
RealPython-中文系列教程-十三-
RealPython 中文系列教程(十三)
原文:RealPython
Python 的 map():不使用循环处理可重复项
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 的 map()函数:变换 Iterables
Python 的 map() 是一个内置函数,允许你处理和转换一个 iterable 中的所有项,而不需要使用显式的 for循环,这种技术通常被称为映射。当您需要将一个转换函数应用到一个可迭代对象中的每一项,并将它们转换成一个新的可迭代对象时,map()非常有用。map()是 Python 中支持函数式编程风格的工具之一。
在本教程中,您将学习:
- Python 的
map()是如何工作的 - 如何使用
map()将转换成不同类型的 Python 可迭代对象 - 如何将
map()与其他功能工具结合起来进行更复杂的变换
*** 你能用什么工具来取代map()并让你的代码更python 化*
*有了这些知识,你将能够在你的程序中有效地使用map(),或者,使用列表理解或生成器表达式来使你的代码更具 Pythonic 化和可读性。
为了更好地理解map(),一些关于如何使用可迭代、for循环、函数和 lambda函数的知识会有所帮助。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 中的函数式编码
在 函数式编程 中,计算是通过组合函数来完成的,这些函数接受参数并返回一个(或多个)具体值作为结果。这些函数不修改它们的输入参数,也不改变程序的状态。它们只是提供给定计算的结果。这几种函数俗称纯函数。
理论上,使用函数式风格构建的程序更容易:
函数式编程通常使用列表、数组和其他可重复项来表示数据,以及一组对数据进行操作和转换的函数。当使用函数式风格处理数据时,至少有三种常用的技术:
-
映射 包括将一个转换函数应用于一个可迭代对象以产生一个新的可迭代对象。新 iterable 中的项目是通过对原始 iterable 中的每个项目调用转换函数来生成的。
-
过滤 包括对一个可迭代对象应用一个谓词或布尔值函数来生成一个新的可迭代对象。新 iterable 中的项是通过过滤掉原始 iterable 中使谓词函数返回 false 的任何项而产生的。
-
归约 包括将归约函数应用于一个迭代项,以产生一个单一的累积值。
根据吉多·范·罗苏姆的说法,与函数式语言相比,Python 受命令式编程语言的影响更大:
我从来不认为 Python 会受到函数式语言的严重影响,不管人们怎么说或怎么想。我更熟悉 C 和 Algol 68 等命令式语言,尽管我已经将函数作为一级对象,但我并不认为 Python 是一种函数式编程语言。(来源)
然而,回到 1993 年,Python 社区需要一些函数式编程特性。他们要求:
- 匿名函数
- 一个
map()功能 - 一个
filter()功能 - 一个
reduce()功能
由于社区成员的贡献,这些功能特性被添加到语言中。如今, map() 、 filter() 、 reduce() 是 Python 中函数式编程风格的基本组成部分。
在本教程中,您将涉及其中一个功能特性,即内置函数map()。您还将学习如何使用列表理解和生成器表达式以 Pythonic 化和可读的方式获得与map()相同的功能。
Python 的map() 入门
有时,您可能会遇到这样的情况,您需要对输入 iterable 的所有项执行相同的操作来构建新的 iterable。解决这个问题的最快和最常见的方法是使用一个 Python for循环。然而,您也可以通过使用map()在没有显式循环的情况下解决这个问题。
在接下来的三个部分中,您将了解到map()是如何工作的,以及如何使用它来处理和转换可重复数据而不产生循环。
理解map()
map()循环遍历一个输入 iterable(或多个 iterables)的项,并返回一个迭代器,该迭代器是通过对原始输入 iterable 中的每一项应用转换函数而得到的。
根据文档 , map()将一个函数对象和一个可迭代对象(或多个可迭代对象)作为参数,并返回一个迭代器,该迭代器根据需要生成转换后的项。该函数的签名定义如下:
map(function, iterable[, iterable1, iterable2,..., iterableN])
map()将function应用于循环中iterable中的每一项,并返回一个新的迭代器,该迭代器根据需要生成转换后的项。function可以是任何一个 Python 函数,它接受的参数数量等于传递给map()的可迭代次数。
注意:map()的第一个参数是一个函数对象,这意味着你需要传递一个函数而不需要调用它。也就是说,不使用一对括号。
map()的第一个参数是一个转换函数。换句话说,就是这个函数将每个原始项转换成一个新的(转换后的)项。即使 Python 文档调用这个参数function,它也可以是任何 Python 可调用的。这包括内置函数,类,方法, lambda函数,以及用户自定义函数。
map()执行的操作通常被称为映射,因为它将输入 iterable 中的每个项目映射到结果 iterable 中的一个新项目。为此,map()对输入 iterable 中的所有项应用一个转换函数。
为了更好地理解map(),假设您需要获取一个数值列表,并将其转换为包含原始列表中每个数字的平方值的列表。在这种情况下,您可以使用一个for循环并编写如下代码:
>>> numbers = [1, 2, 3, 4, 5] >>> squared = [] >>> for num in numbers: ... squared.append(num ** 2) ... >>> squared [1, 4, 9, 16, 25]当您在
numbers上运行这个循环时,您会得到一个平方值列表。for循环对numbers进行迭代,并对每个值进行幂运算。最后,它将结果值存储在squared中。通过使用
map(),您可以在不使用显式循环的情况下获得相同的结果。看一下上面例子的重新实现:
>>> def square(number):
... return number ** 2
...
>>> numbers = [1, 2, 3, 4, 5]
>>> squared = map(square, numbers)
>>> list(squared)
[1, 4, 9, 16, 25]
square()是将数字映射到其平方值的变换函数。对map()的调用将square()应用于numbers中的所有值,并返回一个产生平方值的迭代器。然后在map()上调用list()来创建一个包含平方值的列表对象。
由于map()是用 C 编写的,并且经过了高度优化,其内部隐含循环可以比常规 Python for循环更高效。这是使用map()的一个优势。
使用map()的第二个优势与内存消耗有关。使用一个for循环,您需要将整个列表存储在系统内存中。使用map(),你可以按需获得物品,并且在给定的时间内,只有一个物品在你的系统内存中。
注意:在 Python 2.x 中, map() 返回一个列表。这种行为在 Python 3.x 中有所改变。现在,map()返回一个 map 对象,这是一个迭代器,可以按需生成条目。这就是为什么你需要调用list()来创建想要的列表对象。
再举一个例子,假设您需要将列表中的所有条目从一个字符串转换成一个整数。为此,您可以将map()与int()一起使用,如下所示:
>>> str_nums = ["4", "8", "6", "5", "3", "2", "8", "9", "2", "5"] >>> int_nums = map(int, str_nums) >>> int_nums <map object at 0x7fb2c7e34c70> >>> list(int_nums) [4, 8, 6, 5, 3, 2, 8, 9, 2, 5] >>> str_nums ["4", "8", "6", "5", "3", "2", "8", "9", "2", "5"]
map()将int()应用于str_nums中的每一个值。因为map()返回一个迭代器(一个 map 对象),所以你需要调用list(),这样你就可以用尽迭代器并把它变成一个 list 对象。请注意,原始序列在此过程中不会被修改。将
map()与不同种类的功能一起使用您可以使用任何类型的可通过
map()调用的 Python。唯一的条件是 callable 接受一个参数并返回一个具体的有用的值。例如,您可以使用类、实现名为__call__()的特殊方法的实例、实例方法、类方法、静态方法和函数。有一些内置函数可以和
map()一起使用。考虑下面的例子:
>>> numbers = [-2, -1, 0, 1, 2]
>>> abs_values = list(map(abs, numbers))
>>> abs_values
[2, 1, 0, 1, 2]
>>> list(map(float, numbers))
[-2.0, -1.0, 0.0, 1.0, 2.0]
>>> words = ["Welcome", "to", "Real", "Python"]
>>> list(map(len, words))
[7, 2, 4, 6]
您可以使用任何带有map()的内置函数,只要该函数接受一个参数并返回值。
使用map()的一个常见模式是使用lambda函数作为第一个参数。当您需要将基于表达式的函数传递给map()时,lambda函数非常方便。例如,您可以使用lambda函数重新实现平方值的示例,如下所示:
>>> numbers = [1, 2, 3, 4, 5] >>> squared = map(lambda num: num ** 2, numbers) >>> list(squared) [1, 4, 9, 16, 25]使用
map()时,函数非常有用。他们可以起到第一个论证map()的作用。你可以使用lambda函数和map()来快速处理和转换你的可重复项。用
map()处理多个输入项如果您向
map()提供多个 iterables,那么转换函数必须接受与您传入的 iterables 一样多的参数。map()的每次迭代都会将每个 iterable 中的一个值作为参数传递给function。迭代在最短的迭代结束时停止。考虑下面这个使用
pow()的例子:
>>> first_it = [1, 2, 3]
>>> second_it = [4, 5, 6, 7]
>>> list(map(pow, first_it, second_it))
[1, 32, 729]
pow()接受两个参数x和y,并将x返回给y的幂。第一次迭代,x会是1,y会是4,结果是1。在第二次迭代中,x将是2,y将是5,结果将是32,以此类推。最终的可迭代式只有最短的可迭代式那么长,在本例中是first_it。
这种技术允许您使用不同种类的数学运算来合并两个或多个数值的可迭代项。下面是一些使用lambda函数对几个输入变量执行不同数学运算的例子:
>>> list(map(lambda x, y: x - y, [2, 4, 6], [1, 3, 5])) [1, 1, 1] >>> list(map(lambda x, y, z: x + y + z, [2, 4], [1, 3], [7, 8])) [10, 15]在第一个示例中,您使用减法运算来合并两个各包含三项的 iterables。在第二个示例中,您将三个 iterables 的值相加。
用 Python 的
map()转换字符串的可重复项当您处理 string 对象的 iterables 时,您可能会对使用某种转换函数转换所有对象感兴趣。在这些情况下,Python 的
map()可以成为你的盟友。接下来的部分将带您浏览一些如何使用map()来转换 string 对象的 iterables 的例子。使用
str的方法一种很常见的字符串操作方法是使用类
str的一些方法将一个给定的字符串转换成一个新的字符串。如果您正在处理字符串的可重复项,并且需要对每个字符串应用相同的转换,那么您可以使用map()和各种字符串方法:
>>> string_it = ["processing", "strings", "with", "map"]
>>> list(map(str.capitalize, string_it))
['Processing', 'Strings', 'With', 'Map']
>>> list(map(str.upper, string_it))
['PROCESSING', 'STRINGS', 'WITH', 'MAP']
>>> list(map(str.lower, string_it))
['processing', 'strings', 'with', 'map']
您可以使用map()和 string 方法对string_it中的每一项执行一些转换。大多数时候,你会使用不带附加参数的方法,比如 str.capitalize() 、 str.lower() 、 str.swapcase() 、 str.title() 和 str.upper() 。
您还可以使用一些方法,这些方法采用带有默认值的附加参数,例如 str.strip() ,它采用一个名为char的可选参数,默认情况下移除空白:
>>> with_spaces = ["processing ", " strings", "with ", " map "] >>> list(map(str.strip, with_spaces)) ['processing', 'strings', 'with', 'map']当你像这样使用
str.strip()时,你依赖于char的默认值。在这种情况下,使用map()删除with_spaces条目中的所有空格。注意:如果你需要提供参数而不是依赖默认值,那么你可以使用
lambda函数。下面是一个使用
str.strip()来删除点而不是默认空白的例子:
>>> with_dots = ["processing..", "...strings", "with....", "..map.."]
>>> list(map(lambda s: s.strip("."), with_dots))
['processing', 'strings', 'with', 'map']
lambda函数调用字符串对象s上的.strip()并删除所有的前导和尾随点。
例如,当您处理文本文件时,其中的行可能有尾随空格(或其他字符)并且您需要删除它们,这种技术会很方便。如果是这种情况,那么您需要考虑在没有自定义char的情况下使用str.strip()也会删除换行符。
删除标点符号
在处理文本时,有时需要删除将文本拆分成单词后留下的标点符号。为了解决这个问题,您可以创建一个自定义函数,使用一个匹配最常见标点符号的正则表达式来删除单个单词的标点符号。
下面是使用 sub() 实现该函数的一种可能,T3 是一个正则表达式函数,位于 Python 标准库中的 re 模块中:
>>> import re >>> def remove_punctuation(word): ... return re.sub(r'[!?.:;,"()-]', "", word) >>> remove_punctuation("...Python!") 'Python'在
remove_punctuation()中,您使用了一个正则表达式模式,该模式匹配任何英文文本中最常见的标点符号。对re.sub()的调用使用空字符串("")替换匹配的标点符号,并返回一个干净的word。有了转换函数,您可以使用
map()对文本中的每个单词进行转换。它是这样工作的:
>>> text = """Some people, when confronted with a problem, think
... "I know, I'll use regular expressions."
... Now they have two problems. Jamie Zawinski"""
>>> words = text.split()
>>> words
['Some', 'people,', 'when', 'confronted', 'with', 'a', 'problem,', 'think'
, '"I', 'know,', "I'll", 'use', 'regular', 'expressions."', 'Now', 'they',
'have', 'two', 'problems.', 'Jamie', 'Zawinski']
>>> list(map(remove_punctuation, words))
['Some', 'people', 'when', 'confronted', 'with', 'a', 'problem', 'think',
'I', 'know', "I'll", 'use', 'regular', 'expressions', 'Now', 'they', 'have
', 'two', 'problems', 'Jamie', 'Zawinski']
在这段文字中,有些单词包含标点符号。例如,你用'people,'代替'people',用'problem,'代替'problem',等等。对map()的调用将remove_punctuation()应用于每个单词,并删除任何标点符号。所以,在第二个list中,你已经清理了单词。
请注意,撇号(')不在您的正则表达式中,因为您希望像I'll这样的缩写保持原样。
实现凯撒密码算法
罗马政治家朱利叶斯·凯撒,曾用一种密码对他发送给他的将军们的信息进行加密保护。一个凯撒密码将每个字母移动若干个字母。例如,如果将字母a移动三位,则得到字母d,依此类推。
如果移位超出了字母表的末尾,那么你只需要旋转回到字母表的开头。在旋转三次的情况下,x将变成a。这是旋转后字母表的样子:
- 原字母表:
abcdefghijklmnopqrstuvwxyz - 字母旋转三次:
defghijklmnopqrstuvwxyzabc
下面的代码实现了rotate_chr(),这个函数获取一个字符并将其旋转三圈。rotate_chr()将返回旋转后的字符。代码如下:
1def rotate_chr(c):
2 rot_by = 3
3 c = c.lower()
4 alphabet = "abcdefghijklmnopqrstuvwxyz"
5 # Keep punctuation and whitespace 6 if c not in alphabet:
7 return c
8 rotated_pos = ord(c) + rot_by
9 # If the rotation is inside the alphabet 10 if rotated_pos <= ord(alphabet[-1]):
11 return chr(rotated_pos)
12 # If the rotation goes beyond the alphabet 13 return chr(rotated_pos - len(alphabet))
在rotate_chr()中,你首先检查这个字符是否在字母表中。如果不是,那么你返回相同的字符。这样做的目的是保留标点符号和其他不常用的字符。在第 8 行,您计算字符在字母表中新的旋转位置。为此,您使用内置函数 ord() 。
ord()接受一个 Unicode 字符并返回一个表示输入字符的 Unicode 码位的整数。比如ord("a")返回97,ord("b")返回98:
>>> ord("a") 97 >>> ord("b") 98
ord()以字符为参数,返回输入字符的 Unicode 码位。如果你把这个整数加到目标数字
rot_by上,那么你将得到新字母在字母表中的旋转位置。在这个例子中,rot_by就是3。所以,字母"a"旋转三圈后将成为位置100的字母,也就是字母"d"。字母"b"旋转三个会变成位置101的字母,也就是字母"e",以此类推。如果字母的新位置没有超出最后一个字母(
alphabet[-1])的位置,那么就在这个新位置返回字母。为此,您使用内置函数chr()。
chr()是ord()的逆。它接受一个表示 Unicode 字符的 Unicode 码位的整数,并返回该位置的字符。比如chr(97)会返回'a',chr(98)会返回'b':
>>> chr(97)
'a'
>>> chr(98)
'b'
chr()取一个表示字符的 Unicode 码位的整数,并返回相应的字符。
最后,如果新的旋转位置超出了最后一个字母(alphabet[-1])的位置,那么就需要旋转回到字母表的开头。为此,您需要从旋转后的位置(rotated_pos - len(alphabet))减去字母表的长度,然后使用chr()将字母返回到新的位置。
用rotate_chr()作为你的变换函数,你可以用map()用凯撒密码算法加密任何文本。下面是一个使用 str.join() 连接字符串的例子:
>>> "".join(map(rotate_chr, "My secret message goes here.")) 'pb vhfuhw phvvdjh jrhv khuh.'字符串在 Python 中也是可迭代的。因此,对
map()的调用将rotate_chr()应用于原始输入字符串中的每个字符。在这种情况下,"M"变成了"p","y"变成了"b",以此类推。最后,对str.join()的调用将最终加密消息中的每个旋转字符连接起来。用 Python 的
map()转换数字的迭代式
map()在处理和转换数值的迭代时也有很大的潜力。您可以执行各种数学和算术运算,将字符串值转换为浮点数或整数,等等。在接下来的几节中,您将会看到一些如何使用
map()来处理和转换数字的迭代的例子。使用数学运算
使用数学运算转换可迭代数值的一个常见例子是使用幂运算符(
**) 。在下面的示例中,您编写了一个转换函数,该函数接受一个数字并返回该数字的平方和立方:
>>> def powers(x):
... return x ** 2, x ** 3
...
