RealPython-中文系列教程-十五-
RealPython 中文系列教程(十五)
原文:RealPython
PyQt 布局:创建专业外观的 GUI 应用程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深你的理解: 为 GUI 应用程序创建 PyQt 布局
PyQt 的布局管理器提供了一种在 GUI 上排列图形组件或者小部件的用户友好且高效的方式。恰当地布局窗口小部件会让你的 GUI 应用程序看起来更加精致和专业。学会高效地这样做是使用 Python 和 PyQt 开始并运行 GUI 应用程序开发的一项基本技能。
在本教程中,您将学习:
- 使用 PyQt 的布局管理器有什么好处
- 如何使用 PyQt 的布局管理器在 GUI 上以编程方式布置小部件
- 如何为你的 GUI 应用选择正确的布局管理器
- 如何在基于主窗口的和基于对话框的应用程序中布局控件
有了这些知识和技能,您将能够使用 Python 和 PyQt 创建专业外观的 GUI 应用程序。
为了更好地理解如何使用布局管理器,一些关于如何创建 PyQt GUI 应用程序以及如何使用 PyQt 窗口小部件的知识会有所帮助。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
在 GUI 上布置图形元素
当你创建图形用户界面(GUI) 应用程序时,一个常见的问题是如何让你的图形组件——T2 按钮、菜单、工具栏、标签等等——在你的表单和窗口上连贯地布局。这个过程被称为 GUI 布局,它是创建 GUI 应用程序的重要步骤。
在过去,如果你想在一个窗口上布局图形组件,或者说小部件,那么你会遵循以下方法之一:
- 决定并手动设置窗口上每个小部件的静态大小和位置。
- 动态计算和设置每个小工具的大小和位置。
第一种方法相当直接,但它至少有以下缺点:
- 您的窗口将不可调整大小,这可能会导致在不同的屏幕分辨率上显示它们时出现问题。
- 您的标签可能无法正确支持本地化,因为给定文本的长度会因语言而异。
- 您的小部件在不同的平台上会有不同的显示,这使得编写好看的多平台应用程序变得困难。
第二种方法更加灵活。然而,它也有缺点:
- 你必须做大量的手工计算来确定每个部件的正确尺寸和位置。
- 你必须做一些额外的计算来正确响应窗口大小调整。
- 每当你修改窗口的布局时,你必须重做所有的计算。
尽管你仍然可以使用这两种方法中的任何一种来布局你的 GUI,但是大多数时候你会希望使用第三种更方便的方法,这种方法是由大多数现代的 GUI 框架或工具包实现的:布局管理器。
注:在一些 GUI 框架中,如 Tkinter ,布局管理器也被称为几何管理器。
布局管理器根据您的具体需求自动在 GUI 上排列小部件。它们避免了第一种方法的兼容性缺点以及第二种方法的烦人和复杂的计算。
在接下来的小节中,您将了解 PyQt 的内置布局管理器,以及如何使用它们来有效地布局 GUI 应用程序的图形组件。
获得 PyQt 布局图库
在 PyQt 中,小部件是图形组件,用作 GUI 应用程序的构建块。当你在一个窗口上放置一堆小部件来创建一个 GUI 时,你需要给它们一些顺序。您需要设置窗口小部件的大小和位置,还需要定义它们在用户调整底层窗口大小时的行为。
注:可惜 PyQt5 的官方文档有一些不完整的章节。要解决这个问题,您可以查看 PyQt4 文档,Python 文档的 Qt,或者原始的 Qt 文档。
在本教程中,您会发现大多数链接会将您带到最初的 Qt 文档,在大多数情况下,这是一个更好的信息来源。
要在 PyQt 中排列窗口或表单上的小部件,可以使用以下技术:
- 使用小部件上的
.resize()和.move()来提供绝对大小和位置。 - 重新实现
.resizeEvent()并动态计算你的部件的大小和位置。 - 使用布局管理器,让他们为你做所有的计算和艰苦的工作。
这些技术通常对应于您在上一节中看到的布局 GUI 的三种不同方法。
同样,动态计算大小和位置可能是一个好方法,但是大多数时候使用布局管理器会更好。在 PyQt 中,布局管理器是提供所需功能的类,用于自动管理布局中小部件的大小、位置和调整行为。
使用布局管理器,您可以在任何父或容器、小部件中自动排列子小部件。使用布局管理器可以确保你充分利用 GUI 上的可用空间,并且当用户调整窗口大小时,你的应用程序仍然可用。
布局管理器是小部件和其他布局的容器。要将小部件添加到布局管理器,您可以在手边的布局上调用 .addWidget() 。要将一个布局添加到另一个布局中,您可以在手头的布局上调用.addLayout()。在嵌套布局构建复杂图形用户界面一节中,您将更深入地了解嵌套布局。
一旦将所有需要的小部件添加到布局管理器中,就可以使用 .setLayout() 在给定的小部件上设置布局管理器。您可以在 QWidget 的任何子类上设置布局管理器,包括窗口或窗体。
注意: QMainWindow 是一个 PyQt 类,您可以用它来创建主寡妇风格的应用程序。这个类有自己的内置布局管理器。所以,如果你使用的是QMainWindow,那么你通常不需要在主窗口对象上设置布局管理器。
布局中的所有微件都会自动设置为安装布局的微件的子件,而不是布局本身的子件。这是因为小部件只能有其他小部件,而不能有布局作为它们的父部件。
PyQt 的布局管理器提供了一些很酷的特性,让您在创建好看的 GUI 应用程序时更加轻松:
- 无需任何计算即可处理微件的尺寸和位置
- 当用户调整底层窗口大小时,处理小部件的调整大小和重新定位
- 调整标签大小以更好地支持国际化
- 为多平台应用提供本地窗口布局
从长远来看,使用布局管理器还将极大地提高您的生产率并改善代码的可维护性。
PyQt 提供了四个通用布局管理器类:
QHBoxLayout将小工具排列在一个水平框中。QVBoxLayout将小工具排列在垂直框中。QGridLayout将小工具排列成网格。QFormLayout将小工具排成两列。
在接下来的几节中,您将学习如何使用这些通用布局管理器的基础知识。
使用通用布局管理器
在使用 PyQt 创建 GUI 应用程序时,您通常会使用上一节末尾提到的四种通用布局中的一种或多种来将小部件布置在您的窗口和表单上。
在接下来的几节中,您将借助一些示例学习如何创建和使用四个通用布局管理器。
建筑平面布置:QHBoxLayout
盒子布局管理器从它们的父布局或窗口小部件中获取空间,将其分成许多盒子,或单元,并使布局中的每个窗口小部件填满一个盒子。
QHBoxLayout 是 PyQt 中两个可用的框布局之一。这个布局管理器允许你水平排列小部件**,一个挨着一个。小部件从左到右添加到布局中。这意味着您在代码中首先添加的小部件将是布局中最左边的小部件。*
*要向一个QHBoxLayout对象添加小部件,您可以在布局对象上调用.addWidget(widget, stretch, alignment)。此方法采用一个必需参数和两个可选参数:
-
widget是一个必需的参数,用于保存要添加到布局中的特定小部件。 -
stretch是一个可选参数,它保存一个表示要应用于widget的拉伸因子的整数。具有较高拉伸系数的窗口小部件在调整窗口大小时增长更多。默认为0,这意味着小部件没有分配拉伸因子。 -
alignment是可选参数,保存水平和垂直标志。您可以组合这些标志来产生小部件在其包含的单元格内的期望的对齐方式。它默认为0,这意味着小部件将填充整个单元格。
这里有一个小应用程序,展示了如何使用QHBoxLayout创建一个水平布局。在本例中,您将使用 QPushButton 对象来更好地显示每个小部件在布局中的位置,这取决于您将小部件添加到代码中的顺序:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QHBoxLayout,
6 QPushButton,
7 QWidget,
8)
9
10class Window(QWidget):
11 def __init__(self):
12 super().__init__()
13 self.setWindowTitle("QHBoxLayout Example")
14 # Create a QHBoxLayout instance
15 layout = QHBoxLayout() 16 # Add widgets to the layout
17 layout.addWidget(QPushButton("Left-Most")) 18 layout.addWidget(QPushButton("Center"), 1) 19 layout.addWidget(QPushButton("Right-Most"), 2) 20 # Set the layout on the application's window
21 self.setLayout(layout) 22 print(self.children())
23
24if __name__ == "__main__":
25 app = QApplication(sys.argv)
26 window = Window()
27 window.show()
28 sys.exit(app.exec_())
在第 15 行,您创建了一个名为layout的QHBoxLayout对象。在第 17 到 19 行,您使用.addWidget()向layout添加了三个按钮。请注意,您分别将1和2传递给中间和最右边按钮中的stretch参数。在第 21 行,使用.setLayout()将layout设置为窗口的顶层布局。
注意:如果你是使用 PyQt 进行 GUI 编程的新手,那么你可以看看 Python 和 PyQt:构建 GUI 桌面计算器来更好地了解如何使用 PyQt 创建 GUI 应用程序。
如果您运行这个应用程序,那么您会在屏幕上看到以下窗口:

该窗口包含三个以水平方式排列的按钮。请注意,最左边的按钮对应于您在代码中添加的第一个按钮。因此,按钮的显示顺序(从左到右)与您在代码中添加它们的顺序(从上到下)相同。
最右边的中心和按钮有不同的拉伸系数,因此当您调整窗口大小时,它们会按比例扩展。
此外,layout中的所有按钮和布局本身都被设置为Window的子元素。这是由布局对象自动完成的,它在内部调用每个小部件上的.setParent()。第 22 行对 print() 的调用在您的终端上打印了Window的孩子的列表,作为这种行为的证据。
建筑竖向布局:QVBoxLayout
QVBoxLayout 垂直排列小工具**,一个在另一个下面。您可以使用这个类创建垂直布局,并从上到下排列您的小部件。由于QVBoxLayout是另一个盒子布局,其.addWidget()方法与QHBoxLayout中的方法相同。*
*下面是一个 PyQt 应用程序,展示了如何创建和使用一个QVBoxLayout对象来在 GUI 中创建垂直排列的小部件:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QPushButton,
6 QVBoxLayout,
7 QWidget,
8)
9
10class Window(QWidget):
11 def __init__(self):
12 super().__init__()
13 self.setWindowTitle("QVBoxLayout Example")
14 self.resize(270, 110)
15 # Create a QVBoxLayout instance
16 layout = QVBoxLayout() 17 # Add widgets to the layout
18 layout.addWidget(QPushButton("Top")) 19 layout.addWidget(QPushButton("Center")) 20 layout.addWidget(QPushButton("Bottom")) 21 # Set the layout on the application's window
22 self.setLayout(layout)
23
24if __name__ == "__main__":
25 app = QApplication(sys.argv)
26 window = Window()
27 window.show()
28 sys.exit(app.exec_())
在第 16 行,您创建了一个QVBoxLayout的实例。在第 18 到 20 行,您向layout添加了三个按钮。最后,将layout设置为窗口的顶层布局。
如果您运行这个应用程序,那么您将得到以下窗口:
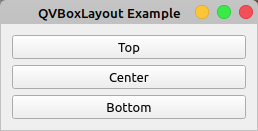
您的窗口显示三个垂直排列的按钮,一个在另一个的下面。按钮出现的顺序(从上到下)与您在代码中添加它们的顺序(从上到下)相同。
在网格中排列部件:QGridLayout
您可以使用 QGridLayout 将小部件排列在由行和列组成的网格中。每个小部件在网格中都有一个相对位置。要定义小部件的位置或网格中的单元格,可以使用一对形式为(row, column)的坐标。这些坐标应该是从零开始的整数。
QGridLayout获取其父控件上的可用空间,将其分成行和列,并将每个小部件放入其自己的单元格或框中。QGridLayout根据小部件的数量及其坐标,自动计算出最终布局的行数和列数。如果你不给一个给定的单元格添加一个小部件,那么QGridLayout会让这个单元格为空。
要将小部件添加到网格布局中,可以在布局上调用.addWidget()。这个方法有两个不同的重载实现:
addWidget(widget, row, column, alignment)在(row、column)处的单元格增加widget。addWidget(widget, fromRow, fromColumn, rowSpan, columnSpan, alignment)将widget添加到单元格中,跨越多行、多列或两者。
第一个实现采用以下参数:
widget是一个必需的参数,用于保存您需要添加到布局中的特定小部件。row是一个必需的参数,用于保存代表网格中行坐标的整数。column是一个必需的参数,用于保存代表网格中某列坐标的整数。alignment是一个可选参数,用于保存小工具在其包含的单元格内的对齐方式。它默认为0,这意味着小部件将填充整个单元格。
下面是一个如何使用QGridLayout创建小部件网格的例子:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QGridLayout,
6 QPushButton,
7 QWidget,
8)
9
10class Window(QWidget):
11 def __init__(self):
12 super().__init__()
13 self.setWindowTitle("QGridLayout Example")
14 # Create a QGridLayout instance
15 layout = QGridLayout() 16 # Add widgets to the layout
17 layout.addWidget(QPushButton("Button at (0, 0)"), 0, 0) 18 layout.addWidget(QPushButton("Button at (0, 1)"), 0, 1) 19 layout.addWidget(QPushButton("Button at (0, 2)"), 0, 2) 20 layout.addWidget(QPushButton("Button at (1, 0)"), 1, 0) 21 layout.addWidget(QPushButton("Button at (1, 1)"), 1, 1) 22 layout.addWidget(QPushButton("Button at (1, 2)"), 1, 2) 23 layout.addWidget(QPushButton("Button at (2, 0)"), 2, 0) 24 layout.addWidget(QPushButton("Button at (2, 1)"), 2, 1) 25 layout.addWidget(QPushButton("Button at (2, 2)"), 2, 2) 26 # Set the layout on the application's window
27 self.setLayout(layout)
28
29if __name__ == "__main__":
30 app = QApplication(sys.argv)
31 window = Window()
32 window.show()
33 sys.exit(app.exec_())
在第 15 行,您创建了QGridLayout对象。然后,在第 17 到 25 行,使用.addWidget()向布局添加小部件。要查看网格布局如何在没有分配小部件的情况下管理单元格,请注释掉这些行中的一行或多行,然后再次运行应用程序。
如果您从命令行运行这段代码,您将会看到如下窗口:
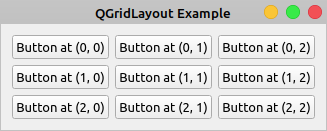
QGridLayout对象中的每个小部件占据了由您在.addWidget()中提供的一对坐标定义的单元。每个按钮上的文字反映了这些坐标。坐标是从零开始的,所以第一个单元格在(0, 0)。
在.addWidget()的第二个实现中,参数widget和alignment保持不变,并且有四个额外的参数允许您将小部件放置在几行或几列中:
fromRow取一个整数,表示小部件将从哪一行开始。fromColumn取一个整数,表示小部件将开始的列。rowSpan取一个整数,表示小部件将在网格中占据的行数。columnSpan取一个整数,表示小部件将在网格中占据的列数。
这里有一个应用程序展示了.addWidget()的这种变体是如何工作的:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QGridLayout,
6 QPushButton,
7 QWidget,
8)
9
10class Window(QWidget):
11 def __init__(self):
12 super().__init__()
13 self.setWindowTitle("QGridLayout Example")
14 # Create a QGridLayout instance
15 layout = QGridLayout()
16 # Add widgets to the layout
17 layout.addWidget(QPushButton("Button at (0, 0)"), 0, 0)
18 layout.addWidget(QPushButton("Button at (0, 1)"), 0, 1)
19 layout.addWidget(QPushButton("Button Spans two Cols"), 1, 0, 1, 2) 20 # Set the layout on the application's window
21 self.setLayout(layout)
22
23if __name__ == "__main__":
24 app = QApplication(sys.argv)
25 window = Window()
26 window.show()
27 sys.exit(app.exec_())
在第 19 行,您使用第二个实现.addWidget()来添加一个按钮,它占据了网格中的两列。按钮从第二行(fromRow=1)和第一列(fromColumn=0)开始。最后,按钮占据一行(rowSpan=1)和两列(columnSpan=2)。
注意:由于 PyQt 是为 Qt 绑定的 Python,是一组 C++ 库,所以有时候调用 PyQt 方法时不能使用关键字参数。上一段中使用的关键字参数的唯一目的是显示分配给每个参数的值。
如果运行此应用程序,您将在屏幕上看到以下窗口:
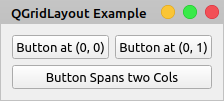
在这种布局中,你可以让一个小部件占据多个单元格,就像你用按钮跨越两列按钮一样。
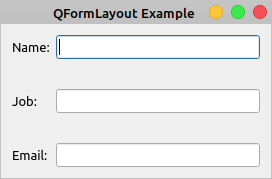
快速创建表单:QFormLayout
如果您经常创建表单来执行像将数据输入数据库这样的操作,那么 QFormLayout 就是为您准备的。这个类在一个两列布局中排列小部件。第一列通常显示一个描述预期输入的标签,第二列通常包含允许用户输入或编辑数据的输入小部件,如 QLineEdit 、 QComboBox 或 QSpinBox 。
要向表单布局添加小部件,可以使用.addRow()。这种方法有几种变体,但大多数情况下,您会从以下两种方法中进行选择:
-
.addRow(label, field)在表格布局底部添加新行。该行应该包含一个QLabel对象(label)和一个输入小部件(field)。 -
.addRow(labelText, field)自动创建并添加一个新的QLabel对象,其文本为labelText。field持有一个输入控件。
下面是一个使用QFormLayout对象来排列小部件的示例应用程序:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QFormLayout,
6 QLabel,
7 QLineEdit,
8 QWidget,
9)
10
11class Window(QWidget):
12 def __init__(self):
13 super().__init__()
14 self.setWindowTitle("QFormLayout Example")
15 self.resize(270, 110)
16 # Create a QFormLayout instance
17 layout = QFormLayout() 18 # Add widgets to the layout
19 layout.addRow("Name:", QLineEdit()) 20 layout.addRow("Job:", QLineEdit()) 21 emailLabel = QLabel("Email:")
22 layout.addRow(emailLabel, QLineEdit()) 23 # Set the layout on the application's window
24 self.setLayout(layout)
25
26if __name__ == "__main__":
27 app = QApplication(sys.argv)
28 window = Window()
29 window.show()
30 sys.exit(app.exec_())
在第 17 行,您创建了一个QFormLayout对象。然后,在第 19 到 22 行,向布局添加一些行。请注意,在第 19 行和第 20 行,您使用了该方法的第二种变体,在第 22 行,您使用了第一种变体,将一个QLabel对象作为第一个参数传递给.addRow()。
如果您运行这段代码,您将在屏幕上看到以下窗口:
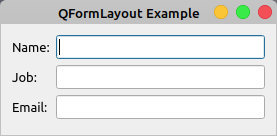
使用QFormLayout,你可以以两列的方式组织你的小部件。第一列包含要求用户提供一些信息的标签。第二列显示允许用户输入或编辑信息的小部件。
嵌套布局构建复杂的图形用户界面
您可以使用嵌套的布局来创建复杂的 GUI,这些 GUI 很难使用一个通用的 PyQt 布局管理器来创建。为此,您需要在一个外部布局上调用.addLayout()。这样,内部布局成为外部布局的子布局。
假设您需要创建一个对话框,在表单布局中显示一个标签和一行编辑,并且您希望在这些小部件下面放置几个垂直布局的复选框。这里有一个对话框的模型:

蓝色矩形代表您的外部布局。绿色矩形是保存标签和行编辑的表单布局。红色矩形是放置选项复选框的垂直布局。绿色布局和红色布局都嵌套在蓝色布局中,蓝色布局是垂直布局。
下面是如何使用 PyQt 构建这种布局的示例:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QCheckBox,
6 QFormLayout,
7 QLineEdit,
8 QVBoxLayout,
9 QWidget,
10)
11
12class Window(QWidget):
13 def __init__(self):
14 super().__init__()
15 self.setWindowTitle("Nested Layouts Example")
16 # Create an outer layout
17 outerLayout = QVBoxLayout() 18 # Create a form layout for the label and line edit
19 topLayout = QFormLayout() 20 # Add a label and a line edit to the form layout
21 topLayout.addRow("Some Text:", QLineEdit()) 22 # Create a layout for the checkboxes
23 optionsLayout = QVBoxLayout() 24 # Add some checkboxes to the layout
25 optionsLayout.addWidget(QCheckBox("Option one")) 26 optionsLayout.addWidget(QCheckBox("Option two")) 27 optionsLayout.addWidget(QCheckBox("Option three")) 28 # Nest the inner layouts into the outer layout
29 outerLayout.addLayout(topLayout) 30 outerLayout.addLayout(optionsLayout) 31 # Set the window's main layout
32 self.setLayout(outerLayout)
33
34if __name__ == "__main__":
35 app = QApplication(sys.argv)
36 window = Window()
37 window.show()
38 sys.exit(app.exec_())
下面是您在这段代码中要做的事情:
- 在第 17 行中,你创建了外部或者顶层布局,你将把它作为父布局和窗口的主布局。在这种情况下,您使用
QVBoxLayout,因为您希望小部件在表单上垂直排列。在你的模型中,这是蓝色的布局。 - 在第 19 行,您创建一个表单布局来保存一个标签和一个行编辑。
- 在第 21 行,您将所需的小部件添加到布局中。这相当于你的绿色布局。
- 在第 23 行上,你创建一个垂直布局来放置复选框。
- 在第 25 到 27 行上,添加所需的复选框。这是你的红色布局。
- 在第 29 行和第 30 行,你在
outerLayout下嵌套topLayout和optionsLayout。
就是这样!如果您运行该应用程序,您将看到如下窗口:
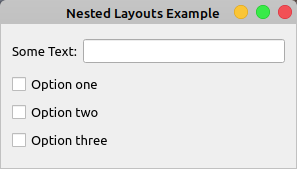
在这个应用程序中,您将两个不同的布局嵌套在一个外部布局下,为您的窗口创建一个通用布局。在窗口顶部,使用水平布局放置标签和行编辑。然后使用垂直布局在下面放置一些复选框。
使用多页面布局和小部件
到目前为止,您已经看到了如何使用传统的或通用的布局管理器来安排应用程序窗口中的小部件。这些布局管理器将在单页布局上排列小部件。换句话说,您的 GUI 将总是向用户显示同一组小部件。
有时,您需要创建一个布局来显示一组不同的小部件,以响应 GUI 上的某些用户操作。例如,如果你正在为一个给定的应用程序创建一个首选项对话框,那么你可能希望向用户呈现一个基于选项卡的,或者多页,其中每个选项卡或页面包含一组不同的密切相关的选项。每当用户点击一个标签或页面,应用程序就会显示不同的小部件。
PyQt 提供了一个名为 QStackedLayout 的内置布局,以及一些方便的小部件,如 QTabWidget ,允许您创建这种多页面布局。接下来的几节将带您了解这些工具。
创建一堆小部件
QStackedLayout 提供了一个布局管理器,允许你将你的小部件排列在栈上,一个在另一个之上。在这种布局中,一次只能看到一个小部件。
要用小部件填充堆叠布局,需要在布局对象上调用.addWidget()。这将把每个部件添加到布局内部部件列表的末尾。您还可以分别使用.insertWidget(index)或.removeWidget(widget)在小部件列表中的给定位置插入或移除小部件。
小部件列表中的每个小部件都显示为一个独立的页面。如果您想在一个页面上显示几个小部件,那么为每个页面使用一个QWidget对象,并为页面小部件设置一个适当的小部件布局。如果您需要获得布局中部件(页面)的总数,那么您可以调用.count()。
使用QStackedLayout对象时要记住的重要一点是,您需要明确地提供一种在页面之间切换的机制。否则,您的布局将总是向用户显示相同的页面。要在页面之间切换,需要在 layout 对象上调用.setCurrentIndex()。
下面的示例显示了如何使用带有组合框的堆叠布局在页面之间切换:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QComboBox,
6 QFormLayout,
7 QLineEdit,
8 QStackedLayout,
9 QVBoxLayout,
10 QWidget,
11)
12
13class Window(QWidget):
14 def __init__(self):
15 super().__init__()
16 self.setWindowTitle("QStackedLayout Example")
17 # Create a top-level layout
18 layout = QVBoxLayout()
19 self.setLayout(layout)
20 # Create and connect the combo box to switch between pages
21 self.pageCombo = QComboBox() 22 self.pageCombo.addItems(["Page 1", "Page 2"]) 23 self.pageCombo.activated.connect(self.switchPage) 24 # Create the stacked layout
25 self.stackedLayout = QStackedLayout() 26 # Create the first page
27 self.page1 = QWidget() 28 self.page1Layout = QFormLayout() 29 self.page1Layout.addRow("Name:", QLineEdit()) 30 self.page1Layout.addRow("Address:", QLineEdit()) 31 self.page1.setLayout(self.page1Layout) 32 self.stackedLayout.addWidget(self.page1) 33 # Create the second page
34 self.page2 = QWidget() 35 self.page2Layout = QFormLayout() 36 self.page2Layout.addRow("Job:", QLineEdit()) 37 self.page2Layout.addRow("Department:", QLineEdit()) 38 self.page2.setLayout(self.page2Layout) 39 self.stackedLayout.addWidget(self.page2) 40 # Add the combo box and the stacked layout to the top-level layout
41 layout.addWidget(self.pageCombo)
42 layout.addLayout(self.stackedLayout)
43
44 def switchPage(self):
45 self.stackedLayout.setCurrentIndex(self.pageCombo.currentIndex())
46
47if __name__ == "__main__":
48 app = QApplication(sys.argv)
49 window = Window()
50 window.show()
51 sys.exit(app.exec_())
在第 21 到 23 行,您创建了一个QComboBox对象,它将允许您在布局中的页面之间切换。然后在一个列表中添加两个选项到组合框中,并将其连接到.switchPage(),这是为了处理页面切换。
在.switchPage()中,您调用布局对象上的.setCurrentIndex(),将组合框的当前索引作为参数传递。这样,当用户更改组合框中的选项时,堆叠布局上的页面也会相应地更改。
在第 25 行,您创建了QStackedLayout对象。在第 27 到 32 行,您将第一页添加到布局中,在第 34 到 39 行,您将第二页添加到布局中。每个页面由一个QWidget对象表示,该对象包含几个布局方便的小部件。
让一切正常工作的最后一步是将组合框和布局添加到应用程序的主布局中。
下面是您的应用程序现在的行为:
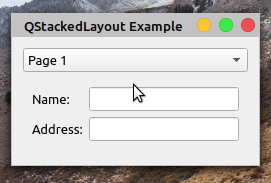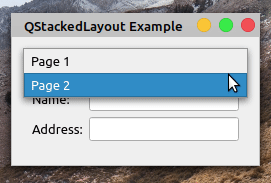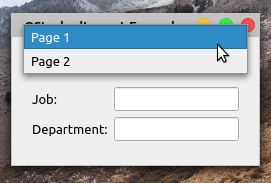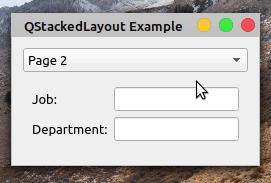
在这种情况下,您的应用程序布局中有两个页面。每个页面由一个QWidget对象表示。当您在窗口顶部的组合框中选择一个新页面时,布局会发生变化以显示所选页面。
注: PyQt 提供了一个方便的类叫做 QStackedWidget ,构建在QStackedLayout之上。您也可以使用这个类来创建多页布局。
这个类提供了一个窗口小部件堆栈,其中一次只有一个窗口小部件可见。就像堆叠布局一样,QStackedWidget没有提供内在的页面切换机制。
除了堆叠布局和堆叠小部件,您还可以使用 QTabWidget 来创建多页面用户界面。您将在下一节中了解如何操作。
使用 PyQt 的选项卡小部件
在 PyQt 中创建多页排列的另一种流行方式是使用名为 QTabWidget 的类。这个类提供了一个标签栏和一个页面区域。您可以使用选项卡栏在页面和页面区域之间切换,以显示与所选选项卡相关联的页面。
默认情况下,选项卡栏位于页面区域的顶部。但是,您可以使用 .setTabPosition() 和四个可能的标签位置中的一个来改变这种行为:
| 制表位置 | 标签栏位置 |
|---|---|
QTabWidget.North |
页面顶部 |
QTabWidget.South |
页面底部 |
QTabWidget.West |
页面左侧 |
QTabWidget.East |
页面右侧 |
要向选项卡小部件添加选项卡,可以使用.addTab()。此方法有两种变体,即重载实现:
.addTab(page, label).addTab(page, icon, label)
在这两种情况下,该方法都会添加一个新的选项卡,用label作为选项卡的标题。page需要是一个小部件,代表与手头的选项卡相关联的页面。
在该方法的第二个变体中,icon需要是一个 QIcon 对象。如果你传递一个图标给.addTab(),那么这个图标将会显示在标签标题的左边。
创建选项卡小部件时的一个常见做法是为每个页面使用一个QWidget对象。这样,您将能够使用包含所需部件的布局向页面添加额外的部件。
大多数情况下,您将使用选项卡小部件为 GUI 应用程序创建对话框。这种布局允许你在相对较小的空间内为用户提供多种选择。你也可以利用标签系统根据一些分类标准来组织你的选项。
下面是一个示例应用程序,展示了如何创建和使用一个QTabWidget对象的基本知识:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QCheckBox,
6 QTabWidget,
7 QVBoxLayout,
8 QWidget,
9)
10
11class Window(QWidget):
12 def __init__(self):
13 super().__init__()
14 self.setWindowTitle("QTabWidget Example")
15 self.resize(270, 110)
16 # Create a top-level layout
17 layout = QVBoxLayout()
18 self.setLayout(layout)
19 # Create the tab widget with two tabs
20 tabs = QTabWidget() 21 tabs.addTab(self.generalTabUI(), "General") 22 tabs.addTab(self.networkTabUI(), "Network") 23 layout.addWidget(tabs)
24
25 def generalTabUI(self): 26 """Create the General page UI."""
27 generalTab = QWidget()
28 layout = QVBoxLayout()
29 layout.addWidget(QCheckBox("General Option 1"))
30 layout.addWidget(QCheckBox("General Option 2"))
31 generalTab.setLayout(layout)
32 return generalTab
33
34 def networkTabUI(self): 35 """Create the Network page UI."""
36 networkTab = QWidget()
37 layout = QVBoxLayout()
38 layout.addWidget(QCheckBox("Network Option 1"))
39 layout.addWidget(QCheckBox("Network Option 2"))
40 networkTab.setLayout(layout)
41 return networkTab
42
43if __name__ == "__main__":
44 app = QApplication(sys.argv)
45 window = Window()
46 window.show()
47 sys.exit(app.exec_())
在这个例子中,您使用一个选项卡小部件向用户呈现一个简洁的对话框,显示与假想的首选项菜单的 General 和 Network 部分相关的选项。在第 20 行,您创建了QTabWidget对象。然后使用.addTab()向选项卡小部件添加两个选项卡。
在.generalTabUI()和networkTabUI()中,您为每个选项卡创建特定的 GUI。为此,您使用一个QWidget对象、一个QVBoxLayout对象和一些复选框来保存选项。
如果您现在运行该应用程序,您将在屏幕上看到以下对话框:
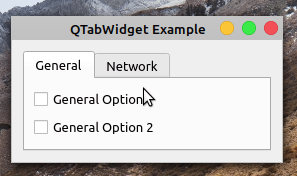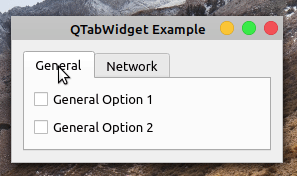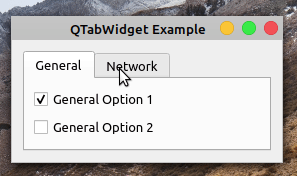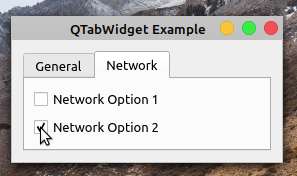
就是这样!您拥有了一个功能齐全的基于选项卡的 GUI。请注意,要在页面之间切换,您只需单击相应的选项卡。
布置应用程序的主窗口
如果你使用 PyQt 来创建你的 GUI 应用程序,那么大多数时候你会使用 QMainWindow 来创建一个基于它的 GUI。这个类允许你创建主窗口风格的应用。QMainWindow自带预定义布局。此布局允许您将以下图形组件添加到主窗口中:
- 窗口顶部的菜单栏
- 一个或多个工具栏位于窗口的四边
- 窗口底部有一个状态栏
- 一个或多个 dock widgets 位于窗口的四边(但不占据工具栏区域)
- 位于窗口正中央的中心小工具
对于大多数应用程序来说,除了中央小部件之外,所有这些图形组件都是可选的,中央小部件是应用程序正常工作所必需的。
注意:如果你使用QMainWindow创建 GUI 应用程序,那么你必须有一个中心部件,即使它只是一个占位符。
一些应用程序使用一个独特的全功能小部件作为它们的中心小部件。例如,如果你正在编写一个文本编辑器,那么你可能会使用一个 QTextEdit 对象作为编辑器的中心部件。
其他种类的 GUI 应用程序可能需要更复杂的中央小部件。在这种情况下,您可以使用一个QWidget对象作为您的中心小部件,然后创建一个布局,其中包含您的应用程序 GUI 所需的特定小部件排列。最后一步是将该布局设置为中心小部件的布局。
大多数时候,QMainWindow提供的布局足以创建任何种类的 GUI 应用程序。这种布局将有效地管理窗口小部件的行为,所以您不必担心这一点。
布局应用程序的对话框
GUI 应用程序通常使用一个主窗口和一个或多个对话框来构建。对话框是允许你和用户交流的小窗口。PyQt 提供了 QDialog 来处理对话框的创建。
与QMainWindow不同,QDialog没有预定义或默认的顶层布局。这是因为对话框可以有很多种,包括各种各样的小部件排列和组合。
一旦将所有的小部件放在对话框的 GUI 上,就需要在该对话框上设置一个顶层布局。为此,您必须调用对话框对象上的.setLayout(),就像您对任何其他小部件所做的那样。
这里有一个对话框风格的应用程序,展示了如何设置一个QDialog对象的顶层布局:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication,
5 QDialog,
6 QDialogButtonBox,
7 QFormLayout,
8 QLineEdit,
9 QVBoxLayout,
10)
11
12class Dialog(QDialog):
13 def __init__(self):
14 super().__init__()
15 self.setWindowTitle("QDialog's Top-Level Layout Example")
16 dlgLayout = QVBoxLayout() 17 # Create a form layout and add widgets
18 formLayout = QFormLayout() 19 formLayout.addRow("Name:", QLineEdit()) 20 formLayout.addRow("Job:", QLineEdit()) 21 formLayout.addRow("Email:", QLineEdit()) 22 # Add a button box
23 btnBox = QDialogButtonBox()
24 btnBox.setStandardButtons(
25 QDialogButtonBox.Ok | QDialogButtonBox.Cancel
26 )
27 # Set the layout on the dialog
28 dlgLayout.addLayout(formLayout) 29 dlgLayout.addWidget(btnBox) 30 self.setLayout(dlgLayout) 31
32if __name__ == "__main__":
33 app = QApplication(sys.argv)
34 dlg = Dialog()
35 dlg.show()
36 sys.exit(app.exec_())
在这种情况下,应用程序的窗口继承自QDialog,所以你有一个对话框风格的应用程序。在第 16 行,您创建了将用作对话框顶层布局的布局。在第 18 到 21 行,您创建了一个表单布局来安排表单中的一些小部件。
在第 24 行,你添加一个 QDialogButtonBox 对象。您将经常使用QDialogButtonBox来处理对话框上的按钮。在这个例子中,您使用了两个按钮,一个确定按钮和一个取消按钮。这些按钮没有任何功能,它们只是为了让对话框更真实。
一旦所有的小部件和布局就绪,就可以将它们添加到顶层布局中。这就是你在第 28 和 29 行所做的。最后一步,在第 30 行,使用.setLayout()将顶层布局设置为对话框的布局。
如果您运行此应用程序,您将在屏幕上看到以下窗口:
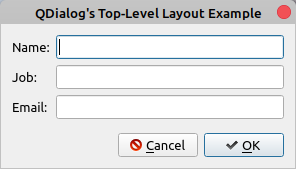
为所有对话框设置顶层布局是一个最佳实践。这确保了当用户调整底层窗口大小时,对话框的 GUI 行为一致。否则,在用户看来,你的对话框会显得杂乱无章,未经修饰。
管理 PyQt 布局中的空间
当使用 PyQt 的布局管理器在窗口或表单上排列小部件时,管理空间——空白空间、小部件之间的空间等等——是一个常见的问题。能够管理这个空间是一项重要的技能。
在内部,布局使用以下一些小部件属性来管理窗口上的可用空间:
.sizeHint()包含小部件的推荐尺寸.minimumSizeHint()包含小工具在保持可用时可以拥有的最小尺寸.sizePolicy()保存布局中小部件的默认行为
布局使用这些属性自动定位和调整小部件的大小,根据可用空间为每个小部件分配给定的空间量。这确保了小部件被一致地排列并保持可用。
在接下来的三节中,您将了解不同类型的布局如何管理 PyQt 中的空间。
管理盒子布局中的空间
盒子布局在小部件之间分配可用空间方面做得很好。然而,有时它们的默认行为是不够的,您需要手动处理可用空间。为了在这种情况下帮助你,PyQt 提供了 QSpacerItem 。这个类允许你添加空白空间(或者空框)到一个框布局中。
正常情况下不需要直接使用QSpacerItem。相反,您可以在框布局对象上调用以下一些方法:
-
.addSpacing(i)在布局中增加一个固定大小i的不可拉伸空间(或空框)。i必须是一个整数,以像素表示空间的大小。 -
.addStretch(i)为盒子布局添加最小尺寸为0的可拉伸空间和拉伸系数i。i必须是整数。 -
.insertSpacing(index, size)在index位置插入一个不可拉伸的空格,大小size。如果index为负,则在方框布局的末尾添加空格。 -
insertStretch(index, stretch)在index位置插入一个可拉伸的空格,最小尺寸0,拉伸系数stretch。如果index是负数,那么空格被添加到方框布局的末尾。
当用户调整底层窗口大小时,可拉伸的间隔条会膨胀或收缩以填充空白空间。不可拉伸的垫片将保持相同的尺寸,不管底层窗户的尺寸如何变化。
回到如何使用垂直布局的例子,并再次运行该应用程序。如果你拉下窗口的边框,你会注意到越往下,按钮之间出现的空间越大:
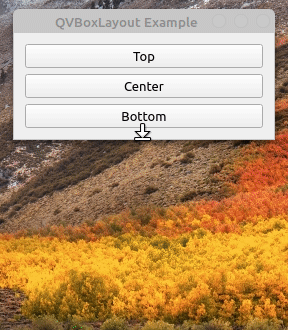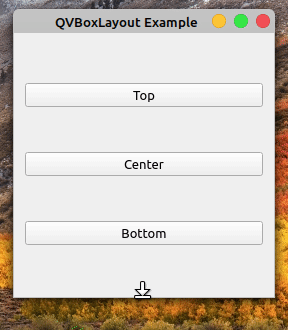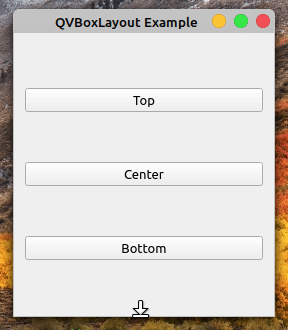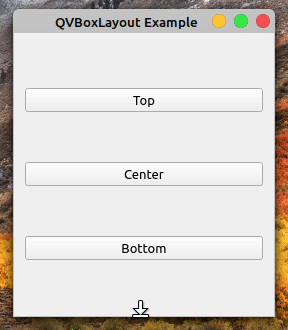
这是因为布局通过自动扩展其框来处理新的可用空间。您可以通过在布局的末尾添加一个可拉伸的QSpacerItem对象来改变这种行为。
在您的示例代码中,更新Window的初始化器,如下所示:
class Window(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle("QVBoxLayout Example")
self.resize(270, 110)
# Create a QVBoxLayout instance
layout = QVBoxLayout()
# Add widgets to the layout
layout.addWidget(QPushButton("Top"))
layout.addWidget(QPushButton("Center"))
layout.addWidget(QPushButton("Bottom"))
layout.addStretch() # Set the layout on the application's window
self.setLayout(layout)
在突出显示的行中,通过调用布局上的.addStretch()将可拉伸的QSpacerItem对象添加到布局的末尾。如果您再次运行该应用程序,您将获得以下行为:
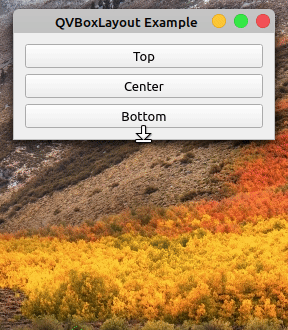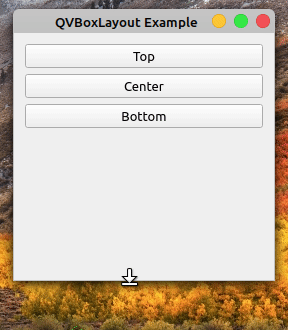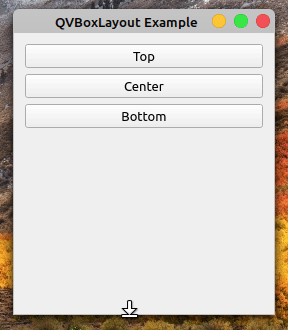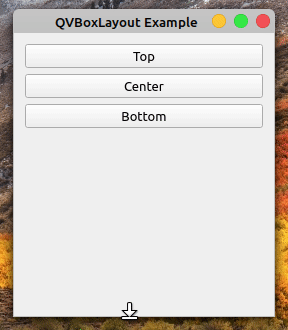
现在,所有额外的空间都自动分配给布局底部的可拉伸的QSpacerItem对象,而不会影响其余小部件的位置或大小。您可以使用这种和其他空间管理技术来使您的 GUI 应用程序看起来更好、更完美。
管理网格和表单布局中的空间
网格和表单布局以不同的方式处理可用空间。在这些类型的布局中,您只能处理小部件之间的垂直和水平空间。这些布局提供了三种管理这些空间的方法:
setSpacing(spacing)将小工具之间的垂直和水平间距设置为spacing。setVerticalSpacing(spacing)仅将布局中微件之间的垂直间距设置为spacing。setHorizontalSpacing(spacing)仅将布局中部件之间的水平间距设置为spacing。
在所有情况下,spacing是表示像素的整数。现在回到如何创建一个表单布局并像这样更新Window的初始化器的例子:
class Window(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle("QFormLayout Example")
self.resize(270, 110)
# Create a QHBoxLayout instance
layout = QFormLayout()
# Add widgets to the layout
layout.setVerticalSpacing(30) layout.addRow("Name:", QLineEdit())
layout.addRow("Job:", QLineEdit())
emailLabel = QLabel("Email:")
layout.addRow(emailLabel, QLineEdit())
# Set the layout on the application's window
self.setLayout(layout)
在突出显示的行中,您将小部件之间的垂直间距设置为30像素。如果您再次运行该应用程序,您将看到以下窗口:
现在小部件的行之间有了更多的空间。您还可以尝试通过添加一些垂直或水平空间来修改如何使用网格布局的示例,以便了解所有这些间距机制是如何工作的。
结论
创建高质量的 GUI 应用程序需要将所有的图形组件以一种连贯和完美的方式排列。在 PyQt 中,一种有效的方法是使用 PyQt 的布局管理器,它提供了一种用户友好且高效的方法来完成这项任务。
在本教程中,您已经学习了:
- 在 GUI 上正确布局小部件的好处是什么
- 如何使用 PyQt 内置的布局管理器以编程方式排列小部件
- 哪个布局管理器用于您的特定用例
- 如何在 PyQt 中布局主窗口式和对话框式应用
有了这些知识,您将能够使用 PyQt 的内置布局创建好看且专业的 GUI 应用程序。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深你的理解: 为 GUI 应用程序创建 PyQt 布局***********
使用 PyQt 的 QThread 来防止 GUI 冻结
PyQt 图形用户界面(GUI)应用程序有一个执行的主线程,它运行事件循环和 GUI。如果你在这个线程中启动一个长时间运行的任务,那么你的 GUI 将会冻结,直到任务终止。在此期间,用户将无法与应用程序进行交互,从而导致糟糕的用户体验。幸运的是,PyQt 的 QThread 类允许您解决这个问题。
在本教程中,您将学习如何:
- 使用 PyQt 的
QThread防止冻结 GUI - 用
QThreadPool和QRunnable创建可重用线程 - 使用信号和插槽管理线程间通信
- 通过 PyQt 的锁安全地使用共享资源
- 利用 PyQt 的线程支持,使用最佳实践开发 GUI 应用程序
为了更好地理解如何使用 PyQt 的线程,一些以前关于使用 PyQt 和 Python 多线程编程的 GUI 编程的知识将会有所帮助。
免费奖励: 从 Python 基础:Python 3 实用入门中获取一个示例章节,看看如何通过完整的课程(最新的 Python 3.9)从 Python 初学者过渡到中级。
冻结长时间运行任务的 GUI
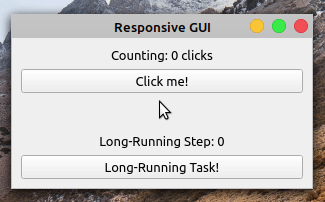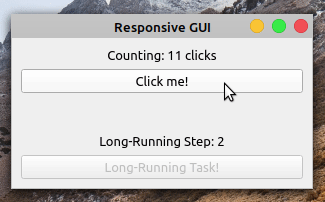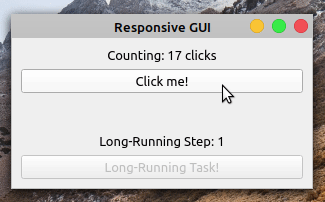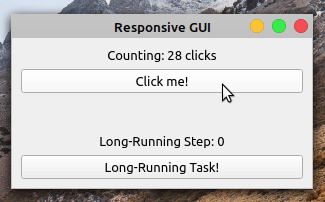
长时间运行的任务占用 GUI 应用程序的主线程,并导致应用程序冻结,这是 GUI 编程中的一个常见问题,几乎总是会导致糟糕的用户体验。例如,考虑下面的 GUI 应用程序:
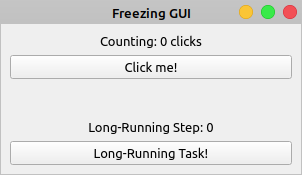
比方说你需要计数标签来反映点击我的总点击次数!按钮。点击长时间运行的任务!按钮将启动一项需要很长时间才能完成的任务。长时间运行的任务可能是文件下载、大型数据库查询或任何其他资源密集型操作。
下面是使用 PyQt 和单线程执行编写该应用程序的第一种方法:
import sys
from time import sleep
from PyQt5.QtCore import Qt
from PyQt5.QtWidgets import (
QApplication,
QLabel,
QMainWindow,
QPushButton,
QVBoxLayout,
QWidget,
)
class Window(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.clicksCount = 0
self.setupUi()
def setupUi(self):
self.setWindowTitle("Freezing GUI")
self.resize(300, 150)
self.centralWidget = QWidget()
self.setCentralWidget(self.centralWidget)
# Create and connect widgets
self.clicksLabel = QLabel("Counting: 0 clicks", self)
self.clicksLabel.setAlignment(Qt.AlignHCenter | Qt.AlignVCenter)
self.stepLabel = QLabel("Long-Running Step: 0")
self.stepLabel.setAlignment(Qt.AlignHCenter | Qt.AlignVCenter)
self.countBtn = QPushButton("Click me!", self)
self.countBtn.clicked.connect(self.countClicks)
self.longRunningBtn = QPushButton("Long-Running Task!", self)
self.longRunningBtn.clicked.connect(self.runLongTask)
# Set the layout
layout = QVBoxLayout()
layout.addWidget(self.clicksLabel)
layout.addWidget(self.countBtn)
layout.addStretch()
layout.addWidget(self.stepLabel)
layout.addWidget(self.longRunningBtn)
self.centralWidget.setLayout(layout)
def countClicks(self):
self.clicksCount += 1
self.clicksLabel.setText(f"Counting: {self.clicksCount} clicks")
def reportProgress(self, n):
self.stepLabel.setText(f"Long-Running Step: {n}")
def runLongTask(self):
"""Long-running task in 5 steps."""
for i in range(5):
sleep(1)
self.reportProgress(i + 1)
app = QApplication(sys.argv)
win = Window()
win.show()
sys.exit(app.exec())
在这个冻结的 GUI 应用程序中,.setupUi()为 GUI 创建所有需要的图形组件。点击点击我!按钮调用.countClicks(),使得计数标签的文本反映按钮点击的次数。
注意: PyQt 最初是针对 Python 2 开发的,它有一个exec关键字。为了避免 PyQt 早期版本的名称冲突,在.exec_()的末尾添加了一个下划线。
尽管 PyQt5 只针对 Python 3,Python 3 没有exec关键字,但是该库提供了两种方法来启动应用程序的事件循环:
.exec_().exec()
这两种方法的工作原理是一样的,所以您可以在您的应用程序中使用其中任何一种。
点击长时间运行的任务!按钮调用.runLongTask(),执行一个需要5秒完成的任务。这是一个假设的任务,您使用 time.sleep(secs) 对其进行编码,该任务在给定的秒数secs内暂停调用线程的执行。
在.runLongTask()中,您还调用.reportProgress()来使长时间运行的步骤标签反映操作的进度。
该应用程序是否如您所愿工作?运行应用程序并检查其行为:
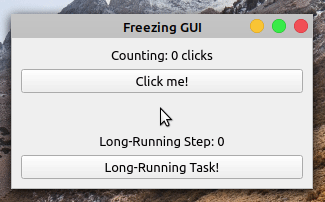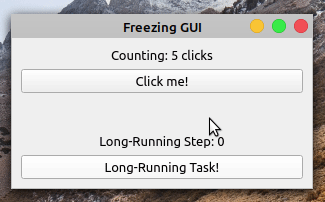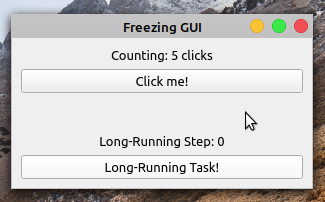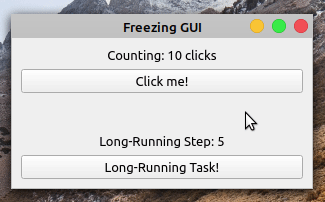
当你点击的时候点击我!按钮,标签显示点击次数。但是,如果你点击了长时间运行的任务!按钮,则应用程序冻结且无响应。按钮不再响应点击,标签也不反映应用程序的状态。
五秒钟后,应用程序的 GUI 再次更新。计数标签显示十次点击,反映了 GUI 冻结时发生的五次点击。长时间运行步骤标签不能反映你长时间运行操作的进度。它从零跳到五,没有显示中间步骤。
注意:即使您的应用程序的 GUI 在长时间运行的任务中冻结,应用程序仍然会注册诸如点击和击键之类的事件。它只是无法处理它们,直到主线程被释放。
应用程序的 GUI 由于主线程被阻塞而冻结。主线程忙于处理一个长时间运行的任务,不会立即响应用户的操作。这是一个令人讨厌的行为,因为用户不能确定应用程序是正常工作还是崩溃了。
幸运的是,您可以使用一些技巧来解决这个问题。一个常用的解决方案是使用一个工作线程在应用程序的主线程之外运行您的长期运行任务。
在下面几节中,您将了解如何使用 PyQt 的内置线程支持来解决 GUI 无响应或冻结的问题,并在您的应用程序中提供最佳的用户体验。
多线程:基础知识
有时你可以把你的程序分成几个更小的子程序,或者任务,你可以在几个线程中运行。这可能会使您的程序更快,或者通过防止程序在执行长时间运行的任务时冻结来帮助您改善用户体验。
一个线程是一个独立的执行流。在大多数操作系统中,一个线程是一个进程的组成部分,进程可以有多个线程并发执行。每个进程代表当前在给定计算机系统中运行的程序或应用程序的一个实例。
您可以根据需要拥有任意多的线程。挑战在于确定要使用的线程的正确数量。如果您使用的是受 I/O 限制的线程,那么线程的数量将受到可用系统资源的限制。另一方面,如果您正在使用受 CPU 限制的线程,那么您将受益于线程数量等于或少于系统中 CPU 内核的数量。
构建能够使用不同线程运行多个任务的程序是一种被称为多线程编程的编程技术。理想情况下,使用这种技术,几个任务可以同时独立运行。然而,这并不总是可能的。至少有两个因素可以阻止程序并行运行多个线程:
- 中央处理器( CPU
- 编程语言
比如你有一个单核 CPU 的机器,那么你就不能同时运行多个线程。然而,一些单核 CPU 可以通过允许操作系统调度多线程之间的处理时间来模拟并行线程执行。这使得您的线程看起来并行运行,即使它们实际上是一次运行一个。
另一方面,如果你有一台多核 CPU 机器或者一台计算机集群,那么你可能能够同时运行多个线程。在这种情况下,你的编程语言就成了一个重要的因素。
一些编程语言的内部组件实际上禁止了多线程的实际并行执行。在这些情况下,线程看起来只是并行运行,因为它们利用了任务调度系统。
多线程程序通常比单线程程序更难编写、维护和调试,因为与线程间共享资源、同步数据访问和协调线程执行相关的复杂性。这可能会导致几个问题:
-
竞争条件是指由于事件顺序的不可预测性,应用程序的行为变得不确定。这通常是由于两个或多个线程在没有正确同步的情况下访问共享资源造成的。例如,如果读取和写入操作以错误的顺序执行,从不同线程读取和写入内存可能会导致争用情况。
-
死锁发生在线程无限期等待锁定资源被释放的时候。例如,如果一个线程锁定了一个资源,并且在使用后没有解锁,那么其他线程将无法使用该资源,并将无限期等待。如果线程 A 正在等待线程 B 解锁一个资源,而线程 B 正在等待线程 A 解锁另一个资源,也会发生死锁。两个线程都将永远等待下去。
-
活锁是两个或多个线程为了响应对方的动作而重复动作的情况。活锁线程无法在其特定任务上取得进一步进展,因为它们太忙于相互响应。然而,他们没有被封锁或死亡。
-
当一个进程无法获得完成工作所需的资源时,就会发生饥饿。例如,如果有一个进程不能获得 CPU 时间访问权,那么这个进程就渴望 CPU 时间,不能完成它的工作。
当构建多线程应用程序时,您需要小心保护您的资源不被并发写入或状态修改访问。换句话说,您需要防止多个线程同时访问给定的资源。
许多应用程序至少可以从三个方面受益于多线程编程:
- 利用多核处理器让您的应用速度更快
- 通过将应用程序划分为更小的子任务来简化应用程序结构
- 通过将长时间运行的任务卸载到工作线程,使您的应用保持快速响应和最新状态
在 Python 的 C 实现,也称为 CPython 中,线程不是并行运行的。CPython 有一个全局解释器锁(GIL) ,这是一个锁,基本上一次只允许一个 Python 线程运行。
这可能会对线程化 Python 应用程序的性能产生负面影响,因为线程间的上下文切换会产生开销。但是,Python 中的多线程可以帮助您在处理长时间运行的任务时解决应用程序冻结或无响应的问题。
PyQt 中的多线程与QThread
Qt ,因此 PyQt ,使用 QThread 提供自己的基础设施来创建多线程应用。PyQt 应用程序可以有两种不同的线程:
- 主流中泓线
- 工作线程
应用程序的主线程总是存在的。这是应用程序及其 GUI 运行的地方。另一方面,工作线程的存在取决于应用程序的处理需求。例如,如果您的应用程序经常运行需要大量时间才能完成的繁重任务,那么您可能希望使用工作线程来运行这些任务,以避免冻结应用程序的 GUI。
主线程
在 PyQt 应用程序中,执行的主线程也被称为 GUI 线程,因为它处理所有的小部件和其他 GUI 组件。当您运行应用程序时,Python 会启动这个线程。在您对QApplication对象调用.exec()之后,应用程序的事件循环在这个线程中运行。这个线程处理你的窗口、对话框以及与主机操作系统的通信。
默认情况下,发生在应用程序主线程中的任何事件或任务,包括 GUI 本身上的用户事件,都将同步运行**,或者一个接一个地运行任务。因此,如果您在主线程中启动一个长时间运行的任务,那么应用程序需要等待该任务完成,并且 GUI 变得没有响应。*
*值得注意的是,您必须在 GUI 线程中创建和更新所有的小部件。但是,您可以在工作线程中执行其他长时间运行的任务,并使用它们的结果来为应用程序的 GUI 组件提供信息。这意味着 GUI 组件将充当消费者,从执行实际工作的线程获得信息。
工作线程
在 PyQt 应用程序中,您可以根据需要创建任意数量的工作线程。工作线程是执行的辅助线程,可以用来从主线程中卸载长时间运行的任务,并防止 GUI 冻结。
您可以使用QThread创建工作线程。每个工作线程可以有自己的事件循环,并支持 PyQt 的信号和插槽机制与主线程通信。如果你在一个特定的线程中从继承了 QObject 的任何类中创建一个对象,那么这个对象被称为属于,或者对那个线程的有一个亲缘关系。它的子线程也必须属于同一线程。
不是一根线本身。它是操作系统线程的包装器。真正的线程对象是在你调用 QThread.start() 时创建的。
QThread提供高级应用编程接口( API )来管理线程。这个 API 包括信号,例如 .started() 和 .finished() ,这些信号在线程开始和结束时发出。还包括方法和槽,如.start().wait().exit().quit().isFinished().isRunning()。
与任何其他线程解决方案一样,使用QThread,您必须保护您的数据和资源免受并发或同时访问。否则,您将面临许多问题,包括死锁、数据损坏等等。
使用QThread vs Python 的threading
当谈到在 Python 中使用线程的时,你会发现 Python 标准库通过 threading 模块提供了一致且健壮的解决方案。这个模块为用 Python 进行多线程编程提供了一个高级 API。
通常,您会在 Python 应用程序中使用threading。但是,如果您正在使用 PyQt 通过 Python 构建 GUI 应用程序,那么您还有另一个选择。PyQt 为多线程提供了一个完整的、完全集成的高级 API。
您可能想知道,我应该在我的 PyQt 应用程序中使用什么,Python 的线程支持还是 PyQt 的线程支持?答案是视情况而定。
例如,如果您正在构建一个 GUI 应用程序,它也有一个 web 版本,那么 Python 的线程可能更有意义,因为您的后端根本不依赖于 PyQt。然而,如果您构建的是简单的 PyQt 应用程序,那么 PyQt 的线程是适合您的。
使用 PyQt 的线程支持有以下好处:
- 与线程相关的类与 PyQt 基础设施的其余部分完全集成。
- 工作线程可以拥有自己的事件循环,从而支持事件处理。
- 线程间通信可以使用信号和插槽。
一个经验法则可能是,如果要与库的其余部分交互,使用 PyQt 的线程支持,否则使用 Python 的线程支持。
使用QThread防止冻结图形用户界面
线程在 GUI 应用程序中的一个常见用途是将长时间运行的任务卸载给工作线程,以便 GUI 保持对用户交互的响应。在 PyQt 中,您使用 QThread 来创建和管理工作线程。
根据 Qt 的文档,用QThread创建工作线程有两种主要方式:
- 直接实例化
QThread并创建一个工人QObject,然后使用线程作为参数在工人上调用.moveToThread()。工作者必须包含执行特定任务所需的所有功能。 - 子类
QThread和重新实现.run()。.run()的实现必须包含执行特定任务所需的所有功能。
实例化QThread提供了一个并行事件循环。事件循环允许线程拥有的对象在它们的槽上接收信号,这些槽将在线程内执行。
另一方面,子类化QThread允许在没有事件循环的情况下运行并行代码。使用这种方法,您可以通过显式调用 exec() 来创建事件循环。
在本教程中,您将使用第一种方法,这需要以下步骤:
- 通过子类化
QObject准备一个 worker 对象,并将您的长期运行任务放入其中。 - 创建 worker 类的新实例。
- 创建一个新的
QThread实例。 - 通过调用
.moveToThread(thread),将 worker 对象移动到新创建的线程中。 - 连接所需的信号和插槽,以保证线程间的通信。
- 在
QThread对象上调用.start()。
您可以使用以下步骤将冻结的 GUI 应用程序转变为响应性 GUI 应用程序:
from PyQt5.QtCore import QObject, QThread, pyqtSignal
# Snip...
# Step 1: Create a worker class
class Worker(QObject):
finished = pyqtSignal()
progress = pyqtSignal(int)
def run(self):
"""Long-running task."""
for i in range(5):
sleep(1)
self.progress.emit(i + 1)
self.finished.emit()
class Window(QMainWindow):
# Snip...
def runLongTask(self):
# Step 2: Create a QThread object
self.thread = QThread()
# Step 3: Create a worker object
self.worker = Worker()
# Step 4: Move worker to the thread
self.worker.moveToThread(self.thread)
# Step 5: Connect signals and slots
self.thread.started.connect(self.worker.run)
self.worker.finished.connect(self.thread.quit)
self.worker.finished.connect(self.worker.deleteLater)
self.thread.finished.connect(self.thread.deleteLater)
self.worker.progress.connect(self.reportProgress)
# Step 6: Start the thread
self.thread.start()
# Final resets
self.longRunningBtn.setEnabled(False)
self.thread.finished.connect(
lambda: self.longRunningBtn.setEnabled(True)
)
self.thread.finished.connect(
lambda: self.stepLabel.setText("Long-Running Step: 0")
)
首先,你做一些必需的导入。然后你运行你之前看到的步骤。
在步骤 1 中,您创建了QObject的子类Worker。在Worker中,你创建了两个信号,finished和progress。注意,您必须将信号创建为类属性。
您还创建了一个名为.runLongTask()的方法,将所有需要的代码放在其中,以执行您的长期运行任务。在这个例子中,您使用一个 for循环来模拟一个长时间运行的任务,这个循环迭代5次,每次迭代有一秒钟的延迟。该循环还发出progress信号,指示操作的进度。最后,.runLongTask()发出finished信号,表示加工已经完成。
在步骤 2 到 4 中,您创建了一个QThread的实例,它将提供运行这个任务的空间,以及一个Worker的实例。您通过调用worker上的.moveToThread(),使用thread作为参数,将您的工人对象移动到线程中。
在步骤 5 中,连接以下信号和插槽:
-
线程的
started信号发送到工作线程的.runLongTask()插槽,以确保当你启动线程时,.runLongTask()将被自动调用 -
当
worker完成工作时,工人的finished信号给线程的.quit()槽以退出thread -
当工作完成时,
finished向两个对象中的.deleteLater()槽发送信号,以删除工人和线程对象
最后,在步骤 6 中,使用.start()启动线程。
一旦线程开始运行,就要进行一些重置,以使应用程序的行为一致。你禁用了长时间运行的任务!按钮,防止用户在任务运行时点击它。您还将线程的finished信号与启用长期运行任务的 lambda函数连接起来!线程结束时的按钮。您的最终连接重置了长期运行步骤标签的文本。
如果您运行此应用程序,您将在屏幕上看到以下窗口:
因为您将长时间运行的任务卸载到了一个工作线程,所以您的应用程序现在完全响应了。就是这样!您已经成功地使用 PyQt 的QThread解决了您在前面章节中看到的 GUI 冻结问题。
重用线程:QRunnable和QThreadPool
如果您的 GUI 应用程序严重依赖多线程,那么您将面临与创建和销毁线程相关的巨大开销。您还必须考虑在给定的系统上可以启动多少个线程,以便您的应用程序保持高效。幸运的是,PyQt 的线程支持也为您提供了这些问题的解决方案。
每个应用程序都有一个全局线程池。你可以通过调用 QThreadPool.globalInstance() 来获得对它的引用。
注意:尽管使用默认线程池是一个相当常见的选择,但是您也可以通过实例化 QThreadPool 来创建自己的线程池,它提供了一个可重用线程的集合。
全局线程池通常根据当前 CPU 中的内核数量来维护和管理建议的线程数量。它还处理应用程序线程中任务的排队和执行。池中的线程是可重用的,这避免了与创建和销毁线程相关的开销。
要创建任务并在线程池中运行它们,可以使用 QRunnable 。该类表示需要运行的任务或代码段。创建和执行可运行任务的过程包括三个步骤:
- 子类
QRunnable并用您想要运行的任务的代码重新实现.run()。 - 实例化
QRunnable的子类来创建一个可运行的任务。 - 调用
QThreadPool.start()以可运行任务为自变量。
必须包含手头任务所需的代码。对.start()的调用在池中的一个可用线程中启动您的任务。如果没有可用的线程,那么.start()将任务放入池的运行队列中。当一个线程变得可用时,.run()中的代码将在该线程中执行。
下面是一个 GUI 应用程序,展示了如何在代码中实现这一过程:
1import logging
2import random
3import sys
4import time
5
6from PyQt5.QtCore import QRunnable, Qt, QThreadPool
7from PyQt5.QtWidgets import (
8 QApplication,
9 QLabel,
10 QMainWindow,
11 QPushButton,
12 QVBoxLayout,
13 QWidget,
14)
15
16logging.basicConfig(format="%(message)s", level=logging.INFO)
17
18# 1\. Subclass QRunnable
19class Runnable(QRunnable):
20 def __init__(self, n):
21 super().__init__()
22 self.n = n
23
24 def run(self):
25 # Your long-running task goes here ...
26 for i in range(5):
27 logging.info(f"Working in thread {self.n}, step {i + 1}/5")
28 time.sleep(random.randint(700, 2500) / 1000)
29
30class Window(QMainWindow):
31 def __init__(self, parent=None):
32 super().__init__(parent)
33 self.setupUi()
34
35 def setupUi(self):
36 self.setWindowTitle("QThreadPool + QRunnable")
37 self.resize(250, 150)
38 self.centralWidget = QWidget()
39 self.setCentralWidget(self.centralWidget)
40 # Create and connect widgets
41 self.label = QLabel("Hello, World!")
42 self.label.setAlignment(Qt.AlignHCenter | Qt.AlignVCenter)
43 countBtn = QPushButton("Click me!")
44 countBtn.clicked.connect(self.runTasks)
45 # Set the layout
46 layout = QVBoxLayout()
47 layout.addWidget(self.label)
48 layout.addWidget(countBtn)
49 self.centralWidget.setLayout(layout)
50
51 def runTasks(self):
52 threadCount = QThreadPool.globalInstance().maxThreadCount()
53 self.label.setText(f"Running {threadCount} Threads")
54 pool = QThreadPool.globalInstance()
55 for i in range(threadCount):
56 # 2\. Instantiate the subclass of QRunnable
57 runnable = Runnable(i)
58 # 3\. Call start()
59 pool.start(runnable)
60
61app = QApplication(sys.argv)
62window = Window()
63window.show()
64sys.exit(app.exec())
下面是这段代码的工作原理:
- 在第 19 行到第 28 行,你子类化
QRunnable并用你想要执行的代码重新实现.run()。在这种情况下,您使用通常的循环来模拟长时间运行的任务。对logging.info()的调用通过在终端屏幕上打印消息来通知您操作的进度。 - 在第 52 行,你得到了可用线程的数量。这个数字将取决于您的具体硬件,通常基于您的 CPU 的核心。
- 在第 53 行上,你更新了标签的文本以反映你可以运行多少个线程。
- 在第 55 行上,你开始了一个
for循环,遍历可用的线程。 - 在第 57 行,你实例化
Runnable,传递循环变量i作为参数来标识当前线程。然后在线程池上调用.start(),使用可运行的任务作为参数。
值得注意的是,本教程中的一些例子使用带有基本配置的logging.info()将消息打印到屏幕上。您需要这样做,因为 print()不是线程安全函数,所以使用它可能会导致输出混乱。幸运的是,logging中的函数是线程安全的,所以您可以在多线程应用程序中使用它们。
如果您运行这个应用程序,那么您将得到以下行为:
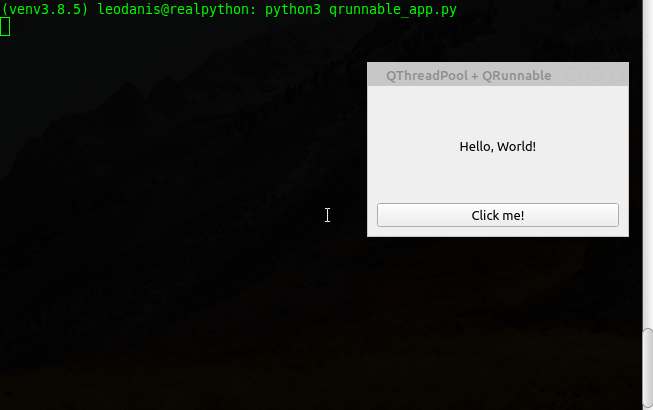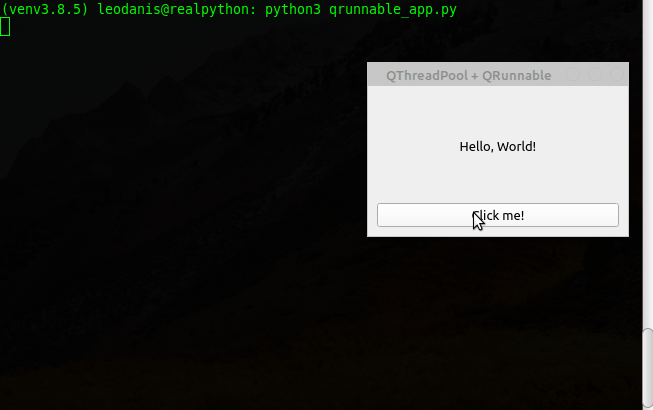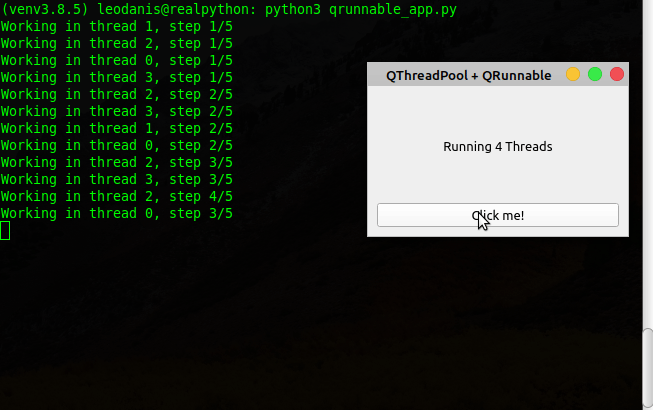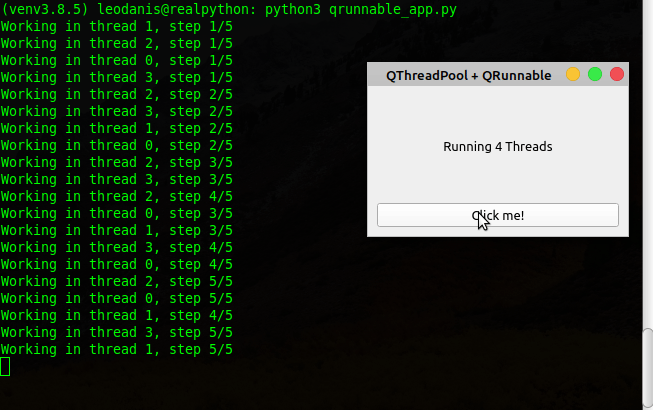
当你点击的时候点击我!按钮,应用程序启动多达四个线程。在后台终端,应用程序报告每个线程的进度。如果关闭应用程序,线程将继续运行,直到完成各自的任务。
在 Python 中没有办法从外部停止一个QRunnable对象。为了解决这个问题,你可以创建一个全局的布尔变量,并从你的QRunnable子类中系统地检查它,当你的变量变成True时终止它们。
使用QThreadPool和QRunnable的另一个缺点是QRunnable不支持信号和插槽,所以线程间的通信可能很有挑战性。
另一方面,QThreadPool自动管理一个线程池,并处理那些线程中可运行任务的排队和执行。池中的线程是可重用的,这有助于减少应用程序的开销。
与工作线程通信
如果您正在使用 PyQt 进行多线程编程,那么您可能需要在应用程序的主线程和工作线程之间建立通信。这允许您获得关于工作线程进度的反馈,并相应地更新 GUI,向您的线程发送数据,允许用户中断执行,等等。
PyQt 的信号和插槽机制在 GUI 应用程序中提供了一种健壮和安全的与工作线程通信的方式。
另一方面,您可能还需要在工作线程之间建立通信,比如共享数据缓冲区或任何其他类型的资源。在这种情况下,您需要确保正确地保护您的数据和资源免受并发访问。
使用信号和插槽
一个线程安全的对象是一个可以被多个线程并发访问的对象,并且保证处于有效状态。PyQt 的信号和插槽是线程安全的,因此您可以使用它们来建立线程间通信以及在线程间共享数据。
您可以将线程发出的信号连接到该线程或不同线程中的插槽。这意味着您可以在一个线程中执行代码,以响应在同一个线程或另一个线程中发出的信号。这在线程之间建立了一个安全的通信桥梁。
信号也可以包含数据,因此,如果您发出一个包含数据的信号,那么您将在与该信号连接的所有插槽中接收该数据。
在响应式 GUI 应用示例中,您使用了信号和插槽机制来建立线程间的通信。例如,您将工作者的progress信号连接到应用程序的.reportProgress()插槽。progress保存一个指示长期运行任务进度的整数值,.reportProgress()接收该值作为参数,以便更新长期运行步骤标签。
在不同线程中的信号和插槽之间建立连接是 PyQt 中线程间通信的基础。在这一点上,您可以尝试的一个好的练习可能是使用一个 QToolBar 对象来代替长期运行的步骤标签,以使用信号和槽来显示响应式 GUI 应用程序中的操作进度。
线程间共享数据
创建多线程应用程序通常需要多个线程能够访问相同的数据或资源。如果多个线程同时访问相同的数据或资源,并且其中至少有一个线程写入或修改这个共享资源,那么您可能会面临崩溃、内存或数据损坏、死锁或其他问题。
至少有两种方法可以保护您的数据和资源免受并发访问:
如果您需要共享资源,那么您应该使用第二种方法。原子操作在单个执行步骤中进行,因此不能被其他线程中断。它们确保在给定时间只有一个线程会修改资源。
注意:关于 CPython 如何管理原子操作的参考,请查看哪些类型的全局值变异是线程安全的?
注意,其他 Python 实现的行为可能不同,所以如果您使用不同的实现,那么请看一下它的文档,以获得关于原子操作和线程安全的更多细节。
互斥是多线程编程中常见的模式。使用锁保护对数据和资源的访问,这是一种同步机制,通常只允许一个线程在给定时间访问一个资源。
例如,如果线程 A 需要更新一个全局变量,那么它可以获取该变量的锁。这可以防止线程 B 同时访问该变量。一旦线程 A 完成了变量的更新,它就释放锁,线程 B 就可以访问变量了。这是基于互斥的原理,它通过让线程在访问数据和资源时相互等待来强制同步访问。
值得一提的是,使用锁的成本很高,并且会降低应用程序的整体性能。线程同步迫使大多数线程等待资源变得可用,因此您将无法再利用并行执行。
PyQt 提供了一些方便的类来保护资源和数据免受并发访问:
-
QMutex是一个锁类,允许你管理互斥。您可以锁定给定线程中的互斥体,以获得对共享资源的独占访问。一旦互斥体被解锁,其他线程就可以访问该资源。 -
QReadWriteLock类似于QMutex但区别于读写访问。使用这种类型的锁,您可以允许多个线程同时对一个共享资源进行只读访问。如果一个线程需要写入资源,那么所有其他线程必须被阻塞,直到写入完成。 -
QSemaphore是保护一定数量相同资源的QMutex的概括。如果一个信号量正在保护 n 资源,并且您试图锁定 n + 1 资源,那么这个信号量就会被阻塞,阻止线程访问这些资源。
使用 PyQt 的锁类,您可以保护您的数据和资源,并防止许多问题。下一节展示了如何使用QMutex来实现这些目的的例子。
用QMutex 保护共享数据
QMutex常用于多线程 PyQt 应用中,防止多个线程并发访问共享数据和资源。在这一节中,您将编写一个 GUI 应用程序,它使用一个QMutex对象来保护一个全局变量免受并发写访问。
为了学习如何使用QMutex,您将编写一个管理银行账户的例子,两个人可以随时从这个账户中取钱。在这种情况下,您需要保护帐户余额免受并行访问。否则,人们最终提取的钱可能会超过他们在银行的存款。
例如,假设你有一个 100 美元的账户。两个人同时查看可用余额,看到账户有 100 美元。他们每个人都认为他们可以提取 60 美元,并在帐户中留下 40 美元,因此他们继续交易。帐户中的最终余额将是-20 美元,这可能是一个严重的问题。
要编写这个示例,首先要导入所需的模块、函数和类。您还添加了一个基本的logging配置并定义了两个全局变量:
import logging
import random
import sys
from time import sleep
from PyQt5.QtCore import QMutex, QObject, QThread, pyqtSignal
from PyQt5.QtWidgets import (
QApplication,
QLabel,
QMainWindow,
QPushButton,
QVBoxLayout,
QWidget,
)
logging.basicConfig(format="%(message)s", level=logging.INFO)
balance = 100.00
mutex = QMutex()
balance是一个全局变量,用于存储银行账户的当前余额。mutex是一个QMutex对象,您将使用它来保护balance免受并行访问。换句话说,有了mutex,你可以防止多个线程同时访问balance。
下一步是创建一个QObject的子类,它保存着管理如何从银行账户中取钱的代码。您将调用这个类AccountManager:
class AccountManager(QObject):
finished = pyqtSignal()
updatedBalance = pyqtSignal()
def withdraw(self, person, amount):
logging.info("%s wants to withdraw $%.2f...", person, amount)
global balance
mutex.lock()
if balance - amount >= 0:
sleep(1)
balance -= amount
logging.info("-$%.2f accepted", amount)
else:
logging.info("-$%.2f rejected", amount)
logging.info("===Balance===: $%.2f", balance)
self.updatedBalance.emit()
mutex.unlock()
self.finished.emit()
在AccountManager中,首先定义两个信号:
finished表示该类何时处理其工作。updatedBalance表示balance更新的时间。
然后你定义.withdraw()。在此方法中,您执行以下操作:
- 显示一条消息,指出想取钱的人
- 使用
global语句从.withdraw()内部使用balance - 调用
mutex上的.lock()来获取锁并保护balance不被并行访问 - 检查账户余额是否允许提取手头的金额
- 调用
sleep()来模拟操作需要一些时间来完成 - 从余额中减去所需的金额
- 显示消息以通知交易是否被接受
- 发出
updatedBalance信号,通知余额已更新 - 释放锁以允许其他线程访问
balance - 发出
finished信号,通知操作已经完成
该应用程序将显示如下窗口:
下面是创建这个 GUI 所需的代码:
class Window(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.setupUi()
def setupUi(self):
self.setWindowTitle("Account Manager")
self.resize(200, 150)
self.centralWidget = QWidget()
self.setCentralWidget(self.centralWidget)
button = QPushButton("Withdraw Money!")
button.clicked.connect(self.startThreads)
self.balanceLabel = QLabel(f"Current Balance: ${balance:,.2f}")
layout = QVBoxLayout()
layout.addWidget(self.balanceLabel)
layout.addWidget(button)
self.centralWidget.setLayout(layout)
当前余额标签显示账户的可用余额。如果你点击取钱!按钮,那么应用程序将模拟两个人同时试图从账户中取钱。您将使用线程模拟这两个人:
class Window(QMainWindow):
# Snip...
def createThread(self, person, amount):
thread = QThread()
worker = AccountManager()
worker.moveToThread(thread)
thread.started.connect(lambda: worker.withdraw(person, amount))
worker.updatedBalance.connect(self.updateBalance)
worker.finished.connect(thread.quit)
worker.finished.connect(worker.deleteLater)
thread.finished.connect(thread.deleteLater)
return thread
这个方法包含为每个人创建一个线程所需的代码。在这个例子中,您将线程的started信号与工作线程的.withdraw()信号连接起来,因此当线程启动时,这个方法将自动运行。您还可以将工人的updatedBalance信号连接到一个叫做.updateBalance()的方法。该方法将使用当前账户balance更新当前余额标签。
以下是.updateBalance()的代码:
class Window(QMainWindow):
# Snip...
def updateBalance(self):
self.balanceLabel.setText(f"Current Balance: ${balance:,.2f}")
任何时候一个人取钱,账户的余额就会减少所要求的金额。该方法更新当前余额标签的文本,以反映账户余额的变化。
要完成应用程序,您需要创建两个人,并为他们每个人启动一个线程:
class Window(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.setupUi()
self.threads = []
# Snip...
def startThreads(self):
self.threads.clear()
people = {
"Alice": random.randint(100, 10000) / 100,
"Bob": random.randint(100, 10000) / 100,
}
self.threads = [
self.createThread(person, amount)
for person, amount in people.items()
]
for thread in self.threads:
thread.start()
首先,将.threads作为实例属性添加到Window的初始化器中。这个变量将保存一个线程列表,以防止线程在.startThreads()返回时超出范围。然后定义.startThreads()来创建两个人,并为他们每个人创建一个线程。
在.startThreads()中,您执行以下操作:
- 清除
.threads中的线程,如果有的话,清除已经被破坏的线程 - 创建一个包含两个人的字典,
Alice和Bob。每个人将尝试从银行账户中提取随机金额的钱 - 使用列表理解和
.createThread()为每个人创建一个线索 - 在
for循环中启动线程
有了这最后一段代码,您就差不多完成了。您只需要创建应用程序和窗口,然后运行事件循环:
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())
如果您从命令行运行此应用程序,您将获得以下行为:
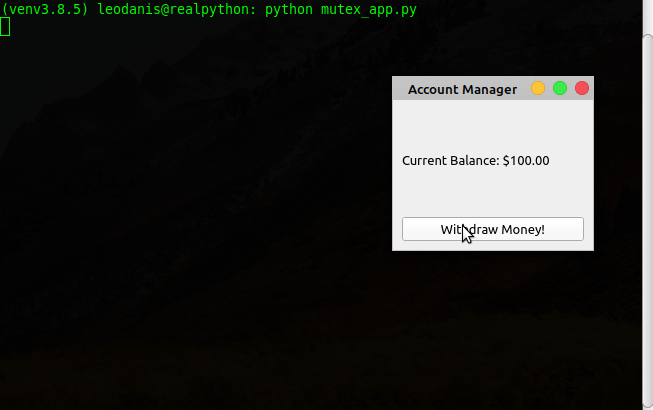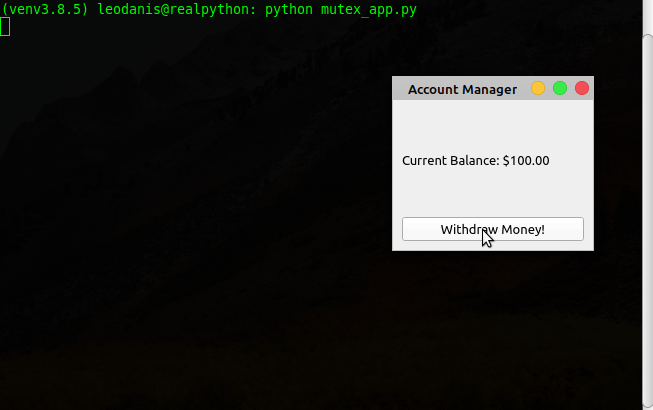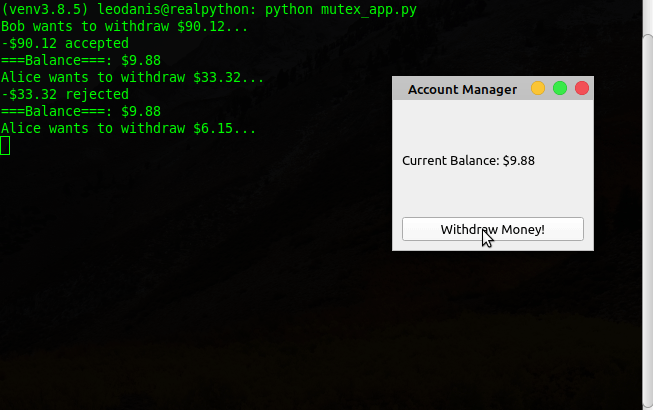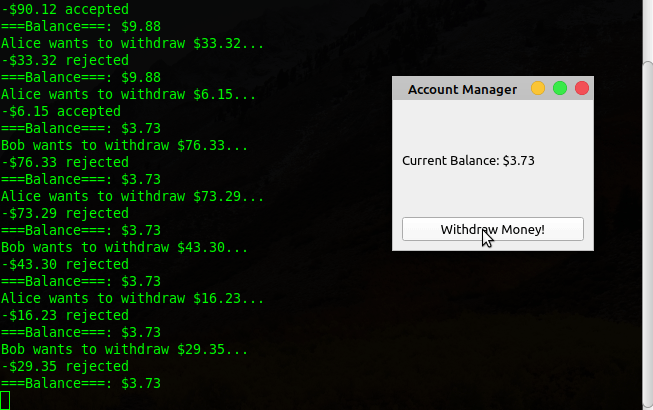
后台终端的输出显示线程工作正常。在本例中使用一个QMutex对象允许您保护银行账户余额并同步对它的访问。这可以防止用户提取超过可用余额的金额。
PyQt 中的多线程:最佳实践
在 PyQt 中构建多线程应用程序时,您可以应用一些最佳实践。下面是一个不完整的列表:
- 避免在 PyQt 应用程序的主线程中启动长时间运行的任务。
- 使用
QObject.moveToThread()和QThread对象创建工作线程。 - 如果您需要管理一个工作线程池,请使用
QThreadPool和QRunnable。 - 使用信号和插槽建立安全的线程间通信。
- 使用
QMutex、QReadWriteLock或QSemaphore来防止线程同时访问共享数据和资源。 - 在完成一个线程之前,确保解锁或释放
QMutex、QReadWriteLock或QSemaphore。 - 在有多个
return语句的函数中,解除对所有可能执行路径的锁定。 - 不要试图从工作线程中创建、访问或更新 GUI 组件或小部件。
- 不要试图将具有父子关系的
QObject移动到不同的线程。
如果您在 PyQt 中使用线程时坚持应用这些最佳实践,那么您的应用程序将更不容易出错,并且更加准确和健壮。您将防止数据损坏、死锁、竞争条件等问题。您还将为您的用户提供更好的体验。
结论
在 PyQt 应用程序的主线程中执行长时间运行的任务可能会导致应用程序的 GUI 冻结,变得没有响应。这是 GUI 编程中的一个常见问题,会导致糟糕的用户体验。使用 PyQt 的QThread 创建工作线程来卸载长时间运行的任务可以有效地解决 GUI 应用程序中的这个问题。
在本教程中,您已经学会了如何:
- 使用 PyQt 的
QThread来防止 GUI 应用程序冻结 - 用 PyQt 的
QThreadPool和QRunnable创建可重用的QThread对象 - 在 PyQt 中使用信号和插槽进行线程间通信
- 通过 PyQt 的锁类安全地使用共享资源
您还了解了一些适用于使用 PyQt 及其内置线程支持进行多线程编程的最佳实践。*******
用 Python 构建一个测验应用程序
在本教程中,您将为终端构建一个 Python 问答应用程序。竞猜这个词是在 1781 年首次使用来表示古怪的人。如今,它主要用于描述一些琐事或专业知识的简短测试,问题如下:
单词的第一次使用是在什么时候?
通过遵循这个逐步的项目,您将构建一个可以测试一个人在一系列主题上的专业知识的应用程序。你可以用这个项目来强化你自己的知识或者挑战你的朋友来一场有趣的斗智。
在本教程中,您将学习如何:
- 在终端与用户交互
- 提高应用程序的可用性
- 重构你的应用程序,不断改进它
- 将数据存储在专用数据文件中
测验应用程序是一个综合性的项目,适合任何熟悉 Python 基础的人。在整个教程中,您将在单独的小步骤中获得所需的所有代码。您也可以通过点击下面的链接找到该应用程序的完整源代码:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
不管你是不是一个古怪的人,继续读下去,学习如何创建你自己的测验。
演示:您的 Python 测试应用程序
在这个循序渐进的项目中,您将构建一个终端应用程序,它可以就一系列主题对您和您的朋友进行测验:
https://player.vimeo.com/video/717554866?background=1
你首先为你的问题选择一个主题。然后,对于每个问题,你将从一组选项中选择一个答案。有些问题可能有多个正确答案。你可以访问一个提示来帮助你。回答完一个问题后,你会读到一个解释,它可以为答案提供更多的背景信息。
项目概述
首先,您将创建一个基本的 Python 测验应用程序,它只能提问、收集答案并检查答案是否正确。从那里开始,你将添加越来越多的功能,以使你的应用程序更有趣,更友好,更有趣。
您将通过以下步骤迭代构建测验应用程序:
- 创建一个可以提出多项选择问题的基本应用程序。
- 通过改善应用程序的外观和处理用户错误的方式,使应用程序更加用户友好。
- 重构代码以使用函数。
- 通过将问题存储在专用数据文件中,将问题数据与源代码分开。
- 扩展应用程序以处理多个正确答案,给出提示,并提供解释。
- 支持不同的测验题目供选择,增加趣味性。
随着您的深入,您将获得从一个小脚本开始并扩展它的经验。这本身就是一项重要的技能。你最喜欢的程序、应用或游戏可能是从一个小的概念验证开始的,后来发展成今天的样子。
先决条件
在本教程中,您将使用 Python 的基本构件构建一个测验应用程序。在完成这些步骤时,如果您熟悉以下概念,将会很有帮助:
如果你对这些先决条件的知识没有信心,那也没关系!事实上,阅读本教程将有助于你实践这些概念。如果遇到困难,你可以随时停下来复习上面链接的资源。
第一步:提问
在这一步中,您将学习如何创建一个可以提问和检查答案的程序。这将是您的测验应用程序的基础,您将在本教程的剩余部分对其进行改进。在这一步结束时,您的程序将如下所示:
https://player.vimeo.com/video/717554848?background=1
你的程序将能够提问和检查答案。这个版本包括您需要的基本功能,但是您将在后面的步骤中添加更多的功能。如果您愿意,那么您可以通过点击下面的链接并进入source_code_step_1目录来下载完成这一步后的源代码:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
用input() 获取用户信息
Python 的内置函数之一是 input() 。您可以使用它从用户那里获取信息。对于第一个例子,在 Python REPL 中运行以下代码:
>>> name = input("What's your name? ") What's your name? Geir Arne >>> name 'Geir Arne'
input()在用户输入信息前显示可选提示。在上面的例子中,提示显示在突出显示的行中,用户在点击Enter之前输入Geir Arne。无论用户输入什么,都会从input()返回。这在 REPL 的例子中可以看到,因为字符串'Geir Arne'被分配给了name。你可以使用
input()让 Python 向你提问并检查你的答案。尝试以下方法:
>>> answer = input("When was the first known use of the word 'quiz'? ")
When was the first known use of the word 'quiz'? 1781
>>> answer == 1781
False
>>> answer == "1781"
True
这个例子显示了您需要注意的一件事:input()总是返回一个文本字符串,即使该字符串只包含数字。您很快就会看到,这对于测验应用程序来说不是问题。然而,如果你想用input()的结果进行数学计算,那么你需要先用转换。
是时候开始构建您的测验应用程序了。打开编辑器,创建包含以下内容的文件quiz.py:
# quiz.py
answer = input("When was the first known use of the word 'quiz'? ")
if answer == "1781":
print("Correct!")
else:
print(f"The answer is '1781', not {answer!r}")
这段代码与您在上面的 REPL 中所做的实验非常相似。您可以运行您的应用程序来检查您的知识:
$ python quiz.py
When was the first known use of the word 'quiz'? 1871 The answer is '1781', not '1871'
如果你碰巧给出了错误的答案,那么你会被温和地纠正,这样你下次就有希望做得更好。
注意:在else子句中,您引用的字符串文字前面的f表示该字符串是一个格式的字符串,通常称为 f 字符串。Python 对 f-strings 中花括号({})内的表达式求值,并将它们插入到字符串中。你可以选择添加不同的格式说明符。
例如,!r 指示应该根据其repr()表示插入answer。实际上,这意味着字符串用单引号括起来,就像'1871'。
只有一个问题的测验并不令人兴奋!您可以通过重复您的代码来提出另一个问题:
# quiz.py
answer = input("When was the first known use of the word 'quiz'? ")
if answer == "1781":
print("Correct!")
else:
print(f"The answer is '1781', not {answer!r}")
answer = input("Which built-in function can get information from the user? ")
if answer == "input":
print("Correct!")
else:
print(f"The answer is 'input', not {answer!r}")
您通过复制和粘贴前面的代码添加了一个问题,然后更改了问题文本和正确答案。同样,您可以通过运行脚本来测试这一点:
$ python quiz.py
When was the first known use of the word 'quiz'? 1781 Correct!
Which built-in function can get information from the user? get The answer is 'input', not 'get'
有用!然而,像这样复制和粘贴代码并不好。有一个编程原则叫做不要重复自己(干),它说你通常应该避免重复的代码,因为它变得难以维护。
接下来,您将开始改进您的代码,使其更容易使用。
使用列表和元组避免重复代码
Python 提供了几种灵活而强大的数据结构。通常可以用一个元组、一个列表或者一个字典结合一个 for 循环或者一个 while 循环来替换重复的代码。
代替重复代码,您将把您的问题和答案视为数据,并将它们移动到您的代码可以循环的数据结构中。接下来,迫在眉睫且通常具有挑战性的问题变成了应该如何组织数据。
从来没有唯一完美的数据结构。你通常会在几个选项中做出选择。在本教程中,随着应用程序的增长,您将多次重新考虑数据结构的选择。
现在,选择一个相当简单的数据结构:
- 一个列表将包含几个问题元素。
- 每个问题元素都是由问题文本和答案组成的二元组。
然后,您可以按如下方式存储您的问题:
[
("When was the first known use of the word 'quiz'", "1781"),
("Which built-in function can get information from the user", "input"),
]
这非常符合您希望如何使用您的数据。您将循环每个问题,对于每个问题,您都希望访问问题和答案。
更改您的quiz.py文件,以便将您的问题和答案存储在QUESTIONS数据结构中:
# quiz.py
QUESTIONS = [
("When was the first known use of the word 'quiz'", "1781"),
("Which built-in function can get information from the user", "input"),
("Which keyword do you use to loop over a given list of elements", "for")
]
for question, correct_answer in QUESTIONS:
answer = input(f"{question}? ")
if answer == correct_answer:
print("Correct!")
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
当您运行这段代码时,它看起来与之前没有任何不同。事实上,您没有添加任何新功能。相反,你已经重构了你的代码,这样就可以更容易地向你的应用程序添加更多的问题。
在先前版本的代码中,您需要为添加的每个问题添加五行新代码。现在,for循环负责为每个问题运行这五行。要添加一个新问题,您只需要添加一行拼写出问题和相应的答案。
注意:在本教程中,你将学习一些小测验,所以问题和答案很重要。每个代码示例都会引入一个新问题。为了将本教程中的代码清单保持在可管理的大小,一些旧的问题可能会被删除。但是,请随意在代码中保留所有问题,或者甚至用您自己的问题和答案来替换它们。
你将在示例中看到的问题与教程相关,即使你不会在文本中找到所有的答案。如果你对某个问题或某个答案的更多细节感到好奇,请随意在网上搜索。
接下来,您将通过为每个问题添加备选答案来使您的测验应用程序更易于使用。
提供多种选择
使用input()是读取用户输入的一个好方法。然而,你目前使用它的方式可能会令人沮丧。例如,有人可能会这样回答你的一个问题:
Which built-in function can get information from the user? input() The answer is 'input', not 'input()'
它们真的应该被标记为错误的吗?因为它们包含了括号来表示函数是可调用的。通过给用户提供替代方案,你可以为他们省去许多猜测。例如:
- get
- input
- print
- write
Which built-in function can get information from the user? input Correct!
这里,备选项表明您希望输入不带括号的答案。在本例中,选项列在问题之前。这有点违反直觉,但更容易在您当前的代码中实现。您将在下一步的中对此进行改进。
为了实现备选答案,您需要您的数据结构能够记录每个问题的三条信息:
- 问题文本
- 正确答案
- 回答备选方案
是时候第一次——但不是最后一次——重访QUESTIONS,并对它做些改变了。将备选答案存储在列表中是有意义的,因为可以有任意数量的备选答案,而您只想将它们显示在屏幕上。此外,您可以将正确的答案视为备选答案之一,并将其包含在列表中,只要您以后能够检索到它。
你决定将QUESTIONS改成一本字典,其中的关键字是你的问题,值是备选答案列表。你总是把正确的答案放在选项列表的第一项,这样你就能识别它。
注意:您可以继续使用二元组列表来保存您的问题。事实上,您只是在迭代问题和答案,而不是通过使用问题作为关键字来查找答案。因此,您可能会认为元组列表比字典更适合您的用例。
但是,您使用字典是因为它在您的代码中看起来更好,并且问题和答案选项的角色更明显。
您更新了代码,以循环遍历新生成的字典中的每个条目。对于每个问题,您从选项中选出正确答案,并在提问前打印出所有选项:
# quiz.py
QUESTIONS = {
"When was the first known use of the word 'quiz'": [
"1781", "1771", "1871", "1881"
],
"Which built-in function can get information from the user": [
"input", "get", "print", "write"
],
"Which keyword do you use to loop over a given list of elements": [
"for", "while", "each", "loop"
],
"What's the purpose of the built-in zip() function": [
"To iterate over two or more sequences at the same time",
"To combine several strings into one",
"To compress several files into one archive",
"To get information from the user",
],
}
for question, alternatives in QUESTIONS.items():
correct_answer = alternatives[0]
for alternative in sorted(alternatives):
print(f" - {alternative}")
answer = input(f"{question}? ")
if answer == correct_answer:
print("Correct!")
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
如果你总是把正确的答案作为第一选择,那么你的用户很快就会明白,并且每次都能猜出正确的答案。相反,你可以通过对选项进行排序来改变它们的顺序。测试您的应用:
$ python quiz.py
- 1771
- 1781
- 1871
- 1881
When was the first known use of the word 'quiz'? 1781 Correct!
...
- To combine several strings into one
- To compress several files into one archive
- To get information from the user
- To iterate over two or more sequences at the same time
What's the purpose of the built-in zip() function?
To itertate over two or more sequences at the same time The answer is 'To iterate over two or more sequences at the same time',
not 'To itertate over two or more sequences at the same time'
最后一个问题揭示了另一个让用户感到沮丧的体验。在这个例子中,他们选择了正确的选项。然而,当他们打字的时候,一个打字错误溜了进来。你能让你的应用程序更宽容吗?
你知道用户会用其中一个选项来回答,所以你只需要一种方式让他们交流他们选择了哪个选项。您可以为每个备选项添加一个标签,并且只要求用户输入标签。
更新应用程序,使用 enumerate() 打印每个备选答案的索引:
# quiz.py
QUESTIONS = {
"Which keyword do you use to loop over a given list of elements": [
"for", "while", "each", "loop"
],
"What's the purpose of the built-in zip() function": [
"To iterate over two or more sequences at the same time",
"To combine several strings into one",
"To compress several files into one archive",
"To get information from the user",
],
"What's the name of Python's sorting algorithm": [
"Timsort", "Quicksort", "Merge sort", "Bubble sort"
],
}
for question, alternatives in QUESTIONS.items():
correct_answer = alternatives[0]
sorted_alternatives = sorted(alternatives) for label, alternative in enumerate(sorted_alternatives): print(f" {label}) {alternative}")
answer_label = int(input(f"{question}? ")) answer = sorted_alternatives[answer_label] if answer == correct_answer:
print("Correct!")
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
您将重新排序的选项存储为sorted_alternatives,这样您就可以根据用户输入的答案标签来查找完整的答案。回想一下,input()总是返回一个字符串,所以在将它作为一个列表索引之前,您需要用将它转换成一个整数。
现在,回答问题更方便了:
$ python quiz.py
0) each
1) for
2) loop
3) while
Which keyword do you use to loop over a given list of elements? 2 The answer is 'for', not 'loop'
0) To combine several strings into one
1) To compress several files into one archive
2) To get information from the user
3) To iterate over two or more sequences at the same time
What's the purpose of the built-in zip() function? 3 Correct!
0) Bubble sort
1) Merge sort
2) Quicksort
3) Timsort
What's the name of Python's sorting algorithm? 3 Correct!
太好了!您已经创建了一个相当有能力的测验应用程序!在下一步中,您不会添加更多的功能。相反,您将使您的应用程序更加用户友好。
步骤 2:让你的应用程序对用户友好
在第二步中,您将改进测验应用程序,使其更易于使用。特别是,您将改进以下内容:
- 应用程序的外观和感觉
- 你如何总结用户的结果
- 如果你的用户输入了一个不存在的选项,会发生什么
- 你以什么顺序提出问题和选择
在这一步结束时,您的应用程序将如下工作:
https://player.vimeo.com/video/717554822?background=1
你的程序仍然会像现在一样工作,但是它会更健壮,更有吸引力。您可以通过点击下面的链接在source_code_step_2目录中找到源代码,因为它将在本步骤结束时出现:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
更好地格式化输出
回顾一下你的测验申请目前是如何呈现的。不是很吸引人。没有空行告诉你新问题从哪里开始,备选项列在问题上面,有点混乱。此外,不同选项的编号从0开始,而不是从1开始,这将更加自然。
在下一次对quiz.py的更新中,你将对问题本身进行编号,并在备选答案上方显示问题文本。此外,您将使用小写字母而不是数字来标识答案:
# quiz.py
from string import ascii_lowercase
QUESTIONS = {
"What's the purpose of the built-in zip() function": [
"To iterate over two or more sequences at the same time",
"To combine several strings into one",
"To compress several files into one archive",
"To get information from the user",
],
"What's the name of Python's sorting algorithm": [
"Timsort", "Quicksort", "Merge sort", "Bubble sort"
],
"What does dict.get(key) return if key isn't found in dict": [
"None", "key", "True", "False",
]
}
for num, (question, alternatives) in enumerate(QUESTIONS.items(), start=1):
print(f"\nQuestion {num}:") print(f"{question}?") correct_answer = alternatives[0]
labeled_alternatives = dict(zip(ascii_lowercase, sorted(alternatives))) for label, alternative in labeled_alternatives.items(): print(f" {label}) {alternative}")
answer_label = input("\nChoice? ") answer = labeled_alternatives.get(answer_label) if answer == correct_answer:
print("⭐ Correct! ⭐") else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
您使用string.ascii_lowercase来获得标记您的备选答案的字母。您用zip()组合字母和备选词,并将其存储在字典中,如下所示:
>>> import string >>> dict(zip(string.ascii_lowercase, ["1771", "1781", "1871", "1881"])) {'a': '1771', 'b': '1781', 'c': '1871', 'd': '1881'}当您向用户显示选项时,以及当您根据用户输入的标签查找用户的答案时,可以使用这些带标签的备选项。注意特殊转义字符串
"\n"的使用。这被解释为换行并在屏幕上添加一个空行。这是向输出添加一些组织的简单方法:$ python quiz.py Question 1: What's the purpose of the built-in zip() function? a) To combine several strings into one b) To compress several files into one archive c) To get information from the user d) To iterate over two or more sequences at the same time Choice? d ⭐ Correct! ⭐ Question 2: What's the name of Python's sorting algorithm? a) Bubble sort b) Merge sort c) Quicksort d) Timsort Choice? c The answer is 'Timsort', not 'Quicksort'在终端中,您的输出仍然大多是单色的,但它在视觉上更令人愉悦,也更容易阅读。
保持分数
既然您已经对问题进行了编号,那么跟踪用户正确回答了多少问题也是很好的。您可以添加一个变量
num_correct来处理这个问题:# quiz.py from string import ascii_lowercase QUESTIONS = { "What does dict.get(key) return if key isn't found in dict": [ "None", "key", "True", "False", ], "How do you iterate over both indices and elements in an iterable": [ "enumerate(iterable)", "enumerate(iterable, start=1)", "range(iterable)", "range(iterable, start=1)", ], } num_correct = 0 for num, (question, alternatives) in enumerate(QUESTIONS.items(), start=1): print(f"\nQuestion {num}:") print(f"{question}?") correct_answer = alternatives[0] labeled_alternatives = dict(zip(ascii_lowercase, sorted(alternatives))) for label, alternative in labeled_alternatives.items(): print(f" {label}) {alternative}") answer_label = input("\nChoice? ") answer = labeled_alternatives.get(answer_label) if answer == correct_answer: num_correct += 1 print("⭐ Correct! ⭐") else: print(f"The answer is {correct_answer!r}, not {answer!r}") print(f"\nYou got {num_correct} correct out of {num} questions")你每答对一个,就增加
num_correct。num循环变量已经计算了问题的总数,因此您可以使用它来报告用户的结果。处理用户错误
到目前为止,您还没有太担心如果用户输入无效的答案会发生什么。在不同版本的应用程序中,这种疏忽可能会导致程序产生一个错误,或者——不太明显——将用户的无效答案注册为错误。
当用户输入无效内容时,允许用户重新输入他们的答案,可以更好地处理用户错误。一种方法是将
input()包装在一个while循环中:
>>> while (text := input()) != "quit":
... print(f"Echo: {text}")
...
Hello! Echo: Hello!
Walrus ... Echo: Walrus ...
quit
条件(text := input()) != "quit"同时做几件事。它使用一个赋值表达式(:=),通常称为 walrus 操作符,将用户输入存储为text,并将其与字符串"quit"进行比较。while 循环将一直运行,直到您在提示符下键入quit。更多例子见海象操作符:Python 3.8 赋值表达式。
注意:如果你使用的是比 3.8 更老的 Python 版本,那么赋值表达式将导致一个语法错误。你可以重写代码来避免使用 walrus 操作符。在您之前下载的源代码中有一个运行在 Python 3.7 上的测验应用程序版本。
在您的测验应用程序中,您使用类似的构造进行循环,直到用户给出有效答案:
# quiz.py
from string import ascii_lowercase
QUESTIONS = {
"How do you iterate over both indices and elements in an iterable": [
"enumerate(iterable)",
"enumerate(iterable, start=1)",
"range(iterable)",
"range(iterable, start=1)",
],
"What's the official name of the := operator": [
"Assignment expression",
"Named expression",
"Walrus operator",
"Colon equals operator",
],
}
num_correct = 0
for num, (question, alternatives) in enumerate(QUESTIONS.items(), start=1):
print(f"\nQuestion {num}:")
print(f"{question}?")
correct_answer = alternatives[0]
labeled_alternatives = dict(zip(ascii_lowercase, sorted(alternatives)))
for label, alternative in labeled_alternatives.items():
print(f" {label}) {alternative}")
while (answer_label := input("\nChoice? ")) not in labeled_alternatives: print(f"Please answer one of {', '.join(labeled_alternatives)}")
answer = labeled_alternatives[answer_label] if answer == correct_answer:
num_correct += 1
print("⭐ Correct! ⭐")
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
print(f"\nYou got {num_correct} correct out of {num} questions")
