RealPython-中文系列教程-四-
RealPython 中文系列教程(四)
原文:RealPython
用 Django 建立一个社交网络——第 1 部分
在这个由四部分组成的教程系列中,您将与 Django 一起构建一个可以在文件夹中展示的社交网络。这个项目将加强你对 Django 模型之间关系的理解,并向你展示如何使用表单,以便用户可以与你的应用程序以及彼此之间进行交互。你还将学习如何通过使用布尔玛 CSS 框架让你的网站看起来更好。
在本系列教程的第一部分,您将学习如何:
- Django 模型之间实现一对一和多对多关系
- 用定制的
Profile模型扩展 Django 用户模型 - 定制 Django 管理界面
在完成这个系列的第一部分后,你将继续第二部分,在那里你将学习整合布尔玛来设计你的应用程序并实现前端界面和逻辑,这样你的用户就可以互相跟随和不跟随。
您可以通过点击下面的链接并转到source_code_final/文件夹来下载该项目的第一部分代码:
获取源代码: 点击此处获取源代码,您将使用开始与 Django 建立社交网络。
演示
在这个由四部分组成的教程系列中,您将构建一个小型社交网络,允许用户发布基于文本的简短消息。您的应用程序的用户可以关注其他用户以查看他们的帖子,或者取消关注以停止查看他们的帖子:
https://player.vimeo.com/video/643455270?background=1
在本系列教程结束时,您还将学会使用 CSS 框架布尔玛来赋予您的应用程序一个用户友好的外观,并使它成为您的 web 开发组合中令人印象深刻的一部分,您可以自豪地炫耀它。
在本系列的第一部分中,您将规划项目,创建一个基本的 Django web 应用程序,并使用 post-save 钩子扩展内置的用户模型。在本部分结束时,您将能够通过 Django 管理界面创建新用户,您的应用程序将自动为每个新用户生成一个配置文件,并建立必要的连接:
https://player.vimeo.com/video/643455088?background=1
后端用户实现为接下来的部分奠定了基础。
项目概述
在这一节中,您将对要构建什么以及为什么要以这种方式构建它有一个明确的想法。您还将深入研究您将实现的数据库关系,并且您将提出一个完整的项目大纲。简而言之,你将留出一些时间来集思广益你的项目想法。
一旦您制定了计划,您将开始本系列的第一部分的实际实现步骤,该部分主要关注 Django 模型及其关系:
| 第一步 | 设置基础项目 |
| 第二步 | 扩展 Django 用户模型 |
| 第三步 | 实现保存后挂钩 |
为了更好地了解如何构建你的 Django 社交网络,你可以展开下面的可折叠部分:
您将通过分布在四个部分的一系列步骤来实现该项目。有很多内容需要介绍,您将会一路详细介绍:
- 步骤 1: 设置基础项目
- 步骤 2: 扩展 Django 用户模型
- 步骤 3: 实现一个保存后挂钩
- 第四步:用布尔玛创建一个基础模板
- 第 5 步:列出所有用户资料
- 第 6 步:访问个人资料页面
- 第 7 步:关注和取消关注其他个人资料
- 步骤 8: 为 Dweets 创建后端逻辑
- 第九步:在前端显示 Dweets
- 步骤 10: 通过 Django 表单提交 Dweets
- 步骤 11: 防止重复提交并处理错误
- 第十二步:改善前端用户体验
这些步骤中的每一步都将提供到任何必要资源的链接,并给你一个暂停的机会,如果你想休息一下的话,你可以稍后再回来。
你可能渴望开始编程,但是在开始任何编码项目之前,考虑一下你想要构建的结构是有帮助的。
你可以使用伪代码,书面规范,数据库图表,笔记本涂鸦,或任何感觉容易接近,并帮助你思考的东西。不要跳过这一部分!这是构建任何项目的基本步骤。您在规划上投入的时间将大大减少您的实施时间。
那么,你需要什么样的社交网络呢?在最基本的形式中,你需要两样东西:
- 用户对用户的连接允许人们互相联系
- 内容创建和显示功能以便您的用户可以创建输出供其连接的用户查看
你可以认为这两个主题是相互独立的,但是你需要它们两者来让你的社交网络正常运行。
用户对用户连接的配置文件
对于本系列教程的第一部分,您需要规划如何允许用户连接,以及这如何转化为数据库模式。这部分重点介绍连接。
如何在 Django 模型中实现连接?首先,您将记下这些连接的基本版本可能是什么样子:
- 你的社交网络中会有多个用户。
- 他们需要互相了解,这样他们才能决定他们想追随谁。
在这个项目中,你将实现你的社交网络用户之间的联系,遵循两个假设,这两个假设是在上面提到的两个基石上展开的:
- 您的用户可以关注或不关注其他用户。
- 如果他们关注某人,他们会看到该用户的内容。如果他们没有,他们就不会。
- 你的用户可以跟踪一个人而不会被跟踪回来。你的社交网络中的关系可能是不对称的,这意味着用户可以关注某人并看到他们的内容,而不是相反。
- 你的用户需要知道谁存在,这样他们才知道他们可以关注谁。
- 用户还应该知道谁在关注他们。
- 在你的应用程序的最基本的形式中,用户不会有很多额外的功能。您不会实现一种方法来阻止人们,也不会有一种方法来直接响应其他人发布的内容。
本质上,你可以把你的社交网络想象成一个简短博客或 RSS 源的仓库,用户可以订阅也可以不订阅。这是您将在这个由四部分组成的系列文章中构建的实现。稍后,你可以在这个基础上构建,使你的社交网络更加具体和复杂。
通过将 Django 的内置User模型与扩展默认User模型的自定义Profile模型相结合,您将获得所需的功能:
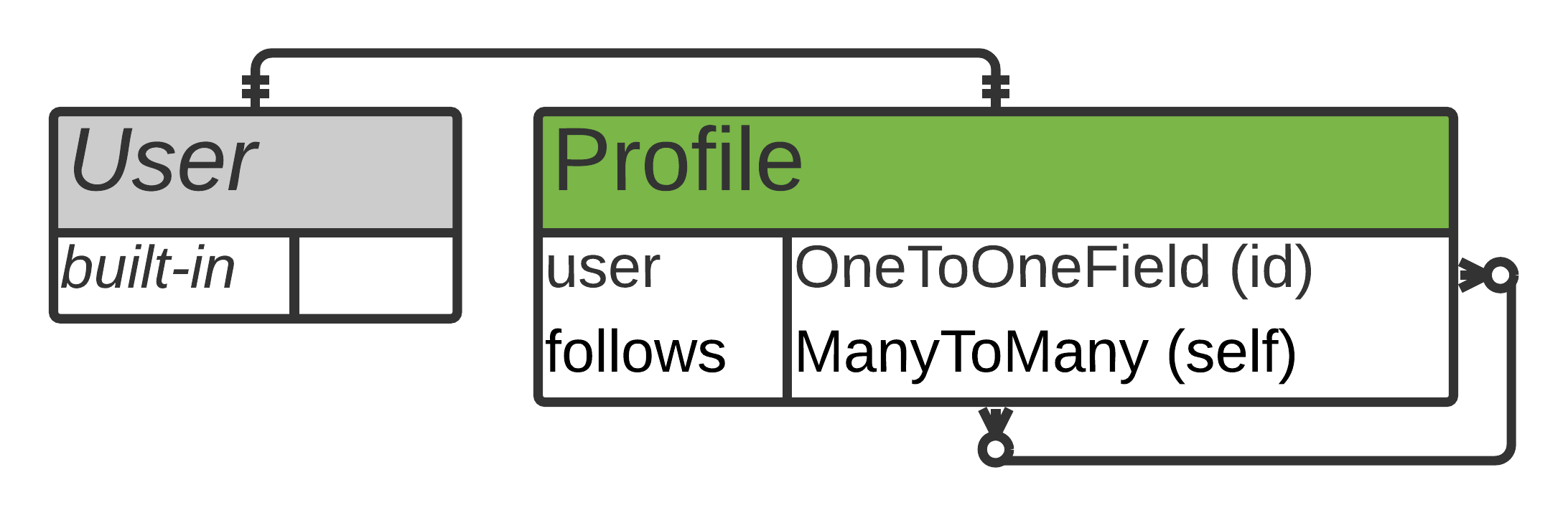
在上图中,您可以看到一个实体-关系(ER)图的草图,显示每个用户都有一个简档,并且简档可以不对称地跟随另一个简档。
这个图表并不旨在完美或完整。对于你自己的过程,也许你会想在一张纸上画出一些稍微不同的东西。你在头脑风暴,所以用最适合你的方式。
基于文本的内容
除了在用户之间建立关系,你的平台还需要一种让用户创建和分享内容的方式。内容可以是任何东西。它可以包括图像、文本、视频、网络漫画等等。
在这个项目中,您将构建一个处理有限字符文本消息的社交网络,类似于 Twitter 。因为您将使用 Django web 框架来制作它,所以它将带有一个时髦的名字 Dwitter 。
您的 Dwitter 网络将需要一个模型来存储用户可以创建的基于文本的消息,您将称之为 dweets 。您将只记录每个 dweet 的三条信息:
- 谁写的
- 这条信息说了什么
- 当用户写的时候
您只需要为您的Dweet模型定义一个关系,即它与内置User模型的连接:
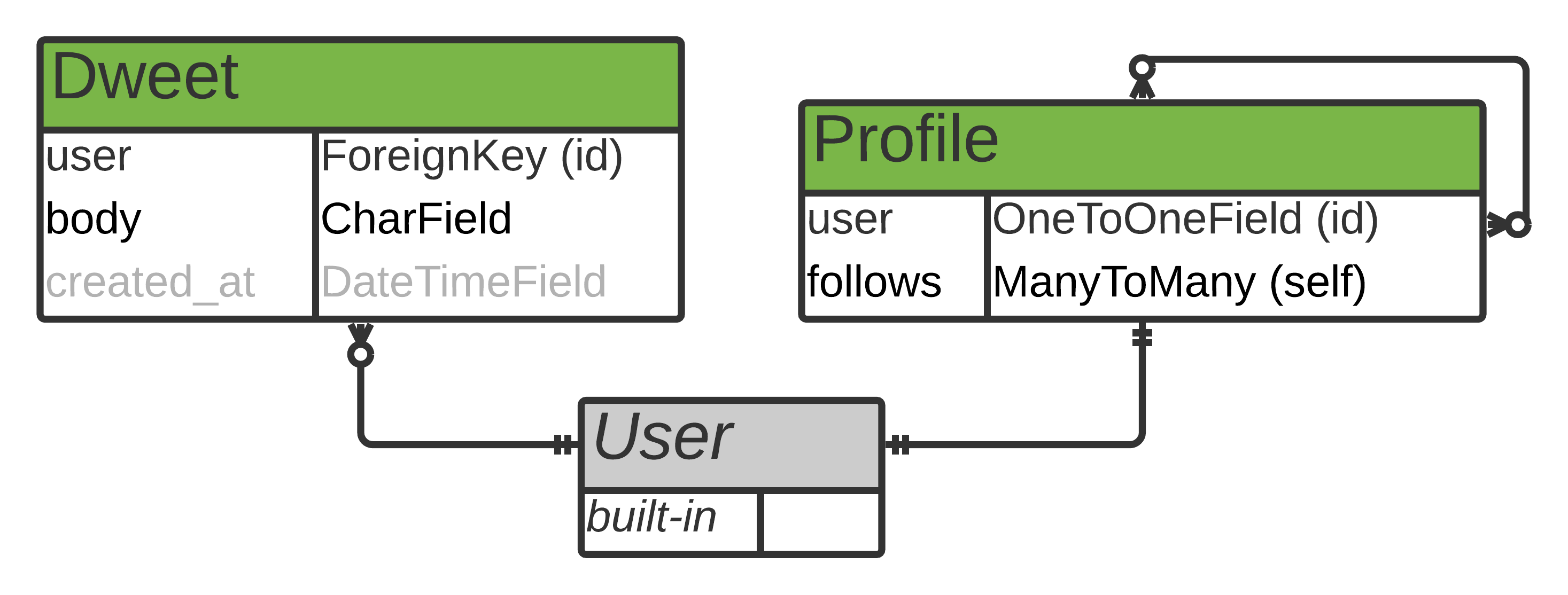
ER 图显示了内置的用户表如何通过一对多关系连接到 Dweet 表。这种关系意味着一个用户可以有许多 dweet,而每个 dweet 只属于一个用户。
您还可以在表中看到不同的字段,这些字段对应于您要收集的关于每个 dweet 的信息:
user:保存消息作者的信息body:保存消息的文本内容created_at:保存用户发布消息的日期和时间
在 ER 图中,created_at字段是灰色的,因为您不允许您的用户自己编辑它。相反,每当用户提交新消息时,Django 会自动填充该字段。
注意:你起草的两个模型都没有很多字段,这是好事!你想创建一个基本社交网络实现,满足你之前头脑风暴的标准。以后你总是可以把它变得更复杂。
您还需要一种方式让您的用户创建内容并查看他们和他们网络中的其他人创建的内容。为了方便用户,您必须执行以下一些任务来设置前端:
- 提供提交内容的表单
- 创建视图来处理这些提交
- 构建模板以显示现有内容
- 让它看起来体面
本系列中涉及的大多数主题都是适用于许多 Django web 应用程序的一般主题。您可能已经知道如何做其中的一些,但是在这里您将在一个全新的项目环境中探索它们。即使你还没有遇到任何相关的任务,你也将学会如何一个接一个地应对每个挑战。
既然您已经花了一些时间来集思广益您的项目想法,您可以准备建立它!
先决条件
要完成本系列教程,您应该熟悉以下概念:
- 在 Python 中使用面向对象编程
- 建立 Django 基础项目
- 在 Django 中管理路由和重定向、视图功能、模板、模型和迁移
- 使用和定制 Django 管理界面
- 用类属性读写 HTML
如果您在开始本教程之前没有掌握所有这些知识,那也没关系!你可以通过直接开始来学习更多。如果遇到困难,你可以随时停下来复习上面链接的资源。
因为您将使用 Django 构建您的社交网络的后端,所以您将希望熟悉 Django 框架,以便从本系列中获得最大收益。如果您以前没有怎么使用过 Django,您可能想尝试构建一个侧重于基础的 Django 项目。对于一个好的介绍,你可以通过构建一个投资组合应用来了解 Django。
步骤 1:建立基础项目
此时,您已经知道要构建什么,并且理解了要实现的数据库关系。在这一步的最后,您将已经建立了一个 Django 项目,并编辑了 Django 管理界面,以允许集中和最小化的用户创建。
你将一个接一个地解决几个步骤:
- 创建一个虚拟环境和安装 Django
- 创建一个 Django 项目和应用
- 定制 Django 管理界面
- 为您的应用程序创建个用户
在做任何事情之前,您将首先创建一个虚拟环境并安装 Django。
创建一个虚拟环境并安装 Django
首先创建一个新的项目根文件夹,您将在此文件夹中放置在此项目中制作的所有文件,然后导航到该文件夹:
$ mkdir django-social
$ cd django-social
导航到您将开发项目的父文件夹后,您可以创建并激活一个虚拟环境,并从 Python 打包索引(PyPI) 安装 Django:
$ python3 -m venv venv --prompt=social
$ source ./venv/bin/activate
(social) $ python -m pip install django==3.2.5
这些命令创建一个名为social的新虚拟环境,激活这个环境,并安装 Django。
创建 Django 项目和应用程序
一旦安装完成,您就可以开始一个名为social的新 Django 项目。您的项目名称不必与您的虚拟环境名称一致,但这样,它将更容易记忆。
创建 Django 项目后,创建一个名为dwitter的新 Django 应用程序来配合它:
(social) $ django-admin startproject social .
(social) $ python manage.py startapp dwitter
您还需要在social/settings.py的INSTALLED_APPS中注册新的dwitter应用程序:
# social/settings.py
# ...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"dwitter", ]
将您的应用程序的名称添加到此列表将使 Django 意识到您想要将该应用程序包含在您的 Django 项目中。这一步是必要的,这样您在dwitter中所做的编辑将会影响您的项目。
注意:如果你想要更详细的说明来帮助你设置,你可以了解一下如何设置 Django 。
在继续学习本教程之前,请确保您已经:
- 激活的虚拟环境
- 一个新的 Django 项目叫做
social - 一个叫
dwitter的 Django app - 您的项目的带有注册为应用程序的
dwitter的settings.py文件
如果您在这些步骤中遇到了困难,那么您会在上面链接的关于如何设置 Django 的专门教程中找到所有必要的设置步骤。
定制 Django 管理界面
Django 的内置管理接口是管理应用程序的强大工具,在本教程中,您将使用它来处理用户创建和管理。
注意:在本教程中,您不会实现任何面向用户的注册功能。然而,你可以通过跟随关于 Django 用户管理的教程来添加这个功能。
为了让您对管理界面的体验集中在本质上,您将应用一些定制。在此之前,您将查看一下默认状态。您需要设置 Django 的默认 SQLite 数据库并创建一个超级用户,这样您就可以登录到 Django 管理门户:
(social) $ python manage.py migrate
(social) $ python manage.py createsuperuser
Username: admin
Email address: admin@example.com
Password:
Password (again):
运行这两个命令并输入超级用户帐户的信息后,您可以启动 Django 的开发服务器:
(social) $ python manage.py runserver
导航到本地主机端口 8000 上的/admin URL,并登录到管理门户:
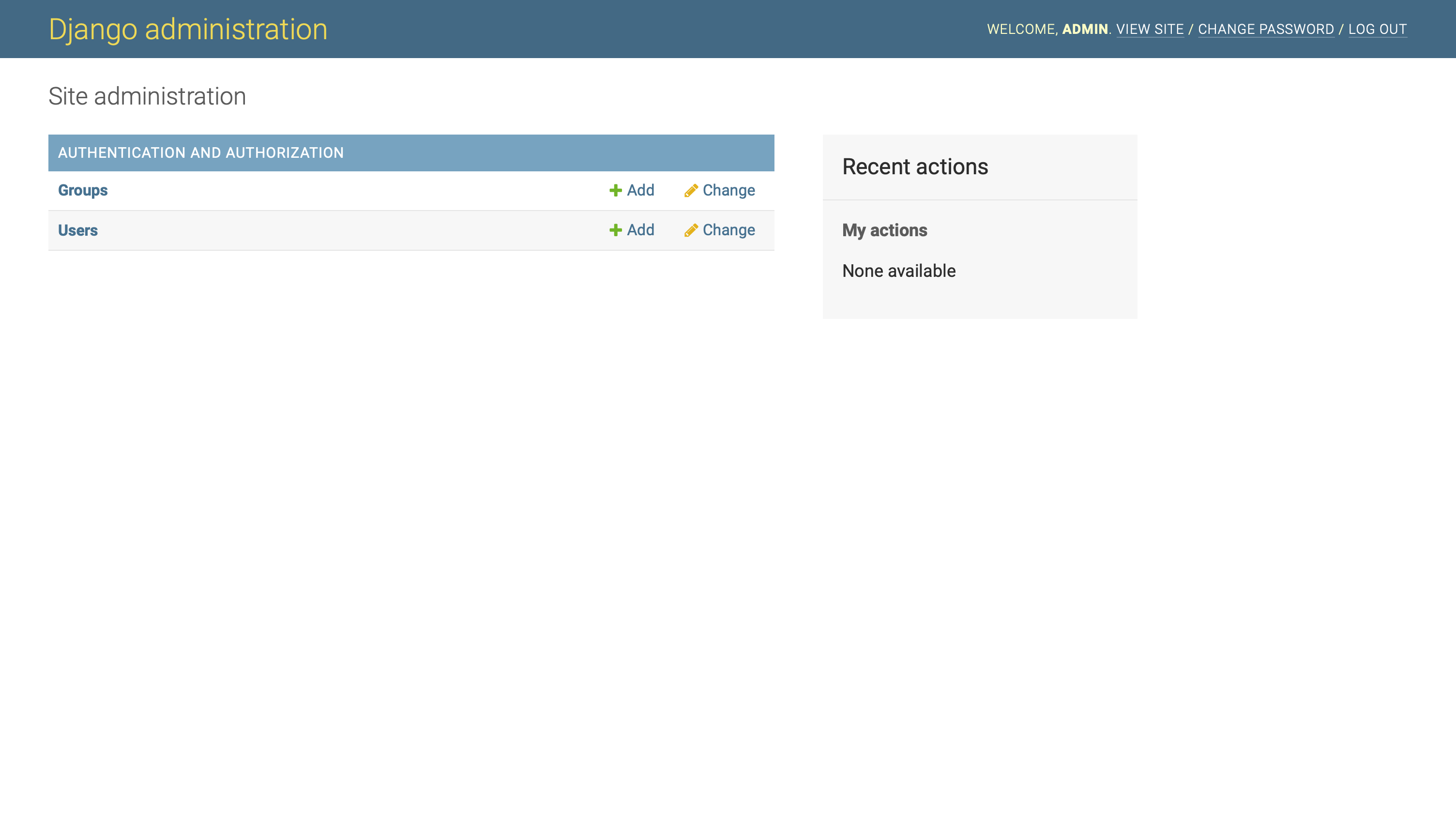
您可以看到组和用户的默认模型条目。这些来自 Django 内置的认证和用户管理应用。如果你还不熟悉他们,请随意四处看看。
里面有很多!然而,你想让这个项目尽可能地贴近基本原理,把重点放在模型关系和社交网络的内容上。
为了简化您的管理,您可以减少一些事情:
- 您不会使用 Django 的组,因此您可以将其从您的管理视图中完全删除。
- 在 Django 中创建用户最基本的方法是只传递一个用户名。您也可以从用户模型显示中删除所有其他字段。
首先取消注册Group模型,这将从您的管理界面中删除该模型:
# dwitter/admin.py
from django.contrib import admin
from django.contrib.auth.models import Group
admin.site.unregister(Group)
要取消注册Group,首先从django.contrib.auth.models导入。然后,使用.unregister()将其从你的管理显示中移除。
检查您的管理界面,注意这样做之后,组的条目是如何消失的。
接下来,您将更改 Django 内置User模型的管理部分中显示的字段。为此,您需要首先取消注册它,因为默认情况下模型是注册的。然后,您可以重新注册默认的User模型来限制 Django admin 应该显示哪些字段。为此,您将使用一个定制的UserAdmin类:
1# dwitter/admin.py
2
3from django.contrib import admin
4from django.contrib.auth.models import User, Group 5
6class UserAdmin(admin.ModelAdmin): 7 model = User 8 # Only display the "username" field
9 fields = ["username"] 10
11admin.site.unregister(User) 12admin.site.register(User, UserAdmin) 13admin.site.unregister(Group)
将这段代码添加到您的admin.py文件中可以简化User的管理站点中显示的内容,以及您在创建新用户时需要输入的信息。概括一下,下面是您在不同代码行中所做的事情:
-
第 4 行:您添加了另一个导入,从
django.contrib.auth.models中获取内置的User模型。 -
第 6 到 9 行:您创建了
UserAdmin,一个基于导入的User模型的定制类。 -
第 9 行:您将管理界面显示的字段限制为只有
username,这足以创建一个测试用户。 -
第 11 行:您在管理界面中取消注册默认注册的
User模型。 -
第 12 行:您再次注册了
User模型,另外还传递了您创建的自定义UserAdmin类,它应用了您想要的更改。
如果您现在导航到主页→认证和授权→用户中的用户概览页面,那么您会注意到您的管理门户显示的信息比以前少得多:
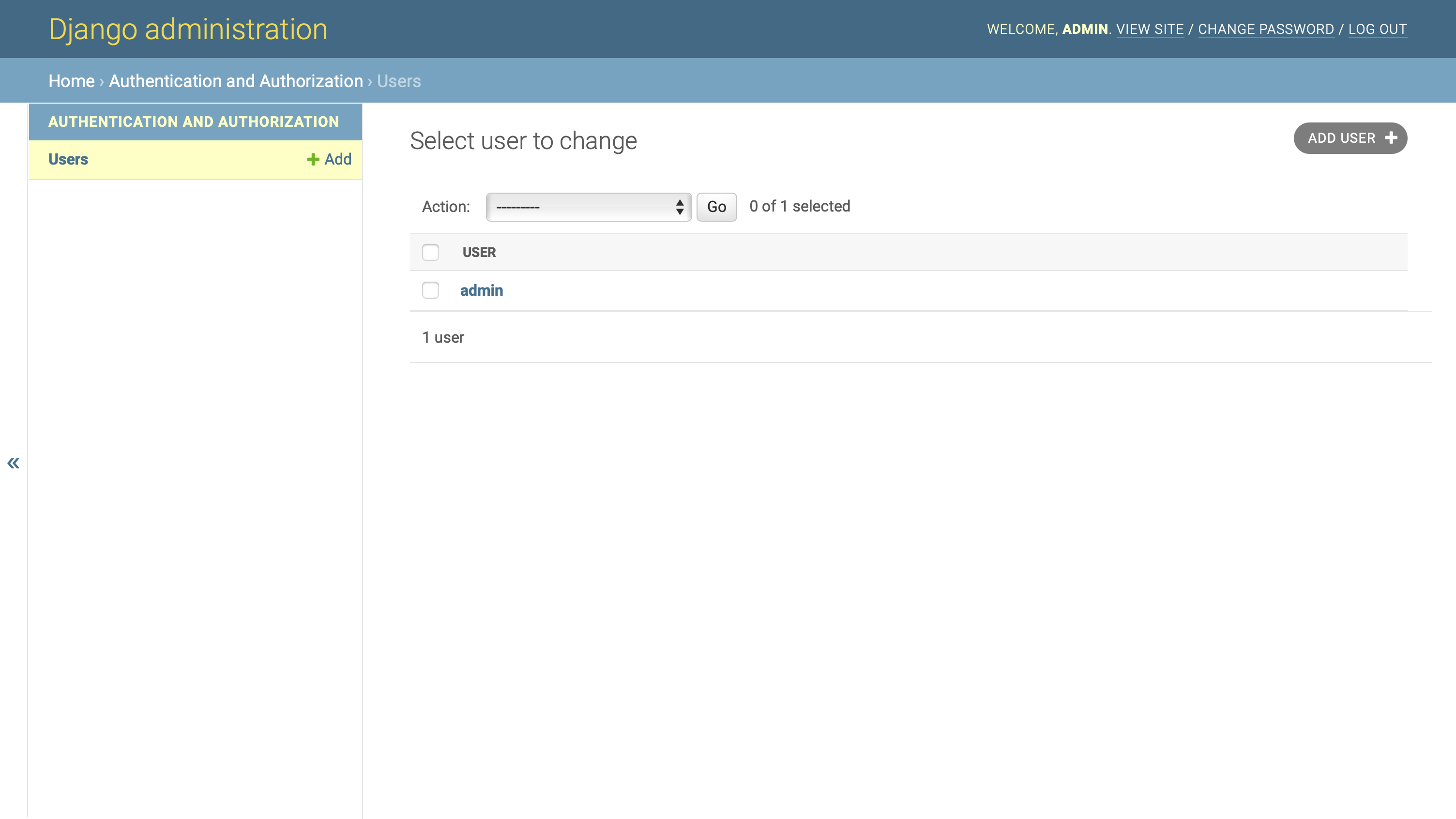
设置好 Django 管理界面的这些定制后,现在只需提供用户名就可以快速为应用程序创建测试用户。
为您的应用程序创建用户
点击界面右上角的添加用户按钮,导航至首页→认证授权→用户→添加用户。点击这个按钮将会把你带到默认的 Django 用户模型的用户创建表单:
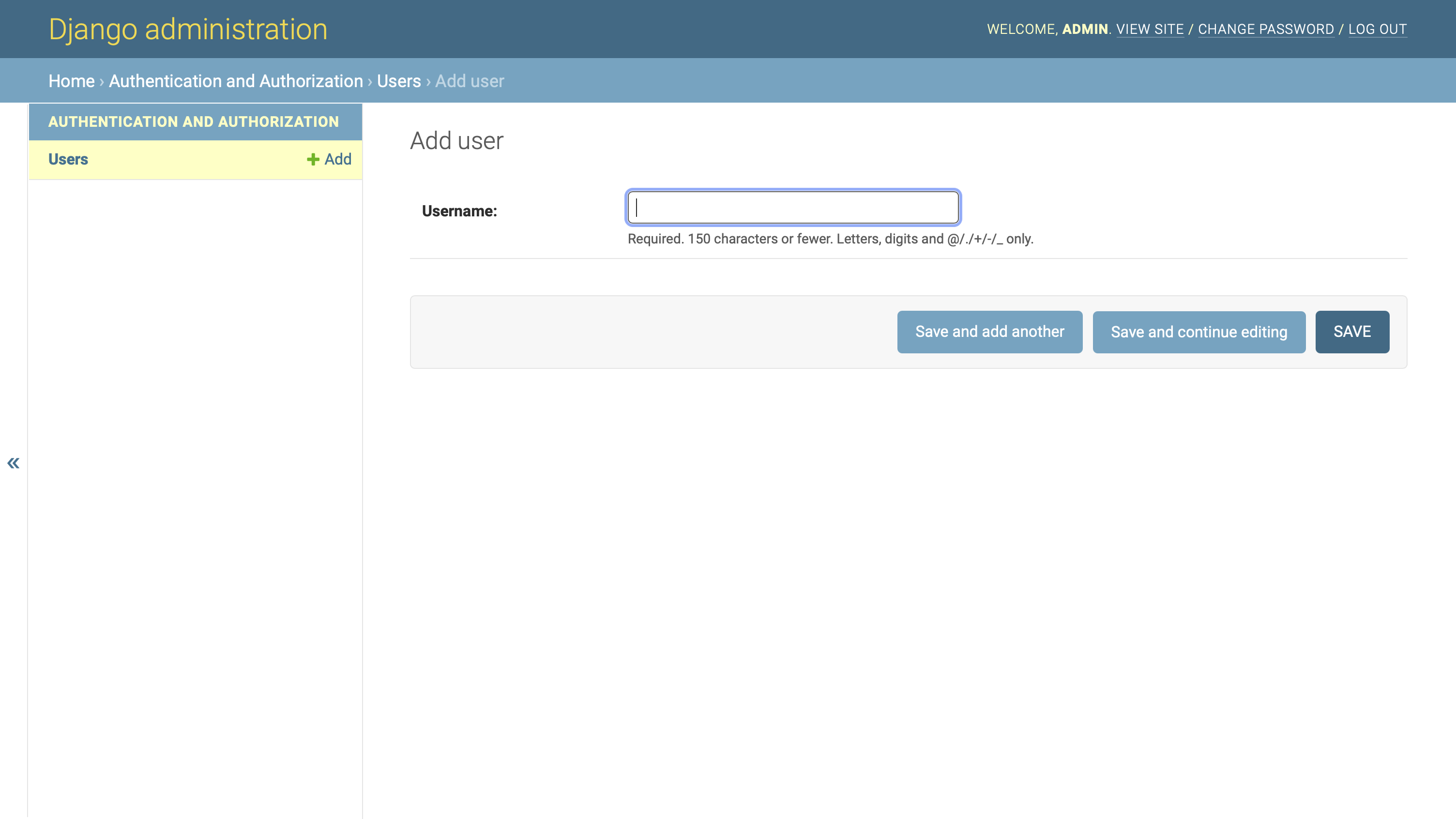
这个简化的管理门户允许您在任何需要的时候为 Django 社交网络快速创建额外的测试用户,并且您只需要为他们提供一个用户名。
注意:仅将这些用户帐户用于开发目的。设置用户而不定义其密码或任何附加信息是不安全的。
继续通过这个界面创建另外两个用户。你可以给它们起任何你喜欢的名字,比如爱丽丝和鲍勃。一旦您设置了额外的用户,那么您就完成了项目的初始设置。
此时,您已经完成了几件重要的事情:
- 你创建了一个 Django 项目叫做
social。 - 你创建了一个名为
dwitter的 Django 应用。 - 您清理了您的管理门户,将重点放在您需要的基本功能上。
- 你为你的社交网络创建了一些用户。
现在是时候考虑你想要在社交网络中实现的功能了。如果您研究刚刚创建的 Django 用户,您可能会注意到内置的User模型没有任何允许用户连接的功能。为了建模用户之间的连接,您需要扩展默认的 Django User模型。
步骤 2:扩展 Django 用户模型
至此,您已经有了一个有几个注册用户的功能性 Django 项目。在这一步的最后,您将拥有一个链接到内置 Django User模型的每个用户的概要文件,允许用户进行连接。
你需要一种方法来保存你的应用程序的用户信息。如果你从零开始,你必须为此建立一个全新的用户模型。相反,您将使用内置的 Django User模型来依赖 Django 经过良好测试的实现,这样您就可以避免重新发明身份验证机制。
然而,您还需要默认User模型没有包含的额外功能:一个用户如何跟随另一个用户?你需要一种方法来连接用户和其他用户。
虽然 Django 中内置的User模型很有帮助,但在构建定制应用程序时,它通常是不够的,因为它专注于认证所需的最小设置。继续利用 Django 内置的用户管理能力,同时添加您的特定定制的一个好方法是扩展User模型。
注意:在一般编程术语中,你会看到在谈论继承时使用的术语扩展。但是,在 Django 社区中扩展User模型也可以参考其他不涉及继承的定制内置User模型的方式。
在本教程中,您将使用一对一关系链接两个独立的模型,这是官方建议的解决这一挑战的方法之一。
创建一个Profile模型
您将扩展 Django 的内置User模型,通过使用一个小的和集中的新模型Profile的一对一关系。你将从零开始建造这个Profile。这个Profile模型将跟踪您想要收集的关于每个用户的附加信息。
除了 Django User模型已经包含的用户信息,你还需要什么?在寻找可能的解决方案之前,拿出你的笔记本,集体讨论你的基本社交网络需要的其他用户属性:
关于每个用户,您至少需要收集三条信息:
- 他们追随谁
- 谁跟踪他们
- 他们写了哪些数据
您将在Profile模型中实现其中的前两个,而您将为本系列教程的后面部分保存 dweets。
您可以添加关于每个用户的更多信息,比如传记信息。在你完成这个系列教程之后,给Profile模型添加更多的细节将是一个很好的练习。
Profile模型只包含您的用户在之后创建的信息,他们已经有了一个用户帐户,这允许您让 Django 处理注册和认证过程。这是扩展现有User型号的建议方式之一,所以你会坚持下去。
您的Profile模型应该记录用户与其他用户档案的联系。在你成功地建立用户对用户的连接模型之前,这是最基本的信息。这意味着您使用Profile模型的主要焦点将是设置它来记录谁关注了一个简档,以及从另一个方向,简档关注了谁。
您只需要创建一个字段来模拟这两种连接。这是因为 Django 可以将执行以下操作的概要文件视为与被跟踪的概要文件有相反的关系:
ER 图显示了概要文件模型通过遵循多对多关系连接到自身。
在你的dwitter应用中打开models.py,为你的新Profile模型编写代码:
1# dwitter/models.py
2
3from django.db import models
4from django.contrib.auth.models import User
5
6class Profile(models.Model):
7 user = models.OneToOneField(User, on_delete=models.CASCADE)
8 follows = models.ManyToManyField(
9 "self",
10 related_name="followed_by",
11 symmetrical=False,
12 blank=True
13 )
通过以这种方式设置Profile,您可以将每个概要文件精确地耦合到一个用户:
-
第 4 行:您导入想要扩展的内置
User模型。 -
第 7 行:您定义了一个名为
user的OneToOneField对象,表示概要文件与用户的连接,该连接是用 Django 内置的用户管理应用程序创建的。您还可以定义,如果相关用户被删除,任何配置文件也将被删除。 -
第 8 行到第 13 行:您用字段名
follows定义了一个ManyToManyField对象,它可以保存到其他用户配置文件的连接。 -
第 10 行:在这一行中,您在
follows字段中为related_name关键字传递一个值,这允许您通过描述性名称"followed_by"从该关系的另一端访问数据条目。 -
第 11 行:你还设置了
symmetrical到False,这样你的用户就可以跟踪某人而不会被跟踪回来。 -
第 12 行:最后,你设置
blank=True,这意味着你的用户不需要跟随任何人。follows字段可以保持为空。
设置好Profile之后,您可以运行 Django 的数据库命令来将模型更新传播到您的数据库:
(social) $ python manage.py makemigrations
(social) $ python manage.py migrate
运行makemigrations会创建一个迁移文件,将更改注册到您的数据库中,migrate会将更改应用到数据库中。
您现在可以将Profile模型注册到您的管理界面,这样除了内置的User模型之外,管理员还会显示它:
# dwitter/admin.py
# ...
from .models import Profile
# ...
admin.site.register(Profile)
从当前应用程序导入Profile并注册到管理界面后,您可以重启开发服务器:
(social) $ python manage.py runserver
一旦它开始运行,就进入你的管理界面。资料显示在资料面板中的User模型下方:
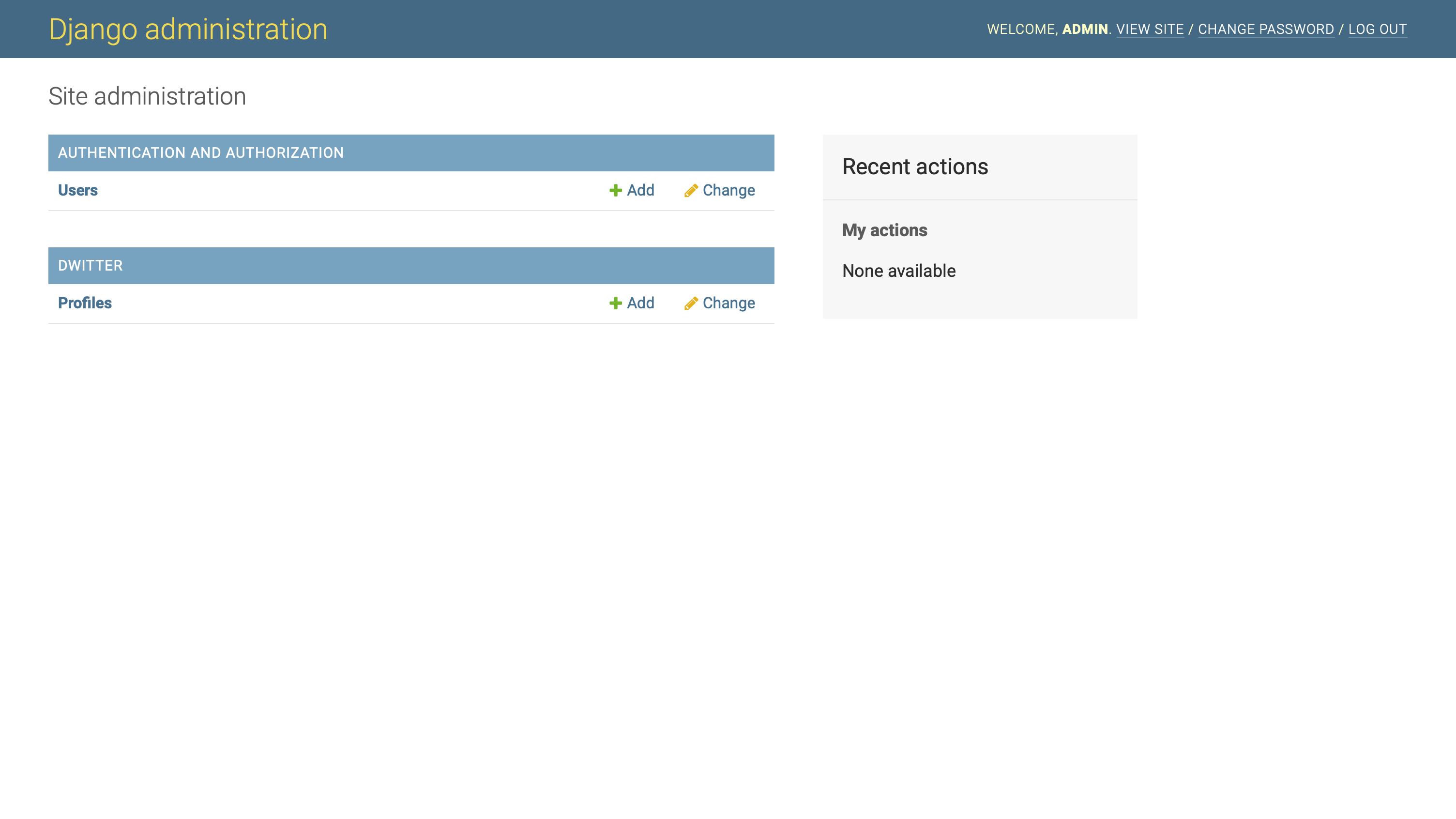
如果你点击档案旁边的 +添加,Django 会呈现给你一个profile create视图:
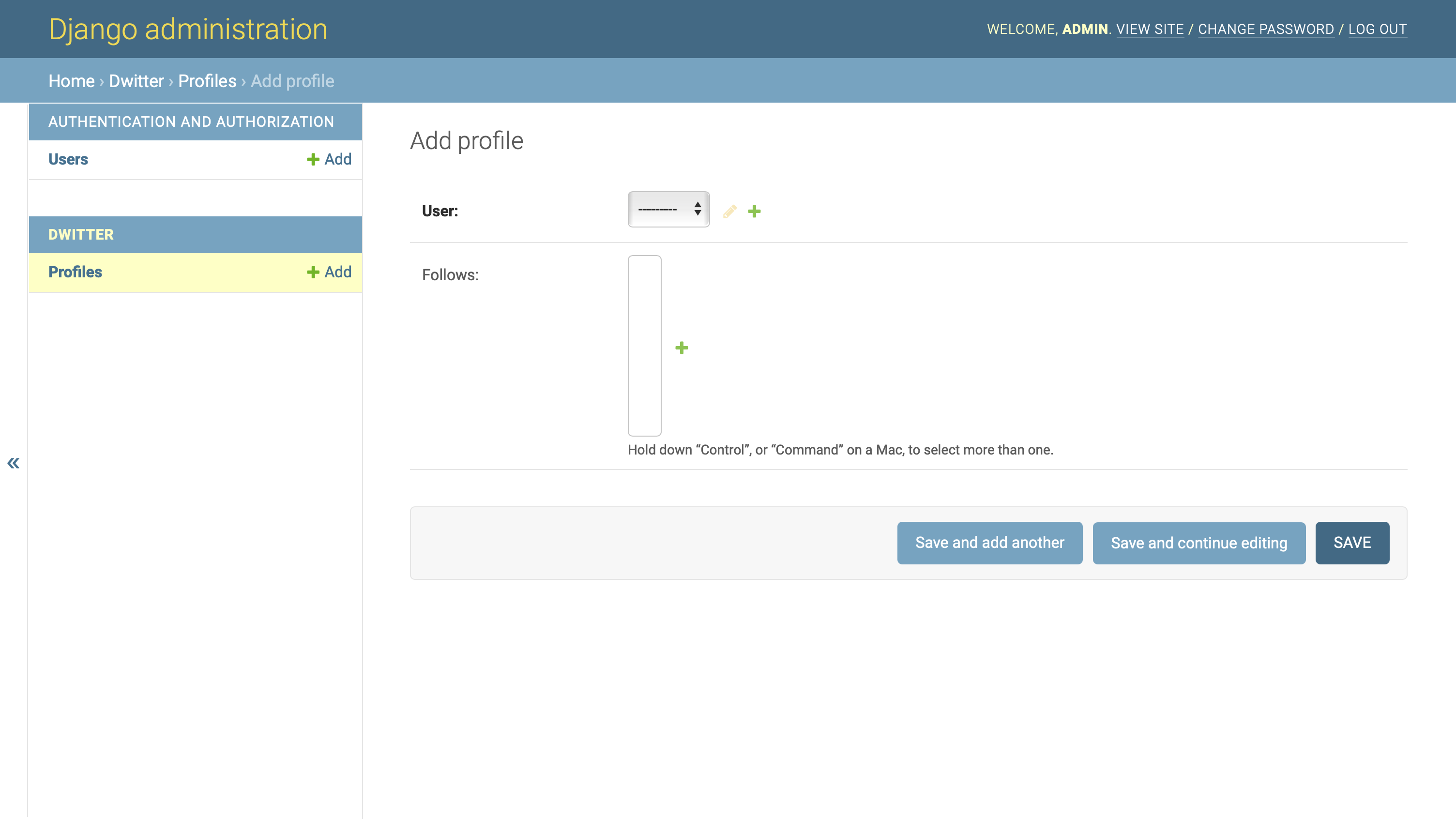
您需要选择一个用户来与该档案相关联。一旦你从下拉列表中选择了一个用户,你可以点击保存来创建你的第一个用户档案。之后,轮廓将在之后的中显示为可选对象:
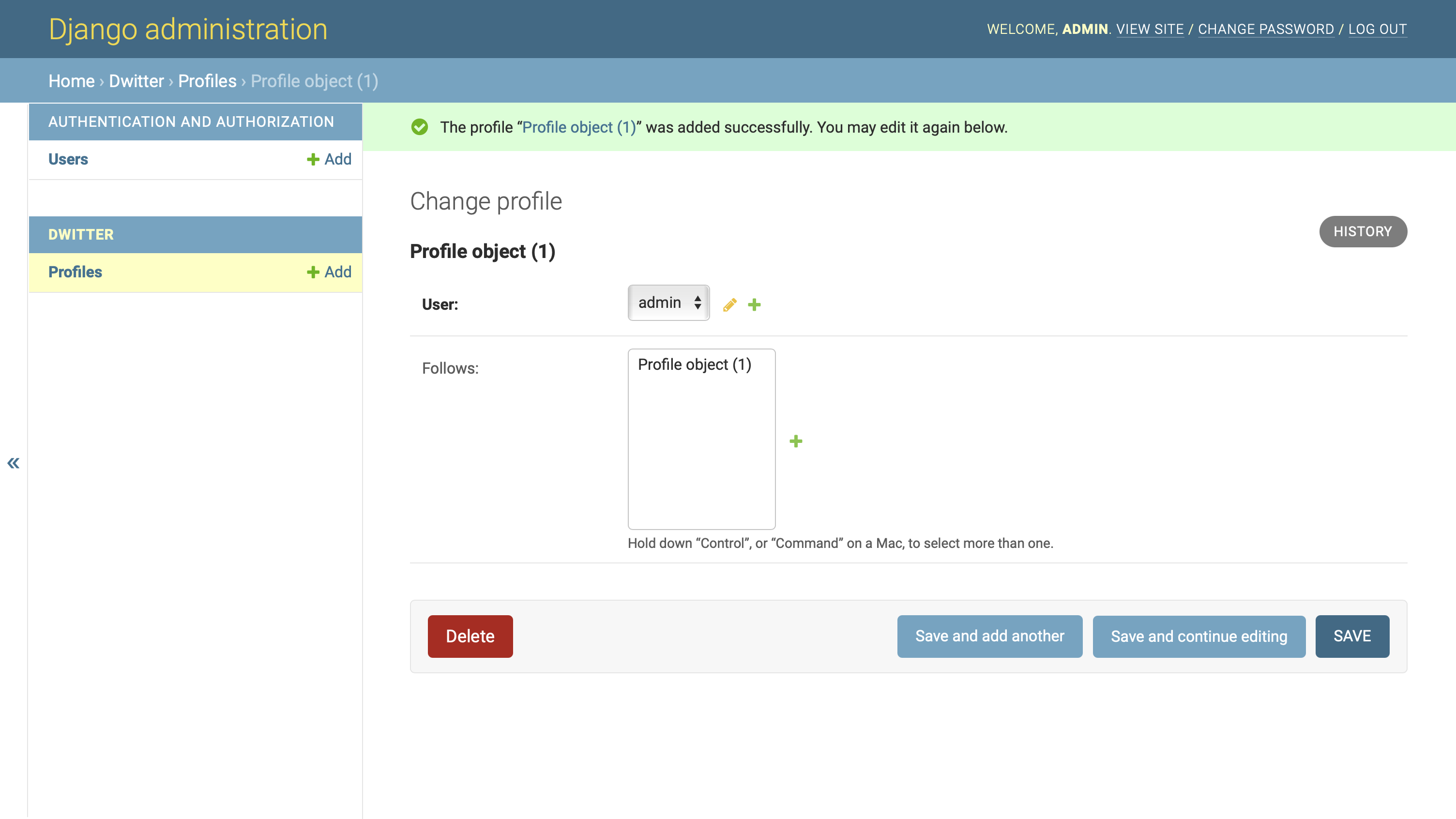
您可以选择新的配置文件对象配置文件对象(1) 并再次点击保存以关注您自己的用户配置文件。如果此时您已经创建了其他用户,那么请确保也为他们创建一个配置文件。
注意:在继续阅读之前,请确保您为所有现有用户创建了个人资料。否则,您可能会在本教程的后面遇到错误。
至此,您已经拥有了创建概要文件和关注其他概要文件所需的所有功能。然而,让User和Profile显示在两个不同的地方,当它们联系如此紧密并且信息最少时,可能会显得不方便。通过对您的管理界面进行更多的定制,您可以改进这个设置。
在用户管理页面中显示个人资料信息
在本系列教程中,您将通过管理员来处理用户创建。您的每个用户都需要一个用户帐户和一个配置文件,这两者需要连接起来。
不是在两个不同的地方创建用户和他们的配置文件,而是通过添加一个 admin inline 来定制您的管理界面,这允许您在一个区域编辑两者。
返回到dwitter/admin.py将您的新Profile模型注册为堆叠内联模型,而不是注册模型的标准方式。您可以使用您之前创建的UserAdmin类,并通过添加相关的模型作为内联来定制它:
# dwitter/admin.py
# ...
class ProfileInline(admin.StackedInline):
model = Profile
class UserAdmin(admin.ModelAdmin):
model = User
fields = ["username"]
inlines = [ProfileInline]
admin.site.unregister(User)
admin.site.register(User, UserAdmin)
admin.site.unregister(Group)
# Remove: admin.site.register(Profile)
在这个代码片段中,您通过创建ProfileInline并从admin.StackedInline继承来为Profile创建一个堆栈内联。然后,您可以将ProfileInline作为inlines的成员添加到您的UserAdmin中。
注意: inlines是一个可以取多个条目的列表,但是在这种情况下,你只想添加一个。
最后,您还删除了最后一行,这是您之前单独注册的Profile型号。
当你进入你的管理界面时,你会看到个人资料的条目已经从主页上消失了。但是,当您通过用户页面导航到一个用户条目时,您会在您的用户信息旁边看到个人资料信息:
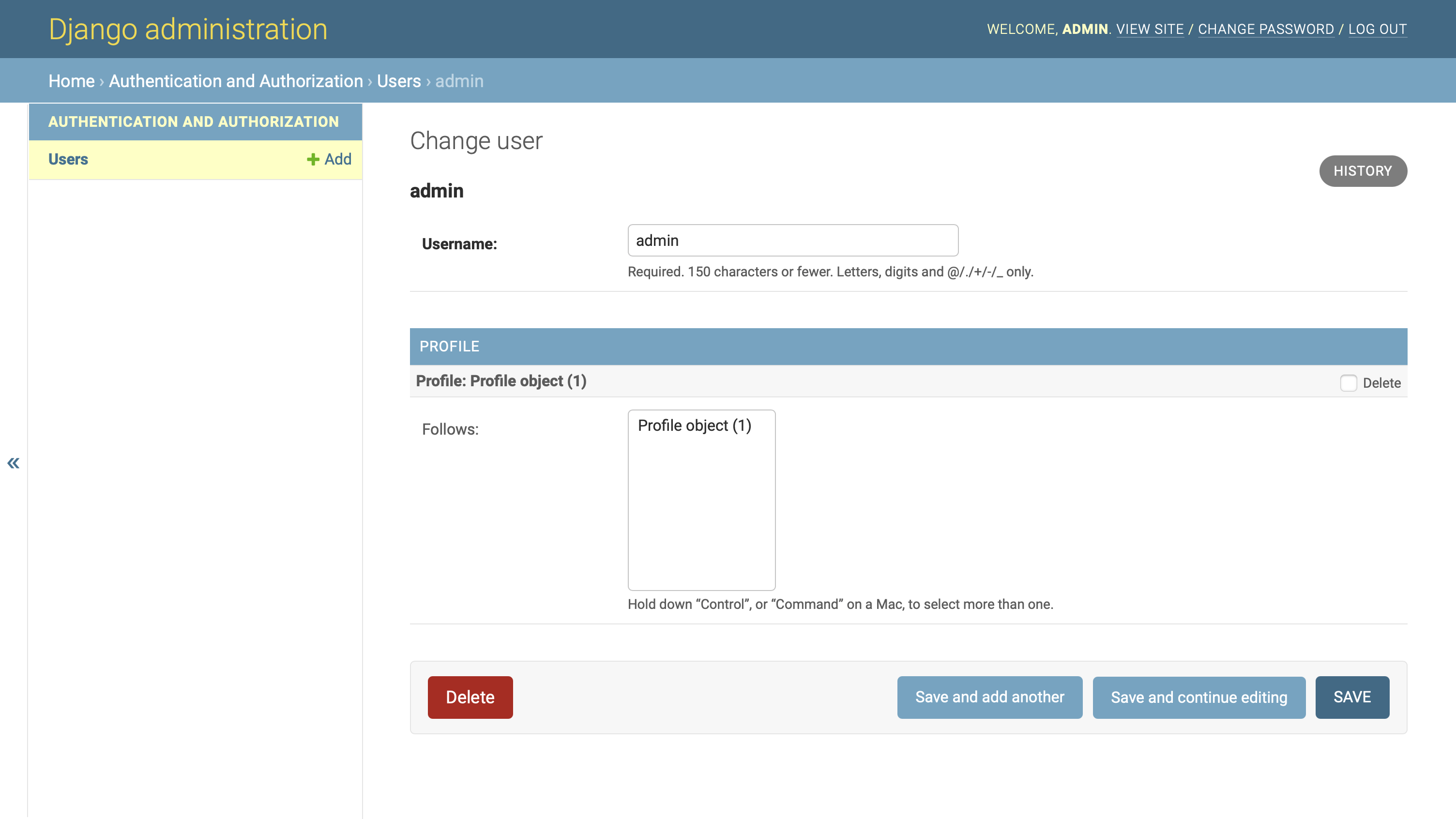
来自Profile的信息现在与来自 Django 内置User模型的信息一起显示,而 Django 内置User模型只显示用户名字段。
这是一个显著的改进,使得通过管理界面处理用户变得更加方便!
但是,您的档案名称目前很难解释。你怎么知道配置文件对象(1) 是管理员的用户配置文件?如果没有与您的Profile型号相关的描述信息,这很难猜测。要改变这一点,返回到dwitter/models.py并为Profile添加一个.__str__()方法:
# dwitter/models.py
class Profile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
follows = models.ManyToManyField(
"self", related_name="followed_by", symmetrical=False, blank=True
)
def __str__(self): return self.user.username
通过这一添加,您重载了默认的.__str__()方法,以便它从User模型的相关实例中返回username的值。通过重新加载页面,在管理界面中检查结果:
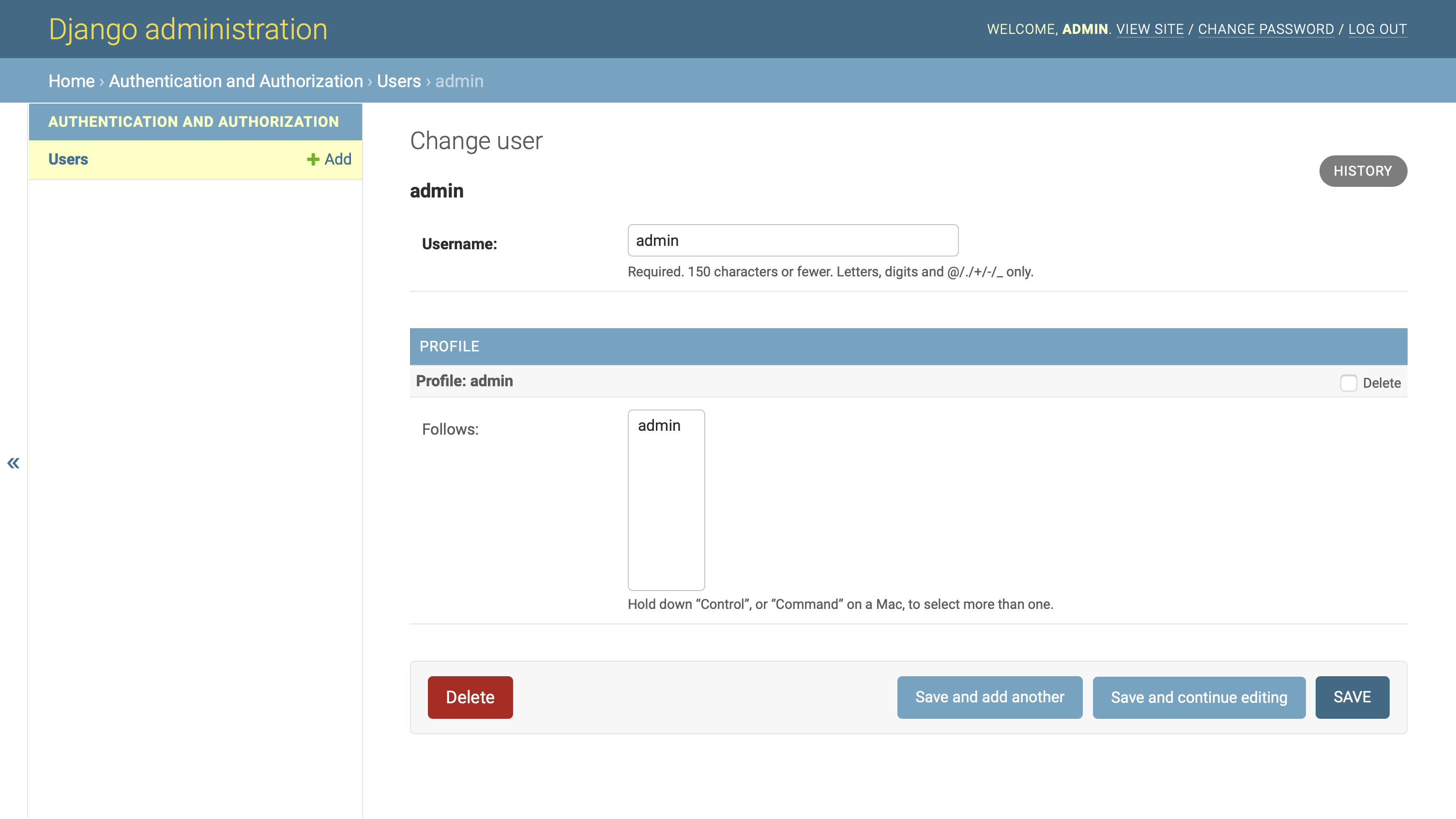
更改之后,连接到管理员用户的配置文件对象在关注列表中显示该用户的名称。
但是,到目前为止,您创建的其他用户都没有个人资料。最终,您会希望每个用户都有一个包含与该用户相关的附加信息的配置文件。
您可以通过在您的管理界面中创建一个新的配置文件,并通过您的管理内联将它与一个用户帐户相关联,来尝试您的模型设置。
在您创建了更多具有相关简档的用户后,您会看到他们填充了 Follows 列表。您可以选择列表中显示的一个或多个配置文件。一旦你点击保存,那么个人资料就会开始跟随他们。
你能想出一个如何改进这个过程的主意吗?
因为您希望每个用户总是有一个关联的概要文件,所以您可以设置 Django 来为您完成这项任务。每次创建新用户时,Django 也应该自动创建 fitting 用户概要文件。此外,它应该立即与该用户相关联。你可以在models.py中通过使用信号来实现这一点。
步骤 3:实现一个保存后挂钩
现在,您已经有了用户和配置文件,并且可以通过您的管理界面创建用户和配置文件并将它们相互关联。在这一步的最后,您已经将它们连接起来,这样创建一个新的用户将会自动创建一个新的概要文件并将它们关联起来。在这一步,您还将练习解释 Django 的错误消息,并通过错误驱动开发找到调查和解决挑战的方法。
用信号协调用户和配置文件
您已经扩展了内置的User模型,但是您还没有创建用户和概要文件之间的自动连接。到目前为止,您只能通过管理界面手动创建用户和简档,并将简档与用户相关联。
如果您还没有尝试过手动操作,现在就试试吧。在 Django admin 中创建一个新的配置文件,然后将它与一个现有的用户帐户相关联。
当用户被创建时,自动地关联一个新的概要文件和一个用户是非常好的,不是吗?你可以用 Django signals 做到这一点。回到你的dwitter/models.py文件。
注意:Django 文档提到,放置信号的最佳位置是在你的应用程序的一个新的signals.py子模块中。但是,这需要您在应用程序配置中进行额外的更改。因为在本教程中您只需要构建一个信号,所以您将它保存在models.py中。
您已经规划了想要实现的目标:当您在数据库中创建一个新用户时,您还想要创建一个新的概要文件并将其链接到该用户。
您可以在post_save的帮助下实现这个功能,每次您的代码执行用户模型的.save()时,它都会调用create_profile函数对象。请注意,create_profile()是一个顶层函数,您在Profile的之外定义了:
1# dwitter/models.py
2
3from django.db.models.signals import post_save
4
5# ...
6
7def create_profile(sender, instance, created, **kwargs):
8 if created:
9 user_profile = Profile(user=instance)
10 user_profile.save()
11
12# Create a Profile for each new user.
13post_save.connect(create_profile, sender=User)
您已经向您的models.py文件添加了额外的代码行:
-
第 3 行:你从导入
post_save开始。 -
第 7 行到第 10 行:您编写了一个名为
create_profile的新函数,它使用post_save提供的created来决定是否创建一个新的Profile实例。只有当 post-save 信号表明 Django 成功创建了用户对象时,您的代码才会继续。 -
第 9 行:因为您在
User和Profile之间建立了一对一的连接,所以您需要将一个User对象传递给Profile构造函数。你可以通过将instance作为参数传递给Profile来实现。 -
第 10 行:在这里,您用
.save()将新的概要文件提交到您的数据库。 -
第 13 行:每次
User模型执行.save()时,你设置 post-save 信号执行create_profile()。您可以通过将User作为关键字参数传递给sender来实现这一点。
这种后保存信号的实现为每个新用户创建了新的简档。通过将新创建的用户传递给Profile构造函数,可以自动将两者关联起来。
注意:当一个 post-save 信号被触发时,它返回多个变量,所以你正在用create_profile()的函数定义中的**kwargs捕捉你现在不需要的变量。
你可以在这里为每一个新用户留下一个闪亮干净的空档案。但是,您会自动将用户自己的简档添加到他们关注的简档列表中,因此每个用户也会看到他们自己编写的 dweets。
当你冒险去学习新的东西时,你很可能会遇到各种各样的错误。在下一节中,您将练习在面对错误信息时保持冷静,并学习当您不可避免地发现自己与 Django 的沟通出现问题时,如何保持正确的方向。
通过错误驱动的开发增加功能
如果您使用的 post-save 信号与前一节中构建的完全相同,那么当您实际位于稍后将设置的仪表板上时,您将看不到任何您的 dweets。但是因为回忆自己的个人想法和帖子可能很有趣,所以您将更改代码,以便默认用户在创建个人资料时自动关注自己。
当你尝试按照一步一步的指南去做你自己的事情时,通常很难第一次就把代码做好。与此同时,学习如何坚持下去并找到解决方案是必不可少的!因此,您将练习在开发这个特性时遇到错误,并学习如何解决这些挑战。
注意:如果你已经习惯了按照错误消息开发代码,或者如果你以前已经使用过 Django 信号,那么可以跳过这一节,继续使用装饰器重构代码。
因为您希望在自己的概要文件创建后立即跟踪它,所以回想一下Profile中可选的follows字段。也许你可以在创建Profile实例时,通过follows关键字在保存后钩子函数中添加instance:
def create_profile(sender, instance, created, **kwargs):
if created:
user_profile = Profile(user=instance, follows=[instance]) user_profile.save()
似乎很快!启动您的开发服务器并创建一个新用户来检查它是否按预期工作。
不完全是。您最终会遇到一条错误消息:
Direct assignment to the forward side of a many-to-many set is prohibited.
Use follows.set() instead.
Django 不知道如何处理你的指令,但它试图猜测,然后给你一个建议。从Profile中移除follows=[instance],并尝试使用follows.set()代替,如错误信息所示:
def create_profile(sender, instance, created, **kwargs):
if created:
user_profile = Profile(user=instance) user_profile.follows.set(instance) user_profile.save()
通过在 Django admin 中创建另一个新用户,清洗并重复您的手动测试。Django 仍然对您的代码不完全满意,但是它理解得更多了,这意味着它会给您一个不同的错误消息:
ValueError at /admin/auth/user/add/
"<Profile: name>" needs to have a value for field "id" before this
many-to-many relationship can be used.
您可能记得,在数据库中有条目之前,您需要用.save()提交您的对象。当 Django 创建数据库条目时,它也会自动在条目中创建id字段。
在这个错误消息中,Django 告诉您数据库中首先需要有一个User实例,这样您就可以使用.set()向follows添加一个实例。这是一个可行的建议!也许您可以先将新的个人资料保存到您的数据库,然后将其添加到follows并再次保存:
def create_profile(sender, instance, created, **kwargs):
if created:
user_profile = Profile(user=instance)
user_profile.save() user_profile.follows.set(instance)
user_profile.save()
这一次,当您创建一个新用户时,您的期望很高!然而,姜戈再次感到困惑:
TypeError at /admin/auth/user/add/
'User' object is not iterable
错误消息读起来好像 Django 试图迭代instance,它引用新创建的User对象。这就是.set()所做的吗?是时候看看 Django 关于多对多关系的文档了:
可以设置关系集:
`>>> a4.publications.all() <QuerySet [<Publication: Science News>]> >>> a4.publications.set([p3]) >>> a4.publications.all() <QuerySet [<Publication: Science Weekly>]>`
看起来.set()确实需要一个可迭代的输入,Django 试图在错误消息中告诉您这一点。因此,您可能能够将带有instance的列表作为单个项目传递,就像 Django 文档告诉您的那样:
def create_profile(sender, instance, created, **kwargs):
if created:
user_profile = Profile(user=instance)
user_profile.save()
user_profile.follows.set([instance]) user_profile.save()
这一更改应该允许.set()遍历您传递的列表,并将与您的新用户帐户相关联的配置文件添加到用户关注的帐户列表中。交叉手指,再次尝试创建一个新用户,但是又出现了另一个错误:
TypeError at /admin/auth/user/add/
TypeError: Field 'id' expected a number but got <User: name>.
太好了!您的错误消息不断变化,这为您提供了额外的信息。你在正确的道路上。
现在 Django 告诉你,它得到了一个User对象,但期望得到一个id字段。您设置了配置文件来跟随其他配置文件,然而 Django 只寻找Profile对象的.id。在扩展了User模型之后,您可以使用.profile通过用户实例访问用户的概要文件,然后更深入地进入对象以获得.id:
def create_profile(sender, instance, created, **kwargs):
if created:
user_profile = Profile(user=instance)
user_profile.save()
user_profile.follows.set([instance.profile.id]) user_profile.save()
又是转圈的时候了。您使用管理界面创建一个新用户,例如, martin ,现在它可以工作了:
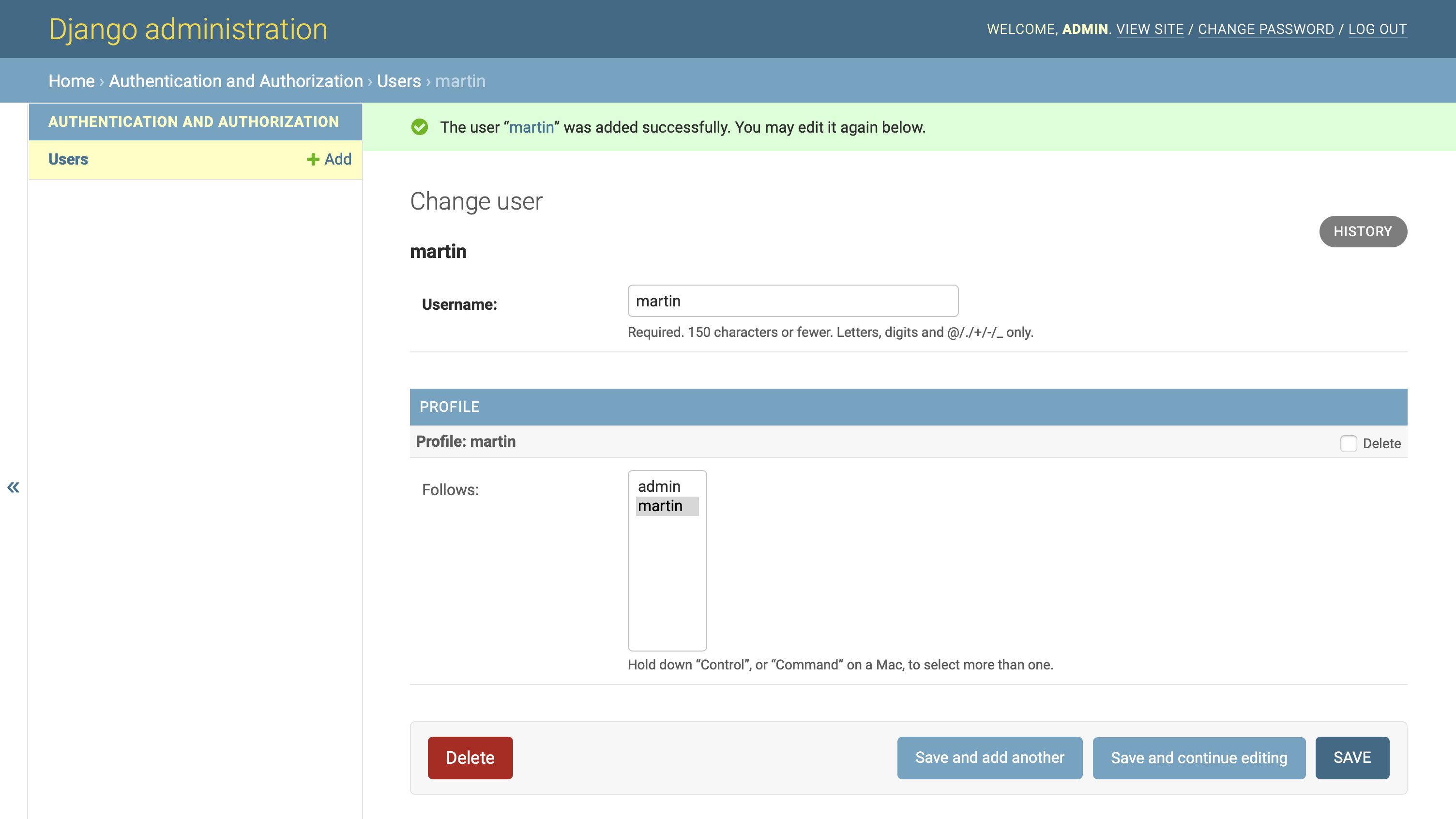
恭喜你!您设置了 post-save 挂钩,以便新创建的用户自动关注他们自己的配置文件。同一个 post-save 钩子也自动创建了这个概要文件。
在开发这个功能的同时,您还练习了在面对重复的错误信息时保持冷静。你加深了对发生误解时 Django 如何与你沟通的理解。
您可以用不同的方式解决这个挑战,按照建议的方式,使用.add()而不是.set()将单个对象添加到多对多关系中。搜索多对多关系文档并使用.add()重构你的代码,使其工作。
您可以重构代码,使用.add()而不是.set(),这是添加单个实例的推荐方式:
def create_profile(sender, instance, created, **kwargs):
if created:
user_profile = Profile(user=instance)
user_profile.save()
user_profile.follows.add(instance.profile) user_profile.save()
您可能还注意到,您不需要传递链接的Profile对象的.id,但是您可以传递整个对象。这也适用于前一个解决方案,但是对于那个解决方案,您遵循了 Django 的错误消息,该消息将您引向使用.id。
所有这些解决方案都有效!请记住,在编程中,解决一个任务的方法总是不止一种。让它正常工作是最重要的,但是重新审视和重构你的代码也是一个很好的实践。
在这种情况下,因为总是只向集合中添加一个实例,所以不需要迭代。这意味着使用.add()比使用.set()更有效。还有,既然效果一样,而且更有描述性,你可以直接通过instance.profile而不用.id。
通过这一更改,您解决了用户在仪表板上看不到自己的 dweets 的问题。现在,他们的电子表格将与他们关注的其他人的电子表格一起显示。
此时,您可以让这段代码保持原样,但是 Django 还提供了一种更优雅的方法,通过使用装饰器来注册信号。在下一节中,您将使用receiver来重构您的 post-save 钩子。
使用装饰器重构代码
Django 附带了一个receiver 装饰器,它允许你使你写的代码更加简洁,而不改变它的功能:
1# dwitter/models.py
2
3from django.db.models.signals import post_save
4from django.dispatch import receiver 5
6# ...
7
8@receiver(post_save, sender=User) 9def create_profile(sender, instance, created, **kwargs):
10 if created:
11 user_profile = Profile(user=instance)
12 user_profile.save()
13 user_profile.follows.add(instance.profile)
14 user_profile.save()
15
16# Remove: post_save.connect(create_profile, sender=User)
通过这种重构,您已经对代码库进行了三项更改:
-
第 4 行:您从
django.dispatch为receiver添加一个导入。 -
第 8 行:将装饰器应用于
create_profile,传递给post_save,并将User模型传递给sender。通过传递模型,您将post_save与和User模型相关的事件关联起来,就像您之前与.connect()关联一样。 -
第 16 行:您删除了之前将
post_save与作为发送者的User连接起来的代码行,因为您已经通过第 8 行提供给装饰者的参数建立了关联。
请记住,您需要先保存新创建的Profile对象,以使其存在。只有这样,您才能将新创建的用户的.profile添加到您的新user_profile中。最后,您需要再次保存更改,以便将更新的关联传播到您的数据库。
注意:如果您对上面代码片段中.add()的使用感到惊讶,那么再看一下上一节中名为的可折叠部分的替代实现。
恭喜你,你已经成功设置了 Django 社交网络的大部分后端。您实现了用户和 Django 社交网络档案之间的模型关系!每次你创建一个新用户,他们也会收到一个用户资料,并立即关注他们自己的资料。此外,用户配置文件可以相互跟随。但是这有用吗?
在您的管理员中确认自动关联
回到您的管理界面,通过提供的表单创建一个新用户。你所要做的就是提供一个用户名,然后点击保存。例如,您可以添加另一个名为 rainn 的用户:
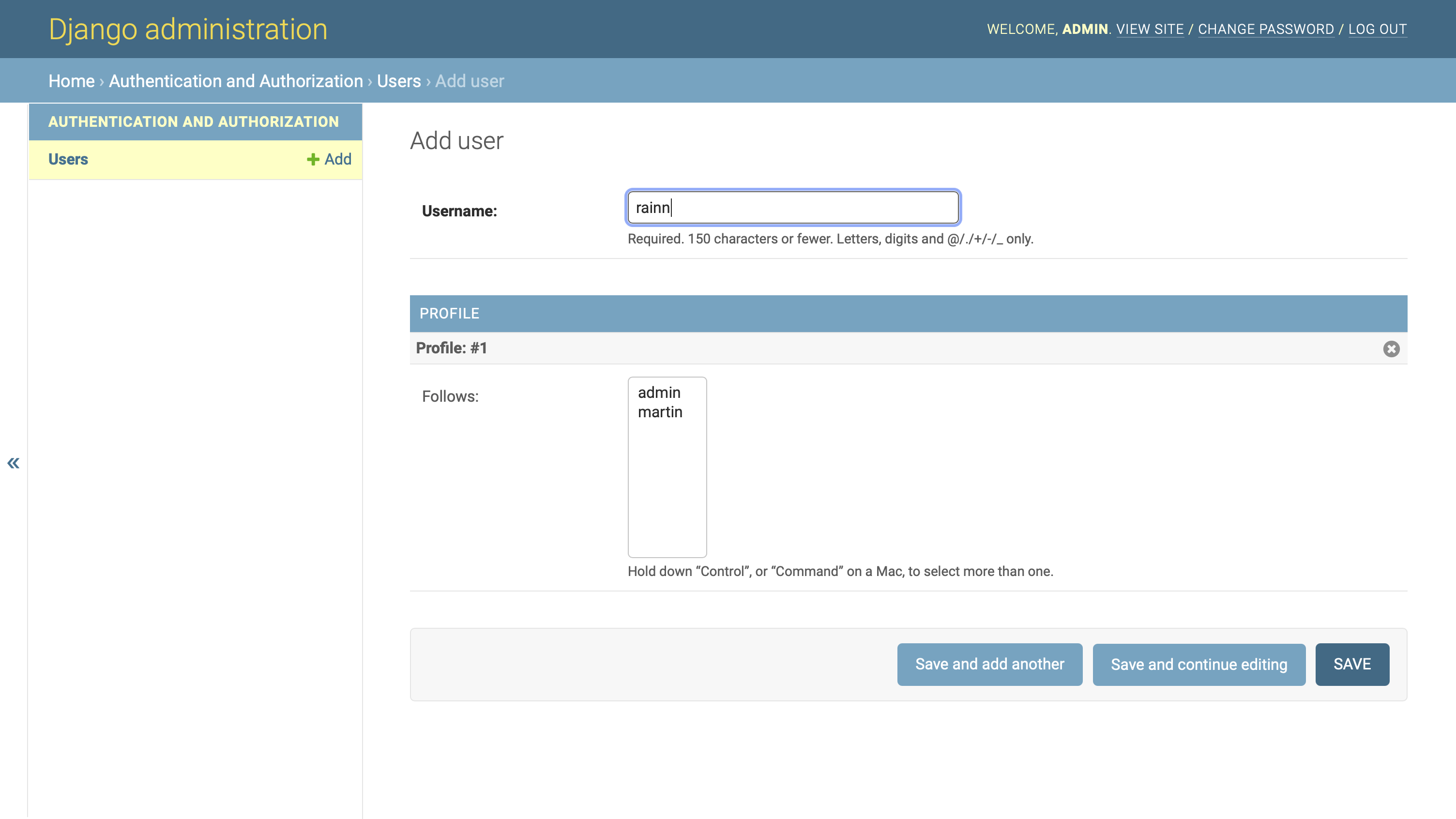
当您检查用户的 Change 页面时,您会看到 Django 自动为新用户创建了一个配置文件,并将该配置文件添加到他们关注的配置文件列表中:
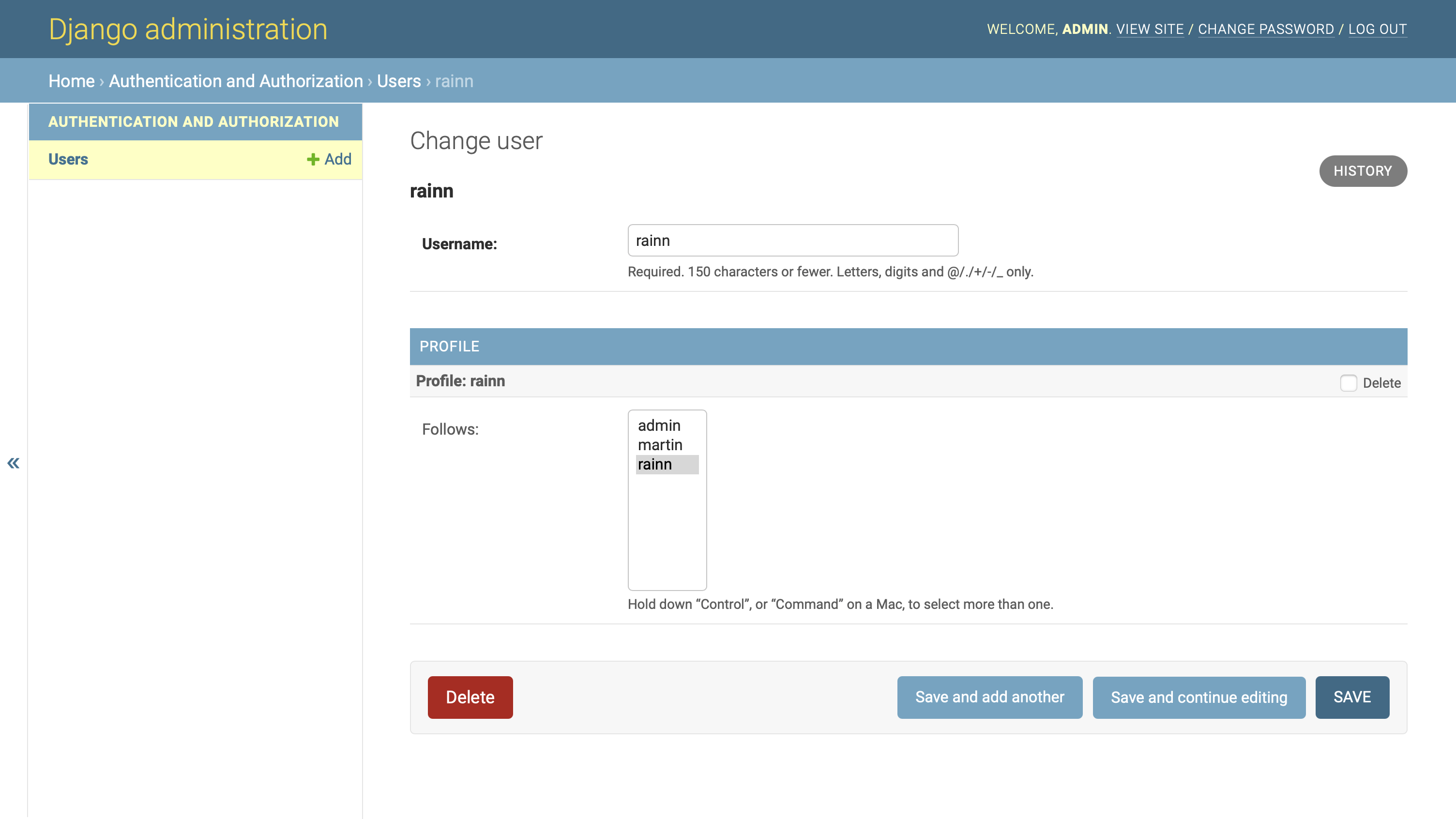
您可以看到用户关注他们自己的个人资料,因为他们在关注列表中的个人资料名称具有灰色背景。
现在,您可以通过 Django 管理界面创建新用户,他们也会自动收到一个相关的配置文件。Django 还将设置他们的个人资料来跟随自己,这将使得在他们的仪表板上显示他们自己的 dweet 和其他人的 dweet 成为可能。
您可以通过选择或取消选择【T2 关注】列表中的简档名称并点击保存来更改用户关注的简档。要选择多个配置文件或取消选择特定配置文件,您需要在 Windows 和 Linux 上按住 Ctrl ,或在 macOS 上按住 Cmd ,同时单击配置文件名称。
注意:您可以稍后通过 Django 内置的用户管理系统设置前端身份验证,并且您不需要在后端进行任何更改来保持功能按预期工作。
当有人创建了一个新的用户帐户,他们将收到一个个人资料,此外,他们将免费获得他们的第一个自我关注!
但是这里还没什么可看的。到目前为止,你只是潜伏在 Django admin 里。也许你开始厌倦 Django 提供的预建页面,并渴望编写一些 Django 模板来看看如何在你的应用程序的面向用户的界面中显示这些模型关系。
这就是你在本系列教程的第二部分要做的事情!你将开始构建你的 web 应用的前端,你将学习如何使用 CSS 框架布尔玛让它看起来更好。
结论
恭喜你!至此,您已经完成了关于用 Django 构建基本社交网络的系列教程的第一部分。
在本系列教程的第一部分中,您学习了如何:
- Django 模型之间实现一对一和多对多关系
- 用定制的
Profile模型扩展 Django 用户模型 - 定制 Django 管理界面
您还获得了设置 Django 项目以及与此相关的任务的额外实践。您已经练习了阅读 Django 错误消息,并根据它们提供的信息找到解决方案。
您可以通过点击下面的链接并转到source_code_final/文件夹来下载该项目的第一部分代码:
获取源代码: 点击此处获取源代码,您将使用开始与 Django 建立社交网络。
Django 基础社交网络的后续步骤
现在你已经完成了这个系列的第一部分,你可以继续第二部分,在那里你将构建一个布尔玛风格的 Django 前端。在本系列教程的第二部分中,您将为您的用户资料构建前端页面,并使它们看起来更好。
当你继续做这个项目时,你可以回头参考本系列教程的这一部分,参考你在项目概述中起草的计划,并在这个过程中更新你的计划。
在 Django 中构建和处理 POST 请求——第 3 部分
在这个由四部分组成的教程系列中,您将与 Django 一起构建一个社交网络,您可以在文件夹中展示这个网络。这个项目加强并展示了你对 Django 模型之间关系的理解,并向你展示了如何使用表单,以便用户可以与你的应用程序以及彼此之间进行交互。你也可以通过使用 CSS 框架布尔玛让你的网站看起来更好。
在本系列教程的前一部分中,您构建了用于显示所有概要文件列表以及单个概要文件页面的模板和视图。您还了解了如何应用 CSS 框架布尔玛定义的样式规则来使页面看起来更好。
在本系列教程的第三部分,您将学习如何:
- 创建前端界面让用户关注和不关注配置文件
- 使用按钮在 Django 中提交和处理 POST 请求
- 为您的基于文本的内容设置模型
- 构建风格化模板以在前端显示内容
- 在模板代码中使用复杂的模型关系
在这一部分结束时,你的社交网络将拥有你所期望的所有页面,你将能够在后端创建 dweets 并在前端显示它们。您的用户将能够发现和关注其他用户,并阅读他们所关注的个人资料的内容。如果他们想停止阅读某个用户的内容,他们还可以点击一个按钮,发送一个由 Django 处理的 HTTP POST 请求,取消对某个档案的关注。
你可以点击下面的链接,进入source_code_start/文件夹,下载启动项目第三部分所需的代码:
获取源代码: 单击此处获取源代码,您将使用来构建和处理 Django 的 POST 请求。
演示
在这个由四部分组成的教程系列中,您将构建一个小型社交网络,允许用户发布基于文本的简短消息。您的应用程序用户还可以关注其他用户简档以查看这些用户的帖子,或者取消关注他们以停止查看他们基于文本的帖子:
https://player.vimeo.com/video/643455270?background=1
您还将学习如何使用 CSS 框架布尔玛来为您的应用程序提供用户友好的外观,并使其成为您可以自豪地炫耀的投资组合项目!
在本系列教程的第三部分中,您将继续使用布尔玛风格的模板,并为基于文本的消息内容创建模型。您还将在 Django 应用的前端设置和处理 HTTP POST 请求提交,这将允许用户通过点击一个按钮来关注或取消关注彼此:
https://player.vimeo.com/video/643455207?background=1
在本教程结束时,每个用户都将能够转到一个新的仪表板页面,访问基于他们所关注的简档的 dweets 个人摘要。他们还可以关注和取消关注其他用户。这对你的 Django 社交网络来说是一个巨大的飞跃!
项目概述
在本节中,您将大致了解本系列教程的第三部分将涵盖哪些主题。您还将有机会重温完整的项目实现步骤,以防您需要跳回到本系列前面的某个步骤,或者如果您想看看前面还有什么。
至此,你应该已经完成了本教程系列的第部分第一和第部分第二部分。如果是的话,那么您现在已经准备好继续本系列教程的下一步了。这些步骤集中在跟随和取消跟随配置文件的代码逻辑,以及如何设置 dweets:
| 第七步 | 关注和取消关注其他档案 |
| 第 8 步 | 为数据工作表创建后端逻辑 |
| 第 9 步 | 在前端显示数据表 |
完成教程系列第三部分的所有步骤后,可以继续第四部分。
为了更好地了解如何构建你的 Django 社交网络,你可以展开下面的可折叠部分:
在本系列的多个独立教程中,您将分多个步骤实现该项目。有很多内容需要讨论,您将一路深入细节:
- 步骤 1: 设置基础项目
- 步骤 2: 扩展 Django 用户模型
- 步骤 3: 实现一个保存后挂钩
- 第四步:用布尔玛创建一个基础模板
- 第 5 步:列出所有用户资料
- 第 6 步:访问个人资料页面
- 第 7 步:关注和取消关注其他个人资料
- 步骤 8: 为 Dweets 创建后端逻辑
- 第九步:在前端显示 Dweets
- 步骤 10: 通过 Django 表单提交 Dweets
- 步骤 11: 防止重复提交并处理错误
- 第十二步:改善前端用户体验
这些步骤中的每一步都将提供任何必要资源的链接。通过一次完成一个步骤,你将有机会停下来,在你想休息一下的时候再回来。
记住了本系列教程的高级结构,您就可以很好地了解自己所处的位置,以及在最后一部分中将处理哪些实现步骤。
在开始下一步之前,快速浏览一下先决条件,浏览一下可能有帮助的其他资源的链接。
先决条件
为了成功地完成项目的这一部分,你需要完成关于模型和关系的第一部分和关于模板和样式的第二部分,并且你应该确认你的项目正在如那里描述的那样工作。最好你也能熟悉以下概念:
- 在 Python 中使用面向对象编程
- 建立 Django 基础项目
- 管理路由和重定向,查看功能,模板,模型,以及 Django 中的迁移
- 使用和定制 Django 管理界面
- 用类属性读写 HTML
记得确保你已经完成了本系列教程的前两部分。第三部分将从你在第二部分结束时停下的地方继续。
注意:如果您没有准备好前几部分的工作项目,您将无法继续学习本系列教程的这一部分。
您也可以通过点击下面的链接并转到source_code_start/文件夹来下载启动该项目第三部分所需的代码:
获取源代码: 单击此处获取源代码,您将使用来构建和处理 Django 的 POST 请求。
关于额外的要求和进一步的链接,请查看本系列教程第一部分中提到的关于在 Django 构建基本社交网络的先决条件。
步骤 7:关注和取消关注其他个人资料
此时,您可以访问简档列表页面上的所有简档,还可以访问用户的简档页面。此外,您可以使用动态链接在前端的这些视图之间导航。在这一步结束时,您将能够通过个人资料页面上的按钮关注和取消关注个人资料。
一旦您添加了关注和取消关注概要文件的可能性,您就已经重新创建了 Django 管理界面在本系列教程的第一部分中为您提供的后端功能。
向您的个人资料添加按钮
添加带有布尔玛按钮样式的 HTML 代码,以创建两个用于与配置文件交互的按钮:
<div class="buttons has-addons">
</div>
关注和不关注用户的按钮可以放在用户档案名称的正下方。弄清楚它在你自己的模板代码中的位置,然后添加上面显示的 HTML。
如果您正在使用来自profile.html模板的 HTML,那么您可以添加它,如下面的可折叠部分所示:
<!-- dwitter/templates/dwitter/profile.html -->
{% extends 'base.html' %}
{% block content %}
<div class="column">
<div class="block">
<h1 class="title is-1">
{{profile.user.username|upper}}'s Dweets
</h1>
</div>
<div class="buttons has-addons"> </div> </div>
<div class="column is-one-third">
<div class="block">
<a href="{% url 'dwitter:profile_list' %}">
<button class="button is-dark is-outlined is-fullwidth">
All Profiles
</button>
</a>
</div>
<div class="block">
<h3 class="title is-4">
{{profile.user.username}} follows:
</h3>
<div class="content">
<ul>
{% for following in profile.follows.all %}
<li>
<a href="{% url 'dwitter:profile' following.id %}">
{{ following }}
</a>
</li>
{% endfor %}
</ul>
</div>
</div>
<div class="block">
<h3 class="title is-4">
{{profile.user.username}} is followed by:
</h3>
<div class="content">
<ul>
{% for follower in profile.followed_by.all %}
<li>
<a href="{% url 'dwitter:profile' follower.id %}">
{{ follower }}
</a>
</li>
{% endfor %}
</ul>
</div>
</div>
</div>
{% endblock content %}
在将这个 HTML 代码片段添加到profile.html之后,您将看到两个按钮呈现在用户的档案名称下。
例如,如果您转到http://127.0.0.1:8000/profile/1,您可以确保 Django 的开发服务器正在运行,并且您可以访问本地主机上的配置文件页面。此 URL 向您显示 ID 为1的用户配置文件的配置文件页面,并包括新按钮:
按钮看起来不错!然而,似乎你可以点击关注一个个人资料,即使你已经在关注它。
为了在这里创造一些区别,你可以把不相关的按钮变灰,这样相关的动作对你的用户来说就更明显了。如果你添加一个名为is-static的 HTML 类,布尔玛应该将你的按钮变灰。您可以根据登录用户是否已经关注他们正在查看的简档来应用此类:
1<div class="buttons has-addons">
2 {% if profile in user.profile.follows.all %}
3
4
5 {% else %}
6
7
8 {% endif %}
9</div>
您一直在处理 Django 在每个 GET 和 POST 请求中发送的user变量。注意,您甚至不需要在views.py中将这个变量显式地传递给上下文字典。user变量保存当前登录用户的信息:
-
第 2 行:在这个条件语句中,您将检查您当前查看的配置文件是否在登录用户跟踪的所有配置文件的查询集中。
-
第 3 行到第 4 行:如果用户已经关注了他们正在查看的个人资料,那么关注按钮将通过添加
is-static类而变灰。取消跟随按钮将被着色并显示为可点击。 -
第 6 行到第 7 行:如果用户没有关注他们正在查看的个人资料,那么关注按钮将显示为可点击,而取消关注按钮将显示为灰色。
-
第 8 行:在这一行,你要结束条件语句。
通过 Django 的模板标签和样式添加一点代码逻辑,你已经让用户更清楚地知道他们只能关注他们当前没有关注的简档,他们只能取消关注他们已经关注的简档。
导航到个人资料页面 URL,如http://127.0.0.1:8000/profile/1,或者,如果您还在那里,那么只需重新加载页面以查看更改:
然而,即使信息现在以更加用户友好的方式显示,点击可点击的按钮实际上并不做任何事情。为此,您需要创建一个 HTML 表单,并在代码逻辑中处理表单提交。
在 Django 代码逻辑中处理 POST 请求
下一步是实现当有人点击这些按钮时应该发生什么的逻辑。为此,您需要一个 HTML 表单,以便可以提交数据并在视图中处理它:
1<form method="post"> 2 {% csrf_token %} 3 <div class="buttons has-addons">
4 {% if profile in user.profile.follows.all %}
5
6 <button class="button is-danger" name="follow" value="unfollow"> 7 Unfollow
8 </button>
9 {% else %}
10 <button class="button is-success" name="follow" value="follow"> 11 Follow
12 </button>
13
14 {% endif %}
15 </div>
16</form>
通过更新以下代码,您对模板进行了一些必要的更改:
-
第 1 行和第 16 行:您将两个按钮包装在一个 HTML
<form>元素中,并添加了值为"post"的 HTML 属性method,以表明您将使用该表单发送数据。 -
第 2 行:您通过 Django 提供的一个方便的模板标签添加了一个 CSRF 令牌。如果您希望允许您的用户在您的 Django 应用程序中提交表单,出于安全原因,您需要添加这个。
-
第 6 行和第 10 行:您向两个
<button>元素添加了两个 HTML 属性:
添加这段代码后,您不会在 web 应用程序的前端看到任何变化,但是这些变化是必要的,以便 Django 可以将用户提交的数据转发到您的视图逻辑。您还需要第 6 行和第 10 行中定义的属性值来区分用户在后端按下了哪个按钮。
在profile.html中设置好所有前端逻辑后,您可以切换到views.py,在这里您可以获取用户提交的数据并对其进行处理:
1# dwitter/views.py
2
3# ...
4
5def profile(request, pk):
6 profile = Profile.objects.get(pk=pk)
7 if request.method == "POST": 8 current_user_profile = request.user.profile 9 data = request.POST 10 action = data.get("follow") 11 if action == "follow": 12 current_user_profile.follows.add(profile) 13 elif action == "unfollow": 14 current_user_profile.follows.remove(profile) 15 current_user_profile.save() 16 return render(request, "dwitter/profile.html", {"profile": profile})
由于您在profile.html中设置表单的方式,表单将重定向回同一个页面,这意味着 Django 将通过profile()获取请求。它这样工作是因为你如何设置你的网址配置。然而,这一次 Django 发送了一个包含用户提交数据的 HTTP POST 请求,您可以在代码更新中解决这个问题:
-
第 7 行:您引入了一个条件检查来查看传入 Django 视图函数的请求是否是 HTTP POST 请求。只有当某人通过点击跟随或取消跟随按钮在
profile.html提交表格时,才会出现这种情况。 -
第 8 行:您使用 Django 的
request对象中的user属性(指当前登录的用户)来访问该用户的.profile对象并将其分配给current_user_profile。您稍后将需要访问此用户的个人资料来更改他们关注的人。 -
第 9 行:从
request.POST字典中获取用户提交的数据,并存储在data中。当用户提交带有属性method="post"的表单时,Django 将数据放入request.POST。 -
第 10 行:通过访问键
"follow"处的数据来检索提交的值,这个键是在模板中用<button>元素上的nameHTML 属性定义的。 -
第 11 到 14 行:您设置了一个条件语句,根据用户按下的按钮,在当前登录用户的
.follows中添加或删除用户概要文件。这两个按钮为"follow"数据键提交不同的值,您可以用它来区分这两个按钮。 -
第 15 行:您使用
current_user_profile上的.save()将对.follows的更改传播回数据库。
最后,在所有这些条件动作之后 Django 只在表单提交的 POST 请求调用页面时执行这些动作——再次呈现同一个模板。点击按钮后,将重新加载页面并正确显示更改后的关注者列表。
注意:如果您还没有为您和您的现有用户创建简档,您可能会在执行发布请求时遇到RelatedObjectDoesNotExist错误。为防止此错误,您可以验证您的用户在您的profile视图中是否有个人资料:
# dwitter/views.py
# ...
def profile(request, pk):
if not hasattr(request.user, 'profile'): missing_profile = Profile(user=request.user) missing_profile.save()
profile = Profile.objects.get(pk=pk)
if request.method == "POST":
current_user_profile = request.user.profile
data = request.POST
action = data.get("follow")
if action == "follow":
current_user_profile.follows.add(profile)
elif action == "unfollow":
current_user_profile.follows.remove(profile)
current_user_profile.save()
return render(request, "dwitter/profile.html", {"profile": profile})
当调用profile视图时,首先检查request.user是否包含带有 hasattr() 的profile。如果缺少配置文件,那么在继续之前,您需要为您的用户创建一个配置文件。
您现在可以关注和取消关注您社交网络上其他用户的个人资料。通过浏览您的配置文件列表中的配置文件,并有选择地跟踪和取消跟踪它们,确认这按预期工作。您应该会在侧边栏中看到相应的更新列表。
这样,您就将跟随和取消跟随后端逻辑与前端完全连接起来了。您在profile.html中添加了一个 HTML <form>元素和两个按钮。您还在profile()中实现了代码逻辑,它将按钮的按下转化为影响数据库的变化。
步骤 8:为 Dweets 创建后端逻辑
此时,您可以通过应用程序的前端选择关注和取消关注用户资料。然而,即使你跟随另一个个人资料,也没什么可看的!此时,你的社交网络的用户不能创建任何内容。改变这一点将是你的下一个挑战。
在这一步结束时,您已经为您的社交网络内容创建了后端——基于短文本的消息,称为dweets——用户可以发布到您的应用程序。您还可以通过 Django admin 为用户创建 dweets。
正如你在第一部分的项目概述中头脑风暴一样,你的社交网络将专注于简短的文本信息。为了纪念老派的 Twitter,您将把字符限制设置为 140 个字符。
注意:到目前为止,用户发布的内容类型可以是任何类型。你只关注应用程序用户之间的联系。
现在你越来越具体了。如果你想在你的社交网络中允许不同形式的内容,你需要在这一点上转向另一个方向。
您计划创建一个模型,关注用户将在您的社交网络上分享哪些内容的基本原则。您还决定将 dweets 绑定到一个用户帐户,除了文本正文之外,dweets 唯一需要记录的是提交时间:
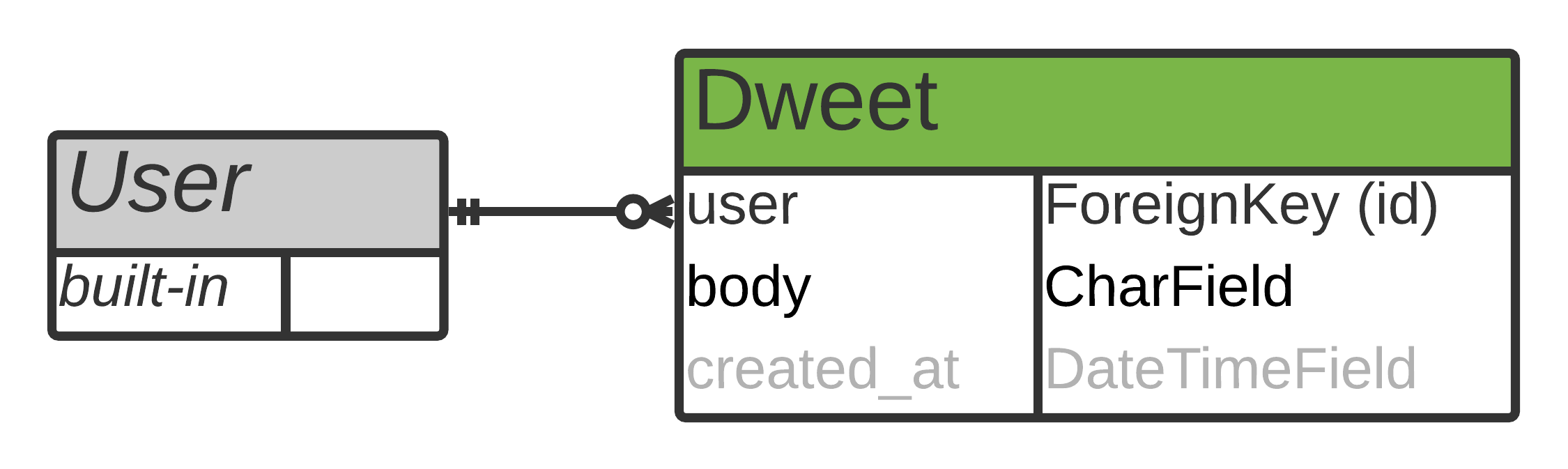
实体关系(ER)图显示您的Dweet模型将与 Django 的内置User模型有一个外键关系。您的社交网络的每个用户将能够创建许多与其帐户相关联的 dweets。
制作模型
您需要一种方法在数据库中存储用户创建的基于文本的消息。为此,您需要在dwitter/models.py中创建一个新模型:
# dwitter/models.py
# ...
class Dweet(models.Model):
user = models.ForeignKey(
User, related_name="dweets", on_delete=models.DO_NOTHING
)
body = models.CharField(max_length=140)
created_at = models.DateTimeField(auto_now_add=True)
您的Dweet模型只需要三个字段:
-
user: 该字段建立与 Django 内置User模型的模型关系。您定义它将是一个外键关系,这意味着每个 dweet 将与一个用户相关联。您还将"dweets"传递给related_name,这允许您通过.dweets从关系的用户端访问 dweet 对象。最后,通过将on_delete设置为models.DO_NOTHING来指定孤立的 dweets 应该保留。 -
body: 此字段定义您的内容类型。您将其设置为最大长度为 140 个字符的字符字段。 -
created_at: 新模型的最后一个字段记录了提交文本消息的日期和时间。在一个DateTimeField对象上将auto_now_add设置为True可以确保当用户提交一个 dweet 时这个值被自动添加。
设置好这三个字段后,您就完成了Dweet模型的创建!接下来,您需要通过运行makemigrations和migrate管理命令将更改应用到您的数据库:
(social) $ python manage.py makemigrations
(social) $ python manage.py migrate
运行这两个命令后,您在models.py中的更改已经应用到您的数据库中。您的后端已经设置好记录 dweets,但是到目前为止,您还没有办法通过 web 应用程序提交它们。
通过管理界面添加 Dweets
最终,您希望您的社交网络用户通过 web 应用程序的前端提交 dweets。然而,首先,您要确保到目前为止您构建的所有东西都按预期工作。首先,您将通过管理界面添加创建 dweets 的功能。
要在管理界面中访问您的新Dweet模型,您需要注册它:
# dwitter/admin.py
from django.contrib import admin
from django.contrib.auth.models import Group, User
from .models import Dweet, Profile
# ...
admin.site.register(Dweet)
如果你在这样做之后进入你的管理界面,你会看到 Dwitter → Dweets 选项现在出现了。点击旁边的 +添加按钮,创建一个新的 dweet:
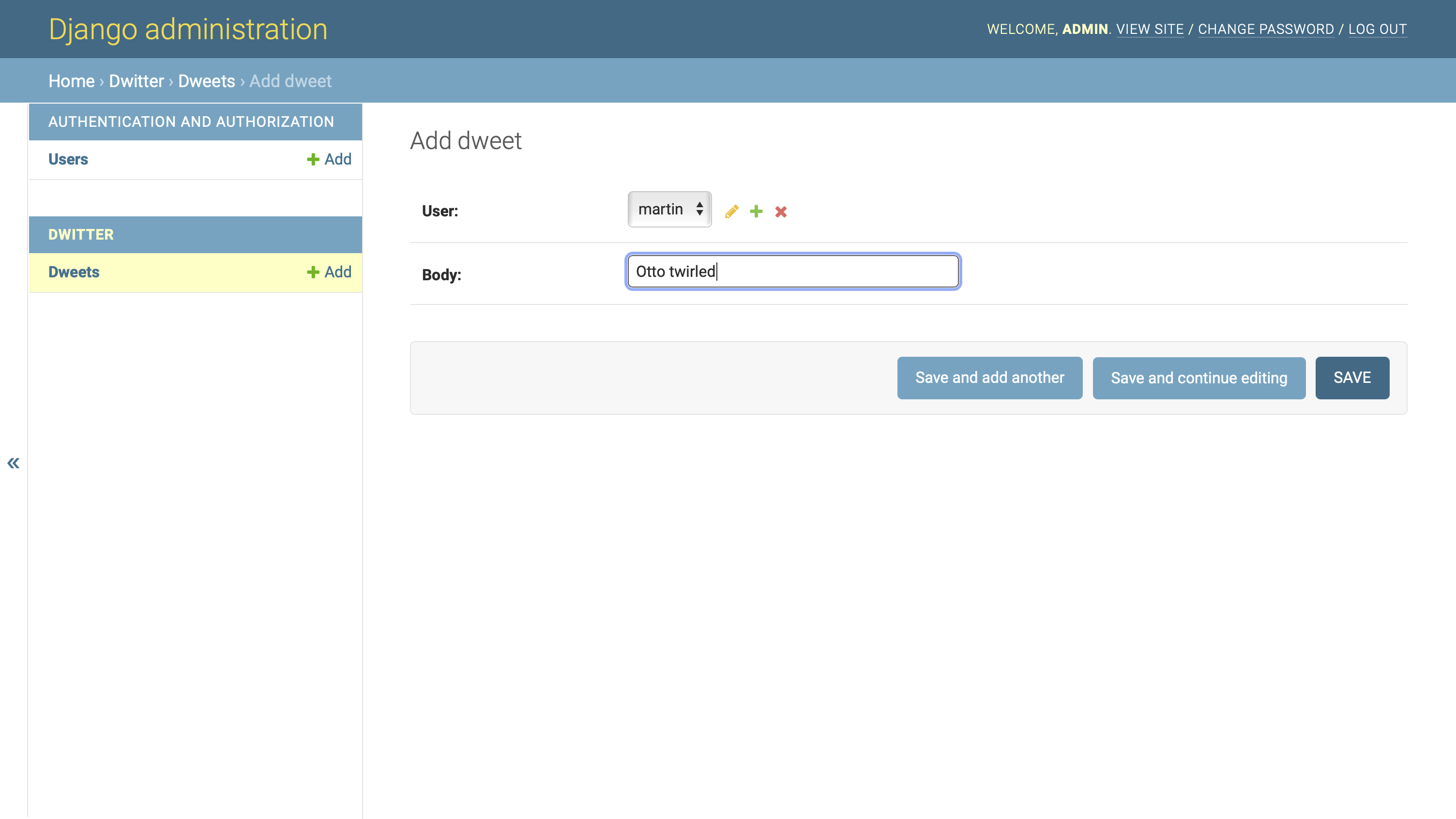
请注意,您需要将现有用户对象分配给要创建的 dweet。您可以从下拉列表中选择一个。您还需要为 dweet 的主体添加文本。你不需要在创建时添加日期,因为 Django 会在你点击保存后自动处理。
通过提供用户和文本主体,您可以通过管理界面创建新的 dweet:
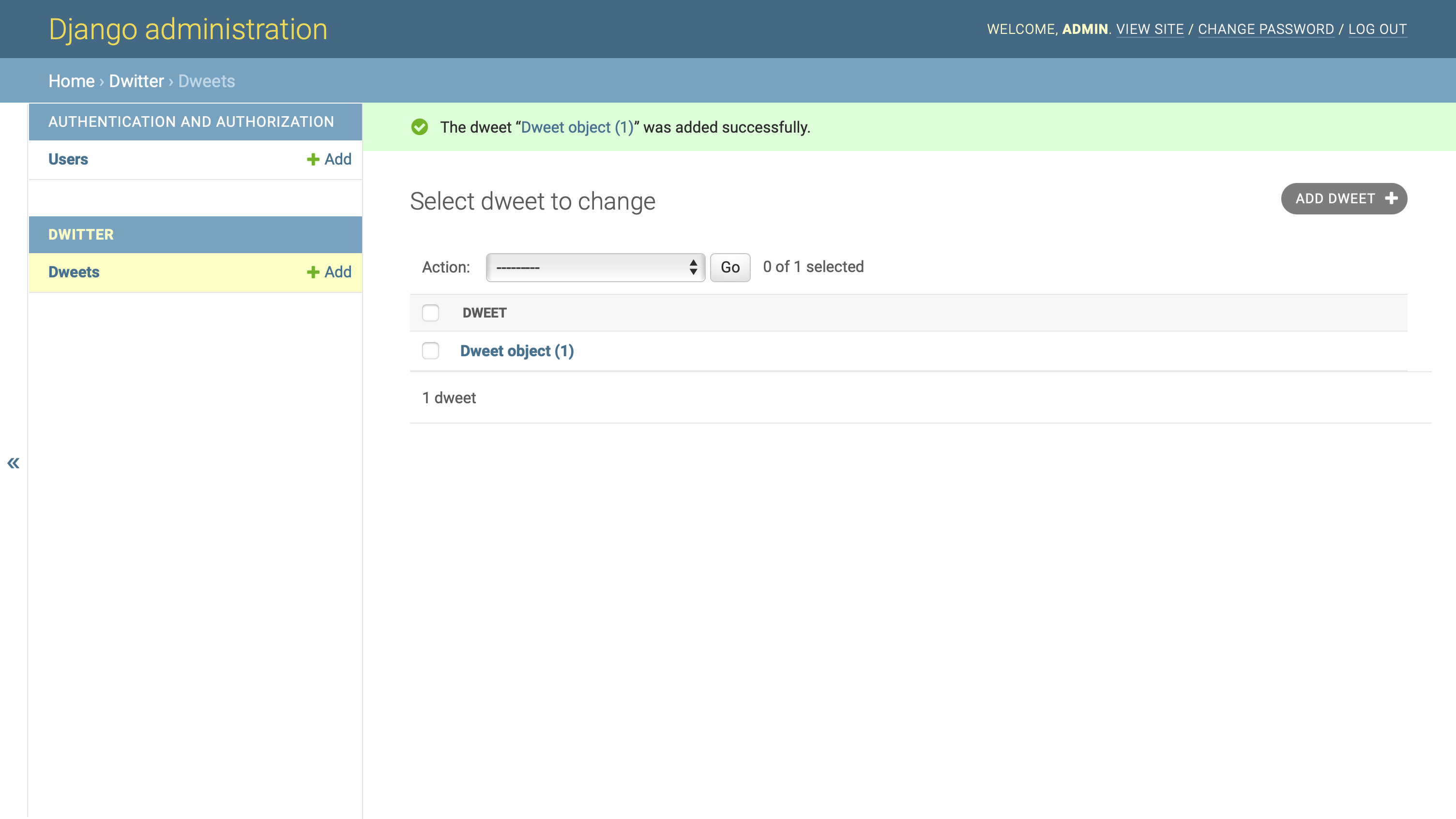
然而, Dweet object (1) 对于提交的 Dweet 来说并不是一个非常具有描述性的名称。如果你能看到是谁写的,什么时候写的,至少能看到正文的开头,那就更好用了。您可以通过在Dweet的类定义中覆盖.__str__()来改变 Django 显示Dweet对象的方式:
# dwitter/models.py
class Dweet(models.Model):
user = models.ForeignKey(User,
related_name="dweets",
on_delete=models.DO_NOTHING)
body = models.CharField(max_length=140)
created_at = models.DateTimeField(auto_now_add=True)
def __str__(self):
return (
f"{self.user} "
f"({self.created_at:%Y-%m-%d %H:%M}): "
f"{self.body[:30]}..."
)
通过添加一个定制的.__str__()方法,返回一个由用户名、创建日期和消息体的前三十个字符组成的 Python f 字符串,您已经改进了 Django 在管理界面上呈现 dweets 的方式:
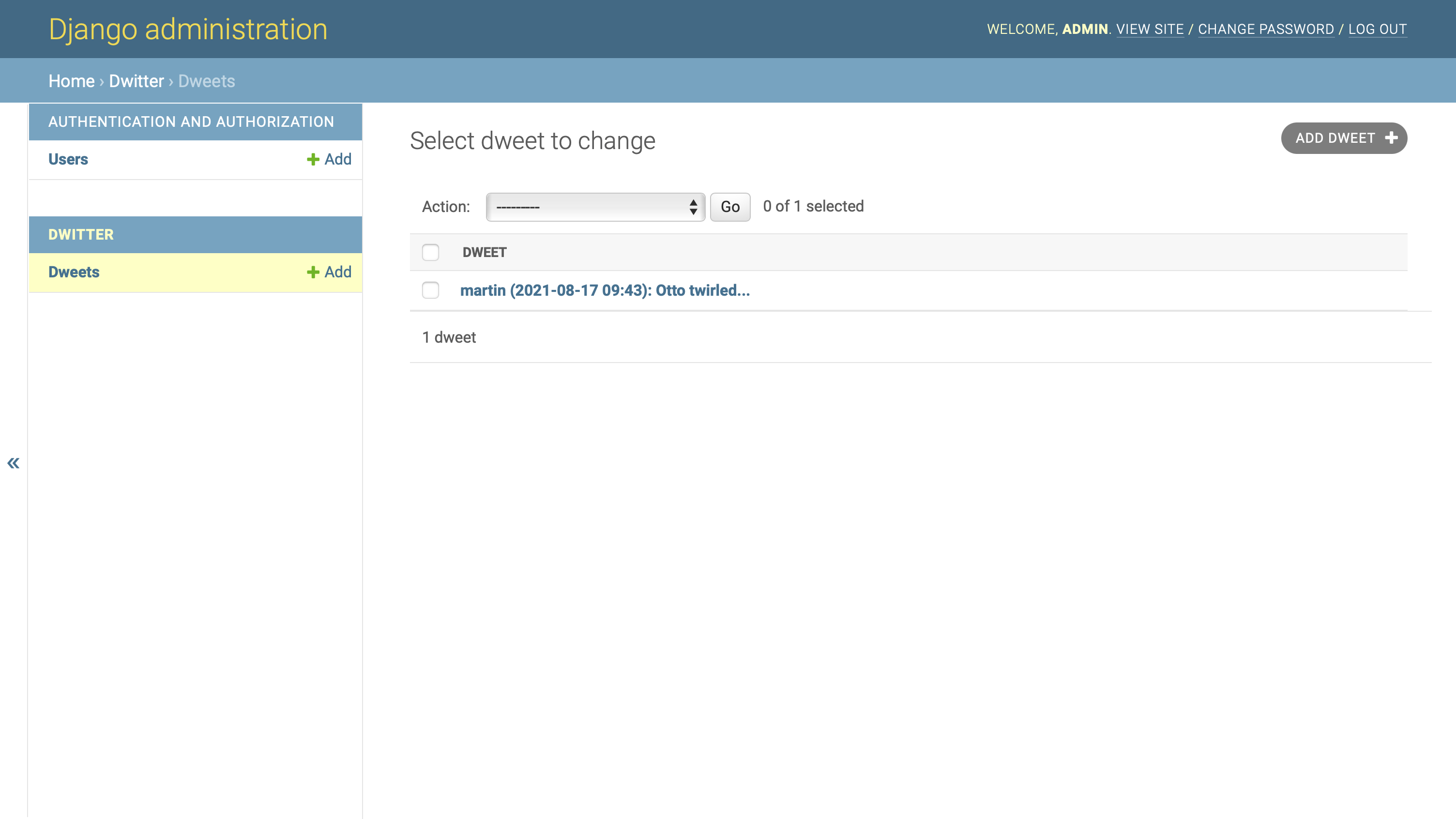
应用这一更改后,Django 管理界面中的 dweet 概述页面将保持有用和可读,即使您的用户已经添加了许多额外的 dweet。
注意:在准备接下来的步骤时,您应该创建几个 dweets,并将它们分配给应用程序的不同用户。确保您至少有三个用户,并且他们都有一些示例 dweet,以便您可以在关注或取消关注简档时看到哪些 dweet 出现。
在这一步中,您为 Django 社交网络的文本内容创建了一个新模型,在您的管理界面中注册了它,并改进了 Django 显示对象的方式。在下一节中,您将添加代码来告诉 Django 在 web 应用程序的前端显示这些 dweets。
第九步:在前端显示 Dweets
至此,您已经建立了概要文件,并且可以通过 Django 管理界面创建 dweets。在此步骤结束时,您将能够通过前端查看 dweets,并且能够在仪表板页面上显示您关注的概要文件的 dweets。
如果您还没有通过管理界面创建任何 dweet,那么回到那里,创建几个 dweet,并将它们分配给不同的用户。一旦您设置了仪表板页面来显示您所关注的简档的 dweet,那么拥有一些要检查的 dweet 将会很有帮助。
在每个个人资料页面上显示个人资料
首先,您将返回到profile.html,在这里您将添加代码来显示与这个概要文件相关联的用户的所有 dweets。稍后,您将创建另一个网站,显示您关注的所有人的 dweets。
在个人资料页面上,您可以访问profile。如何像处理简档的关注者一样迭代用户的 dweets?