>>> numbers = [1, 2, 3, 4]
>>> list(map(powers, numbers))
[(1, 1), (4, 8), (9, 27), (16, 64)]
powers()取一个数x并返回它的平方和立方。由于 Python 将多个返回值作为元组来处理,所以每次调用powers()都会返回一个包含两个值的元组。当您使用powers()作为参数调用map()时,您会得到一个元组列表,其中包含输入 iterable 中每个数字的平方和立方。
使用map()可以执行许多与数学相关的转换。您可以向每个值中添加常数,也可以从每个值中减去常数。您还可以使用 math模块中的一些功能,如 sqrt() 、 factorial() 、 sin() 、 cos() 等等。这里有一个使用factorial()的例子:
>>> import math >>> numbers = [1, 2, 3, 4, 5, 6, 7] >>> list(map(math.factorial, numbers)) [1, 2, 6, 24, 120, 720, 5040]在这种情况下,您将
numbers转换成一个新列表,其中包含原始列表中每个数字的阶乘。您可以使用
map()对可迭代的数字执行各种数学转换。你能在这个话题上走多远将取决于你的需求和你的想象力。考虑一下,编写你自己的例子!转换温度
map()的另一个用例是在测量单位之间进行转换。假设您有一个以摄氏度或华氏度测量的温度列表,您需要将它们转换为以华氏度或摄氏度为单位的相应温度。您可以编写两个转换函数来完成这项任务:
def to_fahrenheit(c): return 9 / 5 * c + 32 def to_celsius(f): return (f - 32) * 5 / 9
to_fahrenheit()以摄氏度为单位进行温度测量,并将其转换为华氏度。类似地,to_celsius()采用华氏温度并将其转换为摄氏温度。这些函数就是你的转换函数。您可以将它们与
map()一起使用,分别将温度测量值转换为华氏温度和摄氏温度:
>>> celsius_temps = [100, 40, 80]
>>> # Convert to Fahrenheit
>>> list(map(to_fahrenheit, celsius_temps))
[212.0, 104.0, 176.0]
>>> fahr_temps = [212, 104, 176]
>>> # Convert to Celsius
>>> list(map(to_celsius, fahr_temps))
[100.0, 40.0, 80.0]
如果你用to_fahrenheit()和celsius_temps调用map(),那么你会得到一个华氏温度的度量列表。如果您用to_celsius()和fahr_temps调用map(),那么您会得到一个以摄氏度为单位的温度测量列表。
为了扩展这个例子并涵盖任何其他类型的单位转换,您只需要编写一个适当的转换函数。
将字符串转换为数字
当处理数字数据时,您可能会遇到所有数据都是字符串值的情况。要做进一步的计算,您需要将字符串值转换成数值。对这些情况也有帮助。
如果你确定你的数据是干净的,没有包含错误的值,那么你可以根据你的需要直接使用 float() 或者int()。以下是一些例子:
>>> # Convert to floating-point >>> list(map(float, ["12.3", "3.3", "-15.2"])) [12.3, 3.3, -15.2] >>> # Convert to integer >>> list(map(int, ["12", "3", "-15"])) [12, 3, -15]在第一个例子中,您使用
float()和map()将所有值从字符串值转换为浮点值。在第二种情况下,使用int()将字符串转换为整数。注意,如果其中一个值不是有效的数字,那么您将得到一个ValueError。如果您不确定您的数据是否干净,那么您可以使用一个更复杂的转换函数,如下所示:
>>> def to_float(number):
... try:
... return float(number.replace(",", "."))
... except ValueError:
... return float("nan")
...
>>> list(map(to_float, ["12.3", "3,3", "-15.2", "One"]))
[12.3, 3.3, -15.2, nan]
在to_float()中,您使用了一个 try语句,如果在转换number时float()失败,该语句将捕获一个ValueError。如果没有错误发生,那么您的函数返回转换成有效浮点数的number。否则,您会得到一个 nan(不是数字)值,这是一个特殊的float值,您可以用它来表示不是有效数字的值,就像上面例子中的"One"一样。
可以根据需要定制to_float()。例如,您可以用语句return 0.0替换语句return float("nan"),等等。
将map()与其他功能工具结合
到目前为止,您已经讲述了如何使用map()来完成不同的涉及 iterables 的任务。但是,如果您使用map()和其他功能工具,如 filter() 和 reduce() ,那么您可以对您的可迭代对象执行更复杂的转换。这就是您将在接下来的两个部分中涉及的内容。
map()和filter()
有时,您需要处理一个输入可迭代对象,并返回另一个可迭代对象,该对象是通过过滤掉输入可迭代对象中不需要的值而得到的。那样的话,Python 的 filter() 可以是你不错的选择。filter()是一个内置函数,接受两个位置参数:
function将是一个谓词或布尔值函数,一个根据输入数据返回True或False的函数。iterable将是任何 Python 可迭代的。
filter()产生function返回True的输入iterable的项目。如果您将None传递给function,那么filter()将使用 identity 函数。这意味着filter()将检查iterable中每个项目的真值,并过滤掉所有为假值的项目。
为了说明如何使用map()和filter(),假设您需要计算列表中所有值的平方根。因为您的列表可能包含负值,所以您会得到一个错误,因为平方根不是为负数定义的:
>>> import math >>> math.sqrt(-16) Traceback (most recent call last): File "<input>", line 1, in <module> math.sqrt(-16) ValueError: math domain error以负数为自变量,
math.sqrt()引出一个ValueError。为了避免这个问题,你可以使用filter()来过滤掉所有的负值,然后找到剩余正值的平方根。看看下面的例子:
>>> import math
>>> def is_positive(num):
... return num >= 0
...
>>> def sanitized_sqrt(numbers):
... cleaned_iter = map(math.sqrt, filter(is_positive, numbers))
... return list(cleaned_iter)
...
>>> sanitized_sqrt([25, 9, 81, -16, 0])
[5.0, 3.0, 9.0, 0.0]
is_positive()是一个谓词函数,它将一个数字作为参数,如果该数字大于或等于零,则返回True。你可以通过is_positive()到filter()来清除numbers的所有负数。因此,对map()的调用将只处理正数,而math.sqrt()不会给你一个ValueError。
map()和reduce()
Python 的 reduce() 是一个函数,驻留在 Python 标准库中一个名为 functools 的模块中。reduce()是 Python 中的另一个核心函数工具,当你需要将一个函数应用于一个可迭代对象并将其简化为一个累积值时,它非常有用。这种操作俗称 缩小或 。reduce()需要两个参数:
function可以是任何接受两个参数并返回值的 Python 可调用函数。iterable可以是任何 Python 可迭代的。
reduce()将function应用于iterable中的所有项目,并累计计算出最终值。
下面这个例子结合了map()和reduce()来计算您的主目录中所有文件的累积总大小:
>>> import functools >>> import operator >>> import os >>> import os.path >>> files = os.listdir(os.path.expanduser("~")) >>> functools.reduce(operator.add, map(os.path.getsize, files)) 4377381在这个例子中,您调用
os.path.expanduser("~")来获得您的主目录的路径。然后你调用这个路径上的os.listdir()来获得一个包含所有文件路径的列表。对
map()的调用使用os.path.getsize()来获取每个文件的大小。最后,您使用reduce()和operator.add()来获得每个文件大小的累积和。最终结果是您的主目录中所有文件的总大小,以字节为单位。注:几年前,谷歌开发并开始使用一种编程模型,他们称之为 MapReduce 。这是一种新的数据处理方式,旨在使用集群上的并行和分布式计算来管理大数据。
这个模型的灵感来自于函数式编程中常用的映射和归约操作的组合。
MapReduce 模型对谷歌在合理的时间内处理大量数据的能力产生了巨大的影响。然而,到 2014 年,谷歌不再使用 MapReduce 作为他们的主要处理模型。
如今,你可以找到一些 MapReduce 的替代实现,比如 Apache Hadoop T1,这是一个使用 MapReduce 模型的开源软件工具的集合。
尽管您可以使用
reduce()来解决本节中涉及的问题,但是 Python 提供了其他工具来实现更 Python 化和更高效的解决方案。例如,您可以使用内置函数sum()来计算您的主目录中文件的总大小:
>>> import os
>>> import os.path
>>> files = os.listdir(os.path.expanduser("~"))
>>> sum(map(os.path.getsize, files))
4377381
这个例子比你之前看到的例子可读性更强,效率更高。如果您想更深入地了解如何使用reduce()以及可以使用哪些替代工具以 Python 的方式取代reduce(),那么请查看 Python 的 reduce():从函数式到 Python 式。
用starmap() 处理基于元组的可重复项
Python 的 itertools.starmap() 构造了一个迭代器,它将函数应用于从元组的可迭代对象中获得的参数,并产生结果。当您处理已经分组为元组的可重复项时,这很有用。
map()和starmap()的主要区别在于,后者使用解包操作符(* ) 调用其转换函数,将每个参数元组解包成几个位置参数。因此,转换函数被称为function(*args),而不是function(arg1, arg2,... argN)。
starmap() 的官方文档称该函数大致相当于以下 Python 函数:
def starmap(function, iterable):
for args in iterable:
yield function(*args)
该函数中的for循环迭代iterable中的项目,并产生转换后的项目。对function(*args)的调用使用解包操作符将元组解包成几个位置参数。下面是一些starmap()如何工作的例子:
>>> from itertools import starmap >>> list(starmap(pow, [(2, 7), (4, 3)])) [128, 64] >>> list(starmap(ord, [(2, 7), (4, 3)])) Traceback (most recent call last): File "<input>", line 1, in <module> list(starmap(ord, [(2, 7), (4, 3)])) TypeError: ord() takes exactly one argument (2 given)在第一个示例中,您使用
pow()来计算每个元组中第一个值的第二次幂。元组将采用(base, exponent)的形式。如果 iterable 中的每个元组都有两个条目,那么
function也必须有两个参数。如果元组有三项,那么function必须有三个参数,依此类推。否则,你会得到一个TypeError。如果您使用
map()而不是starmap(),那么您将得到不同的结果,因为map()从每个元组中取出一个项目:
>>> list(map(pow, (2, 7), (4, 3)))
[16, 343]
注意map()采用两个元组,而不是一个元组列表。map()在每次迭代中也从每个元组中取一个值。为了让map()返回与starmap()相同的结果,您需要交换值:
>>> list(map(pow, (2, 4), (7, 3))) [128, 64]在这种情况下,您有两个元组,而不是一个元组列表。你还交换了
7和4。现在,第一个元组提供了基数,第二个元组提供了指数。Pythonic 风格编码:替换
map()像
map()、filter()和reduce()这样的函数式编程工具已经存在很久了。然而,列表理解和生成器表达式几乎在每个用例中都成为它们的自然替代品。例如,
map()提供的功能几乎总是用列表理解或生成器表达式来更好地表达。在接下来的两节中,您将学习如何用列表理解或生成器表达式替换对map()的调用,以使您的代码更具可读性和 Pythonic 性。使用列表理解
有一个通用的模式,你可以用列表理解来代替对
map()的调用。方法如下:# Generating a list with map list(map(function, iterable)) # Generating a list with a list comprehension [function(x) for x in iterable]注意,列表理解几乎总是比调用
map()读起来更清楚。因为列表理解在 Python 开发人员中非常流行,所以到处都能找到它们。因此,用列表理解替换对map()的调用将使您的代码对其他 Python 开发人员来说更熟悉。Here’s an example of how to replace
map()with a list comprehension to build a list of square numbers:
>>> # Transformation function
>>> def square(number):
... return number ** 2
>>> numbers = [1, 2, 3, 4, 5, 6]
>>> # Using map()
>>> list(map(square, numbers))
[1, 4, 9, 16, 25, 36]
>>> # Using a list comprehension
>>> [square(x) for x in numbers]
[1, 4, 9, 16, 25, 36]
如果你比较两种解决方案,那么你可能会说,使用列表理解的解决方案更具可读性,因为它读起来几乎像普通英语。此外,列表理解避免了显式调用map()上的list()来构建最终列表的需要。
使用生成器表达式
map()返回一个地图对象,它是一个迭代器,根据需要生成项目。因此,map()的自然替代物是生成器表达式,因为生成器表达式返回生成器对象,这些对象也是按需生成项目的迭代器。
众所周知,Python 迭代器在内存消耗方面非常高效。这就是为什么map()现在返回迭代器而不是list的原因。
列表理解和生成器表达式之间有微小的语法差异。第一个使用一对方括号([])来分隔表达式。第二种使用一对括号(())。因此,要将列表理解转化为生成器表达式,只需用圆括号替换方括号。
您可以使用生成器表达式来编写比使用map()的代码更清晰的代码。看看下面的例子:
>>> # Transformation function >>> def square(number): ... return number ** 2 >>> numbers = [1, 2, 3, 4, 5, 6] >>> # Using map() >>> map_obj = map(square, numbers) >>> map_obj <map object at 0x7f254d180a60> >>> list(map_obj) [1, 4, 9, 16, 25, 36] >>> # Using a generator expression >>> gen_exp = (square(x) for x in numbers) >>> gen_exp <generator object <genexpr> at 0x7f254e056890> >>> list(gen_exp) [1, 4, 9, 16, 25, 36]这段代码与上一节中的代码有一个主要区别:您将方括号改为一对圆括号,将列表理解转换为生成器表达式。
生成器表达式通常用作函数调用中的参数。在这种情况下,您不需要使用括号来创建生成器表达式,因为用于调用函数的括号也提供了构建生成器的语法。有了这个想法,你可以像这样调用
list()得到和上面例子一样的结果:
>>> list(square(x) for x in numbers)
[1, 4, 9, 16, 25, 36]
如果在函数调用中使用生成器表达式作为参数,那么就不需要额外的一对括号。用于调用函数的括号提供了构建生成器的语法。
生成器表达式在内存消耗方面和map()一样高效,因为它们都返回按需生成条目的迭代器。然而,生成器表达式几乎总能提高代码的可读性。在其他 Python 开发人员看来,它们也使您的代码更加 Python 化。
结论
Python 的 map() 可以让你对 iterables 进行 映射 操作。映射操作包括将转换函数应用于 iterable 中的项目,以生成转换后的 iterable。一般来说,map()将允许您在不使用显式循环的情况下处理和转换可迭代对象。
在本教程中,您已经学习了map()是如何工作的,以及如何使用它来处理 iterables。您还了解了一些可以用来替换代码中的map()的python 化的工具。
你现在知道如何:
- 用 Python 创作的
map() - 使用
map()到处理和转换迭代,而不使用显式循环 - 将
map()与filter()和reduce()等函数结合起来执行复杂的变换 - 用类似于列表理解和生成器表达式的工具替换
map()
有了这些新知识,你将能够在你的代码中使用map(),并且用函数式编程风格来处理你的代码。您还可以通过用一个列表理解或一个生成器表达式替换map()来切换到一个更 Pythonic 和现代的风格。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 的 map()函数:变换 Iterables*********
Python 数学模块:你需要知道的一切
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 数学模块
在本文中,您将了解 Python 的 math 模块。数学计算是大多数 Python 开发的基本部分。无论你是在做一个科学项目,一个金融应用,还是任何其他类型的编程工作,你都无法逃避对数学的需求。
对于 Python 中简单明了的数学计算,可以使用内置的数学运算符,比如加法(+)、减法(-)、除法(/)和乘法(*)。但更高级的运算,如指数、对数、三角函数或幂函数,并没有内置。这是否意味着您需要从头开始实现所有这些功能?
