RealPython-中文系列教程-十一-
RealPython 中文系列教程(十一)
原文:RealPython
Python 中什么时候用省略号?
在英语写作中,你可以用省略号来表示你漏掉了什么。本质上,您使用三个点(...)来替换内容。但是省略号不仅仅存在于散文中——你可能也在 Python 源代码中看到过三个点。
省略号文字(...)计算为 Python 的 Ellipsis 。因为EllipsisT8 是一个内置的常量,你可以使用Ellipsis或者...而不用导入它:
>>> ... Ellipsis >>> Ellipsis Ellipsis >>> ... is Ellipsis True虽然三个点作为 Python 语法看起来很奇怪,但是在某些情况下使用
...会很方便。但是在 Python 中什么时候应该使用Ellipsis?源代码: 点击这里下载免费的源代码,你将使用它来掌握省略号文字。
简而言之:在 Python 中使用省略号作为占位符
虽然您可以互换使用
...和Ellipsis,但您通常会在代码中选择...。类似于在英语中使用三个点来省略内容,可以使用 Python 中的省略号作为未写代码的占位符:# ellipsis_example.py def do_nothing(): ... do_nothing()当您运行
ellipsis_example.py并执行do_nothing()时,Python 会毫无怨言地运行:$ python ellipsis_example.py $当您在 Python 中执行一个函数体中只包含
...的函数时,不会出现错误。这意味着您可以使用省略号作为占位符,类似于pass关键字。使用三个点创建最小的视觉混乱。所以,当你在线分享你的代码时,替换不相关的代码是很方便的。
省略代码的常见情况是使用存根的时候。您可以将存根视为实函数的替身。当您只需要一个函数签名但不想执行函数体中的代码时,存根就可以派上用场了。例如,在开发应用程序时,您可能希望阻止外部请求。
假设你有一个烧瓶项目,你在
custom_stats.count_visitor()创建了自己的访客计数器。count_visitor()功能连接到跟踪访问者数量的数据库。为了在调试模式下测试应用程序时不把自己算进去,可以创建一个count_visitor()的存根:1# app.py 2 3from flask import Flask 4 5from custom_stats import count_visitor 6 7app = Flask(__name__) 8 9if app.debug: 10 def count_visitor(): ... 11 12@app.route("/") 13def home(): 14 count_visitor() 15 return "Hello, world!"因为在这种情况下
count_visitor()的内容无关紧要,所以在函数体中使用省略号是个好主意。当您在调试模式下运行 Flask 应用程序时,Python 调用count_visitor()没有错误或不必要的副作用:$ flask --app app --debug run * Serving Flask app 'app' * Debug mode: on如果您在调试模式下运行 Flask 应用程序,那么第 14 行中的
count_visitor()引用第 10 行中的存根。在count_visitor()的函数体中使用...可以帮助你测试你的应用程序而不会有副作用。上面的例子显示了如何在较小的范围内使用存根。对于更大的项目,存根经常用在单元测试中,因为它们有助于以一种隔离的方式测试你的部分代码。
此外,如果您熟悉 Python 中的类型检查,那么关于省略号和存根的讨论可能会让您想起一些事情。
进行类型检查最常用的工具是 mypy 。为了确定标准库和第三方库定义的类型, mypy 使用存根文件:
存根文件是一个包含 Python 模块公共接口框架的文件,包括类、变量、函数——最重要的是它们的类型。(来源)
您可以访问 Python 的类型化存储库,并探索这个存储库包含的存根文件中
...的用法。当你深入到静态类型的主题时,你可能会发现Ellipsis常量的另一个用例。在下一节中,您将学习何时在类型提示中使用...。类型提示中的省略号是什么意思?
在上一节中,您了解了可以使用
Ellipsis作为存根文件的占位符,包括在类型检查时。但是你也可以在类型提示中使用...。在本节中,您将学习如何使用...来:
- 指定同质类型的可变长度元组
- 替换可调用函数的参数列表
类型提示是一种很好的方式,可以明确您在代码中期望的数据类型。但有时,您希望在不完全限制用户如何使用对象的情况下使用类型提示。例如,您可能希望指定一个只包含整数的元组,但是整数的数量可以是任意的。这时省略号就派上用场了:
1# tuple_example.py 2 3numbers: tuple[int, ...] 4 5# Allowed: 6numbers = () 7numbers = (1,) 8numbers = (4, 5, 6, 99) 9 10# Not allowed: 11numbers = (1, "a") 12numbers = [1, 3]在第 3 行,您定义了一个类型为元组的变量
numbers。numbers变量必须是只包含整数的元组。总量不重要。第 6、7 和 8 行中的变量定义是有效的,因为它们符合类型提示。不允许使用
numbers的其他定义:
- 第 11 行不包含同质项目。
- 第 12 行不是元组,是列表。
如果您安装了 mypy,那么您可以使用 mypy 运行代码来列出这两个错误:
$ mypy tuple_example.py tuple_example.py:11: error: Incompatible types in assignment (expression has type "Tuple[int, str]", variable has type "Tuple[int, ...]") tuple_example.py:12: error: Incompatible types in assignment (expression has type "List[int]", variable has type "Tuple[int, ...]")在 tuple 类型提示中使用
...意味着您希望 tuple 中的所有项都是相同的类型。另一方面,当您对可调用类型使用省略号文字时,您实际上解除了对如何调用可调用类型的一些限制,可能是在参数的数量或类型方面:
1from typing import Callable 2 3def add_one(i: int) -> int: 4 return i + 1 5 6def multiply_with(x: int, y: int) -> int: 7 return x * y 8 9def as_pixels(i: int) -> str: 10 return f"{i}px" 11 12def calculate(i: int, action: Callable[..., int], *args: int) -> int: 13 return action(i, *args) 14 15# Works: 16calculate(1, add_one) 17calculate(1, multiply_with, 3) 18 19# Doesn't work: 20calculate(1, 3) 21calculate(1, as_pixels)在第 12 行,您定义了一个可调用的参数,
action。这个可调用函数可以接受任意数量和类型的参数,但必须返回一个整数。有了*args: int,你还允许可变数量的可选参数,只要它们是整数。在第 13 行的calculate()函数体中,用整数i和任何其他传入的参数调用action。当你定义一个可调用类型时,你必须让 Python 知道你允许什么类型作为输入,以及你期望这个可调用类型返回什么类型。通过使用
Callable[..., int],您说您不介意这个可调用函数接受多少和哪些类型的参数。然而,您已经指定它必须返回一个整数。您在第 16 行和第 17 行中作为参数传递给
calculate()的函数符合您设置的规则。add_one()和multiply_with()都是返回整数的可调用函数。第 20 行的代码无效,因为
3是不可调用的。可调用函数必须是你可以调用的东西,因此得名。虽然
as_pixels()是可调用的,但是它在第 21 行的用法也是无效的。在第 10 行,你正在创建一个 f 弦。您得到一个字符串作为返回值,这不是您期望的整数类型。在上面的例子中,您已经研究了如何在元组和可调用的类型提示中使用省略号文字:
类型 Ellipsis用法tuple用统一类型定义未知长度的数据元组 Callable代表可调用的参数列表,移除限制 接下来,您将学习如何在 NumPy 中使用
Ellipsis。在 NumPy 中如何使用省略号进行切片?
如果你以前和 NumPy 一起工作过,那么你可能会遇到
Ellipsis的另一种用法。在 NumPy 中,您可以用省略号文本分割多维数组。从一个没有利用 NumPy 中的
Ellipsis的例子开始:
>>> import numpy as np
>>> dimensions = 3
>>> items_per_dimension = 2
>>> max_items = items_per_dimension**dimensions
>>> axes = np.repeat(items_per_dimension, dimensions)
>>> arr = np.arange(max_items).reshape(axes)
>>> arr
array([[[0, 1],
[2, 3]],
[[4, 5],
[6, 7]]])
在本例中,您将通过组合 NumPy 中的 .arange() 和 .reshape() 来创建一个三维数组。
如果您想指定最后一个维度的第一项,那么您可以借助冒号(:)用分割 NumPy 数组:
>>> arr[:, :, 0] array([[0, 2], [4, 6]])因为
arr有三个维度,所以需要指定三个切片。但是想象一下,如果你增加更多的维度,语法会变得多么烦人!更糟糕的是,你无法判断一个数组有多少个维度:
>>> import numpy as np
>>> dimensions = np.random.randint(1,10)
>>> items_per_dimension = 2
>>> max_items = items_per_dimension**dimensions
>>> axes = np.repeat(items_per_dimension, dimensions)
>>> arr = np.arange(max_items).reshape(axes)
在本例中,您正在创建一个最多可以有十个维度的数组。你可以使用 NumPy 的.ndim()T4 来找出arr有多少个维度。但是在这种情况下,使用...是更好的方法:
>>> arr[..., 0] array([[[[ 0, 2], [ 4, 6]], [[ 8, 10], [12, 14]]], [[[16, 18], [20, 22]], [[24, 26], [28, 30]]]])这里,
arr有五个维度。因为维度的数量是随机的,所以您的输出可能看起来不同。尽管如此,用...来指定你的多维数组还是可以的。NumPy 提供了更多的选项来使用
Ellipsis来指定一个元素或者数组的范围。查看 NumPy:Ellipsis(...) forndarray,发现这三个小点的更多用例。Python 中的三个点永远是省略号吗?
一旦你学习了 Python 的
Ellipsis,你可能会更加注意 Python 世界中每个省略号的出现。然而,你可能会在 Python 中看到三个点,不代表Ellipsis常量。在 Python 交互 shell 中,三个点表示二级提示:
>>> def hello_world():
... print("Hello, world!")
...
例如,当您在 Python 解释器中定义函数时,或者当您创建 for循环时,提示会持续多行。
在上面的例子中,这三个点不是省略号,而是函数体的二级提示。
在 Python 中,你还在其他地方发现过三个点吗?请在下面的评论中与真正的 Python 社区分享您的发现!
结论
省略号文字(...)计算为Ellipsis常量。最常见的是,你可以使用...作为占位符,例如当你创建函数的存根时。
在类型提示中,这三个点可以在你需要灵活性的时候派上用场。您可以指定一个同质类型的可变长度元组,并用省略号文本替换可调用类型的参数列表。
如果您使用 NumPy,那么您可以使用...通过用Ellipsis对象替换可变长度维度来简化切片语法。有了这三个点提供的整洁的语法,您可以使您的代码更具可读性。
根据经验,你可以记住你通常使用 Python 的Ellipsis来省略代码。有些人甚至会说省略号可以让不完整的代码看起来很可爱(T2)
源代码: 点击这里下载免费的源代码,你将使用它来掌握省略号文字。***
Python 中的 Unicode 和字符编码:轻松指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的 Unicode:使用字符编码
用 Python 或任何其他语言处理字符编码有时看起来很痛苦。像栈溢出这样的地方有成千上万的问题,这些问题源于对像UnicodeDecodeError和UnicodeEncodeError这样的异常的混淆。本教程旨在消除Exception的迷雾,说明在 Python 3 中处理文本和二进制数据是一种流畅的体验。Python 的 Unicode 支持很强大,但是需要一些时间来掌握。
本教程是不同的,因为它不是语言不可知的,而是有意以 Python 为中心的。你仍然会得到一本与语言无关的初级读本,但是你将会深入到 Python 中的插图中,将文本段落保持在最少。您将看到如何在实时 Python 代码中使用字符编码的概念。
本教程结束时,您将:
- 获取字符编码和编号系统的概念性概述
- 理解编码是如何与 Python 的
str和bytes一起发挥作用的 - 了解 Python 中通过各种形式的
int文字对编号系统的支持 - 熟悉 Python 中与字符编码和编号系统相关的内置函数
字符编码和编号系统是如此紧密地联系在一起,以至于它们需要在同一个教程中讨论,否则对其中任何一个的讨论都是不充分的。
注意:本文以 Python 3 为中心。具体来说,本教程中的所有代码示例都是从 CPython 3.7.2 shell 中生成的,尽管 Python 3 的所有次要版本在处理文本时应该(大部分)表现相同。
如果您仍在使用 Python 2,并且被 Python 2 和 Python 3 处理文本和二进制数据的不同所吓倒,那么希望本教程能帮助您做出改变。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
什么是字符编码?
即使没有数百种字符编码,也有数十种。开始理解它们是什么的最好方法是了解最简单的字符编码之一,ASCII。
无论您是自学还是有正式的计算机科学背景,您都有可能见过一两次 ASCII 表。ASCII 是开始学习字符编码的一个好地方,因为它是一种小型的封闭编码。(事实证明,太小了。)
它包括以下内容:
- 小写英文字母 : a 到 z
- 大写英文字母 : A 到 Z
- 一些标点符号 :
"$"和"!",举几个例子 - 空白字符:一个实际的空格(
" "),以及换行符、回车符、水平制表符、垂直制表符和其他一些字符 - 一些不可打印的字符:比如退格键、
"\b"这样的字符,它们不能像字母 A 那样逐字打印
那么字符编码更正式的定义是什么呢?
在很高的层次上,它是一种将字符(如字母、标点、符号、空白和控制字符)转换成整数并最终转换成位的方法。每个字符可以被编码成一个独特的位序列。如果您对位的概念不确定,也不要担心,因为我们很快就会谈到它们。
概述的各种类别代表字符组。每个单个字符都有一个对应的码位,你可以把它想象成只是一个整数。在 ASCII 表中,字符被分成不同的范围:
| 代码点范围 | 班级 |
|---|---|
| 0 到 31 | 控制/不可打印字符 |
| 32 岁到 64 岁 | 标点符号、符号、数字和空格 |
| 65 到 90 岁 | 大写英文字母 |
| 91 到 96 | 额外的字素,如[和\ |
| 97 到 122 | 小写英文字母 |
| 123 到 126 | 额外的字素,如{和| |
| One hundred and twenty-seven | 控制/不可打印字符(DEL) |
整个 ASCII 表包含 128 个字符。这个表捕获了 ASCII 允许的完整的字符集。如果您在这里看不到某个字符,那么在 ASCII 编码方案下,您根本无法将其表示为打印文本。
| 码点 | 人物(姓名) | 码点 | 人物(姓名) |
|---|---|---|---|
| Zero | null_ null) | Sixty-four | @ |
| one | SOH(标题开始) | Sixty-five | A |
| Two | STX(文本开始) | Sixty-six | B |
| three | ETX(文末) | Sixty-seven | C |
| four | 传输结束 | sixty-eight | D |
| five | ENQ(询问) | sixty-nine | E |
| six | ACK(确认) | Seventy | F |
| seven | 贝尔 | Seventy-one | G |
| eight | 退格键 | seventy-two | H |
| nine | HT(水平制表符) | Seventy-three | I |
| Ten | 换行 | Seventy-four | J |
| Eleven | 垂直标签 | Seventy-five | K |
| Twelve | 换页 | Seventy-six | L |
| Thirteen | 回车符 | Seventy-seven | M |
| Fourteen | 所以(移出) | seventy-eight | N |
| Fifteen | SI(移入) | Seventy-nine | O |
| Sixteen | DLE(数据链路转义) | Eighty | P |
| Seventeen | DC1(设备控制 1) | Eighty-one | Q |
| Eighteen | DC2(设备控制 2) | Eighty-two | R |
| Nineteen | DC3(设备控制 3) | Eighty-three | S |
| Twenty | DC4(设备控制 4) | Eighty-four | T |
| Twenty-one | 否定确认 | eighty-five | U |
| Twenty-two | 同步空闲 | Eighty-six | V |
| Twenty-three | ETB(传输块结束) | Eighty-seven | W |
| Twenty-four | 可以(取消) | Eighty-eight | X |
| Twenty-five | EM(媒体结束) | eighty-nine | Y |
| Twenty-six | SUB(替代) | Ninety | Z |
| Twenty-seven | ESC(退出) | Ninety-one | [ |
| Twenty-eight | 文件分隔符 | Ninety-two | \ |
| Twenty-nine | 组分隔符 | Ninety-three | ] |
| Thirty | 记录分隔符 | Ninety-four | ^ |
| Thirty-one | 美国(单位分隔符) | Ninety-five | _ |
| Thirty-two | 警司(空间) | Ninety-six | ```py |
| Thirty-three | ! |
Ninety-seven | a |
| Thirty-four | " |
Ninety-eight | b |
| Thirty-five | # |
Ninety-nine | c |
| Thirty-six | $ |
One hundred | d |
| Thirty-seven | % |
One hundred and one | e |
| Thirty-eight | & |
One hundred and two | f |
| Thirty-nine | ' |
One hundred and three | g |
| Forty | ( |
One hundred and four | h |
| Forty-one | ) |
One hundred and five | i |
| forty-two | * |
One hundred and six | j |
| Forty-three | + |
One hundred and seven | k |
| forty-four | , |
One hundred and eight | l |
| Forty-five | - |
One hundred and nine | m |
| Forty-six | . |
One hundred and ten | n |
| Forty-seven | / |
One hundred and eleven | o |
| Forty-eight | 0 |
One hundred and twelve | p |
| forty-nine | 1 |
One hundred and thirteen | q |
| Fifty | 2 |
One hundred and fourteen | r |
| Fifty-one | 3 |
One hundred and fifteen | s |
| fifty-two | 4 |
One hundred and sixteen | t |
| Fifty-three | 5 |
One hundred and seventeen | u |
| Fifty-four | 6 |
One hundred and eighteen | v |
| Fifty-five | 7 |
One hundred and nineteen | w |
| fifty-six | 8 |
One hundred and twenty | x |
| Fifty-seven | 9 |
One hundred and twenty-one | y |
| Fifty-eight | : |
One hundred and twenty-two | z |
| Fifty-nine | ; |
One hundred and twenty-three | { |
| Sixty | < |
One hundred and twenty-four | | |
| Sixty-one | = |
One hundred and twenty-five | } |
| Sixty-two | > |
One hundred and twenty-six | ~ |
| Sixty-three | ? |
One hundred and twenty-seven | 删除 |
string模块
Python 的string模块是 ASCII 字符集中的字符串常量的便捷一站式商店。
以下是该模块的核心部分:
# From lib/python3.7/string.py
whitespace = ' \t\n\r\v\f'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
digits = '0123456789'
hexdigits = digits + 'abcdef' + 'ABCDEF'
octdigits = '01234567'
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""
printable = digits + ascii_letters + punctuation + whitespace
```py
这些常量中的大多数应该在它们的标识符名称中是自文档化的。我们将很快介绍什么是`hexdigits`和`octdigits`。
您可以在日常字符串操作中使用这些常量:
>>>
import string
s = "What's wrong with ASCII?!?!?"
s.rstrip(string.punctuation)
'What's wrong with ASCII'
**注** : `string.printable`包括所有的`string.whitespace`。这与另一种测试字符是否可打印的方法略有不同,即`str.isprintable()`,它会告诉你`{'\v', '\n', '\r', '\f', '\t'}`都不可打印。
细微的差别是因为定义:`str.isprintable()`认为一些东西是可打印的,如果“它的所有字符在`repr()`中都被认为是可打印的。”
### 稍微复习一下
现在是对第**位**进行简短复习的好时机,这是计算机知道的最基本的信息单位。
一个比特是一个只有两种可能状态的信号。象征性地表示一个比特有不同的方式,都表示同一件事:
* 0 或 1
* “是”还是“不是”
* `True`或`False`
* “开”或“关”
上一节中的 ASCII 表使用了我们称之为[的数字](https://realpython.com/python-numbers/) (0 到 127),但更准确的说法是十进制数字。
您也可以用一系列位(以 2 为基数)来表示这些以 10 为基数的数字。以下是十进制中 0 到 10 的二进制版本:
| 小数 | 二进制(紧凑) | 二进制(填充形式) |
| --- | --- | --- |
| Zero | Zero | 00000000 |
| one | one | 00000001 |
| Two | Ten | 00000010 |
| three | Eleven | 00000011 |
| four | One hundred | 00000100 |
| five | One hundred and one | 00000101 |
| six | One hundred and ten | 00000110 |
| seven | One hundred and eleven | 00000111 |
| eight | One thousand | 00001000 |
| nine | One thousand and one | 00001001 |
| Ten | One thousand and ten | 00001010 |
请注意,随着十进制数 *n* 的增加,您需要更多的 [**有效位**](https://chortle.ccsu.edu/AssemblyTutorial/Chapter-14/ass14_4.html) 来表示一直到并包括该数的字符集。
这里有一种在 Python 中将 ASCII 字符串表示为位序列的简便方法。ASCII 字符串中的每个字符都被伪编码为 8 位,8 位序列之间有空格,每个空格代表一个字符:
>>>
def make_bitseq(s: str) -> str:
... if not s.isascii():
... raise ValueError("ASCII only allowed")
... return " ".join(f"{ord(i):08b}" for i in s)
make_bitseq("bits")
'01100010 01101001 01110100 01110011'
make_bitseq("CAPS")
'01000011 01000001 01010000 01010011'
make_bitseq("$25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
make_bitseq("~5")
'01111110 00110101'
**注意** : `.isascii()`是在 Python 3.7 中引入的。
[f 字符串](https://realpython.com/python-f-strings/) `f"{ord(i):08b}"`使用 Python 的[格式规范迷你语言](https://docs.python.org/3/library/string.html#formatspec),这是一种为格式字符串中的替换字段指定格式的方式:
* 冒号左边的`ord(i)`是实际的对象,其值将被格式化并插入到输出中。使用 Python `ord()`函数可以为单个`str`字符提供以 10 为基数的码位。
* 冒号的右边是格式说明符。`08`表示*宽度 8,0 填充*,`b`作为符号输出以 2 为基数的结果数(二进制)。
这个技巧主要是为了好玩,对于任何你在 ASCII 表中看不到的字符,它都会非常失败。稍后我们将讨论其他编码如何解决这个问题。
[*Remove ads*](/account/join/)
### 我们需要更多的钻头!
有一个至关重要的公式与 bit 的定义有关。给定比特数 *n* ,可以用 *n* 比特表示的不同可能值的数量是*2<sup>n</sup>T7:*
def n_possible_values(nbits: int) -> int:
return 2 ** nbits
这意味着:
* 1 bit 会让你表达 *2 <sup>1</sup> == 2* 可能的值。
* 8 位将让你表达 *2 <sup>8</sup> == 256* 可能的值。
* 64 位会让你表达*2<sup>64</sup>= = 18446744073709551616*个可能值。
这个公式有一个推论:给定一个不同的可能值的范围,我们如何找到这个范围被完全表示所需的位数, *n* ?你要解的是方程 *2 <sup>n</sup> = x* 中的 *n* (这里你已经知道 *x* )。
结果是这样的:
>>>
from math import ceil, log
def n_bits_required(nvalues: int) -> int:
... return ceil(log(nvalues) / log(2))
n_bits_required(256)
8
您需要在`n_bits_required()`中使用上限的原因是考虑到不是 2 的纯幂的值。假设您需要存储总共 110 个字符的字符集。天真的说,这个应该取`log(110) / log(2) == 6.781`位,但是没有 0.781 位这种东西。110 个值将需要 7 位,而不是 6 位,最后的槽是不需要的:
>>>
n_bits_required(110)
7
所有这些都证明了一个概念:严格来说,ASCII 是一种 7 位代码。您在上面看到的 ASCII 表包含 128 个代码点和字符,从 0 到 127,包括 0 和 127。这需要 7 位:
>>>
n_bits_required(128) # 0 through 127
7
n_possible_values(7)
128
这个问题是,现代计算机在 7 位插槽中存储的东西不多。它们以 8 位为单位进行通信,通常称为一个**字节**。
注意:在整个教程中,我假设一个字节指的是 8 位,从 20 世纪 60 年代开始就是这样,而不是其他存储单位。如果你愿意,你可以称之为 [*八位字节*](https://en.wikipedia.org/wiki/Octet_(computing)) 。
这意味着 ASCII 使用的存储空间有一半是空的。如果不清楚这是为什么,回想一下上面的十进制到二进制表。你*可以*只用 1 位表示数字 0 和 1,也可以用 8 位分别表示为 00000000 和 00000001。
你*可以*只用 2 位表示数字 0 到 3,或者 00 到 11,或者你可以用 8 位分别表示为 00000000,00000001,00000010,0000011。最高的 ASCII 码位 127 只需要 7 个有效位。
了解了这一点,您可以看到`make_bitseq()`将 ASCII 字符串转换成字节的`str`表示,其中每个字符消耗一个字节:
>>>
make_bitseq("bits")
'01100010 01101001 01110100 01110011'
ASCII 没有充分利用现代计算机提供的 8 位字节,导致了一系列相互冲突的非正式编码,每个编码都指定了附加字符,用于 8 位字符编码方案中允许的剩余 128 个可用码位。
这些不同的编码不仅相互冲突,而且每一种编码本身仍然是世界字符的一个非常不完整的表示,尽管它们使用了一个额外的位。
多年来,一个字符编码的大计划开始统治他们。然而,在我们到达那里之前,让我们花一点时间谈谈编号系统,它是字符编码方案的基础。
[*Remove ads*](/account/join/)
## 涵盖所有基数:其他数系
在上面关于 ASCII 的讨论中,您看到了每个字符都映射到 0 到 127 范围内的一个整数。
这个数字范围用十进制表示(基数为 10)。这是你、我和我们人类习惯的数数方式,没有比我们有 10 个手指更复杂的原因。
但是在整个 [CPython 源代码](https://realpython.com/cpython-source-code-guide/)中,还有其他特别流行的编号系统。虽然“基本数字”是相同的,但所有的编号系统只是表示相同数字的不同方式。
如果我问你字符串`"11"`代表什么数字,你会奇怪地看我一眼,然后回答它代表 11。
但是,这种字符串表示可以在不同的编号系统中表示不同的基础数字。除了十进制之外,还有以下几种常用的计数系统:
* **二进制**:基数 2
* **八进制**:基数 8
* **Hexadecimal (hex)** : base 16
但是如果我们说,在一个特定的计数系统中,数字是用基数 *N* 来表示的,这又意味着什么呢?
这是我所知道的最好的方式来表达这个意思:它是你在那个系统中可以指望的手指的数量。
如果你想要一个更全面但仍然温和的编号系统介绍,查尔斯·佩佐德的 [*代码*](https://realpython.com/asins/073560505X/) 是一本非常酷的书,详细探讨了计算机代码的基础。
演示不同的编号系统如何解释同一事物的一种方法是使用 Python 的`int()`构造函数。如果您[将一个`str`传递给`int()`](https://realpython.com/convert-python-string-to-int/) ,Python 将默认假定该字符串表示一个基数为 10 的数字,除非您另外告诉它:
>>>
int('11')
11
int('11', base=10) # 10 is already default
11
int('11', base=2) # Binary
3
int('11', base=8) # Octal
9
int('11', base=16) # Hex
17
有一种更常见的方法告诉 Python 你的整数是以 10 以外的基数输入的。Python 接受上述三种可选编号系统中每一种的**文字**形式:
| 文字类型 | 前缀 | 例子 |
| --- | --- | --- |
| 不适用的 | 不适用的 | `11` |
| 二进制文字 | `0b`或`0B` | `0b11` |
| 八进制文字 | `0o`或`0O` | `0o11` |
| 十六进制文字 | `0x`或`0X` | `0x11` |
所有这些都是**整数文字**的子形式。您可以看到,这两个函数分别产生了与使用非默认的`base`值调用`int()`相同的结果。它们都只是`int`地巨蟒:
>>>
11
11
0b11 # Binary literal
3
0o11 # Octal literal
9
0x11 # Hex literal
17
以下是如何输入十进制数字 0 到 20 的二进制、八进制和十六进制的等价形式。所有这些在 Python 解释器外壳或源代码中都是完全有效的,并且都属于类型`int`:
| 小数 | 二进制的 | 八进制的 | 十六进制 |
| --- | --- | --- | --- |
| `0` | `0b0` | `0o0` | `0x0` |
| `1` | `0b1` | `0o1` | `0x1` |
| `2` | `0b10` | `0o2` | `0x2` |
| `3` | `0b11` | `0o3` | `0x3` |
| `4` | `0b100` | `0o4` | `0x4` |
| `5` | `0b101` | `0o5` | `0x5` |
| `6` | `0b110` | `0o6` | `0x6` |
| `7` | `0b111` | `0o7` | `0x7` |
| `8` | `0b1000` | `0o10` | `0x8` |
| `9` | `0b1001` | `0o11` | `0x9` |
| `10` | `0b1010` | `0o12` | `0xa` |
| `11` | `0b1011` | `0o13` | `0xb` |
| `12` | `0b1100` | `0o14` | `0xc` |
| `13` | `0b1101` | `0o15` | `0xd` |
| `14` | `0b1110` | `0o16` | `0xe` |
| `15` | `0b1111` | `0o17` | `0xf` |
| `16` | `0b10000` | `0o20` | `0x10` |
| `17` | `0b10001` | `0o21` | `0x11` |
| `18` | `0b10010` | `0o22` | `0x12` |
| `19` | `0b10011` | `0o23` | `0x13` |
| `20` | `0b10100` | `0o24` | `0x14` |
令人惊讶的是,这些表达式在 Python 标准库中如此普遍。如果您想亲自查看,请导航到您的`lib/python3.7/`目录所在的位置,并查看十六进制文字的用法,如下所示:
$ grep -nri --include "*.py" -e "\b0x" lib/python3.7
这应该可以在任何安装了`grep`的 Unix 系统上运行。您可以使用`"\b0o"`来搜索八进制文本,或者使用“\b0b”来搜索二进制文本。
使用这些替代的`int`字面语法的理由是什么?简而言之,是因为 2、8、16 都是 2 的幂,而 10 不是。这三种交替的数字系统偶尔提供了一种以计算机友好的方式表达数值的方法。例如,数字 65536 或*2<sup>16</sup>T5,只是十六进制的 10000,或作为 Python 十六进制文字的`0x10000`。*
[*Remove ads*](/account/join/)
## 输入 Unicode
正如您所看到的,ASCII 的问题是它不是一个足够大的字符集来容纳世界上的语言、方言、符号和字形。(光是英语[都不够大](https://en.wikipedia.org/wiki/English_terms_with_diacritical_marks)。)
Unicode 基本上与 ASCII 服务于相同的目的,但是它只是包含了一个更大的代码点集合。有一些编码是按时间顺序出现在 ASCII 和 Unicode 之间的,但它们现在还不值得一提,因为 Unicode 和它的编码方案之一 UTF-8 已经被广泛使用。
可以把 Unicode 想象成一个庞大的 ASCII 表——它有 1,114,112 个可能的代码点。也就是 0 到 1,114,111,或者 0 到 *17 * (2 <sup>16</sup> ) - 1* ,或者`0x10ffff`十六进制。事实上,ASCII 是 Unicode 的完美子集。Unicode 表中的前 128 个字符与您合理预期的 ASCII 字符完全对应。
为了技术上的精确起见, **Unicode 本身是*而不是*编码**。相反,Unicode 是由不同的字符编码实现的,您很快就会看到。Unicode 最好被认为是一个映射(类似于`dict`)或一个两列数据库表。它将字符(如`"a"`、`"¢"`,甚至`"ቈ"`)映射到不同的正整数。字符编码需要提供更多的功能。
Unicode 包含了几乎所有你能想到的字符,还包括其他不可打印的字符。我最喜欢的一个是讨厌的从右到左标记,它的代码点是 8207,用于从左到右和从右到左语言脚本的文本中,例如同时包含英语和阿拉伯语段落的文章。
**注意:**字符编码的世界是一些人喜欢挑剔的许多精细技术细节之一。一个这样的细节是,由于[一些古老的原因](https://www.quora.com/How-do-you-determine-how-many-characters-Unicode-can-store),只有 1111998 个 Unicode 码点实际上是可用的。
### Unicode vs UTF-8
没过多久,人们就意识到,世界上所有的字符都不能装进一个字节。很明显,现代的、更全面的编码需要使用多个字节来编码一些字符。
您在上面也看到了,从技术上讲,Unicode 不是一种成熟的字符编码。这是为什么呢?
Unicode 没有告诉您一件事:它没有告诉您如何从文本中获取实际的位—只是代码点。它没有告诉您如何将文本转换为二进制数据,反之亦然。
Unicode 是一种抽象编码标准,而不是编码。这就是 UTF 8 和其他编码方案发挥作用的地方。Unicode 标准(字符到代码点的映射)从其单个字符集定义了几种不同的编码。
UTF-8 及其较少使用的同类产品 UTF-16 和 UTF-32 是将 Unicode 字符表示为每个字符一个或多个字节的二进制数据的编码格式。我们一会儿将讨论 UTF-16 和 UTF-32,但是 UTF-8 已经获得了最大的份额。
这给我们带来了一个期待已久的定义。从形式上来说,**编码**和**解码**是什么意思?
### Python 3 中的编码和解码
Python 3 的`str`类型表示人类可读的文本,可以包含任何 Unicode 字符。
相反,`bytes`类型表示二进制数据或原始字节序列,它们本身没有附加编码。
编码和解码是从一个到另一个的过程:
[](https://files.realpython.com/media/encode-decode.3e665ad9b455.png)
<figcaption class="figure-caption text-center">Encoding vs decoding (Image: Real Python)</figcaption>
在`.encode()`和`.decode()`中,`encoding`参数默认为`"utf-8"`,尽管指定它通常更安全、更明确:
>>>
"résumé".encode("utf-8")
b'r\xc3\xa9sum\xc3\xa9'
"El Niño".encode("utf-8")
b'El Ni\xc3\xb1o'
b"r\xc3\xa9sum\xc3\xa9".decode("utf-8")
'résumé'
b"El Ni\xc3\xb1o".decode("utf-8")
'El Niño'
`str.encode()`的结果是一个 [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes-objects) 的对象。字节文字(如`b"r\xc3\xa9sum\xc3\xa9"`)和字节的表示都只允许 ASCII 字符。
这也是为什么在调用`"El Niño".encode("utf-8")`时,ASCII 兼容的`"El"`被允许原样表示,但是带颚化符的 *n* 被转义为`"\xc3\xb1"`。这个看起来杂乱的序列代表两个字节,十六进制的`0xc3`和`0xb1`:
>>>
" ".join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'
也就是说,[字符`ñ`](https://unicode-table.com/en/00F1/) 在 UTF-8 下的二进制表示需要两个字节。
**注意**:如果你输入`help(str.encode)`,你可能会看到默认的`encoding='utf-8'`。在排除这一点而只使用`"résumé".encode()`时要小心,因为在 Python 3.6 之前的 Windows 中,默认的[可能与](https://docs.python.org/3/whatsnew/3.6.html#pep-528-change-windows-console-encoding-to-utf-8)不同。
[*Remove ads*](/account/join/)
### Python 3:全在 Unicode 上
Python 3 完全支持 Unicode,尤其是 UTF 8。这意味着:
* 默认情况下,Python 3 源代码被认为是 UTF 8。这意味着在 Python 3 中不需要在`.py`文件的顶部放置`# -*- coding: UTF-8 -*-`。
* 默认情况下,所有文本(`str`)都是 Unicode。编码的 Unicode 文本表示为二进制数据(`bytes`)。`str`类型可以包含任何文本 Unicode 字符,比如`"Δv / Δt"`,所有这些字符都将被存储为 Unicode。
* [Python 3 在标识符](https://docs.python.org/3/reference/lexical_analysis.html#identifiers)中接受许多 Unicode 码位,这意味着如果您喜欢的话`résumé = "~/Documents/resume.pdf"`是有效的。
* Python 的 [`re`模块](https://docs.python.org/3/library/re.html)默认为`re.UNICODE`标志而不是`re.ASCII`。例如,这意味着`r"\w"`匹配 Unicode 单词字符,而不仅仅是 ASCII 字母。
* `str.encode()`和`bytes.decode()`中默认的`encoding`是 UTF-8。
还有一个更微妙的属性,即内置`open()`的默认`encoding`是平台相关的,并且取决于`locale.getpreferredencoding()`的值:
>>>
Mac OS X High Sierra
import locale
locale.getpreferredencoding()
'UTF-8'
Windows Server 2012; other Windows builds may use UTF-16
import locale
locale.getpreferredencoding()
'cp1252'
同样,这里的教训是,当谈到 UTF-8 的普遍性时,要小心做出假设,即使它是主要的编码。在你的代码中明确一点没有坏处。
### 一个字节,两个字节,三个字节,四个
一个至关重要的特点是,UTF-8 是一种**可变长度编码**。掩盖这意味着什么很有诱惑力,但值得深入研究。
回想一下关于 ASCII 的部分。扩展 ASCII 域中的所有内容最多需要一个字节的空间。你可以用下面的[生成器表达式](https://realpython.com/introduction-to-python-generators/)快速证明这一点:
>>>
all(len(chr(i).encode("ascii")) == 1 for i in range(128))
True
UTF 8 号完全不同。给定的 Unicode 字符可以占用一到四个字节。下面是一个占用四个字节的单个 Unicode 字符的示例:
>>>
ibrow = "🤨"
len(ibrow)
1
ibrow.encode("utf-8")
b'\xf0\x9f\xa4\xa8'
len(ibrow.encode("utf-8"))
4
Calling list() on a bytes object gives you
the decimal value for each byte
list(b'\xf0\x9f\xa4\xa8')
[240, 159, 164, 168]
这是`len()`的一个微妙但重要的特性:
* 作为 Python 的单个 Unicode 字符的长度`str`将*总是*为 1,不管它占用多少字节。
* 编码到`bytes`的相同字符的长度将在 1 和 4 之间。
下表总结了适合每个字节长度存储桶的一般字符类型:
| 小数范围 | 十六进制范围 | 包括什么 | 例子 |
| --- | --- | --- | --- |
| 0 到 127 | `"\u0000"`至`"\u007F"` | 美国 ASCII | `"A"`、`"\n"`、`"7"`、`"&"` |
| 128 年至 2047 年 | `"\u0080"`至`"\u07FF"` | 大多数拉丁字母* | `"ę"`、`"±"`、`"ƌ"`、`"ñ"` |
| 2048 转 65535 | `"\u0800"`至`"\uFFFF"` | 多语言平面的附加部分(BMP)** | `"ത"`、`"ᄇ"`、`"ᮈ"`、`"‰"` |
| 65536 转 1114111 | `"\U00010000"`至`"\U0010FFFF"` | 其他*** | `"𝕂"`,`"𐀀"`,`"😓"`,`"🂲"`, |
<sub>*如英语、阿拉伯语、希腊语和爱尔兰语</sub>
<sub>* *大量的语言和符号—按容量计主要是中文、日文和韩文(还有 ASCII 和拉丁字母)</sub>
<sub>* * *附加的中文、日文、韩文和越南语字符,以及更多的符号和表情符号</sub>
**注意**:为了不忽略大局,UTF-8 还有一组额外的技术特性没有在这里介绍,因为 Python 用户很少能看到它们。
例如,UTF-8 实际上使用前缀码来表示序列中的字节数。这使得解码器能够判断哪些字节属于可变长度编码,并让第一个字节作为即将到来的序列中字节数的指示符。
维基百科的 [UTF-8](https://en.wikipedia.org/wiki/UTF-8) 文章没有回避技术细节,而且总有官方的 [Unicode 标准](http://www.unicode.org/versions/latest/)供你阅读享受。
### UTF-16 和 UTF-32 呢?
让我们回到另外两种编码变体,UTF-16 和 UTF-32。
这些与 UTF-8 之间的区别在实践中是实质性的。以下示例说明了往返转换的差异有多大:
>>>
letters = "αβγδ"
rawdata = letters.encode("utf-8")
rawdata.decode("utf-8")
'αβγδ'
rawdata.decode("utf-16") # 😧
'뇎닎돎듎'
在这种情况下,用 UTF-8 编码四个希腊字母,然后解码回 UTF-16 的文本,会产生一个完全不同语言(朝鲜语)的文本`str`。
当不双向使用相同的编码时,像这样明显错误的结果是可能的。解码同一个`bytes`对象的两种变体可能产生甚至不是同一种语言的结果。
下表总结了 UTF-8、UTF-16 和 UTF-32 下的字节范围或数量:
| 编码 | 每个字符的字节数(含) | 可变长度 |
| --- | --- | --- |
| UTF-8 | 1 到 4 | 是 |
| UTF-16 | 2 比 4 | 是 |
| UTF-32 | four | 不 |
UTF 家族另一个奇怪的方面是,UTF-8 不会总是比 UTF-16 占用更少的空间。这似乎在数学上违反直觉,但很有可能:
>>>
text = "記者 鄭啟源 羅智堅"
len(text.encode("utf-8"))
26
len(text.encode("utf-16"))
22
原因是范围`U+0800`到`U+FFFF`(十进制的 2048 到 65535)中的代码点在 UTF-8 中占用了三个字节,而在 UTF-16 中只有两个字节。
我绝不建议您加入 UTF-16 行列,不管您使用的语言中的字符是否在这个范围内。除了其他原因,使用 UTF-8 的一个强有力的理由是,在编码的世界里,融入人群是一个好主意。
更不用说,现在是 2019 年:计算机内存很便宜,所以特意使用 UTF-16 来节省 4 个字节可以说是不值得的。
[*Remove ads*](/account/join/)
## Python 的内置函数
你已经熬过了最艰难的部分。是时候使用到目前为止在 Python 中看到的内容了。
Python 有一组内置函数,这些函数以某种方式与编号系统和字符编码相关:
* [T2`ascii()`](https://docs.python.org/3/library/functions.html#ascii)
* [T2`bin()`](https://docs.python.org/3/library/functions.html#bin)
* [T2`bytes()`](https://docs.python.org/3/library/functions.html#bytes)
* [T2`chr()`](https://docs.python.org/3/library/functions.html#chr)
* [T2`hex()`](https://docs.python.org/3/library/functions.html#hex)
* [T2`int()`](https://docs.python.org/3/library/functions.html#int)
* [T2`oct()`](https://docs.python.org/3/library/functions.html#oct)
* [T2`ord()`](https://docs.python.org/3/library/functions.html#ord)
* [T2`str()`](https://docs.python.org/3/library/functions.html#str)
这些可以根据其用途进行逻辑分组:
* **`ascii()`、`bin()`、`hex()`和`oct()`** 用于获得输入的不同表示。每一个都产生一个`str`。第一个是`ascii()`,产生一个对象的纯 ASCII 表示,非 ASCII 字符被转义。其余三个分别给出整数的二进制、十六进制和八进制表示。这些只是*表示*,并不是输入的根本变化。
* **`bytes()`、`str()`、`int()`、**是各自类型的类构造函数`bytes`、`str`、`int`。它们都提供了将输入强制转换成所需类型的方法。例如,正如您之前看到的,虽然`int(11.0)`可能更常见,但您也可能会看到`int('11', base=16)`。
* **`ord()`和`chr()`** 是彼此相反的,因为 Python `ord()`函数将一个`str`字符转换为其基数为 10 的码位,而`chr()`则相反。
以下是对这九项功能的详细介绍:
| 功能 | 签名 | 接受 | 返回类型 | 目的 |
| --- | --- | --- | --- | --- |
| `ascii()` | `ascii(obj)` | 变化 | `str` | 对象的纯 ASCII 表示,非 ASCII 字符被转义 |
| `bin()` | `bin(number)` | `number: int` | `str` | 整数的二进制表示,带有前缀`"0b"` |
| `bytes()` | `bytes(iterable_of_ints)`
`bytes(s, enc[, errors])`
`bytes(bytes_or_buffer)`
| 变化 | `bytes` | 将输入强制(转换)为`bytes`,原始二进制数据 |
| `chr()` | `chr(i)` | `i: int`
`i>=0`
`i<=1114111` | `str` | 将整数码位转换为单个 Unicode 字符 |
| `hex()` | `hex(number)` | `number: int` | `str` | 整数的十六进制表示,带有前缀`"0x"` |
| `int()` | `int([x])`
T1】 | 变化 | `int` | 强制(转换)输入到`int` |
| `oct()` | `oct(number)` | `number: int` | `str` | 一个整数的八进制表示,带有前缀`"0o"` |
| `ord()` | `ord(c)` | `c: str`
T1】 | `int` | 将单个 Unicode 字符转换为它的整数码位 |
| `str()` | `str(object=’‘)`
T1】 | 变化 | `str` | 将输入强制(转换)为`str`,文本 |
您可以展开下面的部分,查看每个功能的一些示例。
`ascii()`给出一个对象的纯 ASCII 表示,非 ASCII 字符被转义:
>>>
ascii("abcdefg")
"'abcdefg'"
ascii("jalepeño")
"'jalepe\xf1o'"
ascii((1, 2, 3))
'(1, 2, 3)'
ascii(0xc0ffee) # Hex literal (int)
'12648430'
`bin()`给出一个整数的二进制表示,前缀为`"0b"`:
>>>
bin(0)
'0b0'
bin(400)
'0b110010000'
bin(0xc0ffee) # Hex literal (int)
'0b110000001111111111101110'
[bin(i) for i in [1, 2, 4, 8, 16]] #
int+ list comprehension
['0b1', '0b10', '0b100', '0b1000', '0b10000']
`bytes()`强制输入到`bytes`,代表原始二进制数据:
>>>
Iterable of ints
bytes((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world'
bytes(range(97, 123)) # Iterable of ints
b'abcdefghijklmnopqrstuvwxyz'
bytes("real 🐍", "utf-8") # String + encoding
b'real \xf0\x9f\x90\x8d'
bytes(10)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
bytes.fromhex('c0 ff ee')
b'\xc0\xff\xee'
bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'
`chr()`将整数码位转换为单个 Unicode 字符:
>>>
chr(97)
'a'
chr(7048)
'ᮈ'
chr(1114111)
'\U0010ffff'
chr(0x10FFFF) # Hex literal (int)
'\U0010ffff'
chr(0b01100100) # Binary literal (int)
'd'
`hex()`给出一个整数的十六进制表示,前缀为`"0x"`:
>>>
hex(100)
'0x64'
[hex(i) for i in [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
[hex(i) for i in range(16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']
`int()`强制输入到`int`,可选地在给定的基础上解释输入:
>>>
int(11.0)
11
int('11')
11
int('11', base=2)
3
int('11', base=8)
9
int('11', base=16)
17
int(0xc0ffee - 1.0)
12648429
int.from_bytes(b"\x0f", "little")
15
int.from_bytes(b'\xc0\xff\xee', "big")
12648430
Python `ord()`函数将单个 Unicode 字符转换为它的整数码位:
>>>
ord("a")
97
ord("ę")
281
ord("ᮈ")
7048
[ord(i) for i in "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
`str()`强制输入到`str`,表示文本:
>>>
str("str of string")
'str of string'
str(5)
'5'
str([1, 2, 3, 4]) # Like [1, 2, 3, 4].str(), but use str()
'[1, 2, 3, 4]'
str(b"\xc2\xbc cup of flour", "utf-8")
'¼ cup of flour'
str(0xc0ffee)
'12648430'
## Python 字符串文字:剥猫皮的方法
通常不使用`str()`构造函数,而是直接键入`str`:
>>>
meal = "shrimp and grits"
这似乎很容易。但是有趣的一面是,因为 Python 3 完全是以 Unicode 为中心的,所以您可以“输入”Unicode 字符,而您可能在键盘上找不到这些字符。您可以将其复制并粘贴到 Python 3 解释器 shell 中:
>>>
alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ'
print(alphabet)
αβγδεζηθικλμνξοπρςστυφχψ
除了在控制台中放置实际的、非转义的 Unicode 字符之外,还有其他方法来键入 Unicode 字符串。
Python 文档中最密集的部分之一是关于词法分析的部分,特别是关于[字符串和字节文字](https://docs.python.org/3/reference/lexical_analysis.html#string-and-bytes-literals)的部分。就我个人而言,我不得不把这一部分读一遍、两遍或者九遍,才能真正理解。
它说的一部分是,Python 允许你以多达六种方式输入同一个 Unicode 字符。
第一种也是最常见的方法是逐字键入字符本身,正如您已经看到的那样。这种方法的难点在于找到实际的击键。这就是获取和表示字符的其他方法发挥作用的地方。以下是完整列表:
| 换码顺序 | 意义 | 如何表达`"a"` |
| --- | --- | --- |
| `"\ooo"` | 具有八进制值的字符`ooo` | `"\141"` |
| `"\xhh"` | 带十六进制值的字符`hh` | `"\x61"` |
| `"\N{name}"` | Unicode 数据库中名为`name`的字符 | `"\N{LATIN SMALL LETTER A}"` |
| `"\uxxxx"` | 具有 16 位(2 字节)十六进制值的字符`xxxx` | `"\u0061"` |
| `"\Uxxxxxxxx"` | 具有 32 位(4 字节)十六进制值的字符`xxxxxxxx` | `"\U00000061"` |
以下是对上述内容的一些证明和验证:
>>>
(
... "a" ==
... "\x61" ==
... "\N{LATIN SMALL LETTER A}" ==
... "\u0061" ==
... "\U00000061"
... )
True
现在,有两个主要的警告:
1. 并非所有这些形式都适用于所有角色。整数 300 的十六进制表示是`0x012c`,它根本不适合 2 个十六进制数字的转义码`"\xhh"`。你能挤进这个转义序列的最高代码点是`"\xff"` ( `"ÿ"`)。对于`"\ooo"`也是一样,它只会工作到`"\777"` ( `"ǿ"`)。
2. 对于`\xhh`、`\uxxxx`和`\Uxxxxxxxx`,需要的位数与这些示例中所示的一样多。这可能会让您陷入一个循环,因为 Unicode 表通常显示字符的代码,带有前导的`U+`和可变数量的十六进制字符。关键是 Unicode 表通常不会用零填充这些代码。
例如,如果你咨询 unicode-table.com[的哥特字母 faihu(或 fehu)`"𐍆"`的信息,你会看到它被列为代码`U+10346`。](https://unicode-table.com/en/10336)
这个怎么放入`"\uxxxx"`或者`"\Uxxxxxxxx"`?嗯,你不能把它放在`"\uxxxx"`中,因为它是一个 4 字节的字符,要用`"\Uxxxxxxxx"`来表示这个字符,你需要在序列的左边填充:
>>>
"\U00010346"
'𐍆'
这也意味着`"\Uxxxxxxxx"`形式是唯一能够保存*任何* Unicode 字符的转义序列。
**注意**:这里有一个简短的函数,将看起来像`"U+10346"`的字符串转换成 Python 可以处理的东西。它使用`str.zfill()`:
>>>
def make_uchr(code: str):
... return chr(int(code.lstrip("U+").zfill(8), 16))
make_uchr("U+10346")
'𐍆'
make_uchr("U+0026")
'&'
[*Remove ads*](/account/join/)
## Python 中可用的其他编码
到目前为止,您已经看到了四种字符编码:
1. 美国信息交换标准代码
2. UTF-8
3. UTF-16
4. UTF-32
外面还有很多其他的。
一个例子是 Latin-1(也称为 ISO-8859-1),根据 RFC 2616 ,它在技术上是超文本传输协议(HTTP)的默认协议。Windows 有自己的 Latin-1 变体,称为 cp1252。
**注意** : ISO-8859-1 仍然广泛存在。 [`requests`](https://realpython.com/python-requests/) 库遵循 RFC 2616“不折不扣”地使用它作为 HTTP 或 [HTTPS](https://realpython.com/python-https/) 响应内容的默认编码。如果在`Content-Type`头中发现单词“text”,并且没有指定其他编码,那么`requests` [将使用 ISO-8859-1](https://github.com/kennethreitz/requests/blob/75bdc998e2d430a35d869b2abf1779bd0d34890e/requests/utils.py#L473) 。
被接受的编码的[完整列表隐藏在`codecs`模块的文档中,它是 Python 标准库的一部分。](https://docs.python.org/3/library/codecs.html#standard-encodings)
还有一个更有用的编码需要注意,那就是`"unicode-escape"`。如果您有一个解码的`str`,并且想要快速获得它的转义 Unicode 文字的表示,那么您可以在`.encode()`中指定这个编码:
>>>
alef = chr(1575) # Or "\u0627"
alef_hamza = chr(1571) # Or "\u0623"
alef, alef_hamza
('ا', 'أ')
alef.encode("unicode-escape")
b'\u0627'
alef_hamza.encode("unicode-escape")
b'\u0623'
## 你知道他们是怎么说假设的吗…
仅仅因为 Python 对你生成的*文件和代码做了 UTF-8 编码的假设,并不意味着你,程序员,应该对外部数据做同样的假设。*
让我们再说一遍,因为这是一条必须遵守的规则:当您从第三方来源接收二进制数据(字节)时,无论是从文件还是通过网络,最佳实践是检查数据是否指定了编码。如果没有,那就由你来问了。
所有的 I/O 都是以字节为单位的,而不是文本,字节对计算机来说只是 1 和 0,除非你通过告诉它一种编码来告诉它不是这样。
这是一个可能出错的例子。你订阅了一个 API,它会向你发送当天的食谱,你会在`bytes`中收到,并且总是使用`.decode("utf-8")`解码,没有任何问题。在这特殊的一天,食谱的一部分是这样的:
>>>
data = b"\xbc cup of flour"
看起来食谱需要一些面粉,但我们不知道需要多少:
>>>
data.decode("utf-8")
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byte
*嗯哦*。当你对编码做出假设时,有一个讨厌的问题会咬你一口。您可以检查 API 主机。你瞧,数据实际上是用拉丁文 1 编码发送的:
>>>
data.decode("latin-1")
'¼ cup of flour'
我们走吧。在 [Latin-1](https://en.wikipedia.org/wiki/ISO/IEC_8859-1#Code_page_layout) 中,每个字符都适合一个字节,而在 UTF-8 ( `"\xc2\xbc"`)中,“”字符占用两个字节。
这里的教训是,对任何交给你的数据进行编码可能是危险的。这些天通常是*UTF-8,但这是小比例的情况下,它不会把事情搞砸。*
如果你真的需要弃船猜测编码,那么看看 [`chardet`](https://chardet.readthedocs.io/en/latest/) 库,它使用 Mozilla 的方法论对含糊不清的编码文本进行有根据的猜测。也就是说,像`chardet`这样的工具应该是你最后的选择,而不是你的第一选择。
[*Remove ads*](/account/join/)
## 零零碎碎:`unicodedata`
如果不提到 Python 标准库中的 [`unicodedata`](https://docs.python.org/3/library/unicodedata.html) ,那将是我们的疏忽,该标准库允许您与 Unicode 字符数据库(UCD)进行交互和查找:
>>>
import unicodedata
unicodedata.name("€")
'EURO SIGN'
unicodedata.lookup("EURO SIGN")
'€'
## 总结
在本文中,您已经解读了 Python 中字符编码这一广泛而重要的主题。
您已经涉及了很多领域:
* 字符编码和编号系统的基本概念
* Python 中的整数、二进制、八进制、十六进制、字符串和字节文字
* Python 内置的与字符编码和编号系统相关的函数
* Python 3 对文本和二进制数据的处理
现在,去编码吧!
## 资源
有关本文所涉及主题的更多详细信息,请查看以下资源:
* 乔尔·斯波尔斯基: [绝对的最小值每个软件开发人员绝对地、肯定地必须了解 Unicode 和字符集(没有借口!)](https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/)
* **大卫·岑特格拉夫:** [每个程序员绝对需要了解的关于编码和字符集的知识,以处理文本](http://kunststube.net/encoding/)
* **Mozilla:** [一种综合的语言/编码检测方法](https://www-archive.mozilla.org/projects/intl/UniversalCharsetDetection.html)
* **维基百科:** [UTF-8](https://en.wikipedia.org/wiki/UTF-8)
* **约翰·斯基特:** [Unicode and。网](http://csharpindepth.com/Articles/General/Unicode.aspx)
* **Charles Petzold:**[T3】代码:计算机硬件和软件的隐藏语言 T5】](https://realpython.com/asins/073560505X/)
* **网络工作组,RFC 3629:** [UTF-8,ISO 10646 的一种转换格式](https://tools.ietf.org/html/rfc3629)
* **Unicode 技术标准#18:** [Unicode 正则表达式](https://unicode.org/reports/tr18/)
Python 文档有两页是关于这个主题的:
* [Python 3.0 的新特性](https://docs.python.org/3.0/whatsnew/3.0.html#text-vs-data-instead-of-unicode-vs-8-bit)
* [Unicode HOWTO](https://docs.python.org/3/howto/unicode.html#unicode-howto)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:[**Python 中的 Unicode:使用字符编码**](/courses/python-unicode/)**********
# 用 Python 的 Enum 构建常量的枚举
> 原文:<https://realpython.com/python-enum/>
一些编程语言,比如 Java 和 C++,包括支持一种数据类型的语法,这种数据类型被称为**枚举**,或者简称为**枚举**。此数据类型允许您创建语义相关的常量集,您可以通过枚举本身访问这些常量。Python 没有针对枚举的专用语法。然而,Python [标准库](https://docs.python.org/3/library/index.html)有一个`enum`模块,通过`Enum`类支持枚举。
如果你来自一个有枚举的语言,并且你习惯于使用它们,或者如果你只是想学习如何在 Python 中使用枚举,那么本教程就是为你准备的。
**在本教程中,您将学习如何:**
* 使用 Python 的 **`Enum`** 类创建常量的**枚举**
* 在 Python 中使用枚举及其**成员**
* 使用**新功能**定制枚举类
* 编写**实用示例**来理解为什么要使用枚举
此外,您将探索位于`enum`中的其他特定枚举类型,包括`IntEnum`、`IntFlag`和`Flag`。他们会帮助你创建专门的枚举。
要跟随本教程,您应该熟悉 Python 中的[面向对象编程](https://realpython.com/python3-object-oriented-programming/)和[继承](https://realpython.com/inheritance-composition-python/)。
**源代码:** [点击这里下载免费的源代码](https://realpython.com/bonus/python-enum-code/),您将使用它在 Python 中构建枚举。
## 了解 Python 中的枚举
几种编程语言,包括 [Java](https://realpython.com/java-vs-python/) 和 [C++](https://realpython.com/python-vs-cpp/) ,都有一个本地**枚举**或**枚举**数据类型作为它们语法的一部分。该数据类型允许您创建一组名为[的常量](https://realpython.com/python-constants/),它们被视为包含枚举的**成员**。您可以通过枚举本身访问成员。
当您需要定义一组[不可变的](https://docs.python.org/3/glossary.html#term-immutable)和[离散的](https://en.wikipedia.org/wiki/Continuous_or_discrete_variable#Discrete_variable)相似或相关的常量值时,枚举就派上了用场,这些常量值在您的代码中可能有语义意义,也可能没有。
一周中的日子、一年中的月份和季节、地球的基本方向、程序的状态代码、HTTP 状态代码、交通灯的颜色以及 web 服务的定价计划都是编程中枚举的很好的例子。一般来说,只要有一个变量可以取一组有限的可能值中的一个,就可以使用枚举。
Python 的语法中没有枚举数据类型。好在 Python 3.4 在[标准库](https://docs.python.org/3/library/index.html)中增加了 [`enum`](https://docs.python.org/3/whatsnew/3.4.html#whatsnew-enum) 模块。这个模块提供了 [`Enum`](https://docs.python.org/3/library/enum.html#enum.Enum) 类,用于支持 Python 中的通用枚举。
PEP 435 引入了枚举,其定义如下:
> 枚举是绑定到唯一常数值的一组符号名。在枚举中,值可以通过标识进行比较,枚举本身可以迭代。([来源](https://peps.python.org/pep-0435/))
在添加到标准库中之前,您可以通过定义一系列相似或相关的常数来创建类似于枚举的东西。为此,Python 开发者经常使用以下习语:
>>>
```py
>>> RED, GREEN, YELLOW = range(3)
>>> RED
0
>>> GREEN
1
尽管这个习语可以工作,但是当你试图对大量相关的常量进行分组时,它的伸缩性并不好。另一个不便是第一个常量会有一个值0,在 Python 中是 falsy。在某些情况下,这可能是一个问题,尤其是那些涉及到布尔测试的情况。
注意:如果您使用的是 Python 之前的版本,那么您可以通过安装 enum34 库来创建枚举,这是标准库enum的一个反向移植。第三方库也是你的一个选择。
在大多数情况下,枚举可以帮助您避免上述习语的缺点。它们还将帮助您生成更有组织性、可读性和健壮性的代码。枚举有几个好处,其中一些与编码的简易性有关:
- 允许方便地将相关常数分组在一种命名空间中
- 允许对枚举成员或枚举本身进行操作的自定义方法的额外行为
- 为枚举成员提供快速灵活的访问
- 启用对成员的直接迭代,包括它们的名称和值
- 在ide 和编辑器中促进代码完成
- 用静态检查器启用类型和错误检查
- 提供一个可搜索名称的中心
- 使用枚举成员时减少拼写错误
它们还通过提供以下好处使您的代码更加健壮:
- 确保常量值在代码执行过程中不会改变
- 通过区分几个枚举共享的相同值来保证类型安全
- 通过使用描述性名称代替神秘值或幻数来提高可读性和可维护性
- 通过利用可读的名称而不是没有明确含义的值来帮助调试
- 在整个代码中提供单一的真理来源和一致性
现在您已经了解了编程和 Python 中枚举的基础,您可以开始使用 Python 的Enum类创建自己的枚举类型。
用 Python 的Enum 创建枚举
Python 的enum模块提供了Enum类,允许您创建枚举类型。为了创建你自己的枚举,你可以子类化Enum或者使用它的函数 API。这两个选项都允许您将一组相关的常数定义为枚举成员。
在接下来的小节中,您将学习如何使用Enum类在代码中创建枚举。您还将学习如何为枚举设置自动生成的值,以及如何创建包含别名和唯一值的枚举。首先,您将学习如何通过子类化Enum来创建枚举。
通过子类化Enum 创建枚举
enum模块定义了一个具有迭代和比较能力的通用枚举类型。您可以使用此类型创建命名常量集,用于替换常见数据类型的文字,如数字和字符串。
何时应该使用枚举的一个经典示例是,当您需要创建一组表示一周中各天的枚举常量时。每一天都有一个符号名称和一个介于1和7之间的数值,包括 T0 和 T1。
下面是如何通过使用Enum作为你的超类或父类来创建这个枚举:
>>> from enum import Enum >>> class Day(Enum): ... MONDAY = 1 ... TUESDAY = 2 ... WEDNESDAY = 3 ... THURSDAY = 4 ... FRIDAY = 5 ... SATURDAY = 6 ... SUNDAY = 7 ... >>> list(Day) [ <Day.MONDAY: 1>, <Day.TUESDAY: 2>, <Day.WEDNESDAY: 3>, <Day.THURSDAY: 4>, <Day.FRIDAY: 5>, <Day.SATURDAY: 6>, <Day.SUNDAY: 7> ]您的
Day类是Enum的子类。所以,你可以称Day为枚举,或者只是一个枚举。Day.MONDAY、Day.TUESDAY等为枚举成员,也称为枚举成员,或者简称为成员。每个成员必须有一个值,该值需要是常量。因为枚举成员必须是常量,Python 不允许在运行时给枚举成员赋值:
>>> Day.MONDAY = 0
Traceback (most recent call last):
...
AttributeError: Cannot reassign members.
>>> Day
<enum 'Day'>
>>> # Rebind Day
>>> Day = "Monday"
>>> Day
'Monday'
如果你试图改变一个枚举成员的值,那么你会得到一个AttributeError。与成员名称不同,包含枚举本身的名称不是常量,而是变量。因此,在程序执行的任何时候都有可能重新绑定这个名字,但是你应该避免这样做。
在上面的例子中,您已经重新分配了Day,它现在保存一个字符串而不是原来的枚举。这样做,您就失去了对枚举本身的引用。
通常,映射到成员的值是连续的整数。但是,它们可以是任何类型,包括用户定义的类型。在这个例子中,Day.MONDAY的值是1,Day.TUESDAY的值是2,以此类推。
注意:你可能注意到了Day的成员都是大写的。原因如下:
因为枚举是用来表示常量的,所以我们建议对枚举成员使用大写名称… ( Source )
您可以将枚举视为常数的集合。像列表、元组或字典一样,Python 枚举也是可迭代的。这就是为什么你可以用 list() 把一个枚举变成一个枚举成员的list。
Python 枚举的成员是容器枚举本身的实例:
>>> from enum import Enum >>> class Day(Enum): ... MONDAY = 1 ... TUESDAY = 2 ... WEDNESDAY = 3 ... THURSDAY = 4 ... FRIDAY = 5 ... SATURDAY = 6 ... SUNDAY = 7 ... >>> type(Day.MONDAY) <enum 'Day'> >>> type(Day.TUESDAY) <enum 'Day'>你不应该混淆像
Day这样的自定义枚举类和它的成员:Day.MONDAY、Day.TUESDAY等等。在这个例子中,Day枚举类型是枚举成员的中枢,这些成员恰好属于Day类型。您也可以使用基于
range()的习语来构建枚举:
>>> from enum import Enum
>>> class Season(Enum):
... WINTER, SPRING, SUMMER, FALL = range(1, 5)
...
>>> list(Season)
[
<Season.WINTER: 1>,
<Season.SPRING: 2>,
<Season.SUMMER: 3>,
<Season.FALL: 4>
]
在这个例子中,你使用带有start和stop偏移量的range()。start偏移量允许您提供开始范围的数字,而stop偏移量定义范围停止生成数字的数字。
即使您使用class语法来创建枚举,它们也是不同于普通 Python 类的特殊类。与常规类不同,枚举:
- 不能被实例化
- 除非基本枚举没有成员,否则不能将子类化为
- 为他们的成员提供一个可读的字符串表示
- 是可迭代的,按顺序返回它们的成员
- 提供可用作字典键的可散列成员
- 支持方括号语法、调用语法、点符号来访问成员
- 不允许成员重新分配
当您开始在 Python 中创建和使用自己的枚举时,您应该记住所有这些细微的差别。
通常,枚举的成员采用连续的整数值。然而,在 Python 中,成员的值可以是任何类型,包括用户定义的类型。例如,下面是一个学校成绩的枚举,它以降序使用不连续的数值:
>>> from enum import Enum >>> class Grade(Enum): ... A = 90 ... B = 80 ... C = 70 ... D = 60 ... F = 0 ... >>> list(Grade) [ <Grade.A: 90>, <Grade.B: 80>, <Grade.C: 70>, <Grade.D: 60>, <Grade.F: 0> ]这个例子表明 Python 枚举非常灵活,允许您为它们的成员使用任何有意义的值。您可以根据代码的意图设置成员值。
还可以为枚举成员使用字符串值。这里有一个你可以在网上商店使用的
Size枚举的例子:
>>> from enum import Enum
>>> class Size(Enum):
... S = "small"
... M = "medium"
... L = "large"
... XL = "extra large"
...
>>> list(Size)
[
<Size.S: 'small'>,
<Size.M: 'medium'>,
<Size.L: 'large'>,
<Size.XL: 'extra large'>
]
在本例中,与每个大小相关联的值包含一个描述,可以帮助您和其他开发人员理解代码的含义。
您还可以创建布尔值的枚举。在这种情况下,您的枚举成员将只有两个值:
>>> from enum import Enum >>> class SwitchPosition(Enum): ... ON = True ... OFF = False ... >>> list(SwitchPosition) [<SwitchPosition.ON: True>, <SwitchPosition.OFF: False>] >>> class UserResponse(Enum): ... YES = True ... NO = False ... >>> list(UserResponse) [<UserResponse.YES: True>, <UserResponse.NO: False>]这两个例子展示了如何使用枚举向代码中添加额外的上下文。在第一个例子中,任何阅读您的代码的人都会知道代码模拟了一个具有两种可能状态的开关对象。这些附加信息极大地提高了代码的可读性。
您还可以定义具有异类值的枚举:
>>> from enum import Enum
>>> class UserResponse(Enum):
... YES = 1
... NO = "No"
...
>>> UserResponse.NO
<UserResponse.NO: 'No'>
>>> UserResponse.YES
<UserResponse.YES: 1>
然而,从类型安全的角度来看,这种做法会使你的代码不一致。因此,不建议这样做。理想情况下,如果您有相同数据类型的值,这将会有所帮助,这与在枚举中将相似、相关的常数分组的想法是一致的。
最后,您还可以创建空枚举:
>>> from enum import Enum >>> class Empty(Enum): ... pass ... >>> list(Empty) [] >>> class Empty(Enum): ... ... ... >>> list(Empty) [] >>> class Empty(Enum): ... """Empty enumeration for such and such purposes.""" ... >>> list(Empty) []在这个例子中,
Empty表示一个空的枚举,因为它没有定义任何成员常量。注意,您可以使用pass语句、Ellipsis文字(...)或类级 docstring 来创建空枚举。最后一种方法可以通过在 docstring 中提供额外的上下文来帮助您提高代码的可读性。现在,你为什么需要定义一个空的枚举呢?当您需要构建一个枚举类的层次结构来通过继承重用功能时,空枚举可以派上用场。
考虑下面的例子:
>>> from enum import Enum
>>> import string
>>> class BaseTextEnum(Enum):
... def as_list(self):
... try:
... return list(self.value)
... except TypeError:
... return [str(self.value)]
...
>>> class Alphabet(BaseTextEnum):
... LOWERCASE = string.ascii_lowercase
... UPPERCASE = string.ascii_uppercase
...
>>> Alphabet.LOWERCASE.as_list()
['a', 'b', 'c', 'd', ..., 'x', 'y', 'z']
在本例中,您将BaseTextEnum创建为一个没有成员的枚举。如果自定义枚举没有成员,你只能继承它的子类,所以BaseTextEnum符合条件。Alphabet类继承自你的空枚举,这意味着你可以访问.as_list()方法。此方法将给定成员的值转换为列表。
使用函数式 API 创建枚举
Enum类提供了一个函数 API ,您可以用它来创建枚举,而不需要使用通常的类语法。你只需要调用带有适当参数的Enum,就像你调用函数或任何其他可调用函数一样。
这个功能性的 API 类似于 namedtuple() 工厂函数的工作方式。在Enum的情况下,功能签名具有以下形式:
Enum(
value,
names,
*,
module=None,
qualname=None,
type=None,
start=1
)
从这个签名,你可以得出结论:Enum需要两个位置参数,value和names。它还可以带多达四个可选和仅关键字参数。这些自变量是module、qualname、type和start。
下表总结了Enum签名中每个参数的内容和含义:
| 争吵 | 描述 | 需要 |
|---|---|---|
value |
保存具有新枚举类名称的字符串 | 是 |
names |
为枚举成员提供名称 | 是 |
module |
采用定义枚举类的模块的名称 | 不 |
qualname |
保存定义枚举类的模块的位置 | 不 |
type |
保存一个类作为第一个 mixin 类 | 不 |
start |
从枚举值开始取起始值 | 不 |
要提供names参数,您可以使用以下对象:
- 包含用空格或逗号分隔的成员名称的字符串
- 可重复的成员名称
- 一个名值对的 iterable
当您需要清理和取消清理您的枚举时,module和qualname参数起着重要的作用。如果没有设置module,那么 Python 将试图找到这个模块。如果失败,那么这个类将不可选择。类似地,如果没有设置qualname,那么 Python 会将其设置为全局范围,这可能会导致您的枚举在某些情况下无法取消选取。
当您想要为您的枚举提供一个 mixin 类时,type参数是必需的。使用 mixin 类可以为您的自定义枚举提供新的功能,比如扩展的比较功能,您将在关于将枚举与其他数据类型混合的章节中了解到这一点。
最后,start参数提供了一种定制枚举初始值的方法。这个参数默认为1,而不是0。使用这个默认值的原因是0在布尔意义上是假的,但是枚举成员的计算结果是True。因此,从0开始似乎令人惊讶和困惑。
大多数情况下,在创建枚举时,您只需使用前两个参数Enum。下面是一个创建普通 HTTP 方法枚举的例子:
>>> from enum import Enum >>> HTTPMethod = Enum( ... "HTTPMethod", ["GET", "POST", "PUSH", "PATCH", "DELETE"] ... ) >>> list(HTTPMethod) [ <HTTPMethod.GET: 1>, <HTTPMethod.POST: 2>, <HTTPMethod.PUSH: 3>, <HTTPMethod.PATCH: 4>, <HTTPMethod.DELETE: 5> ]这个对
Enum的调用返回一个名为HTTPMethod的新枚举。要提供成员名称,可以使用字符串列表。每个字符串代表一个 HTTP 方法。注意,成员值被自动设置为从1开始的连续整数。您可以使用start参数更改这个初始值。请注意,使用类语法定义上述枚举将产生相同的结果:
>>> from enum import Enum
>>> class HTTPMethod(Enum):
... GET = 1
... POST = 2
... PUSH = 3
... PATCH = 4
... DELETE = 5
...
>>> list(HTTPMethod)
[
<HTTPMethod.GET: 1>,
<HTTPMethod.POST: 2>,
<HTTPMethod.PUSH: 3>,
<HTTPMethod.PATCH: 4>,
<HTTPMethod.DELETE: 5>
]
这里,您使用类语法来定义HTTPMethod枚举。这个例子完全等同于上一个例子,你可以从list()的输出中得出结论。
使用类语法还是函数式 API 来创建枚举是你自己的决定,主要取决于你的喜好和具体情况。但是,如果您想要动态创建枚举,那么函数式 API 可能是您唯一的选择。
请考虑以下示例,其中您使用用户提供的成员创建了一个枚举:
>>> from enum import Enum >>> names = [] >>> while True: ... name = input("Member name: ") ... if name in {"q", "Q"}: ... break ... names.append(name.upper()) ... Member name: YES Member name: NO Member name: q >>> DynamicEnum = Enum("DynamicEnum", names) >>> list(DynamicEnum) [<DynamicEnum.YES: 1>, <DynamicEnum.NO: 2>]这个例子有点极端,因为从用户的输入中创建任何对象都是一种非常冒险的做法,考虑到您无法预测用户将输入什么。然而,该示例旨在表明,当您需要动态创建枚举时,函数式 API 是一种可行的方法。
最后,如果您需要为您的枚举成员设置自定义值,那么您可以使用一个名值对的 iterable 作为您的
names参数。在下面的示例中,您使用名称-值元组的列表来初始化所有枚举成员:
>>> from enum import Enum
>>> HTTPStatusCode = Enum(
... value="HTTPStatusCode",
... names=[
... ("OK", 200),
... ("CREATED", 201),
... ("BAD_REQUEST", 400),
... ("NOT_FOUND", 404),
... ("SERVER_ERROR", 500),
... ],
... )
>>> list(HTTPStatusCode)
[
<HTTPStatusCode.OK: 200>,
<HTTPStatusCode.CREATED: 201>,
<HTTPStatusCode.BAD_REQUEST: 400>,
<HTTPStatusCode.NOT_FOUND: 404>,
<HTTPStatusCode.SERVER_ERROR: 500>
]
像上面那样提供一个名称-值元组列表,可以为成员创建带有自定义值的HTTPStatusCode枚举。在这个例子中,如果您不想使用名称-值元组的列表,那么您也可以使用一个将名称映射到值的字典。
从自动值构建枚举
Python 的enum模块提供了一个叫做 auto() 的便利函数,允许你为你的枚举成员设置自动值。该函数的默认行为是为成员分配连续的整数值。
下面是auto()的工作原理:
>>> from enum import auto, Enum >>> class Day(Enum): ... MONDAY = auto() ... TUESDAY = auto() ... WEDNESDAY = 3 ... THURSDAY = auto() ... FRIDAY = auto() ... SATURDAY = auto() ... SUNDAY = 7 ... >>> list(Day) [ <Day.MONDAY: 1>, <Day.TUESDAY: 2>, <Day.WEDNESDAY: 3>, <Day.THURSDAY: 4>, <Day.FRIDAY: 5>, <Day.SATURDAY: 6>, <Day.SUNDAY: 7> ]您需要为您需要的每个自动值调用一次
auto()。您还可以将auto()与具体的值结合起来,就像本例中您对Day.WEDNESDAY和Day.SUNDAY所做的那样。默认情况下,
auto()从1开始为每个目标成员分配连续的整数。您可以通过覆盖._generate_next_value_()方法来调整这种默认行为,auto()使用该方法来生成自动值。下面是一个如何做到这一点的示例:
>>> from enum import Enum, auto
>>> class CardinalDirection(Enum):
... def _generate_next_value_(name, start, count, last_values):
... return name[0]
... NORTH = auto()
... SOUTH = auto()
... EAST = auto()
... WEST = auto()
...
>>> list(CardinalDirection)
[
<CardinalDirection.NORTH: 'N'>,
<CardinalDirection.SOUTH: 'S'>,
<CardinalDirection.EAST: 'E'>,
<CardinalDirection.WEST: 'W'>
]
在本例中,您创建了一个地球的主方向的枚举,其中的值被自动设置为包含每个成员名字的第一个字符的字符串。请注意,在定义任何成员之前,您必须提供您的覆盖版本的._generate_next_value_()。这是因为成员将通过调用方法来构建。
使用别名和唯一值创建枚举
您可以创建两个或多个成员具有相同常数值的枚举。冗余成员被称为别名,在某些情况下非常有用。例如,假设您有一个包含一组操作系统(OS)的枚举,如以下代码所示:
>>> from enum import Enum >>> class OperatingSystem(Enum): ... UBUNTU = "linux" ... MACOS = "darwin" ... WINDOWS = "win" ... DEBIAN = "linux" ... >>> # Aliases aren't listed >>> list(OperatingSystem) [ <OperatingSystem.UBUNTU: 'linux'>, <OperatingSystem.MACOS: 'darwin'>, <OperatingSystem.WINDOWS: 'win'> ] >>> # To access aliases, use __members__ >>> list(OperatingSystem.__members__.items()) [ ('UBUNTU', <OperatingSystem.UBUNTU: 'linux'>), ('MACOS', <OperatingSystem.MACOS: 'darwin'>), ('WINDOWS', <OperatingSystem.WINDOWS: 'win'>), ('DEBIAN', <OperatingSystem.UBUNTU: 'linux'>) ]Linux 发行版被认为是独立的操作系统。所以,Ubuntu 和 Debian 都是独立的系统,有不同的目标和目标受众。然而,它们共享一个叫做 Linux 的通用内核。
上面的枚举将操作系统映射到它们相应的内核。这种关系将
DEBIAN变成了UBUNTU的别名,当您拥有与内核相关的代码以及特定于给定 Linux 发行版的代码时,这可能会很有用。在上面的例子中需要注意的一个重要行为是,当你直接迭代枚举时,不考虑别名。如果您需要迭代所有成员,包括别名,那么您需要使用
.__members__。在关于遍历枚举的章节中,您将了解到更多关于迭代和.__members__属性的知识。
>>> from enum import Enum, unique
>>> @unique
... class OperatingSystem(Enum):
... UBUNTU = "linux"
... MACOS = "darwin"
... WINDOWS = "win"
... DEBIAN = "linux"
...
Traceback (most recent call last):
...
ValueError: duplicate values in <enum 'OperatingSystem'>: DEBIAN -> UBUNTU
在这个例子中,你用@unique来修饰OperatingSystem。如果任何成员值是重复的,那么您将得到一个ValueError。这里,异常消息指出DEBIAN和UBUNTU共享相同的值,这是不允许的。
在 Python 中使用枚举
到目前为止,您已经了解了什么是枚举,何时使用它们,以及在代码中使用它们有什么好处。您还了解了如何使用Enum类作为超类或可调用类在 Python 中创建枚举。
现在是时候开始研究 Python 的枚举是如何工作的,以及如何在代码中使用它们了。
访问枚举成员
当在代码中使用枚举时,访问它们的成员是要执行的基本操作。在 Python 中,您将有三种不同的方法来访问枚举成员。
例如,假设您需要访问下面的CardinalDirection枚举的NORTH成员。在这种情况下,你可以这样做:
>>> from enum import Enum >>> class CardinalDirection(Enum): ... NORTH = "N" ... SOUTH = "S" ... EAST = "E" ... WEST = "W" ... >>> # Dot notation >>> CardinalDirection.NORTH <CardinalDirection.NORTH: 'N'> >>> # Call notation >>> CardinalDirection("N") <CardinalDirection.NORTH: 'N'> >>> # Subscript notation >>> CardinalDirection["NORTH"] <CardinalDirection.NORTH: 'N'>本例中突出显示的第一行显示了如何使用点符号来访问一个枚举成员,这非常直观和易读。第二个突出显示的行通过调用枚举并以成员的值作为参数来访问目标成员。
注意:需要注意的是,用成员的值作为参数调用枚举会让你感觉像是在实例化该枚举。然而,正如您已经知道的,枚举不能被实例化:
>>> week = Day()
Traceback (most recent call last):
...
TypeError: EnumMeta.__call__() missing 1 required positional argument: 'value'
试图创建一个现有枚举的实例是不允许的,所以如果你试图这样做,你会得到一个TypeError。因此,不能将实例化与通过枚举调用访问成员相混淆。
最后,突出显示的第三行显示了如何使用类似于字典的符号或下标符号来访问一个成员,并将该成员的名称作为目标键。
Python 的枚举为您访问成员提供了极大的灵活性。点符号可以说是 Python 代码中最常用的方法。然而,其他两种方法也有帮助。因此,使用满足您特定需求、惯例和风格的符号。
使用.name和.value属性
Python 枚举的成员是其包含类的实例。在 enum 类解析过程中,每个成员都会自动获得一个.name属性,该属性将成员的名称保存为一个字符串。成员还获得一个.value属性,该属性在类定义中存储分配给成员本身的值。
您可以像处理常规属性一样,使用点符号来访问.name和.value。考虑下面的例子,它模拟了一个信号量,通常被称为交通灯:
>>> from enum import Enum >>> class Semaphore(Enum): ... RED = 1 ... YELLOW = 2 ... GREEN = 3 ... >>> Semaphore.RED.name 'RED' >>> Semaphore.RED.value 1 >>> Semaphore.YELLOW.name 'YELLOW'枚举成员的
.name和.value属性分别让你直接访问成员的字符串名称和成员的值。当您遍历枚举时,这些属性会派上用场,这将在下一节中探讨。遍历枚举
与常规类相比,Python 枚举的一个显著特征是枚举在默认情况下是可迭代的。因为它们是可迭代的,你可以在
for循环中使用它们,也可以和其他接受并处理可迭代的工具一起使用。Python 的枚举支持按照定义顺序对成员进行直接迭代:
>>> from enum import Enum
>>> class Flavor(Enum):
... VANILLA = 1
... CHOCOLATE = 2
... MINT = 3
...
>>> for flavor in Flavor:
... print(flavor)
...
Flavor.VANILLA
Flavor.CHOCOLATE
Flavor.MINT
在这个例子中,您使用一个for循环来迭代Flavor的成员。请注意,成员的产生顺序与它们在类定义中的定义顺序相同。
当你迭代一个枚举时,你可以访问.name和.value属性:
>>> for flavor in Flavor: ... print(flavor.name, "->", flavor.value) ... VANILLA -> 1 CHOCOLATE -> 2 MINT -> 3这种迭代技术看起来非常类似于对字典的迭代。因此,如果您熟悉字典迭代,那么使用这种技术遍历枚举将是一项简单的任务,有许多潜在的用例。
或者,枚举有一个名为
.__members__的特殊属性,您也可以用它来迭代它们的成员。该属性包含一个将名称映射到成员的字典。遍历这个字典和直接遍历枚举的区别在于,字典允许您访问枚举的所有成员,包括您可能拥有的所有别名。下面是一些使用
.__members__遍历Flavor枚举的例子:
>>> for name in Flavor.__members__:
... print(name)
...
VANILLA
CHOCOLATE
MINT
>>> for name in Flavor.__members__.keys():
... print(name)
...
VANILLA
CHOCOLATE
MINT
>>> for member in Flavor.__members__.values():
... print(member)
...
Flavor.VANILLA
Flavor.CHOCOLATE
Flavor.MINT
>>> for name, member in Flavor.__members__.items():
... print(name, "->", member)
...
VANILLA -> Flavor.VANILLA
CHOCOLATE -> Flavor.CHOCOLATE
MINT -> Flavor.MINT
您可以使用.__members__特殊属性对 Python 枚举的成员进行详细的编程访问。因为.__members__拥有一个常规字典,所以您可以使用适用于这个内置数据类型的所有迭代技术。这些技术包括使用字典方法,如 .key() 、 .values() 和 .items() 。
在if和match语句中使用枚举
链式 if … elif 语句和相对较新的 match … case 语句是可以使用枚举的常见且自然的地方。这两种结构都允许您根据特定条件采取不同的操作过程。
例如,假设您有一段处理交通控制应用程序中的信号量或交通灯的代码。您必须根据信号量的当前指示灯执行不同的操作。在这种情况下,您可以使用枚举来表示信号量及其指示灯。然后,您可以使用一系列if … elif语句来决定要运行的操作:
>>> from enum import Enum >>> class Semaphore(Enum): ... RED = 1 ... YELLOW = 2 ... GREEN = 3 ... >>> def handle_semaphore(light): ... if light is Semaphore.RED: ... print("You must stop!") ... elif light is Semaphore.YELLOW: ... print("Light will change to red, be careful!") ... elif light is Semaphore.GREEN: ... print("You can continue!") ... >>> handle_semaphore(Semaphore.GREEN) You can continue! >>> handle_semaphore(Semaphore.YELLOW) Light will change to red, be careful! >>> handle_semaphore(Semaphore.RED) You must stop!您的
handle_semaphore()函数中的if…elif语句链检查当前灯光的值,以决定要采取的行动。注意对handle_semaphore()中的print()的调用只是占位符。在真正的代码中,你可以用更复杂的操作来代替它们。如果您使用的是 Python 3.10 或更高版本,那么您可以快速将上面的
if…elif语句链转换成等价的match…case语句:
>>> from enum import Enum
>>> class Semaphore(Enum):
... RED = 1
... YELLOW = 2
... GREEN = 3
...
>>> def handle_semaphore(light):
... match light:
... case Semaphore.RED:
... print("You must stop!")
... case Semaphore.YELLOW:
... print("Light will change to red, be careful!")
... case Semaphore.GREEN:
... print("You can continue!")
...
>>> handle_semaphore(Semaphore.GREEN)
You can continue!
>>> handle_semaphore(Semaphore.YELLOW)
Light will change to red, be careful!
>>> handle_semaphore(Semaphore.RED)
You must stop!
这个新的handle_semaphore()实现等同于之前使用if … elif语句的实现。使用任何一种技术都是一个品味和风格的问题。这两种技术都工作得很好,并且在可读性方面不相上下。但是,请注意,如果您需要保证向后兼容低于 3.10 的 Python 版本,那么您必须使用链式if … elif语句。
最后,请注意,尽管枚举似乎可以很好地处理if … elif和match … case语句,但是您必须记住,这些语句不能很好地伸缩。如果您向目标枚举添加新成员,那么您需要更新处理函数来考虑这些新成员。
比较枚举数
能够在if … elif语句和match … case语句中使用枚举意味着枚举成员可以进行比较。默认情况下,枚举支持两种类型的比较运算符:
身份比较依赖于每个枚举成员是其枚举类的单例实例这一事实。这个特性允许使用is和is not操作符对成员进行快速廉价的身份比较。
请考虑下面的示例,这些示例比较了枚举成员的不同组合:
>>> from enum import Enum >>> class AtlanticAveSemaphore(Enum): ... RED = 1 ... YELLOW = 2 ... GREEN = 3 ... PEDESTRIAN_RED = 1 ... PEDESTRIAN_GREEN = 3 ... >>> red = AtlanticAveSemaphore.RED >>> red is AtlanticAveSemaphore.RED True >>> red is not AtlanticAveSemaphore.RED False >>> yellow = AtlanticAveSemaphore.YELLOW >>> yellow is red False >>> yellow is not red True >>> pedestrian_red = AtlanticAveSemaphore.PEDESTRIAN_RED >>> red is pedestrian_red True每个枚举成员都有自己的标识,不同于其同级成员的标识。这条规则不适用于成员别名,因为它们只是对现有成员的引用,并且共享相同的标识。这就是为什么在最后一个例子中比较
red和pedestrian_red会返回True。注意:在 Python 中获取给定对象的标识,可以使用内置的
id()函数,将对象作为参数。不同枚举的成员之间的身份检查总是返回
False:
>>> class EighthAveSemaphore(Enum):
... RED = 1
... YELLOW = 2
... GREEN = 3
... PEDESTRIAN_RED = 1
... PEDESTRIAN_GREEN = 3
...
>>> AtlanticAveSemaphore.RED is EighthAveSemaphore.RED
False
>>> AtlanticAveSemaphore.YELLOW is EighthAveSemaphore.YELLOW
False
产生这个错误结果的原因是不同枚举的成员是独立的实例,它们有自己的身份,所以对它们的任何身份检查都返回False。
相等运算符==和!=也在枚举成员之间起作用:
>>> from enum import Enum >>> class AtlanticAveSemaphore(Enum): ... RED = 1 ... YELLOW = 2 ... GREEN = 3 ... PEDESTRIAN_RED = 1 ... PEDESTRIAN_GREEN = 3 ... >>> red = AtlanticAveSemaphore.RED >>> red == AtlanticAveSemaphore.RED True >>> red != AtlanticAveSemaphore.RED False >>> yellow = AtlanticAveSemaphore.YELLOW >>> yellow == red False >>> yellow != red True >>> pedestrian_red = AtlanticAveSemaphore.PEDESTRIAN_RED >>> red == pedestrian_red TruePython 的枚举通过分别委托给
is和is not操作符来支持操作符==和!=。正如您已经了解的,枚举成员总是有一个具体的值,可以是数字、字符串或任何其他对象。正因为如此,在枚举成员和公共对象之间运行相等比较可能很有诱惑力。
然而,这种比较并不像预期的那样工作,因为实际的比较是基于对象的身份:
>>> from enum import Enum
>>> class Semaphore(Enum):
... RED = 1
... YELLOW = 2
... GREEN = 3
...
>>> Semaphore.RED == 1
False
>>> Semaphore.YELLOW == 2
False
>>> Semaphore.GREEN != 3
True
即使每个示例中的成员值都等于整数,这些比较也会返回False。这是因为常规枚举成员按对象标识而不是按值进行比较。在上面的例子中,您将枚举成员与整数进行比较,这就像比较苹果和橙子一样。他们永远不会平等比较,因为他们有不同的身份。
注意: 稍后的,你会了解到IntEnum是可以和整数进行比较的特殊枚举。
最后,枚举的另一个与比较相关的特性是,您可以使用in和not in操作符对它们执行成员测试:
>>> from enum import Enum >>> class Semaphore(Enum): ... RED = 1 ... YELLOW = 2 ... GREEN = 3 ... >>> Semaphore.RED in Semaphore True >>> Semaphore.GREEN not in Semaphore FalsePython 的枚举默认支持
in和not in操作符。使用这些运算符,可以检查给定成员是否存在于给定的枚举中。排序枚举
默认情况下,Python 的枚举不支持比较运算符,如
>、<、>=和<=。这就是为什么不能直接使用内置的sorted()函数对枚举成员进行排序,如下例所示:
>>> from enum import Enum
>>> class Season(Enum):
... SPRING = 1
... SUMMER = 2
... AUTUMN = 3
... WINTER = 4
...
>>> sorted(Season)
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'Season' and 'Season'
当您使用枚举作为sorted()的参数时,您会得到一个TypeError,因为枚举不支持<操作符。然而,有一种方法可以通过使用sorted()调用中的key参数,成功地按照成员的名称和值对枚举进行排序。
以下是如何做到这一点:
>>> sorted(Season, key=lambda season: season.value) [ <Season.SPRING: 1>, <Season.SUMMER: 2>, <Season.AUTUMN: 3>, <Season.WINTER: 4> ] >>> sorted(Season, key=lambda season: season.name) [ <Season.AUTUMN: 3>, <Season.SPRING: 1>, <Season.SUMMER: 2>, <Season.WINTER: 4> ]在第一个示例中,您使用了一个
lambda函数,该函数将一个枚举成员作为参数,并返回其.value属性。使用这种技术,您可以根据输入枚举的值对其进行排序。在第二个例子中,lambda函数接受一个枚举成员并返回它的.name属性。这样,您可以按成员名称对枚举进行排序。用新行为扩展枚举
在前面的章节中,您已经学习了如何在 Python 代码中创建和使用枚举。到目前为止,您已经使用了默认枚举。这意味着您只使用了 Python 枚举的标准特性和行为。
有时,您可能需要为您的枚举提供自定义行为。为此,您可以向枚举中添加方法并实现所需的功能。也可以使用 mixin 类。在接下来的小节中,您将学习如何利用这两种技术来自定义您的枚举。
添加和调整成员方法
您可以像处理任何常规 Python 类一样,通过向枚举类添加新方法来为枚举提供新功能。枚举是具有特殊功能的类。像常规类一样,枚举可以有方法和特殊方法。
考虑下面的例子,改编自 Python 文档:
>>> from enum import Enum
>>> class Mood(Enum):
... FUNKY = 1
... MAD = 2
... HAPPY = 3
...
... def describe_mood(self):
... return self.name, self.value
...
... def __str__(self):
... return f"I feel {self.name}"
...
... @classmethod
... def favorite_mood(cls):
... return cls.HAPPY
...
>>> Mood.HAPPY.describe_mood()
('HAPPY', 3)
>>> print(Mood.HAPPY)
I feel HAPPY
>>> Mood.favorite_mood()
<Mood.HAPPY: 3>
在这个例子中,您有一个包含三个成员的Mood枚举。像.describe_mood()这样的常规方法被绑定到包含它们的枚举的实例上,这些实例是枚举成员。因此,您必须在枚举成员上调用常规方法,而不是在枚举类本身上。
注意:记住 Python 的枚举是不能实例化的。枚举的成员是枚举的允许实例。因此,self参数代表当前成员。
类似地, .__str__() 特殊方法对成员进行操作,提供每个成员的可打印表示。
最后,.favorite_mood()方法是一个类方法,它对类或枚举本身进行操作。像这样的类方法提供了从类内部对所有枚举成员的访问。
当您需要实现策略模式时,您也可以利用这种能力来包含额外的行为。例如,假设您需要一个类,该类允许您使用两种策略对数字列表进行升序和降序排序。在这种情况下,可以使用如下所示的枚举:
>>> from enum import Enum >>> class Sort(Enum): ... ASCENDING = 1 ... DESCENDING = 2 ... def __call__(self, values): ... return sorted(values, reverse=self is Sort.DESCENDING) ... >>> numbers = [5, 2, 7, 6, 3, 9, 8, 4] >>> Sort.ASCENDING(numbers) [2, 3, 4, 5, 6, 7, 8, 9] >>> Sort.DESCENDING(numbers) [9, 8, 7, 6, 5, 4, 3, 2]
Sort的每个成员代表一种排序策略。.__call__()方法使得Sort的成员是可调用的。在.__call__()中,您使用内置的sorted()函数根据被调用的成员对输入值进行升序或降序排序。注意:上面的例子是一个使用 enum 来实现策略设计模式的示范例子。实际上,没有必要为了包装
sorted()函数而创建这个Sort枚举。相反,你可以直接使用sorted()和它的reverse参数,避免过度设计你的解决方案。调用
Sort.ASCENDING时,输入的数字按升序排序。相比之下,当您调用Sort.DESCENDING时,数字会按降序排列。就是这样!您已经使用枚举快速实现了策略设计模式。将枚举与其他类型混合
Python 支持多重继承作为其面向对象特性的一部分。这意味着在 Python 中,创建类层次结构时可以继承多个类。当您想同时重用几个类的功能时,多重继承就很方便了。
面向对象编程中的一个常见做法是使用所谓的混合类。这些类提供了其他类可以使用的功能。在 Python 中,可以将 mixin 类添加到给定类的父类列表中,以自动获得 mixin 功能。
例如,假设您想要一个支持整数比较的枚举。在这种情况下,您可以在定义枚举时使用内置的
int类型作为 mixin:
>>> from enum import Enum
>>> class Size(int, Enum):
... S = 1
... M = 2
... L = 3
... XL = 4
...
>>> Size.S > Size.M
False
>>> Size.S < Size.M
True
>>> Size.L >= Size.M
True
>>> Size.L <= Size.M
False
>>> Size.L > 2
True
>>> Size.M < 1
False
在这个例子中,你的Size类继承自int和Enum。从int类型继承可以通过>、<、>=和<=比较操作符在成员之间进行直接比较。它还支持在Size成员和整数之间进行比较。
最后,请注意,当您将一个数据类型用作 mixin 时,成员的.value属性与成员本身并不相同,尽管它是等效的,并且会以同样的方式进行比较。这就是为什么你可以直接用整数来比较Size的成员。
注意:使用整数枚举成员值是一种非常常见的做法。这就是为什么enum模块提供了一个IntEnum来直接用整数值创建枚举。在名为探索其他枚举类的章节中,您将了解到关于这个类的更多信息。
上面的例子表明,当您需要重用一个给定的功能时,用 mixin 类创建枚举通常会有很大的帮助。如果你决定在你的一些枚举中使用这种技术,那么你必须坚持下面的签名:
class EnumName([mixin_type, ...], [data_type,] enum_type):
# Members go here...
这个签名意味着您可以拥有一个或多个 mixin 类,最多一个数据类型类,以及父 enum 类。
考虑下面的例子:
>>> from enum import Enum >>> class MixinA: ... def a(self): ... print(f"MixinA: {self.value}") ... >>> class MixinB: ... def b(self): ... print(f"MixinB: {self.value}") ... >>> class ValidEnum(MixinA, MixinB, str, Enum): ... MEMBER = "value" ... >>> ValidEnum.MEMBER.a() # Call .a() from MixinA MixinA: value >>> ValidEnum.MEMBER.b() # Call .b() from MixinB MixinB: value >>> ValidEnum.MEMBER.upper() # Call .upper() from str 'VALUE' >>> class WrongMixinOrderEnum(Enum, MixinA, MixinB): ... MEMBER = "value" ... Traceback (most recent call last): ... TypeError: new enumerations should be created as `EnumName([mixin_type, ...] [data_type,] enum_type)` >>> class TooManyDataTypesEnum(int, str, Enum): ... MEMBER = "value" ... Traceback (most recent call last): ... TypeError: 'TooManyDataTypesEnum': too many data types: {<class 'int'>, <class 'str'>}
ValidEnum类表明,在碱基序列中,您必须根据需要放置尽可能多的 mixin 类——但只能放置一种数据类型——在Enum之前。
WrongMixinOrderEnum显示,如果您将Enum放在最后一个位置之外的任何位置,那么您将得到一个TypeError,其中包含要使用的正确签名的信息。同时,TooManyDataTypesEnum确认你的 mixin 类列表必须最多有一个具体的数据类型,比如int或者str。请记住,如果您在 mixin 类列表中使用具体的数据类型,那么成员值必须与该特定数据类型的类型相匹配。
探索其他枚举类
除了
Enum之外,enum模块还提供了一些额外的类,允许您创建具有特定行为的枚举。您将拥有用于创建枚举常数的IntEnum类,该类也是int的子类,这意味着所有成员将拥有整数的所有特性。你还会发现更多的专业类,比如
IntFlag和Flag。这两个类都允许你创建常量的枚举集合,你可以使用位操作符来组合它们。在下一节中,您将探索这些类以及它们如何在 Python 中工作。构建整数枚举:
IntEnum整数枚举是如此常见,以至于
enum模块导出了一个名为IntEnum的专用类,它是专门为涵盖这种用例而创建的。如果您需要您的枚举成员表现得像整数,那么您应该从IntEnum继承而不是从Enum继承。子类化
IntEnum相当于使用多重继承,将int作为 mixin 类:
>>> from enum import IntEnum
>>> class Size(IntEnum):
... S = 1
... M = 2
... L = 3
... XL = 4
...
>>> Size.S > Size.M
False
>>> Size.S < Size.M
True
>>> Size.L >= Size.M
True
>>> Size.L <= Size.M
False
>>> Size.L > 2
True
>>> Size.M < 1
False
现在Size直接继承IntEnum而不是继承int和Enum。和以前版本的Size一样,这个新版本拥有完整的比较功能,并支持所有的比较操作符。也可以在整数运算中直接使用类成员。
Size将自动尝试将不同数据类型的任何值转换为整数。如果这种转换是不可能的,那么您将得到一个ValueError:
>>> from enum import IntEnum >>> class Size(IntEnum): ... S = 1 ... M = 2 ... L = 3 ... XL = "4" ... >>> list(Size) [<Size.S: 1>, <Size.M: 2>, <Size.L: 3>, <Size.XL: 4>] >>> class Size(IntEnum): ... S = 1 ... M = 2 ... L = 3 ... XL = "4.o" ... Traceback (most recent call last): ... ValueError: invalid literal for int() with base 10: '4.o'在第一个例子中,
Size自动将字符串"4"转换为整数值。在第二个例子中,因为字符串"4.o"不包含有效的数值,所以得到一个ValueError,转换失败。在当前稳定的 Python 版本 3.10 中,
enum模块不包含StrEnum类。然而,这个类是枚举的另一个流行用例。因此,Python 3.11 将包含一个StrEnum类型,直接支持常见的字符串操作。同时,您可以通过创建一个以str和Enum为父类的 mixin 类来模拟一个StrEnum类的行为。创建整数标志:
IntFlag和Flag您可以使用
IntFlag作为应该支持位运算符的枚举的基类。对IntFlag子类的成员执行按位操作将返回一个对象,该对象也是底层枚举的成员。下面是一个
Role枚举的例子,它允许您在单个组合对象中管理不同的用户角色:
>>> from enum import IntFlag
>>> class Role(IntFlag):
... OWNER = 8
... POWER_USER = 4
... USER = 2
... SUPERVISOR = 1
... ADMIN = OWNER | POWER_USER | USER | SUPERVISOR
...
>>> john_roles = Role.USER | Role.SUPERVISOR
>>> john_roles
<Role.USER|SUPERVISOR: 3>
>>> type(john_roles)
<enum 'Role'>
>>> if Role.USER in john_roles:
... print("John, you're a user")
...
John, you're a user
>>> if Role.SUPERVISOR in john_roles:
... print("John, you're a supervisor")
...
John, you're a supervisor
>>> Role.OWNER in Role.ADMIN
True
>>> Role.SUPERVISOR in Role.ADMIN
True
在此代码片段中,您将创建一个枚举,该枚举保存给定应用程序中的一组用户角色。此枚举的成员保存整数值,您可以使用按位 OR 运算符(|)组合这些整数值。例如,名为约翰的用户同时拥有USER和SUPERVISOR两个角色。注意,存储在john_roles中的对象是您的Role枚举的成员。
注意:你应该记住基于IntFlag的枚举的单个成员,也称为标志,应该取 2 的幂(1,2,4,8,…)的值。然而,这并不是像Role.ADMIN这样的标志组合的必要条件。
在上面的例子中,您将Role.ADMIN定义为角色的组合。它的值是通过对枚举中以前角色的完整列表应用按位 OR 运算符而得到的。
IntFlag也支持整数运算,比如算术和比较运算。但是,这些类型的操作返回整数而不是成员对象:
>>> Role.ADMIN + 1 16 >>> Role.ADMIN - 2 13 >>> Role.ADMIN / 3 5.0 >>> Role.ADMIN < 20 True
IntFlag成员也是int的子类。这就是为什么你可以在涉及整数的表达式中使用它们。在这些情况下,结果值将是一个整数,而不是枚举成员。最后,您还可以在
enum中找到Flag类。这个类的工作方式类似于IntFlag,并且有一些额外的限制:
>>> from enum import Flag
>>> class Role(Flag): ... OWNER = 8
... POWER_USER = 4
... USER = 2
... SUPERVISOR = 1
... ADMIN = OWNER | POWER_USER | USER | SUPERVISOR
...
>>> john_roles = Role.USER | Role.SUPERVISOR
>>> john_roles
<Role.USER|SUPERVISOR: 3>
>>> type(john_roles)
<enum 'Role'>
>>> if Role.USER in john_roles:
... print("John, you're a user")
...
John, you're a user
>>> if Role.SUPERVISOR in john_roles:
... print("John, you're a supervisor")
...
John, you're a supervisor
>>> Role.OWNER in Role.ADMIN
True
>>> Role.SUPERVISOR in Role.ADMIN
True
>>> Role.ADMIN + 1 Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +: 'Role' and 'int'
IntFlag和Flag的主要区别在于后者不是从int继承的。因此,不支持整数运算。当您试图在整数运算中使用Role的成员时,您会得到一个TypeError。
就像IntFlag枚举的成员一样,Flag枚举的成员的值应该是 2 的幂。同样,这不适用于旗帜的组合,就像上面例子中的Role.ADMIN。
使用枚举:两个实际例子
Python 的枚举可以帮助你提高代码的可读性和组织性。您可以使用它们对相似的常数进行分组,然后在代码中使用这些常数将字符串、数字和其他值替换为可读且有意义的名称。
在接下来的部分中,您将编写几个处理常见枚举用例的实际例子。这些示例将帮助您决定何时您的代码可以从使用枚举中受益。
替换幻数
当您需要替换相关幻数集时,例如 HTTP 状态代码、计算机端口和退出代码,枚举非常有用。通过枚举,可以将这些数值常量分组,并为它们分配可读的描述性名称,以便以后在代码中使用和重用。
假设您有以下函数作为应用程序的一部分,该应用程序直接从 web 检索和处理 HTTP 内容:
>>> from http.client import HTTPSConnection >>> def process_response(response): ... match response.getcode(): ... case 200: ... print("Success!") ... case 201: ... print("Successfully created!") ... case 400: ... print("Bad request") ... case 404: ... print("Not Found") ... case 500: ... print("Internal server error") ... case _: ... print("Unexpected status") ... >>> connection = HTTPSConnection("www.python.org") >>> try: ... connection.request("GET", "/") ... response = connection.getresponse() ... process_response(response) ... finally: ... connection.close() ... Success!您的
process_response()函数接受一个 HTTPresponse对象作为参数。然后它使用.getcode()方法从response获取状态码。match…case语句按顺序将当前状态代码与您的示例中作为幻数提供的一些标准状态代码进行比较。如果出现匹配,则运行匹配的
case中的代码块。如果不匹配,那么默认的case运行。注意,默认的case是使用下划线(_)作为匹配标准的。其余代码连接到一个示例网页,执行一个
GET请求,检索响应对象,并使用您的process_response()函数处理它。finally子句关闭活动连接以避免资源泄漏。尽管这些代码可以工作,但是对于不熟悉 HTTP 状态代码及其相应含义的人来说,阅读和理解这些代码可能会很有挑战性。要解决这些问题并使您的代码更具可读性和可维护性,您可以使用枚举对 HTTP 状态代码进行分组,并为它们提供描述性的名称:
>>> from enum import IntEnum
>>> from http.client import HTTPSConnection
>>> class HTTPStatusCode(IntEnum): ... OK = 200
... CREATED = 201
... BAD_REQUEST = 400
... NOT_FOUND = 404
... SERVER_ERROR = 500
...
>>> def process_response(response):
... match response.getcode():
... case HTTPStatusCode.OK: ... print("Success!")
... case HTTPStatusCode.CREATED: ... print("Successfully created!")
... case HTTPStatusCode.BAD_REQUEST: ... print("Bad request")
... case HTTPStatusCode.NOT_FOUND: ... print("Not Found")
... case HTTPStatusCode.SERVER_ERROR: ... print("Internal server error")
... case _:
... print("Unexpected status")
...
>>> connection = HTTPSConnection("www.python.org")
>>> try:
... connection.request("GET", "/")
... response = connection.getresponse()
... process_response(response)
... finally:
... connection.close()
...
Success!
这段代码向您的应用程序添加了一个名为HTTPStatusCode的新枚举。该枚举将目标 HTTP 状态代码分组,并给它们一个可读的名称。这也使它们严格保持不变,从而使你的应用程序更加可靠。
在process_response()中,您使用人类可读的描述性名称来提供上下文和内容信息。现在,任何阅读您的代码的人都会立即知道匹配标准是 HTTP 状态代码。他们还会很快发现每个目标代码的含义。
创建状态机
枚举的另一个有趣的用例是当你使用它们来重新创建一个给定系统的不同的可能状态时。如果您的系统在任何给定的时间都能处于有限状态中的一种,那么您的系统就像一个状态机一样工作。当您需要实现这种常见的设计模式时,枚举非常有用。
作为如何使用 enum 实现状态机模式的例子,您创建了一个最小的磁盘播放器模拟器。首先,创建一个包含以下内容的disk_player.py文件:
# disk_player.py
from enum import Enum, auto
class State(Enum):
EMPTY = auto()
STOPPED = auto()
PAUSED = auto()
PLAYING = auto()
在这里,您定义了State类。这个类将你的磁盘播放器的所有可能状态分组:EMPTY、STOPPED、PAUSED和PLAYING。现在你可以编写DiskPlayer播放器类,看起来像这样:
# disk_player.py
# ...
class DiskPlayer:
def __init__(self):
self.state = State.EMPTY
def insert_disk(self):
if self.state is State.EMPTY:
self.state = State.STOPPED
else:
raise ValueError("disk already inserted")
def eject_disk(self):
if self.state is State.EMPTY:
raise ValueError("no disk inserted")
else:
self.state = State.EMPTY
def play(self):
if self.state in {State.STOPPED, State.PAUSED}:
self.state = State.PLAYING
def pause(self):
if self.state is State.PLAYING:
self.state = State.PAUSED
else:
raise ValueError("can't pause when not playing")
def stop(self):
if self.state in {State.PLAYING, State.PAUSED}:
self.state = State.STOPPED
else:
raise ValueError("can't stop when not playing or paused")
DiskPlayer类实现了您的播放器可以执行的所有可能的操作,包括插入和弹出磁盘、播放、暂停和停止播放器。注意DiskPlayer中的每个方法如何利用你的State枚举来检查和更新玩家的当前状态。
为了完成您的示例,您将使用传统的 if __name__ == "__main__": 习语来包装几行代码,这些代码将允许您试用DiskPlayer类:
# disk_player.py
# ...
if __name__ == "__main__":
actions = [
DiskPlayer.insert_disk,
DiskPlayer.play,
DiskPlayer.pause,
DiskPlayer.stop,
DiskPlayer.eject_disk,
DiskPlayer.insert_disk,
DiskPlayer.play,
DiskPlayer.stop,
DiskPlayer.eject_disk,
]
player = DiskPlayer()
for action in actions:
action(player)
print(player.state)
在这段代码中,您首先定义了一个actions 变量,它保存了您将从DiskPlayer调用的方法序列,以便测试该类。然后创建一个磁盘播放器类的实例。最后,启动一个for循环来遍历动作列表,并通过player实例运行每个动作。
就是这样!您的磁盘播放器模拟器已准备好进行测试。要运行它,请在命令行执行以下命令:
$ python disk_player.py
State.STOPPED
State.PLAYING
State.PAUSED
State.STOPPED
State.EMPTY
State.STOPPED
State.PLAYING
State.STOPPED
State.EMPTY
该命令的输出显示您的应用程序已经经历了所有可能的状态。当然,这个例子是最小的,没有考虑所有潜在的场景。这是一个演示性的例子,说明了如何使用枚举在代码中实现状态机模式。
结论
您现在知道如何在 Python 中创建和使用枚举。枚举,或简称为枚举,是许多编程语言中常见和流行的数据类型。使用枚举,您可以将相关常量集合分组,并通过枚举本身访问它们。
Python 不提供专用的枚举语法。然而,enum模块通过Enum类支持这种常见的数据类型。
在本教程中,您已经学会了如何:
- 使用 Python 的
Enum类创建自己的枚举 - 使用枚举及其成员
- 为你的枚举类提供新功能
- 通过一些实际例子使用枚举
您还了解了其他有用的枚举类型,比如IntEnum、IntFlag和Flag。它们在enum中可用,将帮助你创建专门的枚举。
有了这些知识,现在就可以开始使用 Python 的枚举对语义相关的常量集进行分组、命名和处理了。枚举允许你更好地组织你的代码,使它更可读,更明确,更易维护。
源代码: 点击这里下载免费的源代码,您将使用它在 Python 中构建枚举。*********
Python enumerate():用计数器简化循环
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python enumerate()循环
在 Python 中, for循环通常被写成对可迭代对象的循环。这意味着您不需要计数变量来访问 iterable 中的项。但是,有时您确实希望有一个在每次循环迭代中都发生变化的变量。您可以使用 Python 的 enumerate() 同时从 iterable 中获取计数器和值,而不是自己创建和递增变量!
在本教程中,您将了解如何:
- 使用
enumerate()在循环中获得一个计数器 - 将
enumerate()应用到显示项目计数 - 将
enumerate()与条件语句一起使用 - 实现自己的等价函数到
enumerate() - 解包
enumerate()返回的值
我们开始吧!
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
用 Python 中的for循环迭代
Python 中的for循环使用了基于集合的迭代。这意味着 Python 会在每次迭代时将 iterable 中的下一项分配给循环变量,如下例所示:
>>> values = ["a", "b", "c"] >>> for value in values: ... print(value) ... a b c在这个例子中,
values是一个带有三个字符串、"a"、"b"和"c"的列表。在 Python 中,列表是一种可迭代对象。在for循环中,循环变量是value。在循环的每次迭代中,value被设置为从values开始的下一项。接下来,你将打印到屏幕上。基于集合的迭代的优点是它有助于避免其他编程语言中常见的逐个错误。
现在想象一下,除了值本身之外,您还想在每次迭代时将列表中项的索引打印到屏幕上。完成这项任务的一种方法是创建一个变量来存储索引,并在每次迭代中更新它:
>>> index = 0
>>> for value in values:
... print(index, value)
... index += 1
...
0 a
1 b
2 c
在这个例子中,index是一个整数,记录你在列表中的位置。在循环的每次迭代中,你打印出index和value。循环的最后一步是将存储在index中的数字更新 1。当你忘记在每次迭代中更新index时,会出现一个常见的错误:
>>> index = 0 >>> for value in values: ... print(index, value) ... 0 a 0 b 0 c在这个例子中,
index在每次迭代中都停留在0上,因为没有代码在循环结束时更新它的值。特别是对于长的或复杂的循环,这种错误是出了名的难以追踪。
>>> for index in range(len(values)):
... value = values[index]
... print(index, value)
...
0 a
1 b
2 c
本例中,len(values)返回values的长度,也就是3。然后 range() 创建一个迭代器,从默认的起始值0开始运行,直到到达len(values)减 1。在这种情况下,index成为你的循环变量。在循环中,您将value设置为等于当前值index的values中的项目。最后,你打印出index和value。
在这个例子中,一个可能发生的常见错误是在每次迭代开始时忘记更新value。这类似于之前忘记更新索引的 bug。这是这个循环不被认为是python 式的一个原因。
这个例子也有一些限制,因为values必须允许使用整数索引来访问它的项目。允许这种访问的可重复项在 Python 中被称为序列。
技术细节:根据 Python 文档,一个 iterable 是任何可以一次返回一个成员的对象。根据定义,iterables 支持迭代器协议,该协议指定了在迭代器中使用对象时如何返回对象成员。Python 有两种常用的可迭代类型:
任何 iterable 都可以在for循环中使用,但是只有序列可以被整数索引访问。试图通过索引从生成器或迭代器中访问项目将引发TypeError:
>>> enum = enumerate(values) >>> enum[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'enumerate' object is not subscriptable在这个例子中,你把
enumerate()的返回值赋给enum。enumerate()是一个迭代器,所以试图通过索引访问它的值会引发一个TypeError。幸运的是,Python 的
enumerate()让你避免了所有这些问题。这是一个内置的函数,这意味着自从 2003 年在 Python 2.3 中添加了以来,它在 Python 的每个版本中都可用。使用 Python 的
enumerate()你可以在一个循环中使用
enumerate(),就像你使用原始的 iterable 对象一样。不是将 iterable 直接放在for循环中的in之后,而是放在enumerate()的括号内。您还必须稍微更改循环变量,如下例所示:
>>> for count, value in enumerate(values):
... print(count, value)
...
0 a
1 b
2 c
当您使用enumerate()时,该函数会返回给两个循环变量:
- 当前迭代的计数
- 当前迭代中项的值
就像普通的for循环一样,循环变量可以被命名为您想要的任何名称。在这个例子中使用了count和value,但是它们可以被命名为i和v或者任何其他有效的 Python 名称。
使用enumerate(),您不需要记得从 iterable 中访问项,也不需要记得在循环结束时推进索引。Python 的魔力会自动为您处理所有事情!
技术细节:使用逗号分隔的两个循环变量count和value是参数解包的一个例子。本文稍后将进一步讨论这个强大的 Python 特性。
Python 的enumerate()有一个额外的参数,可以用来控制计数的起始值。默认情况下,起始值是0,因为 Python 序列类型的索引是从零开始的。换句话说,当你想检索一个列表的第一个元素时,你可以使用 index 0:
>>> print(values[0]) a在这个例子中可以看到,用索引
0访问values给出了第一个元素a。然而,很多时候您可能不希望从enumerate()开始计数,而是从0开始计数。例如,您可能希望为用户输出一个自然计数。在这种情况下,您可以使用enumerate()的start参数来更改起始计数:
>>> for count, value in enumerate(values, start=1):
... print(count, value)
...
1 a
2 b
3 c
在这个例子中,您传递了start=1,它在第一次循环迭代中以值1开始count。将它与前面的例子进行比较,在前面的例子中,start的默认值是0,看看您是否能发现不同之处。
用 Python enumerate()练习
每当你需要在循环中使用计数和一个项目时,你都应该使用enumerate()。请记住,enumerate()会在每次迭代时将计数递增 1。然而,这只是稍微限制了您的灵活性。因为 count 是一个标准的 Python 整数,所以可以以多种方式使用它。在接下来的几节中,您将看到enumerate()的一些用法。
可迭代项目的自然计数
在上一节中,您看到了如何使用enumerate()和start来为用户创建一个自然计数。enumerate()在 Python 代码库中也是这样使用的。您可以在一个脚本中看到一个例子,它读取 reST 文件并在出现格式问题时告诉用户。
注意: reST,也称为重构文本,是 Python 用于文档的文本文件的标准格式。在 Python 类和函数中,您会经常看到 reST 格式的字符串作为文档字符串出现。读取源代码文件并告诉用户格式问题的脚本被称为linter,因为它们在代码中寻找隐喻的 lint 。
这个例子是由 rstlint.py 略加修改而来。不要太担心这个函数如何检查问题。重点是展示enumerate()的真实使用情况:
1def check_whitespace(lines):
2 """Check for whitespace and line length issues."""
3 for lno, line in enumerate(lines): 4 if "\r" in line:
5 yield lno+1, "\\r in line" 6 if "\t" in line:
7 yield lno+1, "OMG TABS!!!1" 8 if line[:-1].rstrip(" \t") != line[:-1]:
9 yield lno+1, "trailing whitespace"
check_whitespace()接受一个参数lines,它是应该被评估的文件的行。在check_whitespace()的第三行,enumerate()在lines上方循环使用。这将返回行号,缩写为lno和line。因为没有使用start,所以lno是文件中行的从零开始的计数器。check_whitespace()然后对错位字符进行多次检查:
- 回车(
\r) - 制表符(
\t) - 行尾有空格或制表符吗
当这些项目之一出现时,check_whitespace() 产生当前行号和对用户有用的消息。计数变量lno中添加了1,因此它返回计数行号,而不是从零开始的索引。当rstlint.py的用户阅读消息时,他们会知道去哪一行和修复什么。
跳过项目的条件语句
使用条件语句处理项目可能是一种非常强大的技术。有时,您可能只需要在循环的第一次迭代中执行操作,如下例所示:
>>> users = ["Test User", "Real User 1", "Real User 2"] >>> for index, user in enumerate(users): ... if index == 0: ... print("Extra verbose output for:", user) ... print(user) ... Extra verbose output for: Test User Real User 1 Real User 2在这个例子中,您使用一个列表作为用户的模拟数据库。第一个用户是您的测试用户,因此您想要打印关于该用户的额外诊断信息。因为您已经设置了系统,测试用户是第一个,所以您可以使用循环的第一个索引值来打印额外的详细输出。
您还可以将数学运算与计数或索引的条件结合起来。例如,您可能需要从 iterable 中返回项,但前提是它们有偶数索引。您可以通过使用
enumerate()来完成此操作:
>>> def even_items(iterable):
... """Return items from ``iterable`` when their index is even."""
... values = []
... for index, value in enumerate(iterable, start=1):
... if not index % 2:
... values.append(value)
... return values
...
even_items()接受一个名为iterable的参数,它应该是某种 Python 可以循环的对象类型。首先,values被初始化为一个空列表。然后用enumerate()在iterable上创建一个for循环,并设置start=1。
在for循环中,检查index除以2的余数是否为零。如果是,那么您将项添加到values中。最后,你返回 values。
你可以通过使用一个列表理解在一行中做同样的事情,而不用初始化空列表,从而使代码更加python 化:
>>> def even_items(iterable): ... return [v for i, v in enumerate(iterable, start=1) if not i % 2] ...在这个示例代码中,
even_items()使用一个列表理解而不是一个for循环来从列表中提取索引为偶数的每个项目。您可以通过从从
1到10的整数范围中获取偶数索引项来验证even_items()是否按预期工作。结果将是[2, 4, 6, 8, 10]:
>>> seq = list(range(1, 11))
>>> print(seq)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> even_items(seq)
[2, 4, 6, 8, 10]
正如所料,even_items()从seq返回偶数索引的项目。当你处理整数时,这不是获得偶数的最有效的方法。然而,现在您已经验证了even_items()工作正常,您可以获得 ASCII 字母表的偶数索引字母:
>>> alphabet = "abcdefghijklmnopqrstuvwxyz" >>> even_items(alphabet) ['b', 'd', 'f', 'h', 'j', 'l', 'n', 'p', 'r', 't', 'v', 'x', 'z']
alphabet是包含 ASCII 字母表中所有 26 个小写字母的字符串。调用even_items()并传递alphabet会返回字母表中交替字母的列表。Python 字符串是序列,可以在循环中使用,也可以在整数索引和切片中使用。所以在字符串的情况下,您可以使用方括号来更有效地实现与
even_items()相同的功能:
>>> list(alphabet[1::2])
['b', 'd', 'f', 'h', 'j', 'l', 'n', 'p', 'r', 't', 'v', 'x', 'z']
在这里使用字符串切片,给出起始索引1,它对应于第二个元素。第一个冒号后没有结束索引,所以 Python 转到了字符串的末尾。然后添加第二个冒号,后跟一个2,这样 Python 将接受所有其他元素。
然而,正如您之前看到的,生成器和迭代器不能被索引或切片,所以您仍然会发现enumerate()很有用。继续前面的例子,您可以创建一个生成器函数,它按需生成字母表中的字母:
>>> def alphabet(): ... alpha = "abcdefghijklmnopqrstuvwxyz" ... for a in alpha: ... yield a >>> alphabet[1::2] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'function' object is not subscriptable >>> even_items(alphabet()) ['b', 'd', 'f', 'h', 'j', 'l', 'n', 'p', 'r', 't', 'v', 'x', 'z']在这个例子中,您定义了
alphabet(),一个生成器函数,当在一个循环中使用这个函数时,它会一个接一个地生成字母表中的字母。Python 函数,无论是生成器还是常规函数,都不能通过方括号索引来访问。你在第二行试试这个,它引发了一个TypeError。不过,您可以在循环中使用生成器函数,在最后一行通过将
alphabet()传递给even_items()来这样做。可以看到结果和前面两个例子是一样的。了解 Python
enumerate()在前几节中,您已经看到了何时以及如何使用
enumerate()的例子。现在您已经掌握了enumerate()的实际方面,您可以学习更多关于函数内部如何工作的内容。为了更好地理解
enumerate()是如何工作的,您可以用 Python 实现自己的版本。你版本的enumerate()有两个要求。它应该:
- 接受 iterable 和起始计数值作为参数
- 从 iterable 发回一个包含当前计数值和相关项的元组
编写满足这些规范的函数的一种方法在 Python 文档中给出:
>>> def my_enumerate(sequence, start=0):
... n = start
... for elem in sequence:
... yield n, elem
... n += 1
...
my_enumerate()有两个论点:sequence和start。start的默认值为0。在函数定义中,您将n初始化为start的值,并在sequence上运行for循环。
对于sequence中的每个elem,你yield控制回调用位置,发回n和elem的当前值。最后,增加n为下一次迭代做准备。你可以在这里看到my_enumerate()的动作:
>>> seasons = ["Spring", "Summer", "Fall", "Winter"] >>> my_enumerate(seasons) <generator object my_enumerate at 0x7f48d7a9ca50> >>> list(my_enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] >>> list(my_enumerate(seasons, start=1)) [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]首先,创建一个四季列表。接下来,您将看到用
seasons作为sequence调用my_enumerate()会创建一个生成器对象。这是因为您使用了yield关键字将值发送回调用者。最后,从
my_enumerate()开始创建两个列表,其中一个列表的起始值保留为默认值0,另一个列表的start更改为1。在这两种情况下,最终都会得到一个元组列表,其中每个元组的第一个元素是计数,第二个元素是来自seasons的值。虽然您可以只用几行 Python 代码实现一个与
enumerate()等价的函数,但是enumerate()的实际代码是用 C 编写的。这意味着它是超级快速和高效的。用
enumerate()解包参数当您在一个
for循环中使用enumerate()时,您告诉 Python 使用两个变量,一个用于计数,一个用于值本身。你可以通过使用一个叫做参数解包的 Python 概念来做到这一点。参数解包的思想是一个元组可以根据序列的长度分成几个变量。例如,您可以将两个元素的元组解包为两个变量:
>>> tuple_2 = (10, "a")
>>> first_elem, second_elem = tuple_2
>>> first_elem
10
>>> second_elem
'a'
首先,创建一个包含两个元素的元组,10和"a"。然后将该元组解包为first_elem和second_elem,每个元组被赋予一个来自该元组的值。
当您调用enumerate()并传递一系列值时,Python 返回一个迭代器。当您向迭代器请求下一个值时,它会产生一个包含两个元素的元组。元组的第一个元素是计数,第二个元素是您传递的序列中的值:
>>> values = ["a", "b"] >>> enum_instance = enumerate(values) >>> enum_instance <enumerate at 0x7fe75d728180> >>> next(enum_instance) (0, 'a') >>> next(enum_instance) (1, 'b') >>> next(enum_instance) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration在本例中,您创建了一个名为
values的列表,其中包含两个元素"a"和"b"。然后将values传递给enumerate(),并将返回值赋给enum_instance。当您打印enum_instance时,您可以看到它是一个具有特定内存地址的enumerate()的实例。然后你用 Python 内置的
next()从enum_instance中获取下一个值。enum_instance返回的第一个值是一个计数为0的元组,来自values的第一个元素是"a"。在
enum_instance上再次调用next()产生另一个元组,这一次使用计数1和来自values、"b"的第二个元素。最后,再次调用next()会引发StopIteration,因为enum_instance不再返回任何值。当在
for循环中使用 iterable 时,Python 会在每次迭代开始时自动调用next(),直到引发StopIteration为止。Python 将从 iterable 中检索到的值赋给循环变量。如果 iterable 返回一个元组,那么可以使用参数解包将元组的元素分配给多个变量。这就是你在本教程前面通过使用两个循环变量所做的。
另一次你可能会看到用
for循环解包参数是用内置的zip(),它允许你同时迭代两个或更多的序列。在每次迭代中,zip()返回一个元组,该元组收集所有传递的序列中的元素:
>>> first = ["a", "b", "c"]
>>> second = ["d", "e", "f"]
>>> third = ["g", "h", "i"]
>>> for one, two, three in zip(first, second, third):
... print(one, two, three)
...
a d g
b e h
c f i
通过使用zip(),你可以同时迭代first、second和third。在for循环中,从first到one,从second到two,从third到three分配元素。然后打印这三个值。
您可以通过使用嵌套参数解包来组合zip()和enumerate():
>>> for count, (one, two, three) in enumerate(zip(first, second, third)): ... print(count, one, two, three) ... 0 a d g 1 b e h 2 c f i在本例的
for循环中,您将zip()嵌套在enumerate()中。这意味着每次for循环迭代时,enumerate()产生一个元组,第一个值作为计数,第二个值作为另一个元组,包含从参数到zip()的元素。为了解开嵌套结构,您需要添加括号来捕获来自zip()的嵌套元素元组中的元素。还有其他方法可以模仿
enumerate()结合zip()的行为。一种方法使用itertools.count(),默认情况下返回从零开始的连续整数。你可以把前面的例子改成使用itertools.count():
>>> import itertools
>>> for count, one, two, three in zip(itertools.count(), first, second, third):
... print(count, one, two, three)
...
0 a d g
1 b e h
2 c f i
在这个例子中使用itertools.count()允许您使用一个单独的zip()调用来生成计数以及循环变量,而不需要对嵌套参数进行解包。
结论
Python 的enumerate()允许您在需要来自 iterable 的计数和值时编写 python 式的for循环。enumerate()的一大优点是它返回一个带有计数器和值的元组,因此您不必自己递增计数器。它还为您提供了更改计数器初始值的选项。
在本教程中,您学习了如何:
- 在你的
for循环中使用 Python 的enumerate() - 在几个真实世界的例子中应用
enumerate() - 使用参数解包从
enumerate()获取值 - 实现自己的等价函数到
enumerate()
您还看到了在一些真实世界的代码中使用的enumerate(),包括在 CPython 代码库中。现在,您拥有了简化循环并使 Python 代码变得时尚的超能力!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python enumerate()循环***
Python eval():动态评估表达式
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python eval() 动态计算表达式
Python 的 eval() 允许您从基于字符串或基于编译代码的输入中计算任意 Python 表达式 。当您试图从任何作为字符串或编译的代码对象的输入中动态计算 Python 表达式时,这个函数会很方便。
虽然 Python 的eval()是一个非常有用的工具,但是这个函数有一些重要的安全隐患,您应该在使用它之前考虑一下。在本教程中,您将学习eval()是如何工作的,以及如何在您的 Python 程序中安全有效地使用它。
在本教程中,您将学习:
- Python 的
eval()是如何工作的 - 如何使用
eval()到动态评估任意基于字符串或基于编译代码的输入 - 如何使你的代码不安全,如何最小化相关的安全风险
**此外,您将学习如何使用 Python 的eval()编写一个应用程序,以交互方式计算数学表达式。在这个例子中,你将把你所学到的关于eval()的一切应用到现实世界的问题中。如果你想得到这个应用程序的代码,那么你可以点击下面的方框:
下载示例代码: 单击此处获取代码,您将在本教程中使用来学习 Python 的 eval()。
了解 Python 的eval()
您可以使用内置的 Python eval() 从基于字符串或基于编译代码的输入中动态计算表达式。如果您将一个字符串传递给eval(),那么函数会解析它,将其编译成字节码,并将其作为一个 Python 表达式进行求值。但是如果你用一个编译过的代码对象调用eval(),那么这个函数只执行评估步骤,如果你用相同的输入多次调用eval(),这是非常方便的。
Python 的eval()的签名定义如下:
eval(expression[, globals[, locals]])
该函数有一个名为expression的第一个参数,它保存了需要计算的表达式。eval()还带有两个可选参数:
globalslocals
在接下来的三节中,您将了解这些参数是什么,以及eval()如何使用它们来动态计算 Python 表达式。
注意:还可以使用 exec() 动态执行 Python 代码。eval()和exec()的主要区别在于eval()只能执行或计算表达式,而exec()可以执行任何一段 Python 代码。
第一个参数:expression
eval()的第一个自变量叫做 expression 。这是一个必需的参数,用于保存函数的基于字符串的或基于编译代码的输入。当您调用eval()时,expression的内容被评估为一个 Python 表达式。查看以下使用基于字符串的输入的示例:****
>>> eval("2 ** 8") 256 >>> eval("1024 + 1024") 2048 >>> eval("sum([8, 16, 32])") 56 >>> x = 100 >>> eval("x * 2") 200当您使用一个字符串作为参数调用
eval()时,该函数返回对输入字符串求值的结果。默认情况下,eval()可以访问全局名称,比如上面例子中的x。为了评估基于字符串的
expression,Python 的eval()运行以下步骤:
- 解析
expression- 将编译成字节码
- 将评估为 Python 表达式
- 返回评估的结果
eval()的第一个参数的名称expression强调了该函数只适用于表达式,不适用于复合语句。 Python 文档将表达式定义如下:表情
一段可以被赋值的语法。换句话说,表达式是像文字、名称、属性访问、操作符或函数调用这样的表达式元素的集合,它们都返回值。与许多其他语言相比,并不是所有的语言结构都是表达式。还有不能做表达式的语句,比如
while。赋值也是语句,不是表达式。(来源)另一方面,Python 语句具有以下定义:
声明
一个语句是一个套件(一个“代码块”)的一部分。一个语句可以是一个表达式,也可以是带有关键字的几个结构之一,比如
if、while或for。(来源)如果你试图将一个复合语句传递给
eval(),那么你将得到一个SyntaxError。看看下面的例子,在这个例子中,您试图使用eval()执行一个if语句:
>>> x = 100
>>> eval("if x: print(x)")
File "<string>", line 1
if x: print(x)
^
SyntaxError: invalid syntax
如果您尝试使用 Python 的eval()来评估一个复合语句,那么您将得到一个SyntaxError,就像上面的回溯一样。那是因为eval()只接受表情。任何其他语句,如if、、for、、while、、、import、、、def、或、class、,都会引发错误。
注意:一个for循环是一个复合语句,但是for 关键字也可以用在综合中,被认为是表达式。你可以使用eval()来评估理解,即使他们使用了for关键字。
也不允许使用eval()进行赋值操作:
>>> eval("pi = 3.1416") File "<string>", line 1 pi = 3.1416 ^ SyntaxError: invalid syntax如果您试图将赋值操作作为参数传递给 Python 的
eval(),那么您将得到一个SyntaxError。赋值操作是语句而不是表达式,语句不允许使用eval()。每当解析器不理解输入表达式时,您也会得到一个
SyntaxError。请看以下示例,在该示例中,您尝试对违反 Python 语法的表达式求值:
>>> # Incomplete expression
>>> eval("5 + 7 *")
File "<string>", line 1
5 + 7 *
^
SyntaxError: unexpected EOF while parsing
您不能向eval()传递违反 Python 语法的表达式。在上面的例子中,您试图计算一个不完整的表达式("5 + 7 *")并得到一个SyntaxError,因为解析器不理解表达式的语法。
也可以将编译后的代码对象传递给 Python 的eval()。为了编译你将要传递给eval()的代码,你可以使用 compile() 。这是一个内置函数,它可以将输入字符串编译成一个代码对象或一个 AST 对象,这样您就可以用eval()对其进行评估。
如何使用compile()的细节已经超出了本教程的范围,但是这里快速浏览一下它的前三个必需参数:
source保存着你要编译的源代码。该参数接受普通字符串、字节字符串和 AST 对象。filename给出从中读取代码的文件。如果要使用基于字符串的输入,那么这个参数的值应该是"<string>"。mode指定你想要得到哪种编译后的代码。如果你想用eval()处理编译后的代码,那么这个参数应该设置为"eval"。
注:关于compile()的更多信息,查看官方文档。
你可以使用compile()向eval()提供代码对象,而不是普通的字符串。看看下面的例子:
>>> # Arithmetic operations >>> code = compile("5 + 4", "<string>", "eval") >>> eval(code) 9 >>> code = compile("(5 + 7) * 2", "<string>", "eval") >>> eval(code) 24 >>> import math >>> # Volume of a sphere >>> code = compile("4 / 3 * math.pi * math.pow(25, 3)", "<string>", "eval") >>> eval(code) 65449.84694978735如果你使用
compile()来编译你要传递给eval()的表达式,那么eval()会经历以下步骤:
- 评估编译后的代码
- 返回评估的结果
如果您使用基于编译代码的输入调用 Python 的
eval(),那么该函数将执行评估步骤并立即返回结果。当您需要多次计算同一个表达式时,这非常方便。在这种情况下,最好预编译表达式,并在后续调用eval()时重用得到的字节码。如果你预先编译输入表达式,那么对
eval()的连续调用将运行得更快,因为你不会重复解析和编译的步骤。如果计算复杂的表达式,不必要的重复会导致高 CPU 时间和过多的内存消耗。第二个论点:
globals
eval()的第二个自变量叫做globals。它是可选的,拥有一个为eval()提供全局名称空间的字典。有了globals,你可以告诉eval()在评估expression时使用哪些全局名称。全局名称是在您的当前全局范围或名称空间中可用的所有名称。您可以从代码中的任何地方访问它们。
字典中传递给
globals的所有名字在执行时都可以被eval()使用。看看下面的例子,它展示了如何使用一个定制的字典为eval()提供一个全局的名称空间:
>>> x = 100 # A global variable
>>> eval("x + 100", {"x": x})
200
>>> y = 200 # Another global variable
>>> eval("x + y", {"x": x})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'y' is not defined
如果你给eval()的globals参数提供一个自定义字典,那么eval()将只把这些名字作为全局变量。在这个自定义字典之外定义的任何全局名称都不能从eval()内部访问。这就是为什么当你试图访问上面代码中的y时,Python 会抛出一个NameError:传递给globals的字典不包含y。
您可以通过在字典中列出名称来将它们插入到globals中,然后这些名称将在评估过程中可用。例如,如果您将y插入到globals,那么上述示例中对"x + y"的求值将按预期进行:
>>> eval("x + y", {"x": x, "y": y}) 300因为您将
y添加到您的自定义globals字典中,所以对"x + y"的求值是成功的,并且您得到了期望的返回值300。您也可以提供当前全局范围中不存在的名称。为此,您需要为每个名称提供一个具体的值。运行时,
eval()会将这些名称解释为全局名称:
>>> eval("x + y + z", {"x": x, "y": y, "z": 300})
600
>>> z
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'z' is not defined
即使z没有在您当前的全局作用域中定义,变量的值仍然存在于globals中,其值为300。在这种情况下,eval()可以访问z,就像它是一个全局变量一样。
globals背后的机制相当灵活。可以将任何可见变量(全局、局部或非局部传递给globals。你也可以像上面例子中的"z": 300一样传递自定义的键值对。eval()会把它们都当作全局变量。
关于globals重要的一点是,如果你向它提供一个不包含键"__builtins__"值的自定义字典,那么在expression被解析之前,对 builtins 字典的引用将自动插入到"__builtins__"下。这确保了在评估expression时eval()可以完全访问 Python 的所有内置名称。
下面的例子表明,即使您向globals提供一个空字典,对eval()的调用仍然可以访问 Python 的内置名称:
>>> eval("sum([2, 2, 2])", {}) 6 >>> eval("min([1, 2, 3])", {}) 1 >>> eval("pow(10, 2)", {}) 100在上面的代码中,您提供了一个空字典(
{})到globals。由于该字典不包含名为"__builtins__"的键,Python 自动插入一个引用了builtins中的名字的键。这样,eval()在解析expression时就可以完全访问 Python 的所有内置名称。如果调用
eval()而没有将自定义字典传递给globals,那么参数将默认为调用eval()的环境中globals()返回的字典:
>>> x = 100 # A global variable
>>> y = 200 # Another global variable
>>> eval("x + y") # Access both global variables
300
当您调用eval()而没有提供globals参数时,该函数使用globals()返回的字典作为其全局名称空间来计算expression。所以,在上面的例子中,你可以自由地访问x和y,因为它们是包含在你当前全局作用域中的全局变量。
第三个论点:locals
Python 的eval()带第三个参数,叫做 locals 。这是另一个保存字典的可选参数。在这种情况下,字典包含了eval()在评估expression时用作本地名称的变量。
局部名称是您在给定函数中定义的那些名称(变量、函数、类等等)。局部名称仅在封闭函数内部可见。当你写一个函数的时候,你可以定义这些类型的名字。
因为eval()已经写好了,所以你不能给它的代码或者局部范围添加局部名字。但是,您可以将一个字典传递给locals,eval()会将这些名称视为本地名称:
>>> eval("x + 100", {}, {"x": 100}) 200 >>> eval("x + y", {}, {"x": 100}) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<string>", line 1, in <module> NameError: name 'y' is not defined对
eval()的第一次调用中的第二个字典保存变量x。该变量被eval()解释为局部变量。换句话说,它被视为定义在eval()主体中的变量。你可以在
expression中使用x,eval()将可以访问它。相反,如果您尝试使用y,那么您将得到一个NameError,因为y既没有在globals名称空间中定义,也没有在locals名称空间中定义。像使用
globals一样,您可以将任何可见变量(全局、局部或非局部)传递给locals。你也可以像上面例子中的"x": 100一样传递自定义的键值对。eval()会把它们都当作局部变量。注意,要向
locals提供字典,首先需要向globals提供字典。不能在eval()中使用关键字参数:
>>> eval("x + 100", locals={"x": 100})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: eval() takes no keyword arguments
如果你试图在调用eval()时使用关键字参数,那么你会得到一个TypeError解释说eval()没有关键字参数。因此,在提供locals字典之前,您需要提供一个globals字典。
如果您没有将字典传递给locals,那么它默认为传递给globals的字典。这里有一个例子,你将一个空字典传递给globals,而没有传递给locals:
>>> x = 100 >>> eval("x + 100", {}) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<string>", line 1, in <module> NameError: name 'x' is not defined假设您没有向
locals提供自定义字典,那么参数默认为传递给globals的字典。在这种情况下,eval()不能访问x,因为globals持有一个空字典。
globals和locals的主要实际区别在于,如果一个"__builtins__"键不存在,Python 会自动将该键插入到globals中。无论您是否向globals提供自定义词典,都会发生这种情况。另一方面,如果您向locals提供一个自定义词典,那么该词典将在eval()执行期间保持不变。用 Python 的
eval()对表达式求值您可以使用 Python 的
eval()来计算任何类型的 Python 表达式,但不能计算 Python 语句,比如基于关键字的复合语句或赋值语句。当您需要动态评估表达式时,使用其他 Python 技术或工具会大大增加您的开发时间和工作量,这会非常方便。在本节中,您将了解如何使用 Python 的
eval()来计算布尔、数学和通用 Python 表达式。布尔表达式
布尔表达式 是 Python 表达式,当解释器对其求值时,返回一个真值(
True或False)。它们通常用在if语句中,以检查某个条件是真还是假。因为布尔表达式不是复合语句,所以可以使用eval()来计算它们:
>>> x = 100
>>> y = 100
>>> eval("x != y")
False
>>> eval("x < 200 and y > 100")
False
>>> eval("x is y")
True
>>> eval("x in {50, 100, 150, 200}")
True
您可以将eval()与使用以下任何 Python 运算符的布尔表达式一起使用:
在所有情况下,该函数返回您正在评估的表达式的真值。
现在,你可能在想,我为什么要用eval()而不是直接用布尔表达式呢?好吧,假设你需要实现一个条件语句,但是你想动态地改变条件:
>>> def func(a, b, condition): ... if eval(condition): ... return a + b ... return a - b ... >>> func(2, 4, "a > b") -2 >>> func(2, 4, "a < b") 6 >>> func(2, 2, "a is b") 4在
func()中,您使用eval()对提供的condition进行评估,并根据评估结果返回a + b或a - b。在上面的例子中,您只使用了几个不同的条件,但是如果您坚持使用您在func()中定义的名称a和b,您可以使用任何数量的其他条件。现在想象一下,如果不使用 Python 的
eval(),你将如何实现这样的东西。这会花费更少的代码和时间吗?不会吧!数学表达式
Python 的
eval()的一个常见用例是从基于字符串的输入中计算数学表达式。例如,如果您想创建一个 Python 计算器,那么您可以使用eval()来评估用户的输入并返回计算结果。以下示例显示了如何使用
eval()和math来执行数学运算:
>>> # Arithmetic operations
>>> eval("5 + 7")
12
>>> eval("5 * 7")
35
>>> eval("5 ** 7")
78125
>>> eval("(5 + 7) / 2")
6.0
>>> import math
>>> # Area of a circle
>>> eval("math.pi * pow(25, 2)")
1963.4954084936207
>>> # Volume of a sphere
>>> eval("4 / 3 * math.pi * math.pow(25, 3)")
65449.84694978735
>>> # Hypotenuse of a right triangle
>>> eval("math.sqrt(math.pow(10, 2) + math.pow(15, 2))")
18.027756377319946
当使用eval()计算数学表达式时,可以传入任何种类或复杂度的表达式。eval()将解析它们,对它们进行评估,如果一切正常,将给出预期的结果。
通用表达式
到目前为止,您已经学习了如何在布尔和数学表达式中使用eval()。然而,您可以将eval()用于更复杂的 Python 表达式,包括函数调用、对象创建、属性访问、理解等等。
例如,您可以调用内置函数或通过标准或第三方模块导入的函数:
>>> # Run the echo command >>> import subprocess >>> eval("subprocess.getoutput('echo Hello, World')") 'Hello, World' >>> # Launch Firefox (if available) >>> eval("subprocess.getoutput('firefox')") ''在这个例子中,您使用 Python 的
eval()来执行一些系统命令。你可以想象,你可以用这个特性做很多有用的事情。然而,eval()也可能让您面临严重的安全风险,比如允许恶意用户在您的机器上运行系统命令或任意代码。在下一节中,您将了解解决与 eval()相关的一些安全风险的方法。
最大限度地减少
eval()的安全问题尽管 Python 的用途几乎是无限的,但它的
eval()也有重要的安全隐患。eval()被认为是不安全的,因为它允许您(或您的用户)动态执行任意 Python 代码。这被认为是糟糕的编程实践,因为你正在读(或写)的代码是而不是你将要执行的代码。如果您计划使用
eval()来评估来自用户或任何其他外部来源的输入,那么您将无法确定将要执行什么代码。如果您的应用程序运行在错误的人手中,这将是一个严重的安全风险。出于这个原因,良好的编程实践通常建议不要使用
eval()。但是如果你选择使用这个函数,那么经验法则是永远不要用不可信的输入来使用它。这条规则的棘手之处在于弄清楚哪种输入可以信任。作为不负责任地使用
eval()会使您的代码不安全的一个例子,假设您想要构建一个在线服务来评估任意的 Python 表达式。您的用户将引入表达式,然后单击Run按钮。该应用程序将获得用户的输入,并将其传递给eval()进行评估。该应用程序将在您的个人服务器上运行。是的,就是你保存所有有价值文件的那台服务器。如果您运行的是 Linux 机器,并且应用程序的进程具有正确的权限,那么恶意用户可能会引入如下的危险字符串:
"__import__('subprocess').getoutput('rm –rf *')"上面的代码将删除应用程序当前目录中的所有文件。那太可怕了,不是吗?
注意:
__import__()是一个内置函数,以模块名为字符串,返回对模块对象的引用。__import__()是一个函数,与import语句完全不同。你不能用eval()来评估一个import语句。当输入不可信时,没有完全有效的方法来避免与
eval()相关的安全风险。但是,您可以通过限制eval()的执行环境来最小化您的风险。在接下来的几节中,您将学习一些这样做的技巧。限制
globals和locals您可以通过将自定义字典传递给
globals和locals参数来限制eval()的执行环境。例如,您可以将空字典传递给两个参数,以防止eval()访问调用者的当前作用域或名称空间中的名称:
>>> # Avoid access to names in the caller's current scope
>>> x = 100
>>> eval("x * 5", {}, {})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'x' is not defined
如果您将空字典({})传递给globals和locals,那么eval()在计算字符串"x * 5"时,无论是在其全局名称空间还是其本地名称空间中都不会找到名称x。结果,eval()会抛出一个NameError。
不幸的是,像这样限制globals和locals参数并不能消除与使用 Python 的eval()相关的所有安全风险,因为您仍然可以访问 Python 的所有内置名称。
限制内置名称的使用
正如您之前看到的,Python 的eval()在解析expression之前会自动将对builtins的字典的引用插入到globals中。恶意用户可以利用这种行为,通过使用内置函数__import__()来访问标准库和您系统上安装的任何第三方模块。
以下示例显示,即使在限制了globals和locals之后,您也可以使用任何内置函数和任何标准模块,如math或subprocess:
>>> eval("sum([5, 5, 5])", {}, {}) 15 >>> eval("__import__('math').sqrt(25)", {}, {}) 5.0 >>> eval("__import__('subprocess').getoutput('echo Hello, World')", {}, {}) 'Hello, World'即使你限制
globals和locals使用空字典,你仍然可以使用任何内置函数,就像你在上面的代码中使用sum()和__import__()一样。你可以使用
__import__()来导入任何标准或第三方模块,就像你在上面用math和subprocess所做的一样。使用这种技术,您可以访问在math、subprocess或任何其他模块中定义的任何函数或类。现在想象一下恶意用户使用subprocess或标准库中任何其他强大的模块会对您的系统做什么。为了最小化这种风险,您可以通过覆盖
globals中的"__builtins__"键来限制对 Python 内置函数的访问。良好的实践建议使用包含键值对"__builtins__": {}的定制字典。看看下面的例子:
>>> eval("__import__('math').sqrt(25)", {"__builtins__": {}}, {})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name '__import__' is not defined
如果你传递一个包含键值对"__builtins__": {}到globals的字典,那么eval()将不能直接访问 Python 的内置函数,比如__import__()。然而,正如您将在下一节看到的,这种方法仍然不能使eval()完全安全。
限制输入中的名称
即使您可以使用自定义的globals和locals字典来限制 Python 的eval()的执行环境,该函数仍然容易受到一些花哨技巧的攻击。例如,您可以使用类型的文字来访问类 object ,比如""、[]、{}或()以及一些特殊的属性:
>>> "".__class__.__base__ <class 'object'> >>> [].__class__.__base__ <class 'object'> >>> {}.__class__.__base__ <class 'object'> >>> ().__class__.__base__ <class 'object'>一旦你可以访问
object,你可以使用特殊的方法.__subclasses__()来访问所有从object继承的类。它是这样工作的:
>>> for sub_class in ().__class__.__base__.__subclasses__():
... print(sub_class.__name__)
...
type
weakref
weakcallableproxy
weakproxy
int
...
这段代码将打印一个大的类列表到你的屏幕上。其中一些职业非常强大,如果落入坏人之手会非常危险。这打开了另一个重要的安全漏洞,仅仅限制eval()的执行环境是无法弥补的:
>>> input_string = """[ ... c for c in ().__class__.__base__.__subclasses__() ... if c.__name__ == "range" ... ][0](10)""" >>> list(eval(input_string, {"__builtins__": {}}, {})) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]上面代码中的 list comprehension 过滤从
object继承的类,返回一个包含类range的list。第一个索引([0])返回类别range。一旦访问了range,就调用它来生成一个range对象。然后在range对象上调用list()来生成一个包含十个整数的列表。在这个例子中,您使用
range来说明eval()中的一个安全漏洞。现在想象一下,如果你的系统暴露了像subprocess.Popen这样的类,恶意用户会做什么。注:要更深入地了解
eval()的漏洞,请查看 Ned Batchelder 的文章, Eval 真的很危险。这个漏洞的一个可能的解决方案是限制输入中名字的使用,要么限制为一堆安全的名字,要么限制为完全没有名字的名字。要实现这一技术,您需要完成以下步骤:
- 创建一个字典,其中包含您想在
eval()中使用的名字。- 使用模式
"eval"中的compile()将输入字符串编译成字节码。- 检查字节码对象上的
.co_names以确保它只包含允许的名字。- 如果用户试图输入一个不允许的名字,引发 a
NameError。看看下面的函数,您在其中实现了所有这些步骤:
>>> def eval_expression(input_string):
... # Step 1
... allowed_names = {"sum": sum}
... # Step 2
... code = compile(input_string, "<string>", "eval")
... # Step 3
... for name in code.co_names:
... if name not in allowed_names:
... # Step 4
... raise NameError(f"Use of {name} not allowed")
... return eval(code, {"__builtins__": {}}, allowed_names)
在eval_expression()中,您实现了之前看到的所有步骤。这个函数将您可以与eval()一起使用的名字限制为字典allowed_names中的那些名字。为此,该函数使用了.co_names,它是一个代码对象的属性,返回一个包含代码对象中名称的元组。
以下示例展示了eval_expression()在实践中是如何工作的:
>>> eval_expression("3 + 4 * 5 + 25 / 2") 35.5 >>> eval_expression("sum([1, 2, 3])") 6 >>> eval_expression("len([1, 2, 3])") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 10, in eval_expression NameError: Use of len not allowed >>> eval_expression("pow(10, 2)") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 10, in eval_expression NameError: Use of pow not allowed如果您调用
eval_expression()来计算算术运算,或者如果您使用包含允许名称的表达式,那么您将得到预期的结果。否则你会得到一个NameError。在上面的例子中,你唯一允许的名字是sum()。像len()和pow()这样的名字是不允许的,所以当你试图使用它们时,这个函数会抛出一个NameError。如果你想完全禁止使用名字,那么你可以重写
eval_expression()如下:
>>> def eval_expression(input_string):
... code = compile(input_string, "<string>", "eval")
... if code.co_names:
... raise NameError(f"Use of names not allowed")
... return eval(code, {"__builtins__": {}}, {})
...
>>> eval_expression("3 + 4 * 5 + 25 / 2")
35.5
>>> eval_expression("sum([1, 2, 3])")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 4, in eval_expression
NameError: Use of names not allowed
现在你的函数不允许在输入字符串中有任何名字。为了实现这一点,您检查.co_names中的名字,如果找到一个名字,就抛出一个NameError。否则,你评估input_string并返回评估结果。在这种情况下,您也使用一个空字典来限制locals。
您可以使用这种技术来最小化eval()的安全问题,并增强您抵御恶意攻击的能力。
将输入限制为文字
Python 的eval()的一个常见用例是评估包含标准 Python 文字的字符串,并将它们转换成具体的对象。
标准库提供了一个名为 literal_eval() 的函数,可以帮助实现这个目标。该函数不支持运算符,但它支持列表、元组、数字、字符串等:
>>> from ast import literal_eval >>> # Evaluating literals >>> literal_eval("15.02") 15.02 >>> literal_eval("[1, 15]") [1, 15] >>> literal_eval("(1, 15)") (1, 15) >>> literal_eval("{'one': 1, 'two': 2}") {'one': 1, 'two': 2} >>> # Trying to evaluate an expression >>> literal_eval("sum([1, 15]) + 5 + 8 * 2") Traceback (most recent call last): ... ValueError: malformed node or string: <_ast.BinOp object at 0x7faedecd7668>注意
literal_eval()只适用于标准类型的文字。它不支持使用运算符或名称。如果你试图给literal_eval()输入一个表达式,那么你会得到一个ValueError。这个函数还可以帮助您最小化与使用 Python 的eval()相关的安全风险。使用 Python 的
eval()与input()在 Python 3.x 中,内置的
input()在命令行读取用户输入,将其转换为字符串,剥离尾部换行符,并将结果返回给调用者。由于input()的结果是一个字符串,您可以将它提供给eval(),并将其作为一个 Python 表达式进行计算:
>>> eval(input("Enter a math expression: "))
Enter a math expression: 15 * 2
30
>>> eval(input("Enter a math expression: "))
Enter a math expression: 5 + 8
13
你可以用 Python 的eval()包装input()来自动评估用户的输入。这是eval()的一个常见用例,因为它模拟了 Python 2.x 中 input()的行为,其中input()将用户的输入作为 Python 表达式进行评估并返回结果。
Python 2.x 中input()的这种行为在 Python 3.x 中被改变了,因为它有安全隐患。
构建数学表达式评估器
到目前为止,您已经了解了 Python 的eval()如何工作,以及如何在实践中使用它。您还了解了eval()具有重要的安全含义,并且通常认为在代码中避免使用eval()是一种好的做法。但是,有些情况下 Python 的eval()可以帮你节省很多时间和精力。
在本节中,您将编写一个应用程序来动态计算数学表达式。如果你想在不使用eval()的情况下解决这个问题,那么你需要完成以下步骤:
- 解析输入的表达式。
- 将表达式的组成部分改为 Python 对象(数字、运算符、函数等)。
- 把一切都组合成一个表达式。
- 确认该表达式在 Python 中有效。
- 评估最终表达式并返回结果。
考虑到 Python 可以处理和评估的各种可能的表达式,这将是一项繁重的工作。幸运的是,您可以使用eval()来解决这个问题,并且您已经学习了几种技术来降低相关的安全风险。
您可以通过单击下面的框来获取您将在本节中构建的应用程序的源代码:
下载示例代码: 单击此处获取代码,您将在本教程中使用来学习 Python 的 eval()。
首先,启动你最喜欢的代码编辑器。创建一个名为mathrepl.py的新 Python 脚本,然后添加以下代码:
1import math
2
3__version__ = "1.0"
4
5ALLOWED_NAMES = {
6 k: v for k, v in math.__dict__.items() if not k.startswith("__")
7}
8
9PS1 = "mr>>"
10
11WELCOME = f"""
12MathREPL {__version__}, your Python math expressions evaluator!
13Enter a valid math expression after the prompt "{PS1}".
14Type "help" for more information.
15Type "quit" or "exit" to exit.
16"""
17
18USAGE = f"""
19Usage:
20Build math expressions using numeric values and operators.
21Use any of the following functions and constants:
22
23{', '.join(ALLOWED_NAMES.keys())} 24"""
在这段代码中,首先导入 Python 的math模块。这个模块将允许你使用预定义的函数和常量来执行数学运算。常量ALLOWED_NAMES保存了一个字典,其中包含了math中的非特殊名称。这样,你就可以用eval()来使用它们了。
您还定义了另外三个字符串常量。您将使用它们作为脚本的用户界面,并根据需要将它们打印到屏幕上。
现在,您已经准备好编写应用程序的核心功能了。在这种情况下,您希望编写一个接收数学表达式作为输入并返回其结果的函数。为此,您编写了一个名为evaluate()的函数:
26def evaluate(expression):
27 """Evaluate a math expression."""
28 # Compile the expression
29 code = compile(expression, "<string>", "eval")
30
31 # Validate allowed names
32 for name in code.co_names:
33 if name not in ALLOWED_NAMES:
34 raise NameError(f"The use of '{name}' is not allowed")
35
36 return eval(code, {"__builtins__": {}}, ALLOWED_NAMES)
该函数的工作原理如下:
-
在行
26中,你定义evaluate()。这个函数将字符串expression作为一个参数,并返回一个浮点数,它将字符串的计算结果表示为一个数学表达式。 -
在行
29中,你用compile()把输入的字符串expression变成编译好的 Python 代码。如果用户输入一个无效的表达式,编译操作将引发一个SyntaxError。 -
在行
32中,你启动一个for循环来检查expression中包含的名字,并确认它们可以在最终的表达式中使用。如果用户提供了一个不在允许名称列表中的名称,那么您将引发一个NameError。 -
在行
36中,执行数学表达式的实际求值。注意,按照良好实践的建议,您将自定义词典传递给了globals和locals。ALLOWED_NAMES保存在math中定义的函数和常数。
注意:因为这个应用程序使用了在math中定义的函数,你需要考虑到当你用一个无效的输入值调用这些函数时,其中的一些函数会引发一个ValueError。
例如,math.sqrt(-10)会产生一个错误,因为-10的平方根未定义。稍后,您将看到如何在您的客户机代码中捕捉这个错误。
使用globals和locals参数的自定义值,以及检查行33和中的名称,可以最大限度地降低与使用eval()相关的安全风险。
当您在 main() 中编写其客户端代码时,您的数学表达式计算器就完成了。在这个函数中,您将定义程序的主循环,并结束读取和评估用户在命令行中输入的表达式的循环。
对于此示例,应用程序将:
- 打印给用户的欢迎信息
- 显示准备读取用户输入的提示
- 提供选项以获取使用说明并终止应用程序
- 读取用户的数学表达式
- 评估用户的数学表达式
- 将评估结果打印到屏幕上
查看下面的main()实现:
38def main():
39 """Main loop: Read and evaluate user's input."""
40 print(WELCOME)
41 while True:
42 # Read user's input
43 try:
44 expression = input(f"{PS1} ")
45 except (KeyboardInterrupt, EOFError):
46 raise SystemExit()
47
48 # Handle special commands
49 if expression.lower() == "help":
50 print(USAGE)
51 continue
52 if expression.lower() in {"quit", "exit"}:
53 raise SystemExit()
54
55 # Evaluate the expression and handle errors
56 try:
57 result = evaluate(expression)
58 except SyntaxError:
59 # If the user enters an invalid expression
60 print("Invalid input expression syntax")
61 continue
62 except (NameError, ValueError) as err:
63 # If the user tries to use a name that isn't allowed
64 # or an invalid value for a given math function
65 print(err)
66 continue
67
68 # Print the result if no error occurs
69 print(f"The result is: {result}")
70
71if __name__ == "__main__":
72 main()
在main()中,首先打印WELCOME消息。然后在一个 try语句中读取用户的输入,以捕捉KeyboardInterrupt和EOFError。如果出现这两种异常中的任何一种,就要终止应用程序。
如果用户输入help选项,则应用程序显示您的USAGE指南。同样,如果用户输入quit或exit,那么应用程序终止。
最后,您使用evaluate()来评估用户的数学表达式,然后您将结果打印到屏幕上。需要注意的是,调用evaluate()会引发以下异常:
SyntaxError:当用户输入不符合 Python 语法的表达式时,就会出现这种情况。NameError:当用户试图使用不允许的名称(函数、类或属性)时,就会发生这种情况。ValueError:当用户试图使用一个不允许作为math中给定函数输入的值时,就会发生这种情况。
注意,在main()中,您捕获了所有这些异常,并相应地向用户打印消息。这将允许用户检查表达式,修复问题,并再次运行程序。
就是这样!您已经使用 Python 的eval()用大约 70 行代码构建了一个数学表达式求值器。为了运行应用程序,打开您系统的命令行并键入以下命令:
$ python3 mathrepl.py
该命令将启动数学表达式计算器的命令行界面 (CLI)。您会在屏幕上看到类似这样的内容:
MathREPL 1.0, your Python math expressions evaluator!
Enter a valid math expression after the prompt "mr>>".
Type "help" for more information.
Type "quit" or "exit" to exit.
mr>>
一旦你到了那里,你就可以输入并计算任何数学表达式。例如,键入以下表达式:
mr>> 25 * 2
The result is: 50
mr>> sqrt(25)
The result is: 5.0
mr>> pi
The result is: 3.141592653589793
如果您输入一个有效的数学表达式,那么应用程序将对其进行计算,并将结果打印到您的屏幕上。如果你的表达式有任何问题,应用程序会告诉你:
mr>> 5 * (25 + 4
Invalid input expression syntax
mr>> sum([1, 2, 3, 4, 5])
The use of 'sum' is not allowed
mr>> sqrt(-15)
math domain error
mr>> factorial(-15)
factorial() not defined for negative values
在第一个例子中,您错过了右括号,所以您得到一条消息,告诉您语法不正确。然后你调用sum(),这是不允许的,你得到一个解释性的错误信息。最后,您用一个无效的输入值调用一个math函数,应用程序生成一条消息,指出您的输入中的问题。
这就是你要做的——你的数学表达式计算器已经准备好了!随意添加一些额外的功能。让您开始的一些想法包括扩大允许名称的字典,并添加更详细的警告消息。试一试,让我们在评论中了解它的进展。
结论
您可以使用 Python 的 eval() 从基于字符串或基于代码的输入中计算 Python 的表达式。当您尝试动态计算 Python 表达式,并且希望避免从头开始创建自己的表达式计算器的麻烦时,这个内置函数非常有用。
在本教程中,您已经学习了eval()如何工作,以及如何安全有效地使用它来计算任意 Python 表达式。
您现在能够:
- 使用 Python 的
eval()来动态地评估基本的 Python 表达式 - 使用
eval()运行更复杂的语句,如函数调用、对象创建,以及属性访问 - 最小化与使用 Python 的
eval()相关的安全风险
此外,您已经编写了一个应用程序,它使用命令行界面使用eval()来交互式地评估数学表达式。您可以点击下面的链接下载该应用程序的代码:
下载示例代码: 单击此处获取代码,您将在本教程中使用来学习 Python 的 eval()。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python eval() 动态计算表达式********
Python 异常:简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 异常的饲养和处理
Python 程序一遇到错误就终止。在 Python 中,错误可以是语法错误或异常。在本文中,您将看到什么是异常,以及它与语法错误有何不同。之后,您将学习如何引发异常和做出断言。然后,您将完成 try and except 块的演示。