如果你回想一下写Dweet的时候,你可能记得你将related_name设置为"dweets"。您在那里定义的名称让您可以通过User模型反向访问关联的Dweet对象。此外,您可以通过在上下文字典中传递的Profile对象来访问链接的User实例:
profile.user.dweets
不错!有了这段代码,您就可以完整地浏览您在这个项目中建立的所有模型关系。继续在profile.html中使用它,这样您就可以在每个用户的个人资料页面上看到他们的 dweets:
<!-- dwitter/templates/dwitter/profile.html -->
<!-- ... -->
<div class="content">
{% for dweet in profile.user.dweets.all %}
<div class="box">
{{ dweet.body }}
<span class="is-small has-text-grey-light">
({{ dweet.created_at }})
</span>
</div>
{% endfor %}
</div>
在关闭<div class="block">之后添加这个包含布尔玛样式的 HTML 片段:
<!-- dwitter/templates/dwitter/profile.html -->
{% extends 'base.html' %}
{% block content %}
<div class="column">
<div class="block">
<h1 class="title is-1">
{{profile.user.username|upper}}'s Dweets
</h1>
<form method="post">
{% csrf_token %}
<div class="buttons has-addons">
{% if profile in user.profile.follows.all %}
<button class="button is-success is-static">
Follow
</button>
<button class="button is-danger"
name="follow"
value="unfollow">
Unfollow
</button>
{% else %}
<button class="button is-success"
name="follow"
value="follow">
Follow
</button>
<button class="button is-danger is-static">
Unfollow
</button>
{% endif %}
</div>
</form>
</div>
<div class="content"> {% for dweet in profile.user.dweets.all %} <div class="box"> {{ dweet.body }} <span class="is-small has-text-grey-light"> ({{ dweet.created_at }}) </span> </div> {% endfor %} </div>
</div>
<div class="column is-one-third">
<div class="block">
<a href="{% url 'dwitter:profile_list' %}">
<button class="button is-dark is-outlined is-fullwidth">
All Profiles
</button>
</a>
</div>
<div class="block">
<h3 class="title is-4">
{{profile.user.username}} follows:
</h3>
<div class="content">
<ul>
{% for following in profile.follows.all %}
<li>
<a href="{% url 'dwitter:profile' following.id %} ">
{{ following }}
</a>
</li>
{% endfor %}
</ul>
</div>
</div>
<div class="block">
<h3 class="title is-4">
{{profile.user.username}} is followed by:
</h3>
<div class="content">
<ul>
{% for follower in profile.followed_by.all %}
<li>
<a href="{% url 'dwitter:profile' follower.id %} ">
{{ follower }}
</a>
</li>
{% endfor %}
</ul>
</div>
</div>
</div>
{% endblock content %}
这很管用!迭代在遍历完模型关系后开始,由于布尔玛的样式表,您可以以一种愉快的方式查看当前用户的 dweets:
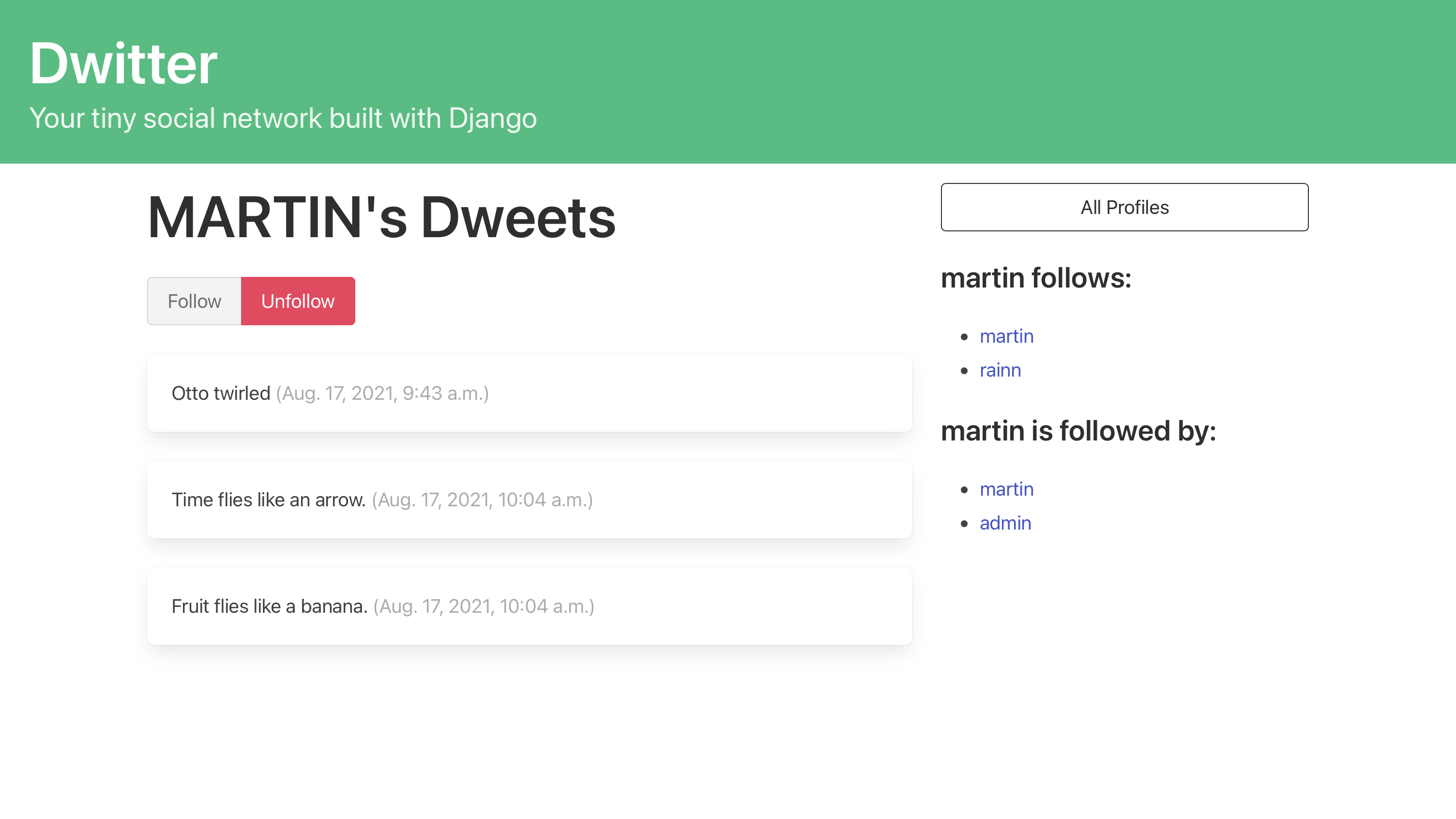
通过单击您之前设置的链接之一,查看另一个用户配置文件。你所有的个人资料页面都在按预期工作,它们看起来很可爱!您现在可以浏览每个人的关注者、他们关注的人以及他们的电子表格。您还可以点击一个按钮来关注或取消关注每个个人资料。这正是大多数用户希望在他们的个人资料页面上看到的。
您仍然缺少一种方法来显示您关注的所有配置文件的所有 dweets 的提要。您将通过更新您的仪表板视图来实现此功能。
创建仪表板视图
- 阅读您关注的个人资料中的所有电子表格
- 提交 dweet
在本系列的下一部分中,您将处理第二个任务。现在,您将专注于显示您关注的所有概要文件的 dweets。更新views.py中的dashboard(),将其指向不同的模板:
# dwitter/views.py
from django.shortcuts import render
from .models import Profile
def dashboard(request):
return render(request, "dwitter/dashboard.html")
当然,那个模板还不存在。为了不让 Django 抱怨,您去了dwitter/templates/dwitter/并创建了一个名为dashboard.html的新模板,并添加了一些代码逻辑草案以确保它按预期工作:
1<!-- dwitter/templates/dwitter/dashboard.html -->
2
3{% for followed in user.profile.follows.all %}
4 {% for dweet in followed.user.dweets.all %}
5 <li>{{dweet.user.username}} ({{ dweet.created_at }}): {{ dweet.body }}</li>
6 {% endfor %}
7{% endfor %}
在将这个代码片段添加到dashboard.html并导航到位于localhost:8000/的基本 URL 之后,您应该会看到一个未格式化的列表,其中包含了您所关注的所有概要文件的所有 dweets。
注意:如果没有新的消息出现,请确保您的管理员用户关注它自己和至少两个其他配置文件。您还可以检查这些用户在您的数据库中是否有一些现有的 dweets。
在用布尔玛的风格让这个列表看起来更好之前,首先回顾一下你在 Django 模板中链接在一起的模型关系是值得的:
-
第 3 行:深入 Django 在每个 POST 或 GET 请求中发送的
user对象。它指的是登录的用户,当前是您的管理员用户。使用.profile,您可以访问您的管理员用户的配置文件,这是您在扩展 DjangoUser模型时设置的。这个概要文件有一个名为.follows的属性,它保存了这个概要文件所遵循的所有用户概要文件的集合。最后,使用.all,您可以访问集合的一个 iterable。 -
第 4 行:将另一个
for循环嵌套到前一个循环中。在这里,您访问followed以获得当前登录用户关注的每个用户配置文件。然后遍历.user对象及其related_name、.dweets,以访问该用户编写的所有 dweets。使用.all,您再次访问该集合的一个 iterable。 -
第 5 行:你现在可以访问
dweet中的每个 dweet。您可以使用它从每个基于文本的消息中挑选出您想要的信息,并将这些信息组合到一个 HTML 列表项中。
您可以使用 Django 的模型关系来精确地找到您正在寻找的信息,这是非常强大的,即使这需要您钻过一系列不同的步骤!请记住,其工作方式取决于您在前面步骤中设置模型的方式:
你可以拿起铅笔,取出你在第一部分中创建的数据库草稿。试着思考你的模型是如何连接的,并确保在继续之前,你理解了如何以及为什么你能以上述方式访问 dweets。
现在你可以调整一下dashboard.html,使其符合你社交网络的其他设计:
<!-- dwitter/templates/dwitter/dashboard.html -->
{% extends 'base.html' %}
{% block content %}
<div class="column">
{% for followed in user.profile.follows.all %}
{% for dweet in followed.user.dweets.all %}
<div class="box">
{{ dweet.body }}
<span class="is-small has-text-grey-light">
({{ dweet.created_at }} by {{ dweet.user.username }}
</span>
</div>
{% endfor %}
{% endfor %}
</div>
{% endblock content %}
通过扩展您的基本模板并通过布尔玛的 CSS 类添加一些样式,您已经创建了一个有吸引力的仪表板页面,该页面显示您关注的所有个人资料的所有 dweets:
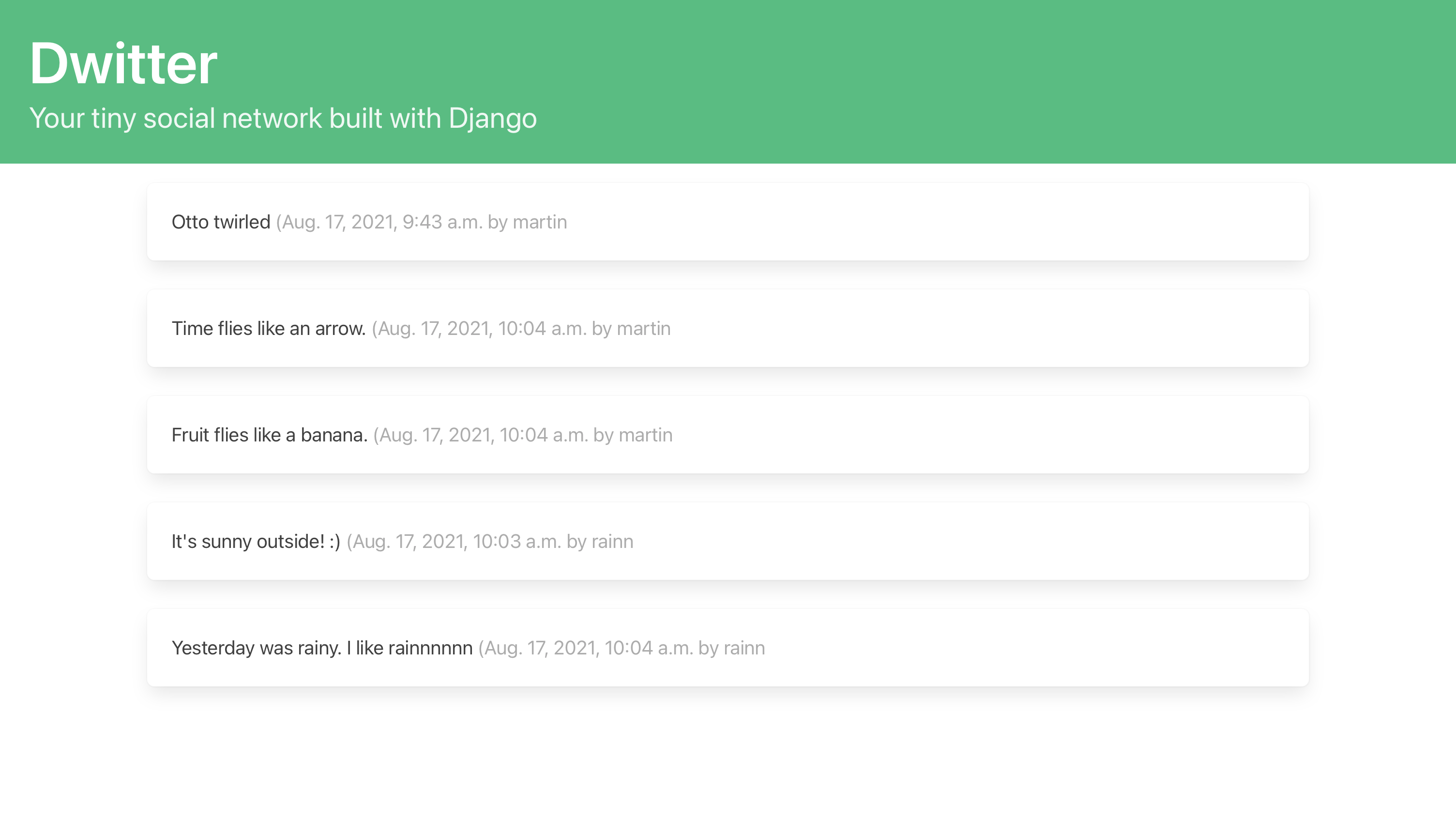
每个用户将根据他们关注的个人资料看到他们自己的 dweets。这对你的 Django 社交网络来说是一个巨大的飞跃!
在这一步中,您添加了一个新的指示板模板来显示 dweets 的个人提要,并且您还向profile.html添加了代码来显示每个用户在其个人资料页面上的 dweets。在下一步中,您将添加一个 Django 表单,允许用户从他们的仪表板页面提交 dweets。
结论
在本系列教程的这一部分中,您继续使用 Django 构建小型社交网络的前端和后端。您的应用程序用户现在可以关注和取消关注其他用户简档,并查看他们关注的简档的文本消息。
在构建这个项目的过程中,您已经学会了如何:
- 创建前端接口到跟随和解除跟随剖面
- 使用按钮在 Django 提交并处理 POST 请求
- 为基于文本的内容设置模型
- 构建样式的模板以在前端显示内容
- 在模板代码中使用复杂的模型关系
在本系列教程的下一部分,也是最后一部分,您将创建一个 Django 表单,允许您的用户通过前端提交新的 dweets。您还将确保内容提交是有效的。最后,您将通过添加导航和排序 dweets 以首先显示最新消息来改善用户体验。
您可以点击下面的链接,进入source_code_final/文件夹,下载您在项目的这一部分结束时应该拥有的代码:
获取源代码: 单击此处获取源代码,您将使用来构建和处理 Django 的 POST 请求。
Django 基础社交网络的后续步骤
现在您已经完成了本教程系列的第三部分,您可以继续最后一部分,在这里您将使用 Django 构建并提交 HTML 表单。
在本教程系列的下一部分中,您将添加代码逻辑,允许您的用户通过使用表单在您的 web 应用程序上创建内容。您将在forms.py中制作一个 Django 表单,将其连接到views.py中的代码逻辑,并将其呈现在一个模板中,以便您的用户可以从前端提交 dweets。
您将把仪表板页面构建成您社交网络的主页。然后,用户可以提交他们的内容,这样这些内容就会与他们关注的个人资料的 dweets 一起显示在平台上。
请记住,在进行这个项目时,您可以继续参考前面的步骤。例如,参考您在本系列教程第一部分的项目概述中起草的计划,并在您完成其余步骤的过程中更新您的计划可能会有所帮助。
Django 模板:实现定制标签和过滤器
原文:https://realpython.com/django-template-custom-tags-filters/
Django 模板帮助你管理你的网络应用的 HTML。模板使用带有变量、标签和过滤器的小型语言。在显示变量之前,您可以有条件地包含块、创建循环和修改变量。Django 自带了许多内置标签和过滤器,但是如果这些还不够呢?既然如此,那就自己写吧!本教程涵盖了编写你自己的 Django 模板定制标签和过滤器的细节。
在本教程中,您将学习如何:
- 写和寄存器一个函数作为自定义过滤器
- 理解自动转义如何在自定义标签和过滤器中工作
- 使用
@simple_tag编写一个自定义模板标签 - 使用
@inclusion_tag来呈现基于子模板的标签 - 用解析器和渲染器编写一个复杂的模板标签
本教程结束时,您将能够编写自定义过滤器来修改模板和自定义标记中的数据,从而在模板中获得 Python 的全部功能。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
开始使用
要使用您自己的 Django 模板定制标签和过滤器,您需要一个 Django 项目。你将建立一个 dinosoar ,一个拥有各种恐龙信息的小网站。虽然名字暗示你将只包括飞行恐龙,这只是为了营销自旋。所有你喜欢的重量级人物也会到场。
如果你以前从未建立过 Django 项目,或者如果你需要复习,你可能想先阅读Django 入门第 1 部分:构建投资组合应用。
Django 是第三方库,所以应该安装在虚拟环境中。如果你是虚拟环境的新手,看看 Python 虚拟环境:初级读本。为您自己创建并激活一个新的虚拟环境,然后运行以下命令:
1$ python -m pip install django==3.2.5
2$ django-admin startproject dinosoar
3$ cd dinosoar
4$ python manage.py startapp dinofacts
5$ python manage.py migrate
这些命令执行以下操作:
- 行 1 运行
pip命令安装 Django。 - 第 2 行创建你的新 Django 项目。
- 第 3 行将当前工作目录更改为
dinosoar项目。 - 第 4 行使用
manage.py命令创建一个名为dinofacts的 Django 应用,你的主视图将驻留在其中。 - 第 5 行迁移任何数据库更改。即使您没有创建模型,这一行也是必需的,因为 Django admin 在默认情况下是活动的。
随着项目的创建,是时候进行一些配置更改并编写一个快速视图来帮助您测试您的定制标签和过滤器了。
建立 Django 项目
您需要对项目的设置进行一些更改,让 Django 知道您新创建的应用程序,并配置您的模板。编辑dinosoar/dinosoar/settings.py并将dinofacts添加到INSTALLED_APPS列表中:
34# dinosoar/dinosoar/settings.py
35
36INSTALLED_APPS = [
37 "django.contrib.admin",
38 "django.contrib.auth",
39 "django.contrib.contenttypes",
40 "django.contrib.sessions",
41 "django.contrib.messages",
42 "django.contrib.staticfiles", 43 "dinofacts",
44]
在同一个文件中,您需要更新TEMPLATES属性中的DIR值。这告诉 Django 在哪里寻找你的模板文件:
57# dinosoar/dinosoar/settings.py
58
59TEMPLATES = [
60 {
61 "BACKEND": "django.template.backends.django.DjangoTemplates",
62 "DIRS": [ 63 BASE_DIR / "templates",
64 ],
65 "APP_DIRS": True,
66 "OPTIONS": {
67 "context_processors": [
68 "django.template.context_processors.debug",
69 "django.template.context_processors.request",
70 "django.contrib.auth.context_processors.auth",
71 "django.contrib.messages.context_processors.messages",
72 ],
73 },
从 Django 3.1 开始,指定项目所在位置的BASE_DIR值是一个pathlib对象。上面对DIRS值的更改告诉 Django 在项目目录的templates/子目录中查找。
注意:如果您使用 Django 3.0 或更早版本,您将使用os.path模块设置BASE_DIR。在这种情况下,使用os.path.join()来指定路径。
更改设置后,不要忘记在项目中创建templates/目录:
$ pwd
/home/realpython/dinosoar
$ mkdir templates
是时候开始写一些代码了。要测试您的定制模板标签和过滤器,您需要一个视图。编辑dinosoar/dinofacts/views.py如下:
1# dinosoar/dinofacts/views.py
2
3from datetime import datetime
4from django.shortcuts import render
5
6def show_dino(request, name):
7 data = {
8 "dinosaurs": [
9 "Tyrannosaurus",
10 "Stegosaurus",
11 "Raptor",
12 "Triceratops",
13 ],
14 "now": datetime.now(),
15 }
16
17 return render(request, name + ".html", data)
第 7 行到第 15 行用一些样本数据创建了一个字典。您将在模板中使用它来测试您的标签和过滤器。这个视图的其余部分做了一些有点不寻常的事情:它接受一个指定模板名称的参数。
render()函数加载并呈现一个模板。这里,name值以".html"为后缀,将其转换为要加载的模板的名称。这不是您通常会做的事情,但是本文的其余部分将向您展示许多模板。不需要为每个实验编写一个新的视图,这个视图就可以完成任务。
编写模板前的最后一步是将视图注册为 URL。编辑dinosoar/dinosoar/urls.py,使其看起来像这样:
1# dinosoar/dinosoar/urls.py
2
3from django.urls import path
4
5from dinofacts.views import show_dino
6
7urlpatterns = [
8 path("show_dino/<str:name>/", show_dino),
9]
第 8 行向show_dino视图注册了/show_dino/ URL。这个 URL 需要一个名为name的参数,这个参数将被转换成要加载到视图中的模板的名称。
使用 Django 模板
视图就绪后,就可以呈现一些 HTML 了。下一步是创建一个模板。大多数 HTML 页面是相当重复的,包含样板标题信息、关于页面的元信息和导航工具。Django 模板使用继承的力量来最小化重复。要查看这一过程,请创建dinosoar/templates/base.html:
1<!-- dinosoar/templates/base.html -->
2
3<html>
4<body>
5 {% block content %}
6 <h1>Dino Soar</h1>
7 {% endblock content %}
8</body>
9</html>
通过定义块和扩展父模板,您可以避免在整个站点的 HTML 文件中经常发生的大量千篇一律的重复。上面的模板是本教程中所有未来模板的基础。
本教程中的许多例子都在它们自己的模板文件中。您将创建每一个,并且每一个都将从上面的基本文件继承。您需要创建的第一个示例子文件是dinosoar/templates/eoraptor.html:
1<!-- dinosoar/templates/eoraptor.html -->
2
3{% extends "base.html" %}
4
5{% block content %}
6
7<h1>Eoraptor</h1>
8
9<p>
10 Eoraptor was one of the earliest dinosaurs and its name
11 is based on the Greek word for "dawn".
12
13 {% comment %} Add something about height here {% endcomment %}
14
15</p>
16
17<p>
18 Some other popular dinosaurs were:
19
20 <ul>
21 {% for dino in dinosaurs %}
22 <li> {{dino|lower}} </li>
23 {% endfor %}
24 </ul>
25</p>
26
27{% endblock content %}
该模板使用一些常见的内置模板标签和过滤器:
- 第 3 行通过使用
{% extends %}标签声明该模板继承自"base.html"。 - 第 5 行和第 27 行声明了一个叫做
content的块。在eoraptor.html的渲染过程中,模板引擎会在其父块中寻找一个同名的块。发动机替换base.html中相应的挡位。 - 第 13 行使用
{% comment %}标签来写评论。呈现的输出将不包括该标签的内容。 - 第 21 行和第 23 行定义了一个
{% for %}块标签。这类似于 Python 中的一个for循环。它对值dinosaurs进行迭代,并在块中为每个成员呈现该行。 - 第 22 行为
dinosaurs列表中的每一项渲染一次。每个值都放在 HTML<li>标签中。注意与值一起使用的lower过滤器。过滤器通过管道符号(|)应用于一个值。过滤器使用一个值,然后修改渲染结果。lower过滤器类似于 Python 中的.lower()方法,将值呈现为小写。
现在一切就绪。运行 Django 开发服务器来查看结果:
$ python manage.py runserver
要查看视图,请访问http://127.0.0.1:8000/show_dino/eoraptor/。您的结果应该如下所示:
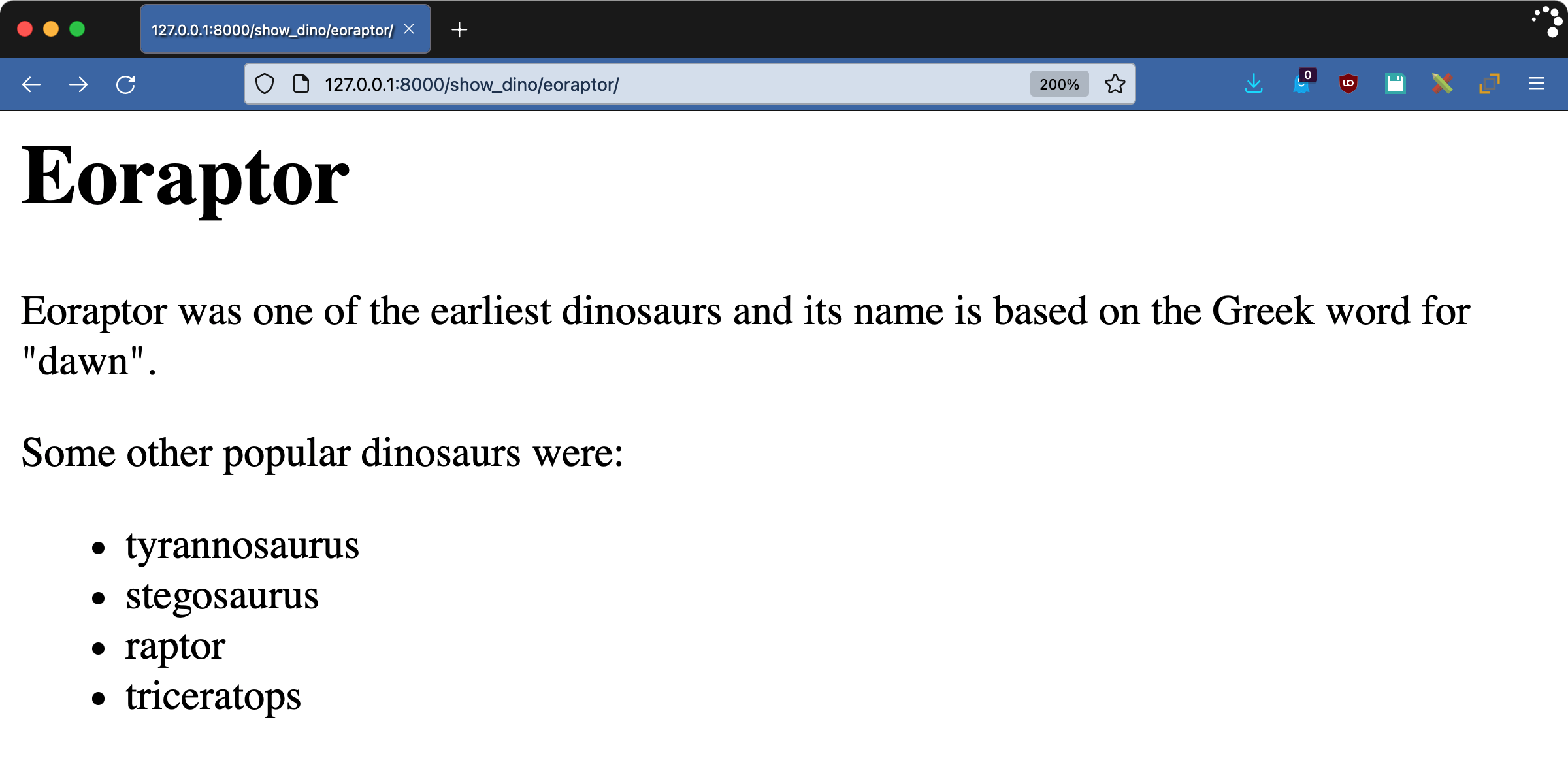
评论不见了,恐龙列表是小写的。
你可以通过查看 Django 文档中关于内置模板标签和过滤器的内容或者查看 Django 模板:内置标签和过滤器来找到更多信息。
加载模块和第三方标签库
Django 内置了超过 75 个标签和过滤器,除此之外还有几个模块,但这对于您的用例来说可能还不够。但是在编写您自己的定制标签和过滤器之前,您应该首先做一些研究,看看另一个包是否满足您的需要。
要使用 Django 附带的但不在标准集中的标签或过滤器,您需要:
- 注册包的 Django 应用
- 将模板库加载到您的模板中
许多第三方软件包也是可用的。使用第三方包没有什么不同,除了您需要首先使用pip安装这个包。
Django 附带的一个流行的包是 humanize ,但不是内置库的一部分。该库具有将数字数据转换成更可读形式的过滤器。因为它是作为 Django 中的contrib模块的一部分发布的,所以没有额外的安装步骤。
要注册应用程序,请在dinosoar/dinosoar/settings.py中更新您的INSTALLED_APPS列表:
32# dinosoar/dinosoar/settings.py
33
34INSTALLED_APPS = [
35 "django.contrib.admin",
36 "django.contrib.auth",
37 "django.contrib.contenttypes",
38 "django.contrib.sessions",
39 "django.contrib.messages",
40 "django.contrib.staticfiles",
41 "dinofacts", 42 "django.contrib.humanize",
43]
创建一个名为dinosoar/templates/iggy.html的新模板:
1<!-- dinosoar/templates/iggy.html -->
2
3{% extends "base.html" %}
4{% load humanize %}
5
6{% block content %}
7
8<h1>Iguanodon</h1>
9
10<p>
11 Iguanodon (iguana-tooth) were large herbivores. They weighed
12 {{3080|intcomma}}kg ({{6800|intcomma}}lbs).
13 Wow, {{3080000|intword}} grams is a lot!
14
15</p>
16
17{% endblock content %}
使用非内置标签或过滤器的关键是您在第 4 行使用的{% load %}标签。这相当于 Python 代码中的一个import语句。
iggy.html模板使用了来自humanize的两个过滤器:
intcomma将一个数字转换成每三位数加一个逗号的字符串。intword将大数转换成它们的英语等值。
访问http://127.0.0.1:8000/show_dino/iggy/查看结果:
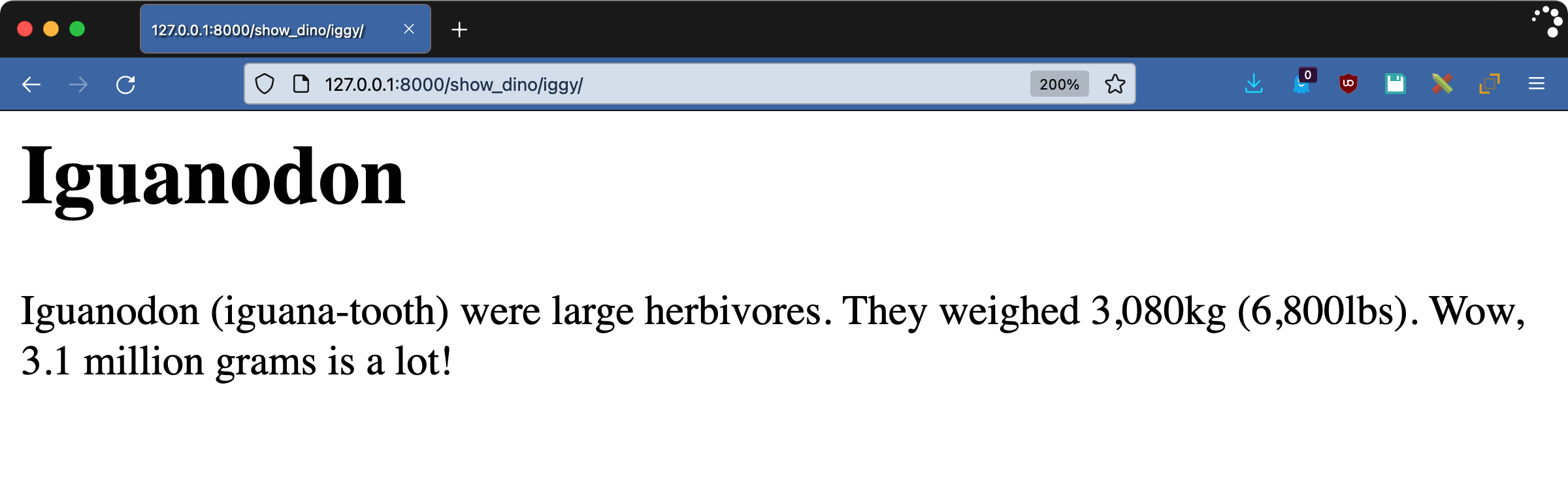
Django 中有很多标签,有内置的,也有包含在contrib模块中的。甚至还有更多第三方库。但是如果你找不到解决你问题的东西呢?是时候自己动手写一些 Django 定制标签和过滤器了。
建筑标签和过滤器
自定义标签和过滤器位于 Django 应用程序的templatetags/目录中。您可以使用{% load %}标签将该目录中的任何文件导入到模板中。您创建的模块的名称将是您用来加载标记库的名称。
对于这个项目,结构将如下所示:
dinosoar/dinofacts/templatetags/
├── __init__.py
└── dinotags.py
这个目录像任何其他 Python 代码一样是一个模块,所以它需要__init__.py文件。dinotags.py文件将包含定制标签和过滤器的所有代码。
正如您将很快了解到的,过滤器是函数。标签可以是函数,也可以是类,这取决于它们的复杂性。仅仅编写函数和类是不够的——您还需要向 Django 注册代码。
注册需要一个Library类的实例,然后您可以用它作为装饰器来包装您的标签和过滤器。以下代码是内置过滤器lower的简化版本:
1from django import template
2
3register = template.Library()
4
5@register.filter
6def lower(value):
7 return value.lower()
想想这个例子是如何工作的:
- 1 号线导入 Django 的
template模块。 - 第 3 行创建一个用于注册的
Library实例。 - 第 5 行使用
Library实例的filter方法作为装饰器。这告诉 Djangolower()函数是一个过滤器。 - 第 6 行到第 7 行定义了实现过滤器的函数。筛选后的值是函数的第一个参数。该实现假设该值是一个字符串。调用字符串的
.lower()方法并返回结果。从过滤函数返回的内容会在模板中呈现。
Library对象提供了注册标签和过滤器的方法。您可以直接调用这些方法,但是更好的方法是将它们用作装饰器。修饰函数可以让其他程序员清楚地知道它是作为标签或过滤器注册的。
编写 Django 模板自定义过滤器
您设置了您的项目并编写了一个用于测试的视图。然后,您使用了内置标签和过滤器以及从库中加载的标签。在上一节中,您学习了如何注册标签和过滤器。在本节中,您已经准备好编写您的第一个 Django 自定义过滤器了!
作为函数的过滤器
如前所述,过滤器是 Python 函数。最基本的过滤器只有一个参数:要过滤的值。模板引擎呈现过滤函数的结果。
首先,您将编写一个过滤器来呈现由列表中每一项的首字母组成的字符串。如果您还没有,您需要设置您的模板标记文件:
$ pwd
/home/realpython/dinosoar
$ mkdir dinofacts/templatetags
$ touch dinofacts/templatetags/__init__.py
有了这个结构,创建或编辑名为dinosoar/dinofacts/templatetags/dinotags.py的模板标记文件:
1# dinosoar/dinofacts/templatetags/dinotags.py
2
3from django import template
4
5register = template.Library()
6
7@register.filter
8def first_letters(iterable):
9 result = ""
10 for item in iterable:
11 result += item[0]
12
13 return result
上面的代码注册了一个名为first_letters的过滤器。该函数需要一个 iterable,如 list。它遍历列表并构建result字符串。如果要过滤的值是一个字符串列表,那么result就是每个字符串的第一个字母。
要使用这个过滤器,创建dinosoar/templates/raptor.html:
1<!-- dinosoar/templates/raptor.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Velociraptor</h1>
9
10<p>
11 The Velociraptor (swift seizer) was made famous by their appearance
12 in the movie <i>Jurassic Park</i>. Unlike in the movie, these
13 dinosaurs were smaller, about the size of a turkey. They shared
14 something else with turkeys: they likely had feathers.
15
16</p>
17<p>
18 The first letters of our dinosaur variable are {{dinosaurs|first_letters}}.
19
20</p>
21
22{% endblock content %}
模板准备就绪后,请访问http://127.0.0.1:8000/show_dino/raptor/查看结果:

回想一下dinofacts/views.py中的dinosaurs值是一个包含"Tyrannosaurus"、"Stegosaurus"、"Raptor"和"Triceratops"的列表。上面的结果是这些强大的爬行动物的第一个字母:"TSRT"。
过滤器也可以接受参数。现在,您将通过编写一个返回 iterable 中每一项的第 n 个字母的过滤器来增强first_letters的能力。将此功能添加到dinotags.py:
23# dinosoar/dinofacts/templatetags/dinotags.py
24
25@register.filter(name="nth_letters", is_safe=True)
26def other_letters(iterable, num):
27 result = ""
28 for item in iterable:
29 if len(item) <= num or not item[num - 1].isalpha():
30 result += " "
31 else:
32 result += item[num - 1]
33
34 return result
这里发生了一些新的事情:
- 第 25 行将
name参数添加到@register.filter()装饰器中。这使得模板中的过滤器名称不同于实现函数。这里,过滤器被命名为nth_letters,尽管实现它的函数是other_letters()。请注意,is_safe=True向 Django 表明这个过滤器的输出不包含会破坏 HTML 的字符。您将在下面对此进行更多的探索。 - 第 26 行定义了函数。要筛选的值是第一个参数,筛选器的参数是第二个。
- 第 28 到 32 行遍历该值并构建结果字符串。
- 29 线是安全检查。如果您在八个字母的字符串中查找第十个索引,它将使用一个空格(
" ")来代替。另外,如果第 n 个字符不是一个字母,你可以使用一个空格来避免意外返回破坏 HTML 的字符。 - 第 34 行返回要渲染的
result字符串。
在 HTML 中安全地使用字符串是一个很深的话题。HTML 由带有某些字符的字符串组成,这些字符改变了浏览器显示页面的方式。您必须小心传递给呈现引擎的字符串数据,如果数据是用户输入的,就更要小心了。
Django 用一个名为SafeString的类扩展了原始 Python 字符串。一个SafeString对象有额外的信息在里面,指示模板引擎是否应该在渲染之前对它进行转义。
当 Django 渲染一个模板时,部分模板可能处于自动退出模式。这些区域自动对里面的值进行转义,所以 Django 会把任何麻烦的字符变成相应的 HTML 实体进行显示。有时你渲染的值应该包含 HTML,所以它们需要被标记为安全的。
在上面的例子中,registration decorator 的is_safe=True参数告诉 Django,这个过滤器保证不输出任何麻烦的字符。传递给过滤器的安全字符串不会被 Django 转义。is_safe的默认值是False。
请注意,is_safe=True是而不是将您的过滤结果标记为安全。那是你要负责的一个单独的步骤。对上面的.isalpha()的调用确保了这个函数的所有输出都是安全的,所以不需要额外的步骤。
确定过滤器是否安全时要小心,尤其是删除字符时。移除所有分号的过滤器会破坏依赖分号的 HTML 实体,如 & 。
要使用nth_letters滤镜,请创建dinosoar/templates/alberto.html:
1<!-- dinosoar/templates/alberto.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Albertosaurus</h1>
9
10<p>
11 Albertosaurus ('Alberta lizard') is a smaller cousin of
12 the T-Rex. These dinosaurs were named after the location
13 of their first discovery, Alberta, Canada.
14
15</p>
16
17<p>
18 The nth letters of our dinosaur variable are:
19 <ul>
20 <li> 3rd: "{{dinosaurs|nth_letters:3}}"</li>
21 <li> 5th: "{{dinosaurs|nth_letters:5}}"</li>
22 <li> 10th: "{{dinosaurs|nth_letters:10}}"</li>
23 </ul>
24</p>
25
26{% endblock content %}
访问http://127.0.0.1:8000/show_dino/alberto/以获得结果 HTML:
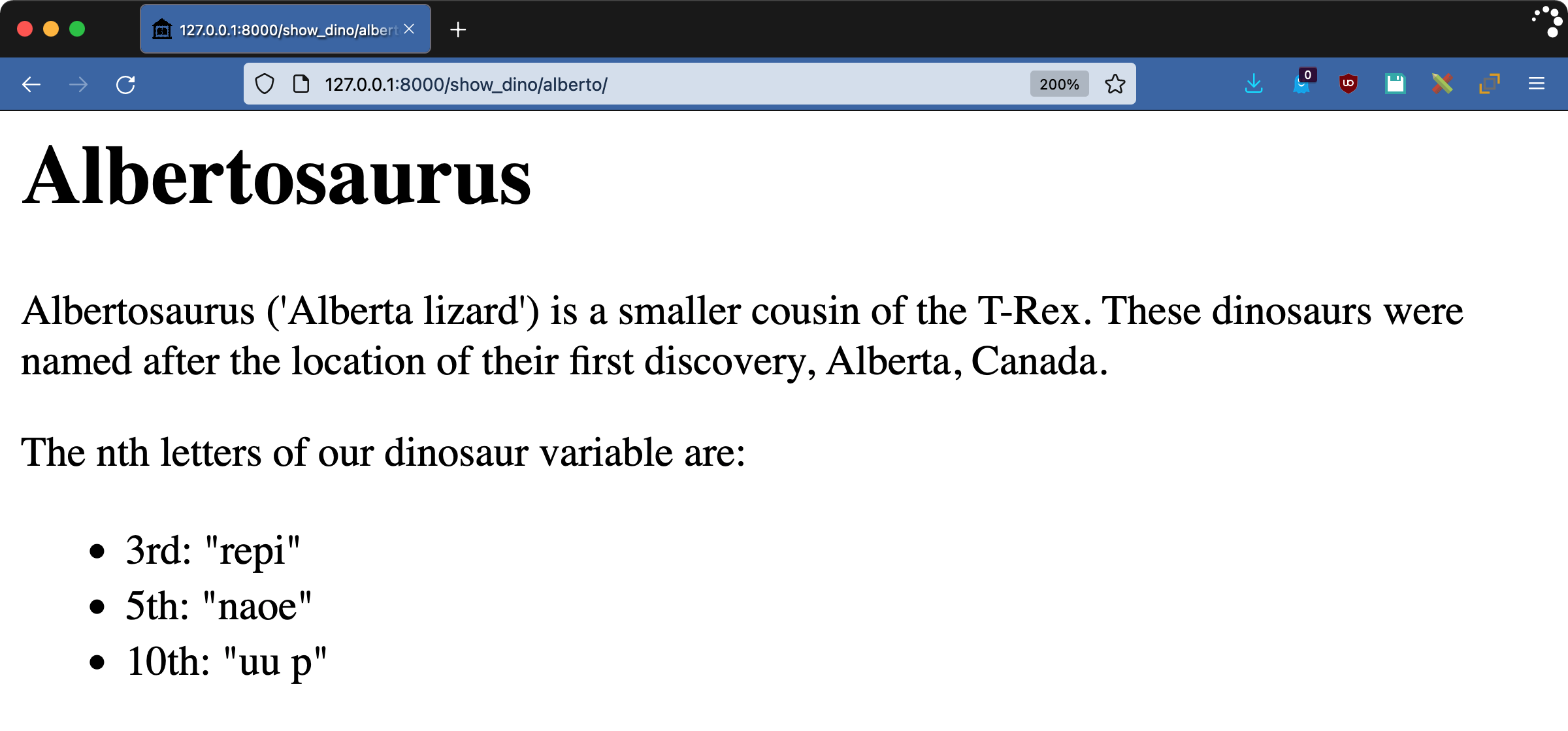
浏览文本并检查您的nth_letters过滤器是否如您所愿地工作。
加拿大蜥蜴可能不是国王,但你可能仍然不想在黑暗的小巷里遇见它。
字符串过滤器
筛选器参数的数据类型是模板中使用的值的数据类型。HTML 文档中最常见的数据类型是字符串。Django 提供了一种将过滤器的输入强制转换成字符串的方法,因此您不必手动完成这项工作。现在,您将编写一个新的过滤器,输出一个总结字符串中某个字母出现次数的句子。
将以下内容添加到您的dinotags.py文件中:
35# dinosoar/dinofacts/templatetags/dinotags.py
36
37from django.template.defaultfilters import stringfilter
38from django.utils.html import conditional_escape, mark_safe
39
40@register.filter(needs_autoescape=True)
41@stringfilter
42def letter_count(value, letter, autoescape=True):
43 if autoescape:
44 value = conditional_escape(value)
45
46 result = (
47 f"<i>{value}</i> has <b>{value.count(letter)}</b> "
48 f"instance(s) of the letter <b>{letter}</b>"
49 )
50
51 return mark_safe(result)
第 41 行的@stringfilter装饰符表示这个过滤器只接受字符串。Django 在将过滤器的值传递给过滤器之前,将其转换为一个字符串。这个函数中还有其他一些有趣的事情:
- 第 40 行使用注册装饰器中的
needs_autoescape参数。这告诉 Django 向过滤函数添加另一个参数:autoescape。此参数的值将指示对于此筛选器的范围,自动转义是打开还是关闭。 - 第 42 行声明了过滤函数,并包含了上面提到的
autoescape参数。这个参数应该默认为True,这样如果你的代码直接调用这个函数,你就处于自动转义模式。 - 第 43 至 44 行如果
autoescape为True,用conditional_escape()的结果替换value。conditional_escape()函数对字符串进行转义,但它足够聪明,不会对已经转义的内容进行转义。 - 第 46 到 49 行构建返回字符串。因为
letter_count过滤器输出带有粗体和斜体标签的 HTML,所以它必须能够自动转义。第 47 行上的 f 字符串使用了value的内容,根据需要,它在第 43 到 44 行中被适当地转义。result字符串包含斜体的value,粗体的字母 count。 - 行 51 在
result变量上调用mark_safe()。因为过滤器正在输出应该显示的 HTML,所以该函数必须将字符串标记为安全。这告诉 Django 不要对内容进行进一步的转义,这样粗体和斜体标签就可以在浏览器中呈现出来。
为了测试这个过滤器,在dinosoar/templates/mosa.html中创建以下内容:
1<!-- dinosoar/templates/mosa.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Mosasaurus</h1>
9
10<p>
11 Mosasaurus ('Meuse River lizard') was an aquatic reptile that lived in
12 the Late Cretaceous. Estimated lengths reach up to 17 meters
13 (56 feet)! {{"Mosasaurus"|letter_count:"s"}}
14
15</p>
16
17{% endblock content %}
启动您的开发服务器并转到http://127.0.0.1:8000/show_dino/mosa/查看以下结果:

装饰器是一个快捷的方式,确保你的过滤器只需要处理字符串。needs_autoescape参数及其对应的autoescape参数让您可以细粒度地控制过滤器做什么和不做什么自动转义。
日期过滤器
日期和时区可能是很难处理的事情。在网站上处理这些问题还有一个额外的难题:谁的时区?服务器的?用户的?还有别的吗?
Django 有内置工具来帮助处理这个问题。Django 解决方案的一部分是两个关键设置:
USE_TZTIME_ZONE
当USE_TZ为True时,Django 根据您在TIME_ZONE中设置的时区进行所有日期工作。默认设置为 UTC 。
很容易忘记模板渲染发生在服务器端。每个访问者都有自己的页面,所以很自然地认为浏览器是负责任的。然而,由于渲染确实发生在服务器上,所以服务器的时区就是所使用的时区——除非 Django 的设置另有规定。服务器的时区和 Django 的设置都不必与用户的时区相对应。
这使得过滤器和日期变得复杂。为此,过滤器注册支持一个名为expects_localtime的参数。当expects_localtime为True时,Django 将datetime对象转换为配置的时区。要了解这是如何工作的,将下面的代码添加到dinotags.py中:
57# dinosoar/dinofacts/templatetags/dinotags.py
58
59@register.filter(expects_localtime=True)
60def bold_time(when):
61 return mark_safe(f"<b>{when}</b>")
此筛选器返回 datetime 对象中传递的粗体版本。没有过滤器也有更好的方法,但那不会显示时区效果。在上面的代码中将expects_localtime设置为True后,Django 将呈现一个日期时间对象,该对象被移动到由TIME_ZONE设置指定的时区中。为了玩这个游戏,创建dinosoar/templates/ptero.html:
1<!-- dinosoar/templates/ptero.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Pterodactyl</h1>
9
10<p>
11 Pterodactyl ('winged finger') is the common name for Pterodactylus,
12 the first of the genus pterosaur to be identified as a flying
13 reptile. This species is thought to have gone extinct 150 million
14 years ago, which is a long time before now ({{now|bold_time}}).
15
16</p>
17
18{% endblock content %}
访问页面http://127.0.0.1:8000/show_dino/ptero/查看过滤器的运行情况:
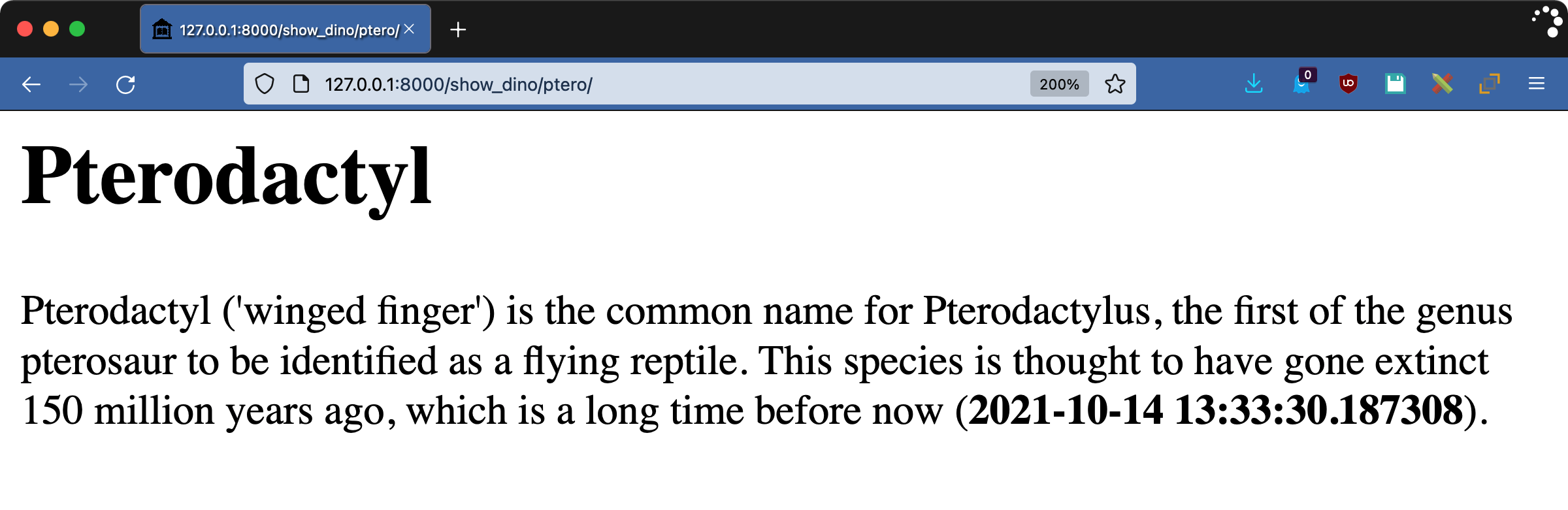
要查看差异,编辑dinosoar/dinosoar/settings.py并更改USE_TZ或TIME_ZONE的值,然后重新加载页面。根据您的选择,时间甚至可能是日期都会改变。
自定义过滤器可以让您更好地控制 HTML 输出。它们使您能够通过可重用的组件来更改数据的外观。然而,由于过滤器是以数据为中心的,它们是有限的。要完全控制一个块,您需要自定义标记。
编写 Django 模板定制标签
滤镜对单个值进行操作,修改它们的渲染方式。标签比这灵活得多,允许您插入或修改内容块以及操纵数据上下文。
与过滤器一样,您可以通过以下方式使用标签:
- 在应用程序的
templatetags/目录中的模块中声明它们 - 使用一个
Library实例注册它们 - 将实现为函数
此外,对于更复杂的标签,可以使用呈现类来代替函数。这是实现呈现块的标签所必需的。
使用简单标签
为了让标记编写更加简单,Django 使用了@simple_tag装饰器。在结构上,这类似于一个过滤器:你注册一个函数作为标签,Django 呈现它的返回值。与过滤器不同,标签不与值相关联。他们只能靠自己了。通过编辑dinosoar/dinofacts/templatetags/dinotags.py文件,您将从最简单的简单标记开始:
57# dinosoar/dinofacts/templatetags/dinotags.py
58
59@register.simple_tag
60def mute(*args):
61 return ""
Django 的{% comment %}标签是一个块,需要大量的输入。上面的标签是同一想法的一个更基本的版本:任何作为参数传入标签的内容都会被忽略,Django 将标签呈现为一个空字符串。创建dinosoar/templates/rex.html来测试您的mute标签:
1<!-- dinosoar/templates/rex.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Tyrannosaurus {% mute "The King" %} Rex</h1>
9
10<p>
11 Tyrannosaurus rex ('lizard-tyrant king'), or T-Rex for short, is the
12 largest of a genus of theropods.
13
14 It had very {% mute "chomp chomp chomp" %} big teeth.
15</p>
16
17{% endblock content %}
访问页面http://127.0.0.1:8000/show_dino/rex/查看过滤器的运行情况:
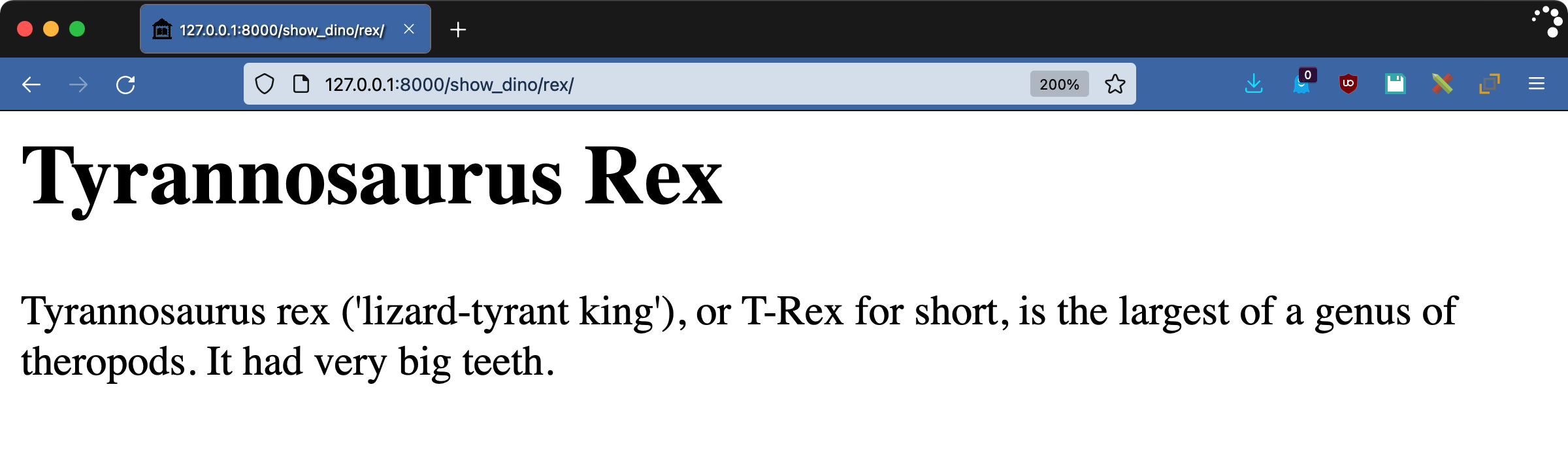
结果没什么看头,这才是重点。标签内的所有内容都被删除了。
逸出内容
标签和过滤器一样,必须考虑它们生成的内容对 HTML 是否安全。用@simple_tag创建的标签会自动转义,但是如果包含 HTML,仍然需要将它们的内容标记为安全。
考虑下面的标记,它接受一个列表并呈现一个 HTML 项目符号列表。打开dinotags.py并添加以下功能:
71# dinosoar/dinofacts/templatetags/dinotags.py
72
73from django.utils.html import escape, mark_safe
74
75@register.simple_tag
76def make_ul(iterable):
77 content = ["<ul>"]
78 for item in iterable:
79 content.append(f"<li>{escape(item)}</li>")
80
81 content.append("</ul>")
82 content = "".join(content)
83 return mark_safe(content)
这个函数接受一个 iterable——比如一个 list——并将它的每一项包装在一个 HTML <li>块中。注意第 79 行中escape()的使用。你不想相信传入标签的内容。content变量是一个列表,以<ul>标签开始,附加每一项,然后以相应的结束</ul>标签结束。所有的东西都被连接成一个字符串,这个字符串被标记为安全。
通过创建dinosoar/templates/bronto.html在模板中使用make_ul:
1<!-- dinosoar/templates/bronto.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Brontosaurus</h1>
9
10<p>
11 Brontosaurus (thunder lizard) is a long necked quadruped whose existence
12 was debated for a long time, with original finds being found to be
13 composed of different animals. In 2015 the name was resurrected after
14 an extensive study showed that there was a distinction between it and
15 its cousin the Apatosaurus.
16
17</p>
18
19<h2>Other Dinosaurs</h2>
20
21{% make_ul dinosaurs %}
22
23{% endblock content %}
访问http://127.0.0.1:8000/show_dino/bronto/获取结果:
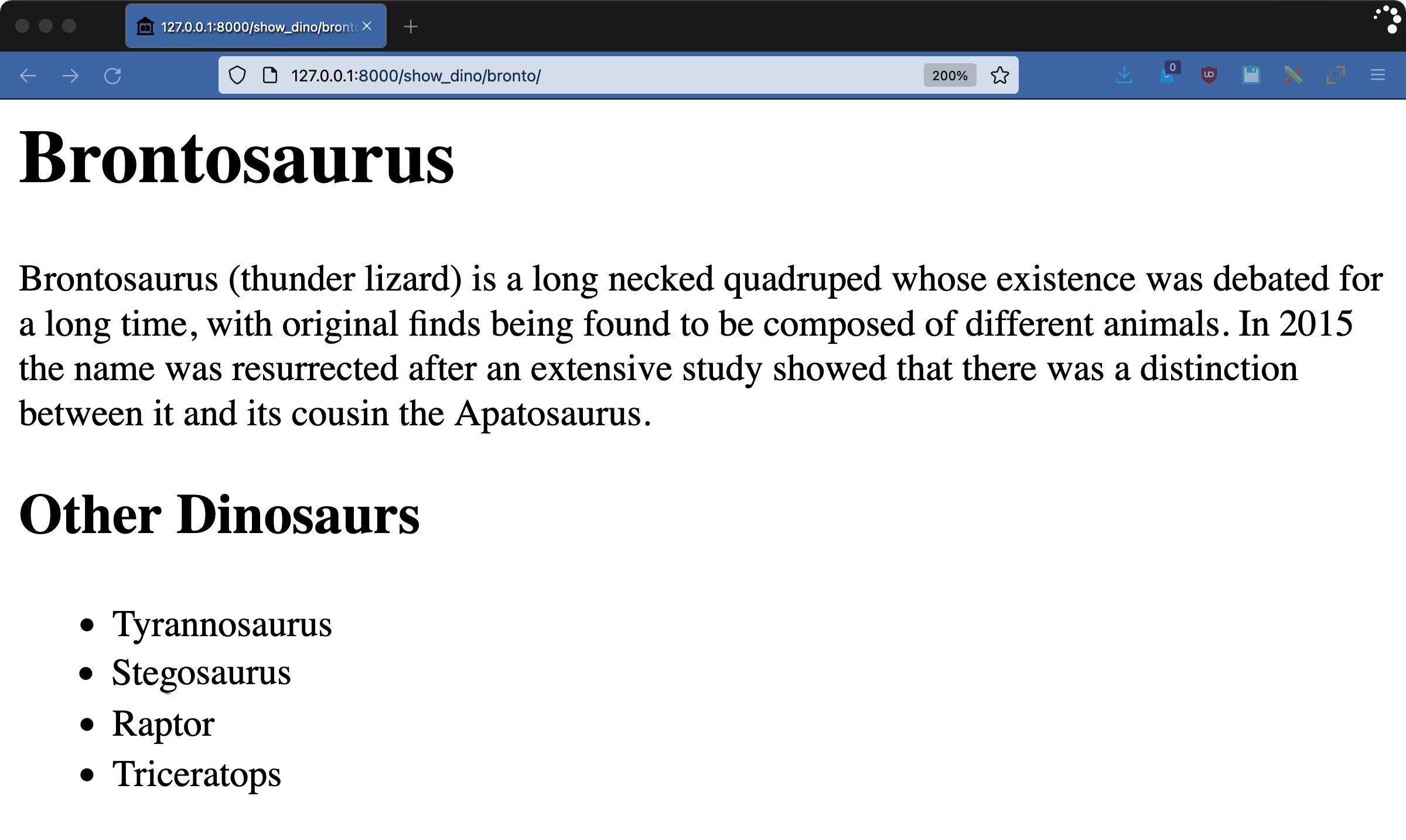
在dinosoar/dinofacts/views.py中摆弄show_dino()视图中的dinosaurs值,看看转义是如何工作的。例如,给"Tyrannosaurus"添加粗体标签,使其成为"<b>Tyrannosaurus</b>",您将看到显示的标签,而不是真正的粗体。
使用上下文
当您的视图呈现模板时,您可以通过一个名为 Context 的字典将数据传递给模板引擎。页面中呈现的所有值都来自于Context对象,您可以从标签中获取和设置它们。在dinotags.py中创建一个新标签:
87# dinosoar/dinofacts/templatetags/dinotags.py
88
89@register.simple_tag(takes_context=True)
90def dino_list(context, title):
91 output = [f"<h2>{title}</h2><ul>"]
92 for dino in context["dinosaurs"]:
93 output.append(f"<li>{escape(dino)}</li>")
94
95 output.append("</ul>")
96 output = "".join(output)
97
98 context["weight"] = "20 tons"
99 return mark_safe(output)
这段代码与make_ul相似,但有一些关键的变化:
- 第 89 行将
takes_context参数添加到标签注册调用中。将这个设置为True告诉 Django 向包含Context对象的标签函数调用添加一个参数。 - 第 90 行声明了标签的功能。请注意,
context参数在最前面。标签可以接受可变数量的参数,所以context必须排在前面。 - 第 92 行像字典一样访问
context参数,获得dinosaurs的值,这与许多其他示例中使用的恐龙列表相同。 - 第 98 行使用键
"weight"将字符串"20 tons"写入上下文。
创建一个名为dinosoar/templates/apato.html的新文件来测试这个标签:
1<!-- dinosoar/templates/apato.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Apatosaurus</h1>
9
10<p>
11 Apatosaurus (deceptive lizard) is a long necked quadruped that when
12 originally discovered was confused with parts of what is now called
13 a Brontosaurus. Apatosaurus weighed on average {{weight}}.
14
15</p>
16
17{% dino_list "Other Big Lizards" %}
18
19<p>
20 Let's try this again: Apatosaurus weighed on average {{weight}}.
21</p>
22
23{% endblock content %}
注意第 13 行和第 20 行中使用的值weight。第一次使用在{% dino_list %}标签之前,第二次使用在之后。由于weight的值是作为标签的副作用添加的,所以第一个实例应该是未定义的,因此是空白的。
上下文改变的范围严格地在渲染引擎内。修改上下文字典不会影响视图中的任何原始值。请前往http://127.0.0.1:8000/show_dino/apato/试用该模板:
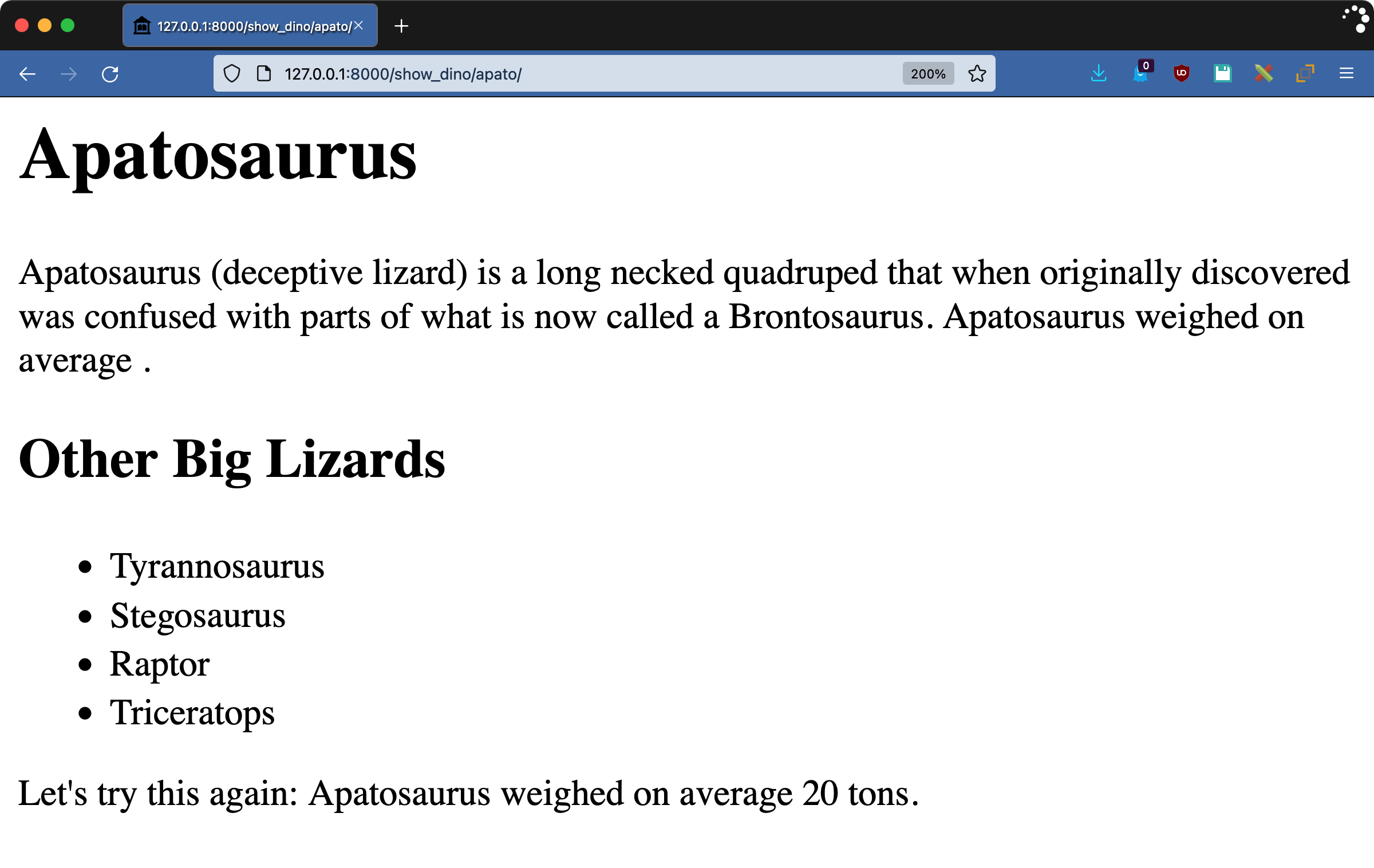
正如承诺的那样,这句话虚龙平均体重相当突然地结束了。在模板引擎渲染标签之前,weight的值不会被赋值。在标签中使用上下文是一个强大的工具,可以在标签之间进行通信,或者保存多次运行的标签的状态。
编写包含标签
模板引擎呈现标签函数返回的任何内容。正如您在前面的示例中所探索的,您经常在标记中编写 HTML 代码片段。在字符串中编写 HTML 可能很麻烦,因此包含标记为您提供了另一种实现方式:您的标记本身可以使用模板。要了解这是如何实现的,首先创建子模板dinosoar/templates/sublist.html:
1<!-- dinosoar/templates/sublist.html -->
2
3<ul>
4 {% for item in iterator %}
5 <li>{{item}}</li>
6 {% endfor %}
7</ul>
您的标签将使用此模板。现在您可以将下面的标签函数添加到dinotags.py:
103# dinosoar/dinofacts/templatetags/dinotags.py
104
105@register.inclusion_tag("sublist.html")
106def include_list(iterator):
107 return {"iterator": iterator}
sublist.html模板和这个新标签的组合实现了和make_ul相同的功能,但是代码更少。@inclusion_tag装饰器指定用这个标签呈现哪个模板,标签函数返回一个字典作为模板中的上下文。
要查看结果,创建一个名为dinosoar/templates/brachio.html的测试页面:
1<!-- dinosoar/templates/brachio.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Brachiosaurus</h1>
9
10<p>
11 Brachiosaurus (arm lizard) is yet another long-necked quadruped.
12
13</p>
14
15<h2> Using include_list </h2>
16{% include_list dinosaurs %}
17
18{% endblock content %}
转到常用视图查看页面http://127.0.0.1:8000/show_dino/brachio/:
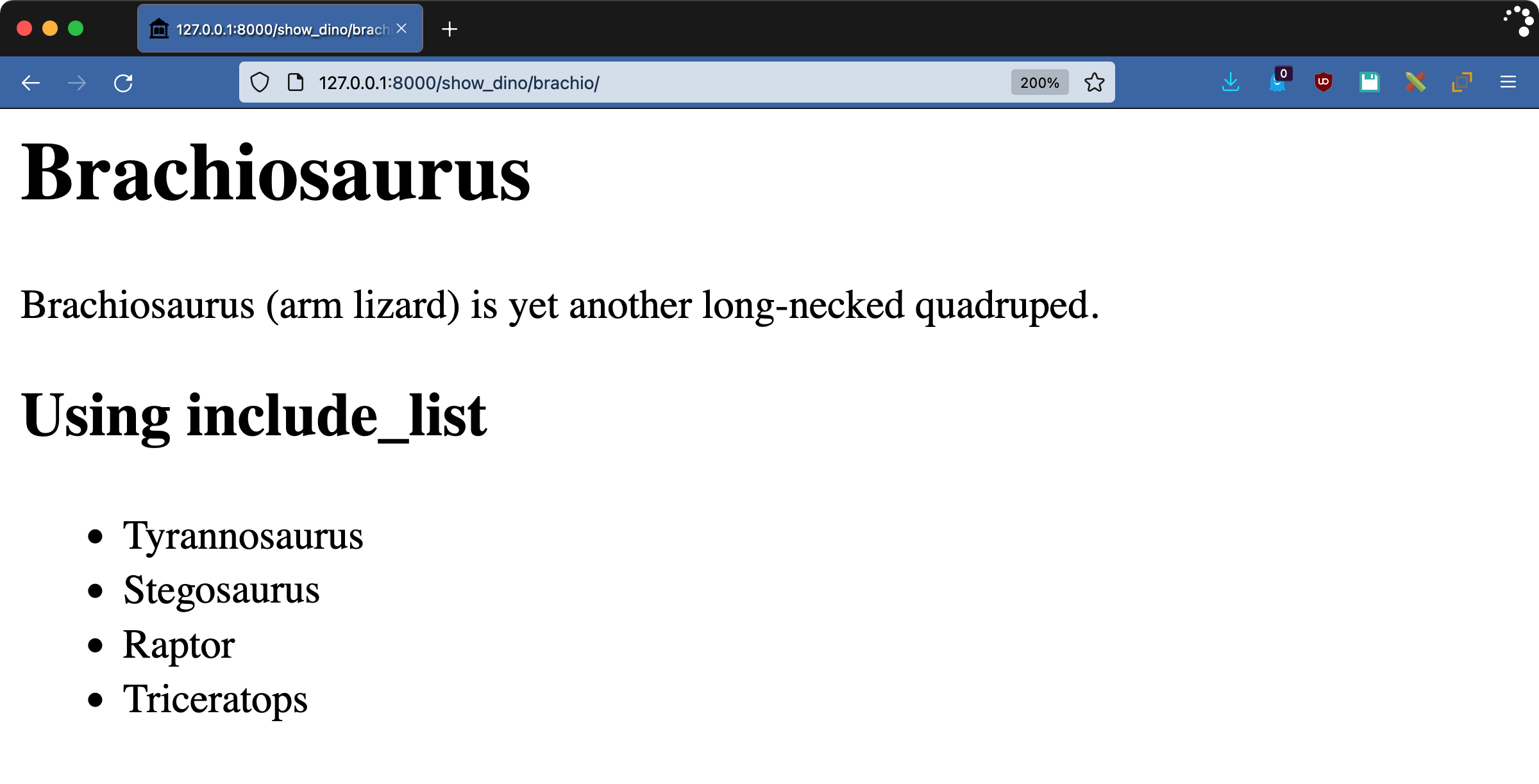
如果你正在编写一个使用大量 HTML 的标签,使用@inclusion_tag是一个更好的方法来保持 HTML 与代码的分离。
创建高级定制标签
简单标签是为渲染引擎编写标签以替换内联标签的一种快捷方式。你不能用一个简单的标签做的事情是建立封闭的区域。考虑一下{% comment %}和{% endcomment %}是如何配对在一起的,去掉它们之间的所有东西。在本节中,您将探索如何构建高级 Django 定制标记。
解析内容
要构建成对的 block 标签,您需要实现一个扩展django.template.Node的类。这个类负责呈现标签。Django 提供了一个实用程序来解析成对的 block 标签之间的内容,然后传递给你的Node类进行渲染。
为了演示成对的块标签,您将实现一个 Markdown 呈现标签。一个名为mistune的库已经为此做了大量工作。使用pip安装mistune:
1$ python -m pip install mistune==0.8.4
在写这篇教程的时候,mistune正在经历一次大修。2.0 版本处于测试阶段,与这里展示的例子有很大的不同。确保安装版本 0.8.4,或者准备调整对库的调用。
将以下代码添加到dinosoar/dinofacts/templatetags/dinotags.py:
109# dinosoar/dinofacts/templatetags/dinotags.py
110
111import mistune
112
113@register.tag(name="markdown")
114def do_markdown(parser, token):
115 nodelist = parser.parse(("endmarkdown",))
116 parser.delete_first_token()
117 return MarkdownNode(nodelist)
118
119class MarkdownNode(template.Node):
120 def __init__(self, nodelist):
121 self.nodelist = nodelist
122
123 def render(self, context):
124 content = self.nodelist.render(context)
125 result = mistune.markdown(str(content))
126 return result
要构建块标记,您需要一个函数和一个类。它们是这样工作的:
- 第 113 行将
do_markdown()功能注册为标签。注意,它使用了name参数来命名标签,并且使用了.tag()装饰器,而不是.simple_tag()。 - 第 114 行声明了标签。参数不同于简单的标记,它带有一个解析器和一个令牌。解析器是对模板引擎解析模板的解析器的引用。在这种情况下,您不需要使用
token参数,稍后您将探索它。 - 第 115 行使用
parser对象继续解析模板,直到它看到结束标签,在本例中为{% endmarkdown %}。 - 第 116 行调用
.delete_first_token()删除开始标签。传递给Node类的只是开始和结束标记之间的内容。 - 第 117 行实例化呈现模板的
Node类,模板引擎从解析后的标记块传入标记。 - 第 119 到 121 行声明并初始化
Node类。 - 第 123 到 126 行呈现内容。对于这个标签,需要使用
mistune将标签块从 Markdown 转换成 HTML。 - 行 124 调用
.render()块的内容。这确保了任何嵌入的模板内容得到处理,并允许您在嵌入的 Markdown 中使用值和过滤器。 - 第 125 行将呈现的内容转换成字符串,然后使用
mistune将其转换成 HTML。 - 第 126 行返回要插入到渲染页面中的结果。请注意,结果是而不是自动转义。Django 希望你知道如何保护你的用户免受 HTML 攻击,如果你正在写一个高级标签的话。
现在,您将使用一些降价内容来测试这个新标签。创建dinosoar/templates/steg.html:
1<!-- dinosoar/templates/steg.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Stegosaurus</h1>
9
10<p>
11{% markdown %}
12**Stegosaurus** ('roof-lizard') is a four-legged plant eater from the
13*Late Jurassic*. It had:
14
15* Bony back plates
16* Large hindquarters
17* A tail tipped with spikes
18{% endmarkdown %}
19</p>
20
21{% endblock content %}
将http://127.0.0.1:8000/show_dino/steg/加载到您的浏览器中查看成品:
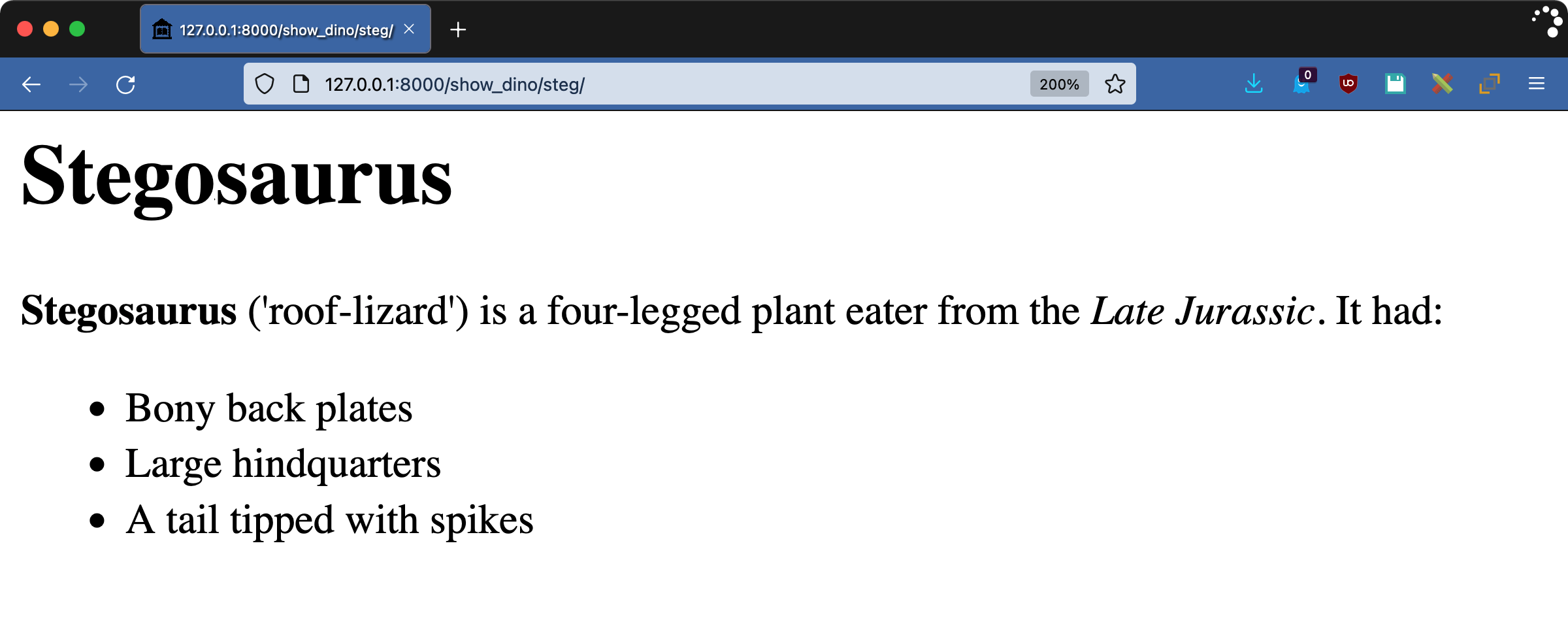
模板引擎将块标签对中的降价呈现为 HTML。使用 Markdown 时要记住的一点是缩进是有意义的。如果标签及其内容没有左对齐,mistune库就不能正确地转换它。这类似于在 HTML 中使用一个<pre>标签。突然间,间距变得很重要。
渲染内容
是时候深入研究块标签了。要查看解析器如何处理标签的内容,将以下内容添加到dinotags.py:
130# dinosoar/dinofacts/templatetags/dinotags.py
131
132@register.tag()
133def shownodes(parser, token):
134 nodelist = parser.parse(("endshownodes",))
135 parser.delete_first_token()
136 return ShowNodesNode(token, nodelist)
137
138class ShowNodesNode(template.Node):
139 def __init__(self, token, nodelist):
140 self.token = token
141 self.nodelist = nodelist
142
143 def render(self, context):
144 result = [
145 "<ul><li>Token info:</li><ul>",
146 ]
147
148 for part in self.token.split_contents():
149 content = escape(str(part))
150 result.append(f"<li>{content}</li>")
151
152 result.append("</ul><li>Block contents:</li><ul>")
153 for node in self.nodelist:
154 content = escape(str(node))
155 result.append(f"<li>{content}</li>")
156
157 result.append("</ul>")
158 return "".join(result)
shownodes()的内容与do_markdown()颇为相似。唯一的不同是,这一次,Node类将把token和解析的内容作为参数。ShowNodesNode的.render()方法执行以下操作:
- 第 144 到 146 行创建一个包含结果的列表。列表以一个 HTML 项目符号列表标签和一个标题开始。
- 第 148 到 150 行通过调用
token.split_contents()遍历令牌的内容。这个标记包含来自开始标记的信息,包括它的参数。令牌的各个部分作为项目符号子列表添加到结果中。 - 第 153 行到第 155 行做了一些类似的事情,但是它们不是对令牌进行操作,而是对块标签的内容进行操作。这个带项目符号的子列表中的每一项都将是从标记块中解析出来的一个标记。
要查看标签解析是如何工作的,创建dinosoar/templates/tri.html并如下使用{% shownodes %}:
1<!-- dinosoar/templates/tri.html -->
2
3{% extends "base.html" %}
4{% load dinotags %}
5
6{% block content %}
7
8<h1>Triceratops</h1>
9
10<p>
11 Triceratops (three-horned face) is a plant eating quadruped from the
12 Late Cretaceous period.
13
14</p>
15
16{% shownodes "pointy face" "stubby tail"%}
17It has a large bony frill around its neck. A fully grown adult weighed
18{{ weight }}. {% comment %} put more info here {% endcomment %}
19{% endshownodes %}
20
21{% endblock content %}
您的{% shownodes %}标签包含一些文本、一个Context值和一个{% comment %}标签。通过访问http://127.0.0.1:8000/show_dino/tri/来看看您的调试标签做了什么:
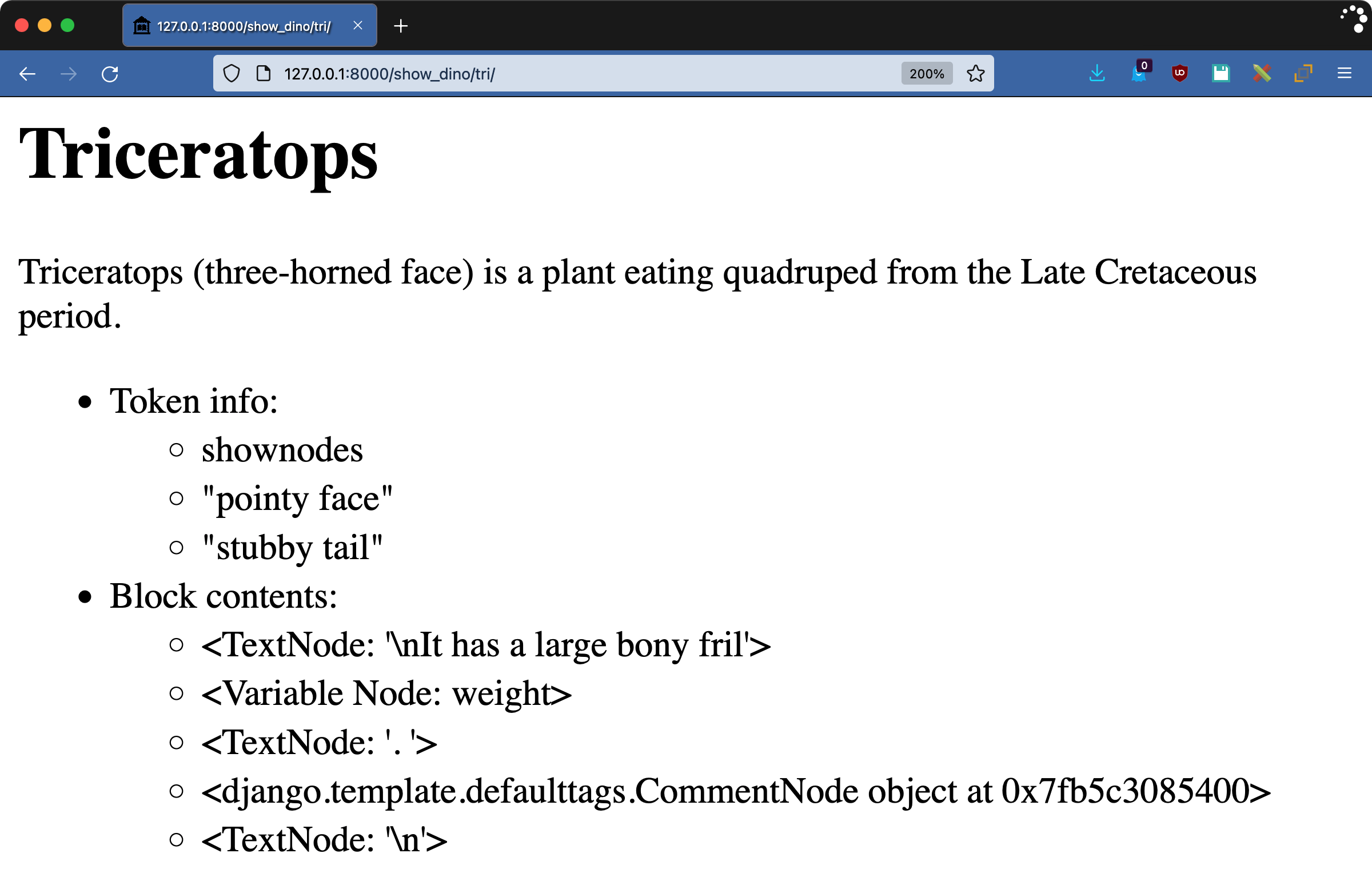
这个页面向您展示了当您编写块级 Django 自定义标记时会发生什么。开始标签有两个参数,"pointy face"和"stubby tail",可以通过token.split_contents()访问。解析器将块内容分成五部分:
- 句子开头部分的宾语
- 一个
VariableNode对象,表示通常会呈现的值weight - 另一个
TextNode对象,结束第一句话 CommentNode一个孩子- 包含最后一个空行的
TextNode对象
通常在 block 标签中,你可以对任何子内容调用.render(),这将解析weight,并在这种情况下删除注释,但是你不必这样做。你的标签块内的任何东西都在你的控制之下。
结论
Django 的结构通过使用视图和模板将业务逻辑与表示代码分离开来。模板语言是有意限制的,以帮助加强这种分离。
Django 的最初开发者试图将 HTML 设计人员的工作从 Python 程序员中分离出来。然而,这并不意味着你被内置的机制所束缚。Django 定制的模板标签和过滤器给了你工具箱中一件有价值的武器。
在本教程中,您学习了:
- 自定义模板标签和过滤器住在哪里
- 如何编写一个自定义过滤器
- 当自动转义会修改你的结果,如何处理
- 如何用
@simple_tag****@inclusion_tag装饰器编写简单的标签 - 关于高级定制标签和解析块标签的内容
有关 Django 的更多信息,请访问 Django 项目的主页。有关标签和过滤器的更多信息,请查阅 Django 文档,尤其是关于内置模板标签和过滤器以及定制模板标签和过滤器的章节。
在 Django for Web Development 学习路径上还有很多关于 Django 的内容可以学习。挖进去,吃下去,咬一大口,然后变成一只姜龙。********
Django 模板:内置标签和过滤器
Django 是用 Python 创建 web 应用程序的强大框架。它的特性包括数据库模型、路由 URL、认证、用户管理、管理工具,以及一个模板语言。您可以根据传递给模板语言的数据编写可重用的 HTML。Django 模板使用标签和过滤器来定义一种类似于 Python 的迷你语言——但不是 Python。
您将通过用于构建可重用 HTML 的标签和过滤器来了解 Django 模板。
在本教程中,您将学习如何:
- 编写、编译和呈现一个 Django 模板
- 使用视图中的
render()快捷键快速使用模板 - 对模板中的条件和循环使用模板标签
- 通过继承和包含创建可重用模板
- 通过模板过滤器修改数据的显示
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
创建 Django 项目
为了试验 Django 模板,您需要一个项目,这样您就可以摆弄代码了。你将建立movie place:世界上最小、最简单的电影网站。关于开始一个新项目的更详细的例子,你可以阅读Django 入门第一部分:建立一个投资组合应用。
Django 不是标准 Python 库的一部分,所以您首先需要安装它。在处理第三方库时,应该使用虚拟环境。对于虚拟环境的复习,你可以阅读 Python 虚拟环境:初级读本。
有了虚拟环境后,运行以下命令开始运行:
1$ python -m pip install django==3.2.5
2$ django-admin startproject moviepalace
3$ cd moviepalace
4$ python manage.py startapp moviefacts
第 1 行使用 pip 将 Django 安装到您的虚拟环境中。在第 2 行,django-admin命令创建了一个名为moviepalace的新 Django 项目。Django 项目由应用程序组成,你的代码就在其中。第四个命令创建一个名为moviefacts的应用程序。
你差不多可以走了。最后一步是告诉 Django 你新创建的moviefacts应用。您可以通过编辑moviepalace/settings.py文件并将"moviefacts"添加到INSTALLED_APPS列表中来实现这一点:
33INSTALLED_APPS = [
34 "django.contrib.admin",
35 "django.contrib.auth",
36 "django.contrib.contenttypes",
37 "django.contrib.sessions",
38 "django.contrib.messages",
39 "django.contrib.staticfiles",
40 "moviefacts", 41]
随着moviefacts注册为一个应用程序,你现在可以编写一个包含模板的视图。
准备使用 Django 模板
Django 是由一家报纸创建的,旨在帮助快速构建网络应用程序。该框架的目标之一是将业务逻辑的关注点从表示逻辑中分离出来。
网页设计师,而不是 Python 程序员,经常在报社做 HTML 开发。正因为如此,开发人员决定不允许在模板语言中执行 Python。这个决定简化了设计者需要知道的东西,并出于安全原因将他们的代码沙箱化。最终的结果是一种独立的迷你语言。这种方法与 PHP 方法形成对比,后者的代码直接嵌入在 HTML 中。
编译和呈现 Django 模板
Django 模板允许您在呈现上下文中动态地改变输出内容。你可以把模板想象成一个格式的信件,信件的内容包括可以插入信息的地方。您可以使用不同的数据多次运行渲染过程,每次都会得到不同的结果。
Django 提供了 Template 和 Context 类来表示正在呈现的字符串模板和生成过程中使用的数据。Context类是 dict 的包装器,提供键值对来填充生成的内容。呈现模板的结果可以是任何文本,但通常是 HTML。Django 毕竟是一个 web 框架。
是时候构建你的第一个模板了。要看到一个实际的例子,你首先需要一个视图。将以下代码添加到moviefacts/views.py:
1# moviefacts/views.py
2from django.http import HttpResponse
3from django.template import Context, Template
4
5def citizen_kane(request):
6 content = """{{movie}} was released in {{year}}"""
7 template = Template(content)
8 context = Context({"movie": "Citizen Kane", "year": 1941})
9
10 result = template.render(context)
11 return HttpResponse(result)
在这个视图中,您可以看到组成 Django 模板语言的一些主要概念:
- 第 6 行包含对
movie和year的引用。这类似于蟒蛇的 f 弦。双括号,或小胡子括号,表示 Django 在呈现模板时替换的项目。 - 第 7 行通过传入指定模板的字符串来实例化一个
Template对象。 - 第 8 行通过用字典填充来创建一个
Context对象。当 Django 呈现模板时,Context对象包含模板可用的所有数据。该模板包含两个要替换的项目:用"Citizen Kane"替换{{movie}},用1941替换{{year}}。 - 第 10 行调用生成结果的
.render()方法。 - 第 11 行返回包装在
HttpResponse对象中的渲染内容。
为了测试这一点,您需要使这个视图在浏览器中可用,因此您需要添加一条路线。修改moviepalace/urls.py如下:
# moviepalace/urls.py
from django.urls import path
from moviefacts import views
urlpatterns = [
path("citizen_kane/", views.citizen_kane),
]
确保您使用的是安装 Django 的虚拟环境,然后运行 Django 开发服务器来查看结果:
$ python manage.py runserver
通过访问http://127.0.0.1:8000/citizen_kane/运行您的视图。
HttpResponse对象将这些内容作为 HTML 返回,但是由于字符串不包含任何标签,您的浏览器将把它视为<body>标签内的文本。它返回格式不正确的 HTML,但是现在已经足够好了。如果一切顺利,您应该看到您的模板呈现了来自您的上下文的数据:
Citizen Kane was released in 1941
你的模板已经编译好了,Django 用Citizen Kane和1941替换了movie和year变量。
配置 Django 加载文件模板
在 web 应用程序中,您最有可能使用模板来输出 HTML——大量的 HTML。Django 模板语言就是为了简化这个过程而构建的。与前面的例子不同,您通常不会在视图中使用模板字符串。相反,您可以从其他文件中加载模板。
要从磁盘加载模板,首先需要告诉 Django 在哪里可以找到它。在moviepalace/settings.py内,修改TEMPLATES中的"DIRS"值:
1TEMPLATES = [
2 {
3 "BACKEND": "django.template.backends.django.DjangoTemplates",
4 "DIRS": [
5 BASE_DIR / "templates", 6 ],
7 "APP_DIRS": True,
8 "OPTIONS": {
9 "context_processors": [
10 "django.template.context_processors.debug",
11 "django.template.context_processors.request",
12 "django.contrib.auth.context_processors.auth",
13 "django.contrib.messages.context_processors.messages",
14 ],
15 },
在django-admin命令创建的默认settings.py文件中,DIRS列表为空。Django 现在将在名为moviepalace/templates的目录中寻找模板。注意,Django 为自己的配置使用了双文件夹结构。比如moviepalace/moviepalace里有settings.py。模板的目录应该在项目根目录中,而不是在配置目录中。
当第 7 行的APP_DIRS为True时,Django 也会在 app 子目录中寻找模板。Django 希望应用程序模板位于应用程序文件夹下名为templates的目录中。
在 Django 3.1 中,settings.py文件中的BASE_DIR参数从使用os.path更改为pathlib:
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
"DIRS": [os.path.join(BASE_DIR, "templates"), ], "APP_DIRS": True,
"OPTIONS": {
"context_processors": [
"django.template.context_processors.debug",
"django.template.context_processors.request",
"django.contrib.auth.context_processors.auth",
"django.contrib.messages.context_processors.messages",
],
},
},
]
如果您使用的是 Django 3.0 或更早版本,DIRS值将需要使用os.path来代替。
你如何决定在哪里存储你的模板?如果你的应用程序可以在其他项目中重用,并且有特定的模板,那么就把模板和应用程序放在一起。否则,请将模板一起保存在项目模板目录中。有关如何构建 Django 项目的更多信息,请参见课程Django 入门中关于 Django 双文件夹结构的课程。
对moviepalace/settings.py文件进行更改后,不要忘记创建templates目录:
$ pwd
/home/realpython/moviepalace
$ mkdir templates
配置完成并创建了目录后,现在就可以从文件中加载模板了。
从文件中加载 Django 模板
让我们使用一个文件来重建公民凯恩体验。创建templates/simple.txt并添加在citizen_kane()视图中使用的模板字符串:
{{movie}} was released in {{year}}
您可以编写代码以字符串的形式加载文件,构建一个Template对象,并做与在citizen_kane()视图中相同的事情,或者您可以使用render()快捷方式,它会为您完成所有这些工作。将以下内容添加到您的moviefacts/views.py文件中:
# moviefacts/views.py
⋮
from django.shortcuts import render
def casablanca(request):
return render(
request, "simple.txt", {"movie": "Casablanca", "year": 1942}
)
新视图就绪后,不要忘记添加到moviepalace/urls.py的路线:
# moviepalace/urls.py
from django.urls import path
from moviefacts import views
urlpatterns = [
path("citizen_kane/", views.citizen_kane),
path("casablanca/", views.casablanca), ]
访问http://127.0.0.1:8000/casablanca/应该会产生与《公民凯恩》相似的结果:
Casablanca was released in 1942
render()快捷方式是渲染模板的常用方式。只在极少数情况下才直接使用Template对象,比如当你想给用户提供模板的能力时。
直接使用Template的一个例子是允许用户输入套用信函。套用信函可能包含变量,如信函的收件人。通过允许用户使用 Django 模板,您可以利用内置的变量替换机制来替换接收者的姓名。
选择模板语言
Django 支持多种模板引擎。它配有两个:
- Django 模板语言:最初的 Django 模板语言,也是您在本教程中学习的语言
- Jinja2 :以前是一个第三方专用的库,现在包含在 Django 中,但不在本教程的讨论范围之内
您可以通过编辑moviepalace/settings.py中的TEMPLATES值来更改使用的模板引擎:
1TEMPLATES = [
2 {
3 "BACKEND": "django.template.backends.django.DjangoTemplates", 4 "DIRS": [
5 BASE_DIR / "templates",
6 ],
7 "APP_DIRS": True,
8 "OPTIONS": {
9 "context_processors": [
10 "django.template.context_processors.debug",
11 "django.template.context_processors.request",
12 "django.contrib.auth.context_processors.auth",
13 "django.contrib.messages.context_processors.messages",
14 ],
15 },
第 3 行的BACKEND设置是指定渲染引擎的地方。通过将BACKEND改为引擎的点路径模块名,您可以选择 Django 模板引擎或 Jinja2 引擎:
django.template.backends.django.DjangoTemplatesdjango.template.backends.jinja2.Jinja2
也可以使用第三方模板引擎。使用它们需要通过pip安装库,并将BACKEND值改为引擎的点路径名。
本教程的其余部分将只关注原始的 Django 模板后端,为您在 Django 项目中创建 HTML 打下坚实的基础。
了解 Django 模板、标签和过滤器
到目前为止,您已经看到了包含简单变量替换的模板。Django 模板语言比这更深入。您可以访问 Python 中的许多结构和控件,除了在它自己的迷你语言中。
Django 模板标签和过滤器
Django 模板语言有三种方式来控制呈现的内容:值、标签和过滤器。你放入模板中的所有东西,如果不是这三者之一,就会像你写的那样呈现出来。在本教程中,您将了解模板语言的三个主要部分:
- 被解释的数据,你用双括号注意,
{{ value }} - 标签,用大括号和百分号标注,
{% tag_name %} - 过滤器,它修改被解释的数据,你用管道操作符(
|)来应用,就像在{{ value | filter }}中一样
正如您在上一节中看到的,当 Django 将模板呈现为文本时,它会使用一个名为Context的特殊字典。上下文是呈现模板的状态。除了包含要用双括号呈现的解释数据之外,Context对象的内容还可以用于做出逻辑决策。
标签就像模板语言的关键字和函数。在 Python 中,关键字和函数提供了控制流和构建代码的工具。同样,Django 的内置标签提供了继承、条件操作、循环、注释和文本管理。例如,{% lorem %}标签在呈现时被替换为样本 lorem ipsum 文本。
Django 过滤器在双括号内运行,允许您改变显示数据的表示方式。例如,date过滤器格式化日期-时间对象,类似于 Python 中的 strftime() 的工作方式。如果Context字典包含一个名为today的datetime对象,{{ today | date:"Y"}}将date过滤器应用于today,返回年份。
本教程的其余部分将引导您了解常见的标签和过滤器,并举例说明如何使用它们。
模板继承和包含
HTML 中有很多样板文件。大多数网站的每个页面都有一个共同的外观。呈现的每个页面经常重复相同的页眉和页脚,包括相同的样式表,并且经常包括相同的用于度量和测量的 JavaScript 文件。手动在每个页面上重复这一过程意味着需要做大量的工作。模板继承和包容的拯救!
有两种方法可以将 Django 模板的各个部分组合在一起。继承的工作方式类似于 Python 中的类继承,模板覆盖了其父类的值。包含将内容从另一个模板注入到该模板中。这类似于 C 编程语言中的#include指令。
要查看这些操作,请创建templates/base.html:
1<!-- templates/base.html -->
2<html>
3<body>
4 {% block heading %}
5 <h1>Movie Palace</h1>
6 {% endblock heading %}
7
8 {% block content %}
9 {% endblock content %}
10</body>
11</html>
这个声明就像是面向对象编程中的一个基类。您可以单独使用它,也可以设置其他模板来继承它。如果这个模板按原样呈现,{% block %}标签的内容将按原样显示。在子进程没有覆盖该块的情况下,这提供了一个有用的缺省值。
在base.html里,有一个标题写着<h1>Movie Palace</h1>,没有内容。当另一个模板继承了这个模板时,奇迹就发生了。在子模板中,可以选择替代任何已定义的块。一种常见的做法是用页面内容填充content块,同时将样板 HTML 留在这个基本文件中。创建一个继承自base.html的模板,名为templates/falcon.html:
1<!-- templates/falcon.html -->
2{% extends "base.html" %}
3
4{% block heading %}
5 {{block.super}}
6 <h2>The stuff that dreams are made of</h2>
7{% endblock heading %}
8
9{% block content %}
10 <p>
11 {% include "simple.txt" %}
12 </p>
13{% endblock content %}
falcon.html文件显示了两件事:继承和包含。您通过使用{% extends %}标签继承了一个父文件。在这里,falcon.html继承了base.html。Django 完整地呈现了base.html文件,除非子文件falcon.html覆盖了一个块。例如,falcon.html中的content部分覆盖了base.html中同名的块。
在block部分中,定义了一个特殊变量:{{block.super}}。该变量包含父块中的任何内容。在第 5 行,父块引入了<h1>Movie Palace</h1>标题,而falcon.html将<h2>添加到第 6 行的块中。
除了继承,还可以做包容。在第 11 行,{% include %}标签插入了simple.txt的内容。这允许您重用 HTML 的片段。这里,它重用了最初为casablanca()视图定义的模板。
要查看所有这些,您需要一个新的视图来渲染它们。在moviefacts/views.py中创建以下内容:
# moviefacts/views.py
⋮
def maltese_falcon(request):
return render(
request,
"falcon.html",
{"movie": "Maltese Falcon", "year": 1941},
)
这个视图与casablanca()几乎相同,除了它渲染falcon.html并传入适当的电影数据。用maltese_falcon视图的路线更新您的moviepalace/urls.py文件,然后访问页面:
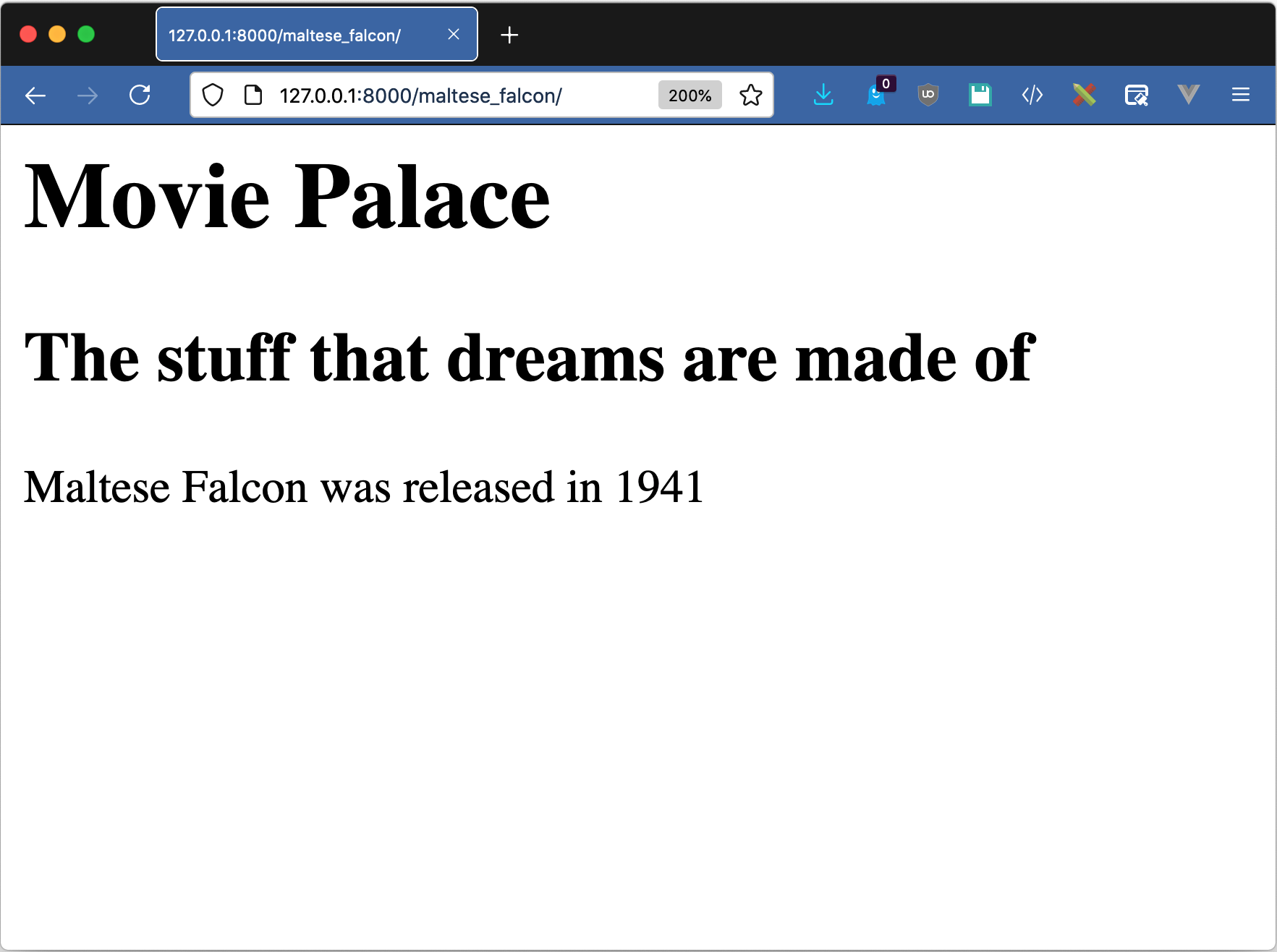
您覆盖了标题,包含了simple.txt,Django 用马耳他之鹰电影数据渲染了它。
在falcon.html内部,{% extends %}标签硬编码了父模板的名称。这是最常见的情况,但是父模板可以在上下文变量中命名。这个技巧允许您在登录状态和公共状态下使用同一个子页面,并根据情况更改父模板。
模板只使用一个层次的继承,但是你并不仅限于此。孙辈可以继承子女,子女又可以继承父母。您可以根据需要使用任意多的图层来组织输出。
探索通用模板标签
您可以利用 Django 3.2.5 包含的超过 25 个内置标签。这些标签就像模板语言的关键字和函数。它们允许你做条件逻辑、循环、继承、文本操作等等。
条件代码
在 Python 中,使用if、elif和else关键字有条件地执行代码。在 Django 模板中,您使用标签来完成同样的事情。
要查看这些标签的运行情况,您需要一个包含更多数据的视图。编辑您的moviefacts/views.py文件并添加以下函数:
# moviefacts/views.py
⋮
def psycho(request):
data = {
"movie": "Psycho",
"year": 1960,
"is_scary": True,
"color": False,
"tomato_meter": 96,
"tomato_audience": 95,
}
return render(request, "psycho.html", data)
为psycho到moviepalace/urls.py增加一条对应的路线,然后创建templates/psycho.html:
1<!-- templates/psycho.html -->
2{% extends "base.html" %}
3
4{% block content %}
5 <p>
6 {{movie}} was released in {{year}}. It was {% if not is_scary %}not
7 {% endif %}scary.
8 </p>
9
10 <p>
11 {% if color %}
12 Color
13 {% else %}
14 Black and white
15 {% endif %}
16 </p>
17
18 <p>
19 {% if THX %}
20 Sound was awesome
21 {% endif %}
22 </p>
23
24 <p>
25 {% if tomato_meter > tomato_audience %}
26 Critics liked it better than audience
27 {% elif tomato_meter == tomato_audience %}
28 Critics liked it the same as audience
29 {% else %}
30 The audience liked it better than the critics
31 {% endif %}
32 </p>
33
34 <p>Copyright <b>MoviePalace</b></p>
35{% endblock content %}
{% if %}标签的工作方式类似于 Python 的if关键字。如果测试的条件是True,那么块被渲染。
- 第 6 行到第 7 行显示了内联 if-conditional 的用法,用
not关键字对is_scary值求反。 - 第 11 到 15 行展示了多行 if-condition 的使用。这个条件块还包含一个
{% else %}子句。然而,与用 Python 编写if语句不同,不要忘记结束的{% endif %}标记。 - 第 19 行检查
THX变量,Django 找不到。不在上下文中的变量被认为是False,所以这个关于声音质量的块不会被渲染。 - 第 25 行到第 31 行显示了使用布尔比较运算符的条件。您可以在标记内使用与 Python 中相同的操作符。
如果您运行开发服务器并访问视图,您会注意到条件标签已经起作用了:
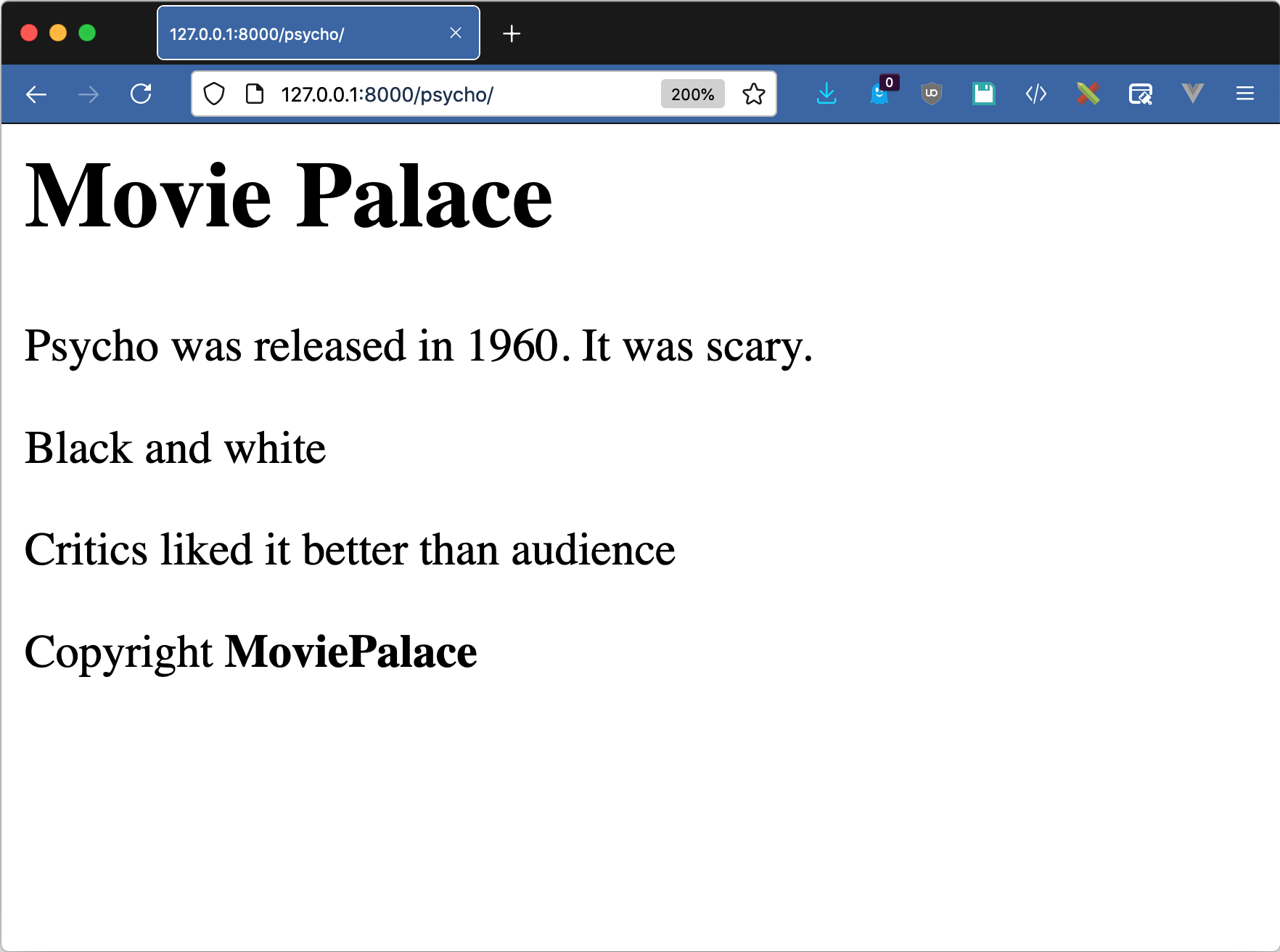
条件标记允许您控制 HTML 块的显示,其功能与 Python 代码中的条件部分相同。摆弄一下psycho()视图中的数据,看看它如何改变条件块的输出。
循环
有一个用于循环的 Django 模板标签:{% for %}。它使用了与 Python 的 for 语句相似的语法,并提供了一些内置变量,这些变量给出了关于您在迭代中所处位置的信息。
到目前为止,电影视图中只有非常少的数据,没有任何东西可以循环。要播放循环,您需要给moviefacts/views.py添加另一个视图:
# moviefacts/views.py
⋮
def listing(request):
data = {
"movies": [
(
"Citizen Kane", # Movie
1941, # Year
),
(
"Casablanca",
1942,
),
(
"Psycho",
1960,
),
]
}
return render(request, "listing.html", data)
这个视图有一个名为movies的上下文变量,它是一个列表。您将要构建的模板将使用循环标签来遍历这个列表。如下创建templates/listing.html:
1<!-- templates/listing.html -->
2{% extends "base.html" %}
3
4{% block content %}
5 <h2> Movies</h2>
6 <ul>
7 {% for movie in movies %}
8 <li>
9 #{{forloop.counter}} {{movie.0}} was released in {{movie.1}}
10 </li>
11 {% endfor %}
12 </ul>
13
14 <h2> Goodies </h2>
15 <ul>
16 {% for goodie in confectionaries %}
17 <li> {{goodie.0}} — ${{goodie.1}}</li>
18 {% empty %}
19 <li> <i>There are no goodies available</i> </li>
20 {% endfor %}
21 </ul>
22{% endblock content %}
第 7 到 11 行包含一个{% for %}块,类似于 Python 中的for关键字。该块在movies上迭代,并在每次循环中分配一个名为movie的局部变量。在代码块内部,您编写了利用双括号对来显示<li>标签内部内容的 HTML。
第 8 到 10 行在每次迭代中重复一次。该循环使用一个名为forloop的特殊对象。这是 Django 在模板上下文中插入的一个局部变量。该对象有几个成员,每个成员都包含有关循环当前迭代的信息:
| 可变的 | 描述 |
|---|---|
forloop.counter |
迭代的从 1 开始的索引号 |
forloop.counter0 |
迭代的从 0 开始的索引号 |
forloop.revcounter |
循环中剩余的迭代次数(1 索引) |
forloop.revcounter0 |
循环中剩余的迭代次数(0 索引) |
forloop.first |
如果这是第一次迭代 |
forloop.last |
如果这是最后一次迭代 |
forloop.parentloop |
包含嵌套循环中父循环的上下文 |
让我们进一步检查循环块内部的代码行:
7<!-- From inside of templates/listing.html -->
8<li>
9 #{{forloop.counter}} {{movie.0}} was released in {{movie.1}}
10</li>
movies的内容是元组列表。每个元组包含电影的名称和年份。Django 模板标签不允许使用下标。不像在 Python 中那样使用方括号来访问元组或列表中的值,而是使用数字作为对象的属性。{{movie.0}}和{{movie.1}}的值是movie元组的第一个和第二个值。
Django 循环还支持一个名为{% empty %}的特殊标签。再次打开listing.html看这个标签的例子:
13<!-- From inside of templates/listing.html -->
14{% for goodie in confectionaries %}
15 <li> {{goodie.0}} — ${{goodie.1}}</li>
16{% empty %}
17 <li> <i>There are no goodies available</i> </li>
18{% endfor %}
这个标签就像一个else子句。如果在{% for %}标签中没有需要迭代的内容,Django 就会运行{% empty %}块。
为了达到同样的效果,{% empty %}标签比将{% for %}块包装在{% if %}块中更方便。在这种情况下,上下文中没有定义confectionaries。Django 模板语言将缺少的值视为空,因此它呈现块的{% empty %}部分。
在moviepalace/urls.py中添加一条路线,启动 Django 开发服务器,然后访问http://127.0.0.1:8000/listing/查看结果:
还支持一个类似循环的标签:{% cycle %}。该标记接受一系列参数,并在每次调用时依次返回每个参数:
{% for movie in movies %}
<tr class="{% cycle 'row1' 'row2' %}">
...
</tr>
{% endfor %}
当{% cycle %}用完所有参数时,它会循环回到起点。这种方法最常见的用途是向表格中添加条纹,交替每一行的样式值:
您可以用一个{% for %}标签获得同样的结果,但是这种方法需要更多的代码。
评论
虽然您可以使用<!-- -->在 HTML 中编写注释,但是下载到用户浏览器的响应包含这些注释。Django 包含一个{% comment %}标签,它的内容被完全去掉:
{% comment %} Nothing to see here!
{% endcomment %}
您还可以在{% comment %}标签中包含一个字符串参数,作为注释。这可能看起来有点奇怪,但是如果您正在注释掉代码,这是很有用的。您使用块来注释掉代码,然后使用注释来提醒自己为什么注释掉代码。
特殊字符
默认情况下,Django 模板渲染器会自动转义它所渲染的任何变量。如果一个字符串包含 HTML 特有的字符,比如 HTML 标签中使用的尖括号(<、>),这样可以防止 HTML 被破坏。{% autoescape %}标签允许你控制这种行为:
{% autoescape off %}
{{ content }}
{% endautoescape %}
{% autoescape %}标签接受一个参数on或off,分别打开或关闭转义机制。考虑以下模板:
<pre>
{% autoescape on %}
Escaped: {{ my_text }}
{% endautoescape %}
{% autoescape off %}
Not Escaped: {{ my_text }}
{% endautoescape %}
</pre>
如果my_text包含"Hello <b>world</b>",呈现的内容将有两个版本的字符串:
autoescape on更改 HTML 特殊字符,使其呈现为字符串中的样子。相比之下,使用autoescape off,粗体标签被传递给浏览器。
所有使用特殊字符的语言都需要一种直接使用这些特殊字符的方法。如果您想要使用表示标签的字符,您可以将它们放在{% verbatim %}标签中:
{% verbatim %}
Django uses mustaches braces to render variables: {{ is_scary }}.
{% endverbatim %}
许多 JavaScript 框架都有自己的模板语言。变量或标签的双括号格式很常见。如果您需要在 Django 模板中包含 JavaScript 模板,那么将它们包装在{% verbatim %}标签中会导致 Django 的模板呈现器忽略它们,让 JavaScript 保留它们。
日期和时间
你经常需要在网站上显示日期和时间信息。Django 模板语言中的{% now %}标签给出了当前的日期和时间。它采用一个字符串参数来指定要显示的日期时间的格式。出于历史原因,格式字符串基于 PHP 的date()函数,而不是 Python 的strftime。在文档中提供了可能的格式字符列表。
标签{% now %}的一个常见用途是显示当前年份作为版权声明的一部分:
<p>Copyright 2012-{% now "Y" %}</p>
上面的例子将呈现从 2012 年到当前年份的版权声明。
URLs
Django 的视图和路由机制有一种内置的方式来命名你的 URL。硬编码 URL 是不好的做法。如果有些东西改变了,那么你必须找出你在代码中使用它的所有时间。您可以使用{% url %}标签,而不是在视图中解析 URL 并将其作为上下文传递:
<a href="{% url 'home_page' filter %}">Home</a>
{% url %}的参数是任何 URL 模式名称,与 Django 的 reverse() 的工作方式相同。它可以选择接受被引用的基础视图的位置或命名参数。
探索关键模板过滤器
正如您之前所学的,Django 模板标签是模板语言的关键字和函数。过滤器就像是在 Django 呈现数据之前就地修改数据的小函数。
通过在变量后添加管道(|)和过滤器名称,可以将过滤器放在双括号内。这是受到了在 Unix shells 中如何通过管道相互发送命令的启发。
现在,您将看到一些用于字符串、列表、日期和时间的常见过滤器,以及展示如何使用它们的示例。
字符串过滤器
过滤器可以对各种数据进行操作。它们中的许多直接对应于具有相同目的的 Python 函数。upper过滤器与 Python 中的str.upper()方法相同。使用它将变量的内容改为大写。通过修改templates/listing.html,将upper过滤器添加到movie.0变量中来尝试一下:
<!-- templates/listing.html -->
{% extends "base.html" %}
{% block content %}
<h2> Movies</h2>
<ul>
<li>
#{{forloop.counter}} {{movie.0|upper}} was released in {{movie.1}} </li>
⋮
随着上面的变化,列表中的每个电影名称都将出现在 shour-case 中。毫不奇怪,也有一个相应的lower过滤器。
center滤镜将填充添加到字符串的两边。填充是一个空格字符,因此根据您的字体和包装它的标签,此过滤器的效果可能有限:
<pre>{{value}} becomes *{{ value|center:"16" }}*</pre>
如果value包含"Elephant",此示例会在每边产生四个空格:
<pre>Elephant becomes * Elephant *</pre>
如果需要从字符串中删除字符,可以使用cut过滤器。cut的参数是要删除的子字符串:
<pre>*{{value}}* becomes *{{ value|cut:" " }}*</pre>
看看当你使用带有"Bates Motel"的value的cut滤镜时会发生什么:
<pre>*Bates Motel* becomes *BatesMotel*</pre>
请注意,cut的参数不是您想要剪切的字符列表,而是您想要剪切的序列。如果您尝试用"ae"来削减这个值,什么都不会发生。"Bates Motel"中没有"ae"子串。
列表过滤器
过滤器可以对类似列表的值进行操作。first和last过滤器分别返回 iterable 中的第一项和最后一项:
{{ goodies|first }}
如果goodies包含["popcorn", "peanuts", "cola"],那么这个例子产生"popcorn"。使用last过滤器会导致"cola"。
除了使用筛选器来访问列表的各个部分之外,还可以使用筛选器从列表中获取数据。join过滤器类似于 Python str.join()方法。它返回由列表的各个部分组成的字符串:
{{ goodies|join:", " }}
使用冒号(:)将参数传递给过滤器。用逗号作为参数连接goodies列表将返回包含逗号分隔列表的单个字符串:"popcorn, peanuts, cola"。
要查找列表的长度,可以使用length过滤器。这在与其他过滤器结合使用时尤其有用。在处理多个项目时,pluralize过滤器会在单词末尾添加一个"s"。尝试在<h2>Movies</h2>标题下的templates/listing.html中添加以下一行:
<!-- templates/listing.html -->
{% extends "base.html" %}
{% block content %}
<h2> Movies</h2>
<p>{{movies|length}} movie{{movies|length|pluralize}} found.</p>
⋮
Django 用movies列表的长度替换第一组双括号。第二组做了一些聪明的事情:链接过滤器。pluralize过滤器接受一个数字。如果数字是2或更大,它返回一个"s"。通过使用length和pluralize,你将把movies的长度传递给pluralize。
如果加一个"s"不是单词的复数形式,你会怎么做?筛选器支持指定结尾后缀的参数:
You have {{num_boxes}} box{{num_boxes|pluralize:"es"}}.