幸运的是,没有。Python 提供了一个专门为高级数学运算设计的模块:模块math。
到本文结束时,您将了解到:
- Python
math模块是什么 - 如何使用
math模块函数解决实际问题 math模块的常数是什么,包括圆周率、τ和欧拉数- 内置函数和
math函数有什么区别 math、cmath和 NumPy 有什么区别
数学背景会有所帮助,但如果数学不是你的强项,也不用担心。这篇文章将解释你需要知道的所有基础知识。
所以让我们开始吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
了解 Python math模块
Python math模块是为处理数学运算而设计的一个重要特性。它与标准 Python 版本打包在一起,并且从一开始就存在。大多数math模块的函数都是围绕 C 平台的数学函数的薄薄的包装。由于其底层函数是用 CPython 编写的,math模块是高效的,并且符合 C 标准。
Python math模块为您提供了在应用程序中执行常见且有用的数学计算的能力。以下是math模块的一些实际用途:
- 使用阶乘计算组合和排列
- 使用三角函数计算杆的高度
- 用指数函数计算放射性衰变
- 用双曲函数计算悬索桥的曲线
- 解二次方程
- 使用三角函数模拟周期函数,如声波和光波
由于math模块是随 Python 发行版一起打包的,所以您不必单独安装它。使用它只是一个导入模块的问题:
>>> import math您可以使用上面的命令导入Python
math模块。导入后就可以直接使用了。
math模块的常数Python
math模块提供了各种预定义的常量。访问这些常量有几个好处。首先,您不必手动将它们硬编码到您的应用程序中,这将节省您大量的时间。此外,它们在整个代码中提供了一致性。该模块包括几个著名的数学常数和重要值:
- 圆周率
- 希腊语的第十九个字母
- 欧拉数
- 无穷
- 不是数字(NaN)
在本节中,您将了解这些常量以及如何在 Python 代码中使用它们。
圆周率
π是一个圆的周长( c 与其直径( d )的比值:
π = c/d
这个比例对于任何圆都是一样的。
圆周率是一个无理数,也就是说不能用简单的分数来表示。所以圆周率的小数位数是无限的,但可以近似为 22/7,或者 3.141。
有趣的事实:圆周率是世界上最公认、最知名的数学常数。它有自己的庆祝日期,叫做圆周率日,在 3 月 14 日(3/14)。
您可以按如下方式访问 pi:
>>> math.pi
3.141592653589793
如你所见,在 Python 中圆周率的值被赋予了 15 位小数。提供的位数取决于基础 C 编译器。Python 默认打印前十五位数字,math.pi总是返回一个浮点值。
那么圆周率在哪些方面对你有用呢?你可以用 2π r 计算一个圆的周长,其中 r 是圆的半径:
>>> r = 3 >>> circumference = 2 * math.pi * r >>> f"Circumference of a Circle = 2 * {math.pi:.4} * {r} = {circumference:.4}" 'Circumference of a Circle = 2 * 3.142 * 3 = 18.85'可以用
math.pi来计算一个圆的周长。您也可以使用公式π r 计算圆的面积,如下所示:
>>> r = 5
>>> area = math.pi * r * r
>>> f"Area of a Circle = {math.pi:.4} * {r} * {r} = {area:.4}"
'Area of a Circle = 3.142 * 5 * 5 = 78.54'
可以用math.pi计算圆的面积和周长。当您使用 Python 进行数学计算,并且遇到一个使用π的公式时,最好使用由math模块给出的 pi 值,而不是硬编码该值。
τ
τ(τ)是圆的周长与其半径之比。这个常数等于 2π,或大约 6.28。像圆周率一样,τ也是一个无理数,因为它只是圆周率乘以 2。
许多数学表达式使用 2π,而使用τ可以帮助简化您的方程。比如不用 2π r 来计算一个圆的周长,我们可以代入τ,用更简单的方程τ r 。
然而,使用τ作为圆常数仍在争论中。您可以根据需要自由使用 2π或τ。
您可以使用 tau,如下所示:
>>> math.tau 6.283185307179586与
math.pi一样,math.tau返回十五位数字,是一个浮点值。可以用τ来计算τ r 的圆的周长,其中 r 为半径,如下:
>>> r = 3
>>> circumference = math.tau * r
>>> f"Circumference of a Circle = {math.tau:.4} * {r} = {circumference:.4}"
'Circumference of a Circle = 6.283 * 3 = 18.85'
你可以用math.tau代替2 * math.pi来整理包含表达式 2π的方程。
欧拉数
欧拉数( e )是以自然对数为底的常数,自然对数是一种数学函数,通常用于计算增长率或衰减率。和圆周率、圆周率一样,欧拉数是一个小数位数无限的无理数。 e 的值通常近似为 2.718。
欧拉数是一个重要的常数,因为它有许多实际用途,如计算人口随时间的增长或确定放射性衰变率。您可以从math模块访问欧拉数,如下所示:
>>> math.e 2.718281828459045与
math.pi和math.tau一样,math.e的值被赋予十五位小数,并作为浮点值返回。无穷大
无限不能用数字来定义。相反,它是一个数学概念,代表永无止境或无限的事物。无限可以是正向的,也可以是负向的。
当您想要将一个给定值与一个绝对最大值或最小值进行比较时,您可以在算法中使用无穷大。Python 中正负无穷大的值如下:
>>> f"Positive Infinity = {math.inf}"
'Positive Infinity = inf'
>>> f"Negative Infinity = {-math.inf}"
'Negative Infinity = -inf'
无穷大不是一个数值。而是定义为math.inf。Python 在 3.5 版本中引入了这个常量,作为float("inf")的等价物:
>>> float("inf") == math.inf True
float("inf")和math.inf都代表无穷大的概念,使得math.inf大于任何数值:
>>> x = 1e308
>>> math.inf > x
True
在上面的代码中,math.inf大于x的值,10 308 (一个浮点数的最大大小),是一个双精度数。
同样,-math.inf比任何值都小:
>>> y = -1e308 >>> y > -math.inf True负无穷大小于
y的值,为-10 308 。任何数字都不能大于无穷大或小于负无穷大。这就是为什么用math.inf进行数学运算不会改变无穷大的值:
>>> math.inf + 1e308
inf
>>> math.inf / 1e308
inf
如你所见,加法和除法都不会改变math.inf的值。
不是数字(NaN)
不是一个数,或者 NaN,不是一个真正的数学概念。它起源于计算机科学领域,是对非数值的引用。一个 NaN 值可能是由于无效的输入,或者它可以指示一个变量应该是数字的已经被文本字符或符号破坏。
检查一个值是否为 NaN 始终是一个最佳实践。如果是,那么它可能会导致程序中的无效值。Python 在 3.5 版本中引入了 NaN 常量。
你可以观察下面math.nan的值:
>>> math.nan nanNaN 不是一个数值。你可以看到
math.nan的值是nan,与float("nan")的值相同。算术函数
数论是纯数学的一个分支,是对自然数的研究。数论通常处理正整数或整数。
Python
math模块提供了在数论以及相关领域表示理论中有用的函数。这些函数允许您计算一系列重要值,包括:
- 一个数的阶乘
- 两个数的最大公约数
- 项的总和
用 Python
factorial()求阶乘你可能见过像 7 这样的数学表达式!还是 4!之前。感叹号不代表数字激动。而是,“!”是阶乘符号。阶乘用于寻找排列或组合。您可以通过将所选数字的所有整数乘以 1 来确定该数字的阶乘。
下表显示了 4、6 和 7 的阶乘值:
标志 用语言 表示 结果 4! 四因子 4 x 3 x 2 x 1 Twenty-four 6! 六阶乘 6 x 5 x 4 x 3 x 2 x 1 Seven hundred and twenty 7! 七阶乘 7 x 6 x 5 x 4 x 3 x 2 x 1 Five thousand and forty 从表中可以看出 4!或四阶乘,通过将从 4 到 1 的整数范围相乘得出值 24。同理,6!还有 7!分别给出值 720 和 5040。
您可以使用以下工具之一在 Python 中实现阶乘函数:
for循环- 递归函数
math.factorial()首先你将看到一个使用
for循环的阶乘实现。这是一种相对简单的方法:def fact_loop(num): if num < 0: return 0 if num == 0: return 1 factorial = 1 for i in range(1, num + 1): factorial = factorial * i return factorial你也可以使用一个递归函数来寻找阶乘。这比使用
for循环更复杂,但也更优雅。您可以按如下方式实现递归函数:def fact_recursion(num): if num < 0: return 0 if num == 0: return 1 return num * fact_recursion(num - 1)注意:Python 中的递归深度是有限制的,但是这个主题超出了本文的范围。
以下示例说明了如何使用
for循环和递归函数:
>>> fact_loop(7)
5040
>>> fact_recursion(7)
5040
尽管它们的实现不同,但它们的返回值是相同的。
然而,仅仅为了得到一个数的阶乘而实现自己的函数是费时低效的。比较好的方法是使用math.factorial()。下面是如何使用math.factorial()找到一个数的阶乘:
>>> math.factorial(7) 5040这种方法用最少的代码返回期望的输出。
factorial()只接受正整数值。如果你试图输入一个负值,那么你将得到一个ValueError:
>>> math.factorial(-5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: factorial() not defined for negative values
输入负值将导致ValueError读数factorial() not defined for negative values。
也不接受十进制数字。它会给你一个ValueError:
>>> math.factorial(4.3) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: factorial() only accepts integral values输入十进制数值会导致
ValueError读数factorial() only accepts integral values。您可以使用
timeit()来比较每个阶乘方法的执行时间:
>>> import timeit
>>> timeit.timeit("fact_loop(10)", globals=globals())
1.063997201999996
>>> timeit.timeit("fact_recursion(10)", globals=globals())
1.815312818999928
>>> timeit.timeit("math.factorial(10)", setup="import math")
0.10671788000001925
上面的示例说明了三种阶乘方法中每一种方法的timeit()结果。
timeit()每次运行时执行一百万次循环。下表比较了三种阶乘方法的执行时间:
| 类型 | 执行时间 |
|---|---|
| 带循环 | 1.0640 秒 |
| 使用递归 | 1.8153 秒 |
用factorial() |
0.1067 秒 |
从执行时间可以看出,factorial()比其他方法快。这是因为它的底层 C 实现。基于递归的方法是三种方法中最慢的。尽管根据你的 CPU 不同,你可能得到不同的计时,但是函数的顺序应该是一样的。
不仅比其他方法更快,而且更稳定。当你实现自己的函数时,你必须为灾难事件显式编码,比如处理负数或十进制数。实现中的一个错误可能会导致错误。但是当使用factorial()时,您不必担心灾难情况,因为该函数会处理所有情况。因此,尽可能使用factorial()是一个最佳实践。
用ceil() 求上限值
math.ceil()将返回大于或等于给定数字的最小整数值。如果数字是正或负的小数,那么函数将返回大于给定值的下一个整数值。
例如,输入 5.43 将返回值 6,输入-12.43 将返回值-12。math.ceil()可以接受正或负的实数作为输入值,并且总是返回一个整数值。
当您向ceil()输入一个整数值时,它将返回相同的数字:
>>> math.ceil(6) 6 >>> math.ceil(-11) -11当输入一个整数时,
math.ceil()总是返回相同的值。要了解ceil()的真实性质,您必须输入十进制值:
>>> math.ceil(4.23)
5
>>> math.ceil(-11.453)
-11
当值为正数(4.23)时,函数返回下一个大于值(5)的整数。当该值为负(-11.453)时,该函数同样返回下一个大于该值的整数(-11)。
如果您输入一个非数字的值,该函数将返回一个TypeError:
>>> math.ceil("x") Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str您必须向该函数输入一个数字。如果您尝试输入任何其他值,那么您将得到一个
TypeError。用
floor()和求地板值
floor()将返回小于或等于给定数字的最接近的整数值。该功能与ceil()相反。例如,输入 8.72 将返回 8,输入-12.34 将返回-13。floor()可以接受正数或负数作为输入,并将返回一个整数值。如果您输入一个整数值,那么函数将返回相同的值:
>>> math.floor(4)
4
>>> math.floor(-17)
-17
与ceil()一样,当floor()的输入为整数时,结果将与输入的数字相同。只有当您输入十进制值时,输出才与输入不同:
>>> math.floor(5.532) 5 >>> math.floor(-6.432) -7当您输入一个正十进制值(5.532)时,它将返回小于输入数(5)的最接近的整数。如果您输入一个负数(-6.432),那么它将返回下一个最小的整数值(-7)。
如果您试图输入一个不是数字的值,那么该函数将返回一个
TypeError:
>>> math.floor("x")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: must be real number, not str
您不能给非数字值作为ceil()的输入。这样做会导致一个TypeError。
用trunc()和截断数字
当您得到一个带小数点的数字时,您可能希望只保留整数部分,去掉小数部分。math模块有一个名为trunc()的函数可以让你做到这一点。
丢弃小数值是舍入的一种。使用trunc(),负数总是向上舍入为零,正数总是向下舍入为零。
下面是trunc()函数如何舍入正数或负数:
>>> math.trunc(12.32) 12 >>> math.trunc(-43.24) -43如您所见,12.32 向下舍入为 0,结果为 12。同样,将-43.24 向上舍入为 0,得到的值为-43。
trunc()无论数字是正还是负,总是向零舍入。处理正数时,
trunc()的行为与floor()相同:
>>> math.trunc(12.32) == math.floor(12.32)
True
trunc()的行为与正数的floor()相同。如您所见,两个函数的返回值是相同的。
处理负数时,trunc()的行为与ceil()相同:
>>> math.trunc(-43.24) == math.ceil(-43.24) True当数字为负数时,
floor()的行为与ceil()相同。两个函数的返回值是相同的。用 Python
isclose()求数字的接近度在某些情况下,尤其是在数据科学领域,您可能需要确定两个数字是否彼此接近。但要做到这一点,你首先需要回答一个重要的问题:如何接近**接近?换句话说,接近的定义是什么?
嗯,韦氏词典会告诉你 close 的意思是“在时间、空间、效果或程度上接近”不是很有帮助,是吗?
