你可以使用它们来提供封装和隐藏你的外部访问的函数,你可以编写助手内部函数,你也可以创建闭包和装饰器。在本节中,您将了解内部函数的前两个用例,在后面的章节中,您将了解如何创建闭包工厂函数和装饰器。
提供封装
内部函数的一个常见用例是,当你需要保护或隐藏一个给定的函数,使其不被外部发生的任何事情影响时,这个函数就完全隐藏在全局作用域之外了。这种行为俗称封装。
这里有一个例子突出了这个概念:
>>> def increment(number): ... def inner_increment(): ... return number + 1 ... return inner_increment() ... >>> increment(10) 11 >>> # Call inner_increment() >>> inner_increment() Traceback (most recent call last): File "<input>", line 1, in <module> inner_increment() NameError: name 'inner_increment' is not defined在这个例子中,你不能直接访问
inner_increment()。如果你尝试去做,那么你会得到一个NameError。那是因为increment()完全隐藏了inner_increment(),防止你从全局范围内访问它。构建助手内部函数
有时你有一个函数,它在体的几个地方执行相同的代码块。例如,假设您想编写一个函数来处理包含纽约市 Wi-Fi 热点信息的 CSV 文件。要查找纽约热点的总数以及提供大多数热点的公司,您可以创建以下脚本:
# hotspots.py import csv from collections import Counter def process_hotspots(file): def most_common_provider(file_obj): hotspots = [] with file_obj as csv_file: content = csv.DictReader(csv_file) for row in content: hotspots.append(row["Provider"]) counter = Counter(hotspots) print( f"There are {len(hotspots)} Wi-Fi hotspots in NYC.\n" f"{counter.most_common(1)[0][0]} has the most with " f"{counter.most_common(1)[0][1]}." ) if isinstance(file, str): # Got a string-based filepath file_obj = open(file, "r") most_common_provider(file_obj) else: # Got a file object most_common_provider(file)这里,
process_hotspots()以file为自变量。该函数检查file是一个物理文件的基于字符串的路径还是一个文件对象。然后它调用助手内部函数most_common_provider(),该函数接受一个文件对象并执行以下操作:
- 将文件内容读入一个生成器,该生成器使用
csv.DictReader生成字典。- 创建 Wi-Fi 提供商列表。
- 使用
collections.Counter对象统计每个提供商的 Wi-Fi 热点数量。- 打印包含检索信息的消息。
如果运行该函数,您将获得以下输出:
>>> from hotspots import process_hotspots
>>> file_obj = open("./NYC_Wi-Fi_Hotspot_Locations.csv", "r")
>>> process_hotspots(file_obj)
There are 3319 Wi-Fi hotspots in NYC.
LinkNYC - Citybridge has the most with 1868.
>>> process_hotspots("./NYC_Wi-Fi_Hotspot_Locations.csv")
There are 3319 Wi-Fi hotspots in NYC.
LinkNYC - Citybridge has the most with 1868.
无论是用基于字符串的文件路径还是用文件对象调用process_hotspots(),都会得到相同的结果。
使用内部与私有帮助函数
通常,当您想要提供封装时,可以创建类似于most_common_provider()的帮助器内部函数。如果您认为除了包含函数之外不会在其他地方调用内部函数,您也可以创建内部函数。
虽然将助手函数编写为内部函数可以达到预期的效果,但是将它们提取为顶级函数可能会更好。在这种情况下,您可以在函数名中使用一个前导下划线(_)来表示它是当前模块或类的私有函数。这将允许您从当前模块或类中的任何地方访问您的助手函数,并在需要时重用它们。
将内部函数提取到顶级私有函数中可以让你的代码更整洁,可读性更好。这种实践可以产生应用单一责任原则的函数。
内部函数保持状态:闭包
在 Python 中,函数是一等公民。这意味着它们与任何其他对象一样,比如数字、字符串、列表、元组、模块等等。您可以动态地创建或销毁它们,将它们存储在数据结构中,将它们作为参数传递给其他函数,将它们作为返回值等等。
也可以在 Python 中创建高阶函数。高阶函数是对其他函数进行操作的函数,将它们作为参数,返回它们,或者两者都做。
到目前为止,您看到的所有内部函数的例子都是普通函数,只是碰巧嵌套在其他函数中。除非你需要对外界隐藏你的函数,否则没有必要嵌套它们。您可以将这些函数定义为私有的顶级函数,这样就可以了。
在本节中,您将了解到闭包工厂函数。闭包是由其他函数返回的动态创建的函数。它们的主要特性是,即使封闭函数已经返回并完成执行,它们也可以完全访问在创建闭包的本地名称空间中定义的变量和名称。
在 Python 中,当您返回一个内部函数对象时,解释器会将函数与其包含的环境或闭包一起打包。function 对象保存了在其包含范围内定义的所有变量和名称的快照。要定义一个闭包,您需要采取三个步骤:
- 创建一个内部函数。
- 来自封闭函数的引用变量。
- 返回内部函数。
有了这些基础知识,您就可以马上开始创建您的闭包,并利用它们的主要特性:在函数调用之间保持状态。
关闭时的保持状态
闭包使得内部函数在被调用时保持其环境的状态。闭包不是内部函数本身,而是内部函数及其封闭环境。闭包捕获包含函数中的局部变量和名称,并保存它们。
考虑下面的例子:
1# powers.py
2
3def generate_power(exponent):
4 def power(base):
5 return base ** exponent
6 return power
下面是该函数中发生的情况:
- 第 3 行创建
generate_power(),这是一个闭包工厂函数。这意味着它每次被调用时都会创建一个新的闭包,然后将其返回给调用者。 - 第 4 行定义了
power(),这是一个内部函数,它接受一个参数base,并返回表达式base ** exponent的结果。 - 第 6 行将
power作为函数对象返回,不调用它。
power()从哪里得到exponent的值?这就是闭包发挥作用的地方。在这个例子中,power()从外部函数generate_power()中获取exponent的值。当您调用generate_power()时,Python 会这样做:
- 定义一个新的
power()实例,它接受一个参数base。 - 拍摄
power()周围状态的快照,其中包括exponent及其当前值。 - 返回
power()连同它的整个周围状态。
这样,当你调用由generate_power()返回的power()的实例时,你会看到函数记住了exponent的值:
>>> from powers import generate_power >>> raise_two = generate_power(2) >>> raise_three = generate_power(3) >>> raise_two(4) 16 >>> raise_two(5) 25 >>> raise_three(4) 64 >>> raise_three(5) 125在这些例子中,
raise_two()记得那个exponent=2,而raise_three()记得那个exponent=3。注意,两个闭包都会在调用之间记住它们各自的exponent。现在考虑另一个例子:
>>> def has_permission(page):
... def permission(username):
... if username.lower() == "admin":
... return f"'{username}' has access to {page}."
... else:
... return f"'{username}' doesn't have access to {page}."
... return permission
...
>>> check_admin_page_permision = has_permission("Admin Page")
>>> check_admin_page_permision("admin")
"'admin' has access to Admin Page."
>>> check_admin_page_permision("john")
"'john' doesn't have access to Admin Page."
内部函数检查给定用户是否有访问给定页面的正确权限。您可以快速修改它,以获取会话中的用户,检查他们是否拥有访问某个路由的正确凭证。
不用检查用户是否等于"admin",您可以查询一个 SQL 数据库来检查权限,然后根据凭证是否正确返回正确的视图。
您通常会创建不修改其封闭状态的闭包,或者创建具有静态封闭状态的闭包,正如您在上面的例子中所看到的。但是,您也可以创建闭包,通过使用可变对象,比如字典、集合或列表,来修改它们的封闭状态。
假设你需要计算一个数据集的平均值。数据来自于正在分析的参数的连续测量流,您需要您的函数在调用之间保留先前的测量。在这种情况下,您可以像这样编写一个闭包工厂函数:
>>> def mean(): ... sample = [] ... def inner_mean(number): ... sample.append(number) ... return sum(sample) / len(sample) ... return inner_mean ... >>> sample_mean = mean() >>> sample_mean(100) 100.0 >>> sample_mean(105) 102.5 >>> sample_mean(101) 102.0 >>> sample_mean(98) 101.0分配给
sample_mean的闭包在连续调用之间保持sample的状态。即使您在mean()中定义了sample,它仍然在闭包中可用,因此您可以修改它。在这种情况下,sample作为一种动态的封闭状态。修改关闭状态
通常,闭包变量对外界是完全隐藏的。但是,您可以为它们提供 getter 和 setter 内部函数:
>>> def make_point(x, y):
... def point():
... print(f"Point({x}, {y})")
... def get_x():
... return x
... def get_y():
... return y
... def set_x(value):
... nonlocal x
... x = value
... def set_y(value):
... nonlocal y
... y = value
... # Attach getters and setters
... point.get_x = get_x
... point.set_x = set_x
... point.get_y = get_y
... point.set_y = set_y
... return point
...
>>> point = make_point(1, 2)
>>> point.get_x()
1
>>> point.get_y()
2
>>> point()
Point(1, 2)
>>> point.set_x(42)
>>> point.set_y(7)
>>> point()
Point(42, 7)
这里,make_point()返回一个表示一个point对象的闭包。这个对象附带了 getter 和 setter 函数。您可以使用这些函数来获得对变量x和y的读写访问,这些变量在封闭范围中定义,并随闭包一起提供。
尽管这个函数创建的闭包可能比等价的类运行得更快,但是您需要注意,这种技术并没有提供主要的特性,包括继承,属性,描述符,以及类和静态方法。如果您想更深入地研究这项技术,那么请查看使用闭包和嵌套作用域模拟类的简单工具(Python Recipe) 。
用内部函数添加行为:装饰者
pythondecorator是内部函数的另一个流行且方便的用例,尤其是对于闭包。decorator是高阶函数,它将一个可调用函数(函数、方法、类)作为参数,并返回另一个可调用函数。
您可以使用 decorator 函数向现有的可调用程序动态添加职责,并透明地扩展其行为,而不会影响或修改原始的可调用程序。
注意:关于 Python 可调用对象的更多细节,请查看 Python 文档中的标准类型层次的,并向下滚动到“可调用类型”
要创建一个装饰器,您只需要定义一个 callable(一个函数、方法或类),它接受一个 function 对象作为参数,处理它,并返回另一个带有附加行为的 function 对象。
一旦有了 decorator 函数,就可以将它应用于任何可调用的。为此,您需要在装饰器名称前面使用 at 符号(@),然后将它放在自己的行上,紧接在被装饰的可调用函数之前:
@decorator def decorated_func():
# Function body...
pass
这个语法让decorator()自动将decorated_func()作为参数,并在其主体中处理。该操作是以下赋值的简写:
decorated_func = decorator(decorated_func)
下面是一个如何构建装饰函数来向现有函数添加新功能的示例:
>>> def add_messages(func): ... def _add_messages(): ... print("This is my first decorator") ... func() ... print("Bye!") ... return _add_messages ... >>> @add_messages ... def greet(): ... print("Hello, World!") ... >>> greet() This is my first decorator Hello, World! Bye!在这种情况下,你用
@add_messages来修饰greet()。这给修饰函数增加了新的功能。现在,当您调用greet()时,您的函数打印两条新消息,而不仅仅是打印Hello, World!。Python decorators 的用例多种多样。以下是其中的一些:
调试 Python 代码的一个常见做法是插入对
print()的调用,以检查变量值,确认代码块被执行,等等。添加和删除对print()的呼叫可能很烦人,而且你可能会忘记其中的一些。为了防止这种情况,您可以像这样编写一个装饰器:
>>> def debug(func):
... def _debug(*args, **kwargs):
... result = func(*args, **kwargs)
... print(
... f"{func.__name__}(args: {args}, kwargs: {kwargs}) -> {result}"
... )
... return result
... return _debug
...
>>> @debug
... def add(a, b):
... return a + b
...
>>> add(5, 6)
add(args: (5, 6), kwargs: {}) -> 11
11
这个例子提供了debug(),这是一个 decorator,它将一个函数作为参数,并用每个参数的当前值及其对应的返回值打印其签名。您可以使用这个装饰器来调试您的函数。一旦您获得了想要的结果,您就可以移除装饰器调用@debug,并且您的函数将为下一步做好准备。
注意:如果你有兴趣深入探究*args和**kwargs在 Python 中是如何工作的,那么就去看看 Python args 和 kwargs:去神秘化。
这是最后一个如何创建装饰器的例子。这一次,您将重新实现generate_power()作为装饰函数:
>>> def generate_power(exponent): ... def power(func): ... def inner_power(*args): ... base = func(*args) ... return base ** exponent ... return inner_power ... return power ... >>> @generate_power(2) ... def raise_two(n): ... return n ... >>> raise_two(7) 49 >>> @generate_power(3) ... def raise_three(n): ... return n ... >>> raise_three(5) 125这个版本的
generate_power()产生的结果与您在最初的实现中获得的结果相同。在这种情况下,您使用一个闭包来记住exponent和一个 decorator 来返回输入函数的修改版本func()。在这里,装饰器需要带一个参数(
exponent),所以你需要有两层嵌套的内部函数。第一级用power()表示,以修饰函数为自变量。第二层以inner_power()为代表,将args中的自变量exponent打包,进行幂的最终计算,并返回结果。结论
如果你在另一个函数中定义了一个函数,那么你就创建了一个内部函数,也称为嵌套函数。在 Python 中,内部函数可以直接访问您在封闭函数中定义的变量和名称。这为您创建助手函数、闭包和装饰器提供了一种机制。
在本教程中,您学习了如何:
- 通过在其他函数中嵌套函数来提供封装
- 编写助手函数来重用代码片段
- 实现闭包工厂函数,在调用之间保留状态
- 构建装饰函数来提供新的功能
现在,您已经准备好在自己的代码中利用内部函数的许多用途了。如果您有任何问题或意见,请务必在下面的评论区分享。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 内部函数***
如何用 Python 和 InstaPy 制作一个 Instagram Bot
SocialCaptain 、 Kicksta 、 Instavast 和其他很多公司有什么共同点?它们都有助于你在 Instagram 上接触到更多的观众,获得更多的关注者,获得更多的喜欢,而你几乎不用动一根手指。他们都是通过自动化来完成的,人们为此付给他们很多钱。但是你可以免费使用 InstaPy 做同样的事情!
在本教程中,你将学习如何用 Python 和 InstaPy 构建一个机器人,这是一个由蒂姆·格罗曼创建的库,它自动化你的 Instagram 活动,以便你用最少的手动输入获得更多的关注者和喜欢。在这一过程中,您将学习使用 Selenium 和页面对象模式实现浏览器自动化,它们共同作为 InstaPy 的基础。
在本教程中,您将学习:
- Instagram 机器人如何工作
- 如何用 Selenium 自动化浏览器
- 如何使用页面对象模式获得更好的可读性和可测试性
- 如何用 InstaPy 搭建 Instagram bot
在你创建一个 Instagram 机器人之前,你首先要学习它是如何工作的。
重要提示:在实施任何自动化或抓取技术之前,请务必查看 Instagram 的使用条款。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Instagram 机器人如何工作
一个自动化脚本如何让你获得更多的关注者和喜欢?在回答这个问题之前,先想想一个实际存在的人是如何获得更多的关注者和喜欢的。
他们通过在平台上的持续活跃来做到这一点。他们经常发帖,关注其他人,喜欢并评论其他人的帖子。机器人的工作方式完全相同:它们根据你设定的标准,在一致的基础上跟随、喜欢和评论。
你设定的标准越好,你的结果就越好。你要确保你瞄准了正确的群体,因为你的机器人在 Instagram 上互动的人更有可能与你的内容互动。
例如,如果你在 Instagram 上销售女装,那么你可以指示你的机器人喜欢、评论和关注大多数女性或其帖子包含标签如
#beauty、#fashion或#clothes的个人资料。这使得你的目标受众更有可能注意到你的个人资料,关注你,并开始与你的帖子互动。但是,它在技术方面是如何工作的呢?你不能使用 Instagram 开发者 API ,因为它在这方面相当有限。进入浏览器自动化。它的工作方式如下:
- 你给它你的凭证。
- 您可以设置关注谁、留下什么评论以及喜欢哪种类型的帖子的标准。
- 你的机器人打开浏览器,在地址栏输入
https://instagram.com,用你的凭证登录,然后开始做你指示它做的事情。接下来,您将构建 Instagram bot 的初始版本,它会自动登录到您的个人资料。请注意,您现在还不会使用 InstaPy。
如何自动化浏览器
对于这个版本的 Instagram 机器人,你将使用 Selenium ,这是 InstaPy 在引擎盖下使用的工具。
首先,装硒。在安装过程中,确保你也安装了 Firefox WebDriver ,因为最新版本的 InstaPy 放弃了对 Chrome 的支持。这也意味着你需要在电脑上安装 Firefox 浏览器。
现在,创建一个 Python 文件,并在其中编写以下代码:
1from time import sleep 2from selenium import webdriver 3 4browser = webdriver.Firefox() 5 6browser.get('https://www.instagram.com/') 7 8sleep(5) 9 10browser.close()运行代码,你会看到一个 Firefox 浏览器打开,把你导向 Instagram 登录页面。下面是代码的逐行分解:
- 1、2 号线进口
sleep和webdriver。- 第 4 行初始化火狐驱动,并设置为
browser。- 第 6 行在地址栏键入
https://www.instagram.com/,点击Enter。- 第 8 行等待五秒钟,以便您可以看到结果。否则,它会立即关闭浏览器。
- 第 10 行关闭浏览器。
这是
Hello, World的硒版。现在,您可以添加登录 Instagram 个人资料的代码了。但是首先,想想你将如何手动登录到你的个人资料。您将执行以下操作:
- 转到
https://www.instagram.com/。- 单击登录链接。
- 输入您的凭据。
- 点击登录按钮。
上面的代码已经完成了第一步。现在修改一下,让它点击 Instagram 主页上的登录链接:
1from time import sleep 2from selenium import webdriver 3 4browser = webdriver.Firefox() 5browser.implicitly_wait(5) 6 7browser.get('https://www.instagram.com/') 8 9login_link = browser.find_element_by_xpath("//a[text()='Log in']") 10login_link.click() 11 12sleep(5) 13 14browser.close()注意突出显示的行:
- 第 5 行设定五秒钟的等待时间。如果 Selenium 找不到某个元素,那么它会等待五秒钟来加载所有内容,然后再次尝试。
- 第 9 行找到文本等于
Log in的元素<a>。它使用了 XPath 来实现这个功能,但是还有一些其他的方法可以使用。- 第 10 行为登录链接点击找到的元素
<a>。运行脚本,您将看到您的脚本在运行。它会打开浏览器,进入 Instagram,点击登录链接,进入登录页面。
在登录页面上,有三个重要元素:
- 用户名输入
- 密码输入
- 登录按钮
接下来,更改脚本,使其找到这些元素,输入您的凭证,然后单击登录按钮:
1from time import sleep 2from selenium import webdriver 3 4browser = webdriver.Firefox() 5browser.implicitly_wait(5) 6 7browser.get('https://www.instagram.com/') 8 9login_link = browser.find_element_by_xpath("//a[text()='Log in']") 10login_link.click() 11 12sleep(2) 13 14username_input = browser.find_element_by_css_selector("input[name='username']") 15password_input = browser.find_element_by_css_selector("input[name='password']") 16 17username_input.send_keys("<your username>") 18password_input.send_keys("<your password>") 19 20login_button = browser.find_element_by_xpath("//button[@type='submit']") 21login_button.click() 22 23sleep(5) 24 25browser.close()以下是这些变化的详细情况:
- 第 12 行休眠两秒钟让页面加载。
- 第 14 行和第 15 行查找 CSS 输入的用户名和密码。你可以使用或者任何你喜欢的方法。
- 第 17 行和第 18 行在各自的输入框中输入你的用户名和密码。别忘了填
<your username>和<your password>!- 第 20 行通过 XPath 找到登录按钮。
- 第 21 行点击登录按钮。
运行该脚本,您将自动登录到您的 Instagram 个人资料。
你的 Instagram 机器人有了一个良好的开端。如果您继续编写这个脚本,那么其余部分看起来会非常相似。你可以通过向下滚动 feed 找到你喜欢的帖子,通过 CSS 找到 like 按钮,点击它,找到评论区,留下评论,然后继续。
好消息是,所有这些步骤都可以由 InstaPy 来处理。但是在您开始使用 InstaPy 之前,还有一件事您应该知道,以便更好地理解 Instapy 是如何工作的:页面对象模式。
如何使用页面对象模式
现在您已经编写了登录代码,您将如何为它编写一个测试呢?它看起来会像下面这样:
def test_login_page(browser): browser.get('https://www.instagram.com/accounts/login/') username_input = browser.find_element_by_css_selector("input[name='username']") password_input = browser.find_element_by_css_selector("input[name='password']") username_input.send_keys("<your username>") password_input.send_keys("<your password>") login_button = browser.find_element_by_xpath("//button[@type='submit']") login_button.click() errors = browser.find_elements_by_css_selector('#error_message') assert len(errors) == 0你能看出这段代码有什么问题吗?它不遵循干原理。也就是说,代码在应用程序和测试代码中都是重复的。
复制代码在这种情况下尤其糟糕,因为 Selenium 代码依赖于 UI 元素,而 UI 元素往往会发生变化。当它们发生变化时,您希望在一个地方更新您的代码。这就是页面对象模式的用武之地。
使用这种模式,您可以为最重要的页面或片段创建页面对象类,这些页面或片段提供易于编程的接口,并隐藏窗口中的底层 widgetry。考虑到这一点,您可以重写上面的代码并创建一个
HomePage类和一个LoginPage类:from time import sleep class LoginPage: def __init__(self, browser): self.browser = browser def login(self, username, password): username_input = self.browser.find_element_by_css_selector("input[name='username']") password_input = self.browser.find_element_by_css_selector("input[name='password']") username_input.send_keys(username) password_input.send_keys(password) login_button = browser.find_element_by_xpath("//button[@type='submit']") login_button.click() sleep(5) class HomePage: def __init__(self, browser): self.browser = browser self.browser.get('https://www.instagram.com/') def go_to_login_page(self): self.browser.find_element_by_xpath("//a[text()='Log in']").click() sleep(2) return LoginPage(self.browser)除了主页和登录页面被表示为类之外,代码是相同的。这些类封装了在 UI 中查找和操作数据所需的机制。也就是说,有方法和访问器允许软件做任何人类能做的事情。
另一件要注意的事情是,当您使用 page 对象导航到另一个页面时,它会为新页面返回一个 page 对象。注意
go_to_log_in_page()的返回值。如果你有另一个名为FeedPage的类,那么LoginPage类的login()将返回一个实例:return FeedPage()。下面是使用页面对象模式的方法:
from selenium import webdriver browser = webdriver.Firefox() browser.implicitly_wait(5) home_page = HomePage(browser) login_page = home_page.go_to_login_page() login_page.login("<your username>", "<your password>") browser.close()它看起来好多了,上面的测试现在可以重写为这样:
def test_login_page(browser): home_page = HomePage(browser) login_page = home_page.go_to_login_page() login_page.login("<your username>", "<your password>") errors = browser.find_elements_by_css_selector('#error_message') assert len(errors) == 0有了这些变化,如果 UI 中有什么变化,您将不必修改您的测试。
关于页面对象模式的更多信息,请参考官方文档和马丁·福勒的文章。
既然您已经熟悉了 Selenium 和页面对象模式,那么您将会对 InstaPy 如鱼得水。接下来,您将使用它构建一个基本的机器人。
注意:Selenium 和 Page Object 模式都广泛用于其他网站,而不仅仅是 Instagram。
如何用 InstaPy 搭建 insta gram Bot
在本节中,您将使用 InstaPy 构建一个 Instagram 机器人,它会自动喜欢、关注和评论不同的帖子。首先,您需要安装 InstaPy:
$ python3 -m pip install instapy这将在您的系统中安装
instapy。注意:最佳实践是为每个项目使用虚拟环境,这样依赖关系就被隔离了。
基本特征
现在,您可以用 InstaPy 重写上面的代码,以便比较这两个选项。首先,创建另一个 Python 文件,并将以下代码放入其中:
from instapy import InstaPy InstaPy(username="<your_username>", password="<your_password>").login()用你自己的替换用户名和密码,运行脚本,瞧!仅仅用一行代码,你就实现了同样的结果。
尽管结果相同,但您可以看到行为并不完全相同。除了简单地登录你的个人资料,InstaPy 还会做一些其他的事情,比如检查你的互联网连接和 Instagram 服务器的状态。这可以在浏览器或日志中直接观察到:
INFO [2019-12-17 22:03:19] [username] -- Connection Checklist [1/3] (Internet Connection Status) INFO [2019-12-17 22:03:20] [username] - Internet Connection Status: ok INFO [2019-12-17 22:03:20] [username] - Current IP is "17.283.46.379" and it's from "Germany/DE" INFO [2019-12-17 22:03:20] [username] -- Connection Checklist [2/3] (Instagram Server Status) INFO [2019-12-17 22:03:26] [username] - Instagram WebSite Status: Currently Up对于一行代码来说已经很不错了,不是吗?现在是时候让脚本做比登录更有趣的事情了。
出于本例的目的,假设您的个人资料都是关于汽车的,并且您的机器人打算与对汽车感兴趣的人的个人资料进行交互。
首先,你可以喜欢一些使用
like_by_tags()标记为#bmw或#mercedes的帖子:1from instapy import InstaPy 2 3session = InstaPy(username="<your_username>", password="<your_password>") 4session.login() 5session.like_by_tags(["bmw", "mercedes"], amount=5)这里,您为该方法提供了一个标签列表,以及每个标签的点赞数量。在本例中,您指示它喜欢十篇文章,两个标签各五篇。但是看看运行脚本后会发生什么:
INFO [2019-12-17 22:15:58] [username] Tag [1/2] INFO [2019-12-17 22:15:58] [username] --> b'bmw' INFO [2019-12-17 22:16:07] [username] desired amount: 14 | top posts [disabled]: 9 | possible posts: 43726739 INFO [2019-12-17 22:16:13] [username] Like# [1/14] INFO [2019-12-17 22:16:13] [username] https://www.instagram.com/p/B6MCcGcC3tU/ INFO [2019-12-17 22:16:15] [username] Image from: b'mattyproduction' INFO [2019-12-17 22:16:15] [username] Link: b'https://www.instagram.com/p/B6MCcGcC3tU/' INFO [2019-12-17 22:16:15] [username] Description: b'Mal etwas anderes \xf0\x9f\x91\x80\xe2\x98\xba\xef\xb8\x8f Bald ist das komplette Video auf YouTube zu finden (n\xc3\xa4here Infos werden folgen). Vielen Dank an @patrick_jwki @thehuthlife und @christic_ f\xc3\xbcr das bereitstellen der Autos \xf0\x9f\x94\xa5\xf0\x9f\x98\x8d#carporn#cars#tuning#bagged#bmw#m2#m2competition#focusrs#ford#mk3#e92#m3#panasonic#cinematic#gh5s#dji#roninm#adobe#videography#music#bimmer#fordperformance#night#shooting#' INFO [2019-12-17 22:16:15] [username] Location: b'K\xc3\xb6ln, Germany' INFO [2019-12-17 22:16:51] [username] --> Image Liked! INFO [2019-12-17 22:16:56] [username] --> Not commented INFO [2019-12-17 22:16:57] [username] --> Not following INFO [2019-12-17 22:16:58] [username] Like# [2/14] INFO [2019-12-17 22:16:58] [username] https://www.instagram.com/p/B6MDK1wJ-Kb/ INFO [2019-12-17 22:17:01] [username] Image from: b'davs0' INFO [2019-12-17 22:17:01] [username] Link: b'https://www.instagram.com/p/B6MDK1wJ-Kb/' INFO [2019-12-17 22:17:01] [username] Description: b'Someone said cloud? \xf0\x9f\xa4\x94\xf0\x9f\xa4\xad\xf0\x9f\x98\x88 \xe2\x80\xa2\n\xe2\x80\xa2\n\xe2\x80\xa2\n\xe2\x80\xa2\n#bmw #bmwrepost #bmwm4 #bmwm4gts #f82 #bmwmrepost #bmwmsport #bmwmperformance #bmwmpower #bmwm4cs #austinyellow #davs0 #mpower_official #bmw_world_ua #bimmerworld #bmwfans #bmwfamily #bimmers #bmwpost #ultimatedrivingmachine #bmwgang #m3f80 #m5f90 #m4f82 #bmwmafia #bmwcrew #bmwlifestyle' INFO [2019-12-17 22:17:34] [username] --> Image Liked! INFO [2019-12-17 22:17:37] [username] --> Not commented INFO [2019-12-17 22:17:38] [username] --> Not following默认情况下,除了你的
amount值,InstaPy 还会喜欢前九个热门帖子。在这种情况下,每个标签的总赞数为 14(9 个热门帖子加上您在amount中指定的 5 个)。还要注意,InstaPy 会记录它采取的每一个动作。正如你在上面看到的,它提到了它喜欢的帖子以及它的链接,描述,位置,以及机器人是否对帖子发表了评论或关注了作者。
你可能已经注意到,几乎每个动作之后都有延迟。那是故意的。它可以防止你的个人资料在 Instagram 上被封禁。
现在,你可能不希望你的机器人喜欢不合适的帖子。为了防止这种情况发生,您可以使用
set_dont_like():from instapy import InstaPy session = InstaPy(username="<your_username>", password="<your_password>") session.login() session.like_by_tags(["bmw", "mercedes"], amount=5) session.set_dont_like(["naked", "nsfw"])随着这一改变,描述中带有
naked或nsfw字样的帖子将不会被喜欢。你可以标记任何你希望你的机器人避免使用的单词。接下来,你可以告诉机器人不仅要喜欢这些帖子,还要关注这些帖子的作者。你可以用
set_do_follow()来做:from instapy import InstaPy session = InstaPy(username="<your_username>", password="<your_password>") session.login() session.like_by_tags(["bmw", "mercedes"], amount=5) session.set_dont_like(["naked", "nsfw"]) session.set_do_follow(True, percentage=50)如果你现在运行这个脚本,那么这个机器人将会关注 50%的用户,他们的帖子是它喜欢的。像往常一样,每个动作都会被记录。
也可以在帖子上留下一些评论。你需要做两件事。首先,用
set_do_comment()启用注释:from instapy import InstaPy session = InstaPy(username="<your_username>", password="<your_password>") session.login() session.like_by_tags(["bmw", "mercedes"], amount=5) session.set_dont_like(["naked", "nsfw"]) session.set_do_follow(True, percentage=50) session.set_do_comment(True, percentage=50)接下来,告诉机器人给
set_comments()留下什么评论:from instapy import InstaPy session = InstaPy(username="<your_username>", password="<your_password>") session.login() session.like_by_tags(["bmw", "mercedes"], amount=5) session.set_dont_like(["naked", "nsfw"]) session.set_do_follow(True, percentage=50) session.set_do_comment(True, percentage=50) session.set_comments(["Nice!", "Sweet!", "Beautiful :heart_eyes:"])运行这个脚本,机器人会在它交互的一半帖子上留下这三条评论中的一条。
现在您已经完成了基本设置,最好用
end()结束会话:from instapy import InstaPy session = InstaPy(username="<your_username>", password="<your_password>") session.login() session.like_by_tags(["bmw", "mercedes"], amount=5) session.set_dont_like(["naked", "nsfw"]) session.set_do_follow(True, percentage=50) session.set_do_comment(True, percentage=50) session.set_comments(["Nice!", "Sweet!", "Beautiful :heart_eyes:"]) session.end()这将关闭浏览器,保存日志,并准备一份您可以在控制台输出中看到的报告。
InstaPy 中的附加功能
InstaPy 是一个相当大的项目,有很多完整记录的特性。好消息是,如果您对上面使用的特性感到满意,那么其余的应该感觉非常相似。本节将概述 InstaPy 的一些更有用的功能。
定额主管
你不能整天刮 Instagram,天天刮。该服务将很快注意到你正在运行一个机器人,并将禁止它的一些行动。这就是为什么对你的机器人的一些行为设置限额是个好主意。以下面的例子为例:
session.set_quota_supervisor(enabled=True, peak_comments_daily=240, peak_comments_hourly=21)该机器人将继续评论,直到它达到每小时和每天的限制。配额期过后,它将恢复评论。
无头浏览器
该特性允许您在没有浏览器 GUI 的情况下运行 bot。如果你想把你的机器人部署到一个没有或者不需要图形界面的服务器上,这是非常有用的。它对 CPU 的占用也更少,因此可以提高性能。你可以这样使用它:
session = InstaPy(username='test', password='test', headless_browser=True)请注意,您在初始化
InstaPy对象时设置了该标志。利用人工智能分析帖子
前面你已经看到了如何忽略描述中包含不恰当词语的帖子。描述的很好但是图像本身不合适怎么办?您可以将 InstaPy bot 与提供图像和视频识别服务的 ClarifAI 集成在一起:
session.set_use_clarifai(enabled=True, api_key='<your_api_key>') session.clarifai_check_img_for(['nsfw'])现在你的机器人不会喜欢或评论任何 ClarifAI 认为 NSFW 的图像。你每月可以获得 5000 次免费的 API 调用。
关系界限
有很多粉丝的人跟帖子互动往往是浪费时间。在这种情况下,设置一些关系界限是个好主意,这样你的机器人就不会浪费你宝贵的计算资源:
session.set_relationship_bounds(enabled=True, max_followers=8500)这样,你的机器人就不会与拥有超过 8500 名粉丝的用户的帖子进行互动。
关于 InstaPy 的更多功能和配置,请查看文档。
结论
InstaPy 让你可以毫不费力地自动化你的 Instagram 活动。这是一个非常灵活的工具,有很多有用的功能。
在本教程中,您学习了:
- Instagram 机器人如何工作
- 如何用 Selenium 自动化浏览器
- 如何使用页面对象模式使你的代码更易维护和测试
- 如何使用 InstaPy 构建一个基本的 Instagram bot
阅读 InstaPy 文档并对你的机器人进行一点点试验。很快你就会开始用最少的努力获得新的关注者和喜欢。在写这篇教程的时候,我自己也获得了一些新的追随者。如果你更喜欢视频教程,还有一个由 InstaPy 的创建者 Tim gro Mann提供的 Udemy 课程。
您还可以探索聊天机器人、 Tweepy 、 Discord 和 Alexa Skills 的可能性,以了解如何使用 Python 为不同平台制作机器人。
如果你有什么想问或分享的,请在下面的评论中提出。****
如何编写可安装的 Django 应用程序
在 Django 框架中,项目指的是特定网站的配置文件和代码的集合。Django 将业务逻辑分组到它所谓的应用中,这些应用是 Django 框架的模块。有很多关于如何构建项目和其中的应用程序的文档,但是当要打包一个可安装的 Django 应用程序时,信息就很难找到了。
在本教程中,你将学习如何从 Django 项目中取出一个应用程序并打包,使其可安装。一旦你打包了你的应用,你就可以在 PyPI 上分享它,这样其他人就可以通过
pip install获取它。在本教程中,您将学习:
- 编写独立应用和在项目中编写应用有什么区别
- 如何创建一个
setup.cfg文件来发布你的 Django 应用- 如何在 Django 项目之外引导 Django ,以便测试你的应用
- 如何使用
tox跨多个版本的 Python 和 Django 进行测试- 如何使用 Twine 将可安装的 Django 应用程序发布到 PyPI
请务必通过以下链接下载源代码来了解示例:
下载示例代码: 单击此处获取代码,您将使用在本教程中学习如何编写可安装的 Django 应用程序。
先决条件
本教程要求对 Django 、
pip、 PyPI 、pyenv(或者一个等效的虚拟环境工具)和tox有所熟悉。要了解有关这些主题的更多信息,请访问:在项目中启动一个示例 Django 应用程序
本教程包括一个工作包,帮助你完成制作一个可安装的 Django 应用程序的过程。您可以从下面的链接下载源代码:
下载示例代码: 单击此处获取代码,您将使用在本教程中学习如何编写可安装的 Django 应用程序。
即使你最初打算把你的 Django 应用作为一个包提供,你也可能从一个项目开始。为了演示从 Django 项目到可安装的 Django 应用程序的过程,我在 repo 中提供了两个分支。项目分支是 Django 项目中一个应用的开始状态。主分支就是完成的可安装 app。
你也可以在PyPI real python-django-receipts package 页面下载完成的 app。你可以通过运行
pip install realpython-django-receipts来安装包。示例应用程序是收据上的行项目的简短表示。在项目分支中,您会发现一个名为
sample_project的目录,其中包含一个正在运行的 Django 项目。该目录如下所示:sample_project/ │ ├── receipts/ │ ├── fixtures/ │ │ └── receipts.json │ │ │ ├── migrations/ │ │ ├── 0001_initial.py │ │ └── __init__.py │ │ │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py │ ├── sample_project/ │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ ├── db.sqlite3 ├── manage.py ├── resetdb.sh └── runserver.sh撰写本教程时,Django 的最新版本是 3.0.4,所有测试都是用 Python 3.7 完成的。本教程中概述的所有步骤都不应该与 Django 的早期版本不兼容——我从 Django 1.8 就开始使用这些技术了。但是,如果您使用 Python 2,一些更改是必要的。为了让例子简单,我假设代码库都是 Python 3.7。
从头开始创建 Django 项目
示例项目和收据应用程序是使用 Django
admin命令和一些小的编辑创建的。首先,在干净的虚拟环境中运行以下代码:$ python -m pip install Django $ django-admin startproject sample_project $ cd sample_project $ ./manage.py startapp receipts这将创建一个
sample_project项目目录结构和一个receiptsapp 子目录,其中包含用于创建可安装 Django 应用程序的模板文件。接下来,
sample_project/settings.py文件需要一些修改:
- 将
'127.0.0.1'添加到ALLOWED_HOSTS设置中,这样您就可以进行本地测试。- 将
'receipts'添加到INSTALLED_APPS列表中。您还需要在
sample_project/urls.py文件中注册receipts应用程序的 URL。为此,将path('receipts/', include('receipts.urls'))添加到url_patterns列表中。探索收据示例应用程序
app 由两个 ORM 模型类组成:
Item和Receipt。Item类包含描述和成本的数据库字段声明。成本包含在DecimalField中。使用浮点数来表示货币是危险的——在处理货币时,你应该总是使用定点数。
Receipt类是Item对象的收集点。这是通过指向Receipt的Item上的ForeignKey实现的。Receipt还包括total(),用于获取Receipt中包含的Item对象的总成本:# receipts/models.py from decimal import Decimal from django.db import models class Receipt(models.Model): created = models.DateTimeField(auto_now_add=True) def __str__(self): return f"Receipt(id={self.id})" def total(self) -> Decimal: return sum(item.cost for item in self.item_set.all()) class Item(models.Model): created = models.DateTimeField(auto_now_add=True) description = models.TextField() cost = models.DecimalField(max_digits=7, decimal_places=2) receipt = models.ForeignKey(Receipt, on_delete=models.CASCADE) def __str__(self): return f"Item(id={self.id}, description={self.description}, " \ f"cost={self.cost})"模型对象为您提供了数据库的内容。一个简短的 Django 视图返回一个 JSON 字典,其中包含数据库中的所有
Receipt对象及其Item对象:# receipts/views.py from django.http import JsonResponse from receipts.models import Receipt def receipt_json(request): results = { "receipts":[], } for receipt in Receipt.objects.all(): line = [str(receipt), []] for item in receipt.item_set.all(): line[1].append(str(item)) results["receipts"].append(line) return JsonResponse(results)
receipt_json()视图遍历所有的Receipt对象,创建一对Receipt对象和一个包含在其中的Item对象列表。所有这些都被放入字典,并通过 Django 的JsonResponse()返回。为了使模型在 Django 管理界面中可用,您使用一个
admin.py文件来注册模型:# receipts/admin.py from django.contrib import admin from receipts.models import Receipt, Item @admin.register(Receipt) class ReceiptAdmin(admin.ModelAdmin): pass @admin.register(Item) class ItemAdmin(admin.ModelAdmin): pass这段代码为每个
Receipt和Item类创建一个 DjangoModelAdmin,并向 Django admin 注册它们。最后,一个
urls.py文件根据一个 URL 在应用程序中注册了一个视图:# receipts/urls.py from django.urls import path from receipts import views urlpatterns = [ path("receipt_json/", views.receipt_json), ]现在,您可以将
receipts/urls.py包含在项目的url.py文件中,使收据视图在您的网站上可用。一切就绪后,您可以运行
./manage.py makemigrations receipts,使用 Django admin 添加数据,然后访问/receipts/receipt_json/查看结果:$ curl -sS http://127.0.0.1:8000/receipts/receipt_json/ | python3.8 -m json.tool { "receipts": [ [ "Receipt(id=1)", [ "Item(id=1, description=wine, cost=15.25)", "Item(id=2, description=pasta, cost=22.30)" ] ], [ "Receipt(id=2)", [ "Item(id=3, description=beer, cost=8.50)", "Item(id=4, description=pizza, cost=12.80)" ] ] ] }在上面的块中,您使用
curl来访问receipt_json视图,得到一个包含Receipt对象及其对应的Item对象的 JSON 响应。测试项目中的应用程序
Django 用自己的测试功能增强了 Python
unittest包,使您能够将夹具预加载到数据库中并运行您的测试。receipts 应用程序定义了一个tests.py文件和一个用于测试的夹具。这个测试并不全面,但它是一个足够好的概念证明:# receipts/tests.py from decimal import Decimal from django.test import TestCase from receipts.models import Receipt class ReceiptTest(TestCase): fixtures = ["receipts.json", ] def test_receipt(self): receipt = Receipt.objects.get(id=1) total = receipt.total() expected = Decimal("37.55") self.assertEqual(expected, total)夹具创建两个
Receipt对象和四个相应的Item对象。点击下面的可折叠部分,仔细查看夹具的代码。Django 测试夹具是数据库中对象的序列化。下面的 JSON 代码创建了用于测试的
Receipt和Item对象:[ { "model": "receipts.receipt", "pk": 1, "fields": { "created": "2020-03-24T18:16:39.102Z" } }, { "model": "receipts.receipt", "pk": 2, "fields": { "created": "2020-03-24T18:16:41.005Z" } }, { "model": "receipts.item", "pk": 1, "fields": { "created": "2020-03-24T18:16:59.357Z", "description": "wine", "cost": "15.25", "receipt": 1 } }, { "model": "receipts.item", "pk": 2, "fields": { "created": "2020-03-24T18:17:25.548Z", "description": "pasta", "cost": "22.30", "receipt": 1 } }, { "model": "receipts.item", "pk": 3, "fields": { "created": "2020-03-24T18:19:37.359Z", "description": "beer", "cost": "8.50", "receipt": 2 } }, { "model": "receipts.item", "pk": 4, "fields": { "created": "2020-03-24T18:19:51.475Z", "description": "pizza", "cost": "12.80", "receipt": 2 } } ]上面的 fixture 在
ReceiptTestCase类中被引用,并由 Django 测试工具自动加载。您可以使用 Django
manage.py命令测试 receipts 应用程序:$ ./manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). . ---------------------------------------------------------------------- Ran 1 test in 0.013s OK Destroying test database for alias 'default'...运行
manage.py test运行receipts/tests.py中定义的单一测试并显示结果。制作可安装的 Django 应用程序
您的目标是在没有项目的情况下共享 receipts 应用程序,并让其他人可以重复使用它。您可以压缩
receipts/目录并分发出去,但这多少有些限制。相反,你想把应用程序分离成一个包,这样它就可以安装了。创建可安装的 Django 应用程序的最大挑战是 Django 需要一个项目。没有项目的 app 只是一个包含代码的目录。没有项目,Django 不知道如何处理你的代码,包括运行测试。
将 Django 应用程序移出项目
保留一个示例项目是个好主意,这样您就可以运行 Django dev 服务器并使用您的应用程序的实时版本。您不会将这个示例项目包含在应用程序包中,但是它仍然可以存在于您的存储库中。按照这个想法,您可以开始打包您的可安装 Django 应用程序,方法是将它移到一个目录中:
$ mv receipts ..目录结构现在看起来像这样:
django-receipts/ │ ├── receipts/ │ ├── fixtures/ │ │ └── receipts.json │ │ │ ├── migrations/ │ │ ├── 0001_initial.py │ │ └── __init__.py │ │ │ ├── __init__.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ ├── views.py │ ├── admin.py │ └── apps.py │ ├── sample_project/ │ ├── sample_project/ │ │ ├── __init__.py │ │ ├── asgi.py │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ │ │ ├── db.sqlite3 │ ├── manage.py │ ├── resetdb.sh │ └── runserver.sh │ ├── LICENSE └── README.rst要打包您的应用程序,您需要将其从项目中取出。移动它是第一步。我通常会保留原始项目进行测试,但不会将它包含在最终的包中。
在项目外引导 Django
现在你的应用程序在 Django 项目之外,你需要告诉 Django 如何找到它。如果你想测试你的应用,那么运行一个 Django shell,它可以找到你的应用或者运行你的迁移。您需要配置 Django 并使其可用。
Django 的
settings.configure()和django.setup()是在项目之外与你的应用程序交互的关键。Django 文档中提供了关于这些调用的更多信息。您可能在几个地方需要 Django 的这种配置,所以在函数中定义它是有意义的。创建一个名为
boot_django.py的文件,包含以下代码:1# boot_django.py 2# 3# This file sets up and configures Django. It's used by scripts that need to 4# execute as if running in a Django server. 5import os 6import django 7from django.conf import settings 8 9BASE_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), "receipts")) 10 11def boot_django(): 12 settings.configure( 13 BASE_DIR=BASE_DIR, 14 DEBUG=True, 15 DATABASES={ 16 "default":{ 17 "ENGINE":"django.db.backends.sqlite3", 18 "NAME": os.path.join(BASE_DIR, "db.sqlite3"), 19 } 20 }, 21 INSTALLED_APPS=( 22 "receipts", 23 ), 24 TIME_ZONE="UTC", 25 USE_TZ=True, 26 ) 27 django.setup()12 号线和 27 号线设置 Django 环境。
settings.configure()调用接受一个参数列表,这些参数等同于在settings.py文件中定义的变量。你在settings.py中运行应用程序所需的任何东西都会被传递到settings.configure()中。上面的代码是一个相当精简的配置。receipts 应用不对会话或模板做任何事情,所以
INSTALLED_APPS只需要"receipts",并且您可以跳过任何中间件定义。USE_TZ=True值是必需的,因为Receipt模型包含一个created时间戳。否则,您会在加载测试夹具时遇到问题。使用可安装的 Django 应用程序运行管理命令
现在您已经有了
boot_django.py,您可以用一个非常短的脚本运行任何 Django 管理命令:#!/usr/bin/env python # makemigrations.py from django.core.management import call_command from boot_django import boot_django boot_django() call_command("makemigrations", "receipts")Django 允许您通过
call_command()以编程方式调用管理命令。您现在可以通过导入并调用boot_django()然后调用call_command()来运行任何管理命令。你的应用现在在项目之外,允许你对它做各种 Django-y 的事情。我经常定义四个实用程序脚本:
load_tests.py测试你的 appmakemigrations.py创建迁移文件migrate.py执行表迁移djangoshell.py生成一个 Django shell,它可以感知你的应用测试可安装的 Django 应用程序
load_test.py文件可以像makemigrations.py脚本一样简单,但是它只能同时运行所有的测试。通过几行额外的代码,您可以将命令行参数传递给测试运行程序,允许您运行选择性测试:1#!/usr/bin/env python 2# load_tests.py 3import sys 4from unittest import TestSuite 5from boot_django import boot_django 6 7boot_django() 8 9default_labels = ["receipts.tests", ] 10 11def get_suite(labels=default_labels): 12 from django.test.runner import DiscoverRunner 13 runner = DiscoverRunner(verbosity=1) 14 failures = runner.run_tests(labels) 15 if failures: 16 sys.exit(failures) 17 18 # In case this is called from setuptools, return a test suite 19 return TestSuite() 20 21if __name__ == "__main__": 22 labels = default_labels 23 if len(sys.argv[1:]) > 0: 24 labels = sys.argv[1:] 25 26 get_suite(labels)Django 的
DiscoverRunner是与 Python 的unittest兼容的测试发现类。它负责建立测试环境,构建测试套件,建立数据库,运行测试,然后全部拆除。从第 11 行开始,get_suite()取一个测试标签列表,直接调用标签上的DiscoverRunner。这个脚本类似于 Django 管理命令
test的功能。__main__块将任何命令行参数传递给get_suite(),如果没有,则传递给应用程序的测试套件receipts.tests。您现在可以使用测试标签参数调用load_tests.py,并运行一个单独的测试。第 19 行是一个特例,有助于用
tox进行测试。在稍后的章节中,您将了解更多关于tox的内容。你也可以在下面的可折叠部分找到DiscoverRunner的潜在替代品。我写的一个可安装的 Django 应用是 django-awl 。这是我多年来编写 Django 项目时积累的一个松散的实用程序集合。软件包中包含了一个名为
WRunner的DiscoverRunner的替代品。使用
WRunner的关键优势是它支持测试标签的通配符匹配。传入一个以等号(=)开头的标签将匹配任何包含该标签作为子串的测试套件或方法名称。例如,标签=rec将匹配并在receipt/tests.py运行测试ReceiptTest.test_receipt()。用
setup.cfg定义你的可安装包要将可安装的 Django 应用程序放在 PyPI 上,首先需要将其放在一个包中。PyPI 期望一个
egg,wheel,或者源分布。这些都是用setuptools建造的。为此,您需要在与您的receipts目录相同的目录级别创建一个setup.cfg文件和一个setup.py文件。不过,在深入研究之前,您需要确保您有一些文档。您可以在
setup.cfg中包含一个项目描述,它会自动显示在 PyPI 项目页面上。一定要写一个README.rst或类似的关于你的包裹的信息。PyPI 默认支持 reStructuredText 格式,但是它也可以使用额外参数处理降价:
1# setup.cfg 2[metadata] 3name = realpython-django-receipts 4version = 1.0.3 5description = Sample installable django app 6long_description = file:README.rst 7url = https://github.com/realpython/django-receipts 8license = MIT 9classifiers = 10 Development Status :: 4 - Beta 11 Environment :: Web Environment 12 Intended Audience :: Developers 13 License :: OSI Approved :: MIT License 14 Operating System :: OS Independent 15 Programming Language :: Python :: 3 :: Only 16 Programming Language :: Python :: 3.7 17 Programming Language :: Python :: Implementation :: CPython 18 Topic :: Software Development :: Libraries :: Application Frameworks 19 Topic :: Software Development :: Libraries :: Python Modules 20 21[options] 22include_package_data = true 23python_requires = >=3.6 24setup_requires = 25 setuptools >= 38.3.0 26install_requires = 27 Django>=2.2这个
setup.cfg文件描述了您将要构建的包。第 6 行使用file:指令读入你的README.rst文件。这样你就不用在两个地方写很长的描述了。第 26 行上的
install_requires条目告诉任何安装者,比如pip install,关于你的应用程序的依赖关系。您总是希望将您的可安装 Django 应用程序绑定到其最低支持版本的 Django 上。如果您的代码有任何只需要运行测试的依赖项,那么您可以添加一个
tests_require =条目。例如,在mock成为标准 Python 库的一部分之前,在setup.cfg中看到tests_require = mock>=2.0.0是很常见的。在包中包含一个
pyproject.toml文件被认为是最佳实践。Brett Cannon 的关于这个主题的优秀文章可以带你浏览细节。示例代码中还包含一个pyproject.toml文件。您几乎已经准备好为您的可安装 Django 应用程序构建包了。测试它最简单的方法是使用您的示例项目——这是保留一个示例项目的另一个好理由。
pip install命令支持本地定义的包。这可用于确保您的应用程序仍可用于项目。然而,有一点需要注意的是,在这种情况下,setup.cfg不会自己工作。你还必须创建一个setup.py的填充版本:#!/usr/bin/env python if __name__ == "__main__": import setuptools setuptools.setup()这个脚本将自动使用您的
setup.cfg文件。你现在可以安装一个本地可编辑的版本的包来从sample_project内部测试它。为了更加确定,最好从一个全新的虚拟环境开始。在sample_project目录中添加以下requirements.txt文件:# requirements.txt -e ../../django-receipts
-e告诉pip这是一个本地可编辑的安装。您现在可以安装:$ pip install -r requirements.txt Obtaining django-receipts (from -r requirements.txt (line 1)) Collecting Django>=3.0 Using cached Django-3.0.4-py3-none-any.whl (7.5 MB) Collecting asgiref~=3.2 Using cached asgiref-3.2.7-py2.py3-none-any.whl (19 kB) Collecting pytz Using cached pytz-2019.3-py2.py3-none-any.whl (509 kB) Collecting sqlparse>=0.2.2 Using cached sqlparse-0.3.1-py2.py3-none-any.whl (40 kB) Installing collected packages: asgiref, pytz, sqlparse, Django, realpython-django-receipts Running setup.py develop for realpython-django-receipts Successfully installed Django-3.0.4 asgiref-3.2.7 pytz-2019.3 realpython-django-receipts sqlparse-0.3.1
setup.cfg中的install_requires列表告诉pip install它需要 Django。姜戈需要asgiref、pytz和sqlparse。所有的依赖关系都已经处理好了,现在您应该能够运行您的sample_projectDjango dev 服务器了。恭喜您,您的应用程序现在已经打包并在示例项目中引用了!用
tox测试多个版本Django 和 Python 都在不断前进。如果你要与世界分享你的可安装 Django 应用,那么你可能需要在多种环境下进行测试。这个工具需要一点帮助来测试你的 Django 应用。继续在
setup.cfg中进行以下更改:1# setup.cfg 2[metadata] 3name = realpython-django-receipts 4version = 1.0.3 5description = Sample installable django app 6long_description = file:README.rst 7url = https://github.com/realpython/django-receipts 8license = MIT 9classifiers = 10 Development Status :: 4 - Beta 11 Environment :: Web Environment 12 Intended Audience :: Developers 13 License :: OSI Approved :: MIT License 14 Operating System :: OS Independent 15 Programming Language :: Python :: 3 :: Only 16 Programming Language :: Python :: 3.7 17 Programming Language :: Python :: Implementation :: CPython 18 Topic :: Software Development :: Libraries :: Application Frameworks 19 Topic :: Software Development :: Libraries :: Python Modules 20 21[options] 22include_package_data = true 23python_requires = >=3.6 24setup_requires = 25 setuptools >= 38.3.0 26install_requires = 27 Django>=2.2 28test_suite = load_tests.get_suite第 28 行告诉包管理器使用
load_tests.py脚本来获得它的测试套件。tox实用程序使用它来运行它的测试。回忆load_tests.py中的get_suite():1# Defined inside load_tests.py 2def get_suite(labels=default_labels): 3 from django.test.runner import DiscoverRunner 4 runner = DiscoverRunner(verbosity=1) 5 failures = runner.run_tests(labels) 6 if failures: 7 sys.exit(failures) 8 9 # If this is called from setuptools, then return a test suite 10 return TestSuite()这里发生的事情确实有点奇怪。通常情况下,
setup.cfg中的test_suite字段指向一个返回一组测试的方法。当tox调用setup.py时,它读取test_suite参数并运行load_tests.get_suite()。如果这个调用没有返回一个
TestSuite对象,那么tox就会抱怨。奇怪的是,你实际上并不希望tox得到一套测试,因为tox并不知道 Django 测试环境。相反,get_suite()创建一个DiscoverRunner并在第 10 行返回一个空的TestSuite对象。您不能简单地让
DiscoverRunner返回一组测试,因为您必须调用DiscoverRunner.run_tests()来正确执行 Django 测试环境的设置和拆卸。仅仅将正确的测试传递给tox是行不通的,因为数据库不会被创建。get_suite()运行所有的测试,但是作为函数调用的副作用,而不是作为返回测试套件给tox执行的正常情况。
tox工具允许您测试多种组合。一个tox.ini文件决定测试哪些环境组合。这里有一个例子:[tox] envlist = py{36,37}-django220, py{36,37}-django300 [testenv] deps = django220: Django>=2.2,<3 django300: Django>=3 commands= python setup.py test该文件声明应该结合 Django 2.2 和 3.0 运行 Python 3.6 和 3.7 的测试。总共有四个测试环境。
commands=部分是你告诉tox通过setup.py调用测试的地方。这就是你在setup.cfg中调用test_suite = load_tests.get_suite钩子的方法。注:
setup.py的test子命令已被弃用。Python 中的打包目前变化很快。虽然一般不建议打电话给python setup.py test,但是在这种特定的情况下,打电话是可行的。发布到 PyPI
最后,是时候在 PyPI 上分享你的可安装 Django 应用了。上传包有多种工具,但在本教程中,您将重点关注 Twine 。以下代码构建包并调用 Twine:
$ python -m pip install -U wheel twine setuptools $ python setup.py sdist $ python setup.py bdist_wheel $ twine upload dist/*前两个命令构建包的源代码和二进制发行版。对
twine的调用上传到 PyPI。如果您的主目录中有一个.pypirc文件,那么您可以预设您的用户名,这样唯一提示您的就是您的密码:[disutils] index-servers = pypi [pypi] username: <YOUR_USERNAME>我经常用一个小的 shell 脚本从代码中
grep出版本号。然后我调用git tag用版本号标记 repo,删除旧的build/和dist/目录,调用上面三个命令。关于使用 Twine 的更多细节,请参见如何将开源 Python 包发布到 PyPI 。Twine 的两个流行替代品是诗歌和 Flit 。Python 中的包管理变化很快。PEP 517 和 PEP 518 正在重新定义如何描述 Python 包和依赖关系。
结论
Django 应用程序依赖于 Django 项目结构,因此单独打包它们需要额外的步骤。您已经看到了如何通过从项目中提取、打包并在 PyPI 上共享来制作可安装的 Django 应用程序。请务必从以下链接下载示例代码:
下载示例代码: 单击此处获取代码,您将使用在本教程中学习如何编写可安装的 Django 应用程序。
在本教程中,您已经学会了如何:
- 在项目之外使用 Django 框架
- 在独立于项目的应用上调用 Django 管理命令
- 编写一个调用 Django 测试的脚本,可选地使用一个测试标签
- 构建一个
setup.py文件来定义你的包- 修改
setup.py脚本以适应tox- 使用 Twine 上传你的可安装 Django 应用
你已经准备好与全世界分享你的下一款应用了。编码快乐!