在这个例子中,pluralize没有追加"s",而是追加"es",返回"boxes"。对于具有不同结尾的单词,您可以指定单个和多个结尾:
You have {{num_cherries}} cherr{{num_cherries|pluralize:"y,ies"}}.
在上面的示例中,pluralize如果结果是单数,则在逗号前添加指定的字符串,如果结果是复数,则在逗号后添加指定的字符串。这样,你就正确地得到了"cherry"或"cherries"。
日期和时间过滤器
日期或时间的表示应该特定于用户的语言环境。在你的代码中,建议你只使用一个 Python datetime 对象。您应该将此对象的格式设置留给呈现时间。有过滤器可以帮你做到这一点。
date过滤器的参数类似于您在本教程前面看到的{% now %}标签。像那个标签一样,date过滤器的参数指定了日期的表示格式:
<p> {{release_date|date:"Y-m-d"}}</p>
这个例子将以年-月-日 ISO 8601 的格式显示release_date的内容。对于《公民凯恩》来说,它的大范围上映时间是 1941 年 9 月 5 日。虽然它被称为date过滤器,但它也支持时间,假设它与一个datetime对象而不仅仅是一个date对象一起工作。
如果你只对时间感兴趣,也有一个过滤器。time过滤器使用date配置参数的子集,只是那些与时间有关的参数。用法是相似的:
<p> {{showing_at|time:"H:i"}}</p>
本示例以 24 小时制显示放映时间。对于一部晚上 9:30 的电影,Django 将其渲染为"21:30"。
一种使时间更具可读性的流行格式是显示事件发生后经过的时间。你可以在许多网络邮件客户端看到类似于你在“3 天前”收到了一封电子邮件的信息。Django timesince滤镜赋予你这种力量:
<p> {{release_date|timesince}}</p>
本示例显示了电影上映后经过的时间。默认情况下,该过滤器会计算从现在起经过的时间。或者,您可以向timesince添加一个参数来指定比较日期。
有一个与timesince相伴的过滤器叫做timeuntil。它不是回顾过去,而是展望未来。您可以用它来显示会议或类似事件的倒计时。
timesince和timeuntil都是根据 Django 渲染模板时的服务器计算时间差。使用settings.py中的时区信息进行计算。如果您的服务器不使用 UTC,而您的 Django 配置使用 UTC 默认值,这会产生奇怪的结果。请确保这两个配置匹配,否则您的时差计算将会不正确。
第三方标签和过滤器库
除了内置的 Django 模板标签和过滤器,你还可以编写自己的。您可以找到包含自定义标签和过滤器的有用的第三方库。一个这样的库是 django-simple-tags 。不要把这个与 Django 中类似命名的函数 simple_tag() 混淆。
要在模板中使用第三方库,您需要遵循三个步骤:
- 安装应用程序库
- 在
settings.py中注册带有INSTALLED_APPS的 app - 加载模板中的标签
安装 Django 应用程序库和其他任何包没有什么不同。您可以使用pip来安装它:
$ python -m pip install django-simple-tags
安装好软件包后,更新settings.py文件的INSTALLED_APPS部分,让 Django 知道这个应用程序:
33INSTALLED_APPS = [
34 "django.contrib.admin",
35 "django.contrib.auth",
36 "django.contrib.contenttypes",
37 "django.contrib.sessions",
38 "django.contrib.messages",
39 "django.contrib.staticfiles",
40 "moviefacts",
41 "django_simple_tags", 42]
现在 Django 知道了这个应用,但是你还不能使用标签。在使用它们之前,首先需要将它们加载到模板中。您可以用{% load %}标签来完成:
1{% load django_simple_tags %}
2
3Current value of DEBUG is {% get_setting "DEBUG" %}
在第 1 行,{% load %}标签将来自django-simple-tags的所有标签添加到模板上下文中。请注意,django_simple_tags周围没有引号。这将与import声明保持一致。 django-simple-tags 库有二十多个标签和过滤器。这个例子显示了{% get_setting %}从 Django 设置中返回DEBUG的值。
有许多第三方库和大量的标签可以简化你的 HTML。使用它们只需要一个pip install和一个{% load %}标签。
结论
Django 模板标签和过滤器为您提供了一种以可重用方式构建 HTML 输出的强大方法。模板是用它们自己的语言定义的,以便将业务逻辑与显示逻辑分开。标签就像语言的关键字和功能,而过滤器允许您在显示数据之前修改现有数据。
在本教程中,您学习了如何:
- 使用 Django
Template和Context对象编译一个模板 - 从文件中加载模板,并使用
render()快捷键将其返回 - 用条件块和循环块编写模板
- 使用
extends和include编写可复用的模板组件 - 使用模板过滤器修改数据
- 从第三方库加载并使用自定义模板标签和过滤器
**你可以在优秀的文档中找到更多关于 Django 的一般信息。在同一文档中,您还可以找到关于模板标签和过滤器的更多具体信息。
如果你想了解一些 Django 关于真正 Python 的教程,你可以查看Django 入门第一部分:构建一个文件夹应用、Django Web 开发学习路径,以及可用 Django 教程列表。
电影广场教程中最后一个合适的词应该是:玫瑰花蕾。**********
使用 Python 和 Django 管理你的待办事项列表
你有没有努力去跟踪你需要做的事情?也许你习惯于用手写的待办事项清单来提醒你需要做什么,什么时候做。但是手写笔记很容易丢失或被遗忘。因为您是 Python 程序员,所以构建 Django 待办事项列表管理器是有意义的!
在这个分步教程中,您将使用 Django 创建一个 web 应用程序。您将了解 Django 如何与数据库集成,该数据库将您所有的待办事项存储在您可以定义的列表中。每一项都有标题、描述和截止日期。有了这个应用程序,您可以管理自己的截止日期,并帮助您的整个团队保持正轨!
在本教程中,您将学习如何:
- 使用 Django 创建一个 web 应用程序
- 用一对多关系构建数据模型
- 使用 Django admin 接口来探索您的数据模型并添加测试数据
- 设计用于显示列表的模板
- 利用基于类的视图来处理标准数据库操作
- 通过创建 URL 配置来控制 Django URL 分配器
在这个过程中,您将了解 Django 的基于类的视图如何利用面向对象编程的力量。这将为您节省大量的开发工作!
获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
演示
在本教程中,您将构建一个 Django 待办事项列表管理器。你的主页会显示你所有的待办事项。通过点击添加新列表按钮,您将显示一个页面,您可以在其中命名和创建新列表:
https://player.vimeo.com/video/662503907?background=1
您可以通过点击添加新项目将待办事项添加到您的列表中。在那里,你可以给你的物品起一个标题,并且你可以在描述框中添加更多的细节。你甚至可以设定一个截止日期。
项目概述
要构建这个应用程序,首先要创建一个虚拟环境,并设置一个 Django 项目。接下来,您将设计一个数据模型,它表示待办事项和列表之间的关系。您将使用 Django 内置的对象关系映射工具来自动生成支持该模型的数据库和表。
当你开发 Django 待办事项应用程序时,只要你需要验证事情是否按预期运行,你就可以使用 Django 的便捷的 runserver 命令。多亏了 Django 现成的管理界面,这甚至在你的网页准备好之前就能帮上忙。
接下来,您将开发自己的网页来显示您的应用程序。在 Django 中,这些采用了模板的形式。模板是框架 HTML 页面,可以填充真实的应用程序数据。
模板并不意味着提供太多的逻辑,比如决定显示哪个模板和发送什么数据。为了执行这个逻辑,你需要视图。Django 的视图是应用程序逻辑的自然归宿。
您将为列表创建和更新以及这些列表将包含的项目编写视图和模板代码。您将学习如何使用 Django 的 URL dispatcher 来连接您的页面并传递它们需要的数据。接下来,您将添加更多视图和模板,使您的用户能够删除列表和项目。
最后,您将通过添加、编辑和删除待办事项列表和待办事项来测试您的新用户界面。
通过完成这个项目,你将学习如何构建这个应用程序,并了解各种组件如何配合在一起。然后,你就可以自己开始下一个 Django 项目了。
先决条件
要完成本教程,您应该熟悉以下技能:
- 从命令行运行 Python 脚本
- 用 Python IDLE 编码,或者你喜欢的代码编辑器
- 使用 Python 模块和包
- 了解 Python 中的面向对象编程,包括对象继承
如果您在开始本教程之前没有掌握所有的必备知识,那也没关系。事实上,你可以通过前进和开始学习更多!如果遇到困难,您可以随时停下来查看此处链接的资源。
您不需要以前使用过 Django,因为您将在下面获得安装和使用它的分步说明。然而,如果你对这个强大的 web 框架的更详细的介绍感兴趣,你可以参考一系列的 Django 教程。
步骤 1:设置你的虚拟环境和 Django
在这一步中,您将执行一些标准的内务处理任务,这些任务在每个 Django 项目中只需要执行一次。具体来说,您将创建并激活一个虚拟环境,安装 Django,并测试 Django 是否安装正确。
完成这些小杂务后,您就可以开始构建您的 Django 待办事项列表应用程序了!要下载该项目的初始代码,请单击以下链接并导航到source_code_step_1/文件夹:
获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
创建虚拟环境和项目目录
无论何时使用 Python 开发东西,尤其是如果您将使用外部库,创建一个虚拟环境非常重要。这样,您就为您的代码创建了一个隔离的世界,这样您选择的 Python 和库版本就不会意外地破坏您为其他版本编写的任何其他应用程序。
然后,如果您以后为另一个项目使用不同版本的 Python 或更新的库,您不会破坏这个项目的任何东西,因为它将继续使用自己的 Python 和库版本。
创建虚拟环境只需要几个步骤。首先,创建一个目录作为新应用程序的根目录,并使用适合您的操作系统的语法进入该目录:
- 视窗
** Linux + macOS*
C:\> mkdir projects\todo_list
C:\> cd projects\todo_list
$ mkdir projects/todo_list
$ cd projects/todo_list
至此,您已经创建了您的项目根。您在本教程中所做的一切都将发生在该文件夹中。您将它命名为todo_list,为了保持整洁,您将它放在主目录中名为projects/的现有文件夹中。
确保您安装了 Python 3.6 或更新版本,然后您可以使用 Python 的内置模块venv来创建和激活您的虚拟环境:
- 视窗
** Linux + macOS*
C:\> python -m venv venv
C:\> venv\Scripts\activate.bat
$ python -m venv venv
$ source venv/bin/activate
第一行在子目录venv/中创建您的虚拟环境。它还将pip和setuptools复制到其中。第二行激活虚拟环境,你的控制台提示可能会改变来提醒你这个事实。
激活后,你正在使用一个完全独立的 Python 解释器和生态系统。从现在开始安装的任何库,包括 Django,都将被隔离到这个环境中。
稍后,当你在虚拟环境中完成工作后,你只需输入deactivate,之后一切都会恢复原样。系统的默认 Python 解释器将被恢复,同时恢复的还有全局安装的 Python 库。
注意:不要立即停用,因为您想在激活的环境中继续!
需要时,您可以通过重复上面的activate步骤来重新激活环境。
安装并测试 Django
下一步是安装 Django 库及其依赖项。您将在这里指定一个特定的版本,尽管也可以不指定版本,在这种情况下pip将只安装最新的版本。
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install django=="3.2.9"
(venv) $ python -m pip install django=="3.2.9"
从滚动过去的包列表中,您会注意到,pip机器也负责安装所有的 Django 依赖项。点击和旋转完成后,您应该会看到一条成功消息:
Successfully installed asgiref-3.4.1 django-3.2.9 pytz-2021.3 sqlparse-0.4.2
Django 库现在已经安装在您的虚拟环境中了。只要这个环境是活动的,Django、它的命令行工具和它的库都将保持可用。
您可以使用 Python 解释器来检查 Django 是否安装正确。从命令行调用python之后,您可以导入 Django 并交互地检查它的版本:
>>> import django >>> django.get_version() '3.2.9' >>> exit()如果您得到了一个版本号,如上所述,而不是一个
ImportError,那么您就可以确信您的 Django 安装已经准备好了。现在把你的依赖关系固定下来是个好主意。这记录了当前安装在虚拟环境中的所有 Python 库的版本:
- 视窗
** Linux + macOS*(venv) C:\> python -m pip freeze > requirements.txt(venv) $ python -m pip freeze > requirements.txt文本文件
requirements.txt现在列出了您正在使用的所有软件包的确切版本,因此您或其他开发人员可以在以后准确地复制您的虚拟环境。至此,您已经建立了代码环境并安装了必要的库。是时候开始生成一些 Django 代码了!
第二步:创建你的 Django 待办应用程序
现在您的环境已经激活,Django 也准备好了,您几乎可以开始自己的编码了。不过,首先,您需要使用 Django 的工具来执行一些特定于项目的步骤。其中包括:
- 生成父项目框架
- 创建 web 应用程序的框架
- 将 web 应用程序集成到项目中
所有的 Django 项目都有相似的结构,所以理解这种布局也将有利于您未来的项目。一旦你熟悉了这个过程,你应该能在几分钟内完成。
要下载项目此阶段的代码,请单击以下链接并导航至
source_code_step_2/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
脚手架父项目
Django 区分了项目和应用程序。一个项目可以管理一个或多个应用程序。对于本教程,您只是创建了一个应用程序,但是它仍然必须由一个项目来管理,您可以将其称为
todo_project。立即开始您的新项目:
- 视窗
** Linux + macOS*(venv) C:\> django-admin startproject todo_project .(venv) $ django-admin startproject todo_project .注意这里的最后一个点(
.)。它阻止django-admin创建额外的文件夹。这个命令已经自动创建了一个名为manage.py的文件,以及一个名为todo_project/的包含几个 Python 文件的子文件夹:todo_list/ │ ├── todo_project/ │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ ├── venv/ │ ├── manage.py └── requirements.txt
todo_list/venv/文件夹的内容太大,无法在此显示。您将了解下面的一些其他文件。名为
__init__.py的文件为空。它的存在只是为了告诉 Python 它的包含文件夹应该被当作一个包。从概念上讲,Python 模块是一个单独的源文件,而包是一堆模块的容器。通过在包内组织模块,您可以减少名称污染并改善代码隔离。
todo_list/todo_project/中的两个文件对你的应用很重要:
settings.py保存项目范围的配置。这包括项目知道的所有应用程序的列表,以及描述它将使用哪个数据库的设置。urls.py列出了服务器必须监听的所有 URL。在设置时,您将很快需要编辑这两个文件。您需要将应用程序的名称添加到
settings.py中,并提供一个 URL 作为想要访问该应用程序的浏览器的入口点。开始使用 Django 待办事项应用程序
现在是时候使用
django-admin命令行工具创建您的应用程序了。你只需要提供一个名字。你不妨称之为todo_app:
- 视窗
** Linux + macOS*(venv) C:\> django-admin startapp todo_app(venv) $ django-admin startapp todo_app这个命令设置了一个新的 Django 应用程序,带有一些启动文件和文件夹。如果您检查您的文件夹,那么您会发现您的项目根目录中现在有三个子文件夹:
todo_list/ │ ├── todo_app/ │ ├── todo_project/ │ └── venv/记住
todo_project/是您的项目文件夹并且包含项目范围的信息是有帮助的。这意味着常规项目设置,以及 web 服务器查找项目中包含的应用程序所需的信息。另一方面,您的最后一个命令只是创建了
todo_app/文件夹及其内容。todo_app/是你的应用文件夹,包含你的应用特有的文件。看看这个文件夹里的文件:todo_app/ │ ├── migrations/ │ └── __init__.py │ ├── __init__.py ├── admin.py ├── apps.py ├── models.py ├── tests.py └── views.py
django-admin工具为您创建了所有这些文件,但是您现在不需要关心所有这些文件。然而,有几个绝对值得注意:
- 像往常一样,这两个
__init__.py文件只是将它们包含的文件夹定义为包。migrations/子文件夹将保存未来数据库的变更信息。models.py文件将为您的应用程序定义数据模型。views.py文件将处理控制应用程序显示的逻辑。在这个过程中,您还将创建一些自己的文件。这些将包括一个数据模型,新的视图,以及新的模板。
不过,首先,您需要配置您的项目,以便它了解您的应用程序。项目级配置位于项目目录的文件
todo_list/todo_project/settings.py中。现在打开这个文件,浏览一下代码,了解一下有什么可用的。配置您的项目
您会注意到一个名为
INSTALLED_APPS的数组,其中有一个简短的应用程序名称列表,以django.contrib开头。Django 提供了这些应用程序,并在默认情况下安装它们以满足常见需求。但是列表中缺少了一个非常重要的应用名称:你的!所以你需要添加todo_app作为数组INSTALLED_APPS中的一项:# todo_list/todo_project/settings.py INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", "todo_app", ]当您打开
settings.py时,请注意它包含了一些其他有趣的变量。这种变量的一个例子是DATABASES:# Database # https://docs.djangoproject.com/en/3.2/ref/settings/#databases DATABASES = { "default": { "ENGINE": "django.db.backends.sqlite3", "NAME": BASE_DIR / "db.sqlite3", } }
DATABASES默认设置为使用 sqlite3 数据库。这是最容易使用的选项,但是如果您感兴趣的话,以后可以尝试使用其他数据库。影响应用安全性的两个变量是
SECRET_KEY和DEBUG:- # SECURITY WARNING: keep the secret key used in production secret SECRET_KEY = ( "django-insecure-!r4sgi-w($+vmxpe12rg%bvyf$7kz$co3tzw6klpu#f)yfmy#3" ) # SECURITY WARNING: don't run with debug turned on in production DEBUG = True在开发过程中,这两个键可以不考虑,但是对于任何计划发布到 Web 上的应用程序,你都应该知道它们。
- 如果你打算把你的应用放在公共服务器上,这一点很重要。Django 为每个新项目生成一个新的随机密钥。你可以暂时忽略它。
- 在你开发应用程序时,
DEBUG是一个非常有用的设置,但是你应该确保在你的应用程序在大坏网上发布之前将它设置为False,因为它揭示了太多关于你的代码的工作方式!现在保存文件
settings.py并关闭它。您需要在项目文件夹中修改的第二个文件是
urls.py,它在项目级别控制 URL 查找。Django 的 URL dispatcher 使用这个文件中的urlpatterns数组中的元素来决定如何分派传入的请求。您将向此数组添加一个新的urlpattern元素,这将导致 URL dispatcher 将传入的 URL 流量重定向到您的新待办事项应用程序:1# todo_list/todo_project/urls.py 2from django.contrib import admin 3from django.urls import include, path 4 5urlpatterns = [ 6 path("admin/", admin.site.urls), 7 path("", include("todo_app.urls")) 8]上面突出显示了需要更改或添加的行。看看这段代码中发生了什么:
第 6 行包含原始的
urlpatterns元素,它告诉 Django 以"admin/"开头的传入 URL 应该由管理应用程序处理。第 7 行添加了一个可以处理空字符串的元素,比如没有前导应用名称的 URL 。这样的 URL 将被传递给
todo_appURL 配置。如果项目中有其他应用程序,那么您可以通过使用不同的 URL 模式来区分它们,但在这里没有必要。反过来,todo_app的 URL 配置保存在一个名为todo_list/todo_app/urls.py的文件中的urlpatterns数组中。现在,您将创建应用程序级 URL 配置文件。在编辑器中打开一个新文件,并以名称
urls.py保存在todo_list/todo_app目录中:1# todo_list/todo_app/urls.py 2 3urlpatterns = [ 4]暂时将应用程序的
urlpatterns数组留空。你很快就会添加一些真正的路线。你现在已经有了一个完整的、可运行的项目和应用程序设置,尽管它还没做多少。整个基础设施已经就绪,但是您需要添加一些内容。您可以通过启动 Django 开发服务器来测试您到目前为止的工作:
- 视窗
** Linux + macOS*(venv) C:\> python manage.py runserver(venv) $ python manage.py runserver忽略关于迁移的警告消息。你很快就会处理这些。控制台上显示的最后一条消息应该是您的服务器正在运行,这就足够了!
注意:上面显示的
runserver命令值得记住,因为您可以在开发的每一步使用它来测试您的代码是否按预期工作。在浏览器中导航至
http://localhost:8000/。在这个阶段,Django 没有要显示的应用程序页面,所以您应该会看到框架的通用成功页面:
Django 的默认页面提供了大量有用文档的链接。您可以稍后探索这些链接。
注意:当你完成测试后,你可以在控制台窗口输入
Ctrl+C或Cmd+C来停止服务器。您已经完成了新 Django 应用程序的所有标准设置任务。是时候开始编写应用程序的独特特性了。
第三步:设计你的待办数据
任何应用程序的核心都是它的数据结构。在这一步中,您将设计和编码应用程序数据模型以及应用程序对象之间的关系。然后,您将使用 Django 的对象关系建模工具将数据模型映射到数据库表中。
要下载项目此阶段的代码,请单击以下链接并导航至
source_code_step_3/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
每种类型的用户数据都需要自己的数据模型。你的待办事项应用程序将只包含两种基本类型的数据:
- 一个带标题的
ToDoList:你想要多少就有多少。- 链接到特定列表的
ToDoItem:同样,ToDoItem对象的数量没有限制。每个ToDoItem都有自己的标题、更长的描述、创建日期和截止日期。你的数据模型将构成你的应用程序的主干。接下来,您将通过编辑文件
models.py来定义它们。定义您的数据模型
在编辑器中打开文件
models.py。目前这种可能性很小:# todo_list/todo_app/models.py from django.db import models # Create your models here.这只是占位符文本,帮助您记住在哪里定义数据模型。用您的数据模型的代码替换此文本:
1# todo_list/todo_app/models.py 2from django.utils import timezone 3 4from django.db import models 5from django.urls import reverse 6 7def one_week_hence(): 8 return timezone.now() + timezone.timedelta(days=7) 9 10class ToDoList(models.Model): 11 title = models.CharField(max_length=100, unique=True) 12 13 def get_absolute_url(self): 14 return reverse("list", args=[self.id]) 15 16 def __str__(self): 17 return self.title 18 19class ToDoItem(models.Model): 20 title = models.CharField(max_length=100) 21 description = models.TextField(null=True, blank=True) 22 created_date = models.DateTimeField(auto_now_add=True) 23 due_date = models.DateTimeField(default=one_week_hence) 24 todo_list = models.ForeignKey(ToDoList, on_delete=models.CASCADE) 25 26 def get_absolute_url(self): 27 return reverse( 28 "item-update", args=[str(self.todo_list.id), str(self.id)] 29 ) 30 31 def __str__(self): 32 return f"{self.title}: due {self.due_date}" 33 34 class Meta: 35 ordering = ["due_date"]文件
models.py定义了你的整个数据模型。在其中,您定义了一个函数和两个数据模型类:
第 7 行到第 8 行定义了一个独立的实用函数
one_week_hence(),该函数对于设置ToDoItem默认到期日很有用。第 10 到 35 行定义了两个扩展 Django 的
django.db.models.Model超类的类。那个班为你做了大部分繁重的工作。您在子类中需要做的就是定义每个模型中的数据字段,如下所述。
Model超类还定义了一个id字段,它对于每个对象来说是自动唯一的,并作为其标识符。对于您可能想要定义的所有字段类型,
django.db.models子模块也有方便的类。这些允许您设置有用的默认行为:
第 11 行和第 20 行声明了
title字段,每个字段限制在 100 个字符以内。另外,ToDoList.title必须唯一。你不能拥有两个标题相同的ToDoList对象。第 21 行声明了一个可能为空的
ToDoItem.description字段。第 22 行和第 23 行分别为它们的日期字段提供了有用的默认值。Django 会在第一次保存
ToDoItem对象时自动将.created_date设置为当前日期,而.due_date使用one_week_hence()设置一个默认的未来一周的到期日。当然,如果这个默认值不适合用户,应用程序将允许用户更改到期日。第 24 行声明了可能是最有趣的字段
ToDoItem.todo_list。该字段被声明为外键。它将ToDoItem链接回它的ToDoList,因此每个ToDoItem必须恰好有一个它所属的ToDoList。在数据库行话中,这是一个一对多的关系。同一行中的on_delete关键字确保如果删除一个待办事项列表,那么所有关联的待办事项也会被删除。第 16 到 17 行和第 31 到 32 行为每个模型类声明
.__str__()方法。这是创建对象的可读表示的标准 Python 方式。编写这个函数并不是绝对必要的,但是它有助于调试。第 13 到 14 行和第 26 到 29 行实现了
.get_absolute_url()方法,这是 Django 对数据模型的约定。这个函数返回特定数据项的 URL。这允许您在代码中方便、可靠地引用 URL。.get_absolute_url()的两个实现的 return 语句都使用了reverse()来避免对 URL 及其参数进行硬编码。第 34 行定义了嵌套的
Meta类,它允许你设置一些有用的选项。这里,您将使用它来设置ToDoItem记录的默认排序。现在保存带有两个模型类的
models.py文件。有了这个文件,您就为整个应用程序声明了数据模型。很快,您将使用 Django 工具将模型映射到您的数据库。创建数据库
到目前为止,您已经在 Python 代码中定义了两个模型类。现在奇迹发生了!使用命令行创建并激活迁移:
- 视窗
** Linux + macOS*(venv) C:\> python manage.py makemigrations todo_app (venv) C:\> python manage.py migrate(venv) $ python manage.py makemigrations todo_app (venv) $ python manage.py migrate这两个子命令,
makemigrations和migrate,由manage.py提供,有助于使您的物理数据库结构与代码中的数据模型保持一致的过程自动化。使用
makemigrations,您告诉 Django 您已经更改了应用程序的数据模型,并且您想要记录这些更改。在这个特例中,您定义了两个全新的表,每个表对应一个数据模型。此外,Django 已经为管理界面和自己的内部使用自动创建了自己的数据模型。每当您对数据模型进行更改并调用
makemigrations时,Django 都会向文件夹todo_app/migrations/中添加一个文件。该文件夹中的文件存储了您对数据库结构所做的更改的历史记录。这允许您在需要时恢复并重新应用这些更改。使用
migrate命令,通过对数据库运行命令来使这些更改生效。就这样,您创建了新表,以及一些有用的管理表。您的数据模型现在被镜像到数据库中,并且您还创建了一个审计跟踪,为您以后可能应用的任何结构更改做准备。
第四步:添加你的样本待办事项数据
所以现在你有了一个数据模型和一个数据库,但是你还没有任何实际的数据以待办事项列表或条目的形式。很快,您将构建网页来创建和操作这些,但是现在,您可以用最简单的方式创建一些测试数据,通过使用 Django 现成的管理接口。该工具不仅使您能够管理模型数据,还能够验证用户、显示和处理表单以及验证输入。
要下载项目此阶段的代码,请单击以下链接并导航至
source_code_step_4/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
了解 Django 管理界面
要使用管理界面,你应该有一个超级用户。这将是一个拥有非凡力量的人,可以信任他拥有整个 Django 服务器的密钥。这听起来像你吗?立即创建您的新超级用户:
- 视窗
** Linux + macOS*(venv) C:\> python manage.py createsuperuser(venv) $ python manage.py createsuperuser只需按照提示将自己注册为超级用户。你的超能力已经安装好了!
虽然您现在可以访问管理界面,但是在它可以使用您的新数据模型之前,还需要完成一个步骤。您需要在管理应用程序中注册模型,这可以通过编辑文件
admin.py来完成:# todo_list/todo_app/admin.py from django.contrib import admin from todo_app.models import ToDoItem, ToDoList admin.site.register(ToDoItem) admin.site.register(ToDoList)现在您已经准备好使用 Django 管理应用程序了。启动开发服务器并开始探索。首先,确保开发服务器正在运行:
- 视窗
** Linux + macOS*(venv) C:\> python manage.py runserver(venv) $ python manage.py runserver现在打开网络浏览器,转到地址
http://127.0.0.1:8000/admin/。您应该会看到管理应用程序的登录屏幕。输入您新创建的凭据,将出现管理登录页面:
注意,它已经显示了待办事项列表和待办事项的链接。您已经准备好查看和更改数据。
开始一个待办事项列表
在 Django 管理主页的左侧,点击待办事项列表。在下一个屏幕上,点击右上角的按钮添加到任务列表。
你已经准备好创建你的第一个待办事项列表了。给它一个标题,例如“今天要做的事情”,然后点击屏幕最右边的保存按钮。新列表现在出现在标题为选择要更改的待办事项列表的页面上。你可以忽略这一点,而是点击屏幕左侧出现在旁边的 +添加按钮来做事情。出现一个新表单:
用一些示例数据填充该项。将您的项目命名为“开始我的待办事项列表”,并将描述命名为“首先要做的事情”让到期日保持原样,从今天算起正好一周。对于待办事项列表,从下拉菜单中选择您新创建的待办事项列表标题。然后打救。
就是这样。您已经使用管理界面创建了一个列表和一个项目。请随意留下来浏览这些页面,感受一下它们是如何工作的。作为开发人员,管理界面对您来说是很好的,可以用来对数据进行快速和肮脏的攻击,但它不适合普通用户使用。重要的事情在等着我们。您需要创建公共用户界面!
步骤 5:创建 Django 视图
在这一步中,您将了解如何为您的应用程序创建公共接口。在 Django 中,这涉及到使用视图和模板。一个视图是编排网页的代码,是你的 web 应用程序的表现逻辑。正如您将看到的,模板是一个更像 HTML 页面的组件。
要下载项目此阶段的代码,请单击以下链接并导航至
source_code_step_5/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
编写您的第一个视图
一个视图是 Python 代码,它告诉 Django 如何在页面之间导航,以及要显示哪些数据。web 应用程序的工作方式是接收来自浏览器的 HTTP 请求,决定如何处理它,然后发回一个响应。然后,应用程序停止工作,等待下一个请求。
在 Django 中,这个请求-响应循环由视图控制,其最基本的形式是一个位于文件
views.py中的 Python 函数。视图函数的主要输入数据是一个HttpRequestPython 对象,它的工作是返回一个HttpResponsePython 对象。对视图进行编码有两种基本方法。你可以创建一个函数,如上所述,或者你可以使用一个 Python 类,它的方法将处理请求。无论哪种情况,您都需要通知 Django 您的视图是为了处理特定类型的请求。
使用类有一些明确的优点:
一致性:每个 HTTP 请求都与一个给服务器的命令相关联,称为它的方法或动词。根据所需的响应,这可能是 GET、POST、HEAD 或其他。每个动词在你的类中都有自己匹配的方法名。例如,处理 HTTP GET 请求的方法被命名为
.get()。继承:您可以通过扩展现有的类来使用继承的力量,这些类已经完成了您需要视图完成的大部分工作。
在本教程中,您将使用基于类的方法,并利用 Django 预先构建的通用视图来实现最大程度的代码重用。在这里,你可以从 Django 设计师的智慧中获益。有很多很多不同的数据库和数据模型,但从根本上来说,它们都基于被称为记录的信息单元,以及你可以对它们进行的四种基本操作:
- 创建条记录
- 读取记录
- 更新记录
- 删除记录
这些活动通常被称为 CRUD ,它们或多或少是许多应用程序的标准。
例如,用户希望能够选择一个记录,编辑其字段,并保存它,而不管该记录是代表待办事项、库存项目还是其他任何内容。所以 Django 为开发人员提供了基于类的视图,这是预构建的视图,作为类实现,已经包含了完成这些事情的大部分代码。
作为开发人员,您所要做的就是为您的数据模型和应用程序定制它们,也许在您这样做的时候,在这里或那里调整它们的行为。
在编辑器中,打开文件
todo_app/views.py。目前,它不包含有用的代码。清除文件并创建您的第一个视图:# todo_list/todo_app/views.py from django.views.generic import ListView from .models import ToDoList class ListListView(ListView): model = ToDoList template_name = "todo_app/index.html"
ListListView类将显示待办事项列表标题的列表。如您所见,这里不需要太多代码。您正在使用泛型类django.views.generic.ListView。它已经知道如何从数据库中检索对象列表,所以您只需要告诉它两件事:
- 您想要获取的数据模型类
- 将列表格式化为可显示形式的模板的名称
在本例中,数据模型类是您在步骤 3 中创建的
ToDoList。现在是时候了解一下模板了。了解模板
一个模板只是一个包含 HTML 标记的文件,带有一些额外的占位符来容纳动态数据。因为您希望能够重用您的代码,所以您将从创建一个基础模板开始,该模板包含您希望出现在每个页面上的所有样本 HTML 代码。实际的应用程序页面将继承所有这些样板文件,就像你的视图将如何从基类继承它们的大部分功能。
注意:你可以从模板的官方文档中了解更多信息。
创建一个基础模板
在
todo_app/目录下创建一个名为templates/的新文件夹。现在向该文件夹添加一个新文件。你可以称它为base.html。创建您的基础模板:1<!-- todo_list/todo_app/templates/base.html --> 2<!-- Base template --> 3<!doctype html> 4<html lang="en"> 5 6<head> 7 <!-- Required meta tags --> 8 <meta charset="utf-8"> 9 <meta name="viewport" content="width=device-width, initial-scale=1"> 10 <!--Simple.css--> 11 <link rel="stylesheet" href="https://cdn.simplecss.org/simple.min.css"> 12 <title>Django To-do Lists</title> 13</head> 14 15<body> 16 <div> 17 <h1 onclick="location.href='{% url "index" %}'"> 18 Django To-do Lists 19 </h1> 20 </div> 21 <div> 22 {% block content %} 23 This content will be replaced by different html code for each page. 24 {% endblock %} 25 </div> 26</body> 27 28</html>在很大程度上,这只是一个具有标准结构的框架 HTML 页面。然而,第 22 到 24 行声明了特殊的
{% block content %}…{% endblock %}标签。这些占位符保留了一个空间,可以从从这个页面继承的页面接收更多的 HTML 标记。11 号线导入开源的
Simple.css库。没有 CSS 的原始 HTML 以一种大多数人都觉得很难看的方式呈现。仅仅通过像这样导入Simple.css,你就自动让你的网站看起来更好,不需要更多的努力。现在您可以开发和测试您的站点逻辑,而不会伤害您的眼睛。当然,您仍然可以选择在以后添加自己的创意!第 17 行引入模板语法
{% url "index" %}作为onclick事件处理程序的目标。Django 模板引擎将在 URLConf 文件todo_app/urls.py中找到名为"index"的urlpatterns条目,并用正确的路径替换这个模板。这样做的效果是,点击 Django To-do Lists 标题将使浏览器重定向到名为"index"的 URL,这将是您的主页。注意:这意味着你可以在应用的任何地方点击 Django 待办事项列表标题返回应用的主页。
所以
base.html是一个完整的网页,但并不令人兴奋。为了让它更有趣,你需要一些标记在{% block content %}和{% endblock %}标签之间。每个继承模板都将提供自己的标记来填充这个块。添加主页模板
Django 对于属于应用程序的模板的约定是,它们位于应用程序文件夹内名为
templates/<appname>的文件夹中。因此,尽管基础模板base.html放在了todo_app/templates/文件夹中,但其他模板都将放在名为todo_app/templates/todo_app/的文件夹中:
- 视窗
** Linux + macOS*(venv) C:\> mkdir todo_app\templates\todo_app(venv) $ mkdir todo_app/templates/todo_app你的第一个目标是为你的网站的主页编写模板,通常命名为
index.html。在编辑器中创建一个新文件,并将其保存在刚刚创建的文件夹中:1<!-- todo_list/todo_app/templates/todo_app/index.html --> 2 3{% extends "base.html" %} 4{% block content %} 5<!--index.html--> 6{% if object_list %} 7<h3>All my lists</h3> 8{% endif %} 9<ul> 10 {% for todolist in object_list %} 11 <li> 12 <div 13 role="button" 14 onclick="location.href='{% url "list" todolist.id %}'"> 15 {{ todolist.title }} 16 </div> 17 </li> 18 {% empty %} 19 <h4>You have no lists!</h4> 20 {% endfor %} 21</ul> 22 23{% endblock %}第 3 行设置场景:你正在扩展基础模板。这意味着来自基础模板的所有内容都将出现在
index.html、的渲染版本中,除了介于{% block content %}和{% endblock %}标签之间的所有内容。取而代之的是,base.html的那一段将被index.html中相应的一对{% block content %}和{% endblock %}标签内的代码所取代。在
index.html中可以发现更多的模板魔法,更多的模板标签允许一些类似 Python 的逻辑:
第 6 行到第 8 行定义了一个由
{% if object_list %}和{% endif %}标签分隔的代码块。这些确保了如果object_list为空,标题All my lists不会出现。ListView自动提供上下文变量object_list给模板,object_list包含待办事项列表。第 10 到 20 行定义了一个由
{% for todolist in object_list %}和{% endfor %}标签括起来的循环。这个构造为列表中的每个对象呈现一次包含的 HTML。另外,如果列表为空,第 18 行的{% empty %}标签可以让你定义应该呈现什么。第 15 行演示了小胡子语法。双花括号(
{{…}})使模板引擎发出 HTML,显示包含的变量的值。在本例中,您正在呈现循环变量todolist的title属性。现在您已经创建了应用程序的主页,它将显示您所有待办事项的列表(如果有),如果没有,则显示一条信息性消息。你的用户会被的 URL 分配器引导到其他页面,或者回到这个页面。在下一节中,您将看到调度程序是如何工作的。
构建一个请求处理器
web 应用程序的大部分时间都在等待来自浏览器的 HTTP 请求。两个最常见的 HTTP 请求动词是 GET 和 POST 。由 GET 请求执行的动作主要由其 URL 定义,URL 不仅将请求路由回正确的服务器,还包含参数,这些参数告诉服务器浏览器正在请求什么信息。典型的 HTTP URL 可能类似于
http://example.com/list/3/item/4。这个与 GET 请求一起发送的假想 URL 可能在
example.com被服务器解释为请求使用默认应用程序来显示列表三中的第四项。一个 POST 请求也可能有 URL 参数,但是它的行为稍有不同。除了 URL 参数之外,POST 还向服务器发送一些进一步的信息。例如,这些信息不会显示在浏览器的搜索栏中,但可以用来更新 web 表单中的记录。
注意:关于 HTTP 请求还有很多需要学习的地方。用 Python 探索 HTTPS 的第一部分提供了更多关于 HTTP 如何工作的细节。然后,它继续探索 HTTPS,协议的安全形式。
Django 的 URL dispatcher 负责解析 URL 并将请求转发给适当的视图。URL 可以从浏览器接收,或者有时在内部从服务器本身接收。
URL 分配器通过参考被称为 URLconf 的一组映射到视图的 URL 模式来完成它的工作。这些映射通常存储在名为
urls.py的文件中。一旦 URL dispatcher 找到匹配项,它就会调用带有 URL 参数的匹配视图。回到步骤 2 ,您在项目级 URLconf 文件
todo_project/urls.py中创建了一个urlpatterns项。那个urlpattern确保任何以http://example.com[:port]/...开头的 HTTP 请求都将被传递到你的应用程序。 app 级urls.py从那里接手。您已经创建了应用程序级别的 URL 文件。现在是时候将第一条路线添加到该文件中了。编辑文件
todo_app/urls.py以添加路线:1# todo_list/todo_app/urls.py 2from django.urls import path 3from . import views 4 5urlpatterns = [ 6 path("", views.ListListView.as_view(), name="index"), 7]第 6 行告诉 Django,如果 URL 的其余部分为空,应该调用您的
ListListView类来处理请求。请注意,name="index"参数与您在base.html模板的行 18 中看到的{% url "index" %}宏的目标相匹配。所以现在你有了制作你的第一个家庭自制视图的所有材料。请求-响应周期如下进行:
- 当服务器从浏览器接收到一个带有这个 URL 的 GET 请求时,它创建一个
HTTPRequest对象并将其发送到您之前在views.py中定义的ListListView。- 这个特定的视图是一个基于
ToDoList模型的ListView,所以它从数据库中获取所有的ToDoList记录,将它们转换成ToDoListPython 对象,并将它们附加到一个默认名为object_list的列表中。- 然后,视图使用指定的模板
index.html将列表传递给模板引擎进行显示。- 模板引擎从
index.html构建 HTML 代码,自动将其与base.html结合,并使用传入的数据和模板的嵌入逻辑来填充 HTML 元素。- 视图构建一个包含完整构建的 HTML 的
HttpResponse对象,并将其返回给 Django。- Django 将
HttpResponse转换成 HTTP 消息,并将其发送回浏览器。- 浏览器看到一个完整的 HTTP 页面,将其显示给用户。
您已经创建了第一个端到端 Django 请求处理程序!但是,您可能已经注意到,您的
index.html文件引用了一个尚不存在的 URL 名称:"list"。这意味着,如果你现在尝试运行你的应用程序,它将无法工作。您需要定义该 URL 并创建相应的视图,以使应用程序正常工作。这个新视图,像本教程中的
ListListView和所有其他视图一样,将是基于类的。在深入研究更多代码之前,理解这意味着什么是很重要的。重用基于类的通用视图
在本教程中,您将使用基于类的通用视图。打算作为视图工作的类应该扩展类
django.views.View并覆盖该类的方法,比如处理相应的HttpRequest类型的.get()和.post()。这些方法都接受一个HttpRequest,并返回一个HttpResponse。基于类的通用视图将可重用性提升到一个新的水平。大多数预期的功能已经编码在基类中。例如,基于通用视图类
ListView的视图类只需要知道两件事:
- 它列出的是什么数据类型
- 它将使用什么样的模板来呈现 HTML
有了这些信息,它可以呈现一个对象列表。当然,
ListView和其他通用视图一样,并不局限于这种非常基本的模式。您可以根据自己的需要调整基类并创建子类。但是基本的功能已经存在,而且不需要花费你一分钱。子类
ListView显示待办事项列表您已经创建了第一个视图,将泛型类
django.views.generic.list.ListView扩展为一个新的子类ListListView,其工作是显示待办事项列表。现在你可以做一些非常类似的事情来显示待办事项列表条目。您将从创建另一个视图类开始,这次称为
ItemListView。像类ListListView,ItemListView将扩展通用的 Django 类ListView。打开views.py,添加你的新类:1# todo_list/todo_app/views.py 2from django.views.generic import ListView 3from .models import ToDoList, ToDoItem 4 5class ListListView(ListView): 6 model = ToDoList 7 template_name = "todo_app/index.html" 8 9class ItemListView(ListView): 10 model = ToDoItem 11 template_name = "todo_app/todo_list.html" 12 13 def get_queryset(self): 14 return ToDoItem.objects.filter(todo_list_id=self.kwargs["list_id"]) 15 16 def get_context_data(self): 17 context = super().get_context_data() 18 context["todo_list"] = ToDoList.objects.get(id=self.kwargs["list_id"]) 19 return context在您的
ItemListView实现中,您稍微专门化了一下ListView。当你显示一个ToDoItem对象的列表时,你不想显示数据库中每一个ToDoItem的,只显示那些属于当前列表的。为此,第 13 到 14 行通过使用模型的objects.filter()方法来限制返回的数据,从而覆盖了ListView.get_queryset()方法。每个
View类的后代也有一个.get_context_data()方法。由此返回的值是模板的context,这是一个 Python 字典,它决定了哪些数据可用于呈现。.get_queryset()的结果自动包含在键object_list下的context中,但是您希望模板能够访问todo_list对象本身,而不仅仅是查询返回的其中的项目。第 16 行到第 19 行覆盖
.get_context_data()将这个引用添加到context字典中。重要的是行 17 首先调用超类的.get_context_data(),这样新数据可以与现有的上下文合并,而不是破坏它。注意,这两个被覆盖的方法都使用了
self.kwargs["list_id"]。这意味着在构造类时,必须有一个名为list_id的关键字参数传递给该类。你很快就会知道这个论点从何而来。显示待办事项列表中的项目
您的下一个任务是创建一个在给定列表中显示
TodoItems的模板。同样,{% for <item> in <list> %}…{% endfor %}构造也是不可或缺的。创建新模板,todo_list.html:1<!-- todo_list/todo_app/templates/todo_app/todo_list.html --> 2{% extends "base.html" %} 3 4{% block content %} 5<div> 6 <div> 7 <div> 8 <h3>Edit list:</h3> 9 <h5>{{ todo_list.title | upper }}</h5> 10 </div> 11 <ul> 12 {% for todo in object_list %} 13 <li> 14 <div> 15 <div 16 role="button" 17 onclick="location.href='#'"> 18 {{ todo.title }} 19 (Due {{ todo.due_date | date:"l, F j" }}) 20 </div> 21 </div> 22 </li> 23 {% empty %} 24 <p>There are no to-do items in this list.</p> 25 {% endfor %} 26 </ul> 27 <p> 28 <input 29 value="Add a new item" 30 type="button" 31 onclick="location.href='#'" /> 32 </p> 33 </div> 34</div> 35{% endblock %}这个显示单个列表及其待办事项的模板与
index.html类似,只是多了几处:
第 9 行和第 19 行展示了一个奇怪的语法。这些带有竖线符号(
|)的表达式被称为模板过滤器,它们提供了一种使用竖线右边的模式分别格式化标题和截止日期的便捷方式。第 15 到 17 行和第 28 到 31 行定义了几个按钮状的元素。现在,他们的
onclick事件处理程序没有做任何有用的事情,但是你很快就会解决这个问题。所以你已经编写了一个
ItemListView类,但是到目前为止,你的用户还没有办法调用它。您需要在urls.py中添加一条新路线,以便使用ItemListView:1# todo_list/todo_app/urls.py 2from todo_app import views 3 4urlpatterns = [ 5 path("", 6 views.ListListView.as_view(), name="index"), 7 path("list/<int:list_id>/", 8 views.ItemListView.as_view(), name="list"), 9]第 7 行声明一个占位符作为新路径的第一个参数。该占位符将匹配浏览器返回的 URL 路径中的位置参数。语法
list/<int:list_id>/意味着这个条目将匹配一个类似于list/3/的 URL,并将命名参数list_id = 3传递给ItemListView实例。如果您重新查看views.py中的ItemListView代码,您会注意到它以self.kwargs["list_id"]的形式引用了这个参数。现在,由于您创建了路线、视图和模板,您可以查看您的所有列表。您还创建了一个路线、视图和模板,用于列出各个待办事项。
是时候测试一下你到目前为止做了什么了。现在尝试以通常的方式运行您的开发服务器:
- 视窗
** Linux + macOS*(venv) C:\> python manage.py runserver(venv) $ python manage.py runserver根据您从管理界面添加的内容,您应该会看到一个或多个列表名称。您可以单击每一项来显示特定列表包含的项目。你可以点击主 Django 待办事项列表标题,导航回应用的主页面。
你的应用现在可以显示列表和项目。您已经实现了 CRUD 操作的 Read 部分。立即运行您的开发服务器。您应该能够在待办事项列表和单个列表中的项目之间来回导航,但是您还不能添加或删除列表,或者添加、编辑和移除项目。
步骤 6:在 Django 中创建和更新模型对象
在这一步,您将通过启用列表和项目的创建和更新来增强您的应用程序。您将通过扩展 Django 的一些通用视图类来实现这一点。通过这个过程,你会注意到已经嵌入到这些类中的逻辑是如何解释许多典型的 CRUD 用例的。但是请记住,你并不局限于预先烘焙的逻辑。您几乎可以覆盖请求-响应周期的任何部分。
要下载项目此阶段的代码,请单击以下链接并导航至
source_code_step_6/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
议程上的第一项是添加支持创建和更新操作的新视图。接下来,您将添加引用这些视图的 URL,最后,您将更新
todo_items.html模板以提供允许用户导航到新 URL 的链接。将新的导入和视图类添加到
views.py:1# todo_list/todo_app/views.py 2from django.urls import reverse 3 4from django.views.generic import ( 5 ListView, 6 CreateView, 7 UpdateView, 8) 9from .models import ToDoItem, ToDoList 10 11class ListListView(ListView): 12 model = ToDoList 13 template_name = "todo_app/index.html" 14 15class ItemListView(ListView): 16 model = ToDoItem 17 template_name = "todo_app/todo_list.html" 18 19 def get_queryset(self): 20 return ToDoItem.objects.filter(todo_list_id=self.kwargs["list_id"]) 21 22 def get_context_data(self): 23 context = super().get_context_data() 24 context["todo_list"] = ToDoList.objects.get(id=self.kwargs["list_id"]) 25 return context 26 27class ListCreate(CreateView): 28 model = ToDoList 29 fields = ["title"] 30 31 def get_context_data(self): 32 context = super(ListCreate, self).get_context_data() 33 context["title"] = "Add a new list" 34 return context 35 36class ItemCreate(CreateView): 37 model = ToDoItem 38 fields = [ 39 "todo_list", 40 "title", 41 "description", 42 "due_date", 43 ] 44 45 def get_initial(self): 46 initial_data = super(ItemCreate, self).get_initial() 47 todo_list = ToDoList.objects.get(id=self.kwargs["list_id"]) 48 initial_data["todo_list"] = todo_list 49 return initial_data 50 51 def get_context_data(self): 52 context = super(ItemCreate, self).get_context_data() 53 todo_list = ToDoList.objects.get(id=self.kwargs["list_id"]) 54 context["todo_list"] = todo_list 55 context["title"] = "Create a new item" 56 return context 57 58 def get_success_url(self): 59 return reverse("list", args=[self.object.todo_list_id]) 60 61class ItemUpdate(UpdateView): 62 model = ToDoItem 63 fields = [ 64 "todo_list", 65 "title", 66 "description", 67 "due_date", 68 ] 69 70 def get_context_data(self): 71 context = super(ItemUpdate, self).get_context_data() 72 context["todo_list"] = self.object.todo_list 73 context["title"] = "Edit item" 74 return context 75 76 def get_success_url(self): 77 return reverse("list", args=[self.object.todo_list_id])这里有三个新的视图类,都来自 Django 的通用视图类。两个新类扩展了
django.view.generic.CreateView,而第三个扩展了django.view.generic.UpdateView:
- 第 27 到 34 行定义
ListCreate。这个类定义了一个表单,包含唯一的公共属性ToDoList,它的title。表单本身也有一个标题,在上下文数据中传递。- 第 36 到 59 行定义了
ItemCreate类。这将生成一个包含四个字段的表单。覆盖.get_initial()和.get_context_data()方法,为模板提供有用的信息。.get_success_url()方法为视图提供了一个在新项目创建后显示的页面。在这种情况下,它在表单提交成功后调用list视图来显示包含新项目的完整待办事项列表。- 第 61 到 77 行定义了
ItemUpdate,它与ItemCreate非常相似,但是提供了一个更合适的标题。现在,您已经定义了三个新的视图类,用于创建和更新待办事项列表及其项目。您的代码和模板将按需实例化这些类,并用相关的列表或项目数据完成。
列表和项目
ListCreate和ItemCreate都扩展了CreateView类。这是一个通用视图,可用于任何Model子类。Django 文件对CreateView描述如下:一种视图,显示用于创建对象、重新显示表单并突出显示所有验证错误,以及最终保存对象的表单。(来源)
所以
CreateView可以是任何用于创建对象的视图的基类。
ItemUpdate将扩展通用视图类UpdateView。这与CreateView非常相似,你可以为两者使用相同的模板。主要的区别在于,ItemUpdate视图将使用来自现有ToDoItem的数据预先填充模板表单。通用视图知道如何处理表单在一个成功的
submit动作上生成的 POST 请求。像往常一样,子类需要被告知它们基于哪个
Model。这些型号将分别是ToDoList和ToDoItem。视图还有一个fields属性,可以用来限制向用户显示哪些Model数据字段。例如,ToDoItem.created_date字段是在数据模型中自动完成的,你可能不希望用户更改它,所以可以从fields数组中省略它。现在您需要定义路线,以便用户可以使用适当的数据值集到达每个新视图。将路线作为新项目添加到
urlpatterns数组中,命名为"list-add"、"item-add"和"item-update":1# todo_list/todo_app/urls.py 2from django.urls import path 3from todo_app import views 4 5urlpatterns = [ 6 path("", views.ListListView.as_view(), name="index"), 7 path("list/<int:list_id>/", views.ItemListView.as_view(), name="list"), 8 # CRUD patterns for ToDoLists 9 path("list/add/", views.ListCreate.as_view(), name="list-add"), 10 # CRUD patterns for ToDoItems 11 path( 12 "list/<int:list_id>/item/add/", 13 views.ItemCreate.as_view(), 14 name="item-add", 15 ), 16 path( 17 "list/<int:list_id>/item/<int:pk>/", 18 views.ItemUpdate.as_view(), 19 name="item-update", 20 ), 21]现在,您已经将名称、URL 模式和视图与三个新的路由相关联,其中的每一个都对应于数据上的一个操作。
注意,
"item-add"和"item-update"URL 模式包含参数,就像"list"路径一样。要创建一个新项目,您的视图代码需要知道它的父列表的list_id。要更新一个条目,视图必须知道它的list_id和条目自己的 ID,这里称为pk。新视图
接下来,您需要在模板中提供一些链接来激活新视图。就在
index.html中的{% endblock %}标签之前,添加一个按钮:<p> <input value="Add a new list" type="button" onclick="location.href='{% url "list-add" %}'"/> </p>点击这个按钮将会生成一个带有
"list-add"模式的请求。如果您回头看一下todo_app/urls.py中相应的urlpattern项,那么您会看到关联的 URL 看起来像"list/add/",并且它导致 URL dispatcher 实例化一个ListCreate视图。现在您将更新
todo_list.html中的两个虚拟onclick事件:1<!-- todo_list/todo_app/templates/todo_app/todo_list.html --> 2{% extends "base.html" %} 3 4{% block content %} 5<div> 6 <div> 7 <div> 8 <h3>Edit list:</h3> 9 <h5>{{ todo_list.title | upper }}</h5> 10 </div> 11 <ul> 12 {% for todo in object_list %} 13 <li> 14 <div> 15 <div 16 role="button" 17 onclick="location.href= 18 '{% url "item-update" todo_list.id todo.id %}'"> 19 {{ todo.title }} 20 (Due {{ todo.due_date | date:"l, F j"}}) 21 </div> 22 </div> 23 </li> 24 {% empty %} 25 <p>There are no to-do items in this list.</p> 26 {% endfor %} 27 </ul> 28 <p> 29 <input 30 value="Add a new item" 31 type="button" 32 onclick="location.href='{% url "item-add" todo_list.id %}'" 33 /> 34 </p> 35 </div> 36</div> 37{% endblock %}
onclick事件处理程序现在调用名为"item-update"和"item-add"的新 URL。再次注意第 18 行和第 32 行中的语法{% url "key" [param1 [, param2 [,...]]]%},其中urlpattern名称与来自context的数据相结合以构建超链接。例如,在的第 15 行到第 21 行中,您设置了一个带有
onclick事件处理程序的类似按钮的div元素。请注意,
"item-update"URL 需要列表和要更新的项目的 id,而"item-add"只需要todo_list.id。您将需要模板来呈现新的
ListCreate、ItemCreate和ItemUpdate视图。您要处理的第一个问题是创建新列表的表单。创建一个名为todolist_form.html的新模板文件:1<!-- todo_list/todo_app/templates/todo_app/todolist_form.html --> 2{% extends "base.html" %} 3 4{% block content %} 5 6<h3>{{ title }}</h3> 7<div> 8 <div> 9 <form method="post"> 10 {% csrf_token %} 11 {{ form.as_p }} 12 <input 13 value="Save" 14 type="submit"> 15 <input 16 value="Cancel" 17 type="button" 18 onclick="location.href='{% url "index" %}';"> 19 </form> 20 </div> 21</div> 22 23{% endblock %}该页面在的第 9 行到第 19 行包含一个
<form>元素,当用户提交请求时,它将生成一个 POST 请求,用户更新的表单内容作为其有效负载的一部分。在这种情况下,表单只包含列表title。
第 10 行使用了
{% csrf_token %}宏,该宏生成了一个跨站点请求伪造令牌,这是现代 web 表单的必要预防措施。第 11 行使用
{{ form.as_p }}标签来调用视图类的.as_p()方法。这将从fields属性和模型结构中自动生成表单内容。该表单将在一个<p>标签中呈现为 HTML。接下来,您将创建另一个表单,允许用户创建新的
ToDoItem,或者编辑现有表单的详细信息。添加新模板todoitem_form.html:1<!-- todo_list/todo_app/templates/todo_app/todoitem_form.html --> 2{% extends "base.html" %} 3 4{% block content %} 5 6<h3>{{ title }}</h3> 7<form method="post"> 8 {% csrf_token %} 9 <table> 10 {{ form.as_table }} 11 </table> 12 <input 13 value="Submit" 14 type="submit"> 15 <input 16 value="Cancel" 17 type="button" 18 onclick="location.href='{% url "list" todo_list.id %}'"> 19</form> 20 21{% endblock %}这一次,您将表单呈现为一个表格(第 9 行到第 11 行),因为每个条目有几个字段。
CreateView和UpdateView都包含一个.form成员,通过form.as_p()和form.as_table()等方便的方法进行自动布局。提交按钮将使用表单内容生成一个 POST 请求。取消按钮会将用户重定向到"list"URL,并将当前列表id作为参数传递。再次运行开发服务器,验证您现在可以创建新列表并向这些列表中添加项。
第七步:删除待办事项和项目
您已经编写了代码来创建和更新待办事项列表和待办事项。但是没有删除功能,没有 CRUD 应用是完整的。在这一步中,您将向表单添加链接,以允许用户一次删除一个项目,甚至删除整个列表。Django 也提供了处理这些情况的通用视图。
要下载项目此阶段的代码,请单击以下链接并导航至
source_code_step_7/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
创建删除视图子类
您将从添加扩展
django.views.generic.DeleteView的视图类开始。打开views.py并确保您有所有必要的导入:# todo_list/todo_app/views.py from django.urls import reverse, reverse_lazy from django.views.generic import ( ListView, CreateView, UpdateView, DeleteView, )另外,添加两个支持删除对象的新视图类。您需要一个用于列表,一个用于项目:
# todo_list/todo_app/views.py class ListDelete(DeleteView): model = ToDoList # You have to use reverse_lazy() instead of reverse(), # as the urls are not loaded when the file is imported. success_url = reverse_lazy("index") class ItemDelete(DeleteView): model = ToDoItem def get_success_url(self): return reverse_lazy("list", args=[self.kwargs["list_id"]]) def get_context_data(self, **kwargs): context = super().get_context_data(**kwargs) context["todo_list"] = self.object.todo_list return context你的两个新类都扩展了
django.views.generic.edit.DeleteView。Django 的官方文档是这样描述DeleteView的:显示确认页面并删除现有对象的视图。仅当请求方法为 POST 时,才会删除给定的对象。如果这个视图是通过 GET 获取的,它将显示一个确认页面,该页面应该包含一个发送到相同 URL 的表单。(来源)
定义删除确认和 URL
因为您将在编辑页面中为用户提供删除选项,所以您只需要为相应的确认页面创建新的模板。这些确认模板甚至有一个默认名称:
<modelname>_confirm_delete.html。如果存在这样的模板,那么当提交相关表单时,从DeleteView派生的类将自动呈现它。在文件
todolist_confirm_delete.html中创建一个新模板:<!-- todo_list/todo_app/templates/todo_app/todolist_confirm_delete.html --> {% extends "base.html" %} {% block content %} <!--todolist_confirm_delete.html--> <h3>Delete List</h3> <p>Are you sure you want to delete the list <i>{{ object.title }}</i>?</p> <form method="POST"> {% csrf_token %} <input value="Yes, delete." type="submit"> </form> <input value="Cancel" type="button" onclick="location.href='{% url "index" %}';"> {% endblock %}当这个模板被渲染时,
DeleteView子类将仍然被控制。通过点击是,删除。按钮,您提交表单,然后这个类继续从数据库中删除列表。如果你点击取消,它什么也不做。无论哪种情况,Django 都会将您重定向到主页。删除
ToDoList对象到此为止。现在您可以为删除ToDoItem对象做同样的事情。创建另一个新模板,命名为todoitem_confirm_delete.html:<!-- todo_list/todo_app/templates/todo_app/todoitem_confirm_delete.html --> {% extends "base.html" %} {% block content %} <h3>Delete To-do Item</h3> <p>Are you sure you want to delete the item: <b>{{ object.title }}</b> from the list <i>{{ todo_list.title }}</i>?</p> <form method="POST"> {% csrf_token %} <input value="Yes, delete." type="submit"> <input value="Cancel" type="button" onclick="location.href='{% url "list" todo_list.id %}';"> </form> {% endblock %}完全相同的逻辑适用,尽管这一次如果按下取消按钮,用户将被重定向到
"list"URL 以显示父列表,而不是应用程序的索引页面。现在您需要为删除 URL 定义路由。您可以通过将突出显示的行添加到应用程序的
urls.py中来实现:1# todo_list/todo_app/urls.py 2from django.urls import path 3from todo_app import views 4 5urlpatterns = [ 6 path("", views.ListListView.as_view(), name="index"), 7 path("list/<int:list_id>/", views.ItemListView.as_view(), name="list"), 8 # CRUD patterns for ToDoLists 9 path("list/add/", views.ListCreate.as_view(), name="list-add"), 10 path( 11 "list/<int:pk>/delete/", views.ListDelete.as_view(), name="list-delete" 12 ), 13 # CRUD patterns for ToDoItems 14 path( 15 "list/<int:list_id>/item/add/", 16 views.ItemCreate.as_view(), 17 name="item-add", 18 ), 19 path( 20 "list/<int:list_id>/item/<int:pk>/", 21 views.ItemUpdate.as_view(), 22 name="item-update", 23 ), 24 path( 25 "list/<int:list_id>/item/<int:pk>/delete/", 26 views.ItemDelete.as_view(), 27 name="item-delete", 28 ), 29]这些新的 URL 将加载
DeleteView子类作为视图。不需要为删除确认定义特殊的 URL,因为 Django 在默认情况下会处理这个需求,用您刚刚添加的<modelname>_confirm_delete模板呈现确认页面。启用删除
到目前为止,您已经创建了视图和 URL 来删除内容,但是还没有让您的用户调用该功能的机制。接下来你会解决的。
首先向
todoitem_form.html添加一个按钮,允许用户删除当前项目。打开todoitem_form.html并添加高亮显示的行:<!-- todo_list/todo_app/templates/todo_app/todoitem_form.html --> {% extends "base.html" %} {% block content %} <h3>{{ title }}</h3> <form method="post"> {% csrf_token %} <table> {{ form.as_table }} </table> <input value="Submit" type="submit"> <input value="Cancel" type="button" onclick="location.href='{% url "list" todo_list.id %}'"> {% if object %} <input value="Delete this item" type="button" onclick="location.href= '{% url "item-delete" todo_list.id object.id %}'"> {% endif %} </form> {% endblock %}回想一下,这个视图既用于创建项目,也用于更新项目。在创建的情况下,表单中不会加载任何项目实例。因此,为了避免混淆用户,您需要将新的输入元素包装在条件模板块
{% if object %}…{% endif %}中,以便仅当该项已经存在时,删除此项选项才会出现。现在您需要添加用户界面元素来删除整个列表。将高亮显示的行添加到
todolist.html:<!-- todo_list/todo_app/templates/todo_app/todo_list.html --> {% extends "base.html" %} {% block content %} <div> <div> <div> <h3>Edit list:</h3> <h5>{{ todo_list.title | upper }}</h5> </div> <ul> {% for todo in object_list %} <li> <div> <div role="button" onclick="location.href= '{% url "item-update" todo_list.id todo.id %}'"> {{ todo.title }} (Due {{ todo.due_date | date:"l, F j" }}) </div> </div> </li> {% empty %} <p>There are no to-do items in this list.</p> {% endfor %} </ul> <p> <input value="Add a new item" type="button" onclick="location.href= '{% url "item-add" todo_list.id %}'" /> <input value="Delete this list" type="button" onclick="location.href= '{% url "list-delete" todo_list.id %}'" /> </p> </div> </div> {% endblock %}在这种情况下,总有一个
ToDoList实例与模板相关联,所以提供删除这个列表选项总是有意义的。第八步:使用你的 Django 待办事项应用程序
您的项目代码现在已经完成。您可以通过点击以下链接并导航到
source_code_step_final文件夹来下载该项目的完整代码:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
您已经构建了整个待办事项列表应用程序。这意味着您已经准备好测试整个应用程序了!
再次启动您的开发服务器。如果控制台显示错误,那么您必须在继续之前解决它们。否则,使用浏览器导航至
http://localhost:8000/。如果一切正常,您应该会看到应用程序的主页:
app heading Django 待办事项列表会出现在每一页。它作为返回主页的链接,允许用户从应用程序的任何地方返回。
应用程序中可能已经有一些数据,这取决于您之前的测试。现在你可以开始练习应用程序逻辑了。
- 点击添加新列表。出现一个新屏幕,为新列表的标题提供一个空白文本框。
- 为您的新列表命名,然后按保存。你被带到编辑列表页面,显示消息该列表中没有待办事项。
- 点击添加新项目。出现创建新项目表单。填写标题和描述,注意默认的截止日期正好是一周前。如果你喜欢,你可以改变它。
该表单允许您填写和编辑待办事项的所有相关字段。这可能是这样的:
再次点击 Django 待办事项列表返回主页。现在,您可以通过添加更多列表、向列表添加更多项目、修改项目详细信息以及删除项目和列表来继续测试应用程序的导航和功能。
以下是添加了几个列表后主页的外观示例:
这是其中一个列表在你点击它的链接后的样子:
如果有些东西不工作,尝试使用上面的解释,以及一步一步的代码下载,找出可能是什么地方出了问题。或者你还是解决不了,可以下载完整的项目代码,看看你的哪里不一样。点击下面的链接并导航至
source_code_final/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的待办事项应用程序。
如果您能够像这里描述的那样与您的应用程序进行交互,那么您可以确信您已经构建了一个功能正常的应用程序。恭喜你!
结论
所以现在您已经从头开始编写了一个成熟的、数据库支持的 Django web 应用程序。
一路上,您已经了解了 web 应用程序,以及 Django 及其架构。您已经应用了现代的面向对象原则和继承来实现代码重用和提高可维护性。
在本教程中,您已经学会了如何:
- 使用 Django 创建一个 web 应用
- 用一对多关系构造一个数据模型
- 探索您的数据模型,并通过 Django admin 接口添加测试数据
- 通过编码模板显示您的列表
- 通过基于类的视图处理标准数据库操作
- 创建 URL 配置来控制 Django URL 分配器并将请求路由到适当的视图
Django 基于类的视图旨在帮助你在最短的时间内启动一个应用程序。它们以未修改的形式覆盖了大多数用例。但是因为它们是基于类的,所以没有限制。您几乎可以更改任何您想要更改的视图行为。
基于类的视图不是唯一的方法。对于一个基本的应用程序,您可能会发现旧的基于函数的视图方法更简单,也更容易理解。即使你认为类是最好的,你也不一定要使用 Django 的通用视图。您可以将任何满足请求-响应契约的函数或方法插入到您的应用程序中,并且您将继续受益于 Django 丰富的基础设施和生态系统。
根据您在本教程中获得的经验,您知道如何处理构建 web 应用程序的具体细节。这取决于你将这些技巧应用到你的下一个创意中!
接下来的步骤
既然您已经完成了本教程,是时候考虑一下您可以从这里走向何方了。通过进一步开发此应用程序,您可以积累知识和巩固技能,同时为您的编程组合增加一个有吸引力的内容。以下是对您下一步可能要做的事情的一些建议:
应用程序风格:待办事项应用程序的用户界面(UI)平淡无奇,毫无修饰。帮助你创建了一个可接受的用户界面,但仅此而已。您可能想研究一些方法来改进它:
Simple.css网站有几个网站的链接,这些网站建立在Simple.css的基础 CSS 之上,以产生更有吸引力的东西。也可以使用 raw CSS 。CSS 是一个非常强大的样式工具,如果你愿意花时间学习它的来龙去脉,你可以让它做任何事情。
增强应用程序:你可以给这个应用程序添加许多有用的特性。一个明显的改进是处理任务完成和截止日期。您可以在待办事项中添加一个
completed字段,这样您的用户就可以区分已经完成的任务和那些仍然需要行动的任务。你甚至可以添加逻辑到发送电子邮件提醒,如果他们错过了截止日期。多用户化:如果你发现待办事项列表管理器很有用,那么合理的做法可能是将它扩展到多个用户,比如你的团队成员。每个用户都可以有自己的空间,有自己的待办事项列表,你可以考虑实现共享列表来实现合作计划。在这种情况下,您应该探索一下 Django 的一些安全选项,并了解一下多用户数据库,如 MySQL 或 Postgres 。
探索更多基于类的视图:在这个项目中,您已经使用了 Django 的几个通用的基于类的视图。但是 Django 有一个丰富的基于类的视图和 mixins 体系结构,可以最大限度地重用代码,在这里您几乎还没有触及到它的表面。你可以在关于基于类的视图的 Django 官方文档中读到更多关于你的选项。
通过更多的 Django 项目建立您的专业知识: Real Python 有许多不同级别的 Django 项目教程。既然您已经完成了这一项,您可能需要研究其中的一些内容:
- Django 第 1 部分入门:构建投资组合应用
- 用 Django 和 GeoDjango 制作基于位置的网络应用
- 用 Python 定制 Django 管理
- 与 Django 建立社交网络**********************************************
Django 入门第 2 部分:Django 用户管理
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 搭建 Django 用户管理系统
如果您已经完成了本系列的第一部分,那么您可能已经对自己的 Django 应用程序有了很多想法。在某些时候,您可能会决定用用户帐户来扩展它们。在这个循序渐进的教程中,您将学习如何使用 Django 用户管理并将其添加到您的程序中。
本教程结束时,你将能够:
- 创建一个用户可以注册、登录、重置和自行更改密码的应用程序
- 编辑默认 Django 模板负责用户管理
- 向实际电子邮件地址发送密码重置电子邮件
- 使用外部服务认证
我们开始吧!
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
建立 Django 项目
本教程使用 Django 3.0 和 Python 3.6。它侧重于用户管理,所以您不会使用任何高级或响应性样式。它也不处理组和权限,只处理创建和管理用户帐户。
在使用 Python 项目时,使用虚拟环境是一个好主意。这样,您可以始终确保
python命令指向正确的 Python 版本,并且项目所需的模块具有正确的版本。要了解更多,请查看 Python 虚拟环境:初级读本。要在 Linux 和 macOS 上设置虚拟环境,请运行以下命令:
$ python3 -m venv venv $ source venv/bin/activate (venv) $ python -m pip install --upgrade pip (venv) $ python -m pip install django要在 Windows 上激活虚拟环境,请运行以下命令:
C:\> venv\Scripts\activate现在环境已经准备好了,您可以创建一个新项目和一个应用程序来存储您的所有用户管理代码:
(venv) $ django-admin startproject awesome_website (venv) $ cd awesome_website (venv) $ python manage.py startapp users在本例中,您的应用程序名为
users。请记住,您需要通过将它添加到INSTALLED_APPS来安装它:# awesome_website/settings.py INSTALLED_APPS = [ "users", "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", ]接下来,应用迁移并运行服务器:
(venv) $ python manage.py migrate (venv) $ python manage.py runserver这将在数据库中创建所有与用户相关的模型,并在
http://localhost:8000/启动您的应用程序。注意:在本教程中,您将使用 Django 的内置用户模型。实际上,您更有可能创建一个定制的用户模型,扩展 Django 提供的功能。你可以在 Django 的文档中了解更多关于定制默认用户模型的信息。
对于这个设置,您还需要做一件事情。默认情况下,Django 强制使用强密码,使用户帐户不容易受到攻击。但是在本教程的学习过程中,您会经常更改密码,每次都要计算一个强密码会非常不方便。
您可以通过在“设置”中禁用密码验证器来解决此问题。只需将它们注释掉,留下一个空列表:
# awesome_website/settings.py AUTH_PASSWORD_VALIDATORS = [ # { # "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator", # }, # { # "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator", # }, # { # "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator", # }, # { # "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator", # }, ]现在 Django 将允许你设置类似于
password甚至pass的密码,这使得你使用用户管理系统更加容易。只要记住在你的实际应用中启用验证器就行了!对于本教程,访问管理面板也很有用,这样您就可以跟踪新创建的用户及其密码。继续创建一个管理员用户:
(venv) $ python manage.py createsuperuser Username (leave blank to use 'pawel'): admin Email address: admin@example.com Password: Password (again): Superuser created successfully.禁用密码验证器后,您可以使用任何您喜欢的密码。
创建仪表板视图
大多数用户管理系统都有某种主页,通常被称为仪表板。在本节中,您将创建一个仪表板,但是因为它不是应用程序中的唯一页面,所以您还将创建一个基本模板来保持网站的外观一致。
您不会使用 Django 的任何高级模板特性,但是如果您需要复习模板语法,那么您可能想要查看 Django 的模板文档。
注意:本教程使用的所有模板都要放在
users/templates目录下。如果教程提到一个模板文件users/dashboard.html,那么实际的文件路径是users/templates/users/dashboard.html。对于base.html,实际路径是users/templates/base.html,以此类推。默认情况下,
users/templates目录不存在,所以您必须先创建它。您的项目的结构将如下所示:awesome_website/ │ ├── awesome_website/ │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ ├── users/ │ │ │ ├── migrations/ │ │ └── __init__.py │ │ │ ├── templates/ │ │ │ │ │ ├── registration/ ← Templates used by Django user management │ │ │ │ │ ├── users/ ← Other templates of your application │ │ │ │ │ └── base.html ← The base template of your application │ │ │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── models.py │ ├── tests.py │ └── views.py │ ├── db.sqlite3 └── manage.py创建一个名为
base.html的基础模板,内容如下:<!--users/templates/base.html--> <h1>Welcome to Awesome Website</h1> {% block content %} {% endblock %}基本模板没有做太多事情。它显示消息
Welcome to Awesome Website并定义一个名为content的块。这个块现在是空的,其他模板将使用它来包含自己的内容。现在,您可以为仪表板创建一个模板。它应该被称为
users/dashboard.html,看起来应该是这样的:<!--users/templates/users/dashboard.html--> {% extends 'base.html' %} {% block content %} Hello, {{ user.username|default:'Guest' }}! {% endblock %}这并没有给基础模板增加很多东西。它只显示带有当前用户用户名的欢迎消息。如果用户没有登录,那么 Django 仍然会使用一个
AnonymousUser对象来设置user变量。匿名用户总是有一个空的用户名,所以仪表板会显示Hello, Guest!为了让模板工作,您需要创建一个呈现它的视图和一个使用该视图的 URL:
# users/views.py from django.shortcuts import render def dashboard(request): return render(request, "users/dashboard.html")现在创建一个
users/urls.py文件,并为dashboard视图添加一个路径:# users/urls.py from django.conf.urls import url from users.views import dashboard urlpatterns = [ url(r"^dashboard/", dashboard, name="dashboard"), ]不要忘记将应用程序的 URL 添加到项目的 URL 中:
# awesome_website/urls.py from django.conf.urls import include, url from django.contrib import admin urlpatterns = [ url(r"^", include("users.urls")), url(r"^admin/", admin.site.urls), ]您现在可以测试仪表板视图了。在浏览器中打开
http://localhost:8000/dashboard/。您应该会看到与此类似的屏幕:
现在在
http://localhost:8000/admin/打开管理面板,以管理员用户身份登录。您的仪表板现在看起来应该有点不同:
正如您所看到的,您的新模板正确地显示了当前登录用户的名称。
与 Django 用户管理合作
一个完整的网站需要的不仅仅是一个仪表板。幸运的是,Django 有很多与用户管理相关的资源,可以处理几乎所有的事情,包括登录、注销、密码更改和密码重置。不过,模板不是这些资源的一部分。你必须自己创造它们。
首先将 Django 身份验证系统提供的 URL 添加到您的应用程序中:
# users/urls.py from django.conf.urls import include, url from users.views import dashboard urlpatterns = [ url(r"^accounts/", include("django.contrib.auth.urls")), url(r"^dashboard/", dashboard, name="dashboard"), ]这将使您能够访问以下所有 URL:
accounts/login/用于登录用户进入你的应用程序。用名字"login"来称呼它。
accounts/logout/用于注销用户的应用程序。用名字"logout"来称呼它。
accounts/password_change/用于修改密码。用名字"password_change"来称呼它。
accounts/password_change/done/用于显示密码被更改的确认。用名字"password_change_done"来称呼它。
accounts/password_reset/用于请求带有密码重置链接的邮件。用名字"password_reset"来称呼它。
accounts/password_reset/done/用于显示确认密码重置邮件已发送。用名字"password_reset_done"来称呼它。
accounts/reset/<uidb64>/<token>/用于使用密码重置链接设置新密码。用名字"password_reset_confirm"来称呼它。
accounts/reset/done/用于显示密码被重置的确认。用名字"password_reset_complete"来称呼它。这可能看起来有点让人不知所措,但是不要担心。在接下来的部分中,您将了解这些 URL 的作用以及如何将它们添加到您的应用程序中。
创建登录页面
对于登录页面,Django 将尝试使用一个名为
registration/login.html的模板。继续创建它:<!--users/templates/registration/login.html--> {% extends 'base.html' %} {% block content %} <h2>Login</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Login"> </form> <a href="{% url 'dashboard' %}">Back to dashboard</a> {% endblock %}这将显示一个
Login标题,后面是一个登录表单。Django 使用一个字典,也称为上下文,在呈现数据时将数据传递给模板。在这种情况下,名为form的变量已经包含在上下文中——您需要做的就是显示它。使用{{ form.as_p }}会将表单呈现为一系列 HTML 段落,使其看起来比仅仅使用{{ form }}更好。
{% csrf_token %}行插入一个跨站请求伪造 (CSRF)令牌,这是每个 Django 表单都需要的。还有一个提交表单的按钮,在模板的末尾,有一个链接会把你的用户带回到仪表板。您可以通过向基本模板添加一个小的 CSS 脚本来进一步改善表单的外观:
<!--users/templates/base.html--> <style> label, input { display: block; } span.helptext { display: none; } </style> <h1>Welcome to Awesome Website</h1> {% block content %} {% endblock %}通过将上述代码添加到基本模板中,您将改进所有表单的外观,而不仅仅是仪表板中的表单。
您现在可以在浏览器中打开
http://localhost:8000/accounts/login/,您应该会看到类似这样的内容:
使用您的管理员用户的凭证并按下登录。如果您看到错误屏幕,请不要惊慌:
根据错误消息,Django 找不到
accounts/profile/的路径,这是您的用户成功登录后的默认目的地。与其创建一个新视图,不如在这里重用仪表板视图更有意义。幸运的是,Django 使得更改默认重定向变得很容易。您需要做的只是在设置文件的末尾添加一行:
# awesome_website/settings.py LOGIN_REDIRECT_URL = "dashboard"尝试再次登录。这一次,您应该被重定向到仪表板,没有任何错误。
创建注销页面
现在,您的用户可以登录,但他们也应该能够注销。这个过程更简单,因为没有表格,他们只需要点击一个链接。之后,Django 会将你的用户重定向到
accounts/logout,并尝试使用一个名为registration/logged_out.html的模板。然而,就像以前一样,您可以更改重定向。例如,将用户重定向回仪表板是有意义的。为此,您需要在设置文件的末尾添加一行:
# awesome_website/settings.py LOGOUT_REDIRECT_URL = "dashboard"现在登录和注销都可以工作了,向您的仪表板添加适当的链接是一个好主意:
<!--users/templates/users/dashboard.html--> {% extends 'base.html' %} {% block content %} Hello, {{ user.username|default:'Guest' }}! <div> {% if user.is_authenticated %} <a href="{% url 'logout' %}">Logout</a> {% else %} <a href="{% url 'login' %}">Login</a> {% endif %} </div> {% endblock %}如果用户已经登录,那么
user.is_authenticated将返回True,仪表板将显示Logout链接。如果用户没有登录,那么user变量将被设置为AnonymousUser,并且user.is_authenticated将返回False。在这种情况下,将显示Login链接。对于未经身份验证的用户,更新后的仪表板应该如下所示:
如果您登录,您应该会看到以下屏幕:
恭喜你!您刚刚完成了用户管理系统最重要的部分:让用户登录和退出应用程序。但是你前面还有几步路。
更改密码
在某些时候,您的用户可能想要更改他们的密码。您可以在您的应用程序中添加一个密码更改表单,而不是让他们要求管理员为他们做这件事。Django 需要两个模板来完成这项工作:
registration/password_change_form.html显示密码修改表单
registration/password_change_done.html显示确认密码修改成功从
registration/password_change_form.html开始:<!--users/templates/registration/password_change_form.html--> {% extends 'base.html' %} {% block content %} <h2>Change password</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Change"> </form> <a href="{% url 'dashboard' %}">Back to dashboard</a> {% endblock %}该模板看起来与您之前创建的登录模板几乎相同。但是这次 Django 会在这里放一个密码更改表单,而不是登录表单,所以浏览器会有不同的显示。
您需要创建的另一个模板是
registration/password_change_done.html:<!--users/templates/registration/password_change_done.html--> {% extends 'base.html' %} {% block content %} <h2>Password changed</h2> <a href="{% url 'dashboard' %}">Back to dashboard</a> {% endblock %}这将向您的用户保证密码更改成功,并让他们返回到仪表板。
仪表板是一个完美的地方,可以包含一个到您新创建的密码更改表单的链接。您只需要确保它只显示给登录的用户:
<!--users/templates/users/dashboard.html--> {% extends 'base.html' %} {% block content %} Hello, {{ user.username|default:'Guest' }}! <div> {% if user.is_authenticated %} <a href="{% url 'logout' %}">Logout</a> <a href="{% url 'password_change' %}">Change password</a> {% else %} <a href="{% url 'login' %}">Login</a> {% endif %} </div> {% endblock %}如果您在浏览器中点击该链接,您应该会看到以下表单:
继续测试它。更改密码,注销,然后再次登录。您也可以尝试通过直接在浏览器中访问 URL
http://localhost:8000/accounts/password_change/来访问密码更改页面,而无需登录。Django 足够聪明,可以检测到你应该先登录,并且会自动将你重定向到登录页面。发送密码重置链接
我们每个人都会犯错误,时不时会有人忘记密码。您的 Django 用户管理系统也应该处理这种情况。这个功能有点复杂,因为为了提供密码重置链接,您的应用程序必须发送电子邮件。
别担心,你不必配置自己的电子邮件服务器。对于本教程,您只需要一个本地测试服务器来确认电子邮件已发送。打开您的终端并运行以下命令:
(venv) $ python -m smtpd -n -c DebuggingServer localhost:1025这将在
http://localhost:1025启动一个简单的 SMTP 服务器。它不会发送任何电子邮件到实际的电子邮件地址。相反,它会在命令行中显示消息的内容。你现在需要做的就是让姜戈知道你要用它。在设置文件的末尾添加这两行:
# awesome_website/settings.py EMAIL_HOST = "localhost" EMAIL_PORT = 1025Django 需要两个模板来发送密码重置链接:
registration/password_reset_form.html显示用于请求重设密码邮件的表单
registration/password_reset_done.html显示确认密码重置邮件已发送它们与您之前创建的密码更改模板非常相似。从表格开始:
<!--users/templates/registration/password_reset_form.html--> {% extends 'base.html' %} {% block content %} <h2>Send password reset link</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Reset"> </form> <a href="{% url 'dashboard' %}">Back to dashboard</a> {% endblock %}现在添加一个确认模板:
<!--users/templates/registration/password_reset_done.html--> {% extends 'base.html' %} {% block content %} <h2>Password reset done</h2> <a href="{% url 'login' %}">Back to login</a> {% endblock %}在登录页面上包含密码重置表单的链接也是一个好主意:
<!--users/templates/registration/login.html--> {% extends 'base.html' %} {% block content %} <h2>Login</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Login"> </form> <a href="{% url 'dashboard' %}">Back to dashboard</a> <a href="{% url 'password_reset' %}">Reset password</a> {% endblock %}新创建的密码重置表单应该如下所示:
键入管理员的电子邮件地址(
admin@example.com),然后按重置。您应该会在运行电子邮件服务器的终端中看到以下消息:---------- MESSAGE FOLLOWS ---------- b'Content-Type: text/plain; charset="utf-8"' b'MIME-Version: 1.0' b'Content-Transfer-Encoding: 7bit' b'Subject: Password reset on localhost:8000' b'From: webmaster@localhost' b'To: admin@example.com' b'Date: Wed, 22 Apr 2020 20:32:39 -0000' b'Message-ID: <20200422203239.28625.15187@pawel-laptop>' b'X-Peer: 127.0.0.1' b'' b'' b"You're receiving this email because you requested a password reset for your user account at localhost:8000." b'' b'Please go to the following page and choose a new password:' b'' b'http://localhost:8000/accounts/reset/MQ/5fv-f18a25af38f3550a8ca5/' b'' b"Your username, in case you've forgotten: admin" b'' b'Thanks for using our site!' b'' b'The localhost:8000 team' b'' ------------ END MESSAGE ------------这是将发送给您的管理员的电子邮件的内容。它包含发送它的应用程序的信息以及一个密码重置链接。
重置密码
Django 发送的每封密码重置邮件都包含一个可用于重置密码的链接。为了正确处理这个链接,Django 还需要两个模板:
registration/password_reset_confirm.html显示实际密码重置表单
registration/password_reset_complete.html显示确认密码被重置这些看起来与密码更改模板非常相似。从表格开始:
<!--users/templates/registration/password_reset_confirm.html--> {% extends 'base.html' %} {% block content %} <h2>Confirm password reset</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Confirm"> </form> {% endblock %}和以前一样,Django 会自动提供一个表单,但这次是一个密码重置表单。您还需要添加一个确认模板:
<!--users/templates/registration/password_reset_complete.html--> {% extends 'base.html' %} {% block content %} <h2>Password reset complete</h2> <a href="{% url 'login' %}">Back to login</a> {% endblock %}现在,如果您点击其中一封电子邮件中的密码重置链接,您应该会在浏览器中看到如下表单:
你现在可以检查它是否工作。在表单中插入一个新密码,点击确认,退出,并使用新密码登录。
更改电子邮件模板
您可以像更改任何其他用户管理相关模板一样更改 Django 电子邮件的默认模板:
registration/password_reset_email.html决定了邮件的正文registration/password_reset_subject.txt决定了邮件的主题Django 在电子邮件模板上下文中为提供了许多变量,您可以使用它们来编写自己的消息:
<!--users/templates/registration/password_reset_email.html--> Someone asked for password reset for email {{ email }}. Follow the link below: {{ protocol}}://{{ domain }}{% url 'password_reset_confirm' uidb64=uid token=token %}你也可以把话题换成更简短的,比如
Reset password。如果您实施这些更改并再次发送密码重置电子邮件,您应该会看到以下消息:---------- MESSAGE FOLLOWS ---------- b'Content-Type: text/plain; charset="utf-8"' b'MIME-Version: 1.0' b'Content-Transfer-Encoding: 7bit' b'Subject: Reset password' b'From: webmaster@localhost' b'To: admin@example.com' b'Date: Wed, 22 Apr 2020 20:36:36 -0000' b'Message-ID: <20200422203636.28625.36970@pawel-laptop>' b'X-Peer: 127.0.0.1' b'' b'Someone asked for password reset for email admin@example.com.' b'Follow the link below:' b'http://localhost:8000/accounts/reset/MQ/5fv-f18a25af38f3550a8ca5/' ------------ END MESSAGE ------------如你所见,邮件的主题和内容都变了。
注册新用户
您的应用程序现在可以处理所有与 Django 用户管理相关的 URL。但是有一个功能还没有发挥作用。
您可能已经注意到,没有创建新用户的选项。不幸的是,Django 不提供开箱即用的用户注册。但是,您可以自己添加它。
Django 提供了许多可以在项目中使用的表单。其中一个是
UserCreationForm。它包含创建新用户所需的所有字段。但是,它不包括电子邮件字段。在许多应用程序中,这可能不是问题,但是您已经实现了密码重置功能。您的用户需要配置电子邮件地址,否则他们将无法接收密码重置电子邮件。
要解决这个问题,您需要添加自己的用户创建表单。不要担心——您几乎可以重用整个
UserCreationForm。你只需要添加创建一个名为
users/forms.py的新 Python 文件,并在其中添加一个定制表单:# users/forms.py from django.contrib.auth.forms import UserCreationForm class CustomUserCreationForm(UserCreationForm): class Meta(UserCreationForm.Meta): fields = UserCreationForm.Meta.fields + ("email",)如你所见,你的
CustomUserCreationForm扩展了 Django 的UserCreationForm。内部类Meta保存了关于表单的附加信息,并且在本例中扩展了UserCreationForm.Meta,因此 Django 表单中的几乎所有内容都将被重用。主要的区别是
fields属性,它决定了表单中包含的字段。您的定制表单将使用来自UserCreationForm的所有字段,并将添加现在表单已经准备好了,创建一个名为
register的新视图:1# users/views.py 2 3from django.contrib.auth import login 4from django.shortcuts import redirect, render 5from django.urls import reverse 6from users.forms import CustomUserCreationForm 7 8def dashboard(request): 9 return render(request, "users/dashboard.html") 10 11def register(request): 12 if request.method == "GET": 13 return render( 14 request, "users/register.html", 15 {"form": CustomUserCreationForm} 16 ) 17 elif request.method == "POST": 18 form = CustomUserCreationForm(request.POST) 19 if form.is_valid(): 20 user = form.save() 21 login(request, user) 22 return redirect(reverse("dashboard"))下面是对
register()视图的细分:
第 12 到 16 行:如果视图是由浏览器显示的,那么它将被一个
GET方法访问。在这种情况下,将呈现一个名为users/register.html的模板。.render()的最后一个参数是一个上下文,在这种情况下,它包含您的定制用户创建表单。第 17 到 18 行:如果表单被提交,那么视图将被一个
POST方法访问。在这种情况下,Django 将尝试创建一个用户。使用提交给表单的值创建一个新的CustomUserCreationForm,它包含在request.POST对象中。第 19 到 22 行:如果表单有效,那么在第 20 行使用
form.save()创建一个新用户。然后用户使用login()登录到行 21 上。最后, line 22 将用户重定向到仪表板。模板本身应该是这样的:
<!--users/templates/users/register.html--> {% extends 'base.html' %} {% block content %} <h2>Register</h2> <form method="post"> {% csrf_token %} {{form}} <input type="submit" value="Register"> </form> <a href="{% url 'login' %}">Back to login</a> {% endblock %}这与前面的模板非常相似。就像以前一样,它从上下文中获取表单并进行渲染。唯一的区别是,这次您必须自己将表单添加到上下文中,而不是让 Django 来做。
记得为注册视图添加一个 URL:
# users/urls.py from django.conf.urls import include, url from users.views import dashboard, register urlpatterns = [ url(r"^accounts/", include("django.contrib.auth.urls")), url(r"^dashboard/", dashboard, name="dashboard"), url(r"^register/", register, name="register"), ]在登录页面上添加注册表单的链接也是一个好主意:
<!--users/templates/registration/login.html--> {% extends 'base.html' %} {% block content %} <h2>Login</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Login"> </form> <a href="{% url 'dashboard' %}">Back to dashboard</a> <a href="{% url 'password_reset' %}">Reset password</a> <a href="{% url 'register' %}">Register</a> {% endblock %}新创建的表单应该如下所示:
请记住,这只是注册表的一个例子。在现实世界中,您可能会在有人创建用户帐户后发送带有确认链接的电子邮件,如果有人试图注册一个已经存在的帐户,您也会显示适当的错误消息。
向外界发送电子邮件
目前,您的应用程序可以向本地 SMTP 服务器发送电子邮件,因此您可以在命令行中阅读它们。将电子邮件发送到实际的电子邮件地址会有用得多。一种方法是使用射枪。
对于这一步,你需要一个 Mailgun 账户。基本版是免费的,可以让你从一个不太知名的领域发送电子邮件,但是它可以满足本教程的目的。
创建帐户后,转到仪表板页面并向下滚动,直到到达“发送域”在那里你会找到你的沙盒域:
单击该域。您将被重定向到一个页面,在那里您可以选择发送电子邮件的方式。选择 SMTP :
向下滚动,直到找到您帐户的凭据:
您应该找到以下值:
- SMTP 主机名
- 港口
- 用户名
- 默认密码
您需要做的就是将这些值添加到设置文件中。请记住,永远不要在代码中直接包含任何凭据。相反,将它们作为环境变量添加,并在 Python 中读取它们的值。
在 Linux 和 macOS 上,您可以像这样在终端中添加一个环境变量:
(venv) $ export EMAIL_HOST_USER=your_email_host_user在 Windows 上,您可以在命令提示符下运行此命令:
C:\> set EMAIL_HOST_USER=your_email_host_user对
EMAIL_HOST_PASSWORD重复相同的过程,记住在运行 Django 服务器的同一个终端窗口中导出变量。添加两个变量后,更新设置:# awesome_website/settings.py EMAIL_HOST = "smtp.mailgun.org" EMAIL_PORT = 587 EMAIL_HOST_USER = os.environ.get("EMAIL_HOST_USER") EMAIL_HOST_PASSWORD = os.environ.get("EMAIL_HOST_PASSWORD") EMAIL_USE_TLS = True对于所有沙盒域,
EMAIL_HOST和EMAIL_PORT的值应该是相同的,但是你必须使用自己的用户名和密码。还有一个额外的值叫做EMAIL_USE_TLS,需要设置为True。要检查这是否有效,你必须创建一个新用户,并使用你自己的电子邮件地址。转到
http://localhost:8000/admin/并以管理员用户身份登录。转到用户并点击添加用户。选择任意用户名和密码,点击保存并继续编辑。然后在电子邮件地址字段中插入您用作邮箱帐户的电子邮件地址,并保存该用户。创建用户后,导航至
http://localhost:8000/accounts/password_reset/。输入你的电子邮件地址并按下发送。发送电子邮件的过程将比使用本地服务器花费更多的时间。几分钟后,密码重置电子邮件应该会到达您的收件箱。它也可能在你的垃圾邮件文件夹里,所以别忘了也去那里看看。沙盒域将只与您用来创建 Mailgun 帐户的电子邮件地址一起工作。若要向其他收件人发送电子邮件,您必须添加一个自定义域。
用 GitHub 登录
许多现代网站提供了使用社交媒体帐户进行身份验证的选项。一个这样的例子是谷歌登录,但是在本教程中你将学习如何与 GitHub 集成。
幸运的是,有一个非常有用的 Python 模块来完成这项任务。叫
social-auth-app-django。本教程只展示了模块的基本配置,但是你可以从的文档中了解更多,尤其是关于 Django 配置的部分。设置社交认证
从安装模块开始:
(venv) $ python -m pip install social-auth-app-django像任何其他 Django 应用程序一样,您必须将它添加到
INSTALLED_APPS中。注意,在这种情况下,Django 应用程序的名称不同于 Python 模块的名称:# awesome_website/settings.py INSTALLED_APPS = [ "users", "social_django", "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", ]接下来,向
awesome_website/settings.py添加两个上下文处理器:# awesome_website/settings.py TEMPLATES = [ { "BACKEND": "django.template.backends.django.DjangoTemplates", "DIRS": [], "APP_DIRS": True, "OPTIONS": { "context_processors": [ "django.template.context_processors.debug", "django.template.context_processors.request", "django.contrib.auth.context_processors.auth", "django.contrib.messages.context_processors.messages", "social_django.context_processors.backends", "social_django.context_processors.login_redirect", ], }, }, ]完成后,应用迁移:
(venv) $ python manage.py migrate您还需要在应用程序中包含社交认证 URL,就像您对 Django 提供的 URL 所做的那样:
# users/urls.py from django.conf.urls import include, url from users.views import dashboard, register urlpatterns = [ url(r"^accounts/", include("django.contrib.auth.urls")), url(r"^dashboard/", dashboard, name="dashboard"), url(r"^oauth/", include("social_django.urls")), url(r"^register/", register, name="register"), ]所有这些都是 Django 的一般配置。要在 GitHub 中使用社交认证,必须添加一个专用的认证后端。
默认情况下,Django 设置不指定认证后端,Django 使用的默认后端是
django.contrib.auth.backends.ModelBackend。因此,要使用社交认证,您必须在设置中创建新值:# awesome_website/settings.py AUTHENTICATION_BACKENDS = [ "django.contrib.auth.backends.ModelBackend", "social_core.backends.github.GithubOAuth2", ]列表中的第一个后端是 Django 使用的默认后端。如果这里不包含它,那么 Django 将无法登录标准用户。第二个后端用于 GitHub 登录。
最后要做的是在您的登录页面上添加一个 GitHub 登录链接:
<!--users/templates/registration/login.html--> {% extends 'base.html' %} {% block content %} <h2>Login</h2> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Login"> </form> <a href="{% url 'dashboard' %}">Back to dashboard</a> <a href="{% url 'social:begin' 'github' %}">Login with GitHub</a> <a href="{% url 'password_reset' %}">Reset password</a> <a href="{% url 'register' %}">Register</a> {% endblock %}您可能会注意到新的 URL 使用了名称空间
social。名称空间是 Django 在更复杂的项目中组织 URL 的方式。使用唯一的名称空间可以确保您的应用程序的 URL 和其他应用程序的 URL 之间没有冲突。社交认证应用程序使用名称空间
social,因此您想要使用的每个 URL 都必须以social:开头。创建 GitHub 应用程序
要在 Django 用户管理中使用 GitHub 认证,首先必须创建一个应用程序。登录您的 GitHub 帐户,进入 GitHub 的页面注册一个新的 OAuth 应用程序,并填写表格:
最重要的部分是授权回调 URL 。它必须指向你的应用程序。
注册应用程序后,您将被重定向到一个包含凭据的页面:
将客户端 ID 和客户端密码的值添加到设置中,方法与添加 Mailgun 电子邮件凭证相同:
# awesome_website/settings.py SOCIAL_AUTH_GITHUB_KEY = os.environ.get("SOCIAL_AUTH_GITHUB_KEY") SOCIAL_AUTH_GITHUB_SECRET = os.environ.get("SOCIAL_AUTH_GITHUB_SECRET")您现在可以检查这是否有效。转到您的应用程序的登录页面,选择使用 GitHub 登录的选项。假设您在上一步创建应用程序后已经注销,您应该会被重定向到 GitHub 的登录页面:
下一步将要求您授权 GitHub 应用程序:
如果您确认,那么您将被重定向回您的应用程序。现在,您可以在管理面板中找到一个新用户:
新创建的用户与您的 GitHub handle 拥有相同的用户名,并且没有密码。
选择认证后端
上面的例子有一个问题:通过启用 GitHub 登录,您意外地破坏了正常的用户创建过程。
这是因为 Django 以前只有一个认证后端可供选择,现在有两个了。Django 不知道在创建新用户时使用哪一个,所以您必须帮助它决定。为此,请在您的注册视图中替换行
user = form.save():# users/views.py from django.contrib.auth import login from django.shortcuts import redirect, render from django.urls import reverse from users.forms import CustomUserCreationForm def dashboard(request): return render(request, "users/dashboard.html") def register(request): if request.method == "GET": return render( request, "users/register.html", {"form": CustomUserCreationForm} ) elif request.method == "POST": form = CustomUserCreationForm(request.POST) if form.is_valid(): user = form.save(commit=False) user.backend = "django.contrib.auth.backends.ModelBackend" user.save() login(request, user) return redirect(reverse("dashboard"))像以前一样,从表单中创建了一个用户,但是由于
commit=False,这次没有立即保存。在下一行中,一个后端与用户相关联,然后用户才被保存到数据库中。这样,您可以在同一个 Django 用户管理系统中使用普通用户创建和社交媒体认证。结论
Django 是一个通用的框架,它尽最大努力帮助您完成每一项可能的任务,包括用户管理。它提供了许多现成的资源,但有时您需要对它们进行一点扩展。
在本教程中,您已经学会了如何:
- 用全套的用户管理特性扩展您的 Django 应用程序
- 调整默认的 Django 模板以更好地满足您的需求
- 使用邮件枪发送密码重置邮件
- 添加一个选项用 GitHub 登录
这应该为你自己的惊人想法提供了一个很好的起点。如果你觉得少了什么,或者有任何问题,请不要犹豫,告诉我!
« Get Started With Django Part 1: Build a Portfolio AppGet Started With Django Part 2: Django User ManagementGet Started With Django Part 3: Django View Authorization »
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 搭建 Django 用户管理系统********
Django 入门第 3 部分:Django 视图授权
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Django 查看授权:限制访问
在本系列的第 1 部分中,您学习了 Django 模型和视图的基础知识。在第二部分中,你学习了用户管理。在本教程中,您将看到如何结合这些概念来实现 Django 视图授权,并基于用户的角色限制用户在您的视图中可以看到什么和做什么。
允许用户登录你的网站解决了两个问题:认证和授权。认证是验证用户身份的行为,确认他们是他们所说的那个人。授权是决定是否允许用户执行某个操作。这两个概念是相辅相成的:如果你的网站上的某个页面只允许登录的用户访问,那么用户在被授权查看该页面之前必须进行身份验证。
Django 提供了认证和授权工具。Django 视图授权通常是由装饰者完成的。本教程将向您展示如何使用这些视图装饰器来强制对 Django 站点中的页面进行授权查看。
本教程结束时,你将知道如何:
- 使用
HttpRequest和HttpRequest.user对象- 认证和授权用户
- 区分普通、员工和管理员用户
- 用
@login_required装饰器保护一个视图- 使用
@user_passes_test装饰器将一个视图限制为不同的角色- 使用 Django 消息框架通知您的用户
开始使用
为了更好地理解授权,您需要一个项目来进行实验。本教程中的代码与第 1 部分和第 2 部分中显示的非常相似。您可以通过从下面的链接下载示例代码来继续学习:
获取源代码: 单击此处获取源代码,您将在本教程中使用了解 Django 视图授权。
所有演示代码都是用 Python 3.8 和 Django 3.0.7 测试的。它应该与其他版本一起工作,但可能会有细微的差异。
创建项目
首先,您需要创建一个新的 Django 项目。因为 Django 不是标准库的一部分,所以使用虚拟环境被认为是最佳实践。一旦有了虚拟环境,您需要采取以下步骤:
- 安装 Django。
- 创建新项目。
- 在项目中创建一个应用程序。
- 将模板目录添加到项目中。
- 创建站点超级用户。
要完成所有这些,请使用以下命令:
$ python -m pip install django==3.0.7 $ django-admin startproject Blog $ cd Blog $ python manage.py startapp core $ mkdir templates $ python manage.py migrate $ python manage.py createsuperuser Username: superuser Email address: superuser@example.com Password: Password (again):您现在有了一个
Blog项目,但是您仍然需要告诉 Django 您创建的应用程序和您为模板添加的新目录。你可以通过修改Blog/settings.py文件来做到这一点,首先通过改变INSTALLED_APPS:INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", "core", ]突出显示的行表示将
core应用程序添加到已安装应用程序列表中。一旦添加了应用程序,您需要修改TEMPLATES声明:TEMPLATES = [ { "BACKEND": "django.template.backends.django.DjangoTemplates", "DIRS": [os.path.join(BASE_DIR, "templates")], "APP_DIRS": True, "OPTIONS": { "context_processors": [ "django.template.context_processors.debug", "django.template.context_processors.request", "django.contrib.auth.context_processors.auth", "django.contrib.messages.context_processors.messages", ], }, }, ]突出显示的行表示您需要进行的更改。它会修改
DIRS列表以包含您的templates文件夹。这告诉 Django 在哪里寻找你的模板。注意: Django 3.1 已经从使用
os库转移到了pathlib,默认不再导入os。如果您使用的是 Django 3.1,那么您需要在TEMPLATES声明上面添加import os,或者将"DIRS"条目转换为使用pathlib。您将使用的示例站点是一个基本的博客应用程序。
core应用程序需要一个models.py文件来包含在数据库中存储博客内容的模型。编辑core/models.py并添加以下内容:from django.db import models class Blog(models.Model): title = models.CharField(max_length=50) content = models.TextField()现在来看一些网页。创建两个视图,一个用于列出所有博客,另一个用于查看博客。您的视图代码放在
core/views.py中:from django.http import HttpResponse from django.shortcuts import render, get_object_or_404 from core.models import Blog def listing(request): data = { "blogs": Blog.objects.all(), } return render(request, "listing.html", data) def view_blog(request, blog_id): blog = get_object_or_404(Blog, id=blog_id) data = { "blog": blog, } return render(request, "view_blog.html", data)
listing()视图执行一个查询,寻找所有的Blog对象,并将其传递给render()快捷函数。render()接受为视图提供上下文的request对象、要呈现的模板名称(listing.html)和包含Blog对象查询集的data对象。
view_blog()视图将一个blog_id作为参数,并使用它来查找相应的Blog对象。这个对象通过render()快捷方式作为上下文传递给view_blog.html模板。这两个视图有三个模板文件。第一个是包含通用 HTML 元素的基本模板。另外两个扩展了这个基础,并且对应于视图本身。如下创建
templates/base.html:<html> <body> {% block content %} {% endblock content %} </body> </html>然后这个文件被视图使用的模板扩展。
listing()视图使用了一个名为templates/listing.html的文件,如下所示:{% extends "base.html" %} {% block content %} <h1>Blog Listing</h1> <ul> {% for blog in blogs %} <li> <a href="{% url 'view_blog' blog.id %}">{{blog.title}}</a> </li> {% endfor %} </ul> {% endblock content %}注意它是如何使用视图发送的
blogs查询集的。查询集是循环的,打印出找到的每个Blog对象的title属性。最后,要查看一个真实的博客,创建templates/view_blog.html:{% extends "base.html" %} {% block content %} <h1>{{blog.title}}</h1> {{blog.content|safe}} <hr/> <a href="{% url 'listing' %}">All Blogs</a> {% endblock content %}
templates/listing.html和templates/view_blog.html文件使用{% url %}标签来查找与listing()和view_blog()视图相关的 URL。这些 URL 需要在Blog/urls.py中注册。按如下方式修改该文件:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), ]默认的
urls.py文件没有导入include(),所以请注意第二行的变化。其余突出显示的行导入core/views.py,并为listing()和view_blog()视图函数创建 URL 模式。到目前为止,你还没有办法创造内容。Django admin 提供了一种快速修改模型对象的方法。修改
core/admin.py来注册Blog对象:from django.contrib import admin from core.models import Blog @admin.register(Blog) class BlogAdmin(admin.ModelAdmin): pass一切都已就绪。使用以下 Django 管理命令来创建和迁移数据库模型,并运行服务器:
$ python manage.py makemigrations core $ python manage.py migrate $ python manage.py runserver最后一个命令运行 Django 开发服务器。当它运行时,您可以使用浏览器访问
http://127.0.0.1:8000/。您应该看到您的listing页面,但是没有任何数据。添加一些数据
因为您还没有创建任何东西,所以页面将只显示标题。在
http://127.0.0.1:8000/admin/访问 Django 管理员,使用您创建的超级用户证书登录。一旦进入,您可以点击
Blogs对象旁边的添加链接来创建一些测试数据。或者,示例代码有一个包含示例数据的 fixture。您可以使用loaddata管理命令加载示例数据:$ python manage.py loaddata core.jsonfixture 文件包含两个示例博客条目。如果你访问该网站的主页,那么它现在应该显示一些内容。
在视图中检测登录用户及其角色
每个 Django 视图至少有一个参数,一个
HttpRequest。该请求包含有关用户及其正在访问的页面的状态信息。以下是请求中的一些关键信息:
属性 描述 例子 schemeURL 方案 "http"或"https"pathURL 的路径部分 "/music/bands/"method使用的 HTTP 方法 "GET"或"POST"GET查询字符串参数 <QueryDict: {'band_id':['123']}>POSTHTTP 帖子中的字段 <QueryDict: {'name':['Bob']}>user描述用户的对象 Django 有能力通过一个叫做中间件的插件机制运行每个请求的代码。
AuthenticationMiddleware插件将user属性添加到HttpRequest对象中。当您创建一个新项目时,这个中间件是默认启用的,因此您不需要做任何特殊的事情来利用它。如果您对中间件感兴趣,那么文章构建 Django 中间件将介绍相关概念。要查看一些正在运行的
HttpRequest属性,向core/views.py添加以下视图:def see_request(request): text = f""" Some attributes of the HttpRequest object: scheme: {request.scheme} path: {request.path} method: {request.method} GET: {request.GET} user: {request.user} """ return HttpResponse(text, content_type="text/plain")现在将新视图添加到
Blog/urls.py:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), path("see_request/", core_views.see_request), ]准备就绪后,您可以访问
http://127.0.0.1:8000/see_request/并查看一些请求参数。如果您在 URL 的末尾添加一个查询字符串,那么您也可以看到GET是如何工作的。例如,http://127.0.0.1:8000/see_request/?breakfast=spam&lunch=spam会产生以下结果:Some attributes of the HttpRequest object: scheme: http path: /see_request/ method: GET GET: <QueryDict: {"breakfast": ["spam"], "lunch": ["spam"]}> user: AnonymousUser你问
AnonymousUser是谁?HttpRequest.user对象总是填充一些东西。如果你网站的访问者没有通过认证,那么HttpRequest.user将包含一个AnonymousUser对象。如果您之前登录创建了一些数据,那么您可能会看到superuser。如果您已登录,请访问http://127.0.0.1/admin/logout/,然后重新访问该页面以查看不同之处。包括
AnonymousUser在内的所有用户对象都有一些属性,为您提供关于用户的更多信息。要查看这些是如何工作的,将下面的代码添加到core/views.py:def user_info(request): text = f""" Selected HttpRequest.user attributes: username: {request.user.username} is_anonymous: {request.user.is_anonymous} is_staff: {request.user.is_staff} is_superuser: {request.user.is_superuser} is_active: {request.user.is_active} """ return HttpResponse(text, content_type="text/plain")将此视图添加到
Blog/urls.py:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), path("see_request/", core_views.see_request), path("user_info/", core_views.user_info), ]添加 URL 后,您可以访问
http://127.0.0.1/user_info/来查看HttpRequest.user包含的内容。如果您没有登录,您将看到以下结果:Selected HttpRequest.user attributes: username: is_anonymous: True is_staff: False is_superuser: False is_active: False使用您通过访问
http://127.0.0.1/admin/创建的superuser凭证登录管理区域。登录后,返回/user_info/并注意不同之处:Selected HttpRequest.user attributes: username: superuser is_anonymous: False is_staff: True is_superuser: True is_active: True用户登录后,
is_anonymous从True变为False。username属性告诉您用户是谁。在这种情况下,您使用使用manage.py createsuperuser命令创建的超级用户帐户登录。is_staff、is_superuser和is_active属性现在都是True。Django 使用会话来管理用户的状态。会话通过中间件进行管理。你可以在关于会话和中间件的 Django 文档中读到更多关于这些概念的内容。
实现 Django 视图授权
创建带授权的 Django 视图就是检查
HttpRequest.user对象,看看用户是否被允许访问您的页面。如果用户没有登录或没有访问权限,您会怎么做?如果用户没有登录,那么最好将他们发送到登录页面,当他们完成登录后,将他们带回到原来的位置。这样做需要相当多的逻辑,但幸运的是 Django 附带了一些工具来帮助您快速完成。
将视图限制为登录用户
Django 支持不同的方式来控制用户可以看到什么和做什么。它包括一个针对组和权限的完整机制,以及一个基于用户账户的轻量级系统。本教程将重点讨论后者。
Python 有一个特性叫做装饰者。装饰器是用一个函数包装另一个函数的一种方式。Django 使用这些装饰器来帮助实施认证。关于装饰者如何工作的更多信息,请查看 Python 装饰者的初级读本。
在 Django 中,你使用装饰者来包装你的视图。然后装饰器在视图之前被调用,如果需要的话,它可以阻止视图被调用。这对于身份验证很有用,因为它检查是否允许用户实际访问视图。下面是语法:
from django.contrib.auth.decorators import login_required @login_required def private_place(request): return HttpResponse("Shhh, members only!", content_type="text/plain")上面的代码展示了
@login_required装饰器的使用。当调用private_place()视图函数时,首先调用 Djangologin_required()包装函数。装饰器检查用户是否通过了身份验证,如果没有,那么它将用户发送到登录页面。登录页面 URL 用当前 URL 参数化,这样它可以将访问者返回到初始页面。要查看
@login_required的运行情况,将上面的代码添加到core/views.py中,并在Blog/urls.py中注册相关的 URL:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), path("see_request/", core_views.see_request), path("user_info/", core_views.user_info), path("private_place/", core_views.private_place), ]以上示例显示了如何限制基于函数的视图。如果您使用基于类的视图,那么 Django 提供了一个 LoginRequired mixin 来实现相同的结果。
到目前为止,您一直使用管理站点的身份验证机制。这只有在你进入管理网站时才有效。如果你去那里登录,然后你就可以访问
http://127.0.0.1:8000/private_place/。然而,如果您没有登录就直接进入private_place(),那么您将得到一个错误。Django 附带了认证工具,但是它不知道你的网站是什么样子,所以它不附带常规的登录页面。在本系列的第 2 部分中,您学习了如何创建登录模板。对于博客项目,您也必须这样做。
首先,将认证 URL 添加到
Blog/urls.py:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), path("see_request/", core_views.see_request), path("user_info/", core_views.user_info), path("private_place/", core_views.private_place), path("accounts/", include("django.contrib.auth.urls")), ]这允许您利用 Django 的所有内置认证视图。您还需要一个相应的登录模板。在
templates/中创建一个registration/子文件夹,然后在里面创建login.html:{% extends 'base.html' %} {% block content %} <h1>Login</h1> <form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Login"> </form> <a href="{% url 'listing' %}">All Blogs</a> {% endblock %}当您访问
http://127.0.0.1:8000/private_place/时,登录重定向现在将正确工作。此外,通过添加django.contrib.auth.urls,您现在也可以使用/accounts/logout/。限制管理员和员工查看
现在,您已经编写了一个经过授权的 Django 视图。但是授权可能比简单地检查用户是否经过身份验证更复杂。Django 有三个现成的角色:
- 用户
- 员工
- 超级用户
上面的
private_place()视图使用@login_required装饰器来查看用户是否通过了身份验证,以及他们的帐户是否处于活动状态。也可以基于三个角色进行授权。要玩这个功能,你需要更多的用户帐户。通过访问
http://127.0.0.1:8000/admin/进入管理区。点击Users对象链接旁边的添加按钮。使用此屏幕添加用户名为bob的新用户:
开箱即用的 Django 现在强制执行密码要求。您需要在创建的任何密码中使用字母和数字。例如,您可以使用
tops3cret作为您的密码。创建用户后,您将被自动转到编辑用户页面,在这里您可以指定更多的详细信息。默认设置对
bob来说已经足够好了。滚动到底部,点击保存并添加另一个。再次提示您创建一个用户。这一次,创造silvia。当系统提示输入 Silvia 的更多详细信息时,向下滚动到权限部分并选中员工状态复选框:
设置了 staff 属性后,您可以向下滚动并保存该帐户。您应该能够使用
superuser或silvia帐户登录管理区域。作为员工,你可以进入管理区,但默认情况下你看不到任何东西。你没有权限。现在,您有了一个普通用户、一名职员和一名超级用户。使用这三个帐号,尝试访问
/admin/、/private_place/和/user_info/,看看有什么不同。装饰者要么全有,要么全无:你要么登录,要么不登录。Django 也有
@user_passes_test的装饰工。这个装饰器允许您指定一个检查,如果通过,就允许用户进入。尝试将此视图添加到
core/views.py:from django.contrib.auth.decorators import user_passes_test @user_passes_test(lambda user: user.is_staff) def staff_place(request): return HttpResponse("Employees must wash hands", content_type="text/plain")
@user_passes_test装饰器接受至少一个参数,即要通过的测试。这个测试或者是一个函数,或者更常见的是一个lambda。如果你以前没见过lambda,那就把它想象成一个微型的匿名函数。在lambda关键字之后是lambda的命名参数,在本例中是user。冒号(:)的右边是测试。这个测试着眼于
HttpRequest.user.is_staff属性。如果是True,那么测试通过。有关lambda函数及其工作原理的更多信息,请查看如何使用 Python Lambda 函数。新视图就绪后,更新您的
Blog/urls.py文件以注册它:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), path("see_request/", core_views.see_request), path("user_info/", core_views.user_info), path("private_place/", core_views.private_place), path("accounts/", include("django.contrib.auth.urls")), path("staff_place/", core_views.staff_place), ]尝试访问使用不同帐户登录的
http://127.0.0.1:8000/staff_place/,看看会发生什么。别忘了,你可以随时去/accounts/logout/从你当前的用户账户注销。结果如下:
bob不是职员,所以他被送回了登录页面。silvia是工作人员,所以她可以看到视图。superuser既是职员又是超级用户,也可以进入。您用来创建超级用户的
manage.py createsuperuser命令会自动将超级用户帐户设置为 staff。在幕后,
@login_required装饰器实际上调用了@user_passes_test装饰器并使用了下面的测试:lambda user: user.is_authenticated所有的
@login_required装饰器所做的就是检查用户的is_authenticated值是否为True,对于任何认证的账户都是如此。试着自己尝试一下。添加其他视图,或者改变给
@user_passes_test装饰器的测试,看看它如何影响代码。给登录用户发消息
Django 包括一个通知用户的机制。这与他们的认证相关联,可以在任何授权的 Django 视图中使用。消息框架使用中间件使用户的任何未完成通知在任何视图中都可用。默认情况下,消息支持五个级别:
DEBUGINFOSUCCESSWARNINGERROR消息框架主要用于与用户的异步通信。例如,如果一个后台作业出错,那么您可以通过发送一个带有
ERROR级别的消息来通知用户。不幸的是,在管理中没有创建消息的区域——它们必须在代码中创建。为了演示这一点,将以下代码添加到您的
core/views.py中:from django.contrib import messages @login_required def add_messages(request): username = request.user.username messages.add_message(request, messages.INFO, f"Hello {username}") messages.add_message(request, messages.WARNING, "DANGER WILL ROBINSON") return HttpResponse("Messages added", content_type="text/plain")这个视图向登录用户的会话添加了两条消息,一条是具有
INFO级别的问候,另一条是具有WARNING级别的警告。messages.add_message()需要三个参数:
HttpRequest对象- 信息电平
- 消息
要使用
messages.add_message(),您需要将视图注册为 URL:from django.contrib import admin from django.urls import path, include from core import views as core_views urlpatterns = [ path("admin/", admin.site.urls), path("", core_views.listing, name="listing"), path("view_blog/<int:blog_id>/", core_views.view_blog, name="view_blog"), path("see_request/", core_views.see_request), path("user_info/", core_views.user_info), path("private_place/", core_views.private_place), path("accounts/", include("django.contrib.auth.urls")), path("staff_place/", core_views.staff_place), path("add_messages/", core_views.add_messages), ]您可以使用
get_messages()在代码中访问消息,或者使用模板上下文中的messages值直接在模板中访问消息。将以下代码添加到templates/listing.html中,以便在博客列表页面上向用户显示任何消息:{% extends "base.html" %} {% block content %} <h1>Blog Listing</h1> {% if messages %} <ul class="messages" style="background-color:#ccc"> {% for message in messages %} <li {% if message.tags %} class="{{ message.tags }}" {% endif %}> {{ message }} </li> {% endfor %} </ul> {% endif %} <ul> {% for blog in blogs %} <li> <a href="{% url 'view_blog' blog.id %}">{{blog.title}}</a> </li> {% endfor %} </ul> {% endblock content %}上面突出显示的代码使用了中间件放在模板上下文中的列表
messages。如果有消息,那么就会创建一个 HTML 无序列表来显示每条消息。访问
http://127.0.0.1:8000/add_messages/创建一些消息,然后到http://127.0.0.1:8000/的博客列表页面查看它们。刷新页面,您会注意到消息都不见了。Django 自动识别通知已经被查看过的事实,并将它们从会话中删除。结论
大多数复杂的网站都需要用户帐户。一旦你有了用户账号,你需要限制他们能去哪里,不能去哪里。Django 提供了基于角色的认证来帮助您解决这些限制。
在本教程中,您学习了如何:
- 使用
HttpRequest和HttpRequest.user对象- 认证和授权用户
- 区分普通、员工和管理员用户
- 用
@login_required装饰器保护一个视图- 使用
@user_passes_test装饰器将一个视图限制为不同的角色- 使用 Django 消息框架通知您的用户
要重新创建上面看到的示例,您可以从下面的链接下载示例代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用了解 Django 视图授权。
如果三个用户角色不足以满足您的需求,那么 Django 还附带了组和权限。使用这些特性,您可以进一步细化您的授权。编码快乐!