例如,取下面一组数字:2.32、2.33 和 2.331。当你用小数点后两位来衡量接近度时,2.32 和 2.33 是接近的。但实际上 2.33 和 2.331 更接近。因此,亲近是一个相对的概念。如果没有某种门槛,你就无法确定亲密度。
幸运的是,
math模块提供了一个名为isclose()的功能,可以让你为亲密度设置自己的阈值,或容差。如果两个数字在你设定的接近度范围内,它返回True,否则返回False。让我们看看如何使用默认容差来比较两个数字:
- 相对容差或相对容差,是相对于输入值大小被认为“接近”的最大差值。这是容忍的百分比。默认值为 1e-09 或 0.00000001。
- 绝对公差或 abs_tol ,是被认为“接近”的最大差值,与输入值的大小无关。默认值为 0.0。
满足以下条件时,
isclose()将返回True:ABS(a-b)< = max(rel _ tol * max(ABS(a),abs(b)),abs_tol)。
isclose使用上面的表达式来确定两个数的接近程度。可以代入自己的数值,观察任意两个数是否接近。在以下情况下,6 和 7 不接近:
>>> math.isclose(6, 7)
False
数字 6 和 7 被认为是不接近的,因为相对容差被设置为九个小数位。但是如果在相同的容差下输入 6.999999999 和 7,那么它们被认为接近:
>>> math.isclose(6.999999999, 7) True可以看到值 6.999999999 在 7 的小数点后 9 位以内。因此,根据默认的相对容差,6.999999999 和 7 被视为接近。
您可以根据需要调整相对公差。如果将
rel_tol设置为 0.2,那么 6 和 7 被认为是接近的:
>>> math.isclose(6, 7, rel_tol=0.2)
True
你可以观察到 6 和 7 现在很接近。这是因为它们之间的误差在 20%以内。
与rel_tol一样,可以根据需要调整abs_tol值。要被视为接近,输入值之间的差值必须小于或等于绝对容差值。您可以如下设置abs_tol:
>>> math.isclose(6, 7, abs_tol=1.0) True >>> math.isclose(6, 7, abs_tol=0.2) False当您将绝对容差设置为 1 时,数字 6 和 7 很接近,因为它们之间的差等于绝对容差。然而,在第二种情况下,6 和 7 之间的差值不小于或等于 0.2 的既定绝对公差。
您可以将
abs_tol用于非常小的值:
>>> math.isclose(1, 1.0000001, abs_tol=1e-08)
False
>>> math.isclose(1, 1.00000001, abs_tol=1e-08)
True
如你所见,你可以用isclose确定非常小的数的接近程度。使用nan和inf值可以说明一些关于接近度的特殊情况:
>>> math.isclose(math.nan, 1e308) False >>> math.isclose(math.nan, math.nan) False >>> math.isclose(math.inf, 1e308) False >>> math.isclose(math.inf, math.inf) True从上面的例子可以看出,
nan没有接近任何值,甚至没有接近它本身。另一方面,inf不接近任何数值,甚至不接近非常大的数值,但是它接近它自己。幂函数
幂函数以任意数 x 作为输入,将 x 提升到某次方 n ,返回 x n 作为输出。Python 的
math模块提供了几个与功率相关的函数。在本节中,您将学习幂函数、指数函数和平方根函数。用
pow()计算一个数的幂幂函数具有以下公式,其中变量 x 是基数,变量 n 是幂,并且 a 可以是任意常数:
Power Function 在上面的公式中,基数 x 的值被提升到 n 的幂。
你可以用
math.pow()得到一个数的幂。有一个内置函数pow(),与math.pow()不同。您将在本节的后面部分了解两者的区别。
math.pow()取两个参数如下:
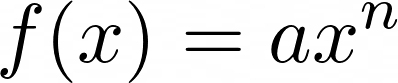
>>> math.pow(2, 5)
32.0
>>> math.pow(5, 2.4)
47.59134846789696
第一个参数是基值,第二个参数是幂值。您可以给定一个整数或十进制值作为输入,函数总是返回一个浮点值。math.pow()中定义了一些特殊情况。
当以 1 为底的任意 n 次方幂时,结果为 1.0:
>>> math.pow(1.0, 3) 1.0当您将基值 1 提升到任何幂值时,结果将始终是 1.0。同样,任何基数的 0 次方都是 1.0:
>>> math.pow(4, 0.0)
1.0
>>> math.pow(-4, 0.0)
1.0
如您所见,任何数字的 0 次幂都将得到 1.0 的结果。即使基数为nan,也可以看到结果:
>>> math.pow(math.nan, 0.0) 1.0零的任意正数幂将得到 0.0 的结果:
>>> math.pow(0.0, 2)
0.0
>>> math.pow(0.0, 2.3)
0.0
但是如果你试图将 0.0 提高到负幂,那么结果将是一个ValueError:
>>> math.pow(0.0, -2) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: math domain error
ValueError只在基数为 0 时出现。如果基数是除 0 以外的任何其他数字,则该函数将返回有效的幂值。除了
math.pow()之外,在 Python 中还有两种内置的方法来计算一个数的幂:
x ** ypow()第一种选择很简单。你可能已经用过一两次了。值的返回类型由输入决定:
>>> 3 ** 2
9
>>> 2 ** 3.3
9.849155306759329
当你使用整数时,你得到一个整数值。当您使用小数值时,返回类型会更改为小数值。
第二个选项是一个多功能的内置函数。不一定要用什么进口的才能用。内置的pow()方法有三个参数:
- 基数数
- 号电源号
- 模数号
前两个参数是必需的,而第三个参数是可选的。您可以输入整数或小数,函数将根据输入返回适当的结果:
>>> pow(3, 2) 9 >>> pow(2, 3.3) 9.849155306759329内置的
pow()有两个必需的参数,与x ** y语法中的基数和幂相同。pow()还有第三个可选参数:模数。该参数常用于密码术中。带有可选模数参数的内置pow()等同于方程(x ** y) % z。Python 语法如下所示:
>>> pow(32, 6, 5)
4
>>> (32 ** 6) % 5 == pow(32, 6, 5)
True
pow()将基数(32)提升到幂(6),然后结果值是模除以模数(5)。在这种情况下,结果是 4。您可以替换您自己的值,并看到pow()和给定的等式提供了相同的结果。
尽管这三种计算功耗的方法做的是同样的事情,但它们之间存在一些实现差异。每种方法的执行时间如下:
>>> timeit.timeit("10 ** 308") 1.0078728999942541 >>> timeit.timeit("pow(10, 308)") 1.047615700008464 >>> timeit.timeit("math.pow(10, 308)", setup="import math") 0.1837239999877056下表比较了由
timeit()测量的三种方法的执行时间:
类型 执行时间 x ** y1.0079 秒 pow(x, y)1.0476 s math.pow(x, y)0.1837 秒 从表中可以看出,
math.pow()比其他方法快,而内置的pow()最慢。
math.pow()效率背后的原因是它的实现方式。它依赖于底层的 C 语言。另一方面,pow()和x ** y使用输入对象自己的**操作符的实现。然而,math.pow()不能处理复数(将在后面的章节中解释),而pow()和**可以。用
exp()求自然指数在上一节中,您学习了幂函数。对于指数函数,情况有所不同。基数不再是变量,权力成为变量。它看起来像这样:
General Exponential Function 这里 a 可以是任意常数,作为幂值的 x 成为变量。
那么指数函数有什么特别之处呢?随着 x 值的增加,函数值快速增加。如果基数大于 1,那么函数的值随着 x 的增加而不断增加。指数函数的一个特殊性质是,函数的斜率也随着 x 的增加而连续增加。
在前面的章节中,你已经了解了欧拉数。它是自然对数的底数。它还与指数函数一起发挥作用。当欧拉数被并入指数函数时,它就变成了自然指数函数:
Natural Exponential Function 这个函数在很多实际情况下都会用到。你可能听说过术语指数增长,它经常被用于人类人口增长或放射性衰变率。这两者都可以使用自然指数函数来计算。
Python
math模块提供了一个函数exp(),可以让您计算一个数字的自然指数。您可以按如下方式找到该值:
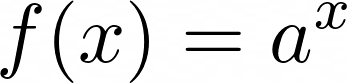
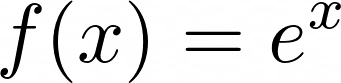
>>> math.exp(21)
1318815734.4832146
>>> math.exp(-1.2)
0.30119421191220214
输入数字可以是正数也可以是负数,函数总是返回一个浮点值。如果数字不是数值,那么该方法将返回一个TypeError:
>>> math.exp("x") Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str如您所见,如果输入是一个字符串值,那么函数返回一个读数为
must be real number, not str的TypeError。您也可以使用
math.e ** x表达式或使用pow(math.e, x)来计算指数。这三种方法的执行时间如下:
>>> timeit.timeit("math.e ** 308", setup="import math")
0.17853009998701513
>>> timeit.timeit("pow(math.e, 308)", setup="import math")
0.21040189999621361
>>> timeit.timeit("math.exp(308)", setup="import math")
0.125878200007719
下表比较了由timeit()测量的上述方法的执行时间:
| 类型 | 执行时间 |
|---|---|
e ** x |
0.1785 秒 |
pow(e, x) |
0.2104 秒 |
math.exp(x) |
0.1259 秒 |
您可以看到,math.exp()比其他方法快,而pow(e, x)最慢。由于math模块的底层 C 实现,这是预期的行为。
同样值得注意的是,e ** x和pow(e, x)返回相同的值,但是exp()返回稍微不同的值。这是由于实现的差异。Python 文档指出exp()比其他两种方法更准确。
实际例子有exp()
当一个不稳定的原子通过发射电离辐射失去能量时,就会发生放射性衰变。放射性衰变率是用半衰期来衡量的,半衰期是母核衰变一半所需的时间。您可以使用以下公式计算衰变过程:
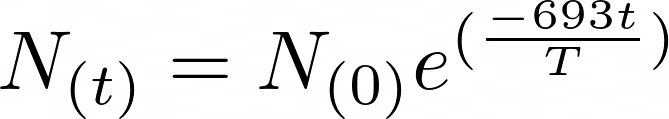
你可以用上面的公式来计算某种放射性元素在一定年限后的剩余量。给定公式的变量如下:
- N(0) 是物质的初始量。
- N(t) 是一段时间( t )后仍然存在且尚未衰变的量。
- T 是衰变量的半衰期。
- e 是欧拉数。
科学研究已经确定了所有放射性元素的半衰期。你可以把数值代入方程式来计算任何放射性物质的剩余量。让我们现在试试。
放射性同位素锶-90 的半衰期为 38.1 年。一个样本含有 100 毫克的锶-90。你可以计算 100 年后 Sr-90 的剩余毫克数:
>>> half_life = 38.1 >>> initial = 100 >>> time = 100 >>> remaining = initial * math.exp(-0.693 * time / half_life) >>> f"Remaining quantity of Sr-90: {remaining}" 'Remaining quantity of Sr-90: 16.22044604811303'可以看到,半衰期设为 38.1,持续时间设为 100 年。你可以用
math.exp来简化方程。将这些值代入方程,你可以发现,100 年后,Sr-90 的 16.22mg 剩余。对数函数
对数函数可以认为是指数函数的逆。它们以下列形式表示:
General Logarithmic Function 这里 a 是对数的底数,可以是任意数。在上一节中,您已经学习了指数函数。指数函数可以用对数函数的形式表示,反之亦然。
带
log()的 Python 自然日志一个数的自然对数是其以数学常数 e 为底的对数,或欧拉数:
Natural Logarithmic Function 与指数函数一样,自然对数使用常数 e 。它通常被描述为 f(x) = ln(x),其中 e 是隐式的。
您可以像使用指数函数一样使用自然对数。它用于计算诸如人口增长率或元素放射性衰变率等数值。
log()有两个论点。第一个是强制的,第二个是可选的。用一个参数你可以得到输入数字的自然对数(以 e 为底):
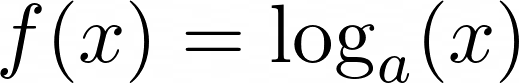
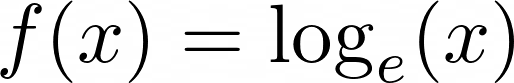
>>> math.log(4)
1.3862943611198906
>>> math.log(3.4)
1.2237754316221157
但是,如果您输入一个非正数,该函数将返回一个ValueError:
>>> math.log(-3) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: math domain error如你所见,你不能给
log()输入一个负值。这是因为对数值对于负数和零是未定义的。使用两个参数,可以计算第一个参数对第二个参数的对数:
>>> math.log(math.pi, 2)
1.651496129472319
>>> math.log(math.pi, 5)
0.711260668712669
当对数基数改变时,您可以看到该值是如何变化的。
了解log2()和log10()
Python math模块还提供了两个独立的函数,让您计算以 2 和 10 为底的对数值:
log2()用于计算以 2 为基数的对数值。log10()用于计算以 10 为基数的对数值。
用log2()你可以得到以 2 为底的对数值:
>>> math.log2(math.pi) 1.6514961294723187 >>> math.log(math.pi, 2) 1.651496129472319这两个函数有相同的目标,但是 Python 文档指出
log2()比使用log(x, 2)更准确。您可以用
log10()计算一个数以 10 为底的对数值:
>>> math.log10(math.pi)
0.4971498726941338
>>> math.log(math.pi, 10)
0.4971498726941338
Python 文档也提到log10()比log(x, 10)更准确,尽管两个函数的目标相同。
自然测井实例
在的前一节中,您看到了如何使用math.exp()来计算一段时间后放射性元素的剩余量。有了math.log(),可以通过间隔测量质量,求出未知放射性元素的半衰期。以下等式可用于计算放射性元素的半衰期:
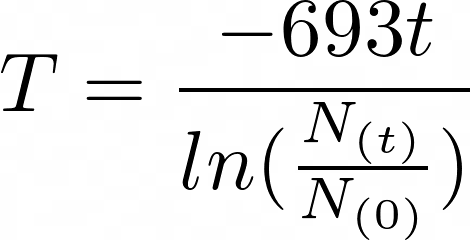
通过重新排列放射性衰变公式,可以把半衰期( T )作为公式的主语。给定公式的变量如下:
- T 是衰变量的半衰期。
- N(0) 是物质的初始量。
- N(t) 是一段时间后剩余的尚未衰变的量( t )。
- ln 是自然对数。
你可以把已知值代入方程式来计算放射性物质的半衰期。
例如,想象你正在研究一种未知的放射性元素样本。100 年前发现时,样本量为 100 毫克。经过 100 年的腐烂,只剩下 16.22 毫克。使用上面的公式,您可以计算这种未知元素的半衰期:
>>> initial = 100 >>> remaining = 16.22 >>> time = 100 >>> half_life = (-0.693 * time) / math.log(remaining / initial) >>> f"Half-life of the unknown element: {half_life}" 'Half-life of the unknown element: 38.09942398335152'你可以看到未知元素的半衰期大约是 38.1 年。根据这些信息,你可以确定未知元素是锶-90。
其他重要的
math模块功能Python
math模块有许多用于数学计算的有用函数,本文只深入讨论了其中的一部分。在本节中,您将简要了解math模块中的其他一些重要功能。计算最大公约数
两个正数的最大公约数(GCD) 是两个数相除没有余数的最大正整数。
比如 15 和 25 的 GCD 是 5。你可以把 15 和 25 都除以 5,没有余数。没有更多的人做同样的事情。如果你取 15 和 30,那么 GCD 就是 15,因为 15 和 30 都可以被 15 整除,没有余数。
您不必实现自己的函数来计算 GCD。Python
math模块提供了一个名为math.gcd()的函数,可以让你计算两个数的 GCD。您可以给出正数或负数作为输入,它会返回适当的 GCD 值。但是,您不能输入十进制数。计算迭代的总和
如果你想在不使用循环的情况下找到一个可迭代的值的和,那么
math.fsum()可能是最简单的方法。您可以使用数组、元组或列表等可迭代对象作为输入,函数将返回这些值的总和。一个名为sum()的内置函数也可以让你计算可迭代的和,但是fsum()比sum()更精确。您可以在文档中了解更多信息。计算平方根
一个数的平方根是一个值,当它与自身相乘时,给出该数。可以用
math.sqrt()求任意正实数(整数或小数)的平方根。返回值总是一个浮点值。如果您试图输入一个负数,该函数将抛出一个ValueError。转换角度值
在现实生活和数学中,您经常会遇到必须测量角度来执行计算的情况。角度可以用度数或弧度来度量。有时你必须将角度转换成弧度,反之亦然。
math模块提供了允许您这样做的函数。如果你想把度数转换成弧度,那么你可以使用
math.radians()。它返回度数输入的弧度值。同样,如果你想将弧度转换成度数,那么你可以使用math.degrees()。计算三角值
三角学是对三角形的研究。它研究三角形的角和边之间的关系。三角学最感兴趣的是直角三角形(其中一个内角为 90 度),但它也可以应用于其他类型的三角形。Python
math模块提供了非常有用的函数,可以让您执行三角计算。可以用
math.sin()计算角度的正弦值,用math.cos()计算余弦值,用math.tan()计算正切值。math模块还提供了用math.asin()计算反正弦,用math.acos()计算反正弦,用math.atan()计算反正切的功能。最后,你可以使用math.hypot()计算三角形的斜边。Python 3.8 中
math模块的新增内容随着Python 3.8 版的发布,对
math模块进行了一些新的添加和更改。新增内容和变化如下:
comb(n, k)返回从 n 项中选择 k 项的方式数,无重复,无先后。**
perm(n, k)返回从无重复的 n 项和有顺序的项中选择 k 项的方式数。* **`isqrt()`** 返回非负整数的整数平方根。 * **`prod()`** 计算输入 iterable 中所有元素的乘积。与`fsum()`一样,该方法可以接受数组、列表或元组等可迭代对象。 * **`dist()`** 返回两点 *p* 和 *q* 之间的[欧几里德距离](https://en.wikipedia.org/wiki/Euclidean_distance),每个点都作为坐标序列(或可迭代的)给出。这两点必须具有相同的尺寸。 * **`hypot()`** 现在处理两个以上的维度。以前,它最多支持两个维度。**##
cmathvsmathT2】复数是实数和虚数的组合。它的公式为 a + bi ,其中 a 为实数 bi 为虚数。实数和虚数可以解释如下:
- 实数是你能想到的任何一个数字。
- 一个虚数是一个平方后给出负结果的数。
实数可以是任何数字。比如 12,4.3,-19.0 都是实数。虚数显示为 i 。下图显示了一个复数的示例:
Complex Number 在上面的例子中, 7 是实数, 3i 是虚数。复数主要用于几何、微积分、科学计算,尤其是电子学。
Python 模块
math的函数不能处理复数。然而,Python 提供了一个可以专门处理复数的不同模块,即cmath模块。Python 的math模块由cmath模块补充,后者实现了许多相同的功能,但用于复数。您可以导入
cmath模块,如下所示:
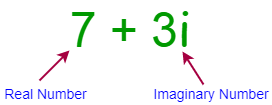
>>> import cmath
因为cmath模块也是用 Python 打包的,所以可以像导入math模块一样导入它。在使用cmath模块之前,你必须知道如何定义一个复数。您可以如下定义一个复数:
>>> c = 2 + 3j >>> c (2+3j) >>> type(c) <class 'complex'>如你所见,你可以通过使用
type()来确定一个数确实是复数。注:在数学中,虚数单位通常表示为 i 。在某些领域,更习惯于使用 j 来表示同一件事。在 Python 中,使用
j来表示虚数。Python 还提供了一个名为
complex()的特殊内置函数,可以创建复数。您可以按如下方式使用complex():
>>> c = complex(2, 3)
>>> c
(2+3j)
>>> type(c)
<class 'complex'>
您可以使用任何一种方法来创建复数。您也可以使用cmath模块计算复数的数学函数,如下所示:
>>> cmath.sqrt(c) (1.8581072140693775+0.6727275964137814j) >>> cmath.log(c) (1.3622897515267103+0.6947382761967031j) >>> cmath.exp(c) (-16.091399670844+12.02063434789931j)这个例子向你展示了如何计算一个复数的平方根、对数值和指数值。如果你想了解更多关于
cmath模块的信息,你可以阅读文档。NumPy vs
math几个著名的 Python 库可以用于数学计算。最著名的库之一是 Numerical Python,或称 NumPy 。它主要用于科学计算和数据科学领域。与标准 Python 版本中的
math模块不同,您必须安装 NumPy 才能使用它。NumPy 的核心是高性能的 N 维(多维)数组数据结构。这个数组允许你在整个数组上执行数学运算,而不需要遍历元素。函数库中的所有函数都经过优化,可以处理 N 维数组对象。
math模块和 NumPy 库都可以用于数学计算。NumPy 与math模块有几个相似之处。NumPy 有一个函数的子集,类似于math模块函数,处理数学计算。NumPy 和math都提供了处理三角、指数、对数、双曲线和算术计算的函数。
math和 NumPy 也有几个根本的区别。Pythonmath模块更适合处理标量值,而 NumPy 更适合处理数组、向量甚至矩阵。当处理标量值时,
math模块函数可以比它们的 NumPy 对应函数更快。这是因为 NumPy 函数将值转换成数组,以便对它们执行计算。NumPy 在处理 N 维数组时要快得多,因为对它们进行了优化。除了fsum()和prod()之外,math模块函数不能处理数组。结论
在本文中,您了解了 Python
math模块。该模块提供了用于执行数学计算的有用函数,这些函数有许多实际应用。在这篇文章中,你学到了:
- Python
math模块是什么- 用实例说明如何使用
math功能math模块的常数是什么,包括圆周率、τ和欧拉数- 内置函数和
math函数有什么区别math、cmath和 NumPy 有什么区别理解如何使用
math功能是第一步。现在是时候把你学到的东西应用到现实生活中了。如果你有任何问题或意见,请在下面的评论区留下。立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 数学模块************
Python + Memcached:分布式应用中的高效缓存
原文:https://realpython.com/python-memcache-efficient-caching/
编写 Python 应用程序时,缓存很重要。使用缓存来避免重新计算数据或访问缓慢的数据库可以为您提供巨大的性能提升。
Python 为缓存提供了内置的可能性,从简单的字典到更完整的数据结构如
functools.lru_cache。后者可以使用最近最少使用算法来限制缓存大小,从而缓存任何项目。然而,根据定义,这些数据结构对于您的 Python 进程来说是本地的。当应用程序的多个副本跨大型平台运行时,使用内存中的数据结构不允许共享缓存的内容。对于大规模和分布式应用程序来说,这可能是一个问题。
因此,当系统跨网络分布时,它也需要跨网络分布的缓存。如今,有很多网络服务器提供了缓存功能——我们已经介绍了如何使用 Redis 和 Django 进行缓存。
正如您将在本教程中看到的, memcached 是分布式缓存的另一个很好的选择。在快速介绍了 memcached 的基本用法之后,您将了解高级模式,如“缓存和设置”以及使用后备缓存来避免冷缓存性能问题。
安装 memcached
Memcached 是可用于许多平台:
- 如果运行 Linux ,可以用
apt-get install memcached或者yum install memcached安装。这将从预构建的包中安装 memcached,但是你也可以从源代码中构建 memcached,如这里所解释的。- 对于 macOS ,使用家酿是最简单的选择。安装好家酿软件包管理器后,运行
brew install memcached即可。- 在 Windows 上,你必须自己编译 memcached 或者找到预编译的二进制文件。
一旦安装完毕, memcached 可以通过调用
memcached命令简单地启动:$ memcached在可以从 Python-land 与 memcached 交互之前,您需要安装一个 memcached 客户端库。您将在下一节看到如何实现这一点,以及一些基本的缓存访问操作。
使用 Python 存储和检索缓存值
如果你从未使用过 memcached ,这很容易理解。它基本上提供了一个巨大的网络可用字典。本词典有几个不同于传统 Python 词典的属性,主要是:
- 键和值必须是字节
- 过期后,密钥和值会被自动删除
因此,与 memcached 交互的两个基本操作是
set和get。正如您可能已经猜到的,它们分别用于给一个键赋值或从一个键获取值。我与 memcached 交互的首选 Python 库是
pymemcache——我推荐使用它。您可以简单地使用 pip 安装它:$ pip install pymemcache以下代码显示了如何连接到 memcached 并在 Python 应用程序中将其用作网络分布式缓存:
>>> from pymemcache.client import base # Don't forget to run `memcached' before running this next line: >>> client = base.Client(('localhost', 11211)) # Once the client is instantiated, you can access the cache: >>> client.set('some_key', 'some value') # Retrieve previously set data again: >>> client.get('some_key') 'some value'memcached 网络协议非常简单,其实现速度极快,这使得存储数据非常有用,否则从规范数据源检索或再次计算时会很慢:
虽然这个例子足够简单,但它允许在网络上存储键/值元组,并通过应用程序的多个分布式运行副本来访问它们。这很简单,但是很强大。这是优化您的应用程序的第一步。
自动终止缓存数据
当将数据存储到 memcached 中时,您可以设置一个到期时间,这是 memcached 保存密钥和值的最大秒数。延迟之后, memcached 会自动从缓存中移除密钥。
您应该将这个缓存时间设置为多少?这种延迟没有神奇的数字,它完全取决于数据类型和您正在使用的应用程序。可能是几秒钟,也可能是几个小时。
缓存失效,定义何时移除缓存,因为它与当前数据不同步,这也是您的应用程序必须处理的事情。尤其是如果要避免呈现太旧或陈旧的数据。
同样,这里没有神奇的配方;这取决于您正在构建的应用程序的类型。然而,有几个无关紧要的情况需要处理——我们在上面的例子中还没有涉及到。
缓存服务器不能无限增长——内存是有限的资源。因此,一旦缓存服务器需要更多的空间来存储其他内容,它就会刷新密钥。
一些密钥也可能因为达到其到期时间(有时也称为“生存时间”或 TTL)而到期。)在这些情况下,数据会丢失,必须再次查询规范数据源。
这听起来比实际更复杂。在 Python 中使用 memcached 时,通常可以使用以下模式:
from pymemcache.client import base def do_some_query(): # Replace with actual querying code to a database, # a remote REST API, etc. return 42 # Don't forget to run `memcached' before running this code client = base.Client(('localhost', 11211)) result = client.get('some_key') if result is None: # The cache is empty, need to get the value # from the canonical source: result = do_some_query() # Cache the result for next time: client.set('some_key', result) # Whether we needed to update the cache or not, # at this point you can work with the data # stored in the `result` variable: print(result)注意:由于正常的冲洗操作,处理丢失的钥匙是强制性的。处理冷缓存场景也是必须的,即当 memcached 刚刚启动时。在这种情况下,缓存将完全为空,需要完全重新填充缓存,一次一个请求。
这意味着您应该将任何缓存的数据视为短暂的。您永远不应该期望缓存中包含您以前写入的值。
预热冷缓存
有些冷缓存场景是无法避免的,例如 memcached 崩溃。但是有些可以,例如迁移到一个新的 memcached 服务器。
当可以预测冷缓存场景将会发生时,最好避免它。需要重新填充的缓存意味着,突然之间,缓存数据的规范存储将被所有缺少缓存数据的缓存用户大量占用(也称为迅雷羊群问题)。)
pymemcache 提供了一个名为
FallbackClient的类来帮助实现这个场景,如下所示:from pymemcache.client import base from pymemcache import fallback def do_some_query(): # Replace with actual querying code to a database, # a remote REST API, etc. return 42 # Set `ignore_exc=True` so it is possible to shut down # the old cache before removing its usage from # the program, if ever necessary. old_cache = base.Client(('localhost', 11211), ignore_exc=True) new_cache = base.Client(('localhost', 11212)) client = fallback.FallbackClient((new_cache, old_cache)) result = client.get('some_key') if result is None: # The cache is empty, need to get the value # from the canonical source: result = do_some_query() # Cache the result for next time: client.set('some_key', result) print(result)
FallbackClient查询传递给它的构造函数的旧缓存,考虑顺序。在这种情况下,将总是首先查询新的缓存服务器,在缓存未命中的情况下,将查询旧的缓存服务器,从而避免可能返回到主数据源。如果设置了任何键,它只会被设置到新的缓存中。一段时间后,旧缓存可以退役,并且可以直接用
new_cache客户端替换FallbackClient。检查并设置
当与远程缓存通信时,常见的并发性问题又出现了:可能有几个客户端试图同时访问同一个键。 memcached 提供了一个检查和设置操作,简称为 CAS ,有助于解决这个问题。
最简单的例子是一个想要计算用户数量的应用程序。每次有访问者连接,计数器就加 1。使用 memcached ,一个简单的实现是:
def on_visit(client): result = client.get('visitors') if result is None: result = 1 else: result += 1 client.set('visitors', result)但是,如果应用程序的两个实例试图同时更新这个计数器,会发生什么情况呢?
第一个调用
client.get('visitors')将为两者返回相同数量的访问者,假设是 42。然后两者都会加 1,计算 43,将访客数设置为 43。那个数不对,结果应该是 44,也就是 42 + 1 + 1。为了解决这个并发问题, memcached 的 CAS 操作非常方便。以下代码片段实现了一个正确的解决方案:
def on_visit(client): while True: result, cas = client.gets('visitors') if result is None: result = 1 else: result += 1 if client.cas('visitors', result, cas): break
gets方法返回值,就像get方法一样,但是它也返回一个 CAS 值。这个值中的内容是不相关的,但是它用于下一个方法
cas调用。这个方法等同于set操作,除了如果值在gets操作后改变了,这个方法就会失败。在成功的情况下,循环被打破。否则,操作从头重新开始。在应用程序的两个实例试图同时更新计数器的场景中,只有一个成功地将计数器从 42 移动到 43。第二个实例获得由
client.cas调用返回的False值,并且必须重试循环。这次它将检索 43 作为值,将它递增到 44,它的cas调用将成功,从而解决我们的问题。递增计数器作为解释 CAS 如何工作的例子很有趣,因为它很简单。然而, memcached 也提供了
incr和decr方法来在单个请求中增加或减少一个整数,而不是进行多次gets/cas调用。在实际应用中,gets和cas用于更复杂的数据类型或操作大多数远程缓存服务器和数据存储都提供了这种机制来防止并发问题。了解这些情况对于正确使用它们的功能至关重要。
超越缓存
本文中展示的简单技术向您展示了利用 memcached 来提高 Python 应用程序的性能是多么容易。
仅仅通过使用两个基本的“设置”和“获取”操作,您通常可以加速数据检索或避免一次又一次地重新计算结果。使用 memcached,您可以在大量分布式节点上共享缓存。
您在本教程中看到的其他更高级的模式,如检查和设置(CAS) 操作,允许您跨多个 Python 线程或进程同时更新存储在缓存中的数据,同时避免数据损坏。
如果您有兴趣了解更多关于编写更快、更可伸缩的 Python 应用程序的高级技术,请查看 Scaling Python 。它涵盖了许多高级主题,如网络分布、排队系统、分布式散列和代码分析。***
Python 中的内存管理
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 如何管理内存
想知道 Python 是如何在幕后处理数据的吗?你的变量是如何存储在内存中的?它们什么时候被删除?
在本文中,我们将深入 Python 的内部,以理解它是如何处理内存管理的。
本文结束时,你将:
- 了解有关低级计算的更多信息,特别是与内存相关的信息
- 理解 Python 如何抽象底层操作
- 了解 Python 的内部内存管理算法
了解 Python 的内部也将让您更好地了解 Python 的一些行为。希望您也能对 Python 有新的认识。如此多的逻辑在幕后发生,以确保你的程序按你期望的方式工作。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
记忆是一本空书
你可以先把计算机的内存想象成一本用来写短篇故事的空书。纸上还什么都没写。最终,不同的作者会出现。每个作者都想要一些空间来写他们的故事。
因为他们不允许互相覆盖,所以他们必须小心他们写的是哪一页。在他们开始写作之前,他们会咨询图书经理。然后经理决定他们可以在书的什么地方写。
由于这本书已经存在很久了,里面的许多故事已经不再相关了。当没有人阅读或引用这些故事时,它们就会被删除,以便为新的故事腾出空间。
本质上,计算机内存就像那本空书。事实上,通常将固定长度的连续内存块称为页面,因此这个类比非常适用。
作者就像需要在内存中存储数据的不同应用程序或进程。经理决定作者可以在书中何处书写,扮演着某种记忆经理的角色。清除旧故事为新故事腾出空间的人是垃圾收集者。
内存管理:从硬件到软件
内存管理是应用程序读写数据的过程。内存管理器决定将应用程序的数据放在哪里。因为内存块是有限的,就像我们书中类比的页面一样,管理器必须找到一些空闲空间,并将其提供给应用程序。这个提供内存的过程一般被称为内存分配。
另一方面,当不再需要数据时,可以将其删除,或者释放**。但是自由到哪里去呢?这个“记忆”从何而来?*
*当你运行 Python 程序时,在你计算机的某个地方,有一个存储数据的物理设备。在对象真正到达硬件之前,Python 代码要经过许多抽象层。
硬件(如 RAM 或硬盘)之上的一个主要层是操作系统(OS)。它执行(或拒绝)读写内存的请求。
在操作系统之上,有一些应用程序,其中一个是默认的 Python 实现(包含在你的操作系统中或者从python.org下载)。)Python 代码的内存管理由 Python 应用程序处理。Python 应用程序用于内存管理的算法和结构是本文的重点。
默认的 Python 实现
默认的 Python 实现 CPython ,实际上是用 C 编程语言编写的。
当我第一次听到这个消息时,我大吃一惊。用另一种语言写的语言?!不完全是,但算是吧。
Python 语言是在用英语编写的参考手册中定义的。然而,该手册本身并不那么有用。您仍然需要一些东西来根据手册中的规则解释编写的代码。
您还需要一些东西来在计算机上实际执行解释的代码。默认的 Python 实现满足了这两个要求。它将您的 Python 代码转换成指令,然后在虚拟机上运行。
注:虚拟机就像物理计算机,只是用软件实现。他们通常处理类似于汇编指令的基本指令。
Python 是一种解释型编程语言。你的 Python 代码实际上被编译成更多的计算机可读指令,称为字节码。当你运行代码时,这些指令被虚拟机解释为**。*
*你见过
.pyc文件或者__pycache__文件夹吗?这是由虚拟机解释的字节码。值得注意的是,除了 CPython 之外还有其他实现。IronPython 编译下来运行在微软的公共语言运行时上。 Jython 编译成 Java 字节码,运行在 Java 虚拟机上。然后是 PyPy ,但那值得自己的整篇文章,所以我只是顺便提一下。
出于本文的目的,我将把重点放在 Python 的默认实现 CPython 的内存管理上。
免责声明:虽然这些信息中的很多将会被带到 Python 的新版本中,但将来事情可能会发生变化。注意,本文引用的版本是当前最新版本的 Python,
3.7。好了,CPython 是用 C 写的,它解释 Python 字节码。这和内存管理有什么关系?内存管理算法和结构存在于 c 语言的 CPython 代码中。要理解 Python 的内存管理,您必须对 CPython 本身有一个基本的了解。
CPython 是用 C 写的,不原生支持面向对象编程。因此,CPython 代码中有很多有趣的设计。
你可能听说过 Python 中的一切都是对象,甚至是像
int和str这样的类型。嗯,在 CPython 的实现层面上确实如此。有一个名为PyObject的struct,CPython 中的所有其他对象都使用它。注意:C 中的
struct或结构是一种自定义数据类型,它将不同的数据类型组合在一起。与面向对象语言相比,它就像一个只有属性而没有方法的类。Python 中所有对象的始祖
PyObject,只包含两个东西:
ob_refcnt: 引用计数ob_type: 指针指向另一种类型引用计数用于垃圾收集。然后你就有了一个指向实际对象类型的指针。那个对象类型只是另一个描述 Python 对象的
struct(比如dict或int)。每个对象都有自己的特定于对象的内存分配器,它知道如何获取内存来存储该对象。每个对象还有一个特定于对象的内存释放器,一旦不再需要,它就会“释放”内存。