延伸阅读
Django、打包和测试都是非常深入的话题。外面有很多信息。要深入了解,请查看以下资源:
- Django 文档
- Django 入门:构建投资组合应用
- Django 教程
- 使用 pyenv 管理多个 Python 版本
- pip 是什么?新蟒蛇指南
- 如何将开源 Python 包发布到 PyPi
- Python 测试入门
- 诗歌
- 掠过
PyPI 有大量值得一试的可安装 Django 应用。以下是一些最受欢迎的:
- 姜戈-CSP
- Django reCAPTCHA
- 姜戈-阿劳斯
- 草堆
- 响应式 Django 管理员
- Django 调试工具栏*****
Python 3 安装和设置指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 基础知识:设置 Python
在电脑上安装或更新 Python 是成为 Python 程序员的第一步。有多种安装方法:你可以从 Python.org 下载官方的 Python 发行版,从包管理器安装,甚至为科学计算、物联网和嵌入式系统安装专门的发行版。
本教程主要关注官方发行版,因为它们通常是开始学习 Python 编程的最佳选择。
在本教程中,你将学习如何:
- 检查您的机器上安装了哪个版本的 Python
- 在 Windows 、 macOS 和 Linux 上安装或更新 Python
- 在手机或平板电脑等移动设备上使用 Python
- 通过在线解释器在网络上使用 Python
无论你在什么操作系统上,本教程都涵盖了你。在下面找到您的操作系统,然后开始学习吧!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
如何在 Windows 上安装 Python
Windows 上有三种安装方法:
- 微软商店
- 完整安装程序
- 用于 Linux 的 Windows 子系统
在本节中,您将了解如何检查您的 Windows 计算机上安装了哪个版本的 Python(如果有的话)。您还将了解应该使用三种安装方法中的哪一种。要获得更全面的指南,请查看您在 Windows 上的 Python 编码环境:设置指南。
如何在 Windows 上检查你的 Python 版本
要检查您的 Windows 机器上是否已经安装了 Python,首先打开一个命令行应用程序,比如 PowerShell。
提示:以下是打开 PowerShell 的方法:
- 按下
Win键。- 类型
PowerShell。- 按下
Enter。或者,您可以右键单击开始按钮,选择 Windows PowerShell 或 Windows PowerShell(管理)。
也可以使用
cmd.exe或 Windows 终端。在命令行打开的情况下,键入以下命令并按下
Enter:C:\> python --version Python 3.8.4使用
--version开关将显示已安装的版本。或者,您可以使用-V开关:C:\> python -V Python 3.8.4在这两种情况下,如果您看到一个低于
3.8.4的版本,这是撰写本文时的最新版本,那么您将需要升级您的安装。注意:如果您的系统上没有 Python 版本,那么上述两个命令将启动 Microsoft Store,并将您重定向到 Python 应用程序页面。在下一节中,您将看到如何从 Microsoft Store 完成安装。
如果您对安装的位置感兴趣,那么您可以使用
cmd.exe或 PowerShell 中的where.exe命令:C:\> where.exe python C:\Users\mertz\AppData\Local\Programs\Python\Python37-32\python.exe请注意,只有为您的用户帐户安装了 Python 之后,
where.exe命令才会起作用。你有什么选择
如前所述,在 Windows 上安装官方 Python 发行版有三种方式:
Microsoft Store 软件包:Windows 上最简单的安装方法是从 Microsoft Store 应用程序安装。这是推荐给初学 Python 的用户的,他们正在寻找一种易于设置的交互体验。
完整安装:这种方法包括直接从 Python.org网站下载 Python。对于在安装过程中需要更多控制的中级和高级开发人员,建议这样做。
Linux 的 Windows 子系统(WSL):WSL 允许您直接在 Windows 中运行 Linux 环境。通过阅读Windows 10的 Windows 子系统 for Linux 安装指南,可以了解如何启用 WSL。
在本节中,我们将只关注前两个选项,它们是 Windows 环境中最流行的安装方法。
如果你想在 WSL 中安装,那么在你安装了你选择的 Linux 发行版之后,你可以阅读本教程的第节。
注意:你也可以使用其他发行版在 Windows 上完成安装,比如 Anaconda ,但是本教程只涵盖官方发行版。
Anaconda 是一个用 Python 进行科学计算和数据科学的流行平台。要了解如何在 Windows 上安装 Anaconda,请查看在 Windows 上为机器学习设置 Python。
Windows 的两个官方 Python 安装程序并不相同。Microsoft Store 包有一些重要的限制。
微软商店包的局限性
官方 Python 文档是这样描述微软商店包的:
Microsoft Store 包是一个易于安装的 Python 解释器,主要供交互式使用,例如,供学生使用。(来源)
这里关键的一点是微软商店包“主要用于交互使用”也就是说,Microsoft Store 包是为学生和第一次学习使用 Python 的人设计的。
除了面向初级 Pythonistas 之外,Microsoft Store 包还有一些限制,使其不适合专业开发环境。特别是,它没有对共享位置如
TEMP或注册表的完全写访问权。Windows 安装程序建议
如果您是 Python 的新手,并且主要关注于学习语言而不是构建专业软件,那么您应该从 Microsoft Store 包中安装。这提供了最短和最简单的途径,以最少的麻烦开始。
另一方面,如果你是一个有经验的开发者,想在 Windows 环境下开发专业软件,那么官方的 Python.org 安装程序是正确的选择。您的安装将不会受到微软商店政策的限制,您可以控制可执行文件的安装位置,甚至在必要时将 Python 添加到
PATH。如何从微软商店安装
如果您是 Python 的新手,并且希望快速入门,那么 Microsoft Store 包是轻松入门的最佳方式。您可以分两步从 Microsoft Store 安装。
第一步:在微软商店打开 Python 应用页面
打开微软商店应用,搜索
Python。您可能会看到可以选择安装的多个版本:
选择 Python 3.8 ,或者你在应用中看到的最高版本号,打开安装页面。
警告:确保您选择的 Python 应用程序是由 Python 软件基金会创建的。
微软官方商店的软件包将永远是免费的,所以如果应用程序需要花钱,那么它就是错误的应用程序。
或者,您可以打开 PowerShell 并键入以下命令:
C:\> python如果您的系统上还没有 Python 的版本,那么当您按下
Enter时,微软商店将自动启动并带您进入商店中最新版本的 Python。第二步:安装 Python 应用
选择要安装的版本后,按照以下步骤完成安装:
点击获取。
等待应用程序下载。下载完成后,获取按钮将被一个显示在我的设备上安装的按钮取代。
点击在我的设备上安装并选择您想要完成安装的设备。
点击立即安装,然后点击确定开始安装。
如果安装成功,您将在 Microsoft Store 页面的顶部看到消息“此产品已安装”。
恭喜你!你现在已经可以接触到 Python 了,包括
pip和闲!如何从完整安装程序安装
对于需要全功能 Python 开发环境的专业开发人员来说,从完整安装程序安装是正确的选择。与从 Microsoft 商店安装相比,它提供了更多的自定义和对安装的控制。
您可以分两步从完整安装程序进行安装。
步骤 1:下载完整的安装程序
按照以下步骤下载完整的安装程序:
打开浏览器窗口,导航至 Windows 的 Python.org下载页面。
在“Python Releases for Windows”标题下,单击最新 Python 3 版本- Python 3.x.x 的链接。在撰写本文时,最新版本是 Python 3.8.4。
滚动到底部,选择 64 位的 Windows x86-64 可执行安装程序或 32 位的 Windows x86 可执行安装程序。
如果您不确定是选择 32 位还是 64 位安装程序,那么您可以展开下面的框来帮助您做出决定。
对于 Windows,您可以选择 32 位或 64 位安装程序。这两者的区别如下:
如果您的系统有 32 位处理器,那么您应该选择 32 位安装程序。如果您试图在 32 位处理器上安装 64 位版本,那么您将在开始时得到一个错误,并且安装将失败。
在 64 位系统上,这两种安装程序都可以满足大多数用途。32 位版本通常使用较少的内存,但 64 位版本对于计算密集型应用程序来说性能更好。
如果您不确定选择哪个版本,请选择 64 位版本。
如果你有一个 64 位系统,想从 64 位 Python 切换到 32 位(反之亦然),那么你可以卸载 Python,然后通过从Python.org下载另一个安装程序来重新安装。
安装程序下载完成后,继续下一步。
第二步:运行安装程序
一旦你选择并下载了一个安装程序,双击下载的文件运行它。将出现如下所示的对话框:
关于此对话框,有四点需要注意:
默认安装路径在当前 Windows 用户的
AppData/目录下。定制安装按钮可用于定制安装位置以及安装哪些附加功能,包括
pip和 IDLE。默认选中为所有用户安装启动器(推荐)复选框。这意味着机器上的每个用户都可以访问
py.exe启动器。您可以取消选中此框,将 Python 限制为当前 Windows 用户。默认情况下,将 Python 3.8 添加到
PATH复选框未选中。有几个原因让你可能不希望 Python 出现在PATH上,所以在你勾选这个框之前,确保你理解其中的含义。完整安装程序让您可以完全控制安装过程。
警告:如果你不知道什么是
PATH,那么强烈建议你不要安装完整的安装程序。请改用微软商店包。使用对话框中的可用选项自定义安装以满足您的需求。然后点击立即安装。这就是全部了!
祝贺您——您现在已经在 Windows 机器上安装了最新版本的 Python 3!
如何在 macOS 上安装 Python
Python 2 预装在旧版本的 macOS 上。从 macOS Catalina 开始,MAC OS 的当前版本不再如此。
macOS 上有两种安装方法:
- 官方安装人员
- 家酿软件包管理器
在本节中,您将了解如何检查 macOS 设备上安装了哪个版本的 Python(如果有)。您还将了解应该使用这两种安装方法中的哪一种。
如何在 Mac 上检查你的 Python 版本
要检查 Mac 上的 Python 版本,首先打开命令行应用程序,如“终端”。
提示:以下是打开终端的方法:
- 按下
Cmd+Space键。- 类型
Terminal。- 按下
Enter。或者,您可以打开 Finder 并导航至应用程序→实用程序→终端。
在命令行打开的情况下,键入以下命令:
# Check the system Python version $ python --version # Check the Python 2 version $ python2 --version # Check the Python 3 version $ python3 --version如果您的系统上有 Python,那么这些命令中的一个或多个应该响应一个版本号。
例如,如果您的计算机上已经安装了 Python 3.6.10,那么
python3命令将显示该版本号:$ python3 --version Python 3.6.10You’ll want to get the latest version of Python if any of these conditions is true:
- 以上命令都不会返回版本号。
- 您看到显示的唯一版本是 Python 2。x 系列。
- 您拥有的 Python 3 版本不是最新的,在撰写本文时是 3.8.4 版本。
你有什么选择
在 macOS 上安装官方 Python 发行版有两种方法:
官方安装程序:这种方法包括从 Python.org 网站下载官方安装程序,并在你的机器上运行。
家酿软件包管理器:这种方法包括下载并安装家酿软件包管理器(如果你还没有安装的话),然后在终端应用程序中键入命令。
官方安装程序和家酿软件包管理器都可以工作,但是只有官方安装程序由 Python 软件基金会维护。
注意:你也可以使用替代发行版在 macOS 上完成安装,比如 Anaconda ,但是本教程只涵盖官方发行版。
Anaconda 是一个用 Python 进行科学计算和数据科学的流行平台。要了解如何在 macOS 上安装 Anaconda,请查看 Anaconda 官方文档中的 macOS 安装指南。
官方安装程序和家酿软件包管理器安装的发行版并不相同。从自制软件安装有一些限制。
从自制软件安装的限制
Homebrew 上可用的 MAC OS Python 发行版不包括 Tkinter 模块所需的 Tcl/Tk 依赖关系。Tkinter 是用 Python 开发图形用户界面的标准库模块,实际上是 Tk GUI 工具包的接口,它不是 Python 的一部分。
Homebrew 不安装 Tk GUI 工具包依赖项。相反,它依赖于系统上安装的现有版本。Tcl/Tk 的系统版本可能已经过时或完全丢失,这可能会阻止您导入 Tkinter 模块。
macOS 安装程序建议
家酿软件包管理器是在 macOS 上安装 Python 的一种流行方法,因为它很容易从命令行管理,并且提供了升级 Python 的命令,而不必访问网站。因为 Homebrew 是一个命令行实用程序,所以可以用 bash 脚本实现自动化。
然而,由 Homebrew 提供的 Python 发行版不受 Python 软件基金会的控制,可能会随时改变。macOS 上最可靠的方法是使用官方安装程序,尤其是如果你打算用 Tkinter 进行 Python GUI 编程。
如何从官方安装程序安装
从官方安装程序安装 Python 是 macOS 上最可靠的安装方式。它包括用 Python 开发应用程序所需的所有系统依赖。
您可以分两步从官方安装程序安装。
第一步:下载官方安装程序
按照以下步骤下载完整的安装程序:
打开浏览器窗口,导航至 macOS 的 Python.org下载页面。
在“适用于 Mac OS X 的 Python 版本”标题下,单击最新 Python 3 版本- Python 3.x.x 的链接。在撰写本文时,最新版本是 Python 3.8.4。
滚动到底部,点击 macOS 64 位安装程序开始下载。
安装程序下载完成后,继续下一步。
第二步:运行安装程序
双击下载的文件运行安装程序。您应该会看到以下窗口:
按照以下步骤完成安装:
按几次继续,直到要求您同意软件许可协议。然后点击同意。
你会看到一个窗口,告诉你安装的目的地和需要多少空间。你很可能不想改变默认位置,所以继续点击 Install 开始安装。
当安装程序完成文件复制后,点击关闭关闭安装程序窗口。
祝贺您——您现在已经在 macOS 计算机上安装了最新版本的 Python 3!
如何从自制软件安装
对于需要从命令行安装的用户,尤其是那些不会使用 Python 来开发带有 Tkinter 模块的图形用户界面的用户,Homebrew package manager 是一个不错的选择。您可以分两步从 Homebrew 软件包管理器安装。
第一步:安装自制软件
如果你已经安装了自制软件,那么你可以跳过这一步。如果您没有安装 Homebrew,请使用以下步骤安装 Homebrew:
打开浏览器,导航至http://brew.sh/。
您应该在页面顶部的“安装自制软件”标题下看到一个安装自制软件的命令该命令类似于以下内容:
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"`用光标高亮显示该命令,并按下
Cmd+C将其复制到剪贴板。打开一个终端窗口,粘贴命令,然后按
Enter。这将开始家酿安装。出现提示时,输入您的 macOS 用户密码。
根据您的互联网连接,可能需要几分钟来下载所有家酿所需的文件。安装完成后,您将回到终端窗口中的 shell 提示符处。
注意:如果你在全新安装的 macOS 上这么做,你可能会得到一个弹出提示,要求你安装苹果的命令行开发工具。这些工具是安装所必需的,点击安装可以确认对话框。
开发者工具安装完成后,你需要按
Enter继续安装自制软件。既然已经安装了 Homebrew,就可以安装 Python 了。
第二步:安装 Python
按照以下步骤完成自制软件的安装:
打开终端应用程序。
键入以下命令来升级 Homebrew:
$ brew update && brew upgrade`用 Homebrew 安装现在就像运行命令
brew install python3一样简单。这将在您的机器上下载并设置最新版本的 Python。您可以通过测试是否可以从终端访问 Python 来确保一切正常:
打开一个终端。
键入
pip3并按下Enter。你应该看到来自 Python 的
pip包管理器的帮助文本。如果您在运行pip3时得到一个错误消息,那么再次执行安装步骤以确保您有一个工作的安装。祝贺您——您现在已经在 macOS 系统上安装了 Python!
如何在 Linux 上安装 Python
Linux 上有两种安装方法:
- 使用操作系统的软件包管理器
- 从源代码构建 Python
在这一节中,您将学习如何检查 Linux 计算机上的 Python 版本(如果有的话)。您还将了解应该使用这两种安装方法中的哪一种。
如何在 Linux 上检查你的 Python 版本
许多 Linux 发行版都打包了 Python,但它可能不是最新版本,甚至可能是 Python 2 而不是 Python 3。你应该检查版本以确保。
要找出您使用的 Python 版本,请打开终端窗口并尝试以下命令:
# Check the system Python version $ python --version # Check the Python 2 version $ python2 --version # Check the Python 3 version $ python3 --version如果您的机器上有 Python,那么这些命令中的一个或多个应该用版本号来响应。
例如,如果您的计算机上已经安装了 Python 3.6.10,那么
python3 --version命令将显示该版本号:$ python3 --version Python 3.6.10如果您的当前版本是 Python 2,那么您将希望获得 Python 的最新版本。x 系列或不是 Python 3 的最新版本,在撰写本文时是 3.8.4。
你有什么选择
在 Linux 上安装官方 Python 发行版有两种方法:
从软件包管理器安装:这是大多数 Linux 发行版上最常见的安装方法。它涉及到从命令行运行命令。
从源代码构建:这种方法比使用包管理器更难。它包括从命令行运行一系列命令,以及确保安装了正确的依赖项来编译 Python 源代码。
不是每个 Linux 发行版都有包管理器,也不是每个包管理器的包存储库中都有 Python。根据您的操作系统,从源代码构建 Python 可能是您唯一的选择。
注意:您也可以使用其他发行版在 Linux 上完成安装,比如 Anaconda ,但是本教程只涵盖官方发行版。
Anaconda 是一个用 Python 进行科学计算和数据科学的流行平台。要了解如何在 Linux 上安装 Anaconda,请查看 Anaconda 官方文档中的 Linux 安装指南。
您使用哪种安装方法主要归结于您的 Linux OS 是否有包管理器,以及您是否需要控制安装的细节。
Linux 安装建议
在 Linux 上安装 Python 最流行的方法是使用操作系统的包管理器,这对大多数用户来说是个不错的选择。然而,根据您的 Linux 发行版,Python 可能无法通过包管理器获得。在这种情况下,您需要从源代码构建 Python。
选择从源代码构建 Python 有三个主要原因:
不能从操作系统的包管理器下载 Python。
您需要控制 Python 的编译方式,比如当您想要降低嵌入式系统的内存占用时。
您希望在正式发布之前试用测试版,并发布最新最好版本的候选版本。
要在您的 Linux 机器上完成安装,请在下面找到您的 Linux 发行版,并按照提供的步骤操作。
如何在 Ubuntu 和 Linux Mint 上安装
在本节中,您将学习如何使用 Ubuntu 的
apt包管理器安装 Python。如果你想从源代码构建 Python,请跳到如何从源代码构建 Python一节。注意: Linux Mint 用户可以跳到“Linux Mint 和 Ubuntu 17 及以下”一节。
根据您运行的 Ubuntu 发行版的版本,在您的系统上设置 Python 的过程会有所不同。您可以通过运行以下命令来确定您的本地 Ubuntu 版本:
$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 16.04.4 LTS Release: 16.04 Codename: xenial遵循以下与您在控制台输出中的
Release下看到的版本号相匹配的说明:
Ubuntu 18.04,Ubuntu 20.04 及以上:Ubuntu 18.04 及以上默认没有 Python 3.8,但在 Universe 库中有。要安装 3.8 版,请打开终端应用程序并键入以下命令:
$ sudo apt-get update $ sudo apt-get install python3.8 python3-pip`安装完成后,您可以用
python3.8命令运行 Python 3.8,用pip3命令运行pip。Linux Mint 和 Ubuntu 17 及以下: Python 3.8 不在 Universe 库中,所以你需要从个人包存档(PPA)中获取。例如,要从“死蛇”PPA 安装,请使用以下命令:
$ sudo add-apt-repository ppa:deadsnakes/ppa $ sudo apt-get update $ sudo apt-get install python3.8 python3-pip`安装完成后,您可以用
python3.8命令运行 Python 3.8,用pip3命令运行pip。恭喜你!现在,您的机器上已经安装了 Python 3!
如何在 Debian Linux 上安装
在 Debian 上安装 Python 3.8 之前,您需要安装
sudo命令。要安装它,请在终端中执行以下命令:$ su $ apt-get install sudo $ sudo vim /etc/sudoers之后,使用
sudo vim命令或您喜欢的文本编辑器打开/etc/sudoers文件。将下面一行文本添加到文件的末尾,用您实际的用户名替换your_username:your_username ALL=(ALL) ALL现在您可以跳到如何从源代码构建 Python部分来完成 Python 的安装。
如何在 openSUSE 上安装
从源代码构建是在 openSUSE 上设置 Python 最可靠的方式。为此,您需要安装开发工具,这可以通过菜单或使用
zypper在YaST中完成:$ sudo zypper install -t pattern devel_C_C这可能需要一段时间才能完成,因为它安装了超过 150 个软件包。一旦完成,就跳到如何从源代码构建 Python部分。
如何在 CentOS 和 Fedora 上安装
CentOS 和 Fedora 库中没有 Python 3.8,所以您必须从源代码构建 Python。但是,在编译 Python 之前,您需要确保您的系统已经准备好了。
首先,更新
yum包管理器:$ sudo yum -y update一旦
yum完成更新,您可以使用以下命令安装必要的构建依赖项:$ sudo yum -y groupinstall "Development Tools" $ sudo yum -y install gcc openssl-devel bzip2-devel libffi-devel安装完成后,请跳到如何从源代码构建 Python部分。
如何在 Arch Linux 上安装
Arch Linux 在跟上 Python 版本方面相当勤奋。很可能您已经有了最新版本。如果没有,请使用以下命令更新 Python:
$ packman -S python当 Python 完成更新时,您应该已经准备好了!
如何从源代码构建 Python
有时您的 Linux 发行版没有最新版本的 Python,或者您可能只想自己构建最新、最好的版本。以下是从源代码构建 Python 所需的步骤:
第一步:下载源代码
首先,您需要获得 Python 源代码。Python.org 让这变得相当简单。如果你进入下载页面,你会在顶部看到 Python 3 的最新源代码。只要确保你没有抓住传统的 Python,Python 2!
当您选择 Python 3 版本时,您会在页面底部看到“文件”部分。选择gzip source tarball并下载到你的机器上。如果您喜欢命令行方法,您可以使用
wget将文件下载到您的当前目录:$ wget https://www.python.org/ftp/python/3.8.4/Python-3.8.4.tgz当 tarball 完成下载后,您需要做一些事情来为构建 Python 准备您的系统。
步骤 2:准备您的系统
从头开始构建 Python 需要几个特定于发行版的步骤。每个步骤的目标在所有发行版上都是一样的,但是如果发行版不使用
apt-get,您可能需要翻译成您的发行版:
首先,更新您的软件包管理器并升级您的软件包:
$ sudo apt-get update $ sudo apt-get upgrade`接下来,确保您已经安装了所有的构建需求:
# For apt-based systems (like Debian, Ubuntu, and Mint) $ sudo apt-get install -y make build-essential libssl-dev zlib1g-dev \ libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \ libncurses5-dev libncursesw5-dev xz-utils tk-dev # For yum-based systems (like CentOS) $ sudo yum -y groupinstall "Development Tools" $ sudo yum -y install gcc openssl-devel bzip2-devel libffi-devel`如果您的系统上已经安装了一些需求,这是没问题的。您可以执行上述命令,任何现有的包都不会被覆盖。
既然您的系统已经准备就绪,是时候开始构建 Python 了!
步骤 3:构建 Python
一旦有了先决条件和 TAR 文件,就可以将源代码解压到一个目录中。请注意,以下命令将在您所在的目录下创建一个名为
Python-3.8.3的新目录:$ tar xvf Python-3.8.4.tgz $ cd Python-3.8.4`现在您需要运行
./configure工具来准备构建:$ ./configure --enable-optimizations --with-ensurepip=install`
enable-optimizations标志将启用 Python 中的一些优化,使其运行速度提高大约 10%。这样做可能会增加二三十分钟的编译时间。with-ensurepip=install标志将安装与本次安装捆绑在一起的pip。接下来,使用
make构建 Python。-j选项只是告诉make将建筑分割成平行的步骤,以加快编译速度。即使是并行构建,这一步也需要几分钟:$ make -j 8`最后,您需要安装新版本的 Python。这里您将使用
altinstall目标来避免覆盖系统 Python。因为您正在安装到/usr/bin中,所以您需要以 root 用户身份运行:$ sudo make altinstall`完成安装可能需要一段时间。一旦完成,您就可以验证 Python 的设置是否正确。
步骤 4:验证您的安装
测试
python3.8 --version命令是否返回最新版本:$ python3.8 --version Python 3.8.4如果你看到
Python 3.8.4,那么你就一切就绪了!如果你有多余的时间,你也可以运行测试套件来确保你的系统一切正常。
要运行测试套件,请键入以下命令:
$ python3.8 -m test你可能想暂时找点别的事情做,因为你的计算机将运行测试一段时间。如果所有测试都通过了,那么您就可以确信您的全新 Python 版本正在按预期工作!
如何在 iOS 上安装 Python
用于 iOS 的 Pythonista 应用是一个成熟的 Python 开发环境,你可以在你的 iPhone 或 iPad 上运行。它将 Python 编辑器、技术文档和解释器整合到一个应用程序中。
Pythonista 使用起来非常有趣。当你被困在没有笔记本电脑的地方,想要在旅途中学习 Python 技能时,这是一个非常棒的小工具。它附带了完整的 Python 3 标准库,甚至包括可以离线浏览的完整文档。
要设置 Pythonista,你需要从 iOS 应用商店下载。
如何在 Android 上安装 Python
如果您有一台 Android 平板电脑或手机,并且想在旅途中练习 Python,有几个选项可供选择。我们发现最可靠地支持 Python 3.8 的是 Pydroid 3 。
Pydroid 3 具有一个解释器,可以用于 REPL 会话,还允许编辑、保存和执行 Python 代码。
你可以从 Google Play 商店下载并安装 Pydroid 3。有一个免费版本和一个付费的高级版本,支持代码预测和代码分析。
在线 Python 解释器
如果您想尝试本教程中的示例,而不在您的机器上设置 Python,那么有几个网站提供在线 Python 解释器:
这些基于云的 Python 解释器可能无法执行本教程中一些更复杂的例子,但是它们足以运行大多数代码,并且可能是一个不错的入门方式。关于使用这些站点的更多信息将在本系列的下一篇教程中介绍。
结论
恭喜你!您现在可以访问适用于您的系统的最新版本的 Python。您的 Python 之旅才刚刚开始。
在本教程中,你已经学会了如何:
- 检查 Python 的哪个版本,如果有的话,安装在您的系统上
- 在 Windows 、 macOS 和 Linux 上安装最新版本的 Python
- 在手机或平板电脑等移动设备上使用 Python
- 通过在线解释器在网络上使用 Python
现在,您已经准备好开始使用 Python 编程了!请务必在下面的评论中分享你的进步和任何问题。
« Introduction to PythonInstalling PythonInteracting with Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 基础知识:设置 Python*********
Python 的实例、类和静态方法不再神秘
原文:https://realpython.com/instance-class-and-static-methods-demystified/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的 OOP 方法类型:@ class Method vs @ static Method vs Instance Methods
在本教程中,我将帮助揭开 类方法 、 静态方法 和常规实例方法背后的秘密。
如果你对它们的区别有了直观的理解,你就能写出面向对象的 Python,更清楚地表达它的意图,从长远来看也更容易维护。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
实例、类和静态方法——概述
让我们从编写一个(Python 3)类开始,该类包含所有三种方法类型的简单示例:
class MyClass: def method(self): return 'instance method called', self @classmethod def classmethod(cls): return 'class method called', cls @staticmethod def staticmethod(): return 'static method called'注意:对于 Python 2 用户:
@staticmethod和@classmethod装饰器从 Python 2.4 开始可用,这个例子将照常工作。不要使用普通的class MyClass:声明,你可以选择用class MyClass(object):语法声明一个继承自object的新型类。除此之外你可以走了。实例方法
MyClass上的第一个方法叫做method,是一个常规的实例方法。这是基本的、没有多余装饰的方法类型,您将在大多数时间使用。您可以看到该方法有一个参数self,当调用该方法时,它指向MyClass的一个实例(当然,实例方法可以接受不止一个参数)。通过
self参数,实例方法可以自由访问同一个对象上的属性和其他方法。在修改对象的状态时,这给了它们很大的权力。实例方法不仅可以修改对象状态,还可以通过
self.__class__属性访问类本身。这意味着实例方法也可以修改类状态。类方法
让我们将它与第二种方法
MyClass.classmethod进行比较。我用一个@classmethod装饰器标记了这个方法,以将其标记为一个类方法。类方法不是接受一个
self参数,而是接受一个cls参数,该参数在方法被调用时指向类,而不是对象实例。因为类方法只能访问这个
cls参数,所以它不能修改对象实例状态。这需要访问self。但是,类方法仍然可以修改应用于该类所有实例的类状态。静态方法
第三种方法,
MyClass.staticmethod被标记为@staticmethod装饰者将其标记为静态方法。这种类型的方法既不接受
self也不接受cls参数(当然,它可以接受任意数量的其他参数)。因此,静态方法既不能修改对象状态,也不能修改类状态。静态方法在它们可以访问的数据方面受到限制——它们主要是一种给你的方法命名空间的方式。
让我们看看他们的行动吧!
我知道这个讨论到目前为止还只是理论性的。我相信,对这些方法类型在实践中的不同之处有一个直观的理解是很重要的。我们现在来看一些具体的例子。
让我们看看当我们调用这些方法时,它们是如何工作的。我们将首先创建该类的一个实例,然后调用它的三个不同的方法。
MyClass是以这样的方式建立的,每个方法的实现返回一个包含信息的元组,以便我们跟踪发生了什么——以及该方法可以访问类或对象的哪些部分。下面是当我们调用一个实例方法时发生的情况:
>>> obj = MyClass()
>>> obj.method()
('instance method called', <MyClass instance at 0x10205d190>)
这证实了method(实例方法)可以通过self参数访问对象实例(打印为<MyClass instance>)。
当调用该方法时,Python 用实例对象obj替换self参数。我们可以忽略点调用语法的语法糖(obj.method())并手动传递实例对象以获得相同的结果:
*>>>
>>> MyClass.method(obj)
('instance method called', <MyClass instance at 0x10205d190>)
如果不先创建实例就试图调用该方法,您能猜到会发生什么吗?
顺便说一下,实例方法也可以通过self.__class__属性访问类本身。这使得实例方法在访问限制方面非常强大——它们可以修改对象实例的状态和类本身的状态。
接下来让我们试试类方法:
>>> obj.classmethod() ('class method called', <class MyClass at 0x101a2f4c8>)调用
classmethod()向我们展示了它不能访问<MyClass instance>对象,只能访问代表类本身的<class MyClass>对象(Python 中的一切都是对象,甚至是类本身)。注意当我们调用
MyClass.classmethod()时,Python 如何自动将类作为第一个参数传递给函数。通过点语法调用 Python 中的方法会触发这种行为。实例方法上的self参数以同样的方式工作。请注意,命名这些参数
self和cls只是一种约定。你可以很容易地将它们命名为the_object和the_class,并得到相同的结果。重要的是它们在方法的参数列表中位于第一位。现在是调用静态方法的时候了:
>>> obj.staticmethod()
'static method called'
你看到我们是如何在对象上调用staticmethod()并成功完成的吗?当一些开发人员得知可以在对象实例上调用静态方法时,他们感到很惊讶。
在幕后,Python 只是通过在使用点语法调用静态方法时不传入self或cls参数来实施访问限制。
这证实了静态方法既不能访问对象实例状态,也不能访问类状态。它们像常规函数一样工作,但是属于类(和每个实例)的名称空间。
现在,让我们看看当我们试图在类本身上调用这些方法时会发生什么——而不事先创建对象实例:
>>> MyClass.classmethod() ('class method called', <class MyClass at 0x101a2f4c8>) >>> MyClass.staticmethod() 'static method called' >>> MyClass.method() TypeError: unbound method method() must be called with MyClass instance as first argument (got nothing instead)我们能够很好地调用
classmethod()和staticmethod(),但是尝试调用实例方法method()失败,出现了TypeError。这是意料之中的——这一次我们没有创建对象实例,而是尝试直接在类蓝图本身上调用实例函数。这意味着 Python 无法填充
self参数,因此调用失败。这应该会使这三种方法类型之间的区别更加清晰。但我不会就此罢休。在接下来的两节中,我将通过两个稍微现实一点的例子来说明何时使用这些特殊的方法类型。
我将围绕这个基本类给出我的例子:
class Pizza: def __init__(self, ingredients): self.ingredients = ingredients def __repr__(self): return f'Pizza({self.ingredients!r})'
>>> Pizza(['cheese', 'tomatoes'])
Pizza(['cheese', 'tomatoes'])
注意:这个代码示例和本教程后面的代码示例使用 Python 3.6 f-strings 来构造由
__repr__返回的字符串。在 Python 2 和 Python 3.6 之前的版本中,您可以使用不同的字符串格式表达式,例如:`def __repr__(self): return 'Pizza(%r)' % self.ingredients`
美味披萨工厂@classmethod
如果你在现实生活中接触过比萨,你会知道有许多美味的变化:
Pizza(['mozzarella', 'tomatoes'])
Pizza(['mozzarella', 'tomatoes', 'ham', 'mushrooms'])
Pizza(['mozzarella'] * 4)
几个世纪前,意大利人就想出了他们的比萨饼分类,所以这些美味的比萨饼都有自己的名字。我们应该好好利用这一点,给我们的Pizza类的用户一个更好的界面来创建他们渴望的披萨对象。
一个漂亮而干净的方法是使用类方法作为我们可以创建的不同种类的披萨的工厂函数:
class Pizza:
def __init__(self, ingredients):
self.ingredients = ingredients
def __repr__(self):
return f'Pizza({self.ingredients!r})'
@classmethod
def margherita(cls):
return cls(['mozzarella', 'tomatoes'])
@classmethod
def prosciutto(cls):
return cls(['mozzarella', 'tomatoes', 'ham'])
注意我是如何在margherita和prosciutto工厂方法中使用cls参数,而不是直接调用Pizza构造函数的。
这是一个你可以用来遵循不要重复自己(干)原则的窍门。如果我们决定在某个时候重命名这个类,我们就不需要记住更新所有 classmethod 工厂函数中的构造函数名。
现在,我们能用这些工厂方法做什么呢?让我们尝试一下:
>>> Pizza.margherita() Pizza(['mozzarella', 'tomatoes']) >>> Pizza.prosciutto() Pizza(['mozzarella', 'tomatoes', 'ham'])如您所见,我们可以使用工厂函数来创建新的
Pizza对象,这些对象按照我们想要的方式进行配置。它们都在内部使用相同的__init__构造函数,只是提供了一个记住所有不同成分的捷径。看待类方法这种用法的另一种方式是,它们允许您为类定义可选的构造函数。
Python 只允许每个类有一个
__init__方法。使用类方法可以根据需要添加尽可能多的可选构造函数。这可以使您的类的接口自文档化(在一定程度上)并简化它们的使用。何时使用静态方法
在这里想出一个好的例子有点困难。但是告诉你,我会继续把披萨比喻的越来越薄…(好吃!)
这是我想到的:
import math class Pizza: def __init__(self, radius, ingredients): self.radius = radius self.ingredients = ingredients def __repr__(self): return (f'Pizza({self.radius!r}, ' f'{self.ingredients!r})') def area(self): return self.circle_area(self.radius) @staticmethod def circle_area(r): return r ** 2 * math.pi我在这里改变了什么?首先,我修改了构造函数和
__repr__来接受一个额外的radius参数。我还添加了一个计算并返回比萨饼面积的
area()实例方法(这也是一个很好的@property的候选方法——但是,嘿,这只是一个玩具示例)。我没有使用众所周知的圆形面积公式直接在
area()中计算面积,而是将其分解到一个单独的circle_area()静态方法中。我们来试试吧!
>>> p = Pizza(4, ['mozzarella', 'tomatoes'])
>>> p
Pizza(4, ['mozzarella', 'tomatoes'])
>>> p.area()
50.26548245743669
>>> Pizza.circle_area(4)
50.26548245743669
当然,这是一个有点简单的例子,但是它可以很好地帮助解释静态方法提供的一些好处。
正如我们所了解的,静态方法不能访问类或实例状态,因为它们没有带cls或self参数。这是一个很大的限制——但这也是一个很好的信号,表明一个特定的方法独立于它周围的一切。
在上面的例子中,很明显circle_area()不能以任何方式修改类或类实例。(当然,你可以用一个全局变量和来解决这个问题,但这不是这里的重点。)
这为什么有用呢?
将一个方法标记为静态方法不仅仅是暗示一个方法不会修改类或实例状态 Python 运行时也强制实施了这一限制。
像这样的技术可以让你清楚地交流你的类架构的各个部分,这样新的开发工作就可以自然地在这些设定的界限内进行。当然,无视这些限制是很容易的。但在实践中,它们通常有助于避免违背原始设计的意外修改。
换句话说,使用静态方法和类方法是传达开发人员意图的方式,同时充分实施该意图以避免大多数会破坏设计的疏忽错误和 bug。
谨慎应用,当有意义时,以这种方式编写一些方法可以提供维护好处,并减少其他开发人员错误使用您的类的可能性。
静态方法在编写测试代码时也有好处。
因为circle_area()方法完全独立于类的其余部分,所以更容易测试。
在单元测试中测试方法之前,我们不必担心设置一个完整的类实例。我们可以像测试一个常规函数一样开始工作。同样,这使得将来的维护更加容易。
关键要点
- 实例方法需要一个类实例,可以通过
self访问实例。 - 类方法不需要类实例。他们不能访问实例(
self),但是他们可以通过cls访问类本身。 - 静态方法不能访问
cls或self。它们像常规函数一样工作,但是属于类的命名空间。 - 静态方法和类方法相互交流,并(在一定程度上)强化开发人员对类设计的意图。这有利于维护。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的 OOP 方法类型:@ class Method vs @ static Method vs Instance Methods***
与 Python 交互
此时,您应该已经有了一个可用的 Python 3 解释器。如果你需要正确设置 Python 的帮助,请参考本教程系列的前一节。
下面是您将在本教程中学到的内容:现在您已经有了一个可以工作的 Python 设置,您将看到如何实际执行 Python 代码和运行 Python 程序。在本文结束时,您将知道如何:
- 通过直接在解释器中键入代码来交互式地使用 Python
- 从命令行执行脚本文件中包含的代码
- 在 Python 集成开发环境(IDE)中工作
是时候写点 Python 代码了!
你好,世界!
在计算机编程领域有一个由来已久的习惯,用新安装的语言编写的第一个代码是一个简短的程序,它只是向控制台显示字符串Hello, World!。
注意:这是一个历史悠久的传统,可以追溯到 20 世纪 70 年代。参见你好,世界!简史。如果你不遵守这个习俗,你很可能会扰乱宇宙的气。
显示Hello, World!的最简单的 Python 3 代码是:
print("Hello, World!")
下面您将探索几种不同的方法来执行这段代码。
交互式使用 Python 解释器
开始与 Python 对话最直接的方式是在交互式读取-评估-打印循环(REPL) 环境中。这仅仅意味着启动解释器并直接向它输入命令。口译员:
- 朗读你输入的命令
- E 评估并执行命令
- 将输出(如果有的话)打印到控制台
- L 返回并重复这个过程
会话以这种方式继续,直到您指示解释器终止。本系列教程中的大多数示例代码都是以 REPL 交互的形式呈现的。
启动解释器
在 GUI 桌面环境中,安装过程可能会在桌面上放置一个图标,或者在启动 Python 的桌面菜单系统中放置一个项目。
例如,在 Windows 中,开始菜单中可能会有一个名为 Python 3.x 的程序组,在它下面会有一个名为 Python 3.x (32 位)、或类似的菜单项,这取决于您选择的特定安装。
单击该项将启动 Python 解释器:
或者,您可以打开一个终端窗口,从命令行运行解释器。如何打开终端窗口取决于您使用的操作系统:
- 在 Windows 中,它被称为命令提示符。
- 在 macOS 或者 Linux 里面应该叫终端。
用你操作系统的搜索功能在 Windows 中搜索“command”或者在 macOS 或者 Linux 中搜索“terminal”应该能找到。
一旦终端窗口打开,如果 Python 安装过程已经正确设置了路径,您应该能够只输入python。然后,您应该会看到来自 Python 解释器的响应。
此示例来自 Windows 命令提示符窗口:
C:\Users\john>python
Python 3.6.0 (v3.6.0:41df79263a11, Dec 23 2016, 07:18:10) [MSC v.1900 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
技术提示:如果你在 Linux 系统上,并且安装了 Python 3,那么可能 Python 2 和 Python 3 都被安装了。在这种情况下,在提示符下键入python可能会启动 Python 2。启动 Python 3 可能需要输入其他东西,比如python3。
如果您安装了比发行版中包含的版本更新的 Python 3 版本,您甚至可能需要特别指定您安装的版本——例如python3.6。
如果您没有看到>>>提示符,那么您没有与 Python 解释器对话。这可能是因为 Python 没有安装或者不在您的终端窗口会话的路径中。也有可能您只是没有找到正确的命令来执行它。你可以参考我们的安装 Python 教程寻求帮助。
执行 Python 代码
如果您看到了提示,那么您已经开始运行了!下一步是执行向控制台显示Hello, World!的语句:
- 确保显示
>>>提示符,并且光标位于其后。 - 完全按照所示键入命令
print("Hello, World!")。 - 按下
Enter键。
解释器的响应应该出现在下一行。您可以看出这是控制台输出,因为没有>>>提示符:
>>> print("Hello, World!") Hello, World!如果您的会话看起来如上,那么您已经执行了您的第一个 Python 代码!花点时间庆祝一下。
Congratulations! 出了什么问题吗?也许你犯了这些错误中的一个:
- 您忘记了将要打印的字符串用引号括起来:

```py
>>> print(Hello, World!)
File "<stdin>", line 1
print(Hello, World!)
^
SyntaxError: invalid syntax`
```
-
你记住了开始的引号,但忘记了结束的引号:
>>> print("Hello, World!) File "<stdin>", line 1 print("Hello, World!) ^ SyntaxError: EOL while scanning string literal`>>> print("Hello, World!') File "<stdin>", line 1 print("Hello, World!') ^ SyntaxError: EOL while scanning string literal` -
你忘了括号:
>>> print "Hello, World!" File "<stdin>", line 1 print "Hello, World!" ^ SyntaxError: Missing parentheses in call to 'print'`>>> print("Hello, World!") File "<stdin>", line 1 print("Hello, World!") ^ IndentationError: unexpected indent`
(您将在接下来的章节中看到这一点的重要性。)
如果您得到了某种错误消息,请返回并验证您是否完全按照上面显示的方式键入了命令。
退出解释器
当您完成与解释器的交互后,您可以通过几种方式退出 REPL 会话:
-
键入
exit()并按下Enter:>>> exit() C:\Users\john>`>>> ^Z C:\Users\john>` -
在 Linux 或 macOS 中,输入
Ctrl+D。解释器立即终止;不需要按Enter。 -
如果所有这些都失败了,你可以简单地关闭解释器窗口。这不是最好的方法,但能完成任务。
从命令行运行 Python 脚本
以交互方式向 Python 解释器输入命令对于快速测试和探索特性或功能非常有用。
但是,最终,随着您创建更复杂的应用程序,您将开发更长的代码体,您将希望编辑并重复运行这些代码。您显然不想每次都在解释器中重新输入代码!这是您想要创建脚本文件的地方。
Python 脚本是一组可重用的代码。它本质上是一个包含在文件中的 Python 程序——一系列 Python 指令。您可以通过向解释器指定脚本文件的名称来运行程序。
Python 脚本只是纯文本,因此您可以使用任何文本编辑器编辑它们。如果你有一个最喜欢的操作文本文件的程序员编辑器,用起来应该没问题。如果没有,通常会在各自的操作系统中本机安装以下软件:
- Windows:记事本
- Unix/Linux: vi 还是 vim
- macOS: TextEdit
使用您选择的任何编辑器,创建一个名为hello.py的脚本文件,包含以下内容:
print("Hello, World!")
现在保存文件,跟踪您选择保存到的目录或文件夹。
启动命令提示符或终端窗口。如果当前的工作目录与您保存文件的位置相同,您可以简单地将文件名指定为 Python 解释器的一个命令行参数:python hello.py
例如,在 Windows 中,它看起来像这样:
C:\Users\john\Documents\test>dir
Volume in drive C is JFS
Volume Serial Number is 1431-F891
Directory of C:\Users\john\Documents\test
05/20/2018 01:31 PM <DIR> .
05/20/2018 01:31 PM <DIR> ..
05/20/2018 01:31 PM 24 hello.py
1 File(s) 24 bytes
2 Dir(s) 92,557,885,440 bytes free
C:\Users\john\Documents\test>python hello.py
Hello, World!
如果脚本不在当前工作目录中,您仍然可以运行它。您只需指定它的路径名:
C:\>cd
C:\
C:\>python c:\Users\john\Documents\test\hello.py
Hello, World!
在 Linux 或 macOS 中,您的会话可能看起来更像这样:
jfs@jfs-xps:~$ pwd
/home/jfs
jfs@jfs-xps:~$ ls
hello.py
jfs@jfs-xps:~$ python hello.py
Hello, World!
脚本文件不需要有.py扩展名。只要您在命令行上正确指定文件名,Python 解释器就会运行该文件,不管它的名称是什么:
jfs@jfs-xps:~$ ls
hello.foo
jfs@jfs-xps:~$ cat hello.foo
print("Hello, World!")
jfs@jfs-xps:~$ python hello.foo
Hello, World!
但是给 Python 文件一个.py扩展名是一个有用的约定,因为这使得它们更容易识别。在面向桌面的文件夹/图标环境中,如 Windows 和 macOS,这通常也允许设置适当的文件关联,这样您只需单击图标就可以运行脚本。
通过 IDE 与 Python 交互
集成开发环境(IDE)是一个应用程序,它或多或少地结合了您到目前为止看到的所有功能。ide 通常提供 REPL 功能以及一个编辑器,您可以用它来创建和修改代码,然后提交给解释器执行。
您可能还会发现一些很酷的功能,例如:
- 语法突出显示:ide 经常给代码中不同的语法元素着色,以便于阅读。
- 上下文相关帮助:高级 ide 可以显示 Python 文档中的相关信息,甚至是常见代码错误的修复建议。
- 代码完成:一些 ide 可以为您完成部分键入的代码(比如函数名)——这是一个非常节省时间和方便的特性。
- 调试:调试器允许你一步一步地运行代码,并在运行过程中检查程序数据。当你试图确定一个程序为什么行为不正常时,这是非常宝贵的,因为这是不可避免的。
空闲
大多数 Python 安装都包含一个名为 IDLE 的基本 IDE。这个名字表面上代表集成开发和学习环境,但是 Monty Python 团队的一个成员被命名为埃里克·艾多尔,这看起来不像是巧合。
运行 IDLE 的过程因操作系统而异。
在 Windows 中开始空闲
进入开始菜单,选择所有程序或所有应用。应该会有一个标注为 IDLE (Python 3.x 32 位)或者类似的程序图标。这在 Win 7、8 和 10 之间会略有不同。空闲图标可能在名为 Python 3.x 的程序组文件夹中。您也可以从开始菜单使用 Windows 搜索工具并输入IDLE来找到空闲程序图标。
点击图标开始空闲。
在 macOS 中开始空闲
打开 Spotlight 搜索。键入 Cmd + Space 是实现这一点的几种方法之一。在搜索框中,输入terminal,按 Enter 。
在终端窗口中,键入idle3并按下 Enter 。
在 Linux 中开始空闲
Python 3 发行版提供了 IDLE,但默认情况下可能没有安装。要查明是否如此,请打开终端窗口。这取决于 Linux 发行版,但是您应该能够通过使用桌面搜索功能和搜索terminal找到它。在终端窗口中,键入idle3并按下 Enter 。
如果你得到一个错误消息说command not found或者类似的话,那么 IDLE 显然没有安装,所以你需要安装它。
安装应用程序的方法也因 Linux 发行版的不同而不同。比如用 Ubuntu Linux,安装 IDLE 的命令是sudo apt-get install idle3。许多 Linux 发行版都有基于 GUI 的应用程序管理器,您也可以用它来安装应用程序。
遵循适合您的发行版的任何过程来安装 IDLE。然后,在终端窗口中键入idle3,按 Enter 运行。您的安装过程可能还在桌面上的某个位置设置了一个程序图标,也可以开始空闲。
咻!
使用空闲
一旦安装了 IDLE 并且成功启动了它,您应该会看到一个标题为 Python 3.x.x Shell 的窗口,其中 3.x.x 对应于您的 Python 版本:
提示应该看起来很熟悉。您可以交互地键入 REPL 命令,就像从控制台窗口启动解释器一样。忌惮宇宙的之气,再次施展Hello, World!:
解释器的行为与您直接从控制台运行它时大致相同。IDLE 界面增加了以不同颜色显示不同语法元素的额外功能,使内容更具可读性。
它还提供上下文相关的帮助。例如,如果您键入print(而没有键入 print 函数的任何参数或右括号,那么应该会出现一个浮动文本,指定print()函数的用法信息。
IDLE 提供的另一个特性是语句回调:
- 如果你输入了几条语句,在 Windows 或 Linux 中可以用
Alt+P和Alt+N来回忆。 Alt+P循环返回之前执行的语句;Alt+N循环前进。- 调用语句后,您可以使用键盘上的编辑键对其进行编辑,然后再次执行。macOS 中对应的命令有
Cmd+P``Cmd+N。
您也可以创建脚本文件并在空闲时运行它们。从 Shell 窗口菜单中,选择文件→新文件。这将打开一个额外的编辑窗口。键入要执行的代码:
在该窗口的菜单中,选择文件→保存或文件→另存为… ,将文件保存到磁盘。然后选择运行→运行模块。输出应该出现在解释器 Shell 窗口中:
好了,大概够了Hello, World!。宇宙的气应该是安全的。
两个窗口都打开后,您可以来回切换,在一个窗口中编辑代码,在另一个窗口中运行代码并显示其输出。这样,IDLE 提供了一个基本的 Python 开发平台。
尽管它有些基础,但它支持相当多的附加功能,包括代码完成、代码格式化和调试器。更多细节参见空闲文档。
汤妮
Thonny 是由爱沙尼亚塔尔图大学计算机科学研究所开发和维护的免费 Python IDE。它是专门针对 Python 初学者的,所以界面简单而整洁,易于理解并很快适应。
像 IDLE 一样,Thonny 支持 REPL 交互以及脚本文件编辑和执行:
Thonny 除了提供一个分步调试器之外,还执行语法突出显示和代码完成。对学习 Python 的人特别有帮助的一个特性是,在您单步执行代码时,调试器会在表达式中显示求值结果:
Thonny 特别容易上手,因为它内置了 Python 3.6。因此,您只需要执行一次安装,就可以开始了!