« Get Started With Django Part 2: Django User ManagementGet Started With Django Part 3: Restricting Access With Django View Authorization
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Django 查看授权:限制访问***
Docker 行动——更健康、更快乐、更高效
原文:https://realpython.com/docker-in-action-fitter-happier-more-productive/
有了 Docker,你可以轻松地部署一个 web 应用程序及其依赖关系,环境变量和配置设置——快速高效地重建环境所需的一切。
本教程正是着眼于这一点。
我们将从创建一个 Docker 容器来运行 Python Flask 应用程序开始。从那里,我们将看到一个很好的开发工作流程来管理应用程序的本地开发以及持续集成和交付,一步一步……
我( Michael Herman )最初于 2015 年 2 月 8 日在 PyTennessee 展示了这个工作流程。如果有兴趣,你可以在这里观看幻灯片。
2019 年 4 月 4 日更新:升级了 Docker (v18.09.2)、Docker Compose (v1.23.2)、Docker Machine (v0.16.1)、Python (v3.7.3)、CircleCI (v2)。感谢弗洛里安·戴利茨!
更新于 2015 年 2 月 28 日:新增 Docker 作曲,升级 Docker 和 boot2docker 至最新版本。
工作流程
- 在特征分支上本地编码
- 针对主分支在 Github 上打开一个拉取请求
- 对 Docker 容器运行自动化测试
- 如果测试通过,手动将拉请求合并到主服务器中
- 一旦合并,自动化测试再次运行
- 如果第二轮测试通过,就会在 Docker Hub 上创建一个构建
- 一旦构建被创建,它就被自动地(呃,自动地)部署到生产中
本教程面向 Mac OS X 用户,我们将使用以下工具/技术——Python v 3 . 7 . 3、Flask v1.0.2、Docker v18.09.2、Docker Compose v1.23.2、Docker Machine 0.16.1、Redis v5.0.4
让我们开始吧…
首先,一些码头专用术语:
- 一个 Dockerfile 是一个包含一组用于创建图像的指令的文件。
- 一个映像用于构建和保存环境的快照(状态)。
- 一个容器是一个实例化的、活动的映像,它运行一组进程。
为什么是 Docker?
您可以在本地机器上真实地模拟您的生产环境。再也不用调试特定环境的错误,也不用担心应用程序在生产中的表现会有所不同。
- 基础设施的版本控制
- 轻松分发/重新创建您的整个开发环境
- 构建一次,运行在任何地方-又名圣杯!
对接设置
为了能够在我们的 Mac OS X 系统上运行 Docker 容器,我们需要安装 Mac 版 Docker 桌面。如果你使用的是 Windows 系统,一定要检查 Docker 桌面 Windows 。如果你使用的是旧版本的 Mac OS X 或 Windows,你应该试试 Docker 工具箱来代替。无论您基于您的操作系统选择哪种安装,您最终都会安装三个主要的 Docker 工具:Docker (CLI)、Docker Compose 和 Docker Machine。
现在让我们检查您的 Docker 安装:
$ docker --version Docker version 18.09.2, build 6247962 $ docker-compose --version docker-compose version 1.23.2, build 1110ad01 $ docker-machine --version docker-machine version 0.16.1, build cce350d7创建新机器
在我们开始开发之前,我们需要创建一个新的 Docker 机器。因为我们想开发某样东西,所以我们把这台新机器叫做
dev:$ docker-machine create -d virtualbox dev; Creating CA: /Users/realpython/.docker/machine/certs/ca.pem Creating client certificate: /Users/realpython/.docker/machine/certs/cert.pem Running pre-create checks... (dev) Image cache directory does not exist, creating it at /Users/realpython/.docker/machine/cache... (dev) No default Boot2Docker ISO found locally, downloading the latest release... (dev) Latest release for github.com/boot2docker/boot2docker is v18.09.3 (dev) Downloading /Users/realpython/.docker/machine/cache/boot2docker.iso from https://github.com/boot2docker/boot2docker/releases/download/v18.09.3/boot2docker.iso... (dev) 0%....10%....20%....30%....40%....50%....60%....70%....80%....90%....100% Creating machine... (dev) Copying /Users/realpython/.docker/machine/cache/boot2docker.iso to /Users/realpython/.docker/machine/machines/dev/boot2docker.iso... (dev) Creating VirtualBox VM... (dev) Creating SSH key... (dev) Starting the VM... (dev) Check network to re-create if needed... (dev) Found a new host-only adapter: "vboxnet0" (dev) Waiting for an IP... Waiting for machine to be running, this may take a few minutes... Detecting operating system of created instance... Waiting for SSH to be available... Detecting the provisioner... Provisioning with boot2docker... Copying certs to the local machine directory... Copying certs to the remote machine... Setting Docker configuration on the remote daemon... Checking connection to Docker... Docker is up and running! To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env dev让 Docker 客户机通过以下方式指向新机器:
$ eval $(docker-machine env dev)运行以下命令查看当前正在运行的计算机:
$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS dev * virtualbox Running tcp://192.168.99.100:2376 v18.09.3振作起来!
Docker Compose 是一个编排框架,它使用一个简单的来处理多个服务(通过独立的容器)的构建和运行。yml 文件。它使得将运行在不同容器中的服务链接在一起变得非常容易。
首先使用 git 从 GitHub 克隆库:
$ git clone https://github.com/realpython/fitter-happier-docker $ cd fitter-happier-docker $ tree . . ├── article.md ├── circle.yml ├── docker-compose.yml ├── presentation │ ├── images │ │ ├── circleci.png │ │ ├── docker-logo.jpg │ │ ├── fig.png │ │ ├── figup.png │ │ ├── heart.jpg │ │ ├── holy-grail.jpg │ │ ├── oh-my.jpg │ │ ├── rp_logo_color_small.png │ │ └── steps.jpg │ └── presentation.md ├── readme.md └── web ├── Dockerfile ├── app.py ├── requirements.txt └── tests.py 3 directories, 18 files现在让我们启动 Flask 应用程序,并与 Redis 一起运行。
我们来看看根目录下的 docker-compose.yml :
version: '3' services: web: build: ./web volumes: - ./web:/code ports: - "80:5000" links: - redis:redis command: python app.py redis: image: redis:5.0.4 ports: - "6379:6379" volumes: - db-data:/data volumes: db-data:在这里,我们添加了组成堆栈的服务:
- web :首先,我们从“web”目录构建映像,然后将该目录挂载到 Docker 容器中的“code”目录。Flask 应用程序通过
python app.py命令运行。这暴露了容器上的端口 5000,该端口被转发到主机环境上的端口 80。- redis :接下来,redis 服务从 Docker Hub“Redis”镜像构建。端口 6379 被暴露并被转发。此外,我们通过
db-data卷将数据保存到我们的主机系统中。你注意到“web”目录中的 Dockerfile 文件了吗?该文件用于构建我们的映像,从一个正式的 Python 基础映像开始,安装所需的依赖项并构建应用程序。
构建并运行
通过一个简单的命令,我们可以构建映像并运行容器:
$ docker-compose up --build
这个命令为我们的 Flask 应用程序构建一个映像,提取 Redis 映像,然后启动一切。
拿杯咖啡。或者两个。第一次构建容器时,这需要一些时间。也就是说,由于 Docker 从 Docker 文件中缓存构建过程的每个步骤(或 层 ),所以重建会发生更快,因为只有自上次构建以来已更改的步骤才会被重建。
如果你改变了 docker 文件中的某一行/步骤/层,它将重新创建/重建该行的所有内容——所以在构建 docker 文件时要注意这一点。
Docker Compose 并行地一次打开每个容器。每个容器都有一个唯一的名称,并且堆栈跟踪/日志中的每个进程都用颜色编码,以便于阅读。
准备测试了吗?
打开 web 浏览器,导航到与
DOCKER_HOST变量相关联的 IP 地址——在本例中为 http://192.168.99.100/。(运行docker-machine ip dev获取地址。)你应该会看到这样的文字,“你好!此页面已被浏览 1 次。在您的浏览器中:
刷新。页面计数器应该已经增加。
杀死进程(
Ctrl+C),然后运行下面的命令在后台运行进程。$ docker-compose up -d我们不需要附加
--build标志,因为图像已经构建好了。想要查看当前正在运行的进程吗?
$ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------- fitter-happier-docker_redis_1 docker-entrypoint.sh redis ... Up 0.0.0.0:6379->6379/tcp fitter-happier-docker_web_1 python app.py Up 0.0.0.0:80->5000/tcp这两个进程运行在不同的容器中,通过 Docker Compose 连接!
接下来的步骤
一旦完成,通过
docker-compose down终止进程。在本地提交您的更改,然后推送到 Github。那么,我们完成了什么?
我们设置了本地环境,详细描述了从一个 Dockerfile 构建一个图像,然后创建一个被称为容器的图像的实例的基本过程。我们用 Docker Compose 将所有东西捆绑在一起,为 Flask 应用程序和 Redis 流程构建和连接不同的容器。
现在,让我们来看一个由circle ciT3】支持的持续集成工作流。
坞站枢纽〔t0〕
到目前为止,我们已经使用了 Docker 文件、图像和容器(当然是由 Docker Compose 抽象的)。
你熟悉 Git 的工作流程吗?图像类似于 Git 存储库,而容器类似于克隆的存储库。坚持这个比喻, Docker Hub 是 Docker 图片的仓库,类似于 Github。
- 使用您的 Github 凭证在此注册。
- 然后添加一个新的自动化构建。这可以通过点击“创建存储库”,向下滚动并点击 GitHub 符号来完成。这让您可以指定一个组织(您的 GitHub 名称)和您想要为其创建自动化构建的存储库。只需接受所有默认选项,除了“构建上下文”——将其更改为“/web”。
一旦添加,这将触发初始构建。确保构建成功。
CI 码头枢纽〔t0〕
Docker Hub 本身充当了一个持续集成服务器,因为你可以配置它在每次向 Github 提交新的提交时创建一个自动构建。换句话说,它确保您不会在代码库更新时导致完全中断构建过程的回归。
这种方法有一些缺点——也就是说,你不能(通过
docker push)直接将更新的图像推送到 Docker Hub。Docker Hub 必须从您的 repo 中提取更改,并自己创建图像,以确保它们没有错误。在执行此工作流程时,请记住这一点。关于此事,Docker 文档不清楚。让我们来测试一下。向测试套件添加一个断言:
self.assertNotEqual(four, 102)提交并推送到 Github,在 Docker Hub 上生成新的构建。成功?
底线:如果一个提交确实导致了一个回归,Docker Hub 将会发现它,这是一件好事,但是由于这是部署之前的最后一道防线(无论是准备阶段还是生产阶段),您最好在 Docker Hub 上生成新的构建之前发现任何中断。另外,您还想从一个真正的持续集成服务器上运行您的单元和集成测试——这正是 CircleCI 发挥作用的地方。
循环〔t0〕
CircleCI 是一个持续集成和交付平台,支持 Docker 容器内的测试。给定一个 Dockerfile,CircleCI 构建一个映像,启动一个新容器,然后在该容器中运行测试。
还记得我们想要的工作流程吗?链接。
让我们来看看如何实现这一点…
设置
最好从优秀的circle ci入门指南开始…
注册你的 Github 帐户,然后添加 Github repo 来创建一个新项目。这将自动向 repo 添加一个 webhook,这样每当你推 Github 时,就会触发一个新的构建。添加挂钩后,您应该会收到一封电子邮件。
CircleCI 配置文件位于中。circleci 目录。我们来看看 config.yml :
version: 2 jobs: build: docker: - image: circleci/python:3.7.3 working_directory: ~/repo steps: - checkout - setup_remote_docker: docker_layer_caching: true version: 18.06.0-ce - run: name: Install Docker client command: | set -x VER="17.03.0-ce" curl -L -o /tmp/docker-$VER.tgz https://download.docker.com/linux/static/stable/x86_64/docker-$VER.tgz tar -xz -C /tmp -f /tmp/docker-$VER.tgz sudo mv /tmp/docker/* /usr/bin - run: name: run tests command: | docker image build -t fitter-happier-docker web docker container run -d fitter-happier-docker python -m unittest discover web - store_artifacts: path: test-reports destination: test-reports publish-image: machine: true steps: - checkout - deploy: name: Publish application to Docker Hub command: | docker login -u $DOCKER_HUB_USER_ID -p $DOCKER_HUB_PWD docker image build -t fitter-happier-docker web docker tag fitter-happier-docker $DOCKER_HUB_USER_ID/fitter-happier-docker:$CIRCLE_SHA1 docker tag fitter-happier-docker $DOCKER_HUB_USER_ID/fitter-happier-docker:latest docker push $DOCKER_HUB_USER_ID/fitter-happier-docker:$CIRCLE_SHA1 docker push $DOCKER_HUB_USER_ID/fitter-happier-docker:latest workflows: version: 2 build-master: jobs: - build - publish-image: requires: - build filters: branches: only: master基本上,我们定义了两种工作。首先,我们设置 Docker 环境,构建映像并运行测试。其次,我们将映像部署到 Docker Hub。
此外,我们定义了一个工作流。为什么我们需要工作流?如您所见,构建作业总是被执行,而发布图像作业只在主服务器上运行,因为我们不想在打开新的拉取请求时发布新的图像。
可以在 CircleCI 的项目设置中设置环境变量
DOCKER_HUB_USER_ID和DOCKER_HUB_PWD。创建了 config.yml 文件后,将更改推送到 Github 以触发新的构建。记住:这也将触发 Docker Hub 的一个新版本。
成功?
在继续之前,我们需要改变我们的工作流程,因为我们将不再直接推进到主分支。
特征分支工作流程
对于这些不熟悉特性分支工作流的人,请查看这篇精彩的介绍。
让我们快速看一个例子…
创建特征分支
$ git checkout -b circle-test master Switched to a new branch 'circle-test'更新应用程序
在 tests.py 中添加一个新断言:
self.assertNotEqual(four, 60)发出拉取请求
$ git add web/tests.py $ git commit -m "circle-test" $ git push origin circle-test甚至在您创建实际的 pull 请求之前,CircleCI 就已经开始创建构建了。继续创建 pull 请求,然后一旦测试在 CircleCI 上通过,就按下 Merge 按钮。一旦合并,构建就在 Docker Hub 上触发。
结论
因此,我们回顾了一个很好的开发工作流程,包括通过 CircleCI (步骤 1 到 6)建立一个与持续集成相结合的本地环境:
- 在特征分支上本地编码
- 针对主分支机构在 Github 上打开一个拉请求
- 对 Docker 容器运行自动化测试
- 如果测试通过,手动将拉请求合并到主服务器中
- 一旦合并,自动化测试再次运行
- 如果第二轮测试通过,就会在 Docker Hub 上创建一个构建
- 一旦构建被创建,它就被自动地(呃,自动地)部署到生产中
那么最后一步——将这个应用程序交付到生产环境中(步骤 7)呢?实际上,你可以关注我的 Docker 博客中的另一篇文章来扩展这个工作流程,使之包括送货。
如有疑问,请在下方评论。在这里抓取最终代码。干杯!
如果您有自己的工作流程,请告诉我们。我目前正在尝试使用 Salt 和 Tutum 来更好地处理数字海洋和 Linode 上的编排和交付。****
Dockerizing Flask 与 Compose 和 Machine——从本地主机到云
原文:https://realpython.com/dockerizing-flask-with-compose-and-machine-from-localhost-to-the-cloud/
Docker 是一个强大的工具,用于构建隔离的、可复制的应用环境容器。这篇文章关注的正是这一点——如何为本地开发封装 Flask 应用程序,并通过 Docker Compose 和 Docker Machine 将应用程序交付给云托管提供商。
更新:
- 03/31/2019:更新至 Docker - Docker client (v18.09.2)、Docker compose (v1.23.2)、Docker Machine (v0.16.1)最新版本感谢 Florian Dahlitz !
- 2015 年 11 月 16 日:更新至 Docker - Docker client (v1.9.0)、Docker compose (v1.5.0)和 Docker Machine (v0.5.0)的最新版本
- 04/25/2015:修复了小错别字,更新了 docker-compose.yml 文件,可以正确复制静态文件。
- 04/19/2015:添加了用于复制静态文件的 shell 脚本。
有兴趣为 Django 创造一个类似的环境吗?查看这篇博客文章。
本地设置
与 Docker (v18.09.2)一起,我们将使用-
- Docker Compose(v 1 . 23 . 2)——之前称为 fig——用于将多容器应用编排到单个应用中,以及
- Docker Machine(v 0 . 16 . 1)用于在本地和云中创建 Docker 主机。
按照此处和此处的指示分别安装 Docker Compose 和 Machine。
运行旧的 Mac OS X 或 Windows 版本,那么你最好的选择是安装 Docker 工具箱。
测试安装:
$ docker-machine --version docker-machine version 0.16.1, build cce350d7 $ docker-compose --version docker-compose version 1.23.2, build 1110ad01接下来,从存储库克隆项目,或者基于 repo 上的项目结构创建您自己的项目:
├── docker-compose.yml ├── nginx │ ├── Dockerfile │ └── sites-enabled │ └── flask_project └── web ├── Dockerfile ├── app.py ├── config.py ├── create_db.py ├── models.py ├── requirements.txt ├── static │ ├── css │ │ ├── bootstrap.min.css │ │ └── main.css │ ├── img │ └── js │ ├── bootstrap.min.js │ └── main.js └── templates ├── _base.html └── index.html我们现在准备让容器启动并运行。输入对接机。
对接机
要启动 Docker Machine,首先确保您在项目根目录中,然后简单地运行:
$ docker-machine create -d virtualbox dev; Creating CA: /Users/realpython/.docker/machine/certs/ca.pem Creating client certificate: /Users/realpython/.docker/machine/certs/cert.pem Running pre-create checks... (dev) Image cache directory does not exist, creating it at /Users/realpython/.docker/machine/cache... (dev) No default Boot2Docker ISO found locally, downloading the latest release... (dev) Latest release for github.com/boot2docker/boot2docker is v18.09.3 (dev) Downloading /Users/realpython/.docker/machine/cache/boot2docker.iso from https://github.com/boot2docker/boot2docker/releases/download/v18.09.3/boot2docker.iso... (dev) 0%....10%....20%....30%....40%....50%....60%....70%....80%....90%....100% Creating machine... (dev) Copying /Users/realpython/.docker/machine/cache/boot2docker.iso to /Users/realpython/.docker/machine/machines/dev/boot2docker.iso... (dev) Creating VirtualBox VM... (dev) Creating SSH key... (dev) Starting the VM... (dev) Check network to re-create if needed... (dev) Found a new host-only adapter: "vboxnet0" (dev) Waiting for an IP... Waiting for machine to be running, this may take a few minutes... Detecting operating system of created instance... Waiting for SSH to be available... Detecting the provisioner... Provisioning with boot2docker... Copying certs to the local machine directory... Copying certs to the remote machine... Setting Docker configuration on the remote daemon... Checking connection to Docker... Docker is up and running! To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env dev
create命令为 Docker 开发设置了一个“机器”(称为 dev )。本质上,它下载了 boot2docker 并启动了一个运行 docker 的 VM。现在只需将 Docker 客户端指向 dev 机器,方法是:$ eval "$(docker-machine env dev)"运行以下命令查看当前正在运行的计算机:
$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS dev * virtualbox Running tcp://192.168.99.100:2376 v18.09.3接下来,让我们用 Docker Compose 启动容器,让 Flask 应用程序和 Postgres 数据库启动并运行。
坞站组成〔t0〕
看一下 docker-compose.yml 文件:
version: '3' services: web: restart: always build: ./web expose: - "8000" links: - postgres:postgres volumes: - web-data:/usr/src/app/static env_file: - .env command: /usr/local/bin/gunicorn -w 2 -b :8000 app:app nginx: restart: always build: ./nginx ports: - "80:80" volumes: - .:/www/static - web-data:/usr/src/app/static links: - web:web data: image: postgres:latest volumes: - db-data:/var/lib/postgresql/data command: "true" postgres: restart: always image: postgres:latest volumes: - db-data:/var/lib/postgresql/data ports: - "5432:5432" volumes: db-data: web-data:这里,我们定义了四个服务- web 、 nginx 、 postgres 和数据。
- 首先, web 服务是通过“web”目录下的 Dockerfile 中的指令构建的——在这里设置 Python 环境,安装需求,并在端口 8000 上启动 Flask 应用程序。该端口然后被转发到主机环境(例如对接机)上的端口 80。该服务还将在中定义的环境变量添加到容器中。env 文件。
- nginx 服务用于反向代理,将请求转发给 Flask 应用程序或静态文件。
- 接下来,从来自 Docker Hub 的官方 PostgreSQL 镜像构建 postgres 服务,Docker Hub 安装 postgres 并在默认端口 5432 上运行服务器。
- 最后,注意有一个单独的卷容器用于存储数据库数据 db-data 。这有助于确保即使 Postgres 容器被完全破坏,数据仍然存在。
现在,要让容器运行,构建映像,然后启动服务:
$ docker-compose build $ docker-compose up -d提示:您甚至可以在一个单独的命令中运行以上命令:
$ docker-compose up --build -d拿杯咖啡。或者两个。查看真正的 Python 课程。第一次运行时,这需要一段时间。
我们还需要创建数据库表:
$ docker-compose run web /usr/local/bin/python create_db.py打开浏览器,导航到与 Docker Machine (
docker-machine ip)关联的 IP 地址:
不错!
要查看哪些环境变量可用于 web 服务,请运行:
$ docker-compose run web env要查看日志:
$ docker-compose logs您还可以进入 Postgres Shell——因为我们在 docker-compose.yml 文件中将端口转发到主机环境——通过以下方式添加用户/角色以及数据库:
$ docker-compose run postgres psql -h 192.168.99.100 -p 5432 -U postgres --password一旦完成,通过
docker-compose down停止过程。部署
因此,随着我们的应用程序在本地运行,我们现在可以将这个完全相同的环境推送给一个拥有 Docker Machine 的云托管提供商。让我们部署到一个数字海洋液滴。
在您注册了数字海洋的之后,生成一个个人访问令牌,然后运行以下命令:
$ docker-machine create \ -d digitalocean \ --digitalocean-access-token ADD_YOUR_TOKEN_HERE \ production这将需要几分钟的时间来供应 droplet 并设置一个名为 production 的新 Docker 机器:
Running pre-create checks... Creating machine... Waiting for machine to be running, this may take a few minutes... Machine is running, waiting for SSH to be available... Detecting operating system of created instance... Provisioning created instance... Copying certs to the local machine directory... Copying certs to the remote machine... Setting Docker configuration on the remote daemon... To see how to connect Docker to this machine, run: docker-machine env production现在我们有两台机器在运行,一台在本地,一台在数字海洋上:
$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS dev * virtualbox Running tcp://192.168.99.100:2376 v18.09.3 production - digitalocean Running tcp://104.131.93.156:2376 v18.09.3然后将 production 设置为活动机器,并将 Docker 环境加载到 shell 中:
$ eval "$(docker-machine env production)"最后,让我们在云中再次构建 Flask 应用程序:
$ docker-compose build $ docker-compose up -d $ docker-compose run web /usr/local/bin/python create_db.py从控制面板获取与该数字海洋账户相关的 IP 地址,并在浏览器中查看。如果一切顺利,您应该看到您的应用程序正在运行。
结论
干杯!
- 从 Github repo 中抓取代码(也开始!).
- 带着问题在下面评论。
- 下一次,我们将扩展这个工作流,以包括两个以上运行 Flask 应用程序的 Docker 容器,并将负载平衡纳入其中。敬请期待!**
记录 Python 代码:完整指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 记录 Python 代码:完整指南
欢迎阅读完整的 Python 代码文档指南。无论你是在记录一个小脚本还是一个大项目,无论你是一个初学者还是经验丰富的 python 爱好者,这个指南将涵盖你需要知道的一切。
我们将本教程分为四个主要部分:
- 为什么编写代码文档如此重要 : 文档及其重要性介绍
- 注释与记录代码 : 注释和记录的主要区别,以及使用注释的适当时间和方式
- 使用文档字符串记录您的 Python 代码库 : 深入探究类、类方法、函数、模块、包和脚本的文档字符串,以及在每个文档字符串中应该找到的内容
- 记录您的 Python 项目 : 必要的元素以及它们应该包含哪些内容
随意从头到尾通读这篇教程,或者跳到你感兴趣的部分。它的设计是双向的。
为什么记录代码如此重要
如果你正在阅读本教程,希望你已经知道了编写代码文档的重要性。如果没有,那么让我引用圭多在最近的一次 PyCon 上对我说的话:
"读代码比写代码更常见."
-基多·范罗斯
当你写代码时,你是为两个主要的读者写的:你的用户和你的开发者(包括你自己)。这两种受众同等重要。如果你像我一样,你可能会打开旧的代码库,对自己说:“我到底在想什么?”如果你在阅读自己的代码时有问题,想象一下当你的用户或其他开发者试图使用你的代码或向你的代码贡献 T1 时,他们会经历什么。
相反,我敢肯定你遇到过这样的情况,你想用 Python 做点什么,却发现了一个看起来很棒的库,可以完成这项工作。然而,当你开始使用这个库的时候,你会寻找一些例子,文章,甚至是关于如何做一些具体事情的官方文档,但是却不能立即找到解决方案。
搜索之后,您开始意识到缺少文档,甚至更糟,完全丢失了。这是一种令人沮丧的感觉,让你不敢使用这个库,不管代码有多棒或多高效。Daniele Procida 对这种情况做了最好的总结:
“你的软件有多好并不重要,因为如果文档不够好,人们就不会使用它。
— 丹尼尔·普罗西达
在本指南中,您将从头开始学习如何正确地记录您的 Python 代码,从最小的脚本到最大的 Python 项目,以帮助防止您的用户因过于沮丧而无法使用或贡献您的项目。
注释与记录代码
在我们讨论如何记录 Python 代码之前,我们需要区分记录和注释。
一般来说,注释是向开发人员描述你的代码。预期的主要受众是 Python 代码的维护者和开发者。结合编写良好的代码,注释有助于引导读者更好地理解您的代码及其目的和设计:
“代码告诉你怎么做;评论告诉你为什么。”
——杰夫·阿特伍德(又名编码恐怖)
记录代码就是向用户描述它的用途和功能。虽然它可能对开发过程有所帮助,但主要的目标受众是用户。下一节描述如何以及何时对代码进行注释。
注释代码的基础知识
在 Python 中,注释是使用井号(
#)创建的,应该是不超过几个句子的简短语句。这里有一个简单的例子:def hello_world(): # A simple comment preceding a simple print statement print("Hello World")根据 PEP 8 ,评论的最大长度应该是 72 个字符。即使您的项目将最大行长度更改为大于建议的 80 个字符,也是如此。如果注释将超过注释字符限制,使用多行注释是合适的:
def hello_long_world(): # A very long statement that just goes on and on and on and on and # never ends until after it's reached the 80 char limit print("Hellooooooooooooooooooooooooooooooooooooooooooooooooooooooo World")注释你的代码有多种用途,包括:
计划和评审:当你开发代码的新部分时,首先使用注释作为计划或概述代码部分的方法可能是合适的。请记住,一旦实际的编码已经实现并经过审查/测试,就要删除这些注释:
# First step # Second step # Third step`代码描述:注释可以用来解释特定代码段的意图:
# Attempt a connection based on previous settings. If unsuccessful, # prompt user for new settings.`算法描述:当使用算法时,尤其是复杂的算法时,解释算法如何工作或如何在代码中实现会很有用。描述为什么选择了一个特定的算法而不是另一个算法可能也是合适的。
# Using quick sort for performance gains`标记:标记的使用可以用来标记代码中已知问题或改进区域所在的特定部分。一些例子有:
BUG、FIXME和TODO。# TODO: Add condition for when val is None`对你的代码的注释应该保持简短和集中。尽可能避免使用长注释。此外,你应该使用杰夫·阿特伍德建议的以下四条基本规则:
尽可能让注释靠近被描述的代码。不在描述代码附近的注释会让读者感到沮丧,并且在更新时很容易被忽略。
不要使用复杂的格式(如表格或 ASCII 数字)。复杂的格式会导致内容分散注意力,并且随着时间的推移很难维护。
不要包含多余的信息。假设代码的读者对编程原则和语言语法有基本的了解。
设计自己注释的代码。理解代码最简单的方法就是阅读它。当你使用清晰、易于理解的概念设计代码时,读者将能够很快理解你的意图。
记住注释是为读者设计的,包括你自己,帮助引导他们理解软件的目的和设计。
通过类型提示注释代码(Python 3.5+)
Python 3.5 中添加了类型提示,它是帮助代码读者的一种额外形式。事实上,它把杰夫的第四个建议从上面提到了下一个层次。它允许开发人员设计和解释他们的部分代码,而无需注释。这里有一个简单的例子:
def hello_name(name: str) -> str: return(f"Hello {name}")通过检查类型提示,您可以立即看出函数期望输入
name是类型str或字符串。您还可以看出函数的预期输出也将是类型str,或者字符串。虽然类型提示有助于减少注释,但是要考虑到这样做也可能会在您创建或更新项目文档时增加额外的工作量。你可以从 Dan Bader 制作的视频中了解更多关于类型提示和类型检查的信息。
使用文档字符串记录您的 Python 代码库
既然我们已经学习了注释,让我们深入研究一下如何记录 Python 代码库。在本节中,您将了解 docstrings 以及如何在文档中使用它们。本节进一步分为以下小节:
- 文档字符串背景 : 关于文档字符串如何在 Python 内部工作的背景
- Docstring 类型 : 各种 Docstring“类型”(函数、类、类方法、模块、包和脚本)
- 文档字符串格式 : 不同的文档字符串“格式”(Google、NumPy/SciPy、reStructuredText 和 Epytext)
文档字符串背景
记录 Python 代码都是以文档字符串为中心的。这些是内置的字符串,如果配置正确,可以帮助您的用户和您自己处理项目的文档。除了 docstring,Python 还有一个内置函数
help(),它将对象 docstring 打印到控制台。这里有一个简单的例子:
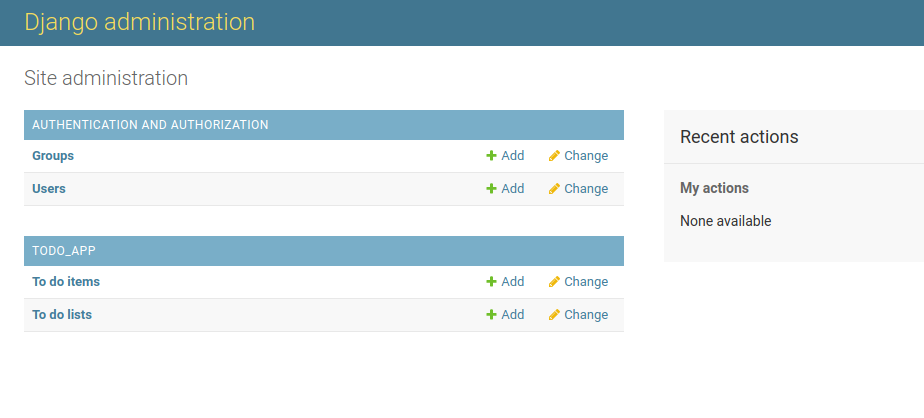
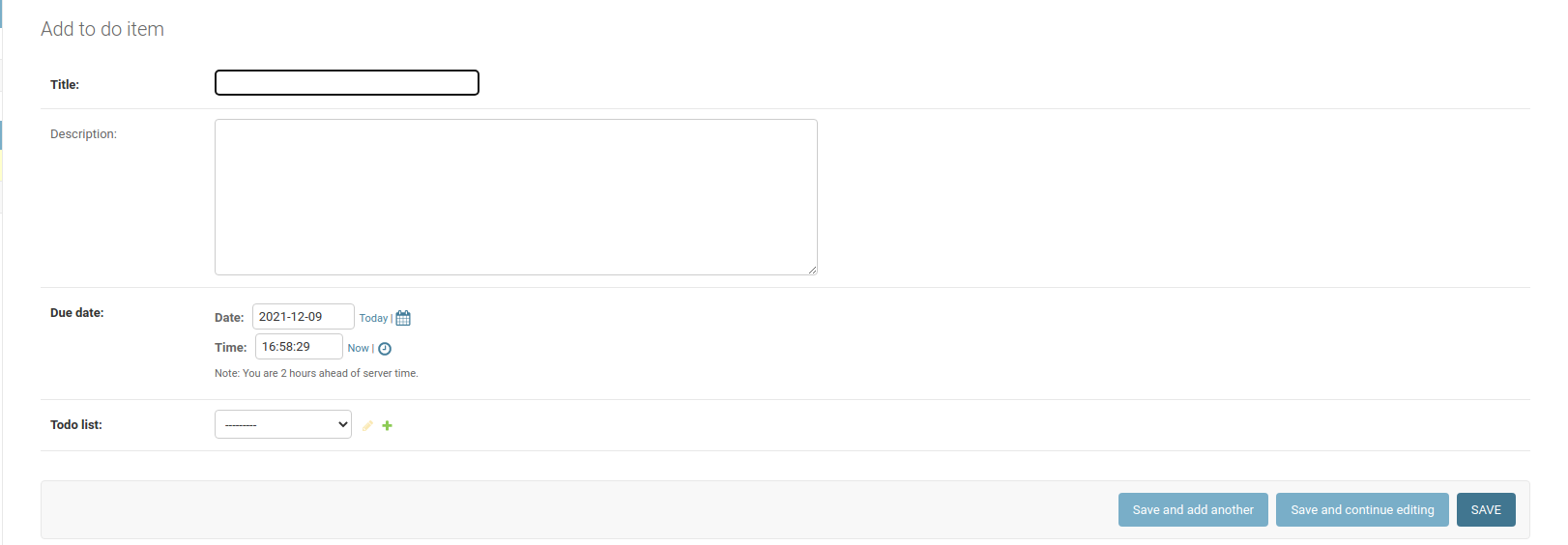
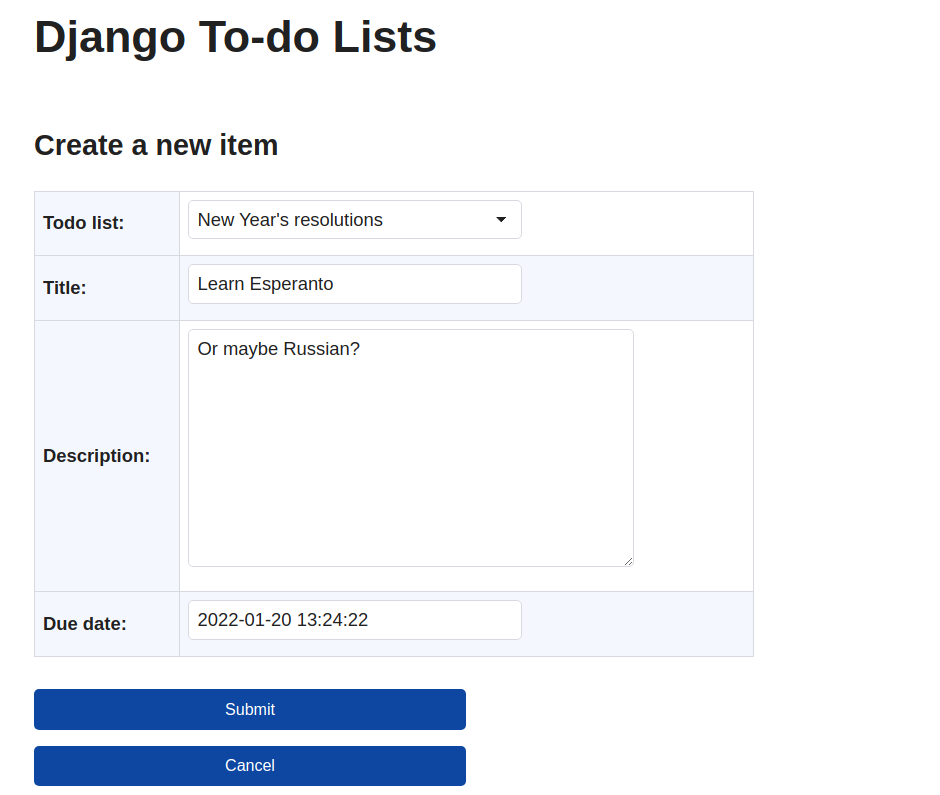





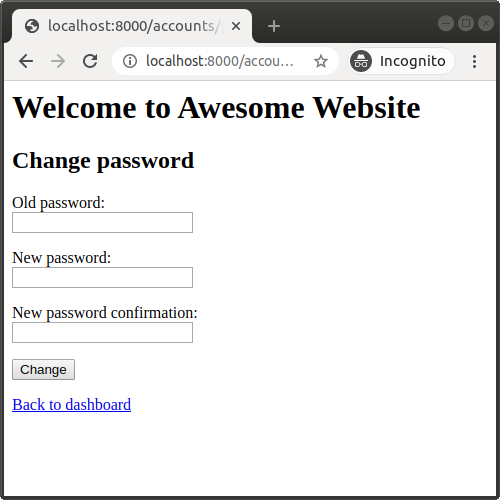









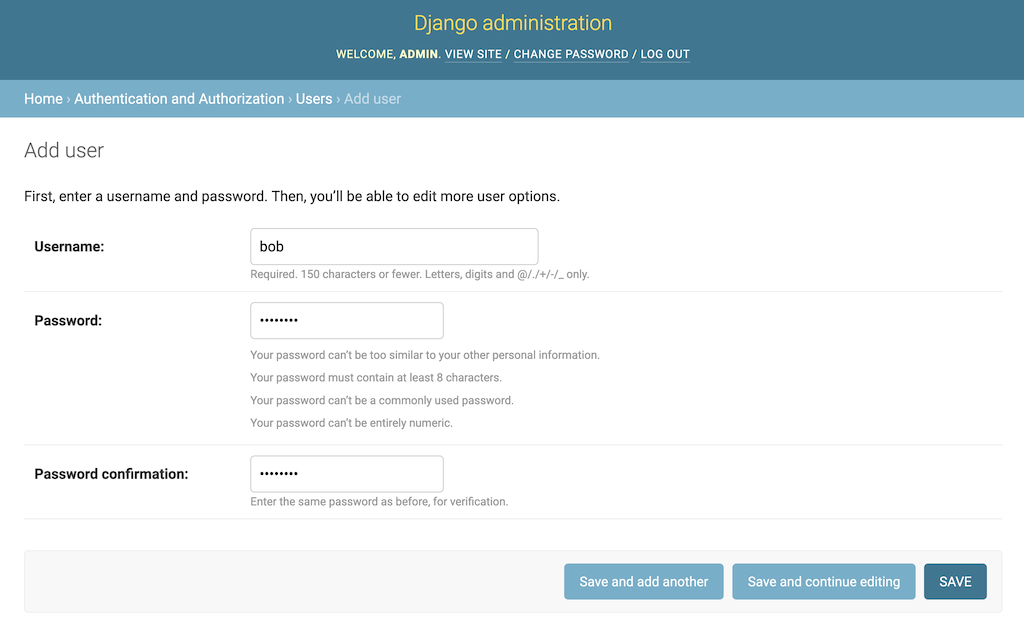
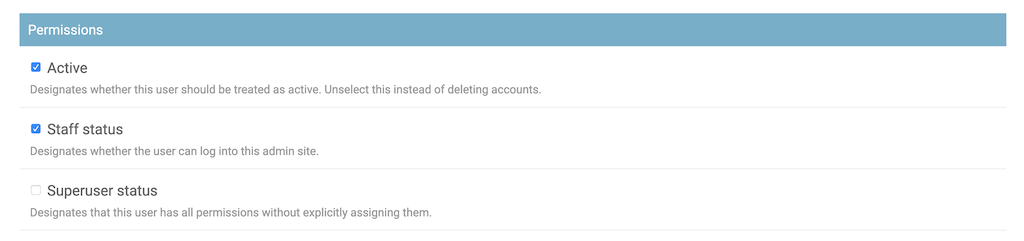



>>> help(str)
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors are specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
# Truncated for readability
这个输出是如何产生的?因为 Python 中的一切都是对象,所以可以使用dir()命令检查对象的目录。让我们这样做,看看有什么发现:
>>> dir(str) ['__add__', ..., '__doc__', ..., 'zfill'] # Truncated for readability在这个目录输出中,有一个有趣的属性,
__doc__。如果你检查一下那处房产,你会发现:
>>> print(str.__doc__)
str(object='') -> str
str(bytes_or_buffer[, encoding[, errors]]) -> str
Create a new string object from the given object. If encoding or
errors are specified, then the object must expose a data buffer
that will be decoded using the given encoding and error handler.
Otherwise, returns the result of object.__str__() (if defined)
or repr(object).
encoding defaults to sys.getdefaultencoding().
errors defaults to 'strict'.
瞧啊。您已经找到了文档字符串存储在对象中的位置。这意味着您可以直接操作该属性。但是,内置有一些限制:
>>> str.__doc__ = "I'm a little string doc! Short and stout; here is my input and print me for my out" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't set attributes of built-in/extension type 'str'可以操作任何其他自定义对象:
def say_hello(name): print(f"Hello {name}, is it me you're looking for?") say_hello.__doc__ = "A simple function that says hello... Richie style"
>>> help(say_hello)
Help on function say_hello in module __main__:
say_hello(name)
A simple function that says hello... Richie style
Python 还有一个简化文档字符串创建的特性。不是直接操作__doc__属性,而是将字符串直接放在对象的下面,这将自动设置__doc__值。下面是上面的同一个例子所发生的情况:
def say_hello(name):
"""A simple function that says hello... Richie style"""
print(f"Hello {name}, is it me you're looking for?")
>>> help(say_hello) Help on function say_hello in module __main__: say_hello(name) A simple function that says hello... Richie style这就对了。现在你了解了 docstrings 的背景。现在是时候了解不同类型的文档字符串以及它们应该包含什么信息了。
文档字符串类型
在 PEP 257 中描述了 Docstring 约定。它们的目的是为您的用户提供对象的简要概述。它们应该保持足够的简洁,以便于维护,但仍然足够详细,以便新用户理解它们的目的以及如何使用文档对象。
在所有情况下,文档字符串都应该使用三重双引号(
""")字符串格式。无论文档字符串是否是多行的,都应该这样做。至少,docstring 应该是对您所描述的内容的快速总结,并且应该包含在一行中:"""This is a quick summary line used as a description of the object."""多行文档字符串用于进一步阐述摘要之外的对象。所有多行文档字符串都有以下部分:
- 单行摘要行
- 摘要前的空行
- 对 docstring 的任何进一步阐述
- 另一个空行
"""This is the summary line This is the further elaboration of the docstring. Within this section, you can elaborate further on details as appropriate for the situation. Notice that the summary and the elaboration is separated by a blank new line. """ # Notice the blank line above. Code should continue on this line.所有文档字符串的最大字符长度应该与注释相同(72 个字符)。文档字符串可以进一步分为三个主要类别:
- 类文档字符串:类和类方法
- 包和模块文档字符串:包、模块和函数
- 脚本文件字符串:脚本和函数
类文档字符串
类文档字符串是为类本身以及任何类方法创建的。文档字符串紧跟在缩进一级的类或类方法之后:
class SimpleClass: """Class docstrings go here.""" def say_hello(self, name: str): """Class method docstrings go here.""" print(f'Hello {name}')类文档字符串应包含以下信息:
- 对其目的和行为的简要总结
- 任何公共方法,以及简短的描述
- 任何类属性(特性)
- 任何与子类化的接口相关的东西,如果这个类打算被子类化的话
类构造函数的参数应该记录在
__init__类方法 docstring 中。各个方法应该使用各自的文档字符串进行记录。类方法 docstrings 应包含以下内容:
- 对该方法及其用途的简要描述
- 传递的任何参数(必需的和可选的),包括关键字参数
- 标记任何被认为是可选的或具有默认值的参数
- 执行该方法时出现的任何副作用
- 出现的任何异常
- 对何时可以调用该方法有任何限制吗
让我们举一个表示动物的数据类的简单例子。这个类将包含一些类属性、实例属性、一个
__init__和一个实例方法:class Animal: """ A class used to represent an Animal ... Attributes ---------- says_str : str a formatted string to print out what the animal says name : str the name of the animal sound : str the sound that the animal makes num_legs : int the number of legs the animal has (default 4) Methods ------- says(sound=None) Prints the animals name and what sound it makes """ says_str = "A {name} says {sound}" def __init__(self, name, sound, num_legs=4): """ Parameters ---------- name : str The name of the animal sound : str The sound the animal makes num_legs : int, optional The number of legs the animal (default is 4) """ self.name = name self.sound = sound self.num_legs = num_legs def says(self, sound=None): """Prints what the animals name is and what sound it makes. If the argument `sound` isn't passed in, the default Animal sound is used. Parameters ---------- sound : str, optional The sound the animal makes (default is None) Raises ------ NotImplementedError If no sound is set for the animal or passed in as a parameter. """ if self.sound is None and sound is None: raise NotImplementedError("Silent Animals are not supported!") out_sound = self.sound if sound is None else sound print(self.says_str.format(name=self.name, sound=out_sound))包和模块文档字符串
包文档字符串应该放在包的
__init__.py文件的顶部。这个 docstring 应该列出由包导出的模块和子包。模块文档字符串类似于类文档字符串。不再记录类和类方法,而是记录模块和其中的任何函数。模块文档字符串甚至在任何导入之前就被放在文件的顶部。模块文档字符串应包括以下内容:
- 模块及其用途的简要描述
- 模块导出的任何类、异常、函数和任何其他对象的列表
模块函数的 docstring 应该包含与类方法相同的项目:
- 对该功能及其用途的简要描述
- 传递的任何参数(必需的和可选的),包括关键字参数
- 标记所有被认为是可选的参数
- 执行函数时出现的任何副作用
- 出现的任何异常
- 对何时调用该函数有任何限制吗
脚本文件字符串
脚本被视为从控制台运行的单个文件可执行文件。脚本的 Docstrings 放在文件的顶部,应该记录得足够好,以便用户能够充分理解如何使用脚本。当用户错误地传入一个参数或使用
-h选项时,它应该可以用于它的“用法”消息。如果您使用
argparse,那么您可以省略特定于参数的文档,假设它已经被正确地记录在argparser.parser.add_argument函数的help参数中。建议在argparse.ArgumentParser的构造函数中使用__doc__作为description参数。查看我们关于命令行解析库的教程,了解更多关于如何使用argparse和其他常见命令行解析器的细节。最后,任何自定义或第三方导入都应该在 docstrings 中列出,以便让用户知道运行脚本可能需要哪些包。下面是一个简单打印电子表格列标题的脚本示例:
"""Spreadsheet Column Printer This script allows the user to print to the console all columns in the spreadsheet. It is assumed that the first row of the spreadsheet is the location of the columns. This tool accepts comma separated value files (.csv) as well as excel (.xls, .xlsx) files. This script requires that `pandas` be installed within the Python environment you are running this script in. This file can also be imported as a module and contains the following functions: * get_spreadsheet_cols - returns the column headers of the file * main - the main function of the script """ import argparse import pandas as pd def get_spreadsheet_cols(file_loc, print_cols=False): """Gets and prints the spreadsheet's header columns Parameters ---------- file_loc : str The file location of the spreadsheet print_cols : bool, optional A flag used to print the columns to the console (default is False) Returns ------- list a list of strings used that are the header columns """ file_data = pd.read_excel(file_loc) col_headers = list(file_data.columns.values) if print_cols: print("\n".join(col_headers)) return col_headers def main(): parser = argparse.ArgumentParser(description=__doc__) parser.add_argument( 'input_file', type=str, help="The spreadsheet file to pring the columns of" ) args = parser.parse_args() get_spreadsheet_cols(args.input_file, print_cols=True) if __name__ == "__main__": main()文档字符串格式
您可能已经注意到,在本教程给出的所有示例中,有一些特定的格式带有公共元素:
Arguments、Returns和Attributes。有一些特定的文档字符串格式可用于帮助文档字符串解析器和用户拥有熟悉和已知的格式。本教程示例中使用的格式是 NumPy/SciPy 样式的文档字符串。一些最常见的格式如下:
格式化类型 描述 由 Sphynx 支持 形式规范 谷歌文档字符串 谷歌推荐的文档格式 是 不 重组文本 官方 Python 文档标准;不适合初学者,但功能丰富 是 是 NumPy/SciPy docstrings NumPy 的 reStructuredText 和 Google Docstrings 的组合 是 是 Epytext Epydoc 的 Python 改编版;非常适合 Java 开发人员 不是正式的 是 docstring 格式的选择取决于您,但是您应该在整个文档/项目中坚持使用相同的格式。下面是每种类型的示例,让您了解每种文档格式的外观。
谷歌文档字符串示例
"""Gets and prints the spreadsheet's header columns Args: file_loc (str): The file location of the spreadsheet print_cols (bool): A flag used to print the columns to the console (default is False) Returns: list: a list of strings representing the header columns """重构文本示例
"""Gets and prints the spreadsheet's header columns :param file_loc: The file location of the spreadsheet :type file_loc: str :param print_cols: A flag used to print the columns to the console (default is False) :type print_cols: bool :returns: a list of strings representing the header columns :rtype: list """NumPy/SciPy 文档字符串示例
"""Gets and prints the spreadsheet's header columns Parameters ---------- file_loc : str The file location of the spreadsheet print_cols : bool, optional A flag used to print the columns to the console (default is False) Returns ------- list a list of strings representing the header columns """Epytext 示例
"""Gets and prints the spreadsheet's header columns @type file_loc: str @param file_loc: The file location of the spreadsheet @type print_cols: bool @param print_cols: A flag used to print the columns to the console (default is False) @rtype: list @returns: a list of strings representing the header columns """记录您的 Python 项目
Python 项目有各种形状、大小和用途。您记录项目的方式应该适合您的具体情况。记住你的项目的用户是谁,并适应他们的需求。根据项目类型,推荐文档的某些方面。项目及其文件的总体布局应如下:
project_root/ │ ├── project/ # Project source code ├── docs/ ├── README ├── HOW_TO_CONTRIBUTE ├── CODE_OF_CONDUCT ├── examples.py项目通常可以细分为三种主要类型:私有、共享和公共/开源。
私人项目
私人项目是仅供个人使用的项目,通常不会与其他用户或开发人员共享。对于这种类型的项目,文档可能很简单。根据需要,可以添加一些推荐的部件:
- 自述:项目及其目的的简要概述。包括安装或运营项目的任何特殊要求。
examples.py: 一个 Python 脚本文件,给出了如何使用这个项目的简单例子。记住,即使私人项目是为你个人设计的,你也被认为是一个用户。思考任何可能让你感到困惑的事情,并确保在注释、文档字符串或自述文件中记录下来。
共享项目
共享项目是指在开发和/或使用项目的过程中,您与其他人进行协作的项目。项目的“客户”或用户仍然是你自己和那些使用项目的少数人。
文档应该比私人项目更严格,主要是为了帮助项目的新成员,或者提醒贡献者/用户项目的新变化。以下是一些建议添加到项目中的部件:
- 自述:项目及其目的的简要概述。包括安装或运行项目的任何特殊要求。此外,添加自上一版本以来的任何主要更改。
examples.py: 一个 Python 脚本文件,给出了如何使用项目的简单例子。- 如何贡献:这应该包括项目的新贡献者如何开始贡献。
公共和开源项目
公共和开放源代码项目是那些旨在与一大群用户共享的项目,并且可能涉及大型开发团队。这些项目应该像项目本身的实际开发一样优先考虑项目文件。以下是一些建议添加到项目中的部件:
自述:项目及其目的的简要概述。包括安装或运行项目的任何特殊要求。此外,添加自上一版本以来的任何主要变化。最后,添加进一步的文档、错误报告和项目的任何其他重要信息的链接。丹·巴德为整理了一个很棒的教程,告诉你应该在你的自述文件中包含哪些内容。
如何贡献:这应该包括项目的新贡献者如何提供帮助。这包括开发新功能、修复已知问题、添加文档、添加新测试或报告问题。
行为准则:定义了其他贡献者在开发或使用你的软件时应该如何对待彼此。这也说明了如果代码被破坏会发生什么。如果你正在使用 Github,可以用推荐的措辞生成一个行为准则模板。特别是对于开源项目,考虑添加这个。
License: 一个描述您的项目正在使用的许可证的纯文本文件。特别是对于开源项目,考虑添加这个。
docs: 包含更多文档的文件夹。下一节将更全面地描述应该包含的内容以及如何组织该文件夹的内容。
docs文件夹的四个主要部分Daniele Procida 在 PyCon 2017 上发表了精彩的演讲和随后的博客文章关于记录 Python 项目。他提到,所有项目都应该有以下四个主要部分来帮助你集中精力工作:
- 教程:带领读者完成一个项目(或有意义的练习)的一系列步骤的课程。面向用户的学习。
- How-To Guides :引导读者完成解决常见问题所需步骤的指南(面向问题的食谱)。
- 参考文献:澄清和阐明某一特定主题的解释。面向理解。
- 解释:机器的技术描述以及如何操作(关键类、功能、API 等)。想想百科文章。
下表显示了所有这些部分之间的相互关系及其总体目的:
在我们学习的时候最有用 当我们编码时最有用 实际步骤 教程 操作指南 理论知识 解释 参考 最后,您希望确保您的用户能够获得他们可能有的任何问题的答案。通过以这种方式组织你的项目,你将能够容易地回答这些问题,并且以一种他们能够快速浏览的格式。
文档工具和资源
记录您的代码,尤其是大型项目,可能会令人望而生畏。幸运的是,有一些工具和参考资料可以帮助您入门:
工具 描述 斯芬克斯 自动生成多种格式文档的工具集 Epydoc 一个基于文档字符串为 Python 模块生成 API 文档的工具 阅读文档 为您自动构建、版本控制和托管您的文档 脱氧核糖核酸 一个用于生成支持 Python 和多种其他语言的文档的工具 MkDocs 使用 Markdown 语言帮助构建项目文档的静态站点生成器。查看使用 MkDocs 构建您的 Python 项目文档以了解更多信息。 pycco 一个“快速而肮脏”的文档生成器,并排显示代码和文档。查看我们关于如何使用它的教程,了解更多信息。 T2 doctest一个标准库模块,用于将使用示例作为自动化测试运行。查看 Python 的 doctest:立即记录并测试您的代码 除了这些工具,还有一些额外的教程、视频和文章,在您记录项目时会很有用:
- 卡罗尔·威林-实用狮身人面像- PyCon 2018
- Daniele Procida -文档驱动的开发 Django 项目的经验教训- PyCon 2016
- Eric Holscher -用 Sphinx 记录您的项目&阅读文档- PyCon 2016
- Titus Brown,Luiz Irber——创建、构建、测试和记录 Python 项目:2016 年 PyCon 实用指南
- 重组文本正式文档
- 斯芬克斯的重组文本引物
有时候,最好的学习方法是模仿别人。下面是一些很好地使用文档的项目的例子:
我从哪里开始?
项目文档有一个简单的进程:
- 没有文档
- 一些文件
- 完整的文档
- 良好的文档
- 出色的文档
如果你不知道你的文档下一步该做什么,看看你的项目相对于上面的进展现在处于什么位置。你有任何文件吗?如果没有,那就从那里开始。如果您有一些文档,但是缺少一些关键的项目文件,可以从添加这些文件开始。
最后,不要因为记录代码所需的工作量而气馁或不知所措。一旦你开始记录你的代码,继续下去会变得更容易。如果您有任何问题,请随时发表评论,或者在社交媒体上联系真正的 Python 团队,我们会提供帮助。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 记录 Python 代码:完整指南******
一个有效的 Python 环境:宾至如归
当你第一次学习一门新的编程语言时,你会花费大量的时间和精力去理解语法、代码风格和内置工具。对于 Python 和其他任何语言来说都是如此。一旦您对 Python 的来龙去脉有了足够的了解,您就可以开始投入时间来构建一个能够提高您的工作效率的 Python 环境。
您的 shell 不仅仅是按原样提供给您的预构建程序。这是一个框架,你可以在这个框架上建立一个生态系统。这个生态系统将会满足你的需求,这样你就可以花更少的时间去思考你正在做的下一个大项目。
注意:如果你正在 Windows 上设置一个全新的 Python 环境,那么你可能想看看这个综合指南,它将带你完成整个过程。
尽管没有两个开发人员有相同的设置,但是在开发 Python 环境时,每个人都面临许多选择。理解每一个决定和你可用的选择是很重要的!
到本文结束时,你将能够回答如下问题:
- 我应该使用什么外壳?我应该使用什么终端?
- 我可以使用什么版本的 Python?
- 如何管理不同项目的依赖关系?
- 我如何让我的工具为我做一些工作?
一旦你自己回答了这些问题,你就可以开始创建属于你自己的 Python 环境了。我们开始吧!
免费奖励: ,向您展示如何使用 Pip、PyPI、Virtualenv 和需求文件等工具避免常见的依赖管理问题。
炮弹
当您使用命令行界面 (CLI)时,您执行命令并查看它们的输出。一个 shell 就是为你提供这个(通常是基于文本的)界面的程序。Shells 通常提供自己的编程语言,您可以用它来操作文件、安装软件等等。
独特的贝壳比这里合理列出的要多,所以你会看到几个突出的。其他的在语法或增强特性上有所不同,但是它们通常提供相同的核心功能。
UNIX shell
Unix 是一个操作系统家族,最初是在计算的早期发展起来的。Unix 的流行一直持续到今天,极大地鼓舞了 Linux 和 macOS。第一批 shells 是为 Unix 和类似 Unix 的操作系统开发的。
伯恩·谢尔(
sh)Bourne shell——由 Stephen Bourne 于 1979 年为 Bell Labs 开发——是第一个包含环境变量、条件和循环概念的 shell。它为今天使用的许多其他 shells 提供了一个强大的基础,并且在大多数系统上仍然可用。
伯恩-再贝(
bash)基于最初的 Bourne shell 的成功,
bash引入了改进的用户交互功能。使用bash,您可以获得Tab完成、历史以及命令和路径的通配符搜索。bash编程语言提供了更多的数据类型,比如数组。z 壳(
zsh)将其他 shells 的许多最佳特性以及一些自己的技巧结合到一次体验中。
zsh提供拼写错误命令的自动纠正,操作多个文件的速记,以及定制命令提示符的高级选项。
zsh还提供了深度定制的框架。 Oh My Zsh 项目提供了丰富的主题和插件,通常与zsh一起使用。macOS 将从 Catalina 开始以
zsh作为默认外壳,这说明了该外壳的受欢迎程度。现在就考虑让自己熟悉zsh,这样你会对它的发展感到舒适。Xonsh
如果你特别喜欢冒险,你可以试一试。Xonsh 是一个外壳,它结合了其他类 Unix 外壳的一些特性和 Python 语法的强大功能。您可以使用您已经知道的语言来完成文件系统上的任务等等。
尽管 Xonsh 功能强大,但它缺乏其他 shells 所共有的兼容性。因此,您可能无法在 Xonsh 中运行许多现有的 shell 脚本。如果你发现你喜欢 Xonsh,但是兼容性是个问题,那么你可以在一个更广泛使用的 shell 中使用 Xonsh 作为你活动的补充。
视窗外壳
与类 Unix 操作系统类似,Windows 在 shells 方面也提供了许多选项。Windows 中提供的 shells 在特性和语法上各不相同,因此您可能需要尝试几种来找到您最喜欢的一种。
CMD (
cmd.exe)CMD(“命令”的缩写)是 Windows 的默认 CLI shell。它是 COMMAND.COM 的继任者,为 DOS(磁盘操作系统)构建的 shell。
因为 DOS 和 Unix 是独立发展的,所以 CMD 中的命令和语法与为类 Unix 系统构建的 shells 明显不同。然而,CMD 仍然为浏览和操作文件、运行命令以及查看输出提供了相同的核心功能。
PowerShell
PowerShell 于 2006 年发布,也随 Windows 一起发布。它为大多数命令提供了类似 Unix 的别名,因此,如果您从 macOS 或 Linux 进入 Windows,或者必须使用这两者,那么 PowerShell 可能非常适合您。
PowerShell 比 CMD 强大得多。使用 PowerShell,您可以:
- 将一个命令的输出通过管道传输到另一个命令的输入
- 通过公开的 Windows 管理功能自动执行任务
- 使用脚本语言完成复杂的任务
用于 Linux 的 Windows 子系统
微软发布了一个用于 Linux 的 Windows 子系统 (WSL),可以直接在 Windows 上运行 Linux。如果您安装了 WSL,那么您可以使用
zsh、bash或任何其他类似 Unix 的 shell。如果您想要跨 Windows 和 macOS 或 Linux 环境的强兼容性,那么一定要试试 WSL。你也可以考虑双启动 Linux 和 Windows 作为替代。参见这个命令 shell 的比较,以获得详尽的覆盖范围。
终端仿真器
早期的开发者使用终端与中央主机进行交互。这些设备带有键盘、屏幕或打印机,可以显示计算结果。
今天,计算机是便携式的,不需要单独的设备与它们交互,但术语仍然存在。尽管 shell 提供了提示和解释器,用于与基于文本的 CLI 工具进行交互,但是终端仿真器(通常简称为终端)是您运行来访问 shell 的图形应用程序。
您遇到的几乎所有终端都应该支持相同的基本功能:
- 文本颜色用于在代码中突出显示语法,或者在命令输出中区分有意义的文本
- 滚动查看之前的命令或其输出
- 复制/粘贴用于将文本从其他程序传入或传出外壳
- 选项卡用于同时运行多个程序或将您的工作分成不同的会话
macOS 终端
适用于 macOS 的终端选项都是全功能的,主要区别在于美观和与其他工具的特定集成。
终端
如果你用的是 Mac,那么你之前可能用过内置的终端应用。终端支持所有常用的功能,您也可以自定义配色方案和一些热键。如果你不需要很多花里胡哨的东西,这是一个足够好的工具。你可以在 macOS 上的应用→实用程序→终端中找到终端 app。
iTerm2
我是 iTerm2 的长期用户。它将开发人员在 Mac 上的体验向前推进了一步,提供了更广泛的定制和生产力选项,使您能够:
- 与 shell 集成以快速跳转到先前输入的命令
- 在命令的输出中创建自定义搜索词高亮显示
- 打开终端中显示的网址和文件用
Cmd+clickiTerm2 的最新版本附带了一个 Python API,因此您甚至可以通过开发更复杂的定制来提高您的 Python 能力!
iTerm2 足够受欢迎,可以与其他几个工具进行一流的集成,并拥有健康的社区构建插件等等。这是一个很好的选择,因为与终端相比,它的发布周期更频繁,而终端的更新频率只相当于 macOS。
超级
相对来说, Hyper 是一个基于 Electron 的终端,这是一个使用网络技术构建桌面应用程序的框架。电子应用程序是高度可定制的,因为它们“只是罩下的 JavaScript”。您可以创建任何您可以为其编写 JavaScript 的功能。
另一方面,JavaScript 是一种高级编程语言,并不总是像 Objective-C 或 Swift 这样的低级语言那样表现良好。当心你安装或创建的插件!
Windows 终端
与 shell 选项一样,Windows 终端选项在实用程序方面也有很大不同。有些还与特定的外壳紧密结合。
命令提示符
命令提示符是一个图形应用程序,您可以在 Windows 中使用 CMD。像 CMD 一样,它是完成一些小事情的基本工具。尽管 Command Prompt 和 CMD 提供的功能比其他替代产品少,但您可以确信,它们将在几乎每个 Windows 安装中可用,并且位于一个一致的位置。
Cygwin
Cygwin 是一个用于 Windows 的第三方工具套件,它提供了一个类似 Unix 的包装器。当我使用 Windows 时,这是我的首选设置,但是您可以考虑为 Linux 采用 Windows 子系统,因为它得到了更多的关注和改进。
Windows 终端
微软最近发布了一款名为 Windows 终端的 Windows 10 开源终端。它允许您在 CMD、PowerShell 甚至 Linux 的 Windows 子系统中工作。如果您需要在 Windows 中做大量的外壳工作,那么 Windows 终端可能是您的最佳选择!Windows 终端仍处于后期测试阶段,因此它尚未随 Windows 一起发布。查看文档以获取有关访问权限的说明。
Python 版本管理
选择好终端和 shell 后,您就可以将注意力集中在 Python 环境上了。
你最终会遇到的事情是需要运行 Python 的多个版本。您使用的项目可能只在某些版本上运行,或者您可能对创建支持多个 Python 版本的项目感兴趣。您可以配置您的 Python 环境来满足这些需求。
macOS 和大多数 Unix 操作系统都默认安装了 Python 版本。这通常被称为系统 Python 。Python 系统工作得很好,但是它通常是过时的。在撰写本文时,macOS High Sierra 仍然附带 Python 2.7.10 作为系统 Python。
注意:你几乎肯定希望至少安装最新版本的 Python ,所以你至少已经有了两个版本的 Python。
将系统 Python 作为默认的很重要,因为系统的许多部分依赖于特定版本的默认 Python。这是定制 Python 环境的众多理由之一!
你如何驾驭它?工装是来帮忙的。
pyenv
pyenv是在 macOS 上安装和管理多个 Python 版本的成熟工具。我推荐用家酿安装。如果你用的是 Windows,可以用pyenv-win。安装了pyenv之后,您可以用几个简短的命令将多个版本的 Python 安装到您的 Python 环境中:$ pyenv versions * system $ python --version Python 2.7.10 $ pyenv install 3.7.3 # This may take some time $ pyenv versions * system 3.7.3您可以管理您希望在当前会话中使用的 Python,可以是全局的,也可以是基于每个项目的。
pyenv将使python命令指向您指定的 Python。请注意,这些都不会覆盖其他应用程序的默认系统 Python,因此您可以安全地使用它们,但是它们在您的 Python 环境中最适合您:$ pyenv global 3.7.3 $ pyenv versions system * 3.7.3 (set by /Users/dhillard/.pyenv/version) $ pyenv local 3.7.3 $ pyenv versions system * 3.7.3 (set by /Users/dhillard/myproj/.python-version) $ pyenv shell 3.7.3 $ pyenv versions system * 3.7.3 (set by PYENV_VERSION environment variable) $ python --version Python 3.7.3因为我在工作中使用特定版本的 Python,在个人项目中使用最新版本的 Python,在测试开源项目中使用多个版本,
pyenv已经被证明是我在自己的 Python 环境中管理所有这些不同版本的一种相当顺畅的方式。关于该工具的详细概述,请参见使用pyenvT4 管理多个 Python 版本。你也可以使用pyenv来安装 Python 的预发布版本。
conda如果你在数据科学社区,你可能已经在使用 Anaconda (或者 Miniconda )。Anaconda 是一种数据科学软件的一站式商店,它不仅仅支持 Python。
如果你不需要数据科学包或者 Anaconda 预打包的所有东西,
pyenv可能是你更好的轻量级解决方案。不过,管理 Python 版本在每个版本中都非常相似。您可以使用conda命令安装类似于pyenv的 Python 版本:$ conda install python=3.7.3你会看到一个详细的清单,列出了所有
conda将要安装的相关软件,并要求你确认。没有办法设置“默认”Python 版本,甚至没有好办法查看你已经安装了哪些版本的 Python。相反,它取决于“环境”的概念,您可以在接下来的章节中了解更多。
虚拟环境
现在您知道了如何管理多个 Python 版本。通常,你会从事多个项目,这些项目需要相同的 Python 版本。
因为每个项目都有自己的依赖项集,所以避免混淆它们是一个好的做法。如果所有的依赖项都安装在一个 Python 环境中,那么就很难辨别每个依赖项的来源。在最坏的情况下,两个不同的项目可能依赖于一个包的两个不同版本,但是使用 Python,一次只能安装一个包的一个版本。真是一团糟!
进入虚拟环境。你可以把虚拟环境想象成 Python 基础版本的翻版。例如,如果您安装了 Python 3.7.3,那么您可以基于它创建许多虚拟环境。当您在虚拟环境中安装一个包时,您可以将它与您可能拥有的其他 Python 环境隔离开来。每个虚拟环境都有自己的
python可执行文件副本。提示:大多数虚拟环境工具都提供了一种方法来更新您的 shell 的命令提示符,以显示当前活动的虚拟环境。如果您经常在项目之间切换,请确保这样做,这样您就可以确保在正确的虚拟环境中工作。
venv
venv搭载 Python 版本 3.3+。您可以创建虚拟环境,只需向它传递一个路径,在这个路径上存储环境的python、已安装的包等等:$ python -m venv ~/.virtualenvs/my-env您可以通过获取其
activate脚本来激活虚拟环境:$ source ~/.virtualenvs/my-env/bin/activate您可以使用
deactivate命令退出虚拟环境,该命令在您激活虚拟环境时可用:(my-env)$ deactivate
venv是建立在独立的virtualenv项目的出色工作和成功之上的。virtualenv仍然提供了一些有趣的特性,但是venv很好,因为它提供了虚拟环境的效用,而不需要你安装额外的软件。如果您在自己的 Python 环境中主要使用单个 Python 版本,那么您可能已经做得很好了。如果您已经在管理多个 Python 版本(或计划管理多个版本),那么集成该工具来简化使用特定 Python 版本创建新虚拟环境的过程是有意义的。
pyenv和conda生态系统都提供了在创建新的虚拟环境时指定 Python 版本的方法,这将在下面的章节中介绍。
pyenv-virtualenv如果您使用的是
pyenv,那么pyenv-virtualenv用一个管理虚拟环境的子命令增强了pyenv:// Create virtual environment $ pyenv virtualenv 3.7.3 my-env // Activate virtual environment $ pyenv activate my-env // Exit virtual environment (my-env)$ pyenv deactivate我每天在大量项目之间切换环境。因此,在我的 Python 环境中,我至少要管理十几个不同的虚拟环境。
pyenv-virtualenv真正的好处在于,你可以使用pyenv local命令配置虚拟环境,并让pyenv-virtualenv在你切换到不同目录时自动激活正确的环境:$ pyenv virtualenv 3.7.3 proj1 $ pyenv virtualenv 3.7.3 proj2 $ cd /Users/dhillard/proj1 $ pyenv local proj1 (proj1)$ cd ../proj2 $ pyenv local proj2 (proj2)$ pyenv versions system 3.7.3 3.7.3/envs/proj1 3.7.3/envs/proj2 proj1 * proj2 (set by /Users/dhillard/proj2/.python-version)
pyenv和pyenv-virtualenv在我的 Python 环境中提供了特别流畅的工作流。
conda您之前看到过,
conda将环境而不是 Python 版本作为主要的工作方法。conda内置管理虚拟环境的支持:// Create virtual environment $ conda create --name my-env python=3.7.3 // Activate virtual environment $ conda activate my-env // Exit virtual environment (my-env)$ conda deactivate
conda将安装指定版本的 Python(如果尚未安装),因此您不必先运行conda install python=3.7.3。
pipenv
pipenv是一个相对较新的工具,旨在将包管理(稍后将详细介绍)与虚拟环境管理结合起来。它主要是从您那里抽象出虚拟环境管理,只要事情进展顺利,这就很好:$ cd /Users/dhillard/myproj // Create virtual environment $ pipenv install Creating a virtualenv for this project… Pipfile: /Users/dhillard/myproj/Pipfile Using /path/to/pipenv/python3.7 (3.7.3) to create virtualenv… ✔ Successfully created virtual environment! Virtualenv location: /Users/dhillard/.local/share/virtualenvs/myproj-nAbMEAt0 Creating a Pipfile for this project… Pipfile.lock not found, creating… Locking [dev-packages] dependencies… Locking [packages] dependencies… Updated Pipfile.lock (a65489)! Installing dependencies from Pipfile.lock (a65489)… 🐍 ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 0/0 — 00:00:00 To activate this project's virtualenv, run pipenv shell. Alternatively, run a command inside the virtualenv with pipenv run. // Activate virtual environment (uses a subshell) $ pipenv shell Launching subshell in virtual environment… . /Users/dhillard/.local/share/virtualenvs/test-nAbMEAt0/bin/activate // Exit virtual environment (by exiting subshell) (myproj-nAbMEAt0)$ exit ```py 为您完成创建虚拟环境并激活它的所有繁重工作。如果你仔细观察,你会发现它还创建了一个名为`Pipfile`的文件。在您第一次运行`pipenv install`之后,这个文件只包含几样东西:[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] [requires] python_version = "3.7"
特别注意,它显示的是`python_version = "3.7"`。默认情况下,`pipenv`创建一个虚拟 Python 环境,使用的 Python 版本与它安装时的版本相同。如果您想使用不同的 Python 版本,那么您可以在运行`pipenv install`之前自己创建`Pipfile`,并指定您想要的版本。如果你已经安装了`pyenv`,那么`pipenv`会在必要的时候用它来安装指定的 Python 版本。 抽象虚拟环境管理是`pipenv`的一个崇高目标,但是它偶尔会因为难以理解的错误而被挂起。试一试,但如果你感到困惑或不知所措,不要担心。随着它的成熟,工具、文档和社区将围绕它成长和改进。 要深入了解虚拟环境,请务必阅读 [Python 虚拟环境:初级读本](https://realpython.com/python-virtual-environments-a-primer)。 [*Remove ads*](/account/join/) ## 包装管理 对于您从事的许多项目,您可能需要一些第三方包。这些包可能依次有自己的依赖项。在 Python 的早期,使用包需要手动下载文件,并让 Python 指向它们。今天,我们很幸运有各种各样的包管理工具可供我们使用。 大多数包管理器与虚拟环境协同工作,将您在一个 Python 环境中安装的包与另一个环境隔离开来。将这两者结合使用,您将真正开始看到可用工具的威力。 ### `pip` [`pip`](https://realpython.com/courses/what-is-pip/)(**p**IP**I**installs**p**packages)几年来一直是 Python 中包管理事实上的标准。它很大程度上受到了一个叫做`easy_install`的早期工具的启发。Python 从 3.4 版本开始将 [`pip`](https://realpython.com/what-is-pip/) 合并到标准发行版中。`pip`自动化下载包并让 Python 知道它们的过程。 如果您有多个虚拟环境,那么您可以看到它们是通过在一个环境中安装几个包来隔离的:$ pyenv virtualenv 3.7.3 proj1
$ pyenv activate proj1
(proj1)$ pip list
Package Version
pip 19.1.1
setuptools 40.8.0(proj1)$ python -m pip install requests
Collecting requests
Downloading .../requests-2.22.0-py2.py3-none-any.whl (57kB)
100% |████████████████████████████████| 61kB 2.2MB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading .../chardet-3.0.4-py2.py3-none-any.whl (133kB)
100% |████████████████████████████████| 143kB 1.7MB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading .../certifi-2019.6.16-py2.py3-none-any.whl (157kB)
100% |████████████████████████████████| 163kB 6.0MB/s
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests)
Downloading .../urllib3-1.25.3-py2.py3-none-any.whl (150kB)
100% |████████████████████████████████| 153kB 1.7MB/s
Collecting idna<2.9,>=2.5 (from requests)
Downloading .../idna-2.8-py2.py3-none-any.whl (58kB)
100% |████████████████████████████████| 61kB 26.6MB/s
Installing collected packages: chardet, certifi, urllib3, idna, requests
Successfully installed packages$ pip list
Package Version
certifi 2019.6.16
chardet 3.0.4
idna 2.8
pip 19.1.1
requests 2.22.0
setuptools 40.8.0
urllib3 1.25.3`pip`已安装`requests`,以及它所依赖的几个包。`pip list`显示所有当前安装的软件包及其版本。 **警告**:例如,你可以使用`pip uninstall requests`卸载软件包,但是这将*只*卸载`requests`——而不是它的任何依赖项。 为`pip`指定项目依赖关系的一种常见方式是使用`requirements.txt`文件。文件中的每一行都指定了一个包名,并且可以选择要安装的版本:scipy1.3.0
requests2.22.0然后,您可以运行`python -m pip install -r requirements.txt`来一次安装所有指定的依赖项。有关`pip`的更多信息,请参见[什么是 Pip?新蟒蛇指南](https://realpython.com/what-is-pip/)。 ### `pipenv` [`pipenv`](https://docs.pipenv.org/en/latest/) 与`pip`有着大部分相同的基本操作,但是考虑包的方式有点不同。还记得`pipenv`创造的`Pipfile`吗?当你安装一个包时,`pipenv`会将这个包添加到`Pipfile`中,同时也会将更多的详细信息添加到一个名为`Pipfile.lock`的新**锁文件**中。锁定文件充当已安装软件包的精确集合的快照,包括直接依赖项及其子依赖项。 你可以看到`pipenv`在你安装包的时候整理包管理:$ pipenv install requests
Installing requests…
Adding requests to Pipfile's [packages]…
✔ Installation Succeeded
Pipfile.lock (444a6d) out of date, updating to (a65489)…
Locking [dev-packages] dependencies…
Locking [packages] dependencies…
✔ Success!
Updated Pipfile.lock (444a6d)!
Installing dependencies from Pipfile.lock (444a6d)…
🐍 ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 5/5 — 00:00:00`pipenv`将使用这个锁文件,如果存在的话,来安装同一套软件包。您可以确保在使用这种方法创建的任何 Python 环境中,您总是拥有相同的工作依赖集。 `pipenv`还区分**开发依赖**和**生产(常规)依赖**。在开发过程中,您可能需要一些工具,例如 [`black`](https://github.com/python/black) 或 [`flake8`](http://flake8.pycqa.org/en/latest/) ,而在生产中运行您的应用程序时,您并不需要这些工具。您可以在安装软件包时指定该软件包用于开发:$ pipenv install --dev flake8
Installing flake8…
Adding flake8 to Pipfile's [dev-packages]…
✔ Installation Succeeded
...默认情况下,`pipenv install`(没有任何参数)将只安装您的产品包,但是您也可以使用`pipenv install --dev`告诉它安装开发依赖项。 [*Remove ads*](/account/join/) ### `poetry` [`poetry`](https://poetry.eustace.io) 解决了包管理的其他方面,包括创建和发布你自己的包。安装`poetry`后,您可以使用它创建一个新项目:$ poetry new myproj
Created package myproj in myproj
$ ls myproj/
README.rst myproj pyproject.toml tests类似于`pipenv`如何创建`Pipfile`,`poetry`创建一个 [`pyproject.toml`](https://realpython.com/courses/packaging-with-pyproject-toml/) 文件。这个[最新标准](https://www.python.org/dev/peps/pep-0518/#file-format)包含关于项目的元数据以及依赖版本:[tool.poetry] name = "myproj" version = "0.1.0" description = "" authors = ["Dane Hillard github@danehillard.com"] [tool.poetry.dependencies] python = "^3.7" [tool.poetry.dev-dependencies] pytest = "^3.0" [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"
可以用`poetry add`安装包(或者用`poetry add --dev`作为开发依赖):$ poetry add requests
Using version ^2.22 for requestsUpdating dependencies
Resolving dependencies... (0.2s)Writing lock file
Package operations: 5 installs, 0 updates, 0 removals
- Installing certifi (2019.6.16)
- Installing chardet (3.0.4)
- Installing idna (2.8)
- Installing urllib3 (1.25.3)
- Installing requests (2.22.0)
`poetry`也维护一个锁文件,它比`pipenv`有优势,因为它跟踪哪些包是子依赖包。这样一来,你就可以卸载`requests` *和*与其`poetry remove requests`的依赖关系。 ### `conda` 有了`conda`,你可以照常使用`pip`安装包,但是你也可以使用`conda install`安装包来自不同的**通道**,这些通道是 Anaconda 或者其他提供者提供的包的集合。要从`conda-forge`通道安装`requests`,可以运行`conda install -c conda-forge requests`。 在[中的`conda`中了解更多关于包管理的信息在 Windows](https://realpython.com/python-windows-machine-learning-setup/) 上设置 Python 进行机器学习。 ## Python 解释器 如果您对 Python 环境的进一步定制感兴趣,可以选择与 Python 交互时的命令行体验。Python 解释器提供了一个**读取-评估-打印循环** (REPL),这是当您在 shell 中键入不带参数的`python`时出现的情况:
Python 3.7.3 (default, Jun 17 2019, 14:09:05)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> 2 + 2
4
>>> exit()
```py
REPL **读取**您键入的内容,**将**评估为 Python 代码,**打印**结果。然后它等待重新做一遍。这大约是默认的 Python REPL 提供的数量,足以完成大部分典型工作。
### IPython
像 Anaconda 一样, [IPython](https://ipython.org/) 是一套不仅仅支持 Python 的工具,但是它的主要特性之一是一个替代的 Python REPL。IPython 的 REPL 对每个命令进行编号,并明确标记每个命令的输入和输出。安装 IPython ( `python -m pip install ipython`)后,您可以运行`ipython`命令代替`python`命令来使用 IPython REPL:
>>>
Python 3.7.3
Type 'copyright', 'credits' or 'license' for more information
IPython 6.0.0.dev -- An enhanced Interactive Python. Type '?' for help.
In [1]: 2 + 2
Out[1]: 4
In [2]: print("Hello!")
Out[2]: Hello!
IPython 还支持 `Tab` 完成,更强大的帮助特性,以及与其他工具如 [`matplotlib`](https://matplotlib.org/) 的强大集成,用于绘图。IPython 为 [Jupyter](https://jupyter.org/) 提供了基础,两者都因为与其他工具的集成而在数据科学社区中得到了广泛的应用。
IPython REPL 也是高度可配置的,所以尽管它还算不上一个完整的开发环境,但它仍然可以提高您的工作效率。它内置的可定制的[魔法命令](https://ipython.org/ipython-doc/3/interactive/tutorial.html#magic-functions)值得一试。
[*Remove ads*](/account/join/)
### `bpython`
[`bpython`](https://bpython-interpreter.org) 是另一个可选择的 REPL,它提供了行内语法高亮显示、制表符补全,甚至在您键入时提供自动建议。它提供了 IPython 的许多快捷的好处,而没有对接口做太多改变。如果没有集成等等的权重,`bpython`可能会很好地添加到您的清单中一段时间,看看它如何改进您对 REPL 的使用。
## 文本编辑器
你一生中有三分之一的时间在睡觉,所以投资一张好床是有意义的。作为一名开发人员,您花了大量时间阅读和编写代码,因此您应该投入时间按照您喜欢的方式设置 Python 环境的文本编辑器。
每个编辑器都提供了一组不同的按键绑定和操作文本的模型。一些需要鼠标来有效地与它们交互,而另一些只需要键盘就可以控制。有些人认为他们选择的文本编辑器和定制是他们做出的最个人的决定!
在这个舞台上有如此多的选择,所以我不会试图在这里详细介绍它。查看[Python ide 和代码编辑器(指南)](https://realpython.com/python-ides-code-editors-guide/)获得广泛的概述。一个好的策略是找一个简单的小文本编辑器来快速修改,找一个全功能的 IDE 来完成更复杂的工作。 [Vim](https://www.vim.org/) 和 [PyCharm](https://www.jetbrains.com/pycharm/) 分别是我选择的编辑器。
## Python 环境提示和技巧
一旦您做出了关于 Python 环境的重大决定,剩下的路就由一些小的调整铺就,让您的生活变得更加轻松。这些调整每个都可以节省几分钟或几秒钟,但是它们合起来可以节省你几个小时的时间。
让某项活动变得更容易可以减少你的认知负荷,这样你就可以专注于手头的任务,而不是围绕它的后勤工作。如果你注意到自己一遍又一遍地执行一个动作,那么考虑自动化它。使用 XKCD 的这张美妙的图表来决定是否值得自动化一项特定的任务。
这里是一些最后的提示。
**了解您当前的虚拟环境**
如前所述,在命令提示符中显示活动的 Python 版本或虚拟环境是一个好主意。大多数工具会为您做到这一点,但是如果不这样做(或者如果您想要定制提示),该值通常包含在`VIRTUAL_ENV`环境变量中。
**禁用不必要的临时文件**
你有没有注意到`*.pyc`文件遍布你的项目目录?这些文件是预编译的 Python 字节码——它们帮助 Python 更快地启动应用程序。在生产中,这是一个很好的主意,因为它们会给你一些性能增益。然而,在本地开发过程中,它们很少有用。设置`PYTHONDONTWRITEBYTECODE=1`禁用该行为。如果您以后发现了它们的用例,那么您可以很容易地从 Python 环境中移除它们。
**定制您的 Python 解释器**
您可以使用一个**启动文件**来影响 REPL 的行为。Python 将在进入 REPL 之前读取这个启动文件并执行其中包含的代码。将`PYTHONSTARTUP`环境变量设置为启动文件的路径。(我的在`~/.pystartup`。)如果您想像您的 shell 提供的那样点击 `Up` 查看命令历史,点击 `Tab` 查看完成,那么尝试一下[这个启动文件](https://github.com/daneah/dotfiles/blob/master/source/pystartup)。
## 结论
您了解了典型 Python 环境的许多方面。有了这些知识,您可以:
* 选择具有您喜欢的美感和增强功能的终端
* 根据您的需要选择带有任意多(或少)定制选项的 shell
* 管理系统上多个版本的 Python
* 使用虚拟 Python 环境管理使用单一版本 Python 的多个项目
* 在您的虚拟环境中安装软件包
* 选择适合您的交互式编码需求的 REPL
当你已经有了自己的 Python 环境,我希望你能分享关于你的完美设置✨的截图、截屏或博客帖子*******
# Emacs:最好的 Python 编辑器?
> 原文:<https://realpython.com/emacs-the-best-python-editor/>
为 Python 开发找到合适的[代码编辑器](https://realpython.com/python-ides-code-editors-guide/)可能很棘手。许多开发人员在成长和学习的过程中探索了大量的编辑器。要选择正确的代码编辑器,您必须从了解哪些特性对您来说很重要开始。然后,您可以尝试找到具有这些功能的编辑器。功能最丰富的编辑器之一是 [Emacs](https://www.gnu.org/software/emacs/) 。
Emacs 开始于 20 世纪 70 年代中期,是一组用于不同代码编辑器的宏扩展。它在 20 世纪 80 年代初被理查德·斯托尔曼采用到了 GNU 项目中,此后 GNU Emacs 得到了持续的维护和发展。直到今天,GNU Emacs 和 XEmacs 变种在每一个主流平台上都可以使用,GNU Emacs 仍然是[编辑器战争](https://en.wikipedia.org/wiki/Editor_war)中的一员。
**在本教程中,您将学习如何使用 Emacs 进行 Python 开发,包括如何:**
* 在您选择的平台上安装 Emacs
* 设置 Emacs 初始化文件来配置 Emacs
* 为 Emacs 构建基本的 Python 配置
* 编写 Python 代码来探索 Emacs 的功能
* 在 Emacs 环境中运行和测试 Python 代码
* 使用集成的 Emacs 工具调试 Python 代码
* 使用 Git 添加源代码控制功能
对于本教程,您将使用 GNU Emacs 25 或更高版本,尽管这里展示的大多数技术也适用于旧版本(和 XEmacs)。你应该有一些用 Python 开发的经验,你的机器应该已经安装了 Python 发行版并且准备好了。
**更新:**
* *10/09/2019:* 主要更新增加了新的代码示例、更新的包可用性和信息、基础教程、Jupyter 走查、调试走查、测试走查和更新的视觉效果。
* *2015 年 11 月 3 日:*初始教程发布。
您可以从下面的链接下载本教程中引用的所有文件:
**下载代码:** [单击此处下载代码,您将在本教程中使用](https://realpython.com/bonus/emacs/)来了解用于 Python 的 Emacs。
## 安装和基础知识
在探索 Emacs 及其为 Python 开发人员提供的一切之前,您需要安装它并学习一些基础知识。
[*Remove ads*](/account/join/)
### 安装
当你安装 Emacs 时,你必须考虑你的平台。由 [ErgoEmacs](http://ergoemacs.org/) 提供的这个[指南](http://ergoemacs.org/emacs/which_emacs.html),提供了在 Linux、Mac 或 Windows 上启动和运行基本 Emacs 安装所需的一切。
安装完成后,您可以启动 Emacs:
[](https://files.realpython.com/media/emacsv2-fresh-launch.2fb60d356a34.png)
您应该会看到默认的启动屏幕。
### 基本 Emacs
首先,让我们通过一个简单的例子来介绍 Python 开发的一些基本 Emacs。您将看到如何使用普通的 Emacs 编辑程序,以及程序内置了多少 Python 支持。在 Emacs 打开的情况下,使用以下步骤创建一个快速 Python 程序:
1. 点击`Ctrl`+`X``Ctrl`+`F`打开一个新文件。
2. 键入`sieve.py`来命名文件。
3. 点击 `Enter` 。
4. Emacs 可能会要求您确认您的选择。如果是,那么再点击 `Enter` 。
现在键入以下代码:
```py
1MAX_PRIME = 100
2
3sieve = [True] * MAX_PRIME
4for i in range(2, MAX_PRIME):
5 if sieve[i]:
6 print(i)
7 for j in range(i * i, MAX_PRIME, i):
8 sieve[j] = False
你可能认识到这个代码是厄拉多塞的筛子,它寻找低于给定最大值的所有素数。当您键入代码时,您会注意到:
- Emacs 突出变量和常量的方式不同于 Python 关键字。
- Emacs 自动缩进
for和if语句后面的行。 - 当您在缩进行上点击
Tab时,Emacs 会将缩进修改到适当的位置。 - 每当您键入右括号或圆括号时,Emacs 都会突出显示左括号或圆括号。
- Emacs 对箭头键以及
Enter、Backspace、Del、Home、End和Tab键的响应与预期一致。
然而,在 Emacs 中有一些奇怪的键映射。例如,如果你试图将代码粘贴到 Emacs 中,那么你可能会发现标准的 Ctrl + V 击键不起作用。
了解 Emacs 中哪些键做什么的最简单的方法是遵循内置教程。您可以通过将光标定位在 Emacs 开始屏幕上的 Emacs 教程上并按下 Enter 来访问它,或者在此后的任何时间通过键入Ctrl+H``T来访问它。你会看到下面这段话:
Emacs commands generally involve the CONTROL key (sometimes labeled
CTRL or CTL) or the META key (sometimes labeled EDIT or ALT). Rather than
write that in full each time, we'll use the following abbreviations:
C-<chr> means hold the CONTROL key while typing the character <chr>
Thus, C-f would be: hold the CONTROL key and type f.
M-<chr> means hold the META or EDIT or ALT key down while typing <chr>.
If there is no META, EDIT or ALT key, instead press and release the
ESC key and then type <chr>. We write <ESC> for the ESC key.
Important Note: to end the Emacs session, type C-x C-c. (Two characters.)
To quit a partially entered command, type C-g.
当您浏览文章中的文本时,您会看到 Emacs 文档中使用符号C-x C-s显示了 Emacs 击键。这是保存当前缓冲区内容的命令。这个符号表示 Ctrl 和 X 键被同时按下,接着是 Ctrl 和 S 键。
注:在本教程中,Emacs 击键显示为Ctrl+X``Ctrl+S。
Emacs 使用的一些术语可以追溯到其基于文本的 UNIX 根源。因为这些术语现在有不同的含义,所以最好复习一下,因为随着教程的进行,你会读到它们:
-
启动 Emacs 时看到的窗口被称为 帧 。您可以在任意数量的显示器上打开任意数量的 Emacs 框架,Emacs 会对它们进行跟踪。
-
每个 Emacs 框架内的窗格被称为 窗口 。Emacs 框架最初包含一个窗口,但是您可以在每个框架中打开多个窗口,可以手动打开,也可以通过运行特殊命令打开。
-
在每个窗口内,显示的内容被称为一个。缓冲区可以包含文件内容、命令输出、菜单选项列表或其他项目。缓冲区是您与 Emacs 交互的地方。
*** 当 Emacs 需要你的输入时,它会在当前活动帧底部的一个特殊的单行区域请求,这个区域叫做 迷你缓冲区 。如果你意外地发现自己在那里,那么你可以用 Ctrl + G 取消任何让你在那里的东西。**
**现在您已经了解了基础知识,是时候开始为 Python 开发定制和配置 Emacs 了!
初始化文件
Emacs 的一大优势是它强大的配置选项。Emacs 配置的核心是初始化文件,Emacs 每次启动都会处理这个文件。
该文件包含用 Emacs Lisp 编写的命令,每次启动 Emacs 时都会执行这些命令。不过,别担心!使用或定制 Emacs 不需要了解 Lisp。在本教程中,您将找到入门所需的一切。(毕竟这是真正的 Python ,不是真正的 Lisp !)
启动时,Emacs 在三个地方寻找初始化文件:
- 首先,它在您的家庭用户文件夹中查找文件
.emacs。 - 如果不存在,那么 Emacs 会在您的主用户文件夹中查找文件
emacs.el。 - 最后,如果都没有找到,那么它会在您的主文件夹中查找
.emacs.d/init.el。
最后一个选项.emacs.d/init.el,是当前推荐的初始化文件。但是,如果您以前使用并配置过 Emacs,那么您可能已经有了其他初始化文件之一。如果是这样,那么在阅读本教程时继续使用该文件。
当您第一次安装 Emacs 时,没有.emacs.d/init.el,但是您可以相当快地创建这个文件。在 Emacs 窗口打开的情况下,按照下列步骤操作:
- 击
Ctrl+X``Ctrl+F。 - 在迷你缓冲区中键入
~/.emacs.d/init.el。 - 点击
Enter。 - Emacs 可能会要求您确认您的选择。如果是,那么再点击
Enter。
让我们仔细看看这里发生了什么:
-
你告诉 Emacs 你想通过按键
Ctrl+X``Ctrl+F找到并打开一个文件。 -
您通过给 Emacs 一个文件路径来告诉它打开什么文件。路径
~/.emacs.d/init.el有三个部分:- 前导波浪号
~是您的个人文件夹的快捷方式。在 Linux 和 Mac 机器上,这通常是/home/<username>。在 Windows 机器上,它是在 HOME 环境变量中指定的路径。 - 文件夹
.emacs.d是 Emacs 存储所有配置信息的地方。您可以使用该文件夹在新机器上快速设置 Emacs。为此,将该文件夹的内容复制到您的新机器上,Emacs 就可以使用了! - 文件
init.el是你的初始化文件。
- 前导波浪号
-
您告诉 Emacs,“是的,我确实想创建这个新文件。”(这一步是必需的,因为文件不存在。通常,Emacs 会简单地打开指定的文件。)
Emacs 创建新文件后,会在新的缓冲区中打开该文件供您编辑。不过,这个操作实际上并没有创建文件。您必须使用Ctrl+X``Ctrl+S保存空白文件,以便在磁盘上创建它。
在本教程中,您将看到启用不同特性的初始化代码片段。如果您想继续操作,现在就创建初始化文件!您也可以在下面的链接中找到完整的初始化文件:
下载代码: 单击此处下载代码,您将在本教程中使用来了解用于 Python 的 Emacs。
定制包
现在您已经有了一个初始化文件,您可以添加定制选项来为 Python 开发定制 Emacs。有几种方法可以定制 Emacs,但是步骤最少的一种是添加 Emacs 包。这些来自各种来源,但是主要的包存储库是 MELPA ,或者 Milkypostman 的 Emacs Lisp 包存档。
把 MELPA 想象成 Emacs 包的 PyPI(T2)。你在本教程中需要用到的所有东西都可以在那里找到。要开始使用它,请展开下面的代码块,并将配置代码复制到您的init.el文件:
1;; .emacs.d/init.el 2
3;; =================================== 4;; MELPA Package Support 5;; =================================== 6;; Enables basic packaging support 7(require 'package) 8
9;; Adds the Melpa archive to the list of available repositories 10(add-to-list 'package-archives 11 '("melpa" . "http://melpa.org/packages/") t) 12
13;; Initializes the package infrastructure 14(package-initialize) 15
16;; If there are no archived package contents, refresh them 17(when (not package-archive-contents) 18 (package-refresh-contents)) 19
20;; Installs packages 21;; 22;; myPackages contains a list of package names 23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 material-theme ;; Theme 26 ) 27 ) 28
29;; Scans the list in myPackages 30;; If the package listed is not already installed, install it 31(mapc #'(lambda (package) 32 (unless (package-installed-p package) 33 (package-install package))) 34 myPackages) 35
36;; =================================== 37;; Basic Customization 38;; =================================== 39
40(setq inhibit-startup-message t) ;; Hide the startup message 41(load-theme 'material t) ;; Load material theme 42(global-linum-mode t) ;; Enable line numbers globally 43
44;; User-Defined init.el ends here
当您通读代码时,您会看到init.el被分成几个部分。每个部分由以两个分号(;;)开头的注释块分隔。第一部分的标题是MELPA Package Support:
1;; .emacs.d/init.el 2
3;; =================================== 4;; MELPA Package Support 5;; =================================== 6;; Enables basic packaging support 7(require 'package) 8
9;; Adds the Melpa archive to the list of available repositories 10(add-to-list 'package-archives 11 '("melpa" . "http://melpa.org/packages/") t) 12
13;; Initializes the package infrastructure 14(package-initialize) 15
16;; If there are no archived package contents, refresh them 17(when (not package-archive-contents) 18 (package-refresh-contents))
本节从设置打包基础结构开始:
- 第 7 行告诉 Emacs 使用包。
- 第 10 行和第 11 行将 MELPA 档案添加到包源列表中。
- 第 14 行初始化包装系统。
- 第 17 行和第 18 行构建当前的包内容列表,如果它还不存在的话。
第一部分从第 20 行继续:
20;; Installs packages 21;; 22;; myPackages contains a list of package names 23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 material-theme ;; Theme 26 ) 27 ) 28
29;; Scans the list in myPackages 30;; If the package listed is not already installed, install it 31(mapc #'(lambda (package) 32 (unless (package-installed-p package) 33 (package-install package))) 34 myPackages)
至此,您已经准备好以编程方式安装 Emacs 包了:
- 第 23 到 27 行定义了要安装的软件包名称列表。随着教程的进行,您将添加更多的包:
- 第 24 行增加了
better-defaults。这是对 Emacs 默认设置的一些小改动,使其更加用户友好。这也是进一步定制的良好基础。 - 25 线增加了
material-theme包,这是在其他环境中发现的不错的暗黑风格。
- 第 24 行增加了
- 第 31 到 34 行遍历列表并安装任何尚未安装的包。
注意:不需要使用素材主题。MELPA 上有许多不同的 Emacs 主题供你选择。挑一个适合自己风格的吧!
安装完软件包后,您可以进入标题为Basic Customization的部分:
36;; =================================== 37;; Basic Customization 38;; =================================== 39
40(setq inhibit-startup-message t) ;; Hide the startup message 41(load-theme 'material t) ;; Load material theme 42(global-linum-mode t) ;; Enable line numbers globally 43
44;; User-Defined init.el ends here
在这里,您可以添加一些其他定制:
- 第 40 行禁用包含教程信息的初始 Emacs 屏幕。您可能想用双分号(
;;)把这个注释掉,直到您对 Emacs 更熟悉为止。 - 第 41 行加载并激活素材主题。如果你想安装一个不同的主题,那么在这里使用它的名字。您也可以注释掉这一行以使用默认的 Emacs 主题。
- 第 42 行显示每个缓冲器中的行号。
现在您已经有了一个完整的基本配置文件,您可以使用Ctrl+X``Ctrl+S保存文件。然后,关闭并重新启动 Emacs 以查看更改。
Emacs 第一次使用这些选项运行时,可能需要几秒钟来启动,因为它设置了打包基础结构。完成后,您会看到您的 Emacs 窗口看起来有点不同:
重启后,Emacs 跳过初始屏幕,打开最后一个活动文件。应用了材质主题,并在缓冲区中添加了行号。
注意:您可以在打包基础设施建立之后交互式地添加包。点击 Alt + X ,然后输入package-show-package-list查看 Emacs 中所有可安装的软件包。在撰写本文时,有超过 4300 个可用。
看到包列表后,您可以:
- 点击
F快速过滤包名列表。 - 通过单击任何包的名称来查看其详细信息。
- 通过单击安装链接,从软件包视图安装软件包。
- 使用
Q关闭套餐列表。
使用elpy 进行 Python 开发的 Emacs
Emacs 可以随时编辑 Python 代码。库文件python.el提供了 python 模式,支持基本的缩进和语法高亮显示。然而,这个内置的包并没有提供太多其他的东西。为了与特定于 Python 的ide(集成开发环境)竞争,您将添加更多的功能。
elpy 包( Emacs Lisp Python 环境)提供了一套近乎完整的 Python IDE 特性,包括:
- 自动缩进
- 语法突出显示
- 自动完成
- 语法检查
- Python REPL 集成
- 虚拟环境支持
要安装并启用elpy,您需要将这个包添加到您的 Emacs 配置中。对init.el的以下更改将达到目的:
23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 elpy ;; Emacs Lisp Python Environment 26 material-theme ;; Theme 27 ) 28 )
一旦elpy被安装,你需要启用它。在您的init.el文件的末尾之前添加以下代码:
45;; ==================================== 46;; Development Setup 47;; ==================================== 48;; Enable elpy 49(elpy-enable) 50
51;; User-Defined init.el ends here
您现在有了一个名为Development Setup的新部分。线 49 使能elpy。
注意:遗憾的是,Emacs 在启动时只会读取一次初始化文件的内容。如果您对它做了任何更改,那么加载它们最简单、最安全的方法就是重启 Emacs。
要查看新模式的运行情况,请返回到您之前输入的的厄拉多塞代码的屏幕。创建一个新的 Python 文件,并直接重新键入 Sieve 代码:
1MAX_PRIME = 100
2
3sieve = [True] * MAX_PRIME
4for i as range(2, MAX_PRIME): 5 if sieve[i]:
6 print(i)
7 for j in range(i*i, MAX_PRIME, i):
8 sieve[j] = False
注意第 4 行的故意的语法错误。
这是您的 Python 文件在 Emacs 中的样子:
自动缩进和关键字突出显示仍然像以前一样工作。但是,您还应该在第 4 行看到一个错误指示器:
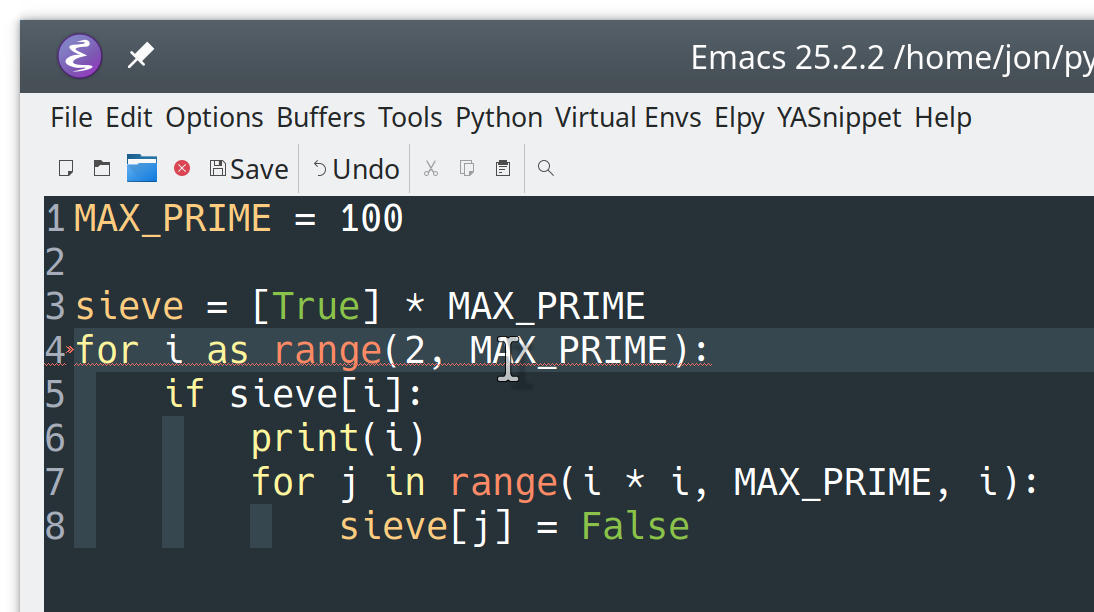
当你键入as而不是in时,这个错误指示器会在for循环中弹出。
更正该错误,然后在 Python 缓冲区中键入Ctrl++C``Ctrl+C来运行文件,而不离开 Emacs:
使用该命令时,Emacs 将执行以下操作:
- 创建一个名为 Python 的新缓冲区
- 打开 Python 解释器并将其连接到缓冲区
- 在当前代码窗口下创建一个新窗口来显示缓冲区
- 将代码发送给解释器执行
您可以滚动浏览 Python 缓冲区,查看运行了哪个解释器以及代码是如何启动的。你甚至可以在底部的提示符(>>>)下输入命令。
通常,您会希望在一个虚拟环境中使用为该环境指定的解释器和包来执行您的代码。幸运的是,elpy包含了 pyvenv 包,为虚拟环境提供了内置支持。
要使用 Emacs 中现有的虚拟环境,请键入 Alt + X pyvenv-workon。Emacs 将询问虚拟环境的名称以使用并激活它。可以用Alt+X``pyvenv-deactivate停用当前虚拟环境。您也可以从 Emacs 菜单的虚拟环境下访问该功能。
您也可以在 Emacs 中配置elpy。键入 Alt + X elpy-config显示如下对话框:
您应该看到有价值的调试信息,以及配置elpy的选项。
现在,您已经具备了在 Python 中使用 Emacs 的所有基础知识。是时候在蛋糕上加点糖霜了!