如果您在提示符下输入了一个无效的选项,那么系统会提醒您有效的选项:
$ python quiz.py
Question 1:
How do you iterate over both indices and elements in an iterable?
a) enumerate(iterable)
b) enumerate(iterable, start=1)
c) range(iterable)
d) range(iterable, start=1)
Choice? e Please answer one of a, b, c, d
Choice? a ⭐ Correct! ⭐
请注意,一旦while循环退出,就可以保证answer_label是labeled_alternatives中的一个键,所以直接查找answer是安全的。接下来,您将通过在测验中注入一些随机性来增加一项改进。
为您的测验增加多样性
目前,当您运行测验应用程序时,您总是按照问题在源代码中列出的顺序来提问。此外,给定问题的备选答案也有固定的顺序,从不改变。
你可以稍微改变一下,给你的测验增加一些变化。您可以随机化问题的顺序和每个问题的备选答案的顺序:
# quiz.py
import random from string import ascii_lowercase
NUM_QUESTIONS_PER_QUIZ = 5 QUESTIONS = {
"What's the official name of the := operator": [
"Assignment expression",
"Named expression",
"Walrus operator",
"Colon equals operator",
],
"What's one effect of calling random.seed(42)": [
"The random numbers are reproducible.",
"The random numbers are more random.",
"The computer clock is reset.",
"The first random number is always 42.",
]
}
num_questions = min(NUM_QUESTIONS_PER_QUIZ, len(QUESTIONS)) questions = random.sample(list(QUESTIONS.items()), k=num_questions)
num_correct = 0
for num, (question, alternatives) in enumerate(questions, start=1):
print(f"\nQuestion {num}:")
print(f"{question}?")
correct_answer = alternatives[0]
labeled_alternatives = dict( zip(ascii_lowercase, random.sample(alternatives, k=len(alternatives))) ) for label, alternative in labeled_alternatives.items():
print(f" {label}) {alternative}")
while (answer_label := input("\nChoice? ")) not in labeled_alternatives:
print(f"Please answer one of {', '.join(labeled_alternatives)}")
answer = labeled_alternatives[answer_label]
if answer == correct_answer:
num_correct += 1
print("⭐ Correct! ⭐")
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
print(f"\nYou got {num_correct} correct out of {num} questions")
你使用 random.sample() 来随机排列你的问题和答案选项的顺序。通常,random.sample()从一个集合中随机挑选几个样本。但是,如果您要求的样本数与序列中的项目数一样多,那么您实际上是在随机地对整个序列进行重新排序:
>>> import random >>> random.sample(["one", "two", "three"], k=3) ['two', 'three', 'one']此外,您将测验中的问题数量限制为
NUM_QUESTIONS_PER_QUIZ,最初设置为五个。如果你在申请中包含了五个以上的问题,那么除了提问的顺序之外,这也增加了提问问题的多样性。注:你也可以用
random.shuffle()来洗牌你的问题和备选方案。不同之处在于shuffle()就地重新排序序列,这意味着它改变了底层的QUESTIONS数据结构。sample()创建新的问题和替代列表。在您当前的代码中,使用
shuffle()不会有问题,因为QUESTIONS会在您每次运行测验应用程序时重置。这可能会成为一个问题,例如,如果你实现了多次询问同一个问题的可能性。如果不改变或改变底层数据结构,您的代码通常更容易推理。在这一步中,您已经改进了测验应用程序。现在是时候退一步考虑代码本身了。在下一节中,您将重新组织代码,以便保持它的模块化并为进一步的开发做好准备。
步骤 3:用函数组织你的代码
在这一步,你将重构你的代码。重构意味着你将改变你的代码,但是你的应用程序的行为和用户的体验将保持不变。这听起来可能不是很令人兴奋,但它最终会非常有用,因为好的重构会使维护和扩展代码更加方便。
注意:如果你想看两个真正的 Python 团队成员如何重构一些代码,那么看看重构:准备你的代码以获得帮助。您还将学习如何提出清晰、简洁的编程问题。
目前,你的代码不是特别有条理。你所有的陈述都是相当低级的。您将定义函数来改进您的代码。它们的一些优点如下:
- 函数名为更高层次的操作,可以帮助你获得代码的概观。
- 功能可以被重用。
要查看代码重构后的样子,请点击下面的链接,查看
source_code_step_3文件夹:获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
准备数据
许多游戏和应用程序都遵循一个共同的生命周期:
- 预处理:准备初始数据。
- 流程:运行主循环。
- 后处理:清理并关闭应用程序。
在您的测验应用程序中,您首先阅读可用的问题,然后询问每个问题,最后报告最终分数。如果你回头看看你当前的代码,你会在代码中看到这三个步骤。但是这个组织仍然隐藏在所有的细节中。
通过将主要功能封装在一个函数中,可以使其更加清晰。您还不需要更新您的
quiz.py文件,但是请注意,您可以将前面的段落翻译成如下所示的代码:def run_quiz(): # Preprocess questions = prepare_questions() # Process (main loop) num_correct = 0 for question in questions: num_correct += ask_question(question) # Postprocess print(f"\nYou got {num_correct} correct")这段代码不会像现在这样运行。函数
prepare_questions()和ask_question()还没有定义,还缺少一些其他的细节。尽管如此,run_quiz()在高层次上封装了应用程序的功能。像这样在一个高层次上写下你的应用程序流可以是一个很好的开始来发现哪些函数是你的代码中的自然构建块。在本节的其余部分,您将填写缺失的详细信息:
- 执行
prepare_questions()。- 执行
ask_question()。- 重访
run_quiz()。您现在将对您的测验应用程序的代码进行相当大的修改,因为您正在重构它以使用函数。在这样做之前,最好确保您可以恢复到当前状态,您知道这是可行的。如果您使用的是版本控制系统,那么您可以通过用不同的文件名保存您代码的副本或者通过提交来做到这一点。
一旦你安全地存储了你当前的代码,从一个新的
quiz.py开始,它只包含你的导入和全局变量。您可以从以前的版本中复制这些内容:# quiz.py import random from string import ascii_lowercase NUM_QUESTIONS_PER_QUIZ = 5 QUESTIONS = { "What's one effect of calling random.seed(42)": [ "The random numbers are reproducible.", "The random numbers are more random.", "The computer clock is reset.", "The first random number is always 42.", ], "When does __name__ == '__main__' equal True in a Python file": [ "When the file is run as a script", "When the file is imported as a module", "When the file has a valid name", "When the file only has one function", ] }记住你只是在重组你的代码。您没有添加新的功能,所以您不需要导入任何新的库。
接下来,您将实现必要的预处理。在这种情况下,这意味着您将准备好
QUESTIONS数据结构,以便在主循环中使用。目前,您可能会限制问题的数量,并确保它们以随机顺序列出:# quiz.py # ... def prepare_questions(questions, num_questions): num_questions = min(num_questions, len(questions)) return random.sample(list(questions.items()), k=num_questions)注意,
prepare_questions()处理一般的questions和num_questions参数。随后,您将传入特定的QUESTIONS和NUM_QUESTIONS_PER_QUIZ作为参数。这意味着prepare_questions()不依赖于你的全局变量。有了这种分离,您的函数就更通用了,并且您以后可以更容易地替换问题的来源。提问
回头看看
run_quiz()函数的草图,记住它包含了你的主循环。对于每个问题,您将调用ask_question()。您下一个任务是实现助手函数。思考
ask_question()需要做什么:
- 从选项列表中选出正确答案
- 打乱选择
- 将问题打印到屏幕上
- 将所有备选项打印到屏幕上
- 从用户那里得到答案
- 检查用户的答案是否有效
- 检查用户回答是否正确
- 如果答案正确,将
1加到正确答案的计数中在一个功能中有很多小事情要做,你可以考虑是否有进一步模块化的潜力。例如,上面列表中的第 3 到第 6 项都是关于与用户交互的,您可以将它们放入另一个助手功能中。
为了实现这种模块化,将下面的
get_answer()助手函数添加到您的源代码中:# quiz.py # ... def get_answer(question, alternatives): print(f"{question}?") labeled_alternatives = dict(zip(ascii_lowercase, alternatives)) for label, alternative in labeled_alternatives.items(): print(f" {label}) {alternative}") while (answer_label := input("\nChoice? ")) not in labeled_alternatives: print(f"Please answer one of {', '.join(labeled_alternatives)}") return labeled_alternatives[answer_label]该函数接受一个问题文本和一个备选项列表。然后,使用与前面相同的技术来标记替代项,并要求用户输入一个有效的标签。最后,你返回用户的答案。
使用
get_answer()简化了ask_question()的实现,因为您不再需要处理用户交互。您可以执行如下操作:# quiz.py # ... def ask_question(question, alternatives): correct_answer = alternatives[0] ordered_alternatives = random.sample(alternatives, k=len(alternatives)) answer = get_answer(question, ordered_alternatives) if answer == correct_answer: print("⭐ Correct! ⭐") return 1 else: print(f"The answer is {correct_answer!r}, not {answer!r}") return 0像前面一样,首先使用
random.shuffle()对答案选项进行随机重新排序。接下来,您调用get_answer(),它处理从用户那里获得答案的所有细节。因此,你可以通过检查答案的正确性来结束ask_question()。注意,您返回了1或0,这向调用函数表明答案是否正确。注意:你可以用布尔值替换返回值。代替
1,你可以返回True,代替0,你可以返回False。这是可行的,因为 Python 在计算中将布尔值视为整数:
>>> True + True
2
>>> True * False
0
在某些情况下,当你使用True和False时,你的代码读起来更自然。在这种情况下,您正在计算正确答案,因此使用数字似乎更直观。
您现在已经准备好正确地实现run_quiz()。在实现prepare_questions()和ask_question()时,你学到的一件事是你需要传递哪些参数:
# quiz.py
# ...
def run_quiz():
questions = prepare_questions(
QUESTIONS, num_questions=NUM_QUESTIONS_PER_QUIZ
)
num_correct = 0
for num, (question, alternatives) in enumerate(questions, start=1):
print(f"\nQuestion {num}:")
num_correct += ask_question(question, alternatives)
print(f"\nYou got {num_correct} correct out of {num} questions")
如前所述,您使用enumerate()来保存一个计数器,对您提出的问题进行计数。你可以根据ask_question()的返回值增加num_correct。观察run_quiz()是您唯一直接与QUESTIONS和NUM_QUESTIONS_PER_QUIZ交互的功能。
您的重构现在已经完成,除了一件事。如果你现在跑quiz.py,那就好像什么都没发生。事实上,Python 会读取你的全局变量并定义你的函数。但是,您没有调用任何这些函数。因此,您需要添加一个启动应用程序的函数调用:
# quiz.py
# ...
if __name__ == "__main__":
run_quiz()
你在quiz.py的末尾调用run_quiz(),在任何函数之外。用一个 if __name__ == "__main__" 测试来保护这样一个对主函数的调用是一个很好的实践。这个特殊咒语是一个 Python 约定,意思是当你作为脚本运行quiz.py时会调用run_quiz(),但是当你作为模块导入quiz时不会调用。
就是这样!您已经将代码重构为几个函数。这将有助于您跟踪应用程序的功能。这在本教程中也很有用,因为您可以考虑更改单个函数,而不是更改整个脚本。
对于本教程的其余部分,您将看到您的完整代码列在如下所示的可折叠框中。展开这些以查看当前状态,并获得整个应用程序的概述:
下面列出了测验应用程序的完整源代码:
# quiz.py
import random
from string import ascii_lowercase
NUM_QUESTIONS_PER_QUIZ = 5
QUESTIONS = {
"When was the first known use of the word 'quiz'": [
"1781", "1771", "1871", "1881",
],
"Which built-in function can get information from the user": [
"input", "get", "print", "write",
],
"Which keyword do you use to loop over a given list of elements": [
"for", "while", "each", "loop",
],
"What's the purpose of the built-in zip() function": [
"To iterate over two or more sequences at the same time",
"To combine several strings into one",
"To compress several files into one archive",
"To get information from the user",
],
"What's the name of Python's sorting algorithm": [
"Timsort", "Quicksort", "Merge sort", "Bubble sort",
],
"What does dict.get(key) return if key isn't found in dict": [
"None", "key", "True", "False",
],
"How do you iterate over both indices and elements in an iterable": [
"enumerate(iterable)",
"enumerate(iterable, start=1)",
"range(iterable)",
"range(iterable, start=1)",
],
"What's the official name of the := operator": [
"Assignment expression",
"Named expression",
"Walrus operator",
"Colon equals operator",
],
"What's one effect of calling random.seed(42)": [
"The random numbers are reproducible.",
"The random numbers are more random.",
"The computer clock is reset.",
"The first random number is always 42.",
],
"When does __name__ == '__main__' equal True in a Python file": [
"When the file is run as a script",
"When the file is imported as a module",
"When the file has a valid name",
"When the file only has one function",
]
}
def run_quiz():
questions = prepare_questions(
QUESTIONS, num_questions=NUM_QUESTIONS_PER_QUIZ
)
num_correct = 0
for num, (question, alternatives) in enumerate(questions, start=1):
print(f"\nQuestion {num}:")
num_correct += ask_question(question, alternatives)
print(f"\nYou got {num_correct} correct out of {num} questions")
def prepare_questions(questions, num_questions):
num_questions = min(num_questions, len(questions))
return random.sample(list(questions.items()), k=num_questions)
def ask_question(question, alternatives):
correct_answer = alternatives[0]
ordered_alternatives = random.sample(alternatives, k=len(alternatives))
answer = get_answer(question, ordered_alternatives)
if answer == correct_answer:
print("⭐ Correct! ⭐")
return 1
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
return 0
def get_answer(question, alternatives):
print(f"{question}?")
labeled_alternatives = dict(zip(ascii_lowercase, alternatives))
for label, alternative in labeled_alternatives.items():
print(f" {label}) {alternative}")
while (answer_label := input("\nChoice? ")) not in labeled_alternatives:
print(f"Please answer one of {', '.join(labeled_alternatives)}")
return labeled_alternatives[answer_label]
if __name__ == "__main__":
run_quiz()
使用python quiz.py运行您的应用程序。
通过这一步,您已经重构了代码,使其更便于使用。您将命令分成了组织良好的功能,您可以继续开发这些功能。下一步,您将利用这一点,改进将问题读入应用程序的方式。
步骤 4:将数据分离到自己的文件中
在这一步中,您将继续您的重构之旅。现在你的重点是如何向你的申请提出问题。
到目前为止,您已经将问题直接存储在源代码的QUESTIONS数据结构中。通常最好将数据与代码分开。这种分离可以使您的代码更具可读性,但更重要的是,如果数据没有隐藏在您的代码中,您可以利用为处理数据而设计的系统。
在本节中,您将学习如何将您的问题存储在一个根据 TOML 标准格式化的单独数据文件中。其他选项——你不会在本教程中涉及——是以不同的文件格式存储问题,如 JSON 或 YAML ,或者将它们存储在数据库中,或者是传统的关系数据库或者是 NoSQL 数据库。
要查看在这一步中您将如何改进您的代码,请单击下面并转到source_code_step_4目录:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
将问题移至 TOML 文件
TOML 被标榜为“人类的一种配置文件格式”(来源)。它被设计成人类可读,计算机解析也不复杂。信息用键值对表示,可以映射到一个散列表数据结构,就像 Python 字典一样。
TOML 支持几种数据类型,包括字符串、整数、浮点数、布尔值和日期。此外,数据可以以数组和表的形式组织,分别类似于 Python 的列表和字典。TOML 在过去几年里越来越受欢迎,在格式规范的版本 1.0.0 于 2021 年 1 月发布后,该格式已经稳定。
创建一个名为questions.toml的新文本文件,并添加以下内容:
# questions.toml "When does __name__ == '__main__' equal True in a Python file" = [ "When the file is run as a script", "When the file is imported as a module", "When the file has a valid name", "When the file only has one function", ] "Which version of Python is the first with TOML support built in" = [ "3.11", "3.9", "3.10", "3.12" ]
虽然 TOML 语法和 Python 语法之间存在差异,但是您可以识别出一些元素,例如使用引号(")表示文本,使用方括号([])表示元素列表。
要在 Python 中处理 TOML 文件,您需要一个解析它们的库。在本教程中,您将使用 tomli 。这将是您在这个项目中使用的唯一一个不属于 Python 标准库的包。
注意: TOML 支持是在 Python 3.11 中加入了到 Python 的标准库中。如果您已经在使用 Python 3.11,那么您可以跳过下面的说明来创建一个虚拟环境并安装tomli。相反,您可以通过用兼容的tomllib替换代码中提到的任何tomli来立即开始编码。
在本节的后面,您将学习如何编写可以使用tomllib的代码(如果可用的话),并在必要时回退到tomli。
在安装tomli之前,您应该创建并激活一个虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> venv\Scripts\activate
$ python -m venv venv
$ source venv/bin/activate
然后可以用 pip 安装tomli:
- 视窗
** Linux + macOS*
(venv) PS> python -m pip install tomli
(venv) $ python -m pip install tomli
您可以通过解析之前创建的questions.toml来检查是否有可用的tomli。打开您的 Python REPL 并测试以下代码:
>>> import tomli >>> with open("questions.toml", mode="rb") as toml_file: ... questions = tomli.load(toml_file) ... >>> questions {"When does __name__ == '__main__' equal True in a Python file": ['When the file is run as a script', 'When the file is imported as a module', 'When the file has a valid name', 'When the file only has one function'], 'Which version of Python is the first with TOML support built-in': ['3.11', '3.9', '3.10', '3.12']}首先,注意到
questions是一个常规的 Python 字典,它与您目前使用的QUESTIONS数据结构具有相同的形式。您可以使用
tomli以两种不同的方式解析 TOML 信息。在上面的例子中,您使用tomli.load()从一个打开的文件句柄中读取 TOML。或者,您可以使用tomli.loads()从文本字符串中读取 TOML。注意:在将文件传递给
tomli.load()之前,需要使用mode="rb"以二进制模式打开文件。这样tomli可以确保 TOML 文件的 UTF-8 编码被正确处理。如果你使用
tomli.loads(),那么你传入的字符串将被解释为 UTF-8。通过更新代码的序言,您可以将 TOML 文件集成到测验应用程序中,您可以在其中进行导入并定义全局变量:
# quiz.py # ... import pathlib try: import tomllib except ModuleNotFoundError: import tomli as tomllib NUM_QUESTIONS_PER_QUIZ = 5 QUESTIONS_PATH = pathlib.Path(__file__).parent / "questions.toml" QUESTIONS = tomllib.loads(QUESTIONS_PATH.read_text()) # ...您没有像前面那样做一个简单的
import tomli,而是将您的导入包装在一个try…except语句中,该语句首先尝试导入tomllib。如果失败,那么你导入tomli,但将其重命名为tomllib。这样做的效果是,如果 Python 3.11tomllib可用,您将使用它,如果不可用,将退回到状态。您正在使用
pathlib来处理到questions.toml的路径。不是硬编码到questions.toml的路径,而是依赖特殊的__file__变量。实际上,你说它和你的quiz.py文件位于同一个目录。最后,使用
read_text()将 TOML 文件作为文本字符串读取,然后使用loads()将该字符串解析到字典中。正如您在前面的示例中看到的,加载 TOML 文件会产生与您之前的问题相同的数据结构。一旦您对quiz.py做了更改,您的测验应用程序应该仍然运行,尽管问题是在 TOML 文件中定义的,而不是在您的源代码中。继续向您的 TOML 文件添加几个问题,以确认它正在被使用。
增加数据格式的灵活性
您已经将问题数据从源代码中移出,并将其转换为专用的数据文件格式。与常规的 Python 字典相比,TOML 的一个优点是,您可以在保持数据可读性和可维护性的同时,为数据添加更多的结构。
TOML 的一个显著特征是表。这些是映射到 Python 中嵌套字典的命名部分。此外,您可以使用表的数组,它们由 Python 中的字典列表表示。
你可以利用这些来更明确地定义你的问题。考虑下面的 TOML 片段:
[[questions]] question = "Which version of Python is the first with TOML support built in" answer = "3.11" alternatives = ["3.9", "3.10", "3.12"]常规表格以类似
[questions]的单括号线开始。您可以使用双括号来表示一个表格数组,如上所示。您可以用tomli解析 TOML:
>>> toml = """
... [[questions]]
... question = "Which version of Python is the first with TOML support built in"
... answer = "3.11"
... alternatives = ["3.9", "3.10", "3.12"]
... """
>>> import tomli
>>> tomli.loads(toml)
{'questions': [
{
'question': 'Which version of Python is the first with TOML support built in',
'answer': '3.11',
'alternatives': ['3.9', '3.10', '3.12']
}
]}
这导致了一个嵌套的数据结构,带有一个外部字典,其中的questions键指向一个字典列表。内部字典有question、answer和alternatives键。
这个结构比你到目前为止使用的要复杂一些。然而,它也更加明确,您不需要依赖于约定,例如代表正确答案的第一个答案选项。
现在,您将转换您的测验应用程序,以便它利用这个新的数据结构来回答您的问题。首先,在questions.toml中重新格式化你的问题。您应该将它们格式化如下:
# questions.toml [[questions]] question = "Which version of Python is the first with TOML support built in" answer = "3.11" alternatives = ["3.9", "3.10", "3.12"] [[questions]] question = "What's the name of the list-like data structure in TOML" answer = "Array" alternatives = ["List", "Sequence", "Set"]
每个问题都存储在一个单独的questions表中,表中有问题文本、正确答案和备选答案的键值对。
原则上,要使用新格式,您需要对应用程序源代码进行两处修改:
- 阅读内部
questions列表中的问题。 - 提问时,使用内部问题词典。
这些更改触及到您的主数据结构,因此它们需要在整个代码中进行一些小的代码更改。
首先,改变从 TOML 文件中读取问题的方式:
# quiz.py
# ...
NUM_QUESTIONS_PER_QUIZ = 5
QUESTIONS_PATH = pathlib.Path(__file__).parent / "questions.toml"
def run_quiz():
questions = prepare_questions( QUESTIONS_PATH, num_questions=NUM_QUESTIONS_PER_QUIZ )
num_correct = 0
for num, question in enumerate(questions, start=1): print(f"\nQuestion {num}:")
num_correct += ask_question(question)
print(f"\nYou got {num_correct} correct out of {num} questions")
def prepare_questions(path, num_questions):
questions = tomllib.loads(path.read_text())["questions"] num_questions = min(num_questions, len(questions))
return random.sample(questions, k=num_questions)
您更改prepare_questions()来读取 TOML 文件并挑选出questions列表。此外,您可以简化run_quiz()中的主循环,因为关于一个问题的所有信息都包含在字典中。您不需要分别跟踪问题文本和备选方案。
后一点也需要对ask_question()进行一些修改:
# quiz.py
# ...
def ask_question(question):
correct_answer = question["answer"] alternatives = [question["answer"]] + question["alternatives"] ordered_alternatives = random.sample(alternatives, k=len(alternatives))
answer = get_answer(question["question"], ordered_alternatives) if answer == correct_answer:
print("⭐ Correct! ⭐")
return 1
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
return 0
现在,您可以从新的question字典中明确地挑选出问题文本、正确答案和备选答案。这样做的一个好处是,它比早期假设第一个答案是正确答案的惯例更具可读性。
您不需要在get_answer()中做任何修改,因为该函数已经处理了问题文本和一般的备选项列表。这一点没有改变。
您可以在下面折叠的部分中找到您的应用程序的当前完整源代码:
完整的questions.toml数据文件复制如下:
# questions.toml [[questions]] question = "When was the first known use of the word 'quiz'" answer = "1781" alternatives = ["1771", "1871", "1881"] [[questions]] question = "Which built-in function can get information from the user" answer = "input" alternatives = ["get", "print", "write"] [[questions]] question = "What's the purpose of the built-in zip() function" answer = "To iterate over two or more sequences at the same time" alternatives = [ "To combine several strings into one", "To compress several files into one archive", "To get information from the user", ] [[questions]] question = "What does dict.get(key) return if key isn't found in dict" answer = "None" alternatives = ["key", "True", "False"] [[questions]] question = "How do you iterate over both indices and elements in an iterable" answer = "enumerate(iterable)" alternatives = [ "enumerate(iterable, start=1)", "range(iterable)", "range(iterable, start=1)", ] [[questions]] question = "What's the official name of the := operator" answer = "Assignment expression" alternatives = ["Named expression", "Walrus operator", "Colon equals operator"] [[questions]] question = "What's one effect of calling random.seed(42)" answer = "The random numbers are reproducible." alternatives = [ "The random numbers are more random.", "The computer clock is reset.", "The first random number is always 42.", ] [[questions]] question = "When does __name__ == '__main__' equal True in a Python file" answer = "When the file is run as a script" alternatives = [ "When the file is imported as a module", "When the file has a valid name", "When the file only has one function", ] [[questions]] question = "Which version of Python is the first with TOML support built in" answer = "3.11" alternatives = ["3.9", "3.10", "3.12"] [[questions]] question = "What's the name of the list-like data structure in TOML" answer = "Array" alternatives = ["List", "Sequence", "Set"]
将该文件保存在与quiz.py相同的文件夹中。
下面列出了测验应用程序的完整源代码:
# quiz.py
import pathlib
import random
from string import ascii_lowercase
try:
import tomllib
except ModuleNotFoundError:
import tomli as tomllib
NUM_QUESTIONS_PER_QUIZ = 5
QUESTIONS_PATH = pathlib.Path(__file__).parent / "questions.toml"
def run_quiz():
questions = prepare_questions(
QUESTIONS_PATH, num_questions=NUM_QUESTIONS_PER_QUIZ
)
num_correct = 0
for num, question in enumerate(questions, start=1):
print(f"\nQuestion {num}:")
num_correct += ask_question(question)
print(f"\nYou got {num_correct} correct out of {num} questions")
def prepare_questions(path, num_questions):
questions = tomllib.loads(path.read_text())["questions"]
num_questions = min(num_questions, len(questions))
return random.sample(questions, k=num_questions)
def ask_question(question):
correct_answer = question["answer"]
alternatives = [question["answer"]] + question["alternatives"]
ordered_alternatives = random.sample(alternatives, k=len(alternatives))
answer = get_answer(question["question"], ordered_alternatives)
if answer == correct_answer:
print("⭐ Correct! ⭐")
return 1
else:
print(f"The answer is {correct_answer!r}, not {answer!r}")
return 0
def get_answer(question, alternatives):
print(f"{question}?")
labeled_alternatives = dict(zip(ascii_lowercase, alternatives))
for label, alternative in labeled_alternatives.items():
print(f" {label}) {alternative}")
while (answer_label := input("\nChoice? ")) not in labeled_alternatives:
print(f"Please answer one of {', '.join(labeled_alternatives)}")
return labeled_alternatives[answer_label]
if __name__ == "__main__":
run_quiz()
使用python quiz.py运行您的应用程序。
您定义问题的新灵活格式为您提供了一些选项,可以为测验应用程序添加更多功能。在下一步中,您将深入了解其中的一些内容。
步骤 5:扩展您的测验功能
在第五步中,您将向测验应用程序添加更多功能。最后,您在前面的步骤中所做的重构将会得到回报!您将添加以下功能:
- 有多个正确答案的问题
- 可以指向正确答案的提示
- 可以作为教学时机的解释
在这一步结束时,您的应用程序将如下工作:
https://player.vimeo.com/video/717554892?background=1
这些新功能为通过测验应用程序挑战自我的人提供了更有趣的体验。完成这一步后,您可以点击下方并进入source_code_step_5目录,查看应用程序的源代码:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
允许多个正确答案
有些问题可能有多个正确答案,如果你的测验也能回答这些问题,那就太好了。在本节中,您将添加对多个正确答案的支持。
首先,你需要考虑如何在你的questions.toml数据文件中表示几个正确的答案。您在上一步中介绍的更明确的数据结构的一个优点是,您也可以使用数组来指定正确的答案。将 TOML 文件中的每个answer键替换为一个answers键,将每个正确的答案放在方括号中([])。
您的问题文件将如下所示:
# questions.toml [[questions]] question = "What's the name of the list-like data structure in TOML" answers = ["Array"] alternatives = ["List", "Sequence", "Set"] [[questions]] question = "How can you run a Python script named quiz.py" answers = ["python quiz.py", "python -m quiz"] alternatives = ["python quiz", "python -m quiz.py"]
对于只有一个正确答案的老问题,在answers数组中只会列出一个答案。上面的最后一个问题显示了一个有两个正确答案选项的问题示例。
一旦更新了数据结构,您还需要在代码中实现该特性。不需要对run_quiz()或者prepare_questions()做任何改动。在ask_question()中,你需要检查是否给出了所有的正确答案,而在get_answer()中,你需要能够阅读用户的多个答案。
从后一个挑战开始。用户如何输入多个答案,您如何验证每个答案都是有效的?一种可能是以逗号分隔的字符串形式输入多个答案。然后,您可以将字符串转换为列表,如下所示:
>>> answer = "a,b, c" >>> answer.replace(",", " ").split() ['a', 'b', 'c']你可以使用
.split(",")直接在逗号上分割。然而,首先用空格替换逗号,然后在缺省的空格上进行拆分,这增加了逗号周围允许空格的宽容度。这对你的用户来说会是一个更好的体验,因为他们可以不用逗号来写a,b、a, b,甚至a b,你的程序应该按照预期来解释它。然而,有效答案的测试变得有点复杂。因此,你用一个更灵活的环替换了这个紧的环。为了循环直到得到一个有效的答案,您启动了一个无限循环,一旦所有的测试都通过,您就返回。将
get_answer()重命名为get_answers(),并更新如下:# quiz.py # ... def get_answers(question, alternatives, num_choices=1): print(f"{question}?") labeled_alternatives = dict(zip(ascii_lowercase, alternatives)) for label, alternative in labeled_alternatives.items(): print(f" {label}) {alternative}") while True: plural_s = "" if num_choices == 1 else f"s (choose {num_choices})" answer = input(f"\nChoice{plural_s}? ") answers = set(answer.replace(",", " ").split()) # Handle invalid answers if len(answers) != num_choices: plural_s = "" if num_choices == 1 else "s, separated by comma" print(f"Please answer {num_choices} alternative{plural_s}") continue if any( (invalid := answer) not in labeled_alternatives for answer in answers ): print( f"{invalid!r} is not a valid choice. " f"Please use {', '.join(labeled_alternatives)}" ) continue return [labeled_alternatives[answer] for answer in answers]在仔细查看代码中的细节之前,先测试一下这个函数:
>>> from quiz import get_answers
>>> get_answers(
... "Pick two numbers", ["one", "two", "three", "four"], num_choices=2
... )
Pick two numbers?
a) one
b) two
c) three
d) four
Choices (choose 2)? a Please answer 2 alternatives, separated by comma
Choices (choose 2)? d, e 'e' is not a valid choice. Please use a, b, c, d
Choices (choose 2)? d, b ['four', 'two']
您的函数首先检查答案是否包含适当数量的选项。然后检查每一个以确保它是一个有效的选择。如果这些检查中有任何一项失败,那么就会向用户打印一条有用的消息。
在代码中,当涉及到语法时,您还需要努力处理一个和几个项目之间的区别。您可以使用plural_s来修改文本字符串,以便在需要时包含多个 s 。
此外,您将答案转换为一个集合,以快速忽略重复的选项。类似于"a, b, a"的答案字符串被解释为{"a", "b"}。
最后,注意get_answers()返回一个字符串列表,而不是由get_answer()返回的普通字符串。
接下来,您使ask_question()适应多个正确答案的可能性。既然get_answers()已经处理了大部分的复杂问题,剩下的就是检查所有的答案,而不是只有一个。回想一下,question是一本包含关于一个问题的所有信息的字典,所以你不再需要通过alternatives。
因为答案的顺序无关紧要,所以在将给出的答案与正确答案进行比较时,可以使用set():
# quiz.py
# ...
def ask_question(question):
correct_answers = question["answers"] alternatives = question["answers"] + question["alternatives"] ordered_alternatives = random.sample(alternatives, k=len(alternatives))
answers = get_answers( question=question["question"],
alternatives=ordered_alternatives,
num_choices=len(correct_answers), )
if set(answers) == set(correct_answers): print("⭐ Correct! ⭐")
return 1
else:
is_or_are = " is" if len(correct_answers) == 1 else "s are" print("\n- ".join([f"No, the answer{is_or_are}:"] + correct_answers)) return 0
如果用户找到了所有的正确答案,你只能为他们赢得一分。否则,请列出所有正确答案。现在,您可以再次运行 Python 测验应用程序:
$ python quiz.py
Question 1:
How can you run a Python script named quiz.py?
a) python -m quiz
b) python quiz
c) python quiz.py
d) python -m quiz.py
Choices (choose 2)? a Please answer 2 alternatives, separated by comma
Choices (choose 2)? a, c ⭐ Correct! ⭐
Question 2:
What's the name of the list-like data structure in TOML?
a) Array
b) Set
c) Sequence
d) List
Choice? e 'e' is not a valid choice. Please use a, b, c, d
Choice? c No, the answer is:
- Array
You got 1 correct out of 2 questions
允许多个正确答案可以让你在测验中更灵活地提问。
添加提示以帮助用户
有时候当你被问到一个问题时,你需要一点帮助来唤起你的记忆。给用户看到提示的选项可以让你的测验更有趣。在这一节中,您将扩展您的应用程序以包含提示。
您可以在您的questions.toml数据文件中包含提示,例如通过添加hint作为可选的键值对:
# questions.toml [[questions]] question = "How can you run a Python script named quiz.py" answers = ["python quiz.py", "python -m quiz"] alternatives = ["python quiz", "python -m quiz.py"] hint = "One option uses the filename, and the other uses the module name."
[[questions]] question = "What's a PEP" answers = ["A Python Enhancement Proposal"] alternatives = [ "A Pretty Exciting Policy", "A Preciously Evolved Python", "A Potentially Epic Prize", ] hint = "PEPs are used to evolve Python."
TOML 文件中的每个问题都由 Python 中的一个字典表示。新的hint字段在那些字典中显示为新的键。这样做的一个效果是,您不需要改变读取问题数据的方式,即使您对数据结构做了很小的更改。
相反,您可以修改代码以利用新的可选字段。在ask_question()中,你只需要做一个小小的改变:
# quiz.py
# ...
def ask_question(question):
# ...
answers = get_answers(
question=question["question"],
alternatives=ordered_alternatives,
num_choices=len(correct_answers),
hint=question.get("hint"), )
# ...
你用question.get("hint")而不是question["hint"],因为不是所有的问题都有提示。如果其中一个question字典没有将"hint"定义为一个键,那么question.get("hint")返回None,然后将其传递给get_answers()。
同样,您将对get_answers()进行更大的更改。您将使用特殊的问号(?)标签将提示添加为备选答案之一:
# quiz.py
# ...
def get_answers(question, alternatives, num_choices=1, hint=None):
print(f"{question}?")
labeled_alternatives = dict(zip(ascii_lowercase, alternatives))
if hint: labeled_alternatives["?"] = "Hint"
for label, alternative in labeled_alternatives.items():
print(f" {label}) {alternative}")
while True:
plural_s = "" if num_choices == 1 else f"s (choose {num_choices})"
answer = input(f"\nChoice{plural_s}? ")
answers = set(answer.replace(",", " ").split())
# Handle hints
if hint and "?" in answers: print(f"\nHINT: {hint}") continue
# Handle invalid answers
# ...
return [labeled_alternatives[answer] for answer in answers]
如果提供了提示,则将其添加到labeled_alternatives的末尾。然后,用户可以使用?查看打印到屏幕上的提示。如果您测试您的测验应用程序,那么您现在会得到一些友好的帮助:
$ python quiz.py
Question 1:
What's a PEP?
a) A Potentially Epic Prize
b) A Preciously Evolved Python
c) A Python Enhancement Proposal
d) A Pretty Exciting Policy
?) Hint
Choice? ?
HINT: PEPs are used to evolve Python.
Choice? c ⭐ Correct! ⭐
在下一节中,您将添加一个类似的特性。除了在用户回答问题之前显示可选提示之外,您还将在用户回答问题之后显示解释。
添加解释以强化学习
你可以实现解释,就像你在上一节中实现提示一样。首先,您将在数据文件中添加一个可选的explanation字段。然后,在您的应用程序中,您将在用户回答问题后显示解释。
从在questions.toml中添加explanation键开始:
# questions.toml [[questions]] question = "What's a PEP" answers = ["A Python Enhancement Proposal"] alternatives = [ "A Pretty Exciting Policy", "A Preciously Evolved Python", "A Potentially Epic Prize", ] hint = "PEPs are used to evolve Python." explanation = """
Python Enhancement Proposals (PEPs) are design documents that provide information to the Python community. PEPs are used to propose new features for the Python language, to collect community input on an issue, and to document design decisions made about the language. """
[[questions]] question = "How can you add a docstring to a function" answers = [ "By writing a string literal as the first statement in the function", "By assigning a string to the function's .__doc__ attribute", ] alternatives = [ "By using the built-in @docstring decorator", "By returning a string from the function", ] hint = "They're parsed from your code and stored on the function object." explanation = """
Docstrings document functions and other Python objects. A docstring is a string literal that occurs as the first statement in a module, function, class, or method definition. Such a docstring becomes the .__doc__ special attribute of that object. See PEP 257 for more information. There is no built-in @docstring decorator. Many functions naturally return strings. Such a feature can therefore not be used for docstrings. """
TOML 通过像 Python 一样使用三重引号(""")来支持多行字符串。这对于可能跨越几个句子的解释非常有用。
用户回答问题后,解释将打印到屏幕上。换句话说,解释不是在get_answers()中完成的用户交互的一部分。相反,您将在ask_question()中打印它们:
# quiz.py
# ...
def ask_question(question):
correct_answers = question["answers"]
alternatives = question["answers"] + question["alternatives"]
ordered_alternatives = random.sample(alternatives, k=len(alternatives))
answers = get_answers(
question=question["question"],
alternatives=ordered_alternatives,
num_choices=len(correct_answers),
hint=question.get("hint"),
)
if correct := (set(answers) == set(correct_answers)):
print("⭐ Correct! ⭐")
else:
is_or_are = " is" if len(correct_answers) == 1 else "s are"
print("\n- ".join([f"No, the answer{is_or_are}:"] + correct_answers))
if "explanation" in question: print(f"\nEXPLANATION:\n{question['explanation']}")
return 1 if correct else 0
因为您在向用户反馈他们的答案是否正确后打印了解释,所以您不能再返回到if … else块内。你因此把 return 语句移到了函数的末尾。
当您运行测验应用程序时,您的解释如下所示:
$ python quiz.py
Question 1:
How can you add a docstring to a function?
a) By returning a string from the function
b) By assigning a string to the function's .__doc__ attribute
c) By writing a string literal as the first statement in the function
d) By using the built-in @docstring decorator
?) Hint
Choices (choose 2)? a, b No, the answers are:
- By writing a string literal as the first statement in the function
- By assigning a string to the function's .__doc__ attribute
EXPLANATION:
Docstrings document functions and other Python objects. A docstring is a
string literal that occurs as the first statement in a module, function,
class, or method definition. Such a docstring becomes the .__doc__ special
attribute of that object. See PEP 257 for more information.
There is no built-in @docstring decorator. Many functions naturally return
strings. Such a feature can therefore not be used for docstrings.
Python 测验应用程序的改进是累积的。请随意展开下面折叠的部分,查看包含所有新特性的完整源代码:
完整的questions.toml数据文件复制如下:
# questions.toml [[questions]] question = "When was the first known use of the word 'quiz'" answers = ["1781"] alternatives = ["1771", "1871", "1881"] [[questions]] question = "Which built-in function can get information from the user" answers = ["input"] alternatives = ["get", "print", "write"] [[questions]] question = "What's the purpose of the built-in zip() function" answers = ["To iterate over two or more sequences at the same time"] alternatives = [ "To combine several strings into one", "To compress several files into one archive", "To get information from the user", ] [[questions]] question = "What does dict.get(key) return if key isn't found in dict" answers = ["None"] alternatives = ["key", "True", "False"] [[questions]] question = "How do you iterate over both indices and elements in an iterable" answers = ["enumerate(iterable)"] alternatives = [ "enumerate(iterable, start=1)", "range(iterable)", "range(iterable, start=1)", ] [[questions]] question = "What's the official name of the := operator" answers = ["Assignment expression"] alternatives = ["Named expression", "Walrus operator", "Colon equals operator"] [[questions]] question = "What's one effect of calling random.seed(42)" answers = ["The random numbers are reproducible."] alternatives = [ "The random numbers are more random.", "The computer clock is reset.", "The first random number is always 42.", ] [[questions]] question = "When does __name__ == '__main__' equal True in a Python file" answers = ["When the file is run as a script"] alternatives = [ "When the file is imported as a module", "When the file has a valid name", "When the file only has one function", ] [[questions]] question = "Which version of Python is the first with TOML support built in" answers = ["3.11"] alternatives = ["3.9", "3.10", "3.12"] [[questions]] question = "What's the name of the list-like data structure in TOML" answers = ["Array"] alternatives = ["List", "Sequence", "Set"] [[questions]] question = "How can you run a Python script named quiz.py" answers = ["python quiz.py", "python -m quiz"] alternatives = ["python quiz", "python -m quiz.py"] hint = "One option uses the filename, and the other uses the module name." [[questions]] question = "What's a PEP" answers = ["A Python Enhancement Proposal"] alternatives = [ "A Pretty Exciting Policy", "A Preciously Evolved Python", "A Potentially Epic Prize", ] hint = "PEPs are used to evolve Python." explanation = """
Python Enhancement Proposals (PEPs) are design documents that provide
information to the Python community. PEPs are used to propose new features
for the Python language, to collect community input on an issue, and to
document design decisions made about the language.
""" [[questions]] question = "How can you add a docstring to a function" answers = [ "By writing a string literal as the first statement in the function", "By assigning a string to the function's .__doc__ attribute", ] alternatives = [ "By using the built-in @docstring decorator", "By returning a string from the function", ] hint = "They are parsed from your code and stored on the function object." explanation = """
Docstrings document functions and other Python objects. A docstring is a
string literal that occurs as the first statement in a module, function,
class, or method definition. Such a docstring becomes the .__doc__ special
attribute of that object. See PEP 257 for more information.
There is no built-in @docstring decorator. Many functions naturally return
strings. Such a feature can therefore not be used for docstrings.
"""
将该文件保存在与quiz.py相同的文件夹中。
下面列出了测验应用程序的完整源代码:
# quiz.py
import pathlib
import random
from string import ascii_lowercase
try:
import tomllib
except ModuleNotFoundError:
import tomli as tomllib
NUM_QUESTIONS_PER_QUIZ = 5
QUESTIONS_PATH = pathlib.Path(__file__).parent / "questions.toml"
def run_quiz():
questions = prepare_questions(
QUESTIONS_PATH, num_questions=NUM_QUESTIONS_PER_QUIZ
)
num_correct = 0
for num, question in enumerate(questions, start=1):
print(f"\nQuestion {num}:")
num_correct += ask_question(question)
print(f"\nYou got {num_correct} correct out of {num} questions")
def prepare_questions(path, num_questions):
questions = tomllib.loads(path.read_text())["questions"]
num_questions = min(num_questions, len(questions))
return random.sample(questions, k=num_questions)
def ask_question(question):
correct_answers = question["answers"]
alternatives = question["answers"] + question["alternatives"]
ordered_alternatives = random.sample(alternatives, k=len(alternatives))
answers = get_answers(
question=question["question"],
alternatives=ordered_alternatives,
num_choices=len(correct_answers),
hint=question.get("hint"),
)
if correct := (set(answers) == set(correct_answers)):
print("⭐ Correct! ⭐")
else:
is_or_are = " is" if len(correct_answers) == 1 else "s are"
print("\n- ".join([f"No, the answer{is_or_are}:"] + correct_answers))
if "explanation" in question:
print(f"\nEXPLANATION:\n{question['explanation']}")
return 1 if correct else 0
def get_answers(question, alternatives, num_choices=1, hint=None):
print(f"{question}?")
labeled_alternatives = dict(zip(ascii_lowercase, alternatives))
if hint:
labeled_alternatives["?"] = "Hint"
for label, alternative in labeled_alternatives.items():
print(f" {label}) {alternative}")
while True:
plural_s = "" if num_choices == 1 else f"s (choose {num_choices})"
answer = input(f"\nChoice{plural_s}? ")
answers = set(answer.replace(",", " ").split())
# Handle hints
if hint and "?" in answers:
print(f"\nHINT: {hint}")
continue
# Handle invalid answers
if len(answers) != num_choices:
plural_s = "" if num_choices == 1 else "s, separated by comma"
print(f"Please answer {num_choices} alternative{plural_s}")
continue
if any(
(invalid := answer) not in labeled_alternatives
for answer in answers
):
print(
f"{invalid!r} is not a valid choice. "
f"Please use {', '.join(labeled_alternatives)}"
)
continue
return [labeled_alternatives[answer] for answer in answers]
if __name__ == "__main__":
run_quiz()
使用python quiz.py运行您的应用程序。
在最后一步,您将添加另一个特性:在您的应用程序中支持几个测验主题。
第六步:支持几个测验题目
在本节中,您将进行最后一项改进,这将使您的 Python 测验应用程序更加有趣、多样和有趣。您将添加将问题分组到不同主题的选项,并让您的用户选择他们将被提问的主题。
Python 测验应用程序的最终版本将如下所示:
https://player.vimeo.com/video/717554866?background=1
更多的主题和新问题将使您的测验申请保持新鲜。点击下面并导航到source_code_final目录,查看添加这些内容后源代码的外观:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
TOML 文件中的节可以嵌套。您可以通过在节标题中添加句点(.)来创建嵌套表。作为一个说明性的例子,考虑下面的 TOML 文档:
>>> toml = """ ... [python] ... label = "Python" ... ... [python.version] ... number = "3.10" ... release.date = 2021-10-04 ... release.manager = "@pyblogsal" ... """ >>> import tomli >>> tomli.loads(toml) {'python': {'label': 'Python', 'version': { 'release': {'date': datetime.date(2021, 10, 4), 'manager': '@pyblogsal'}, 'number': '3.10'}}}这里,节头
[python.version]被表示为嵌套在python内的version。类似地,带句点的键也被解释为嵌套字典,如本例中的release所示。您可以重新组织
questions.toml,为每个主题包含一个部分。除了嵌套的questions数组,您将添加一个label键,为每个主题提供一个名称。更新您的数据文件以使用以下格式:# questions.toml [python] label = "Python" [[python.questions]] question = "How can you add a docstring to a function" answers = [ "By writing a string literal as the first statement in the function", "By assigning a string to the function's .__doc__ attribute", ] alternatives = [ "By using the built-in @docstring decorator", "By returning a string from the function", ] hint = "They're parsed from your code and stored on the function object." explanation = """ Docstrings document functions and other Python objects. A docstring is a string literal that occurs as the first statement in a module, function, class, or method definition. Such a docstring becomes the .__doc__ special attribute of that object. See PEP 257 for more information. There's no built-in @docstring decorator. Many functions naturally return strings. Such a feature can therefore not be used for docstrings. """ [[python.questions]] question = "When was the first public version of Python released?" answers = ["February 1991"] alternatives = ["January 1994", "October 2000", "December 2008"] hint = "The first public version was labeled version 0.9.0." explanation = """ Guido van Rossum started work on Python in December 1989\. He posted Python v0.9.0 to the alt.sources newsgroup in February 1991\. Python reached version 1.0.0 in January 1994\. The next major versions, Python 2.0 and Python 3.0, were released in October 2000 and December 2008, respectively. """ [capitals] label = "Capitals" [[capitals.questions]] question = "What's the capital of Norway" answers = ["Oslo"] hint = "Lars Onsager, Jens Stoltenberg, Trygve Lie, and Børge Ousland." alternatives = ["Stockholm", "Copenhagen", "Helsinki", "Reykjavik"] explanation = """ Oslo was founded as a city in the 11th century and established as a trading place. It became the capital of Norway in 1299\. The city was destroyed by a fire in 1624 and rebuilt as Christiania, named in honor of the reigning king. The city was renamed back to Oslo in 1925. """ [[capitals.questions]] question = "What's the state capital of Texas, USA" answers = ["Austin"] alternatives = ["Harrisburg", "Houston", "Galveston", "Columbia"] hint = "SciPy is held there each year." explanation = """ Austin is named in honor of Stephen F. Austin. It was purpose-built to be the capital of Texas and was incorporated in December 1839\. Houston, Harrisburg, Columbia, and Galveston are all earlier capitals of Texas. """现在,数据文件中包含了两个主题:Python 和 Capitals。在每个主题部分中,问题表的结构仍然和以前一样。这意味着你需要做的唯一改变就是你准备问题的方式。
你从阅读和解析
questions.toml开始。接下来,您挑选出每个主题并将其存储在一个新的临时字典中。你需要问用户他们想尝试哪个话题。幸运的是,您可以重用get_answers()来获得这方面的输入。最后,你挑出属于所选主题的问题,并把它们混在一起:# quiz.py # ... def prepare_questions(path, num_questions): topic_info = tomllib.loads(path.read_text()) topics = { topic["label"]: topic["questions"] for topic in topic_info.values() } topic_label = get_answers( question="Which topic do you want to be quizzed about", alternatives=sorted(topics), )[0] questions = topics[topic_label] num_questions = min(num_questions, len(questions)) return random.sample(questions, k=num_questions)
prepare_questions()返回的数据结构仍然和以前一样,所以不需要对run_quiz()、ask_question()或get_answers()做任何修改。当这些类型的更新只需要您编辑一个或几个函数时,这是一个好的迹象,表明您的代码结构良好,具有良好的抽象。运行 Python 测试应用程序。你会看到新的主题提示:
$ python quiz.py Which topic do you want to be quizzed about? a) Capitals b) Python Choice? a Question 1: What's the capital of Norway? a) Reykjavik b) Helsinki c) Stockholm d) Copenhagen e) Oslo ?) Hint Choice? ? HINT: Lars Onsager, Jens Stoltenberg, Trygve Lie, and Børge Ousland. Choice? e ⭐ Correct! ⭐ EXPLANATION: Oslo was founded as a city in the 11th century and established as a trading place. It became the capital of Norway in 1299\. The city was destroyed by a fire in 1624 and rebuilt as Christiania, named in honor of the reigning king. The city was renamed back to Oslo in 1925.这就结束了这个旅程的引导部分。您已经在终端中创建了一个强大的 Python 测验应用程序。您可以通过展开下面的框来查看完整的源代码以及问题列表:
完整的
questions.toml数据文件复制如下:# questions.toml [python] label = "Python" [[python.questions]] question = "When was the first known use of the word 'quiz'" answers = ["1781"] alternatives = ["1771", "1871", "1881"] [[python.questions]] question = "Which built-in function can get information from the user" answers = ["input"] alternatives = ["get", "print", "write"] [[python.questions]] question = "What's the purpose of the built-in zip() function" answers = ["To iterate over two or more sequences at the same time"] alternatives = [ "To combine several strings into one", "To compress several files into one archive", "To get information from the user", ] [[python.questions]] question = "What does dict.get(key) return if key isn't found in dict" answers = ["None"] alternatives = ["key", "True", "False"] [[python.questions]] question = "How do you iterate over both indices and elements in an iterable" answers = ["enumerate(iterable)"] alternatives = [ "enumerate(iterable, start=1)", "range(iterable)", "range(iterable, start=1)", ] [[python.questions]] question = "What's the official name of the := operator" answers = ["Assignment expression"] alternatives = [ "Named expression", "Walrus operator", "Colon equals operator", ] [[python.questions]] question = "What's one effect of calling random.seed(42)" answers = ["The random numbers are reproducible."] alternatives = [ "The random numbers are more random.", "The computer clock is reset.", "The first random number is always 42.", ] [[python.questions]] question = "Which version of Python is the first with TOML support built in" answers = ["3.11"] alternatives = ["3.9", "3.10", "3.12"] [[python.questions]] question = "How can you run a Python script named quiz.py" answers = ["python quiz.py", "python -m quiz"] alternatives = ["python quiz", "python -m quiz.py"] hint = "One option uses the filename, and the other uses the module name." [[python.questions]] question = "What's the name of the list-like data structure in TOML" answers = ["Array"] alternatives = ["List", "Sequence", "Set"] [[python.questions]] question = "What's a PEP" answers = ["A Python Enhancement Proposal"] alternatives = [ "A Pretty Exciting Policy", "A Preciously Evolved Python", "A Potentially Epic Prize", ] hint = "PEPs are used to evolve Python." explanation = """ Python Enhancement Proposals (PEPs) are design documents that provide information to the Python community. PEPs are used to propose new features for the Python language, to collect community input on an issue, and to document design decisions made about the language. """ [[python.questions]] question = "How can you add a docstring to a function" answers = [ "By writing a string literal as the first statement in the function", "By assigning a string to the function's .__doc__ attribute", ] alternatives = [ "By using the built-in @docstring decorator", "By returning a string from the function", ] hint = "They are parsed from your code and stored on the function object." explanation = """ Docstrings document functions and other Python objects. A docstring is a string literal that occurs as the first statement in a module, function, class, or method definition. Such a docstring becomes the .__doc__ special attribute of that object. See PEP 257 for more information. There's no built-in @docstring decorator. Many functions naturally return strings. Such a feature can therefore not be used for docstrings. """ [[python.questions]] question = "When was the first public version of Python released" answers = ["February 1991"] alternatives = ["January 1994", "October 2000", "December 2008"] hint = "The first public version was labeled version 0.9.0." explanation = """ Guido van Rossum started work on Python in December 1989\. He posted Python v0.9.0 to the alt.sources newsgroup in February 1991\. Python reached version 1.0.0 in January 1994\. The next major versions, Python 2.0 and Python 3.0, were released in October 2000 and December 2008, respectively. """ [capitals] label = "Capitals" [[capitals.questions]] question = "What's the capital of Norway" answers = ["Oslo"] hint = "Lars Onsager, Jens Stoltenberg, Trygve Lie, and Børge Ousland." alternatives = ["Stockholm", "Copenhagen", "Helsinki", "Reykjavik"] explanation = """ Oslo was founded as a city in the 11th century and established as a trading place. It became the capital of Norway in 1299\. The city was destroyed by a fire in 1624 and rebuilt as Christiania, named in honor of the reigning king. The city was renamed back to Oslo in 1925. """ [[capitals.questions]] question = "What's the state capital of Texas, USA" answers = ["Austin"] alternatives = ["Harrisburg", "Houston", "Galveston", "Columbia"] hint = "SciPy is held there each year." explanation = """ Austin is named in honor of Stephen F. Austin. It was purpose-built to be the capital of Texas and was incorporated in December 1839\. Houston, Harrisburg, Columbia, and Galveston are all earlier capitals of Texas. """将该文件保存在与
quiz.py相同的文件夹中。下面列出了您的测验应用程序的完整源代码:
# quiz.py import pathlib import random from string import ascii_lowercase try: import tomllib except ModuleNotFoundError: import tomli as tomllib NUM_QUESTIONS_PER_QUIZ = 5 QUESTIONS_PATH = pathlib.Path(__file__).parent / "questions.toml" def run_quiz(): questions = prepare_questions( QUESTIONS_PATH, num_questions=NUM_QUESTIONS_PER_QUIZ ) num_correct = 0 for num, question in enumerate(questions, start=1): print(f"\nQuestion {num}:") num_correct += ask_question(question) print(f"\nYou got {num_correct} correct out of {num} questions") def prepare_questions(path, num_questions): topic_info = tomllib.loads(path.read_text()) topics = { topic["label"]: topic["questions"] for topic in topic_info.values() } topic_label = get_answers( question="Which topic do you want to be quizzed about", alternatives=sorted(topics), )[0] questions = topics[topic_label] num_questions = min(num_questions, len(questions)) return random.sample(questions, k=num_questions) def ask_question(question): correct_answers = question["answers"] alternatives = question["answers"] + question["alternatives"] ordered_alternatives = random.sample(alternatives, k=len(alternatives)) answers = get_answers( question=question["question"], alternatives=ordered_alternatives, num_choices=len(correct_answers), hint=question.get("hint"), ) if correct := (set(answers) == set(correct_answers)): print("⭐ Correct! ⭐") else: is_or_are = " is" if len(correct_answers) == 1 else "s are" print("\n- ".join([f"No, the answer{is_or_are}:"] + correct_answers)) if "explanation" in question: print(f"\nEXPLANATION:\n{question['explanation']}") return 1 if correct else 0 def get_answers(question, alternatives, num_choices=1, hint=None): print(f"{question}?") labeled_alternatives = dict(zip(ascii_lowercase, alternatives)) if hint: labeled_alternatives["?"] = "Hint" for label, alternative in labeled_alternatives.items(): print(f" {label}) {alternative}") while True: plural_s = "" if num_choices == 1 else f"s (choose {num_choices})" answer = input(f"\nChoice{plural_s}? ") answers = set(answer.replace(",", " ").split()) # Handle hints if hint and "?" in answers: print(f"\nHINT: {hint}") continue # Handle invalid answers if len(answers) != num_choices: plural_s = "" if num_choices == 1 else "s, separated by comma" print(f"Please answer {num_choices} alternative{plural_s}") continue if any( (invalid := answer) not in labeled_alternatives for answer in answers ): print( f"{invalid!r} is not a valid choice. " f"Please use {', '.join(labeled_alternatives)}" ) continue return [labeled_alternatives[answer] for answer in answers] if __name__ == "__main__": run_quiz()使用
python quiz.py运行您的应用程序。您也可以通过单击下面的链接访问源代码和问题文件:
获取源代码: 单击此处获取您将用于构建测验应用程序的源代码。
您将在目录
source_code_final中找到应用程序的最终版本。结论
干得好!您已经用 Python 创建了一个灵活而有用的测验应用程序。在这个过程中,您已经了解了如何从一个基本脚本开始,然后将它构建成一个更复杂的程序。
在本教程中,您已经学会了如何:
- 在终端与用户交互
- 提高应用程序的可用性
- 重构你的应用程序,不断改进它
- 将数据存储在专用数据文件中
现在,去玩你的测验应用程序吧。自己补充一些问题,向朋友挑战。在下面的评论中分享你最好的问题和测验主题!
接下来的步骤
在本教程中,您已经创建了一个功能完善的测验应用程序。然而,这个项目仍然有很多改进的机会。
以下是一些关于附加功能的想法:
- 测验创建者:添加一个独立的应用程序,它可以交互地询问问题和答案,并以适当的 TOML 格式存储它们。
- 在数据库中存储数据:用合适的数据库替换 TOML 数据文件。
- 问题中心:在线创建一个你的应用程序可以连接的中央问题数据库。
- 多用户挑战:允许不同用户在一场琐事比赛中互相挑战。
您还可以重用这个测验应用程序中的逻辑,但是要改变前端表示层。也许你可以将这个项目转换成一个网络应用程序或者创建一个 T2 的抽认卡应用程序来帮助你准备考试。欢迎在下面的评论中分享你的进步。****************
在 Python 中生成随机数据(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 生成随机数据
随机有多随机?这是一个奇怪的问题,但在涉及信息安全的情况下,这是最重要的问题之一。每当你在 Python 中生成随机数据、字符串或数字时,最好至少对这些数据是如何生成的有一个大致的了解。
在这里,您将讨论在 Python 中生成随机数据的几种不同选择,然后从安全性、通用性、用途和速度的角度对每种选择进行比较。
我保证这篇教程不会是数学或密码学的课程,因为我一开始就没有能力讲授这些内容。你需要多少数学知识就有多少数学知识,不会更多。
随机有多随机?
首先,一个突出的免责声明是必要的。用 Python 生成的大多数随机数据在科学意义上并不是完全随机的。相反,它是伪随机:由伪随机数发生器(PRNG)生成,本质上是用于生成看似随机但仍可再现的数据的任何算法。
“真”随机数可以由真随机数发生器(TRNG)产生,你猜对了。一个例子是反复从地板上捡起一个骰子,把它抛向空中,让它以它可能的方式落地。
假设你的投掷是无偏的,你真的不知道骰子会落在哪个数字上。掷骰子是使用硬件产生一个不确定的数字的一种原始形式。(或者,您可以让 dice-o-matic 为您完成这项工作。)TRNGs 超出了本文的范围,但是为了便于比较,还是值得一提。
PRNGs 通常用软件而不是硬件来完成,工作方式略有不同。这里有一个简明的描述:
他们从一个被称为种子的随机数开始,然后使用一种算法基于它生成一个伪随机比特序列。(来源)
你可能被告知“阅读文件!”在某个时候。嗯,那些人没有错。这里有一个来自
random模块文档的特别值得注意的片段,你一定不想错过:警告:该模块的伪随机发生器不应用于安全目的。(来源)
你可能见过 Python 中的
random.seed(999)、random.seed(1234)之类的。这个函数调用正在播种 Python 的random模块使用的底层随机数生成器。正是这一点使得后续调用生成随机数具有确定性:输入 A 总是产生输出 b。如果被恶意使用,这种祝福也可能是一种诅咒。也许“随机”和“确定性”这两个术语看起来不能共存。为了让这一点更清楚,这里有一个极其精简的版本
random(),它通过使用x = (x * 3) % 19迭代地创建一个“随机”数。x最初被定义为一个种子值,然后根据该种子值变成一个确定的数字序列:class NotSoRandom(object): def seed(self, a=3): """Seed the world's most mysterious random number generator.""" self.seedval = a def random(self): """Look, random numbers!""" self.seedval = (self.seedval * 3) % 19 return self.seedval _inst = NotSoRandom() seed = _inst.seed random = _inst.random不要从字面上理解这个例子,因为它主要是为了说明这个概念。如果使用种子值 1234,那么对
random()的后续调用序列应该总是相同的:
>>> seed(1234)
>>> [random() for _ in range(10)]
[16, 10, 11, 14, 4, 12, 17, 13, 1, 3]
>>> seed(1234)
>>> [random() for _ in range(10)]
[16, 10, 11, 14, 4, 12, 17, 13, 1, 3]
您将很快看到一个更严肃的例子。
什么是“密码安全?”
如果你还没有受够“RNG”的缩写,让我们再加入一个:CSPRNG,或加密安全 PRNG。CSPRNGs 适用于生成敏感数据,如密码、授权码和令牌。给定一个随机字符串,恶意 Joe 实际上没有办法确定在随机字符串序列中哪个字符串在该字符串之前或之后。
你可能会看到的另一个术语是熵。简而言之,这指的是引入或期望的随机性的数量。例如,您将在这里讨论的一个 Python 模块定义了DEFAULT_ENTROPY = 32,默认情况下返回的字节数。开发人员认为这是“足够”的字节,足以产生足够的噪音。
注:在本教程中,我假设一个字节指的是 8 位,从 20 世纪 60 年代开始就是这样,而不是其他的数据存储单位。如果你愿意,你可以称之为 八位字节 。
关于 CSPRNGs 的一个关键点是它们仍然是伪随机的。它们是以某种内在确定性的方式设计的,但是它们添加了一些其他的变量或者具有一些属性,使得它们“足够随机”以禁止回退到任何实施确定性的函数。
您将在此介绍的内容
实际上,这意味着您应该使用普通 PRNGs 进行统计建模、模拟,并使随机数据可重复。稍后您会看到,它们也比 CSPRNGs 快得多。对于数据敏感性至关重要的安全和加密应用,请使用 CSPRNGs。
除了扩展上面的用例之外,在本教程中,您将深入研究使用 PRNGs 和 CSPRNGs 的 Python 工具:
- PRNG 选项包括 Python 标准库中的
random模块及其基于数组的对应 NumPy 模块numpy.random。 - Python 的
os、secrets和uuid模块包含生成加密安全对象的函数。
您将触及以上所有内容,并以一个高层次的比较结束。
Python 中的 PRNGs
random模块
可能 Python 中最广为人知的生成随机数据的工具是它的random模块,它使用梅森图 PRNG 算法作为其核心生成器。
早些时候,您简要地提到了random.seed(),现在是了解它如何工作的好时机。首先,让我们构建一些没有播种的随机数据。random.random()函数返回一个区间为[0.0,1.0]的随机浮点数。结果将总是小于右边的端点(1.0)。这也称为半开放范围:
>>> # Don't call `random.seed()` yet >>> import random >>> random.random() 0.35553263284394376 >>> random.random() 0.6101992345575074如果你自己运行这段代码,我敢用我一生的积蓄打赌,你的机器上返回的数字会不同。当你没有设置生成器的时候,默认设置是使用你当前的系统时间或者你操作系统中的一个“随机源”(如果有的话)。
使用
random.seed(),您可以使结果可重复,并且random.seed()之后的调用链将产生相同的数据轨迹:
>>> random.seed(444)
>>> random.random()
0.3088946587429545
>>> random.random()
0.01323751590501987
>>> random.seed(444) # Re-seed
>>> random.random()
0.3088946587429545
>>> random.random()
0.01323751590501987
注意“随机”数字的重复。随机数序列变得确定,或者完全由种子值确定,444。
让我们来看看random的一些更基本的功能。上面,您生成了一个随机的 float。您可以使用random.randint()函数在 Python 中的两个端点之间生成一个随机整数。这跨越整个[x,y]区间,并且可能包括两个端点:
>>> random.randint(0, 10) 7 >>> random.randint(500, 50000) 18601使用
random.randrange(),您可以排除区间的右侧,这意味着生成的数字始终位于[x,y]内,并且始终小于右端点:
>>> random.randrange(1, 10)
5
如果您需要生成位于特定[x,y]区间内的随机浮点数,您可以使用从连续均匀分布中选取的random.uniform():
>>> random.uniform(20, 30) 27.42639687016509 >>> random.uniform(30, 40) 36.33865802745107要从非空序列中挑选一个随机元素(比如一个列表或者一个元组,可以使用
random.choice()。还有random.choices()用于从序列中选择多个元素进行替换(可能是重复的):>>> items = ['one', 'two', 'three', 'four', 'five'] >>> random.choice(items) 'four' >>> random.choices(items, k=2) ['three', 'three'] >>> random.choices(items, k=3) ['three', 'five', 'four']要模拟取样而不更换,使用
random.sample():
>>> random.sample(items, 4)
['one', 'five', 'four', 'three']
您可以使用random.shuffle()就地随机化一个序列。这将修改序列对象并随机化元素的顺序:
>>> random.shuffle(items) >>> items ['four', 'three', 'two', 'one', 'five']如果你不想改变原始列表,你需要先做一个副本,然后打乱副本。您可以使用
copy模块创建 Python 列表的副本,或者只使用x[:]或x.copy(),其中x是列表。在继续使用 NumPy 生成随机数据之前,让我们看一个稍微复杂一点的应用程序:生成一个长度一致的唯一随机字符串序列。
首先考虑函数的设计会有所帮助。您需要从字母、数字和/或标点符号等字符“池”中进行选择,将它们组合成一个字符串,然后检查该字符串是否已经生成。Python
set非常适合这种类型的成员测试:import string def unique_strings(k: int, ntokens: int, pool: str=string.ascii_letters) -> set: """Generate a set of unique string tokens. k: Length of each token ntokens: Number of tokens pool: Iterable of characters to choose from For a highly optimized version: https://stackoverflow.com/a/48421303/7954504 """ seen = set() # An optimization for tightly-bound loops: # Bind these methods outside of a loop join = ''.join add = seen.add while len(seen) < ntokens: token = join(random.choices(pool, k=k)) add(token) return seen
''.join()将来自random.choices()的字母连接成一条长度为k的单个 Pythonstr。这个令牌被添加到集合中,集合不能包含重复的元素,并且while循环会一直执行,直到集合中的元素达到您指定的数量。资源 : Python 的
string模块包含了许多有用的常量:ascii_lowercase、ascii_uppercase、string.punctuation、ascii_whitespace以及其他一些常量。让我们试试这个功能:
>>> unique_strings(k=4, ntokens=5)
{'AsMk', 'Cvmi', 'GIxv', 'HGsZ', 'eurU'}
>>> unique_strings(5, 4, string.printable)
{"'O*1!", '9Ien%', 'W=m7<', 'mUD|z'}
对于这个函数的微调版本,这个堆栈溢出答案使用生成器函数、名称绑定和一些其他高级技巧来制作上面的unique_strings()的更快、更安全的版本。
数组的 prng:numpy.random
您可能已经注意到的一点是,random中的大多数函数都返回一个标量值(单个int、float或其他对象)。如果你想生成一个随机数序列,一种方法是用 Python 列表理解:
>>> [random.random() for _ in range(5)] [0.021655420657909374, 0.4031628347066195, 0.6609991871223335, 0.5854998250783767, 0.42886606317322706]但是有另一个选项是专门为此设计的。你可以认为 NumPy 自己的
numpy.random包就像标准库的random,但是对于 NumPy 数组。(它还具有从更多统计分布中提取数据的能力。)请注意,
numpy.random使用自己的 PRNG,与普通的老式random不同。您不会通过调用 Python 自己的random.seed()来产生确定随机的 NumPy 数组:
>>> import numpy as np
>>> np.random.seed(444)
>>> np.set_printoptions(precision=2) # Output decimal fmt.
事不宜迟,这里有几个例子可以吊起你的胃口:
>>> # Return samples from the standard normal distribution >>> np.random.randn(5) array([ 0.36, 0.38, 1.38, 1.18, -0.94]) >>> np.random.randn(3, 4) array([[-1.14, -0.54, -0.55, 0.21], [ 0.21, 1.27, -0.81, -3.3 ], [-0.81, -0.36, -0.88, 0.15]]) >>> # `p` is the probability of choosing each element >>> np.random.choice([0, 1], p=[0.6, 0.4], size=(5, 4)) array([[0, 0, 1, 0], [0, 1, 1, 1], [1, 1, 1, 0], [0, 0, 0, 1], [0, 1, 0, 1]])在
randn(d0, d1, ..., dn)的语法中,参数d0, d1, ..., dn是可选的,并指示最终对象的形状。这里,np.random.randn(3, 4)创建了一个 3 行 4 列的二维数组。数据将为 i.i.d. ,这意味着每个数据点都是独立于其他数据点绘制的。另一个常见的操作是创建一系列随机的布尔值、
True或False。一种方法是与np.random.choice([True, False])合作。然而,实际上从(0, 1)中选择然后将这些整数视图转换成它们相应的布尔值要快 4 倍:
>>> # NumPy's `randint` is [inclusive, exclusive), unlike `random.randint()`
>>> np.random.randint(0, 2, size=25, dtype=np.uint8).view(bool)
array([ True, False, True, True, False, True, False, False, False,
False, False, True, True, False, False, False, True, False,
True, False, True, True, True, False, True])
生成相关数据呢?假设您想要模拟两个相关的时间序列。一种方法是使用 NumPy 的 multivariate_normal() 函数,该函数考虑了协方差矩阵。换句话说,要从单个正态分布的随机变量中提取,您需要指定其均值和方差(或标准差)。
要从多元正态分布中进行采样,您需要指定均值和协方差矩阵,最终得到多个相关的数据序列,每个序列都近似正态分布。
然而,与协方差相比,相关性是一种对大多数人来说更熟悉和直观的度量。它是由标准差的乘积归一化的协方差,因此您也可以根据相关性和标准差来定义协方差:

那么,您能通过指定相关矩阵和标准偏差从多元正态分布中抽取随机样本吗?是的,但是你需要先把上面的变成矩阵形式。这里, S 是标准差的向量, P 是它们的相关矩阵, C 是结果(平方)协方差矩阵:

这可以用 NumPy 表示如下:
def corr2cov(p: np.ndarray, s: np.ndarray) -> np.ndarray:
"""Covariance matrix from correlation & standard deviations"""
d = np.diag(s)
return d @ p @ d
现在,您可以生成两个相关但仍然随机的时间序列:
>>> # Start with a correlation matrix and standard deviations. >>> # -0.40 is the correlation between A and B, and the correlation >>> # of a variable with itself is 1.0. >>> corr = np.array([[1., -0.40], ... [-0.40, 1.]]) >>> # Standard deviations/means of A and B, respectively >>> stdev = np.array([6., 1.]) >>> mean = np.array([2., 0.5]) >>> cov = corr2cov(corr, stdev) >>> # `size` is the length of time series for 2d data >>> # (500 months, days, and so on). >>> data = np.random.multivariate_normal(mean=mean, cov=cov, size=500) >>> data[:10] array([[ 0.58, 1.87], [-7.31, 0.74], [-6.24, 0.33], [-0.77, 1.19], [ 1.71, 0.7 ], [-3.33, 1.57], [-1.13, 1.23], [-6.58, 1.81], [-0.82, -0.34], [-2.32, 1.1 ]]) >>> data.shape (500, 2)你可以把
data想象成 500 对反向相关的数据点。这里有一个健全性检查,您可以返回到最初的输入,大约是上面的corr、stdev和mean:
>>> np.corrcoef(data, rowvar=False)
array([[ 1\. , -0.39],
[-0.39, 1\. ]])
>>> data.std(axis=0)
array([5.96, 1.01])
>>> data.mean(axis=0)
array([2.13, 0.49])
在继续讨论 CSPRNGs 之前,总结一些random函数及其对应的numpy.random函数可能会有所帮助:
Python random模块 |
NumPy 对应项 | 使用 |
|---|---|---|
random() |
T2rand() |
在[0.0,1.0]内随机浮动 |
randint(a, b) |
T2random_integers() |
[a,b]中的随机整数 |
randrange(a, b[, step]) |
T2randint() |
[a,b]中的随机整数 |
uniform(a, b) |
T2uniform() |
在[a,b]中随机浮动 |
choice(seq) |
T2choice() |
来自seq的随机元素 |
choices(seq, k=1) |
T2choice() |
替换来自seq的随机k元素 |
sample(population, k) |
choice() 同replace=False |
来自seq的随机k元素,无需替换 |
shuffle(x[, random]) |
T2shuffle() |
将序列x打乱到位 |
normalvariate(mu, sigma)或gauss(mu, sigma) |
T2normal() |
具有平均值mu和标准偏差sigma的正态分布样本 |
注意 : NumPy 专门用于构建和操作大型多维数组。如果只需要一个值,random就足够了,而且可能会更快。对于小序列,random甚至可能更快,因为 NumPy 确实会带来一些开销。
既然您已经介绍了 PRNGs 的两个基本选项,那么让我们转到几个更安全的适应选项。
Python 中的 c sprngs
os.urandom():尽可能随机
Python 的 os.urandom() 函数被 secrets 和 uuid 两者都使用(这两者你稍后会在这里看到)。os.urandom()不涉及太多细节,它生成依赖于操作系统的随机字节,可以安全地称为密码安全的:
-
在 Unix 操作系统上,它从特殊文件
/dev/urandom中读取随机字节,这反过来“允许访问从设备驱动程序和其他来源收集的环境噪声。”(谢谢,维基百科。)这是特定于某一时刻的硬件和系统状态的乱码信息,但同时具有足够的随机性。 -
在 Windows 上,使用 C++函数
CryptGenRandom()。这个函数在技术上仍然是伪随机的,但它通过从变量(如进程 ID、内存状态等)生成种子值来工作。
有了os.urandom(),就没有手动播种的概念了。虽然在技术上仍然是伪随机的,但这个函数更符合我们对随机性的看法。唯一的参数是要返回的字节的数量:
>>> os.urandom(3) b'\xa2\xe8\x02' >>> x = os.urandom(6) >>> x b'\xce\x11\xe7"!\x84' >>> type(x), len(x) (bytes, 6)在我们继续之前,这可能是一个很好的时间来深入研究一个关于字符编码的迷你课程。许多人,包括我自己,在看到
bytes物体和一长串\x字符时都会有某种类型的过敏反应。然而,了解像上面的x这样的序列最终如何变成字符串或数字是很有用的。
os.urandom()返回单字节序列:
>>> x
b'\xce\x11\xe7"!\x84'
但是这最终是如何变成 Python str或者数字序列的呢?
首先,回想一下计算的一个基本概念,即一个字节由 8 位组成。你可以把一个位想象成一个 0 或 1 的单个数字。一个字节有效地在 0 和 1 之间选择八次,所以01101100和11110000都可以表示字节。在您的解释器中,尝试使用 Python 3.6 中引入的 Python f 字符串:
>>> binary = [f'{i:0>8b}' for i in range(256)] >>> binary[:16] ['00000000', '00000001', '00000010', '00000011', '00000100', '00000101', '00000110', '00000111', '00001000', '00001001', '00001010', '00001011', '00001100', '00001101', '00001110', '00001111']这相当于
[bin(i) for i in range(256)],有一些特殊的格式。bin()将整数转换为二进制表示的字符串。这给我们留下了什么?使用上面的
range(256)不是随机选择。(无意双关。)假设我们有 8 位,每一位有 2 种选择,那么就有2 ** 8 == 256种可能的字节“组合”这意味着每个字节映射到一个 0 到 255 之间的整数。换句话说,我们需要 8 位以上来表示整数 256。您可以通过检查
len(f'{256:0>8b}')现在是 9,而不是 8 来验证这一点。好了,现在让我们回到上面看到的
bytes数据类型,通过构造一个对应于整数 0 到 255 的字节序列:
>>> bites = bytes(range(256))
如果您调用list(bites),您将返回一个从 0 到 255 的 Python 列表。但是如果你只是打印bites,你会得到一个难看的序列,里面布满了反斜杠:
>>> bites b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15' '\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJK' 'LMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86' '\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b' # ...这些反斜杠是转义序列,
\xhh代表十六进制值hh的字符。bites的一些元素按字面意思显示(可打印的字符,如字母、数字和标点)。大多数用转义来表达。\x08代表键盘的退格键,而\x13是一个回车符(在 Windows 系统上是新行的一部分)。如果你需要复习十六进制,Charles Petzold 的 代码:隐藏语言 是一个很好的地方。十六进制是一种以 16 为基数的计数系统,它不使用 0 到 9,而是使用 0 到 9 和 a 到 f 作为它的基本数字。
最后,让我们回到你开始的地方,随机字节序列
x。希望现在这能更有意义一点。在一个bytes对象上调用.hex()会给出一个十六进制数的str,每个对应一个从 0 到 255 的十进制数:
>>> x
b'\xce\x11\xe7"!\x84'
>>> list(x)
[206, 17, 231, 34, 33, 132]
>>> x.hex()
'ce11e7222184'
>>> len(x.hex())
12
最后一个问题:虽然x只有 6 个字节,但是b.hex()怎么会超过 12 个字符?这是因为两个十六进制数字正好对应一个字节。就我们的眼睛而言,bytes的str版本将永远是两倍长。
即使字节(如\x01)不需要一个完整的 8 位来表示,b.hex()也会一直使用每个字节两个十六进制数字,所以数字 1 会被表示为01而不仅仅是1。虽然从数学上来说,这两者的大小是一样的。
技术细节:这里你主要剖析的是bytes对象如何变成 Python str。另一个技术性问题是os.urandom()产生的bytes如何在区间【0.0,1.0】转换为float,就像random.random()的加密安全版本一样。如果您有兴趣进一步探索这个问题,这段代码片段演示了int.from_bytes()如何使用基数为 256 的计数系统进行整数的初始转换。
了解了这些之后,让我们来看看最近推出的模块secrets,它使得生成安全令牌变得更加用户友好。
Python 最好保存的secrets
在 Python 3.6 中由更加丰富多彩的 pep 之一引入的secrets模块旨在成为事实上的 Python 模块,用于生成加密安全的随机字节和字符串。
您可以查看该模块的源代码,它很短,只有 25 行代码。secrets基本上是围绕os.urandom()的一个包装器。它只导出了一些用于生成随机数、字节和字符串的函数。这些例子中的大多数应该是不言自明的:
>>> n = 16 >>> # Generate secure tokens >>> secrets.token_bytes(n) b'A\x8cz\xe1o\xf9!;\x8b\xf2\x80pJ\x8b\xd4\xd3' >>> secrets.token_hex(n) '9cb190491e01230ec4239cae643f286f' >>> secrets.token_urlsafe(n) 'MJoi7CknFu3YN41m88SEgQ' >>> # Secure version of `random.choice()` >>> secrets.choice('rain') 'a'现在,举个具体的例子怎么样?你可能已经使用过类似于tinyurl.com或 bit.ly 的网址缩写服务,它们将一个笨拙的网址变成类似于https://bit.ly/2IcCp9u的东西。大多数简化器从输入到输出不做任何复杂的散列;它们只是生成一个随机的字符串,确保这个字符串以前没有生成过,然后将它绑定到输入 URL。
假设看了一下根区域数据库,你已经注册了网站简称。这里有一个让您开始使用服务的功能:
# shortly.py from secrets import token_urlsafe DATABASE = {} def shorten(url: str, nbytes: int=5) -> str: ext = token_urlsafe(nbytes=nbytes) if ext in DATABASE: return shorten(url, nbytes=nbytes) else: DATABASE.update({ext: url}) return f'short.ly/{ext}这是一个丰满的真实例证吗?不。我敢打赌,bit.ly 做事情的方式比将其金矿存储在会话间不持久的全局 Python 字典中稍微高级一些。
注意:如果你想建立一个自己的成熟的网址缩短器,那么看看用 FastAPI 和 Python 建立一个网址缩短器。
然而,它在概念上大致准确:
>>> urls = (
... 'https://realpython.com/',
... 'https://docs.python.org/3/howto/regex.html'
... )
>>> for u in urls:
... print(shorten(u))
short.ly/p_Z4fLI
short.ly/fuxSyNY
>>> DATABASE
{'p_Z4fLI': 'https://realpython.com/',
'fuxSyNY': 'https://docs.python.org/3/howto/regex.html'}
稍等:您可能会注意到,当您请求 5 个字节时,这两个结果的长度都是 7。等等,我以为你说结果会是两倍长?嗯,不完全是,在这种情况下。这里还有一点:token_urlsafe()使用 base64 编码,每个字符是 6 位数据。(是 0 到 63,以及对应的字符。这些字符是 a-z、A-Z、0-9 和+/。)
如果您最初指定了一定数量的字节nbytes,那么从secrets.token_urlsafe(nbytes)得到的长度将是math.ceil(nbytes * 8 / 6),您可以用证明,如果您好奇的话,可以进一步研究。
这里的底线是,虽然secrets实际上只是现有 Python 函数的包装器,但是当安全性是您最关心的问题时,它可以是您的首选。
最后一名候选人:uuid
生成随机令牌的最后一个选项是 Python 的 uuid 模块中的uuid4()函数。一个 UUID 是一个全球唯一标识符,一个 128 位的序列(str长度为 32),旨在“保证跨空间和时间的唯一性”uuid4()是模块最有用的功能之一,这个功能也使用os.urandom()T10:
>>> import uuid >>> uuid.uuid4() UUID('3e3ef28d-3ff0-4933-9bba-e5ee91ce0e7b') >>> uuid.uuid4() UUID('2e115fcb-5761-4fa1-8287-19f4ee2877ac')好的一面是,
uuid的所有函数都产生了一个UUID类的实例,它封装了 ID 并具有类似于.int、.bytes和.hex的属性:
>>> tok = uuid.uuid4()
>>> tok.bytes
b'.\xb7\x80\xfd\xbfIG\xb3\xae\x1d\xe3\x97\xee\xc5\xd5\x81'
>>> len(tok.bytes)
16
>>> len(tok.bytes) * 8 # In bits
128
>>> tok.hex
'2eb780fdbf4947b3ae1de397eec5d581'
>>> tok.int
62097294383572614195530565389543396737
你可能还见过其他一些变体:uuid1()、uuid3()和uuid5()。这些函数与uuid4()的主要区别在于,这三个函数都采用某种形式的输入,因此不符合第 4 版 UUID 所定义的“随机”的程度:
-
uuid1()默认使用机器的主机 ID 和当前时间。由于对当前时间的依赖低至纳秒级的分辨率,这个版本是 UUID 得出“保证跨时间的唯一性”这一说法的地方 -
uuid3()和uuid5()都有一个名称空间标识符和一个名称。前者使用一个 MD5 散列,后者使用 SHA-1。
uuid4()相反,完全是伪随机的(或随机的)。它包括通过os.urandom()获得 16 个字节,将其转换成一个大端整数,并进行一些位操作以符合形式规范。
希望到现在为止,您已经很好地了解了不同“类型”的随机数据之间的区别以及如何创建它们。然而,可能想到的另一个问题是碰撞。
在这种情况下,冲突只是指生成两个匹配的 UUIDs。这种可能性有多大?嗯,从技术上讲,它不是零,但也许它足够接近:有2 ** 128或 340 个十亿分之一个可能的uuid4值。所以,我将由你来判断这是否足以保证睡个好觉。
uuid的一个常见用法是在 Django 中,它有一个 UUIDField ,通常用作模型底层关系数据库中的主键。
为什么不直接“默认为”SystemRandom?
除了这里讨论的安全模块如secrets,Python 的random模块实际上还有一个很少使用的类叫做 SystemRandom ,它使用了os.urandom()。(SystemRandom反过来也被secrets所利用。这是一个追溯到urandom()的网络。)
此时,您可能会问自己为什么不“默认”这个版本呢?为什么不“总是安全的”而不是默认使用不安全的确定性random函数呢?
我已经提到了一个原因:有时您希望您的数据是确定性的和可重复的,以便其他人遵循。
但是第二个原因是,至少在 Python 中,CSPRNGs 比 PRNGs 慢得多。让我们用一个脚本 timed.py 来测试一下,这个脚本使用 Python 的timeit.repeat()来比较randint()的 PRNG 和 CSPRNG 版本:
# timed.py
import random
import timeit
# The "default" random is actually an instance of `random.Random()`.
# The CSPRNG version uses `SystemRandom()` and `os.urandom()` in turn.
_sysrand = random.SystemRandom()
def prng() -> None:
random.randint(0, 95)
def csprng() -> None:
_sysrand.randint(0, 95)
setup = 'import random; from __main__ import prng, csprng'
if __name__ == '__main__':
print('Best of 3 trials with 1,000,000 loops per trial:')
for f in ('prng()', 'csprng()'):
best = min(timeit.repeat(f, setup=setup))
print('\t{:8s} {:0.2f} seconds total time.'.format(f, best))
现在从 shell 中执行这个命令:
$ python3 ./timed.py
Best of 3 trials with 1,000,000 loops per trial:
prng() 1.07 seconds total time.
csprng() 6.20 seconds total time.
当在两者之间进行选择时,除了加密安全性之外,5x 的时间差异当然是一个有效的考虑因素。
零零碎碎:杂凑
在本教程中没有得到太多关注的一个概念是散列,这可以用 Python 的 hashlib 模块来完成。
散列被设计成从输入值到固定大小的字符串的单向映射,这实际上是不可能反向工程的。因此,虽然散列函数的结果可能“看起来像”随机数据,但它并不真正符合这里的定义。
重述
在本教程中,您已经涉及了很多内容。概括地说,下面是 Python 中工程随机性可用选项的高级比较:
| 包装/模块 | 描述 | 密码安全 |
|---|---|---|
T2random |
快速和简单的随机数据使用梅森捻线机 | 不 |
T2numpy.random |
类似于random但是对于(可能是多维的)数组 |
不 |
T2os |
包含urandom(),此处涉及的其他函数的基础 |
是 |
T2secrets |
设计为 Python 的事实模块,用于生成安全的随机数、字节和字符串 | 是 |
T2uuid |
这是一些用于构建 128 位标识符的函数的家园 | 是的,uuid4() |
请随意在下面留下一些完全随机的评论,感谢您的阅读。
附加链接
- Random.org 向互联网上的任何人提供来自大气噪音的“真随机数”。
- 来自
random模块的食谱部分有一些额外的技巧。 - 关于墨西哥龙卷风的开创性论文发表于 1997 年,如果你对这类事情感兴趣的话。
- Itertools 配方定义了从组合集中随机选择的函数,例如从组合或排列中选择。
- Scikit-Learn 包括各种随机样本生成器,可用于构建大小和复杂性可控的人工数据集。
- Eli Bendersky 在他的文章中深入探讨了在 Python 中生成随机整数的慢速和快速方法。
- Peter Norvig 的《使用 Python 的概率的具体介绍》也是一个全面的资源。
- Pandas 库包括一个上下文管理器,可以用来设置一个临时的随机状态。
- 从堆栈溢出:
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 生成随机数据******
Python range()函数(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python range()函数
当你需要执行一个动作特定的次数时,Python 内置的 range 函数非常方便。作为一个有经验的 python 爱好者,你很可能以前用过它。但是它有什么用呢?
学完本指南后,您将:
- 理解 Python
range函数的工作原理 - 了解 Python 2 和 Python 3 中的实现有何不同
- 我看到了许多实际操作的例子
- 准备好解决它的一些限制
让我们开始吧!
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 的range()函数的历史
虽然 Python 2 中的range()和 Python 3 中的range()可能共用一个名字,但它们是完全不同的动物。事实上,Python 3 中的range()只是 Python 2 中一个名为xrange的函数的重命名版本。
最初,range()和xrange()都产生可以用 for 循环迭代的数字,但是前者一次产生这些数字的列表,而后者产生延迟的数字,这意味着数字在需要时一次返回一个。
庞大的列表会占用内存,所以用xrange()代替range()、name 等等也就不足为奇了。你可以在 PEP 3100 中了解更多关于这个决定和xrange() vs range()的背景。
注: PEP 代表 Python 增强提案。pep 是可以涵盖广泛主题的文档,包括提议的新特性、风格、治理和理念。
有很多这样的人。 PEP 1 解释了它们是如何工作的,这是一个很好的起点。
在本文的其余部分,您将使用 Python 3 中的函数。
开始了。
让我们循环
在我们深入了解range()如何工作之前,我们需要了解一下循环是如何工作的。循环是一个关键的计算机科学概念。如果你想成为一名优秀的程序员,掌握循环是你需要采取的第一步。
下面是 Python 中 for 循环的一个例子:
captains = ['Janeway', 'Picard', 'Sisko']
for captain in captains:
print(captain)
输出如下所示:
Janeway
Picard
Sisko
如您所见,for 循环使您能够执行特定的代码块,无论您想执行多少次。在这种情况下,我们循环遍历一个船长列表,并打印出他们每个人的名字。
尽管《星际迷航》很棒,但你可能想做的不仅仅是浏览船长名单。有时,您只想执行一段代码特定的次数。循环可以帮你做到这一点!
用能被 3 整除的数字尝试下面的代码:
numbers_divisible_by_three = [3, 6, 9, 12, 15]
for num in numbers_divisible_by_three:
quotient = num / 3
print(f"{num} divided by 3 is {int(quotient)}.")
该循环的输出将如下所示:
3 divided by 3 is 1.
6 divided by 3 is 2.
9 divided by 3 is 3.
12 divided by 3 is 4.
15 divided by 3 is 5.
这就是我们想要的输出,所以这个循环很好地完成了工作,但是还有一种方法可以通过使用range()得到相同的结果。
注意:最后一个代码示例有一些字符串格式。要了解这个主题的更多信息,您可以查看 Python 字符串格式最佳实践和 Python 3 的 f-Strings:一个改进的字符串格式语法(指南)。
现在你对循环已经比较熟悉了,让我们看看如何使用range()来简化你的生活。
Python range()基础知识
那么 Python 的range函数是如何工作的呢?简单来说,range()允许你在给定范围内生成一系列数字。根据传递给函数的参数数量,您可以决定一系列数字的开始和结束位置,以及一个数字和下一个数字之间的差异有多大。
下面先睹为快range()的行动:
for i in range(3, 16, 3):
quotient = i / 3
print(f"{i} divided by 3 is {int(quotient)}.")
在这个 for 循环中,您可以简单地创建一系列可以被3整除的数字,因此您不必自己提供每一个数字。
注意:虽然这个例子展示了range()的正确用法,但是在 for 循环中过于频繁地使用range()通常是不可取的。
例如,下面对range()的使用通常被认为不是 Pythonic 式的:
captains = ['Janeway', 'Picard', 'Sisko']
for i in range(len(captains)):
print(captains[i])
range()非常适合创建数字的可迭代项,但是当你需要迭代可以用 in操作符循环的数据时,它不是最佳选择。
如果你想知道更多,查看如何让你的 Python 循环更 Python 化。
有三种方法可以调用range():
range(stop)采用一个参数。range(start, stop)需要两个参数。range(start, stop, step)需要三个参数。
range(stop)
当您用一个参数调用range()时,您将得到一系列从0开始的数字,包括所有整数,但不包括您作为stop提供的数字。
实际情况是这样的:
for i in range(3):
print(i)
循环的输出将如下所示:
0
1
2
这表明:我们有从0到不包括3的所有整数,你提供的数字是stop。
range(start, stop)
当你用两个参数调用range()时,你不仅要决定数列在哪里结束,还要决定它从哪里开始,所以你不必总是从0开始。您可以使用range()生成一系列数字,从 A 到 B 使用一个range(A, B)。让我们看看如何生成从1开始的范围。
尝试用两个参数调用range():
for i in range(1, 8):
print(i)
您的输出将如下所示:
1
2
3
4
5
6
7
到目前为止,一切顺利:您拥有从1(您提供的作为start的数字)到不包括8(您提供的作为stop的数字)的所有整数。
但是如果您再添加一个参数,那么您将能够再现您在使用名为numbers_divisible_by_three的列表时得到的输出。
range(start, stop, step)
当你用三个参数调用range()时,你不仅可以选择数字序列的开始和结束位置,还可以选择一个数字和下一个数字之间的差异有多大。如果你不提供一个step,那么range()将自动表现为step就是1。
注意: step可以是正数,也可以是负数,但不能是0:
>>> range(1, 4, 0) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: range() arg 3 must not be zero如果你试图使用
0作为你的步骤,那么你会得到一个错误。现在你知道了如何使用
step,你终于可以重温我们之前看到的用3除的循环了。自己尝试一下:
for i in range(3, 16, 3): quotient = i / 3 print(f"{i} divided by 3 is {int(quotient)}.")您的输出将与您在本文前面看到的 for 循环的输出完全一样,当时您使用了名为
numbers_divisible_by_three的列表:3 divided by 3 is 1. 6 divided by 3 is 2. 9 divided by 3 is 3. 12 divided by 3 is 4. 15 divided by 3 is 5.正如您在这个例子中看到的,您可以使用
step参数增加到一个更大的数字。这叫做递增。用
range()递增如果你想递增,那么你需要
step是一个正数。要了解这在实践中意味着什么,请键入以下代码:for i in range(3, 100, 25): print(i)如果您的
step是25,那么您的循环的输出将如下所示:3 28 53 78你得到了一系列的数字,每个数字都比前一个数字大了
25,即你提供的step。现在,您已经看到了如何在一个范围内前进,是时候看看如何后退了。
用
range()和递减如果你的
step是正的,那么你移动通过一系列增加的数字,并且正在增加。如果你的step是负的,那么你会经历一系列递减的数字,并且是递减的。这可以让你倒着看这些数字。在下面的例子中,你的
step是-2。这意味着每循环你将减少2:for i in range(10, -6, -2): print(i)递减循环的输出如下所示:
10 8 6 4 2 0 -2 -4你得到了一系列的数字,每一个都比前一个数字小了
2,即你提供的step的绝对值。创建递减范围的最有效方法是使用
range(start, stop, step)。但是 Python 确实内置了reversed函数。如果您将range()包装在reversed()中,那么可以以相反的顺序打印整数。试试这个:
for i in reversed(range(5)): print(i)你会得到这个:
4 3 2 1 0
range()可以遍历一个递减的数字序列,而reversed()通常用于以相反的顺序遍历一个序列。注:
reversed()也适用于弦乐。你可以在如何在 Python 中反转一个字符串中了解更多关于reversed()带字符串的功能。Python 的
range()函数的高级用法示例现在你已经知道了如何使用
range()的基本知识,是时候深入一点了。
range()主要用于两个目的:
- 执行特定次数的 for 循环体
- 创建比使用列表或元组更有效的整数可迭代表
第一种用法可能是最常见的,你可以证明 itertools 提供了一种比
range()更有效的构造可迭代对象的方法。在使用 range 时,还有几点需要记住。
range()是 Python 中的一种类型:
>>> type(range(3))
<class 'range'>
您可以通过索引访问range()中的项目,就像使用列表一样:
>>> range(3)[1] 1 >>> range(3)[2] 2您甚至可以在
range()上使用切片符号,但是 REPL 的输出乍一看可能有点奇怪:
>>> range(6)[2:5]
range(2, 5)
虽然这个输出看起来很奇怪,但是切分一个range()只是返回另一个range()。
您可以通过索引访问一个range()的元素并切片一个range()的事实凸显了一个重要的事实:range()是懒惰的,不像列表,但是不是迭代器。
浮动和range()
你可能已经注意到,到目前为止,我们处理的所有数字都是整数,也称为整数。那是因为range()只能接受整数作为参数。
关于浮动的一句话
在 Python 中,如果一个数不是整数,那么它就是浮点数。整数和浮点数之间有一些区别。
一个整数(int数据类型):
- 是一个整数
- 不包括小数点
- 可以是正的、负的或
0
浮点数(float数据类型):
- 可以是包含小数点的任何数字
- 可以是正面的,也可以是负面的
尝试用浮点数调用range(),看看会发生什么:
for i in range(3.3):
print(i)
您应该会看到以下错误消息:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'float' object cannot be interpreted as an integer
如果您需要找到一种允许您使用 floats 的变通方法,那么您可以使用 NumPy。
将range()与 NumPy 一起使用
NumPy 是第三方 Python 库。如果您打算使用 NumPy,您的第一步是检查您是否安装了它。
以下是如何在您的 REPL 中实现这一点:
>>> import numpy如果你得到了一个
ModuleNotFoundError,那么你需要安装它。为此,请在命令行中输入pip install numpy。安装好之后,输入以下内容:
import numpy as np np.arange(0.3, 1.6, 0.3)它将返回以下内容:
array([0.3, 0.6, 0.9, 1.2, 1.5])如果要在单独的行上打印每个数字,可以执行以下操作:
import numpy as np for i in np.arange(0.3, 1.6, 0.3): print(i)这是输出:
0.3 0.6 0.8999999999999999 1.2 1.5
0.8999999999999999从何而来?计算机很难将十进制浮点数保存为二进制浮点数。这导致了各种意想不到的数字表现。
注意:要了解更多关于为什么会有代表小数的问题,你可以查看这篇文章和 Python 文档。
您可能还想看看十进制库,它在性能和可读性方面有所下降,但允许您精确地表示十进制数。
另一个选择是使用
round(),你可以在如何在 Python 中舍入数字中读到更多。请记住,round()有自己的怪癖,可能会产生一些令人惊讶的结果!这些浮点错误对您来说是否是一个问题取决于您正在解决的问题。误差大约在小数点后第 16 位,这在大多数情况下是不重要的。它们是如此之小,除非你正在计算卫星轨道或其他东西,否则你不需要担心它。
或者,您也可以使用
np.linspace()。它本质上做同样的事情,但是使用不同的参数。使用np.linspace(),您可以指定start和end(包含两端)以及数组的长度(而不是step)。例如,
np.linspace(1, 4, 20)给出 20 个等间距的数字:1.0, ..., 4.0。另一方面,np.linspace(0, 0.5, 51)给出了0.00, 0.01, 0.02, 0.03, ..., 0.49, 0.50。注:要了解更多信息,你可以阅读 Look Ma,No For-Loops:Array Programming With NumPy和这个方便的 NumPy 参考。
前进并循环
您现在了解了如何使用
range()并解决其局限性。您也知道这个重要的功能在 Python 2 和 Python 3 之间是如何发展的。下一次当你需要执行一个动作特定的次数时,你就可以全心投入了!
快乐的蟒蛇!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python range()函数******
在 Raspberry Pi 上用 Python 构建物理项目
Raspberry Pi 是市场上领先的物理计算板之一。从构建 DIY 项目的爱好者到第一次学习编程的学生,人们每天都在使用 Raspberry Pi 与周围的世界进行交互。Python 内置于 Raspberry Pi 之上,因此您可以利用您的技能,从今天开始构建您自己的 Raspberry Pi 项目。
在本教程中,您将学习:
- 设置新的树莓派
- 使用 Mu 编辑器或通过 SSH 远程运行 Python
- 从连接到 Raspberry Pi 的物理传感器读取输入
- 使用 Python 将输出发送到外部组件
- 在 Raspberry Pi 上使用 Python 创建独特的项目
我们开始吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
了解树莓派
树莓派是由英国慈善组织树莓派基金会开发的单板电脑。它最初旨在为年轻人提供一种负担得起的计算选择,以学习如何编程,由于其紧凑的尺寸、完整的 Linux 环境和通用输入输出( GPIO )引脚,它在制造商和 DIY 社区中拥有大量追随者。
这个小小的板中包含了所有的特性和功能,因此不缺少 Raspberry Pi 的项目和用例。
一些示例项目包括:
如果你能想到一个项目能从一个信用卡大小的电脑上受益,那么有人可能已经用树莓 Pi 来做了。Raspberry Pi 是将您的 Python 项目想法变为现实的一种奇妙方式。
Raspberry Pi 板概述
树莓派有多种外形规格用于不同的用例。在本教程中,你将看到最新版本的树莓派 4 。
下面是树莓 Pi 4 的电路板布局。虽然这种布局与以前的 Raspberry Pi 模型略有不同,但大多数连接是相同的。下一节中描述的设置对于 Raspberry Pi 3 和 Raspberry Pi 4 应该是相同的:
Raspberry Pi 4 板包含以下组件:
通用输入-输出引脚:这些引脚用于将 Raspberry Pi 连接到电子元件。
以太网端口:该端口将 Raspberry Pi 连接到有线网络。Raspberry Pi 还内置了 Wi-Fi 和蓝牙,用于无线连接。
两个 USB 3.0 和两个 USB 2.0 端口:这些 USB 端口用于连接键盘或鼠标等外设。两个黑色端口是 USB 2.0,两个蓝色端口是 USB 3.0。
AV 插孔:这个 AV 插孔可以让你把扬声器或者耳机连接到树莓 Pi 上。
相机模块端口:该端口用于连接官方树莓 Pi 相机模块,使树莓 Pi 能够捕捉图像。
HDMI 端口:这些 HDMI 端口将 Raspberry Pi 连接到外部显示器。Raspberry Pi 4 具有两个微型 HDMI 端口,允许它同时驱动两个独立的显示器。
USB 电源端口:这个 USB 端口给树莓 Pi 供电。树莓 Pi 4 有一个 USB Type-C 端口,而旧版本的 Pi 有一个微型 USB 端口。
外接显示端口:该端口用于连接官方七寸树莓派触摸显示屏,在树莓派上进行触控输入。
microSD 卡插槽(主板下方):此卡插槽用于包含 Raspberry Pi 操作系统和文件的 microSD 卡。
在本教程的稍后部分,您将使用上面的组件来设置您的 Raspberry Pi。
树莓派 vs Arduino
人们经常想知道树莓派和 Arduino 之间的区别。Arduino 是另一种广泛用于物理计算的设备。虽然 Arduino 和 Raspberry Pi 的功能有一些重叠,但也有一些明显的不同。
Arduino 平台为编程微控制器提供硬件和软件接口。微控制器是一个集成电路,它允许你从电子元件中读取输入并向其发送输出。Arduino 板通常内存有限,因此它们通常用于重复运行与电子设备交互的单个程序。
Raspberry Pi 是一种基于 Linux 的通用计算机。它有一个完整的操作系统和一个 GUI 界面,能够同时运行许多不同的程序。
Raspberry Pi 预装了各种软件,包括网络浏览器、办公套件、终端,甚至《我的世界》。Raspberry Pi 还内置了 Wi-Fi 和蓝牙,可以连接互联网和外部设备。
对于运行 Python 来说,Raspberry Pi 通常是更好的选择,因为您无需任何配置就可以获得完整的 Python 安装。
设置树莓派
不像 Arduino 只需要一根 USB 线和一台电脑来设置,Raspberry Pi 对启动和运行有更多的硬件要求。不过,在初始设置之后,其中一些外设将不再需要。
所需硬件
Raspberry Pi 的初始设置需要以下硬件。如果你最终通过 SSH 连接到你的 Raspberry Pi,你将在本教程的后面看到,那么下面的一些硬件在初始设置后将不再需要。
监视器
在操作系统的初始设置和配置过程中,您需要一台显示器。如果您将使用 SSH 连接到您的 Raspberry Pi,那么在设置后您将不再需要监视器。确保您的显示器有 HDMI 输入。
micross 卡
Raspberry Pi 使用 microSD 卡来存储操作系统和文件。如果你买了一个 Raspberry Pi kit ,那么它会包含一个预格式化的 microSD 卡供你使用。如果你单独购买 microSD 卡,那么你需要自己格式化它。找一个至少有 16GB 容量的 microSD 卡。
键盘和鼠标
在 Raspberry Pi 的初始设置期间,需要 USB 键盘和鼠标。设置完成后,如果您愿意,可以切换到使用这些外设的蓝牙版本。在本教程的后面,您将看到如何通过 SSH 连接到 Raspberry Pi。如果您选择以这种方式连接,那么在初始设置后就不需要物理键盘和鼠标了。
HDMI 线缆
你需要一根 HDMI 线将 Raspberry Pi 连接到显示器上。不同的 Raspberry Pi 型号有不同的 HDMI 电缆要求:
树莓 Pi 4 树莓派 3/2/1 树莓派零度 微型 HDMI 高清晰度多媒体接口 迷你 HDMI 微型 HDMI 转 HDMI HDMI 至 HDMI 迷你 HDMI 至 HDMI 根据您的型号,您可能需要购买特殊的 HDMI 电缆或适配器。
电源
Raspberry Pi 使用 USB 连接为电路板供电。同样,不同的 Raspberry Pi 型号有不同的 USB 连接和电源要求。
以下是不同型号的连接和电源要求:
树莓 Pi 4 树莓派 3/2/1/零 USB-C 微型 USB 至少 3.0 安培 至少 2.5 安培 为了避免在选择电源时出现任何混乱,建议您使用您的树莓 Pi 4 或其他型号的官方电源。
可选硬件
您可以在 Raspberry Pi 上使用一系列附加硬件来扩展它的功能。下面列出的硬件不是使用你的树莓派所必需的,但是手头有这些硬件会很有用。
案例
为你的树莓派准备一个盒子,让它的组件在正常使用过程中不受损坏,这很好。选择盒子时,请确保您购买的是适合您的覆盆子 Pi 型号的正确类型。
扬声器
如果你想用你的树莓派手机播放音乐或声音,那么你需要扬声器。这些可以是任何具有 3.5 毫米插孔的标准扬声器。您可以使用主板侧面的 AV 插孔将扬声器连接到树莓接口。
散热器(推荐)
树莓派可以用一块小小的板子做大量的计算。这也是它如此牛逼的原因之一!但这确实意味着有时天气会变得有点热。建议你购买一套散热器,以防止树莓派在过热时抑制 CPU 。
软件
Raspberry Pi 的操作系统存储在 microSD 卡上。如果你的卡不是来自官方的 Raspberry Pi 套件,那么你需要在上面安装操作系统。
有多种方法可以在您的 Raspberry Pi 上设置操作系统。你可以在 Raspberry Pi 网站上找到更多关于不同安装选项的信息。
在这一节中,您将看到安装官方支持的基于 Debian Linux 的 Raspberry Pi 操作系统的两种方法。
选项 1: Raspberry Pi 成像仪(推荐)
Raspberry Pi 基金会建议您使用 Raspberry Pi 成像仪对 SD 卡进行初始设置。您可以从 Raspberry Pi 下载页面下载成像仪。进入此页面后,下载适用于您的操作系统的版本:
下载 Raspberry Pi 成像仪后,启动应用程序。您将看到一个屏幕,允许您选择要安装的操作系统以及要格式化的 SD 卡:
第一次加载应用程序时会给你两个选项:选择 OS 和选择 SD 卡。选择先选择 OS 。
注意:【Windows 可能会阻止 Raspberry Pi 成像仪启动,因为它是一个无法识别的应用程序。如果你收到一个弹出窗口说 Windows 保护了你的电脑,那么你仍然可以通过点击更多信息并选择无论如何运行来运行应用程序。
应用程序运行时,点击选择操作系统按钮,选择第一个 Raspbian 选项:
选择 Raspbian 操作系统后,您需要选择您要使用的 SD 卡。确保您的 microSD 卡已插入电脑,点击选择 SD 卡,然后从菜单中选择 SD 卡:
选择操作系统和 SD 卡后,您现在可以点击 Write 按钮开始格式化 SD 卡并将操作系统安装到卡上。此过程可能需要几分钟才能完成:
格式化和安装完成后,您应该会看到一条消息,说明操作系统已写入 SD 卡:
您可以从电脑中弹出 SD 卡。Raspbian 现已安装在您的 SD 卡上,您可以开始将硬件连接到 Raspberry Pi 了!
选项 2:安装 NOOBS 的 Raspbian】
如果出于某种原因你不能使用 Raspberry Pi 成像仪,那么你可以下载 NOOBS (新的开箱即用软件)并用它在 microSD 卡上安装 Raspbian。首先,前往 NOOBS 下载页面下载最新版本。点击第一个 NOOBS 选项下方的下载 ZIP :
NOOBS 将开始在你的系统上下载。
注意:确保下载 NOOBS 和而不是 NOOBS 建兴。
下载完 ZIP 文件后,将内容解压缩到计算机上的某个位置。你很快就会将这些文件复制到 SD 卡上,但首先你需要正确格式化 SD 卡。
您将使用 SD 协会的官方 SD 存储卡格式器。前往 SD 协会网站下载格式化程序。滚动到底部,下载适用于 Windows 或 macOS 的 SD 格式化程序:
下载 SD 存储卡格式化程序后,您就可以格式化 SD 卡,以便在 Raspberry Pi 上使用。
注意: Linux 用户可以使用
fdisk对一个 microSD 卡进行分区并格式化成所需的 FAT32 磁盘格式。下载 SD 格式化程序后,打开应用程序。要格式化 SD 卡,您需要执行以下操作:
- 将 SD 卡插入电脑。
- 从选择卡下拉菜单中选择 SD 卡。
- 点击格式化选项下的快速格式化选项。
- 在卷标文本框中输入 NOOBS 。
以上项目完成后,点击格式化:
格式化卡之前,会要求您确认操作,因为这将抹掉卡上的所有数据。点击继续开始格式化 SD 卡。完成格式化可能需要几分钟时间:
一旦格式化完成,你需要将之前解压的 NOOBS 文件复制到 SD 卡上。选择您之前提取的所有文件:
将它们拖到 SD 卡上:
现在您已经在 SD 卡上安装了 NOOBS,请从电脑中弹出该卡。你就快到了!在下一节中,您将为您的 Raspberry Pi 做最后的设置。
最终设置
现在您已经准备好了 microSD 卡和所需的硬件,最后一步是将所有东西连接在一起并配置操作系统。让我们从连接所有外设开始:
- 将 microSD 卡插入 Raspberry Pi 底部的卡槽。
- 将键盘和鼠标连接到四个 USB 端口中的任何一个。
- 使用特定于您的 Raspberry Pi 型号的 HDMI 电缆将显示器连接到其中一个 HDMI 端口。
- 将电源连接到 USB 电源端口。
连接好外设后,打开 Raspberry Pi 的电源来配置操作系统。如果你用 Raspbian 安装了 Raspberry Pi 成像仪,那么你就没什么可做的了。您可以跳到下一节的来完成设置。
如果您在 SD 卡上安装了 NOOBS,那么您需要完成几个步骤来在 SD 卡上安装 Raspbian:
- 首先,打开 Raspberry Pi 来加载 NOOBS 接口。
- 然后,在要安装的软件列表中勾选 Raspbian 选项旁边的复选框。
- 最后点击界面左上角的安装按钮,开始在 SD 卡上安装 Raspbian。
一旦安装完成,Raspberry Pi 将重新启动,您将被引导到 Raspbian 以完成安装向导。
设置向导
在第一次启动时,Raspbian 会提供一个设置向导来帮助您配置密码、设置语言环境、选择 Wi-Fi 网络以及更新操作系统。继续并按照说明完成这些步骤。
一旦你完成了这些步骤,重启操作系统,你就可以开始在 Raspberry Pi 上编程 Python 了!
在 Raspberry Pi 上运行 Python
在 Raspberry Pi 上使用 Python 的最大好处之一就是 Python 是这个平台上的一等公民。Raspberry Pi 基金会特别选择 Python 作为主要语言,因为它功能强大、功能多样且易于使用。Python 预装在 Raspbian 上,因此您可以从一开始就做好准备。
在 Raspberry Pi 上编写 Python 有许多不同的选择。在本教程中,您将看到两种流行的选择:
- 使用管理部门编辑器
- 通过 SSH 远程编辑
让我们从使用 Mu 编辑器在 Raspberry Pi 上编写 Python 开始。
使用管理部门编辑器
Raspbian 操作系统附带了几个预安装的 Python IDEs,您可以使用它们来编写您的程序。其中一个 ide 就是 Mu 。它可以在主菜单中找到:
树莓派图标→编程→ Mu
当你第一次打开 Mu 时,你可以选择编辑器的 Python 模式。对于本教程中的代码,可以选择 Python 3 :
您的 Raspbian 版本可能没有预装 Mu。如果没有安装 Mu,那么您总是可以通过转到以下文件位置来安装它:
树莓派图标→偏好设置→推荐软件
这将打开一个对话框,其中包含为您的树莓 Pi 推荐的软件。勾选 Mu 旁边的复选框,点击 OK 进行安装:
虽然 Mu 提供了一个很好的编辑器来帮助你在 Raspberry Pi 上开始使用 Python,但是你可能想要一些更健壮的东西。在下一节中,您将通过 SSH 连接到您的 Raspberry Pi。
通过 SSH 远程编辑
通常你不会想花时间连接显示器、键盘和鼠标在 Raspberry Pi 上编写 Python。幸运的是,Raspbian 允许你通过 SSH 远程连接到 Raspberry Pi。在本节中,您将学习如何在 Raspberry Pi 上启用和使用 SSH 来编程 Python。
启用 SSH
在通过 SSH 连接到 Raspberry Pi 之前,您需要在 Raspberry Pi 偏好设置区域内启用 SSH 访问。通过转到以下文件路径启用 SSH:
树莓 Pi 图标→偏好设置→树莓 Pi 配置
出现配置后,选择接口选项卡,然后启用 SSH 选项:
您已经在 Raspberry Pi 上启用了 SSH。现在你需要获得树莓 Pi 的 IP 地址,这样你就可以从另一台电脑连接到它。
确定 Raspberry Pi 的 IP 地址
要远程访问 Raspberry Pi,您需要确定本地网络上 Raspberry Pi 的 IP 地址。要确定 IP 地址,需要访问终端应用。您可以在此处访问终端:
树莓派图标→配件→端子
终端打开后,在命令提示符下输入以下内容:
pi@raspberrypi:~ $ hostname -I这将显示您的 Raspberry Pi 的当前 IP 地址。有了这个 IP 地址,您现在可以远程连接到您的 Raspberry Pi。
连接到树莓派
使用 Raspberry Pi 的 IP 地址,您现在可以从另一台计算机 SSH 到它:
$ ssh pi@[IP ADDRESS]在 Raspbian 安装过程中,当运行设置向导时,系统会提示您输入您创建的密码。如果你没有设置密码,那么默认密码是
raspberry。输入密码,连接后您会看到 Raspberry Pi 命令提示符:pi@raspberrypi:~ $既然您已经知道了如何连接,您就可以开始在 Raspberry Pi 上编程 Python 了。您可以立即开始使用 Python REPL:
pi@raspberrypi:~ $ python3键入一些 Python 来在 Raspberry Pi 上运行它:

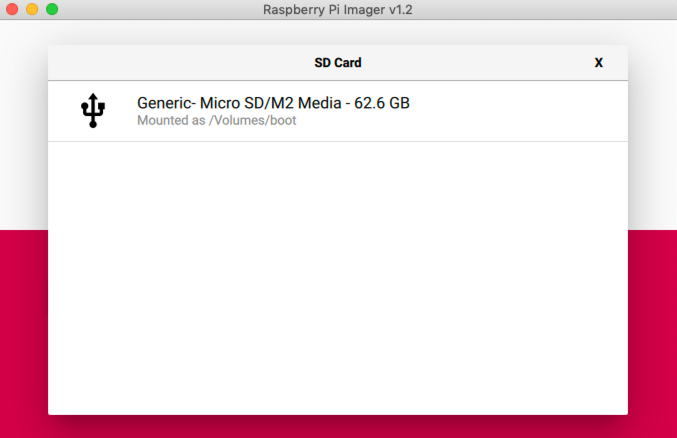



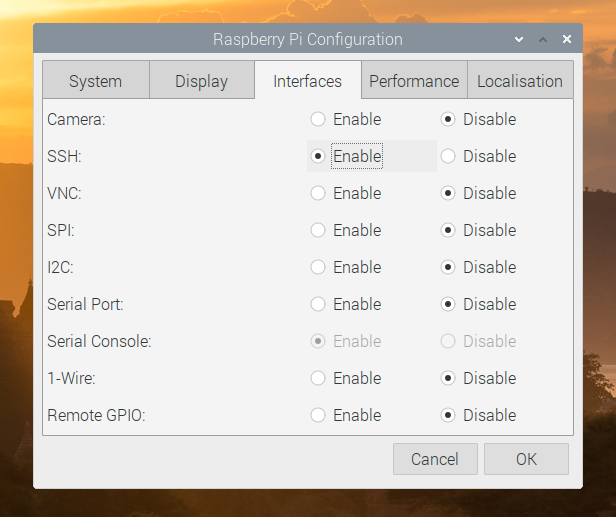
>>> print("Hello from your Raspberry Pi!")
Hello from your Raspberry Pi!
太棒了,你在树莓派上运行 Python!
创建一个python-projects目录
在您开始在 Raspberry Pi 上用 Python 构建项目之前,为您的代码建立一个专用目录是一个好主意。Raspberry Pi 有一个包含许多不同目录的完整文件系统。为您的 Python 代码保留一个位置将有助于保持一切井然有序并易于查找。
让我们创建一个名为python-projects的目录,您可以在其中存储项目的 Python 代码。
使用管理部门
如果您计划使用 Mu 来完成本教程中的项目,那么您现在可以使用它来创建python-projects目录。要创建这个目录,您需要执行以下操作:
- 进入树莓 Pi 图标→编程→ Mu 打开 Mu。
- 点击菜单栏中的新建创建一个空文件。
- 点击菜单栏中的保存。
- 在目录下拉列表中导航到
/home/pi目录。 - 点击右上角的新建文件夹图标。
- 将这个新目录命名为
python-projects并点击Enter。 - 点击取消关闭。
您已经为 Python 代码创建了一个专用目录。进入下一节,学习与 Python 中的物理组件交互。
通过 SSH
如果您更愿意使用 SSH 来访问您的 Raspberry Pi,那么您将使用命令行来创建python-projects目录。
注意:因为您将访问 Raspberry Pi 命令行,所以您需要使用命令行文本编辑器来编辑您的项目文件。
nano和vim都预装在 Raspbian 上,可以用来编辑项目文件。你也可以使用 VS 代码远程编辑 Raspberry Pi 上的文件,但是需要一些设置。
让我们创建python-projects目录。如果您当前没有登录到 Raspberry Pi,则使用 Raspberry Pi 的 IP 地址从您的计算机 SSH 到它:
$ ssh pi@[IP ADDRESS]
登录后,您将看到 Raspberry Pi 命令提示符:
pi@raspberry:~ $
默认情况下,当您 SSH 进入 Raspberry Pi 时,您将从/home/pi目录开始。现在通过运行pwd来确认这一点:
pi@raspberry:~ $ pwd
/home/pi
如果由于某种原因,您不在/home/pi目录中,那么使用cd /home/pi切换到该目录:
pi@raspberry:~/Desktop $ cd /home/pi
pi@raspberry:~ $ pwd
/home/pi
现在在/home/pi目录中,创建一个新的python-projects目录:
pi@raspberry:~ $ mkdir python-projects
创建了python-projects目录后,使用cd python-projects进入该目录:
pi@raspberry:~ $ cd python-projects
pi@raspberry:~/python-projects $
太好了!您已经准备好在 Raspberry Pi 上使用 Python 编写您的第一个电路了。
与物理组件交互
在本节中,您将学习如何在 Raspberry Pi 上使用 Python 与不同的物理组件进行交互。
您将使用 Raspbian 上预装的 gpiozero 库。它提供了一个易于使用的接口来与连接到 Raspberry Pi 的各种 GPIO 设备进行交互。
电子元件
在 Raspberry Pi 上编程之前,您需要一些电子组件来构建接下来几节中的项目。你应该可以在亚马逊或者当地的电子商店找到下面的每一件商品。
试验板
构建电路时,试验板是必不可少的工具。它允许您快速制作电路原型,而无需将元件焊接在一起。
试验板遵循一般布局。在右侧和左侧,两条导轨贯穿试验板的长度。这些铁轨上的每个洞都是相连的。通常,这些被指定为正(电压,或 VCC )和负(地,或 GND )。
在大多数试验板上,正轨标有正号(+),旁边会有一条红线。负轨标有负号(-),旁边有一条蓝线。
在电路板内部,元件轨道垂直于试验板侧面的正负轨道。这些轨道中的每一个都包含用于放置组件的孔。
单条轨道上的所有孔都是相连的。中间是一个槽,将试验板的两侧分开。檐槽相对两侧的栏杆没有连接。
下图对此进行了说明:
在上图中,三种颜色用于标记不同类型的试验板导轨:
- 红色:正轨
- 黑色:负轨
- 蓝色:部件导轨
在本教程的后面,您将使用这些不同的轨来构建连接到 Raspberry Pi 的完整电路。
跳线
跳线允许您制作电路连接的原型,而不必在 GPIO 引脚和元件之间焊接路径。它们有三种不同的类型:
在用 Python 构建 Raspberry Pi 项目时,每种类型至少有 10 到 20 个就很好了。
其他组件
除了试验板和跳线,本教程中的项目还将使用以下元件:
有了所需的组件,让我们看看如何使用 GPIO 引脚将它们连接到 Raspberry Pi。
GPIO 引脚
Raspberry Pi 沿电路板顶部边缘有 40 个 GPIO 引脚。您可以使用这些 GPIO 引脚将 Raspberry Pi 连接到外部元件。
下面的引脚布局显示了不同类型的引脚及其位置。此布局基于引脚俯视图,Raspberry Pi 的 USB 端口面向您:
Raspberry Pi 有五种不同类型的引脚:
- GPIO: 这些是通用引脚,可用于输入或输出。
- 3V3: 这些引脚为组件提供 3.3 V 电源。3.3 V 也是所有 GPIO 引脚提供的内部电压。
- 5V: 这些引脚提供 5V 电源,与为 Raspberry Pi 供电的 USB 电源输入相同。无源红外运动传感器等一些器件需要 5 V 电压。
- GND: 这些引脚为电路提供接地连接。
- ADV: 这些特殊用途的引脚是高级的,不在本教程中讨论。
在下一节中,您将使用这些不同的引脚类型来设置您的第一个组件,一个触觉按钮。
触觉按钮
在第一个电路中,你要将一个触觉按钮连接到树莓派上。触觉按钮是一个电子开关,当按下时,关闭电路。当电路闭合时,Raspberry Pi 将在信号上记录一个。你可以用这个 ON 信号来触发不同的动作。
在这个项目中,您将使用一个触觉按钮来根据按钮的状态运行不同的 Python 功能。让我们从将按钮连接到树莓派开始:
- 将树莓派的 GND 引脚的母到公跳线连接到试验板的负极轨。
- 在试验板中间的凹槽上放置一个触摸按钮。
- 将公对公跳线从试验板的负轨连接到按钮的左下腿所在的行。
- 将树莓 Pi 的 GPIO4 引脚的母到公跳线连接到按钮的右下腿所在的试验板行。
您可以通过下图确认您的接线:
现在您已经连接好了电路,让我们编写 Python 代码来读取按钮的输入。
注意:如果您在寻找特定引脚时遇到困难,那么在构建电路时,请确保参考 GPIO 引脚布局图。你也可以购买一个分线板来轻松进行实验。
在您之前创建的python-projects目录中,保存一个名为button.py的新文件。如果您使用 SSH 来访问您的 Raspberry Pi,那么创建如下文件:
pi@raspberrypi:~/ cd python-projects
pi@raspberrypi:~/python-projects $ touch button.py
如果您使用的是 Mu,那么按照以下步骤创建文件:
- 点击新建菜单项。
- 点击保存。
- 导航到
/home/pi/python-projects目录。 - 将文件另存为
button.py。
创建好文件后,您就可以开始编码了。从从gpiozero模块导入Button类开始。你还需要从signal模块导入pause。稍后你会看到为什么你需要pause:
from gpiozero import Button
from signal import pause
创建一个Button类的实例,并将 pin 号作为参数传递。在这种情况下,您使用的是 GPIO4 引脚,因此您将传入4作为参数:
button = Button(4)
接下来,定义在Button实例上可用的不同按钮事件将调用的函数:
def button_pressed():
print("Button was pressed")
def button_held():
print("Button was held")
def button_released():
print("Button was released")
Button类有三个事件属性:.when_pressed、.when_held和.when_released。这些属性可以用来连接不同的事件函数。
虽然.when_pressed和.when_released属性是不言自明的,但是.when_held需要一个简短的解释。如果一个函数被设置为.when_held属性,那么只有当按钮被按下并保持一定时间时,它才会被调用。
.when_held的保持时间由Button实例的.hold_time属性决定。.hold_time的默认值是一秒。您可以通过在创建一个Button实例时传递一个float值来覆盖它:
button = Button(4, hold_time=2.5)
button.when_held = button_held
这将创建一个Button实例,该实例将在按钮被按下并保持两秒半后调用button_held()函数。
现在您已经了解了Button上的不同事件属性,将它们分别设置为您之前定义的功能:
button.when_pressed = button_pressed
button.when_held = button_held
button.when_released = button_released
太好了!您已经设置了按钮事件。你需要做的最后一件事是调用文件末尾的pause()。需要调用pause()来保持程序监听不同的事件。如果不存在,那么程序将运行一次并退出。
您的最终程序应该是这样的:
from gpiozero import Button
from signal import pause
button = Button(4)
def button_pressed():
print("Button was pressed")
def button_held():
print("Button was held")
def button_released():
print("Button was released")
button.when_pressed = button_pressed
button.when_held = button_held
button.when_released = button_released
pause()
完成布线和设置代码后,您就可以测试您的第一个电路了。在python-projects目录中,运行程序:
pi@raspberrypi:~/python-projects $ python3 button.py
如果你使用的是 Mu,首先确保文件已经保存,然后点击运行启动程序。
程序现在正在运行并监听事件。按下按钮,您应该会在控制台中看到以下内容:
Button was pressed
按住按钮至少一秒钟,您应该会看到以下输出:
Button was held
最后,当您释放按钮时,您应该会看到以下内容:
Button was released
厉害!您刚刚在 Raspberry Pi 上使用 Python 连接并编码了您的第一个电路。
因为您在代码中使用了pause(),所以您需要手动停止程序。如果您正在 Mu 中运行程序,那么您可以点击停止来退出程序。如果你从命令行运行这个程序,那么你可以用 Ctrl + C 来停止程序。
有了第一个电路,你就可以开始控制其他一些组件了。
发光二极管
对于您的下一个电路,您将使用 Python 使 LED 每秒闪烁一次。 LED 代表发光二极管,这些元件通上电流就会发光。你会发现它们在电子产品中无处不在。
每个 LED 都有两条腿。较长的腿是正极腿,或阳极。电流通过这个引脚进入 LED。较短的腿是负腿,或阴极。电流通过此引脚流出 LED。
电流只能沿一个方向流过 LED,因此请确保将跳线连接到 LED 的正确引脚。
以下是为该电路布线需要采取的步骤:
-
将树莓派的 GND 引脚的母到公跳线连接到试验板的负极轨。
-
将一个 LED 放入试验板上相邻但不在同一行的两个孔中。
-
将 LED 的较长的正极引脚放入右侧的孔中。
-
将 LED 的较短的负极引脚放入左侧的孔中。
-
将330ω电阻器的一端放入与 LED 的负极引脚相同的试验板排的孔中。
-
将电阻器的另一端放入试验板的负极轨
-
将树莓 Pi 的 GPIO4 引脚的母到公跳线连接到与 LED 的正极引脚相同的试验板行中的孔。
您可以通过下图确认您的接线:
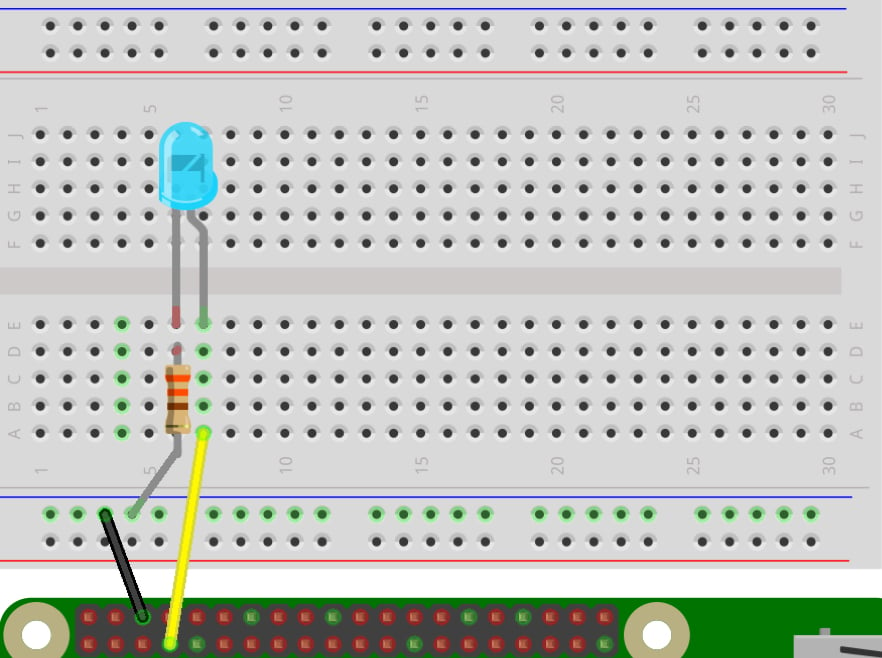
如果接线看起来不错,那么您就可以编写一些 Python 来让 LED 闪烁。首先在python-projects目录中为该电路创建一个文件。调用这个文件led.py:
pi@raspberrypi:~/python-projects $ touch led.py
在这段代码中,您将创建一个LED类的实例,并调用它的.blink()方法来使 LED 闪烁。.blink()方法的默认超时是一秒钟。LED 将继续每秒闪烁一次,直到程序退出。
从gpiozero模块导入LED,从signal模块导入pause开始:
from gpiozero import LED
from signal import pause
接下来,创建一个名为led的LED实例。将 GPIO 引脚设置为4:
led = LED(4)
在led上调用.blink()方法:
led.blink()
最后,添加对pause()的调用以确保程序不会退出:
pause()
您的完整程序应该如下所示:
from gpiozero import LED
from signal import pause
led = LED(4)
led.blink()
pause()
保存文件并运行它,查看 LED 的闪烁:
pi@raspberrypi:~/python-projects $ python3 led.py
LED 现在应该每秒闪烁一次。当你欣赏完运行中的 Python 代码后,在 Mu 中用 Ctrl + C 或 Stop 停止程序。
现在你知道如何在 Raspberry Pi 上用 Python 控制 LED 了。在下一个电路中,您将使用 Python 从 Raspberry Pi 中产生声音。
蜂鸣器
在这个电路中,你将把一个有源压电蜂鸣器连接到树莓派。当施加电流时,压电蜂鸣器发出声音。使用这个组件,您的树莓 Pi 将能够生成声音。
像发光二极管一样,蜂鸣器也有正极和负极。蜂鸣器的正极引线比负极引线长,或者蜂鸣器顶部有一个正极符号(+),表示哪条引线是正极引线。
让我们继续安装蜂鸣器:
-
在试验板上放置一个蜂鸣器,注意蜂鸣器的正极引脚的位置。
-
将树莓派的 GND 引脚的母到公跳线连接到与蜂鸣器的负极引脚相同的试验电路板排的孔中。
-
将树莓 Pi 的 GPIO4 引脚的母到公跳线连接到与蜂鸣器的正极引脚相同的试验板排的孔中。
对照下图确认您的接线:
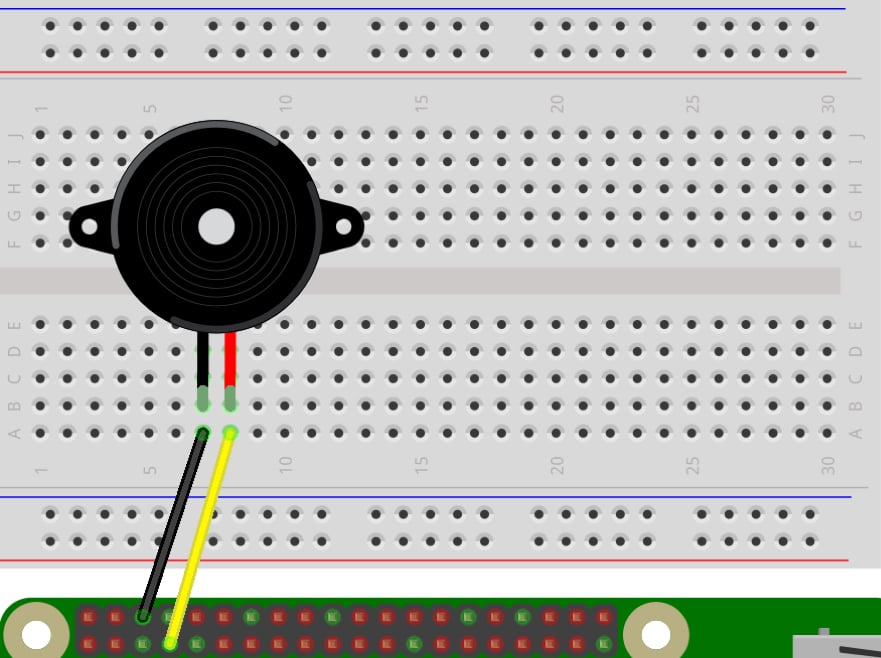
设置好线路后,让我们继续看代码。在python-projects目录下为该电路创建一个文件。调用这个文件buzzer.py:
pi@raspberrypi:~/python-projects $ touch buzzer.py
在这段代码中,您将创建一个Buzzer类的实例,并调用它的.beep()方法来使蜂鸣器发出嘟嘟声。.beep()方法的前两个参数是on_time和off_time。这些参数采用一个float值来设置蜂鸣器应该响多长时间。两者的默认值都是一秒。
从gpiozero模块导入Buzzer,从signal模块导入pause开始:
from gpiozero import Buzzer
from signal import pause
接下来,创建一个名为buzzer的Buzzer实例。将 GPIO 引脚设置为4:
buzzer = Buzzer(4)
在buzzer上调用.beep()方法。将on_time和off_time参数设置为0.5。这将使蜂鸣器每半秒发出一次蜂鸣声:
buzzer.beep(0.5, 0.5)
最后,添加对pause()的调用以确保程序不会退出:
pause()
您的完整程序应该如下所示:
from gpiozero import Buzzer
from signal import pause
buzzer = Buzzer(4)
buzzer.beep(0.5, 0.5)
pause()
保存文件并运行它,每半秒钟听到一次蜂鸣声:
pi@raspberrypi:~/python-projects $ python3 buzzer.py
在 Mu 中用 Ctrl + C 或 Stop 停止程序之前,应听到蜂鸣声时断时续。
注意:如果你正在使用 Mu,那么当你停止程序时,提示音有可能会继续。要停止声音,移除 GND 线以断开电路。
重新连接 GND 线时,如果声音仍然存在,您可能还需要重新启动 Mu。
太好了!到目前为止,您已经学习了如何在 Raspberry Pi 上用 Python 控制三种不同类型的电子组件。对于下一个电路,我们来看看一个稍微复杂一点的元件。
运动传感器
在这个电路中,你将把一个被动红外(PIR)运动传感器连接到树莓 Pi。被动红外运动传感器检测其视野内的任何运动,并将信号发送回 Raspberry Pi。
调整传感器
使用运动传感器时,您可能需要调整它对运动的敏感度,以及在检测到运动后多长时间发出信号。
您可以使用传感器侧面的两个刻度盘进行调整。你会知道它们是哪个拨号盘,因为它们的中心有一个十字形的凹痕,可以用十字螺丝刀调整。
下图显示了运动传感器侧面的这些转盘:

如图所示,左边的转盘设置信号超时,右边的转盘设置传感器灵敏度。你可以顺时针或逆时针转动这些刻度盘来调整它们:
- 顺时针增加超时和灵敏度。
- 逆时针减少超时和灵敏度。
您可以根据您的项目需要调整这些,但对于本教程来说,逆时针旋转两个转盘。这将把它们设置为最低值。
注意:有时候,一个运动传感器和一个树莓 Pi 3 不会正确地一起工作。这导致传感器偶尔出现误报。
如果你用的是 Raspberry Pi 3,那么一定要把传感器移动到离 Raspberry Pi 尽可能远的地方。
一旦你调整好了运动传感器,你就可以设置线路了。运动传感器的设计不允许它轻易连接到试验板。你需要用跳线将 Raspberry Pi 的 GPIO 引脚直接连接到运动传感器上的引脚。
下图显示了销在运动传感器下侧的位置:

你可以看到有三个引脚:
- VCC 为电压
- OUT 用于与树莓 Pi 通信
- GND 为地
使用这些引脚,您需要采取以下步骤:
- 将母到母跳线从树莓 Pi 的 5V 引脚连接到传感器的 VCC 引脚。
- 将一根母到母跳线从树莓 Pi 的 GPIO4 引脚连接到传感器的 OUT 引脚。
- 从树莓 Pi 的 GND 引脚到传感器的 GND 引脚连接母到母跳线。
现在用下图确认接线:
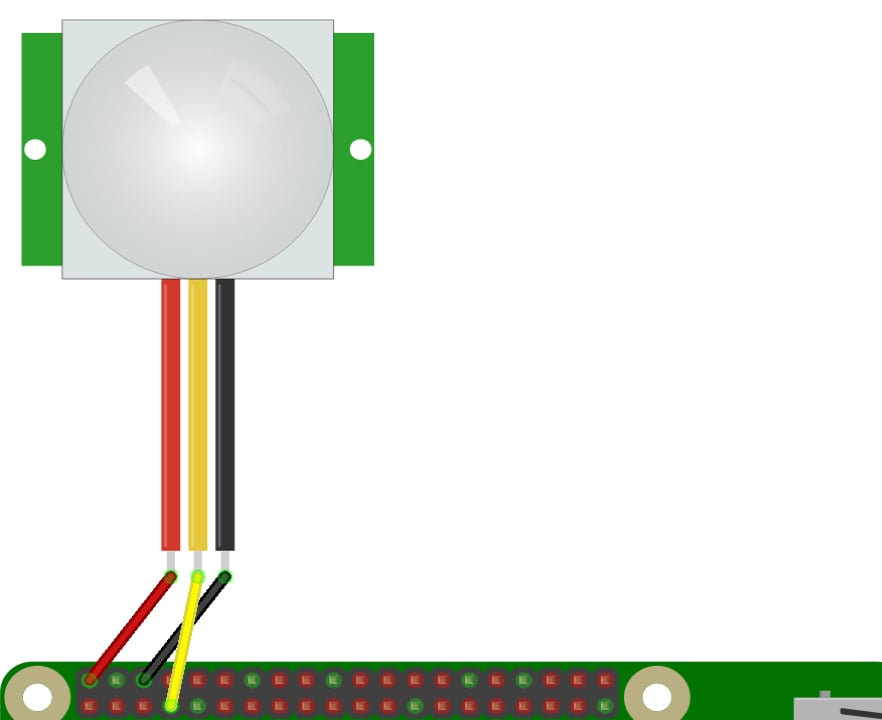
将运动传感器调整好并连接到 Raspberry PI 后,让我们来看看用于检测运动的 Python 代码。首先在python-projects目录下为这个电路创建一个文件。调用这个文件pir.py:
pi@raspberrypi:~/python-projects $ touch pir.py
该电路的代码将类似于您之前制作的按钮电路。您将创建一个MotionSensor类的实例,并将 GPIO 管脚号4作为参数传入。然后定义两个函数,并将它们设置为MotionSensor实例上的.when_motion和.when_no_motion属性。
让我们看一下代码:
from gpiozero import MotionSensor
from signal import pause
motion_sensor = MotionSensor(4)
def motion():
print("Motion detected")
def no_motion():
print("Motion stopped")
print("Readying sensor...")
motion_sensor.wait_for_no_motion()
print("Sensor ready")
motion_sensor.when_motion = motion
motion_sensor.when_no_motion = no_motion
pause()
motion()被设置为.when_motion属性,并在传感器检测到运动时调用。no_motion()被设置为.when_no_motion属性,并在运动停止一段时间后被调用。该时间由传感器侧面的超时刻度盘决定。
您会注意到,在设置.when_motion和.when_no_motion属性之前,在MotionSensor实例上有一个对.wait_for_no_motion()的调用。该方法将暂停代码的执行,直到运动传感器不再检测到任何运动。这是为了使传感器忽略程序启动时可能出现的任何初始运动。
注意:运动传感器有时可能过于敏感或不够敏感。如果您在运行上面的代码时在控制台中看到不一致的结果,那么请确保检查所有的连接都是正确的。您可能还需要调整传感器上的灵敏度旋钮。
如果您的结果在控制台中被延迟,那么尝试下调MotionSensor实例上的.threshold属性。默认值为 0.5:
pir = MotionSensor(4, threshold=0.2)
这将减少激活传感器所需的运动量。关于MotionSensor类的更多信息,参见 gpiozero 文档。
保存代码并运行它来测试您的运动检测电路:
pi@raspberrypi:~/python-projects $ python3 pir.py
Readying sensor...
Sensor ready
在传感器前挥动你的手。当第一次检测到运动时,调用motion(),控制台显示以下内容:
Motion detected
现在不要在传感器前挥动你的手。几秒钟后,将显示以下内容:
Motion stopped
太好了!你现在可以用你的树莓皮来探测运动了。一旦你完成了对你的树莓的挥手,继续在命令行中点击 Ctrl + C 或者在 Mu 中按 Stop 来终止程序。
通过这个最后的电路,您已经学会了如何在 Raspberry Pi 上使用 Python 来控制四个不同的组件。在下一节中,您将在一个完整的项目中将所有这些联系在一起。
建立一个运动激活报警系统
现在,您已经有机会将 Raspberry Pi 连接到各种输入和输出,您将创建一个使用您目前所学内容的项目。
在这个项目中,您将构建一个运动激活报警系统,当它检测到房间中的运动时,会闪烁 LED 并发出警报。在此基础上,您将使用 Python 将时间戳保存到 CSV 文件中,详细记录每次运动发生的时间。
布线
以下是完成接线的步骤:
-
将树莓派的 5V 和 GND 引脚的母到公跳线连接到试验板侧面的正极和负极轨道。
-
将 LED 放在试验板上,用母到公跳线将树莓 Pi 的 GPIO14 引脚连接到 LED。
-
通过一个330ω电阻将 LED 的负极引脚连接到试验板的负极轨。
-
将蜂鸣器放在试验板上,用母到公跳线将树莓 Pi 的 GPIO15 引脚连接到蜂鸣器。
-
用一根凸对凸跳线将蜂鸣器的负极脚连接到试验板的负极轨。
-
从试验板的正极轨到传感器的 VCC 引脚连接一根母到公跳线。
-
将一根母到母跳线从树莓 Pi 的 GPIO4 引脚连接到传感器的 OUT 引脚。
-
将母到公跳线从试验板的负轨连接到传感器的 GND 引脚。
根据下图确认接线:
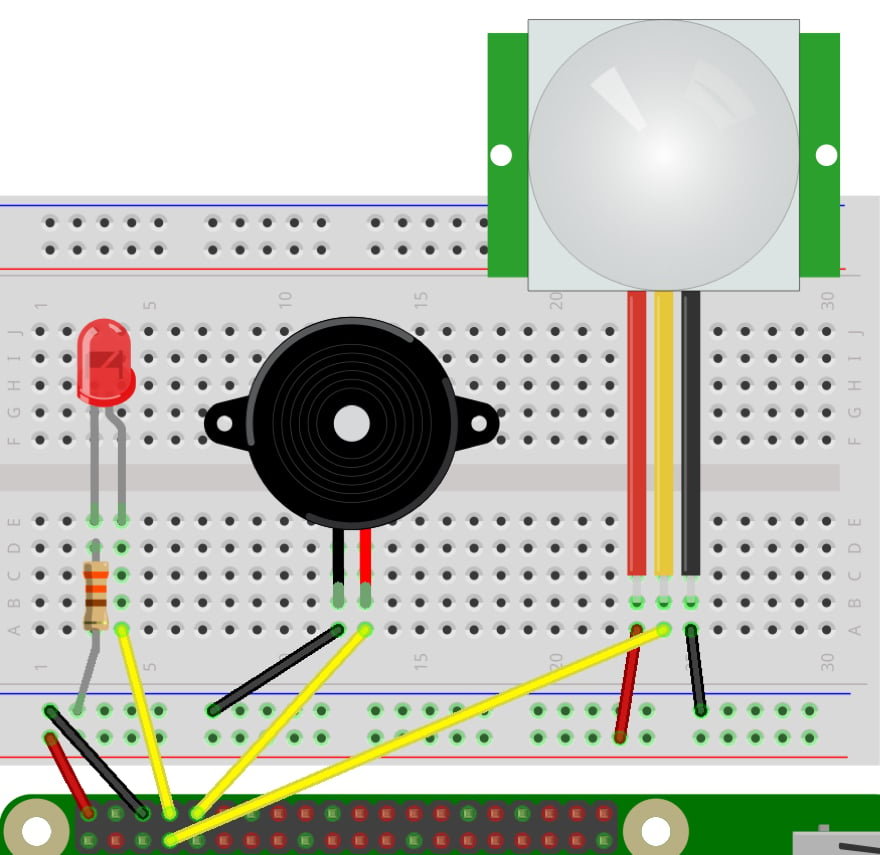
好了,现在你已经连接好了电路,让我们深入研究 Python 代码来设置你的运动激活报警系统。
代码
像往常一样,首先在python-projects目录中为这个项目创建一个文件。对于这个项目,调用这个文件motion_detector.py:
pi@raspberrypi:~/python-projects $ touch motion_detector.py
您要做的第一件事是导入csv模块,以便在检测到运动时保存时间戳。另外,从 pathlib 模块导入Path,这样你就可以引用你的 CSV 文件了:
import csv
from pathlib import Path
接下来,从的datetime模块中导入datetime,这样您就可以创建运动事件的时间戳:
from datetime import datetime
最后,从gpiozero导入所需的组件类,并从signal模块导入pause:
from gpiozero import LED, Buzzer, MotionSensor
from signal import pause
导入准备就绪后,您可以设置将要使用的三个电子组件。创建LED、Buzzer和MotionSensor类的实例。对于其中的每一个,将它们的 pin 号作为参数传入:
led = LED(14)
buzzer = Buzzer(15)
motion_sensor = MotionSensor(4)
接下来,定义 CSV 文件的位置,该文件将在每次检测到运动时存储时间戳。你就叫它detected_motion.csv。创建一个字典来保存将写入 CSV 的时间戳值:
output_csv_path = Path("detected_motion.csv")
motion = {
"start_time": None,
"end_time": None,
}
创建一个将时间戳数据保存到 CSV 文件的方法。首次创建文件时,会添加一个标题行:
def write_to_csv():
first_write = not output_csv_path.is_file()
with open(output_csv_path, "a") as file:
field_names = motion.keys()
writer = csv.DictWriter(file, field_names)
if first_write:
writer.writeheader()
writer.writerow(motion)
定义一个start_motion()函数。该函数将有几个行为:
- 开始每半秒闪烁一次
led - 使
buzzer发出嘟嘟声 - 将
start_time时间戳保存到motion字典中
添加对print()的调用,这样您就可以在程序运行时观察事件的发生:
def start_motion():
led.blink(0.5, 0.5)
buzzer.beep(0.5, 0.5)
motion["start_time"] = datetime.now()
print("motion detected")
然后定义一个具有以下行为的end_motion()函数:
- 关闭
led和buzzer - 保存
end_time时间戳 - 调用
write_to_csv()将运动数据保存到 CSV 文件 - 重置
motion字典
您还将在运行任何其他代码之前检查一个motion["start_time"]值是否存在。如果记录了一个start_time时间戳,您只希望写入 CSV:
def end_motion():
if motion["start_time"]:
led.off()
buzzer.off()
motion["end_time"] = datetime.now()
write_to_csv()
motion["start_time"] = None
motion["end_time"] = None
print("motion ended")
添加对.wait_for_no_motion()的调用,以便忽略任何初始运动:
print("Readying sensor...")
motion_sensor.wait_for_no_motion()
print("Sensor ready")
在MotionSensor实例上设置.when_motion和.when_no_motion属性:
motion_sensor.when_motion = start_motion
motion_sensor.when_no_motion = end_motion
最后,通过调用pause()来结束代码,以保持程序运行。完整的 Python 代码应该如下所示:
import csv
from pathlib import Path
from datetime import datetime
from gpiozero import LED, Buzzer, MotionSensor
from signal import pause
led = LED(14)
buzzer = Buzzer(15)
motion_sensor = MotionSensor(4)
output_csv_path = Path("detected_motion.csv")
motion = {
"start_time": None,
"end_time": None,
}
def write_to_csv():
first_write = not output_csv_path.is_file()
with open(output_csv_path, "a") as file:
field_names = motion.keys()
writer = csv.DictWriter(file, field_names)
if first_write:
writer.writeheader()
writer.writerow(motion)
def start_motion():
led.blink(0.5, 0.5)
buzzer.beep(0.5, 0.5)
motion["start_time"] = datetime.now()
print("motion detected")
def end_motion():
if motion["start_time"]:
led.off()
buzzer.off()
motion["end_time"] = datetime.now()
write_to_csv()
motion["start_time"] = None
motion["end_time"] = None
print("motion ended")
print("Readying sensor...")
motion_sensor.wait_for_no_motion()
print("Sensor ready")
motion_sensor.when_motion = start_motion
motion_sensor.when_no_motion = end_motion
pause()
保存文件并运行它来测试您的新运动检测器警报:
pi@raspberrypi:~/python-projects $ python3 motion_detector.py
Readying sensor...
Sensor ready
现在,如果你在运动检测器前挥动你的手,那么蜂鸣器应该开始发出蜂鸣声,LED 应该闪烁。如果你停止移动几秒钟,警报就会停止。在控制台中,您应该看到以下内容:
pi@raspberrypi:~/python-projects $ python3 motion_detector.py
Readying sensor...
Sensor ready
motion detected
motion ended
motion detected
motion ended
...
用 Mu 中的停止或 Ctrl + C 停止程序。让我们来看看生成的 CSV 文件:
pi@raspberrypi:~/python-projects $ cat detected_motion.csv
start_time,end_time
2020-04-21 10:53:07.052609,2020-04-21 10:53:13.966061
2020-04-21 10:56:56.477952,2020-04-21 10:57:03.490855
2020-04-21 10:57:04.693970,2020-04-21 10:57:12.007095
如您所见,运动的start_time和end_time的时间戳已经添加到 CSV 文件中。
恭喜你!您已经在 Raspberry Pi 上用 Python 创建了一个重要的电子项目。
接下来的步骤
你不必停在这里。通过在 Raspberry Pi 上利用 Python 的功能,有很多方法可以改进这个项目。
以下是提升这个项目的一些方法:
-
连接 Raspberry Pi 摄像头模块并让其在检测到运动时拍照。
-
将扬声器连接到树莓 Pi,并使用 PyGame 播放声音文件来恐吓入侵者。
-
在电路中添加一个按钮,允许用户手动开启或关闭运动检测。
有很多方法可以升级这个项目。让我们知道你想出了什么!
结论
树莓派是一个神奇的计算设备,而且越来越好。它的众多特性使其成为物理计算的首选设备。
在本教程中,您已经学会了如何:
- 设置一个 Raspberry Pi 并在上面运行 Python 代码
- 从传感器读取输入
- 将输出发送到电子元件
- 在 Raspberry Pi 上使用 Python 构建一个很酷的项目
Python 是 Raspberry Pi 的完美补充,利用您所学到的技能,您已经准备好处理酷的和创新的物理计算项目。我们迫不及待地想听听你的作品!**********
Python 中的递归:简介
如果您熟悉 Python 中的函数,那么您会知道一个函数调用另一个函数是很常见的。在 Python 中,函数也可以调用自己!一个调用自身的函数被称为递归,使用递归函数的技术被称为递归。
一个函数调用它自己可能看起来很奇怪,但是许多类型的编程问题最好用递归来表达。当你遇到这样的问题时,递归是你工具箱中不可或缺的工具。
本教程结束时,你会明白:
- 一个函数递归地调用自己意味着什么
- Python 函数的设计如何支持递归
- 当选择是否递归解决问题时,需要考虑哪些因素
- 如何用 Python 实现一个递归函数
然后,您将研究几个使用递归的 Python 编程问题,并将递归解决方案与可比较的非递归解决方案进行对比。
免费奖励: 从 Python 基础:Python 3 实用入门中获取一个示例章节,看看如何通过完整的课程(最新的 Python 3.9)从 Python 初学者过渡到中级。
什么是递归?
单词 recursion 来源于拉丁语 recurrere ,意思是奔跑或急速返回、返回、复原或重现。以下是递归的一些在线定义:
- :返回或往回跑的行为或过程
*** 根据一个对象本身定义该对象(通常是一个函数)的行为* 自由字典 : 一种定义对象序列的方法,例如表达式、函数或集合,其中给定一些初始对象,并且根据前面的对象定义每个连续的对象*
*递归定义是定义的术语出现在定义本身中。自我参照的情况经常在现实生活中突然出现,即使它们不能立即被识别出来。例如,假设您想要描述组成您祖先的一组人。你可以这样描述他们:

注意被定义的概念,祖先,是如何出现在它自己的定义中的。这是一个递归定义。
在编程中,递归有非常精确的含义。它指的是一种函数调用自身的编码技术。
为什么要用递归?
大多数编程问题不需要递归就可以解决。因此,严格地说,递归通常是不必要的。
然而,一些情况特别适合于自引用定义——例如,上面显示的祖先的定义。如果您正在设计一种算法来以编程方式处理这种情况,那么递归解决方案可能会更干净、更简洁。
遍历树状数据结构是另一个很好的例子。因为这些是嵌套结构,它们很容易符合递归定义。遍历嵌套结构的非递归算法可能有些笨拙,而递归解决方案则相对优雅。本教程后面会给出一个例子。
另一方面,递归并不适用于所有情况。以下是一些需要考虑的其他因素:
- 对于某些问题,递归解决方案虽然可行,但会显得笨拙而不优雅。
- 递归实现通常比非递归实现消耗更多的内存。
- 在某些情况下,使用递归可能会导致执行时间变慢。
通常,代码的可读性将是最大的决定因素。但要看情况。下面的例子可以帮助你了解什么时候应该选择递归。
Python 中的递归
当你在 Python 中调用一个函数时,解释器会创建一个新的本地名称空间,这样函数中定义的名字就不会与其他地方定义的相同名字冲突。一个函数可以调用另一个函数,即使它们都用相同的名字定义对象,一切都很好,因为这些对象存在于不同的名称空间。
如果同一功能的多个实例同时运行,情况也是如此。例如,考虑以下定义:
def function():
x = 10
function()
当function()第一次执行时,Python 创建一个名称空间,并在该名称空间中给x赋值10。然后function()递归调用自己。第二次function()运行时,解释器创建第二个名称空间,并在那里将10赋给x。名称x的这两个实例彼此不同,并且可以共存而不冲突,因为它们位于不同的名称空间中。
不幸的是,按照现状运行function()产生的结果并不令人鼓舞,正如下面的回溯所示:
>>> function() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in function File "<stdin>", line 3, in function File "<stdin>", line 3, in function [Previous line repeated 996 more times] RecursionError: maximum recursion depth exceeded正如所写的那样,
function()理论上会永远继续下去,一遍又一遍地调用自己,而没有任何调用会返回。当然,在实践中,没有什么是真正永恒的。你的电脑只有这么多内存,最终会用完的。Python 不允许这种情况发生。解释器限制了一个函数可以递归调用自己的最大次数,当它达到这个限制时,它会引发一个
RecursionError异常,如上所示。技术提示:你可以用来自
sys模块的一个名为getrecursionlimit()的函数来找出 Python 的递归极限:
>>> from sys import getrecursionlimit
>>> getrecursionlimit()
1000
你也可以用setrecursionlimit()来改变它:
>>> from sys import setrecursionlimit >>> setrecursionlimit(2000) >>> getrecursionlimit() 2000你可以把它设置得很大,但你不能把它无限放大。
对于一个函数来说,不加选择地无限制地递归调用自己是没有多大用处的。这让人想起你有时在洗发水瓶子上看到的说明:“起泡,冲洗,重复。”如果你真的按照这些说明去做,你会永远洗你的头发!
一些洗发水制造商显然发现了这一逻辑缺陷,因为一些洗发水瓶子上写着“起泡、冲洗,必要时重复*”这为指令提供了终止条件。据推测,你最终会觉得你的头发足够干净,认为额外的重复是不必要的。洗发可以停止了。
类似地,递归调用自身的函数必须有一个最终停止的计划。递归函数通常遵循以下模式:
- 有一个或多个不需要进一步递归就可以直接求解的基本情况。
- 每一次递归调用都使解决方案逐渐接近基本情况。
现在,您已经准备好通过一些示例来了解这是如何工作的。
开始:倒数到零
第一个例子是一个名为
countdown()的函数,它将一个正数作为参数,并打印从指定参数开始一直到零的数字:
>>> def countdown(n):
... print(n)
... if n == 0: ... return # Terminate recursion ... else:
... countdown(n - 1) # Recursive call ...
>>> countdown(5)
5
4
3
2
1
0
注意countdown()是如何符合上述递归算法的范例的:
- 基本情况发生在
n为零时,此时递归停止。 - 在递归调用中,参数比当前值
n小 1,因此每次递归都向基本情况靠近。
注意:为了简单起见,countdown()不检查它的参数的有效性。如果n不是整数或者是负数,你会得到一个RecursionError异常,因为基本情况永远不会发生。
上面显示的版本countdown()清楚地强调了基本情况和递归调用,但是有一种更简洁的方式来表达它:
def countdown(n):
print(n)
if n > 0:
countdown(n - 1)
下面是一个可能的非递归实现进行比较:
>>> def countdown(n): ... while n >= 0: ... print(n) ... n -= 1 ... >>> countdown(5) 5 4 3 2 1 0在这种情况下,非递归解决方案至少和递归解决方案一样清晰直观,甚至可能更清晰直观。
计算阶乘
下一个例子涉及到阶乘的数学概念。正整数 n 的阶乘,记为 n !,定义如下:
换句话说, n !是从 1 到 n 的所有整数的乘积,包括 1 和 T3。
阶乘非常适合递归定义,以至于编程文本几乎总是把它作为第一个例子。可以表达一下 n 的定义!像这样递归:
和上面的例子一样,有些基本情况不需要递归就可以解决。更复杂的情况是简化,这意味着它们简化为基本情况之一:
- 基本情况( n = 0 或 n = 1)无需递归即可求解。
- 对于大于 1 的 n 的值, n !是用( n - 1)来定义的!,所以递归解逐渐接近基本情况。
比如 4 的递归计算!看起来像这样:
Recursive Calculation of 4! 4 的计算!, 3!,和 2!暂停,直到算法到达 n = 1 的基本情况。此时,1!无需进一步递归即可计算,并且延迟的计算运行至完成。
定义一个 Python 阶乘函数
下面是一个计算阶乘的递归 Python 函数。请注意它有多简洁,以及它如何很好地反映了上面显示的定义:


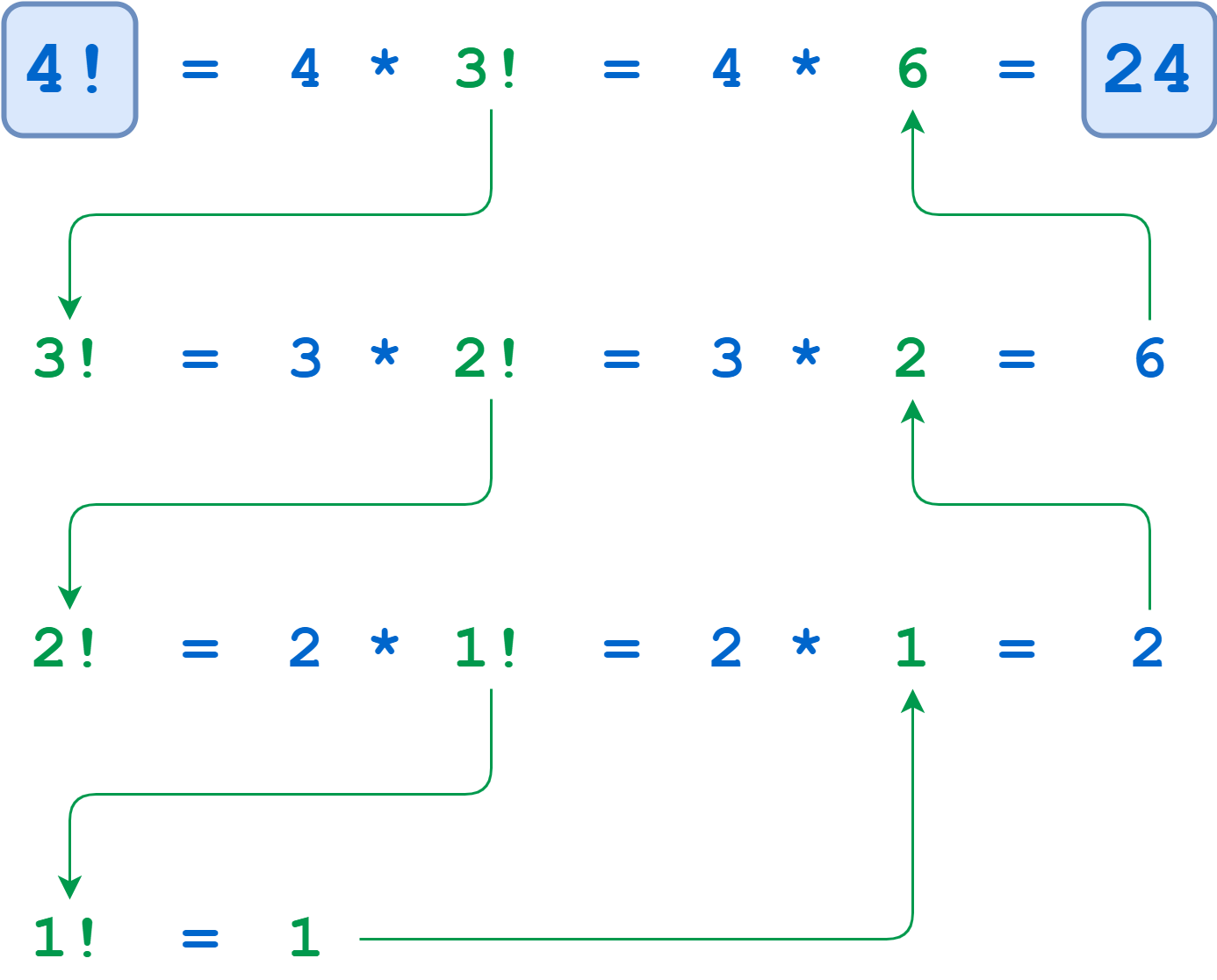
>>> def factorial(n):
... return 1 if n <= 1 else n * factorial(n - 1)
...
>>> factorial(4)
24
用一些 print() 语句稍微修饰一下这个函数,就可以更清楚地了解调用和返回序列:
>>> def factorial(n): ... print(f"factorial() called with n = {n}") ... return_value = 1 if n <= 1 else n * factorial(n -1) ... print(f"-> factorial({n}) returns {return_value}") ... return return_value ... >>> factorial(4) factorial() called with n = 4 factorial() called with n = 3 factorial() called with n = 2 factorial() called with n = 1 -> factorial(1) returns 1 -> factorial(2) returns 2 -> factorial(3) returns 6 -> factorial(4) returns 24 24注意所有的递归调用是如何堆积起来的。在任何调用返回之前,该函数会被连续调用
n=4、3、2和1。最后当n为1时,问题就可以解决了,不用再递归了。然后,每个堆叠的递归调用都展开,从最外层的调用返回1、2、6,最后是24。这里不需要递归。您可以使用一个
for循环迭代地实现factorial():
>>> def factorial(n):
... return_value = 1
... for i in range(2, n + 1):
... return_value *= i
... return return_value
...
>>> factorial(4)
24
你也可以使用 Python 的 reduce() 实现阶乘,你可以从functools模块导入:
>>> from functools import reduce >>> def factorial(n): ... return reduce(lambda x, y: x * y, range(1, n + 1) or [1]) ... >>> factorial(4) 24这再次表明,如果一个问题可以用递归来解决,也可能有几个可行的非递归解决方案。您通常会根据哪一个会产生可读性最强、最直观的代码来进行选择。
另一个要考虑的因素是执行速度。递归和非递归解决方案之间可能存在显著的性能差异。在下一节中,您将进一步探究这些差异。
阶乘实现的速度比较
要评估执行时间,您可以使用一个名为
timeit()的函数,该函数来自一个名为timeit的模块。该函数支持许多不同的格式,但在本教程中您将使用以下格式:timeit(<command>, setup=<setup_string>, number=<iterations>)
timeit()首先执行指定<setup_string>中包含的命令。然后它执行<command>给定数量的<iterations>,并以秒为单位报告累计执行时间:
>>> from timeit import timeit
>>> timeit("print(string)", setup="string='foobar'", number=100)
foobar
foobar
foobar
.
. [100 repetitions]
.
foobar
0.03347089999988384
这里,setup参数给string赋值'foobar'。然后timeit()打印string一百次。总执行时间刚刚超过 3/100 秒。
下面的例子使用timeit()来比较上面阶乘的递归、迭代和reduce()实现。在每种情况下,setup_string包含一个定义相关factorial()功能的设置字符串。timeit()然后总共执行factorial(4)一千万次,并报告总的执行情况。
首先,这是递归版本:
>>> setup_string = """ ... print("Recursive:") ... def factorial(n): ... return 1 if n <= 1 else n * factorial(n - 1) ... """ >>> from timeit import timeit >>> timeit("factorial(4)", setup=setup_string, number=10000000) Recursive: 4.957105500000125接下来是迭代实现:
>>> setup_string = """
... print("Iterative:")
... def factorial(n):
... return_value = 1
... for i in range(2, n + 1):
... return_value *= i
... return return_value
... """
>>> from timeit import timeit
>>> timeit("factorial(4)", setup=setup_string, number=10000000)
Iterative:
3.733752099999947
最后,这里是使用reduce()的版本:
>>> setup_string = """ ... from functools import reduce ... print("reduce():") ... def factorial(n): ... return reduce(lambda x, y: x * y, range(1, n + 1) or [1]) ... """ >>> from timeit import timeit >>> timeit("factorial(4)", setup=setup_string, number=10000000) reduce(): 8.101526299999932在这种情况下,迭代实现是最快的,尽管递归解决方案并不落后。使用
reduce()的方法最慢。如果您在自己的机器上尝试这些示例,您的里程数可能会有所不同。你肯定得不到同样的次数,甚至可能得不到同样的排名。有关系吗?迭代实现和使用
reduce()的实现在执行时间上有将近 4 秒的差异,但是需要 1000 万次调用才能看到。如果您将多次调用一个函数,那么在选择实现时,您可能需要考虑执行速度。另一方面,如果函数运行的频率相对较低,那么执行时间的差异可能可以忽略不计。在这种情况下,您最好选择能够最清楚地表达问题解决方案的实现。
对于阶乘,上面记录的时间表明递归实现是一个合理的选择。
坦率地说,如果你用 Python 编程,你根本不需要实现阶乘函数。它已经在标准
math模块中可用:
>>> from math import factorial
>>> factorial(4)
24
也许您会有兴趣知道它在计时测试中的表现:
>>> setup_string = "from math import factorial" >>> from timeit import timeit >>> timeit("factorial(4)", setup=setup_string, number=10000000) 0.3724050999999946哇!
math.factorial()的性能比上面显示的其他三种最好的实现要好大约 10 倍。技术提示:
math.factorial()快得多的事实可能与它是否递归实现无关。更有可能是因为这个函数是用 C 而不是 Python 实现的。有关 Python 和 C 的更多阅读资料,请参见以下资源:用 C 实现的函数实际上总是比用纯 Python 实现的相应函数要快。
遍历嵌套列表
下一个例子涉及到访问嵌套列表结构中的每一项。考虑下面的 Python 列表:
names = [ "Adam", [ "Bob", [ "Chet", "Cat", ], "Barb", "Bert" ], "Alex", [ "Bea", "Bill" ], "Ann" ]如下图所示,
names包含两个子列表。第一个子列表本身包含另一个子列表:
假设您想要计算这个列表中的叶元素的数量——最低级别的
str对象——就好像您已经展平了这个列表。叶子元素有"Adam"、"Bob"、"Chet"、"Cat"、"Barb"、"Bert"、"Alex"、"Bea"、"Bill"、"Ann",所以答案应该是10。仅仅在列表上调用
len()并不能给出正确答案:
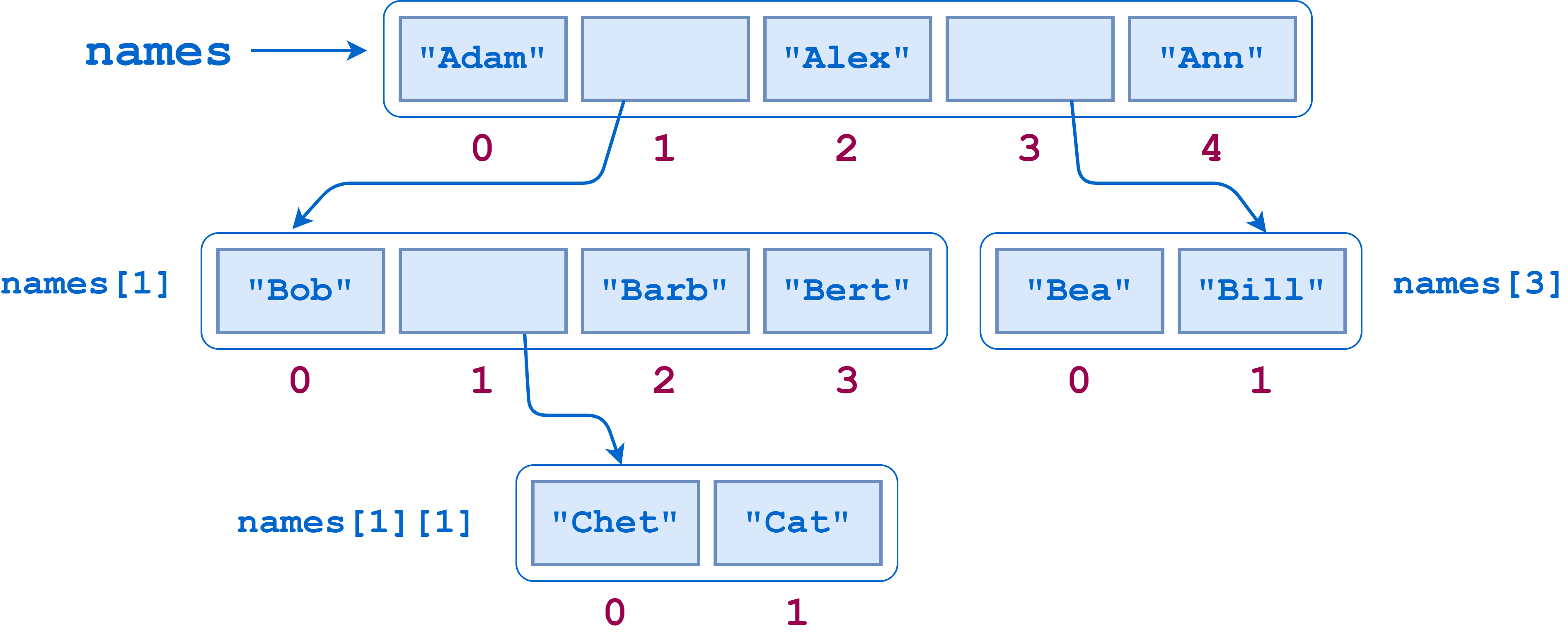
>>> len(names)
5
len()统计names顶层的对象,分别是三个叶子元素"Adam"、"Alex"、"Ann"和两个子列表["Bob", ["Chet", "Cat"], "Barb", "Bert"]和["Bea", "Bill"]:
>>> for index, item in enumerate(names): ... print(index, item) ... 0 Adam 1 ['Bob', ['Chet', 'Cat'], 'Barb', 'Bert'] 2 Alex 3 ['Bea', 'Bill'] 4 Ann这里需要的是一个遍历整个列表结构的函数,包括子列表。算法是这样的:
- 浏览列表,依次检查每一项。
- 如果您找到一个叶元素,那么将其添加到累计计数中。
- 如果遇到子列表,请执行以下操作:
- 下拉到子列表中,同样地遍历它。
- 一旦您用完了子列表,返回到上一步,将子列表中的元素添加到累计计数中,并从您停止的地方继续遍历父列表。
注意这个描述的自引用性质:遍历列表。如果你遇到一个子列表,那么类似地遍历列表。这种情况需要递归!
递归遍历嵌套列表
递归非常适合这个问题。要解决这个问题,您需要能够确定给定的列表项是否是叶项。为此,您可以使用内置的 Python 函数
isinstance()。在
names列表的情况下,如果一个条目是类型list的实例,那么它是一个子列表。否则,它是一个叶项目:
>>> names
['Adam', ['Bob', ['Chet', 'Cat'], 'Barb', 'Bert'], 'Alex', ['Bea', 'Bill'], 'Ann']
>>> names[0]
'Adam'
>>> isinstance(names[0], list)
False
>>> names[1]
['Bob', ['Chet', 'Cat'], 'Barb', 'Bert']
>>> isinstance(names[1], list)
True
>>> names[1][1]
['Chet', 'Cat']
>>> isinstance(names[1][1], list)
True
>>> names[1][1][0]
'Chet'
>>> isinstance(names[1][1][0], list)
False
现在您已经有了实现一个函数的工具,该函数计算列表中的叶元素,递归地考虑子列表:
def count_leaf_items(item_list):
"""Recursively counts and returns the
number of leaf items in a (potentially
nested) list.
"""
count = 0
for item in item_list:
if isinstance(item, list):
count += count_leaf_items(item)
else:
count += 1
return count
如果您在几个列表上运行count_leaf_items(),包括上面定义的names列表,您会得到:
>>> count_leaf_items([1, 2, 3, 4]) 4 >>> count_leaf_items([1, [2.1, 2.2], 3]) 4 >>> count_leaf_items([]) 0 >>> count_leaf_items(names) 10 >>> # Success!与阶乘示例一样,添加一些
print()语句有助于演示递归调用和返回值的顺序:1def count_leaf_items(item_list): 2 """Recursively counts and returns the 3 number of leaf items in a (potentially 4 nested) list. 5 """ 6 print(f"List: {item_list}") 7 count = 0 8 for item in item_list: 9 if isinstance(item, list): 10 print("Encountered sublist") 11 count += count_leaf_items(item) 12 else: 13 print(f"Counted leaf item \"{item}\"") 14 count += 1 15 16 print(f"-> Returning count {count}") 17 return count下面是上例中发生的事情的概要:
- 第 9 行:
isinstance(item, list)是True,所以count_leaf_items()找到了一个子列表。- 第 11 行:该函数递归地调用自身来计算子列表中的项目数,然后将结果加到累计总数中。
- 第 12 行:
isinstance(item, list)是False,所以count_leaf_items()遇到了一个叶项。- 第 14 行:该函数将累计总数加 1,以说明叶项目。
注意:为了简单起见,这个实现假设传递给
count_leaf_items()的列表只包含叶条目或子列表,而不包含任何其他类型的复合对象,如字典或元组。当在
names列表上执行时,来自count_leaf_items()的输出现在看起来像这样:
>>> count_leaf_items(names)
List: ['Adam', ['Bob', ['Chet', 'Cat'], 'Barb', 'Bert'], 'Alex', ['Bea', 'Bill'], 'Ann']
Counted leaf item "Adam"
Encountered sublist
List: ['Bob', ['Chet', 'Cat'], 'Barb', 'Bert']
Counted leaf item "Bob"
Encountered sublist
List: ['Chet', 'Cat']
Counted leaf item "Chet"
Counted leaf item "Cat"
-> Returning count 2
Counted leaf item "Barb"
Counted leaf item "Bert"
-> Returning count 5
Counted leaf item "Alex"
Encountered sublist
List: ['Bea', 'Bill']
Counted leaf item "Bea"
Counted leaf item "Bill"
-> Returning count 2
Counted leaf item "Ann"
-> Returning count 10
10
每次对count_leaf_items()的调用终止时,它都返回它在传递给它的列表中记录的叶子元素的数量。顶层调用返回10,这是应该的。
非递归遍历嵌套列表
像目前为止展示的其他例子一样,这个列表遍历不需要递归。也可以迭代完成。这里有一种可能性:
def count_leaf_items(item_list):
"""Non-recursively counts and returns the
number of leaf items in a (potentially
nested) list.
"""
count = 0
stack = []
current_list = item_list
i = 0
while True:
if i == len(current_list):
if current_list == item_list:
return count
else:
current_list, i = stack.pop()
i += 1
continue
if isinstance(current_list[i], list):
stack.append([current_list, i])
current_list = current_list[i]
i = 0
else:
count += 1
i += 1
如果您在前面显示的相同列表上运行这个非递归版本的count_leaf_items(),您会得到相同的结果:
>>> count_leaf_items([1, 2, 3, 4]) 4 >>> count_leaf_items([1, [2.1, 2.2], 3]) 4 >>> count_leaf_items([]) 0 >>> count_leaf_items(names) 10 >>> # Success!这里采用的策略是使用一个栈来处理嵌套的子列表。当这个版本的
count_leaf_items()遇到子列表时,它将当前正在进行的列表和该列表中的当前索引推到堆栈上。一旦对子列表计数完毕,函数就从堆栈中弹出父列表和索引,这样就可以从停止的地方继续计数。事实上,递归实现中也发生了本质上相同的事情。当您递归调用一个函数时,Python 将执行实例的状态保存在一个堆栈上,以便递归调用可以运行。当递归调用完成时,从堆栈中弹出状态,以便被中断的实例可以恢复。这是相同的概念,但是在递归解决方案中,Python 为您完成了状态保存工作。
请注意,与非递归版本相比,递归代码是多么的简洁和易读:
Recursive vs Non-Recursive Nested List Traversal 在这种情况下,使用递归绝对是一种优势。
检测回文
是否使用递归来解决问题的选择在很大程度上取决于问题的性质。例如,阶乘自然地转化为递归实现,但是迭代解决方案也非常简单。在那种情况下,可以说是胜负难分。
列表遍历问题是一个不同的故事。在这种情况下,递归解决方案非常优雅,而非递归解决方案则非常麻烦。
对于下一个问题,使用递归无疑是愚蠢的。
回文是一个反向读起来和正向读起来一样的单词。例子包括以下单词:
- 赛车
- 水平
- 皮船
- 使复活的人
- 公民的
如果让你设计一个算法来判断一个字符串是否是回文,你可能会想到类似“反转字符串,看看它是否和原来的一样。”没有比这更简单的了。
更有帮助的是,Python 的用于反转字符串的
[::-1]切片语法提供了一种方便的编码方式:
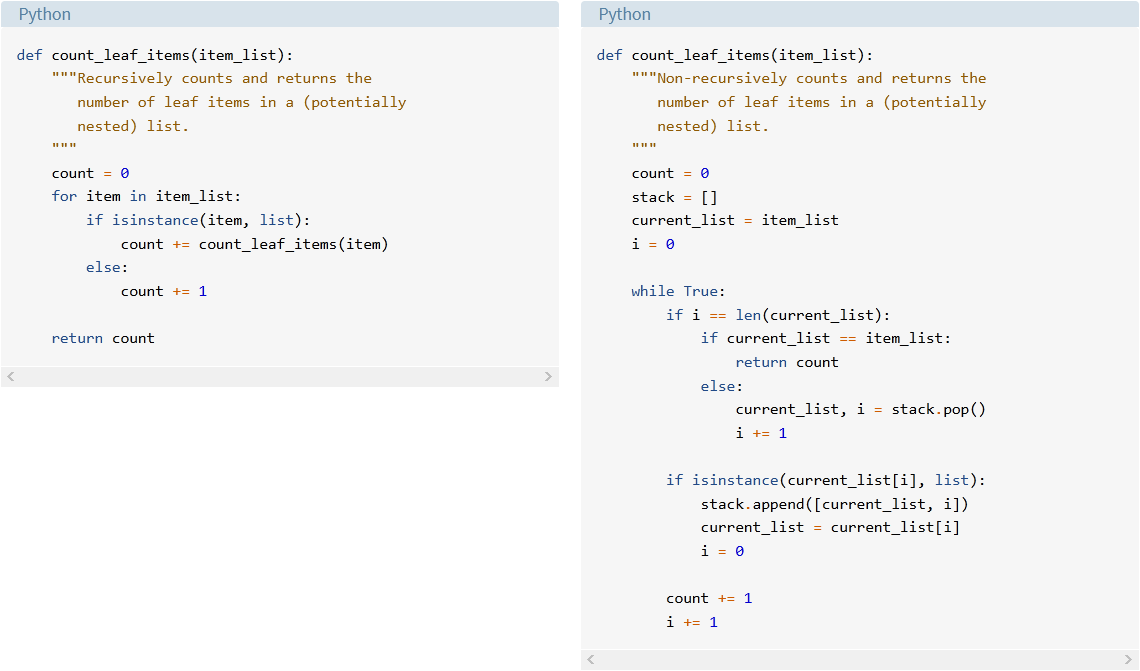
>>> def is_palindrome(word):
... """Return True if word is a palindrome, False if not."""
... return word == word[::-1]
...
>>> is_palindrome("foo")
False
>>> is_palindrome("racecar")
True
>>> is_palindrome("troglodyte")
False
>>> is_palindrome("civic")
True
这是清晰简洁的。几乎没有必要寻找替代方案。但是为了好玩,考虑一下这个回文的递归定义:
- 基本情况:空字符串和由单个字符组成的字符串本身就是回文。
- 归约递归:长度为 2 或更长的字符串是回文,如果它满足这两个条件:
- 第一个和最后一个字符是相同的。
- 第一个和最后一个字符之间的子串是一个回文。
切片也是你的朋友。对于字符串word,索引和切片给出了以下子字符串:
- 第一个角色是
word[0]。 - 最后一个字符是
word[-1]。 - 第一个和最后一个字符之间的子串是
word[1:-1]。
所以你可以像这样递归地定义is_palindrome():
>>> def is_palindrome(word): ... """Return True if word is a palindrome, False if not.""" ... if len(word) <= 1: ... return True ... else: ... return word[0] == word[-1] and is_palindrome(word[1:-1]) ... >>> # Base cases >>> is_palindrome("") True >>> is_palindrome("a") True >>> # Recursive cases >>> is_palindrome("foo") False >>> is_palindrome("racecar") True >>> is_palindrome("troglodyte") False >>> is_palindrome("civic") True递归思考是一种有趣的练习,即使不是特别必要。
使用快速排序进行排序
最后一个例子,像嵌套列表遍历一样,是一个很好的例子,很自然地暗示了递归方法。快速排序算法是一种高效的排序算法,由英国计算机科学家东尼·霍尔于 1959 年开发。
快速排序是一种分治算法。假设您有一个要排序的对象列表。首先在列表中选择一个项目,称为枢轴项目。这可以是列表中的任何项目。然后根据枢纽项将列表划分为两个子列表,并递归排序子列表。
该算法的步骤如下:
- 选择透视项目。
- 将列表分成两个子列表:
- 那些少于透视项目的项目
- 大于透视项的那些项
- 递归快速排序子列表。
每次划分都会产生更小的子列表,因此算法是简化的。基本情况发生在子列表为空或者只有一个元素的时候,因为这些元素是固有排序的。
选择枢纽项目
无论列表中的哪一项是透视项,快速排序算法都会起作用。但是有些选择比其他的更好。请记住,在进行分区时,会创建两个子列表:一个子列表中的项目少于 pivot 项目,另一个子列表中的项目多于 pivot 项目。理想情况下,两个子列表的长度大致相等。
假设您的初始排序列表包含八个项目。如果每个划分产生长度大致相等的子列表,那么您可以通过三个步骤达到基本情况:
Optimal Partitioning, Eight-Item List 另一方面,如果您选择的 pivot 项特别不吉利,每个分区都会产生一个包含除 pivot 项之外的所有原始项的子列表和另一个空的子列表。在这种情况下,需要七个步骤来将列表缩减为基本案例:
Suboptimal Partitioning, Eight-Item List 快速排序算法在第一种情况下会更有效。但是,为了系统地选择最佳的枢纽项目,您需要提前了解要排序的数据的性质。在任何情况下,没有任何一种选择对所有情况都是最好的。因此,如果您正在编写一个快速排序函数来处理一般情况,那么选择 pivot 项就有些随意了。
列表中的第一项是常见的选择,最后一项也是如此。如果列表中的数据是随机分布的,那么这些方法就可以很好地工作。但是,如果数据已经排序,或者几乎已经排序,那么这将导致如上所示的次优分区。为了避免这种情况,一些快速排序算法选择列表中的中间项作为透视项。
另一种选择是找到列表中第一、最后和中间项的中间值,并将其用作透视项。这是下面的示例代码中使用的策略。
实现分区
一旦选择了 pivot 项,下一步就是对列表进行分区。同样,目标是创建两个子列表,一个包含小于枢轴项的项目,另一个包含大于枢轴项的项目。
你可以直接就地完成。换句话说,通过交换项目,您可以随意移动列表中的项目,直到枢轴项目位于中间,所有较小的项目位于其左侧,所有较大的项目位于其右侧。然后,当您递归地快速排序子列表时,您将把列表的片段传递到 pivot 项的左边和右边。
或者,您可以使用 Python 的列表操作功能来创建新列表,而不是就地操作原始列表。这是下面代码中采用的方法。算法如下:
- 使用上述三中值方法选择透视项目。
- 使用透视项,创建三个子列表:
- 原始列表中少于透视项的项
- 枢纽项目本身
- 原始列表中大于透视项的项
- 递归快速排序列表 1 和 3。
- 将所有三个列表连接在一起。
请注意,这涉及到创建第三个子列表,其中包含 pivot 项本身。这种方法的一个优点是,它可以平稳地处理透视表项在列表中出现不止一次的情况。在这种情况下,列表 2 将有不止一个元素。
使用快速排序实现
现在基础工作已经就绪,您已经准备好进入快速排序算法了。以下是 Python 代码:
1import statistics 2 3def quicksort(numbers): 4 if len(numbers) <= 1: 5 return numbers 6 else: 7 pivot = statistics.median( 8 [ 9 numbers[0], 10 numbers[len(numbers) // 2], 11 numbers[-1] 12 ] 13 ) 14 items_less, pivot_items, items_greater = ( 15 [n for n in numbers if n < pivot], 16 [n for n in numbers if n == pivot], 17 [n for n in numbers if n > pivot] 18 ) 19 20 return ( 21 quicksort(items_less) + 22 pivot_items + 23 quicksort(items_greater) 24 )这就是
quicksort()的每个部分正在做的事情:
- 第 4 行:列表为空或者只有一个元素的基本情况
- 第 7 行到第 13 行:用三中值法计算枢纽项目
- 第 14 到 18 行:创建三个分区列表
- 第 20 到 24 行:分区列表的递归排序和重组
注:这个例子的优点是简洁,相对可读性强。然而,这并不是最有效的实现。特别是,在第 14 到 18 行创建分区列表需要遍历列表三次,从执行时间的角度来看,这并不是最佳的。
下面是一些
quicksort()的例子:
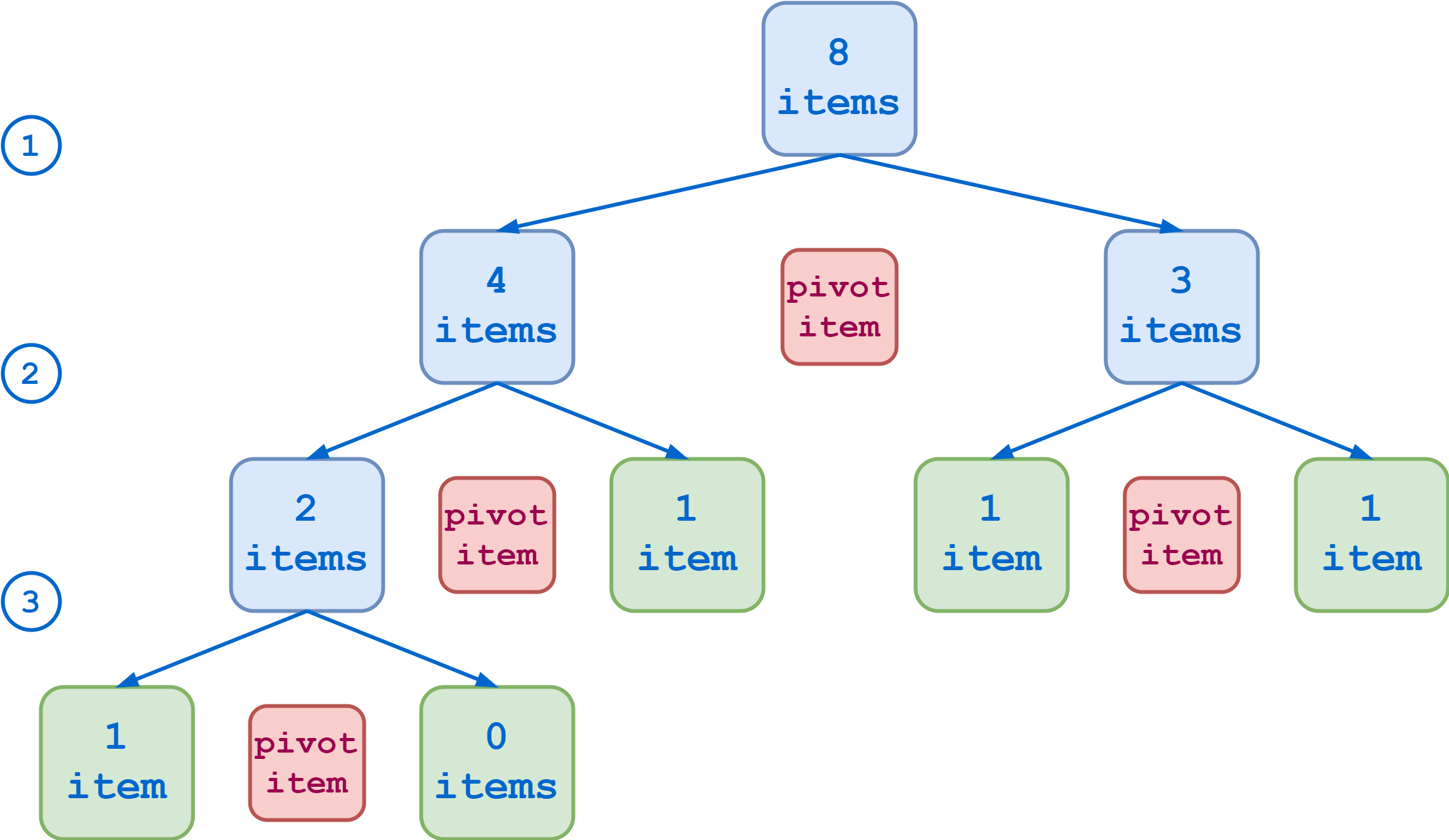
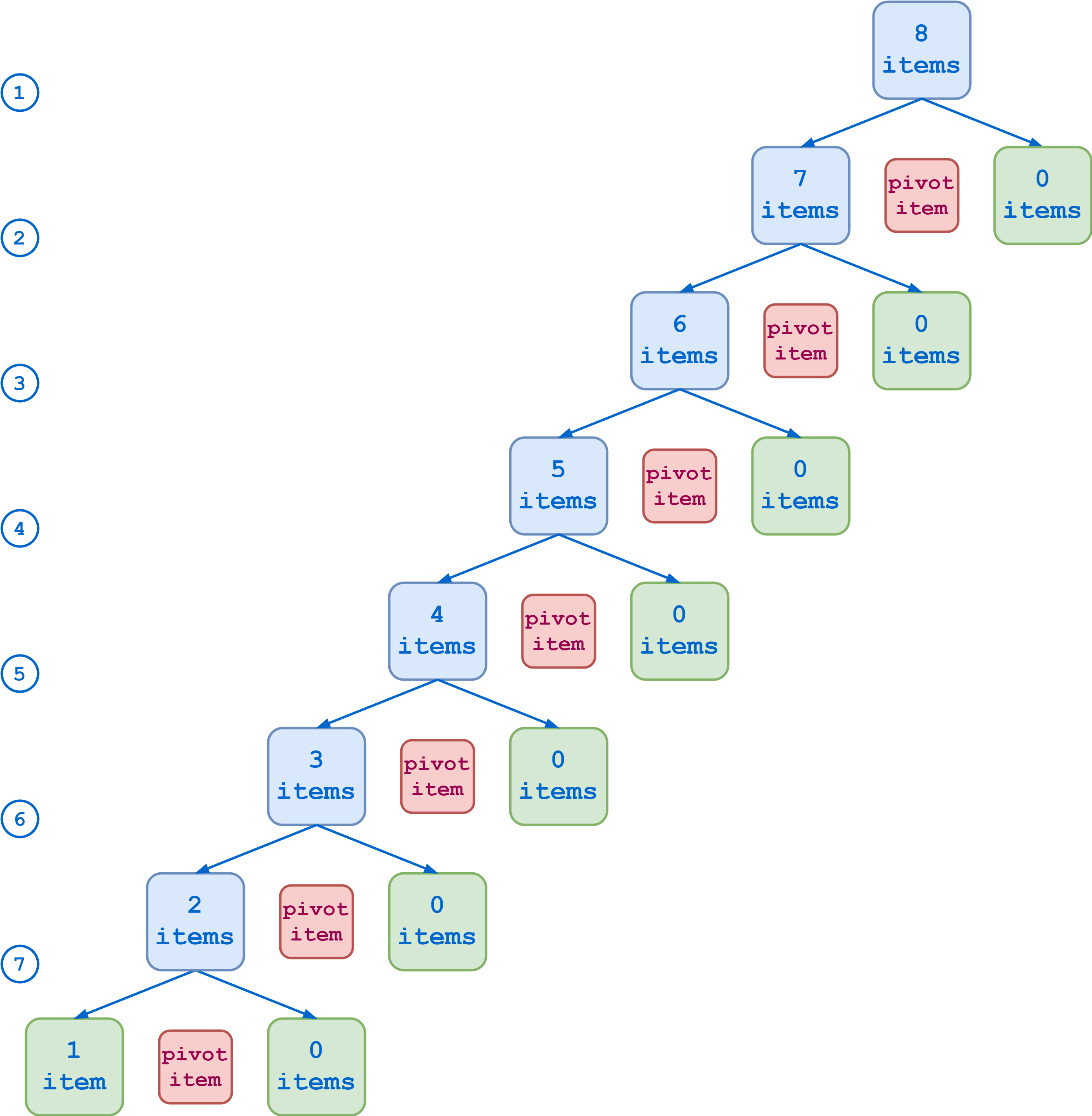
>>> # Base cases
>>> quicksort([])
[]
>>> quicksort([42])
[42]
>>> # Recursive cases
>>> quicksort([5, 2, 6, 3])
[2, 3, 5, 6]
>>> quicksort([10, -3, 21, 6, -8])
[-8, -3, 6, 10, 21]
出于测试目的,您可以定义一个短函数来生成一个在1和100之间的随机数列表:
import random
def get_random_numbers(length, minimum=1, maximum=100):
numbers = []
for _ in range(length):
numbers.append(random.randint(minimum, maximum))
return numbers
现在您可以使用get_random_numbers()来测试quicksort():
>>> numbers = get_random_numbers(20) >>> numbers [24, 4, 67, 71, 84, 63, 100, 94, 53, 64, 19, 89, 48, 7, 31, 3, 32, 76, 91, 78] >>> quicksort(numbers) [3, 4, 7, 19, 24, 31, 32, 48, 53, 63, 64, 67, 71, 76, 78, 84, 89, 91, 94, 100] >>> numbers = get_random_numbers(15, -50, 50) >>> numbers [-2, 14, 48, 42, -48, 38, 44, -25, 14, -14, 41, -30, -35, 36, -5] >>> quicksort(numbers) [-48, -35, -30, -25, -14, -5, -2, 14, 14, 36, 38, 41, 42, 44, 48] >>> quicksort(get_random_numbers(10, maximum=500)) [49, 94, 99, 124, 235, 287, 292, 333, 455, 464] >>> quicksort(get_random_numbers(10, 1000, 2000)) [1038, 1321, 1530, 1630, 1835, 1873, 1900, 1931, 1936, 1943]要进一步了解
quicksort()的工作原理,请参见下图。这显示了对十二元素列表排序时的递归序列:
Quicksort Algorithm, Twelve-Element List 在第一步中,第一、中间和最后的列表值分别是
31、92和28。中间值是31,所以成为枢纽项目。第一个分区由以下子列表组成:
子表 项目 [18, 3, 18, 11, 28]少于透视项目的项目 [31]枢纽项目本身 [72, 79, 92, 44, 56, 41]大于透视项的项 每个子列表随后以同样的方式递归划分,直到所有子列表要么包含单个元素,要么为空。当递归调用返回时,列表按排序顺序重新组合。注意,在左边的倒数第二步中,透视项
18在列表中出现了两次,因此透视项列表有两个元素。结论
这就结束了你的递归之旅,递归是一种函数调用自身的编程技术。递归并不适合所有的任务。但是一些编程问题实际上迫切需要它。在这种情况下,这是一个很好的方法。
在本教程中,您学习了:
- 一个函数递归地调用自己意味着什么
- Python 函数的设计如何支持递归
- 当选择是否递归解决问题时,需要考虑哪些因素
- 如何用 Python 实现一个递归函数
您还看到了几个递归算法的例子,并将它们与相应的非递归解决方案进行了比较。
现在,您应该能够很好地认识到什么时候需要递归,并准备好在需要的时候自信地使用它!如果你想探索更多关于 Python 中递归的知识,那么看看 Python 中的递归思维。**********
如何在 Python 中使用 Redis
原文:# t0]https://realython . com/python-redis/
在本教程中,您将学习如何将 Python 与 Redis(读作 RED-iss ,或者可能是 REE-diss 或 Red-DEES ,这取决于您问的是谁)一起使用,Redis 是一个闪电般快速的内存中键值存储,可用于从 A 到 z 的任何内容。下面是关于数据库的畅销书七周七个数据库对 Redis 的评论:
它不只是简单易用;这是一种快乐。如果 API 是程序员的 UX,那么 Redis 应该和 Mac Cube 一起放在现代艺术博物馆里。
…
而且说到速度,Redis 很难被打败。读取速度很快,写入速度更快,根据一些基准测试,每秒可处理超过 100,000 次
SET操作。(来源)好奇吗?本教程是为没有或很少有 Redis 经验的 Python 程序员编写的。我们将同时处理两个工具,并介绍 Redis 本身以及它的一个 Python 客户端库,
redis-py。
redis-py(你将作为redis导入的)是 Redis 的众多 Python 客户端之一,但它的特点是被 Redis 开发者自己宣传为“当前 Python 的发展方向”。它允许您从 Python 调用 Redis 命令,并返回熟悉的 Python 对象。在本教程中,您将学习:
- 从源代码安装 Redis 并理解生成的二进制文件的用途
- 学习 Redis 本身,包括它的语法、协议和设计
- 掌握
redis-py的同时也看到了它是如何实现 Redis 协议的- 设置 Amazon ElastiCache Redis 服务器实例并与之通信
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
从源安装 Redis】
正如我的曾曾祖父所说,没有什么比从源头安装更能磨练意志了。本节将引导您下载、制作和安装 Redis。我保证这一点也不疼!
注意:本节主要针对 Mac OS X 或 Linux 上的安装。如果你使用的是 Windows,有一个微软的 Redis】分支可以作为 Windows 服务安装。我只想说,Redis 作为一个程序,在 Linux 上运行最舒适,在 Windows 上的安装和使用可能很挑剔。
首先,下载 Redis 源代码作为一个 tarball:
$ redisurl="http://download.redis.io/redis-stable.tar.gz" $ curl -s -o redis-stable.tar.gz $redisurl接下来,切换到
root并将档案的源代码提取到/usr/local/lib/:$ sudo su root $ mkdir -p /usr/local/lib/ $ chmod a+w /usr/local/lib/ $ tar -C /usr/local/lib/ -xzf redis-stable.tar.gz或者,您现在可以删除归档本身:
$ rm redis-stable.tar.gz这将在
/usr/local/lib/redis-stable/为您留下一个源代码库。Redis 是用 C 编写的,所以你需要用make实用程序编译、链接和安装:$ cd /usr/local/lib/redis-stable/ $ make && make install使用
make install做两个动作:
第一个
make命令编译并链接源代码。
make install部分获取二进制文件并将其复制到/usr/local/bin/,这样您就可以从任何地方运行它们(假设/usr/local/bin/在PATH中)。以下是到目前为止的所有步骤:
$ redisurl="http://download.redis.io/redis-stable.tar.gz" $ curl -s -o redis-stable.tar.gz $redisurl $ sudo su root $ mkdir -p /usr/local/lib/ $ chmod a+w /usr/local/lib/ $ tar -C /usr/local/lib/ -xzf redis-stable.tar.gz $ rm redis-stable.tar.gz $ cd /usr/local/lib/redis-stable/ $ make && make install此时,花点时间确认 Redis 在您的
PATH中,并检查它的版本:$ redis-cli --version redis-cli 5.0.3如果您的 shell 找不到
redis-cli,检查以确保/usr/local/bin/在您的PATH环境变量中,如果没有,添加它。除了
redis-cli,make install实际上导致一些不同的可执行文件(和一个符号链接)被放置在/usr/local/bin/:$ # A snapshot of executables that come bundled with Redis $ ls -hFG /usr/local/bin/redis-* | sort /usr/local/bin/redis-benchmark* /usr/local/bin/redis-check-aof* /usr/local/bin/redis-check-rdb* /usr/local/bin/redis-cli* /usr/local/bin/redis-sentinel@ /usr/local/bin/redis-server*虽然所有这些都有一些预期的用途,但您可能最关心的两个是
redis-cli和redis-server,我们将简要介绍一下。但是在我们开始之前,先设置一些基线配置。配置 Redis
Redis 是高度可配置的。虽然它开箱即可运行,但让我们花点时间来设置一些与数据库持久性和基本安全性相关的基本配置选项:
$ sudo su root $ mkdir -p /etc/redis/ $ touch /etc/redis/6379.conf现在,把下面的内容写到
/etc/redis/6379.conf。我们将在整个教程中逐步介绍其中大部分的含义:# /etc/redis/6379.conf port 6379 daemonize yes save 60 1 bind 127.0.0.1 tcp-keepalive 300 dbfilename dump.rdb dir ./ rdbcompression yesRedis 配置是自文档化的,为了方便阅读,在 Redis 源代码中有一个样本
redis.conf文件。如果您在生产系统中使用 Redis,排除所有干扰,花时间完整阅读这个示例文件,熟悉 Redis 的来龙去脉,并调整您的设置是值得的。一些教程,包括 Redis 的部分文档,也可能建议运行位于
redis/utils/install_server.sh的 Shell 脚本install_server.sh。无论如何欢迎你运行这个作为上面的一个更全面的选择,但是注意关于install_server.sh的几个更好的点:
- 它不能在 Mac OS X 上运行——只能在 Debian 和 Ubuntu Linux 上运行。
- 它将为
/etc/redis/6379.conf注入一组更完整的配置选项。- 它会写一个系统 V
init脚本到/etc/init.d/redis_6379让你做sudo service redis_6379 start。Redis 快速入门指南还包含一个关于更合适的 Redis 设置的章节,但是上面的配置选项对于本教程和入门来说应该完全足够了。
安全提示:几年前,Redis 的作者指出了早期版本的 Redis 在没有设置配置的情况下存在的安全漏洞。Redis 3.2(截至 2019 年 3 月的当前版本 5.0.3)采取措施防止这种入侵,默认情况下将
protected-mode选项设置为yes。我们显式设置
bind 127.0.0.1让 Redis 只监听来自本地主机接口的连接,尽管您需要在实际的生产服务器中扩展这个白名单。如果您没有在bind选项下指定任何内容,那么protected-mode的作用是作为一种安全措施来模拟这种绑定到本地主机的行为。解决了这个问题,我们现在可以开始使用 Redis 本身了。
10 分钟左右到 Redis
本节将为您提供足够的 Redis 知识,概述它的设计和基本用法。
开始使用
Redis 有一个客户端-服务器架构,使用 T2 请求-响应模型。这意味着您(客户端)通过 TCP 连接连接到 Redis 服务器,默认情况下是在端口 6379 上。你请求一些动作(比如某种形式的读、写、获取、设置或更新),服务器服务给你一个响应。
可以有许多客户机与同一个服务器对话,这正是 Redis 或任何客户机-服务器应用程序的真正意义所在。每个客户端在套接字上进行一次读取(通常是阻塞式的),等待服务器响应。
redis-cli中的cli代表命令行接口,redis-server中的server是用来,嗯,运行服务器的。与您在命令行运行python的方式相同,您可以运行redis-cli跳转到交互式 REPL (Read Eval Print Loop ),在这里您可以直接从 shell 运行客户端命令。然而,首先,您需要启动
redis-server以便有一个正在运行的 Redis 服务器与之对话。在开发中,这样做的一个常见方法是在 localhost (IPv4 地址127.0.0.1)启动一个服务器,这是默认设置,除非您告诉 Redis。您还可以向redis-server传递您的配置文件的名称,这类似于将它的所有键值对指定为命令行参数:$ redis-server /etc/redis/6379.conf 31829:C 07 Mar 2019 08:45:04.030 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 31829:C 07 Mar 2019 08:45:04.030 # Redis version=5.0.3, bits=64, commit=00000000, modified=0, pid=31829, just started 31829:C 07 Mar 2019 08:45:04.030 # Configuration loaded我们将
daemonize配置选项设置为yes,因此服务器在后台运行。(否则,使用--daemonize yes作为redis-server的选项。)现在,您已经准备好启动 Redis REPL。在命令行上输入
redis-cli。您将看到服务器的主机:端口对,后跟一个>提示符:127.0.0.1:6379>下面是一个最简单的 Redis 命令,
PING,它只是测试与服务器的连接,如果一切正常,就返回"PONG":127.0.0.1:6379> PING PONGRedis 命令不区分大小写,尽管它们的 Python 对应物绝对不区分大小写。
注意:作为另一个健全性检查,您可以使用
pgrep搜索 Redis 服务器的进程 ID:$ pgrep redis-server 26983要终止服务器,从命令行使用
pkill redis-server。在 Mac OS X 上,你也可以使用redis-cli shutdown。接下来,我们将使用一些常见的 Redis 命令,并将它们与纯 Python 中的命令进行比较。
Redis 作为 Python 字典
Redis 代表远程词典服务。
“你是说,像 Python 字典?”你可能会问。
是的。概括地说,在 Python 字典(或通用的散列表)和 Redis 是什么以及做什么之间有许多相似之处:
Redis 数据库保存键:值对,并支持
GET、SET和DEL等命令,以及几百个附加命令。Redis 键永远是弦。
Redis 值可以是多种不同的数据类型。我们将在本教程中介绍一些更重要的数值数据类型:
string、list、hashes和sets。一些高级类型包括地理空间项目和新的流类型。许多 Redis 命令以常数 O(1)时间运行,就像从 Python
dict或任何哈希表中检索值一样。Redis 的创建者 Salvatore Sanfilippo 可能不喜欢将 Redis 数据库比作普通的 Python。他将该项目称为“数据结构服务器”(而不是键值存储,如 memcached ),因为值得称赞的是,Redis 支持存储除 string:string 之外的其他类型的 key:value 数据类型。但是对于我们这里的目的,如果您熟悉 Python 的 dictionary 对象,这是一个有用的比较。
让我们跳进来,通过例子来学习。我们的第一个玩具数据库(ID 为 0)将是一个国家:首都的映射,其中我们使用
SET来设置键-值对:127.0.0.1:6379> SET Bahamas Nassau OK 127.0.0.1:6379> SET Croatia Zagreb OK 127.0.0.1:6379> GET Croatia "Zagreb" 127.0.0.1:6379> GET Japan (nil)纯 Python 中相应的语句序列如下所示:
>>> capitals = {}
>>> capitals["Bahamas"] = "Nassau"
>>> capitals["Croatia"] = "Zagreb"
>>> capitals.get("Croatia")
'Zagreb'
>>> capitals.get("Japan") # None
我们用capitals.get("Japan")而不是capitals["Japan"]是因为 Redis 在找不到键的时候会返回nil而不是错误,类似于 Python 的 None 。
Redis 还允许在一个命令中设置和获取多个键值对,分别是 MSET 和 MGET :
127.0.0.1:6379> MSET Lebanon Beirut Norway Oslo France Paris
OK
127.0.0.1:6379> MGET Lebanon Norway Bahamas
1) "Beirut"
2) "Oslo"
3) "Nassau"
Python 中最接近的是dict.update():
>>> capitals.update({ ... "Lebanon": "Beirut", ... "Norway": "Oslo", ... "France": "Paris", ... }) >>> [capitals.get(k) for k in ("Lebanon", "Norway", "Bahamas")] ['Beirut', 'Oslo', 'Nassau']我们使用
.get()而不是.__getitem__()来模拟 Redis 在没有找到键时返回类似 null 值的行为。作为第三个例子,
EXISTS命令就像它听起来那样,检查一个键是否存在:127.0.0.1:6379> EXISTS Norway (integer) 1 127.0.0.1:6379> EXISTS Sweden (integer) 0Python 有
in关键字来测试同一个东西,哪个路由到dict.__contains__(key):
>>> "Norway" in capitals
True
>>> "Sweden" in capitals
False
这几个例子旨在使用原生 Python 展示一些常见的 Redis 命令在高层次上发生了什么。Python 示例中没有客户机-服务器组件,而且redis-py还没有出现。这只是为了举例说明 Redis 的功能。
下面是您见过的几个 Redis 命令及其 Python 功能等效物的总结:
capitals["Bahamas"] = "Nassau"
capitals.get("Croatia")
capitals.update(
{
"Lebanon": "Beirut",
"Norway": "Oslo",
"France": "Paris",
}
)
[capitals[k] for k in ("Lebanon", "Norway", "Bahamas")]
"Norway" in capitals
Python Redis 客户端库redis-py(您将在本文中深入研究)的工作方式有所不同。它封装了到 Redis 服务器的实际 TCP 连接,并向服务器发送原始命令,这些命令是使用 REdis 序列化协议 (RESP)序列化的字节。然后,它获取原始回复,并将其解析回一个 Python 对象,如bytes、int,甚至是datetime.datetime。
注意:到目前为止,你一直通过交互式redis-cli REPL 与 Redis 服务器对话。你也可以直接发布命令,就像你将一个脚本的名字传递给python可执行文件一样,比如python myscript.py。
到目前为止,您已经看到了 Redis 的一些基本数据类型,它们是 string:string 的映射。虽然这种键-值对在大多数键-值存储中很常见,但是 Redis 提供了许多其他可能的值类型,您将在下面看到。
Python 与 Redis 中的更多数据类型
在启动redis-py Python 客户端之前,对一些 Redis 数据类型有一个基本的了解也是有帮助的。需要明确的是,所有 Redis 键都是字符串。到目前为止,除了示例中使用的字符串值之外,它还是可以采用数据类型(或结构)的值。
一个散列是一个字符串:字符串的映射,称为字段-值对,位于一个顶级键下:
127.0.0.1:6379> HSET realpython url "https://realpython.com/"
(integer) 1
127.0.0.1:6379> HSET realpython github realpython
(integer) 1
127.0.0.1:6379> HSET realpython fullname "Real Python"
(integer) 1
这为一个键、"realpython"设置了三个字段-值对。如果您习惯于 Python 的术语和对象,这可能会令人困惑。Redis 散列大致类似于嵌套一层的 Python dict:
data = {
"realpython": {
"url": "https://realpython.com/",
"github": "realpython",
"fullname": "Real Python",
}
}
Redis 字段类似于上面内部字典中每个嵌套的键-值对的 Python 键。Redis 将术语 key 保留给保存散列结构本身的顶级数据库键。
就像基本的字符串有MSET一样:字符串有键-值对,散列也有 HMSET 在散列值对象中设置多个对:
127.0.0.1:6379> HMSET pypa url "https://www.pypa.io/" github pypa fullname "Python Packaging Authority"
OK
127.0.0.1:6379> HGETALL pypa
1) "url"
2) "https://www.pypa.io/"
3) "github"
4) "pypa"
5) "fullname"
6) "Python Packaging Authority"
使用HMSET可能更类似于我们将data赋给上面的嵌套字典的方式,而不是像使用HSET那样设置每个嵌套对。
另外两个值类型是 列表 和 集合 ,它们可以代替 hash 或 string 作为 Redis 值。它们很大程度上是它们听起来的样子,所以我不会用额外的例子来占用你的时间。散列、列表和集合每个都有一些特定于给定数据类型的命令,在某些情况下由它们的首字母表示:
-
哈希:对哈希进行操作的命令以
H开头,比如HSET、HGET或者HMSET。 -
集合:对集合进行操作的命令以一个
S开始,比如SCARD,它获取一个给定键对应的集合值的元素个数。 -
列表:操作列表的命令以
L或R开始。例子包括LPOP和RPUSH。L或R指的是对单子的哪一面进行操作。一些列表命令也以B开头,这意味着阻塞。一个阻塞操作不会让其他操作在它执行的时候打断它。例如,BLPOP在一个列表结构上执行一个阻塞的左弹出。
注意:Redis 列表类型的一个值得注意的特点是它是一个链表而不是数组。这意味着追加是 O(1 ),而在任意索引号索引是 O(N)。
下面是 Redis 中特定于字符串、散列、列表和集合数据类型的命令的快速列表:
| 类型 | 命令 |
|---|---|
| 设置 | SADD、SCARD、SDIFF、SDIFFSTORE、SINTER、SINTERSTORE、SISMEMBER、SMEMBERS、SMOVE、SPOP、SRANDMEMBER、SREM、SSCAN、SUNION、SUNIONSTORE |
| 混杂 | HDEL、HEXISTS、HGET、HGETALL、HINCRBY、HINCRBYFLOAT、HKEYS、HLEN、HMGET、HMSET、HSCAN、HSET、HSETNX、HSTRLEN、HVALS |
| 列表 | BLPOP、BRPOP、BRPOPLPUSH、LINDEX、LINSERT、LLEN、LPOP、LPUSH、LPUSHX、LRANGE、LREM、LSET、LTRIM、RPOP、RPOPLPUSH、RPUSH、RPUSHX |
| 用线串 | APPEND,BITCOUNT,BITFIELD,BITOP,BITPOS,DECR,DECRBY,GET,GETBIT,GETRANGE,GETSET,INCR,INCRBY,INCRBYFLOAT,MGET,MSET,MSETNX,PSETEX,SET,SETBIT,SETEX,SETNX,SETRANGE,STRLEN |
这个表并不是 Redis 命令和类型的完整描述。还有更高级数据类型的大杂烩,比如地理空间项目、排序集和超级日志。在 Redis commands 页面,您可以按数据结构组进行过滤。还有数据类型总结和Redis 数据类型介绍。
既然我们要切换到用 Python 做事,你现在可以用 FLUSHDB 清空你的玩具数据库,退出redis-cli REPL:
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> QUIT
这将把您带回您的 shell 提示符。您可以让redis-server在后台运行,因为您在本教程的剩余部分也需要它。
在 Python 中使用redis-py:Redis
现在您已经掌握了 Redis 的一些基础知识,是时候进入redis-py了,Python 客户端允许您从用户友好的 Python API 与 Redis 对话。
第一步
redis-py 是一个完善的 Python 客户端库,允许您通过 Python 调用直接与 Redis 服务器对话:
$ python -m pip install redis
接下来,确保您的 Redis 服务器仍然在后台运行。您可以使用pgrep redis-server进行检查,如果您空手而归,那么使用redis-server /etc/redis/6379.conf重新启动一个本地服务器。
现在,让我们进入以 Python 为中心的部分。下面是redis-py的“hello world”:
1>>> import redis 2>>> r = redis.Redis() 3>>> r.mset({"Croatia": "Zagreb", "Bahamas": "Nassau"}) 4True 5>>> r.get("Bahamas") 6b'Nassau'第 2 行中使用的
Redis是包的中心类,是执行(几乎)任何 Redis 命令的主要工具。TCP 套接字连接和重用是在后台完成的,您可以使用类实例r上的方法调用 Redis 命令。还要注意,第 6 行中返回对象的类型
b'Nassau'是 Python 的bytes类型,而不是str。在redis-py中最常见的返回类型是bytes而不是str,所以你可能需要调用r.get("Bahamas").decode("utf-8"),这取决于你想对返回的字节字符串做什么。上面的代码看着眼熟吗?几乎所有情况下的方法都与 Redis 命令的名称相匹配,Redis 命令执行相同的操作。这里调用了
r.mset()和r.get(),分别对应于原生 Redis API 中的MSET和GET。这也意味着
HGETALL变成了r.hgetall(),PING变成了r.ping(),以此类推。有几个例外,但是这个规则适用于大多数命令。虽然 Redis 命令参数通常会转换成外观相似的方法签名,但它们采用 Python 对象。例如,上例中对
r.mset()的调用使用 Pythondict作为第一个参数,而不是一系列字节串。我们构建了没有参数的
Redis实例r,但是如果你需要的话,它附带了许多参数:# From redis/client.py class Redis(object): def __init__(self, host='localhost', port=6379, db=0, password=None, socket_timeout=None, # ...您可以看到默认的主机名:端口对是
localhost:6379,这正是我们在本地保存的redis-server实例中所需要的。
db参数是数据库号。您可以在 Redis 中一次管理多个数据库,每个数据库由一个整数标识。默认情况下,数据库的最大数量是 16。当您只从命令行运行
redis-cli时,这会从数据库 0 开始。使用-n标志启动一个新的数据库,就像在redis-cli -n 5中一样。允许的密钥类型
值得知道的一件事是,
redis-py要求你传递给它的键是bytes、str、int或float。(在将它们发送到服务器之前,它会将最后 3 种类型转换为bytes。)考虑这样一种情况,您希望使用日历日期作为键:
>>> import datetime
>>> today = datetime.date.today()
>>> visitors = {"dan", "jon", "alex"}
>>> r.sadd(today, *visitors)
Traceback (most recent call last):
# ...
redis.exceptions.DataError: Invalid input of type: 'date'.
Convert to a byte, string or number first.
您需要显式地将 Python date对象转换成str,这可以通过.isoformat()来实现:
>>> stoday = today.isoformat() # Python 3.7+, or use str(today) >>> stoday '2019-03-10' >>> r.sadd(stoday, *visitors) # sadd: set-add 3 >>> r.smembers(stoday) {b'dan', b'alex', b'jon'} >>> r.scard(today.isoformat()) 3概括地说,Redis 本身只允许字符串作为键。
redis-py在接受何种 Python 类型方面更自由一些,尽管它最终会在将数据发送到 Redis 服务器之前将其转换为字节。例子:PyHats.com
是时候拿出一个更完整的例子了。让我们假设我们已经决定建立一个利润丰厚的网站,PyHats.com,向任何愿意购买的人出售价格高得离谱的帽子,并雇佣你来建立这个网站。
您将使用 Redis 来处理 PyHats.com 的一些产品目录、库存和 bot 流量检测。
今天是网站的第一天,我们将出售三顶限量版的帽子。每个 hat 保存在字段-值对的 Redis 散列中,该散列有一个作为前缀的随机整数的键,例如
hat:56854717。使用hat:前缀是 Redis 在 Redis 数据库中创建一种名称空间的惯例:import random random.seed(444) hats = {f"hat:{random.getrandbits(32)}": i for i in ( { "color": "black", "price": 49.99, "style": "fitted", "quantity": 1000, "npurchased": 0, }, { "color": "maroon", "price": 59.99, "style": "hipster", "quantity": 500, "npurchased": 0, }, { "color": "green", "price": 99.99, "style": "baseball", "quantity": 200, "npurchased": 0, }) }让我们从数据库
1开始,因为我们在前面的例子中使用了数据库0:
>>> r = redis.Redis(db=1)
要将这些数据初始写入 Redis,我们可以使用.hmset() (hash multi-set),为每个字典调用它。“multi”是对设置多个字段-值对的引用,这里的“field”对应于hats中任何嵌套字典的一个键:
1>>> with r.pipeline() as pipe:
2... for h_id, hat in hats.items():
3... pipe.hmset(h_id, hat)
4... pipe.execute()
5Pipeline<ConnectionPool<Connection<host=localhost,port=6379,db=1>>>
6Pipeline<ConnectionPool<Connection<host=localhost,port=6379,db=1>>>
7Pipeline<ConnectionPool<Connection<host=localhost,port=6379,db=1>>>
8[True, True, True]
9
10>>> r.bgsave()
11True
上面的代码块还引入了 Redis 管道 的概念,这是一种减少从 Redis 服务器读写数据所需的往返事务数量的方法。如果您刚刚调用了三次r.hmset(),那么这将需要对写入的每一行进行一次往返操作。
通过管道,所有的命令都在客户端进行缓冲,然后使用第 3 行中的pipe.hmset()一次性发送出去。这就是当您在第 4 行调用pipe.execute()时,三个True响应同时返回的原因。您将很快看到一个更高级的管道用例。
注意:Redis 文档提供了一个的例子用redis-cli做同样的事情,你可以通过管道把本地文件的内容进行批量插入。
让我们快速检查一下 Redis 数据库中的所有内容:
>>> pprint(r.hgetall("hat:56854717")) {b'color': b'green', b'npurchased': b'0', b'price': b'99.99', b'quantity': b'200', b'style': b'baseball'} >>> r.keys() # Careful on a big DB. keys() is O(N) [b'56854717', b'1236154736', b'1326692461']我们首先要模拟的是当用户点击购买时会发生什么。如果该物品有库存,则将其
npurchased增加 1,并将其quantity(库存)减少 1。你可以使用.hincrby()来做到这一点:
>>> r.hincrby("hat:56854717", "quantity", -1)
199
>>> r.hget("hat:56854717", "quantity")
b'199'
>>> r.hincrby("hat:56854717", "npurchased", 1)
1
注意 : HINCRBY仍然对一个字符串哈希值进行操作,但是它试图将该字符串解释为一个以 10 为基数的 64 位有符号整数来执行操作。
这适用于与其他数据结构的递增和递减相关的其他命令,即INCR、INCRBY、INCRBYFLOAT、ZINCRBY和HINCRBYFLOAT。如果值处的字符串不能用整数表示,就会出现错误。
然而,事情并没有那么简单。在两行代码中更改quantity和npurchased隐藏了点击、购买和支付所包含的更多内容。我们需要多做一些检查,以确保我们不会给某人留下一个较轻的钱包和一顶帽子:
- 步骤 1: 检查商品是否有货,否则在后端引发异常。
- 第二步:如果有货,则执行交易,减少
quantity字段,增加npurchased字段。 - 第三步:警惕前两步之间任何改变库存的变化(一个竞争条件)。
第 1 步相对简单:它包括一个.hget()来检查可用数量。
第二步稍微复杂一点。这对增加和减少操作需要被原子地执行**:要么两个都应该成功完成,要么都不应该(在至少一个失败的情况下)。*
*对于客户机-服务器框架,关注原子性并注意在多个客户机试图同时与服务器对话的情况下会出现什么问题总是至关重要的。Redis 对此的回答是使用一个 事务 块,这意味着要么两个命令都通过,要么都不通过。
在redis-py中,Pipeline默认是一个事务管道类。这意味着,即使这个类实际上是以别的东西命名的(管道),它也可以用来创建一个事务块。
在 Redis 中,交易以MULTI开始,以EXEC结束:
1127.0.0.1:6379> MULTI
2127.0.0.1:6379> HINCRBY 56854717 quantity -1
3127.0.0.1:6379> HINCRBY 56854717 npurchased 1
4127.0.0.1:6379> EXEC
MULTI(第 1 行)标志交易开始,EXEC(第 4 行)标志结束。两者之间的一切都作为一个全有或全无的缓冲命令序列来执行。这意味着不可能减少quantity(第 2 行),但是平衡npurchased增加操作失败(第 3 行)。
让我们回到第 3 步:我们需要注意在前两步之间任何改变库存的变化。
第三步是最棘手的。假设我们的库存中只剩下一顶孤零零的帽子。在用户 A 检查剩余的帽子数量和实际处理他们的交易之间,用户 B 也检查库存,并且同样发现库存中列出了一顶帽子。两个用户都将被允许购买帽子,但我们有 1 顶帽子要卖,而不是 2 顶,所以我们陷入了困境,一个用户的钱用完了。不太好。
Redis 对步骤 3 中的困境有一个聪明的答案:它被称为,并且不同于典型的锁定在 RDBMS(如 PostgreSQL)中的工作方式。简而言之,乐观锁定意味着调用函数(客户端)不获取锁,而是在它持有锁的时间内监视它正在写入*的数据的变化。如果在此期间出现冲突,调用函数会再次尝试整个过程。
*您可以通过使用WATCH命令(redis-py中的.watch())来实现乐观锁定,该命令提供了一个 检查并设置 行为。
让我们引入一大块代码,然后一步一步地浏览它。你可以想象当用户点击立即购买或购买按钮时buyitem()被调用。其目的是确认商品是否有货,并根据结果采取行动,所有这些都以安全的方式进行,即寻找竞争条件并在检测到竞争条件时重试:
1import logging
2import redis
3
4logging.basicConfig()
5
6class OutOfStockError(Exception):
7 """Raised when PyHats.com is all out of today's hottest hat"""
8
9def buyitem(r: redis.Redis, itemid: int) -> None:
10 with r.pipeline() as pipe:
11 error_count = 0
12 while True:
13 try:
14 # Get available inventory, watching for changes
15 # related to this itemid before the transaction
16 pipe.watch(itemid)
17 nleft: bytes = r.hget(itemid, "quantity")
18 if nleft > b"0":
19 pipe.multi()
20 pipe.hincrby(itemid, "quantity", -1)
21 pipe.hincrby(itemid, "npurchased", 1)
22 pipe.execute()
23 break
24 else:
25 # Stop watching the itemid and raise to break out
26 pipe.unwatch()
27 raise OutOfStockError(
28 f"Sorry, {itemid} is out of stock!"
29 )
30 except redis.WatchError:
31 # Log total num. of errors by this user to buy this item,
32 # then try the same process again of WATCH/HGET/MULTI/EXEC
33 error_count += 1
34 logging.warning(
35 "WatchError #%d: %s; retrying",
36 error_count, itemid
37 )
38 return None
关键行出现在第 16 行的pipe.watch(itemid),它告诉 Redis 监控给定的itemid的值的任何变化。该程序通过调用第 17 行中的r.hget(itemid, "quantity")来检查库存:
16pipe.watch(itemid)
17nleft: bytes = r.hget(itemid, "quantity")
18if nleft > b"0":
19 # Item in stock. Proceed with transaction.
如果在用户检查商品库存并试图购买它的这段短暂时间内,库存被触动,那么 Redis 将返回一个错误,redis-py将引发一个WatchError(第 30 行)。也就是说,如果在第 20 行和第 21 行的.hget()调用之后,但在后续的.hincrby()调用之前,itemid指向的任何散列发生了变化,那么我们将在while True循环的另一次迭代中重新运行整个过程。
这是锁定的“乐观”部分:我们没有让客户机通过获取和设置操作对数据库进行耗时的完全锁定,而是让 Redis 仅在需要重试库存检查的情况下通知客户机和用户。
这里的一个关键是理解客户端和服务器端操作之间的区别:
nleft = r.hget(itemid, "quantity")
这个 Python 赋值带来了客户端r.hget()的结果。相反,您在pipe上调用的方法有效地将所有命令缓冲成一个,然后在一个请求中将它们发送给服务器:
16pipe.multi()
17pipe.hincrby(itemid, "quantity", -1)
18pipe.hincrby(itemid, "npurchased", 1)
19pipe.execute()
在事务管道的中间,没有数据返回到客户端。您需要调用.execute()(第 19 行)来一次获得结果序列。
尽管这个块包含两个命令,但它只包含一个从客户端到服务器的往返操作。
这意味着客户端不能立即使用第 20 行pipe.hincrby(itemid, "quantity", -1)的结果,因为Pipeline上的方法返回的只是pipe实例本身。此时,我们还没有向服务器请求任何东西。虽然通常.hincrby()会返回结果值,但是在整个事务完成之前,您不能在客户端立即引用它。
这里有一个第 22 条军规:这也是为什么不能将对.hget()的调用放入事务块。如果您这样做了,那么您将无法知道是否要增加npurchased字段,因为您无法从插入到事务管道中的命令中获得实时结果。
最后,如果库存为零,那么我们UNWATCH商品 ID 并产生一个OutOfStockError(第 27 行),最终显示令人垂涎的售罄页面,这将使我们的帽子购买者不顾一切地想以更奇怪的价格购买更多的帽子:
24else:
25 # Stop watching the itemid and raise to break out
26 pipe.unwatch()
27 raise OutOfStockError(
28 f"Sorry, {itemid} is out of stock!"
29 )
这里有一个例子。请记住,我们的起始数量是 hat 56854717 的199,因为我们在上面调用了.hincrby()。让我们模拟 3 次购买,这将修改quantity和npurchased字段:
>>> buyitem(r, "hat:56854717") >>> buyitem(r, "hat:56854717") >>> buyitem(r, "hat:56854717") >>> r.hmget("hat:56854717", "quantity", "npurchased") # Hash multi-get [b'196', b'4']现在,我们可以快进更多的购买,模拟一连串的购买,直到股票耗尽为零。同样,想象这些来自一大堆不同的客户端,而不仅仅是一个
Redis实例:
>>> # Buy remaining 196 hats for item 56854717 and deplete stock to 0
>>> for _ in range(196):
... buyitem(r, "hat:56854717")
>>> r.hmget("hat:56854717", "quantity", "npurchased")
[b'0', b'200']
现在,当一些可怜的用户在游戏中迟到时,他们应该会遇到一个OutOfStockError,告诉我们的应用程序在前端呈现一个错误消息页面:
>>> buyitem(r, "hat:56854717") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 20, in buyitem __main__.OutOfStockError: Sorry, hat:56854717 is out of stock!看来是时候进货了。
使用密钥到期
下面介绍一下 key expiry ,这是 Redis 中的另一个特色。当您的 密钥 到期时,该密钥及其对应的值将在一定的秒数后或在某个时间戳自动从数据库中删除。
在
redis-py中,您可以通过.setex()来实现这一点,它允许您设置一个基本的字符串:带有有效期的字符串键值对:
1>>> from datetime import timedelta
2
3>>> # setex: "SET" with expiration
4>>> r.setex(
5... "runner",
6... timedelta(minutes=1),
7... value="now you see me, now you don't"
8... )
9True
您可以将第二个参数指定为一个以秒为单位的数字或一个timedelta对象,如上面的第 6 行所示。我喜欢后者,因为它看起来不那么暧昧,更刻意。
还有一些方法(当然还有相应的 Redis 命令)可以获得您设置为过期的密钥的剩余寿命(生存时间):
>>> r.ttl("runner") # "Time To Live", in seconds 58 >>> r.pttl("runner") # Like ttl, but milliseconds 54368下面,你可以加速窗口直到过期,然后看着密钥过期,之后
r.get()会返回None,.exists()会返回0:
>>> r.get("runner") # Not expired yet
b"now you see me, now you don't"
>>> r.expire("runner", timedelta(seconds=3)) # Set new expire window
True
>>> # Pause for a few seconds
>>> r.get("runner")
>>> r.exists("runner") # Key & value are both gone (expired)
0
下表总结了与键值过期相关的命令,包括上面提到的命令。解释直接取自redis-py方法文档字符串:
| 签名 | 目的 |
|---|---|
r.setex(name, time, value) |
将密钥name的值设置为在time秒后到期的value,其中time可以由一个int或一个 Python timedelta对象表示 |
r.psetex(name, time_ms, value) |
将 key name的值设置为value,该值在time_ms毫秒后到期,其中time_ms可以由一个int或一个 Python timedelta对象表示 |
r.expire(name, time) |
在键name上设置一个过期标志time秒,其中time可以用一个int或一个 Python timedelta对象来表示 |
r.expireat(name, when) |
在键name上设置一个 expire 标志,其中when可以表示为一个表示 Unix 时间的int或一个 Python datetime 对象 |
r.persist(name) |
移除name的到期时间 |
r.pexpire(name, time) |
在键name上设置一个过期标志time毫秒,time可以用一个int或一个 Python timedelta对象来表示 |
r.pexpireat(name, when) |
在键name上设置一个过期标志,其中when可以表示为一个以毫秒为单位表示 Unix 时间的int(Unix time * 1000)或一个 Python datetime对象 |
r.pttl(name) |
返回密钥name到期前的毫秒数 |
r.ttl(name) |
返回密钥name到期前的秒数 |
PyHats.com 第二部
首次亮相几天后,PyHats.com 吸引了如此多的炒作,以至于一些有事业心的用户正在创建机器人,在几秒钟内购买数百件商品,你已经决定这对你的帽子业务的长期健康不利。
现在您已经看到了如何使密钥过期,让我们在 PyHats.com 的后端使用它。
我们将创建一个新的 Redis 客户端,充当消费者(或观察者)并处理传入的 IP 地址流,这些地址可能来自到网站服务器的多个 HTTPS 连接。
观察器的目标是监视来自多个来源的 IP 地址流,留意在可疑的短时间内来自单个地址的大量请求。
网站服务器上的一些中间件用.lpush()将所有传入的 IP 地址推送到 Redis 列表中。这里有一个简单的方法来模仿一些入侵的 IP,使用一个新的 Redis 数据库:
>>> r = redis.Redis(db=5) >>> r.lpush("ips", "51.218.112.236") 1 >>> r.lpush("ips", "90.213.45.98") 2 >>> r.lpush("ips", "115.215.230.176") 3 >>> r.lpush("ips", "51.218.112.236") 4可以看到,
.lpush()在推送操作成功后返回列表的长度。每次调用.lpush()都会将 IP 放在 Redis 列表的开头,这个列表由字符串"ips"作为关键字。在这个简化的模拟中,从技术上讲,请求都来自同一个客户机,但是您可以认为它们可能来自许多不同的客户机,并且都被推送到同一个 Redis 服务器上的同一个数据库。
现在,打开一个新的 shell 选项卡或窗口,启动一个新的 Python REPL。在这个 shell 中,您将创建一个新的客户端,它的用途与其他客户端完全不同,它位于一个无限的
while True循环中,并在ips列表上执行一个阻塞的左弹出BLPOP调用,处理每个地址:1# New shell window or tab 2 3import datetime 4import ipaddress 5 6import redis 7 8# Where we put all the bad egg IP addresses 9blacklist = set() 10MAXVISITS = 15 11 12ipwatcher = redis.Redis(db=5) 13 14while True: 15 _, addr = ipwatcher.blpop("ips") 16 addr = ipaddress.ip_address(addr.decode("utf-8")) 17 now = datetime.datetime.utcnow() 18 addrts = f"{addr}:{now.minute}" 19 n = ipwatcher.incrby(addrts, 1) 20 if n >= MAXVISITS: 21 print(f"Hat bot detected!: {addr}") 22 blacklist.add(addr) 23 else: 24 print(f"{now}: saw {addr}") 25 _ = ipwatcher.expire(addrts, 60)让我们看一下几个重要的概念。
ipwatcher就像一个消费者,无所事事,等待新的 IP 被推上"ips"Redis 列表。它以bytes的形式接收它们,如 b“51 . 218 . 112 . 236”,并用ipaddress模块将它们变成更合适的地址对象:15_, addr = ipwatcher.blpop("ips") 16addr = ipaddress.ip_address(addr.decode("utf-8"))然后,使用地址和
ipwatcher看到地址时的分钟形成 Redis 字符串键,将相应的计数增加1,并在此过程中获得新的计数:17now = datetime.datetime.utcnow() 18addrts = f"{addr}:{now.minute}" 19n = ipwatcher.incrby(addrts, 1)如果这个地址被浏览的次数超过了
MAXVISITS,那么看起来就好像我们手上有一个 PyHats.com 的网页抓取器试图创造下一个郁金香泡沫。唉,我们别无选择,只能给这个用户返回类似可怕的 403 状态码的东西。我们使用
ipwatcher.expire(addrts, 60)来终止(地址分钟)组合,从它最后一次被看到起 60 秒。这是为了防止我们的数据库被陈旧的一次性页面查看器堵塞。如果您在新的 shell 中执行这个代码块,您应该会立即看到以下输出:
2019-03-11 15:10:41.489214: saw 51.218.112.236 2019-03-11 15:10:41.490298: saw 115.215.230.176 2019-03-11 15:10:41.490839: saw 90.213.45.98 2019-03-11 15:10:41.491387: saw 51.218.112.236输出立即出现,因为这四个 IP 位于由
"ips"键入的队列式列表中,等待由我们的ipwatcher取出。使用.blpop()(或BLPOP命令)将阻塞,直到列表中有一个项目可用,然后弹出它。它的行为类似于 Python 的Queue.get(),也是阻塞直到一个项目可用。除了提供 IP 地址,我们的
ipwatcher还有第二份工作。对于一个小时中给定的一分钟(第 1 分钟到第 60 分钟),ipwatcher会将一个 IP 地址分类为 hat-bot,如果它在该分钟内发送了 15 个或更多的GET请求。切换回您的第一个 shell,模拟一个页面抓取器,在几毫秒内用 20 个请求将站点炸开:
for _ in range(20): r.lpush("ips", "104.174.118.18")最后,切换回包含
ipwatcher的第二个 shell,您应该会看到如下输出:2019-03-11 15:15:43.041363: saw 104.174.118.18 2019-03-11 15:15:43.042027: saw 104.174.118.18 2019-03-11 15:15:43.042598: saw 104.174.118.18 2019-03-11 15:15:43.043143: saw 104.174.118.18 2019-03-11 15:15:43.043725: saw 104.174.118.18 2019-03-11 15:15:43.044244: saw 104.174.118.18 2019-03-11 15:15:43.044760: saw 104.174.118.18 2019-03-11 15:15:43.045288: saw 104.174.118.18 2019-03-11 15:15:43.045806: saw 104.174.118.18 2019-03-11 15:15:43.046318: saw 104.174.118.18 2019-03-11 15:15:43.046829: saw 104.174.118.18 2019-03-11 15:15:43.047392: saw 104.174.118.18 2019-03-11 15:15:43.047966: saw 104.174.118.18 2019-03-11 15:15:43.048479: saw 104.174.118.18 Hat bot detected!: 104.174.118.18 Hat bot detected!: 104.174.118.18 Hat bot detected!: 104.174.118.18 Hat bot detected!: 104.174.118.18 Hat bot detected!: 104.174.118.18 Hat bot detected!: 104.174.118.18现在,
Ctrl+C退出while True循环,您会看到该违规 IP 已被添加到您的黑名单中:
>>> blacklist
{IPv4Address('104.174.118.18')}
你能发现这个检测系统的缺陷吗?过滤器检查分钟为.minute而不是最后 60 秒(一个滚动分钟)。实现滚动检查来监控用户在过去 60 秒内被查看了多少次将会更加棘手。有一个巧妙的解决方案,在 ClassDojo 使用 Redis 的排序集合。Josiah Carlson 的 Redis in Action 还使用 IP-to-location 缓存表给出了这一部分的一个更详细的通用示例。
持久性和快照
Redis 的读写速度如此之快的原因之一是数据库保存在服务器的内存(RAM)中。然而,Redis 数据库也可以在一个叫做快照的过程中被存储(持久化)到磁盘。这背后的要点是以二进制格式保存物理备份,以便在需要时(比如在服务器启动时)可以重建数据并将其放回内存。
当您在本教程开始时使用save选项设置基本配置时,您已经在不知情的情况下启用了快照:
# /etc/redis/6379.conf
port 6379
daemonize yes
save 60 1 bind 127.0.0.1
tcp-keepalive 300
dbfilename dump.rdb
dir ./
rdbcompression yes
格式为save <seconds> <changes>。这告诉 Redis,如果发生了给定秒数和数量的数据库写操作,就将数据库保存到磁盘。在这种情况下,我们告诉 Redis 每 60 秒将数据库保存到磁盘,如果在这 60 秒内至少发生了一次修改写操作。相对于示例 Redis 配置文件,这是一个相当激进的设置,它使用以下三个save指令:
# Default redis/redis.conf
save 900 1
save 300 10
save 60 10000
RDB 快照是数据库的完整(而非增量)时间点捕获。(RDB 指的是 Redis 数据库文件。)我们还指定了写入的结果数据文件的目录和文件名:
# /etc/redis/6379.conf
port 6379
daemonize yes
save 60 1
bind 127.0.0.1
tcp-keepalive 300
dbfilename dump.rdb dir ./ rdbcompression yes
这将指示 Redis 保存到一个名为dump.rdb的二进制数据文件中,该文件位于执行redis-server的当前工作目录下:
$ file -b dump.rdb
data
您也可以使用 Redis 命令 BGSAVE 手动调用保存:
127.0.0.1:6379> BGSAVE
Background saving started
BGSAVE中的“BG”表示保存在后台进行。该选项在redis-py方法中也可用:
>>> r.lastsave() # Redis command: LASTSAVE datetime.datetime(2019, 3, 10, 21, 56, 50) >>> r.bgsave() True >>> r.lastsave() datetime.datetime(2019, 3, 10, 22, 4, 2)这个例子介绍了另一个新的命令和方法
.lastsave()。在 Redis 中,它返回最后一次 DB 保存的 Unix 时间戳,Python 将其作为一个datetime对象返回给您。上面,你可以看到r.lastsave()结果由于r.bgsave()而改变。如果使用
save配置选项启用自动快照,则r.lastsave()也会改变。换句话说,有两种方法可以启用快照:
- 显式地,通过 Redis 命令
BGSAVE或redis-py方法.bgsave()- 隐式地,通过
save配置选项(也可以在redis-py中用.config_set()设置)RDB 快照的速度很快,因为父进程使用
fork()系统调用将耗时的磁盘写入任务传递给子进程,以便父进程可以继续执行。这就是BGSAVE中的背景所指的。还有
SAVE(redis-py中的.save()),但是这是同步(阻塞)保存而不是使用fork(),所以没有特定的原因你不应该使用它。尽管
.bgsave()发生在后台,但这也不是没有代价的。如果 Redis 数据库首先足够大,那么fork()本身发生的时间实际上可能相当长。如果这是一个问题,或者如果您不能因为 RDB 快照的周期性而丢失哪怕一丁点数据,那么您应该研究一下作为快照替代方案的仅附加文件 (AOF)策略。AOF 将 Redis 命令实时复制到磁盘,允许您通过重放这些命令来进行基于命令的重建。
序列化变通办法
让我们回到谈论 Redis 数据结构。借助其散列数据结构,Redis 实际上支持一级嵌套:
127.0.0.1:6379> hset mykey field1 value1Python 客户端的等效内容如下所示:
r.hset("mykey", "field1", "value1")在这里,您可以将
"field1": "value1"视为 Python 字典{"field1": "value1"}的键值对,而mykey是顶级键:
重复命令 纯 Python 等价物 r.set("key", "value")r = {"key": "value"}r.hset("key", "field", "value")r = {"key": {"field": "value"}}但是,如果您希望这个字典的值(Redis hash)包含字符串以外的内容,比如以字符串为值的
list或嵌套字典,该怎么办呢?这里有一个例子,使用一些类似于 JSON 的数据来使区别更加清晰:
restaurant_484272 = { "name": "Ravagh", "type": "Persian", "address": { "street": { "line1": "11 E 30th St", "line2": "APT 1", }, "city": "New York", "state": "NY", "zip": 10016, } }假设我们想要设置一个 Redis 散列,其中的键
484272和字段-值对对应于来自restaurant_484272的键-值对。Redis 不直接支持这个,因为restaurant_484272是嵌套的:
>>> r.hmset(484272, restaurant_484272)
Traceback (most recent call last):
# ...
redis.exceptions.DataError: Invalid input of type: 'dict'.
Convert to a byte, string or number first.
事实上,你可以用 Redis 来实现这一点。在redis-py和 Redis 中有两种不同的模拟嵌套数据的方法:
- 用类似
json.dumps()的代码将值序列化成一个字符串 - 在键字符串中使用分隔符来模拟值中的嵌套
让我们来看一个例子。
选项 1:将值序列化为字符串
您可以使用json.dumps()将dict序列化为 JSON 格式的字符串:
>>> import json >>> r.set(484272, json.dumps(restaurant_484272)) True如果调用
.get(),得到的值将是一个bytes对象,所以不要忘了反序列化它以得到原来的对象。json.dumps()和json.loads()互为反码,分别用于序列化和反序列化数据:
>>> from pprint import pprint
>>> pprint(json.loads(r.get(484272)))
{'address': {'city': 'New York',
'state': 'NY',
'street': '11 E 30th St',
'zip': 10016},
'name': 'Ravagh',
'type': 'Persian'}
这适用于任何序列化协议,另一个常见的选择是 yaml :
>>> import yaml # python -m pip install PyYAML >>> yaml.dump(restaurant_484272) 'address: {city: New York, state: NY, street: 11 E 30th St, zip: 10016}\nname: Ravagh\ntype: Persian\n'无论您选择使用哪种序列化协议,概念都是相同的:您获取一个 Python 特有的对象,并将其转换为可跨多种语言识别和交换的字节串。
选项 2:在关键字串中使用分隔符
还有第二种选择,通过在 Python
dict中串联多层键来模仿“嵌套”。这包括通过递归来展平嵌套字典,这样每个键都是一个串联的键串,并且值是原始字典中嵌套最深的值。考虑我们的字典对象restaurant_484272:restaurant_484272 = { "name": "Ravagh", "type": "Persian", "address": { "street": { "line1": "11 E 30th St", "line2": "APT 1", }, "city": "New York", "state": "NY", "zip": 10016, } }我们想把它做成这样的形式:
{ "484272:name": "Ravagh", "484272:type": "Persian", "484272:address:street:line1": "11 E 30th St", "484272:address:street:line2": "APT 1", "484272:address:city": "New York", "484272:address:state": "NY", "484272:address:zip": "10016", }这就是下面的
setflat_skeys()所做的,增加的特性是它在Redis实例本身上执行.set()操作,而不是返回输入字典的副本:1from collections.abc import MutableMapping 2 3def setflat_skeys( 4 r: redis.Redis, 5 obj: dict, 6 prefix: str, 7 delim: str = ":", 8 *, 9 _autopfix="" 10) -> None: 11 """Flatten `obj` and set resulting field-value pairs into `r`. 12 13 Calls `.set()` to write to Redis instance inplace and returns None. 14 15 `prefix` is an optional str that prefixes all keys. 16 `delim` is the delimiter that separates the joined, flattened keys. 17 `_autopfix` is used in recursive calls to created de-nested keys. 18 19 The deepest-nested keys must be str, bytes, float, or int. 20 Otherwise a TypeError is raised. 21 """ 22 allowed_vtypes = (str, bytes, float, int) 23 for key, value in obj.items(): 24 key = _autopfix + key 25 if isinstance(value, allowed_vtypes): 26 r.set(f"{prefix}{delim}{key}", value) 27 elif isinstance(value, MutableMapping): 28 setflat_skeys( 29 r, value, prefix, delim, _autopfix=f"{key}{delim}" 30 ) 31 else: 32 raise TypeError(f"Unsupported value type: {type(value)}")该函数遍历
obj的键-值对,首先检查值的类型(第 25 行),看它是否应该停止进一步递归并设置该键-值对。否则,如果值看起来像一个dict(第 27 行),那么它递归到那个映射中,添加以前看到的键作为键前缀(第 28 行)。让我们看看它是如何工作的:
>>> r.flushdb() # Flush database: clear old entries
>>> setflat_skeys(r, restaurant_484272, 484272)
>>> for key in sorted(r.keys("484272*")): # Filter to this pattern
... print(f"{repr(key):35}{repr(r.get(key)):15}")
...
b'484272:address:city' b'New York'
b'484272:address:state' b'NY'
b'484272:address:street:line1' b'11 E 30th St'
b'484272:address:street:line2' b'APT 1'
b'484272:address:zip' b'10016'
b'484272:name' b'Ravagh'
b'484272:type' b'Persian'
>>> r.get("484272:address:street:line1")
b'11 E 30th St'
上面的最后一个循环使用了r.keys("484272*"),其中"484272*"被解释为一个模式,匹配数据库中所有以"484272"开头的键。
还要注意setflat_skeys()如何只调用.set()而不是.hset(),因为我们正在使用普通的字符串:字符串字段-值对,并且 484272 ID 键被添加到每个字段字符串的前面。
加密
另一个帮助你晚上睡得好的技巧是在发送任何东西到 Redis 服务器之前添加对称加密。把这看作是安全性的一个附加组件,您应该通过在您的 Redis 配置中设置适当的值来确保安全性。下面的例子使用了 cryptography 包:
$ python -m pip install cryptography
举例来说,假设您有一些敏感的持卡人数据(CD ),无论如何,您都不希望这些数据以明文形式存放在任何服务器上。在 Redis 中缓存它之前,您可以序列化数据,然后使用 Fernet 对序列化的字符串进行加密:
>>> import json >>> from cryptography.fernet import Fernet >>> cipher = Fernet(Fernet.generate_key()) >>> info = { ... "cardnum": 2211849528391929, ... "exp": [2020, 9], ... "cv2": 842, ... } >>> r.set( ... "user:1000", ... cipher.encrypt(json.dumps(info).encode("utf-8")) ... ) >>> r.get("user:1000") b'gAAAAABcg8-LfQw9TeFZ1eXbi' # ... [truncated] >>> cipher.decrypt(r.get("user:1000")) b'{"cardnum": 2211849528391929, "exp": [2020, 9], "cv2": 842}' >>> json.loads(cipher.decrypt(r.get("user:1000"))) {'cardnum': 2211849528391929, 'exp': [2020, 9], 'cv2': 842}因为
info包含的值是一个list,您需要将它序列化成 Redis 可以接受的字符串。(您可以使用json、yaml或任何其他序列化方式来实现这个目的。)接下来,使用cipher对象加密和解密该字符串。您需要使用json.loads()对解密的字节进行反序列化,这样您就可以将结果恢复为初始输入的类型,即dict。注 : Fernet 在 CBC 模式下使用 AES 128 加密。有关使用 AES 256 的示例,请参见
cryptography文档。无论您选择做什么,都使用cryptography,而不是pycrypto(作为Crypto导入),后者不再被主动维护。如果安全性至关重要,那么在字符串通过网络连接之前对其进行加密绝对不是一个坏主意。
压缩
最后一个快速优化是压缩。如果带宽是一个问题,或者您对成本很敏感,那么当您从 Redis 发送和接收数据时,您可以实现无损压缩和解压缩方案。下面是一个使用 bzip2 压缩算法的示例,在这种极端情况下,该算法将通过连接发送的字节数减少了 2000 多倍:
1>>> import bz2
2
3>>> blob = "i have a lot to talk about" * 10000
4>>> len(blob.encode("utf-8"))
5260000
6
7>>> # Set the compressed string as value
8>>> r.set("msg:500", bz2.compress(blob.encode("utf-8")))
9>>> r.get("msg:500")
10b'BZh91AY&SY\xdaM\x1eu\x01\x11o\x91\x80@\x002l\x87\' # ... [truncated]
11>>> len(r.get("msg:500"))
12122
13>>> 260_000 / 122 # Magnitude of savings
142131.1475409836066
15
16>>> # Get and decompress the value, then confirm it's equal to the original
17>>> rblob = bz2.decompress(r.get("msg:500")).decode("utf-8")
18>>> rblob == blob
19True
序列化、加密和压缩在这里的关联方式是它们都发生在客户端。您在客户端对原始对象进行一些操作,一旦您将字符串发送到服务器,这些操作最终会更有效地利用 Redis。当您请求最初发送给服务器的内容时,客户端会再次执行相反的操作。
使用 Hiredis
对于像redis-py这样的客户端库来说,遵循协议来构建它是很常见的。在这种情况下,redis-py实现了 REdis 序列化协议,即 RESP。
实现该协议的一部分包括转换原始字节串中的一些 Python 对象,将其发送到 Redis 服务器,并将响应解析回可理解的 Python 对象。
例如,字符串响应“OK”将作为"+OK\r\n"返回,而整数响应 1000 将作为":1000\r\n"返回。对于其他数据类型,如 RESP 数组,这可能会变得更加复杂。
一个解析器是请求-响应循环中的一个工具,它解释这个原始响应并把它加工成客户机可识别的东西。redis-py自带解析器类PythonParser,它用纯 Python 进行解析。(见 .read_response() 如果你好奇的话。)
然而,还有一个 C 库, Hiredis ,它包含一个快速解析器,可以为一些 redis 命令提供显著的加速,比如LRANGE。你可以把 Hiredis 看作是一个可选的加速器,在特殊情况下使用它没有坏处。
要使redis-py能够使用 Hiredis 解析器,您所要做的就是在与redis-py相同的环境中安装 Python 绑定:
$ python -m pip install hiredis
你在这里实际安装的是 hiredis-py ,它是 hiredis C 库的一部分的 Python 包装器。
好的一面是,你真的不需要亲自打电话给hiredis。只要pip install它,这将让redis-py看到它是可用的,并使用它的HiredisParser而不是PythonParser。
在内部,redis-py将尝试导入 hiredis,并使用一个HiredisParser类来匹配它,但将回退到它的PythonParser,这在某些情况下可能会慢一些:
# redis/utils.py
try:
import hiredis
HIREDIS_AVAILABLE = True
except ImportError:
HIREDIS_AVAILABLE = False
# redis/connection.py
if HIREDIS_AVAILABLE:
DefaultParser = HiredisParser
else:
DefaultParser = PythonParser
使用企业 Redis 应用程序
虽然 Redis 本身是开源的和免费的,但一些托管服务已经出现,它们提供以 Redis 为核心的数据存储,并在开源的 Redis 服务器上构建一些附加功能:
-
Amazon elastic cache for Redis:这是一个 web 服务,它让您在云中托管 Redis 服务器,您可以从 Amazon EC2 实例连接到该服务器。关于完整的设置说明,你可以浏览亚马逊的elastic cache for Redis启动页面。
-
微软的 Azure Cache for Redis:这是另一项强大的企业级服务,让您可以在云中建立一个可定制的、安全的 Redis 实例。
两者的设计有一些共性。您通常为您的缓存指定一个自定义名称,该名称作为 DNS 名称的一部分嵌入,例如demo.abcdef.xz.0009.use1.cache.amazonaws.com (AWS)或demo.redis.cache.windows.net (Azure)。
设置完成后,这里有一些关于如何连接的快速提示。
从命令行来看,这与我们前面的例子基本相同,但是您需要用h标志指定一个主机,而不是使用默认的 localhost。对于 Amazon AWS ,从您的实例 shell 执行以下命令:
$ export REDIS_ENDPOINT="demo.abcdef.xz.0009.use1.cache.amazonaws.com"
$ redis-cli -h $REDIS_ENDPOINT
对于微软 Azure ,可以使用类似的调用。Azure Cache for Redis 默认使用 SSL (端口 6380)而不是端口 6379,允许进出 Redis 的加密通信,TCP 就不能这么说了。除此之外,您需要提供的只是一个非默认端口和访问密钥:
$ export REDIS_ENDPOINT="demo.redis.cache.windows.net"
$ redis-cli -h $REDIS_ENDPOINT -p 6380 -a <primary-access-key>
-h标志指定了一个主机,如您所见,默认情况下是127.0.0.1 (localhost)。
当你在 Python 中使用redis-py时,最好不要在 Python 脚本中使用敏感变量,并且要小心你对这些文件的读写权限。Python 版本如下所示:
>>> import os >>> import redis >>> # Specify a DNS endpoint instead of the default localhost >>> os.environ["REDIS_ENDPOINT"] 'demo.abcdef.xz.0009.use1.cache.amazonaws.com' >>> r = redis.Redis(host=os.environ["REDIS_ENDPOINT"])这就是全部了。除了指定不同的
host,您现在可以像平常一样调用命令相关的方法,比如r.get()。注意:如果你想单独使用
redis-py和 AWS 或 Azure Redis 实例的组合,那么你真的不需要在你的机器上本地安装和制作 Redis 本身,因为你既不需要redis-cli也不需要redis-server。如果你正在部署一个中型到大型的生产应用程序,Redis 在其中起着关键作用,那么使用 AWS 或 Azure 的服务解决方案可能是一种可扩展的、经济高效的、有安全意识的操作方式。
总结
这就结束了我们通过 Python 访问 Redis 的旋风之旅,包括安装和使用连接到 Redis 服务器的 Redis REPL,以及在实际例子中使用
redis-py。以下是你学到的一些东西:
- 通过直观的 Python API,您可以(几乎)完成使用 Redis CLI 所能完成的一切。
- 掌握持久性、序列化、加密和压缩等主题可以让您充分发挥 Redis 的潜力。
- 在更复杂的情况下,Redis 事务和管道是库的基本部分。
- 企业级 Redis 服务可以帮助您在生产中顺利使用 Redis。
Redis 有一系列广泛的特性,其中一些我们在这里没有真正涉及到,包括服务器端 Lua 脚本、分片和主从复制。如果你认为 Redis 是你的拿手好戏,那么请确保关注它的发展,因为它实现了一个更新的协议。
延伸阅读
这里有一些资源,您可以查看以了解更多信息。
书籍:
正在使用的重定向:
- Twitter:Twitter 上的实时交付架构
- Spool: Redis 位图——快速、简单、实时的指标
- 3scale: 享受亚马逊和 Rackspace 之间 Redis 复制的乐趣
- Instagram: 在 Redis 中存储上亿个简单的键值对
- Craigslist:Redis sharing at Craigslist
- 圆盘:t1】T2【圆盘上的铆钉】
其他:
- 数字海洋: 如何保护你的 Redis 安装
- AWS:riz 用户指南的弹性缓存
- 微软: 用于 Redis 的 Azure 缓存
- 速查表: 速查表
- ClassDojo: 用 Redis 排序集进行更好的速率限制
- 抗雷(Salvatore sanfilippo):【redis 坚持不懈】
- 马丁·克莱普曼: 如何做分布式锁定
- 高可扩展性:Redis 解决的 11 个常见 Web 用例**************
Python 的 reduce():从函数式到 python 式
Python 的
reduce()是一个函数,实现了一种叫做 折叠 或者还原的数学技术。当您需要将一个函数应用于一个 iterable 并将它简化为一个累积值时,reduce()非常有用。Python 的reduce()在具有函数式编程背景的开发者中很受欢迎,但是 Python 还能提供更多。在本教程中,你将会了解到
reduce()是如何工作的,以及如何有效地使用它。您还将介绍一些替代的 Python 工具,它们可能比 T1 更加Python 化、可读和高效。在本教程中,您将学习:
- Python 的
reduce()是如何工作的- 更常见的缩减用例有哪些
- 如何用
reduce()来解决这些用例- 有哪些替代的 Python 工具可用于解决这些相同的用例
有了这些知识,您将能够决定在解决 Python 中的归约或折叠问题时使用哪些工具。
为了更好地理解 Python 的
reduce(),了解一下如何使用 Python iterables ,尤其是如何使用for循环来循环它们,将会很有帮助。免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
探索 Python 中的函数式编程
函数式编程是一种基于将问题分解成一组独立函数的编程范式。理想情况下,每个函数只接受一组输入参数并产生一个输出。
在函数式编程中,对于给定的输入,函数没有任何影响输出的内部状态。这意味着任何时候你用相同的输入参数调用一个函数,你将得到相同的结果或输出。
在函数式程序中,输入数据流经一组函数。每个函数对其输入进行操作,并产生一些输出。函数式编程尽量避免可变的数据类型和状态变化。它处理函数间流动的数据。
函数式编程的其他核心特性包括:
*这个列表中有几个重要的概念。以下是对其中一些的近距离观察:
递归是一种技术,在这种技术中,函数直接或间接地调用自己,以便进行循环。它允许程序在长度未知或不可预测的数据结构上循环。
纯函数是完全没有副作用的函数。换句话说,它们是不更新或修改程序中任何全局变量、对象或数据结构的函数。这些函数产生仅取决于输入的输出,这更接近于数学函数的概念。
高阶函数是通过将函数作为参数、返回函数或两者兼而有之来操作其他函数的函数,就像Python decorator一样。
由于 Python 是一种多范例编程语言,它提供了一些支持函数式编程风格的工具:
- 功能为一级对象
- 递归功能
- 匿名函数有
lambda- 迭代器和生成器
- 标准模块,如
functools和itertools- 工具有
map()filter()reduce()sum()len()any()all()min()``max()等等尽管 Python 没有受到函数式编程语言的很大影响,但早在 1993 年,就有对上面列出的一些函数式编程特性的明确需求。
作为回应,一些功能工具被添加到语言中。据吉多·范·罗苏姆称,它们是由一名社区成员提供的:
Python 获得了
lambda、reduce()、filter()和map(),感谢(我相信)一个 Lisp 黑客错过了它们并提交了工作补丁。(来源)多年来,一些新特性,如列表理解、生成器表达式,以及内置函数如
sum()、min()、max()、all()和any(),被视为python 式对、map()、、filter()、reduce()的替代。Guido 计划从 Python 3 的语言中删除map()``filter()``reduce(),甚至lambda。幸运的是,这个移除并没有生效,主要是因为 Python 社区不想放过这么受欢迎的特性。它们仍然存在,并在具有强大函数式编程背景的开发人员中广泛使用。
在本教程中,你将讲述如何使用 Python 的
reduce()来处理可重复项,并在不使用for循环的情况下将它们减少到一个累积值。您还将了解到一些 Python 工具,您可以用它们来代替reduce(),使您的代码更加 Python 化、可读和高效。Python 的
reduce()入门Python 的
reduce()实现了一种俗称 折叠 或还原的数学技巧。当您将一系列项目缩减为单个累积值时,您正在进行折叠或缩减。Python 的reduce()操作任何可迭代的——不仅仅是列表——并执行以下步骤:
- 将一个函数(或可调用函数)应用于 iterable 中的前两项,并生成部分结果。
- 使用该部分结果,连同 iterable 中的第三项,生成另一个部分结果。
- 重复该过程,直到 iterable 用尽,然后返回一个累积值。
Python 的
reduce()背后的思想是获取一个现有的函数,将其累积应用于 iterable 中的所有项,并生成一个最终值。一般来说,Python 的reduce()在处理可重复项时很方便,无需编写显式的for循环。由于reduce()是用 C 写的,它的内部循环可以比显式的 Pythonfor循环更快。Python 的
reduce()原本是内置函数(在 Python 2.x 中依然如此),但在 Python 3.0 中被移到了functools.reduce()。这个决定是基于一些可能的性能和可读性问题。将
reduce()移至functools的另一个原因是引入了内置函数,如sum()、any()、all()、max()、min()和len(),这些函数为reduce()提供了更高效、更易读和更 Pythonic 化的处理常见用例的方式。在本教程的后面,您将学习如何使用它们来代替reduce()。在 Python 3.x 中,如果你需要使用
reduce(),那么你首先必须使用一个import语句将函数导入到你的当前作用域中,方法如下:
import functools然后像functools.reduce()一样使用全限定名。from functools import reduce然后直接调用reduce()。根据
reduce()的文档,该函数具有以下特征:functools.reduce(function, iterable[, initializer])Python 文档还指出
reduce()大致相当于以下 Python 函数:def reduce(function, iterable, initializer=None): it = iter(iterable) if initializer is None: value = next(it) else: value = initializer for element in it: value = function(value, element) return value像这个 Python 函数一样,
reduce()的工作原理是在一个从左到右的循环中将一个双参数函数应用到iterable的项上,最终将iterable减少到一个累积的value。Python 的
reduce()还接受第三个可选参数initializer,它为计算或归约提供一个种子值。在接下来的两节中,您将深入了解 Python 的
reduce()是如何工作的,以及每个参数背后的含义。所需参数:
function和iterablePython 的
reduce()的第一个参数是一个两个参数的函数,方便地称为function。该函数将应用于 iterable 中的项目,以累计计算最终值。尽管官方文档将
reduce()的第一个参数称为“两个参数的函数”,但是只要可调用对象接受两个参数,您就可以将任何 Python 可调用对象传递给reduce()。可调用对象包括类,实现一个叫做__call__()的特殊方法的实例,实例方法,类方法,静态方法,以及函数。注意:关于 Python 可调用对象的更多细节,您可以查看 Python 文档并向下滚动到“可调用类型”
第二个必需参数
iterable,顾名思义,将接受任何 Python iterable。这包括列表、元组、、range对象、生成器、迭代器、集合、字典键和值,以及任何其他可以迭代的 Python 对象。注意:如果你给 Python 的
reduce()传递一个迭代器,那么这个函数需要穷尽迭代器才能得到最终值。所以,手头的迭代器不会保持懒惰。为了理解
reduce()是如何工作的,你将编写一个函数来计算两个数字和的和,并将等价的数学运算打印到屏幕上。代码如下:
>>> def my_add(a, b):
... result = a + b
... print(f"{a} + {b} = {result}")
... return result
该函数计算a和b的和,使用 f 串打印一条操作消息,并返回计算结果。它是这样工作的:
>>> my_add(5, 5) 5 + 5 = 10 10
my_add()是一个双参数函数,所以可以将它和一个 iterable 一起传递给 Python 的reduce(),以计算 iterable 中项的累积和。查看以下使用数字列表的代码:
>>> from functools import reduce
>>> numbers = [0, 1, 2, 3, 4]
>>> reduce(my_add, numbers)
0 + 1 = 1
1 + 2 = 3
3 + 3 = 6
6 + 4 = 10
10
当您调用reduce(),传递my_add()和numbers作为参数时,您会得到一个输出,显示reduce()执行的所有操作,以得出10的最终结果。在这种情况下,操作等同于((((0 + 1) + 2) + 3) + 4) = 10。
上例中对reduce()的调用将my_add()应用于numbers ( 0和1)中的前两项,并得到结果1。然后reduce()使用1和numbers中的下一项(即2)作为参数调用my_add(),得到结果3。重复该过程,直到numbers用完所有项目,并且reduce()返回10的最终结果。
initializer可选参数:
Python 的reduce()的第三个参数叫做initializer,是可选的。如果你给initializer提供一个值,那么reduce()会把它作为第一个参数提供给function的第一个调用。
这意味着对function的第一次调用将使用initializer的值和iterable的第一项来执行它的第一次部分计算。之后,reduce()继续处理iterable的后续项目。
下面是一个使用my_add()并将initializer设置为100的例子:
>>> from functools import reduce >>> numbers = [0, 1, 2, 3, 4] >>> reduce(my_add, numbers, 100) 100 + 0 = 100 100 + 1 = 101 101 + 2 = 103 103 + 3 = 106 106 + 4 = 110 110因为您为
initializer提供了一个值100,Python 的reduce()在第一次调用中使用这个值作为my_add()的第一个参数。注意,在第一次迭代中,my_add()使用100和0,即numbers的第一项,来执行计算100 + 0 = 100。另一点需要注意的是,如果你给
initializer提供一个值,那么reduce()将比没有initializer时多执行一次迭代。如果您计划使用
reduce()来处理可能为空的 iterables,那么最好为initializer提供一个值。当iterable为空时,Python 的reduce()将使用该值作为其默认返回值。如果你不提供一个initializer值,那么reduce()将引发一个TypeError。看一下下面的例子:
>>> from functools import reduce
>>> # Using an initializer value >>> reduce(my_add, [], 0) # Use 0 as return value
0
>>> # Using no initializer value >>> reduce(my_add, []) # Raise a TypeError with an empty iterable
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: reduce() of empty sequence with no initial value
如果你用空的iterable调用reduce(),那么函数将返回提供给initializer的值。如果你不提供一个initializer,那么reduce()在处理空的可重复项时会抛出一个TypeError。
注意:要深入了解什么是 Python 回溯,请查看了解 Python 回溯。
既然您已经熟悉了reduce()的工作方式,那么您就可以学习如何将它应用于一些常见的编程问题。
用 Python 的reduce() 减少迭代次数
到目前为止,您已经学习了 Python 的reduce()是如何工作的,以及如何使用一个用户定义函数来使用它减少迭代次数。您还了解了reduce()的每个参数的含义以及它们是如何工作的。
在这一节中,您将看到reduce()的一些常见用例,以及如何使用函数解决它们。您还将了解到一些替代的 Python 工具,您可以使用它们来代替reduce()来使您的代码更加 Python 化、高效和可读。
对数值求和
Python 的reduce()的"Hello, World!"就是 sum 用例。它包括计算一系列数字的累积和。假设你有一个类似[1, 2, 3, 4]的数字列表。其总和将为1 + 2 + 3 + 4 = 10。这里有一个如何使用 Python for循环解决这个问题的简单例子:
>>> numbers = [1, 2, 3, 4] >>> total = 0 >>> for num in numbers: ... total += num ... >>> total 10
for循环迭代numbers中的每个值,并在total中累加它们。最终结果是所有值的总和,在本例中是10。像本例中的total一样使用的变量有时被称为累加器。这可以说是 Python 的
reduce()最常见的用例。要用reduce()实现这个操作,您有几种选择。其中一些包括使用具有以下功能之一的reduce():
- 一个用户自定义函数
- 一个
lambda功能- 一个函数叫做
operator.add()要使用用户定义的函数,您需要编写一个将两个数相加的函数。然后你就可以用
reduce()来使用那个功能了。对于这个例子,您可以如下重写my_add():
>>> def my_add(a, b):
... return a + b
...
>>> my_add(1, 2)
3
my_add()将两个数a和b相加,并返回结果。有了my_add(),您可以使用reduce()来计算 Python iterable 中值的总和。方法如下:
>>> from functools import reduce >>> numbers = [1, 2, 3, 4] >>> reduce(my_add, numbers) 10对
reduce()的调用将my_add()应用于numbers中的项目,以计算它们的累积和。最后的结果是10,不出所料。您也可以通过使用
lambda函数来执行相同的计算。在这种情况下,您需要一个lambda函数,它接受两个数字作为参数并返回它们的和。看一下下面的例子:
>>> from functools import reduce
>>> numbers = [1, 2, 3, 4]
>>> reduce(lambda a, b: a + b, numbers)
10
lambda函数接受两个参数并返回它们的和。reduce()在循环中应用lambda函数来计算numbers中各项的累计和。
同样,您可以利用名为 operator 的 Python 模块。这个模块导出了一堆对应于 Python 内部操作符的函数。对于手头的问题,您可以将operator.add()与 Python 的reduce()一起使用。看看下面的例子:
>>> from operator import add >>> from functools import reduce >>> add(1, 2) 3 >>> numbers = [1, 2, 3, 4] >>> reduce(add, numbers) 10在这个例子中,
add()接受两个参数并返回它们的和。所以,你可以使用add()和reduce()来计算numbers所有项目的总和。由于add()是用 C 语言编写的,并且针对效率进行了优化,所以当使用reduce()来解决 sum 用例时,它可能是您的最佳选择。注意使用operator.add()也比使用lambda函数更具可读性。sum 用例在编程中如此常见,以至于 Python 从版本 2.3 开始就包含了一个专用的内置函数
sum()来解决这个问题。sum()被声明为sum(iterable[, start])。
start是sum()的可选参数,默认为0。该函数将start的值从左到右加到iterable的项目上,并返回总数。看一下下面的例子:
>>> numbers = [1, 2, 3, 4]
>>> sum(numbers)
10
由于sum()是内置函数,所以不需要导入任何东西。你随时都可以得到它。使用sum()是解决 sum 用例的最巧妙的方法。它干净、易读、简洁。它遵循一个核心 Python 原则:
简单比复杂好。(来源)
与使用reduce()或for循环相比,sum()的加入在可读性和性能方面是一个巨大的胜利。
注意:关于比较reduce()与其他 Python reduction 工具的性能的更多细节,请查看性能是关键一节。
如果您正在处理 sum 用例,那么良好的实践推荐使用sum()。
数值相乘
Python 的reduce()的乘积用例与 sum 用例颇为相似,但这次的运算是乘法。换句话说,您需要计算 iterable 中所有值的乘积。
例如,假设您有一个列表[1, 2, 3, 4]。它的产品将是1 * 2 * 3 * 4 = 24。您可以使用 Python for循环来计算。看看下面的例子:
>>> numbers = [1, 2, 3, 4] >>> product = 1 >>> for num in numbers: ... product *= num ... >>> product 24循环迭代
numbers中的项目,将每个项目乘以前一次迭代的结果。在这种情况下,累加器product的起始值应该是1而不是0。因为任何数乘以零都是零,所以起始值0将总是使你的乘积等于0。这个计算也是 Python 的
reduce()的一个非常流行的用例。同样,您将涉及解决问题的三种方法。您将把reduce()用于:
- 用户定义的函数
- 一个
lambda功能- 一个函数叫做
operator.mul()对于选项 1,您需要编写一个自定义函数,它接受两个参数并返回它们的乘积。然后您将使用这个函数和
reduce()来计算 iterable 中各项的乘积。看一下下面的代码:
>>> from functools import reduce
>>> def my_prod(a, b):
... return a * b
...
>>> my_prod(1, 2)
2
>>> numbers = [1, 2, 3, 4]
>>> reduce(my_prod, numbers)
24
函数my_prod()将两个数a和b相乘。对reduce()的调用遍历numbers的项,并通过将my_prod()应用于连续的项来计算它们的乘积。最终结果是numbers中所有项目的乘积,在本例中是24。
如果您喜欢使用一个lambda函数来解决这个用例,那么您需要一个接受两个参数并返回它们的乘积的函数。这里有一个例子:
>>> from functools import reduce >>> numbers = [1, 2, 3, 4] >>> reduce(lambda a, b: a * b, numbers) 24当
reduce()遍历numbers时,匿名函数通过将连续的项目相乘来变魔术。同样,结果是numbers中所有项目的乘积。您还可以使用
operator.mul()来处理产品用例。operator.mul()取两个数,返回两个数相乘的结果。这是解决当前问题的正确功能。看看下面的例子:
>>> from operator import mul
>>> from functools import reduce
>>> mul(2, 2)
4
>>> numbers = [1, 2, 3, 4]
>>> reduce(mul, numbers)
24
由于mul()是高度优化的,如果你使用这个函数,而不是用户定义的函数或lambda函数,你的代码会执行得更好。请注意,这个解决方案的可读性也更好。
最后,如果您使用的是 Python 3.8 ,那么您就可以获得这个用例的更 Python 化、可读性更强的解决方案。Python 3.8 增加了一个名为 prod() 的新函数,它驻留在 Python math模块中。这个函数类似于sum(),但是返回一个start值乘以一个iterable数的乘积。
对于math.prod(),参数start是可选的,默认为1。它是这样工作的:
>>> from math import prod >>> numbers = [1, 2, 3, 4] >>> prod(numbers) 24与使用
reduce()相比,这在可读性和效率方面也是一大胜利。所以,如果你使用的是 Python 3.8 ,并且产品缩减是你代码中的常见操作,那么你使用math.prod()会比使用 Python 的reduce()更好。寻找最小值和最大值
在 iterable 中寻找最小和最大值的问题也是一个归约问题,您可以使用 Python 的
reduce()来解决。这个想法是比较 iterable 中的项目,找出最小值或最大值。假设你有一个数字列表
[3, 5, 2, 4, 7, 1]。在这个列表中,最小值是1,最大值是7。要找到这些值,可以使用 Pythonfor循环。查看以下代码:
>>> numbers = [3, 5, 2, 4, 7, 1]
>>> # Minimum >>> min_value, *rest = numbers
>>> for num in rest:
... if num < min_value:
... min_value = num
...
>>> min_value
1
>>> # Maximum >>> max_value, *rest = numbers
>>> for num in rest:
... if num > max_value:
... max_value = num
...
>>> max_value
7
两个循环都迭代rest中的项目,并根据连续比较的结果更新min_value或max_value的值。注意最初,min_value和max_value持有数字3,这是numbers中的第一个值。变量rest保存numbers中的剩余值。换句话说,rest = [5, 2, 4, 7, 1]。
注意:在上面的例子中,你使用 Python iterable 解包操作符(* ) 到解包或将numbers中的值展开成两个变量。在第一种情况下,净效果是min_value获得numbers中的第一个值,即3,而rest将剩余的值收集到一个列表中。
查看以下示例中的详细信息:
>>> numbers = [3, 5, 2, 4, 7, 1] >>> min_value, *rest = numbers >>> min_value 3 >>> rest [5, 2, 4, 7, 1] >>> max_value, *rest = numbers >>> max_value 3 >>> rest [5, 2, 4, 7, 1]Python iterable 解包操作符(
*)在您需要将一个序列或 iterable 解包成几个变量时非常有用。为了更好地理解 Python 中的解包操作,你可以查看一下 PEP 3132 扩展的可迭代解包和 PEP 448 附加解包一般化。
现在,考虑如何使用 Python 的
reduce()找到 iterable 中的最小值和最大值。同样,您可以根据需要使用用户定义的函数或lambda函数。下面的代码实现了一个使用两个不同的用户定义函数的解决方案。第一个函数将接受两个参数,
a和b,并返回它们的最小值。第二个函数将使用类似的过程,但它将返回最大值。下面是一些函数,以及如何将它们与 Python 的
reduce()一起使用来查找 iterable 中的最小值和最大值:
>>> from functools import reduce
>>> # Minimum >>> def my_min_func(a, b):
... return a if a < b else b
...
>>> # Maximum >>> def my_max_func(a, b):
... return a if a > b else b
...
>>> numbers = [3, 5, 2, 4, 7, 1]
>>> reduce(my_min_func, numbers)
1
>>> reduce(my_max_func, numbers)
7
当你用my_min_func()和my_max_func()运行reduce()时,你分别得到numbers中的最小值和最大值。reduce()遍历numbers的条目,进行累积对比较,最终返回最小值或最大值。
注意:为了实现my_min_func()和my_max_func(),您使用了一个 Python 条件表达式,或者三元运算符,作为一个return值。要深入了解什么是条件表达式以及它们如何工作,请查看 Python 中的条件语句(if/elif/else) 。
你也可以使用一个lambda函数来解决最小值和最大值问题。看看下面的例子:
>>> from functools import reduce >>> numbers = [3, 5, 2, 4, 7, 1] >>> # Minimum >>> reduce(lambda a, b: a if a < b else b, numbers) 1 >>> # Maximum >>> reduce(lambda a, b: a if a > b else b, numbers) 7这一次,您使用两个
lambda函数来确定a是小于还是大于b。在这种情况下,Python 的reduce()将lambda函数应用于numbers中的每个值,并与之前的计算结果进行比较。在这个过程的最后,你得到最小值或最大值。最小值和最大值问题在编程中非常常见,因此 Python 添加了内置函数来执行这些缩减。这些函数被方便地称为
min()和max(),你不需要导入任何东西就能使用它们。它们是这样工作的:
>>> numbers = [3, 5, 2, 4, 7, 1]
>>> min(numbers)
1
>>> max(numbers)
7
当您使用min()和max()来查找 iterable 中的最小值和最大值时,您的代码比使用 Python 的reduce()更具可读性。此外,由于min()和max()是高度优化的 C 函数,你也可以说你的代码会更有效率。
所以,在用 Python 解决这个问题时,最好使用min()和max()而不是reduce()。
检查所有值是否为真
Python 的reduce()的全真用例涉及到发现一个 iterable 中的所有项是否都为真。要解决这个问题,您可以将reduce()与用户定义的函数或lambda函数一起使用。
首先编写一个for循环,看看 iterable 中的所有项是否都为真。代码如下:
>>> def check_all_true(iterable): ... for item in iterable: ... if not item: ... return False ... return True ... >>> check_all_true([1, 1, 1, 1, 1]) True >>> check_all_true([1, 1, 1, 1, 0]) False >>> check_all_true([]) True如果
iterable中的所有值都为真,那么check_all_true()返回True。否则返回False。它也返回空的可重复项True。check_all_true()执行一个短路评估。这意味着函数一发现假值就返回,而不处理iterable中的其余项目。为了使用 Python 的
reduce()解决这个问题,您需要编写一个函数,它接受两个参数,如果两个参数都为真,则返回True。如果一个或两个参数都为假,那么函数将返回False。代码如下:
>>> def both_true(a, b):
... return bool(a and b)
...
>>> both_true(1, 1)
True
>>> both_true(1, 0)
False
>>> both_true(0, 0)
False
这个函数有两个参数,a和b。然后使用 and操作符来测试两个参数是否都为真。如果两个参数都为真,返回值将是True。否则,它将成为False。
在 Python 中,以下对象被认为是假的:
- 常数像
None和False - 具有零值的数字类型,如
0、0.0、0j、、Decimal(0)、、Fraction(0, 1)、 - 空序列和集合,如
""、()、[]、{}、、和range(0) - 实现返回值为
False的__bool__()或返回值为0的__len__()的对象
任何其他对象都将被视为真。
你需要使用 bool() 将and的返回值转换成True或者False。如果你不使用bool(),那么你的函数不会像预期的那样运行,因为and返回表达式中的一个对象,而不是True或False。看看下面的例子:
>>> a = 0 >>> b = 1 >>> a and b 0 >>> a = 1 >>> b = 2 >>> a and b 2如果表达式中的第一个值为 false,则返回该值。否则,它将返回表达式中的最后一个值,而不考虑其真值。这就是为什么在这种情况下需要使用
bool()的原因。bool()返回对布尔表达式或对象求值后得到的布尔值 (True或False)。使用bool()查看示例:
>>> a = 0
>>> b = 1
>>> bool(a and b)
False
>>> a = 1
>>> b = 2
>>> bool(a and b)
True
在对表达式或手边的对象求值后,bool()将总是返回True或False。
注意:为了更好的理解 Python 中的操作符和表达式,可以查阅 Python 中的操作符和表达式。
你可以通过both_true()到reduce()来检查一个 iterable 的所有项是否为真。这是如何工作的:
>>> from functools import reduce >>> reduce(both_true, [1, 1, 1, 1, 1]) True >>> reduce(both_true, [1, 1, 1, 1, 0]) False >>> reduce(both_true, [], True) True如果您将
both_true()作为参数传递给reduce(),那么如果 iterable 中的所有项都为真,您将得到True。否则你会得到False。在第三个例子中,您将
True传递给reduce()的initializer,以获得与check_all_true()相同的行为,并避免出现TypeError。你也可以使用一个
lambda函数来解决reduce()的全真用例。以下是一些例子:
>>> from functools import reduce
>>> reduce(lambda a, b: bool(a and b), [0, 0, 1, 0, 0])
False
>>> reduce(lambda a, b: bool(a and b), [1, 1, 1, 2, 1])
True
>>> reduce(lambda a, b: bool(a and b), [], True)
True
这个lambda函数与both_true()非常相似,使用相同的表达式作为返回值。如果两个参数都为真,则返回True。否则返回False。
请注意,与check_all_true()不同,当您使用reduce()来解决全真用例时,没有短路评估,因为reduce()直到遍历整个可迭代对象后才返回。这会给代码增加额外的处理时间。
例如,假设您有一个列表lst = [1, 0, 2, 0, 0, 1],您需要检查lst中的所有项目是否都为真。在这种情况下,check_all_true()将在它的循环处理完第一对条目(1和0)后立即结束,因为0为假。你不需要继续迭代,因为你手头已经有了问题的答案。
另一方面,reduce()解决方案直到处理完lst中的所有项目才会结束。那是五次迭代之后。现在想象一下,如果您正在处理一个大的可迭代对象,这会对您的代码性能产生什么影响!
幸运的是,Python 提供了正确的工具,以一种 Python 式的、可读的、高效的方式解决所有真实的问题:内置函数 all() 。
您可以使用all(iterable)来检查iterable中的所有项目是否都为真。以下是all()的工作方式:
>>> all([1, 1, 1, 1, 1]) True >>> all([1, 1, 1, 0, 1]) False >>> all([]) True循环遍历 iterable 中的项目,检查每个项目的真值。如果
all()发现一个错误的条目,那么它返回False。否则返回True。如果你用一个空的 iterable 调用all(),那么你会得到True,因为在一个空的 iterable 中没有 false 项。
all()是一个针对性能优化的 C 函数。该功能也通过短路评估来实现。所以,如果你正在处理 Python 中的全真问题,那么你应该考虑使用all()而不是reduce()。检查是否有值为真
Python 的
reduce()的另一个常见用例是任意真实用例。这一次,您需要确定 iterable 中是否至少有一项为真。要解决这个问题,您需要编写一个函数,它接受一个 iterable,如果 iterable 中的任何一项为真,则返回True,否则返回False。看看这个函数的如下实现:
>>> def check_any_true(iterable):
... for item in iterable:
... if item:
... return True
... return False
...
>>> check_any_true([0, 0, 0, 1, 0])
True
>>> check_any_true([0, 0, 0, 0, 0])
False
>>> check_any_true([])
False
如果iterable中至少有一项为真,那么check_any_true()返回True。只有当所有项为假或者 iterable 为空时,它才返回False。这个函数还实现了一个短路评估,因为它一找到真值(如果有的话)就返回。
为了使用 Python 的reduce()解决这个问题,您需要编写一个函数,它接受两个参数,如果其中至少有一个为真,则返回True。如果两者都为假,那么函数应该返回False。
下面是这个函数的一个可能的实现:
>>> def any_true(a, b): ... return bool(a or b) ... >>> any_true(1, 0) True >>> any_true(0, 1) True >>> any_true(0, 0) False如果至少有一个参数为真,则
any_true()返回True。如果两个参数都为假,那么any_true()返回False。与上面部分中的both_true()一样,any_true()使用bool()将表达式a or b的结果转换为True或False。Python
or操作符的工作方式与and略有不同。它返回表达式中的第一个真对象或最后一个对象。看看下面的例子:
>>> a = 1
>>> b = 2
>>> a or b
1
>>> a = 0
>>> b = 1
>>> a or b
1
>>> a = 0
>>> b = []
>>> a or b
[]
Python or操作符返回第一个真对象,或者,如果两个都为假,则返回最后一个对象。因此,您还需要使用bool()从any_true()获得一致的返回值。
一旦你有了这个功能,你就可以继续减少。看看下面对reduce()的调用:
>>> from functools import reduce >>> reduce(any_true, [0, 0, 0, 1, 0]) True >>> reduce(any_true, [0, 0, 0, 0, 0]) False >>> reduce(any_true, [], False) False您已经使用 Python 的
reduce()解决了这个问题。请注意,在第三个例子中,您将False传递给reduce()的初始化器,以重现原始check_any_true()的行为,同时避免出现TypeError。注:和上一节的例子一样,
reduce()的这些例子不做短路评价。这意味着它们会影响代码的性能。您还可以使用带有
reduce()的lambda函数来解决任何真实的用例。你可以这样做:
>>> from functools import reduce
>>> reduce(lambda a, b: bool(a or b), [0, 0, 1, 1, 0])
True
>>> reduce(lambda a, b: bool(a or b), [0, 0, 0, 0, 0])
False
>>> reduce(lambda a, b: bool(a or b), [], False)
False
这个lambda功能和any_true()挺像的。如果两个参数中有一个为真,它将返回True。如果两个参数都为假,那么它返回False。
尽管这种解决方案只需要一行代码,但它仍然会使您的代码不可读,或者至少难以理解。同样,Python 提供了一个不使用reduce()就能高效解决任意真问题的工具:内置函数 any() 。
any(iterable)循环遍历iterable中的项目,测试每个项目的真值,直到找到一个真项目。该函数一找到真值就返回True。如果any()没有找到真值,那么它返回False。这里有一个例子:
>>> any([0, 0, 0, 0, 0]) False >>> any([0, 0, 0, 1, 0]) True >>> any([]) False同样,您不需要导入
any()来在代码中使用它。any()按预期工作。如果 iterable 中的所有项都是假的,它将返回False。否则返回True。注意,如果你用一个空的 iterable 调用any(),那么你会得到False,因为在一个空的 iterable 中没有 true 项。与
all()一样,any()是一个针对性能优化的 C 函数。它也是通过短路评估实现的。所以,如果你正在处理 Python 中的任意真问题,那么考虑使用any()而不是reduce()。比较
reduce()和accumulate()T2一个名为
accumulate()的 Python 函数驻留在itertools中,行为类似于reduce()。accumulate(iterable[, func])接受一个必需的参数iterable,它可以是任何 Python iterable。可选的第二个参数func需要是一个函数(或一个可调用对象),它接受两个参数并返回一个值。返回一个迭代器。这个迭代器中的每一项都将是
func执行的计算的累积结果。默认计算是总和。如果你不给accumulate()提供一个函数,那么结果迭代器中的每一项都将是iterable中前面的项加上手边的项的累加和。看看下面的例子:
>>> from itertools import accumulate
>>> from operator import add
>>> from functools import reduce
>>> numbers = [1, 2, 3, 4]
>>> list(accumulate(numbers))
[1, 3, 6, 10]
>>> reduce(add, numbers)
10
注意,结果迭代器中的最后一个值与reduce()返回的值相同。这是这两个函数的主要相似之处。
注意:由于accumulate()返回一个迭代器,所以需要调用list()来消耗迭代器,得到一个 list 对象作为输出。
另一方面,如果您为accumulate()的func参数提供一个双参数函数(或可调用函数),那么结果迭代器中的项将是由func执行的计算的累积结果。这里有一个使用operator.mul()的例子:
>>> from itertools import accumulate >>> from operator import mul >>> from functools import reduce >>> numbers = [1, 2, 3, 4] >>> list(accumulate(numbers, mul)) [1, 2, 6, 24] >>> reduce(mul, numbers) 24在这个例子中,您可以再次看到
accumulate()返回值中的最后一项等于reduce()返回的值。考虑性能和可读性
Python 的
reduce()可能会有非常糟糕的性能,因为它通过多次调用函数来工作。这可能会使您的代码运行缓慢且效率低下。当使用复杂的用户定义函数或lambda函数时,使用reduce()也会损害代码的可读性。在本教程中,您已经了解到 Python 提供了一系列工具,可以优雅地替代
reduce(),至少对于它的主要用例是这样。以下是到目前为止你阅读的主要收获:
尽可能使用专用函数来解决 Python 的
reduce()用例。诸如sum()、all()、any()、max()、min()、len()、math.prod()等函数会让你的代码更快,可读性更好,可维护性更强,并且python 化。使用
reduce()时避免复杂的用户自定义函数。这些类型的函数会使你的代码难以阅读和理解。您可以使用一个显式的、可读的for循环来代替。使用
reduce()时避免复杂的lambda功能。它们还会让你的代码变得不可读和混乱。第二点和第三点是圭多本人关切的问题,他说:
所以现在
reduce()。这实际上是我最讨厌的一个,因为除了几个涉及+或*的例子,几乎每次我看到一个带有重要函数参数的reduce()调用,我都需要拿起笔和纸来画出实际输入到那个函数中的内容,然后我才明白reduce()应该做什么。因此,在我看来,reduce()的适用性仅限于关联操作符,在其他情况下,最好显式写出累加循环。(来源)接下来的两节将帮助您在代码中实现这个一般建议。他们还提供了一些额外的建议,帮助你在真正需要使用 Python 的
reduce()时有效地使用它。性能是关键
如果您打算使用
reduce()来解决您在本教程中所涉及的用例,那么您的代码将会比使用专用内置函数的代码慢得多。在下面的例子中,您将使用timeit.timeit()来快速测量少量 Python 代码的执行时间,并了解它们的总体性能。
timeit()需要几个参数,但是对于这些例子,你只需要使用下面的:看一下下面的例子,这些例子对使用不同工具的
reduce()和使用 Python 的sum()的和用例进行了计时:
>>> from functools import reduce
>>> from timeit import timeit
>>> # Using a user-defined function >>> def add(a, b):
... return a + b
...
>>> use_add = "functools.reduce(add, range(100))"
>>> timeit(use_add, "import functools", globals={"add": add})
13.443158069014316
>>> # Using a lambda expression >>> use_lambda = "functools.reduce(lambda x, y: x + y, range(100))"
>>> timeit(use_lambda, "import functools")
11.998800784000196
>>> # Using operator.add() >>> use_operator_add = "functools.reduce(operator.add, range(100))"
>>> timeit(use_operator_add, "import functools, operator")
5.183870767941698
>>> # Using sum() >>> timeit("sum(range(100))", globals={"sum": sum})
1.1643308430211619
即使你会得到不同的数字,取决于你的硬件,你可能会得到最好的时间测量使用sum()。这个内置函数也是 sum 问题可读性最强、最 Pythonic 化的解决方案。
注意:关于如何为你的代码计时的更详细的方法,请查看 Python 计时器函数:监控你的代码的三种方法。
第二个最好的选择是将reduce()和operator.add()一起使用。operator中的函数是用 C 语言编写的,并且针对性能进行了高度优化。因此,它们应该比用户定义的函数、lambda函数或for循环执行得更好。
可读性计数
当使用 Python 的reduce()时,代码可读性也是一个重要的关注点。尽管reduce()通常会比 Python for循环执行得更好,正如 Guido 自己所说,干净的Python 循环通常比使用reduce()更容易理解。
Python 3.0 指南中的新特性强调了这一观点,它说:
如果真的需要就用
functools.reduce();然而,99%的情况下,显式的for循环更具可读性。(来源
为了更好地理解可读性的重要性,假设您开始学习 Python,并试图解决一个关于计算 iterable 中所有偶数之和的练习。
如果你已经知道 Python 的reduce()并且在过去做过一些函数式编程,那么你可能会想到下面的解决方案:
>>> from functools import reduce >>> def sum_even(it): ... return reduce(lambda x, y: x + y if not y % 2 else x, it, 0) ... >>> sum_even([1, 2, 3, 4]) 6在这个函数中,使用
reduce()对 iterable 中的偶数进行累加求和。lambda函数接受两个参数x和y,如果它们是偶数,则返回它们的和。否则,它返回x,其中保存了前一次求和的结果。此外,您将
initializer设置为0,因为否则您的 sum 将有一个初始值1(iterable中的第一个值),它不是一个偶数,会在您的函数中引入一个 bug。该函数按照您的预期工作,并且您对结果感到满意。但是,您将继续深入研究 Python,了解
sum()和生成器表达式。您决定使用这些新工具重新设计您的函数,现在您的函数如下所示:
>>> def sum_even(iterable):
... return sum(num for num in iterable if not num % 2)
...
>>> sum_even([1, 2, 3, 4])
6
当你看到这些代码时,你会感到非常自豪,你应该这样做。你做得很好!这是一个漂亮的 Python 函数,读起来几乎像普通英语。它也是高效的和 Pythonic 式的。你怎么想呢?
结论
Python 的reduce()允许你使用 Python 调用和lambda函数对 iterables 执行归约操作。reduce()将函数应用于 iterable 中的项目,并将它们简化为单个累积值。
在本教程中,您已经学习了:
- 什么是还原,或者折叠,以及它什么时候可能有用
- 如何使用 Python 的
reduce()解决常见的数字相加或相乘等归约问题 - 哪些python 工具可以用来有效地替换代码中的
reduce()
有了这些知识,在解决 Python 中的归约问题时,您将能够决定哪些工具最适合您的编码需求。
这些年来,reduce()已经被更多的 Pythonic 工具所取代,比如sum()、min()、max()、any()等等。但是,reduce()还在,还在函数式程序员中流行。如果你对使用reduce()或它的任何 Python 替代品有任何问题或想法,那么一定要在下面的评论中发表。*********
为简单起见重构 Python 应用程序
你想要更简单的 Python 代码吗?你总是带着最好的意图、干净的代码库和良好的结构开始一个项目。但是随着时间的推移,你的应用程序会发生变化,事情会变得有点混乱。
如果你能编写和维护干净、简单的 Python 代码,那么从长远来看,它将为你节省大量的时间。当您的代码布局良好且易于遵循时,您可以花费更少的时间来测试、查找 bug 和进行更改。
在本教程中,你将学习:
- 如何衡量 Python 代码和应用程序的复杂性
- 如何在不破坏代码的情况下更改代码
- Python 代码中导致额外复杂性的常见问题是什么,以及如何修复它们
在整个教程中,我将使用地下铁路网络的主题来解释复杂性,因为在大城市的地铁系统中导航可能是复杂的!有些设计得很好,有些似乎过于复杂。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 中的代码复杂性
应用程序及其代码库的复杂性与其执行的任务相关。如果你正在为 NASA 的喷气推进实验室(字面意思是火箭科学)编写代码,那么这将会很复杂。
问题不在于“我的代码复杂吗?”比如,“我的代码比它需要的更复杂吗?”
东京铁路网是世界上最广泛和最复杂的网络之一。这部分是因为东京是一个超过 3000 万人口的大都市,但也是因为有 3 个网络相互重叠。