版本适用于 Windows、macOS 和 Linux。Thonny 网站有下载和安装说明。
IDLE 和 Thonny 当然不是唯一的游戏。还有许多其他 ide 可用于 Python 代码编辑和开发。查看我们的Python ide 和代码编辑器指南获取更多建议。
在线 Python REPL 网站
正如您在上一节中看到的,有一些可用的网站可以为您提供对在线 Python 解释器的交互式访问,而无需您在本地安装任何东西。
对于本教程中一些更复杂或更长的例子来说,这种方法可能并不令人满意。但是对于简单的 REPL 会话,它应该工作得很好。
Python 软件基金会在其网站上提供了一个交互式外壳。在主页上,点击看起来像以下按钮之一的按钮:


或者直接去https://www.python.org/shell。
您应该得到一个带有类似如下窗口的页面:
熟悉的>>>提示符显示您正在与 Python 解释器对话。
以下是其他几个提供 Python REPL 的站点:
结论
较大的应用程序通常包含在脚本文件中,这些文件被传递给 Python 解释器来执行。
但是解释语言的一个优点是你可以运行解释器并交互地执行命令。Python 以这种方式使用起来很容易,而且这是一种让您尝试学习这种语言如何工作的好方法。
本教程中的示例是通过与 Python 解释器的直接交互生成的,但是如果您选择使用 IDLE 或其他一些可用的 IDE,这些示例应该仍然可以正常工作。
继续下一节,您将开始探索 Python 语言本身的元素。
« Installing PythonInteracting with PythonBasic Data Types »*****
中级 Python 开发人员的 13 个项目想法
原文:https://realpython.com/intermediate-python-project-ideas/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 用 13 个中级项目想法 增长您的 Python 作品集
学习 Python 的基础是一次美妙的经历。但是仅仅学习的兴奋感可能会被对动手项目的渴望所取代。想要建立项目是正常的,因此需要项目想法。
但问题是,有些项目对于中级 Python 开发人员来说要么太简单,要么太难。本文将建议您作为中级 Python 开发人员可以参与的项目。这些项目想法将为你提供适当水平的挑战。
在这篇文章中,你将了解到:
- 建筑工程的重要性
- 您可以为其构建项目的主要平台
- 你可以着手的 13 个项目想法
- 关于项目工作的一些提示
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
建设项目的重要性
参与项目对于推动您作为 Python 开发人员的职业发展至关重要。他们让你应用你所获得的技能和知识。
项目可以帮助您:
-
建立信心:无论软件的复杂程度如何,你都会更加相信自己创造软件的能力。
-
探索其他技术:你将了解构建完整产品所需的其他技术,如数据库、服务器和其他语言。
-
更好地理解编程概念:你将学会更好地编写代码,理解设计模式和面向对象编程等概念。
-
体验一个完整的软件开发生命周期:你将学习如何在编写代码之前进行规划,管理编码过程,更新软件。
作为 Python 开发人员,构建项目会有很多收获。
选择项目平台
你需要构建你的软件运行在一个平台上,让缺乏一定技术知识的人也能使用你的软件。web、桌面和命令行是您想要构建项目的三个主要平台。
网页
Web 应用程序是在 web 上运行的应用程序,只要可以访问互联网,就可以在任何设备上访问它们,而无需下载。如果你希望你的项目能被所有能上网的人访问,它需要是一个网络应用程序。
web 应用程序有后端和前端。后端是业务逻辑所在的部分:您的后端代码将操作和存储数据。前端是应用程序的界面:你的前端代码将决定一个 web 应用程序的外观。
作为一名中级 Python 开发人员,您主要关注的是后端代码。然而,前端代码也很重要,所以你需要一些关于 HTML和 CSS 的知识,也许还有 T2 JavaScript 来创建一个简单的界面。只要最基本的就够了。
另一个选择是对前端和后端都使用 Python。感谢 anvil 库,它消除了对 HTML、CSS 和 JavaScript 的需求,您可以专注于 Python 代码。
可以通过djangoflask等 web 框架用 Python 构建 web 应用。使用 Python 构建 web 应用程序的框架清单很长。有很多可供选择,但是django和flask仍然是最受欢迎的 web 框架。
桌面图形用户界面
每当你在电脑上执行任务时,无论是台式机还是笔记本电脑,都是通过应用程序完成的。作为一名中级 Python 开发者,你可以制作自己的桌面应用。
您不必学习任何前端技术来创建自己的图形用户界面(GUI)应用程序,就像您在 web 应用程序中看到的那样。您可以使用 Python 构建所有部分。
有一些构建桌面应用程序的框架。 PySimpleGUI 就是其中之一,对于一个中级 Python 开发者来说,它非常用户友好。
像 PyQt5 这样的高级 GUI 框架相当强大,但是它可能有一个陡峭的学习曲线。
您为桌面 GUI 创建的软件能够在任何 Windows、Linux 或 Mac 操作系统上工作。创建项目后,您所要做的就是将它编译成您所选择的操作系统的可执行文件。
命令行
命令行应用程序是那些在控制台窗口中工作的应用程序。这是 Windows 上的命令提示符,Linux 和 Mac 上的终端。
您可以点击使用 web 或 GUI 应用程序,但是您需要为命令行应用程序键入命令。命令行应用程序的用户需要有一些技术知识,因为他们需要使用命令。
命令行应用程序可能不如 web 或 GUI 应用程序漂亮或易用,但这并不意味着它们不如 web 或 GUI 应用程序强大。
您可以通过对文本应用颜色来改善命令行应用程序的外观。有可以用来上色的库,比如coloramacolored。你可以用一些颜色来增加情趣。
您可以使用诸如docopt``argparse和click 等框架来构建您的应用程序。
网络项目创意
在本节中,您将看到针对 web 的项目创意。这些项目创意可以归类为实用工具和教育工具。
以下是项目构想:
- 内容聚合器
- 正则表达式查询工具
- URL 缩写
- 便利贴
- 测验应用程序
内容聚合器
内容为王。它在网络上无处不在,从博客到社交媒体平台。为了跟上,你需要不断地在互联网上搜索新的信息。保持更新的一个方法是手动检查所有网站,看看有什么新帖子。但是这很费时间,也很累。
这就是内容聚合器的用武之地:内容聚合器从网上的各个地方获取信息,并将所有这些信息收集到一个地方。因此,你不必访问多个网站来获取最新信息:一个网站就足够了。
注意:按照这个基于项目的教程,用 Python 和 Django 为播客构建一个内容聚合器。使用定制管理命令、feedparser 和 django-apscheduler,您将设置一个应用程序来定期解析 Python 播客的 RSS 提要,并向您的用户显示最新的剧集。
有了内容聚合器,所有最新的信息都可以从一个聚合了所有内容的站点获得。人们可以看到他们感兴趣的帖子,并可以决定找到更多关于他们的信息,而不必在互联网上到处闲逛。
内容聚合器的例子
以下是内容聚合器理念的一些实现:
技术细节
这个项目理念的主要目标是聚合内容。首先,您需要知道您希望内容聚合器从哪些站点获取内容。然后,您可以使用诸如 requests 之类的库来发送 HTTP 请求,并使用 BeautifulSoup 来解析和抓取站点中的必要内容。
您的应用程序可以将其内容聚合作为后台进程来实现。像 celery 或apscheduler这样的库可以在这方面提供帮助。你可以试试apscheduler。它非常适合小型后台进程。
从各个网站抓取内容后,你需要把它保存在某个地方。因此,您将使用一个数据库来保存抓取的内容。
额外挑战
对于更艰难的挑战,你可以添加更多的网站。这将帮助你学会如何从网站上学习和提取信息。
您还可以让用户订阅您聚合的某些站点。然后,在一天结束时,内容聚合器会将当天的文章发送到用户的电子邮件地址。
正则表达式查询工具
你和我每天都和短信打交道。这篇文章也是正文,是有结构的。这让你更容易理解。有时,您需要在文本中查找某些信息,使用文本编辑器中的常规搜索工具可能会无效。
这就是正则表达式查询工具的用武之地。regex 是一组字符串,因此 regex 查询工具将检查查询的有效性。当正则表达式匹配文本中的模式时,它会告诉用户并突出显示匹配的模式。因此,您的正则表达式查询工具将检查用户传入的正则表达式字符串的有效性。
使用正则表达式查询工具,用户可以在网上快速检查他们的正则表达式字符串的有效性。这对他们来说更容易,而不是用文本编辑器检查字符串。
正则表达式查询工具示例
以下是正则表达式查询工具思想的一些实现:
技术细节
这类项目的主要目标是告诉用户输入的查询字符串的有效性。您可以让它给出肯定或否定的响应,如Query String Is Valid和Query String Is Invalid,用绿色实现肯定响应,用红色实现否定响应。
您不必从头开始实现查询工具。您可以使用 Python 的标准re库,您可以使用它在输入的文本上运行查询字符串。当查询字符串不匹配任何内容时,re库将返回None,当结果为正时,它将返回匹配的字符串。
有些用户可能不完全理解 regex,所以你可以制作一个页面来解释 regex 是如何工作的。您可以制作足够有趣的文档,让用户对学习和理解 regex 充满兴趣。
额外挑战
创建一个只返回正则表达式有效性的项目是没问题的。但是您也可以添加替换功能。这意味着应用程序将检查正则表达式的有效性,并允许用户用其他内容替换匹配的字符串。因此,该工具不再是查找工具,而是替换工具。
网址缩写
URL 可能会非常长,而且对用户不友好。当人们分享链接,甚至试图记住一个网址时,这是很困难的,因为大多数网址都充满了更难的字符,没有形成有意义的单词。
这就是网址缩写的用武之地。URL 缩写减少了 URL 中的字符或字母,使它们更容易阅读和记忆。像xyz.com/wwryb78&svnhkn%sghq?sfiyh这样的网址可以简称为xyz.com/piojwr。
有了 URL Shortener,使用 URL 变成了一种乐趣。
网址缩写示例
以下是 URL 缩写思想的一些实现:
- 一点点
- TinyURL
技术细节
这个项目想法的主要目标是缩短网址。该应用程序将完成的主要任务是缩短 URL,然后在访问缩短的 URL 时将用户重定向到原始 URL。
注意:如果你想通过一步一步的支持来构建一个网址缩短器,那么请查看用 FastAPI 和 Python 构建一个网址缩短器。
在应用程序中,用户将输入原始的 URL,他们将得到新的、缩短的 URL 作为结果。为此,您可以使用random和string模块的组合来为缩短的 URL 生成字符。
因为用户会在几天、几个月甚至几年后访问缩短的 URL,所以您需要将原始的和缩短的 URL 保存在数据库中。当请求进来时,应用程序检查 URL 是否存在,并重定向到原来的 URL,否则它重定向到 404 页面。
额外挑战
用随机字符生成一个短的 URL 比长的随机的 URL 更好。但是,您可以为用户提供更好的结果。您可以添加一个特性来定制 URL,这样用户就可以自己定制生成的 URL。
毫无疑问,自定义的xyz.com/mysite URL 比随机生成的xyz.com/piojwr URL 要好。
便利贴
一天有很多想法和想法是人之常情,但是忘记也是人之常情。解决忘记事情的一个方法是在事情消失之前把它们记下来。虽然有些被遗忘的想法和观念可能是微不足道的,但有些可能是非常强大的。
这就是便利贴的用武之地:便利贴是一种背面带有低粘性粘合剂的小纸,可以贴在文件、墙壁等表面上。便利贴让记下事情变得更容易。便利贴项目的想法是类似的。因为它是一个网络应用程序,所以它允许用户记下东西,让他们在任何地方都可以访问。
有了便利贴,人们现在可以在任何地方记下事情,而不用担心忘记事情或放错笔记——这是物理笔记的一种可能性。
便利贴示例
以下是便利贴创意的一些实现:
技术细节
这个项目的主要目标是让用户记下想法。这意味着每个用户都有自己的笔记,所以应用程序需要有一个帐户创建功能。这确保了每个用户的笔记对他们来说是私有的。
django自带用户认证系统,所以可能是个不错的选择。您可以使用其他框架,如bottle或flask,但是您必须自己实现用户认证系统。
由于用户可能需要将他们的笔记放在不同的部分,实现一个允许用户对他们的笔记进行分类的特性将使应用程序更加有用。
举个例子,你可能需要关于算法和数据结构的笔记,所以你需要能够把这些笔记分门别类。
您需要存储每个用户的信息和笔记,因此数据库成为这个项目的一个重要部分。如果您想使用一个 MySQL 数据库或 PostgreSQL 数据库的psycopg2模块,可以使用MySQLdb模块。您还可以使用其他模块,但这完全取决于您选择使用的数据库。
额外挑战
既然用户忘记他们的想法是人之常情,那么他们忘记他们甚至在某个地方做了笔记也是人之常情。您可以添加一个功能来提醒用户他们的笔记。这个特性将允许用户设置提醒的时间,所以应用程序将通过电子邮件发送提醒给用户。
测验应用程序
知识就是力量。世界上有如此多的东西需要学习,测验有助于测试对这些概念的理解。作为一名中级 Python 开发人员,您不需要了解该语言的所有内容。参加考试是找出你不完全理解的东西的一种方法。
注意:如果你想一步一步地构建一个测验,你可以查看用 Python 构建一个测验应用。
这就是问答应用程序的用武之地。测验应用程序将向用户提出问题,并期待这些问题的正确答案。可以将测验应用程序想象成一种问卷。
使用测验应用程序,可以称为管理员的特殊用户将被允许创建测试,因此普通用户可以回答问题并测试他们对测验主题的理解。
问答应用示例
下面是测验应用程序思想的一些实现:
技术细节
这个项目的主要目标是设置测验,并让人们回答它们。因此,用户应该能够设置问题,其他用户应该能够回答这些问题。该应用程序将显示最终分数和正确答案。
如果您希望用户能够记录他们的分数,您可能需要实现一个帐户创建功能。
创建测试的用户应该能够通过简单地上传一个文本文件来创建带有问题和答案的测试。该文本文件将有一个您可以决定的格式,因此应用程序可以从文件转换为测验。
你需要为这个项目实现一个数据库。该数据库将存储每个用户的问题、可能的答案、正确答案和分数。
额外挑战
对于更多的挑战,您可以允许用户在测验中添加计时器。这样,测验的创建者可以确定用户在测验中的每个问题上应该花费多少秒或多少分钟。
如果能有一个测验分享功能就太好了,这样用户就可以和其他平台上的朋友分享有趣的测验。
GUI 项目创意
在本节中,您将看到图形用户界面的项目构想。这些项目创意可以分为娱乐、金融和实用工具。
以下是项目构想:
- MP3 播放器
- 警报工具
- 文件管理器
- 费用跟踪器
MP3 播放器
如今,音频和文本一样重要,甚至更重要。由于音频文件是数字文件,你需要一个可以播放它们的工具。没有播放器,您将永远无法听到音频文件的内容。
这就是 MP3 播放器的用武之地。MP3 播放器是一种播放 MP3 和其他数字音频文件的设备。这个 MP3 播放器 GUI 项目想法试图模仿物理 MP3 播放器。你可以开发软件,让你在台式机或笔记本电脑上播放 MP3 文件。
当您完成构建 MP3 播放器项目时,用户可以播放他们的 MP3 文件和其他数字音频文件,而不必购买物理 MP3 播放器。他们可以用电脑播放 MP3 文件。
MP3 播放器示例
以下是 MP3 播放器理念的一些实现:
技术细节
这个项目的主要目标是允许用户播放 MP3 和数字音频文件。为了吸引用户,应用程序必须有一个简单但漂亮的用户界面。
你可以有一个列出可用 MP3 文件的界面。您还可以让用户选择列出其他非 MP3 的数字音频文件。
用户还期望 MP3 播放器具有显示正在播放的文件的信息的界面。您可以包括的一些信息有文件名、文件长度、播放量和未播放量,以分钟和秒为单位。
Python 有可以播放音频文件的库,比如 pygame ,让你用几行代码就能处理多媒体文件。还可以查看pymediasimpleaudio。
这些库可以处理大量的数字音频文件。它们可以处理其他文件类型,而不仅仅是 MP3 文件。
您还可以实现允许用户创建播放列表的功能。为此,您需要一个数据库来存储创建的播放列表的信息。Python 的sqlite3模块允许你使用 SQLite 数据库。
在这种情况下,SQLite 数据库是更好的选择,因为它是基于文件的,比其他 SQL 数据库更容易设置。虽然 SQLite 是基于文件的,它比常规文件更适合保存数据。
额外挑战
对于更令人兴奋的挑战,您可以添加一个功能,允许 MP3 播放器重复当前播放的文件,甚至随机播放要播放的文件列表。
还可以实现一个功能,允许用户提高或降低音频文件的播放速度。用户会发现这很有趣,因为他们可以比平时更慢或更快地播放文件。
报警工具
就像他们说的,“时间不等人。”但是随着我们生活中许多事情的发生,很难不忘记时间。为了能够掌握时间,需要一个提醒。
这就是报警工具的用武之地。警报器是一种在特定条件下发出声音或视觉信号的装置。这个报警工具项目的想法是试图建立一个软件报警。当满足特定条件时,警报工具会发出声音信号。设定时间是这种情况下的特定条件。
使用闹铃工具,用户可以设置闹铃,在一天中的特定时间提醒他们一些事情。警报工具项目将在用户的笔记本电脑或桌面设备上工作,因此他们不必购买物理计时器。
报警工具示例
以下是警报工具理念的一些实现:
技术细节
这个项目的主要目标是在一天中的特定时间激活音频信号。因此,定时和要播放的音频信号是报警工具最重要的部分。
警报工具应该允许用户创建、编辑和删除警报。它还应该有一个列出所有警报的界面,前提是它们没有被用户删除。因此,它应该列出活动和非活动的警报。
由于是闹铃,应用程序必须在设定的时间播放铃声。有播放音频的库,像 pygame 库。
在您的代码逻辑中,应用程序必须不断检查设置的报警时间。当时间到了,它会触发一个功能来播放闹铃。
由于应用程序将检查设置的报警时间,这意味着应用程序必须将报警保存在数据库中。数据库应该存储像报警日期、时间和音调位置这样的东西。
额外挑战
作为一个额外的功能,您可以允许用户设置重复报警。他们可以设置闹钟,在每周的某一天的某个时间响起。例如,可以在每周一下午 2:00 设置闹钟。
您还可以添加一个暂停功能,这样您的用户就可以暂停提醒,而不仅仅是解除它们。
文件管理器
普通个人电脑用户个人电脑上的文件数量相当多。如果所有这些文件都放在一个目录中,将很难导航和找到文件或目录。因此,有必要合理地安排和管理这些文件。
这就是文件管理器的用武之地。文件管理器允许用户通过用户界面管理文件和目录。虽然可以通过命令行管理文件,但并非所有用户都知道如何操作。
使用文件管理器,用户可以正确地安排、访问和管理他们的文件和目录,而不需要知道如何使用命令行。文件管理器允许用户执行的一些任务包括复制、移动和重命名文件或目录。
文件管理器工具示例
以下是文件管理器思想的一些实现:
技术细节
文件管理器项目的主要目标是给用户一个界面来管理他们的文件。用户想要一个文件管理器,它有一个看起来不错并且容易使用的文件管理工具。
您可以使用PySimpleGUI库通过强大的小部件创建独特的用户界面,而不必处理大量的复杂性。
您的用户应该能够执行简单的任务,如创建新目录或空文本文件。他们还应该能够复制和移动文件或目录。
对于这个项目来说,sys、os和shutil库将会非常有用,因为当用户点击离开时,它们可以用来在后台对文件执行操作。
网格和列表视图是当今流行的视图,因此您可以在应用程序中实现这两种视图。这为用户提供了选择适合他们的视图选项的选项。
额外挑战
为了让文件管理器更高级一点,你可以实现一个搜索特性。因此用户可以搜索文件和目录,而不必手动查找。
您还可以实现排序功能。这将允许用户根据不同的顺序对文件进行排序,例如时间、字母顺序或大小。
费用跟踪器
我们有日常开销,从杂货到衣服到账单。开支如此之多,以至于忘记它们并一直花下去直到我们几乎没有现金是很正常的。追踪器可以帮助人们观察他们的开销。
这就是费用跟踪器的用武之地。费用追踪器是一个软件工具,允许用户追踪他们的费用。它还可以分析费用,这取决于它有多先进,但现在让我们保持简单。
使用费用跟踪器,用户可以设置预算并跟踪他们的支出,以便做出更好的财务决策。
费用追踪器示例
以下是费用追踪器理念的一些实现:
- 布迪
- gnucash
技术细节
这个项目的主要目标是跟踪用户的费用。必须进行一些统计分析,才能给用户提供正确的费用信息,帮助他们更好地消费。
虽然跟踪费用是关键,但一个好的界面也很重要。使用PySimpleGUI,你可以创建一个独特的界面来改善用户的体验。
PyData 库,比如pandas和matplotlib,对于构建费用跟踪器很有帮助。
pandas 库可用于数据分析, matplotlib 库可用于绘制图形。图表将为用户提供一个直观的费用表示,而直观的表示通常更容易理解。
应用程序将从用户那里接收数据。这里的数据是输入的费用。因此,您必须将费用存储在数据库中。对于这个项目来说,SQLite 数据库是一个很好的数据库选择,因为它可以快速设置。您可以将sqlite3模块用于 SQLite 数据库。
额外挑战
为了让你的用户从这个项目中受益,他们必须定期输入他们的费用,这可能会让他们忘记。实现一个提醒功能可能对你有用。因此,应用程序将在一天或一周的特定时间发送通知,提醒他们使用费用跟踪器。
命令行项目理念
在本节中,您将看到命令行的项目思路。讨论的项目想法可以归类为实用工具。
以下是项目构想:
- 联系簿
- 站点连接检查器
- 批量文件重命名工具
- 目录树生成器
通讯录
我们每天都会遇到很多人。我们结交熟人和朋友。我们让他们的联系人保持联系。遗憾的是,保留收到的联系方式可能很难。一种方法是写下联系方式。但是这并不安全,因为实体书很容易丢失。
这就是联系簿项目的用武之地。通讯录是保存联系人详细信息的工具,如姓名、地址、电话号码和电子邮件地址。有了这个通讯录项目,您可以构建一个软件工具,人们可以使用它来保存和查找联系人的详细信息。
利用联系簿项目理念,用户可以保存他们的联系人,而丢失保存的联系人详细信息的风险更小。它总是可以从他们的计算机上通过命令行访问。
通讯录工具示例
有通讯录应用程序,但很少找到命令行通讯录产品,因为大多数是 web、移动或 GUI 应用程序。
注意:要深入了解如何构建基于 GUI 的通讯录,请查看用 Python、PyQt 和 SQLite 构建通讯录。
以下是联系簿理念的一些实现:
技术细节
这个项目的主要目标是保存联系方式。设置用户可以用来输入联系人详细信息的命令非常重要。您可以使用argparse或click命令行框架。它们抽象了很多复杂的东西,所以你只需要关注执行命令时要运行的逻辑。
您应该实现的一些功能包括删除联系人、更新联系人信息和列出保存的联系人的命令。您还可以允许用户使用不同的参数列出联系人,如字母顺序或联系人创建日期。
由于这是一个命令行项目,SQLite 数据库可以很好地保存联系人。SQLite 易于用户设置。您可以将联系人的详细信息保存在文件中,但是文件不能提供使用 SQLite 所能获得的好处,比如性能和安全性。
为了在这个项目中使用 SQLite 数据库,Python sqlite3模块将非常有用。
额外挑战
还记得数据库是如何存储在用户计算机上的吗?如果发生了什么事情,比如用户丢失了文件,该怎么办?这意味着他们也将失去联系方式。
您可以进一步挑战自己,将数据库备份到在线存储平台。为此,您可以每隔一段时间将数据库文件上传到云中。
您还可以添加一个命令,允许用户自己备份数据库。这样,如果数据库文件丢失,用户仍然可以访问联系人。
您应该注意到,您可能需要某种形式的标识,以便通讯录可以告诉哪个数据库文件属于哪个用户。实现用户认证特性是一种方法。
站点连接检查器
当你访问一个 URL 时,你期望在你的浏览器上得到所请求的页面。但情况并非总是如此。有时,网站可能会关闭,所以你不会得到想要的结果。相反,您将看到错误消息。你可以不断尝试一个关闭的网站,直到它出现,你得到你需要的信息。
这就是站点连通性检查器项目的用武之地。站点连接检查器访问 URL 并返回 URL 的状态:它是活动的还是非活动的。站点连接检查器将定期访问 URL,并返回每次访问的结果。
取代手动访问 URL,站点连接检查器可以为您完成所有的手动工作。这样,你将只得到检查的结果,而不必花时间在浏览器上,等待网站上线。
站点连接检查器示例
以下是站点连通性检查器理念的一些实现:
技术细节
这个项目的主要目标是检查网站的状态。因此,您需要编写代码来检查网站的状态。
您可以选择使用 TCP 或 ICMP 进行连接。 socket 模块是一个要检出的模块。也可以阅读 Python 中的 Socket 编程(指南)。
注意:查看用 Python 构建站点连通性检查器查看创建站点连通性检查器的分步示例。
通过您选择的框架,无论是docopt、click还是argparse框架,您都可以添加命令来允许用户在要检查的站点列表中添加和删除站点。
用户还应该能够启动该工具,停止它,并确定时间间隔。
由于您必须保存要检查的文件列表,您可以将它保存在一个文件中(只是一个站点列表),或者通过sqlite3模块使用 SQLite 数据库。
额外挑战
应用程序可以检查站点的连接状态,并将结果显示在命令行上。但是这将要求用户不断检查命令行。
您可以增加挑战并实现通知功能。通知功能可以是在后台播放的声音,以在网站状态发生变化时提醒用户。你需要一个数据库来存储网站以前的状态。这是该工具判断状态何时改变的唯一方式。
批量文件重命名工具
有时,您需要根据某些约定命名目录中的所有文件。例如,您可以用File0001.jpg命名目录中的所有文件,其中数字根据目录中文件的数量增加。手动完成这项工作可能会有压力且重复。
批量文件重命名工具允许用户重命名大量文件,而不必手动重命名文件。
这为用户节省了大量时间。这让他们免去了不得不做无聊的重复性工作和犯错误的麻烦。使用批量文件重命名工具,用户可以在几秒钟内正确地重命名文件。
批量文件重命名工具示例
下面是批量文件重命名思想的一些实现:
技术细节
这个项目想法的主要目标是重命名文件。因此,应用程序需要找到一种方法来操作目标文件。这个os、sys和shutil库对这个项目的大部分都很有用。
注意:要深入了解如何构建基于 GUI 的通讯录,请查看用 Python 和 PyQt 构建批量文件重命名工具。
您的用户将能够使用命名约定重命名目录中的所有文件。因此,它们应该能够传递选择的命名约定。如果您理解 regex 是如何工作的,那么regex模块将有助于匹配所需的命名模式。
用户可能希望在命令中传递一个命名约定,如myfiles,并期望该工具像myfilesXYZ一样重命名所有文件,其中XYZ是一个数字。他们还应该能够选择要重命名的文件所在的目录。
额外挑战
这个项目的主要挑战是重命名一个目录中的所有文件。但是用户可能只需要命名一定数量的文件。为了测试您的技能,您可以实现一个特性,允许用户选择要重命名的文件数量,而不是所有文件。
请注意,仅重命名一定数量的文件将需要该工具根据字母顺序、文件创建时间或文件大小对文件进行排序,这取决于用户的要求。
目录树生成器
目录就像家谱:每个目录都与其他目录有特定的关系。除了一个空的根目录,没有任何目录是独立的。
当您处理文件和目录时,很难看到目录之间的关系,因为您只能看到当前目录中存在的内容。您要么使用文件管理器,要么从命令行工作。
使用目录树生成器,您可以像查看树或地图一样查看文件和目录之间的关系。
这使得理解文件和目录的定位更加容易。当您解释某些概念时,目录树图很重要,目录树生成器可以更容易地获得文件和目录关系的可视化表示。
目录树生成器示例
下面是目录树生成器思想的一些实现:
技术细节
目录树生成器的主要目的是可视化文件和目录之间的关系。在列出所选目录中的文件和目录时,os库非常有用。
使用像docopt或argparse这样的框架有助于抽象很多东西,让你专注于为应用程序的逻辑编写代码。
注意: 为命令行构建一个 Python 目录树生成器是一个循序渐进的教程,向您展示了一种构建目录树生成器的方法。
在应用程序的逻辑中,您可以决定如何表示文件或目录。使用不同的颜色是一个聪明的方法。您可以使用colored库以不同的颜色打印文件和目录。
您还可以决定目录树生成器的深度。例如,如果一个目录有 12 层的子目录,您可以决定只到第 5 层。
如果您愿意,您还可以让用户决定他们希望目录树生成器进行到多深。
额外挑战
由于生成的目录树的结果将出现在命令行上,您可以更进一步。您可以让生成器创建目录树的图像,所以它基本上会将文本转换成图像。
你会发现 pillow 库对此很有用。
关于项目工作的提示
从事项目工作可能会很困难。这就是为什么对一个项目的动机和兴趣会使它不那么令人生畏的原因之一。
如果你对一个项目感兴趣,你可以花时间去研究,找到对你的项目有帮助的库和工具。
以下是一些建议:
- 找到动力的来源
- 将项目分解成子任务
- 研究子任务
- 一步一步地构建每个子任务
- 如果你被困住了,就寻求帮助
- 将子任务放在一起
结论
在本文中,您已经看到了一些您可能会感兴趣的 Python 项目想法。
项目理念涵盖了一系列平台。您看到了 Web、GUI 和命令行平台的项目构想。
您可以选择为不同的平台构建一个项目。以 URL Shortener 为例,您可以选择为 Web、GUI 或命令行构建一个。
由于您是一名中级 Python 开发人员,这些项目可能很有挑战性,但也很有趣。
让一个项目发生的最好方法就是开始。很快,你就会完成并发现你从一个项目中获益良多!
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 用 13 个中级项目想法 增长您的 Python 作品集*********
与 Al Sweigart 的 Python 社区访谈
本周,我邀请到了 Al Sweigart ,这是 Python 社区中一个熟悉的名字。Al 是一名出色的开发人员、会议发言人、教师和折纸艺术家。(是的,你没看错!)但有些人可能最了解他,因为他是许多 Python 编程书籍的作者,包括畅销书 用 Python 自动化枯燥的东西 和我们的顶级精选, 用 Python 发明你自己的电脑游戏 。所以,事不宜迟,让我们开始吧!
瑞奇: 欢迎来到真正的巨蟒,艾尔。我们很高兴你能加入我们的采访。让我们像对待所有客人一样开始吧。你是如何开始编程的,你是什么时候开始使用 Python 的?

艾尔:谢谢!嘿,我绝对不喜欢告诉别人我是如何进入编程的,因为我是那些大约在三年级左右开始学习基础知识的孩子之一。
我不喜欢告诉人们这一点,因为我觉得这助长了这样一种想法,即为了成为一名程序员,你必须在很小的时候就开始。就像,如果你不是在胎儿时期调试子程序,你就没有机会成为职业。所以我告诉人们我小时候就开始了。
我还告诉他们,几年来,我的大多数项目都相当平庸。我没有维基百科或谷歌或 Stack Overflow,所以我一直在做“猜数字”游戏的变体,或者开始我没有技术知识来完成的项目。我的领先并不意味着什么。我在童年和青少年时期学习的关于编程和计算机的所有知识,今天在几十个周末就能学会。
我认为年轻时开始的主要好处是我不知道编程应该是很难的。今天,每个人都会想到人工智能和机器学习以及具有令人惊叹的 3D 图形的视频游戏。我只是在业余时间以一种完全不专注的方式闲荡,但我对此完全无所谓。
我没有学到太多的知识,但我确实明白了编程只是一件你可以像学习其他事情一样学习的事情。这不需要超级聪明或者奥林匹克级别的训练。
我的第一门编程语言是 BASIC,在 Qbasic 之后不久,但我也学了一点点 C ,Visual Basic,Perl, Java ,PHP 和 JavaScript。看起来很多,但是我从来没有真正掌握过其中的任何一个。我只是学会了足够完成我当时用这些语言做的任何项目。
我在 2005 年左右开始学习 Python,从那以后就不再学习新的语言了。我一直有探索新技术的冲动(Kotlin、Rust 和 Dart 已经进入我的视线有一段时间了),但是 Python 在很多领域都很容易使用,我还没有足够的动力离开它。
里奇: 你知道,我的第一本 Python 编程书是你的书 用 Python 把枯燥的东西自动化。这是我至今仍在引用的一句话。我很想知道是什么激发了你写这本书,它并不一定是针对那些想成为传统意义上的职业程序员的人?
艾尔:哈哈,我总是惊讶于那本书变得如此受欢迎!我自己仍然会参考这本书:当我在做一些事情,不太记得函数名时,我会意识到,“等等,我之前写下来了。”我真的很讨厌工作面试,他们禁止你查阅编码面试的书籍或文档。当我编程的时候,我会参考我写的的书。
我在 2008 年或 2009 年左右开始写书。我当时的女朋友是一个 10 岁孩子的保姆,想学编码,但是我在网上找不到我喜欢的给他的教程。所有的东西要么是软件工程师的,要么是老一套的“让我们来计算斐波那契数”的东西。
我回想起我是如何通过那些列出小游戏源代码的杂志和书籍进入编码的。我只理解了一半的说明文字,但是复制源代码并做一些小的修改确实向我展示了如何将程序组合在一起。
所以我写了一个教程,越写越长,最终变成了 用 Python 发明你自己的电脑游戏。我把它放在网上,然后把它作为自己出版的书名出售。我的日常工作仍然是软件开发人员,我从未真正认为写书是一种职业。
我在知识共享版权许可下发布了这本书,人们可以免费下载和分享。这被证明是至关重要的,因为它让人们分享这本书,并产生口碑。如果没有知识共享许可,它将只是亚马逊上的又一个自我出版清单,我也不会有现在的职业生涯。免费提供这本书导致了更多的销售。
所以我写了一本书又一本书,为了我的第四本书(将成为用 Python 自动化枯燥的东西),我和没有淀粉出版社签了合同。我真的很喜欢和他们一起工作:他们的编辑很棒,他们的书都是高质量的,他们对我继续在知识共享许可下发行图书也很满意。
大约在 2012 年,“每个人都应该学习编码”再次成为新闻焦点,在过去的几十年里,似乎每隔五年或十年就会出现一次。我想,“当然,但是为什么?”不是每个人都需要成为软件工程师,也没有人需要计算斐波那契数。
我想到了非程序员可以用编码做什么。二十年前,如果你每天都在网上和你的朋友聊天,你可能是一个超级书呆子。但是今天,你只是一个普通的脸书用户。许多人在办公室或家里使用电脑。
他们希望自动化哪些不需要计算机科学学位的事情?事实证明,有很多!我有一个朋友开玩笑说,如果你想成为一个百万富翁创业创始人,只要找到一个仍然使用传真机和 Excel 电子表格的行业,然后编写被整个领域采用的 web 应用程序。
所以我有一个类似“更新电子表格”和“发送通知电子邮件”的东西的列表,所有这些都变成了用 Python 自动处理无聊的东西。我当时的软件开发工作已经有点过时了,所以我想我会花一年时间完成自动化,然后再找一份软件开发工作。我已经做了六年的全职作家和在线课程开发者。
运气真好。我很幸运,有数百人对像 Python 这样的免费开源语言做出了贡献,这使得编程变得如此简单。我很幸运,我有存款,所以我可以冒险写书。我很幸运,其他人创造了自由软件文化,导致了像知识共享许可这样的事情。
所以当人们问我写书的建议时,有点像问一个彩票中奖者选什么号码。我仍然认为我们的社会中有许多不必要的障碍需要被拆除,让人们发挥他们的全部潜力,所以这个目标一直是我的指路明灯。
任何在 Twitter 上关注你一段时间的人都会知道你热衷于向学习编程的人教授 Python。你似乎特别喜欢用视频游戏作为切入点。你是否发现更多地关注“有趣”的话题有助于你接触到更多的人,并帮助他们进入 Python?这是故意的,还是你在挠自己的痒?
Al: 前几天,我发现了一张来自马哈茂德·哈希米 2019 年 PyBay 演讲的幻灯片,标题是“开始想编码的两个原因”,它有一个维恩图,上面写着“我想制作一个视频游戏”和“我想摆脱 Excel”我从未见过我的整个教学和写作生涯被如此概括。视频游戏是编程的绝佳入口,尤其是有了像麻省理工学院的 Scratch 这样的工具。但是有时候用电子游戏有点困难。
我会站在一个 9 岁孩子的教室前说,“我们要做一个游戏,”他们会想到《我的世界》或野性的呼吸或其他一些有一个一亿美元预算的专业开发团队的名字,而我会说,“我们做一个迷宫或西蒙说游戏怎么样?”这都是关于管理期望。创造一些东西,告诉计算机做什么,看着它做,这仍然是最基本的乐趣。
我一直致力于用 Python 创建一系列小的、容易理解的、基于文本的游戏,我已经把这些游戏放到了网上。这个想法是,一旦你知道了像循环和变量这样的编程概念,你就可以在这些游戏的实际程序中看到这些概念。
当人们告诉新程序员通过阅读开源项目的代码变得更好时,我不寒而栗,因为这些项目通常是巨大的,并且没有很好的文档记录。他们中很少有人有入门指南来帮助新志愿者熟悉代码库,所以很难理解这些代码。
新的编码员只是感到害怕。所以我的简单游戏就像自行车上的训练轮,我遵循的强制简化的约束实际上很好地让我想出了有创意但简单的程序。
我绝不是游戏设计师。我制作的所有游戏最多只有几百行代码,而且都是机械性很强的东西,比如俄罗斯方块和 T2 成长蠕虫游戏 T3,每个人都可以在他们的诺基亚手机上玩。这些游戏不需要太多的图形和关卡设计。
我对像托比·福克斯和埃里克·巴隆这样的人感到敬畏,他们花了数年时间分别创造了地下谷和明星谷。但即使是那些游戏也是站在巨人的肩膀上。 Undertale 和 Stardew Valley 受到 Earthbound 和 Harvest Moon 的启发,但受益于现代游戏设计的洞察力(以及 Fox 和 Barone 压倒性的天赋)。
同样,我所有的基于文本的游戏都类似于你会在大卫·阿尔的《基础电脑游戏》书或七八十年代的《T2 字节》杂志中找到的那些游戏,但是受益于几十年的游戏设计理论。所有这些对我来说都是有意的(如果不是为了从中获得编程教程,我不会创建这些小游戏),但我不认为我能以任何其他方式做到这一点;没有什么比这些有趣的小视频游戏更能吸引孩子和成年人编程了。
此外,任何在 Twitter 上关注我一段时间的人都会知道,我热衷于政治演说。至少,我试着站在建设性的一方。
你是为数不多的在 Twitch 上运行代码的程序员之一(而且绝对是我所知道的为数不多的 Python 程序员之一)。这种体验如何,你从这个过程中学到了什么?我们需要鼓励更多的 Python Twitch 飘带吗?
艾尔:在过去的几年里,我断断续续地在流,有时在流之间有几周或几个月。这是一个不幸的事实,你必须把它作为一份全职工作做大约一年,然后才能把受众扩大到可以维持职业生涯的规模,而我没有那样的时间。但是作为一种爱好还是不错的。
我可以一边玩小游戏,一边录制自己创建的在线课程。它让我在编码和叙述时练习在镜头前,这对我的在线视频课程工作很有用。它让我接触到初学者,所以我可以了解他们有什么问题。
Twitch 在我上传视频一周后删除了我的视频,一些人要求我将它们永久保存,但我真的不认为这比在后台保存更多。我更喜欢制作精美的 10 分钟视频,而不是花四个小时漫无边际地查找文档。
里基: 现在我们最后几个问题。你在业余时间还做些什么?除了 Python 和编码,你还有什么其他的爱好和兴趣?
Al: 业余时间,嗯?恐怕我不明白这个问题…
我目前职业的一个好处是,它确实让我很忙。编写编程教程几乎是我的业余爱好,现在我开始全职做这件事,这带来了所有的好处和坏处。我有足够的项目持续到 2021 年,但同时,我希望它们现在就全部完成。
完成我目前的书和视频的最大动力是我将能够开始我的下一本书和视频。我开玩笑地问一个朋友,开始吸食可卡因是否会提高我的工作效率,她说,“当然,首先。”
但是除了写程序和写关于程序的书,我喜欢做折纸。这是我小时候感兴趣的东西,但我总是在书中的折叠图中读到一半,然后到达一个我无法理解的步骤,我不得不放弃它。
这是我童年时代的另一件事,互联网有了巨大的进步:这些天,网上有一百万个折纸视频,所以我能够把模型放在一起,这比我小时候做的任何事情都更令人印象深刻。
另一个朋友指出,写软件,写书,折纸,本质上我所有的爱好都有一个共同点:都很便宜!给我一台旧笔记本电脑和一叠纸,我就相当满足了。
如果你想知道艾尔在做什么,你可以在推特上和他打招呼。他的博客和他的大量书籍可以在他的网站上找到,用 Python 发明。谢谢你,艾尔,和我聊天!
如果你有想让我采访的人,请在下面留言告诉我。
与阿里·斯皮特尔的 Python 社区访谈
2019 快乐!在我们今年的第一次社区采访中,我和阿里·斯皮特尔一起。
Ali 是一个热爱 CSS 艺术和教授 Python 的 Python 爱好者。加入我们,一起讨论她学习编码的非传统途径,在训练营教学,以及她最近加入最积极的开发者社区之一。
里基: 欢迎你,阿里!谢谢你来参加这次面试。让我们从通常的第一个问题开始。你是怎么进入编程的?你是什么时候开始用 Python 的?
阿里:谢谢你邀请我!我是在大学二年级的时候开始接触编程的。我随机去了一个计算机科学班,因为这学期我有额外的学分。
那是一门 Python 课,我爱上了它。我在学期中途决定尝试双修计算机科学。他们甚至给了我一份下学期的助教工作!
然后,下学期,我上了 C++的数据结构和算法。我讨厌它,我不得不把这么多的工作放在课堂上。我觉得编程不适合我,所以我放弃了编程。我之所以重新进入这个领域,是因为我得到了一份带薪编程实习的工作,但在政治领域找不到,而这正是我当时感兴趣的领域!

Ricky: 直到最近,你还是在华盛顿特区大会上 Web 开发沉浸式项目的首席讲师
我很想知道在编码训练营教学是什么样的,随着训练营变得越来越普遍并被接受为成为开发人员的非传统途径,它有什么变化?
阿里:教书是我做过的最有回报的事情之一。看到素材为学生点击,看到他们的成长,很牛逼。我也喜欢建立一个课程,塑造人们在旅程开始时如何看待代码。
我认为训练营对于增加技术多样性非常重要,训练营中有很多很好的项目,为经济困难或技术领域代表性不足的人群服务。
在 GA 工作的最后 9 个月,我为他们的企业项目工作,在那里我为培训员工的公司现场授课。
我喜欢这些公司真的投资于他们的员工,这些学生可以真正专注于他们的教育,而不必担心做编码训练营的财务问题。
事实上,我仍然在华盛顿教授他们的 Python 兼职课程,尽管我不再全职授课了!
在大学做助教和在大会工作之间,教学似乎是你喜欢做的事情。去年,你在此基础上进行了扩展,T3 开了一个博客,这个博客变得非常受欢迎。是什么让你决定开始写博客,早期的成功有没有让你感到惊讶?
阿里:我开始写得很随意。我有一个 CSS 艺术博客帖子的想法,然后决定我可以更进一步,写一系列关于学习新东西的文章。我开始在 Medium 上,在那里我几乎没有得到任何关注,然后过了一会儿,我发现发展到,那里有更多的人在阅读我的作品。
我放弃写作几个月,因为我得到了越来越多的演讲角色,我更加专注于此。
然后今年夏天我搬到康涅狄格工作,我不认识很多人。我有一个博客的概念,它是编程博客和生活博客的混合体。这些帖子开始获得一些关注,这很棒。
瑞奇: 你也是华盛顿 meetup circuit 的成员,最值得一提的是女性编码的华盛顿分会,该分会现在有近 9000 名会员!华盛顿的聚会怎么样,尤其是对女性和少数族裔?你会给想去参加第一次聚会的人什么建议?
阿里:DC 的 meetup 场景太棒了!几乎每天晚上都有一个活动(通常是多个),我总是从他们那里学到很多东西,遇到很多很棒的人。
我给第一次去聚会的人的建议是,如果你第一次感到紧张,就带一个朋友去!在去聚会之前,我还是会确保自己认识一些人。当我至少有一个人可以倾诉的时候,事情会变得更容易。
瑞奇: 当我们第一次在推特上见面时,你正在发布来自代码大战的每日代码挑战,然后用 Python 解决它们。很高兴看到这么多其他人的参与,因为他们用不同的语言比较答案。你还在做那些吗?你和社区一起做这样的事情得到了什么?
Ali: 我喜欢在 Twitter 上做代码挑战!我想我已经做了六个月了,我很想再做一次。
不幸的是,我的生活现在有点忙,在新的小狗和新的工作之间。不过,我可能很快就能重新把它们放上去。我和他们在一起很开心。
我这样做有几个原因:首先是为了证明我真的能编码,因为有人怀疑这一点,其次是因为这样做很有趣。希望它们对一些人有教育意义!
你刚刚提到了你的新工作。为什么不告诉我们更多关于你激动人心的消息和改变的原因呢?
阿里:我上周刚开始一份新工作!我现在是一名前端开发者,为 DEV.to 做开发者宣传工作。
我将致力于他们的开源代码库,这将是令人敬畏的。最重要的是,我将为他们做更多的演讲和写作,以及开发者社区拓展!
我很高兴能为他们工作,因为他们是一个非常棒的社区。他们的口号是,程序员在这里分享想法,互相帮助成长。
这是一个分享和发现伟大想法、进行辩论和交朋友的在线社区。作为一名社区成员,我一直都是这样。这是我为我的博客赢得读者群的重要原因——他们的用户非常支持我。我很高兴成为这个社区的一员!
里基: 现在我的最后一个问题。你在业余时间还做些什么?除了 Python 和编码,你还有什么其他的爱好和兴趣?
在业余时间,我会攀岩,看看华盛顿棒极了的食物和酒吧,还会和我的小狗一起玩!
感谢 Ali 抽出时间与我交谈,祝你在新的岗位上好运!为了跟上阿里,你可以查看她的博客,在 Twitter 上关注她,或者查看她在 DEV.to 上的精彩内容。
安东尼·肖的 Python 社区访谈
今天, NTT 有限公司负责人才转化和创新的全球高级副总裁 Anthony Shaw 和我在一起。Anthony 也是一名真正的 Python 教程作者,并写了一本名为CPython Internals的新书。
在这次采访中,我们讨论了各种各样的话题,包括 Python 安全性、给初学者的建议以及他对海滩的热爱。事不宜迟,让我们欢迎安东尼。
安东尼,谢谢你加入我的节目。我很高兴你能和我一起参加这次面试。我想以我们对所有来宾一样的方式开始:你是如何开始编程的,你是什么时候开始使用 Python 的?

安东尼:嘿,瑞奇。感谢有机会与真正的 Python 读者对话!
我在 90 年代初开始接触编程,学习如何为比可编程计算器小不了多少的设备编写代码。十几岁时,我把一轮送报的大部分收入都花在了编程书籍和计算机硬件上。
我基本上是自学的,从一些较老的基本类型语言开始,到像 C++和 C#这样的面向对象语言。我一直在用 C#。NET 工作了大约八年,在为一个开源项目做贡献的时候发现了 Python,这个项目需要我在工作中开发的一个 API 的支持。
我在 2010 年的一个长周末学习了 Python 的基础知识,并爱上了这种语言在处理流动数据结构方面的灵活性,以及使用面向对象编程和过程编程的自然方式。
你最近似乎对 Python 安全产生了兴趣,为 Django 编写了一个 PyCharm 安全插件和一个跨站点脚本库。你甚至在 SQL 注入制作了一个视频。你是如何进入 infosec 的,这是你职业生涯中一个永久性的焦点变化吗?
安东尼:这一直是我好奇的事情。我想这是从我上大学的时候开始的,当时任何接入没有防火墙的校园局域网的东西都会在 60 秒内被安装木马。
我成了走廊 IT 支持工程师,修理人们的电脑以换取啤酒供应。不久之后,我在当地一家服务器托管公司找到了一份实实在在的技术支持工作。
当 PHP 在网络上流行的时候,带有非常不安全的 PHP 代码的服务器到处都被黑客攻击。如果你想要有动力去艰难地学习一些东西,试着在凌晨 3 点被客户叫醒,因为他们的服务器被黑客攻击了。
在客户允许的情况下,我可以远程访问服务器,弄清楚它们是如何被入侵的,与客户协商,然后重新安装所有的东西。该公司没有开发软件。我们只是在托管服务器。当他们习惯了僵尸网络(或者更糟),它真的会开始影响其他人。
为了尽量减少我在通话时的睡眠中断,我编写了一系列脚本来扫描网络,寻找已知的漏洞和常见的未打补丁的系统。我可以提前提醒客户。
现在,您可以购买现成的软件来实现这一点,但通过访问 Shodan 等数据库和 Metasploit 等自动化漏洞利用工具,任何人只要有鼠标和键盘就可以点击进入 root 访问。
今年,我一直在为 Python 代码分析编写一些工具。这包括代码复杂性分析器 Wily ,以及 PyCharm 的安全代码分析插件 PyCharm Security 。它们有着共同的目标,那就是以尽可能小的性能代价来提高代码的质量和安全性。
与测试一样,修复 bug 最容易的时候是在写的时候!PyCharm Security 会在您输入 PyCharm 时分析您的代码,并突出显示您可能引入的任何安全漏洞。它附带了一个大型文档网站,解释了这些漏洞存在的原因以及如何修复它们。在有明显变化的情况下,PyCharm 可以自动进行重构。
不是转行。我只是对这个话题感兴趣,并对开发人员学习编写安全和可维护的软件充满热情。
虽然这些采访是关于社区成员的个人故事,但我也试图给我们的读者留下一些可操作的东西,他们可以带走并应用到他们的代码中。因此,考虑到这一点,你能给出哪些大多数人可能没有意识到的安全提示呢?
安东尼:如果你有时间的话,我有一份列出的十件事的清单!Python 面临的最大挑战是反序列化。
pickle库和pyYAML库都带有允许定制反序列化过程的逻辑。这意味着攻击者可以在 YAML 或 pickled 文件中嵌入任何 Python 代码,包括向您的生产服务器添加根用户或窃取您的数据库的代码。这些都是记录在案的问题,但不是常识。
Ricky: 众所周知,你不仅是 Real Python 的教程作者,还是新书 CPython Internals 的作者。你希望人们读这本书时能从中得到什么?在写作过程中,你有没有学到什么让你惊讶的语言,或者你认为你已经掌握了但没有掌握的东西?
Anthony: 我希望读者能够理解 CPython 编译器这种看似复杂的东西,将其分解成小部分,并将其与他们知道或能够学习的概念联系起来。我希望他们不仅能理解它,还能利用它并在此基础上发展。如果只有一个人阅读了这本书并为 CPython 项目做出了贡献,那么这将是一个巨大的胜利。
我已经收到了一些早期版本读者的来信。他们分享了自己重新编译自定义 CPython 编译器的兴奋之情,并分享了书中的一些例子。许多开发人员认为这些事情超出了他们的技能水平,但事实并非如此。
在写这本书的时候,我学到了一件重要的事情,那就是所有的并行性和并发性是如何实现的——而且是相当多的!—在 CPython 工作。Async 对我来说一直是一个有点神秘的黑匣子,我在写这本书之前没有怎么使用它,因为我不知道它是如何工作的,并且不信任它。
在探索了概念和导致关键字async和await的构件之后,比如生成器和协程,async 绝对有意义。后来,我用它来提高一些应用程序的性能。
迄今为止,你已经在一些 PyCon 上讲过话,但我最感兴趣的是你在非洲 PyCon 上的最后一次演讲,题目是“在 2000 万开发者的世界中脱颖而出是什么激发了你做这个演讲,你经常给任何水平的开发者什么建议?
安东尼:看到这么多初级开发人员努力获得他们想要的工作,激发了我做那个演讲的灵感。我采访过很多软件开发人员,也辅导过很多人。我给你的一个建议是深入了解一两个主题。在其他话题上变得宽泛和浅薄。
不要做万事通,但也不要做只会一招的小马。试着真正了解两件事,比如 PyTorch 和 GPU 加速,Django 和 PostgreSQL,或者 Vue.js 和 Jinja。学习足够多的关于其他主题和技术的知识,不要害怕使用它们。了解 SQL,JavaScript,HTML,CSS,MLPs。
你不需要成为每件事的专家,但是如果你能把自己投入到一系列不同的问题中,那么你会更成功。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
安东尼:我喜欢去海滩,步行五分钟就到了。所以一年中有六个月,你会发现我在海边。在这一年剩下的时间里,我喜欢用我的双手建造东西。澳大利亚的冬天凉爽多了,所以我会做很多 DIY 项目。
安东尼,谢谢你加入我的行列,祝你的新书发行好运。
如果你想就我们今天谈论的任何事情与安东尼联系,那么你可以在 Twitter 上联系他。如果你想更深入地研究 CPython,了解它是如何工作的,那么你可以拿一本 CPython 内部的书。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。编码快乐!