额外的 Python 语言特性
除了上面描述的所有基本 IDE 特性之外,还有其他语法特性可以与 Emacs 一起用于 Python 开发。在本教程中,您将涉及这三个方面:
然而,这并不是一个详尽的列表!请随意使用 Emacs 和 Python,看看还能发现哪些语法特性。
语法检查
默认情况下,elpy使用一个名为 flymake 的语法检查包。虽然flymake内置在 Emacs 中,但它只支持四种语言,而且要支持新的语言还需要很大的努力。
幸运的是,有一个更新更完整的解决方案可用!语法检查包 flycheck 支持 50 多种语言的实时语法检查,并设计用于快速配置新语言。你可以在文档中读到flymake和flycheck的区别。
可以快速切换elpy用flycheck代替flymake。首先,给你的init.el加上flycheck:
23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 elpy ;; Emacs Lisp Python Environment 26 flycheck ;; On the fly syntax checking 27 material-theme ;; Theme 28 ) 29 )
flycheck现在将与其他软件包一起安装。
然后,在Development Setup部分添加以下几行:
46;; ==================================== 47;; Development Setup 48;; ==================================== 49;; Enable elpy 50(elpy-enable) 51
52;; Enable Flycheck 53(when (require 'flycheck nil t) 54 (setq elpy-modules (delq 'elpy-module-flymake elpy-modules)) 55 (add-hook 'elpy-mode-hook 'flycheck-mode))
这将在 Emacs 运行您的初始化文件时启用flycheck。现在,无论何时使用 Emacs 编辑 Python 代码,您都会看到实时的语法反馈:
请注意 range() 的语法提醒,它会在您键入时出现在窗口的底部。
代码格式化
爱它或恨它, PEP 8 在这里停留。如果您想要遵循所有或部分标准,那么您可能想要一种自动化的方式来做到这一点。比较流行的两种方案是 autopep8 和 black 。这些代码格式化工具必须安装在 Python 环境中才能使用。要了解更多关于如何安装自动格式化程序的信息,请查看如何用 PEP 8 编写漂亮的 Python 代码。
一旦自动格式化程序可用,您就可以安装适当的 Emacs 包来启用它:
py-autopep8将autopep8连接到 Emacs。blacken使black能够从 Emacs 内部运行。
您只需要在 Emacs 中安装其中一个。为此,在您的init.el中添加以下突出显示的行之一:
23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 elpy ;; Emacs Lisp Python Environment 26 flycheck ;; On the fly syntax checking 27 py-autopep8 ;; Run autopep8 on save 28 blacken ;; Black formatting on save 29 material-theme ;; Theme 30 ) 31 )
如果你正在使用black,那么你就完成了!elpy识别blacken包并自动启用。
但是,如果您使用的是autopep8,那么您需要启用Development Setup部分中的格式化程序:
48;; ==================================== 49;; Development Setup 50;; ==================================== 51;; Enable elpy 52(elpy-enable) 53
54;; Enable Flycheck 55(when (require 'flycheck nil t) 56 (setq elpy-modules (delq 'elpy-module-flymake elpy-modules)) 57 (add-hook 'elpy-mode-hook 'flycheck-mode)) 58
59;; Enable autopep8 60(require 'py-autopep8) 61(add-hook 'elpy-mode-hook 'py-autopep8-enable-on-save) 62
63;; User-Defined init.el ends here
现在,每次保存 Python 代码时,都会自动格式化和保存缓冲区,并重新加载内容。您可以看到这是如何与一些格式错误的 Sieve 代码和black格式化程序一起工作的:
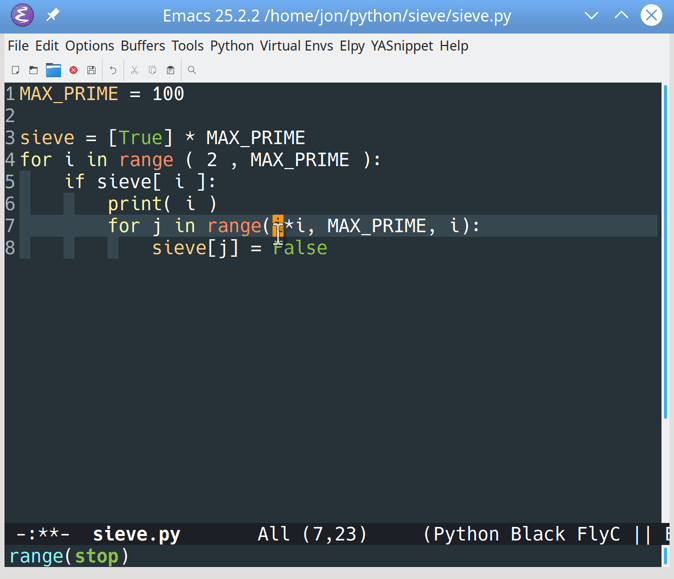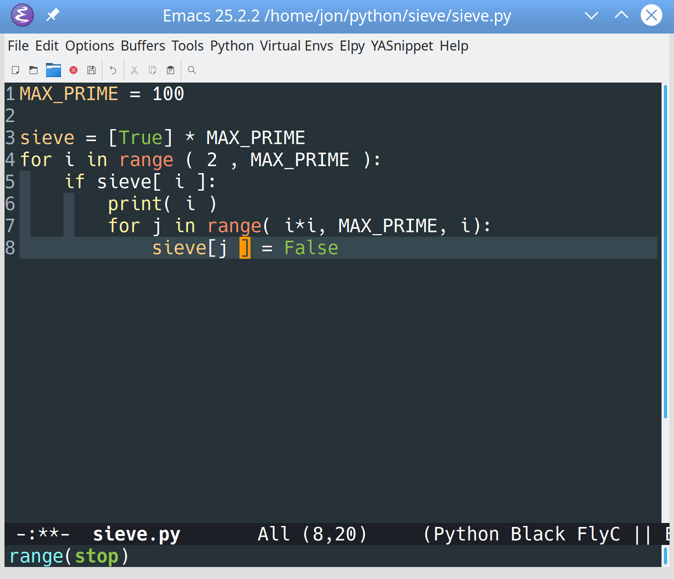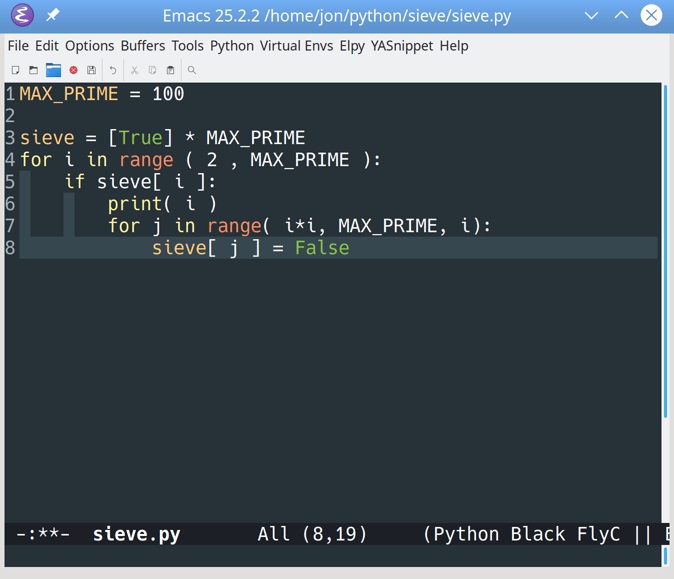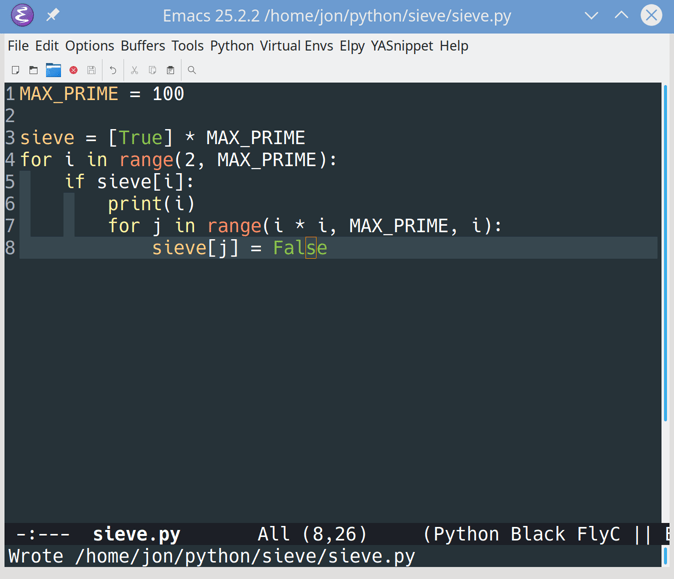
您可以看到,文件保存后,它被重新加载到缓冲区中,并应用了适当的black格式。
与 Jupyter 和 IPython 的集成
Emacs 也可以与 Jupyter 笔记本和 IPython REPL 一起工作。如果你还没有安装 Jupyter,那么看看 Jupyter 笔记本:简介。一旦 Jupyter 准备就绪,在调用启用elpy后,将以下行添加到您的init.el中:
48;; ==================================== 49;; Development Setup 50;; ==================================== 51;; Enable elpy 52(elpy-enable) 53
54;; Use IPython for REPL 55(setq python-shell-interpreter "jupyter" 56 python-shell-interpreter-args "console --simple-prompt" 57 python-shell-prompt-detect-failure-warning nil) 58(add-to-list 'python-shell-completion-native-disabled-interpreters 59 "jupyter") 60
61;; Enable Flycheck 62(when (require 'flycheck nil t) 63 (setq elpy-modules (delq 'elpy-module-flymake elpy-modules)) 64 (add-hook 'elpy-mode-hook 'flycheck-mode))
这将更新 Emacs 以使用 IPython,而不是标准的 Python REPL。现在当你用Ctrl+C``Ctrl+C运行你的代码时,你会看到 IPython REPL:
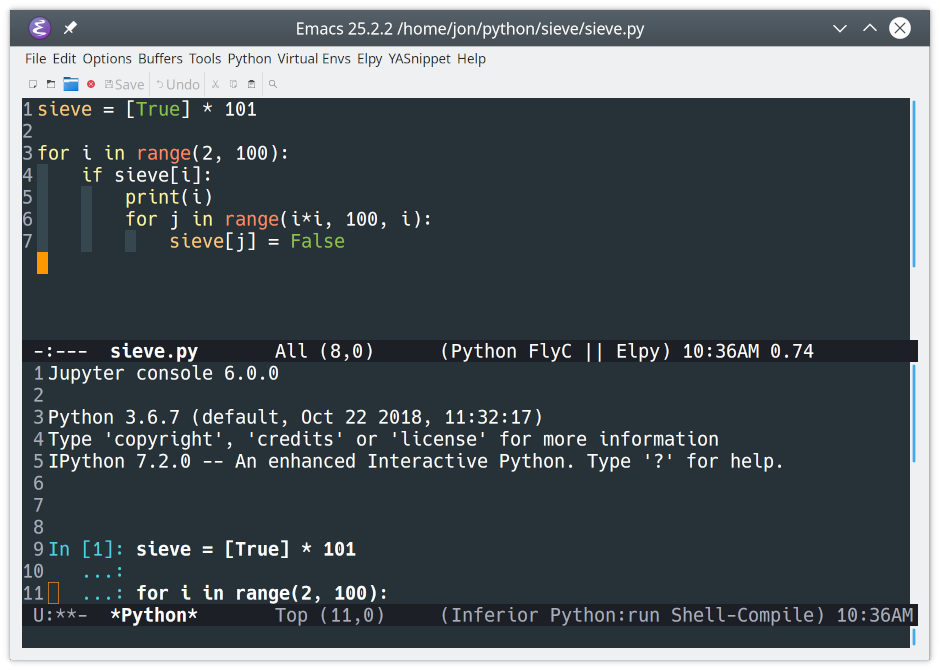
虽然这本身非常有用,但真正的魔力在于 Jupyter 笔记本的集成。和往常一样,您需要添加一些配置来实现所有功能。 ein 包启用 Emacs 中的 IPython 笔记本客户端。您可以像这样将其添加到您的init.el中:
23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 elpy ;; Emacs Lisp Python Environment 26 flycheck ;; On the fly syntax checking 27 py-autopep8 ;; Run autopep8 on save 28 blacken ;; Black formatting on save 29 ein ;; Emacs IPython Notebook 30 material-theme ;; Theme 31 ) 32 )
您现在可以启动 Jupyter 服务器,并在 Emacs 中使用笔记本电脑。
要启动服务器,使用命令 Alt + X ein:jupyter-server-start。然后提供一个运行服务器的文件夹。您将看到一个新的缓冲区,显示所选文件夹中可用的 Jupyter 笔记本:
在这里,您可以通过点击新建笔记本来创建一个具有选定内核的新笔记本,或者通过点击打开来打开底部列表中的现有笔记本:
你可以通过键入Ctrl+X``Ctrl+F,然后键入Ctrl+C``Ctrl+Z来完成完全相同的任务。这将直接在 Emacs 中以文件形式打开 Jupyter 笔记本。
打开笔记本后,您可以:
- 使用箭头键在笔记本单元格中移动
- 使用
Ctrl+A在当前单元格上方添加一个新单元格 - 使用
Ctrl+B在当前单元格下方添加一个新单元格 - 使用
Ctrl++C``Ctrl+C或Alt+Enter执行新单元格
以下是如何在笔记本上移动、添加新单元格并执行它的示例:
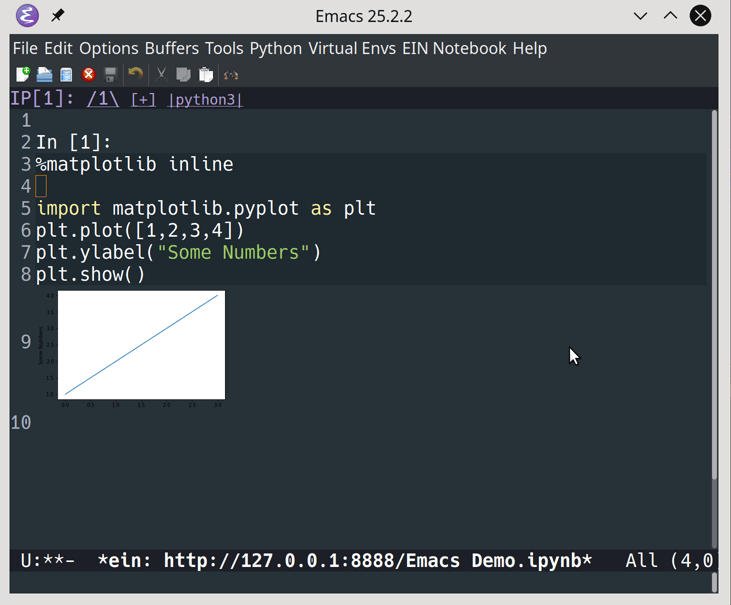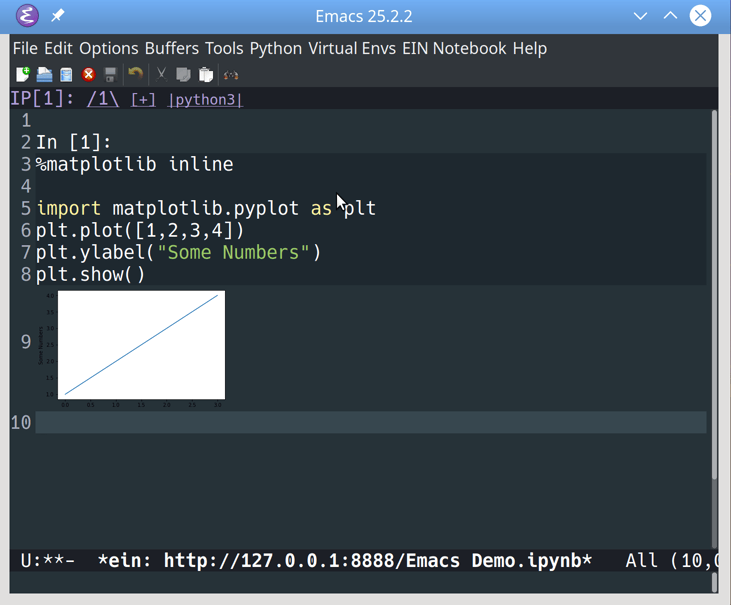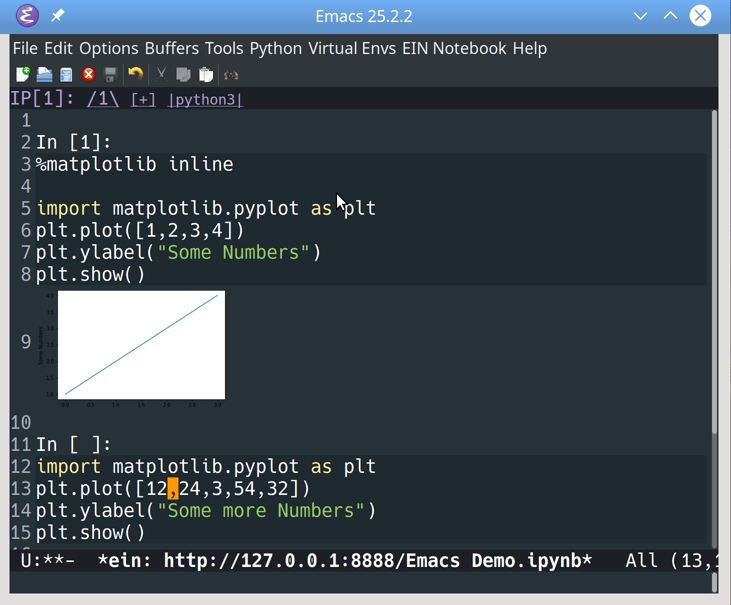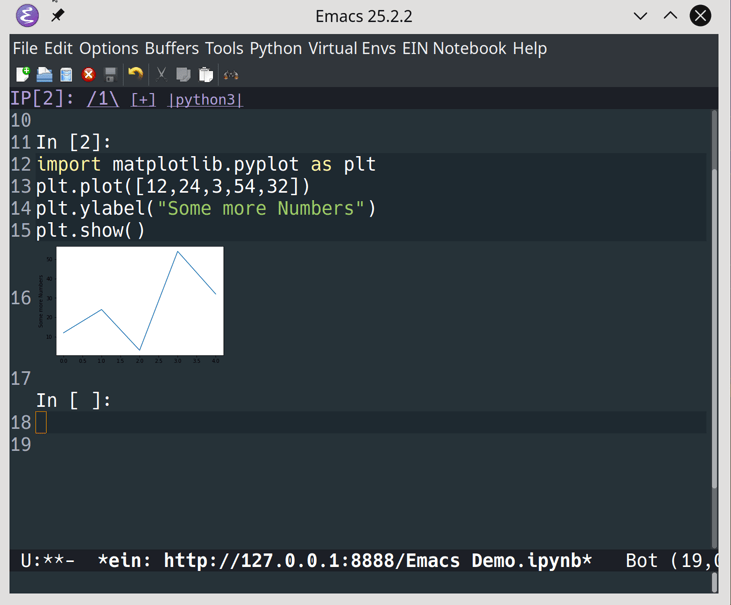
您可以使用Ctrl+X``Ctrl+S保存您的工作。
当您完成笔记本中的工作后,您可以使用Ctrl+C``Ctrl+Shift+3关闭笔记本。点击Alt+X``ein:jupyter-server-stop可以完全停止 Jupyter 服务器。Emacs 会问你是否要杀死服务器,关闭所有打开的笔记本。
当然,这只是 Jupyter 的冰山一角!你可以在文档中探索ein包能做的一切。
测试支架
你能写出完美的代码,没有副作用,并且在任何情况下都运行良好吗?当然…不是!如果这听起来像你,那么你可以跳过一点。但是对于大多数开发人员来说,测试代码是一项要求。
elpy为运行测试提供广泛的支持,包括支持:
为了展示测试能力,本教程的代码包括 Edsger Dijkstra 的调车场算法的一个版本。该算法解析使用中缀符号编写的数学方程。您可以从下面的链接下载代码:
下载代码: 单击此处下载代码,您将在本教程中使用来了解用于 Python 的 Emacs。
首先,让我们通过查看项目文件夹来更全面地了解项目。您可以使用Ctrl+X``D在 Emacs 中打开文件夹。接下来,您将通过使用Ctrl+X``3垂直拆分框架,在同一框架中显示两个窗口。最后,您导航到左侧窗口中的测试文件,并单击它以在右侧窗口中打开它:
测试文件expr_test.py是一个基本的unittest文件,它包含一个包含六个测试的测试用例。要运行测试用例,键入Ctrl+C``Ctrl+T:
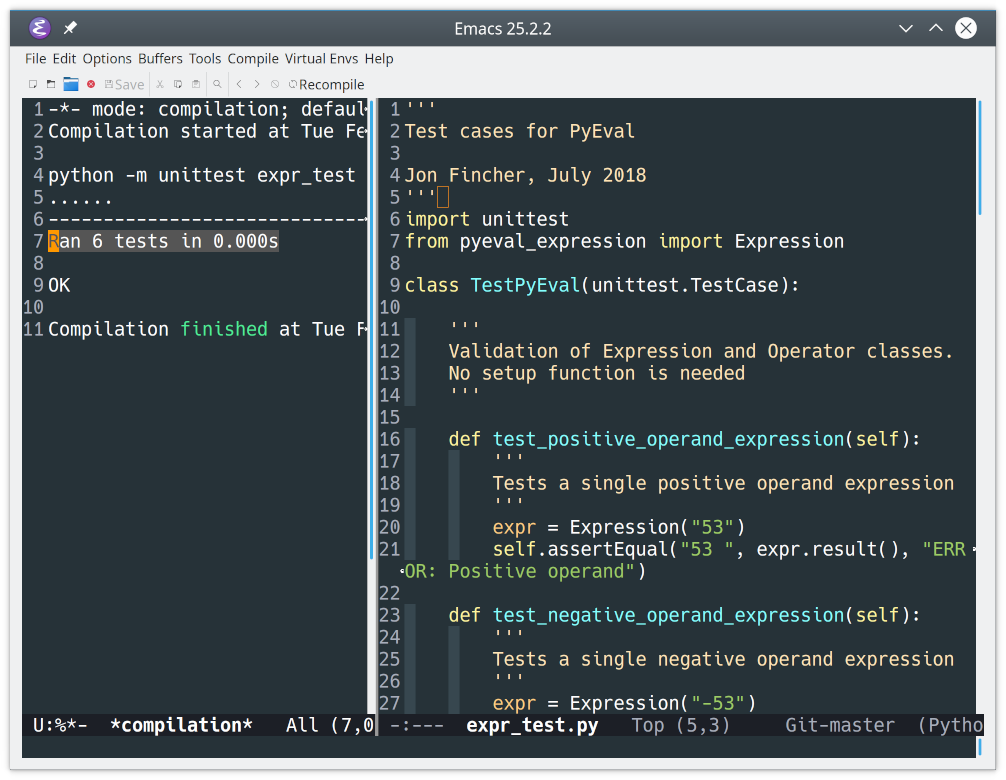
结果显示在左侧窗口中。请注意所有六个测试是如何运行的。在键入Ctrl+C``Ctrl+T之前,您可以将光标放在测试文件中运行单个测试。
调试支持
当测试失败时,您需要钻研代码来找出原因。内置的 python 模式允许你使用 Emacs 通过pdb进行 python 代码调试。关于pdb的介绍,请查看用 Pdb 进行 Python 调试。
下面是如何在 Emacs 中使用pdb:
- 打开 PyEval 项目中的
debug-example.py文件。 - 键入
Alt+Xpdb启动 Python 调试器。 - 键入
debug-example.pyEnter在调试器下运行文件。
一旦运行,pdb将水平分割框架,并在您正在调试的文件上方的窗口中打开它自己:
Emacs 中的所有调试器都作为 大统一调试器库 的一部分运行,也称为 GUD。这个库为调试所有支持的语言提供了一致的接口。创建的缓冲区名称 gud-debug-example.py ,显示调试窗口是由 gud 创建的。
GUD 还将pdb连接到底部窗口中的实际源文件,该文件跟踪您的当前位置。让我们浏览一下这段代码,看看它是如何工作的:
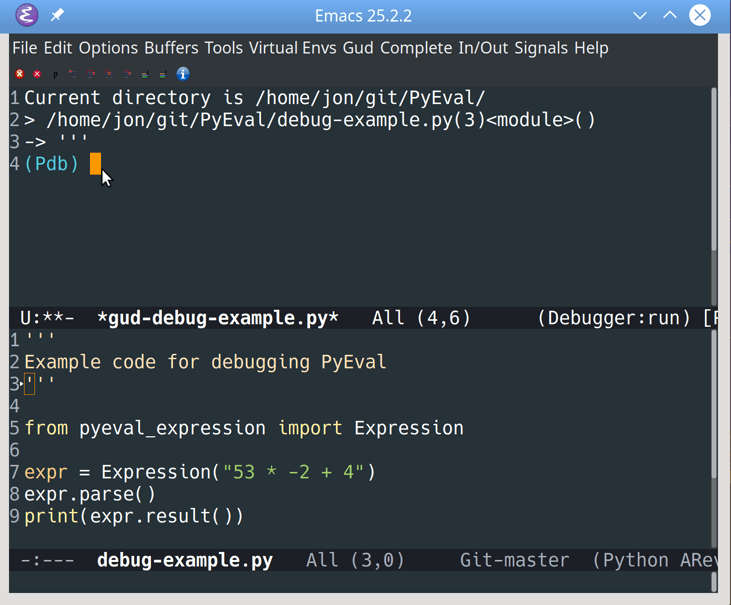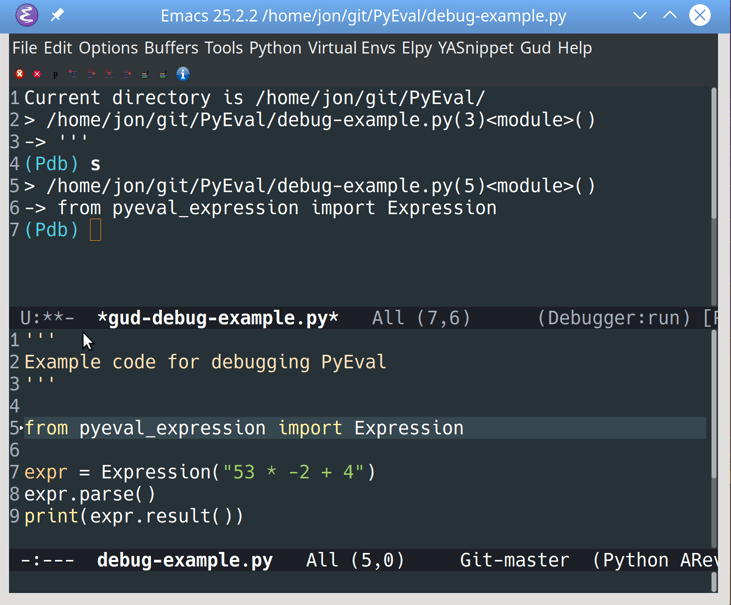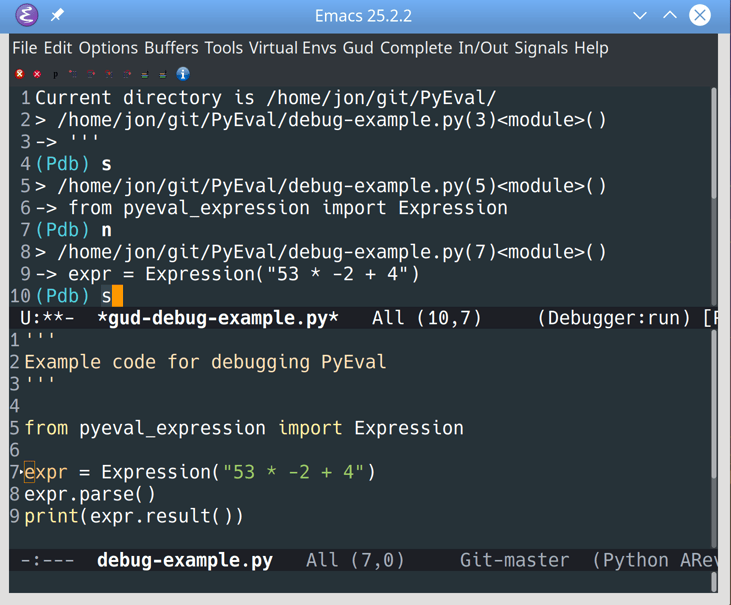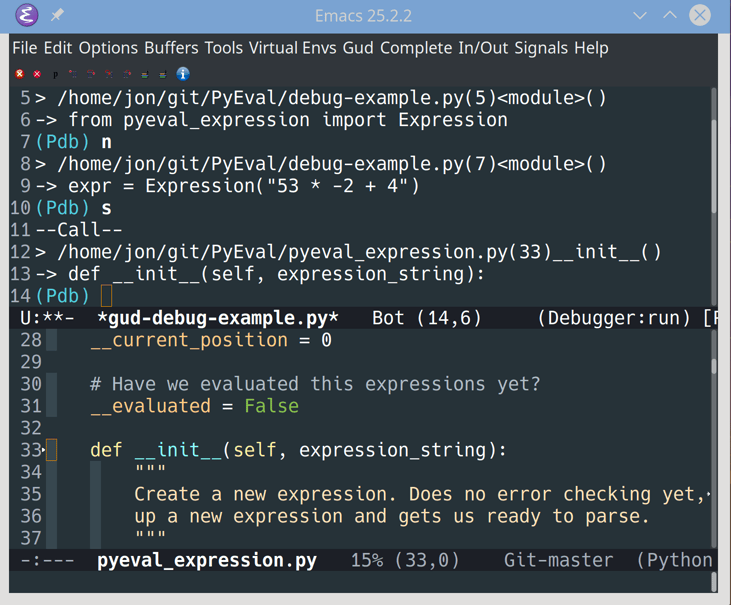
您可以使用两个键中的一个来单步调试pdb中的代码:
S步骤进入其他功能。N步骤结束其他功能。
您将看到光标在下面的源代码窗口中移动,以跟踪执行点。当您执行函数调用时,pdb会根据需要打开本地文件以保持前进。
Git 支持
没有对源代码控制的支持,任何现代的 IDE 都是不完整的。虽然存在许多源代码控制选项,但可以肯定的是大多数程序员都在使用 Git 。如果你没有使用源代码控制,或者需要学习更多关于 Git 的知识,那么请查看为 Python 开发者提供的 Git 和 GitHub 介绍。
在 Emacs 中,源代码控制支持由 magit 包提供。通过在您的init.el文件中列出来安装magit:
23(defvar myPackages 24 '(better-defaults ;; Set up some better Emacs defaults 25 elpy ;; Emacs Lisp Python Environment 26 ein ;; Emacs iPython Notebook 27 flycheck ;; On the fly syntax checking 28 py-autopep8 ;; Run autopep8 on save 29 blacken ;; Black formatting on save 30 magit ;; Git integration 31 material-theme ;; Theme 32 ) 33 )
重启 Emacs 后,magit就可以使用了。
让我们看一个例子。打开PyEval文件夹中的任意文件,然后输入 Alt + X magit-status。您将看到以下内容:
激活后,magit分割 Emacs 帧,并在下方窗口显示其状态缓冲区。此快照列出了 repo 文件夹中已转移、未转移、未跟踪的文件以及任何其他文件。
你与magit的大部分交互都在这个状态缓冲区中。例如,您可以:
- 使用
P和N在状态缓冲区的各部分之间移动 - 使用
Tab展开或折叠一个部分 - 阶段变化使用
S - 使用
U取消登台变更 - 使用
G刷新状态缓冲区的内容
一旦一个变更开始实施,您就可以使用 C 来提交它。您将看到各种提交变化。对于正常提交,再次点击 C 。您将看到两个新的缓冲区出现:
- 下面的窗口包含 COMMIT_EDITMSG 缓冲区,这是您添加提交消息的地方。
- 上面的窗口包含 magit-diff 缓冲区,显示您正在提交的更改。
输入提交消息后,键入Ctrl+C``Ctrl+C提交更改:
您可能已经注意到状态缓冲区的顶部显示了头(本地)和合并(远程)分支。这允许您快速地将您的更改推送到远程分支。
查看未合并到原点/主下的状态缓冲区,找到您想要推送的更改。然后,点击 Shift + P 打开推送选项,点击 P 推送修改:
开箱即用,magit将与 GitHub 和 GitLab 以及许多其他源代码控制工具对话。关于magit及其功能的更多信息,请查看的完整文档。
附加 Emacs 模式
在特定于 Python 的 IDE 上使用 Emacs 的主要好处之一是能够使用其他语言。作为一名开发人员,您可能需要在一天之内处理 Python、Golang、JavaScript、Markdown、JSON、shell 脚本等等。在一个代码编辑器中对所有这些语言提供复杂而完整的支持将会提高您的效率。
有大量的示例 Emacs 初始化文件可供您查看并用来构建自己的配置。最好的来源之一是 GitHub。在 GitHub 上搜索 emacs.d 会出现大量选项供你筛选。
替代品
当然,Emacs 只是 Python 开发人员可以使用的几种编辑器之一。如果您对替代产品感兴趣,请查看:
- 为全栈 Python 开发设置 Sublime Text 3
- Thonny:初学者友好的 Python 编辑器
- Python 开发中的 Visual Studio 代码
- VIM 和 Python——天作之合
- PyCharm for Production Python 开发(指南)
结论
作为功能最丰富的编辑器之一,Emacs 非常适合 Python 程序员。Emacs 可在各种主流平台上使用,可定制性极强,可适应许多不同的任务。
现在您可以:
- 在您选择的平台上安装 Emacs
- 设置 Emacs 初始化文件来配置 Emacs
- 为 Emacs 构建基本的 Python 配置
- 编写 Python 代码来探索 Emacs 的功能
- 在 Emacs 环境中运行和测试 Python 代码
- 使用集成的 Emacs 工具调试 Python 代码
- 使用 Git 添加源代码控制功能
在您的下一个 Python 项目中尝试 Emacs 吧!您可以从下面的链接下载本教程中引用的所有文件:
下载代码: 单击此处下载代码,您将在本教程中使用来了解用于 Python 的 Emacs。**********
嵌入式 Python:在 BBC micro 上构建游戏:bit
编写在终端或网络浏览器中运行的代码很有趣。然而,编写影响现实世界的代码在另一个层面上是令人满意的。编写这种代码被称为嵌入式开发,Python 使得它比以往任何时候都更容易访问!
在本教程中,您将学习:
- 什么是嵌入式开发以及为什么你会使用 Python 来做这件事
- 在嵌入式系统上运行 Python,你的硬件和软件选项分别是什么
- 什么时候 Python 适合嵌入式系统,什么时候不适合
- 如何用 MicroPython 在 BBC micro:bit 上写一个基础游戏
本教程包含代码片段,允许你在 BBC micro:bit 上构建一个简单的游戏。要访问完整代码并预览您将要构建的内容,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习使用 Python 进行嵌入式开发。
什么是嵌入式开发?
嵌入式开发是为任何非通用计算机的设备编写代码。这个定义有点模糊,所以一些例子可能会有帮助:
- 通用计算机包括笔记本电脑、台式电脑、智能手机等等。
- 嵌入式系统包括洗衣机、数码机、机器人等等。
一般来说,如果你不把某个东西叫做计算机,但是它仍然有代码在上面运行,那么它很可能是一个嵌入式系统。这个名字来自于将一台计算机嵌入到一个物理系统中来执行一些任务的想法。
嵌入式系统往往被设计为执行单一任务,这就是为什么我们将普通计算机称为“通用计算机”:它们被设计为执行多项任务。
就像你需要一台计算机来运行常规代码一样,要运行嵌入式代码,你需要某种硬件。这些硬件通常被称为开发板,本教程将向您介绍一些用于运行 Python 的开发板。
用于嵌入式开发的 python
学习 Python 最大的好处之一就是它适用于很多地方。您可以编写在任何地方运行的代码,甚至可以在嵌入式系统上运行。在本节中,您将了解在嵌入式项目中使用 Python 的利弊,以及开始时需要注意的一些事情。
使用 Python 的好处
Python 在构建嵌入式系统时带来的核心好处是开发速度。Python 有可用于大多数任务的库,这对于它的嵌入式实现来说仍然是正确的。您可以专注于构建您的系统,因为您遇到的许多问题已经解决了。
因为 Python 比其他常见的嵌入式语言更高级,所以你将编写的代码会更简洁。这有助于提高开发速度,意味着您可以更快地编写代码,但也有助于让您的代码易于理解。
Python 是内存管理的。嵌入式开发的常见选择 C++,却不是。在 C++中,你负责在用完内存后释放内存,这是很容易忘记的事情,会导致你的程序耗尽内存。Python 会帮你做到这一点。
使用 Python 的缺点
虽然 Python 的内存管理很有帮助,但它确实会导致较小的速度和内存开销。MicroPython 文档对内存问题进行了很好的讨论。
另外要考虑的是 Python 解释器本身占用空间。使用编译语言,程序的大小仅仅取决于你的程序,但是 Python 程序需要运行它们的解释器。Python 解释器也占用 RAM。在 micro:bit 上,你不能用 Python 写蓝牙代码,因为没有足够的空间同时容纳 Python 和蓝牙。
因为 Python 是被解释的,所以它永远不可能像编译语言一样快。解释语言在运行之前需要解码每条指令,但是编译语言可以直接运行。然而在实践中,这并不重要,因为 Python 程序对于大多数用例来说仍然运行得足够快。
初涉嵌入式开发时需要注意的事项
现代计算机有大量的内存可供使用。当你对它们编程时,你不必太担心你创建的列表的大小或者一次加载整个文件。然而,嵌入式系统的内存有限。当你写程序的时候,你必须小心,不要一次在内存中有太多的东西。
同样,嵌入式系统上的处理器速度比台式电脑慢得多。处理器的速度决定了代码执行的速度,所以在嵌入式计算机上运行程序比在台式计算机上运行要花更长的时间。更重要的是考虑嵌入式代码的效率——你不希望它永远运行下去!
对嵌入式系统进行编程时,最大的变化可能是电源需求。笔记本电脑、电话和台式电脑要么插在墙上,要么有大电池。嵌入式系统通常有很小的电池,并且必须持续很长时间,有时甚至几年。你运行的每一行代码都要消耗一点点电池寿命,所有这些加起来。
以下是你开始工作时应该注意的其他一些事情:
- 如果您的设备上有网络连接,那么它可能很慢或不可靠。
- 可供选择的库要少得多。
- 嵌入式系统通常没有大量的持久存储。
嵌入式开发是一个很大的领域,新人需要学习很多东西。但是现在,请记住在嵌入式系统上编写精益代码更重要。这使得嵌入式系统非常有利于提高代码的学习效率!
运行嵌入式 Python 的硬件选项
在编写任何嵌入式代码之前,您必须选择代码将在什么硬件上运行。有大量的开发板可供选择,即使是运行 Python 的开发板。您的选择将取决于您使用它们的项目。在本节中,您将了解一些可用的选项。
BBC 微:位
BBC micro:bit 是一个为教育用途而设计的嵌入式系统。在 micro:bit 上有许多组件,包括按钮、5x5 LED 屏幕、扬声器和麦克风、加速度计和蓝牙模块。不幸的是,蓝牙模块无法与 Python 一起使用,但你仍然可以直接使用收音机。它可以在 Scratch、、JavaScript 以及最重要的 Python 中编程。
这里有一张背面的照片,展示了一些可用的酷组件:

micro:bit 在网上有很多很棒的资源可以帮助你开始并提出项目想法。
树莓派
大多数 Raspberry Pis 在技术上是单板计算机,而不是嵌入式系统,但它们仍然允许通过 GPIO 引脚访问外部硬件。该规则的一个例外是 Raspberry Pi Pico ,它是一个微控制器开发板。其他 Raspberry Pis 运行 Linux,这意味着您可以将它们用作完整的计算机,并且所有 pi 都支持 Python。
有一些不同型号的 Raspberry Pi 可用,但它们都能够运行 Python 并与电子设备一起工作。您应该选择哪种模型取决于您的项目需求。这是最新型号之一:

你可以在官方网站上找到更多关于不同型号的树莓派的信息。关于一个你可以用 Raspberry Pi 和 Python 做的项目的例子,请看在 Raspberry Pi 上用 Python 构建物理项目。
pyboard
pyboard 是一种电子开发板,设计用于运行 MicroPython。它比 micro:bit 强大得多,但没有任何额外的好处,如 micro:bit 的板载屏幕和传感器。这是 pyboard 1.0:

你可能会注意到黑板上有许多金色的圆圈。这些被称为引脚,用于将 pyboard 连接到其他电子元件。例如,如果你正在制造一辆遥控汽车,你可能会连接一些马达。
其他
有很多兼容 Python 的板和工具包,这里就不一一列举了。然而,有几个有趣的问题值得一提:
- 来自 Pycom 的 LoPy 连接到专门的物联网网络,如 LoRa 和 Sigfox 。
- 基于 ESP8266 的主板都运行 MicroPython。ESP8266 是一款支持 Wi-Fi 的廉价微控制器。它的继任者, ESP32 系列芯片也全部运行 MicroPython。
- Python 也在任天堂 DS 上运行。对于初学者来说,设置看起来有点复杂,但这个项目太有趣了,不能不提。
有许多兼容 MicroPython 的主板,超出了本教程的篇幅。你应该做一些研究,为你的项目找到合适的。一个好的起点可能是 Adafruit 的 MicroPython 商店。
编写嵌入式 Python 的软件选项
当你在电脑上安装 Python 时,你通常会安装 Python 的一个特定的实现,叫做 CPython 。Python 的实现是运行 Python 代码的程序。
您可以将 CPython 称为默认的 Python 实现,因为它是由定义语言本身的人编写的。然而,CPython 并不是 Python 的唯一实现。在这一节中,您将了解一些专门针对编写嵌入式代码的实现。
MicroPython
MicroPython 是事实上的标准嵌入式 Python 实现。它是一个 Python 3.x 实现,设计用于在微控制器上运行。它不是 100%兼容 CPython,但是非常接近。这意味着,如果您已经编写了在 Python 3.4 版本上运行的代码,那么您很有可能让它在 MicroPython 上运行。
电路表面
CircuitPython 是 MicroPython 的一个分支,支持略有不同的电路板列表,并做了一些更改,使其对初学者更加友好。在很大程度上,使用 CircuitPython 和使用 MicroPython 的体验是非常相似的。如果您的主板只支持 CircuitPython 而不支持其他实现,您可能会选择使用 circuit python。
项目:一个西蒙说游戏在 BBC 微:位
没有什么比得上实践经验,所以在这一节中,您将在 BBC micro:bit 上构建一个 Simon Says 游戏。没有也不用担心!网上有模拟器供你入门。
西蒙说是一种儿童游戏,一个人向一群人发出指令。如果他们在他们的指令前加上“西蒙说”,那么团队就必须这么做。如果他们没有先说“西蒙说”就给出了指令,那么这个小组必须忽略这个指令。为了使我们的游戏更简单,我们将只关注给出指令的部分。
游戏将按如下方式运行:
- 微:bit 会想到一个方向,并告诉玩家。
- 玩家将尝试在那个方向倾斜微型钻头。
- 如果玩家设法及时正确地倾斜微型钻头,那么他们就得一分!
- 如果玩家没有及时做出正确的倾斜,那么 micro:bit 会显示他们的分数,游戏重新开始。
在开始编码之前,您需要设置您的环境。
设置您的环境
无论您是否有实际的 micro:bit,开始编码的最快途径是使用可用的在线编辑器。对于本教程,您将使用create . with 代码编辑器。当您打开编辑器时,您将看到以下屏幕:
文本缓冲区占据了屏幕的大部分,您可以在这里输入代码。在右下角,你会看到一个播放按钮。一旦你写了代码,这将允许你运行它。
在屏幕上显示指令
你的游戏需要做的第一件事是想出一个方向并告诉玩家。为了这个游戏的目的,你可以使用三个方向:left、right和stay still。您的代码需要选择其中一个方向,并显示给玩家。这将被包裹在一个无限while循环中,这样它就可以多次运行。
注意:无限while循环在嵌入式编程中比在其他类型的编程中更常见。这是因为嵌入式系统倾向于只做一项工作,所以没有挂起系统和阻止其他程序运行的风险。
下面是您的代码可能的样子:
from microbit import *
from random import randrange
# Define left, stay still, and right
directions = ["L", "O", "R"]
# While the micro:bit is on
while True:
# Pick a random direction
direction = directions[randrange(3)]
display.show(direction)
# Sleep for a second (1000ms)
sleep(1000)
这段代码将每秒显示一个不同的随机方向。前两行导入了必要的函数:
microbit模块包含与 micro:bit 接口所需的所有代码。例如,display和accelerometer模块就在这里。microbit模块在 micro:bit 上预装了 MicroPython,因此当您在计算机上运行代码时,如果您试图导入它,可能会遇到错误。random模块允许你选择一个随机数。
在导入后,代码定义了directions列表。这包含三个代表可用方向的字符。用字符定义该列表的优点是它们可以直接显示,因为 micro:bit 屏幕一次只能显示一个字符。
while True:循环告诉 micro:bit 永远运行其中的代码。实际上,这意味着它将在 micro:bit 通电时运行。在内部,代码首先用randrange()选择一个随机方向并显示出来。之后,它睡了一秒钟。这迫使 micro:bit 在一秒钟内什么也不做,这确保了播放器有时间看到指令。
运行您的代码
现在您已经有了一些代码,您可以运行它了!谢天谢地,你不需要一个 micro:bit 来运行你的代码,因为你的编辑器自带了一个内置的模拟器。您可以通过单击右下角的 play 按钮来访问它并运行您的代码。
当您点按播放按钮时,您将在编辑器中看到以下叠层弹出式菜单:
https://player.vimeo.com/video/529426743?background=1
在它里面,你会看到一个 micro:bit,屏幕会显示方向列表中的随机字符。如果没有,那么尝试将上面的代码复制到编辑器中,然后再次单击 play 按钮。
注意:create . with code 模拟器是一个很好的资源,但是它有时会有一些问题。如果您遇到问题,以下内容可能会有所帮助:
- 有时,当您将代码粘贴到编辑器中时,它看起来像是编辑器屏幕的一半已经消失了。单击编辑器中的任意位置,让它返回。
- 如果在再次运行代码之前没有按下红色按钮来停止代码,它有时会同时运行代码的两个实例,从而导致奇怪的输出。在再次运行代码之前按下红色的停止按钮可以解决这个问题。
如果你是一个更高级的程序员,你可以使用用于代码自动完成的Device Simulator Express extension和伪 microbit 模块将 Visual Studio 代码设置为 micro:bit 开发环境。
这是您将在本教程的剩余部分遵循的一般开发流程。
可选:在物理微处理器上运行代码:bit
如果您有一个物理的 micro:bit,那么运行您的代码需要几个额外的步骤。你需要下载一个.hex文件,然后把它复制到你的 micro:bit 上。
要下载.hex文件,请在编辑器中查找以下按钮:
这将要求您将文件保存到您的计算机。保存它,然后抓住你的微:位。使用 USB 电缆将 micro:bit 连接到计算机。您应该会看到它以与 USB 驱动器相同的方式出现。
要对 micro:bit 编程,请将下载的.hex文件拖到您的 micro:bit 上。micro:bit 背面的红色 LED 应该会闪烁。一旦它停止,你的程序就被加载到设备上,并立即开始执行!
小贴士:如果你遇到困难,这里有一些小贴士可以帮到你:
- 如果你需要从头开始重新启动程序,在 micro:bit 的背面,USB 连接器旁边有一个重置按钮。
- 代码中的错误会在屏幕上滚动。如果你有耐心观察他们,他们会给你一些如何修改脚本的好线索。
你必须非常努力地打破你的微型钻头!如果出现问题,仔细检查你的代码,不要害怕尝试,即使你不确定它是否可行。
现在您已经为开发设置好了 micro:bit,您已经准备好继续进行一些编码工作了。
获取玩家输入
既然 micro:bit 可以告诉玩家该做什么,那么是时候获取玩家的输入了。为此,您将使用加速度计。加速度计是一种测量运动的设备。它可以判断 micro:bit 是否正在向特定方向移动,对于游戏来说重要的是,micro:bit 是否正在向特定方向倾斜。请看下图:
在图中,你会看到三个轴 : X、Y 和 z。这些轴就像你可能在学校的图表中看到的轴一样。X 轴代表左右运动,Y 轴代表上下运动,Z 轴代表朝向或远离你的运动。
micro:bit 上的加速度计返回这三个轴的值。因为你的游戏只关心左右倾斜,所以现在你只需要 X 轴。accelerometer.get_x()返回范围(-2000, 2000)内的值,其中-2000一直向左倾斜,2000一直向右倾斜。
您获取玩家输入的代码需要采取三个步骤:
- 读取加速度计的 X 值。
- 决定 X 值是代表向左、向右还是静止不动。
- 判断这是否是正确的前进方向。
下面是完成这些步骤的代码:
# Previous code...
while True:
# Previous code...
# Get the X-axis (left-right) tilt
acc_x = accelerometer.get_x()
# Determine direction
if acc_x < -200:
player_in = "L"
elif abs(acc_x) < 200:
player_in = "O"
elif acc_x > 200:
player_in = "R"
# Check win condition
if player_in == direction:
# Player input correctly
display.show(Image.HAPPY)
else:
display.show(Image.SAD)
sleep(1000)
这段代码有点长,因为你必须检查许多不同的条件。你要做的第一件事是用accelerometer.get_x()从加速度计获得 X 轴值。记住,这将在(-2000, 2000)范围内。
获得 X 值后,您将运行一系列检查来确定它代表哪个运动。任何方向上大于200的都被认为是倾斜的,任何小于200的都被认为是静止的。
abs()通过从加速度计值中去除负号来帮助缩短代码。这意味着范围(-200, 200)内的数字将被视为静止不动。你可能想用这个门槛来让游戏变得更有挑战性。
从玩家那里得到方向输入后,你检查它是否正确。如果方向正确,那么代码会显示一张笑脸。否则,它会显示一张悲伤的脸。然后代码休眠一秒钟,让玩家看到结果,而不会很快消失。
在模拟器中测试加速度计代码
由于加速度计是一种检测物理运动的传感器,您可能想知道如何在模拟器中与之交互。幸运的是,模拟器提供了一个虚拟加速度计,你可以用鼠标控制。
https://player.vimeo.com/video/529426412?background=1
通过单击右下角的 play 按钮,像以前一样运行代码。您将看到微:位叠加出现。覆盖图的顶部有一些选项卡,用于控制 micro:bit 的各个组件。点击标签为加速计的标签。
在该选项卡中,您将看到三个滑块,每个轴一个。您将使用 X 轴滑块来测试您的游戏。
当您向右移动滑块时,加速度计的 X 值将增加。同样,当您向左移动滑块时,X 值将减小。这相当于左右倾斜 micro:bit,让你在浏览器里玩游戏。
分与失
现在基础游戏已经就绪,是时候考虑增加点数和输掉来完成游戏了。请记住,规范中描述的行为是,当玩家失败时,micro:bit 将显示玩家到该点为止的总点数。如果玩家答对了,那么 micro:bit 不应该显示任何内容:
# Previous code...
points = 0
while True:
# Previous code...
if player_in == direction:
# Player's input is correct
points += 1
else:
display.scroll(points)
display.show(Image.SAD)
points = 0
sleep(1000)
谢天谢地,这是一个比前一步更小的变化。在while循环之外,定义一个变量 points来跟踪玩家的点数。
再往下,您已经更改了对玩家输入方向是否正确的检查。如果玩家移动了正确的方向,你将增加他们的总点数1。否则,你用display.scroll()使总点数在屏幕上滚动,显示一张悲伤的脸,并重置总点数。
您还将sleep()移动到损失代码中,因为没有显示图像来纠正它。这使得游戏稍微更具挑战性!
为了帮助你检查你的代码并巩固你所学到的,这里是游戏的完整代码:
from microbit import display, Image, accelerometer, sleep
from random import randrange
# Define left, stay still, and right
directions = ["L", "O", "R"]
points = 0
# While the micro:bit is on
while True:
# Pick a random direction
direction = directions[randrange(3)]
display.show(direction)
# Sleep for a second (1000ms)
sleep(1000)
# Get the X-axis (left-right) tilt
acc_x = accelerometer.get_x()
# Determine direction
if acc_x < -200:
player_in = "L"
elif abs(acc_x) < 200:
player_in = "O"
elif acc_x > 200:
player_in = "R"
# Check win condition
if player_in == direction:
# Player's input is correct
points += 1
else:
display.scroll(points)
display.show(Image.SAD)
points = 0
sleep(1000)
恭喜你建立了自己的游戏!您会注意到,这段代码包括注释在内仅占 30 多行,比传统嵌入式语言中的等效程序要短得多。
更进一步
现在,您已经在嵌入式系统上构建了一个完整的游戏!如果你想要一些额外的挑战,这里有一些想法:
- 合并其他加速度计轴,并将其转换为微型:位版本的 Bop It !
- 缩短玩家移动微型钻头的时间,如果他们得到正确的数字。你能做到的最短时间是多少?你认为这是为什么?
- 包括加速度计手势。开箱后,micro:bit 可以检测抖动、面朝下或面朝上,甚至是自由落体。
- 加入多人游戏功能,这样你就可以和朋友一起玩了。micro:bit 有一个无线电模块,允许 micro:bit 之间的通信。
这份清单并不确定,但应该会让你思考。如果你想出了一个很酷的延长游戏的方法,那么请在评论中分享吧!
延伸阅读
嵌入式开发是一个巨大的领域,有很多东西需要学习。如果你想学习更多关于 Python 嵌入式开发的知识,那么谢天谢地,这里有很多很棒的资源。这里有一些链接让你开始。
微:位资源
micro:bit 最大的好处之一就是它收集了大量的教育资源:
- 【microbit.org】:官微:bit 网站,有项目、课程和更多代码编辑器
- micro:bit MicroPython docs:micro:bit 上 Python 的高可读性文档
- 在 BBC 上建立一个贪吃蛇游戏微:bit :一个更复杂游戏的教程,带你慢慢完成这个过程
micro:bit 教育基金会最近发布了 Micro:bit 第二版,这将有望鼓励全新的资源浪潮。
其他运行 Python 的主板
micro:bit 并不是唯一的主板。为您的项目找到合适的解决方案绝对值得探索:
- MicroPython 板卡教程 : MicroPython 对其支持的部分板卡有一些官方教程。例如,这里有一个用于 ESP8266 的。
- 【Hackaday project tagged MicroPython】:这个网站的特色是记录人们已经建立的项目,可以给你一些灵感!
- Pycom 教程 : Pycom 制作兼容 MicroPython 的板卡,有能力连接各种网络。这些教程是了解可能性的好方法。
还有许多运行 Python 的有趣设备。你一定会找到一个适合你的项目。
结论
Python 是为嵌入式系统编写代码的绝佳选择。它使您能够更快地开发您的代码,并提供您在低级语言中找不到的安全保证。现在,您已经掌握了使用 Python 开始嵌入式开发之旅的知识,并且熟悉了一些可用的选项。
在本教程中,您学习了:
- 什么是嵌入式开发以及为什么你会使用 Python 来做这件事
- 编程嵌入式系统和通用计算机有什么区别
- 为嵌入式系统编写 Python 代码有哪些选项
- 如何用 MicroPython 在 BBC micro:bit 上写一个基础游戏
嵌入式开发是一个广阔而令人兴奋的领域,充满了有趣的发现。继续学习,一定要在下面的评论里分享你的发现!
如果您想从本教程下载代码以供离线参考,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习使用 Python 进行嵌入式开发。******
使用网络摄像头在 Python 中进行人脸检测
原文:https://realpython.com/face-detection-in-python-using-a-webcam/
本教程是 Python 中 人脸识别的后续,所以确保你已经过了第一篇帖子。
正如在第一篇文章中提到的,从检测图像中的人脸到通过网络摄像头检测视频中的人脸非常容易——这正是我们将在这篇文章中详细介绍的。
在评论区提问之前:
- 不要跳过博客文章并试图运行代码。您必须理解代码的作用,不仅要正确运行它,还要对它进行故障排除。
- 确保使用 OpenCV v2。
- 您需要一个正常工作的网络摄像头,此脚本才能正常工作。
- 查看其他评论/问题,因为您的问题可能已经得到解答。
谢谢你。
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
注意:也可以查看我们的更新教程,使用 Python 进行人脸检测。
先决条件
- OpenCV 已安装(详见之前的博文)
- 正常工作的网络摄像头
代码
让我们直接进入从这个库中取出的代码。
import cv2
import sys
cascPath = sys.argv[1]
faceCascade = cv2.CascadeClassifier(cascPath)
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags=cv2.cv.CV_HAAR_SCALE_IMAGE
)
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# Display the resulting frame
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything is done, release the capture
video_capture.release()
cv2.destroyAllWindows()
现在我们来分解一下…
import cv2
import sys
cascPath = sys.argv[1]
faceCascade = cv2.CascadeClassifier(cascPath)
这个你应该很熟悉。我们正在创建一个面部层叠,就像我们在图像示例中所做的那样。
video_capture = cv2.VideoCapture(0)
这一行将视频源设置为默认的网络摄像头,OpenCV 可以很容易地捕捉到。
注意:你也可以在这里提供一个文件名,Python 会读入视频文件。然而,你需要安装 ffmpeg ,因为 OpenCV 本身不能解码压缩视频。Ffmpeg 充当 OpenCV 的前端,理想情况下,它应该直接编译到 OpenCV 中。这并不容易做到,尤其是在 Windows 上。
while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
在这里,我们捕捉视频。read()函数从视频源读取一帧,在本例中是网络摄像头。这将返回:
- 实际视频帧读取(每个循环一帧)
- 返回代码
返回代码告诉我们是否已经用完了帧,这在我们从文件中读取时会发生。当通过网络摄像头阅读时,这并不重要,因为我们可以永远记录,所以我们会忽略它。
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags=cv2.cv.CV_HAAR_SCALE_IMAGE
)
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# Display the resulting frame
cv2.imshow('Video', frame)
同样,这段代码应该很熟悉。我们只是在捕捉的画面中寻找人脸。
if cv2.waitKey(1) & 0xFF == ord('q'):
break
我们等待按下“q”键。如果是,我们退出脚本。
# When everything is done, release the capture
video_capture.release()
cv2.destroyAllWindows()
在这里,我们只是在清理。
测试!
https://player.vimeo.com/video/100839478
所以,那是我手里拿着驾照。你可以看到这个算法同时跟踪真实的我和照片上的我。注意,我移动慢的时候,算法能跟上。但是,当我把我的手移到我的脸上时,它会混淆,把我的手腕误认为是一张脸。
就像我在上一篇文章中所说的,基于机器学习的算法很少是 100%准确的。我们还没有达到机械战警以每小时 100 英里的速度驾驶摩托车,用低质量的闭路电视摄像机追踪罪犯的阶段。
该代码逐帧搜索面部,因此需要相当大的处理能力。例如,在我用了五年的笔记本电脑上,它几乎占用了 90%的 CPU。
接下来的步骤
好吧,你知道如何识别人脸。但是,如果你想检测你自己的物体,比如你的汽车、电视或你最喜欢的玩具呢?
OpenCV 允许你创建自己的级联,但是这个过程并没有很好的记录。这里有一篇博客文章,向你展示如何训练你自己的级联来探测香蕉。
如果你想更进一步,识别每个人的脸——也许是在许多陌生人中发现和识别你的脸——这个任务是惊人的困难。这主要是由于涉及大量的图像预处理。但是,如果你愿意解决这个挑战,通过使用机器学习算法是可能的,如这里描述的。
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
想了解更多?
在我接下来的课程中,将会更详细地介绍这一点,以及许多计算科学和机器学习的主题。该课程基于一个非常成功的 Kickstarter。
Kickstarter 已经结束,但你仍然可以在 Python for Engineers 上订购课程。请访问了解更多信息。
此外,请在下面张贴您的视频链接,以获得我的直接反馈。有问题就评论。
哦——下次我们将讨论一些运动检测。敬请期待!**
用 Python 实现人脸识别,不到 25 行代码
在这篇文章中,我们将看看一种令人惊讶的简单方法,使用 Python 和开源库 OpenCV 开始面部识别。
在评论区提问之前:
- 不要跳过这篇文章,只尝试运行代码。您必须了解代码的作用,不仅要正确运行它,还要对它进行故障排除。
- 确保使用 OpenCV v2。
- 有一个工作的网络摄像头,使这个脚本可以正常工作。
- 回顾其他的评论和问题,因为你的问题可能已经被解决了。
谢谢你。
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
注意:也可以查看我们的更新教程,使用 Python 进行人脸检测。
OpenCV
OpenCV 是最流行的计算机视觉库。最初用 C/C++编写,现在为 Python 提供绑定。
OpenCV 使用机器学习算法来搜索图片中的人脸。因为人脸是如此复杂,没有一个简单的测试可以告诉你它是否找到了人脸。相反,有成千上万的小图案和特征必须匹配。这些算法将识别人脸的任务分解成数千个更小的任务,每个任务都很容易解决。这些任务也被称为分类器。
对于像人脸这样的东西,你可能有 6000 个或更多的分类器,所有这些分类器都必须匹配才能检测到人脸(当然是在误差范围内)。但问题就在这里:对于人脸检测,算法从图片的左上角开始,向下移动穿过小块数据,查看每个块,不断地问:“这是一张脸吗?…这是脸吗?……这是脸吗?”由于每个程序块有 6000 次或更多的测试,你可能有数百万次的计算要做,这将使你的计算机陷入停顿。
为了解决这个问题,OpenCV 使用了级联。什么是级联?最佳答案可以在词典中找到:“一个瀑布或一系列瀑布。”
像一系列瀑布一样,OpenCV cascade 将检测人脸的问题分成多个阶段。对于每一块,它都做一个非常粗略和快速的测试。如果通过,它会做一个稍微详细一点的测试,以此类推。该算法可能有 30 到 50 个这样的阶段或级联,如果所有阶段都通过,它将只检测一个面部。
优势在于,图片的大部分在最初几个阶段将返回否定的结果,这意味着该算法不会浪费时间测试它的所有 6000 个特征。人脸检测现在可以实时完成,而不是几个小时。
实践中的级联
虽然这个理论听起来很复杂,但实际上很容易。级联本身只是一堆包含用于检测对象的 OpenCV 数据的 XML 文件。你用你想要的级联初始化你的代码,然后它为你工作。
由于人脸检测是如此常见的情况,OpenCV 带有许多内置级联,用于检测从人脸到眼睛到手到腿的一切。甚至还有针对非人类事物的级联。例如,如果你开了一家香蕉店,想要追踪偷香蕉的人,这个家伙已经为此建了一个!
安装 OpenCV
首先,你需要为你的操作系统找到正确的安装文件。
我发现安装 OpenCV 是这项任务中最难的部分。如果您得到奇怪的无法解释的错误,这可能是由于库冲突、32/64 位差异等等。我发现最简单的方法就是使用 Linux 虚拟机,从头开始安装 OpenCV。
完成安装后,您可以通过启动 Python 会话并键入以下命令来测试它是否工作:
>>> import cv2
如果你没有得到任何错误,你可以进入下一部分。
## 理解代码
让我们分解实际的代码,您可以从 [repo](https://github.com/shantnu/FaceDetect/) 下载。抓取 **face_detect.py** 脚本、**abba.png**pic、**Haar scade _ frontal face _ default . XML**。
```py
# Get user supplied values
imagePath = sys.argv[1]
cascPath = sys.argv[2]
首先将图像和层叠名称作为命令行参数传入。我们将使用 ABBA 图像以及 OpenCV 提供的默认级联来检测人脸。
# Create the haar cascade
faceCascade = cv2.CascadeClassifier(cascPath)
现在我们创建层叠,并用我们的面部层叠初始化它。这会将面层叠加载到内存中,以便随时使用。请记住,级联只是一个 XML 文件,其中包含用于检测人脸的数据。
# Read the image
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
在这里,我们读取图像并将其转换为灰度。OpenCV 中的很多操作都是在灰度中完成的。
# Detect faces in the image
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags = cv2.cv.CV_HAAR_SCALE_IMAGE
)
这个函数检测实际的人脸,并且是我们代码的关键部分,所以让我们来看一下选项:
-
detectMultiScale函数是检测物体的通用函数。因为我们在 face cascade 上调用它,所以它检测的就是这个。 -
第一个选项是灰度图像。
-
第二个是
scaleFactor。因为有些脸可能离镜头更近,所以看起来会比后面的脸大。比例因子对此进行了补偿。 -
检测算法使用移动窗口来检测对象。
minNeighbors定义在当前物体附近检测到多少个物体后,它才宣布找到人脸。同时,minSize给出了每个窗口的大小。
注:我取了这些字段的常用值。在现实生活中,您可以尝试不同的窗口大小、比例因子等值,直到找到最适合您的值。
该函数返回它认为找到人脸的矩形列表。接下来,我们将在它认为找到了什么的地方循环。
print "Found {0} faces!".format(len(faces))
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
该函数返回 4 个值:矩形的x和y位置,以及矩形的宽度和高度(w、h)。
我们使用这些值通过内置的rectangle()函数绘制一个矩形。
cv2.imshow("Faces found", image)
cv2.waitKey(0)
最后,我们显示图像并等待用户按键。
检查结果
让我们对照 ABBA 照片进行测试:
$ python face_detect.py abba.png haarcascade_frontalface_default.xml
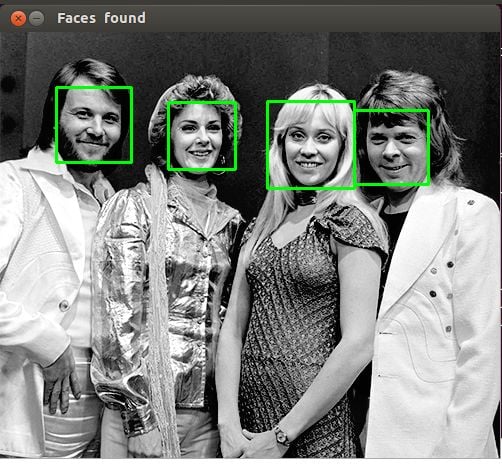
奏效了。另一张照片怎么样:
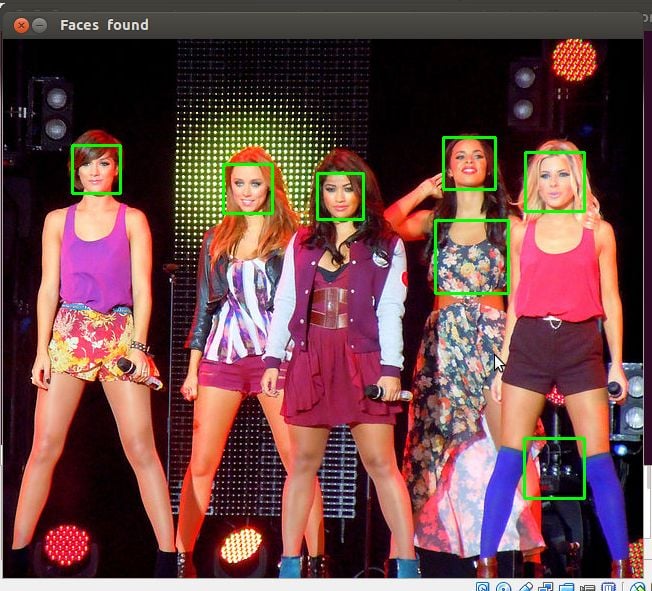
那…不是一张脸。让我们再试一次。我改变了参数,发现设置scaleFactor为 1.2 去掉了错误的脸。
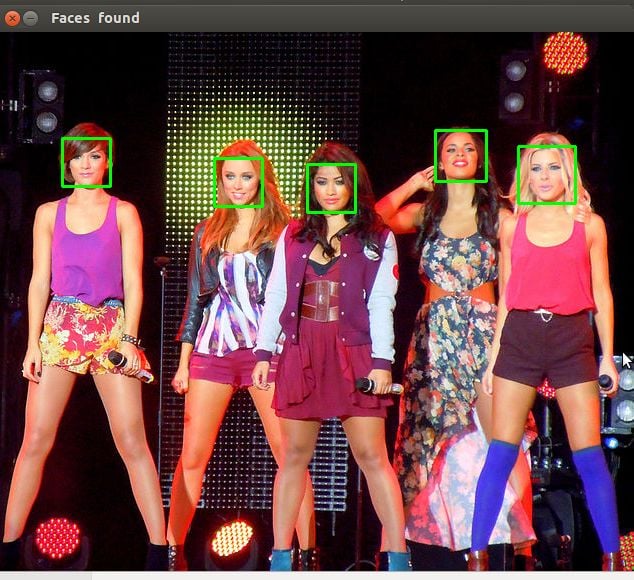
发生了什么事?
嗯,第一张照片是用高质量相机近距离拍摄的。第二张似乎是从远处拍的,可能是用手机拍的。这就是为什么scaleFactor必须被修改的原因。正如我所说的,你必须根据具体情况设置算法,以避免误报。
不过要注意的是,由于这是基于机器学习的,结果永远不会 100%准确。在大多数情况下,您会获得足够好的结果,但偶尔该算法会将不正确的对象识别为面部。
最终代码可以在这里找到。
扩展到网络摄像头
如果你想使用网络摄像头呢?OpenCV 从网络摄像头抓取每一帧,然后您可以通过处理每一帧来检测人脸。你需要一台功能强大的电脑,但我这台用了五年的笔记本电脑似乎也能应付自如,只要我不跳来跳去。
更新:下篇直播。使用网络摄像头查看 Python 中的人脸检测!
想了解更多?
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
我将在我即将出版的《科学与工程的 Python》一书中涉及这一点以及更多,这本书目前正在 Kickstarter 上。对于那些对机器学习感兴趣的人,我还会介绍机器学习。
谢谢!**
工厂方法模式及其在 Python 中的实现
本文探索工厂方法设计模式及其在 Python 中的实现。在所谓的四人组(GoF: Gamma、Helm、Johson 和 Vlissides)出版了他们的书Design Patterns:Elements of Reusable Object-Oriented Software之后,设计模式在 90 年代后期成为了一个热门话题。
这本书将设计模式描述为解决软件中反复出现的问题的核心设计方案,并根据问题的性质将每个设计模式分为类。每个模式都有一个名称、一个问题描述、一个设计解决方案,以及对使用它的后果的解释。
GoF 书将工厂方法描述为一种创造性的设计模式。创建性设计模式与对象的创建相关,工厂方法是一种使用公共接口创建对象的设计模式。
这是一个反复出现的问题使得工厂方法成为最广泛使用的设计模式之一,理解它并知道如何应用它是非常重要的。
本文结束时,您将:
- 理解工厂方法的组成部分
- 识别在应用程序中使用工厂方法的机会
- 学习使用该模式修改现有代码并改进其设计
- 学会识别工厂方法是合适的设计模式的机会
- 选择适当的工厂方法实现
- 知道如何实现工厂方法的可重用、通用的解决方案
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
介绍工厂方法
工厂方法是一种创造性的设计模式,用于创建公共接口的具体实现。
它将创建对象的过程与依赖于对象接口的代码分开。
例如,应用程序需要一个具有特定接口的对象来执行其任务。接口的具体实现由一些参数来标识。
应用程序没有使用复杂的if/elif/else条件结构来决定具体的实现,而是将这个决定委托给一个创建具体对象的独立组件。使用这种方法,应用程序代码得到了简化,使其更易于重用和维护。
假设一个应用程序需要使用指定的格式将一个Song对象转换成它的 string 表示。将对象转换为不同的表示形式通常称为序列化。您经常会看到这些需求在包含所有逻辑和实现的单个函数或方法中实现,如下面的代码所示:
# In serializer_demo.py
import json
import xml.etree.ElementTree as et
class Song:
def __init__(self, song_id, title, artist):
self.song_id = song_id
self.title = title
self.artist = artist
class SongSerializer:
def serialize(self, song, format):
if format == 'JSON':
song_info = {
'id': song.song_id,
'title': song.title,
'artist': song.artist
}
return json.dumps(song_info)
elif format == 'XML':
song_info = et.Element('song', attrib={'id': song.song_id})
title = et.SubElement(song_info, 'title')
title.text = song.title
artist = et.SubElement(song_info, 'artist')
artist.text = song.artist
return et.tostring(song_info, encoding='unicode')
else:
raise ValueError(format)
在上面的例子中,有一个基本的Song类来表示一首歌,还有一个SongSerializer类可以根据format参数的值将song对象转换成它的string表示。
.serialize()方法支持两种不同的格式: JSON 和 XML 。任何其他指定的format都不被支持,因此会引发一个ValueError异常。
让我们使用 Python 交互式 shell 来看看代码是如何工作的:
>>> import serializer_demo as sd >>> song = sd.Song('1', 'Water of Love', 'Dire Straits') >>> serializer = sd.SongSerializer() >>> serializer.serialize(song, 'JSON') '{"id": "1", "title": "Water of Love", "artist": "Dire Straits"}' >>> serializer.serialize(song, 'XML') '<song id="1"><title>Water of Love</title><artist>Dire Straits</artist></song>' >>> serializer.serialize(song, 'YAML') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "./serializer_demo.py", line 30, in serialize raise ValueError(format) ValueError: YAML您创建了一个
song对象和一个serializer,并通过使用.serialize()方法将歌曲转换成它的字符串表示。该方法将song对象作为参数,以及一个表示所需格式的字符串值。最后一个调用使用YAML作为格式,serializer不支持,因此引发了ValueError异常。这个例子简短而简化,但是仍然很复杂。根据
format参数的值,有三种逻辑或执行路径。这看起来没什么大不了的,你可能见过比这更复杂的代码,但是上面的例子仍然很难维护。复杂条件代码的问题
上面的例子展示了你会在复杂的逻辑代码中发现的所有问题。复杂的逻辑代码使用
if/elif/else结构来改变应用程序的行为。使用if/elif/else条件结构使得代码更难阅读、理解和维护。上面的代码可能看起来不难阅读或理解,但是请等到您看到本节中的最终代码!
然而,上面的代码很难维护,因为它做的太多了。单一责任原则声明一个模块,一个类,甚至一个方法应该有一个单一的、定义明确的责任。它应该只做一件事,并且只有一个改变的理由。
由于许多不同的原因,
SongSerializer中的.serialize()方法将需要更改。这增加了引入新缺陷或破坏现有功能的风险。让我们看一下需要修改实施的所有情况:
当一种新的格式被引入时:方法将不得不改变以实现对该格式的序列化。
当
Song对象改变时:向Song类添加或移除属性将需要实现改变以适应新的结构。当格式的字符串表示发生变化时(普通的JSONvsJSON API):如果格式所需的字符串表示发生变化,那么
.serialize()方法也必须发生变化,因为该表示在.serialize()方法实现中是硬编码的。理想的情况是,在不改变
.serialize()方法的情况下,可以实现需求中的任何变化。让我们在接下来的几节中看看如何做到这一点。寻找通用接口
当您在应用程序中看到复杂的条件代码时,第一步是确定每个执行路径(或逻辑路径)的共同目标。
使用
if/elif/else的代码通常有一个共同的目标,在每个逻辑路径中以不同的方式实现。上面的代码在每个逻辑路径中使用不同的格式将一个song对象转换成它的string表示。基于这个目标,你寻找一个公共接口来替换每一条路径。上面的例子需要一个接口,它接受一个
song对象并返回一个string。一旦有了公共接口,就可以为每个逻辑路径提供单独的实现。在上面的例子中,您将提供一个序列化为 JSON 的实现和另一个序列化为 XML 的实现。
然后,您提供一个单独的组件,它根据指定的
format决定要使用的具体实现。该组件评估format的值,并返回由其值标识的具体实现。在下面几节中,您将学习如何在不改变行为的情况下对现有代码进行更改。这被称为重构代码。
Martin Fowler 在他的书Refactoring:Improving the Design of Existing Code中将重构定义为“以不改变代码的外部行为但改善其内部结构的方式改变软件系统的过程。”如果你想看看重构的实际操作,看看真正的 Python 代码对话重构:准备你的代码以获得帮助。
让我们开始重构代码,以获得使用工厂方法设计模式的所需结构。
将代码重构为所需的界面
所需的接口是一个对象或函数,它接受一个
Song对象并返回一个string表示。第一步是将其中一个逻辑路径重构到这个接口中。您可以通过添加一个新方法
._serialize_to_json()并将 JSON 序列化代码移动到其中来实现这一点。然后,您更改客户端来调用它,而不是在if语句的主体中实现它:class SongSerializer: def serialize(self, song, format): if format == 'JSON': return self._serialize_to_json(song) # The rest of the code remains the same def _serialize_to_json(self, song): payload = { 'id': song.song_id, 'title': song.title, 'artist': song.artist } return json.dumps(payload)一旦进行了这种更改,您就可以验证行为是否没有改变。然后,对 XML 选项做同样的事情,引入一个新方法
._serialize_to_xml(),将实现移到它上面,并修改elif路径来调用它。以下示例显示了重构后的代码:
class SongSerializer: def serialize(self, song, format): if format == 'JSON': return self._serialize_to_json(song) elif format == 'XML': return self._serialize_to_xml(song) else: raise ValueError(format) def _serialize_to_json(self, song): payload = { 'id': song.song_id, 'title': song.title, 'artist': song.artist } return json.dumps(payload) def _serialize_to_xml(self, song): song_element = et.Element('song', attrib={'id': song.song_id}) title = et.SubElement(song_element, 'title') title.text = song.title artist = et.SubElement(song_element, 'artist') artist.text = song.artist return et.tostring(song_element, encoding='unicode')新版本的代码更容易阅读和理解,但仍然可以通过工厂方法的基本实现进行改进。
工厂方法的基本实现
工厂方法的中心思想是提供一个独立的组件,负责根据一些指定的参数来决定应该使用哪个具体的实现。我们示例中的参数是
format。为了完成工厂方法的实现,您添加了一个新方法
._get_serializer(),它采用了所需的format。该方法计算format的值,并返回匹配的序列化函数:class SongSerializer: def _get_serializer(self, format): if format == 'JSON': return self._serialize_to_json elif format == 'XML': return self._serialize_to_xml else: raise ValueError(format)注意:
._get_serializer()方法不调用具体的实现,它只是返回函数对象本身。现在,您可以将
SongSerializer的.serialize()方法改为使用._get_serializer()来完成工厂方法实现。下一个示例显示了完整的代码:class SongSerializer: def serialize(self, song, format): serializer = self._get_serializer(format) return serializer(song) def _get_serializer(self, format): if format == 'JSON': return self._serialize_to_json elif format == 'XML': return self._serialize_to_xml else: raise ValueError(format) def _serialize_to_json(self, song): payload = { 'id': song.song_id, 'title': song.title, 'artist': song.artist } return json.dumps(payload) def _serialize_to_xml(self, song): song_element = et.Element('song', attrib={'id': song.song_id}) title = et.SubElement(song_element, 'title') title.text = song.title artist = et.SubElement(song_element, 'artist') artist.text = song.artist return et.tostring(song_element, encoding='unicode')最终的实现展示了工厂方法的不同组件。
.serialize()方法是依赖一个接口来完成其任务的应用程序代码。这被称为模式的客户端组件。定义的接口被称为产品组件。在我们的例子中,产品是一个函数,它接受一个
Song并返回一个字符串表示。
._serialize_to_json()和._serialize_to_xml()方法是产品的具体实现。最后,._get_serializer()方法是创建者组件。创建者决定使用哪个具体的实现。因为您是从一些现有代码开始的,所以 Factory Method 的所有组件都是同一个类
SongSerializer的成员。通常情况并非如此,正如您所见,添加的方法都不使用
self参数。这很好地表明它们不应该是SongSerializer类的方法,它们可以成为外部函数:class SongSerializer: def serialize(self, song, format): serializer = get_serializer(format) return serializer(song) def get_serializer(format): if format == 'JSON': return _serialize_to_json elif format == 'XML': return _serialize_to_xml else: raise ValueError(format) def _serialize_to_json(song): payload = { 'id': song.song_id, 'title': song.title, 'artist': song.artist } return json.dumps(payload) def _serialize_to_xml(song): song_element = et.Element('song', attrib={'id': song.song_id}) title = et.SubElement(song_element, 'title') title.text = song.title artist = et.SubElement(song_element, 'artist') artist.text = song.artist return et.tostring(song_element, encoding='unicode')注意:
SongSerializer中的.serialize()方法不使用self参数。上面的规则告诉我们它不应该是类的一部分。这是正确的,但是您处理的是现有的代码。
如果您删除了
SongSerializer并将.serialize()方法改为一个函数,那么您必须更改应用程序中使用SongSerializer的所有位置,并替换对新函数的调用。除非你的单元测试有很高的代码覆盖率,否则这不是你应该做的改变。
工厂方法的机制总是相同的。客户端(
SongSerializer.serialize())依赖于接口的具体实现。它使用某种标识符(format)向创建者组件(get_serializer())请求实现。创建者根据参数的值将具体实现返回给客户端,客户端使用提供的对象完成其任务。
您可以在 Python 交互式解释器中执行相同的指令集,以验证应用程序行为没有改变:
>>> import serializer_demo as sd
>>> song = sd.Song('1', 'Water of Love', 'Dire Straits')
>>> serializer = sd.SongSerializer()
>>> serializer.serialize(song, 'JSON')
'{"id": "1", "title": "Water of Love", "artist": "Dire Straits"}'
>>> serializer.serialize(song, 'XML')
'<song id="1"><title>Water of Love</title><artist>Dire Straits</artist></song>'
>>> serializer.serialize(song, 'YAML')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "./serializer_demo.py", line 13, in serialize
serializer = get_serializer(format)
File "./serializer_demo.py", line 23, in get_serializer
raise ValueError(format)
ValueError: YAML
您创建了一个song和一个serializer,并使用serializer将歌曲转换为其指定了一个format的string表示。由于 YAML 不是受支持的格式,因此引发ValueError。
识别使用工厂方法的机会
工厂方法应该用在应用程序(客户端)依赖于接口(产品)来执行任务,并且该接口有多个具体实现的每种情况下。你需要提供一个可以标识具体实现的参数,并在 creator 中使用它来决定具体的实现。
符合这种描述的问题范围很广,所以让我们看一些具体的例子。
替换复杂的逻辑代码:if/elif/else格式的复杂逻辑结构很难维护,因为随着需求的变化,需要新的逻辑路径。
工厂方法是一个很好的替代方法,因为您可以将每个逻辑路径的主体放入具有公共接口的独立函数或类中,并且创建者可以提供具体的实现。
在条件中评估的参数成为识别具体实现的参数。上面的例子代表了这种情况。
从外部数据构建相关对象:假设一个应用程序需要从数据库或其他外部来源检索员工信息。
这些记录代表不同角色或类型的雇员:经理、办公室职员、销售助理等等。应用程序可以在记录中存储一个代表雇员类型的标识符,然后使用工厂方法从记录中的其余信息创建每个具体的Employee对象。
支持同一功能的多种实现:一个图像处理应用程序需要将卫星图像从一个坐标系转换到另一个坐标系,但是有多种不同精度级别的算法来执行转换。
应用程序可以允许用户选择识别具体算法的选项。工厂方法可以提供基于该选项的算法的具体实现。
在公共接口下组合相似的特征:在图像处理示例之后,应用程序需要对图像应用滤镜。要使用的特定过滤器可以通过一些用户输入来识别,工厂方法可以提供具体的过滤器实现。
集成相关的外部服务:一个音乐播放器应用程序想要集成多个外部服务,并允许用户选择他们的音乐来自哪里。应用程序可以为音乐服务定义一个公共接口,并使用工厂方法根据用户偏好创建正确的集成。
这些情况都差不多。它们都定义了一个客户端,该客户端依赖于一个称为产品的公共接口。它们都提供了识别产品具体实现的方法,所以它们都可以在设计中使用工厂方法。
现在,您可以从前面的示例中了解序列化问题,并通过考虑工厂方法设计模式来提供更好的设计。
一个对象序列化的例子
上例的基本要求是您希望将Song对象序列化为它们的string表示。这个应用程序似乎提供了与音乐相关的特性,所以这个应用程序可能需要序列化其他类型的对象,比如Playlist或Album。
理想情况下,设计应该支持通过实现新类来为新对象添加序列化,而不需要对现有实现进行更改。应用程序需要将对象序列化为多种格式,如 JSON 和 XML,因此定义一个可以有多种实现的接口Serializer似乎是很自然的,每种格式一个实现。
接口实现可能如下所示:
# In serializers.py
import json
import xml.etree.ElementTree as et
class JsonSerializer:
def __init__(self):
self._current_object = None
def start_object(self, object_name, object_id):
self._current_object = {
'id': object_id
}
def add_property(self, name, value):
self._current_object[name] = value
def to_str(self):
return json.dumps(self._current_object)
class XmlSerializer:
def __init__(self):
self._element = None
def start_object(self, object_name, object_id):
self._element = et.Element(object_name, attrib={'id': object_id})
def add_property(self, name, value):
prop = et.SubElement(self._element, name)
prop.text = value
def to_str(self):
return et.tostring(self._element, encoding='unicode')
注意:上面的例子没有实现一个完整的Serializer接口,但是对于我们的目的和演示工厂方法来说已经足够好了。
由于 Python 语言的动态特性,Serializer接口是一个抽象的概念。像 Java 或 C#这样的静态语言要求显式定义接口。在 Python 中,任何提供所需方法或函数的对象都被称为实现了接口。该示例将Serializer接口定义为实现以下方法或函数的对象:
.start_object(object_name, object_id).add_property(name, value).to_str()
这个接口是由具体的类JsonSerializer和XmlSerializer实现的。
最初的例子使用了一个SongSerializer类。对于新的应用程序,您将实现一些更通用的东西,比如ObjectSerializer:
# In serializers.py
class ObjectSerializer:
def serialize(self, serializable, format):
serializer = factory.get_serializer(format)
serializable.serialize(serializer)
return serializer.to_str()
ObjectSerializer的实现是完全通用的,它只提到了一个serializable和一个format作为参数。
format用于标识Serializer的具体实现,由factory对象解析。serializable参数指的是另一个抽象接口,它应该在您想要序列化的任何对象类型上实现。
让我们来看看Song类中serializable接口的具体实现:
# In songs.py
class Song:
def __init__(self, song_id, title, artist):
self.song_id = song_id
self.title = title
self.artist = artist
def serialize(self, serializer):
serializer.start_object('song', self.song_id)
serializer.add_property('title', self.title)
serializer.add_property('artist', self.artist)
Song类通过提供一个.serialize(serializer)方法来实现Serializable接口。在该方法中,Song类使用serializer对象来编写自己的信息,而不需要任何格式知识。
事实上,Song类甚至不知道目标是将数据转换成字符串。这很重要,因为您可以使用这个接口来提供不同种类的serializer,如果需要的话,它可以将Song信息转换成完全不同的表示。例如,您的应用程序将来可能需要将Song对象转换成二进制格式。
到目前为止,我们已经看到了客户端(ObjectSerializer)和产品(serializer)的实现。是时候完成工厂方法的实现并提供创建者了。例子中的创建者是ObjectSerializer.serialize()中的变量 factory。
作为对象工厂的工厂方法
在最初的例子中,您将 creator 实现为一个函数。对于非常简单的例子来说,函数很好,但是当需求改变时,它们不能提供太多的灵活性。
类可以提供额外的接口来添加功能,并且可以派生它们来自定义行为。除非你有一个非常基本的将来永远不会改变的 creator,你想把它实现成一个类而不是一个函数。这些类型的类被称为对象工厂。
在ObjectSerializer.serialize()的实现中可以看到SerializerFactory的基本接口。该方法使用factory.get_serializer(format)从对象工厂中检索serializer。
您现在将实现SerializerFactory来满足这个接口:
# In serializers.py
class SerializerFactory:
def get_serializer(self, format):
if format == 'JSON':
return JsonSerializer()
elif format == 'XML':
return XmlSerializer()
else:
raise ValueError(format)
factory = SerializerFactory()
.get_serializer()的当前实现与您在原始示例中使用的相同。该方法评估format的值,并决定创建和返回的具体实现。这是一个相对简单的解决方案,允许我们验证所有工厂方法组件的功能。
让我们转到 Python 交互式解释器,看看它是如何工作的:
>>> import songs >>> import serializers >>> song = songs.Song('1', 'Water of Love', 'Dire Straits') >>> serializer = serializers.ObjectSerializer() >>> serializer.serialize(song, 'JSON') '{"id": "1", "title": "Water of Love", "artist": "Dire Straits"}' >>> serializer.serialize(song, 'XML') '<song id="1"><title>Water of Love</title><artist>Dire Straits</artist></song>' >>> serializer.serialize(song, 'YAML') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "./serializers.py", line 39, in serialize serializer = factory.get_serializer(format) File "./serializers.py", line 52, in get_serializer raise ValueError(format) ValueError: YAML工厂方法的新设计允许应用程序通过添加新的类来引入新的特性,而不是改变现有的类。您可以通过在其他对象上实现
Serializable接口来序列化它们。您可以通过在另一个类中实现Serializer接口来支持新格式。缺少的部分是
SerializerFactory必须改变以包括对新格式的支持。这个问题在新设计中很容易解决,因为SerializerFactory是一个类。支持附加格式
当引入新格式时,
SerializerFactory的当前实现需要改变。您的应用程序可能永远不需要支持任何额外的格式,但是您永远不知道。您希望您的设计是灵活的,正如您将看到的,支持额外的格式而不改变
SerializerFactory是相对容易的。想法是在
SerializerFactory中提供一个方法,为我们想要支持的格式注册一个新的Serializer实现:# In serializers.py class SerializerFactory: def __init__(self): self._creators = {} def register_format(self, format, creator): self._creators[format] = creator def get_serializer(self, format): creator = self._creators.get(format) if not creator: raise ValueError(format) return creator() factory = SerializerFactory() factory.register_format('JSON', JsonSerializer) factory.register_format('XML', XmlSerializer)
.register_format(format, creator)方法允许通过指定一个用于识别格式的format值和一个creator对象来注册新格式。creator 对象恰好是具体Serializer的类名。这是可能的,因为所有的Serializer类都提供了默认的.__init__()来初始化实例。注册信息存储在
_creators字典中。.get_serializer()方法检索注册的创建者并创建所需的对象。如果所请求的format尚未注册,则ValueError被引发。您现在可以通过实现一个
YamlSerializer来验证设计的灵活性,并去掉您之前看到的烦人的ValueError:# In yaml_serializer.py import yaml import serializers class YamlSerializer(serializers.JsonSerializer): def to_str(self): return yaml.dump(self._current_object) serializers.factory.register_format('YAML', YamlSerializer)注意:要实现这个例子,您需要使用
pip install PyYAML在您的环境中安装PyYAML。JSON 和 YAML 是非常相似的格式,所以你可以重用
JsonSerializer的大部分实现,覆盖.to_str()来完成实现。然后用factory对象注册该格式,使其可用。让我们使用 Python 交互式解释器来看看结果:
>>> import serializers
>>> import songs
>>> import yaml_serializer
>>> song = songs.Song('1', 'Water of Love', 'Dire Straits')
>>> serializer = serializers.ObjectSerializer()
>>> print(serializer.serialize(song, 'JSON'))
{"id": "1", "title": "Water of Love", "artist": "Dire Straits"}
>>> print(serializer.serialize(song, 'XML'))
<song id="1"><title>Water of Love</title><artist>Dire Straits</artist></song>
>>> print(serializer.serialize(song, 'YAML'))
{artist: Dire Straits, id: '1', title: Water of Love}
通过使用对象工厂实现工厂方法并提供注册接口,您能够支持新的格式,而无需更改任何现有的应用程序代码。这将破坏现有功能或引入细微错误的风险降至最低。
通用对象工厂
SerializerFactory的实现是对原始示例的巨大改进。它提供了很大的灵活性来支持新的格式,并避免修改现有的代码。
尽管如此,当前的实现是专门针对上面的序列化问题的,它在其他上下文中不可重用。
工厂方法可以用来解决广泛的问题。当需求改变时,对象工厂为设计提供了额外的灵活性。理想情况下,您会想要一个无需复制实现就可以在任何情况下重用的对象工厂实现。
提供对象工厂的通用实现存在一些挑战,在接下来的部分中,您将关注这些挑战并实现一个可以在任何情况下重用的解决方案。
并非所有对象都可以被创建为相同的
实现通用对象工厂的最大挑战是,并非所有对象都是以相同的方式创建的。
并非所有情况都允许我们使用默认的.__init__()来创建和初始化对象。创建者(在本例中是对象工厂)返回完全初始化的对象是很重要的。
这一点很重要,因为如果不这样做,客户机就必须完成初始化,并使用复杂的条件代码来完全初始化所提供的对象。这违背了工厂方法设计模式的目的。
为了理解通用解决方案的复杂性,让我们看一个不同的问题。假设一个应用程序想要集成不同的音乐服务。这些服务可以在应用程序外部,也可以在应用程序内部,以便支持本地音乐收藏。每种服务都有不同的需求。
注意:我为这个例子定义的需求是为了说明的目的,并不反映你将不得不实现的与像 Pandora 或 Spotify 这样的服务集成的真实需求。
目的是提供一组不同的需求,展示实现通用对象工厂的挑战。
假设应用程序想要与 Spotify 提供的服务集成。该服务需要一个授权过程,在该过程中,提供客户端密钥和秘密用于授权。
该服务返回应该在任何进一步的通信中使用的访问代码。这个授权过程非常慢,而且应该只执行一次,所以应用程序希望保留初始化的服务对象,并在每次需要与 Spotify 通信时使用它。
与此同时,其他用户希望与 Pandora 集成。潘多拉可能会使用完全不同的授权过程。它还需要一个客户端密钥和秘密,但是它返回一个应该用于其他通信的消费者密钥和秘密。与 Spotify 一样,授权过程很慢,而且应该只执行一次。
最后,应用程序实现了本地音乐服务的概念,音乐集合存储在本地。该服务要求指定音乐集合在本地系统中的位置。创建新的服务实例非常快,因此每当用户想要访问音乐集合时,都可以创建一个新的实例。
这个例子提出了几个挑战。每个服务都用一组不同的参数初始化。此外,Spotify 和 Pandora 在创建服务实例之前需要一个授权过程。
他们还希望重用该实例,以避免多次授权应用程序。本地服务更简单,但它与其他服务的初始化接口不匹配。
在下面几节中,您将通过一般化创建接口和实现通用对象工厂来解决这个问题。
单独创建对象以提供公共接口
每个具体音乐服务的创建都有自己的一套要求。这意味着每个服务实现的公共初始化接口是不可能的,也不推荐这样做。
最好的方法是定义一种新类型的对象,它提供一个通用接口并负责创建一个具体的服务。这种新型物体将被称为Builder。Builder对象拥有创建和初始化服务实例的所有逻辑。您将为每个支持的服务实现一个Builder对象。
让我们先来看看应用程序配置:
# In program.py
config = {
'spotify_client_key': 'THE_SPOTIFY_CLIENT_KEY',
'spotify_client_secret': 'THE_SPOTIFY_CLIENT_SECRET',
'pandora_client_key': 'THE_PANDORA_CLIENT_KEY',
'pandora_client_secret': 'THE_PANDORA_CLIENT_SECRET',
'local_music_location': '/usr/data/music'
}
config字典包含初始化每个服务所需的所有值。下一步是定义一个接口,该接口将使用这些值来创建音乐服务的具体实现。该接口将在一个Builder中实现。
让我们看看SpotifyService和SpotifyServiceBuilder的实现:
# In music.py
class SpotifyService:
def __init__(self, access_code):
self._access_code = access_code
def test_connection(self):
print(f'Accessing Spotify with {self._access_code}')
class SpotifyServiceBuilder:
def __init__(self):
self._instance = None
def __call__(self, spotify_client_key, spotify_client_secret, **_ignored):
if not self._instance:
access_code = self.authorize(
spotify_client_key, spotify_client_secret)
self._instance = SpotifyService(access_code)
return self._instance
def authorize(self, key, secret):
return 'SPOTIFY_ACCESS_CODE'
注意:音乐服务接口定义了一个.test_connection()方法,对于演示来说应该足够了。
这个例子展示了一个实现了.__call__(spotify_client_key, spotify_client_secret, **_ignored)的SpotifyServiceBuilder。
该方法用于创建和初始化具体的SpotifyService。它指定所需的参数,并忽略通过**_ignored提供的任何附加参数。一旦检索到access_code,它就创建并返回SpotifyService实例。
请注意,SpotifyServiceBuilder保留了服务实例,并且只在第一次请求服务时创建一个新实例。这避免了在需求中多次经历授权过程。
让我们为潘多拉做同样的事情:
# In music.py
class PandoraService:
def __init__(self, consumer_key, consumer_secret):
self._key = consumer_key
self._secret = consumer_secret
def test_connection(self):
print(f'Accessing Pandora with {self._key} and {self._secret}')
class PandoraServiceBuilder:
def __init__(self):
self._instance = None
def __call__(self, pandora_client_key, pandora_client_secret, **_ignored):
if not self._instance:
consumer_key, consumer_secret = self.authorize(
pandora_client_key, pandora_client_secret)
self._instance = PandoraService(consumer_key, consumer_secret)
return self._instance
def authorize(self, key, secret):
return 'PANDORA_CONSUMER_KEY', 'PANDORA_CONSUMER_SECRET'
PandoraServiceBuilder实现了相同的接口,但是它使用不同的参数和过程来创建和初始化PandoraService。它还保留了服务实例,因此授权只发生一次。
最后,让我们看看本地服务实现:
# In music.py
class LocalService:
def __init__(self, location):
self._location = location
def test_connection(self):
print(f'Accessing Local music at {self._location}')
def create_local_music_service(local_music_location, **_ignored):
return LocalService(local_music_location)
LocalService只需要一个存储集合的位置来初始化LocalService。
每次请求服务时都会创建一个新的实例,因为没有缓慢的授权过程。要求更简单,不需要Builder类。相反,使用返回初始化的LocalService的函数。该函数匹配构建器类中实现的.__call__()方法的接口。
对象工厂的通用接口
通用对象工厂(ObjectFactory)可以利用通用的Builder接口来创建各种对象。它提供了一个基于key值注册Builder的方法和一个基于key创建具体对象实例的方法。
让我们看看我们的泛型ObjectFactory的实现:
# In object_factory.py
class ObjectFactory:
def __init__(self):
self._builders = {}
def register_builder(self, key, builder):
self._builders[key] = builder
def create(self, key, **kwargs):
builder = self._builders.get(key)
if not builder:
raise ValueError(key)
return builder(**kwargs)
ObjectFactory的实现结构和你在SerializerFactory中看到的一样。
不同之处在于接口,该接口公开以支持创建任何类型的对象。构建器参数可以是实现可调用接口的任何对象。这意味着Builder可以是实现.__call__()的函数、类或对象。
.create()方法要求额外的参数被指定为关键字参数。这允许Builder对象指定它们需要的参数,并忽略其余的参数。例如,您可以看到create_local_music_service()指定了一个local_music_location参数,并忽略了其余的参数。
让我们创建工厂实例,并为您想要支持的服务注册构建器:
# In music.py
import object_factory
# Omitting other implementation classes shown above
factory = object_factory.ObjectFactory()
factory.register_builder('SPOTIFY', SpotifyServiceBuilder())
factory.register_builder('PANDORA', PandoraServiceBuilder())
factory.register_builder('LOCAL', create_local_music_service)
music模块通过factory属性公开ObjectFactory实例。然后,构建器向实例注册。对于 Spotify 和 Pandora,你注册了它们对应的 builder 的一个实例,但是对于本地服务,你只是传递了函数。
让我们编写一个演示该功能的小程序:
# In program.py
import music
config = {
'spotify_client_key': 'THE_SPOTIFY_CLIENT_KEY',
'spotify_client_secret': 'THE_SPOTIFY_CLIENT_SECRET',
'pandora_client_key': 'THE_PANDORA_CLIENT_KEY',
'pandora_client_secret': 'THE_PANDORA_CLIENT_SECRET',
'local_music_location': '/usr/data/music'
}
pandora = music.factory.create('PANDORA', **config)
pandora.test_connection()
spotify = music.factory.create('SPOTIFY', **config)
spotify.test_connection()
local = music.factory.create('LOCAL', **config)
local.test_connection()
pandora2 = music.services.get('PANDORA', **config)
print(f'id(pandora) == id(pandora2): {id(pandora) == id(pandora2)}')
spotify2 = music.services.get('SPOTIFY', **config)
print(f'id(spotify) == id(spotify2): {id(spotify) == id(spotify2)}')
应用程序定义了一个代表应用程序配置的config字典。配置被用作工厂的关键字参数,与您想要访问的服务无关。工厂根据指定的key参数创建音乐服务的具体实现。
您现在可以运行我们的程序来看看它是如何工作的:
$ python program.py
Accessing Pandora with PANDORA_CONSUMER_KEY and PANDORA_CONSUMER_SECRET
Accessing Spotify with SPOTIFY_ACCESS_CODE
Accessing Local music at /usr/data/music
id(pandora) == id(pandora2): True
id(spotify) == id(spotify2): True
您可以看到根据指定的服务类型创建了正确的实例。您还可以看到,请求 Pandora 或 Spotify 服务总是返回相同的实例。
专门化对象工厂以提高代码可读性
通用解决方案是可重用的,并且避免了代码重复。不幸的是,它们也会模糊代码,降低可读性。
上例显示,要访问音乐服务,需要调用music.factory.create()。这可能会导致混乱。其他开发人员可能认为每次都会创建一个新的实例,并决定他们应该保留服务实例以避免缓慢的初始化过程。
您知道不会发生这种情况,因为Builder类保留了初始化的实例并返回它以供后续调用,但是从阅读代码来看这并不清楚。
一个好的解决方案是专门化一个通用的实现来提供一个特定于应用程序上下文的接口。在这一节中,您将在我们的音乐服务环境中专门化ObjectFactory,这样应用程序代码就能更好地传达意图,变得更具可读性。
以下示例显示了如何专门化ObjectFactory,为应用程序的上下文提供一个显式接口:
# In music.py
class MusicServiceProvider(object_factory.ObjectFactory):
def get(self, service_id, **kwargs):
return self.create(service_id, **kwargs)
services = MusicServiceProvider()
services.register_builder('SPOTIFY', SpotifyServiceBuilder())
services.register_builder('PANDORA', PandoraServiceBuilder())
services.register_builder('LOCAL', create_local_music_service)
你从ObjectFactory中派生出MusicServiceProvider,并公开了一个新方法.get(service_id, **kwargs)。
这个方法调用泛型.create(key, **kwargs),所以行为保持不变,但是代码在我们的应用程序上下文中读起来更好。您还将之前的factory变量重命名为services,并将其初始化为MusicServiceProvider。
如您所见,更新后的应用程序代码现在看起来更好了:
import music
config = {
'spotify_client_key': 'THE_SPOTIFY_CLIENT_KEY',
'spotify_client_secret': 'THE_SPOTIFY_CLIENT_SECRET',
'pandora_client_key': 'THE_PANDORA_CLIENT_KEY',
'pandora_client_secret': 'THE_PANDORA_CLIENT_SECRET',
'local_music_location': '/usr/data/music'
}
pandora = music.services.get('PANDORA', **config)
pandora.test_connection()
spotify = music.services.get('SPOTIFY', **config)
spotify.test_connection()
local = music.services.get('LOCAL', **config)
local.test_connection()
pandora2 = music.services.get('PANDORA', **config)
print(f'id(pandora) == id(pandora2): {id(pandora) == id(pandora2)}')
spotify2 = music.services.get('SPOTIFY', **config)
print(f'id(spotify) == id(spotify2): {id(spotify) == id(spotify2)}')
运行程序表明行为没有改变:
$ python program.py
Accessing Pandora with PANDORA_CONSUMER_KEY and PANDORA_CONSUMER_SECRET
Accessing Spotify with SPOTIFY_ACCESS_CODE
Accessing Local music at /usr/data/music
id(pandora) == id(pandora2): True
id(spotify) == id(spotify2): True
结论
工厂方法是一种广泛使用的、创造性的设计模式,可以用在许多存在多个具体接口实现的情况下。
该模式删除了难以维护的复杂逻辑代码,并用可重用和可扩展的设计取而代之。该模式避免修改现有代码来支持新的需求。
这一点很重要,因为更改现有代码可能会引入行为变化或细微的错误。
在本文中,您了解了:
- 工厂方法设计模式是什么,它的组件是什么
- 如何重构现有代码以利用工厂方法
- 应该使用工厂方法的情况
- 对象工厂如何为实现工厂方法提供更大的灵活性
- 如何实现通用对象工厂及其挑战
- 如何专门化一个通用解决方案来提供一个更好的环境
延伸阅读
如果你想学习更多关于工厂方法和其他设计模式的知识,我推荐 GoF 的Design Patterns:Elements of Reusable Object-Oriented Software,这是一个广泛采用的设计模式的很好的参考。
此外, Heads First Design Patterns:一本由 Eric Freeman 和 Elisabeth Robson 编写的对大脑友好的指南提供了一个有趣、易读的设计模式解释。
维基百科有一个很好的设计模式的目录,里面有最常见和最有用模式的链接。******
快速、灵活、简单和直观:如何加快您的熊猫项目
如果您使用大数据集,您可能还记得在您的 Python 旅程中发现 Pandas 库的“啊哈”时刻。Pandas 是数据科学和分析的游戏规则改变者,特别是如果你来到 Python,因为你正在寻找比 Excel 和 VBA 更强大的东西。
那么,是什么让像我这样的数据科学家、分析师和工程师对熊猫赞不绝口呢?熊猫文件上说它使用了:
"快速、灵活,以及富有表现力的数据结构,旨在使处理“关系型”或“标签型”数据既简单又直观。"
快速、灵活、简单、直观?听起来很棒!如果您的工作涉及构建复杂的数据模型,您不希望花费一半的开发时间来等待模块在大数据集中产生。您希望将您的时间和智慧用于解释您的数据,而不是费力地使用功能较弱的工具。
但是我听说熊猫很慢…
当我第一次开始使用 Pandas 时,我被告知,虽然它是一个剖析数据的伟大工具,但 Pandas 太慢了,不能用作统计建模工具。一开始,这被证明是正确的。我花了几分钟多的时间摆弄我的拇指,等待熊猫通过数据搅动。
但后来我了解到,Pandas 是建立在 NumPy 数组结构之上的,它的许多操作都是用 C 实现的,要么通过 NumPy,要么通过 Pandas 自己的 Python 扩展模块的库,这些模块是用 Cython 编写并编译成 C 的。所以,Pandas 不应该也很快吗?
如果你按照预期的方式使用它,它绝对应该是!
矛盾的是,就效率而言,本来“看起来”像“T0”的 Pythonic 代码在熊猫身上可能不是最理想的。像 NumPy 一样, Pandas 是为矢量化操作而设计的,可以在一次扫描中对整个列或数据集进行操作。单独考虑每个“单元格”或行通常应该是最后一招,而不是第一招。
本教程
需要明确的是,这不是一个关于如何过度优化你的熊猫代码的指南。如果使用正确,熊猫已经可以跑得很快。此外,优化和编写干净的代码有很大的区别。
这是一个使用熊猫 python 化的指南,以充分利用其强大和易于使用的内置功能。此外,您将学到一些实用的省时技巧,这样您就不会每次处理数据时都笨手笨脚。
在本教程中,您将涵盖以下内容:
- 将
datetime数据用于时间序列的优势 - 进行批量计算的最有效途径
- 通过 HDFStore 存储数据节省时间
为了演示这些主题,我将举一个我日常工作中的例子,看看电力消耗的时间序列。加载完数据后,您将通过更有效的方式继续前进,以获得最终结果。对大多数熊猫来说都适用的一个格言是,从 A 到 b 有不止一种方法。然而,这并不意味着所有可用的选项都将同样适用于更大、要求更高的数据集。
假设你已经知道如何在熊猫中做一些基本的数据选择,那就开始吧。
手头的任务
此示例的目标是应用分时电价来计算一年的总能耗成本。也就是说,在一天中的不同时间,电价是不同的,因此任务是将每小时消耗的电力乘以该小时消耗电力的正确价格。
让我们从一个 CSV 文件中读取数据,该文件有两列:一列是日期加时间,另一列是以千瓦时(kWh)为单位的电能消耗:
这些行包含每个小时的用电量,因此全年有 365 x 24 = 8760 行。每一行表示当时“小时开始”的用法,因此 1/1/13 0:00 表示 1 月 1 日第一个小时的用法。
使用日期时间数据节省时间
您需要做的第一件事是使用 Pandas 的一个 I/O 函数从 CSV 文件中读取数据:
>>> import pandas as pd >>> pd.__version__ '0.23.1' # Make sure that `demand_profile.csv` is in your # current working directory. >>> df = pd.read_csv('demand_profile.csv') >>> df.head() date_time energy_kwh 0 1/1/13 0:00 0.586 1 1/1/13 1:00 0.580 2 1/1/13 2:00 0.572 3 1/1/13 3:00 0.596 4 1/1/13 4:00 0.592乍一看这没什么问题,但是有一个小问题。熊猫和 NumPy 有一个
dtypes(数据类型)的概念。如果没有指定参数,date_time将采用object数据类型:
>>> df.dtypes
date_time object
energy_kwh float64
dtype: object
>>> type(df.iat[0, 0])
str
这并不理想。object不仅仅是str的容器,也是任何不适合一种数据类型的列的容器。将日期作为字符串来处理将是困难和低效的。(这也会造成内存效率低下。)
为了处理时间序列数据,您会希望将date_time列格式化为 datetime 对象的数组。(熊猫称这个为Timestamp。)熊猫让这里的每一步变得相当简单:
>>> df['date_time'] = pd.to_datetime(df['date_time']) >>> df['date_time'].dtype datetime64[ns](注意,在这种情况下,你也可以使用熊猫
PeriodIndex。)您现在有了一个名为
df的数据帧,它看起来很像我们的 CSV 文件。它有两列和一个用于引用行的数字索引。
>>> df.head()
date_time energy_kwh
0 2013-01-01 00:00:00 0.586
1 2013-01-01 01:00:00 0.580
2 2013-01-01 02:00:00 0.572
3 2013-01-01 03:00:00 0.596
4 2013-01-01 04:00:00 0.592
上面的代码简单易行,但是它有多快呢?让我们用一个计时装饰器来测试它,我最初称它为@timeit。这个装饰器很大程度上模仿了 Python 标准库中的timeit.repeat(),但是它允许您返回函数本身的结果,并打印多次试验的平均运行时间。(Python 的timeit.repeat()返回的是计时结果,而不是函数结果。)
创建一个函数并将@timeit装饰器直接放在它的上面,这意味着每次调用这个函数时,它都会被计时。装饰器运行一个外部循环和一个内部循环:
>>> @timeit(repeat=3, number=10) ... def convert(df, column_name): ... return pd.to_datetime(df[column_name]) >>> # Read in again so that we have `object` dtype to start >>> df['date_time'] = convert(df, 'date_time') Best of 3 trials with 10 function calls per trial: Function `convert` ran in average of 1.610 seconds.结果呢?8760 行数据 1.6 秒。“太好了,”你可能会说,“根本没时间。”但是,如果您遇到更大的数据集,比如说,一年中每一分钟的用电量,该怎么办呢?这是数据量的 60 倍,所以你最终要等大约一分半钟。这听起来越来越难以忍受了。
实际上,我最近分析了 330 个站点 10 年的每小时电力数据。你认为我等了 88 分钟才转换日期时间吗?绝对不行!
你如何能加快这个速度?一般来说,熊猫解释你的数据越少,速度就越快。在这种情况下,只需使用 format 参数告诉 Pandas 您的时间和日期数据是什么样子,您就会看到速度的巨大提高。你可以通过使用在找到的的
strftime代码,并像这样输入它们:
>>> @timeit(repeat=3, number=100)
>>> def convert_with_format(df, column_name):
... return pd.to_datetime(df[column_name],
... format='%d/%m/%y %H:%M')
Best of 3 trials with 100 function calls per trial:
Function `convert_with_format` ran in average of 0.032 seconds.
新的结果?0.032 秒,快了 50 倍!所以你刚刚为我的 330 个站点节省了大约 86 分钟的处理时间。不错的进步!
一个更好的细节是 CSV 中的日期时间不是 ISO 8601 的格式:您需要YYYY-MM-DD HH:MM。如果不指定格式,Pandas 将使用 dateutil 包将每个字符串转换成日期。
相反,如果原始日期时间数据已经是 ISO 8601 格式,熊猫可以立即采取快速路线来解析日期。这就是为什么在这里明确格式是如此有益的一个原因。另一种选择是传递infer_datetime_format=True参数,但是显式传递通常更好。
注意 : Pandas 的 read_csv() 也允许你解析日期作为文件 I/O 步骤的一部分。参见parse_dates、infer_datetime_format和date_parser参数。
简单循环熊猫数据
现在,您的日期和时间已经有了方便的格式,您可以开始计算电费了。请记住,成本随小时而变化,因此您需要有条件地将成本系数应用于一天中的每个小时。在本例中,使用时间成本定义如下:
| 关税类型 | 每千瓦时美分 | 时间范围 |
|---|---|---|
| 山峰 | Twenty-eight | 17 时至 24 时 |
| 肩膀 | Twenty | 7 时至 17 时 |
| 非高峰时间 | Twelve | 零点至七点 |
如果价格是每天每小时每度电 28 美分,大多数熟悉熊猫的人都会知道这个计算可以用一行代码来实现:
>>> df['cost_cents'] = df['energy_kwh'] * 28这将导致创建一个包含该小时电费的新列:
date_time energy_kwh cost_cents 0 2013-01-01 00:00:00 0.586 16.408 1 2013-01-01 01:00:00 0.580 16.240 2 2013-01-01 02:00:00 0.572 16.016 3 2013-01-01 03:00:00 0.596 16.688 4 2013-01-01 04:00:00 0.592 16.576 # ...但是我们的成本计算是以一天中的时间为条件的。在这里,你会看到很多人使用 Pandas 的方式并不符合预期:通过编写一个循环来进行条件计算。
在本教程的其余部分,您将从一个不太理想的基线解决方案开始,逐步发展到一个完全利用 Pandas 的 Pythonic 解决方案。
但是对于熊猫来说,蟒蛇是什么呢?具有讽刺意味的是,那些对其他(不太友好的)编码语言如 C++或 Java 有经验的人特别容易受到这种影响,因为他们本能地“循环思考”
让我们来看一个循环方法,它不是 Pythonic 式的,当许多人不知道熊猫是如何被设计使用时,他们会采取这种方法。我们将再次使用
@timeit来看看这种方法有多快。首先,让我们创建一个函数,将适当的费率应用于给定的小时:
def apply_tariff(kwh, hour): """Calculates cost of electricity for given hour.""" if 0 <= hour < 7: rate = 12 elif 7 <= hour < 17: rate = 20 elif 17 <= hour < 24: rate = 28 else: raise ValueError(f'Invalid hour: {hour}') return rate * kwh这是一个不属于 Pythonic 的循环,尽管如此:
>>> # NOTE: Don't do this!
>>> @timeit(repeat=3, number=100)
... def apply_tariff_loop(df):
... """Calculate costs in loop. Modifies `df` inplace."""
... energy_cost_list = []
... for i in range(len(df)):
... # Get electricity used and hour of day
... energy_used = df.iloc[i]['energy_kwh']
... hour = df.iloc[i]['date_time'].hour
... energy_cost = apply_tariff(energy_used, hour)
... energy_cost_list.append(energy_cost)
... df['cost_cents'] = energy_cost_list
...
>>> apply_tariff_loop(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_loop` ran in average of 3.152 seconds.
对于那些在之前写了一段时间《纯 Python》后接触熊猫的人来说,这种设计可能看起来很自然:你有一个典型的“for each x ,conditional withy,do z
然而,这个循环是笨拙的。出于几个原因,您可以将上述内容视为 Pandas 中的“反模式”。首先,它需要初始化一个列表,其中将记录输出。
其次,它使用不透明对象range(0, len(df))进行循环,然后在应用apply_tariff()之后,它必须将结果附加到一个用于创建新 DataFrame 列的列表中。它还使用df.iloc[i]['date_time']做所谓的链式索引,这经常会导致意想不到的结果。
但是这种方法的最大问题是计算的时间成本。在我的机器上,对于 8760 行数据,这个循环用了 3 秒多。接下来,您将看到 Pandas 结构迭代的一些改进解决方案。
用.itertuples()和.iterrows() 循环
你还能采取什么方法?嗯,Pandas 通过引入DataFrame.itertuples()和DataFrame.iterrows()方法,实际上使得for i in range(len(df))语法变得多余。这两个生成器方法都是yield一次一行。
.itertuples()为每一行产生一个 namedtuple ,该行的索引值作为元组的第一个元素。nametuple是来自 Python 的collections模块的数据结构,其行为类似于 Python 元组,但具有可通过属性查找访问的字段。
.iterrows()为数据帧中的每一行生成(index,Series)对(元组)。
虽然.itertuples()可能会快一点,但在这个例子中,我们还是使用.iterrows(),因为有些读者可能没有遇到过nametuple。让我们看看这实现了什么:
>>> @timeit(repeat=3, number=100) ... def apply_tariff_iterrows(df): ... energy_cost_list = [] ... for index, row in df.iterrows(): ... # Get electricity used and hour of day ... energy_used = row['energy_kwh'] ... hour = row['date_time'].hour ... # Append cost list ... energy_cost = apply_tariff(energy_used, hour) ... energy_cost_list.append(energy_cost) ... df['cost_cents'] = energy_cost_list ... >>> apply_tariff_iterrows(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_iterrows` ran in average of 0.713 seconds.已经取得了一些边际收益。语法更加明确,行值引用中的混乱更少,因此可读性更好。就时间增益而言,几乎快了 5 五倍!
然而,还有更大的改进空间。您仍然在使用某种形式的 Python for-loop,这意味着每一个函数调用都是用 Python 完成的,而理想情况下可以用 Pandas 内部架构中内置的更快的语言来完成。
熊猫的
.apply()您可以使用
.apply()方法代替.iterrows()来进一步改进这个操作。Pandas 的.apply()方法接受函数(可调用的),并沿着数据帧的轴(所有行或所有列)应用它们。在这个例子中,一个 lambda 函数将帮助您将两列数据传递到apply_tariff():
>>> @timeit(repeat=3, number=100)
... def apply_tariff_withapply(df):
... df['cost_cents'] = df.apply(
... lambda row: apply_tariff(
... kwh=row['energy_kwh'],
... hour=row['date_time'].hour),
... axis=1)
...
>>> apply_tariff_withapply(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_withapply` ran in average of 0.272 seconds.
.apply()的语法优势是显而易见的,它显著减少了行数,并且代码可读性很强。在这种情况下,花费的时间大约是.iterrows()方法的一半。
然而,这还不是“惊人的快”一个原因是.apply()将尝试在内部循环遍历 Cython 迭代器。但是在这种情况下,您传递的lambda不能在 Cython 中处理,所以它在 Python 中被调用,因此速度不是很快。
如果您使用.apply()来获得我 10 年来 330 个站点的每小时数据,您将会看到大约 15 分钟的处理时间。如果这个计算是一个更大模型的一小部分,你真的想加快速度。这就是矢量化运算派上用场的地方。
用.isin() 选择数据
在前面,您看到了如果有一个单一的电价,您可以在一行代码(df['energy_kwh'] * 28)中将该价格应用于所有的电力消耗数据。这个特殊的操作是向量化操作的一个例子,这是在 Pandas 中最快的操作方式。
但是在 Pandas 中,如何将条件计算应用为矢量化运算呢?一个技巧是根据您的条件选择和分组数据帧的各个部分,然后对每个选择的组应用矢量化运算。
在下一个例子中,您将看到如何使用 Pandas 的.isin()方法选择行,然后在矢量化操作中应用适当的关税。在您这样做之前,如果您将date_time列设置为 DataFrame 的索引,事情会变得更方便一些:
df.set_index('date_time', inplace=True)
@timeit(repeat=3, number=100)
def apply_tariff_isin(df):
# Define hour range Boolean arrays
peak_hours = df.index.hour.isin(range(17, 24))
shoulder_hours = df.index.hour.isin(range(7, 17))
off_peak_hours = df.index.hour.isin(range(0, 7))
# Apply tariffs to hour ranges
df.loc[peak_hours, 'cost_cents'] = df.loc[peak_hours, 'energy_kwh'] * 28
df.loc[shoulder_hours,'cost_cents'] = df.loc[shoulder_hours, 'energy_kwh'] * 20
df.loc[off_peak_hours,'cost_cents'] = df.loc[off_peak_hours, 'energy_kwh'] * 12
让我们来比较一下:
>>> apply_tariff_isin(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_isin` ran in average of 0.010 seconds.要理解这段代码中发生了什么,您需要知道
.isin()方法正在返回一个由布尔值组成的数组,如下所示:[False, False, False, ..., True, True, True]这些值标识哪些数据帧索引(日期时间)在指定的小时范围内。然后,当您将这些布尔数组传递给数据帧的
.loc索引器时,您会得到一个数据帧切片,其中只包含与这些小时相匹配的行。之后,只需将切片乘以适当的关税,这是一个快速的矢量化操作。这与我们上面的循环操作相比如何?首先,您可能会注意到不再需要
apply_tariff(),因为所有的条件逻辑都应用于行的选择。因此,您需要编写的代码行数和调用的 Python 代码都大大减少了。办理时间呢?比非 Pythonic 循环快 315 倍,比
.iterrows()快 71 倍,比.apply()快 27 倍。现在,您正以又好又快地处理大数据集所需的速度前进。我们能做得更好吗?
在
apply_tariff_isin()中,我们仍然承认通过调用df.loc和df.index.hour.isin()三次来做一些“手工工作”。如果我们有一个更细粒度的时隙范围,你可能会认为这个解决方案是不可扩展的。(每小时不同的费率将需要 24 次.isin()呼叫。幸运的是,在这种情况下,您可以使用 Pandas 的pd.cut()功能以更加程序化的方式做事:@timeit(repeat=3, number=100) def apply_tariff_cut(df): cents_per_kwh = pd.cut(x=df.index.hour, bins=[0, 7, 17, 24], include_lowest=True, labels=[12, 20, 28]).astype(int) df['cost_cents'] = cents_per_kwh * df['energy_kwh']让我们花点时间看看这里发生了什么。根据每小时属于哪个箱子,应用一系列标签(我们的成本)。注意,
include_lowest参数指示第一个区间是否应该是左包含的。(您想将time=0包含在一个组中。)这是获得预期结果的完全矢量化的方法,并且在时间方面表现最佳:
>>> apply_tariff_cut(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_cut` ran in average of 0.003 seconds.
到目前为止,您已经从可能需要一个多小时到不到一秒的时间来处理完整的 300 个站点数据集。还不错!不过,还有最后一个选择,即使用 NumPy 函数来操作每个数据帧的底层 NumPy 数组,然后将结果集成回 Pandas 数据结构。
别忘了 NumPy!
当您使用 Pandas 时,不应该忘记的一点是 Pandas 系列和 DataFrames 是在 NumPy 库之上设计的。这为您提供了更大的计算灵活性,因为 Pandas 可以无缝地处理 NumPy 数组和操作。
在下一个例子中,您将使用 NumPy 的digitize()函数。它与 Pandas 的cut()相似,数据将被分箱,但这次它将由一个表示每小时属于哪个箱的索引数组来表示。然后将这些指数应用于价格数组:
@timeit(repeat=3, number=100)
def apply_tariff_digitize(df):
prices = np.array([12, 20, 28])
bins = np.digitize(df.index.hour.values, bins=[7, 17, 24])
df['cost_cents'] = prices[bins] * df['energy_kwh'].values
像cut()函数一样,这个语法非常简洁,易于阅读。但是在速度上相比如何?让我们看看:
>>> apply_tariff_digitize(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_digitize` ran in average of 0.002 seconds.在这一点上,性能仍然有所提高,但本质上变得越来越微不足道。这可能是一个很好的时间来结束一天的代码改进,并考虑更大的图片。
对于 Pandas,它可以帮助维护“层次结构”,如果你愿意的话,就像你在这里所做的那样进行批量计算的首选选项。这些通常从最快到最慢排列(从最灵活到最不灵活):
- 使用向量化操作:没有 for 循环的 Pandas 方法和函数。
- 使用带有可调用函数的
.apply()方法。- 使用
.itertuples():从 Python 的collections模块中以namedtuples的形式迭代 DataFrame 行。- 使用
.iterrows():以(index,pd.Series)对的形式迭代 DataFrame 行。虽然 Pandas 系列是一种灵活的数据结构,但是将每一行构建成一个系列,然后访问它,成本可能会很高。- 使用“逐个元素”进行循环,用
df.loc或df.iloc一次更新一个单元格或一行。(或者,.at/.iat用于快速标量访问。)不要相信我的话:上面的优先顺序是直接来自熊猫核心开发者的建议。
下面是上面的“优先顺序”,您在这里构建的每个函数:
功能 运行时间(秒) apply_tariff_loop()Three point one five two apply_tariff_iterrows()Zero point seven one three apply_tariff_withapply()Zero point two seven two apply_tariff_isin()Zero point zero one apply_tariff_cut()Zero point zero zero three apply_tariff_digitize()Zero point zero zero two 用 HDFStore 防止再处理
现在你已经看到了熊猫的快速数据处理,让我们来探索如何使用最近集成到熊猫中的 HDFStore 来完全避免重新处理时间。
通常,在构建复杂的数据模型时,对数据进行一些预处理是很方便的。例如,如果您有 10 年的分钟频率用电量数据,即使您指定了 format 参数,简单地将日期和时间转换为 datetime 也可能需要 20 分钟。您真的只想做一次,而不是每次运行模型进行测试或分析。
您可以在这里做的一件非常有用的事情是预处理,然后以处理后的形式存储数据,以便在需要时使用。但是,如何以正确的格式存储数据,而不必再次对其进行重新处理呢?如果您要另存为 CSV,您将会丢失日期时间对象,并且在再次访问时必须重新处理它。
Pandas 对此有一个内置的解决方案,它使用了 HDF5 ,这是一种高性能的存储格式,专门用于存储数据的表格数组。Pandas 的
HDFStore类允许您将数据帧存储在 HDF5 文件中,以便可以有效地访问它,同时仍然保留列类型和其他元数据。这是一个类似字典的类,所以您可以像对待 Pythondict对象一样读写。以下是将预处理后的耗电量数据帧
df存储在 HDF5 文件中的方法:# Create storage object with filename `processed_data` data_store = pd.HDFStore('processed_data.h5') # Put DataFrame into the object setting the key as 'preprocessed_df' data_store['preprocessed_df'] = df data_store.close()现在,您可以关闭计算机,休息一会儿,因为您知道您可以回来,并且您处理的数据将在您需要时等待您。不需要再加工。以下是如何从 HDF5 文件中访问数据,并保留数据类型:
# Access data store data_store = pd.HDFStore('processed_data.h5') # Retrieve data using key preprocessed_df = data_store['preprocessed_df'] data_store.close()一个数据存储可以包含多个表,每个表的名称作为一个键。
关于在 Pandas 中使用 HDFStore 的一个注意事项:您需要安装 PyTables >= 3.0.0,所以在您安装 Pandas 之后,请确保像这样更新 PyTables:
pip install --upgrade tables结论
如果你不觉得你的熊猫项目是快速、灵活、简单和直观,考虑一下你如何使用这个库。
您在这里探索的例子相当简单,但是说明了正确应用 Pandas 特性可以极大地提高运行时和代码可读性。下面是一些经验法则,下次在 Pandas 中处理大型数据集时可以应用:
尽可能使用向量化操作,而不是用
for x in df...的心态来处理问题。如果您的代码中有很多 for 循环,那么它可能更适合使用原生 Python 数据结构,因为 Pandas 会带来很多开销。如果你有更复杂的操作,矢量化根本不可能或太难有效地完成,使用
.apply()方法。如果你不得不遍历你的数组(这种情况确实会发生),使用
.iterrows()或.itertuples()来提高速度和语法。Pandas 有很多可选性,从 A 到 b 几乎总是有几种方法。请记住这一点,比较不同路线的表现,并选择最适合您的项目环境的路线。
一旦您构建了数据清理脚本,通过使用 HDFStore 存储中间结果来避免重新处理。
将 NumPy 集成到 Pandas 操作中通常可以提高速度并简化语法。*****
使用 FastAPI 构建 Python Web APIs
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python REST API 搭配 FastAPI
创建 API,或者说应用编程接口,是让你的软件能够被广大用户访问的一个重要部分。在本教程中,您将学习 FastAPI 的主要概念,以及如何使用它快速创建默认情况下实现最佳实践的 web APIs。
学完本课程后,您将能够开始创建生产就绪的 web APIs,并且您将具备深入了解和学习更多特定用例所需的知识。
在本教程中,你将学习如何:
- 使用路径参数获得每个项目的唯一 URL 路径
- 使用 pydantic 在您的请求中接收 JSON 数据
- 使用 API 最佳实践,包括验证、序列化和文档
- 继续学习针对您的用例的 FastAPI
本教程由 FastAPI 的作者撰写。它包含从官方文档中精心挑选的片段,避免迷失在技术细节中,同时帮助您尽快上手。
为了从本教程中获得最大收益,了解一下什么是 HTTP 以及它是如何工作的、什么是 JSON以及 Python 类型提示会对你有所帮助。您还将从使用虚拟环境中受益,任何 Python 项目都是如此。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是 FastAPI?