东京市中心有东映和东京地铁快速运输网络以及日本铁路东线列车。即使对最有经验的旅行者来说,在东京市中心导航也是令人难以置信的复杂。
这里有一张东京铁路网的地图,给你一些视角:

如果你的代码开始看起来有点像这个地图,那么这就是你的教程。
首先,我们将讨论 4 个复杂度指标,这些指标可以给你一个尺度来衡量你在简化代码的任务中的相对进度:

在您探索了这些指标之后,您将了解一个叫做wily的工具来自动计算这些指标。
衡量复杂性的标准
大量的时间和研究被投入到分析计算机软件的复杂性上。过于复杂和不可维护的应用程序会有很高的成本。
软件的复杂性与质量相关。易于阅读和理解的代码将来更有可能被开发人员更新。
这里有一些编程语言的标准。它们适用于许多语言,不仅仅是 Python。
代码行
LOC,或代码行数,是复杂性的最粗略的度量。在代码行和应用程序的复杂性之间是否有任何直接的联系是有争议的,但是间接的联系是清楚的。毕竟,一个只有 5 行代码的程序可能比一个有 500 万行代码的程序简单。
当查看 Python 指标时,我们试图忽略空行和包含注释的行。
可以在 Linux 和 Mac OS 上使用wc命令来计算代码行,其中file.py是您想要测量的文件的名称:
$ wc -l file.py
如果你想通过递归搜索所有.py文件来添加文件夹中的组合行,你可以将wc与find命令组合起来:
$ find . -name \*.py | xargs wc -l
对于 Windows,PowerShell 在Measure-Object中提供了字数统计命令,在Get-ChildItem中提供了递归文件搜索:
PS C:\> Get-ChildItem -Path *.py -Recurse | Measure-Object –Line
在响应中,您将看到总行数。
为什么要用代码行数来量化应用程序中的代码量?假设一行代码大致相当于一条语句。行是比字符更好的度量,因为字符包括空白。
在 Python 中,我们被鼓励在每一行放一条语句。这个例子有 9 行代码:
1x = 5
2value = input("Enter a number: ")
3y = int(value)
4if x < y:
5 print(f"{x} is less than {y}")
6elif x == y:
7 print(f"{x} is equal to {y}")
8else:
9 print(f"{x} is more than {y}")
如果你只使用代码行来度量复杂性,这可能会鼓励错误的行为。
Python 代码应该易于阅读和理解。以最后一个例子为例,您可以将代码行数减少到 3:
1x = 5; y = int(input("Enter a number:"))
2equality = "is equal to" if x == y else "is less than" if x < y else "is more than"
3print(f"{x} {equality} {y}")
但是结果很难阅读,PEP 8 有关于最大行长和换行的指导方针。您可以查看如何使用 PEP 8 编写漂亮的 Python 代码以了解更多关于 PEP 8 的信息。
这个代码块使用了两个 Python 语言特性来缩短代码:
- 复合语句:使用
; - 链式条件或三元语句:
name = value if condition else value if condition2 else value2
我们减少了代码行数,但是违反了 Python 的一个基本法则:
"可读性很重要"
—蒂姆·彼得斯,Python 之禅
这种缩短的代码可能更难维护,因为代码维护者是人,而且这种短代码更难阅读。我们将探索一些更高级、更有用的复杂性度量标准。
圈复杂度
圈复杂度是对应用程序中有多少独立代码路径的度量。路径是一系列的语句,解释器可以跟随它到达应用程序的末尾。
考虑圈复杂度和代码路径的一种方式是把你的代码想象成一个铁路网。
对于一次旅行,你可能需要换乘火车才能到达目的地。葡萄牙的里斯本大都会铁路系统简单易行。任何旅行的圈复杂度等于您需要旅行的线路数:

如果你需要从阿尔瓦拉德到安茹斯,那么你将在哈林维德(绿线)上行驶 5 站:

这次旅行的圈复杂度为 1,因为你只乘坐 1 次火车。这是一次轻松的旅行。在这个类比中,这种训练相当于一个代码分支。
如果你需要从机场(机场)前往贝伦 区品尝美食,那么这是一个更复杂的旅程。你必须在阿拉梅达和卡伊斯多索德转车:

这次旅行的圈复杂度是 3,因为你要乘坐 3 次火车。你最好乘出租车去。
看起来你不是在浏览里斯本,而是在写代码,火车线路的变化变成了执行中的一个分支,就像一个 if语句。
让我们来看看这个例子:
x = 1
这段代码只有一种执行方式,因此它的圈复杂度为 1。
如果我们添加一个决策,或者将代码分支为一个if语句,就会增加复杂性:
x = 1
if x < 2:
x += 1
尽管这段代码只有一种执行方式,但由于x是一个常数,因此圈复杂度为 2。所有圈复杂度分析器都将一个if语句视为一个分支。
这也是过度复杂代码的一个例子。因为x有一个固定值,所以if语句没有用。您可以简单地将此示例重构如下:
x = 2
这是一个玩具示例,所以让我们来探索一些更真实的东西。
main()的圈复杂度为 5。我将在代码中注释每个分支,这样您就可以看到它们在哪里:
# cyclomatic_example.py
import sys
def main():
if len(sys.argv) > 1: # 1 filepath = sys.argv[1]
else:
print("Provide a file path")
exit(1)
if filepath: # 2 with open(filepath) as fp: # 3 for line in fp.readlines(): # 4 if line != "\n": # 5 print(line, end="")
if __name__ == "__main__": # Ignored.
main()
当然有方法可以将代码重构为更简单的替代方案。我们稍后会谈到这一点。
注:圈复杂度是由托马斯·j·麦凯布于 1976 年提出的。你可能会看到它被称为麦凯比指标或麦凯比数。
在下面的例子中,我们将使用 PyPI 中的 radon 库来计算指标。您现在可以安装它:
$ pip install radon
要使用radon计算圈复杂度,您可以将示例保存到名为cyclomatic_example.py的文件中,并从命令行使用radon。
radon命令有两个主要参数:
- 分析的类型(
cc表示圈复杂度) - 要分析的文件或文件夹的路径
针对cyclomatic_example.py文件执行带有cc分析的radon命令。添加-s将给出输出中的圈复杂度:
$ radon cc cyclomatic_example.py -s
cyclomatic_example.py
F 4:0 main - B (6)
输出有点神秘。以下是每个部分的含义:
F表示函数,M表示方法,C表示类。main是函数的名称。4是函数开始的行。B是从 A 到 f 的等级,A 是最好的等级,意味着最不复杂。- 括号中的数字
6,是代码的圈复杂度。
霍尔斯特德指标
霍尔斯特德复杂度指标与程序代码库的大小有关。它们是由莫里斯·h·霍尔斯特德于 1977 年开发的。霍尔斯特德方程中有 4 个测量值:
- 操作数是变量的值和名称。
- 运算符均为内置关键字,如
if、else、for或while。 - Length (N) 是程序中操作符的数量加上操作数的数量。
- 词汇(h) 是你一个程序中唯一运算符的个数加上唯一操作数的个数。
然后,这些测量有 3 个额外的指标:
- 体积(V) 代表长度和词汇的乘积。
- 难度(D) 表示一半唯一操作数和操作数复用的乘积。
- 努力(E) 是总体指标,是量和难度的乘积。
所有这些都很抽象,所以让我们用相对的术语来说:
- 如果你使用大量的操作符和唯一的操作数,你的应用程序的效率是最高的。
- 如果使用较少的操作符和变量,应用程序的工作量会较低。
对于cyclomatic_complexity.py的例子,操作符和操作数都出现在第一行:
import sys # import (operator), sys (operand)
import是操作符,sys是模块名,所以是操作数。
在一个稍微复杂一点的例子中,有许多运算符和操作数:
if len(sys.argv) > 1:
...
本例中有 5 个运算符:
if()>:
此外,还有 2 个操作数:
sys.argv1
要知道radon只计算操作符的子集。例如,括号不包括在任何计算中。
要计算radon中的 Halstead 度量,您可以运行以下命令:
$ radon hal cyclomatic_example.py
cyclomatic_example.py:
h1: 3
h2: 6
N1: 3
N2: 6
vocabulary: 9
length: 9
calculated_length: 20.264662506490406
volume: 28.529325012980813
difficulty: 1.5
effort: 42.793987519471216
time: 2.377443751081734
bugs: 0.009509775004326938
为什么radon给出了时间和 bug 的度量?
霍尔斯特德认为,你可以通过将工作量(E)除以 18 来估计编码所用的时间(秒)。
霍尔斯特德还指出,预期的错误数量可以通过将体积(V)除以 3000 来估计。请记住,这是 1977 年写的,甚至在 Python 发明之前!所以不要惊慌,现在就开始寻找漏洞。
可维护性指数
可维护性指数将 McCabe 圈复杂度和 Halstead 容量度量值大致划分在 0 到 100 之间。
如果你感兴趣,原始方程如下:

在等式中,V是霍尔斯特德容量度量,C是圈复杂度,L是代码行数。
如果你和我第一次看到这个等式时一样困惑,那么它的意思是:它计算一个范围,包括变量 T1、操作、决策路径和代码行的数量。
它被许多工具和语言使用,所以它是更标准的度量之一。然而,这个等式有许多修正,所以确切的数字不应该被当作事实。radon、wily,Visual Studio 将数字限制在 0 到 100 之间。
在可维护性指数等级上,你需要注意的是你的代码何时变得非常低(接近 0)。该量表认为低于 25 的为难以维持,高于 75 的为易于维持。维修性指数也称为 MI 。
可维护性指数可以用来衡量应用程序的当前可维护性,并在重构时查看是否取得了进展。
要从radon计算可维护性指数,运行以下命令:
$ radon mi cyclomatic_example.py -s
cyclomatic_example.py - A (87.42)
在这个结果中,A是radon应用于数字87.42的等级。在这个尺度上,A最易维护,F最难维护。
使用wily来捕捉和跟踪项目的复杂性
wily是一个开源软件项目,用于收集代码复杂度指标,包括我们到目前为止已经介绍过的 Halstead、Cyclomatic 和 LOC。wily与 Git 集成,可以自动收集跨 Git 分支和修订的指标。
wily的目的是让您能够看到代码复杂度随时间变化的趋势和变化。如果你试图微调一辆车或提高你的体能,你会从测量基线开始,并随着时间的推移跟踪改进。
安装wily
wily在 PyPI 上可用,可以使用 pip 安装:
$ pip install wily
一旦安装了wily,您的命令行中就有了一些可用的命令:
wily build: 遍历 Git 历史并分析每个文件的指标wily report: 查看给定文件或文件夹的度量历史趋势wily graph: 在 HTML 文件中绘制一组指标
构建缓存
在你使用wily之前,你需要分析你的项目。这是使用wily build命令完成的。
对于教程的这一部分,我们将分析非常流行的requests包,用于与 HTTP APIs 对话。因为这个项目是开源的,可以在 GitHub 上获得,我们可以很容易地访问和下载源代码的副本:
$ git clone https://github.com/requests/requests
$ cd requests
$ ls
AUTHORS.rst CONTRIBUTING.md LICENSE Makefile
Pipfile.lock _appveyor docs pytest.ini
setup.cfg tests CODE_OF_CONDUCT.md HISTORY.md
MANIFEST.in Pipfile README.md appveyor.yml
ext requests setup.py tox.ini
注意:对于以下示例,Windows 用户应该使用 PowerShell 命令提示符,而不是传统的 MS-DOS 命令行。要启动 PowerShell CLI,请按下 Win + R 并键入powershell,然后键入 Enter 。
您将在这里看到许多文件夹,用于测试、文档和配置。我们只对requests Python 包的源代码感兴趣,它位于一个名为requests的文件夹中。
从克隆的源代码中调用wily build命令,并提供源代码文件夹的名称作为第一个参数:
$ wily build requests
这将需要几分钟的时间进行分析,具体取决于计算机的 CPU 能力:

收集项目数据
一旦您分析了requests源代码,您就可以查询任何文件或文件夹来查看关键指标。在本教程的前面,我们讨论了以下内容:
- 代码行
- 保养率指数
- 圈复杂度
这些是wily中的 3 个默认指标。要查看特定文件(如requests/api.py)的指标,请运行以下命令:
$ wily report requests/api.py
wily将以相反的日期顺序打印每个 Git 提交的默认指标的表格报告。您将在顶部看到最近的提交,在底部看到最早的提交:
| 修订本 | 作者 | 日期 | 大调音阶的第三音 | 代码行 | 圈复杂度 |
|---|---|---|---|---|---|
| f37daf2 | 内特·普鲁伊特 | 2019-01-13 | 100 (0.0) | 158 (0) | 9 (0) |
| 6dd410f | Ofek Lev | 2019-01-13 | 100 (0.0) | 158 (0) | 9 (0) |
| 5c1f72e | 内特·普鲁伊特 | 2018-12-14 | 100 (0.0) | 158 (0) | 9 (0) |
| c4d7680 | 马蒂厄·莫伊 | 2018-12-14 | 100 (0.0) | 158 (0) | 9 (0) |
| c452e3b | 内特·普鲁伊特 | 2018-12-11 | 100 (0.0) | 158 (0) | 9 (0) |
| 5a1e738 | 内特·普鲁伊特 | 2018-12-10 | 100 (0.0) | 158 (0) | 9 (0) |
这告诉我们,requests/api.py文件有:
- 158 行代码
- 完美的可维护性指数为 100
- 圈复杂度为 9
要查看其他指标,您首先需要知道它们的名称。通过运行以下命令可以看到这一点:
$ wily list-metrics
您将看到一个操作符、分析代码的模块以及它们所提供的度量标准的列表。
要在报告命令中查询替代指标,请在文件名后添加它们的名称。您可以添加任意数量的指标。下面是一个关于可维护性等级和源代码行的示例:
$ wily report requests/api.py maintainability.rank raw.sloc
您将会看到该表现在有两个不同的列,包含备选指标。
图表指标
现在您已经知道了指标的名称以及如何在命令行上查询它们,您还可以在图形中可视化它们。wily支持 HTML 和交互式图表,界面类似于报表命令:
$ wily graph requests/sessions.py maintainability.mi
您的默认浏览器将打开一个交互式图表,如下所示:

您可以将鼠标悬停在特定的数据点上,它会显示 Git commit 消息和数据。
如果您想将 HTML 文件保存在文件夹或存储库中,您可以添加带有文件路径的-o标志:
$ wily graph requests/sessions.py maintainability.mi -o my_report.html
现在会有一个名为my_report.html的文件,您可以与其他人共享。该命令非常适合团队仪表板。
wily作pre-commit勾
可以进行配置,以便在您提交项目变更之前,它可以提醒您复杂性的提高或降低。
wily有一个wily diff命令,将最后一个索引数据与文件的当前工作副本进行比较。
要运行wily diff命令,请提供您已更改的文件名。例如,如果我对requests/api.py做了一些更改,您将通过使用文件路径运行wily diff看到对指标的影响:
$ wily diff requests/api.py
在响应中,您将看到所有已更改的指标,以及圈复杂度已更改的函数或类:

diff命令可以与名为pre-commit的工具配对。pre-commit在您的 Git 配置中插入一个钩子,每次运行git commit命令时它都会调用一个脚本。
要安装pre-commit,您可以从 PyPI 安装:
$ pip install pre-commit
将以下内容添加到项目根目录中的一个.pre-commit-config.yaml中:
repos: - repo: local hooks: - id: wily name: wily entry: wily diff verbose: true language: python additional_dependencies: [wily]
设置好之后,运行pre-commit install命令来完成事情:
$ pre-commit install
每当您运行git commit命令时,它将调用wily diff以及您已经添加到您的阶段性变更中的文件列表。
wily是一个非常有用的工具,可以基线化代码的复杂性,并衡量在开始重构时所取得的改进。
Python 中的重构
重构是一种改变应用程序(代码或架构)的技术,使它在外表上表现相同,但在内部有所改进。这些改进可以是稳定性、性能或复杂性的降低。
伦敦地铁是世界上最古老的地下铁路之一,始于 1863 年大都会线的开通。它有由蒸汽机车牵引的点燃煤气的木制车厢。在铁路开通时,它是符合目的的。1900 年带来了电气化铁路的发明。
到 1908 年,伦敦地铁已经扩展到 8 条铁路。第二次世界大战期间,伦敦地铁站对火车关闭,被用作防空洞。现代伦敦地铁每天运送数百万乘客,有 270 多个车站:

第一次写出完美的代码几乎是不可能的,需求经常变化。如果你要求铁路的最初设计者设计一个适合 2020 年每天 1000 万乘客的网络,他们不会设计今天存在的网络。
相反,铁路经历了一系列不断的变化,以优化其运营,设计和布局,以适应城市的变化。已经重构了。
在这一节中,您将探索如何通过利用测试和工具来安全地进行重构。您还将看到如何在 Visual Studio 代码和 PyCharm 中使用重构功能:

用重构规避风险:利用工具和测试
如果重构的目的是在不影响外部的情况下改进应用程序的内部,那么如何确保外部没有改变呢?
在你开始一个大的重构项目之前,你需要确保你的应用程序有一个可靠的测试套件。理想情况下,测试套件应该大部分是自动化的,这样当您进行更改时,您可以看到对用户的影响并快速解决它。
如果你想学习更多关于 Python 测试的知识,那么开始使用 Python 测试是一个很好的起点。
在你的申请中没有完美的测试次数。但是,测试套件越健壮和彻底,你就越能积极地重构你的代码。
进行重构时,您将执行的两个最常见的任务是:
- 重命名模块、函数、类和方法
- 查找函数、类和方法的用法,以查看它们在哪里被调用
您可以使用搜索并替换来简单地手工完成这项工作,但是这既耗时又有风险。相反,有一些很好的工具来执行这些任务。
使用rope进行重构
rope是一个免费的 Python 工具,用于重构 Python 代码。它附带了一个扩展的API 集,用于重构和重命名 Python 代码库中的组件。
rope可以用两种方式:
- 通过使用编辑器插件,对于 Visual Studio 代码、 Emacs 或 Vim
- 直接通过编写脚本来重构您的应用程序
要使用 rope 作为库,首先通过执行pip来安装rope:
$ pip install rope
在 REPL 上使用rope非常有用,这样您可以探索项目并实时查看变化。首先,导入Project类型并用项目路径实例化它:
>>> from rope.base.project import Project >>> proj = Project('requests')
proj变量现在可以执行一系列命令,比如get_files和get_file,来获取一个特定的文件。获取文件api.py,并将其赋给一个名为api的变量:
>>> [f.name for f in proj.get_files()]
['structures.py', 'status_codes.py', ...,'api.py', 'cookies.py']
>>> api = proj.get_file('api.py')
如果您想重命名这个文件,您可以简单地在文件系统上重命名它。但是,项目中导入旧名称的任何其他 Python 文件现在都将被破坏。让我们将api.py重命名为new_api.py:
>>> from rope.refactor.rename import Rename >>> change = Rename(proj, api).get_changes('new_api') >>> proj.do(change)运行
git status,您将看到rope对存储库做了一些更改:$ git status On branch master Your branch is up to date with 'origin/master'. Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: requests/__init__.py deleted: requests/api.py Untracked files: (use "git add <file>..." to include in what will be committed) requests/.ropeproject/ requests/new_api.py no changes added to commit (use "git add" and/or "git commit -a")
rope所做的三项更改如下:
- 删除了
requests/api.py并创建了requests/new_api.py- 修改
requests/__init__.py以从new_api而不是api导入- 创建了一个名为
.ropeproject的项目文件夹要重置更改,运行
git reset。有数百种其他的重构可以用
rope来完成。使用 Visual Studio 代码进行重构
Visual Studio 代码通过自己的 UI 开放了
rope中可用的重构命令的一个小子集。您可以:
- 从语句中提取变量
- 从代码块中提取方法
- 将导入按逻辑顺序排序
下面是一个从命令面板中使用提取方法命令的例子:
使用 PyCharm 进行重构
如果您使用或正在考虑使用 PyCharm 作为 Python 编辑器,那么值得注意它强大的重构功能。
在 Windows 和 macOS 上使用
Ctrl+T命令可以访问所有的重构快捷方式。Linux 中访问重构的快捷键是Ctrl+Shift+Alt++T。寻找函数和类的调用者和用法
在你移除一个方法或者类或者改变它的行为方式之前,你需要知道哪些代码依赖于它。PyCharm 可以搜索项目中方法、函数或类的所有用法。
要访问此功能,通过右键单击选择一个方法、类或变量,然后选择查找用法:
使用您的搜索标准的所有代码都显示在底部的面板中。您可以双击任何项目,直接导航到有问题的行。
使用 PyCharm 重构工具
其他一些重构命令包括以下功能:
- 从现有代码中提取方法、变量和常量
- 从现有的类签名中提取抽象类,包括指定抽象方法的能力
- 几乎可以重命名任何东西,从变量到方法、文件、类或模块
下面是一个例子,将您之前使用
rope模块重命名的同一个api.py模块重命名为new_api.py:
rename 命令与 UI 相关联,这使得重构变得快速而简单。它已经用新的模块名自动更新了
__init__.py中的导入。另一个有用的重构是更改签名命令。这可用于添加、移除或重命名函数或方法的参数。它将搜索用法并为您更新它们:
您可以设置默认值,也可以决定重构应该如何处理新的参数。
总结
重构对于任何开发人员来说都是一项重要的技能。正如你在本章中了解到的,你并不孤单。这些工具和 ide 已经带有强大的重构特性,能够快速地做出改变。
复杂性反模式
既然你已经知道了如何度量复杂性,如何度量复杂性,以及如何重构代码,那么是时候学习 5 种常见的反模式了,它们会使代码变得比实际需要的更复杂:
如果您能够掌握这些模式并知道如何重构它们,您将很快步入更易于维护的 Python 应用程序的轨道。
1.应该是对象的函数
Python 支持使用函数的程序化编程以及可继承类。两者都非常强大,应该适用于不同的问题。
以这个处理图像的模块为例。为简洁起见,函数中的逻辑已被删除:
# imagelib.py def load_image(path): with open(path, "rb") as file: fb = file.load() image = img_lib.parse(fb) return image def crop_image(image, width, height): ... return image def get_image_thumbnail(image, resolution=100): ... return image这种设计有几个问题:
不清楚
crop_image()和get_image_thumbnail()是修改原始的image变量还是创建新的图像。如果您想加载一个图像,然后创建一个裁剪和缩略图图像,您是否必须先复制实例?您可以阅读函数中的源代码,但是您不能依赖每个开发人员都这样做。您必须在每次调用图像函数时将图像变量作为参数传递。
调用代码可能是这样的:
from imagelib import load_image, crop_image, get_image_thumbnail image = load_image('~/face.jpg') image = crop_image(image, 400, 500) thumb = get_image_thumbnail(image)以下是使用可重构为类的函数的代码的一些症状:
- 跨函数的相似参数
- Halstead
h2唯一操作数的更高数量- 可变和不可变函数的混合
- 函数分布在多个 Python 文件中
下面是这 3 个函数的重构版本,其中发生了以下情况:
.__init__()取代load_image()。crop()变成了类方法。get_image_thumbnail()成为财产。缩略图分辨率已成为一个类属性,因此可以全局更改或在特定实例上更改:
# imagelib.py class Image(object): thumbnail_resolution = 100 def __init__(self, path): ... def crop(self, width, height): ... @property def thumbnail(self): ... return thumb如果这段代码中有更多与图像相关的函数,那么对类的重构可能会带来巨大的变化。接下来要考虑的是消费代码的复杂性。
重构后的示例如下所示:
from imagelib import Image image = Image('~/face.jpg') image.crop(400, 500) thumb = image.thumbnail在生成的代码中,我们解决了最初的问题:
- 很明显,
thumbnail返回一个缩略图,因为它是一个属性,并且它不修改实例。- 代码不再需要为裁剪操作创建新的变量。
2.应该是函数的对象
有时候,情况正好相反。有一些面向对象的代码更适合一两个简单的函数。
下面是一些不正确使用类的迹象:
- 具有 1 个方法的类(除了
.__init__())- 仅包含静态方法的类
举一个身份验证类的例子:
# authenticate.py class Authenticator(object): def __init__(self, username, password): self.username = username self.password = password def authenticate(self): ... return result如果有一个名为
authenticate()的简单函数,将username和password作为参数,那就更有意义了:# authenticate.py def authenticate(username, password): ... return result您不必坐下来手动寻找符合这些标准的类:
pylint附带了一个规则,即类应该至少有两个公共方法。关于 PyLint 和其他代码质量工具的更多信息,你可以查看 Python 代码质量和用 PyLint 编写更干净的 Python 代码。要安装
pylint,请在您的控制台中运行以下命令:$ pip install pylint
pylint接受一些可选参数,然后是一个或多个文件和文件夹的路径。如果使用默认设置运行pylint,它会给出很多输出,因为pylint有大量的规则。相反,您可以运行特定的规则。too-few-public-methods规则 id 是R0903。您可以在文档网站上查找:$ pylint --disable=all --enable=R0903 requests ************* Module requests.auth requests/auth.py:72:0: R0903: Too few public methods (1/2) (too-few-public-methods) requests/auth.py:100:0: R0903: Too few public methods (1/2) (too-few-public-methods) ************* Module requests.models requests/models.py:60:0: R0903: Too few public methods (1/2) (too-few-public-methods) ----------------------------------- Your code has been rated at 9.99/10这个输出告诉我们,
auth.py包含了两个只有一个公共方法的类。这些课程在第 72 行和第 100 行。还有一个类在models.py的第 60 行,只有 1 个公共方法。3.将“三角形”代码转换为平面代码
如果你缩小你的源代码,把你的头向右倾斜 90 度,空白看起来是像荷兰一样平坦还是像喜马拉雅山一样多山?堆积如山的代码表明您的代码包含大量嵌套。
下面是 Python 中 禅的一个原理:
“扁平比嵌套好”
—蒂姆·彼得斯,Python 之禅
为什么平面代码会比嵌套代码更好?因为嵌套代码使得阅读和理解正在发生的事情变得更加困难。读者必须理解并记住他们通过分支时的条件。
这些是高度嵌套代码的症状:
- 由于代码分支的数量,圈复杂度很高
- 较低的可维护性指数,因为相对于代码行数而言,圈复杂度较高
以这个例子为例,它在参数
data中查找匹配单词error的字符串。它首先检查data参数是否是一个列表。然后,它遍历每个条目并检查该条目是否是字符串。如果它是一个字符串并且值是"error",那么它返回True。否则,返回False:def contains_errors(data): if isinstance(data, list): for item in data: if isinstance(item, str): if item == "error": return True return False这个函数的可维护性指数很低,因为它很小,但是它的圈复杂度很高。
相反,我们可以通过“提前返回”来重构这个函数,如果
data的值不在列表中,则删除一层嵌套并返回False。然后使用列表对象上的.count()来计数"error"的实例。返回值是对.count()大于零的评估:def contains_errors(data): if not isinstance(data, list): return False return data.count("error") > 0另一种减少嵌套的技术是利用列表理解。创建新列表的常见模式,检查列表中的每个项目以查看它是否匹配某个标准,然后将所有匹配项添加到新列表中:
results = [] for item in iterable: if item == match: results.append(item)这段代码可以替换为更快、更有效的列表理解。
将最后一个例子重构为一个列表理解和一个
if语句:results = [item for item in iterable if item == match]这个新例子更小,复杂度更低,性能更好。
如果您的数据不是单维列表,那么您可以利用标准库中的 itertools 包,它包含从数据结构创建迭代器的函数。您可以使用它将可重复项链接在一起,映射结构,循环或重复现有的可重复项。
Itertools 还包含过滤数据的函数,像
filterfalse()。关于 Itertools 的更多信息,请查看 Python 3 中的 Itertools,例如。4.用查询工具处理复杂词典
Python 最强大、使用最广泛的核心类型之一是字典。它快速、高效、可扩展且高度灵活。
如果你不熟悉字典,或者认为你可以更多地利用它们,你可以阅读 Python 中的字典以获得更多信息。
它确实有一个主要的副作用:当词典高度嵌套时,查询它们的代码也会嵌套。
以这个数据为例,你之前看到的东京地铁线路的样本:
data = { "network": { "lines": [ { "name.en": "Ginza", "name.jp": "銀座線", "color": "orange", "number": 3, "sign": "G" }, { "name.en": "Marunouchi", "name.jp": "丸ノ内線", "color": "red", "number": 4, "sign": "M" } ] } }如果您想得到匹配某个数字的行,这可以通过一个小函数来实现:
def find_line_by_number(data, number): matches = [line for line in data if line['number'] == number] if len(matches) > 0: return matches[0] else: raise ValueError(f"Line {number} does not exist.")即使函数本身很小,调用函数也是不必要的复杂,因为数据是嵌套的:





>>> find_line_by_number(data["network"]["lines"], 3)
Python 中有查询字典的第三方工具。其中最受欢迎的有 JMESPath 、 glom 、 asq 和 flupy 。
JMESPath 可以帮助我们训练网络。JMESPath 是一种为 JSON 设计的查询语言,它有一个可用于 Python 的插件,可以与 Python 字典一起工作。要安装 JMESPath,请执行以下操作:
$ pip install jmespath
然后打开一个 Python REPL 来探索 JMESPath API,复制到data字典中。首先,导入jmespath并调用search(),将查询字符串作为第一个参数,数据作为第二个参数。查询字符串"network.lines"表示返回data['network']['lines']:
>>> import jmespath >>> jmespath.search("network.lines", data) [{'name.en': 'Ginza', 'name.jp': '銀座線', 'color': 'orange', 'number': 3, 'sign': 'G'}, {'name.en': 'Marunouchi', 'name.jp': '丸ノ内線', 'color': 'red', 'number': 4, 'sign': 'M'}]使用列表时,可以使用方括号并在其中提供查询。“一切”查询就是简单的
*。然后,您可以在要返回的每个匹配项中添加属性的名称。如果您想获得每一行的行号,您可以这样做:
>>> jmespath.search("network.lines[*].number", data)
[3, 4]
您可以提供更复杂的查询,比如一个==或<。该语法对于 Python 开发人员来说有点不寻常,所以请将文档放在手边以供参考。
如果我们想找到带有数字3的行,这可以在一个查询中完成:
>>> jmespath.search("network.lines[?number==`3`]", data) [{'name.en': 'Ginza', 'name.jp': '銀座線', 'color': 'orange', 'number': 3, 'sign': 'G'}]如果我们想获得那条线的颜色,可以在查询的末尾添加属性:
>>> jmespath.search("network.lines[?number==`3`].color", data)
['orange']
JMESPath 可用于减少和简化在复杂字典中查询和搜索的代码。
5.使用attrs和dataclasses减少代码
重构的另一个目标是简单地减少代码库中的代码量,同时实现相同的行为。到目前为止展示的技术对于将代码重构为更小更简单的模块大有帮助。
其他一些技术需要了解标准库和一些第三方库。
什么是样板文件?
样板代码是必须在许多地方使用的代码,很少或没有修改。
以我们的火车网络为例,如果我们使用 Python 类和 Python 3 类型提示将它转换成类型,它可能看起来像这样:
from typing import List
class Line(object):
def __init__(self, name_en: str, name_jp: str, color: str, number: int, sign: str):
self.name_en = name_en
self.name_jp = name_jp
self.color = color
self.number = number
self.sign = sign
def __repr__(self):
return f"<Line {self.name_en} color='{self.color}' number={self.number} sign='{self.sign}'>"
def __str__(self):
return f"The {self.name_en} line"
class Network(object):
def __init__(self, lines: List[Line]):
self._lines = lines
@property
def lines(self) -> List[Line]:
return self._lines
现在,你可能还想添加其他神奇的方法,比如.__eq__()。这段代码是样板文件。这里没有业务逻辑或任何其他功能:我们只是将数据从一个地方复制到另一个地方。
一种情况为dataclasses
在 Python 3.7 的标准库中引入了 dataclasses 模块,并在 PyPI 上为 Python 3.6 提供了一个 backport 包,它可以帮助删除这些类型的类的大量样板文件,在这些类中,您只是存储数据。
要将上面的Line类转换为 dataclass,请将所有字段转换为类属性,并确保它们具有类型注释:
from dataclasses import dataclass
@dataclass
class Line(object):
name_en: str
name_jp: str
color: str
number: int
sign: str
然后,您可以创建一个Line类型的实例,它具有与前面相同的参数和相同的字段,甚至还实现了.__str__()、.__repr__()和.__eq__():
>>> line = Line('Marunouchi', "丸ノ内線", "red", 4, "M") >>> line.color red >>> line2 = Line('Marunouchi', "丸ノ内線", "red", 4, "M") >>> line == line2 True数据类是减少代码的一个很好的方法,只需要一个标准库中已经有的导入。对于完整的演练,您可以查看 Python 3.7 中数据类的最终指南。
一些
attrs用例是一个第三方包,它比 dataclasses 存在的时间要长得多。
attrs有更多的功能,它在 Python 2.7 和 3.4+上可用。如果您使用的是 Python 3.5 或更低版本,
attrs是dataclasses的一个很好的替代品。此外,它还提供了更多的功能。
attrs中的等价数据类示例看起来类似。不使用类型注释,类属性被赋予一个来自attrib()的值。这可以采用额外的参数,例如默认值和用于验证输入的回调:from attr import attrs, attrib @attrs class Line(object): name_en = attrib() name_jp = attrib() color = attrib() number = attrib() sign = attrib()
attrs可以是一个有用的包,用于删除样板代码和数据类的输入验证。结论
现在,您已经了解了如何识别和处理复杂的代码,回想一下您现在可以采取哪些步骤来使您的应用程序更易于更改和管理:
- 首先,使用类似
wily的工具创建项目基线。- 查看一些指标,从可维护性指数最低的模块开始。
- 使用测试中提供的安全性以及 PyCharm 和
rope等工具的知识重构该模块。一旦您遵循了这些步骤和本文中的最佳实践,您就可以对您的应用程序做其他令人兴奋的事情,比如添加新功能和提高性能。*********
Python 的请求库(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 制作 HTTP 请求
requests库是在 Python 中进行 HTTP 请求的事实上的标准。它将发出请求的复杂性抽象在一个漂亮、简单的 API 后面,这样您就可以专注于与服务交互和在应用程序中使用数据。在整篇文章中,您将看到一些
requests必须提供的最有用的特性,以及如何针对您可能遇到的不同情况定制和优化这些特性。您还将学习如何有效地使用requests,以及如何防止对外部服务的请求降低应用程序的速度。在本教程中,您将学习如何:
- 使用最常见的 HTTP 方法发出请求
- 使用查询字符串和消息体定制您的请求的标题和数据
- 检查来自您的请求和响应的数据
- 发出个经过验证的个请求
- 配置您的请求,以帮助防止您的应用程序备份或变慢
尽管我已经尽力包含您理解本文中的特性和示例所需的尽可能多的信息,但我确实假设您对 HTTP 有一个非常 的基本常识。也就是说,无论如何,你仍然可以很好地理解。
既然已经解决了这个问题,让我们深入研究一下,看看如何在您的应用程序中使用
requests!参加测验:通过我们的交互式“HTTP 请求与请求库”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
requests入门让我们从安装
requests库开始。为此,请运行以下命令:$ pip install requests如果您更喜欢使用 Pipenv 来管理 Python 包,您可以运行以下代码:
$ pipenv install requests一旦安装了
requests,您就可以在您的应用程序中使用它了。导入requests看起来像这样:import requests现在你已经设置好了,是时候开始你的
requests之旅了。你的第一个目标是学习如何提出GET请求。获取请求
HTTP 方法,比如
GET和POST,决定了在发出 HTTP 请求时你试图执行的动作。除了GET和POST之外,在本教程的后面部分,您还会用到其他几种常见的方法。最常见的 HTTP 方法之一是
GET。GET方法表明您正试图从指定的资源中获取或检索数据。要发出一个GET请求,调用requests.get()。为了测试这一点,您可以通过使用以下 URL 调用
get()向 GitHub 的根 REST API 发出GET请求:
>>> requests.get('https://api.github.com')
<Response [200]>
恭喜你!你已经提出了第一个请求。让我们更深入地研究一下该请求的响应。
回应
一个Response是检查请求结果的强大对象。让我们再次发出同样的请求,但是这次将返回值存储在一个变量中,这样您可以更仔细地查看它的属性和行为:
>>> response = requests.get('https://api.github.com')在这个例子中,您捕获了
get()的返回值,它是Response的一个实例,并将它存储在一个名为response的变量中。您现在可以使用response来查看关于您的GET请求的结果的大量信息。状态代码
您可以从
Response收集的第一点信息是状态代码。状态代码通知您请求的状态。例如,
200 OK状态意味着您的请求成功,而404 NOT FOUND状态意味着您要寻找的资源没有找到。还有许多其他可能的状态代码也可以让你具体了解你的请求发生了什么。通过访问
.status_code,您可以看到服务器返回的状态代码:
>>> response.status_code
200
.status_code返回了一个200,这意味着您的请求成功了,服务器响应了您所请求的数据。
有时,您可能希望使用这些信息在代码中做出决策:
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
按照这个逻辑,如果服务器返回一个200状态码,你的程序将打印 Success!。如果结果是一个404,你的程序将打印Not Found。
requests为您进一步简化这一过程。如果您在条件表达式中使用一个Response实例,如果状态代码在200和400之间,它将计算为True,否则为False。
因此,您可以通过重写if语句来简化最后一个示例:
if response:
print('Success!')
else:
print('An error has occurred.')
技术细节:这个真值测试之所以成为可能,是因为 __bool__()是Response上的重载方法。
这意味着Response的默认行为已被重新定义,以在确定对象的真值时考虑状态代码。
请记住,该方法是而不是验证状态代码是否等于200。其原因是在200到400范围内的其他状态码,如204 NO CONTENT和304 NOT MODIFIED,在提供一些可行响应的意义上也被认为是成功的。
例如,204告诉您响应成功,但是消息体中没有要返回的内容。
因此,确保只有当您想知道请求是否总体上成功时,才使用这种方便的简写方式,然后,如果必要的话,根据状态代码适当地处理响应。
假设您不想在if语句中检查响应的状态代码。相反,如果请求不成功,您希望引发一个异常。您可以使用.raise_for_status()来完成此操作:
import requests
from requests.exceptions import HTTPError
for url in ['https://api.github.com', 'https://api.github.com/invalid']:
try:
response = requests.get(url)
# If the response was successful, no Exception will be raised
response.raise_for_status()
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}') # Python 3.6
except Exception as err:
print(f'Other error occurred: {err}') # Python 3.6
else:
print('Success!')
如果您调用.raise_for_status(),将会为某些状态代码产生一个HTTPError。如果状态代码指示请求成功,程序将继续运行,不会引发异常。
延伸阅读:如果你不熟悉 Python 3.6 的 f-strings ,我鼓励你利用它们,因为它们是简化格式化字符串的好方法。
现在,您已经非常了解如何处理从服务器返回的响应的状态代码。然而,当您发出一个GET请求时,您很少只关心响应的状态代码。通常,你想看到更多。接下来,您将看到如何查看服务器在响应正文中发回的实际数据。
内容
GET请求的响应通常在消息体中包含一些有价值的信息,称为有效负载。使用Response的属性和方法,您可以查看各种不同格式的有效载荷。
要在 bytes 中查看响应的内容,可以使用.content:
>>> response = requests.get('https://api.github.com') >>> response.content b'{"current_user_url":"https://api.github.com/user","current_user_authorizations_html_url":"https://github.com/settings/connections/applications{/client_id}","authorizations_url":"https://api.github.com/authorizations","code_search_url":"https://api.github.com/search/code?q={query}{&page,per_page,sort,order}","commit_search_url":"https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}","emails_url":"https://api.github.com/user/emails","emojis_url":"https://api.github.com/emojis","events_url":"https://api.github.com/events","feeds_url":"https://api.github.com/feeds","followers_url":"https://api.github.com/user/followers","following_url":"https://api.github.com/user/following{/target}","gists_url":"https://api.github.com/gists{/gist_id}","hub_url":"https://api.github.com/hub","issue_search_url":"https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}","issues_url":"https://api.github.com/issues","keys_url":"https://api.github.com/user/keys","notifications_url":"https://api.github.com/notifications","organization_repositories_url":"https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}","organization_url":"https://api.github.com/orgs/{org}","public_gists_url":"https://api.github.com/gists/public","rate_limit_url":"https://api.github.com/rate_limit","repository_url":"https://api.github.com/repos/{owner}/{repo}","repository_search_url":"https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}","current_user_repositories_url":"https://api.github.com/user/repos{?type,page,per_page,sort}","starred_url":"https://api.github.com/user/starred{/owner}{/repo}","starred_gists_url":"https://api.github.com/gists/starred","team_url":"https://api.github.com/teams","user_url":"https://api.github.com/users/{user}","user_organizations_url":"https://api.github.com/user/orgs","user_repositories_url":"https://api.github.com/users/{user}/repos{?type,page,per_page,sort}","user_search_url":"https://api.github.com/search/users?q={query}{&page,per_page,sort,order}"}'虽然
.content允许您访问响应有效负载的原始字节,但是您通常会希望使用字符编码(如 UTF-8 )将它们转换成一个字符串。response将在您访问.text时为您完成:
>>> response.text
'{"current_user_url":"https://api.github.com/user","current_user_authorizations_html_url":"https://github.com/settings/connections/applications{/client_id}","authorizations_url":"https://api.github.com/authorizations","code_search_url":"https://api.github.com/search/code?q={query}{&page,per_page,sort,order}","commit_search_url":"https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}","emails_url":"https://api.github.com/user/emails","emojis_url":"https://api.github.com/emojis","events_url":"https://api.github.com/events","feeds_url":"https://api.github.com/feeds","followers_url":"https://api.github.com/user/followers","following_url":"https://api.github.com/user/following{/target}","gists_url":"https://api.github.com/gists{/gist_id}","hub_url":"https://api.github.com/hub","issue_search_url":"https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}","issues_url":"https://api.github.com/issues","keys_url":"https://api.github.com/user/keys","notifications_url":"https://api.github.com/notifications","organization_repositories_url":"https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}","organization_url":"https://api.github.com/orgs/{org}","public_gists_url":"https://api.github.com/gists/public","rate_limit_url":"https://api.github.com/rate_limit","repository_url":"https://api.github.com/repos/{owner}/{repo}","repository_search_url":"https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}","current_user_repositories_url":"https://api.github.com/user/repos{?type,page,per_page,sort}","starred_url":"https://api.github.com/user/starred{/owner}{/repo}","starred_gists_url":"https://api.github.com/gists/starred","team_url":"https://api.github.com/teams","user_url":"https://api.github.com/users/{user}","user_organizations_url":"https://api.github.com/user/orgs","user_repositories_url":"https://api.github.com/users/{user}/repos{?type,page,per_page,sort}","user_search_url":"https://api.github.com/search/users?q={query}{&page,per_page,sort,order}"}'
因为从bytes到str的解码需要一个编码方案,所以如果你不指定编码方案,requests会根据响应的头来猜测编码。您可以通过在访问.text之前设置.encoding来提供显式编码:
>>> response.encoding = 'utf-8' # Optional: requests infers this internally >>> response.text '{"current_user_url":"https://api.github.com/user","current_user_authorizations_html_url":"https://github.com/settings/connections/applications{/client_id}","authorizations_url":"https://api.github.com/authorizations","code_search_url":"https://api.github.com/search/code?q={query}{&page,per_page,sort,order}","commit_search_url":"https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}","emails_url":"https://api.github.com/user/emails","emojis_url":"https://api.github.com/emojis","events_url":"https://api.github.com/events","feeds_url":"https://api.github.com/feeds","followers_url":"https://api.github.com/user/followers","following_url":"https://api.github.com/user/following{/target}","gists_url":"https://api.github.com/gists{/gist_id}","hub_url":"https://api.github.com/hub","issue_search_url":"https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}","issues_url":"https://api.github.com/issues","keys_url":"https://api.github.com/user/keys","notifications_url":"https://api.github.com/notifications","organization_repositories_url":"https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}","organization_url":"https://api.github.com/orgs/{org}","public_gists_url":"https://api.github.com/gists/public","rate_limit_url":"https://api.github.com/rate_limit","repository_url":"https://api.github.com/repos/{owner}/{repo}","repository_search_url":"https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}","current_user_repositories_url":"https://api.github.com/user/repos{?type,page,per_page,sort}","starred_url":"https://api.github.com/user/starred{/owner}{/repo}","starred_gists_url":"https://api.github.com/gists/starred","team_url":"https://api.github.com/teams","user_url":"https://api.github.com/users/{user}","user_organizations_url":"https://api.github.com/user/orgs","user_repositories_url":"https://api.github.com/users/{user}/repos{?type,page,per_page,sort}","user_search_url":"https://api.github.com/search/users?q={query}{&page,per_page,sort,order}"}'如果您看一看响应,您会发现它实际上是序列化的 JSON 内容。要获得一个字典,您可以从
.text中获取str,并使用json.loads()对其进行反序列化。然而,完成这项任务的一个更简单的方法是使用.json():
>>> response.json()
{'current_user_url': 'https://api.github.com/user', 'current_user_authorizations_html_url': 'https://github.com/settings/connections/applications{/client_id}', 'authorizations_url': 'https://api.github.com/authorizations', 'code_search_url': 'https://api.github.com/search/code?q={query}{&page,per_page,sort,order}', 'commit_search_url': 'https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}', 'emails_url': 'https://api.github.com/user/emails', 'emojis_url': 'https://api.github.com/emojis', 'events_url': 'https://api.github.com/events', 'feeds_url': 'https://api.github.com/feeds', 'followers_url': 'https://api.github.com/user/followers', 'following_url': 'https://api.github.com/user/following{/target}', 'gists_url': 'https://api.github.com/gists{/gist_id}', 'hub_url': 'https://api.github.com/hub', 'issue_search_url': 'https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}', 'issues_url': 'https://api.github.com/issues', 'keys_url': 'https://api.github.com/user/keys', 'notifications_url': 'https://api.github.com/notifications', 'organization_repositories_url': 'https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}', 'organization_url': 'https://api.github.com/orgs/{org}', 'public_gists_url': 'https://api.github.com/gists/public', 'rate_limit_url': 'https://api.github.com/rate_limit', 'repository_url': 'https://api.github.com/repos/{owner}/{repo}', 'repository_search_url': 'https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}', 'current_user_repositories_url': 'https://api.github.com/user/repos{?type,page,per_page,sort}', 'starred_url': 'https://api.github.com/user/starred{/owner}{/repo}', 'starred_gists_url': 'https://api.github.com/gists/starred', 'team_url': 'https://api.github.com/teams', 'user_url': 'https://api.github.com/users/{user}', 'user_organizations_url': 'https://api.github.com/user/orgs', 'user_repositories_url': 'https://api.github.com/users/{user}/repos{?type,page,per_page,sort}', 'user_search_url': 'https://api.github.com/search/users?q={query}{&page,per_page,sort,order}'}
.json()返回值的type是一个字典,所以可以通过键访问对象中的值。
您可以对状态代码和消息体做很多事情。但是,如果需要更多信息,比如关于响应本身的元数据,就需要查看响应的头。
标题
响应头可以为您提供有用的信息,比如响应负载的内容类型和缓存响应的时间限制。要查看这些标题,请访问.headers:
>>> response.headers {'Server': 'GitHub.com', 'Date': 'Mon, 10 Dec 2018 17:49:54 GMT', 'Content-Type': 'application/json; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Status': '200 OK', 'X-RateLimit-Limit': '60', 'X-RateLimit-Remaining': '59', 'X-RateLimit-Reset': '1544467794', 'Cache-Control': 'public, max-age=60, s-maxage=60', 'Vary': 'Accept', 'ETag': 'W/"7dc470913f1fe9bb6c7355b50a0737bc"', 'X-GitHub-Media-Type': 'github.v3; format=json', 'Access-Control-Expose-Headers': 'ETag, Link, Location, Retry-After, X-GitHub-OTP, X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset, X-OAuth-Scopes, X-Accepted-OAuth-Scopes, X-Poll-Interval, X-GitHub-Media-Type', 'Access-Control-Allow-Origin': '*', 'Strict-Transport-Security': 'max-age=31536000; includeSubdomains; preload', 'X-Frame-Options': 'deny', 'X-Content-Type-Options': 'nosniff', 'X-XSS-Protection': '1; mode=block', 'Referrer-Policy': 'origin-when-cross-origin, strict-origin-when-cross-origin', 'Content-Security-Policy': "default-src 'none'", 'Content-Encoding': 'gzip', 'X-GitHub-Request-Id': 'E439:4581:CF2351:1CA3E06:5C0EA741'}返回一个类似字典的对象,允许你通过键访问头值。例如,要查看响应负载的内容类型,您可以访问
Content-Type:
>>> response.headers['Content-Type']
'application/json; charset=utf-8'
不过,这个类似字典的 headers 对象有一些特殊之处。HTTP 规范将头定义为不区分大小写,这意味着我们能够访问这些头,而不用担心它们的大小写:
>>> response.headers['content-type'] 'application/json; charset=utf-8'无论您使用键
'content-type'还是'Content-Type',您都会得到相同的值。现在,你已经了解了关于
Response的基本知识。您已经看到了它最有用的属性和方法。让我们后退一步,看看当您定制您的GET请求时,您的响应是如何变化的。查询字符串参数
定制
GET请求的一种常见方式是通过 URL 中的查询字符串参数传递值。要使用get()完成这项工作,您需要将数据传递给params。例如,您可以使用 GitHub 的搜索 API 来查找requests库:import requests # Search GitHub's repositories for requests response = requests.get( 'https://api.github.com/search/repositories', params={'q': 'requests+language:python'}, ) # Inspect some attributes of the `requests` repository json_response = response.json() repository = json_response['items'][0] print(f'Repository name: {repository["name"]}') # Python 3.6+ print(f'Repository description: {repository["description"]}') # Python 3.6+通过将字典
{'q': 'requests+language:python'}传递给.get()的params参数,您能够修改从搜索 API 返回的结果。您可以像刚才那样以字典的形式将
params传递给get(),或者以元组列表的形式传递:
>>> requests.get(
... 'https://api.github.com/search/repositories',
... params=[('q', 'requests+language:python')],
... )
<Response [200]>
您甚至可以将这些值作为bytes:
>>> requests.get( ... 'https://api.github.com/search/repositories', ... params=b'q=requests+language:python', ... ) <Response [200]>查询字符串对于参数化
GET请求很有用。您还可以通过添加或修改发送的邮件头来自定义您的请求。请求标题
要定制头,可以使用
headers参数将 HTTP 头的字典传递给get()。例如,通过在Accept标题中指定text-match媒体类型,您可以更改之前的搜索请求,以在结果中突出显示匹配的搜索词:import requests response = requests.get( 'https://api.github.com/search/repositories', params={'q': 'requests+language:python'}, headers={'Accept': 'application/vnd.github.v3.text-match+json'}, ) # View the new `text-matches` array which provides information # about your search term within the results json_response = response.json() repository = json_response['items'][0] print(f'Text matches: {repository["text_matches"]}')
Accept头告诉服务器您的应用程序可以处理什么类型的内容。在本例中,由于您希望匹配的搜索词被高亮显示,所以您使用了头值application/vnd.github.v3.text-match+json,这是一个专有的 GitHubAccept头,其中的内容是一种特殊的 JSON 格式。在学习更多定制请求的方法之前,让我们通过探索其他 HTTP 方法来拓宽视野。
其他 HTTP 方法
除了
GET,其他流行的 HTTP 方法还有POST、PUT、DELETE、HEAD、PATCH和OPTIONS。requests为每个 HTTP 方法提供了一个与get()相似的方法:
>>> requests.post('https://httpbin.org/post', data={'key':'value'})
>>> requests.put('https://httpbin.org/put', data={'key':'value'})
>>> requests.delete('https://httpbin.org/delete')
>>> requests.head('https://httpbin.org/get')
>>> requests.patch('https://httpbin.org/patch', data={'key':'value'})
>>> requests.options('https://httpbin.org/get')
每个函数调用都使用相应的 HTTP 方法向httpbin服务发出请求。对于每种方法,您可以像以前一样检查它们的响应:
>>> response = requests.head('https://httpbin.org/get') >>> response.headers['Content-Type'] 'application/json' >>> response = requests.delete('https://httpbin.org/delete') >>> json_response = response.json() >>> json_response['args'] {}每个方法的头、响应体、状态代码等等都在
Response中返回。接下来,您将仔细查看POST、PUT和PATCH方法,并了解它们与其他请求类型的不同之处。消息正文
根据 HTTP 规范,
POST、PUT和不太常见的PATCH请求通过消息体传递数据,而不是通过查询字符串中的参数。使用requests,您将把有效载荷传递给相应函数的data参数。
data采用字典、元组列表、字节或类似文件的对象。您将希望使您在请求正文中发送的数据适应您正在交互的服务的特定需求。例如,如果您的请求的内容类型是
application/x-www-form-urlencoded,您可以将表单数据作为字典发送:
>>> requests.post('https://httpbin.org/post', data={'key':'value'})
<Response [200]>
您还可以将相同数据作为元组列表发送:
>>> requests.post('https://httpbin.org/post', data=[('key', 'value')]) <Response [200]>但是,如果需要发送 JSON 数据,可以使用
json参数。当您通过json传递 JSON 数据时,requests将序列化您的数据并为您添加正确的Content-Type头。【httpbin.org】是
requests的作者肯尼斯·雷兹创造的一个伟大资源。这是一个接受测试请求并以请求数据进行响应的服务。例如,您可以使用它来检查一个基本的POST请求:
>>> response = requests.post('https://httpbin.org/post', json={'key':'value'})
>>> json_response = response.json()
>>> json_response['data']
'{"key": "value"}'
>>> json_response['headers']['Content-Type']
'application/json'
您可以从响应中看到,当您发送请求数据和报头时,服务器收到了它们。requests也以PreparedRequest的形式向您提供这些信息。
检查您的请求
当您发出请求时,requests库会在将请求发送到目的服务器之前准备好请求。请求准备包括诸如验证头和序列化 JSON 内容之类的事情。
您可以通过访问.request来查看PreparedRequest:
>>> response = requests.post('https://httpbin.org/post', json={'key':'value'}) >>> response.request.headers['Content-Type'] 'application/json' >>> response.request.url 'https://httpbin.org/post' >>> response.request.body b'{"key": "value"}'检查
PreparedRequest可以让您访问关于请求的各种信息,比如有效负载、URL、头、认证等等。到目前为止,您已经发出了许多不同类型的请求,但是它们都有一个共同点:它们都是对公共 API 的未经验证的请求。您可能遇到的许多服务都希望您以某种方式进行身份验证。
认证
身份验证有助于服务了解您是谁。通常,您可以通过服务定义的
Authorization头或自定义头传递数据,从而向服务器提供您的凭证。到目前为止,您看到的所有请求函数都提供了一个名为auth的参数,它允许您传递凭证。需要认证的 API 的一个例子是 GitHub 的认证用户 API。此端点提供关于已验证用户的配置文件的信息。要向认证用户 API 发出请求,您可以将您的 GitHub 用户名和密码以元组的形式传递给
get():
>>> from getpass import getpass
>>> requests.get('https://api.github.com/user', auth=('username', getpass()))
<Response [200]>
如果您在元组中传递给auth的凭证有效,则请求成功。如果您尝试在没有凭证的情况下发出这个请求,您会看到状态代码是401 Unauthorized:
>>> requests.get('https://api.github.com/user') <Response [401]>当您将用户名和密码以元组的形式传递给
auth参数时,requests正在使用 HTTP 的基本访问认证方案来应用凭证。因此,您可以通过使用
HTTPBasicAuth传递显式的基本认证凭证来发出相同的请求:
>>> from requests.auth import HTTPBasicAuth
>>> from getpass import getpass
>>> requests.get(
... 'https://api.github.com/user',
... auth=HTTPBasicAuth('username', getpass())
... )
<Response [200]>
尽管基本身份验证不需要明确,但您可能希望使用另一种方法进行身份验证。requests提供其他现成的认证方法,如HTTPDigestAuth和HTTPProxyAuth。
您甚至可以提供自己的身份验证机制。为此,您必须首先创建一个AuthBase的子类。然后,您实现__call__():
import requests
from requests.auth import AuthBase
class TokenAuth(AuthBase):
"""Implements a custom authentication scheme."""
def __init__(self, token):
self.token = token
def __call__(self, r):
"""Attach an API token to a custom auth header."""
r.headers['X-TokenAuth'] = f'{self.token}' # Python 3.6+
return r
requests.get('https://httpbin.org/get', auth=TokenAuth('12345abcde-token'))
在这里,您的定制TokenAuth机制接收一个令牌,然后将该令牌包含在您的请求的X-TokenAuth头中。
糟糕的身份验证机制会导致安全漏洞,所以除非服务出于某种原因需要定制的身份验证机制,否则您总是希望使用像 Basic 或 OAuth 这样可靠的身份验证方案。
当您考虑安全性时,让我们考虑使用requests处理 SSL 证书。
SSL 证书验证
任何时候你试图发送或接收的数据都是敏感的,安全是很重要的。通过 HTTP 与安全站点通信的方式是使用 SSL 建立加密连接,这意味着验证目标服务器的 SSL 证书至关重要。
好消息是requests默认为你做这件事。但是,在某些情况下,您可能希望改变这种行为。
如果您想要禁用 SSL 证书验证,您可以将False传递给请求函数的verify参数:
>>> requests.get('https://api.github.com', verify=False) InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) <Response [200]>甚至在您提出不安全的请求时发出警告,帮助您保护数据安全!
注意:
requests使用一个名为certifi的包来提供认证机构。这让requests知道它可以信任哪些权威。因此,您应该经常更新certifi以尽可能保证您的连接安全。性能
当使用
requests时,尤其是在生产应用程序环境中,考虑性能影响很重要。超时控制、会话和重试限制等功能可以帮助您保持应用程序平稳运行。超时
当您向外部服务发出内联请求时,您的系统需要等待响应才能继续。如果应用程序等待响应的时间太长,对服务的请求可能会备份,用户体验可能会受到影响,或者后台作业可能会挂起。
默认情况下,
requests将无限期地等待响应,因此您应该总是指定一个超时持续时间来防止这些事情发生。要设置请求的超时,请使用timeout参数。timeout可以是一个整数或浮点数,表示超时前等待响应的秒数:
>>> requests.get('https://api.github.com', timeout=1)
<Response [200]>
>>> requests.get('https://api.github.com', timeout=3.05)
<Response [200]>
在第一个请求中,请求将在 1 秒钟后超时。在第二个请求中,请求将在 3.05 秒后超时。
您还可以将一个元组传递给timeout,第一个元素是连接超时(它允许客户端建立到服务器的连接的时间),第二个元素是读取超时(一旦您的客户端建立连接,它将等待响应的时间):
>>> requests.get('https://api.github.com', timeout=(2, 5)) <Response [200]>如果请求在 2 秒内建立连接,并在连接建立后的 5 秒内收到数据,则响应将像以前一样返回。如果请求超时,那么该函数将引发一个
Timeout异常:import requests from requests.exceptions import Timeout try: response = requests.get('https://api.github.com', timeout=1) except Timeout: print('The request timed out') else: print('The request did not time out')您的程序可以捕捉到
Timeout异常并做出相应的响应。会话对象
到目前为止,你一直在处理高级的
requestsAPI,比如get()和post()。这些函数是当你发出请求时发生的事情的抽象。它们隐藏了实现细节,比如如何管理连接,这样您就不必担心它们了。在这些抽象的下面是一个名为
Session的类。如果您需要微调对如何发出请求的控制或者提高请求的性能,您可能需要直接使用一个Session实例。会话用于跨请求保存参数。例如,如果希望在多个请求中使用相同的身份验证,可以使用会话:
import requests from getpass import getpass # By using a context manager, you can ensure the resources used by # the session will be released after use with requests.Session() as session: session.auth = ('username', getpass()) # Instead of requests.get(), you'll use session.get() response = session.get('https://api.github.com/user') # You can inspect the response just like you did before print(response.headers) print(response.json())每次使用
session发出请求时,一旦使用认证凭证对其进行了初始化,凭证将被持久化。会话的主要性能优化以持久连接的形式出现。当您的应用程序使用
Session连接到服务器时,它会将该连接保存在连接池中。当您的应用程序想要再次连接到同一个服务器时,它将重用池中的连接,而不是建立一个新的连接。最大重试次数
当请求失败时,您可能希望应用程序重试同一请求。但是,默认情况下,
requests不会这样做。为了应用这个功能,您需要实现一个定制的传输适配器。传输适配器允许您为正在交互的每个服务定义一组配置。例如,假设您希望所有对
https://api.github.com的请求在最终引发ConnectionError之前重试三次。您将构建一个传输适配器,设置它的max_retries参数,并将其挂载到现有的Session:import requests from requests.adapters import HTTPAdapter from requests.exceptions import ConnectionError github_adapter = HTTPAdapter(max_retries=3) session = requests.Session() # Use `github_adapter` for all requests to endpoints that start with this URL session.mount('https://api.github.com', github_adapter) try: session.get('https://api.github.com') except ConnectionError as ce: print(ce)当您挂载
HTTPAdapter、github_adapter、session、session时,将会按照其配置对 https://api.github.com 发出每一个请求。超时、传输适配器和会话是为了保持代码的高效和应用程序的弹性。
结论
在学习 Python 强大的
requests库的过程中,你已经走了很长的路。您现在能够:
- 使用各种不同的 HTTP 方法发出请求,例如
GET、POST和PUT- 通过修改标题、身份验证、查询字符串和消息正文来自定义您的请求
- 检查您发送给服务器的数据和服务器发回给您的数据
- 使用 SSL 证书验证
- 使用
max_retries、timeout、会话和传输适配器有效地使用requests因为您学习了如何使用
requests,所以您已经准备好探索 web 服务的广阔世界,并使用它们提供的迷人数据构建令人惊叹的应用程序。参加测验:通过我们的交互式“HTTP 请求与请求库”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 制作 HTTP 请求*********
Python return 语句:用法和最佳实践
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 有效使用 Python 返回语句
Python
return语句是函数和方法的关键组件。您可以使用return语句让您的函数将 Python 对象发送回调用者代码。这些对象称为函数的返回值。您可以使用它们在您的程序中执行进一步的计算。如果你想编写具有python 式和健壮的定制函数,有效地使用
return语句是一项核心技能。在本教程中,您将学习:
- 如何在函数中使用 Python
return语句- 如何从函数中返回单值或多值
- 使用
return语句时,要遵循哪些最佳实践有了这些知识,您将能够用 Python 编写更具可读性、可维护性和简洁的函数。如果你对 Python 函数完全陌生,那么在深入本教程之前,你可以查看定义你自己的 Python 函数的。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 函数入门
大多数编程语言都允许您为执行具体计算的代码块指定一个名称。这些命名的代码块可以快速重用,因为您可以使用它们的名称从代码中的不同位置调用它们。
程序员将这些命名的代码块称为 子程序 、例程、过程或函数,这取决于它们使用的语言。在某些语言中,例程或过程和函数之间有明显的区别。
有时这种差别如此之大,以至于您需要使用一个特定的关键字来定义一个过程或子例程,而使用另一个关键字来定义一个函数。例如, Visual Basic 编程语言使用
Sub和Function来区分这两者。一般来说,过程是一个命名的代码块,它执行一组动作而不计算最终值或结果。另一方面,函数是一个命名的代码块,它执行一些动作,目的是计算最终值或结果,然后将结果发送回调用者代码。过程和函数都可以作用于一组输入值,通常称为参数。
在 Python 中,这类命名代码块被称为函数,因为它们总是向调用者发回一个值。Python 文档对函数的定义如下:
尽管官方文档声明函数“向调用者返回一些值”,但是您很快就会看到函数可以向调用者代码返回任何 Python 对象。
一般来说,一个函数带个参数(如果有的话),执行一些操作,返回一个值(或者对象)。函数返回给调用者的值通常被称为函数的返回值。所有 Python 函数都有一个返回值,或者是显式的,或者是隐式的。在本教程的后面,您将讨论显式返回值和隐式返回值之间的区别。
要编写一个 Python 函数,您需要一个以
def关键字开头的头,后面是函数名、一个可选的逗号分隔参数列表(在一对必需的括号内)和一个最后的冒号。函数的第二个组成部分是它的代码块,或体。Python 使用缩进而不是括号、
begin和end关键字等来定义代码块。因此,要在 Python 中定义函数,可以使用以下语法:def function_name(arg1, arg2,..., argN): # Function's code goes here... pass当您编写 Python 函数时,您需要定义一个带有关键字
def的头、函数名和括号中的参数列表。注意,参数列表是可选的,但是括号在语法上是必需的。然后您需要定义函数的代码块,它将开始向右缩进一级。在上面的例子中,你使用了一个
pass语句。当您需要在代码中使用占位符语句来确保语法正确,但不需要执行任何操作时,这种语句非常有用。pass语句也被称为空操作,因为它们不执行任何操作。注意:定义函数及其参数的完整语法超出了本教程的范围。关于这个主题的深入资源,请查看定义自己的 Python 函数。
要使用一个函数,你需要调用它。函数调用由函数名和括号中的函数参数组成:
function_name(arg1, arg2, ..., argN)只有在函数需要时,才需要将参数传递给函数调用。另一方面,圆括号在函数调用中总是必需的。如果你忘记了它们,那么你就不能调用这个函数,而是作为一个函数对象来引用它。
为了让你的函数返回值,你需要使用 Python
return语句。这就是从现在开始你要报道的内容。理解 Python
return语句Python
return语句是一个特殊的语句,您可以在函数或方法内部使用它来将函数的结果发送回调用者。一条return语句由return关键字和可选的返回值组成。Python 函数的返回值可以是任何 Python 对象。Python 中的一切都是对象。所以,你的函数可以返回数值(
int,float,complex值),对象的集合和序列(list,tuple,dictionary或set对象),用户定义的对象,类,函数,甚至模块或包。您可以省略函数的返回值,使用不带返回值的空
return。您也可以省略整个return语句。在这两种情况下,返回值都将是None。在接下来的两节中,您将了解到
return语句是如何工作的,以及如何使用它将函数的结果返回给调用者代码。显式
return语句一个显式
return语句立即终止一个函数的执行,并将返回值发送回调用者代码。要向 Python 函数添加显式的return语句,您需要使用return,后跟一个可选的返回值:
>>> def return_42():
... return 42 # An explicit return statement
...
>>> return_42() # The caller code gets 42
42
定义return_42()时,在函数代码块的末尾添加一个显式的return语句(return 42)。42是return_42()的显式返回值。这意味着任何时候你调用return_42(),这个函数都会把42发送回调用者。
注意:您可以使用显式的return语句,不管有没有返回值。如果你构建一个没有指定返回值的return语句,那么你将隐式返回None。
如果用显式的return语句定义一个函数,该语句有一个显式的返回值,那么可以在任何表达式中使用该返回值:
>>> num = return_42() >>> num 42 >>> return_42() * 2 84 >>> return_42() + 5 47由于
return_42()返回一个数值,您可以在数学表达式或任何其他类型的表达式中使用该值,在这些表达式中,该值具有逻辑或连贯的含义。这就是调用方代码利用函数返回值的方式。请注意,您只能在函数或方法定义中使用
return语句。如果你在别的地方使用它,那么你会得到一个SyntaxError:
>>> return 42
File "<stdin>", line 1
SyntaxError: 'return' outside function
当您在函数或方法之外使用return时,您会得到一个SyntaxError,告诉您该语句不能在函数之外使用。
注意: 常规方法、类方法、静态方法只是 Python 类上下文中的函数。因此,您将涉及的所有return陈述概念也适用于它们。
您可以使用任何 Python 对象作为返回值。由于 Python 中的一切都是对象,所以可以返回字符串,列表,元组,字典,函数,类,实例,用户定义的对象,甚至模块或包。
例如,假设您需要编写一个函数,它接受一个整数列表并返回一个只包含原始列表中偶数的列表。这里有一种编码这个函数的方法:
>>> def get_even(numbers): ... even_nums = [num for num in numbers if not num % 2] ... return even_nums ... >>> get_even([1, 2, 3, 4, 5, 6]) [2, 4, 6]
get_even()使用一个列表理解来创建一个过滤掉原始numbers中奇数的列表。然后,该函数返回结果列表,其中只包含偶数。一个常见的做法是使用一个表达式的结果作为一个
return语句的返回值。为了应用这个想法,您可以将get_even()重写如下:
>>> def get_even(numbers):
... return [num for num in numbers if not num % 2]
...
>>> get_even([1, 2, 3, 4, 5, 6])
[2, 4, 6]
列表理解得到评估,然后函数返回结果列表。注意,你只能在一个return语句中使用表达式。表达式不同于语句,就像条件句或循环。
注意:尽管list理解是使用for和(可选)if关键字构建的,但它们被认为是表达式而不是陈述。这就是为什么您可以在return语句中使用它们。
再举一个例子,假设您需要计算一个数值样本的平均值。为此,您需要将值的总和除以值的个数。下面是一个使用内置函数 sum() 和 len() 的例子:
>>> def mean(sample): ... return sum(sample) / len(sample) ... >>> mean([1, 2, 3, 4]) 2.5在
mean()中,你不用一个局部变量来存储计算的结果。相反,您可以直接使用表达式作为返回值。Python 首先对表达式sum(sample) / len(sample)求值,然后返回求值结果,在本例中是值2.5。隐式
return语句Python 函数总是有返回值。Python 中没有过程或例程的概念。因此,如果您没有在
return语句中显式地使用返回值,或者如果您完全省略了return语句,那么 Python 将隐式地为您返回一个默认值。默认返回值将永远是None。假设您正在编写一个将
1加到一个数字x的函数,但是您忘记了提供一个return语句。在这种情况下,您将得到一个使用None作为返回值的隐式return语句:
>>> def add_one(x):
... # No return statement at all
... result = x + 1
...
>>> value = add_one(5)
>>> value
>>> print(value)
None
如果你不提供一个带有显式返回值的显式return语句,那么 Python 将使用None作为返回值提供一个隐式return语句。在上面的例子中,add_one()将1加到x上,并将值存储在result中,但它不返回result。所以才会得到value = None而不是value = 6。要解决这个问题,你需要或者return result或者直接return x + 1。
返回None的函数的一个例子是 print() 。这个函数的目标是将对象打印到文本流文件,这通常是标准输出(您的屏幕)。所以,这个函数不需要显式的return语句,因为它不返回任何有用或有意义的东西:
>>> return_value = print("Hello, World") Hello, World >>> print(return_value) None对
print()的调用将Hello, World打印到屏幕上。由于这是print()的目的,函数不需要返回任何有用的东西,所以你得到None作为返回值。注意:Python 解释器不显示
None。因此,要在交互会话中显示None的返回值,您需要显式使用print()。不管你的函数有多长多复杂,任何没有显式
return语句的函数,或者有return语句但没有返回值的函数,都将返回None。返回 vs 打印
如果您正在一个交互式会话中工作,那么您可能会认为打印一个值和返回一个值是等效的操作。考虑以下两个函数及其输出:
>>> def print_greeting():
... print("Hello, World")
...
>>> print_greeting()
Hello, World
>>> def return_greeting():
... return "Hello, World"
...
>>> return_greeting()
'Hello, World'
这两个功能似乎做同样的事情。在这两种情况下,你都会看到Hello, World印在你的屏幕上。只有一个细微的明显区别——第二个例子中的单引号。但是看看如果返回另一种数据类型会发生什么,比如说一个int对象:
>>> def print_42(): ... print(42) ... >>> print_42() 42 >>> def return_42(): ... return 42 ... >>> return_42() 42现在看不出有什么不同了。在这两种情况下,您都可以在屏幕上看到
42。如果您刚刚开始使用 Python,这种行为可能会令人困惑。您可能认为返回和打印一个值是等效的操作。现在,假设您对 Python 越来越深入,并且开始编写您的第一个脚本。您打开一个文本编辑器,键入以下代码:
1def add(a, b): 2 result = a + b 3 return result 4 5add(2, 2)
add()取两个数,相加,并返回结果。在第 5 行,你调用add()对2加2求和。由于您仍在学习返回和打印值之间的区别,您可能希望您的脚本将4打印到屏幕上。然而,事实并非如此,您的屏幕上什么也看不到。自己试试吧。将您的脚本保存到一个名为
adding.py和的文件中,从您的命令行运行它,如下所示:$ python3 adding.py如果你从命令行运行
adding.py,那么你不会在屏幕上看到任何结果。这是因为当您运行脚本时,您在脚本中调用的函数的返回值不会像在交互式会话中那样打印到屏幕上。如果您希望您的脚本在屏幕上显示调用
add()的结果,那么您需要显式调用print()。查看adding.py的以下更新:1def add(a, b): 2 result = a + b 3 return result 4 5print(add(2, 2))现在,当你运行
adding.py时,你会在屏幕上看到数字4。因此,如果你在一个交互式会话中工作,那么 Python 会直接在你的屏幕上显示任何函数调用的结果。但是如果你正在写一个脚本,你想看到一个函数的返回值,那么你需要显式地使用
print()。返回多个值
您可以使用一个
return语句从一个函数中返回多个值。为此,您只需提供几个用逗号分隔的返回值。例如,假设您需要编写一个函数,该函数获取数字数据的样本并返回统计度量的摘要。要编写该函数,可以使用 Python 标准模块
statistics,它提供了几个用于计算数值数据的数理统计的函数。下面是您的函数的一个可能的实现:
import statistics as st def describe(sample): return st.mean(sample), st.median(sample), st.mode(sample)在
describe()中,通过同时返回样本的平均值、中值和众数,利用 Python 在单个return语句中返回多个值的能力。注意,要返回多个值,您只需要按照您希望它们返回的顺序将它们写在一个逗号分隔的列表中。一旦你编写了
describe(),你就可以利用一个强大的 Python 特性,即 iterable unpacking ,将三个度量值解包成三个独立的变量,或者你可以将所有内容存储在一个变量中:
>>> sample = [10, 2, 4, 7, 9, 3, 9, 8, 6, 7]
>>> mean, median, mode = describe(sample)
>>> mean
6.5
>>> median
7.0
>>> mode
7
>>> desc = describe(sample)
>>> desc
(6.5, 7.0, 7)
>>> type(desc)
<class 'tuple'>
在这里,您将describe()的三个返回值解包到变量mean、median和mode中。注意,在最后一个例子中,您将所有的值存储在一个变量desc中,这个变量是一个 Python tuple。
注意:你可以通过给一个变量分配几个逗号分隔的值来构建一个 Python tuple。没有必要使用括号来创建一个tuple。这就是为什么多个返回值被打包在一个tuple中。
内置函数 divmod() 也是返回多个值的函数的一个例子。该函数将两个(非复数)数字作为参数,并返回两个数字、两个输入值的商和除法的余数:
>>> divmod(15, 3) (5, 0) >>> divmod(8, 3) (2, 2)对
divmod()的调用返回一个元组,该元组包含作为参数提供的两个非复数的商和余数。这是一个有多个返回值的函数的例子。使用 Python
return语句:最佳实践到目前为止,您已经了解了 Python
return语句的基本工作原理。您现在知道如何编写向调用者返回一个或多个值的函数。此外,您已经了解到,如果您没有为给定的函数添加带有显式返回值的显式return语句,那么 Python 会为您添加。该值将是None。在这一节中,您将会看到几个例子,这些例子将会引导您通过一组良好的编程实践来有效地使用
return语句。这些实践将帮助您用 Python 编写可读性更强、可维护性更好、更健壮、更高效的函数。显式返回
None一些程序员依赖 Python 添加到任何没有显式函数的函数中的隐式
return语句。这可能会让来自其他编程语言的开发人员感到困惑,在其他编程语言中,没有返回值的函数被称为过程。在某些情况下,您可以向函数中添加一个显式的
return None。然而,在其他情况下,您可以依赖 Python 的默认行为:
如果你的函数执行动作,但是没有一个清晰而有用的
return值,那么你可以省略返回None,因为这样做是多余的和令人困惑的。你也可以使用一个没有返回值的空的return来表明你从函数中返回的意图。如果你的函数有多个
return语句,并且返回None是一个有效的选项,那么你应该考虑明确使用return None,而不是依赖 Python 的默认行为。这些实践可以通过明确传达您的意图来提高代码的可读性和可维护性。
当需要返回
None时,您可以使用三种可能的方法之一:
- 省略
return语句,依赖返回None的默认行为。- 使用不带返回值的空
return,它也返回None。- 显式返回
None。这在实践中是如何工作的:
>>> def omit_return_stmt():
... # Omit the return statement
... pass
...
>>> print(omit_return_stmt())
None
>>> def bare_return():
... # Use a bare return
... return
...
>>> print(bare_return())
None
>>> def return_none_explicitly():
... # Return None explicitly
... return None
...
>>> print(return_none_explicitly())
None
是否显式返回None是个人决定。然而,您应该考虑到,在某些情况下,显式的return None可以避免可维护性问题。对于来自其他编程语言的开发人员来说尤其如此,因为他们的行为不像 Python 那样。
记住返回值
编写自定义函数时,您可能会不小心忘记从函数中返回值。在这种情况下,Python 会为你返回None。这可能会导致一些细微的错误,对于一个初学 Python 的开发者来说,理解和调试是很困难的。
您可以通过在函数头之后立即编写return语句来避免这个问题。然后,您可以第二次编写函数体。这里有一个模板,您可以在编写 Python 函数时使用:
def template_func(args):
result = 0 # Initialize the return value
# Your code goes here...
return result # Explicitly return the result
如果你习惯了这样开始你的函数,那么你就有可能不再错过return语句。使用这种方法,您可以编写函数体,测试它,并在知道函数可以工作后重命名变量。
这种做法可以提高您的生产率,并使您的功能不容易出错。也可以为你节省很多调试的时间。
避免复杂的表达式
正如您之前看到的,在 Python 函数中使用表达式的结果作为返回值是一种常见的做法。如果您使用的表达式变得太复杂,那么这种做法会导致函数难以理解、调试和维护。
例如,如果您正在进行一项复杂的计算,那么使用带有有意义名称的临时变量来增量计算最终结果将更具可读性。
考虑以下计算数字数据样本的方差的函数:
>>> def variance(data, ddof=0): ... mean = sum(data) / len(data) ... return sum((x - mean) ** 2 for x in data) / (len(data) - ddof) ... >>> variance([3, 4, 7, 5, 6, 2, 9, 4, 1, 3]) 5.24你在这里使用的表达很复杂,很难理解。调试起来也很困难,因为您要在一个表达式中执行多个操作。要解决这个特殊的问题,您可以利用增量开发方法来提高函数的可读性。
看看下面这个
variance()的替代实现:
>>> def variance(data, ddof=0):
... n = len(data)
... mean = sum(data) / n
... total_square_dev = sum((x - mean) ** 2 for x in data)
... return total_square_dev / (n - ddof)
...
>>> variance([3, 4, 7, 5, 6, 2, 9, 4, 1, 3])
5.24
在variance()的第二个实现中,您通过几个步骤计算方差。每一步都由一个具有有意义名称的临时变量表示。
在调试代码时,像n、mean和total_square_dev这样的临时变量通常很有帮助。例如,如果其中一个出错,那么您可以调用print()来了解在return语句运行之前发生了什么。
一般来说,你应该避免在你的return语句中使用复杂的表达式。相反,您可以将代码分成多个步骤,并在每个步骤中使用临时变量。使用临时变量可以使代码更容易调试、理解和维护。
返回值 vs 修改全局
没有带有有意义返回值的显式return语句的函数通常会执行有副作用的动作。一个副作用可以是,例如,打印一些东西到屏幕上,修改一个全局变量,更新一个对象的状态,写一些文本到一个文件,等等。
修改全局变量通常被认为是一种糟糕的编程实践。就像带有复杂表达式的程序一样,修改全局变量的程序可能很难调试、理解和维护。
当你修改一个全局变量时,你可能会影响到所有的函数、类、对象以及依赖于这个全局变量的程序的其他部分。
要理解一个修改全局变量的程序,你需要知道程序中可以看到、访问和改变这些变量的所有部分。因此,良好的实践建议编写自包含函数,它接受一些参数并返回一个(或多个)有用的值,而不会对全局变量产生任何副作用。
此外,使用显式return语句返回有意义值的函数比修改或更新全局变量的函数更容易测试。
以下示例显示了一个更改全局变量的函数。该函数使用了 global语句,这在 Python 中也被认为是一种糟糕的编程实践:
>>> counter = 0 >>> def increment(): ... global counter ... counter += 1 ... >>> increment() >>> counter 1在这个例子中,首先创建一个全局变量
counter,初始值为0。在increment()中,你使用一个global语句告诉函数你想要修改一个全局变量。最后一条语句将counter增加1。调用
increment()的结果将取决于counter的初始值。counter不同的初始值会产生不同的结果,所以函数的结果不能由函数本身控制。为了避免这种行为,您可以编写一个自包含的
increment(),它接受参数并返回一个仅依赖于输入参数的一致值:
>>> counter = 0
>>> def increment(var):
... return var + 1
...
>>> increment(counter)
1
>>> counter
0
>>> # Explicitly assign a new value to counter
>>> counter = increment(counter)
>>> counter
1
现在调用increment()的结果只取决于输入参数而不是counter的初始值。这使得函数更加健壮,也更容易测试。
注意:为了更好地理解如何测试你的 Python 代码,请查看用 PyTest 进行测试驱动开发。
此外,当您需要更新counter时,您可以通过调用increment()来显式地完成。通过这种方式,您可以在整个代码中更好地控制counter所发生的事情。
一般来说,避免使用修改全局变量的函数是一个好习惯。如果可能的话,试着编写带有显式return语句的自包含函数,该语句返回一致且有意义的值。
将return与条件句一起使用
Python 函数并不局限于单个return语句。如果一个给定的函数有不止一个return语句,那么遇到的第一个语句将决定函数执行的结束以及它的返回值。
用多个return语句编写函数的一种常见方式是使用条件语句,它允许你根据评估某些条件的结果提供不同的return语句。
假设您需要编写一个函数,它接受一个数字并返回它的绝对值。如果数字大于0,那么你将返回相同的数字。如果这个数字小于0,那么你将返回它的相反值,或者非负值。
下面是这个函数的一个可能的实现:
>>> def my_abs(number): ... if number > 0: ... return number ... elif number < 0: ... return -number ... >>> my_abs(-15) 15 >>> my_abs(15) 15
my_abs()有两个显式的return语句,每个都包装在自己的if语句中。它还有一个隐式的return语句。如果number恰好是0,那么这两个条件都不成立,函数结束时没有命中任何显式的return语句。当这种情况发生时,你自动得到None。看看下面使用
0作为参数对my_abs()的调用:
>>> print(my_abs(0))
None
当你使用0作为参数调用my_abs()时,你得到的结果是None。这是因为执行流到达了函数的末尾,而没有到达任何显式的return语句。可惜的是,0的绝对值是0,不是None。
要解决这个问题,您可以在新的elif子句或最终的else子句中添加第三个return语句:
>>> def my_abs(number): ... if number > 0: ... return number ... elif number < 0: ... return -number ... else: ... return 0 ... >>> my_abs(0) 0 >>> my_abs(-15) 15 >>> my_abs(15) 15现在,
my_abs()检查每一个可能的条件,number > 0,number < 0和number == 0。这个例子的目的是说明当你使用条件语句来提供多个return语句时,你需要确保每个可能的选项都有自己的return语句。否则,你的函数会有一个隐藏的 bug。最后,您可以使用一条
if语句以更简洁、高效和的方式实现my_abs():
>>> def my_abs(number):
... if number < 0:
... return -number
... return number
...
>>> my_abs(0)
0
>>> my_abs(-15)
15
>>> my_abs(15)
15
在这种情况下,如果number < 0,您的函数将命中第一个return语句。在所有其他情况下,无论是number > 0还是number == 0,它都命中第二个return语句。有了这个新的实现,您的函数看起来好多了。它可读性更强,更简洁,也更高效。
注意:有一个方便的内置 Python 函数叫做 abs() 用于计算一个数的绝对值。上面例子中的函数仅仅是为了说明正在讨论的问题。
如果您使用if语句来提供几个return语句,那么您不需要一个else子句来涵盖最后一个条件。只需在函数代码块的末尾和缩进的第一级添加一个return语句。
返回True或False
组合使用if和return语句的另一个常见用例是当你编写一个谓词或布尔值函数时。这种函数根据给定的条件返回True或False。
例如,假设您需要编写一个函数,它接受两个整数a和b,如果a能被b整除,则返回True。否则,函数应该返回False。下面是一个可能的实现:
>>> def is_divisible(a, b): ... if not a % b: ... return True ... return False ... >>> is_divisible(4, 2) True >>> is_divisible(7, 4) False如果
a除以b的余数等于0,则is_divisible()返回True。否则返回False。注意,在 Python 中,一个0值是 falsy ,所以需要使用not运算符对条件的真值求反。有时,您会编写包含如下运算符的谓词函数:
在这些情况下,你可以在你的
return语句中直接使用一个布尔表达式。这是可能的,因为这些操作符要么返回True要么返回False。按照这个想法,这里有一个is_divisible()的新实现:
>>> def is_divisible(a, b):
... return not a % b
...
>>> is_divisible(4, 2)
True
>>> is_divisible(7, 4)
False
如果a能被b整除,那么a % b返回0,在 Python 中是 falsy。所以,要返回True,你需要使用not操作符。
注意: Python 遵循一套规则来确定一个对象的真值。
例如,以下物体被认为是假的:
- 常数像
None和False - 具有零值的数字类型,如
0、0.0、0j、、Decimal(0)、、Fraction(0, 1)、 - 空序列和集合,如
""、()、[]、{}、、和range(0) - 实现返回值为
False的__bool__()或返回值为0的__len__()的对象
任何其他物体都将被认为是真实的。
另一方面,如果您试图以之前看到的方式使用包含布尔运算符的条件,如 or 和 and ,那么您的谓词函数将无法正常工作。这是因为这些操作符的行为不同。它们返回条件中的一个操作数,而不是True或False:
>>> 0 and 1 0 >>> 1 and 2 2 >>> 1 or 2 1 >>> 0 or 1 1一般情况下,
and返回第一个假操作数或最后一个操作数。另一方面,or返回第一个真操作数或最后一个操作数。因此,要编写一个包含这些操作符之一的谓词,您需要使用一个显式的if语句或者调用内置函数bool()。假设您想要编写一个谓词函数,它接受两个值,如果两个值都为真,则返回
True,否则返回False。这是实现该功能的第一种方法:
>>> def both_true(a, b):
... return a and b
...
>>> both_true(1, 2)
2
由于and返回操作数,而不是True或False,你的函数不能正常工作。解决这个问题至少有三种可能性:
- 一个明确的
if陈述 - 一个条件表达式(三元运算符)
- 内置的 Python 函数
bool()
如果你使用第一种方法,那么你可以写both_true()如下:
>>> def both_true(a, b): ... if a and b: ... return True ... return False ... >>> both_true(1, 2) True >>> both_true(1, 0) False
if语句检查a和b是否都是真的。如果是,那么both_true()返回True。否则返回False。另一方面,如果您使用 Python 条件表达式或三元运算符,那么您可以按如下方式编写谓词函数:
>>> def both_true(a, b):
... return True if a and b else False
...
>>> both_true(1, 2)
True
>>> both_true(1, 0)
False
这里,您使用一个条件表达式为both_true()提供一个返回值。如果a和b都为真,则条件表达式被评估为True。否则,最后的结果就是False。
最后,如果您使用bool(),那么您可以将both_true()编码如下:
>>> def both_true(a, b): ... return bool(a and b) ... >>> both_true(1, 2) True >>> both_true(1, 0) False如果
a和b为真,则bool()返回True,否则False返回。用什么方法解决这个问题取决于你。然而,第二种解决方案似乎更具可读性。你怎么想呢?短路回路
循环中的
return语句执行某种短路。它中断循环执行并使函数立即返回。为了更好地理解这种行为,您可以编写一个模拟any()的函数。这个内置函数接受一个 iterable,如果至少有一个 iterable 项为 true,则返回True。为了模拟
any(),您可以编写如下函数:
>>> def my_any(iterable):
... for item in iterable:
... if item:
... # Short-circuit
... return True
... return False
>>> my_any([0, 0, 1, 0, 0])
True
>>> my_any([0, 0, 0, 0, 0])
False
如果iterable中的任意item为真,那么执行流程进入if块。return语句中断循环并立即返回,返回值为True。如果iterable中没有值为真,则my_any()返回False。
该功能实现了短路评估。例如,假设您传递了一个包含一百万项的 iterable。如果 iterable 中的第一项恰好为真,那么循环只运行一次,而不是一百万次。这可以在运行代码时节省大量处理时间。
需要注意的是,要在循环中使用return语句,您需要将该语句包装在if语句中。否则,循环将总是在第一次迭代中中断。
识别死代码
一旦一个函数命中一个return语句,它就终止而不执行任何后续代码。因此,出现在函数的return语句之后的代码通常被称为死代码。Python 解释器在运行函数时完全忽略死代码。因此,在函数中包含这样的代码是无用的,也是令人困惑的。
考虑下面的函数,它在其return语句后添加了代码:
>>> def dead_code(): ... return 42 ... # Dead code ... print("Hello, World") ... >>> dead_code() 42本例中的语句
print("Hello, World")永远不会执行,因为该语句出现在函数的return语句之后。识别死代码并删除它是一个很好的实践,可以用来编写更好的函数。值得注意的是,如果你使用条件语句来提供多个
return语句,那么你可以在一个return语句之后有代码,只要它在if语句之外,就不会死:
>>> def no_dead_code(condition):
... if condition:
... return 42
... print("Hello, World")
...
>>> no_dead_code(True)
42
>>> no_dead_code(False)
Hello, World
尽管对print()的调用是在return语句之后,但它不是死代码。当condition被评估为False时,运行print()调用,并且将Hello, World打印到您的屏幕上。
返回多个命名对象
当你在编写一个在单个return语句中返回多个值的函数时,你可以考虑使用一个 collections.namedtuple 对象来使你的函数更具可读性。namedtuple是一个集合类,它返回tuple的一个子类,该子类有字段或属性。您可以使用点符号或索引操作来访问这些属性。
namedtuple的初始化器有几个参数。然而,要开始在代码中使用namedtuple,您只需要知道前两个:
typename保存您正在创建的类似元组的类的名称。它需要是一个字符串。field_names保存元组类的字段或属性的名称。它可以是一系列字符串,如["x", "y"],也可以是单个字符串,每个名称用空格或逗号分隔,如"x y"或"x, y"。
当你需要返回多个值时,使用一个namedtuple可以让你的函数更加易读,而不需要太多的努力。考虑以下使用namedtuple作为返回值的describe()的更新:
import statistics as st
from collections import namedtuple
def describe(sample):
Desc = namedtuple("Desc", ["mean", "median", "mode"])
return Desc(
st.mean(sample),
st.median(sample),
st.mode(sample),
)
在describe()中,你创建了一个叫做Desc的namedtuple。该对象可以具有命名属性,您可以使用点标记法或索引操作来访问这些属性。在这个例子中,这些属性是"mean"、"median"和"mode"。
您可以创建一个Desc对象,并将其用作返回值。为此,您需要像处理任何 Python 类一样实例化Desc。注意,您需要为每个命名属性提供一个具体的值,就像您在return语句中所做的那样。
下面是describe()现在的工作方式:
>>> sample = [10, 2, 4, 7, 9, 3, 9, 8, 6, 7] >>> stat_desc = describe(sample) >>> stat_desc Desc(mean=5.7, median=6.0, mode=6) >>> # Get the mean by its attribute name >>> stat_desc.mean 5.7 >>> # Get the median by its index >>> stat_desc[1] 6.0 >>> # Unpack the values into three variables >>> mean, median, mode = describe(sample) >>> mean 5.7 >>> mode 6当您用数字数据的样本调用
describe()时,您会得到一个包含样本的平均值、中值和众数的namedtuple对象。请注意,您可以通过使用点符号或索引操作来访问元组的每个元素。最后,还可以使用 iterable 解包操作将每个值存储在它自己的独立变量中。
返回函数:闭包
在 Python 中,函数是一级对象。一级对象是可以赋给变量、作为参数传递给函数或在函数中用作返回值的对象。因此,您可以在任何
return语句中使用函数对象作为返回值。以一个函数作为自变量,返回一个函数作为结果,或者两者都是的函数是一个高阶函数。一个闭包工厂函数是 Python 中高阶函数的一个常见例子。这种函数接受一些参数并返回一个内部函数。内部函数通常被称为闭包。
闭包携带关于其封闭执行范围的信息。这提供了一种在函数调用之间保留状态信息的方法。当您需要基于懒惰或延迟评估的概念编写代码时,闭包工厂函数非常有用。
假设您需要编写一个 helper 函数,它接受一个数字并返回该数字乘以给定因子的结果。您可以编写如下函数:
def by_factor(factor, number): return factor * number
by_factor()以factor和number为自变量,返回它们的乘积。因为factor很少在你的应用程序中改变,你会发现在每个函数调用中提供相同的因子很烦人。因此,您需要一种方法来在对by_factor()的调用之间保留factor的状态或值,并仅在需要时更改它。要在两次调用之间保留当前的值factor,可以使用闭包。下面的
by_factor()实现使用闭包在调用之间保留factor的值:
>>> def by_factor(factor):
... def multiply(number):
... return factor * number
... return multiply
...
>>> double = by_factor(2)
>>> double(3)
6
>>> double(4)
8
>>> triple = by_factor(3)
>>> triple(3)
9
>>> triple(4)
12
在by_factor()内部,您定义了一个名为multiply()的内部函数,并在不调用它的情况下返回它。您返回的函数对象是一个闭包,它保留了关于factor状态的信息。换句话说,它在两次调用之间记住了factor的值。这就是为什么double记得factor等于2而triple记得factor等于3。
请注意,您可以自由地重用double和triple,因为它们不会忘记各自的状态信息。
你也可以使用一个 lambda函数来创建闭包。有时候使用一个lambda函数可以让你的闭包工厂更加简洁。这里有一个使用lambda函数的by_factor()的替代实现:
>>> def by_factor(factor): ... return lambda number: factor * number ... >>> double = by_factor(2) >>> double(3) 6 >>> double(4) 8这个实现就像最初的例子一样工作。在这种情况下,使用
lambda函数提供了一种快速简洁的方式来编码by_factor()。接受和返回函数:装饰者
使用
return语句返回函数对象的另一种方式是编写装饰函数。一个装饰函数接受一个函数对象作为参数并返回一个函数对象。装饰器以某种方式处理被装饰的函数,并返回它或者用另一个函数或可调用对象替换它。当您需要在不修改现有函数的情况下向其添加额外的逻辑时,Decorators 非常有用。例如,您可以编写一个装饰器来记录函数调用,验证函数的参数,测量给定函数的执行时间,等等。
以下示例显示了一个装饰函数,您可以使用它来了解给定 Python 函数的执行时间:
>>> import time
>>> def my_timer(func):
... def _timer(*args, **kwargs):
... start = time.time()
... result = func(*args, **kwargs)
... end = time.time()
... print(f"Execution time: {end - start}")
... return result
... return _timer
...
>>> @my_timer
... def delayed_mean(sample):
... time.sleep(1)
... return sum(sample) / len(sample)
...
>>> delayed_mean([10, 2, 4, 7, 9, 3, 9, 8, 6, 7])
Execution time: 1.0011096000671387
6.5
delayed_mean()头上面的语法@my_timer等价于表达式delayed_mean = my_timer(delayed_mean)。在这种情况下,你可以说my_timer()在装修delayed_mean()。
一旦你导入或者运行一个模块或者脚本,Python 就会运行装饰函数。所以,当你调用delayed_mean()时,你实际上是在调用my_timer()的返回值,也就是函数对象_timer。对修饰的delayed_mean()的调用将返回样本的平均值,还将测量原始delayed_mean()的执行时间。
在这种情况下,您使用 time() 来测量装饰器内部的执行时间。time()驻留在一个名为 time 的模块中,该模块提供了一组与时间相关的函数。time()以浮点数形式返回自纪元以来的时间(秒)。调用delayed_mean()前后的时间差将让您了解函数的执行时间。
注意:在delayed_mean()中,您使用函数 time.sleep() ,它将调用代码的执行暂停给定的秒数。为了更好地理解如何使用sleep(),请查看 Python sleep():如何向代码添加时间延迟。
Python 中其他常见的装饰器例子有 classmethod()、staticmethod() 、 property()、T6】。如果你想更深入地了解 Python decorator,那么看看 Python decorator的初级读本。你也可以看看 Python Decorators 101 。
返回用户定义的对象:工厂模式
Python return语句也可以返回用户定义的对象。换句话说,您可以使用自己的自定义对象作为函数中的返回值。这种能力的一个常见用例是工厂模式。
工厂模式定义了一个接口,用于动态创建对象,以响应您在编写程序时无法预测的情况。您可以使用一个函数实现用户定义对象的工厂,该函数接受一些初始化参数,并根据具体的输入返回不同的对象。
假设您正在编写一个绘画应用程序。您需要根据用户的选择动态创建不同的形状。你的程序将会有正方形、圆形、长方形等等。要动态创建这些形状,首先需要创建将要使用的形状类:
class Circle:
def __init__(self, radius):
self.radius = radius
# Class implementation...
class Square:
def __init__(self, side):
self.side = side
# Class implementation...
一旦您为每个形状创建了一个类,您就可以编写一个函数,该函数将形状的名称作为一个字符串以及一个可选的参数(*args)和关键词参数(**kwargs ) 列表,来动态创建和初始化形状:
def shape_factory(shape_name, *args, **kwargs):
shapes = {"circle": Circle, "square": Square}
return shapes[shape_name](*args, **kwargs)
该函数创建具体形状的实例,并将其返回给调用者。现在,您可以使用shape_factory()来创建不同形状的对象,以满足用户的需求:
>>> circle = shape_factory("circle", radius=20) >>> type(circle) <class '__main__.Circle'> >>> circle.radius 20 >>> square = shape_factory("square", side=10) >>> type(square) <class '__main__.Square'> >>> square.side 10如果您以所需形状的名称作为字符串调用
shape_factory(),那么您将获得一个与您刚刚传递给工厂的shape_name相匹配的形状的新实例。使用
try…finally模块中的return当您在带有
finally子句的try语句内使用return语句时,该finally子句总是在return语句之前执行。这确保了finally子句中的代码将一直运行。看看下面的例子:
>>> def func(value):
... try:
... return float(value)
... except ValueError:
... return str(value)
... finally:
... print("Run this before returning")
...
>>> func(9)
Run this before returning
9.0
>>> func("one")
Run this before returning
'one'
当您调用func()时,您会将value转换为浮点数或字符串对象。在此之前,您的函数运行finally子句并在屏幕上打印一条消息。您添加到finally子句的任何代码都将在函数运行其return语句之前执行。
在发生器功能中使用return
一个主体中带有 yield语句的 Python 函数就是一个 生成器函数 。当你调用一个生成器函数时,它返回一个生成器迭代器。所以,你可以说一个生成器函数是一个生成器工厂。
您可以在生成器函数中使用一个return语句来表示生成器已经完成。return语句将使发电机发出 StopIteration 。返回值将作为参数传递给StopIteration的初始化器,并赋给它的.value属性。
这里有一个生成器,它按需生成1和2,然后返回3:
>>> def gen(): ... yield 1 ... yield 2 ... return 3 ... >>> g = gen() >>> g <generator object gen at 0x7f4ff4853c10> >>> next(g) 1 >>> next(g) 2 >>> next(g) Traceback (most recent call last): File "<input>", line 1, in <module> next(g) StopIteration: 3
gen()根据需要返回产生1和2的生成器对象。要从生成器对象中检索每个数字,可以使用next(),这是一个内置函数,用于从 Python 生成器中检索下一个项目。对
next()的前两个调用分别检索1和2。第三次调用,发电机耗尽,你得到一个StopIteration。注意,生成器函数(3)的返回值变成了StopIteration对象的.value属性。结论
Python
return语句允许您将任何 Python 对象从您的自定义函数发送回调用者代码。该语句是任何 Python 函数或方法的基础部分。如果您掌握了如何使用它,那么您就可以编写健壮的函数了。在本教程中,您已经学会了如何:
- 在你的函数中有效地使用 Python
return语句- 从你的函数中返回单值或多值给调用者代码
- 使用
return语句时,应用最佳实践此外,您还学习了一些关于
return语句的更高级的用例,比如如何编写一个闭包工厂函数和一个装饰函数。有了这些知识,你将能够用 Python 编写更多的Python 化的、健壮的、可维护的函数。立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 有效使用 Python 返回语句********
反向 Python 列表:超越。反转()和反转()
您是否正在深入研究 Python 列表,并想了解反转它们的不同方法?如果是这样,那么这篇教程就是为你准备的。在这里,您将了解一些 Python 工具和技术,它们在反转列表或以相反的顺序操作列表时非常方便。这些知识将补充和提高你与列表相关的技能,并使你更加精通它们。
在本教程中,您将学习如何:
- 使用
.reverse()和其他技术将现有列表反转到位- 使用
reversed()和切片创建现有列表的反向副本- 使用迭代、理解和递归来创建反向列表
- 以相反的顺序遍历列表中的
- 使用
.sort()和sorted()对你的列表进行逆序排序为了从本教程中获得最大收益,了解一下可迭代、、
for循环、列表、列表理解、生成器表达式和递归的基础知识会很有帮助。免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
反转 Python 列表
有时,您需要从最后一个元素开始处理 Python 列表,直到第一个元素——换句话说,以相反的顺序。一般来说,逆向处理列表有两个主要挑战:
- 原地反转列表
- 创建现有列表的反向副本
为了应对第一个挑战,您可以使用
.reverse()或者通过索引交换项目的循环。对于第二种,您可以使用reversed()或切片操作。在接下来的部分中,您将了解在代码中实现这两者的不同方法。将列表反转到位
像其他的可变序列类型一样,Python 列表实现了
.reverse()。当你反转大列表对象时,这个方法反转底层列表来代替以提高内存效率。以下是如何使用.reverse():
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> digits.reverse()
>>> digits
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
当您在一个已存在的列表上调用.reverse()时,该方法会就地反转它。这样,当您再次访问该列表时,您会以相反的顺序获得它。注意.reverse()没有返回一个新的列表而是 None :
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> reversed_digits = digits.reverse() >>> reversed_digits is None True试图将
.reverse()的返回值赋给一个变量是使用这种方法的常见错误。返回None的目的是提醒它的用户.reverse()是通过副作用来操作的,改变了底层列表。注意:本教程中的大多数例子都使用一列数字作为输入。然而,同样的工具和技术适用于任何类型的 Python 对象的列表,例如字符串的列表。
好吧!真是又快又直!现在,如何手动反转一个列表?一种常见的技术是遍历列表的前半部分,同时在列表的后半部分将每个元素与其镜像元素进行交换。
Python 为从左到右的遍历序列提供了从零开始的正索引。它还允许您使用负索引从右向左导航序列:
这个图显示了你可以通过索引操作符使用
0或-5来访问列表(或序列)的第一个元素,就像分别在sequence[0]和sequence[-5]中一样。您可以使用这个 Python 特性来就地反转底层序列。例如,要反转图中表示的列表,您可以循环遍历列表的前半部分,并在第一次迭代中将索引
0处的元素与其索引-1处的镜像交换。然后,您可以将索引1处的元素与其索引-2处的镜像进行交换,依此类推,直到列表反转。这是整个过程的示意图:
要将这个过程翻译成代码,可以在列表的前半部分使用带有
range对象的for循环,可以通过len(digits) // 2获得。然后,您可以使用并行赋值语句来交换元素,如下所示:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> for i in range(len(digits) // 2):
... digits[i], digits[-1 - i] = digits[-1 - i], digits[i]
...
>>> digits
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
这个循环遍历一个从0到len(digits) // 2的range对象。每次迭代都将列表前半部分的一个项目与其后半部分的镜像项目进行交换。索引操作符[]中的表达式-1 - i保证了对镜像项的访问。你也可以使用表达式-1 * (i + 1)来提供相应的镜像索引。
除了利用索引替换的上述算法之外,还有一些不同的手动反转列表的方法。例如,您可以这样使用.pop()和.insert():
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> for i in range(len(digits)): ... last_item = digits.pop() ... digits.insert(i, last_item) ... >>> digits [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]在循环中,您调用原始列表上的
.pop()而没有参数。该调用移除并返回列表中的最后一项,因此您可以将它存储在last_item中。然后.insert()将last_item移动到索引i的位置。例如,第一次迭代从列表的右端移除
9,并将其存储在last_item中。然后在索引0处插入9。下一次迭代采用8并将其移动到索引1,依此类推。在循环的最后,你把列表颠倒过来。创建反向列表
如果您想在 Python 中创建一个现有列表的反向副本,那么您可以使用
reversed()。使用一个列表作为参数,reversed()返回一个迭代器,它以相反的顺序生成条目:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> reversed_digits = reversed(digits)
>>> reversed_digits
<list_reverseiterator object at 0x7fca9999e790>
>>> list(reversed_digits)
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
在这个例子中,你用digits作为参数调用reversed()。然后将结果迭代器存储在reversed_digits中。对list()的调用消耗迭代器并返回一个新的列表,该列表包含与digits相同的条目,但顺序相反。
使用reversed()时需要注意的重要一点是,它不会创建输入列表的副本,因此对它的更改会影响结果迭代器:
>>> fruits = ["apple", "banana", "orange"] >>> reversed_fruit = reversed(fruits) # Get the iterator >>> fruits[-1] = "kiwi" # Modify the last item >>> next(reversed_fruit) # The iterator sees the change 'kiwi'在这个例子中,您调用
reversed()来获取fruits中条目的相应迭代器。然后你修改最后一个水果。这种变化会影响迭代器。您可以通过调用next()获得reversed_fruit中的第一个项目来确认。如果你需要使用
reversed()获得fruits的副本,那么你可以调用list():
>>> fruits = ["apple", "banana", "orange"]
>>> list(reversed(fruits))
['orange', 'banana', 'apple']
正如您已经知道的,对list()的调用消耗了调用reversed()产生的迭代器。这样,您可以创建一个新列表,作为原始列表的反向副本。
Python 2.4 增加了reversed(),一个通用工具,方便对序列进行反向迭代,如 PEP 322 所述。一般来说,reversed()可以接受任何实现 .__reversed__() 方法或者支持序列协议的对象,包括 .__len__() 和 .__getitem__() 特殊方法。所以,reversed()不仅限于列表:
>>> list(reversed(range(10))) [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] >>> list(reversed("Python")) ['n', 'o', 'h', 't', 'y', 'P']这里,您传递一个
range对象和一个字符串作为reversed()的参数,而不是一个列表。该函数按预期完成了工作,您得到的是输入数据的反向版本。需要强调的另一个要点是,不能将
reversed()与任意迭代器一起使用:
>>> digits = iter([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> reversed(digits)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list_iterator' object is not reversible
在这个例子中, iter() 在你的数字列表上构建一个迭代器。当你在digits上调用reversed()时,你会得到一个TypeError。
迭代器实现了 .__next__() 特殊方法来遍历底层数据。他们还需要实现 .__iter__() 特殊方法来返回当前迭代器实例。然而,他们并不期望实现.__reversed__()或者序列协议。所以,reversed()对他们不起作用。如果你需要像这样反转一个迭代器,那么你应该首先使用list()把它转换成一个列表。
另一点需要注意的是,不能对无序的可重复项使用reversed():
>>> digits = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} >>> reversed(digits) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'set' object is not reversible在这个例子中,当您尝试将
reversed()与一个set对象一起使用时,您会得到一个TypeError。这是因为集合不保持它们的项目有序,所以 Python 不知道如何反转它们。切片反转列表
从 Python 1.4 开始,切片语法有了第三个参数,叫做
step。然而,这种语法最初并不适用于内置类型,比如列表、元组和字符串。 Python 2.3 将语法扩展到了内置类型,所以你现在可以对它们使用step。下面是完整的切片语法:a_list[start:stop:step]这个语法允许你通过
step从start到stop − 1提取a_list中的所有项目。第三个偏移量step默认为1,这就是为什么正常的切片操作从左到右提取项目:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> digits[1:5]
[1, 2, 3, 4]
使用[1:5],您可以获得从索引1到索引5 - 1的项目。索引等于stop的项目是从不包含在最终结果中。这个切片返回目标范围内的所有项目,因为step默认为1。
注意:当缺省值(1)满足当前需要时,可以省略切片操作符中的第二个冒号(:)。
如果您使用不同的step,那么切片将跳转与step的值一样多的项目:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> digits[0::2] [0, 2, 4, 6, 8] >>> digits[::3] [0, 3, 6, 9]在第一个例子中,
[0::2]提取从索引0到digits结尾的所有项目,每次跳过两个项目。在第二个例子中,切片过程中会跳转到3项。如果你不给start和stop提供值,那么它们分别被设置为0和目标序列的长度。如果您将
step设置为-1,那么您将得到一个项目顺序相反的切片:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> # Set step to -1
>>> digits[len(digits) - 1::-1]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>> digits
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
由于省略了第二个偏移量,这个切片将列表右端(len(digits) - 1)的所有项目返回到左端。这个例子中其余的神奇之处来自于对step使用一个值-1。当您运行这个技巧时,您会得到一个逆序的原始列表的副本,而不会影响输入数据。
如果您完全依赖隐式偏移量,那么切片语法会变得更短、更清晰、更不容易出错:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> # Rely on default offset values >>> digits[::-1] [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]在这里,你要求 Python 给出完整的列表(
[::-1]),但是通过将step设置为-1从后向前检查所有的条目。这很简洁,但是reversed()在执行时间和内存使用方面更有效。它也更具可读性和明确性。所以这些是你在代码中要考虑的问题。创建现有列表的反向副本的另一个技巧是使用
slice()。这个内置函数的签名如下:slice(start, stop, step)该函数的工作方式类似于索引运算符。它接受三个与切片操作符中使用的参数含义相似的参数,并返回一个代表由
range(start, stop, step)返回的一组索引的切片对象。这听起来很复杂,所以这里有一些slice()如何工作的例子:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> slice(0, len(digits))
slice(0, 10, None)
>>> digits[slice(0, len(digits))]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> slice(len(digits) - 1, None, -1)
slice(9, None, -1)
>>> digits[slice(len(digits) - 1, None, -1)]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
第一次调用slice()相当于[0:len(digits)]。第二个呼叫的工作原理与[len(digits) - 1::-1]相同。您也可以使用slice(None, None, -1)来模拟切片[::-1]。在这种情况下,将None传递给start和stop意味着您想要从目标序列的开头到结尾的一个切片。
注意:在底层,切片文字创建slice对象。因此,当您像在[::-1]中一样省略一个偏移量时,它的工作方式就像您在对slice()的调用中将None传递给相应的偏移量一样。
下面是如何使用slice()创建现有列表的反向副本:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> digits[slice(None, None, -1)] [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
slice对象从digits中提取所有项目,从右端开始回到左端,并返回目标列表的反向副本。手工生成倒序表
到目前为止,您已经看到了一些工具和技术,它们可以就地反转列表或者创建现有列表的反转副本。大多数时候,这些工具和技术是在 Python 中反转列表的好方法。然而,如果你需要手工反转列表,那么理解这个过程背后的逻辑会对你有好处。
在本节中,您将学习如何使用循环、递归和理解来反转 Python 列表。这个想法是获得一个列表,并以相反的顺序创建它的副本。
使用循环
用于反转列表的第一个技术涉及到一个
for循环和一个使用加号(+)的列表连接:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> def reversed_list(a_list):
... result = []
... for item in a_list:
... result = [item] + result
... return result
...
>>> reversed_list(digits)
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
for循环的每一次迭代都从a_list中获取一个后续项,并创建一个新的列表,该列表由串联的[item]和result产生,它们最初保存一个空列表。新创建的列表被重新分配给result。该功能不修改a_list。
注意:上面的例子使用了一种浪费的技术,因为它创建了几个列表,只是为了在下一次迭代中扔掉它们。
您还可以利用.insert()在循环的帮助下创建反向列表:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> def reversed_list(a_list): ... result = [] ... for item in a_list: ... result.insert(0, item) ... return result ... >>> reversed_list(digits) [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]循环内部对
.insert()的调用在result的0索引处插入后续项目。在循环结束时,您会得到一个新的列表,其中包含了逆序排列的a_list项。在上面的例子中使用
.insert()有一个明显的缺点。众所周知,Python 列表左端的插入操作在执行时间方面效率很低。这是因为 Python 需要将所有的项向后移动一步,以便在第一个位置插入新的项。使用递归
你也可以使用递归来反转你的列表。递归是指你定义一个调用自身的函数。如果你不提供一个产生结果的基础用例而不再次调用函数,这将创建一个无限循环。
您需要基本案例来结束递归循环。当涉及到反转列表时,当递归调用到达输入列表的末尾时,将达到基本情况。您还需要定义递归用例,它将所有连续的用例减少到基本用例,因此减少到循环的结尾。
下面是如何定义递归函数来返回给定列表的反向副本:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> def reversed_list(a_list):
... if len(a_list) == 0: # Base case
... return a_list
... else:
... # print(a_list)
... # Recursive case
... return reversed_list(a_list[1:]) + a_list[:1]
...
>>> reversed_list(digits)
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
在reversed_list()内部,首先检查基本情况,其中输入列表为空,并使函数返回。else子句提供了递归情况,这是对reversed_list()本身的调用,但是使用了原始列表的一部分a_list[1:]。这个切片包含了a_list中除第一项之外的所有项,第一项作为一个单项列表(a_list[:1])添加到递归调用的结果中。
注意:在递归的情况下,可以用[a_list[0]]代替a_list[:1]得到类似的结果。
在else子句开始的对 print() 的注释调用只是一个技巧,旨在展示后续调用如何将输入列表减少到基本情况。继续,取消对该行的注释,看看会发生什么!
使用列表理解
如果你在 Python 中使用列表,那么你可能想考虑使用一个列表理解。这个工具在 Python 领域非常流行,因为它代表了处理列表的 Python 方式。
下面是一个如何使用列表理解来创建反向列表的示例:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> last_index = len(digits) - 1 >>> [digits[i] for i in range(last_index, -1, -1)] [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]这个列表理解的魔力来自于对
range()的调用。在这种情况下,range()将索引从len(digits) - 1返回到0。这使得理解循环反向迭代digits中的条目,在这个过程中创建新的反向列表。反向遍历列表
到目前为止,您已经学习了如何创建反向列表,以及如何在适当的位置反向现有的列表,或者使用专门设计的工具来完成这项任务,或者使用您自己的手工编码的解决方案。
在日常编程中,您可能会发现以相反的顺序遍历现有的列表和序列,通常被称为反向迭代,这是一个相当常见的需求。如果这是你的情况,那么你有几个选择。根据您的具体需求,您可以使用:
- 内置函数
reversed()[::]切片操作符- 特殊方法
.__reversed__()在接下来的几节中,您将了解所有这些选项,以及它们如何帮助您以逆序遍历列表。
内置的
reversed()函数以逆序遍历列表的第一种方法可能是使用
reversed()。这个内置函数是专门为支持反向迭代而设计的。使用一个列表作为参数,它返回一个迭代器,以逆序生成输入列表项。下面是如何使用
reversed()以逆序遍历列表中的项目:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> for digit in reversed(digits):
... print(digit)
...
9
8
7
6
5
4
3
2
1
0
在这个例子中首先要注意的是,for循环是高度可读的。reversed()的名字清楚地表达了它的意图,用微妙的细节传达了这个函数不会产生任何副作用。换句话说,它不会修改输入列表。
该循环在内存使用方面也是高效的,因为reversed()返回一个迭代器,该迭代器根据需要产生项目,而不是同时将它们全部存储在内存中。同样,需要注意一个微妙的细节,如果输入列表在迭代过程中发生了变化,那么迭代器会看到变化。
[::-1]切片操作符,
反向迭代的第二种方法是使用您之前看到的扩展切片语法。这种语法无助于提高记忆效率、美观和清晰。尽管如此,它还是提供了一种快速的方法来迭代现有列表的反向副本,而没有受到原始列表中的更改影响的风险。
下面是如何使用[::-1]以相反的顺序遍历一个现有列表的副本:
>>> digits = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> for digit in digits[::-1]: ... print(digit) ... 9 8 7 6 5 4 3 2 1 0当您像在这个例子中一样分割一个列表时,您创建了一个原始列表的反向副本。最初,两个列表都包含对同一组项目的引用。然而,如果你给原始列表中的一个给定条目分配一个新值,就像在
digits[0] = "zero"中一样,那么引用就会改变,指向新值。这样,输入列表上的更改不会影响拷贝。注意:与扩展切片相比,
reversed()可读性更强,运行速度更快,使用的内存也更少。但是,它会受到输入列表变化的影响。您可以利用这种切片安全地修改原始列表,同时以相反的顺序迭代它的旧项目。例如,假设您需要以逆序遍历一系列数字,并用平方值替换每个数字。在这种情况下,您可以这样做:
>>> numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> for i, number in enumerate(numbers[::-1]):
... numbers[i] = number ** 2
...
>>> # Square values in reverse order
>>> numbers
[81, 64, 49, 36, 25, 16, 9, 4, 1, 0]
这里,循环遍历了一个numbers的反向副本。对 enumerate() 的调用为反向副本中的每个项目提供了从零开始的升序索引。这允许您在迭代过程中修改numbers。然后,循环通过用每一项的平方值替换每一项来修改numbers。结果,numbers最终以相反的顺序包含平方值。
.__reversed__()特殊方法
Python 列表实现了一个叫做.__reversed__()的特殊方法,它支持反向迭代。这个方法提供了reversed()背后的逻辑。换句话说,用列表作为参数调用reversed()会触发对输入列表上的.__reversed__()的隐式调用。
这个特殊的方法以逆序返回当前列表项的迭代器。然而,.__reversed__()并不打算直接使用。大多数时候,您将使用它来为自己的类配备反向迭代功能。
例如,假设您想要迭代一系列浮点数。您不能使用range(),所以您决定创建自己的类来处理这个特定的用例。你会得到这样一个类:
# float_range.py
class FloatRange:
def __init__(self, start, stop, step=1.0):
if start >= stop:
raise ValueError("Invalid range")
self.start = start
self.stop = stop
self.step = step
def __iter__(self):
n = self.start
while n < self.stop:
yield n
n += self.step
def __reversed__(self):
n = self.stop - self.step
while n >= self.start:
yield n
n -= self.step
这门课并不完美。这只是你的第一个版本。但是,它允许您使用固定的增量值step遍历一个浮点数区间。在你的类中, .__iter__() 支持正迭代,.__reversed__()支持逆迭代。
要使用FloatRange,您可以这样做:
>>> from float_range import FloatRange >>> for number in FloatRange(0.0, 5.0, 0.5): ... print(number) ... 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5该类支持普通迭代,如前所述,是由
.__iter__()提供的。现在您可以尝试使用reversed()以相反的顺序进行迭代:
>>> from float_range import FloatRange
>>> for number in reversed(FloatRange(0.0, 5.0, 0.5)):
... print(number)
...
4.5
4.0
3.5
3.0
2.5
2.0
1.5
1.0
0.5
0.0
在这个例子中,reversed()依赖于您的.__reversed__()实现来提供反向迭代功能。这样,您就有了一个工作的浮点迭代器。
反转 Python 列表:概述
到目前为止,您已经学习了很多关于使用不同工具和技术反转列表的知识。下表总结了您已经讲述过的更重要的内容:
| 特征 | .reverse() |
reversed() |
[::-1] |
环 | 列表排版 | 递归 |
|---|---|---|---|---|---|---|
| 就地修改列表 | ✔ | -好的 | -好的 | ✔/❌ | -好的 | -好的 |
| 创建列表的副本 | -好的 | -好的 | ✔ | ✔/❌ | ✔ | ✔ |
| 很快 | ✔ | ✔ | -好的 | -好的 | ✔ | -好的 |
| 是通用的 | -好的 | ✔ | ✔ | ✔ | ✔ | ✔ |
快速浏览一下这个摘要,可以让你决定当你在适当的位置反转列表,创建已有列表的反转副本,或者以逆序遍历列表时,使用哪种工具或技术。
逆序排序 Python 列表
在 Python 中,另一个有趣的选项是使用.sort()和sorted()对列表进行逆序排序。为此,您可以将True传递给它们各自的reverse参数。
注:要深入了解如何使用.sort()和sorted(),请查看如何在 Python 中使用 sorted()和 sort()。
.sort()的目标是对列表中的条目进行排序。排序是就地完成的,所以它不会创建一个新的列表。如果您将reverse关键字参数设置为True,那么您将得到按降序或逆序排序的列表:
>>> digits = [0, 5, 7, 3, 4, 9, 1, 6, 3, 8] >>> digits.sort(reverse=True) >>> digits [9, 8, 7, 6, 5, 4, 3, 3, 1, 0]现在你的列表已经完全排序了,而且是逆序排序。当你在处理一些数据时,这是非常方便的,你需要同时对它进行排序和反转。
另一方面,如果您想以逆序遍历一个排序列表,那么您可以使用
sorted()。这个内置函数返回一个新列表,该列表按顺序包含输入 iterable 的所有项目。如果您将True传递给它的reverse关键字参数,那么您将得到一个初始列表的反向副本:
>>> digits = [0, 5, 7, 3, 4, 9, 1, 6, 3, 8]
>>> sorted(digits, reverse=True)
[9, 8, 7, 6, 5, 4, 3, 3, 1, 0]
>>> for digit in sorted(digits, reverse=True):
... print(digit)
...
9
8
7
6
5
4
3
3
1
0
sorted()的reverse参数允许你以降序而不是升序对可重复项进行排序。所以,如果你需要创建逆序排序列表,那么sorted()就是为你准备的。
结论
在 Python 程序员的日常工作中,反转和处理列表中的逆序可能是一项相当常见的任务。在本教程中,您利用了一些 Python 工具和技术来反转列表并以相反的顺序管理它们。
在本教程中,您学习了如何:
- 使用
.reverse()和其他技巧将你的清单颠倒过来 - 使用
reversed()和切片来创建列表的反向副本 - 使用迭代、理解和递归来创建反向列表
- 以相反的顺序遍历列表中的
- 使用
.sort()和sorted()对列表进行逆序排序
所有这些知识都有助于你提高与列表相关的技能。它为您提供了在使用 Python 列表时更加熟练所需的工具。*******
制作你的第一个 Python 游戏:石头、剪子、布!
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 石头剪子布用 Python:一个命令行游戏
游戏编程是学习如何编程的好方法。您将使用许多在现实世界中看到的工具,此外,您还可以玩游戏来测试您的结果!开始 Python 游戏编程之旅的理想游戏是石头剪刀布。
在本教程中,你将学习如何:
- 编写你自己的石头剪刀布游戏
- 取用用户输入的
input() - 使用
while循环连续玩几个游戏 - 用
Enum和函数清理你的代码 - 用字典定义更复杂的规则
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是石头剪刀布?
你可能以前玩过石头剪子布。也许你已经用它来决定谁为晚餐买单,或者谁为一个队获得第一选择。
如果你不熟悉,石头剪子布是一个两个或更多玩家玩的手游。参与者说“石头、布、剪刀”,然后同时将手形成石头(拳头)、一张纸(手掌朝下)或一把剪刀(伸出两个手指)的形状。规则很简单:
- 石头砸碎剪刀。
- 纸盖岩石。
- 剪刀剪纸。
现在您已经有了规则,您可以开始考虑如何将它们转换成 Python 代码。
用 Python 玩石头剪子布的单人游戏
使用上面的描述和规则,你可以做一个石头剪刀布的游戏。在您开始之前,您需要导入您将用来模拟计算机选择的模块:
import random
厉害!现在你可以使用random中不同的工具来随机化电脑在游戏中的动作。现在怎么办?因为您的用户还需要能够选择他们的动作,所以您需要的第一件合乎逻辑的事情是接收用户输入的方法。
接受用户输入
在 Python 中,接受用户的输入非常简单。这里的目标是询问用户他们想选择什么作为动作,然后将该选择分配给一个变量:
user_action = input("Enter a choice (rock, paper, scissors): ")
这将提示用户输入一个选择,并将其保存到一个变量中以备后用。现在用户已经选择了一个动作,计算机需要决定做什么。
让计算机选择
一场石头剪刀布的竞技游戏涉及策略。不过,你可以通过让计算机选择一个随机动作来节省时间,而不是试图为此开发一个模型。随机选择是让计算机选择一个伪随机值的好方法。
您可以使用 random.choice() 让电脑随机选择动作:
possible_actions = ["rock", "paper", "scissors"]
computer_action = random.choice(possible_actions)
这允许从列表中选择随机元素。您还可以打印用户和计算机做出的选择:
print(f"\nYou chose {user_action}, computer chose {computer_action}.\n")
打印用户和计算机的操作对用户很有帮助,如果结果不太对劲,它还可以帮助您以后进行调试。
确定获胜者
现在两个玩家都做出了选择,你只需要一个方法来决定谁赢。使用if … elif … else方块,您可以比较玩家的选择并确定赢家:
if user_action == computer_action:
print(f"Both players selected {user_action}. It's a tie!")
elif user_action == "rock":
if computer_action == "scissors":
print("Rock smashes scissors! You win!")
else:
print("Paper covers rock! You lose.")
elif user_action == "paper":
if computer_action == "rock":
print("Paper covers rock! You win!")
else:
print("Scissors cuts paper! You lose.")
elif user_action == "scissors":
if computer_action == "paper":
print("Scissors cuts paper! You win!")
else:
print("Rock smashes scissors! You lose.")
通过首先比较平局的情况,你排除了相当多的情况。如果您没有这样做,那么您需要检查user_action的每个可能动作,并将其与computer_action的每个可能动作进行比较。通过首先检查约束条件,你能够知道计算机选择了什么,只有两个条件检查computer_action。
就是这样!综上所述,您的代码现在应该如下所示:
import random
user_action = input("Enter a choice (rock, paper, scissors): ")
possible_actions = ["rock", "paper", "scissors"]
computer_action = random.choice(possible_actions)
print(f"\nYou chose {user_action}, computer chose {computer_action}.\n")
if user_action == computer_action:
print(f"Both players selected {user_action}. It's a tie!")
elif user_action == "rock":
if computer_action == "scissors":
print("Rock smashes scissors! You win!")
else:
print("Paper covers rock! You lose.")
elif user_action == "paper":
if computer_action == "rock":
print("Paper covers rock! You win!")
else:
print("Scissors cuts paper! You lose.")
elif user_action == "scissors":
if computer_action == "paper":
print("Scissors cuts paper! You win!")
else:
print("Rock smashes scissors! You lose.")
现在,您已经编写了代码来接受用户输入,为计算机选择一个随机动作,并决定获胜者!但这只能让你在程序结束运行前玩一个游戏。
连续玩几局
虽然石头剪子布单人游戏超级好玩,但是如果能连续玩几局不是更好吗?循环是创建重复事件的好方法。具体来说,你可以用一个 while循环来无限玩下去:
import random
while True:
user_action = input("Enter a choice (rock, paper, scissors): ")
possible_actions = ["rock", "paper", "scissors"]
computer_action = random.choice(possible_actions)
print(f"\nYou chose {user_action}, computer chose {computer_action}.\n")
if user_action == computer_action:
print(f"Both players selected {user_action}. It's a tie!")
elif user_action == "rock":
if computer_action == "scissors":
print("Rock smashes scissors! You win!")
else:
print("Paper covers rock! You lose.")
elif user_action == "paper":
if computer_action == "rock":
print("Paper covers rock! You win!")
else:
print("Scissors cuts paper! You lose.")
elif user_action == "scissors":
if computer_action == "paper":
print("Scissors cuts paper! You win!")
else:
print("Rock smashes scissors! You lose.")
play_again = input("Play again? (y/n): ") if play_again.lower() != "y": break
注意上面突出显示的行。重要的是检查用户是否想再玩一次,如果不想就break。如果没有这种检查,用户将被迫玩游戏,直到他们使用 Ctrl + C 或类似的方法终止控制台。
再次弹奏的检查是针对琴弦"y"的检查。但是检查像这样特定的东西可能会使用户更难停止游戏。如果用户输入"yes"或者"no"会怎么样?字符串比较通常很棘手,因为您永远不知道用户可能会输入什么。他们可能全部小写,全部大写,甚至两者混合。
以下是一些不同字符串比较的结果:
>>> play_again = "yes" >>> play_again == "n" False >>> play_again != "y" True嗯。这不是你想要的。如果用户进入
"yes"期望再次玩游戏却被踢出游戏,他们可能会不太高兴。用
enum.IntEnum形容一个动作因为字符串比较可能会导致如上所述的问题,所以尽可能避免它们是一个好主意。然而,程序首先要求用户输入一个字符串!用户误输入
"Rock"或"rOck"怎么办?大小写很重要,所以它们不会相等:
>>> print("rock" == "Rock")
False
因为大写很重要,"r"和"R"不相等。一个可能的解决方案是使用号来代替。给每个动作分配一个数字可以省去你一些麻烦:
ROCK_ACTION = 0
PAPER_ACTION = 1
SCISSORS_ACTION = 2
这允许您通过分配的编号引用不同的操作。整数没有字符串那样的比较问题,所以这是可行的。现在,您可以让用户输入一个数字,并直接与这些值进行比较:
user_input = input("Enter a choice (rock[0], paper[1], scissors[2]): ")
user_action = int(user_input)
if user_action == ROCK_ACTION:
# Handle ROCK_ACTION
因为input()返回一个字符串,所以需要使用int()将返回值转换为整数。然后,您可以将输入与上面的每个操作进行比较。这很好,但是它可能依赖于你正确地命名变量来跟踪它们。更好的方法是使用 enum.IntEnum 并定义自己的动作类!
使用enum.IntEnum允许你创建属性并给它们赋值,类似于上面显示的那些。这有助于通过将动作分组到它们自己的名称空间中来清理代码,并使代码更具表现力:
from enum import IntEnum
class Action(IntEnum):
Rock = 0
Paper = 1
Scissors = 2
这创建了一个定制的Action,您可以用它来引用您支持的不同类型的动作。它的工作方式是将其中的每个属性赋予您指定的值。
比较仍然很简单,现在它们有了一个有用的类名:
>>> Action.Rock == Action.Rock True因为成员值相同,所以比较是相等的。类名也使你想要比较两个动作变得更加明显。
注意:要了解关于
enum的更多信息,请查看用 Python 的枚举构建常量枚举。您甚至可以从一个
int创建一个Action:
>>> Action.Rock == Action(0)
True
>>> Action(0)
<Action.Rock: 0>
Action查看传入的值并返回适当的Action。这很有帮助,因为现在您可以接受用户输入作为一个int,并从中创建一个Action。再也不用担心拼写了!
你的程序流程图
虽然石头剪子布看起来并不复杂,但仔细考虑玩它的步骤是很重要的,这样你就可以确保你的程序涵盖了所有可能的场景。对于任何项目,即使是小项目,创建期望行为的流程图并围绕它实现代码都是有帮助的。使用项目符号列表可以获得类似的结果,但是很难捕捉到像循环和条件逻辑这样的东西。
流程图不必过于复杂,甚至不必使用真正的代码。仅仅提前描述期望的行为就可以帮助你在问题发生之前解决问题!
下面是一个流程图,描述了一个石头剪刀布的游戏:

每个玩家选择一个动作,然后决定赢家。这个流程图对于你编写的单个游戏来说是准确的,但是对于现实生活中的游戏来说不一定准确。在现实生活中,玩家同时选择他们的行动,而不是像流程图建议的那样一次选择一个。
然而,在编码版本中,这是可行的,因为玩家的选择对计算机是隐藏的,而计算机的选择对玩家也是隐藏的。两个玩家可以在不同的时间做出选择,而不会影响游戏的公平性。
流程图可以帮助您尽早发现可能的错误,还可以让您了解是否需要添加更多功能。例如,下面的流程图描述了如何反复玩游戏,直到用户决定停止为止:

不用写代码,可以看到第一个流程图没有办法再玩了。这种方法允许您在编程之前处理这些问题,这有助于您创建更整洁、更易于管理的代码!
将你的代码分成几个函数
现在,您已经使用流程图概述了程序的流程,您可以尝试组织代码,使其更接近您确定的步骤。一种自然的方法是为流程图中的每一步创建一个函数。函数是将大块代码分成更小、更易管理的小块的好方法。
您不一定需要为条件检查创建一个函数来再次播放,但是如果您愿意,您可以这样做。如果您还没有导入random并定义您的Action类,那么您可以从导入开始:
import random
from enum import IntEnum
class Action(IntEnum):
Rock = 0
Paper = 1
Scissors = 2
希望这一切看起来都很熟悉!下面是get_user_selection()的代码,它不接受任何参数,并且返回一个Action:
def get_user_selection():
user_input = input("Enter a choice (rock[0], paper[1], scissors[2]): ")
selection = int(user_input)
action = Action(selection)
return action
请注意您是如何接受用户输入作为一个int并返回一个Action。但是,对于用户来说,这个长消息有点麻烦。如果你想添加更多的动作,会发生什么?您必须在提示中添加更多的文本。
相反,你可以使用一个列表理解来生成输入的一部分:
def get_user_selection():
choices = [f"{action.name}[{action.value}]" for action in Action]
choices_str = ", ".join(choices)
selection = int(input(f"Enter a choice ({choices_str}): "))
action = Action(selection)
return action
现在,您不再需要担心将来添加或删除动作!通过测试,您可以看到代码是如何提示用户并返回与用户输入值相关联的操作的:
>>> get_user_selection() Enter a choice (rock[0], paper[1], scissors[2]): 0 <Action.Rock: 0>现在你需要一个函数来获取计算机的动作。像
get_user_selection()一样,这个函数应该不带参数并返回一个Action。因为Action的值的范围是从0到2,所以您需要在这个范围内生成一个随机数。random.randint()能帮上忙。
random.randint()返回指定最小值和最大值之间的随机值。您可以使用len()来帮助确定代码中的上限应该是什么:def get_computer_selection(): selection = random.randint(0, len(Action) - 1) action = Action(selection) return action因为
Action值从0开始计数,len()从1开始计数,所以做len(Action) - 1很重要。当你测试这个的时候,不会有提示。它将简单地返回与随机数相关联的动作:
>>> get_computer_selection()
<Action.Scissors: 2>
看起来不错!接下来,您需要一种方法来确定获胜者。这个函数有两个参数,用户的动作和计算机的动作。它不需要返回任何东西,因为它只是将结果显示到控制台:
def determine_winner(user_action, computer_action):
if user_action == computer_action:
print(f"Both players selected {user_action.name}. It's a tie!")
elif user_action == Action.Rock:
if computer_action == Action.Scissors:
print("Rock smashes scissors! You win!")
else:
print("Paper covers rock! You lose.")
elif user_action == Action.Paper:
if computer_action == Action.Rock:
print("Paper covers rock! You win!")
else:
print("Scissors cuts paper! You lose.")
elif user_action == Action.Scissors:
if computer_action == Action.Paper:
print("Scissors cuts paper! You win!")
else:
print("Rock smashes scissors! You lose.")
这与你用来决定赢家的第一次比较非常相似。现在你可以直接比较Action类型,而不用担心那些讨厌的字符串!
您甚至可以通过将不同的选项传递给determine_winner()并查看打印出的内容来测试这一点:
>>> determine_winner(Action.Rock, Action.Scissors) Rock smashes scissors! You win!因为你是从一个数字创建一个动作,如果你的用户试图从
3创建一个动作会发生什么?请记住,到目前为止您定义的最大数字是2:
>>> Action(3)
ValueError: 3 is not a valid Action
哎呦!你不想发生这种事。您可以在流程图的哪里添加一些逻辑来确保用户输入了有效的选择?
在用户做出选择后立即包含检查是有意义的:

如果用户输入了一个无效值,那么您重复该步骤以获得用户的选择。对用户选择的唯一真正要求是它在0和2之间,包括这两个值。如果用户的输入在这个范围之外,那么就会产生一个ValueError异常。为了避免向用户显示默认的错误消息,您可以处理异常。
注意:异常可能很棘手!更多信息,请查看 Python 异常:简介。
既然您已经定义了一些反映流程图中步骤的函数,那么您的游戏逻辑就更加有组织和紧凑了。这是您的while循环现在需要包含的所有内容:
while True:
try:
user_action = get_user_selection()
except ValueError as e:
range_str = f"[0, {len(Action) - 1}]"
print(f"Invalid selection. Enter a value in range {range_str}")
continue
computer_action = get_computer_selection()
determine_winner(user_action, computer_action)
play_again = input("Play again? (y/n): ")
if play_again.lower() != "y":
break
看起来是不是干净多了?请注意,如果用户未能选择有效的范围,那么您将使用continue而不是break。这使得代码继续循环的下一次迭代,而不是从循环中跳出。
石头剪刀布…蜥蜴史波克
如果你看过《生活大爆炸》,那么你可能对石头剪刀布蜥蜴史波克很熟悉。如果不是,那么这里有一个描述游戏和决定赢家的规则的图表:
*
你可以使用上面学到的工具来实现这个游戏。例如,您可以添加到Action并为 lizard 和 Spock 创建值。然后你只需要修改get_user_selection()和get_computer_selection()来合并这些选项。然而,更新determine_winner()将会有更多的工作。
您可以使用字典来帮助显示动作之间的关系,而不是在代码中添加大量的if … elif … else语句。字典是展示键值关系的好方法。在这种情况下,键可以是一个动作,比如剪刀,值可以是它敲打的动作列表。
那么,对于只有三个选项的你来说,这会是什么样子呢?嗯,每个Action只能击败一个其他的Action,所以列表将只包含一个项目。下面是您的代码之前的样子:
def determine_winner(user_action, computer_action):
if user_action == computer_action:
print(f"Both players selected {user_action.name}. It's a tie!")
elif user_action == Action.Rock:
if computer_action == Action.Scissors:
print("Rock smashes scissors! You win!")
else:
print("Paper covers rock! You lose.")
elif user_action == Action.Paper:
if computer_action == Action.Rock:
print("Paper covers rock! You win!")
else:
print("Scissors cuts paper! You lose.")
elif user_action == Action.Scissors:
if computer_action == Action.Paper:
print("Scissors cuts paper! You win!")
else:
print("Rock smashes scissors! You lose.")
现在,不需要与每个Action进行比较,您可以有一个描述胜利条件的字典:
def determine_winner(user_action, computer_action):
victories = {
Action.Rock: [Action.Scissors], # Rock beats scissors
Action.Paper: [Action.Rock], # Paper beats rock
Action.Scissors: [Action.Paper] # Scissors beats paper
}
defeats = victories[user_action]
if user_action == computer_action:
print(f"Both players selected {user_action.name}. It's a tie!")
elif computer_action in defeats:
print(f"{user_action.name} beats {computer_action.name}! You win!")
else:
print(f"{computer_action.name} beats {user_action.name}! You lose.")
你还是和以前一样,先检查一下领带状况。但是你不是比较每一个Action,而是比较user_input击败computer_action的动作。因为键-值对是一个列表,所以可以使用成员操作符 in来检查其中是否有元素。
因为您不再使用长的if … elif … else语句,所以为这些新动作添加检查相对来说比较容易。你可以从给Action添加蜥蜴和斯波克开始:
class Action(IntEnum):
Rock = 0
Paper = 1
Scissors = 2
Lizard = 3
Spock = 4
接下来,添加图表中的所有胜利关系。确保在Action下面这样做,以便victories能够引用Action中的所有内容:
victories = {
Action.Scissors: [Action.Lizard, Action.Paper],
Action.Paper: [Action.Spock, Action.Rock],
Action.Rock: [Action.Lizard, Action.Scissors],
Action.Lizard: [Action.Spock, Action.Paper],
Action.Spock: [Action.Scissors, Action.Rock]
}
注意现在每个Action都有一个包含两个元素的列表。在基本的石头剪刀布实现中,只有一个元素。
因为您有意编写了get_user_selection()来适应新的动作,所以您不必对代码做任何修改。get_computer_selection()也是如此。由于Action的长度改变了,随机数的范围也会改变。
看看现在的代码有多短,多容易管理!要查看完整程序的完整代码,请展开下面的框。
import random
from enum import IntEnum
class Action(IntEnum):
Rock = 0
Paper = 1
Scissors = 2
Lizard = 3
Spock = 4
victories = {
Action.Scissors: [Action.Lizard, Action.Paper],
Action.Paper: [Action.Spock, Action.Rock],
Action.Rock: [Action.Lizard, Action.Scissors],
Action.Lizard: [Action.Spock, Action.Paper],
Action.Spock: [Action.Scissors, Action.Rock]
}
def get_user_selection():
choices = [f"{action.name}[{action.value}]" for action in Action]
choices_str = ", ".join(choices)
selection = int(input(f"Enter a choice ({choices_str}): "))
action = Action(selection)
return action
def get_computer_selection():
selection = random.randint(0, len(Action) - 1)
action = Action(selection)
return action
def determine_winner(user_action, computer_action):
defeats = victories[user_action]
if user_action == computer_action:
print(f"Both players selected {user_action.name}. It's a tie!")
elif computer_action in defeats:
print(f"{user_action.name} beats {computer_action.name}! You win!")
else:
print(f"{computer_action.name} beats {user_action.name}! You lose.")
while True:
try:
user_action = get_user_selection()
except ValueError as e:
range_str = f"[0, {len(Action) - 1}]"
print(f"Invalid selection. Enter a value in range {range_str}")
continue
computer_action = get_computer_selection()
determine_winner(user_action, computer_action)
play_again = input("Play again? (y/n): ")
if play_again.lower() != "y":
break
就是这样!你已经用 Python 代码实现了石头剪刀布蜥蜴史波克。仔细检查,确保你没有错过任何东西,并给它一个机会。
结论
恭喜你!你刚刚完成了你的第一个 Python 游戏!您现在知道如何从头开始创建石头剪刀布,并且能够以最小的努力在游戏中扩展可能的动作数量。
在本教程中,您学习了如何:
- 编写你自己的石头剪刀布游戏
- 取用用户输入的
input() - 使用
while循环连续玩几个游戏 - 用
Enum和函数清理你的代码 - 用字典描述更复杂的规则
这些工具将继续在您的许多编程冒险中帮助您。如果你有任何问题,请在下面的评论区联系我们。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 石头剪子布用 Python:一个命令行游戏******
如何在 Python 中舍入数字
现在是大数据时代,每天都有越来越多的企业试图利用他们的数据做出明智的决策。许多企业正在转向 Python 强大的数据科学生态系统来分析他们的数据,正如 Python 在数据科学领域日益流行所证明的那样。
每个数据科学从业者必须牢记的一件事是数据集可能会有偏差。从有偏见的数据中得出结论会导致代价高昂的错误。
偏见可以通过多种方式渗入数据集。如果你学过一些统计学,你可能对报告偏差、选择偏差和抽样偏差等术语很熟悉。当您处理数字数据时,还有另一种类型的偏差起着重要作用:舍入偏差。
在本文中,您将了解到:
- 为什么四舍五入的方法很重要
- 如何根据各种舍入策略对一个数进行舍入,如何用纯 Python 实现每种方法
- 舍入如何影响数据,以及哪种舍入策略可以最小化这种影响
- 如何对 NumPy 数组和 Pandas 数据帧中的数字进行舍入
- 何时应用不同的舍入策略
参加测验:通过我们的交互式“Python 中的舍入数字”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
这篇文章不是关于计算中的数值精度的论文,尽管我们会简单地触及这个主题。只需要熟悉 Python 的基础,这里涉及的数学应该让任何熟悉高中代数的人感到舒服。
我们先来看看 Python 内置的舍入机制。
Python 内置的round()函数
Python 有一个内置的round()函数,它接受两个数字参数n和ndigits,并返回四舍五入为ndigits的数字 n。ndigits参数缺省为零,因此省略它会得到一个舍入到整数的数字。正如您将看到的,round()可能不会像您预期的那样工作。
大多数人被教导的四舍五入方法是这样的:
通过将
n乘以 10ᵖ (10 的 T5 次幂)将n中的小数点移动p位,将n四舍五入到p位,得到新的数字m。然后看
m第一位小数的数字d。如果d小于 5,则将m向下舍入到最接近的整数。否则,圆m了。最后,通过将
m除以 10ᵖ.,将小数点向后移p位
这是一个简单的算法!例如,舍入到最接近的整数的数字2.5是3。四舍五入到小数点后一位的数字1.64为1.6。
现在打开一个解释器会话,并使用 Python 内置的 round() 函数将2.5舍入到最接近的整数:
>>> round(2.5) 2喘息!
round()如何处理数字1.5?
>>> round(1.5)
2
所以,round()将1.5向上舍入到2,将2.5向下舍入到2!
在你提出 Python bug tracker 的问题之前,让我向你保证round(2.5)应该返回2。round()如此行事是有充分理由的。
在本文中,您将了解到有比您想象的更多的舍入方法,每种方法都有独特的优点和缺点。根据特定的舍入策略行事——这可能是也可能不是你在特定情况下需要的策略。
你可能会想,“我舍入数字的方式真的有那么大的影响吗?”让我们来看看舍入的影响到底有多极端。
四舍五入能有多大影响?
假设你有一天非常幸运,在地上发现了 100 美元。你没有一次花光所有的钱,而是决定明智地把钱投资到不同的股票上。
股票的价值取决于供给和需求。想买一只股票的人越多,这只股票的价值就越大,反之亦然。在高交易量的股票市场中,特定股票的价值会在一秒一秒的基础上波动。
让我们做一个小实验。我们假设你所购买的股票的总价值每秒钟都会有一个小的随机数字波动,比如在 0.05 美元到-0.05 美元之间。这种波动不一定是只有两位小数的好值。例如,总价值可能一秒钟增加 0.031286 美元,下一秒钟减少 0.028476 美元。
您不想跟踪您的值到第五或第六位小数,所以您决定将第三位小数之后的所有内容都去掉。在舍入行话中,这被称为将数字截断到第三个小数位。这里可能会有一些误差,但是保留三个小数位,这个误差不会很大。对吗?
为了使用 Python 运行我们的实验,让我们从编写一个将数字截断到三位小数的truncate()函数开始:
>>> def truncate(n): ... return int(n * 1000) / 1000通过将
n乘以1000,首先将数字n中的小数点向右移动三位,从而实现truncate()功能。这个新数字的整数部分用int()取。最后,通过用n除以1000将小数点左移三位。接下来,让我们定义模拟的初始参数。你需要两个变量:一个在模拟完成后跟踪你股票的实际价值,另一个在你每一步都截断到三位小数后跟踪你股票的价值。
首先将这些变量初始化为
100:
>>> actual_value, truncated_value = 100, 100
现在让我们运行 1,000,000 秒的模拟(大约 11.5 天)。对于每一秒,用random模块中的uniform()函数产生一个在-0.05和0.05之间的随机值,然后更新actual和truncated:
>>> import random >>> random.seed(100) >>> for _ in range(1000000): ... randn = random.uniform(-0.05, 0.05) ... actual_value = actual_value + randn ... truncated_value = truncate(truncated_value + randn) ... >>> actual_value 96.45273913513529 >>> truncated_value 0.239模拟的实质发生在
for循环中,该循环遍历0和999,999之间的range(1000000)个数字。每步从range()获取的值存储在变量_中,我们在这里使用它是因为我们在循环中实际上不需要这个值。在循环的每一步,使用
random.randn()生成一个介于-0.05和0.05之间的新随机数,并将其分配给变量randn。通过将randn加到actual_value来计算您投资的新价值,通过将randn加到truncated_value然后用truncate()截断该价值来计算截断的总额。通过在运行循环后检查
actual_value变量可以看到,您只损失了大约 3.55 美元。然而,如果你一直在看truncated_value,你会认为你已经失去了几乎所有的钱!注意:在上面的例子中,
random.seed()函数用于播种伪随机数生成器,这样您就可以重现这里显示的输出。要了解 Python 中随机性的更多信息,请查看 Real Python 的在 Python 中生成随机数据(指南)。
暂时忽略
round()的行为不完全符合您的预期,让我们尝试重新运行模拟。这次我们将使用round()在每一步舍入到三个小数位,并再次使用seed()模拟来获得与之前相同的结果:
>>> random.seed(100)
>>> actual_value, rounded_value = 100, 100
>>> for _ in range(1000000):
... randn = random.uniform(-0.05, 0.05)
... actual_value = actual_value + randn
... rounded_value = round(rounded_value + randn, 3)
...
>>> actual_value
96.45273913513529
>>> rounded_value
96.258
差别真大!
虽然看起来令人震惊,但这个精确的错误在 20 世纪 80 年代初引起了不小的轰动,当时为记录温哥华证券交易所的价值而设计的系统将整体指数值截断到小数点后三位,而不是四舍五入。舍入误差影响了的选举,甚至导致了的死亡。
如何舍入数字很重要,作为一个负责任的开发人员和软件设计人员,您需要知道常见的问题是什么以及如何处理它们。让我们深入研究不同的舍入方法是什么,以及如何在纯 Python 中实现每种方法。
一群方法
有太多的舍入策略,每一种都有优点和缺点。在本节中,您将了解一些最常见的技术,以及它们如何影响您的数据。
截断
最简单但也是最粗糙的舍入方法是将数字截断成给定的位数。截断一个数字时,用 0 替换给定位置后的每个数字。以下是一些例子:
| 价值 | 截断到 | 结果 |
|---|---|---|
| Twelve point three four five | 十位 | Ten |
| Twelve point three four five | 某人的位置 | Twelve |
| Twelve point three four five | 十分之一位置 | Twelve point three |
| Twelve point three four five | 百分之一位置 | Twelve point three four |
您已经看到了在的truncate()函数中实现这一点的一种方法,舍入能产生多大的影响?一节。在该函数中,输入的数字被截断为三个小数位:
- 将数字乘以
1000将小数点向右移动三位 - 用
int()取新数字的整数部分 - 通过除以
1000将小数位左移三位
您可以通过用数字 10ᵖ ( 10的 p 次方)替换1000来概括这一过程,其中 p 是要截断的小数位数:
def truncate(n, decimals=0):
multiplier = 10 ** decimals
return int(n * multiplier) / multiplier
在这个版本的truncate()中,第二个参数默认为0,因此如果没有第二个参数传递给函数,那么truncate()将返回传递给它的任何数字的整数部分。
truncate()函数适用于正数和负数:
>>> truncate(12.5) 12.0 >>> truncate(-5.963, 1) -5.9 >>> truncate(1.625, 2) 1.62您甚至可以向
decimals传递一个负数来截断小数点左边的数字:
>>> truncate(125.6, -1)
120.0
>>> truncate(-1374.25, -3)
-1000.0
当你截断一个正数时,你是在向下舍入。同样,截断负数会将该数字向上舍入。从某种意义上来说,截断是根据要舍入的数字的符号对舍入方法的组合。
让我们从向上舍入开始,分别看一下这些舍入方法。
四舍五入
我们要看的第二个舍入策略叫做“舍入”这种策略总是将一个数向上舍入到指定的位数。下表总结了这一策略:
| 价值 | 要凑够 | 结果 |
|---|---|---|
| Twelve point three four five | 十位 | Twenty |
| Twelve point three four five | 某人的位置 | Thirteen |
| Twelve point three four five | 十分之一位置 | Twelve point four |
| Twelve point three four five | 百分之一位置 | Twelve point three five |
为了在 Python 中实现“舍入”策略,我们将使用 math模块中的 ceil() 函数。
ceil()函数的名字来源于术语“ceiling”,它在数学中用于描述大于或等于给定数字的最接近的整数。
每个不是整数的数字都位于两个连续的整数之间。例如,数字1.2位于1和2之间的区间。“上限”是区间的两个端点中较大的一个。两个端点中较小的一个称为“地板”这样,1.2的天花板就是2,而1.2的地板就是1。
在数学中,一个叫做上限函数的特殊函数将每个数字映射到它的上限。为了允许 ceiling 函数接受整数,整数的上限被定义为整数本身。所以数字2的上限是2。
在 Python 中,math.ceil()实现了 ceiling 函数,并且总是返回大于或等于其输入的最接近的整数:
>>> import math >>> math.ceil(1.2) 2 >>> math.ceil(2) 2 >>> math.ceil(-0.5) 0注意
-0.5的天花板是0,不是-1。这是有意义的,因为0是大于或等于-0.5的最接近-0.5的整数。让我们编写一个名为
round_up()的函数来实现“舍入”策略:def round_up(n, decimals=0): multiplier = 10 ** decimals return math.ceil(n * multiplier) / multiplier你可能会注意到
round_up()看起来很像truncate()。首先,通过将n乘以10 ** decimals,将n中的小数点向右移动正确的位数。使用math.ceil()将该新值向上舍入到最接近的整数,然后通过除以10 ** decimals将小数点移回左侧。随着我们研究更多的舍入方法,这种移动小数点,应用某种舍入方法舍入到整数,然后将小数点移回的模式将会反复出现。毕竟,这是我们人类用来手工舍入数字的心算算法。
让我们来看看
round_up()对于不同的输入效果如何:
>>> round_up(1.1)
2.0
>>> round_up(1.23, 1)
1.3
>>> round_up(1.543, 2)
1.55
就像truncate()一样,可以传递一个负值给decimals:
>>> round_up(22.45, -1) 30.0 >>> round_up(1352, -2) 1400当您将一个负数传递给
decimals时,round_up()的第一个参数中的数字被舍入到小数点左边的正确位数。猜猜
round_up(-1.5)会返回什么:
>>> round_up(-1.5)
-1.0
是你所期待的吗?
如果您检查定义round_up()时使用的逻辑,特别是math.ceil()函数的工作方式,那么round_up(-1.5)返回-1.0是有意义的。然而,有些人自然希望在舍入数字时围绕零对称,因此如果1.5被舍入到2,那么-1.5应该被舍入到-2。
让我们建立一些术语。出于我们的目的,我们将根据下图使用术语“向上取整”和“向下取整”:

向上舍入总是将数字在数字行上向右舍入,向下舍入总是将数字在数字行上向左舍入。
向下舍入
与“向上舍入”相对应的是“向下舍入”策略,它总是将一个数字向下舍入到指定的位数。以下是说明这种策略的一些例子:
| 价值 | 向下舍入到 | 结果 |
|---|---|---|
| Twelve point three four five | 十位 | Ten |
| Twelve point three four five | 某人的位置 | Twelve |
| Twelve point three four five | 十分之一位置 | Twelve point three |
| Twelve point three four five | 百分之一位置 | Twelve point three four |
为了在 Python 中实现“向下舍入”策略,我们可以遵循用于trunctate()和round_up()的相同算法。先移小数点,然后四舍五入到整数,最后再把小数点移回来。
在round_up()中,我们用math.ceil()在移动小数点后向上舍入到数字的上限。但是,对于“向下舍入”策略,我们需要在移动小数点后舍入到数字的下限。
幸运的是, math 模块有一个 floor() 函数,返回其输入的楼层:
>>> math.floor(1.2) 1 >>> math.floor(-0.5) -1下面是
round_down()的定义:def round_down(n, decimals=0): multiplier = 10 ** decimals return math.floor(n * multiplier) / multiplier那看起来就像
round_up(),除了math.ceil()被替换成了math.floor()。您可以在几个不同的值上测试
round_down():
>>> round_down(1.5)
1
>>> round_down(1.37, 1)
1.3
>>> round_down(-0.5)
-1
round_up()和round_down()的影响可能相当极端。通过向上或向下舍入大型数据集中的数字,您可能会降低大量精度,并极大地改变根据数据进行的计算。
在我们讨论任何更多的舍入策略之前,让我们停下来花点时间来讨论舍入如何使您的数据有偏差。
插曲:舍入偏差
您现在已经看到了三种舍入方法:truncate()、round_up()和round_down()。当涉及到为给定的数字保持合理的精度时,这三种技术都相当粗糙。
truncate()和round_up()以及round_down()之间有一个重要的区别,这突出了舍入的一个重要方面:关于零的对称性。
回想一下round_up()并不是围绕零对称的。用数学术语来说,如果对于 x 的任意值,f(x) + f(-x) = 0,则函数 f(x)关于零是对称的。比如round_up(1.5)返回2,但是round_up(-1.5)返回-1。round_down()函数也不是关于 0 对称的。
另一方面,truncate()函数是围绕零对称的。这是因为,将小数点右移后,truncate()会砍掉剩余的数字。当初始值为正时,这相当于将数字向下舍入。负数向上取整。于是,truncate(1.5)返回1,truncate(-1.5)返回-1。
对称性的概念引入了舍入偏差的概念,它描述了舍入如何影响数据集中的数字数据。
“向上舍入”策略有一个朝向正无穷大偏差的舍入,因为值总是在正无穷大的方向上向上舍入。同样,“向下舍入”策略有一个朝向负无穷大偏差的舍入。
“截断”策略表现为正值偏向负无穷大,负值偏向正无穷大。一般来说,具有这种行为的舍入函数被称为具有朝向零偏差的舍入。
让我们看看这在实践中是如何工作的。考虑下面的浮动列表:
>>> data = [1.25, -2.67, 0.43, -1.79, 4.32, -8.19]让我们使用
statistics.mean()函数计算data中值的平均值:
>>> import statistics
>>> statistics.mean(data)
-1.1083333333333332
现在应用列表理解中的round_up()、round_down()和truncate()中的每一个,将data中的每一个数字四舍五入到小数点后一位,并计算新的平均值:
>>> ru_data = [round_up(n, 1) for n in data] >>> ru_data [1.3, -2.6, 0.5, -1.7, 4.4, -8.1] >>> statistics.mean(ru_data) -1.0333333333333332 >>> rd_data = [round_down(n, 1) for n in data] >>> statistics.mean(rd_data) -1.1333333333333333 >>> tr_data = [truncate(n, 1) for n in data] >>> statistics.mean(tr_data) -1.0833333333333333
data中的每一个数字四舍五入后,新的平均值约为-1.033,大于实际平均值约为1.108。向下舍入将平均值向下移动到大约-1.133。截断值的平均值约为-1.08,最接近实际平均值。这个例子并不意味着当你需要在尽可能保持平均值的同时舍入单个值时,你应该总是截断。
data列表包含相同数量的正值和负值。truncate()函数的行为就像所有正值列表中的round_up(),以及所有负值列表中的round_down()。这个例子说明了舍入偏差对从已舍入的数据中计算出的值的影响。当从四舍五入的数据中得出结论时,你需要记住这些影响。
通常,在舍入时,您感兴趣的是以某个指定的精度舍入到最接近的数字,而不仅仅是向上或向下舍入。
例如,如果有人让你将数字
1.23和1.28四舍五入到小数点后一位,你可能会迅速用1.2和1.3来回答。truncate()、round_up()和round_down()功能不做这样的事情。数字
1.25呢?你可能会立即想到将这个四舍五入到1.3,但实际上,1.25与1.2和1.3是等距的。从某种意义上说,1.2和1.3都是最接近1.25的数字,具有单个小数位的精度。数字1.25被称为相对于1.2和1.3的结。在这种情况下,你必须分配一个加时赛。大多数人被教导打破平局的方法是四舍五入到两个可能数字中较大的一个。
四舍五入
“向上舍入一半”策略以指定的精度将每个数字舍入到最接近的数字,并通过向上舍入来打破平局。以下是一些例子:
价值 将一半向上舍入到 结果 Thirteen point eight two five 十位 Ten Thirteen point eight two five 某人的位置 Fourteen Thirteen point eight two five 十分之一位置 Thirteen point eight Thirteen point eight two five 百分之一位置 Thirteen point eight three 要在 Python 中实现“四舍五入”策略,首先要像往常一样将小数点向右移动所需的位数。不过,在这一点上,您需要一种方法来确定小数点后的数字是小于还是大于或等于
5。一种方法是将
0.5加到移位后的值上,然后用math.floor()向下舍入。这是因为:
如果移位值的第一个小数位小于 5,那么加上
0.5不会改变移位值的整数部分,所以底数等于整数部分。如果小数点后第一位大于或等于
5,那么加上0.5将使移位值的整数部分增加1,所以下限等于这个更大的整数。这是 Python 中的样子:
def round_half_up(n, decimals=0): multiplier = 10 ** decimals return math.floor(n*multiplier + 0.5) / multiplier注意
round_half_up()看起来很像round_down()。这可能有点违背直觉,但在内部round_half_up()只向下舍入。诀窍是在移动小数点后加上0.5,这样向下舍入的结果就与预期值相匹配。让我们在几个值上测试
round_half_up(),看看它是否有效:
>>> round_half_up(1.23, 1)
1.2
>>> round_half_up(1.28, 1)
1.3
>>> round_half_up(1.25, 1)
1.3
因为round_half_up()总是通过舍入到两个可能值中的较大值来打破平局,所以负值如-1.5舍入到-1,而不是-2:
>>> round_half_up(-1.5) -1.0 >>> round_half_up(-1.25, 1) -1.2太好了!现在您终于可以得到内置
round()函数拒绝给您的结果了:
>>> round_half_up(2.5)
3.0
不过,在你兴奋之前,让我们看看当你尝试将-1.225四舍五入到2位小数时会发生什么:
>>> round_half_up(-1.225, 2) -1.23等等。我们刚刚讨论了领带如何四舍五入到两个可能值中的较大值。
-1.225正好在-1.22和-1.23的中间。由于-1.22是这两个中较大的一个,round_half_up(-1.225, 2)应该返回-1.22。但是相反,我们得到了-1.23。
round_half_up()函数有 bug 吗?当
round_half_up()将-1.225四舍五入到小数点后两位时,它做的第一件事就是将-1.225乘以100。让我们确保这按预期工作:
>>> -1.225 * 100
-122.50000000000001
嗯…那不对!但它确实解释了为什么round_half_up(-1.225, 2)返回-1.23。让我们一步一步地继续round_half_up()算法,利用 REPL 中的_来回忆每一步最后输出的值:
>>> _ + 0.5 -122.00000000000001 >>> math.floor(_) -123 >>> _ / 100 -1.23即使
-122.00000000000001真的很接近-122,但小于或等于它的最近的整数是-123。当小数点向左回移时,最终值为-1.23。好了,现在你知道了
round_half_up(-1.225, 2)即使没有逻辑错误也是如何返回-1.23的,但是为什么 Python 会说-1.225 * 100是-122.50000000000001?Python 有 bug 吗?旁白:在 Python 解释器会话中,键入以下内容:
>>> 0.1 + 0.1 + 0.1
0.30000000000000004
第一次看到这个可能会很震惊,但这是一个典型的浮点表示错误的例子。与 Python 无关。这个错误与机器在内存中存储浮点数的方式有关。
大多数现代计算机将浮点数存储为二进制小数,精度为 53 位。只有可以用 53 位表示的有限二进制/十进制数才存储为精确值。不是每个数字都有有限的二进制十进制表示。
比如十进制数0.1有一个有限的十进制表示,但是无限的二进制表示。就像分数 1/3 只能用十进制表示为无限重复的十进制0.333...,分数1/10只能用二进制表示为无限重复的十进制0.0001100110011...。
具有无限二进制表示形式的值被舍入为近似值以存储在内存中。大多数机器用于舍入的方法是根据 IEEE-754 标准确定的,该标准规定舍入到最接近的可表示的二进制分数。
Python 文档中有一个名为浮点运算:问题和限制的部分,其中提到了数字 0.1:
在大多数机器上,如果 Python 要打印为
0.1存储的二进制近似值的真实十进制值,它必须显示`>>> 0.1 0.1000000000000000055511151231257827021181583404541015625`这比大多数人认为有用的数字要多,所以 Python 通过显示一个舍入值来保持数字的可管理性
`>>> 1 / 10 0.1`请记住,即使打印的结果看起来像
1/10的精确值,实际存储的值是最接近的可表示的二进制分数。(来源)
有关浮点运算的更深入的论文,请查阅 David Goldberg 的文章每个计算机科学家都应该知道的浮点运算知识,该文章最初发表在 1991 年 3 月的期刊 ACM 计算调查第 23 卷第 1 期。
Python 说-1.225 * 100是-122.50000000000001的事实是浮点表示错误的假象。你可能会问自己,“好吧,但是有办法解决这个问题吗?”问自己一个更好的问题是“我需要来解决这个问题吗?”
浮点数没有精确的精度,因此不应该在精度至关重要的情况下使用。对于需要精确精度的应用程序,可以使用 Python 的decimal模块中的Decimal类。你将在下面了解更多关于Decimal类的内容。
如果您已经确定 Python 的标准float类对于您的应用程序来说已经足够了,那么由于浮点表示错误而导致的round_half_up()中的一些偶然错误不应该成为问题。
现在您已经了解了机器如何在内存中舍入数字,让我们通过查看另一种打破平局的方法来继续讨论舍入策略。
向下舍入一半
“向下舍入一半”策略以期望的精度舍入到最接近的数字,就像“向上舍入一半”方法一样,只是它通过舍入到两个数字中较小的一个来打破平局。以下是一些例子:
| 价值 | 向下舍入一半到 | 结果 |
|---|---|---|
| Thirteen point eight two five | 十位 | Ten |
| Thirteen point eight two five | 某人的位置 | Fourteen |
| Thirteen point eight two five | 十分之一位置 | Thirteen point eight |
| Thirteen point eight two five | 百分之一位置 | Thirteen point eight two |
通过用math.ceil()替换round_half_up()函数中的math.floor(),并减去0.5而不是相加,可以在 Python 中实现“四舍五入”策略:
def round_half_down(n, decimals=0):
multiplier = 10 ** decimals
return math.ceil(n*multiplier - 0.5) / multiplier
让我们对照几个测试用例来检查round_half_down():
>>> round_half_down(1.5) 1.0 >>> round_half_down(-1.5) -2.0 >>> round_half_down(2.25, 1) 2.2
round_half_up()和round_half_down()一般都没有偏差。然而,用很多关系来舍入数据确实会引入偏差。举个极端的例子,考虑下面的数字列表:*>>>
>>> data = [-2.15, 1.45, 4.35, -12.75]让我们计算这些数字的平均值:
>>> statistics.mean(data)
-2.275
接下来,用round_half_up()和round_half_down()计算四舍五入到小数点后一位的数据的平均值:
>>> rhu_data = [round_half_up(n, 1) for n in data] >>> statistics.mean(rhu_data) -2.2249999999999996 >>> rhd_data = [round_half_down(n, 1) for n in data] >>> statistics.mean(rhd_data) -2.325
data中的每个数字都四舍五入到小数点后一位。round_half_up()函数引入一个朝向正无穷大的舍入偏差,round_half_down()引入一个朝向负无穷大的舍入偏差。我们将讨论的其余舍入策略都试图以不同的方式减轻这些偏差。
从零开始四舍五入一半
如果你仔细检查
round_half_up()和round_half_down(),你会注意到这两个函数都不是关于零对称的:
>>> round_half_up(1.5)
2.0
>>> round_half_up(-1.5)
-1.0
>>> round_half_down(1.5)
1.0
>>> round_half_down(-1.5)
-2.0
引入对称性的一种方法是总是将领带从零开始四舍五入。下表说明了这是如何工作的:
| 价值 | 从零开始四舍五入一半到 | 结果 |
|---|---|---|
| Fifteen point two five | 十位 | Twenty |
| Fifteen point two five | 某人的位置 | Fifteen |
| Fifteen point two five | 十分之一位置 | Fifteen point three |
| -15.25 | 十位 | -20 |
| -15.25 | 某人的位置 | -15 |
| -15.25 | 十分之一位置 | -15.3 |
要对一个数字n执行“四舍五入”策略,您可以像往常一样将小数点向右移动给定的位数。然后你会看到这个新数字的小数点右边的数字d。此时,有四种情况需要考虑:
- 如果
n为正而d >= 5为负,则向上取整 - 如果
n为正而d < 5为负,则向下舍入 - 如果
n为负,而d >= 5为负,则向下舍入 - 如果
n为负而d < 5为正,则向上取整
在根据上述四个规则之一进行舍入后,您可以将小数位移回左侧。
给定一个数字n和一个值decimals,您可以通过使用round_half_up()和round_half_down()在 Python 中实现它:
if n >= 0:
rounded = round_half_up(n, decimals)
else:
rounded = round_half_down(n, decimals)
这很简单,但实际上还有更简单的方法!
如果先用 Python 内置的 abs() 函数取n的绝对值,用round_half_up()取整数即可。然后你需要做的就是给四舍五入后的数字和n一样的符号。一种方法是使用 math.copysign() 功能。
math.copysign()取两个数a和b,返回带有b符号的a:
>>> math.copysign(1, -2) -1.0注意,
math.copysign()返回一个float,即使它的两个参数都是整数。使用
abs()、round_half_up()和math.copysign(),你可以在仅仅两行 Python 代码中实现“从零四舍五入一半”的策略:def round_half_away_from_zero(n, decimals=0): rounded_abs = round_half_up(abs(n), decimals) return math.copysign(rounded_abs, n)在
round_half_away_from_zero()中,使用round_half_up()将n的绝对值四舍五入到decimals小数位,并将该结果赋给变量rounded_abs。然后使用math.copysign()将n的原始符号应用于rounded_abs,该函数返回具有正确符号的最终值。在几个不同的值上检查
round_half_away_from_zero(),显示该函数的行为符合预期:
>>> round_half_away_from_zero(1.5)
2.0
>>> round_half_away_from_zero(-1.5)
-2.0
>>> round_half_away_from_zero(-12.75, 1)
-12.8
round_half_away_from_zero()函数对数字进行舍入,就像大多数人在日常生活中对数字进行舍入一样。除了是迄今为止最熟悉的舍入函数之外,round_half_away_from_zero()还在正负关系数量相等的数据集中很好地消除了舍入偏差。
让我们检查一下round_half_away_from_zero()在上一节的示例中如何减轻舍入偏差:
>>> data = [-2.15, 1.45, 4.35, -12.75] >>> statistics.mean(data) -2.275 >>> rhaz_data = [round_half_away_from_zero(n, 1) for n in data] >>> statistics.mean(rhaz_data) -2.2750000000000004当您用
round_half_away_from_zero()将data中的每个数字四舍五入到小数点后一位时,data中数字的平均值几乎完全保留!然而,当您对数据集中的每个数字进行舍入时,
round_half_away_from_zero()将会表现出舍入偏差,这些数据仅具有正关系、负关系或者一个符号的关系多于另一个符号的关系。只有当数据集中有相似数量的正负联系时,偏差才能得到很好的缓解。你如何处理积极和消极联系的数量相差很大的情况?这个问题的答案让我们兜了一圈回到了本文开头那个欺骗我们的函数:Python 内置的
round()函数。四舍五入成偶数
在对数据集中的值进行舍入时,减轻舍入偏差的一种方法是以所需的精度将关系舍入到最接近的偶数。以下是如何做到这一点的一些例子:
价值 四舍五入到偶数 结果 Fifteen point two five five 十位 Twenty Fifteen point two five five 某人的位置 Fifteen Fifteen point two five five 十分之一位置 Fifteen point three Fifteen point two five five 百分之一位置 Fifteen point two six “四舍五入策略”是 Python 内置的
round()函数使用的策略,也是 IEEE-754 标准中的默认四舍五入规则。此策略在假设数据集中向下舍入或向上舍入的概率相等的情况下有效。在实践中,通常是这样。现在你知道为什么
round(2.5)返回2了。这不是一个错误。这是基于可靠建议的有意识的设计决策。为了向自己证明
round()确实能舍入到偶数,请尝试几个不同的值:
>>> round(4.5)
4
>>> round(3.5)
4
>>> round(1.75, 1)
1.8
>>> round(1.65, 1)
1.6
round()函数几乎没有偏差,但它并不完美。例如,如果数据集中的大部分连接向上舍入到偶数而不是向下舍入,仍会引入舍入偏差。减轻偏差的策略甚至比“四舍五入”更好确实存在,但它们有些晦涩,只有在极端情况下才有必要。
最后,由于浮点表示错误,round()遇到了与您在round_half_up()中看到的相同的问题:
>>> # Expected value: 2.68 >>> round(2.675, 2) 2.67如果浮点精度对您的应用程序来说足够了,您就不应该担心这些偶然的错误。
当精度是至高无上时,你应该使用 Python 的
Decimal类。
Decimal类Python 的十进制模块是这种语言的“内置电池”特性之一,如果你是 Python 新手,你可能不会意识到。
decimal模块的指导原则可在文档中找到:“Decimal”基于一种浮点模型,这种模型是以人为本设计的,并且必然有一个最高的指导原则——计算机必须提供一种与人们在学校学习的算法相同的算法。–摘自十进制算术规范。(来源)
decimal模块的优势包括:
- 精确的十进制表示 :
0.1实际上是0.1,0.1 + 0.1 + 0.1 - 0.3返回0,如你所料。
** 保留有效数字:将1.20和2.50相加,结果为3.70,保留尾随零表示有效。* 用户可更改的精度:decimal模块的默认精度是 28 位,但是用户可以根据手头的问题更改该值。让我们探索一下在
decimal模块中舍入是如何工作的。首先在 Python REPL 中输入以下内容:
>>> import decimal
>>> decimal.getcontext()
Context(
prec=28,
rounding=ROUND_HALF_EVEN,
Emin=-999999,
Emax=999999,
capitals=1,
clamp=0,
flags=[],
traps=[
InvalidOperation,
DivisionByZero,
Overflow
]
)
decimal.getcontext()返回一个代表decimal模块默认上下文的Context对象。上下文包括默认精度和默认舍入策略等。
正如你在上面的例子中看到的,decimal模块的默认舍入策略是ROUND_HALF_EVEN。这与内置的round()函数一致,应该是大多数用途的首选舍入策略。
让我们使用decimal模块的Decimal类来声明一个数字。为此,通过传递包含所需值的string来创建一个新的Decimal实例:
>>> from decimal import Decimal >>> Decimal("0.1") Decimal('0.1')注意:可以从浮点数创建一个
Decimal实例,但是这样做会立刻引入浮点表示错误。例如,看看当您从浮点数0.1创建一个Decimal实例时会发生什么:
>>> Decimal(0.1)
Decimal('0.1000000000000000055511151231257827021181583404541015625')
为了保持精确的精度,您必须从包含您需要的十进制数的字符串中创建Decimal实例。
只是为了好玩,让我们测试一下断言Decimal保持精确的十进制表示:
>>> Decimal('0.1') + Decimal('0.1') + Decimal('0.1') Decimal('0.3')啊啊。那是令人满意的,不是吗?
用
.quantize()方法对Decimal进行舍入:
>>> Decimal("1.65").quantize(Decimal("1.0"))
Decimal('1.6')
好吧,这可能看起来有点古怪,让我们来分析一下。.quantize()中的Decimal("1.0")参数决定了舍入数字的小数位数。因为1.0有一个小数位,所以数字1.65四舍五入到一个小数位。默认的舍入策略是“将一半舍入到一半”,所以结果是1.6。
回想一下round()函数,它也使用了“四舍五入策略”,未能正确地将2.675四舍五入到两位小数。round(2.675, 2)返回的不是2.68,而是2.67。得益于decimal模块的精确十进制表示,您将不会遇到Decimal类的这个问题:
>>> Decimal("2.675").quantize(Decimal("1.00")) Decimal('2.68')
decimal模块的另一个好处是执行算术运算后的舍入被自动处理,有效数字被保留。为了查看实际效果,让我们将默认精度从 28 位改为两位,然后添加数字1.23和2.32:
>>> decimal.getcontext().prec = 2
>>> Decimal("1.23") + Decimal("2.32")
Decimal('3.6')
要改变精度,可以调用decimal.getcontext()并设置.prec属性。如果在函数调用中设置属性对您来说很奇怪,您可以这样做,因为.getcontext()返回一个特殊的Context对象,它代表当前的内部上下文,包含了decimal模块使用的默认参数。
1.23加上2.32的精确值是3.55。由于精度现在是两位数,并且舍入策略被设置为默认值“舍入一半到偶数”,值3.55被自动舍入到3.6。
要更改默认的舍入策略,您可以将decimal.getcontect().rounding属性设置为几个标志中的任何一个。下表总结了这些标志及其实施的舍入策略:
| 旗 | 舍入策略 |
|---|---|
decimal.ROUND_CEILING |
舍入 |
decimal.ROUND_FLOOR |
舍入 |
decimal.ROUND_DOWN |
截断 |
decimal.ROUND_UP |
从零开始舍入 |
decimal.ROUND_HALF_UP |
从零开始四舍五入一半 |
decimal.ROUND_HALF_DOWN |
向零舍入一半 |
decimal.ROUND_HALF_EVEN |
四舍五入到偶数 |
decimal.ROUND_05UP |
向上舍入和向零舍入 |
首先要注意的是,decimal模块使用的命名方案与我们在本文前面同意的不同。例如,decimal.ROUND_UP实现了“舍零取整”策略,实际上是将负数向下取整。
其次,表中提到的一些舍入策略可能看起来很陌生,因为我们没有讨论过它们。您已经看到了decimal.ROUND_HALF_EVEN是如何工作的,所以让我们来看看其他的每一个是如何工作的。
decimal.ROUND_CEILING策略就像我们之前定义的round_up()函数一样工作:
>>> decimal.getcontext().rounding = decimal.ROUND_CEILING >>> Decimal("1.32").quantize(Decimal("1.0")) Decimal('1.4') >>> Decimal("-1.32").quantize(Decimal("1.0")) Decimal('-1.3')请注意,
decimal.ROUND_CEILING的结果不是关于零对称的。
decimal.ROUND_FLOOR策略就像我们的round_down()函数一样工作:
>>> decimal.getcontext().rounding = decimal.ROUND_FLOOR
>>> Decimal("1.32").quantize(Decimal("1.0"))
Decimal('1.3')
>>> Decimal("-1.32").quantize(Decimal("1.0"))
Decimal('-1.4')
和decimal.ROUND_CEILING一样,decimal.ROUND_FLOOR策略也不是围绕零对称的。
decimal.ROUND_DOWN和decimal.ROUND_UP策略有一些欺骗性的名字。ROUND_DOWN和ROUND_UP都是关于零对称的;
>>> decimal.getcontext().rounding = decimal.ROUND_DOWN >>> Decimal("1.32").quantize(Decimal("1.0")) Decimal('1.3') >>> Decimal("-1.32").quantize(Decimal("1.0")) Decimal('-1.3') >>> decimal.getcontext().rounding = decimal.ROUND_UP >>> Decimal("1.32").quantize(Decimal("1.0")) Decimal('1.4') >>> Decimal("-1.32").quantize(Decimal("1.0")) Decimal('-1.4')
decimal.ROUND_DOWN策略将数字四舍五入为零,就像truncate()函数一样。另一方面,decimal.ROUND_UP将所有值从零开始四舍五入。这与我们在文章前面同意的术语明显不同,所以在使用decimal模块时要记住这一点。在
decimal模块中有三种策略允许更细微的舍入。decimal.ROUND_HALF_UP方法将所有内容舍入到最接近的数字,并通过从零开始舍入来打破平局:
>>> decimal.getcontext().rounding = decimal.ROUND_HALF_UP
>>> Decimal("1.35").quantize(Decimal("1.0"))
Decimal('1.4')
>>> Decimal("-1.35").quantize(Decimal("1.0"))
Decimal('-1.4')
请注意,decimal.ROUND_HALF_UP的工作方式就像我们的round_half_away_from_zero()一样,而不像round_half_up()。
还有一种decimal.ROUND_HALF_DOWN策略,通过向零舍入来打破平局:
>>> decimal.getcontext().rounding = decimal.ROUND_HALF_DOWN >>> Decimal("1.35").quantize(Decimal("1.0")) Decimal('1.3') >>> Decimal("-1.35").quantize(Decimal("1.0")) Decimal('-1.3')
decimal模块中可用的最终舍入策略与我们迄今为止看到的任何策略都非常不同:
>>> decimal.getcontext().rounding = decimal.ROUND_05UP
>>> Decimal("1.38").quantize(Decimal("1.0"))
Decimal('1.3')
>>> Decimal("1.35").quantize(Decimal("1.0"))
Decimal('1.3')
>>> Decimal("-1.35").quantize(Decimal("1.0"))
Decimal('-1.3')
在上面的例子中,看起来好像decimal.ROUND_05UP将所有东西都四舍五入为零。事实上,这正是decimal.ROUND_05UP的工作方式,除非舍入的结果以0或5结束。在这种情况下,数字从零开始四舍五入:
>>> Decimal("1.49").quantize(Decimal("1.0")) Decimal('1.4') >>> Decimal("1.51").quantize(Decimal("1.0")) Decimal('1.6')在第一个示例中,数字
1.49首先在第二个小数位四舍五入为零,产生1.4。因为1.4没有以0或5结尾,所以它就保持原样。另一方面,1.51在第二个小数位四舍五入为零,得到数字1.5。这以一个5结束,所以第一个小数位从零四舍五入到1.6。在本节中,我们只关注了
decimal模块的舍入方面。还有大量其他特性使decimal成为标准浮点精度不足的应用程序的绝佳选择,例如银行业和科学计算中的一些问题。关于
Decimal的更多信息,请查看 Python 文档中的快速入门教程。接下来,让我们把注意力转向 Python 的科学计算和数据科学堆栈的两个主要部分:NumPy 和 Pandas 。
舍入 NumPy 数组
在数据科学和科学计算领域,你经常将你的数据存储为 NumPy
array。NumPy 最强大的特性之一是它使用了向量化和广播来一次将操作应用到整个数组,而不是一次一个元素。让我们通过创建伪随机数的 3×4 NumPy 数组来生成一些数据:
>>> import numpy as np
>>> np.random.seed(444)
>>> data = np.random.randn(3, 4)
>>> data
array([[ 0.35743992, 0.3775384 , 1.38233789, 1.17554883],
[-0.9392757 , -1.14315015, -0.54243951, -0.54870808],
[ 0.20851975, 0.21268956, 1.26802054, -0.80730293]])
首先,我们播种np.random模块,以便您可以轻松地再现输出。然后用np.random.randn()创建一个 3×4 的浮点数 NumPy 数组。
注意:如果您的环境中还没有 NumPy,那么在将上述代码输入到您的 REPL 之前,您需要pip3 install numpy。如果你安装了 Python 和 Anaconda ,你就已经设置好了!
如果你以前没有使用过 NumPy,你可以在 Brad Solomon 的 Look Ma,No For-Loops:Array Programming With NumPy中的进入状态部分得到一个快速介绍。
有关 NumPy 的随机模块的更多信息,请查看 Brad 的在 Python 中生成随机数据(指南)的 PRNG 的 For 数组部分。
要舍入data数组中的所有值,可以将data作为参数传递给 np.around() 函数。使用decimals关键字参数设置所需的小数位数。使用了圆整一半到均匀的策略,就像 Python 内置的round()函数一样。
例如,下面将data中的所有值四舍五入到三位小数:
>>> np.around(data, decimals=3) array([[ 0.357, 0.378, 1.382, 1.176], [-0.939, -1.143, -0.542, -0.549], [ 0.209, 0.213, 1.268, -0.807]])
np.around()受浮点表示错误的支配,就像round()一样。例如,
data数组中第一列第三行的值是0.20851975。当您使用“四舍五入”策略将其四舍五入到小数点后三位时,您希望该值为0.208。但是您可以在np.around()的输出中看到,该值被舍入到0.209。然而,第二列第一行中的值0.3775384正确地舍入到0.378。如果您需要将数组中的数据四舍五入为整数,NumPy 提供了几个选项:
np.ceil()函数将数组中的每个值四舍五入为大于或等于原始值的最接近的整数:
>>> np.ceil(data)
array([[ 1., 1., 2., 2.],
[-0., -1., -0., -0.],
[ 1., 1., 2., -0.]])
嘿,我们发现了一个新号码!负零!
实际上, IEEE-754 标准要求同时实现正零和负零。这样的东西可能有什么用呢?维基百科知道答案:
非正式地,可以使用符号“
−0”来表示四舍五入为零的负值。当负号很重要时,这种符号可能是有用的;例如,当将摄氏温度制成表格时,负号表示低于冰点。(来源)
要将每个值向下舍入到最接近的整数,请使用np.floor():
>>> np.floor(data) array([[ 0., 0., 1., 1.], [-1., -2., -1., -1.], [ 0., 0., 1., -1.]])您还可以使用
np.trunc()将每个值截断为其整数部分:
>>> np.trunc(data)
array([[ 0., 0., 1., 1.],
[-0., -1., -0., -0.],
[ 0., 0., 1., -0.]])
最后,要使用“舍入一半到偶数”策略舍入到最接近的整数,请使用np.rint():
>>> np.rint(data) array([[ 0., 0., 1., 1.], [-1., -1., -1., -1.], [ 0., 0., 1., -1.]])您可能已经注意到,我们之前讨论的许多舍入策略在这里都被忽略了。对于绝大多数情况,
around()函数就是你所需要的。如果您需要实现另一个策略,比如round_half_up(),您可以通过简单的修改来实现:def round_half_up(n, decimals=0): multiplier = 10 ** decimals # Replace math.floor with np.floor return np.floor(n*multiplier + 0.5) / multiplier多亏了 NumPy 的矢量化运算,这正如你所期望的那样工作:
>>> round_half_up(data, decimals=2)
array([[ 0.36, 0.38, 1.38, 1.18],
[-0.94, -1.14, -0.54, -0.55],
[ 0.21, 0.21, 1.27, -0.81]])
既然你是一个数字舍入大师,让我们看看 Python 的另一个数据科学的重头戏:熊猫库。
圆圆的熊猫Series和DataFrame
熊猫库已经成为使用 Python 的数据科学家和数据分析师的主要工具。用真正的 Python 自己的 Joe Wyndham 的话说:
熊猫是数据科学和分析的游戏规则改变者,特别是如果你来到 Python,因为你正在寻找比 Excel 和 VBA 更强大的东西。(来源)
注意:在继续之前,如果您的环境中还没有它,您需要pip3 install pandas。就像 NumPy 的情况一样,如果你安装了 Python 和 Anaconda ,你应该已经准备好了!
两个主要的 Pandas 数据结构是 DataFrame ,用非常宽松的术语来说,它的工作方式有点像 Excel 电子表格和Series,你可以把它想象成电子表格中的一列。使用Series.round()和DataFrame.round()方法也可以有效地对Series和DataFrame对象进行圆角处理:
>>> import pandas as pd >>> # Re-seed np.random if you closed your REPL since the last example >>> np.random.seed(444) >>> series = pd.Series(np.random.randn(4)) >>> series 0 0.357440 1 0.377538 2 1.382338 3 1.175549 dtype: float64 >>> series.round(2) 0 0.36 1 0.38 2 1.38 3 1.18 dtype: float64 >>> df = pd.DataFrame(np.random.randn(3, 3), columns=["A", "B", "C"]) >>> df A B C 0 -0.939276 -1.143150 -0.542440 1 -0.548708 0.208520 0.212690 2 1.268021 -0.807303 -3.303072 >>> df.round(3) A B C 0 -0.939 -1.143 -0.542 1 -0.549 0.209 0.213 2 1.268 -0.807 -3.303
DataFrame.round()方法也可以接受字典或Series,为每一列指定不同的精度。例如,以下示例显示了如何将第一列df四舍五入到小数点后一位,第二列四舍五入到小数点后两位,第三列四舍五入到小数点后三位:
>>> # Specify column-by-column precision with a dictionary
>>> df.round({"A": 1, "B": 2, "C": 3})
A B C
0 -0.9 -1.14 -0.542
1 -0.5 0.21 0.213
2 1.3 -0.81 -3.303
>>> # Specify column-by-column precision with a Series
>>> decimals = pd.Series([1, 2, 3], index=["A", "B", "C"])
>>> df.round(decimals)
A B C
0 -0.9 -1.14 -0.542
1 -0.5 0.21 0.213
2 1.3 -0.81 -3.303
如果您需要更多的舍入灵活性,您可以将 NumPy 的floor()、ceil()和rint()函数应用于熊猫Series和DataFrame对象:
>>> np.floor(df) A B C 0 -1.0 -2.0 -1.0 1 -1.0 0.0 0.0 2 1.0 -1.0 -4.0 >>> np.ceil(df) A B C 0 -0.0 -1.0 -0.0 1 -0.0 1.0 1.0 2 2.0 -0.0 -3.0 >>> np.rint(df) A B C 0 -1.0 -1.0 -1.0 1 -1.0 0.0 0.0 2 1.0 -1.0 -3.0上一节修改过的
round_half_up()函数在这里也适用:
>>> round_half_up(df, decimals=2)
A B C
0 -0.94 -1.14 -0.54
1 -0.55 0.21 0.21
2 1.27 -0.81 -3.30
恭喜你,你正在迈向四舍五入的精通!你现在知道了,除了玉米卷的组合之外,还有更多的方法来舍入一个数字。(嗯…也许不是!)您可以在纯 Python 中实现许多舍入策略,并且您已经提高了舍入 NumPy 数组和 Pandas Series和DataFrame对象的技能。
还有一步:知道何时应用正确的策略。
应用和最佳实践
通往精湛技艺的最后一段路是理解何时应用你的新知识。在本节中,您将学习一些最佳实践,以确保您以正确的方式舍入数字。
储多轮晚
当您处理大型数据集时,存储可能是一个问题。在大多数关系数据库中,表中的每一列都被设计为存储特定的数据类型,而数字数据类型通常被赋予精度以帮助节省内存。
例如,温度传感器可以每十秒钟报告一次长时间运行的工业烘箱中的温度,精确到小数点后八位。由此得到的读数用于检测温度的异常波动,这种异常波动可能指示加热元件或一些其他部件的故障。因此,可能会运行一个 Python 脚本,将每个传入的读数与最后一个读数进行比较,以检查大的波动。
该传感器的读数也存储在 SQL 数据库中,这样每天午夜就可以计算出烤箱内的日平均温度。烤箱内加热元件的制造商建议,每当日平均温度低于正常温度.05度时,更换元件。
对于这个计算,你只需要三个小数位的精度。但是你从温哥华证券交易所的事件中知道,去除太多的精度会极大地影响你的计算。
如果有可用的空间,您应该完全精确地存储数据。如果存储是一个问题,一个好的经验法则是存储比计算所需精度多两到三位的小数。
最后,当你计算日平均温度时,你应该计算到可用的最大精度,并对最终结果进行四舍五入。
遵守当地货币法规
当你在咖啡店点一杯 2.40 美元的咖啡时,商家通常会加收所需的税费。税收的多少很大程度上取决于你所处的地理位置,但为了便于讨论,我们假设税率为 6%。要加的税是 0.144 美元。你应该把它向上舍入到 0.15 美元还是向下舍入到 0.14 美元?答案大概取决于当地政府制定的规定!
当您将一种货币转换为另一种货币时,也可能会出现这种情况。1999 年,欧洲经济和金融事务委员会规定了在将货币兑换成欧元时使用“从零四舍五入一半”的策略,但是其他货币可能采用了不同的规则。
另一种情况是,“瑞典舍入”,当一个国家的会计级别的最小货币单位小于物理货币的最小单位时,就会出现这种情况。例如,如果一杯咖啡的税后价格为 2.54 美元,但没有 1 美分的硬币在流通,你会怎么办?买家不会有确切的金额,商家也找不出确切的零钱。
如何处理这种情况通常由一个国家的政府决定。你可以在维基百科上找到各国使用的舍入方法列表。
如果你正在设计计算货币的软件,你应该总是检查你的用户所在地的当地法律和法规。
当有疑问时,四舍五入到偶数
当您对用于复杂计算的大型数据集中的数字进行舍入时,主要考虑的是限制由于舍入而导致的误差增长。
在本文讨论的所有方法中,“四舍五入”策略最大程度地减少了舍入偏差。幸运的是,Python、NumPy 和 Pandas 都默认采用这种策略,所以通过使用内置的舍入函数,您已经得到了很好的保护!
总结
咻!这是一次怎样的旅行啊!
在本文中,您了解到:
-
有各种舍入策略,您现在知道如何在纯 Python 中实现了。
-
每种舍入策略都固有地引入了舍入偏差,而“一半舍入到一半”策略在大多数情况下很好地缓解了这种偏差。
-
计算机在内存中存储浮点数的方式自然会引入微妙的舍入误差,但是您已经学习了如何使用 Python 标准库中的
decimal模块来解决这个问题。 -
您可以对 NumPy 数组和熊猫
Series和DataFrame对象进行舍入。 -
现实世界的数据舍入有一些最佳实践。
参加测验:通过我们的交互式“Python 中的舍入数字”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
如果你有兴趣了解更多,深入我们所涉及的每件事情的本质细节,下面的链接会让你忙上一阵子。
至少,如果你喜欢这篇文章,并从中学到了一些新东西,把它传给你的朋友或团队成员吧!请务必在评论中与我们分享你的想法。我们很想听听你自己的一些与舍入相关的战斗故事!
快乐的蟒蛇!
额外资源
舍入策略和偏差:
浮点和十进制规格:
- IEEE-754 ,维基百科
- IBM 的通用十进制算术规范
有趣的阅读:
- 每个计算机科学家应该知道的关于浮点运算的知识,David Goldberg,ACM 计算调查,1991 年 3 月
- 浮点运算:问题与局限,来自 python.org
- 为什么 Python 的整数除法楼层,作者吉多·范·罗苏姆*************
Python、Ruby 和 Golang:命令行应用程序比较
原文:https://realpython.com/python-ruby-and-golang-a-command-line-application-comparison/
2014 年末,我开发了一个名为 pymr 的工具。我最近觉得有必要学习 golang 并更新我的 ruby 知识,所以我决定重温 pymr 的想法,并用多种语言构建它。在这篇文章中,我将分解“Mr”(Merr)应用程序(pymr,gomr,rumr)并展示每种语言中特定部分的实现。我会在最后提供一个总体的个人偏好,但会把个人作品的比较留给你。
对于那些想直接跳到代码的人,请查看 repo 。
应用程序结构
这个应用程序的基本思想是,您有一些相关的目录,您希望在这些目录上执行一个命令。“mr”工具提供了一种注册目录的方法,以及一种在已注册目录组上运行命令的方法。该应用程序具有以下组件:
- 命令行界面
- 注册命令(用给定的标签写一个文件)
- 运行命令(在注册的目录上运行给定的命令)
命令行界面
“mr”工具的命令行界面是:
$ pymr --help
Usage: pymr [OPTIONS] COMMAND [ARGS]...
Options:
--help Show this message and exit.
Commands:
register register a directory
run run a given command in matching...
为了比较命令行界面的构建,我们来看看每种语言中的 register 命令。
Python (pymr)
为了用 python 构建命令行界面,我选择使用 click 包。
@pymr.command()
@click.option('--directory', '-d', default='./')
@click.option('--tag', '-t', multiple=True)
@click.option('--append', is_flag=True)
def register(directory, tag, append):
...
红宝石(鲁姆)
为了在 ruby 中构建命令行界面,我选择了使用 thor gem。
desc 'register', 'Register a directory'
method_option :directory,
aliases: '-d',
type: :string,
default: './',
desc: 'Directory to register'
method_option :tag,
aliases: '-t',
type: :array,
default: 'default',
desc: 'Tag/s to register'
method_option :append,
type: :boolean,
desc: 'Append given tags to any existing tags?'
def register
...
戈朗(gomr)
为了在 Golang 中构建命令行界面,我选择使用 cli.go 包。
app.Commands = []cli.Command{ { Name: "register", Usage: "register a directory", Action: register, Flags: []cli.Flag{ cli.StringFlag{ Name: "directory, d", Value: "./", Usage: "directory to tag", }, cli.StringFlag{ Name: "tag, t", Value: "default", Usage: "tag to add for directory", }, cli.BoolFlag{ Name: "append", Usage: "append the tag to an existing registered directory", }, }, }, }
注册
注册逻辑如下:
- 如果用户要求
--append读取存在的.[py|ru|go]mr文件。 - 将现有标签与给定标签合并。
- 用新标签写一个新的
.[...]mr文件。
这可以分解成几个小任务,我们可以用每种语言进行比较:
- 搜索和读取文件。
- 合并两个项目(仅保留唯一的集合)
- 编写文件
文件搜索
Python (pymr)
对于 python 来说,这涉及到 os 模块。
pymr_file = os.path.join(directory, '.pymr')
if os.path.exists(pymr_file):
# ...
红宝石(鲁姆)
对于 ruby 来说,这涉及到了文件类。
rumr_file = File.join(directory, '.rumr')
if File.exist?(rumr_file)
# ...
戈朗(gomr)
对于 golang,这涉及到路径包。
fn := path.Join(directory, ".gomr") if _, err := os.Stat(fn); err == nil { // ... }
唯一合并
Python (pymr)
对于 python,这涉及到使用一个集合。
# new_tags and cur_tags are tuples
new_tags = tuple(set(new_tags + cur_tags))
红宝石(鲁姆)
对于 ruby 来说,这涉及到的使用。uniq 数组方法。
# Edited (5/31)
# old method:
# new_tags = (new_tags + cur_tags).uniq
# new_tags and cur_tags are arrays
new_tags |= cur_tags
戈朗(gomr)
对于 golang,这涉及到自定义函数的使用。
func AppendIfMissing(slice []string, i string) []string { for _, ele := range slice { if ele == i { return slice } } return append(slice, i) } for _, tag := range strings.Split(curTags, ",") { newTags = AppendIfMissing(newTags, tag) }
文件读/写
我试图选择每种语言中最简单的文件格式。
Python (pymr)
对于 python 来说,这涉及到使用 pickle模块。
# read
cur_tags = pickle.load(open(pymr_file))
# write
pickle.dump(new_tags, open(pymr_file, 'wb'))
红宝石(鲁姆)
对于 ruby 来说,这涉及到使用 YAML 模块。
# read
cur_tags = YAML.load_file(rumr_file)
# write
# Edited (5/31)
# old method:
# File.open(rumr_file, 'w') { |f| f.write new_tags.to_yaml }
IO.write(rumr_file, new_tags.to_yaml)
戈朗(gomr)
对于 golang,这涉及到使用配置包。
// read cfg, _ := config.ReadDefault(".gomr") // write outCfg.WriteFile(fn, 0644, "gomr configuration file")
运行(命令执行)
运行逻辑如下:
- 递归地从给定的基本路径开始搜索
.[...]mr文件 - 加载一个找到的文件,看看给定的标签是否在其中
- 在匹配文件的目录中调用给定的命令。
这可以分解成几个小任务,我们可以用每种语言进行比较:
- 递归目录搜索
- 字符串比较
- 调用 Shell 命令
递归目录搜索
Python (pymr)
对于 python 来说,这涉及到 os 模块和 fnmatch 模块。
for root, _, fns in os.walk(basepath):
for fn in fnmatch.filter(fns, '.pymr'):
# ...
红宝石(鲁姆)
# Edited (5/31)
# old method:
# Find.find(basepath) do |path|
# next unless File.basename(path) == '.rumr'
Dir[File.join(options[:basepath], '**/.rumr')].each do |path|
# ...
戈朗(gomr)
对于 golang,这需要 filepath 包和一个自定义回调函数。
func RunGomr(ctx *cli.Context) filepath.WalkFunc { return func(path string, f os.FileInfo, err error) error { // ... if strings.Contains(path, ".gomr") { // ... } } } filepath.Walk(root, RunGomr(ctx))
字符串比较
Python (pymr)
对于这个任务,python 中不需要任何额外的东西。
if tag in cur_tags:
# ...
红宝石(鲁姆)
在 ruby 中,这个任务不需要额外的东西。
if cur_tags.include? tag
# ...
戈朗(gomr)
对于 golang,这需要字符串包。
if strings.Contains(cur_tags, tag) { // ... }
调用外壳命令
Python (pymr)
os.chdir(root)
subprocess.call(command, shell=True)
红宝石(鲁姆)
对于 ruby,这涉及到内核模块和反勾号语法。
# Edited (5/31)
# old method
# puts `bash -c "cd #{base_path} && #{command}"`
Dir.chdir(File.dirname(path)) { puts `#{command}` }
戈朗(gomr)
对于 golang 来说,这涉及到 os 包和 os/exec 包。
os.Chdir(filepath.Dir(path)) cmd := exec.Command("bash", "-c", command) stdout, err := cmd.Output()
包装
该工具的理想分发模式是通过一个包。然后用户可以安装它tool install [pymr,rumr,gomr],并在系统路径上执行一个新命令。我不想在这里介绍打包系统,我只想展示每种语言所需的基本配置文件。
Python (pymr)
对于 python 来说,需要一个setup.py。一旦创建并上传了包,就可以用pip install pymr进行安装。
from setuptools import setup, find_packages
classifiers = [
'Environment :: Console',
'Operating System :: OS Independent',
'License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)',
'Intended Audience :: Developers',
'Programming Language :: Python',
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7'
]
setuptools_kwargs = {
'install_requires': [
'click>=4,<5'
],
'entry_points': {
'console_scripts': [
'pymr = pymr.pymr:pymr',
]
}
}
setup(
name='pymr',
description='A tool for executing ANY command in a set of tagged directories.',
author='Kyle W Purdon',
author_email='kylepurdon@gmail.com',
url='https://github.com/kpurdon/pymr',
download_url='https://github.com/kpurdon/pymr',
version='2.0.1',
packages=find_packages(),
classifiers=classifiers,
**setuptools_kwargs
)
红宝石(鲁姆)
对于 ruby,需要一个rumr.gemspec。一旦宝石被创建并上传,就可以安装gem install rumr。
Gem::Specification.new do |s|
s.name = 'rumr'
s.version = '1.0.0'
s.summary = 'Run system commands in sets' \
' of registered and tagged directories.'
s.description = '[Ru]by [m]ulti-[r]epository Tool'
s.authors = ['Kyle W. Purdon']
s.email = 'kylepurdon@gmail.com'
s.files = ['lib/rumr.rb']
s.homepage = 'https://github.com/kpurdon/rumr'
s.license = 'GPLv3'
s.executables << 'rumr'
s.add_dependency('thor', ['~>0.19.1'])
end
戈朗(gomr)
对于 golang 来说,源代码只是被编译成可以重新分发的二进制文件。不需要额外的文件,当前也没有要推送的包存储库。
结论
对于这个工具,Golang 感觉是个错误的选择。我不需要它有很高的性能,我也没有利用 Golang 提供的本地并发性。这就给我留下了 Ruby 和 Python。对于大约 80%的逻辑,我个人的偏好是两者之间的一个掷硬币。以下是我觉得用一种语言写更好的作品:
命令行接口声明
Python 是这里的赢家。 click 库装饰风格声明简洁明了。请记住,我只尝试了红宝石雷神宝石,所以红宝石可能有更好的解决方案。这也不是对任何一种语言的评论,而是我在 python 中使用的 CLI 库是我的首选。
递归目录搜索
鲁比是这里的赢家。我发现使用 ruby 的Find.find()尤其是next unless语法,这一整段代码更加清晰易读。
包装
鲁比是这里的赢家。文件要简单得多,建造和推销宝石的过程也简单得多。捆绑器工具也使得在半隔离环境中安装变得轻而易举。
最终决定
由于打包和递归目录搜索偏好,我会选择 Ruby 作为这个应用程序的工具。然而,偏好上的差异是如此之小,以至于 Python 也非常适合。然而,Golang 并不是这里的正确工具。
这篇文章最初发表在凯尔的个人博客上,并在 Reddit 上引起了热烈的讨论。*****
Python、Ruby 和 Golang:Web 服务应用程序的比较
原文:https://realpython.com/python-ruby-and-golang-a-web-service-application-comparison/
在最近对 Python、Ruby 和 Golang 的命令行应用程序进行了比较之后,我决定使用相同的模式来比较构建一个简单的 web 服务。我选择了烧瓶(Python)辛纳特拉 (Ruby),和马丁尼 (Golang)来做这个对比。是的,每种语言的 web 应用程序库都有很多其他的选择,但是我觉得这三个很适合比较。
图书馆概述
下面是由 Stackshare 提供的库的高级比较。
烧瓶(Python)
Flask 是一个基于 Werkzeug、Jinja2 和 good intentions 的 Python 微框架。
对于非常简单的应用程序,如本演示中所示,Flask 是一个很好的选择。基本的 Flask 应用程序在一个 Python 源文件中只有 7 行代码(LOC)。与其他 Python web 库(如 Django 或 Pyramid )相比,Flask 的优势在于,您可以从小处着手,根据需要构建更复杂的应用程序。
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run()
辛纳特拉(红宝石)
Sinatra 是一个用 Ruby 快速创建 web 应用程序的 DSL。
就像 Flask 一样,Sinatra 非常适合简单的应用程序。基本 Sinatra 应用程序只被锁定在一个 Ruby 源文件中。出于与 Flask 相同的原因,使用 Sinatra 而不是像 Ruby on Rails 这样的库——您可以从小处着手,并根据需要扩展应用程序。
require 'sinatra'
get '/hi' do
"Hello World!"
end
马提尼(Golang)
Martini 是一个用 Golang 快速编写模块化 web 应用程序/服务的强大软件包。
Martini 配备了比 Sinatra 和 Flask 更多的电池,但仍然非常轻便,基本应用只需 9 LOC。Martini 受到了 Golang 社区的一些批评,但它仍然是 Golang web 框架中评价最高的 Github 项目之一。《马提尼》的作者在这里直接回应了批评。其他一些框架包括 Revel 、 Gin ,甚至还有内置的 net/http 库。
package main import "github.com/go-martini/martini" func main() { m := martini.Classic() m.Get("/", func() string { return "Hello world!" }) m.Run() }
有了基本的方法,让我们建立一个应用程序!
服务描述
创建的服务提供了一个非常基本的博客应用程序。构建了以下路线:
GET /:返回博客(使用模板渲染)。GET /json:返回 JSON 格式的博客内容。- 向博客添加新文章(标题、摘要、内容)。
对于每种语言,博客服务的外部接口完全相同。为了简单起见, MongoDB 将被用作这个例子的数据存储,因为它是最容易设置的,我们根本不需要担心模式。在一个普通的“类似博客”的应用程序中,关系数据库可能是必要的。
添加一个帖子
POST /new
$ curl --form title='Test Post 1' \
--form summary='The First Test Post' \
--form content='Lorem ipsum dolor sit amet, consectetur ...' \
http://[IP]:[PORT]/new
查看 HTML
GET /