与 Brett Slatkin 的 Python 社区访谈
今天我要和布雷特·斯莱特金 对话,他是谷歌的首席软件工程师,也是 Python 编程书籍 有效 Python 的作者。加入我们,讨论 Brett 在 Google 使用 Python 的经历,重构,以及他在撰写他的书的第二版时所面临的挑战。事不宜迟,让我们开始吧!
瑞奇: 欢迎来到真正的巨蟒,布雷特。我很高兴你能和我一起参加这次面试。让我们像对待所有客人一样开始吧。你是如何开始编程的,你是什么时候开始使用 Python 的?

布雷特:谢谢你邀请我!我的编程之路漫长而多变。Python 是我教育结束时一个令人惊讶的转折。这是我从未预料到的,但却是一种祝福。一旦我学会了这门语言,我就爱上了它。
在我成长的过程中,我们家有电脑,这是一种巨大的特权。我总是喜欢把东西拆开来看看它们是如何工作的,我不记得有哪一次我不使用电脑并试图弄清楚它们。我已故的祖父最喜欢的故事之一是关于他有一次印刷问题,我帮他解决了。(当时我 3 岁。)
五年级的时候,有一天,我们全班去了一个计算机实验室,在一个苹果 IIgs 上用 Logo 编程。幸运的是,从那以后,我妈妈鼓励我对编程感兴趣,给我买书,让我参加书呆子夏令营。我用乐高技术控制中心工具包给小机器编程。这些就是今天的乐高头脑风暴的前身。
我还使用 Borland Delphi 构建了简单的 GUI 应用程序,比如猜数字游戏。然后,我当地网吧的工作人员给我看了 Unix、Linux 和 C,让我大吃一惊。那时候我就知道我长大了要当程序员。
高中期间,我在当地的社区大学免费上课,学习了 C ,C++,x86 汇编,游戏开发。我读了 Scott Meyers 的第二版有效 C++ ,成为 C++及其所有神秘特性的超级粉丝。有一年夏天,我在一家网络泡沫初创公司实习,期间我用 ASP 和 VBScript 编写 web 应用程序。我对网络编程最感兴趣,并试图构建自己版本的 DikuMUD 和热线。
在大学里,我主修计算机工程,因为我想了解计算机如何在晶体管层面上工作。我的大部分课程是电气工程,在那里我使用了编程工具,如 SPICE 、 VHDL 和 MATLAB 。计算机科学课,学了 LISP,写了很多 Java 。我是各种课程的助教,非常喜欢教别人。
最后,我第一次接触 Python 是在 2003 年,当时我正在研究 BitTorrent T2 客户端是如何工作的。(那时候是开源的。)我认为代码很难看,因为所有的__dunder__特殊方法,我忽略了我所有项目的语言!
2005 年大学毕业后,我去了谷歌,因为它似乎是学习更多网络编程知识的最佳地方。但是在公司的早期,你不能选择你所从事的工作作为新员工。你刚刚被分配到一个团队。
在我的第一天,我的老板给了我一本书 Python 概要,并告诉我去修复一个大约 25KLOC 的代码库。我原以为在工作中我会为网络系统编写 C++,但是我最终不得不做一些完全不同的事情。更糟糕的是,我只能靠自己了,因为原来的程序员已经因为精疲力竭而去强制休假了!
幸运的是,亚历克斯·马尔泰利是我加入的团队中的一位同事。他是《简而言之的 T2 Python》一书的作者,他帮助我学习了这门语言。我能够重写我继承的大部分代码库,修复它的基本问题,并将其扩展到 Google 的整个机器生产舰队。信不信由你,近 15 年后的今天,这个代码仍在使用。
与我使用 C++和 Java 的经验相比,我从使用 Python 中获得的生产力是惊人的。我对编程和语言的看法已经完全改变了。我现在对 Python 很感兴趣!
你已经在谷歌接触过使用 Python,你现在是谷歌的首席软件工程师,但是在你的任期内,你推出了谷歌的第一个云产品,App Engine。现在你是谷歌调查和其他项目的技术负责人。Python 在帮助你开发这些方面发挥了多大的作用,Python 在 Google 的未来是什么样的?
Brett: 毫无疑问,我在谷歌的职业生涯要归功于 Python,但事情远不止如此。作为背景,你要知道创建 App Engine 的五位工程师最初使用的是 JavaScript,类似于网景公司 1995 年的 Livewire 服务器。然而,这是在 Chrome 发布和 V8 大幅性能改进导致 NodeJS 之前。
创始人担心服务器端 JavaScript 会让系统显得过于小众。他们想提供灯栈,当时很流行。LAMP 中的“P”代表 Perl、PHP 或 Python。Perl 通常会过时,PHP 也不是谷歌内部使用的语言。但是 Python 是,感谢彼得·诺维格,所以它是自然的选择。
2006 年末,当我用 Python 实现了 dev_appserver 时,我开始在 App Engine 团队中做一个 20%的项目。在此之前,没有办法在部署应用程序之前在本地运行它。我对该产品的潜力及其对 Python 的使用感到非常兴奋,以至于不久后我就转而全职从事这项工作。
当时也在谷歌工作的吉多·范·罗苏姆很快加入了我们。在 2008 年的发布会上,我非常荣幸地做了现场演示,在那里我用 Python 从头开始编写了一个 web 应用程序,并在几分钟内完成了部署。这些年来,我和 Guido 在各种项目上合作,其中最有趣的是我广泛测试的ndb(asyncio的前身)。
我最喜欢的是在 App Engine 环境中用 Python 编写完整的应用程序,以推动产品的极限。我经常用我的演示程序打破系统,碰到我们没有意识到的新障碍。这将导致我们改进基础设施,以确保下一个需要扩展的应用程序,如 Snapchat ,不会遇到同样的问题。
我最喜欢的演示应用是我和 T2 一起开发的 PubSubHubbub 协议和 hub。该协议将 RSS 源转化为实时流。它给开放网络带来了 Twitter 等服务的活力。
在其鼎盛时期,我们的 hub 应用程序每秒钟处理数百万个提要和数千个请求,所有这些都使用 Python on App Engine。从那时起,这个中心就被整合到了谷歌的标准网络爬行基础设施中。PubSubHubbub(现在叫做 WebSub )成为组成 OStatus 的更大规范组的一部分,帮助 Mastadon 起步。
谷歌调查作为 App Engine 上的另一个 Python 演示应用开始。我在短短几周内就完成了整个系统的端到端原型。我和我的联合创始人有机会向拉里·佩奇展示它,他批准了这个项目。由于 Python 提供的杠杆作用,我们在一年后推出了一个精益团队。
我们的服务现在每秒处理 50 多万个请求,影响了谷歌的大部分用户和收入。代码库已经从大约 10KLOC 增长到超过 1MLOC,其中大部分是 Python。我们不得不将一些服务迁移到 Go、C++和 Java,因为我们遇到了各种 CPU 成本和延迟限制,但 Python 仍然是我们所做一切的核心。
Python 已经在谷歌找到了自己的位置,主要是作为数据科学的工具、机器学习的工具和 DevOps / SRE 的工具。现在,整个公司的工程师都在努力放弃 Python 2,将整个 monorepo 迁移到 Python 3,以保持与 Python 社区和开源包的一致。
Ricky: 除了你刚刚谈到的,你还是广受欢迎的 Python 编程书籍 有效 Python的作者,我们之前在最佳 Python 书籍中评论过这些书籍。你最近出版了第二版,有实质性的更新。更新包括什么,自第一版以来有什么变化?
布雷特:感谢你认为我的书是最好的书之一!第一版的反响非常好。它甚至被翻译成了八种语言!在官方网站上有很多关于这本新书的信息,包括所有项目标题的完整目录、各种样本和示例代码。
第二版 Effective Python 的长度几乎是原版的两倍,除了提供 30 多条新建议外,还对所有建议进行了重大修改。这本书的第一版是在 2014 年写的,当时考虑的是 Python 2.7 和 Python 3.4。在过去的 5 年里,Python 3.5 到 Python 3.8 增加了太多东西,所以有很多东西可以写!总的风格是一样的,它仍然包括多色语法突出。
新书涵盖了 walrus 操作符、 f-strings 、字典、类装饰器的最佳实践,以及函数的所有重要特性(包括异步执行)。我将详细介绍标准库中的解包归纳、定制排序、测试工具和算法性能。我还解释了如何利用更高级的工具,比如打字模块和memoryview类型。
在这个新版本中,我对元类的建议完全改变了,这要感谢语言中添加了__init_subclass__和__set_name__。我对使用send()和throw()的高级发生器的建议现在与第一版相反。(现在我说避开他们。)我将 asyncio 的优势与线程和进程进行了比较,这在以前是完全没有的。我提供了关于如何将同步代码转换为异步代码,以及如何将异步代码与线程混合的指导。
任何读过这本书的人,请随时给我发送问题或反馈!
瑞奇: 在 PyCon 2016 上,你做了一个题为重构 Python:为什么以及如何重构你的代码的演讲,这个演讲也在我们的十大必看 PyCon 演讲之列。我很想知道你演讲的动机。是什么关于重构(或者说缺乏重构)激发了你做一个关于重构的演讲?人们似乎很纠结于重构吗?他们会陷入同样的陷阱吗?
Brett: 谢谢你把我的演讲列入你的十大清单!
当我做这个演讲的时候,我已经在同一个代码库工作了大约六年。那个时代的任何代码都需要不断地重构和更新,以防止它腐烂和变得不可用。
当依赖性以向后不兼容的方式改变时,当底层基础设施转变为具有不同的性能特征时,或者当产品决策打破了大量先前的假设时,我所说的 rot 就会发生。因此,重构是一种持续的需要,它经常出现在我的脑海中。这次经历让我对重构技巧的重要性有了新的认识。
人们经常谈论测试、工具和框架如何使他们成为更有效的程序员。但是我相信重构是一项被低估的基本技能,每个程序员都需要集中精力去提高。为什么?在我看来,最好的代码是不存在的、已经被删除或从未被写过的代码。你能拥有的最好的程序是一个空的.py文件。问题是你如何从你在一个项目中的位置更接近那个理想?通过重构。
我想帮助我团队中的其他程序员学习如何更好地重构,但是马丁·福勒的《重构》这本书自 1999 年以来就没有更新过。所以我在考虑为这本书写一个 Python 专用版本,使它现代化,成为我的同事们可以阅读的东西。然而,当我得知 Fowler 正在开发第二版的重构时,我就把它搁置了,该版本已经发布,并且使用 JavaScript 作为实现语言。
不幸的是,它仍然达不到我所需要的。我希望看到一本专门针对 Python 的重构书,或者一组可行的例子,充分利用这种语言所提供的一切。
里基: 现在我的最后几个问题。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
布雷特:我们家里有两个很小的孩子,所以我和妻子花很多时间陪他们。唱歌和演奏音乐(主要是钢琴,但有时吉他、尤克里里琴、木琴和口琴)是享受我们在一起时光的最好方式。我对所有这些乐器都很糟糕,也不是一个伟大的歌手,但我们仍然有很多美好的时光。
我喜欢每天都在外面,要么在旧金山的山上散步,要么去跑步(通常推着婴儿车)。我一有机会就喜欢冲浪。我喜欢阅读,尤其是长篇新闻,但事实上,主要是 reddit 和 T2 龙虾。我想成为一名更好的厨师,在懒惰和美味之间找到正确的平衡。我还试图自学如何使用贝叶斯方法建立统计模型。如果说这些年来我学到了什么,那就是没有什么是确定的。
谢谢你,Brett,这周和我一起!你可以在 Twitter 或者 GitHub 上找到 Brett,在effectivepython.com了解更多关于第二版有效 Python 的信息。
如果你想让我在未来采访谁,请在下面的评论中联系我,或者在 Twitter 上给我发消息。编码快乐!
Brian Okken 对 Python 社区的采访
本周,我很荣幸采访到布莱恩·奥肯。Brian 最出名的可能是《用 pytest 测试 Python》的作者,以及两个播客的主持人。请继续阅读,了解更多关于这个声音背后的人,他在波特兰的新聚会,以及他对软件测试新手的建议。
瑞奇: 让我们从我问所有客人的相同问题开始。你是怎么进入编程的?你是什么时候开始用 Python 的?

大概在我 14 岁的时候,父母给了我一台 TRS-80 作为礼物。我并没有真正学会在那上面编码,但我确实从杂志背面输入了小应用和游戏的基本程序列表。然后我在高中上了一个基础课,除此之外就没怎么上了。我不知道你能以此为职业。
直到大学 2 到 3 年后,当我从数学和美术转向计算机科学时,我才重新开始编程。到我的学士和硕士学位结束时,我已经使用了 Scheme、Perl、Tcl、C、C++和 ksh,都是在计算机科学领域。然后,我加入了一家制造电子测试系统和仪器的测试和测量公司。
在 21 世纪初,我们的团队引入了一个基于 Python 的测试框架。尽管我开发的是嵌入式 C++代码,但这些年来,我使用 Python 来驱动系统测试的次数越来越多。自从我在 2012 年和 2015 年开始写博客和播客以来,我已经扩大了对 Python 的使用,无论是在项目内部还是在工作中,以至于现在它是我花费大部分时间的地方。
是什么吸引你将软件测试作为一种职业?你最喜欢它的什么?
布莱恩:我有点喜欢这个问题,但同时又有些畏缩。我从来没有以“软件测试”为职业。不过,我想这是我经常做的事情。
成功、有效、高效的软件开发包括软件测试。我们依靠坚实、可靠、彻底而快速的测试套件,为 CI/CD 管道中的合并开绿灯。我们越来越依赖自动化测试的质量来保证我们软件的质量。这使我们能够更快地开发,更快地发货,更快地迭代,更快地转向,更快地犯错误并从中学习,等等。
然而,很少有开发人员知道如何高效且有效地编写自动化测试,交付我们赋予自动化测试套件的所有责任。许多人被告知(或相信)他们需要编写单元测试,却不知道这意味着什么。大多数人在理论上相信测试金字塔,但并不真正使用它,也不知道它意味着什么。所以,我的工作逐渐转向敲鼓吹响号角站在讲台上,为自动化测试唱赞歌,并试图教人们如何去做。
我喜欢从一些代码的第一次实现,即第一份草案中了解问题。我真的很喜欢写第二稿、第三稿等等。我喜欢修补软件项目。我喜欢撕掉丑陋的部分,努力让它变得可读,或者至少不那么丑陋。为了做到这一点,我需要依靠测试来告诉我是否做错了什么。
这是它的核心。我想玩软件,所以我想花尽可能少的时间写测试、调试和分类问题。这样,我可以花尽可能多的时间写新东西和重构旧东西。我想开发自己引以为豪的软件。自动化软件测试允许这样做。我不知道还有其他方法。这是我从测试中最享受的。
对于我们刚接触测试(或者编程)的读者,你会给他们什么建议?
布莱恩不要把测试拖到最后。你不必先做。你不必做测试驱动的开发。但也不要做到最后。在构建代码的同时构建测试,并积累知识。
您的自动化测试应该允许您更快地开发,因为您不必返回并手动检查所有曾经工作的东西。如果感觉添加自动化测试增加了您的工作量,那么可能会发生一些事情。也许你只是新手,学习一项新技能需要时间。您可能编写了太多的测试。在更高的层次,或更大的块,或参数化,或以上所有的测试可能会使你的测试写作时间更有效率。
测试并不容易。但也不复杂。给自己时间学习。测试让你了解你的软件。学习将帮助你开发更好的软件。这种学习是有价值的,所以在愿意把这种学习给别人的时候要非常小心。让工程师开发他们自己的测试的团队将会比把测试扔给独立团队的团队培养出更好的工程师。
我想这不仅仅是一点建议。😃
如果你能预测未来,你认为我们未来测试软件的最大挑战是什么?
布莱恩:除非现在有所改变,否则未来将会面临和我们现在一样的挑战。教编程的人并没有教测试与开发齐头并进。与电气工程相比。获得学士或硕士学位的电子工程专业毕业生将花费大量时间使用示波器、逻辑分析仪、频谱分析仪、频率计数器、功率计和其他设备,以验证他们的电路和系统是否按预期工作。
然而对于计算机科学来说,我们根本没有花太多时间来确保毕业生知道如何验证他们开发的软件。互联网是一堆相互矛盾的信息。测试被如此误解真的不奇怪。我正试图在它上面留下凹痕。但实际上,最大的挑战是教育和反对旧的假设。
瑞奇: 如果我没有提到你主持的播客(测试和编码)和联合主持的播客( Python Bytes ),那我就失职了。有没有从播客中吸取的经验教训转移到你的代码中?它有没有以任何方式帮助你提高你的编程水平?
布莱恩:有这么多课!但是我认为我学到的最重要的事情是发展倾听技巧和经常练习的重要性。提问是一种很好的学习方法,但只有当你让自己听并听到答案时,它才会起作用。在编辑过程中,我不得不删除剧集中的后续问题,因为很明显我没有真正倾听受访者已经告诉我的内容。
仔细倾听比我们想象的要难,而且如此强大。成为一个更好的倾听者肯定会延续到我生活的所有其他部分,包括管理、编程、测试,甚至家庭。
最后但同样重要的是,当你不写代码的时候,你在业余时间还会做些什么?你还有什么其他的爱好和兴趣?你想插什么?
布莱恩:我最喜欢和我的妻子和孩子在一起。我的妻子和我一直是美丽的古董和古董物品的收藏家,我们试图建立一个充满折衷主义和戏剧元素的家。我们把我们的生活空间当作一个巨大的阴影盒艺术装置。最近,这种兴趣转移到了零售领域,我们通过当地的古董商场进行销售。随意在 Instagram 上看照片,我们在那里 FrivolityPDX 。
我刚刚和我的 Python Bytes 联合主持人 Michael Kennedy 为西波特兰开了 Python PDX 西聚会。我还写了一本书。您不仅可以很好地学习使用 pytest,还可以在一本短到可以在一个周末阅读的书中获得很多测试策略建议。用 pytest 进行 Python 测试可以在务实或者亚马逊上找到。还有请听测试&代码。测试不仅仅是测试,而是开发。播客也是如此。这就是为什么名称中有一个“&代码”部分。😃
谢谢你,布莱恩,参加我的面试!有你在采访麦克风的另一边真好(可以这么说)。
一如既往,如果你想让我在未来采访某人,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
与 Brian Peterson 的 Python 社区访谈
到目前为止,我已经采访了一些你以前可能听说过的来自 Python 社区的人。但是这个专栏不仅仅是采访摇滚明星和核心开发者。这也是一种方式,让人们看到对社区的巨大贡献,而这些贡献往往会被忽视。因此,我向你们介绍布莱恩·彼得森。
布莱恩白天是项目经理,晚上是 Pythonista 的点对点学习社区 Pythonista Café 的主持人之一。在我们的采访中,我们讨论了 Python 如何帮助他担任项目经理,以及主持 Python 爱好者的大型论坛如何影响了他的编码能力。让我们开始吧!
瑞奇: 欢迎来到真正的 Python!先说我问大家的问题。你是怎么进入编程的,什么时候开始用 Python 的?
嗯……回想起来,我第一次真正接触编程是在使用一台旧的 HP-87 测试物体探测系统原型附近。该程序用于在汽车实验室消声室内沿测试轨迹移动和改变目标和旋转天线位置,同时从频谱分析仪收集和处理数据。看到代码转化为动作对我来说是这样的——一些真实的、可触摸的东西。我迷上了将编程作为一种研发工具,让事情变得生动起来。

这些年来,我开始花更多的时间研究 Linux 自动化、控制系统、数据收集和分析,这自然导致我花更多的时间编写 C 代码,然后就好像“嘿,Python 已经在系统上了。为什么不带它去兜一圈?”
我觉得当时是 Python 2.3。我喜欢 Python 是因为它感觉很自然,而且我不用扔掉我所有的 C 语言知识。它有一些函数式编程,以及一套令人印象深刻的工程和科学库。最重要的是,我可以在脚本编写、交互式数据分析和编写代码时无缝地使用同一种语言。Python 语法的可读性非常好,我个人认为很难不喜欢它。我被迷住了。
对某些人来说,从事项目管理和使用 Python 似乎不是天生的合适人选。在项目管理办公室中,你是如何使用 Python 来帮助你的,在日常工作中,哪些工具和库对你最有帮助?
Brian: 是的,乍一看,Python 似乎不太适合。这在很大程度上是由于项目管理通常被教授的方式——就像根据食谱烹饪,而不是学习和理解烹饪艺术。
千篇一律的项目管理工具就像微波炉一样。是啊,当然,用它们来做预包装的,盒装的,罐装的,但是每顿饭呢?真的吗?当您考虑不同风格的项目管理时,Python 也开始变得有意义:
- 传统的项目经理使用模板驱动的方法。
- 敏捷实践者使用故事驱动的方法。
- 适应性实践者融合现有的、新的、新兴的方法和创造力,为每个独特的项目或项目组开发最适合的方法。
因此,虽然现成的项目管理工具和服务非常适合传统项目,也非常适合一些敏捷项目,但是适应性项目管理需要不同的种类。换句话说,与其强迫所有项目都适合一种工具,为什么不使用 Python 来构建一个装满最佳工具的工具箱,为不同类型的项目解决不同类型的问题呢?
同样值得考虑的是,现代项目管理办公室(PMO)不仅仅管理项目:还有构思、项目组合管理、路线图、战略规划、KPI 监控、通信、治理、仪表板、利益相关者门户,与开发人员、业务分析师、架构师、开发人员、UX 设计师、CX 人、主题专家、其他技术人员密切合作,等等。
现在想象一下,一个对你的特定项目或 PMO 服务一无所知的供应商拿着一大箱乐高积木,把它们粘在一起,然后卖给你。是啊,这可能是一个不错的装置,否则它不会在市场上待得太久。
但与拥有自己的一大箱乐高玩具(Python 和 goodies)相比,你可以将乐高玩具添加到预先构建的装置中,使用乐高玩具将多个装置连接在一起,将它们与组织中现有的乐高玩具一起使用,或者构建自己的乐高玩具并混合和匹配上述任何或所有功能。
为了回答问题的第二部分,我目前使用 Python 和 RESTful API与各种灵活的 SaaS 工具进行交互,例如 ProductPlan 、 Smartsheet (带有仪表板扩展)、 Airtable ,以及一个商业票务系统和企业可视化软件。Python 使得以创造性的方式将这些工具连接在一起并填补功能上的空白以解决许多不同类型的问题变得容易。
这些工具如何改变了你的工作方式?你如何看待他们未来的变化?Python 会在项目管理办公室的未来继续发挥作用吗?
Brian: 我认为最显著的变化是一种自由感,即创造性地解决问题的能力,专注于必要的事情,并利用现代解决方案,而不是被工具束缚,陷入工具陷阱,或遭受工具腐烂的痛苦。作为一个额外的好处,Python 使项目管理变得有趣和令人耳目一新。
我不确定 Python 是否会成为项目管理的主流,但我确实认为它可以让学习它的项目经理在繁琐任务的自动化、解决复杂问题、适应组织的发展以及提供有价值的开箱即用的 PMO 服务方面拥有独特的优势。
你现在有任何与 Python 或技术相关的兼职项目吗?
Brian: 是的,“未来路线图”是一个与志愿者网络合作的项目,也是一个与机构合作帮助试点的项目。仅在美国就有超过 80,000 个地方政府,我相信需要一种更好的方式来规划我们现在的位置,我们未来的方向,以及到达那里的最佳方式。
在 Python 中,我们有各种各样的工具来处理数据,我们在收集离散数据方面做得越来越好。
但是,在探索和非线性收集想法、识别看不见的问题、服务差距、整体客户体验中需要改进的领域、开发解决这些问题的创造性和可行的替代解决方案,然后将它们转化为具有明显优势的成功项目方面,仍然存在机会。
未来的路线图不仅仅是用新的方法收集信息的随机想法的汇编,而是通过组织项目将想法付诸行动所必需的核心要素、流程和伙伴关系的凝聚集合。
为了使它可持续发展,它必须是可发现的、简单的、快速的和有趣的,所以很多额外的焦点被放在项目的 UX 方面。目前的设计使用了 Python,Vue.js,Azure Cosmos DB,Service Bus 和认知服务。它仍处于早期开发阶段。项目信息、细节和代码将于明年公开发布。
我渴望采访你的原因之一是因为你对 Python 社区的贡献。你是 Pythonista 咖啡馆的两名版主之一,这是一个面向 Python 爱好者的点对点学习社区。你从会员到版主的旅程是怎样的,这对你的 Python 印章有什么影响?
布莱恩:太棒了!丹·巴德做了如此出色的工作,还有你、珍妮弗(共同主持人)、真正的 Python 团队,特别是所有来自各种背景、地理位置和经验水平的出色贡献者,他们使咖啡馆成为今天这样活跃的论坛。
它真的是从底层开始由社区驱动的。它有一个有趣的,多产的,开源的氛围,不用担心公众的羞辱。犯错和学习是没关系的。你可以发布东西,而不必担心全世界会如何解读或曲解它。
我最初加入咖啡馆有几个原因。这就像一个非派系的 24/7/365 Python 聚会,你可以随时进出。正如论坛成员所提到的,它比公共论坛有更好的信噪比,更不用说免受广告和操纵行为的社交媒体算法的影响。
它非常友好,对 Python 超级友好。对编程的热情是非常具有传染性的,这导致了你对它如何影响我的 Python 能力的疑问。答案是它让 Python 变得更加有趣,我现在更加致力于 Python 及其生态系统的持续学习。这也增加了我对未来用 Python 做什么的可能性的兴奋感。
里基: 现在我的最后一个问题。除了 Python,你还有什么其他的爱好和兴趣?有你想分享和/或插入的吗?
Brian: 在工作和 Python 之外,我喜欢把它们混合在一起。我目前在狭长地带工作,在第一海岸度过我的业余时间,所以最近我最喜欢做的事情之一就是在南部的许多河流和沼泽中划着皮划艇四处游荡;在特定条件下,这绝对是超现实的。你可以阅读和观看所有你想看的关于沼泽的东西,但是没有什么可以替代真实的东西。
每年我也会挑选一两个新的课题来研究和学习,以此为乐。我是一个业余无线电操作员,我热爱音乐,我是一个书籍的狂热读者,尤其是历史,生存故事和科幻小说。
我也很幸运有一个了不起的妻子和儿子。在我的项目之外,我的妻子让家庭项目保持活跃,参加节日和其他活动,帮助动物救援,以及探索新的领域和带着狗徒步旅行。无聊是一个陌生的概念——它绝对让生活充满乐趣。
谢谢你,布莱恩,这周和我在一起。如果你正在寻找一个友好的 Python 地方来挂你的隐喻帽子,你可以在这里找到 Pythonista 咖啡馆。你到了那里一定要向布莱恩问好。
你认识 Python 社区的无名英雄吗?如果他们希望我将来采访他们,可以在下面的评论中找到我,或者你可以在 Twitter 上给我发消息。
Bruno Oliveira 的 Python 社区访谈
今天和我一起的还有布鲁诺·奥利维拉,他可能是最著名的 pytest 核心开发者。在这次采访中,我们涵盖了将大型代码库从 C++迁移到 Python,如何开始使用pytest,以及他对黑暗灵魂的热爱。
里基: 欢迎来到真正的 Python,布鲁诺。我很高兴你能加入我们。让我们像对待所有客人一样开始:你是如何开始编程的,你是什么时候开始使用 Python 的?
布鲁诺:嗨,瑞奇。谢谢你邀请我。

我大约在 23 年前开始编程。我刚开始接触计算机时,我的一个朋友给我看了这本关于 Visual Basic 的书,我非常惊讶你能自己编写计算器。
过了一段时间,我爸爸给我买了《德尔福圣经》。我如饥似渴,过了一会儿,我开始用 DirectX 编程,制作非常简单的游戏。
之后,我上了大学,在第二学期,我设法得到了一份实习工作,从事一个图像处理的 Delphi 应用程序。实习结束后,我加入了 ESSS ,这是我至今工作的公司。
我在 ESSS 的角色是一名技术领导者,负责管理我所从事项目的技术方面,包括设计和日常代码审查。我目前参与了四个项目。
与其他技术负责人一起,我还开发和监督我们的高级工作,例如将所有代码从一个 Python 版本迁移到下一个版本,解决我们 CI 中的问题,实现开发工作流,等等。
在 ESSS,我们专门为石油和天然气行业开发工程应用。当我加入时,所有东西都用 C++编写,团队自己开发所有东西,包括多平台 GUI 库。在我被雇佣大约一年后,我们开始研究 Python(当时是 2.4 版本),以及如何将它与 PyQt 结合起来快速开发我们的应用程序。
今天,我们的绝大部分代码都是用 Python 编写的,还有一些 C++用于模拟和数值计算。2019 年 1 月,我们完成了所有项目从 Python 2 到 Python 3(当时是 3.5 版)的迁移,这是一项涉及整个团队在四年多时间里尽可能工作的努力。
里基: 你成为 pytest 的核心开发者已经有一段时间了。你是如何发现 pytest 的,为什么会一跃成为它的贡献者之一?
Bruno: 自从我们开始使用 Python,我们立即看到了自动化测试的价值,这不仅仅是因为 Python 是动态的。当我们所有的代码都是普通的 C++时,应用程序会一直崩溃,即使有编译器也相对安全。
我们有机地发展了我们的测试代码库,增加了对 Qt、并行性、丰富的测试集合等的支持。2013 年左右,我发现了pytest,被图书馆惊艳到了。它包含了我们在内部实现的所有东西以及一堆我们想要的东西,它还具有一个非常有表现力的插件系统,然后可以扩展到尚未提供的功能。
我一直喜欢自动化测试,所以大约在那个时候我创建了pytest-qt插件,而pytest-mock就在那之后被创建了。然后,我开始参与邮件列表,并贡献错误修复和新功能。最终,pytest, Holger Krekel 的创造者,把我变成了核心开发者。
几年后,我们设法用pytest和插件替换了我们所有的定制测试代码库。
瑞奇: 本次面试时, pytest 6.0 目前处于发布候选人阶段。新版本最让你兴奋的是什么?有什么新特性可能会改变人们测试代码的方式吗?
Bruno: 我认为对许多人来说最令人兴奋的特性是pytest现在是完全类型注释的,允许用户使用mypy对他们的测试代码进行类型检查。这花了好几个月的努力,由我们最新的核心贡献者之一, Ran Benita 带头。
另一个期待已久的特性是使用pyproject.toml文件进行配置的能力。
里奇: 你还与 Packt 出版社合作写了一本书,名为 pytest 快速入门指南:用简单且可维护的测试编写更好的 Python 代码 。你是如何找到写书的体验的,这个过程对你自己的 Python 测试有什么帮助?
Bruno: 虽然尝试写出与我们通常在编程书籍和文章中看到的不同的代码示例很有趣,比如《黑暗灵魂》和《电视参考》,但老实说,总体体验有点令人疲惫。
这与出版商和编辑无关,他们真的帮了大忙。只是我不认为我对它有热情,所以与编程相比,一切都是艰苦的工作,编程是我喜欢的东西,给我带来快乐。
但总体体验是积极的。必须以一种易于理解的方式写下一堆模式,比如如何将大型测试套件从unittest移植到pytest,这帮助我将它们固化在脑海中。
对于任何阅读这篇文章的初学者来说,为什么测试你的代码很重要,以及如何开始使用 pytest ?
Bruno: 编写自动化测试与大多数人在编写新代码时已经做的事情没有太大区别。通常他们会打开 REPL 快速尝试一些东西,就像这样:
>>> from mymodule import mysum >>> mysum(4, 5) 9 >>> mysum(1, -1) 0 >>> # Woot! it works人们可能还会在模块中的
if __name__ == __main__:下编写一些快速代码,如下所示:if __name__ == "__main__": print(mysum(4, 5)) print(mysum(1, -1)) # See that it prints '9' and '0' and woot! it works虽然这适合于查看事情是否在工作,但是跨越到编写自动化测试是非常简单的。我们需要做的就是创建一个
test_mymodule.py文件,并编写以下内容:def test_mysum(): assert mysum(4, 5) == 9 assert mysum(1, -1) == 0就是这样。现在你可以执行
pytest,它会检查mysum()还在工作。当你已经知道某个功能可以工作的时候,测试它可能看起来很傻,但是重要的是要意识到这个自动化测试确保了这个功能在将来会保持工作。您添加的测试越多,您的整个系统一直被验证的就越多。对我来说,这是自动化测试最精彩的部分。它不仅确保了您的系统能够工作,而且确保了它在未来能够继续工作,即使您决定重构一切。至少,它会指出你可能犯的任何错误。手动测试无法扩展。
里基: 现在我的最后几个问题。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
布鲁诺:我真的很喜欢看电视剧(谁不喜欢?)和在我的电脑上玩游戏。我是一个超级黑暗灵魂迷,我真的很喜欢和我的朋友一起玩像《巫师 3》这样丰富的角色扮演游戏和多人合作游戏。
谢谢你加入我的节目,布鲁诺。这是我的荣幸。
如果你想和布鲁诺联系,你可以在推特上找到他。你也可以拿一本他的《T2》书。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。
编码快乐!
Python 社区采访克里斯托弗·贝利
今天我和真正的 Python 播客的主持人克里斯托弗·贝利交谈。我们挖掘他在音乐和视频制作方面的过去,以及他制作在线视频内容的方法。Christopher 还提供了一些有用的提示和技巧,供任何希望创建自己的第一个编码视频教程的初露头角的内容创作者参考。
克里斯多夫,谢谢你加入我的节目,欢迎来到采访台的另一边。让我们像对待所有客人一样开始:你是如何开始编程的,你是什么时候开始使用 Python 的?
克里斯托弗:谢谢你邀请我。我是在一个朋友家开始编程的,那家有一台 Apple II。我们输入一本杂志上的代码来创造一个文本冒险。我记不清具体细节了,但是在 Ultima 的会议间隙,我们尝试了一些基础的东西。
我的下一个重大经历是省下所有送报的钱,为自己买了一台 ColecoVision。然后,我的父母给了我一个惊喜,买了一台附带的亚当电脑。它基本上是一个苹果 II 克隆版,配有一个可怕的菊花轮式打印机和一个“高速”磁带机。我自学了 BASIC,制作了几个简单的游戏和一个龙与地下城角色生成器。
快进到大学,我在亚利桑那州立大学学习电子工程。我在一个巨大的 Unix 实验室里学了一些 C 和 Fortran。第二年就退学了,一直没拿到学位。我沉浸在音乐场景中,组建乐队,尽我所能学习关于家庭录音和 MIDI(乐器数字接口)的一切。
我一直有学习软件和电子硬件的诀窍。它总是有意义的。我把它变成了一份在乐器店的工作,这让我可以做一对一的咨询,教人们如何使用他们的音乐硬件。那变成了作为韦曼·蒂斯戴尔的技术人员的巡回演出。后来,我成了萨克拉门托一家录音室的录音工程师,在那里,我为泰瑞斯·吉布森的第一张专辑制作了一张白金唱片。
当我离开加州搬回亚利桑那州时,一位前同事问我是否想在一所录音工程师学校教书。我在录音艺术与科学学院教了十年书。我教授从 MIDI 到数字音频、环绕声、视频游戏音频、专业工具和逻辑的所有内容。之后,我搬到了我妻子出生的夏威夷,我在苹果公司做培训师,然后做维修技师。
我要感谢我的妻子,是她让我重新回到了编程的道路上。她在一家银行工作,他们需要一个能创建 SQL 查询的人。我利用尽可能多的资源自学:琳达在线培训、艰难地学习 SQL、SQLZoo.net。
在我工作的第一天,我的任务是基于程序中所有表的原始导出重新创建一个抵押贷款数据库工具。我拥有的工具是 Microsoft SQL Server 和报表生成器。我没有关系图,只有原始数据和要重新创建的表单类型的示例。我很快学会了很多关于抵押贷款和 SQL 的知识!
最终,夏威夷的另一家银行出现了另一份工作,但他们正在寻找会使用 Python 的人。面试前,我又一次尽可能地死记硬背。在那里我找到了真正的 Python 和丹的书, Python 的招数 。我在“Python 对我说”播客上听过他的演讲。我亲自做了一个简短的编码测试,还有一个带回家的测试。我得到了这份工作,成为他们市场部的数据分析师。
你有一个兼收并蓄的背景,但有一点引起了我的注意,那就是你所担任的各种教学和培训角色。你现在是真正的 Python 的视频课程作者之一。你以前的经历对你第一次创作视频内容有什么帮助?对于那些想录制自己第一个教程视频的人,你有什么建议吗?
克里斯托弗:当我在音乐学院工作时,我迷上了数码视频。这真的是非线性编辑器的黎明,成本不到几千美元。苹果最近收购了 Macromedia,并发布了 Final Cut Pro,重点是 DV 和 FireWire。
很长一段时间以来,我一直在制作器乐,并试图与一些当地的视频制作人合作项目。我最终为费尔蒙特酒店的斯科茨代尔公主度假村的宣传活动创作了定制音乐。
我开始向学校的朋友展示成品,他们认为我已经完成了所有的东西。所以他们突然想让我为学校做广告。我雇人帮我拍摄,并自学如何在 Final Cut 中编辑视频。
我迷上了这个 bug,开始创作大量视频。我买了一台 DV 摄像机,开始推动自己,参加了几个 24 小时或 48 小时的电影制作比赛。这个想法是你在周五晚上见面,给你一个特定的主题或类型,一行对话,以及一个需要在电影成品中使用的道具。你赶着写剧本,拍摄,编辑,最后在周日晚上的最后期限前交付完成的 DVD。
我教妻子如何记录和捕捉录像带,这样我就可以在开始剪辑前睡上几个小时。没有比被截止日期逼着学习更好的方法了。
我创建了一个 YouTube 频道,在那里我分享关于音频、视频和其他创意项目的知识。我还试着为 Skillshare 制作内容,在那里我创建了一个教程,介绍如何使用一个叫做 Actionbound 的工具制作一个数字寻宝游戏。
当丹打算组建视频团队时,我收到了他们发出的简讯,心想,真是太合适了。我热爱教学,有很好的视频制作背景。我和他分享了我的一些工作,他让我加入了这个团队。此外,我仍然在深入研究 Python,我认为这是我学习更多知识的好方法。如果你想学好某样东西,试着把它教给别人。
我认为学习如何制作你的第一个教程的最好方法之一是通过在 REPL 工作来交流。当丹向我展示 bpython 时,我坠入了爱河。这是一个很好的工具,可以向学生展示你需要提及的内容。
在 Real Python,视频课程的创建者拥有建立在现有文章之上的优势。接下来的步骤包括将材料翻译成几大块,它们将成为本课程的内容。我一直在寻找给文章添加更多内容的方法,比如额外的例子和潜在的陷阱。我不喜欢跳过步骤,我想确保学生能跟上。
当我为自己的课程创建材料时,我会从一个大纲开始。我试图确保所有的步骤都在那里,以便学生能够重新创建代码。我总是试图展示可能犯的错误以及如何避免它们。我还认为举例说明这些技术或代码可以应用到哪里也很重要。
就硬件而言,我认为最重要的是声音。当然基于我的背景我完全有偏见。但是没有什么能让我更快地关掉电视。你需要一个像样的麦克风。几乎任何东西都比电脑的内置麦克风好。甚至使用一套带麦克风的耳塞,比如手机自带的耳塞,也会有所帮助。
一个启动器 USB 麦克风大约 90 美元。买一副像样的耳机,确保真的听你的录音,并想办法改进它们。你不一定需要一个有声学泡沫的华丽工作室,但是你应该尽量减少你周围环境的反射。录音时在周围放一些枕头、被子或其他柔软的东西有助于限制回声。
此外,不要害怕站在麦克风前。这会让你听起来更好。你可能需要一个挡风玻璃或塞子,但是如果你没有足够的资金购买,这可能是一个简单的 DIY 项目。
对于截屏,我用的是 Mac,它附带了 QuickTime,这让截屏变得相当容易。我最近改用了一个叫 iShowU Instant 的工具,这个工具更容易配置,并且允许我的捕获的屏幕尺寸保持一致。
有许多工具可供选择。如果你想变得有趣并做一些编辑,DaVinci Resolve 可以免费用于 1080p 及以下的项目。这是一个非常专业的编辑器,适用于 Mac 和 Windows。我最近一直在做 4k 的东西,所以我必须购买它才能得到那个输出。
编辑的优势是巨大的。它可以让你修改音频以修复小错误,对现有视频再做一遍,或者将多个视频粘在一起。达芬奇网站上有一些非常好的入门教程。我喜欢在键入代码或放映幻灯片时录制画外音,但我知道有几个人会分别完成这些步骤。
里奇: 我想祝贺你最近推出了由你主持的真正的 Python 播客。我们已经谈到了一点,但是以你在音频技术方面的广泛背景,这些技能是如何转移到播客制作领域的呢?你从制作播客中学到了什么,可以带回你的音乐或 Python 编程吗?
克里斯托弗:我在录制和编辑播客时运用了我作为音频工程师的许多技能。我在过去花了一点时间做法医音频修复,修复嘈杂的声源,以挽救他们的修复项目或审判。有很多非常棒的工具可以帮助你。
我不认为每个人都需要用这个来做播客,但我喜欢 iZotope 的一套工具,叫做 RX 7。我买的那个版本有工具可以消除混响、嘴巴咔哒声和数字爆音,还能降低呼吸噪音和减弱咝咝声。使用它们需要一些技巧,但我对结果真的很满意。
录制播客时,我想让我的客人尽可能轻松,因为他们中的许多人可能没有花哨的麦克风或安静的地方来录制。所以我希望我能让它听起来尽可能接近面对面的对话。
我不确定我是否会把许多技能带回到音乐制作中,但它激励我重新回到录音中。主题曲是我做的,丹很喜欢草稿版,我马上就用上了。我想将来我可能会在节目中加入一些更短的音乐过渡。
至于把东西带回 Python,我学到了很多。我可以写问题,邀请客人。我学到了很多。我希望与大家分享我所学到的一切,不仅在播客中,而且在我未来的视频课程中。如果您有任何想在播客中听到的问题或话题,请告诉我们。
我曾有幸采访过其他 Python 播客的主持人(即 Michael Kennedy、Brian Okken、Kelly Paredes 和 Sean Tibor)。你对这个播客有什么计划,它和 Python 领域其他成功的播客有什么不同?
克里斯托弗:我想我会给这个领域带来不同层次的体验。我非常渴望学习更多关于 Python 的知识,我还处于中级水平。我希望向这些专家嘉宾提出独特的问题,我的目标是让一些更复杂的话题变得更容易理解。
在播客上尝试这样做是可行的。比如说,它和教程有很大的不同。首先,没有可视化组件,看到代码确实有助于学习。此外,这些客人需要在谈论话题时感到舒适,而不是感觉像在讲课。这真的需要一次对话。
但我的工作是尝试问一些有助于揭示和简化概念的问题。我在未来一年左右的主要工作是成为一名熟练的面试官,这对我来说是全新的。
我一直在努力确保每集都有资源来帮助我的客人们开启所有额外的学习途径,而这些途径是我们在一起的短暂时间内无法发现的。我有很多其他演讲、文章、GitHub 库以及更多内容的链接供听众探索。
我还为所有涉及的主题输入了时间码,这样听众就可以回去重新听一个特定的主题,或者如果他们愿意的话可以直接跳到前面。对于专用的 podcast 播放器,如 covery、Apple Podcasts 或 Pocket Casts,可以直接在播放器中访问章节、节目注释和链接。
在我们结束之前,问几个小问题:你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
克里斯托弗:我有两只非常活跃的狗。我喜欢带他们在科罗拉多徒步旅行。我的妻子和我继续寻找这么多伟大的地点,与他们一起探索。我喜欢烹饪,并一直在努力提高这些技能。我们去年从夏威夷搬走了,我在新家有一个漂亮的厨房。我喜欢玩电子游戏,我妻子也喜欢。我们喜欢在《命运》或《战争机器》这样的游戏中合作。
我期待着设置我的音乐设备和录制一些新歌。我用 Tripnet 这个名字创作器乐。它可以在 Spotify、Apple Music 和大多数其他流媒体服务上使用。它是西古尔·罗斯、彼特·加布埃尔、非洲凯尔特音响系统、后摇滚或配乐的风格。
如果你更喜欢硬摇滚或垃圾摇滚,我在 90 年代参加了一个叫 Beats the Hell Out of Me 的乐队。本人涉猎电子,希望在未来的一些项目中结合 Python 和音乐创作。
克里斯托弗,今天和你聊天很愉快。如果你想和克里斯托弗打招呼,或者为即将到来的播客节目推荐一位播客嘉宾,那么你可以在 Twitter 上找到他,或者给播客留一条语音信息。你可以查看在 Real Python 上的个人资料,获取他所有视频课程的列表。
一如既往,如果你想让我在未来采访某人,请在下面的评论中联系我,或者在 Twitter 上给我发消息。编码快乐!
科里·斯查费的 Python 社区访谈
在本周的社区采访中,我和因 YouTube 而出名的科里·斯查费在一起。
Corey 是一名全职内容创建者,定期在 YouTube 上发布 Python 教程。在这次采访中,我们与科里谈论了他的 YouTube 频道,以及他对初露头角的 YouTube 和内容创作者的建议,得到了他的第一份开发工作,以及他对木工的热情。
瑞奇: 欢迎来到真正的 Python!我们不妨从头开始。你是如何开始编程的,你是什么时候开始使用 Python 的?
科里:谢谢你邀请我。事实上,我开始编程的时间比你可能采访过的大多数人都要晚一些。我过去对晚一点开始感到有点难为情,但现在我试着站在前面,这样其他人就不会因为他们在“更大”的年龄开始而感到害怕。
我想严格来说,我是在大学开始攻读计算机科学学位的,但即使在那个时候,我也没有把它看得很重。我会尽全力通过测试,但我没有吸收任何信息。我绝对没有做任何副业,也没有在任何现实世界的应用程序中使用编码。
直到我 25 岁左右,我随机申请了肯尼迪航天中心的美国宇航局实习,并开始认真对待编程。令我惊讶的是,我被选中参加实习。冒名顶替综合症在第一天全面爆发。我绝对不是我的对手。
但是我在那里工作的时间越长,我越意识到这些人不是超人。这些人和我一样,只是他们花了更多的时间在工作上来掌握他们的技能。
我心想,“如果他们能做到,我没有理由做不到。”因此,我带着一种新的动力离开了卡纳维拉尔角,开始真正投入编程,尽可能多地学习。直到我快 30 岁的时候,我才觉得我可以称自己为真正的程序员。我现在 30 出头,所以我觉得我还没有掌握我想要的技能。
至于学习 Python,大概是 4 年前才开始用的。我是西弗吉尼亚大学 GIS 技术中心的全职前端 JavaScript 开发人员,从事一些地图绘制工作。我们使用 Python 编写一些后端脚本,我被分配去维护/更新其中的一些。我发现我比前端 JavaScript 工作更喜欢这个,并开始每天使用 Python。
瑞奇: 你提到你开始编程的时间晚了一点(尽管还很年轻)。有了这样的背景,你获得第一份初级开发人员工作的经历是怎样的,你对以后寻找第一份开发人员工作的人有什么建议吗?
在卡纳维拉尔角实习结束后,我在 25 岁左右找到了第一份开发工作。那份工作是在西弗吉尼亚州的一家小研究公司。在 WV 的竞争不像在旧金山或硅谷那样激烈,所以我能够在没有太多经验的情况下找到工作。
当我第一次去那里时,我非常害怕。我从来不想让任何人看到我写的任何代码,因为我害怕这样会暴露我和其他人知道的一样少。我后来发现,这是社区内的一种普遍恐惧。
事实上,作为一名全职开发人员,我学到的东西比我在学校或自学中学到的要多得多。了解基础知识肯定是有帮助的,但是实际编写真实世界的应用程序并让多年来一直从事这项工作的人来评论您的代码是无可替代的。
让你的同事看到你的错误肯定是不舒服的,但是一旦你克服了这种不舒服,你就不太可能在将来犯同样的错误。我的许多观众问我,“你是怎么知道如何解决这些问题的?”好吧,事实是,编程中的很多问题都很相似。
一旦你多年来错误地解决问题,并被展示了越来越好的方法,你最终会学会识别某些模式,并从一开始就使用最有效的方法。这不是大多数人天生就有的技能。它是在多年的反复试验中发展起来的。
大多数读者可能会从你非常受欢迎的 YouTube 频道认出你。我当然通过它听说过你。它不仅在我们的Python YouTube 频道终极列表上,而且我经常观看你的视频,甚至作为你的 Flask 课程的直接结果,我开发了一个最新的 Flask 应用。从教学的角度来看,你是如何发现 YouTube 这个平台的?有什么令人惊讶的经验教训吗?
科里:谢谢。我很荣幸在你的文章中介绍了我的频道。YouTube 是一个非常棒的学习平台,我很高兴看到在线学习在未来的发展方向。像 YouTube 这样的网站无疑降低了任何想创作内容的人的准入门槛。
许多人认为在你开始之前,你需要一个好的录音棚或一些资金支持,但现在情况不再是这样了。只要你有一台电脑和一部手机,那么你基本上就拥有了开始工作所需的所有工具。随着时间的推移,我已经升级了我的设备,但我最初是在 YouTube 上使用内置麦克风在一台廉价的笔记本电脑上进行屏幕录制。
对于任何正在考虑开设 YouTube 频道或创建内容的人来说,我确实有一些随着时间的推移而学到的经验。我相信我学到的最重要的一课是,你应该为自己制作内容。我试着不为某个主题创建教程,仅仅是为了让它们受欢迎,或者什么会获得最多的浏览量…相反,我试着创建我希望在学习那个主题时就有的课程。
在你学习某些科目的时候做笔记,并记录下你发现难以消化的内容及其原因。如果你被某件事困住了,那么很可能其他人也会被它困住。一旦你找到了这些问题的解决方案,那么你可以回头看看是否有任何人可以向你解释的方法,可以帮助你更容易地理解。如果有,那么一定要把它传递给其他人。
我真的相信这个建议适用于其他领域。如果你是一名教育工作者,那么制作一些你个人会觉得有帮助的内容。如果你是一个音乐家,那就做你个人喜欢的音乐。如果你是一个喜剧演员,那就讲你认为有趣的笑话。如果你这样做了,那么很可能会有很多像你一样的人和你有同样的想法,喜欢你的内容。
里基:YouTube 频道的下一步是什么?有没有扩展到付费课程或其他教学形式的计划?
科里:目前,我坚持上 YouTube 的课程。我感到非常幸运,有一个平台可以让我免费发布我的内容,并由广告收入资助。这使得那些负担不起课程费用或目前无法支付内容费用的人可以访问我的所有内容。
理想情况下,只要我有足够的收入来维持生活,我的内容将永远免费。如果没有慷慨的支持者通过像 Patreon 和 T2 这样的网站捐款,这也是不可能的。他们按月资助我,这样那些负担不起的人就可以继续免费观看这些内容。我希望在未来尽可能长的时间内继续这种模式。
至于扩展到其他形式的教学,我考虑过创建某种在线学习平台。我在个人生活中使用了很多工具,帮助我快速学习主题。工具,如间隔重复学习应用程序和日常编码挑战。
我很想解决一个项目,将这些概念带到一个学习平台上,帮助学生更快更充分地吸收材料。不过,像这样的任何类型的项目都是我在一段时间内不会去做的。目前,我专注于创作视频内容。
瑞奇: 先生,你是一个天才的木工!你的东西看起来令人印象深刻。这是你的新爱好还是长期爱好?你是怎么开始的?
科里:哦,谢谢你这么说。这是一个我希望有更多时间去探索的爱好。这是我多年来一直在玩弄的东西。就我个人而言,这是一个很好的方式来清理我的大脑,释放任何累积的压力。
木工和编程在很多方面可以是相似的。有时候,我会开始一个木工项目,并有一个想法,我希望成品看起来像什么,但不是一个详细的了解从哪里开始。因此,你开始写下一些大纲,然后敲出较小的组成部分,然后经过许多小时的工作,你可以将所有这些结合在一起,形成你所希望的结果。完成这些类型的项目会让你感到非常自豪。
里基: 现在我的最后一个问题。你在业余时间还做些什么?除了 Python,你还有什么其他的爱好和兴趣?有你想分享和/或插入的吗?
由于我的职业生涯是在电脑前度过的,我喜欢尽可能地在户外度过业余时间。这包括徒步旅行、划独木舟、露营、游泳和去狗公园。现在我在家工作,有了更灵活的时间表,我和我的女朋友想开始更多的旅行。我相信我可能会在我的日历上标记一些国际 PyCons,并以此为借口访问一些我们很久以来一直想去的地方,并额外结识更多来自 Python 社区的人。
谢谢你,科里,这周和我在一起。你可以在这里找到科里的 YouTube 频道。你可以通过推特或他的网站与他取得联系。如果你已经从 Corey 的视频中受益,考虑用 via Patreon 支持他的努力。
如果你想让我采访 Python 社区的某个人,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
与 Dane Hillard 的 Python 社区访谈
今天和我一起的还有Dane Hillard,it haka的首席 web 应用程序开发人员和《Python Pro 的T5】实践的作者。戴恩也是真正的 Python 教程作者。
在这次采访中,我们讨论了各种主题,包括代码复杂性、Python 包维护和爆米花。事不宜迟,让我们欢迎戴恩。
谢谢你参加我的采访,戴恩。我想以我们对所有来宾一样的方式开始:你是如何开始编程的,你是什么时候开始使用 Python 的?