FastAPI 是一个现代的高性能 web 框架,用于基于标准类型提示用 Python 构建 API。它具有以下主要特点:
- 跑得快:它提供了非常高的性能,与 NodeJS 和 Go 不相上下,多亏了 Starlette 和 pydantic 。
- 快速编码:它可以显著提高开发速度。
- 减少 bug 数量:减少人为错误的可能性。
- 直观的:它提供了强大的编辑器支持,随处完成,调试时间更少。
- 简单明了:它的设计使使用和学习变得简单,因此您可以花更少的时间阅读文档。
- Short :最大限度减少代码重复。
- 健壮的:它为生产就绪代码提供自动交互文档。
- 基于标准:基于 API 开放标准, OpenAPI 和 JSON Schema 。
该框架旨在优化您的开发人员体验,以便您可以编写简单的代码来构建默认情况下具有最佳实践的生产就绪型 API。
Install FastAPI
与任何其他 Python 项目一样,最好从创建虚拟环境开始。如果你不熟悉如何做到这一点,那么你可以看看虚拟环境的初级读本。
第一步,使用
pip安装 FastAPI 和uvicon:$ python -m pip install fastapi uvicorn[standard]至此,您已经安装了 FastAPI 和 Uvicorn,并准备学习如何使用它们。FastAPI 是您将用来构建 API 的框架,而 Uvicorn 是将使用您构建的 API 来服务请求的服务器。
第一步
首先,在本节中,您将创建一个最小的 FastAPI 应用程序,在使用 Uvicorn 的服务器上运行它,然后学习所有的交互部分。这将让你很快了解一切是如何工作的。
创建第一个 API
基本的 FastAPI 文件如下所示:
# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}将上面的代码复制到一个名为
main.py的文件中,就这样,您就有了一个全功能的 API 应用程序,其中内置了一些最佳实践,比如自动文档和序列化。接下来,您将了解关于这些功能的更多信息。这段代码定义了你的应用程序,但是如果你直接用
python调用它,它不会自己运行。要运行它,你需要一个服务器程序。在上面的步骤中,你已经安装了uvicon。那将是你的服务器。用 Uvicorn 运行第一个 API 应用程序
使用 Uvicorn 运行实时服务器:
$ uvicorn main:app --reload INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process [28720] INFO: Started server process [28722] INFO: Waiting for application startup. INFO: Application startup complete.输出中突出显示的一行显示了您的应用程序在本地机器中的 URL。由于您使用了
--reload进行开发,所以当您更新应用程序代码时,服务器会自动重新加载。检查响应
打开您的浏览器至
http://127.0.0.1:8000,这将使您的浏览器向您的应用程序发送请求。然后,它将发送一个 JSON 响应,内容如下:{"message": "Hello World"}该 JSON 消息与您从应用程序中的函数返回的字典相同。FastAPI 负责将 Python
dict序列化为 JSON 对象,并设置适当的Content-Type。查看交互式 API 文档
现在在浏览器中打开
http://127.0.0.1:8000/docs。你会看到 Swagger UI 提供的自动交互 API 文档:
默认情况下,提供并集成了记录 API 的基于浏览器的用户界面。使用 FastAPI,您不需要做任何其他事情就可以利用它。
查看替代交互式 API 文档
现在,在浏览器中转到
http://127.0.0.1:8000/redoc。您将看到由 ReDoc 提供的替代自动文档:
由于 FastAPI 是基于 OpenAPI 之类的标准,所以有许多替代方法来显示 API 文档。默认情况下,FastAPI 提供了这两种选择。
第一个 API,循序渐进
现在让我们一步一步地分析这些代码,并理解每一部分的作用。
第一步是导入
FastAPI:# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}
FastAPI是一个 Python 类,为你的 API 提供所有的功能。第二步是创建一个
FastAPI实例:# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}这里的
app变量将是类FastAPI的一个实例。这将是创建 API 的主要交互点。这个
app就是您在上面使用uvicorn运行实时服务器的命令中提到的那个:$ uvicorn main:app --reload INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)在继续第 3 步之前,有必要花点时间熟悉一些术语。路径是指从第一个正斜杠字符(
/)开始的 URL 的最后一部分。因此,在类似于https://example.com/items/foo的 URL 中,路径应该是/items/foo。路径通常也被称为端点或路线,但是在本教程中将使用术语路径。当你构建一个 API 时,路径是你分离资源的主要方式。
另一个需要了解的重要术语是操作,它用于引用任何 HTTP 请求方法:
POSTGETPUTDELETEOPTIONSHEADPATCHTRACE使用 HTTP ,您可以使用这些操作中的一个(或多个)与每个路径进行通信。知道了这两个术语的意思,你就可以继续第三步了。
步骤 3 是定义一个路径操作装饰器:
# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}
@app.get("/")告诉 FastAPI 下面的函数负责处理使用get操作到达路径/的请求。这是一个与路径操作相关的装饰器,或者路径操作装饰器。如果你想学习更多关于 decorator 的知识,那么看看 Python decorator 的初级读本。您也可以使用上面提到的其他操作:
@app.post()@app.put()@app.delete()@app.options()@app.head()@app.patch()@app.trace()在每种情况下,您都可以在负责处理这些请求的函数上使用适当的路径操作装饰器。
提示:你可以随意使用每个操作(HTTP 方法)。
FastAPI 不强制任何特定的含义。此处提供的信息是一个指南,而不是一个要求。
例如,当使用 GraphQL 时,通常只使用
POST操作来执行大多数动作。步骤 4 是定义路径操作函数,或者路径操作装饰器下面的函数:
# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}每当 FastAPI 使用一个
GET操作接收到对指定 URL (/)的请求时,就会调用这个函数。在本例中,它是一个async功能。您也可以将其定义为一个普通函数,而不是使用
async def:# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") def root(): return {"message": "Hello World"}如果您不知道普通函数和
async函数之间的区别以及何时使用它们,请查看 FastAPI 文档中的并发和异步/等待。第五步是向返回内容:
# main.py from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}可以返回一个字典、列表,或者作为字符串、整数等的奇异值。您还可以返回 pydantic 模型,稍后您将了解更多。
还有很多其他的对象和模型会被自动转换成 JSON,包括对象关系映射器 (ORMs)等等。试着使用你最喜欢的——它们很可能已经被支持了。
路径参数:按 ID 获取项目
你可以声明路径参数或者变量,使用与 Python 格式化字符串相同的语法:
# main.py from fastapi import FastAPI app = FastAPI() @app.get("/items/{item_id}") async def read_item(item_id): return {"item_id": item_id}路径参数
item_id的值将作为参数item_id传递给函数。因此,如果您运行此示例并转到
http://127.0.0.1:8000/items/foo,您将看到以下响应:{"item_id":"foo"}响应包含
"foo",它是在item_id路径参数中传递的,然后在字典中返回。类型为的路径参数
您可以使用标准 Python 类型提示在函数中声明路径参数的类型:
# main.py from fastapi import FastAPI app = FastAPI() @app.get("/items/{item_id}") async def read_item(item_id: int): return {"item_id": item_id}在这种情况下,您声明
item_id是一个int。声明路径参数的类型将为您提供函数内部的编辑器支持,包括错误检查、完成等等。
数据转换
如果您运行上面的示例,并将浏览器导航到
http://127.0.0.1:8000/items/3,那么您将看到以下响应:{"item_id":3}请注意,您的函数接收并返回的值是
3,这是一个 Pythonint,而不是一个字符串("3")。因此,通过类型声明,FastAPI 为您提供了自动的请求解析。数据验证
如果你将浏览器指向
http://127.0.0.1:8000/items/foo,那么你会看到一个漂亮的 HTTP 错误:{ "detail": [ { "loc": [ "path", "item_id" ], "msg": "value is not a valid integer", "type": "type_error.integer" } ] }这是因为路径参数
item_id的值为"foo",它不是一个int。如果你提供了一个
float而不是一个int,同样的错误也会出现,比如你在浏览器中打开了http://127.0.0.1:8000/items/4.2。因此,使用相同的 Python 类型提示,FastAPI 既给你数据解析又给你数据验证。还要注意,错误清楚地指出了验证没有通过的确切位置。这在开发和调试与 API 交互的代码时非常有用。
文档
当您在
http://127.0.0.1:8000/docs打开浏览器时,您会看到一个自动的交互式 API 文档:
同样,通过同样的 Python 类型声明,FastAPI 为您提供了集成了 Swagger UI 的自动化交互式文档。注意,path 参数被声明为一个整数。
因为 FastAPI 构建在 OpenAPI 标准之上,所以它还提供了一个使用 ReDoc 的替代 API 文档,您可以在
http://127.0.0.1:8000/redoc访问:
还有许多其他兼容的工具,包括许多语言的代码生成工具。
用 pydantic 进行数据处理
所有的数据验证都是由 pydantic 在幕后执行的,因此您可以从中获得所有的好处,并且您知道您会得到很好的处理。
您可以对
str、float、bool和许多其他复杂数据类型使用相同的类型声明。顺序问题:将固定路径放在第一位
创建路径操作时,你可能会发现有固定路径的情况,比如
/users/me。假设是为了获取当前用户的数据。您还可以使用路径/users/{user_id}通过某个用户 ID 获取特定用户的数据。因为路径操作是按顺序计算的,所以需要确保在声明
/users/{user_id}的路径之前声明/users/me的路径:# main.py from fastapi import FastAPI app = FastAPI() @app.get("/users/me") async def read_user_me(): return {"user_id": "the current user"} @app.get("/users/{user_id}") async def read_user(user_id: str): return {"user_id": user_id}否则,
/users/{user_id}的路径也会与/users/me匹配,认为它正在接收值为"me"的参数user_id。请求体:接收 JSON 数据
当您需要将数据从客户机发送到 API 时,您可以将它作为请求体发送。
一个请求体是客户端发送给你的 API 的数据。一个响应体是你的 API 发送给客户端的数据。您的 API 几乎总是要发送一个响应体。但是客户端不一定需要一直发送请求体。
注意:发送数据,你要用
POST(最常用的方法)、PUT、DELETE或者PATCH。发送带有GET请求的主体在规范中有未定义的行为。然而,FastAPI 支持使用
GET请求,尽管只是针对非常复杂或极端的用例。不鼓励这样做,当使用GET时,Swagger UI 的交互文档不会显示主体的文档,中间的代理可能不支持它。要声明一个请求体,您可以使用 pydantic 模型及其所有的功能和好处。你将在下面了解更多。
使用 pydantic 声明 JSON 数据模型(数据形状)
首先,您需要从
pydantic导入BaseModel,然后使用它来创建子类,定义您想要接收的模式,或者数据形状。接下来,将数据模型声明为从
BaseModel继承的类,对所有属性使用标准 Python 类型:# main.py from typing import Optional from fastapi import FastAPI from pydantic import BaseModel class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None app = FastAPI() @app.post("/items/") async def create_item(item: Item): return item当模型属性有默认值时,它不是必需的。否则,它是必需的。要使属性可选,可以使用
None。例如,上面的模型像这样声明了一个 JSON 对象(或 Python
dict):{ "name": "Foo", "description": "An optional description", "price": 45.2, "tax": 3.5 }在这种情况下,因为
description和tax是可选的,因为它们有一个默认值None,所以这个 JSON 对象也是有效的:{ "name": "Foo", "price": 45.2 }省略默认值的 JSON 对象也是有效的。
接下来,将新的 pydantic 模型作为参数添加到路径操作中。声明它的方式与声明路径参数的方式相同:
# main.py from typing import Optional from fastapi import FastAPI from pydantic import BaseModel class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None app = FastAPI() @app.post("/items/") async def create_item(item: Item): return item参数
item有一个类型提示Item,这意味着item被声明为类Item的一个实例。通过 Python 类型声明,FastAPI 将:
- 将请求的主体作为 JSON 读取
- 如果需要,转换相应的类型
- 验证数据,如果无效,则返回一个明确的错误
- 在参数
item中为您提供接收到的数据——因为您将它声明为类型Item,所以您还将拥有所有编辑器支持,对所有属性及其类型进行完成和类型检查- 为您的模型生成 JSON Schema 定义,您也可以在任何对您的项目有意义的地方使用这些定义
通过在 pydantic 中使用标准类型提示,FastAPI 可以帮助您轻松地构建默认情况下具备所有这些最佳实践的 API。
使用 pydantic 自动记录文件
您的 pydantic 模型的 JSON 模式将是为您的应用程序生成的 OpenAPI 的一部分,并将显示在交互式 API 文档中:
您可以看到 API 文档中的属性
Item正是您用 pydantic 模型声明的属性。这些 JSON 模式也将在需要它们的每个路径操作中的 API 文档中使用:
请注意,所有这些自动文档都是基于您的数据,使用您的 pydantic 模型。
编辑器支持、自动完成和类型检查
在你的编辑器中,在你的函数中,你会得到类型提示和补全。如果你收到一个
dict而不是一个 pydantic 模型,这就不会发生:
这样,您可以触发所有数据的自动完成。
您还可以对不正确的类型操作进行错误检查:
在这种情况下,您不能将一个
str和一个float相加,因为编辑器知道这些类型,它可以警告您代码中有错误。这不是偶然的:整个框架都是围绕这个设计构建的。在任何实现之前,它在设计阶段就经过了彻底的测试,以确保它能与所有的编辑器一起工作。甚至对 pydantic 本身也做了一些修改来支持这个特性。之前的截图都是用 Visual Studio 代码拍摄的。但是你可以用 PyCharm 和大多数其他 Python 编辑器得到同样的编辑器支持:
如果您使用 PyCharm 作为您的编辑器,那么您可以使用 pydantic PyCharm 插件来改进您的编辑器支持。如果你使用 VS 代码,那么你将通过 Pylance 获得最好的开发者体验。
使用 pydantic 模型
在函数内部,您可以直接访问模型对象的所有属性:
# main.py from typing import Optional from fastapi import FastAPI from pydantic import BaseModel class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None app = FastAPI() @app.post("/items/") async def create_item(item: Item): item_dict = item.dict() if item.tax: price_with_tax = item.price + item.tax item_dict.update({"price_with_tax": price_with_tax}) return item_dict参数
item被声明为类Item的实例,FastAPI 将确保您在函数中接收到的与完全相同,而不是字典或其他东西。请求体和路径参数
您可以同时声明路径参数和请求体。
FastAPI 将识别与路径参数匹配的函数参数应该从路径中获取,而被声明为 pydantic 模型的函数参数应该从请求体中获取:
# main.py from typing import Optional from fastapi import FastAPI from pydantic import BaseModel class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None app = FastAPI() @app.put("/items/{item_id}") async def create_item(item_id: int, item: Item): return {"item_id": item_id, **item.dict()}这样,您就可以声明路径参数和 JSON 请求体,FastAPI 将为您完成所有的数据验证、序列化和文档。你可以通过在
/docs访问相同的 API 文档或者使用其他工具来验证它,比如带有图形界面的 Postman 或者命令行中的 Curl 。以类似的方式,您可以声明更复杂的请求体,如列表,以及其他类型的请求数据,如查询参数、cookies、标题、表单输入、文件等等。
了解有关 FastAPI 的更多信息
至此,您已经对 FastAPI 以及如何使用它来创建健壮的、生产就绪的 API 有了很多了解。
但是你可以学习的还有很多:
- 查询参数定制请求
- 依赖注入处理权限、数据库会话等可重用逻辑
- 安全实用程序基于标准集成认证和授权
- 后台任务用于发送电子邮件通知等简单操作
async和await支持并发并提高性能- WebSockets 用于需要实时通信的高级用例
- 多个文件中更大的应用程序
FastAPI 可以覆盖后端框架所需的大部分用例,甚至是那些严格意义上不是 API 的用例。您可以更深入地研究文档以解决您的特定用例。
FastAPI 基于现代 Python 特性,您也可以通过了解这些特性来充分利用 FastAPI。查看Python 中的异步特性入门和Python 中的异步 IO:完整演练,了解更多关于异步编程的信息。您还可以查看 Python 类型检查(指南),从代码中的类型提示中获得所有传统的好处。
结论
在本教程中,您了解了 FastAPI 以及如何使用它来创建生产就绪的 API,这些 API 在默认情况下具有最佳实践,同时尽可能提供最佳的开发人员体验。您学习了如何:
- 使用路径参数获得每个项目的唯一 URL 路径
- 使用 pydantic 在您的请求中接收 JSON 数据
- 使用 API 最佳实践,如验证、序列化和文档
- 继续了解针对不同用例的 FastAPI 和 pydantic
现在,您可以开始为您的项目创建自己的高性能 API 了。如果您想更深入地了解 FastAPI 的世界,那么您可以遵循 FastAPI 文档中的官方用户指南。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python REST API 搭配 FastAPI******
斐波纳契数列的 Python 指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 探索斐波那契数列
斐波纳契数列是一个非常著名的整数数列。这个序列在许多问题中自然出现,并且有一个很好的递归定义。学习如何生成它是务实的程序员掌握递归之旅的重要一步。在本教程中,您将重点学习什么是斐波纳契数列,以及如何使用 Python 生成它。
在本教程中,您将学习如何:
- 使用递归算法生成斐波那契数列
- 使用记忆优化递归斐波那契算法
- 使用迭代算法生成斐波那契数列
为了充分利用本教程,您应该了解大 O 符号、面向对象编程、 Python 的特殊方法、条件语句、函数和基本数据结构如列表、队列和堆栈。熟悉这些概念将极大地帮助您理解本教程中将要探索的新概念。
让我们开始吧!
免费下载: 从《Python 基础:Python 3 实用入门》中获取一个示例章节,看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
斐波纳契数列入门
列奥纳多·斐波那契是一位意大利数学家,他能够很快回答斯瓦比亚皇帝腓特烈二世提出的一个问题:“假设每对夫妇每个月生一对兔子,最年轻的夫妇在出生后第二个月就已经能够繁殖后代,除去死亡的情况,一年可以得到多少对兔子?”
答案如下:
该模式在前两个数字 0 和 1 之后开始,其中序列中的每个数字总是它前面两个数字的和。自六世纪以来,印度数学家就知道这个序列,斐波那契利用它来计算兔子数量的增长。
F ( n )用来表示 n 月份中出现的兔子对的数量,所以顺序可以这样表示:
在数学术语中,你会称之为递归关系,这意味着序列中的每一项(超过 0 和 1)都是前一项的函数。
还有一个版本的序列,其中前两个数字都是 1,如下所示:
在这个备选版本中, F (0)仍然隐式为 0,但你改为从 F (1)和 F (2)开始。算法保持不变,因为您总是将前两个数字相加来获得序列中的下一个数字。
出于本教程的目的,您将使用从 0 开始的序列版本。
检查斐波那契数列背后的递归
生成斐波那契数列是一个经典的递归问题。递归是当一个函数引用它自己来分解它试图解决的问题。在每一次函数调用中,问题变得越来越小,直到它到达一个基础用例,之后它会将结果返回给每个中间调用者,直到将最终结果返回给最初的调用者。
如果你想计算 Fibonacci 数 F (5),你需要先计算它的前辈, F (4)和 F (3)。为了计算 F (4)和 F (3),你需要计算它们的前辈。将 F (5)分解成更小的子问题看起来像这样:
每次调用斐波那契函数,它都会被分解成两个更小的子问题,因为这就是你定义递归关系的方式。当它到达基础用例 F (0)或 F (1)时,它最终可以将一个结果返回给它的调用者。
为了计算斐波纳契数列中的第五个数字,您要解决较小但相同的问题,直到到达基本情况,在那里您可以开始返回一个结果:
该图中的彩色子问题代表同一问题的重复解决方案。如果你在树上走得更远,你会发现更多这些重复的解决方案。这意味着要递归生成斐波那契数列,你必须反复计算许多中间数。这是斐波纳契数列递归方法中的一个基本问题。
用 Python 递归生成斐波那契数列
生成斐波纳契数列的最常见和最简单的算法要求您编写一个递归函数,该函数根据需要多次调用自身,直到计算出所需的斐波纳契数:




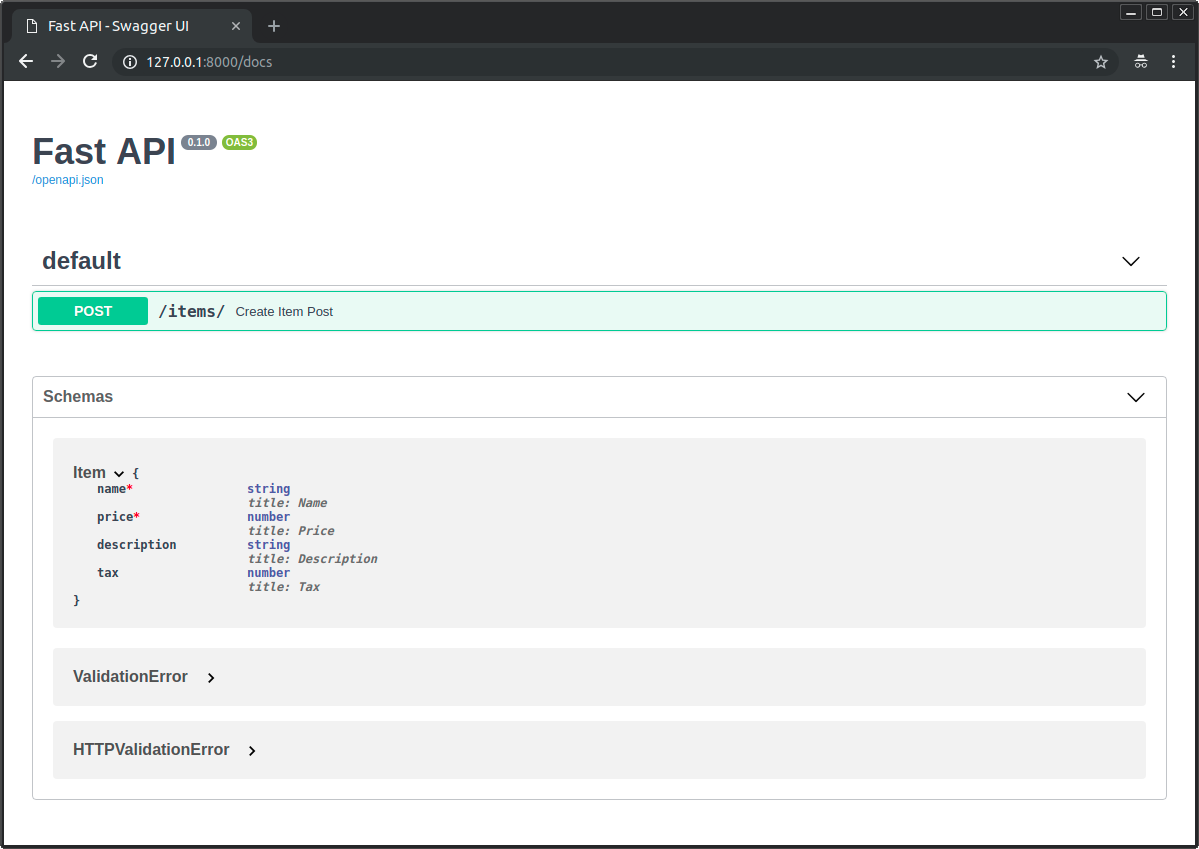







>>> def fibonacci_of(n):
... if n in {0, 1}: # Base case
... return n
... return fibonacci_of(n - 1) + fibonacci_of(n - 2) # Recursive case
...
>>> [fibonacci_of(n) for n in range(15)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377]
在fibonacci_of()里面,你首先检查基本情况。然后,返回调用带有前面两个值n的函数所得到的值的总和。示例末尾的列表理解生成一个包含前十五个数字的斐波那契数列。
这个函数很快就陷入了你在上一节中看到的重复问题。随着n变大,计算变得越来越昂贵。所需时间呈指数增长,因为该函数反复计算许多相同的子问题。
注意:号码大于 50 的不要在家尝试此功能。取决于你的硬件,你可能要等很长时间才能看到结果——如果你坚持到最后的话。
为了计算 F (5),fibonacci_of()要调用自己十五次。计算 F ( n ),调用树的最大深度为 n ,由于每个函数调用产生两个额外的函数调用,所以这个递归函数的时间复杂度为O(2n)。
大多数调用都是多余的,因为你已经计算了它们的结果。 F (3)出现两次, F (2)出现三次。 F (1)和 F (0)是基例,多次调用也没问题。您可能希望避免这种浪费的重复,这是下面几节的主题。
优化斐波那契数列的递归算法
至少有两种技术可以用来提高生成斐波那契数列的算法的效率,换句话说,就是减少计算时间。这些技术确保您不会一遍又一遍地计算相同的值,而这正是最初的算法效率如此之低的原因。它们被称为记忆化和迭代。
记忆递归算法
正如您在上面的代码中看到的,Fibonacci 函数用相同的输入调用了自己几次。您可以将之前调用的结果存储在类似于内存缓存的东西中,而不是每次都进行新的调用。您可以使用 Python list 来存储之前计算的结果。这种技术叫做记忆化。
记忆化通过将先前计算的结果存储在高速缓存中来加速昂贵的递归函数的执行。这样,当相同的输入再次出现时,函数只需查找相应的结果并返回,而不必再次运行计算。您可以将这些结果称为缓存的或记忆的:
有了记忆化,您只需在从基础用例返回后遍历一次深度为 n 的调用树,因为您从之前的缓存中检索了所有之前计算的值,这些值以黄色突出显示, F (2)和 F (3)。
橙色的路径显示斐波纳契函数的输入没有被调用一次以上。这大大降低了算法的时间复杂度,从指数级的O(2T3】nT5)降低到线性的 O ( n )。
即使对于基本情况,您也可以用直接从缓存中检索索引 0 和 1 处的值来代替调用 F (0)和 F (1 ),因此您最终只调用了该函数 6 次,而不是 15 次!
下面是将这种优化转换成 Python 代码的一种可能方式:
>>> cache = {0: 0, 1: 1} >>> def fibonacci_of(n): ... if n in cache: # Base case ... return cache[n] ... # Compute and cache the Fibonacci number ... cache[n] = fibonacci_of(n - 1) + fibonacci_of(n - 2) # Recursive case ... return cache[n] >>> [fibonacci_of(n) for n in range(15)] [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377]在这个例子中,您使用 Python 字典来缓存计算出的斐波那契数。最初,
cache包含斐波纳契数列的起始值,0 和 1。在函数内部,首先检查当前输入值n的斐波那契数是否已经在cache中。如果是这样,那么你把手头的号码还回去。如果
n的当前值没有斐波那契数,那么通过递归调用fibonacci_of()并更新cache来计算它。最后一步是返回请求的斐波那契数。探索迭代算法
如果你根本不需要调用递归的斐波那契函数呢?您实际上可以使用迭代算法来计算斐波那契数列中位置
n处的数字。您知道序列中的前两个数字是 0 和 1,并且序列中的每个后续数字是其前两个前置数字的总和。因此,您可以创建一个循环,将前面的两个数字
n - 1和n - 2加在一起,找到序列中位置n处的数字。下图中加粗的紫色数字代表在每个迭代步骤中需要计算并添加到
cache的新数字:
为了计算位置
n处的斐波那契数,将序列的前两个数字 0 和 1 存储在cache中。然后,连续计算下一个数字,直到你可以返回cache[n]。在 Python 中生成斐波那契数列
现在您已经知道了如何生成斐波那契数列的基础知识,是时候更深入地探索用 Python 实现底层算法的不同方法了。在接下来的几节中,您将探索如何使用递归、Python 面向对象编程以及迭代来实现不同的算法来生成斐波那契数列。
使用递归和 Python 类
生成斐波那契数列的第一种方法将使用 Python 类和递归。与之前看到的记忆化递归函数相比,使用该类的一个优点是,一个类将状态和行为(封装)一起保存在同一个对象中。然而,在函数示例中,
cache是一个完全独立的对象,因此您无法控制它。下面是实现基于类的解决方案的代码:
1# fibonacci_class.py 2 3class Fibonacci: 4 def __init__(self): 5 self.cache = [0, 1] 6 7 def __call__(self, n): 8 # Validate the value of n 9 if not (isinstance(n, int) and n >= 0): 10 raise ValueError(f'Positive integer number expected, got "{n}"') 11 12 # Check for computed Fibonacci numbers 13 if n < len(self.cache): 14 return self.cache[n] 15 else: 16 # Compute and cache the requested Fibonacci number 17 fib_number = self(n - 1) + self(n - 2) 18 self.cache.append(fib_number) 19 20 return self.cache[n]下面是代码中发生的事情的分类:
第 3 行定义了
Fibonacci类。第 4 行定义了类初始化器,
.__init__()。这是一个特殊的方法,你可以用它来初始化你的类实例。特殊方法有时被称为双下划线方法,是双下划线方法的缩写。第 5 行创建了
.cache实例属性,这意味着无论何时你创建一个Fibonacci对象,都会有一个针对它的缓存。该属性最初包含斐波那契数列中的第一个数字。第 7 行定义了另一个特殊的方法
.__call__()。这个方法将Fibonacci的实例转换成可调用的对象。第 9 行和第 10 行通过使用条件语句来验证
n的值。如果n不是正整数,那么该方法产生一个ValueError。第 13 行定义了一个条件语句来检查那些已经计算过的并且在
.cache中可用的斐波纳契数。如果索引n处的数字已经在.cache中,那么第 14 行返回它。否则,第 17 行计算这个数字,第 18 行把它附加到.cache上,这样就不用再计算了。第 20 行返回请求的斐波那契数。
要尝试此代码,请将其保存到
fibonacci_class.py中。然后在您的交互式 shell 中运行以下代码:

>>> from fibonacci_class import Fibonacci
>>> fibonacci_of = Fibonacci()
>>> fibonacci_of(5)
5
>>> fibonacci_of(6)
8
>>> fibonacci_of(7)
13
>>> [fibonacci_of(n) for n in range(15)]
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377]
在这里,您创建并调用名为fibonacci_of的Fibonacci类的实例。第一个调用使用5作为参数并返回5,这是第六个斐波那契数,因为您使用的是从零开始的索引。
斐波那契数列算法的这种实现是非常有效的。一旦有了这个类的实例,.cache属性就保存了从一个调用到另一个调用已经计算好的数字。
可视化记忆的斐波那契数列算法
您可以有效地理解如何使用调用栈表示来处理对递归 Fibonacci 函数的每个调用。每个调用被压入堆栈和弹出的方式准确地反映了程序的运行方式。它清楚地表明,如果不优化算法,计算大数将需要很长时间。
在调用堆栈中,每当函数返回结果时,表示函数调用的堆栈帧就会弹出堆栈。每当你调用一个函数,你就在栈顶添加一个新的栈帧。一般来说,这个操作有一个 O ( n )的空间复杂度,因为一次调用栈上的栈帧不超过 n 。
注意:有一个初学者友好的代码编辑器叫 Thonny,它允许你以图形化的方式可视化递归函数的调用栈。你可以查看 Thonny:初学者友好的 Python 编辑器来了解更多。
为了可视化记忆化的递归 Fibonacci 算法,您将使用一组表示调用堆栈的图表。步骤号由每个调用堆栈下面的蓝色标签表示。
说你要计算 F (5)。为此,您将对该函数的第一次调用推送到调用堆栈上:

要计算 F (5),您必须按照斐波纳契递归关系计算 F (4),因此您将新的函数调用添加到堆栈中:
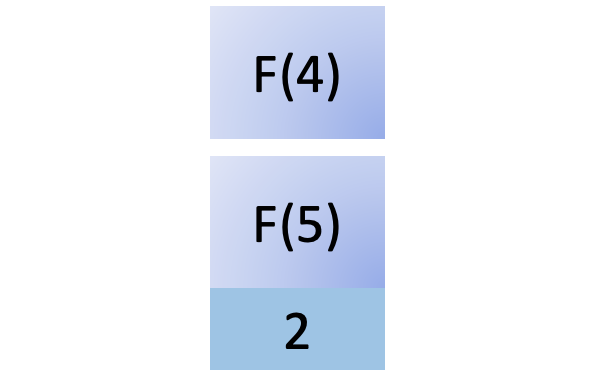
为了计算 F (4),你必须计算 F (3),所以你向堆栈添加了另一个函数调用:
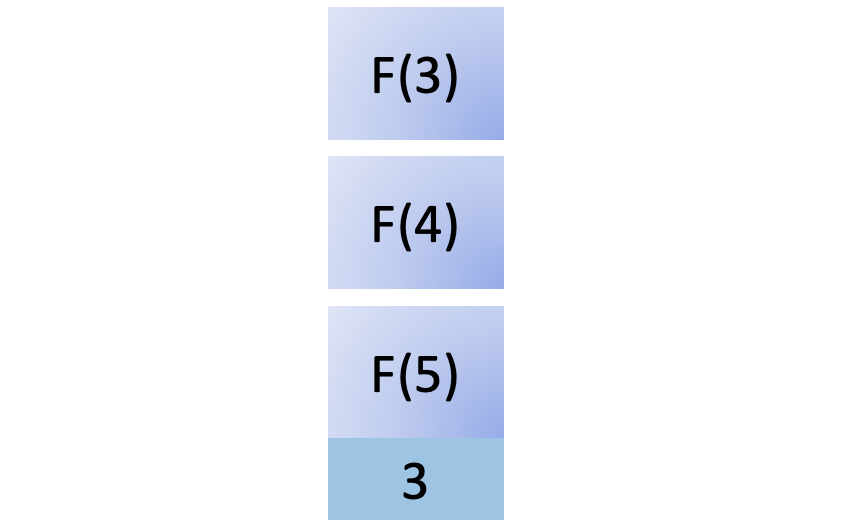
为了计算 F (3),您必须计算 F (2),因此您向调用堆栈添加了另一个函数调用:
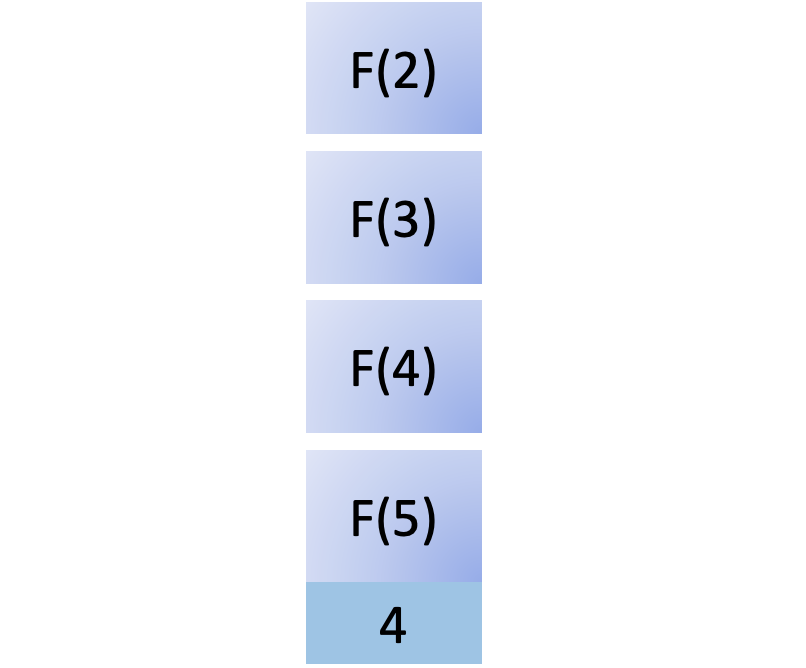
为了计算 F (2),你必须计算 F (1),所以你把它添加到堆栈中。由于 F (1)是一个基本情况,它立即返回 1,您从堆栈中删除这个调用:
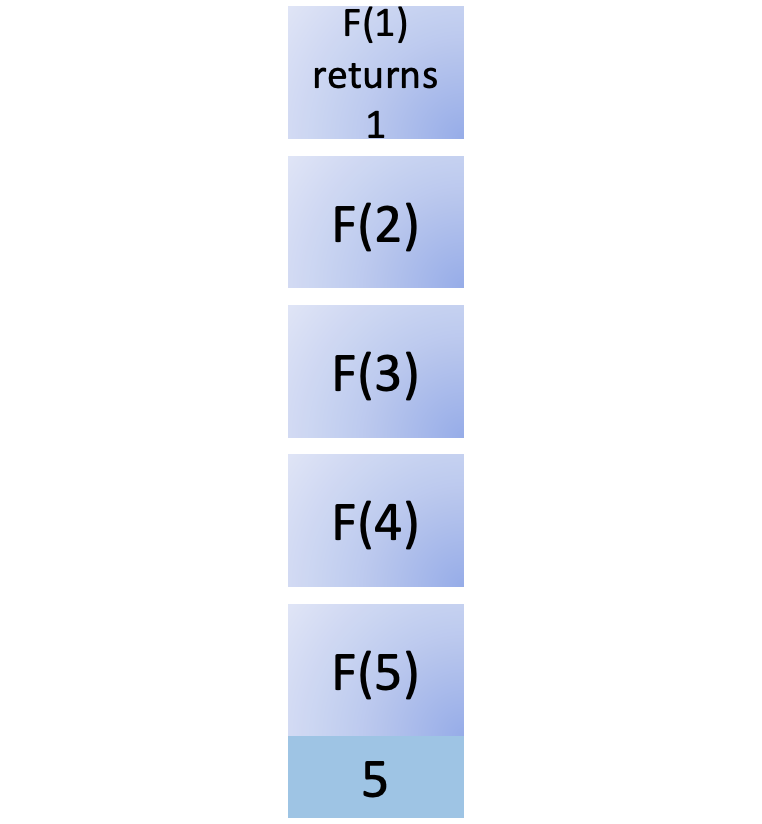
现在你开始递归展开结果。 F (1)将结果返回给它的调用函数, F (2)。要计算 F (2),还需要计算 F (0):
你将 F (0)添加到堆栈中。由于 F (0)是一个基本情况,它立即返回,给你 0。现在您可以将它从调用堆栈中移除:
这个调用 F (0)的结果返回给 F (2)。现在你有了计算 F (2)所需的东西,并将其从堆栈中移除:
将 F (2)的结果返回给它的调用者, F (3)。 F (3)也需要 F (1)的结果来完成它的计算,所以你把它加回堆栈:
F (1)是一个基础用例,它的值在缓存中可用,所以您可以立即返回结果,并将 F (1)从堆栈中移除:
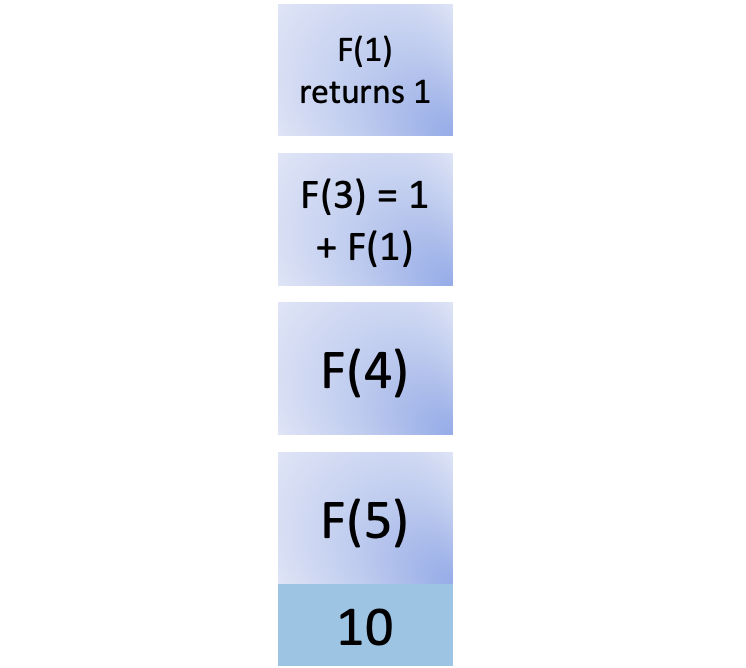
可以完成对 F (3)的计算,即 2:
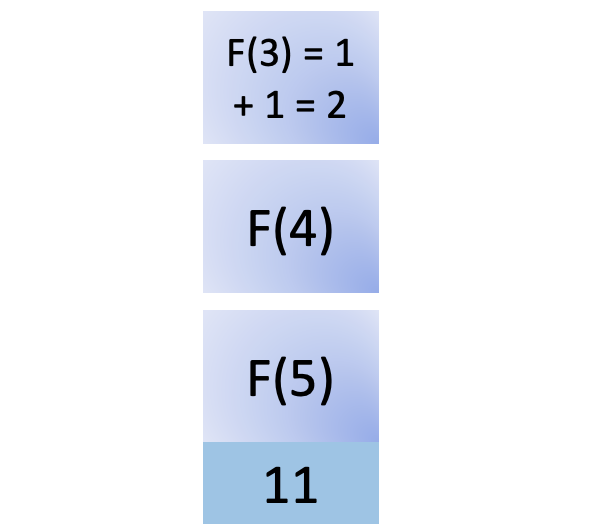
你在完成计算后从堆栈中移除 F (3),并将结果返回给它的调用者, F (4)。 F (4)也需要 F (2)的结果来计算其值:

您将对 F (2)的调用推送到堆栈上。这就是漂亮的缓存发挥作用的地方。您之前已经计算过了,所以您可以从缓存中检索该值,避免再次递归调用来计算 F (2)的结果。缓存返回 1,你从堆栈中移除 F (2):
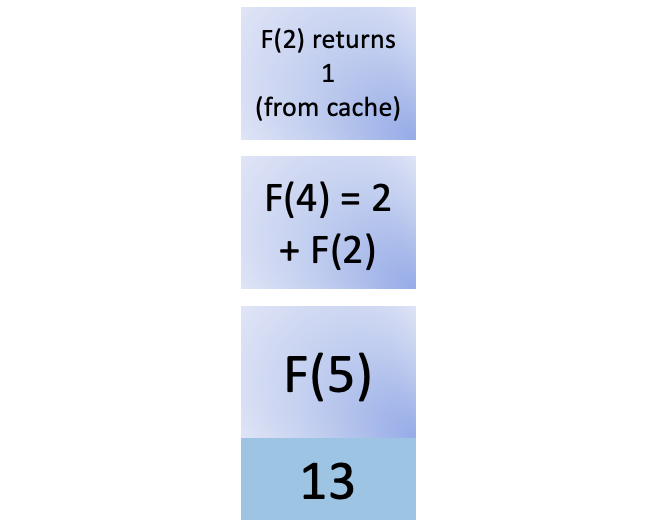
F (2)被返回给它的调用者,现在 F (4)拥有了计算它的值所需的所有东西,即 3:

接下来,您从堆栈中移除 F (4),并将其结果返回给最终和最初的调用者, F (5):

F (5)现在有了 F (4)的结果,也有了 F (3)的结果。您将一个 F (3)调用压入堆栈,漂亮的缓存再次发挥作用。您之前已经计算了 F (3),所以您需要做的就是从缓存中检索它。没有计算 F (3)的递归过程。它返回 2,你从堆栈中移除 F (3):
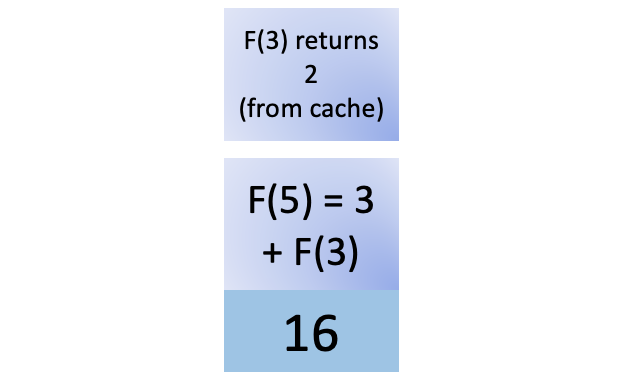
现在 F (5)有了计算自己值所需的所有值。将 3 和 2 相加得到 5,这是将 F (5)调用弹出堆栈之前的最后一步。此操作结束递归函数调用序列:

调用堆栈现在是空的。您已经完成了计算 F (5)的最后一步:

使用调用堆栈图表示递归函数调用有助于您理解在幕后发生的所有工作。它还允许您查看递归函数可以占用多少资源。
将所有这些图表放在一起,可以让您直观地看到整个过程:
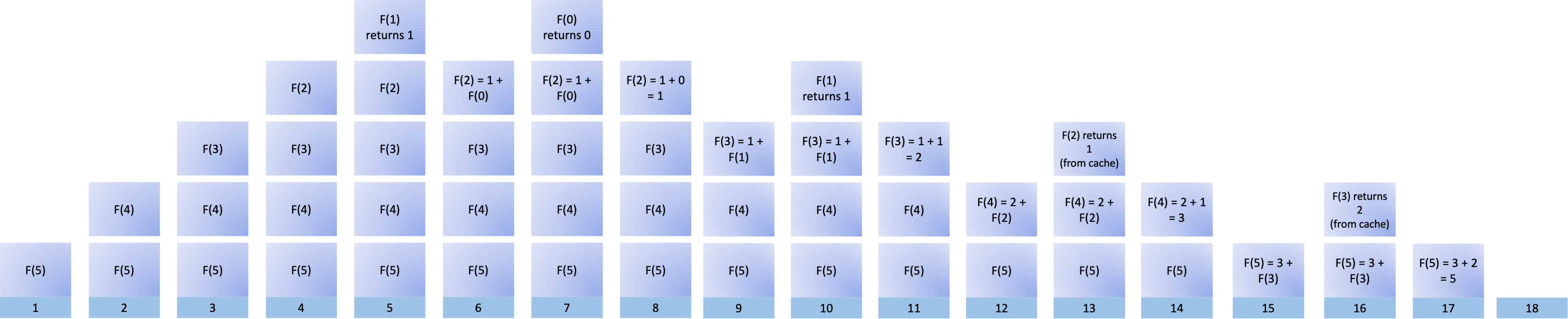
你可以点击上面的图片放大单个步骤。如果不缓存之前计算的斐波那契数,这个图中的一些堆栈阶段会高得多,这意味着它们需要更长的时间向各自的调用方返回结果。
使用迭代和 Python 函数
前面几节中的例子实现了一个递归解决方案,它使用记忆化作为优化策略。在本节中,您将编写一个使用迭代的函数。下面的代码实现了斐波那契数列算法的迭代版本:
1# fibonacci_func.py
2
3def fibonacci_of(n):
4 # Validate the value of n
5 if not (isinstance(n, int) and n >= 0):
6 raise ValueError(f'Positive integer number expected, got "{n}"')
7
8 # Handle the base cases
9 if n in {0, 1}:
10 return n
11
12 previous, fib_number = 0, 1
13 for _ in range(2, n + 1):
14 # Compute the next Fibonacci number, remember the previous one
15 previous, fib_number = fib_number, previous + fib_number
16
17 return fib_number
现在,你不用在fibonacci_of()中使用递归,而是使用迭代。斐波那契序列算法的这种实现以 O ( n )的线性时间运行。下面是代码的细目分类:
-
第 3 行定义了
fibonacci_of(),它以一个正整数n作为参数。 -
第 5 行和第 6 行执行
n的常规验证。 -
第 9 行和第 10 行处理
n为 0 或 1 的基本情况。 -
第 12 行定义了两个局部变量
previous和fib_number,并用斐波那契数列中的前两个数初始化它们。 -
第 13 行开始一个
for循环,从2迭代到n + 1。循环使用下划线(_)作为循环变量,因为它是一个一次性变量,您不会在代码中使用这个值。 -
第 15 行计算序列中的下一个斐波那契数,并记住前一个。
-
第 17 行返回请求的斐波那契数。
要尝试一下这段代码,请返回到您的交互式会话并运行以下代码:
>>> from fibonacci_func import fibonacci_of >>> fibonacci_of(5) 5 >>> fibonacci_of(6) 8 >>> fibonacci_of(7) 13 >>> [fibonacci_of(n) for n in range(15)] [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377]这个
fibonacci_of()的实现非常简单。它使用可迭代解包来计算循环中的斐波纳契数,这在内存方面非常有效。然而,每次你用不同的值n调用函数时,它必须重新计算一遍序列。要解决这个问题,你可以使用闭包,让你的函数记住调用之间已经计算过的值。来吧,试一试!结论
斐波那契数列可以帮助你提高对递归的理解。在本教程中,你已经学习了什么是斐波纳契数列。您还了解了生成序列的一些常用算法,以及如何将它们转换成 Python 代码。
斐波那契数列可以成为进入递归世界的一个很好的跳板和切入点,这是一个程序员必须掌握的基本技能。
在本教程中,您学习了如何:
- 使用递归算法生成斐波那契数列
- 使用记忆优化您的递归斐波那契算法
- 使用迭代算法生成斐波那契数列
您还可视化了记忆化的递归算法,以便更好地理解它在幕后是如何工作的。为此,您使用了一个调用栈图。
一旦您掌握了本教程中的概念,您的 Python 编程技能将随着您的递归算法思维一起提高。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 探索斐波那契数列**
用于近似重复检测的指纹图像
原文:https://realpython.com/fingerprinting-images-for-near-duplicate-detection/
这是来自PyImageSearch.com的 Adrian Rosebrock 的客座博文,这是一个关于计算机视觉、图像处理和构建图像搜索引擎的博客。
更新:
- 2014 年 12 月 22 日-删除了代码中对行号的引用。
- 2015 年 5 月 22 日-添加了依赖版本。
大约五年前,我在一个交友网站做开发工作。他们是一家早期创业公司,但开始看到一些初步的牵引力。与其他交友网站不同,这家公司以清白的名声推销自己。这不是一个你可以去勾搭的网站——这是一个你可以去寻找真诚关系的地方。
在数百万风险资本的推动下(这是在美国经济衰退之前),他们关于真爱和寻找灵魂伴侣的在线广告像大片一样转化了。他们被福布斯报道过。他们甚至出现在国家电视台的聚光灯下。这些早期的成功导致了令人垂涎的创业公司的指数增长——他们的用户数量每月翻一番。事情看起来对他们非常有利。
但是他们有一个严重的问题——色情问题。
交友网站的一小部分用户上传色情图片,并将其设置为个人资料图片。这种行为破坏了许多顾客的体验,导致他们取消了会员资格。
现在,也许对一些约会网站来说,这里有一些色情图片可能不是问题。或者它甚至可能被认为是“正常的”或“预期的”,只是被简单接受和忽视的网恋的副产品。
然而,这种行为既不能被接受,也不能被忽视。
请记住,这是一家将自己标榜为高级约会天堂的初创公司,没有困扰其他约会网站的污秽和垃圾。简而言之,他们需要维护一个非常真实的由风险投资支持的声誉。
绝望的是,约会网站争先恐后地阻止色情的爆发。他们雇佣了图像管理员团队,他们什么也不做,每天盯着管理页面 8 个多小时,删除上传到社交网络的任何新的色情图像。
他们实际上在这个问题上投入了数万美元(更不用说无数工时),只是试图缓和和遏制疫情,而不是在源头上阻止它。
疫情在 2009 年 7 月达到临界水平。八个月来,用户数量首次未能翻番(甚至开始下降)。更糟糕的是,投资者威胁说,如果该公司不解决这个问题,他们就会撤资。
事实上,污秽的潮水冲击着象牙塔,威胁着要将它倾入大海。
随着约会巨头的膝盖开始弯曲,我提出了一个更稳健和长期的解决方案:如果我们使用图像指纹来对抗疫情会怎么样?
你看,每张照片都有指纹。就像指纹可以识别人一样,它也可以识别图像。
这导致三阶段算法的实现:
- 对我们的一组不适当的图像进行指纹识别,并将图像指纹存储在数据库中。
- 当用户上传新的个人资料图片时,我们会将其与我们的图像指纹数据库进行比较。如果上传的指纹与任何不适当图片的指纹匹配,我们会阻止用户将该图片设置为他们的个人资料图片。
- 随着图像版主标记新的色情图像,它们也被采集指纹并存储在我们的数据库中,创建了一个不断发展的数据库,可用于防止无效上传。
我们的过程虽然不完美,但很有效。疫情缓慢但稳定地减缓了。它从未完全停止——但通过使用这种算法,我们成功地将不适当的上传数量减少了 80% 。
我们还设法让投资者满意。他们继续资助我们——直到经济衰退来袭。然后我们都失业了。
回想起来,我不禁笑了。我的工作没持续多久。公司没有持续下去。甚至有几个投资者被抛弃了。
但是有一件事幸存了下来。图像指纹算法。几年后,我想与你分享这个算法的基础,希望你能在自己的项目中使用它。
但最大的问题是,我们如何创建这个图像指纹?
请继续阅读,寻找答案。
我们要做什么?
我们将利用图像指纹来执行近似重复图像检测。这种技术通常被称为“感知图像哈希”或简称为“图像哈希”。
什么是图像指纹/哈希?
图像哈希是检查图像内容,然后基于这些内容构造唯一标识图像的值的过程。
例如,看看这篇文章顶部的图片。给定一个输入图像,我们将应用一个哈希函数,并根据图像的视觉外观计算一个“图像哈希”。“相似”的图像也应该有“相似”的散列。使用图像散列算法使得执行近似重复图像检测变得更加容易。
特别是,我们将使用“差异哈希”,或简单的 dHash 算法来计算我们的图像指纹。简单地说,dHash 算法查看相邻像素值之间的差异。然后,根据这些差异,创建一个哈希值。
为什么不能用 md5,sha-1 等。?
不幸的是,我们不能在实现中使用加密哈希算法。由于加密哈希算法的性质,输入文件中非常微小的变化都会导致一个完全不同的哈希。在图像指纹的情况下,我们实际上希望我们的相似的输入也有相似的输出散列。
图像指纹可以用在哪里?
就像我上面的例子一样,您可以使用图像指纹来维护一个不合适图像的数据库,并在用户试图上传这样的图像时提醒他们。
你可以建立一个反向图片搜索引擎,比如 TinEye 来跟踪图片和它们出现的相关网页。
你甚至可以使用图像指纹来帮助管理你自己的个人照片收藏。想象一下,你有一个硬盘驱动器,里面装满了你的照片库的部分备份,但需要一种方法来修剪部分备份,只保留图像的唯一副本-图像指纹也可以帮助实现这一点。
简而言之,您可以在几乎任何与检测图像的近似副本有关的设置中使用图像指纹/散列。
我们需要什么样的图书馆?
为了构建我们的图像指纹解决方案,我们将利用三个主要的 Python 包:
您可以通过执行以下命令来安装所有必需的先决条件:
$ pip install pillow==2.6.1 imagehash==0.3步骤 1:对数据集进行指纹识别
第一步是采集图像数据集的指纹。
在你问之前,不,我们不会像我在约会网站工作时那样使用色情图片。相反,我创造了一个我们可以使用的人工数据集。
在计算机视觉研究人员中, CALTECH-101 数据集是传奇。它包含来自 101 个不同类别的 7,500 多张图像,包括人、摩托车和飞机。
从这 7500 张图片中,我随机选择了其中的 17 张。
然后,从这 17 个随机选择的图像中,我通过随机调整+/-几个百分点的大小,创建了 N 个新图像。我们的目标是找到这些近乎重复的图像——有点像大海捞针。
想要创建一个相似的数据集来使用吗?下载 CALTECH-101 数据集,抓取 17 张左右的图像,然后运行在 repo 中找到的 gather.py 脚本。
同样,这些图像在各个方面都是相同的,除了宽度和高度。由于它们没有相同的维数,我们不能依赖简单的 md5 校验和。更重要的是,内容相似的图像可能有显著不同的* md5 散列。相反,我们可以求助于图像哈希,其中具有相似内容的图像也将具有相似的哈希指纹。*
因此,让我们从编写代码来采集数据集的指纹开始。打开一个新文件,命名为
index.py,让我们开始工作:# import the necessary packages from PIL import Image import imagehash import argparse import shelve import glob # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", required = True, help = "path to input dataset of images") ap.add_argument("-s", "--shelve", required = True, help = "output shelve database") args = vars(ap.parse_args()) # open the shelve database db = shelve.open(args["shelve"], writeback = True)我们要做的第一件事是导入我们需要的包。我们将使用来自
PIL或Pillow的Image类从磁盘上加载我们的图像。然后可以利用imagehash库来构建感知哈希。从那里,
argparse被用于解析命令行参数,shelve被用作驻留在磁盘上的简单的键值数据库(Python 字典),而glob被用于轻松地收集到我们的图像的路径。然后我们解析我们的命令行参数。第一个,
--dataset是图像输入目录的路径。第二个,--shelve是我们的shelve数据库的输出路径。接下来,我们打开我们的
shelve数据库进行写入。这个db将存储我们的图像散列。更多关于下一个:# loop over the image dataset for imagePath in glob.glob(args["dataset"] + "/*.jpg"): # load the image and compute the difference hash image = Image.open(imagePath) h = str(imagehash.dhash(image)) # extract the filename from the path and update the database # using the hash as the key and the filename append to the # list of values filename = imagePath[imagePath.rfind("/") + 1:] db[h] = db.get(h, []) + [filename] # close the shelf database db.close()这里是大部分工作发生的地方。我们开始遍历上的图像数据集,从磁盘加载它,然后创建图像指纹。
现在,我们来看整个教程中最重要的两行代码:
filename = imagePath[imagePath.rfind("/") + 1:] db[h] = db.get(h, []) + [filename]就像我之前在这篇文章中提到的,指纹相同的图片被认为是相同的。
因此,如果我们的目标是找到几乎相同的图像,我们需要维护一个具有相同指纹值的图像列表。
这正是这些线条的作用。
前者提取图像的文件名。然后后者维护具有相同图像散列的文件名列表。
要从我们的数据集中提取图像指纹并构建我们的哈希数据库,发出以下命令:
$ python index.py --dataset images --shelve db.shelve该脚本将运行几秒钟,一旦完成,您将拥有一个名为
db.shelve的文件,其中包含图像指纹和文件名的键值对。这个相同的基本算法是我几年前为约会创业公司工作时使用的。我们获取不合适图像的数据集,为每个图像构建一个图像指纹,然后将它们存储在我们的数据库中。当一张新图片到达时,我简单地计算了图片的散列值,并检查数据库,看看上传的图片是否已经被标记为无效内容。
在下一步中,我将向您展示如何执行实际的搜索,以确定数据库中是否已经存在具有相同哈希值的图像。
步骤 2:搜索数据集
现在我们已经建立了一个图像指纹数据库,是时候搜索我们的数据集了。
打开一个新文件,命名为
search.py,我们将得到代码:# import the necessary packages from PIL import Image import imagehash import argparse import shelve # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", required = True, help = "path to dataset of images") ap.add_argument("-s", "--shelve", required = True, help = "output shelve database") ap.add_argument("-q", "--query", required = True, help = "path to the query image") args = vars(ap.parse_args())我们将再次在上导入我们的相关包。然后我们解析命令行参数。我们需要三个开关,
–dataset,它是到我们的原始图像数据集的路径,–shelve,它是到我们的键-值对的shelve数据库的路径,以及–query,它是到我们的查询/上传图像的路径。我们的目标是获取查询图像并确定它是否已经存在于我们的数据库中。现在,让我们编写代码来执行实际的搜索:
# open the shelve database db = shelve.open(args["shelve"]) # load the query image, compute the difference image hash, and # and grab the images from the database that have the same hash # value query = Image.open(args["query"]) h = str(imagehash.dhash(query)) filenames = db[h] print "Found %d images" % (len(filenames)) # loop over the images for filename in filenames: image = Image.open(args["dataset"] + "/" + filename) image.show() # close the shelve database db.close()我们首先打开数据库,然后从磁盘上加载图像,计算图像指纹,并找到具有相同指纹值的所有图像。
如果有任何图像具有相同的哈希值,我们循环遍历这些图像,并将它们显示在屏幕上。
使用这个代码,我们将能够确定一个图像是否已经存在于我们的数据库中,只使用指纹值。
结果
正如我在这篇文章前面提到的,我已经从 CALTECH-101 数据集中提取了大约 7500 张原始图像,随机选择了其中的 17 张,然后通过随机调整几个百分点的大小来生成 N 张新图像。
这些图像的尺寸仅相差几个像素,但正因为如此,我们不能依赖文件的 md5 散列(这一点将在“改进我们的算法”一节中进一步阐述)。相反,我们需要利用图像散列来找到近似重复的图像。
打开您的终端并执行以下命令:
$ python search.py --dataset images --shelve db.shelve --query images/84eba74d-38ae-4bf6-b8bd-79ffa1dad23a.jpg如果一切顺利,您应该会看到以下结果:
左边的是我们的输入图像。我们获取这个图像,计算它的图像指纹,然后在我们的数据库中查找指纹,看看是否有任何其他图像具有相同的指纹。
果不其然,我们的数据集中还有另外两张图像具有完全相同的指纹,如右边的所示。虽然从截图上看不太明显,但这些图片虽然有完全相同的视觉内容,但并不完全相同!这三张图片都有不同的宽度和高度。
让我们尝试另一个输入图像:
$ python search.py --dataset images --shelve db.shelve --query images/9d355a22-3d59-465e-ad14-138a4e3880bc.jpg结果如下:
我们再次将输入图像放在 左边 。我们的图像指纹算法能够找到三个具有相同指纹的相同图像,如右侧的 和 所示。
最后一个例子:
$ python search.py --dataset images --shelve db.shelve --query images/5134e0c2-34d3-40b6-9473-98de8be16c67.jpg
这次我们输入的图像是一辆摩托车上的 左边的 。我们拍摄了这张摩托车图像,计算了它的图像指纹,然后在我们的指纹数据库中查找。正如我们在右侧的 和 上看到的,我们能够确定数据库中还有另外三张图像具有相同的指纹。
改进我们的算法
有很多方法可以改进我们的算法——但最关键的方法是考虑到那些相似,但不相同的散列。
例如,这篇文章中的图片只被调整了几个百分点。如果一幅图像的大小被放大了一倍,或者纵横比改变了,那么散列就不一样了。
然而,图像仍然是相似的。
为了找到相似但不相同的图像,我们需要探索汉明距离。汉明距离可以用来计算散列中不同的比特数。因此,散列值只有 1 位差异的两个图像比散列值有 10 位差异的图像更加相似。
然而,我们遇到了第二个问题——我们算法的可扩展性。
考虑一下:给我们一个输入图像,并要求我们在数据库中找到所有相似的图像。然后,我们必须计算我们的输入图像和数据库中的每一个图像之间的汉明距离。
随着数据库规模的增长,比较所有哈希值所需的时间也会增长。最终,我们的散列数据库将达到这样的大小,以至于这种线性比较是不实际的。
解决方案,虽然超出了本文的范围,是利用 K-d 树和 VP 树将搜索问题的复杂性从线性降低到子线性。
总结
在这篇博文中,我们学习了如何构建和利用图像哈希来执行近似重复图像检测。这些图像哈希是使用图像的可视内容构建的。
就像指纹可以识别一个人一样,图像哈希也可以唯一地识别图像。
利用我们的图像指纹知识,我们构建了一个系统,只使用图像哈希就可以找到并识别具有相似内容的图像。
然后,我们演示了如何使用这个图像散列来快速查找具有近似重复内容的图像。
哦,一定要从回购那里拿到代码。
在一个周末学习计算机视觉:如果你喜欢这篇文章,并想了解更多关于计算机视觉、图像处理和构建图像搜索引擎的知识,请访问我在 PyImageSearch.com的博客。
干杯!***
使用 Flask 蓝图来构建您的应用程序
Flask 是一个非常流行的网络应用框架,它将几乎所有的设计和架构决策留给了开发者。在本教程中,你将了解到一个 Flask Blueprint ,或者简称为 Blueprint ,如何通过将它的功能组合成可重用的组件来帮助你构建你的 Flask 应用程序。
在本教程中,您将学习:
- 什么是烧瓶设计图以及它们是如何工作的
- 如何创建和使用 Flask 蓝图来组织你的代码
- 如何使用自己或第三方的 Flask 蓝图来提高代码的可重用性
本教程假设您有一些使用 Flask 的经验,并且您以前已经构建过一些应用程序。如果你以前没有使用过 Flask,那么就用 Flask(教程系列)来看看 Python Web 应用。
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
烧瓶应用程序是什么样子的
让我们从回顾一个小 Flask 应用程序的结构开始。您可以按照本节中的步骤创建一个小型 web 应用程序。要开始,您需要安装
FlaskPython 包。您可以使用pip运行以下命令来安装 Flask:$ pip install Flask==1.1.1上面的命令安装 Flask 版本
1.1.1。这是您将在本教程中使用的版本,尽管您也可以将在此学到的内容应用到其他版本中。注意:关于如何在虚拟环境中安装 Flask 和其他
pip选项的更多信息,请查看 Python 虚拟环境:入门和什么是 Pip?新蟒蛇指南。安装 Flask 后,就可以开始实现它的功能了。因为 Flask 没有对项目结构施加任何限制,所以您可以按照自己的意愿组织项目代码。对于您的第一个应用程序,您可以使用非常简单的布局,如下所示。一个文件将包含所有应用程序逻辑:
app/ | └── app.py文件
app.py将包含应用程序及其视图的定义。创建 Flask 应用程序时,首先创建一个代表应用程序的
Flask对象,然后将视图与路线关联起来。Flask 负责根据请求 URL 和您定义的路由将传入的请求分派到正确的视图。在 Flask 中,视图可以是接收请求并返回该请求的响应的任何可调用对象(比如函数)。Flask 负责将响应发送回用户。
以下代码块是您的应用程序的完整源代码:
from flask import Flask app = Flask(__name__) @app.route('/') def index(): return "This is an example app"这段代码创建了对象
app,它属于Flask类。使用app.route装饰器将视图功能index()链接到路线/。要了解更多关于装饰者的信息,请查看 Python 装饰者入门和 Python 装饰者 101 。您可以使用以下命令运行该应用程序:
$ flask run默认情况下,Flask 将在端口 5000 上运行您在
app.py中定义的应用程序。当应用程序运行时,使用您的网络浏览器进入http://localhost:5000。你会看到一个页面显示消息,This is an example app。所选择的项目布局对于非常小的应用程序来说是非常好的,但是它不能很好地伸缩。随着代码的增长,在一个文件中维护所有内容会变得更加困难。所以,当你的应用程序变得越来越大或者越来越复杂时,你可能想用不同的方式来组织你的代码,以保持它的可维护性和清晰易懂。在本教程中,你将学习如何使用 Flask 蓝图来实现这一点。
烧瓶蓝图是什么样子的
Flask 蓝图封装了功能,比如视图、模板和其他资源。为了体验 Flask Blueprint 是如何工作的,您可以通过将
index视图移动到 Flask Blueprint 中来重构之前的应用程序。为此,您必须创建一个包含index视图的 Flask 蓝图,然后在应用程序中使用它。这是这个新应用程序的文件结构:
app/ | ├── app.py └── example_blueprint.py
example_blueprint.py将包含烧瓶蓝图实现。然后您将修改app.py来使用它。下面的代码块展示了如何在
example_blueprint.py中实现这个 Flask 蓝图。它包含一个在路线/上的视图,该视图返回文本This is an example app:from flask import Blueprint example_blueprint = Blueprint('example_blueprint', __name__) @example_blueprint.route('/') def index(): return "This is an example app"在上面的代码中,您可以看到大多数 Flask Blueprint 定义共有的步骤:
- 创建一个名为
example_blueprint的Blueprint对象。- 使用
route装饰器将视图添加到example_blueprint中。以下代码块显示了您的应用程序如何导入和使用 Flask Blueprint:
from flask import Flask from example_blueprint import example_blueprint app = Flask(__name__) app.register_blueprint(example_blueprint)要使用任何一个 Flask Blueprint,你必须导入它,然后用
register_blueprint()在应用程序中注册。当一个 Flask Blueprint 被注册时,这个应用程序会用它的内容进行扩展。您可以使用以下命令运行该应用程序:
$ flask run当应用程序运行时,使用您的网络浏览器进入
http://localhost:5000。您将看到一个显示消息This is an example app的页面。烧瓶蓝图如何工作
在本节中,您将详细了解如何实现和使用 Flask 蓝图。每个 Flask 蓝图都是一个对象,其工作方式与 Flask 应用程序非常相似。它们都可以拥有资源,例如静态文件、模板和与路由相关联的视图。
然而,Flask Blueprint 实际上不是一个应用程序。它需要在应用程序中注册,然后才能运行。当你在应用程序中注册一个 Flask 蓝图时,你实际上是用蓝图的内容来扩展应用程序。
这是任何烧瓶蓝图背后的关键概念。当您在应用程序中注册它们时,它们记录了以后要执行的操作。例如,当您将一个视图与 Flask 蓝图中的一条路线相关联时,它会记录这种关联,以便以后在注册蓝图时在应用程序中进行。
制作烧瓶蓝图
让我们重新回顾一下您之前看到的 Flask Blueprint 定义,并详细回顾一下。下面的代码显示了
Blueprint对象的创建:from flask import Blueprint example_blueprint = Blueprint('example_blueprint', __name__)注意,在上面的代码中,一些参数是在创建
Blueprint对象时指定的。第一个参数"example_blueprint",是蓝图的名称,Flask 的路由机制使用它。第二个参数__name__是蓝图的导入名称,Flask 用它来定位蓝图的资源。您还可以提供其他可选参数来改变蓝图的行为:
静态文件夹:可以找到蓝图静态文件的文件夹
静态 url 路径:提供静态文件的 URL
template_folder: 包含蓝图模板的文件夹
url_prefix: 要添加到所有蓝图 url 前面的路径
子域:默认情况下,该蓝图的路由将匹配的子域
url_defaults: 一个字典,该蓝图的视图将接收默认值
root_path: 蓝图的根目录路径,默认值取自蓝图的导入名称
注意,除了
root_path之外,所有的路径都是相对于蓝图的目录的。
Blueprint对象example_blueprint有方法和装饰器,允许你记录在应用程序中注册 Flask 蓝图以扩展它时要执行的操作。最常用的装饰者之一是route。它允许您将查看功能与 URL 路由相关联。下面的代码块显示了如何使用这个装饰器:@example_blueprint.route('/') def index(): return "This is an example app"您使用
example_blueprint.route修饰index(),并将函数关联到 URL/。对象还提供了其他有用的方法:
- 。errorhandler() 注册一个错误处理函数
- 。before_request() 在每个请求之前执行一个动作
- 。after_request() 在每次请求后执行一个动作
- 。app_template_filter() 在应用层注册一个模板过滤器
你可以在烧瓶蓝图文档中了解更多关于使用蓝图和
Blueprint类的知识。在您的应用程序中注册蓝图
回想一下,Flask Blueprint 实际上不是一个应用程序。当你在一个应用程序中注册 Flask Blueprint 时,你用它的内容扩展这个应用程序。以下代码显示了如何在应用程序中注册之前创建的 Flask 蓝图:
from flask import Flask from example_blueprint import example_blueprint app = Flask(__name__) app.register_blueprint(example_blueprint)当您调用
.register_blueprint()时,您将把烧瓶蓝图example_blueprint中记录的所有操作应用到app。现在,应用程序对 URL/的请求将使用 Flask Blueprint 中的.index()来处理。您可以通过向
register_blueprint提供一些参数来定制 Flask Blueprint 如何扩展应用程序:
- url_prefix 是所有蓝图路线的可选前缀。
- 子域是蓝图路由将匹配的子域。
- url_defaults 是一个字典,具有视图参数的默认值。
当您在不同的项目中共享同一个 Flask 蓝图时,能够在注册时而不是创建时进行一些定制特别有用。
在本节中,您已经看到了 Flask Blueprints 是如何工作的,以及如何创建和使用它们。在接下来的部分中,您将了解如何利用 Flask 蓝图来构建您的应用程序,将它们构造成独立的组件。在某些情况下,您还可以在不同的应用程序中重用这些组件,以减少开发时间!
如何使用 Flask Blueprints 来构建你的应用程序代码
在这一节中,您将看到如何使用 Flask Blueprint 对一个示例应用程序进行重构。示例应用程序是一个电子商务站点,具有以下特征:
- 访客可以注册,登录,恢复密码。
- 参观者可以搜索产品并查看其详细信息。
- 用户可以将产品添加到他们的购物车中,然后结账。
- API 使外部系统能够搜索和检索产品信息。
你不需要太在意实现的细节。相反,您将主要关注如何使用 Flask 蓝图来改进应用程序的架构。
理解项目布局的重要性
记住,Flask 不强制任何特定的项目布局。如下组织该应用程序的代码是完全可行的:
ecommerce/ | ├── static/ | ├── logo.png | ├── main.css | ├── generic.js | └── product_view.js | ├── templates/ | ├── login.html | ├── forgot_password.html | ├── signup.html | ├── checkout.html | ├── cart_view.html | ├── index.html | ├── products_list.html | └── product_view.html | ├── app.py ├── config.py └── models.py该应用程序的代码使用以下目录和文件进行组织:
- static/ 包含应用程序的静态文件。
- templates/ 包含应用程序的模板。
- models.py 包含应用程序模型的定义。
- app.py 包含应用逻辑。
- config.py 包含应用程序配置参数。
这是一个有多少申请开始的例子。尽管这种布局非常简单,但随着应用程序复杂性的增加,它也有一些缺点。例如,您将很难在其他项目中重用应用程序逻辑,因为所有功能都捆绑在
app.py中。如果你把这个功能分解成模块,那么你可以在不同的项目中重用完整的模块。此外,如果您只有一个应用程序逻辑文件,那么您最终会得到一个非常大的
app.py,它混合了几乎不相关的代码。这可能会使您难以导航和维护脚本。更重要的是,当你在团队中工作时,大的代码文件是冲突的来源,因为每个人都将对同一个文件进行修改。这些只是为什么以前的布局只适合非常小的应用程序的几个原因。
组织您的项目
您可以利用 Flask 蓝图将代码分割成不同的模块,而不是使用之前的布局来构建应用程序。在这一节中,您将看到如何构建以前的应用程序,以制作封装相关功能的蓝图。在这个布局中,有五个烧瓶设计图:
- API 蓝图支持外部系统搜索和检索产品信息
- 认证蓝图允许用户登录并恢复密码
- 购物车和结账功能的购物车蓝图
- 首页总蓝图
- 产品蓝图用于搜索和查看产品
如果您为每个 Flask 蓝图及其资源使用单独的目录,那么项目布局将如下所示:
ecommerce/ | ├── api/ | ├── __init__.py | └── api.py | ├── auth/ | ├── templates/ | | └── auth/ | | ├── login.html | | ├── forgot_password.html | | └── signup.html | | | ├── __init__.py | └── auth.py | ├── cart/ | ├── templates/ | | └── cart/ | | ├── checkout.html | | └── view.html | | | ├── __init__.py | └── cart.py | ├── general/ | ├── templates/ | | └── general/ | | └── index.html | | | ├── __init__.py | └── general.py | ├── products/ | ├── static/ | | └── view.js | | | ├── templates/ | | └── products/ | | ├── list.html | | └── view.html | | | ├── __init__.py | └── products.py | ├── static/ | ├── logo.png | ├── main.css | └── generic.js | ├── app.py ├── config.py └── models.py为了以这种方式组织代码,您将所有视图从
app.py移动到相应的 Flask 蓝图中。您还移动了模板和非全局静态文件。这种结构使您更容易找到与给定功能相关的代码和资源。例如,如果您想找到关于产品的应用逻辑,那么您可以转到products/products.py中的产品蓝图,而不是滚动浏览app.py。让我们看看
products/products.py中的产品蓝图实现:from flask import Blueprint, render_template from ecommerce.models import Product products_bp = Blueprint('products_bp', __name__, template_folder='templates', static_folder='static', static_url_path='assets') @products_bp.route('/') def list(): products = Product.query.all() return render_template('products/list.html', products=products) @products_bp.route('/view/<int:product_id>') def view(product_id): product = Product.query.get(product_id) return render_template('products/view.html', product=product)这段代码定义了
products_bpFlask 蓝图,并且只包含与产品功能相关的代码。因为这个 Flask 蓝图有自己的模板,所以您需要在Blueprint对象创建中指定相对于蓝图根的template_folder。由于您指定了static_folder='static'和static_url_path='assets',因此ecommerce/products/static/中的文件将在/assets/URL 下提供。现在您可以将代码的其余功能转移到相应的 Flask Blueprint 中。换句话说,您可以为 API、身份验证、购物车和一般功能创建蓝图。一旦你这样做了,
app.py中剩下的唯一代码将是处理应用程序初始化和 Flask Blueprint 注册的代码:from flask import Flask from ecommmerce.api.api import api_bp from ecommmerce.auth.auth import auth_bp from ecommmerce.cart.cart import cart_bp from ecommmerce.general.general import general_bp from ecommmerce.products.products import products_bp app = Flask(__name__) app.register_blueprint(api_bp, url_prefix='/api') app.register_blueprint(auth_bp) app.register_blueprint(cart_bp, url_prefix='/cart') app.register_blueprint(general_bp) app.register_blueprint(products_bp, url_prefix='/products')现在,
app.py只需导入并注册蓝图来扩展应用程序。因为使用了url_prefix,所以可以避免 Flask Blueprint 路由之间的 URL 冲突。例如,URL/products/和/cart/解析到同一路线/的products_bp和cart_bp蓝图中定义的不同端点。包括模板
在 Flask 中,当一个视图呈现一个模板时,在应用程序的模板搜索路径中注册的所有目录中搜索模板文件。默认情况下,这个路径是
["/templates"],所以只在应用程序根目录下的/templates目录中搜索模板。如果在创建蓝图时设置了
template_folder参数,那么当注册 Flask 蓝图时,它的 templates 文件夹将被添加到应用程序的模板搜索路径中。然而,如果模板搜索路径的不同目录下有重复的文件路径,那么将优先于,这取决于它们的注册顺序。例如,如果一个视图请求模板
view.html,并且在模板搜索路径的不同目录中有相同名称的文件,那么其中一个将优先于另一个。因为可能很难记住优先顺序,所以最好避免在不同的模板目录中的同一个路径下有文件。这就是应用程序中模板的以下结构有意义的原因:ecommerce/ | └── products/ └── templates/ └── products/ ├── search.html └── view.html首先,让 Flask Blueprint 名称出现两次可能看起来是多余的:
- 作为蓝图的根目录
- 在模板目录内
然而,要知道通过这样做,你可以避免不同蓝图之间可能的模板名称冲突。使用这个目录结构,任何需要产品的
view.html模板的视图都可以在调用render_template时使用products/view.html作为模板文件名。这避免了与属于 Cart 蓝图的view.html的冲突。最后一点,重要的是要知道应用程序的
template目录中的模板比蓝图的模板目录中的模板具有更高的优先级**。如果您想覆盖 Flask Blueprint 模板,而不实际修改模板文件,这可能很有用。**例如,如果您想要覆盖产品蓝图中的模板
products/view.html,那么您可以通过在应用程序templates目录中创建一个新文件products/view.html来实现:ecommerce/ | ├── products/ | └── templates/ | └── products/ | ├── search.html | └── view.html | └── templates/ └── products/ └── view.html当你这样做时,每当一个视图需要模板
products/view.html时,你的程序将使用templates/products/view.html而不是products/templates/products/view.html。提供视图以外的功能
到目前为止,您只看到了用视图扩展应用程序的蓝图,但是 Flask 蓝图不一定只提供视图!他们可以用模板、静态文件和模板过滤器扩展应用程序。例如,您可以创建一个 Flask Blueprint 来提供一组图标,并在您的应用程序中使用它。这将是这种蓝图的文件结构:
app/ | └── icons/ ├── static/ | ├── add.png | ├── remove.png | └── save.png | ├── __init__.py └── icons.py
static文件夹包含图标文件,而icons.py是烧瓶蓝图定义。这是
icons.py可能的样子:from flask import Blueprint icons_bp = Blueprint('icons_bp', __name__, static_folder='static', static_url_path='icons')这段代码定义了
icons_bpFlask 蓝图,该蓝图公开了位于/icons/URL 下的静态目录中的文件。请注意,此蓝图没有定义任何路线。当您可以创建将视图和其他类型的内容打包的蓝图时,您的代码和资产在应用程序中的可重用性就更高了。在下一节中,您将了解更多关于 Flask Blueprint 可重用性的内容。
如何使用 Flask Blueprints 改进代码重用
除了代码组织之外,将 Flask 应用程序组织成独立组件的集合还有另一个好处。您甚至可以跨不同的应用程序重用这些组件!例如,如果您创建了一个为联系人表单提供功能的 Flask 蓝图,那么您可以在所有应用程序中重用它。
您还可以利用其他开发人员创建的蓝图来加速您的工作。虽然现有的 Flask 蓝图没有集中的存储库,但是你可以使用 Python 包索引、 GitHub 搜索和网络搜索引擎来找到它们。你可以在了解更多关于搜索 PyPI 包的信息什么是 Pip?新蟒蛇指南。
有各种各样的 Flask Blueprints 和 Flask Extensions (它们是使用 blue print 实现的),它们提供的功能可能对您有用:
- 证明
- 管理/CRUD 生成
- CMS 功能
- 还有更多!
您可以考虑搜索一个可以重用的现有 Flask 蓝图或扩展,而不是从头开始编写应用程序。利用第三方蓝图和扩展可以帮助您减少开发时间,并将精力集中在应用程序的核心逻辑上!
结论
在本教程中,您已经了解了 Flask Blueprints 如何工作,如何使用它们,以及它们如何帮助您组织应用程序的代码。Flask Blueprints 是处理不断增加的应用程序复杂性的一个很好的工具。
你已经学会:
- 什么是烧瓶蓝图以及它们是如何工作的
- 你如何实现和使用一个烧瓶蓝图
- Flask Blueprints 如何帮助你组织应用程序的代码
- 如何使用 Flask Blueprints 来简化自己和第三方组件的可重用性
- 如何在你的项目中使用 Flask 蓝图来减少开发时间
您可以使用在本教程中学到的知识,开始将您的应用程序组织成一组蓝图。当您以这种方式设计您的应用程序时,您将改进代码重用、可维护性和团队合作!******
烧瓶示例–带有 D3 的自定义角度指示
原文:https://realpython.com/flask-by-example-custom-angular-directive-with-d3/
欢迎回来。随着 Angular 设置以及加载微调器和我们重构的角度控制器,让我们继续到最后一部分,创建一个自定义角度指令,用 JavaScript 和 D3 库显示频率分布图。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
更新:
- 03/02/2020:更新代码以匹配新的响应对象。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署一个试运行环境和一个生产环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和 Natural Language Toolkit (NLTK)库从网页中抓取并处理字数。
- 第四部分:实现一个 Redis 任务队列来处理文本处理。
- 第五部分:在前端设置 Angular,持续轮询后端,看请求是否处理完毕。
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。
- 第七部分:更新前端,使其更加人性化。
- 第八部分:使用 JavaScript 和 D3 创建一个自定义的角度指令来显示频率分布图。(当前 )
需要代码吗?从回购中抢过来。
让我们看看我们目前拥有什么…
当前用户界面
在终端窗口中启动 Redis:
$ redis-server然后让您的流程工人进入另一个窗口:
$ cd flask-by-example $ python worker.py 17:11:39 RQ worker started, version 0.4.6 17:11:39 17:11:39 *** Listening on default...最后,在第三个窗口中,启动应用程序:
$ cd flask-by-example $ python manage.py runserver你应该看到你的单词计数器在工作。现在我们可以添加一个自定义的角度指令来在 D3 图表中显示结果。
角度指令
首先将 D3 库( v3 )添加到【index.html】文件中:
<!-- scripts --> <script src="//d3js.org/d3.v3.min.js" charset="utf-8"></script> <script src="//code.jquery.com/jquery-2.2.1.min.js"></script> <script src="//netdna.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js"></script> <script src="//ajax.googleapis.com/ajax/libs/angularjs/1.4.5/angular.min.js"></script> <script src="{{ url_for('static', filename='main.js') }}"></script>现在让我们建立一个新的自定义指令。
角度指令是 DOM 元素上的标记,它允许我们插入带有特定事件和属性的 HTML 部分。让我们通过在 main.js 中的控制器下方添加以下代码来构建我们指令的第一部分:
.directive('wordCountChart', ['$parse', function ($parse) { return { restrict: 'E', replace: true, template: '<div id="chart"></div>', link: function (scope) {} }; }]);创建一个只限于 HTML 元素的指令。
replace: true简单地用template中的 HTML 替换 HTML 指令。link函数让我们可以访问控制器中定义的范围内的变量。接下来,添加一个
watch函数来“观察”变量的任何变化,并做出适当的响应。将它添加到link函数中,如下所示:link: function (scope) { scope.$watch('wordcounts', function() { // add code here }, true); }最后,将结束分隔符正下方的指令添加到
<div class="row">:<br> <word-count-chart data="wordcounts"></word-count-chart>随着指令的建立,让我们把注意力转向 D3 库…
D3 条形图
D3 是一个强大的库,它利用 HTML、CSS 和 SVG 在 DOM 和 JavaScript 上显示数据,使之具有交互性。我们将使用它来创建一个基本的条形图。
第一步:功能逻辑
将以下内容添加到角度指令内的
watch功能中:scope.$watch('wordcounts', function() { var data = scope.wordcounts; for (var word in data) { d3.select('#chart') .append('div') .selectAll('div') .data(word[0]) .enter() .append('div'); } }, true);现在,每当
scope.wordcounts改变时,这个函数就会被触发,从而更新 DOM。因为 AJAX 请求返回了一个对象,所以我们遍历它,将特定的数据添加到图表中。本质上,每个单词都通过一个数据连接附加到一个新的div上。尝试运行代码。
会发生什么?什么都没出现,对吧?提交新网站后,在 Chrome 的开发者工具中查看 DOM。您应该会看到许多嵌套的
divs。我们只需要添加样式…步骤 2:设计条形图的样式
从一些简单的 CSS 开始:
#chart { overflow-y: scroll; } #chart { background: #eee; padding: 3px; } #chart div { width: 0; transition: all 1s ease-out; -moz-transition: all 1s ease-out; -webkit-transition: all 1s ease-out; } #chart div { height: 30px; font: 15px; background-color: #006dcc; text-align: right; padding: 3px; color: white; box-shadow: 2px 2px 2px gray; }确保在 HTML 页面的顶部,在引导样式表之后包含以下内容:
<link rel="stylesheet" type="text/css" href="../static/main.css">在我们的浏览器中启动应用程序。现在发生了什么?
当你搜索一个网站时,你现在应该会看到一个灰色区域,在左边有一些细的蓝色条。因此,您可以看到,我们为获得的每个数据元素生成了一个条形,总共 10 个。然而,我们需要修改我们的 D3 代码,以便增加每个条形的宽度,使它们可读。
第三步:让条形图更具互动性
我们可以将它链接到我们现有的代码上,并使用 D3 风格的函数:
scope.$watch('wordcounts', function() { var data = scope.wordcounts; for (var word in data) { var key = data[word][0]; var value = data[word][1]; d3.select('#chart') .append('div') .selectAll('div') .data(word) .enter() .append('div') .style('width', function() { return (value * 3) + 'px'; }) .text(function(d){ return key; }); } }, true);现在,我们根据一个单词在网页上出现的频率来动态创建一个宽度:
.style('width', function() { return (value * 3) + 'px'; }) .text(function(d){ return key; });样式的计算方法是返回与每个单词相关联的值,将该数字乘以 3,然后将其转换为像素。我们还可以通过插入单词的字符串值以及它在页面上出现的频率来为每个 bar 元素添加文本。
试试这个。您应该会看到类似这样的内容:
但是还缺少一样东西。当你搜索一个新网站时会发生什么?试试看。新图表附加在前一个图表的下面。我们需要在创建新的图表 div 之前清空它。
第四步:为下一次 URL 搜索做准备
更新指令中的
link函数:link: function (scope) { scope.$watch('wordcounts', function() { d3.select('#chart').selectAll('*').remove(); var data = scope.wordcounts; for (var word in data) { var key = data[word][0]; var value = data[word][1]; d3.select('#chart') .append('div') .selectAll('div') .data(word) .enter() .append('div') .style('width', function() { return (value * 3) + 'px'; }) .text(function(d){ return key; }); } }, true); }每次触发
$scope.watch函数时,d3.select('#chart').selectAll('*').remove();简单地清除图表。现在我们有了一个在每次新的使用之前被清除的图表,并且我们有了一个全功能的字数统计应用程序!!测试一下!
结论和后续步骤
就是这样。将您的更改推送到临时服务器和生产服务器。让我们回顾一下我们解决的问题:
- 我们从配置和工作流开始,设置试运行和生产服务器
- 从那里,我们添加了基本的功能——web 抓取、数据分析——并用 Redis 建立了一个任务队列
- 随着后端功能的建立,注意力转向了前端,我们添加了 Angular,构建了一个自定义指令,并在组合中添加了 D3
我们有一个 MVP,但仍有许多工作要做:
想帮忙吗?增加一个功能,写第 9 部分,获得付费,成为互联网名人!
链接:
flask by Example–实现 Redis 任务队列
原文:https://realpython.com/flask-by-example-implementing-a-redis-task-queue/
教程的这一部分详细介绍了如何实现 Redis 任务队列来处理文本处理。
更新:
- 02/12/2020:升级到 Python 版本 3.8.1 以及 Redis、Python Redis、RQ 的最新版本。详见下面的。提到最新 RQ 版本的一个 bug,并提供解决方案。解决了 https 之前的 https bug。
- 03/22/2016:升级到 Python 版本 3.5.1 以及 Redis、Python Redis、RQ 的最新版本。详见下面的。
- 2015 年 2 月 22 日:添加了 Python 3 支持。
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署一个试运行环境和一个生产环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和自然语言工具包(NLTK) 库从网页中抓取并处理字数。
- 第四部分:实现一个 Redis 任务队列来处理文本处理。(当前 )
- 第五部分:在前端设置 Angular,持续轮询后端,看请求是否处理完毕。
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。
- 第七部分:更新前端,使其更加人性化。
- 第八部分:使用 JavaScript 和 D3 创建一个自定义角度指令来显示频率分布图。
需要代码吗?从回购中抢过来。
安装要求
使用的工具:
首先从官方网站或者自制软件
brew install redis下载并安装 Redis。安装后,启动 Redis 服务器:$ redis-server接下来,在新的终端窗口中安装 Python Redis 和 RQ:
$ cd flask-by-example $ python -m pip install redis==3.4.1 rq==1.2.2 $ python -m pip freeze > requirements.txt设置工人
让我们首先创建一个工作进程来监听排队的任务。创建一个新文件 worker.py ,并添加以下代码:
import os import redis from rq import Worker, Queue, Connection listen = ['default'] redis_url = os.getenv('REDISTOGO_URL', 'redis://localhost:6379') conn = redis.from_url(redis_url) if __name__ == '__main__': with Connection(conn): worker = Worker(list(map(Queue, listen))) worker.work()这里,我们监听了一个名为
default的队列,并在localhost:6379上建立了一个到 Redis 服务器的连接。在另一个终端窗口中启动它:
$ cd flask-by-example $ python worker.py 17:01:29 RQ worker started, version 0.5.6 17:01:29 17:01:29 *** Listening on default...现在我们需要更新我们的 app.py 来发送任务到队列…
更新app . pyT2】
将以下导入添加到 app.py :
from rq import Queue from rq.job import Job from worker import conn然后更新配置部分:
app = Flask(__name__) app.config.from_object(os.environ['APP_SETTINGS']) app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True db = SQLAlchemy(app) q = Queue(connection=conn) from models import *
q = Queue(connection=conn)建立 Redis 连接,并基于该连接初始化队列。将文本处理功能从我们的索引路径中移出,放到一个名为
count_and_save_words()的新函数中。这个函数接受一个参数,一个 URL,当我们从我们的索引路径调用它时,我们将传递给它。def count_and_save_words(url): errors = [] try: r = requests.get(url) except: errors.append( "Unable to get URL. Please make sure it's valid and try again." ) return {"error": errors} # text processing raw = BeautifulSoup(r.text).get_text() nltk.data.path.append('./nltk_data/') # set the path tokens = nltk.word_tokenize(raw) text = nltk.Text(tokens) # remove punctuation, count raw words nonPunct = re.compile('.*[A-Za-z].*') raw_words = [w for w in text if nonPunct.match(w)] raw_word_count = Counter(raw_words) # stop words no_stop_words = [w for w in raw_words if w.lower() not in stops] no_stop_words_count = Counter(no_stop_words) # save the results try: result = Result( url=url, result_all=raw_word_count, result_no_stop_words=no_stop_words_count ) db.session.add(result) db.session.commit() return result.id except: errors.append("Unable to add item to database.") return {"error": errors} @app.route('/', methods=['GET', 'POST']) def index(): results = {} if request.method == "POST": # this import solves a rq bug which currently exists from app import count_and_save_words # get url that the person has entered url = request.form['url'] if not url[:8].startswith(('https://', 'http://')): url = 'http://' + url job = q.enqueue_call( func=count_and_save_words, args=(url,), result_ttl=5000 ) print(job.get_id()) return render_template('index.html', results=results)请注意以下代码:
job = q.enqueue_call( func=count_and_save_words, args=(url,), result_ttl=5000 ) print(job.get_id())注意:我们需要在我们的函数
index中导入count_and_save_words函数,因为 RQ 包目前有一个 bug,它在同一个模块中找不到函数。这里我们使用了之前初始化的队列,并调用了
enqueue_call()函数。这向队列中添加了一个新的作业,该作业使用 URL 作为参数运行count_and_save_words()函数。result_ttl=5000行参数告诉 RQ 保持作业结果多长时间,在本例中为-5000 秒。然后,我们将作业 id 输出到终端。需要此 id 来查看作业是否已完成处理。让我们为那建立一条新的路线…
获取结果*
@app.route("/results/<job_key>", methods=['GET']) def get_results(job_key): job = Job.fetch(job_key, connection=conn) if job.is_finished: return str(job.result), 200 else: return "Nay!", 202让我们来测试一下。
启动服务器,导航到 http://localhost:5000/ ,使用 URLhttps://realpython.com,从终端获取作业 id。然后在“/results/”端点中使用该 id——即http://localhost:5000/results/ef 600206-3503-4b 87-a436-DDD 9438 f 2197。
只要在您检查状态之前经过的时间不到 5,000 秒,您就会看到一个 id 号,它是在我们将结果添加到数据库中时生成的:
# save the results try: from models import Result result = Result( url=url, result_all=raw_word_count, result_no_stop_words=no_stop_words_count ) db.session.add(result) db.session.commit() return result.id现在,让我们稍微重构一下路由,从 JSON 中的数据库返回实际结果:
@app.route("/results/<job_key>", methods=['GET']) def get_results(job_key): job = Job.fetch(job_key, connection=conn) if job.is_finished: result = Result.query.filter_by(id=job.result).first() results = sorted( result.result_no_stop_words.items(), key=operator.itemgetter(1), reverse=True )[:10] return jsonify(results) else: return "Nay!", 202确保添加导入:
from flask import jsonify再次测试这个。如果一切顺利,您应该会在浏览器中看到类似的内容:
[ [ "Python", 315 ], [ "intermediate", 167 ], [ "python", 161 ], [ "basics", 118 ], [ "web-dev", 108 ], [ "data-science", 51 ], [ "best-practices", 49 ], [ "advanced", 45 ], [ "django", 43 ], [ "flask", 41 ] ]下一步是什么?
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
在第 5 部分中,我们将通过在混合中添加 Angular 来创建一个轮询器,它将每五秒钟向
/results/<job_key>端点发送一个请求,请求更新。一旦数据可用,我们将把它添加到 DOM 中。干杯!
这是创业公司埃德蒙顿的联合创始人卡姆·克林和 Real Python 的人合作的作品**
烧瓶示例–整合烧瓶和角形烧瓶
原文:https://realpython.com/flask-by-example-integrating-flask-and-angularjs/
欢迎回来。使用 Redis 任务队列设置,让我们使用 AngularJS 来轮询后端以查看任务是否完成,然后在数据可用时更新 DOM。
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
更新:
- 02/29/2020:升级到 Python 版本 3.8.1 。
- 03/22/2016:升级到 Python 版本 3.5.1 和 Angular 版本 1.4.9 。
- 2015 年 2 月 22 日:添加了 Python 3 支持。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署一个试运行环境和一个生产环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和 Natural Language Toolkit (NLTK)库从网页中抓取并处理字数。
- 第四部分:实现一个 Redis 任务队列来处理文本处理。
- 第五部分:在前端设置 Angular 来持续轮询后端,看请求是否处理完毕。(当前 )
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。
- 第七部分:更新前端,使其更加人性化。
- 第八部分:使用 JavaScript 和 D3 创建一个自定义角度指令来显示频率分布图。
需要代码吗?从回购中抢过来。
新来的有棱角?回顾以下教程: AngularJS by Example:搭建比特币投资计算器
准备好了吗?让我们先来看看我们应用程序的当前状态…
当前功能
首先,在一个终端窗口中启动 Redis:
$ redis-server在另一个窗口中,导航到您的项目目录,然后运行 worker:
$ cd flask-by-example $ python worker.py 20:38:04 RQ worker started, version 0.5.6 20:38:04 20:38:04 *** Listening on default...最后,打开第三个终端窗口,导航到您的项目目录,启动主应用程序:
$ cd flask-by-example $ python manage.py runserver打开 http://localhost:5000/ 用网址 https://realpython.com 测试。在终端中,作业 id 应该已经输出。获取 id 并导航到以下 url:
http://localhost:5000/results/add _ the _ job _ id _ here
您应该会在浏览器中看到类似的 JSON 响应:
[ [ "Python", 315 ], [ "intermediate", 167 ], [ "python", 161 ], [ "basics", 118 ], [ "web-dev", 108 ], [ "data-science", 51 ], [ "best-practices", 49 ], [ "advanced", 45 ], [ "django", 43 ], [ "flask", 41 ] ]现在我们准备添加角度。
更新index.htmlT2】
给index.html添加角度:
<script src="//ajax.googleapis.com/ajax/libs/angularjs/1.4.9/angular.min.js"></script>将以下指令添加到【index.html】的中:
- :
<html ng-app="WordcountApp">- ng-控制器 :
<body ng-controller="WordcountController">- ng-提交 :
<form role="form" ng-submit="getResults()">因此,我们引导 Angular——它告诉 Angular 将这个 HTML 文档视为 Angular 应用程序——添加了一个控制器,然后添加了一个名为
getResults()的函数——它在表单提交时被触发。创建角度模块
创建一个“静态”目录,然后向该目录添加一个名为 main.js 的文件。务必将该要求添加到 index.html 文件的中;
<script src="{{ url_for('static', filename='main.js') }}"></script>让我们从这个基本代码开始:
(function () { 'use strict'; angular.module('WordcountApp', []) .controller('WordcountController', ['$scope', '$log', function($scope, $log) { $scope.getResults = function() { $log.log("test"); }; } ]); }());这里,当提交表单时,
getResults()被调用,它只是将文本“test”记录到浏览器中的 JavaScript 控制台。一定要测试出来。依赖注入和$scope
在上面的例子中,我们利用依赖注入来“注入”对象
$scope和服务$log。停在这里。理解$scope非常重要。从角度文档开始,如果您还没有浏览过角度介绍教程,请务必浏览一遍。听起来可能很复杂,但它确实只是提供了视图和控制器之间的一种交流方式。两者都可以访问它,当你在一个中改变一个附属于
$scope的变量时,这个变量会在另一个中自动更新(数据绑定)。依赖注入也是如此:它比听起来要简单得多。可以把它看作是获得各种服务的一点魔法。因此,通过注入服务,我们现在可以在控制器中使用它。回到我们的应用程序…
如果您测试一下,您会看到表单提交不再向后端发送 POST 请求。这正是我们想要的。相反,我们将使用 Angular
$http服务来异步处理这个请求:.controller('WordcountController', ['$scope', '$log', '$http', function($scope, $log, $http) { $scope.getResults = function() { $log.log("test"); // get the URL from the input var userInput = $scope.url; // fire the API request $http.post('/start', {"url": userInput}). success(function(results) { $log.log(results); }). error(function(error) { $log.log(error); }); }; } ]);另外,更新index.html中的
input元素:<input type="text" ng-model="url" name="url" class="form-control" id="url-box" placeholder="Enter URL..." style="max-width: 300px;">我们注入了
$http服务,从输入框中抓取 URL(通过ng-model="url"),然后向后端发出 POST 请求。success和error回调处理响应。在 200 响应的情况下,它将由success处理程序处理,该处理程序反过来将响应记录到控制台。在测试之前,让我们重构后端,因为
/start端点目前并不存在。重构app . pyT2】
从索引视图函数中重构出 Redis 作业创建,然后将其添加到一个名为
get_counts()的新视图函数中:@app.route('/', methods=['GET', 'POST']) def index(): return render_template('index.html') @app.route('/start', methods=['POST']) def get_counts(): # this import solves a rq bug which currently exists from app import count_and_save_words # get url data = json.loads(request.data.decode()) url = data["url"] if not url[:8].startswith(('https://', 'http://')): url = 'http://' + url # start job job = q.enqueue_call( func=count_and_save_words, args=(url,), result_ttl=5000 ) # return created job id return job.get_id()确保在顶部也添加以下导入:
import json这些变化应该很简单。
现在我们测试。刷新你的浏览器,提交一个新的网址。您应该在 JavaScript 控制台中看到作业 id。完美。现在 Angular 有了作业 id,我们可以添加轮询功能。
基本轮询
通过向控制器添加以下代码来更新 main.js :
function getWordCount(jobID) { var timeout = ""; var poller = function() { // fire another request $http.get('/results/'+jobID). success(function(data, status, headers, config) { if(status === 202) { $log.log(data, status); } else if (status === 200){ $log.log(data); $timeout.cancel(timeout); return false; } // continue to call the poller() function every 2 seconds // until the timeout is cancelled timeout = $timeout(poller, 2000); }); }; poller(); }然后在 POST 请求中更新成功处理程序:
$http.post('/start', {"url": userInput}). success(function(results) { $log.log(results); getWordCount(results); }). error(function(error) { $log.log(error); });确保将
$timeout服务也注入到控制器中。这里发生了什么事?
- 成功的 HTTP 请求会触发
getWordCount()函数。- 在
poller()函数中,我们称之为/results/job_id端点。- 使用
$timeout服务,该函数继续每隔 2 秒触发一次,直到超时被取消,此时返回 200 响应和字数。查看有棱角的文档,获得关于$timeout服务如何工作的精彩描述。测试时,请确保打开 JavaScript 控制台。您应该会看到类似这样的内容:
Nay! 202 Nay! 202 Nay! 202 Nay! 202 Nay! 202 Nay! 202 (10) [Array(2), Array(2), Array(2), Array(2), Array(2), Array(2), Array(2), Array(2), Array(2), Array(2)]所以,在上面的例子中,
poller()函数被调用了七次。前六个调用返回 202,而最后一个调用返回 200 和字数统计数组。完美。
现在我们需要将字数添加到 DOM 中。
更新 DOM
更新index.html:
<div class="container"> <div class="row"> <div class="col-sm-5 col-sm-offset-1"> <h1>Wordcount 3000</h1> <br> <form role="form" ng-submit="getResults()"> <div class="form-group"> <input type="text" name="url" class="form-control" id="url-box" placeholder="Enter URL..." style="max-width: 300px;" ng-model="url" required> </div> </form> </div> <div class="col-sm-5 col-sm-offset-1"> <h2>Frequencies</h2> <br> {% raw %} <div id="results"> {{wordcounts}} </div> {% endraw %} </div> </div> </div>我们改变了什么?
input标签现在有了一个required属性,表明在提交表单之前必须填写输入框。- 告别 Jinja2 模板标签。Jinja2 从服务器端提供服务,由于轮询完全在客户端处理,我们需要使用 Angular 标记。也就是说,由于 Jinja2 和 Angular 模板标签都使用了双花括号
{{}},我们必须使用{% raw %}和{% endraw %}来转义 Jinja2 标签。如果你需要使用多个角度标签,最好用$interpolateProvider改变 AngularJS 使用的模板标签。更多信息,请查看角度文档。其次,更新
poller()函数中的成功处理程序:success(function(data, status, headers, config) { if(status === 202) { $log.log(data, status); } else if (status === 200){ $log.log(data); $scope.wordcounts = data; $timeout.cancel(timeout); return false; } // continue to call the poller() function every 2 seconds // until the timeout is cancelled timeout = $timeout(poller, 2000); });这里,我们将结果附加到了
$scope对象上,这样它在视图中就可用了。测试一下。如果一切顺利,您应该在 DOM 上看到该对象。不太漂亮,但这是一个简单的 Bootstrap 修复方法,在带有
id=results的 div 下添加以下代码,并从上面的代码中删除包装结果 div 的{% raw %}和{% endraw %}标签:<div id="results"> <table class="table table-striped"> <thead> <tr> <th>Word</th> <th>Count</th> </tr> </thead> <tbody> {% raw %} <tr ng-repeat="element in wordcounts"> <td>{{ element[0] }}</td> <td>{{ element[1] }}</td> </tr> {% endraw %} </tbody> </table> </div>结论和后续步骤
在继续使用 D3 制作图表之前,我们还需要:
- 添加一个加载微调器:也称为跳动器,它会一直显示,直到任务完成,这样最终用户就知道有事情发生了。
- 重构角度控制器:现在控制器中发生了太多的事情(逻辑)。我们需要将大部分功能转移到一个服务中。我们将讨论为什么和如何。
- 更新登台:我们需要更新 Heroku 上的登台环境——添加代码变更、我们的工人和 Redis。
下次时间见!
另一个加深你的烧瓶技能的推荐资源是这个视频系列:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。***
使用 Heroku 部署 Python Flask 示例应用程序
原文:https://realpython.com/flask-by-example-part-1-project-setup/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 使用 Heroku 部署 Flask 应用程序
在本教程中,您将创建一个 Python Flask 示例应用程序,并使用 Heroku 部署它,使它在 web 上公开可用。Heroku 消除了许多与构建和运行网络应用相关的基础设施负担,让你专注于创建一个令人敬畏的应用。
除了部署应用程序之外,您还将使用 Git 来跟踪代码的更改,并且您还将使用不同的环境来配置一个部署工作流,以进行准备和生产。使用此设置,您将能够在发布应用程序之前对其进行测试和预览。
在本教程中,您将学习如何:
- 创建一个 Python Flask 示例 web 应用
- 使用 Heroku 部署 web 应用程序
- 使用 Heroku 管道实现部署工作流
- 以安全的方式管理不同环境的配置和机密
本教程假设您了解 web 应用程序的基本工作原理,并且有一些使用 Git 的经验。要快速了解这些主题,请查看Python Web Applications with Flask(教程系列)和Python 开发人员 Git 和 GitHub 简介。
正如您将通过本教程了解到的,通过结合 Flask 和 Heroku,您可以最大限度地减少创建和运行 web 应用程序所需的工作量。您可以单击下面的链接获得本教程应用程序的完整源代码:
示例代码: 单击此处下载源代码,您将使用它来构建 Python Flask 示例应用程序。
创建 Python Flask 示例应用程序
在本节中,您将学习如何创建一个 Python Flask 示例应用程序并在本地运行它。您将初始化项目,安装 Flask,创建应用程序,并在您的计算机上运行它。您还将学习如何使用 Git 来版本化您的应用程序代码。
正在初始化项目
项目初始化包括为您的应用程序创建一个目录,设置一个将要安装依赖项的 Python 虚拟环境,以及初始化 Git 存储库。您不必使用虚拟环境或 Git 进行本地开发,但它们非常方便,会使开发和部署到 Heroku 更简单。
首先为 Python Flask 示例应用程序创建一个新目录。您可以通过运行以下命令来实现:
$ mkdir realpython-example-app $ cd realpython-example-app以上命令创建一个
realpython-example-app/文件夹,并将当前工作目录更改为该文件夹。接下来,您必须创建一个 Python 虚拟环境。使用虚拟环境允许您管理项目的依赖关系,而不会弄乱所有应用程序共享的系统级文件。运行以下命令,为您的应用程序创建并激活一个虚拟环境。如果您还没有将目录更改为
realpython-example-app/,请记住:$ python3 -m venv venv $ source venv/bin/activate这些命令创建了一个名为
venv的虚拟环境并激活它,因此将从这个环境中加载和安装包,而不是使用系统级的包。安装依赖关系
第一步是安装 Flask Python 包。您可以使用
pip运行以下命令来安装 Flask:$ python3 -m pip install Flask==1.1.2上面的命令安装 Flask 版本
1.1.2。这是您将在整个教程中使用的版本。接下来,您需要创建一个列出项目依赖项的requirements.txt文件。您可以使用python3 -m pip freeze命令来完成这项任务:$ python3 -m pip freeze > requirements.txt在部署项目时,您将使用
requirements.txt来告诉 Heroku 必须安装哪些包才能运行您的应用程序代码。要了解更多关于如何在虚拟环境中安装 Flask 和其他pip选项的信息,请查看 Flask 安装文档和什么是 Pip?新蟒蛇指南。现在,应用程序目录应该如下所示:
realpython-example-app/ │ ├── venv/ │ └── requirements.txt在接下来的小节中,您将添加更多的文件来实现应用程序逻辑,设置 Git,然后将其部署到 Heroku。
编写应用程序代码
在本节中,您将创建一个带有单个路由、
index的小 Flask 应用程序,它在被请求时返回文本Hello World!。要创建 Flask 应用程序,您必须创建一个代表您的应用程序的Flask对象,然后将视图与路线关联起来。Flask 负责根据请求 URL 和您定义的路由将传入的请求分派到正确的视图。您可以单击下面的链接获得本教程应用程序的完整源代码:
示例代码: 单击此处下载源代码,您将使用它来构建 Python Flask 示例应用程序。
对于小型应用程序,如您在本教程中使用的应用程序,您可以在一个文件中编写所有代码,并按如下方式组织项目:
realpython-example-app/ │ ├── venv/ │ ├── app.py └── requirements.txt
app.py包含应用程序的代码,您可以在其中创建应用程序及其视图。以下代码块显示了应用程序的完整源代码:from flask import Flask app = Flask(__name__) @app.route("/") def index(): return "Hello World!"在您导入
flask之后,代码创建了对象app,它属于Flask类。使用app.route()装饰器将视图功能index()链接到主路线。当主路由被请求时,Flask 将通过调用index()并使用其返回值作为响应来服务请求。在本地运行 Python Flask 示例
有不同的方法可以运行您在上一节中创建的应用程序。启动 Flask 应用程序进行本地开发的最直接的方法之一是从终端使用
flask run命令:$ flask run默认情况下,Flask 将在端口
5000上运行您在app.py中定义的应用程序。当应用程序运行时,使用您的网络浏览器进入http://localhost:5000。您将看到一个包含消息Hello World!的网页在开发过程中,您通常希望在对应用程序进行更改时自动重新加载应用程序。您可以通过将环境变量
FLASK_ENV=development传递给flask run来实现这一点:$ FLASK_ENV=development flask run当你设置
FLASK_ENV=development时,Flask 会监控应用文件的变化,并在有变化时重新加载服务器。这样,您就不需要在每次修改后手动停止并重启应用服务器。使用 Git 跟踪变更
在本教程中,您将使用 Git 跟踪项目文件的变更,Git 是一个非常流行的版本控制系统(VCS) 。因此,作为第一步,您应该为您的项目创建一个 Git 存储库。您可以通过在项目目录中执行以下命令来实现这一点:
$ git init上面的命令初始化将用于跟踪项目文件的存储库。存储库元数据存储在一个名为
.git/的隐藏目录中。注意,有些文件夹不应该包含在 Git 存储库中,比如
venv/和__pycache__/。您可以通过创建一个名为.gitignore的文件来告诉 Git 忽略它们。使用以下命令创建该文件:$ echo venv > .gitignore $ echo __pycache__ >> .gitignore $ git add .gitignore app.py requirements.txt $ git commit -m "Initialize Git repository"运行上述命令后,Git 将跟踪应用程序文件的变化,但它会忽略
venv/和__pycache__/文件夹。现在的项目目录,realpython-example-app/,应该是这样的:realpython-example-app/ │ ├── .git/ │ ├── venv/ │ ├── .gitignore ├── app.py └── requirements.txt您现在可以使用 Heroku 部署您的应用程序了。查看面向 Python 开发者的 Git 和 GitHub 简介,了解更多关于 Git 的信息,以及如何在 GitHub 中托管您的存储库。
将应用程序部署到 Heroku
Heroku 使得构建和部署应用程序对开发者来说非常友好。它消除了许多与构建和运行 web 应用程序相关的负担,负责大多数基础设施细节,让您专注于创建和改进应用程序。Heroku 处理的一些细节包括:
- 设置 HTTPS 证书
- 管理 DNS 记录
- 运行和维护服务器
在本节的其余部分,您将学习如何使用 Heroku 将之前创建的 web 应用程序部署到互联网上。到本节结束时,你的应用程序将在一个漂亮的网址下公开,并使用 HTTPS 提供服务。
Heroku 帐户设置
您的第一步是创建一个 Heroku 帐户。如果你还没有,你可以使用免费和业余爱好计划。它允许你在不花钱的情况下部署非商业应用程序、个人项目和实验。
如果您进入 Heroku 注册页面,您将在注册表单上看到以下字段:
完成所需信息并确认您的电子邮件地址后,您就可以开始使用 Heroku 了。
Heroku 命令行界面
Heroku 命令行界面(CLI)是一个允许您从终端创建和管理 Heroku 应用程序的工具。这是部署应用程序最快捷、最方便的方式。你可以查阅开发者文档来获得你的操作系统的安装说明。在大多数 Linux 发行版上,您可以通过运行以下命令来安装 Heroku CLI:
$ curl https://cli-assets.heroku.com/install.sh | sh前面的命令下载并执行 Heroku CLI 安装程序。接下来,您必须通过运行以下命令登录:
$ heroku login这将打开一个带有按钮的网站,以完成登录过程。点击登录完成认证过程并开始使用 Heroku CLI:
登录后,您就可以开始使用 Heroku CLI 来管理您的应用程序和工作流了。
Heroku 的应用程序部署
在本节中,您将学习如何使用 Heroku CLI 和 Git 来部署您的 web 应用程序。第一步是在项目的根目录下创建一个名为
Procfile的文件。这个文件告诉 Heroku 如何运行应用程序。您可以通过运行以下命令来创建它:$ echo "web: gunicorn app:app" > Procfile注意,这个文件名必须以大写字母开头。这个文件告诉 Heroku 使用 Gunicorn 为您的应用程序提供服务,这是一个 Python Web 服务器网关接口(WSGI) HTTP 服务器,兼容各种 Web 框架,包括 Flask。确保安装 Gunicorn 并使用
pip更新requirements.txt文件:$ python3 -m pip install gunicorn==20.0.4 $ python3 -m pip freeze > requirements.txt前面的命令安装 Gunicorn 并更新
requirements.txt以包含所有依赖项的列表。因为您添加并更改了文件,所以您需要将它们提交给 Git。您可以通过执行以下两个命令来实现这一点:$ git add Procfile requirements.txt $ git commit -m "Add Heroku deployment files"当您执行上述命令时,您将把最新版本的
Procfile和requirements.txt提交给 Git 存储库。现在您已经准备好将应用程序部署到 Heroku 了。从使用 Heroku CLI 创建一个 Heroku 应用程序开始。注意:本教程使用
realpython-example-app作为应用程序名称。因为应用程序名称在 Heroku 上需要是唯一的,所以您需要为您的部署选择一个不同的名称。您可以通过运行以下命令在 Heroku 中创建应用程序:
$ heroku create realpython-example-app运行上面的命令初始化 Heroku 应用程序,创建一个名为
heroku的 Git remote 。接下来,您可以将 Git 存储库推送到这个远程,以触发构建和部署过程:$ git push heroku master在将
master分支推送到heroku遥控器之后,您会看到输出显示了关于构建和部署过程的信息:1Enumerating objects: 6, done. 2Counting objects: 100% (6/6), done. 3Delta compression using up to 8 threads 4Compressing objects: 100% (4/4), done. 5Writing objects: 100% (6/6), 558 bytes | 558.00 KiB/s, done. 6Total 6 (delta 0), reused 0 (delta 0) 7remote: Compressing source files... done. 8remote: Building source: 9remote: 10remote: -----> Building on the Heroku-18 stack 11remote: -----> Python app detected 12remote: -----> Installing python-3.6.12 13remote: -----> Installing pip 20.1.1, setuptools 47.1.1 and wheel 0.34.2 14remote: -----> Installing SQLite3 15remote: -----> Installing requirements with pip 16remote: Collecting click==7.1.2 17remote: Downloading click-7.1.2-py2.py3-none-any.whl (82 kB) 18remote: Collecting Flask==1.1.2 19remote: Downloading Flask-1.1.2-py2.py3-none-any.whl (94 kB) 20remote: Collecting itsdangerous==1.1.0 21remote: Downloading itsdangerous-1.1.0-py2.py3-none-any.whl (16 kB) 22remote: Collecting Jinja2==2.11.2 23remote: Downloading Jinja2-2.11.2-py2.py3-none-any.whl (125 kB) 24remote: Collecting MarkupSafe==1.1.1 25remote: Downloading MarkupSafe-1.1.1-cp36-cp36m-manylinux1_x86_64.whl 26remote: Collecting Werkzeug==1.0.1 27remote: Downloading Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB) 28remote: Installing collected packages: click, Werkzeug, itsdangerous, 29MarkupSafe, Jinja2, Flask 30remote: Successfully installed Flask-1.1.2 Jinja2-2.11.2 MarkupSafe-1.1.1 31Werkzeug-1.0.1 click-7.1.2 itsdangerous-1.1.0 32remote: -----> Discovering process types 33remote: Procfile declares types -> (none) 34remote: 35remote: -----> Compressing... 36remote: Done: 45.1M 37remote: -----> Launching... 38remote: Released v1 39remote: https://realpython-example-app.herokuapp.com/ deployed to Heroku 40remote: 41remote: Verifying deploy... done. 42To https://git.heroku.com/realpython-example-app.git 43 * [new branch] master -> master恭喜你,该应用程序现已上线!输出显示了构建过程,包括依赖项的安装和部署。在第 39 行,您将找到您的应用程序的 URL。这种情况下是
https://realpython-example-app.herokuapp.com/。您也可以使用以下 Heroku CLI 命令打开您的应用程序的 URL:$ heroku open上述命令将使用默认的 web 浏览器打开您的应用程序。
注意:输出的第 12 行表明 Python 3.6.12 将被用作应用程序的运行时。这是撰写本教程时的默认版本。要了解如何定制 Python 版本和其他运行时设置,请查看 Heroku 的 Python 运行时文档。
现在,让我们对应用程序做一个小小的更改,看看如何重新部署它。编辑
app.py并修改index()返回的字符串,如下一个代码块所示:1from flask import Flask 2 3app = Flask(__name__) 4 5@app.route("/") 6def index(): 7 return "Hello this is the new version!"正如您在第 7 行看到的,
"Hello World!"被替换为"Hello this is the new version!"。您可以通过将更改提交并推送到heroku遥控器来将这个版本部署到 Heroku:$ git add app.py $ git commit -m "Change the welcome message" $ git push heroku master使用这些命令,您可以将更改提交到本地 Git 存储库,并将它们推送到
herokuremote。这将再次触发构建和部署过程。每当您需要部署应用程序的新版本时,都可以重复这些步骤。您会注意到后续的部署通常会花费更少的时间,因为需求已经安装好了。在本节中,您学习了如何使用 Git 和 Heroku CLI 在 Heroku 上创建和部署应用程序。有关使用 Heroku CLI 部署 Python 应用程序的更多详细信息,请查看使用 Python 开始使用 Heroku。
使用 Heroku 管道实现部署工作流程
在本节中,您将学习如何使用 Heroku pipelines 为您的应用程序部署实现工作流。这个特殊的工作流程使用三个独立的环境,分别叫做本地、筹备和生产。这种设置在专业项目中广泛使用,因为它允许在将新版本部署到生产环境并呈现给实际用户之前对其进行测试和检查。
了解部署工作流程
正如您在上面看到的,当您使用这个工作流时,您将在三个独立的环境中运行应用程序:
- 发展是当地的环境。
- 试运行是用于预览和测试的预生产环境。
- 生产是最终用户访问的实时站点。
在前面的小节中,您看到了如何在本地环境和 Heroku 上的生产环境中运行应用程序。添加一个登台环境可以极大地有利于开发过程。这个环境的主要目的是集成来自所有新分支的变更,并针对构建运行集成测试,这将成为下一个版本。
接下来,您将看到如何在 Heroku 中创建登台环境,以及如何创建一个管道来将版本从登台推广到生产。下图显示了此工作流程:
上图显示了三个环境、每个环境中发生的活动以及部署和升级步骤。
在 Heroku 中实现部署工作流
在 Heroku 中实施工作流包括两个步骤:
- 为试运行和生产创建单独的应用程序
- 使两个应用程序成为同一管道的一部分
Heroku pipeline 是一组由工作流联系在一起的应用程序。这些应用程序中的每一个都是开发工作流中的一个环境,就像登台或生产一样。使用管道可以保证,在升级后,产品将运行与您在试运行中审查的代码完全相同的代码。
在本教程中,之前创建的 Heroku 应用程序
realpython-example-app用作生产环境。您应该使用以下命令为暂存环境创建一个新的 Heroku 应用程序:$ heroku create realpython-example-app-staging --remote staging $ git push staging master运行这些命令会创建一个名为
realpython-example-app-staging的新 Heroku 应用程序,并使用 Git 将应用程序部署到其中。然后您可以在https://realpython-example-app-staging.herokuapp.com/访问分期应用程序。注意,名为staging的 Git remote 与这个应用程序相关联。现在您已经有了用于生产和登台的 Heroku 应用程序,您已经准备好创建一个 Heroku 管道来将它们连接在一起。您可以使用 Heroku CLI 创建管道:
$ heroku pipelines:create --app realpython-example-app \ --stage production \ realpython-example-app Creating realpython-example-app pipeline... done Adding ⬢ realpython-example-app to realpython-example-app pipeline as production ... done上面的命令创建了一个名为
realpython-example-app的管道,并将名为realpython-example-app的应用程序添加为生产环境。接下来,运行下面的命令来创建一个指向这个应用程序的 Git remote,将其命名为prod:$ heroku git:remote --app realpython-example-app --remote prod从现在开始,你可以把生产部署称为
prod。接下来,通过运行以下命令,将临时应用程序添加到同一管道中:
$ heroku pipelines:add realpython-example-app \ --app realpython-example-app-staging \ --stage staging Adding ⬢ realpython-example-app-staging to realpython-example-app pipeline as staging... done该命令将应用程序
realpython-example-app-staging添加到同一管道中,并指定该应用程序必须用于staging阶段。这意味着您的渠道现在由两个应用组成:
realpython-example-apprealpython-example-app-staging第一个用作生产环境,第二个用作暂存环境。
部署并升级到试运行和生产
现在您已经配置了应用程序和管道,您可以使用它将应用程序部署到试运行,在那里进行检查,然后将其提升到生产环境。
例如,假设您想要再次更改由
index()视图返回的消息。在这种情况下,您必须编辑app.py并更改由index()返回的字符串。以下代码块显示了新版本:1from flask import Flask 2 3app = Flask(__name__) 4 5@app.route("/") 6def index(): 7 return "This is yet another version!"如第 7 行所示,
index()返回"This is yet another version!"您可以通过运行以下命令将这个新版本部署到您的登台环境中:$ git add app.py $ git commit -m "Another change to the welcome message" $ git push staging master这些命令提交
app.py并将更改推送到staging遥控器,从而触发该环境的构建和部署过程。你应该会看到部署在https://realpython-example-app-staging.herokuapp.com/的新版本。请注意,生产环境仍然使用以前的版本。当您对这些更改感到满意时,您可以使用 Heroku CLI 将新版本升级到生产环境:
$ heroku pipelines:promote --remote staging上述命令将与当前在试运行中运行的版本完全相同的版本部署到生产中。正如您将注意到的,在这种情况下,没有构建步骤,因为从产品化到生产环境使用和部署的是同一个构建。您可以在
https://realpython-example-app.herokuapp.com/验证应用程序已经升级,并且运行的是最新版本。在本节中,您了解了部署工作流,并在 Heroku 中实现了它。要了解有关使用管道和更高级的工作流的更多信息,请查看 Heroku pipelines 文档。
管理不同环境的设置和密码
大多数应用程序需要为每个环境进行不同的设置,以实现调试功能或指向其他数据库。其中一些设置,如认证凭证、数据库密码和 API 密钥,非常敏感,因此您必须避免将它们硬编码到应用程序文件中。
您可以创建一个
config.py文件来保存不敏感的配置值,并从环境变量中读取敏感的配置值。在下面的代码块中,您可以看到config.py的源代码:1import os 2 3class Config: 4 DEBUG = False 5 DEVELOPMENT = False 6 SECRET_KEY = os.getenv("SECRET_KEY", "this-is-the-default-key") 7 8class ProductionConfig(Config): 9 pass 10 11class StagingConfig(Config): 12 DEBUG = True 13 14class DevelopmentConfig(Config): 15 DEBUG = True 16 DEVELOPMENT = True这段代码声明了一个
Config类,用作每个环境配置的基础。注意,在第 6 行,SECRET_KEY是使用os.getenv()从环境变量中读取的。这避免了在源代码中公开实际的密钥。同时,您可以为每个环境定制任何选项。接下来,您必须修改
app.py以根据环境使用不同的配置类。这是app.py的完整源代码:1import os 2from flask import Flask 3 4app = Flask(__name__) 5env_config = os.getenv("APP_SETTINGS", "config.DevelopmentConfig") 6app.config.from_object(env_config) 7 8@app.route("/") 9def index(): 10 secret_key = app.config.get("SECRET_KEY") 11 return f"The configured secret key is {secret_key}."在第 5 行和第 6 行,从先前在
config.py中定义的一个类中加载配置。具体的配置类将取决于存储在APP_SETTINGS环境变量中的值。如果变量未定义,配置将默认回退到DevelopmentConfig。注意:对于这个例子,第 11 行的消息被修改以显示由
app.config.get()获得的SECRET_KEY。你通常不会在回答中显示敏感信息。这只是一个展示如何读取这些值的示例。现在,通过在启动应用程序时传递一些环境变量,您可以看到这是如何在本地工作的:
$ SECRET_KEY=key-read-from-env-var flask run上面的命令设置了
SECRET_KEY环境变量并启动了应用程序。如果您导航到http://localhost:5000,那么您应该会看到消息The configured secret key is key-read-from-env-var。接下来,通过运行以下命令,提交更改并将它们推送到暂存环境:
$ git add app.py config.py $ git commit -m "Add config support" $ git push staging master这些命令将
app.py中的更改和新的config.py文件提交到本地 Git 存储库,然后将它们推送到登台环境,这触发了新的构建和部署过程。在继续之前,您可以使用 Heroku CLI 为此环境自定义环境变量:$ heroku config:set --remote staging \ SECRET_KEY=the-staging-key \ APP_SETTINGS=config.StagingConfig使用
config:set命令,您已经为 staging 设置了SECRET_KEY和APP_SETTINGS的值。您可以通过转到https://realpython-example-app-staging.herokuapp.com/并检查页面是否显示消息The configured secret key is the-staging-key来验证变更是否已经部署。使用 Heroku CLI,您还可以获得任何应用程序的环境变量的值。以下命令从 Heroku 获取为转移环境设置的所有环境变量:
$ heroku config --remote staging === realpython-example-app-staging Config Vars APP_SETTINGS: config.StagingConfig SECRET_KEY: the-staging-key如您所见,这些值与之前设置的值相匹配。
最后,您可以使用 Heroku CLI 将新版本升级到具有不同配置值的生产环境:
$ heroku config:set --remote prod \ SECRET_KEY=the-production-key \ APP_SETTINGS=config.ProductionConfig $ heroku pipelines:promote --remote staging第一个命令为生产环境设置
SECRET_KEY和APP_SETTINGS的值。第二个命令升级新的应用程序版本,这个版本有config.py文件。同样,您可以通过转到https://realpython-example-app.herokuapp.com/并检查页面是否显示The configured secret key is the-production-key来验证变更是否已经部署。在本节中,您学习了如何为每个环境使用不同的配置,以及如何使用环境变量处理敏感设置。请记住,在现实世界的应用程序中,您不应该暴露像
SECRET_KEY这样的敏感信息。结论
恭喜你,你现在知道了如何使用 Flask 创建一个 web 应用程序,以及如何通过使用 Heroku 部署它来使它公开可用。您还知道如何设置不同的环境,以便您、您的团队和您的客户可以在发布应用程序之前对其进行审查。虽然本教程中创建的示例应用程序非常小,但是您可以将它作为下一个项目的起点!