免费 PDF 下载: Python 3 备忘单
异常与语法错误
语法错误当解析器检测到不正确的语句时发生。观察下面的例子:
>>> print( 0 / 0 ))
File "<stdin>", line 1
print( 0 / 0 ))
^
SyntaxError: invalid syntax
箭头指示解析器在哪里遇到了语法错误。在这个例子中,多了一个括号。移除它并再次运行您的代码:
>>> print( 0 / 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: integer division or modulo by zero
这一次,您遇到了一个异常错误。每当语法正确的 Python 代码导致错误时,就会发生这种类型的错误。消息的最后一行指出了您遇到的异常错误的类型。
Python 没有显示消息exception error,而是详细说明遇到了什么类型的异常错误。在这种情况下,它是一个ZeroDivisionError。Python 附带了各种内置异常以及创建自定义异常的可能性。
引发异常
如果条件发生,我们可以使用raise抛出一个异常。可以用自定义异常来补充该语句。
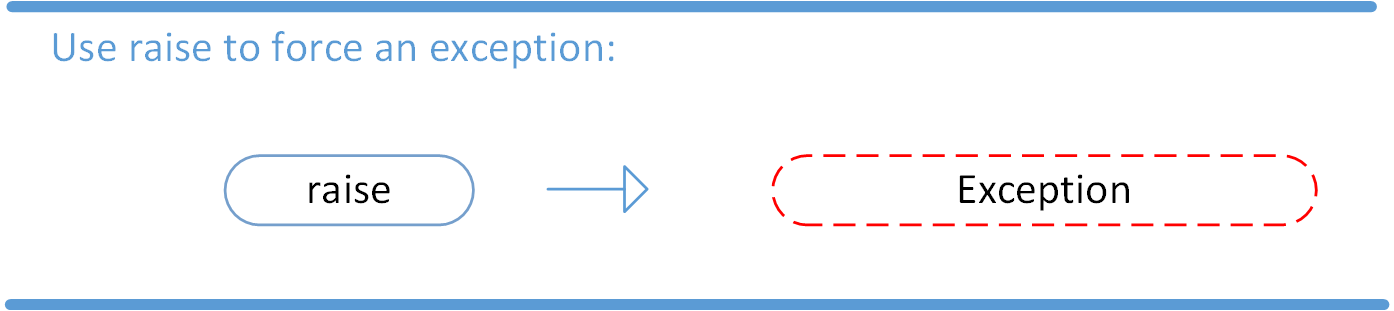
如果您想在某个条件发生时使用raise抛出一个错误,您可以这样做:
x = 10
if x > 5:
raise Exception('x should not exceed 5\. The value of x was: {}'.format(x))
运行此代码时,输出如下:
Traceback (most recent call last):
File "<input>", line 4, in <module>
Exception: x should not exceed 5\. The value of x was: 10
程序停止并在屏幕上显示我们的异常,提供出错的线索。
AssertionError异常
你也可以从用 Python 做断言开始,而不是等待程序中途崩溃。我们认为某个条件得到了满足。如果这个条件原来是True,那就太好了!程序可以继续。如果条件是False,你可以让程序抛出一个AssertionError异常。
看看下面的例子,其中断言代码将在 Linux 系统上执行:
import sys
assert ('linux' in sys.platform), "This code runs on Linux only."
如果您在 Linux 机器上运行这段代码,断言就会通过。如果您在 Windows 机器上运行这段代码,断言的结果将是False,结果如下:
Traceback (most recent call last):
File "<input>", line 2, in <module>
AssertionError: This code runs on Linux only.
在这个例子中,抛出一个AssertionError异常是程序将做的最后一件事。程序将停止,不会继续。如果这不是你想要的呢?
try和except块:处理异常
Python 中的try和except块用于捕捉和处理异常。Python 执行遵循try语句的代码,作为程序的“正常”部分。except语句后面的代码是程序对前面try子句中任何异常的响应。
正如您之前看到的,当语法正确的代码遇到错误时,Python 会抛出异常错误。如果不处理这个异常错误,它将使程序崩溃。except子句决定了你的程序如何响应异常。
以下函数可以帮助您理解try和except块:
def linux_interaction():
assert ('linux' in sys.platform), "Function can only run on Linux systems."
print('Doing something.')
linux_interaction()只能在 Linux 系统上运行。如果您在 Linux 之外的操作系统上调用这个函数中的assert,它将抛出一个AssertionError异常。
您可以使用下面的代码给函数一个try:
try:
linux_interaction()
except:
pass
这里处理错误的方式是发出一个pass。如果您在 Windows 机器上运行此代码,您将得到以下输出:
你什么都没有。这里的好事情是程序没有崩溃。但是如果能看到在运行代码时是否发生了某种类型的异常,那就更好了。为此,您可以将pass更改为能够生成信息性消息的内容,如下所示:
try:
linux_interaction()
except:
print('Linux function was not executed')
在 Windows 计算机上执行以下代码:
Linux function was not executed
当运行该函数的程序出现异常时,程序将继续运行,并通知您函数调用不成功。
您没有看到的是作为函数调用的结果而抛出的错误类型。为了查看到底哪里出错了,您需要捕捉函数抛出的错误。
下面的代码是一个示例,其中您捕获了AssertionError并将该消息输出到屏幕:
try:
linux_interaction()
except AssertionError as error:
print(error)
print('The linux_interaction() function was not executed')
在 Windows 计算机上运行此函数会输出以下内容:
Function can only run on Linux systems.
The linux_interaction() function was not executed
第一条消息是AssertionError,通知您该功能只能在 Linux 机器上执行。第二条消息告诉您哪个函数没有被执行。
在前面的例子中,您调用了自己编写的函数。当您执行该函数时,您捕获了AssertionError异常并将其打印到屏幕上。
这是另一个打开文件并使用内置异常的例子:
try:
with open('file.log') as file:
read_data = file.read()
except:
print('Could not open file.log')
如果 file.log 不存在,这段代码将输出如下内容:
Could not open file.log
这是一条信息性消息,我们的程序仍将继续运行。在 Python 文档中,您可以看到这里有许多您可以使用的内置异常。该页面上描述的一个例外如下:
异常
FileNotFoundError当文件或目录被请求但不存在时引发。对应于 errno ENOENT。
要捕捉这种类型的异常并将其打印到屏幕上,可以使用以下代码:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
在这种情况下,如果 file.log 不存在,则输出如下:
[Errno 2] No such file or directory: 'file.log'
您可以在您的try子句中有不止一个函数调用,并预期捕捉各种异常。这里需要注意的一点是,一旦遇到异常,try子句中的代码就会停止。
警告:捕捉Exception隐藏所有错误……甚至是那些完全意想不到的错误。这就是为什么您应该在 Python 程序中避免裸露的except子句。相反,你会想要引用你想要捕捉和处理的特定异常类。你可以在本教程中了解更多为什么这是个好主意。
看看下面的代码。在这里,首先调用linux_interaction()函数,然后尝试打开一个文件:
try:
linux_interaction()
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
except AssertionError as error:
print(error)
print('Linux linux_interaction() function was not executed')
如果文件不存在,在 Windows 计算机上运行此代码将输出以下内容:
Function can only run on Linux systems.
Linux linux_interaction() function was not executed
在try子句中,您立即遇到了一个异常,并且没有到达您试图打开 file.log 的部分。现在看看在 Linux 机器上运行代码时会发生什么:
[Errno 2] No such file or directory: 'file.log'
以下是关键要点:
- 执行一个
try子句,直到遇到第一个异常。 - 在
except子句或异常处理程序中,您决定程序如何响应异常。 - 您可以预测多个异常,并区分程序应该如何响应它们。
- 避免使用裸露的子句。
else条款
在 Python 中,使用else语句,您可以指示程序仅在没有异常的情况下执行某个代码块。
请看下面的例子:
try:
linux_interaction()
except AssertionError as error:
print(error)
else:
print('Executing the else clause.')
如果您在 Linux 系统上运行这段代码,输出将如下所示:
Doing something.
Executing the else clause.
因为程序没有遇到任何异常,所以执行了else子句。
您还可以try在else子句中运行代码,并在那里捕捉可能的异常:
try:
linux_interaction()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
如果您在 Linux 机器上执行这段代码,您将得到以下结果:
Doing something.
[Errno 2] No such file or directory: 'file.log'
从输出中,您可以看到linux_interaction()函数运行了。因为没有遇到异常,所以尝试打开 file.log 。该文件不存在,您没有打开该文件,而是捕捉到了FileNotFoundError异常。
使用finally后清理
想象一下,在执行完代码后,您总是需要执行某种清理操作。Python 使您能够使用finally子句来做到这一点。
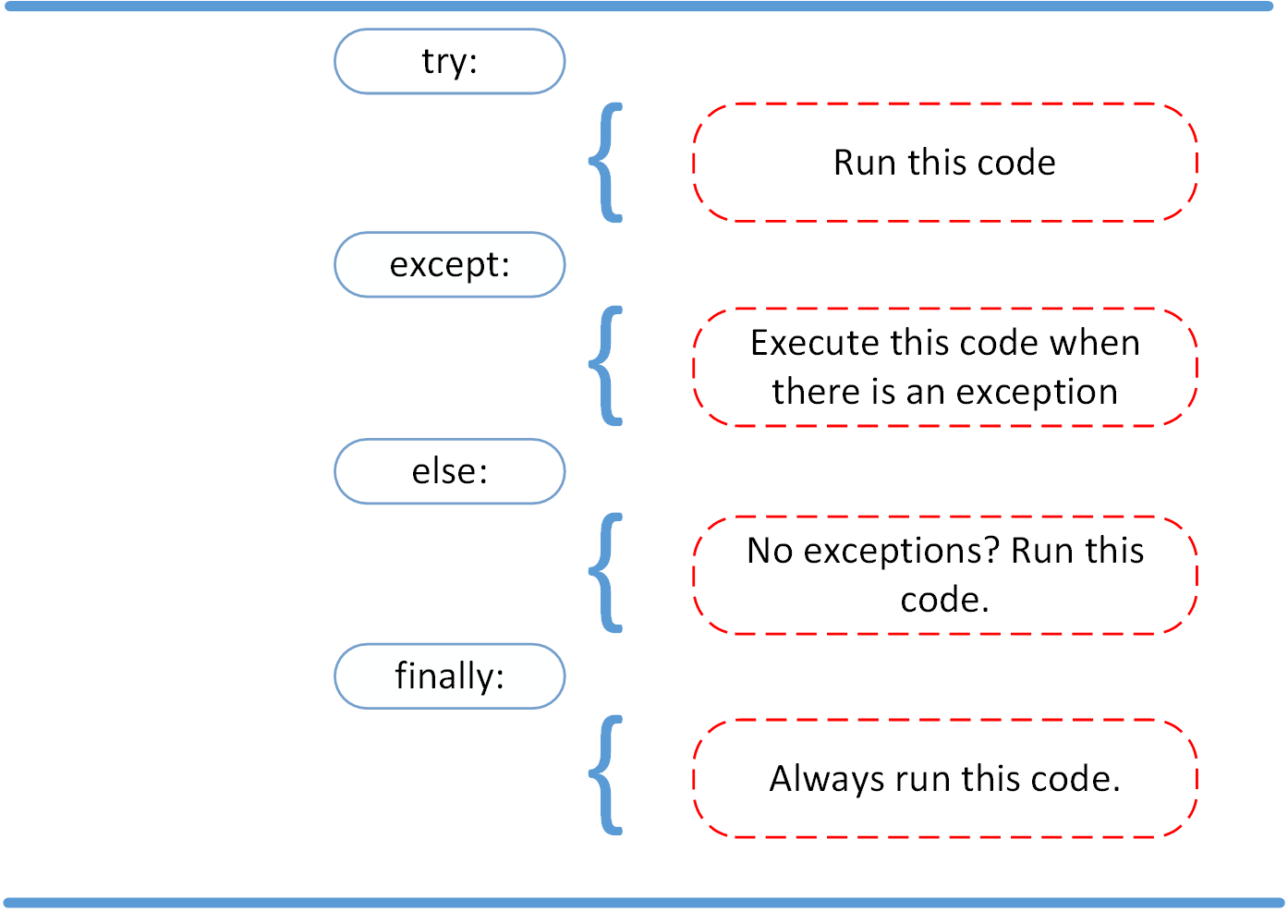
看看下面的例子:
try:
linux_interaction()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('Cleaning up, irrespective of any exceptions.')
在前面的代码中,finally子句中的所有内容都将被执行。如果您在try或else条款中遇到异常,这并不重要。在 Windows 计算机上运行前面的代码将输出以下内容:
Function can only run on Linux systems.
Cleaning up, irrespective of any exceptions.
总结
在了解了语法错误和异常之间的区别之后,您了解了在 Python 中引发、捕捉和处理异常的各种方法。在本文中,您看到了以下选项:
- 允许你在任何时候抛出一个异常。
- 使您能够验证是否满足特定条件,如果不满足,则抛出异常。
- 在
try子句中,所有语句都被执行,直到遇到异常。 except用于捕获和处理 try 子句中遇到的异常。else允许您编写只有在 try 子句中没有遇到异常时才运行的代码段。finally使您能够执行应该总是运行的代码段,不管是否有任何先前遇到的异常。
免费 PDF 下载: Python 3 备忘单
希望本文能帮助您理解 Python 在处理异常时必须提供的基本工具。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 异常的饲养和处理**
Python 的 exec():执行动态生成的代码
Python 内置的 exec() 函数可以让你从一个字符串或者编译后的代码输入中执行任意的 Python 代码。
当您需要运行动态生成的 Python 代码时,exec()函数会很方便,但是如果您不小心使用它,它会非常危险。在本教程中,您不仅将学习如何使用exec(),而且同样重要的是,何时可以在您的代码中使用该函数。
在本教程中,您将学习如何:
- 使用 Python 内置的
exec()函数 - 使用
exec()执行作为字符串或编译代码对象的代码 - 评估并最小化与在代码中使用
exec()相关的安全风险
此外,您将编写一些使用exec()解决与动态代码执行相关的不同问题的例子。
为了充分利用本教程,您应该熟悉 Python 的名称空间和范围,以及字符串。你也应该熟悉 Python 的一些内置函数。
示例代码: 单击此处下载免费的示例代码,您将使用它来探索 exec()函数的用例。
了解 Python 的exec()
Python 内置的 exec() 函数可以让你执行任何一段 Python 代码。通过这个函数,你可以执行动态生成的代码。这是您在程序执行期间读取、自动生成或获取的代码。正常情况下是字符串。
exec()函数获取一段代码,并像 Python 解释器一样执行它。Python 的exec()就像 eval() 但更强大,也容易出现安全问题。虽然eval()只能评估表达式,exec()可以执行语句序列,以及导入,函数调用和定义,类定义和实例化,等等。本质上,exec()可以执行一个完整的全功能 Python 程序。
exec()的签名形式如下:
exec(code [, globals [, locals]])
函数执行code,可以是包含有效 Python 代码的字符串,也可以是编译的代码对象。
注: Python 是解释的语言,而不是编译的语言。然而,当你运行一些 Python 代码时,解释器将其翻译成字节码,这是一个 Python 程序在 CPython 实现中的内部表示。这个中间翻译也被称为编译代码,并且是 Python 的虚拟机执行的。
如果code是一个字符串,那么它就被解析为一套 Python 语句,然后在内部编译成字节码,最后执行,除非在解析或编译步骤中出现语法错误。如果code持有一个编译过的代码对象,那么它将被直接执行,从而使这个过程更加高效。
globals和locals参数允许你提供代表全局和局部名称空间的字典,其中exec()将运行目标代码。
exec()函数的返回值为 None ,大概是因为并不是每一段代码都有一个最终的、唯一的、具体的结果。可能只是有些副作用。这种行为与eval()明显不同,后者返回计算表达式的结果。
为了初步感受一下exec()是如何工作的,您可以用两行代码创建一个基本的 Python 解释器:
>>> while True: ... exec(input("->> ")) ... ->> print("Hello, World!") Hello, World! ->> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. ... ->> x = 10 ->> if 1 <= x <= 10: print(f"{x} is between 1 and 10") 10 is between 1 and 10在这个例子中,您使用一个无限的
while循环来模仿 Python 解释器或 REPL 的行为。在循环内部,您使用input()在命令行获取用户的输入。然后使用exec()来处理和运行输入。这个例子展示了
exec(): 执行以字符串形式出现的代码的主要用例。注意:你已经知道使用
exec()可能意味着安全风险。现在你已经看到了exec()的主要用例,你认为那些安全风险可能是什么?您将在本教程的后面找到答案。当需要动态运行字符串形式的代码时,通常会使用
exec()。例如,您可以编写一个程序来生成包含有效 Python 代码的字符串。您可以从程序执行的不同时刻获得的部分构建这些字符串。您还可以使用用户输入或任何其他输入源来构造这些字符串。一旦将目标代码构建成字符串,就可以使用
exec()来执行它们,就像执行任何 Python 代码一样。在这种情况下,您很难确定您的字符串将包含什么。这就是为什么
exec()意味着严重的安全风险的一个原因。如果您在构建代码时使用不可信的输入源,比如用户的直接输入,这一点尤其正确。在编程中,像
exec()这样的函数是一个非常强大的工具,因为它允许你编写能够动态生成和执行新代码的程序。为了生成这个新代码,您的程序将只使用运行时可用的信息。为了运行代码,您的程序将使用exec()。然而,权力越大,责任越大。这个
exec()函数意味着严重的安全风险,你很快就会知道。所以,大部分时间应该避免使用exec()。在接下来的几节中,您将了解到
exec()是如何工作的,以及如何使用这个函数来执行以字符串或编译后的代码对象形式出现的代码。从字符串输入运行代码
调用
exec()最常见的方式是使用来自基于字符串的输入的代码。要构建这个基于字符串的输入,可以使用:
- 单行代码或单行代码片段
- 用分号分隔的多行代码
- 由换行符分隔的多行代码
- 在三重引用的字符串中有多行代码,并且有适当的缩进
一行程序由一行代码组成,一次执行多个动作。假设您有一个数字序列,并且您想要构建一个包含输入序列中所有偶数的平方和的新序列。
要解决这个问题,您可以使用下面的一行代码:
>>> numbers = [2, 3, 7, 4, 8]
>>> sum(number**2 for number in numbers if number % 2 == 0) 84
在突出显示的行中,您使用一个生成器表达式来计算输入值序列中所有偶数的平方值。然后你用 sum() 来计算总平方和。
要用exec()运行这段代码,您只需要将您的单行代码转换成一个单行字符串:
>>> exec("result = sum(number**2 for number in numbers if number % 2 == 0)") >>> result 84在本例中,您将一行代码表示为一个字符串。然后你把这个字符串送入
exec()执行。原始代码和字符串之间的唯一区别是,后者将计算结果存储在一个变量中,供以后访问。记住exec()返回的是None,而不是具体的执行结果。为什么?因为不是每一段代码都有一个最终唯一的结果。Python 允许你在一行代码中编写多个语句,用分号分隔。即使不鼓励这种做法,也没有什么能阻止你这样做:
>>> name = input("Your name: "); print(f"Hello, {name}!")
Your name: Leodanis
Hello, Leodanis!
您可以使用分号来分隔多个语句,并构建一个单行字符串作为exec()的参数。方法如下:
>>> exec("name = input('Your name: '); print(f'Hello, {name}!')") Your name: Leodanis Hello, Leodanis!这个例子的思想是,通过使用分号分隔多个 Python 语句,可以将它们组合成一个单行字符串。在这个例子中,第一个语句接受用户的输入,而第二个语句将问候消息打印到屏幕上。
您还可以使用换行符
\n在一个单行字符串中聚合多个语句:
>>> exec("name = input('Your name: ')\nprint(f'Hello, {name}!')")
Your name: Leodanis
Hello, Leodanis!
换行符使exec()将单行字符串理解为多行 Python 语句集。然后exec()在一行中运行聚合语句,这就像一个多行代码文件。
构建用于输入exec()的基于字符串的输入的最后一种方法是使用三重引号字符串。这种方法可以说更加灵活,允许您生成基于字符串的输入,其外观和工作方式与普通 Python 代码相似。
值得注意的是,这种方法要求您使用正确的缩进和代码格式。考虑下面的例子:
>>> code = """ ... numbers = [2, 3, 7, 4, 8] ... ... def is_even(number): ... return number % 2 == 0 ... ... even_numbers = [number for number in numbers if is_even(number)] ... ... squares = [number**2 for number in even_numbers] ... ... result = sum(squares) ... ... print("Original data:", numbers) ... print("Even numbers:", even_numbers) ... print("Square values:", squares) ... print("Sum of squares:", result) ... """ >>> exec(code) Original data: [2, 3, 7, 4, 8] Even numbers: [2, 4, 8] Square values: [4, 16, 64] Sum of squares: 84在这个例子中,您使用一个三重引号字符串向
exec()提供输入。注意,这个字符串看起来像任何一段普通的 Python 代码。它使用适当的缩进、命名风格和格式。exec()函数将理解并执行这个字符串作为一个常规的 Python 代码文件。您应该注意到,当您将一个带有代码的字符串传递给
exec()时,该函数将解析目标代码并将其编译成 Python 字节码。在所有情况下,输入字符串都应该包含有效的 Python 代码。如果
exec()在解析和编译步骤中发现任何无效语法,那么输入代码将不会运行:
>>> exec("print('Hello, World!)")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1
print('Hello, World!) ^
SyntaxError: unterminated string literal (detected at line 1)
在这个例子中,目标代码包含对print()的调用,该调用将一个字符串作为参数。这个字符串没有正确地以结束单引号结束,所以exec()抛出一个SyntaxError指出这个问题,并且不运行输入代码。请注意,Python 将错误定位在字符串的开头,而不是应该放在结束单引号的结尾。
运行字符串形式的代码,就像你在上面的例子中所做的那样,可以说是使用exec()的自然方式。但是,如果您需要多次运行输入代码,那么使用字符串作为参数将使函数每次都运行解析和编译步骤。这种行为会使您的代码在执行速度方面效率低下。
在这种情况下,最方便的方法是预先编译目标代码,然后根据需要用exec()多次运行最终的字节码。在下一节中,您将学习如何对编译后的代码对象使用exec()。
执行编译后的代码
实际上,exec()在处理包含代码的字符串时会非常慢。如果您需要不止一次地动态运行一段给定的代码,那么预先编译它将是最有效和推荐的方法。为什么?因为您将只运行一次解析和编译步骤,然后重用编译后的代码。
要编译一段 Python 代码,可以使用 compile() 。这个内置函数将一个字符串作为参数,并在其上运行一次性的字节码编译,生成一个代码对象,然后可以传递给exec()执行。
compile()的签名形式如下:
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
在本教程中,您将只使用compile()的前三个参数。source参数保存了需要编译成字节码的代码。filename参数将保存从中读取代码的文件。要读取一个字符串对象,必须将filename设置为"<string>"值。
注意:要深入了解compile()的其余参数,请查看函数的官方文档。
最后,compile()可以生成代码对象,您可以使用exec()或eval()来执行这些代码对象,这取决于mode参数的值。根据目标执行功能,该参数应设置为"exec"或"eval":
>>> string_input = """ ... def sum_of_even_squares(numbers): ... return sum(number**2 for number in numbers if number % 2 == 0) ... ... print(sum_of_even_squares(numbers)) ... """ >>> compiled_code = compile(string_input, "<string>", "exec") >>> exec(compiled_code) >>> numbers = [2, 3, 7, 4, 8] >>> exec(compiled_code) 84 >>> numbers = [5, 3, 9, 6, 1] >>> exec(compiled_code) 36用
compile()预先编译经常重复的代码可以帮助您稍微提高代码的性能,方法是在每次调用exec()时跳过解析和字节码编译步骤。从 Python 源文件运行代码
你也可以使用
exec()来运行你从你的文件系统或者其他地方的一个可靠的.py文件中读取的代码。为此,您可以使用内置的open()函数以字符串形式读取文件内容,然后您可以将其作为参数传递给exec()。例如,假设您有一个名为
hello.py的 Python 文件,其中包含以下代码:# hello.py print("Hello, Pythonista!") print("Welcome to Real Python!") def greet(name="World"): print(f"Hello, {name}!")这个示例脚本将问候语和欢迎消息打印到屏幕上。它还定义了一个用于测试的示例函数
greet()。该函数将一个名称作为参数,并将定制的问候语打印到屏幕上。现在回到 Python 交互式会话,运行以下代码:
>>> with open("hello.py", mode="r", encoding="utf-8") as hello:
... code = hello.read()
...
>>> exec(code)
Hello, Pythonista!
Welcome to Real Python!
>>> greet()
Hello, World!
>>> greet("Pythonista")
Hello, Pythonista!
在这个例子中,首先使用 with语句中的内置open()函数将目标.py文件作为常规文本文件打开。然后你调用 file 对象上的 .read() 将文件的内容读入code 变量。对.read()的调用将文件内容作为字符串返回。最后一步是用这个字符串作为参数调用exec()。
该示例运行代码,并使位于hello.py中的greet()函数和对象在当前名称空间中可用。这就是为什么你可以直接使用greet()。这种行为背后的秘密与globals和locals参数有关,这将在下一节中介绍。
使用上例中的技术,您可以打开、读取和执行任何包含 Python 代码的文件。当您事先不知道将运行哪些源文件时,这种技术可能会起作用。所以,你不能写import module,因为当你写代码的时候,你不知道模块的名字。
注意:在 Python 中,您会发现获得类似结果的更安全的方法。例如,您可以使用导入系统。要更深入地了解这种替代方案,请查看动态导入。
如果您选择使用这种技术,那么请确保您只执行来自可信源文件的代码。理想情况下,最可靠的源文件是那些你有意识地创建来动态运行的文件。在没有检查代码之前,决不能运行来自外部来源(包括您的用户)的代码文件。
使用globals和locals自变量
您可以使用globals和locals参数将执行上下文传递给exec()。这些参数可以接受字典对象,这些字典对象将作为全局和局部的名称空间,这些名称空间exec()将用来运行目标代码。
这些参数是可选的。如果你省略了它们,那么exec()将执行当前作用域中的输入代码,这个作用域中的所有名字和对象都将对exec()可用。同样,在调用exec()之后,您在输入代码中定义的所有名称和对象都将在当前作用域中可用。
考虑下面的例子:
>>> code = """ ... z = x + y ... """ >>> # Global names are accessible from exec() >>> x = 42 >>> y = 21 >>> z Traceback (most recent call last): ... NameError: name 'z' is not defined >>> exec(code) >>> # Names in code are available in the current scope >>> z 63这个例子表明,如果您调用
exec()而没有为globals和locals参数提供特定的值,那么函数将在当前范围内运行输入代码。在这种情况下,当前范围是全局范围。注意,在调用
exec()之后,输入代码中定义的名字在当前作用域中也是可用的。这就是为什么你可以在最后一行代码中访问z。如果只给
globals提供一个值,那么这个值必须是一个字典。exec()函数将把这个字典用于全局名和本地名。此行为将限制对当前作用域中大多数名称的访问:
>>> code = """
... z = x + y
... """
>>> x = 42
>>> y = 21
>>> exec(code, {"x": x})
Traceback (most recent call last):
...
NameError: name 'y' is not defined
>>> exec(code, {"x": x, "y": y})
>>> z
Traceback (most recent call last):
...
NameError: name 'z' is not defined
在对exec()的第一次调用中,您使用一个字典作为globals参数。因为您的字典没有提供保存y名字的键,所以对exec()的调用不能访问这个名字,并引发了一个NameError异常。
在对exec()的第二次调用中,您向globals提供了一个不同的字典。在这种情况下,字典包含两个变量,x和y,这允许函数正确工作。然而,这一次您在调用exec()后无法访问z。为什么?因为您正在使用一个定制的字典来为exec()提供一个执行范围,而不是回到您当前的范围。
如果您用一个没有明确包含__builtins__键的globals字典调用exec(),那么 Python 将自动在该键下插入一个对内置范围或名称空间的引用。因此,所有内置对象都可以从目标代码中访问:
>>> code = """ ... print(__builtins__) ... """ >>> exec(code, {}) {'__name__': 'builtins', '__doc__': "Built-in functions, ...}在本例中,您已经为
globals参数提供了一个空字典。注意,exec()仍然可以访问内置的名称空间,因为这个名称空间会自动插入到提供的字典中的__builtins__键下。如果您为
locals参数提供一个值,那么它可以是任何一个映射对象。当exec()运行您的目标代码时,这个映射对象将保存本地名称空间:
>>> code = """
... z = x + y
... print(f"{z=}")
... """
>>> x = 42 # Global name
>>> def func():
... y = 21 # Local name
... exec(code, {"x": x}, {"y": y})
...
>>> func()
z=63
>>> z
Traceback (most recent call last):
...
NameError: name 'z' is not defined
在这个例子中,对exec()的调用嵌入在一个函数中。因此,您有一个全局(模块级)作用域和一个局部(函数级)作用域。globals参数提供来自全局范围的x名称,而locals参数提供来自局部范围的y名称。
注意,在运行func()之后,您不能访问z,因为这个名称是在exec()的本地作用域下创建的,从外部是不可用的。
使用globals和locals参数,您可以调整exec()运行代码的上下文。当谈到最小化与exec()相关的安全风险时,这些争论非常有用,但是您仍然应该确保您只运行来自可信来源的代码。在下一节中,您将了解这些安全风险以及如何应对它们。
揭露并最大限度减少exec() 背后的安全风险
到目前为止,您已经了解到,exec()是一个强大的工具,它允许您执行以字符串形式出现的任意代码。你应该非常小心谨慎地使用exec(),因为它能够运行任何一段代码。
通常,提供给exec()的代码是在运行时动态生成的。这段代码可能有许多输入源,包括您的程序用户、其他程序、数据库、数据流和网络连接等等。
在这种情况下,您不能完全确定输入字符串将包含什么。因此,面对不可信和恶意的输入代码源的可能性非常高。
与exec()相关的安全问题是许多 Python 开发者建议完全避免这个函数的最常见原因。找到更好、更快、更健壮、更安全的解决方案几乎总是可能的。
但是,如果您必须在代码中使用exec(),那么通常推荐的方法是使用显式的globals和locals字典。
exec()的另一个关键问题是它打破了编程中的一个基本假设:你当前正在读或写的代码就是你启动程序时将要执行的代码。exec()如何打破这个假设?它让你的程序运行动态生成的新的未知代码。这种新代码可能难以遵循、维护,甚至难以控制。
在接下来的章节中,如果您需要在代码中使用exec(),您将深入了解一些您应该应用的建议、技术和实践。
避免来自不可信来源的输入
如果您的用户可以在运行时为您的程序提供任意 Python 代码,那么如果他们输入违反或破坏您的安全规则的代码,就会出现问题。为了说明这个问题,回到使用exec()执行代码的 Python 解释器示例:
>>> while True: ... exec(input("->> ")) ... ->> print("Hello, World!") Hello, World!现在假设您想使用这种技术在一个 Linux web 服务器上实现一个交互式 Python 解释器。如果您允许您的用户将任意代码直接传递到您的程序中,那么恶意用户可能会提供类似于
"import os; os.system('rm -rf *')"的东西。这段代码可能会删除你服务器磁盘上的所有内容,所以不要运行它。为了防止这种风险,您可以利用
globals字典来限制对import系统的访问:
>>> exec("import os", {"__builtins__": {}}, {})
Traceback (most recent call last):
...
ImportError: __import__ not found
import系统内部使用内置的__import__()函数。所以,如果你禁止访问内置的名称空间,那么import系统将无法工作。
尽管您可以按照上面的例子调整globals字典,但是有一点您绝对不能做,那就是在您自己的计算机上使用exec()来运行外部的和潜在的不安全代码。即使您仔细清理和验证了输入,您也有被黑客攻击的风险。所以,你最好避免这种做法。
限制globals和locals以最小化风险
如果您想在使用exec()运行代码时微调对全局和本地名称的访问,您可以提供自定义字典作为globals和locals参数。例如,如果您将空字典传递给globals和locals,那么exec()将无法访问您当前的全局和本地名称空间:
>>> x = 42 >>> y = 21 >>> exec("print(x + y)", {}, {}) Traceback (most recent call last): ... NameError: name 'x' is not defined如果你用空字典调用
globals和locals来调用exec(),那么你就禁止访问全局和本地名字。这个调整允许您在使用exec()运行代码时限制可用的名称和对象。然而,这种技术不能保证安全使用
exec()。为什么?因为该函数仍然可以访问 Python 的所有内置名称,正如您在部分中了解到的globals和locals参数:
>>> exec("print(min([2, 3, 7, 4, 8]))", {}, {})
2
>>> exec("print(len([2, 3, 7, 4, 8]))", {}, {})
5
在这些例子中,您为globals和locals使用了空字典,但是exec()仍然可以访问内置函数,如 min() 、 len() 和 print() 。你如何阻止exec()访问内置名字?这是下一节的主题。
决定允许的内置名称
正如您已经了解到的,如果您将一个自定义字典传递给没有__builtins__键的globals,那么 Python 将自动使用新的__builtins__键下内置范围内的所有名称更新该字典。为了限制这种隐式行为,您可以使用一个包含具有适当值的__builtins__键的globals字典。
例如,如果您想完全禁止访问内置名称,那么您可以像下面这样调用exec():
>>> exec("print(min([2, 3, 7, 4, 8]))", {"__builtins__": {}}, {}) Traceback (most recent call last): ... NameError: name 'print' is not defined在这个例子中,您将
globals设置为一个包含一个__builtins__键的自定义字典,一个空字典作为它的关联值。这种做法可以防止 Python 将对内置名称空间的引用插入到globals中。通过这种方式,可以确保exec()在执行代码时无法访问内置名称。如果您只需要
exec()访问某些内置名称,您也可以调整您的__builtins__键:
>>> allowed_builtins = {"__builtins__": {"min": min, "print": print}} >>> exec("print(min([2, 3, 7, 4, 8]))", allowed_builtins, {})
2
>>> exec("print(len([2, 3, 7, 4, 8]))", allowed_builtins, {})
Traceback (most recent call last):
...
NameError: name 'len' is not defined
在第一个例子中,exec()成功地运行了您的输入代码,因为min()和print()出现在与__builtins__键相关联的字典中。在第二个例子中,exec()引发了一个NameError,并且不运行您的输入代码,因为len()不在提供的allowed_builtins中。
上面例子中的技术允许你最小化使用exec()的安全隐患。然而,这些技术并不是完全安全的。所以,每当你觉得需要使用exec()的时候,试着去想另一个不使用该功能的解决方案。
将exec()付诸行动
至此,您已经了解了内置的exec()函数是如何工作的。您知道可以使用exec()来运行基于字符串或编译代码的输入。您还了解了这个函数可以接受两个可选参数,globals和locals,这允许您调整exec()的执行名称空间。
此外,您已经了解到使用exec()意味着一些严重的安全问题,包括允许用户在您的计算机上运行任意 Python 代码。您研究了一些推荐的编码实践,它们有助于最小化与代码中的exec()相关的安全风险。
在接下来的部分中,您将编写几个实际的例子,帮助您发现适合使用exec()的用例。
从外部来源运行代码
使用exec()执行来自用户或任何其他来源的字符串代码可能是exec()最常见也是最危险的用例。对于您来说,该函数是接受字符串形式的代码并在给定程序的上下文中将其作为常规 Python 代码运行的最快方式。
你绝不能使用exec()在你的机器上运行任意的外部代码,因为没有安全的方法可以做到这一点。如果你打算使用exec(),那么就用它来让你的用户在他们自己的机器上运行他们自己的代码。
标准库有一些模块使用exec()来执行用户以字符串形式提供的代码。一个很好的例子就是 timeit 模块,吉多·范·罗苏姆原来自己写的。
timeit模块提供了一种快速的方法来计时以字符串形式出现的小块 Python 代码。查看模块文档中的以下示例:
>>> from timeit import timeit >>> timeit("'-'.join(str(n) for n in range(100))", number=10000) 0.1282792080000945
timeit()函数将代码片段作为字符串,运行代码,并返回执行时间的测量值。该函数还接受其他几个参数。例如,number允许您提供想要执行目标代码的次数。在这个函数的核心,你会发现
Timer类。Timer使用exec()运行提供的代码。如果你检查timeit模块中Timer的源代码,那么你会发现这个类的初始化器,.__init__(),包括以下代码:# timeit.py # ... class Timer: """Class for timing execution speed of small code snippets.""" def __init__( self, stmt="pass", setup="pass", timer=default_timer, globals=None ): """Constructor. See class doc string.""" self.timer = timer local_ns = {} global_ns = _globals() if globals is None else globals # ... src = template.format(stmt=stmt, setup=setup, init=init) self.src = src # Save for traceback display code = compile(src, dummy_src_name, "exec") exec(code, global_ns, local_ns) self.inner = local_ns["inner"] # ...高亮行中对
exec()的调用使用global_ns和local_ns作为全局和局部名称空间来执行用户代码。当你为你的用户提供一个工具时,这种使用
exec()的方式是合适的,用户必须提供他们自己的目标代码。这些代码将在用户的机器上运行,因此他们将负责保证输入代码的安全运行。使用
exec()运行字符串代码的另一个例子是doctest模块。这个模块检查文档字符串,寻找看起来像 Python 交互式会话的文本。如果doctest发现任何类似交互式会话的文本,那么它将该文本作为 Python 代码执行,以检查它是否如预期那样工作。例如,假设您有以下将两个数字相加的函数:
# calculations.py def add(a, b): """Return the sum of two numbers. Tests: >>> add(5, 6) 11 >>> add(2.3, 5.4) 7.7 >>> add("2", 3) Traceback (most recent call last): TypeError: numeric type expected for "a" and "b" """ if not (isinstance(a, (int, float)) and isinstance(b, (int, float))): raise TypeError('numeric type expected for "a" and "b"') return a + b # ...在这个代码片段中,
add()用几个测试定义了一个 docstring,这些测试检查函数应该如何工作。注意,这些测试代表了在一个假设的交互会话中使用有效和无效参数类型对add()的调用。一旦在 docstrings 中有了这些交互式测试和它们的预期输出,就可以使用
doctest来运行它们,并检查它们是否发出预期的结果。注意:doctest 模块提供了一个令人惊叹的有用工具,您可以在编写代码时使用它来测试代码。
转到命令行,在包含您的
calculations.py文件的目录中运行以下命令:$ python -m doctest calculations.py如果所有测试都按预期进行,这个命令不会发出任何输出。如果至少有一个测试失败,那么您将得到一个指出问题的异常。要确认这一点,您可以在函数的 docstring 中更改一个预期的输出,并再次运行上面的命令。
doctest模块使用exec()来执行任何交互式嵌入 docstring 的代码,你可以在模块的源代码中确认:# doctest.py class DocTestRunner: # ... def __run(self, test, compileflags, out): # ... try: # Don't blink! This is where the user's code gets run. exec( compile(example.source, filename, "single", compileflags, True), test.globs ) self.debugger.set_continue() # ==== Example Finished ==== exception = None except KeyboardInterrupt: # ...正如您在这个代码片段中可以确认的,用户的代码在一个
exec()调用中运行,该调用使用compile()来编译目标代码。为了运行这段代码,exec()使用test.globs作为它的globals参数。注意,在调用exec()之前的注释开玩笑地说这是用户代码运行的地方。同样,在这个用例
exec()中,提供安全代码示例的责任在用户身上。doctest维护者不负责确保对exec()的调用不会造成任何损害。需要注意的是,
doctest并不能防止与exec()相关的安全风险。换句话说,doctest将运行任何 Python 代码。例如,有人可以修改您的add()函数,在 docstring 中包含以下代码:# calculations.py def add(a, b): """Return the sum of two numbers. Tests: >>> import os; os.system("ls -l") 0 """ if not (isinstance(a, (int, float)) and isinstance(b, (int, float))): raise TypeError('numeric type expected for "a" and "b"') return a + b如果在这个文件上运行
doctest,那么ls -l命令将成功运行。在这个例子中,嵌入的命令基本上是无害的。然而,恶意用户可以修改您的 docstring 并嵌入类似os.system("rm -rf *")或任何其他危险命令的东西。同样,你必须小心使用
exec()和使用该功能的工具,就像doctest一样。在doctest的具体案例中,只要你知道你的嵌入式测试代码来自哪里,这个工具就会相当安全和有用。将 Python 用于配置文件
可以使用
exec()运行代码的另一种情况是当您有一个使用有效 Python 语法的配置文件时。您的文件可以定义几个具有特定值的配置参数。然后,您可以读取该文件并用exec()处理其内容,以构建一个包含所有配置参数及其值的字典对象。例如,假设您正在使用的文本编辑器应用程序有以下配置文件:
# settings.conf font_face = "" font_size = 10 line_numbers = True tab_size = 4 auto_indent = True这个文件具有有效的 Python 语法,所以您可以像处理常规的
.py文件一样使用exec()来执行它的内容。注意:你会发现几种比使用
exec()更好、更安全的方法来处理配置文件。在 Python 标准库中,您有configparser模块,它允许您处理使用 INI 文件格式的配置文件。下面的函数读取您的
settings.conf文件并构建一个配置字典:
>>> from pathlib import Path
>>> def load_config(config_file):
... config_file = Path(config_file)
... code = compile(config_file.read_text(), config_file.name, "exec")
... config_dict = {}
... exec(code, {"__builtins__": {}}, config_dict)
... return config_dict
...
>>> load_config("settings.conf")
{
'font_face': '',
'font_size': 10,
'line_numbers': True,
'tab_size': 4,
'auto_indent': True
}
load_config()函数获取配置文件的路径。然后,它将目标文件作为文本读取,并将该文本传递给exec()以供执行。在exec()运行期间,该函数将配置参数注入到locals字典中,该字典稍后将返回给调用者代码。
注:本节的技术是大概是exec()的一个安全用例。在这个例子中,您的系统上运行着一个应用程序,特别是一个文本编辑器。
如果你修改应用程序的配置文件以包含恶意代码,那么你只会伤害自己,而你很可能不会这么做。然而,您仍然有可能在应用程序的配置文件中意外包含潜在的危险代码。所以,如果你不小心的话,这项技术可能会变得不安全。
当然,如果您自己编写应用程序,并且发布了带有恶意代码的配置文件,那么您将会损害整个社区。
就是这样!现在,您可以从生成的字典中读取所有配置参数及其相应的值,并使用这些参数来设置编辑器项目。
结论
您已经学习了如何使用内置的 exec() 函数从字符串或字节码输入中执行 Python 代码。这个函数为执行动态生成的 Python 代码提供了一个快捷的工具。您还了解了如何最小化与exec()相关的安全风险,以及何时可以在代码中使用该函数。
在本教程中,您已经学会了如何:
- 使用 Python 内置的
exec()函数 - 使用 Python 的
exec()来运行基于字符串的和编译代码的输入 - 评估并最小化与使用
exec()相关的安全风险
此外,您编写了一些实用的例子,帮助您更好地理解何时以及如何在 Python 代码中使用exec()。
示例代码: 单击此处下载免费的示例代码,您将使用它来探索 exec()函数的用例。******
Python 3 的 f-Strings:改进的字符串格式化语法(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 3 的 f-Strings:改进的字符串格式化语法
从 Python 3.6 开始,f 字符串是格式化字符串的一种很好的新方法。它们不仅比其他格式更易读、更简洁、更不易出错,而且速度也更快!
到本文结束时,您将了解如何以及为什么今天开始使用 f 弦。
但首先,这是在 f 弦出现之前的生活,那时你必须在雪地里走着上山去上学。
参加测验:通过我们的交互式“Python f-Strings”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
Python 中的“老派”字符串格式
在 Python 3.6 之前,有两种将 Python 表达式嵌入字符串文字进行格式化的主要方式:%-formatting 和str.format()。您将看到如何使用它们以及它们的局限性。
选项# 1:%-格式化
这是 Python 格式的 OG,从一开始就存在于语言中。你可以在 Python 文档中阅读更多内容。请记住,文档中不建议使用%格式,文档中包含以下说明:
这里描述的格式化操作展示了导致许多常见错误的各种怪癖(比如不能正确显示元组和字典)。
使用新的格式化字符串或
str.format()接口有助于避免这些错误。这些替代方案还提供了更强大、更灵活、更可扩展的文本格式化方法。"(来源)
如何使用%格式
String 对象有一个使用%操作符的内置操作,可以用来格式化字符串。实际情况是这样的:
>>> name = "Eric" >>> "Hello, %s." % name 'Hello, Eric.'为了插入多个变量,必须使用这些变量的元组。你可以这样做:
>>> name = "Eric"
>>> age = 74
>>> "Hello, %s. You are %s." % (name, age)
'Hello Eric. You are 74.'
为什么%格式不好
您刚才看到的代码示例足够易读。然而,一旦你开始使用几个参数和更长的字符串,你的代码将很快变得不容易阅读。事情已经开始变得有些混乱了:
>>> first_name = "Eric" >>> last_name = "Idle" >>> age = 74 >>> profession = "comedian" >>> affiliation = "Monty Python" >>> "Hello, %s %s. You are %s. You are a %s. You were a member of %s." % (first_name, last_name, age, profession, affiliation) 'Hello, Eric Idle. You are 74\. You are a comedian. You were a member of Monty Python.'不幸的是,这种格式不是很好,因为它冗长并且会导致错误,比如不能正确显示元组或字典。幸运的是,前方有更光明的日子。
选项 2: str.format()
Python 2.6 中引入了这种完成工作的新方法。你可以查看最新的 Python 字符串格式技术指南以获得更多信息。
如何使用 str.format()
str.format()是对%格式的改进。它使用普通的函数调用语法,并且通过被转换为字符串的对象上的__format__()方法是可扩展的。使用
str.format(),替换字段由花括号标记:
>>> "Hello, {}. You are {}.".format(name, age)
'Hello, Eric. You are 74.'
您可以通过引用变量的索引来以任意顺序引用变量:
>>> "Hello, {1}. You are {0}.".format(age, name) 'Hello, Eric. You are 74.'但是如果您插入变量名,您将获得额外的好处,能够传递对象,然后在大括号之间引用参数和方法:
>>> person = {'name': 'Eric', 'age': 74}
>>> "Hello, {name}. You are {age}.".format(name=person['name'], age=person['age'])
'Hello, Eric. You are 74.'
你也可以使用**来用字典做这个巧妙的把戏:
>>> person = {'name': 'Eric', 'age': 74} >>> "Hello, {name}. You are {age}.".format(**person) 'Hello, Eric. You are 74.'与% formatting 相比,这绝对是一个升级,但也不完全是美好的事情。
为什么 str.format()不好
使用
str.format()的代码比使用%格式的代码更容易阅读,但是当您处理多个参数和更长的字符串时,str.format()仍然非常冗长。看看这个:
>>> first_name = "Eric"
>>> last_name = "Idle"
>>> age = 74
>>> profession = "comedian"
>>> affiliation = "Monty Python"
>>> print(("Hello, {first_name} {last_name}. You are {age}. " +
>>> "You are a {profession}. You were a member of {affiliation}.") \
>>> .format(first_name=first_name, last_name=last_name, age=age, \
>>> profession=profession, affiliation=affiliation))
'Hello, Eric Idle. You are 74\. You are a comedian. You were a member of Monty Python.'
如果你在字典中有你想要传递给.format()的变量,那么你可以用.format(**some_dict)解包它,并通过字符串中的键引用值,但是必须有一个更好的方法来做到这一点。
f-Strings:在 Python 中格式化字符串的一种新的改进方法
好消息是 f 弦在这里拯救世界。他们切!他们掷骰子!他们做薯条!好吧,它们什么都不做,但是它们确实使格式化变得更容易。他们加入了 Python 3.6 的聚会。你可以在 2015 年 8 月 Eric V. Smith 写的《PEP 498 中读到所有相关内容。
也称为“格式化字符串”,f-string 是在开头有一个f和花括号的字符串,花括号包含将被其值替换的表达式。表达式在运行时被求值,然后使用__format__协议格式化。一如既往,当你想了解更多时, Python 文档是你的好朋友。
这里有一些 f 弦可以让你的生活更轻松的方法。
简单语法
语法类似于您在str.format()中使用的语法,但不太详细。看看这是多么容易阅读:
>>> name = "Eric" >>> age = 74 >>> f"Hello, {name}. You are {age}." 'Hello, Eric. You are 74.'使用大写字母
F也是有效的:
>>> F"Hello, {name}. You are {age}."
'Hello, Eric. You are 74.'
你喜欢 f 弦了吗?我希望,在这篇文章结束时,你会回答 >>> F"Yes!" 。
任意表达式
因为 f 字符串是在运行时计算的,所以可以在其中放入任何和所有有效的 Python 表达式。这允许你做一些漂亮的事情。
你可以做一些非常简单的事情,就像这样:
>>> f"{2 * 37}" '74'但是你也可以调用函数。这里有一个例子:
>>> def to_lowercase(input):
... return input.lower()
>>> name = "Eric Idle"
>>> f"{to_lowercase(name)} is funny."
'eric idle is funny.'
您也可以选择直接调用方法:
>>> f"{name.lower()} is funny." 'eric idle is funny.'您甚至可以使用从带有 f 字符串的类中创建的对象。假设您有以下类:
class Comedian: def __init__(self, first_name, last_name, age): self.first_name = first_name self.last_name = last_name self.age = age def __str__(self): return f"{self.first_name} {self.last_name} is {self.age}." def __repr__(self): return f"{self.first_name} {self.last_name} is {self.age}. Surprise!"你可以这样做:
>>> new_comedian = Comedian("Eric", "Idle", "74")
>>> f"{new_comedian}"
'Eric Idle is 74.'
__str__()和__repr__()方法处理如何将对象表示为字符串,所以你需要确保在你的类定义中至少包含其中一个方法。如果非要选一个,就选__repr__(),因为它可以代替__str__()。
由__str__()返回的字符串是对象的非正式字符串表示,应该是可读的。__repr__()返回的字符串是官方表示,应该是明确的。调用str()和repr()比直接使用__str__()和__repr__()要好。
默认情况下,f 字符串将使用__str__(),但是如果您包含转换标志!r,您可以确保它们使用__repr__():
>>> f"{new_comedian}" 'Eric Idle is 74.' >>> f"{new_comedian!r}" 'Eric Idle is 74\. Surprise!'如果你想阅读一些导致 f 字符串支持完整 Python 表达式的对话,你可以在这里阅读。
多行 f 字符串
可以有多行字符串:
>>> name = "Eric"
>>> profession = "comedian"
>>> affiliation = "Monty Python"
>>> message = (
... f"Hi {name}. "
... f"You are a {profession}. "
... f"You were in {affiliation}."
... )
>>> message
'Hi Eric. You are a comedian. You were in Monty Python.'
但是请记住,您需要在多行字符串的每一行前面放置一个f。以下代码不起作用:
>>> message = ( ... f"Hi {name}. " ... "You are a {profession}. " ... "You were in {affiliation}." ... ) >>> message 'Hi Eric. You are a {profession}. You were in {affiliation}.'如果你不在每一行前面加一个
f,那么你就只有普通的、旧的、普通的琴弦,而没有闪亮的、新的、花哨的 f 弦。如果您想将字符串分布在多行中,您还可以选择用
\来转义 return:
>>> message = f"Hi {name}. " \
... f"You are a {profession}. " \
... f"You were in {affiliation}."
...
>>> message
'Hi Eric. You are a comedian. You were in Monty Python.'
但是如果你使用"""就会发生这种情况:
>>> message = f""" ... Hi {name}. ... You are a {profession}. ... You were in {affiliation}. ... """ ... >>> message '\n Hi Eric.\n You are a comedian.\n You were in Monty Python.\n'阅读 PEP 8 中的缩进指南。
速度
f 弦中的
f也可以代表“快”。f 字符串比% formatting 和
str.format()都要快。正如您已经看到的,f 字符串是在运行时计算的表达式,而不是常量值。以下是这些文件的摘录:F 字符串提供了一种使用最小语法将表达式嵌入字符串文字的方法。应该注意,f 字符串实际上是一个在运行时计算的表达式,而不是一个常数值。在 Python 源代码中,f-string 是一个文字字符串,前缀为
f,包含大括号内的表达式。表达式将被替换为它们的值。(来源)在运行时,花括号内的表达式在其自身的范围内进行计算,然后与 f 字符串的字符串文字部分放在一起。然后返回结果字符串。这就够了。
这里有一个速度对比:
>>> import timeit
>>> timeit.timeit("""name = "Eric"
... age = 74
... '%s is %s.' % (name, age)""", number = 10000)
0.003324444866599663
>>> timeit.timeit("""name = "Eric" ... age = 74 ... '{} is {}.'.format(name, age)""", number = 10000) 0.004242089427570761
>>> timeit.timeit("""name = "Eric"
... age = 74
... f'{name} is {age}.'""", number = 10000)
0.0024820892040722242
如你所见,f 弦出现在顶部。
然而,情况并非总是如此。当他们第一次实现时,他们有一些速度问题,需要比str.format()更快。引入了一个特殊的 BUILD_STRING操作码。
Python f-Strings:讨厌的细节
既然你已经了解了 f 弦为什么如此伟大,我相信你一定想走出去开始使用它们。当你冒险进入这个勇敢的新世界时,有一些细节要记住。
引号
您可以在表达式中使用各种类型的引号。只要确保在 f 字符串的外部没有使用与表达式中相同类型的引号。
这段代码将起作用:
>>> f"{'Eric Idle'}" 'Eric Idle'此代码也将工作:
>>> f'{"Eric Idle"}'
'Eric Idle'
您也可以使用三重引号:
>>> f"""Eric Idle""" 'Eric Idle'
>>> f'''Eric Idle'''
'Eric Idle'
如果您发现您需要在字符串的内部和外部使用相同类型的引号,那么您可以使用\进行转义:
>>> f"The \"comedian\" is {name}, aged {age}." 'The "comedian" is Eric Idle, aged 74.'字典
说到引号,你在查字典的时候要小心。如果您打算对字典的键使用单引号,那么请记住确保对包含这些键的 f 字符串使用双引号。
这将起作用:
>>> comedian = {'name': 'Eric Idle', 'age': 74}
>>> f"The comedian is {comedian['name']}, aged {comedian['age']}."
The comedian is Eric Idle, aged 74.
但是这将会是一场混乱,因为有一个语法错误:
>>> comedian = {'name': 'Eric Idle', 'age': 74} >>> f'The comedian is {comedian['name']}, aged {comedian['age']}.' File "<stdin>", line 1 f'The comedian is {comedian['name']}, aged {comedian['age']}.' ^ SyntaxError: invalid syntax如果在字典键周围使用与 f 字符串外部相同类型的引号,那么第一个字典键开头的引号将被解释为字符串的结尾。
大括号
为了让大括号出现在字符串中,您必须使用双大括号:
>>> f"{{70 + 4}}"
'{70 + 4}'
请注意,使用三大括号将导致字符串中只有一个大括号:
>>> f"{{{70 + 4}}}" '{74}'但是,如果使用三个以上的大括号,可以显示更多的大括号:
>>> f"{{{{70 + 4}}}}"
'{{70 + 4}}'
反斜杠
正如您前面看到的,您可以在 f 字符串的字符串部分使用反斜杠转义。但是,不能在 f 字符串的表达式部分使用反斜杠进行转义:
>>> f"{\"Eric Idle\"}" File "<stdin>", line 1 f"{\"Eric Idle\"}" ^ SyntaxError: f-string expression part cannot include a backslash您可以通过预先计算表达式并在 f 字符串中使用结果来解决这个问题:
>>> name = "Eric Idle"
>>> f"{name}"
'Eric Idle'
行内注释
表达式不应包含使用#符号的注释。您将得到一个语法错误:
>>> f"Eric is {2 * 37 #Oh my!}." File "<stdin>", line 1 f"Eric is {2 * 37 #Oh my!}." ^ SyntaxError: f-string expression part cannot include '#'开始格式化吧!
您仍然可以使用旧的格式化字符串的方法,但是有了 f 字符串,您现在有了一种更简洁、可读性更好、更方便的方法,既更快又不容易出错。通过使用 f 字符串来简化您的生活是开始使用 Python 3.6 的一个很好的理由,如果您还没有做出改变的话。(如果你还在用 Python 2,别忘了 2020 马上就来了!)
延伸阅读
如果你想阅读关于字符串插值的详细讨论,看看 PEP 502 。此外, PEP 536 草案对 f 弦的未来有更多的想法。
免费 PDF 下载: Python 3 备忘单
要获得更多关于字符串的乐趣,请查看以下文章:
- Dan Bader 的 Python 字符串格式化最佳实践
- Colin OKeefe 的 Python Web 抓取实用介绍
快乐的蟒蛇!
参加测验:通过我们的交互式“Python f-Strings”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 3 的 f-Strings:改进的字符串格式化语法******
Python 的 filter():从 Iterables 中提取值
Python 的
filter()是一个内置函数,允许你处理一个 iterable,提取那些满足给定条件的项。这个过程通常被称为滤波操作。使用filter(),您可以将一个过滤函数应用到一个 iterable,并生成一个新的 iterable,其中包含满足当前条件的条目。在 Python 中,filter()是你可以用来进行函数式编程的工具之一。在本教程中,您将学习如何:
- 在你的代码中使用 Python 的
filter()- 从你的迭代中提取需要的值
- 将
filter()与其他功能工具结合- 用更多的蟒工具替换
filter()有了这些知识,您将能够在代码中有效地使用
filter()。或者,您可以选择使用列表理解或生成器表达式来编写更多的python 式和可读代码。为了更好地理解
filter(),对可迭代、、for循环、函数和、lambda函数有所了解会有所帮助。免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 中的函数式编码
函数式编程是一种范式,提倡使用函数来执行程序中的几乎每一项任务。纯函数式风格依赖于不修改输入参数和不改变程序状态的函数。他们只是采用一组特定的参数,而每次都返回相同的结果。这类函数被称为纯函数。
在函数式编程中,函数通常对数据数组进行操作、转换,并产生具有附加功能的新数组。函数式编程中有三种基本操作:
- 映射将一个转换函数应用于一个可迭代对象,并生成一个新的可迭代的已转换项目。
- 过滤将一个谓词或布尔值函数应用于一个可迭代对象,并生成一个新的可迭代对象,其中包含满足布尔条件的项目。
- 归约将归约函数应用于 iterable,并返回单个累积值。
Python 并没有受到函数式语言的严重影响,而是受到了命令式语言的影响。但是,它提供了几个允许您使用函数样式的特性:
Python 中的函数是一级对象,这意味着你可以像对待任何其他对象一样传递它们。您还可以将它们用作其他函数的参数和返回值。接受其他函数作为参数或者返回函数(或者两者都接受)的函数被称为高阶函数,这也是函数式编程中的一个理想特性。
在本教程中,您将了解到
filter()。这个内置函数是 Python 中比较流行的函数工具之一。理解过滤问题
假设您需要处理一个由数字组成的列表,并返回一个只包含那些大于
0的数字的新列表。解决这个问题的一个快速方法是像这样使用一个for循环:
>>> numbers = [-2, -1, 0, 1, 2]
>>> def extract_positive(numbers):
... positive_numbers = []
... for number in numbers:
... if number > 0: # Filtering condition ... positive_numbers.append(number)
... return positive_numbers
...
>>> extract_positive(numbers)
[1, 2]
extract_positive()中的循环遍历numbers并将每个大于0的数字存储在positive_numbers中。条件语句 过滤掉负数和0。这种功能被称为过滤。
过滤操作包括用一个谓词函数测试 iterable 中的每个值,并只保留那些函数产生真结果的值。过滤操作在编程中相当常见,所以大多数编程语言都提供了处理这些操作的工具。在下一节中,您将了解 Python 过滤 iterables 的方法。
Python 的filter() 入门
Python 提供了一个方便的内置函数filter(),它抽象出了过滤操作背后的逻辑。这是它的签名:
filter(function, iterable)
第一个参数function必须是单参数函数。通常,您为该参数提供一个谓词(布尔值)函数。换句话说,你提供了一个根据特定条件返回True或False的函数。
这个function起到了决策函数的作用,也称为过滤函数,因为它提供了从输入可迭代中过滤掉不需要的值并在结果可迭代中保留那些您想要的值的标准。请注意,术语不需要的值指的是当filter()使用function处理它们时评估为假的那些值。
注意:filter()的第一个参数是一个函数对象,这意味着你需要传递一个函数,而不需要用一对括号来调用它。
第二个参数iterable,可以保存任何 Python iterable,比如一个列表,元组,或者集合。它还可以保存生成器和迭代器对象。关于filter()重要的一点是它只接受一个iterable。
为了执行过滤过程,filter()在一个循环中将function应用于iterable的每一项。结果是一个迭代器,它产生iterable的值,其中function返回一个真值。该过程不会修改原始的输入 iterable。
由于filter()是用 C 编写的,并且经过了高度优化,其内部隐式循环在执行时间方面比常规的for循环更高效。这种效率可以说是在 Python 中使用函数的最重要的优势。
在循环中使用filter()的第二个优点是,它返回一个filter对象,这是一个根据需要产生值的迭代器,促进了一种惰性求值策略。返回迭代器使得filter()比等价的for循环更有内存效率。
注意:在 Python 2.x 中, filter() 返回list对象。这种行为在 Python 3.x 中有所改变。现在,该函数返回一个filter对象,这是一个迭代器,根据需要生成条目。众所周知,Python 迭代器是内存高效的。
在关于正数的例子中,可以使用filter()和一个方便的谓词函数来提取所需的数字。为了编写谓词,您可以使用一个lambda或一个用户定义的函数:
>>> numbers = [-2, -1, 0, 1, 2] >>> # Using a lambda function >>> positive_numbers = filter(lambda n: n > 0, numbers) >>> positive_numbers <filter object at 0x7f3632683610> >>> list(positive_numbers) [1, 2] >>> # Using a user-defined function >>> def is_positive(n): ... return n > 0 ... >>> list(filter(is_positive, numbers)) [1, 2]在第一个例子中,您使用了一个提供过滤功能的
lambda函数。对filter()的调用将lambda函数应用于numbers中的每个值,并过滤掉负数和0。由于filter()返回一个迭代器,所以需要调用list()来消耗迭代器并创建最终列表。注意:因为
filter()是一个内置函数,你不需要导入任何东西来在你的代码中使用它。在第二个示例中,您编写
is_positive()来接受一个数字作为参数,如果该数字大于0,则返回True。否则返回False。对filter()的调用将is_positive()应用于numbers中的每个值,过滤掉负数。这个解决方案比它的对等方案更具可读性。实际上,
filter()并不局限于上面例子中的布尔函数。您可以使用其他类型的函数,并且filter()将评估它们的返回值的真实性:
>>> def identity(x):
... return x
...
>>> identity(42)
42
>>> objects = [0, 1, [], 4, 5, "", None, 8]
>>> list(filter(identity, objects))
[1, 4, 5, 8]
在这个例子中,过滤函数identity()没有显式返回True或False,而是采用了相同的参数。由于0、[]、""、、None、为假,filter()使用它们的真值将其过滤掉。最终的列表只包含那些在 Python 中为真的值。
注意: Python 遵循一套规则来确定一个对象的真值。
例如,下列对象是假的:
- 像
None和False这样的常数 - 带有零值的数字类型,如
0、0.0、0j、、Decimal(0)、、Fraction(0, 1)、 - 空序列和集合,如
""、()、[]、{}、、、range(0) - 实现返回值为
False的__bool__()或返回值为0的__len__()的对象
任何其他物体都将被认为是真实的。
最后,如果您将None传递给function,那么filter()使用标识函数并产生iterable中所有评估为True的元素:
>>> objects = [0, 1, [], 4, 5, "", None, 8] >>> list(filter(None, objects)) [1, 4, 5, 8]在这种情况下,
filter()使用您之前看到的 Python 规则测试输入 iterable 中的每一项。然后它产生那些评估为True的项目。到目前为止,你已经学习了
filter()的基础知识以及它是如何工作的。在接下来的小节中,您将学习如何使用filter()来处理可重复项,并在没有循环的情况下丢弃不需要的值。用
filter()过滤可重复项
filter()的工作是对输入 iterable 中的每个值应用一个决策函数,并返回一个新的 iterable,其中包含那些通过测试的项。以下部分提供了一些实用的例子,这样您就可以开始使用filter()了。提取偶数
作为第一个例子,假设您需要处理一个整数列表,并构建一个包含偶数的新列表。解决这个问题的第一个方法可能是使用如下的
for循环:
>>> numbers = [1, 3, 10, 45, 6, 50]
>>> def extract_even(numbers):
... even_numbers = []
... for number in numbers:
... if number % 2 == 0: # Filtering condition ... even_numbers.append(number)
... return even_numbers
...
>>> extract_even(numbers)
[10, 6, 50]
这里,extract_even()接受一个整数的 iterable 并返回一个只包含偶数的列表。条件语句扮演着过滤器的角色,它测试每个数字,以确定它是否是偶数。
当您遇到这样的代码时,您可以将过滤逻辑提取到一个小的谓词函数中,并与filter()一起使用。这样,您可以在不使用显式循环的情况下执行相同的计算:
>>> numbers = [1, 3, 10, 45, 6, 50] >>> def is_even(number): ... return number % 2 == 0 # Filtering condition ... >>> list(filter(is_even, numbers)) [10, 6, 50]这里,
is_even()接受一个整数,如果是偶数,则返回True,否则返回False。对filter()的调用做了艰苦的工作,过滤掉奇数。结果,你得到一个偶数的列表。这段代码比它的对等for循环更短更有效。寻找质数
另一个有趣的例子可能是提取给定区间内所有的素数。为此,您可以首先编写一个谓词函数,该函数将一个整数作为参数,如果该数字是质数,则返回
True,否则返回False。你可以这样做:
>>> import math
>>> def is_prime(n):
... if n <= 1:
... return False
... for i in range(2, int(math.sqrt(n)) + 1):
... if n % i == 0:
... return False
... return True
...
>>> is_prime(5)
True
>>> is_prime(12)
False
过滤逻辑现在在is_prime()中。该函数遍历2和n的平方根之间的整数。在循环内部,条件语句检查当前数字是否能被区间中的任何其他数字整除。如果是,那么函数返回False,因为这个数不是质数。否则,它返回True来表示输入的数字是质数。
有了is_prime()并经过测试,您可以使用filter()从一个区间中提取素数,如下所示:
>>> list(filter(is_prime, range(1, 51))) [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]对
filter()的调用提取了在1和50之间的所有质数。is_prime()中使用的算法来自维基百科关于素性测试的文章。如果您需要更有效的方法,可以查看那篇文章。去除样本中的异常值
当你试图描述和总结一个样本数据时,你可能会从寻找它的平均值开始。平均值是一种非常流行的集中趋势度量,并且通常是分析数据集的第一种方法。它能让你快速了解数据的中心,或位置。
在某些情况下,对于给定的样本,平均值不是一个足够好的集中趋势度量。异常值是影响平均值准确度的因素之一。异常值是与样本或总体中的其他观察值显著不同的数据点。除此之外,它们在统计学中没有唯一的数学定义。
然而,在正态分布的样本中,异常值通常被定义为距离样本均值超过两个标准偏差的数据点。
现在,假设您有一个正态分布的样本,其中有一些影响平均准确度的异常值。您已经研究了异常值,并且知道它们是不正确的数据点。以下是如何使用
statistics模块中的几个函数和filter()来清理数据:
>>> import statistics as st
>>> sample = [10, 8, 10, 8, 2, 7, 9, 3, 34, 9, 5, 9, 25]
>>> # The mean before removing outliers
>>> mean = st.mean(sample)
>>> mean
10.692307692307692
>>> stdev = st.stdev(sample)
>>> low = mean - 2 * stdev
>>> high = mean + 2 * stdev
>>> clean_sample = list(filter(lambda x: low <= x <= high, sample)) >>> clean_sample
[10, 8, 10, 8, 2, 7, 9, 3, 9, 5, 9, 25]
>>> # The mean after removing outliers
>>> st.mean(clean_sample)
8.75
在突出显示的行中,如果给定的数据点位于平均值和两个标准偏差之间,lambda函数返回True。否则,它返回False。用此功能过滤sample时,34被排除。在这种清理之后,样本的平均值具有显著不同的值。
验证 Python 标识符
您也可以对包含非数字数据的 iterables 使用filter()。例如,假设您需要处理一列字符串,并提取那些有效的 Python 标识符。在做了一些研究之后,您发现 Python 的 str 提供了一个名为 .isidentifier() 的方法,可以帮助您完成验证。
下面是如何使用filter()和str.isidentifier()来快速验证标识符:
>>> words = ["variable", "file#", "header", "_non_public", "123Class"] >>> list(filter(str.isidentifier, words)) ['variable', 'header', '_non_public']在这种情况下,
filter()在words中的每个字符串上运行.isidentifier()。如果字符串是有效的 Python 标识符,那么它将包含在最终结果中。否则,该单词将被过滤掉。注意,在调用filter()时,需要使用str来访问.isidentifier()。注意:除了
.isidentifier(),str提供了一套丰富的.is*()方法,可以用来过滤字符串的可重复项。最后,一个有趣的练习可能是进一步举例,检查标识符是否也是一个关键字。来吧,试一试!提示:您可以使用
keyword模块中的.kwlist。寻找回文单词
当您熟悉 Python 字符串时,经常出现的一个练习是在字符串列表中找到回文单词。回文单词向后读和向前读是一样的。典型的例子是“夫人”和“赛车”
要解决这个问题,首先要编写一个谓词函数,该函数接受一个字符串,并检查它在两个方向(向前和向后)上的读数是否相同。下面是一个可能的实现:
>>> def is_palindrome(word):
... reversed_word = "".join(reversed(word))
... return word.lower() == reversed_word.lower()
...
>>> is_palindrome("Racecar")
True
>>> is_palindrome("Python")
False
在is_palindrome()中,你首先将原来的word反转,存储在reversed_word中。然后返回两个词相等的比较结果。在这种情况下,您使用.lower()来防止与大小写相关的差异。如果你用一个回文单词调用这个函数,那么你会得到True。否则,你得到False。
您已经有了一个可以识别回文单词的谓词函数。以下是你如何使用filter()来完成这项艰巨的工作:
>>> words = ("filter", "Ana", "hello", "world", "madam", "racecar") >>> list(filter(is_palindrome, words)) ['Ana', 'madam', 'racecar']酷!你的
filter()和is_palindrome()组合工作正常。它同样简洁、易读、高效。干得好!将
filter()与其他功能工具结合到目前为止,您已经学习了如何使用
filter()在 iterables 上运行不同的过滤操作。在实践中,您可以将filter()与其他功能工具结合起来,在不使用显式循环的情况下对可迭代对象执行许多不同的任务。在接下来的两节中,你将学习使用filter()以及map()和reduce()的基础知识。偶数的平方:
filter()和map()有时你需要获取一个 iterable,用一个转换函数处理它的每一个项,并用结果项生成一个新的 iterable。那样的话,可以用
map()。该函数具有以下签名:map(function, iterable[, iterable1, ..., iterableN])论点是这样的:
function掌握着转换功能。这个函数应该接受和传递给map()的 iterables 一样多的参数。iterable掌握着一条巨蟒。注意,您可以向map()提供几个 iterables,但这是可选的。
map()将function应用于iterable中的每一项,将其转换为具有附加功能的不同值。然后map()按需产生每个转换的项目。为了说明如何使用
filter()和map(),假设您需要计算给定列表中所有偶数的平方值。在这种情况下,您可以使用filter()提取偶数,然后使用map()计算平方值:
>>> numbers = [1, 3, 10, 45, 6, 50]
>>> def is_even(number):
... return number % 2 == 0
...
>>> even_numbers = list(filter(is_even, numbers))
>>> even_numbers
[10, 6, 50]
>>> list(map(lambda n: n ** 2, even_numbers))
[100, 36, 2500]
>>> list(map(lambda n: n ** 2, filter(is_even, numbers)))
[100, 36, 2500]
首先,您使用filter()和is_even()得到偶数,就像您到目前为止所做的一样。然后用一个接受一个数字并返回其平方值的lambda函数调用map()。对map()的调用将lambda函数应用于even_numbers中的每个数字,因此您得到一个平方偶数的列表。最后一个例子展示了如何在一个表达式中组合filter()和map()。
偶数之和:filter()和reduce()
Python 中的另一个函数式编程工具是reduce()。与filter()和map()仍然是内置函数不同,reduce()被移到了 functools 模块。当您需要将一个函数应用于一个 iterable 并将它简化为一个累积值时,这个函数非常有用。这种操作通常被称为缩小或折叠。
reduce()的签名是这样的:
reduce(function, iterable, initial)
这些论点的意思是:
function保存任何接受两个参数并返回一个值的 Python 可调用函数。iterable容纳任何可迭代的 Python。initial保存一个值,作为第一次部分计算或归约的起点。这是一个可选参数。
对reduce()的调用通过将function应用于iterable中的前两项开始。这样,它计算第一个累积结果,称为累加器。然后reduce()使用累加器和iterable中的第三项计算下一个累加结果。该过程继续,直到函数返回单个值。
如果向initial提供一个值,那么reduce()使用initial和iterable的第一项运行第一个部分计算。
下面是一个结合filter()和reduce()来累计计算列表中所有偶数的总和的例子:
>>> from functools import reduce >>> numbers = [1, 3, 10, 45, 6, 50] >>> def is_even(number): ... return number % 2 == 0 ... >>> even_numbers = list(filter(is_even, numbers)) >>> reduce(lambda a, b: a + b, even_numbers) 66 >>> reduce(lambda a, b: a + b, filter(is_even, numbers)) 66这里,对
reduce()的第一次调用计算了filter()提供的所有偶数的总和。为此,reduce()使用了一个lambda函数,一次将两个数字相加。最后一个例子展示了如何链接
filter()和reduce()来产生与之前相同的结果。用
filterfalse()过滤可重复项在
itertools中,你会发现一个叫做filterfalse()的函数,它执行filter()的逆运算。它将 iterable 作为参数,并返回一个新的迭代器,该迭代器产生决策函数返回 false 结果的项目。如果你使用None作为filterfalse()的第一个参数,那么你会得到错误的条目。拥有
filterfalse()功能的意义在于促进代码重用。如果您已经有了一个决策函数,那么您可以使用它和filterfalse()来获得被拒绝的项目。这使您不必编写逆决策函数。在接下来的部分中,您将编写一些示例,展示如何利用
filterfalse()来重用现有的决策函数并继续进行一些过滤。提取奇数
您已经编写了一个名为
is_even()的谓词函数来检查一个数字是否是偶数。有了这个函数和filterfalse()的帮助,您可以构建一个迭代器,它可以产生奇数,而不必编写一个is_odd()函数:
>>> from itertools import filterfalse
>>> numbers = [1, 3, 10, 45, 6, 50]
>>> def is_even(number):
... return number % 2 == 0
...
>>> list(filterfalse(is_even, numbers))
[1, 3, 45]
在这个例子中,filterfalse()返回一个迭代器,它从输入迭代器中产生奇数。注意,对filterfalse()的调用是简单易懂的。
过滤掉 NaN 值
有时,当您使用浮点运算时,您可能会遇到 NaN(不是一个数字)值的问题。例如,假设您正在计算包含 NaN 值的数据样本的平均值。如果您使用 Python 的statistics模块进行计算,那么您会得到以下结果:
>>> import statistics as st >>> sample = [10.1, 8.3, 10.4, 8.8, float("nan"), 7.2, float("nan")] >>> st.mean(sample) nan在这个例子中,对
mean()的调用返回nan,这不是您能得到的最有价值的值。NaN 值可以有不同的来源。它们可能是由于无效输入、损坏的数据等原因造成的。您应该在应用程序中找到正确的策略来处理它们。一种替代方法是将它们从数据中删除。
math模块提供了一个方便的函数isnan()可以帮你解决这个问题。该函数将数字x作为参数,如果x是 NaN,则返回True,否则返回False。您可以使用该函数在filterfalse()调用中提供过滤标准:
>>> import math
>>> import statistics as st
>>> from itertools import filterfalse
>>> sample = [10.1, 8.3, 10.4, 8.8, float("nan"), 7.2, float("nan")]
>>> st.mean(filterfalse(math.isnan, sample))
8.96
将math.isnan()与filterfalse()一起使用允许您从平均值计算中排除所有 NaN 值。注意,过滤之后,对mean()的调用返回一个值,该值提供了对样本数据的更好描述。
Pythonic 风格编码
尽管map()、filter()和reduce()在 Python 生态系统中已经存在很长时间了,但是列表理解和生成器表达式已经成为 Python 几乎所有用例中强大的竞争对手。
这些函数提供的功能几乎总是使用生成器表达式或列表理解来更明确地表达。在接下来的两节中,您将学习如何用列表理解或生成器表达式替换对filter()的调用。这种替换将使您的代码更加 Pythonic 化。
用列表理解替换filter()
您可以使用以下模式将对filter()的调用快速替换为等价的列表理解:
# Generating a list with filter()
list(filter(function, iterable))
# Generating a list with a list comprehension
[item for item in iterable if function(item)]
在这两种情况下,最终目的都是创建一个列表对象。列表理解方法比其等价的filter()构造更明确。快速阅读理解可以揭示迭代以及if子句中的过滤功能。
使用 list comprehensions 而不是filter()可能是当今大多数 Python 开发人员的做法。然而,与filter()相比,列表理解有一些缺点。最显著的一个就是懒评的缺失。此外,当开发人员开始阅读使用filter()的代码时,他们立即知道代码正在执行过滤操作。然而,这在使用列表理解的代码中并不明显。
在将filter()构造转化为列表理解时,需要注意的一个细节是,如果将None传递给filter()的第一个参数,那么等价的列表理解如下所示:
# Generating a list with filter() and None
list(filter(None, iterable))
# Equivalent list comprehension
[item for item in iterable if item]
在这种情况下,list comprehension 中的if子句测试item的真值。这个测试遵循您已经看到的关于真值的标准 Python 规则。
下面是一个用列表理解替换filter()来构建偶数列表的例子:
>>> numbers = [1, 3, 10, 45, 6, 50] >>> # Filtering function >>> def is_even(x): ... return x % 2 == 0 ... >>> # Use filter() >>> list(filter(is_even, numbers)) [10, 6, 50] >>> # Use a list comprehension >>> [number for number in numbers if is_even(number)] [10, 6, 50]在这个例子中,您可以看到列表理解变体更加明确。它读起来几乎像简单的英语。列表理解解决方案还避免了必须调用
list()来构建最终列表。用生成器表达式替换
filter()对
filter()的自然替换是一个生成器表达式。这是因为filter()返回一个迭代器,它像生成器表达式一样按需生成条目。众所周知,Python 迭代器是内存高效的。这就是为什么filter()现在返回一个迭代器而不是一个列表。下面是如何使用生成器表达式来编写上一节中的示例:
>>> numbers = [1, 3, 10, 45, 6, 50]
>>> # Filtering function
>>> def is_even(x):
... return x % 2 == 0
...
>>> # Use filter()
>>> even_numbers = filter(is_even, numbers)
>>> even_numbers
<filter object at 0x7f58691de4c0>
>>> list(even_numbers)
[10, 6, 50]
>>> # Use a generator expression
>>> even_numbers = (number for number in numbers if is_even(number))
>>> even_numbers
<generator object <genexpr> at 0x7f586ade04a0>
>>> list(even_numbers)
[10, 6, 50]
就内存消耗而言,生成器表达式与调用filter()一样有效。这两个工具都返回按需生成项目的迭代器。使用任何一种都可能是品味、方便或风格的问题。所以,你说了算!
结论
Python 的filter()允许你对 iterables 执行过滤操作。这种操作包括将一个布尔函数应用于 iterable 中的项目,并只保留那些函数返回真结果的值。通常,您可以使用filter()来处理现有的 iterables,并生成包含您当前需要的值的新 iterables。
在本教程中,您学习了如何:
- 用 Python 创作的
filter() - 使用
filter()到过程变量并保持您需要的值 - 将
filter()与map()和reduce()结合起来处理不同的问题 - 将
filter()替换为列表理解和生成器表达式
有了这些新的知识,你现在可以在你的代码中使用filter(),给它一个函数风格。您也可以切换到更 Pythonic 化的风格,用列表理解或生成器表达式替换filter()。******
如何从 Python 列表或 Iterable 中获取第一个匹配
在您的 Python 旅程中的某个时刻,您可能需要在 Python 的可迭代中找到与某个标准匹配的第个项目,例如列表或字典。
最简单的情况是,您需要确认 iterable 中存在一个特定的项。例如,您想在姓名列表中查找一个姓名,或者在字符串中查找一个子字符串。在这些情况下,最好使用in操作符。但是,在很多情况下,您可能希望查找具有特定属性的项目。例如,您可能需要:
本教程将介绍如何最好地处理这三种情况。一种选择是将整个 iterable 转换成一个新的列表,然后使用.index()来查找第一个符合标准的条目:
>>> names = ["Linda", "Tiffany", "Florina", "Jovann"] >>> length_of_names = [len(name) for name in names] >>> idx = length_of_names.index(7) >>> names[idx] 'Tiffany'在这里,您使用了
.index()发现"Tiffany"是您的列表中的第一个名字,有七个字符。这个解决方案不是很好,部分原因是您计算了所有元素的标准,即使第一个项目是匹配的。在上述情况下,您正在搜索您正在迭代的项目的计算属性。在本教程中,您将学习如何匹配这样一个派生属性,而无需进行不必要的计算。
示例代码: 单击此处下载免费源代码,您将使用它来查找 Python 列表或 iterable 中的第一个匹配。
如何获得 Python 列表中的第一个匹配项
您可能已经知道了
inPython 操作符,它可以告诉您一个项目是否在 iterable 中。虽然这是您可以用于此目的的最有效的方法,但有时您可能需要基于项目的计算属性进行匹配,如它们的长度。例如,您可能正在处理一个字典列表,这是处理 JSON 数据时可能得到的典型结果。查看从
country-json获得的数据:
>>> countries = [
... {"country": "Austria", "population": 8_840_521},
... {"country": "Canada", "population": 37_057_765},
... {"country": "Cuba", "population": 11_338_138},
... {"country": "Dominican Republic", "population": 10_627_165},
... {"country": "Germany", "population": 82_905_782},
... {"country": "Norway", "population": 5_311_916},
... {"country": "Philippines", "population": 106_651_922},
... {"country": "Poland", "population": 37_974_750},
... {"country": "Scotland", "population": 5_424_800},
... {"country": "United States", "population": 326_687_501},
... ]
你可能想找到第一本拥有超过一亿人口的字典。由于两个原因,in操作符不是一个很好的选择。首先,您需要完整的字典来匹配它,其次,它不会返回实际的对象,而是一个布尔值:
>>> target_country = {"country": "Philippines", "population": 106_651_922} >>> target_country in countries True如果您需要根据字典的属性(比如人口)来查找字典,就没有办法使用
in。根据计算值查找和操作列表中第一个元素的最容易理解的方法是使用一个简单的
for循环:
>>> for country in countries:
... if country["population"] > 100_000_000:
... print(country)
... break
...
{"country": "Philippines", "population": 106651922}
除了打印目标对象,您可以在for循环体中对它做任何您想做的事情。完成后,一定要打破for循环,这样就不会不必要地搜索列表的其余部分。
注意:使用break语句适用于从 iterable 中寻找第一个匹配。如果您希望获得或处理所有的匹配,那么您可以不使用break。
for循环方法是 first 包采用的方法,这是一个很小的包,你可以从 PyPI 下载,它公开了一个通用函数first()。默认情况下,该函数从 iterable 返回第一个真值,并带有一个可选的key参数,用于在第一个值通过key参数传递后返回该值。
注意:在 Python 3.10 和更高版本中,您可以使用结构模式匹配来以您喜欢的方式匹配这些类型的数据结构。例如,您可以查找第一个人口超过一亿的国家,如下所示:
>>> for country in countries: ... match country: ... case {"population": population} if population > 100_000_000: ... print(country) ... break ... {'country': 'Philippines', 'population': 106651922}在这里,你使用一个守卫,只匹配某些人群。
如果匹配模式足够复杂,那么使用结构化模式匹配代替常规条件语句会更加易读和简洁。
在本教程的后面,您将实现自己的
first()函数变体。但是首先,您将研究返回第一个匹配的另一种方法:使用生成器。使用 Python 生成器获得第一个匹配
Python 生成器迭代器是内存高效的可迭代对象,可用于查找列表中的第一个元素或任何可迭代对象。它们是 Python 的核心特性,被广泛使用。很可能你已经在不知不觉中使用过发电机了!
生成器的潜在问题是它们有点抽象,因此不像
for循环那样易读。您确实从生成器中获得了一些性能上的好处,但是当考虑到可读性的重要性时,这些好处通常是可以忽略的。也就是说,使用它们会很有趣,并真正提升你的 Python 游戏水平!在 Python 中,你可以用各种方式创建一个生成器,但是在本教程中,你将使用生成器理解:
>>> gen = (country for country in countries)
>>> next(gen)
{'country': 'Austria', 'population': 8840521}
>>> next(gen)
{'country': 'Canada', 'population': 37057765}
一旦定义了生成器迭代器,就可以用生成器调用next()函数,一个接一个地产生国家,直到countries列表用完。
为了在列表中找到匹配特定标准的第一个元素,您可以在生成器理解中添加一个条件表达式,这样结果迭代器将只产生匹配您的标准的项目。在以下示例中,您使用条件表达式根据项目的population属性是否超过一亿来生成项目:
>>> gen = ( ... country for country in countries ... if country["population"] > 100_000_000 ... ) >>> next(gen) {'country': 'Philippines', 'population': 106651922}所以现在生成器只会生成
population属性过亿的字典。这意味着你第一次用生成器迭代器调用next()时,它会产生你在列表中寻找的第一个元素,就像for循环版本一样。注意:如果你调用
next()没有匹配或者生成器耗尽,你会得到一个异常。为了防止这种情况,您可以向next()传递一个default参数:
>>> next(gen, None)
{'country': 'United States', 'population': 326687501}
>>> next(gen, None)
一旦生成器完成生成匹配,它将返回传入的默认值。因为您正在返回None,所以在 REPL 上没有输出。如果你没有传入默认值,你会得到一个StopIteration 异常。
就可读性而言,生成器不像for循环那样自然。那么,您为什么要为此使用一个呢?在下一节中,您将进行一个快速的性能比较。
比较回路和发电机的性能
一如往常,在衡量绩效时,你不应该对任何一组结果做过多解读。相反,在你做任何重要的决定之前,用你真实的数据为你自己的代码设计一个测试。你还需要权衡复杂性和可读性——也许减少几毫秒是不值得的!
对于这个测试,您需要创建一个函数,该函数可以创建任意大小的列表,并且在特定位置具有特定值:
>>> from pprint import pp >>> def build_list(size, fill, value, at_position): ... return [value if i == at_position else fill for i in range(size)] ... >>> pp( ... build_list( ... size=10, ... fill={"country": "Nowhere", "population": 10}, ... value={"country": "Atlantis", "population": 100}, ... at_position=5, ... ) ... ) [{'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}, {'country': 'Atlantis', 'population': 100}, {'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}, {'country': 'Nowhere', 'population': 10}]
build_list()功能创建一个包含相同项目的列表。除一项外,列表中所有项目均为fill参数的副本。唯一的异常值是value参数,它被放在at_position参数提供的索引处。您导入了
pprint,并使用它来输出构建的列表,以使其更具可读性。否则,默认情况下,列表将显示在一行中。使用这个函数,您将能够创建一个大的列表集,其中目标值位于列表中的不同位置。您可以使用它来比较在列表的开头和结尾找到一个元素需要多长时间。
为了比较
for循环和生成器,您需要另外两个硬编码的基本函数来查找一个population属性超过 50 的字典:def find_match_loop(iterable): for value in iterable: if value["population"] > 50: return value return None def find_match_gen(iterable): return next( (value for value in iterable if value["population"] > 50), None )这些函数是硬编码的,以保持测试的简单性。在下一节中,您将创建一个可重用的函数。
准备好这些基本组件后,您可以使用
timeit设置一个脚本,用一系列列表测试两个匹配函数,这些列表具有目标位置和列表中的不同位置:from timeit import timeit TIMEIT_TIMES = 100 LIST_SIZE = 500 POSITION_INCREMENT = 10 def build_list(size, fill, value, at_position): ... def find_match_loop(iterable): ... def find_match_gen(iterable): ... looping_times = [] generator_times = [] positions = [] for position in range(0, LIST_SIZE, POSITION_INCREMENT): print( f"Progress {position / LIST_SIZE:.0%}", end=f"{3 * ' '}\r", # Clear previous characters and reset cursor ) positions.append(position) list_to_search = build_list( LIST_SIZE, {"country": "Nowhere", "population": 10}, {"country": "Atlantis", "population": 100}, position, ) looping_times.append( timeit( "find_match_loop(list_to_search)", globals=globals(), number=TIMEIT_TIMES, ) ) generator_times.append( timeit( "find_match_gen(list_to_search)", globals=globals(), number=TIMEIT_TIMES, ) ) print("Progress 100%")这个脚本将生成两个并行列表,每个列表都包含用循环或生成器找到元素所花费的时间。该脚本还将生成第三个列表,其中包含列表中目标元素的相应位置。
您还没有对结果做任何事情,理想情况下,您希望将这些绘制出来。因此,看看下面这个完整的脚本,它使用
matplotlib从输出中生成几个图表:# chart.py from timeit import timeit import matplotlib.pyplot as plt TIMEIT_TIMES = 1000 # Increase number for smoother lines LIST_SIZE = 500 POSITION_INCREMENT = 10 def build_list(size, fill, value, at_position): return [value if i == at_position else fill for i in range(size)] def find_match_loop(iterable): for value in iterable: if value["population"] > 50: return value def find_match_gen(iterable): return next(value for value in iterable if value["population"] > 50) looping_times = [] generator_times = [] positions = [] for position in range(0, LIST_SIZE, POSITION_INCREMENT): print( f"Progress {position / LIST_SIZE:.0%}", end=f"{3 * ' '}\r", # Clear previous characters and reset cursor ) positions.append(position) list_to_search = build_list( size=LIST_SIZE, fill={"country": "Nowhere", "population": 10}, value={"country": "Atlantis", "population": 100}, at_position=position, ) looping_times.append( timeit( "find_match_loop(list_to_search)", globals=globals(), number=TIMEIT_TIMES, ) ) generator_times.append( timeit( "find_match_gen(list_to_search)", globals=globals(), number=TIMEIT_TIMES, ) ) print("Progress 100%") fig, ax = plt.subplots() plot = ax.plot(positions, looping_times, label="loop") plot = ax.plot(positions, generator_times, label="generator") plt.xlim([0, LIST_SIZE]) plt.ylim([0, max(max(looping_times), max(generator_times))]) plt.xlabel("Index of element to be found") plt.ylabel(f"Time in seconds to find element {TIMEIT_TIMES:,} times") plt.title("Raw Time to Find First Match") plt.legend() plt.show() # Ratio looping_ratio = [loop / loop for loop in looping_times] generator_ratio = [ gen / loop for gen, loop in zip(generator_times, looping_times) ] fig, ax = plt.subplots() plot = ax.plot(positions, looping_ratio, label="loop") plot = ax.plot(positions, generator_ratio, label="generator") plt.xlim([0, LIST_SIZE]) plt.ylim([0, max(max(looping_ratio), max(generator_ratio))]) plt.xlabel("Index of element to be found") plt.ylabel("Speed to find element, relative to loop") plt.title("Relative Speed to Find First Match") plt.legend() plt.show()根据您正在运行的系统以及您使用的
TIMEIT_TIMES、LIST_SIZE和POSITION_INCREMENT的值,运行脚本可能需要一段时间,但是它应该会生成一个图表,显示彼此对应的时间:
此外,关闭第一个图表后,您将获得另一个图表,显示两种策略之间的比率:
最后一个图表清楚地说明了在这个测试中,当目标项靠近迭代器的开始时,生成器比
for循环慢得多。然而,一旦要查找的元素位于位置 100 或更高,生成器就会相当一致地以相当大的差距击败for循环:
您可以使用放大镜图标交互式放大上一个图表。放大的图表显示,性能提高了大约 5%或 6%。百分之五可能不是什么值得大书特书的东西,但也是不可忽略的。对您来说是否值得取决于您将使用的特定数据,以及您需要使用它的频率。
注意:对于较低的
TIMEIT_TIMES值,您经常会在图表中看到尖峰,这是在非专用于测试的计算机上进行测试时不可避免的副作用:
如果计算机需要做一些事情,那么它会毫不犹豫地暂停 Python 进程,这可能会夸大某些结果。如果你重复测试不同的时间,那么尖峰会出现在随机的位置。
为了平滑线条,增加
TIMEIT_TIMES的值。有了这些结果,你可以暂时说生成器比
for循环快,即使当要查找的项在 iterable 的前 100 个元素中时,生成器会慢得多。当您处理小列表时,总的来说损失的原始毫秒数并不多。然而,对于 5%的涨幅可能意味着几分钟的大型项目,需要记住的是:
正如您在最后一张图表中看到的,对于非常大的可迭代对象,性能提升稳定在 6%左右。此外,忽略峰值——为了测试这个大的可迭代函数,
TIMEIT_TIMES被大幅降低。制作一个可重用的 Python 函数来寻找第一个匹配
假设您期望使用的可迭代对象比较大,并且您对从代码中挤出每一点性能感兴趣。因此,您将使用生成器而不是
for循环。您还将处理具有各种项目的各种不同的可重复项,并且希望在匹配方式上具有灵活性,因此您将设计能够实现各种目标的函数:
- 返回第一个真值
- 返回第一场比赛
- 返回通过键函数传递的第一个真值结果
- 返回通过键函数传递的第一个匹配值
- 如果不匹配,则返回默认值
虽然有许多方法可以实现这一点,但有一种方法可以用模式匹配来实现:
def get_first(iterable, value=None, key=None, default=None): match value is None, callable(key): case (True, True): gen = (elem for elem in iterable if key(elem)) case (False, True): gen = (elem for elem in iterable if key(elem) == value) case (True, False): gen = (elem for elem in iterable if elem) case (False, False): gen = (elem for elem in iterable if elem == value) return next(gen, default)您可以用多达四个参数调用该函数,根据您传递给它的参数组合,它的行为会有所不同。
函数的行为主要取决于
value和key参数。这就是为什么match语句检查value is None是否是,并使用callable()函数来了解key是否是一个函数。例如,如果两个
match条件都是True,那么就意味着你已经传入了一个key,但是没有传入value。这意味着您希望 iterable 中的每一项都通过key函数传递,返回值应该是第一个真值结果。作为另一个例子,如果两个
match条件都是False,这意味着你已经传入了一个值而不是一个key。传递一个value而不传递key意味着您希望 iterable 中的第一个元素与提供的值直接匹配。一旦
match结束,你就有了你的发电机。剩下要做的就是用生成器和第一次匹配的default参数调用next()。使用此功能,您可以用四种不同的方式搜索匹配项:
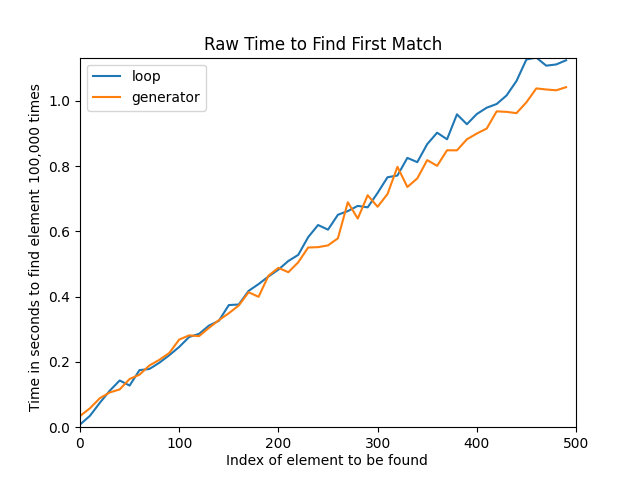
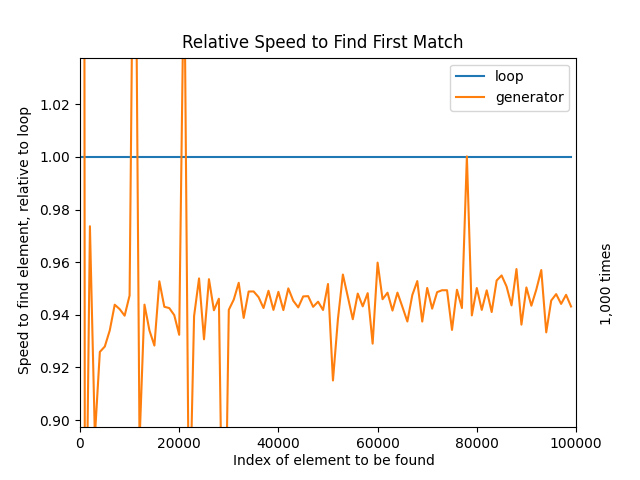
>>> countries = [
... {"country": "Austria", "population": 8_840_521},
... {"country": "Canada", "population": 37_057_765},
... {"country": "Cuba", "population": 11_338_138},
... {"country": "Dominican Republic", "population": 10_627_165},
... {"country": "Germany", "population": 82_905_782},
... {"country": "Norway", "population": 5_311_916},
... {"country": "Philippines", "population": 106_651_922},
... {"country": "Poland", "population": 37_974_750},
... {"country": "Scotland", "population": 5_424_800},
... {"country": "United States", "population": 326_687_501},
... ]
>>> # Get first truthy item
>>> get_first(countries)
{'country': 'Austria', 'population': 8840521}
>>> # Get first item matching the value argument
>>> get_first(countries, value={"country": "Germany", "population": 82_905_782})
{'country': 'Germany', 'population': 82905782}
>>> # Get first result of key(item) that equals the value argument
>>> get_first(
... countries, value=5_311_916, key=lambda country: country["population"]
... )
{'country': 'Norway', 'population': 5311916}
>>> # Get first truthy result of key(item)
>>> get_first(
... countries, key=lambda country: country["population"] > 100_000_000
... )
{'country': 'Philippines', 'population': 106651922}
有了这个功能,你在搭配上就有了很大的灵活性。例如,您可以只处理值,或者只处理key函数,或者两者都处理!
在前面提到的 first 包中,函数签名略有不同。它没有值参数。依靠key参数,您仍然可以实现与上述相同的效果:
>>> from first import first >>> first( ... countries, ... key=lambda item: item == {"country": "Cuba", "population": 11_338_138} ... ) {'country': 'Cuba', 'population': 11338138}在可下载的资料中,您还可以找到
get_first()的替代实现,它镜像了first包的签名:示例代码: 单击此处下载免费源代码,您将使用它来查找 Python 列表或 iterable 中的第一个匹配。
不管您最终使用哪种实现,您现在都有了一个高性能的、可重用的函数,它可以获得您需要的第一项。
结论
在本教程中,你已经学会了如何用各种方法找到列表中的第一个元素或任何可迭代的元素。您已经了解到最快和最基本的匹配方法是使用
in操作符,但是您已经看到它对于任何更复杂的事情都是有限的。因此,您已经检查了简单的for循环,这将是可读性最强、最直接的方法。然而,你也看到了发电机的额外性能和招摇过市。最后,您看到了从 iterable 中获取第一项的函数的一种可能的实现,无论这是第一个真值还是由符合特定条件的函数转换的值。**
如何使用 Python:你的第一步
您是否正在寻找一个地方,从初学者的角度学习如何使用 Python 的基础知识?您是否想开始使用 Python,但是不知道从哪里开始?如果是这样,那么这篇教程就是为你准备的。本教程重点介绍开始使用 Python 编程时需要了解的基本知识。
在本教程中,您将学习:
- 什么是 Python 以及为什么应该使用它
- 开始编码时应该学习哪些基本的 Python 语法
- 如何在 Python 中处理错误
- 如何在 Python 中快速获得帮助
- 你应该在你的代码中应用什么样的代码风格
- 无需重新发明轮子,从哪里获得额外功能
- 哪里可以找到高质量的 Python 内容并增长您的技能
你也将有机会创建你的第一个 Python 程序,并在你的电脑上运行它。最后,你将有机会通过一个小测验来评估你的进步,这个小测验会让你知道你学到了多少。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
为什么应该使用 Python
Python,以英国喜剧组合 Monty Python 命名,是一种高级、解释型、交互型、面向对象型编程语言。它的灵活性让你可以做大大小小的事情。使用 Python,您可以编写基本程序和脚本,还可以创建复杂的大规模企业解决方案。下面是它的一些用法:
在计算机编程的世界里,你到处都可以找到 Python。例如,Python 是世界上一些最受欢迎的网站的基础,包括 Reddit、Dropbox 和 YouTube 等等。Python web 框架 Django 同时支持 Instagram 和 Pinterest 。
Python 有一系列的特性,这些特性使它成为你的第一种编程语言:
- 免费: Python 是免费的,即使是用于商业目的。
- 开源:任何人都可以为 Python 开发做出贡献。
- 无障碍:从在校儿童到退休人员,各个年龄段的人都学过 Python,你也可以。
- 多才多艺: Python 可以帮助你解决很多领域的问题,包括脚本、数据科学、web 开发、GUI 开发等等。
- 功能强大:可以编写小脚本实现重复性任务的自动化,也可以用 Python 创建复杂大规模的企业解决方案。
与其他编程语言相比,Python 具有以下特性:
- 解释:它是可移植的,比编译语言更快。
- Multiparadigm: 可以让你用不同的风格编写代码,包括面向对象、命令式和功能式风格。
- 动态类型化:它在运行时检查变量类型,所以不需要显式声明。
- 强类型:它不会让不兼容类型上的不安全操作被忽视。
关于 Python 还有很多需要学习的地方。但是到目前为止,您应该对为什么 Python 如此受欢迎以及为什么您应该考虑学习用它编程有了更好的理解。
如何下载安装 Python
Python 可以在 Linux、Mac、 Windows 和其他几个平台上工作。它预装在 macOS 和大多数 Linux 发行版中。然而,如果你想保持最新,那么你可能需要下载并安装最新的版本。如果你愿意,你也可以选择在不同的项目中使用不同的 Python 版本。
要检查操作系统中全局安装的 Python 版本,请打开终端或命令行并运行以下命令:
$ python3 -V该命令打印系统默认 Python 3 安装的版本。请注意,您使用了
python3而不是python,因为一些操作系统仍然将 Python 2 作为默认的 Python 安装。从二进制文件安装 Python
不管你的操作系统是什么,你都可以从官方网站下载合适的 Python 版本。去那里获取适合你的操作系统和处理器的 32 位或 64 位版本。
从该语言的官方网站选择并下载 Python 二进制文件通常是一个不错的选择。但是,有一些特定于操作系统的替代方案:
你也可以使用 Anaconda 发行版来安装 Python 以及一组丰富的包和库,或者如果你想只安装你需要的包,你可以使用 Miniconda 。
注意:管理 Python 版本和环境有几个选项。当您开始学习这门语言时,为这项任务选择合适的工具可能会非常困难。
关于这个主题的指南,请查看一个有效的 Python 环境:让自己像在家里一样。
关于在不同平台上安装 Python 的更多说明,你可以查看 Python 3 安装&安装指南。
运行您的 Python 解释器
您可以做一个快速测试来确保 Python 安装正确。启动您的终端或命令行并运行
python3命令。这应该会打开一个 Python 交互式会话,您的命令提示符应该如下所示:

Python 3.9.0 (default, Oct 5 2020, 17:52:02)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
当您在这里时,不妨运行您的第一行代码:
>>> print("Python is fun!") Python is fun!就是这样!您刚刚编写了您的第一个 Python 程序!完成后,您可以使用
exit()或quit()离开交互会话,也可以使用以下组合键:
- macOS 和 Linux:
Ctrl+D- 窗口:
Ctrl+D然后按Enter保持终端或命令行打开。你还有很多要做和要学的!您将从学习 Python 语法的基础开始。
基本的 Python 语法
Python 语法清晰、简洁,并且注重可读性。可读性可以说是语言本身更有吸引力的特性之一。这使得 Python 成为学习编程的人的理想选择。在本节中,您将了解 Python 语法的几个重要组成部分:
这些知识将帮助您开始使用 Python。你几乎马上就能创建自己的程序。
评论
注释是存在于代码中的文本片段,但是在 Python 解释器执行代码时会被忽略。您可以使用注释来描述代码,以便您和其他开发人员能够快速理解代码的作用,或者为什么要以给定的方式编写代码。要用 Python 编写注释,只需在注释文本前添加一个散列标记(
#):# This is a comment on its own linePython 解释器会忽略散列标记之后直到行尾的文本。你也可以添加行内注释到你的代码中。换句话说,如果注释占据了一行的最后一部分,您可以将 Python 表达式或语句与注释组合在一行中:
var = "Hello, World!" # This is an inline comment你应该谨慎地使用行内注释来清理那些本身不明显的代码。一般来说,你的评论应该简明扼要。PEP 8 建议将评论控制在 72 个字符以内。如果你的评论接近或超过这个长度,那么你可能想把它分散在多行中:
# This is a long comment that requires # two lines to be complete.如果给定的注释需要更多的空间,那么可以使用多行,每行加一个散列符号。这样,您可以将评论长度控制在 72 个字符以内。
变量
在 Python 中,变量是附加在特定对象上的名称。它们保存一个引用,或称指针,指向存储对象的内存地址。一旦变量被赋予一个对象,您就可以使用变量名来访问该对象。
你需要预先定义你的变量。下面是语法:
variable_name = variable_value您应该使用一种命名方案,使您的变量直观易读。变量名应该提供一些关于分配给它的值是什么的指示。
有时候程序员会使用简短的变量名,比如
x和y。在数学、代数等领域,这些都是非常合适的名字。在其他情况下,您应该避免使用单字符名称,并使用更具描述性的名称。这样,其他开发人员可以对您的变量进行有根据的猜测。当你写程序的时候,想想别人,也想想你未来的自己。你未来的自己会感谢你。以下是 Python 中有效和无效变量名的一些示例:
>>> numbers = [1, 2, 3, 4, 5]
>>> numbers
[1, 2, 3, 4, 5]
>>> first_num = 1
>>> first_num
1
>>> 1rst_num = 1
File "<input>", line 1
1rst_num = 1
^
SyntaxError: invalid syntax
>>> π = 3.141592653589793
>>> π
3.141592653589793
变量名可以是任意长度,可以由大小写字母(A-Z、a-z)、数字(0-9)以及下划线字符(_)组成。总之,变量名应该是字母数字,但是注意,即使变量名可以包含数字,它们的第一个字符不能是数字。
注:****lower _ case _ with _ 下划线命名约定,也称为 snake_case ,在 Python 中常用。它不是强制性的,但它是一个被广泛采用的标准。
最后,Python 现在提供了完全的 Unicode 支持,所以你也可以在你的变量名中使用 Unicode 字符,就像你在上面看到的变量π一样。
关键词
像任何其他编程语言一样,Python 有一组特殊的单词,是其语法的一部分。这些词被称为关键词。要获得当前 Python 安装中可用关键字的完整列表,可以在交互式会话中运行以下代码:
>>> help("keywords") Here is a list of the Python keywords. Enter any keyword to get more help. False class from or None continue global pass True def if raise and del import return as elif in try assert else is while async except lambda with await finally nonlocal yield break for not这些关键字中的每一个都在 Python 语法中扮演着角色。它们是保留词,在语言中有特定的含义和目的,所以除了这些特定的目的,你不应该使用它们。例如,您不应该在代码中将它们用作变量名。
还有另一种方法可以访问 Python 关键字的完整列表:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'cla
ss', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from
', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pas
s', 'raise', 'return', 'try', 'while', 'with', 'yield']
keyword 提供了一组函数,允许你判断一个给定的字符串是否是关键字。例如,keyword.kwlist保存了 Python 中所有当前关键字的列表。当您需要在 Python 程序中以编程方式操作关键字时,这些非常方便。
内置数据类型
Python 内置的数据类型屈指可数,比如数字(整数、浮点数、复数)布尔、字符串、列表、元组、字典、集合。您可以使用几种工具来操作它们:
在接下来的几节中,您将学习将 Python 的内置数据类型合并到您的程序中的基础知识。
数字
Python 提供整数、浮点数和复数。整数和浮点数是日常编程中最常用的数值类型,而复数在数学和科学中有特定的用例。以下是它们的功能总结:
| 数字 | 描述 | 例子 | Python 数据类型 |
|---|---|---|---|
| 整数 | 整数 | 1、2、42、476、-99999 |
int |
| 浮点型 | 带小数点的数字 | 1.0、2.2、42.09、476.1、-99999.9 |
float |
| 复杂的 | 具有实部和虚部的数字 | complex(1, 2)、complex(-1, 7)、complex("1+2j") |
complex |
整数的精度没有限制。浮点数的精度信息在 sys.float_info 中提供。复数有实部和虚部,都是浮点数。
运算符表示运算,如加、减、乘、除等。当您将它们与数字组合在一起时,它们会形成 Python 可以计算的表达式:
>>> # Addition >>> 5 + 3 8 >>> # Subtraction >>> 5 - 3 2 >>> # Multiplication >>> 5 * 3 15 >>> # Division >>> 5 / 3 1.6666666666666667 >>> # Floor division >>> 5 // 3 1 >>> # Modulus (returns the remainder from division) >>> 5 % 3 2 >>> # Power >>> 5 ** 3 125这些运算符与两个操作数一起工作,通常被称为算术运算符。操作数可以是数字或保存数字的变量。
除了操作符之外,Python 还为您提供了一堆用于操作数字的内置函数。这些功能始终可供您使用。换句话说,你不必导入它们就能在你的程序中使用它们。
注意:Python 标准库中有可用的模块,比如
math,也为你提供了操作数字的函数。要使用与这些模块相关的功能,首先必须导入模块,然后使用
module.function_name()访问功能。或者,您可以使用from module import function_name直接从模块中导入一个函数。给定一个整数或表示数字的字符串作为参数,
float()返回一个浮点数:
>>> # Integer numbers
>>> float(9)
9.0
>>> float(-99999)
-99999.0
>>> # Strings representing numbers
>>> float("2")
2.0
>>> float("-200")
-200.0
>>> float("2.25")
2.25
>>> # Complex numbers
>>> float(complex(1, 2))
Traceback (most recent call last):
File "<input>", line 1, in <module>
float(complex(1, 2))
TypeError: can't convert complex to float
用float()可以把整数和代表数字的字符串转换成浮点数,但是不能把复数转换成浮点数。
给定一个浮点数或字符串作为参数, int()返回一个整数。该函数不会将输入向上舍入到最接近的整数。它只是截断输入,丢弃小数点后的任何内容,然后返回数字。因此,10.6的输入返回10而不是11。同样,3.25返回3:
>>> # Floating-point numbers >>> int(10.6) 10 >>> int(3.25) 3 >>> # Strings representing numbers >>> int("2") 2 >>> int("2.3") Traceback (most recent call last): File "<input>", line 1, in <module> int("2.3") ValueError: invalid literal for int() with base 10: '2.3' >>> # Complex numbers >>> int(complex(1, 2)) Traceback (most recent call last): File "<input>", line 1, in <module> int(complex(1, 2)) TypeError: can't convert complex to int注意,可以将表示整数的字符串传递给
int(),但是不能传递表示浮点数的字符串。复数也不行。除了这些内置函数,还有一些方法与每种类型的数字相关联。您可以使用属性引用来访问它们,也称为点符号:
>>> 10.0.is_integer()
True
>>> 10.2.is_integer()
False
>>> (10).bit_length()
4
>>> 10.bit_length()
File "<input>", line 1
10.bit_length()
^
SyntaxError: invalid syntax
这些方法是学习的有用工具。在整数的情况下,要通过一个文字访问它们的方法,你需要使用一对括号。否则,你会得到一个SyntaxError。
布尔型
在 Python 中,布尔值被实现为整数的一个子类,只有两个可能的值:True或False。请注意,这些值必须以大写字母开头。
您使用布尔值来表达表达式或对象的真值。当您编写谓词函数或者使用比较运算符时,例如大于(>)、小于(<)、等于(==)等等,使用布尔值非常方便:
>>> 2 < 5 True >>> 4 > 10 False >>> 4 <= 3 False >>> 3 >= 3 True >>> 5 == 6 False >>> 6 != 9 True比较运算符计算布尔值、
True或False。在 Python 交互式会话中,您可以随意使用它们。Python 提供了一个内置函数,
bool(),与布尔值密切相关。它是这样工作的:
>>> bool(0)
False
>>> bool(1)
True
>>> bool("")
False
>>> bool("a")
True
>>> bool([])
False
>>> bool([1, 2, 3])
True
bool()以一个对象为自变量,根据对象的真值返回True或False。为了评估对象的真值,该函数使用 Python 的真值测试规则。
另一方面,int()取一个布尔值,并为False返回0,为True返回1:
>>> int(False) 0 >>> int(True) 1这是因为 Python 将其布尔值实现为
int的子类,如您之前所见。字符串
字符串是可以使用单引号、双引号或三引号定义的文本片段或字符序列:
>>> # Use single quotes
>>> greeting = 'Hello there!'
>>> greeting
'Hello there!'
>>> # Use double quotes
>>> welcome = "Welcome to Real Python!"
>>> welcome
'Welcome to Real Python!'
>>> # Use triple quotes
>>> message = """Thanks for joining us!"""
>>> message
'Thanks for joining us!'
>>> # Escape characters
>>> escaped = 'can\'t'
>>> escaped
"can't"
>>> not_escaped = "can't"
>>> not_escaped
"can't"
请注意,您可以使用不同类型的引号在 Python 中创建字符串对象。还可以使用反斜杠字符(\)到来转义具有特殊含义的字符,比如引号本身。
一旦定义了字符串对象,就可以使用加号运算符(+)将和连接成一个新字符串:
>>> "Happy" + " " + "pythoning!" 'Happy pythoning!'当用于字符串时,加号运算符(
+)将它们连接成一个字符串。请注意,您需要在单词之间包含一个空格(" "),以便在结果字符串中有适当的间距。如果你需要连接很多字符串,那么你应该考虑使用.join(),这样效率更高。在本教程的稍后部分,您将了解到.join()。Python 附带了许多用于字符串操作的有用的内置函数和方法。例如,如果您将一个字符串作为参数传递给
len(),那么您将获得该字符串的长度,或者它包含的字符数:
>>> len("Happy pythoning!")
16
当您使用字符串作为参数调用 len() 时,您将获得输入字符串中的字符数,包括任何空格。
string 类(str)提供了一组丰富的方法,这些方法对于操作和处理字符串非常有用。例如,str.join()接受一个可迭代的字符串,并将它们连接成一个新的字符串。对其调用方法的字符串充当分隔符的角色:
>>> " ".join(["Happy", "pythoning!"]) 'Happy pythoning!'
str.upper()返回基础字符串的副本,其中所有字母都转换为大写:
>>> "Happy pythoning!".upper()
'HAPPY PYTHONING!'
str.lower()返回基础字符串的副本,其中所有字母都转换为小写:
>>> "HAPPY PYTHONING!".lower() 'happy pythoning!'
str.format()执行一个字符串格式化操作。这种方法为字符串格式化和插值提供了很大的灵活性:
>>> name = "John Doe"
>>> age = 25
>>> "My name is {0} and I'm {1} years old".format(name, age)
"My name is John Doe and I'm 25 years old"
你也可以使用一个 f 弦来格式化你的弦而不使用.format():
>>> name = "John Doe" >>> age = 25 >>> f"My name is {name} and I'm {age} years old" "My name is John Doe and I'm 25 years old"Python 的 f-strings 是一种改进的字符串格式化语法。它们是以
f开头的字符串,在引号之外。出现在嵌入式花括号({})中的表达式被替换为它们在格式化字符串中的值。字符串是字符序列。这意味着您可以使用位置索引从字符串中检索单个字符。索引是一个与序列中特定位置相关联的从零开始的整数:
>>> welcome = "Welcome to Real Python!"
>>> welcome[0]
'W'
>>> welcome[11]
'R'
>>> welcome[-1]
'!'
索引操作在给定索引指示的位置检索字符。注意,负索引以相反的顺序检索元素,其中-1是字符串中最后一个字符的索引。
你也可以通过切分来获取字符串的一部分:
>>> welcome = "Welcome to Real Python!" >>> welcome[0:7] 'Welcome' >>> welcome[11:22] 'Real Python'切片操作采用
[start:end:step]形式的元素。这里,start是要包含在切片中的第一项的索引,end是最后一项的索引,它不包含在返回的切片中。最后,step是一个可选的整数,表示从原始字符串中提取项目时要跳过的项目数。例如,2的step将返回start和stop之间的所有其他元素。列表
在几乎所有其他编程语言中,列表通常被称为数组。在 Python 中,列表是将各种对象组合在一起的可变序列。要创建一个列表,您可以使用一个赋值语句,在右边的方括号(
[])中包含一系列以逗号分隔的对象:
>>> # Define an empty list
>>> empty = []
>>> empty
[]
>>> # Define a list of numbers
>>> numbers = [1, 2, 3, 100]
>>> numbers
[1, 2, 3, 100]
>>> # Modify the list in place
>>> numbers[3] = 200
>>> numbers
[1, 2, 3, 200]
>>> # Define a list of strings
>>> superheroes = ["batman", "superman", "spiderman"]
>>> superheroes
['batman', 'superman', 'spiderman']
>>> # Define a list of objects with different data types
>>> mixed_types = ["Hello World", [4, 5, 6], False]
>>> mixed_types
['Hello World', [4, 5, 6], False]
列表可以包含不同数据类型的对象,包括其他列表。它们也可以是空的。由于列表是可变的序列,您可以使用索引符号和赋值操作来修改它们而不是。
因为列表就像字符串一样是序列,所以您可以使用从零开始的整数索引来访问它们各自的项:
>>> numbers = [1, 2, 3, 200] >>> numbers[0] 1 >>> numbers[1] 2 >>> superheroes = ["batman", "superman", "spiderman"] >>> superheroes[-1] "spiderman" >>> superheroes[-2] "superman"索引操作也适用于 Python 列表,因此您可以通过使用位置索引来检索列表中的任何项目。负索引以相反的顺序检索项目,从最后一个项目开始。
您也可以使用切片操作从现有列表创建新列表:
>>> numbers = [1, 2, 3, 200]
>>> new_list = numbers[0:3]
>>> new_list
[1, 2, 3]
如果您在另一个列表中嵌套了一个列表、一个字符串或任何其他序列,那么您可以使用多个索引来访问内部项目:
>>> mixed_types = ["Hello World", [4, 5, 6], False] >>> mixed_types[1][2] 6 >>> mixed_types[0][6] 'W'在这种情况下,第一个索引从容器列表中获取项目,第二个索引从内部序列中检索项目。
您也可以使用加号运算符连接列表:
>>> fruits = ["apples", "grapes", "oranges"]
>>> veggies = ["corn", "kale", "mushrooms"]
>>> grocery_list = fruits + veggies
>>> grocery_list
['apples', 'grapes', 'oranges', 'corn', 'kale', 'mushrooms']
因为列表是对象的序列,所以您可以对任何其他序列使用相同的函数,比如字符串。
给定一个列表作为参数,len()返回列表的长度,或者它包含的对象的数量:
>>> numbers = [1, 2, 3, 200] >>> len(numbers) 4您可以查看 Python 文档来查看所有可用的列表方法。下面总结了一些最常用的方法。
list.append()将一个对象作为参数,并将其添加到底层列表的末尾:
>>> fruits = ["apples", "grapes", "oranges"]
>>> fruits.append("blueberries")
>>> fruits
['apples', 'grapes', 'oranges', 'blueberries']
list.sort() 将底层列表排序到位:
>>> fruits.sort() >>> fruits ['apples', 'blueberries', 'grapes', 'oranges']
list.pop()将整数索引作为参数,然后移除并返回基础列表中该索引处的项目:
>>> numbers_list = [1, 2, 3, 200]
>>> numbers_list.pop(2)
3
>>> numbers_list
[1, 2, 200]
列表是 Python 中非常常见和通用的数据结构。它们如此受欢迎,以至于开发人员有时倾向于过度使用它们,这会使代码效率低下。
元组
元组类似于列表,但它们是不可变的序列。这意味着您不能在创建后更改它们。要创建 tuple 对象,可以使用一个赋值操作,在其右侧包含一系列以逗号分隔的项。您通常使用括号来分隔元组,但它们不是强制性的:
>>> employee = ("Jane", "Doe", 31, "Software Developer") >>> employee[0] = "John" Traceback (most recent call last): File "<input>", line 1, in <module> employee[0] = "John" TypeError: 'tuple' object does not support item assignment如果您试图就地改变一个元组,那么您会得到一个
TypeError,表明元组不支持就地修改。就像列表一样,您也可以对元组进行索引和切片:
>>> employee = ("Jane", "Doe", 31, "Software Developer")
>>> employee[0]
'Jane'
>>> employee[1:3]
('Doe', 31)
因为元组是序列,所以可以使用索引来检索元组中的特定项。请注意,您还可以使用切片操作从元组中检索切片。
还可以使用串联运算符添加两个元组:
>>> first_tuple = (1, 2) >>> second_tuple = (3, 4) >>> third_tuple = first_tuple + second_tuple >>> third_tuple (1, 2, 3, 4)具有两个元组的串联操作创建包含两个输入元组中所有项目的新元组。
与列表和字符串一样,您可以使用一些内置函数来操作元组。例如,
len()返回元组的长度,或者它包含的项数:
>>> numbers = (1, 2, 3)
>>> len(numbers)
3
使用元组作为参数,list()返回输入元组中所有项目的列表:
>>> numbers = (1, 2, 3) >>> list(numbers) [1, 2, 3]因为元组是不可变的序列,所以许多可用于列表的方法并不适用于元组。但是,元组有两个内置方法:
.count().index()
tuple.count()以一个对象作为参数,返回该项目在底层元组中出现的次数。如果对象不在元组中,那么.count()返回0:
>>> letters = ("a", "b", "b", "c", "a")
>>> letters.count("a")
2
>>> letters.count("c")
1
>>> letters.count("d")
0
tuple.index()将一个对象作为参数,并返回该对象在当前元组中的第一个实例的索引。如果对象不在元组中,那么.index()产生一个ValueError:
>>> letters = ("a", "b", "b", "c", "a") >>> letters.index("a") 0 >>> letters.index("c") 3 >>> letters.index("d") Traceback (most recent call last): File "<input>", line 1, in <module> letters.index("d") ValueError: tuple.index(x): x not in tuple元组是非常有用的数据结构。它们是内存高效的、不可变的,并且在管理不应该被用户修改的数据方面有很大的潜力。它们也可以用作字典键,这将在下一节中介绍。
字典
字典是一种关联数组,包含一组键-值对,其中每个键都是一个映射到任意对象(值)的哈希对象。创建词典有几种方法。这是其中的两个:
>>> person1 = {"name": "John Doe", "age": 25, "job": "Python Developer"}
>>> person1
{'name': 'John Doe', 'age': 25, 'job': 'Python Developer'}
>>> person2 = dict(name="Jane Doe", age=24, job="Web Developer")
>>> person2
{'name': 'Jane Doe', 'age': 24, 'job': 'Web Developer'}
第一种方法使用一对花括号,在其中添加一个逗号分隔的键-值对列表,使用冒号(:)将键和值分隔开。第二种方法使用内置函数 dict() ,它可以将关键字参数转换成一个字典,以关键字为键,参数为值。
注:从 Python 3.6 开始,字典已经是有序数据结构。但在此之前,它们是无序的。所以,如果你用的是低于 3.6 的 Python 版本,需要一个有序的字典,那就考虑用 collections.OrderedDict() 。
您可以使用以下语法检索与给定键关联的值:
>>> person1 = {"name": "John Doe", "age": 25, "job": "Python Developer"} >>> person1["name"] 'John Doe' >>> person1["age"] 25这非常类似于索引操作,但是这次您使用的是键而不是索引。
您还可以分别使用
.keys()、.values()和.items()在字典中检索键、值和键值对:
>>> # Retrieve all the keys
>>> person1.keys()
dict_keys(['name', 'age', 'job'])
>>> # Retrieve all the values
>>> person1.values()
dict_values(['John Doe', 25, 'Python Developer'])
>>> # Retrieve all the key-value pairs
>>> person1.items()
dict_items([('name', 'John Doe'), ('age', 25), ('job', 'Python Developer')])
这三个方法是在 Python 中操作字典的基本工具,尤其是当你在字典中迭代时。
设置
Python 还提供了一个集合的数据结构。集合是任意但可散列的 Python 对象的无序且可变的集合。您可以通过多种方式创建集合。这是其中的两个:
>>> employees1 = {"John", "Jane", "Linda"} {'John', 'Linda', 'Jane'} >>> employees2 = set(["David", "Mark", "Marie"]) {'Mark', 'David', 'Marie'} >>> empty = set() >>> empty set()在第一个示例中,您使用花括号和逗号分隔的对象列表来创建一个集合。如果您使用
set(),那么您需要提供一个 iterable,其中包含您想要包含在集合中的对象。最后,如果你想创建一个空集,那么你需要使用不带参数的set()。使用一对空的花括号会创建一个空的字典,而不是一个集合。集合的一个最常见的用例是使用它们从现有的 iterable 中删除重复的对象:
>>> set([1, 2, 2, 3, 4, 5, 3])
{1, 2, 3, 4, 5}
因为集合是唯一对象的集合,当你使用set()和一个 iterable 作为参数创建一个集合时,类构造器删除任何重复的对象,并且在结果集中只保留每个对象的一个实例。
注意: Python 还提供了一个名为 frozenset 的集合的不可变变体。您可以通过使用 iterable 作为参数调用frozenset()来创建它们。如果你调用frozenset()而没有参数,那么你将得到一个空的 frozenset。
您可以像处理其他内置数据结构一样,对集合使用一些内置函数。例如,如果您将一个集合作为参数传递给len(),那么您将获得集合中的项目数:
>>> employees1 = {"John", "Jane", "Linda"} >>> len(employees1) 3您还可以使用运算符来管理 Python 中的集合。在这种情况下,大多数运算符代表典型的集合运算,如并集 (
|)、交集 (&)、差集 (-)等等:
>>> primes = {2, 3, 5, 7}
>>> evens = {2, 4, 6, 8}
>>> # Union
>>> primes | evens
{2, 3, 4, 5, 6, 7, 8}
>>> # Intersection
>>> primes & evens
{2}
>>> # Difference
>>> primes - evens
{3, 5, 7}
集合提供了一堆方法,包括执行集合运算的方法,就像上面的例子一样。它们还提供了修改或更新基础集合的方法。例如,set.add()获取一个对象并将其添加到集合中:
>>> primes = {2, 3, 5, 7} >>> primes.add(11) >>> primes {2, 3, 5, 7, 11}
set.remove()获取一个对象并将其从集合中移除:
>>> primes = {2, 3, 5, 7, 11}
>>> primes.remove(11)
>>> primes
{2, 3, 5, 7}
Python 集合是非常有用的数据结构,是 Python 开发人员工具包的重要补充。
条件句
有时,您需要运行(或不运行)给定的代码块,这取决于是否满足某些条件。在这种情况下,条件语句是你的盟友。这些语句根据表达式的真值控制一组语句的执行。您可以使用关键字if和以下通用语法在 Python 中创建条件语句:
if expr0:
# Run if expr0 is true
# Your code goes here...
elif expr1:
# Run if expr1 is true
# Your code goes here...
elif expr2:
# Run if expr2 is true
# Your code goes here...
...
else:
# Run if all expressions are false
# Your code goes here...
# Next statement
if语句只运行一个代码块。换句话说,如果expr0为真,那么只有其关联的代码块才会运行。之后,执行跳转到直接在if语句下面的语句。
只有当expr0为假时,第一个elif子句才会对expr1求值。如果expr0为假而expr1为真,那么只有与expr1相关的代码块才会运行,依此类推。else子句是可选的,只有当所有先前评估的条件都为假时才会运行。您可以根据需要拥有任意多的elif子句,包括根本没有子句,但是您最多只能拥有一个else子句。
以下是这种工作方式的一些例子:
>>> age = 21 >>> if age >= 18: ... print("You're a legal adult") ... You're a legal adult >>> age = 16 >>> if age >= 18: ... print("You're a legal adult") ... else: ... print("You're NOT an adult") ... You're NOT an adult >>> age = 18 >>> if age > 18: ... print("You're over 18 years old") ... elif age == 18: ... print("You're exactly 18 years old") ... You're exactly 18 years old在第一个例子中,
age等于21,所以条件为真,Python 将You're a legal adult打印到屏幕上。在第二个例子中,表达式age >= 18的计算结果为False,因此 Python 运行了else子句的代码块,并在屏幕上打印出You're NOT an adult。在最后一个示例中,第一个表达式
age > 18为 false,因此执行跳转到elif子句。该子句中的条件为真,因此 Python 运行相关的代码块并打印出You're exactly 18 years old。循环
如果您需要多次重复一段代码来获得最终结果,那么您可能需要使用一个循环。循环是多次迭代和在每次迭代中执行一些动作的常见方式。Python 提供了两种类型的循环:
下面是创建一个
for循环的一般语法:for loop_var in iterable: # Repeat this code block until iterable is exhausted # Do something with loop_var... if break_condition: break # Leave the loop if continue_condition: continue # Resume the loop without running the remaining code # Remaining code... else: # Run this code block if no break statement is run # Next statement这种循环执行的迭代次数与
iterable中的项目一样多。通常,您使用每次迭代对loop_var的值执行给定的操作。else子句是可选的,在循环结束时运行。break和continue语句也是可选的。看看下面的例子:
>>> for i in (1, 2, 3, 4, 5):
... print(i)
... else:
... print("The loop wasn't interrupted")
...
1
2
3
4
5
The loop wasn't interrupted
当循环处理元组中的最后一个数字时,执行流跳转到else子句,并在屏幕上打印The loop wasn't interrupted。那是因为你的循环没有被break语句打断。您通常在代码块中有一个break语句的循环中使用一个else子句。否则就没必要了。
如果循环遇到了break_condition,那么break语句会中断循环的执行,并跳转到循环下一条语句,而不会消耗iterable中剩余的项目:
>>> number = 3 >>> for i in (1, 2, 3, 4, 5): ... if i == number: ... print("Number found:", i) ... break ... else: ... print("Number not found") ... Number found: 3当
i == 3时,循环在屏幕上打印Number found: 3,然后点击break语句。这中断了循环,执行跳转到循环的下一行,而不运行else子句。如果您将number设置为6或任何其他不在数字元组中的数字,那么循环不会命中break语句并打印Number not found。如果循环遇到了
continue_condition,那么continue语句将继续循环,而不运行循环代码块中的其余语句:
>>> for i in (1, 2, 3, 4, 5):
... if i == 3:
... continue
... print(i)
...
1
2
4
5
这一次,continue语句在i == 3时重新开始循环。这就是为什么你在输出中看不到数字3。
两个语句break和continue都应该包含在条件语句中。否则,循环总是在碰到break时中断,在碰到continue时继续。
当你事先不知道完成一个给定的操作需要多少次迭代时,你通常使用一个while循环。这就是为什么这个循环被用来执行无限迭代。
下面是 Python 中while循环的一般语法:
while expression:
# Repeat this code block until expression is false
# Do something...
if break_condition:
break # Leave the loop
if continue_condition:
continue # Resume the loop without running the remaining code
# Remaining code...
else:
# Run this code block if no break statement is run
# Next statement
这个循环的工作方式类似于for循环,但是它会一直迭代,直到expression为假。这种类型的循环的一个常见问题是当您提供一个永远不会计算为False的expression时。在这种情况下,循环将永远迭代下去。
下面是一个关于while循环如何工作的例子:
>>> count = 1 >>> while count < 5: ... print(count) ... count = count + 1 ... else: ... print("The loop wasn't interrupted") ... 1 2 3 4 The loop wasn't interrupted同样,
else子句是可选的,通常在循环的代码块中与break语句一起使用。在这里,break和continue的工作方式与for循环相同。有些情况下,你需要一个无限循环。例如,GUI 应用程序运行在一个管理用户事件的无限循环中。这个循环需要一个
break语句来终止循环,例如,当用户退出应用程序时。否则,应用程序将永远继续运行。功能
在 Python 中,函数是一个命名的代码块,它执行操作并选择性地计算结果,然后将结果返回给调用代码。您可以使用以下语法来定义函数:
def function_name(arg1, arg2, ..., argN): # Do something with arg1, arg2, ..., argN return return_value关键字
def启动函数头。然后,您需要函数名和括号中的参数列表。注意,参数列表是可选的,但是括号在语法上是必需的。最后一步是定义函数的代码块,它将开始向右缩进一级。在这种情况下,
return语句也是可选的,如果您需要将return_value发送回调用者代码,您可以使用该语句。注意:定义函数及其参数的完整语法超出了本教程的范围。关于这个主题的深入资源,请查看定义自己的 Python 函数。
要使用一个函数,你需要调用它。函数调用由函数名和括号中的函数参数组成:
function_name(arg1, arg2, ..., argN)您可以拥有在被调用时不需要参数的函数,但是括号总是需要的。如果你忘记了它们,那么你就不能调用这个函数,而是作为一个函数对象来引用它。
如何在 Python 中处理错误
错误是让每个层次的程序员都恼火和沮丧的事情。拥有识别和处理它们的能力是程序员的核心技能。在 Python 中,有两种基于代码的错误:语法错误和异常。
语法错误
当代码的语法在 Python 中无效时,就会出现语法错误。它们会自动停止程序的执行。例如,下面的
if语句在语句头的末尾缺少了一个冒号,Python 很快指出了这个错误:
>>> if x < 9
File "<stdin>", line 1
if x < 9
^
SyntaxError: invalid syntax
if语句末尾缺少的冒号是无效的 Python 语法。Python 解析器捕捉到问题并立即引发一个SyntaxError。箭头(^)指示解析器发现问题的位置。
例外情况
运行时语法正确的代码会引发异常,以表示程序执行过程中出现了问题。例如,考虑下面的数学表达式:
>>> 12 / 0 Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: integer division or modulo by zero在 Python 解析器看来,表达式
12 / 0在语法上是正确的。然而,当解释器试图实际计算表达式时,它会引发一个ZeroDivisionError异常。注意:在 Python 中,你通常会依靠异常来控制程序的流程。Python 开发人员更喜欢这种被称为 EAFP(请求原谅比请求许可更容易)的编码风格,而不是被称为 LBYL(三思而后行)的编码风格,后者基于使用
if语句。有关这两种编码风格的更多信息,请查看 LBYL vs EAFP:防止或处理 Python 中的错误。Python 提供了几个方便的内置异常,允许你捕捉和处理代码中的错误。
语义错误
程序逻辑中的一个或多个问题会导致语义错误。这些错误可能很难找到、调试和修复,因为不会生成错误信息。代码运行,但生成意外输出、不正确输出或根本没有输出。
语义错误的一个经典例子是无限循环,大多数程序员在他们的编码生涯中至少经历过一次。
如何在 Python 中获得帮助
就像一个好朋友一样,Python 总是在你遇到困难时提供帮助。也许你想知道一个特定的函数、方法、类或对象是如何工作的。在这种情况下,您可以打开一个交互式会话并调用
help()。这将把你直接带到 Python 的帮助实用程序:
>>> help()
Welcome to Python 3.9's help utility!
If this is your first time using Python, you should definitely check out
the tutorial on the Internet at https://docs.python.org/3.9/tutorial/.
...
help>
在那里,您可以输入 Python 对象的名称来获得关于它的有用信息:
>>> help() ... help> len Help on built-in function len in module builtins: len(obj, /) Return the number of items in a container.当你在
help>提示符下键入名字len并点击Enter时,你会得到与该内置函数相关的帮助内容。要离开内容并返回到help>提示,您可以按Q。要退出帮助实用程序,您可以键入quit并点击Enter。您还可以使用带有对象名称的
help()作为参数来获取关于该对象的信息:
>>> help(dir)
Help on built-in function dir in module builtins:
dir(...)
dir([object]) -> list of strings
...
说到 dir() ,你可以使用这个函数来检查一个特定对象中可用的方法和属性:
>>> dir(str) ['__add__', '__class__', ..., 'title', 'translate', 'upper', 'zfill'] >>> dir(tuple) ['__add__', '__class__', ..., 'count', 'index']当您使用 Python 对象的名称作为参数调用
dir()时,该函数试图返回该特定对象的有效属性列表。这是了解给定对象能做什么的一种便捷方式。Python 中的编码工具
Python 中有三种主要的编码方法。您已经使用了其中的一个,Python 交互式解释器,也被称为读取-评估-打印循环(REPL) 。尽管 REPL 对于测试小块代码非常有用,但是您不能保存代码供以后使用。
为了保存和重用你的代码,你需要创建一个 Python 脚本或者模块。它们都是扩展名为
.py(或 Windows 上的.pyw)的纯文本文件。要创建脚本和模块,您可以使用代码编辑器或集成开发环境(IDE) ,这是 Python 中编码的第二种和第三种方法。REPLs(读取-评估-打印循环)
虽然您可以在交互式会话中创建函数,但是您通常将 REPL 用于单行表达式和语句,或者用于简短的复合语句,以获得对代码的快速反馈。启动您的 Python 解释器并键入以下内容:
>>> 24 + 10
34
解释器简单地计算24 + 10,将两个数相加,并输出和34。现在再试一个:
>>> import this花一分钟时间阅读输出。它陈述了 Python 中的一些重要原则,这将有助于您编写更好、更多的Python 式代码。
到目前为止,您已经使用了标准的 Python REPL,它随您当前的 Python 发行版一起提供。然而,这并不是唯一的 REPL。第三方复制器提供了许多有用的特性,比如语法高亮、代码补全等等。以下是一些受欢迎的选项:
- IPython 提供了一个丰富的工具包来帮助你用 Python 交互式地编码。
- bpython 是用于 Linux、BSD、macOS 和 Windows 的 python 解释器的接口。
- Ptpython 是一个 Python REPL,也可以在 Linux、BSD、macOS 和 Windows 上工作。
请记住,一旦您关闭了 REPL 会话,您的代码就消失了。换句话说,输入到 REPL 中的代码不是持久的,所以您不能重用它。作为开发人员,您希望代码可以重用,以节省宝贵的击键次数。在这种情况下,代码编辑器和 ide 就派上了用场。
代码编辑器
用 Python 编码的第二种方法是使用代码编辑器。有些人更喜欢集成开发环境(IDE) ,但是出于学习目的,代码编辑器通常更好。为什么?因为当你学习新的东西时,你会想尽可能地去除复杂的层次。将复杂的 IDE 加入其中会使学习 Python 的任务变得更加困难。
一个 Python 程序,以其基本形式,由保存在扩展名为
.py或.pyw的文件中的文本行(代码)组成。你可以在像 Windows 上的记事本这样简单的东西中编写 Python 代码,但是没有理由让自己经历这样的折磨,因为有更好的选择。就其核心而言,代码编辑器应该提供几个特性来帮助程序员创建程序。在大多数情况下,您可以自定义代码编辑器以适应您的需要和风格。那么,您应该在代码编辑器中寻找什么呢?这个问题的答案可能取决于您的个人需求,但一般来说,您至少应该寻找以下特征:
看一下下面的比较示例:
顶部编辑器中的代码( Sublime Text )由于语法突出显示和行号,可读性更好。编辑器还发现了三个错误,其中一个是 showstopper。你能找出是哪一个吗?
同时,底部的编辑器(记事本)不显示错误,因为它是黑白的,很难看。
以下是您可以使用的一些现代代码编辑器的非详尽列表:
- Visual Studio Code 是一个全功能的代码编辑器,可用于 Linux、macOS 和 Windows 平台。
- Sublime Text 3 是一个强大的跨平台代码编辑器。
- Gedit 也是跨平台的,安装在一些使用 GNOME 的 Linux 发行版中。
- Notepad++ 也是一个很棒的编辑器,但它只适用于 Windows。
- Vim 适用于 Mac、Linux 和 Windows。
- GNU Emacs 是免费的,可以在任何平台上使用。
谈到代码编辑器,有许多不同的选择,包括免费的和商业的。做你的研究,不要害怕实验!请记住,您的代码编辑器应该帮助您遵守 Python 编码标准、最佳实践和习惯用法。
ide(集成开发环境)
IDE 是专用于软件开发的程序。ide 通常集成了几个特性,比如代码编辑、调试、、版本控制、构建和运行代码的能力等等。有许多支持 Python 或特定于 Python 的 ide 可供使用。这里有三个流行的例子:
IDLE 是 Python 的集成开发学习环境。您可以像使用 Python 解释器一样以交互方式使用 IDLE。你也可以用它来重用代码,因为你可以用 IDLE 创建和保存你的代码。如果你对使用 IDLE 感兴趣,那么看看Python IDLE 入门。
PyCharm 是一个由 JetBrains 开发的全功能 Python 专用 IDE。如果您有兴趣使用它,那么请查看py charm for Productive Python Development(Guide)。它可以在所有主要平台上使用,有免费的 Edu 版和社区版以及付费的专业版。
Thonny 是一个初学者友好的 IDE,可以让你马上开始使用 Python。如果你正在考虑使用 Thonny,那么看看 Thonny:初学者友好的 Python 编辑器。
这个 ide 列表并不完整。它旨在为您提供一些关于如何获得合适的 Python IDE 的指导。在你做出选择之前,探索和实验。
Python 代码风格
PEP 8 是 Python 代码的官方风格指南。虽然不要求编写可工作的 Python 代码,但是学习 PEP 8 并在 Python 代码中一致地应用它将使您的程序更具可读性和可维护性。幸运的是,您不需要记住 PEP 8 就可以让您的 Python 代码具有 Python 风格。
大多数代码编辑器和内部支持 Python 的 ide 都实现了自动检查,以发现并指出 PEP 8 违规。这将有助于你持续改进你的代码风格,也将在你的脑海中强化 PEP 8 的建议。
你也可以利用代码棉条,比如 Flake8 、 Pylint 和 pycodestyle 。你甚至可以使用代码格式化器,比如 Black 和 isort ,来一致地格式化你的代码。其中一些工具可以方便地集成到一些当前可用的代码编辑器和 ide 中。
如果你想了解更多关于如何使用 PEP 8 和其他代码风格的最佳实践来提高你的代码质量,那么看看如何用 PEP 8 编写漂亮的 Python 代码和 Python 代码质量:工具&最佳实践。
获得 Python 中的额外特性
到目前为止,您已经学习了一些基本的 Python 概念和特性。当你开始深入研究这种语言时,你可能会发现你需要某种特性,并决定自己编码。如果是这样的话,那么考虑一下你可能是在重新发明轮子。
Python 已经使用了将近 30 年。它有一个非常大的开发人员社区,很可能其他人也遇到了和你一样的问题。通过一点研究,您可能会找到一个代码片段、库、框架或其他可以节省您大量时间和精力的解决方案。
首先要看的是 Python 标准库。如果你在那里没有发现什么,那么你也可以看看 Python 包索引(PyPI) 。最后,你可以查看一些其他的第三方库。
标准库
Python 的一大优点是内置于 Python 核心并由第三方开发人员提供的大量可用模块、包和库。这些模块、包和库对 Python 程序员的日常工作非常有帮助。以下是一些最常用的内置模块:
比如这里导入
math使用pi,用sqrt()求一个数的平方根,用pow()求一个数的幂:

>>> import math
>>> math.pi
3.141592653589793
>>> math.sqrt(121)
11.0
>>> math.pow(7, 2)
49.0
一旦导入了math,就可以使用该模块中定义的任何函数或对象。如果你想要一个存在于math中的函数和对象的完整列表,那么你可以在一个交互式会话中运行类似于dir(math)的东西。
您也可以直接从math或任何其他模块导入特定功能:
>>> from math import sqrt >>> sqrt(121) 11.0这种导入语句将名称
sqrt()引入当前的名称空间,因此您可以直接使用它,而不需要引用包含它的模块。如果你使用模块,比如
math或者random,那么确保不要为你的定制模块、函数或者对象使用相同的名字。否则,您可能会遇到名称冲突,这可能会导致意想不到的行为。Python 包索引
pip和Python 包索引,也被称为 PyPI (发音为“派豌豆眼”),是一个包含框架、工具、包和库的庞大的 Python 包库。使用
pip可以安装任何 PyPI 包。这是在 Python 中管理第三方模块、包和库的推荐工具之一。新的程序员在遵循一个例子时经常碰壁,当他们运行代码时会看到
ModuleNotFoundError: No module named module_x。这意味着代码依赖于module_x,但是该模块没有安装在当前的 Python 环境中,从而创建了一个中断的依赖。像module_x这样的模块可以使用pip手动安装。例如,假设你试图运行一个使用熊猫的应用程序,但是你的计算机上没有安装这个库。在这种情况下,您可以打开您的终端并像这样使用
pip:$ pip3 install pandas这个命令从 PyPI 下载 pandas 及其依赖项,并将它们安装到您当前的 Python 环境中。安装完成后,您可以再次运行您的应用程序,如果没有其他中断的依赖关系,代码应该可以工作。
让您的 Python 技能更上一层楼*
*
在这里的 Real Python ,你可以找到各种资源,帮助你学习如何用 Python 编程:
- 教程可以帮助你循序渐进地学习 Python
- 视频课程内容详细深入,而且采用渐进式学习方法
- 测验测试你的知识,衡量你的学习进步
- 学习途径你可以从头开始学习 Python 的不同主题
- 一个社区让你认识 真正的蟒蛇团队和其他积极寻求提高技能的蟒蛇
在 Real Python ,你还可以找到很多其他资源,比如书籍和课程、播客剧集、办公时间时段、一份简讯等等。其中一些是完全免费的,其他的费用适中,支持网站并允许我们继续为您创建和更新内容。
如果你刚刚开始学习 Python,那么看看《Python 基础:Python 3T3 实用介绍》这本书。它将帮助你从初学者跃升为中级 Python 开发者。
当然,网上还有许多关于 Python 的其他课程、教程和资源。还是那句话,这是个人选择。在做决定之前做好你的研究。免费学习资料的一个很好的来源是官方 Python 文档,你应该把它作为可靠而快速的参考资料放在手边。只是要注意,这些材料可能没有你在真实 Python 上找到的那么容易阅读。
最重要的是,你不要陷入寻找有史以来最好的书或视频的困境,并在这个过程中迷失方向。做一些研究。四处打听。但是挑点什么坚持下去!打开代码编辑器,开始编写 Python 项目的代码!给自己一个承诺,找到一种方法来实现你的愿景,并完成你的项目。
编码就像骑自行车
编码就像骑自行车。你可以观察人们学习如何做,有时你可以得到一个推动,但最终,这是一个单独的事件。当你陷入困境或需要温习一个新概念时,你通常可以通过在谷歌上做一些研究来解决这个问题。如果你得到一个错误信息,然后在谷歌中输入准确的错误信息,通常会在第一页显示一个可能解决问题的结果。
堆栈溢出是你寻找答案时的另一个基本去处。用于编码的Q&A对 Python 主题有一些很好的解释。理解切片符号和手动引发(抛出)Python 中的异常就是两个真正优秀的例子。
如果你被一个问题卡住了,那么试试这些建议:
停止编码!
拿一张纸,用简单明了的词语画出解决问题的方法。如有必要,使用流程图。
在代码运行之前,不要使用
try和except块。try可以隐藏有价值的错误消息,帮助识别代码中的问题。使用
print()快速检查您的变量,确保它们具有期望值。这是一个有效的快速解决问题的方法。使用橡皮鸭调试技术。一行一行地向鸭子解释你的代码。在这个过程中,你可能会找到解决问题的方法。
如果你仍然困惑,使用 Python 可视化工具。该工具允许您在代码执行时逐句通过代码。如果需要,Python 可视化工具提供了一些示例来帮助您。
最后也是最重要的一点:沮丧的大脑不会有任何帮助。当你开始因为某件事不顺利而感到烦恼时,休息一下来理清你的思绪。去跑步或者做些别的事情。你会惊讶于这有多么有效。通常,你会带着全新的眼光回来,看到一个简单的错别字,一个拼错的关键词,或者类似的东西。
建议新的 Python 程序员
编码人员希望其他编码人员,甚至是初学者,尝试自己解决问题。不过,在某些时候,你会需要指导。一旦你尝试了所有你能想到的方法,并且真的碰壁了,在你砸碎你的键盘或其他无生命的物体之前,寻求帮助。
有几个地方可以获得帮助,包括代码论坛、脸书小组和 IRC 频道#python ,仅举几例。花一点时间阅读你所使用的任何小组的规则或指导方针。通过解释问题和你所做的努力,让别人更容易帮助你。如果有一个错误,那么也包括那个信息。
祝编码愉快!
编写一个例子:数到 10
许多程序员在开始解决问题时会不知所措。不管问题有多大,帮助你解决问题的一个有效方法是从逻辑上将问题分成更小的部分。
例如,假设你需要编写一个从 1 数到 10 的程序。每次计数增加时,您都希望显示它的值。帮助开发工作流的一种方法是使用伪代码:
因为你将在一个有组织的机器上更有效率,首先创建一个名为
python_code的文件夹,在那里你将存储示例文件。学习编码是一次实践的冒险,所以打开代码编辑器,输入下面的代码。不要只是复制和粘贴代码!自己打出来会对你的学习有益得多:1count = 1 2 3# Code block 1 4while count < 11: 5 print(count) 6 count = count + 1 7 8# Code block 2 9if count == 11: 10 print("Counting complete!")请注意,第 3 行和第 8 行以一个散列字符(
#)开始,后跟一个空格,然后是一个解释。这些是评论。注释可以有很多用途,但是在大多数情况下,您可以使用它们来解释代码或者总结您作为开发人员所采用的特定方法。上面例子中的注释对你有意义吗?如果没有,那就改进它们,甚至删除它们。你是否注意到这些例子同时使用了一个等号(
=)和一个双等号(==)?这可能会令人困惑,所以下面是它的工作原理:
- 在语句
count = count + 1中,=将1的值赋给变量count。你能告诉我count的最终值是多少吗?- 在条件语句
if count == 11:中,==将count的值与11进行比较,根据运算结果返回布尔值True或False。你能说出语句在每次迭代中的计算结果吗?在您创建的文件夹中将文件另存为
count_to_ten.py,然后退出编辑器。打开终端或命令提示符,导航到该文件夹。现在运行以下命令:$ python count_ten.py根据您的设置,您可能需要将
python替换为python3。输出将如下所示:1 2 3 4 5 6 7 8 9 10 Counting complete!就是这样!你刚刚写了你的第一个 Python 程序。你能解释一下程序中的每一行代码是做什么的吗?
测试你的知识
如果到目前为止您已经通读了本教程,那么您可能想要回答一些与 Python 相关的问题,并测试您所学到的内容。继续测试您的知识:
- Python 是一种强大的动态类型语言,这意味着什么?
- 如何运行 Python 解释器?
- 你如何定义一个变量?
- 变量名和变量值有什么区别?
- Python 内置的数据类型有哪些?
- 整数和浮点数有什么区别?
- 什么是布尔值?
%操作符是做什么的?- 链表和元组有什么区别?
- 什么是字典?
- 为什么要在代码中使用注释?
help()是做什么的,什么时候有用?dir()是做什么的,什么时候有用?- 语法错误和异常有什么区别?
- 什么是
pip?现在打开文本编辑器,创建一个名为
exercise.py的新文件。将以下代码复制并粘贴到其中:# Modify the variables so that all of the statements evaluate to True. var1 = var2 = var3 = var4 = var5 = var6 = # Don't edit anything below this comment # Numbers print(isinstance(var1, int)) print(isinstance(var6, float)) print(var1 < 35) print(var1 <= var6) # Strings print(isinstance(var2, str)) print(var2[5] == "n" and var2[0] == "p") # Lists print(isinstance(var3, list)) print(len(var3) == 5) # Tuples print(isinstance(var4, tuple)) print(var4[2] == "Hello, Python!") # Dictionaries print(isinstance(var5, dict)) print("happy" in var5) print(7 in var5.values()) print(var5.get("egg") == "salad") print(len(var5) == 3) var5["tuna"] = "fish" print(len(var5) == 3)按照说明,更新代码。完成后,使用
python exercise.py命令从终端运行代码进行测试。祝你好运!既然您已经了解了 Python 编程的基础,请务必在 Real Python 查看各种 Python 教程、视频课程和资源,继续培养您的技能。
结论
学习如何使用 Python 并让你的编程技能更上一层楼是一件值得努力的事情。Python 是一种流行的、高效的、功能强大的高级编程语言,需求量很大。在本教程中,您学习了 Python 的基本概念,并开始将它们应用到您的 Python 代码中。
在本教程中,您学习了:
- 什么是 Python 以及为什么你应该考虑使用它
- 开始编码时应该学习哪些基本的 Python 语法
- 如何在 Python 中处理错误
- 如何快速获得 Python 中的帮助
- 你应该在你的代码中使用什么样的代码风格
- 无需重新发明轮子,从哪里获得额外功能
- 从哪里获取高质量的 Python 内容并增长您的技能
您还创建了您的第一个 Python 程序,并在您的计算机上运行它。有了这些知识,你就可以更深入地钻研 Python 并学习更多的语言。**********
python“for”循环(明确迭代)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: For Loops in Python(定迭代)
本教程将向你展示如何用 Python
for循环执行确定迭代。在本介绍性系列的之前的教程中,您学习了以下内容:
- 同一代码块的反复执行被称为迭代。
- 迭代有两种类型:
- 确定的迭代,其中预先明确指定重复的次数
- 不定迭代,其中代码块执行直到满足某个条件
- 在 Python 中,无限迭代是通过一个
while循环来执行的。以下是你将在本教程中涉及的内容:
您将从编程语言用来实现明确迭代的一些不同范例的比较开始。
然后你将学习 iterables 和 iterators ,这两个概念构成了 Python 中确定迭代的基础。
最后,您将把它们联系在一起,并了解 Python 的
for循环。免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
程序设计中的有限迭代综述
明确迭代循环经常被称为
for循环,因为for是用于在几乎所有编程语言中引入它们的关键字,包括 Python。历史上,编程语言提供了几种不同风格的
for循环。这些将在下面的章节中简要介绍。数字范围循环
最基本的
for循环是一个带有起始值和结束值的简单数值范围语句。确切的格式因语言而异,但通常如下所示:for i = 1 to 10 <loop body>这里,循环体执行了十次。变量
i在第一次迭代时取值1,在第二次迭代时取值2,依此类推。这种for循环在 BASIC、Algol 和 Pascal 语言中使用。三表达式循环
由 C 编程语言推广的另一种形式的
for循环包含三个部分:
- 初始化
- 指定结束条件的表达式
- 每次迭代结束时要执行的操作。
这种类型的循环具有以下形式:
for (i = 1; i <= 10; i++) <loop body>技术说明:在 C 编程语言中,
i++递增变量i。它大致相当于 Python 中的i += 1。该循环解释如下:
- 将
i初始化为1。- 只要
i <= 10继续循环。- 每次循环迭代后,将
i增加1。三表达式
for循环很受欢迎,因为为这三部分指定的表达式几乎可以是任何东西,所以这比上面显示的更简单的数值范围形式有更多的灵活性。这些for循环在 C++ 、 Java 、PHP 和 Perl 语言中也很常见。基于集合或基于迭代器的循环
这种类型的循环迭代对象集合,而不是指定数值或条件:
for i in <collection> <loop body>每次循环时,变量
i取<collection>中下一个对象的值。这种类型的for循环可以说是最一般化和最抽象的。Perl 和 PHP 也支持这种类型的循环,但是它是由关键字foreach而不是for引入的。延伸阅读:查看 For 循环 Wikipedia 页面,深入了解跨编程语言的明确迭代的实现。
Python
for循环在上面列出的循环类型中,Python 只实现了最后一种:基于集合的迭代。乍一看,这似乎是一个不公平的交易,但是请放心,Python 对确定迭代的实现是如此通用,以至于您最终不会感到被欺骗!
很快,您将详细探究 Python 的
for循环。但是现在,让我们从一个快速原型和例子开始,只是为了熟悉一下。Python 的
for循环是这样的:for <var> in <iterable>: <statement(s)>
<iterable>是对象的集合,例如,列表或元组。与所有 Python 控制结构一样,循环体中的<statement(s)>用缩进表示,并且对<iterable>中的每一项执行一次。每次循环时,循环变量<var>取<iterable>中下一个元素的值。这里有一个代表性的例子:

>>> a = ['foo', 'bar', 'baz']
>>> for i in a:
... print(i)
...
foo
bar
baz
在这个例子中,<iterable>是列表a,而<var>是变量i。每次通过循环,i在a中承担一个连续的项目,因此 print() 分别显示值'foo'、'bar'和'baz'。像这样的for循环是处理 iterable 中项目的 Pythonic 方式。
但是什么是可迭代的呢?在进一步检查for循环之前,更深入地研究 Python 中的可迭代对象是有益的。
可重复项
在 Python 中, iterable 意味着一个对象可以在迭代中使用。该术语用作:
- 形容词:一个物体可以被描述为可重复的。
- 名词:一个对象可以被描述为可重复的。
如果一个对象是可迭代的,它可以被传递给内置的 Python 函数iter(),后者返回一个叫做迭代器的东西。是的,术语有点重复。坚持住。最后一切都解决了。
下例中的每个对象都是可迭代的,当传递给iter()时,返回某种类型的迭代器:
>>> iter('foobar') # String <str_iterator object at 0x036E2750> >>> iter(['foo', 'bar', 'baz']) # List <list_iterator object at 0x036E27D0> >>> iter(('foo', 'bar', 'baz')) # Tuple <tuple_iterator object at 0x036E27F0> >>> iter({'foo', 'bar', 'baz'}) # Set <set_iterator object at 0x036DEA08> >>> iter({'foo': 1, 'bar': 2, 'baz': 3}) # Dict <dict_keyiterator object at 0x036DD990>另一方面,这些对象类型是不可迭代的:
>>> iter(42) # Integer
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
iter(42)
TypeError: 'int' object is not iterable
>>> iter(3.1) # Float
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
iter(3.1)
TypeError: 'float' object is not iterable
>>> iter(len) # Built-in function
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
iter(len)
TypeError: 'builtin_function_or_method' object is not iterable
到目前为止,您遇到的所有集合或容器类型的数据类型都是可迭代的。其中包括字符串,列表,元组,字典,集合,以及 frozenset 类型。
但是这些绝不是唯一可以迭代的类型。Python 中内置的或模块中定义的许多对象都被设计成可迭代的。例如,Python 中的打开文件是可迭代的。正如您将在关于文件 I/O 的教程中看到的,迭代一个打开的文件对象会从文件中读取数据。
事实上,Python 中的几乎任何对象都可以变成可迭代的。即使是用户定义的对象,也可以通过迭代的方式进行设计。(在下一篇关于面向对象编程的文章中,您会发现这是如何做到的。)
迭代器
好了,现在你知道了一个对象是可迭代的意味着什么,你也知道了如何使用iter()从它那里获得一个迭代器。一旦你有了一个迭代器,你能用它做什么?
迭代器本质上是一个值生成器,它从相关的可迭代对象中产生连续的值。内置函数next()用于从迭代器中获取下一个值。
下面是一个使用上述相同列表的示例:
>>> a = ['foo', 'bar', 'baz'] >>> itr = iter(a) >>> itr <list_iterator object at 0x031EFD10> >>> next(itr) 'foo' >>> next(itr) 'bar' >>> next(itr) 'baz'在这个例子中,
a是一个可迭代列表,itr是相关的迭代器,通过iter()获得。每个next(itr)调用从itr获得下一个值。注意迭代器是如何在内部保持状态的。它知道已经获得了哪些值,所以当您调用
next()时,它知道接下来要返回什么值。当迭代器用完值时会发生什么?让我们对上面的迭代器再进行一次
next()调用:
>>> next(itr)
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
next(itr)
StopIteration
如果迭代器中的所有值都已经返回,那么后续的next()调用将引发一个StopIteration异常。从迭代器获取值的任何进一步尝试都将失败。
只能从一个方向的迭代器中获取值。你不能倒退。没有prev()功能。但是您可以在同一个 iterable 对象上定义两个独立的迭代器:
>>> a ['foo', 'bar', 'baz'] >>> itr1 = iter(a) >>> itr2 = iter(a) >>> next(itr1) 'foo' >>> next(itr1) 'bar' >>> next(itr1) 'baz' >>> next(itr2) 'foo'即使迭代器
itr1已经在列表的末尾,itr2仍然在列表的开头。每个迭代器维护自己的内部状态,相互独立。如果想一次从迭代器中获取所有值,可以使用内置的
list()函数。在其他可能的用法中,list()将迭代器作为它的参数,并返回一个由迭代器产生的所有值组成的列表:
>>> a = ['foo', 'bar', 'baz']
>>> itr = iter(a)
>>> list(itr)
['foo', 'bar', 'baz']
类似地,内置的tuple()和set()函数分别从迭代器产生的所有值中返回一个元组和一个集合:
>>> a = ['foo', 'bar', 'baz'] >>> itr = iter(a) >>> tuple(itr) ('foo', 'bar', 'baz') >>> itr = iter(a) >>> set(itr) {'baz', 'foo', 'bar'}不建议你养成这种习惯。迭代器的优雅之处在于它们“懒惰”这意味着当你创建一个迭代器的时候,它不会生成所有它当时能产生的项。它会一直等待,直到你用
next()请求它们。项目直到被请求时才会被创建。当您使用
list()、tuple()等时,您是在强迫迭代器一次生成它的所有值,所以它们都可以被返回。如果迭代器返回的对象总数非常大,这可能需要很长时间。事实上,可以使用生成器函数和
itertools在 Python 中创建一个迭代器,返回一系列无穷无尽的对象。如果你试图从一个无限的迭代器中一次获取所有的值,程序将挂起。Python 的内部
for循环现在已经向您介绍了完全理解 Python 的
for循环如何工作所需的所有概念。继续之前,让我们回顾一下相关术语:
学期 意义 迭代 遍历集合中的对象或项目的过程 可迭代 可以被重复的物体(或用来描述物体的形容词) 迭代器 从关联的 iterable 中产生连续项或值的对象 T2 iter()用于从 iterable 中获取迭代器的内置函数 现在,再次考虑本教程开始时出现的简单的
for循环:
>>> a = ['foo', 'bar', 'baz']
>>> for i in a:
... print(i)
...
foo
bar
baz
这个循环可以完全用你刚刚学到的概念来描述。为了执行这个for循环描述的迭代,Python 执行以下操作:
- 调用
iter()来获得a的迭代器 - 反复调用
next()从迭代器中依次获取每一项 - 当
next()引发StopIteration异常时终止循环
对于每一项next()返回,循环体被执行一次,循环变量i被设置为每次迭代的给定项。
下图总结了这一系列事件:
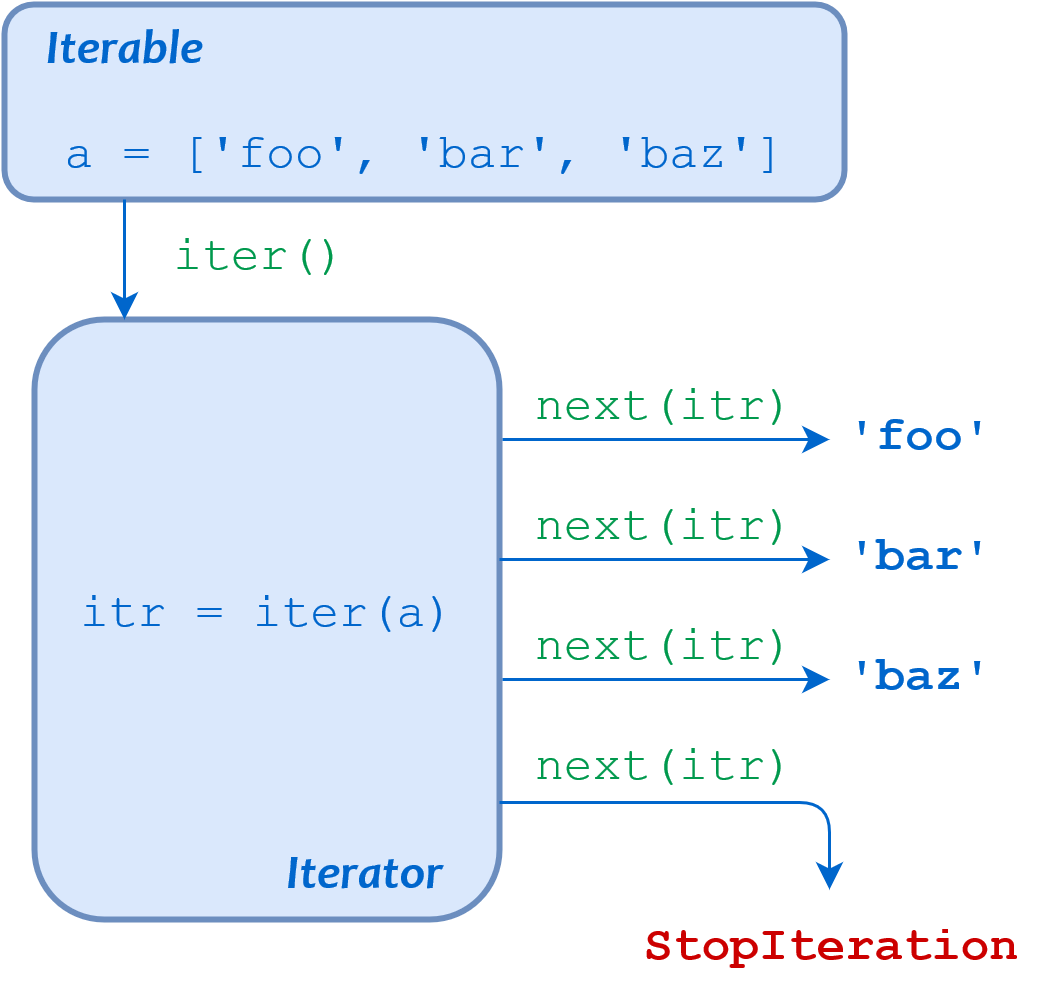
也许这看起来像是许多不必要的恶作剧,但好处是巨大的。Python 完全以这种方式处理所有可迭代对象的循环,在 Python 中,可迭代对象和迭代器比比皆是:
-
许多内置对象和库对象是可迭代的。
-
有一个名为
itertools的标准库模块,包含许多返回 iterables 的函数。 -
使用 Python 的面向对象功能创建的用户定义对象可以是可迭代的。
-
Python 有一个称为生成器的构造,它允许您以简单、直接的方式创建自己的迭代器。
在这一系列文章中,您将会发现更多关于上述内容的信息。它们都可以是一个for循环的目标,并且语法都是相同的。它简洁优雅,功能多样。
遍历字典
您之前看到迭代器可以从带有iter()的字典中获得,所以您知道字典必须是可迭代的。当你在字典中循环时会发生什么?让我们看看:
>>> d = {'foo': 1, 'bar': 2, 'baz': 3} >>> for k in d: ... print(k) ... foo bar baz如您所见,当一个
for循环遍历一个字典时,循环变量被分配给字典的键。要访问循环中的字典值,您可以像往常一样使用键进行字典引用:
>>> for k in d:
... print(d[k])
...
1
2
3
您还可以使用.values()直接遍历字典的值:
>>> for v in d.values(): ... print(v) ... 1 2 3事实上,您可以同时遍历字典的键和值。这是因为
for循环的循环变量不仅限于单个变量。它也可以是元组,在这种情况下,使用打包和解包从 iterable 中的项进行赋值,就像赋值语句一样:
>>> i, j = (1, 2) >>> print(i, j)
1 2
>>> for i, j in [(1, 2), (3, 4), (5, 6)]: ... print(i, j)
...
1 2
3 4
5 6
正如在 Python 字典的教程中所提到的,字典方法.items()有效地返回了一列作为元组的键/值对:
>>> d = {'foo': 1, 'bar': 2, 'baz': 3} >>> d.items() dict_items([('foo', 1), ('bar', 2), ('baz', 3)])因此,遍历字典访问键和值的 Pythonic 方法如下所示:
>>> d = {'foo': 1, 'bar': 2, 'baz': 3}
>>> for k, v in d.items():
... print('k =', k, ', v =', v)
...
k = foo , v = 1
k = bar , v = 2
k = baz , v = 3
range()功能
在本教程的第一部分中,您看到了一种称为数值范围循环的for循环,其中指定了起始和结束数值。虽然这种形式的for循环没有直接内置到 Python 中,但是很容易实现。
例如,如果您想迭代从0到4的值,您可以简单地这样做:
>>> for n in (0, 1, 2, 3, 4): ... print(n) ... 0 1 2 3 4当只有几个数字时,这个解决方案还不错。但是如果数字范围大得多,它会很快变得乏味。
令人高兴的是,Python 提供了一个更好的选项——内置的
range()函数,它返回一个产生整数序列的 iterable。
range(<end>)返回一个 iterable,该 iterable 产生从0开始的整数,直到但不包括<end>:
>>> x = range(5)
>>> x
range(0, 5)
>>> type(x)
<class 'range'>
请注意,range()返回的是一个类range的对象,而不是一个值的列表或元组。因为range对象是可迭代的,所以可以通过用for循环迭代它们来获得值:
>>> for n in x: ... print(n) ... 0 1 2 3 4你也可以用
list()或tuple()一次抓取所有的值。在 REPL 会话中,这是快速显示值的便捷方式:
>>> list(x)
[0, 1, 2, 3, 4]
>>> tuple(x)
(0, 1, 2, 3, 4)
然而,当range()被用在一个更大的应用程序的代码中时,以这种方式使用list()或tuple()通常被认为是不良的做法。像迭代器一样,range对象是懒惰的——指定范围内的值直到被请求时才会生成。在一个range对象上使用list()或tuple()强制所有的值一次返回。这很少是必要的,如果列表很长,会浪费时间和内存。
range(<begin>, <end>, <stride>)返回一个 iterable,该 iterable 产生从<begin>开始的整数,直到但不包括<end>。如果指定,<stride>表示值之间的跳跃量(类似于用于字符串和列表切片的跨距值):
>>> list(range(5, 20, 3)) [5, 8, 11, 14, 17]如果省略
<stride>,则默认为1:
>>> list(range(5, 10, 1))
[5, 6, 7, 8, 9]
>>> list(range(5, 10))
[5, 6, 7, 8, 9]
指定给range()的所有参数必须是整数,但其中任何一个都可以是负数。自然,如果<begin>大于<end>,<stride>一定是负数(如果你想要任何结果的话):
>>> list(range(-5, 5)) [-5, -4, -3, -2, -1, 0, 1, 2, 3, 4] >>> list(range(5, -5)) [] >>> list(range(5, -5, -1)) [5, 4, 3, 2, 1, 0, -1, -2, -3, -4]技术说明:严格来说,
range()并不完全是一个内置函数。它被实现为一个创建不可变序列类型的可调用类。但出于实用目的,它的行为就像一个内置函数。更多关于
range()的信息,请看真正的 Python 文章 Python 的range()函数(指南)。改变
for循环行为在本介绍性系列的上一篇教程中,您已经看到了如何使用
break和continue语句中断while循环的执行,并使用else子句对其进行修改。这些功能在for循环中也是可用的。
break和continue报表
break和continue与for回路的工作方式与while回路相同。break完全终止循环,并继续执行循环后的第一条语句:
>>> for i in ['foo', 'bar', 'baz', 'qux']:
... if 'b' in i:
... break ... print(i)
...
foo
continue终止当前迭代并进行下一次迭代:
>>> for i in ['foo', 'bar', 'baz', 'qux']: ... if 'b' in i: ... continue ... print(i) ... foo qux
else条款一个
for循环也可以有一个else子句。这种解释类似于一个while循环。如果循环因 iterable 用尽而终止,将执行else子句:
>>> for i in ['foo', 'bar', 'baz', 'qux']:
... print(i)
... else:
... print('Done.') # Will execute
...
foo
bar
baz
qux
Done.
如果列表被一个break语句分解,则else子句不会被执行:
>>> for i in ['foo', 'bar', 'baz', 'qux']: ... if i == 'bar': ... break ... print(i) ... else: ... print('Done.') # Will not execute ... foo结论
本教程介绍了
for循环,它是 Python 中确定迭代的主力。您还了解了 iterables 和 iterators 的内部工作原理,这两种重要的对象类型是定义迭代的基础,但在其他各种 Python 代码中也很重要。
在这个介绍性系列的下两个教程中,您将稍微改变一下思路,探索 Python 程序如何通过从键盘的输入和从控制台的输出与用户交互。
« Python "while" Loops (Indefinite Iteration)Python "for" Loops (Definite Iteration)Basic Input and Output in Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: For Loops in Python(定迭代)******
面向社会科学家的 Python
Python 是社会科学家中越来越流行的数据分析工具。在许多已经成熟的库的支持下,R 和 Stata 用户越来越多地转向 Python,以便在不牺牲这些老程序多年来积累的功能的情况下利用 Python 的美丽、灵活和性能。
但是,尽管 Python 提供了很多东西,但现有的 Python 资源并不总是很适合社会科学家的需求。考虑到这一点,我最近创建了一个新资源——www.data-analysis-in-python.org(DAP)——专门为社会科学家 Python 用户的目标和愿望量身定制。
然而,这个网站并不是一套新的教程——世界上有比足够多的 Python 教程还要多的 T2 教程。更确切地说,该网站的目的是管理和注释现有资源,并为用户提供关注哪些主题和跳过哪些主题的指导。
为什么是社会科学家的网站?
社会科学家——事实上,大多数数据科学家——花费大部分时间试图将个体的、特殊的数据集整合成运行统计分析所需的形状。这使得大多数社会科学家使用 Python 的方式与大多数软件开发人员使用 Python 的方式有着根本的不同。
社会科学家主要对编写执行一系列命令(记录变量、合并数据集、解析文本文档等)的相对简单的程序(脚本)感兴趣。)将他们的数据整理成他们可以分析的形式。因为他们通常为特定的、特殊的应用程序和数据集编写脚本,他们通常不会专注于编写具有大量抽象的代码。
换句话说,社会科学家倾向于主要对学习如何有效地使用现有工具感兴趣,而不是开发新工具。
正因为如此,学习 Python 的社会科学家在技能发展方面比软件开发人员有着不同的优先权。然而,大多数在线教程是为开发人员或计算机科学学生编写的,所以 DAP 的目的之一是为社会科学家提供一些指导,让他们知道在早期培训中应该优先考虑的技能。特别是, DAP 建议:
立即需要:
- 数据类型:整数、浮点数、字符串、布尔值、列表、字典和集合(元组是可选的)
- 定义函数
- 写循环
- 理解可变和不可变数据类型
- 操作字符串的方法
- 导入第三方模块
- 阅读和解释错误
你在某个时候会想知道,但不是马上就要知道的事情:
- 高级调试工具(如 pdb
- 文件输入/输出(您将使用的大多数库都有工具来简化这一过程)
不需要:
- 定义或编写类
- 了解异常
熊猫
今天,大多数实证社会科学仍然围绕表格数据组织,这意味着数据在每一列中以不同的变量呈现,在每一行中以不同的观察值呈现。因此,当许多使用 Python 的社会科学家在 Python 入门教程中找不到表格数据结构时,他们会感到有些困惑。为了解决这一困惑,DAP 尽最大努力尽快向用户介绍熊猫图书馆,提供教程链接和一些关于注意陷阱的提示。
pandas 库复制了社会科学家习惯于在 Stata 或 R 中发现的许多功能——数据可以用表格格式表示,列变量可以很容易地标记,不同类型的列(如 floats 和 strings)可以组合在同一个数据集中。
熊猫也是社会科学家可能使用的许多其他工具的门户,如图形库( seaborn 和 ggplot2 )和 statsmodels 计量经济学库。
按研究领域分类的其他图书馆
虽然所有希望使用 Python 的社会科学家都需要理解核心语言,并且大多数人都希望熟悉
pandas,但是 Python 生态系统充满了特定于应用程序的库,这些库只对一部分用户有用。考虑到这一点,DAP 提供了图书馆的概述,以帮助在不同主题领域工作的研究人员,以及最佳使用材料的链接,以及相关注意事项的指导:
- 网络分析 : iGraph
- 文本分析 : NLTK,如果需要的话还有 coreNLP
- 计量经济学:统计模型
- 绘图 : ggplot 和 seaborn
- 大数据 : dask 和 pyspark
- 地理空间分析 : arcpy 或 geopandas
- 让代码更快:iPython(用于评测)和 numba(用于 JIT 编译)
想参与进来吗?
这个网站是年轻的,所以我们渴望尽可能多的内容和设计的投入。如果你有这方面的经验,你想分享请给我发一封的电子邮件或者在 Github 上发一条的评论。
这是范德比尔特大学民主制度研究中心的博士后尼克·尤班克的客座博文*
较新的 Python 字符串格式技术指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 格式化 Python 字符串
在这个介绍性系列的之前的教程中,您已经初步了解了如何用 Python f-strings 格式化您的字符串。在本教程的末尾,您会学到更多关于这种技术的知识。
由于 f-string 对于 Python 语言来说相对较新,所以熟悉第二种稍微老一点的技术也是有好处的。您可能会在较旧的 Python 代码中遇到它。
在本教程中,您将了解到:
- 弦
.format()法- 格式的字符串文字,或者 f-string
您将详细了解这些格式化技术,并将它们添加到 Python 字符串格式化工具包中。
注意:有一个名为
string的标准模块,包含一个名为Template的类,它也通过插值提供一些字符串格式。一种相关的技术,字符串模操作符,提供了或多或少相同的功能。在本教程中,您不会涉及这些技术中的任何一种,但是如果您必须使用 Python 2 编写的代码,您会希望阅读一下字符串模操作符。您可能会注意到,在 Python 中有许多不同的方法来格式化字符串,这违背了 Python 自己的一条原则:
应该有一种——最好只有一种——显而易见的方法来做这件事。—蒂姆·彼得斯,Python 的禅宗
在 Python 存在和发展的这些年里,不同的字符串格式化技术得到了历史性的发展。旧的技术被保留下来以确保向后兼容性,有些甚至有特定的用例。
如果你刚开始使用 Python,并且正在寻找一种格式化字符串的单一方法,那么请坚持使用 Python 3 的 f 字符串。如果您遇到了看起来很奇怪的字符串格式代码并想了解更多,或者您需要使用旧版本的 Python,那么学习其他技术也是一个好主意。
Python 字符串
.format()方法Python string
.format()方法是在 2.6 版本中引入的。它在很多方面都类似于字符串模操作符,但是.format()在通用性方面远远超过它。Python.format()调用的一般形式如下所示:<template>.format(<positional_argument(s)>, <keyword_argument(s)>)请注意,这是一个方法,而不是一个运算符。您调用
<template>上的方法,这是一个包含替换字段的字符串。该方法的<positional_arguments>和<keyword_arguments>指定插入到<template>中代替替换字段的值。得到的格式化字符串是该方法的返回值。在
<template>字符串中,替换字段用花括号({})括起来。花括号中没有包含的内容是直接从模板复制到输出中的文本。如果您需要在模板字符串中包含一个文字花括号字符,如{或},那么您可以通过将它加倍来转义该字符:
>>> '{{ {0} }}'.format('foo')
'{ foo }'
现在输出中包含了花括号。
字符串.format()方法:参数
在深入了解如何在 Python 中使用这个方法格式化字符串的更多细节之前,让我们从一个简单的例子开始。回顾一下,这里是上一篇教程中关于字符串模操作符的第一个例子:
>>> print('%d %s cost $%.2f' % (6, 'bananas', 1.74)) 6 bananas cost $1.74这里,您使用 Python 中的字符串模操作符来格式化字符串。现在,您可以使用 Python 的 string
.format()方法来获得相同的结果,如下所示:
>>> print('{0} {1} cost ${2}'.format(6, 'bananas', 1.74))
6 bananas cost $1.74
在本例中,<template>是字符串'{0} {1} cost ${2}'。替换字段是{0}、{1}和{2},它们包含与从零开始的位置参数6、'bananas'和1.74相对应的数字。每个位置参数都被插入到模板中,代替其对应的替换字段:
下一个例子使用关键字参数而不是位置参数来产生相同的结果:
>>> print('{quantity} {item} cost ${price}'.format( ... quantity=6, ... item='bananas', ... price=1.74)) 6 bananas cost $1.74在这种情况下,替换字段是
{quantity}、{item}和{price}。这些字段指定对应于关键字参数quantity=6、item='bananas'和price=1.74的关键字。每个关键字值都被插入到模板中,代替其对应的替换字段:
Using The String .format() Method in Python to Format a String With Keyword Arguments 在这个介绍性系列的下一篇教程中,您将了解到更多关于位置和关键字参数的知识,该教程将探索函数和参数传递。现在,接下来的两节将向您展示如何在 Python
.format()方法中使用它们。位置参数
位置参数被插入到模板中,代替编号的替换字段。像列表索引一样,替换字段的编号是从零开始的。第一个位置参数编号为
0,第二个编号为1,依此类推:

>>> '{0}/{1}/{2}'.format('foo', 'bar', 'baz')
'foo/bar/baz'
请注意,替换字段不必按数字顺序出现在模板中。它们可以按任何顺序指定,并且可以出现多次:
>>> '{2}.{1}.{0}/{0}{0}.{1}{1}.{2}{2}'.format('foo', 'bar', 'baz') 'baz.bar.foo/foofoo.barbar.bazbaz'当你指定一个超出范围的替换字段号时,你会得到一个错误。在下面的例子中,位置参数被编号为
0、1和2,但是您在模板中指定了{3}:
>>> '{3}'.format('foo', 'bar', 'baz')
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
'{3}'.format('foo', 'bar', 'baz')
IndexError: tuple index out of range
这引发了一个IndexError 异常。
从 Python 3.1 开始,您可以省略替换字段中的数字,在这种情况下,解释器会假定顺序。这被称为自动字段编号:
>>> '{}/{}/{}'.format('foo', 'bar', 'baz') 'foo/bar/baz'指定自动字段编号时,必须提供至少与替换字段一样多的参数:
>>> '{}{}{}{}'.format('foo','bar','baz')
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
'{}{}{}{}'.format('foo','bar','baz')
IndexError: tuple index out of range
在这种情况下,模板中有四个替换字段,但只有三个参数,所以出现了一个IndexError异常。另一方面,如果参数比替换字段多也没关系。多余的参数根本不用:
>>> '{}{}'.format('foo', 'bar', 'baz') 'foobar'这里,参数
'baz'被忽略。请注意,您不能混合使用这两种技术:
>>> '{1}{}{0}'.format('foo','bar','baz')
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
'{1}{}{0}'.format('foo','bar','baz')
ValueError: cannot switch from manual field specification to automatic field
numbering
当使用 Python 格式化带有位置参数的字符串时,必须在自动或显式替换字段编号之间进行选择。
关键字参数
关键字参数被插入到模板字符串中,代替具有相同名称的关键字替换字段:
>>> '{x}/{y}/{z}'.format(x='foo', y='bar', z='baz') 'foo/bar/baz'在这个例子中,关键字参数
x、y和z的值分别代替替换字段{x}、{y}和{z}。如果您引用了一个丢失的关键字参数,那么您将看到一个错误:
>>> '{x}/{y}/{w}'.format(x='foo', y='bar', z='baz')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'w'
这里,您指定了替换字段{w},但是没有相应的名为w的关键字参数。巨蟒召唤出 KeyError异常。
虽然必须按顺序指定位置参数,但是可以按任意顺序指定关键字参数:
>>> '{0}/{1}/{2}'.format('foo', 'bar', 'baz') 'foo/bar/baz' >>> '{0}/{1}/{2}'.format('bar', 'baz', 'foo') 'bar/baz/foo' >>> '{x}/{y}/{z}'.format(x='foo', y='bar', z='baz') 'foo/bar/baz' >>> '{x}/{y}/{z}'.format(y='bar', z='baz', x='foo') 'foo/bar/baz'您可以在一个 Python
.format()调用中同时指定位置参数和关键字参数。请注意,如果您这样做,那么所有的位置参数必须出现在任何关键字参数之前:
>>> '{0}{x}{1}'.format('foo', 'bar', x='baz')
'foobazbar'
>>> '{0}{x}{1}'.format('foo', x='baz', 'bar')
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument
事实上,所有位置参数出现在任何关键字参数之前的要求并不仅仅适用于 Python 格式的方法。这通常适用于任何函数或方法调用。在本系列的下一篇教程中,您将了解到更多关于函数和函数调用的内容。
在迄今为止的所有示例中,传递给 Python .format()方法的值都是文字值,但是您也可以指定变量:
>>> x = 'foo' >>> y = 'bar' >>> z = 'baz' >>> '{0}/{1}/{s}'.format(x, y, s=z) 'foo/bar/baz'在这种情况下,将变量
x和y作为位置参数值传递,将z作为关键字参数值传递。字符串
.format()方法:简单替换字段如您所见,当您调用 Python 的
.format()方法时,<template>字符串包含了替换字段。它们指示在模板中的什么位置插入方法的参数。替换字段由三部分组成:
{[<name>][!<conversion>][:<format_spec>]}这些组件解释如下:
成分 意义 <name>指定要格式化的值的来源 <conversion>指示使用哪个标准 Python 函数来执行转换 <format_spec>指定了有关如何转换值的更多详细信息 每个组件都是可选的,可以省略。让我们更深入地看看每个组件。
<name>组件
<name>组件是替换字段的第一部分:
{[<name>]T2】
<name>表示将参数列表中的哪个参数插入到 Python 格式字符串的给定位置。它要么是位置参数的数字,要么是关键字参数的关键字。在下面的例子中,替换字段的<name>组件分别是0、1和baz:
>>> x, y, z = 1, 2, 3
>>> '{0}, {1}, {baz}'.format(x, y, baz=z)
'1, 2, 3'
如果一个参数是一个列表,那么您可以使用带有<name>的索引来访问列表的元素:
>>> a = ['foo', 'bar', 'baz'] >>> '{0[0]}, {0[2]}'.format(a) 'foo, baz' >>> '{my_list[0]}, {my_list[2]}'.format(my_list=a) 'foo, baz'类似地,如果相应的参数是一个字典,那么您可以使用带有
<name>的键引用:
>>> d = {'key1': 'foo', 'key2': 'bar'}
>>> d['key1']
'foo'
>>> '{0[key1]}'.format(d)
'foo'
>>> d['key2']
'bar'
>>> '{my_dict[key2]}'.format(my_dict=d)
'bar'
您也可以从替换字段中引用对象属性。在本系列的之前的教程中,您了解到 Python 中的几乎每一项数据都是一个对象。对象可能有分配给它们的属性,这些属性使用点符号来访问:
obj.attr
这里,obj是一个属性名为attr的对象。使用点符号来访问对象的属性。让我们看一个例子。Python 中的复数具有名为.real和.imag的属性,分别代表数字的实部和虚部。您也可以使用点符号来访问它们:
>>> z = 3+5j >>> type(z) <class 'complex'> >>> z.real 3.0 >>> z.imag 5.0本系列中有几个即将推出的关于面向对象编程的教程,在这些教程中,您将学到更多关于像这样的对象属性的知识。
在这种情况下,对象属性的相关性在于您可以在 Python
.format()替换字段中指定它们:
>>> z
(3+5j)
>>> 'real = {0.real}, imag = {0.imag}'.format(z)
'real = 3.0, imag = 5.0'
如您所见,在 Python 中使用.format()方法格式化复杂对象的组件相对简单。
<conversion>组件
<conversion>组件是替换字段的中间部分:
{[<name>][!<conversion>]T2】
Python 可以使用三种不同的内置函数将对象格式化为字符串:
str()repr()ascii()
默认情况下,Python .format()方法使用str(),但是在某些情况下,您可能想要强制.format()使用另外两个中的一个。您可以使用替换字段的<conversion>组件来实现这一点。<conversion>的可能值如下表所示:
| 价值 | 意义 |
|---|---|
!s |
用str()转换 |
!r |
用repr()转换 |
!a |
用ascii()转换 |
以下示例分别使用str()、repr()和ascii()强制 Python 执行字符串转换:
>>> '{0!s}'.format(42) '42' >>> '{0!r}'.format(42) '42' >>> '{0!a}'.format(42) '42'在许多情况下,无论您使用哪种转换函数,结果都是一样的,正如您在上面的示例中所看到的。也就是说,您不会经常需要
<conversion>组件,所以您不会在这里花费太多时间。但是,在有些情况下会有所不同,所以最好意识到,如果需要,您可以强制使用特定的转换函数。
<format_spec>组件
<format_spec>组件是替换字段的最后一部分:
{[<name>][!<conversion>][:<format_spec>]T2】
<format_spec>代表 Python.format()方法功能的核心。它包含在将值插入模板字符串之前对如何格式化值进行精细控制的信息。一般形式是这样的::
[[<fill>]<align>][<sign>][#][0][<width>][<group>][.<prec>][<type>]
<format_spec>的十个子组件按所示顺序指定。它们控制格式,如下表所述:
亚成分 影响 :将 <format_spec>与替换字段的其余部分分开<fill>指定如何填充未占据整个字段宽度的值 <align>指定如何对齐未占据整个字段宽度的值 <sign>控制数值中是否包含前导符号 #为某些演示类型选择替代输出形式 0使值在左边用零而不是 ASCII 空格字符填充 <width>指定输出的最小宽度 <group>指定了数字输出的分组字符 .<prec>指定浮点表示类型小数点后的位数,以及字符串表示类型的最大输出宽度 <type>指定表示类型,这是对相应参数执行的转换类型 这些函数类似于字符串模操作符转换说明符中的组件,但是功能更强大。在接下来的几节中,您将看到对它们的功能更全面的解释。
<type>子组件先说
<type>,这是<format_spec>的最后一部分。<type>子组件指定表示类型,表示类型是对相应值执行的转换类型,以产生输出。可能的值如下所示:
价值 演示类型 b二进制整数 c单字符 d十进制整数 e或E指数的 f或F浮点 g或G浮点或指数 o八进制整数 s线 x或X十六进制整数 %百分率 这些就像与字符串模运算符一起使用的转换类型,在许多情况下,它们的功能是相同的。以下示例展示了相似性:
>>> '%d' % 42
'42'
>>> '{:d}'.format(42)
'42'
>>> '%f' % 2.1
'2.100000'
>>> '{:f}'.format(2.1)
'2.100000'
>>> '%s' % 'foobar'
'foobar'
>>> '{:s}'.format('foobar')
'foobar'
>>> '%x' % 31
'1f'
>>> '{:x}'.format(31)
'1f'
然而,在一些 Python .format()表示类型和字符串模操作符转换类型之间有一些细微的差别:
| 类型 | .format()方法 |
字符串模运算符 |
|---|---|---|
| b | 指定二进制整数转换 | 不支持 |
| i,u | 不支持 | 指定整数转换 |
| c | 指定字符转换,相应的值必须是整数 | 指定字符转换,但相应的值可以是整数或单个字符串 |
| g,G | 在浮点或指数输出之间选择,但是控制选择的规则稍微复杂一些 | 根据指数的大小和为<prec>指定的值,选择浮点或指数输出 |
| r,a | 不支持(尽管该功能由替换字段中的!r和!a转换组件提供) |
分别用repr()或ascii()指定转换 |
| % | 将数值参数转换为百分比 | 在输出中插入一个文字字符'%' |
接下来,您将看到几个说明这些差异的例子,以及 Python .format()方法表示类型的一些附加特性。您将看到的第一个演示类型是b,它指定了二进制整数转换:
>>> '{:b}'.format(257) '100000001'模运算符根本不支持二进制转换类型:
>>> '%b' % 257
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: unsupported format character 'b' (0x62) at index 1
然而,模操作符允许十进制整数转换为d、i和u类型。只有d表示类型使用 Python .format()方法表示十进制整数转换。不支持i和u演示类型,也没有必要。
接下来是单字转换。模运算符允许整数或单个字符值使用c转换类型:
>>> '%c' % 35 '#' >>> '%c' % '#' '#'另一方面,Python 的
.format()方法要求对应于c表示类型的值是一个整数:
>>> '{:c}'.format(35)
'#'
>>> '{:c}'.format('#')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Unknown format code 'c' for object of type 'str'
当你试图传递一个不同类型的值时,你会得到一个ValueError。
对于字符串模运算符和 Python 的.format()方法, g转换类型根据指数的大小和为<prec>指定的值选择浮点或指数输出:
>>> '{:g}'.format(3.14159) '3.14159' >>> '{:g}'.format(-123456789.8765) '-1.23457e+08'管理选择的精确规则在
.format()中比在模运算符中稍微复杂一些。一般来说,你可以相信这个选择是有意义的。
G与g相同,除了当输出是指数时,在这种情况下'E'将是大写的:
>>> '{:G}'.format(-123456789.8765)
'-1.23457E+08'
结果与前面的例子相同,但是这次使用了大写的'E'。
注意:在其他一些情况下,你会发现g和G演示类型的不同。
在某些情况下,浮点运算可以产生一个基本上是无限的值。这样的数字在 Python 中的字符串表示是 'inf' 。浮点运算也可能产生无法用数字表示的值。Python 用字符串'NaN'来表示这一点,它代表而不是数字**。*
*当您将这些值传递给 Python 的.format()方法时,g表示类型产生小写输出,G产生大写输出:
>>> x = 1e300 * 1e300 >>> x inf >>> '{:g}'.format(x) 'inf' >>> '{:g}'.format(x * 0) 'nan' >>> '{:G}'.format(x) 'INF' >>> '{:G}'.format(x * 0) 'NAN'您还会看到
f和F演示类型的类似行为:
>>> '{:f}'.format(x)
'inf'
>>> '{:F}'.format(x)
'INF'
>>> '{:f}'.format(x * 0)
'nan'
>>> '{:F}'.format(x * 0)
'NAN'
有关浮点表示、inf和NaN的更多信息,请查看维基百科关于 IEEE 754-1985 的页面。** **模运算符支持 r和a转换类型,分别通过repr()和ascii()强制转换。Python 的.format()方法不支持r和a表示类型,但是您可以使用替换字段中的!r和!a转换组件完成同样的事情。
最后,您可以使用带有模运算符的 %转换类型将文字'%'字符插入到输出中:
>>> '%f%%' % 65.0 '65.000000%'在 Python
.format()方法的输出中插入文字'%'字符并不需要任何特殊的东西,因此%表示类型为百分比输出提供了不同的方便用途。它将指定值乘以 100,并附加一个百分号:
>>> '{:%}'.format(0.65)
'65.000000%'
<format_spec>的其余部分指示如何格式化所选的表示类型,与字符串模操作符的宽度和精度说明符和转换标志非常相似。这些将在以下章节中进行更全面的描述。
<fill> 和 <align> 子组件
<fill>和<align>控制如何在指定的字段宽度内填充和定位格式化的输出。这些子组件只有在格式化字段值没有占据整个字段宽度时才有意义,这种情况只有在用<width>指定最小字段宽度时才会发生。如果没有指定<width>,那么<fill>和<align>将被忽略。在本教程的后面部分,您将会谈到<width>。
以下是<align>子组件的可能值:
<>^=
使用小于号(<)的值表示输出是左对齐的:
>>> '{0:<8s}'.format('foo') 'foo ' >>> '{0:<8d}'.format(123) '123 '这是字符串值的默认行为。
使用大于号(
>)的值表示输出应该右对齐:
>>> '{0:>8s}'.format('foo')
' foo'
>>> '{0:>8d}'.format(123)
' 123'
这是数值的默认行为。
使用插入符号(^)的值表示输出应该在输出字段中居中:
>>> '{0:^8s}'.format('foo') ' foo ' >>> '{0:^8d}'.format(123) ' 123 '最后,您还可以使用等号(
=)为<align>子组件指定一个值。这只对数值有意义,并且只在输出中包含符号时才有意义。当数字输出包含符号时,它通常直接放在数字第一个数字的左边,如上所示。如果
<align>被设置为等号(=,则符号出现在输出字段的左边缘,并且在符号和数字之间放置填充符:
>>> '{0:+8d}'.format(123)
' +123'
>>> '{0:=+8d}'.format(123)
'+ 123'
>>> '{0:+8d}'.format(-123)
' -123'
>>> '{0:=+8d}'.format(-123)
'- 123'
您将在下一节详细介绍<sign>组件。
<fill>指定当格式化值没有完全填充输出宽度时,如何填充额外的空间。可以是除花括号({})以外的任何字符。(如果你真的觉得必须用花括号填充一个字段,那么你只能另寻他法了!)
使用<fill>的一些例子如下所示:
>>> '{0:->8s}'.format('foo') '-----foo' >>> '{0:#<8d}'.format(123) '123#####' >>> '{0:*^8s}'.format('foo') '**foo***'如果您为
<fill>指定了一个值,那么您也应该为<align>包含一个值。
<sign>子组件您可以使用
<sign>组件控制符号是否出现在数字输出中。例如,在下面的例子中,<format_spec>中指定的加号(+)表示该值应该总是以前导符号显示:
>>> '{0:+6d}'.format(123)
' +123'
>>> '{0:+6d}'.format(-123)
' -123'
在这里,您使用加号(+),因此正值和负值都将包含一个符号。如果使用减号(-),则只有负数值会包含前导符号,而正值不会:
>>> '{0:-6d}'.format(123) ' 123' >>> '{0:-6d}'.format(-123) ' -123'当您使用单个空格(
' ')时,这意味着负值包含一个符号,正值包含一个 ASCII 空格字符:
>>> '{0:*> 6d}'.format(123)
'** 123'
>>> '{0:*>6d}'.format(123)
'***123'
>>> '{0:*> 6d}'.format(-123)
'**-123'
因为空格字符是默认的填充字符,所以只有在指定了替代的<fill>字符时,您才会注意到它的影响。
最后,回想一下上面的内容,当您为<align>指定等号(=)并包含一个<sign>说明符时,填充位于符号和值之间,而不是符号的左边。
# 子组件
当您在<format_spec>中指定一个散列字符(#)时,Python 将为某些表示类型选择一个替代的输出形式。这类似于字符串模运算符的#转换标志。对于二进制、八进制和十六进制表示类型,哈希字符(#)导致在值的左侧包含一个显式的基本指示符:
>>> '{0:b}, {0:#b}'.format(16) '10000, 0b10000' >>> '{0:o}, {0:#o}'.format(16) '20, 0o20' >>> '{0:x}, {0:#x}'.format(16) '10, 0x10'如您所见,基本指示器可以是
0b、0o或0x。对于浮点或指数表示类型,哈希字符强制输出包含小数点,即使输出由整数组成:
>>> '{0:.0f}, {0:#.0f}'.format(123)
'123, 123.'
>>> '{0:.0e}, {0:#.0e}'.format(123)
'1e+02, 1.e+02'
对于除上述显示类型之外的任何显示类型,散列字符(#)不起作用。
0 子组件
如果输出小于指示的字段宽度,并且您在<format_spec>中指定了数字零(0),那么值将在左边用零填充,而不是 ASCII 空格字符:
>>> '{0:05d}'.format(123) '00123' >>> '{0:08.1f}'.format(12.3) '000012.3'您通常将它用于数值,如上所示。但是,它也适用于字符串值:
>>> '{0:>06s}'.format('foo')
'000foo'
如果您同时指定了<fill>和<align>,那么<fill>将覆盖0:
>>> '{0:*>05d}'.format(123) '**123'
<fill>和0本质上控制相同的东西,所以没有必要指定两者。事实上,0真的是多余的,可能是为了方便熟悉字符串模运算符类似的0转换标志的开发人员而包含进来的。
<width>子组件
<width>指定输出字段的最小宽度:
>>> '{0:8s}'.format('foo')
'foo '
>>> '{0:8d}'.format(123)
' 123'
注意,这是一个最小字段宽度。假设您指定了一个比最小值长的值:
>>> '{0:2s}'.format('foobar') 'foobar'在这种情况下,
<width>实际上被忽略了。
<group>子组件
<group>允许您在数字输出中包含一个分组分隔符。对于十进制和浮点表示类型,<group>可以指定为逗号字符(,)或下划线字符(_)。然后,该字符在输出中分隔每组三位数:
>>> '{0:,d}'.format(1234567)
'1,234,567'
>>> '{0:_d}'.format(1234567)
'1_234_567'
>>> '{0:,.2f}'.format(1234567.89)
'1,234,567.89'
>>> '{0:_.2f}'.format(1234567.89)
'1_234_567.89'
使用下划线(_)的<group>值也可以用二进制、八进制和十六进制表示类型来指定。在这种情况下,输出中的每组四位数由下划线字符分隔:
>>> '{0:_b}'.format(0b111010100001) '1110_1010_0001' >>> '{0:#_b}'.format(0b111010100001) '0b1110_1010_0001' >>> '{0:_x}'.format(0xae123fcc8ab2) 'ae12_3fcc_8ab2' >>> '{0:#_x}'.format(0xae123fcc8ab2) '0xae12_3fcc_8ab2'如果您试图用除了上面列出的那些之外的任何表示类型来指定
<group>,那么您的代码将会引发一个异常。
.<prec>子组件
.<prec>指定浮点显示类型小数点后的位数:
>>> '{0:8.2f}'.format(1234.5678)
' 1234.57'
>>> '{0:8.4f}'.format(1.23)
' 1.2300'
>>> '{0:8.2e}'.format(1234.5678)
'1.23e+03'
>>> '{0:8.4e}'.format(1.23)
'1.2300e+00'
对于字符串类型,.<prec>指定转换输出的最大宽度:
>>> '{:.4s}'.format('foobar') 'foob'如果输出比指定的值长,那么它将被截断。
字符串
.format()方法:嵌套替换字段回想一下,您可以使用字符串模运算符通过星号指定或者
<width>或者<prec>:
>>> w = 10
>>> p = 2
>>> '%*.*f' % (w, p, 123.456) # Width is 10, precision is 2
' 123.46'
然后从参数列表中获取相关的值。这允许在运行时动态地评估<width>和<prec>,如上面的例子所示。Python 的.format()方法使用嵌套替换字段提供了类似的能力。
在替换字段中,您可以指定一组嵌套的花括号({}),其中包含引用方法的位置或关键字参数之一的名称或数字。然后,替换字段的这一部分将在运行时进行计算,并使用相应的参数进行替换。您可以使用嵌套替换字段实现与上述字符串模运算符示例相同的效果:
>>> w = 10 >>> p = 2 >>> '{2:{0}.{1}f}'.format(w, p, 123.456) ' 123.46'这里,替换字段的
<name>成分是2,表示值为123.456的第三个位置参数。这是要格式化的值。嵌套替换字段{0}和{1}对应于第一和第二位置参数w和p。这些占据了<format_spec>中的<width>和<prec>位置,允许在运行时评估字段宽度和精度。您也可以在嵌套替换字段中使用关键字参数。此示例在功能上与上一个示例相同:
>>> w = 10
>>> p = 2
>>> '{val:{wid}.{pr}f}'.format(wid=w, pr=p, val=123.456)
' 123.46'
在任一情况下,w和p的值在运行时被评估并用于修改<format_spec>。结果实际上与此相同:
>>> '{0:10.2f}'.format(123.456) ' 123.46'字符串模运算符只允许以这种方式在运行时对
<width>和<prec>求值。相比之下,使用 Python 的.format()方法,您可以使用嵌套替换字段指定<format_spec>的任何部分。在以下示例中,演示类型
<type>由嵌套的替换字段指定并动态确定:
>>> bin(10), oct(10), hex(10)
('0b1010', '0o12', '0xa')
>>> for t in ('b', 'o', 'x'):
... print('{0:#{type}}'.format(10, type=t)) ...
0b1010
0o12
0xa
这里,分组字符<group>是嵌套的:
>>> '{0:{grp}d}'.format(123456789, grp='_') '123_456_789' >>> '{0:{grp}d}'.format(123456789, grp=',') '123,456,789'咻!那是一次冒险。模板字符串的规范实际上是一种语言!
正如您所看到的,当您使用 Python 的
.format()方法时,可以非常精细地调整字符串格式。接下来,您将看到另一种字符串和输出格式化技术,它提供了.format()的所有优点,但是使用了更直接的语法。Python 格式的字符串文字(f-String)
在 3.6 版本中,引入了一种新的 Python 字符串格式化语法,称为格式化字符串文字。这些也被非正式地称为 f 弦,这个术语最初是在 PEP 498 中创造的,在那里它们被首次提出。
f 字符串语法
一个 f 字符串看起来非常像一个典型的 Python 字符串,除了它被字符
f加在前面:
>>> f'foo bar baz'
'foo bar baz'
也可以使用大写的F:
>>> s = F'qux quux' >>> s 'qux quux'效果完全一样。就像任何其他类型的字符串一样,您可以使用单引号、双引号或三引号来定义 f 字符串:
>>> f'foo'
'foo'
>>> f"bar"
'bar'
>>> f'''baz'''
'baz'
f-strings 的神奇之处在于,您可以将 Python 表达式直接嵌入其中。用花括号({})括起来的 f 字符串的任何部分都被视为一个表达式。计算表达式并将其转换为字符串表示形式,然后将结果插入到原始字符串的该位置:
>>> s = 'bar' >>> print(f'foo.{s}.baz') foo.bar.baz解释器将 f 字符串的剩余部分——不在花括号内的任何内容——视为普通字符串。例如,转义序列按预期进行处理:
>>> s = 'bar'
>>> print(f'foo\n{s}\nbaz')
foo
bar
baz
这是前面使用 f 弦的例子:
>>> quantity = 6 >>> item = 'bananas' >>> price = 1.74 >>> print(f'{quantity} {item} cost ${price}') 6 bananas cost $1.74这相当于以下内容:
>>> quantity = 6
>>> item = 'bananas'
>>> price = 1.74
>>> print('{0} {1} cost ${2}'.format(quantity, item, price))
6 bananas cost $1.74
f 字符串中嵌入的表达式几乎可以任意复杂。以下示例显示了一些可能性:
-
变量:
>>> quantity, item, price = 6, 'bananas', 1.74 >>> f'{quantity} {item} cost ${price}' '6 bananas cost $1.74'`>>> quantity, item, price = 6, 'bananas', 1.74 >>> print(f'Price per item is ${price/quantity}') Price per item is $0.29 >>> x = 6 >>> print(f'{x} cubed is {x**3}') 6 cubed is 216` -
复合类型的对象:
>>> a = ['foo', 'bar', 'baz'] >>> d = {'foo': 1, 'bar': 2} >>> print(f'a = {a} | d = {d}') a = ['foo', 'bar', 'baz'] | d = {'foo': 1, 'bar': 2}`>>> a = ['foo', 'bar', 'baz'] >>> d = {'foo': 1, 'bar': 2} >>> print(f'First item in list a = {a[0]}') First item in list a = foo >>> print(f'Last two items in list a = {a[-2:]}') Last two items in list a = ['bar', 'baz'] >>> print(f'List a reversed = {a[::-1]}') List a reversed = ['baz', 'bar', 'foo'] >>> print(f"Dict value for key 'bar' is {d['bar']}") Dict value for key 'bar' is 2` -
函数和方法调用:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux'] >>> print(f'List a has {len(a)} items') List a has 5 items >>> s = 'foobar' >>> f'--- {s.upper()} ---' '--- FOOBAR ---' >>> d = {'foo': 1, 'bar': 2} >>> print(f"Dict value for key 'bar' is {d.get('bar')}") Dict value for key 'bar' is 2`>>> x = 3 >>> y = 7 >>> print(f'The larger of {x} and {y} is {x if x > y else y}') The larger of 3 and 7 is 7 >>> age = 13 >>> f'I am {"a minor" if age < 18 else "an adult"}.' 'I am a minor.'` -
对象属性:
>>> z = 3+5j >>> z (3+5j) >>> print(f'real = {z.real}, imag = {z.imag}') real = 3.0, imag = 5.0`
>>> z = 'foobar'
>>> f'{{ {z[::-1]} }}'
'{ raboof }'
你可以在 f 字符串前加上'r'或'R'来表示它是一个原始 f 字符串。在这种情况下,反斜杠序列保持不变,就像普通字符串一样:
>>> z = 'bar' >>> print(f'foo\n{z}\nbaz') foo bar baz >>> print(rf'foo\n{z}\nbaz') foo\nbar\nbaz >>> print(fr'foo\n{z}\nbaz') foo\nbar\nbaz请注意,您可以先指定
'r',然后指定'f',反之亦然。f 字符串表达式限制
f 字符串表达式有一些小的限制。这些不是太限制性的,但是你应该知道它们是什么。首先,f 字符串表达式不能为空:
>>> f'foo{}bar'
File "<stdin>", line 1
SyntaxError: f-string: empty expression not allowed
不清楚你为什么想这么做。但是如果你觉得不得不去尝试,那就知道这是行不通的。
此外,f 字符串表达式不能包含反斜杠(\)字符。其中,这意味着您不能在 f 字符串表达式中使用反斜杠转义序列:
>>> print(f'foo{\n}bar') File "<stdin>", line 1 SyntaxError: f-string expression part cannot include a backslash >>> print(f'foo{\'}bar') File "<stdin>", line 1 SyntaxError: f-string expression part cannot include a backslash您可以通过创建一个包含要插入的转义序列的临时变量来绕过这一限制:
>>> nl = '\n'
>>> print(f'foo{nl}bar')
foo
bar
>>> quote = '\''
>>> print(f'foo{quote}bar')
foo'bar
最后,用三重引号引起的 f 字符串中的表达式不能包含注释:
>>> z = 'bar' >>> print(f'''foo{ ... z ... }baz''') foobarbaz >>> print(f'''foo{ ... z # Comment ... }''') File "<stdin>", line 3 SyntaxError: f-string expression part cannot include '#'但是,请注意,多行 f 字符串可能包含嵌入的换行符。
f 字符串格式化
像 Python 的
.format()方法一样,f 字符串支持大量的修饰符,它们控制输出字符串的最终外观。还有更多好消息。如果你已经掌握了 Python 的.format()方法,那么你已经知道如何使用 Python 来格式化 f 字符串了!f 字符串中的表达式可以通过
<conversion>或<format_spec>来修改,就像在.format()模板中使用的替换字段一样。语法是相同的。事实上,在这两种情况下,Python 都将使用相同的内部函数来格式化替换字段。在下面的示例中,!r被指定为.format()模板字符串中的<conversion>组件:
>>> s = 'foo'
>>> '{0!r}'.format(s)
"'foo'"
这将强制由repr()执行转换。相反,您可以使用 f 字符串获得基本相同的代码:
>>> s = 'foo' >>> f'{s!r}' "'foo'"所有与
.format()一起工作的<format_spec>组件也与 f 弦一起工作:
>>> n = 123
>>> '{:=+8}'.format(n)
'+ 123'
>>> f'{n:=+8}'
'+ 123'
>>> s = 'foo'
>>> '{0:*^8}'.format(s)
'**foo***'
>>> f'{s:*^8}'
'**foo***'
>>> n = 0b111010100001
>>> '{0:#_b}'.format(n)
'0b1110_1010_0001'
>>> f'{n:#_b}'
'0b1110_1010_0001'
嵌套也可以工作,比如用 Python 的.format()方法嵌套替换字段:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux'] >>> w = 4 >>> f'{len(a):0{w}d}' '0005' >>> n = 123456789 >>> sep = '_' >>> f'{(n * n):{sep}d}' '15_241_578_750_190_521'这意味着格式化项可以在运行时计算。
f-strings 和 Python 的
.format()方法或多或少是做同一件事的两种不同方式,f-strings 是一种更简洁的简写方式。以下表达式本质上是相同的:f'{<expr>!<conversion>:<format_spec>}' '{0!<conversion>:<format_spec>}'.format(<expr>)如果你想进一步探索 f 字符串,那么看看 Python 3 的 f 字符串:一个改进的字符串格式语法(教程)。
结论
在本教程中,您掌握了另外两种可以在 Python 中用来格式化字符串数据的技术。现在,您应该拥有了为输出或显示准备字符串数据所需的所有工具!
您可能想知道应该使用哪种 Python 格式化技术。什么情况下你会选择
.format()而不是 f 弦?参见 Python 字符串格式化最佳实践了解一些需要考虑的事项。在下一篇教程中,您将学习更多关于 Python 中的函数的知识。在本系列教程中,您已经看到了许多 Python 的内置函数的例子。在 Python 中,就像在大多数编程语言中一样,你也可以定义自己的自定义用户定义函数。如果你迫不及待地想了解如何继续下一个教程!
« Basic Input, Output, and String Formatting in PythonPython String Formatting TechniquesDefining Your Own Python Function »
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 格式化 Python 字符串*********
用 Python 分数表示有理数
Python 中的
fractions模块可以说是标准库中使用最少的元素之一。尽管它可能不太出名,但它是一个非常有用的工具,因为它可以帮助解决二进制浮点运算的缺点。如果你打算处理财务数据或者如果你需要无限精确进行计算,这是必不可少的。在本教程的末尾,你会看到一些动手的例子,其中分数是最合适和优雅的选择。你还将了解他们的弱点,以及如何在这个过程中充分利用它们。
在本教程中,您将学习如何:
- 在十进制和小数记数法之间转换
- 执行有理数运算
- 近似无理数
- 用无限精度精确表示分数
- 知道什么时候选择
Fraction而不是Decimal或float本教程的大部分内容都是关于
fractions模块的,它本身不需要深入的 Python 知识,只需要理解它的数值类型。然而,如果您熟悉更高级的概念,比如 Python 的内置collections模块、、itertools模块和生成器,那么您将能够很好地完成后面的所有代码示例。如果您想充分利用本教程,您应该已经熟悉了这些主题。免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
十进制与分数记数法
让我们沿着记忆之路走一走,回忆一下你在学校学到的数字知识,避免可能的困惑。这里有四个概念:
- 数学中的数字类型
- 数字系统
- 数字的符号
- Python 中的数字数据类型
现在,您将快速了解其中的每一个,以便更好地理解 Python 中
Fraction数据类型的用途。数字分类
如果你不记得数字的分类,这里有一个快速复习:
Types of Numbers 数学中有更多类型的数字,但这些是与日常生活最相关的。在最顶端,你会发现复数,包括虚数和实数。实数依次由有理数和无理数和无理数组成。最后,有理数包含整数和自然数。
数字系统和符号
几个世纪以来,有各种各样的视觉表达数字的系统。今天,大多数人使用基于印度-阿拉伯符号的位置数字系统。对于这样的系统,你可以选择任意的基或基数。然而,尽管人们更喜欢十进制(基数为 10),计算机在二进制(基数为 2)中工作得最好。
在十进制系统中,您可以使用其他符号来表示一些数字:
- Decimal: 0.75
- 分数:
这两者都不比另一个更好或更精确。用十进制表示数字可能更直观,因为它类似于一个百分比。比较小数也更简单,因为它们已经有了一个共同的分母——系统的基础。最后,十进制数字可以通过保持尾随零和前导零来传达精度。
另一方面,分数在手工进行符号代数时更方便,这就是为什么它们主要在学校使用。但是你能回忆起你最后一次使用分数是什么时候吗?如果你不能,那是因为十进制是当今计算器和计算机的核心。
分数符号通常只与有理数相关联。毕竟,有理数的定义表明,只要分母不为零,它就可以表示为两个整数的商,或 T2 分数。然而,当你考虑到可以近似无理数的无限连分数时,这还不是故事的全部:
无理数总是有一个无终止无重复的小数展开式。例如,圆周率(π)的十进制展开式永远不会用完看起来具有随机分布的数字。如果你画出它们的直方图,那么每个数字将有一个大致相似的频率。
另一方面,大多数有理数都有终止的十进制展开。然而,有些可以有一个无限循环的十进制展开,一个或多个数字在一个周期内重复。重复的数字通常用十进制符号中的省略号(0.33333…)表示。不管它们的十进制扩展如何,有理数(如代表三分之一的数)在分数记数法中总是看起来优雅而紧凑。
Python 中的数字数据类型
当在计算机内存中以浮点数据类型存储时,具有无限小数扩展的数字会导致舍入误差,而计算机内存本身是有限的。更糟糕的是,用二进制的终止十进制扩展通常不可能准确地表示数字!
这就是所谓的浮点表示错误,它影响所有编程语言,包括 Python 。每个程序员迟早都会面临这个问题。例如,您不能在像银行这样的应用程序中使用
float,在这些应用程序中,必须在不损失任何精度的情况下存储和处理数字。Python 的
Fraction就是这些障碍的解决方案之一。虽然它代表一个有理数,但名称Rational已经代表了numbers模块中的一个抽象基类。numbers模块定义了抽象数字数据类型的层次结构,以模拟数学中的数字分类:
Type hierarchy for numbers in Python
Fraction是Rational的直接和具体的子类,它提供了 Python 中有理数的完整实现。像int和bool这样的整型也来源于Rational,但是那些更具体。有了这些理论背景,是时候创建你的第一个分数了!
从不同的数据类型创建 Python 片段
与
int或float不同,分数不是 Python 中的内置数据类型,这意味着您必须从标准库中导入相应的模块才能使用它们。然而,一旦你通过了这个额外的步骤,你会发现分数只是代表了另一种数字类型,你可以在算术表达式中自由地与其他数字和数学运算符混合。注意:分数是用纯 Python 实现的,并且比可以直接在硬件上运行的浮点数慢得多。在大多数需要大量计算的情况下,性能比精度更重要。另一方面,如果你既需要性能又需要精度,那么考虑一种叫做 quicktions 的分数替代方法,它可能会在某种程度上提高你的执行速度。
在 Python 中有几种创建分数的方法,它们都涉及到使用
Fraction类。这是您唯一需要从fractions模块导入的东西。类构造函数接受零个、一个或两个不同类型的参数:
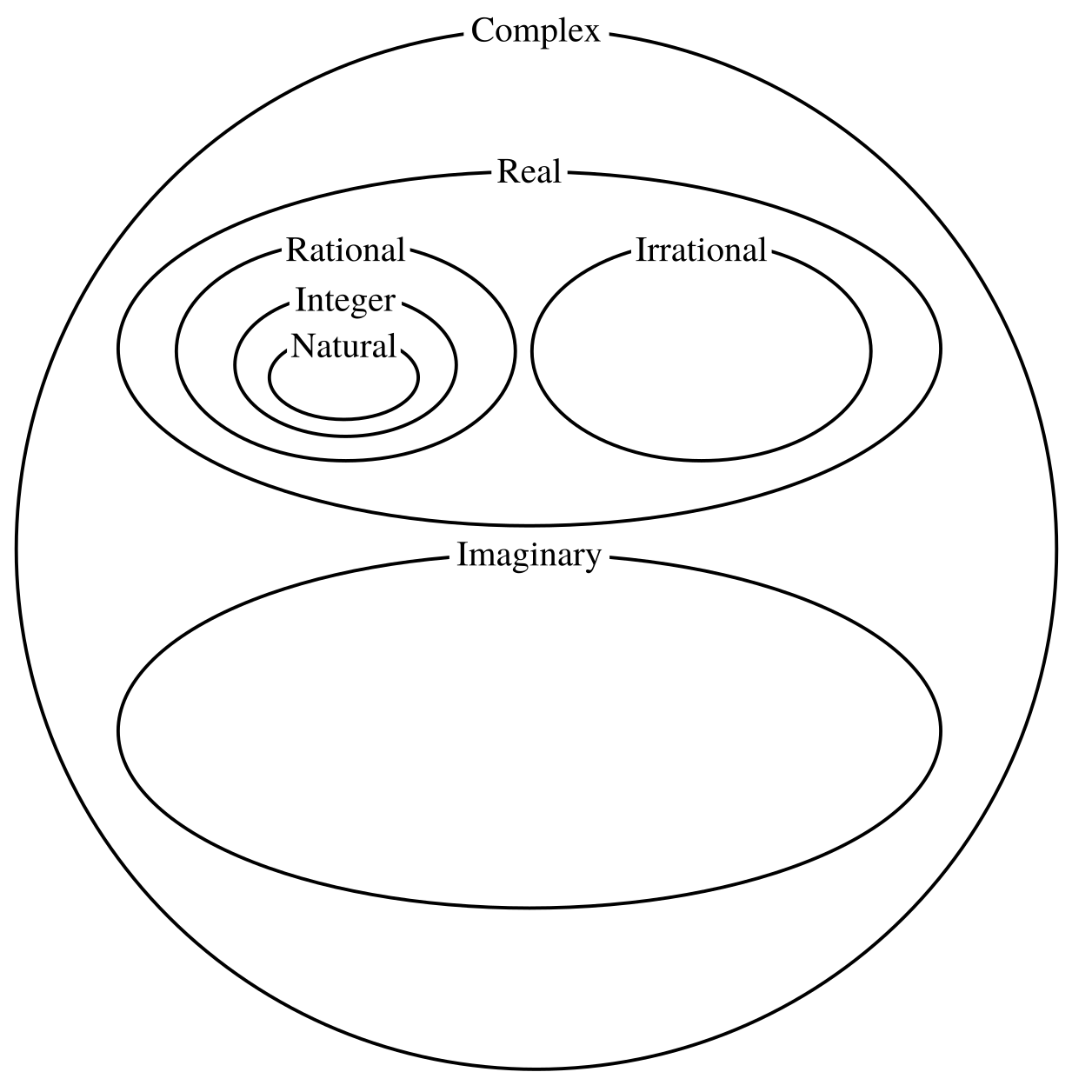
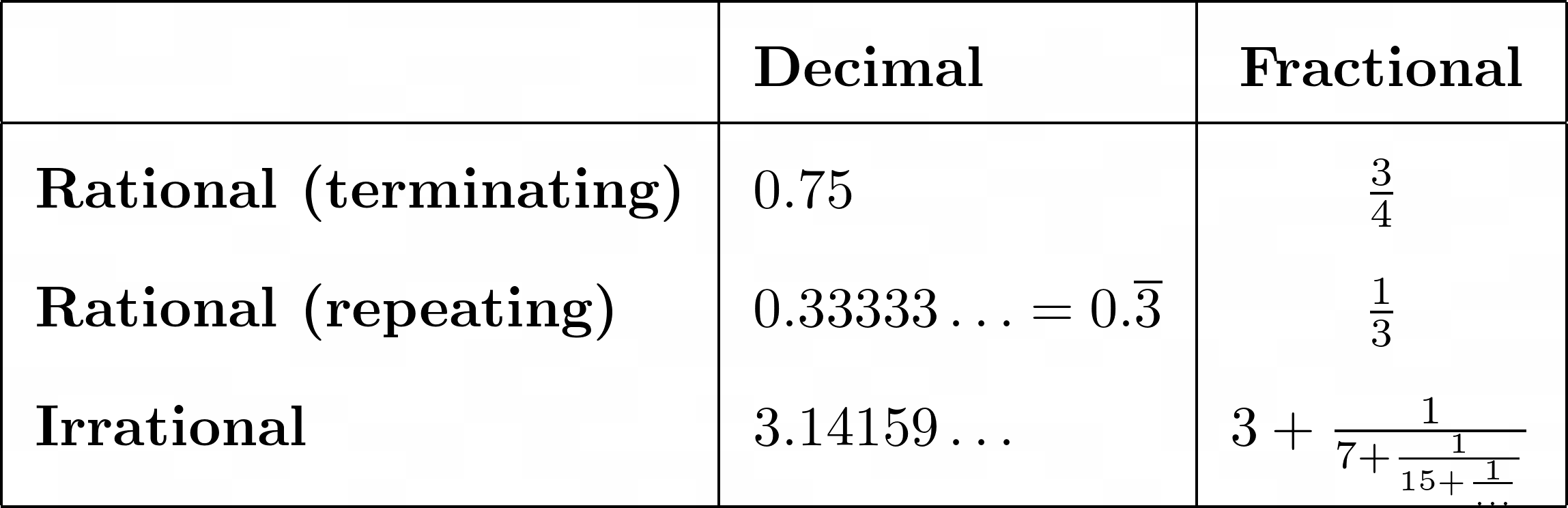
>>> from fractions import Fraction
>>> print(Fraction())
0
>>> print(Fraction(0.75))
3/4
>>> print(Fraction(3, 4))
3/4
当您调用不带参数的类构造函数时,它会创建一个表示数字零的新分数。单参数风格试图将另一种数据类型的值转换为分数。传入第二个参数使得构造函数期望一个分子和一个分母,它们必须是Rational类或其后代的实例。
注意,您必须 print() 一个分数,以显示其友好的文本表示,在分子和分母之间使用斜杠字符(/)。如果不这样做,它将退回到由一段 Python 代码组成的稍微显式一些的字符串表示。在本教程的后面,你将学习如何将分数转换成字符串。
有理数
当你用两个参数调用Fraction()构造函数时,它们必须都是有理数,比如整数或其他分数。如果分子或分母都不是有理数,那么您将无法创建新的分数:
>>> Fraction(3, 4.0) Traceback (most recent call last): ... raise TypeError("both arguments should be " TypeError: both arguments should be Rational instances你反而得到了一个
TypeError。虽然4.0在数学上是一个有理数,但 Python 并不这么认为。这是因为值存储为浮点数据类型,这种数据类型太宽泛,可以用来表示任何实数。注:浮点数据类型不能在计算机内存中精确地存储无理数,因为它们的十进制展开没有终止和不重复。然而实际上,这没什么大不了的,因为他们的近似值通常就足够好了。唯一真正可靠的方法是对π这样的传统符号使用符号计算。
同样,你不能创建一个分母为零的分数,因为这将导致被零除,这在数学上没有定义和意义:
>>> Fraction(3, 0)
Traceback (most recent call last):
...
raise ZeroDivisionError('Fraction(%s, 0)' % numerator)
ZeroDivisionError: Fraction(3, 0)
Python 抛出了ZeroDivisionError。然而,当你指定一个有效的分子和一个有效的分母时,只要它们有一个公约数,它们就会自动被规范化:
>>> Fraction(9, 12) # GCD(9, 12) = 3 Fraction(3, 4) >>> Fraction(0, 12) # GCD(0, 12) = 12 Fraction(0, 1)这两个数值都通过它们的最大公约数(GCD) 得到简化,恰好分别是 3 和 12。当您定义负分数时,归一化也会考虑负号:
>>> -Fraction(9, 12)
Fraction(-3, 4)
>>> Fraction(-9, 12)
Fraction(-3, 4)
>>> Fraction(9, -12)
Fraction(-3, 4)
无论您将减号放在构造函数之前还是放在任何一个参数之前,为了一致性,Python 总是将分数的符号与其分子相关联。目前有一种方法可以禁用这种行为,但它没有记录在案,将来可能会被删除。
你通常将分数定义为两个整数的商。只要你只提供一个整数,Python 就会通过假设分母为1将这个数字转化为不适当的分数:
>>> Fraction(3) Fraction(3, 1)相反,如果跳过这两个参数,分子将是
0:
>>> Fraction()
Fraction(0, 1)
不过,您不必总是为分子和分母提供整数。该文档声明它们可以是任何有理数,包括其他分数:
>>> one_third = Fraction(1, 3) >>> Fraction(one_third, 3) Fraction(1, 9) >>> Fraction(3, one_third) Fraction(9, 1) >>> Fraction(one_third, one_third) Fraction(1, 1)在每种情况下,结果都是一个分数,即使它们有时代表像 9 和 1 这样的整数值。稍后,您将看到如何将分数转换为其他数据类型。
如果给
Fraction构造函数一个参数,这个参数恰好是一个分数,会发生什么?尝试此代码以找出:
>>> Fraction(one_third) == one_third
True
>>> Fraction(one_third) is one_third
False
您得到的是相同的值,但是它是输入分数的不同副本。这是因为调用构造函数总是会产生一个新的实例,这与分数是不可变的这一事实不谋而合,就像 Python 中的其他数值类型一样。
浮点数和十进制数
到目前为止,您只使用了有理数来创建分数。毕竟,Fraction构造函数的双参数版本要求两个数字都是Rational实例。然而,单参数构造函数就不是这样了,它可以接受任何实数,甚至是字符串这样的非数值。
Python 中实数数据类型的两个主要例子是float和 decimal.Decimal 。虽然只有后者可以精确地表示有理数,但两者都可以很好地近似无理数。与此相关,如果你想知道,Fraction在这方面与Decimal相似,因为它是Real的后代。
与float或Fraction不同,Decimal类没有正式注册为numbers.Real的子类,尽管实现了它的方法:
>>> from numbers import Real >>> issubclass(float, Real) True >>> from fractions import Fraction >>> issubclass(Fraction, Real) True >>> from decimal import Decimal >>> issubclass(Decimal, Real) False这是故意的,因为十进制浮点数与二进制数不太协调:
>>> from decimal import Decimal
>>> Decimal("0.75") - 0.25
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'decimal.Decimal' and 'float'
另一方面,在上面的例子中,用等价的Fraction替换Decimal会产生一个float结果。
在 Python 3.2 之前,您只能使用.from_float()和.from_decimal()类方法从实数创建分数。虽然没有被弃用,但今天它们是多余的,因为Fraction构造函数可以直接将这两种数据类型作为参数:
>>> from decimal import Decimal >>> Fraction(0.75) == Fraction(Decimal("0.75")) True无论是从
float还是Decimal对象制作Fraction对象,它们的值都是一样的。您以前见过从浮点值创建的分数:
>>> print(Fraction(0.75))
3/4
结果是用分数表示的相同数字。然而,这段代码只是巧合地按预期工作。在大多数情况下,由于影响float数字的表示错误,您不会得到预期的值,无论它们是否合理:
>>> print(Fraction(0.1)) 3602879701896397/36028797018963968哇哦。这里发生了什么?
让我们用慢动作分解一下。前一个数字可以表示为 0.75 或,也可以表示为和的和,它们是 2 的负幂,具有精确的二进制表示。另一方面,数字⅒只能用二进制数字的无终止重复扩展来近似为:
由于内存有限,二进制字符串最终必须结束,所以它的尾部变圆了。默认情况下,Python 只显示在
sys.float_info.dig中定义的最重要的数字,但是如果你想的话,你可以格式化一个任意位数的浮点数:

>>> str(0.1)
'0.1'
>>> format(0.1, ".17f")
'0.10000000000000001'
>>> format(0.1, ".18f")
'0.100000000000000006'
>>> format(0.1, ".19f")
'0.1000000000000000056'
>>> format(0.1, ".55f")
'0.1000000000000000055511151231257827021181583404541015625'
当您将一个float或一个Decimal数字传递给Fraction构造函数时,它会调用它们的.as_integer_ratio()方法来获得一个由两个不可约整数组成的元组,这两个整数的比值给出了与输入参数完全相同的十进制展开。然后,这两个数字被指定为新分数的分子和分母。
注意:从 Python 3.8 开始,Fraction也实现了.as_integer_ratio()来补充其他数值类型。例如,它可以帮助您将分数转换为元组。
现在,你可以拼凑出这两个大数字的来源:
>>> Fraction(0.1) Fraction(3602879701896397, 36028797018963968) >>> (0.1).as_integer_ratio() (3602879701896397, 36028797018963968)如果你拿出你的袖珍计算器,输入这些数字,那么你将得到 0.1 作为除法的结果。然而,如果你用手或者使用像 WolframAlpha 这样的工具来划分它们,那么你会得到之前看到的 55 位小数。
有一种方法可以找到更接近你分数的近似值,它们有更实际的价值。例如,您可以使用
.limit_denominator(),稍后您将在本教程中了解更多:
>>> one_tenth = Fraction(0.1)
>>> one_tenth
Fraction(3602879701896397, 36028797018963968)
>>> one_tenth.limit_denominator()
Fraction(1, 10)
>>> one_tenth.limit_denominator(max_denominator=int(1e16))
Fraction(1000000000000000, 9999999999999999)
不过,这可能并不总是给你最好的近似值。底线是,如果你想避免可能出现的舍入误差,你应该永远不要试图直接从实数如float中创建分数。如果你不够小心,即使是Decimal类也可能受到影响。
无论如何,分数让你在它们的构造函数中用字符串最准确地表达十进制符号。
字符串
Fraction构造函数接受两种字符串格式,分别对应于十进制和小数表示法:
>>> Fraction("0.1") Fraction(1, 10) >>> Fraction("1/10") Fraction(1, 10)这两种记数法都可以有一个加号(
+)或减号(-),而十进制记数法可以额外包含指数,以防您想要使用科学记数法:
>>> Fraction("-2e-3")
Fraction(-1, 500)
>>> Fraction("+2/1000")
Fraction(1, 500)
两个结果唯一的区别就是一个是负的,一个是正的。
使用分数符号时,不能在斜杠字符(/)周围使用空白字符:
>>> Fraction("1 / 10") Traceback (most recent call last): ... raise ValueError('Invalid literal for Fraction: %r' % ValueError: Invalid literal for Fraction: '1 / 10'要确切地找出哪些字符串是有效的或无效的,可以探索一下模块的源代码中的正则表达式。记住从字符串或正确实例化的
Decimal对象创建分数,而不是从float值创建分数,这样可以保持最大精度。现在你已经创建了一些分数,你可能想知道除了第二组数字之外,它们还能为你做什么。这是一个很好的问题!
检查 Python 片段
Rational抽象基类定义了两个只读属性,用于访问分数的分子和分母:
>>> from fractions import Fraction
>>> half = Fraction(1, 2)
>>> half.numerator
1
>>> half.denominator
2
因为分数是不可变的,你不能改变它们的内部状态:
>>> half.numerator = 2 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute如果您尝试为分数的一个属性指定一个新值,那么您将会得到一个错误。事实上,当您想要修改一个片段时,您必须创建一个新的片段。例如,为了反转你的分数,你可以调用
.as_integer_ratio()得到一个元组,然后使用切片语法反转它的元素:
>>> Fraction(*half.as_integer_ratio()[::-1])
Fraction(2, 1)
一元星形运算符(* ) 解包你的反转元组,并将其元素传递给Fraction构造函数。
每一个分数都有另一个有用的方法,可以让你找到最接近十进制记数法中给定数字的有理逼近。这是.limit_denominator()方法,您在本教程的前面已经提到过。您可以选择请求近似值的最大分母:
>>> pi = Fraction("3.141592653589793") >>> pi Fraction(3141592653589793, 1000000000000000) >>> pi.limit_denominator(20_000) Fraction(62813, 19994) >>> pi.limit_denominator(100) Fraction(311, 99) >>> pi.limit_denominator(10) Fraction(22, 7)初始近似值可能不是最方便使用的,但却是最可靠的。这个方法还可以帮助你恢复一个以浮点数据类型存储的有理数。记住
float可能不会精确地表示所有的有理数,即使它们有终止的十进制展开:
>>> pi = Fraction(3.141592653589793)
>>> pi
Fraction(884279719003555, 281474976710656)
>>> pi.limit_denominator()
Fraction(3126535, 995207)
>>> pi.limit_denominator(10)
Fraction(22, 7)
与前面的代码块相比,您会注意到高亮显示的行上有不同的结果,即使float实例看起来与您之前传递给构造函数的字符串文字相同!稍后,您将探索一个使用.limit_denominator()寻找无理数近似值的例子。
将 Python 片段转换成其他数据类型
您已经学习了如何从以下数据类型创建分数:
strintfloatdecimal.Decimalfractions.Fraction
反过来呢?如何将一个Fraction实例转换回这些类型?你将在这一部分找到答案。
浮点数和整数
Python 中本地数据类型之间的转换通常涉及调用一个内置函数,比如对象上的int()或float()。只要对象实现了相应的特殊方法,如.__int__()或.__float__(),这些转换就会起作用。分数恰好从Rational抽象基类中继承了后者:
>>> from fractions import Fraction >>> three_quarters = Fraction(3, 4) >>> float(three_quarters) 0.75 >>> three_quarters.__float__() # Don't call special methods directly 0.75 >>> three_quarters.__int__() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Fraction' object has no attribute '__int__'您不应该直接调用对象上的特殊方法,但这有助于演示。这里,你会注意到分数只实现了
.__float__()而没有实现.__int__()。当您研究源代码时,您会注意到
.__float__()方法很方便地将一个分数的分子除以它的分母,从而得到一个浮点数:
>>> three_quarters.numerator / three_quarters.denominator
0.75
请记住,将一个Fraction实例转换成一个float实例可能会导致一个有损转换,这意味着您可能会得到一个稍微有些偏差的数字:
>>> float(Fraction(3, 4)) == Fraction(3, 4) True >>> float(Fraction(1, 3)) == Fraction(1, 3) False >>> float(Fraction(1, 10)) == Fraction(1, 10) False虽然分数不提供整数转换的实现,但是所有的实数都可以被截断,这是
int()函数的一个后备:
>>> fraction = Fraction(14, 5)
>>> int(fraction)
2
>>> import math
>>> math.trunc(fraction)
2
>>> fraction.__trunc__() # Don't call special methods directly
2
稍后,在关于舍入分数的章节中,您会发现其他一些相关的方法。
十进制数字
如果您尝试从一个Fraction实例创建一个Decimal数字,那么您会很快发现这样的直接转换是不可能的:
>>> from decimal import Decimal >>> Decimal(Fraction(3, 4)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: conversion from Fraction to Decimal is not supported当你尝试时,你会得到一个
TypeError。因为一个分数代表一个除法,但是,你可以通过仅用Decimal包装其中一个数字并手动分割它们来绕过这个限制:
>>> fraction = Fraction(3, 4)
>>> fraction.numerator / Decimal(fraction.denominator)
Decimal('0.75')
与float不同,但与Fraction相似,Decimal数据类型没有浮点表示错误。因此,当您转换一个无法用二进制浮点精确表示的有理数时,您将保留该数的精度:
>>> fraction = Fraction(1, 10) >>> decimal = fraction.numerator / Decimal(fraction.denominator) >>> fraction == decimal True >>> fraction == 0.1 False >>> decimal == 0.1 False同时,具有无终止重复十进制展开的有理数将在从小数转换为十进制时导致精度损失:
>>> fraction = Fraction(1, 3)
>>> decimal = fraction.numerator / Decimal(fraction.denominator)
>>> fraction == decimal
False
>>> decimal
Decimal('0.3333333333333333333333333333')
这是因为在三分之一的十进制扩展中有无限个三,或者说Fraction(1, 3),而Decimal类型有一个固定的精度。默认情况下,它只存储 28 位小数。如果你想的话,你可以调整它,但是它仍然是有限的。
字符串
分数的字符串表示使用熟悉的分数符号显示它们的值,而它们的规范表示输出一段 Python 代码,其中包含对Fraction构造函数的调用:
>>> one_third = Fraction(1, 3) >>> str(one_third) '1/3' >>> repr(one_third) 'Fraction(1, 3)'不管你用
str()还是repr(),结果都是一个字符串,只是它们的内容不同。与其他数值类型不同,分数不支持 Python 中的字符串格式:
>>> from decimal import Decimal
>>> format(Decimal("0.3333333333333333333333333333"), ".2f")
'0.33'
>>> format(Fraction(1, 3), ".2f")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported format string passed to Fraction.__format__
如果你尝试,你会得到一个TypeError。例如,如果您想在字符串模板中引用一个Fraction实例来填充占位符,这可能是一个问题。另一方面,您可以通过将分数转换为浮点数来快速解决这个问题,特别是在这种情况下,您不需要关心精度。
如果你在 Jupyter 笔记本上工作,那么你可能想要基于你的分数而不是它们的常规文本表示来呈现 LaTeX 公式。为此,您必须 monkey 通过添加 Jupyter Notebook 能够识别的新方法 ._repr_pretty_() 来修补数据类型:
from fractions import Fraction
from IPython.display import display, Math
Fraction._repr_pretty_ = lambda self, *args: \
display(Math(rf"$$\frac{{{self.numerator}}}{{{self.denominator}}}"))
它将一段 LaTeX 标记包装在一个Math对象中,并将其发送到您笔记本的富显示器,该显示器可以使用 MathJax 库来呈现标记:

下一次您评估包含Fraction实例的笔记本单元格时,它将绘制一个漂亮的数学公式,而不是打印文本。
对分数进行有理数运算
如前所述,您可以在由其他数值类型组成的算术表达式中使用分数。分数将与大多数数字类型互操作,除了decimal.Decimal,它有自己的一套规则。此外,另一个操作数的数据类型,无论它位于分数的左边还是右边,都将决定算术运算结果的类型。
加法
您可以将两个或更多分数相加,而不必考虑将它们简化为公分母:
>>> from fractions import Fraction >>> Fraction(1, 2) + Fraction(2, 3) + Fraction(3, 4) Fraction(23, 12)结果是一个新分数,它是所有输入分数的总和。当你把整数和分数相加时,也会发生同样的情况:
>>> Fraction(1, 2) + 3
Fraction(7, 2)
但是,一旦您开始将分数与非有理数混合,即不是numbers.Rational的子类的数字,那么您的分数在被添加之前将首先被转换为该类型:
>>> Fraction(3, 10) + 0.1 0.4 >>> float(Fraction(3, 10)) + 0.1 0.4无论是否显式使用
float(),都会得到相同的结果。这种转换可能会导致精度损失,因为分数和结果现在都以浮点形式存储。尽管数字 0.4 看起来是对的,但它并不完全等于分数 4/10。减法
分数相减和相加没有什么不同。Python 将为您找到共同点:
>>> Fraction(3, 4) - Fraction(2, 3) - Fraction(1, 2)
Fraction(-5, 12)
>>> Fraction(4, 10) - 0.1
0.30000000000000004
这一次,精度损失非常显著,一目了然。请注意,在十进制扩展的末尾,有一长串的零后跟一个数字4。这是对一个值进行舍入的结果,否则它将需要无限多的二进制数字。
乘法运算
当您将两个分数相乘时,它们的分子和分母会逐元素相乘,如果需要,结果分数会自动减少:
>>> Fraction(1, 4) * Fraction(3, 2) Fraction(3, 8) >>> Fraction(1, 4) * Fraction(4, 5) # The result is 4/20 Fraction(1, 5) >>> Fraction(1, 4) * 3 Fraction(3, 4) >>> Fraction(1, 4) * 3.0 0.75同样,根据另一个操作数的类型,结果中会有不同的数据类型。
分部
Python 中有两种除法运算符,分数支持这两种运算符:
- 真师:
/- 楼层划分:
//真正的除法会产生另一个分数,而底数除法总是会返回一个小数部分被截断的整数:
>>> Fraction(7, 2) / Fraction(2, 3)
Fraction(21, 4)
>>> Fraction(7, 2) // Fraction(2, 3)
5
>>> Fraction(7, 2) / 2
Fraction(7, 4)
>>> Fraction(7, 2) // 2
1
>>> Fraction(7, 2) / 2.0
1.75
>>> Fraction(7, 2) // 2.0
1.0
请注意,地板除法的结果并不总是整数!结果可能以一个float结束,这取决于与分数一起使用的数据类型。分数还支持模运算符(% ) 以及 divmod() 函数,这可能有助于从不适当的分数创建混合分数:
>>> def mixed(fraction): ... floor, rest = divmod(fraction.numerator, fraction.denominator) ... return f"{floor} and {Fraction(rest, fraction.denominator)}" ... >>> mixed(Fraction(22, 7)) '3 and 1/7'您可以更新函数,返回一个由整数部分和小数余数组成的元组,而不是像上面的输出那样生成一个字符串。继续尝试修改函数的返回值,看看有什么不同。
求幂运算
你可以用二进制的取幂运算符(
**) 或者内置的pow()函数来计算分数的幂。你也可以用分数本身作为指数。现在回到你的 Python 解释器,开始探索如何计算分数的幂:
>>> Fraction(3, 4) ** 2
Fraction(9, 16)
>>> Fraction(3, 4) ** (-2)
Fraction(16, 9)
>>> Fraction(3, 4) ** 2.0
0.5625
您会注意到,您可以使用正指数值和负指数值。当指数不是一个Rational数时,您的分数在继续之前会自动转换为float。
当指数是一个Fraction实例时,事情变得更加复杂。因为分数幂通常产生无理数,所以两个操作数都转换为float,除非基数和指数是整数:
>>> 2 ** Fraction(2, 1) 4 >>> 2.0 ** Fraction(2, 1) 4.0 >>> Fraction(3, 4) ** Fraction(1, 2) 0.8660254037844386 >>> Fraction(3, 4) ** Fraction(2, 1) Fraction(9, 16)唯一一次得到分数的结果是当指数的分母等于 1,并且你正在产生一个
Fraction实例。对 Python 分数进行舍入
在 Python 中有很多舍入数字的策略,在数学中甚至更多。分数和小数可以使用同一套内置的全局函数和模块级函数。它们可以让你将一个整数赋给一个分数,或者生成一个对应于更少小数位数的新分数。
当您将分数转换为
int时,您已经了解了一种粗略的舍入方法,即截断小数部分,只留下整部分(如果有的话):
>>> from fractions import Fraction
>>> int(Fraction(22, 7))
3
>>> import math
>>> math.trunc(Fraction(22, 7))
3
>>> math.trunc(-Fraction(22, 7))
-3
在这种情况下,调用int()相当于调用math.trunc(),它向下舍入正分数,向上舍入负分数。这两种操作分别被称为地板和天花板。如果需要,您可以直接使用两者:
>>> math.floor(-Fraction(22, 7)) -4 >>> math.floor(Fraction(22, 7)) 3 >>> math.ceil(-Fraction(22, 7)) -3 >>> math.ceil(Fraction(22, 7)) 4将
math.floor()和math.ceil()的结果与您之前对math.trunc()的调用进行比较。每个函数都有不同的舍入偏差,这可能会影响舍入数据集的统计属性。幸运的是,有一种策略叫做四舍五入成偶数,它比截断、下限或上限更少偏差。本质上,它将分数舍入到最接近的整数,而对于等距的两部分,则更倾向于最接近的偶数。您可以调用
round()来利用这一策略:
>>> round(Fraction(3, 2)) # 1.5
2
>>> round(Fraction(5, 2)) # 2.5
2
>>> round(Fraction(7, 2)) # 3.5
4
注意这些分数是如何根据最接近的偶数的位置向上或向下舍入的?自然地,这条规则只适用于左边最接近的整数和右边最接近的整数的距离相同的情况。否则,舍入方向基于到整数的最短距离,而不管它是否是偶数。
您可以选择为round()函数提供第二个参数,该参数指示您想要保留多少个小数位。当你这样做时,你将总是得到一个Fraction而不是一个整数,即使你请求的是零位数:
>>> fraction = Fraction(22, 7) # 3.142857142857143 >>> round(fraction, 0) Fraction(3, 1) >>> round(fraction, 1) # 3.1 Fraction(31, 10) >>> round(fraction, 2) # 3.14 Fraction(157, 50) >>> round(fraction, 3) # 3.143 Fraction(3143, 1000)然而,请注意调用
round(fraction)和round(fraction, 0)之间的区别,它们产生相同的值,但是使用不同的数据类型:
>>> round(fraction)
3
>>> round(fraction, 0)
Fraction(3, 1)
当您省略第二个参数时,round()将返回最接近的整数。否则,您将得到一个缩减的分数,它的分母最初是 10 的幂,对应于您所请求的十进制位数。
在 Python 中比较分数
在现实生活中,比较用分数表示的数字可能比比较用十进制表示的数字更困难,因为分数表示由两个值组成,而不是只有一个值。为了理解这些数字,通常将它们简化为一个公分母,并且只比较它们的分子。例如,尝试根据分数的值以升序排列以下分数:
- 2/3
- 5/8
- 8/13
它不像十进制记数法那样方便。混合符号的情况会变得更糟。然而,当你用一个共同的分母重写这些分数时,对它们进行排序就变得简单了:
- 208/312
- 195/312
- 192/312
3,8,13 的最大公约数是 1。这意味着所有三个分数的最小公分母是它们的乘积 312。一旦你把所有的分数转换成最小的公分母,你就可以忽略分母,专注于比较分子。
在 Python 中,当您比较和排序Fraction对象时,这在幕后工作:
>>> from fractions import Fraction >>> Fraction(8, 13) < Fraction(5, 8) True >>> sorted([Fraction(2, 3), Fraction(5, 8), Fraction(8, 13)]) [Fraction(8, 13), Fraction(5, 8), Fraction(2, 3)]Python 可以使用内置的
sorted()函数对Fraction对象进行快速排序。有益的是,所有的比较操作符都按照预期工作。您甚至可以将它们用于除复数以外的其他数值类型:
>>> Fraction(2, 3) < 0.625
False
>>> from decimal import Decimal
>>> Fraction(2, 3) < Decimal("0.625")
False
>>> Fraction(2, 3) < 3 + 2j
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'Fraction' and 'complex'
比较运算符适用于浮点数和小数,但是当您尝试使用复数3 + 2j时会出现错误。这与复数没有定义自然排序关系的事实有关,所以你不能将它们与任何东西进行比较——包括分数。
在Fraction、Decimal、Float和之间选择
如果你需要从阅读本教程中挑选一件事情来记住,那么它应该是什么时候选择Fraction而不是Decimal和float。所有这些数字类型都有它们的用例,所以了解它们的优缺点是有好处的。在本节中,您将简要了解数字在这三种数据类型中是如何表示的。
二进制浮点:float
在大多数情况下,float数据类型应该是表示实数的默认选择。例如,它适用于科学、工程和计算机图形学,在这些领域中,执行速度比精度更重要。几乎没有任何程序需要比浮点更高的精度。
注意:如果你只需要使用整数,那么int将是一个速度和内存效率更高的数据类型。
浮点运算无与伦比的速度源于其在硬件而非软件中的实现。几乎所有的数学协处理器都符合 IEEE 754 标准,该标准描述了如何用二进制浮点 T2 表示数字。如你所料,使用二进制的缺点是臭名昭著的表示错误。
然而,除非你有特定的理由使用不同的数字类型,否则如果可能的话,你应该坚持使用float或int。
十进制浮点和定点:Decimal
有时使用二进制系统不能为实数提供足够的精度。一个显著的例子是金融计算,它涉及同时处理非常大和非常小的数字。他们还倾向于一遍又一遍地重复相同的算术运算,这可能会累积显著的舍入误差。
您可以使用十进制浮点算法来存储实数,以缓解这些问题并消除二进制表示错误。它类似于float,因为它移动小数点以适应更大或更小的幅度。然而,它以十进制而不是二进制运行。
另一种提高数值精度的策略是定点算术,它为十进制扩展分配特定的位数。例如,最多四位小数的精度要求将分数存储为放大 10,000 倍的整数。为了恢复原来的分数,它们将被相应地缩小。
Python 的decimal.Decimal数据类型是十进制浮点和定点表示的混合。它还遵循以下两个标准:
- 通用十进制算术规范()
- 独立于基数的浮点运算( IEEE 854-1987
它们是在软件中模拟的,而不是在硬件中模拟的,这使得这种数据类型在时间和空间上比float效率低得多。另一方面,它可以用任意和有限精度表示数字,您可以自由调整。请注意,如果算术运算超过最大小数位数,您仍可能面临舍入误差。
然而,今天由固定精度提供的安全缓冲明天可能会变得不足。考虑恶性通货膨胀或处理汇率差异巨大的多种货币,如比特币(0.000029 BTC)和伊朗里亚尔(42,105.00 IRR)。如果你想要无限的精度,那么使用Fraction。
无限精度有理数:Fraction
Fraction和Decimal类型有一些相似之处。它们解决了二进制表示错误,它们在软件中实现,你可以在货币应用中使用它们。尽管如此,分数的主要用途是表示 T2 有理数 T3,所以比起小数来说,它们可能不太方便存储金钱。
注意:虽然Fraction数据类型是用纯 Python 实现的,但大多数 Python 发行版都为Decimal类型提供了一个编译好的动态链接库。如果它对您的平台不可用,那么 Python 也将退回到纯 Python 实现。然而,即使是编译版也不会像float那样充分利用硬件。
使用Fraction比Decimal有两个好处。第一个是无限精度,只受可用内存的限制。这使您可以用无终止和循环的十进制展开来表示有理数,而不会丢失任何信息:
>>> from fractions import Fraction >>> one_third = Fraction(1, 3) >>> print(3 * one_third) 1 >>> from decimal import Decimal >>> one_third = 1 / Decimal(3) >>> print(3 * one_third) 0.9999999999999999999999999999用 1/3 乘以 3 得到的分数正好是 1,但结果在十进制中是四舍五入的。它有 28 个小数位,这是
Decimal类型的默认精度。再来看看分数的另一个好处,这是你之前已经开始学习的。与
Decimal不同,分数可以与二进制浮点数交互操作:
>>> Fraction("0.75") - 0.25
0.5
>>> Decimal("0.75") - 0.25
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'decimal.Decimal' and 'float'
当您将分数与浮点数混合时,结果会得到一个浮点数。另一方面,如果您试图用一个Decimal数据类型混合分数,那么您将遇到一个TypeError。
正在研究 Python 片段
在这一节中,您将浏览一些在 Python 中使用Fraction数据类型的有趣且实用的例子。你可能会惊讶于分数是多么的方便,同时它们又是多么的被低估。准备好开始吧!
近似无理数
无理数在数学中起着重要的作用,这就是为什么它们出现在算术、微积分和几何等许多子领域的原因。一些你可能听说过的最著名的例子是:
- 二的平方根(√2)
- 阿基米德常数(π)
- 黄金比例(φ)
- 欧拉数( e
在数学史上,圆周率(π)一直特别有趣,这导致许多人试图找到它的精确近似值。
虽然古代哲学家不得不竭尽全力,今天你可以用 Python 找到相当不错的圆周率的估计,使用蒙特卡罗方法,比如布冯针或类似的。然而,在大多数日常问题中,只有一个方便的分数形式的粗略近似值就足够了。以下是确定两个整数的商的方法,这两个整数逐渐逼近无理数:
from fractions import Fraction
from itertools import count
def approximate(number):
history = set()
for max_denominator in count(1):
fraction = Fraction(number).limit_denominator(max_denominator)
if fraction not in history:
history.add(fraction)
yield fraction
该函数接受一个无理数,将其转换为一个分数,并找到一个小数位数较少的不同分数。 Python 集合通过保留历史数据来防止产生重复值,而 itertools 模块的count()迭代器计数到无穷大。
现在,您可以使用此函数来查找圆周率的前十个分数近似值:
>>> from itertools import islice >>> import math >>> for fraction in islice(approximate(math.pi), 10): ... print(f"{str(fraction):>7}", "→", float(fraction)) ... 3 → 3.0 13/4 → 3.25 16/5 → 3.2 19/6 → 3.1666666666666665 22/7 → 3.142857142857143 179/57 → 3.1403508771929824 201/64 → 3.140625 223/71 → 3.140845070422535 245/78 → 3.141025641025641 267/85 → 3.1411764705882352不错!有理数 22/7 已经很接近了,这表明圆周率可以很早就被逼近,而且毕竟不是特别无理。
islice()迭代器在收到请求的十个值后停止无限迭代。继续玩这个例子,增加结果的数量或者寻找其他无理数的近似值。获取显示器的宽高比
图像或显示器的纵横比是其宽度与高度的商,方便地表示比例。它通常用于电影和数字媒体,而电影导演喜欢利用纵横比作为艺术手段。举例来说,如果你一直在寻找一部新的智能手机,那么说明书可能会提到屏幕比例,比如 16:9。
您可以通过使用官方 Python 发行版附带的 Tkinter 来测量电脑显示器的宽度和高度,从而找出显示器的长宽比:
>>> import tkinter as tk
>>> window = tk.Tk()
>>> window.winfo_screenwidth()
2560
>>> window.winfo_screenheight()
1440
请注意,如果您连接了多台显示器,则此代码可能不会按预期运行。
计算纵横比就是创建一个会自我缩小的分数:
>>> from fractions import Fraction >>> Fraction(2560, 1440) Fraction(16, 9)给你。显示器的分辨率为 16:9。但是,如果您使用的是屏幕尺寸较小的笔记本电脑,那么您的分数一开始可能无法计算出来,您需要相应地限制其分母:
>>> Fraction(1360, 768)
Fraction(85, 48)
>>> Fraction(1360, 768).limit_denominator(10)
Fraction(16, 9)
请记住,如果您正在处理移动设备的垂直屏幕,您应该交换尺寸,以便第一个尺寸大于下面的尺寸。您可以将此逻辑封装在一个可重用的函数中:
from fractions import Fraction
def aspect_ratio(width, height, max_denominator=10):
if height > width:
width, height = height, width
ratio = Fraction(width, height).limit_denominator(max_denominator)
return f"{ratio.numerator}:{ratio.denominator}"
这将确保一致的纵横比,而不管参数的顺序如何:
>>> aspect_ratio(1080, 2400) '20:9' >>> aspect_ratio(2400, 1080) '20:9'无论你看的是水平屏幕还是垂直屏幕,长宽比都是一样的。
到目前为止,宽度和高度都是整数,但是分数值呢?例如,一些佳能相机有一个 APS-C 作物传感器,其尺寸为 22.8 毫米乘 14.8 毫米。分数在浮点数和十进制数中难以表达,但您可以将其转换为有理近似值:
>>> aspect_ratio(22.2, 14.8)
Traceback (most recent call last):
...
raise TypeError("both arguments should be "
TypeError: both arguments should be Rational instances
>>> aspect_ratio(Fraction("22.2"), Fraction("14.8"))
'3:2'
在这种情况下,纵横比恰好为 1.5 或 3:2,但许多相机的传感器宽度略长,因此纵横比为 1.555…或 14:9。当你做数学计算时,你会发现它是宽格式(16:9) 和四三分制(4:3) 的算术平均值,这是一种妥协,让你在这两种流行格式下都能很好地显示图片。
计算照片的曝光值
在数字图像中嵌入元数据的标准格式 Exif(可交换图像文件格式),使用比率来存储多个值。一些最重要的比率描述了照片的曝光度:
- 光圈值
- 曝光时间
- 曝光偏差
- 焦距
- 光圈挡
- 快门速度
快门速度在口语中与曝光时间同义,但它是使用基于对数标度的 APEX 系统以分数形式存储在元数据中的。这意味着照相机会取你曝光时间的倒数,然后计算它的以 2 为底的对数。因此,例如,1/200 秒的曝光时间将作为 7643856/1000000 写入文件。你可以这样计算:
>>> from fractions import Fraction >>> exposure_time = Fraction(1, 200) >>> from math import log2, trunc >>> precision = 1_000_000 >>> trunc(log2(Fraction(1, exposure_time)) * precision) 7643856如果您在没有任何外部库的帮助下手动读取这些元数据,您可以使用 Python 片段来恢复原始曝光时间:
>>> shutter_speed = Fraction(7643856, 1_000_000)
>>> Fraction(1, round(2 ** shutter_speed))
Fraction(1, 200)
当你组合拼图的各个部分时——即光圈、快门速度和 ISO 速度——你将能够计算出单个曝光值(EV) ,它描述了捕捉到的光的平均量。然后,您可以使用它来获得拍摄场景中亮度的对数平均值,这在后期处理和应用特殊效果时非常有用。
计算曝光值的公式如下:
from math import log2
def exposure_value(f_stop, exposure_time, iso_speed):
return log2(f_stop ** 2 / exposure_time) - log2(iso_speed / 100)
请记住,它没有考虑其他因素,如曝光偏差或闪光灯,你的相机可能适用。无论如何,用一些样本值试一试:
>>> exposure_value( ... f_stop=Fraction(28, 5), ... exposure_time=Fraction(1, 750), ... iso_speed=400 ... ) 12.521600439723727 >>> exposure_value(f_stop=5.6, exposure_time=1/750, iso_speed=400) 12.521600439723727您可以使用分数或其他数值类型作为输入值。这种情况下曝光值在+13 左右,比较亮。这张照片是在一个阳光明媚的日子拍摄的,尽管是在阴凉处。
解决变革问题
你可以用分数来解决计算机科学经典的改变问题,你可能会在求职面试中遇到。它要求获得一定金额的最少硬币数。例如,如果您考虑最受欢迎的美元硬币,那么您可以将 2.67 美元表示为 10 个 25 美分硬币(10 × $0.25)、1 个 1 角硬币(1 × $0.10)、1 个 5 分硬币(1 × $0.05)和 2 个 1 分硬币(2 × $0.01)。
分数可以是表示钱包或收银机中硬币的方便工具。你可以用以下方式定义美元硬币:
from fractions import Fraction penny = Fraction(1, 100) nickel = Fraction(5, 100) dime = Fraction(10, 100) quarter = Fraction(25, 100)其中一些会自动缩减,但没关系,因为您将使用十进制表示法对它们进行格式化。你可以用这些硬币来计算你钱包的总价值:
>>> wallet = [8 * quarter, 5 * dime, 3 * nickel, 2 * penny]
>>> print(f"${float(sum(wallet)):.2f}")
$2.67
你的钱包总共是 2.67 美元,但是里面有多达 18 个硬币。同样数量的硬币可以用更少的硬币。解决改变问题的一种方法是使用贪婪算法,比如这个:
def change(amount, coins):
while amount > 0:
for coin in sorted(coins, reverse=True):
if coin <= amount:
amount -= coin
yield coin
break
else:
raise Exception("There's no solution")
该算法试图找到一个最高面额的硬币,它不大于剩余金额。虽然实现起来相对简单,但它可能无法在所有硬币系统中给出最佳解决方案。这里有一个美元硬币的例子:
>>> from collections import Counter >>> amount = Fraction("2.67") >>> usd = [penny, nickel, dime, quarter] >>> for coin, count in Counter(change(amount, usd)).items(): ... print(f"{count:>2} × ${float(coin):.2f}") ... 10 × $0.25 1 × $0.10 1 × $0.05 2 × $0.01使用有理数来寻找解决方案是强制性的,因为浮点值不能解决问题。由于
change()是一个生成可能重复的硬币的函数,你可以使用Counter将它们分组。你可以通过问一个稍微不同的问题来修改这个问题。例如,给定总价格、收银机中可用的顾客硬币和卖家硬币,最佳硬币组合是什么?
产生和扩展连分数
在本教程开始时,您已经了解到无理数可以表示为无限连分数。这样的分数需要无限量的内存才能存在,但是你可以选择什么时候停止产生它们的系数来得到一个合理的近似值。
下面的发生器函数将以惰性评估的方式不断产生给定数字的系数:
1def continued_fraction(number): 2 while True: 3 yield (whole_part := int(number)) 4 fractional_part = number - whole_part 5 try: 6 number = 1 / fractional_part 7 except ZeroDivisionError: 8 break该函数截断数字,并将剩余的分数表示为作为输入反馈的倒数。为了消除代码重复,它在第 3 行使用了一个赋值表达式,通常称为 Python 3.8 中引入的 walrus 操作符。
有趣的是,您也可以为有理数创建连分数:
>>> list(continued_fraction(42))
[42]
>>> from fractions import Fraction
>>> list(continued_fraction(Fraction(3, 4)))
[0, 1, 3]
数字 42 只有一个系数,没有小数部分。相反,3/4 没有完整的部分和一个由 1/1+1/3 组成的连分数:

像往常一样,您应该注意当您切换到float时可能会出现的浮点表示错误:
>>> list(continued_fraction(0.75)) [0, 1, 3, 1125899906842624]虽然可以用二进制精确地表示 0.75,但它的倒数有无限的十进制扩展,尽管它是一个有理数。当你研究其余的系数时,你最终会在分母中发现这个巨大的数值,代表一个可以忽略不计的小值。这是你的近似误差。
您可以通过用 Python 分数替换实数来消除此错误:
from fractions import Fraction def continued_fraction(number): while True: yield (whole_part := int(number)) fractional_part = Fraction(number) - whole_part try: number = Fraction(1, fractional_part) except ZeroDivisionError: break这个小小的改变让你能够可靠地生成对应于十进制数的连分式的系数。否则,即使终止十进制展开,也可能陷入无限循环。
好吧,让我们做一些更有趣的事情,生成无理数的系数,它们的十进制展开在第五十个小数位被截断。为了精确起见,将它们定义为
Decimal实例:
>>> from decimal import Decimal
>>> pi = Decimal("3.14159265358979323846264338327950288419716939937510")
>>> sqrt2 = Decimal("1.41421356237309504880168872420969807856967187537694")
>>> phi = Decimal("1.61803398874989484820458683436563811772030917980576")
现在,您可以使用熟悉的islice()迭代器检查连分数的前几个系数:
>>> from itertools import islice >>> numbers = { ... " π": pi, ... "√2": sqrt2, ... " φ": phi ... } >>> for label, number in numbers.items(): ... print(label, list(islice(continued_fraction(number), 20))) ... π [3, 7, 15, 1, 292, 1, 1, 1, 2, 1, 3, 1, 14, 2, 1, 1, 2, 2, 2, 2] √2 [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2] φ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]圆周率的前四个系数给出了一个令人惊讶的好的近似值,随后是一个无关紧要的余数。然而,其他两个常数的连分数看起来非常奇怪。他们一遍又一遍地重复同样的数字,直到无穷。知道了这一点,您可以通过将这些系数展开成十进制形式来近似计算它们:
def expand(coefficients): if len(coefficients) > 1: return coefficients[0] + Fraction(1, expand(coefficients[1:])) else: return Fraction(coefficients[0])递归地定义这个函数是很方便的,这样它可以在更小的系数列表中调用自己。在基本情况下,只有一个整数,这是可能的最粗略的近似值。如果有两个或更多,则结果是第一个系数之和,后面是其余展开系数的倒数。
您可以通过调用它们相反的返回值来验证这两个函数是否按预期工作:
>>> list(continued_fraction(3.14159))
[3, 7, 15, 1, 25, 1, 7, 4, 851921, 1, 1, 2, 880, 1, 2]
>>> float(expand([3, 7, 15, 1, 25, 1, 7, 4, 851921, 1, 1, 2, 880, 1, 2]))
3.14159
完美!如果你把continued_fraction()的结果输入到expand()中,那么你就回到了开始时的初始值。不过,在某些情况下,为了更精确,您可能需要将扩展分数转换为Decimal类型,而不是float。
结论
在阅读本教程之前,你可能从未想过计算机是如何存储分数**的。毕竟,也许你的老朋友看起来可以很好地处理它们。然而,历史已经表明,这种误解可能最终导致灾难性的失败可能会花大钱。*
*使用 Python 的Fraction是避免这种灾难的一种方法。您已经看到了分数记数法的优缺点、它的实际应用以及在 Python 中使用它的方法。现在,您可以明智地选择哪种数值类型最适合您的用例。
在本教程中,您学习了如何:
- 在十进制和小数记数法之间转换
- 执行有理数运算
- 近似无理数
- 用无限精度精确表示分数
- 知道什么时候选择
Fraction而不是Decimal或float************
Python 中的函数式编程:何时以及如何使用它
函数式编程是一种编程范式,其中主要的计算方法是函数求值。在本教程中,您将探索 Python 中的函数式编程。
函数式编程通常在 Python 代码中扮演相当小的角色。但是熟悉就好。至少,在阅读他人编写的代码时,您可能会不时遇到这种情况。您甚至会发现在您自己的代码中使用 Python 的函数式编程能力是有利的。
在本教程中,您将学习:
- 函数式编程范式需要什么
- 在 Python 中说函数是一等公民是什么意思
- 如何用
lambda关键字定义匿名函数 - 如何使用
map()、filter()、reduce()实现功能代码
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是函数式编程?
一个纯函数是一个其输出值仅跟随其输入值的函数,没有任何可观察到的副作用。在函数式编程中,一个程序完全由纯函数的求值组成。计算通过嵌套或组合函数调用进行,不改变状态或可变数据。
函数范式之所以流行,是因为它提供了优于其他编程范式的几个优点。功能代码是:
- 高层次:你描述的是你想要的结果,而不是明确指定达到目标所需的步骤。单一陈述往往简洁,但却很有冲击力。
- 透明:纯函数的行为只取决于它的输入和输出,没有中间值。这消除了副作用的可能性,方便了调试。
- 可并行化:不会产生副作用的例程可以更容易地彼此并行运行。
许多编程语言支持某种程度的函数式编程。在一些语言中,几乎所有的代码都遵循函数范式。哈斯克尔就是这样一个例子。相比之下,Python 确实支持函数式编程,但也包含其他编程模型的特性。
虽然对函数式编程的深入描述确实有些复杂,但这里的目标不是给出一个严格的定义,而是向您展示通过 Python 中的函数式编程可以做些什么。
Python 对函数式编程的支持有多好?
为了支持函数式编程,如果给定编程语言中的函数有两种能力,这是很有用的:
- 将另一个函数作为参数
- 将另一个函数返回给它的调用方
Python 在这两方面都做得很好。正如您在本系列之前所学的,Python 程序中的所有东西都是一个对象。Python 中的所有对象都有或多或少的同等地位,函数也不例外。
在 Python 中,函数是一等公民。这意味着函数与像字符串和数字这样的值具有相同的特征。任何你期望可以用字符串或数字做的事情,你也可以用函数来做。
例如,可以将一个函数赋给一个变量。然后,您可以像使用函数本身一样使用该变量:
1>>> def func(): 2... print("I am function func()!") 3... 4 5>>> func() 6I am function func()! 7 8>>> another_name = func 9>>> another_name() 10I am function func()!第 8 行的赋值
another_name = func创建了一个对func()的新引用,名为another_name。然后,您可以通过名字func或another_name调用该函数,如第 5 行和第 9 行所示。你可以用
print()向控制台显示一个函数,将它作为一个元素包含在一个复合数据对象中,比如一个列表,或者甚至将它作为一个字典键:
>>> def func():
... print("I am function func()!")
...
>>> print("cat", func, 42) cat <function func at 0x7f81b4d29bf8> 42
>>> objects = ["cat", func, 42] >>> objects[1]
<function func at 0x7f81b4d29bf8>
>>> objects[1]()
I am function func()!
>>> d = {"cat": 1, func: 2, 42: 3} >>> d[func]
2
在这个例子中,func()出现在与值"cat"和42相同的上下文中,解释器处理得很好。
注意:在 Python 中你能对任何对象做什么或不能做什么,在某种程度上取决于上下文。例如,有些操作适用于某些对象类型,但不适用于其他类型。
您可以添加两个整数对象,或者用加号运算符(+)连接两个字符串对象。但是加号运算符不是为函数对象定义的。
就目前的目的而言,重要的是 Python 中的函数满足上面列出的有利于函数式编程的两个标准。可以将一个函数作为参数传递给另一个函数:
1>>> def inner(): 2... print("I am function inner()!") 3... 4 5>>> def outer(function): 6... function() 7... 8 9>>> outer(inner) 10I am function inner()!上面的例子是这样的:
- 第 9 行的调用将
inner()作为参数传递给outer()。- 在
outer()内,Python 将inner()绑定到函数参数function。outer()可以通过function直接呼叫inner()。这就是所谓的函数组合。
技术提示: Python 提供了一种被称为装饰器的快捷符号,以方便将一个函数包装在另一个函数中。要了解更多信息,请查看 Python Decorators 的初级读本。
当您将一个函数传递给另一个函数时,传入的函数有时被称为回调,因为对内部函数的回调可以修改外部函数的行为。
一个很好的例子就是 Python 函数
sorted()。通常,如果您将一个字符串值列表传递给sorted(),那么它会按照词汇顺序对它们进行排序:
>>> animals = ["ferret", "vole", "dog", "gecko"]
>>> sorted(animals)
['dog', 'ferret', 'gecko', 'vole']
然而,sorted()接受一个可选的key参数,该参数指定了一个可以作为排序键的回调函数。因此,例如,您可以改为按字符串长度排序:
>>> animals = ["ferret", "vole", "dog", "gecko"] >>> sorted(animals, key=len) ['dog', 'vole', 'gecko', 'ferret']
sorted()也可以带一个可选参数,指定以相反的顺序排序。但是您可以通过定义自己的回调函数来管理同样的事情,该函数反转了len()的含义:
>>> animals = ["ferret", "vole", "dog", "gecko"]
>>> sorted(animals, key=len, reverse=True)
['ferret', 'gecko', 'vole', 'dog']
>>> def reverse_len(s):
... return -len(s)
...
>>> sorted(animals, key=reverse_len)
['ferret', 'gecko', 'vole', 'dog']
你可以查看如何在 Python 中使用sorted()和sort()来获得更多关于在 Python 中排序数据的信息。
正如您可以将一个函数作为参数传递给另一个函数一样,一个函数也可以将另一个函数指定为其返回值:
1>>> def outer(): 2... def inner(): 3... print("I am function inner()!") 4... 5... # Function outer() returns function inner() 6... return inner 7... 8 9>>> function = outer() 10>>> function 11<function outer.<locals>.inner at 0x7f18bc85faf0> 12>>> function() 13I am function inner()! 14 15>>> outer()() 16I am function inner()!这个例子中的情况如下:
- 第 2 行到第 3 行:
outer()定义了一个局部函数inner()。- 第 6 行:
outer()传回inner()作为其返回值。- 第 9 行:将
outer()的返回值赋给变量function。接下来,您可以通过
function间接调用inner(),如第 12 行所示。您也可以使用来自outer()的返回值间接调用它,无需中间赋值,如第 15 行所示。正如您所看到的,Python 已经准备好很好地支持函数式编程。不过,在开始编写函数式代码之前,还有一个概念将有助于您的探索:表达式
lambda。用
lambda定义匿名函数函数式编程就是调用函数并传递它们,所以它自然会涉及到定义很多函数。你可以用通常的方式定义一个函数,使用关键字
def,就像你在本系列前面的教程中看到的那样。不过,有时候,能够动态地定义一个匿名函数是很方便的,不需要给它一个名字。在 Python 中,你可以用一个
lambda表达式来实现。技术说明:术语 lambda 来自 lambda calculus ,一种基于函数抽象和应用来表达计算的数学逻辑形式系统。
lambda表达式的语法如下:lambda <parameter_list>: <expression>下表总结了一个
lambda表达式的各个部分:
成分 意义 lambda引入一个 lambda表达式的关键字<parameter_list>可选的逗号分隔的参数名称列表 :分隔 <parameter_list>和<expression>的标点符号<expression>通常包含 <parameter_list>中的名称的表达式一个
lambda表达式的值是一个可调用的函数,就像用def关键字定义的函数一样。它接受由<parameter_list>指定的参数,并返回一个值,如<expression>所示。这是第一个简单的例子:
1>>> lambda s: s[::-1]
2<function <lambda> at 0x7fef8b452e18>
3
4>>> callable(lambda s: s[::-1])
5True
第 1 行的语句本身就是lambda表达式。在第 2 行,Python 显示了表达式的值,您可以看到这是一个函数。
内置的 Python 函数 callable() 如果传递给它的参数是可调用的,则返回 True ,否则返回 False 。第 4 行和第 5 行显示了由lambda表达式返回的值实际上是可调用的,就像函数应该做的那样。
在这种情况下,参数表由单个参数s组成。后续表达式s[::-1]是以逆序返回s中字符的切片语法。所以这个lambda表达式定义了一个临时的、无名的函数,它接受一个字符串参数并返回字符颠倒的参数字符串。
由lambda表达式创建的对象是一等公民,就像 Python 中的标准函数或任何其他对象一样。您可以将它赋给一个变量,然后使用该名称调用函数:
>>> reverse = lambda s: s[::-1] >>> reverse("I am a string") 'gnirts a ma I'这在功能上——没有双关的意思——相当于用关键字
def定义reverse():
1>>> def reverse(s):
2... return s[::-1]
3...
4>>> reverse("I am a string") 5'gnirts a ma I'
6
7>>> reverse = lambda s: s[::-1]
8>>> reverse("I am a string") 9'gnirts a ma I'
上面第 4 行和第 8 行的调用行为相同。
然而,在调用之前,没有必要将变量赋给一个lambda表达式。也可以直接调用由lambda表达式定义的函数:
>>> (lambda s: s[::-1])("I am a string") 'gnirts a ma I'这是另一个例子:
>>> (lambda x1, x2, x3: (x1 + x2 + x3) / 3)(9, 6, 6)
7.0
>>> (lambda x1, x2, x3: (x1 + x2 + x3) / 3)(1.4, 1.1, 0.5)
1.0
这种情况下,参数为x1、x2、x3,表达式为x1 + x2 + x3 / 3。这是一个匿名的lambda函数,用来计算三个数字的平均值。
再举一个例子,回想一下上面您定义了一个reverse_len()作为sorted()的回调函数:
>>> animals = ["ferret", "vole", "dog", "gecko"] >>> def reverse_len(s): ... return -len(s) ... >>> sorted(animals, key=reverse_len) ['ferret', 'gecko', 'vole', 'dog']您也可以在这里使用
lambda函数:
>>> animals = ["ferret", "vole", "dog", "gecko"]
>>> sorted(animals, key=lambda s: -len(s))
['ferret', 'gecko', 'vole', 'dog']
一个lambda表达式通常会有一个参数列表,但这不是必需的。可以定义一个没有参数的lambda函数。返回值不依赖于任何输入参数:
>>> forty_two_producer = lambda: 42 >>> forty_two_producer() 42请注意,您只能用
lambda定义相当基本的函数。lambda表达式的返回值只能是一个表达式。一个lambda表达式不能包含赋值、return之类的语句,也不能包含for、while、if、else或def之类的控制结构。在之前关于定义 Python 函数的教程中,您已经了解到用
def定义的函数可以有效地返回多个值。如果函数中的一个return语句包含几个逗号分隔的值,那么 Python 将它们打包并作为一个元组返回:
>>> def func(x):
... return x, x ** 2, x ** 3
...
>>> func(3)
(3, 9, 27)
这种隐式元组打包不适用于匿名lambda函数:
>>> (lambda x: x, x ** 2, x ** 3)(3) <stdin>:1: SyntaxWarning: 'tuple' object is not callable; perhaps you missed a comma? Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'x' is not defined但是你可以从一个
lambda函数中返回一个元组。你只需要用括号明确地表示元组。您也可以从lambda函数中返回一个列表或字典:
>>> (lambda x: (x, x ** 2, x ** 3))(3)
(3, 9, 27)
>>> (lambda x: [x, x ** 2, x ** 3])(3)
[3, 9, 27]
>>> (lambda x: {1: x, 2: x ** 2, 3: x ** 3})(3)
{1: 3, 2: 9, 3: 27}
一个lambda表达式有自己的本地名称空间,所以参数名不会与全局名称空间中的相同名称冲突。一个lambda表达式可以访问全局名称空间中的变量,但是不能修改它们。
还有最后一个奇怪的地方需要注意。如果您发现需要在一个格式的字符串文字(f-string) 中包含一个lambda表达式,那么您需要用显式括号将它括起来:
>>> print(f"--- {lambda s: s[::-1]} ---") File "<stdin>", line 1 (lambda s) ^ SyntaxError: f-string: invalid syntax >>> print(f"--- {(lambda s: s[::-1])} ---") --- <function <lambda> at 0x7f97b775fa60> --- >>> print(f"--- {(lambda s: s[::-1])('I am a string')} ---") --- gnirts a ma I ---现在你知道如何用
lambda定义一个匿名函数了。关于lambda函数的进一步阅读,请查看如何使用 Python Lambda 函数。接下来,是时候深入研究 Python 中的函数式编程了。您将看到
lambda函数在编写函数代码时是如何特别方便。Python 提供了两个内置函数,
map()和filter(),它们符合函数式编程范式。第三种,reduce(),不再是核心语言的一部分,但仍然可以从一个名为functools的模块中获得。这三个函数都将另一个函数作为其参数之一。使用
map()将函数应用于可迭代对象docket 上的第一个函数是
map(),这是一个 Python 内置函数。使用map(),你可以依次对 iterable 中的每个元素应用一个函数,然后map()将返回一个迭代器产生结果。这可以允许一些非常简洁的代码,因为一个map()语句通常可以代替一个显式循环。用单个可迭代的调用
map()在单个 iterable 上调用
map()的语法如下所示:map(<f>, <iterable>)
map(<f>, <iterable>)在迭代器中返回将函数<f>应用到<iterable>的每个元素的结果。这里有一个例子。假设您已经使用您的老朋友
[::-1]字符串切片机制定义了reverse(),一个接受字符串参数并返回其反向的函数:
>>> def reverse(s):
... return s[::-1]
...
>>> reverse("I am a string")
'gnirts a ma I'
如果您有一个字符串列表,那么您可以使用map()将reverse()应用到列表的每个元素:
>>> animals = ["cat", "dog", "hedgehog", "gecko"] >>> iterator = map(reverse, animals) >>> iterator <map object at 0x7fd3558cbef0>但是记住,
map()不会返回一个列表。它返回一个名为地图对象的迭代器。要从迭代器中获取值,您需要迭代它或者使用list():
>>> iterator = map(reverse, animals)
>>> for i in iterator: ... print(i)
...
tac
god
gohegdeh
okceg
>>> iterator = map(reverse, animals)
>>> list(iterator) ['tac', 'god', 'gohegdeh', 'okceg']
迭代iterator产生原始列表animals中的条目,每个字符串由reverse()反转。
在这个例子中,reverse()是一个非常短的函数,除了使用map()之外,您可能不需要它。你可以使用一个匿名的lambda函数,而不是用一个一次性的函数把代码弄乱:
>>> animals = ["cat", "dog", "hedgehog", "gecko"] >>> iterator = map(lambda s: s[::-1], animals) >>> list(iterator) ['tac', 'god', 'gohegdeh', 'okceg'] >>> # Combining it all into one line: >>> list(map(lambda s: s[::-1], ["cat", "dog", "hedgehog", "gecko"])) ['tac', 'god', 'gohegdeh', 'okceg']如果 iterable 包含不适合指定函数的项目,那么 Python 会抛出一个异常:
>>> list(map(lambda s: s[::-1], ["cat", "dog", 3.14159, "gecko"]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
TypeError: 'float' object is not subscriptable
在这种情况下,lambda函数需要一个字符串参数,并试图对其进行切分。列表中的第二个元素3.14159是一个float对象,它是不可切片的。于是出现了 TypeError 。
这里有一个更真实的例子:在关于内置字符串方法的教程部分,您遇到了str.join(),它将 iterable 中的字符串串联起来,由指定的字符串分隔:
>>> "+".join(["cat", "dog", "hedgehog", "gecko"]) 'cat+dog+hedgehog+gecko'如果列表中的对象是字符串,这就很好。如果不是,那么
str.join()引发一个TypeError异常:
>>> "+".join([1, 2, 3, 4, 5])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence item 0: expected str instance, int found
解决这个问题的一种方法是使用循环。使用一个for循环,您可以创建一个新列表,其中包含原始列表中数字的字符串表示。然后您可以将新列表传递给.join():
>>> strings = [] >>> for i in [1, 2, 3, 4, 5]: ... strings.append(str(i)) ... >>> strings ['1', '2', '3', '4', '5'] >>> "+".join(strings) '1+2+3+4+5'然而,因为
map()依次对列表中的每个对象应用一个函数,它通常可以消除对显式循环的需要。在这种情况下,您可以在连接列表对象之前使用map()将str()应用于列表对象:
>>> "+".join(map(str, [1, 2, 3, 4, 5]))
'1+2+3+4+5'
map(str, [1, 2, 3, 4, 5])返回一个迭代器,该迭代器产生字符串对象的列表["1", "2", "3", "4", "5"],然后您可以成功地将该列表传递给.join()。
虽然map()在上面的例子中实现了想要的效果,但是在这种情况下,使用列表理解来代替显式循环会更python 化。
使用多个可迭代的调用map()
还有另一种形式的map()接受不止一个可迭代的参数:
map(<f>, <iterable₁>, <iterable₂>, ..., <iterableₙ>)
map(<f>, <iterable1>, <iterable2>, ..., <iterablen>)将<f>并行应用于每个<iterable i >中的元素,并返回产生结果的迭代器。
指定给map()的<iterable i >参数的数量必须与<f>期望的参数数量相匹配。<f>作用于每个<iterable i >的第一项,该结果成为返回迭代器产出的第一项。然后<f>作用于每个<iterable i >中的第二个项目,成为第二个产出的项目,以此类推。
一个例子应该有助于澄清:
>>> def f(a, b, c): ... return a + b + c ... >>> list(map(f, [1, 2, 3], [10, 20, 30], [100, 200, 300])) [111, 222, 333]在这种情况下,
f()需要三个参数。相应地,map()有三个可重复的参数:列表[1, 2, 3]、[10, 20, 30]和[100, 200, 300]。返回的第一项是将
f()应用于每个列表中的第一个元素:f(1, 10, 100)的结果。返回的第二项是f(2, 20, 200),第三项是f(3, 30, 300),如下图所示:
从
map()返回的值是一个迭代器,产生列表[111, 222, 333]。同样在这种情况下,由于
f()非常短,您可以很容易地用一个lambda函数代替它:

>>> list(
... map(
... (lambda a, b, c: a + b + c),
... [1, 2, 3],
... [10, 20, 30],
... [100, 200, 300]
... )
... )
这个例子在lambda函数和隐式行继续符周围使用了额外的括号。这两者都不是必需的,但是它们有助于使代码更容易阅读。
用filter() 从 Iterable 中选择元素
filter() 允许您根据给定函数的评估从 iterable 中选择或过滤项目。它的名称如下:
filter(<f>, <iterable>)
filter(<f>, <iterable>)将函数<f>应用于<iterable>的每个元素,并返回一个迭代器,该迭代器产生<f>为真值的所有项目。相反,它过滤掉所有<f>为假的项目。
在下面的例子中,greater_than_100(x)是 true thy ifx > 100:
>>> def greater_than_100(x): ... return x > 100 ... >>> list(filter(greater_than_100, [1, 111, 2, 222, 3, 333])) [111, 222, 333]在这种情况下,
greater_than_100()对于项目111、222和333是真的,因此这些项目保留,而1、2和3被丢弃。和前面的例子一样,greater_than_100()是一个短函数,您可以用一个lambda表达式来代替它:
>>> list(filter(lambda x: x > 100, [1, 111, 2, 222, 3, 333]))
[111, 222, 333]
下一个例子特点 range() 。range(n)产生一个迭代器,该迭代器产生从0到n - 1的整数。以下示例使用filter()从列表中仅选择偶数,并过滤掉奇数:
>>> list(range(10)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> def is_even(x): ... return x % 2 == 0 ... >>> list(filter(is_even, range(10))) [0, 2, 4, 6, 8] >>> list(filter(lambda x: x % 2 == 0, range(10))) [0, 2, 4, 6, 8]下面是一个使用内置字符串方法的示例:
>>> animals = ["cat", "Cat", "CAT", "dog", "Dog", "DOG", "emu", "Emu", "EMU"]
>>> def all_caps(s):
... return s.isupper()
...
>>> list(filter(all_caps, animals)) ['CAT', 'DOG', 'EMU']
>>> list(filter(lambda s: s.isupper(), animals)) ['CAT', 'DOG', 'EMU']
请记住前面关于字符串方法的教程,如果s中的所有字母字符都是大写的,则s.isupper()返回True,否则返回False。
用reduce() 将一个 Iterable 简化为一个值
reduce() 一次对两个可迭代的项目应用一个函数,逐步组合它们以产生一个结果。
reduce()曾经是 Python 中的内置函数。吉多·范·罗苏姆显然相当不喜欢reduce(),并主张将其从语言中完全删除。以下是他对此的看法:
所以现在
reduce()。这实际上是我最讨厌的一个,因为除了几个涉及+或*的例子,几乎每次我看到一个带有重要函数参数的reduce()调用,我都需要拿起笔和纸来画出实际输入到那个函数中的内容,然后我才明白reduce()应该做什么。因此,在我看来,reduce()的适用性仅限于关联操作符,在其他情况下,最好显式写出累加循环。(来源)
Guido 实际上提倡从 Python 中删除所有三个reduce()、map()和filter()。人们只能猜测他的理由。碰巧的是,前面提到的列表理解涵盖了所有这些函数提供的功能以及更多。你可以通过阅读在 Python 中何时使用列表理解来了解更多。
如您所见,map()和filter()仍然是 Python 中的内置函数。reduce()不再是一个内置函数,但它可用于从标准库模块导入,您将在接下来看到。
要使用reduce(),需要从名为functools的模块导入。有几种方法可以做到这一点,但以下是最直接的方法:
from functools import reduce
接下来,解释器将reduce()放入全局名称空间中,并使其可供使用。您将在下面看到的示例假设了这种情况。
使用两个参数调用reduce()
最简单的reduce()调用需要一个函数和一个 iterable,如下所示:
reduce(<f>, <iterable>)
reduce(<f>, <iterable>)使用<f>,它必须是一个正好接受两个参数的函数,来逐步组合<iterable>中的元素。首先,reduce()对<iterable>的前两个元素调用<f>。然后将该结果与第三个元素组合,然后将该结果与第四个元素组合,依此类推,直到列表结束。然后reduce()返回最终结果。
Guido 说reduce()最直接的应用是那些使用关联操作符的应用,他是对的。让我们从加号运算符(+)开始:
>>> def f(x, y): ... return x + y ... >>> from functools import reduce >>> reduce(f, [1, 2, 3, 4, 5]) 15对
reduce()的调用从列表[1, 2, 3, 4, 5]中产生结果15,如下所示:
reduce(f, [1, 2, 3, 4, 5]) 这是对列表中的数字求和的一种相当迂回的方式!虽然这很好,但还有一种更直接的方法。Python 的内置
sum()返回 iterable 中数值的总和:

>>> sum([1, 2, 3, 4, 5])
15
记住,二进制加运算符也连接字符串。因此,这个示例也将逐步连接列表中的字符串:
>>> reduce(f, ["cat", "dog", "hedgehog", "gecko"]) 'catdoghedgehoggecko'同样,有一种方法可以实现这一点,大多数人认为这种方法更典型。这正是
str.join()所做的:
>>> "".join(["cat", "dog", "hedgehog", "gecko"])
'catdoghedgehoggecko'
现在考虑一个使用二进制乘法运算符(*)的例子。正整数n的阶乘定义如下:

您可以使用reduce()和range()实现阶乘函数,如下所示:
>>> def multiply(x, y): ... return x * y ... >>> def factorial(n): ... from functools import reduce ... return reduce(multiply, range(1, n + 1)) ... >>> factorial(4) # 1 * 2 * 3 * 4 24 >>> factorial(6) # 1 * 2 * 3 * 4 * 5 * 6 720同样,有一种更简单的方法可以做到这一点。您可以使用标准模块提供的
factorial():
>>> from math import factorial
>>> factorial(4)
24
>>> factorial(6)
720
作为最后一个例子,假设您需要找到列表中的最大值。Python 提供了内置函数 max() 来完成这项工作,但是您也可以使用reduce():
>>> max([23, 49, 6, 32]) 49 >>> def greater(x, y): ... return x if x > y else y ... >>> from functools import reduce >>> reduce(greater, [23, 49, 6, 32]) 49注意,在上面的每个例子中,传递给
reduce()的函数是一行函数。在每种情况下,您都可以使用一个lambda函数来代替:
>>> reduce(lambda x, y: x + y, [1, 2, 3, 4, 5]) 15
>>> reduce(lambda x, y: x + y, ["foo", "bar", "baz", "quz"]) 'foobarbazquz'
>>> def factorial(n):
... from functools import reduce
... return reduce(lambda x, y: x * y, range(1, n + 1)) ...
>>> factorial(4)
24
>>> factorial(6)
720
>>> reduce((lambda x, y: x if x > y else y), [23, 49, 6, 32]) 49
这是避免将不需要的函数放入名称空间的一种便捷方式。另一方面,当你使用lambda而不是定义一个单独的函数时,阅读代码的人可能更难确定你的意图。通常情况下,这是可读性和便利性之间的平衡。
用初始值调用reduce()
还有另一种方法调用reduce()来指定归约序列的初始值:
reduce(<f>, <iterable>, <init>)
当存在时,<init>指定组合的初始值。在对<f>的第一次调用中,参数是<init>和<iterable>的第一个元素。然后,该结果与第二个元素<iterable>相结合,以此类推:
>>> def f(x, y): ... return x + y ... >>> from functools import reduce >>> reduce(f, [1, 2, 3, 4, 5], 100) # (100 + 1 + 2 + 3 + 4 + 5) 115 >>> # Using lambda: >>> reduce(lambda x, y: x + y, [1, 2, 3, 4, 5], 100) 115现在,函数调用的序列如下所示:
reduce(f, [1, 2, 3, 4, 5], 100) 没有
reduce()你也可以很容易达到同样的结果:

>>> 100 + sum([1, 2, 3, 4, 5])
115
正如你在上面的例子中看到的,即使在你可以使用reduce()完成一项任务的情况下,通常也有可能找到一种更直接和python 式的方法来完成没有它的相同任务。也许不难想象为什么reduce()最终被从核心语言中移除了。
也就是说,reduce()是一个非凡的函数。本节开头的描述指出reduce()组合元素产生一个单一结果。但是结果可以是一个复合对象,如列表或元组。出于这个原因,reduce()是一个非常一般化的高阶函数,通过它可以实现许多其他函数。
比如你可以用reduce()来实现map():
>>> numbers = [1, 2, 3, 4, 5] >>> list(map(str, numbers)) ['1', '2', '3', '4', '5'] >>> def custom_map(function, iterable): ... from functools import reduce ... ... return reduce( ... lambda items, value: items + [function(value)], ... iterable, ... [], ... ) ... >>> list(custom_map(str, numbers)) ['1', '2', '3', '4', '5']您也可以使用
reduce()来实现filter():
>>> numbers = list(range(10))
>>> numbers
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> def is_even(x):
... return x % 2 == 0
...
>>> list(filter(is_even, numbers)) [0, 2, 4, 6, 8]
>>> def custom_filter(function, iterable):
... from functools import reduce
...
... return reduce(
... lambda items, value: items + [value] if function(value) else items,
... iterable,
... []
... )
...
>>> list(custom_filter(is_even, numbers)) [0, 2, 4, 6, 8]
事实上,对对象序列的任何操作都可以表示为归约。
结论
函数式编程是一种编程范式,其中主要的计算方法是对纯函数求值。虽然 Python 主要不是一种函数式语言,但是熟悉lambda、map()、filter()和reduce()还是有好处的,因为它们可以帮助您编写简洁、高级、可并行化的代码。你也会在别人写的代码中看到它们。
在本教程中,您学习了:
- 什么是功能编程
- Python 中的函数如何成为的一等公民,以及这如何使它们适合于函数式编程
- 如何定义一个简单的匿名函数与
lambda - 如何用
map()filter()reduce()实现功能代码
至此,关于使用 Python 的基础知识的介绍性系列已经结束。恭喜你!现在,您已经为以高效的 Pythonic 风格编写有用的程序打下了坚实的基础。
如果你有兴趣让你的 Python 技能更上一层楼,那么你可以查看更多的中级和高级教程。你也可以查看一些 Python 项目创意,开始展示你的 Python 超能力。编码快乐!
« Namespaces and Scope in PythonFunctional Programming in Python******
如何在 Python 中获取和使用当前时间
对于许多与时间相关的操作来说,用 Python 获取当前时间(T2)是一个很好的起点。一个非常重要的用例是创建时间戳。在本教程中,您将学习如何使用 datetime 模块获取、显示、格式化当前时间。
为了在 Python 应用程序中有效地使用当前时间,您将在腰带上添加一些工具。例如,你将学习如何读取当前时间的属性,比如年、分或秒。为了使时间更容易阅读,您将探索打印它的选项。您还将了解不同的时间格式,并学习计算机如何表示时间,如何序列化时间,以及如何处理时区。
源代码: 点击这里下载 Python 中获取和使用当前时间的免费源代码。
如何用 Python 讲时间
获取和打印当前时间最直接的方法是使用datetime模块中datetime 类的.now() 类方法:
>>> from datetime import datetime >>> now = datetime.now() >>> now datetime(2022, 11, 22, 14, 31, 59, 331225) >>> print(now) 2022-11-22 14:31:59.331225类方法
.now()是一个构造器方法,它返回一个datetime对象。当 REPL 对now变量求值时,你会得到一个datetime对象的表示。很难说出每个数字的含义。但是如果您显式打印now变量,那么您会得到一个稍微不同的输出,它以熟悉的时间戳格式显示信息。注意:你在这里得到的
datetime对象是不知道时区的。通常您的操作系统可以正确解析时区,但是datetime对象本身目前没有时区信息。在本教程的部分,您将了解时区感知对象。您可能会认出打印的
datetime对象的格式。它严格遵循国际标准,的时间和日期格式。你会在很多地方发现这种格式!不过,Python 使用的格式与 ISO 8601 标准略有不同。标准规定时间戳的日期和小时部分应该用一个
T字符分隔,但是通过print()函数传递的默认datetime对象用一个空格分隔它们。Python 具有可扩展性和可定制性,使您能够定制打印时间戳的格式。打印时,
datetime类在内部使用它的.isoformat()方法。由于.isoformat()只是一个实例方法,您可以从任何datetime对象中直接调用它来定制 ISO 时间戳:
>>> datetime.now().isoformat()
'2022-11-22T14:31:59.331225'
>>> datetime.now().isoformat(sep=" ")
'2022-11-22 14:31:59.331225'
您会注意到,当您不带任何参数调用.isoformat()时,会使用标准的 ISO 8601 分隔符T。然而,datetime类实现其特殊实例方法.__str__() 的方式是用一个空格作为sep参数。
能够获得完整的日期和时间是很好的,但是有时您可能会寻找一些特定的内容。例如,也许您只想要月份或日期。在这些情况下,您可以从一系列属性中进行选择:
>>> from datetime import datetime >>> now = datetime.now() >>> print(f""" ... {now.month = } ... {now.day = } ... {now.hour = } ... {now.minute = } ... {now.weekday() = } ... {now.isoweekday() = }""" ... ) now.month = 11 now.day = 22 now.hour = 14 now.minute = 31 now.weekday() = 1 now.isoweekday() = 2在这个代码片段中,您使用一个三重引号 f 字符串和花括号内的
=符号来输出表达式及其结果。继续探索不同的属性和方法,用一个
datetime对象调用dir()函数,列出当前作用域中可用的名称。或者你可以查看datetime的文档。无论哪种方式,你都会发现大量的选择。您会注意到上一个示例的结果通常是数字。这可能很适合你,但是将工作日显示为数字可能并不理想。由于
.weekday()和.isoweekday()方法返回不同的数字,这也可能特别令人困惑。注:对于
.weekday()法,周一为0,周日为6。对于.isoweekday(),周一是1,周日是7。ISO 时间戳很好,但是也许您想要比 ISO 时间戳更易读的东西。例如,对于一个人来说,几毫秒可能有点长。在下一节中,您将学习如何以您喜欢的任何方式格式化您的时间戳。
格式化时间戳以提高可读性
为了以一种定制的、人类可读的方式方便地输出时间,
datetime有一个名为.strftime()的方法。.strftime()方法以一个格式代码作为参数。格式代码是一串特殊的标记,这些标记将被来自datetime对象的信息替换。
.strftime()方法会给你很多选择,告诉你如何准确地表示你的datetime对象。例如,采用以下格式:
>>> from datetime import datetime
>>> datetime.now().strftime("%A, %B %d")
'Tuesday, November 22'
在本例中,您使用了以下格式代码:
%A:工作日全名%B:月份全称%d:一个月中的第几天
格式字符串中的逗号和文字空格按原样打印。.strftime()方法只替换它识别为代码的内容。.strftime()中的格式代码总是以一个百分号(%)开始,它遵循一个旧 C 标准。这些代码类似于旧的 printf字符串格式样式,但它们并不相同。
格式代码的文档有一个漂亮的表格,向您展示了您可以使用的所有不同的格式代码。在 strftime.org 的网站上也有一个不错的小抄。去看看他们。
注意: Python 的 f 字符串支持与.strftime()相同的格式代码。你可以这样使用它们:
>>> f"{datetime.now():%A, %B %d}" 'Tuesday, November 22'在 f 字符串中,使用冒号(
:)来分隔表达式和相应的格式代码。所以现在你可以得到你喜欢的时间和格式。这应该能满足你基本的报时需求,但也许你对计算机内部如何表示和处理时间以及如何将时间存储在文件或数据库中感到好奇。在下一节中,您将深入了解这一点。
用 Python 获取当前的 Unix 时间
电脑喜欢数字。但是日期和时间是遵循有趣规则的有趣的人类数字。一天二十四小时?一小时六十分钟?这些聪明的想法是谁的?
为了简化问题,并且考虑到计算机不介意大数,在开发操作系统的时候做出了一个决定。
这个决定是将所有时间表示为自 1970 年 1 月 1 日午夜UTC以来经过的秒数。这个时间点也被称为 Unix 时代。这个时间系统被称为 Unix 时间。今天的大多数计算机系统——甚至是 Windows——都使用 Unix 时间来表示内部时间。
Unix 时间在 UTC 时间 1970 年 1 月 1 日午夜是零。如果你想知道当前的 Unix 时间,那么你可以使用另一种
datetime方法:
>>> from datetime import datetime
>>> datetime.now().timestamp()
1669123919.331225
.timestamp()方法返回自 Unix 纪元以来的秒数,精度很高。毕竟,在所有的属性和方法之下,每个日期对大多数计算机来说只不过是一个大数字。
注意:因为您创建的datetime对象不知道时区,所以您生成的时间戳实际上可能不是 UNIX 时间!这可能没问题,只要您的系统正确配置了时间设置。
在大多数情况下,您可以不去管 Unix 时间。这是一种表示时间的方式,对电脑来说效果很好,但对习惯了公历的人来说就不太好了。不过,Unix 时间戳会在您的日期和时间冒险中突然出现,所以了解它们绝对有好处。
正确生成的 Unix 时间戳的最大好处之一是它明确地捕捉了世界范围内的某个时刻。Unix 纪元总是使用 UTC,所以时区偏移方面没有歧义——也就是说,如果您能够可靠地创建没有 UTC 偏移的时间戳。
但不幸的是,你将不得不经常处理混乱的时区。不过,不要害怕!在下一节中,您将了解时区感知datetime对象。
获取支持时区的 Python 时间和日期对象
Unix 时间戳的明确性是有吸引力的,但是一般来说用 ISO 8601 格式序列化时间和日期更好,因为除了计算机容易解析 T3 之外,它还是人类可读的 T5,并且它是一个国际标准。
更重要的是,尽管 Unix 时间戳在某种程度上是可识别的,但它们可能会被误认为代表其他东西。毕竟,它们只是数字。有了 ISO 时间戳,您马上就知道它代表了什么。引用 Python 的禅,可读性算。
如果你想用完全明确的术语表示你的datetime对象,那么你首先需要让你的对象知道时区。一旦您有了时区感知对象,时区信息就会添加到您的 ISO 时间戳中:
>>> from datetime import datetime >>> now = datetime.now() >>> print(now.tzinfo) None >>> now_aware = now.astimezone() >>> print(now_aware.tzinfo) Romance Standard Time >>> now_aware.tzinfo datetime.timezone(datetime.timedelta(seconds=3600), 'Romance Standard Time') >>> now_aware.isoformat() '2022-11-22T14:31:59.331225+01:00'在这个例子中,您首先演示了
now对象没有任何时区信息,因为它的.tzinfo属性返回了None。当您在没有任何参数的情况下调用now上的.astimezone()时,本地系统时区用于用timezone对象填充.tzinfo。一个
timezone对象本质上只是一个相对于 UTC 时间的偏移量和一个名称。在示例中,当地时区的名称是罗马标准时间,偏移量是 3600 秒,即一个小时。注意:时区的名称也将取决于您的操作系统。
datetime模块经常与操作系统通信,以获取时间和时区信息,以及其他信息,比如您喜欢的语言。在 Python 3.9 中增加了
zoneinfo模块,让你可以访问 IANA 时区数据库。既然
datetime对象有了一个timezone对象,您可以认为它是时区感知的。因此,当您在时区感知对象上调用.isoformat()时,您会注意到+01:00被添加到了末尾。这表示从 UTC 时间偏移一小时。如果您在不同的地方,比如秘鲁的利马,那么您的
.isoformat()输出可能如下所示:
>>> now_aware.isoformat()
'2022-11-22T07:31:59.331225-06:00'
时间会有所不同,您会看到 UTC 偏移现在是-06:00。所以现在你的时间戳看起来很好,并且在它们代表什么时间方面是明确的。
你甚至可以更进一步,像很多人做的那样,用 UTC 时间存储你的时间戳,这样一切都很好地规范化了:
>>> from datetime import datetime, timezone >>> now = datetime.now() >>> now.isoformat() '2022-11-22T14:31:59.331225' >>> now_utc = datetime.now(timezone.utc) >>> now_utc.isoformat() '2022-11-22T13:31:59.331225+00:00'将
timezone.utc时区传递给.now()构造函数方法将返回一个 UTC 时间。请注意,在本例中,时间与本地时间有偏差。ISO 8601 标准也接受用
Z代替+00:00来表示 UTC 时间。这有时被称为祖鲁时间,也就是航空业通常所说的时间。在航空业,你总是使用 UTC 时间。在像航空这样的领域,无论在什么地方,在同一时间运营都是至关重要的。想象一下,空中交通管制必须处理每架飞机,根据它们的出发地报告预计着陆时间。那种情况会导致混乱和灾难!
结论
在本教程中,您已经告诉了时间!您已经生成了一个
datetime对象,并看到了如何挑选对象的不同属性。您还研究了几种以不同格式输出datetime对象的方法。您还了解了 UNIX 时间和 ISO 时间戳,并探索了如何明确地表示您的时间戳。为此,您已经尝试了复杂的时区世界,并让您的
datetime对象知道时区。如果你想知道事情需要多长时间,那么看看教程 Python 计时器函数:三种监控代码的方法。要更深入地研究
datetime模块,请查看使用 Python datetime 处理日期和时间的。现在你可以说时间真的站在你这边!如何使用
datetime模块?在下面的评论中分享你的想法和战争故事。源代码: 点击这里下载 Python 中获取和使用当前时间的免费源代码。**
Getters 和 Setters:在 Python 中管理属性
如果你来自像 Java 或 T2c++这样的语言,那么你可能习惯于为类中的每个属性编写 T4 getter 和 setter 方法。这些方法允许你访问和改变私有属性,同时保持封装。在 Python 中,通常会将属性作为公共 API 的一部分公开,并在需要具有函数行为的属性时使用属性。
尽管属性是 Pythonic 式的方法,但它们也有一些实际的缺点。因此,您会发现有些情况下 getters 和 setters 比属性更好。
在本教程中,您将:
- 在你的类中编写 getter 和 setter 方法
- 用属性替换 getter 和 setter 方法
- 探索其他工具来取代 Python 中的 getter 和 setter 方法
- 决定什么时候 setter 和 getter 方法可以成为作业的正确工具
为了充分利用本教程,您应该熟悉 Python 面向对象编程。如果你有 Python 属性和描述符的基础知识,那将是一个加分项。
源代码: 点击这里获取免费的源代码,它向您展示了如何以及何时使用 Python 中的 getters、setters 和 properties。
了解 Getter 和 Setter 方法
当你在面向对象编程(OOP)中定义一个类时,你可能会以一些实例和类属性结束。这些属性只是可以通过实例、类或两者来访问的变量。
属性保存对象的内部状态。在许多情况下,您需要访问和改变这个状态,这涉及到访问和改变属性。通常,至少有两种方法可以访问和改变属性。您可以:
- 直接访问并变异属性
*** 使用方法来访问和改变属性**如果您向您的用户公开一个类的属性,那么这些属性会自动成为该类的公共 API 的一部分。它们将是公共属性,这意味着你的用户将直接访问和改变他们代码中的属性。
如果您需要更改属性本身的内部实现,拥有一个属于类 API 的属性将会成为一个问题。这个问题的一个明显的例子是当你想把一个存储的属性变成一个计算的属性。存储属性将通过检索和存储数据来立即响应访问和突变操作,而计算属性将在这些操作之前运行计算。
常规属性的问题是它们不能有内部实现*,因为它们只是变量。因此,更改属性的内部实现需要将属性转换成方法,这可能会破坏用户的代码。为什么?因为如果他们希望代码继续工作,就必须在整个代码库中将属性访问和变异操作更改为方法调用。
为了处理这种问题,一些编程语言,如 Java 和 C++,要求你提供操作类属性的方法。这些方法通常被称为 getter 和 setter 方法。您还可以找到被称为访问器和赋值器的方法。
什么是 Getter 和 Setter 方法?
Getter 和 setter 方法在许多面向对象编程语言中非常流行。所以,很可能你已经听说过他们了。作为一个粗略的定义,你可以说 getters 和 setters 是:
- Getter: 一个允许你访问一个给定类中的属性的方法
- Setter: 一个方法,允许你设置或者改变一个类中属性的值
在 OOP 中,getter 和 setter 模式表明,只有当你确定没有人需要将行为附加到公共属性时,才应该使用公共属性。如果一个属性可能改变它的内部实现,那么你应该使用 getter 和 setter 方法。
实现 getter 和 setter 模式需要:
- 使您的属性成为非公共的
- 为每个属性编写 getter 和 setter 方法
例如,假设您需要编写一个具有文本和字体属性的
Label类。如果您要使用 getter 和 setter 方法来管理这些属性,那么您应该编写如下代码所示的类:# label.py class Label: def __init__(self, text, font): self._text = text self._font = font def get_text(self): return self._text def set_text(self, value): self._text = value def get_font(self): return self._font def set_font(self, value): self._font = value在这个例子中,
Label的构造函数有两个参数,text和font。这些参数分别存储在._text和._font非公共实例属性中。然后为这两个属性定义 getter 和 setter 方法。通常,getter 方法返回目标属性的值,而 setter 方法获取一个新值并将其赋给底层属性。
注意: Python 没有访问修饰符的概念,比如
private、protected和public,来限制对类中属性和方法的访问。在 Python 中,区别在于公共和非公共类成员。如果你想表明一个给定的属性或方法是非公共的,那么你应该使用 Python 的约定,在名字前加一个下划线(
_)。注意,这只是一个约定。它不会阻止你和其他程序员使用点符号访问属性,就像在
obj._attr中一样。然而,违反这个惯例是不好的。您可以像下面的例子一样使用您的
Label类:
>>> from label import Label
>>> label = Label("Fruits", "JetBrains Mono NL")
>>> label.get_text()
'Fruits'
>>> label.set_text("Vegetables")
>>> label.get_text()
'Vegetables'
>>> label.get_font()
'JetBrains Mono NL'
对公共访问隐藏它的属性,而公开 getter 和 setter 方法。您可以在需要访问或变更类的属性时使用这些方法,正如您已经知道的,这些属性是非公共的,因此不是类 API 的一部分。
Getter 和 Setter 方法从何而来?
为了理解 getter 和 setter 方法的来源,回到Label的例子,假设您想自动以大写字母存储标签的文本。不幸的是,您不能简单地将这种行为添加到像.text这样的常规属性中。您只能通过方法添加行为,但是将公共属性转换成方法会在您的 API 中引入一个突破性的变化。
那么,你能做什么?嗯,在 Python 中,你最有可能使用一个属性,你很快就会知道。然而,像 Java 和 C++ 这样的编程语言不支持类似属性的构造,或者它们的属性不太像 Python 属性。
这就是为什么这些语言鼓励你永远不要将你的属性作为你的公共 API的一部分。相反,你必须提供 getter 和 setter 方法,这提供了一种快速的方法来改变你的属性的内部实现,而不改变你的公共 API。
封装是另一个与 getter 和 setter 方法起源相关的基本话题。本质上,这一原则指的是将数据与操作该数据的方法捆绑在一起。这样,访问和变异操作将只通过方法来完成。
该原则还与限制对对象属性的直接访问有关,这将防止暴露实现细节或违反状态不变性。
为了给Label提供 Java 或 C++中新需要的功能,必须从一开始就使用 getter 和 setter 方法。如何应用 getter 和 setter 模式来解决 Python 中的问题?
考虑以下版本的Label:
# label.py
class Label:
def __init__(self, text, font):
self.set_text(text) self.font = font
def get_text(self):
return self._text
def set_text(self, value):
self._text = value.upper() # Attached behavior
在这个更新版本的Label中,您为标签的文本提供了 getter 和 setter 方法。保存文本的属性是非公共属性,因为它的名字前面有一个下划线._text。setter 方法执行输入转换,将文本转换成大写字母。
现在,您可以像下面的代码片段一样使用您的Label类:
>>> from label import Label >>> label = Label("Fruits", "JetBrains Mono NL") >>> label.get_text() 'FRUITS' >>> label.set_text("Vegetables") >>> label.get_text() 'VEGETABLES'酷!您已成功将所需行为添加到标签的文本属性中。现在你的 setter 方法有了一个真正的目标,而不仅仅是给 target 属性赋一个新值。它的目标是向
._text属性添加额外的行为。尽管 getter 和 setter 模式在其他编程语言中很常见,但在 Python 中却不是这样。
向类中添加 getter 和 setter 方法可以显著增加代码行数。Getters 和 setters 也遵循一种重复而枯燥的模式,需要额外的时间来完成。这种模式容易出错,而且很乏味。您还会发现,从所有这些额外代码中获得的即时功能通常是零。
所有这些听起来像是 Python 开发人员不想在他们的代码中做的事情。在 Python 中,您可能会编写类似于以下代码片段的
Label类:
>>> class Label:
... def __init__(self, text, font):
... self.text = text
... self.font = font
...
这里,.text,和.font是公共属性,作为类的 API 的一部分公开。这意味着您的用户可以随时更改他们的价值:
>>> label = Label("Fruits", "JetBrains Mono NL") >>> label.text 'Fruits' >>> # Later... >>> label.text = "Vegetables" >>> label.text 'Vegetables'暴露像
.text和.font这样的属性是 Python 中的常见做法。因此,您的用户将在他们的代码中直接访问和改变这种属性。像上面的例子一样,公开属性是 Python 中的一种常见做法。在这些情况下,切换到 getters 和 setters 将会引入突破性的变化。那么,如何处理需要在属性中添加行为的情况呢?Pythonic 式的方法是用属性替换属性。
使用属性代替 Getters 和 setter:Python 方式
将行为附加到属性的 Pythonic 方式是将属性本身变成一个属性。属性将获取、设置、删除和记录基础数据的方法打包在一起。因此,属性是具有附加行为的特殊属性。
您可以像使用常规属性一样使用属性。当您访问属性时,会自动调用其附加的 getter 方法。同样,当您变更属性时,会调用它的 setter 方法。这种行为提供了将功能附加到属性的方法,而不会在代码的 API 中引入重大更改。
作为属性如何帮助您将行为附加到属性的示例,假设您需要一个
Employee类作为员工管理系统的一部分。您从以下基本实现开始:# employee.py class Employee: def __init__(self, name, birth_date): self.name = name self.birth_date = birth_date # Implementation...这个类的构造函数有两个参数,手边雇员的姓名和出生日期。这些属性直接存储在两个实例属性中,
.name和.birth_date。您可以立即开始使用该类:
>>> from employee import Employee
>>> john = Employee("John", "2001-02-07")
>>> john.name
'John'
>>> john.birth_date
'2001-02-07'
>>> john.name = "John Doe"
>>> john.name
'John Doe'
Employee允许您创建实例,以便直接访问相关的姓名和出生日期。注意,您也可以通过使用直接赋值来改变属性。
随着项目的发展,您会有新的需求。您需要用大写字母存储雇员的姓名,并将出生日期转换成一个 date 对象。为了满足这些需求而不破坏您的 API,使用.name和.birth_date的 getter 和 setter 方法,您可以使用属性:
# employee.py
from datetime import date
class Employee:
def __init__(self, name, birth_date):
self.name = name
self.birth_date = birth_date
@property
def name(self): return self._name
@name.setter
def name(self, value): self._name = value.upper()
@property
def birth_date(self): return self._birth_date
@birth_date.setter
def birth_date(self, value): self._birth_date = date.fromisoformat(value)
在这个增强版的Employee中,使用@property装饰器将.name和.birth_date变成属性。现在每个属性都有一个 getter 和一个 setter 方法,以属性本身命名。注意,.name的 setter 把输入的名字变成了大写字母。同样,.birth_date的 setter 自动为你将输入的日期转换成一个date对象。
如前所述,属性的一个简洁的特性是,您可以将它们用作常规属性:
>>> from employee import Employee >>> john = Employee("John", "2001-02-07") >>> john.name 'JOHN' >>> john.birth_date datetime.date(2001, 2, 7) >>> john.name = "John Doe" >>> john.name 'JOHN DOE'酷!您已经向
.name和.birth_date属性添加了行为,而没有影响您的类的 API。有了属性,您就能够像引用常规属性一样引用这些属性。在幕后,Python 负责为您运行适当的方法。您必须避免通过在 API 中引入更改来破坏用户的代码。Python 的
@propertydecorator 是实现这一点的 python 方式。在 PEP 8 中,属性被正式推荐为处理需要功能行为的属性的正确方法:对于简单的公共数据属性,最好只公开属性名,不要使用复杂的访问器/赋值器方法。请记住,如果您发现一个简单的数据属性需要增加功能行为,Python 为未来的增强提供了一个简单的途径。在这种情况下,使用属性将功能实现隐藏在简单的数据属性访问语法后面。(来源)
Python 的属性有很多潜在的用例。例如,您可以使用属性以优雅和简单的方式创建只读、读写和只写属性。属性允许您删除和记录基础属性等等。更重要的是,属性允许您使常规属性的行为像带有附加行为的托管属性一样,而不改变您使用它们的方式。
由于属性的原因,Python 开发人员倾向于使用一些准则来设计他们的类的 API:
- 在适当的时候使用公共属性,即使您预期该属性在将来需要功能行为。
- 避免为你的属性定义 setter 和 getter 方法。如果需要,您可以随时将它们转换为属性。
- 当你需要将行为附加到属性上并在你的代码中将它们作为常规属性使用时,使用属性。
- 避免属性中的副作用,因为没有人会期望像赋值这样的操作会产生任何副作用。
Python 的属性很酷!正因为如此,人们倾向于过度使用它们。通常,只有在需要在特定属性之上添加额外处理时,才应该使用属性。把你所有的属性都变成属性会浪费你的时间。这也可能意味着性能和可维护性问题。
用更高级的工具替换 Getters 和 Setters】
到目前为止,您已经学习了如何创建基本的 getter 和 setter 方法来管理类的属性。您还了解了属性是解决向现有属性添加功能行为问题的 Pythonic 方法。
在接下来的几节中,您将了解到可以用来替换 Python 中 getter 和 setter 方法的其他工具和技术。
Python 的描述符
描述符是 Python 的一个高级特性,允许你在类中创建带有附加行为的属性。要创建一个描述符,你需要使用描述符协议,尤其是
.__get__()和.__set__()T6】的特殊方法。描述符非常类似于属性。事实上,属性是一种特殊类型的描述符。然而,常规描述符比属性更强大,可以通过不同的类重用。
为了说明如何使用描述符创建具有功能行为的属性,假设您需要继续开发您的
Employee类。这一次,您需要一个属性来存储雇员开始为公司工作的日期:# employee.py from datetime import date class Employee: def __init__(self, name, birth_date, start_date): self.name = name self.birth_date = birth_date self.start_date = start_date @property def name(self): return self._name @name.setter def name(self, value): self._name = value.upper() @property def birth_date(self): return self._birth_date @birth_date.setter def birth_date(self, value): self._birth_date = date.fromisoformat(value) @property def start_date(self): return self._start_date @start_date.setter def start_date(self, value): self._start_date = date.fromisoformat(value)在本次更新中,您向
Employee添加了另一个属性。这个新属性将允许您管理每个员工的开始日期。同样,setter 方法将日期从字符串转换成一个date对象。这个类按预期工作。然而,它开始看起来重复和无聊。所以,你决定重构这个类。您注意到您在两个与日期相关的属性中执行相同的操作,并且您想到使用一个描述符来打包重复的功能:
# employee.py from datetime import date class Date: def __set_name__(self, owner, name): self._name = name def __get__(self, instance, owner): return instance.__dict__[self._name] def __set__(self, instance, value): instance.__dict__[self._name] = date.fromisoformat(value) class Employee: birth_date = Date() start_date = Date() def __init__(self, name, birth_date, start_date): self.name = name self.birth_date = birth_date self.start_date = start_date @property def name(self): return self._name @name.setter def name(self, value): self._name = value.upper()这段代码比之前的版本更简洁,重复性更少。在这次更新中,您将创建一个
Date描述符来管理与日期相关的属性。描述符有一个自动存储属性名的.__set_name__()方法。它还有.__get__()和.__set__()方法,分别作为属性的 getter 和 setter。本节中的
Employee的两个实现工作方式类似。来吧,给他们一个尝试!一般来说,如果您发现自己的类中有相似的属性定义,那么您应该考虑使用描述符。
.__setattr__()和.__getattr__()方法另一种替代 Python 中传统 getter 和 setter 方法的方法是使用
.__setattr__()和.__getattr__()特殊方法来管理属性。考虑下面的例子,它定义了一个Point类。该类自动将输入坐标转换为浮点数:# point.py class Point: def __init__(self, x, y): self.x = x self.y = y def __getattr__(self, name: str): return self.__dict__[f"_{name}"] def __setattr__(self, name, value): self.__dict__[f"_{name}"] = float(value)
Point的初始化器取两个坐标,x和y。.__getattr__()方法返回由name表示的坐标。为此,该方法使用实例名称空间字典,.__dict__。请注意,属性的最终名称将在您在name中传递的任何内容之前有一个下划线。每当您使用点符号访问Point的属性时,Python 会自动调用.__getattr__()。
.__setattr__()方法添加或更新属性。在这个例子中,.__setattr__()对每个坐标进行操作,并使用内置的float()函数将其转换为浮点数。同样,每当您对包含类的任何属性运行赋值操作时,Python 都会调用.__setattr__()。下面是这个类在实践中的工作方式:
>>> from point import Point
>>> point = Point(21, 42)
>>> point.x
21.0
>>> point.y
42.0
>>> point.x = 84
>>> point.x
84.0
>>> dir(point)
['__class__', '__delattr__', ..., '_x', '_y']
您的Point类自动将坐标值转换成浮点数。您可以访问坐标、x和y,就像访问任何其他常规属性一样。然而,访问和变异操作分别通过.__getattr__()和.__setattr__()。
请注意,Point允许您将坐标作为公共属性来访问。但是,它将它们存储为非公共属性。您可以使用内置的dir()函数来确认这一行为。
本节中的例子有点奇特,您可能不会在代码中使用类似的东西。但是,您在示例中使用的工具允许您对属性访问和变异执行验证或转换,就像 getter 和 setter 方法一样。
在某种意义上,.__getattr__()和.__setattr__()是 getter 和 setter 模式的一种通用实现。在幕后,这些方法充当 getters 和 setters,支持 Python 中的常规属性访问和变异。
决定是否在 Python 中使用 Getters 和 Setters 或 Properties
在现实世界的编码中,您会发现 getter 和 setter 方法优于属性的一些用例,尽管属性通常是 Pythonic 的方式。
例如,getter 和 setter 方法可能更适合处理您需要:
在接下来的部分中,您将深入这些用例,以及为什么 getter 和 setter 方法比属性更适合处理这些用例。
避免属性背后的缓慢方法
您应该避免将缓慢的操作隐藏在 Python 属性之后。API 的用户希望属性访问和变异像常规变量访问和变异一样执行。换句话说,用户将期望这些操作在瞬间发生,并且没有副作用。
离这个期望太远会让你的 API 使用起来奇怪和不愉快,违反了最小惊奇原则。
此外,如果你的用户在一个循环中反复访问和改变你的属性,那么他们的代码会涉及太多的开销,这可能会产生巨大的意想不到的性能问题。
相比之下,传统的 getter 和 setter 方法使得显式地通过方法调用来访问或改变给定的属性。事实上,您的用户会意识到调用一个方法可能需要时间,并且他们的代码的性能可能会因此而有很大的差异。
在 API 中明确这些事实有助于减少用户在代码中访问和改变属性时的惊讶。
简而言之,如果你打算使用一个属性来管理一个属性,那么就要确保属性背后的方法是快速的,并且不会产生副作用。相比之下,如果您处理的是慢速访问器和赋值器方法,那么与属性相比,您更喜欢传统的 getters 和 setters 方法。
接受额外的参数和标志
与 Python 属性不同,传统的 getter 和 setter 方法允许更灵活的属性访问和变异。例如,假设您有一个带有.birth_date属性的Person类。这个属性在人的一生中应该是不变的。因此,您决定该属性将是只读的。
然而,由于人为错误的存在,您将面临有人在输入给定人员的出生日期时出错的情况。您可以通过提供一个带force标志的 setter 方法来解决这个问题,如下例所示:
# person.py
class Person:
def __init__(self, name, birth_date):
self.name = name
self._birth_date = birth_date
def get_birth_date(self):
return self._birth_date
def set_birth_date(self, value, force=False):
if force:
self._birth_date = value
else:
raise AttributeError("can't set birth_date")
在这个例子中,您为.birth_date属性提供了传统的 getter 和 setter 方法。setter 方法带有一个名为force的额外参数,它允许您强制修改一个人的出生日期。
注意:传统的 setter 方法通常不会接受一个以上的参数。对于一些开发人员来说,上面的例子可能看起来很奇怪,甚至不正确。然而,它的目的是展示一种在某些情况下有用的技术。
这个类是这样工作的:
>>> from person import Person >>> jane = Person("Jane Doe", "2000-11-29") >>> jane.name 'Jane Doe' >>> jane.get_birth_date() '2000-11-29' >>> jane.set_birth_date("2000-10-29") Traceback (most recent call last): ... AttributeError: can't set birth_date >>> jane.set_birth_date("2000-10-29", force=True) >>> jane.get_birth_date() '2000-10-29'当您试图使用
.set_birth_date()修改 Jane 的出生日期,而没有将force设置为True时,您会得到一个AttributeError,表示该属性无法设置。相反,如果您将force设置为True,那么您将能够更新 Jane 的出生日期,以纠正输入日期时出现的任何错误。需要注意的是,Python 属性不接受 setter 方法中的额外参数。它们只是接受要设置或更新的值。
使用继承:Getter 和 setter vs . Properties
Python 属性的一个问题是它们在继承场景中表现不佳。例如,假设您需要扩展或修改子类中属性的 getter 方法。实际上,没有安全的方法可以做到这一点。你不能只覆盖 getter 方法,并期望属性的其余功能保持与父类中的相同。
出现此问题是因为 getter 和 setter 方法隐藏在属性内部。它们不是独立遗传的,而是作为一个整体。因此,当您重写从父类继承的属性的 getter 方法时,您重写了整个属性,包括它的 setter 方法和它的其余内部组件。
例如,考虑以下类层次结构:
# person.py class Person: def __init__(self, name): self._name = name @property def name(self): return self._name @name.setter def name(self, value): self._name = value class Employee(Person): @property def name(self): return super().name.upper()在这个例子中,您覆盖了
Employee中.name属性的 getter 方法。这样,您就隐式地覆盖了整个.name属性,包括它的 setter 功能:
>>> from person import Employee
>>> jane = Employee("Jane")
>>> jane.name
'JANE'
>>> jane.name = "Jane Doe"
Traceback (most recent call last):
...
AttributeError: can't set attribute 'name'
现在.name是一个只读属性,因为父类的 setter 方法没有被继承,而是被一个全新的属性覆盖。你不想那样,是吗?你如何解决这个继承问题?
如果您使用传统的 getter 和 setter 方法,那么这个问题就不会发生:
# person.py
class Person:
def __init__(self, name):
self._name = name
def get_name(self):
return self._name
def set_name(self, value):
self._name = value
class Employee(Person):
def get_name(self):
return super().get_name().upper()
这个版本的Person提供了独立的 getter 和 setter 方法。Employee子类Person,覆盖 name 属性的 getter 方法。这个事实并不影响 setter 方法,该方法Employee成功地从其父类Person继承而来。
下面是这个新版本的Employee的工作原理:
>>> from person import Employee >>> jane = Employee("Jane") >>> jane.get_name() 'JANE' >>> jane.set_name("Jane Doe") >>> jane.get_name() 'JANE DOE'现在
Employee已经完全可以使用了。被重写的 getter 方法按预期工作。setter 方法也可以工作,因为它是从Person成功继承的。在属性访问或突变时引发异常
大多数时候,你不会想到像
obj.attribute = value这样的赋值语句会引发异常。相比之下,您可以期望方法在响应错误时引发异常。在这方面,传统的 getter 和 setter 方法比属性更显式。例如,
site.url = "123"看起来不像是可以引发异常的东西。它看起来应该像一个常规的属性赋值。另一方面,site.set_url("123")看起来确实像是可以引发异常的东西,也许是一个ValueError,因为输入值不是一个网站的有效的 URL 。在这个例子中,setter 方法更加明确。它清楚地表达了代码可能的行为。根据经验,除非使用属性来提供只读属性,否则应避免在 Python 属性中引发异常。如果您需要在属性访问或变异时引发异常,那么您应该考虑使用 getter 和 setter 方法,而不是属性。
在这些情况下,使用 getters 和 setters 将减少用户的惊讶,并使您的代码更符合常见的实践和期望。
促进团队整合和项目迁移
在许多成熟的编程语言中,提供 getter 和 setter 方法是常见的做法。如果你和一个来自其他语言背景的开发团队一起开发一个 Python 项目,那么很可能 getter 和 setter 模式对他们来说比 Python 属性更熟悉。
在这种类型的异构团队中,使用 getters 和 setters 可以促进新开发人员融入团队。
使用 getter 和 setter 模式也可以提高 API 的一致性。它允许您提供基于方法调用的 API,而不是将方法调用与直接属性访问和变异相结合的 API。
通常,当 Python 项目增长时,您可能需要将项目从 Python 迁移到另一种语言。新语言可能没有属性,或者它们的行为可能不像 Python 属性那样。在这些情况下,从一开始就使用传统的 getters 和 setters 会使将来的迁移不那么痛苦。
在上述所有情况下,您应该考虑使用传统的 getter 和 setter 方法,而不是 Python 中的属性。
结论
现在你知道什么是 getter 和 setter 方法,以及它们来自哪里。这些方法允许访问和改变属性,同时避免 API 的改变。然而,由于属性的存在,它们在 Python 中并不流行。属性允许您向属性中添加行为,同时避免 API 中的破坏性更改。
尽管属性是替代传统的 getter 和 setter 的 Pythonic 方式,但是属性也有一些实际的缺点,可以用 getter 和 setter 来克服。
在本教程中,您已经学会了如何:
- 用 Python 写 getter 和 setter 方法
- 使用 Python 属性替换 getter 和 setter 方法
- 使用 Python 工具,比如描述符,来替换 getters 和 setters
- 决定什么时候 setter 和 getter 方法可以成为作业的正确工具
有了这些知识,您现在可以决定何时在 Python 类中使用 getter 和 setter 方法或属性。
源代码: 点击这里获取免费的源代码,它向您展示了如何以及何时使用 Python 中的 getters、setters 和 properties。*********
什么是 Python 全局解释器锁(GIL)?
Python 全局解释器锁或 GIL ,简单来说,就是一个互斥体(或锁),只允许一个线程持有 Python 解释器的控制权。
这意味着在任何时间点都只能有一个线程处于执行状态。执行单线程程序的开发人员看不到 GIL 的影响,但它可能会成为 CPU 受限和多线程代码的性能瓶颈。
由于 GIL 一次只允许一个线程执行,即使在具有一个以上 CPU 内核的多线程架构中,GIL 也获得了 Python“臭名昭著”特性的名声。
在本文中,您将了解 GIL 如何影响您的 Python 程序的性能,以及如何减轻它可能对您的代码造成的影响。
GIL 为 Python 解决了什么问题?
Python 使用引用计数进行内存管理。这意味着用 Python 创建的对象有一个引用计数变量,它跟踪指向该对象的引用的数量。当这个计数达到零时,对象占用的内存被释放。
让我们看一个简短的代码示例来演示引用计数是如何工作的:
>>> import sys
>>> a = []
>>> b = a
>>> sys.getrefcount(a)
3
在上面的例子中,空列表对象[]的引用计数是 3。列表对象被a、b引用,参数传递给sys.getrefcount()。
回到 GIL:
问题是这个引用计数变量需要防止两个线程同时增加或减少其值的竞争情况。如果发生这种情况,可能会导致永远不会释放的内存泄漏,或者更糟糕的是,在对该对象的引用仍然存在的情况下错误地释放内存。这可能会导致 Python 程序崩溃或其他“奇怪”的错误。
通过将锁添加到跨线程共享的所有数据结构中,可以保证引用计数变量的安全,这样它们就不会被不一致地修改。
但是为每个对象或对象组添加一个锁意味着将存在多个锁,这可能导致另一个问题——死锁(死锁只有在有多个锁的情况下才会发生)。另一个副作用是反复获取和释放锁会导致性能下降。
GIL 是解释器本身的一个锁,它增加了一条规则,即任何 Python 字节码的执行都需要获取解释器锁。这可以防止死锁(因为只有一个锁),并且不会引入太多的性能开销。但是它有效地使任何受 CPU 限制的 Python 程序成为单线程的。
GIL 虽然被 Ruby 等其他语言的解释器使用,但并不是这个问题的唯一解决方案。一些语言通过使用引用计数之外的方法(如垃圾收集)来避免线程安全内存管理的 GIL 需求。
另一方面,这意味着这些语言通常必须通过添加其他性能提升功能(如 JIT 编译器)来弥补 GIL 的单线程性能优势的损失。
为什么选择 GIL 作为解决方案?
那么,为什么在 Python 中使用了一种看起来如此阻碍的方法呢?这是 Python 开发者的一个错误决定吗?
用 Larry Hastings 的话来说,GIL 的设计决策是让 Python 像今天这样流行的原因之一。
自从操作系统没有线程概念的时候,Python 就出现了。Python 被设计成易于使用,以使开发更快,越来越多的开发人员开始使用它。
许多扩展是为现有的 C 库编写的,这些库的特性是 Python 所需要的。为了防止不一致的变化,这些 C 扩展需要 GIL 提供的线程安全内存管理。
GIL 易于实现,并且很容易添加到 Python 中。它提高了单线程程序的性能,因为只需要管理一个锁。
非线程安全的 c 库变得更容易集成。这些 C 扩展成为 Python 容易被不同社区采用的原因之一。
如你所见,GIL 是一个实用的解决方案,解决了早期 Python 开发人员面临的一个难题。
对多线程 Python 程序的影响
当你看一个典型的 Python 程序或者任何计算机程序时,在性能上受 CPU 限制的程序和受 I/O 限制的程序之间是有区别的。
CPU 受限程序是那些将 CPU 推向极限的程序。这包括进行数学计算的程序,如矩阵乘法、搜索、图像处理等。
I/O 绑定程序是那些花费时间等待来自用户、文件、数据库、网络等的输入/输出的程序。I/O 绑定的程序有时不得不等待相当长的时间,直到它们从源获得它们需要的东西,这是由于在输入/输出准备好之前,源可能需要做它自己的处理,例如,用户考虑在输入提示中输入什么,或者在它自己的进程中运行数据库查询。
让我们来看一个简单的执行倒计时的 CPU 绑定程序:
# single_threaded.py
import time
from threading import Thread
COUNT = 50000000
def countdown(n):
while n>0:
n -= 1
start = time.time()
countdown(COUNT)
end = time.time()
print('Time taken in seconds -', end - start)
在我的 4 核系统上运行这段代码会产生以下输出:
$ python single_threaded.py
Time taken in seconds - 6.20024037361145
现在我对代码做了一点修改,使用两个并行线程进行相同的倒计时:
# multi_threaded.py
import time
from threading import Thread
COUNT = 50000000
def countdown(n):
while n>0:
n -= 1
t1 = Thread(target=countdown, args=(COUNT//2,))
t2 = Thread(target=countdown, args=(COUNT//2,))
start = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
end = time.time()
print('Time taken in seconds -', end - start)
当我再次运行时:
$ python multi_threaded.py
Time taken in seconds - 6.924342632293701
正如你所看到的,两个版本花了几乎相同的时间来完成。在多线程版本中,GIL 阻止 CPU 绑定的线程并行执行。
GIL 对 I/O 绑定的多线程程序的性能没有太大影响,因为锁是在线程等待 I/O 时共享的
但是线程完全受限于 CPU 的程序,例如,使用线程来部分处理图像的程序,不仅会由于锁而变成单线程,而且与被编写为完全单线程的情况相比,执行时间也会增加,如以上示例所示。
这种增加是锁增加的获取和释放开销的结果。
为什么 GIL 还没有被移除?
Python 的开发者收到了很多关于这方面的抱怨,但是像 Python 这样流行的语言不可能带来像移除 GIL 那样重大的改变而不引起向后不兼容的问题。
GIL 显然可以被移除,开发者和研究人员在过去已经多次这样做了,但所有这些尝试都破坏了现有的 C 扩展,这些扩展严重依赖于 GIL 提供的解决方案。
当然,GIL 还能解决其他问题,但其中一些会降低单线程和多线程 I/O 绑定程序的性能,还有一些太难了。毕竟,你不希望现有的 Python 程序在新版本出来后运行得更慢,对吗?
Python 的创始人和 BDFL 吉多·范·罗苏姆在 2007 年 9 月的文章“移除 GIL 并不容易”中给了社区一个答案:
“只有当单线程程序(以及多线程但 I/O 受限的程序)的性能不下降时,我才会欢迎 Py3k 中的一组补丁。”
从那以后的任何尝试都没有满足这个条件。
为什么在 Python 3 中没有去掉?
Python 3 确实有机会从零开始开发许多特性,在这个过程中,打破了一些现有的 C 扩展,然后需要更新和移植更改才能与 Python 3 一起工作。这就是为什么早期版本的 Python 3 被社区采用的速度较慢的原因。
但是为什么 GIL 没有和他一起被移走呢?
移除 GIL 会使 Python 3 在单线程性能上比 Python 2 慢,你可以想象这会导致什么。你不能否认 GIL 的单线程性能优势。所以结果是 Python 3 仍然有 GIL。
但是 Python 3 确实给现有的 GIL 带来了重大改进—
我们讨论了 GIL 对“只受 CPU 限制”和“只受 I/O 限制”的多线程程序的影响,但是对于一些线程受 I/O 限制而另一些线程受 CPU 限制的程序呢?
在这样的程序中,Python 的 GIL 通过不给 I/O 绑定线程从 CPU 绑定线程获取 GIL 的机会来饿死 I/O 绑定线程。
这是因为 Python 中内置的一种机制,该机制强制线程在连续使用固定间隔后释放 GIL ,如果没有其他人获得 GIL,同一线程可以继续使用。
>>> import sys >>> # The interval is set to 100 instructions: >>> sys.getcheckinterval() 100这种机制的问题是,在大多数情况下,CPU 绑定的线程会在其他线程获得 GIL 之前重新获得它。这是由大卫·比兹利研究的,可视化可以在这里找到。
Antoine Pitrou 在 2009 年的 Python 3.2 中修复了这个问题,他添加了一个机制来查看被丢弃的其他线程的 GIL 获取请求的数量,并且不允许当前线程在其他线程有机会运行之前重新获取 GIL。
如何应对 Python 的 GIL
如果 GIL 给你带来了麻烦,你可以尝试以下几种方法:
多处理 vs 多线程:最流行的方法是使用多处理方法,用多个进程代替线程。每个 Python 进程都有自己的 Python 解释器和内存空间,因此 GIL 不会成为问题。Python 有一个
multiprocessing模块,让我们可以像这样轻松地创建流程:from multiprocessing import Pool import time COUNT = 50000000 def countdown(n): while n>0: n -= 1 if __name__ == '__main__': pool = Pool(processes=2) start = time.time() r1 = pool.apply_async(countdown, [COUNT//2]) r2 = pool.apply_async(countdown, [COUNT//2]) pool.close() pool.join() end = time.time() print('Time taken in seconds -', end - start)在我的系统上运行这个命令会得到以下输出:
$ python multiprocess.py Time taken in seconds - 4.060242414474487与多线程版本相比,性能有了相当大的提高,对吗?
时间没有下降到我们上面看到的一半,因为流程管理有自己的开销。多个进程比多个线程更重,所以请记住,这可能会成为伸缩瓶颈。
替代的 Python 解释器: Python 有多个解释器实现。分别用 C 、 Java 、C#和 Python 编写的 CPython、Jython、IronPython 和 PyPy 是最受欢迎的。GIL 仅存在于原始的 Python 实现 CPython 中。如果您的程序及其库可用于其他实现之一,那么您也可以尝试它们。
耐心等待:尽管许多 Python 用户利用了 GIL 的单线程性能优势。多线程程序员不必担心,因为 Python 社区中一些最聪明的人正在努力将 GIL 从 CPython 中移除。一种这样的尝试被称为直肠切除术。
蟒蛇 GIL 经常被认为是一个神秘而困难的话题。但是请记住,作为一个 Pythonista,如果您正在编写 C 扩展或者如果您在程序中使用 CPU 绑定的多线程,您通常只会受到它的影响。
在这种情况下,本文将为您提供理解什么是 GIL 以及如何在自己的项目中处理它所需的一切。如果你想了解 GIL 的底层内部运作,我建议你观看大卫·比兹利的理解 Python GIL 演讲。**
Python 开发人员 Git 和 GitHub 简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 开发者 Git 和 GitHub 入门
你有没有做过一个 Python 项目,当你在这里做了一个更改或者在那里做了 PEP-8 清理之后,这个项目停止了工作,而你又不确定如何恢复它?版本控制系统可以帮助您解决这个问题以及其他相关问题。Git 是当今最流行的版本控制系统之一。
在本教程中,我将带您了解什么是 Git,如何将它用于您的个人项目,以及如何将它与 GitHub 结合使用,以便在更大的项目中与其他人合作。我们将了解如何创建一个 repo,如何添加新的和修改过的文件,以及如何浏览项目的历史,以便您可以“回到”项目工作的时间。
本文假设您的系统上已经安装了 Git。如果你不这样做,优秀的 Pro Git 书有一个章节告诉你如何去做。
Git 是什么?
Git 是一个分布式版本控制系统 (DVCS)。让我们把它分解一下,看看它意味着什么。
版本控制
一个版本控制系统 (VCS)是一套跟踪一组文件历史的工具。这意味着您可以告诉您的 VCS(在我们的例子中是 Git)在任何时候保存文件的状态。然后,您可以继续编辑文件并存储该状态。保存状态类似于创建工作目录的备份副本。当使用 Git 时,我们将这种状态保存称为提交。
当您在 Git 中提交时,您添加了一条提交消息,该消息从较高的层面解释了您在该提交中所做的更改。Git 可以显示所有提交及其提交消息的历史。这为您所做的工作提供了一个有用的历史记录,并能真正帮助您确定系统中何时出现了 bug。
除了显示您所做更改的日志之外,Git 还允许您比较不同提交之间的文件。正如我前面提到的,Git 还允许您毫不费力地将任何文件(或所有文件)返回到先前的提交。
分布式版本控制
好了,这就是一个版本控制系统。分发的部分是什么?从一点历史开始回答这个问题可能是最简单的。早期版本控制系统的工作方式是将所有提交内容存储在本地硬盘上。这个提交集合被称为库。这解决了“我需要回到我所在的地方”的问题,但是对于一个在相同代码库上工作的团队来说,这并不是一个很好的扩展。
随着更大的团队开始工作(网络变得越来越普遍),VCSs 开始将存储库存储在由许多开发人员共享的中央服务器上。虽然这解决了许多问题,但也产生了新的问题,比如文件锁定。
在其他一些产品的引领下,Git 打破了这种模式。Git 没有一个拥有最终版本存储库的中央服务器。所有用户都有存储库的完整副本。这意味着让所有开发人员回到同一个页面有时会很棘手,但这也意味着开发人员可以大部分时间离线工作,只有当他们需要共享他们的工作时才连接到其他存储库。
最后一段一开始看起来有点混乱,因为有很多开发人员将 GitHub 作为一个中央存储库,每个人都必须从中获取数据。这是真的,但是 Git 并没有强加这一点。在某些情况下,有一个共享代码的中心位置很方便。即使使用 GitHub,完整的存储库仍然存储在所有本地存储库中。
基本用法
既然我们已经讨论了什么是 Git,那么让我们来看一个例子,看看它是如何工作的。我们将从在本地机器上使用 Git 开始。一旦我们掌握了窍门,我们将添加 GitHub 并解释如何与它交互。
创建新的回购
要使用 Git,您首先需要告诉它您是谁。您可以使用
git config命令设置您的用户名:$ git config --global user.name "your name goes here"一旦建立起来,你将需要一个回购工作。创建回购很简单。在目录中使用
git init命令:$ mkdir example $ cd example $ git init Initialized empty Git repository in /home/jima/tmp/example/.git/一旦你有了回购,你可以向 Git 询问。您最常用的 Git 命令是
git status。现在试试:$ git status On branch master Initial commit nothing to commit (create/copy files and use "git add" to track)这向您显示了一些信息:您在哪个分支上,
master(我们稍后将讨论分支),以及您没有要提交的内容。这最后一部分意味着这个目录中没有 Git 不知道的文件。这很好,因为我们刚刚创建了目录。添加新文件
现在创建一个 Git 不知道的文件。使用您最喜欢的编辑器,创建文件
hello.py,其中只有一条打印语句。# hello.py print('hello Git!')如果您再次运行
git status,您将看到不同的结果:$ git status On branch master Initial commit Untracked files: (use "git add <file>..." to include in what will be committed) hello.py nothing added to commit but untracked files present (use "git add" to track)现在 Git 看到了新文件,并告诉您它是未跟踪的。这只是 Git 的说法,即文件不是回购的一部分,不受版本控制。我们可以通过将文件添加到 Git 来解决这个问题。使用
git add命令来实现这一点:$ git add hello.py $ git status On branch master Initial commit Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: hello.py现在 Git 知道了
hello.py,并把它列在要提交的变更下面。将文件添加到 Git 会将它移动到暂存区(将在下面讨论),这意味着我们可以将它提交给回购。提交更改
当您提交变更时,您是在告诉 Git 在回购中制作这个状态的快照。现在使用
git commit命令来完成。-m选项告诉 Git 使用随后的提交消息。如果您不使用-m,Git 将为您打开一个编辑器来创建提交消息。通常,您希望您的提交消息反映提交中发生的变化:$ git commit -m "creating hello.py" [master (root-commit) 25b09b9] creating hello.py 1 file changed, 3 insertions(+) create mode 100755 hello.py $ git status On branch master nothing to commit, working directory clean您可以看到 commit 命令返回了一堆信息,其中大部分都不是很有用,但是它确实告诉您只有一个文件发生了更改(这在我们添加一个文件时是有意义的)。它还告诉您提交(
25b09b9)的 SHA 。稍后我们会有一个关于阿沙的旁白。再次运行
git status命令表明我们有了一个干净的工作目录,这意味着所有的更改都提交给了 Git。在这一点上,我们需要停止我们的教程,并有一个临时区域的快速聊天。
旁白:集结地
与许多版本控制系统不同,Git 有一个暂存区(通常称为索引)。staging area 是 Git 跟踪您希望在下一次提交中进行的更改的方式。当我们运行上面的
git add时,我们告诉 Git 我们想要将新文件hello.py移动到临时区域。这种变化在git status中得到了体现。文件从输出的未跟踪部分转到待提交部分。注意,staging 区域反映了运行
git add时文件的确切内容。如果您再次修改它,该文件将同时出现在状态输出的已暂存的和未暂存的部分。在 Git 中处理文件的任何时候(假设它已经被提交过一次),都有三个版本的文件可以处理:
- 您正在编辑的硬盘上的版本
- Git 存储在您的临时区域中的不同版本
- 最新版本已签入到存储库中
这三者都可以是文件的不同版本。将更改移动到临时区域,然后提交它们,会使所有这些版本重新同步。
当我开始使用 Git 时,我发现 staging area 有点混乱,有点烦人。这似乎给这个过程增加了额外的步骤,却没有带来任何好处。当你第一次学习 Git 的时候,这是真的。过一段时间后,你会发现自己真的很喜欢这个功能。不幸的是,这些情况超出了本教程的范围。
如果你对集结地更详细的信息感兴趣,我可以推荐这篇博文。
.gitignore状态命令非常方便,您会发现自己经常使用它。但是有时你会发现有一堆文件出现在未跟踪部分,而你希望 Git 不要看到它们。这就是
.gitignore文件的用处。让我们看一个例子。在同一个目录中创建一个名为
myname.py的新 Python 文件。# myname.py def get_name(): return "Jim"然后修改 hello.py 以包含
myname并调用它的函数:# hello.py import myname name = myname.get_name() print("hello {}".format(name))当您导入一个本地模块时,Python 会将它编译成字节码,并将该文件保留在您的文件系统中。在 Python 2 中,它会留下一个名为
myname.pyc的文件,但我们会假设您运行的是 Python 3。在这种情况下,它将创建一个__pycache__目录并在那里存储一个 pyc 文件。如下所示:$ ls hello.py myname.py $ ./hello.py hello Jim! $ ls hello.py myname.py __pycache__现在,如果您运行
git status,您将在未跟踪的部分看到该目录。还要注意,您的新myname.py文件没有被跟踪,而您对hello.py所做的更改位于一个新的名为“Changes not staged for commit”的部分中。这仅仅意味着那些变更还没有被添加到临时区域中。让我们试一试:$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: hello.py Untracked files: (use "git add <file>..." to include in what will be committed) __pycache__/ myname.py no changes added to commit (use "git add" and/or "git commit -a")在我们继续讨论 gitignore 文件之前,让我们稍微清理一下我们造成的混乱。首先,我们将添加
myname.py和hello.py文件,就像我们之前做的那样:$ git add myname.py hello.py $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: hello.py new file: myname.py Untracked files: (use "git add <file>..." to include in what will be committed) __pycache__/让我们提交这些更改并完成清理工作:
$ git commit -m "added myname module" [master 946b99b] added myname module 2 files changed, 8 insertions(+), 1 deletion(-) create mode 100644 myname.py现在,当我们运行 status 时,我们所看到是那个
__pycache__目录:$ git status On branch master Untracked files: (use "git add <file>..." to include in what will be committed) __pycache__/ nothing added to commit but untracked files present (use "git add" to track)为了让所有的
__pycache__目录(及其内容)被忽略,我们将添加一个.gitignore文件到我们的 repo 中。这听起来很简单。编辑文件(记住名字前面的点!)在你最喜欢的编辑器里。# .gitignore __pycache__现在当我们运行
git status时,我们不再看到__pycache__目录。然而,我们确实看到了新的.gitignore!看一看:$ git status On branch master Untracked files: (use "git add <file>..." to include in what will be committed) .gitignore nothing added to commit but untracked files present (use "git add" to track)该文件只是一个普通的文本文件,可以像其他文件一样添加到 repo 中。现在就做:
$ git add .gitignore $ git commit -m "created .gitignore" [master 1cada8f] created .gitignore 1 file changed, 1 insertion(+) create mode 100644 .gitignore
.gitignore文件中的另一个常见条目是存储虚拟环境的目录。你可以在这里了解更多关于虚拟人的信息,但虚拟人目录通常被称为env或venv。您可以将这些添加到您的.gitignore文件中。如果文件或目录存在,它们将被忽略。如果不是,那么什么都不会发生。也可以在您的主目录中存储一个全局
.gitignore文件。如果您的编辑器喜欢将临时或备份文件放在本地目录中,这将非常方便。下面是一个简单的 Python
.gitignore文件的例子:# .gitignore __pycache__ venv env .pytest_cache .coverage要查看更完整的示例,请点击这里的,或者,如果你想自己制作一个,
git help gitignore提供了你需要的所有细节。Git 回购中不应添加的内容
当你第一次开始使用任何版本控制工具时,尤其是 Git,你可能会想把所有的东西都放入回购中。这一般是个错误。Git 有一些限制,安全性方面的考虑迫使您限制添加到 repo 中的信息类型。
让我们从关于所有版本控制系统的基本经验法则开始。
只将源文件放入版本控制,从不将生成文件。
在这个上下文中,源文件是您创建的任何文件,通常是通过在编辑器中键入。一个生成的文件是计算机创建的,通常是通过处理一个源文件。例如,
hello.py是一个源文件,而hello.pyc是一个生成的文件。回购中不包括生成的文件有两个原因。首先,这样做是浪费时间和空间。生成的文件可以随时重新创建,并且可能需要以不同的形式创建。如果有人正在使用 Jython 或 IronPython,而您正在使用 Cython 解释器,那么
.pyc文件可能会非常不同。提交一种特定风格的文件会导致冲突不存储生成文件的第二个原因是,这些文件通常比原始源文件大。将它们放在回购中意味着每个人现在都需要下载和存储这些生成的文件,即使他们并没有使用它们。
这第二点引出了关于 Git repos 的另一条一般规则:谨慎提交二进制文件,强烈避免提交大文件。这条规则与 Git 的工作方式有很大关系。
Git 不会存储您提交的每个文件的每个版本的完整副本。相反,它使用基于文件后续版本之间差异的复杂算法来大大减少所需的存储量。二进制文件(如 jpg 或 MP3 文件)没有很好的比较工具,所以 Git 通常只需要在每次提交时存储整个文件。
当你使用 Git 时,尤其是使用 GitHub 时,千万不要将机密信息放入回购协议中,尤其是你可能会公开分享的信息。这很重要,所以我要再说一遍:
注意:切勿将机密信息放入 GitHub 的公共存储库中。密码、API 密钥和类似项目不应提交给回购。有人最终会找到他们。
旁白:什么是阿沙
当 Git 在 repo 中存储东西(文件、目录、提交等)时,它以一种复杂的方式存储它们,包括一个散列函数。我们不需要在这里深入讨论细节,但是哈希函数接受一个东西,并为这个东西生成一个更短的惟一 ID(在我们的例子中是 20 个字节)。这个 ID 在 Git 中称为“SHA”。不能保证它是唯一的,但是对于大多数实际应用来说,它是唯一的。
Git 使用它的哈希算法来索引你的回购协议中的所有内容。每个文件都有反映该文件内容的阿沙。每个目录依次被散列。如果该目录中的文件发生变化,那么该目录的 SHA 也会发生变化。
每个提交都包含您的 repo 中顶级目录的 SHA 以及一些其他信息。这就是一个 20 字节的数字如何描述你的回购的整个状态。
您可能会注意到,有时 Git 使用完整的 20 个字符值来显示阿沙:
commit 25b09b9ccfe9110aed2d09444f1b50fa2b4c979c有时它会向您展示一个简短的版本:
[master (root-commit) 25b09b9] creating hello.py通常,它会向您显示完整的字符串,但您并不总是必须使用它。Git 的规则是,您只需给出足够的字符来确保 SHA 在您的 repo 中是唯一的。一般七个字就够了。
每次提交对 repo 的更改时,Git 都会创建一个描述该状态的新 SHA。我们将在接下来的章节中了解 sha 的用处。
去日志
另一个非常常用的 Git 命令是
git log。Git 日志向您展示了到目前为止您所做的提交的历史:$ git log commit 1cada8f59b43254f621d1984a9ffa0f4b1107a3b Author: Jim Anderson <jima@example.com> Date: Sat Mar 3 13:23:07 2018 -0700 created .gitignore commit 946b99bfe1641102d39f95616ceaab5c3dc960f9 Author: Jim Anderson <jima@example.com> Date: Sat Mar 3 13:22:27 2018 -0700 added myname module commit 25b09b9ccfe9110aed2d09444f1b50fa2b4c979c Author: Jim Anderson <jima@example.com> Date: Sat Mar 3 13:10:12 2018 -0700 creating hello.py正如您在上面的清单中看到的,我们的 repo 的所有提交消息都是按顺序显示的。每次提交的开始都标有单词“commit ”,后跟该提交的 SHA。给你每个 sha 的历史。
回到过去:签出代码的特定版本
因为 Git 会记住你用 SHA 进行的每一次提交,所以你可以告诉 Git 转到任何一次提交,查看当时存在的回购。下图显示了 Git 认为我们的回购中有什么:
不用担心图中的
master和HEAD是什么意思。我们稍后会解释这些。为了改变我们在历史中的位置,我们将使用
git checkout命令告诉 Git 我们想要查看哪个 SHA。让我们试试:$ git checkout 946b99bfe1641102d39f95616ceaab5c3dc960f9 Note: checking out '946b99bfe1641102d39f95616ceaab5c3dc960f9'. You are in 'detached HEAD' state. You can look around, make experimental changes and commit them, and you can discard any commits you make in this state without impacting any branches by performing another checkout. If you want to create a new branch to retain commits you create, you may do so (now or later) by using -b with the checkout command again. Example: git checkout -b <new-branch-name> HEAD is now at 946b99b... added myname module好的,这里有很多令人困惑的信息。让我们从定义这些术语开始。先说
HEAD。Git 是你在任何时候碰巧看到的东西的名字。它并不意味着什么在您的文件系统上,或者什么在您的暂存区中。它意味着 Git 认为你已经签出的内容。所以,如果你编辑了一个文件,你的文件系统上的版本与
HEAD中的版本是不同的(是的,HEAD 是全大写的)。接下来,我们有
branch。看待一家分行最简单的方式是,它是阿沙的一个标签。它还有其他一些有用的属性,但是现在,把一个分支想象成阿沙标签。注意:你们中那些曾经使用过其他版本控制系统(我看着你,Subversion)的人,对分支是什么会有一个非常不同的想法。Git 区别对待分支,这是一件好事。
当我们将所有这些信息放在一起时,我们看到分离的头仅仅意味着您的头指向没有分支(或标签)与之关联的阿沙。Git 非常好地告诉您如何解决这种情况。有时候你会想要修复它,有时候你可以在那种超然的状态下工作。
让我们回到我们的演示。如果您查看系统现在的状态,可以看到
.gitignore文件不再存在。我们回到做那些改变之前的系统状态。下面是我们在这种状态下回购的示意图。注意HEAD和master指针是如何指向不同的 sha 的:
好吧。现在,我们如何回到我们在哪里?有两种方式,其中一种你应该已经知道:
git checkout 1cada8f。这将带你回到你开始走动时的状态。注意:一件奇怪的事情,至少在我的 Git 版本中,是它仍然给你一个分离头警告,即使你回到与分支相关的 SHA。
另一种返回的方式更常见:检查你所在的分支。Git 总是从一个名为
master的分支开始。稍后我们将学习如何创建其他分支,但现在我们将坚持使用master。要回到你想去的地方,你可以简单地做
git checkout master。这将使您返回到提交给master分支的最新 SHA,在我们的例子中,它具有提交消息“created”。gitignore”。换句话说,git checkout master告诉 Git 让 HEAD 指向由标签或者分支master标记的 SHA。请注意,有几种方法可以指定特定的提交。SHA 可能是最容易理解的。其他方法使用不同的符号和名称来指定如何从一个已知的位置(比如 HEAD)到达一个特定的提交。在本教程中,我不会涉及这些细节,但是如果你想了解更多细节,你可以在这里找到它们。
分支基础知识
再多说一点分支吧。分支为您提供了一种将不同的开发流分开的方法。虽然这在你独自工作时很有用,但在团队工作时几乎是必不可少的。
假设我在一个小团队中工作,并且有一个特性要添加到项目中。当我在做的时候,我不想把我的修改添加到
master中,因为它仍然不能正常工作,可能会把我的团队成员搞得一团糟。我可以等到完全完成后再提交更改,但这不太安全,也不总是可行的。因此,我将创建一个新的分支,而不是处理
master:$ git checkout -b my_new_feature Switched to a new branch 'my_new_feature' $ git status On branch my_new_feature nothing to commit, working directory clean我们在
checkout命令中使用了-b选项来告诉 Git 我们希望它创建一个新的分支。正如您在上面看到的,在我们的分支中运行git status向我们显示,分支名称确实已经更改。让我们看看日志:$ git log commit 1cada8f59b43254f621d1984a9ffa0f4b1107a3b Author: Jim Anderson <jima@example.com> Date: Thu Mar 8 20:57:42 2018 -0700 created .gitignore commit 946b99bfe1641102d39f95616ceaab5c3dc960f9 Author: Jim Anderson <jima@example.com> Date: Thu Mar 8 20:56:50 2018 -0700 added myname module commit 25b09b9ccfe9110aed2d09444f1b50fa2b4c979c Author: Jim Anderson <jima@example.com> Date: Thu Mar 8 20:53:59 2018 -0700 creating hello.py正如我希望你所料,日志看起来完全一样。创建新分支时,新分支将从您所在的位置开始。在这种情况下,我们在 master 的顶部,
1cada8f59b43254f621d1984a9ffa0f4b1107a3b,所以这是新分支开始的地方。现在,让我们来研究一下这个特性。对
hello.py文件进行更改并提交。我将向您展示这些命令以供查看,但我将不再向您展示您已经看到的命令的输出:$ git add hello.py $ git commit -m "added code for feature x"现在,如果你做
git log,你会看到我们的新提交出现了。在我这里,它有阿沙 4a 4f 4492 ed256 aa 7b 29 BF 5176 a 17 f 9 EDA 66 efbb,但你的回购极有可能有不同的 SHA:$ git log commit 4a4f4492ded256aa7b29bf5176a17f9eda66efbb Author: Jim Anderson <jima@example.com> Date: Thu Mar 8 21:03:09 2018 -0700 added code for feature x commit 1cada8f59b43254f621d1984a9ffa0f4b1107a3b ... the rest of the output truncated ...现在切换回主分支,查看日志:
git checkout master git log新的提交“为特性 x 添加的代码”在那里吗?
Git 有一个内置的方法来比较两个分支的状态,这样你就不用这么辛苦了。是
show-branch命令。它看起来是这样的:$ git show-branch my_new_feature master * [my_new_feature] added code for feature x ! [master] created .gitignore -- * [my_new_feature] added code for feature x *+ [master] created .gitignore它生成的图表起初有点混乱,所以让我们详细地浏览一下。首先,您通过给命令命名两个分支来调用它。在我们的例子中,那是
my_new_feature和master。输出的前两行是解码其余文本的关键。每行的第一个非空格字符是
*或!,后跟分支的名称,然后是该分支上最近一次提交的提交消息。*字符用于指示该分支当前被检出,而!用于所有其他分支。该字符位于与下表中的提交匹配的列中。第三行是分隔符。
从第四行开始,有些提交在一个分支中,而在另一个分支中没有。在我们目前的情况下,这很容易。在
my_new_feature中有一个提交不在主机中。你可以在第四行看到。注意那一行是如何在第一列以*开始的。这是为了指示该提交在哪个分支中。最后,输出的最后一行显示了两个分支的第一个公共提交。
这个例子非常简单。为了做一个更好的例子,我给
my_new_feature增加了几个提交,给master.增加了几个提交,使输出看起来像这样:$ git show-branch my_new_feature master * [my_new_feature] commit 4 ! [master] commit 3 -- * [my_new_feature] commit 4 * [my_new_feature^] commit 1 * [my_new_feature~2] added code for feature x + [master] commit 3 + [master^] commit 2 *+ [my_new_feature~3] created .gitignore现在您可以看到每个分支中有不同的提交。注意,
[my_new_feature~2]文本是我前面提到的提交选择方法之一。如果您想查看 sha,可以通过在命令中添加–sha1-name 选项来显示它们:$ git show-branch --sha1-name my_new_feature master * [my_new_feature] commit 4 ! [master] commit 3 -- * [6b6a607] commit 4 * [12795d2] commit 1 * [4a4f449] added code for feature x + [de7195a] commit 3 + [580e206] commit 2 *+ [1cada8f] created .gitignore现在你有了一个分支,上面有一堆不同的提交。当你最终完成了那个特性,并准备把它带给你团队的其他成员时,你会做什么?
从一个分支到另一个分支有三种主要的提交方式:合并、重定基础和精选。我们将在下一节中依次讨论这些问题。
合并
合并是三者中最容易理解和使用的。当您进行合并时,Git 将创建一个新的 commit,如果需要的话,它将合并两个分支的顶级 sha。如果另一个分支中的所有提交都在当前分支的顶部之前(基于当前分支的顶部),它将执行一个快速向前合并*,并将这些新提交放在这个分支上。
让我们回到我们的 show-branch 输出看起来像这样的地方:
$ git show-branch --sha1-name my_new_feature master * [my_new_feature] added code for feature x ! [master] created .gitignore -- * [4a4f449] added code for feature x *+ [1cada8f] created .gitignore现在,我们想让 commit
4a4f449成为 master。检查 master 并在那里运行git merge命令:$ git checkout master Switched to branch 'master' $ git merge my_new_feature Updating 1cada8f..4a4f449 Fast-forward hello.py | 1 + 1 file changed, 1 insertion(+)因为我们在分支主服务器上,所以我们合并了 my_new_feature 分支。您可以看到这是一次快进合并,以及哪些文件发生了更改。现在让我们来看看日志:
commit 4a4f4492ded256aa7b29bf5176a17f9eda66efbb Author: Jim Anderson <jima@example.com> Date: Thu Mar 8 21:03:09 2018 -0700 added code for feature x commit 1cada8f59b43254f621d1984a9ffa0f4b1107a3b Author: Jim Anderson <jima@example.com> Date: Thu Mar 8 20:57:42 2018 -0700 created .gitignore [rest of log truncated]如果我们在合并之前对 master 进行了更改,Git 会创建一个新的 commit,它是两个分支的更改的组合。
Git 相当擅长的事情之一是理解不同分支的共同祖先,并自动将更改合并在一起。如果同一段代码在两个分支中都被修改了,Git 不知道该怎么办。当这种情况发生时,它会中途停止合并,并给出如何修复该问题的说明。这被称为合并冲突。
重置基准
重设基础类似于合并,但行为稍有不同。在合并中,如果两个分支都有变化,那么创建一个新的合并提交。在 rebasing 中,Git 将从一个分支获取提交,并在另一个分支的顶部重放它们,一次一个。
我不会在这里做一个详细的重置基础的演示,因为在文本中设置一个演示来显示这一点有点棘手,并且因为有一个很好地涵盖了这个主题的优秀网页,我将在本节的结尾引用它。
摘樱桃
挑选是将提交从一个分支转移到另一个分支的另一种方法。与合并和重定基础不同,通过精选,您可以精确地指定您想要的提交。最简单的方法是指定一个 SHA:
$ git cherry-pick 4a4f4492ded256aa7b29bf5176a17f9eda66efbb这告诉 Git 获取进入
4a4f449的更改,并将它们应用到当前分支。当您想要一个特定的变更,而不是对整个分支进行变更时,这个特性会非常方便。
关于分支的快速提示:我不能不推荐一个学习 Git 分支的优秀资源就离开这个主题。学习 Git 分支有一组练习,使用提交和分支的图形表示来清楚地解释合并、重定基础和精选之间的区别。我高度推荐花些时间完成这些练习。
使用远程仓库
到目前为止,我们讨论的所有命令都只适用于本地 repo。它们不与服务器或网络进行任何通信。事实证明,实际上只有四个主要的 Git 命令与远程回购进行对话:
clonefetchpullpush就是这样。其他所有工作都在您的本地机器上完成。(好吧,准确地说,还有其他与遥控器对话的命令,但它们不属于基本类别。)
让我们依次看看这些命令。
CloneGit
clone是当您有了一个已知存储库的地址并且想要制作一个本地副本时使用的命令。对于这个例子,让我们使用我在 GitHub 账户上的一个小回购,github-playground。用于回购的 GitHub 页面位于这里。在该页面上,您会发现一个“克隆或下载”按钮,该按钮为您提供了使用
git clone命令的 URI。如果你复制了,你就可以clone回购:git clone git@github.com:jima80525/github-playground.git现在,您已经在本地机器上拥有了该项目的完整存储库。这包括所有的提交和所有的分支。(注:这个回购是一些朋友在学 Git 的时候用的。我从别人那里复制或叉了它。)
如果您想使用其他远程命令,您应该在 GitHub 上创建一个新的 repo 并遵循相同的步骤。欢迎您将
github-playground回购转入您的账户并使用。GitHub 上的分叉是通过点击 UI 中的“fork”按钮来完成的。
Fetch为了清楚地解释
fetch命令,我们需要后退一步,讨论 Git 如何管理本地回购和远程回购之间的关系。下一部分是背景,虽然你不会在日常生活中用到,但它会让fetch和pull之间的区别变得更有意义。当你创建一个新的 repo 时,Git 不仅仅是复制那个项目中文件的一个版本。它复制整个存储库,并使用它在您的本地机器上创建一个新的存储库。
Git 除了 master 不为你做本地分支。但是,它会跟踪服务器上的分支。为此,Git 创建了一组以
remotes/origin/<branch_name>开头的分支。你很少(几乎从不)会检查这些
remotes/origin分支,但是知道它们在那里是很方便的。请记住,当您克隆 repo 时,远程上存在的每个分支都将在remotes/origin中有一个分支。当您创建一个新的分支,并且名称与服务器上现有的分支相匹配时,Git 会将您的本地分支标记为一个与远程分支相关联的跟踪分支。当我们到达
pull时,我们将看到它是如何有用的。现在你已经知道了
remotes/origin分支,理解git fetch将会非常容易。所有的fetch所做的就是更新所有的remotes/origin分支。它将只修改存储在remotes/origin的分支,而不是你的任何本地分支。
Pull
Git pull是另外两个命令的简单组合。首先,它执行一个git fetch来更新remotes/origin分支。然后,如果您所在的分支正在跟踪一个远程分支,那么它会对您的分支执行相应的remote/origin分支的git merge。例如,假设您在 my_new_feature 分支,而您的同事刚刚在服务器上向它添加了一些代码。如果你做了一个
git pull,Git 将更新所有的remotes/origin分支,然后做一个git merge remotes/origin/my_new_feature,这将得到新的提交到你所在的分支上!当然,这里有一些限制。如果您修改了本地系统上的文件,Git 甚至不会让您尝试执行
git pull。那会造成太多的混乱。如果您在本地分支上有提交,并且远程也有新的提交(即“分支已经分叉”),那么
pull的git merge部分将创建一个合并提交,正如我们上面讨论的那样。那些一直在仔细阅读的人会发现,你也可以通过做
git pull -r让 Git 做 rebase 而不是 merge。
Push你可能已经猜到了,
git push与git pull正好相反。嗯,几乎相反。Push发送关于你正在推送的分支的信息,并询问遥控器是否愿意更新该分支的版本以匹配你的版本。一般来说,这相当于将您的新更改推送到服务器。这里有很多细节和复杂性,涉及到底什么是快进提交。
这里有一篇精彩的文章。其要点是
git push使您的新提交在远程服务器上可用。综合起来:简单的 g It 工作流
至此,我们已经回顾了几个基本的 Git 命令以及如何使用它们。最后,我将快速描述一下 Git 中可能的工作流。此工作流假设您正在处理本地回购,并且有一个您将
push更改到的远程回购。它可以是 GitHub,但它与其他远程 repos 的工作方式相同。它假设您已经克隆了回购。
- 确保你当前的区域是干净的。
git pull–从遥控器获取最新版本。这避免了以后的合并问题。- 编辑您的文件并进行更改。记得运行你的 linter 并做单元测试!
git status–查找所有更改的文件。确保观看未被跟踪的文件!git add [files]–将更改后的文件添加到暂存区。- 做出新的承诺。
git push origin [branch-name]–将您的更改上传到遥控器。这是系统中最基本的流程之一。使用 Git 的方法有很多很多,本教程只是触及了皮毛。如果你使用 Vim 或 Sublime 作为你的编辑器,你可能想看看这些教程,它们将向你展示如何获得插件来将 Git 集成到你的编辑器中:
如果您想更深入地了解 Git,我可以推荐这些书:
最后,如果你对在你的编码之旅中利用人工智能的力量感兴趣,那么你可能想玩玩 GitHub Copilot 。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 开发者 Git 和 GitHub 入门********
用 Tkinter 进行 Python GUI 编程
Python 有很多 GUI 框架,但是 Tkinter 是唯一内置到 Python 标准库中的框架。Tkinter 有几个优点。它是跨平台,所以同样的代码可以在 Windows、macOS 和 Linux 上运行。视觉元素是使用本地操作系统元素呈现的,因此用 Tkinter 构建的应用程序看起来就像它们属于运行它们的平台。
尽管 Tkinter 被认为是事实上的 Python GUI 框架,但它也不是没有批评。一个值得注意的批评是用 Tkinter 构建的 GUI 看起来过时了。如果你想要一个闪亮、现代的界面,那么 Tkinter 可能不是你要找的。
然而,与其他框架相比,Tkinter 是轻量级的,使用起来相对容易。这使得它成为用 Python 构建 GUI 应用程序的一个令人信服的选择,特别是对于不需要现代光泽的应用程序,当务之急是快速构建功能性的和跨平台的应用程序。
在本教程中,您将学习如何:
- 使用一个 Hello,World 应用程序开始使用 Tkinter
- 使用小部件,例如按钮和文本框
- 使用几何图形管理器控制您的应用布局
- 通过将按钮点击与 Python 函数相关联,使您的应用程序具有交互性
注:本教程改编自 Python 基础知识:Python 实用入门 3 的“图形用户界面”一章。
该书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互。在本教程中,对 IDLE 的引用已经被删除,取而代之的是更通用的语言。
本教程中的大部分内容保持不变,从您选择的编辑器和环境中运行示例代码应该没有问题。
一旦您通过完成每一节末尾的练习掌握了这些技能,您就可以通过构建两个应用程序将所有内容联系起来。第一个是温度转换器,第二个是文本编辑器。是时候开始学习如何用 Tkinter 构建一个应用程序了!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
参加测验:通过我们的交互式“使用 Tkinter 进行 Python GUI 编程”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
用 Tkinter 构建您的第一个 Python GUI 应用程序
Tkinter GUI 的基本元素是窗口。窗口是所有其他 GUI 元素所在的容器。这些其他 GUI 元素,比如文本框、标签和按钮,被称为小部件。窗口中包含小部件。
首先,创建一个包含单个小部件的窗口。启动一个新的 Python shell 会话,然后继续!
注意:本教程中的代码示例都已经在 Windows、macOS 和 Ubuntu Linux 20.04 上用 Python 3.10 版进行了测试。
如果你已经从 python.org 的用官方安装程序为的 Windows 和的 macOS 安装了 Python ,那么运行示例代码应该没有问题。您可以放心地跳过本笔记的其余部分,继续学习教程!
如果你还没有用官方安装程序安装 Python,或者你的系统还没有官方发行版,那么这里有一些开始使用的技巧。
带有自制软件的 macOS 上的 Python:
在 Homebrew 上可用的用于 macOS 的 Python 发行版没有捆绑 Tkinter 所需的 Tcl/Tk 依赖项。而是使用默认的系统版本。此版本可能已过时,并阻止您导入 Tkinter 模块。为了避免这个问题,使用官方 macOS 安装程序。
Ubuntu Linux 20.04:
为了节省内存空间,Ubuntu Linux 20.04 上预装的 Python 解释器的默认版本不支持 Tkinter。但是,如果您想继续使用与您的操作系统捆绑在一起的 Python 解释器,请安装以下软件包:
$ sudo apt-get install python3-tk这将安装 Python GUI Tkinter 模块。
其他 Linux 版本:
如果您无法在自己的 Linux 上安装 Python,那么您可以从源代码中用正确版本的 Tcl/Tk 构建 Python。为了一步一步地完成这个过程,请查看 Python 3 安装&安装指南。你也可以尝试使用 pyenv 来管理多个 Python 版本。
打开 Python shell 后,您需要做的第一件事是导入 Python GUI Tkinter 模块:
>>> import tkinter as tk
一个窗口是 Tkinter 的Tk类的一个实例。继续创建一个新窗口,并将其分配给变量 window:
>>> window = tk.Tk()当您执行上述代码时,屏幕上会弹出一个新窗口。它的外观取决于您的操作系统:
在本教程的其余部分,你会看到 Windows 屏幕截图。
添加微件
现在您有了一个窗口,您可以添加一个小部件。使用
tk.Label类给窗口添加一些文本。用文本"Hello, Tkinter"创建一个Label小部件,并将其分配给一个名为greeting的变量:
>>> greeting = tk.Label(text="Hello, Tkinter")
您之前创建的窗口不会改变。您刚刚创建了一个Label小部件,但是还没有将它添加到窗口中。有几种方法可以将小部件添加到窗口中。现在,您可以使用Label小部件的.pack()方法:
>>> greeting.pack()窗口现在看起来像这样:
当您将一个小部件打包到一个窗口中时,Tkinter 会将窗口调整到尽可能小的大小,同时仍然完全包含该小部件。现在执行以下命令:
>>> window.mainloop()
似乎什么也没发生,但是请注意,shell 中没有出现新的提示。
window.mainloop()告诉 Python 运行 Tkinter 事件循环。这个方法监听事件,比如按钮点击或按键,并且阻止任何跟随它的代码运行,直到你关闭调用这个方法的窗口。继续并关闭您创建的窗口,您将看到 shell 中显示一个新的提示。
警告:当您在 Python REPL 中使用 Tkinter 时,会在执行每一行时应用对 windows 的更新。这是而不是从 Python 文件执行 Tkinter 程序的情况!
如果在 Python 文件中的程序末尾没有包含window.mainloop(),那么 Tkinter 应用程序将永远不会运行,也不会显示任何内容。或者,您可以在 Python REPL 中通过在每个步骤后调用window.update()来逐步构建您的用户界面,以反映变更。
用 Tkinter 创建一个窗口只需要几行代码。但是空白窗口不是很有用!在下一节中,您将了解 Tkinter 中可用的一些小部件,以及如何定制它们来满足您的应用程序的需求。
检查你的理解能力
展开下面的代码块,检查您的理解情况:
编写一个完整的 Python 脚本,用文本"Python rocks!"创建一个 Tkinter 窗口。
窗口应该是这样的:
现在试试这个练习。
您可以展开下面的代码块来查看解决方案:
这里有一个可能的解决方案:
import tkinter as tk
window = tk.Tk()
label = tk.Label(text="Python rocks!")
label.pack()
window.mainloop()
请记住,您的代码可能看起来不同。
当你准备好了,你可以进入下一部分。
使用微件
小部件是 Python GUI 框架 Tkinter 的基础。它们是用户与你的程序交互的元素。Tkinter 中的每个小部件都是由一个类定义的。以下是一些可用的小部件:
| 小部件类 | 描述 |
|---|---|
Label |
用于在屏幕上显示文本的小部件 |
Button |
可以包含文本并可以在单击时执行操作的按钮 |
Entry |
只允许单行文本的文本输入小部件 |
Text |
允许多行文本输入的文本输入小部件 |
Frame |
用于分组相关部件或在部件之间提供填充的矩形区域 |
在接下来的小节中,您将看到如何使用其中的每一个,但是请记住,Tkinter 有比这里列出的更多的小部件。当你考虑到一整套全新的主题窗口小部件时,窗口小部件的选择变得更加复杂。在本教程的剩余部分,你将只使用 Tkinter 的经典部件。
如果您想了解关于这两种小部件类型的更多信息,您可以展开下面的可折叠部分:
值得注意的是,Tkinter 中目前有两大类小部件:
- 经典 widgets:
tkinter包中的,例如tkinter.Label - 主题控件:
ttk子模块中可用的,例如tkinter.ttk.Label
Tkinter 的经典窗口小部件是高度可定制和简单明了的,但在今天的大多数平台上,它们往往显得过时或有些陌生。如果您想利用给定操作系统的用户熟悉的具有本机外观和感觉的小部件,那么您可能想要查看主题小部件。
大多数主题部件都是传统部件的替代物,但是看起来更现代。你也可以使用一些全新的小部件,比如进度条,这是 Tkinter 之前没有的。同时,您需要继续使用一些没有主题替代的经典小部件。
注意:tkinter.ttk模块中的主题小部件默认使用操作系统的本地外观。然而,你可以改变他们的主题来定制视觉外观,比如亮暗模式。主题是可重用的样式定义的集合,您可以将其视为 Tkinter 的级联样式表(CSS) 。
使新的小部件主题化意味着将它们的大部分风格信息提取到单独的对象中。一方面,这种关注点的分离是库设计中期望的属性,但另一方面,它引入了一个额外的抽象层,这使得主题化的小部件比传统的小部件更难设计。
在 Tkinter 中使用常规和主题小部件时,通常会为 Tkinter 包和模块声明以下别名:
>>> import tkinter as tk >>> import tkinter.ttk as ttk像这样的别名允许你显式地引用
tk.Label或ttk.Label,例如,根据你的需要在一个程序中:
>>> tk.Label()
<tkinter.Label object .!label>
>>> ttk.Label()
<tkinter.ttk.Label object .!label2>
然而,有时您可能会发现使用通配符导入(*)来自动覆盖所有带有主题的遗留小部件会更方便,比如:
>>> from tkinter import * >>> from tkinter.ttk import * >>> Label() <tkinter.ttk.Label object .!label> >>> Text() <tkinter.Text object .!text>现在,您不必在小部件的类名前面加上相应的 Python 模块。只要有主题窗口小部件,你就会一直创建它,否则你就会退回到经典窗口小部件。上述两个 import 语句必须按照指定的顺序放置才能生效。因此,通配符导入被认为是一种不好的做法,除非有意识地使用,否则通常应该避免。
要查看 Tkinter 小部件的完整列表,请查看 TkDocs 教程中的基本小部件和更多小部件。尽管它描述了 Tcl/Tk 8.5 中引入的主题小部件,但其中的大部分信息也应该适用于经典小部件。
有趣的事实: Tkinter 字面上代表“Tk 接口”,因为它是一个 Python 绑定或者是一个编程接口到 Tcl 脚本语言中的 Tk 库。
现在,仔细看看
Label小部件。用
Label小工具显示文本和图像
Label控件用于显示文本或图像。用户不能编辑由Label小部件显示的文本。这只是为了展示的目的。正如您在本教程开头的例子中看到的,您可以通过实例化Label类并向text参数传递一个字符串来创建一个Label小部件:label = tk.Label(text="Hello, Tkinter")
Label小工具使用默认系统文本颜色和默认系统文本背景颜色显示文本。它们通常分别是黑色和白色,但是如果您在操作系统中更改了这些设置,您可能会看到不同的颜色。您可以使用
foreground和background参数控制Label文本和背景颜色:label = tk.Label( text="Hello, Tkinter", foreground="white", # Set the text color to white background="black" # Set the background color to black )有许多有效的颜色名称,包括:
"red""orange""yellow""green""blue""purple"许多 HTML 颜色名称都使用 Tkinter。要获得完整的参考,包括当前系统主题控制的特定于 macOS 和 Windows 的系统颜色,请查看颜色手册页。
您也可以使用十六进制 RGB 值指定颜色:
label = tk.Label(text="Hello, Tkinter", background="#34A2FE")这将标签背景设置为漂亮的浅蓝色。十六进制的 RGB 值比命名的颜色更神秘,但也更灵活。幸运的是,有工具可以让获取十六进制颜色代码变得相对容易。
如果你不想一直键入
foreground和background,那么你可以使用简写的fg和bg参数来设置前景和背景颜色:label = tk.Label(text="Hello, Tkinter", fg="white", bg="black")您也可以使用
width和height参数控制标签的宽度和高度:label = tk.Label( text="Hello, Tkinter", fg="white", bg="black", width=10, height=10 )以下是该标签在窗口中的外观:
虽然窗口的宽度和高度都被设置为
10,但是窗口中的标签并不是方形的,这似乎有点奇怪。这是因为宽度和高度是以文本单位测量的。在默认系统字体中,一个水平文本单位由字符0或数字零的宽度决定。类似地,一个垂直文本单位由字符0的高度决定。注意:对于宽度和高度的测量,Tkinter 使用文本单位,而不是英寸、厘米或像素,以确保应用程序跨平台的一致行为。
用字符的宽度来度量单位意味着小部件的大小是相对于用户机器上的默认字体而言的。这确保了无论应用程序在哪里运行,文本都能恰当地适合标签和按钮。
标签对于显示一些文本很有用,但是它们不能帮助你从用户那里得到输入。接下来您将了解的三个小部件都用于获取用户输入。
显示带有
Button小部件的可点击按钮
Button小部件用来显示可点击按钮。您可以将它们配置为在被点击时调用一个函数。您将在下一节讲述如何通过点击按钮来调用函数。现在,让我们看看如何创建和设计一个按钮。
Button和Label小部件有很多相似之处。在很多方面,按钮只是一个你可以点击的标签!用于创建和样式化Label的相同关键字参数将适用于Button小部件。例如,下面的代码创建一个蓝色背景黄色文本的按钮。它还将宽度和高度分别设置为25和5文本单位:button = tk.Button( text="Click me!", width=25, height=5, bg="blue", fg="yellow", )下面是该按钮在窗口中的外观:
相当漂亮!您可以使用接下来的两个小部件来收集用户输入的文本。
使用
Entry小部件获取用户输入当您需要从用户那里获取一些文本时,比如姓名或电子邮件地址,使用一个
Entry小部件。它将显示一个小文本框,用户可以在其中键入一些文本。创建和设计Entry小部件的工作方式与Label和Button小部件非常相似。例如,下面的代码创建了一个小部件,它具有蓝色背景、一些黄色文本和宽度为50的文本单位:entry = tk.Entry(fg="yellow", bg="blue", width=50)然而,关于
Entry小部件有趣的一点不是如何设计它们的样式。而是如何使用它们从用户那里获得输入。您可以使用Entry小部件执行三个主要操作:
- 用
.get()检索文本- 用
.delete()删除文本- 用
.insert()插入文本理解
Entry小部件的最好方法是创建一个并与之交互。打开一个 Python shell,按照本节中的示例进行操作。首先,导入tkinter并创建一个新窗口:
>>> import tkinter as tk
>>> window = tk.Tk()
现在创建一个Label和一个Entry小部件:
>>> label = tk.Label(text="Name") >>> entry = tk.Entry()
Label描述了什么样的文本应该放在Entry小部件中。它没有在Entry上强加任何类型的要求,但是它告诉用户你的程序期望他们在那里放什么。您需要.pack()将小部件放到窗口中,以便它们可见:
>>> label.pack()
>>> entry.pack()
看起来是这样的:
请注意,Tkinter 会自动将标签置于窗口中Entry小部件的中央。这是.pack()的一个特性,您将在后面的章节中了解更多。
用鼠标在Entry小部件内点击并输入Real Python:
现在您已经在Entry小部件中输入了一些文本,但是这些文本还没有发送到您的程序中。您可以使用.get()来检索文本,并将其分配给一个名为name的变量:
>>> name = entry.get() >>> name 'Real Python'您也可以删除文本。这个
.delete()方法接受一个整数参数,告诉 Python 要删除哪个字符。例如,下面的代码块显示了.delete(0)如何从Entry中删除第一个字符:
>>> entry.delete(0)
小部件中剩余的文本现在是eal Python:
注意,就像 Python 字符串对象一样,Entry小部件中的文本从0开始索引。
如果您需要从一个Entry中删除几个字符,那么将第二个整数参数传递给.delete(),指示删除应该停止的字符的索引。例如,以下代码删除了Entry中的前四个字母:
>>> entry.delete(0, 4)剩下的文本现在读作
Python:
Entry.delete()的工作原理和切弦一样。第一个参数决定了起始索引,删除会一直继续,但不会包括作为第二个参数传递的索引。使用特殊常量tk.END作为.delete()的第二个参数,删除Entry中的所有文本:
>>> entry.delete(0, tk.END)
您现在会看到一个空白文本框:
另一方面,您也可以将文本插入到Entry小部件中:
>>> entry.insert(0, "Python")窗口现在看起来像这样:
第一个参数告诉
.insert()在哪里插入文本。如果Entry中没有文本,那么新的文本将总是被插入到小部件的开头,不管您作为第一个参数传递什么值。例如,像上面所做的那样,用100而不是0作为第一个参数调用.insert(),将会生成相同的输出。如果
Entry已经包含一些文本,那么.insert()将在指定位置插入新文本,并将所有现有文本向右移动:
>>> entry.insert(0, "Real ")
小部件文本现在显示为Real Python:
小工具很适合从用户那里获取少量文本,但是因为它们只显示在一行中,所以它们不适合收集大量文本。这就是Text小部件的用武之地!
使用Text小部件获取多行用户输入
Text 小工具用于输入文本,就像Entry小工具一样。不同之处在于Text小部件可能包含多行文本。使用Text小部件,用户可以输入一整段甚至几页的文本!就像使用Entry小部件一样,您可以使用Text小部件执行三个主要操作:
- 用
.get()检索文本 - 用
.delete()删除文本 - 插入文本和
.insert()
尽管方法名与Entry方法相同,但它们的工作方式略有不同。是时候动手创建一个Text小部件,看看它能做什么了。
注意:上一节的窗口是否仍然打开着?
如果是这样,您可以通过执行以下命令来关闭它:
>>> window.destroy()也可以通过点击关闭按钮手动关闭。
在 Python shell 中,创建一个新的空白窗口,并在其中装入一个
Text()小部件:
>>> window = tk.Tk()
>>> text_box = tk.Text()
>>> text_box.pack()
默认情况下,文本框比Entry小部件大得多。下面是上面创建的窗口的样子:
单击窗口内的任意位置激活文本框。键入单词Hello。然后按下 Enter ,在第二行输入World。窗口现在应该看起来像这样:
就像使用Entry小部件一样,您可以使用.get()从Text小部件中检索文本。然而,不带参数调用.get()不会像调用Entry小部件那样返回文本框中的完整文本。它引发一个异常:
>>> text_box.get() Traceback (most recent call last): ... TypeError: get() missing 1 required positional argument: 'index1'
Text.get()至少需要一个参数。用单个索引调用.get()返回单个字符。要检索几个字符,需要传递一个开始索引和一个结束索引。Text小部件中的索引与Entry小部件中的不同。由于Text窗口小部件可以有几行文本,所以一个索引必须包含两条信息:
- 一个字符的行号
- 字符在那一行上的位置
行号以
1开头,字符位置以0开头。要创建一个索引,需要创建一个形式为"<line>.<char>"的字符串,用行号替换<line>,用字符号替换<char>。例如,"1.0"代表第一行的第一个字符,"2.3"代表第二行的第四个字符。使用索引
"1.0"从您之前创建的文本框中获取第一个字母:
>>> text_box.get("1.0")
'H'
单词Hello有五个字母,o的字符数是4,因为字符数从0开始,单词Hello从文本框的第一个位置开始。就像 Python 字符串切片一样,为了从文本框中获取整个单词Hello,结束索引必须比要读取的最后一个字符的索引大 1。
因此,要从文本框中获取单词Hello,使用"1.0"作为第一个索引,使用"1.5"作为第二个索引:
>>> text_box.get("1.0", "1.5") 'Hello'要在文本框的第二行找到单词
World,请将每个索引中的行号更改为2:
>>> text_box.get("2.0", "2.5")
'World'
要获取文本框中的所有文本,请在"1.0"中设置起始索引,并对第二个索引使用特殊的tk.END常量:
>>> text_box.get("1.0", tk.END) 'Hello\nWorld\n'请注意,
.get()返回的文本包含任何换行符。从这个例子中还可以看到,Text小部件中的每一行末尾都有一个换行符,包括文本框中的最后一行文本。
.delete()用于从文本框中删除字符。它的工作原理就像.delete()对于Entry小部件一样。使用.delete()有两种方法:
- 用一个单参数
- 用两个自变量
使用单参数版本,您将待删除的单个字符的索引传递给
.delete()。例如,以下代码从文本框中删除第一个字符H:
>>> text_box.delete("1.0")
窗口中的第一行文本现在显示为ello:
对于双参数版本,您传递两个索引来删除从第一个索引开始到第二个索引的字符范围,但不包括第二个索引。
例如,要删除文本框第一行剩余的ello,请使用索引"1.0"和"1.4":
>>> text_box.delete("1.0", "1.4")注意,文本从第一行开始就消失了。这就在第二行的单词
World后面留下了一个空行:
即使看不到,第一行还是有个人物。是换行符!您可以使用
.get()验证这一点:
>>> text_box.get("1.0")
'\n'
如果删除该字符,文本框的其余内容将上移一行:
>>> text_box.delete("1.0")现在,
World位于文本框的第一行:
尝试清除文本框中的其余文本。将
"1.0"设置为开始索引,并将tk.END用于第二个索引:
>>> text_box.delete("1.0", tk.END)
文本框现在是空的:
您可以使用.insert()将文本插入文本框:
>>> text_box.insert("1.0", "Hello")这将在文本框的开头插入单词
Hello,使用与.get()相同的"<line>.<column>"格式来指定插入位置:
看看如果你试图在第二行插入单词
World会发生什么:
>>> text_box.insert("2.0", "World")
不是在第二行插入文本,而是在第一行的末尾插入文本:
如果您想在新行上插入文本,那么您需要在要插入的字符串中手动插入一个换行符:
>>> text_box.insert("2.0", "\nWorld")现在
World在文本框的第二行:
.insert()会做两件事之一:
- 在指定位置插入文本,如果该位置或其后已经有文本。
- 如果字符数大于文本框中最后一个字符的索引,则将文本追加到指定行。
试图跟踪最后一个字符的索引通常是不切实际的。在
Text小部件末尾插入文本的最佳方式是将tk.END传递给.insert()的第一个参数:
>>> text_box.insert(tk.END, "Put me at the end!")
如果您想将文本放在新的一行,请不要忘记在文本的开头包含换行符(\n):
>>> text_box.insert(tk.END, "\nPut me on a new line!")
Label、Button、Entry和Text小部件只是 Tkinter 中可用的几个小部件。还有其他几个,包括复选框、单选按钮、滚动条和进度条的小部件。有关所有可用小部件的更多信息,请参见附加资源部分的附加小部件列表。使用
Frame小部件将小部件分配给框架在本教程中,您将只使用五个小部件:
LabelButtonEntryTextFrame这是到目前为止你已经看到的四个插件和
Frame插件。Frame小部件对于组织应用程序中小部件的布局很重要。在您详细了解小部件的视觉呈现之前,请仔细看看
Frame小部件是如何工作的,以及如何为它们分配其他小部件。以下脚本创建一个空白的Frame小部件,并将其分配给主应用程序窗口:import tkinter as tk window = tk.Tk() frame = tk.Frame() frame.pack() window.mainloop()
frame.pack()将框架装入窗口,使窗口尽可能小以包含框架。当您运行上面的脚本时,您会得到一些非常无趣的输出:
一个空的
Frame窗口小部件实际上是不可见的。框架最好被认为是其他部件的容器。您可以通过设置小部件的master属性将小部件分配给框架:frame = tk.Frame() label = tk.Label(master=frame)为了感受一下这是如何工作的,编写一个脚本来创建两个名为
frame_a和frame_b的Frame小部件。在这个脚本中,frame_a包含一个带有文本"I'm in Frame A"的标签,frame_b包含标签"I'm in Frame B"。有一种方法可以做到这一点:import tkinter as tk window = tk.Tk() frame_a = tk.Frame() frame_b = tk.Frame() label_a = tk.Label(master=frame_a, text="I'm in Frame A") label_a.pack() label_b = tk.Label(master=frame_b, text="I'm in Frame B") label_b.pack() frame_a.pack() frame_b.pack() window.mainloop()注意
frame_a是在frame_b之前装入窗口的。打开的窗口显示frame_b标签上方的frame_a标签:
现在看看当您交换
frame_a.pack()和frame_b.pack()的顺序时会发生什么:import tkinter as tk window = tk.Tk() frame_a = tk.Frame() label_a = tk.Label(master=frame_a, text="I'm in Frame A") label_a.pack() frame_b = tk.Frame() label_b = tk.Label(master=frame_b, text="I'm in Frame B") label_b.pack() # Swap the order of `frame_a` and `frame_b` frame_b.pack() frame_a.pack() window.mainloop()输出如下所示:
现在
label_b在上面。由于label_b被分配给frame_b,所以frame_b被定位到哪里,它就移动到哪里。您已经了解的所有四种小部件类型—
Label、Button、Entry和Text—都有一个在实例化它们时设置的master属性。这样,您可以控制将小部件分配给哪个Frame。小部件非常适合以逻辑方式组织其他小部件。相关的窗口小部件可以被分配到同一个框架中,这样,如果框架在窗口中移动,那么相关的窗口小部件就保持在一起。注意:如果在创建新的小部件实例时省略了
master参数,那么默认情况下,它将被放置在顶层窗口中。除了对你的小部件进行逻辑分组,
Frame小部件还可以给你的应用程序的视觉呈现添加一点亮点。继续阅读,了解如何为Frame小部件创建各种边框。用浮雕调整框架外观
Frame小部件可以配置一个relief属性,在框架周围创建一个边框。您可以将relief设置为以下任意值:
tk.FLAT: 无边框效果(默认值)tk.SUNKEN: 产生凹陷效果tk.RAISED: 产生凸起效果tk.GROOVE: 创建凹槽边框效果tk.RIDGE: 产生脊状效果要应用边框效果,必须将
borderwidth属性设置为大于1的值。该属性以像素为单位调整边框的宽度。感受每种效果的最佳方式是自己去看。下面的脚本将五个Frame小部件打包到一个窗口中,每个小部件的relief参数都有不同的值:1import tkinter as tk 2 3border_effects = { 4 "flat": tk.FLAT, 5 "sunken": tk.SUNKEN, 6 "raised": tk.RAISED, 7 "groove": tk.GROOVE, 8 "ridge": tk.RIDGE, 9} 10 11window = tk.Tk() 12 13for relief_name, relief in border_effects.items(): 14 frame = tk.Frame(master=window, relief=relief, borderwidth=5) 15 frame.pack(side=tk.LEFT) 16 label = tk.Label(master=frame, text=relief_name) 17 label.pack() 18 19window.mainloop()以下是该脚本的详细内容:
第 3 行到第 9 行创建一个字典,其关键字是 Tkinter 中可用的不同浮雕效果的名称。这些值是相应的 Tkinter 对象。这个字典被分配给
border_effects变量。第 13 行开始一个
for循环来循环遍历border_effects字典中的每个条目。第 14 行创建一个新的
Frame小部件,并将其分配给window对象。将relief属性设置为border_effects字典中相应的浮雕,将border属性设置为5,效果可见。15 号线使用
.pack()将Frame打包到窗口中。side关键字参数告诉 Tkinter 在哪个方向打包frame对象。在下一节中,您将看到更多关于这是如何工作的内容。第 16 行和第 17 行创建一个
Label小部件来显示浮雕的名称,并将其打包到您刚刚创建的frame对象中。上述脚本生成的窗口如下所示:
在此图像中,您可以看到以下效果:
tk.FLAT创建看似平面的帧。tk.SUNKEN添加边框,使框架看起来像凹进了窗口。tk.RAISED给框架一个边框,让它看起来突出于屏幕。tk.GROOVE在原本平坦的框架周围添加一个看起来像凹槽的边框。tk.RIDGE给人一种边框边缘凸起的感觉。这些效果给你的 Python GUI Tkinter 应用程序增加了一点视觉吸引力。
了解小部件命名约定
当你创建一个小部件时,你可以给它起任何你喜欢的名字,只要它是一个有效的 Python 标识符。在分配给小部件实例的变量名中包含小部件类的名称通常是一个好主意。例如,如果使用一个
Label小部件来显示用户名,那么您可以将这个小部件命名为label_user_name。一个用于收集用户年龄的Entry小部件可能被称为entry_age。注意:有时候,你可以定义一个新的小部件,而不用把它赋给一个变量。您将在同一行代码中直接调用它的
.pack()方法:


>>> tk.Label(text="Hello, Tkinter").pack()
当您以后不打算引用小部件的实例时,这可能会有所帮助。由于自动内存管理,Python 通常会垃圾收集这种未分配的对象,但是 Tkinter 通过在内部注册每个新的小部件来防止这种情况。
当您在变量名中包含小部件类名时,您可以帮助自己和任何需要阅读您的代码的人理解变量名所指的小部件类型。然而,使用 widget 类的全名会导致很长的变量名,所以您可能希望采用一种简称来引用每种 widget 类型。在本教程的其余部分,您将使用以下简写前缀来命名小部件:
| 小部件类 | 变量名前缀 | 例子 |
|---|---|---|
Label |
lbl |
lbl_name |
Button |
btn |
btn_submit |
Entry |
ent |
ent_age |
Text |
txt |
txt_notes |
Frame |
frm |
frm_address |
在本节中,您学习了如何创建窗口、使用小部件以及使用框架。此时,您可以创建一些显示消息的普通窗口,但是您还没有创建一个完整的应用程序。在下一节中,您将学习如何使用 Tkinter 强大的几何图形管理器来控制应用程序的布局。
检查你的理解能力
展开下面的代码块,做一个练习来检查您的理解:
编写一个完整的脚本,显示一个 40 个文本单位宽、白底黑字的Entry小部件。使用.insert()在小部件中显示文本What is your name?。
输出窗口应该如下所示:
现在试试这个练习。
您可以展开下面的代码块来查看解决方案:
有几种方法可以解决这个问题。这里有一个解决方案,使用bg和fg参数来设置Entry小部件的背景和前景色:
import tkinter as tk
window = tk.Tk()
entry = tk.Entry(width=40, bg="white", fg="black")
entry.pack()
entry.insert(0, "What is your name?")
window.mainloop()
这个解决方案很棒,因为它明确地为Entry小部件设置了背景和前景色。
在大多数系统中,Entry小部件的默认背景色是白色,默认前景色是黑色。因此,您可能能够生成省略了bg和fg参数的同一个窗口:
import tkinter as tk
window = tk.Tk()
entry = tk.Entry(width=40)
entry.pack()
entry.insert(0, "What is your name?")
window.mainloop()
请记住,您的代码可能看起来不同。
当你准备好了,你可以进入下一部分。
用几何图形管理器控制布局
到目前为止,您已经使用.pack()向窗口和Frame窗口添加了小部件,但是您还没有了解这个方法到底是做什么的。让我们把事情弄清楚!Tkinter 中的应用布局由几何图形管理器控制。虽然.pack()是几何管理者的一个例子,但它不是唯一的一个。Tkinter 还有另外两个:
.place().grid()
应用程序中的每个窗口或Frame只能使用一个几何管理器。但是,不同的框架可以使用不同的几何管理器,即使它们使用另一个几何管理器被指定给框架或窗口。先来仔细看看.pack()。
.pack()几何图形管理器
.pack()几何图形管理器使用打包算法将小部件以指定的顺序放置在Frame或窗口中。对于给定的小部件,打包算法有两个主要步骤:
- 计算一个名为 parcel 的矩形区域,其高度(或宽度)刚好足以容纳小部件,并用空白空间填充窗口中剩余的宽度(或高度)。
- 除非指定了不同的位置,否则将微件置于宗地中心。
很强大,但是很难想象。感受.pack()的最好方法是看一些例子。看看当你把三个.pack()小部件变成一个Frame时会发生什么:
import tkinter as tk
window = tk.Tk()
frame1 = tk.Frame(master=window, width=100, height=100, bg="red")
frame1.pack()
frame2 = tk.Frame(master=window, width=50, height=50, bg="yellow")
frame2.pack()
frame3 = tk.Frame(master=window, width=25, height=25, bg="blue")
frame3.pack()
window.mainloop()
默认情况下,.pack()将每个Frame放置在前一个Frame的下方,按照它们被分配到窗口的顺序:

每个Frame被放置在最高的可用位置。所以,红色的Frame放在窗口的顶部。然后黄色的Frame放在红色的下面,蓝色的Frame放在黄色的下面。
有三个不可见的包裹,每个包裹包含三个Frame部件中的一个。每个包裹和窗户一样宽,和它所装的Frame一样高。因为在为每个Frame,调用.pack()时没有指定锚点,所以它们都在它们的包裹内居中。这就是为什么每个Frame都在窗口中央的原因。
.pack()接受一些关键字参数,以便更精确地配置小部件的位置。例如,您可以设置 fill 关键字参数来指定帧应该填充的方向。选项有tk.X填充水平方向、tk.Y填充垂直方向、tk.BOTH填充两个方向。下面是如何堆叠三个框架,使每个框架水平填充整个窗口:
import tkinter as tk
window = tk.Tk()
frame1 = tk.Frame(master=window, height=100, bg="red")
frame1.pack(fill=tk.X)
frame2 = tk.Frame(master=window, height=50, bg="yellow")
frame2.pack(fill=tk.X)
frame3 = tk.Frame(master=window, height=25, bg="blue")
frame3.pack(fill=tk.X)
window.mainloop()
注意,width没有在任何Frame小部件上设置。width不再必要,因为每一帧都设置.pack()为水平填充,覆盖你可能设置的任何宽度。
该脚本生成的窗口如下所示:
用.pack()填充窗口的一个好处是,填充对窗口大小的响应。尝试扩大前一个脚本生成的窗口,看看这是如何工作的。当您加宽窗口时,三个Frame小部件的宽度会增加以填满窗口:
不过,请注意,Frame小部件不会在垂直方向上扩展。
.pack()的 side 关键字参数指定小工具应放置在窗口的哪一侧。以下是可用的选项:
tk.TOPtk.BOTTOMtk.LEFTtk.RIGHT
如果你不设置side,那么.pack()将自动使用tk.TOP并在窗口顶部放置新的窗口小部件,或者在窗口的最顶端没有被小部件占据的部分。例如,以下脚本从左到右并排放置三个框架,并扩展每个框架以垂直填充窗口:
import tkinter as tk
window = tk.Tk()
frame1 = tk.Frame(master=window, width=200, height=100, bg="red")
frame1.pack(fill=tk.Y, side=tk.LEFT)
frame2 = tk.Frame(master=window, width=100, bg="yellow")
frame2.pack(fill=tk.Y, side=tk.LEFT)
frame3 = tk.Frame(master=window, width=50, bg="blue")
frame3.pack(fill=tk.Y, side=tk.LEFT)
window.mainloop()
这一次,您必须在至少一个框架上指定height关键字参数,以强制窗口具有一定的高度。
生成的窗口如下所示:

就像您设置fill=tk.X在水平调整窗口大小时使框架响应一样,您可以设置fill=tk.Y在垂直调整窗口大小时使框架响应:

为了使布局真正具有响应性,您可以使用width和height属性来设置框架的初始大小。然后,将.pack()的fill关键字参数设置为tk.BOTH,将expand关键字参数设置为True:
import tkinter as tk
window = tk.Tk()
frame1 = tk.Frame(master=window, width=200, height=100, bg="red")
frame1.pack(fill=tk.BOTH, side=tk.LEFT, expand=True)
frame2 = tk.Frame(master=window, width=100, bg="yellow")
frame2.pack(fill=tk.BOTH, side=tk.LEFT, expand=True)
frame3 = tk.Frame(master=window, width=50, bg="blue")
frame3.pack(fill=tk.BOTH, side=tk.LEFT, expand=True)
window.mainloop()
当您运行上面的脚本时,您将看到一个窗口,该窗口最初看起来与您在前面的示例中生成的窗口相同。不同之处在于,现在您可以随意调整窗口大小,框架会相应地扩展并填充窗口:

相当酷!
.place()几何图形管理器
你可以使用.place()来控制窗口中的精确位置或者Frame。您必须提供两个关键字参数,x和y,它们指定小部件左上角的 x 和 y 坐标。x和y都是以像素为单位,而不是文本单位。
记住原点,其中x和y都是0,是Frame或窗口的左上角。因此,您可以将.place()的y参数视为距离窗口顶部的像素数,将x参数视为距离窗口左边缘的像素数。
下面是一个关于.place()几何图形管理器如何工作的例子:
1import tkinter as tk
2
3window = tk.Tk()
4
5frame = tk.Frame(master=window, width=150, height=150)
6frame.pack()
7
8label1 = tk.Label(master=frame, text="I'm at (0, 0)", bg="red")
9label1.place(x=0, y=0)
10
11label2 = tk.Label(master=frame, text="I'm at (75, 75)", bg="yellow")
12label2.place(x=75, y=75)
13
14window.mainloop()
下面是这段代码的工作原理:
- 第 5 行和第 6 行创建一个名为
frame的新的Frame小部件,测量150像素宽和150像素高,并用.pack()将其打包到窗口中。 - 第 8 行和第 9 行创建一个名为
label1的红色背景的新Label,并将其放置在frame1的位置(0,0)。 - 第 11 行和第 12 行创建第二个
Label,名为label2,背景为黄色,并将其放置在frame1的位置(75,75)。
下面是代码生成的窗口:
请注意,如果您在使用不同字体大小和样式的不同操作系统上运行此代码,那么第二个标签可能会被窗口边缘部分遮挡。这就是为什么.place()不常使用的原因。除此之外,它还有两个主要缺点:
- 使用
.place()很难管理布局。如果您的应用程序有很多小部件,这一点尤其正确。 - 用
.place()创建的布局没有响应。它们不会随着窗口大小的改变而改变。
跨平台 GUI 开发的一个主要挑战是让布局无论在哪个平台上看起来都好看,而对于做出响应性和跨平台的布局来说,.place()不是一个好的选择。
这并不是说你不应该使用.place()!在某些情况下,这可能正是你所需要的。例如,如果您正在为地图创建 GUI 界面,那么.place()可能是确保小部件在地图上以正确的距离放置的最佳选择。
.pack()通常是比.place()更好的选择,但即使是.pack()也有一些缺点。窗口小部件的位置取决于调用.pack()的顺序,因此在没有完全理解控制布局的代码的情况下,很难修改现有的应用程序。.grid()几何图形管理器解决了很多这样的问题,你将在下一节看到。
.grid()几何图形管理器
您可能最常使用的几何管理器是.grid(),它以一种更容易理解和维护的格式提供了.pack()的所有功能。
.grid()的工作原理是将一个窗口或Frame分割成行和列。通过调用.grid()并将行和列索引分别传递给row和column关键字参数,可以指定小部件的位置。行索引和列索引都从0开始,因此1的行索引和2的列索引告诉.grid()将小部件放在第二行的第三列。
以下脚本创建了一个 3 × 3 的框架网格,其中包含了Label小部件:
import tkinter as tk
window = tk.Tk()
for i in range(3):
for j in range(3):
frame = tk.Frame(
master=window,
relief=tk.RAISED,
borderwidth=1
)
frame.grid(row=i, column=j)
label = tk.Label(master=frame, text=f"Row {i}\nColumn {j}")
label.pack()
window.mainloop()
下面是生成的窗口的样子:
在本例中,您使用了两个几何体管理器。每个框架通过.grid()几何图形管理器连接到window:
import tkinter as tk
window = tk.Tk()
for i in range(3):
for j in range(3):
frame = tk.Frame(
master=window,
relief=tk.RAISED,
borderwidth=1
)
frame.grid(row=i, column=j) label = tk.Label(master=frame, text=f"Row {i}\nColumn {j}")
label.pack()
window.mainloop()
每个label通过.pack()连接到其主Frame:
import tkinter as tk
window = tk.Tk()
for i in range(3):
for j in range(3):
frame = tk.Frame(
master=window,
relief=tk.RAISED,
borderwidth=1
)
frame.grid(row=i, column=j)
label = tk.Label(master=frame, text=f"Row {i}\nColumn {j}")
label.pack()
window.mainloop()
这里要意识到的重要一点是,即使在每个Frame对象上调用了.grid(),几何管理器也适用于window对象。类似地,每个frame的布局由.pack()几何图形管理器控制。
上例中的框架紧密相邻放置。要在每个框架周围添加一些空间,可以设置网格中每个单元格的填充。填充只是一些空白空间,围绕着一个小部件,在视觉上把它的内容分开。
两种类型的衬垫是外部和内部衬垫。外部填充在网格单元的外部增加了一些空间。它由.grid()的两个关键字参数控制:
padx在水平方向添加填充。pady在垂直方向添加填充。
padx和pady都是以像素度量的,而不是文本单位,因此将它们设置为相同的值将在两个方向上创建相同的填充量。尝试在前面示例中的框架外部添加一些填充:
import tkinter as tk
window = tk.Tk()
for i in range(3):
for j in range(3):
frame = tk.Frame(
master=window,
relief=tk.RAISED,
borderwidth=1
)
frame.grid(row=i, column=j, padx=5, pady=5) label = tk.Label(master=frame, text=f"Row {i}\nColumn {j}")
label.pack()
window.mainloop()
这是生成的窗口:
.pack()也有padx和pady参数。以下代码与前面的代码几乎相同,除了您在每个标签周围的x和y方向添加了五个像素的额外填充:
import tkinter as tk
window = tk.Tk()
for i in range(3):
for j in range(3):
frame = tk.Frame(
master=window,
relief=tk.RAISED,
borderwidth=1
)
frame.grid(row=i, column=j, padx=5, pady=5)
label = tk.Label(master=frame, text=f"Row {i}\nColumn {j}")
label.pack(padx=5, pady=5)
window.mainloop()
在Label小部件周围的额外填充给网格中的每个单元格在Frame边框和标签中的文本之间留有一点空间:
看起来很不错!但是,如果你尝试向任何方向扩展窗口,你会发现布局没有很好的响应:
当窗口扩展时,整个网格停留在左上角。
通过在window对象上使用.columnconfigure()和.rowconfigure(),你可以调整网格的行和列在窗口调整大小时的增长方式。记住,网格是附属于window的,即使你在每个Frame小部件上调用.grid()。.columnconfigure()和.rowconfigure()都有三个基本参数:
- Index: 要配置的网格列或行的索引,或者同时配置多行或多列的索引列表
- Weight: 一个名为
weight的关键字参数,它确定该列或行相对于其他列和行应该如何响应窗口大小调整 - 最小尺寸:一个名为
minsize的关键字参数,以像素为单位设置行高或列宽的最小尺寸
默认情况下,weight被设置为0,这意味着当窗口调整大小时,列或行不会扩展。如果每一列或每一行都被赋予一个1的权重,那么它们都以相同的速度增长。如果一列的权重为1,另一列的权重为2,那么第二列的膨胀速度是第一列的两倍。调整前面的脚本以更好地处理窗口大小调整:
import tkinter as tk
window = tk.Tk()
for i in range(3):
window.columnconfigure(i, weight=1, minsize=75) window.rowconfigure(i, weight=1, minsize=50)
for j in range(0, 3):
frame = tk.Frame(
master=window,
relief=tk.RAISED,
borderwidth=1
)
frame.grid(row=i, column=j, padx=5, pady=5)
label = tk.Label(master=frame, text=f"Row {i}\nColumn {j}")
label.pack(padx=5, pady=5)
window.mainloop()
.columnconfigure()和.rowconfigure()被放置在外部for回路的主体中。您可以在for循环之外显式配置每一列和每一行,但是这需要编写额外的六行代码。
在循环的每次迭代中,第i列和行被配置为具有权重1。这确保了无论何时调整窗口大小时,行和列都以相同的速率扩展。每列的minsize参数被设置为75,每行的50。这确保了Label小部件总是显示它的文本而不截断任何字符,即使窗口非常小。
结果是网格布局随着窗口大小的调整而平滑地扩展和收缩:
亲自尝试一下,感受一下它是如何工作的!摆弄一下weight和minsize参数,看看它们如何影响网格。
默认情况下,小部件在其网格单元中居中。例如,下面的代码创建了两个Label小部件,并将它们放在一个一列两行的网格中:
import tkinter as tk
window = tk.Tk()
window.columnconfigure(0, minsize=250)
window.rowconfigure([0, 1], minsize=100)
label1 = tk.Label(text="A")
label1.grid(row=0, column=0)
label2 = tk.Label(text="B")
label2.grid(row=1, column=0)
window.mainloop()
每个网格单元的宽度为250像素,高度为100像素。标签放置在每个单元格的中央,如下图所示:
您可以使用sticky参数更改网格单元内每个标签的位置,该参数接受包含一个或多个以下字母的字符串:
"n"或"N"向单元格中上部对齐"e"或"E"向单元格的右中央对齐"s"或"S"向单元格的下中部对齐"w"或"W"向单元格的左侧居中对齐
字母"n"、"s"、"e"和"w"来自北、南、东、西四个主要方向。在前面的代码中,将两个标签上的sticky设置为"n"会将每个标签定位在其网格单元的顶部中心:
import tkinter as tk
window = tk.Tk()
window.columnconfigure(0, minsize=250)
window.rowconfigure([0, 1], minsize=100)
label1 = tk.Label(text="A")
label1.grid(row=0, column=0, sticky="n")
label2 = tk.Label(text="B")
label2.grid(row=1, column=0, sticky="n")
window.mainloop()
以下是输出结果:
您可以在单个字符串中组合多个字母,以将每个标签放置在其网格单元格的角上:
import tkinter as tk
window = tk.Tk()
window.columnconfigure(0, minsize=250)
window.rowconfigure([0, 1], minsize=100)
label1 = tk.Label(text="A")
label1.grid(row=0, column=0, sticky="ne")
label2 = tk.Label(text="B")
label2.grid(row=1, column=0, sticky="sw")
window.mainloop()
在这个例子中,label1的sticky参数被设置为"ne",这将标签放置在其网格单元的右上角。通过"sw"到sticky,使label2位于左下角。这是它在窗口中的样子:
当用sticky定位一个小部件时,小部件本身的大小刚好可以容纳任何文本和其他内容。它不会填满整个网格单元。为了填充网格,您可以指定"ns"强制小部件在垂直方向填充单元格,或者指定"ew"在水平方向填充单元格。要填充整个单元格,将sticky设置为"nsew"。以下示例说明了这些选项中的每一个:
import tkinter as tk
window = tk.Tk()
window.rowconfigure(0, minsize=50)
window.columnconfigure([0, 1, 2, 3], minsize=50)
label1 = tk.Label(text="1", bg="black", fg="white")
label2 = tk.Label(text="2", bg="black", fg="white")
label3 = tk.Label(text="3", bg="black", fg="white")
label4 = tk.Label(text="4", bg="black", fg="white")
label1.grid(row=0, column=0)
label2.grid(row=0, column=1, sticky="ew")
label3.grid(row=0, column=2, sticky="ns")
label4.grid(row=0, column=3, sticky="nsew")
window.mainloop()
下面是输出的样子:

上面的例子说明了.grid()几何图形管理器的sticky参数可以用来实现与.pack()几何图形管理器的fill参数相同的效果。下表总结了sticky和fill参数之间的对应关系:
.grid() |
.pack() |
|---|---|
sticky="ns" |
fill=tk.Y |
sticky="ew" |
fill=tk.X |
sticky="nsew" |
fill=tk.BOTH |
.grid()是一个强大的几何图形管理器。它通常比.pack()更容易理解,也比.place()更灵活。当你创建新的 Tkinter 应用时,你应该考虑使用.grid()作为你的主要几何管理器。
注意: .grid()提供了比你在这里看到的更多的灵活性。例如,您可以将单元格配置为跨越多行和多列。更多信息,请查看 TkDocs 教程的网格几何管理器章节。
现在您已经掌握了 Python GUI 框架 Tkinter 的几何管理器的基础,下一步是将动作分配给按钮,使您的应用程序变得生动。
检查你的理解能力
展开下面的代码块,做一个练习来检查您的理解:
下面是用 Tkinter 制作的地址条目表单的图像:
编写一个完整的脚本来重新创建窗口。你可以使用任何你喜欢的几何图形管理器。
您可以展开下面的代码块来查看解决方案:
有许多不同的方法来解决这个问题。如果您的解决方案生成的窗口与练习语句中的窗口相同,那么恭喜您!您已经成功完成了练习!下面,你可以看看两个使用.grid()几何图形管理器的解决方案。
一种解决方案是用每个字段所需的设置创建一个Label和Entry小部件:
import tkinter as tk
# Create a new window with the title "Address Entry Form"
window = tk.Tk()
window.title("Address Entry Form")
# Create a new frame `frm_form` to contain the Label
# and Entry widgets for entering address information
frm_form = tk.Frame(relief=tk.SUNKEN, borderwidth=3)
# Pack the frame into the window
frm_form.pack()
# Create the Label and Entry widgets for "First Name"
lbl_first_name = tk.Label(master=frm_form, text="First Name:")
ent_first_name = tk.Entry(master=frm_form, width=50)
# Use the grid geometry manager to place the Label and
# Entry widgets in the first and second columns of the
# first row of the grid
lbl_first_name.grid(row=0, column=0, sticky="e")
ent_first_name.grid(row=0, column=1)
# Create the Label and Entry widgets for "Last Name"
lbl_last_name = tk.Label(master=frm_form, text="Last Name:")
ent_last_name = tk.Entry(master=frm_form, width=50)
# Place the widgets in the second row of the grid
lbl_last_name.grid(row=1, column=0, sticky="e")
ent_last_name.grid(row=1, column=1)
# Create the Label and Entry widgets for "Address Line 1"
lbl_address1 = tk.Label(master=frm_form, text="Address Line 1:")
ent_address1 = tk.Entry(master=frm_form, width=50)
# Place the widgets in the third row of the grid
lbl_address1.grid(row=2, column=0, sticky="e")
ent_address1.grid(row=2, column=1)
# Create the Label and Entry widgets for "Address Line 2"
lbl_address2 = tk.Label(master=frm_form, text="Address Line 2:")
ent_address2 = tk.Entry(master=frm_form, width=50)
# Place the widgets in the fourth row of the grid
lbl_address2.grid(row=3, column=0, sticky=tk.E)
ent_address2.grid(row=3, column=1)
# Create the Label and Entry widgets for "City"
lbl_city = tk.Label(master=frm_form, text="City:")
ent_city = tk.Entry(master=frm_form, width=50)
# Place the widgets in the fifth row of the grid
lbl_city.grid(row=4, column=0, sticky=tk.E)
ent_city.grid(row=4, column=1)
# Create the Label and Entry widgets for "State/Province"
lbl_state = tk.Label(master=frm_form, text="State/Province:")
ent_state = tk.Entry(master=frm_form, width=50)
# Place the widgets in the sixth row of the grid
lbl_state.grid(row=5, column=0, sticky=tk.E)
ent_state.grid(row=5, column=1)
# Create the Label and Entry widgets for "Postal Code"
lbl_postal_code = tk.Label(master=frm_form, text="Postal Code:")
ent_postal_code = tk.Entry(master=frm_form, width=50)
# Place the widgets in the seventh row of the grid
lbl_postal_code.grid(row=6, column=0, sticky=tk.E)
ent_postal_code.grid(row=6, column=1)
# Create the Label and Entry widgets for "Country"
lbl_country = tk.Label(master=frm_form, text="Country:")
ent_country = tk.Entry(master=frm_form, width=50)
# Place the widgets in the eight row of the grid
lbl_country.grid(row=7, column=0, sticky=tk.E)
ent_country.grid(row=7, column=1)
# Create a new frame `frm_buttons` to contain the
# Submit and Clear buttons. This frame fills the
# whole window in the horizontal direction and has
# 5 pixels of horizontal and vertical padding.
frm_buttons = tk.Frame()
frm_buttons.pack(fill=tk.X, ipadx=5, ipady=5)
# Create the "Submit" button and pack it to the
# right side of `frm_buttons`
btn_submit = tk.Button(master=frm_buttons, text="Submit")
btn_submit.pack(side=tk.RIGHT, padx=10, ipadx=10)
# Create the "Clear" button and pack it to the
# right side of `frm_buttons`
btn_clear = tk.Button(master=frm_buttons, text="Clear")
btn_clear.pack(side=tk.RIGHT, ipadx=10)
# Start the application
window.mainloop()
这个解决方案没什么问题。有点长,但是一切都很露骨。如果你想改变一些东西,那么很清楚地看到具体在哪里这样做。
也就是说,通过认识到每个Entry具有相同的宽度,并且对于每个Label您所需要的只是文本,可以大大缩短解决方案:
import tkinter as tk
# Create a new window with the title "Address Entry Form"
window = tk.Tk()
window.title("Address Entry Form")
# Create a new frame `frm_form` to contain the Label
# and Entry widgets for entering address information
frm_form = tk.Frame(relief=tk.SUNKEN, borderwidth=3)
# Pack the frame into the window
frm_form.pack()
# List of field labels
labels = [
"First Name:",
"Last Name:",
"Address Line 1:",
"Address Line 2:",
"City:",
"State/Province:",
"Postal Code:",
"Country:",
]
# Loop over the list of field labels
for idx, text in enumerate(labels):
# Create a Label widget with the text from the labels list
label = tk.Label(master=frm_form, text=text)
# Create an Entry widget
entry = tk.Entry(master=frm_form, width=50)
# Use the grid geometry manager to place the Label and
# Entry widgets in the row whose index is idx
label.grid(row=idx, column=0, sticky="e")
entry.grid(row=idx, column=1)
# Create a new frame `frm_buttons` to contain the
# Submit and Clear buttons. This frame fills the
# whole window in the horizontal direction and has
# 5 pixels of horizontal and vertical padding.
frm_buttons = tk.Frame()
frm_buttons.pack(fill=tk.X, ipadx=5, ipady=5)
# Create the "Submit" button and pack it to the
# right side of `frm_buttons`
btn_submit = tk.Button(master=frm_buttons, text="Submit")
btn_submit.pack(side=tk.RIGHT, padx=10, ipadx=10)
# Create the "Clear" button and pack it to the
# right side of `frm_buttons`
btn_clear = tk.Button(master=frm_buttons, text="Clear")
btn_clear.pack(side=tk.RIGHT, ipadx=10)
# Start the application
window.mainloop()
在这个解决方案中,一个列表用于存储表单中每个标签的字符串。它们按照每个表单域应该出现的顺序存储。然后, enumerate() 从labels列表中的每个值获取索引和字符串。
当你准备好了,你可以进入下一部分。
让您的应用程序具有交互性
到目前为止,您已经非常了解如何使用 Tkinter 创建一个窗口,添加一些小部件,以及控制应用程序布局。这很好,但是应用程序不应该只是看起来很好——它们实际上需要做一些事情!在本节中,您将学习如何通过在特定的事件发生时执行动作来激活您的应用程序。
使用事件和事件处理程序
创建 Tkinter 应用程序时,必须调用window.mainloop()来启动事件循环。在事件循环期间,您的应用程序检查事件是否已经发生。如果是,那么它将执行一些代码作为响应。
Tkinter 为您提供了事件循环,因此您不必自己编写任何检查事件的代码。但是,您必须编写将被执行以响应事件的代码。在 Tkinter 中,为应用程序中使用的事件编写名为事件处理程序的函数。
注意:一个事件是在事件循环期间发生的任何可能触发应用程序中某些行为的动作,比如当一个键或鼠标按钮被按下时。
当一个事件发生时,一个事件对象被发出,这意味着一个代表该事件的类的实例被创建。您不需要担心自己实例化这些类。Tkinter 将自动为您创建事件类的实例。
为了更好地理解 Tkinter 的事件循环是如何工作的,您将编写自己的事件循环。这样,您可以看到 Tkinter 的事件循环如何适合您的应用程序,以及哪些部分需要您自己编写。
假设有一个包含事件对象的名为events的列表。每当程序中发生一个事件时,一个新的事件对象会自动追加到events中。您不需要实现这种更新机制。在这个概念性的例子中,它会自动发生。使用无限循环,您可以不断地检查events中是否有任何事件对象:
# Assume that this list gets updated automatically
events = []
# Run the event loop
while True:
# If the event list is empty, then no events have occurred
# and you can skip to the next iteration of the loop
if events == []:
continue
# If execution reaches this point, then there is at least one
# event object in the event list
event = events[0]
现在,您创建的事件循环不会对event做任何事情。让我们改变这一点。假设您的应用程序需要响应按键。您需要检查event是否是由用户按下键盘上的一个键生成的,如果是,则将event传递给按键的事件处理函数。
假设event有一个设置为字符串"keypress"的.type属性(如果该事件是一个按键事件对象)和一个包含被按下按键的字符的.char属性。创建一个新的handle_keypress()函数并更新你的事件循环代码:
events = []
# Create an event handler def handle_keypress(event):
"""Print the character associated to the key pressed""" print(event.char)
while True:
if events == []:
continue
event = events[0]
# If event is a keypress event object
if event.type == "keypress":
# Call the keypress event handler
handle_keypress(event)
当您调用window.mainloop()时,类似上面的循环会自动运行。这个方法负责循环的两个部分:
- 它维护一个已经发生的事件的列表。
- 每当一个新事件被添加到列表中时,它就运行一个事件处理程序。
更新您的事件循环以使用window.mainloop()而不是您自己的事件循环:
import tkinter as tk
# Create a window object window = tk.Tk()
# Create an event handler
def handle_keypress(event):
"""Print the character associated to the key pressed"""
print(event.char)
# Run the event loop window.mainloop()
为你做了很多,但是上面的代码缺少了一些东西。Tkinter 怎么知道什么时候用handle_keypress()?Tkinter 小部件有一个名为.bind()的方法就是为了这个目的。
使用.bind()
要在小部件上发生事件时调用事件处理程序,请使用.bind()。事件处理程序被称为绑定到事件,因为它在每次事件发生时被调用。您将继续上一节的按键示例,并使用.bind()将handle_keypress()绑定到按键事件:
import tkinter as tk
window = tk.Tk()
def handle_keypress(event):
"""Print the character associated to the key pressed"""
print(event.char)
# Bind keypress event to handle_keypress() window.bind("<Key>", handle_keypress)
window.mainloop()
这里,使用window.bind()将handle_keypress()事件处理程序绑定到一个"<Key>"事件。当应用程序运行时,只要按下一个键,你的程序就会打印出所按下的键的字符。
注意:上述程序的输出是而不是打印在 Tkinter 应用程序窗口中。它被打印到标准输出流(stdout) 。
如果你在空闲状态下运行程序,那么你会在交互窗口中看到输出。如果您从终端运行程序,那么您应该在终端上看到输出。
.bind()总是需要至少两个参数:
- 一个由形式为
"<event_name>"的字符串表示的事件,其中event_name可以是 Tkinter 的任何事件 - 一个事件处理程序,它是事件发生时要调用的函数的名称
事件处理程序被绑定到调用.bind()的小部件上。当调用事件处理程序时,事件对象被传递给事件处理程序函数。
在上面的例子中,事件处理程序被绑定到窗口本身,但是您可以将事件处理程序绑定到应用程序中的任何小部件。例如,您可以将一个事件处理程序绑定到一个Button小部件,每当按钮被按下时,它就会执行一些操作:
def handle_click(event):
print("The button was clicked!")
button = tk.Button(text="Click me!")
button.bind("<Button-1>", handle_click)
在这个例子中,button小部件上的"<Button-1>"事件被绑定到handle_click事件处理程序。当鼠标在小部件上时,只要按下鼠标左键,就会发生"<Button-1>"事件。鼠标点击还有其他事件,包括鼠标中键的"<Button-2>"和鼠标右键的"<Button-3>"。
注:常用事件列表请参见 Tkinter 8.5 参考的事件类型部分。
您可以使用.bind()将任何事件处理程序绑定到任何类型的小部件,但是有一种更直接的方法可以使用Button小部件的command属性将事件处理程序绑定到按钮点击。
使用command
每个Button小部件都有一个command属性,您可以将其分配给一个函数。每当按下按钮时,该功能就被执行。
看一个例子。首先,您将创建一个窗口,其中有一个保存数值的Label小部件。你将在标签的左右两边放置按钮。左键用于减少Label中的数值,右键用于增加数值。以下是窗口的代码:
1import tkinter as tk
2
3window = tk.Tk()
4
5window.rowconfigure(0, minsize=50, weight=1)
6window.columnconfigure([0, 1, 2], minsize=50, weight=1)
7
8btn_decrease = tk.Button(master=window, text="-")
9btn_decrease.grid(row=0, column=0, sticky="nsew")
10
11lbl_value = tk.Label(master=window, text="0")
12lbl_value.grid(row=0, column=1)
13
14btn_increase = tk.Button(master=window, text="+")
15btn_increase.grid(row=0, column=2, sticky="nsew")
16
17window.mainloop()
窗口看起来像这样:
定义好应用程序布局后,您可以通过给按钮一些命令来赋予它生命。从左边的按钮开始。当按下此按钮时,标签中的值应减少 1。为了做到这一点,你首先需要得到两个问题的答案:
- 如何获取
Label中的文本? - 如何更新
Label中的文字?
Label小工具不像Entry和Text小工具那样有.get()。但是,您可以通过使用字典样式的下标符号访问text属性来从标签中检索文本:
label = tk.Label(text="Hello")
# Retrieve a label's text
text = label["text"]
# Set new text for the label
label["text"] = "Good bye"
现在您已经知道如何获取和设置标签的文本,编写一个将lbl_value中的值增加 1 的increase()函数:
1import tkinter as tk
2
3def increase():
4 value = int(lbl_value["text"])
5 lbl_value["text"] = f"{value + 1}"
6
7# ...
increase()从lbl_value获取文本并用int()将其转换成整数。然后,它将这个值增加 1,并将标签的text属性设置为这个新值。
您还需要decrease()将value_label中的值减一:
5# ...
6
7def decrease():
8 value = int(lbl_value["text"])
9 lbl_value["text"] = f"{value - 1}"
10
11# ...
将increase()和decrease()放在代码中的import语句之后。
要将按钮连接到功能,请将功能分配给按钮的command属性。您可以在实例化按钮时做到这一点。例如,将实例化按钮的两行代码更新为:
14# ...
15
16btn_decrease = tk.Button(master=window, text="-", command=decrease) 17btn_decrease.grid(row=0, column=0, sticky="nsew")
18
19lbl_value = tk.Label(master=window, text="0")
20lbl_value.grid(row=0, column=1)
21
22btn_increase = tk.Button(master=window, text="+", command=increase) 23btn_increase.grid(row=0, column=2, sticky="nsew")
24
25window.mainloop()
这就是将按钮绑定到increase()和decrease()并使程序正常运行所需做的全部工作。尝试保存您的更改并运行应用程序!点按窗口中央的按钮来增大和减小值:
以下是完整的应用程序代码供您参考:
import tkinter as tk
def increase():
value = int(lbl_value["text"])
lbl_value["text"] = f"{value + 1}"
def decrease():
value = int(lbl_value["text"])
lbl_value["text"] = f"{value - 1}"
window = tk.Tk()
window.rowconfigure(0, minsize=50, weight=1)
window.columnconfigure([0, 1, 2], minsize=50, weight=1)
btn_decrease = tk.Button(master=window, text="-", command=decrease)
btn_decrease.grid(row=0, column=0, sticky="nsew")
lbl_value = tk.Label(master=window, text="0")
lbl_value.grid(row=0, column=1)
btn_increase = tk.Button(master=window, text="+", command=increase)
btn_increase.grid(row=0, column=2, sticky="nsew")
window.mainloop()
这个应用程序不是特别有用,但是你在这里学到的技能适用于你将要制作的每个应用程序:
- 使用小部件创建用户界面的组件。
- 使用几何图形管理器控制应用的布局。
- 编写与各种组件交互的事件处理程序来捕获和转换用户输入。
在接下来的两节中,您将构建更有用的应用程序。首先,您将构建一个温度转换器,将温度值从华氏温度转换为摄氏温度。之后,您将构建一个可以打开、编辑和保存文本文件的文本编辑器!
检查你的理解能力
展开下面的代码块,做一个练习来检查您的理解:
写一个模拟滚动六面骰子的程序。应该有一个带有文本Roll的按钮。当用户点击按钮时,应该显示一个从1到6的随机整数。
提示:您可以使用 random 模块中的randint()生成一个随机数。如果你不熟悉random模块,那么查看在 Python 中生成随机数据(指南)了解更多信息。
应用程序窗口应该如下所示:
现在试试这个练习。
您可以展开下面的代码块来查看解决方案:
这里有一个可能的解决方案:
import random
import tkinter as tk
def roll():
lbl_result["text"] = str(random.randint(1, 6))
window = tk.Tk()
window.columnconfigure(0, minsize=150)
window.rowconfigure([0, 1], minsize=50)
btn_roll = tk.Button(text="Roll", command=roll)
lbl_result = tk.Label()
btn_roll.grid(row=0, column=0, sticky="nsew")
lbl_result.grid(row=1, column=0)
window.mainloop()
请记住,您的代码可能看起来不同。
当你准备好了,你可以进入下一部分。
构建温度转换器(示例应用程序)
在本节中,您将构建一个温度转换器应用程序,它允许用户以华氏度为单位输入温度,并按下按钮将该温度转换为摄氏度。您将一步一步地浏览代码。您还可以在本节末尾找到完整的源代码,以供参考。
注意:为了充分利用这一部分,请跟随一个 Python shell 。
在你开始编码之前,你首先要设计应用程序。你需要三个要素:
Entry: 一个名为ent_temperature的控件,用于输入华氏温度值Label: 显示摄氏温度结果的名为lbl_result的小部件Button: 一个名为btn_convert的小部件,它从Entry小部件中读取值,将其从华氏温度转换为摄氏温度,并将Label小部件的文本设置为单击时的结果
您可以将它们排列在一个网格中,每个小部件占一行一列。这让你得到一个最低限度工作的应用程序,但它不是非常用户友好的。所有东西都需要有标签。
您将直接在包含华氏符号(℧)的ent_temperature小部件的右侧放置一个标签,以便用户知道值ent_temperature应该是华氏温度。为此,将标签文本设置为"\N{DEGREE FAHRENHEIT}",它使用 Python 命名的 Unicode 字符支持来显示华氏符号。
您可以通过将文本设置为值"\N{RIGHTWARDS BLACK ARROW}"来给btn_convert增加一点魅力,它会显示一个指向右边的黑色箭头。您还将确保lbl_result的标签文本"\N{DEGREE CELSIUS}"后面总是有摄氏符号(℃),以表明结果是以摄氏度为单位的。这是最终窗口的样子:
现在你已经知道了你需要什么样的小部件,以及这个窗口看起来会是什么样子,你可以开始编写代码了!首先,导入tkinter并创建一个新窗口:
1import tkinter as tk
2
3window = tk.Tk()
4window.title("Temperature Converter")
5window.resizable(width=False, height=False)
window.title()设置一个现有窗口的标题,而window.resizable()的两个参数都设置为False使窗口具有固定的大小。当您最终运行该应用程序时,窗口的标题栏中将会显示文本温度转换器。接下来,创建标签为lbl_temp的ent_temperature小部件,并将二者分配给名为frm_entry的Frame小部件:
5# ...
6
7frm_entry = tk.Frame(master=window)
8ent_temperature = tk.Entry(master=frm_entry, width=10)
9lbl_temp = tk.Label(master=frm_entry, text="\N{DEGREE FAHRENHEIT}")
用户将在ent_temperature中输入华氏温度值,lbl_temp用于给ent_temperature标注华氏温度符号。frm_entry集装箱将ent_temperature和lbl_temp组合在一起。
您希望将lbl_temp直接放在ent_temperature的右边。您可以使用具有一行两列的.grid()几何图形管理器在frm_entry中对它们进行布局:
9# ...
10
11ent_temperature.grid(row=0, column=0, sticky="e")
12lbl_temp.grid(row=0, column=1, sticky="w")
您已经为ent_temperature将sticky参数设置为"e",这样它总是贴在它的网格单元的最右边。您还可以将lbl_temp的sticky设置为"w",使其保持在网格单元的最左边。这确保了lbl_temp总是直接位于ent_temperature的右侧。
现在,使btn_convert和lbl_result转换输入到ent_temperature中的温度并显示结果:
12# ...
13
14btn_convert = tk.Button(
15 master=window,
16 text="\N{RIGHTWARDS BLACK ARROW}"
17)
18lbl_result = tk.Label(master=window, text="\N{DEGREE CELSIUS}")
和frm_entry一样,btn_convert和lbl_result都被分配给window。这三个小部件共同构成了主应用程序网格中的三个单元。现在使用.grid()继续并布置它们:
18# ...
19
20frm_entry.grid(row=0, column=0, padx=10)
21btn_convert.grid(row=0, column=1, pady=10)
22lbl_result.grid(row=0, column=2, padx=10)
最后,运行应用程序:
22# ...
23
24window.mainloop()
看起来棒极了!但是这个按钮还不能做任何事情。在脚本文件的顶部,就在import行的下面,添加一个名为fahrenheit_to_celsius()的函数:
1import tkinter as tk
2
3def fahrenheit_to_celsius():
4 """Convert the value for Fahrenheit to Celsius and insert the
5 result into lbl_result.
6 """
7 fahrenheit = ent_temperature.get()
8 celsius = (5 / 9) * (float(fahrenheit) - 32)
9 lbl_result["text"] = f"{round(celsius, 2)} \N{DEGREE CELSIUS}"
10
11# ...
该函数从ent_temperature中读取数值,将其从华氏温度转换为摄氏温度,然后在lbl_result中显示结果。
现在转到定义btn_convert的那一行,将其command参数设置为fahrenheit_to_celsius:
20# ...
21
22btn_convert = tk.Button(
23 master=window,
24 text="\N{RIGHTWARDS BLACK ARROW}",
25 command=fahrenheit_to_celsius # <--- Add this line 26)
27
28# ...
就是这样!您只用了 26 行代码就创建了一个功能齐全的温度转换器应用程序!很酷,对吧?
您可以展开下面的代码块来查看完整的脚本:
以下是完整的脚本供您参考:
import tkinter as tk
def fahrenheit_to_celsius():
"""Convert the value for Fahrenheit to Celsius and insert the
result into lbl_result.
"""
fahrenheit = ent_temperature.get()
celsius = (5 / 9) * (float(fahrenheit) - 32)
lbl_result["text"] = f"{round(celsius, 2)} \N{DEGREE CELSIUS}"
# Set up the window
window = tk.Tk()
window.title("Temperature Converter")
window.resizable(width=False, height=False)
# Create the Fahrenheit entry frame with an Entry
# widget and label in it
frm_entry = tk.Frame(master=window)
ent_temperature = tk.Entry(master=frm_entry, width=10)
lbl_temp = tk.Label(master=frm_entry, text="\N{DEGREE FAHRENHEIT}")
# Layout the temperature Entry and Label in frm_entry
# using the .grid() geometry manager
ent_temperature.grid(row=0, column=0, sticky="e")
lbl_temp.grid(row=0, column=1, sticky="w")
# Create the conversion Button and result display Label
btn_convert = tk.Button(
master=window,
text="\N{RIGHTWARDS BLACK ARROW}",
command=fahrenheit_to_celsius
)
lbl_result = tk.Label(master=window, text="\N{DEGREE CELSIUS}")
# Set up the layout using the .grid() geometry manager
frm_entry.grid(row=0, column=0, padx=10)
btn_convert.grid(row=0, column=1, pady=10)
lbl_result.grid(row=0, column=2, padx=10)
# Run the application
window.mainloop()
是时候让事情更上一层楼了!请继续阅读,了解如何构建文本编辑器。
构建文本编辑器(示例应用程序)
在本节中,您将构建一个能够创建、打开、编辑和保存文本文件的文本编辑器应用程序。该应用程序有三个基本要素:
- 名为
btn_open的Button小部件,用于打开文件进行编辑 - 用于保存文件的名为
btn_save的Button小部件 - 名为
txt_edit的TextBox小部件,用于创建和编辑文本文件
这三个小部件的排列方式是,两个按钮在窗口的左侧,文本框在右侧。整个窗口的最小高度应该是 800 像素,txt_edit的最小宽度应该是 800 像素。整个布局应该是响应性的,这样如果窗口被调整大小,那么txt_edit也被调整大小。然而,容纳按钮的框架的宽度不应该改变。
这是窗户外观的草图:
您可以使用.grid()几何图形管理器实现所需的布局。布局包含单行和两列:
- 按钮左边的窄栏
- 文本框右侧的宽栏
要设置窗口和txt_edit的最小尺寸,您可以将窗口方法.rowconfigure()和.columnconfigure()的minsize参数设置为800。为了处理调整大小,您可以将这些方法的weight参数设置为1。
为了将两个按钮放在同一列中,您需要创建一个名为frm_buttons的Frame小部件。根据草图,这两个按钮应该垂直堆叠在这个框架内,顶部是btn_open。你可以用.grid()或.pack()几何图形管理器来完成。现在,您将坚持使用.grid(),因为它更容易使用。
既然有了计划,就可以开始编写应用程序了。第一步是创建您需要的所有小部件:
1import tkinter as tk
2
3window = tk.Tk()
4window.title("Simple Text Editor")
5
6window.rowconfigure(0, minsize=800, weight=1)
7window.columnconfigure(1, minsize=800, weight=1)
8
9txt_edit = tk.Text(window)
10frm_buttons = tk.Frame(window, relief=tk.RAISED, bd=2)
11btn_open = tk.Button(frm_buttons, text="Open")
12btn_save = tk.Button(frm_buttons, text="Save As...")
下面是这段代码的分类:
- 1 号线进口
tkinter。 - 第 3 行和第 4 行创建一个标题为
"Simple Text Editor"的新窗口。 - 第 6 行和第 7 行设置行和列配置。
- 第 9 行到第 12 行创建文本框、框架、打开和保存按钮所需的四个部件。
仔细看看第 6 行。.rowconfigure()的minsize参数设置为800,weight设置为1:
window.rowconfigure(0, minsize=800, weight=1)
第一个参数是0,它将第一行的高度设置为800像素,并确保行的高度与窗口的高度成比例增长。应用程序布局中只有一行,因此这些设置适用于整个窗口。
让我们再仔细看看第 7 行。这里,您使用.columnconfigure()将索引为1的列的width和weight属性分别设置为800和1:
window.columnconfigure(1, minsize=800, weight=1)
记住,行和列的索引是从零开始的,所以这些设置只适用于第二列。通过只配置第二列,当调整窗口大小时,文本框将自然地扩展和收缩,而包含按钮的列将保持固定的宽度。
现在,您可以处理应用程序布局了。首先,使用.grid()几何管理器将两个按钮分配给frm_buttons帧:
12# ...
13
14btn_open.grid(row=0, column=0, sticky="ew", padx=5, pady=5)
15btn_save.grid(row=1, column=0, sticky="ew", padx=5)
这两行代码在frm_buttons帧中创建了一个具有两行一列的网格,因为btn_open和btn_save都将其master属性设置为frm_buttons。btn_open放在第一行,btn_save放在第二行,这样btn_open就出现在布局图中btn_save的上方,就像你在草图中计划的那样。
btn_open和btn_save都将它们的sticky属性设置为"ew",这迫使按钮的向两个方向水平扩展并填充整个框架。这确保了两个按钮大小相同。
通过将padx和pady参数设置为5,在每个按钮周围放置五个像素的填充。只有btn_open有垂直填充。因为它在顶部,垂直填充从窗口顶部向下偏移按钮一点,并确保它和btn_save之间有一个小间隙。
现在frm_buttons已经布置好了,可以开始为窗口的其余部分设置网格布局了:
15# ...
16
17frm_buttons.grid(row=0, column=0, sticky="ns")
18txt_edit.grid(row=0, column=1, sticky="nsew")
这两行代码为window创建了一个一行两列的网格。您将frm_buttons放在第一列,将txt_edit放在第二列,这样frm_buttons就会出现在窗口布局中txt_edit的左边。
frm_buttons的sticky参数设置为"ns",强制整个框架垂直扩展并填充其列的整个高度。txt_edit填充其整个网格单元,因为您将其sticky参数设置为"nsew",这迫使其向每个方向扩展。
现在应用程序布局已经完成,将window.mainloop()添加到程序底部,保存并运行文件:
18# ...
19
20window.mainloop()
将显示以下窗口:

看起来棒极了!但是它现在还不能做任何事情,所以您需要开始编写按钮的命令。btn_open需要显示一个文件打开对话框,允许用户选择一个文件。然后需要打开文件并将txt_edit的文本设置为文件的内容。这里有一个open_file()函数可以做到这一点:
1import tkinter as tk
2
3def open_file():
4 """Open a file for editing."""
5 filepath = askopenfilename(
6 filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")]
7 )
8 if not filepath:
9 return
10 txt_edit.delete("1.0", tk.END)
11 with open(filepath, mode="r", encoding="utf-8") as input_file:
12 text = input_file.read()
13 txt_edit.insert(tk.END, text)
14 window.title(f"Simple Text Editor - {filepath}")
15
16# ...
下面是这个函数的分解:
- 第 5 行到第 7 行使用
tkinter.filedialog模块的askopenfilename()对话框显示一个文件打开对话框,并将选择的文件路径保存到filepath。 - 第 8 行和第 9 行检查用户是否关闭对话框或点击取消按钮。如果是,那么
filepath将是None,并且函数将return而不执行任何代码来读取文件和设置txt_edit的文本。 - 第 10 行使用
.delete()清除txt_edit的当前内容。 - 第 11 行和第 12 行在将
text存储为字符串之前,打开所选文件及其内容.read()。 - 第 13 行使用
.insert()将字符串text分配给txt_edit。 - 第 14 行设置窗口的标题,使其包含打开文件的路径。
现在你可以更新程序,这样每当点击时btn_open就会调用open_file()。你需要做一些事情来更新程序。首先,通过将下面的导入添加到程序的顶部,从tkinter.filedialog导入askopenfilename():
1import tkinter as tk
2from tkinter.filedialog import askopenfilename 3
4# ...
接下来,将btn_opn的command属性设置为open_file:
1import tkinter as tk
2from tkinter.filedialog import askopenfilename
3
4def open_file():
5 """Open a file for editing."""
6 filepath = askopenfilename(
7 filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")]
8 )
9 if not filepath:
10 return
11 txt_edit.delete("1.0", tk.END)
12 with open(filepath, mode="r", encoding="utf-8") as input_file:
13 text = input_file.read()
14 txt_edit.insert(tk.END, text)
15 window.title(f"Simple Text Editor - {filepath}")
16
17window = tk.Tk()
18window.title("Simple Text Editor")
19
20window.rowconfigure(0, minsize=800, weight=1)
21window.columnconfigure(1, minsize=800, weight=1)
22
23txt_edit = tk.Text(window)
24frm_buttons = tk.Frame(window, relief=tk.RAISED, bd=2)
25btn_open = tk.Button(frm_buttons, text="Open", command=open_file) 26btn_save = tk.Button(frm_buttons, text="Save As...")
27
28# ...
保存文件并运行它以检查一切是否正常。然后尝试打开一个文本文件!
随着btn_open的运行,是时候为btn_save运行函数了。这需要打开一个保存文件对话框,以便用户可以选择他们想要保存文件的位置。为此,您将使用tkinter.filedialog模块中的asksaveasfilename()对话框。该函数还需要提取当前在txt_edit中的文本,并将其写入选定位置的文件中。这里有一个函数可以做到这一点:
15# ...
16
17def save_file():
18 """Save the current file as a new file."""
19 filepath = asksaveasfilename(
20 defaultextension=".txt",
21 filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")],
22 )
23 if not filepath:
24 return
25 with open(filepath, mode="w", encoding="utf-8") as output_file:
26 text = txt_edit.get("1.0", tk.END)
27 output_file.write(text)
28 window.title(f"Simple Text Editor - {filepath}")
29
30# ...
下面是这段代码的工作原理:
- 第 19 行到第 22 行使用
asksaveasfilename()对话框从用户处获取所需的保存位置。选择的文件路径存储在filepath变量中。 - 第 23 和 24 行检查用户是否关闭对话框或点击取消按钮。如果是,那么
filepath将是None,并且函数将返回,而不执行任何代码来将文本保存到文件中。 - 在选定的文件路径创建一个新文件。
- 第 26 行用
.get()方法从txt_edit中提取文本并赋给变量text。 - 第 27 行将
text写入输出文件。 - 第 28 行更新窗口标题,这样新的文件路径显示在窗口标题中。
现在你可以更新程序,这样当它被点击时,btn_save会调用save_file()。同样,为了更新程序,您需要做一些事情。首先,通过更新脚本顶部的导入,从tkinter.filedialog导入asksaveasfilename(),如下所示:
1import tkinter as tk
2from tkinter.filedialog import askopenfilename, asksaveasfilename 3
4# ...
最后,将btn_save的command属性设置为save_file:
28# ...
29
30window = tk.Tk()
31window.title("Simple Text Editor")
32
33window.rowconfigure(0, minsize=800, weight=1)
34window.columnconfigure(1, minsize=800, weight=1)
35
36txt_edit = tk.Text(window)
37frm_buttons = tk.Frame(window, relief=tk.RAISED, bd=2)
38btn_open = tk.Button(frm_buttons, text="Open", command=open_file)
39btn_save = tk.Button(frm_buttons, text="Save As...", command=save_file) 40
41btn_open.grid(row=0, column=0, sticky="ew", padx=5, pady=5)
42btn_save.grid(row=1, column=0, sticky="ew", padx=5)
43
44frm_buttons.grid(row=0, column=0, sticky="ns")
45txt_edit.grid(row=0, column=1, sticky="nsew")
46
47window.mainloop()
保存文件并运行它。您现在已经有了一个最小但功能齐全的文本编辑器!
您可以展开下面的代码块来查看完整的脚本:
以下是完整的脚本供您参考:
import tkinter as tk
from tkinter.filedialog import askopenfilename, asksaveasfilename
def open_file():
"""Open a file for editing."""
filepath = askopenfilename(
filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")]
)
if not filepath:
return
txt_edit.delete("1.0", tk.END)
with open(filepath, mode="r", encoding="utf-8") as input_file:
text = input_file.read()
txt_edit.insert(tk.END, text)
window.title(f"Simple Text Editor - {filepath}")
def save_file():
"""Save the current file as a new file."""
filepath = asksaveasfilename(
defaultextension=".txt",
filetypes=[("Text Files", "*.txt"), ("All Files", "*.*")],
)
if not filepath:
return
with open(filepath, mode="w", encoding="utf-8") as output_file:
text = txt_edit.get("1.0", tk.END)
output_file.write(text)
window.title(f"Simple Text Editor - {filepath}")
window = tk.Tk()
window.title("Simple Text Editor")
window.rowconfigure(0, minsize=800, weight=1)
window.columnconfigure(1, minsize=800, weight=1)
txt_edit = tk.Text(window)
frm_buttons = tk.Frame(window, relief=tk.RAISED, bd=2)
btn_open = tk.Button(frm_buttons, text="Open", command=open_file)
btn_save = tk.Button(frm_buttons, text="Save As...", command=save_file)
btn_open.grid(row=0, column=0, sticky="ew", padx=5, pady=5)
btn_save.grid(row=1, column=0, sticky="ew", padx=5)
frm_buttons.grid(row=0, column=0, sticky="ns")
txt_edit.grid(row=0, column=1, sticky="nsew")
window.mainloop()
现在,您已经用 Python 构建了两个 GUI 应用程序,并应用了您在本教程中学到的许多技能。这是一个不小的成就,所以花些时间为你所做的感到高兴。您现在已经准备好自己处理一些应用程序了!
结论
在本教程中,您学习了如何开始 Python GUI 编程。对于 Python GUI 框架来说,Tkinter 是一个令人信服的选择,因为它内置于 Python 标准库中,并且使用该框架制作应用程序相对来说不太费力。
在本教程中,您已经学习了几个重要的 Tkinter 概念:
- 如何使用小工具
- 如何用几何图形管理器控制你的应用布局
- 如何让您的应用程序具有交互性
- 如何使用五个基本的 Tkinterwidget:
Label、Button、Entry、Text、Frame
现在您已经掌握了使用 Tkinter 进行 Python GUI 编程的基础,下一步是构建一些您自己的应用程序。你会创造什么?在下面的评论中分享你有趣的项目吧!
额外资源
在本教程中,您仅仅触及了使用 Tkinter 创建 Python GUI 应用程序的基础。还有许多其他主题没有在这里介绍。在本节中,您将找到一些可帮助您继续旅程的最佳资源。
t 内部引用
这里有一些官方资源可供参考:
- 官方 Python Tkinter 参考文档以中等深度介绍了 Python 的 Tkinter 模块。它是为更高级的 Python 开发人员编写的,并不是初学者的最佳资源。
- Tkinter 8.5 参考:Python 的 GUI 是一个广泛的参考,涵盖了 Tkinter 模块的大部分。它是详尽的,但它是以参考风格编写的,没有评论或例子。
- Tk 命令参考是 Tk 库中命令的权威指南。它是为 Tcl 语言编写的,但它回答了许多关于为什么 Tkinter 中的事情会这样工作的问题。
附加部件
在本教程中,您学习了Label、Button、Entry、Text和Frame小部件。Tkinter 中还有其他几个小部件,它们对于构建真实世界的应用程序都是必不可少的。以下是一些继续学习小部件的资源:
- TkDocs Tkinter 教程是一个相当全面的 Tk 指南,Tkinter 使用的底层代码库。用 Python、Ruby、Perl 和 Tcl 给出了例子。除了这两个部分中介绍的以外,您还可以找到几个小部件示例:
- 官方 Python 文档涵盖了额外的小部件:
应用分布
一旦你用 Tkinter 创建了一个应用程序,你可能想把它分发给你的同事和朋友。这里有一些教程可以帮助你完成这个过程:
其他 GUI 框架
Tkinter 不是 Python GUI 框架的唯一选择。如果 Tkinter 不能满足您项目的需求,那么这里有一些其他的框架可以考虑:
- 如何用 wxPython 构建 Python GUI 应用
- Python 和 PyQt:构建 GUI 桌面计算器
- 使用 Kivy Python 框架构建移动应用
- PySimpleGUI:用 Python 创建 GUI 的简单方法
参加测验:通过我们的交互式“使用 Tkinter 进行 Python GUI 编程”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
参加测验***********
如何用 wxPython 构建 Python GUI 应用程序
有许多图形用户界面(GUI)工具包可用于 Python 编程语言。三巨头分别是 Tkinter ,wxPython, PyQt 。这些工具包都可以在 Windows、macOS 和 Linux 上工作,PyQt 还具有在移动设备上工作的能力。
图形用户界面是一个应用程序,它有按钮、窗口和许多其他小部件,用户可以用它们来与应用程序进行交互。web 浏览器就是一个很好的例子。它有按钮、标签和一个主窗口,所有的内容都在这里加载。
在本文中,您将学习如何使用 wxPython GUI 工具包用 Python 构建一个图形用户界面。
以下是涵盖的主题:
- wxPython 入门
- 图形用户界面的定义
- 创建框架应用程序
- 创建工作应用程序
我们开始学习吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
wxPython 入门
wxPython GUI toolkit 是一个 Python 包装器,围绕着一个名为 wxWidgets 的 C++库。wxPython 的首次发布是在 1998 年,所以 wxPython 已经存在了相当长的时间。wxPython 与其他工具包(如 PyQt 或 Tkinter )的主要区别在于,wxPython 尽可能使用原生平台上的实际部件。这使得 wxPython 应用程序看起来是运行它的操作系统的原生程序。
PyQt 和 Tkinter 都是自己绘制小部件,这就是为什么它们不总是匹配原生小部件,尽管 PyQt 非常接近。
这并不是说 wxPython 不支持定制小部件。事实上,wxPython 工具包包含了许多定制的小部件,以及数十个核心小部件。wxPython 下载页面有一个名为额外文件的部分值得一看。
这里有一个 wxPython 演示包的下载。这是一个不错的小应用程序,演示了 wxPython 中包含的绝大多数小部件。该演示允许开发人员在一个选项卡中查看代码,并在另一个选项卡中运行它。您甚至可以编辑并重新运行演示中的代码,以查看您的更改如何影响应用程序。
安装 wxPython
本文将使用最新的 wxPython,即 wxPython 4 ,也称为 Phoenix release。wxPython 3 和 wxPython 2 版本只为 Python 2 打造。当 wxPython 的主要维护者 Robin Dunn 创建 wxPython 4 版本时,他弃用了大量别名,清理了大量代码,使 wxPython 更加 Python 化,更易于维护。
如果您要从旧版本的 wxPython 迁移到 wxPython 4 (Phoenix ),您需要参考以下链接:
wxPython 4 包兼容 Python 2.7 和 Python 3。
您现在可以使用pip来安装 wxPython 4,这在 wxPython 的遗留版本中是不可能的。您可以执行以下操作将它安装到您的计算机上:
$ pip install wxpython
注意:在 Mac OS X 上,你需要安装一个编译器,比如 XCode ,这样安装才能成功完成。Linux 可能还需要您安装一些依赖项,然后pip安装程序才能正常工作。
例如,我需要在 Xubuntu 上安装 freeglut3-dev 、libgstreamer-plugins-base 0.10-dev和 libwebkitgtk-3.0-dev 来安装它。
幸运的是,pip显示的错误消息有助于找出缺少的内容,如果您想在 Linux 上安装 wxPython,可以使用 wxPython Github 页面上的先决条件部分来帮助您找到所需的信息。
在 GTK2 和 GTK3 版本的 Extras Linux 部分,您可以找到一些适用于最流行的 Linux 版本的 Python wheels。要安装其中一个轮子,您可以使用以下命令:
$ pip install -U -f https://extras.wxpython.org/wxPython4/extras/linux/gtk3/ubuntu-18.04/ wxPython
确保您已经修改了上面的命令以匹配您的 Linux 版本。
图形用户界面的定义
正如在引言中提到的,图形用户界面(GUI)是绘制在屏幕上供用户交互的界面。
用户界面有一些通用组件:
- 主窗口
- 菜单
- 工具栏
- 小跟班
- 文本输入
- 标签
所有这些项目统称为小部件。wxPython 还支持许多其他常见的小部件和许多自定义小部件。开发人员将获取这些小部件,并将它们逻辑地排列在一个窗口上,供用户进行交互。
事件循环
图形用户界面通过等待用户做一些事情来工作。这件事被称为一个事件。当您的应用程序处于焦点时,或者当用户使用鼠标按下按钮或其他小部件时,当用户键入某些内容时,就会发生事件。
在幕后,GUI 工具包正在运行一个被称为事件循环的无限循环。事件循环只是等待事件发生,然后根据开发人员编写的应用程序来处理这些事件。当应用程序没有捕捉到一个事件时,它实际上忽略了它的发生。
当你在编写一个图形用户界面时,你会想记住你需要把每个部件挂接到事件处理程序上,这样你的应用程序就会做一些事情。
在处理事件循环时,有一点需要特别注意:它们可能会被阻塞。当您阻塞一个事件循环时,GUI 将变得无响应,并对用户显示为冻结。
在 GUI 中启动的任何进程,如果花费的时间超过四分之一秒,应该作为一个单独的线程或进程启动。这将防止您的 GUI 冻结,并为用户提供更好的用户体验。
wxPython 框架具有特殊的线程安全方法,您可以使用这些方法与您的应用程序进行通信,让它知道线程已经完成或者给它一个更新。
让我们创建一个框架应用程序来演示事件是如何工作的。
创建一个框架应用程序
GUI 环境中的应用程序框架是一个带有小部件的用户界面,这些小部件没有任何事件处理程序。这些对原型制作很有用。在花费大量时间在后端逻辑上之前,您基本上只需要创建 GUI,并将其提交给您的利益相关者签字认可。
让我们从用 wxPython 创建一个Hello World应用程序开始:
import wx
app = wx.App()
frame = wx.Frame(parent=None, title='Hello World')
frame.Show()
app.MainLoop()
注意: Mac 用户可能会得到以下消息:这个程序需要访问屏幕。请使用 python 的框架构建运行,并且仅当您登录到 Mac 的主显示屏时运行。如果您看到这条消息,并且您没有在 virtualenv 中运行,那么您需要使用 pythonw 而不是 python 来运行您的应用程序。如果您在 virtualenv 中运行 wxPython,那么请参见 wxPython wiki 获取解决方案。
在这个例子中,您有两个部分:wx.App和wx.Frame。wx.App是 wxPython 的应用程序对象,是运行 GUI 所必需的。这个wx.App启动了一个叫做.MainLoop()的东西。这是您在上一节中了解到的事件循环。
拼图的另一块是wx.Frame,它将为用户创建一个交互窗口。在这种情况下,您告诉 wxPython 该帧没有父帧,它的标题是Hello World。下面是运行代码时的样子:
注意:在 Mac 或 Windows 上运行时,应用程序看起来会有所不同。
默认情况下,wx.Frame会在顶部包含最小化、最大化和退出按钮。但是,您通常不会以这种方式创建应用程序。大多数 wxPython 代码将要求您子类化wx.Frame和其他小部件,以便您可以获得该工具包的全部功能。
让我们花点时间将您的代码重写为一个类:
import wx
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(parent=None, title='Hello World')
self.Show()
if __name__ == '__main__':
app = wx.App()
frame = MyFrame()
app.MainLoop()
您可以将此代码用作应用程序的模板。然而,这个应用程序做的不多,所以让我们花一点时间来了解一些您可以添加的其他小部件。
小部件
wxPython 工具包有一百多个小部件可供选择。这使您可以创建丰富的应用程序,但是要想知道使用哪个小部件也是一件令人生畏的事情。这就是为什么 wxPython 演示是有用的,因为它有一个搜索过滤器,您可以使用它来帮助您找到可能适用于您的项目的小部件。
大多数 GUI 应用程序允许用户输入一些文本并按下按钮。让我们继续添加这些小部件:
import wx
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(parent=None, title='Hello World')
panel = wx.Panel(self)
self.text_ctrl = wx.TextCtrl(panel, pos=(5, 5))
my_btn = wx.Button(panel, label='Press Me', pos=(5, 55))
self.Show()
if __name__ == '__main__':
app = wx.App()
frame = MyFrame()
app.MainLoop()
当您运行这段代码时,您的应用程序应该如下所示:
您需要添加的第一个小部件叫做wx.Panel。这个小部件不是必需的,但是推荐使用。在 Windows 上,您实际上需要使用一个面板,以便框架的背景颜色是正确的灰色阴影。在 Windows 上,如果没有面板,选项卡遍历将被禁用。
当您将面板小部件添加到框架中,并且面板是框架的唯一子级时,它将自动扩展以用自身填充框架。
下一步是给面板添加一个wx.TextCtrl。几乎所有部件的第一个参数是部件应该放在哪个父部件上。在这种情况下,您希望文本控件和按钮位于面板的顶部,因此它是您指定的父控件。
您还需要告诉 wxPython 在哪里放置小部件,这可以通过用pos参数传入一个位置来完成。在 wxPython 中,原点位置是(0,0),即父对象的左上角。因此,对于文本控件,您告诉 wxPython,您希望将其左上角定位在距离左侧(x)5 个像素和距离顶部(y)5 个像素的位置。
然后将按钮添加到面板中,并给它一个标签。为了防止小部件重叠,您需要将按钮位置的 y 坐标设置为 55。
绝对定位
当您为小部件的位置提供精确坐标时,您使用的技术称为绝对定位。大多数 GUI 工具包都提供了这种功能,但实际上并不推荐。
随着应用程序变得越来越复杂,跟踪所有小部件的位置变得越来越困难,如果你不得不四处移动小部件。重置所有这些位置变成了一场噩梦。
幸运的是,所有现代 GUI 工具包都为此提供了一个解决方案,这也是您接下来将要学习的内容。
分级器(动态分级)
wxPython 工具包包括sizer,用于创建动态布局。它们为您管理小部件的位置,并在您调整应用程序窗口大小时调整它们。其他 GUI 工具包将 sizers 称为布局,这就是 PyQt 所做的。
以下是您最常看到的主要类型的筛分机:
wx.BoxSizerwx.GridSizerwx.FlexGridSizer
让我们给你的例子添加一个wx.BoxSizer,看看我们是否能让它工作得更好一点:
import wx
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(parent=None, title='Hello World')
panel = wx.Panel(self)
my_sizer = wx.BoxSizer(wx.VERTICAL)
self.text_ctrl = wx.TextCtrl(panel)
my_sizer.Add(self.text_ctrl, 0, wx.ALL | wx.EXPAND, 5)
my_btn = wx.Button(panel, label='Press Me')
my_sizer.Add(my_btn, 0, wx.ALL | wx.CENTER, 5)
panel.SetSizer(my_sizer)
self.Show()
if __name__ == '__main__':
app = wx.App()
frame = MyFrame()
app.MainLoop()
这里您创建了一个wx.BoxSizer的实例并传递给它wx.VERTICAL,这是小部件被添加到 sizer 的方向。
在这种情况下,小部件将垂直添加,这意味着它们将从上到下一次添加一个。您也可以将 BoxSizer 的方向设置为wx.HORIZONTAL。当你这样做时,小部件将从左到右添加。
要向 sizer 添加一个小部件,您将使用.Add()。它最多接受五个参数:
window(微件)proportionflagborderuserData
window参数是要添加的小部件,而proportion设置这个小部件相对于 sizer 中的其他小部件应该占用多少空间。默认情况下,它是零,这告诉 wxPython 保持小部件的默认比例。
第三个参数是flag。如果您愿意,您实际上可以传入多个标志,只要您用管道字符:|分隔它们。wxPython 工具包使用一系列按位“或”运算,使用|来添加标志。
在本例中,您添加了带有wx.ALL和wx.EXPAND标志的文本控件。wx.ALL标志告诉 wxPython 您想要在小部件的所有边上添加边框,而wx.EXPAND让小部件在 sizer 中尽可能地扩展。
最后,有一个border参数,它告诉 wxPython 在小部件周围需要多少像素的边框。userData参数仅在您想要对小部件的大小做一些复杂的事情时使用,实际上在实践中很少见到。
将按钮添加到 sizer 遵循完全相同的步骤。然而,为了让事情变得更有趣一点,我把wx.CENTER的wx.EXPAND标志去掉,这样按钮就会在屏幕上居中。
当您运行此版本的代码时,您的应用程序应该如下所示:
如果您想了解关于 sizers 的更多信息,wxPython 文档有一个关于这个主题的很好的页面。
添加事件
虽然你的应用程序看起来更有趣,但它实际上并没有做什么。例如,如果你按下按钮,什么都不会发生。
让我们给按钮一个任务:
import wx
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(parent=None, title='Hello World')
panel = wx.Panel(self)
my_sizer = wx.BoxSizer(wx.VERTICAL)
self.text_ctrl = wx.TextCtrl(panel)
my_sizer.Add(self.text_ctrl, 0, wx.ALL | wx.EXPAND, 5)
my_btn = wx.Button(panel, label='Press Me')
my_btn.Bind(wx.EVT_BUTTON, self.on_press)
my_sizer.Add(my_btn, 0, wx.ALL | wx.CENTER, 5)
panel.SetSizer(my_sizer)
self.Show()
def on_press(self, event):
value = self.text_ctrl.GetValue()
if not value:
print("You didn't enter anything!")
else:
print(f'You typed: "{value}"')
if __name__ == '__main__':
app = wx.App()
frame = MyFrame()
app.MainLoop()
wxPython 中的小部件允许您将事件绑定附加到它们,以便它们可以响应某些类型的事件。
注意:上面的代码块使用了 f 字符串。你可以在 Python 3 的 f-Strings:一个改进的字符串格式化语法(指南)中读到所有关于它们的内容。
当用户按下按钮时,您希望按钮做一些事情。您可以通过调用按钮的.Bind()方法来实现这一点。.Bind()接受您想要绑定的事件、事件发生时要调用的处理程序、一个可选的源和几个可选的 id。
在本例中,您将按钮对象绑定到wx.EVT_BUTTON事件,并告诉它在该事件被触发时调用on_press()。
当用户执行您绑定到的事件时,事件被“激发”。在这种情况下,您设置的事件是按钮按下事件wx.EVT_BUTTON。
.on_press()接受第二个参数,您可以称之为event。这是惯例。如果你愿意,你可以叫它别的名字。然而,这里的 event 参数指的是这样一个事实:当调用这个方法时,它的第二个参数应该是某种类型的 event 对象。
在.on_press()中,您可以通过调用它的GetValue()方法来获取文本控件的内容。然后,根据文本控件的内容,将一个字符串打印到 stdout。
现在你已经有了基本的方法,让我们学习如何创建一个有用的应用程序!
创建工作应用程序
创造新事物的第一步是弄清楚你想创造什么。在这种情况下,我冒昧地为你做了那个决定。你将学习如何创建一个 MP3 标签编辑器!创建新东西的下一步是找出哪些包可以帮助你完成任务。
如果你在谷歌上搜索Python mp3 tagging,你会发现你有几个选项:
mp3-taggereyeD3mutagen
我试用了几个,并决定 eyeD3 有一个不错的 API,你可以使用它而不会陷入 MP3 的 ID3 规范。你可以用pip安装 eyeD3 ,像这样:
$ pip install eyed3
在 macOS 上安装这个包时,可能需要使用brew安装libmagic。Windows 和 Linux 用户安装 eyeD3 应该没有任何问题。
设计用户界面
当设计一个界面的时候,最好只是勾画出你认为用户界面应该是什么样子。
您需要能够做到以下几点:
- 打开一个或多个 MP3 文件
- 显示当前的 MP3 标签
- 编辑 MP3 标签
大多数用户界面使用菜单或按钮来打开文件或文件夹。你可以用一个文件菜单来做这个。因为您可能希望看到多个 MP3 文件的标签,所以您需要找到一个小部件来很好地做到这一点。
带有列和行的表格是理想的,因为这样你就可以为 MP3 标签标记列。wxPython 工具包中有几个小部件可以解决这个问题,其中最重要的两个部件如下:
wx.grid.Gridwx.ListCtrl
在这种情况下,您应该使用wx.ListCtrl,因为Grid小部件太过了,而且坦率地说,它也要复杂得多。最后,您需要一个按钮来编辑所选 MP3 的标签。
现在你知道你想要什么了,你可以把它画出来:

上面的插图让我们了解了应用程序应该是什么样子。现在你知道你想做什么了,是时候编码了!
创建用户界面
在编写新的应用程序时,有许多不同的方法。比如需要遵循模型-视图-控制器的设计模式吗?你是怎么分班的?每个文件一个类?有很多这样的问题,随着你对 GUI 设计越来越有经验,你会知道你想如何回答它们。
在您的情况下,您实际上只需要两个类:
- 一门
wx.Panel课 - 一门
wx.Frame课
你也可以主张创建一个控制器类型的模块,但是对于这样的东西,你真的不需要它。也可以将每个类放入自己的模块中,但是为了保持简洁,您将为所有代码创建一个 Python 文件。
让我们从导入和面板类开始:
import eyed3
import glob
import wx
class Mp3Panel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
main_sizer = wx.BoxSizer(wx.VERTICAL)
self.row_obj_dict = {}
self.list_ctrl = wx.ListCtrl(
self, size=(-1, 100),
style=wx.LC_REPORT | wx.BORDER_SUNKEN
)
self.list_ctrl.InsertColumn(0, 'Artist', width=140)
self.list_ctrl.InsertColumn(1, 'Album', width=140)
self.list_ctrl.InsertColumn(2, 'Title', width=200)
main_sizer.Add(self.list_ctrl, 0, wx.ALL | wx.EXPAND, 5)
edit_button = wx.Button(self, label='Edit')
edit_button.Bind(wx.EVT_BUTTON, self.on_edit)
main_sizer.Add(edit_button, 0, wx.ALL | wx.CENTER, 5)
self.SetSizer(main_sizer)
def on_edit(self, event):
print('in on_edit')
def update_mp3_listing(self, folder_path):
print(folder_path)
这里,您为您的用户界面导入了eyed3包、Python 的glob包和wx包。接下来,您子类化wx.Panel并创建您的用户界面。你需要一本字典来存储你的 MP3 数据,你可以把它命名为row_obj_dict。
然后创建一个wx.ListCtrl,并将其设置为带有凹陷边框(wx.BORDER_SUNKEN)的报告模式(wx.LC_REPORT)。根据传入的样式标志,列表控件可以采用其他几种形式,但报告标志是最常用的。
为了使ListCtrl拥有正确的标题,您需要为每个列标题调用.InsertColumn()。然后提供列的索引、标签以及列的宽度(以像素为单位)。
最后一步是添加您的Edit按钮、事件处理程序和方法。您可以创建事件的绑定,并让它调用的方法暂时为空。
现在,您应该为框架编写代码:
class Mp3Frame(wx.Frame):
def __init__(self):
super().__init__(parent=None,
title='Mp3 Tag Editor')
self.panel = Mp3Panel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(False)
frame = Mp3Frame()
app.MainLoop()
这个类比第一个简单得多,因为您需要做的只是设置框架的标题并实例化面板类Mp3Panel。完成后,您的用户界面应该如下所示:
用户界面看起来几乎没错,但是你没有一个文件菜单。这使得不可能添加 MP3 到应用程序和编辑他们的标签!
让我们现在就解决这个问题。
制作一个有效的应用程序
让您的应用程序工作的第一步是更新应用程序,使它有一个文件菜单,因为这样您就可以将 MP3 文件添加到您的作品中。菜单几乎总是添加到wx.Frame类中,所以这是您需要修改的类。
注意:一些应用程序已经不再有菜单了。第一个这样做的是微软 Office,他们添加了功能区栏。wxPython 工具包有一个定制的小部件,可以用来在wx.lib.agw.ribbon中创建功能区。
另一种最近放弃菜单的应用是网络浏览器,比如谷歌 Chrome 和 Mozilla Firefox。他们现在只使用工具栏。
让我们学习如何在应用程序中添加菜单栏:
class Mp3Frame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, parent=None,
title='Mp3 Tag Editor')
self.panel = Mp3Panel(self)
self.create_menu()
self.Show()
def create_menu(self):
menu_bar = wx.MenuBar()
file_menu = wx.Menu()
open_folder_menu_item = file_menu.Append(
wx.ID_ANY, 'Open Folder',
'Open a folder with MP3s'
)
menu_bar.Append(file_menu, '&File')
self.Bind(
event=wx.EVT_MENU,
handler=self.on_open_folder,
source=open_folder_menu_item,
)
self.SetMenuBar(menu_bar)
def on_open_folder(self, event):
title = "Choose a directory:"
dlg = wx.DirDialog(self, title,
style=wx.DD_DEFAULT_STYLE)
if dlg.ShowModal() == wx.ID_OK:
self.panel.update_mp3_listing(dlg.GetPath())
dlg.Destroy()
这里,您在类的构造函数中添加了对.create_menu()的调用。然后在.create_menu()本身中,您将创建一个wx.MenuBar实例和一个wx.Menu实例。
要将菜单项添加到菜单中,您可以调用菜单实例的.Append(),并向其传递以下内容:
- 唯一的标识符
- 新菜单项的标签
- 帮助字符串
接下来,您需要将菜单添加到菜单栏,因此您需要调用菜单栏的.Append()。它接受菜单实例和菜单标签。这个标签有点奇怪,因为你称它为&File而不是File。“与”号告诉 wxPython 创建一个键盘快捷键 Alt + F ,只需使用键盘就可以打开File菜单。
注意:如果你想在你的应用程序中添加键盘快捷键,那么你需要使用wx.AcceleratorTable的一个实例来创建它们。你可以在 wxPython 文档中阅读更多关于 Accerator 表的内容。
要创建事件绑定,您需要调用self.Bind(),它将帧绑定到wx.EVT_MENU。当您为菜单事件使用self.Bind()时,您不仅需要告诉 wxPython 使用哪个handler,还需要告诉 wxPython 将处理程序绑定到哪个source。
最后,您必须调用框架的.SetMenuBar()并向其传递 menubar 实例,以便向用户显示。
现在,您已经将菜单添加到了框架中,让我们来看一下菜单项的事件处理程序,如下所示:
def on_open_folder(self, event):
title = "Choose a directory:"
dlg = wx.DirDialog(self, title, style=wx.DD_DEFAULT_STYLE)
if dlg.ShowModal() == wx.ID_OK:
self.panel.update_mp3_listing(dlg.GetPath())
dlg.Destroy()
既然你想让用户选择一个包含 MP3 的文件夹,你就应该使用 wxPython 的wx.DirDialog。wx.DirDialog只允许用户打开目录。
您可以设置对话框的标题和各种样式标志。要显示该对话框,您需要调用.ShowModal()。这将导致对话框有模式地显示,这意味着当对话框显示时,用户将不能与您的主应用程序交互。
如果用户按下对话框的 OK 按钮,可以通过对话框的.GetPath()得到用户的路径选择。您需要将该路径传递给 panel 类,这可以通过调用 panel 的.update_mp3_listing()来实现。
最后,您需要关闭对话框。要关闭对话框,推荐的方法是调用它的.Destroy()。
对话框确实有一个.Close()方法,但它基本上只是隐藏对话框,当你关闭应用程序时它不会自我销毁,这可能会导致奇怪的问题,比如你的应用程序现在正常关闭。更简单的方法是在对话框上调用.Destroy()来防止这个问题。
现在让我们更新你的Mp3Panel类。你可以从更新.update_mp3_listing()开始:
def update_mp3_listing(self, folder_path):
self.current_folder_path = folder_path
self.list_ctrl.ClearAll()
self.list_ctrl.InsertColumn(0, 'Artist', width=140)
self.list_ctrl.InsertColumn(1, 'Album', width=140)
self.list_ctrl.InsertColumn(2, 'Title', width=200)
self.list_ctrl.InsertColumn(3, 'Year', width=200)
mp3s = glob.glob(folder_path + '/*.mp3')
mp3_objects = []
index = 0
for mp3 in mp3s:
mp3_object = eyed3.load(mp3)
self.list_ctrl.InsertItem(index,
mp3_object.tag.artist)
self.list_ctrl.SetItem(index, 1,
mp3_object.tag.album)
self.list_ctrl.SetItem(index, 2,
mp3_object.tag.title)
mp3_objects.append(mp3_object)
self.row_obj_dict[index] = mp3_object
index += 1
在这里,您将当前目录设置为指定的文件夹,然后清除列表控件。这使得列表控件保持新鲜,并且只显示你当前正在处理的 MP3。这也意味着您需要再次重新插入所有列。
接下来,您将需要获取传入的文件夹,并使用 Python 的glob 模块来搜索 MP3 文件。
然后你可以循环播放 MP3 并把它们转换成eyed3对象。你可以通过调用eyed3的.load()来实现。假设 MP3 已经有了适当的标签,那么您可以将 MP3 的艺术家、专辑和标题添加到列表控件中。
有趣的是,向列表控件对象添加新行的方法是对第一列调用.InsertItem(),对所有后续列调用SetItem()。
最后一步是将 MP3 对象保存到 Python 字典row_obj_dict。
现在您需要更新.on_edit()事件处理程序,以便编辑 MP3 的标签:
def on_edit(self, event):
selection = self.list_ctrl.GetFocusedItem()
if selection >= 0:
mp3 = self.row_obj_dict[selection]
dlg = EditDialog(mp3)
dlg.ShowModal()
self.update_mp3_listing(self.current_folder_path)
dlg.Destroy()
您需要做的第一件事是通过调用列表控件的.GetFocusedItem()来获取用户的选择。
如果用户没有在列表控件中选择任何内容,它将返回-1。假设用户选择了某个内容,您将希望从字典中提取 MP3 对象并打开一个 MP3 标签编辑器对话框。这将是一个自定义对话框,您将使用它来编辑 MP3 文件的艺术家、专辑和标题标签。
像往常一样,显示对话框。当对话框关闭时,将执行.on_edit()中的最后两行。这两行将更新列表控件,使其显示用户刚刚编辑的当前 MP3 标签信息,并销毁对话框。
创建编辑对话框
拼图的最后一块是创建一个 MP3 标签编辑对话框。为了简洁,我们将跳过这个界面的草图,因为它是一系列包含标签和文本控件的行。文本控件中应该预先填充了现有的标记信息。您可以通过创建wx.StaticText的实例来为文本控件创建标签。
当你需要创建一个自定义对话框时,wx.Dialog类就是你的朋友。您可以使用它来设计编辑器:
class EditDialog(wx.Dialog):
def __init__(self, mp3):
title = f'Editing "{mp3.tag.title}"'
super().__init__(parent=None, title=title)
self.mp3 = mp3
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
self.artist = wx.TextCtrl(
self, value=self.mp3.tag.artist)
self.add_widgets('Artist', self.artist)
self.album = wx.TextCtrl(
self, value=self.mp3.tag.album)
self.add_widgets('Album', self.album)
self.title = wx.TextCtrl(
self, value=self.mp3.tag.title)
self.add_widgets('Title', self.title)
btn_sizer = wx.BoxSizer()
save_btn = wx.Button(self, label='Save')
save_btn.Bind(wx.EVT_BUTTON, self.on_save)
btn_sizer.Add(save_btn, 0, wx.ALL, 5)
btn_sizer.Add(wx.Button(
self, id=wx.ID_CANCEL), 0, wx.ALL, 5)
self.main_sizer.Add(btn_sizer, 0, wx.CENTER)
self.SetSizer(self.main_sizer)
这里你想从子类化wx.Dialog开始,并根据你正在编辑的 MP3 的标题给它一个自定义的标题。
接下来,您可以创建您想要使用的 sizer 和小部件。为了使事情变得简单,您可以创建一个名为.add_widgets()的助手方法,用于将wx.StaticText小部件添加为带有文本控件实例的行。这里唯一的另一个小部件是保存按钮。
接下来让我们编写add_widgets方法:
def add_widgets(self, label_text, text_ctrl):
row_sizer = wx.BoxSizer(wx.HORIZONTAL)
label = wx.StaticText(self, label=label_text,
size=(50, -1))
row_sizer.Add(label, 0, wx.ALL, 5)
row_sizer.Add(text_ctrl, 1, wx.ALL | wx.EXPAND, 5)
self.main_sizer.Add(row_sizer, 0, wx.EXPAND)
add_widgets()获取标签的文本和文本控件实例。然后它创建一个水平方向的BoxSizer。
接下来,您将使用传入的文本为标签参数创建一个wx.StaticText的实例。您还将设置它的大小为50像素宽,默认高度用-1设置。因为您希望标签在文本控件之前,所以您将首先向 BoxSizer 添加 StaticText 小部件,然后添加文本控件。
最后,您希望将水平尺寸标注添加到顶级垂直尺寸标注中。通过将 sizers 相互嵌套,您可以设计复杂的应用程序。
现在您需要创建on_save()事件处理程序,以便保存您的更改:
def on_save(self, event):
self.mp3.tag.artist = self.artist.GetValue()
self.mp3.tag.album = self.album.GetValue()
self.mp3.tag.title = self.title.GetValue()
self.mp3.tag.save()
self.Close()
在这里,您将标签设置为文本控件的内容,然后调用eyed3对象的.save()。最后,你调用对话框的.Close()。你打电话的原因。这里的Close()而不是.Destroy()是你已经在你的 panel 子类的.on_edit()中调用了.Destroy()。
现在你的申请完成了!
结论
在本文中,您学到了很多关于 wxPython 的知识。您已经熟悉了使用 wxPython 创建 GUI 应用程序的基础知识。
您现在对以下内容有了更多的了解:
- 如何使用 wxPython 的一些小部件
- wxPython 中事件的工作方式
- 绝对定位与 sizers 相比如何
- 如何创建一个框架应用程序
最后,您学习了如何创建一个工作应用程序,一个 MP3 标签编辑器。您可以使用在本文中学到的知识来继续增强这个应用程序,或者自己创建一个令人惊叹的应用程序。
wxPython GUI toolkit 是健壮的,并且充满了有趣的小部件,可以用来构建跨平台的应用程序。你只受限于你的想象力。
延伸阅读
如果您想了解更多关于 wxPython 的信息,可以查看以下链接:
- wxPython 官方网站
- Zetcode 的 wxPython 教程
- 鼠标 Vs Python 博客
想了解更多关于 Python 的其他功能,你可能想看看我能用 Python 做什么?如果你想了解更多关于 Python 的super(),那么用 Python super() 增强你的类可能正适合你。
如果您想更深入地研究它,您还可以下载您在本文中创建的 MP3 标签编辑器应用程序的代码。******
使用 TDD 在 Python 中构建哈希表
半个多世纪前发明的哈希表是一种经典的数据结构,是编程的基础。直到今天,它还能帮助解决许多现实生活中的问题,比如索引数据库表、缓存计算值或实现集合。它经常出现在的工作面试中,Python 到处使用散列表,使得名字查找几乎是瞬间完成的。
尽管 Python 自带了名为dict的散列表,但是理解散列表在幕后是如何工作的还是很有帮助的。编码评估甚至会让你去构建一个。本教程将带您从头开始实现散列表的步骤,就好像 Python 中没有散列表一样。在这个过程中,您将面临一些挑战,这些挑战将介绍一些重要的概念,并让您了解为什么散列表如此之快。
除此之外,您还将参加测试驱动开发(TDD) 的实践速成班,并在逐步构建哈希表的同时积极练习。你不需要事先有任何关于 TDD 的经验,但是同时,即使你有,你也不会感到厌烦!
在本教程中,您将学习:
- 一个散列表与一个字典有何不同
- 如何用 Python 从零开始实现散列表
- 如何应对哈希冲突和其他挑战
- 一个散列函数的期望属性是什么
- Python 的
hash()如何在幕后运作
如果你已经熟悉了 Python 字典并且具备了面向对象编程原则的基础知识,这将会有所帮助。要获得本教程中实现的哈希表的完整源代码和中间步骤,请访问下面的链接:
源代码: 点击这里下载源代码,您将使用它在 Python 中构建一个散列表。
了解哈希表数据结构
在深入研究之前,您应该熟悉这些术语,因为它们可能会有点令人困惑。通俗地说,术语散列表或散列表经常与单词字典互换使用。然而,这两个概念之间有细微的区别,因为前者比后者更具体。
哈希表 vs 字典
在计算机科学中,字典是由成对排列的键和值组成的抽象数据类型。此外,它为这些元素定义了以下操作:
- 添加一个键值对
- 删除键值对
- 更新键值对
- 查找与给定键相关联的值
从某种意义上来说,这种抽象数据类型类似于一个双语字典,其中的关键字是外来词,值是它们的定义或对其他语言的翻译。但是键和值之间并不总是有等价的感觉。电话簿是字典的另一个例子,它将姓名和相应的电话号码结合在一起。
注意:每当你将一个东西映射到另一个东西或者将一个值与一个键相关联时,你实际上是在使用一种字典。这就是为什么字典也被称为映射或关联数组。
字典有一些有趣的特性。其中之一是你可以把字典想象成一个数学函数,它将一个或多个参数投射到一个值上。这一事实的直接后果如下:
- 只有键-值对:在字典中,没有值就没有键,反之亦然。他们总是一起去。
- 任意键和值:键和值可以属于相同或不同类型的两个不相交集合。键和值几乎可以是任何东西,比如数字、单词,甚至是图片。
- 无序的键值对:由于最后一点,字典一般不会为它们的键值对定义任何顺序。然而,这可能是特定于实现的。
- 唯一键:字典不能包含重复的键,因为那会违反函数的定义。
- 非唯一值:同一个值可以关联很多键,但不一定要关联。
有一些相关的概念扩展了字典的概念。例如,多重映射允许每个键有多个值,而双向映射不仅将键映射到值,还提供相反方向的映射。然而,在本教程中,您将只考虑常规字典,它为每个键映射一个值。
下面是一个假想字典的图形描述,它将一些抽象概念映射到它们对应的英语单词:
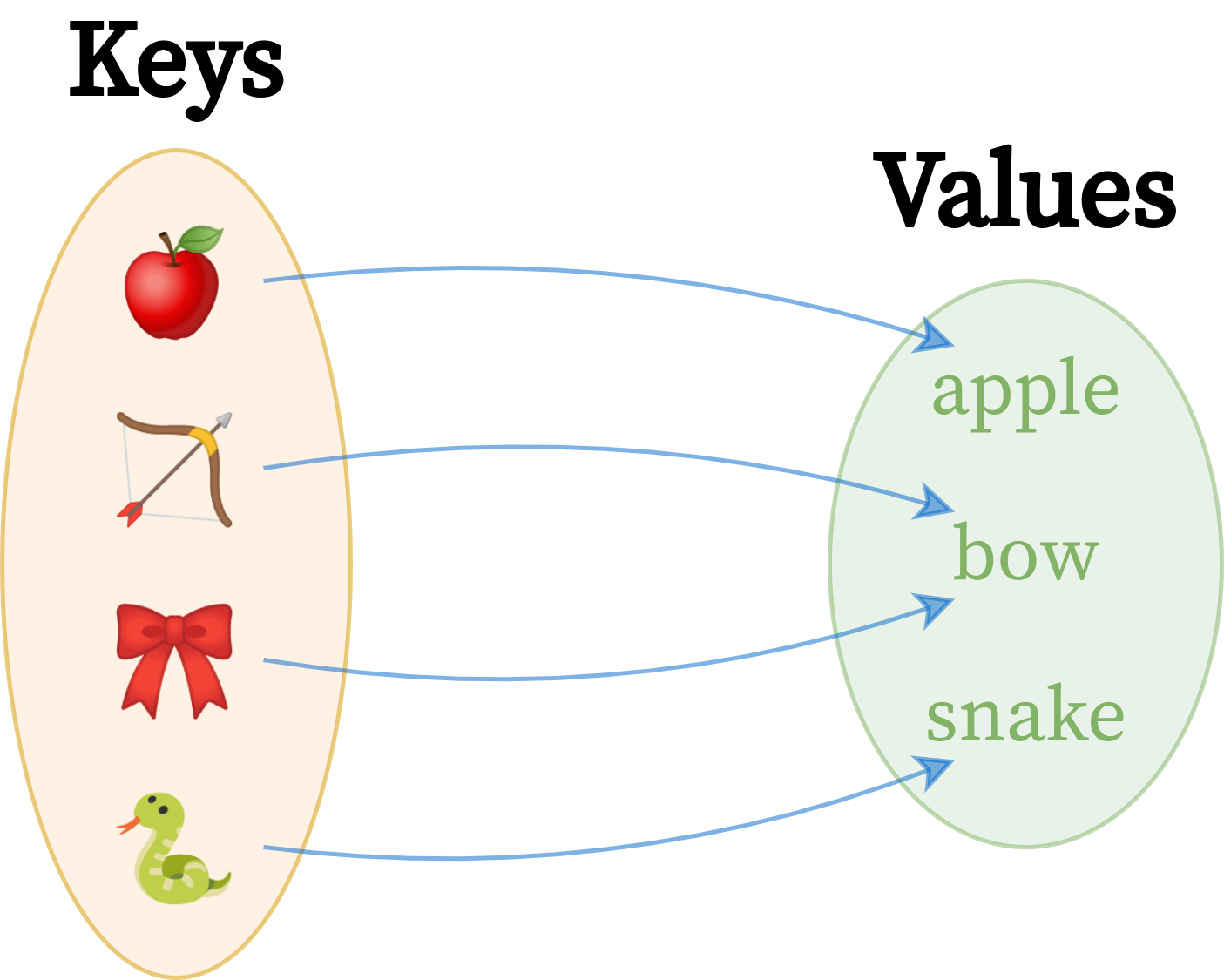
这是键到值的单向映射,值是两组完全不同的元素。马上,您可以看到比键更少的值,因为单词 bow 恰好是一个具有多种含义的同音异义词。从概念上讲,这本字典仍然包含四对。根据您决定如何实现它,您可以重用重复的值以节省内存,或者为了简单起见复制它们。
现在,如何用编程语言编写这样的字典呢?正确的答案是你不要,因为大多数现代语言自带的字典要么是原始数据类型,要么是它们的标准库中的类。Python 附带了一个内置的dict类型,它已经包装了一个用 C 编写的高度优化的数据结构,这样你就不用自己写字典了。
Python 的dict允许您执行本节开头列出的所有字典操作:
>>> glossary = {"BDFL": "Benevolent Dictator For Life"} >>> glossary["GIL"] = "Global Interpreter Lock" # Add >>> glossary["BDFL"] = "Guido van Rossum" # Update >>> del glossary["GIL"] # Delete >>> glossary["BDFL"] # Search 'Guido van Rossum' >>> glossary {'BDFL': 'Guido van Rossum'}使用方括号语法 (
[ ]),您可以向字典添加一个新的键值对。您还可以更新或删除由键标识的现有对的值。最后,您可以查找与给定键相关联的值。也就是说,你可以问一个不同的问题。内置字典实际上是如何工作的?它是如何映射任意数据类型的键的,又是如何做到如此快速的呢?
寻找这种抽象数据类型的有效实现被称为字典问题。最著名的解决方案之一利用了您将要探索的散列表数据结构。但是,请注意,这并不是实现字典的唯一方法。另一个流行的实现建立在红黑树之上。
哈希表:带有哈希函数的数组
您是否曾经想过,为什么在 Python 中访问序列元素如此之快,而不管您请求哪个索引?假设您正在处理一个很长的字符串,就像这样:
>>> import string
>>> text = string.ascii_uppercase * 100_000_000
>>> text[:50] # Show the first 50 characters
'ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWX'
>>> len(text)
2600000000
上面的text变量中有 26 亿个字符来自重复 ASCII 字母,你可以用 Python 的len()函数来统计。然而,从这个字符串中获取第一个、中间的、最后一个或任何其他字符同样很快:
>>> text[0] # The first element 'A' >>> text[len(text) // 2] # The middle element 'A' >>> text[-1] # The last element, same as text[len(text) - 1] 'Z'Python 中的所有序列类型也是如此,比如列表和元组。怎么会这样如此快的速度的秘密在于 Python 中的序列由一个数组支持,这是一个随机存取数据结构。它遵循两个原则:
- 该阵列占用一个连续的内存块。
- 数组中的每个元素都有一个预先已知的固定大小的元素。
当你知道一个数组的内存地址,这个地址被称为偏移量,那么你可以通过计算一个相当简单的公式立即得到数组中想要的元素:
Formula to Calculate the Memory Address of a Sequence Element 从数组的偏移量开始,这也是数组的第一个元素的地址,索引为零。接下来,添加所需的字节数,这是通过将元素大小乘以目标元素的索引得到的。将几个数字相乘并相加总是需要相同的时间。
注意:与数组不同,Python 的列表可以包含不同大小的异构元素,这会破坏上面的公式。为了减轻这一点,Python 通过引入一个指向内存位置的指针的数组而不是将值直接存储在数组中,增加了另一层间接性:
Array of Pointers to Memory Addresses 指针仅仅是整数,总是占据相同的空间。习惯上用十六进制的符号来表示内存地址。Python 和其他一些语言给这些数字加上前缀
0x。好的,你知道在一个数组中找到一个元素是很快的,不管这个元素实际上在哪里。你能把同样的想法在字典中重复使用吗?是啊!
哈希表的名字来源于一种叫做哈希的技巧,这种技巧可以让它们将任意键转换成一个整数,该整数可以作为常规数组中的索引。因此,您不用通过数字索引来搜索值,而是通过任意键来查找,而不会有明显的性能损失。太棒了!
实际上,散列并不适用于每个键,但是 Python 中的大多数内置类型都可以被散列。如果你遵循一些规则,那么你也可以创建自己的散列类型。在下一节中,您将了解更多关于散列的内容。
了解哈希函数
一个散列函数通过将任何数据转换成固定大小的字节序列来执行散列,该字节序列被称为散列值或散列码。这是一个可以作为数字指纹或摘要的数字,通常比原始数据小得多,这让你可以验证它的完整性。如果你曾经从互联网上获取过一个大文件,比如 Linux 发行版的磁盘映像,那么你可能会注意到下载页面上有一个 MD5 或 SHA-2 校验和。
除了验证数据完整性和解决字典问题,哈希函数在其他领域也有帮助,包括安全和 密码学 。例如,您通常将哈希密码存储在数据库中,以降低数据泄露的风险。数字签名包括在加密前哈希生成消息摘要。区块链交易是将哈希函数用于加密目的的另一个主要例子。
注意:加密哈希函数是一种特殊类型的哈希函数,必须满足一些附加要求。在本教程中,您将只遇到哈希表数据结构中使用的最基本形式的哈希函数。
虽然有许多散列算法,但是它们都有一些共同的属性,您将在本节中发现这些属性。正确实现一个好的散列函数是一项艰巨的任务,可能需要理解涉及素数的高等数学。幸运的是,您通常不需要手动实现这样的算法。
Python 自带了一个内置的 hashlib 模块,它提供了各种众所周知的加密哈希函数,以及不太安全的校验和算法。该语言还有一个全局
hash()函数,主要用于在字典和集合中快速查找元素。您可以先研究它是如何工作的,以了解哈希函数最重要的属性。检查 Python 的内置
hash()在从头开始尝试实现散列函数之前,先停下来分析一下 Python 的
hash(),提取它的属性。这将有助于您理解在设计自己的哈希函数时会涉及哪些问题。注意:哈希函数的选择会极大地影响哈希表的性能。因此,在本教程稍后构建自定义哈希表时,您将依赖内置的
hash()函数。在本节中实现散列函数只是作为一个练习。对于初学者来说,试着在 Python 内置的一些数据类型文字上调用
hash(),比如数字和字符串,看看这个函数是如何工作的:

>>> hash(3.14)
322818021289917443
>>> hash(3.14159265358979323846264338327950288419716939937510)
326490430436040707
>>> hash("Lorem")
7677195529669851635
>>> hash("Lorem ipsum dolor sit amet, consectetur adipisicing elit,"
... "sed do eiusmod tempor incididunt ut labore et dolore magna"
... "aliqua. Ut enim ad minim veniam, quis nostrud exercitation"
... "ullamco laboris nisi ut aliquip ex ea commodo consequat."
... "Duis aute irure dolor in reprehenderit in voluptate velit"
... "esse cillum dolore eu fugiat nulla pariatur. Excepteur sint"
... "occaecat cupidatat non proident, sunt in culpa qui officia"
... "deserunt mollit anim id est laborum.")
1107552240612593693
通过查看结果,您已经可以做出一些观察。首先,对于上面显示的一些输入,内置散列函数可能在您的一端返回不同的值。虽然数字输入似乎总是产生相同的哈希值,但字符串很可能不会。这是为什么呢?看起来似乎hash()是一个非确定性的函数,但这与事实相去甚远!
当您在现有的解释器会话中使用相同的参数调用hash()时,您将继续得到相同的结果:
>>> hash("Lorem") 7677195529669851635 >>> hash("Lorem") 7677195529669851635 >>> hash("Lorem") 7677195529669851635这是因为哈希值是不可变的 T2,在对象的整个生命周期中不会改变。然而,一旦您退出 Python 并再次启动它,那么您几乎肯定会在 Python 调用中看到不同的哈希值。您可以通过尝试使用
-c选项在您的终端中运行一行脚本来测试这一点:
- 视窗
** Linux + macOS*C:\> python -c print(hash('Lorem')) 6182913096689556094 C:\> python -c print(hash('Lorem')) 1756821463709528809 C:\> python -c print(hash('Lorem')) 8971349716938911741$ python -c 'print(hash("Lorem"))' 6182913096689556094 $ python -c 'print(hash("Lorem"))' 1756821463709528809 $ python -c 'print(hash("Lorem"))' 8971349716938911741这是预料中的行为,Python 中实现了这一行为,作为对利用 web 服务器中哈希函数的已知漏洞的拒绝服务(DoS)攻击的对策。攻击者可以滥用弱哈希算法来故意制造所谓的哈希冲突,使服务器超载,使其无法访问。赎金是袭击的典型动机,因为大多数受害者通过不间断的在线存在赚钱。
今天,Python 默认为某些输入启用了散列随机化,比如字符串,以使散列值更难预测。这使得
hash()更加安全并且攻击更加困难。不过,您可以通过PYTHONHASHSEED环境变量设置一个固定的种子值来禁用随机化,例如:
- 视窗
** Linux + macOS*C:\> set PYTHONHASHSEED=1 C:\> python -c print(hash('Lorem')) 440669153173126140 C:\> python -c print(hash('Lorem')) 440669153173126140 C:\> python -c print(hash('Lorem')) 440669153173126140$ PYTHONHASHSEED=1 python -c 'print(hash("Lorem"))' 440669153173126140 $ PYTHONHASHSEED=1 python -c 'print(hash("Lorem"))' 440669153173126140 $ PYTHONHASHSEED=1 python -c 'print(hash("Lorem"))' 440669153173126140现在,对于一个已知的输入,每次 Python 调用都会产生相同的哈希值。这有助于在分布式 Python 解释器集群中划分或共享数据。只是要小心并理解禁用散列随机化所涉及的风险。总而言之,Python 的
hash()确实是一个确定性的函数,这是 hash 函数最基本的特性之一。此外,
hash()似乎相当通用,因为它接受任意输入。换句话说,它接受各种类型和大小的值。该函数接受字符串和浮点数,无论它们的长度或大小如何,都不会报错。事实上,您也可以计算更奇特类型的哈希值:
>>> hash(None)
5904497366826
>>> hash(hash)
2938107101725
>>> class Person:
... pass
...
>>> hash(Person)
5904499092884
>>> hash(Person())
8738841746871
>>> hash(Person())
8738841586112
在这里,您调用了 Python 的None对象上的散列函数、hash()函数本身,甚至一个定制的Person类及其一些实例。也就是说,并不是所有的对象都有相应的哈希值。如果您尝试针对以下几个对象之一调用hash()函数,它将引发一个异常:
>>> hash([1, 2, 3]) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list'输入的基础类型将决定您是否可以计算哈希值。在 Python 中,内置可变类型的实例——如列表、集合和字典——是不可散列的。你已经得到了为什么会这样的提示,但是你将在后面的部分中了解更多。现在,您可以假设大多数数据类型通常都应该使用散列函数。
深入探究 Python 的
hash()
hash()的另一个有趣的特性是,不管输入有多大,它总是产生一个固定大小的输出。在 Python 中,哈希值是一个中等大小的整数。偶尔,它可能会显示为负数,所以如果您打算以某种方式依赖哈希值,请考虑这一点:
>>> hash("Lorem")
-972535290375435184
固定大小输出的自然结果是大部分原始信息在此过程中不可逆转地丢失了。这很好,因为毕竟您希望得到的哈希值充当任意大数据的统一摘要。然而,因为散列函数将一组潜在的无限值投射到有限空间上,所以当两个不同的输入产生相同的散列值时,这可能导致散列冲突。
注意:如果你倾向于数学,那么你可以使用鸽笼原理来更正式地描述哈希冲突:
给定 m 个商品和 n 个容器,如果 m > n ,那么至少有一个容器有不止一个商品。
在这种情况下,项是您输入到哈希函数中的无限个值,而容器是从有限的池中分配的哈希值。
哈希冲突是哈希表中的一个基本概念,在实现您的自定义哈希表时,您将稍后更深入地回顾这个概念。现在,你可以认为他们是非常不受欢迎的。您应该尽可能避免哈希冲突,因为它们会导致非常低效的查找,并可能被黑客利用。因此,为了安全性和效率,一个好的散列函数必须最小化散列冲突的可能性。
实际上,这通常意味着散列函数必须在可用空间上分配均匀分布的值。您可以通过在终端中绘制文本直方图来可视化 Python 的hash()产生的哈希值的分布。复制下面的代码块,并将其保存在名为hash_distribution.py的文件中:
# hash_distribution.py
from collections import Counter
def distribute(items, num_containers, hash_function=hash):
return Counter([hash_function(item) % num_containers for item in items])
def plot(histogram):
for key in sorted(histogram):
count = histogram[key]
padding = (max(histogram.values()) - count) * " "
print(f"{key:3} {'■' * count}{padding} ({count})")
它使用一个 Counter 实例来方便地表示所提供项目的哈希值的直方图。通过用模操作符包装容器,散列值分布在指定数量的容器上。例如,现在您可以获取一百个可打印的 ASCII 字符,然后计算它们的哈希值并显示它们的分布:
>>> from hash_distribution import plot, distribute >>> from string import printable >>> plot(distribute(printable, num_containers=2)) 0 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (51) 1 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (49) >>> plot(distribute(printable, num_containers=5)) 0 ■■■■■■■■■■■■■■■ (15) 1 ■■■■■■■■■■■■■■■■■■■■■■■■■■ (26) 2 ■■■■■■■■■■■■■■■■■■■■■■ (22) 3 ■■■■■■■■■■■■■■■■■■ (18) 4 ■■■■■■■■■■■■■■■■■■■ (19)当只有两个容器时,您应该期望大致对半分布。添加更多的容器应该会或多或少地均匀填充它们。如您所见,内置的
hash()函数非常好,但在均匀分布哈希值方面并不完美。与此相关,哈希值的均匀分布通常是伪随机的,这对于加密哈希函数尤其重要。这防止了潜在的攻击者使用统计分析来尝试和预测散列函数的输入和输出之间的相关性。考虑改变字符串中的单个字母,并检查这如何影响 Python 中产生的哈希值:
>>> hash("Lorem")
1090207136701886571
>>> hash("Loren")
4415277245823523757
现在它是一个完全不同的哈希值,尽管只有一个字母不同。哈希值经常受到雪崩效应的影响,因为即使是最小的输入变化也会被放大。然而,散列函数的这一特性对于实现散列表数据结构来说并不重要。
在大多数情况下,Python 的hash()展示了加密哈希函数的另一个非本质特性,这源于前面提到的鸽子洞原理。它的行为就像一个单向函数,因为在大多数情况下找到它的逆函数几乎是不可能的。然而,也有明显的例外:
>>> hash(42) 42小整数的哈希值等于自身,这是 CPython 为了简单和高效而使用的一个实现细节。请记住,实际的哈希值并不重要,只要您能够以确定的方式计算它们。
最后但同样重要的是,在 Python 中计算哈希值是快速的 T2,即使对于非常大的输入也是如此。在现代计算机上,调用带有一亿个字符的字符串的
hash()作为参数会立即返回。如果速度不够快,那么哈希值计算的额外开销会抵消哈希的优势。身份散列函数属性
基于到目前为止您对 Python 的
hash()的了解,您现在可以从总体上对散列函数的期望属性得出结论。下面是对这些功能的总结,比较了常规哈希函数和它的加密功能:
特征 散列函数 加密哈希函数 确定性的 ✔️ ✔️ 通用输入 ✔️ ✔️ 固定大小的输出 ✔️ ✔️ 快速计算 ✔️ ✔️ 均匀分布 ✔️ ✔️ 随机分布 ✔️ 随机种子 ✔️ 单向函数 ✔️ 雪崩效应 ✔️ 两种散列函数类型的目标是重叠的,所以它们有一些共同的特性。另一方面,加密散列函数提供了额外的安全保证。
在构建您自己的散列函数之前,您将看一看 Python 中内置的另一个函数,这似乎是它最直接的替代品。
将对象的身份与其哈希进行比较
Python 中可能最简单的散列函数实现之一是内置的
id(),它告诉你一个对象的身份。在标准 Python 解释器中,标识与表示为整数的对象内存地址相同:
>>> id("Lorem")
139836146678832
id()函数具有大多数期望的散列函数属性。毕竟,它的速度非常快,可以处理任何输入。它以确定的方式返回一个固定大小的整数。与此同时,您不能根据其内存地址轻松地检索原始对象。内存地址本身在对象的生命周期中是不可变的,在解释器运行之间是随机的。
那么,为什么 Python 坚持使用不同的散列函数呢?
首先,id()的意图与hash()不同,所以其他 Python 发行版可能会以替代方式实现 identity。第二,内存地址在没有统一分布的情况下是可预测的,这对于散列来说是不安全的和非常低效的。最后,相等的对象通常应该产生相同的哈希代码,即使它们具有不同的标识。
注意:稍后,您将了解更多关于值的相等性和相应散列码之间的契约的内容。
这样一来,您终于可以考虑自己创建散列函数了。
制作自己的哈希函数
从头开始设计一个满足所有需求的散列函数是很困难的。如前所述,在下一节中,您将使用内置的hash()函数来创建哈希表原型。然而,尝试从头开始构建散列函数是了解其工作原理的一个好方法。到本节结束时,您将只有一个基本的散列函数,离完美还很远,但是您将获得有价值的见解。
在本练习中,您可以先限制自己只使用一种数据类型,并围绕它实现一个粗略的散列函数。例如,您可以考虑字符串,并对其中各个字符的序数值求和:
>>> def hash_function(text): ... return sum(ord(character) for character in text)您使用一个生成器表达式对文本进行迭代,然后使用内置的
ord()函数将每个单独的字符转化为相应的 Unicode 码位,最后将序号值求和在一起。这将为作为参数提供的任何给定文本抛出一个数字:
>>> hash_function("Lorem")
511
>>> hash_function("Loren")
512
>>> hash_function("Loner")
512
马上,您会注意到这个函数的一些问题。它不仅是特定于字符串的,而且还受到哈希代码分布不良的影响,哈希代码往往在相似的输入值处形成集群。输入的微小变化对观察到的输出几乎没有影响。更糟糕的是,该函数仍然对文本中的字符顺序不敏感,这意味着同一单词的变位词,如 Loren 和 Loner ,会导致哈希代码冲突。
要解决第一个问题,尝试通过调用str()将输入转换为字符串。现在,您的函数将能够处理任何类型的参数:
>>> def hash_function(key): ... return sum(ord(character) for character in str(key)) >>> hash_function("Lorem") 511 >>> hash_function(3.14) 198 >>> hash_function(True) 416您可以使用任何数据类型的参数调用
hash_function(),包括字符串、浮点数或布尔值。请注意,这种实现只能与相应的字符串表示一样好。一些对象可能没有适合上面代码的文本表示。特别是,没有正确实现特殊方法
.__str__()和.__repr__()的定制类实例就是一个很好的例子。另外,您将无法再区分不同的数据类型:
>>> hash_function("3.14")
198
>>> hash_function(3.14)
198
实际上,您可能希望将字符串"3.14"和浮点数3.14视为具有不同散列码的不同对象。减轻这种情况的一种方法是将str()替换为 repr() ,用附加的撇号(')将字符串的表示括起来:
>>> repr("3.14") "'3.14'" >>> repr(3.14) '3.14'这将在一定程度上改进您的哈希函数:
>>> def hash_function(key):
... return sum(ord(character) for character in repr(key))
>>> hash_function("3.14")
276
>>> hash_function(3.14)
198
字符串现在可以与数字区分开来。为了解决变位词的问题,比如 Loren 和 Loner ,你可以通过考虑字符的值以及它在文本中的位置来修改你的散列函数:
>>> def hash_function(key): ... return sum( ... index * ord(character) ... for index, character in enumerate(repr(key), start=1) ... )这里,您将字符的序数值与它们对应的索引相乘,得到乘积的和。注意你从 1 开始而不是从 0 开始枚举索引。否则,第一个字符将总是被丢弃,因为它的值将被乘以零。
现在,您的哈希函数相当通用,不会像以前那样导致很多冲突,但是它的输出可以任意增长,因为字符串越长,哈希代码就越大。此外,对于较大的输入,它非常慢:
>>> hash_function("Tiny")
1801
>>> hash_function("This has a somewhat medium length.")
60919
>>> hash_function("This is very long and slow!" * 1_000_000)
33304504435500117
您总是可以通过将您的哈希代码取模(%)与已知的最大大小(比如 100:
>>> hash_function("Tiny") % 100 1 >>> hash_function("This has a somewhat medium length.") % 100 19 >>> hash_function("This is very long and slow!" * 1_000_000) % 100 17请记住,选择较小的哈希代码池会增加哈希代码冲突的可能性。如果您事先不知道输入值的数量,那么最好等到以后再做决定。您还可以通过假设一个合理的最大值来限制您的哈希代码,例如
sys.maxsize,它代表 Python 中本地支持的整数的最大值。暂时忽略函数的缓慢速度,您会注意到哈希函数的另一个特殊问题。通过群集和不利用所有可用的槽,它导致散列码的次优分布:
>>> from hash_distribution import plot, distribute
>>> from string import printable
>>> plot(distribute(printable, 6, hash_function))
0 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (31)
1 ■■■■ (4)
2 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (31)
4 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ (33)
5 ■ (1)
分布不均。此外,有六个容器可用,但是直方图中缺少一个。这个问题源于这样一个事实,即由repr()添加的两个撇号导致本例中几乎所有的键都产生一个偶数散列数。如果左撇号存在,您可以通过删除它来避免这种情况:
>>> hash_function("a"), hash_function("b"), hash_function("c") (350, 352, 354) >>> def hash_function(key): ... return sum( ... index * ord(character) ... for index, character in enumerate(repr(key).lstrip("'"), 1) ... ) >>> hash_function("a"), hash_function("b"), hash_function("c") (175, 176, 177) >>> plot(distribute(printable, 6, hash_function)) 0 ■■■■■■■■■■■■■■■■ (16) 1 ■■■■■■■■■■■■■■■■ (16) 2 ■■■■■■■■■■■■■■■ (15) 3 ■■■■■■■■■■■■■■■■■■ (18) 4 ■■■■■■■■■■■■■■■■■ (17) 5 ■■■■■■■■■■■■■■■■■■ (18)对
str.lstrip()的调用只会影响以指定前缀开始的字符串。当然,您可以继续进一步改进您的散列函数。如果你对 Python 中字符串和字节序列的
hash()实现感到好奇,那么它目前使用的是 SipHash 算法,如果前者不可用,它可能会退回到 FNV 的修改版本。要找出您的 Python 解释器使用的散列算法,请使用sys模块:
>>> import sys
>>> sys.hash_info.algorithm
'siphash24'
至此,您已经很好地掌握了散列函数,它应该如何工作,以及在实现它时可能会面临哪些挑战。在接下来的小节中,您将使用哈希函数来构建哈希表。特定哈希算法的选择会影响哈希表的性能。有了这些知识作为基础,从现在开始,你可以放心地坚持使用内置的hash()。
用 TDD 在 Python 中构建一个哈希表原型
在本节中,您将创建一个表示哈希表数据结构的自定义类。它不会有 Python 字典做后盾,所以你可以从头构建一个哈希表,并实践你目前所学的内容。同时,您将模仿内置字典最基本的特性,在内置字典之后为您的实现建模。
注意:这只是一个快速提醒,实现哈希表只是一个练习和一个教育工具,用来教你这种数据结构解决的问题。就像以前编写自定义哈希函数一样,纯 Python 哈希表实现在现实应用程序中没有实际用途。
下面是您现在要实现的哈希表的高级需求列表。在本节结束时,您的哈希表将展示以下核心特性。它将让您:
- 创建一个空哈希表
- 向哈希表中插入一个键值对
- 从哈希表中删除一个键值对
- 在哈希表中通过键查找值
- 更新与现有键关联的值
- 检查哈希表是否有给定的键
除此之外,您将实现一些不重要的但仍然有用的特性。具体来说,您应该能够:
- 从 Python 字典创建哈希表
- 创建现有哈希表的浅拷贝
- 如果找不到相应的键,则返回默认值
- 报告哈希表中存储的键值对的数量
- 返回键、值和键值对
- 使哈希表可迭代
- 使用相等测试运算符使哈希表具有可比性
- 显示哈希表的文本表示
在实现这些特性的同时,您将通过逐渐向哈希表添加更多的特性来积极地练习测试驱动开发。请注意,您的原型将只涵盖基础知识。在本教程的稍后部分,您将学习如何处理一些更高级的极限情况。具体来说,本节不会介绍如何:
- 解决哈希代码冲突
- 保留插入顺序
- 动态调整哈希表的大小
- 计算负载系数
如果您遇到困难,或者如果您想跳过一些中间的重构步骤,请随意使用补充材料作为控制检查点。每个小节都以一个完整的实现阶段和相应的测试结束,您可以从这些测试开始。获取以下链接并下载支持材料,包括完整的源代码和本教程中使用的中间步骤:
源代码: 点击这里下载源代码,您将使用它在 Python 中构建一个散列表。
参加测试驱动开发的速成班
既然您已经知道了哈希函数的高级属性及其用途,那么您就可以使用测试驱动开发方法来构建哈希表。如果您以前从未尝试过这种编程技术,那么它可以归结为您倾向于在一个循环中重复的三个步骤:
- 🟥·雷德:想出一个单独的测试用例,并使用你选择的单元测试框架将其自动化。在这一点上你的测试会失败,但是没关系。测试运行者通常用红色表示失败的测试,因此这个循环阶段被命名为。
- 🟩·格林:实现最低限度,让你的测试通过,但仅此而已!这将确保更高的代码覆盖率,并避免你写多余的代码。测试报告随后会亮起令人满意的绿色。
- ♻️重构:可选地,修改你的代码而不改变它的行为,只要所有的测试用例仍然通过。您可以将此作为消除重复和提高代码可读性的机会。
Python 自带了开箱即用的 unittest 包,但是第三方 pytest 库的学习曲线相对较浅,所以您将在本教程中使用它。现在就开始在您的虚拟环境中安装pytest:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install pytest
(venv) $ python -m pip install pytest
请记住,您可以根据几个控制检查点来验证每个实施阶段。接下来,创建一个名为test_hashtable.py的文件,并在其中定义一个虚拟测试函数来检查 pytest 是否会选择它:
# test_hashtable.py
def test_should_always_pass():
assert 2 + 2 == 22, "This is just a dummy test"
框架利用内置的 assert语句来运行您的测试并报告它们的结果。这意味着您可以只使用常规的 Python 语法,除非绝对必要,否则不需要导入任何特定的 API。它还检测测试文件和测试函数,只要它们的名字以前缀test开始。
assert语句将一个布尔表达式作为参数,后跟一个可选的错误消息。当条件评估为True时,什么都不会发生,就好像根本没有断言一样。否则,Python 将引发一个AssertionError,并在标准错误流(stderr) 上显示消息。同时,pytest 截获断言错误,并围绕它们构建一个报告。
现在,打开终端,将您的工作目录更改为您保存该测试文件的位置,并不带任何参数地运行pytest命令。它的输出应该如下所示:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pytest
=========================== test session starts ===========================
platform win32 -- Python 3.10.2, pytest-6.2.5, pluggy-1.0.0
rootdir: C:\Users\realpython\hashtable
collected 1 item
test_hashtable.py F [100%]
================================ FAILURES =================================
_________________________ test_should_always_pass _________________________
def test_should_always_pass():
> assert 2 + 2 == 22, "This is just a dummy test"
E AssertionError: This is just a dummy test
E assert (2 + 2) == 22
test_hashtable.py:4: AssertionError
========================= short test summary info =========================
FAILED test_hashtable.py::test_should_always_pass - AssertionError: This...
============================ 1 failed in 0.03s ============================
(venv) $ pytest
=========================== test session starts ===========================
platform linux -- Python 3.10.0, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
rootdir: /home/realpython/hashtable
collected 1 item
test_hashtable.py F [100%]
================================ FAILURES =================================
_________________________ test_should_always_pass _________________________
def test_should_always_pass():
> assert 2 + 2 == 22, "This is just a dummy test"
E AssertionError: This is just a dummy test
E assert (2 + 2) == 22
test_hashtable.py:4: AssertionError
========================= short test summary info =========================
FAILED test_hashtable.py::test_should_always_pass - AssertionError: This...
============================ 1 failed in 0.03s ============================
啊哦。你的测试失败了。要找到根本原因,可以通过在命令后面附加-v标志来增加 pytest 输出的详细程度。现在,您可以确定问题所在:
def test_should_always_pass():
> assert 2 + 2 == 22, "This is just a dummy test"
E AssertionError: This is just a dummy test
E assert 4 == 22
E +4
E -22
输出显示失败断言的实际和预期值。在这种情况下,二加二等于四,而不是二十二。您可以通过更正预期值来修复代码:
# test_hashtable.py
def test_should_always_pass():
assert 2 + 2 == 4, "This is just a dummy test"
当您重新运行 pytest 时,应该不会再有测试失败了:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pytest
=========================== test session starts ===========================
platform win32 -- Python 3.10.2, pytest-6.2.5, pluggy-1.0.0
rootdir: C:\Users\realpython\hashtable
collected 1 item
test_hashtable.py . [100%]
============================ 1 passed in 0.00s ============================
(venv) $ pytest
=========================== test session starts ===========================
platform linux -- Python 3.10.0, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
rootdir: /home/realpython/hashtable
collected 1 item
test_hashtable.py . [100%]
============================ 1 passed in 0.00s ============================
就是这样!您已经学习了为哈希表实现自动化测试用例的基本步骤。当然,如果方便的话,你可以使用 IDE,比如 PyCharm 或者编辑器,比如 VS Code 集成测试框架。接下来,你要将这些新知识付诸实践。
定义一个自定义的HashTable类
记得遵循前面描述的红绿重构循环。因此,您必须从识别您的第一个测试用例开始。例如,您应该能够通过调用从hashtable模块导入的假想的HashTable类来实例化一个新的哈希表。这个调用应该返回一个非空的对象:
# test_hashtable.py
from hashtable import HashTable
def test_should_create_hashtable():
assert HashTable() is not None
此时,您的测试将拒绝运行,因为文件顶部有一个未满足要求的导入语句。毕竟你在的红色阶段。红色阶段是唯一允许添加新特性的时候,所以继续创建另一个名为hashtable.py的模块,并将HashTable类定义放入其中:
# hashtable.py
class HashTable:
pass
这是一个基本的类占位符,但应该足以让您的测试通过。顺便说一下,如果您使用代码编辑器,那么您可以方便地将视图分割成列,并排显示测试下的代码和相应的测试:
如果你对上面截图中描绘的配色方案感到好奇,那么它就是德古拉主题。它适用于许多代码编辑器,而不仅仅是 PyCharm。
一旦运行 pytest 成功,您就可以开始考虑另一个测试用例,因为几乎没有什么需要重构的。例如,一个基本的哈希表应该包含一个值序列。在这个早期阶段,您可以假设序列有一个在哈希表创建时建立的固定大小的序列。相应地修改您现有的测试用例:
# test_hashtable.py
from hashtable import HashTable
def test_should_create_hashtable():
assert HashTable(size=100) is not None
您使用关键字参数来指定大小。然而,在向HashTable类添加新代码之前,重新运行您的测试以确认您已经再次进入红色阶段。见证一次失败的测试可能是非常宝贵的。当您稍后实现一段代码时,您将知道它是否满足一组特定的测试,或者它们是否保持不受影响。否则,您的测试可能会通过验证与您想象的不同的东西来欺骗您!
在确认您处于红色阶段后,用预期的签名声明HashTable类中的.__init__()方法,但不要实现它的主体:
# hashtable.py
class HashTable:
def __init__(self, size): pass
嘣!你又回到了绿色阶段,所以这次来点重构怎么样?例如,如果对您来说更具描述性,您可以将参数size重命名为capacity。不要忘记首先更改测试用例,然后运行 pytest,最后一步总是更新测试中的代码:
# hashtable.py
class HashTable:
def __init__(self, capacity): pass
正如您所知,红绿重构循环由几个简短的阶段组成,每个阶段通常不会超过几秒钟。那么,为什么不继续添加更多的测试用例呢?如果您的数据结构可以使用 Python 内置的len()函数报告哈希表的容量就好了。添加另一个测试用例,观察它是如何悲惨地失败的:
# test_hashtable.py
from hashtable import HashTable
def test_should_create_hashtable():
assert HashTable(capacity=100) is not None
def test_should_report_capacity():
assert len(HashTable(capacity=100)) == 100
为了正确处理len(),你必须在你的类中实现特殊方法 .__len__(),并记住通过类初始化器提供的容量:
# hashtable.py
class HashTable:
def __init__(self, capacity):
self.capacity = capacity
def __len__(self): return self.capacity
你可能认为 TDD 没有把你带到正确的方向。这可能不是您想象的哈希表实现方式。你一开始的值序列在哪里?不幸的是,测试驱动开发受到了很多批评,因为它采取了小步骤并在过程中做了很多修正。因此,它可能不适合涉及大量实验的项目。
另一方面,实现众所周知的数据结构,比如哈希表,是这种软件开发方法的完美应用。您有清晰的期望,可以直接编码为测试用例。很快,您将亲眼看到采取下一步将导致实现中的微小变化。不过,不要担心,因为完善代码本身没有让测试用例通过重要。
随着您通过测试用例不断添加更多的约束,您经常需要重新考虑您的实现。例如,一个新的哈希表可能应该从空的存储值位置开始:
# test_hashtable.py
# ...
def test_should_create_empty_value_slots():
assert HashTable(capacity=3).values == [None, None, None]
换句话说,一个新的哈希表应该公开一个具有请求长度的.values属性,并用None元素填充。顺便说一下,使用如此冗长的函数名是很常见的,因为它们会出现在您的测试报告中。测试的可读性和描述性越强,你就能越快地找出需要修复的部分。
注意:根据经验,你的测试用例应该尽可能的独立和原子化,这通常意味着每个函数只使用一个断言。然而,您的测试场景有时可能需要一点设置或拆卸。它们也可能包括几个步骤。在这种情况下,习惯上围绕所谓的既定时间惯例来构建你的职能:
def test_should_create_empty_value_slots():
# Given
expected_values = [None, None, None]
hash_table = HashTable(capacity=3)
# When
actual_values = hash_table.values
# Then
assert actual_values == expected_values
给定的部分描述了测试用例的初始状态和前提条件,而时的表示测试中代码的动作,而则负责断言最终结果。**
这是满足您现有测试的许多可能方法之一:
# hashtable.py
class HashTable:
def __init__(self, capacity):
self.values = capacity * [None]
def __len__(self):
return len(self.values)
您用一个只包含None元素的请求长度列表替换.capacity属性。将一个数字乘以一个列表或反过来是用给定值填充列表的一种快速方法。除此之外,您更新特殊的方法.__len__(),这样所有的测试都将通过。
注意:Python 字典的长度对应于实际存储的键值对的数量,而不是它的内部容量。你很快就会达到类似的效果。
既然您已经熟悉了 TDD,那么是时候深入研究一下,将剩下的特性添加到您的哈希表中。
插入一个键值对
既然您已经可以创建哈希表,那么是时候赋予它一些存储功能了。传统的哈希表由一个只能存储一种数据类型的数组支持。因此,许多语言(如 Java)中的哈希表实现要求您预先声明它们的键和值的类型:
Map<String, Integer> phonesByNames = new HashMap<>();
例如,这个特定的哈希表将字符串映射为整数。但是,因为数组不是 Python 的固有属性,所以您将继续使用列表。作为副作用,您的哈希表将能够接受任意数据类型的键和值,就像 Python 的dict。
注意: Python 有一个高效的 array 集合,但是它只适用于数值。有时,您可能会发现处理原始二进制数据很方便。
现在添加另一个测试用例,使用熟悉的方括号语法将键值对插入到哈希表中:
# test_hashtable.py
# ...
def test_should_insert_key_value_pairs():
hash_table = HashTable(capacity=100)
hash_table["hola"] = "hello"
hash_table[98.6] = 37
hash_table[False] = True
assert "hello" in hash_table.values
assert 37 in hash_table.values
assert True in hash_table.values
首先,创建一个有 100 个空槽的哈希表,然后用三对不同类型的键和值填充它,包括字符串、浮点数和布尔值。最后,您断言哈希表以任意顺序包含预期的值。注意,你的哈希表只记得值,而不记得当时相关的键!
满足该测试的最简单、或许有点幼稚的实现如下:
# hashtable.py
class HashTable:
def __init__(self, capacity):
self.values = capacity * [None]
def __len__(self):
return len(self.values)
def __setitem__(self, key, value): self.values.append(value)
它完全忽略了键,只是将值追加到列表的右端,增加了列表的长度。您很可能会立即想到另一个测试案例。向哈希表中插入元素不会增加哈希表的大小。类似地,删除一个元素不会缩小哈希表,但是您只需要记住这一点,因为还没有能力删除键-值对。
注意:您也可以编写一个占位符测试,并告诉 pytest 无条件地跳过它,直到以后:
import pytest
@pytest.mark.skip
def test_should_not_shrink_when_removing_elements():
pass
它利用 pytest 提供的一个装饰器。
在现实世界中,您可能希望创建单独的测试用例,这些测试用例具有描述性的名称,专门用于测试这些行为。但是,因为这只是一个教程,为了简洁起见,您将向现有函数添加一个新的断言:
# test_hashtable.py
# ...
def test_should_insert_key_value_pairs():
hash_table = HashTable(capacity=100)
hash_table["hola"] = "hello"
hash_table[98.6] = 37
hash_table[False] = True
assert "hello" in hash_table.values
assert 37 in hash_table.values
assert True in hash_table.values
assert len(hash_table) == 100
您现在处于红色阶段,因此重新编写您的特殊方法,以始终保持容量固定:
# hashtable.py
class HashTable:
def __init__(self, capacity):
self.values = capacity * [None]
def __len__(self):
return len(self.values)
def __setitem__(self, key, value):
index = hash(key) % len(self) self.values[index] = value
您将一个任意键转换成一个数字哈希值,并使用模运算符将结果索引限制在可用的地址空间内。太好了!你的测试报告又变绿了。
注意:上面的代码依赖于 Python 内置的hash()函数,正如你已经了解到的,它有一个随机化的元素。因此,在极少数情况下,当两个键碰巧产生相同的哈希代码时,您的测试可能会失败。因为您稍后将处理哈希代码冲突,所以您可以在运行 pytest 时禁用哈希随机化或使用可预测的种子:
- 视窗
** Linux + macOS*
(venv) C:\> set PYTHONHASHSEED=128
(venv) C:\> python -m pytest
(venv) $ PYTHONHASHSEED=128 pytest
确保选择一个不会在样本数据中引起任何冲突的哈希种子。找到一个可能涉及一点点的尝试和错误。在我的例子中,value 128似乎工作得很好。*** ***但是你能想出一些边缘案例吗?把None插入你的哈希表怎么样?这将在合法值和指定的标记值之间产生冲突,您在散列表中选择该标记值来表示空白。你会想避免的。
像往常一样,首先编写一个测试用例来表达期望的行为:
# test_hashtable.py
# ...
def test_should_not_contain_none_value_when_created():
assert None not in HashTable(capacity=100).values
解决这个问题的一个方法是用另一个用户不太可能插入的唯一值替换.__init__()方法中的None。例如,您可以通过创建一个全新的对象来定义一个特殊的常量,以表示哈希表中的空格:
# hashtable.py
BLANK = object()
class HashTable:
def __init__(self, capacity):
self.values = capacity * [BLANK]
# ...
您只需要一个空白实例来将插槽标记为空。自然地,您需要更新一个旧的测试用例来回到绿色阶段:
# test_hashtable.py
from hashtable import HashTable, BLANK
# ...
def test_should_create_empty_value_slots():
assert HashTable(capacity=3).values == [BLANK, BLANK, BLANK]
# ...
然后,编写一个肯定的测试用例,使用快乐路径来处理None值的插入:
def test_should_insert_none_value():
hash_table = HashTable(capacity=100)
hash_table["key"] = None
assert None in hash_table.values
您创建一个有 100 个槽的空哈希表,并插入与某个任意键相关联的None。如果到目前为止你一直在严格遵循这些步骤,它应该会非常有效。如果没有,那么查看错误消息,因为它们通常包含关于哪里出错的线索。或者,可以通过以下链接下载示例代码:
源代码: 点击这里下载源代码,您将使用它在 Python 中构建一个散列表。
在下一小节中,您将添加通过相关键检索值的功能。
通过按键查找数值
要从哈希表中检索一个值,您需要像以前一样使用相同的方括号语法,只是不使用赋值语句。您还需要一个示例哈希表。为了避免在您的测试套件的各个测试用例中重复相同的设置代码,您可以将它包装在 pytest 公开的测试夹具中:
# test_hashtable.py
import pytest
# ...
@pytest.fixture
def hash_table():
sample_data = HashTable(capacity=100)
sample_data["hola"] = "hello"
sample_data[98.6] = 37
sample_data[False] = True
return sample_data
def test_should_find_value_by_key(hash_table):
assert hash_table["hola"] == "hello"
assert hash_table[98.6] == 37
assert hash_table[False] is True
一个测试夹具是一个用@pytest.fixture装饰器标注的函数。它为您的测试用例返回样本数据,比如用已知的键和值填充的散列表。您的 pytest 将自动为您调用该函数,并将其结果注入到任何一个测试函数中,该函数声明了一个与您的 fixture 同名的参数。在这种情况下,测试函数需要一个hash_table参数,它对应于您的 fixture 名称。
为了能够通过键查找值,您可以在您的HashTable类中通过另一个名为.__getitem__()的特殊方法实现元素查找:
# hashtable.py
BLANK = object()
class HashTable:
def __init__(self, capacity):
self.values = capacity * [BLANK]
def __len__(self):
return len(self.values)
def __setitem__(self, key, value):
index = hash(key) % len(self)
self.values[index] = value
def __getitem__(self, key): index = hash(key) % len(self) return self.values[index]
您根据提供的键的散列码计算元素的索引,并返回该索引下的任何内容。但是丢失钥匙怎么办?到目前为止,当一个给定的键以前没有被使用过时,您可能会返回一个空的实例,这个结果并不那么有用。要复制 Python dict在这种情况下如何工作,您应该引发一个KeyError异常:
# test_hashtable.py
# ...
def test_should_raise_error_on_missing_key():
hash_table = HashTable(capacity=100)
with pytest.raises(KeyError) as exception_info:
hash_table["missing_key"]
assert exception_info.value.args[0] == "missing_key"
您创建了一个空哈希表,并试图通过一个丢失的键访问它的一个值。pytest 框架包括一个用于测试异常的特殊构造。在上面,您使用pytest.raises 上下文管理器来预期下面代码块中的特定类型的异常。处理这种情况就是给你的访问器方法添加一个条件语句:
# hashtable.py
# ...
class HashTable:
# ...
def __getitem__(self, key):
index = hash(key) % len(self)
value = self.values[index]
if value is BLANK:
raise KeyError(key)
return value
如果给定索引处的值为空,则引发异常。顺便说一下,您使用了is操作符而不是等式测试操作符(==)来确保您比较的是标识而不是值。尽管自定义类中相等测试的默认实现退回到比较其实例的标识,但大多数内置数据类型区分这两种运算符,并以不同的方式实现它们。
因为现在可以确定给定的键在哈希表中是否有关联值,所以还不如实现in操作符来模拟 Python 字典。记住单独编写和覆盖这些测试用例,以尊重测试驱动的开发原则:
# test_hashtable.py
# ...
def test_should_find_key(hash_table):
assert "hola" in hash_table
def test_should_not_find_key(hash_table):
assert "missing_key" not in hash_table
这两个测试用例都利用了您之前准备的测试夹具,并验证了.__contains__()特殊方法,您可以通过以下方式实现它:
# hashtable.py
# ...
class HashTable:
# ...
def __contains__(self, key):
try:
self[key]
except KeyError:
return False
else:
return True
当访问给定的键引发一个KeyError时,您拦截该异常并返回False来指示一个丢失的键。否则,您将把try … except块与一个else子句结合起来,并返回True。异常处理很棒,但有时会不方便,这就是为什么dict.get()让你指定一个可选的默认值。您可以在自定义哈希表中复制相同的行为:
# test_hashtable.py
# ...
def test_should_get_value(hash_table):
assert hash_table.get("hola") == "hello"
def test_should_get_none_when_missing_key(hash_table):
assert hash_table.get("missing_key") is None
def test_should_get_default_value_when_missing_key(hash_table):
assert hash_table.get("missing_key", "default") == "default"
def test_should_get_value_with_default(hash_table):
assert hash_table.get("hola", "default") == "hello"
.get()的代码看起来类似于您刚刚实现的特殊方法:
# hashtable.py
# ...
class HashTable:
# ...
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
您试图返回与所提供的键相对应的值。在出现异常的情况下,您返回默认值,这是一个可选参数。当用户不指定它时,它等于None。
为了完整起见,在接下来的小节中,您将添加从哈希表中删除键值对的功能。
删除一个键值对
Python 字典允许您使用内置的del关键字删除以前插入的键-值对,这将删除关于键和值的信息。下面是它如何与您的哈希表一起工作:
# test_hashtable.py
# ...
def test_should_delete_key_value_pair(hash_table):
assert "hola" in hash_table
assert "hello" in hash_table.values
del hash_table["hola"]
assert "hola" not in hash_table
assert "hello" not in hash_table.values
首先,验证样本哈希表是否具有所需的键和值。然后,通过只指出键来删除两者,并以相反的期望重复断言。您可以通过如下测试:
# hashtable.py
# ...
class HashTable:
# ...
def __delitem__(self, key):
index = hash(key) % len(self)
del self.values[index]
计算与某个键相关的索引,并无条件地从列表中删除相应的值。但是,您会立即记起之前的笔记,即断言当您从散列表中删除元素时,散列表不应收缩。因此,您添加了另外两个断言:
# test_hashtable.py
# ...
def test_should_delete_key_value_pair(hash_table):
assert "hola" in hash_table
assert "hello" in hash_table.values
assert len(hash_table) == 100
del hash_table["hola"]
assert "hola" not in hash_table
assert "hello" not in hash_table.values
assert len(hash_table) == 100
这将确保哈希表底层列表的大小不受影响。现在,您需要更新您的代码,以便它将一个插槽标记为空白,而不是完全丢弃它:
# hashtable.py
# ...
class HashTable:
# ...
def __delitem__(self, key):
index = hash(key) % len(self)
self.values[index] = BLANK
考虑到你又处于绿色阶段,你可以借此机会花点时间重构。同一个指数公式在不同的地方出现了三次。您可以提取它并简化代码:
# hashtable.py
# ...
class HashTable:
# ...
def __delitem__(self, key):
self.values[self._index(key)] = BLANK
def __setitem__(self, key, value):
self.values[self._index(key)] = value
def __getitem__(self, key):
value = self.values[self._index(key)] if value is BLANK:
raise KeyError(key)
return value
# ...
def _index(self, key): return hash(key) % len(self)
突然,在仅仅应用了这个微小的修改之后,一个模式出现了。删除项目相当于插入一个空白对象。因此,您可以重写删除例程来利用 mutator 方法:
# hashtable.py
# ...
class HashTable:
# ...
def __delitem__(self, key):
self[key] = BLANK
# ...
通过方括号语法赋值会委托给.__setitem__()方法。好了,重构到此为止。在这一点上,考虑其他测试用例要重要得多。例如,当您请求删除一个丢失的密钥时会发生什么?在这种情况下,Python 的dict会引发一个KeyError异常,因此您也可以这样做:
# hashtable.py
# ...
def test_should_raise_key_error_when_deleting(hash_table):
with pytest.raises(KeyError) as exception_info:
del hash_table["missing_key"]
assert exception_info.value.args[0] == "missing_key"
覆盖这个测试用例相对简单,因为您可以依赖您在实现in操作符时编写的代码:
# hashtable.py
# ...
class HashTable:
# ...
def __delitem__(self, key):
if key in self:
self[key] = BLANK
else:
raise KeyError(key)
# ...
如果您在散列表中找到了这个键,那么您可以用 sentinel 值覆盖相关的值来删除这个键对。否则,您会引发异常。好了,接下来还有一个基本的散列表操作要做。
更新现有对的值
插入方法应该已经负责更新一个键-值对,所以您只需添加一个相关的测试用例,并检查它是否如预期的那样工作:
# test_hashtable.py
# ...
def test_should_update_value(hash_table):
assert hash_table["hola"] == "hello"
hash_table["hola"] = "hallo"
assert hash_table["hola"] == "hallo"
assert hash_table[98.6] == 37
assert hash_table[False] is True
assert len(hash_table) == 100
在修改现有键的值 hello 并将其更改为 hallo 之后,还要检查其他键-值对以及哈希表的长度是否保持不变。就是这样。您已经有了一个基本的哈希表实现,但是仍然缺少一些实现起来相对便宜的额外特性。
获取键-值对
是时候解决房间里的大象了。Python 字典允许你迭代它们的键、值,或者称为项的键值对。然而,您的哈希表实际上只是一个上面有花哨索引的值列表。如果您曾经想要检索放入哈希表中的原始键,那么您将会很不幸,因为当前的哈希表实现将永远不会记住它们。
在这一小节中,您将对哈希表进行大量重构,以添加保留键和值的功能。请记住,这将涉及到几个步骤,许多测试将因此而失败。如果你想跳过这些中间步骤,看看效果,那就直接跳到防御复制。
等一下。您一直在阅读本教程中关于键-值对的内容,那么为什么不用元组替换值呢?毕竟在 Python 中元组是很直接的。更好的是,您可以使用命名元组来利用它们的命名元素查找。但是首先,你需要考虑一个测试。
注意:记住,在设计测试用例时,要关注高级的面向用户的功能。不要根据程序员的经验或直觉去测试一段代码。测试应该最终驱动您在 TDD 中的实现,而不是相反。
首先,在您的HashTable类中需要另一个属性来保存键值对:
# test_hashtable.py
# ...
def test_should_return_pairs(hash_table):
assert ("hola", "hello") in hash_table.pairs
assert (98.6, 37) in hash_table.pairs
assert (False, True) in hash_table.pairs
此时,键-值对的顺序并不重要,所以您可以假设每次请求它们时,它们可能会以任意顺序出现。然而,您可以通过将.values重命名为.pairs并进行其他必要的调整来重用它,而不是向类中引入另一个字段。有几个。请注意,这将暂时使一些测试失败,直到您修复实现。
注意:如果您正在使用代码编辑器,那么您可以利用重构功能,通过单击一个按钮来方便地重命名变量或类成员。例如,在 PyCharm 中,你可以右击一个变量,从上下文菜单中选择重构,然后选择重命名… 。或者您可以使用相应的键盘快捷键:
https://player.vimeo.com/video/680855017?background=1
这是更改项目中变量名称的最直接、最可靠的方式。代码编辑器将更新项目文件中的所有变量引用。
当你在hashtable.py和test_hashtable.py中将.values重命名为.pairs时,你还需要更新.__setitem__()特殊方法。特别是,它现在应该存储键和相关值的元组:
# hashtable.py
# ...
class HashTable:
# ...
def __setitem__(self, key, value):
self.pairs[self._index(key)] = (key, value)
在哈希表中插入一个元素会将键和值包装在一个元组中,然后将该元组放在对列表中所需的索引处。请注意,您的列表最初将只包含空白对象而不是元组,因此您将在对列表中使用两种不同的数据类型。一个是元组,而另一个可以是除了元组之外的任何东西来表示空白槽。
因此,您不再需要任何特殊的 sentinel 常量来将一个槽标记为空。您可以安全地删除您的BLANK常量,并在必要时再次用普通的None替换它,所以现在就去做吧。
注:移除代码一开始可能很难接受,但是越少越好!正如你所看到的,测试驱动的开发有时会让你兜圈子。
您可以再后退一步,重新获得删除项目的控制权:
# hashtable.py
# ...
class HashTable:
# ...
def __delitem__(self, key):
if key in self:
self.pairs[self._index(key)] = None else:
raise KeyError(key)
不幸的是,您的.__delitem__()方法不能再利用方括号语法,因为这会导致将您选择的任何 sentinel 值包装在一个不必要的元组中。这里必须使用显式赋值语句,以避免以后不必要的复杂逻辑。
难题的最后一个重要部分是更新.__getitem__()方法:
# hashtable.py
# ...
class HashTable:
# ...
def __getitem__(self, key):
pair = self.pairs[self._index(key)]
if pair is None:
raise KeyError(key)
return pair[1]
您查看一个索引,期望找到一个键值对。如果您什么也没有得到,那么您将引发一个异常。另一方面,如果您看到一些有趣的东西,那么您可以在索引 1 处获取元组的第二个元素,它对应于映射的值。但是,您可以使用命名元组更优雅地编写它,如前面所建议的:
# hashtable.py
from typing import NamedTuple, Any
class Pair(NamedTuple):
key: Any
value: Any
class HashTable:
# ...
def __setitem__(self, key, value):
self.pairs[self._index(key)] = Pair(key, value)
def __getitem__(self, key):
pair = self.pairs[self._index(key)]
if pair is None:
raise KeyError(key)
return pair.value
# ...
Pair类由.key和.value属性组成,它们可以自由地接受任何数据类型的值。同时,您的类继承了所有常规元组的行为,因为它扩展了NamedTuple父类。注意,您必须在.__setitem__()方法中显式调用键和值上的Pair(),以利用.__getitem__()中的命名属性访问。
注意:尽管使用定制的数据类型来表示键-值对,但是由于两种类型的兼容性,您可以编写期望得到Pair实例或常规元组的测试。
自然,在报告再次变绿之前,您有一些测试用例需要更新。慢慢来,仔细检查你的测试套件。或者,如果您觉得有困难,可以看看支持材料中的代码,或者看一下这里:
# test_hashtable.py
# ...
def test_should_insert_key_value_pairs():
hash_table = HashTable(capacity=100)
hash_table["hola"] = "hello"
hash_table[98.6] = 37
hash_table[False] = True
assert ("hola", "hello") in hash_table.pairs assert (98.6, 37) in hash_table.pairs assert (False, True) in hash_table.pairs
assert len(hash_table) == 100
# ...
def test_should_delete_key_value_pair(hash_table):
assert "hola" in hash_table
assert ("hola", "hello") in hash_table.pairs assert len(hash_table) == 100
del hash_table["hola"]
assert "hola" not in hash_table
assert ("hola", "hello") not in hash_table.pairs assert len(hash_table) == 100
将会有另一个需要特别关注的测试用例。具体来说,就是验证一个空哈希表在创建时没有None值。您刚刚用一个值对列表替换了一个值列表。要再次找出这些值,您可以使用如下的列表理解:
# test_hashtable.py
# ...
def test_should_not_contain_none_value_when_created():
hash_table = HashTable(capacity=100)
values = [pair.value for pair in hash_table.pairs if pair] assert None not in values
如果你担心在测试用例中塞入过多的逻辑,那么你绝对是对的。毕竟,您想要测试哈希表的行为。但是现在还不用担心这个。您将很快再次访问这个测试用例。
使用防御性复制
一旦你回到绿色阶段,试着找出可能的极限情况。例如,.pairs被公开为任何人都可以有意或无意篡改的公共属性。实际上,访问器方法永远不应该泄漏你的内部实现,而是应该制作防御性副本来保护可变属性免受外部修改:
# test_hashtable.py
# ...
def test_should_return_copy_of_pairs(hash_table):
assert hash_table.pairs is not hash_table.pairs
每当从哈希表中请求键值对时,您都希望得到一个具有惟一身份的全新对象。你可以在一个 Python 属性后面隐藏一个私有字段,所以创建一个,并且只在你的HashTable类中用._pairs替换所有对.pairs的引用。前导下划线是 Python 中的标准命名约定,表示内部实现:
# hashtable.py
# ...
class HashTable:
def __init__(self, capacity):
self._pairs = capacity * [None]
def __len__(self):
return len(self._pairs)
def __delitem__(self, key):
if key in self:
self._pairs[self._index(key)] = None else:
raise KeyError(key)
def __setitem__(self, key, value):
self._pairs[self._index(key)] = Pair(key, value)
def __getitem__(self, key):
pair = self._pairs[self._index(key)] if pair is None:
raise KeyError(key)
return pair.value
def __contains__(self, key):
try:
self[key]
except KeyError:
return False
else:
return True
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
@property def pairs(self): return self._pairs.copy()
def _index(self, key):
return hash(key) % len(self)
当您请求存储在哈希表中的键值对列表时,每次都会得到它们的浅层副本。因为您没有对哈希表内部状态的引用,所以它不会受到对其副本的潜在更改的影响。
注意:您得到的类方法的顺序可能与上面给出的代码块略有不同。这没关系,因为从 Python 的角度来看,方法排序并不重要。然而,习惯上从静态或类方法开始,然后是你的类的公共接口,这是你最有可能看到的。内部实现通常应该出现在最后。
为了避免在代码中跳来跳去,以类似于故事的方式组织方法是一个好主意。具体来说,高级函数应该列在被调用的低级函数之前。
为了进一步模仿属性中的dict.items(),生成的对列表不应该包含空白槽。换句话说,列表中不应该有任何None值:
# test_hashtable.py
# ...
def test_should_not_include_blank_pairs(hash_table):
assert None not in hash_table.pairs
为了满足这个测试,您可以通过在您的属性中向列表理解添加一个条件来过滤空值:
# hashtable.py
# ...
class HashTable:
# ...
@property
def pairs(self):
return [pair for pair in self._pairs if pair]
您不需要显式调用.copy(),因为列表理解创建了一个新列表。对于键-值对的原始列表中的每一对,您检查该特定对是否真实,并将其保留在结果列表中。然而,这将破坏另外两个您现在需要更新的测试:
# test_hashtable.py
# ...
def test_should_create_empty_value_slots():
assert HashTable(capacity=3)._pairs == [None, None, None]
# ...
def test_should_insert_none_value():
hash_table = HashTable(100)
hash_table["key"] = None
assert ("key", None) in hash_table.pairs
这并不理想,因为您的测试之一触及内部实现,而不是关注公共接口。然而,这样的测试被称为白盒测试,它有它的位置。
获取键和值
您还记得您通过添加列表理解来从您的键-值对中检索值而修改的测试用例吗?好吧,如果你想恢复记忆,这又是:
# test_hashtable.py
# ...
def test_should_not_contain_none_value_when_created():
hash_table = HashTable(capacity=100)
values = [pair.value for pair in hash_table.pairs if pair] assert None not in values
突出显示的行看起来就像实现.values属性所需的内容,您在前面用.pairs替换了它。您可以更新测试功能,再次利用.values:
# test_hashtable.py
# ...
def test_should_not_contain_none_value_when_created():
assert None not in HashTable(capacity=100).values
这可能会让人觉得这是徒劳的努力。但是,这些值现在通过 getter 属性动态计算,而以前它们存储在固定大小的列表中。为了满足这个测试,您可以重用它的旧实现的一部分,它采用了列表理解:
# hashtable.py
# ...
class HashTable:
# ...
@property
def values(self):
return [pair.value for pair in self.pairs]
注意,您不再需要在这里指定可选的过滤条件,因为已经有一个隐藏在.pairs属性后面。
纯粹主义者可能会考虑使用集合理解而不是列表理解来表达缺乏对值的顺序的保证。但是,这将导致哈希表中关于重复值的信息丢失。通过编写另一个测试用例来保护自己免受这种可能性的影响:
# test_hashtable.py
# ...
def test_should_return_duplicate_values():
hash_table = HashTable(capacity=100)
hash_table["Alice"] = 24
hash_table["Bob"] = 42
hash_table["Joe"] = 42
assert [24, 42, 42] == sorted(hash_table.values)
例如,如果您有一个包含姓名和年龄的散列表,并且不止一个人有相同的年龄,那么.values应该保留所有重复的年龄值。您可以对年龄进行排序,以确保可重复的测试运行。虽然这个测试用例不需要编写新的代码,但是它可以防止回归。
检查期望值、它们的类型和数量是值得的。但是,您不能直接比较两个列表,因为哈希表中的实际值可能会以不可预知的顺序出现。要忽略测试中的顺序,您可以将两个列表都转换为集合,或者像以前一样对它们进行排序。不幸的是,集合删除了潜在的重复,而当列表包含不兼容的类型时,排序是不可能的。
要可靠地检查两个列表是否具有完全相同的任意类型元素(可能重复),同时忽略它们的顺序,可以使用以下 Python 习语:
def have_same_elements(list1, list2):
return all(element in list1 for element in list2)
它利用了内置的 all() 函数,但是相当冗长。你最好使用 pytest-unordered 插件。不要忘记首先将其安装到您的虚拟环境中:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install pytest-unordered
(venv) $ python -m pip install pytest-unordered
接下来,将unordered()函数导入到您的测试套件中,并使用它来包装哈希表的值:
# test_hashtable.py
import pytest
from pytest_unordered import unordered
from hashtable import HashTable
# ...
def test_should_get_values(hash_table):
assert unordered(hash_table.values) == ["hello", 37, True]
这样做会将值转换为无序列表,从而重新定义相等测试操作符,以便在比较列表元素时不考虑顺序。此外,空哈希表的值应该是一个空列表,而.values属性应该总是返回一个新的列表副本:
# test_hashtable.py
# ...
def test_should_get_values_of_empty_hash_table():
assert HashTable(capacity=100).values == []
def test_should_return_copy_of_values(hash_table):
assert hash_table.values is not hash_table.values
另一方面,哈希表的键必须是惟一的,所以通过返回一个集合而不是一个键列表来强调这一点是有意义的。毕竟,根据定义,集合是没有重复项的无序集合:
# test_hashtable.py
# ...
def test_should_get_keys(hash_table):
assert hash_table.keys == {"hola", 98.6, False}
def test_should_get_keys_of_empty_hash_table():
assert HashTable(capacity=100).keys == set()
def test_should_return_copy_of_keys(hash_table):
assert hash_table.keys is not hash_table.keys
Python 中没有空的 set 文字,所以在这种情况下必须直接调用内置的set()函数。相应的 getter 函数的实现看起来很熟悉:
# hashtable.py
# ...
class HashTable:
# ...
@property
def keys(self):
return {pair.key for pair in self.pairs}
它类似于.values属性。不同之处在于,您使用了花括号而不是方括号,并且在命名元组中引用了.key属性而不是.value。或者,如果你想的话,你可以使用pair[0],但是它看起来可读性较差。
这也提醒您需要一个类似的测试用例,您在覆盖.pairs属性时错过了这个测试用例。为了保持一致性,返回一组对是有意义的:
# test_hashtable.py
# ...
def test_should_return_pairs(hash_table):
assert hash_table.pairs == { ("hola", "hello"), (98.6, 37), (False, True) }
def test_should_get_pairs_of_empty_hash_table():
assert HashTable(capacity=100).pairs == set()
所以,.pairs属性从现在开始也将使用一个集合理解:
# hashtable.py
# ...
class HashTable:
# ...
@property
def pairs(self):
return {pair for pair in self._pairs if pair}
您不需要担心丢失任何信息,因为每个键值对都是唯一的。此时,您应该再次处于绿色阶段。
注意,您可以利用.pairs属性将哈希表转换成普通的旧字典,并使用.keys和.values来测试:
def test_should_convert_to_dict(hash_table):
dictionary = dict(hash_table.pairs)
assert set(dictionary.keys()) == hash_table.keys
assert set(dictionary.items()) == hash_table.pairs
assert list(dictionary.values()) == unordered(hash_table.values)
要忽略元素的顺序,请记住在进行比较之前用集合包装字典键和键值对。相比之下,哈希表的值以列表的形式出现,所以一定要使用unordered()函数来比较列表,同时忽略元素顺序。
好了,你的哈希表现在真的开始成型了!
报告哈希表的长度
有一个小细节,为了简单起见,你故意保留到现在。它是你的哈希表的长度,即使只有空的槽,哈希表当前也报告它的最大容量。幸运的是,这并不需要花费太多精力来解决。找到名为test_should_report_capacity()的函数,如下所示重命名,并检查空哈希表的长度是否等于零而不是一百:
# test_hashtable.py
# ...
def test_should_report_length_of_empty_hash_table():
assert len(HashTable(capacity=100)) == 0
为了使容量独立于长度,修改您的特殊方法.__len__(),使其引用带有过滤对的公共属性,而不是所有槽的私有列表:
# hashtable.py
# ...
class HashTable:
# ...
def __len__(self):
return len(self.pairs)
# ...
您只是删除了变量名中的前导下划线。但是这个小小的变化现在导致了一大堆测试突然结束,出现了一个错误,还有一些测试失败了。
注意:失败的测试不太严重,因为它们的断言评估为False,而错误表明代码中完全出乎意料的行为。
看起来大多数测试用例都遇到了相同的未处理异常,这是因为在将键映射到索引时被零除。这是有意义的,因为._index()使用散列表的长度来寻找散列键除以可用槽数的余数。然而,哈希表的长度现在有了不同的含义。您需要取内部列表的长度:
# hashtable.py
class HashTable:
# ...
def _index(self, key):
return hash(key) % len(self._pairs)
现在好多了。仍然失败的三个测试用例使用了关于哈希表长度的错误假设。改变这些假设以通过测试:
# test_hashtable.py
# ...
def test_should_insert_key_value_pairs():
hash_table = HashTable(capacity=100)
hash_table["hola"] = "hello"
hash_table[98.6] = 37
hash_table[False] = True
assert ("hola", "hello") in hash_table.pairs
assert (98.6, 37) in hash_table.pairs
assert (False, True) in hash_table.pairs
assert len(hash_table) == 3
# ...
def test_should_delete_key_value_pair(hash_table):
assert "hola" in hash_table
assert ("hola", "hello") in hash_table.pairs
assert len(hash_table) == 3
del hash_table["hola"]
assert "hola" not in hash_table
assert ("hola", "hello") not in hash_table.pairs
assert len(hash_table) == 2
# ...
def test_should_update_value(hash_table):
assert hash_table["hola"] == "hello"
hash_table["hola"] = "hallo"
assert hash_table["hola"] == "hallo"
assert hash_table[98.6] == 37
assert hash_table[False] is True
assert len(hash_table) == 3
您又回到了游戏中,但是ZeroDivisionError是一个危险信号,应该会立即让您想要添加额外的测试用例:
# test_hashtable.py
# ...
def test_should_not_create_hashtable_with_zero_capacity():
with pytest.raises(ValueError):
HashTable(capacity=0)
def test_should_not_create_hashtable_with_negative_capacity():
with pytest.raises(ValueError):
HashTable(capacity=-100)
创建一个非正容量的HashTable没有多大意义。你怎么会有负长度的容器呢?因此,如果有人试图这样做,无论是有意还是无意,您都应该提出一个异常。在 Python 中指出这种不正确的输入参数的标准方法是引发一个ValueError异常:
# hashtable.py
# ...
class HashTable:
def __init__(self, capacity):
if capacity < 1: raise ValueError("Capacity must be a positive number") self._pairs = capacity * [None]
# ...
如果您很勤奋,那么您可能还应该检查无效的参数类型,但是这超出了本教程的范围。你可以把它当作一种自愿的练习。
接下来,添加另一个场景来测试 pytest 作为 fixture 提供的非空哈希表的长度:
# test_hashtable.py
# ...
def test_should_report_length(hash_table):
assert len(hash_table) == 3
有三个键值对,所以哈希表的长度也应该是三。这个测试不需要任何额外的代码。最后,因为您现在处于重构阶段,所以您可以通过引入.capacity属性并在可能的情况下使用它来添加一点语法糖:
# test_hashtable.py
# ...
def test_should_report_capacity_of_empty_hash_table():
assert HashTable(capacity=100).capacity == 100
def test_should_report_capacity(hash_table):
assert hash_table.capacity == 100
容量是常数,在哈希表创建时确定。您可以从基础配对列表的长度中导出它:
# hashtable.py
# ...
class HashTable:
# ...
@property def capacity(self): return len(self._pairs)
def _index(self, key):
return hash(key) % self.capacity
当你向你的问题域引入新的词汇时,它帮助你发现新的机会来获得更准确、明确的命名。例如,您已经看到单词 pairs 可以互换使用,既指存储在哈希表中的实际键值对,也指用于配对的槽的内部列表。通过在任何地方将._pairs改为._slots,这可能是一个重构代码的好机会。
然后,您的一个早期测试用例将更清楚地传达它的意图:
# test_hashtable.py
# ...
def test_should_create_empty_value_slots():
assert HashTable(capacity=3)._slots == [None, None, None]
通过将单词 value 替换为其中的对,重命名该测试可能会更有意义:
# test_hashtable.py
# ...
def test_should_create_empty_pair_slots():
assert HashTable(capacity=3)._slots == [None, None, None]
你可能认为这样的哲学思考是不必要的。然而,你的名字越有描述性,你的代码就越有可读性——如果不是对其他人,那么肯定是对你将来。甚至还有关于它的书和笑话。您的测试是文档的一种形式,因此对它们保持与您的被测代码相同的关注度是值得的。
使哈希表可迭代
Python 允许您通过键、值或被称为条目的键值对来迭代字典。您希望在您的自定义哈希表中有相同的行为,所以您从勾画几个测试用例开始:
# test_hashtable.py
# ...
def test_should_iterate_over_keys(hash_table):
for key in hash_table.keys:
assert key in ("hola", 98.6, False)
def test_should_iterate_over_values(hash_table):
for value in hash_table.values:
assert value in ("hello", 37, True)
def test_should_iterate_over_pairs(hash_table):
for key, value in hash_table.pairs:
assert key in hash_table.keys
assert value in hash_table.values
通过键、值或键值对的迭代在当前的实现中可以开箱即用,因为底层的集合和列表已经可以处理这些了。另一方面,要使你的HashTable类的实例可迭代,你必须定义另一个特殊的方法,这将让你直接与 for循环合作:
# test_hashtable.py
# ...
def test_should_iterate_over_instance(hash_table):
for key in hash_table:
assert key in ("hola", 98.6, False)
与之前不同的是,您在这里传递一个对HashTable实例的引用,但是行为与您迭代.keys属性是一样的。这种行为与 Python 中内置的dict兼容。
您需要的特殊方法.__iter__()必须返回一个迭代器对象,该对象在循环内部使用:
# hashtable.py
# ...
class HashTable:
# ...
def __iter__(self):
yield from self.keys
这是一个生成器迭代器的例子,它利用了 Python 中的 yield 关键字。
注意:yield from表达式将迭代委托给一个子生成器,这个子生成器可以是另一个可迭代对象,比如一个列表或集合。
关键字yield允许你使用函数风格定义一个就地迭代器,而不需要创建另一个类。名为.__iter__()的特殊方法在开始时被for循环调用。
好了,现在哈希表中只缺少一些不重要的特性。
在文本中表示哈希表
当将打印到标准输出上时,您将在本节中实现的下一点将使您的哈希表看起来更好。哈希表的文本表示看起来类似于 Python dict文字:
# test_hashtable.py
# ...
def test_should_use_dict_literal_for_str(hash_table):
assert str(hash_table) in {
"{'hola': 'hello', 98.6: 37, False: True}",
"{'hola': 'hello', False: True, 98.6: 37}",
"{98.6: 37, 'hola': 'hello', False: True}",
"{98.6: 37, False: True, 'hola': 'hello'}",
"{False: True, 'hola': 'hello', 98.6: 37}",
"{False: True, 98.6: 37, 'hola': 'hello'}",
}
文字使用花括号、逗号和冒号,而键和值有各自的表示。例如,字符串用单引号括起来。由于不知道键-值对的确切顺序,所以要检查哈希表的字符串表示是否符合可能的对排列之一。
要让您的类使用内置的str()函数,您必须在HashTable中实现相应的特殊方法:
# hashtable.py
# ...
class HashTable:
# ...
def __str__(self):
pairs = []
for key, value in self.pairs:
pairs.append(f"{key!r}: {value!r}")
return "{" + ", ".join(pairs) + "}"
您通过.pairs属性迭代键和值,并使用 f 字符串来格式化各个对。注意模板字符串中的!r转换标志,它强制在键和值上调用repr()而不是默认的str()。这确保了更显式的表示,这种表示因数据类型而异。例如,它用单引号将字符串括起来。
str()和repr()的区别更加微妙。一般来说,两者都是为了将对象转换成字符串。然而,虽然您可以期望str()返回人类友好的文本,但是repr()通常会返回一段有效的 Python 代码,您可以对其进行评估以重新创建原始对象:
>>> from fractions import Fraction >>> quarter = Fraction("1/4") >>> str(quarter) '1/4' >>> repr(quarter) 'Fraction(1, 4)' >>> eval(repr(quarter)) Fraction(1, 4)在这个例子中, Python 片段的字符串表示是
'1/4',但是同一对象的规范字符串表示表示对Fraction类的调用。您可以在您的
HashTable类中实现类似的效果。不幸的是,目前你的类初始化器不允许用值创建新的实例。您将通过引入一个类方法来解决这个问题,它将允许您从 Python 字典中创建HashTable实例:# test_hashtable.py # ... def test_should_create_hashtable_from_dict(): dictionary = {"hola": "hello", 98.6: 37, False: True} hash_table = HashTable.from_dict(dictionary) assert hash_table.capacity == len(dictionary) * 10 assert hash_table.keys == set(dictionary.keys()) assert hash_table.pairs == set(dictionary.items()) assert unordered(hash_table.values) == list(dictionary.values())这很好地配合了你之前的转换,那是在相反的方向。但是,您需要假设哈希表有足够大的容量来保存原始字典中的所有键值对。合理的估计似乎是对数的十倍。您现在可以对其进行硬编码:
# hashtable.py # ... class HashTable: @classmethod def from_dict(cls, dictionary): hash_table = cls(len(dictionary) * 10) for key, value in dictionary.items(): hash_table[key] = value return hash_table您创建一个新的哈希表,并使用任意因子设置其容量。然后,通过从作为参数传递给方法的字典中复制键值对来插入键值对。如果您愿意,您可以允许覆盖默认容量,因此添加一个类似的测试用例:
# test_hashtable.py # ... def test_should_create_hashtable_from_dict_with_custom_capacity(): dictionary = {"hola": "hello", 98.6: 37, False: True} hash_table = HashTable.from_dict(dictionary, capacity=100) assert hash_table.capacity == 100 assert hash_table.keys == set(dictionary.keys()) assert hash_table.pairs == set(dictionary.items()) assert unordered(hash_table.values) == list(dictionary.values())为了使容量可选,您可以利用布尔表达式的短路评估:
# hashtable.py # ... class HashTable: @classmethod def from_dict(cls, dictionary, capacity=None): hash_table = cls(capacity or len(dictionary) * 10) for key, value in dictionary.items(): hash_table[key] = value return hash_table如果没有指定
capacity,那么就回到默认行为,将字典的长度乘以 10。这样,您最终能够为您的HashTable实例提供一个规范的字符串表示:# test_hashtable.py # ... def test_should_have_canonical_string_representation(hash_table): assert repr(hash_table) in { "HashTable.from_dict({'hola': 'hello', 98.6: 37, False: True})", "HashTable.from_dict({'hola': 'hello', False: True, 98.6: 37})", "HashTable.from_dict({98.6: 37, 'hola': 'hello', False: True})", "HashTable.from_dict({98.6: 37, False: True, 'hola': 'hello'})", "HashTable.from_dict({False: True, 'hola': 'hello', 98.6: 37})", "HashTable.from_dict({False: True, 98.6: 37, 'hola': 'hello'})", }和前面一样,您检查结果表示中所有可能的属性顺序排列。散列表的规范字符串表示看起来与使用
str()时基本相同,但是它也将 dict 文字包装在对新的.from_dict()类方法的调用中。相应的实现通过调用内置的str()函数委托给特殊方法.__str__():# hashtable.py # ... class HashTable: # ... def __repr__(self): cls = self.__class__.__name__ return f"{cls}.from_dict({str(self)})"注意,不要硬编码类名,以免以后选择重命名类时出现问题。
您的散列表原型几乎已经准备好了,因为您已经实现了本节介绍中提到的列表中几乎所有的核心和非必要特性。您刚刚添加了从 Python
dict创建散列表的能力,并为其实例提供了字符串表示。最后一点是确保哈希表实例可以通过值进行比较。测试哈希表的相等性
哈希表类似于集合,因为它们不对内容强加任何特定的顺序。事实上,哈希表和集合的共同点比你想象的要多,因为它们都是由哈希函数支持的。正是哈希函数使得哈希表中的键值对变得无序。然而,请记住,从 Python 3.6 开始,
dict确实保留了插入顺序作为实现细节。当且仅当两个哈希表具有相同的键值对时,它们的比较结果应该相等。然而,Python 默认比较对象身份,因为它不知道如何解释自定义数据类型的值。因此,哈希表的两个实例总是不相等的,即使它们共享同一组键值对。
要解决这个问题,您可以通过在您的
HashTable类中提供特殊的.__eq__()方法来实现等式测试操作符(==)。此外,Python 将调用这个方法来计算不等于运算符(!=),除非你也显式实现了.__ne__()。您希望哈希表等于自身、其副本或具有相同键值对的另一个实例,而不管它们的顺序。相反,哈希表应该而不是等于具有不同的键值对集或完全不同的数据类型的实例:
# test_hashtable.py # ... def test_should_compare_equal_to_itself(hash_table): assert hash_table == hash_table def test_should_compare_equal_to_copy(hash_table): assert hash_table is not hash_table.copy() assert hash_table == hash_table.copy() def test_should_compare_equal_different_key_value_order(hash_table): h1 = HashTable.from_dict({"a": 1, "b": 2, "c": 3}) h2 = HashTable.from_dict({"b": 2, "a": 1, "c": 3}) assert h1 == h2 def test_should_compare_unequal(hash_table): other = HashTable.from_dict({"different": "value"}) assert hash_table != other def test_should_compare_unequal_another_data_type(hash_table): assert hash_table != 42您使用前面小节中介绍的
.from_dict()来快速地用值填充新的散列表。您可以利用相同的类方法来制作哈希表实例的新副本。下面是满足这些测试用例的代码:# hashtable.py # ... class HashTable: # ... def __eq__(self, other): if self is other: return True if type(self) is not type(other): return False return set(self.pairs) == set(other.pairs) # ... def copy(self): return HashTable.from_dict(dict(self.pairs), self.capacity)特殊的方法
.__eq__()将一些要比较的对象作为参数。如果该对象恰好是HashTable的当前实例,则返回True,因为相同的身份意味着值相等。否则,您将通过比较键-值对的类型和集合来继续。转换为集合有助于使排序变得无关紧要,即使您决定将来将.pairs转换为另一个有序列表。顺便说一下,得到的副本不仅应该具有相同的键-值对,还应该具有与源哈希表相同的容量。同时,两个具有不同容量的哈希表应该仍然是相等的:
# test_hashtable.py # ... def test_should_copy_keys_values_pairs_capacity(hash_table): copy = hash_table.copy() assert copy is not hash_table assert set(hash_table.keys) == set(copy.keys) assert unordered(hash_table.values) == copy.values assert set(hash_table.pairs) == set(copy.pairs) assert hash_table.capacity == copy.capacity def test_should_compare_equal_different_capacity(): data = {"a": 1, "b": 2, "c": 3} h1 = HashTable.from_dict(data, capacity=50) h2 = HashTable.from_dict(data, capacity=100) assert h1 == h2这两个测试将与您当前的
HashTable实现一起工作,因此您不需要编写任何额外的代码。您的定制哈希表原型仍然缺少内置字典提供的一些不重要的特性。作为练习,您可以尝试自己添加它们。例如,您可以从 Python 字典中复制其他方法,比如
dict.clear()或dict.update()。除此之外,你可以实现从 Python 3.9 开始由dict支持的位操作符,它允许联合操作。干得好!这是本教程完成的测试套件,您的哈希表已经通过了所有单元测试。给自己一个受之无愧的鼓励,因为这是一项了不起的工作。或者是吗?
假设您减少了哈希表的容量,只考虑插入的对。下面的哈希表应该容纳源字典中存储的所有三个键值对:
>>> from hashtable import HashTable
>>> source = {"hola": "hello", 98.6: 37, False: True}
>>> hash_table = HashTable.from_dict(source, capacity=len(source))
>>> str(hash_table)
'{False: True}'
然而,当您揭示结果哈希表的键和值时,您有时会发现项目更少了。为了使这个代码片段可重复,通过将PYTHONHASHSEED环境变量设置为0,在禁用散列随机化的情况下运行它。
通常情况下,即使哈希表中有足够的空间,您最终也会丢失信息。这是因为大多数哈希函数并不完美,会导致哈希冲突,接下来您将了解如何解决这个问题。
解决哈希代码冲突
在这一节中,您将探索处理哈希代码冲突的两种最常见的策略,并将在您的HashTable类中实现它们。如果你想遵循下面的例子,那么不要忘记将PYTHONHASHSEED变量设置为0来禁用 Python 的散列随机化。
到目前为止,您应该已经对什么是哈希冲突有了很好的了解。当两个键产生相同的哈希代码,导致不同的值在哈希表中的相同索引处相互冲突。例如,在具有 100 个槽的哈希表中,当禁用哈希随机化时,键"easy"和"difficult"碰巧共享相同的索引:
>>> hash("easy") % 100 43 >>> hash("difficult") % 100 43到目前为止,您的哈希表无法检测在同一个槽中存储不同值的尝试:
>>> from hashtable import HashTable
>>> hash_table = HashTable(capacity=100)
>>> hash_table["easy"] = "Requires little effort"
>>> hash_table["difficult"] = "Needs much skill"
>>> print(hash_table)
{'difficult': 'Needs much skill'}
>>> hash_table["easy"]
'Needs much skill'
您不仅最终会覆盖由"easy"键标识的对,而且更糟糕的是,检索这个现在不存在的键的值会给您一个不正确的答案!
有三种策略可用于解决哈希冲突:
| 战略 | 描述 |
|---|---|
| 完美散列 | 选择一个完美的哈希函数来避免哈希冲突。 |
| 散列地址 | 以一种可预测的方式传播冲突的值,以便以后检索它们。 |
| 封闭式寻址 | 将冲突的值保存在一个单独的数据结构中进行搜索。 |
虽然只有当你预先知道所有的值时,完美的散列才是可能的,但是另外两个散列冲突解决方法更实用,所以在本教程中你将仔细研究它们。注意,开放寻址可以由几种特定的算法来表示,包括:
相比之下,封闭寻址最出名的是分离链接。此外,还有合并哈希,它将开放和封闭寻址背后的思想结合到一个算法中。
为了遵循测试驱动开发,你需要首先设计一个测试用例。但是如何测试哈希冲突呢?Python 的内置函数默认情况下对它的一些数据类型使用哈希随机化,这使得预测它的行为极其困难。用PYTHONHASHSEED环境变量手动选择散列种子是不切实际的,并且会使您的测试用例变得脆弱。
解决这个问题的最好方法是使用一个模仿库,比如 Python 的unittest.mock:
from unittest.mock import patch
@patch("builtins.hash", return_value=42)
def test_should_detect_hash_collision(hash_mock):
assert hash("foobar") == 42
打补丁暂时用一个对象替换另一个对象。例如,您可以用一个总是返回相同期望值的假函数替换内置的hash()函数,使您的测试可重复。这种替换只在函数调用期间有效,之后原始的hash()再次被带回。
您可以对整个测试函数应用@patch装饰器,或者用上下文管理器限制模拟对象的范围:
from unittest.mock import patch
def test_should_detect_hash_collision():
assert hash("foobar") not in [1, 2, 3]
with patch("builtins.hash", side_effect=[1, 2, 3]):
assert hash("foobar") == 1
assert hash("foobar") == 2
assert hash("foobar") == 3
使用上下文管理器,您可以访问内置的hash()函数,以及它在同一个测试用例中的模拟版本。如果你愿意,你甚至可以拥有多种风格的模拟功能。side_effect参数允许您指定要引发的异常,或者您的模拟对象在连续调用时将返回的一系列值。
在本教程的剩余部分,您将继续向您的HashTable类添加更多特性,而不严格遵循测试驱动开发。为了简洁起见,新的测试将被省略,而修改类将导致一些现有的测试失败。但是,您可以在附带的资料中找到一个可以下载的工作测试套件。
通过线性探测找到碰撞的按键
停下来理解哈希代码冲突背后的理论。说到处理它们,线性探测是最古老、最直接、也是最有效的技术之一,所有的同时进行。对于插入、查找、删除和更新**操作,它需要一些额外的步骤,这些您将会学到。*
*考虑一个示例散列表,它用常见的首字母缩略词来表示 Python 词汇表。它总共有十个槽的容量,但是其中四个已经被下列键值对占用:
| 索引 | 钥匙 | 价值 |
|---|---|---|
| Zero | ||
| one | BDFL | 仁慈的终身独裁者 |
| Two | ||
| three | 取代 | 阅读-评估-打印循环 |
| four | ||
| five | ||
| six | ||
| seven | ||
| eight | 精力 | Python 增强提案 |
| nine | WSGI(消歧义) | Web 服务器网关接口 |
现在,您想在您的术语表中添加另一个术语来定义 MRO 首字母缩写词,它代表方法解析顺序。您计算键的散列码,并使用模运算符将其截断,以获得 0 到 9 之间的索引:
>>> hash("MRO") 8199632715222240545 >>> hash("MRO") % 10 5除了使用模操作符,你还可以用一个合适的位掩码来截断哈希代码,这就是 Python 的
dict的内部工作方式。注意:为了获得一致的散列码,将
PYTHONHASHSEED环境变量设置为0以禁用散列随机化。太好了!在哈希表的索引 5 处有一个空位置,您可以在那里插入一个新的键值对:
索引 钥匙 价值 Zero one BDFL 仁慈的终身独裁者 Two three 取代 阅读-评估-打印循环 four 5 MRO 方法解析顺序 six seven eight 精力 Python 增强提案 nine WSGI(消歧义) Web 服务器网关接口 到目前为止,一切顺利。你的哈希表仍然有 50%的空闲空间,所以你不断添加更多的术语,直到你尝试插入 EAFP 缩写词。原来,EAFP 的散列码被截短为 1,这是由 BDFL 项占据的槽的索引:
>>> hash("EAFP")
-159847004290706279
>>> hash("BDFL")
-6396413444439073719
>>> hash("EAFP") % 10
1
>>> hash("BDFL") % 10
1
将两个不同的密钥散列成冲突散列码的可能性相对较小。然而,将这些散列码投射到小范围的数组索引上是另一回事。使用线性探测,您可以通过将冲突的键-值对存储在一起来检测和减轻这种冲突:
| 索引 | 钥匙 | 价值 |
|---|---|---|
| Zero | ||
| one | BDFL | 仁慈的终身独裁者 |
| 2 | EAFP | 请求原谅比请求允许容易 |
| three | 取代 | 阅读-评估-打印循环 |
| four | ||
| five | MRO | 方法解析顺序 |
| six | ||
| seven | ||
| eight | 精力 | Python 增强提案 |
| nine | WSGI(消歧义) | Web 服务器网关接口 |
尽管 BDFL 键和 EAFP 键给出的索引都等于 1,但只有第一个插入的键-值对最终会得到它。无论哪一对排在第二位,都将被放在被占用的索引旁边。因此,线性探测使哈希表对插入顺序敏感。
注意:当你使用线性探测或者其他哈希冲突解决方法时,那么你不能仅仅依靠哈希代码来找到相应的槽。还需要对比一下按键。
考虑为抽象基类添加另一个首字母缩写词 ABC ,其哈希代码截断到索引 8。这次不能在下面的位置插入它,因为它已经被 WSGI 占用了。在正常情况下,您会继续向下寻找一个空闲的位置,但是因为您到达了最后一个索引,所以您必须绕回并在索引 0 处插入新的缩写:
| 索引 | 钥匙 | 价值 |
|---|---|---|
| 0 | ABC | 抽象基类 |
| one | BDFL | 仁慈的终身独裁者 |
| Two | EAFP | 请求原谅比请求允许更容易 |
| three | 取代 | 阅读-评估-打印循环 |
| four | ||
| five | MRO | 方法解析顺序 |
| six | ||
| seven | ||
| eight | 精力 | Python 增强提案 |
| nine | WSGI(消歧义) | Web 服务器网关接口 |
要像这样在中搜索填充到哈希表中的键值对,请遵循类似的算法。先从看预期指数开始。例如,要查找与 ABC 键相关联的值,请计算其哈希代码并将其映射到索引:
>>> hash("ABC") -4164790459813301872 >>> hash("ABC") % 10 8有一个键-值对存储在索引 8 处,但是它有一个不同的键等于 PEP,所以可以通过增加索引来跳过它。同样,那个槽被一个不相关的术语 WSGI 占用了,所以您返回并绕回,最终找到索引为 0 的匹配键对。这就是你的答案。
通常,搜索操作有三种可能的停止条件:
- 你找到了一把匹配的钥匙。
- 您用尽了所有插槽,但没有找到匹配的密钥。
- 您发现了一个空的插槽,这也表明丢失了一把钥匙。
最后一点使得删除现有的键-值对变得更加棘手。如果您只是从哈希表中删除了一个条目,那么您将引入一个空白槽,这将停止查找,而不管之前是否有任何冲突。为了使冲突的键值对再次可达,你必须重新散列它们或者使用延迟删除策略。
后者实现起来不太困难,但是具有增加必要查找步骤数量的额外成本。本质上,不是删除一个键-值对,而是用一个标记值替换它,下面用一个红叉(❌)表示,这样就可以找到以前冲突过的条目。假设您想要删除 BDFL 和 PEP 术语:
索引 钥匙 价值 Zero 字母表 抽象基类 one -好的 Two EAFP 请求原谅比请求允许更容易 three 取代 阅读-评估-打印循环 four five MRO 方法解析顺序 six seven eight -好的 nine WSGI(消歧义) Web 服务器网关接口 您已经用 sentinel 值的两个实例替换了相应的键值对。例如,稍后当您寻找 ABC 密钥时,您在索引 8 处从 sentinel 反弹,然后继续到 WSGI,最后使用匹配的密钥到达索引 0。没有一个哨兵,你会很早就停止搜索,错误地得出没有这把钥匙的结论。
注意:您的哈希表的容量不会受到影响,因为您可以在插入新的键值对时随意覆盖标记。另一方面,如果你要填满哈希表并删除它的大部分元素,那么实际上你会以线性搜索算法结束。
到目前为止,您已经学习了插入、删除和查找。然而,关于用线性探测更新哈希表中现有条目的值,有一个问题。当搜索要更新的对时,只有当该槽被另一个具有不同键的对占用或者包含标记值时,才应该跳过该槽。另一方面,如果槽是空的或者有匹配的键,那么您应该设置新的值。
在下一小节中,您将修改您的
HashTable类,使用线性探测来解决散列冲突。在
HashTable类中使用线性探测在线性探测理论中做了简短的介绍后,您现在又回到了编码上。因为线性探测将在哈希表的所有四个基本 CRUD 操作中使用,所以在您的类中编写一个 helper 方法来封装访问哈希表槽的逻辑是有帮助的:
# hashtable.py # ... class HashTable: # ... def _probe(self, key): index = self._index(key) for _ in range(self.capacity): yield index, self._slots[index] index = (index + 1) % self.capacity给定一个键,首先使用相应的哈希代码在哈希表中查找它的预期索引。然后,从计算出的索引开始,遍历哈希表中所有可用的槽。在每一步,您返回当前索引和相关联的对,它们可能是空的或者被标记为已删除。然后,增加索引,必要时环绕原点。
接下来,你可以重写你的
.__setitem__()方法。不要忘记需要一个新的标记值。通过该值,您可以区分从未被占用的插槽和之前发生冲突但现在已被删除的插槽:# hashtable.py DELETED = object() # ... class HashTable: # ... def __setitem__(self, key, value): for index, pair in self._probe(key): if pair is DELETED: continue if pair is None or pair.key == key: self._slots[index] = Pair(key, value) break else: raise MemoryError("Not enough capacity")如果该槽是空的或者包含一对匹配的键,那么在当前索引处重新分配一个新的键-值对,并停止线性探测。否则,如果另一对占用了该插槽并具有不同的密钥,或者该插槽被标记为已删除,那么您将继续前进,直到找到一个空闲的插槽或用尽所有可用的插槽。如果您用完了可用的槽,您会引发一个
MemoryError异常来指示哈希表的容量不足。注意:巧合的是,
.__setitem__()方法也包括更新现有对的值。因为对是由不可变的元组表示的,所以用匹配的键替换整个对,而不仅仅是它的值部分。使用线性探测从哈希表中获取和删除键值对的工作方式几乎相同:
# hashtable.py DELETED = object() # ... class HashTable: # ... def __getitem__(self, key): for _, pair in self._probe(key): if pair is None: raise KeyError(key) if pair is DELETED: continue if pair.key == key: return pair.value raise KeyError(key) def __delitem__(self, key): for index, pair in self._probe(key): if pair is None: raise KeyError(key) if pair is DELETED: continue if pair.key == key: self._slots[index] = DELETED break else: raise KeyError(key)唯一的区别在于突出显示的行。要删除一个对,您必须知道它在哈希表中的位置,以便用 sentinel 值替换它。另一方面,当按键搜索时,您只对相应的值感兴趣。如果这种代码重复困扰着你,那么你可以尝试把它作为一个练习来重构。然而,明确地写出来有助于说明问题。
注意:这是散列表的教科书式实现,它通过使用相等测试操作符(
==)比较键来探测元素。然而,这是一个潜在的高成本操作,现实生活中的实现通过将散列代码与键和值一起存储在三元组而不是成对中来避免这种操作。另一方面,散列码比较起来很便宜。你可以利用散列等价契约来加速。如果两个散列码不同,那么它们肯定来自不同的键,所以没有必要首先执行昂贵的相等测试。这个技巧极大地减少了键比较的次数。
还有一个重要的细节需要注意。哈希表的槽不再处于两种状态之一,即空或被占用。将 sentinel 值插入哈希表以将一个槽标记为已删除会打乱哈希表的
.pairs、.keys和.values属性,并错误地报告长度。要解决这个问题,在返回键值对时,您必须过滤掉None和DELETED值:# hashtable.py # ... class HashTable: # ... @property def pairs(self): return { pair for pair in self._slots if pair not in (None, DELETED) }有了这个小小的更新,您的哈希表现在应该能够通过分散冲突对并以线性方式查找它们来处理哈希冲突:
>>> from unittest.mock import patch
>>> from hashtable import HashTable
>>> with patch("builtins.hash", return_value=24):
... hash_table = HashTable(capacity=100)
... hash_table["easy"] = "Requires little effort"
... hash_table["difficult"] = "Needs much skill"
>>> hash_table._slots[24]
Pair(key='easy', value='Requires little effort')
>>> hash_table._slots[25]
Pair(key='difficult', value='Needs much skill')
尽管相同的散列码等于 24,但两个冲突的关键字"easy"和"difficult"在._slots列表中彼此相邻出现。请注意,它们的排列顺序与您将它们添加到哈希表的顺序相同。尝试交换插入顺序或改变哈希表的容量,并观察这会如何影响插槽。
到目前为止,哈希表的容量保持不变。在实现线性探测之前,您保持不被注意,并不断覆盖冲突的值。现在,您可以检测哈希表中何时没有更多空间,并引发相应的异常。但是,让哈希表根据需要动态扩展它的容量不是更好吗?
让哈希表自动调整大小
在调整哈希表大小时,有两种不同的策略。您可以等到最后一刻,只在散列表变满时调整其大小,或者您可以在达到某个阈值后急切地这样做。两种方式都有其利弊。可以说懒惰策略实现起来更简单,所以您将首先仔细看看它。但是,这会导致更多的冲突和更差的性能。
唯一必须增加哈希表中的槽数的时候是当一个新对的插入失败时,引发MemoryError异常。继续,用对您将创建的另一个帮助器方法的调用替换raise语句,然后通过方括号语法递归调用.__setitem__():
# hashtable.py
# ...
class HashTable:
# ...
def __setitem__(self, key, value):
for index, pair in self._probe(key):
if pair is DELETED: continue
if pair is None or pair.key == key:
self._slots[index] = Pair(key, value)
break
else:
self._resize_and_rehash() self[key] = value
当您确定所有的插槽都被合法的键值对或 sentinel 值占用时,您必须分配更多的内存,复制现有的键值对,然后再次尝试插入新的键值对。
注意:将旧的键-值对放入一个更大的散列表中会使它们散列到完全不同的槽中。重新散列利用了刚刚创建的额外槽,减少了新哈希表中的冲突数量。此外,它通过回收以前用 sentinel 值标记为已删除的槽来节省空间。您不需要担心过去的冲突,因为键-值对无论如何都会找到新的槽。
现在,以下列方式实现调整大小和重新散列:
# hashtable.py
# ...
class HashTable:
# ...
def _resize_and_rehash(self):
copy = HashTable(capacity=self.capacity * 2)
for key, value in self.pairs:
copy[key] = value
self._slots = copy._slots
创建哈希表的本地副本。因为很难预测您可能还需要多少个插槽,所以大胆猜测一下,将容量增加一倍。然后,迭代现有的一组键-值对,并将它们插入副本。最后,重新分配实例中的._slots属性,使其指向扩大的插槽列表。
您的哈希表现在可以在需要时动态增加其大小,所以试试吧。创建一个容量为 1 的空哈希表,并尝试向其中插入一些键值对:
- 视窗
** Linux + macOS*
***>>>
>>> from hashtable import HashTable
>>> hash_table = HashTable(capacity=1)
>>> for i in range(20):
... num_pairs = len(hash_table)
... num_empty = hash_table.capacity - num_pairs
... print(
... f"{num_pairs:>2}/{hash_table.capacity:>2}",
... ("X" * num_pairs) + ("." * num_empty)
... )
... hash_table[i] = i
...
0/ 1 .
1/ 1 X
2/ 2 XX
3/ 4 XXX.
4/ 4 XXXX
5/ 8 XXXXX...
6/ 8 XXXXXX..
7/ 8 XXXXXXX.
8/ 8 XXXXXXXX
9/16 XXXXXXXXX.......
10/16 XXXXXXXXXX......
11/16 XXXXXXXXXXX.....
12/16 XXXXXXXXXXXX....
13/16 XXXXXXXXXXXXX...
14/16 XXXXXXXXXXXXXX..
15/16 XXXXXXXXXXXXXXX.
16/16 XXXXXXXXXXXXXXXX
17/32 XXXXXXXXXXXXXXXXX...............
18/32 XXXXXXXXXXXXXXXXXX..............
19/32 XXXXXXXXXXXXXXXXXXX.............
>>> from hashtable import HashTable >>> hash_table = HashTable(capacity=1) >>> for i in range(20): ... num_pairs = len(hash_table) ... num_empty = hash_table.capacity - num_pairs ... print( ... f"{num_pairs:>2}/{hash_table.capacity:>2}", ... ("▣" * num_pairs) + ("□" * num_empty) ... ) ... hash_table[i] = i ... 0/ 1 □ 1/ 1 ▣ 2/ 2 ▣▣ 3/ 4 ▣▣▣□ 4/ 4 ▣▣▣▣ 5/ 8 ▣▣▣▣▣□□□ 6/ 8 ▣▣▣▣▣▣□□ 7/ 8 ▣▣▣▣▣▣▣□ 8/ 8 ▣▣▣▣▣▣▣▣ 9/16 ▣▣▣▣▣▣▣▣▣□□□□□□□ 10/16 ▣▣▣▣▣▣▣▣▣▣□□□□□□ 11/16 ▣▣▣▣▣▣▣▣▣▣▣□□□□□ 12/16 ▣▣▣▣▣▣▣▣▣▣▣▣□□□□ 13/16 ▣▣▣▣▣▣▣▣▣▣▣▣▣□□□ 14/16 ▣▣▣▣▣▣▣▣▣▣▣▣▣▣□□ 15/16 ▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣□ 16/16 ▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣ 17/32 ▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣□□□□□□□□□□□□□□□ 18/32 ▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣□□□□□□□□□□□□□□ 19/32 ▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣▣□□□□□□□□□□□□□在成功插入二十个键-值对的过程中,您从未遇到任何错误。通过这个粗略的描述,您可以清楚地看到当哈希表变满并需要更多的槽时,槽会加倍。
感谢您刚刚实现的自动调整大小,您可以为新哈希表假定一个默认容量。这样,创建一个
HashTable类的实例将不再需要指定初始容量,尽管这样做可以提高性能。初始容量的常见选择是 2 的小幂,例如 8:# hashtable.py # ... class HashTable: @classmethod def from_dict(cls, dictionary, capacity=None): hash_table = cls(capacity or len(dictionary)) for key, value in dictionary.items(): hash_table[key] = value return hash_table def __init__(self, capacity=8): if capacity < 1: raise ValueError("Capacity must be a positive number") self._slots = capacity * [None] # ...这使得通过调用无参数初始化器
HashTable()来创建哈希表成为可能。请注意,您也可以更新您的类方法HashTable.from_dict()来使用字典的长度作为初始容量。以前,由于未处理的哈希冲突,您将字典的长度乘以一个任意因子,这是通过测试所必需的。如前所述,延迟调整大小策略有一个问题,那就是增加了冲突的可能性。你接下来要解决这个问题。
计算负载系数
等待哈希表饱和并不是最佳选择。您可以尝试一种急切策略在达到其总容量之前调整哈希表的大小,从一开始就防止冲突发生。你如何决定调整大小和重新散列的最佳时机?使用负载系数!
加载因子是当前被占用的槽的数量(包括被删除的槽)与哈希表中所有槽的比例。负载系数越高,哈希冲突的可能性就越大,从而导致查找性能下降。因此,您希望装载系数始终保持相对较小。每当负载系数达到某个阈值时,就应该增加哈希表的大小。
特定阈值的选择是计算机科学中时空权衡的经典例子。更频繁地调整哈希表大小会更便宜,并以消耗更多内存为代价获得更好的性能。相反,等待更长时间可以节省一些内存,但键查找会更慢。下图描述了分配的内存量和平均冲突数之间的关系:
这个图表背后的数据测量了在一个初始容量为 1 的空哈希表中插入 100 个元素所导致的平均冲突数。对于不同的负载系数阈值,测量被重复多次,在该阈值下,散列表通过使其容量加倍而在离散跳跃中调整自身的大小。
两个图的交点出现在 0.75 左右,表示阈值的最佳点,具有最低的内存量和冲突数量。使用较高的负载系数阈值并不能显著节省内存,但是会成倍增加冲突的数量。较小的阈值可以提高性能,但代价是浪费大量内存。请记住,您真正需要的是一百个插槽!
您可以试验不同的负载系数阈值,但是当 60%的槽被占用时调整哈希表的大小可能是一个好的起点。下面是如何在您的
HashTable类中实现加载因子计算:# hashtable.py # ... class HashTable: # ... @property def load_factor(self): occupied_or_deleted = [slot for slot in self._slots if slot] return len(occupied_or_deleted) / self.capacity您首先过滤真实的插槽,这将是除了
None之外的任何东西,然后根据负载系数的定义获取比率。注意,如果你决定使用一个理解表达式,那么它必须是一个列表理解来计算所有标记值的出现。在这种情况下,使用集合理解将过滤掉删除对的重复标记,只留下一个实例,并导致错误的加载因子。接下来,修改您的类以接受可选的负载因子阈值,并使用它来急切地调整插槽的大小和重新散列插槽:
# hashtable.py # ... class HashTable: # ... def __init__(self, capacity=8, load_factor_threshold=0.6): if capacity < 1: raise ValueError("Capacity must be a positive number") if not (0 < load_factor_threshold <= 1): raise ValueError("Load factor must be a number between (0, 1]") self._slots = capacity * [None] self._load_factor_threshold = load_factor_threshold # ... def __setitem__(self, key, value): if self.load_factor >= self._load_factor_threshold: self._resize_and_rehash() for index, pair in self._probe(key): if pair is DELETED: continue if pair is None or pair.key == key: self._slots[index] = Pair(key, value) break负载系数阈值默认为 0.6,这意味着所有插槽的 60%被占用。您使用弱不等式(
>=)而不是严格不等式(>)来说明负载系数阈值的最大值,该值永远不会大于 1。如果加载因子等于 1,那么在插入另一个键值对之前,还必须调整哈希表的大小。太棒了。你的哈希表变得更快了。本教程中的开放式寻址示例到此结束。接下来,您将使用一种最流行的封闭寻址技术来解决哈希冲突。
用单独的链接隔离碰撞的键
分离链接 是另一种非常流行的哈希冲突解决方法,也许比线性探测更普遍。这个想法是通过一个共同的特征将相似的项目分组到所谓的桶中,以缩小搜索空间。例如,你可以想象收获水果并把它们收集到不同颜色的篮子里:
Fruits Grouped by Color in Each Basket 每个篮子里都装着颜色大致相同的水果。例如,当你想吃苹果时,你只需要在标有红色的篮子里搜寻。在理想的情况下,每个篮子应该包含不超过一个元素,使得搜索是即时的。你可以把标签想象成散列码,把颜色相同的水果想象成冲突的键值对。
基于独立链接的哈希表是对桶的引用列表,通常实现为形成元素的链的链表:
Chains of Collided Key-Value Pairs 每个链表都包含键-值对,由于冲突,它们的键共享相同的哈希代码。通过键查找值时,需要先定位右边的桶,然后使用线性搜索遍历它,找到匹配的键,最后返回对应的值。线性搜索只是意味着一个接一个地遍历桶中的每一项,直到找到正确的键。
注意:链表的元素有很小的内存开销,因为每个节点都包含对下一个元素的引用。同时,与常规数组相比,这种内存布局使得追加和移除元素非常快。
要修改您的
HashTable类以使用单独的链接,首先移除._probe()方法并用桶替换插槽。现在,不是每个索引都有一个None值或一对值,而是让每个索引保存一个可能为空或不为空的桶。每个存储桶将是一个链表:# hashtable.py from collections import deque # ... class HashTable: # ... def __init__(self, capacity=8, load_factor_threshold=0.6): if capacity < 1: raise ValueError("Capacity must be a positive number") if not (0 < load_factor_threshold <= 1): raise ValueError("Load factor must be a number between (0, 1]") self._buckets = [deque() for _ in range(capacity)] self._load_factor_threshold = load_factor_threshold # ... def _resize_and_rehash(self): copy = HashTable(capacity=self.capacity * 2) for key, value in self.pairs: copy[key] = value self._buckets = copy._buckets你可以利用 Python 的双端队列,或者在
collections模块中可用的队列,而不是从头开始实现一个链表,它使用了一个双向链表。它让您能够比普通列表更有效地添加和删除元素。不要忘记更新
.pairs、.capacity和.load_factor属性,以便它们引用桶而不是槽:# hashtable.py # ... class HashTable: # ... @property def pairs(self): return {pair for bucket in self._buckets for pair in bucket} # ... @property def capacity(self): return len(self._buckets) # ... @property def load_factor(self): return len(self) / self.capacity您不再需要 sentinel 值来将元素标记为已删除,所以继续并删除
DELETED常量。这使得键值对和加载因子的定义更加直观。容量与桶的数量是同义的,因为您希望在每个桶中最多保留一个键值对,从而最大限度地减少哈希代码冲突的数量。注意:当哈希表中存储的键值对的数量超过桶的数量时,像这样定义的加载因子可以变得大于 1。
顺便说一句,允许太多的冲突将有效地把你的哈希表退化成一个具有线性时间复杂度的平面列表,显著地降低它的性能。攻击者可能会利用这一事实,人为地制造尽可能多的冲突。
使用单独的链接,所有基本的散列表操作都归结为找到正确的存储桶并在其中进行搜索,这使得相应的方法看起来很相似:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): bucket = self._buckets[self._index(key)] for index, pair in enumerate(bucket): if pair.key == key: del bucket[index] break else: raise KeyError(key) def __setitem__(self, key, value): if self.load_factor >= self._load_factor_threshold: self._resize_and_rehash() bucket = self._buckets[self._index(key)] for index, pair in enumerate(bucket): if pair.key == key: bucket[index] = Pair(key, value) break else: bucket.append(Pair(key, value)) def __getitem__(self, key): bucket = self._buckets[self._index(key)] for pair in bucket: if pair.key == key: return pair.value raise KeyError(key)当您通过索引删除一个项目时,Deque 实例负责更新它们的内部引用。如果你使用了一个定制的链表,你必须在每次修改后手工重新连接冲突的键值对。和以前一样,更新现有的键-值对需要用新的替换旧的,因为键-值对是不可变的。
如果你想避免重复自己,那么尝试使用 Python 3.10 中引入的结构模式匹配来重构上述三种方法。你会在附带的材料中找到一个可能的解决方案。
好了,您知道如何处理哈希代码冲突,现在您已经准备好继续前进了。接下来,您将让哈希表按照插入顺序返回键和值。
在哈希表中保留插入顺序
因为经典的哈希表数据结构使用哈希将键均匀分布,有时还会伪随机分布,所以不能保证它们的顺序。根据经验,你应该永远不要假设当你请求哈希表元素时,它们会以一致的顺序出现。但是有时对你的元素强加一个特定的顺序可能是有用的,甚至是必要的。
直到 Python 3.6,在字典元素上执行顺序的唯一方法是使用标准库中的
OrderedDict包装器。后来,内置的dict数据类型开始保留键值对的插入顺序。无论如何,假设缺少元素顺序以使您的代码与旧的或替代的 Python 版本兼容可能仍然是明智的。如何在自定义的
HashTable类中复制类似的插入顺序保存?一种方法是在插入键时记住它们的顺序,并遍历该顺序以返回键、值和键对。首先在类中声明另一个内部字段:# hashtable.py # ... class HashTable: # ... def __init__(self, capacity=8, load_factor_threshold=0.6): if capacity < 1: raise ValueError("Capacity must be a positive number") if not (0 < load_factor_threshold <= 1): raise ValueError("Load factor must be a number between (0, 1]") self._keys = [] self._buckets = [deque() for _ in range(capacity)] self._load_factor_threshold = load_factor_threshold这是一个空的键列表,当您修改哈希表的内容时,它会增长和收缩:
# hashtable.py # ... class HashTable: # ... def __delitem__(self, key): bucket = self._buckets[self._index(key)] for index, pair in enumerate(bucket): if pair.key == key: del bucket[index] self._keys.remove(key) break else: raise KeyError(key) def __setitem__(self, key, value): if self.load_factor >= self._load_factor_threshold: self._resize_and_rehash() bucket = self._buckets[self._index(key)] for index, pair in enumerate(bucket): if pair.key == key: bucket[index] = Pair(key, value) break else: bucket.append(Pair(key, value)) self._keys.append(key)当哈希表中不再有相关联的键值对时,就删除这个键。另一方面,只有在第一次将一个全新的键-值对插入哈希表时,才添加一个键。您不希望在进行更新时插入一个密钥,因为这将导致同一个密钥的多个副本。
接下来,您可以更改三个属性
.keys、.values和.pairs,以便它们遵循插入键的相同顺序:# hashtable.py # ... class HashTable: # ... @property def keys(self): return self._keys.copy() @property def values(self): return [self[key] for key in self.keys] @property def pairs(self): return [(key, self[key]) for key in self.keys]确保返回密钥的副本,以避免泄露内部实现。另外,请注意,这三个属性现在都返回列表而不是集合,因为您希望它们保持正确的顺序。反过来,这让您可以压缩键和值来进行配对:

>>> from hashtable import HashTable
>>> hash_table = HashTable.from_dict({
... "hola": "hello",
... 98.6: 37,
... False: True
... })
>>> hash_table.keys
['hola', 98.6, False]
>>> hash_table.values
['hello', 37, True]
>>> hash_table.pairs
[('hola', 'hello'), (98.6, 37), (False, True)]
>>> hash_table.pairs == list(zip(hash_table.keys, hash_table.values))
True
键和值总是以相同的顺序返回,例如,第一个键和值可以相互映射。这意味着你可以像上面的例子一样压缩它们。
现在您知道了如何保持哈希表中键值对的插入顺序。另一方面,如果您想按照更高级的标准对它们进行排序,那么您可以遵循与对内置字典进行排序的相同的技术。此时没有额外的代码要写。
使用哈希键
现在,您的哈希表已经完成并且功能齐全。它可以使用内置的hash()函数将任意键映射到值。它可以检测和解决哈希代码冲突,甚至可以保留键值对的插入顺序。如果你愿意,理论上你可以在 Python dict上使用它,除了糟糕的性能和偶尔更冗长的语法之外,你不会注意到太多的不同。
注意:如前所述,你应该很少需要自己实现哈希表这样的数据结构。Python 附带了许多有用的集合,这些集合具有无与伦比的性能,并且经过了无数开发人员的现场测试。对于特殊的数据结构,在尝试创建自己的库之前,您应该检查第三方库的 PyPI 。您将为自己节省大量时间,并显著降低出错的风险。
到目前为止,您已经理所当然地认为 Python 中的大多数内置类型都可以作为散列表键工作。然而,要在实践中使用任何哈希表实现,您必须将键限制为可哈希类型,并理解这样做的含义。当您决定将自定义数据类型引入等式时,这将特别有帮助。
可修改性 vs 不可修改性
您之前了解到,一些数据类型,包括 Python 中的大多数原始数据类型,是可散列的,而其他的则不是。哈希能力的主要特点是能够计算给定对象的哈希代码:
>>> hash(frozenset(range(10))) 3895031357313128696 >>> hash(set(range(10))) Traceback (most recent call last): File "<input>", line 1, in <module> hash(set(range(10))) TypeError: unhashable type: 'set'例如,Python 中的
frozenset数据类型的实例是可散列的,而普通集合根本不实现散列。哈希能力直接影响某些类型的对象能否成为字典键或集合成员,因为这两种数据结构都在内部使用hash()函数:
>>> hashable = frozenset(range(10))
>>> {hashable: "set of numbers"}
{frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}): 'set of numbers'}
>>> {hashable}
{frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})}
>>> unhashable = set(range(10))
>>> {unhashable: "set of numbers"}
Traceback (most recent call last):
File "<input>", line 1, in <module>
{unhashable: "set of numbers"}
TypeError: unhashable type: 'set'
>>> {unhashable}
Traceback (most recent call last):
File "<input>", line 1, in <module>
{unhashable}
TypeError: unhashable type: 'set'
虽然frozenset的实例是可散列的,但是具有完全相同值的对应集合却不是。请注意,您仍然可以对字典值使用不可哈希的数据类型。字典键必须能够计算出它们对应的散列码。
注意:当你把一个不可销毁的对象插入一个可销毁的容器,比如frozenset,那么这个容器也变成不可销毁的。
Hashability 与可变性密切相关,即在对象的生命周期内改变其内部状态的能力。两者的关系有点像换个地址。当你搬到另一个地方,你仍然是同一个人,但你的老朋友可能很难找到你。
Python 中不可销毁的类型,比如列表、集合或字典,恰好是可变容器,因为您可以通过添加或删除元素来修改它们的值。另一方面,Python 中大多数内置的可散列类型都是不可变的。这是否意味着可变类型不能被散列?
正确的答案是它们可以既是可变的又是可散列的,但是它们很少应该是可变的!改变一个键会导致改变它在哈希表中的内存地址。以这个自定义类为例:
>>> class Person: ... def __init__(self, name): ... self.name = name这个类代表一个有名字的人。Python 为您的类中的特殊方法
.__hash__()提供了一个默认实现,它仅仅使用对象的标识来导出它的散列代码:
>>> hash(Person("Joe"))
8766622471691
>>> hash(Person("Joe"))
8766623682281
每个单独的Person实例都有一个唯一的散列码,即使它在逻辑上与其他实例相同。为了让对象的值决定它的散列码,您可以覆盖默认的.__hash__()实现,如下所示:
>>> class Person: ... def __init__(self, name): ... self.name = name ... ... def __hash__(self): ... return hash(self.name) >>> hash(Person("Joe")) == hash(Person("Joe")) True您在
.name属性上调用hash(),这样名称相同的Person类的实例总是具有相同的哈希代码。例如,这便于在字典中查找它们。注意:你可以通过设置你的类的
.__hash__属性等于None来显式地将你的类标记为不可销毁:
>>> class Person:
... __hash__ = None
...
... def __init__(self, name):
... self.name = name
>>> hash(Person("Alice"))
Traceback (most recent call last):
File "<input>", line 1, in <module>
hash(Person("Alice"))
TypeError: unhashable type: 'Person'
这将阻止hash()处理你的类的实例。
可散列类型的另一个特点是能够通过值来比较它们的实例。回想一下,哈希表使用相等测试操作符(==)来比较键,因此您必须在您的类中实现另一个特殊的方法.__eq__(),以实现这一点:
>>> class Person: ... def __init__(self, name): ... self.name = name ... ... def __eq__(self, other): ... if self is other: ... return True ... if type(self) is not type(other): ... return False ... return self.name == other.name ... ... def __hash__(self): ... return hash(self.name)如果你以前经历过哈希表的相等测试,这段代码应该看起来很熟悉。简而言之,您检查另一个对象是否是完全相同的实例、另一种类型的实例、或者与
.name属性具有相同类型和相同值的另一个实例。注意:编码特殊的方法,比如
.__eq__()和.__hash__()可能是重复的、乏味的、容易出错的。如果你使用的是 Python 3.7 或更高版本,那么你可以通过使用数据类更简洁地达到同样的效果:@dataclass(unsafe_hash=True) class Person: name: str当一个数据类基于你的类属性生成
.__eq__()时,你必须设置unsafe_hash选项来启用正确的.__hash__()方法生成。实现了
.__eq__()和.__hash__()之后,您可以使用Person类实例作为字典键:
>>> alice = Person("Alice")
>>> bob = Person("Bob")
>>> employees = {alice: "project manager", bob: "engineer"}
>>> employees[bob]
'engineer'
>>> employees[Person("Bob")]
'engineer'
完美!如果您通过之前创建的bob引用或全新的Person("Bob")实例找到一个雇员,这并不重要。不幸的是,当 Bob 突然决定改名为 Bobby 时,事情变得复杂了:
>>> bob.name = "Bobby" >>> employees[bob] Traceback (most recent call last): File "<input>", line 1, in <module> employees[bob] KeyError: <__main__.Person object at 0x7f607e325e40> >>> employees[Person("Bobby")] Traceback (most recent call last): File "<input>", line 1, in <module> employees[Person("Bobby")] KeyError: <__main__.Person object at 0x7f607e16ed10> >>> employees[Person("Bob")] Traceback (most recent call last): File "<input>", line 1, in <module> employees[Person("Bob")] KeyError: <__main__.Person object at 0x7f607e1769e0>即使您仍然使用之前插入的原始 key 对象,也无法检索相应的值。然而,更令人惊讶的是,您不能通过带有更新后的人名或旧名的新 key 对象来访问该值。你能说出原因吗?
原始键的散列码决定了关联值存储在哪个桶中。改变您的密钥的状态会使其哈希代码指示一个完全不同的桶或槽,其中不包含预期的值。但是使用旧名称的密钥也没有帮助。当它指向正确的桶时,存储的键发生了变化,使得
"Bob"和"Bobby"之间的相等比较评估为False,而不是匹配。因此,散列码必须是不可变的,散列才能按预期工作。因为哈希代码通常是从对象的属性中派生出来的,所以它们的状态应该是固定的,永远不会随时间而改变。实际上,这也意味着作为散列表键的对象本身应该是不可变的。
总而言之,可散列数据类型具有以下特征:
- 有一个
.__hash__()方法来计算实例的散列码- 有一个
.__eq__()方法通过值来比较实例- 有不可变的散列码,在实例的生命周期中不会改变
- 符合哈希相等契约
可散列类型的第四个也是最后一个特征是,它们必须符合散列相等契约,这将在下一小节中详细介绍。简而言之,具有相同值的对象必须具有相同的哈希代码。
哈希等价契约
为了避免使用自定义类作为哈希表键时出现问题,它们应该符合 hash-equal 协定。如果关于那个契约有一件事要记住,那就是当你实现
.__eq__()时,你应该总是实现一个相应的.__hash__()。唯一不需要实现这两种方法的时候是当你使用一个包装器,比如一个数据类或者一个不可变的命名的元组已经为你做了这些。此外,只要您绝对确定不会将您的数据类型的对象用作字典键或集合成员,不实现这两种方法也是可以的。但是你能这么肯定吗?
注意:如果您不能使用数据类或命名元组,并且您想要手动比较和散列一个类中的多个字段,那么将它们包装在元组中:
class Person: def __init__(self, name, date_of_birth, married): self.name = name self.date_of_birth = date_of_birth self.married = married def __hash__(self): return hash(self._fields) def __eq__(self, other): if self is other: return True if type(self) is not type(other): return False return self._fields == other._fields @property def _fields(self): return self.name, self.date_of_birth, self.married如果您的类中有相对较多的字段,那么定义一个私有属性来返回该元组是有意义的。
尽管您可以随意实现这两种方法,但它们必须满足 hash-equal 契约,该契约规定两个相等的对象必须散列到相等的散列代码。这使得根据提供的关键字找到正确的桶成为可能。然而,反过来就不正确了,因为冲突可能偶尔会导致相同的哈希代码被不同的值共享。您可以使用这两种含义更正式地表达这一点:
a = b⇒hash(a) = hash(b)hash(a) = hash(b)⇏a = b哈希相等契约是一个单向契约。如果两个密钥在逻辑上相等,那么它们的散列码也必须相等。另一方面,如果两个键共享相同的哈希代码,很可能它们是同一个键,但也有可能它们是不同的键。你需要比较它们,以确定它们是否真的匹配。根据对位定律,你可以从第一个推导出另一个含义:
hash(a) ≠ hash(b)⇒a ≠ b如果你知道两个键有不同的散列码,那么比较它们就没有意义了。这有助于提高性能,因为相等测试往往代价很高。
一些 ide 提供自动生成
.__hash__()和.__eq__()方法,但是你需要记住在每次修改你的类属性时重新生成它们。因此,尽可能坚持使用 Python 的数据类或命名元组,以保证可散列类型的正确实现。结论
此时,您可以使用不同的策略来解决哈希冲突,从 Python 中的零开始实现哈希表。您知道如何动态调整哈希表的大小并重新散列以容纳更多数据,以及如何保持键值对的插入顺序。在这个过程中,您通过一步一步地向哈希表添加特性,实践了测试驱动开发(TDD)** 。**
除此之外,你对 Python 的内置
hash()函数有很深的理解,可以自己创建一个。你了解了散列等价契约、散列和不散列数据类型的区别,以及它们与不可变类型的关系。您知道如何使用 Python 中的各种工具创建定制的可散列类。在本教程中,您学习了:
- 一个散列表与一个字典有何不同
- 如何用 Python 从零开始实现散列表
- 如何应对哈希冲突和其他挑战
- 一个散列函数的期望属性是什么
- Python 的
hash()如何在幕后运作有了这些知识,你就准备好回答你在工作面试中可能遇到的与散列表数据结构相关的大多数问题。
您可以通过单击下面的链接下载完整的源代码和本教程中使用的中间步骤:
源代码: 点击这里下载源代码,您将使用它在 Python 中构建一个散列表。************************************


 浙公网安备 33010602011771号
浙公网安备 33010602011771号