戴恩:谢谢你让我回来!真正的 Python 是一个花更多时间的好地方。我对编程的一些最初体验对许多来自 LiveJournal 和 MySpace 时代的孩子来说是一样的——我定期定制我的个人资料页面和主题,以确保我的焦虑漫谈看起来是最好的。
大约在同一时间,我开始在 Rhinoceros 中做一些 3D 建模,作为一个主要的艺术出口,但它也提供了一些我修补过的脚本功能。我和一个朋友非常喜欢 Liero ,我甚至做了一些定制的武器给我们玩。所以总的来说,一个令人讨厌的开始来自于一些无关紧要的兴趣。
我在学校学过 C++和 MATLAB,我的第一份实习和全职工作就是用这些语言完成的。一路走来,我学会了 Perl,并用它找到了我的第二份工作。
在那里学到大量 SQL 优化知识的同时,我也开始和一个朋友一起做一些业余项目。他是一个喜欢 Rails 的人,所以我开始接触 Ruby。我一直在用 PHP 和 Spring 为我的摄影作品运行一个网站,决定接下来试试 Rails。“按照惯例编码”的范例当时并不完全符合我的想法。
当我最终决定我的网站需要一个更好的版本时,我四处寻找与 Rails 相似的流行的 web 框架,最终找到了 Django。从那以后 Python 就成了我的最爱!这是一条曲折的道路,但我喜欢它带我到目前为止。
Ricky: 这些天你最感兴趣的 Python 话题是什么?
Dane: Python 包维护是我最近的一个重点。我维护着几个小型开源项目,如 apiron 和django-web reference,我还在 ITHAKA 内部维护着十几个软件包。拥有一个可重复但可迭代的过程,一个固执但灵活的过程,变得非常有价值。
这一切都归结到工具!忘记在一个或两个包中进行更改会导致以后更多的上下文切换,所以尽管包之间仍然有一些重复的任务,但它们更像是菜谱,而不是为每个包重新发明轮子。
我已经尝试了几种依赖管理的解决方案,比如 Pipenv 和 poem,但是我想要的是能够经受住打包中涉及的所有工具的挑战的解决方案,比如 pytest、mypy、Black 和 Pylint 等等。
目前,我已经相当舒适地适应了使用 tox 和
setup.cfg来管理大部分事情的工作流程。我也在关注pyproject.toml。现在所有这些方面都有了一些自动化,我花了更多的时间来考虑代码的复杂性。我在我的书里谈了一点,但是知道足够写一些东西并不意味着它在实践中总是得到适当的关注!我被我们在整个组织中使用的模式所吸引,并为这些模式找到正确的设计,帮助我们更快更安全地前进。
我最近一直在使用 Radon 来快速方便地访问 Python 复杂性统计数据。我已经很快确定了我们经常接触的几个代码区域,它们的复杂性对于解决是有价值的。我们还使用 SonarQube 来跟踪这些数据。每个人都应该看看 Anthony Shaw 的采访,了解更多关于他制作的工具。
虽然这些采访是关于社区成员的个人故事,但我也试图给我们的读者留下一些可操作的东西,他们可以带走并应用到他们的代码中。因此,考虑到这一点,你能给出哪些大多数人可能没有意识到的实用技巧呢?
通过用一个将条件映射到动作的字典来替换条件集,你可以显著地降低很多代码的复杂性。我经常惊讶于使用这种重构会有多少代码崩溃。
Sandi Metz 有一个伟大的演讲,关于镀金玫瑰形中的重构。梅斯谈到了把转换的原因和转换时要做的事情分开。我强烈推荐观看这个和她所有其他的演讲。
瑞奇: 你是这里的教程作者真正的 Python 同时也是《Python Pro 的 练习的作者。你希望人们读这本书时能从中得到什么?你在写这本书的时候学到了什么?
戴恩:这真是个好问题。人们很容易认为一本书涵盖了某人几十年来一直在做的事情,我相信这有时是真的。不过,我在写这本书的时候确实学到了很多。它迫使你做一些结构化的研究,并批判性地审视你当前理解的替代方案。
在写这本书的时候,我学到的最重要的事情之一就是耦合的概念。经常听说我们想要松耦合的代码,但是对我来说,这从来都不是一个很实际的想法。
我开始把面向对象编程中的耦合看作是对象扮演的角色,以及对象如何相互传递消息。这种心理模型揭示了代码中的许多尴尬之处,这通常可以通过尝试为这些交互编写测试来证明。
你会看到这一点在 Metz 的演讲中得到了很好的体现——她最初是一名 Smalltalk 程序员,这些想法通常可以追溯到那群人。
瑞奇: 你谈到过为公共利益而编码。到目前为止你是如何做到的,你对未来有什么想法吗?
戴恩:我坚信集体知识的力量。开源软件经常这样做,但我认为它需要继续发展。投资开放基础设施是一位同事最近分享的一个很好的例子。他们不只是说,“这里有一堆你可以使用的技术,”而是把它带到一个新的水平,并提供战略,研究,社区,等等。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
戴恩: 我是一名歌手兼词曲作者,但我最近没怎么写作。我很喜欢在隔离期间学习打掩护。我已经喝了不少酒,唱了不少亚历克西·默多克盖尔歌曲。我最近最喜欢的是达米安·赖斯的《T4》和狐狸乐队的《群岛》。
我一直在做一些与食物相关的事情。在去疫情之前,我开始了一个酸面团的兴趣爱好,在穿越整个州之后,我刚刚回到这个爱好上。我最近发现营养酵母是人类已知的最好的爆米花配料之一,所以一定要去试试。对我来说,加点辣椒粉、蒜盐、黑胡椒和香草味道很好。
里基: 谢谢你加入我,戴恩!
如果你想就我们今天谈论的任何事情与戴恩取得联系,那么你可以通过他的网站或 T2 的推特联系他。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。编码快乐!
Python 社区采访 David Amos
本周, Real Python 的内容技术主管大卫·阿莫斯加入了我的讨论。
在这次采访中,我们谈论大卫对乐高和数学的热爱。我们还谈到了 Python 基础知识的书,这本书很快就要退出早期访问,以及他与 PyCoder 的周刊 的关系。所以,事不宜迟,我们开始吧。
瑞奇: 大卫,谢谢你加入我的节目。我们的许多读者和成员可能已经知道了你的背景,但对于那些不知道的人,让我们问一些不可避免的问题:你是如何进入编程的,你是什么时候开始使用 Python 的?
大卫:当我在父母的 IBM 386 PS/2 电脑上偶然发现大猩猩游戏的源代码时,我偶然发现了编程。我想我大概七八岁的时候。我发现了一个叫做
.BAS的文件,它打开了一个叫做 QBasic 的程序,里面有各种奇怪的文本。我立刻被吸引住了!文件的顶部有一个说明,解释了如何调整游戏速度。我更改了值并运行了游戏。效果立刻就明显了。这是一次激动人心的经历。
我痴迷于学习用 QBasic 编程。我自己做的文字冒险游戏。我甚至用简单的几何图形制作了一些动画。太有趣了!
对于一个八岁的孩子来说,QBasic 是一门很棒的语言。这很有挑战性,足以让我保持兴趣,但也很容易得到快速的结果,这对一个孩子来说真的很重要。
当我十岁左右的时候,我试图自学 C++。想法太复杂,结果来得太慢。挣扎了几个月后,我停了下来。但是给计算机编程的想法仍然吸引着我——以至于我在高中选修了一门网络技术课,学习了 HTML、CSS 和 JavaScript 的基础知识。
在大学里,我决定主修数学,但我需要辅修。我选择了计算机科学,因为我认为有一些编程经验会更容易达到学位要求。
我用 C++学习了数据结构。我上过 Java 的面向对象编程课。我用 c 语言学习了操作系统和并行计算。我的编程视野大大扩展了,我发现整个主题在实践和智力上都令人愉快。
当时我把编程看作是帮助我进行数学研究的工具。在研究生院,我编写程序为我的研究项目生成例子和测试想法。
大约在 2013 年读研期间,我发现了 Python,并很快爱上了它。我一直使用 C++、MATLAB 和 Mathematica 作为我的主要研究工具,但是 Python 让我可以专注于研究问题,而不会陷入代码中。
有了 Python 令人敬畏的科学计算工具生态系统,如 NumPy 、 SciPy 、 PuLP 和 NetworkX ,我拥有了解决问题所需的一切,就像我用 MATLAB 一样,但表达方式更丰富!
瑞奇: 你经常会听到这样一个神话:强大的数学背景是成为程序员的先决条件。虽然我想你会同意程序员并不总是需要知道高等数学,但我很想知道你的数学和数据科学背景在编写代码时对你有什么帮助。
如果你想成为一名计算机科学家,那么你需要很强的数学背景。然而,并不是所有的程序员都是计算机科学家,也不是所有的计算机科学家都是程序员。
程序员的工作是写代码,但我从来没有做过这样的程序员工作:有人递给你一个用简单英语写的程序,让你把它翻译成 Python。所以程序员的工作不是把人类语言翻译成计算机语言。
数学、计算机科学和编程的交集就是问题解决。也就是说,数学家、计算机科学家和程序员解决的问题不同。
数学家解决关于数学结构的问题。我认为计算机科学家是应用数学家,他们解决计算研究中出现的有关结构的数学问题。
另一方面,程序员更像是建设者和工程师。程序员通常被给予一个设计,并被赋予尽可能高效和有效地实现该设计的任务。
尽管有这些差异,还是有一个通用的框架来解决问题,不管是什么学科。我认为这个框架在 George Pólya 的经典论文 如何解决它:数学方法的一个新方面 中得到了最优雅的阐述。
该框架有四个阶段,并附有您在每个阶段应该问自己的问题:
- 理解问题:未知是什么?条件是什么?
- 设计一个计划:你有什么工具可以使用?你已经解决了一个类似的问题吗,那个问题的解决方案能帮到你吗?
- 执行计划:你能检查计划的每一部分都是正确的吗?
- 回头看:你能证明你的解决方案有效吗?你能想出另一种方法来解决这个问题吗?你能用这个方法解决另一个问题吗?
Pólya 解决问题的方法令人难以置信地强大,尽管这本书是为学数学的学生写的,但每个人都可以从阅读它中学到很多东西。这本书的所有例子都依赖于在美国典型的初中或高中课程中会遇到的数学。
作为一名数学家,我学到的最强有力的观点——同样适用于编程,实际上也适用于日常生活——是很少有问题是无法解决的。通常解决问题的关键是问正确的问题。(实际上,有许多问题无法解决,但是作为一名程序员你不太可能遇到这些问题!)
如果你第一眼不能解决一个问题,那就想出一个你能解决的相关问题。事实上,这是在如何解决中反复重复的咒语:
你不轻视小的成功,相反,你寻求它们:如果你不能解决提出的问题,试着解决一些相关的问题。
-乔治·波兰文
里基: 你在重写和更新最初的 真正的 Python 课程 并把它变成现在的 Python 基础知识这本书方面发挥了重要作用。你能谈谈这本新书吗?谁会从阅读中受益,当他们完成这本书时,读者能期望学到什么?
与丹·巴德、乔安娜·贾布隆斯基和雅各布·施密特就 Python 基础知识:Python 3 实用入门一起工作既有挑战性又有回报。
感谢 Fletcher Heisler,第一个真正的 Python 课程的作者,我有了一个坚实的基础。我确实重写了这本书的大部分内容,并牢记两个主要目标:
- 更新 Python 最新版本的内容。
- 确保编写内容达到或超过与其他真实 Python 编写内容相同的标准。
弗莱彻的书很棒,但风格与典型的真正的 Python 文章大相径庭。我希望这本书尽可能地受到新读者的欢迎,同时也让现有的真正的 Python 读者感到熟悉。
Python 基础知识的目标受众是对学习 Python 感兴趣的初级程序员。你不需要任何编程经验来充分利用 Python 基础。
这本书带你了解在 Windows、macOS 或 Ubuntu Linux 上安装 Python 的过程。但是你可以在任何你喜欢的系统上使用 Python 3.6 或更高版本。
你甚至不需要知道如何使用代码编辑器!Python 附带了一个名为 IDLE 的轻量级编辑器,非常适合初学者。如果你有一个你喜欢使用的编辑器,那么你也可以把它用在书上。书中只有一章需要 IDLE,而且是关于使用 IDLE 的调试窗口。
Python 基础知识涵盖了 Python 入门所需了解的一切,包括:
- 创建变量
- 与数字打交道,进行基本的数学运算
- 使用数据结构,如字符串、列表、元组和字典
- 编写条件语句、函数和循环
- 创建类和用户定义的对象
但这真的只是开始。在你学会了这门语言的基础知识之后,有些章节会教你如何:
- 使用文件
- 安装和使用第三方库
- 创建和修改 PDF 文件
- 从互联网上搜集数据
- 根据数据制作图表和图形
- 构建图形用户界面
几乎每一章都有带答案的练习,挑战性的问题来鼓励你把你的技能提升到一个新的水平,以及互动的测验来帮助验证你所学的一切。
瑞奇: 你是如何找到写这样一本综合性书籍的过程的?它改变了你写技术教程和文章的方式吗?你学到了什么让你感到惊讶或者你现在一直在使用的东西?
大卫:写这本书是一堂关于耐力和毅力的课。花了两年多一点的时间才完全组合起来。
那段时间,我换了工作,开始全职为真正的 Python 工作。我也经历过几次个人试炼。我的房子被淹了两次,我的家人在 2019 年流离失所了 7 个多月。这是一个真正的挑战。
写这本书迫使我花了很多心思在章节的组织上。这无疑是技术文章中的一部分。我一直是大纲的粉丝,但现在我无法想象不先设计一个大纲就写任何东西。
我也成为了垂直列表的大力支持者,这是你在真正的 Python 中随处可见的东西。我必须感谢真正的 Python 、的执行编辑乔安娜·雅布隆斯基,是他们鼓励我更多地使用它们,并帮助我看到它们的价值。
起初,我有点反对他们。也就是说,我觉得乔安娜想让我过度使用它们。回想起来,垂直列表较少的早期草稿现在在我看来很难看,似乎很难阅读。
在你做的所有其他事情中,你还是《PyCoder 周刊》的主编。你每周都要阅读和解析数百篇 Python 相关的文章,所以很难想象这对你自己的学习没有好处。有没有这样的时刻,或者你读过对你自己的编程有重大影响的教程?
大卫: PyCoder 的绝对让我这个程序员和作家受益匪浅。
或许从 PyCoder 周刊的策展文章中最大的收获是 Python 编程的主题有多广泛。我最喜欢的一些文章是关于奇异的事情,比如创建完全用 Rust 编写的 Python 包,或者我从未听说过的设计模式,比如 sans I/O 。
我也越来越喜欢几个作者,以至于当我看到他们发表的新文章时,我会很兴奋。我真的很喜欢杰克·艾治在 LWN 写的新闻报道。我也期待由布雷特·卡农撰写的文章。
有时候,你重新发现的,或者一起错过的简单的事情,会产生最大的影响。Brett 最近的一篇文章让我想起了使用
-c标志从终端运行 Python 命令,我已经完全忘记了这一点,现在已经开始更经常地使用它来检查微小的代码示例。我喜欢关注 Python 生态系统中所有精彩的包。我发现了各种各样令人惊叹的东西,包括用于处理 NASA 太空数据的库、自主机器人模拟器,以及用乐高搭建的 Python 驱动的显微镜。
Pythonistas 是一群有创造力的人!
里基: 现在我的最后几个问题。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
大卫:我有两个孩子,其中一个四岁。你所说的“业余时间”是什么?
如果我不工作,也不忙着成人,那么我真的很喜欢建造乐高,尤其是太空主题的玩具。我的大女儿和我喜欢一起观星,观看美国国家航空航天局和 SpaceX 公司的火箭发射。
我也是《星际迷航》的超级粉丝,我看了很多《星际迷航》的内容。斯波克一直是我最喜欢的角色之一。我很佩服他平衡情感和逻辑的能力。
虽然我不想像典型的瓦肯人那样没有感情,但根据理性和现有的最佳数据做出决定而不让感情影响你的判断的能力是一种很有价值的技能。不过,我希望这是一件容易开发的事情!
谢谢你,大卫。和你谈话总是很愉快。
如果你想和大卫取得联系,那么你可以在推特上找到他,或者你可以访问他的个人网站。如果你是 Python 的新手,想在学习中增加一些结构,那么 Python 基础:Python 实用入门 3 可以帮助你提高 Python 水平。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或通过 Twitter 联系我。编码快乐!
Python 社区采访达斯汀·英格拉姆
今天,我邀请到了谷歌的开发者倡导者达斯汀·英格拉姆,他致力于在谷歌云上支持 Python 社区。他还是 Python 软件基金会(PSF)的董事和 PyPI 的维护者。在这次采访中,我们讨论了谷歌对 Python 的使用与你的使用有何不同,维护 PyPI 需要什么,他作为 PSF 总监的目标,他对 PyCons 的热爱等等。
瑞奇: 谢谢你和我一起,达斯汀。我想从我的常见问题开始:你是如何进入编程的,你是什么时候开始使用 Python 的?
达斯汀:谢谢邀请我!
我喜欢说,我的第一次编程经历是当有人决定允许——如果不是鼓励的话——我在整个高中期间都带着 TI-83 计算器。我在几何课上花了少得多的时间学习几何,而花了多得多的时间用 BASIC 编写基于文本的游戏,以及后来为我做物理作业的程序。
我甚至发布了我的第一个开源程序:一个小动画,让你的计算器屏幕看起来像是《黑客帝国》中流动的乱码(我对此很着迷)将其发布到德州仪器的第三方软件仓库。
但是我第一次真正接触编程可能是在我第一次接触到 Logo 的时候,这是一种以海龟为光标的图形化编程语言。我想那是在小学,任务是尝试复制一些简单的形状,但我清楚地记得被无尽的可能性惊呆了。我不像以前玩的那些点击式电脑游戏那样被限制在一个预定的路径上——我可以让那只乌龟做任何事情。
我爸是工具设计师,我上高中的时候,他开了一家机器店。这家商店有许多传统的金属加工工具:主要由手工操作的车床和铣床。但是他们也有一些更新的计算机数字控制(CNC)机器,这些机器用一种叫做 g 代码的语言编程。
如果你以前从未见过 g 代码,我最多只能把它描述为 BASIC 和 Logo 的混搭,但不是一只可爱的小乌龟四处移动,而是一个连接在半吨重机器上的钻头,每分钟旋转几千转。所有习惯于操作经典的手动机器的老人们都不能完全理解这项新技术,但它对我来说完全有意义!
后来在高中,我参加了一些计算机科学课程,这些课程教会了我一些 Java,并使我相信这个领域值得追求。上大学学计算机,遇到过 Scheme 等 Lisps ,也有一些 C 和 C++,但大多更多的是 Java。
大约在那段时间,我开始在大学的一个研究实验室工作,虽然那也全是 Java,但那里一些年长的、聪明的研究生真的很喜欢这种叫做 Python 的新语言,并且基本上试图尽可能多地将它融入他们的项目中。一旦我接触到它,我也就着了迷,并开始尝试尽可能多地写它。
后来,当我发现围绕这种语言的更大的开源社区,它所体现的自己动手的精神,以及对可用性、可读性和初学者友好性的不可思议的关注——更不用说其中一些不可思议的人了——我被吸引住了。我非常幸运,因为在我接触到它之后不久,它就开始真正地起飞了。我很难想象如果没有 Python 我会是什么样子。为此,我非常感谢社区。
里基: 白天,你是谷歌的一名开发者拥护者,专注于在谷歌云上支持 Python 开发者。我之前和布雷特·斯拉特金(T4)谈过,他在谷歌讨论了 Python 的历史,谷歌最近成为了 PSF 的一个有远见的赞助商。随着谷歌成为 Python 的大力支持者,Python 目前在谷歌的前景是什么样的,Python 和谷歌云未来的路线图是什么?
当人们问我 Python 在谷歌内部是什么样的时候,我通常会说它有点像另一个宇宙。谷歌内部的所有软件工程都存在于这个泡泡中,它有自己的习惯用法、工具和模式,有时在更广泛的生态系统中并不存在。因此,尽管我们每天都有数百万行 Python 代码和数千名工程师编写 Python,但我们内部使用 Python 的一些经验并不能映射到社区其他人的经验中。
例如,你可能听说过 Google monorepo ,但是 monorepo 的一个副作用是我们并不真正使用 Python 包索引(PyPI)——至少不像大多数 PyPI 用户那样使用 PyPI。因此,如果你没有一个完全不同的视角,我现在可以告诉你的关于谷歌如何使用 Python 的任何事情可能都没有多大意义。
也就是说,我可能不能告诉你更多了!不是因为这是机密,而是因为我尽可能少花时间呆在那个泡泡里。我支持编写 Python 并希望使用谷歌云的普通开发者。如果我生活在谷歌的泡沫中,我将无法对他们的经历产生共鸣。我们有一整个团队致力于让 Python 为谷歌的工程师工作。我关注其他人,并帮助我们为这些人开发好的工具。
我认为很多人将“开发者关系”解释为公司如何向开发者进行外部营销以及宣传其产品,虽然这在许多地方可能是真的,但在谷歌,情况恰恰相反:这是一个非常技术性的角色,将开发者的反馈以及对这些用户的理解和同情带给我们的工程和产品团队。
虽然你可能偶尔会在视频中或博客文章的署名上看到我,但这真的是一个更大的冰山的一角,你不能直接归因于我,我一直主张改变我们的产品,报告错误,产品因此变得更好。
我仍然认为自己是一名工程师,有时会为我们的产品做出贡献,但通常是开源部分。例如,使用云函数,我创作了 Python 函数框架,它让你可以在任何地方将单个 Python 函数作为服务提供,并为运行时提供了构建包。这些都是以对 Python 社区有意义的方式构建的,而不是怪异的 Google alternate universe,任何人都可以做出贡献。
我工作的另一部分是利用我在 Python 社区的经验和联系来帮助 Google 管理与它的关系。这包括很多事情,包括确保我们成为良好的软件公民,发布惯用工具,在正确的地方发挥我们的杠杆作用(不要太多),管理我们的存在和会议以及我们对生态系统的财务支持,等等。
谷歌成为了一个有远见的赞助商,不仅仅是因为我们希望 PSF 继续运营(当然,我们也希望如此),还因为我们希望帮助确保 PSF 的一些具体目标能够实现,比如雇佣了一名 CPython 常驻开发人员,他将是第一个由 PSF 支付一年的全职开发 CPython 的开发人员。
你戴的一顶帽子是 PyPI 维护者的帽子。所有 Python 开发人员在 pip 安装包时都曾使用过 PyPI。但是许多读者可能不知道构建和维护像 PyPI 这样的东西需要做些什么。事实上,你最近在推特上提到了 PyPI 的巨大增长。我想知道你是否能解释是什么让 PyPI 持续运行,Python 的发展对 PyPI 有什么影响。
达斯汀:这是一个很好的问题,而且时机恰到好处!我刚刚发表了Python 包索引需要什么动力?,这是对五年前一篇类似帖子的更新,详细介绍了我们的增长情况,从技术角度来看需要做些什么,以及我们如何支持这种增长。我认为这是任何想使用 PyPI 的人的必读书目。
TL;我想让人们从这篇文章中得到的是:PyPI,作为 PSF 的一个项目,是一个 a)非盈利性的,b)几乎完全由志愿者管理,c)依赖于很多捐赠的基础设施。
我认为来自其他语言生态系统的人们可能会对此感到惊讶,在这些语言生态系统中,包索引背后有风险投资基金或数十亿美元的公司,但我认为这一事实确实证明了 Python 社区的力量。但是,当出现问题或者某个特性的开发速度不如预期时,记住这一点很重要。
里基: 你戴的另一顶帽子是作为 Python 软件基金会的董事之一。你已经在董事会一年了。目前进展如何?当你开始的时候,你设定了什么目标?在过去的一年里,这些目标发生了怎样的变化?
达斯汀:其实有点讽刺。当我在 2019 年竞选董事会并失败时,我的目标之一是使 PSF 的资金多元化。当时,PSF 从 PyCon US 获得了惊人的收入——将近 90%。
这让我对 PSF 继续运行的能力有点担心,但我认为大多数人当时并没有真正把这看作一个重要的问题,或者甚至没有意识到 PSF 对这个单点故障有如此大的依赖性。
因此,当我在 2020 年带着同样的目标再次竞选时,我们正处于全球疫情之中,刚刚取消了本来会成为我们主要收入来源的活动。。。我认为这对人们来说更有意义。显然 PSF 没有破产,但这不是因为我现在是董事会成员。
我认为我们在很多方面都非常幸运:PSF 的工作人员在准备像这样的灾难性事件时在财务上非常保守,我们的大多数赞助商和与会者都慷慨地捐出了当年的门票退款,工作人员能够非常努力地为今年的会议制作一个可行的,令人满意的虚拟活动。
我的第二个目标是在员工和基础设施方面进行更大的投资,特别是雇佣更多的专业角色,以帮助 PSF 以面向未来的方式发展,并帮助 PSF 运行和资助有利于社区的项目,如新的 PyPI 功能、改进文档、UX、可访问性、教育等。我们现在已经看到了一些进展,各种 PyPI 改进项目和 PSF 填补了一些新的角色,如资源开发总监和包装生态系统项目经理。
我的最终目标基本上是“倾听社区想要什么,并在 PSF 中倡导什么”——这基本上是我的日常工作。这是一个很大的通配符声明,也是故意这样做的,但在选举后不久,我们就听到了响亮而清晰的声音,即需要进行改进,理事会可以更好地代表投票成员,成员可以更好地代表更广泛的群体。
因此,去年我一直在为此而努力:我们成立了一个新的多元化和包容性工作组,我们已经为即将到来的选举提出了一些章程变更,为董事职位增加了一些限制,我们还会有更多的举措。
不言而喻,我不是这些变化的唯一负责人。所有这些都是多人共同努力的一部分,但这是我作为董事会董事的首要任务之一,也是我特别关注的事情。
Ricky: 你对 Python 大会并不陌生。你的 2020 PyCon talk 有一个复活节彩蛋,上面有来自地区 Python 活动的三十多种不同的 t 恤,你还帮助组织了像 PyTexas 这样的会议。所以我很好奇你的第一个 PyCon 是什么样的。你有最喜欢的发布会吗?在你看来,什么是好的 Python 大会?
Dustin: 我的第一次 Python 大会是在蒙特利尔的PyCon 2015。我最记得的是对这个社区的巨大和友好感到敬畏。我还记得抬头看全会大厅的巨型投影仪屏幕,看到所有的 PSF 赞助商标志,心想:“好吧,这些是值得为之工作的公司”:)我最大的遗憾是,我不知道有大会 t 恤,从来没有得到一件!
我很幸运能够参加很多很多的会议,现在可能已经记不清了。我最美好的回忆包括在 PyCon Taiwan 的弦乐四重奏,在联合国大楼 PyGotham 的演讲,以及在 PyLatam 的泳池边流浪乐队。但是有太多我还没有去过的地方,我希望有一天能去参加,像 PyCon Africa 、 PyCon India 以及南美的任何地方!
在过去的一年里,当我们局限于虚拟活动时,我学到的一件事是,我低估了这些会议上发生的社交方面和面对面关系的重要性。我参加过一些非常好的虚拟会议,与面对面的会议相比,它们永远处于劣势,在面对面的会议中,所有的互动都是默认发生的,我们认为这是理所当然的。网上真的很难做到!
也就是说,虚拟会议也有许多强大的好处。受众可以更广泛,会议也更容易参加——不需要旅行,成本通常也更低。我希望,一旦我们回到面对面的活动中,我们仍能保留一些。
我认为有很多特性使 Python 会议看起来像 Python 会议,但以我的经验,真正好的会议是志愿者和/或帮助举办会议的工作人员的纯粹努力。我想参加过 PyCon US 的人可能没有意识到工作人员已经为这个活动工作了多长时间(场地已经提前很多年预订了!)或者需要多少无偿志愿者来提供会议并保持低成本。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
Dustin: 在我的业余时间,我为 PSF 做志愿者,为一些我关心的开源项目做贡献,并帮助维护像 PyPI 这样的东西:)人们通常认为这些事情是我日常工作的一部分,但它们不是。
除此之外,当我有时间的时候,我通常会做饭,在我的车库或木材店修修补补,播放音乐,骑自行车,在森林里露营,或者只是和我的狗在一起。
里奇 : 谢谢你参加我的采访,达斯汀。聊天很愉快。
如果你想就我们今天谈论的任何事情联系达斯汀,那么你可以通过 Twitter 联系他。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。
与 Emily Morehouse 的 Python 社区访谈
我很高兴本周能邀请到艾米莉·莫尔豪斯。
Emily 是 CPython 核心开发团队的最新成员之一,也是 Cuttlesoft 的创始人和工程总监。Emily 和我谈论最近的 CPython 核心开发人员 sprint,以及她在大学同时完成三个专业的事实!我们还将了解她对编译器和抽象语法树的热情。
让我们从显而易见的开始:你是如何进入编程的,你是什么时候开始使用 Python 的?
Emily: 我的编程之路是从爱上英格玛机器开始的。真的,我是在大学期间偶然接触编程的。我最近把我的一个专业从生物化学转到了犯罪学,而且该系刚刚启动了一个计算机犯罪学项目。
我被鼓励去尝试编程入门课程,看看我有多喜欢它。我们的一个最终项目是建造一个 Enigma 机器模拟器(注意,是用 C++),我被吸引住了。我决定增加第三个专业来获得一个完整的计算机科学学位(稍后会有更多的介绍!).
由于计算机科学课程理论性很强,而且侧重于 C 和 C++等语言,我开始在课程之外寻找方法来学习不同的东西。我在周末学习了 Python,在 web scrapers 上工作,并最终被聘为研究员,在那里我们使用 Python 从各种网站收集和分析公共数据。
对我来说,编程跨越了广泛的挑战性逻辑和技术问题,以及更抽象的概念,如人类如何思考和与机器互动,以及技术如何改善我们的日常生活。它填补了学术和艺术之间的空白,我不知道我需要或者能够填补这个空白。
正如你已经提到的,你曾就读于佛罗里达州立大学,并在那里获得了计算机科学学位。还有犯罪学学位。另一个在剧院…你睡觉了吗?一个学位很难,但是一下子三个?我真的很想知道你的秘密,以及当你有这么多其他事情要做的时候,学习和学习编码的任何时间管理技巧。
艾米莉:我肯定没怎么睡觉。除了所有的学校作业,我还做了一份近乎全职的工作,甚至还在我们当地的咖啡店做夜班经理,同时还参加戏剧排练和演出。
我在计算机科学系找到了一个研究职位,消除了一些压力。我很幸运地以大量的学分开始了大学生活,并通过了一些课程的测试,所以从技术上来说,我已经领先了一年,这给了我更多的自由去尝试像编程这样的课程。
我就是这样长大的。从很小的时候,我就知道我的一天从早上 7 点左右开始。我从学校直接去排练和舞蹈课,然后必须做作业,直到我睡着。我必须学会如何记住信息并快速解决问题——我必须保持条理,所以我列了很多清单。
我问过父母我是怎么变成这样的,他们只是耸耸肩!我一直觉得我能很好地控制自己的时间,以确保这是我想做的事情,我认为在如此忙碌的时候这很重要。你必须想尽一切办法,否则事情就会半途而废。
我明确建议找到一种方式来保存待办事项清单,并对你的时间进行优先排序。我使用一个名为 Bear 的应用程序(类似于一个简化的 Evernote,但具有程序员友好的主题和 markdown 支持)以及许多任务优先级排序。
我还发现,通过多次记下来,我学东西很快。我用这个方法来记忆表演的台词。我会涂掉我的台词,然后回去,凭记忆把它们写在一张单独的纸上,冲洗,然后重复。我到了这样一个地步,如果我把一件事写下 1 到 2 次,它就会坚持下来。
你是卡特尔软件公司的联合创始人和工程总监。看起来好像你在大学毕业前就开了这家公司。你大学一毕业就开始创业而不是申请初级软件开发员的动机是什么?
艾米莉: 卡特尔软件是一个环境问题。我从未想过我会经营自己的公司,尤其是不会和我现在的丈夫弗兰克一起经营。我处于一个奇怪的时间空档,我比预期提前完成了我的本科学位,这意味着我错过了所有研究生院的最后期限。
FSU 同意让我在那里开始我的硕士课程,我打算呆一年,然后转到其他地方,在那里我可以继续从事解析器、编译器和形式验证方面的工作。我也被大型科技公司录用,我有点迷恋住在旧金山或波士顿的想法。(那时我只在佛罗里达住过。)
但后来,弗兰克和我在塔拉哈西找到了进入这个萌芽中的创业生态系统的方法。我们遇到了一些人,他们成为了伟大的导师,在我们开始工作之前,我们已经有了第一批客户。我想,“为什么我要离开所有这些对我的未来和成功投资的人,去成为其他地方成千上万人中的一员?”
我想我应该抓住机会开始自己的事业,并继续沿着这条快速发展的道路前进。我知道我会在更短的时间内学到比在任何地方都要多得多的东西。所以我在研究生院第一学期结束后就退学了,把所有的时间都投入到了 Cuttlesoft 上。
回想起来,我想象不出一条不同于我的道路。在我拒绝那些工作机会后不久,苏珊·福勒的故事就曝光了。我不禁想,“那可能是我。”我真的相信一家公司的文化是自上而下的,我很高兴能为一家公司做出贡献,在那里我可以以积极的方式产生巨大的影响。
今年,你实现了一个梦想,在 PyCon 大会上演讲,题目是《AST 和我》。我承认,有些东西超出了我的理解范围,但我仍在学习。我得到的印象是,语言内部让你着迷。对于刚开始编码之旅并想了解更多香肠制作方法的人,你有什么建议?你会推荐什么资源?
艾米莉:是的!在大学里,我是个古怪的孩子,喜欢几乎所有人都讨厌的课程(编程语言、编译器、计算理论……)。我会花几个小时画出非确定性有限自动机和状态机作为我的课程笔记。
我是 Bruce A. Tate 的《七周七种语言:学习编程语言的实用指南》的超级粉丝。龙书(编译器:原理、技术和工具)是一部经典著作,也是我们今天仍在使用的许多书籍的支柱。(Python 的编译器就是基于此。) Philip Guo 关于 CPython 内部的视频系列也很棒,在我深入了解 Python 如何工作的过程中帮助了我。
Ricky: 祝贺你被提升为 CPython 核心开发者!你一定很激动。最近 CPython sprints 的印心怎么样?有什么激动人心的事要分享或有什么故事要讲吗?别担心,我们会保守秘密……
艾米莉:谢谢!CPython Sprint 非常有趣。我们很少让这么多核心开发人员在同一个房间一起工作。我们都非常感谢 PSF 和今年的 sprint 赞助商微软对 CPython 的支持。
我能够参加 PyCons past 的 sprint 和语言峰会,并有机会了解这个团体的很多情况,所以这次 sprint 感觉非常正常,但能亲自看到每个人并与他们一起工作真是太酷了。
在 Guido 的指导下,我花了 sprint 的大部分时间来实现 PEP 572 ,著名的赋值表达式 PEP。无论你对赋值表达式持何种态度(或者我现在亲切地称之为海象操作符),向语言中添加新语法并深入内部以使变量作用域按预期工作都是非常酷的。它将在明年早些时候出现在 3.8 的 alpha 版本中,所以请密切关注!
sprint 中我最喜欢的部分之一是了解更多关于 CPython 的历史。自从我开始核心开发之路以来,我发现听到别人如何成为核心开发人员的故事真的很有趣,所以我尽可能地向每个人提出这个问题。
了解每个人(尤其是那些从很早就开始参与的人)为一个项目投入如此多时间和精力的历程和动机,是了解如何继续发展团队和增加多样性的重要一步。
现在是我的最后一个问题:除了 Python,你还有什么其他爱好和兴趣?有你想分享和/或插入的吗?
艾米莉:我在业余时间尽量利用科罗拉多州的一切优势——来自佛罗里达州的我仍然完全迷恋落基山脉,喜欢徒步旅行。丹佛也是一个伟大的美食城市。
当我腾出时间的时候,我也真的很喜欢瑜伽、阅读、听播客、玩视频游戏(尽管我还在慢慢研究最近的《战神》),并试图让我的室内植物存活下来。我也喜欢和我的丈夫和我们的狗在一起——他们是我的世界。
谢谢你,艾米丽,这周和我在一起。你可以在 Twitter 或 Github 上关注艾米丽的工作。点击了解更多关于她的公司,卡特尔软件。
如果你想让我在未来采访谁,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
与 Eric Wastl 的 Python 社区访谈
本周, TCGPlayer 的高级架构师、代码降临(AoC) 的创始人埃里克·瓦斯特尔加入了我们。加入我们,讨论 AoC 的起源,如何在解决 AoC 中的代码挑战时避免常见的陷阱,以及 Eric 在他每年“3.8 秒”的空闲时间里做了什么。
如果你在读完这篇访谈后期待参与《代码降临》,那么你可能会对《代码降临》的实用指南感兴趣。
埃里克,谢谢你加入我的节目。你最出名的可能是作为《代码降临》的创始人,我们很快就会谈到这一点,但你也是 TCGPlayer 的高级架构师。告诉我们一些你在那里的日常生活,以及你解决了什么有趣的问题。
Eric: 我和 TCGPlayer 在一起大概一年了。我的工作范围从复杂的算法、Kubernetes、供应商选择和基础设施扩展到培训、架构规划、技术候选人评估和运行大型内部黑客马拉松。
我每天都在做各种事情,比如与团队和个人交谈,帮助他们解决最困难的技术挑战、算法设计、高级技术规划,以及为工具、自动化和可见性构建东西。我的工作涵盖了许多不同类型的问题!
里基: 代码降临节(Advent of Code,AoC)始于 2015 年,此后每年都举办。对于那些不知道这个项目的人来说,什么是 AoC,是什么激发了你开始这个项目?
Eric: Advent of Code 是一本充满编程谜题的降临日历。降临节日历是一种典型的东西,你通过每天得到一点巧克力或玩具来倒数到圣诞节的日子。
我喜欢帮助人们成为更好的程序员,我喜欢做拼图,所以我想出一些东西,我可以发给我的一些朋友。那是在万圣节前后,所以我在想即将到来的事情,比如圣诞节,并提出了拼图加日历的想法,这可能很有趣。
如果我们的读者想参加 AoC 2021,你会给他们什么建议?你在参与者身上看到的常见陷阱和问题是什么?
埃里克:最大的陷阱可能是对自己太苛刻。你可以查找提示,寻求帮助,或者跳过一个谜题,稍后再试。最重要的是,不要因为排行榜上的时代而气馁。竞争最快解决时间的人也全年进行大量竞争性编程,擅长竞争性编程所需的技能与使某人成为优秀工程师的技能非常不同。
相反,专注于学习一种新的编程语言,或一种新的语言功能,或一种新的算法,或寻找一种高效的解决方案,甚至只是解决几个难题——每个人的经验和背景水平都不同,对一些人来说容易的难题对其他人来说可能很难。如果你学到了一些东西,并最终成为比你刚开始时更好的程序员,你就成功了——不管别人做了什么。
里基: 这么成功的项目,对一个人来说肯定是很大的工作量。除了玩拼图,人们还能怎么参与进来?他们如何支持 AoC 以确保它在未来几年继续存在?
Eric: 帮助 AoC 的最好方法就是帮助 AoC 上的其他人解谜。到目前为止,随着代码的增长,我最难处理的事情是社区的规模和学习新事物的人数。你不需要成为专家来帮助别人。通常,仅仅一起讨论一个问题就足以让某人摆脱困境。我不可能一次出现在所有地方,但是只要这个社区继续它令人印象深刻的互相支持的历史,我就不需要出现在所有地方。
你也可以告诉更多的人关于 AoC 的知识,尤其是那些刚刚开始接触编程并且不确定应该构建什么来扩展他们的技能的人。《代码的来临》充满了各种不同的概念和困难,因此每个人都有机会学习新的东西,我的一个很大的希望是,它也可以填补一些空白,供那些刚刚起步的人和那些通过实践学习效果最好但不确定接下来要构建什么的人使用。不幸的是,刚刚起步的人可能是最难找到的,所以我依靠社区来传播消息。
最后,对于那些感到被迫并且有能力这样做的人——而不是你们,学生们!回去学习吧!— 任何支持 AoC 至少一美元的人都会在网站上他们的名字旁边得到一个徽章。这有助于支持基础设施成本、我花在构建和运行 AoC 上的时间以及我对寿司的嗜好。然而,每个人都可以免费使用《代码降临》,所以人们不应该觉得有义务这么做,除非他们真的想这么做。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 AoC 和编程,你还有什么其他的爱好和兴趣?
Eric: 除了工作、吃饭、睡觉、代码降临,我每年大概有 3.8 秒的时间,期间做各种各样的事情。我玩电子游戏——外太空扩张很棒,Zachtronics 的任何东西,Noita,下雨的风险,Factorio,Satisfactory,Terraria,《我的世界》,以及许多其他东西。我也看动漫,在 Otakon(一个大型动漫大会)做志愿者,玩 D & D,和我的狗玩,努力提高自己的厨艺,弹钢琴。
里基: 谢谢你的聊天,埃里克。祝你今年的 AoC 一切顺利。
如果你想与 Eric 取得联系或者注册 AoC,那么你可以前往 Advent of Code 网站开始。如果你正在寻找一个详细的演练,你可能也会对一个实用指南感兴趣,这个指南是关于随着代码的出现而困惑的。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。
Python 社区采访 Ewa Jodlowska
今天我和 Ewa Jodlowska 一起,她是 Python 软件基金会 (PSF)的执行董事,该组织致力于推进与 Python 编程语言相关的开源技术。
在这次采访中,我们讨论了 Ewa 如何开始她的科技之旅,新冠肺炎如何影响 PSF,2021 年 PyCon US 的计划,她对徒步旅行和举重的热爱等等。
瑞奇: 谢谢你加入我的节目,埃娃。到目前为止,你已经在 PSF 工作了九年多,首先是活动协调员,然后是运营总监,现在是执行总监。我很想知道一些关于你的背景,你是如何在 PSF 中找到自己的路的,以及为什么你对 Python 如此有热情。
Ewa: 这是一个很好的问题——也不是我经常被问到的问题!
我第一次被介绍到 PyCon 是通过我以前的雇主,在那里我是一个会议策划人,客户经理,最终是一个软件工程师!我们在 2008 年签约在几个方面提供帮助:我们帮助后勤会议规划,并最终为 PyCon 建立了一个注册网站,并管理酒店预订。当时,我们使用 PHP 和 Informix 4GL 进行编程。
我实现了许多首次注册功能,比如人们如何注册教程!当然,PyCon 现在有了自己的系统,但是它的流程仍然基于为 PyCon 2009 创建的内容。
2008 年和 2009 年去 PyCon 的经历激励我通过夜校拿到了 CS 学位。尽管它没有提供任何 Python 课程,但它帮助我发现了更多的技术场景。
2011 年,我离开了我的前雇主,去欧洲探险了几年,PSF 给了我一个在 PyCon 上工作的兼职职位!到 2012 年 6 月,我获得了全职工作,因为 PyCon 在加州圣克拉拉真正起步了。几个月后,PSF 的兼职管理员离开了,这个责任被加到了我的角色上。
通过这个角色,我接触到了很多 PSF 在 PyCon 和我们美好的社区之外所做的事情。从那时起,PSF 真正开始蓬勃发展,我们为 Python 社区提供的支持也在继续发展。
董事会意识到雇佣一名全职员工(我)和一名兼职员工( Kurt B. Kaiser )是不够的,我们需要提高我们的公共汽车系数。我被提升为运营总监,负责招聘和管理我们的员工。几年过去了,PSF 和它的员工在继续成长,我在 PSF 的角色也随之发展。
借用布雷特·坎农的一句格言,我可以说我来自 PyCon,但我是为了这个社区而留下来的😉
Ricky: 去年 PyCon US 2020 (随后被转移到虚拟赛事)的不幸取消,从资金的角度来看,对 PSF 是一个巨大的打击。但是随着宣布 PyCon US 2021 也将是虚拟的,你对今年的 PyCon 有什么希望,与会者可以期待什么?全球疫情的持续影响如何影响 PSF 的日常运作?
Ewa: Python 本身在不断发展,我们社区的需求也在不断发展。我今年的愿望是让人们关注这些变化,了解最新的新特性,了解人们最近在用 Python 做什么。我的愿望是让人们来到 PyCon US,一起做一些有助于我们开源社区的事情!此外,我对 PyCon US 的期望是为我们的社区提供一些希望。
亲自参加 PyCon 提供了很多满足感,并让我们看到了我们的 Python 家族。这种满足感在过去的一年里已经消失了。我希望看到对方,即使是在聊天,也能提供一些欢乐。我听很多人说人们被虚拟事件搞得精疲力尽,我完全理解这种感觉——这是不一样的。
但是我真的希望今年的 PyCon 能给我们带来一点快乐,让我们对在盐湖城举行的 2022 年 PyCon US 更加兴奋。我们都需要一些有趣的东西来期待!
PyCon US 是 PSF 最大的资金筹集者,所以举办它实际上对资助当前的运营是至关重要的。即使我们正在研究使收入多样化的方法,PyCon US 仍然是我们最大的项目。我们希望人们注册并参加这次活动。我相信会有很多高质量的教程和讲座,以及很多虚拟参与的机会。
PSF 是一家 501(c)(3)非盈利性公司,除了其金融合作伙伴之外,它还依靠社区的支持和贡献来维持运营。除了捐赠之外,读者还可以通过什么方式来支持 PSF,以确保 Python 再成功 30 多年?
非营利组织需要所有利益相关者的支持和参与才能成功。个人捐赠很重要。公司的赞助很重要。新来的赠款很重要。
今年三月,PSF 将会有一位资源开发总监开始帮助我们领导所有这些类型的筹款活动。我们的员工知道我们需要减少对 PyCon US 收入的依赖,因此我们也在努力实现收入多元化。
志愿者同样重要!几年前,我创建了一个页面,列出了人们参与的其他方式。多方面的参与是有帮助的,但是我知道时间和金钱总是需要被考虑的。即使有人只是在推特上关注我们,或者订阅我们的时事通讯,我也很高兴。
读者可以通过向他们的雇主网络推荐 PSF 来提供帮助,这甚至解释了为什么资助我们的非营利组织很重要。PSF 正处于这个关键的增长点,它不仅需要按原样为自己提供资金,而且需要更多的资金来做更多的事情,因为 CPython 和 Packaging 有这样的需求。
如果你认识某个组织的人(技术部门、开源办公室、招聘部门等的联系人)。)可以帮助我们资助一些工作,建立联系。我喜欢会见公司代表,了解他们的需求。
读者可以志愿帮忙!例如,董事会选举将于今年 6 月举行。如果你知道谁可能感兴趣,到时候帮他们提名。提名期将于 5 月 6 日开始。
读者可以通过成为会员来提供帮助!我们还将在整个三月举办会员活动,在庆祝 Python 成立 30 周年。我们需要一个代表 Python 全球使用的投票成员。今天就报名:管理/贡献、支持,或者基础!
通过以上所有的组合,我们可以继续维持 PSF,更重要的是,继续支持我们的社区。
你认为未来 PSF 或整个社区面临的最大挑战是什么?社区如何帮助我们超越它?
我希望资金不是问题的答案,但它确实是。这将是许多年后,直到它不是我们最大的挑战。我们有很多方法可以让资金发挥作用,当然,优先考虑如何使用资金也很重要。
一个巨大的挑战将是确保我们的财务稳定,以便我们雇佣更多的人。PSF 继续增加员工数量至关重要,因此我们有一个适当的结构来支持社区需求。我们希望继续获得项目拨款,所以我们需要员工来管理这项工作。
如果我们想用 CPython 雇佣更多的帮助,甚至是一个打包的项目经理(我可以告诉你,我们想这么做!),我们将需要管理这些新角色的结构。我们现在有七名员工,所以我们已经走了很长的路,但我们还需要做更多的工作来确保我们的员工和计划得到支持。
我真的很感激 PSF 从底层成长起来,我们目前的成功在很大程度上归功于我们拥有使我们的计划成功的员工。这同样适用于我们希望为社区提供的任何附加计划。
资助全职员工,为他们提供成功的环境(并确保他们的需求得到满足,如保险等)。)不是一个小美元数额。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 你还有什么其他的爱好和兴趣?
作为一名教育主管,我的日常工作是零编码(我已经有十多年没有编码了,有点难过!).但是我真的喜欢到处跳来跳去!
我的爱好随着季节的变化而变化。大约在这个时候,芝加哥的冬天即将过去,我开始整理我的花园。今年,我让鳄梨树(室内用)、甜菜、西红柿、黄瓜、南瓜、玉米、向日葵、鲜花和许多药草发芽。到了六月,我的花园就像一片丛林😀
在冬天,我喜欢阅读和烘焙!甚至参加一些周末课程——目前正在学习机器学习!一年到头,我喜欢保持活跃。我喜欢和我们的狗一起去远足、举重和跑步。
瑞奇: 谢谢你加入我的节目,埃娃。这是我的荣幸。祝三月成员之旅好运。
如果你想帮助支持 PSF,以确保 Python 在未来几年内保持相关性,那么前往Python.org成为会员,或者升级或更新你现有的会员资格。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或通过 Twitter 联系我。编码快乐!
Python 社区采访 Katrina Durance
随着 PyCon US 2019 的结束,我决定追上第一次参加 PyCon 的人 Katrina Durance 。我很好奇她是如何找到这次经历的,她的亮点是什么。我还想了解参加像 PyCon 这样的会议对她的编程能力有何影响。
瑞奇: 让我们从我问所有客人的相同问题开始。你是怎么进入编程的?你是什么时候开始用 Python 的?
Katrina: Python 是我 2013 年在研究生院学习的第一门编程课程。还学了 R 和 SQL。我毕业后从事的两份工作都是完全以 SQL 为中心的,所以 Python 和 R 就半途而废了。
因为我在芝加哥的一所艺术学院(芝加哥哥伦比亚学院)工作,所以我可以免费上课。我们有一个游戏程序,所以我们所有的编程课程都与游戏相关。因为我是一个游戏玩家,也是一个非常视觉化的学习者,所以我决定参加一个 C#课程,在那里我们一起构建小游戏。我喜欢它。
当我第一次学习 Python 时,我真的很纠结,但是在可视化环境中使用编程语言开始让我明白了很多概念。在那门课程之后,我知道我想提高自己的技能,以便进入全职编程领域。我最终想出了一个学习计划,并决定在今年年初回到我的 Python 根源。
Ricky: 今年你第一次参加了美国皮肯大会。我很好奇为什么今年是你的第一年。是什么改变了你,让你这次想去?
真正让我下定决心的是,我知道将会有一个来自的 Python safe团队,以及一个来自的 Chicago Python 用户组的大型代表团在那里聚会。所以我知道我会看到一些友好的面孔。我不觉得我是一个人在做这件事。
瑞奇: 每个人的 PyCon 体验都不一样。我想知道你今年是否有突出的时刻?有没有一件事会让你想起你第一次参加 PyCon 的经历?
Katrina: 辅导短跑对我来说很重要。我最终在一个工具(假设)上解决了一个我不理解的问题,因为我还没有学到多少关于测试的知识。
我感到沮丧,担心一切都会超出我的能力范围。但是我们的导师非常了不起,非常鼓舞人心,他向我展示了我正在学习的一系列东西,并让我坚持到了最后。现在我有了一个关于软件的封闭问题,上面有我的名字,这很酷。
里基: 我们当然在周末见过几次面。但最引人注目的是皮托尼斯塔卡费露天广场。你的户外体验如何?你学到什么新东西了吗,或者有什么可行的建议吗?
Katrina: 我对 PythonistaCafe 开放空间感到兴奋,因为我有机会见到一些我在论坛上接触过或刚刚见过的人,我没有失望。
我为像我这样自学成才的程序员开设了一个开放空间。当 30 多岁的人出现时,我惊呆了。我尽了最大努力去管理它,并得到了一些积极的反馈和有益的建议。
PyCon Africameetup 非常有启发性,因为我了解到我们还没有看到非洲创新热潮的原因是互联网在房间里的每个国家都非常昂贵。不管它是政府监管的还是私有的。我很乐意帮助找出解决这个问题的方法。
PythonistaCafe Members Coming Together at a PyCon Open Space 瑞奇: 在 PyCon 上要做的事情太多了,根本没有足够的时间全部做完。那么,有没有什么事情是你希望自己做过的,或者错过了什么演讲,希望自己没有错过?下次你有什么不同的做法吗?
老实说,我第一次觉得 PyCon 是我所希望的样子。明年我想留下来参加短跑比赛,人们一直告诉我这很棒。
对于那些正在阅读这篇文章但还没有参加第一次 PyCon 的人来说,这可能是最重要的问题……参加 PyCon 对你今后如何编写 Python 代码有什么影响?
卡特里娜:我不得不谈谈我的代码。当你自学的时候,你不会有很多机会来讨论你的代码。通过我在 PyCon 上的谈话,我被鼓励更加慎重地利用我的 Slack 和本地 Python 社区来练习那些交流技巧。
换句话说,我需要鼓起勇气,不要担心我没有很好地编码或解释它。我只需要继续编码和解释。
最后但同样重要的是,你在业余时间还会做些什么?除了 Python 和编码,你还有什么其他的爱好和兴趣?你想插什么?
卡特里娜:我喜欢所有科幻和怪异的东西:电影、电视剧、书籍等。我是一个乐高爱好者,出于对 H. P. Lovecraft 故事的热爱,我对建造失落的神庙情有独钟。我真的很喜欢 VR,喜欢在我的 Oculus Go 上玩游戏。我也用毛毡、拾到的物品甚至乐高积木制作珠宝。
如果你想和 Katrina 聊聊天,说声嗨,在推特上给她留言。
如果你想采访 Python 社区的某个人,请在下面留下评论,让我知道。
Python 社区采访 Kattni Rembor
原文:# t0]https://realython . com/interview-kattni-rembor/
本周,我和 Adafruit Industries 的创意工程师 Kattni Rembor 在一起。Kattni 的角色是多种多样的,因为她涵盖了嵌入式软件、硬件设计、技术写作和社区领导。
在这次采访中,我们谈论了她的工作发展 CircuitPython 以及导师在她迄今为止的职业生涯中所扮演的角色。她还分享了她对那些希望使用 CircuitPython 开始第一个硬件项目的人的建议。
里基: 欢迎来到真正的 Python,Kattni。我很高兴你能来参加这次面试。让我们像对待所有客人一样,带着一个不可避免的问题开始:你是如何开始编程的,你是什么时候开始使用 Python 的?