在本教程中,您学习了如何:
- 创建一个 Python Flask 示例 web 应用
- 使用 Heroku 部署 web 应用程序
- 使用 Heroku 管道实现部署工作流
- 以安全的方式管理不同环境的配置和秘密
Heroku 提供了许多前几节没有提到的特性,包括伸缩性、数据库等等。查看 Heroku 开发中心和 Heroku 平台文档,了解将帮助您加速开发的其他特性。最后,看看教程系列 Flask by Example ,看看如何创建和部署更复杂的应用程序。
您可以单击下面的链接获得本教程应用程序的完整源代码:
示例代码: 单击此处下载源代码,您将使用它来构建 Python Flask 示例应用程序。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 使用 Heroku 部署 Flask 应用程序*****
flask by Example–设置 Postgres、SQLAlchemy 和 Alembic
原文:https://realpython.com/flask-by-example-part-2-postgres-sqlalchemy-and-alembic/
在这一部分中,我们将建立一个 Postgres 数据库来存储字数统计的结果,以及一个对象关系映射器 SQLAlchemy 和一个处理数据库迁移的 Alembic。
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
更新:
- 02/09/2020:升级到 Python 版本 3.8.1 以及 Psycopg2、Flask-SQLAlchemy 和 Flask-Migrate 的最新版本。详见下面的。由于 Flask-Migrate 内部接口的更改,请明确安装和使用 Flask-Script。
- 03/22/2016:升级到 Python 版本 3.5.1 以及 Psycopg2、Flask-SQLAlchemy、Flask-Migrate 的最新版本。详见下面的。
- 2015 年 2 月 22 日:添加了 Python 3 支持。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署一个试运行环境和一个生产环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。(当前 )
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和 Natural Language Toolkit (NLTK)库从网页中抓取并处理字数。
- 第四部分:实现一个 Redis 任务队列来处理文本处理。
- 第五部分:在前端设置 Angular,持续轮询后端,看请求是否处理完毕。
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。
- 第七部分:更新前端,使其更加人性化。
- 第八部分:使用 JavaScript 和 D3 创建一个自定义角度指令来显示频率分布图。
需要代码吗?从回购中抢过来。
安装要求
本部分使用的工具:
- PostgreSQL ( 11.6 )
- psycopg 2(2 . 8 . 4)——Postgres 的 Python 适配器
- 烧瓶-SQLAlchemy ( 2.4.1 ) -提供 SQLAlchemy 支持的烧瓶延伸
- Flask-Migrate ( 2.5.2 ) -通过 Alembic 支持 SQLAlchemy 数据库迁移的扩展
首先,如果你还没有安装 Postgres,在你的本地计算机上安装它。既然 Heroku 使用 Postgres,那么在同一个数据库上进行本地开发将对我们有好处。如果你没有安装 Postgres, Postgres.app 对于 Mac OS X 用户来说是一个简单的启动和运行方式。咨询下载页面了解更多信息。
安装并运行 Postgres 后,创建一个名为
wordcount_dev的数据库,用作我们的本地开发数据库:$ psql # create database wordcount_dev; CREATE DATABASE # \q为了在 Flask 应用程序中使用我们新创建的数据库,我们需要安装一些东西:
$ cd flask-by-example$ python -m pip install psycopg2==2.8.4 Flask-SQLAlchemy===2.4.1 Flask-Migrate==2.5.2 $ python -m pip freeze > requirements.txt如果你在 OS X,在安装 psycopg2 时遇到问题,请查看这篇关于堆栈溢出的文章。
如果安装失败,您可能需要安装
psycopg2-binary而不是psycopg2。更新配置
将
SQLALCHEMY_DATABASE_URI字段添加到您的 config.py 文件中的Config()类,以设置您的应用程序在开发(本地)、试运行和生产中使用新创建的数据库:import os class Config(object): ... SQLALCHEMY_DATABASE_URI = os.environ['DATABASE_URL']您的 config.py 文件现在应该是这样的:
import os basedir = os.path.abspath(os.path.dirname(__file__)) class Config(object): DEBUG = False TESTING = False CSRF_ENABLED = True SECRET_KEY = 'this-really-needs-to-be-changed' SQLALCHEMY_DATABASE_URI = os.environ['DATABASE_URL'] class ProductionConfig(Config): DEBUG = False class StagingConfig(Config): DEVELOPMENT = True DEBUG = True class DevelopmentConfig(Config): DEVELOPMENT = True DEBUG = True class TestingConfig(Config): TESTING = True现在,当我们的配置加载到我们的应用程序,适当的数据库将连接到它。
类似于我们在上一篇文章中添加环境变量的方式,我们将添加一个
DATABASE_URL变量。在终端中运行以下命令:$ export DATABASE_URL="postgresql:///wordcount_dev"然后将该行添加到您的中。env 文件。
在您的 app.py 文件中导入 SQLAlchemy 并连接到数据库:
from flask import Flask from flask_sqlalchemy import SQLAlchemy import os app = Flask(__name__) app.config.from_object(os.environ['APP_SETTINGS']) app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False db = SQLAlchemy(app) from models import Result @app.route('/') def hello(): return "Hello World!" @app.route('/<name>') def hello_name(name): return "Hello {}!".format(name) if __name__ == '__main__': app.run()数据模型
通过添加一个 models.py 文件来建立一个基本模型:
from app import db from sqlalchemy.dialects.postgresql import JSON class Result(db.Model): __tablename__ = 'results' id = db.Column(db.Integer, primary_key=True) url = db.Column(db.String()) result_all = db.Column(JSON) result_no_stop_words = db.Column(JSON) def __init__(self, url, result_all, result_no_stop_words): self.url = url self.result_all = result_all self.result_no_stop_words = result_no_stop_words def __repr__(self): return '<id {}>'.format(self.id)这里我们创建了一个表来存储单词计数的结果。
我们首先从 SQLAlchemy 的 PostgreSQL 方言中导入我们在 app.py 文件中创建的数据库连接以及 JSON 。JSON 列对 Postgres 来说是相当新的,并不是在 SQLAlchemy 支持的每个数据库中都可用,所以我们需要专门导入它。
接下来,我们创建了一个
Result()类,并给它分配了一个表名results。然后我们设置想要存储结果的属性-
- 我们存储的结果的
id- 我们统计单词的来源
- 我们统计的完整单词列表
- 我们统计的单词列表减去了停用词(稍后会详细介绍)
然后,我们创建了一个
__init__()方法,它将在我们第一次创建新结果时运行,最后,我们创建了一个__repr__()方法,在我们查询对象时表示该对象。本地迁移
我们将使用 Alembic ,它是 Flask-Migrate 的一部分,来管理数据库迁移以更新数据库的模式。
注意: Flask-Migrate 使用 Flasks 新的 CLI 工具。然而,本文使用了由 Flask-Script 提供的接口,该接口之前由 Flask-Migrate 使用。为了使用它,您需要通过以下方式安装它:
`$ python -m pip install Flask-Script==2.0.6 $ python -m pip freeze > requirements.txt`创建一个名为 manage.py 的新文件:
import os from flask_script import Manager from flask_migrate import Migrate, MigrateCommand from app import app, db app.config.from_object(os.environ['APP_SETTINGS']) migrate = Migrate(app, db) manager = Manager(app) manager.add_command('db', MigrateCommand) if __name__ == '__main__': manager.run()为了使用 Flask-Migrate,我们将
Manager以及Migrate和MigrateCommand导入到我们的 manage.py 文件中。我们还导入了app和db,所以我们可以从脚本中访问它们。首先,我们设置我们的配置来获取我们的环境——基于环境变量——创建一个 migrate 实例,用
app和db作为参数,并设置一个manager命令来初始化我们的应用程序的Manager实例。最后,我们向manager添加了db命令,这样我们就可以从命令行运行迁移。为了运行迁移,初始化 Alembic:
$ python manage.py db init Creating directory /flask-by-example/migrations ... done Creating directory /flask-by-example/migrations/versions ... done Generating /flask-by-example/migrations/alembic.ini ... done Generating /flask-by-example/migrations/env.py ... done Generating /flask-by-example/migrations/README ... done Generating /flask-by-example/migrations/script.py.mako ... done Please edit configuration/connection/logging settings in '/flask-by-example/migrations/alembic.ini' before proceeding.运行数据库初始化后,您将在项目中看到一个名为“migrations”的新文件夹。这是 Alembic 针对项目运行迁移所必需的设置。在“migrations”中,您会看到有一个名为“versions”的文件夹,其中包含创建的迁移脚本。
让我们通过运行
migrate命令来创建我们的第一个迁移。$ python manage.py db migrate INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'results' Generating /flask-by-example/migrations/versions/63dba2060f71_.py ... done现在,您会注意到在“版本”文件夹中有一个迁移文件。该文件由 Alembic 根据模型自动生成。您可以自己生成(或编辑)这个文件;然而,在大多数情况下,自动生成的文件就可以了。
现在我们将使用
db upgrade命令对数据库进行升级:$ python manage.py db upgrade INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.runtime.migration] Running upgrade -> 63dba2060f71, empty message数据库现已准备就绪,可供我们在应用程序中使用:
$ psql # \c wordcount_dev You are now connected to database "wordcount_dev" as user "michaelherman". # \dt List of relations Schema | Name | Type | Owner --------+-----------------+-------+--------------- public | alembic_version | table | michaelherman public | results | table | michaelherman (2 rows) # \d results Table "public.results" Column | Type | Modifiers ----------------------+-------------------+------------------------------------------------------ id | integer | not null default nextval('results_id_seq'::regclass) url | character varying | result_all | json | result_no_stop_words | json | Indexes: "results_pkey" PRIMARY KEY, btree (id)远程迁移
最后,让我们将迁移应用到 Heroku 上的数据库。不过,首先,我们需要将暂存和生产数据库的细节添加到 config.py 文件中。
要检查我们是否在临时服务器上设置了数据库,请运行:
$ heroku config --app wordcount-stage === wordcount-stage Config Vars APP_SETTINGS: config.StagingConfig请确保将
wordcount-stage替换为您的分期应用的名称。因为我们没有看到数据库环境变量,所以我们需要将 Postgres 插件添加到登台服务器。为此,请运行以下命令:
$ heroku addons:create heroku-postgresql:hobby-dev --app wordcount-stage Creating postgresql-cubic-86416... done, (free) Adding postgresql-cubic-86416 to wordcount-stage... done Setting DATABASE_URL and restarting wordcount-stage... done, v8 Database has been created and is available ! This database is empty. If upgrading, you can transfer ! data from another database with pg:copy Use `heroku addons:docs heroku-postgresql` to view documentation.是 Heroku Postgres 插件的自由层。
现在,当我们再次运行
heroku config --app wordcount-stage时,我们应该会看到数据库的连接设置:=== wordcount-stage Config Vars APP_SETTINGS: config.StagingConfig DATABASE_URL: postgres://azrqiefezenfrg:Zti5fjSyeyFgoc-U-yXnPrXHQv@ec2-54-225-151-64.compute-1.amazonaws.com:5432/d2kio2ubc804p7接下来,我们需要提交您对 git 所做的更改,并将其推送到您的临时服务器:
$ git push stage master使用
heroku run命令运行我们创建的迁移,以迁移我们的临时数据库:$ heroku run python manage.py db upgrade --app wordcount-stage Running python manage.py db upgrade on wordcount-stage... up, run.5677 INFO [alembic.runtime.migration] Context impl PostgresqlImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.runtime.migration] Running upgrade -> 63dba2060f71, empty message注意我们是如何只运行
upgrade,而不是像以前一样运行init或migrate命令的。我们已经设置好了迁移文件,可以开始迁移了;我们只需要把它和 Heroku 数据库进行比对。现在让我们为生产做同样的事情。
- 在 Heroku 上为您的生产应用程序设置一个数据库,就像您为 staging 所做的一样:
heroku addons:create heroku-postgresql:hobby-dev --app wordcount-pro- 将您的更改推送到您的生产站点:
git push pro master注意,您不必对配置文件进行任何更改——它会根据新创建的DATABASE_URL环境变量来设置数据库。- 应用迁移:
heroku run python manage.py db upgrade --app wordcount-pro现在,我们的试运行和生产站点都已经设置好了数据库,并且已经完成了迁移——准备就绪!
当您向生产数据库应用新的迁移时,可能会有停机时间。如果这是一个问题,您可以通过添加一个“追随者”(通常称为从属)数据库来设置数据库复制。关于这方面的更多信息,请查看 Heroku 的官方文档。
结论
这就是第二部分。如果你想更深入地了解 Flask,请查看我们附带的视频系列:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
在第 3 部分中,我们将构建字数统计功能,并将其发送到任务队列,以处理更长时间运行的字数统计处理。
下次见。干杯!
这是创业公司埃德蒙顿的联合创始人卡姆·克林和 Real Python 的人合作的作品。**
flask by Example——使用请求、BeautifulSoup 和 NLTK 进行文本处理
原文:https://realpython.com/flask-by-example-part-3-text-processing-with-requests-beautifulsoup-nltk/
在本系列的这一部分,我们将抓取网页内容,然后处理文本以显示字数。
更新:
- 02/10/2020:升级到 Python 版本 3.8.1 以及 requests、BeautifulSoup 和 nltk 的最新版本。详见下面的。
- 03/22/2016:升级到 Python 版本 3.5.1 以及 requests、BeautifulSoup、nltk 的最新版本。详见下面的。
- 2015 年 2 月 22 日:添加了 Python 3 支持。
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署一个试运行环境和一个生产环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和 Natural Language Toolkit (NLTK)库从网页中抓取并处理字数。(当前 )
- 第四部分:实现一个 Redis 任务队列来处理文本处理。
- 第五部分:在前端设置 Angular,持续轮询后端,看请求是否处理完毕。
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。
- 第七部分:更新前端,使其更加人性化。
- 第八部分:使用 JavaScript 和 D3 创建一个自定义角度指令来显示频率分布图。
需要密码吗?从回购中抢过来。
安装要求
使用的工具:
- requests ( 2.22.0 ) -用于发送 HTTP 请求的库
- BeautifulSoup ( 4.8.2 ) -一个用于从网络上抓取和解析文档的工具
- 自然语言工具包( 3.4.5 ) -一个自然语言处理库
通过 autoenv 导航到项目目录以激活虚拟环境,然后安装需求:
$ cd flask-by-example $ python -m pip install requests==2.22.0 beautifulsoup4==4.8.2 nltk==3.4.5 $ python -m pip freeze > requirements.txt重构索引路径
首先,让我们去掉我们的 app.py 文件中索引路由的“hello world”部分,并设置路由来呈现一个接受 URL 的表单。首先,添加一个 templates 文件夹来保存我们的模板,并添加一个 index.html 的文件到其中。
$ mkdir templates $ touch templates/index.html建立一个非常基本的 HTML 页面:
<!DOCTYPE html> <html> <head> <title>Wordcount</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="//netdna.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> .container { max-width: 1000px; } </style> </head> <body> <div class="container"> <h1>Wordcount 3000</h1> <form role="form" method='POST' action='/'> <div class="form-group"> <input type="text" name="url" class="form-control" id="url-box" placeholder="Enter URL..." style="max-width: 300px;" autofocus required> </div> </form> <br> {% for error in errors %} <h4>{{ error }}</h4> {% endfor %} </div> <script src="//code.jquery.com/jquery-2.2.1.min.js"></script> <script src="//netdna.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js"></script> </body> </html>我们使用了 Bootstrap 来增加一点风格,这样我们的页面就不会完全丑陋。然后,我们添加了一个带有文本输入框的表单,供用户输入 URL。此外,我们利用一个 Jinja
for循环来遍历一个错误列表,显示每一个错误。更新 app.py 以提供模板:
import os from flask import Flask, render_template from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) app.config.from_object(os.environ['APP_SETTINGS']) app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False db = SQLAlchemy(app) from models import Result @app.route('/', methods=['GET', 'POST']) def index(): return render_template('index.html') if __name__ == '__main__': app.run()为什么两种 HTTP 方法,
methods=['GET', 'POST']?嗯,我们最终将对 GET 和 POST 请求使用相同的路径——分别服务于index.html页面和处理表单提交。启动应用程序进行测试:
$ python manage.py runserver导航到 http://localhost:5000/ ,您应该会看到表单回视着您。
请求
现在让我们使用请求库从提交的 URL 获取 HTML 页面。
像这样改变你的索引路线:
@app.route('/', methods=['GET', 'POST']) def index(): errors = [] results = {} if request.method == "POST": # get url that the user has entered try: url = request.form['url'] r = requests.get(url) print(r.text) except: errors.append( "Unable to get URL. Please make sure it's valid and try again." ) return render_template('index.html', errors=errors, results=results)确保也更新导入:
import os import requests from flask import Flask, render_template, request from flask_sqlalchemy import SQLAlchemy
这里,我们从 Flask 导入了
requests库和request对象。前者用于发送外部 HTTP GET 请求以获取特定的用户提供的 URL,而后者用于处理 Flask 应用程序内的 GET 和 POST 请求。接下来,我们添加了变量来捕获错误和结果,并将它们传递到模板中。
在视图本身中,我们检查请求是 GET 还是 POST-
- If POST:我们从表单中获取值(URL ),并将其分配给
url变量。然后我们添加了一个异常来处理任何错误,如果有必要的话,将一个通用的错误消息附加到errors列表中。最后,我们渲染了模板,包括errors列表和results字典。- If GET:我们只是渲染了模板。
让我们来测试一下:
$ python manage.py runserver你应该能够输入一个有效的网页,在终端中你会看到返回的网页文本。
注意:确保你的网址包含
http://或https://。否则我们的应用程序不会检测到这是一个有效的 URL。文本处理
有了 HTML,现在让我们统计页面上单词的出现频率,并将它们显示给最终用户。将您在 app.py 中的代码更新为以下内容,然后我们将介绍一下发生了什么:
import os import requests import operator import re import nltk from flask import Flask, render_template, request from flask_sqlalchemy import SQLAlchemy from stop_words import stops from collections import Counter from bs4 import BeautifulSoup app = Flask(__name__) app.config.from_object(os.environ['APP_SETTINGS']) app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True db = SQLAlchemy(app) from models import Result @app.route('/', methods=['GET', 'POST']) def index(): errors = [] results = {} if request.method == "POST": # get url that the person has entered try: url = request.form['url'] r = requests.get(url) except: errors.append( "Unable to get URL. Please make sure it's valid and try again." ) return render_template('index.html', errors=errors) if r: # text processing raw = BeautifulSoup(r.text, 'html.parser').get_text() nltk.data.path.append('./nltk_data/') # set the path tokens = nltk.word_tokenize(raw) text = nltk.Text(tokens) # remove punctuation, count raw words nonPunct = re.compile('.*[A-Za-z].*') raw_words = [w for w in text if nonPunct.match(w)] raw_word_count = Counter(raw_words) # stop words no_stop_words = [w for w in raw_words if w.lower() not in stops] no_stop_words_count = Counter(no_stop_words) # save the results results = sorted( no_stop_words_count.items(), key=operator.itemgetter(1), reverse=True ) try: result = Result( url=url, result_all=raw_word_count, result_no_stop_words=no_stop_words_count ) db.session.add(result) db.session.commit() except: errors.append("Unable to add item to database.") return render_template('index.html', errors=errors, results=results) if __name__ == '__main__': app.run()创建一个名为 stop_words.py 的新文件,并添加以下列表:
stops = [ 'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now', 'id', 'var', 'function', 'js', 'd', 'script', '\'script', 'fjs', 'document', 'r', 'b', 'g', 'e', '\'s', 'c', 'f', 'h', 'l', 'k' ]发生什么事了?
文本处理
在我们的索引路径中,我们使用 beautifulsoup 通过移除 HTML 标签来清理文本,这是我们从 URL 和 nltk 得到的
为了让 nltk 正常工作,你需要下载正确的记号赋予器。首先,创建一个新目录-
mkdir nltk_data-然后运行-python -m nltk.downloader。当安装窗口出现时,将“下载目录”更新为whatever _ the _ absolute _ path _ to _ your _ app _ is/nltk _ data/。
然后点击“型号”选项卡,并在“标识符”栏下选择“punkt”。点击“下载”。查看官方文档了解更多信息。
去掉标点符号,统计生字
- 由于我们不希望在最终结果中计入标点符号,我们创建了一个正则表达式来匹配任何不在标准字母表中的内容。
- 然后,使用列表理解,我们创建了一个没有标点符号或数字的单词列表。
- 最后,我们使用计数器计算每个单词在列表中出现的次数。
停止字
我们当前的输出包含许多我们可能不想统计的单词,例如,“我”、“我”、“the”等等。这些被称为停用词。
- 对于
stops列表,我们再次使用列表理解来创建不包括这些停用词的最终单词列表。- 接下来,我们用单词(作为键)及其相关计数(作为值)创建了一个字典。
- 最后,我们使用排序的方法来获得字典的排序表示。现在,我们可以使用排序后的数据在列表顶部显示计数最高的单词,这意味着我们不必在 Jinja 模板中进行排序。
要获得更强大的停用词表,请使用 NLTK 停用词库。
保存结果
最后,我们使用 try/except 将搜索结果和后续计数保存到数据库中。
显示结果
让我们更新index.html以便显示结果:
<!DOCTYPE html> <html> <head> <title>Wordcount</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="//netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> .container { max-width: 1000px; } </style> </head> <body> <div class="container"> <div class="row"> <div class="col-sm-5 col-sm-offset-1"> <h1>Wordcount 3000</h1> <br> <form role="form" method="POST" action="/"> <div class="form-group"> <input type="text" name="url" class="form-control" id="url-box" placeholder="Enter URL..." style="max-width: 300px;"> </div> </form> <br> {% for error in errors %} <h4>{{ error }}</h4> {% endfor %} <br> </div> <div class="col-sm-5 col-sm-offset-1"> {% if results %} <h2>Frequencies</h2> <br> <div id="results"> <table class="table table-striped" style="max-width: 300px;"> <thead> <tr> <th>Word</th> <th>Count</th> </tr> </thead> {% for result in results%} <tr> <td>{{ result[0] }}</td> <td>{{ result[1] }}</td> </tr> {% endfor %} </table> </div> {% endif %} </div> </div> </div> <br><br> <script src="//code.jquery.com/jquery-1.11.0.min.js"></script> <script src="//netdna.bootstrapcdn.com/bootstrap/3.1.1/js/bootstrap.min.js"></script> </body> </html>这里,我们添加了一个
if语句来查看我们的results字典中是否有任何内容,然后添加了一个for循环来对遍历results并在一个表中显示它们。运行您的应用程序,您应该能够输入一个 URL,并获得页面上的字数。$ python manage.py runserver如果我们想只显示前十个关键字会怎么样?
results = sorted( no_stop_words_count.items(), key=operator.itemgetter(1), reverse=True )[:10]测试一下。
总结
好极了。给定一个 URL,我们可以计算页面上的字数。如果你使用一个没有大量词汇的网站,比如 https://realpython.com,处理应该会很快。但是,如果这个网站有很多 T2 单词会怎么样呢?比如试试 https://gutenberg.ca 。您会注意到这需要更长的处理时间。
如果你有很多用户同时访问你的网站来计算字数,并且他们中的一些人试图计算更大的页面,这可能会成为一个问题。或者,您可能决定更改功能,以便当用户输入 URL 时,我们递归地抓取整个网站,并基于每个单独的页面计算词频。有了足够的流量,这将大大降低网站的速度。
有什么解决办法?
我们不需要在每个用户发出请求后计算字数,而是需要使用一个队列在后台进行处理——这正是下一次第四部分的出发点。
现在,提交您的代码,但是在提交 Heroku 之前,您应该删除除英语之外的所有语言标记符以及 zip 文件。这将显著减小提交的大小。请记住,如果你处理一个非英语网站,它只会处理英语单词。
└── nltk_data └── tokenizers └── punkt ├── PY3 │ └── english.pickle └── english.pickle因为这个新的文本处理功能只完成了一半,所以只将其推送到暂存环境中:
$ git push stage master
在舞台上测试一下。有问题就评论。下次见!
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
这是创业公司埃德蒙顿的联合创始人卡姆·克林和 Real Python 的人合作的作品***
flask by Example–更新用户界面
在本教程的这一部分,我们将致力于用户界面,使其更加友好。
更新:
- 03/22/2016:升级到 Python 版本 3.5.1 。
- 2015 年 2 月 22 日:添加了 Python 3 支持。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署 staging 和 production 环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和自然语言工具包(NLTK) 库从网页中抓取并处理字数。
- 第四部分:实现一个 Redis 任务队列来处理文本处理。
- 第五部分:在前端设置 Angular,持续轮询后端,看请求是否处理完毕。
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。
- 第七部分:更新前端,使其更加人性化。(当前 )
- 第八部分:使用 JavaScript 和 D3 创建一个自定义角度指令来显示频率分布图。
需要代码吗?从回购中抢过来。
让我们看看当前的用户界面…
当前用户界面
在终端窗口中启动 Redis:
$ redis-server然后让你的员工进入另一个窗口:
$ cd flask-by-example $ python worker.py 17:11:39 RQ worker started, version 0.5.6 17:11:39 17:11:39 *** Listening on default...最后,在第三个窗口中,启动应用程序:
$ cd flask-by-example $ python manage.py runserver测试该应用程序,以确保它仍然工作。您应该会看到类似这样的内容:
让我们做一些改变。
- 我们将从禁用提交按钮开始,以防止用户在等待提交的站点被计数时不断点击。
- 接下来,当应用程序计算字数时,我们将添加一个 displayjumper/loading spinner,字数统计列表将向用户显示后端有活动发生。
- 最后,如果无法访问该域,我们将显示一个错误。
更换按钮
将 HTML 中的按钮更改为以下内容:
{% raw %} <button type="submit" class="btn btn-primary" ng-disabled="loading">{{ submitButtonText }}</button> {% endraw %}我们添加了一个
ng-disabled指令,并将其附加到loading上。这将在loading评估为true时禁用按钮。接下来,我们添加了一个变量来显示给名为submitButtonText的用户。这样我们就可以将文本从"Submit"改为"Loading...",这样用户就知道发生了什么。然后我们将按钮包装在
{% raw %}和{% endraw %}中,这样金贾就知道将其作为原始 HTML 进行评估。如果我们不这样做,Flask 将试图把{{ submitButtonText }}作为一个 Jinja 变量来评估,Angular 将没有机会评估它。附带的 JavaScript 相当简单。
在 main.js 中的
WordcountController顶部添加以下代码:$scope.submitButtonText = 'Submit'; $scope.loading = false;这会将
loading的初始值设置为false,这样按钮就不会被禁用。它还将按钮的文本初始化为"Submit"。将发布呼叫更改为:
$http.post('/start', {'url': userInput}). success(function(results) { $log.log(results); getWordCount(results); $scope.wordcounts = null; $scope.loading = true; $scope.submitButtonText = 'Loading...'; }). error(function(error) { $log.log(error); });我们添加了三行,这设置了…
wordcounts到null以便清除旧值。loading到true,这样加载按钮将通过我们添加到 HTML 中的ng-disabled指令被禁用。submitButtonText到"Loading..."以便用户知道为什么按钮被禁用。接下来更新
poller功能:var poller = function() { // fire another request $http.get('/results/'+jobID). success(function(data, status, headers, config) { if(status === 202) { $log.log(data, status); } else if (status === 200){ $log.log(data); $scope.loading = false; $scope.submitButtonText = "Submit"; $scope.wordcounts = data; $timeout.cancel(timeout); return false; } // continue to call the poller() function every 2 seconds // until the timeout is cancelled timeout = $timeout(poller, 2000); }); };当结果成功时,我们将 loading 设置回
false,以便按钮再次被启用,并将按钮文本更改回"Submit",以便用户知道他们可以提交新的 URL。测试一下!
添加微调器
接下来,让我们在字数统计部分下面添加一个微调器,这样用户就知道发生了什么。这是通过在结果
div下面添加一个动画 gif 来实现的,如下所示:<div class="col-sm-5 col-sm-offset-1"> <h2>Frequencies</h2> <br> <div id="results"> <table class="table table-striped"> <thead> <tr> <th>Word</th> <th>Count</th> </tr> </thead> <tbody> {% raw %} <tr ng-repeat="(key, val) in wordcounts"> <td>{{key}}</td> <td>{{val}}</td> </tr> {% endraw %} </tbody> </table> </div> <img class="col-sm-3 col-sm-offset-4" src="{{ url_for('static', filename='spinner.gif') }}" ng-show="loading"> </div>一定要从回购中抓取 spinner.gif 。
你可以看到
ng-show和loading是连在一起的,就像按钮一样。这样,当loading设置为true时,显示微调 gif。当loading设置为false时,例如,当字数统计过程结束时,微调器消失。处理错误
最后,我们想处理用户提交了一个错误 URL 的情况。首先在表单下面添加以下 HTML:
<div class="alert alert-danger" role="alert" ng-show='urlerror'> <span class="glyphicon glyphicon-exclamation-sign" aria-hidden="true"></span> <span class="sr-only">Error:</span> <span>There was an error submitting your URL.<br> Please check to make sure it is valid before trying again.</span> </div>它使用了 Bootstrap 的
alert类来显示一个警告对话框,如果用户提交了一个错误的 URL。我们使用 Angular 的ng-show指令只在urlerror为true时显示对话框。最后,在
WordcountController中将$scope.urlerror初始化为false,这样警告最初就不会出现:$scope.urlerror = false;捕捉
poller函数中的错误:var poller = function() { // fire another request $http.get('/results/'+jobID). success(function(data, status, headers, config) { if(status === 202) { $log.log(data, status); } else if (status === 200){ $log.log(data); $scope.loading = false; $scope.submitButtonText = "Submit"; $scope.wordcounts = data; $timeout.cancel(timeout); return false; } // continue to call the poller() function every 2 seconds // until the timeout is cancelled timeout = $timeout(poller, 2000); }). error(function(error) { $log.log(error); $scope.loading = false; $scope.submitButtonText = "Submit"; $scope.urlerror = true; }); };这将错误记录到控制台,将
loading更改为false,将提交按钮的文本设置回"Submit",以便用户可以再次尝试提交,并将urlerror更改为true,以便显示警告。最后,在对
'/start'的 POST 调用的success函数中,将urlerror设置为false:$scope.urlerror = false;现在,当用户试图提交新的 url 时,警告对话框将会消失。
至此,我们对用户界面进行了一点清理,这样当我们在后台运行字数统计功能时,用户就知道发生了什么。测试一下!
结论
你还能增加或改变什么来改善用户体验?自己做些改变,或者在下面留下评论。完成后,请务必更新您的试运行和生产环境。
下次见!
这是创业公司埃德蒙顿的联合创始人卡姆·克林和 Real Python 的人合作的作品**
使用 Google 登录创建一个 Flask 应用程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用烧瓶使用 Google 登录
你可能在各种网站上看到过谷歌登录的选项。一些网站也有更多选项,如脸书登录或 GitHub 登录。所有这些选项都允许用户利用现有帐户来使用新服务。
在本文中,您将创建一个 Flask web 应用程序。您的应用程序将允许用户使用他们的 Google 身份登录,而不是创建一个新帐户。这种用户管理方法有很多好处。这将比管理传统的用户名和密码组合更加安全和简单。
如果你已经理解了 Python 的基础,这篇文章会更简单。了解一点 web 框架和 HTTP 请求也会有所帮助,但这并不是绝对必要的。
本文结束时,你将能够:
- 创建一个 Flask web 应用程序,允许用户使用 Google 登录
- 创建客户端凭证以与 Google 交互
- 在 Flask 应用程序中使用 Flask-Login 进行用户会话管理
- 更好地理解 OAuth 2 和 OpenID Connect (OIDC)
您可以单击下面的框来获取您将在本文中创建的应用程序的代码:
下载示例项目: 单击此处下载您将在本文中构建的使用 Google 登录的 Flask 应用程序的代码。
为什么为你的用户使用谷歌登录?
您可能希望个人用户拥有个人资料。或者您可能希望只为某些用户提供功能。在任何情况下,您都需要知道谁在与您的应用程序交互。换句话说,您需要对用户进行身份验证,并以某种独特的方式识别他们。
传统的解决方案是使用唯一的用户名和密码。您的应用程序将存储这些信息,并在需要时请求这些信息。然而,这种解决方案也有一些缺点:
- 你必须安全地管理密码。
- 您必须实现任何与帐户相关的功能:
- 双因素认证
- 密码重置
- 您必须防范恶意登录尝试。
- 您的用户必须记住另一个用户名和密码。
通过为你的用户使用谷歌登录,你把所有的责任都推给了他们。您的应用程序等待用户通过身份验证。然后 Google 告诉你的应用程序关于这个用户的信息。此时,您可以有效地将它们记录到您的应用程序中。
你不必存储任何密码,谷歌处理所有的安全问题。
应用程序如何使用谷歌登录
有两个非常流行和重要的规范叫做 OAuth 2 和 OpenID Connect (OIDC) 。OIDC 建立在 OAuth 2 之上,增加了一些新的想法和概念。
这些规范定义了第三方应用程序如何从另一个服务获取信息。这通常需要获得用户的同意。为了更好地理解这一点,让我们看看这是如何应用到您将要构建的应用程序中的。
您将要编写一个第三方应用程序,它将允许用户使用 Google Login 按钮登录。为此,谷歌需要了解你的应用程序。幸运的是,您可以将您的应用程序注册为 Google 的客户端。
一旦用户来到你的应用程序并按下谷歌登录按钮,你就可以把他们发送到谷歌。从那以后,Google 需要确保用户同意将他们的电子邮件和其他信息传递给你的应用程序。如果用户同意,Google 会向您的应用程序发回一些信息。然后,您可以存储这些信息,并在以后引用它们,有效地让用户登录。
OpenID 连接详细信息
要代表用户请求信息,您必须成为认证服务器的
client,也称为提供者。如果深入研究这些规范,您首先会发现有许多重叠的术语和概念。因此,作为第三方应用程序(也称为客户端),您希望代表用户从提供商那里获取信息。要做到这一点,需要一系列的步骤,而且这些步骤必须按照特定的顺序进行。这就是为什么你有时会听到 OAuth 2 和 OpenID Connect 被称为握手、流或舞蹈。
这些步骤大致如下:
- 您将第三方应用程序注册为提供商的客户端:
- 您将从提供商处收到唯一的客户端凭据。
- 稍后,您将使用这些客户端凭证向提供者进行身份验证(证明您是谁)。
- 客户端向提供者的
authorizationURL 发送请求- 提供商要求用户进行身份验证(证明他们是谁)
- 提供商要求用户同意代表他们的客户端:
- 通常这包括有限的访问权限,并且让用户清楚地知道客户要求什么。
- 这就像你必须批准手机上的应用程序才能访问位置或联系人一样。
- 提供商向客户端发送唯一的授权码。
- 客户端将授权码发送回提供者的
tokenURL。- 提供者代表用户发送客户端令牌以与其他提供者 URL 一起使用。
注意:以上步骤针对 OAuth 2 定义的授权代码流。
这些步骤包括到目前为止提到的两个标准。OpenID Connect (OIDC)构建在 OAuth 2 之上,增加了一些额外的特性和要求,主要涉及身份验证过程。除了上面流程中提到的认证,应用程序的重要 OIDC 概念是提供者配置和 userinfo 端点。
提供者配置包含关于提供者的信息,包括您需要用于 OAuth 2 流的确切 URL。在一个 OIDC 提供商那里有一个标准的 URL,你可以用它来取回一个带有标准化字段的文档。
在您完成 OAuth 2 流程后, userinfo 端点 将返回关于用户的信息。这将包括他们的电子邮件和一些您将在申请中使用的基本资料信息。为了获得这些用户信息,您需要一个来自提供商的令牌,如上面流程的最后一步所述。
稍后您将看到关于如何利用提供者配置和用户信息端点的细节。
创建谷歌客户端
启用 Google 登录选项的第一步是将您的应用程序注册为 Google 的客户端。让我们来完成这些步骤。
首先,注意你需要一个谷歌账户。如果你使用 Gmail,你已经有一个了。
接下来,进入谷歌开发者证书页面。
一旦进入,您可能会被提示同意他们的服务条款。如果您同意这些,请按下一页上的创建凭证按钮。选择 OAuth 客户端 ID 的选项:
选择顶部的
Web application选项。您也可以在Name字段中为客户端提供一个名称。当用户代表他们同意您的应用程序时,您提供的名称将显示给他们。现在您将在本地运行您的 web 应用程序,因此您可以将
Authorized JavaScript origins设置为https://127.0.0.1:5000,将Authorized redirect URIs设置为https://127.0.0.1:5000/login/callback。这将允许您的本地 Flask 应用程序与 Google 通信。最后,点击
Create,记下client ID和client secret。你以后会两者都需要的。创建自己的网络应用程序
现在到了有趣的部分,您将应用所学的知识来创建一个实际的 web 应用程序!
让我们从心中的目标开始。您希望创建一个应用程序,让用户使用他们的 Google 帐户登录。该应用程序应该能够从谷歌检索用户的一些基本信息,如他们的电子邮件地址。那么应用程序应该在数据库中存储基本的用户信息。
不过,首先让我们看看您将使用的框架和库。
烧瓶
Flask 是一个轻量级的 web 框架,自称为微框架。它带有用于 web 应用程序将执行的基本任务的内置工具,如路由 URL 和处理 HTTP 请求。
我选择使用 Flask 作为例子,因为它既受欢迎又简单。然而,你所学到的关于 OAuth 2 和 OIDC 的东西并不是 Flask 特有的。事实上,即使是用来简化 OAuth 2 和 OIDC 的库也可以在任何 Python 代码中使用。换句话说,通过一些小的修改,您可以将您在这里学到的东西应用到您选择的另一个框架中。
烧瓶登录
另一个可以用来简化用户操作的工具是 flask_login ,它提供了用户会话管理。
这个库在幕后做一些事情,并为您提供一些工具来帮助用户。也就是说,它为您提供了了解用户何时登录和注销的工具。它通过管理浏览器 cookie 中的用户会话来实现这一点。
它还处理用户的登录和注销,包括为这些用户创建数据库条目。但是从代码的角度来看,它真的让一切变得简单多了(您很快就会看到这一点)。
OAuthLib
对于安全相关和符合标准的代码来说,有一个非常正确的常用短语:“不要重新发明轮子。”
OAuth 2 和 OpenID 连接标准很复杂。看看 RFC 和规范,你就知道了。它们很密集。一个错误意味着你可能在你的应用程序中打开了一个漏洞。
因此,您不需要编写代码来实现这些标准。您将使用根据一些非常具体的标准选择的 Python 包:
- 这是一个受欢迎和普遍推荐的图书馆。许多其他包在内部使用这个库。
- 它非常活跃,人们经常修补漏洞。
- 它久经沙场,从 2012 年就有了。
有一些特定于 web 框架的包使用这个库来更紧密地集成到 Flask、Django、Pyramid 等中。然而,为了使您在这里学到的代码与框架无关,您将直接使用这个库,而不需要任何花哨的包装。
安装依赖关系
有许多第三方依赖关系可以让你的生活更轻松。以下是这些依赖关系的总结:
- 一个使典型的 web 应用程序任务更简单的 web 框架(Flask)
- 管理用户会话的简单方法(Flask-Login)
- 久经沙场的 OIDC 图书馆(
oauthlib)此外,您将使用以下内容:
- 一个数据库,用于存储登录用户的一些信息( SQLite
- 向 Google 发送 HTTP 请求的用户友好方式(
requests)- 一种在本地安全运行
https的快速方法(pyOpenSSL)SQLite 是标准 Python 库的一部分,但其他包不是。因此,您需要安装一些依赖项。现在,让我们一步一步地完成这个应用程序的创建。
首先,您需要安装上面提到的那些第三方依赖项。您将通过创建一个包含以下内容的
requirements.txt文件来实现这一点:requests==2.21.0 Flask==1.0.2 oauthlib==3.0.1 pyOpenSSL==19.0.0 Flask-Login==0.4.1注意:其他版本的包也可以工作,但是这些版本是在本文编写和测试期间使用的。
接下来,您可以使用 Python 的包安装程序
pip来安装这些依赖项。注意:如果您打算在您的计算机上安装不同 Python 应用程序的依赖项,通常建议使用虚拟环境。参见 Python 虚拟环境:初级读本了解更多。
要从
requirements.txt文件安装,请在终端中运行以下命令:$ pip install -r requirements.txt现在你准备好摇滚了!让我们深入研究代码。
导入、配置和设置
首先添加一些文件来支持一些基本的数据库功能和用户管理。这些不会一节一节地描述,主要是因为深入到 Python 数据库实现细节是一个兔子洞,会分散我们对目标的注意力。
这个文件将处理一些数据库功能。这几乎是来自 Flask 的官方数据库教程的一行一行:
# http://flask.pocoo.org/docs/1.0/tutorial/database/ import sqlite3 import click from flask import current_app, g from flask.cli import with_appcontext def get_db(): if "db" not in g: g.db = sqlite3.connect( "sqlite_db", detect_types=sqlite3.PARSE_DECLTYPES ) g.db.row_factory = sqlite3.Row return g.db def close_db(e=None): db = g.pop("db", None) if db is not None: db.close() def init_db(): db = get_db() with current_app.open_resource("schema.sql") as f: db.executescript(f.read().decode("utf8")) @click.command("init-db") @with_appcontext def init_db_command(): """Clear the existing data and create new tables.""" init_db() click.echo("Initialized the database.") def init_app(app): app.teardown_appcontext(close_db) app.cli.add_command(init_db_command)现在您已经有了一些数据库实用程序,可以开始考虑模式了。您可能会注意到,这段代码正在寻找一个
schema.sql文件,接下来您将创建这个文件。
schema.sql文件只是一些 SQL,它将在我们的数据库中创建一个用户表。您可以在这个文件中看到您将为每个用户存储的字段。这里有一个单独的表
user,它将存放一些与用户相关的东西(他们的姓名、他们登录时使用的电子邮件以及他们在 Google 上的个人资料图片):CREATE TABLE user ( id TEXT PRIMARY KEY, name TEXT NOT NULL, email TEXT UNIQUE NOT NULL, profile_pic TEXT NOT NULL );
db.py文件中的代码将实际执行这个 SQL 来创建数据库中的表。下一个文件包含我们的
User类,它将从数据库中存储和检索信息。姓名、电子邮件和个人资料图片都将从 Google 中检索,您将在本文后面看到。
User类有从数据库获取现有用户和创建新用户的方法:from flask_login import UserMixin from db import get_db class User(UserMixin): def __init__(self, id_, name, email, profile_pic): self.id = id_ self.name = name self.email = email self.profile_pic = profile_pic @staticmethod def get(user_id): db = get_db() user = db.execute( "SELECT * FROM user WHERE id = ?", (user_id,) ).fetchone() if not user: return None user = User( id_=user[0], name=user[1], email=user[2], profile_pic=user[3] ) return user @staticmethod def create(id_, name, email, profile_pic): db = get_db() db.execute( "INSERT INTO user (id, name, email, profile_pic) " "VALUES (?, ?, ?, ?)", (id_, name, email, profile_pic), ) db.commit()代码对数据库执行 SQL 语句,数据库是从前面的
db.py文件的get_db()函数中检索的。每个新用户都会在数据库中插入一个额外的行。从上面的代码创建了
db.py、schema.sql和user.py文件后,您可以创建一个新的app.py文件。添加以下导入内容:# Python standard libraries import json import os import sqlite3 # Third-party libraries from flask import Flask, redirect, request, url_for from flask_login import ( LoginManager, current_user, login_required, login_user, logout_user, ) from oauthlib.oauth2 import WebApplicationClient import requests # Internal imports from db import init_db_command from user import User稍后你会用到所有这些,所以现在理解它们并不重要。您的
app.py中的下一部分是一些配置:# Configuration GOOGLE_CLIENT_ID = os.environ.get("GOOGLE_CLIENT_ID", None) GOOGLE_CLIENT_SECRET = os.environ.get("GOOGLE_CLIENT_SECRET", None) GOOGLE_DISCOVERY_URL = ( "https://accounts.google.com/.well-known/openid-configuration" )下面是存储 Google 客户端 ID 和客户端密码的方法,您应该在本文前面创建这些内容。这些将在后面的 OIDC 流程中使用。
您的应用程序将尝试通过读取环境变量来获取客户端凭据。这有几个原因:
- 如果以后想使用不同的凭证,不必修改代码,只需更新环境即可。
- 你不会意外地将你的秘密凭证提交给 GitHub (或者另一个公共存储库)。
许多人不小心将秘密提交给公共存储库,造成了相当严重的安全风险。最好通过使用环境变量来防止这种情况。
提示:您可以使用
export GOOGLE_CLIENT_ID=your_client_id(类似于GOOGLE_CLIENT_SECRET)在 Linux bash 终端和 Mac OS X 终端中将您的客户端凭证设置为环境变量。如果你在 Windows 上,你可以在命令提示符下使用
set GOOGLE_CLIENT_ID=your_client_id。或者,您可以将字符串直接粘贴到这里,并将它们存储在这些变量中。然而,客户端秘密应该而不是被共享或提交给任何公共存储库。换句话说,如果您在这里粘贴真实的客户端凭据,请小心不要签入该文件。
最后,下面是一些带有全局变量的代码和一些简单的数据库初始化逻辑。除了数据库初始化之外,这大部分都是设置 Flask、Flask-Login 和 OAuthLib 的标准方式,您在前面已经了解过:
# Flask app setup app = Flask(__name__) app.secret_key = os.environ.get("SECRET_KEY") or os.urandom(24) # User session management setup # https://flask-login.readthedocs.io/en/latest login_manager = LoginManager() login_manager.init_app(app) # Naive database setup try: init_db_command() except sqlite3.OperationalError: # Assume it's already been created pass # OAuth 2 client setup client = WebApplicationClient(GOOGLE_CLIENT_ID) # Flask-Login helper to retrieve a user from our db @login_manager.user_loader def load_user(user_id): return User.get(user_id)请注意,您已经在使用来自 Google 的客户端 ID 来初始化我们在
WebApplicationClient中的oauthlib客户端。您可以创建另一个环境变量
SECRET_KEY,供 Flask 和 Flask-Login 使用对 cookies 和其他项目进行加密签名。Web 应用程序端点
现在,有趣的是。您将为您的 web 应用程序编写四个端点:
- 一个用于主页
- 一个用于开始用户登录过程
- 一个是回调函数,用户登录后 Google 会重定向到这个函数
- 一个用于注销
这些端点将由应用程序上的不同 URL 定义,并具有非常有创意的名称:
- 首页:
/- 登录:
/login- 登录回拨:
/login/callback- 注销:
/logout当然,您可能希望以后添加额外的页面和功能。这个应用程序的最终结果将是完全可扩展的,可以添加任何你想要的东西。
您将把这些端点的所有以下代码添加到
app.py文件中。让我们一次看一个端点的代码。主页
这在视觉上没有什么特别的,但是如果用户登录,您将添加一些简洁的逻辑来显示不同的内容。当他们没有登录时,会出现一个链接,显示 Google 登录。
点击链接会将他们重定向到您的
/login端点,这将启动登录流程。成功登录后,主页将同时显示用户的 Google 电子邮件和他们公开的 Google 个人资料图片!事不宜迟,您可以开始向您的
app.py文件添加更多代码:@app.route("/") def index(): if current_user.is_authenticated: return ( "<p>Hello, {}! You're logged in! Email: {}</p>" "<div><p>Google Profile Picture:</p>" '<img src="{}" alt="Google profile pic"></img></div>' '<a class="button" href="/logout">Logout</a>'.format( current_user.name, current_user.email, current_user.profile_pic ) ) else: return '<a class="button" href="/login">Google Login</a>'你会注意到,你返回的 HTML 是一个字符串,Flask 能够提供这个字符串。
current_user.is_authenticated是Flask-Login库的一个可爱的补充。这是确定与您的应用程序交互的当前用户是否登录的直接方法。这允许您应用条件逻辑。在这种情况下,如果用户已经登录,它将显示您保存的关于用户的一些信息。您可以从数据库条目中为用户获取字段,只需将它们作为属性访问在
current_user对象上,比如current_user.email。这是Flask-Login的另一个补充。登录
现在让我们来看看 OAuth 2 流。上面的 Google 登录按钮将重定向到这个端点。流程的第一步是找出 Google 的 OAuth 2 授权端点在哪里。
这就是 OAuth 2 和 OpenID Connect (OIDC)定义的界限开始模糊的地方。如前所述,OIDC 为一个提供者配置提供了一个标准端点,它包含一堆 OAuth 2 和 OIDC 信息。具有该信息的文档从任何地方的标准端点
.well-known/openid-configuration提供。假设您复制了前面定义
GOOGLE_DISCOVERY_URL的代码,这里有一个快速、简单的函数来检索 Google 的提供商配置:def get_google_provider_cfg(): return requests.get(GOOGLE_DISCOVERY_URL).json()提示:为了使这更健壮,您应该在 Google API 调用中添加错误处理,以防 Google 的 API 返回失败而不是有效的提供者配置文档。
您需要的提供者配置文档中的字段称为
authorization_endpoint。这将包含您需要用来从您的客户端应用程序启动 OAuth 2 流的 URL。您可以将所有逻辑与以下代码放在一起:
@app.route("/login") def login(): # Find out what URL to hit for Google login google_provider_cfg = get_google_provider_cfg() authorization_endpoint = google_provider_cfg["authorization_endpoint"] # Use library to construct the request for Google login and provide # scopes that let you retrieve user's profile from Google request_uri = client.prepare_request_uri( authorization_endpoint, redirect_uri=request.base_url + "/callback", scope=["openid", "email", "profile"], ) return redirect(request_uri)幸运的是,
oauthlib使得对 Google 的实际请求变得更加容易。您使用了预先配置的client,您已经将您的 Google 客户端 ID 给了它。接下来,您提供了希望 Google 使用的重定向。最后,你问谷歌要了一些 OAuth 2scopes。您可以将每个作用域视为一条独立的用户信息。在您的情况下,您需要从 Google 获得用户的电子邮件和基本个人资料信息。当然,用户必须同意向您提供这些信息。
注意:
openid是告诉 Google 启动 OIDC 流的必需范围,它将通过让用户登录来验证用户。OAuth 2 实际上并没有标准化身份验证是如何发生的,所以在这种情况下这对我们的流程是必要的。登录回拨
让我们分块来做这个,因为它比前几个端点更复杂一些。
一旦重定向到 Google 的授权端点,Google 端会发生很多事情。
应用程序上的登录端点是 Google 验证用户和请求同意的所有工作的起点。一旦用户登录 Google 并同意与您的应用程序共享他们的电子邮件和基本个人资料信息,Google 会生成一个独特的代码并发送给您的应用程序。
提醒一下,下面是你之前读过的 OIDC 步骤:
- 您将第三方应用程序注册为提供商的客户端。
- 客户端向提供者的
authorizationURL 发送一个请求。- 提供商要求用户进行身份验证(证明他们是谁)。
- 提供商要求用户同意代表他们的客户端。
- 提供商向客户端发送唯一的授权码
- 客户端将授权码发送回提供商的
tokenURL- 提供者代表用户发送客户端令牌以与其他 URL 一起使用
当 Google 发回这个唯一的代码时,它会将它发送到应用程序上的这个登录回调端点。因此,您的第一步是定义端点并获得那个
code:@app.route("/login/callback") def callback(): # Get authorization code Google sent back to you code = request.args.get("code")接下来你要做的是将代码发送回 Google 的
token端点。在 Google 验证了您的客户端凭据之后,他们会向您发回令牌,允许您代表用户向其他 Google 端点进行身份验证,包括您之前了解到的userinfo端点。在您的情况下,您只要求查看基本的个人资料信息,所以这是您对令牌唯一能做的事情。首先,你需要弄清楚 Google 的
token端点是什么。您将再次使用提供者配置文档:# Find out what URL to hit to get tokens that allow you to ask for # things on behalf of a user google_provider_cfg = get_google_provider_cfg() token_endpoint = google_provider_cfg["token_endpoint"]在下一个代码块中,它几次帮了你的忙。首先,您需要构造令牌请求。一旦请求被构造,您将使用
requests库来实际发送它。然后oauthlib将再次帮助您解析响应中的令牌:# Prepare and send a request to get tokens! Yay tokens! token_url, headers, body = client.prepare_token_request( token_endpoint, authorization_response=request.url, redirect_url=request.base_url, code=code ) token_response = requests.post( token_url, headers=headers, data=body, auth=(GOOGLE_CLIENT_ID, GOOGLE_CLIENT_SECRET), ) # Parse the tokens! client.parse_request_body_response(json.dumps(token_response.json()))现在您已经有了获取用户个人资料信息的必要工具,您需要向 Google 请求。幸运的是,OIDC 定义了一个用户信息端点,其给定提供者的 URL 在提供者配置中是标准化的。您可以通过检查提供者配置文档中的
userinfo_endpoint字段来获得位置。然后,您可以使用oauthlib将令牌添加到您的请求中,并使用requests将其发送出去:# Now that you have tokens (yay) let's find and hit the URL # from Google that gives you the user's profile information, # including their Google profile image and email userinfo_endpoint = google_provider_cfg["userinfo_endpoint"] uri, headers, body = client.add_token(userinfo_endpoint) userinfo_response = requests.get(uri, headers=headers, data=body)旅程的下一步是解析来自
userinfo端点的响应。Google 使用一个可选字段email_verified来确认用户不仅创建了一个帐户,还验证了电子邮件地址以完成帐户创建。有条件地检查这种验证通常是安全的,因为这是 Google 提供的另一层安全性。也就是说,您将检查这一点,如果 Google 说用户已经过验证,那么您将解析他们的信息。您将使用的 4 条基本个人资料信息是:
sub: 主题,用户在 Google 中的唯一标识符picture: 用户在谷歌中的公开个人资料图片given_name: 用户在谷歌中的名字和姓氏所有这些解析都会产生以下代码:
# You want to make sure their email is verified. # The user authenticated with Google, authorized your # app, and now you've verified their email through Google! if userinfo_response.json().get("email_verified"): unique_id = userinfo_response.json()["sub"] users_email = userinfo_response.json()["email"] picture = userinfo_response.json()["picture"] users_name = userinfo_response.json()["given_name"] else: return "User email not available or not verified by Google.", 400此回调的最后步骤是:
- 用刚刚从 Google 获得的信息在数据库中创建一个用户
- 通过让用户登录来开始用户会话
- 让用户返回主页(在这里您将显示他们的公开个人资料信息)
完成这些步骤的代码如下:
# Create a user in your db with the information provided # by Google user = User( id_=unique_id, name=users_name, email=users_email, profile_pic=picture ) # Doesn't exist? Add it to the database. if not User.get(unique_id): User.create(unique_id, users_name, users_email, picture) # Begin user session by logging the user in login_user(user) # Send user back to homepage return redirect(url_for("index"))因此,您在这里所做的是在数据库中为用户创建一个新行,如果他们还不存在的话。然后,使用 Flask-Login 启动一个会话。
注销
注销端点比最后几个端点代码少得多。你只需调用一个注销功能,并重定向回主页。完了,完了。这是:
@app.route("/logout") @login_required def logout(): logout_user() return redirect(url_for("index"))在这里,
@login_required装饰者是一件重要的事情。这是来自Flask-Login工具箱的另一个工具,它将确保只有登录的用户才能访问这个端点。如果只有登录的用户应该访问某些东西,您可以使用它。在这种情况下,只有登录的用户才能注销。在本地测试您的应用程序
您可以在本地计算机上运行 Flask 应用程序,通过向
app.py添加一些最终代码来测试登录流程:if __name__ == "__main__": app.run(ssl_context="adhoc")您可以在终端中使用以下命令运行 Flask 应用程序:
$ python app.py注意:由于朴素的数据库初始化逻辑,第一次运行这个命令时,它会创建数据库。要启动你的应用程序,你必须再次运行同样的命令*。
Flask 应该打印到运行开发服务器的终端上。应该是
https://127.0.0.1:5000/。请注意,Flask 的开发服务器在本地运行和,使用
https来确保与 Google 的加密连接。这是通过上面代码中的app.run的ssl_context="adhoc"参数实现的。这需要您安装软件包PyOpenSSL。缺点是使用的证书是动态生成的,所以当你在浏览器中进入
https://127.0.0.1:5000/时,它可能会给你一个很大的警告屏幕,告诉你你的连接不安全或不保密。您可以有效地忽略这些警告。一旦越过警告屏幕,您应该会看到一个显示 Google 登录的按钮。按下它会把你带到谷歌的官方登录。登录后,谷歌会提示你同意“第三方应用程序”访问你的电子邮件和个人资料信息。
同意后,您将被重定向回您的 Flask 应用程序,页面将显示您的 Google 电子邮件和公开个人资料图片!最后,一个注销按钮允许你注销。
结论
允许用户使用他们现有的帐户登录您的 web 应用程序有很多好处。最重要的是,帐户管理的安全性和复杂性不必由您来承担。这让您可以自由地编写新的 web 应用程序,而不必担心双因素身份验证之类的琐碎细节。
您在本文中创建的应用程序是一个很好的起点。您可以点击下面的方框获取代码:
下载示例项目: 单击此处下载您将在本文中构建的使用 Google 登录的 Flask 应用程序的代码。
您的下一步可以是执行以下操作:
- 重做数据库初始化,使其与运行应用程序分开进行
- 从 Python 代码中分离出 HTML/CSS 以便于管理:
- 在云中托管您的应用程序
- 购买域名
- 使用真正的 SSL 证书,摆脱讨厌的警告
在本文中,您已经了解了 OAuth 2 和 OpenID Connect 的基础知识。您已经看到了如何使用众所周知的 Python 包来创建一个 web 应用程序,允许用户使用他们现有的 Google 帐户登录。最重要的是,您拥有示例代码,可以作为您下一个 web 应用程序的良好起点!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用烧瓶使用 Google 登录*****
Django 的新 Postgres 功能带来的乐趣
原文:https://realpython.com/fun-with-djangos-new-postgres-features/
这篇博文讲述了如何使用 Django 1.8 中引入的新的 PostgreSQL 特有的模型字段——数组字段、HStoreField 和范围字段。
这篇文章献给由马克·塔姆林组织的 Kickstarter 活动的令人敬畏的支持者,真正的 playa 让它发生了。
Playaz 俱乐部?
因为我是一个超级极客,而且没有机会进入一个真正的 Playaz 俱乐部(而且因为在那个时候 4 Tay 是个炸弹),我决定建立我自己的虚拟在线 Playaz 俱乐部。那到底是什么?一个私人的、只接受邀请的社交网络,面向一小群志同道合的人。
在这篇文章中,我们将关注用户模型,并探索 Django 的新 PostgreSQL 特性如何支持建模。我们所指的新特性是 PostgreSQL 独有的,所以除非您的数据库
ENGINE等于django.db.backends.postgresql_psycopg2,否则不要尝试。你需要psycopg2的版本> = 2.5。好孩子,我们开始吧。如果你和我在一起,你好!😃
塑造 Playa 的形象
每个 playa 都有一个代表,他们希望全世界都知道他们的代表。所以让我们创建一个用户档案(也称为“代表”),让我们的每个 playaz 都能表达他们的个性。
以下是 playaz 代表的基本模型:
from django.db import models from django.contrib.auth.models import User class Rep(models.Model): playa = models.OneToOneField(User) hood = models.CharField(max_length=100) area_code = models.IntegerField()上面 1.8 没什么特别的。只是一个扩展 Django 用户的标准模型,因为 playa 仍然需要用户名和电子邮件地址,对吗?另外,我们添加了两个新字段来存储 playaz hood 和区号。
资金和测距仪
对于一个玩家来说,仅仅戴上兜帽是不够的。Playaz 经常喜欢炫耀他们的资金,但同时又不想让人知道资金的确切数额。我们可以用一个新的 Postgres 值域来建模。当然,我们将使用
BigIntegerRangeField来更好地模拟海量数字,对吗?bankroll = pgfields.BigIntegerRangeField(default=(10, 100))范围字段基于 psycopg2 范围对象,可用于数字和日期范围。将资金字段迁移到数据库后,我们可以通过向其传递一个范围对象来与范围字段进行交互,因此创建我们的第一个 playa 将如下所示:






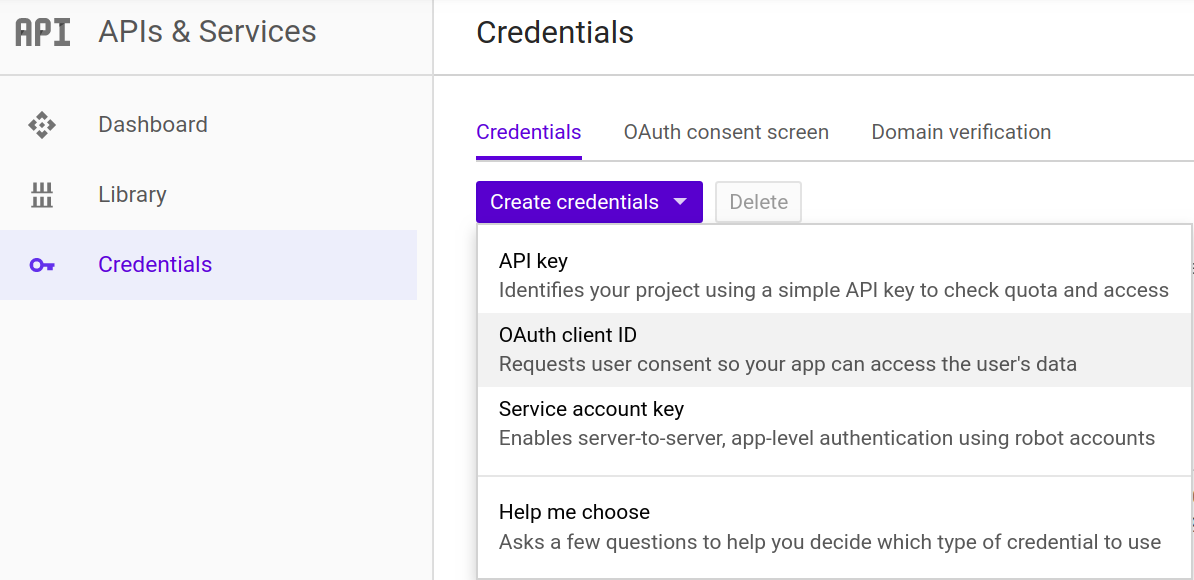
>>> from playa.models import Rep
>>> from django.contrib.auth.models import User
>>> calvin = User.objects.create_user(username="snoop", password="dogg")
>>> calvins_rep = Rep(hood="Long Beach", area_code=213)
>>> calvins_rep.bankroll = (100000000, 150000000)
>>> calvins_rep.playa = calvin
>>> calvins_rep.save()
注意这一行:calvins_rep.bankroll = (100000000, 150000000)。这里我们使用一个简单的元组来设置一个范围字段。也可以使用NumericRange对象来设置值,如下所示:
from psycopg2.extras import NumericRange
br = NumericRange(lower=100000000, upper=150000000)
calvin.rep.bankroll = br
calvin.rep.save()
这与使用元组本质上是一样的。然而,了解NumericRange对象很重要,因为它用于过滤模型。例如,如果我们想找到所有资金大于 5000 万的玩家(意味着整个资金范围大于 5000 万):
Rep.objects.filter(bankroll__fully_gt=NumericRange(50000000, 50000000))
这将返回这些 playas 的列表。或者,如果我们想找到资金“在 1000 万到 1500 万之间”的所有玩家,我们可以使用:
Rep.objects.filter(bankroll__overlap=NumericRange(10000000, 15000000))
这将返回资金范围至少在 1000 万到 1500 万之间的所有玩家。一个更绝对的查询是资金完全在一个范围内的所有玩家,即每个人至少赚 1000 万但不超过 1500 万。该查询类似于:
Rep.objects.filter(bankroll__contained_by=NumericRange(10000000, 15000000))
关于基于范围的查询的更多信息可以在这里找到。
skillz as array file
这不全是资金的问题,playaz 有 skillz,各种 skillz。让我们用一个数组字段来建模。
skillz = pgfields.ArrayField(
models.CharField(max_length=100, blank=True),
blank = True,
null = True,
)
要声明ArrayField,我们必须给它一个第一参数,也就是基字段。与 Python 列表不同,ArrayFields 必须将列表中的每个元素声明为相同的类型。Basefield 声明这是哪种类型,它可以是任何标准的模型字段类型。在上面的例子中,我们刚刚使用了一个CharField作为我们的基本类型,这意味着skillz将是一个字符串数组。
将值存储到ArrayField正如您所期望的那样:
>>> from django.contrib.auth.models import User >>> calvin = User.objects.get(username='snoop') >>> calvin.rep.skillz = ['ballin', 'rappin', 'talk show host', 'merchandizn'] >>> calvin.rep.save()斯奇尔兹寻找玩法
如果我们需要一个有特殊技能的球员,我们怎么找到他们?使用
__contains过滤器:Rep.objects.filter(skillz__contains=['rappin'])对于拥有任何一项技能['说唱',' djing ','制作']但没有其他技能的玩家,您可以执行如下查询:
Rep.objects.filter(skillz__contained_by=['rappin', 'djing', 'producing'])或者,如果您想找到具有某一特定技能列表的任何人:
Rep.objects.filter(skillz__overlap=['rappin', 'djing', 'producing'])你甚至可以找到那些把一项技能列为第一技能的人(因为每个人都把自己最擅长的技能列在第一位):
Rep.objects.filter(skillz__0='ballin')游戏 as HStore
游戏可以被认为是玩家可能拥有的各种随机技能的列表。由于游戏跨越了各种各样的东西,让我们把它建模为一个 HStore 字段,这基本上意味着我们可以把任何旧的 Python 字典放在那里:
game = pgfields.HStoreField()花点时间想想我们刚刚做了什么。HStore 相当大。它基本上允许“NoSQL”类型的数据存储,就在 postgreSQL 内部。另外,由于它在 PostgreSQL 内部,我们可以链接(通过外键)包含 NoSQL 数据的表和存储常规 SQL 类型数据的表。您甚至可以将两者存储在同一个表中的不同列上,就像我们在这里所做的那样。也许玩家们不需要再使用那个只会说废话的 MongoDB 了…
回到实现细节,如果您试图将新的 HStore 字段迁移到数据库中,并以这个错误结束-
django.db.utils.ProgrammingError: type "hstore" does not exist-那么你的 PostgreSQL 数据库是 8.1 之前(升级时间,playa)或者没有安装 HStore 扩展。请记住,在 PostgreSQL 中,HStore 扩展是针对每个数据库安装的,而不是系统范围的。要从 psql 提示符安装它,请运行以下 sql:
CREATE EXTENSION hstore或者,如果您愿意,可以使用以下迁移文件通过 SQL 迁移来完成(假设您以超级用户身份连接到数据库):
from django.db import models, migrations class Migration(migrations.Migration): dependencies = [] operations = [ migrations.RunSQL("CREATE EXTENSION IF NOT EXISTS hstore") ]最后,您还需要确保您已经将
'django.contrib.postgres'添加到'settings.INSTALLED_APPS'中,以利用 HStore 字段。通过这种设置,我们可以像这样用字典向我们的
HStoreFieldgame添加数据:
>>> calvin = User.objects.get(username="snoop")
>>> calvin.rep.game = {'best_album': 'Doggy Style', 'youtube-channel': \
'https://www.youtube.com/user/westfesttv', 'twitter_follows' : '11000000'}
>>> calvin.rep.save()
请记住,字典必须只对所有的键和值使用字符串。
现在来看一些更有趣的例子…
Propz
让我们编写一个“显示游戏”函数来搜索 playaz 游戏,并返回匹配的 playaz 列表。用极客的话来说,我们在 HStore 字段中搜索传递给函数的任何键。它看起来像这样:
def show_game(key):
return Rep.Objects.filter(game__has_key=key).values('game','playa__username')
上面我们已经为 HStore 字段使用了has_key过滤器来返回一个 queryset,然后使用 values 函数进一步过滤它(主要是为了说明您可以将django.contrib.postgres内容与常规查询集内容链接起来)。
返回值将是一个字典列表:
[
{'playa__username': 'snoop',
'game': {'twitter_follows': '11000000',
'youtube-channel': 'https://www.youtube.com/user/westfesttv',
'best_album': 'Doggy Style'
}
}
]
正如他们所说,游戏识别游戏,现在我们也可以搜索游戏了。
豪赌客
如果我们相信 playaz 告诉我们的关于他们资金的信息,那么我们可以用它来对他们进行分类(因为这是一个范围)。让我们根据以下级别的资金添加一个 Playa 排名:
-
年轻的小伙子-资金不足 10 万美元
-
balla——通过“ballin”技能获得 100,000 到 500,000 英镑的资金
-
playa–用两个 skillz 和一些游戏赢得 500,000 到 1,000,000 美元的资金
-
高注玩家–资金超过 100 万英镑
-
有“黑帮”技能和“老派”游戏钥匙
balla 的查询如下。这将是严格的解释,它将只返回那些其整个资金范围在指定限制内的人:
Rep.objects.filter(bankroll__contained_by=[100000, 500000], skillz__contains=['ballin'])
用 DALL E 2 和 OpenAI API 生成图像
原文:https://realpython.com/generate-images-with-dalle-openai-api/
描述任何图像,然后让计算机为您创建它。随着神经网络和潜在扩散模型 (LDM)的进步,几年前听起来很超前的东西已经变成了现实。由 OpenAI 创作的 DALL E 通过令人惊叹的生成艺术和人们用它创造的现实图像引起了轰动。
OpenAI 现在允许通过他们的 API 访问 DALL E,这意味着你可以将其功能整合到你的 Python 应用中。
在本教程中,您将:
- 开始使用 OpenAI Python 库
- 探索与图像生成相关的 API 调用
- 从文本提示创建图像
- 为您生成的图像创建个变体
- 将 Base64 JSON 响应转换为 PNG 图像文件
您需要一些 Python、JSON 和文件操作的经验来轻松完成本教程。你也可以边走边研究这些主题,因为你会在整篇文章中找到相关的链接。
如果你以前没有玩过 DALL E 的 web 用户界面(UI ),那么在回来学习如何用 Python 编程之前,先尝试一下。
源代码: 点击这里下载免费的源代码,你将使用 DALL E 2 和 OpenAI API 来生成令人惊叹的图像。
完成设置要求
如果您已经看到了 DALL E 所能做的事情,并且渴望将其功能融入到您的 Python 应用程序中,那么您就找对了地方!在第一部分中,您将快速浏览在自己的代码中开始使用 DALL E 的图像创建功能需要做的事情。
安装 OpenAI Python 库
确认运行 Python 版本 3.7.1 或更高版本,创建并激活虚拟环境,安装 OpenAI Python 库:
- 视窗
** Linux + macOS*
PS> python --version
Python 3.11.0
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS> python -m pip install openai
$ python --version
Python 3.11.0
$ python -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install openai
这个openai包让你可以访问完整的 OpenAI API 。在本教程中,您将关注于Image类,您可以用它来与 DALL E 交互,从文本提示中创建和编辑图像。
获取您的 OpenAI API 密钥
您需要一个 API 密钥来进行成功的 API 调用。注册 OpenAI API 并创建一个新的 API 密钥,方法是点击您个人资料上的下拉菜单并选择查看 API 密钥T3:
在这个页面上,您可以管理您的 API 密钥,这些密钥允许您通过 API 访问 OpenAI 提供的服务。您可以创建和删除密钥。
点击创建新的密钥创建新的 API 密钥,并复制弹出窗口中显示的值:
永远保持这个密钥的秘密!复制此项的值,以便以后在项目中使用。你只会看到键值一次。
将 API 密钥保存为环境变量
保存 API 密钥并使其对 Python 脚本可用的一个快速方法是将其保存为一个环境变量。选择您的操作系统,了解如何:
- 视窗
** Linux + macOS*
(venv) PS> $ENV:OPENAI_API_KEY = "<your-key-value-here>"
(venv) $ export OPENAI_API_KEY="<your-key-value-here>"
****** *****
加入我们,访问数以千计的教程和 Pythonistas 专家社区。
*已经是会员了?签到
全文仅供会员阅读。加入我们,访问数以千计的教程和 Pythonistas 专家社区。
已经是会员了?签到******
用 Pycco 生成代码文档
原文:https://realpython.com/generating-code-documentation-with-pycco/
作为开发人员,我们喜欢编写代码,尽管当时这对我们来说是有意义的,但我们必须为我们的受众着想。必须有人阅读、使用和/或维护所述代码。可能是另一个开发者,一个客户,或者三个月后我们未来的自己。
即使像 Python 这样漂亮的语言有时也很难理解。所以作为关心我们的程序员同事的优秀编程公民(或者更可能是因为我们的老板希望我们这样),我们应该写一些文档。
但是有规则:
- 写文档一定不能糟糕(例如,我们不能使用 MS Word)。
- 编写文档必须尽可能轻松。
- 编写文档不能要求我们离开我们最喜欢的文本编辑器/ IDE。
- 写文档不能要求我们做任何格式化或者关心最终的演示。
这就是 Pycco 的用武之地:
“Pycco”是 Docco 的 Python 移植:原始的快速、肮脏、长达一百行、有文化的编程风格的文档生成器。它生成 HTML,在你的代码旁边显示你的注释。注释通过 Markdown 和 SmartyPants 传递,而代码通过 Pygments 传递以突出语法。
所以基本上这意味着 Pycco 可以为我们自动生成看起来不错的代码文档。Pycco 还遵守上述代码文档的四个规则。那么有什么不爱呢?让我们来看一些如何使用它的例子。
对于这篇文章,我从一个用 Django 编写的简单的 TODO 应用程序开始,你可以从 repo 中获得它。该应用程序允许用户向列表中添加项目,并在完成后删除它们。这个应用程序可能不会为我赢得一个 Webby,但它应该服务于本文的目的。
请注意,回购中的文件已经包含最终代码,已经记录在案。不过,您仍然可以创建单独的文档文件,所以请随意克隆回购并跟随我。
项目设置
克隆回购:
$ git clone git@github.com:mjhea0/django-todo.git
Setup virtualenv:
$ cd django-todo
$ virtualenv --no-site-packages venv
$ source venv/bin/activate
安装要求:
$ pip install -r requirements.txt
同步数据库:
$ cd todo
$ python manage.py syncdb
生成一些单据
开始很简单:
$ pip install pycco
然后,您可以使用如下命令来运行它:
$ pycco todos/*.py
注意,这样您可以指定单个文件或文件目录。在我们的 TODO repo 上执行上述命令会生成以下结果:
pycco = todo/todos/__init__.py -> docs/__init__.html
pycco = todo/todos/models.py -> docs/models.html
pycco = todo/todos/tests.py -> docs/tests.html
pycco = todo/todos/views.py -> docs/views.html
换句话说,它生成 html 文件(每个 python 文件一个)并将它们全部转储到“docs”目录中。对于较大的项目,您可能希望使用-p 选项来保留原始文件路径。
例如:
pyccoo todo/todos/*.py -p
将生成:
pycco = todo/todos/__init__.py -> docs/todo/todos/__init__.html
pycco = todo/todos/models.py -> docs/todo/todos/models.html
pycco = todo/todos/tests.py -> docs/todo/todos/tests.html
pycco = todo/todos/views.py -> docs/todo/todos/views.html
请注意,它将 todos 应用程序的文档存储在“docs/todo/todos”子文件夹下。这样做的话,对于一个大型项目来说,浏览文档将会更加容易,因为文档结构将会与代码结构相匹配。
生成的单据
pycco 的目的是生成一个两列文档,左边是注释,右边是后续代码。因此,在还没有注释的 models.py 类上调用 pycco 将生成如下所示的页面:

您会注意到左边的栏(应该是注释的地方)是空白的,右边显示的是代码。我们可以通过添加一个 docstring 来改变 models.py ,通过向 models.py 添加以下代码来获得更有趣的文档。
from django.db import models
# === Models for Todos app ===
class ListItem(models.Model):
"""
The ListItem class defines the main storage point for todos.
Each todo has two fields:
text - stores the text of the todo
is_visible - used to control if the todo is displayed on screen
"""
text = models.CharField(max_length=300)
is_visible = models.BooleanField()
在上面的代码片段中,pycco 找到了这一行:
# === Models for Todos app ===
然后在文档中生成一个标题。
文档字符串:
"""
The ListItem class defines the main storage point for todos.
Each todo has two fields:
text - stores the text of the todo
is_visible - used to control if the todo is displayed on screen
"""
Pycco 使用 docstring 来生成文档。再次运行 pycco 后的最终结果将是:

如您所见,左边的文档与右边的代码很好地结合在一起。这使得审查代码和理解发生了什么变得非常容易。
Pycco 还识别代码中以#开头的单行注释来生成文档。
让它变得别致
但是 pycco 并没有就此止步。它还允许使用 markdown 定制注释格式。例如,让我们在 views.py 文件中添加一些注释。首先,让我们在视图的顶部放一个 docstring:
"""
All the views for our todos application
Currently we support the following 3 views:
1\. **Home** - The main view for Todos
2\. **Delete** - called to delete a todo
3\. **Add** - called to add a new todo
"""
from django.http import HttpResponse
from django.shortcuts import render_to_response
from django.template import RequestContext
from todos.models import ListItem
def home(request):
items = ListItem.objects.filter(is_visible=True)
return render_to_response('home.html', {'items': items}, context_instance = RequestContext(request))
# ... code omitted for brevity ...
这将生成如下报告:

我们还可以在文件之间甚至在同一个文件内部添加链接。可以通过使用[[filename.py]]或[[filename.py#section]]添加链接,它们将呈现为带有文件名的链接。让我们更新一下 views.py ,在列表中的每一项末尾添加一些链接:
"""
All the views for our todos application
Currently we support the following 3 views:
1\. **Home** - The main view for Todos (jump to section in [[views.py#home]] )
2\. **Delete** - called to delete a todo ( jump to section in [[views.py#delete]] )
3\. **Add** - called to add a new todo (jump to section in [[views.py#add]])
"""
from django.http import HttpResponse
from django.shortcuts import render_to_response
from django.template import RequestContext
# defined in [[models.py]]
from todos.models import ListItem
# === home ===
def home(request):
items = ListItem.objects.filter(is_visible=True)
return render_to_response('home.html', {'items': items}, context_instance = RequestContext(request))
# === delete ===
def delete(request):
# ... code omitted for brevity ...
正如你所看到的,建立链接有两个组成部分。首先,我们必须在文档中定义一个部分。你可以看到我们已经用代码# === home ===定义了 home 部分。一旦创建了这个部分,我们就可以用代码[[views.py#home]]链接到它。我们还插入了一个到模型文档文件的链接,代码如下:
# defined in [[models.py]]
最终结果是如下所示的文档:

请记住,因为 pycco 允许标记语法,所以您也可以使用完整的 html。所以去疯吧:)
为整个项目自动生成文档
如何使用 pycco 为整个项目生成文档可能并不明显,但如果您使用 bash 或 zsh 或任何支持 globing 的 sh,它实际上非常简单,您只需运行如下命令:
$ pycco todo/**/*.py -p
这将为 todo 的任何/所有子目录中的所有.py文件生成文档。如果你用的是 windows,你应该可以用 cygwin,git bash 或者 power sh 来完成。
非 Python 文件的文档
Pycco 还支持其他几种文件类型,这对经常使用多种文件类型的 web 项目很有帮助。截至本文撰写之时,受支持文件的完整列表如下:
.coffee-咖啡脚本.pl珠光宝气.sql- SQL.c- C.cpp- C++.js- JavaScript.rb-红宝石.py-蟒蛇.scm-方案.lua-卢阿.erl-二郎.tcl- Tcl- 哈斯克尔
这应该可以满足您的文档需求。所以请记住写一些注释,让 pycco 轻松地为您生成好看的代码文档。
项目级文档怎么样?
项目通常有额外的需求,而不仅仅是代码文档——比如自述文件、安装文档、部署文档等等。使用 pycco 来生成文档也不错,这样我们就可以始终坚持使用一种工具。现在,pycco 将只处理带有上面列表中扩展名的文件。但是没有什么可以阻止你创建一个 readme.py 或 installation.py 文件,并使用 pycco 生成文档。你所要做的就是把你的文档放在一个 docstring 中,然后 pycco 会生成它,并给你完全的 markdown 支持。想象一下,如果在项目目录的底部有一个名为project_docs的文件夹,其中包含:
install_docs.pyproject_readme.pydeployment.py
然后,您可以运行以下命令:
$ pycco project_docs/*.py -p
这将在“docs/project_docs 目录”中添加适当的 html 文件。当然,这可能有点笨拙,但是它确实允许您使用一个工具来为您的项目生成所有的文档。
再生
Pycco 还有一个锦囊妙计:自动文档再生。换句话说,您可以让 pycco 监视您的源文件,并在每次保存源文件时自动重新生成必要的文档。如果你想在你的评论中加入一些自定义的 markdown / html,并想确保它能正确呈现,这真的很有用。随着自动文档重新生成的运行,您只需进行更改,保存您的文件并刷新您的浏览器,不需要在中间重新运行 pycco 命令。为此,您需要安装一个监视程序:
$ pip install watchdog
看门狗是监听文件更改的模块。安装完成后,只需执行如下命令:
$ pycco todo/**/*.py -p --watch
它将运行 pycco 并保持运行,直到您用 Ctrl + C 停止它。只要它还在运行,它就会对源文件的每一次更改重新生成文档。这样便于记录怎么样?
Pycoo 是我见过的最简单、最直接的 python 代码文档工具。有人用其他东西吗?给我们留言,让我们知道你的想法。干杯!***
生成性对抗网络:建立你的第一个模型
生成对抗网络 (GANs)是神经网络,它生成类似于人类生产的材料,如图像、音乐、语音或文本。
近年来,gan 已经成为一个活跃的研究课题。脸书的人工智能研究主任 Yann LeCun 将对抗性训练称为机器学习领域“过去 10 年最有趣的想法”。下面,您将在实现您自己的两个生成模型之前学习 gan 是如何工作的。
在本教程中,您将学习:
- 什么是生成模型以及它与判别模型有何不同
- 甘是如何构成的和是如何训练的
- 如何使用 PyTorch 建造自己的 GAN
- 如何使用 GPU 和 PyTorch 为实际应用训练您的 GAN
我们开始吧!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是生成性对抗网络?
生成对抗网络是机器学习系统,可以学习模仿给定的数据分布。深度学习专家 Ian Goodfellow 和他的同事在 2014 年 NeurIPS 论文中首次提出了它们。
GANs 由两个神经网络组成,一个被训练来生成数据,另一个被训练来区分假数据和真实数据(因此模型具有“对抗性”的性质)。虽然生成数据的结构的想法并不新鲜,但在图像和视频生成方面,GANs 已经提供了令人印象深刻的结果,例如:
- 使用 CycleGAN 进行风格转换,它可以对图像执行许多令人信服的风格转换
- 生成具有风格特征的人脸,在网站上显示此人不存在
生成数据的结构,包括 gan,被认为是生成模型,与更广泛研究的判别模型形成对比。在深入研究 GANs 之前,您将看到这两种模型之间的差异。
判别模型与生成模型
如果你研究过神经网络,那么你遇到的大多数应用程序可能都是使用判别模型实现的。另一方面,生成敌对网络是被称为生成模型的另一类模型的一部分。
判别模型是那些用于大多数监督 分类或回归问题的模型。作为分类问题的一个例子,假设您想要训练一个模型来对从 0 到 9 的手写数字图像进行分类。为此,您可以使用一个带标签的数据集,其中包含手写数字的图像及其相关标签,这些标签指示每个图像代表哪个数字。
在训练过程中,您将使用算法来调整模型的参数。目标将是最小化一个损失函数,以便模型学习给定输入的输出的概率分布。在训练阶段之后,您可以使用该模型对新的手写数字图像进行分类,方法是估计输入最可能对应的数字,如下图所示:

您可以将分类问题的判别模型描绘成使用训练数据来学习类之间的界限的块。然后,他们使用这些边界来区分输入并预测其类别。用数学术语来说,判别模型在给定输入 x 的情况下,学习输出 y 的条件概率 P ( y | x )。
除了神经网络之外,其他结构也可以用作判别模型,例如逻辑回归模型和支持向量机 (SVMs)。
然而,像 GANs 这样的生成模型被训练来描述如何根据概率模型生成数据集。通过从创成式模型中采样,您能够生成新数据。虽然判别模型用于监督学习,但生成模型通常用于未标记的数据集,可以被视为一种形式的无监督学习。
使用手写数字的数据集,您可以训练一个生成模型来生成新的数字。在训练阶段,您可以使用某种算法来调整模型的参数,以最小化损失函数,并学习训练集的概率分布。然后,通过训练模型,您可以生成新的样本,如下图所示:
为了输出新的样本,生成模型通常会考虑一个随机或随机元素,它会影响模型生成的样本。用于驱动发生器的随机样本是从一个潜在空间中获得的,在该潜在空间中,向量代表所产生样本的一种压缩形式。
与判别模型不同,生成模型学习输入数据 x 的概率 P ( x ),通过输入数据的分布,它们能够生成新的数据实例。
注意:创成式模型也可用于带标签的数据集。当他们是,他们被训练学习给定输出 y 的输入 x 的概率 P ( x | y )。它们也可以用于分类任务,但一般来说,判别模型在分类方面表现更好。
你可以在文章中找到更多关于区别性和生成性分类器的相对优势和劣势的信息:关于区别性和生成性分类器:逻辑回归和朴素贝叶斯的比较。
尽管 GANs 近年来受到了很多关注,但它们并不是唯一可以用作生成模型的架构。除了 GANs,还有各种其他生成模型架构,例如:
然而,由于在图像和视频生成方面的令人兴奋的结果,gan 最近引起了公众的极大兴趣。
现在您已经了解了生成模型的基础,您将看到 gan 如何工作以及如何训练它们。
生成性对抗网络的架构
生成对抗网络由两个神经网络组成的整体结构组成,一个称为生成器,另一个称为鉴别器。
生成器的作用是估计真实样本的概率分布,以便提供类似真实数据的生成样本。反过来,鉴别器被训练来估计给定样本来自真实数据而不是由生成器提供的概率。
这些结构被称为生成性对抗网络,因为生成器和鉴别器被训练成相互竞争:生成器试图在愚弄鉴别器方面变得更好,而鉴别器试图在识别生成的样本方面变得更好。
为了理解 GAN 训练如何工作,考虑一个玩具示例,其数据集由二维样本( x ₁, x ₂)组成, x ₁在 0 到 2π的区间内, x ₂ = sin( x ₁),如下图所示:
正如你所看到的,这个数据集由位于正弦曲线上的点( x ₁, x ₂)组成,具有非常特殊的分布。生成与数据集样本相似的对( x̃ ₁、 x̃ ₂)的 GAN 的整体结构如下图所示:

发生器 G 由来自潜在空间的随机数据提供,其作用是产生类似真实样本的数据。在本例中,您有一个二维潜在空间,因此生成器被输入随机( z ₁, z ₂)对,并需要对它们进行转换,以便它们与真实样本相似。
神经网络 G 的结构可以是任意的,允许你使用神经网络作为多层感知器(MLP)卷积神经网络 (CNN),或者任何其他结构,只要输入和输出的维度与潜在空间和真实数据的维度相匹配。
鉴别器 D 被输入来自训练数据集的真实样本或者由 G 提供的生成样本。它的作用是估计输入属于真实数据集的概率。执行训练使得 D 在输入真实样本时输出 1,在输入生成样本时输出 0。
和 G 一样,你可以为 D 选择任意的神经网络结构,只要它尊重必要的输入和输出维度。在这个例子中,输入是二维的。对于二进制鉴频器,输出可以是范围从 0 到 1 的标量。
GAN 训练过程由两人游戏 minimax 组成,其中 D 用于最小化真实样本和生成样本之间的辨别误差, G 用于最大化 D 出错的概率。
虽然包含真实数据的数据集没有被标记,但是对 D 和 G 的训练过程是在监督下进行的。在训练的每一步, D 和 G 的参数都会更新。其实在原 GAN 建议中, D 的参数更新 k 次,而 G 的参数每训练一步只更新一次。但是,为了使训练更简单,你可以认为 k 等于 1。
为了训练 D ,在每次迭代中,你将从训练数据中获取的一些真实样本标记为 1,将 G 提供的一些生成样本标记为 0。这样,您可以使用传统的监督训练框架来更新 D 的参数,以便最小化损失函数,如以下方案所示:

对于包含标记的真实样本和生成样本的每批训练数据,您更新 D 的参数以最小化损失函数。在 D 的参数更新后,你训练 G 产生更好的生成样本。 G 的输出连接到 D ,其参数保持不变,如下图所示:
你可以把由 G 和 D 组成的系统想象成一个单一的分类系统,接收随机样本作为输入,输出分类,在这种情况下可以解释为概率。
当 G 做得足够好,骗过 D 的时候,输出概率应该接近 1。您还可以在这里使用传统的监督训练框架:训练由 G 和 D 组成的分类系统的数据集将由随机输入样本提供,与每个输入样本相关联的标签将是 1。
在训练过程中,随着参数 D 和 G 的更新,预计 G 给出的生成样本将更接近真实数据,而 D 将更难区分真实数据和生成数据。
现在您已经知道了 gan 是如何工作的,您已经准备好使用 PyTorch 来实现您自己的 gan 了。
你的第一甘
作为生成性对抗网络的第一个实验,您将实现上一节中描述的示例。
为了运行这个例子,您将使用 PyTorch 库,您可以使用 Anaconda Python 发行版和 conda 包和环境管理系统来安装这个库。要了解关于 Anaconda 和 conda 的更多信息,请查看教程在 Windows 上为机器学习设置 Python。
首先,创建一个 conda 环境并激活它:
$ conda create --name gan
$ conda activate gan
激活 conda 环境后,您的提示符将显示其名称gan。然后,您可以在环境中安装必要的软件包:
$ conda install -c pytorch pytorch=1.4.0
$ conda install matplotlib jupyter
由于 PyTorch 是一个非常活跃的开发框架,API 可能会在新版本中发生变化。为了确保示例代码能够运行,您需要安装特定的版本1.4.0。
除了 PyTorch 之外,您还将使用 Matplotlib 来处理绘图,并使用 Jupyter 笔记本在交互式环境中运行代码。这样做不是强制性的,但它有助于机器学习项目的工作。
关于使用 Matplotlib 和 Jupyter 笔记本的复习,请看一下 Python 使用 Matplotlib 绘图(指南)和 Jupyter 笔记本:介绍。
在打开 Jupyter Notebook 之前,您需要注册 conda gan环境,以便您可以使用它作为内核来创建笔记本。为此,在激活了gan环境的情况下,运行以下命令:
$ python -m ipykernel install --user --name gan
现在运行jupyter notebook就可以打开 Jupyter 笔记本了。点击新建,然后选择干,创建一个新的笔记本。
在笔记本中,首先导入必要的库:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
在这里,您用torch导入 PyTorch 库。您还导入了nn,以便能够以一种不太冗长的方式建立神经网络。然后您导入math来获得 pi 常量的值,并且您像往常一样导入 Matplotlib 绘图工具作为plt。
建立一个随机生成器种子是一个很好的实践,这样实验可以在任何机器上完全相同地复制。要在 PyTorch 中实现这一点,请运行以下代码:
torch.manual_seed(111)
数字111代表用于初始化随机数发生器的随机种子,随机数发生器用于初始化神经网络的权重。尽管实验具有随机性,但只要使用相同的种子,它就必须提供相同的结果。
现在环境已经设置好了,您可以准备训练数据了。
准备训练数据
训练数据由成对的( x ₁, x ₂)组成,使得 x ₂由在从 0 到 2π的区间中对于 x ₁的 x ₁的正弦值组成。您可以按如下方式实现它:
1train_data_length = 1024
2train_data = torch.zeros((train_data_length, 2))
3train_data[:, 0] = 2 * math.pi * torch.rand(train_data_length)
4train_data[:, 1] = torch.sin(train_data[:, 0])
5train_labels = torch.zeros(train_data_length)
6train_set = [
7 (train_data[i], train_labels[i]) for i in range(train_data_length)
8]
在这里,你用1024对( x ₁, x ₂).)组成一个训练集在第 2 行中,你初始化train_data,一个具有1024行和2列维度的张量,都包含零。一个张量是一个类似于 NumPy 数组的多维数组。
在第 3 行中,你用train_data的第一列来存储从0到2π区间的随机值。然后,在第 4 行中,你将张量的第二列计算为第一列的正弦。
接下来,您需要一个标签张量,这是 PyTorch 的数据加载器所需要的。由于 GANs 使用无监督学习技术,标签可以是任何东西。毕竟不会用到它们。
在的第 5 行,你创建了train_labels,一个充满零的张量。最后,在的第 6 行到第 8 行中,您将train_set创建为一个元组列表,每个元组中的每一行train_data和train_labels都由 PyTorch 的数据加载器表示。
您可以通过绘制每个点( x ₁, x ₂):)来检查训练数据
plt.plot(train_data[:, 0], train_data[:, 1], ".")
输出应该类似于下图:
使用train_set,您可以创建 PyTorch 数据加载器:
batch_size = 32
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True
)
在这里,您创建一个名为train_loader的数据加载器,它将混洗来自train_set的数据,并返回一批32样本,您将使用这些样本来训练神经网络。
在设置了训练数据之后,您需要为将组成 GAN 的鉴别器和生成器创建神经网络。在下一节中,您将实现鉴别器。
实施鉴别器
在 PyTorch 中,神经网络模型由继承自nn.Module的类来表示,因此您必须定义一个类来创建鉴别器。关于定义类的更多信息,请看一下 Python 3 中的面向对象编程(OOP)。
鉴别器是一个具有二维输入和一维输出的模型。它将从真实数据或生成器接收样本,并提供样本属于真实训练数据的概率。下面的代码显示了如何创建鉴别器:
1class Discriminator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(2, 256),
6 nn.ReLU(),
7 nn.Dropout(0.3),
8 nn.Linear(256, 128),
9 nn.ReLU(),
10 nn.Dropout(0.3),
11 nn.Linear(128, 64),
12 nn.ReLU(),
13 nn.Dropout(0.3),
14 nn.Linear(64, 1),
15 nn.Sigmoid(),
16 )
17
18 def forward(self, x):
19 output = self.model(x)
20 return output
您使用.__init__()来构建模型。首先,你需要从nn.Module调用super().__init__()来运行.__init__()。你使用的鉴别器是一个 MLP 神经网络,使用nn.Sequential()按顺序定义。它具有以下特点:
-
第 5、6 行:输入是二维的,第一隐层由激活 ReLU 的
256神经元组成。 -
第 8、9、11、12 行:第二和第三隐层分别由
128和64神经元组成,具有 ReLU 激活。 -
第 14 行和第 15 行:输出由单个神经元组成,该神经元具有代表概率的s 形激活。
最后,你用.forward()来描述模型的输出是如何计算的。这里,x代表模型的输入,是一个二维张量。在这个实现中,输出是通过将输入x馈送到您定义的模型而获得的,没有任何其他处理。
声明 discriminator 类后,应该实例化一个Discriminator对象:
discriminator = Discriminator()
discriminator代表您定义的神经网络的一个实例,准备接受训练。然而,在实现训练循环之前,您的 GAN 还需要一个生成器。您将在下一节中实现一个。
实现生成器
在生成性对抗网络中,生成器是从潜在空间中获取样本作为其输入并生成类似于训练集中的数据的模型。在这种情况下,这是一个具有二维输入的模型,它将接收随机点( z ₁, z ₂),并且二维输出必须提供( x̃ ₁, x̃ ₂)类似于来自训练数据的点。
实现类似于您为鉴别器所做的。首先,你必须创建一个继承自nn.Module的Generator类,定义神经网络架构,然后你需要实例化一个Generator对象:
1class Generator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(2, 16),
6 nn.ReLU(),
7 nn.Linear(16, 32),
8 nn.ReLU(),
9 nn.Linear(32, 2),
10 )
11
12 def forward(self, x):
13 output = self.model(x)
14 return output
15
16generator = Generator()
这里,generator代表生成器神经网络。它由两个带有16和32神经元的隐藏层和一个输出带有2神经元的线性激活层组成,两个隐藏层都带有 ReLU 激活。这样,输出将由一个带有两个元素的向量组成,这两个元素可以是从负无穷大到无穷大范围内的任何值,它们将代表( x̃ ₁, x̃ ₂).)
现在您已经为鉴别器和生成器定义了模型,您已经准备好执行训练了!
训练模型
在训练模型之前,您需要设置一些在训练过程中使用的参数:
1lr = 0.001
2num_epochs = 300
3loss_function = nn.BCELoss()
在这里,您可以设置以下参数:
-
第 1 行设置学习率(
lr),您将使用它来调整网络权重。 -
第 2 行设置历元数(
num_epochs),其定义了将使用整个训练集执行多少次重复训练。 -
第 3 行将变量
loss_function分配给二元交叉熵函数BCELoss(),这是您将用来训练模型的损失函数。
二进制交叉熵函数是用于训练鉴别器的合适的损失函数,因为它考虑了二进制分类任务。它也适用于训练发生器,因为它将其输出馈送给鉴别器,后者提供二进制可观察输出。
PyTorch 在torch.optim中实现了模型训练的各种权重更新规则。您将使用 Adam 算法来训练鉴别器和生成器模型。要使用torch.optim创建优化器,请运行以下代码行:
1optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
2optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
最后,您需要实现一个训练循环,在该循环中,训练样本被提供给模型,并且它们的权重被更新以最小化损失函数:
1for epoch in range(num_epochs):
2 for n, (real_samples, _) in enumerate(train_loader):
3 # Data for training the discriminator
4 real_samples_labels = torch.ones((batch_size, 1))
5 latent_space_samples = torch.randn((batch_size, 2))
6 generated_samples = generator(latent_space_samples)
7 generated_samples_labels = torch.zeros((batch_size, 1))
8 all_samples = torch.cat((real_samples, generated_samples))
9 all_samples_labels = torch.cat(
10 (real_samples_labels, generated_samples_labels)
11 )
12
13 # Training the discriminator
14 discriminator.zero_grad()
15 output_discriminator = discriminator(all_samples)
16 loss_discriminator = loss_function(
17 output_discriminator, all_samples_labels)
18 loss_discriminator.backward()
19 optimizer_discriminator.step()
20
21 # Data for training the generator
22 latent_space_samples = torch.randn((batch_size, 2))
23
24 # Training the generator
25 generator.zero_grad()
26 generated_samples = generator(latent_space_samples)
27 output_discriminator_generated = discriminator(generated_samples)
28 loss_generator = loss_function(
29 output_discriminator_generated, real_samples_labels
30 )
31 loss_generator.backward()
32 optimizer_generator.step()
33
34 # Show loss
35 if epoch % 10 == 0 and n == batch_size - 1:
36 print(f"Epoch: {epoch} Loss D.: {loss_discriminator}")
37 print(f"Epoch: {epoch} Loss G.: {loss_generator}")
对于 GANs,您可以在每次训练迭代中更新鉴别器和生成器的参数。正如通常对所有神经网络所做的那样,训练过程包括两个循环,一个用于训练时期,另一个用于每个时期的批次。在内部循环中,您开始准备数据来训练鉴别器:
-
第 2 行:你从数据加载器中获取当前批次的真实样本,并将其分配给
real_samples。注意,张量的第一维的元素数量等于batch_size。这是 PyTorch 中组织数据的标准方式,张量的每一行代表一批中的一个样本。 -
第 4 行:使用
torch.ones()为真实样本创建值为1的标签,然后将标签分配给real_samples_labels。 -
第 5 行和第 6 行:您通过在
latent_space_samples中存储随机数据来创建生成的样本,然后您将这些样本馈送给生成器以获得generated_samples。 -
第 7 行:您使用
torch.zeros()为生成的样本的标签分配值0,然后您将标签存储在generated_samples_labels中。 -
第 8 行到第 11 行:您连接真实的和生成的样本和标签,并将它们存储在
all_samples和all_samples_labels中,您将使用它们来训练鉴别器。
接下来,在第 14 行到第 19 行中,您训练鉴别器:
-
第 14 行:在 PyTorch 中,有必要在每个训练步骤清除梯度以避免累积。您可以使用
.zero_grad()来完成这项工作。 -
第 15 行:使用
all_samples中的训练数据计算鉴频器的输出。 -
第 16 行和第 17 行:使用
output_discriminator中模型的输出和all_samples_labels中的标签计算损失函数。 -
第 18 行:你用
loss_discriminator.backward()计算梯度来更新权重。 -
第 19 行:您通过调用
optimizer_discriminator.step()来更新鉴别器权重。
接下来,在线 22 ,你准备数据来训练发电机。你在latent_space_samples中存储随机数据,行数等于batch_size。您使用两列,因为您提供二维数据作为生成器的输入。
你在行 25 到 32 训练发电机:
-
第 25 行:你用
.zero_grad()清除渐变。 -
第 26 行:你用
latent_space_samples给发电机馈电,把它的输出存储在generated_samples里。 -
第 27 行:你把发生器的输出输入到鉴别器中,并把它的输出存储在
output_discriminator_generated中,你将用它作为整个模型的输出。 -
第 28 到 30 行:你用
output_discriminator_generated中存储的分类系统的输出和real_samples_labels中的标签计算损失函数,都等于1。 -
第 31 和 32 行:您计算梯度并更新生成器权重。请记住,当您训练生成器时,您保持了鉴别器权重不变,因为您创建了第一个参数等于
generator.parameters()的optimizer_generator。
最后,在第 35 到 37 行上,显示每十个时期结束时鉴频器和发电机损耗函数的值。
由于本例中使用的模型参数很少,因此训练将在几分钟内完成。在下一节中,您将使用经过训练的 GAN 来生成一些样本。
检查由 GAN 生成的样本
生成性对抗网络被设计成生成数据。所以,在训练过程完成后,你可以从潜在空间中获取一些随机样本,并将它们提供给生成器,以获得一些生成的样本:
latent_space_samples = torch.randn(100, 2)
generated_samples = generator(latent_space_samples)
然后,您可以绘制生成的样本,并检查它们是否与训练数据相似。在绘制generated_samples数据之前,您需要使用.detach()从 PyTorch 计算图中返回一个张量,然后您将使用它来计算梯度:
generated_samples = generated_samples.detach()
plt.plot(generated_samples[:, 0], generated_samples[:, 1], ".")
输出应该类似于下图:

您可以看到生成数据的分布类似于真实数据的分布。通过使用固定的潜在空间样本张量,并在训练过程中的每个时期结束时将其馈送给生成器,您可以可视化训练的演变:
请注意,在训练过程开始时,生成的数据分布与真实数据有很大不同。然而,随着训练的进行,生成器学习真实的数据分布。
现在你已经完成了你的第一个生成性对抗网络的实现,你将经历一个使用图像的更实际的应用。
带 GAN 的手写数字生成器
生成式对抗网络还可以生成图像等高维样本。在本例中,您将使用 GAN 来生成手写数字的图像。为此,您将使用手写数字的 MNIST 数据集来训练模型,该数据集包含在 torchvision 包中。
首先,您需要在激活的gan conda 环境中安装torchvision:
$ conda install -c pytorch torchvision=0.5.0
同样,您使用特定版本的torchvision来确保示例代码能够运行,就像您使用pytorch一样。设置好环境后,您可以开始实现 Jupyter Notebook 中的模型。打开它,点击新建,然后选择干,创建一个新的笔记本。
与上一个示例一样,首先导入必要的库:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
import torchvision import torchvision.transforms as transforms
除了您之前导入的库之外,您还需要torchvision和transforms来获取训练数据并执行图像转换。
再次设置随机生成器种子,以便能够复制该实验:
torch.manual_seed(111)
由于该示例使用训练集中的图像,因此模型需要更复杂,具有更多参数。这使得训练过程更慢,当在 CPU 上运行时,每个历元花费大约两分钟。你需要大约 50 个历元来获得相关的结果,所以使用 CPU 的总训练时间大约是 100 分钟。
为了减少训练时间,您可以使用一个 GPU 来训练模型,如果您有可用的话。但是,您需要手动将张量和模型移动到 GPU,以便在训练过程中使用它们。
您可以通过创建一个指向 CPU 或 GPU(如果有的话)的device对象来确保您的代码将在任一设置上运行:
device = ""
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
稍后,您将使用这个device来设置应该在哪里创建张量和模型,如果可用的话,使用 GPU。
现在基本环境设置好了,可以准备训练数据了。
准备训练数据
MNIST 数据集由从 0 到 9 的手写数字的 28 × 28 像素灰度图像组成。要在 PyTorch 中使用它们,您需要执行一些转换。为此,您定义了transform,一个在加载数据时使用的函数:
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
该功能有两个部分:
transforms.ToTensor()将数据转换成 PyTorch 张量。transforms.Normalize()转换张量系数的范围。
由transforms.ToTensor()给出的原始系数的范围是从 0 到 1,由于图像背景是黑色的,当使用这个范围表示时,大多数系数等于 0。
transforms.Normalize()通过从原始系数中减去0.5并将结果除以0.5,将系数的范围更改为-1 到 1。通过这种转换,输入样本中等于 0 的元素数量显著减少,这有助于训练模型。
transforms.Normalize()的自变量是二元组(M₁, ..., Mₙ)和(S₁, ..., Sₙ),其中n代表图像的通道的数量。MNIST 数据集中的灰度图像只有一个通道,因此元组只有一个值。然后,对于图像的每个通道i,transforms.Normalize()从系数中减去Mᵢ,并将结果除以Sᵢ。
现在,您可以使用torchvision.datasets.MNIST加载训练数据,并使用transform执行转换:
train_set = torchvision.datasets.MNIST(
root=".", train=True, download=True, transform=transform
)
参数download=True确保第一次运行上述代码时,MNIST 数据集将被下载并存储在当前目录中,如参数root所示。
现在您已经创建了train_set,您可以像以前一样创建数据加载器:
batch_size = 32
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True
)
您可以使用 Matplotlib 绘制一些训练数据的样本。为了提高可视化效果,您可以使用cmap=gray_r反转彩色地图,并在白色背景上用黑色绘制数字:
real_samples, mnist_labels = next(iter(train_loader))
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
plt.imshow(real_samples[i].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
输出应该类似于以下内容:

如你所见,有不同书写风格的数字。随着 GAN 了解数据的分布,它还会生成不同手写风格的数字。
现在您已经准备好了训练数据,可以实现鉴别器和生成器模型了。
实施鉴别器和发生器
在这种情况下,鉴别器是一个 MLP 神经网络,它接收一个 28 × 28 像素的图像,并提供该图像属于真实训练数据的概率。
您可以使用以下代码定义模型:
1class Discriminator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(784, 1024),
6 nn.ReLU(),
7 nn.Dropout(0.3),
8 nn.Linear(1024, 512),
9 nn.ReLU(),
10 nn.Dropout(0.3),
11 nn.Linear(512, 256),
12 nn.ReLU(),
13 nn.Dropout(0.3),
14 nn.Linear(256, 1),
15 nn.Sigmoid(),
16 )
17
18 def forward(self, x):
19 x = x.view(x.size(0), 784)
20 output = self.model(x)
21 return output
要将图像系数输入到 MLP 神经网络中,您需要对进行矢量化处理,以便神经网络接收带有784系数的矢量。
矢量化发生在.forward()的第一行,因为对x.view()的调用转换了输入张量的形状。在这种情况下,输入x的原始形状是 32 × 1 × 28 × 28,其中 32 是您设置的批量大小。转换后,x的形状变成 32 × 784,每一行代表训练集的一幅图像的系数。
要使用 GPU 运行鉴别器模型,必须用.to()将其实例化并发送给 GPU。为了在有可用的 GPU 时使用它,您可以将模型发送到您之前创建的device对象:
discriminator = Discriminator().to(device=device)
因为生成器将生成更复杂的数据,所以有必要增加潜在空间输入的维度。在这种情况下,生成器将被提供一个 100 维的输入,并将提供一个具有 784 个系数的输出,这些系数将被组织成一个表示图像的 28 × 28 张量。
以下是完整的发电机型号代码:
1class Generator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(100, 256),
6 nn.ReLU(),
7 nn.Linear(256, 512),
8 nn.ReLU(),
9 nn.Linear(512, 1024),
10 nn.ReLU(),
11 nn.Linear(1024, 784),
12 nn.Tanh(),
13 )
14
15 def forward(self, x):
16 output = self.model(x)
17 output = output.view(x.size(0), 1, 28, 28)
18 return output
19
20generator = Generator().to(device=device)
在第 12 行中,您使用双曲正切函数 Tanh()作为输出层的激活,因为输出系数应该在-1 到 1 的区间内。在第 20 行中,您实例化生成器并将其发送到device以使用 GPU(如果有可用的 GPU 的话)。
现在您已经定义了模型,您将使用训练数据来训练它们。
训练模型
要训练模型,您需要像在前面的示例中一样定义训练参数和优化器:
lr = 0.0001
num_epochs = 50
loss_function = nn.BCELoss()
optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
为了获得更好的结果,可以降低上一个例子中的学习率。您还将时期数设置为50以减少训练时间。
训练循环与您在前面的示例中使用的非常相似。在突出显示的行中,您将训练数据发送到device以使用 GPU(如果可用的话):
1for epoch in range(num_epochs):
2 for n, (real_samples, mnist_labels) in enumerate(train_loader):
3 # Data for training the discriminator
4 real_samples = real_samples.to(device=device) 5 real_samples_labels = torch.ones((batch_size, 1)).to( 6 device=device 7 ) 8 latent_space_samples = torch.randn((batch_size, 100)).to( 9 device=device 10 ) 11 generated_samples = generator(latent_space_samples)
12 generated_samples_labels = torch.zeros((batch_size, 1)).to( 13 device=device 14 ) 15 all_samples = torch.cat((real_samples, generated_samples))
16 all_samples_labels = torch.cat(
17 (real_samples_labels, generated_samples_labels)
18 )
19
20 # Training the discriminator
21 discriminator.zero_grad()
22 output_discriminator = discriminator(all_samples)
23 loss_discriminator = loss_function(
24 output_discriminator, all_samples_labels
25 )
26 loss_discriminator.backward()
27 optimizer_discriminator.step()
28
29 # Data for training the generator
30 latent_space_samples = torch.randn((batch_size, 100)).to( 31 device=device 32 ) 33
34 # Training the generator
35 generator.zero_grad()
36 generated_samples = generator(latent_space_samples)
37 output_discriminator_generated = discriminator(generated_samples)
38 loss_generator = loss_function(
39 output_discriminator_generated, real_samples_labels
40 )
41 loss_generator.backward()
42 optimizer_generator.step()
43
44 # Show loss
45 if n == batch_size - 1:
46 print(f"Epoch: {epoch} Loss D.: {loss_discriminator}")
47 print(f"Epoch: {epoch} Loss G.: {loss_generator}")
有些张量不需要用device显式发送到 GPU。第 11 行中的generated_samples就是这种情况,因为latent_space_samples和generator之前已经发送到 GPU,所以已经发送到可用的 GPU。
由于本例中的模型更加复杂,因此培训可能需要更多的时间。完成后,您可以通过生成一些手写数字样本来检查结果。
检查由 GAN 生成的样本
要生成手写数字,您必须从潜在空间中随机抽取一些样本,并将它们提供给生成器:
latent_space_samples = torch.randn(batch_size, 100).to(device=device)
generated_samples = generator(latent_space_samples)
为了绘制generated_samples,你需要将数据移回 CPU,以防它在 GPU 上运行。为此,您可以简单地调用.cpu()。正如您之前所做的,在使用 Matplotlib 绘制数据之前,您还需要调用.detach():
generated_samples = generated_samples.cpu().detach()
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
plt.imshow(generated_samples[i].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
输出应该是类似于训练数据的数字,如下图所示:

经过 50 代的训练,产生了几个与真实数字相似的数字。您可以通过考虑更多的训练时期来改善结果。与前面的示例一样,通过使用固定的潜在空间样本张量,并在训练过程中的每个时期结束时将其馈送给生成器,您可以可视化训练的演变:
您可以看到,在训练过程的开始,生成的图像完全是随机的。随着训练的进行,生成器学习真实数据的分布,并且在大约二十个时期,一些生成的数字已经类似于真实数据。
结论
恭喜你!你已经学会了如何实现你自己的生成性对抗网络。在深入研究生成手写数字图像的实际应用程序之前,您首先通过一个玩具示例来了解 GAN 结构。
你可以看到,尽管 GANs 很复杂,但是像 PyTorch 这样的机器学习框架通过提供自动微分和简单的 GPU 设置使实现变得更加简单。
在本教程中,您学习了:
- 区别型和生成型模型有什么区别
- 如何生成对抗网络结构和训练
- 如何使用 PyTorch 和 GPU 等工具实现和训练 GAN 模型
gan 是一个非常活跃的研究课题,近年来提出了几个令人兴奋的应用。如果你对这个主题感兴趣,留意技术和科学文献,寻找新的应用想法。
延伸阅读
现在你已经知道了使用生成式对抗网络的基础,你可以开始研究更复杂的应用了。以下书籍是加深你知识的好方法:
- 由 Jakub Langr 和 Vladimir Bok 撰写的GANs in Action:Deep Learning with Generative adversive Networks更详细地涵盖了这个主题,包括最近的应用,如用于执行风格转移的 CycleGAN 。
- 《生成性深度学习:教机器画画、写字、作曲、玩 》作者大卫·福斯特,调查了生成性对抗网络和其他生成模型的实际应用。
值得一提的是,机器学习是一个广泛的主题,除了生成对抗网络之外,还有大量不同的模型结构。有关机器学习的更多信息,请查看以下资源:
- 在 Windows 上设置 Python 进行机器学习
- 用 Python 和 Keras 进行实用文本分类
- 使用 Python 进行传统人脸检测
- OpenCV+Python 中使用颜色空间的图像分割
- Python 语音识别终极指南
- 用协同过滤构建推荐引擎
在机器学习的世界里,有太多东西需要学习。继续学习,欢迎在下面留下任何问题或评论!********
如何用 Python 获得一个目录中所有文件的列表
原文:https://realpython.com/get-all-files-in-directory-python/
获得一个目录中所有文件和文件夹的列表是 Python 中许多文件相关操作的第一步。然而,当你深入研究它的时候,你可能会惊讶地发现有各种各样的方法去实现它。
当你面对做某事的许多方法时,这可能是一个很好的迹象,表明没有一个放之四海而皆准的解决方案。最有可能的是,每个解决方案都有自己的优势和权衡。在 Python 中获取一个目录的内容列表就是这种情况。
在本教程中,您将重点关注在 pathlib模块中列出目录中的项目的最通用的技术,但是您也将了解一些替代工具。
源代码: 点击这里下载免费的源代码、目录和额外材料,它们展示了用 Python 列出目录中的文件和文件夹的不同方式。
在 Python 3.4 的pathlib出现之前,如果你想处理文件路径,那么你可以使用 os 模块。虽然这在性能方面非常高效,但您必须将所有路径作为字符串来处理。
起初,将路径作为字符串处理似乎还可以,但是一旦您开始将多个操作系统混合在一起,事情就变得更加棘手了。您还会得到一堆与字符串操作相关的代码,这些代码可以从文件路径中抽象出来。事情很快就会变得神秘起来。
注意:查看可下载的材料,了解一些可以在您的机器上运行的测试。测试将比较使用来自pathlib模块、os模块、甚至未来 Python 3.12 版本的pathlib的方法返回一个目录中所有条目的列表所花费的时间。这个新版本包含了众所周知的walk()功能,这在本教程中不会涉及。
这并不是说将路径作为字符串工作是不可行的——毕竟,开发人员在没有pathlib的情况下也能很好地工作很多年!pathlib模块只是负责许多棘手的事情,让您专注于代码的主要逻辑。
这一切都是从创建一个Path对象开始的,这个对象会因操作系统(OS)的不同而不同。在 Windows 上,你会得到一个WindowsPath对象,而 Linux 和 macOS 会返回PosixPath:
- 视窗
** Linux + macOS*
***>>>
>>> import pathlib
>>> desktop = pathlib.Path("C:/Users/RealPython/Desktop")
>>> desktop
WindowsPath("C:/Users/RealPython/Desktop")
>>> import pathlib >>> desktop = pathlib.Path("/home/RealPython/Desktop") >>> desktop PosixPath('/home/RealPython/Desktop')有了这些支持操作系统的对象,您可以利用许多可用的方法和属性,比如获取文件和文件夹列表的方法和属性。
注:如果你有兴趣了解更多关于
pathlib及其特性的信息,那么请查看 Python 3 的 pathlib 模块:驯服文件系统和pathlib文档。现在,是时候开始列出文件夹内容了。请注意,有几种方法可以做到这一点,选择正确的方法将取决于您的特定用例。
用 Python 获取一个目录中所有文件和文件夹的列表
在开始列出清单之前,您需要一组与本教程中遇到的内容相匹配的文件。在补充资料中,你会找到一个名为 Desktop 的文件夹。如果你打算跟随,下载这个文件夹并导航到父文件夹,在那里启动你的 Python REPL :
源代码: 点击这里下载免费的源代码、目录和额外材料,它们展示了用 Python 列出目录中的文件和文件夹的不同方式。
你也可以使用自己的桌面。只需在桌面的父目录中启动 Python REPL,示例应该可以工作,但是输出中会有您自己的文件。
注意:在本教程中,你将主要看到作为输出的
WindowsPath对象。如果你继续使用 Linux 或 macOS,那么你会看到PosixPath。这是唯一的区别。你写的代码在所有平台上都是一样的。如果你只需要列出一个给定目录的内容,而不需要得到每个子目录的内容,那么你可以使用
Path对象的.iterdir()方法。如果你的目标是递归地浏览目录和子目录,那么你可以跳到递归列表的部分。当在一个
Path对象上调用.iterdir()方法时,该方法返回一个生成器,该生成器生成代表子项的Path对象。如果您将生成器包装在一个list()构造函数中,那么您可以看到您的文件和文件夹列表:
>>> import pathlib
>>> desktop = pathlib.Path("Desktop")
>>> # .iterdir() produces a generator
>>> desktop.iterdir()
<generator object Path.iterdir at 0x000001A8A5110740>
>>> # Which you can wrap in a list() constructor to materialize
>>> list(desktop.iterdir())
[WindowsPath('Desktop/Notes'),
WindowsPath('Desktop/realpython'),
WindowsPath('Desktop/scripts'),
WindowsPath('Desktop/todo.txt')]
将由.iterdir()生成的生成器传递给list()构造函数会为您提供一个表示桌面目录中所有项目的Path对象列表。
与所有生成器一样,您也可以使用一个for循环来迭代生成器生成的每个项目。这使您有机会探索每个对象的一些属性:
>>> desktop = pathlib.Path("Desktop") >>> for item in desktop.iterdir(): ... print(f"{item} - {'dir' if item.is_dir() else 'file'}") ... Desktop\Notes - dir Desktop\realpython - dir Desktop\scripts - dir Desktop\todo.txt - file在
for循环主体中,您使用一个 f 字符串来显示每个项目的一些信息。在 f 字符串的第二组花括号(
{})中,如果项目是一个目录,您使用一个条件表达式来打印目录,如果不是,则打印文件。要获得这些信息,您使用.is_dir()方法。将一个
Path对象放在 f 字符串中会自动将该对象转换成一个字符串,这就是为什么不再有WindowsPath或PosixPath注释的原因。像这样用一个
for循环反复遍历对象,对于按文件或目录过滤来说非常方便,如下例所示:
>>> desktop = pathlib.Path("Desktop")
>>> for item in desktop.iterdir():
... if item.is_file():
... print(item)
...