然而,在所有关于分配和释放内存的讨论中,有一个重要的因素。内存是计算机上的共享资源,如果两个不同的进程试图同时写入同一位置,可能会发生不好的事情。
全球解释器锁(GIL)
GIL 是处理共享资源(如计算机中的内存)这一常见问题的解决方案。当两个线程试图同时修改同一个资源时,它们可能会互相妨碍。最终结果可能是一片混乱,没有一个线程得到它们想要的结果。
再考虑一下书的类比。假设两个作者固执地决定轮到他们写了。不仅如此,他们还需要同时写在书的同一页上。
他们都不理会对方编造故事的企图,开始在纸上写作。最终结果是两个故事重叠在一起,使得整个页面完全无法阅读。
这个问题的一个解决方案是,当线程与共享资源(书中的页面)交互时,在解释器上使用一个全局锁。换句话说,一次只能有一个作者写作。
Python 的 GIL 通过锁定整个解释器来实现这一点,这意味着另一个线程不可能踩在当前线程上。当 CPython 处理内存时,它使用 GIL 来确保安全地处理内存。
这种方法有优点也有缺点,GIL 在 Python 社区中引起了激烈的争论。要阅读更多关于 GIL 的内容,我建议查看一下什么是 Python 全局解释器锁(GIL)?。
垃圾收集
让我们重温一下书中的比喻,假设书中的一些故事已经很老了。没有人再阅读或参考那些故事了。如果没有人在阅读或参考他们自己的作品,你可以删除它,为新的写作腾出空间。
那些旧的、未被引用的文字可以比作 Python 中的一个对象,它的引用计数已经降到了
0。记住 Python 中的每个对象都有一个引用计数和一个指向类型的指针。引用计数增加有几个不同的原因。例如,如果将引用计数赋给另一个变量,它将增加:
numbers = [1, 2, 3] # Reference count = 1 more_numbers = numbers # Reference count = 2如果将对象作为参数传递,它也会增加:
total = sum(numbers)最后一个例子是,如果将对象包含在列表中,引用计数将会增加:
matrix = [numbers, numbers, numbers]Python 允许您使用
sys模块检查对象的当前引用计数。您可以使用sys.getrefcount(numbers),但是要记住将对象传递给getrefcount()会增加引用计数1。在任何情况下,如果对象仍然需要留在代码中,那么它的引用计数大于
0。一旦下降到0,该对象就会调用一个特定的释放函数来“释放”内存,以便其他对象可以使用它。但是“释放”内存是什么意思,其他对象是如何使用它的呢?让我们直接进入 CPython 的内存管理。
CPython 的内存管理
我们将深入探究 CPython 的内存架构和算法,所以请系好安全带。
如前所述,从物理硬件到 CPython 有几个抽象层。操作系统(OS)对物理内存进行抽象,并创建应用程序(包括 Python)可以访问的虚拟内存层。
特定于操作系统的虚拟内存管理器为 Python 进程划出一块内存。下图中较暗的灰色方框现在归 Python 进程所有。
Python 将一部分内存用于内部使用和非对象内存。另一部分专用于对象存储(您的
int、dict等等)。请注意,这有些简化。如果您想要完整的图片,您可以查看 CPython 源代码,所有这些内存管理都发生在这里。CPython 有一个对象分配器,负责在对象内存区域内分配内存。这个对象分配器是最神奇的地方。每当一个新对象需要分配或删除空间时,就会调用它。
通常,像
list和int这样的 Python 对象的数据添加和删除一次不会涉及太多数据。因此分配器的设计被调整为一次处理少量数据。它还试图不分配内存,直到它绝对需要。源代码中的注释将分配器描述为“一个快速、专用于小块的内存分配器,将在通用 malloc 之上使用。”本例中,
malloc是 C 的库函数,用于内存分配。现在我们来看看 CPython 的内存分配策略。首先,我们将讨论 3 个主要部分以及它们之间的关系。
竞技场是最大的内存块,在内存中对齐在页面边界上。页面边界是操作系统使用的固定长度的连续内存块的边缘。Python 假设系统的页面大小为 256 千字节。
竞技场内是池,池是一个虚拟内存页面(4kb)。这些就像我们书中类比的页面。这些池被分割成更小的内存块。
给定池中的所有数据块都属于同一“大小级别”给定一定量的请求数据,大小类定义特定的块大小。下图直接取自源代码注释:
请求字节数 分配块的大小 尺寸等级 idx 1-8 eight Zero 9-16 Sixteen one 17-24 Twenty-four Two 25-32 Thirty-two three 33-40 Forty four 41-48 Forty-eight five 49-56 fifty-six six 57-64 Sixty-four seven 65-72 seventy-two eight … … … 497-504 Five hundred and four Sixty-two 505-512 Five hundred and twelve Sixty-three 例如,如果请求 42 字节,数据将被放入 48 字节大小的块中。
池
池由单一大小级别的数据块组成。每个池维护一个双向链表到相同大小类的其他池。通过这种方式,该算法可以轻松找到给定数据块大小的可用空间,甚至跨不同的池。
一个
usedpools列表跟踪所有有一些空间可用于每个大小类别的数据的池。当请求给定的数据块大小时,该算法会检查此usedpools列表以获取该数据块大小的池列表。池本身必须处于以下三种状态之一:
used、full或empty。一个used池有可用于存储数据的块。一个full池的所有块都被分配并包含数据。一个empty池不存储任何数据,并且可以在需要时为块分配任何大小的类。一个
freepools列表跟踪处于empty状态的所有池。但是什么时候使用空池呢?假设您的代码需要 8 字节的内存块。如果在 8 字节大小类的
usedpools中没有池,则初始化一个新的empty池来存储 8 字节块。然后这个新的池被添加到usedpools列表中,这样它就可以用于将来的请求。假设一个
full池因为不再需要内存而释放了一些内存块。该池将被添加回其大小类别的usedpools列表中。您现在可以看到,使用这种算法,池可以在这些状态(甚至内存大小类别)之间自由移动。
块
如上图所示,池包含一个指向其“空闲”内存块的指针。这种工作方式略有不同。根据源代码中的注释,这个分配器“在所有级别(arena、pool 和 block)上努力不去碰一块内存,直到它真正被需要为止”。
这意味着一个池可以有三种状态的块。这些状态可以定义如下:
untouched: 尚未分配的内存部分free: 被 CPython 分配但后来“释放”的一部分内存,不再包含相关数据allocated: 实际包含相关数据的内存部分
freeblock指针指向内存自由块的单链表。换句话说,就是存放数据的可用位置列表。如果需要多于可用的空闲块,分配器将在池中获得一些untouched块。随着内存管理器释放块,那些现在的
free块被添加到freeblock列表的前面。实际的列表可能不是连续的内存块,就像第一个漂亮的图表一样。它可能类似于下图:
竞技场
竞技场包含水池。这些池可以是
used、full或empty。但是竞技场本身并不像泳池那样有明确的状态。竞技场被组织成一个叫做
usable_arenas的双向链表。该列表按可用的空闲池数量排序。免费池越少,竞技场越靠近列表的前面。
这意味着将选择数据最多的区域来放置新数据。但是为什么不相反呢?为什么不把数据放在最有空间的地方呢?
这给我们带来了真正释放内存的想法。你会注意到我经常用引号提到“免费”。原因是当一个块被认为是“自由的”时,该内存实际上并没有被释放回操作系统。Python 进程保持它的分配状态,并在以后将它用于新数据。真正释放内存是将它返回给操作系统使用。
竞技场是唯一可以真正自由的东西。因此,有理由认为那些接近空的竞技场应该被允许变空。这样,可以真正释放内存块,减少 Python 程序的整体内存占用。
结论
内存管理是使用计算机不可或缺的一部分。Python 几乎在幕后处理所有的事情,不管是好是坏。
在本文中,您了解了:
- 什么是内存管理,为什么它很重要
- 默认的 Python 实现 CPython 是如何用 C 编程语言编写的
- 数据结构和算法如何在 CPython 的内存管理中协同工作来处理数据
Python 抽象出了许多与计算机打交道的具体细节。这使您能够在更高的层次上开发您的代码,而不必担心所有这些字节是如何以及在哪里存储的。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 如何管理内存*********
Python 和 PyQt:创建菜单、工具栏和状态栏
当使用 Python 和 PyQt 开发图形用户界面(GUI) 应用程序时,你会用到的一些最有用和最通用的图形元素是菜单、工具栏和状态栏。
菜单和工具栏可以让你的应用程序看起来精致和专业,为用户提供一组可访问的选项,而状态栏允许你显示应用程序状态的相关信息。
在本教程中,您将学习:
- 什么是菜单、工具栏、状态栏
- 如何以编程方式创建菜单、工具栏和状态栏
*** 如何使用 PyQt 动作填充 Python 菜单和工具栏* 如何使用状态栏显示状态信息**此外,您将学习一些在使用 Python 和 PyQt 创建菜单、工具栏和状态栏时可以应用的编程最佳实践。如果你是使用 PyQt 进行 GUI 编程的新手,那么你可以看看 Python 和 PyQt:构建 GUI 桌面计算器。
您可以通过单击下面的框来下载您将在本教程中构建的示例应用程序的代码和资源:
下载示例代码: 单击此处获取代码,您将使用来学习如何使用 Python 和 PyQt 向您的 GUI 应用程序添加菜单、工具栏和状态栏。
在 PyQt 中构建 Python 菜单栏、菜单和工具栏
一个菜单栏是一个 GUI 应用程序的主窗口的一个区域,它保存着菜单。菜单是选项的下拉列表,提供对应用程序选项的方便访问。例如,如果您正在创建一个文本编辑器,那么您的菜单栏中可能会有以下一些菜单:
- 一个文件菜单,提供以下一些菜单选项:
- New 用于创建新文档
- 打开用于打开已有的文档
- 打开最近的打开最近的文档
- 保存用于保存文档
- 退出退出应用程序
- 一个编辑菜单,提供以下一些菜单选项:
- 复印用于复印一些文本
- 粘贴用于粘贴一些文本
- 剪切用于剪切一些文本
- 一个帮助菜单,提供以下一些菜单选项:
- 帮助内容用于启动用户手册和帮助内容
- 关于用于启动关于对话框
您也可以将这些选项添加到工具栏中。工具栏是一个带有有意义图标的按钮面板,通过它可以快速访问应用程序中最常用的选项。在您的文本编辑器示例中,您可以添加类似于新建、打开、保存、复制和粘贴到工具栏的选项。
注意:在本教程中,您将开发一个实现上述所有菜单和选项的示例应用程序。您可以使用这个示例应用程序作为创建文本编辑器项目的起点。
在本节中,您将学习如何使用 Python 和 PyQt 向 GUI 应用程序添加菜单栏、菜单和工具栏的基础知识。
在继续之前,您将创建一个示例 PyQt 应用程序,您将在本教程中使用它。在每一节中,您将向这个示例应用程序添加新的特性和功能。该应用程序将是一个主窗口风格的应用程序。这意味着它将有一个菜单栏、一个工具栏、一个状态栏和一个中央小部件。
打开你最喜欢的代码编辑器或者 IDE ,创建一个名为
sample_app.py的 Python 文件。然后向其中添加以下代码:import sys from PyQt5.QtCore import Qt from PyQt5.QtWidgets import QApplication, QLabel, QMainWindow class Window(QMainWindow): """Main Window.""" def __init__(self, parent=None): """Initializer.""" super().__init__(parent) self.setWindowTitle("Python Menus & Toolbars") self.resize(400, 200) self.centralWidget = QLabel("Hello, World") self.centralWidget.setAlignment(Qt.AlignHCenter | Qt.AlignVCenter) self.setCentralWidget(self.centralWidget) if __name__ == "__main__": app = QApplication(sys.argv) win = Window() win.show() sys.exit(app.exec_())现在
sample_app.py包含了创建示例 PyQt 应用程序所需的所有代码。在这种情况下,Window继承自QMainWindow。因此,您正在构建一个主窗口风格的应用程序。注:可惜 PyQt5 的官方文档有一些不完整的章节。为了解决这个问题,你可以查看 PyQt4 文档或者原始的 Qt 文档。
在类初始化器
.__init__()中,首先使用super()调用父类的初始化器。然后使用.setWindowTitle()设置窗口标题,使用.resize()调整窗口大小。注意:如果您不熟悉 PyQt 应用程序以及如何创建它们,那么您可以查看 Python 和 PyQt:构建 GUI 桌面计算器。
窗口的中心小部件是一个
QLabel对象,您将使用它来显示响应某些用户操作的消息。这些消息将显示在窗口的中央。要做到这一点,你可以用几个对齐标志调用QLabel对象上的.setAlignment()。如果您从命令行运行应用程序,那么您将在屏幕上看到以下窗口:
就是这样!您已经用 Python 和 PyQt 创建了一个主窗口样式的应用程序。在本教程接下来的所有示例中,您都将使用这个示例应用程序。
创建菜单栏
在 PyQt 主窗口样式的应用程序中,
QMainWindow默认提供一个空的QMenuBar对象。要访问这个菜单栏,你需要在你的QMainWindow对象上调用.menuBar()。这个方法将返回一个空的菜单栏。这个菜单栏的父对象将是你的主窗口对象。现在回到您的示例应用程序,在
Window的定义中添加以下方法:class Window(QMainWindow): # Snip... def _createMenuBar(self): menuBar = self.menuBar()这是在 PyQt 中创建菜单栏的首选方式。在这里,
menuBar变量将保存一个空的菜单栏,这将是你的主窗口的菜单栏。注意:PyQt 编程中的一个常见实践是,在对象的定义方法之外,对那些您不会使用或不需要的对象使用局部变量。Python 对范围之外的所有对象进行垃圾收集,所以你可能会认为一旦
._createMenuBar()返回,上面例子中的menuBar就会消失。事实是,PyQt 使用本地对象的所有权或父子关系来保存对本地对象的引用,如
menuBar。换句话说,由于menuBar属于主窗口对象,Python 将无法对其进行垃圾收集。向 PyQt 应用程序添加菜单栏的另一种方法是创建一个
QMenuBar对象,然后使用.setMenuBar()将其设置为主窗口的菜单栏。考虑到这一点,你也可以这样写._createMenuBar():from PyQt5.QtWidgets import QMenuBar # Snip... class Window(QMainWindow): # Snip... def _createMenuBar(self): menuBar = QMenuBar(self) self.setMenuBar(menuBar)在上面的例子中,
menuBar持有一个父对象设置为self的QMenuBar对象,这是应用程序的主窗口。一旦你有了菜单栏对象,你可以使用.setMenuBar()把它添加到你的主窗口。最后,请注意,为了让这个例子工作,您首先需要从PyQt5.QWidgets中导入QMenuBar。在 GUI 应用程序中,菜单栏将根据底层操作系统显示在不同的位置:
- 窗口:在应用程序主窗口的顶部,标题栏下
- macOS: 在屏幕上方
- Linux: 要么在主窗口的顶部,要么在屏幕的顶部,这取决于你的桌面环境
为应用程序创建菜单栏的最后一步是从主窗口的初始化器
.__init__()中调用._createMenuBar():class Window(QMainWindow): """Main Window.""" def __init__(self, parent=None): # Snip... self._createMenuBar()如果您用这些新的变化运行您的示例应用程序,那么您将不会在应用程序的主窗口上看到菜单栏。那是因为你的菜单栏还是空的。要在应用程序的主窗口上看到菜单栏,您需要创建一些菜单。这就是你接下来要学的。
向菜单栏添加菜单
菜单是菜单选项的下拉列表,你可以通过点击它们或点击键盘快捷键来触发。在 PyQt 中,至少有三种方法可以向菜单栏对象添加菜单:
QMenuBar.addMenu(menu)向菜单栏对象追加一个QMenu对象(menu)。它返回与该菜单相关的动作。
QMenuBar.addMenu(title)创建一个新的QMenu对象,并将字符串(title)作为其标题添加到菜单栏。菜单栏获得菜单的所有权,该方法返回新的QMenu对象。
QMenuBar.addMenu(icon, title)创建一个新的QMenu对象,并将一个icon和一个title添加到菜单栏对象中。菜单栏获取菜单的所有权,该方法返回新的QMenu对象。如果您使用第一个选项,那么您需要首先创建您的定制
QMenu对象。为此,您可以使用以下构造函数之一:
QMenu(parent)QMenu(title, parent)在这两种情况下,
parent是持有QMenu对象所有权的QWidget。您通常会将parent设置为使用菜单的窗口。在第二个构造函数中,title将保存一个描述菜单选项的文本字符串。下面是如何将文件、编辑和帮助菜单添加到示例应用程序的菜单栏中:
from PyQt5.QtWidgets import QMenu # Snip... class Window(QMainWindow): # Snip... def _createMenuBar(self): menuBar = self.menuBar() # Creating menus using a QMenu object fileMenu = QMenu("&File", self) menuBar.addMenu(fileMenu) # Creating menus using a title editMenu = menuBar.addMenu("&Edit") helpMenu = menuBar.addMenu("&Help")首先,你从
PyQt5.QtWidgets导入QMenu。然后在._createMenuBar()中,你使用.addMenu()的前两个变体向菜单栏添加三个菜单。第三种变化需要一个图标对象,但是您还没有学会如何创建和使用图标。在使用 PyQt 中的图标和资源一节中,您将了解如何使用图标。如果您运行示例应用程序,那么您会看到现在有一个菜单栏,如下所示:
应用程序的菜单栏有菜单文件、编辑和帮助。当您单击这些菜单时,它们不会显示菜单选项的下拉列表。那是因为你还没有添加菜单选项。在用动作填充菜单一节中,您将学习如何向菜单添加菜单选项。
最后,请注意,您在每个菜单标题中包含的&字符(
&)会在菜单栏显示中创建带下划线的字母。这将在定义菜单和工具栏选项的快捷键一节中详细讨论。创建工具栏
一个工具栏是一个可移动的面板,包含按钮和其他小部件,提供对 GUI 应用程序最常用选项的快速访问。工具栏按钮可以显示图标和/或文本来表示它们执行的任务。PyQt 中工具栏的基类是
QToolBar。这个类将允许你为你的 GUI 应用程序创建自定义工具栏。当您将工具栏添加到主窗口样式的应用程序时,默认位置是在窗口的顶部。但是,您可以将工具栏放置在以下四个工具栏区域中的任何一个:
工具栏区域 主窗口中的位置 Qt.LeftToolBarArea左侧 Qt.RightToolBarArea正面 Qt.TopToolBarArea顶端 Qt.BottomToolBarArea底部 在 PyQt 中,工具栏区域被定义为常量。如果你需要使用它们,那么你必须从
PyQt5.QtCore导入Qt,然后使用全限定名,就像在Qt.LeftToolBarArea一样。在 PyQt 中,有三种方法可以将工具栏添加到主窗口应用程序中:
QMainWindow.addToolBar(title)新建一个空的QToolBar对象,并将其窗口标题设置为title。该方法将工具栏插入顶部工具栏区域,并返回新创建的工具栏。
QMainWindow.addToolBar(toolbar)在顶部工具栏区域插入一个QToolBar对象(toolbar)。
QMainWindow.addToolBar(area, toolbar)将QToolBar对象(toolbar)插入指定工具栏区域(area)。如果主窗口已经有工具栏,那么toolbar会被放在最后一个现有工具栏的后面。如果toolbar已经存在于主窗口中,那么它只会被移动到area。如果您使用最后两个选项中的一个,那么您需要自己创建工具栏。为此,可以使用下列构造函数之一:
QToolBar(parent)QToolBar(title, parent)在这两种情况下,
parent代表拥有工具栏所有权的QWidget对象。您通常会将工具栏的所有权设置为您将在其中使用工具栏的窗口。在第二个构造函数中,title将是一个带有工具栏的窗口标题的字符串。PyQt 使用这个窗口标题构建一个默认的上下文菜单,允许你隐藏和显示你的工具栏。现在,您可以返回到您的示例应用程序,并将下面的方法添加到
Window:from PyQt5.QtWidgets import QToolBar # Snip... class Window(QMainWindow): # Snip... def _createToolBars(self): # Using a title fileToolBar = self.addToolBar("File") # Using a QToolBar object editToolBar = QToolBar("Edit", self) self.addToolBar(editToolBar) # Using a QToolBar object and a toolbar area helpToolBar = QToolBar("Help", self) self.addToolBar(Qt.LeftToolBarArea, helpToolBar)首先,从
PyQt5.QtWidgets导入QToolBar。然后,在._createToolBars()中,首先使用带有标题的.addToolBar()创建文件工具栏。接下来,创建一个标题为"Edit"的QToolBar对象,并使用.addToolBar()将其添加到工具栏中,而不传递工具栏区域。在这种情况下,编辑工具栏位于顶部工具栏区域。最后,创建帮助工具栏,并使用Qt.LeftToolBarArea将其放置在左侧工具栏区域。完成这项工作的最后一步是从
Window的初始化器中调用._createToolBars():class Window(QMainWindow): """Main Window.""" def __init__(self, parent=None): # Snip... self._createToolBars()在
Window的初始化器中调用._createToolBars()将会创建三个工具栏并将它们添加到你的主窗口中。下面是您的应用程序现在的样子:
现在,菜单栏正下方有两个工具栏,窗口左侧有一个工具栏。每个工具栏都有一条双虚线。当您将鼠标移到虚线上时,指针会变成手形。如果您单击并按住虚线,那么您可以将工具栏移动到窗口上的任何其他位置或工具栏区域。
如果右键单击工具栏,PyQt 会显示一个上下文菜单,允许您根据需要隐藏和显示现有的工具栏。
到目前为止,您的应用程序窗口上有三个工具栏。这些工具栏仍然是空的,你需要添加一些工具栏按钮来使它们起作用。为此,您可以使用 PyQt 动作,它们是
QAction的实例。在后面的部分中,您将学习如何在 PyQt 中创建动作。现在,您将学习如何在 PyQt 应用程序中使用图标和其他资源。使用 PyQt 中的图标和资源
Qt 库包括 Qt 资源系统,这是一种向应用程序添加二进制文件(如图标、图像、翻译文件和其他资源)的便捷方式。
要使用资源系统,您需要在一个资源收集文件或
.qrc文件中列出您的资源。一个.qrc文件是一个XML文件,它包含文件系统中每个资源的位置,或者说路径。假设您的示例应用程序有一个
resources目录,其中包含您想要在应用程序的 GUI 中使用的图标。你有像新、开放等选项的图标。您可以创建一个包含每个图标路径的.qrc文件:<!DOCTYPE RCC><RCC version="1.0"> <qresource> <file alias="file-new.svg">resources/file-new.svg</file> <file alias="file-open.svg">resources/file-open.svg</file> <file alias="file-save.svg">resources/file-save.svg</file> <file alias="file-exit.svg">resources/file-exit.svg</file> <file alias="edit-copy.svg">resources/edit-copy.svg</file> <file alias="edit-cut.svg">resources/edit-cut.svg</file> <file alias="edit-paste.svg">resources/edit-paste.svg</file> <file alias="help-content.svg">resources/help-content.svg</file> </qresource> </RCC>每个
<file>条目必须包含文件系统中资源的路径。指定的路径相对于包含.qrc文件的目录。在上面的例子中,resources目录需要和.qrc文件在同一个目录中。
alias是一个可选属性,它定义了一个简短的替代名称,您可以在代码中使用它来访问每个资源。一旦您有了应用程序的资源,您就可以针对您的
.qrc文件运行命令行工具pyrcc5。pyrcc5是 PyQt 附带的,一旦安装了 PyQt,它就必须在您的 Python 环境中完全可用。
pyrcc5读取一个.qrc文件并生成一个 Python 模块,其中包含所有资源的二进制代码:$ pyrcc5 -o qrc_resources.py resources.qrc该命令将读取
resources.qrc并生成包含每个资源的二进制代码的qrc_resources.py。通过导入qrc_resources,你将能够在你的 Python 代码中使用这些资源。注意:如果在运行
pyrcc5时出错,那么要确保你使用的是正确的 Python 环境。如果您在 Python 虚拟环境中安装 PyQt,那么您将无法从该环境外部使用pyrcc5。下面是与您的
resources.qrc对应的qrc_resources.py中的一段代码:# -*- coding: utf-8 -*- # Resource object code # # Created by: The Resource Compiler for PyQt5 (Qt v5.9.5) # # WARNING! All changes made in this file will be lost! from PyQt5 import QtCore qt_resource_data = b"\ \x00\x00\x03\xb1\ \x3c\ \x73\x76\x67\x20\x78\x6d\x6c\x6e\x73\x3d\x22\x68\x74\x74\x70\x3a\ ...有了
qrc_resources.py,您可以将它导入到您的应用程序中,并通过键入冒号(:)然后键入它的alias或它的路径来引用每个资源。例如,要使用别名访问file-new.svg,您可以使用访问字符串":file-new.svg"。如果您没有一个alias,那么您将使用访问字符串":resources/file-new.svg"通过它的路径来访问它。如果您有别名,但是出于某种原因,您希望通过路径访问给定的资源,那么您可能必须从访问字符串中删除冒号,以便使其正常工作。
要在操作中使用图标,首先需要导入资源模块:
import qrc_resources一旦导入了包含资源的模块,就可以在应用程序的 GUI 中使用这些资源。
注意: Linters 、 editors 和 IDEs 可能会将上面的 import 语句标记为未使用,因为您的代码不会包含对它的任何显式使用。有些 ide 甚至会自动删除这一行。
在这些情况下,您必须覆盖 linter、编辑器或 ide 的建议,并将该导入保留在您的代码中。否则,您的应用程序将无法显示您的资源。
要使用资源系统创建图标,需要实例化
QIcon,将别名或路径传递给类构造函数:newIcon = QIcon(":file-new.svg")在这个例子中,您用文件
file-new.svg创建了一个QIcon对象,它位于您的资源模块中。这为在整个 GUI 应用程序中使用图标和资源提供了一种方便的方式。现在回到您的示例应用程序,更新最后一行
._createMenuBar():from PyQt5.QtGui import QIcon import qrc_resources # Snip... class Window(QMainWindow): # Snip... def _createMenuBar(self): menuBar = self.menuBar() # Using a QMenu object fileMenu = QMenu("&File", self) menuBar.addMenu(fileMenu) # Using a title editMenu = menuBar.addMenu("&Edit") # Using an icon and a title helpMenu = menuBar.addMenu(QIcon(":help-content.svg"), "&Help")为了让这段代码工作,首先需要从
PyQt5.QtGui导入QIcon。还需要导入qrc_resources。在最后一行突出显示的代码中,您使用资源模块中的help-content.svg向helpMenu添加了一个图标。如果您用这个更新运行您的示例应用程序,那么您将得到以下输出:
应用程序的主窗口现在在其帮助菜单上显示一个图标。点击图标时,菜单显示文本
Help。在菜单栏中使用图标并不常见,但是 PyQt 允许您这样做。在 PyQt 中为 Python 菜单和工具栏创建动作
PyQt 动作是代表应用程序中给定命令、操作或动作的对象。当您需要为不同的 GUI 组件(如菜单选项、工具栏按钮和键盘快捷键)提供相同的功能时,它们非常有用。
可以通过实例化
QAction来创建动作。一旦您创建了一个动作,您需要将它添加到一个小部件中,以便能够在实践中使用它。您还需要将您的操作与一些功能联系起来。换句话说,您需要将它们连接到您想要在动作被触发时运行的函数或方法。这将允许您的应用程序响应 GUI 中的用户操作来执行操作。
动作相当多才多艺。它们允许您在菜单选项、工具栏按钮和键盘快捷键之间重复使用相同的功能并保持同步。这在整个应用程序中提供了一致的行为。
例如,当用户点击打开… 菜单选项,点击打开工具栏按钮,或者按键盘上的
Ctrl+O时,用户可能期望应用程序执行相同的动作。
QAction提供了一个抽象概念,允许您跟踪以下元素:
- 菜单选项上的文本
- 工具栏按钮上的文本
- 工具栏上的帮助提示选项(工具提示
- 这是什么帮助提示
- 状态栏上的帮助提示(状态提示
- 与选项关联的键盘快捷键
- 与菜单和工具栏选项相关联的图标
- 动作的
enabled或disabled状态- 动作的
on或off状态要创建动作,需要实例化
QAction。至少有三种方法可以做到这一点:
QAction(parent)QAction(text, parent)QAction(icon, text, parent)在所有这三种情况下,
parent都表示持有动作所有权的对象。这个参数可以是任何QObject。最佳实践是将动作创建为将要使用它们的窗口的子窗口。在第二个和第三个构造函数中,
text保存了操作将在菜单选项或工具栏按钮上显示的文本。动作文本在菜单选项和工具栏按钮上的显示方式不同。例如,文本
&Open...在菜单选项中显示为打开……,在工具栏按钮中显示为打开。在第三个构造函数中,
icon是一个保存动作图标的QIcon对象。该图标将显示在菜单选项文本的左侧。图标在工具栏按钮中的位置取决于工具栏的.toolButtonStyle属性,可以取下列值之一:
风格 按钮显示 Qt.ToolButtonIconOnly只有图标 Qt.ToolButtonTextOnly只有文本 Qt.ToolButtonTextBesideIcon图标旁边的文本 Qt.ToolButtonTextUnderIcon图标下的文本 Qt.ToolButtonFollowStyle遵循底层平台的一般风格 您还可以使用各自的设置器方法、
.setText()和.setIcon()来设置动作的文本和图标。注:关于
QAction属性的完整列表,可以查看文档。下面是如何使用
QAction的不同构造函数为示例应用程序创建一些动作:from PyQt5.QtWidgets import QAction # Snip... class Window(QMainWindow): # Snip... def _createActions(self): # Creating action using the first constructor self.newAction = QAction(self) self.newAction.setText("&New") # Creating actions using the second constructor self.openAction = QAction("&Open...", self) self.saveAction = QAction("&Save", self) self.exitAction = QAction("&Exit", self) self.copyAction = QAction("&Copy", self) self.pasteAction = QAction("&Paste", self) self.cutAction = QAction("C&ut", self) self.helpContentAction = QAction("&Help Content", self) self.aboutAction = QAction("&About", self)在
._createActions()中,您为示例应用程序创建了一些动作。这些操作将允许您向应用程序的菜单和工具栏添加选项。注意,您正在创建作为实例属性的动作,因此您可以使用
self从._createActions()外部访问它们。这样,您将能够在菜单和工具栏上使用这些操作。注意:在
._createActions()中,你没有使用QAction的第三个构造函数,因为如果你还看不到动作,使用图标是没有意义的。你将在用动作填充工具栏一节中学习如何给动作添加图标。下一步是从
Window的初始化器中调用._createActions():class Window(QMainWindow): """Main Window.""" def __init__(self, parent=None): # Snip... self._createActions() self._createMenuBar() self._createToolBars()如果您现在运行应用程序,那么您将不会在 GUI 上看到任何变化。这是因为动作在被添加到菜单或工具栏之前不会显示。请注意,您在调用
._createMenuBar()和._createToolBars()之前调用了._createActions(),因为您将在菜单和工具栏上使用这些动作。如果您将动作添加到菜单中,则该动作将成为菜单选项。如果您将动作添加到工具栏,则该动作会变成工具栏按钮。这是接下来几节的主题。
向 PyQt 中的 Python 菜单添加选项
如果您想在 PyQt 中给定的菜单添加一个选项列表,那么您需要使用 actions。到目前为止,您已经学习了如何使用
QAction的不同构造函数创建动作。在 PyQt 中创建菜单时,动作是一个关键组件。在本节中,您将学习如何使用动作来用菜单选项填充菜单。
用动作填充菜单
要用菜单选项填充菜单,您将使用动作。在菜单中,一个动作被表示为一个水平选项,其中至少有一个描述性文本,如新建、打开、保存等等。菜单选项也可以在其左侧显示图标,在其右侧显示快捷键序列,如
Ctrl+S。您可以使用
.addAction()向QMenu对象添加动作。这个方法有几种变体。他们中的大多数被认为是在飞行中创造动作。然而,在本教程中,您将使用QMenu从QWidget继承而来的.addAction()的变体。这是这种变化的特征:QWidget.addAction(action)参数
action表示您想要添加到给定的QWidget对象的QAction对象。有了这个.addAction()的变体,您可以预先创建您的动作,然后根据需要将它们添加到菜单中。注:
QWidget还提供.addActions()。这个方法获取一个动作列表,并将它们附加到当前的 widget 对象中。使用这个工具,您可以开始向示例应用程序的菜单添加操作。为此,您需要更新
._createMenuBar():class Window(QMainWindow): # Snip... def _createMenuBar(self): menuBar = self.menuBar() # File menu fileMenu = QMenu("&File", self) menuBar.addMenu(fileMenu) fileMenu.addAction(self.newAction) fileMenu.addAction(self.openAction) fileMenu.addAction(self.saveAction) fileMenu.addAction(self.exitAction) # Edit menu editMenu = menuBar.addMenu("&Edit") editMenu.addAction(self.copyAction) editMenu.addAction(self.pasteAction) editMenu.addAction(self.cutAction) # Help menu helpMenu = menuBar.addMenu(QIcon(":help-content.svg"), "&Help") helpMenu.addAction(self.helpContentAction) helpMenu.addAction(self.aboutAction)通过对
._createMenuBar()的更新,您可以向示例应用程序的三个菜单中添加许多选项。现在文件菜单有四个选项:
- 新建 用于创建新文件
- 【打开】……用于打开已有的文件
- 保存对文件所做的修改
** 退出 关闭应用程序编辑菜单有三个选项:
- 将 为应对内容复制到系统剪贴板
- 粘贴 用于粘贴系统剪贴板中的内容
- 剪切 用于将内容剪切到系统剪贴板
帮助菜单有两个选项:
- 帮助内容 用于启动应用程序的帮助手册
- 关于 用于显示关于对话框
选项在菜单中从上到下的显示顺序对应于您在代码中添加选项的顺序。
如果您运行该应用程序,您将在屏幕上看到以下窗口:
如果你点击一个菜单,应用程序会显示一个下拉列表,包含你之前看到的选项。
创建 Python 子菜单
有时你需要在你的 GUI 应用程序中使用子菜单。子菜单是一个嵌套菜单,当您将光标移到给定的菜单选项上时,它会显示出来。要向应用程序添加子菜单,需要调用容器菜单对象上的
.addMenu()。假设您需要在示例应用程序的编辑菜单中添加一个子菜单。您的子菜单将包含查找和替换内容的选项,因此您将称之为查找和替换。该子菜单有两个选项:
- 查找… 用于查找某些内容
- 【替换……】用于查找旧内容并用新内容替换旧内容
以下是将该子菜单添加到示例应用程序的方法:
class Window(QMainWindow): # Snip... def _createMenuBar(self): # Snip... editMenu.addAction(self.cutAction) # Find and Replace submenu in the Edit menu findMenu = editMenu.addMenu("Find and Replace") findMenu.addAction("Find...") findMenu.addAction("Replace...") # Snip...在第一个突出显示的行中,使用
editMenu上的.addMenu()将带有文本"Find and Replace"的QMenu对象添加到编辑菜单中。下一步是用操作填充子菜单,就像您到目前为止所做的那样。如果您再次运行您的示例应用程序,那么您会在 Edit 菜单下看到一个新的菜单选项:
编辑菜单现在有了一个名为查找和替换的新条目。当您将鼠标悬停在这个新菜单选项上时,会出现一个子菜单,呈现给您两个新选项:查找… 和替换… 。就是这样!您已经创建了一个子菜单。
向 PyQt 中的工具栏添加选项
在用 Python 和 PyQt 构建 GUI 应用程序时,工具栏是一个非常有用的组件。您可以使用工具栏为用户提供快速访问应用程序中最常用选项的方法。你也可以在工具栏中添加类似微调框和组合框的小部件,允许用户直接从应用程序的 GUI 中修改一些属性和变量。
在接下来的几节中,您将学习如何使用动作向工具栏添加选项或按钮,以及如何使用
.addWidget()向工具栏添加小部件。用动作填充工具栏
要向工具栏添加选项或按钮,需要调用
.addAction()。在本节中,您将依赖于QToolBar从QWidget继承而来的.addAction()的变体。所以,你会调用.addAction()作为一个参数。这将允许您在菜单和工具栏之间共享您的操作。当你创建工具栏时,你通常会面临决定添加什么选项的问题。通常,您会希望只将最常用的动作添加到工具栏中。