对我来说,这两个问题是同一个问题。2017 年 7 月开始编程,从 Python 开始。我失业了,有很多空闲时间。
我决定尝试学习 Python。我环顾四周,发现官方教程是最好的起点。原来是写给程序员的,不是写给新手的。我到了第四区,碰壁了,放弃了。
硬件方面的事情始于 Raspberry Pi Zero Ws 上的一次销售,我的一个朋友给了我一个。我立刻做了你在得到一个树莓派后总是做的事情,那就是买所有的东西来搭配你的树莓派。
我找到了一个名为 Sense HAT 的配件,它内置了一堆传感器和 led,但它不是为 Raspberry Pi Zero W 设计的,所以我试图用单独的传感器重新创建它,这很快就变得昂贵了。
我发现了一种名为 Circuit Playground Express 的东西,它也内置了许多传感器和 led,并认为这应该可以工作。我点了一个,不知道它和树莓派不兼容。原来是一个微控制器。
我把它带回家,看了一眼,觉得它太复杂了,就把它放了两个星期,最后才拿起来插上电源。我记得当时想,我再也不会写出像这个演示这么酷的东西了。这是 LED 上的彩虹漩涡,为每个亮起的 LED 播放一个音调。
我研究了一下我能做些什么。有三种选择。Arduino 对我来说太难了,我没有任何学习它的欲望。MakeCode 简单到令人沮丧。我发现其中只提到了一个叫做 CircuitPython 的东西,我想,嘿,我正在努力学习 Python——这太棒了!
我找到了一个关于入门的 Adafruit 视频,安装了它,在很短的时间内,我就有了一个闪烁的 led。虽然听起来很简单,但在那之前,我用 Python 做的任何事情都没有那个时候吸引我。自从尝试学习 Python 以来,我第一次感觉到了与我正在做的事情的联系。我找到了我的激情。
瑞奇: Adafruit 的微控制器以嵌入 CircuitPython 而闻名。对于那些不熟悉 CircuitPython 的人来说,这与其他微控制器有什么不同?这对你在工作坊和 Adafruit 的学习教程中的授课方式有什么影响?
不同之处取决于你指的是哪种微控制器。 Arduino 基本上是 C++,通常使用 IDE,在你可以把它加载到主板上之前需要编译。作为 Python 的一个版本,MicroPython 需要复杂的额外步骤才能运行。
使用 CircuitPython,你将电路板插入 USB,它就显示为一个 USB 驱动器。使用您最喜欢的 Python 编辑器打开一个
code.py文件,并开始编写代码。一旦保存到电路板上,CircuitPython 就会重新加载并运行代码。您可以立即得到满足,但更重要的是,可以快速迭代您的代码。这是典型的 CircuitPython 体验,这种能力是微控制器被认为与 CircuitPython 正式兼容的必要条件。
我们关注用户对 CircuitPython 的第一次体验——前五分钟。对我们来说,这是一次积极的体验,这一点尤为重要,我们已经尽了很大努力来确保这一点。
当有人拿起一个微控制器,并在五分钟内有一个闪烁的 LED 时,这不仅令人难以置信,而且令人满意。这是新用户决定继续使用 CircuitPython 的成败所在,我认为我们在创造这种体验方面取得了巨大的成功。
在指导教程方面,CircuitPython 的经验创造了一种情况,我不必花一半的教程来解释如何设置或要求参与者安装大量无关的软件。我给他们一个微控制器,让他们打开一个编辑器,然后我就可以立即开始动手编写代码示例。
在大多数情况下,它只是工作。我可以花更多的时间在概念和内容上,从而更好地利用我的时间。我也能够向可能不了解 Python 的硬件人员展示相同的教程,就像我向可能不了解硬件的 Python 人员展示一样。
不管观众是谁,反馈总是积极的。CircuitPython 以一种广泛人群都可以理解的方式将编程和电子学联系起来。
至于 Adafruit 学习教程,我写了主要的circuit python入门指南。所有其他 CircuitPython 指南都可以参考入门指南,这意味着作者可以直接进入项目或教程内容,而不必解释基础知识。
这也意味着我们有一个单一的地方,我们可以向任何想要开始使用 CircuitPython 的人推荐,我们将知道他们正在获得他们需要的信息。
许多 Real Python 的读者已经知道如何用 Python 编程了。但是他们可能从来没有考虑过从事微控制器的副业。你会给第一次涉足 it 的人什么建议?
Kattni: 跳进来。不要犹豫。拿起电子设备可能会令人生畏,但最终它是在使用 Python 来操纵物理世界。如果你已经熟悉 Python,CircuitPython 会有一种熟悉的感觉。
区别在于理解如何在代码中进行适当的设置以与硬件交互。这就是 Adafruit 学习指南和教程的用武之地,有很多可供选择。找到一个适合你的项目,然后努力去做。
如果你正在寻找一个特定的起点,Circuit Playground Express 和它的姐姐 Circuit Playground Bluefruit 是内置了一系列传感器、led 和输入的微控制器。ada fruit Circuit python Circuit Playground 库在幕后为您完成所有设置,因此您可以直接创建项目,而不必担心如何与 LED 或按钮通信。
这种硬件和库的结合允许您开始理解代码和硬件之间的交互,而不需要电子背景或任何电子知识。你可以通过轻松实现你的想法来建立自信,然后随着你的进展继续进行更复杂的项目。
迄今为止,你做过的最喜欢的项目是什么?是什么使那一个从所有其他人中脱颖而出?
这是一个很难回答的问题,但我的思考还是回到了我做的第一个项目,那是一架发光的电容式触摸钢琴。最后,我添加了柠檬——水果是电容性的!—并出版了一本名为《酸橙调的 T2 钢琴》的指南。
项目的中心是我订购的第一个 Circuit Playground Express,它显然是我编写的第一个 CircuitPython。这也让我建立了一个桌面灯箱照相馆,运行 Python 并使用我收到的第一个 Raspberry Pi,为指南拍摄照片。
它脱颖而出有多种原因。我最初启动它的原因是,当时这个板太新了,几乎没有文档。我觉得有必要创建一个项目,我可以与其他想要开始的人分享。我要求写一个学习指南来记录我的 Adafruit 项目,我得到了批准。
这个项目让我开始编写 Circuit Playground 库,这是我对 CircuitPython 的第一个真正贡献。该库写入了 Circuit Playground Express 的三个最简单的特性,并建议我添加更多特性。
我认为这个建议很可笑。我没有电子或编程方面的背景,但在掌握了这两方面知识的几周内,我提交了第一个 pull 请求,向库中添加了一个特性。
一个月后,当我完成项目的学习指南时,我已经实现了 Express 的大部分特性,并将我最初的项目代码从 90 多行缩短到大约 45 行。我创造了一些东西,其他人可以用它来使他们的 CircuitPython 体验更简单、更好。这是一种奇妙的感觉。
这也是阿达果付给我的第一笔钱。这将导致我最终全职加入他们。
我开始为 CircuitPython 做贡献,因为我真的喜欢这样做,这为我带来了职业生涯。这一切都始于跌跌撞撞地购买 Circuit Playground Express,并决定我要创建这个项目。
Ricky: 在 2019 年的 PyOhio,你做了一个题为“通过开源、激情和指导改变生活”的演讲到目前为止,导师在你的科技职业生涯中发挥了怎样的作用?你是如何将这笔钱用于帮助科技领域的其他人的?
我把我的职业生涯完全归功于导师。当我开始学习编程和电子学时,我会满足于让 led 闪烁。我的导师鼓励我去做自己不熟悉的事情,扩展我的知识和技能。
我学得非常快,但这也导致我很快进入超出我水平的概念,这反过来导致我很容易沮丧。我的导师提供了指导和支持,并在我可能放弃的时候让我继续前进。
我从我的导师那里了解到,我需要在所有事情上为自己辩护。我的职业生涯开始于我主动要求加入 Adafruit,如果没有重大的鼓励,我是不会这么做的。我学到的最宝贵的东西之一是,师友可以来自任何地方,重要的是要对所有的可能性保持开放,包括朋友。
我做过的最了不起的事是帮助别人实现他们的梦想。有三个人和我一起工作,他们认为加入 Adafruit 至少部分是因为我的指导。如果你在此之前问我是否能成为一名导师,我会告诉你“不,我没有什么有用的东西可以提供。”
事实证明,无论你处于什么样的技能水平,你都有一个故事可以分享。我不是一个有经验的程序员,但我成功地学习了一些全新的东西并找到了职业。这些技巧值得分享。有时候,作为导师,你能做的最重要的事情就是给予支持和鼓励。
事实是,要成为导师,你不需要成为你所在领域的专家。你只需要分享你的经验。不管你是谁,也不管你在职业生涯中处于什么位置,你都经历过别人会面临的事情,他们会从你通过成功和失败获得的知识中受益。
分享失败尤其重要,因为这可以让别人知道他们并不孤独,失败也有可能继续走向成功。尽你所能与任何人分享一切,你会发现有人会从你的经历中有所收获。
里基: 现在我的最后几个问题。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
我不觉得我有很多空闲时间,但不管怎样,目前的情况已经导致我的时间发生了很多变化。除了必要的旅行之外,不能离开家已经成为严重的限制。
我对摄影深感兴趣,已经有一段时间没有能够走出去做了。上次我去的时候,我参观了一个美丽的联邦公园。不用说,我期待着能够再次探索美丽的地方,并将令人惊叹的照片带回家。
另一方面,不能离开家也让我开始做一些我通常不会在意的事情,比如每天做晚饭。我一直很喜欢我的食物。然而,我会经常选择外卖或简单的选择。因为一切都变了,我一直在做更复杂的饭菜。
我甚至努力调整复杂的食谱来适应我的口味。今晚是姜汁牛排和烤胡桃南瓜。这并不总是那么新奇——我也非常喜欢新鲜百吉饼上的早餐三明治。不管怎样,晚餐时间已经变成了值得花时间去做的事情。
Python 和编程已经成为我生活中的一大部分,这也让它成为了我的爱好。我目前正在我的第二个家重建我的桌面灯箱照相馆,这次我用 Feather nRF52840 微控制器和 CircuitPython 替换了 Raspberry Pi 和 Python。
我也在尝试记录它,这是我第一次忽略的事情。这是我曾经建立的第二个编程和电子项目的翻拍,所以它离我很近,对我很重要。希望我最终能够把一些东西放在一起分享。
谢谢你加入我,凯特妮。很高兴听到你的经验和建议。
如果你想联系 Kattni,你可以在 Twitter 上找到她。如果你想第一次接触 CircuitPython 和硬件,那么 Adafruit 的学习教程将是一个很好的起点。你也可以在我们的 Real Python 播客采访 Thea Flowers 中了解更多关于 CircuitPython 的信息。
和往常一样,如果你想让我在即将发布的社区帖子中采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。
编码快乐!
与 Kenneth Reitz 的 Python 社区访谈
本周,我很兴奋能采访多产的肯尼斯·雷兹!
肯尼斯是极受欢迎的
requests和pipenv库的作者。加入我们,一起讨论他的最新项目和他迄今为止编写的最具挑战性的代码。Ricky: 从头说起吧……你是怎么进入编程的,什么时候开始用 Python 的?
肯尼斯:我很小的时候就开始编程了。我爸是程序员,我 9 岁就自学了 BASIC 和 C(在这个帮助下)。我在大学开始使用 Python,当时我上了第一门 CS 课程。不久后,我辍学并学习了许多其他编程语言,但我总是不断回到 Python。
瑞奇: 祝贺你在数字海洋的新工作。你是开发商关系团队的资深成员。你如何看待你在 Heroku 的前一份工作中的角色转变,我们对数字海洋在 Python 领域的发展有何期待?
肯尼斯:谢谢!我真的很享受这个新角色,也很享受为整个开发社区服务的机会,而不仅仅是 Python 社区。然而,我的最新作品, Responder ,是一个数字海洋项目,所以在 Python 领域我们有更多的期待空间😊
当然,你最出名的是编写了非常流行的
requests库和新的pipenv库。Python.org 现在推荐使用pipenv进行依赖管理。社区收到了怎样的pipenv?你有没有看到来自社区的很多阻力,开发者更喜欢坚持venv或者更老的依赖管理方法?Kenneth: 社区反响很好,甚至像 GitHub 这样的公司也在使用它的安全漏洞扫描标准。除了 reddit 上的一些仇恨之外,我根本没有看到来自社区的太多抵制。我花了一段时间才意识到 /r/python 与其说代表了 python 社区,不如说代表了使用 Python 的 redditors。
里奇: 现在在你的请求库上达到 3 亿次下载很酷,但作为一名吉他手,我更兴奋的是你的最新项目皮瑟里。你能告诉我们一些关于它和你对这个项目未来的计划吗?
PyTheory 是一个非常有趣的库,它试图将所有已知的音乐系统封装到一个库中。目前,有一个系统:西方。它可以以编程方式呈现西方体系的所有不同音阶,并告诉您音符的音高(以十进制或符号表示法)。此外,还有指板和和弦图表,因此您可以为吉他指定自定调音,并使用它生成和弦图表。很抽象。
绝对是我写过的最有挑战性的东西。
里基: 所以在最近放弃你的 Mac 电脑,转而使用微软的 VS Code 进行 Python 开发之后,作为一名 Windows 用户,你感到高兴和自豪吗?对于那些从 Windows 95 年开始就没用过 Windows 的读者来说,他们错过了什么?
肯尼斯:我喜欢苹果电脑,比起 Windows 我更喜欢它。我只是目前对我的设置感到厌倦,并决定通过运行 Windows 来挑战自己。不过,我很开心,也很有收获。感觉就像在家一样。
Windows 已经不是过去的样子了。它现在是一个真正坚实的操作系统。我在我的 iMac Pro 上运行它,它像做梦一样嗡嗡作响。
里基: 我知道你是个热衷于摄影的人。你从事这项工作多久了,你拍过的最喜欢的照片是什么?除了 Python,你还有其他爱好和兴趣吗?
肯尼斯:我认真地投入摄影已经有 10 年了。我拍过的最喜欢的照片大概是这张。这是在我患了几个星期的偏头痛之后,用胶片相机拍摄的,那是我第一次能够在户外行走。
里基: 最后,有什么智慧的临别赠言吗?你有什么想分享和/或宣传的吗?
肯尼斯:响应者!我的新 Python web 服务框架。它是 ASGI,看起来很熟悉,速度很快,而且比 Flask 更容易使用!非常适合构建 API。看看吧!
谢谢你,肯尼斯,这周和我在一起。在 Twitter 上实时观看 Responder 的开发真是太棒了。你可以关注它的发展或者在这里提出一个问题。
一如既往,如果你想让我在未来采访某人,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
Python 社区采访 Mahdi Yusuf
今天我邀请到了 Pycoder 周刊的创始人之一 Mahdi Yusuf。
白天,他是人体操作系统陀螺仪的首席技术官。到了晚上,他是一个体育和电影迷,对谁是最好的蝙蝠侠有着争议的看法…让我们开始吧。
瑞奇: 让我们从简单的开始。你是如何开始编程的,你是什么时候开始使用 Python 的?
我实际上是一个大器晚成的人。我甚至不知道指针是什么,直到我在大学学习计算机工程,但我总是对计算机感兴趣,总是摆弄机器。(大多是 Windows。喘息!)
我在大学的最后几年开始使用 Python,我真的很喜欢它的简单和“包括电池”。几乎所有我想做的事情都有一个图书馆,在过去的 10 年里,它变得越来越好。
吸引我的是你可以做任何你想做的事情。你没有像使用其他编程语言那样被定位到一个特定的角色中。
瑞奇: 人们可能知道你是 Pycoder 周刊的创始人之一。对于那些可能不知道 Pycoder 周刊的读者,你能简要地解释一下你为你的读者提供了什么,以及它是如何实现的吗?
Mahdi: 这实际上只是无法以一种良好的、有条理的、一致的方式获取 Python 新闻的副产品。
迈克(联合创始人)和我只是聊天,认为这将是一件很酷的事情,所以我们就开始了。我买下了域名,创建了我们的第一个登陆页面,然后我们开始了比赛。
接下来你知道,在我们发出第一期之前,我们已经有 2000 个订户了。
Ricky: 你在加拿大 2013 年 PyCon 大会上做了一个演讲,题目是“如何结交朋友并影响开发者这是一个很好的演讲,你可以强调开发者如何通过关注他们可以提供的价值而不仅仅是他们可以解决的问题来发展他们的社区和产品。你还觉得这是 2018 年开发者可以努力的领域吗?你认为 2019 年开发者将面临哪些挑战?
绝对是。展望未来,我认为大多数问题都被淡化了,从 2000 年代初的服务器升级到 2010 年代的点击量。事情只是变得越来越容易,但人们遇到的问题将永远存在,因此关注用户目标而不是问题永远是最好的思考方式。
你的日常工作是陀螺仪的首席技术官。我第一次听说这款应用是在你在 Hanselminutes 播客上采访传奇人物斯科特·汉森曼时。这是一个令人惊叹的应用程序,对其用户有非常明显的好处。你能告诉我们一些关于这款应用的信息,以及你对它未来的计划吗?
迈赫迪: 陀螺仪本质上是你身体的操作系统。它帮助人们跟踪他们的身体,就像他们跟踪他们的电脑一样。跟踪重要的健康指标,如他们的心率、血压和血糖,以及更简单的事情,如他们的时间都花在哪里以及他们在工作时间的生产力如何。
我们正在做一些事情,以弥合你的健康和你产生的所有数据之间的差距,并成为你日常生活的一部分。敬请期待!你可以关注我们 @gyroscope_app 如果这是你感兴趣的,也可以联系我 @myusuf3 。
你还有哪些正在进行的项目想与大家分享?除了 Gyroscope 和 Pycoder 之外,还有什么占用了你的时间?
我一直在研究构建一个由人工智能驱动的家庭监控系统,它可以通过训练有素的家庭成员聚集在房子周围的照片来识别他们。它可以发出谁在房子周围的通知,并可能检测到不认识的人何时进入摄像头的视野,并在我的家人经过房子时忽略他们。
它已经在架子上放了几个星期了。我一直忙于工作,但这让我最近写了更多的 Python。
里基: 现在是我的最后一个问题:除了编程,我们还有其他爱好和兴趣吗?有你想分享和/或插入的吗?
我喜欢运动,也是个超级电影迷。
我从小就打篮球,这是我最喜欢的运动,但随着年龄的增长,我花在冰敷膝盖上的时间比我想象的要多。
至于电影,这个夏天刚刚结束,这个夏天有很多很棒的东西,但我只是想把它放在那里…我是漫威团队。本·阿弗莱克是真正的蝙蝠侠。
谢谢你的采访。你可以在推特上关注迈赫迪。如果你还没有,你可以在这里注册 Pycoder 的每周简讯。
如果将来你想让我采访谁,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
python 社区采访 marietta wijaya
在本周的社区采访中,Mariatta Wijaya 和我一起。
Mariatta 是 Zapier 的一名网站开发人员。她还花了很多时间在 Python 社区做志愿者:她是一名核心开发人员,为会议和聚会做贡献。
如果你有幸见到她,那么你可以和她一起参加一个# icecreamselfi或者谈论她的机器人接管 GitHub。你可以在采访的最后找到 Mariatta 喜欢的联系方式。
瑞奇: 让我们从简单的开始。你是如何开始编程的,你是什么时候开始使用 Python 的?
玛利亚塔:初中左右开始。我们在我的学校有课外活动,其中之一是“计算机”课。起初,它是 MS-DOS 和 Windows 的介绍。向我们展示了如何使用 WordStar 和 Lotus 电子表格。(我真的老了。)
后来,我们开始接触用 QBASIC 编程。过了一段时间,我接触了“万维网”,我开始学习 HTML 和如何自己建立网页。高中毕业后,我搬到了加拿大,学习计算机科学。
在 Python 之前,我是一名开发人员,使用。NET 框架和 C#。2008 年,我在一家初创公司从事 Windows 项目。那个项目结束后,他们把我调到了另一个团队。
这个团队使用 Python、 Django 和谷歌应用引擎开发基于网络的应用。当时我不想再找另一份工作。所以我留了下来,开始学习 Python,并开始了新的职业道路,成为一名 web 开发人员。
大多数人可能因为你作为 Python 核心开发人员的工作而认识你。事实上,你在今年的 PyCon 上做了一个题为什么是 Python 核心开发者的演讲?对于那些没看过你演讲的人来说,TL 是什么;作为核心开发人员,您的角色是什么?
玛利亚塔:TL;DR version 是成为 Python 核心开发者伴随着很多责任,它不仅仅是向 CPython 中编写更多的代码。事实上,写代码是我们现在对核心开发人员最起码的期望。作为一个核心开发人员,你将被期望做更多的代码审查、指导、提供反馈和做决策,而不是自己写更多的 PRs。
我想强调的另一点是我们都是志愿者。我没有被任何公司或PSF雇佣为 Python 核心开发者。很多人仍然没有意识到这一点。通常,人们给 bug tracker 写信,就好像他们给客户支持写信一样,希望得到立即的回应,而不是接受否定的回答,并把各种问题归咎于我们。我们不仅仅是在有限的空闲时间里做这些的志愿者,而且与成千上万的用户和贡献者相比,我们中真的很少有人。
作为一名核心开发人员,我更关注于帮助工作流,让核心开发人员和贡献者更容易贡献和协作。我编写实用工具和机器人,如 cherry_picker 、 miss-islington ,以及最近的 check_python_cla 网站。
我还重点审查首次投稿人的 PRs 和与文档相关的问题。我喜欢确保我们的 devguide 是最新的,因为当贡献者对我们的工作流程有疑问时,这是我们首先指向的地方之一。
我现在也在 Zulipchat 做每周 Python 办公时间。太平洋标准时间每周四晚上 7 点。在上班时间,我可以通过 DM 联系到你,我可以几乎实时地做出回应并提供帮助。在其他时间,我通常每天只去一次祖利普。
似乎你为这个社区做的还不够,你还联合组织了皮拉迪丝温哥华聚会和皮喀斯会议。你能告诉我们一点你是如何参与其中的吗?如果人们想要参加,他们能期待什么?
玛丽雅塔:皮卡斯是如何建立的故事并不清楚,甚至对我来说也是如此。我所知道的是,有一天我收到了 Seb 的一封电子邮件,向其他人(Alan、Eric、Don 和 Bryan)介绍了我,似乎有一封电子邮件主题是:“让我们在太平洋西北部举办一次 Python 会议。”
我几乎马上就回复了。我没有过多考虑责任是什么,甚至没有考虑我要为此付出多少努力。我只是想,“为什么不呢?”几周之内,我们开始在温哥华寻找场地,其他的一切都井井有条。
PyCascades 是一个独一无二的会议。我们重点突出第一次发言的人和来自太平洋西北社区的发言人。2019 年 PyCascades 的 CFP 从 8 月 20 日到 10 月底开放。请务必提交一份报告!今年我不参加项目委员会。相反,我将专注于指导演讲者,尤其是第一次演讲的人和那些来自未被充分代表的群体的人。
大约两年前,我才开始帮助皮拉迪斯温哥华。当时,有两个组织者——其中一个刚刚下台——他们呼吁更多的组织者。那时,尽管我没有参加很多聚会,但我已经从 PyLadies 那里得到了足够多的资助。因此,我觉得这是一个机会,我可以通过积极参与并确保温哥华皮拉迪斯社区的连续性来回报社区,而不只是等待下一次聚会的发生。
我们的社区现在变得更大了。我回顾了过去几年我们的活动,我们举办了这么多精彩的讲座和研讨会。我们的活动中有 Python 核心开发人员和国际 PyCon 演讲者。我为此感到非常自豪!
通过你的 Github,我发现你似乎对机器人很有兴趣。您为 Python 核心 devs Github 维护了两个,但是您的 Github 上有更多。我很想知道你觉得它们有什么吸引人的地方?
我第一次接触 GitHub 机器人是在两年前我开始为 coala 做贡献的时候。他们有一个 GitHub 机器人,非常像所有维护人员的私人助理。这个机器人总是在运行,回复和评论。当时,我甚至没有意识到机器人可以做所有这些事情,所以我对它的工作方式印象深刻,也很着迷。我一直认为机器人是一个非常复杂的系统。
随着我开始帮助创建和维护 Python 的 GitHub 机器人,我对机器人的架构有了更好的理解,并且我能够满足我最初对 GitHub 机器人如何工作的好奇心。
但后来我开始有了不同的想法。现在我知道了它们是如何工作的,也知道了有哪些 GitHub APIs 可用,我一直在问自己,“还有什么可以自动化的?我还能委托给机器人什么?我们真的已经达到自动化的巅峰了吗?”原来有很多任务我可以自动化,而我所需要的就是 Python。现在我知道哪些任务可以由机器人完成,当我不得不自己做这些杂务时,我会变得暴躁。
里基: 我不能不谈论冰淇淋自拍来采访你。这已经成为你的一个传统了。现在我们的读者可能会有一些困惑的表情,所以你为什么不解释一下关于令人敬畏的#冰激淋先生的一切呢?
我做的第一个 #icecreamselfie 是在 2016 年 7 月费城的 DjangoCon 之后。我刚刚做了我的第一次会议演讲,我感觉棒极了,只想庆祝一下。另外,那是一个炎热的夏天。所以我去了酒店附近的一家冰淇淋店。不知何故,我只是决定拿着冰淇淋自拍。这对我来说很不寻常。通常我只是给食物拍照,而不是自拍。
我的下一个演讲是在波多黎各的 PyCaribbean。我甚至没有打算吃冰淇淋,我们(我和我的室友,另一位演讲者金·克雷顿)正在海滩上享受,一辆冰淇淋车出现了。
之后去了意大利参加 DjangoCon Europe 和 PyCon Italy。当然,我得吃点冰淇淋。没有它,意大利之旅就不完整。即使在那个时候,我也不认为#icecreamselfie 是一个传统。自拍更多的是一种巧合。
但是在我在 PyCon US 的演讲之后,那是一个非常情绪化的演讲,我所能想到的就是我需要去吃冰淇淋。所以我的朋友杰夫带我去了他在波特兰认识的一个地方。吃完冰淇淋后,我感觉真的很好!从那时起,#icecreamselfie 就成了我的一个正式传统,我会竭尽全力在我的演讲被接受后寻找最好的冰淇淋。
现在是我的最后一个问题:除了 Python,你还有什么其他爱好和兴趣?有你想分享和/或插入的吗?
我喜欢在大自然中散步、旅游和露营。我有一个奇怪的爱好,给我的食物拍照,我会把它们发布到 Instagram 上。我另一个喜欢的消遣是打麻将。不是麻将纸牌(一种配对游戏),而是港式麻将。我仍然很难找到愿意和我一起玩这个游戏的人。
如果人们在寻找支持我的方式,请一定给我发一个快乐包,在帕特伦支持我,或者说声谢谢。
谢谢你的采访。你可以在推特上找到玛丽雅塔,或者在的网站上找到她,如果你想了解她更多。
如果你想让我将来采访谁,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
Python 社区采访 Marlene Mhangami
今天我们请到了玛琳·汉加米。Marlene 是一个充满热情的 Pythonista,她不仅利用技术来促进社会变革和赋予津巴布韦妇女权力,而且还是首届 PyCon Africa 的主席。请和我一起谈论她在科技领域的非传统开端,以及她对利用科技创造社会变革的热情。
里基: 欢迎你,玛琳!我很高兴你能来参加这次面试。先说通常的第一个问题。你是如何开始编程的,你是什么时候开始使用 Python 的?
Marlene: 我的背景是分子生物学,所以在大学里,虽然我与代码有过一些互动,但这并不是我经常使用的东西。我一直对技术及其对世界的影响感兴趣,但在成长过程中,没有人向我介绍编码的概念。我们在家里共用一台电脑,我的兄弟们都非常喜欢游戏。他们一直都在上面。
高中时,我上过计算机课,但我的老师们,我相信他们都是很好的人,除了使用微软 Office 和让我们记住硬件不同部分的名称之外,并没有做更多的事情。所以,总的来说,我更关注生命和物理科学,我今天仍然对这些领域非常感兴趣。
我在美国读了一段时间的大学,我记得有一年夏天回家时,我真正意识到津巴布韦与美国有多么不同。从人们如何解决冲突这样非常小的文化差异(这是我仍在试图与我的美国朋友一起解决的问题),到获得知识和教育这样更有影响力的事情。
我决定开始更多地参与当地社区,出于某种原因,我决定利用技术来帮助我做到这一点。我还做了一个非常生动的梦,让我重新评估我的人生。
在四处搜索并组织了一次聚会后,我被介绍给了我的联合创始人之一 Ronald Maravanykia,他当时在哈拉雷经营着一家 Django girls 工作室。他向我介绍 Python 是一个很好的教育工具,可以教没有计算机科学背景的人编程。那几乎是三年前的事了,我非常感激 Python 最终成为我选择关注的语言。真的太棒了!
作为一名津巴布韦人,你热衷于在科技领域为津巴布韦女性赋权,并帮助当今的年轻女孩追求科技职业。以至于你是非营利组织 ZimboPy 的项目主管?
Marlene: 是的,正如我之前提到的,利用技术来创造有益的社会变革是我一直以来的想法。我和我的联合创始人决定创建 ZimboPy ,为 Zim 的女孩提供在这个国家的其他地方不一定能获得的知识和经验。
我认为对我来说,最终的目标是创造一种模式,在这种模式下,我们向女孩们介绍编程,如果她们喜欢编程,就为她们提供一条在该领域获得工作的途径。科技世界并不完美,但与大多数领域不同的是,无论你是否有接受正规高等教育的特权,你都有办法绕过传统的看门人并取得成功。
我们仍然是一个小型非营利组织,我每天都在学习新的东西,但是我们已经有了一些伟大的成功故事,给了我这么多的希望!此外,我们的导师周是我全年最喜欢做的事情,在那里我们把女孩介绍给在这个领域做着令人难以置信的事情的女性,并帮助她们建立新的东西!我们有像阿什利·麦克纳马拉和艾米丽·弗里曼这样不可思议的女性发言。总是这么有趣!
瑞奇: 你是 Python 软件基金会(PSF) 董事会的 13 名成员之一。你是如何参与 PSF 的,当我们展望 2020 年及以后,你认为最大的挑战是什么?
玛琳:实际上,我今年准备再次竞选,所以希望 2020 年我还会在董事会。到目前为止,我真的有一个非常好的体验!
事实上,我是被 Lorena Mesa 介绍给 PSF 的,她在 2017 年初的一次 ZimboPy 导师周上自愿发言。她当时是董事会成员,我们在选举即将到来的时候谈论了这件事。她真的觉得我会是董事会的一大亮点。当时非洲还没有人坐过席,所以她超级鼓励。
我记得看着提名名单,心想我不属于那里。我曾经在津巴布韦的当地 Python 社区做过一些工作,但是我真的被每个人的简介吓到了。我最后同意让洛雷纳提名我,主要是因为我没什么可损失的,哈哈!令人惊讶的是,我被投票通过了,我认为这完全证明了 Python 社区对多样性和全球代表性的承诺。
在过去的几年里发生了很多变化:指导委员会的形成,PyCon 的指数增长,以及这种语言在全球的传播。所有这些都是我们能够作为董事会讨论的事情。
我认为定义最大的挑战是棘手的,因为它确实取决于每个人的观点。董事会中有比我更精通技术的董事,他们可能会从更技术性的角度谈论 Python 未来的各种挑战。
对我来说,我的重点是帮助 Python 及其社区尽可能地具有包容性和代表性。最近,我和 Lorena 一起成为了董事会的沟通联***,并一直和博客团队一起工作。我希望看到来自世界各地社区的声音越来越多,也许有一天官方网站上有各种语言的博客帖子和内容。
所有这些都是我认为重要的事情,也是我们必须好好应对的挑战。
Ricky: 我有幸在 2019 年的 PyCon 上见到你本人。这是你的第一个 PyCon(也是我的)。你在那里的经历如何?对你来说最突出的时刻是什么?
Marlene: 我真的很喜欢 Pycon 2019,当然也很高兴见到你,Ricky,以及真正的 Python 团队的其他成员!我去过非洲和世界其他地方的几个 PyCon,但 PyCon US 绝对是一次独特的经历。
关于这次会议,我最喜欢的事情之一是每个人都非常友好和放松。我真的会路过我在 Twitter 上关注的人,他们做了令人惊讶的事情,他们只是坐在那里,吃着三明治!我在这里有点搞笑,但老实说,每个人都很热情和有趣。我仍然不能完全理解这件事。
我有很多突出的时刻,但我想我会说,沙华莱士和杰西卡麦克凯勒的联合基调是这个世界上。我热泪盈眶,因为这是一个很好的例子,说明了我们作为一个社区可以如何创造积极的变化!我从那次演讲中学到了很多,我想在津巴布韦实施。
我知道这是一件额外的事情,但我也想说,我在会议中心外有很多突出的时刻,比如与来自世界各地的人共进晚餐,去当地的美术馆,尝试泡喝茶,也通常只是在城市里闲逛。我度过了最美好的时光,我真的很期待 2020 年的匹兹堡!
Ricky: 如果我没记错的话,在 PyCon 结束的时候,微软和 Adafruit 捐赠了一堆 Circuit Playground 便当盒套装让你带回去给你在津巴布韦指导的女孩们。我很好奇你是否已经把它们投入使用了?或者你有什么计划,除了用它们来教他们如何写一些 CircuitPython?
玛琳:是的!这是另一个突出的时刻(添加到上面的二十个其他人,哈哈)。我和来自 Adafruit 的妮娜·扎哈伦科和卡特尼聊天,他们是我见过的最可爱的人!我们一起吃了晚饭,之后,他们决定把这些工具捐赠给我,让我带回家用于我们的 ZimboPy 项目。
我最近才回到津巴布韦,我已经开始自己摆弄这些工具包了。目前的计划是举办一个专门以 CircuitPython 为中心的研讨会,向女孩们展示她们可以在编写代码的时候玩得开心。我对此超级兴奋!
我还和 Kat 谈到了我在 PyCon Africa 举办 Adafruit 板教程的可能性,类似于她在微软展台演示的内容。如果我有足够的信心在 7 月前完成,我认为这是与会者应该注意的事情!
似乎你做的所有社区工作还不够,你还是第一届非洲 PyCon 的组织者!计划进行得怎么样了?可以分享一下细节吗?
Marlene: 我真的很兴奋,我们正处于会议筹备的最后阶段。PyCon Africa 是 Python 社区的第一次地区性/泛非洲聚会!我们有一个很棒的组织委员会,在尼日利亚、加纳、纳米比亚、乌干达、南非甚至英国都有帮助组织 PyCons 的人,所以在这方面,我真的很幸运能加入这个团队。
全球 Python 社区的反应也非常令人鼓舞。真正的 Python 居然是我们赞助商之一的,太神奇了。喊出来给你听!我认为我们正朝着正确的方向前进。
我是今年的主席,虽然到目前为止一切都很顺利,但我对规划过程有时会让人感到如此耗费精力感到惊讶。每次我抬头看,就好像过了 3 个月!在 PyCon US 上,我与其他一些地区会议组织者交谈,很高兴地发现我不是唯一一个有这种感觉的人。有时会感觉很强大,但在大多数情况下,我对我们取得的进步感到高兴,并对我们将举办一场伟大的赛事感到乐观!
会议将于今年 8 月 6 日至 10 日在加纳首都阿克拉举行。我们正在寻找赞助商,个人可以选择购买一张共享票来赞助一个没有能力自己买票的蟒蛇!你可以在我们的网站上找到更多的信息:【africa.pycon.org T4】
里基: 现在我的最后一个问题。你在业余时间还做些什么?除了 Python 和编码,还有其他爱好和兴趣吗?
我真的很喜欢在沙滩上漫步,哈哈。我在开玩笑,但我也是真心实意的!我最近迷上了跑步,我希望努力让自己达到足够好的状态,在某个时候参加马拉松。
我也很喜欢绘画,但不是以一种有教养的、酷的方式。我有时只是喜欢画画,把它作为一种放松的方式。冥想和感恩写日记也是我每天早上喜欢做的事情,作为开始一天的好方法。
和玛琳谈话绝对是一种享受。如果你想参加 PyCon Africa,还有张票。如果你想更多地了解玛琳,或者联系她,讨论她正在做的任何令人惊讶的事情,那么你可以在 Twitter 上找到她。
Python 社区采访迈克尔·肯尼迪
本周,我们的 Python 社区采访对象不是别人,正是因《向我讲述 Python》而出名的的 Michael Kennedy 。
你可能知道他权威的声音,但你知道他的 Python 故事吗?请继续阅读,了解他的 Python 之旅,他在堵车时的想法,以及他对两个轮子的热爱。
瑞奇: 欢迎来到真正的 Python!如果我没记错的话,您最初是一名. NET 开发人员,甚至是微软认证的培训师。所以我很好奇你是怎么来到 Python 的,是什么让你留了下来?
迈克尔:谢谢你邀请我。哦,这勾起了我的回忆。是的,我是全职的。NET 用 C#开发了大概 10 年。这是一种我至今仍尊重的语言。
在想要扩展到微软空间之外的领域之后,我找到了使用 Python 的方法。我猜这可能是 2012 年左右。在那之前的一段时间里,除了 JavaScript,我没有在 C++和 C#之外做过什么。(谁都逃不过 JavaScript!)我查看了流行的语言,这正是 Python 变得流行并且越来越流行的时候。
我花了几周时间学习 Python,并且非常着迷,但并不知道它。
我研究了语言和生态系统,发现它真的很好——比我想象的好得多。但是我遇到了一个问题,每个精通某种语言的人在尝试不同的语言时都会遇到这个问题。我熟记于心的一切又是一次挑战。如何创建 web 应用程序?我如何主持它?如何查询数据库?等等等等。
我愿意学习,也做到了。但这只是任何人都会有的不安,放弃熟悉的道路。然而,当我回去写一些 C#代码,发现它比我几周前写的更没品味时,我知道我会被迷住。
这并不是要抨击这种语言。但是像所有基于 C 的语言一样,它有很多符号噪声。为什么我们又需要分号了?为什么人们如此热爱括号和花括号,即使(现在)很明显它们是不需要的,等等。这里有一个例子:
class Thing { public int TotalSales { get { int total = 0; foreach (var b in items) { total += b.value; } return total; } } }class Thing: @property def total_sales(self): total = 0 for b in items: total += b.value return total让人不禁想知道为什么这么多年来你一直在输入那些符号。
从那时起,随着我学习越来越多的流行包和标准库模块,我每天都在享受它。现在,我在 Python 堆栈上运行我的整个业务,它还没有让我失望。
你当然是最受欢迎的 Python 播客——跟我说说 Python——的主持人,该播客现已超过 180 集。你也是布莱恩·奥肯主持的 Python Bytes 播客的主持人。内容真多啊!你是如何继续保持每周如此一致,并保持节目的相关性和新闻价值的?那一定是很大的工作量?
迈克尔:那绝对是很多内容。但这是一个非常值得的项目,因为 【跟我说 Python】已经进入第四年,而 Python Bytes 也进入了第三年。
我怎么还始终如一?这个问题问得好。我开始播客是因为其他人不一致。在我之前已经有了基于 Python 的播客。但他们都在我入行前很久就停止制作剧集了。事实上,这就是为什么我觉得我可以开始,因为内容太缺乏了。
我始终如一有几个原因。首先,当我开始播客时,我向自己承诺在六个月内每周都这样做,然后决定社区和我是否喜欢它。在做了这么多一致的内容创作之后,你已经习惯这么做了。
第二,那时我已经有几家公司赞助播客了。我想也许,只是也许,我可以找到一种方法来使用播客,以独立于我的日常工作。我并不讨厌我的日常工作,但它比不上做你认为对社区和世界真正有价值的事情。一旦你接受金钱来长时间生产一个东西,一致性只是协议的一部分。
最后,听众非常支持我的工作。为每个人制作内容的感觉真的很棒。我期待着我创作的每一集。毕竟,我从每一个人身上学到了很多,并且一直到今天还在继续。
至于保持节目的相关性和新闻价值,这很容易。对于 Python Bytes ,这就是字面意义上的主题(每周新闻项目),我们从听众那里得到了大量的帮助,他们每周都在推荐很棒的新项目。
对于跟我说 Python,这个比较难。每集深入挖掘一个话题。对于前 20 集左右,这对我来说很容易。例如,我使用过 SQLAlchemy,所以向 Mike Bayer 询问它只是回想我的经历。但是它很快就变成了我没有经验的空间。我现在每周都要花相当多的时间研究课题。在我们按下录制键之前,任何一集都有 4-8 小时的研究。
这就引出了你问题的最后一部分:是的,这是一项很大的工作。有人问我每周在节目上花多少时间。他们甚至说,“你做了一笔好交易。你每集花多少钱在播客上?几个小时?”那就太好了。我可能每集要花大约 2 天的时间来做研究、联系客人、收发电子邮件、开发网站、建立赞助关系等等。
这是一段很长的时间,但也是我事业的基础。只有当播客和课程都是众所周知的高质量的时候,它们才会起作用。非常幸运的是,我已经能够将我的兼职播客转变为全职工作(播客和课程)。这让我真正保持专注,保持一致。
Ricky: 如果我们的读者不知道你的播客,他们一定会知道你在 Talk Python 培训上的精彩课程。当我开始学习 Python 时,我参加的第一个课程是你的 Python Jumpstart by Building 10 Apps 课程——顺便说一句,它非常棒。你们刚刚发布了一门名为异步技术和实例的新课程。你能告诉我们更多的信息吗?为什么你决定特别关注异步?
迈克尔:谢谢!这些课程对我来说是真正充满激情的项目。很久以来,我就想为 Python 课程创建一个最好的在线图书馆。
当我第一次开始播客时,我也想开始课程。我看到它们携手并进,互相支持。然而,当时我在一家为开发人员提供面对面和在线培训课程的公司工作。
他们给了我很多自由和灵活性。但行不通的是,我在业余时间有效地创建了一家竞争性公司。所以我从播客开始,然后一旦我可以独立全职工作,我的第一个行动就是通过在 Kickstarter 上构建 10 个应用来启动培训公司和 Python Jumpstart。那真是一次有趣的经历,也是一次巨大的成功。
新的异步课程非常有趣,我觉得它对于社区来说是非常必要的。它需要存在有几个原因。对于许多人来说,Python 异步/并发编程的故事有点难以理解。我们有 GIL,它实际上被很好地覆盖在真正的 Python 上。这意味着普通线程只对 IO 绑定的工作有效。CPU 绑定的工作需要另一个 API,用它自己的古怪和技术进行多重处理。
现在,从 Python 3.5 开始,我们有了惊人的
async和await关键字。它们强大而干净,但给形势增加了更多的选择和更多的迷雾。这还没有考虑 Cython 的异步特性和它的nogil关键字。第一个原因是围绕异步和 Python 有很多混淆。你听说过有人因为 Go“更好”的并发性而放弃 Python 转而使用 Go。通常,人们寻找的并发类型是 IO 绑定的,这在 Python 中工作得非常好。
下一个原因是异步和并发编程被奇怪地以错误的顺序教授。我这么说的意思是,通常很多令人困惑的低级细节会出现在前面。最后,它被放在一起成为有用的和令人信服的例子。但是学习者必须走那么远才能有回报。这也经常伴随着线程安全的可怕警告,以及竞争条件有多艰难。所有这些都是真实准确的。但是为什么要从那里开始呢?
我想要一门课程来展示异步在很多情况下是多么的高效、有趣和简单。一旦学生看到了它的价值,你就可以深入到线程安全等方面。
最后,真的没有多少 Python 的异步课程。我只知道另外一家,在订阅墙后面。
瑞奇: 众所周知,你是 MongoDB 的忠实粉丝。你觉得它最吸引你的是什么?如果有人以前从未使用过它,为什么他们会考虑在下一个 Python 项目中使用它呢?
迈克尔:我是 MongoDB 的忠实粉丝。很久以前,我向一个朋友抱怨部署关系数据库应用程序是多么痛苦。关于在不停机的情况下应用迁移脚本是一件多么痛苦的事情。他说:“那你为什么不用 MongoDB,就不会有那个问题了?”。
我接受了他的建议,他是对的!从那以后,我已经在 MongoDB 上启动了 4 或 5 个主要项目。我的两个播客网站( talkpython.fm 和 pythonbytes.fm )和课程网站都在 MongoDB 上运行。
我知道有些人对 MongoDB 有不好的体验。早期在 MongoDB 中有一些“最佳实践”不是默认的,并且有很多关于这些的故事。其中大部分已经被修复,如果你知道要避免它们,你的情况就很好。还有一个主要问题就是 MongoDB 运行时不需要认证,除非你明确创建一个帐户。
也就是说,MongoDB 对我和我的项目来说完全是防弹的。它已经为上面提到的这些站点提供了多年的电力,没有任何停机时间。我从未运行过迁移或升级脚本来部署新的模式或数据模型。
Mongo 灵活的模式模型和 MongoEngine 基于类的 ODM(想想 ORM for MongoDB)正好适合我的项目。网站运行的延迟时间极低。对于不重要的页面,10-20 毫秒的响应时间是很常见的(从请求到服务器的响应)。
我个人完全可以为您的项目推荐 MongoDB。我还创建了一个免费课程,如果人们对 freemongodbcourse.com 感兴趣的话。
里基: 现在 Python 已经过时了,是时候谈谈有趣的东西了……数学!你有一个数学硕士学位,而且你确实开始了你的博士学位。有计划在将来完成它吗,或者那艘船已经起航了吗?我可以想象你仍然对它充满热情。你每天都有机会挠痒痒吗?
迈克尔:它起航了,在地平线上,在去南极洲的半路上!我确实学过数学,并且仍然非常欣赏它的一切美。上周堵车的时候,我在想不同类型的无穷大,不同大小的无穷大,在[0,1]之间的简单数轴上。
但这在数学中并不奏效。我相信软件开发是我真正的职业。我喜欢每天都这样做。我在数学上所学到的是为发展做的极好的准备。数学的规则和“规则”(语言、API、算法、big-O 等。)的软件惊人的相似。思维类型和解决问题的方式也是相当有可比性的。
软件和创业相对于数学的职业机会没有可比性。建造人们可以使用的东西(软件)比世界上只有 5-20 个人理解和关心的理论(如今的数学)更好。
所以我喜欢它,并且仍然阅读有关它的书籍,但是这些天我没有做任何实际的数学工作。
除了 Python,你还有其他爱好或兴趣吗?
迈克尔:这些年来,我有许多有趣的爱好。我确实认为在电脑时间和生活中的其他事情之间保持平衡是很重要的。
我很幸运,因为我的工作基本上有三个真正吸引人的方面,我几乎会把它们视为爱好。我经营播客,并真的致力于提高技巧和与听众沟通。我几乎每天都在做软件开发。经营我的生意和整个创业方面的事情是惊人的和有趣的。
就实际爱好而言,我喜欢赛车和任何有两个轮子的东西!我在 1-5 年级的时候参加了 BMX 自行车比赛,然后在初中和高中参加了摩托车越野赛,最后在大学参加了山地自行车赛。我和我的兄弟们在我们的后院建了一个摩托车越野赛赛道,这是很常见的,从学校回家,放下我们的背包,花一两个小时互相挑战,以清除这一系列的跳跃或只是玩得开心。
这些天,我只看摩托车越野赛,也是印地赛车的超级粉丝。我仍然骑着摩托车,但我和我的妻子在波特兰的山上骑着我们的街道摩托车,进行着成熟的冒险。能够与她和我的女儿们分享骑行的经历真是太棒了,她们跳上了我们的一辆自行车的后座。
瑞奇: 从 Talk Python 我们对未来有什么期待?有什么秘密项目想告诉我们,或者有什么想分享和/或宣传的吗?
迈克尔:我有一些项目,涉及即将推出的激动人心的课程。实际上,我希望能更快地了解我在那里的工作,但是“抄袭”我的热门课程的数量惊人。
我们现在至少有 4 门课程在积极开发中,还有一大堆我们想要建造的东西。因此,就课程而言,只要我们看到社区需要新的课程,就可以期待我们继续努力。你还可以期待更多世界级的作者在那里创作内容。我真的很荣幸能够为每个人的课程工作,并使我对这一资源和业务的梦想成为现实。
就播客而言,不要减速。我们有 Talk Python 和 Python Bytes ,两者都很强大。我只是希望在 Talk Python 上给社区带来更好更深入的故事,并与我的搭档 Brian Okken 一起每周更新 Python Bytes 上最令人兴奋的编程语言。
感谢大家邀请我参加真实 Python 节目。我是你们创造的资源的忠实粉丝。如果读者对我的项目感兴趣,请在 talkpython.fm 和 pythonbytes.fm 订阅播客。如果他们有 Python 的某些方面想亲自或为他们的团队学习,请访问 training.talkpython.fm 查看我们 100 多个小时的课程。
迈克尔,谢谢你参加我本周的采访。有你在采访麦克风的另一边真是太好了。
一如既往,如果你想让我在未来采访某人,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
Python 社区采访 Mike Driscoll
欢迎来到 Python 社区成员系列访谈的第一部分。
如果你还不认识我,我叫 Ricky,我是 Real Python 的社区经理。我是一个相对较新的开发人员,从 2017 年 1 月我第一次学习 Python 开始,我就成为了 Python 社区的一员。
在此之前,我主要是为了好玩而涉猎其他语言(C++、PHP、C#)。只是在我爱上 Python 之后,我才决定成为一名“认真”的开发者。当我不从事真正的 Python 项目时,我为当地企业制作网站。
本周,我将与《老鼠大战蟒蛇》的迈克·德里斯科尔对话。作为 Python 的长期倡导者和教师,Mike 分享了他如何成为 Python 开发者和作者的故事。他还分享了他对未来的计划,以及对如何使用时间机器的见解…
让我们开始吧。
Ricky: 首先,我想了解一下你是如何进入编程的,以及你是如何爱上 Python 的?
迈克:当我上大学的时候,我决定成为一名计算机程序员。我最初从事计算机科学,但由于很久以前一位教授给我的一些令人困惑的建议,我最终获得了一个 MIS 学位。总之,那是在互联网泡沫破裂之前,所以我毕业的时候没有科技行业的工作。在一家拍卖行担任信息技术团队的唯一成员后,我被当地政府聘为软件开发员。
那个地方的老板喜欢 Python,我被要求学习它,因为所有新的开发都是用它来完成的。火的考验!将 Kixtart 代码转换成我们登录脚本的 Python 代码,这是令人紧张的几个月。我还面临着挑战,要找到一种用 Python 创建桌面用户界面的方法,这样我们就可以从这些在 MS Office 上创建的真正糟糕的 VBA 应用程序中迁移出来。
我的老板喜欢 Python,而我在学习 Python 和在工作中使用它的过程中获得了很多乐趣,最终我也喜欢上了它。我们用 wxPython 制作了 GUI,用 ReportLab 制作了报表,用 TurboGears 制作了 web 应用程序,还用普通 Python 制作了更多。
你已经在你的博客《鼠标与 Python》上写了 10 多年了。你是如何保持每周写作的一致性和积极性的?
迈克:我并不总是始终如一。有一些空白我根本没怎么写。有一年,我有好几个月没有写作了。但我注意到,在我休息的时候,我的读者人数实际上增加了。事实上,我发现这真的很激励人,因为有那么多人阅读旧帖子,我希望我的博客继续保持新鲜。
此外,我的读者一直非常支持我的博客。因为他们的支持,我一直致力于在博客上写东西,或者至少记下一些想法以备后用。
里奇: 到目前为止,你已经写了五本书, Python 访谈:与 Python 专家的讨论于今年早些时候出版。在与 Python 社区中这么多杰出的开发人员交谈后,您个人从书中获得了哪些帮助您开发的技巧或智慧(无论是专业的还是个人的)?
迈克:我真的很喜欢在创作 Python 采访 这本书的时候和开发人员交谈。他们对充实 Python 和 PyCon USA 以及 Python 软件基金会的历史很有帮助。
我了解到一些核心开发人员认为 Python 在未来可能会走向何方,以及为什么它是以过去的方式设计的。例如,我没有意识到 Python 没有内置 Unicode 支持的原因是 Python 实际上比 Unicode 早了几个月。
我认为其中一个教训是数据科学和教育现在对 Python 来说有多重要。我采访的很多人都谈到了这些话题,看到 Python 的影响范围不断扩大很有趣。
我注意到你又开始为你的 Python 101 系列创作 YouTube 视频了。是什么让你决定重新开始创作视频内容?
迈克:Python 101 截屏是我作为 Python 101 书的分支放在一起的。虽然许多出版商说视频内容越来越受欢迎,但我的经历却恰恰相反。我的截屏系列从来没有很多人接受,所以我决定在 YouTube 上与我的读者分享。我将会把这个系列的大部分或者全部贴在那里,并且很可能不再把它作为我销售的产品。
我认为我需要更多创建视频培训的经验,所以我也计划用 Python 做更多其他主题的视频,看看他们是如何被接受的。尝试与我的观众互动的其他方法总是很有趣。
里奇: 你不仅为在线社区做了这么多,还创建并运营了你当地的 Python 用户组。你会给那些想参加第一次本地用户组会议的人(比如我)什么建议?
Mike: Pyowa,我创立的本地 Python 团体,现在已经有好几个组织者了,真的很不错。但是回到你的问题。如果你想去一个团体,首先要做的是找到一个在你附近的地方和是否存在。大多数群组都列在了 Python wiki 上。
接下来,你需要查看他们的网站或 Meetup,看看他们的下一次会议是关于什么的。我在爱荷华州参加过的大多数会议在开始或结束时都有某种形式的社交时间。然后,他们进行某种形式的谈话或其他活动,如群氓编程或闪电谈话。最重要的是准备好谈论和学习 Python。大多数时候,你会发现当地的用户群就像参加 PyCon 的人一样热情。
瑞奇: 如果可以时光倒流,你会对 Python 有什么改变?你希望这种语言能做些什么?或者你想从语言中删除一些东西?