Desktop\todo.txt
这里,您使用一个条件语句和 .is_file() 方法只打印文件项。
您还可以将生成器放入理解中,这可以产生非常简洁的代码:
>>> desktop = pathlib.Path("Desktop") >>> [item for item in desktop.iterdir() if item.is_dir()] [WindowsPath('Desktop/Notes'), WindowsPath('Desktop/realpython'), WindowsPath('Desktop/scripts')]这里,您通过在理解中使用一个条件表达式来过滤结果列表,以检查项目是否是一个目录。
但是,如果您也需要文件夹子目录中的所有文件和目录,该怎么办呢?您可以将
.iterdir()改编为递归函数,就像您将在教程的后面做的一样,但是使用.rglob()可能会更好,您将在接下来进行讨论。用
.rglob()和递归列表由于目录的递归性质,目录经常被比作树。在树木中,主干分裂成各种各样的主枝。每个主枝又分成更多的次枝。每个子分支也从自身分支,等等。同样,目录包含子目录,子目录包含子目录,子目录包含更多子目录,等等。
递归地列出目录中的项目意味着不仅要列出目录的内容,还要列出子目录及其子目录的内容,等等。
有了
pathlib,遍历一个目录出奇的容易。您可以使用.rglob()返回所有内容:
>>> import pathlib
>>> desktop = pathlib.Path("Desktop")
>>> # .rglob() produces a generator too
>>> desktop.rglob("*")
<generator object Path.glob at 0x000001A8A50E2F00>
>>> # Which you can wrap in a list() constructor to materialize
>>> list(desktop.rglob("*"))
[WindowsPath('Desktop/Notes'),
WindowsPath('Desktop/realpython'),
WindowsPath('Desktop/scripts'),
WindowsPath('Desktop/todo.txt'),
WindowsPath('Desktop/Notes/hash-tables.md'),
WindowsPath('Desktop/realpython/iterate-dict.md'),
WindowsPath('Desktop/realpython/tictactoe.md'),
WindowsPath('Desktop/scripts/rename_files.py'),
WindowsPath('Desktop/scripts/request.py')]
以"*"作为参数的.rglob()方法产生一个生成器,该生成器递归地从Path对象产生所有文件和文件夹。
但是.rglob()的星号参数是什么?在下一节中,您将研究 glob 模式,看看除了列出目录中的所有项目之外,您还能做些什么。
使用 Python Glob 模式进行条件列表
有时候你不想要所有的文件。有时候,您只需要一种类型的文件或目录,或者名称中包含某种字符模式的所有项目。
与.rglob()相关的一种方法是.glob()方法。这两种方法都利用了 glob 模式。glob 模式表示路径的集合。Glob 模式利用通配符来匹配某些标准。例如,单个星号*匹配目录中的所有内容。
您可以利用许多不同的 glob 模式。查看以下 glob 模式选择,了解一些想法:
| 球状图案 | 比赛 |
|---|---|
* |
每次 |
*.txt |
以.txt结尾的每一项,如notes.txt或hello.txt |
?????? |
名称长度为六个字符的每一项,如01.txt、A-01.c或.zshrc |
A* |
以字符 A 开头的每一项,如Album、A.txt或AppData |
[abc][abc][abc] |
名称为三个字符但仅由字符 a 、 b 、 c 组成的项目,如abc、aaa或cba |
使用这些模式,您可以灵活地匹配许多不同类型的文件。查看关于fnmatch 的文档,这是控制.glob()行为的底层模块,感受一下 Python 中可以使用的其他模式。
注意,在 Windows 上,glob 模式是不区分大小写的,因为路径通常是不区分大小写的。在像 Linux 和 macOS 这样的类 Unix 系统上,glob 模式是区分大小写的。
条件清单使用.glob()
一个Path对象的.glob()方法的行为与.rglob()非常相似。如果您传递了"*"参数,那么您将获得目录中的条目列表,但是没有递归:
>>> import pathlib >>> desktop = pathlib.Path("Desktop") >>> # .glob() produces a generator too >>> desktop.glob("*") <generator object Path.glob at 0x000001A8A50E2F00> >>> # Which you can wrap in a list() constructor to materialize >>> list(desktop.glob("*")) [WindowsPath('Desktop/Notes'), WindowsPath('Desktop/realpython'), WindowsPath('Desktop/scripts'), WindowsPath('Desktop/todo.txt')]在一个
Path对象上使用带有"*"glob 模式的.glob()方法会产生一个生成器,该生成器生成由Path对象表示的目录中的所有项目,而不进入子目录。这样,它产生与.iterdir()相同的结果,你可以在for循环或理解中使用生成的生成器,就像你使用iterdir()一样。但是正如您已经了解到的,真正使 glob 方法与众不同的是可以用来匹配特定路径的不同模式。例如,如果您只想要以
.txt结尾的路径,那么您可以执行以下操作:
>>> desktop = pathlib.Path("Desktop")
>>> list(desktop.glob("*.txt"))
[WindowsPath('Desktop/todo.txt')]
因为这个目录只有一个文本文件,所以您得到的列表只有一项。例如,如果您只想获得以 real 开头的项目,那么您可以使用下面的 glob 模式:
>>> list(desktop.glob("real*")) [WindowsPath('Desktop/realpython')]这个示例也只生成一个项目,因为只有一个项目的名称以字符
real开头。请记住,在类 Unix 系统上,glob 模式是区分大小写的。注意:名称在这里指的是路径的最后一部分,而不是路径的其他部分,在这种情况下,其他部分将从
Desktop开始。您还可以通过包含子目录的名称、正斜杠(
/)和星号来获取子目录的内容。这种类型的模式将产生目标目录中的所有内容:
>>> list(desktop.glob("realpython/*"))
[WindowsPath('Desktop/realpython/iterate-dict.md'),
WindowsPath('Desktop/realpython/tictactoe.md')]
在这个例子中,使用"realpython/*"模式产生了realpython目录中的所有文件。它会给你与创建一个代表Desktop/realpython路径的路径对象并在其上调用.glob("*")相同的结果。
接下来,您将进一步研究使用.rglob()进行过滤,并了解它与.glob()的不同之处。
条件清单使用.rglob()
就像使用.glob()方法一样,你可以调整.rglob()的 glob 模式,只给你一个特定的文件扩展名,除了.rglob()将总是递归搜索:
>>> list(desktop.rglob("*.md")) [WindowsPath('Desktop/Notes/hash-tables.md'), WindowsPath('Desktop/realpython/iterate-dict.md'), WindowsPath('Desktop/realpython/tictactoe.md')]通过将
.md添加到 glob 模式中,现在.rglob()只在不同的目录和子目录中生成.md文件。您实际上可以使用
.glob(),通过调整作为参数传递的 glob 模式,让它以与.rglob()相同的方式运行:
>>> list(desktop.glob("**/*.md"))
[WindowsPath('Desktop/Notes/hash-tables.md'),
WindowsPath('Desktop/realpython/iterate-dict.md'),
WindowsPath('Desktop/realpython/tictactoe.md')]
在这个例子中,你可以看到对.glob("**/*.md")的调用等同于.rglob(*.md)。同样,对.glob("**/*")的调用相当于.rglob("*")。
.rglob()方法是使用递归模式调用.glob()的一个稍微更显式的版本,所以使用更显式的版本可能比使用普通.glob()的递归模式更好。
使用 Glob 方法进行高级匹配
glob 方法的一个潜在缺点是,您只能根据 glob 模式选择文件。如果你想在物品的属性上做更高级的匹配或过滤,那么你需要额外的东西。
要运行更复杂的匹配和过滤,您至少可以遵循三种策略。您可以使用:
- 带有条件检查的
for循环 - 有条件表达的理解
- 内置的
filter()功能
方法如下:
>>> import pathlib >>> desktop = pathlib.Path("Desktop") >>> # Using a for loop >>> for item in desktop.rglob("*"): ... if item.is_file(): ... print(item) ... Desktop\todo.txt Desktop\Notes\hash-tables.md Desktop\realpython\iterate-dict.md Desktop\realpython\tictactoe.md Desktop\scripts\rename_files.py Desktop\scripts\request.py >>> # Using a comprehension >>> [item for item in desktop.rglob("*") if item.is_file()] [WindowsPath('Desktop/todo.txt'), WindowsPath('Desktop/Notes/hash-tables.md'), WindowsPath('Desktop/realpython/iterate-dict.md'), WindowsPath('Desktop/realpython/tictactoe.md'), WindowsPath('Desktop/scripts/rename_files.py'), WindowsPath('Desktop/scripts/request.py')] >>> # Using the filter() function >>> list(filter(lambda item: item.is_file(), desktop.rglob("*"))) [WindowsPath('Desktop/todo.txt'), WindowsPath('Desktop/Notes/hash-tables.md'), WindowsPath('Desktop/realpython/iterate-dict.md'), WindowsPath('Desktop/realpython/tictactoe.md'), WindowsPath('Desktop/scripts/rename_files.py'), WindowsPath('Desktop/scripts/request.py')]在这些示例中,您首先使用
"*"模式调用了.rglob()方法,以递归方式获取所有项目。这将生成目录及其子目录中的所有项目。然后使用上面列出的三种不同的方法来过滤掉不是文件的项目。注意,在filter()的例子中,你使用了一个λ函数。glob 方法非常通用,但是对于大型目录树,它们可能有点慢。在下一节中,您将研究一个例子,在这个例子中,使用
.iterdir()来实现更可控的迭代可能是一个更好的选择。选择不列出垃圾目录
比方说,你想找到你系统上的所有文件,但是你有各种各样的子目录,这些子目录有很多很多的子目录和文件。一些最大的子目录是你不感兴趣的临时文件。
例如,检查这个目录树,它有很多垃圾目录!实际上,这个完整的目录树有 1850 行长。无论你在哪里看到一个省略号(
...),这意味着在那个位置有数百个垃圾文件:large_dir/ ├── documents/ │ ├── notes/ │ │ ├── temp/ │ │ │ ├── 2/ │ │ │ │ ├── 0.txt │ │ │ │ ... │ │ │ │ │ │ │ ├── 0.txt │ │ │ ... │ │ │ │ │ ├── 0.txt │ │ └── find_me.txt │ │ │ ├── tools/ │ │ ├── temporary_files/ │ │ │ ├── logs/ │ │ │ │ ├──0.txt │ │ │ │ ... │ │ │ │ │ │ │ ├── temp/ │ │ │ │ ├──0.txt │ │ │ │ ... │ │ │ │ │ │ │ ├── 0.txt │ │ │ ... │ │ │ │ │ ├── 33.txt │ │ ├── 34.txt │ │ ├── 36.txt │ │ ├── 37.txt │ │ └── real_python.txt │ │ │ ├── 0.txt │ ├── 1.txt │ ├── 2.txt │ ├── 3.txt │ └── 4.txt │ ├── temp/ │ ├── 0.txt │ ... │ └── temporary_files/ ├── 0.txt ...这里的问题是你有垃圾目录。垃圾目录有时叫做
temp,有时叫做temporary files,有时叫做logs。更糟糕的是,它们无处不在,可以在任何层次筑巢。好消息是您不必列出它们,因为您将在接下来学习。使用
.rglob()过滤整个目录如果使用
.rglob(),只要在.rglob()生产出来之后就可以过滤掉了。要正确丢弃垃圾目录中的路径,您可以检查路径中的任何元素是否与目录列表中的任何元素匹配,以跳过:
>>> SKIP_DIRS = ["temp", "temporary_files", "logs"]
这里,您将SKIP_DIRS定义为一个列表,其中包含您想要排除的路径字符串。
用一个星号作为参数调用.rglob()将产生所有项目,甚至是那些您不感兴趣的目录中的项目。因为您必须遍历所有项目,所以如果您只查看路径的名称,可能会有一个问题:
large_dir/documents/notes/temp/2/0.txt
由于名称只是0.txt,它不会匹配SKIP_DIRS中的任何项目。您需要检查被阻止名称的整个路径。
您可以使用.parts属性获取路径中的所有元素,该属性包含路径中所有元素的元组:
>>> import pathlib >>> temp_file = pathlib.Path("large_dir/documents/notes/temp/2/0.txt") >>> temp_file.parts ('large_dir', 'documents', 'notes', 'temp', '2', '0.txt')然后,您需要做的就是检查
.parts元组中的任何元素是否在要跳过的目录列表中。你可以通过利用集合来检查任意两个可重复项是否有一个公共项。如果您将其中一个 iterables 转换为一个集合,那么您可以使用
.isdisjoint()方法来确定它们是否有任何共同的元素:
>>> {"documents", "notes", "find_me.txt"}.isdisjoint({"temp", "temporary"})
True
>>> {"documents", "temp", "find_me.txt"}.isdisjoint({"temp", "temporary"})
False
如果两个集合没有共同的元素,那么.isdisjoint()返回True。如果两个集合至少有一个元素相同,那么.isdisjoint()返回False。您可以将该检查合并到一个for循环中,该循环遍历由.rglob("*")返回的所有项目:
>>> SKIP_DIRS = ["temp", "temporary_files", "logs"] >>> large_dir = pathlib.Path("large_dir") >>> # With a for loop >>> for item in large_dir.rglob("*"): ... if set(item.parts).isdisjoint(SKIP_DIRS): ... print(item) ... large_dir\documents large_dir\documents\0.txt large_dir\documents\1.txt large_dir\documents\2.txt large_dir\documents\3.txt large_dir\documents\4.txt large_dir\documents\notes large_dir\documents\tools large_dir\documents\notes\0.txt large_dir\documents\notes\find_me.txt large_dir\documents\tools\33.txt large_dir\documents\tools\34.txt large_dir\documents\tools\36.txt large_dir\documents\tools\37.txt large_dir\documents\tools\real_python.txt在这个例子中,您打印了
large_dir中不在任何垃圾目录中的所有项目。要检查路径是否在某个不想要的文件夹中,您将
item.parts转换为一个集合,并使用.isdisjoint()来检查SKIP_DIRS和.parts是否没有任何共同的项目。如果是这种情况,则打印该项目。您也可以使用
filter()和理解来实现相同的效果,如下所示:
>>> # With a comprehension
>>> [
... item
... for item in large_dir.rglob("*")
... if set(item.parts).isdisjoint(SKIP_DIRS)
... ]
>>> # With filter()
>>> list(
... filter(
... lambda item: set(item.parts).isdisjoint(SKIP_DIRS),
... large_dir.rglob("*")
... )
... )
不过,这些方法已经变得有点晦涩难懂了。不仅如此,它们的效率也不是很高,因为.rglob()生成器必须生成所有的项,这样匹配操作才能丢弃那个结果。
你肯定可以用.rglob()过滤掉整个文件夹,但是你不能逃避这样一个事实,即生成的生成器将产生所有的项目,然后一个接一个地过滤掉不需要的项目。这可能会使 glob 方法非常慢,这取决于您的用例。这就是为什么您可能选择递归.iterdir()函数,您将在接下来探索它。
创建递归.iterdir()函数
在垃圾目录的例子中,如果给定子目录中的所有文件与SKIP_DIRS中的某个名称匹配,那么理想情况下,您希望能够选择退出来迭代这些文件:
# skip_dirs.py
import pathlib
SKIP_DIRS = ["temp", "temporary_files", "logs"]
def get_all_items(root: pathlib.Path, exclude=SKIP_DIRS):
for item in root.iterdir():
if item.name in exclude:
continue
yield item
if item.is_dir():
yield from get_all_items(item)
在这个模块中,您定义了一个字符串列表SKIP_DIRS,它包含了您想要忽略的目录的名称。然后定义一个生成器函数,它使用.iterdir()遍历每一项。
生成器函数在第一个参数后使用了类型注释 : pathlib.Path来表示不能只传入代表路径的字符串。参数需要是一个Path对象。
如果项目名称在exclude列表中,那么您只需移动到下一个项目,一次性跳过整个子目录树。
如果这个项目不在列表中,那么您就放弃这个项目,如果它是一个目录,那么您就在这个目录上再次调用这个函数。也就是说,在函数体内,函数有条件地再次调用同一个函数。这是递归函数的标志。
这个递归函数可以有效地产生您想要的所有文件和目录,排除您不感兴趣的所有文件和目录:
>>> import pathlib >>> import skip_dirs >>> large_dir = pathlib.Path("large_dir") >>> list(skip_dirs.get_all_items(large_dir)) [WindowsPath('large_dir/documents'), WindowsPath('large_dir/documents/0.txt'), WindowsPath('large_dir/documents/1.txt'), WindowsPath('large_dir/documents/2.txt'), WindowsPath('large_dir/documents/3.txt'), WindowsPath('large_dir/documents/4.txt'), WindowsPath('large_dir/documents/notes'), WindowsPath('large_dir/documents/notes/0.txt'), WindowsPath('large_dir/documents/notes/find_me.txt'), WindowsPath('large_dir/documents/tools'), WindowsPath('large_dir/documents/tools/33.txt'), WindowsPath('large_dir/documents/tools/34.txt'), WindowsPath('large_dir/documents/tools/36.txt'), WindowsPath('large_dir/documents/tools/37.txt'), WindowsPath('large_dir/documents/tools/real_python.txt')]至关重要的是,您已经设法避免了检查不需要的目录中的所有文件。一旦您的生成器识别出该目录在
SKIP_DIRS列表中,它就会跳过整个过程。因此,在这种情况下,使用
.iterdir()将比同等的 glob 方法更有效。事实上,如果您需要过滤比 glob 模式更复杂的东西,您会发现
.iterdir()通常比 glob 方法更有效。然而,如果您需要做的只是递归地获得所有.txt文件的列表,那么 glob 方法会更快。查看一些测试的可下载资料,这些测试展示了用 Python 列出文件的不同方法的相对速度:
源代码: 点击这里下载免费的源代码、目录和额外材料,它们展示了用 Python 列出目录中的文件和文件夹的不同方式。
有了这些信息,您就可以选择列出所需文件和文件夹的最佳方式了!
结论
在本教程中,您已经研究了 Python
pathlib模块中的.glob()、.rglob()和.iterdir()方法,以便将给定目录中的所有文件和文件夹放入一个列表中。您已经讨论了列出目录的直接后代的文件和文件夹,并且您还查看了递归列表。总的来说,您已经看到,如果您只需要目录中的基本条目列表,而不需要递归,那么
.iterdir()是最干净的方法,这要归功于它的描述性名称。这项工作效率也更高。然而,如果你需要一个递归列表,那么你最好使用.rglob(),这将比一个等价的递归.iterdir()更快。您还研究了一个例子,在这个例子中,使用
.iterdir()递归地列出可以产生巨大的性能优势——当您有垃圾文件夹而您想选择不迭代时。在可下载的资料中,您会发现从
pathlib和os模块中获取基本文件列表的方法的各种实现,以及对它们进行计时的几个脚本:源代码: 点击这里下载免费的源代码、目录和额外材料,它们展示了用 Python 列出目录中的文件和文件夹的不同方式。
检查它们,修改它们,并在评论中分享你的发现!*******
Django 入门第 1 部分:构建投资组合应用程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Django 入门:建立作品集 App
Django 是一个功能齐全的 Python web 框架,可用于构建复杂的 web 应用程序。在本教程中,你将通过例子来学习 Django。您将按照步骤创建一个功能完整的 web 应用程序,并在此过程中学习该框架的一些最重要的特性以及它们是如何协同工作的。
在本系列的后续文章中,您将会看到如何使用比本教程更多的 Django 特性来构建更复杂的网站。
本教程结束时,您将能够:
- 理解 Django 是什么,为什么它是一个伟大的 web 框架
- 理解 Django 站点的架构,以及它与其他框架的比较
- 设置新的 Django 项目和应用程序
- 用 Django 建立一个个人作品集网站
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
为什么你应该学习 Django
有无穷无尽的 web 开发框架,那么你为什么要学习 Django 而不是其他的呢?首先,它是用 Python 编写的,Python 是目前可读性最强、对初学者最友好的编程语言之一。
注意:本教程假设读者对 Python 语言有一定的了解。如果你是 Python 编程的新手,可以看看我们的初学者教程或入门课程。
您应该学习 Django 的第二个原因是它的特性范围。如果需要搭建网站,选择 Django 就不需要依赖任何外部库或包。这意味着您不需要学习如何使用其他任何东西,并且语法是无缝的,因为您只使用一个框架。
还有一个额外的好处是,你不必担心更新一个库或框架会使你安装的其他库或框架变得无用。
如果您发现自己需要添加额外的功能,有一系列外部库可以用来增强您的站点。
Django 框架的一大优点是它的深度文档。它有关于 Django 各个方面的详细文档,也有很好的例子,甚至还有一个教程可以帮助你入门。
还有一个 Django 开发者的奇妙社区,所以如果你遇到困难,几乎总有一个方法可以解决,要么查看文档,要么询问社区。
Django 是一个高级 web 应用程序框架,具有很多特性。由于它出色的文档,对任何 web 开发新手来说都是很棒的,尤其是如果你也熟悉 Python 的话。
Django 网站的结构
Django 网站由一个单独的项目组成,这个项目被分成几个独立的应用。这个想法是每个应用程序处理一个网站需要执行的独立功能。举个例子,想象一个像 Instagram 这样的应用。需要执行几个不同的功能:
- 用户管理:登录、注销、注册等
- 图像馈送:上传、编辑和显示图像
- 私人消息:用户和通知之间的私人消息
这些都是独立的功能,所以如果这是一个 Django 站点,那么每个功能都应该是一个 Django 项目中不同的 Django 应用程序。
Django 项目包含一些适用于整个项目的配置,比如项目设置、URL、共享模板和静态文件。每个应用程序都可以有自己的数据库,并有自己的函数来控制数据如何在 HTML 模板中显示给用户。
每个应用程序都有自己的 URL,自己的 HTML 模板和静态文件,比如 JavaScript 和 CSS。
Django 应用程序的结构是逻辑分离的。它支持模型-视图-控制器模式,这是大多数 web 框架所基于的架构。基本原则是,在每个应用程序中都有三个单独的文件,分别处理三个主要的逻辑部分:
- 模型定义了数据结构。这通常是一个数据库,是应用程序的基础层。
- 视图用 HTML 和 CSS 向用户显示部分或全部数据。
- 控制器处理数据库和视图如何交互。
如果你想了解更多关于 MVC 模式的知识,那么看看模型-视图-控制器(MVC)解释——用乐高。
在 Django,建筑略有不同。尽管基于 MVC 模式,Django 自己处理控制器部分。不需要定义数据库和视图如何交互。都给你做好了!
Django 使用的模式被称为模型-视图-模板(MVT)模式。MVT 模式中的视图和模板组成了 MVC 模式中的视图。您所需要做的就是添加一些 URL 配置来映射视图,Django 会处理剩下的事情!
Django 站点从一个项目开始,由许多应用程序组成,每个应用程序处理不同的功能。每个应用程序都遵循模型-视图-模板模式。现在您已经熟悉了 Django 站点的结构,让我们看看您将要构建什么!
你要建造什么
在开始任何 web 开发项目之前,最好想出一个你要构建什么的计划。在本教程中,我们将构建一个具有以下特性的应用程序:
一个功能齐全的博客:如果你想展示你的编程能力,博客是一个很好的方式。在这个应用程序中,您将能够创建、更新和删除博客文章。文章将有类别,可以用来排序。最后,用户可以在帖子上发表评论。
作品集:你可以在这里展示之前的网页开发项目。您将构建一个图库样式页面,其中包含指向您已经完成的项目的可点击链接。
注意:在你开始之前,你可以拉下源代码,跟着教程走。
如果您喜欢自己编写代码,不要担心。我从头到尾都引用了源代码的相关部分,所以你可以回头参考。
在本教程中,我们不会使用任何外部 Python 库。Django 的一个优点是它有如此多的特性,以至于你不需要依赖外部库。但是,我们将在模板中添加 Bootstrap 4 样式。
通过构建这两个应用程序,您将学习 Django 模型、视图函数、表单、模板和 Django 管理页面的基础知识。有了这些特性的知识,您就能够构建更多的应用程序。您还将拥有学习更多知识和构建复杂 Django 站点的工具。
你好,世界!
现在您已经知道了 Django 应用程序的结构,以及您将要构建的内容,我们将经历在 Django 中创建应用程序的过程。稍后您将把它扩展到您的个人投资组合应用程序中。
设置您的开发环境
每当您开始一个新的 web 开发项目时,首先设置您的开发环境是一个好主意。为您的项目创建一个新目录,并进入其中:
$ mkdir rp-portfolio $ cd rp-portfolio一旦进入主目录,创建一个虚拟环境来管理依赖项是个好主意。有许多不同的方法来设置虚拟环境,但是这里您将使用
venv:$ python3 -m venv venv该命令将在您的工作目录中创建一个文件夹
venv。在这个目录中,您将找到几个文件,包括 Python 标准库的副本。稍后,当您安装新的依赖项时,它们也将存储在此目录中。接下来,您需要通过运行以下命令来激活虚拟环境:$ source venv/bin/activate注意:如果你没有使用 bash shell,你可能需要使用一个不同的命令来激活你的虚拟环境。例如,在 windows 上,您需要以下命令:
C:\> venv\Scripts\activate.bat您将知道您的虚拟环境已经被激活,因为您在终端中的控制台提示符将会改变。它应该是这样的:
(venv) $注意:你的虚拟环境目录不一定要叫
venv。如果您想以不同的名称创建一个,例如my_venv,只需将第二个venv替换为my_venv。然后,当激活您的虚拟环境时,再次用
my_venv替换venv。提示符现在也将以(my_venv)为前缀。现在您已经创建了一个虚拟环境,是时候安装 Django 了。您可以使用
pip来完成此操作:(venv) $ pip install Django一旦设置好虚拟环境并安装了 Django,现在就可以开始创建应用程序了。
创建 Django 项目
正如您在上一节中看到的,Django web 应用程序由一个项目和它的组成应用程序组成。确保您在
rp_portfolio目录中,并且您已经激活了您的虚拟环境,运行以下命令来创建项目:$ django-admin startproject personal_portfolio这将创建一个新目录
personal_portfolio。如果你cd进入这个新目录,你会看到另一个目录叫做personal_portfolio和一个文件叫做manage.py。您的目录结构应该如下所示:rp-portfolio/ │ ├── personal_portfolio/ │ ├── personal_portfolio/ │ │ ├── __init__.py │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ │ │ └── manage.py │ └── venv/你所做的大部分工作都在第一个
personal_portfolio目录中。为了避免每次处理项目时不得不浏览几个目录,通过将所有文件上移一个目录来稍微重新排序会有所帮助。当您在rp-portfolio目录中时,运行以下命令:$ mv personal_portfolio/manage.py ./ $ mv personal_portfolio/personal_portfolio/* personal_portfolio $ rm -r personal_portfolio/personal_portfolio/您应该会得到这样的结果:
rp-portfolio/ │ ├── personal_portfolio/ │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ ├── venv/ │ └── manage.py一旦建立了文件结构,现在就可以启动服务器并检查设置是否成功。在控制台中,运行以下命令:
$ python manage.py runserver然后,在您的浏览器中转至
localhost:8000,您应该会看到以下内容:
恭喜你,你已经创建了一个 Django 网站!这部分教程的源代码可以在 GitHub 上找到。下一步是创建应用程序,这样您就可以向您的站点添加视图和功能。
创建 Django 应用程序
对于教程的这一部分,我们将创建一个名为
hello_world的应用程序,您随后将删除它,因为它对于我们的个人作品集网站是不必要的。要创建应用程序,请运行以下命令:
$ python manage.py startapp hello_world这将创建另一个名为
hello_world的目录,其中包含几个文件:
__init__.py告诉 Python 把目录当作一个 Python 包。admin.py包含 Django 管理页面的设置。apps.py包含对应用程序配置的设置。models.py包含了 Django 的 ORM 转换成数据库表的一系列类。tests.py包含测试类。views.py包含处理在 HTML 模板中显示什么数据的函数和类。创建应用程序后,需要将其安装到项目中。在
rp-portfolio/personal_portfolio/settings.py中,在INSTALLED_APPS下添加以下代码行:INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'hello_world', ]这一行代码意味着您的项目现在知道您刚刚创建的应用程序存在。下一步是创建一个视图,这样就可以向用户显示一些内容。
创建视图
Django 中的视图是应用程序目录中的
views.py文件中的函数或类的集合。每次访问不同的 URL 时,每个函数或类都会处理被处理的逻辑。导航到
hello_world目录中的views.py文件。已经有一行代码导入了render()。添加以下代码:from django.shortcuts import render def hello_world(request): return render(request, 'hello_world.html', {})在这段代码中,您定义了一个名为
hello_world()的视图函数。当这个函数被调用时,它将呈现一个名为hello_world.html的 HTML 文件。该文件尚不存在,但我们很快会创建它。view 函数接受一个参数
request。这个对象是一个HttpRequestObject,每当页面被加载时都会被创建。它包含关于请求的信息,比如方法,它可以取几个值,包括GET和POST。现在您已经创建了视图函数,您需要创建 HTML 模板来显示给用户。
render()在您的应用程序目录中的一个名为templates的目录中查找 HTML 模板。创建这个目录,然后在里面创建一个名为hello_world.html的文件:$ mkdir hello_world/templates/ $ touch hello_world/templates/hello_world.html将下列 HTML 行添加到文件中:
<h1>Hello, World!</h1>现在,您已经创建了一个函数来处理您的视图和模板,以便向用户显示。最后一步是连接你的 URL,这样你就可以访问你刚刚创建的页面。您的项目有一个名为
urls.py的模块,您需要在其中包含一个用于hello_world应用程序的 URL 配置。在personal_portfolio/urls.py内,添加以下内容:from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('hello_world.urls')), ]它在
hello_world应用程序中寻找一个名为urls.py的模块,并注册在那里定义的任何 URL。每当您访问您的 URL 的根路径(localhost:8000)时,hello_world应用程序的 URL 将被注册。hello_world.urls模块还不存在,所以您需要创建它:$ touch hello_world/urls.py在这个模块中,我们需要导入 path 对象以及我们应用程序的
views模块。然后,我们希望创建一个 URL 模式列表,这些模式对应于各种视图功能。目前,我们只创建了一个视图函数,所以我们只需要创建一个 URL:from django.urls import path from hello_world import views urlpatterns = [ path('', views.hello_world, name='hello_world'), ]现在,当您重启服务器并访问
localhost:8000时,您应该能够看到您创建的 HTML 模板:
再次祝贺你!您已经创建了您的第一个 Django 应用程序,并将其连接到您的项目。不要忘记查看本节和上一节的源代码。现在唯一的问题就是看起来不太好看。在下一节中,我们将为您的项目添加引导样式,使其更加美观!
将引导程序添加到您的应用程序
如果你不添加任何样式,那么你创建的应用程序看起来不会太好。在本教程中,我们不讨论 CSS 样式,我们只讨论如何在你的项目中添加引导样式。这将使我们无需太多的努力就能改善网站的外观。
在我们开始使用引导样式之前,我们将创建一个基础模板,我们可以将它导入到每个后续视图中。这个模板是我们随后添加引导样式导入的地方。
创建另一个名为
templates的目录,这次在personal_portfolio中,并在新目录中创建一个名为base.html的文件:$ mkdir personal_portfolio/templates/ $ touch personal_portfolio/templates/base.html我们创建这个额外的模板目录来存储 HTML 模板,这些模板将在项目的每个 Django 应用程序中使用。正如您之前看到的,每个 Django 项目可以包含多个处理独立逻辑的应用程序,每个应用程序都包含自己的
templates目录来存储与应用程序相关的 HTML 模板。这个应用程序结构很适合后端逻辑,但我们希望我们的整个网站在前端看起来一致。我们可以创建一个或一组由所有应用共享的模板,而不必将引导样式导入每个应用。只要 Django 知道在这个新的共享目录中寻找模板,它就可以保存许多重复的样式。
在这个新文件(
personal_portfolio/templates/base.html)中,添加以下代码行:{% block page_content %}{% endblock %}现在,在
hello_world/templates/hello_world.html中,我们可以扩展这个基础模板:{% extends "base.html" %} {% block page_content %} <h1>Hello, World!</h1> {% endblock %}这里发生的事情是,
page_content块中的任何 HTML 都被添加到了base.html中的同一个块中。要在你的应用中安装 Bootstrap,你将使用 Bootstrap CDN 。这是一种非常简单的安装 Bootstrap 的方法,只需要在
base.html中添加几行代码。查看源代码,了解如何将 CDN 链接添加到您的项目中。我们将来创建的所有模板都将扩展
base.html,这样我们就可以在每个页面上包含引导样式,而不必再次导入样式。在我们看到新样式的应用程序之前,我们需要告诉 Django 项目
base.html的存在。默认设置在每个应用程序中注册template目录,但不在项目目录本身中注册。在personal_portfolio/settings.py中,更新TEMPLATES:TEMPLATES = [ { "BACKEND": "django.template.backends.django.DjangoTemplates", "DIRS": ["personal_portfolio/templates/"], "APP_DIRS": True, "OPTIONS": { "context_processors": [ "django.template.context_processors.debug", "django.template.context_processors.request", "django.contrib.auth.context_processors.auth", "django.contrib.messages.context_processors.messages", ] }, } ]现在,当您访问
localhost:8000时,您应该会看到页面的格式略有不同:
每当您想要创建模板或导入脚本以在项目中的所有 Django 应用程序中使用时,您可以将它们添加到这个项目级目录中,并在您的应用程序模板中扩展它们。
添加模板是构建你的 Hello,World 的最后一步!姜戈遗址。您了解了 Django 模板引擎是如何工作的,以及如何创建可以由 Django 项目中的所有应用程序共享的项目级模板。
在本节中,您学习了如何创建一个简单的 Hello,World! Django 站点,使用单个应用程序创建项目。在下一节中,您将创建另一个应用程序来展示 web 开发项目,并且您将在 Django 中学习所有关于模型的知识!
这一部分的源代码可以在 GitHub 上找到。
展示您的项目
任何希望创建作品集的 web 开发人员都需要一种方式来展示他们参与过的项目。这就是你现在要建造的。您将创建另一个名为
projects的 Django 应用程序,它将保存一系列将向用户显示的示例项目。用户可以点击项目,看到更多关于你的工作的信息。在我们构建
projects应用之前,让我们先删除hello_world应用。您需要做的就是删除hello_world目录,并从settings.py中的INSTALLED_APPS中删除行"hello_world",:INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'hello_world', # Delete this line ]最后,您需要删除在
personal_portfolio/urls.py中创建的 URL 路径:from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('hello_world.urls')), # Delete this line ]现在您已经删除了
hello_world应用程序,我们可以创建projects应用程序了。确保您在rp-portfolio目录中,在您的控制台中运行以下命令:$ python manage.py startapp projects这将创建一个名为
projects的目录。创建的文件与我们设置hello_world应用程序时创建的文件相同。为了连接我们的应用程序,我们需要将它添加到settings.py中的INSTALLED_APPS:INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'projects', ]在 GitHub 上查看这一部分的源代码。我们现在还不需要担心这个应用程序的 URL。相反,我们将专注于构建一个
Project模型。项目应用:模型
如果你想存储数据并显示在网站上,那么你需要一个数据库。通常,如果您想要创建一个包含表和这些表中的列的数据库,您需要使用 SQL 来管理数据库。但是当你使用 Django 的时候,你不需要学习一门新的语言,因为它有一个内置的对象关系映射器(ORM)。
ORM 是一个允许你创建对应于数据库表的类的程序。类属性对应于列,类的实例对应于数据库中的行。因此,不用学习一种全新的语言来创建我们的数据库和它的表,我们可以只写一些 Python 类。
当你使用 ORM 时,你构建的代表数据库表的类被称为模型。在 Django 中,它们生活在每个 Django 应用的
models.py模块中。在您的项目应用程序中,您只需要一个表来存储您将向用户显示的不同项目。这意味着您只需要在
models.py中创建一个模型。您将创建的模型将被称为
Project,并将具有以下字段:
title将用一个短字符串字段来保存你的项目名称。description将一个更大的字符串字段用来容纳一段更长的文本。technology将是一个字符串字段,但是它的内容将被限制为一个选择的数量。image将是一个图像字段,保存存储图像的文件路径。为了创建这个模型,我们将在
models.py中创建一个新类,并在我们的字段中添加以下内容:from django.db import models class Project(models.Model): title = models.CharField(max_length=100) description = models.TextField() technology = models.CharField(max_length=20) image = models.FilePathField(path="/img")Django 模型带有许多内置的模型字段类型。我们在这个模型中只使用了三个。
CharField用于短字符串,指定最大长度。
TextField与CharField相似,但可用于更长的格式文本,因为它没有最大长度限制。最后,FilePathField也保存一个字符串,但是必须指向一个文件路径名。现在我们已经创建了我们的
Project类,我们需要 Django 来创建数据库。默认情况下,Django ORM 在 SQLite 中创建数据库,但是您可以通过 Django ORM 使用其他使用 SQL 语言的数据库,比如 PostgreSQL 或者 MySQL 。为了开始创建我们的数据库,我们需要创建一个迁移。一个迁移是一个包含一个
Migration类的文件,这个类的规则告诉 Django 需要对数据库做什么改变。要创建迁移,请在控制台中键入以下命令,确保您位于rp-portfolio目录中:$ python manage.py makemigrations projects Migrations for 'projects': projects/migrations/0001_initial.py - Create model Project您应该看到在项目应用程序中创建了一个文件
projects/migrations/0001_initial.py。检查一下源代码中文件,确保您的迁移是正确的。现在您已经创建了一个迁移文件,您需要应用迁移文件中设置的迁移,并使用
migrate命令创建您的数据库:$ python manage.py migrate projects Operations to perform: Apply all migrations: projects Running migrations: Applying projects.0001_initial... OK注意:当运行
makemigrations和migrate命令时,我们在命令中添加了projects。这告诉 Django 只查看projects应用中的模型和迁移。Django 附带了几个已经创建好的模型。如果您在没有
projects标志的情况下运行makemigrations和migrate,那么您的 Django 项目中所有默认模型的所有迁移都将被创建和应用。这不是问题,但是对于本节来说,它们是不需要的。您还应该看到在您的项目的根目录下已经创建了一个名为
db.sqlite3的文件。现在您的数据库已经设置好了,可以开始运行了。现在,您可以在表格中创建行,这些行是您想要在您的投资组合站点上显示的各种项目。为了创建我们的
Project类的实例,我们将不得不使用 Django shell。Django shell 类似于 Python shell,但是允许您访问数据库和创建条目。为了访问 Django shell,我们使用另一个 Django 管理命令:$ python manage.py shell一旦您访问了 shell,您会注意到命令提示符将从
$变为>>>。然后您可以导入您的模型:
>>> from projects.models import Project
我们首先要创建一个具有以下属性的新项目:
name:My First Projectdescription:A web development project.technology:Djangoimage:img/project1.png
为此,我们在 Django shell 中创建了一个项目类的实例:
>>> p1 = Project( ... title='My First Project', ... description='A web development project.', ... technology='Django', ... image='img/project1.png' ... ) >>> p1.save()这将在项目表中创建一个新条目,并将其保存到数据库中。现在您已经创建了一个可以在您的作品集网站上显示的项目。
本节的最后一步是创建另外两个示例项目:
>>> p2 = Project(
... title='My Second Project',
... description='Another web development project.',
... technology='Flask',
... image='img/project2.png'
... )
>>> p2.save()
>>> p3 = Project(
... title='My Third Project',
... description='A final development project.',
... technology='Django',
... image='img/project3.png'
... )
>>> p3.save()
干得好,完成了本节的结尾!现在您已经知道了如何在 Django 中创建模型和构建迁移文件,以便将这些模型类转换成数据库表。您还使用 Django shell 创建了模型类的三个实例。
在下一节中,我们将使用您创建的这三个项目,并创建一个视图函数,在 web 页面上向用户显示它们。你可以在 GitHub 上找到本节教程的源代码。
项目应用程序:视图
现在您已经创建了要在您的 portfolio 站点上显示的项目,您将需要创建视图函数来将数据从数据库发送到 HTML 模板。
在projects应用程序中,您将创建两个不同的视图:
- 显示每个项目信息片段的索引视图
- 显示特定主题更多信息的详细视图
让我们从索引视图开始,因为逻辑稍微简单一些。在views.py中,您将需要从models.py导入Project类,并创建一个函数project_index()来呈现一个名为project_index.html的模板。在这个函数的主体中,您将创建一个 Django ORM 查询来选择Project表中的所有对象:
1from django.shortcuts import render
2from projects.models import Project
3
4def project_index(request):
5 projects = Project.objects.all()
6 context = {
7 'projects': projects
8 }
9 return render(request, 'project_index.html', context)
这个代码块中发生了很多事情,所以让我们来分解一下。
在第 5 行,你执行一个查询。查询只是一个命令,允许您在数据库中创建、检索、更新或删除对象(或行)。在本例中,您正在检索projects表中的所有对象。
数据库查询返回与查询匹配的所有对象的集合,称为查询集。在这种情况下,您需要表中的所有对象,因此它将返回所有项目的集合。
在上面代码块的第 6 行中,我们定义了一个字典context。字典只有一个条目projects,我们将包含所有项目的 Queryset 分配给它。上下文字典用于向我们的模板发送信息。您创建的每个视图函数都需要有一个上下文字典。
在的第 9 行中,context作为参数添加到render()中。只要将context参数传递给render(),模板中就可以使用context字典中的任何条目。您需要创建一个上下文字典,并在您创建的每个视图函数中将其传递给render。
我们还渲染了一个名为project_index.html的模板,这个模板还不存在。现在不要担心那个。在下一节中,您将为这些视图创建模板。
接下来,您需要创建project_detail()视图函数。这个函数需要一个额外的参数:正在查看的项目的 id。
否则,逻辑是相似的:
13def project_detail(request, pk):
14 project = Project.objects.get(pk=pk)
15 context = {
16 'project': project
17 }
18 return render(request, 'project_detail.html', context)
在的第 14 行,我们执行另一个查询。该查询检索主键pk等于函数参数中主键的项目。然后,我们在我们的context字典中分配这个项目,并将其传递给render()。同样,还有一个模板project_detail.html,我们还没有创建它。
一旦创建了视图函数,我们需要将它们连接到 URL。我们将首先创建一个文件projects/urls.py来保存应用程序的 URL 配置。该文件应包含以下代码:
1from django.urls import path
2from . import views
3
4urlpatterns = [
5 path("", views.project_index, name="project_index"),
6 path("<int:pk>/", views.project_detail, name="project_detail"),
7]
在第 5 行,我们将应用程序的根 URL 连接到project_index视图。连接project_detail视图稍微复杂一些。为此,我们希望 URL 是/1,或/2,依此类推,这取决于项目的pk。
URL 中的pk值与传递给 view 函数的pk值相同,因此您需要根据您想要查看的项目动态生成这些 URL。为此,我们使用了<int:pk>符号。这只是告诉 Django,URL 中传递的值是一个整数,它的变量名是pk。
现在已经设置好了,我们需要将这些 URL 连接到项目 URL。在personal_portfolio/urls.py中,添加以下突出显示的代码行:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("projects/", include("projects.urls")), ]
这一行代码包含了项目应用程序中的所有 URL,但意味着它们在以projects/为前缀时被访问。我们的项目现在可以访问两个完整的 URL:
localhost:8000/projects: 项目索引页面localhost:8000/projects/3: 带pk=3的项目详图
这些网址仍然不能正常工作,因为我们没有任何 HTML 模板。但是我们的视图和逻辑已经建立并运行,所以剩下要做的就是创建那些模板。如果你想检查你的代码,看看本节的源代码。
项目应用程序:模板
唷!有了这个应用程序,你就快成功了。我们的最后一步是创建两个模板:
project_index模板project_detail模板
由于我们已经在应用程序中添加了引导样式,我们可以使用一些预样式的组件来使视图看起来更好。让我们从project_index模板开始。
对于project_index模板,您将创建一个由自举卡组成的网格,每个卡显示项目的细节。当然,我们不知道会有多少项目。从理论上讲,可能有数百个要展示。
我们不希望必须创建 100 个不同的引导卡,并在每个项目的所有信息中进行硬编码。相反,我们将使用 Django 模板引擎的一个特性: 用于循环 。
使用这个特性,您将能够遍历所有的项目,并为每个项目创建一个卡片。Django 模板引擎中的 for 循环语法如下:
{% for project in projects %}
{# Do something... #}
{% endfor %}
现在您已经知道了 for 循环是如何工作的,您可以将下面的代码添加到名为projects/templates/project_index.html的文件中:
1{% extends "base.html" %}
2{% load static %}
3{% block page_content %}
4<h1>Projects</h1>
5<div class="row">
6{% for project in projects %}
7 <div class="col-md-4">
8 <div class="card mb-2">
9 <img class="card-img-top" src="{% static project.image %}">
10 <div class="card-body">
11 <h5 class="card-title">{{ project.title }}</h5>
12 <p class="card-text">{{ project.description }}</p>
13 <a href="{% url 'project_detail' project.pk %}"
14 class="btn btn-primary">
15 Read More
16 </a>
17 </div>
18 </div>
19 </div>
20 {% endfor %}
21</div>
22{% endblock %}
这里有很多引导 HTML,这不是本教程的重点。如果您有兴趣了解更多信息,请随意复制和粘贴,并查看引导文档。在这个代码块中,有几件事情需要强调,而不是关注引导程序。
在第 1 行中,我们扩展了base.html,就像我们在 Hello,World 中所做的那样! app 教程。我给这个文件添加了更多样式,包括一个导航栏,这样所有内容都包含在一个引导容器中。对base.html的改动可以在 GitHub 上的源代码中看到。
在的第 2 行,我们添加了一个{% load static %}标签来包含静态文件,比如图像。还记得在 Django 模型的部分,当您创建Project模型时。它的属性之一是文件路径。这个文件路径是我们将要为每个项目存储实际图像的地方。
Django 自动注册存储在每个应用程序中名为static/的目录中的静态文件。我们的图像文件路径名的结构是:img/<photo_name>.png。
当加载静态文件时,Django 在static/目录中查找与static/中给定文件路径匹配的文件。因此,我们需要创建一个名为static/的目录,其中包含另一个名为img/的目录。在img/里面,你可以复制 GitHub 上源代码的图片。
在第 6 行,我们开始 for 循环,遍历由context字典传入的所有项目。
在这个 for 循环中,我们可以访问每个单独的项目。要访问项目的属性,您可以在双花括号内使用点符号。例如,要访问项目的标题,可以使用{{ project.title }}。同样的符号可以用来访问项目的任何属性。
在9 号线,我们展示了我们的项目形象。在src属性中,我们添加了代码{% static project.image %}。这告诉 Django 在静态文件中查找匹配project.image的文件。
我们需要强调的最后一点是13 号线的链接。这是我们project_detail页面的链接。在 Django 中访问 URL 类似于访问静态文件。URL 的代码具有以下形式:
{% url '<url path name>' <view_function_arguments> %}
在本例中,我们正在访问一个名为project_detail的 URL 路径,它接受与项目的pk号相对应的整数参数。
有了所有这些,如果您启动 Django 服务器并访问localhost:8000/projects,那么您应该会看到类似这样的内容:
有了project_index.html模板,就该创建project_detail.html模板了。该模板的代码如下:
{% extends "base.html" %}
{% load static %}
{% block page_content %}
<h1>{{ project.title }}</h1>
<div class="row">
<div class="col-md-8">
<img src="{% static project.image %}" alt="" width="100%">
</div>
<div class="col-md-4">
<h5>About the project:</h5>
<p>{{ project.description }}</p>
<br>
<h5>Technology used:</h5>
<p>{{ project.technology }}</p>
</div>
</div>
{% endblock %}
该模板中的代码与project_index.html模板中的每个项目卡具有相同的功能。唯一的区别是引入了一些引导列。
如果您访问localhost:8000/projects/1,您应该会看到您创建的第一个项目的详细页面:
在本节中,您学习了如何使用模型、视图和模板为您的个人投资组合项目创建一个功能齐全的应用程序。在 GitHub 上查看这一部分的源代码。
在下一节中,您将为您的站点构建一个功能完整的博客,您还将了解 Django 管理页面和表单。
用博客分享你的知识
博客是任何个人作品集网站的绝佳补充。无论你是每月还是每周更新,这都是一个分享你所学知识的好地方。在本节中,您将构建一个功能完整的博客,它将允许您执行以下任务:
- 创建、更新和删除博客文章
- 以索引视图或详细视图的形式向用户显示帖子
- 给帖子分配类别
- 允许用户对帖子发表评论
您还将学习如何使用 Django 管理界面,在这里您可以根据需要创建、更新和删除帖子和类别。
在开始构建网站这一部分的功能之前,创建一个名为blog的新 Django 应用程序。不要删除projects。您会希望 Django 项目中包含这两个应用程序:
$ python manage.py startapp blog
这可能对你来说很熟悉,因为这是你第三次这么做。不要忘记在personal_porfolio/settings.py中将blog添加到INSTALLED_APPS中:
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"projects",
"blog", ]
暂时不要连接 URL。与projects应用程序一样,您将从添加您的模型开始。
博客应用:模特
这个 app 里的models.py文件比projects app 里的复杂多了。
博客需要三个独立的数据库表:
PostCategoryComment
这些表需要相互关联。这变得更容易,因为 Django 模型带有专门用于此目的的字段。
以下是Category和Post型号的代码:
1from django.db import models
2
3class Category(models.Model):
4 name = models.CharField(max_length=20)
5
6class Post(models.Model):
7 title = models.CharField(max_length=255)
8 body = models.TextField()
9 created_on = models.DateTimeField(auto_now_add=True)
10 last_modified = models.DateTimeField(auto_now=True)
11 categories = models.ManyToManyField('Category', related_name='posts')
Category模型很简单。我们只需要一个CharField来存储类别的名称。
Post模型上的title和body字段与您在Project模型中使用的字段类型相同。我们只需要一个title的CharField,因为我们只想要一个简短的文章标题字符串。正文需要是一个长格式的文本,所以我们使用一个TextField。
接下来的两个字段created_on和last_modified是姜戈DateTimeFields。它们分别存储一个 datetime 对象,包含文章创建和修改的日期和时间。
在的第 9 行上,DateTimeField接受一个参数auto_now_add=True。每当创建该类的实例时,都会将当前日期和时间分配给该字段。
在第 10 行的上,DateTimeField接受一个参数auto_now=True。每当保存该类的实例时,都会将当前日期和时间分配给该字段。这意味着每当你编辑这个类的一个实例时,date_modified就会被更新。
post 模型上的最后一个字段是最有趣的。我们希望以这样一种方式链接我们的类别和帖子模型,即多个类别可以分配给多个帖子。幸运的是,Django 通过提供一个ManytoManyField字段类型让我们更容易做到这一点。该字段链接了Post和Category模型,并允许我们在两个表之间创建一个关系。
ManyToManyField有两个参数。第一个是关系的模型,在这个例子中是它的Category。第二个允许我们从一个Category对象访问关系,即使我们没有在那里添加一个字段。通过添加一个posts的related_name,我们可以访问category.posts来给出该类别的帖子列表。
我们需要添加的第三个也是最后一个模型是Comment。我们将使用另一个关系字段,类似于关联Post和Category的ManyToManyField。然而,我们只希望关系是单向的:一个帖子应该有许多评论。
在我们定义了Comment类之后,您将看到这是如何工作的:
16class Comment(models.Model):
17 author = models.CharField(max_length=60)
18 body = models.TextField()
19 created_on = models.DateTimeField(auto_now_add=True)
20 post = models.ForeignKey('Post', on_delete=models.CASCADE)
这个模型的前三个字段应该看起来很熟悉。有一个供用户添加姓名或别名的author字段,一个用于评论正文的body字段,以及一个与Post模型上的created_on字段相同的created_on字段。
在的第 20 行,我们使用了另一个关系字段,即ForeignKey字段。这与ManyToManyField类似,但是定义了一个多对一关系。这背后的原因是,许多评论可以分配给一个帖子。但是你不能有一个评论对应很多帖子。
ForeignKey字段有两个参数。第一个是关系中的另一个模型,在本例中是Post。第二个告诉 Django 当一个帖子被删除时该做什么。如果一个帖子被删除了,那么我们不希望与它相关的评论到处都是。因此,我们也想删除它们,所以我们添加了参数on_delete=models.CASCADE。
一旦您创建了模型,您就可以使用makemigrations创建迁移文件:
$ python manage.py makemigrations blog
最后一步是迁移表。这一次,不要添加特定于应用程序的标志。稍后,您将需要 Django 为您创建的User模型:
$ python manage.py migrate
现在您已经创建了模型,我们可以开始添加一些帖子和类别。您不会像在项目中那样从命令行完成这项工作,因为在命令行中键入一整篇博客文章至少会令人不愉快!
相反,您将学习如何使用 Django Admin,它将允许您在一个漂亮的 web 界面中创建模型类的实例。
不要忘记,在进入下一节之前,您可以在 GitHub 上查看本节的源代码。
博客应用:Django Admin
Django Admin 是一个非常棒的工具,也是使用 Django 的最大好处之一。因为你是唯一一个将要写博客和创建类别的人,所以没有必要创建一个用户界面来做这些。
另一方面,您不希望必须在命令行中写博文。这就是管理员介入的地方。它允许您创建、更新和删除模型类的实例,并为此提供了一个很好的界面。
在访问管理员之前,您需要将自己添加为超级用户。这就是为什么在上一节中,您在项目范围内应用了迁移,而不是仅仅针对应用程序。Django 带有内置的用户模型和一个用户管理系统,允许你登录管理员。
首先,您可以使用以下命令将自己添加为超级用户:
$ python manage.py createsuperuser
然后,系统会提示您输入用户名,然后输入您的电子邮件地址和密码。一旦您输入了所需的详细信息,您将被通知超级用户已经创建。如果你犯了错误,不要担心,因为你可以重新开始:
Username (leave blank to use 'jasmine'): jfiner
Email address: jfiner@example.com
Password:
Password (again):
Superuser created successfully.
导航到localhost:8000/admin并使用您刚刚用来创建超级用户的凭证登录。您将看到一个类似于下图的页面:
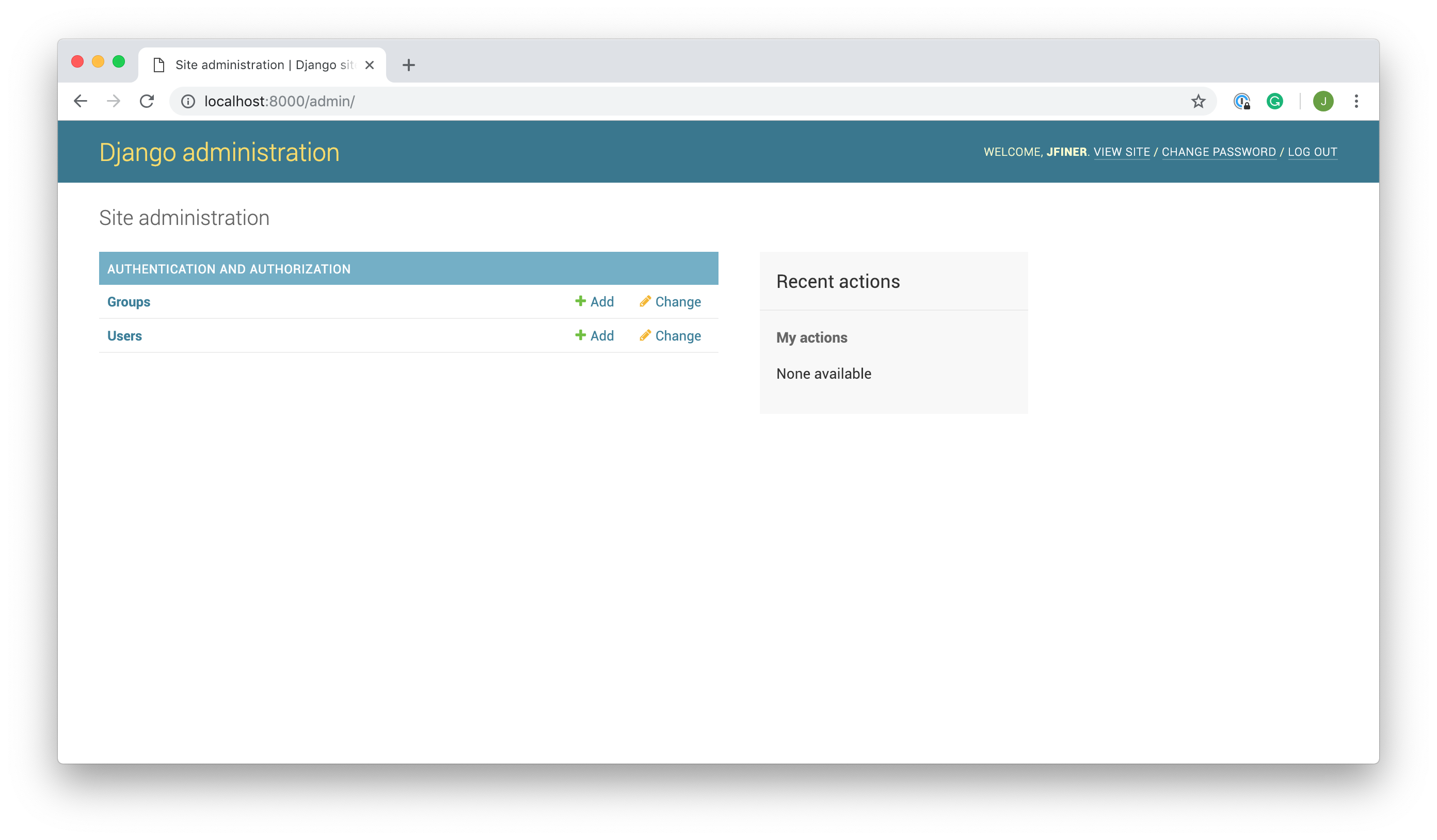
用户和组模型应该会出现,但是您会注意到没有对您自己创建的模型的引用。那是因为你需要在管理员里面注册它们。
在blog目录中,打开文件admin.py并键入以下代码行:
1from django.contrib import admin
2from blog.models import Post, Category
3
4class PostAdmin(admin.ModelAdmin):
5 pass
6
7class CategoryAdmin(admin.ModelAdmin):
8 pass
9
10admin.site.register(Post, PostAdmin)
11admin.site.register(Category, CategoryAdmin)
在第 2 行的上,您导入想要在管理页面上注册的模型。
注意:我们不会向管理员添加评论。这是因为通常不需要自己编辑或创建评论。
如果您想添加一个评论被审核的特性,那么继续添加评论模型。这样做的步骤是完全一样的!
在4 线和7 线上,定义空班PostAdmin和CategoryAdmin。出于本教程的目的,您不需要向这些类添加任何属性或方法。它们用于定制管理页面上显示的内容。对于本教程,默认配置就足够了。
最后两行是最重要的。这些向管理类注册模型。如果你现在访问localhost:8000/admin,那么你应该看到Post和Category模型现在是可见的:
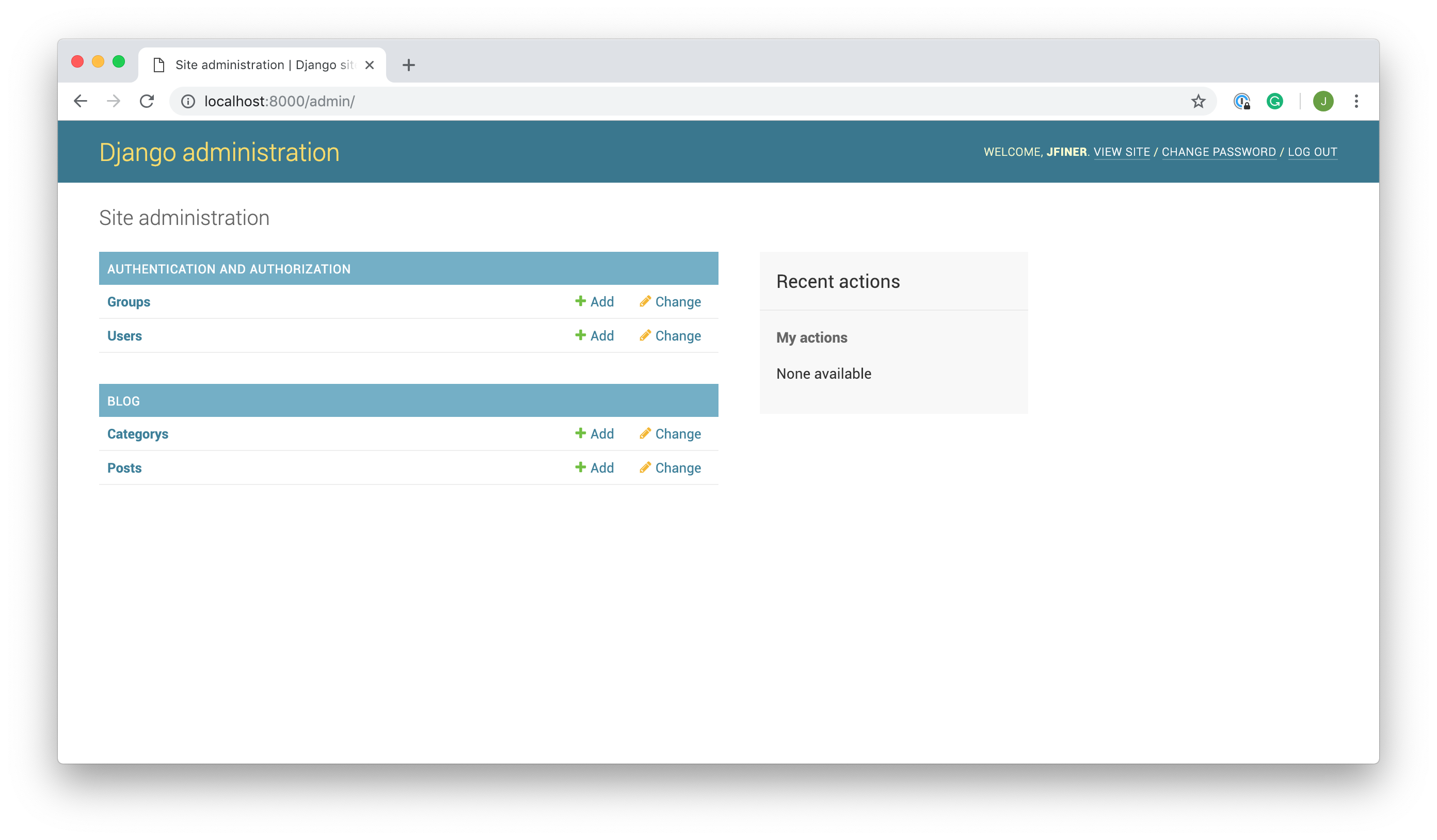
如果你点击进入帖子或类别,你应该能够添加两个模型的新实例。我喜欢通过使用 lorem ipsum 虚拟文本来添加虚假博客文章的文本。
在进入下一部分之前,创建几个虚假的帖子,并给它们分配虚假的类别。这样,当我们创建模板时,您就可以查看帖子了。
在继续为我们的应用构建视图之前,不要忘记查看本部分的源代码。
博客应用:浏览量
您需要在blog目录下的views.py文件中创建三个视图函数:
blog_index会显示你所有帖子的列表。blog_detail将显示完整的帖子以及评论和一个允许用户创建新评论的表单。blog_category将与blog_index类似,但是所查看的帖子将仅属于用户选择的特定类别。
最简单的视图函数是blog_index()。这将非常类似于你的project应用程序中的project_index()视图。您只需查询Post模型并检索它的所有对象:
1from django.shortcuts import render
2from blog.models import Post, Comment
3
4def blog_index(request):
5 posts = Post.objects.all().order_by('-created_on')
6 context = {
7 "posts": posts,
8 }
9 return render(request, "blog_index.html", context)
在第 2 行中,您导入了Post和Comment模型,在第 5 行的视图函数中,您获得了一个包含数据库中所有文章的查询集。order_by()根据给定的参数对查询集进行排序。减号告诉 Django 从最大值开始,而不是从最小值开始。我们使用这个方法,因为我们希望文章从最近的文章开始排序。
最后,定义context字典并呈现模板。先不要担心创建它。您将在下一节开始创建它们。
接下来,您可以开始创建blog_category()视图。view 函数将需要一个类别名称作为参数,并查询Post数据库中所有已被分配给给定类别的帖子:
13def blog_category(request, category):
14 posts = Post.objects.filter( 15 categories__name__contains=category 16 ).order_by( 17 '-created_on' 18 ) 19 context = {
20 "category": category,
21 "posts": posts
22 }
23 return render(request, "blog_category.html", context)
在第 14 行,您使用了 Django Queryset 过滤器。过滤器的参数告诉 Django 要检索一个对象需要满足什么条件。在这种情况下,我们只希望帖子的类别包含与 view 函数的参数中给出的名称相对应的类别。同样,您使用order_by()从最近的文章开始排序。
然后,我们将这些帖子和类别添加到context字典中,并呈现我们的模板。
最后添加的查看功能是blog_detail()。这就更复杂了,因为我们要包含一个表单。在添加表单之前,只需设置视图功能来显示一篇特定的文章,并附上相关的评论。该功能将几乎等同于projects应用中的project_detail()查看功能:
21def blog_detail(request, pk):
22 post = Post.objects.get(pk=pk)
23 comments = Comment.objects.filter(post=post)
24 context = {
25 "post": post,
26 "comments": comments,
27 }
28
29 return render(request, "blog_detail.html", context)
view 函数将一个pk值作为参数,在的第 22 行上,用给定的pk检索对象。
在第 23 行的上,我们再次使用 Django 过滤器检索分配给给定帖子的所有评论。
最后,将post和comments添加到context字典中,并呈现模板。
要向页面添加表单,您需要在blog目录中创建另一个名为forms.py的文件。Django 表单与模型非常相似。表单由一个类组成,其中类属性是表单字段。Django 附带了一些内置的表单字段,可以用来快速创建所需的表单。
对于这个表单,您需要的唯一字段是author,它应该是一个CharField和body,它也可以是一个CharField。
注意:如果你的表单的CharField对应一个型号CharField,确保两者有相同的max_length值。
blog/forms.py应包含以下代码:
from django import forms
class CommentForm(forms.Form):
author = forms.CharField(
max_length=60,
widget=forms.TextInput(attrs={
"class": "form-control",
"placeholder": "Your Name"
})
)
body = forms.CharField(widget=forms.Textarea(
attrs={
"class": "form-control",
"placeholder": "Leave a comment!"
})
)
您还会注意到一个参数widget被传递给了这两个字段。author字段有一个forms.TextInput小部件。这告诉 Django 将这个字段作为 HTML 文本输入元素加载到模板中。body字段使用了一个forms.TextArea小部件,因此该字段被呈现为一个 HTML 文本区域元素。
这些小部件还带有一个参数attrs,这是一个字典,允许我们指定一些 CSS 类,这将有助于以后格式化这个视图的模板。它还允许我们添加一些占位符文本。
当一个表单被发布时,一个POST请求被发送到服务器。因此,在 view 函数中,我们需要检查是否收到了一个POST请求。然后,我们可以从表单字段创建注释。Django 的表单上有一个方便的is_valid(),所以我们可以检查所有的字段是否输入正确。
一旦你从表单中创建了评论,你需要使用save()保存它,然后查询数据库中分配给给定文章的所有评论。您的视图函数应该包含以下代码:
21def blog_detail(request, pk):
22 post = Post.objects.get(pk=pk)
23
24 form = CommentForm() 25 if request.method == 'POST': 26 form = CommentForm(request.POST) 27 if form.is_valid(): 28 comment = Comment( 29 author=form.cleaned_data["author"], 30 body=form.cleaned_data["body"], 31 post=post 32 ) 33 comment.save() 34
35 comments = Comment.objects.filter(post=post)
36 context = {
37 "post": post,
38 "comments": comments,
39 "form": form, 40 }
41 return render(request, "blog_detail.html", context)
在第 24 行的上,我们创建了一个表单类的实例。不要忘记在文件开头导入表单:
from .forms import CommentForm
然后,我们继续检查是否收到了POST请求。如果有,那么我们创建一个新的表单实例,用输入表单的数据填充。
然后使用is_valid()验证该表单。如果表单有效,就会创建一个新的Comment实例。您可以使用form.cleaned_data(一个字典)从表单中访问数据。
字典的键对应于表单字段,所以您可以使用form.cleaned_data['author']访问作者。创建评论时,不要忘记将当前文章添加到评论中。
注意:提交表单的生命周期可能有点复杂,所以这里有一个关于它如何工作的概述:
- 当用户访问包含表单的页面时,他们向服务器发送一个
GET请求。在本例中,表单中没有输入任何数据,所以我们只想呈现并显示表单。 - 当用户输入信息并点击提交按钮时,一个包含随表单提交的数据的
POST请求被发送到服务器。此时,必须处理数据,可能会发生两件事:- 表单有效,用户被重定向到下一页。
- 表单无效,再次显示空表单。用户返回到步骤 1,并重复该过程。
Django 表单模块将输出一些错误,您可以将这些错误显示给用户。这超出了本教程的范围,但是您可以在 Django 文档中阅读更多关于呈现表单错误消息的内容。
在的第 33 行,保存注释并继续将form添加到context字典中,这样您就可以访问 HTML 模板中的表单。
在你开始创建模板并真正看到这个博客开始运行之前,最后一步是连接 URL。您需要在blog/中创建另一个urls.py文件,并添加三个视图的 URL:
# blog/urls.py
from django.urls import path
from . import views
urlpatterns = [
path("", views.blog_index, name="blog_index"),
path("<int:pk>/", views.blog_detail, name="blog_detail"),
path("<category>/", views.blog_category, name="blog_category"),
]
一旦特定于博客的 URL 就位,您需要使用include()将它们添加到personal_portfolio/urls.py中的项目 URL 配置中:
# personal_portfolio/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("projects/", include("projects.urls")),
path("blog/", include("blog.urls")), ]
这样设置后,所有博客的 URL 都将以blog/为前缀,您将拥有以下 URL 路径:
localhost:8000/blog: 博客索引localhost:8000/blog/1: 与pk=1博客的博客详细视图localhost:8000/blog/python: 类别为python的所有帖子的博客索引视图
这些 URL 还不能工作,因为您仍然需要创建模板。
在本节中,您为您的博客应用程序创建了所有的视图。您了解了如何在进行查询时使用过滤器,以及如何创建 Django 表单。用不了多久,你就可以看到你的博客应用程序在运行了!
和往常一样,不要忘记您可以在 GitHub 上查看本节的源代码。
博客应用:模板
我们博客应用的最后一部分是模板。在本节结束时,你将创建一个功能齐全的博客。
您会注意到模板中包含了一些引导元素,使界面更加美观。这些都不是本教程的重点,所以我忽略了它们的功能,但是请查看 Bootstrap 文档以了解更多信息。
您将创建的第一个模板是用于新文件blog/templates/blog_index.html中的博客索引。这将非常类似于项目索引视图。
您将使用一个 for 循环来遍历所有的帖子。对于每篇文章,您将显示标题和正文片段。和往常一样,您将扩展基本模板personal_porfolio/templates/base.html,它包含我们的导航栏和一些额外的格式:
1{% extends "base.html" %}
2{% block page_content %}
3<div class="col-md-8 offset-md-2">
4 <h1>Blog Index</h1>
5 <hr>
6 {% for post in posts %}
7 <h2><a href="{% url 'blog_detail' post.pk%}">{{ post.title }}</a></h2>
8 <small>
9 {{ post.created_on.date }} |
10 Categories:
11 {% for category in post.categories.all %}
12 <a href="{% url 'blog_category' category.name %}">
13 {{ category.name }}
14 </a>
15 {% endfor %}
16 </small>
17 <p>{{ post.body | slice:":400" }}...</p>
18 {% endfor %}
19</div>
20{% endblock %}
在第 7 行,我们有文章标题,这是一个超链接。该链接是一个 Django 链接,我们指向名为blog_detail的 URL,它以一个整数作为参数,应该对应于帖子的pk值。
在标题下面,我们将显示文章的created_on属性及其类别。在第 11 行,我们使用另一个 for 循环来遍历分配给文章的所有类别。
在第 17 行上,我们使用一个模板过滤器 slice 将帖子正文截掉 400 个字符,这样博客索引更具可读性。
一旦准备就绪,您应该能够通过访问localhost:8000/blog访问该页面:
接下来,创建另一个 HTML 文件blog/templates/blog_category.html,你的blog_category模板将存放在这里。这应该与blog_index.html相同,除了在h1标签内的类别名称而不是Blog Index:
1{% extends "base.html" %}
2{% block page_content %}
3<div class="col-md-8 offset-md-2">
4 <h1>{{ category | title }}</h1> 5 <hr>
6 {% for post in posts %}
7 <h2><a href="{% url 'blog_detail' post.pk%}">{{ post.title }}</a></h2>
8 <small>
9 {{ post.created_on.date }} |
10 Categories:
11 {% for category in post.categories.all %}
12 <a href="{% url 'blog_category' category.name %}">
13 {{ category.name }}
14 </a>
15 {% endfor %}
16 </small>
17 <p>{{ post.body | slice:":400" }}...</p>
18 {% endfor %}
19</div>
20{% endblock %}
这个模板的大部分与前面的模板相同。唯一的区别是在第 4 行的上,我们使用了另一个 Django 模板过滤器 title 。这会将 titlecase 应用于字符串,并使单词以大写字符开头。
模板完成后,您将能够访问您的类别视图。如果您定义了一个名为python的类别,您应该能够访问localhost:8000/blog/python并看到该类别的所有帖子:
最后创建的模板是blog_detail模板。在这个模板中,您将显示文章的标题和正文。
在文章的标题和正文之间,您将显示文章的创建日期和任何类别。在此之下,您将包括一个评论表单,以便用户可以添加新的评论。在这下面,会有一个已经留下的评论列表:
1{% extends "base.html" %}
2{% block page_content %}
3<div class="col-md-8 offset-md-2">
4 <h1>{{ post.title }}</h1>
5 <small>
6 {{ post.created_on.date }} |
7 Categories:
8 {% for category in post.categories.all %}
9 <a href="{% url 'blog_category' category.name %}">
10 {{ category.name }}
11 </a>
12 {% endfor %}
13 </small>
14 <p>{{ post.body | linebreaks }}</p>
15 <h3>Leave a comment:</h3>
16 <form action="/blog/{{ post.pk }}/" method="post">
17 {% csrf_token %}
18 <div class="form-group">
19 {{ form.author }}
20 </div>
21 <div class="form-group">
22 {{ form.body }}
23 </div>
24
25 </form>
26 <h3>Comments:</h3>
27 {% for comment in comments %}
28 <p>
29 On {{comment.created_on.date }}
30 <b>{{ comment.author }}</b> wrote:
31 </p>
32 <p>{{ comment.body }}</p>
33 <hr>
34 {% endfor %}
35</div>
36{% endblock %}
模板的前几行显示文章标题、日期和类别,其逻辑与前面的模板相同。这一次,在渲染帖子正文时,使用了 linebreaks 模板滤镜。该标签将换行符注册为新段落,这样正文就不会显示为一个很长的文本块。
在帖子下面的第 16 行,你将显示你的表单。表单动作指向页面的 URL 路径,您要将POST请求发送到该页面。在这种情况下,它与当前正在访问的页面相同。然后添加一个csrf_token,它提供安全性并呈现表单的 body 和 author 字段,后跟一个提交按钮。
为了在 author 和 body 字段上获得引导样式,您需要将form-control类添加到文本输入中。
因为 Django 会在包含{{ form.body }}和{{ form.author }}时为您呈现输入,所以您不能在模板中添加这些类。这就是为什么您在前一节中向表单小部件添加了属性。
在表单下面,还有另一个 for 循环,它循环遍历给定帖子上的所有评论。注释、body、author和created_on属性都被显示。
一旦模板准备就绪,你应该可以访问localhost:8000/blog/1并查看你的第一篇文章:
您还应该能够通过在blog_index视图中点击文章标题来访问文章详细信息页面。
最后的点睛之笔是在base.html中添加一个blog_index到导航栏的链接。这样,当你点击导航栏中的博客,你就可以访问这个博客了。查看源代码中对base.html的更新,看看如何添加那个链接。
现在,你的个人作品集网站已经完成,你已经创建了你的第一个 Django 网站。包含所有特性的源代码最终版本可以在 GitHub 上找到,快来看看吧!在网站周围点击一下,看看所有的功能,并尝试在你的帖子上留下一些评论!
你可能会发现一些你认为需要改进的地方。去把它们整理好。了解这个 web 框架的最好方法是通过实践,所以试着扩展这个项目,让它变得更好!如果你不确定从哪里开始,我在下面的结论中为你留下了一些想法!
结论
恭喜你,你已经到达教程的结尾!我们已经讲了很多,所以请确保继续练习和构建。你构建得越多,它就会变得越简单,你也就越少需要参考这篇文章或者文档。您将很快构建出复杂的 web 应用程序。
在本教程中,您已经看到:
- 如何创建 Django 项目和应用
- 如何添加带有视图和模板的网页
- 如何用表单获取用户输入
- 如何将您的视图和模板与 URL 配置联系起来
- 如何通过 Django 的对象关系映射器使用关系数据库向您的站点添加数据
- 如何使用 Django Admin 来管理你的模型
此外,您还了解了 Django web 应用程序的 MVT 结构,以及为什么 Django 是 web 开发的最佳选择。
如果您想了解更多关于 Django 的知识,请务必阅读文档,并确保阅读本系列的第 2 部分!
Get Started With Django Part 1: Build a Portfolio AppGet Started With Django Part 2: Django User Management »
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Django 入门:建立作品集 App*********
Bootstrap 3 入门
尽管给自己贴上后端开发者的标签,我已经越来越多地涉足前端设计,也就是因为 JavaScript 模糊了两者之间的界限。在我的上一个项目中,我用 HTML 和 CSS 开发了一些响应式风格——这可能很痛苦。
令人欣慰的是,Bootstrap(以前称为 Twitter Bootstrap)这样的框架使得这样的设计请求变得相当简单——在 Bootstrap 3 的新版本中甚至更简单。
让我们来看看。
这是一个由 3 部分组成的系列。在第一部分中,我们将只关注 Bootstrap 3 以及如何使用 HTML 和 CSS 定制它。在第二部分,我们将看看如何建立一个有效的销售登录页面。点击查看。最后,在最后一部分,我们将使用 Flask + Bootstrap 3 将 Python 加入到构建登陆页面的组合中。
你可以从这个报告中获得最终的样式/页面。
创建一个最小的网站布局
从官方网站下载 Bootstrap 开始。打开 zip 文件并获取 dist 目录。这将是我们这个小项目的根文件夹。请务必将assets/js中的jquery.js添加到dist/js中。
.
├── css
│ ├── bootstrap-theme.css
│ ├── bootstrap-theme.min.css
│ ├── bootstrap.css
│ └── bootstrap.min.css
├── fonts
│ ├── glyphicons-halflings-regular.eot
│ ├── glyphicons-halflings-regular.svg
│ ├── glyphicons-halflings-regular.ttf
│ └── glyphicons-halflings-regular.woff
├── index.html
└── js
├── bootstrap.js
├── bootstrap.min.js
└── jquery.js
添加包含以下内容的 index.html 文件:
<!DOCTYPE html>
<html>
<head>
<title>Bootstrap Template</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="css/bootstrap.min.css" rel="stylesheet" media="screen">
<!-- HTML5 shim and Respond.js IE8 support of HTML5 elements and media queries -->
<!--[if lt IE 9]>
<script src="../../assets/js/html5shiv.js"></script>
<script src="../../assets/js/respond.min.js"></script>
<![endif]-->
</head>
<body>
<div class ="container">
<h1>Hello, world!</h1>
</div>
</body>
</html>
添加一个导航条(现在总是有响应的)、一个容器、大屏幕、一些 ipsum 文本和一个按钮:
<!DOCTYPE html>
<html>
<head>
<title>Bootstrap Template</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="css/bootstrap.min.css" rel="stylesheet" media="screen">
<!-- HTML5 shim and Respond.js IE8 support of HTML5 elements and media queries -->
<!--[if lt IE 9]>
<script src="../../assets/js/html5shiv.js"></script>
<script src="../../assets/js/respond.min.js"></script>
<![endif]-->
</head>
<body>
<div class="navbar navbar-inverse navbar-fixed-top">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle" data-toggle="collapse" data-target=".navbar-collapse">
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="#">Bootstrap <3</a>
</div>
<div class="collapse navbar-collapse">
<ul class="nav navbar-nav navbar-right">
<li class="active"><a href="#">Home</a></li>
<li><a href="#about">About</a></li>
<li><a href="#contact">Contact</a></li>
</ul>
</div><!--/.nav-collapse -->
</div>
</div>
<div class="jumbotron">
<div class="container">
<h1>Bootstrap starter template</h1>
<p class="lead">Bacon ipsum dolor sit amet tenderloin chuck jowl, drumstick pork loin kevin andouille tri-tip. Turkey biltong sirloin, tongue rump pork belly t-bone tail sausage venison corned beef. Jerky pig shoulder beef, tri-tip turducken kevin ribeye prosciutto spare ribs.</p>
<a class="btn btn-primary btn-lg btn-block">Big ASS Learn more button</a>
</div>
</div>
</body>
</html>
在头部添加以下样式:
<style> body {padding-top: 50px;} </style>
最后,为了增加完整的响应,在</body>标签之前添加以下脚本:
<script src="js/jquery.js"></script>
<script src="js/bootstrap.min.js"></script>
乍一看,你可以看到所有组件都是平的。如果你不喜欢平面设计,还有一个可供选择的主题。通过调整浏览器大小来调整响应速度。看起来不错。在 Bootstrap 3 中,响应能力现在是默认的——所以现在你没有选择:你必须首先为移动开发。
电网系统
网格系统现在更容易使用了。默认情况下,它最多可扩展到 12 列,可以针对四种设备进行更改——大型台式机、台式机、平板电脑和手机。你很快就会看到,默认情况下它也是可变的。
在结束的大屏幕 div 后添加一行、一个基本的网格系统和更多的 ipsum 文本:
<div class="container">
<div class="row">
<div class="col-md-4">
<p>Yr umami selfies Carles DIY, pop-up Tonx meggings stumptown freegan street art Vice ethnic. Pickled gastropub lo-fi polaroid, ennui selvage meh Tumblr organic iPhone kale chips narwhal Echo Park. Tonx literally distillery Pitchfork McSweeney's semiotics. Stumptown YOLO fanny pack bespoke, kitsch Carles gastropub vegan. Biodiesel ennui church-key McSweeney's, selvage hoodie Brooklyn 90's lomo. Quinoa photo booth cliche semiotics. Roof party Etsy ethnic, fashion axe mlkshk 8-bit paleo.</p>
</div>
<div class="col-md-4">
<p>Yr umami selfies Carles DIY, pop-up Tonx meggings stumptown freegan street art Vice ethnic. Pickled gastropub lo-fi polaroid, ennui selvage meh Tumblr organic iPhone kale chips narwhal Echo Park. Tonx literally distillery Pitchfork McSweeney's semiotics. Stumptown YOLO fanny pack bespoke, kitsch Carles gastropub vegan. Biodiesel ennui church-key McSweeney's, selvage hoodie Brooklyn 90's lomo. Quinoa photo booth cliche semiotics. Roof party Etsy ethnic, fashion axe mlkshk 8-bit paleo.</p>
</div>
<div class="col-md-4">
<p>Yr umami selfies Carles DIY, pop-up Tonx meggings stumptown freegan street art Vice ethnic. Pickled gastropub lo-fi polaroid, ennui selvage meh Tumblr organic iPhone kale chips narwhal Echo Park. Tonx literally distillery Pitchfork McSweeney's semiotics. Stumptown YOLO fanny pack bespoke, kitsch Carles gastropub vegan. Biodiesel ennui church-key McSweeney's, selvage hoodie Brooklyn 90's lomo. Quinoa photo booth cliche semiotics. Roof party Etsy ethnic, fashion axe mlkshk 8-bit paleo.</p>
</div>
</div>
</div>
由于每行有 12 个单位,我们做了三列,每列 4 个单位。请记住,所有列的总和必须是 12。尝试一下:尝试将第一列更改为 2 个单位,将最后一列更改为 8 个单位,或者用另一组列一起添加一个新行(或者等到下一步)。
用下面的网格在旧行下面添加一个新行(确保它在container元素内):
<div class="col-md-8 col-md-offset-2">
<p>Yr umami selfies Carles DIY, pop-up Tonx meggings stumptown freegan street art Vice ethnic. Pickled gastropub lo-fi polaroid, ennui selvage meh Tumblr organic iPhone kale chips narwhal Echo Park. Tonx literally distillery Pitchfork McSweeney's semiotics. Stumptown YOLO fanny pack bespoke, kitsch Carles gastropub vegan. Biodiesel ennui church-key McSweeney's, selvage hoodie Brooklyn 90's lomo. Quinoa photo booth cliche semiotics. Roof party Etsy ethnic, fashion axe mlkshk 8-bit paleo.</p>
</div>
这里,我们使用了
offset,它将列向右移动,使其居中。本质上,我们移动了 2 个单位,然后使用了一个 8 单位的列,之后留下另外 2 个单位,等于 12: 2 + 8 + 2 = 12。
因为 Bootstrap 3 中的网格系统响应迅速,所以可以将一行嵌套在另一行中(这是另一个新特性)。内部行(例如行内的行)将有 12 列。把这个拖出来可能会有帮助。在看我的例子之前,先自己尝试一下。
<div class="row">
<div class="col-md-4">
<div class="row">
<div class="col-md-6">
<p>Yr umami selfies Carles DIY, pop-up Tonx meggings stumptown freegan street art Vice ethnic.</p>
</div>
<div class="col-md-6">
<p>Stumptown YOLO fanny pack bespoke, kitsch Carles gastropub vegan.</p>
</div>
</div>
<div class="row">
<div class="col-md-6">
<p>Pickled gastropub lo-fi polaroid, ennui selvage meh Tumblr organic iPhone kale chips narwhal Echo Park.</p>
</div>
<div class="col-md-6">
<p>Biodiesel ennui church-key McSweeney's, selvage hoodie Brooklyn 90's lomo.</p>
</div>
</div>
</div>
<div class="col-md-4">
<p>Yr umami selfies Carles DIY, pop-up Tonx meggings stumptown freegan street art Vice ethnic. Pickled gastropub lo-fi polaroid, ennui selvage meh Tumblr organic iPhone kale chips narwhal Echo Park. Tonx literally distillery Pitchfork McSweeney's semiotics. Stumptown YOLO fanny pack bespoke, kitsch Carles gastropub vegan. Biodiesel ennui church-key McSweeney's, selvage hoodie Brooklyn 90's lomo. Quinoa photo booth cliche semiotics. Roof party Etsy ethnic, fashion axe mlkshk 8-bit paleo.</p>
</div>
<div class="col-md-4">
<p>
<ul class="list-group">
<li class="list-group-item"><span class="badge">14</span>Quinoa photo booth</li>
<li class="list-group-item"><span class="badge">10</span>iPhone kale chips</li>
<li class="list-group-item"><span class="badge">6</span>fanny pack bespoke</li>
<li class="list-group-item"><span class="badge">4</span>lo-fi polaroid</li>
<li class="list-group-item"><span class="badge">2</span>Tonx meggings stumptown</li>
</ul>
</p>
</div>
</div>
因此,我们采用跨度为 4 的第一列,并对其进行嵌套,使其具有四个大小相等的盒子。此外,您可能注意到了最右边一列中的列表。这是 Bootstrap 3 中的另一个新特性,叫做列表组。
您还可以用<div class="list-group">替换无序列表,然后使用锚标记来显示链接,而不是列表项:
<div class="list-group">
<a href="#" class="list-group-item"><span class="badge">14</span>Quinoa photo booth</a>
<a href="#" class="list-group-item"><span class="badge">10</span>iPhone kale chips</a>
<a href="#" class="list-group-item active"><span class="badge">6</span>fanny pack bespoke</a>
<a href="#" class="list-group-item"><span class="badge">4</span>lo-fi polaroid</a>
<a href="#" class="list-group-item"><span class="badge">2</span>Tonx meggings stumptown</a>
</div>
测试一下。找点乐子吧。尝试通过添加图像、渐变甚至基本颜色来改变大屏幕的背景颜色。
这样的小变化可以产生很大的不同。确保你的页面看起来像我的页面。
一个例子:狭义营销自举 3
让我们更进一步,创建一个工作示例。Bootstrap 2 中我最喜欢的一个例子是狭义营销模板,遗憾的是,它不属于 Bootstrap 3 中的示例。所以我们自己从头开始创造吧。
从基础页面开始。
<!DOCTYPE html>
<html>
<head>
<title>Bootstrap Template</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="css/bootstrap.min.css" rel="stylesheet" media="screen">
<!-- HTML5 shim and Respond.js IE8 support of HTML5 elements and media queries -->
<!--[if lt IE 9]>
<script src="../../assets/js/html5shiv.js"></script>
<script src="../../assets/js/respond.min.js"></script>
<![endif]-->
</head>
<style> body {padding-top: 50px;} </style>
<body>
<div class="container">
<h1>Nothing to see .. yet.<h1>
</div>
<script src="js/jquery.js"></script>
<script src="js/bootstrap.min.js"></script>
</body>
</html>
添加导航栏并更新样式:
<style> body { padding-top: 20px; padding-bottom: 20px; } .container-narrow { margin: 0 auto; max-width: 700px; } .container-narrow > hr { margin: 40px 0 0 0; } </style>
<body>
<div class="container-narrow">
<ul class="nav nav-pills pull-right">
<li class="active"><a href="#">Home</a></li>
<li><a href="#">About</a></li>
<li><a href="#">Contact</a></li>
</ul>
<h3 class="text-muted">Project name</h3>
<hr>
大屏幕。先添加样式,然后在<hr>下面添加大屏幕。
.jumbotron {
margin: 5px 0;
text-align: center;
background-color:white;
}
.jumbotron h1 {
font-size: 72px;
line-height: 1;
font-weight: bold;
}
.jumbotron .btn {
font-size: 21px;
padding: 14px 24px;
}
...
<div class="jumbotron">
<h1>Super awesome marketing speak!</h1>
<p class="lead">Cras justo odio, dapibus ac facilisis in, egestas eget quam. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus.</p>
<a class="btn btn-large btn-success" href="#">Sign up today</a>
</div>
营销科。同样,首先添加样式,然后移除<container></container>元素并添加到 marketing 行中。
.marketing {
margin: 40px 0;
}
.marketing p + h4 {
margin-top: 28px;
}
...
<div class="row marketing">
<div class="col-md-6">
<h4>Subheading</h4>
<p>Donec id elit non mi porta gravida at eget metus. Maecenas faucibus mollis interdum.</p>
<h4>Subheading</h4>
<p>Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Cras mattis consectetur purus sit amet fermentum.</p>
<h4>Subheading</h4>
<p>Maecenas sed diam eget risus varius blandit sit amet non magna.</p>
</div>
<div class="col-md-6">
<h4>Subheading</h4>
<p>Donec id elit non mi porta gravida at eget metus. Maecenas faucibus mollis interdum.</p>
<h4>Subheading</h4>
<p>Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Cras mattis consectetur purus sit amet fermentum.</p>
<h4>Subheading</h4>
<p>Maecenas sed diam eget risus varius blandit sit amet non magna.</p>
</div>
</div>
页脚。注意多余的</div>。这应该会关闭<div class="container-narrow">。
<div class="footer">
<p>© Company 2013</p>
</div>
</div>
就是这样。将这个版本与 Bootstrap 2 版本进行比较。类似。但是很平。
让它成为你自己的
让我们看看一些快速定制这个例子的方法,让它看起来不那么“自举”。
首先,添加一个名为main.css的新样式表,并向其中添加嵌入的样式。不要忘记将新样式表添加到第一个样式表下面的head中。此外,添加以下谷歌字体以及一个链接到字体真棒风格:
<link href="css/main.css" rel="stylesheet" media="screen">
<link href="http://fonts.googleapis.com/css?family=Arvo" rel="stylesheet" type="text/css">
<link href="http://fonts.googleapis.com/css?family=PT+Sans" rel="stylesheet" type="text/css">
<link href="//netdna.bootstrapcdn.com/font-awesome/3.2.1/css/font-awesome.css" rel="stylesheet">
让我们使用这些新字体:
h1, h2, h3, h4, h5, h6 {
font-family: 'Arvo', Georgia, Times, serif;
}
p, div {
font-family: 'PT Sans', Helvetica, Arial, sans-serif;
}
你可能知道,很难找到两种字体搭配起来好看。幸运的是,有很多好的资源——比如这里的和这里的。
纹理可以产生很大的不同,这就是为什么我喜欢微妙的图案。用下面的代码更新body类。确保大屏幕也是透明的。
body {
padding-top: 10px;
padding-bottom: 20px;
background: url(http://subtlepatterns.com/patterns/lightpaperfibers.png) repeat 0 0;
}
...
.jumbotron {
margin: 5px 0;
text-align: center;
background-color:transparent;
}
更新 Marketing 部分,以便只有一行三列(每列跨越 4 个单元)。让我们也使用新的雕刻图标。或者你可以使用字体,因为我们添加了样式表。
<div class="row marketing">
<div class="col-md-4">
<h3><span class="glyphicon glyphicon-info-sign" style="color:#428bca;"></span> Subheading</h3>
<p>Donec id elit non mi porta gravida at eget metus. Maecenas faucibus mollis interdum.</p>
</div>
<div class="col-md-4">
<h3><span class="glyphicon glyphicon-info-sign" style="color:#428bca;"></span> Subheading</h3>
<p>Morbi leo risus, porta ac consectetur ac, vestibulum at eros. Cras mattis consectetur purus sit amet fermentum.</p>
</div>
<div class="col-md-4">
<h3><span class="glyphicon glyphicon-info-sign" style="color:#428bca;"></span> Subheading</h3>
<p>Maecenas sed diam eget risus varius blandit sit amet non magna.</p>
</div>
</div>
在营销部分的上方,让我们添加一个新的包含两个视频的行,希望与您的产品或服务有关(或者至少解释了您的网站存在的原因)。
<div class="row">
<div class="col-md-6">
<center><iframe width="320" height="240" style="max-width:100%" src="http://www.youtube.com/embed/D0MoGRZRtcA?rel=0" frameborder="0" allowfullscreen></iframe>
</div>
<div class="col-md-6">
<iframe width="320" height="240" style="max-width:100%" src="http://www.youtube.com/embed/EuOJRop5aBE?rel=0" frameborder="0" allowfullscreen></iframe></center>
</div>
</div>
顺便说一下,我在几个月前录制了这些视频,其中详细介绍了如何开始一个 Django 项目。将它们签出,创建一个基本项目,然后添加一些样式。😃
更新大屏幕,增加一些社交分享按钮和图标。❤️
<div class="jumbotron">
<h1>we <span class="glyphicon glyphicon-heart" style="color:#428bca;"></span> awesome marketing speak!</h1>
<p class="lead">Cras justo odio, dapibus ac facilisis in, egestas eget quam. Fusce dapibus, tellus ac cursus commodo, tortor mauris condimentum nibh, ut fermentum massa justo sit amet risus.</p>
<a class="btn btn-large btn-success" href="#">Sign up today <span class="glyphicon glyphicon-ok-circle"></span></a>
<br/><br/>
<a href="https://twitter.com/RealPython" class="twitter-follow-button" data-show-count="false" data-size="large">Follow @RealPython</a>
<script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs'); </script>
<a href="https://twitter.com/intent/tweet?screen_name=RealPython" class="twitter-mention-button" data-size="large">Tweet to @RealPython</a>
<script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs'); </script>
<a href="https://twitter.com/share" class="twitter-share-button" data-url="https://realpython.com" data-text="RealPython yo -" data-size="large">Tweet</a>
<script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs'); </script>
</div>
最后,从导航栏中删除text-mute类,并添加一个图标:
<h3><span class="glyphicon glyphicon-asterisk" style="color:#5cb85c"></span> Project name</h3>
这里是最终的版本。
好吗?至少,有了这些基本的改变——花了整整五分钟——你现在已经开始着手一个通用的主题,并使它变得更加专业。干杯。
准备好了吗?查看这三部分系列中的第二部分部分。哦——看看这些入门模板,快速入门。只需添加新的字体、颜色和一些纹理…**
Django 频道入门
原文:https://realpython.com/getting-started-with-django-channels/
在本教程中,我们将使用 Django Channels 创建一个实时应用程序,在用户登录和退出时更新用户列表。
使用 WebSockets(通过 Django 通道)管理客户端和服务器之间的通信,每当用户通过身份验证时,就会向所有其他连接的用户广播一个事件。每个用户的屏幕会自动改变,而不需要他们重新加载浏览器。
注意:我们建议你在开始本教程之前有一些使用 Django 的经验。另外,你应该熟悉 WebSockets 的概念。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
我们的应用程序使用:
- python(3 . 6 . 0 版)
- django(1 . 10 . 5 版)
- Django 频道(1.0.3 版)
- Redis (v3.2.8)
目标
本教程结束时,您将能够…
- 通过 Django 通道向 Django 项目添加 Web 套接字支持
- 在 Django 和 Redis 服务器之间建立一个简单的连接
- 实施基本用户身份验证
- 利用 Django 信号在用户登录或退出时采取行动
开始使用
首先,创建一个新的虚拟环境来隔离我们项目的依赖关系:
$ mkdir django-example-channels
$ cd django-example-channels
$ python3.6 -m venv env
$ source env/bin/activate
(env)$
安装 Django ,Django 频道, ASGI Redis ,然后创建一个新的 Django 项目和 app:
(env)$ pip install django==1.10.5 channels==1.0.2 asgi_redis==1.0.0
(env)$ django-admin.py startproject example_channels
(env)$ cd example_channels
(env)$ python manage.py startapp example
(env)$ python manage.py migrate
注意:在本教程中,我们将创建各种不同的文件和文件夹。如果你卡住了,请参考项目的库中的文件夹结构。
接下来,下载并安装 Redis 。如果你在苹果电脑上,我们建议你使用自制软件:
$ brew install redis
在新的终端窗口中启动 Redis 服务器,并确保它运行在默认端口 6379 上。当我们告诉 Django 如何与 Redis 通信时,端口号将非常重要。
通过更新项目的 settings.py 文件中的INSTALLED_APPS来完成设置:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'channels',
'example',
]
然后通过设置默认后端和路由来配置CHANNEL_LAYERS:
CHANNEL_LAYERS = {
'default': {
'BACKEND': 'asgi_redis.RedisChannelLayer',
'CONFIG': {
'hosts': [('localhost', 6379)],
},
'ROUTING': 'example_channels.routing.channel_routing',
}
}
这使用了生产中也需要的 Redis 后端。
WebSockets 101
通常,Django 使用 HTTP 在客户机和服务器之间进行通信:
- 客户端向服务器发送一个 HTTP 请求。
- Django 解析请求,提取一个 URL,然后将其匹配到一个视图。
- 视图处理请求并向客户机返回 HTTP 响应。
与 HTTP 不同,WebSockets 协议允许双向通信,这意味着服务器可以将数据推送到客户端,而无需用户提示。对于 HTTP,只有发出请求的客户端会收到响应。使用 WebSockets,服务器可以同时与多个客户端通信。正如我们将在本教程后面看到的,我们使用前缀ws://发送 WebSockets 消息,而不是http://。
注意:在开始之前,快速回顾一下渠道概念文档。
消费者和团体
让我们创建第一个消费者,它处理客户机和服务器之间的基本连接。创建一个名为的新文件 example _ channels/example/consumers . py:
from channels import Group
def ws_connect(message):
Group('users').add(message.reply_channel)
def ws_disconnect(message):
Group('users').discard(message.reply_channel)
消费者是 Django 观点的对应者。任何连接到我们的应用程序的用户都将被添加到“用户”组,并将接收服务器发送的消息。当客户端与我们的应用断开连接时,该频道将从群中删除,用户将停止接收消息。
接下来,让我们通过将以下代码添加到名为example _ channels/routing . py的新文件来设置路由,其工作方式与 Django URL 配置几乎相同:
from channels.routing import route
from example.consumers import ws_connect, ws_disconnect
channel_routing = [
route('websocket.connect', ws_connect),
route('websocket.disconnect', ws_disconnect),
]
所以,我们定义了channel_routing而不是urlpatterns,定义了route()而不是url()。请注意,我们将消费者函数链接到了 WebSockets。
模板
让我们写一些可以通过 WebSocket 与服务器通信的 HTML。在“示例”中创建一个“模板”文件夹,然后在“模板”-“示例 _ 频道/示例/模板/示例”中添加一个“示例”文件夹。
添加一个 _base.html 文件:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link href="//maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css" rel="stylesheet">
<title>Example Channels</title>
</head>
<body>
<div class="container">
<br>
{% block content %}{% endblock content %}
</div>
<script src="//code.jquery.com/jquery-3.1.1.min.js"></script>
{% block script %}{% endblock script %}
</body>
</html>
以及 user_list.html :
{% extends 'example/_base.html' %}
{% block content %}{% endblock content %}
{% block script %}
<script> var socket = new WebSocket('ws://' + window.location.host + '/users/'); socket.onopen = function open() { console.log('WebSockets connection created.'); }; if (socket.readyState == WebSocket.OPEN) { socket.onopen(); } </script>
{% endblock script %}
现在,当客户机使用 WebSocket 成功打开与服务器的连接时,我们将看到一条确认消息打印到控制台。
视图
在example _ channels/example/views . py中设置一个支持 Django 视图来呈现我们的模板:
from django.shortcuts import render
def user_list(request):
return render(request, 'example/user_list.html')
将 URL 添加到example _ channels/example/URLs . py:
from django.conf.urls import url
from example.views import user_list
urlpatterns = [
url(r'^$', user_list, name='user_list'),
]
更新example _ channels/example _ channels/URLs . py中的项目 URL:
from django.conf.urls import include, url
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^', include('example.urls', namespace='example')),
]
测试
准备测试了吗?
(env)$ python manage.py runserver
注意:您可以在两个不同的终端中交替运行
python manage.py runserver --noworker和python manage.py runworker,作为两个独立的进程来测试接口和工作服务器。两种方法都管用!
当您访问 http://localhost:8000/ 时,您应该看到打印到终端的连接消息:
[2017/02/19 23:24:57] HTTP GET / 200 [0.02, 127.0.0.1:52757]
[2017/02/19 23:24:58] WebSocket HANDSHAKING /users/ [127.0.0.1:52789]
[2017/02/19 23:25:03] WebSocket DISCONNECT /users/ [127.0.0.1:52789]
用户认证
既然我们已经证明了我们可以打开一个连接,我们的下一步就是处理用户认证。请记住:我们希望用户能够登录到我们的应用程序,并看到所有其他用户谁订阅了该用户组的列表。首先,我们需要一种用户创建帐户和登录的方法。首先创建一个简单的登录页面,允许用户使用用户名和密码进行身份验证。
在“example _ channels/example/templates/example”中创建一个名为 log_in.html 的新文件:
{% extends 'example/_base.html' %}
{% block content %}
<form action="{% url 'example:log_in' %}" method="post">
{% csrf_token %}
{% for field in form %}
<div>
{{ field.label_tag }}
{{ field }}
</div>
{% endfor %}
</form>
<p>Don't have an account? <a href="{% url 'example:sign_up' %}">Sign up!</a></p>
{% endblock content %}
接下来,像这样更新example _ channels/example/views . py:
from django.contrib.auth import login, logout
from django.contrib.auth.forms import AuthenticationForm
from django.core.urlresolvers import reverse
from django.shortcuts import render, redirect
def user_list(request):
return render(request, 'example/user_list.html')
def log_in(request):
form = AuthenticationForm()
if request.method == 'POST':
form = AuthenticationForm(data=request.POST)
if form.is_valid():
login(request, form.get_user())
return redirect(reverse('example:user_list'))
else:
print(form.errors)
return render(request, 'example/log_in.html', {'form': form})
def log_out(request):
logout(request)
return redirect(reverse('example:log_in'))
Django 带有支持通用认证功能的表单。我们可以使用AuthenticationForm来处理用户登录。该表单检查所提供的用户名和密码,如果找到有效的用户,则返回一个User对象。我们登录通过验证的用户,并将他们重定向到我们的主页。用户还应该能够注销应用程序,因此我们创建了一个提供该功能的注销视图,然后将用户带回到登录屏幕。
然后更新example _ channels/example/URLs . py:
from django.conf.urls import url
from example.views import log_in, log_out, user_list
urlpatterns = [
url(r'^log_in/$', log_in, name='log_in'),
url(r'^log_out/$', log_out, name='log_out'),
url(r'^$', user_list, name='user_list')
]
我们还需要一种创造新用户的方式。通过将名为 sign_up.html 的新文件添加到“example _ channels/example/templates/example”中,以与登录相同的方式创建一个注册页面:
{% extends 'example/_base.html' %}
{% block content %}
<form action="{% url 'example:sign_up' %}" method="post">
{% csrf_token %}
{% for field in form %}
<div>
{{ field.label_tag }}
{{ field }}
</div>
{% endfor %}
<p>Already have an account? <a href="{% url 'example:log_in' %}">Log in!</a></p>
</form>
{% endblock content %}
请注意,登录页面有一个指向注册页面的链接,注册页面有一个指向登录页面的链接。
向视图添加以下函数:
def sign_up(request):
form = UserCreationForm()
if request.method == 'POST':
form = UserCreationForm(data=request.POST)
if form.is_valid():
form.save()
return redirect(reverse('example:log_in'))
else:
print(form.errors)
return render(request, 'example/sign_up.html', {'form': form})
我们使用另一个内置表单来创建用户。表单验证成功后,我们重定向到登录页面。
确保导入表单:
from django.contrib.auth.forms import AuthenticationForm, UserCreationForm
再次更新example _ channels/example/URLs . py:
from django.conf.urls import url
from example.views import log_in, log_out, sign_up, user_list
urlpatterns = [
url(r'^log_in/$', log_in, name='log_in'),
url(r'^log_out/$', log_out, name='log_out'),
url(r'^sign_up/$', sign_up, name='sign_up'),
url(r'^$', user_list, name='user_list')
]
此时,我们需要创建一个用户。运行服务器并在浏览器中访问http://localhost:8000/sign_up/。使用有效的用户名和密码填写表单,并提交以创建我们的第一个用户。
注意:尝试使用
michael作为用户名,johnson123作为密码。
sign_up视图将我们重定向到log_in视图,从那里我们可以验证我们新创建的用户。
登录后,我们可以测试新的身份验证视图。
使用注册表单创建几个新用户,为下一部分做准备。
登录提醒
我们有基本的用户认证工作,但我们仍然需要显示一个用户列表,我们需要服务器告诉组,当一个用户登录和退出。我们需要编辑我们的消费者函数,以便它们在客户端连接之后和客户端断开之前发送消息。消息数据将包括用户的用户名和连接状态。
更新example _ channels/example/consumers . py如下:
import json
from channels import Group
from channels.auth import channel_session_user, channel_session_user_from_http
@channel_session_user_from_http
def ws_connect(message):
Group('users').add(message.reply_channel)
Group('users').send({
'text': json.dumps({
'username': message.user.username,
'is_logged_in': True
})
})
@channel_session_user
def ws_disconnect(message):
Group('users').send({
'text': json.dumps({
'username': message.user.username,
'is_logged_in': False
})
})
Group('users').discard(message.reply_channel)
注意,我们在函数中添加了 decorators 来从 Django 会话中获取用户。此外,所有消息都必须是 JSON 可序列化的,所以我们将数据转储到一个 JSON 字符串中。
接下来,更新example _ channels/example/templates/example/user _ list . html:
{% extends 'example/_base.html' %}
{% block content %}
<a href="{% url 'example:log_out' %}">Log out</a>
<br>
<ul>
{% for user in users %}
<!-- NOTE: We escape HTML to prevent XSS attacks. -->
<li data-username="{{ user.username|escape }}">
{{ user.username|escape }}: {{ user.status|default:'Offline' }}
</li>
{% endfor %}
</ul>
{% endblock content %}
{% block script %}
<script> var socket = new WebSocket('ws://' + window.location.host + '/users/'); socket.onopen = function open() { console.log('WebSockets connection created.'); }; socket.onmessage = function message(event) { var data = JSON.parse(event.data); // NOTE: We escape JavaScript to prevent XSS attacks. var username = encodeURI(data['username']); var user = $('li').filter(function () { return $(this).data('username') == username; }); if (data['is_logged_in']) { user.html(username + ': Online'); } else { user.html(username + ': Offline'); } }; if (socket.readyState == WebSocket.OPEN) { socket.onopen(); } </script>
{% endblock script %}
在我们的主页上,我们展开用户列表以显示用户列表。我们将每个用户的用户名存储为一个数据属性,以便于在 DOM 中找到用户条目。我们还向 WebSocket 添加了一个事件监听器,它可以处理来自服务器的消息。当我们收到消息时,我们解析 JSON 数据,找到给定用户的<li>元素,并更新该用户的状态。
Django 不跟踪用户是否登录,所以我们需要创建一个简单的模型来完成这项工作。在example _ channels/example/models . py中创建一个与我们的User模型一对一连接的LoggedInUser模型:
from django.conf import settings
from django.db import models
class LoggedInUser(models.Model):
user = models.OneToOneField(
settings.AUTH_USER_MODEL, related_name='logged_in_user')
我们的 app 会在用户登录时创建一个LoggedInUser实例,用户注销时 app 会删除该实例。
进行模式迁移,然后迁移我们的数据库以应用更改。
(env)$ python manage.py makemigrations
(env)$ python manage.py migrate
接下来,在example _ channels/example/views . py中更新我们的用户列表视图,以检索要呈现的用户列表:
from django.contrib.auth import get_user_model, login, logout
from django.contrib.auth.decorators import login_required
from django.contrib.auth.forms import AuthenticationForm, UserCreationForm
from django.core.urlresolvers import reverse
from django.shortcuts import render, redirect
User = get_user_model()
@login_required(login_url='/log_in/')
def user_list(request):
"""
NOTE: This is fine for demonstration purposes, but this should be
refactored before we deploy this app to production.
Imagine how 100,000 users logging in and out of our app would affect
the performance of this code!
"""
users = User.objects.select_related('logged_in_user')
for user in users:
user.status = 'Online' if hasattr(user, 'logged_in_user') else 'Offline'
return render(request, 'example/user_list.html', {'users': users})
def log_in(request):
form = AuthenticationForm()
if request.method == 'POST':
form = AuthenticationForm(data=request.POST)
if form.is_valid():
login(request, form.get_user())
return redirect(reverse('example:user_list'))
else:
print(form.errors)
return render(request, 'example/log_in.html', {'form': form})
@login_required(login_url='/log_in/')
def log_out(request):
logout(request)
return redirect(reverse('example:log_in'))
def sign_up(request):
form = UserCreationForm()
if request.method == 'POST':
form = UserCreationForm(data=request.POST)
if form.is_valid():
form.save()
return redirect(reverse('example:log_in'))
else:
print(form.errors)
return render(request, 'example/sign_up.html', {'form': form})
如果用户有关联的LoggedInUser,那么我们记录用户的状态为“在线”,如果没有,则用户为“离线”。我们还在用户列表和注销视图中添加了一个@login_required装饰器,将访问权限仅限于注册用户。
也添加导入:
from django.contrib.auth import get_user_model, login, logout
from django.contrib.auth.decorators import login_required
此时,用户可以登录和退出,这将触发服务器向客户端发送消息,但我们没有办法知道用户第一次登录时有哪些用户登录。当另一个用户的状态改变时,该用户只能看到更新。这就是LoggedInUser发挥作用的地方,但是我们需要一种方法在用户登录时创建一个LoggedInUser实例,然后在用户注销时删除它。
Django 库包含一个被称为信号的特性,当某些动作发生时,它会广播通知。应用程序可以监听这些通知,然后根据它们采取行动。我们可以利用两个有用的内置信号(user_logged_in和user_logged_out)来处理我们的LoggedInUser行为。
在“示例 _ 通道/示例”中,添加一个名为 signals.py 的新文件:
from django.contrib.auth import user_logged_in, user_logged_out
from django.dispatch import receiver
from example.models import LoggedInUser
@receiver(user_logged_in)
def on_user_login(sender, **kwargs):
LoggedInUser.objects.get_or_create(user=kwargs.get('user'))
@receiver(user_logged_out)
def on_user_logout(sender, **kwargs):
LoggedInUser.objects.filter(user=kwargs.get('user')).delete()
我们必须在应用配置中提供信号,example _ channels/example/apps . py:
from django.apps import AppConfig
class ExampleConfig(AppConfig):
name = 'example'
def ready(self):
import example.signals
更新example _ channels/example/_ _ init _ _。py 也一样:
default_app_config = 'example.apps.ExampleConfig'
健全性检查
现在,我们已经完成了编码,并准备好连接到我们的多用户服务器来测试我们的应用程序。
运行 Django 服务器,以用户身份登录,访问主页。我们应该看到应用程序中所有用户的列表,每个用户的状态都是“离线”。接下来,打开一个新的匿名窗口,以不同的用户身份登录,观看两个屏幕。当我们登录时,常规浏览器会将用户状态更新为“在线”。从我们的匿名窗口,我们看到登录的用户也有一个“在线”的状态。我们可以通过不同用户在不同设备上登录和退出来测试 WebSockets。
观察客户机上的开发人员控制台和我们终端中的服务器活动,我们可以确认当用户登录时正在形成 WebSocket 连接,而当用户注销时则被破坏。
[2017/02/20 00:15:23] HTTP POST /log_in/ 302 [0.07, 127.0.0.1:55393]
[2017/02/20 00:15:23] HTTP GET / 200 [0.04, 127.0.0.1:55393]
[2017/02/20 00:15:23] WebSocket HANDSHAKING /users/ [127.0.0.1:55414]
[2017/02/20 00:15:23] WebSocket CONNECT /users/ [127.0.0.1:55414]
[2017/02/20 00:15:25] HTTP GET /log_out/ 302 [0.01, 127.0.0.1:55393]
[2017/02/20 00:15:26] HTTP GET /log_in/ 200 [0.02, 127.0.0.1:55393]
[2017/02/20 00:15:26] WebSocket DISCONNECT /users/ [127.0.0.1:55414]
注意:您也可以使用 ngrok 将本地服务器安全地暴露给互联网。这样做将允许您从各种设备(如手机或平板电脑)访问本地服务器。
结束语
我们在本教程中讨论了很多内容——Django 通道、WebSockets、用户认证、信号和一些前端开发。主要的收获是:Channels 扩展了传统 Django 应用程序的功能,允许我们通过 WebSockets 从服务器向用户组推送消息。
这是强大的东西!
想想其中的一些应用。我们可以创建聊天室、多人游戏和协作应用,让用户能够实时交流。即使是平凡的任务也可以通过 WebSockets 得到改善。例如,服务器可以在任务完成时向客户端推送状态更新,而不是定期轮询服务器来查看长时间运行的任务是否已经完成。
本教程也只是触及了 Django 通道的皮毛。浏览 Django Channels 文档,看看你还能创造什么。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
从django-example-channelsrepo 中获取最终代码。干杯!*****


 浙公网安备 33010602011771号
浙公网安备 33010602011771号