查看 JSON
GET /json
[ { content:"Lorem ipsum dolor sit amet, consectetur ...", title:"Test Post 1", _id:{ $oid:"558329927315660001550970" }, summary:"The First Test Post" } ]
应用程序结构
每个应用程序都可以分为以下几个部分:
应用程序设置
- 初始化应用程序
- 运行应用程序
请求
- 定义用户可以请求数据(GET)的路线
- 定义用户可以提交数据(POST)的路线
响应
- 渲染 JSON (
GET /json) - 渲染模板(
GET /)
数据库
- 初始化连接
- 插入日期
- 检索数据
应用程序部署
- 码头工人!
本文的其余部分将对每个库的这些组件进行比较。我们的目的并不是暗示这三个库哪一个更好,而是提供三个工具之间的具体比较:
项目设置
所有的项目都是使用 docker 和 docker-compose 引导的。在深入了解每个应用程序是如何启动的之前,我们可以使用 docker 以完全相同的方式启动并运行每个应用程序
说真的,就是这样!现在,对于每个应用程序,都有一个Dockerfile和一个docker-compose.yml文件来指定当您运行上面的命令时会发生什么。
python(flask)-docker file
FROM python:3.4
ADD . /app
WORKDIR /app
RUN pip install -r requirements.txt
这个Dockerfile表示我们从安装了 Python 3.4 的基础映像开始,将我们的应用程序添加到/app目录,并使用 pip 来安装在requirements.txt中指定的应用程序需求。
红宝石(辛纳特拉)
FROM ruby:2.2
ADD . /app
WORKDIR /app
RUN bundle install
这个Dockerfile表示我们从安装了 Ruby 2.2 的基础映像开始,将我们的应用程序添加到/app目录,并使用捆绑器来安装在Gemfile中指定的应用程序需求。
Golang (martini)
FROM golang:1.3
ADD . /go/src/github.com/kpurdon/go-blog
WORKDIR /go/src/github.com/kpurdon/go-blog
RUN go get github.com/go-martini/martini && \
go get github.com/martini-contrib/render && \
go get gopkg.in/mgo.v2 && \
go get github.com/martini-contrib/binding
这个Dockerfile表示我们从一个安装了 Golang 1.3 的基础映像开始,将我们的应用程序添加到/go/src/github.com/kpurdon/go-blog目录,并使用go get命令获得所有必要的依赖项。
初始化/运行应用程序
Python (Flask) - app.py
# initialize application
from flask import Flask
app = Flask(__name__)
# run application
if __name__ == '__main__':
app.run(host='0.0.0.0')
$ python app.py
红宝石(辛纳特拉)- app.rb
# initialize application
require 'sinatra'
$ ruby app.rb
Golang(马提尼)- app.go
// initialize application package main import "github.com/go-martini/martini" import "github.com/martini-contrib/render" func main() { app := martini.Classic() app.Use(render.Renderer()) // run application app.Run() }
$ go run app.go
定义一条路线(GET/POST)
Python(烧瓶)
# get
@app.route('/') # the default is GET only
def blog():
# ...
#post
@app.route('/new', methods=['POST'])
def new():
# ...
红宝石(辛纳特拉)
# get
get '/' do
# ...
end
# post
post '/new' do
# ...
end
Golang (Martini)
// define data struct type Post struct { Title string `form:"title" json:"title"` Summary string `form:"summary" json:"summary"` Content string `form:"content" json:"content"` } // get app.Get("/", func(r render.Render) { // ... } // post import "github.com/martini-contrib/binding" app.Post("/new", binding.Bind(Post{}), func(r render.Render, post Post) { // ... }
呈现一个 JSON 响应
Python(烧瓶)
Flask 提供了一个 jsonify() 方法,但是因为服务使用的是 MongoDB,所以使用了 mongodb bson 实用程序。
from bson.json_util import dumps
return dumps(posts) # posts is a list of dicts [{}, {}]
红宝石(辛纳特拉)
require 'json'
content_type :json
posts.to_json # posts is an array (from mongodb)
Golang (Martini)
r.JSON(200, posts) // posts is an array of Post{} structs
呈现 HTML 响应(模板化)
Python(烧瓶)
return render_template('blog.html', posts=posts)
<!doctype HTML>
<html>
<head>
<title>Python Flask Example</title>
</head>
<body>
{% for post in posts %}
<h1> {{ post.title }} </h1>
<h3> {{ post.summary }} </h3>
<p> {{ post.content }} </p>
<hr>
{% endfor %}
</body>
</html>
红宝石(辛纳特拉)
erb :blog
<!doctype HTML>
<html>
<head>
<title>Ruby Sinatra Example</title>
</head>
<body>
<% @posts.each do |post| %>
<h1><%= post['title'] %></h1>
<h3><%= post['summary'] %></h3>
<p><%= post['content'] %></p>
<hr>
<% end %>
</body>
</html>
Golang (Martini)
r.HTML(200, "blog", posts)
<!doctype HTML>
<html>
<head>
<title>Golang Martini Example</title>
</head>
<body>
{{range . }}
<h1>{{.Title}}</h1>
<h3>{{.Summary}}</h3>
<p>{{.Content}}</p>
<hr>
{{ end }}
</body>
</html>
数据库连接
所有的应用程序都使用特定于该语言的 mongodb 驱动程序。环境变量DB_PORT_27017_TCP_ADDR是链接的 docker 容器的 ip(数据库 IP)。
Python(烧瓶)
from pymongo import MongoClient
client = MongoClient(os.environ['DB_PORT_27017_TCP_ADDR'], 27017)
db = client.blog
红宝石(辛纳特拉)
require 'mongo'
db_ip = [ENV['DB_PORT_27017_TCP_ADDR']]
client = Mongo::Client.new(db_ip, database: 'blog')
Golang (Martini)
import "gopkg.in/mgo.v2" session, _ := mgo.Dial(os.Getenv("DB_PORT_27017_TCP_ADDR")) db := session.DB("blog") defer session.Close()
从帖子中插入数据
Python(烧瓶)
from flask import request
post = {
'title': request.form['title'],
'summary': request.form['summary'],
'content': request.form['content']
}
db.blog.insert_one(post)
红宝石(辛纳特拉)
client[:posts].insert_one(params) # params is a hash generated by sinatra
Golang (Martini)
db.C("posts").Insert(post) // post is an instance of the Post{} struct
检索数据
Python(烧瓶)
posts = db.blog.find()
红宝石(辛纳特拉)
@posts = client[:posts].find.to_a
Golang (Martini)
var posts []Post db.C("posts").Find(nil).All(&posts)
应用部署(Docker!)
部署所有这些应用程序的一个很好的解决方案是使用 docker 和 docker-compose 。
Python(烧瓶)
Dockerfile
FROM python:3.4
ADD . /app
WORKDIR /app
RUN pip install -r requirements.txt
码头-化合物. yml
web: build: . command: python -u app.py ports: - "5000:5000" volumes: - .:/app links: - db db: image: mongo:3.0.4 command: mongod --quiet --logpath=/dev/null
红宝石(辛纳特拉)
Dockerfile
FROM ruby:2.2
ADD . /app
WORKDIR /app
RUN bundle install
码头-化合物. yml
web: build: . command: bundle exec ruby app.rb ports: - "4567:4567" volumes: - .:/app links: - db db: image: mongo:3.0.4 command: mongod --quiet --logpath=/dev/null
Golang (Martini)
Dockerfile
FROM golang:1.3
ADD . /go/src/github.com/kpurdon/go-todo
WORKDIR /go/src/github.com/kpurdon/go-todo
RUN go get github.com/go-martini/martini && go get github.com/martini-contrib/render && go get gopkg.in/mgo.v2 && go get github.com/martini-contrib/binding
码头-化合物. yml
web: build: . command: go run app.go ports: - "3000:3000" volumes: # look into volumes v. "ADD" - .:/go/src/github.com/kpurdon/go-todo links: - db db: image: mongo:3.0.4 command: mongod --quiet --logpath=/dev/null
结论
最后,让我们来看看我认为的几个类别,在这些类别中,所呈现的库是彼此独立的。
简单性
虽然 Flask 非常轻便,阅读清晰,但 Sinatra 应用程序是三个应用程序中最简单的,价格为 23 LOC(相比之下 Flask 为 46,Martini 为 42)。由于这些原因,辛纳特拉是这个类别的赢家。然而应该注意的是,Sinatra 的简单是由于更多的默认“魔法”——例如,在幕后发生的隐含工作。对于新用户来说,这经常会导致困惑。
以下是辛纳屈“魔法”的一个具体例子:
params # the "request.form" logic in python is done "magically" behind the scenes in Sinatra.
以及等效的烧瓶代码:
from flask import request
params = {
'title': request.form['title'],
'summary': request.form['summary'],
'content': request.form['content']
}
对于编程初学者来说,Flask 和 Sinatra 当然更简单,但是对于一个花时间在其他静态类型语言上的有经验的程序员来说,Martini 确实提供了一个相当简单的界面。
文档
Flask 文档是最容易搜索和最容易接近的。虽然 Sinatra 和 Martini 都有很好的记录,但文件本身并不容易接近。由于这个原因,Flask 是这个类别的赢家。
社区
弗拉斯克无疑是这一类别的获胜者。Ruby 社区经常武断地认为,如果你需要除基本服务之外的任何东西,Rails 是唯一的好选择(尽管在 Sinatra 的基础上,Padrino 也提供这种服务)。Golang 社区仍然没有就一个(甚至几个)web 框架达成共识,这是意料之中的,因为该语言本身还很年轻。然而 Python 已经采用了许多 web 开发方法,包括用于开箱即用的全功能 web 应用程序的 Django 和用于微框架方法的 Flask、Bottle、CheryPy 和 Tornado。
最终决定
请注意,本文的目的不是推广一种工具,而是对 Flask、Sinatra 和 Martini 进行公正的比较。也就是说,我会选择 Flask (Python)或 Sinatra (Ruby)。如果你来自像 C 语言或 T2 Java 语言这样的语言,也许 Golang 的静态类型特性会吸引你。如果你是一个初学者,Flask 可能是最好的选择,因为它很容易启动和运行,而且几乎没有默认的“魔法”。我的建议是,在为项目选择库时,您可以灵活地做出决定。
有问题吗?反馈?请在下面评论。谢谢大家!
另外,如果您有兴趣查看一些基准测试,请告诉我们。******
科学 Python:使用 SciPy 进行优化
当你想用 Python 做科学工作时,你可以求助的第一个库是 SciPy 。正如你将在本教程中看到的, SciPy 不仅仅是一个库,而是一个完整的库生态系统,它们协同工作,帮助你快速可靠地完成复杂的科学任务。
在本教程中,您将学习如何:
- 查找关于您可以使用 SciPy 做的所有事情的信息
- 在你的电脑上安装 SciPy
- 使用 SciPy 通过几个变量对数据集进行聚类
- 使用 SciPy 找到函数的最优值
您可以通过下载下面链接中的源代码来学习本教程中的示例:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来了解 SciPy。
区分科学生态系统和科学图书馆
当您想要使用 Python 执行科学计算任务时,可能会建议您使用几个库,包括:
- NumPy
- 我的天啊
- Matplotlib
- IPython
- 交响乐
- 熊猫
总的来说,这些库组成了 SciPy 生态系统 ,并且被设计成一起工作。他们中的许多人直接依赖 NumPy 数组来进行计算。本教程希望您对创建 NumPy 数组和操作它们有所了解。
注意:如果你需要一个关于 NumPy 的快速入门或者复习,那么你可以看看这些教程:
在本教程中,您将了解到 SciPy 库,它是 SciPy 生态系统的核心组件之一。SciPy 库是 Python 中科学计算的基础库。它为诸如数值积分、优化、信号处理、线性代数等任务提供了许多高效且用户友好的界面。
了解 SciPy 模块
SciPy 库由许多模块组成,这些模块将库分成不同的功能单元。如果您想了解 SciPy 包含的不同模块,那么您可以在scipy上运行help(),如下所示:
>>> import scipy >>> help(scipy)这为整个 SciPy 库产生了一些帮助输出,其中一部分如下所示:
Subpackages ----------- Using any of these subpackages requires an explicit import. For example, ``import scipy.cluster``. :: cluster --- Vector Quantization / Kmeans fft --- Discrete Fourier transforms fftpack --- Legacy discrete Fourier transforms integrate --- Integration routines ...这个代码块显示了帮助输出的
Subpackages部分,这是 SciPy 中可以用于计算的所有可用模块的列表。请注意该部分顶部的文本,它声明,
"Using any of these subpackages requires an explicit import."当您想要使用 SciPy 中某个模块的功能时,您需要导入您想要使用的模块特别是。稍后在教程中你会看到一些这样的例子,从 SciPy 导入库的指南显示在 SciPy 文档中。一旦决定要使用哪个模块,就可以查看 SciPy API 参考,其中包含了 SciPy 中每个模块的所有细节。如果你正在寻找一些有更多解释的东西,那么 SciPy 课堂笔记是深入许多 SciPy 模块的一个很好的资源。
在本教程的后面,您将了解到
cluster和optimize,它们是 SciPy 库中的两个模块。但是首先,你需要在你的电脑上安装 SciPy。在你的电脑上安装 SciPy
和大多数 Python 包一样,在你的电脑上安装 SciPy 有两种主要方式:
- 蟒蛇
- PyPI 和 pip
在这里,您将学习如何使用这两种方法来安装库。SciPy 唯一的直接依赖项是 NumPy 包。如果需要,这两种安装方法都会自动安装除 SciPy 之外的 NumPy。
蟒蛇
Anaconda 是 Python 的一个流行的发行版,主要是因为它包含了针对 Windows、macOS 和 Linux 的最流行的科学 Python 包的预构建版本。如果您的计算机上还没有安装 Python,那么 Anaconda 是一个很好的入门选择。Anaconda 预装了 SciPy 及其所需的依赖项,因此一旦安装了 Anaconda,就不需要做任何其他事情了!
你可以从他们的下载页面下载并安装 Anaconda。确保下载最新的 Python 3 版本。一旦您的计算机上安装了安装程序,您就可以根据您的平台遵循应用程序的默认设置过程。
注意:确保将 Anaconda 安装在不需要管理员权限修改的目录下。这是安装程序中的默认设置。
如果您已经安装了 Anaconda,但是您想安装或更新 SciPy,那么您也可以这样做。在 macOS 或 Linux 上打开一个终端应用程序,或者在 Windows 上打开 Anaconda 提示符,然后键入以下代码行之一:
$ conda install scipy $ conda update scipy如果您需要安装 SciPy,您应该使用第一行;如果您只想更新 SciPy,您应该使用第二行。要确保安装了 SciPy,请在您的终端中运行 Python 并尝试导入 SciPy:
>>> import scipy
>>> print(scipy.__file__)
/.../lib/python3.7/site-packages/scipy/__init__.py
在这段代码中,你已经导入了scipy并且打印了文件的位置,从那里scipy被加载。上面的例子是针对 macOS 的。您的计算机可能会显示不同的位置。现在,您已经在计算机上安装了 SciPy,可以使用了。您可以跳到的下一部分开始使用 SciPy!
Pip
如果您已经安装了不是 Anaconda 的 Python 版本,或者您不想使用 Anaconda,那么您将使用pip来安装 SciPy。要了解更多关于什么是pip的信息,请查看什么是 Pip?新蟒蛇指南和Pip 初学者指南。
注意: pip使用一种叫做轮子的格式安装包。在轮盘格式中,代码在发送到你的计算机之前被编译。这几乎与 Anaconda 采用的方法相同,尽管 wheel 格式文件与 Anaconda 格式略有不同,而且两者不可互换。
要使用pip安装 SciPy,请打开您的终端应用程序,并键入以下代码行:
$ python -m pip install -U scipy
如果尚未安装 SciPy,该代码将安装它,如果已经安装了 SciPy,则升级它。要确保安装了 SciPy,请在您的终端中运行 Python 并尝试导入 SciPy:
>>> import scipy >>> print(scipy.__file__) /.../lib/python3.7/site-packages/scipy/__init__.py在这段代码中,您已经导入了
scipy并打印了文件的位置,即scipy被加载的位置。上面的例子是针对使用 pyenv 的 macOS。您的计算机可能会显示不同的位置。现在你已经在电脑上安装了 SciPy。让我们看看如何使用 SciPy 来解决您可能会遇到的一些问题!使用 SciPy 中的集群模块
聚类是一种流行的技术,通过将数据关联成组来对数据进行分类。SciPy 库包括一个 k 均值聚类算法以及几个层次聚类算法的实现。在本例中,您将在
scipy.cluster.vq中使用 k 均值算法,其中vq代表矢量量化。首先,您应该看一看您将在这个示例中使用的数据集。该数据集由 4827 条真实短信和 747 条垃圾短信组成。原始数据集可以在 UCI 机器学习库或作者的网页上找到。
注:这些数据由 Tiago A. Almeida 和 José María Gómez Hidalgo 收集,并发表在 2011 年在美国加利福尼亚州山景城举办的2011 年 ACM 文档工程研讨会(DOCENG'11) 的一篇题为“对垃圾短信过滤研究的贡献:新的收集和结果”的文章中。
在数据集中,每条消息都有两个标签之一:
ham为合法消息
spam为垃圾短信完整的文本消息与每个标签相关联。当您浏览数据时,您可能会注意到垃圾邮件中往往有许多数字。它们通常包括电话号码或奖金。让我们根据消息中的位数来预测消息是否是垃圾邮件。为此,您将根据消息中出现的位数将数据分成三组:
非垃圾邮件:位数最小的消息被预测为非垃圾邮件。
未知:中间位数的消息未知,需要更高级的算法处理。
垃圾邮件:位数最高的消息被预测为垃圾邮件。
让我们开始对短信进行聚类。首先,您应该导入将在本例中使用的库:
1from pathlib import Path 2import numpy as np 3from scipy.cluster.vq import whiten, kmeans, vq您可以看到您正在从
scipy.cluster.vq导入三个函数。每个函数都接受一个 NumPy 数组作为输入。这些数组应该在列中有数据集的特征,在行中有观察值。一个特征是一个感兴趣的变量,而每次记录每个特征时都会创建一个观察。在本例中,数据集中有 5,574 条观察结果或单个消息。此外,您会看到有两个特性:
- 短信中的位数
- 该位数在整个数据集中出现的次数
接下来,您应该从 UCI 数据库加载数据文件。数据以文本文件的形式出现,其中消息的类用制表符与消息分开,每条消息占一行。您应该使用
pathlib.Path将数据读入一个列表:4data = Path("SMSSpamCollection").read_text() 5data = data.strip() 6data = data.split("\n")在这段代码中,您使用
pathlib.Path.read_text()将文件读入一个字符串。然后,使用.strip()删除任何尾随空格,并将字符串拆分成一个带有.split()的列表。接下来,你可以开始分析数据。你需要计算每条短信中出现的位数。Python 在标准库中包含了
collections.Counter,以类似字典的结构收集对象的计数。然而,因为scipy.cluster.vq中的所有函数都期望 NumPy 数组作为输入,所以在这个例子中不能使用collections.Counter。相反,您使用 NumPy 数组并手动实现计数。同样,您感兴趣的是给定 SMS 消息中的位数,以及有多少 SMS 消息具有该位数。首先,您应该创建一个 NumPy 数组,该数组将给定消息的位数与消息的结果相关联,无论该消息是垃圾邮件还是垃圾邮件:
7digit_counts = np.empty((len(data), 2), dtype=int)在这段代码中,您将创建一个空的 NumPy 数组
digit_counts,它有两列和 5,574 行。行数等于数据集中的消息数。您将使用digit_counts将消息中的位数与消息是否是垃圾邮件联系起来。您应该在进入循环之前创建数组,这样就不必在数组扩展时分配新的内存。这提高了代码的效率。接下来,您应该处理数据以记录位数和消息的状态:
8for i, line in enumerate(data): 9 case, message = line.split("\t") 10 num_digits = sum(c.isdigit() for c in message) 11 digit_counts[i, 0] = 0 if case == "ham" else 1 12 digit_counts[i, 1] = num_digits下面是这段代码如何工作的逐行分析:
第 8 行:循环结束
data。您使用enumerate()将列表中的值放到line中,并为该列表创建一个索引i。要了解更多关于enumerate()的内容,请查看 Python enumerate():用计数器简化循环。第 9 行:拆分制表符上的行,创建
case和message。case是表示消息是ham还是spam的字符串,而message是包含消息文本的字符串。第 10 行:用一个理解的
sum()计算消息的位数。在理解中,使用isdigit()检查消息中的每个字符,如果元素是数字,则返回True,否则返回False。sum()然后将每个True结果视为 1,将每个False结果视为 0。因此,sum()在这次理解中的结果是isdigit()返回True的字符数。第 11 行:赋值到
digit_counts。如果消息是合法的(ham),则将i行的第一列指定为 0,如果消息是垃圾邮件,则指定为 1。第 12 行:赋值到
digit_counts。您将i行的第二列指定为消息中的位数。现在您有了一个 NumPy 数组,其中包含了每条消息的位数。但是,您希望将聚类算法应用于一个数组,该数组中的消息数量具有特定的位数。换句话说,您需要创建一个数组,其中第一列包含消息中的位数,第二列包含具有该位数的消息数。查看下面的代码:
13unique_counts = np.unique(digit_counts[:, 1], return_counts=True)
np.unique()将一个数组作为第一个参数,并返回另一个包含该参数中唯一元素的数组。它还需要几个可选参数。这里,您使用return_counts=True来指示np.unique()返回一个数组,其中包含每个唯一元素在输入数组中出现的次数。这两个输出作为存储在unique_counts中的元组返回。接下来,您需要将
unique_counts转换成适合集群的形状:14unique_counts = np.transpose(np.vstack(unique_counts))使用
np.vstack()将来自np.unique()的两个 1xN 输出组合成一个 2xN 数组,然后将它们转置成一个 Nx2 数组。这种格式将在聚类函数中使用。unique_counts中的每一行现在都有两个元素:
- 信息中的位数
- 具有该位数的消息数
这两个操作的输出子集如下所示:
[[ 0 4110] [ 1 486] [ 2 160] ... [ 40 4] [ 41 2] [ 47 1]]在数据集中,有 4110 条消息没有数字,486 条消息有 1 个数字,依此类推。现在,您应该对这个数组应用 k-means 聚类算法:
15whitened_counts = whiten(unique_counts) 16codebook, _ = kmeans(whitened_counts, 3)您使用
whiten()归一化每个特征,使其具有单位方差,这改进了来自kmeans()的结果。然后,kmeans()将白化数据和要创建的聚类数作为参数。在这个例子中,您想要创建 3 个集群,分别是肯定是火腿、肯定是垃圾邮件和未知的。kmeans()返回两个值:
一个三行两列的数组,代表每组的质心:
kmeans()算法通过最小化观测值到每个质心的距离,计算每个聚类质心的最佳位置。这个数组被分配给codebook。从观察值到质心的平均欧几里德距离:这个例子的其余部分不需要这个值,所以可以把它赋给
_。接下来,您应该使用
vq()来确定每个观察值属于哪个集群:17codes, _ = vq(whitened_counts, codebook)
vq()将来自codebook的代码分配给每个观察值。它返回两个值:
第一个值是一个与
unique_counts长度相同的数组,其中每个元素的值都是一个整数,表示该观察被分配到哪个集群。因为您在这个例子中使用了三个集群,所以每个观察都被分配到集群0、1或2。第二个值是每个观察与其质心之间的欧几里德距离的数组。
现在您已经有了聚类的数据,您应该使用它来预测 SMS 消息。您可以检查计数,以确定聚类算法在绝对垃圾邮件和未知邮件之间以及未知邮件和绝对垃圾邮件之间划出了多少位数的界限。
聚类算法随机给每个聚类分配代码
0、1或2,所以你需要识别哪个是哪个。您可以使用此代码来查找与每个集群相关联的代码:18ham_code = codes[0] 19spam_code = codes[-1] 20unknown_code = list(set(range(3)) ^ set((ham_code, spam_code)))[0]在这段代码中,第一行查找与 ham 消息相关的代码。根据我们上面的假设,ham 消息具有最少的数字,并且数字数组从最少到最多的数字排序。因此,ham 消息簇在
codes的开始处开始。类似地,垃圾消息具有最多的数字,并且形成了
codes中的最后一个簇。因此,垃圾消息的代码将等于codes的最后一个元素。最后,您需要找到未知消息的代码。由于代码只有 3 个选项,并且您已经确定了其中的两个,您可以在一个 Pythonset上使用symmetric_difference操作符来确定最后一个代码值。然后,您可以打印与每种消息类型相关联的群:21print("definitely ham:", unique_counts[codes == ham_code][-1]) 22print("definitely spam:", unique_counts[codes == spam_code][-1]) 23print("unknown:", unique_counts[codes == unknown_code][-1])在这段代码中,每一行都获得了
unique_counts中的行,其中vq()被赋予了不同的代码值。因为该操作返回一个数组,所以您应该获取该数组的最后一行,以确定分配给每个分类的最大位数。输出如下所示:definitely ham: [0 4110] definitely spam: [47 1] unknown: [20 18]在此输出中,您会看到肯定是垃圾消息是消息中的零位数消息,未知消息是 1 到 20 位数之间的所有数字,肯定是垃圾消息是 21 到 47 位数之间的所有数字,这是数据集中的最大位数。
现在,您应该检查您对该数据集的预测有多准确。首先,为
digit_counts创建一些掩码,这样您就可以轻松地获取消息的ham或spam状态:24digits = digit_counts[:, 1] 25predicted_hams = digits == 0 26predicted_spams = digits > 20 27predicted_unknowns = np.logical_and(digits > 0, digits <= 20)在这段代码中,您将创建
predicted_hams掩码,其中消息中没有数字。然后,为所有超过 20 位的消息创建predicted_spams掩码。最后,中间的消息是predicted_unknowns。接下来,将这些掩码应用于实际数字计数以检索预测:
28spam_cluster = digit_counts[predicted_spams] 29ham_cluster = digit_counts[predicted_hams] 30unk_cluster = digit_counts[predicted_unknowns]这里,您将在最后一个代码块中创建的掩码应用到
digit_counts数组。这将创建三个新数组,其中仅包含已被聚类到每个组中的消息。最后,您可以看到每种消息类型中有多少属于每个集群:31print("hams:", np.unique(ham_cluster[:, 0], return_counts=True)) 32print("spams:", np.unique(spam_cluster[:, 0], return_counts=True)) 33print("unknowns:", np.unique(unk_cluster[:, 0], return_counts=True))这段代码打印了分类中每个唯一值的计数。记住,
0表示消息是ham,1表示消息是spam。结果如下所示:hams: (array([0, 1]), array([4071, 39])) spams: (array([0, 1]), array([ 1, 232])) unknowns: (array([0, 1]), array([755, 476]))从这个输出中,您可以看到有 4110 条消息属于绝对是垃圾邮件的组,其中 4071 条实际上是垃圾邮件,只有 39 条是垃圾邮件。相反,在 233 条被归入肯定是垃圾邮件组的消息中,只有 1 条是真正的垃圾邮件,其余的都是垃圾邮件。
当然,超过 1200 封邮件属于未知类别,因此需要一些更高级的分析来对这些邮件进行分类。你可能想研究一下像自然语言处理这样的东西来帮助提高你预测的准确性,你可以使用 Python 和 Keras 来帮助解决。
使用 SciPy 中的优化模块
当您需要优化一个函数的输入参数时,
scipy.optimize包含许多用于优化不同类型函数的有用方法:
minimize_scalar()和minimize()分别最小化一个变量和多个变量的函数curve_fit()用函数来拟合一组数据root_scalar()和root()分别求一元和多元函数的零点linprog()最小化带有线性不等式和等式约束的线性目标函数实际上,所有这些功能都在执行这样或那样的 优化 。在本节中,您将了解两个最小化函数,
minimize_scalar()和minimize()。最小化一元函数
接受一个数字并产生一个输出的数学函数称为标量函数。它通常与接受多个数字并产生多个输出数字的多元函数形成对比。在下一节中,您将看到一个优化多元函数的示例。
对于这一部分,你的标量函数将是一个四次多项式,你的目标是找到函数的最小值。函数是 y = 3x⁴ - 2x + 1。下图绘制了 x 从 0 到 1 范围内的函数:
在图中,你可以看到这个函数在大约 x = 0.55 处有一个最小值。你可以用
minimize_scalar()来确定 x 和 y 坐标的最小值。首先,从scipy.optimize进口minimize_scalar()。然后,您需要定义要最小化的目标函数:1from scipy.optimize import minimize_scalar 2 3def objective_function(x): 4 return 3 * x ** 4 - 2 * x + 1
objective_function()接受输入x并对其应用必要的数学运算,然后返回结果。在函数定义中,你可以使用任何你想要的数学函数。唯一的限制是函数最后必须返回一个数字。接下来用
minimize_scalar()求这个函数的最小值。minimize_scalar()只有一个必需的输入,即目标函数定义的名称:5res = minimize_scalar(objective_function)
minimize_scalar()的输出是OptimizeResult的一个实例。这个类收集了优化器运行的许多相关细节,包括优化是否成功,以及如果成功,最终结果是什么。该功能的minimize_scalar()输出如下所示:fun: 0.17451818777634331 nfev: 16 nit: 12 success: True x: 0.5503212087491959这些结果都是
OptimizeResult的属性。success是一个布尔值,表示优化是否成功完成。如果优化成功,那么fun就是目标函数值在最优值x。从输出中可以看出,正如所料,这个函数的最佳值接近 x = 0.55。注:你可能知道,并不是每个函数都有最小值。例如,尝试看看如果你的目标函数是 y = x 会发生什么。对于
minimize_scalar(),没有最小值的目标函数通常会导致OverflowError,因为优化器最终会尝试一个太大而无法由计算机计算的数字。与没有最小值的函数相对的是有几个最小值的函数。在这些情况下,
minimize_scalar()不能保证找到函数的全局最小值。然而,minimize_scalar()有一个method关键字参数,您可以指定它来控制用于优化的求解器。SciPy 库有三种内置的标量最小化方法:
brent是布伦特算法的一个实现。这是默认方法。golden是黄金分割搜索的一个实现。文档指出布伦特的方法通常更好。bounded是布伦特算法的有界实现。当最小值在已知范围内时,限制搜索区域是有用的。当
method为brent或golden时,minimize_scalar()取另一个自变量,称为bracket。这是一个由两个或三个元素组成的序列,提供了对最小值区域边界的初步猜测。但是,这些解算器不保证找到的最小值在此范围内。另一方面,当
method为bounded时,minimize_scalar()取另一个名为bounds的自变量。这是严格限定最小值搜索区域的两个元素的序列。使用函数 y = x⁴ - x 尝试bounded方法。该函数绘制在下图中:
使用前面的示例代码,您可以像这样重新定义
objective_function():7def objective_function(x): 8 return x ** 4 - x ** 2首先,尝试默认的
brent方法:9res = minimize_scalar(objective_function)在这段代码中,您没有为
method传递一个值,所以默认情况下minimize_scalar()使用了brent方法。输出是这样的:fun: -0.24999999999999994 nfev: 15 nit: 11 success: True x: 0.7071067853059209您可以看到优化是成功的。它在 x = 0.707 和 y = -1/4 附近找到了最佳值。如果你解析求解了方程的最小值,那么你会发现最小值在 x = 1/√2,这与最小化函数找到的答案非常接近。然而,如果你想找到 x = -1/√2 处的对称最小值呢?您可以通过向
brent方法提供bracket参数来返回相同的结果:10res = minimize_scalar(objective_function, bracket=(-1, 0))在这段代码中,您提供了序列
(-1, 0)到bracket来开始在-1 和 0 之间的区域进行搜索。你期望在这个区域有一个最小值,因为目标函数是关于 y 轴对称的。然而,即使有了bracket,brent方法仍然返回 x = +1/√2 处的最小值。要找到 x = -1/√2 处的最小值,您可以使用带有bounds的bounded方法:11res = minimize_scalar(objective_function, method='bounded', bounds=(-1, 0))在这段代码中,您将
method和bounds作为参数添加到minimize_scalar(),并将bounds设置为从-1 到 0。此方法的输出如下:fun: -0.24999999999998732 message: 'Solution found.' nfev: 10 status: 0 success: True x: -0.707106701474177不出所料,最小值出现在 x = -1/√2 处。注意这个方法的附加输出,它在
res中包含了一个message属性。该字段通常用于一些最小化求解器的更详细输出。最小化多变量函数
scipy.optimize还包括更一般的minimize()。该函数可以处理多变量输入和输出,并具有更复杂的优化算法来处理这种情况。另外,minimize()可以处理约束对你问题的解决。您可以指定三种类型的约束:
LinearConstraint:通过用用户输入的数组取解的 x 值的内积,并将结果与一个下限和一个上限进行比较,来约束解。NonlinearConstraint:通过将用户提供的函数应用于解的 x 值并将返回值与下限和上限进行比较来约束解。Bounds:解 x 值被约束在一个下限和一个上限之间。当您使用这些约束时,它会限制您能够使用的优化方法的具体选择,因为并非所有可用的方法都以这种方式支持约束。
让我们来演示一下如何使用
minimize()。假设你是一名股票经纪人,对出售固定数量股票的总收入最大化感兴趣。你已经确定了一组特定的买家,对于每一个买家,你知道他们将支付的价格和他们手头有多少现金。你可以把这个问题表述为一个约束优化问题。目标函数是你想收入最大化。然而,
minimize()会找到一个函数的最小值,所以您需要将您的目标函数乘以-1 来找到产生最大负数的 x 值。这个问题有一个约束,就是买家购买的股份总数不超过你手头的股份数。每个解决方案变量也有界限,因为每个买家都有可用现金的上限,下限为零。负的解 x 值意味着你要向买家付款!
尝试下面的代码来解决这个问题。首先,导入您需要的模块,然后设置变量以确定市场中的买家数量和您想要出售的股票数量:
1import numpy as np 2from scipy.optimize import minimize, LinearConstraint 3 4n_buyers = 10 5n_shares = 15在这段代码中,您从
scipy.optimize导入numpy、minimize()和LinearConstraint。然后,你设定一个有 10 个买家的市场,他们将从你这里总共购买 15 股。接下来,在给定前两个数组的情况下,创建数组来存储每个买家支付的价格、他们能够支付的最大金额以及每个买家能够支付的最大股票数量。对于这个例子,您可以使用
np.random中的随机数生成来生成数组:6np.random.seed(10) 7prices = np.random.random(n_buyers) 8money_available = np.random.randint(1, 4, n_buyers)在这段代码中,您为 NumPy 的随机数生成器设置了种子。这个函数确保每次你运行这个代码,你都会得到相同的随机数。它在这里是为了确保你的输出与教程相同,以便比较。
在第 7 行中,您生成了买方将支付的价格数组。
np.random.random()在半开区间[0,1]上创建一个随机数数组。数组中元素的数量由参数的值决定,在本例中是买方的数量。在第 8 行中,您从[1,4]的半开区间上生成一个整数数组,同样包含购买者数量的大小。这个数组表示每个买家的可用现金总额。现在,您需要计算每个买家可以购买的最大股份数:
9n_shares_per_buyer = money_available / prices 10print(prices, money_available, n_shares_per_buyer, sep="\n")在第 9 行,您用
money_available与prices的比值来确定每个买家可以购买的最大股票数量。最后,打印每个数组,用换行符隔开。输出如下所示:[0.77132064 0.02075195 0.63364823 0.74880388 0.49850701 0.22479665 0.19806286 0.76053071 0.16911084 0.08833981] [1 1 1 3 1 3 3 2 1 1] [ 1.29647768 48.18824404 1.57816269 4.00638948 2.00598984 13.34539487 15.14670609 2.62974258 5.91328161 11.3199242 ]第一行是价格数组,价格是介于 0 和 1 之间的浮点数。该行后面是从 1 到 4 的整数形式的最大可用现金。最后,您会看到每个买家可以购买的股票数量。
现在,您需要为求解器创建约束和边界。约束条件是购买的股票总数不能超过可用的股票总数。这是一个约束而不是界限,因为它涉及到不止一个解变量。
从数学上来说,你可以说
x[0] + x[1] + ... + x[n] = n_shares,其中n是购买者的总数。更简洁地说,你可以用一个向量的点或内积来表示解的值,并约束它等于n_shares。记住LinearConstraint取输入数组与解值的点积,并将其与下限和上限进行比较。您可以用它来设置对n_shares的约束:11constraint = LinearConstraint(np.ones(n_buyers), lb=n_shares, ub=n_shares)在这段代码中,您创建了一个长度为
n_buyers的 1 的数组,并将其作为第一个参数传递给LinearConstraint。因为LinearConstraint用这个参数取解向量的点积,它将产生购买股票的总和。这个结果被限制在另外两个参数之间:
- 下界
lb- 上限
ub由于
lb = ub = n_shares,这是一个等式约束,因为值的总和必须等于lb和ub。如果lb不同于ub,那么它将是一个不等式约束。接下来,为解决方案变量创建边界。界限将购买的股份数量限制为下限为 0,上限为
n_shares_per_buyer。minimize()期望的边界格式是下限和上限的元组序列:12bounds = [(0, n) for n in n_shares_per_buyer]在这段代码中,您使用一个理解为每个买家生成一个元组列表。运行优化之前的最后一步是定义目标函数。回想一下,你正在努力使你的收入最大化。换句话说,你想让你收入的负数尽可能的大。
你从每笔交易中获得的收入是买家支付的价格乘以他们购买的股票数量。从数学上来说,你可以把它写成
prices[0]*x[0] + prices[1]*x[1] + ... + prices[n]*x[n],这里n也是买家的总数。同样,你可以用内积或
x.dot(prices)来更简洁地表示这一点。这意味着您的目标函数应该将当前解值x和价格数组作为参数:13def objective_function(x, prices): 14 return -x.dot(prices)在这段代码中,您将
objective_function()定义为接受两个参数。然后你取x和prices的点积,并返回该值的负值。请记住,您必须返回负值,因为您试图使该数字尽可能小,或者尽可能接近负无穷大。最后可以调用minimize():15res = minimize( 16 objective_function, 17 x0=10 * np.random.random(n_buyers), 18 args=(prices,), 19 constraints=constraint, 20 bounds=bounds, 21)在这段代码中,
res是OptimizeResult的一个实例,就像minimize_scalar()一样。正如你将看到的,有许多相同的领域,尽管问题是完全不同的。在对minimize()的调用中,您传递了五个参数:
objective_function:第一个位置参数必须是你要优化的函数。
x0:下一个参数是对解的值的初步猜测。在这种情况下,您只需提供一个 0 到 10 之间的随机值数组,长度为n_buyers。对于某些算法或某些问题,选择一个合适的初始猜测可能很重要。但是,对于这个例子来说,似乎并不太重要。
args:下一个参数是需要传递到目标函数中的其他参数的元组。minimize()将总是把解的当前值x传递到目标函数中,所以这个参数用作收集任何其他必要输入的地方。在这个例子中,您需要将prices传递给objective_function(),所以在这里。
constraints:接下来的论证是对问题的一系列约束。您已经越过了之前生成的关于可用份额数量的约束。
bounds:最后一个参数是您之前生成的解变量的边界序列。一旦求解器运行,您应该通过打印来检查
res:fun: -8.783020157087478 jac: array([-0.7713207 , -0.02075195, -0.63364828, -0.74880385, -0.49850702, -0.22479665, -0.1980629 , -0.76053071, -0.16911089, -0.08833981]) message: 'Optimization terminated successfully.' nfev: 204 nit: 17 njev: 17 status: 0 success: True x: array([1.29647768e+00, 2.78286565e-13, 1.57816269e+00, 4.00638948e+00, 2.00598984e+00, 3.48323773e+00, 3.19744231e-14, 2.62974258e+00, 2.38121197e-14, 8.84962214e-14])在这个输出中,您可以看到
message和status表示优化的最终状态。对于这个优化器,0状态意味着优化成功终止,这也可以在message中看到。由于优化是成功的,fun显示目标函数值在优化的解决方案值。这次销售你将获得 8.78 美元的收入。你可以在
res.x中看到优化函数的x的值。在这种情况下,结果是你应该向第一个买家出售大约 1.3 股,向第二个买家出售零股,向第三个买家出售 1.6 股,向第四个买家出售 4.0 股,以此类推。您还应该检查并确保满足您设置的约束和界限。您可以使用以下代码来实现这一点:
22print("The total number of shares is:", sum(res.x)) 23print("Leftover money for each buyer:", money_available - res.x * prices)在这段代码中,您打印每个买家购买的股票的总和,它应该等于
n_shares。然后,你打印每个买家手头的现金和他们花费的金额之间的差额。这些值中的每一个都应该是正数。这些检查的输出如下所示:The total number of shares is: 15.000000000000002 Leftover money for each buyer: [3.08642001e-14 1.00000000e+00 3.09752224e-14 6.48370246e-14 3.28626015e-14 2.21697984e+00 3.00000000e+00 6.46149800e-14 1.00000000e+00 1.00000000e+00]如您所见,解决方案的所有约束和界限都得到了满足。现在你应该试着改变问题,这样求解者就不能找到解决方案。将
n_shares的值更改为 1000,这样您就可以尝试向这些相同的买家出售 1000 股。当你运行minimize()时,你会发现结果如下所示:fun: nan jac: array([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]) message: 'Iteration limit exceeded' nfev: 2182 nit: 101 njev: 100 status: 9 success: False x: array([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan])请注意,
status属性现在有了一个值9,并且message表示已经超过了迭代限制。鉴于每个买家的钱数和市场上的买家数量,不可能卖出 1000 股。然而,minimize()仍然返回一个OptimizeResult实例,而不是引发一个错误。在继续进一步计算之前,您需要确保检查状态代码。结论
在本教程中,您了解了 SciPy 生态系统以及它与 SciPy 库的不同之处。您阅读了 SciPy 中的一些可用模块,并学习了如何使用 Anaconda 或 pip 安装 SciPy。然后,您关注了一些使用 SciPy 中的集群和优化功能的例子。
在聚类的例子中,您开发了一种算法来将垃圾短信从合法短信中分类出来。使用
kmeans(),你发现超过 20 位数左右的消息极有可能是垃圾消息!在优化的例子中,你首先在一个只有一个变量的数学上清晰的函数中找到最小值。然后,你解决了更复杂的问题,最大化你卖股票的利润。使用
minimize(),你找到了卖给一群买家的最优股票数量,获利 8.79 美元!SciPy 是一个巨大的库,有更多的模块可以深入研究。有了现在的知识,你就可以开始探索了!
您可以通过下载下面链接中的源代码来学习本教程中的示例:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来了解 SciPy。*****
使用 scipy.fft 的傅里叶变换:Python 信号处理
傅立叶变换是分析信号的强大工具,用于从音频处理到图像压缩的方方面面。SciPy 在其
scipy.fft模块中提供了一个成熟的实现,在本教程中,您将学习如何使用它。
scipy.fft模块可能看起来令人生畏,因为有许多函数,通常有相似的名字,并且文档使用了许多没有解释的技术术语。好消息是,您只需要理解一些核心概念就可以开始使用该模块。如果你对数学不适应,也不用担心!您将通过具体的示例对算法有所了解,如果您想深入研究这些等式,还可以找到更多资源的链接。对于傅立叶变换如何工作的直观介绍,你可能会喜欢 3Blue1Brown 的视频。
在本教程中,您将学习:
- 如何以及何时使用傅立叶变换
- 如何从
scipy.fft中为您的使用案例选择正确的功能- 如何查看和修改信号的频谱
- 在
scipy.fft中有哪些不同的变换如果你想在读完这篇教程后保留它的摘要,请下载下面的备忘单。它解释了
scipy.fft模块中的所有功能,并对可用的不同转换类型进行了分类:scipy.fft 备忘单: 点击这里获得免费的 scipy.fft 备忘单,它总结了本教程中介绍的技术。
scipy.fft模块傅立叶变换在许多应用中是至关重要的工具,尤其是在科学计算和数据科学中。因此,SciPy 很早就提供了它及其相关转换的实现。最初,SciPy 提供了
scipy.fftpack模块,但是他们已经更新了他们的实现,并把它移到了scipy.fft模块。SciPy 功能齐全。关于这个库的更一般的介绍,请查看 Scientific Python:使用 SciPy 进行优化。
安装 SciPy 和 Matplotlib
在开始之前,您需要安装 SciPy 和 Matplotlib 。您可以通过以下两种方式之一实现这一点:
用 Anaconda 安装:下载安装 Anaconda 个人版。它附带了 SciPy 和 Matplotlib,所以一旦您按照安装程序中的步骤操作,就大功告成了!
用
pip安装:如果你已经安装了pip,那么你可以用下面的命令安装这些库:$ python -m pip install -U scipy matplotlib`您可以通过在您的终端中键入
python并运行以下代码来验证安装是否有效:
>>> import scipy, matplotlib
>>> print(scipy.__file__)
/usr/local/lib/python3.6/dist-packages/scipy/__init__.py
>>> print(matplotlib.__file__)
/usr/local/lib/python3.6/dist-packages/matplotlib/__init__.py
这段代码导入 SciPy 和 Matplotlib 并打印模块的位置。您的计算机可能会显示不同的路径,但只要它打印一个路径,安装工作。
SciPy 现已安装!现在是时候来看看scipy.fft和scipy.fftpack的区别了。
scipy.fftvsscipy.fftpackT2】
在查看 SciPy 文档时,您可能会遇到两个看起来非常相似的模块:
scipy.fftscipy.fftpack
scipy.fft模块较新,应优先于scipy.fftpack。你可以在 SciPy 1.4.0 的发行说明中读到更多关于这一变化的信息,但这里有一个简短的总结:
scipy.fft拥有改进的 API。scipy.fft支持使用多个工人,这在某些情况下可以提供速度提升。scipy.fftpack被认为是遗留的,SciPy 建议使用scipy.fft来代替。
除非你有充分的理由使用scipy.fftpack,否则你应该坚持使用scipy.fft。
scipy.fftvsnumpy.fftT2】
SciPy 的快速傅立叶变换(FFT) 实现比 NumPy 的实现包含更多的特性,并且更有可能获得错误修复。如果可以选择,您应该使用 SciPy 实现。
NumPy 保持了 FFT 实现的向后兼容性,尽管作者认为像傅立叶变换这样的功能最好放在 SciPy 中。更多详情见 SciPy 常见问题解答。
傅立叶变换
傅立叶分析是研究如何将一个数学函数分解成一系列更简单的三角函数的领域。傅立叶变换是这一领域的一个工具,用于将一个函数分解成它的分量频率。
好吧,这个定义太深奥了。出于本教程的目的,傅立叶变换是一种工具,允许您获取信号并查看其中每个频率的功率。看一下这句话中的重要术语:
- 信号是随时间变化的信息。例如,音频、视频和电压轨迹都是信号的例子。
- 一个频率是某物重复的速度。例如,时钟以一赫兹(Hz)的频率滴答作响,即每秒重复一次。
- 功率,这里只是指每个频率的强弱。
下图是一些正弦波的频率和功率的直观演示:
高频正弦波的波峰比低频正弦波的波峰靠得更近,因为它们重复的频率更高。低功率正弦波的峰值比其他两个正弦波小。
为了更具体地说明这一点,假设您对某人同时在钢琴上弹奏三个音符的录音进行了傅立叶变换。得到的频谱将显示三个峰值,每个音符一个。如果这个人演奏一个音符比其他的更柔和,那么这个音符的频率会比其他两个低。
以下是钢琴示例的视觉效果:
钢琴上最高的音符比其他两个音符演奏得更安静,因此该音符产生的频谱具有较低的峰值。
为什么需要傅立叶变换?
傅立叶变换在许多应用中是有用的。比如 Shazam 等音乐识别服务,就是利用傅立叶变换来识别歌曲。JPEG 压缩使用傅立叶变换的一种变体来移除图像的高频成分。语音识别使用傅立叶变换和相关变换从原始音频中恢复口语单词。
一般来说,如果需要查看信号中的频率,就需要傅里叶变换。如果在时域处理信号很困难,那么使用傅立叶变换将其移到频域是值得一试的。在下一节中,您将了解时域和频域之间的差异。
时域与频域
在本教程的其余部分,你会看到术语时域和频域。这两个术语指的是看待信号的两种不同方式,要么将其视为分量频率,要么视为随时间变化的信息。
在时域中,信号是振幅(y 轴)随时间(x 轴)变化的波。您很可能习惯于看到时间域中的图表,例如下图:
这是某音频的图像,是一个时域信号。横轴表示时间,纵轴表示振幅。
在频域中,信号表示为一系列频率(x 轴),每个频率都有一个相关的功率(y 轴)。下图是经过傅里叶变换后的上述音频信号:
这里,来自之前的音频信号由其组成频率表示。底部的每个频率都有一个相关的能量,产生你所看到的光谱。
有关频域的更多信息,请查看 DeepAI 词汇表条目。
傅立叶变换的类型
傅立叶变换可以细分为不同类型的变换。最基本的细分基于转换操作的数据类型:连续函数或离散函数。本教程将只讨论离散傅立叶变换(DFT) 。
即使在本教程中,你也会经常看到术语 DFT 和 FFT 互换使用。然而,它们并不完全一样。快速傅立叶变换(FFT) 是一种计算离散傅立叶变换(DFT)的算法,而 DFT 就是变换本身。
你将在scipy.fft库中看到的另一个区别是不同类型的输入。fft()接受复数值输入,rfft()接受实数值输入。向前跳到章节使用快速傅立叶变换(FFT) 来解释复数和实数。
另外两种变换与 DFT 密切相关:离散余弦变换(DCT)和离散正弦变换(T2 变换)。你将在一节中了解离散余弦和正弦变换。
实际例子:从音频中去除不想要的噪声
为了帮助您理解傅立叶变换以及可以做些什么,您需要过滤一些音频。首先,您将创建一个带有高音调嗡嗡声的音频信号,然后使用傅立叶变换消除嗡嗡声。
产生信号
正弦波有时被称为纯音,因为它们代表单一频率。您将使用正弦波来生成音频,因为它们会在生成的频谱中形成明显的峰值。
正弦波的另一个优点是可以直接使用 NumPy 生成。如果你以前没有用过 NumPy,那么你可以看看什么是 NumPy?
下面是一些生成正弦波的代码:
import numpy as np
from matplotlib import pyplot as plt
SAMPLE_RATE = 44100 # Hertz
DURATION = 5 # Seconds
def generate_sine_wave(freq, sample_rate, duration):
x = np.linspace(0, duration, sample_rate * duration, endpoint=False)
frequencies = x * freq
# 2pi because np.sin takes radians
y = np.sin((2 * np.pi) * frequencies)
return x, y
# Generate a 2 hertz sine wave that lasts for 5 seconds
x, y = generate_sine_wave(2, SAMPLE_RATE, DURATION)
plt.plot(x, y)
plt.show()
在您导入 NumPy 和 Matplotlib 之后,您定义了两个常量:
SAMPLE_RATE决定了信号每秒用多少个数据点来表示正弦波。因此,如果信号的采样速率为 10 Hz,并且是一个 5 秒的正弦波,那么它将有10 * 5 = 50个数据点。DURATION是生成样本的长度。
接下来,定义一个函数来生成一个正弦波,因为以后会多次用到它。该函数获取一个频率freq,然后返回你将用来绘制波形的x和y值。
正弦波的 x 坐标在0和DURATION之间均匀分布,因此代码使用 NumPy 的 linspace() 来生成它们。它需要一个起始值、一个结束值和要生成的样本数。设置endpoint=False对于傅立叶变换正常工作很重要,因为它假设信号是周期性的。
np.sin() 计算正弦函数在每个 x 坐标的值。结果乘以频率使正弦波以该频率振荡,乘积乘以 2π将输入值转换为弧度。
注意:如果你以前没怎么学过三角学,或者你需要复习,那么就去看看可汗学院的三角学课程。
定义函数后,使用它生成一个持续 5 秒的 2 赫兹正弦波,并使用 Matplotlib 绘制它。你的正弦波图应该是这样的:
x 轴表示以秒为单位的时间,由于时间的每一秒都有两个峰值,所以可以看到正弦波每秒振荡两次。这种正弦波的频率太低,听不到,因此在下一节中,您将生成一些频率更高的正弦波,并了解如何混合它们。
混合音频信号
好消息是混合音频信号只需两步:
- 将信号加在一起
- 归一化结果
在将信号混合在一起之前,您需要生成它们:
_, nice_tone = generate_sine_wave(400, SAMPLE_RATE, DURATION)
_, noise_tone = generate_sine_wave(4000, SAMPLE_RATE, DURATION)
noise_tone = noise_tone * 0.3
mixed_tone = nice_tone + noise_tone
这个代码示例中没有什么新内容。它生成分别分配给变量 nice_tone和noise_tone的中音和高音。你将使用高音调作为你不想要的噪音,所以它会乘以0.3来降低它的功率。然后代码将这些音调加在一起。注意,您使用下划线(_)来丢弃由generate_sine_wave()返回的x值。
下一步是标准化,或者缩放信号以适合目标格式。由于您稍后将如何存储音频,您的目标格式是一个 16 位整数,其范围从-32768 到 32767:
normalized_tone = np.int16((mixed_tone / mixed_tone.max()) * 32767)
plt.plot(normalized_tone[:1000])
plt.show()
在这里,代码对mixed_tone进行缩放,使其适合一个 16 位整数,然后使用 NumPy 的np.int16将其转换为该数据类型。将mixed_tone除以其最大值,将其缩放到-1和1之间。当这个信号乘以32767后,缩放在-32767和32767之间,大致是np.int16的范围。代码只绘制第一个1000样本,这样您可以更清楚地看到信号的结构。
你的情节应该是这样的:
信号看起来像一个扭曲的正弦波。你看到的正弦波就是你产生的 400 Hz 的音,失真就是 4000 Hz 的音。如果你仔细观察,你会发现扭曲的形状是正弦波。
要收听音频,您需要将其存储为音频播放器可以读取的格式。最简单的方法是使用 SciPy 的 wavfile.write 方法将其存储在一个 WAV 文件中。16 位整数是 WAV 文件的标准数据类型,因此您将把信号规范化为 16 位整数:
from scipy.io.wavfile import write
# Remember SAMPLE_RATE = 44100 Hz is our playback rate
write("mysinewave.wav", SAMPLE_RATE, normalized_tone)
这段代码将写入运行 Python 脚本的目录中的文件mysinewave.wav。然后你可以使用任何音频播放器或者甚至是使用 Python 的来听这个文件。你会听到一个低音和一个高音。这些是您混合的 400 Hz 和 4000 Hz 正弦波。
完成这一步后,您就准备好了音频样本。下一步是使用傅立叶变换去除高音音调!
使用快速傅立叶变换
是时候对你生成的音频使用 FFT 了。FFT 是一种实现傅里叶变换的算法,可以在时域中计算信号的频谱,例如您的音频:
from scipy.fft import fft, fftfreq
# Number of samples in normalized_tone
N = SAMPLE_RATE * DURATION
yf = fft(normalized_tone)
xf = fftfreq(N, 1 / SAMPLE_RATE)
plt.plot(xf, np.abs(yf))
plt.show()
这段代码将计算你生成的音频的傅立叶变换并绘制出来。在分解它之前,先看看它产生的情节:
你可以在正频率上看到两个峰值,在负频率上看到这些峰值的镜像。正频率峰值位于 400 Hz 和 4000 Hz,这对应于您输入音频的频率。
傅立叶变换将复杂多变的信号转换成它所包含的频率。因为你只输入了两个频率,所以只输出了两个频率。正负对称是将实值输入放入傅立叶变换的副作用,但稍后你会听到更多。
在前几行中,您从稍后将使用的scipy.fft导入函数,并定义一个变量N,该变量存储信号中的样本总数。
接下来是最重要的部分,计算傅立叶变换:
yf = fft(normalized_tone)
xf = fftfreq(N, 1 / SAMPLE_RATE)
代码调用了两个非常重要的函数:
一个 bin 是一个已经分组的数值范围,就像一个直方图一样。关于仓的更多信息,参见本信号处理堆栈交换问题。出于本教程的目的,您可以认为它们只是单个值。
一旦获得傅立叶变换的结果值及其相应的频率,就可以绘制它们:
plt.plot(xf, np.abs(yf))
plt.show()
这段代码有趣的部分是在绘制之前对yf所做的处理。你在yf上调用 np.abs() 是因为它的值是复数。
一个复数是一个数,它有两个部分,一个实数部分和一个虚数部分。有很多理由说明这样定义数字是有用的,但是你现在需要知道的是它们的存在。
数学家一般将复数写成 a + bi 的形式,其中 a 为实部, b 为虚部。 b 后面的 i 表示 b 是虚数。
注:有时候你会看到用 i 写的复数,有时候你会看到用 j 写的复数,比如 2 + 3 i 和 2 + 3 j 。两者是一样的,只是 i 被数学家用的多, j 被工程师用的多。
想了解更多关于复数的知识,请看一看可汗学院的课程或数学趣味网页。
由于复数有两个部分,在二维轴上绘制它们相对于频率的图形需要从它们中计算出一个值。这就是np.abs()的用武之地。它计算复数的√(a + b ),这是两个数字加在一起的总幅度,重要的是是单个值。
注意:作为题外话,你可能已经注意到fft()返回的最大频率刚刚超过 20 千赫兹,准确地说是 22050 赫兹。这个值正好是我们采样率的一半,被称为奈奎斯特频率。
这是信号处理中的一个基本概念,意味着采样速率必须至少是信号最高频率的两倍。
使用rfft()和加快速度
fft()输出的频谱围绕 y 轴反射,因此负半部分是正半部分的镜像。这种对称性是通过将实数**(非复数)输入到变换中产生的。*
*您可以利用这种对称性,通过只计算一半来加快傅立叶变换的速度。scipy.fft以 rfft() 的形式实现这种速度黑客。
关于rfft()的伟大之处在于它是fft()的替代者。记住之前的 FFT 代码:
yf = fft(normalized_tone)
xf = fftfreq(N, 1 / SAMPLE_RATE)
换入rfft(),代码基本保持不变,只是有一些关键的变化:
from scipy.fft import rfft, rfftfreq
# Note the extra 'r' at the front
yf = rfft(normalized_tone)
xf = rfftfreq(N, 1 / SAMPLE_RATE)
plt.plot(xf, np.abs(yf))
plt.show()
由于rfft()返回的输出只有fft()的一半,它使用不同的函数来获得频率映射,rfftfreq()而不是fftfreq()。
rfft()仍然产生复杂的输出,所以绘制其结果的代码保持不变。然而,由于负频率已经消失,该图应该如下所示:

你可以看到上面的图像只是fft()产生的频谱的正侧。rfft()从不计算频谱的负半部分,这使得它比使用fft()更快。
使用rfft()的速度是使用fft()的两倍,但是有些输入长度比其他的要快。如果你知道你将只与实数打交道,那么这是一个值得了解的速度技巧。
现在你已经有了信号的频谱,你可以继续过滤它。
过滤信号
傅立叶变换的一大优点是它是可逆的,因此当您将信号变换回时域时,您在频域对信号所做的任何更改都会生效。您将利用这一点来过滤您的音频并消除高音频率。
警告:本节演示的滤波技术不适用于真实世界的信号。参见章节避免过滤陷阱了解原因的解释。
rfft()返回的值代表每个频率仓的功率。如果给定频段的功率设置为零,则该频段中的频率将不再出现在结果时域信号中。
使用xf的长度、最大频率以及频率仓均匀间隔的事实,您可以计算出目标频率的索引:
# The maximum frequency is half the sample rate
points_per_freq = len(xf) / (SAMPLE_RATE / 2)
# Our target frequency is 4000 Hz
target_idx = int(points_per_freq * 4000)
然后,您可以在目标频率附近的索引处设置yf至0以消除它:
yf[target_idx - 1 : target_idx + 2] = 0
plt.plot(xf, np.abs(yf))
plt.show()
您的代码应该产生以下图形:

因为只有一个峰值,所以看起来它起作用了!接下来,您将应用傅里叶逆变换回到时域。
应用逆 FFT
应用逆 FFT 类似于应用 FFT:
from scipy.fft import irfft
new_sig = irfft(yf)
plt.plot(new_sig[:1000])
plt.show()
既然使用的是rfft(),那么就需要使用irfft()来进行逆运算。然而,如果你使用了fft(),那么反函数将会是ifft()。您的绘图现在应该看起来像这样:
可以看到,现在有一个频率为 400 Hz 的正弦波振荡,并且成功消除了 4000 Hz 噪声。
同样,在将信号写入文件之前,需要对其进行规范化。你可以像上次一样做:
norm_new_sig = np.int16(new_sig * (32767 / new_sig.max()))
write("clean.wav", SAMPLE_RATE, norm_new_sig)
当你听这个文件的时候,你会听到烦人的噪音已经消失了!
避免过滤陷阱
上面的例子更多的是出于教育目的,而不是现实世界的使用。在真实世界的信号上复制这个过程,比如一段音乐,可能会引入比它消除的更多的嗡嗡声。
在现实世界中,您应该使用 scipy.signal 包中的滤波器设计功能对信号进行滤波。过滤是一个涉及大量数学知识的复杂话题。为了更好的介绍,看看科学家和工程师的数字信号处理指南。
离散余弦和正弦变换
如果不看一下离散余弦变换(DCT) 和离散正弦变换(DST) ,关于scipy.fft模块的教程是不完整的。这两种变换与傅立叶变换密切相关,但完全是对实数进行操作。这意味着它们将一个实值函数作为输入,产生另一个实值函数作为输出。
SciPy 将这些变换实现为 dct() 和 dst() 。i*和*n变量分别是函数的逆和 n 维版本。
DCT 和 DST 有点像傅立叶变换的两个部分。这并不完全正确,因为数学要复杂得多,但这是一个有用的心理模型。
那么,如果 DCT 和 DST 就像傅立叶变换的两半,那么它们为什么有用呢?
首先,它们比完全傅立叶变换更快,因为它们有效地完成了一半的工作。他们甚至可以比rfft()更快。最重要的是,它们完全以实数工作,所以你永远不用担心复数。
在学习如何在它们之间进行选择之前,您需要了解偶数和奇数函数。偶数函数关于 y 轴对称,而奇数函数关于原点对称。为了直观地想象这一点,请看下图:
你可以看到偶数函数是关于 y 轴对称的。奇函数关于 y = - x 对称,被描述为关于原点对称的。
当你计算傅立叶变换时,你假设你计算的函数是无穷的。全傅里叶变换(DFT)假设输入函数无限重复。然而,DCT 和 DST 假设函数是通过对称性扩展的。DCT 假设函数以偶对称扩展,DST 假设函数以奇对称扩展。
下图说明了每个变换如何将函数扩展到无穷大:
在上图中,DFT 按原样重复该函数。DCT 垂直镜像该函数以扩展它,DST 水平镜像它。
注意,DST 暗示的对称性导致函数的大跳跃。这些被称为的不连续性和在产生的频谱中产生更多的高频成分。因此,除非你知道你的数据具有奇对称性,否则你应该使用 DCT 而不是 DST。
DCT 是非常常用的。还有很多例子,但是 JPEG、MP3 和 WebM 标准都使用 DCT。
结论
傅立叶变换是一个强有力的概念,它被用于从纯数学到音频工程甚至金融的各个领域。你现在已经熟悉了离散傅立叶变换,并且已经准备好使用scipy.fft模块将其应用于滤波问题。
在本教程中,您学习了:
- 如何以及何时使用傅立叶变换
- 如何从
scipy.fft中为您的使用案例选择正确的功能 - 时域和频域有什么区别
- 如何查看和修改信号的频谱
- 如何使用
rfft()加速你的代码
在上一节中,您还学习了离散余弦变换和离散正弦变换。您看到了调用哪些函数来使用它们,并且了解了何时使用其中一个而不是另一个。
如果你想要本教程的摘要,那么你可以下载下面的备忘单。它解释了scipy.fft模块中的所有功能,并对可用的不同转换类型进行了分类:
scipy.fft 备忘单: 点击这里获得免费的 scipy.fft 备忘单,它总结了本教程中介绍的技术。
继续探索这个迷人的话题,尝试变换,一定要在下面的评论中分享你的发现!********
使用 scipy.linalg 在 Python 中处理线性系统
线性代数广泛应用于各种学科,一旦你使用像向量和线性方程这样的概念组织信息,你就可以用它来解决许多问题。在 Python 中,与这个主题相关的大多数例程都是在 scipy.linalg 中实现的,这提供了非常快的线性代数能力。
特别是,线性系统在建模各种现实世界问题中发挥着重要作用,scipy.linalg提供了以高效方式研究和解决它们的工具。
在本教程中,您将学习如何:
- 利用
scipy.linalg将线性代数概念应用到实际问题中 - 使用 Python 和 NumPy 处理向量和矩阵
- 使用线性系统模拟实际问题
- 如何用
scipy.linalg解线性方程组
我们开始吧!
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
scipy.linalg 入门
SciPy 是一个用于科学计算的开源 Python 库,包括几个用于科学和工程中常见任务的模块,如线性代数、优化、积分、插值、信号处理。它是 SciPy 栈的一部分,后者包括其他几个用于科学计算的包,如 NumPy 、 Matplotlib 、 SymPy 、 IPython 和 pandas 。
线性代数是数学的一个分支,涉及线性方程及其使用向量和矩阵的表示。这是一个在工程的几个领域使用的基础学科,也是更深入理解机器学习的先决条件。
scipy.linalg 包括几个处理线性代数问题的工具,包括执行矩阵计算的函数,如行列式、逆矩阵、特征值、特征向量和奇异值分解。
在本教程中,你将使用scipy.linalg中的一些函数来处理涉及线性系统的实际问题。为了使用scipy.linalg,你必须安装和设置 SciPy 库,这可以通过使用 Anaconda Python 发行版和 conda 包和环境管理系统来完成。
注意:要了解更多关于 Anaconda 和 conda 的信息,请查看在 Windows 上设置 Python 进行机器学习。
首先,创建一个 conda 环境并激活它:
$ conda create --name linalg
$ conda activate linalg
激活 conda 环境后,您的提示符将显示其名称linalg。然后,您可以在环境中安装必要的软件包:
(linalg) $ conda install scipy jupyter
执行此命令后,系统需要一段时间来确定依赖项并继续安装。
注意:除了 SciPy,您还将使用 Jupyter Notebook 在交互式环境中运行代码。这样做不是强制性的,但它有助于处理数值和科学应用程序。
要复习使用 Jupyter 笔记本,请看一下 Jupyter 笔记本:简介。
如果您喜欢使用不同的 Python 发行版和 pip包管理器来阅读本文,那么展开下面的可折叠部分来看看如何设置您的环境。
首先,建议创建一个虚拟环境,在其中安装软件包。假设您安装了 Python,您可以创建一个名为linalg的虚拟环境:
$ python -m venv linalg
创建环境后,您需要激活它,这样您就可以使用pip在环境中安装包。如果您使用的是 Linux 或 macOS,那么您可以使用以下命令激活环境:
$ source ./linalg/bin/activate
在 Windows 上,您必须使用的命令略有不同:
C:> \linalg\Scripts\activate.bat
激活 conda 环境后,您的提示符将显示其名称linalg。然后,您可以使用pip在环境中安装必要的包:
(linalg) $ python -m pip install scipy jupyter
系统需要一段时间来找出依赖关系并继续安装。命令结束后,您就可以打开 Jupyter 并使用scipy.linalg了。
在打开 Jupyter Notebook 之前,您需要注册 conda linalg环境,以便您可以使用它作为内核来创建笔记本。为此,在激活了linalg环境的情况下,运行以下命令:
(linalg) $ python -m ipykernel install --user --name linalg
现在,您可以通过运行以下命令来打开 Jupyter 笔记本:
$ jupyter notebook
Jupyter 加载到你的浏览器后,点击新建 → 直线创建一个新的笔记本,如下图所示:

在笔记本内部,您可以通过导入包scipy来测试安装是否成功:
In [1]: import scipy现在您已经完成了环境的设置,您将看到如何在 Python 中处理向量和矩阵,这是使用
scipy.linalg处理线性代数应用程序的基础。使用 NumPy 处理向量和矩阵
矢量是一个数学实体,用于表示既有大小又有方向的物理量。它是解决工程和机器学习问题的一个基本工具,正如用于表示向量变换的矩阵以及其他应用一样。
NumPy 是在 Python 中使用矩阵和向量最多的库,与
scipy.linalg一起用于线性代数应用。在本节中,您将了解使用它创建矩阵和向量以及对它们执行操作的基本知识。要开始处理矩阵和向量,你需要在 Jupyter 笔记本上做的第一件事是导入
numpy。通常的方法是使用别名np:
In [2]: import numpy as np
为了表示矩阵和向量,NumPy 使用了一种叫做 ndarray 的特殊类型。
要创建一个ndarray对象,可以使用np.array(),它需要一个类似数组的对象,比如一个列表或者一个嵌套列表。
例如,假设您需要创建以下矩阵:
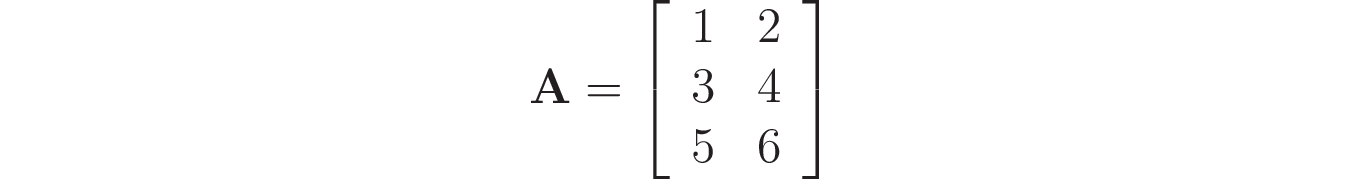
要用 NumPy 创建它,您可以使用np.array(),提供一个包含矩阵每行元素的嵌套列表:
In [3]: A = np.array([[1, 2], [3, 4], [5, 6]]) ...: A Out[3]: array([[1, 2], [3, 4], [5, 6]])正如您可能注意到的,NumPy 提供了矩阵的可视化表示,您可以在其中识别它的列和行。
值得注意的是,NumPy 数组的元素必须是同一类型。您可以使用
.dtype来检查 NumPy 数组的类型:
In [4]: A.dtype
Out[4]:
dtype('int64')
由于A的所有元素都是整数,所以数组是用类型int64创建的。如果其中一个元素是一个浮点数,那么这个数组将被创建为类型float64:
In [5]: A = np.array([[1.0, 2], [3, 4], [5, 6]]) ...: A Out[5]: array([[1., 2.], [3., 4.], [5., 6.]]) In [6]: A.dtype Out[6]: dtype('float64')要检查
ndarray对象的尺寸,可以使用.shape。例如,要检查A的尺寸,可以使用A.shape:
In [7]: A.shape
Out[7]:
(3, 2)
正如所料,A矩阵的维数是3 × 2,因为A有三行两列。
当处理涉及矩阵的问题时,你经常需要使用转置操作,它交换矩阵的列和行。
要转置由ndarray对象表示的向量或矩阵,可以使用.transpose()或.T。比如你可以用A.T获得A的转置:
In [8]: A.T Out[8]: array([[1., 3., 5.], [2., 4., 6.]])通过转置,
A的列变成了A.T的行,行变成了列。要创建一个向量,可以使用
np.array(),提供一个包含向量元素的列表:
In [9]: v = np.array([1, 2, 3])
...: v
Out[9]:
array([1, 2, 3])
要检查向量的维度,您可以像之前一样使用.shape:
In [10]: v.shape Out[10]: (3,)注意这个向量的形状是
(3,),而不是(3, 1)或者(1, 3)。这是一个与那些习惯于使用 MATLAB 的人相关的 NumPy 特性。在 NumPy 中,可以创建像v这样的一维数组,这可能会在执行矩阵和向量之间的运算时产生问题。例如,转置操作对一维数组没有影响。每当您向
np.array()提供一个类似一维数组的参数时,得到的数组将是一个一维数组。要创建二维数组,您必须提供一个类似二维数组的参数,如嵌套列表:
In [11]: v = np.array([[1, 2, 3]])
...: v.shape
Out[11]:
(1, 3)
上例中,v的维数为1 × 3,对应一个二维线矢量的维数。要创建列向量,可以使用嵌套列表:
In [12]: v = np.array([[1], [2], [3]]) ...: v.shape Out[12]: (3, 1)在这种情况下,
v的维数为3×1,对应一个二维列向量的维数。使用嵌套列表来创建向量可能很费力,尤其是使用最多的列向量。或者,您可以创建一个一维向量,向
np.array提供一个平面列表,并使用.reshape()来改变ndarray对象的尺寸:
In [13]: v = np.array([1, 2, 3]).reshape(3, 1)
...: v.shape
Out[13]:
(3, 1)
在上面的例子中,您使用.reshape()从形状为(3,)的一维向量中获得形状为(3, 1)的列向量。值得一提的是.reshape()期望新数组的元素个数与原数组的元素个数兼容。换句话说,具有新形状的数组中的元素数量必须等于原始数组中的元素数量。
在这个例子中,您也可以使用.reshape()而不用显式定义数组的行数:
In [14]: v = np.array([1, 2, 3]).reshape(-1, 1) ...: v.shape Out[14]: (3, 1)这里,作为参数提供给
.reshape()的-1表示新数组只有一列所需的行数,由第二个参数指定。在这种情况下,由于原始数组有三个元素,新数组的行数将是3。在实际应用中,您经常需要创建由 0、1 或随机元素组成的矩阵。为此,NumPy 提供了一些方便的函数,您将在接下来看到。
使用便利函数创建数组
NumPy 还提供了一些方便的函数来创建数组。例如,要创建一个用零填充的数组,可以使用
np.zeros():
In [15]: A = np.zeros((3, 2))
...: A
Out[15]:
array([[0., 0.],
[0., 0.],
[0., 0.]])
作为它的第一个参数,np.zeros()期望一个元组来指示您想要创建的数组的形状,并且它返回一个类型为float64的数组。
类似地,要创建填充 1 的数组,可以使用np.ones():
In [16]: A = np.ones((2, 3)) ...: A Out[16]: array([[1., 1., 1.], [1., 1., 1.]])值得注意的是,
np.ones()也返回一个类型为float64的数组。要创建包含随机元素的数组,可以使用
np.random.rand():
In [17]: A = np.random.rand(3, 2)
...: A
Out[17]:
array([[0.8206045 , 0.54470809],
[0.9490381 , 0.05677859],
[0.71148476, 0.4709059 ]])
np.random.rand()返回一个从0到1的随机元素数组,取自均匀分布。注意,与np.zeros()和np.ones()不同的是,np.random.rand()不期望元组作为它的参数。
类似地,要获得一个数组,其中的随机元素来自平均值和单位方差为零的正态分布,您可以使用np.random.randn():
In [18]: A = np.random.randn(3, 2) ...: A Out[18]: array([[-1.20019512, -1.78337814], [-0.22135221, -0.38805899], [ 0.17620202, -2.05176764]])现在您已经创建了数组,您将看到如何使用它们执行操作。
对 NumPy 数组执行操作
在数组上使用加法(
+)、减法(-)、乘法(*)、除法(/)和指数(**)运算符的常见 Python 操作总是按元素执行的。如果其中一个操作数是一个标量,那么这个操作将在这个标量和数组的每个元素之间执行。例如,要创建一个填充了等于
10的元素的矩阵,您可以使用np.ones()并用*将输出乘以10:
In [19]: A = 10 * np.ones((2, 2))
...: A
Out[19]:
array([[10., 10.],
[10., 10.]])
如果两个操作数都是相同形状的数组,则运算将在数组的相应元素之间执行:
In [20]: A = 10 * np.ones((2, 2)) ...: B = np.array([[2, 2], [5, 5]]) ...: C = A * B ...: C Out[20]: array([[20., 20.], [50., 50.]])这里,您将矩阵
A的每个元素乘以矩阵B的相应元素。要根据线性代数规则执行矩阵乘法,可以使用
np.dot():
In [21]: A = np.array([[1, 2], [3, 4]])
...: v = np.array([[5], [6]])
...: x = np.dot(A, v)
...: x
Out[21]:
array([[17],
[39]])
这里,您将一个名为A的 2 × 2 矩阵乘以一个名为v的 2 × 1 向量。
您可以使用@操作符获得相同的结果,从 PEP 465 和 Python 3.5 开始,NumPy 和原生 Python 都支持该操作符:
In [22]: A = np.array([[1, 2], [3, 4]]) ...: v = np.array([[5], [6]]) ...: x = A @ v ...: x Out[22]: array([[17], [39]])除了处理矩阵和向量的基本操作,NumPy 还提供了一些特定的函数来处理
numpy.linalg中的线性代数。然而,对于那些应用程序来说,scipy.linalg提供了一些优势,您将在下面看到。将
scipy.linalg与numpy.linalg进行比较NumPy 在
numpy.linalg模块中包含了一些处理线性代数应用程序的工具。然而,除非您不想将 SciPy 作为依赖项添加到您的项目中,否则通常最好使用scipy.linalg,原因如下:
正如官方文档中解释的那样,
scipy.linalg包含了numpy.linalg中的所有功能,加上一些numpy.linalg中没有的额外高级功能。
scipy.linalg的编译总是支持 BLAS 和 LAPACK ,它们是包含以优化方式执行数值运算的例程的库。对于numpy.linalg,BLAS 和 LAPACK 的使用是可选的。因此,根据你如何安装 NumPy,scipy.linalg功能可能会比numpy.linalg快。总之,考虑到科学和技术应用程序通常没有关于依赖性的限制,安装 SciPy 并使用
scipy.linalg而不是numpy.linalg通常是个好主意。在下一节中,您将使用
scipy.linalg工具来处理线性系统。您将从一个简单的例子开始,然后将这些概念应用到一个实际问题中。用
scipy.linalg.solve()解线性系统线性系统可以是一个有用的工具,用于找到几个实际和重要问题的解决方案,包括与车辆交通、平衡化学方程式、电路和多项式插值相关的问题。
在这一节中,你将学习如何使用
scipy.linalg.solve()来求解线性系统。但是在着手编写代码之前,理解基础知识是很重要的。了解线性系统
线性系统,或者更准确地说,线性方程组,是与一组变量线性相关的一组方程。这里有一个与变量 x ₁、 x ₂和 x ₃:相关的线性系统的例子
这里有三个包含三个变量的方程。为了有一个线性系统,值k₁……k₉和b₁……b₃必须是常数。
当只有两三个方程和变量时,可以手动执行计算,合并方程,并找到变量的值。然而,对于四个或更多的变量,手动求解一个线性系统需要相当长的时间,并且出错是很常见的。
实际应用一般涉及大量变量,这使得手动求解线性系统不可行。幸运的是,有一些工具可以完成这项艰巨的工作,比如
scipy.linalg.solve()。使用
scipy.linalg.solve()SciPy 提供了
scipy.linalg.solve()来快速可靠地求解线性系统。要了解其工作原理,请考虑以下系统:
为了使用
scipy.linalg.solve(),你需要首先将线性系统写成一个矩阵乘积,如下式所示:
注意,计算完矩阵乘积后,你会得到系统的原始方程。
scipy.linalg.solve()期望解决的输入是矩阵A和向量b,它们可以使用 NumPy 数组来定义。这样,您可以使用以下代码求解系统:

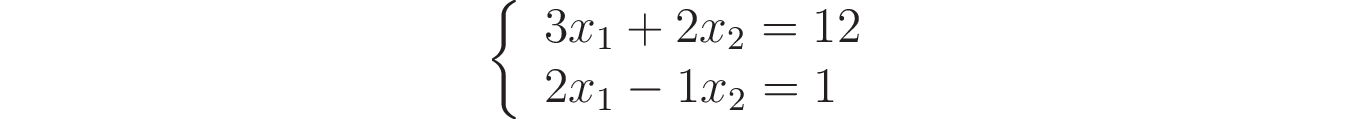
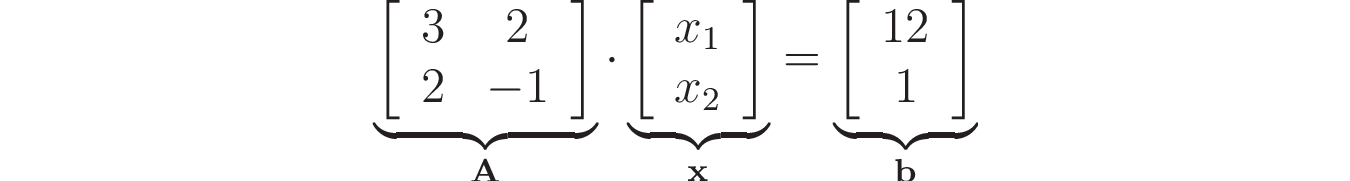
1In [1]: import numpy as np
2 ...: from scipy.linalg import solve
3
4In [2]: A = np.array(
5 ...: [
6 ...: [3, 2],
7 ...: [2, -1],
8 ...: ]
9 ...: )
10
11In [3]: b = np.array([12, 1]).reshape((2, 1))
12
13In [4]: x = solve(A, b)
14 ...: x
15Out[4]:
16array([[2.],
17 [3.]])
下面是正在发生的事情的分类:
- 1、2 号线从
scipy.linalg随solve()一起导入编号为np。 - 第 4 行到第 9 行使用名为
A的 NumPy 数组创建系数矩阵。 - 第 11 行使用名为
b的 NumPy 数组创建独立的术语向量。要使它成为两行的列向量,可以使用.reshape((2, 1))。 - 第 13 行和第 14 行调用
solve()求解由A和b表征的线性系统,结果存储在x中,并打印出来。请注意,solve()返回的是浮点成分的解,即使原始数组的所有元素都是整数。
如果你在原始方程中替换掉 x ₁=2 和 x ₂=3,那么你可以验证这就是系统的解。
既然您已经学习了使用scipy.linalg.solve()的基础知识,那么是时候看看线性系统的实际应用了。
解决实际问题:制定饮食计划
线性系统通常解决的一类问题是,当你需要找到获得某种混合物所需的组分比例时。下面,你将使用这个想法来建立一个膳食计划,混合不同的食物,以获得均衡的饮食。
为此,考虑均衡饮食应包括以下内容:
- 170 单位的维生素 A
- 180 单位的维生素 B
- 140 单位的维生素 C
- 180 单位的维生素 D
- 350 单位的维生素 E
你的任务是找出每种不同食物的数量,以获得规定量的维生素。在下表中,您得到了根据每种维生素的单位分析每种食物一克的结果:
| 食物 | 维生素 a | 维生素 b | 维生素 c | 钙化醇 | 生育酚 |
|---|---|---|---|---|---|
| #1 | one | Ten | one | Two | Two |
| #2 | nine | one | Zero | one | one |
| #3 | Two | Two | five | one | Two |
| #4 | one | one | one | Two | Thirteen |
| #5 | one | one | one | nine | Two |
通过将食物 1 表示为 x ₁等等,并考虑到你将混合 x ₁单位的食物 1、 x ₂单位的食物 2 等等,你可以写一个表达式来表示你在组合中得到的维生素 a 的量。考虑到均衡饮食应包含 170 单位的维生素 A,您可以使用维生素 A 栏中的数据写出以下等式:

对维生素 B、C、D 和 E 重复同样的过程,你得到下面的线性系统:

要使用scipy.linalg.solve(),您必须获得系数矩阵A和独立项向量b,它们由下式给出:
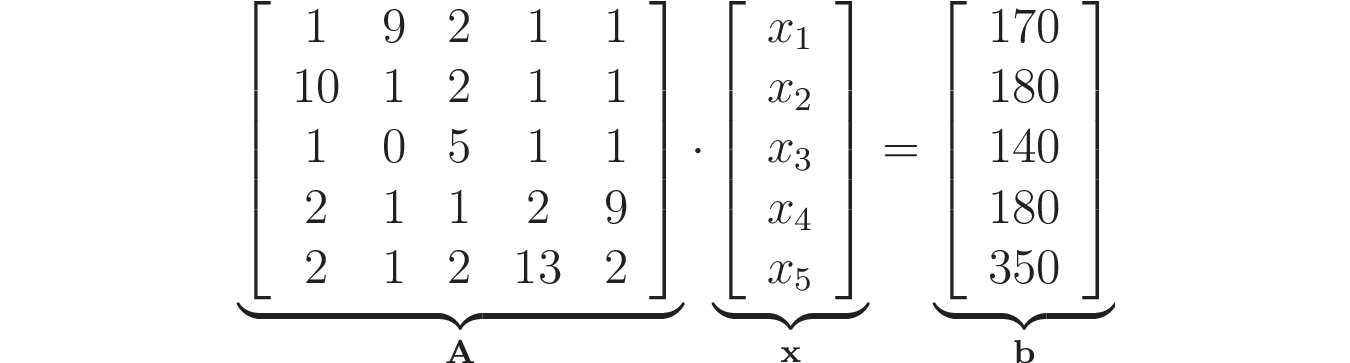
现在你只需要用scipy.linalg.solve()找出数量 x ₁,…, x ₅:
In [1]: import numpy as np ...: from scipy.linalg import solve In [2]: A = np.array( ...: [ ...: [1, 9, 2, 1, 1], ...: [10, 1, 2, 1, 1], ...: [1, 0, 5, 1, 1], ...: [2, 1, 1, 2, 9], ...: [2, 1, 2, 13, 2], ...: ] ...: ) In [3]: b = np.array([170, 180, 140, 180, 350]).reshape((5, 1)) In [4]: x = solve(A, b) ...: x Out[4]: array([[10.], [10.], [20.], [20.], [10.]])这表明均衡饮食应该包括
10单位食物 1、10单位食物 2、20单位食物 3、20单位食物 4 和10单位食物 5。结论
恭喜你!您已经学习了如何使用一些线性代数概念,以及如何使用
scipy.linalg来解决涉及线性系统的问题。您已经看到向量和矩阵对于表示数据非常有用,并且通过使用线性代数概念,您可以对实际问题进行建模并以高效的方式解决它们。在本教程中,您学习了如何:
- 利用
scipy.linalg将线性代数概念应用到实际问题中- 使用 Python 和 NumPy 处理向量和矩阵
- 使用线性系统模拟实际问题
- 利用
scipy.linalg求解线性系统线性代数是一个非常广泛的话题。有关其他线性代数应用程序的更多信息,请查看以下资源:
继续学习,欢迎在下面留下任何问题或评论!****
Python 作用域 LEGB 规则:解析代码中的名称
范围的概念决定了如何在你的代码中查找变量和名字。它决定了代码中变量的可见性。名称或变量的范围取决于您在代码中创建该变量的位置。Python 作用域的概念通常使用一个称为 LEGB 规则的规则来表示。
首字母缩写词 LEGB 中的字母代表局部、封闭、全局和内置作用域。这不仅总结了 Python 的作用域级别,还总结了 Python 在程序中解析名称时遵循的步骤顺序。
在本教程中,您将学习:
- 什么是范围以及它们在 Python 中是如何工作的
- 为什么了解 Python 作用域很重要
- 什么是 LEGB 规则以及 Python 如何使用它来解析名称
- 如何使用
global和nonlocal修改 Python 作用域的标准行为- Python 提供了哪些范围相关的工具以及如何使用它们
有了这些知识,您就可以利用 Python 作用域来编写更可靠、更易维护的程序。使用 Python 作用域将帮助您避免或最小化与名称冲突相关的错误,以及在您的程序中对全局名称的错误使用。
如果你熟悉 Python 的中级概念,比如类、函数、内部函数、变量、异常、综合、内置函数和标准的数据结构,你将从本教程中获益匪浅。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
理解范围
在编程中,一个名字的作用域定义了一个程序的区域,在这个区域中你可以明确地访问这个名字,比如变量、函数、对象等等。名称仅对其范围内的代码可见和可访问。一些编程语言利用作用域来避免名称冲突和不可预知的行为。最常见的情况是,您将区分两个通用范围:
全局作用域:你在这个作用域中定义的名字对你所有的代码都是可用的。
局部作用域:您在这个作用域中定义的名字只对这个作用域中的代码可用或可见。
范围的出现是因为早期的编程语言(比如 BASIC)只有全局名。有了这样的名字,程序的任何部分都可以在任何时候修改任何变量,因此维护和调试大型程序可能会成为一场真正的噩梦。要使用全局名称,您需要同时记住所有代码,以便随时了解给定名称的值。这是没有示波器的一个重要副作用。
像 Python 这样的一些语言使用范围来避免这种问题。当你使用一种实现作用域的语言时,你没有办法在程序的所有位置访问程序中的所有变量。在这种情况下,您访问给定名称的能力将取决于您在哪里定义了该名称。
注意:您将使用术语 name 来指代变量、常量、函数、类或任何其他可以被赋予名称的对象的标识符。
程序中的名字将具有定义它们的代码块的范围。当您可以从代码中的某个地方访问给定名称的值时,您会说该名称是作用域中的。如果你不能访问这个名字,那么你会说这个名字是超出范围。
Python 中的名称和作用域
因为 Python 是一种动态类型的语言,所以当你第一次给变量赋值时,Python 中的变量就存在了。另一方面,在您分别使用
def或class定义函数和类之后,它们就可用了。最后,模块在你导入后存在。总之,您可以通过以下操作之一创建 Python 名称:
操作 声明 分配任务 x = value导入操作 import module或from module import name函数定义 def my_func(): ...函数上下文中的参数定义 def my_func(arg1, arg2,... argN): ...类别定义 class MyClass: ...所有这些操作都会创建或在赋值的情况下更新新的 Python 名称,因为所有这些操作都会为变量、常量、函数、类、实例、模块或其他 Python 对象赋值。
注:****赋值操作和引用或访问操作有一个重要的区别。当您引用一个名称时,您只是检索它的内容或值。当您分配名称时,您要么创建该名称,要么修改它。
Python 使用名称分配或定义的位置将其与特定范围相关联。换句话说,您在代码中分配或定义名称的位置决定了该名称的范围或可见性。
例如,如果在函数内部给一个名字赋值,那么这个名字将有一个本地 Python 作用域。相比之下,如果你在所有函数之外给一个名字赋值——比如说,在一个模块的顶层——那么这个名字将会有一个全局 Python 作用域。
Python 作用域与名称空间
在 Python 中,作用域的概念与名称空间的概念密切相关。到目前为止,您已经了解到,Python 作用域决定了名字在程序中的可见位置。Python 作用域被实现为将名称映射到对象的字典。这些字典俗称名称空间。这些是 Python 用来存储名称的具体机制。它们存储在一个名为
.__dict__的特殊属性中。模块顶层的名称存储在模块的命名空间中。换句话说,它们存储在模块的
.__dict__属性中。看一下下面的代码:
>>> import sys
>>> sys.__dict__.keys() dict_keys(['__name__', '__doc__', '__package__',..., 'argv', 'ps1', 'ps2'])
导入 sys 后,可以使用.keys()来检查sys.__dict__的按键。这将返回一个列表,其中包含模块顶层定义的所有名称。在这种情况下,你可以说.__dict__持有sys的名称空间,并且是模块范围的具体表示。
注意:为了节省空间,本教程中一些示例的输出被缩写为(...)。根据您的平台、Python 版本,甚至根据您使用当前 Python 交互式会话的时间长短,输出可能会有所不同。
作为进一步的例子,假设您需要使用名称ps1,它在sys中定义。如果您知道 Python 中的.__dict__和名称空间是如何工作的,那么您至少可以用两种不同的方式引用ps1:
看一下下面的代码:
>>> sys.ps1 '>>> ' >>> sys.__dict__['ps1'] '>>> '一旦你导入了
sys,你就可以使用sys上的点符号来访问ps1。您也可以使用关键字'ps1'通过字典关键字查找来访问ps1。这两个操作返回相同的结果'>>> '。注意:
ps1是一个字符串指定 Python 解释器的主要提示。ps1仅在解释器处于交互模式时定义,其初始值为'>>> '。无论何时使用一个名称,比如变量或函数名,Python 都会搜索不同的作用域级别(或名称空间)来确定该名称是否存在。如果这个名字存在,那么你将总是得到它的第一个出现。否则,你会得到一个错误。您将在下一节中介绍这种搜索机制。
将 LEGB 规则用于 Python 范围
Python 使用所谓的 LEGB 规则来解析名称,该规则以 Python 的名称范围命名。LEGB 中的字母代表本地、封闭、全局和内置。以下是这些术语含义的简要概述:
局部(或函数)作用域是任意 Python 函数或
lambda表达式的代码块或代码体。这个 Python 范围包含您在函数中定义的名称。这些名称只能从函数的代码中看到。它是在函数调用时创建的,而不是在函数定义时创建的,所以你会有和函数调用一样多的不同局部作用域。即使多次调用同一个函数,或者递归调用,也是如此。每个调用都将导致创建一个新的本地范围。封闭(或非局部)作用域是一个特殊的作用域,只存在于嵌套函数中。如果局部作用域是一个内部或嵌套函数,那么封闭作用域就是外部或封闭函数的作用域。该作用域包含您在封闭函数中定义的名称。从内部函数和封闭函数的代码中可以看到封闭范围内的名称。
全局(或模块)作用域是 Python 程序、脚本或模块中最顶层的作用域。这个 Python 作用域包含您在程序或模块的顶层定义的所有名称。这个 Python 范围内的名称在代码中随处可见。
内置作用域是一个特殊的 Python 作用域,每当你运行一个脚本或打开一个交互式会话时,它就会被创建或加载。这个范围包含诸如关键字、函数、异常和其他内置于 Python 的属性。这个 Python 范围内的名称也可以在代码中的任何地方找到。当你运行一个程序或脚本时,Python 会自动加载它。
LEGB 规则是一种名称查找过程,它决定了 Python 查找名称的顺序。例如,如果您引用一个给定的名称,那么 Python 将在本地、封闭、全局和内置范围内依次查找该名称。如果该名称存在,那么您将获得它的第一次出现。否则,你会得到一个错误。
注意:注意,只有在函数(局部作用域)或嵌套或内部函数(局部和封闭作用域)中使用名称时,才会搜索局部和封闭 Python 作用域。
总之,当您使用嵌套函数时,通过首先检查局部范围或最内部函数的局部范围来解析名称。然后,Python 从最内部的范围到最外部的范围查看外部函数的所有封闭范围。如果没有找到匹配,那么 Python 会查看全局和内置范围。如果它找不到名字,那么你会得到一个错误。
在执行过程中的任何时候,根据您在代码中的位置,您最多有四个活动的 Python 作用域——本地、封闭、全局和内置。另一方面,您将始终拥有至少两个活动范围,它们是全局范围和内置范围。这两个范围将永远为您提供。
功能:局部范围
局部作用域或函数作用域是在函数调用时创建的 Python 作用域。每次你调用一个函数,你也在创建一个新的局部作用域。另一方面,您可以将每个
def语句和lambda表达式视为新局部范围的蓝图。每当您调用手边的函数时,这些局部作用域就会出现。默认情况下,在函数内部分配的参数和名称仅存在于与函数调用相关联的函数或局部范围内。当函数返回时,局部作用域被破坏,名字被遗忘。这是如何工作的:
>>> def square(base):
... result = base ** 2
... print(f'The square of {base} is: {result}')
...
>>> square(10)
The square of 10 is: 100
>>> result # Isn't accessible from outside square() Traceback (most recent call last):
File "<stdin>", line 1, in <module>
result
NameError: name 'result' is not defined
>>> base # Isn't accessible from outside square() Traceback (most recent call last):
File "<stdin>", line 1, in <module>
base
NameError: name 'base' is not defined
>>> square(20)
The square of 20 is: 400
square()是计算给定数字base的平方的函数。当您调用该函数时,Python 会创建一个包含名称base(一个参数)和result(一个局部变量)的局部范围。在第一次调用square()之后,base保存值10,而result保存值100。第二次,本地名称将不会记得第一次调用函数时存储在其中的值。注意base现在保存值20,而result保存值400。
注意:如果你在函数调用后试图访问result或base,那么你会得到一个 NameError ,因为这些只存在于调用square()所创建的局部作用域中。每当你试图访问一个没有在任何 Python 作用域中定义的名字时,你都会得到一个NameError。错误消息将包含找不到的名称。
由于不能从函数外部的语句中访问局部名称,不同的函数可以用相同的名称定义对象。看看这个例子:
>>> def cube(base): ... result = base ** 3 ... print(f'The cube of {base} is: {result}') ... >>> cube(30) The cube of 30 is: 27000注意,您使用在
square()中使用的相同变量和参数来定义cube()。然而,由于cube()看不到square()的本地范围内的名字,反之亦然,两个函数都像预期的那样工作,没有任何名字冲突。通过正确使用本地 Python 作用域,可以避免程序中的名称冲突。这也使得函数更加独立,并创建可维护的程序单元。此外,由于您不能从代码中的远程位置更改本地名称,因此您的程序将更容易调试、阅读和修改。
您可以使用
.__code__检查函数的名称和参数,这是一个保存函数内部代码信息的属性。看看下面的代码:
>>> square.__code__.co_varnames ('base', 'result')
>>> square.__code__.co_argcount
1
>>> square.__code__.co_consts
(None, 2, 'The square of ', ' is: ')
>>> square.__code__.co_name
'square'
在这个代码示例中,您在square()上检查.__code__。这是一个特殊的属性,用于保存 Python 函数代码的相关信息。在这种情况下,您会看到.co_varnames持有一个元组,其中包含您在square()中定义的名称。
嵌套函数:封闭范围
当将函数嵌套在其他函数中时,会观察到封闭或非局部作用域。封闭范围是在 Python 2.2 中添加的。它采用任何封闭函数的局部范围的形式。您在封闭 Python 作用域中定义的名称通常被称为非本地名称。考虑以下代码:
>>> def outer_func(): ... # This block is the Local scope of outer_func() ... var = 100 # A nonlocal var ... # It's also the enclosing scope of inner_func() ... def inner_func(): ... # This block is the Local scope of inner_func() ... print(f"Printing var from inner_func(): {var}") ... ... inner_func() ... print(f"Printing var from outer_func(): {var}") ... >>> outer_func() Printing var from inner_func(): 100 Printing var from outer_func(): 100 >>> inner_func() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'inner_func' is not defined当你调用
outer_func()时,你也在创建一个局部作用域。outer_func()的局部范围同时也是inner_func()的包围范围。从inner_func()内部看,这个作用域既不是全局作用域,也不是局部作用域。这是一个介于这两个作用域之间的特殊作用域,被称为包围作用域。注:从某种意义上来说,
inner_func()是一个临时函数,只有在它的封闭函数outer_func()执行的时候才会有生命。注意inner_func()仅对outer_func()中的代码可见。您在封闭范围内创建的所有名字在
inner_func()内部都是可见的,除了那些在您调用inner_func()之后创建的名字。这里有一个新版本的outer_fun()表明了这一点:
>>> def outer_func():
... var = 100
... def inner_func():
... print(f"Printing var from inner_func(): {var}")
... print(f"Printing another_var from inner_func(): {another_var}")
...
... inner_func()
... another_var = 200 # This is defined after calling inner_func() ... print(f"Printing var from outer_func(): {var}")
...
>>> outer_func()
Printing var from inner_func(): 100
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
outer_func()
File "<stdin>", line 7, in outer_func
inner_func()
File "<stdin>", line 5, in inner_func
print(f"Printing another_var from inner_func(): {another_var}")
NameError: free variable 'another_var' referenced before assignment in enclosing
scope
当你调用outer_func()时,代码运行到你调用inner_func()的地方。inner_func()的最后一条语句试图访问another_var。此时,another_var还没有定义,所以 Python 抛出了一个NameError,因为它找不到您试图使用的名称。
最后但同样重要的是,您不能从嵌套函数内部修改封闭作用域中的名称,除非您在嵌套函数中将它们声明为nonlocal。在本教程中,你将在后面的中讲述如何使用nonlocal 。
模块:全局范围
从你开始一个 Python 程序的那一刻起,你就在全局 Python 的范围内。在内部,Python 将程序的主脚本转换成一个名为 __main__ 的模块来保存主程序的执行。这个模块的名称空间是你的程序的主全局范围。
注意:在 Python 中,全局范围和全局名称的概念与模块文件紧密相关。例如,如果您在任何 Python 模块的顶层定义了一个名称,那么该名称就被认为是该模块的全局名称。这就是为什么这种作用域也被称为模块作用域的原因。
如果您正在 Python 交互式会话中工作,那么您会注意到'__main__'也是其主模块的名称。要检查这一点,请打开一个交互式会话并键入以下内容:
>>> __name__ '__main__'每当你运行一个 Python 程序或者一个交互式会话,比如上面的代码,解释器就执行模块或者脚本中的代码,作为你程序的入口点。这个模块或脚本以特殊名称
__main__加载。从这一点开始,你可以说你的主要全局作用域是__main__的作用域。要查看主全局范围内的名称,可以使用
dir()。如果您不带参数调用dir(),那么您将获得当前全局范围内的名字列表。看一下这段代码:
>>> dir()
['__annotations__', '__builtins__',..., '__package__', '__spec__']
>>> var = 100 # Assign var at the top level of __main__ >>> dir()
['__annotations__', '__builtins__',..., '__package__', '__spec__', 'var']
当您不带参数调用dir()时,您将获得在您的主全局 Python 作用域中可用的名称列表。注意,如果你在模块(这里是__main__)的顶层指定一个新名字(比如这里的var,那么这个名字将被添加到dir()返回的列表中。
注意:你将在本教程的部分更详细地讲述dir()。
每个程序执行只有一个全局 Python 作用域。这个作用域一直存在,直到程序终止,所有的名字都被遗忘。否则,下一次运行程序时,这些名称会记住上次运行时的值。
您可以从代码中的任何位置访问或引用任何全局名称的值。这包括函数和类。这里有一个例子来阐明这些观点:
>>> var = 100 >>> def func(): ... return var # You can access var from inside func() ... >>> func() 100 >>> var # Remains unchanged 100在
func()内部,可以自由访问或引用var的值。这对你的全局名var没有影响,但是它告诉你var可以在func()内自由访问。另一方面,除非使用global语句将函数显式声明为全局名称,否则不能在函数内部分配全局名称,稍后您将会看到这一点。每当在 Python 中为名称赋值时,会发生以下两种情况之一:
- 你给起了一个新名字
- 您更新了一个现有的名称
具体行为将取决于您在其中分配名称的 Python 范围。如果你试图在一个函数中给一个全局名字赋值,那么你将会在函数的局部作用域中创建这个名字,隐藏或者覆盖这个全局名字。这意味着你不能从函数内部改变大多数在函数外部定义的变量。
如果您遵循这一逻辑,那么您将意识到下面的代码不会像您预期的那样工作:
>>> var = 100 # A global variable >>> def increment():
... var = var + 1 # Try to update a global variable ...
>>> increment()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
increment()
File "<stdin>", line 2, in increment
var = var + 1
UnboundLocalError: local variable 'var' referenced before assignment
在increment()中,您尝试增加全局变量var。由于var没有在increment()中声明global,Python 在函数中创建了一个同名的新局部变量var。在这个过程中,Python 意识到您试图在第一次赋值(var + 1)之前使用局部var,所以它引发了一个UnboundLocalError。
这是另一个例子:
>>> var = 100 # A global variable >>> def func(): ... print(var) # Reference the global variable, var ... var = 200 # Define a new local variable using the same name, var ... >>> func() Traceback (most recent call last): File "<stdin>", line 1, in <module> func() File "<stdin>", line 2, in func print(var) UnboundLocalError: local variable 'var' referenced before assignment您可能希望能够打印全局
var并能够稍后更新var,但是您再次得到了一个UnboundLocalError。这里发生的事情是,当你运行func()的主体时,Python 决定var是一个局部变量,因为它是在函数范围内赋值的。这不是一个 bug,而是一个设计选择。Python 假设在函数体中分配的名称对于该函数是局部的。注意:全局名称可以在您的全局 Python 范围内的任何地方更新或修改。除此之外,
global语句可以用来从代码中的几乎任何地方修改全局名称,正如你将在的global语句中看到的。修改全局名称通常被认为是糟糕的编程实践,因为它会导致代码:
- 难调试:程序中几乎任何语句都可以改变一个全局名的值。
- 难以理解:你需要注意所有访问和修改全局名的语句。
- 无法重用:代码依赖于特定于具体程序的全局名称。
良好的编程实践建议使用本地名称而不是全局名称。以下是一些建议:
- 写依赖局部名字而不是全局名字的自包含函数。
- 尝试使用唯一的对象名,不管你在什么范围。
- 在你的程序中避免修改全局名字。
- 避免跨模块修改名称。
- 使用全局名作为常量,它们在程序执行过程中不会改变。
到目前为止,您已经讨论了三个 Python 范围。下面的例子总结了它们在代码中的位置,以及 Python 如何通过它们查找名称:
>>> # This area is the global or module scope >>> number = 100
>>> def outer_func():
... # This block is the local scope of outer_func() ... # It's also the enclosing scope of inner_func() ... def inner_func():
... # This block is the local scope of inner_func() ... print(number)
...
... inner_func()
...
>>> outer_func()
100
当您调用outer_func()时,您会在屏幕上看到100。但是在这种情况下 Python 如何查找名字number?遵循 LEGB 规则,您将在以下位置查找number:
- 在
inner_func()里面:这是本地范围,但是number在那里不存在。 outer_func()里面的:这是封闭的范围,但是number也没有在这里定义。- 在模块作用域:这是全局作用域,你在那里找到
number,就可以把number打印到屏幕上。
如果number没有在全局范围内定义,那么 Python 通过查看内置范围继续搜索。这是 LEGB 规则的最后一个组成部分,您将在下一节看到。
builtins:内置范围
内置作用域是一个特殊的 Python 作用域,在 Python 3.x 中被实现为一个名为 builtins 的标准库模块,Python 的所有内置对象都在这个模块中。当您运行 Python 解释器时,它们会自动加载到内置范围。Python 在其 LEGB 查找中最后搜索builtins,因此您可以免费获得它定义的所有名称。这意味着您可以在不导入任何模块的情况下使用它们。
请注意,builtins中的名称总是以特殊名称__builtins__加载到您的全局 Python 范围中,如您在以下代码中所见:
>>> dir() ['__annotations__', '__builtins__',..., '__package__', '__spec__'] >>> dir(__builtins__) ['ArithmeticError', 'AssertionError',..., 'tuple', 'type', 'vars', 'zip']在第一次调用
dir()的输出中,您可以看到__builtins__总是出现在全局 Python 范围内。如果您使用dir()检查__builtins__本身,那么您将获得 Python 内置名称的完整列表。内置范围为您当前的全局 Python 范围带来了 150 多个名称。例如,在 Python 3.8 中,您可以知道名称的确切数量,如下所示:
>>> len(dir(__builtins__))
152
通过调用 len() ,可以得到dir()返回的list中的物品数量。这将返回 152 个名称,包括异常、函数、类型、特殊属性和其他 Python 内置对象。
即使您可以免费访问所有这些 Python 内置对象(无需导入任何内容),您也可以显式导入builtins并使用点符号访问名称。这是如何工作的:
>>> import builtins # Import builtins as a regular module >>> dir(builtins) ['ArithmeticError', 'AssertionError',..., 'tuple', 'type', 'vars', 'zip'] >>> builtins.sum([1, 2, 3, 4, 5]) 15 >>> builtins.max([1, 5, 8, 7, 3]) 8 >>> builtins.sorted([1, 5, 8, 7, 3]) [1, 3, 5, 7, 8] >>> builtins.pow(10, 2) 100您可以像导入任何其他 Python 模块一样导入
builtins。从这一点开始,您可以通过使用带点的属性查找或全限定名称来访问builtins中的所有名称。如果您希望确保在任何全局名称覆盖任何内置名称时不会发生名称冲突,这将非常有用。您可以在全局范围内覆盖或重新定义任何内置名称。如果您这样做,那么请记住,这将影响您的所有代码。看一下下面的例子:
>>> abs(-15) # Standard use of a built-in function 15
>>> abs = 20 # Redefine a built-in name in the global scope >>> abs(-15)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not callable
如果你覆盖或者重新赋值abs,那么原来内置的 abs() 会影响你所有的代码。现在,假设你需要调用原来的abs(),而你忘记了你已经重新分配了名字。在这种情况下,当您再次调用abs()时,您会得到一个TypeError,因为abs现在保存了一个对整数的引用,这是不可调用的。
注意:在你的全局作用域中偶然或不经意地覆盖或重定义内置名称可能是危险且难以发现的 bug 的来源。最好尽量避免这种做法。
如果您正在试验一些代码,并且意外地在交互提示符下重新分配了一个内置名称,那么您可以重新启动您的会话或者运行del name来从您的全局 Python 作用域中移除重新定义。这样,您就在内置范围内恢复了原来的名称。如果你重温一下abs()的例子,那么你可以这样做:
>>> del abs # Remove the redefined abs from your global scope >>> abs(-15) # Restore the original abs() 15当您删除自定义
abs名称时,您将从全局范围中删除该名称。这允许您再次访问内置作用域中的原始abs()。要解决这种情况,您可以显式导入
builtins,然后使用完全限定的名称,如以下代码片段所示:
>>> import builtins
>>> builtins.abs(-15)
15
一旦显式导入了builtins,就可以在全局 Python 范围内使用模块名称。从这一点开始,您可以使用完全限定的名称从builtins中明确地获得您需要的名称,就像您在上面的例子中对builtins.abs()所做的那样。
作为快速总结,下表显示了 Python 范围的一些含义:
| 行动 | 全球代码 | 本地代码 | 嵌套功能代码 |
|---|---|---|---|
| 访问或引用全局范围内的名称 | 是 | 是 | 是 |
| 修改或更新全局范围内的名称 | 是 | 否(除非声明为global) |
否(除非声明为global) |
| 访问或引用本地范围内的名称 | 不 | 是(它自己的本地范围),否(其他本地范围) | 是(它自己的本地范围),否(其他本地范围) |
| 覆盖内置范围中的名称 | 是 | 是(在功能执行期间) | 是(在功能执行期间) |
| 访问或引用位于其封闭范围内的名称 | 不适用的 | 不适用的 | 是 |
| 修改或更新位于其封闭范围内的名称 | 不适用的 | 不适用的 | 否(除非声明为nonlocal) |
此外,不同范围内的代码可以对不同的对象使用相同的名称。这样,您可以使用一个名为spam的局部变量和一个同名的全局变量spam。然而,这被认为是糟糕的编程实践。
修改 Python 作用域的行为
到目前为止,您已经了解了 Python 作用域是如何工作的,以及它们如何将变量、函数、类和其他 Python 对象的可见性限制在代码的特定部分。您现在知道可以从代码中的任何地方访问或引用全局名称,但是可以在全局 Python 范围内修改或更新它们。
您还知道,您只能从创建它们的本地 Python 作用域内部或从嵌套函数内部访问本地名称,但是您不能从全局 Python 作用域或其他本地作用域访问它们。此外,您已经了解到非本地名称可以从嵌套函数内部访问,但是不能从那里修改或更新。
尽管 Python 作用域在默认情况下遵循这些通用规则,但是有一些方法可以修改这种标准行为。Python 提供了两个关键字,允许您修改全局和非本地名称的内容。这两个关键字是:
在接下来的两节中,您将介绍如何使用这些 Python 关键字来修改 Python 范围的标准行为。
global语句
您已经知道,当您试图在函数内部给全局名称赋值时,您会在函数范围内创建一个新的局部名称。要修改这个行为,你可以使用一个 global语句。使用这个语句,您可以定义一个将被视为全局名称的名称列表。
该语句由关键字global组成,后跟一个或多个用逗号分隔的名称。您还可以在一个名称(或一个名称列表)中使用多个global语句。您在global语句中列出的所有名字都将被映射到您定义它们的全局或模块范围。
这里有一个例子,你试图从一个函数中更新一个全局变量:
>>> counter = 0 # A global name >>> def update_counter(): ... counter = counter + 1 # Fail trying to update counter ... >>> update_counter() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in update_counter UnboundLocalError: local variable 'counter' referenced before assignment当你试图在
update_counter()中赋值counter时,Python 假设counter是update_counter()的本地变量,并引发一个UnboundLocalError,因为你试图访问一个还没有定义的名字。如果您希望这段代码以您期望的方式工作,那么您可以使用如下的
global语句:
>>> counter = 0 # A global name
>>> def update_counter():
... global counter # Declare counter as global ... counter = counter + 1 # Successfully update the counter ...
>>> update_counter()
>>> counter
1
>>> update_counter()
>>> counter
2
>>> update_counter()
>>> counter
3
在这个新版本的update_counter()中,在试图改变counter之前,您将语句global counter添加到函数体中。通过这个微小的改变,您将函数作用域中的名称counter映射到全局或模块作用域中的相同名称。从这一点开始,你可以在update_counter()里面自由修改counter。所有的改变都会反映在全局变量中。
使用语句global counter,您告诉 Python 在全局范围内查找名称counter。这样,表达式counter = counter + 1不会在函数范围内创建一个新名字,而是在全局范围内更新它。
注意:使用global通常被认为是不好的做法。如果你发现自己在使用global来解决上述问题,那么停下来想想是否有更好的方法来编写你的代码。
例如,您可以尝试编写一个依赖于本地名称而不是全局名称的自包含函数,如下所示:
>>> global_counter = 0 # A global name >>> def update_counter(counter): ... return counter + 1 # Rely on a local name ... >>> global_counter = update_counter(global_counter) >>> global_counter 1 >>> global_counter = update_counter(global_counter) >>> global_counter 2 >>> global_counter = update_counter(global_counter) >>> global_counter 3这个
update_counter()的实现将counter定义为一个参数,并在每次调用函数时返回增加了1单位的值。这样,update_counter()的结果取决于您用作输入的counter,而不是其他函数(或代码段)可以对全局变量global_counter执行的更改。还可以使用
global语句通过在函数中声明来创建惰性全局名。看一下下面的代码:
>>> def create_lazy_name():
... global lazy # Create a global name, lazy ... lazy = 100
... return lazy
...
>>> create_lazy_name()
100
>>> lazy # The name is now available in the global scope 100
>>> dir()
['__annotations__', '__builtins__',..., 'create_lazy_name', 'lazy']
当您调用create_lazy_name()时,您也创建了一个名为lazy的全局变量。注意,在调用函数之后,名字lazy在全局 Python 范围内是可用的。如果您使用dir()检查全局名称空间,那么您会看到lazy出现在列表的最后。
注意:尽管您可以使用global语句来创建懒惰的全局名称,但这可能是一种危险的做法,会导致错误的代码。所以,最好在你的代码中避免这样的事情。
例如,假设您试图访问其中一个惰性名称,由于某种原因,您的代码还没有调用创建该名称的函数。在这种情况下,你会得到一个NameError并且你的程序会崩溃。
最后,值得注意的是,您可以在任何函数或嵌套函数内部使用global,所列出的名称将总是映射到全局 Python 范围内的名称。
还要注意,尽管在模块的顶层使用global语句是合法的,但这并没有多大意义,因为在全局作用域中分配的任何名称根据定义都已经是全局名称了。看一下下面的代码:
>>> name = 100 >>> dir() ['__annotations__', '__builtins__',..., '__spec__', 'name'] >>> global name >>> dir() ['__annotations__', '__builtins__',..., '__spec__', 'name']像
global name这样的global语句的使用不会改变你当前的全局范围,正如你在dir()的输出中看到的。无论你是否使用global,变量name都是一个全局变量。
nonlocal语句与全局名称类似,非局部名称可以从内部函数访问,但不能赋值或更新。如果你想修改它们,那么你需要使用一个
nonlocal语句。使用nonlocal语句,您可以定义一个将被视为非本地的名称列表。
nonlocal语句由nonlocal关键字组成,后跟一个或多个用逗号分隔的名称。这些名称将引用封闭 Python 范围中的相同名称。下面的例子展示了如何使用nonlocal来修改在封闭或非本地作用域中定义的变量:
>>> def func():
... var = 100 # A nonlocal variable ... def nested():
... nonlocal var # Declare var as nonlocal ... var += 100
...
... nested()
... print(var)
...
>>> func()
200
通过语句nonlocal var,你告诉 Python 你将在nested()中修改var。然后,使用一个增加的赋值操作来增加var。这种变化反映在非本地名称var中,该名称现在的值为200。
与global不同,您不能在嵌套或封闭函数之外使用nonlocal。更准确地说,你不能在全局范围或局部范围内使用nonlocal语句。这里有一个例子:
>>> nonlocal my_var # Try to use nonlocal in the global scope File "<stdin>", line 1 SyntaxError: nonlocal declaration not allowed at module level >>> def func(): ... nonlocal var # Try to use nonlocal in a local scope ... print(var) ... File "<stdin>", line 2 SyntaxError: no binding for nonlocal 'var' found这里,您首先尝试在全局 Python 范围内使用一个
nonlocal语句。由于nonlocal只在内部或嵌套函数中起作用,你得到一个SyntaxError告诉你不能在模块范围内使用nonlocal。注意nonlocal也不能在局部范围内工作。注意:要了解关于
nonlocal声明的更多详细信息,请查看PEP 3104——访问外部作用域中的名称。与
global相反,你不能使用nonlocal来创建懒惰的非本地名字。如果要将名称用作非本地名称,则名称必须已经存在于封闭 Python 范围中。这意味着你不能通过在嵌套函数的nonlocal语句中声明来创建非本地名字。看一下下面的代码示例:
>>> def func():
... def nested():
... nonlocal lazy_var # Try to create a nonlocal lazy name ...
File "<stdin>", line 3
SyntaxError: no binding for nonlocal 'lazy_var' found
在这个例子中,当您试图使用nonlocal lazy_var定义一个非本地名称时,Python 会立即抛出一个SyntaxError,因为lazy_var不存在于nested()的封闭范围内。
使用封闭作用域作为闭包
闭包是封闭 Python 范围的特殊用例。当您将嵌套函数作为数据处理时,组成该函数的语句与它们执行的环境打包在一起。由此产生的对象称为闭包。换句话说,闭包是一个内部或嵌套的函数,它携带关于其封闭范围的信息,即使这个范围已经完成了它的执行。
注意:你也可以将这种函数称为工厂、工厂函数,或者更准确地说,称为闭包工厂,以指定该函数构建并返回闭包(内部函数),而不是类或实例。
闭包提供了一种在函数调用之间保留状态信息的方法。当您想要基于懒惰或延迟评估的概念编写代码时,这可能是有用的。请看下面的代码,这是一个闭包如何工作以及如何在 Python 中利用它们的例子:
>>> def power_factory(exp): ... def power(base): ... return base ** exp ... return power ... >>> square = power_factory(2) >>> square(10) 100 >>> cube = power_factory(3) >>> cube(10) 1000 >>> cube(5) 125 >>> square(15) 225您的闭包工厂函数
power_factory()接受一个名为exp的参数。您可以使用这个函数来构建运行不同 power 操作的闭包。这是可行的,因为每个对power_factory()的调用都获得自己的一组状态信息。换句话说,它为exp获取它的值。注:类似
exp的变量称为自由变量。它们是在代码块中使用但没有定义的变量。自由变量是闭包用来在调用之间保留状态信息的机制。在上面的例子中,内部函数
power()首先被赋值给square。在这种情况下,该函数会记住exp等于2。在第二个例子中,您使用3作为参数来调用power_factory()。这样,cube持有一个函数对象,它记住了exp就是3。注意,您可以自由地重用square和cube,因为它们不会忘记各自的状态信息。关于如何使用闭包的最后一个例子,假设您需要计算一些样本数据的平均值。您通过对正在分析的参数的一系列连续测量来收集数据。在这种情况下,您可以使用闭包工厂来生成一个闭包,该闭包会记住样本中以前的度量。看一下下面的代码:
>>> def mean():
... sample = []
... def _mean(number):
... sample.append(number)
... return sum(sample) / len(sample)
... return _mean
...
>>> current_mean = mean()
>>> current_mean(10)
10.0
>>> current_mean(15)
12.5
>>> current_mean(12)
12.333333333333334
>>> current_mean(11)
12.0
>>> current_mean(13)
12.2
您在上面的代码中创建的闭包会在调用current_mean之间记住sample的状态信息。这样,你就可以用优雅而蟒的方式解决问题。
注意:如果你想学习更多关于作用域和闭包的知识,那么可以看看探索 Python 中的作用域和闭包视频课程。
请注意,如果您的数据流变得太大,那么这个函数在内存使用方面会成为一个问题。这是因为每次调用current_mean,sample都会保存越来越大的值列表。使用nonlocal查看下面的替代实现代码:
>>> def mean(): ... total = 0 ... length = 0 ... def _mean(number): ... nonlocal total, length ... total += number ... length += 1 ... return total / length ... return _mean ... >>> current_mean = mean() >>> current_mean(10) 10.0 >>> current_mean(15) 12.5 >>> current_mean(12) 12.333333333333334 >>> current_mean(11) 12.0 >>> current_mean(13) 12.2尽管这个解决方案更加冗长,但是您不再需要一个不断增长的列表。现在
total和length只有一个值。与之前的解决方案相比,这种实现在内存消耗方面要高效得多。最后,您可以在 Python 标准库中找到一些使用闭包的例子。例如,
functools提供了一个名为partial()的函数,它利用闭包技术来创建新的函数对象,可以使用预定义的参数来调用这些对象。这里有一个例子:
>>> from functools import partial
>>> def power(exp, base):
... return base ** exp
...
>>> square = partial(power, 2)
>>> square(10)
100
您使用partial构建一个记住状态信息的函数对象,其中exp=2。然后,调用这个对象执行乘幂运算,得到最终结果。
用import 将名称带入范围
当您编写 Python 程序时,通常会将代码组织成几个模块。为了让你的程序工作,你需要把那些独立模块中的名字带到你的__main__模块中。为此,您需要显式地import模块或名称。这是在主全局 Python 范围内使用这些名称的唯一方式。
请看下面的代码,这是一个当您导入一些标准模块和名称时会发生什么的例子:
>>> dir() ['__annotations__', '__builtins__',..., '__spec__'] >>> import sys >>> dir() ['__annotations__', '__builtins__',..., '__spec__', 'sys'] >>> import os >>> dir() ['__annotations__', '__builtins__',..., '__spec__', 'os', 'sys'] >>> from functools import partial >>> dir() ['__annotations__', '__builtins__',..., '__spec__', 'os', 'partial', 'sys']你先从 Python 标准库中导入
sys和os。通过不带参数地调用dir(),您可以看到这些模块现在可以作为名称在您当前的全局作用域中使用了。这样,您可以使用点符号来访问在sys和os中定义的名称。注意:如果你想更深入地了解 Python 中导入是如何工作的,那么看看 Python 中的绝对与相对导入。
在最近的
import操作中,您使用表单from <module> import <name>。这样,您可以在代码中直接使用导入的名称。换句话说,你不需要明确地使用点符号。发现不寻常的 Python 作用域
您会发现一些 Python 结构的名称解析似乎不符合 Python 作用域的 LEGB 规则。这些结构包括:
在接下来的几节中,您将讨论 Python 作用域如何作用于这三种结构。有了这些知识,您将能够避免与在这些类型的 Python 结构中使用名称相关的微妙错误。
理解变量范围
你要覆盖的第一个结构是 理解 。理解是处理集合或序列中所有或部分元素的一种简洁方式。你可以使用理解来创建列表、字典和集合。
理解由一对包含表达式的括号(
[])或花括号({})组成,后跟一个或多个for子句,然后每个for子句有零个或一个if子句。理解中的
for子句类似于传统的for循环。理解中的循环变量是结构的局部变量。查看以下代码:
>>> [item for item in range(5)]
[0, 1, 2, 3, 4]
>>> item # Try to access the comprehension variable Traceback (most recent call last):
File "<stdin>", line 1, in <module>
item
NameError: name 'item' is not defined
一旦你运行了列表理解,变量item被遗忘,你不能再访问它的值。不太可能需要在理解之外使用这个变量,但是不管怎样,Python 会确保一旦理解完成,它的值就不再可用。
请注意,这只适用于理解。对于常规的for循环,循环变量保存循环处理的最后一个值:
>>> for item in range(5): ... print(item) ... 0 1 2 3 4 >>> item # Access the loop variable 4一旦循环结束,您可以自由访问循环变量
item。这里,循环变量保存循环处理的最后一个值,在本例中是4。异常变量范围
您将遇到的另一个 Python 作用域的非典型情况是异常变量的情况。异常变量是保存对由
try语句引发的异常的引用的变量。在 Python 3.x 中,这样的变量对于except块来说是局部的,当块结束时就会被遗忘。查看以下代码:
>>> lst = [1, 2, 3]
>>> try:
... lst[4]
... except IndexError as err:
... # The variable err is local to this block ... # Here you can do anything with err ... print(err)
...
list index out of range
>>> err # Is out of scope Traceback (most recent call last):
File "<stdin>", line 1, in <module>
err
NameError: name 'err' is not defined
err保存对由try子句引发的异常的引用。您只能在except子句的代码块中使用err。这样,您可以说异常变量的 Python 范围对于except代码块来说是局部的。还要注意,如果您试图从except块外部访问err,那么您将得到一个NameError。那是因为一旦except块结束,名字就不存在了。
要解决这个问题,您可以在try语句中定义一个辅助变量,然后将异常分配给except块中的那个变量。看看下面的例子:
>>> lst = [1, 2, 3] >>> ex = None >>> try: ... lst[4] ... except IndexError as err: ... ex = err ... print(err) ... list index out of range >>> err # Is out of scope Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'err' is not defined >>> ex # Holds a reference to the exception list index out of range您使用
ex作为辅助变量来保存对由try子句引发的异常的引用。当您需要在代码块完成后对异常对象做一些事情时,这可能会很有用。注意,如果没有出现异常,那么ex保持None。类别和实例属性范围
当您定义一个类时,您正在创建一个新的本地 Python 范围。在类的顶层分配的名字存在于这个局部作用域中。您在
class语句中指定的名字不会与其他地方的名字冲突。你可以说这些名字遵循了 LEGB 规则,其中类块代表了 L 级别。与函数不同,类局部范围不是在调用时创建的,而是在执行时创建的。每个类对象都有自己的
.__dict__属性,保存所有类属性所在的类范围或名称空间。查看以下代码:
>>> class A:
... attr = 100
...
>>> A.__dict__.keys() dict_keys(['__module__', 'attr', '__dict__', '__weakref__', '__doc__'])
当您检查.__dict__的键时,您会看到attr和其他特殊名称一起出现在列表中。这个字典表示类的局部范围。此范围内的名称对该类的所有实例和该类本身都是可见的。
要从类外部访问类属性,您需要使用点符号,如下所示:
>>> class A: ... attr = 100 ... print(attr) # Access class attributes directly ... 100 >>> A.attr # Access a class attribute from outside the class 100 >>> attr # Isn't defined outside A Traceback (most recent call last): File "<stdin>", line 1, in <module> attr NameError: name 'attr' is not defined在
A的局部范围内,可以直接访问类属性,就像在语句print(attr)中一样。一旦类的代码块被执行,要访问任何类属性,你需要使用点符号或属性引用,就像你使用A.attr一样。否则,您将得到一个NameError,因为属性attr对于类块来说是局部的。另一方面,如果你试图访问一个没有在类中定义的属性,那么你会得到一个
AttributeError。看看下面的例子:
>>> A.undefined # Try to access an undefined class attribute Traceback (most recent call last):
File "<stdin>", line 1, in <module>
A.undefined
AttributeError: type object 'A' has no attribute 'undefined'
在这个例子中,您试图访问属性undefined。由于这个属性在A中不存在,您会得到一个AttributeError,告诉您A没有名为undefined的属性。
还可以使用类的实例访问任何类属性,如下所示:
>>> obj = A() >>> obj.attr 100一旦有了实例,就可以使用点符号访问类属性,就像这里使用
obj.attr一样。类属性是特定于类对象的,但是您可以从该类的任何实例中访问它们。值得注意的是,类属性对于一个类的所有实例都是通用的。如果您修改了一个类属性,那么这些更改将在该类的所有实例中可见。注意:把点符号想象成你在告诉 Python,“在
obj中寻找名为attr的属性。如果你找到了,就把它还给我。”无论何时调用一个类,你都在创建该类的一个新实例。实例有自己的
.__dict__属性,该属性保存实例本地范围或名称空间中的名称。这些名称通常被称为实例属性,并且是本地的,特定于每个实例。这意味着,如果您修改实例属性,则更改将仅对该特定实例可见。要在类内部创建、更新或访问任何实例属性,需要使用
self和点符号。这里,self是表示当前实例的特殊属性。另一方面,要从类外部更新或访问任何实例属性,您需要创建一个实例,然后使用点符号。这是如何工作的:
>>> class A:
... def __init__(self, var):
... self.var = var # Create a new instance attribute ... self.var *= 2 # Update the instance attribute ...
>>> obj = A(100)
>>> obj.__dict__ {'var': 200}
>>> obj.var
200
类A接受一个名为var的参数,该参数使用赋值操作self.var *= 2在 .__init__() 中自动加倍。注意,当您在obj上检查.__dict__时,您会得到一个包含所有实例属性的字典。在这种情况下,字典只包含名字var,它的值现在是200。
注意:关于 Python 中类如何工作的更多信息,请查看Python 中面向对象编程的介绍。
尽管您可以在一个类的任何方法中创建实例属性,但是在.__init__()中创建和初始化它们是一个很好的实践。看看这个新版本的A:
>>> class A: ... def __init__(self, var): ... self.var = var ... ... def duplicate_var(self): ... return self.var * 2 ... >>> obj = A(100) >>> obj.var 100 >>> obj.duplicate_var() 200 >>> A.var Traceback (most recent call last): File "<stdin>", line 1, in <module> A.var AttributeError: type object 'A' has no attribute 'var'这里,您修改
A来添加一个名为duplicate_var()的新方法。然后,通过将100传递给类初始化器,创建一个A的实例。之后,您现在可以在obj上调用duplicate_var()来复制存储在self.var中的值。最后,如果您试图使用类对象而不是实例来访问var,那么您将得到一个AttributeError,因为实例属性不能使用类对象来访问。一般来说,当你用 Python 写面向对象的代码并试图访问一个属性时,你的程序会采取以下步骤:
- 首先检查实例的本地范围或名称空间。
- 如果在那里没有找到该属性,那么检查类的局部范围或名称空间。
- 如果这个名字也不存在于类名称空间中,那么您将得到一个
AttributeError。这是 Python 解析类和实例中的名称的底层机制。
尽管类定义了类的局部作用域或命名空间,但它们并没有为方法创建封闭的作用域。因此,当您实现一个类时,对属性和方法的引用必须使用点符号:
>>> class A:
... var = 100
... def print_var(self):
... print(var) # Try to access a class attribute directly ...
>>> A().print_var()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
A().print_var()
File "<stdin>", line 4, in print_var
print(var)
NameError: name 'var' is not defined
因为类不会为方法创建封闭范围,所以您不能像这里尝试的那样从print_var()中直接访问var。要从任何方法内部访问类属性,您需要使用点符号。要解决这个例子中的问题,将print_var()中的语句print(var)改为print(A.var),看看会发生什么。
可以用实例属性重写类属性,这将修改类的一般行为。但是,您可以使用点符号明确地访问这两个属性,如下例所示:
>>> class A: ... var = 100 ... def __init__(self): ... self.var = 200 ... ... def access_attr(self): ... # Use dot notation to access class and instance attributes ... print(f'The instance attribute is: {self.var}') ... print(f'The class attribute is: {A.var}') ... >>> obj = A() >>> obj.access_attr() The instance attribute is: 200 The class attribute is: 100 >>> A.var # Access class attributes 100 >>> A().var # Access instance attributes 200 >>> A.__dict__.keys() dict_keys(['__module__', 'var', '__init__',..., '__getattribute__']) >>> A().__dict__.keys() dict_keys(['var'])上面的类有一个实例属性和一个同名的类属性
var。您可以使用以下代码来访问它们:
- 实例:使用
self.var来访问这个属性。- 类:使用
A.var访问该属性。因为这两种情况都使用点符号,所以不存在名称冲突问题。
注意:一般来说,良好的 OOP 实践建议不要用具有不同职责或执行不同操作的实例属性来隐藏类属性。这样做可能会导致细微且难以发现的错误。
最后,请注意,类
.__dict__和实例.__dict__是完全不同且独立的字典。这就是为什么在运行或导入定义类的模块后,类属性立即可用。相比之下,实例属性只有在对象或实例创建之后才具有生命力。使用与范围相关的内置函数
有许多内置函数与 Python 范围和名称空间的概念密切相关。在前面的小节中,您已经使用了
dir()来获取给定范围内存在的名称的信息。除了dir()之外,当您试图获取关于 Python 作用域或名称空间的信息时,还有其他一些内置函数可以帮助您。在本节中,您将了解如何使用:因为所有这些都是内置函数,所以它们在内置范围内是免费的。这意味着您可以随时使用它们,而无需导入任何内容。这些函数中的大部分旨在用于交互式会话中,以获取关于不同 Python 对象的信息。然而,您也可以在您的代码中找到一些有趣的用例。
globals()在 Python 中,
globals()是一个内置函数,返回对当前全局作用域或命名空间字典的引用。这个字典总是存储当前模块的名称。这意味着如果你在一个给定的模块中调用globals(),那么在调用globals()之前,你会得到一个字典,包含你在那个模块中定义的所有名字。这里有一个例子:
>>> globals()
{'__name__': '__main__',..., '__builtins__': <module 'builtins' (built-in)>}
>>> my_var = 100
>>> globals()
{'__name__': '__main__',..., 'my_var': 100}
对globals()的第一次调用返回一个字典,其中包含了__main__模块或程序中的名字。注意,当你在模块的顶层指定一个新名字时,比如在my_var = 100中,这个名字被添加到由globals()返回的字典中。
如何在代码中使用globals()的一个有趣的例子是动态地分派位于全局范围内的函数。假设您想要动态调度平台相关的功能。为此,您可以如下使用globals():
1# Filename: dispatch.py
2
3from sys import platform
4
5def linux_print():
6 print('Printing from Linux...')
7
8def win32_print():
9 print('Printing from Windows...')
10
11def darwin_print():
12 print('Printing from macOS...')
13
14printer = globals()[platform + '_print'] 15
16printer()
如果您在命令行中运行这个脚本,那么您将得到一个依赖于您当前平台的输出。
如何使用globals()的另一个例子是在全局范围内检查特殊名称的列表。看看下面的列表理解:
>>> [name for name in globals() if name.startswith('__')] ['__name__', '__doc__', '__package__',..., '__annotations__', '__builtins__']这个列表理解将返回一个列表,其中包含当前全局 Python 作用域中定义的所有特殊名称。请注意,您可以像使用任何常规词典一样使用
globals()词典。例如,您可以使用这些传统方法通过它对进行迭代:
.keys().values().items()您还可以通过使用类似于
globals()['name']中的方括号在globals()上执行常规订阅操作。例如,您可以修改globals()的内容,尽管我们不建议这样做。看一下这个例子:
>>> globals()['__doc__'] = """Docstring for __main__.""" >>> __doc__
'Docstring for __main__.'
在这里,您更改键__doc__,为__main__包含一个文档字符串,这样从现在开始,主模块的文档字符串将具有值'Docstring for __main__.'。
locals()
另一个与 Python 作用域和名称空间相关的函数是 locals() 。该函数更新并返回一个字典,该字典保存了本地 Python 范围或名称空间的当前状态的副本。当你在一个函数块中调用locals()时,你会得到直到你调用locals()时在局部或函数作用域中分配的所有名字。这里有一个例子:
>>> def func(arg): ... var = 100 ... print(locals()) ... another = 200 ... >>> func(300) {'var': 100, 'arg': 300}每当您在
func()中调用locals()时,结果字典包含映射到值100的名称var和映射到300的arg。因为locals()只在你调用它之前获取指定的名字,所以another不在字典中。如果您在全局 Python 范围内调用
locals(),那么您将获得与调用globals()时相同的字典:
>>> locals()
{'__name__': '__main__',..., '__builtins__': <module 'builtins' (built-in)>}
>>> locals() is globals() True
当您在全局 Python 范围内调用locals()时,您会得到一个与调用globals()返回的字典相同的字典。
请注意,您不应该修改locals()的内容,因为更改可能对本地和自由名称的值没有影响。看看下面的例子:
>>> def func(): ... var = 100 ... locals()['var'] = 200 ... print(var) ... >>> func() 100当您试图使用
locals()修改var的内容时,这种变化不会反映在var的值中。所以,你可以说locals()只对读操作有用,因为 Python 忽略了对locals字典的更新。
vars()
vars()是一个 Python 内置函数,返回模块、类、实例或任何其他具有字典属性的对象的.__dict__属性。记住.__dict__是 Python 用来实现名称空间的特殊字典。看看下面的例子:
>>> import sys
>>> vars(sys) # With a module object {'__name__': 'sys',..., 'ps1': '>>> ', 'ps2': '... '}
>>> vars(sys) is sys.__dict__ True
>>> class MyClass:
... def __init__(self, var):
... self.var = var
...
>>> obj = MyClass(100)
>>> vars(obj) # With a user-defined object {'var': 100}
>>> vars(MyClass) # With a class mappingproxy({'__module__': '__main__',..., '__doc__': None})
当你使用sys作为参数调用vars()时,你得到了sys的.__dict__。你也可以使用不同类型的 Python 对象来调用vars(),只要它们具有这个字典属性。
没有任何参数,vars()的行为类似于locals(),返回一个包含本地 Python 范围内所有名称的字典:
>>> vars() {'__name__': '__main__',..., '__builtins__': <module 'builtins' (built-in)>} >>> vars() is locals() True在这里,您在交互式会话的顶层调用
vars()。如果没有参数,该调用将返回一个包含全局 Python 范围内所有名称的字典。注意,在这个级别,vars()和locals()返回相同的字典。如果你用一个没有
.__dict__的对象调用vars(),那么你将得到一个TypeError,如下例所示:
>>> vars(10) # Call vars() with objects that don't have a .__dict__ Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: vars() argument must have __dict__ attribute
如果你用一个整数对象调用vars(),那么你会得到一个 TypeError ,因为这种类型的 Python 对象没有.__dict__。
dir()
可以使用不带参数的 dir() 来获取当前 Python 范围内的名称列表。如果您用一个参数调用dir(),那么该函数将尝试返回该对象有效属性的list:
>>> dir() # With no arguments ['__annotations__', '__builtins__',..., '__package__', '__spec__'] >>> dir(zip) # With a function object ['__class__', '__delattr__',..., '__str__', '__subclasshook__'] >>> import sys >>> dir(sys) # With a module object ['__displayhook__', '__doc__',..., 'version_info', 'warnoptions'] >>> var = 100 >>> dir(var) # With an integer variable ['__abs__', '__add__',..., 'imag', 'numerator', 'real', 'to_bytes']如果您不带参数调用
dir(),那么您将得到一个包含全局范围内的名字的列表。您还可以使用dir()来检查不同对象的名称或属性列表。这包括函数、模块、变量等等。尽管官方文档说
dir()是用于交互使用的,但是你可以使用该函数来提供一个给定对象的属性的完整列表。注意,您也可以从函数内部调用dir()。在这种情况下,您将获得在函数作用域中定义的名称列表:
>>> def func():
... var = 100
... print(dir())
... another = 200 # Is defined after calling dir() ...
>>> func()
['var']
在这个例子中,您在func()中使用了dir()。当您调用该函数时,您会得到一个包含您在局部范围内定义的名称的列表。值得注意的是,在这种情况下,dir()只显示你在函数调用前声明的名字。
结论
变量或名称的范围定义了它在整个代码中的可见性。在 Python 中,作用域实现为局部、封闭、全局或内置作用域。当您使用变量或名称时,Python 会按顺序搜索这些范围来解析它。如果找不到这个名字,你会得到一个错误。这是 Python 用于名称解析的一般机制,被称为 LEGB 规则。
您现在能够:
- 利用Python 作用域的优势来避免或最小化与名称冲突相关的错误
- 在你的程序中充分利用全局和局部名字来提高代码的可维护性
- 使用一致的策略来访问、修改或更新所有 Python 代码的名称
此外,您还了解了 Python 提供的一些与作用域相关的工具和技术,以及如何使用它们来收集关于存在于给定作用域中的名称的信息,或者修改 Python 作用域的标准行为。当然,这个主题的更多内容已经超出了本教程的范围,所以请出去继续学习 Python 中的名称解析吧!**********
使用 Python 发送电子邮件
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 发邮件
你可能会发现这个教程,因为你想使用 Python 发送电子邮件。也许您希望从您的代码中接收电子邮件提醒,在用户创建帐户时向他们发送确认电子邮件,或者向您组织的成员发送电子邮件以提醒他们缴纳会费。手动发送电子邮件是一项耗时且容易出错的任务,但使用 Python 很容易实现自动化。
在本教程中,你将学习如何:
-
使用
SMTP_SSL()和.starttls()建立一个安全连接 -
使用 Python 内置的
smtplib库发送基本邮件 -
使用
email包发送包含 HTML 内容和附件的电子邮件 -
使用包含联系人数据的 CSV 文件发送多封个性化电子邮件
-
使用 Yagmail 软件包,只需几行代码就可以通过您的 gmail 帐户发送电子邮件
在本教程的最后,你会发现一些事务性的电子邮件服务,当你想发送大量的电子邮件时,它们会很有用。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
开始使用
Python 自带内置 smtplib 模块,使用简单邮件传输协议(SMTP)发送邮件。smtplib对 SMTP 使用 RFC 821 协议。本教程中的示例将使用 Gmail SMTP 服务器发送电子邮件,但同样的原则也适用于其他电子邮件服务。尽管大多数电子邮件提供商使用与本教程中相同的连接端口,但您可以快速运行谷歌搜索来确认您的连接端口。
要开始学习本教程,设置一个 Gmail 开发账户,或者设置一个 SMTP 调试服务器,它会丢弃你发送的电子邮件并打印到命令提示符下。下面为您展示了这两种选择。本地 SMTP 调试服务器可用于修复电子邮件功能的任何问题,并确保您的电子邮件功能在发送任何电子邮件之前没有错误。
选项 1:为开发设立一个 Gmail 账户
如果你决定使用 Gmail 帐户发送邮件,我强烈建议你为代码开发设置一个一次性帐户。这是因为你必须调整你的 Gmail 帐户的安全设置,以允许从你的 Python 代码访问,也因为你可能会意外暴露你的登录信息。此外,我发现我的测试账户的收件箱很快就被测试邮件塞满了,这足以成为我建立一个新的 Gmail 账户进行开发的理由。
Gmail 的一个很好的特性是,你可以使用+符号给你的电子邮件地址添加任何修饰语,就在@符号之前。例如,发往my+person1@gmail.com和my+person2@gmail.com的邮件都会到达my@gmail.com。在测试电子邮件功能时,您可以使用它来模拟指向同一个收件箱的多个地址。
要设置用于测试代码的 Gmail 地址,请执行以下操作:
- 创建一个新的 Google 帐户。
- 将 转到 上允许不太安全的应用到。请注意,这使得其他人更容易访问您的帐户。
如果你不想降低你的 Gmail 帐户的安全设置,查看一下谷歌的文档关于如何使用 OAuth2 授权框架获得你的 Python 脚本的访问凭证。
选项 2:设置本地 SMTP 服务器
您可以使用 Python 预安装的smtpd模块,通过运行本地 SMTP 调试服务器来测试电子邮件功能。它不是将电子邮件发送到指定的地址,而是丢弃它们并将它们的内容打印到控制台。运行本地调试服务器意味着没有必要处理消息加密或使用凭证登录到电子邮件服务器。
您可以通过在命令提示符下键入以下命令来启动本地 SMTP 调试服务器:
$ python -m smtpd -c DebuggingServer -n localhost:1025
在 Linux 上,使用前面带sudo的相同命令。
通过此服务器发送的任何电子邮件都将被丢弃,并在终端窗口中显示为每行一个 bytes 对象:
---------- MESSAGE FOLLOWS ----------
b'X-Peer: ::1'
b''
b'From: my@address.com'
b'To: your@address.com'
b'Subject: a local test mail'
b''
b'Hello there, here is a test email'
------------ END MESSAGE ------------
在本教程的其余部分,我将假设您使用的是 Gmail 帐户,但如果您使用的是本地调试服务器,请确保使用localhost作为您的 SMTP 服务器,并使用端口 1025 而不是端口 465 或 587。除此之外,您不需要使用login()或使用 SSL/TLS 加密通信。
发送纯文本电子邮件
在我们开始发送带有 HTML 内容和附件的电子邮件之前,您将学习使用 Python 发送纯文本电子邮件。这些电子邮件你可以用简单的文本编辑器写出来。没有像文本格式或超链接这样的花哨东西。你过一会儿就会明白。
启动安全 SMTP 连接
当您通过 Python 发送电子邮件时,您应该确保您的 SMTP 连接是加密的,这样您的消息和登录凭证就不会被他人轻易访问。SSL(安全套接字层)和 TLS(传输层安全性)是可用于加密 SMTP 连接的两种协议。在使用本地调试服务器时,没有必要使用这两种方法。
有两种方法可以启动与电子邮件服务器的安全连接:
- 使用
SMTP_SSL()启动一个从一开始就受到保护的 SMTP 连接。 - 启动一个不安全的 SMTP 连接,然后可以使用
.starttls()进行加密。
在这两种情况下,Gmail 将使用 TLS 加密电子邮件,因为这是 SSL 的更安全的继任者。根据 Python 的安全考虑,强烈建议您使用 ssl 模块中的create_default_context()。这将加载系统的可信 CA 证书,启用主机名检查和证书验证,并尝试选择合理的安全协议和密码设置。
如果您想检查 Gmail 收件箱中电子邮件的加密情况,请进入更多 → 显示原文,查看列在收到的标题下的加密类型。
smtplib 是 Python 的内置模块,用于向任何装有 SMTP 或 ESMTP 监听守护程序的互联网机器发送电子邮件。
我将首先向您展示如何使用SMTP_SSL(),因为它实例化了一个从一开始就安全的连接,并且比.starttls()选项稍微简洁一些。请记住,Gmail 要求您在使用SMTP_SSL()时连接到 465 端口,在使用.starttls()时连接到 587 端口。
选项 1:使用SMTP_SSL()
下面的代码示例创建了一个与 Gmail 的 SMTP 服务器的安全连接,使用smtplib的SMTP_SSL()启动一个 TLS 加密的连接。ssl的默认上下文验证主机名及其证书,并优化连接的安全性。确保填写您自己的电子邮件地址,而不是my@gmail.com:
import smtplib, ssl
port = 465 # For SSL
password = input("Type your password and press enter: ")
# Create a secure SSL context
context = ssl.create_default_context()
with smtplib.SMTP_SSL("smtp.gmail.com", port, context=context) as server:
server.login("my@gmail.com", password)
# TODO: Send email here
使用with smtplib.SMTP_SSL() as server:确保连接在缩进代码块的末尾自动关闭。如果port为零,或者没有指定,.SMTP_SSL()将使用 SSL 上 SMTP 的标准端口(端口 465)。
将您的电子邮件密码存储在您的代码中是不安全的做法,尤其是当您打算与其他人共享它时。相反,使用input()让用户在运行脚本时输入密码,如上面的例子所示。如果您不想让您的密码在键入时显示在屏幕上,您可以导入 getpass 模块,使用.getpass()代替盲输入您的密码。
选项二:使用.starttls()
我们可以创建一个不安全的 SMTP 连接,并使用.starttls()对其进行加密,而不是使用.SMTP_SSL()来创建一个从一开始就是安全的连接。
为此,创建一个smtplib.SMTP的实例,它封装了一个 SMTP 连接并允许您访问它的方法。我建议在脚本开始时定义您的 SMTP 服务器和端口,以便于配置它们。
下面的代码片段使用了结构server = SMTP(),而不是我们在前面的例子中使用的格式with SMTP() as server:。为了确保你的代码在出错时不会崩溃,把你的主代码放在一个try块中,让一个except块把任何错误信息打印到stdout:
import smtplib, ssl
smtp_server = "smtp.gmail.com"
port = 587 # For starttls
sender_email = "my@gmail.com"
password = input("Type your password and press enter: ")
# Create a secure SSL context
context = ssl.create_default_context()
# Try to log in to server and send email
try:
server = smtplib.SMTP(smtp_server,port)
server.ehlo() # Can be omitted
server.starttls(context=context) # Secure the connection
server.ehlo() # Can be omitted
server.login(sender_email, password)
# TODO: Send email here
except Exception as e:
# Print any error messages to stdout
print(e)
finally:
server.quit()
为了向服务器标识自己,应该在创建一个.SMTP()对象后调用.helo() (SMTP)或.ehlo() (ESMTP),在.starttls()后再调用一次。如果需要,这个函数由.starttls()和.sendmail()隐式调用,所以除非你想检查服务器的 SMTP 服务扩展,否则没有必要显式使用.helo()或.ehlo()。
发送您的纯文本电子邮件
使用上述方法之一启动安全 SMTP 连接后,您可以使用.sendmail()发送您的电子邮件,这与 tin 上显示的差不多:
server.sendmail(sender_email, receiver_email, message)
我建议在导入之后,在脚本的顶部定义电子邮件地址和消息内容,这样您可以很容易地更改它们:
sender_email = "my@gmail.com"
receiver_email = "your@gmail.com"
message = """\
Subject: Hi there
This message is sent from Python."""
# Send email here
message 字符串以"Subject: Hi there"开头,后跟两个换行符(\n)。这确保了Hi there显示为电子邮件的主题,并且换行后的文本将被视为消息正文。
下面的代码示例使用SMTP_SSL()发送一封纯文本电子邮件:
import smtplib, ssl
port = 465 # For SSL
smtp_server = "smtp.gmail.com"
sender_email = "my@gmail.com" # Enter your address
receiver_email = "your@gmail.com" # Enter receiver address
password = input("Type your password and press enter: ")
message = """\
Subject: Hi there
This message is sent from Python."""
context = ssl.create_default_context()
with smtplib.SMTP_SSL(smtp_server, port, context=context) as server:
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message)
作为比较,这里有一个代码示例,它通过受.starttls()保护的 SMTP 连接发送一封纯文本电子邮件。如果需要,可以省略server.ehlo()行,因为它们被.starttls()和.sendmail()隐式调用:
import smtplib, ssl
port = 587 # For starttls
smtp_server = "smtp.gmail.com"
sender_email = "my@gmail.com"
receiver_email = "your@gmail.com"
password = input("Type your password and press enter:")
message = """\
Subject: Hi there
This message is sent from Python."""
context = ssl.create_default_context()
with smtplib.SMTP(smtp_server, port) as server:
server.ehlo() # Can be omitted
server.starttls(context=context)
server.ehlo() # Can be omitted
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message)
发送精美的电子邮件
Python 的内置email包允许你构建更多奇特的电子邮件,然后可以像你已经做的那样用smtplib传输。下面,你将学习如何使用email包发送带有 HTML 内容和附件的电子邮件。
包括 HTML 内容
如果你想格式化电子邮件中的文本(粗体、斜体等等),或者如果你想添加任何图像、超链接或响应内容,那么 HTML 就非常方便了。当今最常见的电子邮件类型是 MIME(多用途互联网邮件扩展)多部分电子邮件,结合了 HTML 和纯文本。MIME 消息由 Python 的email.mime模块处理。有关详细描述,请查看文档。
由于并非所有的电子邮件客户端都默认显示 HTML 内容,而且出于安全原因,有些人选择只接收纯文本电子邮件,因此为 HTML 邮件添加纯文本替代内容非常重要。因为电子邮件客户端将首先呈现最后一个多部分附件,所以请确保在纯文本版本之后添加 HTML 消息。
在下面的例子中,我们的MIMEText()对象将包含我们的消息的 HTML 和纯文本版本,并且MIMEMultipart("alternative")实例将这些合并成一个具有两个可选呈现选项的消息:
import smtplib, ssl
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
sender_email = "my@gmail.com"
receiver_email = "your@gmail.com"
password = input("Type your password and press enter:")
message = MIMEMultipart("alternative")
message["Subject"] = "multipart test"
message["From"] = sender_email
message["To"] = receiver_email
# Create the plain-text and HTML version of your message
text = """\
Hi,
How are you?
Real Python has many great tutorials:
www.realpython.com"""
html = """\
<html>
<body>
<p>Hi,<br>
How are you?<br>
<a href="http://www.realpython.com">Real Python</a>
has many great tutorials.
</p>
</body>
</html>
"""
# Turn these into plain/html MIMEText objects
part1 = MIMEText(text, "plain")
part2 = MIMEText(html, "html")
# Add HTML/plain-text parts to MIMEMultipart message
# The email client will try to render the last part first
message.attach(part1)
message.attach(part2)
# Create secure connection with server and send email
context = ssl.create_default_context()
with smtplib.SMTP_SSL("smtp.gmail.com", 465, context=context) as server:
server.login(sender_email, password)
server.sendmail(
sender_email, receiver_email, message.as_string()
)
在这个例子中,首先将纯文本和 HTML 消息定义为字符串,然后将它们存储为plain / html MIMEText对象。然后,这些可以按此顺序添加到MIMEMultipart("alternative")消息中,并通过您与电子邮件服务器的安全连接发送出去。记得在纯文本选项后添加 HTML 消息,因为电子邮件客户端会尝试先呈现最后一个子部分。
使用email包添加附件
为了将二进制文件发送到设计用于处理文本数据的电子邮件服务器,需要在传输之前对它们进行编码。这通常使用 base64 来完成,它将二进制数据编码成可打印的 ASCII 字符。
下面的代码示例显示了如何发送附件为 PDF 文件的电子邮件:
import email, smtplib, ssl
from email import encoders
from email.mime.base import MIMEBase
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
subject = "An email with attachment from Python"
body = "This is an email with attachment sent from Python"
sender_email = "my@gmail.com"
receiver_email = "your@gmail.com"
password = input("Type your password and press enter:")
# Create a multipart message and set headers
message = MIMEMultipart()
message["From"] = sender_email
message["To"] = receiver_email
message["Subject"] = subject
message["Bcc"] = receiver_email # Recommended for mass emails
# Add body to email
message.attach(MIMEText(body, "plain"))
filename = "document.pdf" # In same directory as script
# Open PDF file in binary mode
with open(filename, "rb") as attachment:
# Add file as application/octet-stream
# Email client can usually download this automatically as attachment
part = MIMEBase("application", "octet-stream")
part.set_payload(attachment.read())
# Encode file in ASCII characters to send by email
encoders.encode_base64(part)
# Add header as key/value pair to attachment part
part.add_header(
"Content-Disposition",
f"attachment; filename= {filename}",
)
# Add attachment to message and convert message to string
message.attach(part)
text = message.as_string()
# Log in to server using secure context and send email
context = ssl.create_default_context()
with smtplib.SMTP_SSL("smtp.gmail.com", 465, context=context) as server:
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, text)
MIMEultipart()消息接受 RFC5233 样式的键/值对形式的参数,这些参数存储在一个字典中,并传递给 Message 基类的 .add_header方法。
查看 Python 的email.mime模块的文档,了解更多关于使用 MIME 类的信息。
发送多封个性化邮件
假设您想给组织成员发送电子邮件,提醒他们缴纳会费。或者,您可能想给班上的学生发送个性化的电子邮件,告知他们最近作业的分数。在 Python 中,这些任务轻而易举。
用相关的个人信息制作一个 CSV 文件
发送多封个性化电子邮件的一个简单起点是创建一个包含所有必需个人信息的 CSV(逗号分隔值)文件。(确保不要在未经他人同意的情况下分享他人的隐私信息。)CSV 文件可以被视为一个简单的表格,其中第一行通常包含列标题。
下面是文件contacts_file.csv的内容,我将它保存在与我的 Python 代码相同的文件夹中。它包含一组虚构人物的姓名、地址和等级。我使用了my+modifier@gmail.com结构来确保所有的电子邮件都在我自己的收件箱里,在这个例子中是 my@gmail.com 的:
name,email,grade
Ron Obvious,my+ovious@gmail.com,B+
Killer Rabbit of Caerbannog,my+rabbit@gmail.com,A
Brian Cohen,my+brian@gmail.com,C
创建 CSV 文件时,请确保用逗号分隔值,周围没有任何空格。
循环发送多封电子邮件
下面的代码示例向您展示了如何打开一个 CSV 文件并遍历其内容行(跳过标题行)。为了确保在您向所有联系人发送电子邮件之前代码能够正常工作,我为每个联系人打印了Sending email to ...,稍后我们可以用实际发送电子邮件的功能来替换它:
import csv
with open("contacts_file.csv") as file:
reader = csv.reader(file)
next(reader) # Skip header row
for name, email, grade in reader:
print(f"Sending email to {name}")
# Send email here
在上面的例子中,使用with open(filename) as file:确保你的文件在代码块的末尾关闭。csv.reader()使得逐行读取 CSV 文件并提取其值变得容易。next(reader)行跳过标题行,因此下面的行for name, email, grade in reader:在每个逗号处拆分后续行,并将结果值存储在当前联系人的字符串name、email和grade中。
如果您的 CSV 文件中的值在一侧或两侧包含空格,您可以使用.strip()方法删除它们。
个性化内容
您可以使用 str.format() 来填充花括号占位符,从而在消息中添加个性化内容。比如"hi {name}, you {result} your assignment".format(name="John", result="passed")会给你"hi John, you passed your assignment"。
从 Python 3.6 开始,使用 f-strings 可以更优雅地完成字符串格式化,但是这需要在 f-string 本身之前定义占位符。为了在脚本的开头定义电子邮件消息,并在循环 CSV 文件时为每个联系人填充占位符,使用了较老的.format()方法。
考虑到这一点,您可以设置一个通用的邮件正文,其中的占位符可以根据个人情况进行定制。
代码示例
下面的代码示例允许您向多个联系人发送个性化电子邮件。它循环遍历每个联系人的带有name,email,grade的 CSV 文件,如上面的示例所示。
一般消息在脚本的开头定义,对于 CSV 文件中的每个联系人,其{name}和{grade}占位符被填充,个性化电子邮件通过与 Gmail 服务器的安全连接发送出去,如您之前所见:
import csv, smtplib, ssl
message = """Subject: Your grade
Hi {name}, your grade is {grade}"""
from_address = "my@gmail.com"
password = input("Type your password and press enter: ")
context = ssl.create_default_context()
with smtplib.SMTP_SSL("smtp.gmail.com", 465, context=context) as server:
server.login(from_address, password)
with open("contacts_file.csv") as file:
reader = csv.reader(file)
next(reader) # Skip header row
for name, email, grade in reader:
server.sendmail(
from_address,
email,
message.format(name=name,grade=grade),
)
雅格邮件
有多个旨在使发送电子邮件更容易的库,如信封、侧翼和 Yagmail 。Yagmail 是专门为 gmail 设计的,它通过友好的 API 极大地简化了发送电子邮件的过程,正如你在下面的代码示例中看到的:
import yagmail
receiver = "your@gmail.com"
body = "Hello there from Yagmail"
filename = "document.pdf"
yag = yagmail.SMTP("my@gmail.com")
yag.send(
to=receiver,
subject="Yagmail test with attachment",
contents=body,
attachments=filename,
)
这个代码示例使用email和smtplib 发送一封带有 PDF 附件的电子邮件,这只是我们的示例所需行数的一小部分。
设置 Yagmail 时,你可以将 gmail 验证添加到操作系统的密钥环中,如文档中的所述。如果不这样做,Yagmail 会在需要时提示您输入密码,并自动将其存储在 keyring 中。
交易电子邮件服务
如果你打算发送大量的电子邮件,希望看到电子邮件的统计数据,并希望确保可靠的交付,它可能值得看看交易电子邮件服务。虽然以下所有服务都有发送大量电子邮件的付费计划,但它们也有免费计划,所以你可以尝试一下。其中一些免费计划无限期有效,可能足以满足您的电子邮件需求。
下面是一些主要交易电子邮件服务的免费计划的概述。点击提供商名称会将您带到他们网站的定价部分。
| 供应者 | 免费计划 |
|---|---|
| 发送网格 | 前 30 天 40,000 封电子邮件,然后每天 100 封 |
| 正在发送 | 300 封电子邮件/天 |
| 气枪 | 前 10,000 封电子邮件免费 |
| 里程数 | 200 封电子邮件/天 |
| 亚马逊 SES | 每月 62,000 封电子邮件 |
你可以运行谷歌搜索来看看哪个提供商最适合你的需求,或者尝试几个免费计划来看看你最喜欢使用哪个 API。
发送网格代码示例
这里有一个使用 Sendgrid 发送电子邮件的代码示例,让您感受一下如何使用 Python 的事务性电子邮件服务:
import os
import sendgrid
from sendgrid.helpers.mail import Content, Email, Mail
sg = sendgrid.SendGridAPIClient(
apikey=os.environ.get("SENDGRID_API_KEY")
)
from_email = Email("my@gmail.com")
to_email = Email("your@gmail.com")
subject = "A test email from Sendgrid"
content = Content(
"text/plain", "Here's a test email sent through Python"
)
mail = Mail(from_email, subject, to_email, content)
response = sg.client.mail.send.post(request_body=mail.get())
# The statements below can be included for debugging purposes
print(response.status_code)
print(response.body)
print(response.headers)
要运行此代码,您必须首先:
- 注册一个(免费的)Sendgrid 账户
- 请求 API 密钥用于用户验证
- 通过在命令提示符下键入
setx SENDGRID_API_KEY "YOUR_API_KEY"来添加您的 API 密钥(永久存储此 API 密钥)或键入set SENDGRID_API_KEY YOUR_API_KEY来仅存储当前客户端会话的 API 密钥
关于如何为 Mac 和 Windows 设置 Sendgrid 的更多信息可以在 Github 上的知识库自述文件中找到。
结论
您现在可以启动安全的 SMTP 连接,并向联系人列表中的人发送多封个性化电子邮件!
您已经学习了如何发送一封包含纯文本选项的 HTML 电子邮件,以及如何在电子邮件中附加文件。当你使用 gmail 账户时, Yagmail 包简化了所有这些任务。如果你打算发送大量的电子邮件,值得考虑交易电子邮件服务。
享受用 Python 发送电子邮件的乐趣,记住:请勿发送垃圾邮件!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 发邮件***
Python 中的集合
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 套在 Python 里
也许你记得在数学教育的某个时候学习过集合和集合论。也许你还记得维恩图:
如果这没有让你想起什么,不要担心!本教程对你来说应该还是很容易理解的。
在数学中,集合的严格定义可能是抽象的,难以理解。然而实际上,集合可以简单地认为是定义明确的不同对象的集合,通常称为元素或成员。
将对象分组到一个集合中在编程中也很有用,Python 提供了一个内置的集合类型来做到这一点。集合与其他对象类型的区别在于可以对其执行的独特操作。
以下是你将在本教程中学到的:你将看到如何在 Python 中定义 set 对象,并发现它们支持的操作。与前面的列表和词典教程一样,当您完成本教程后,您应该会很好地感觉到什么时候集合是合适的选择。你还将了解到冷冻布景,除了一个重要的细节外,它们与布景相似。
参加测验:通过我们的交互式“Python 集”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
定义集合
Python 的内置set类型有以下特点:
- 集合是无序的。
- 集合元素是唯一的。不允许重复的元素。
- 集合本身可以被修改,但是集合中包含的元素必须是不可变的类型。
让我们看看这意味着什么,以及如何在 Python 中使用集合。
可以通过两种方式创建集合。首先,您可以使用内置的set()函数定义一个集合:
x = set(<iter>)
在这种情况下,参数<iter>是一个 iterable——现在再一次考虑 list 或 tuple——它生成包含在集合中的对象列表。这类似于给予.extend()列表方法的<iter>参数:
>>> x = set(['foo', 'bar', 'baz', 'foo', 'qux']) >>> x {'qux', 'foo', 'bar', 'baz'} >>> x = set(('foo', 'bar', 'baz', 'foo', 'qux')) >>> x {'qux', 'foo', 'bar', 'baz'}字符串也是可迭代的,所以一个字符串也可以传递给
set()。您已经看到list(s)生成了字符串s中的字符列表。类似地,set(s)生成了一组s中的人物:
>>> s = 'quux'
>>> list(s)
['q', 'u', 'u', 'x']
>>> set(s)
{'x', 'u', 'q'}
您可以看到结果集是无序的:定义中指定的原始顺序不一定被保留。此外,重复值在集合中只出现一次,就像前两个例子中的字符串'foo'和第三个例子中的字母'u'一样。
或者,可以用花括号({})来定义集合:
x = {<obj>, <obj>, ..., <obj>}
当一个集合以这种方式定义时,每个<obj>成为集合中的一个独特元素,即使它是可迭代的。这种行为类似于.append()列表方法。
因此,上面显示的集合也可以这样定义:
>>> x = {'foo', 'bar', 'baz', 'foo', 'qux'} >>> x {'qux', 'foo', 'bar', 'baz'} >>> x = {'q', 'u', 'u', 'x'} >>> x {'x', 'q', 'u'}概括一下:
set()的参数是可迭代的。它生成一个要放入集合的元素列表。- 花括号中的对象被原封不动地放入集合中,即使它们是可迭代的。
观察这两个集合定义之间的差异:
>>> {'foo'}
{'foo'}
>>> set('foo')
{'o', 'f'}
集合可以是空的。然而,回想一下 Python 将空花括号({})解释为空字典,因此定义空集的唯一方法是使用set()函数:
>>> x = set() >>> type(x) <class 'set'> >>> x set() >>> x = {} >>> type(x) <class 'dict'>在布尔上下文中,空集是假的:
>>> x = set()
>>> bool(x)
False
>>> x or 1
1
>>> x and 1
set()
你可能认为最直观的集合会包含相似的对象——例如,甚至是数字或姓氏:
>>> s1 = {2, 4, 6, 8, 10} >>> s2 = {'Smith', 'McArthur', 'Wilson', 'Johansson'}但是 Python 并不要求这样。集合中的元素可以是不同类型的对象:
>>> x = {42, 'foo', 3.14159, None}
>>> x
{None, 'foo', 42, 3.14159}
不要忘记集合元素必须是不可变的。例如,一个元组可以包含在一个集合中:
>>> x = {42, 'foo', (1, 2, 3), 3.14159} >>> x {42, 'foo', 3.14159, (1, 2, 3)}但是列表和字典是可变的,所以它们不能是集合元素:
>>> a = [1, 2, 3]
>>> {a}
Traceback (most recent call last):
File "<pyshell#70>", line 1, in <module>
{a}
TypeError: unhashable type: 'list'
>>> d = {'a': 1, 'b': 2}
>>> {d}
Traceback (most recent call last):
File "<pyshell#72>", line 1, in <module>
{d}
TypeError: unhashable type: 'dict'
设置规模和成员资格
len()函数返回集合中元素的数量,而in和not in操作符可用于测试成员资格:
>>> x = {'foo', 'bar', 'baz'} >>> len(x) 3 >>> 'bar' in x True >>> 'qux' in x False在器械包上操作
许多可用于 Python 其他复合数据类型的操作对集合没有意义。例如,集合不能被索引或切片。然而,Python 提供了一整套对集合对象的操作,这些操作通常模仿为数学集合定义的操作。
运算符与方法
Python 中的大多数(尽管不是全部)集合操作可以通过两种不同的方式执行:通过操作符或通过方法。以 set union 为例,让我们看看这些操作符和方法是如何工作的。
给定两个集合
x1和x2,x1和x2的并集是由任一集合中的所有元素组成的集合。考虑这两组:
x1 = {'foo', 'bar', 'baz'} x2 = {'baz', 'qux', 'quux'}
x1和x2的并集就是{'foo', 'bar', 'baz', 'qux', 'quux'}。注意:注意,同时出现在
x1和x2中的元素'baz',在联合中只出现一次。集合从不包含重复值。在 Python 中,可以用
|操作符执行集合并集:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'baz', 'qux', 'quux'}
>>> x1 | x2
{'baz', 'quux', 'qux', 'bar', 'foo'}
集合并集也可以用.union()方法获得。方法在其中一个集合上调用,另一个集合作为参数传递:
>>> x1.union(x2) {'baz', 'quux', 'qux', 'bar', 'foo'}在上面的例子中,操作符和方法的行为是一样的。但是它们之间有一个微妙的区别。当使用
|操作符时,两个操作数都必须是集合。另一方面,.union()方法将任何 iterable 作为参数,将其转换为集合,然后执行 union。观察这两种说法的区别:
>>> x1 | ('baz', 'qux', 'quux')
Traceback (most recent call last):
File "<pyshell#43>", line 1, in <module>
x1 | ('baz', 'qux', 'quux')
TypeError: unsupported operand type(s) for |: 'set' and 'tuple'
>>> x1.union(('baz', 'qux', 'quux'))
{'baz', 'quux', 'qux', 'bar', 'foo'}
两者都试图计算x1和元组('baz', 'qux', 'quux')的并集。使用|操作符会失败,但使用.union()方法会成功。
可用的运算符和方法
下面是 Python 中可用的集合操作列表。有些是由操作符执行的,有些是由方法执行的,有些是由两者执行的。上面概述的原则通常适用:在需要集合的地方,方法通常接受任何 iterable 作为参数,但是操作符需要实际的集合作为操作数。
x1.union(x2[, x3 ...])
x1 | x2 [| x3 ...]
计算两个或多个集合的并集。
x1.union(x2)和x1 | x2都返回x1或x2中所有元素的集合:
>>> x1 = {'foo', 'bar', 'baz'} >>> x2 = {'baz', 'qux', 'quux'} >>> x1.union(x2) {'foo', 'qux', 'quux', 'baz', 'bar'} >>> x1 | x2 {'foo', 'qux', 'quux', 'baz', 'bar'}可以使用运算符或方法指定两个以上的集合:
>>> a = {1, 2, 3, 4}
>>> b = {2, 3, 4, 5}
>>> c = {3, 4, 5, 6}
>>> d = {4, 5, 6, 7}
>>> a.union(b, c, d)
{1, 2, 3, 4, 5, 6, 7}
>>> a | b | c | d
{1, 2, 3, 4, 5, 6, 7}
结果集包含存在于任何指定集中的所有元素。
x1.intersection(x2[, x3 ...])
x1 & x2 [& x3 ...]
计算两个或多个集合的交集。
x1.intersection(x2)和x1 & x2返回x1和x2共有的元素集合:
>>> x1 = {'foo', 'bar', 'baz'} >>> x2 = {'baz', 'qux', 'quux'} >>> x1.intersection(x2) {'baz'} >>> x1 & x2 {'baz'}可以使用交集方法和运算符指定多个集合,就像使用集合并集一样:
>>> a = {1, 2, 3, 4}
>>> b = {2, 3, 4, 5}
>>> c = {3, 4, 5, 6}
>>> d = {4, 5, 6, 7}
>>> a.intersection(b, c, d)
{4}
>>> a & b & c & d
{4}
结果集只包含所有指定集中存在的元素。
x1.difference(x2[, x3 ...])
x1 - x2 [- x3 ...]
计算两个或多个集合之间的差。
x1.difference(x2)和x1 - x2返回所有在x1而不在x2的元素的集合:
>>> x1 = {'foo', 'bar', 'baz'} >>> x2 = {'baz', 'qux', 'quux'} >>> x1.difference(x2) {'foo', 'bar'} >>> x1 - x2 {'foo', 'bar'}另一种思考方式是,
x1.difference(x2)和x1 - x2返回当x2中的任何元素从x1中移除或减去时产生的集合。同样,您可以指定两个以上的集合:
>>> a = {1, 2, 3, 30, 300}
>>> b = {10, 20, 30, 40}
>>> c = {100, 200, 300, 400}
>>> a.difference(b, c)
{1, 2, 3}
>>> a - b - c
{1, 2, 3}
当指定多个集合时,操作从左到右执行。在上面的例子中,首先计算a - b,得到{1, 2, 3, 300}。然后从那个集合中减去c,剩下{1, 2, 3}:
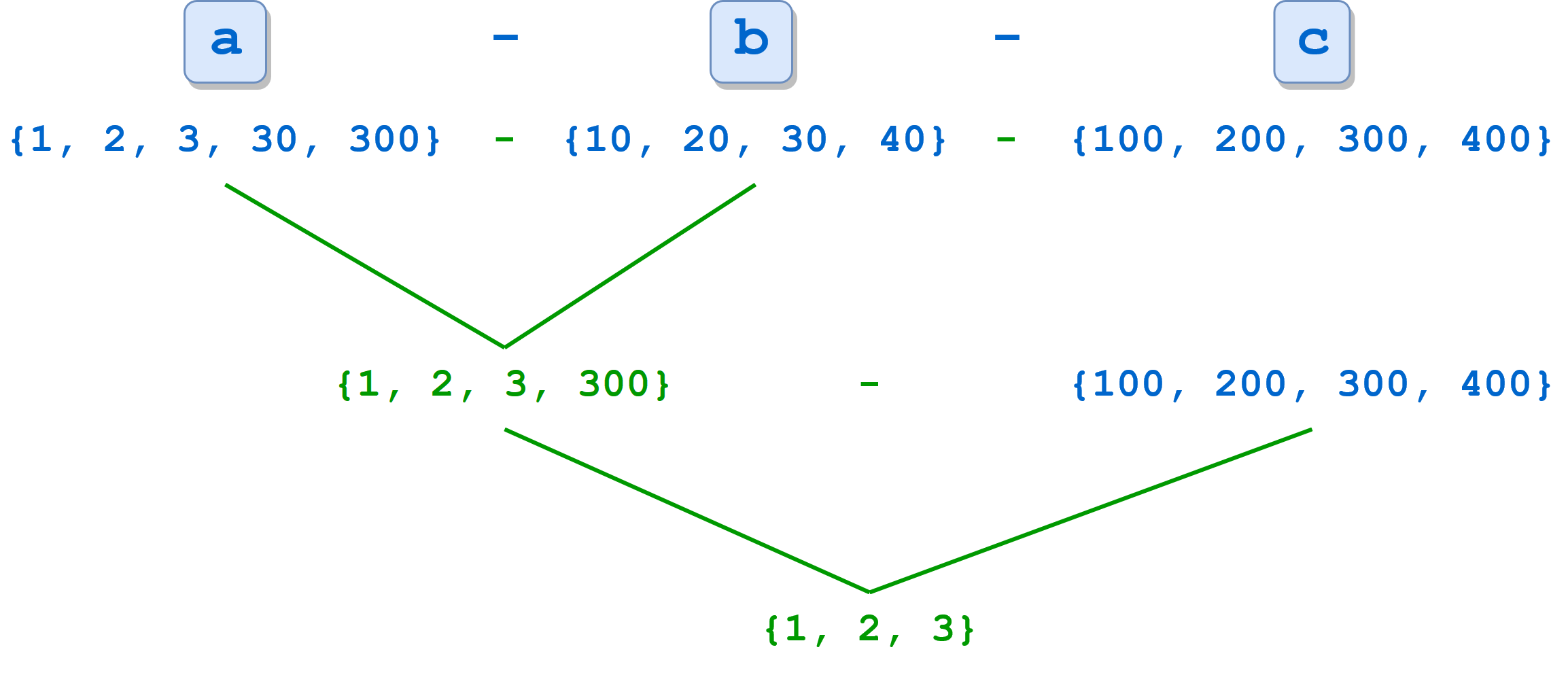
x1.symmetric_difference(x2)
x1 ^ x2 [^ x3 ...]
计算集合之间的对称差。
x1.symmetric_difference(x2)和x1 ^ x2返回x1或x2中所有元素的集合,但不能同时返回:
>>> x1 = {'foo', 'bar', 'baz'} >>> x2 = {'baz', 'qux', 'quux'} >>> x1.symmetric_difference(x2) {'foo', 'qux', 'quux', 'bar'} >>> x1 ^ x2 {'foo', 'qux', 'quux', 'bar'}
^操作符也允许两个以上的集合:
>>> a = {1, 2, 3, 4, 5}
>>> b = {10, 2, 3, 4, 50}
>>> c = {1, 50, 100}
>>> a ^ b ^ c
{100, 5, 10}
与差运算符一样,当指定多个集合时,运算从左到右执行。
奇怪的是,尽管^操作符允许多个集合,但是.symmetric_difference()方法不允许:
>>> a = {1, 2, 3, 4, 5} >>> b = {10, 2, 3, 4, 50} >>> c = {1, 50, 100} >>> a.symmetric_difference(b, c) Traceback (most recent call last): File "<pyshell#11>", line 1, in <module> a.symmetric_difference(b, c) TypeError: symmetric_difference() takes exactly one argument (2 given)
x1.isdisjoint(x2)确定两个集合是否有任何共同的元素。
如果
x1和x2没有共同的元素,则x1.isdisjoint(x2)返回True:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'baz', 'qux', 'quux'}
>>> x1.isdisjoint(x2)
False
>>> x2 - {'baz'}
{'quux', 'qux'}
>>> x1.isdisjoint(x2 - {'baz'})
True
如果x1.isdisjoint(x2)是True,那么x1 & x2就是空集:
>>> x1 = {1, 3, 5} >>> x2 = {2, 4, 6} >>> x1.isdisjoint(x2) True >>> x1 & x2 set()注意:没有对应于
.isdisjoint()方法的运算符。
x1.issubset(x2)
x1 <= x2确定一个集合是否是另一个集合的子集。
在集合论中,如果
x1的每个元素都在x2中,那么集合x1被认为是另一个集合x2的子集。如果
x1是x2的子集,x1.issubset(x2)和x1 <= x2返回True:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x1.issubset({'foo', 'bar', 'baz', 'qux', 'quux'})
True
>>> x2 = {'baz', 'qux', 'quux'}
>>> x1 <= x2
False
集合被认为是自身的子集:
>>> x = {1, 2, 3, 4, 5} >>> x.issubset(x) True >>> x <= x True这似乎很奇怪,也许。但是它符合定义——
x的每个元素都在x中。
x1 < x2确定一个集合是否是另一个集合的真子集。
真子集和子集是一样的,除了集合不能相同。如果
x1的每个元素都在x2中,并且x1和x2不相等,则集合x1被认为是另一个集合x2的真子集。如果
x1是x2的真子集,则x1 < x2返回True:
>>> x1 = {'foo', 'bar'}
>>> x2 = {'foo', 'bar', 'baz'}
>>> x1 < x2
True
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'foo', 'bar', 'baz'}
>>> x1 < x2
False
虽然集合被认为是自身的子集,但它不是自身的真子集:
>>> x = {1, 2, 3, 4, 5} >>> x <= x True >>> x < x False注意:
<运算符是检验一个集合是否是真子集的唯一方法。没有相应的方法。
x1.issuperset(x2)
x1 >= x2确定一个集合是否是另一个集合的超集。
超集是子集的逆集。如果
x1包含x2的所有元素,那么集合x1被认为是另一个集合x2的超集。如果
x1是x2的超集,x1.issuperset(x2)和x1 >= x2返回True:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x1.issuperset({'foo', 'bar'})
True
>>> x2 = {'baz', 'qux', 'quux'}
>>> x1 >= x2
False
你已经看到一个集合被认为是它自身的子集。集合也被认为是其自身的超集:
>>> x = {1, 2, 3, 4, 5} >>> x.issuperset(x) True >>> x >= x True
x1 > x2确定一个集合是否是另一个集合的适当超集。
正确的超集与超集是相同的,除了集合不能相同。如果
x1包含x2的所有元素,并且x1和x2不相等,那么一个集合x1被认为是另一个集合x2的真超集。如果
x1是x2的适当超集,则x1 > x2返回True:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'foo', 'bar'}
>>> x1 > x2
True
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'foo', 'bar', 'baz'}
>>> x1 > x2
False
集合不是其自身的适当超集:
>>> x = {1, 2, 3, 4, 5} >>> x > x False注意:
>操作符是测试一个集合是否是一个恰当超集的唯一方法。没有相应的方法。修改器械包
尽管集合中包含的元素必须是不可变的类型,但是集合本身是可以修改的。和上面的操作一样,也有混合的操作符和方法可以用来改变集合的内容。
扩充赋值运算符和方法
上面列出的每个并集、交集、差集和对称差集运算符都有一个扩充的赋值表,可用于修改集合。对于每一种,也有相应的方法。
x1.update(x2[, x3 ...])
x1 |= x2 [| x3 ...]通过联合修改集合。
x1.update(x2)和x1 |= x2向x1添加x2中x1还没有的任何元素:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'foo', 'baz', 'qux'}
>>> x1 |= x2
>>> x1
{'qux', 'foo', 'bar', 'baz'}
>>> x1.update(['corge', 'garply'])
>>> x1
{'qux', 'corge', 'garply', 'foo', 'bar', 'baz'}
x1.intersection_update(x2[, x3 ...])
x1 &= x2 [& x3 ...]
通过交集修改集合。
x1.intersection_update(x2)和x1 &= x2更新x1,仅保留在x1和x2中发现的元素:
>>> x1 = {'foo', 'bar', 'baz'} >>> x2 = {'foo', 'baz', 'qux'} >>> x1 &= x2 >>> x1 {'foo', 'baz'} >>> x1.intersection_update(['baz', 'qux']) >>> x1 {'baz'}
x1.difference_update(x2[, x3 ...])
x1 -= x2 [| x3 ...]通过差异修改集合。
x1.difference_update(x2)和x1 -= x2更新x1,删除x2中发现的元素:
>>> x1 = {'foo', 'bar', 'baz'}
>>> x2 = {'foo', 'baz', 'qux'}
>>> x1 -= x2
>>> x1
{'bar'}
>>> x1.difference_update(['foo', 'bar', 'qux'])
>>> x1
set()
x1.symmetric_difference_update(x2)
x1 ^= x2
通过对称差修改集合。
x1.symmetric_difference_update(x2)和x1 ^= x2更新x1,保留在x1或x2中找到的元素,但不能同时保留:
>>> x1 = {'foo', 'bar', 'baz'} >>> x2 = {'foo', 'baz', 'qux'}
x1 ^= x2
x1x1.symmetric_difference_update(['qux', 'corge'])
x1
[*Remove ads*](/account/join/)
### 修改集合的其他方法
除了上面增加的操作符,Python 还支持几个额外的修改集合的方法。
`x.add(<elem>)`
> 向集合中添加元素。
`x.add(<elem>)`将`<elem>`添加到`x`中,T1 必须是单个不可变对象:
>>>
```py
>>> x = {'foo', 'bar', 'baz'}
>>> x.add('qux')
>>> x
{'bar', 'baz', 'foo', 'qux'}
x.remove(<elem>)
从集合中移除元素。
x.remove(<elem>)从x中删除<elem>。如果<elem>不在x中,Python 会引发异常:
>>> x = {'foo', 'bar', 'baz'} >>> x.remove('baz') >>> x {'bar', 'foo'} >>> x.remove('qux') Traceback (most recent call last): File "<pyshell#58>", line 1, in <module> x.remove('qux') KeyError: 'qux'
x.discard(<elem>)从集合中移除元素。
x.discard(<elem>)也从x中删除<elem>。但是,如果<elem>不在x中,这个方法什么也不做,而是引发一个异常:
>>> x = {'foo', 'bar', 'baz'}
>>> x.discard('baz')
>>> x
{'bar', 'foo'}
>>> x.discard('qux')
>>> x
{'bar', 'foo'}
x.pop()
从集合中移除随机元素。
x.pop()从x中移除并返回任意选择的元素。如果x为空,x.pop()会引发一个异常:
>>> x = {'foo', 'bar', 'baz'} >>> x.pop() 'bar' >>> x {'baz', 'foo'} >>> x.pop() 'baz' >>> x {'foo'} >>> x.pop() 'foo' >>> x set() >>> x.pop() Traceback (most recent call last): File "<pyshell#82>", line 1, in <module> x.pop() KeyError: 'pop from an empty set'
x.clear()清除集合。
x.clear()删除x中的所有元素:
>>> x = {'foo', 'bar', 'baz'}
>>> x
{'foo', 'bar', 'baz'}
>>>
>>> x.clear()
>>> x
set()
冻结器械包
Python 提供了另一个名为 frozenset 的内置类型,除了 frozenset 是不可变的之外,它在所有方面都与 set 完全一样。您可以对冷冻集执行非修改操作:
>>> x = frozenset(['foo', 'bar', 'baz']) >>> x frozenset({'foo', 'baz', 'bar'}) >>> len(x) 3 >>> x & {'baz', 'qux', 'quux'} frozenset({'baz'})但是试图修改冷冻集的方法会失败:
>>> x = frozenset(['foo', 'bar', 'baz'])
>>> x.add('qux')
Traceback (most recent call last):
File "<pyshell#127>", line 1, in <module>
x.add('qux')
AttributeError: 'frozenset' object has no attribute 'add'
>>> x.pop()
Traceback (most recent call last):
File "<pyshell#129>", line 1, in <module>
x.pop()
AttributeError: 'frozenset' object has no attribute 'pop'
>>> x.clear()
Traceback (most recent call last):
File "<pyshell#131>", line 1, in <module>
x.clear()
AttributeError: 'frozenset' object has no attribute 'clear'
>>> x
frozenset({'foo', 'bar', 'baz'})
深潜:冷冻集和扩充任务
由于 frozenset 是不可变的,您可能会认为它不可能是增强赋值操作符的目标。但是请注意:
`>>> f = frozenset(['foo', 'bar', 'baz']) >>> s = {'baz', 'qux', 'quux'} >>> f &= s >>> f frozenset({'baz'})`怎么回事?
Python 不会就地对 frozensets 执行增强赋值。语句
x &= s实际上等同于x = x & s。它没有修改原来的x。它正在将x重新分配给一个新的对象,而最初引用的对象x不见了。您可以使用
id()功能验证这一点:`>>> f = frozenset(['foo', 'bar', 'baz']) >>> id(f) 56992872 >>> s = {'baz', 'qux', 'quux'} >>> f &= s >>> f frozenset({'baz'}) >>> id(f) 56992152`
f在扩充赋值后具有不同的整数标识符。它已被重新分配,而不是就地修改。Python 中的一些对象在作为增强赋值操作符的目标时会被就地修改。但是冰冻人不是。
当你想使用一个集合,但是你需要一个不可变的对象时,Frozensets 是很有用的。例如,您不能定义其元素也是集合的集合,因为集合元素必须是不可变的:
>>> x1 = set(['foo']) >>> x2 = set(['bar']) >>> x3 = set(['baz']) >>> x = {x1, x2, x3} Traceback (most recent call last): File "<pyshell#38>", line 1, in <module> x = {x1, x2, x3} TypeError: unhashable type: 'set'如果您真的觉得必须定义一组集合(嘿,这是可能的),如果元素是 frozensets,您可以这样做,因为它们是不可变的:
>>> x1 = frozenset(['foo'])
>>> x2 = frozenset(['bar'])
>>> x3 = frozenset(['baz'])
>>> x = {x1, x2, x3}
>>> x
{frozenset({'bar'}), frozenset({'baz'}), frozenset({'foo'})}
同样,回想一下前面关于字典的教程,字典键必须是不可变的。您不能将内置集合类型用作字典键:
>>> x = {1, 2, 3} >>> y = {'a', 'b', 'c'}
d = {x: 'foo', y: 'bar'}
Traceback (most recent call last):
File "<pyshell#3>", line 1, in
d = {x: 'foo', y: 'bar'}
TypeError: unhashable type: 'set'
如果您发现自己需要使用集合作为字典键,您可以使用 frozensets:
>>>
```py
>>> x = frozenset({1, 2, 3})
>>> y = frozenset({'a', 'b', 'c'})
>>>
>>> d = {x: 'foo', y: 'bar'}
>>> d
{frozenset({1, 2, 3}): 'foo', frozenset({'c', 'a', 'b'}): 'bar'}
结论
在本教程中,您学习了如何在 Python 中定义 set 对象,并且熟悉了可用于处理 set 的函数、运算符和方法。
现在,您应该已经熟悉 Python 提供的基本内置数据类型了。
接下来,您将开始探索如何在 Python 程序中组织和构建对这些对象进行操作的代码。
参加测验:通过我们的交互式“Python 集”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Dictionaries in PythonSets in PythonPython Program Lexical Structure »
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 套在 Python 里******


 浙公网安备 33010602011771号
浙公网安备 33010602011771号