Mike: 我希望 Guido 能够说服谷歌的 Android 工程部门将 Python 作为 Android 的原生语言之一。事实上,除了托加和基维,我们目前没有太多的方法来编写移动应用程序。我认为这两个库都很棒,但是托加仍然是测试版,尤其是在 Android 上,Kivy 在它运行的任何东西上看起来都不是本地的。
我喜欢庆祝生活中大大小小的胜利。到目前为止,你最自豪的 Python 时刻是什么?
Mike: 就我个人而言,我很自豪以书籍和博客的形式写 Python,并且有这么多读者发现我的漫谈很有帮助。我也很自豪认识社区里这么多伟大的人,他们会以许多有意义的方式互相帮助。这就像有一个你甚至不一定见过面的朋友网络。我发现这是 Python 社区独有的。
Ricky: 我很好奇除了 Python,你还有什么其他爱好和兴趣?有你想分享和/或插入的吗?
迈克:我大部分的业余时间都花在和我三岁的女儿玩上了。然而,我也喜欢摄影。拍出你想要的照片可能很有挑战性,但数码摄影也让这变得容易得多,因为如果你拍得不好,你可以获得即时反馈并进行调整,前提是你的拍摄对象愿意。
如果你想关注迈克的博客或查阅他的任何一本书,去他的网站吧。你也可以在的推特和的 YouTube 上给迈克发信息问好。
你想让我们采访社区里的什么人吗?在下面留下他们的名字,他们可能就是下一个。
Python 社区采访 Mike Grouchy
如果你看过上一期 Python 社区对 Mahdi Yusuf 的采访,那么你已经见过 Pycoder 每周团队的一半成员了。这一次,我和迈赫迪的犯罪搭档迈克·格鲁希在一起。
迈克告诉我们 Pycoder 是如何真正开始的,以及成为一个“篮球迷”意味着什么我们也将了解更多关于迈克的秘密项目。让我们开始吧。
瑞奇: 欢迎光临!先说你是怎么进入编程的,什么时候开始使用 Python 的。
迈克:嗨!我第一次接触电脑是在我大概 8、9 岁的时候,我爸爸告诉我的。无论从哪方面来说,他都不精通计算机,但他一直是个修补匠,当他了解了 BBSs 和那里存在的社区后,他就摆弄它们,并向我展示如何用我们的 2400 波特调制解调器在它们上面玩游戏。(哈!)
当时,我只是着迷于你可以远程连接到其他计算机,玩游戏,写消息等。这激起了我的兴趣,让我开始摆弄电脑,直到几年后,我们通过当地大学获得了拨号上网。(我爸在那里边工作边上了一门课。)
对我来说就是这样。互联网吸引了我,就像 BBSs 早期吸引我一样。你可以与来自世界各地的人在互联网上发布的网页互动,这一事实开启了我的想象力。
所以,像许多人一样,我编程做的第一件事就是学习如何把网页放到互联网上。这里有一个合乎逻辑的进展。由于我想制作更复杂的网站,我钻研了用 Perl 编写 CGI 脚本,后来在高中我学习了 PHP 并真正迷上了 Linux。
这自然导致我开始编写大量 Python 来在我的 Linux 机器上实现自动化。那是我第一次真正接触 Python。
瑞奇: 人们可能知道你是《Pycoder》周刊的一半,该周刊至今已发行近 7 年。Pycoder 的想法是如何产生的,它符合你的期望吗?
迈克:皮科德的想法很自然地出现了。当时,我和马赫迪是一家初创公司的同事,在此之前,我们曾在工作之余参与过一些项目。
但是,日复一日,我们都在写 Python,参加当地的聚会小组。(我曾创建了一个 Django 组,后来被并入了本地 Python 组。)我们一直在寻找 Python 资源。
那时编程简讯变得有点“热”,我们真的找不到我们想要阅读的简讯,所以我们决定尝试看看人们是否对这类东西感兴趣。我们只是立即创建了一个带有收集电子邮件表格的登陆页面,并将其发布在黑客新闻上。尽管在这个不起眼的帖子里有一些怀疑论者,我们还是得到了大约 2000 个注册,并在 2 周后发行了第一期。
我想说 Pycoder 的远远超出了我的预期。我们已经存在很长时间了,这有点疯狂。这无疑帮助我和 Mahdi 增长了我们的 Python 知识。我们还了解了一些关于创建和管理社区以及建立受众的事情。
在这段时间里,最棒的事情是我们这些年来接触过的所有伟大的人。这些年来,我们通过 PyCons 认识了很多人,在认识这些人和成为社区的活跃分子方面,我们有一些非常有趣的经历。
瑞奇: 为时事通讯整理内容一定要花不少时间?但是你有没有遇到过帮助你解决问题或者改变你完成任务的方式的事情,而这些事情是你以前没有遇到过的?
迈克:这可能有点耗时,但这只是我日常生活中的一部分,而且我通常会阅读很多书,所以这不是一件苦差事。
至于它是否帮助我解决了一个问题或以不同的方式完成了一项任务,我不能确定是哪一件,但我向你保证它是有帮助的。阅读和积累关于一个主题(或许多主题)的广泛知识的一个好处是,多年来你最终会看到如此多的东西,这有助于你认识到你已经看到的东西,这样你就可以回去找到解决你可能遇到的一些问题的新方法。
此外,看到所有这些事情会改变你对如何解决各种问题的看法,并能真正帮助你磨练解决问题的方法。
里基: 好了,该换个话题,谈谈篮球了。你自称是“篮球迷”篮球到底是什么让你如此着迷,你有没有找到一种方法把你对编码的热爱和篮球结合起来?
迈克:我确实热爱篮球。(加油湖人!)
我从小就玩,游戏对我来说一直很美好。这是一场需要技巧和惊人运动能力的比赛,所以我一直很喜欢看。随着体育分析的新时代,它增加了一种全新的方式来看待比赛。(我会不好意思告诉你我在篮球参考上花了多少时间。)但你能深入挖掘一场篮球赛的深度是不可思议的。
与棒球等游戏不同,分析对于篮球来说仍然是新的,所以人们仍然只是在弄明白它,所以它真的很令人兴奋。我很想参加麻省理工学院-斯隆体育分析会议。
NBA 真的有很多角色,当然也有不少好的体育文章。这启发我在几年前从事一个项目,试图将一点点 NLP 与机器学习(ML)结合起来,以自动管理体育新闻——类似于 Techmeme,但不使用编辑器。它叫做 hoopsmachine!
不用说,这是一个从未真正启动过的项目,但我认为它是随着当今所有新的和改进的 ML 工具的出现而不时出现的。
现在是我的最后一个问题:除了 Python,你还有什么其他爱好和兴趣?有你想分享和/或插入的吗?
迈克:我家里有两个孩子(一个 4 岁,一个 2 岁),我是 PageCloud 的工程副总裁,这是一家开发下一代网站创建工具的软件初创公司。所以那会占用相当多的时间!
然而,在我仅有的一点空闲时间里,我读了很多书,而找到下一本书总是一件麻烦事。所以我一直在做一个小的兼职项目,我希望它能帮助我和其他人发现他们接下来应该读的书。
我也很喜欢摆弄家庭自动化、家庭实验室、黑树莓 Pis 之类的东西。(马赫迪也是。)我们正在为对此感兴趣的人做一个项目。这两件事还没有公开,但如果听起来有趣,请在 Twitter 上关注我,当有东西展示时,我一定会发布这两件事!
迈克,谢谢你参加我本周的采访。为了及时了解迈克的秘密项目,你可以在推特上关注他,或者在他的网站上查找他。就我个人而言,我要去窥探他的 GitHub 寻找线索…
如果将来你想让我采访谁,请在下面的评论中联系我,或者在 Twitter 上给我发消息。
Python 社区采访 Moshe Zadka
本周,SurveyMonkey 的高级现场可靠性工程师 Moshe Zadka 加入了我的讨论。Moshe 是扭曲框架和真实 Python作者的核心开发者。
在这次采访中,我们讨论了各种各样的话题,包括 Twisted 框架、Python for DevOps、编写 Python 书籍和太极。
里基: 谢谢你和我一起,摩西。我想从我问所有采访嘉宾的相同问题开始:你是如何进入编程的,你是什么时候开始使用 Python 的?
我记得我做的第一个编程项目是 class 的项目,在 Basic 中将数字从十进制转换成二进制。老师认为这对一个七岁的孩子来说有点超前,这是我完成它的主要动力。
我是 99 年进入 Python 的。我对我们在项目中使用的数据格式感到沮丧,并认为将东西转移到 XML 可能是一种改进。我寻找一种能够很好地支持 XML 并且易于在 Linux 上安装的语言。Python 似乎是最好的选择。晚上下载了教程,第二天发现自己在 Python 上很有生产力。
里基: 你是扭曲图书馆的核心开发者。对于那些以前没有听说过 Twisted 的人来说,它是什么,什么样的应用程序最适合使用它?
Moshe: Twisted 是一个基于事件的框架。它非常适合编写网络应用程序。事件模型非常适合处理多个连接,同时保持一致的状态,因为它避免了竞争条件。这使得 Twisted 适用于游戏服务器或客户端、聊天应用程序和长时间运行的 web 应用程序,如服务器发送的事件。
里基: 白天,你是 SurveyMonkey 的高级现场可靠性工程师。作为一名 SRE,Python 如何适应你的日常实践?
Moshe: Python 在站点可靠性和自动化领域的许多方面都很流行,但是一个经常被忽视的用途是小数据处理。有时我需要分析来自少数机器的日志数据或度量流,以便对问题进行故障排除。
在最近的一次类似事件中,我需要分析的典型数据块是几千个数据点。这对于 Python 来说并不是很多数据,即使是纯 Python,但手动查看也是很多的。用 Python 编写即席分析允许我诊断问题。
瑞奇: 到目前为止你已经写了几本书,包括专家扭曲、Python 中的 devo PS、 和来自 python import better 的。你承担写书这样一项艰巨任务的动机是什么,你从写作中收获最多的是什么?
Moshe: 我成功地进入了一个不太投入的实验: Expert Twisted 是几个作者的联合项目。我只需要写两章,这样就不那么可怕了。我喜欢写这些章节,但是和这么多作者一起工作是一项复杂的协调工作。虽然他们中的许多人是密友,但我学到的第一件事是,我再也不想合作写一本书了!
我写 python import 的 更好 是因为我已经有了日常写作的习惯,并且对自己出版一本电子书的感觉很感兴趣。这是一个有趣的实验,但我决定让出版商处理一些后勤工作。
为了 Python 中的 DevOps,我和我在专家扭曲工作中认识的同一个出版商一起工作。那绝对是我最棒的写书经历。然而,这仍然是一项艰巨的工作,我发现人们常说的很难从技术书籍中赚钱的原则是正确的。读完三本书后,我决定暂时离开书本——至少一段时间。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
现在,我正在尝试编写另一个 Python 版本管理器。我对 pyenv 的一些设计决策不满意,想做得更好。我的个人项目 pyver 对我来说已经足够好了,我正在清理它,以便对其他人有用。我还参加了一个在线课程,学习如何使用 PyTorch。
我的主要“疫情爱好”是太极。多年来,我一直在寻找一种适合我个性和生活方式的运动方式,太极就是其中之一。我喜欢在家练习。我也开始定期冥想,我发现这种练习有助于我保持注意力集中在重要的事情上。
里基: 谢谢你,摩西,抽出时间和我谈话。
如果你想就 Twisted 或我们今天谈论的任何事情与 Moshe 联系,那么你可以在 Twitter 上联系他。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。
Python 社区采访罗素·基思-麦咭
今天我和拉塞尔·基思·麦咭一起参加了这个节目。Russell 是 Django 的核心开发人员,也是 BeeWare 项目的创始人和维护者。在采访中,我们谈到了他帮助 Python 成为编写和打包移动应用程序的可行选择的使命,以及他对开源项目的热情。我们还谈到了他的 PyCon 2020 演讲,该演讲已被录制并上传到 PyCon YouTube 频道。
所以,事不宜迟,我们开始吧!
里基: 欢迎来到真正的 Python,Russell。谢谢你来参加这次采访。让我们像往常一样开始吧。你是如何开始编程的,你是什么时候开始使用 Python 的?
Russell: 我父亲一直是技术的早期接受者,因此,在我八九岁的时候,他带回了澳大利亚进口的首批 Commodore 64s 中的一款。
与那个时代的许多计算机一样,你无法避免使用 Commodore 64 进行编程,因为当你打开它时,你会直接进入一个基本的编程环境。
当时也有很多儿童书籍,其中包括你可以输入的程序代码。那些书会把自己标榜为超级刺激的太空游戏,但它们实际上只是真正好的书籍艺术的随机数字游戏。然而,这足以激起我的兴趣。
很难确定我开始使用 Python 的确切日期。我记得在 20 世纪 90 年代后期,大约在 Python 1.5 的时间框架内,作为一种主要用于 Red Hat 配置管理的语言,我遇到了它。我对它的认真使用始于 2003 年左右,那时我刚开始接触 web 编程。当我成为 Django 贡献者的时候,我的日常工作变成了全职 Python——并且一直如此。
有趣的是,我的起源故事和我的 Python 背景最近发生了碰撞。我最喜欢的一些 Commodore 时代编程书籍的出版商 usborne开源了他们书籍的内容,所以我开始了一个有趣的项目,将书籍移植到 Python 的。
即使你是 Django 的核心开发人员之一,但你把大部分开源时间都花在了 BeeWare 项目上,这公平吗?对于那些还没有听说过 BeeWare 的人来说,它是什么,是什么激发了你开始这个项目?
Russell: 我从 2005 年开始参与 Django,2006 年初加入核心团队。但自从 2016 年底卸任 Django Software Foundation 总裁以来,我一直没有非常积极地参与该项目。
从那以后,我主要关注于 BeeWare 项目。BeeWare 是用于开发桌面和移动应用程序的工具和库的集合。就像 Django 让一个数据库支持的网站容易建立和运行一样,BeeWare 的目标是让为 macOS、Windows、Linux、iOS 或 Android 编写一个原生应用程序变得容易,然后你可以将它作为一个可安装的应用程序分发给最终用户。
最初的灵感来自两个不同的方向。首先,我是一个两人网络创业公司的整个工程团队。Django 让我在我们的 web 堆栈上快速迭代新特性。但是我们需要一个匹配的移动应用程序,我不能使用 Python,因为用 Python 编写移动应用程序没有可行的选择。
我最终使用了一个跨平台的 JavaScript 工具包,但我真的对此很不满意,部分原因是我没有使用我喜欢的语言,还因为最终的 UI 感觉不太好。它不是一个本地应用程序,而是一个包装在方便的包装中的网络浏览器。我想解决这个问题,用 Python 编写一个真正的原生跨平台应用。
另一个灵感来自我过去的编程经历。我在 Commodore 64 上学习编程,但是当我开始认真时,我开始使用 Borland 工具套件(Turbo C、Turbo Pascal 等)。Borland 套件有一个非常好的编辑器,更重要的是,还有一个非常好的可视化调试器。
我想重新构建调试器,但对于 Python 和使用我的现代 macOS 笔记本电脑的完整 UI 功能。然而,我找不到一个跨平台的、易于分发的、有 Pythonic API 的 GUI 工具包。
结合这个事实,我需要一个新的 GUI 工具包在移动设备上工作,我认为构建一个专注于 Python 原生和跨平台的新 GUI 工具包将是最简单的方法。毕竟,这能有多难呢?著名的遗言,我知道。
Ricky: 在今年的 PyCon US 大会上,你本来要做一个题为“案例中的蛇:打包 Python 应用程序以供分发”的演讲,主题是公文包,这是一个将 Python 驱动的应用程序转换为 macOS、Windows、Linux 和移动设备上的本机安装程序的工具。Python 传统上一直在努力使打包和共享应用程序像在其他语言中一样简单。这种情况正在改变吗?原生移动应用是 Python 的未来吗?
Russell: 我认为这种情况必须改变——如果不改变,Python 可能会被取代。
Python 来源于服务器端代码的悠久传统,这种传统永远不会消失。但是计算生态系统正在发生变化。
我儿子两年前才开始上高中。学校用电子方式呈现教材。然而,他的学校规定的计算设备不是笔记本电脑。这是一个 iPad。这也不是什么不寻常的经历。iPads、智能手机和平板电脑正在获得笔记本电脑从未见过的市场渗透率。
因此,当我的儿子(或任何其他人)想学习编程时,他为什么要学习一种他不能在自己的计算设备上使用的编程语言呢?如果 Python 没有为 iOS 和 Android 开发应用程序开发一个故事,那么我们将会发现,传统上学习 Python 的用户将会学习其他编程语言,如 JavaScript、Swift 和 Kotlin——这些语言都有一个移动故事。
包装是一个密切相关的问题。如果你想在这些新设备上安装应用程序,你不需要从网站上下载安装程序。你必须通过厂商的 app store。
这种理念在桌面操作系统上也开始变得越来越普遍。macOS 和 Windows 不会阻止你安装从互联网上下载的应用程序,但它们肯定会让安装变得更加困难,最终用户喜欢从 App Store 链接进行简单的安装。
完全抛开技术限制,对于这个问题有一个好的答案,我如何把我的代码给别人?至关重要。如果你的新游戏演示或数据可视化的发布故事包括“下载 Python,然后创建一个虚拟环境,然后
pip安装…然后找出为什么pip不工作”,这不是一个令人信服的体验。这一点尤其重要,因为竞争对手 JavaScript 默认安装在几乎每台计算机上,并且附加在一个内置的分发机制上:网络。所以,BeeWare 是我对这个挑战的回答。
BeeWare 包括一个跨平台的小部件工具包(托加)和库,可以让你在 iOS 和 Android 上运行 Python。它还包括公文包,这是一个工具,可以将 Python 代码的集合转换成可分发的单元,您可以将它提供给最终用户。
对于 macOS,公文包会生成一个
.app包,您可以将它放入应用程序文件夹中。在 Linux 上,它生成 AppImages。在 Windows 上,它生产 MSI 安装程序,在 iOS 和 Android 上,它生产可以上传到 iOS 应用商店或谷歌 Play 商店的项目。然而,公文包并没有绑定到 BeeWare 库。您可以使用公文包来打包一个 PursuedPyBear 游戏、一个 PySide Qt、一个 Tkinter 应用程序或任何其他 Python GUI 工具包。公文包不会让 Tkinter 在移动上工作,但它会解决在 Tk 工作的平台上打包应用的问题。
瑞奇: 蜂产品的未来会怎样?你对这个项目的未来有什么看法?
Russell: 短期内,我想让全套房达到 1.0 状态。实际上,这意味着在所有五个受支持的平台上拥有至少相当于 Tkinter(嵌入 Python 本身的 GUI 工具包)的特性。
我们已经非常接近这个目标了。多亏了 PSF 最近的拨款,一向落后的 Android 后端在过去的几个月里经历了快速的进步。我们最近也有一些非常好的社区贡献来改进 Windows 后端。
从长远来看,我希望看到 BeeWare 开始吃自己的狗粮。正如我前面说过的,BeeWare 开始(部分)是试图构建一个调试器。我仍然希望与其他开发工具一起重新审视它,比如覆盖工具、测试运行程序和圣杯:编辑器。
我还希望看到我们开发用于开发 GUI 应用程序的工具——通过一次点击机制定义用户界面的拖放工具,用于构建应用程序并将它们部署到应用程序商店。由于 BeeWare 工具都是跨平台的,任何在桌面上工作的东西也将在移动设备上工作,因此拥有在 iOS 和 Android 上运行的开发工具是这一愿景的一部分。
我想说的一个大的技术领域是网络。过去,我们演示了一个纯 Python web 应用程序,即浏览器中所有客户端行为都以 Python 而非 JavaScript 运行的 web 应用程序。作为一种技术,WASM 的出现使这变得更有可能,所以我希望能够扩展 BeeWare,使 Web 成为 BeeWare 开发人员眼中的另一个部署平台。
从项目的角度来看,我希望看到 BeeWare 在财务上自给自足,在这个项目中,正在进行的开发和维护不依赖于志愿者的业余时间。我想找到支付核心项目维护人员的方法,理想情况下,也支付实习生和初级工程师的费用,这样有经验的团队成员可以与下一代 FLOSS 开发人员分享他们的知识和经验。
找到一个可行的模式来产生持续的收入,而不破坏项目的开源目标,是我目前最大的挑战之一。如果你的观众中有人在这方面有任何想法,我绝对有兴趣听听。
里基: 现在我的最后几个问题。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
Russell: 听起来可能很无聊,但我对 BeeWare(和开源软件)充满了热情,因此它消耗了我大量的业余时间。有些人在业余时间玩数独或纵横字谜。我黑过奇怪的开源项目。
然而,当我不编程时,我喜欢桌面桌游,我也是科幻电视和电影的粉丝。
很高兴和你聊天,拉塞尔。如果你想和 Russell 打招呼,你可以在 Twitter 和 T2 的个人博客上找到他。如果你想尝试——或者参与 BeeWare 项目,那么去他们的网站看看文件。
如果你想让我接下来采访谁,请在下面的评论中联系我,或者在 Twitter 上给我发消息。编码快乐!
Python 社区采访 sebastán ramírez
今天,我和爆炸人工智能的软件开发员塞巴斯蒂安·拉米雷斯在一起。他也是流行框架 FastAPI 和 Typer 的创造者。在这次采访中,我们将讨论 Python 中的类型、他创建 FastAPI 的动机以及该框架的未来等等。事不宜迟,我们开始吧。
Sebastián,感谢你的参与。我想从我问所有客人的问题开始:你是如何进入编程的,你是什么时候开始使用 Python 的?
塞巴斯蒂安:感谢邀请我😁
我大约十五岁时开始从事编码工作,试图为我父母的生意建立一个网站。我写的第一个真正的“代码”是一个带有
alert("Hello World")的 HTML 中的一些 JavaScript 。我仍然记得看到那条小小的警告信息时的激动,以及想到我已经把它编码成的强烈感觉。多年来,我害怕学习任何其他语言,认为我必须“至少”先掌握 JavaScript。几年后,我当时参加的许多在线课程中有一门需要 Python 来控制 AI 吃豆人和其他东西。这门课有一个很长的教程,里面只有 Python 的基础知识,这对于这门课来说已经足够了。我真的很想尝试一下,所以我继续学习基础教程。
当然,我很快就爱上了 Python,并希望我能早点开始😅
你目前是 Explosion AI 的软件开发人员,该公司开发了流行的自然语言处理(NLP)框架 spaCy 。你能谈谈你的日常生活吗?人工智能和机器学习有哪些让你感兴趣的地方,Explosion AI 创造了哪些工具来帮助开发者推动这两个领域的边界?
Sebastián: 是的,Explosion 最出名的是开源 NLP 工具包 spaCy 。他们还创造了 Prodigy ,这是一个商业的、可脚本化的工具,用于有效地注释机器学习数据集。我的工作主要是在 Prodigy Teams 上,Prodigy 的云版本专注于有多个用户的团队。由于该产品非常以隐私为中心,制作团队/云版本有许多特殊的挑战。
然而,我最近决定离开公司。我目前(在我写这篇文章的时候)正在结束我积累的所有假期😁
我的计划是安排一种方式,将我大部分的工作时间用于 FastAPI、Typer 和其他开源项目,同时可能做一些咨询,帮助其他团队和公司使其可持续发展🚀
里奇: 人们可能知道你是 FastAPI 的创造者,这是一个用于构建API的高性能 web 框架,已经迅速成为最受欢迎的 Python web 框架之一。是什么给了你建造它的灵感,你对它的未来有什么规划?对于那些还没有尝试 FastAPI 的人来说,为什么他们会选择在他们的下一个 API 中使用它,而不是其他流行的框架,比如 Flask 和 Django ?
Sebastián: 事实上,多年来我一直避免构建一个新的框架。
我首先学习并使用了许多框架、插件和工具,总是改进我的工作流程(以及我所领导的开发人员的工作流程),同时使我们正在构建的产品更好。当我在创业公司工作的时候,我总是在转换,快速创造新产品,等等。,我有机会在寻找“正确的”工作流和工具的过程中重复了很多,将现有的框架与许多插件和工具相结合。
与此同时,我也有机会从事其他领域的工作,比如 JavaScript 前端、TypeScript、几个框架、一些混合应用程序、一些电子桌面应用程序等等。大多数或所有的项目都是以数据为中心的(数据科学、机器学习等)。),所以拥有良好的数据通信方式总是很重要的。
到那时,我已经从几个框架、工具甚至其他语言和生态系统中获得了许多我喜欢的特性:
- 编辑器中的自动完成功能
- 编辑器中的自动错误检测(类型检查)
- 代码简单性
- 自动数据验证
- 自动数据转换(序列化)
- 自动化 API 文档
- 对标准的支持,比如用于 web APIs 的 OpenAPI、用于身份验证和授权的 OAuth 2.0 以及用于数据文档的 JSON 模式
- 依赖注入来简化代码并提高实用程序的重用性
- 良好的性能/并发性
但是在构建 web APIs 时,我没有办法同时拥有所有这些特性,我想出的最佳工作流程仍然有缺陷和警告。它需要困难的插件集成、过时的组件、没有文档记录的工具、重复的代码等等。
但是到了某个时候,就没有别的方法可以尝试了。那是我的暗示。我开始研究标准,比如 OpenAPI、JSON Schema、OAuth 2.0 等等。我开始设计我希望它如何工作,首先在几个编辑器上测试,在编写实际的内部代码之前优化开发人员的体验。
然后,我确保我为 FastAPI 准备了正确的构件: Starlette (用于所有的 web 部件)和 pydantic (用于所有的数据部件),它们都有很好的性能和特性。最后,我开始实现那些基于标准和我能想到的最好的开发者体验的设计,加上一些额外的东西(比如依赖注入系统)。
文档中有更多关于 FastAPI 的历史、设计和未来的背景,还有关于 T2 的替代方案、灵感和比较。简而言之,FastAPI 诞生于许多其他工具、API 设计和想法的学习和灵感,并建立在非常坚实的基础之上(Starlette 和 pydantic)。
对于那些好奇想尝试一下的人,我建议查看一下主页或自述并跟随那个迷你教程。在 15 到 20 分钟内,你将会非常清楚 FastAPI 是如何工作的,不管你喜不喜欢,也不管它对你是否有用。
对于那些已经在现有产品中使用其他框架的人来说,不要仅仅因为 FastAPI 看起来光鲜亮丽就急于迁移到它。如果你的产品运行良好,你不需要新的特性,或者如果你不需要 FastAPI 的好处,那么就不值得更换。
然而,如果您想迁移到 FastAPI,这实际上相对简单,因为没有复杂的集成。你可以直接使用普通的 Python 包结合 FastAPI,你可以通过小部分进行迁移,或者用 FastAPI 只创建新的组件。
Ricky: Typer 是你建立的一个命令行界面(CLI)框架,与 FastAPI 类似,它严重依赖于 Python 的类型化。我注意到一个模式😉是什么让你如此喜欢类型化,你觉得应该有更多的库拥抱 Python 的类型化吗?
塞巴斯蒂安:是的,完全!这里有一个非常强大的模式。类型注释(或类型提示)是编辑器中自动完成和类型检查的动力。这些类型注释就是为了这个目的而发明的。仅仅这两个特性就证明了使用它们的合理性。
更重要的是,如果它在一个工具中,预计会被其他开发者使用,我真的希望许多 Python 包可以处理,例如,基础设施或 SaaS 客户端将完全采用类型注释。这将极大地改善开发人员的生活,并使他们的工具更容易被采用。
但是现在,在 pydantic、FastAPI 和 Typer 的情况下,那些类型注释已经包含了许多可以用来制作更强大工具的信息。它们隐式包含文档信息,如“姓名应该是字符串”和“年龄应该是浮点数”
关于类型注释的信息也可以用于数据验证,例如,如果函数期望一个字符串,但收到一个字典。这是一个可能被报告的错误,如果框架是基于接收参数的函数,那么框架(比如 FastAPI 或 Typer)可以解决这个问题。
然后这些类型注释也可以用于数据序列化。例如,在 URL 中,一切都是字符串,在 CLI 中也是如此。但是,如果我们在类型注释中声明我们想要一个整数,框架(FastAPI 或 Typer)可以尝试将来自 URL 或 CLI 的类似
"42"的字符串转换为我们代码的实际整数。因此,通过一个非常直观和简单的代码片段来声明变量的类型,我们可以在两个原始特性(自动完成和类型检查)的基础上突然获得三个额外的特性(验证、序列化、文档)。这是从很少的编码工作中提取的大量价值。
在绝大多数情况下,所有这些特征都需要完全相同的信息:“年龄是一个整数。”因此,通过重用同一段代码(类型注释)来声明它,我们可以避免大量的代码重复。如果我们决定在某个地方改变类型(比如为了验证),但是忘记在其他地方更新它(比如文档),我们可以保持真实的单一来源并避免将来的错误。
通过单一的类型声明,我们可以避免许多与不同步的重复代码相关的错误。而这些特性正是 FastAPI 和 Typer 所提供的。
现在你已经创建了非常流行的现代 CLI 和 web 框架,你对未来有什么计划?你对其他正在进行的项目感到兴奋吗?
是的,我有很多计划。也许太多了😬
我想给 FastAPI 和 Typer 添加几个特性。我还想为 FastAPI 开发一个独立于数据库的自动管理用户界面(基于 OpenAPI)。我想为需要 SQL 数据库的用例研究一种混合 pydantic 和 SQLAlchemy 的方法(同样,利用这些类型注释并减少代码重复)。
我还想对项目生成器进行大量改进。我想改进、简化并更好地记录 OAuth 2.0 的所有实用程序,使用范围、与第三方进行认证等等。
我也想,在某个时候,尝试做一些视频,可能是一门课程,多做一些关于学习所有这些东西的内容。
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
塞巴斯蒂安:我最近没有太多时间做其他事情,但我希望这种情况在未来会有所改变😅当我可以的时候,我喜欢和我的妻子玩电子游戏(或者有时自己一个人),看电影,和柏林的朋友一起去吃早餐或者喝咖啡(当周围没有疫情的时候)。
我也真的很喜欢从事这些开源项目,所以我可以很容易地在周末花上几个小时而不会注意到它😁
非常感谢邀请我!很荣幸能和很多我追随和敬佩的人分享这个舞台。
谢谢你参加我的采访,塞巴斯蒂安。很高兴与你交谈。
如果你想就 FastAPI 或我们今天谈论的任何事情与 Sebastián 联系,那么你可以通过 Twitter 与他联系。
如果你想让我采访 Python 社区中的某个人,请在下面留下评论或在 Twitter 上联系我。
Will McGugan 的 Python 社区访谈
今天和我一起的是威尔·麦古根。Will 是苏格兰的一名自由 Python 开发者,也是流行的 Python 库
Rich的创建者。在这次采访中,我们讨论了
Rich的起源,维护一个流行的 Python 包是什么感觉,构建象棋引擎,以及 Will 对摄影的热爱。谢谢你参加我的采访,威尔。我想以我们对所有来宾一样的方式开始:你是如何开始编程的,你是什么时候开始使用 Python 的?
威尔:谢谢你邀请我!
我在 80 年代还是个孩子的时候就发现了编程。对于年轻读者来说,这就像是更奇怪的东西,只是少了 CGI 怪物。那时我们有一台 ZX 频谱+计算机。图像闪烁不定,声音微弱,但我被吸引住了。在某个时候,我发现你可以在键盘上输入东西,如果你做得恰到好处,电脑会按照你说的去做。
几年后,我在视频游戏行业工作。我正在构建一个游戏引擎,并寻找一种脚本语言来处理游戏机制,而 C++则负责图形和繁重的工作。我想,那时我遇到了 Python 2.1 版。
我当时并不认为它是一门合适的编程语言,可能是因为它太好用了,编程应该很难吧?即便如此,我发现自己又回到 Python 来寻找脚本和工具,这些逐渐变得更加复杂。
我在 Python 中的“大突破”发生在我为互联网象棋俱乐部工作的时候。他们正在寻找一个 Python 开发者来构建一个新的象棋界面。幸运的是,我已经编写了一个国际象棋游戏,并渴望更好地利用我的 Python 技能。从那以后,Python 成了我职业生涯的主要重心,我没有回头。
过去十年来,你一直是 Python 的自由开发者。在过去的十年中,Python 自由职业空间发生了怎样的变化?而且是随着 Python 的流行而增长的吗?
威尔:我的经历是在家工作的自由职业者。这在当今相当普遍,但当我开始时,它真的让大多数人感到惊讶。如果你是一个有经验的开发人员,你可能不再需要在办公室工作了。
现在 Python 是主流。大型科技公司采用了 Python,它已经从人们用来提高生产率的第二语言变成了一种受欢迎的技能。我很幸运有一份长期合同,但这年头似乎不缺合同工。
瑞奇: 人们可能知道你是
Rich的创造者,这是一个日益流行的用于格式化终端输出的库。你创建这个库的动机是什么,它越来越受欢迎(每月超过 619,000 次下载)对Rich的发展有什么影响?将:
Rich是很久以前制作的!2015 年的某个时候,我在做Moya,一个 web 应用平台,也是我当时的副业项目。Moya有一个命令行应用程序,可以生成奇特的终端输出。我在那里实现的控制台类是
Rich的原型版本。这个控制台类并没有经过深思熟虑——更像是一个与终端相关的东西的垃圾场——但是这里有一些好的想法。在我停止
Moya的工作后,我打算重新制作这个 uberconsole,以便它可以用于其他项目。每当我在终端中艰难地读取一些格式不佳的输出时,我会希望它已经存在了。2019 年底的某个时候,我开始着手这项工作。首先出现的是富文本,这也是这个名字的由来。我有一个类,可以用类似于 HTML 的方式用颜色和样式标记文本的跨度。后来出现的许多其他特性都是建立在这个核心特性之上的。我用它来实现语法高亮显示、表格、降价等等。
当
Rich开始流行时,最明显的变化是我在大多数日子里收到的大量 bug 和功能请求。我意识到Rich不再是我的玩物了。人们在日常工作中使用它,开发人员与客户、老板和最后期限打交道。我感到有责任及时修复错误并实现人们要求的功能。老实说,它开始不像是一个在晚上进行的有趣的项目,而更像是一份工作。这其中有某种失落感。
让我坚持下去的是积极的反馈。许多用户说他们发现和 T2 一起工作很有趣。我很高兴我坚持下来了,因为我喜欢看到人们在命令行应用程序中使用
Rich的创造性方式。瑞奇: 你最近给
Rich添加了终端仪表盘,和 htop 一样,只是好看多了!这是人们要求的功能吗?您在实施过程中面临哪些技术挑战?威尔:终端仪表盘功能是在我读到一条关于
ghtop的推文时想到的。这个项目是由 GitHub 的首席执行官纳特·弗里德曼发起的。哈默尔·侯赛因和杰瑞米·霍华德用Rich美化了ghtop的输出,看起来棒极了!看到这一点,我意识到Rich在这类接口上有很大的潜力。为了使这些类似 htop 的界面更容易实现,我添加了一个 layout 类,它可以将终端屏幕细分为多个部分,每个部分都有自己的内容。
唯一真正的技术障碍是
Rich没有意识到身高是一个维度。Rich中的输出可以有一个宽度,但是假设它可以写尽可能多的行,因为用户可以向上滚动来查看它。在全屏显示时,你不能滚动,所以我不得不将内容限制在一个固定的高度。幸运的是,这并不是很大的变化。瑞奇: 人们如何开始使用
Rich,如果已经在使用,如何帮助项目继续成功?会:
Rich超级容易上手。一个小程序from rich import print,可以用一个拥有超能力的print()。你可以免费获得自动换行、语法高亮和漂亮的打印。打印表格、面板和减价商品并不需要做太多的工作。细节在自述文件和文档中,加上 GitHub 库中的大量示例。我目前正在尝试让 GitHub 赞助商继续支持
Rich。每月的前 200 美元将捐给肠癌慈善机构。有很多非金融的方式来帮助这个项目。错误报告和功能建议总是受欢迎的。我也很欣赏自述文件的翻译,目前为止有五种语言(包括英语)。如果自述文件不是您的母语,请考虑提交一份带有翻译的 PR!
里基: 现在只剩下最后几个问题了。你在业余时间还做些什么?除了 Python 和编程,你还有什么其他的爱好和兴趣?
在疫情之前,我非常喜欢野生动物摄影。我很幸运能够在熊、科莫多龙和猩猩的自然栖息地拍摄这些神奇的动物。当世界恢复正常时,我想做更多那样的事。
如今,我的兴趣更贴近家庭。我喜欢烹饪,主要是我在 YouTube 上看到的食谱。最近,我一直试图掌握经典的意大利面食。
瑞奇: 谢谢你,威尔,和我一起。祝
Rich及其持续发展好运。
如果你想就我们今天谈论的任何事情与威尔联系,那么你可以通过推特联系他。你可能也想从
Rich开始。如果你想让我采访 Python 社区中的某个人,请在下面留下评论或通过 Twitter 联系我。编码快乐!
使用 pyenv 管理多个 Python 版本
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 pyenv 开始管理多个 Python 版本
你是否曾经想要为一个支持多个版本 Python 的项目做贡献,但是不确定如何轻松地测试所有版本?你有没有对 Python 最新最棒的版本感到好奇?也许你想尝试这些新特性,但是你不想担心搞乱你的开发环境。幸运的是,如果您使用
pyenv,管理多个版本的 Python 不会令人困惑。本文将为您提供一个很好的概述,介绍如何最大化您在项目上花费的时间,以及如何最小化在尝试使用正确版本的 Python 上花费的时间。
在这篇文章中,你将学习如何:
- 安装多个版本的 Python
- 安装 Python 的最新开发版本
- 在已安装的版本之间切换
- 通过
pyenv使用虚拟环境- 自动激活不同的 Python 版本和虚拟环境
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
为什么要用
pyenv?
pyenv是一个管理多个 Python 版本的优秀工具。即使您已经在系统上安装了 Python,安装pyenv也是值得的,这样您就可以轻松地尝试新的语言特性,或者为不同版本 Python 上的项目做出贡献。使用pyenv也是安装 Python 预发布版本的一个好方法,这样你就可以测试它们是否有 bug。为什么不用系统 Python?
“系统 Python”是安装在操作系统上的 Python。如果你在 Mac 或 Linux 上,那么默认情况下,当你在终端上输入
python时,你会得到一个漂亮的 Python REPL。那么,为什么不用呢?看待它的一种方式是,这个 Python 实际上属于操作系统的。毕竟它是随操作系统一起安装的。这甚至会在您运行
which时反映出来:$ which python /usr/bin/python这里,
python对所有用户可用,如其位置/usr/bin/python所示。很可能,这也不是您想要的 Python 版本:$ python -V Pyhton 2.7.12要将包安装到您的系统 Python 中,您必须运行
sudo pip install。这是因为您正在全局安装 Python 包,如果另一个用户想安装稍微旧一点版本的包,这将是一个真正的问题。同一个包的多个版本的问题往往会在你最意想不到的时候悄悄靠近你并咬你一口。这个问题出现的一个常见方式是,一个流行且稳定的软件包突然在您的系统上行为失常。经过数小时的故障排除和谷歌搜索,你可能会发现你安装了错误版本的依赖关系,这毁了你的一天。
即使您的 Python 版本安装在
/usr/local/bin/python3中,您仍然不安全。您将遇到上述相同的权限和灵活性问题。此外,对于在您的操作系统上安装什么版本的 Python,您实际上没有多少控制权。如果你想使用 Python 中的最新特性,比如你正在使用 Ubuntu,你可能就没那么幸运了。默认版本可能太旧了,这意味着你只能等待新操作系统的出现。
最后,有些操作系统其实是用打包的 Python 进行操作的。以
yum为例,它大量使用 Python 来完成工作。如果你安装了一个新版本的 Python,并且不小心把它安装到你的用户空间,你可能会严重损害你使用操作系统的能力。包经理呢?
下一个合乎逻辑的地方是包管理器。像
apt、yum、brew或port这样的程序是典型的下一个选项。毕竟,这是你安装大多数软件包到你的系统的方式。不幸的是,在使用包管理器时,您会发现一些同样的问题。默认情况下,包管理器倾向于将他们的包安装到全局系统空间,而不是用户空间。同样,这些系统级的包污染了您的开发环境,使您很难与其他人共享一个工作空间。
同样,您仍然无法控制可以安装哪个版本的 Python。的确,有些存储库给了你更多的选择,但是默认情况下,你看到的是你的特定供应商在某一天发布的 Python 版本。
即使您确实从包管理器安装了 Python,也要考虑如果您正在编写一个包并想要在 Python 3.4 - 3.7 上支持和测试会发生什么。
当你输入
python3时,你的系统会发生什么?你如何在不同版本之间快速切换?您当然可以这样做,但是这很繁琐,而且容易出错。如果你想要 PyPy 、Jython 或者 Miniconda,那么你可能只是不太喜欢你的软件包管理器。考虑到这些限制,让我们回顾一下让您轻松灵活地安装和管理 Python 版本的标准:
- 在您的用户空间中安装 Python
- 安装多个版本的 Python
- 指定您想要的确切 Python 版本
- 在已安装的版本之间切换
让您可以做所有这些事情,甚至更多。
安装
pyenv在安装
pyenv本身之前,您将需要一些特定于操作系统的依赖项。这些依赖项主要是用 C 编写的开发工具,并且是必需的,因为pyenv通过从源代码构建来安装 Python。对于构建依赖的更详细的分解和解释,你可以查看官方文档。在本教程中,您将看到安装这些依赖项的最常见方式。注:
pyenv原本不支持 Windows。然而,最近开始活跃的 pyenv-win 项目似乎获得了一些基本支持。如果您使用 Windows,请随意查看。构建依赖关系
pyenv从源代码构建 Python,这意味着您将需要构建依赖项来实际使用pyenv。构建依赖关系因平台而异。如果你在 Ubuntu/Debian 上并且想要安装构建依赖,你可以使用下面的:$ sudo apt-get install -y make build-essential libssl-dev zlib1g-dev \ libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev \ libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python-openssl这使用 Apt 来安装所有的构建依赖项。让它运行起来,你就可以准备好使用 Debian 系统了。
如果您使用 Fedora/CentOS/RHEL ,您可以使用
yum来安装您的构建依赖项:$ sudo yum install gcc zlib-devel bzip2 bzip2-devel readline-devel sqlite \ sqlite-devel openssl-devel xz xz-devel libffi-devel该命令将使用
yum安装 Python 的所有构建依赖项。macOS 用户可以使用以下命令:
$ brew install openssl readline sqlite3 xz zlib这个命令依赖于自制软件,并为 macOS 用户安装一些依赖项。
提示:运行 Mojave 或更高版本(10.14+)时,您还需要安装附加 SDK 头文件:
$ sudo installer -pkg /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg -target /感谢罗德里戈·维耶拉的更新。
如果你使用的是 openSUSE ,那么你可以运行下面的代码:
$ zypper in zlib-devel bzip2 libbz2-devel libffi-devel \ libopenssl-devel readline-devel sqlite3 sqlite3-devel xz xz-devel同样,这个命令会为您的系统安装所有 Python 构建依赖项。
最后,对于 Alpine 用户,可以这样使用:
$ apk add libffi-dev ncurses-dev openssl-dev readline-dev \ tk-dev xz-dev zlib-dev该命令使用
apk作为包管理器,并将在 Alpine 上安装 Python 的所有构建依赖项。使用 pyenv 安装程序
安装完构建依赖项后,就可以安装
pyenv本身了。我推荐使用 pyenv-installer 项目:$ curl https://pyenv.run | bash这将安装
pyenv以及一些有用的插件:
pyenv:实际的pyenv应用pyenv-virtualenv:用于pyenv和虚拟环境的插件pyenv-update:更新pyenv的插件pyenv-doctor:验证pyenv和构建依赖项是否安装的插件pyenv-which-ext:自动查找系统命令的插件注意:上述命令与下载 pyenv-installer 脚本并在本地运行相同。所以如果你想知道你到底在运行什么,你可以自己查看这个文件。或者,如果你真的不想运行脚本,你可以查看手册的安装说明。
运行结束时,您应该会看到类似这样的内容:
WARNING: seems you still have not added 'pyenv' to the load path. Load pyenv automatically by adding the following to ~/.bashrc: export PATH="$HOME/.pyenv/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)"输出将基于您的 shell。但是你应该按照说明将
pyenv添加到你的路径中,并初始化pyenv/pyenv-virtualenv自动完成。一旦完成了这些,您需要重新加载您的 shell:$ exec "$SHELL" # Or just restart your terminal就是这样。你现在已经安装了
pyenv和四个有用的插件。使用
pyenv安装 Python既然已经安装了
pyenv,下一步就是安装 Python。您有许多 Python 版本可供选择。如果您想查看所有可用的 CPython 3.6 到 3.8,您可以这样做:$ pyenv install --list | grep " 3\.[678]" 3.6.0 3.6-dev 3.6.1 3.6.2 3.6.3 3.6.4 3.6.5 3.6.6 3.6.7 3.6.8 3.7.0 3.7-dev 3.7.1 3.7.2 3.8-dev上面显示了
pyenv知道的所有匹配正则表达式的 Python 版本。在本例中,这是所有可用的 CPython 版本 3.6 到 3.8。同样,如果您想查看所有的 Jython 版本,您可以这样做:$ pyenv install --list | grep "jython" jython-dev jython-2.5.0 jython-2.5-dev jython-2.5.1 jython-2.5.2 jython-2.5.3 jython-2.5.4-rc1 jython-2.7.0 jython-2.7.1同样,您可以看到
pyenv提供的所有 Jython 版本。如果您想要查看所有版本,您可以执行以下操作:$ pyenv install --list ... # There are a lot一旦找到您想要的版本,您可以用一个命令安装它:
$ pyenv install -v 3.7.2 /tmp/python-build.20190208022403.30568 ~ Downloading Python-3.7.2.tar.xz... -> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz Installing Python-3.7.2... /tmp/python-build.20190208022403.30568/Python-3.7.2 /tmp/python-build.20190208022403.30568 ~ [...] Installing collected packages: setuptools, pip Successfully installed pip-18.1 setuptools-40.6.2 Installed Python-3.7.2 to /home/realpython/.pyenv/versions/3.7.2有问题?
pyenv文档有很棒的安装说明以及有用的 FAQ 和常见构建问题。这将需要一段时间,因为
pyenv正在从源代码构建 Python,但是一旦完成,您将可以在本地机器上使用 Python 3.7.2。如果您不想看到所有的输出,只需移除-v标志。甚至可以安装 CPython 的开发版本:$ pyenv install 3.8-dev专业提示:如果你使用
pyenv有一段时间了,没有看到你要找的版本,你可能需要运行pyenv update来更新工具,并确保你可以获得最新版本。对于本教程的其余部分,示例假设您已经安装了
3.6.8和2.7.15,但是您可以自由地用这些值替换您实际安装的 Python 版本。还要注意例子中的系统 Python 版本是2.7.12。安装位置
如前所述,
pyenv的工作原理是从源代码构建 Python。您安装的每个版本都位于您的pyenv根目录中:$ ls ~/.pyenv/versions/ 2.7.15 3.6.8 3.8-dev您的所有版本都将位于此处。这很方便,因为删除这些版本很简单:
$ rm -rf ~/.pyenv/versions/2.7.15当然
pyenv也提供了卸载特定 Python 版本的命令:$ pyenv uninstall 2.7.15使用您的新 Python
现在您已经安装了几个不同的 Python 版本,让我们看看如何使用它们的一些基础知识。首先,检查您有哪些版本的 Python 可用:
$ pyenv versions * system (set by /home/realpython/.pyenv/version) 2.7.15 3.6.8 3.8-dev
*表示systemPython 版本当前是活动的。您还会注意到这是由您的根pyenv目录中的一个文件设置的。这意味着,默认情况下,您仍在使用您的系统 Python:$ python -V Python 2.7.12如果您尝试使用
which来确认这一点,您会看到:$ which python /home/realpython/.pyenv/shims/python这可能令人惊讶,但这就是
pyenv的工作方式。pyenv插入到你的PATH中,从你的操作系统的角度来看是被调用的可执行文件。如果您想查看实际路径,可以运行以下命令:$ pyenv which python /usr/bin/python例如,如果您想使用版本 2.7.15,那么您可以使用
global命令:$ pyenv global 2.7.15 $ python -V Python 2.7.15 $ pyenv versions system * 2.7.15 (set by /home/realpython/.pyenv/version) 3.6.8 3.8-dev专业提示:运行内置测试套件是确保您刚刚安装的 Python 版本工作正常的一个好方法:
$ pyenv global 3.8-dev $ python -m test这将启动大量的内部 Python 测试来验证您的安装。你可以放松下来,看着考试通过。
如果您想回到 Python 的默认系统版本,您可以运行以下命令:
$ pyenv global system $ python -V Python 2.7.12现在,您可以轻松地在不同版本的 Python 之间切换。这只是开始。如果您想要在多个版本之间进行切换,那么一致地输入这些命令是很乏味的。本节讲述了基础知识,但是在使用多种环境中描述了一个更好的工作流程。
探索
pyenv命令
pyenv提供了许多命令。您可以看到所有可用命令的完整列表,如下所示:$ pyenv commands activate commands completions deactivate ... virtualenvs whence which这将输出所有命令名。每个命令都有一个
--help标志,可以提供更详细的信息。例如,如果您想查看关于shims命令的更多信息,您可以运行以下命令:$ pyenv shims --help Usage: pyenv shims [--short] List existing pyenv shims帮助消息描述了该命令的用途以及可以与该命令结合使用的任何选项。在接下来的几节中,您将找到最常用命令的快速、高层次概述。
install您已经看到了上面的
install命令。此命令可用于安装特定版本的 Python。例如,如果你想安装3.6.8,你可以使用这个:$ pyenv install 3.6.8输出向我们展示了
pyenv下载和安装 Python。您可能希望使用的一些常见标志如下:
旗 描述 -l/--list列出所有可供安装的 Python 版本 -g/--debug构建 Python 的调试版本 -v/--verbose详细模式:将编译状态打印到标准输出
versions
versions命令显示所有当前安装的 Python 版本:$ pyenv versions * system (set by /home/realpython/.pyenv/version) 2.7.15 3.6.8 3.8-dev这个输出不仅显示了
2.7.15、3.6.8、3.8-dev和您的systemPython 已经安装,还显示了systemPython 是活动的。如果您只关心当前的活动版本,可以使用以下命令:$ pyenv version system (set by /home/realpython/.pyenv/version)该命令类似于
versions,但只显示当前活动的 Python 版本。
which
which命令有助于确定系统可执行文件的完整路径。因为pyenv通过使用垫片来工作,这个命令允许你看到可执行文件pyenv运行的完整路径。例如,如果您想查看pip安装在哪里,您可以运行:$ pyenv which pip /home/realpython/.pyenv/versions/3.6.8/bin/pip输出显示了
pip的完整系统路径。当您已经安装了命令行应用程序时,这可能会很有帮助。
global
global命令设置全局 Python 版本。这可以用其他命令覆盖,但对于确保默认使用特定的 Python 版本非常有用。如果您想默认使用3.6.8,那么您可以运行:$ pyenv global 3.6.8该命令将
~/.pyenv/version设置为3.6.8。有关更多信息,请参见关于指定您的 Python 版本的一节。
local
local命令通常用于设置特定于应用程序的 Python 版本。您可以使用它将版本设置为2.7.15:$ pyenv local 2.7.15该命令在当前目录下创建一个
.python-version文件。如果您的环境中有活动的pyenv,这个文件将自动为您激活这个版本。
shell
shell命令用于设置特定于 shell 的 Python 版本。例如,如果您想测试 Python 的3.8-dev版本,您可以这样做:$ pyenv shell 3.8-dev该命令激活通过设置
PYENV_VERSION环境变量指定的版本。此命令会覆盖您可能拥有的任何应用程序或全局设置。如果您想停用该版本,您可以使用--unset标志。指定您的 Python 版本
pyenv最令人困惑的部分之一是python命令是如何被解析的,以及哪些命令可以用来修改它。正如命令中提到的,有 3 种方法可以修改你正在使用的python的版本。那么,所有这些命令是如何相互作用的呢?解决顺序看起来有点像这样:
这个金字塔应该从上到下阅读。
pyenv可以找到的第一个选项是它将使用的选项。让我们看一个简单的例子:$ pyenv versions * system (set by /home/realpython/.pyenv/version) 2.7.15 3.6.8 3.8-dev这里,您的
systemPython 被使用,如*所示。要练习下一个最全局的设置,您可以使用global:$ pyenv global 3.6.8 $ pyenv versions system 2.7.15 * 3.6.8 (set by /home/realpython/.pyenv/version) 3.8-dev你可以看到现在
pyenv想用3.6.8作为我们的 Python 版本。它甚至指出找到的文件的位置。该文件确实存在,您可以列出其内容:$ cat ~/.pyenv/version 3.6.8现在,让我们用
local创建一个.python-version文件:$ pyenv local 2.7.15 $ pyenv versions system * 2.7.15 (set by /home/realpython/.python-version) 3.6.8 3.8-dev $ ls -a . .. .python-version $ cat .python-version 2.7.15这里,
pyenv再次表明它将如何解析我们的python命令。这次它来自~/.python-version。注意对.python-version的搜索是递归的:$ mkdir subdirectory $ cd subdirectory $ ls -la # Notice no .python-version file . .. $ pyenv versions system * 2.7.15 (set by /home/realpython/.python-version) 3.6.8 3.8-dev即使
subdirectory中没有.python-version,版本仍然被设置为2.7.15,因为.python-version存在于父目录中。最后,可以用
shell设置 Python 版本:$ pyenv shell 3.8-dev $ pyenv versions system 2.7.15 3.6.8 * 3.8-dev (set by PYENV_VERSION environment variable)所有这些只是设置了
$PYENV_VERSION环境变量:$ echo $PYENV_VERSION 3.8-dev如果你对这些选项感到不知所措,那么关于使用多种环境的章节回顾了一个自以为是的管理这些文件的过程,主要是使用
local。虚拟环境和
pyenv虚拟环境是管理 Python 安装和应用程序的重要部分。如果你以前没有听说过虚拟环境,你可以看看 Python 虚拟环境:初级读本。
虚拟环境和
pyenv是天作之合。pyenv有一个名为pyenv-virtualenv的奇妙插件,使得使用多个 Python 版本和多个虚拟环境变得轻而易举。如果你想知道pyenv、pyenv-virtualenv和像virtualenv或venv这样的工具之间的区别,那么不要担心。你并不孤单。你需要知道的是:
- pyenv 管理 Python 本身的多个版本。
- virtualenv/venv 管理特定 Python 版本的虚拟环境。
- pyenv-virtualenv 管理不同版本 Python 的虚拟环境。
如果你是一个死忠的
virtualenv或venv用户,不要担心:pyenv与任何一个都玩得很好。事实上,如果你愿意的话,你可以保留原来的工作流,尽管我认为当你在需要不同 Python 版本的多个环境之间切换时,pyenv-virtualenv会带来更好的体验。好消息是,既然您使用了
pyenv-installer脚本来安装pyenv,那么您已经安装了pyenv-virtualenv并准备好了。创建虚拟环境
创建虚拟环境是一个简单的命令:
$ pyenv virtualenv <python_version> <environment_name>从技术上讲,
<python_version>是可选的,但是您应该考虑总是指定它,这样您就可以确定您使用的是哪个 Python 版本。
<environment_name>只是一个名称,用于帮助您保持环境的独立性。一个好的做法是将您的环境命名为与您的项目相同的名称。例如,如果您正在开发myproject,并且想要针对 Python 3.6.8 进行开发,那么您应该运行以下代码:$ pyenv virtualenv 3.6.8 myproject输出包括显示安装了几个额外的 Python 包,即
wheel、pip和setuptools的消息。这完全是为了方便,只是为您的每个虚拟环境设置了一个功能更全面的环境。激活您的版本
既然您已经创建了虚拟环境,下一步就是使用它。通常,您应该通过运行以下命令来激活您的环境:
$ pyenv local myproject您以前见过
pyenv local命令,但是这一次,您没有指定 Python 版本,而是指定了一个环境。这将在您当前的工作目录中创建一个.python-version文件,因为您在您的环境中运行了eval "$(pyenv virtualenv-init -)",所以该环境将自动被激活。您可以通过运行以下命令来验证这一点:
$ pyenv which python /home/realpython/.pyenv/versions/myproject/bin/python您可以看到已经创建了一个名为
myproject的新版本,并且python可执行文件指向该版本。如果您查看该环境提供的任何可执行文件,您会看到同样的情况。就拿pip来说吧:$ pyenv which pip /home/realpython/.pyenv/versions/myproject/bin/pip如果您没有将
eval "$(pyenv virtualenv-init -)"配置为在您的 shell 中运行,您可以使用以下命令手动激活/停用您的 Python 版本:$ pyenv activate <environment_name> $ pyenv deactivate以上是
pyenv-virtualenv在进入或退出一个包含.python-version文件的目录时所做的事情。使用多种环境
将你所学的一切放在一起,你可以在多种环境下有效地工作。假设您安装了以下版本:
$ pyenv versions * system (set by /home/realpython/.pyenv/version) 2.7.15 3.6.8 3.8-dev现在您想要处理两个不同的、名称恰当的项目:
- project1 支持 Python 2.7 和 3.6。
- project2 支持 Python 3.6,实验用 3.8-dev。
您可以看到,默认情况下,您使用的是系统 Python,这由
pyenv versions输出中的*表示。首先,为第一个项目创建一个虚拟环境:$ cd project1/ $ pyenv which python /usr/bin/python $ pyenv virtualenv 3.6.8 project1 ... $ pyenv local project1 $ python -V /home/realpython/.pyenv/versions/project1/bin/python最后,请注意,当您
cd离开目录时,您默认回到系统 Python:$ cd $HOME $ pyenv which python /usr/bin/python您可以按照上面的步骤为 project2 创建一个虚拟环境:
$ cd project2/ $ pyenv which python /usr/bin/python $ pyenv virtualenv 3.8-dev project2 ... $ pyenv local 3.8-dev $ pyenv which python /home/realpython/.pyenv/versions/3.8-dev/bin/python这些是项目的一次性步骤。现在,当您在项目之间
cd时,您的环境将自动激活:$ cd project2/ $ python -V Python 3.8.0a0 $ cd ../project1 $ python -V Python 3.6.8不再需要记住激活环境:你可以在所有项目之间切换,并且
pyenv会自动激活正确的 Python 版本和正确的虚拟环境。同时激活多个版本
如上例所述,
project2使用 3.8 中的实验特征。假设您想要确保您的代码仍然在 Python 3.6 上工作。如果你试着运行python3.6,你会得到这个:$ cd project2/ $ python3.6 -V pyenv: python3.6: command not found The `python3.6' command exists in these Python versions: 3.6.8 3.6.8/envs/project1 project1
pyenv通知您,虽然 Python 3.6 在当前活动环境中不可用,但它在其他环境中可用。pyenv为您提供了一种使用熟悉的命令同时激活多个环境的方法:$ pyenv local project2 3.6.8这向
pyenv表明您希望使用虚拟环境project2作为第一选项。因此,如果一个命令,例如python,可以在两种环境中被解析,它将在3.6.8之前选择project2。让我们看看如果你运行这个会发生什么:$ python3.6 -V Python 3.6.8这里,
pyenv试图找到python3.6命令,因为它在一个活动的环境中找到了它,所以它允许该命令执行。这对于像 tox 这样需要在你的PATH上有多个版本的 Python 才能执行的工具来说非常有用。专业提示:如果你正在使用 tox 和
pyenv,你应该检查一下 tox-pyenv 包装。假设在上面的例子中,您发现了库的兼容性问题,并且想要做一些本地测试。测试要求您安装所有的依赖项。您应该按照以下步骤创建新环境:
$ pyenv virtualenv 3.6.8 project2-tmp $ pyenv local project2-tmp一旦您对本地测试感到满意,您就可以轻松地切换回您的默认环境:
$ pyenv local project2 3.6.8结论
现在,您可以更轻松地为想要支持多种环境的项目做出贡献。您还可以更容易地测试最新和最棒的 Python 版本,而不必担心搞乱您的开发机器,所有这些都有一个很棒的工具:
pyenv。您已经看到了
pyenv如何帮助您:
- 安装多个版本的 Python
- 在已安装的版本之间切换
- 通过
pyenv使用虚拟环境- 自动激活不同的 Python 版本和虚拟环境
如果你还有问题,请在评论区或 Twitter 上联系我们。此外, pyenv 文档是一个很好的资源。
奖励:在你的命令提示符下显示你的环境名
如果你像我一样,经常在各种虚拟环境和 Python 版本之间切换,很容易弄不清哪个版本是当前活动的。我使用 oh-my-zsh 和不可知论者主题,默认情况下,我的提示如下所示:
一看就不知道哪个 Python 版本是活动的。为了找出答案,我必须运行
python -V或pyenv version。为了帮助减少我花在弄清楚我的活动 Python 环境上的时间,我将我正在使用的pyenv虚拟环境添加到我的提示中:
在这种情况下,我的 Python 版本是
project1-venv,并立即显示在提示符的开头。这让我可以很快看到我正在使用的 Python 版本。如果你也想用这个,你可以用我的 agnoster-pyenv 主题。立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 pyenv 开始管理多个 Python 版本********
Python 中的线程介绍
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的线程
Python 线程化允许您同时运行程序的不同部分,并且可以简化您的设计。如果你有一些 Python 的经验,并且想用线程加速你的程序,那么这个教程就是为你准备的!
在这篇文章中,你将了解到:
- 什么是线程
- 如何创建线程并等待它们完成
- 如何使用
ThreadPoolExecutor- 如何避免竞态条件
- 如何使用 Python
threading提供的常用工具本文假设您已经很好地掌握了 Python 基础知识,并且正在使用至少 3.6 版本来运行这些示例。如果你需要复习,你可以从 Python 学习路径开始,快速上手。
如果你不确定是否要使用 Python
threading、asyncio或multiprocessing,那么你可以看看用并发加速你的 Python 程序。本教程中使用的所有源代码都可以在Real PythonGitHub repo中找到。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
参加测验:通过我们的交互式“Python 线程”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
什么是线程?
线程是一个独立的执行流。这意味着你的程序将同时发生两件事。但是对于大多数 Python 3 实现来说,不同的线程实际上并不同时执行:它们只是看起来像。
很容易将线程化想象成在程序上运行两个(或更多)不同的处理器,每个处理器同时执行独立的任务。那几乎是正确的。线程可能运行在不同的处理器上,但是它们一次只能运行一个。
让多个任务同时运行需要 Python 的非标准实现,用不同的语言编写一些代码,或者使用带来一些额外开销的
multiprocessing。由于 Python 的 CPython 实现的工作方式,线程化可能不会加速所有任务。这是因为与 GIL 的交互本质上限制了一次只能运行一个 Python 线程。
花费大量时间等待外部事件的任务通常很适合线程化。需要大量 CPU 计算和花费很少时间等待外部事件的问题可能根本不会运行得更快。
对于用 Python 编写并在标准 CPython 实现上运行的代码来说,情况确实如此。如果你的线程是用 C 写的,它们就有能力释放 GIL 并同时运行。如果您在不同的 Python 实现上运行,请查阅文档,了解它是如何处理线程的。
如果你正在运行一个标准的 Python 实现,只用 Python 编写,并且有一个 CPU 绑定的问题,你应该检查一下
multiprocessing模块。构建使用线程的程序还可以提高设计的清晰度。您将在本教程中了解的大多数示例并不一定会运行得更快,因为它们使用了线程。在它们中使用线程有助于使设计更简洁,更容易推理。
所以,我们不要再说线程了,开始用吧!
开始线程
现在你已经知道什么是线了,让我们来学习如何制作线。Python 标准库提供了
threading,其中包含了您将在本文中看到的大多数原语。在这个模块中,很好地封装了线程,提供了一个干净的接口来处理它们。要启动一个单独的线程,您需要创建一个
Thread实例,然后告诉.start():1import logging 2import threading 3import time 4 5def thread_function(name): 6 logging.info("Thread %s: starting", name) 7 time.sleep(2) 8 logging.info("Thread %s: finishing", name) 9 10if __name__ == "__main__": 11 format = "%(asctime)s: %(message)s" 12 logging.basicConfig(format=format, level=logging.INFO, 13 datefmt="%H:%M:%S") 14 15 logging.info("Main : before creating thread") 16 x = threading.Thread(target=thread_function, args=(1,)) 17 logging.info("Main : before running thread") 18 x.start() 19 logging.info("Main : wait for the thread to finish") 20 # x.join() 21 logging.info("Main : all done")如果您查看一下日志语句,您可以看到
main部分正在创建和启动线程:x = threading.Thread(target=thread_function, args=(1,)) x.start()当您创建一个
Thread时,您向它传递一个函数和一个包含该函数参数的列表。在这种情况下,你告诉Thread运行thread_function()并把它作为参数传递给1。在本文中,您将使用连续整数作为线程的名称。还有
threading.get_ident(),它为每个线程返回一个唯一的名称,但是这些通常既不短也不容易阅读。
thread_function()本身没多大作用。它只是记录一些消息,在它们之间有一个time.sleep()。当您按原样运行这个程序(第二十行被注释掉)时,输出将如下所示:
$ ./single_thread.py Main : before creating thread Main : before running thread Thread 1: starting Main : wait for the thread to finish Main : all done Thread 1: finishing您会注意到代码的
Thread部分在Main部分之后结束。在下一节中,你将回到为什么会这样,并谈论神秘的第二十行。守护线程
在计算机科学中,
daemon是在后台运行的进程。Python
threading对daemon有更具体的含义。当程序退出时,一个daemon线程将立即关闭。考虑这些定义的一种方式是将daemon线程视为在后台运行的线程,而不用担心关闭它。如果一个程序正在运行不是
daemons的Threads,那么该程序将在终止前等待那些线程完成。Threads那些是守护进程,然而,当程序退出时,无论它们在哪里都会被杀死。让我们更仔细地看看上面程序的输出。最后两行是有趣的部分。当你运行程序时,你会注意到在
__main__打印完它的all done消息后,线程结束前有一个暂停(大约 2 秒)。这个暂停是 Python 等待非后台线程完成。当 Python 程序结束时,关闭过程的一部分是清理线程例程。
如果你查看 Python
threading的源代码,你会看到threading._shutdown()遍历所有正在运行的线程,并在每个没有设置daemon标志的线程上调用.join()。所以你的程序等待退出,因为线程本身在睡眠中等待。一旦完成并打印出信息,
.join()将返回,程序可以退出。通常,这种行为是您想要的,但是我们还有其他选择。让我们先用一个
daemon线程重复这个程序。您可以通过改变构造Thread的方式,添加daemon=True标志来实现:x = threading.Thread(target=thread_function, args=(1,), daemon=True)当您现在运行该程序时,您应该会看到以下输出:
$ ./daemon_thread.py Main : before creating thread Main : before running thread Thread 1: starting Main : wait for the thread to finish Main : all done这里的区别是输出的最后一行丢失了。
thread_function()没有机会完成。这是一个daemon线程,所以当__main__到达它的代码末尾,程序想要结束时,守护进程被杀死。
join()一根线守护线程很方便,但是当您想等待线程停止时怎么办呢?当你想这样做而又不想退出程序的时候呢?现在让我们回到原来的程序,看看注释掉的第二十行:
# x.join()要让一个线程等待另一个线程完成,可以调用
.join()。如果取消注释该行,主线程将暂停并等待线程x完成运行。你用守护线程还是普通线程在代码上测试了这个吗?事实证明,这并不重要。如果你
.join()一个线程,该语句将一直等待,直到任一种线程结束。使用多个线程
到目前为止,示例代码只使用了两个线程:主线程和一个用
threading.Thread对象启动的线程。通常,您会希望启动多个线程,并让它们完成有趣的工作。让我们从比较难的方法开始,然后你会转向比较容易的方法。
启动多线程的更难的方法是您已经知道的:
import logging import threading import time def thread_function(name): logging.info("Thread %s: starting", name) time.sleep(2) logging.info("Thread %s: finishing", name) if __name__ == "__main__": format = "%(asctime)s: %(message)s" logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S") threads = list() for index in range(3): logging.info("Main : create and start thread %d.", index) x = threading.Thread(target=thread_function, args=(index,)) threads.append(x) x.start() for index, thread in enumerate(threads): logging.info("Main : before joining thread %d.", index) thread.join() logging.info("Main : thread %d done", index)这段代码使用与上面相同的机制来启动一个线程,创建一个
Thread对象,然后调用.start()。这个程序保存了一个Thread对象的列表,这样它就可以在以后使用.join()来等待它们。多次运行这段代码可能会产生一些有趣的结果。这是我的机器输出的一个例子:
$ ./multiple_threads.py Main : create and start thread 0. Thread 0: starting Main : create and start thread 1. Thread 1: starting Main : create and start thread 2. Thread 2: starting Main : before joining thread 0. Thread 2: finishing Thread 1: finishing Thread 0: finishing Main : thread 0 done Main : before joining thread 1. Main : thread 1 done Main : before joining thread 2. Main : thread 2 done如果您仔细查看输出,您会看到所有三个线程都按照您预期的顺序开始,但是在这种情况下,它们以相反的顺序结束!多次运行将产生不同的排序。寻找
Thread x: finishing消息来告诉你每个线程什么时候完成。线程运行的顺序由操作系统决定,很难预测。它可能(并且很可能)会随着运行的不同而不同,所以当您设计使用线程的算法时,您需要意识到这一点。
幸运的是,Python 为您提供了几个原语,稍后您将看到这些原语有助于协调线程并让它们一起运行。在此之前,让我们看看如何使管理一组线程变得更容易一些。
使用
ThreadPoolExecutor有一种比上面看到的更简单的方法来启动一组线程。它叫做
ThreadPoolExecutor,是concurrent.futures(从 Python 3.2 开始)中标准库的一部分。创建它最简单的方法是作为上下文管理器,使用
with语句来管理池的创建和销毁。下面是上一个例子中的
__main__被改写成使用一个ThreadPoolExecutor:import concurrent.futures # [rest of code] if __name__ == "__main__": format = "%(asctime)s: %(message)s" logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S") with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor: executor.map(thread_function, range(3))代码创建一个
ThreadPoolExecutor作为上下文管理器,告诉它池中需要多少工作线程。然后,它使用.map()遍历一个可迭代的对象,在您的例子中是range(3),将每个对象传递给池中的一个线程。
with块的结尾导致ThreadPoolExecutor对池中的每个线程进行.join()。强烈建议您尽可能使用ThreadPoolExecutor作为上下文管理器,这样您就不会忘记.join()线程。注意:使用
ThreadPoolExecutor会导致一些令人困惑的错误。例如,如果您调用一个不带参数的函数,但是您在
.map()中给它传递了参数,线程将抛出一个异常。不幸的是,
ThreadPoolExecutor将隐藏该异常,并且(在上面的例子中)程序终止,没有输出。一开始调试起来可能会很混乱。运行更正后的示例代码将产生如下所示的输出:
$ ./executor.py Thread 0: starting Thread 1: starting Thread 2: starting Thread 1: finishing Thread 0: finishing Thread 2: finishing同样,请注意
Thread 1是如何在Thread 0之前完成的。线程的调度是由操作系统完成的,并不遵循一个容易理解的计划。竞赛条件
在继续学习 Python
threading中隐藏的一些其他特性之前,让我们先来谈谈编写线程程序时会遇到的一个更困难的问题:竞争条件。一旦您了解了什么是竞争条件,并且看到了一个正在发生的情况,您将继续学习标准库提供的一些原语来防止竞争条件的发生。
当两个或多个线程访问共享的数据或资源时,可能会发生争用情况。在本例中,您将创建一个每次都会发生的大型竞争条件,但是请注意,大多数竞争条件并没有这么明显。通常,它们很少发生,并且会产生令人困惑的结果。可以想象,这使得它们很难调试。
幸运的是,这种竞争情况每次都会发生,您将详细地了解它,解释发生了什么。
对于本例,您将编写一个更新数据库的类。好吧,你不会真的有一个数据库:你只是要伪造它,因为这不是本文的重点。
您的
FakeDatabase将有.__init__()和.update()方法:class FakeDatabase: def __init__(self): self.value = 0 def update(self, name): logging.info("Thread %s: starting update", name) local_copy = self.value local_copy += 1 time.sleep(0.1) self.value = local_copy logging.info("Thread %s: finishing update", name)
FakeDatabase正在跟踪单个号码:.value。这将是共享数据,您将在上面看到竞争情况。
.__init__()简单地将.value初始化为零。到目前为止,一切顺利。
.update()看起来有些奇怪。它模拟从数据库中读取一个值,对其进行一些计算,然后将新值写回数据库。在这种情况下,从数据库读取只是意味着将
.value复制到一个局部变量。计算只是在值上加 1,然后再加一点点.sleep()。最后,它通过将本地值复制回.value来写回值。下面是你如何使用这个
FakeDatabase:if __name__ == "__main__": format = "%(asctime)s: %(message)s" logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S") database = FakeDatabase() logging.info("Testing update. Starting value is %d.", database.value) with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor: for index in range(2): executor.submit(database.update, index) logging.info("Testing update. Ending value is %d.", database.value)程序创建一个有两个线程的
ThreadPoolExecutor,然后在每个线程上调用.submit(),告诉它们运行database.update()。
.submit()的签名允许将位置和命名参数传递给线程中运行的函数:.submit(function, *args, **kwargs)在上面的用法中,
index作为第一个也是唯一一个位置参数传递给database.update()。在本文的后面,您将看到可以用类似的方式传递多个参数。因为每个线程运行
.update(),并且.update()给.value加 1,所以当最后打印出来的时候,你可能期望database.value是2。但是如果是这样的话,你就不会看这个例子了。如果运行上述代码,输出如下所示:$ ./racecond.py Testing unlocked update. Starting value is 0. Thread 0: starting update Thread 1: starting update Thread 0: finishing update Thread 1: finishing update Testing unlocked update. Ending value is 1.您可能已经预料到会发生这种情况,但是让我们来看看这里到底发生了什么,因为这将使这个问题的解决方案更容易理解。
一个线程
在深入讨论这个关于两个线程的问题之前,让我们后退一步,谈一谈线程如何工作的一些细节。
你不会在这里深入所有的细节,因为这在这个层次上并不重要。我们还将简化一些东西,虽然在技术上不太准确,但会让你对正在发生的事情有一个正确的概念。
当你告诉你的
ThreadPoolExecutor运行每个线程时,你告诉它运行哪个函数,传递什么参数给它:executor.submit(database.update, index)。这样做的结果是池中的每个线程都将调用
database.update(index)。注意,database是对在__main__中创建的一个FakeDatabase对象的引用。在该对象上调用.update()会调用该对象上的一个实例方法。每个线程都将有一个对同一个
FakeDatabase对象database的引用。每个线程还将有一个唯一的值index,使日志记录语句更容易阅读:
当线程开始运行
.update()时,它有自己版本的所有数据本地到函数。在.update()的情况下,这是local_copy。这绝对是好事。否则,运行同一个函数的两个线程总是会互相混淆。这意味着所有作用于函数的变量都是线程安全的。现在,您可以开始浏览如果您用单线程和对
.update()的单个调用运行上面的程序会发生什么。如果只运行一个线程,下图显示了
.update()的执行过程。该语句显示在左侧,后面是一个图表,显示线程的local_copy和共享的database.value中的值:
图表的布局使得时间随着你从上到下的移动而增加。它从
Thread 1创建时开始,到终止时结束。当
Thread 1启动时,FakeDatabase.value为零。方法中的第一行代码local_copy = self.value将值零复制到局部变量。接下来,它用local_copy += 1语句增加local_copy的值。你可以看到Thread 1中的.value被设置为 1。接下来
time.sleep()被调用,使得当前线程暂停,允许其他线程运行。因为在这个例子中只有一个线程,所以这没有影响。当
Thread 1醒来并继续时,它将新值从local_copy复制到FakeDatabase.value,然后线程完成。你可以看到database.value被设置为 1。到目前为止,一切顺利。你跑了一次
.update(),FakeDatabase.value加 1。两个线程
回到竞争条件,两个线程将并发运行,但不是同时运行。他们每个人都有自己版本的
local_copy,并且都指向同一个database。正是这个共享的database对象将会导致问题。程序从
Thread 1运行.update()开始:
当
Thread 1调用time.sleep()时,它允许另一个线程开始运行。这就是事情变得有趣的地方。
Thread 2启动并执行相同的操作。它还将database.value复制到它的私有local_copy中,这个共享的database.value还没有更新:
当
Thread 2最终休眠时,共享的database.value仍未修改为零,两个私有版本的local_copy的值都为 1。
Thread 1现在醒来并保存它的版本local_copy,然后终止,给Thread 2最后一次运行的机会。Thread 2不知道Thread 1在它睡觉的时候运行并更新了database.value。它将的local_copy版本存储到database.value中,并将其设置为 1:
这两个线程交叉访问单个共享对象,覆盖彼此的结果。当一个线程在另一个线程完成访问之前释放内存或关闭文件句柄时,也会出现类似的争用情况。
为什么这不是一个愚蠢的例子
上面的例子是为了确保每次运行程序时都会出现竞争情况。因为操作系统可以在任何时候换出一个线程,所以在它已经读取了
x的值之后,但是在它写回增加的值之前,有可能中断像x = x + 1这样的语句。这是如何发生的细节非常有趣,但在本文的其余部分并不需要,所以可以跳过这个隐藏的部分。
上面的代码并不像您最初想象的那样普遍。它被设计成在每次运行时强制一个竞争条件,但是这使得它比大多数竞争条件更容易解决。
当考虑竞争条件时,有两件事要记住:
甚至像
x += 1这样的操作也需要处理器很多步骤。这些步骤中的每一步对处理器来说都是单独的指令。操作系统可以在任何时候交换哪个线程正在运行。在这些小指令之后,一个线程可以被换出。这意味着可以让一个线程休眠,让另一个线程在 Python 语句的中间运行。
我们来详细看看这个。下面的 REPL 显示了一个采用参数并递增参数的函数:






















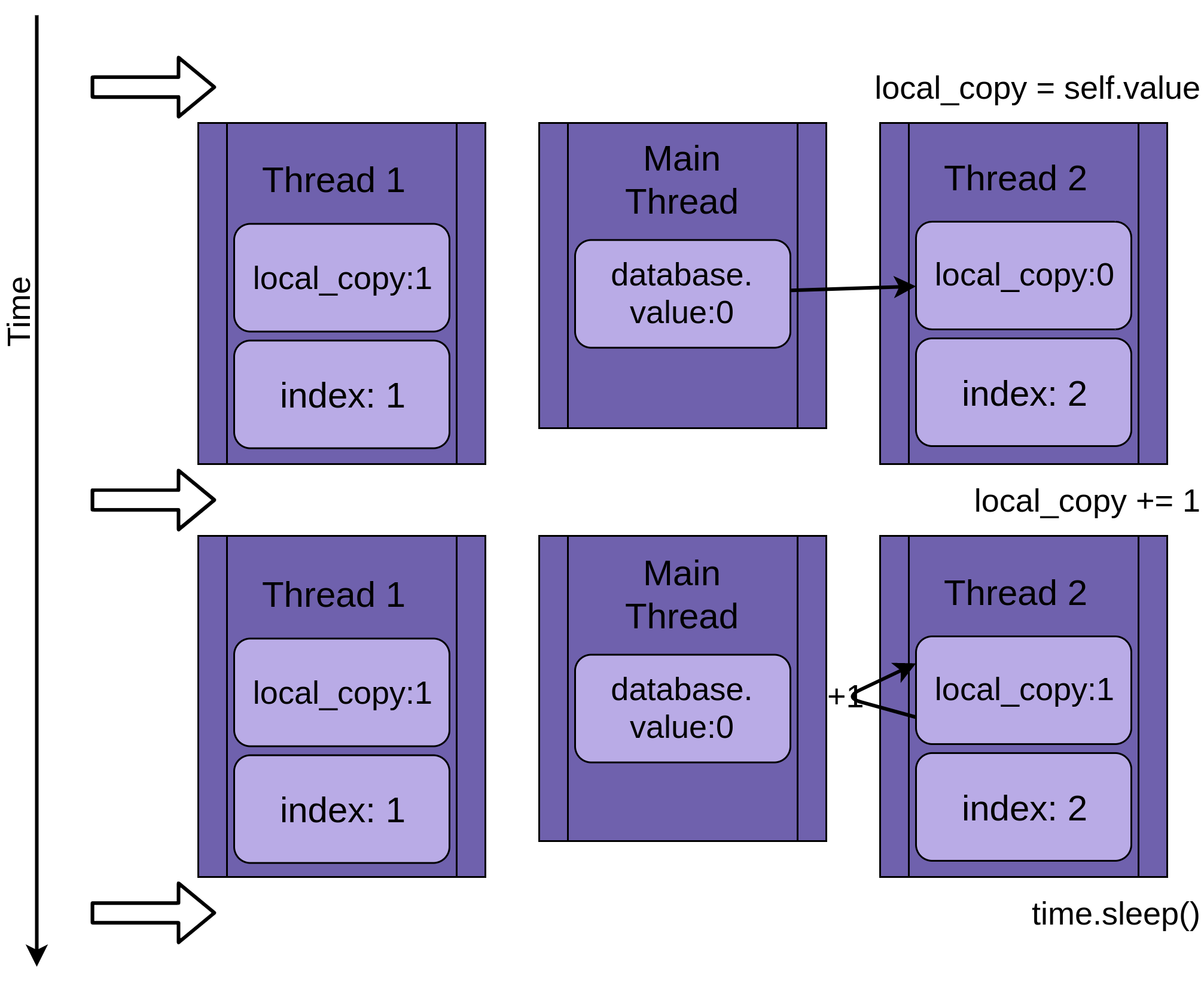
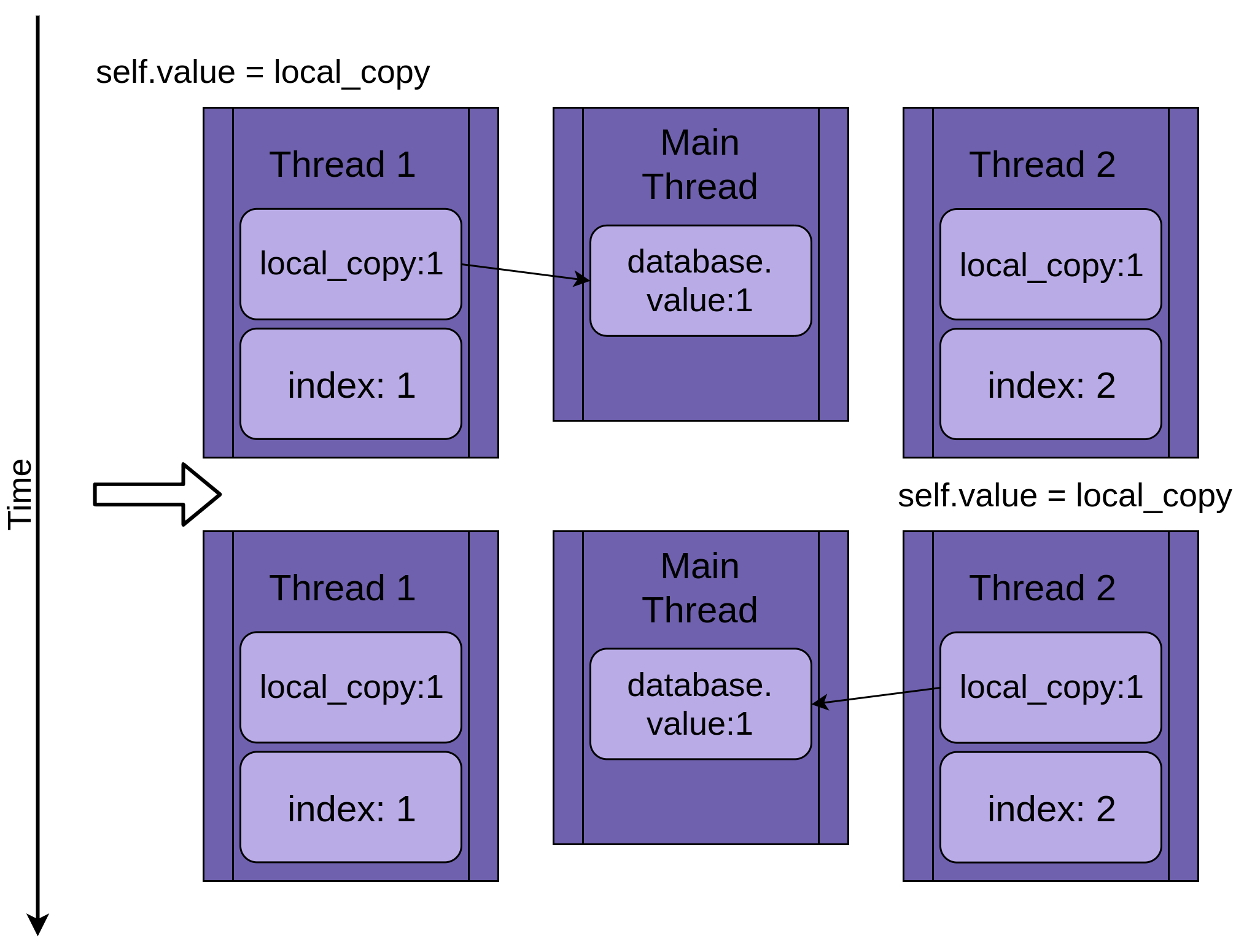
>>> def inc(x):
... x += 1
...
>>> import dis
>>> dis.dis(inc)
2 0 LOAD_FAST 0 (x)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (x)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
REPL 的例子使用 Python 标准库中的 dis 来展示处理器实现您的功能的较小步骤。它对数据值x执行LOAD_FAST,执行LOAD_CONST 1,然后使用INPLACE_ADD将这些值相加。
我们在这里停下来是有特殊原因的。这是上面.update()中time.sleep()强制线程切换的地方。即使没有sleep(),操作系统也完全有可能每隔一段时间就在那个点切换线程,但是对sleep()的调用使得每次都发生这种情况。
如上所述,操作系统可以在任何时候交换线程。您已经沿着这个列表走到了标记为4的语句。如果操作系统换出这个线程并运行一个不同的线程来修改x,那么当这个线程恢复时,它会用一个不正确的值覆盖x。
从技术上讲,这个例子不会有竞争条件,因为x对于inc()是局部的。但是,它确实说明了在一个 Python 操作中线程是如何被中断的。相同的加载、修改、存储操作集也发生在全局值和共享值上。你可以用dis模块探索并证明自己。
像这样的竞争情况很少发生,但是请记住,一个不经常发生的事件在经过数百万次迭代后很可能会发生。这些竞争条件的罕见性使得它们比普通的错误更难调试。
现在回到你的常规教程!
既然您已经看到了实际运行中的竞争条件,那么让我们来看看如何解决它们吧!
基本同步使用Lock
有许多方法可以避免或解决竞态条件。你不会在这里看到所有的,但有几个是经常使用的。先说Lock。
为了解决上面的竞争情况,您需要找到一种方法,一次只允许一个线程进入代码的读-修改-写部分。最常见的方法是在 Python 中调用Lock。在其他一些语言中,同样的想法被称为mutex。互斥来自互斥,这正是Lock所做的。
一个Lock是一个类似于大厅通行证的物体。一次只有一个线程可以拥有Lock。任何其他需要Lock的线程必须等到Lock的所有者放弃它。
实现这一点的基本函数是.acquire()和.release()。一个线程将调用my_lock.acquire()来获得锁。如果锁已经被持有,调用线程将等待直到它被释放。这里有很重要的一点。如果一个线程得到了锁,但没有归还,你的程序就会被卡住。稍后你会读到更多相关内容。
幸运的是,Python 的Lock也将作为上下文管理器运行,因此您可以在with语句中使用它,并且当with块出于任何原因退出时,它会自动释放。
让我们看看添加了一个Lock的FakeDatabase。调用函数保持不变:
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock()
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
logging.debug("Thread %s about to lock", name)
with self._lock:
logging.debug("Thread %s has lock", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s about to release lock", name)
logging.debug("Thread %s after release", name)
logging.info("Thread %s: finishing update", name)
除了添加一些调试日志以便您可以更清楚地看到锁定之外,这里最大的变化是添加了一个名为._lock的成员,它是一个threading.Lock()对象。该._lock在解锁状态下初始化,并由with语句锁定和释放。
这里值得注意的是,运行这个函数的线程将保持这个Lock,直到它完全完成更新数据库。在这种情况下,这意味着当它复制、更新、休眠,然后将值写回数据库时,它将保存Lock。
如果您在日志设置为警告级别的情况下运行此版本,您将看到以下内容:
$ ./fixrace.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 1: starting update
Thread 0: finishing update
Thread 1: finishing update
Testing locked update. Ending value is 2.
看那个。你的程序终于成功了!
在__main__中配置日志记录输出后,您可以通过添加以下语句将级别设置为DEBUG来打开完整日志记录:
logging.getLogger().setLevel(logging.DEBUG)
在打开DEBUG日志记录的情况下运行该程序,如下所示:
$ ./fixrace.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 0 about to lock
Thread 0 has lock
Thread 1: starting update
Thread 1 about to lock
Thread 0 about to release lock
Thread 0 after release
Thread 0: finishing update
Thread 1 has lock
Thread 1 about to release lock
Thread 1 after release
Thread 1: finishing update
Testing locked update. Ending value is 2.
在这个输出中,您可以看到Thread 0获得了锁,并且在它进入睡眠状态时仍然持有锁。Thread 1然后启动并尝试获取同一个锁。因为Thread 0还拿着它,Thread 1还要等。这是一个Lock提供的互斥。
本文剩余部分中的许多例子都有WARNING和DEBUG级别的日志记录。我们通常只显示WARNING级别的输出,因为DEBUG日志可能会很长。尝试打开日志记录的程序,看看它们会做什么。
死锁
在继续之前,你应该看看使用Locks时的一个常见问题。如您所见,如果已经获得了Lock,那么对.acquire()的第二次调用将会等到持有Lock的线程调用.release()时。运行这段代码时,您认为会发生什么:
import threading
l = threading.Lock()
print("before first acquire")
l.acquire()
print("before second acquire")
l.acquire()
print("acquired lock twice")
当程序第二次调用l.acquire()时,它挂起等待Lock被释放。在本例中,您可以通过移除第二个调用来修复死锁,但是死锁通常是由以下两种微妙情况之一引起的:
- 一个实现错误,其中一个
Lock没有被正确释放 - 一个设计问题,其中一个实用函数需要被已经有或者没有
Lock的函数调用
第一种情况有时会发生,但是使用一个Lock作为上下文管理器会大大减少发生的频率。建议尽可能使用上下文管理器来编写代码,因为它们有助于避免出现异常跳过.release()调用的情况。
在某些语言中,设计问题可能有点棘手。幸运的是,Python 线程有第二个对象,叫做RLock,就是为这种情况设计的。它允许一个线程在调用.release()之前多次调用.acquire()一个RLock。那个线程仍然被要求调用.release()和它调用.acquire()的次数一样多,但是无论如何它都应该这样做。
Lock和RLock是线程编程中用来防止竞态条件的两个基本工具。还有一些其他的工作方式不同。在你看它们之前,让我们转移到一个稍微不同的问题领域。
生产者-消费者线程
生产者-消费者问题是一个标准的计算机科学问题,用于研究线程或进程同步问题。您将看到它的一个变体,以了解 Python threading模块提供了哪些原语。
对于这个例子,你可以想象一个程序需要从网络上读取信息并把它们写到磁盘上。程序在需要时不会请求消息。它必须监听并接受传入的信息。这些信息不会以固定的速度出现,而是以突发的方式出现。节目的这一部分叫制作人。
另一方面,一旦有了消息,就需要将其写入数据库。数据库访问很慢,但足够快,可以跟上消息的平均速度。当大量信息进来时,它的速度不够快,跟不上。这部分是消费者。
在生产者和消费者之间,您将创建一个Pipeline,当您了解不同的同步对象时,这个部分将发生变化。
这是基本布局。让我们看一个使用Lock的解决方案。它不能完美地工作,但是它使用了您已经知道的工具,所以它是一个很好的起点。
生产者-消费者使用Lock
因为这是一篇关于 Python threading的文章,并且因为你刚刚阅读了关于Lock原语的文章,所以让我们尝试使用一个或两个Lock用两个线程来解决这个问题。
一般的设计是,有一个producer线程从伪网络中读取,并将消息放入一个Pipeline:
import random
SENTINEL = object()
def producer(pipeline):
"""Pretend we're getting a message from the network."""
for index in range(10):
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
# Send a sentinel message to tell consumer we're done
pipeline.set_message(SENTINEL, "Producer")
为了生成假消息,producer得到一个 1 到 100 之间的随机数。它调用pipeline上的.set_message()将其发送给consumer。
在发送了十个值之后,producer还使用一个SENTINEL值来通知消费者停止。这有点尴尬,但是不要担心,在你完成这个例子之后,你会看到去掉这个SENTINEL值的方法。
pipeline的另一边是消费者:
def consumer(pipeline):
"""Pretend we're saving a number in the database."""
message = 0
while message is not SENTINEL:
message = pipeline.get_message("Consumer")
if message is not SENTINEL:
logging.info("Consumer storing message: %s", message)
consumer从pipeline读取一条消息,并将其写入一个假数据库,在这种情况下,该数据库只是将其打印到显示器上。如果它得到了SENTINEL值,它从函数中返回,这将终止线程。
在看真正有趣的部分Pipeline之前,这里是__main__部分,它产生了这些线程:
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline)
executor.submit(consumer, pipeline)
这看起来应该很熟悉,因为它与前面例子中的__main__代码很接近。
请记住,您可以打开DEBUG日志来查看所有的日志消息,方法是取消对该行的注释:
# logging.getLogger().setLevel(logging.DEBUG)
浏览DEBUG日志消息来查看每个线程获取和释放锁的确切位置是值得的。
现在让我们看看从producer向consumer传递消息的Pipeline:
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
logging.debug("%s:about to acquire getlock", name)
self.consumer_lock.acquire()
logging.debug("%s:have getlock", name)
message = self.message
logging.debug("%s:about to release setlock", name)
self.producer_lock.release()
logging.debug("%s:setlock released", name)
return message
def set_message(self, message, name):
logging.debug("%s:about to acquire setlock", name)
self.producer_lock.acquire()
logging.debug("%s:have setlock", name)
self.message = message
logging.debug("%s:about to release getlock", name)
self.consumer_lock.release()
logging.debug("%s:getlock released", name)
哇哦。代码太多了。其中很大一部分只是记录语句,以便在运行时更容易看到发生了什么。下面是删除了所有日志记录语句的相同代码:
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
self.consumer_lock.acquire()
message = self.message
self.producer_lock.release()
return message
def set_message(self, message, name):
self.producer_lock.acquire()
self.message = message
self.consumer_lock.release()
这似乎更容易管理。这个版本的代码中的Pipeline有三个成员:
.message商店传递消息。.producer_lock是一个threading.Lock对象,限制producer线程对消息的访问。.consumer_lock也是一个threading.Lock,限制consumer线程对消息的访问。
__init__()初始化这三个成员,然后在.consumer_lock上调用.acquire()。这是你想要开始的状态。允许producer添加新的消息,但是consumer需要等到消息出现。
.get_message()和.set_messages()几乎是对立的。.get_message()在consumer_lock上呼唤.acquire()。这个调用将使consumer等待消息准备好。
一旦consumer获得了.consumer_lock,它就复制出.message中的值,然后调用.producer_lock上的.release()。释放该锁允许producer将下一条消息插入到pipeline中。
在你进入.set_message()之前,在.get_message()中有些微妙的事情很容易被忽略。去掉message并让函数以return self.message结束似乎很诱人。在继续前进之前,看看你是否能弄清楚为什么你不想那样做。
下面是答案。一旦consumer调用.producer_lock.release(),它就可以被换出,producer就可以开始运行。那可能发生在.release()回来之前!这意味着当函数返回self.message时,有一点可能性,那实际上可能是生成的下一个消息,所以你会丢失第一个消息。这是另一个竞争条件的例子。
转到.set_message(),您可以看到交易的另一面。producer将调用这个消息。它将获取.producer_lock,设置.message,然后consumer_lock调用.release(),这将允许consumer读取该值。
让我们运行将日志设置为WARNING的代码,看看它是什么样子的:
$ ./prodcom_lock.py
Producer got data 43
Producer got data 45
Consumer storing data: 43
Producer got data 86
Consumer storing data: 45
Producer got data 40
Consumer storing data: 86
Producer got data 62
Consumer storing data: 40
Producer got data 15
Consumer storing data: 62
Producer got data 16
Consumer storing data: 15
Producer got data 61
Consumer storing data: 16
Producer got data 73
Consumer storing data: 61
Producer got data 22
Consumer storing data: 73
Consumer storing data: 22
起初,您可能会觉得奇怪,生产者在消费者运行之前就收到两条消息。如果你回头看一下producer和.set_message(),你会注意到它唯一会等待Lock的地方是当它试图将消息放入管道时。这是在producer获得消息并记录它拥有该消息之后完成的。
当producer试图发送第二条消息时,它将第二次调用.set_message()并阻塞。
操作系统可以在任何时候交换线程,但是它通常会让每个线程在交换之前有一段合理的时间来运行。这就是为什么producer通常会运行,直到它在第二次调用.set_message()时被阻塞。
然而,一旦一个线程被阻塞,操作系统总是会将它换出,并找到一个不同的线程来运行。在这种情况下,唯一有所作为的线程是consumer。
consumer调用.get_message(),T1 读取消息并调用.producer_lock上的.release(),从而允许producer在下一次线程交换时再次运行。
注意,第一条消息是43,这正是consumer读取的内容,尽管producer已经生成了45消息。
虽然它适用于这个有限的测试,但对于一般的生产者-消费者问题,它并不是一个很好的解决方案,因为它一次只允许管道中有一个值。当producer收到大量消息时,它将无处可放。
让我们用一个更好的方法来解决这个问题,使用一个Queue。
生产者-消费者使用Queue
如果您希望能够在管道中一次处理多个值,那么您将需要一个管道数据结构,它允许数量随着数据从producer开始备份而增长和收缩。
Python 的标准库有一个queue模块,该模块又有一个Queue类。让我们把Pipeline改成使用一个Queue,而不仅仅是一个受Lock保护的变量。您还将使用不同的方式来停止工作线程,方法是使用 Python 中不同的原语threading,即Event。
让我们从Event开始。threading.Event对象允许一个线程发出一个event信号,而许多其他线程可以等待那个event发生。这段代码的主要用途是,等待事件的线程不一定需要停止它们正在做的事情,它们可以只是偶尔检查一下Event的状态。
事件的触发可以是许多事情。在这个例子中,主线程将简单地休眠一会儿,然后.set()它:
1if __name__ == "__main__":
2 format = "%(asctime)s: %(message)s"
3 logging.basicConfig(format=format, level=logging.INFO,
4 datefmt="%H:%M:%S")
5 # logging.getLogger().setLevel(logging.DEBUG)
6
7 pipeline = Pipeline()
8 event = threading.Event()
9 with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
10 executor.submit(producer, pipeline, event)
11 executor.submit(consumer, pipeline, event)
12
13 time.sleep(0.1)
14 logging.info("Main: about to set event")
15 event.set()
这里唯一的变化是在第 8 行创建了event对象,在第 10 行和第 11 行将event作为参数传递,在第 13 行到第 15 行的最后一部分,它休眠一秒钟,记录一条消息,然后在事件上调用.set()。
producer也没有改变太多:
1def producer(pipeline, event):
2 """Pretend we're getting a number from the network."""
3 while not event.is_set():
4 message = random.randint(1, 101)
5 logging.info("Producer got message: %s", message)
6 pipeline.set_message(message, "Producer")
7
8 logging.info("Producer received EXIT event. Exiting")
它现在将循环,直到看到事件设置在第 3 行。它也不再将SENTINEL值放入pipeline中。
consumer不得不多改一点:
1def consumer(pipeline, event):
2 """Pretend we're saving a number in the database."""
3 while not event.is_set() or not pipeline.empty():
4 message = pipeline.get_message("Consumer")
5 logging.info(
6 "Consumer storing message: %s (queue size=%s)",
7 message,
8 pipeline.qsize(),
9 )
10
11 logging.info("Consumer received EXIT event. Exiting")
当您取出与SENTINEL值相关的代码时,您确实需要做一个稍微复杂一些的while条件。它不仅循环直到event被置位,而且还需要保持循环直到pipeline被清空。
确保在消费者结束之前队列是空的可以防止另一个有趣的问题。如果consumer确实退出了,而pipeline中有消息,那么会发生两件坏事。首先是您丢失了那些最终的消息,但是更严重的是producer在试图将一条消息添加到一个满队列中时会被发现,并且永远不会返回。
如果在producer检查了.is_set()条件之后,调用pipeline.set_message()之前event被触发,就会发生这种情况。
如果发生这种情况,消费者可能会在队列仍然完全填满的情况下醒来并退出。然后,producer将调用.set_message(),它将等待直到队列中有空间容纳新消息。consumer已经退出,所以这不会发生,producer也不会退出。
其余的consumer应该看着眼熟。
然而,Pipeline发生了巨大的变化:
1class Pipeline(queue.Queue):
2 def __init__(self):
3 super().__init__(maxsize=10)
4
5 def get_message(self, name):
6 logging.debug("%s:about to get from queue", name)
7 value = self.get()
8 logging.debug("%s:got %d from queue", name, value)
9 return value
10
11 def set_message(self, value, name):
12 logging.debug("%s:about to add %d to queue", name, value)
13 self.put(value)
14 logging.debug("%s:added %d to queue", name, value)
可以看到Pipeline是queue.Queue的子类。Queue有一个可选参数,在初始化时指定队列的最大大小。
如果给maxsize一个正数,它会将队列限制在这个元素数,导致.put()阻塞,直到少于maxsize个元素。如果不指定maxsize,那么队列将增长到计算机内存的极限。
.get_message()和.set_message()变小了很多。他们基本上是把.get()和.put()包在Queue上。您可能想知道所有防止线程引起争用情况的锁定代码都到哪里去了。
编写标准库的核心开发人员知道Queue经常在多线程环境中使用,并且将所有的锁定代码合并到了Queue本身中。Queue是线程安全的。
运行该程序如下所示:
$ ./prodcom_queue.py
Producer got message: 32
Producer got message: 51
Producer got message: 25
Producer got message: 94
Producer got message: 29
Consumer storing message: 32 (queue size=3)
Producer got message: 96
Consumer storing message: 51 (queue size=3)
Producer got message: 6
Consumer storing message: 25 (queue size=3)
Producer got message: 31
[many lines deleted]
Producer got message: 80
Consumer storing message: 94 (queue size=6)
Producer got message: 33
Consumer storing message: 20 (queue size=6)
Producer got message: 48
Consumer storing message: 31 (queue size=6)
Producer got message: 52
Consumer storing message: 98 (queue size=6)
Main: about to set event
Producer got message: 13
Consumer storing message: 59 (queue size=6)
Producer received EXIT event. Exiting
Consumer storing message: 75 (queue size=6)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 13 (queue size=0)
Consumer received EXIT event. Exiting
如果您通读我的例子中的输出,您可以看到一些有趣的事情发生。在顶部,您可以看到producer创建了五条消息,并将其中四条放在队列中。它在放置第五个之前就被操作系统换出了。
然后,consumer运行并完成了第一条消息。它打印出该消息以及当时的队列长度:
Consumer storing message: 32 (queue size=3)
这就是你如何知道第五条消息还没有进入pipeline的原因。删除一条消息后,队列的大小减少到三。您也知道queue可以容纳十条消息,所以producer线程没有被queue阻塞。它被操作系统换出。
注意:你的输出会不一样。每次运行时,您的输出都会发生变化。这就是使用线程的乐趣所在!
当程序开始结束时,你能看到生成event的主线程导致producer立即退出吗?consumer还有一堆工作要做,所以它会继续运行,直到它清理完pipeline。
尝试在producer或consumer中使用不同的队列大小和对time.sleep()的调用来分别模拟更长的网络或磁盘访问时间。即使对程序的这些元素稍作改动,也会使你的结果有很大的不同。
对于生产者-消费者问题,这是一个更好的解决方案,但是你可以进一步简化它。这个问题真的不需要Pipeline。一旦你拿走了日志,它就变成了一个queue.Queue。
下面是直接使用queue.Queue的最终代码:
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(queue, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
queue.put(message)
logging.info("Producer received event. Exiting")
def consumer(queue, event):
"""Pretend we're saving a number in the database."""
while not event.is_set() or not queue.empty():
message = queue.get()
logging.info(
"Consumer storing message: %s (size=%d)", message, queue.qsize()
)
logging.info("Consumer received event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
这更容易阅读,并展示了如何使用 Python 的内置原语来简化复杂的问题。
Lock和Queue是解决并发问题的便利类,但是标准库还提供了其他类。在您结束本教程之前,让我们快速浏览一下其中的一些。
线程对象
Python threading模块提供了更多的原语。虽然在上面的例子中您不需要这些,但是它们在不同的用例中会派上用场,所以熟悉它们是有好处的。
旗语
要查看的第一个 Python threading对象是threading.Semaphore。一个Semaphore是一个有一些特殊属性的计数器。第一个是计数是原子的。这意味着可以保证操作系统不会在递增或递减计数器的过程中换出线程。
内部计数器在您调用.release()时递增,在您调用.acquire()时递减。
下一个特殊属性是,如果一个线程在计数器为零时调用.acquire(),那么这个线程将会阻塞,直到另一个线程调用.release()并将计数器加 1。
信号量经常用于保护容量有限的资源。例如,如果您有一个连接池,并希望将该池的大小限制为一个特定的数字。
小时数
一个threading.Timer是一种在一定的时间过去后安排一个函数被调用的方法。您通过传入等待的秒数和要调用的函数来创建一个Timer:
t = threading.Timer(30.0, my_function)
你通过调用.start()来启动Timer。该函数将在指定时间后的某个时刻在新线程上被调用,但请注意,不能保证它会在您希望的时间被调用。
如果您想要停止已经开始的Timer,您可以通过调用.cancel()来取消它。在Timer触发后调用.cancel()不会做任何事情,也不会产生异常。
一个Timer可以用来在一段特定的时间后提示用户采取行动。如果用户在Timer到期前做了这个动作,就可以调用.cancel()。
屏障
一个threading.Barrier可以用来保持固定数量的线程同步。当创建一个Barrier时,调用者必须指定有多少线程将在其上同步。每个线程在Barrier上调用.wait()。它们都将保持阻塞状态,直到指定数量的线程正在等待,然后同时全部释放。
请记住,线程是由操作系统调度的,因此,即使所有线程同时被释放,它们也将被调度为一次运行一个线程。
Barrier的一个用途是允许线程池初始化自己。让线程在初始化后等待一个Barrier将确保在所有线程完成初始化之前没有线程开始运行。
结论:Python 中的线程
现在您已经看到了 Python threading所提供的大部分内容,以及一些如何构建线程化程序和它们所解决的问题的例子。您还看到了编写和调试线程化程序时出现的一些问题。
如果您想探索 Python 中并发性的其他选项,请查看使用并发性加速您的 Python 程序。
如果你对深入研究asyncio模块感兴趣,去读一下Python 中的异步 IO:完整演练。
无论您做什么,现在您都有了使用 Python 线程编写程序所需的信息和信心!
特别感谢读者 JL·迪亚兹帮助清理引言。
参加测验:通过我们的交互式“Python 线程”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的线程*********


 浙公网安备 33010602011771号
浙公网安备 33010602011771号