如果您返回到示例应用程序,那么您会记得您添加了三个工具栏:
- 文件
- 编辑
- 帮助
在文件工具栏中,您可以添加如下选项:
- 新
- 打开
- 保存
在编辑工具栏中,可以添加以下选项:
- 复制
- 粘贴
- 切
通常,当您想要在工具栏上添加按钮时,首先要选择要在每个按钮上使用的图标。这不是强制性的,但这是最佳实践。选择图标后,您需要将它们添加到相应的操作中。
下面是如何将图标添加到示例应用程序的动作中:
class Window(QMainWindow): # Snip... def _createActions(self): # File actions self.newAction = QAction(self) self.newAction.setText("&New") self.newAction.setIcon(QIcon(":file-new.svg")) self.openAction = QAction(QIcon(":file-open.svg"), "&Open...", self) self.saveAction = QAction(QIcon(":file-save.svg"), "&Save", self) self.exitAction = QAction("&Exit", self) # Edit actions self.copyAction = QAction(QIcon(":edit-copy.svg"), "&Copy", self) self.pasteAction = QAction(QIcon(":edit-paste.svg"), "&Paste", self) self.cutAction = QAction(QIcon(":edit-cut.svg"), "C&ut", self) # Snip...要将图标添加到您的操作中,您需要更新突出显示的行。在
newAction的情况下,你用.setIcon()。在其余的操作中,您使用带有一个icon、title和一个parent对象作为参数的构造函数。一旦您选择的动作有了图标,您可以通过调用工具栏对象上的
.addAction()将这些动作添加到相应的工具栏:class Window(QMainWindow): # Snip... def _createToolBars(self): # File toolbar fileToolBar = self.addToolBar("File") fileToolBar.addAction(self.newAction) fileToolBar.addAction(self.openAction) fileToolBar.addAction(self.saveAction) # Edit toolbar editToolBar = QToolBar("Edit", self) self.addToolBar(editToolBar) editToolBar.addAction(self.copyAction) editToolBar.addAction(self.pasteAction) editToolBar.addAction(self.cutAction)随着对
._createToolBars()的更新,您将为新的、打开和保存选项添加按钮到文件工具栏。您还可以将复制、粘贴和剪切选项的按钮添加到编辑工具栏中。注意:按钮在工具栏上从左到右显示的顺序对应于您在代码中添加按钮的顺序。
如果您现在运行示例应用程序,那么您将在屏幕上看到以下窗口:
示例应用程序现在显示了两个工具栏,每个工具栏都有几个按钮。您的用户可以单击这些按钮来快速访问应用程序最常用的选项。
注意:当你在创建工具栏一节中第一次写
._createToolBars()时,你创建了一个帮助工具栏。该工具栏旨在展示如何使用.addToolBar()的不同变体添加工具栏。在上面对
._createToolBars()的更新中,你去掉了帮助工具栏,只是为了让例子简洁明了。请注意,由于您在菜单和工具栏之间共享相同的操作,菜单选项也将在它们的左侧显示图标,这在生产率和资源使用方面是一个巨大的胜利。这是使用 PyQt 动作用 Python 创建菜单和工具栏的优势之一。
向工具栏添加小部件
在某些情况下,您会发现在工具栏中添加特定的小部件很有用,比如微调框、组合框或其他小部件。一个常见的例子是组合框,大多数字处理器使用它来允许用户改变文档的字体或所选文本的大小。
要向工具栏添加小部件,首先需要创建小部件,设置其属性,然后调用工具栏对象上的
.addWidget(),将小部件作为参数传递。假设您想在示例应用程序的编辑工具栏中添加一个
QSpinBox对象,以允许用户更改某些内容的大小,比如字体大小。您需要更新._createToolBars():from PyQt5.QtWidgets import QSpinBox # Snip... class Window(QMainWindow): # Snip... def _createToolBars(self): # Snip... # Adding a widget to the Edit toolbar self.fontSizeSpinBox = QSpinBox() self.fontSizeSpinBox.setFocusPolicy(Qt.NoFocus) editToolBar.addWidget(self.fontSizeSpinBox)在这里,首先导入数字显示框类。然后你创建一个
QSpinBox对象,将其focusPolicy设置为Qt.NoFocus,最后将其添加到你的编辑工具栏中。注意:在上面的代码中,您将数字显示框的
focusPolicy属性设置为Qt.NoFocus,因为如果这个小部件获得焦点,那么应用程序的键盘快捷键将无法正常工作。现在,如果您运行该应用程序,您将获得以下输出:
这里,编辑工具栏显示了一个
QSpinBox对象,用户可以用它来设置字体的大小或应用程序上的任何其他数字属性。自定义工具栏
PyQt 工具栏非常灵活且可定制。您可以在工具栏对象上设置一系列属性。下表显示了一些最有用的属性:
财产 特征受控 默认设置 allowedAreas可以放置给定工具栏的工具栏区域 Qt.AllToolBarAreasfloatable是否可以将工具栏作为独立窗口拖放 Truefloating工具栏是否是独立的窗口 TrueiconSize工具栏按钮上显示的图标的大小 由应用程序的风格决定 movable是否可以在工具栏区域内或工具栏区域之间移动工具栏 Trueorientation工具栏的方向 Qt.Horizontal所有这些属性都有一个关联的 setter 方法。比如可以用
.setAllowedAreas()设置allowedAreas,.setFloatable()设置floatable等等。现在,假设你不希望你的用户在窗口周围移动文件工具栏。在这种情况下,您可以使用
.setMovable()将movable设置为False:class Window(QMainWindow): # Snip... def _createToolBars(self): # File toolbar fileToolBar = self.addToolBar("File") fileToolBar.setMovable(False) # Snip...突出显示的线条在这里创造了奇迹。现在,您的用户无法在应用程序窗口中移动工具栏:
文件工具栏不再显示双虚线,所以你的用户不能移动它。注意编辑工具栏仍然是可移动的。您可以使用相同的方法更改工具栏上的其他属性,并根据您的需要自定义它们。
组织菜单和工具栏选项
为了在 GUI 应用程序中增加清晰度并改善用户体验,您可以使用分隔符来组织菜单选项和工具栏按钮。分隔符呈现为限定或分隔菜单选项的水平线,或者呈现为分隔工具栏按钮的垂直线。
要向菜单、子菜单或工具栏对象插入或添加分隔符,可以对这些对象中的任何一个调用
.addSeparator()。例如,你可以使用一个分隔符将你的文件菜单上的退出选项与其余选项分开,只是为了明确退出与菜单上的其余选项没有逻辑关系。您也可以使用分隔符将编辑菜单上的查找和替换选项与遵循相同规则的其余选项分开。
转到您的示例应用程序并更新
._createMenuBar(),如以下代码所示:class Window(QMainWindow): # Snip... def _createMenuBar(self): # File menu # Snip... fileMenu.addAction(self.saveAction) # Adding a separator fileMenu.addSeparator() fileMenu.addAction(self.exitAction) # Edit menu # Snip... editMenu.addAction(self.cutAction) # Adding a separator editMenu.addSeparator() # Find and Replace submenu in the Edit menu findMenu = editMenu.addMenu("Find and Replace") # Snip...在第一个突出显示的行中,您在文件菜单中的保存和退出选项之间添加了一个分隔符。在第二个突出显示的行中,添加一个分隔符,将查找和替换选项与编辑菜单中的其余选项分开。这些附加功能是如何工作的:
你的文件菜单现在显示一条水平线,将编辑选项与菜单中的其他选项分开。编辑菜单也在下拉选项列表的末尾显示一个分隔符。分隔符的连贯使用可以微妙地提高菜单和工具栏的清晰度,使你的 GUI 应用程序更加用户友好。
作为练习,您可以找到
._createToolBars()的定义并添加一个分隔符,将QSpinBox对象与工具栏上的其他选项分开。在 PyQt 中构建上下文或弹出菜单
上下文菜单,也称为弹出菜单,是一种特殊类型的菜单,出现在对特定用户动作的响应中,比如在给定的小工具或窗口上右击。这些菜单提供了在您使用的操作系统或应用程序的给定上下文中可用的一小部分选项。
例如,如果你右击一台 Windows 机器的桌面,你会得到一个菜单,其中的选项对应于操作系统的特定上下文或空间。如果你右击一个文本编辑器的工作区,你会得到一个完全不同的上下文菜单,这取决于你使用的编辑器。
在 PyQt 中,有几个创建上下文菜单的选项。在本教程中,您将了解其中的两个选项:
将特定小部件上的
contextMenuPolicy属性设置为Qt.ActionsContextMenu通过
contextMenuEvent()处理应用程序窗口上的上下文菜单事件第一个选项是两个选项中最常见和用户友好的,因此您将首先了解它。
第二个选项稍微复杂一点,依赖于对用户事件的处理。在 GUI 编程中,事件是应用程序上的任何用户动作,比如单击按钮或菜单、从组合框中选择一项、在文本字段中输入或更新文本、按下键盘上的一个键等等。
通过上下文菜单策略创建上下文菜单
所有从
QWidget派生的 PyQt 图形组件或小部件都继承了一个名为contextMenuPolicy的属性。该属性控制小部件如何显示上下文菜单。该属性最常用的值之一是Qt.ActionsContextMenu。这使得小部件以上下文菜单的形式显示其内部动作列表。要让小部件显示基于其内部动作的上下文菜单,您需要运行两个步骤:
使用
QWidget.addAction()向小部件添加一些动作。使用
.setContextMenuPolicy()将微件上的contextMenuPolicy设置为Qt.ActionsContextMenu。将
contextMenuPolicy设置为Qt.ActionsContextMenu会导致具有动作的小部件在上下文菜单中显示它们。这是用 Python 和 PyQt 创建上下文菜单的一种非常快速的方法。使用这种技术,您可以向示例应用程序的中央小部件添加上下文菜单,并为您的用户提供一种快速访问应用程序的一些选项的方法。为此,您可以向
Window添加以下方法:class Window(QMainWindow): # Snip... def _createContextMenu(self): # Setting contextMenuPolicy self.centralWidget.setContextMenuPolicy(Qt.ActionsContextMenu) # Populating the widget with actions self.centralWidget.addAction(self.newAction) self.centralWidget.addAction(self.openAction) self.centralWidget.addAction(self.saveAction) self.centralWidget.addAction(self.copyAction) self.centralWidget.addAction(self.pasteAction) self.centralWidget.addAction(self.cutAction)在
._createContextMenu()中,首先使用 setter 方法.setContextMenuPolicy()将contextMenuPolicy设置为Qt.ActionsContextMenu。然后像往常一样使用.addAction()向小部件添加动作。最后一步是从Window的初始化器中调用._createContextMenu():class Window(QMainWindow): """Main Window.""" def __init__(self, parent=None): # Snip... self._createToolBars() self._createContextMenu()如果您在添加了这些内容之后运行示例应用程序,那么当您右键单击它时,您会看到应用程序的中央小部件显示一个上下文菜单:
现在,您的示例应用程序有了一个上下文菜单,每当您右键单击应用程序的中央小部件时,它就会弹出。中间的小部件会扩展到占据窗口中的所有可用空间,因此您不必局限于右键单击标签文本来查看上下文菜单。
最后,因为您在整个应用程序中使用相同的操作,所以上下文菜单上的选项显示相同的图标集。
通过事件处理创建上下文菜单
在 PyQt 中创建上下文菜单的另一种方法是处理应用程序主窗口的上下文菜单事件。为此,您需要运行以下步骤:
在
QMainWindow对象上覆盖事件处理方法.contextMenuEvent()。创建一个
QMenu对象,传递一个小部件(上下文小部件)作为其父对象。用动作填充菜单对象。
使用
QMenu.exec()启动菜单对象,将事件的.globalPos()作为参数。这种管理上下文菜单的方式有点复杂。但是,它可以让您很好地控制上下文菜单被调用时会发生什么。例如,您可以根据应用程序的状态等来启用或禁用菜单选项。
注意:在继续本节之前,您需要禁用您在上一节中编写的代码。为此,只需转到
Window的初始化器,注释掉调用self._createContextMenu()的代码行。下面是如何重新实现示例应用程序的上下文菜单,覆盖主窗口对象上的事件处理程序方法:
class Window(QMainWindow): # Snip... def contextMenuEvent(self, event): # Creating a menu object with the central widget as parent menu = QMenu(self.centralWidget) # Populating the menu with actions menu.addAction(self.newAction) menu.addAction(self.openAction) menu.addAction(self.saveAction) menu.addAction(self.copyAction) menu.addAction(self.pasteAction) menu.addAction(self.cutAction) # Launching the menu menu.exec(event.globalPos())在
contextMenuEvent()中,首先创建一个QMenu对象(menu),将centralWidget作为其父小部件。接下来,使用.addAction在菜单中填充动作。最后,您调用QMenu对象上的.exec()来在屏幕上显示它。
.contextMenuEvent()的第二个参数表示该方法捕获的事件。在这种情况下,event将在应用程序的中央小部件上单击鼠标右键。在对
.exec()的调用中,您使用event.globalPos()作为参数。当用户单击 PyQt 窗口或小部件时,该方法返回鼠标指针的全局位置。鼠标位置会告诉.exec()在窗口的哪个位置显示上下文菜单。如果您用这些新的变化运行您的示例应用程序,那么您将得到与前一节中相同的结果。
组织上下文菜单选项
与菜单和工具栏不同,在上下文菜单中,你不能使用
.addSeparator()来添加分隔符,并根据它们之间的关系直观地分隔你的菜单选项。在组织上下文菜单时,您需要创建一个分隔符操作:separator = QAction(parent) separator.setSeparator(True)在一个动作对象上调用
.setSeparator(True)会把那个动作变成一个分隔符。一旦有了分隔符动作,您需要使用QMenu.addAction()将其插入到上下文菜单中的正确位置。如果你回头看看你的示例应用程序,那么你可能想在视觉上将来自文件菜单的选项与来自编辑菜单的选项分开。为此,您可以更新
.contextMenuEvent():class Window(QMainWindow): # Snip... def contextMenuEvent(self, event): # Snip... menu.addAction(self.saveAction) # Creating a separator action separator = QAction(self) separator.setSeparator(True) # Adding the separator to the menu menu.addAction(separator) menu.addAction(self.copyAction) # Snip...在前两行突出显示的代码中,您创建了 separator 操作。在第三个突出显示的行中,您使用
.addAction()将分隔符操作添加到菜单中。这将在文件选项和编辑选项之间添加一条水平线。这是您的上下文菜单的外观:
现在你的上下文菜单包括了一条水平线,它将来自文件的选项和来自编辑的选项视觉上分开。这样,您提高了菜单的视觉质量,并提供了更好的用户体验。
连接菜单和工具栏中的信号和插槽
在 PyQt 中,您使用信号和槽来为您的 GUI 应用程序提供功能。每当鼠标点击、按键或窗口大小调整等事件发生时,PyQt 小部件就会发出信号。
一个槽是 Python 可调用的,你可以连接到一个小部件的信号来执行一些动作以响应用户事件。如果一个信号和一个插槽是连接的,那么每次发出信号时,插槽都会被自动调用。如果一个给定的信号没有连接到一个插槽,那么当信号发出时什么也不会发生。
为了让你的菜单选项和工具栏按钮在用户点击时启动一些操作,你需要把底层动作的信号和一些定制的或者内置的插槽连接起来。
QAction物体可以发出各种信号。但是,菜单和工具栏中最常用的信号是.triggered()。每当用户单击菜单选项或工具栏按钮时,都会发出此信号。要将.triggered()与插槽连接,可以使用以下语法:action = QAction("Action Text", parent) # Connect action's triggered() with a slot action.triggered.connect(slot)在这个例子中,
slot是一个可调用的 Python。换句话说,slot可以是实现.__call__()的函数、方法、类或者类的实例。在您的示例应用程序中已经有了一组操作。现在,您需要编写每次用户单击菜单选项或工具栏按钮时将调用的插槽。转到
Window的定义,添加以下方法:class Window(QMainWindow): # Snip... def newFile(self): # Logic for creating a new file goes here... self.centralWidget.setText("<b>File > New</b> clicked") def openFile(self): # Logic for opening an existing file goes here... self.centralWidget.setText("<b>File > Open...</b> clicked") def saveFile(self): # Logic for saving a file goes here... self.centralWidget.setText("<b>File > Save</b> clicked") def copyContent(self): # Logic for copying content goes here... self.centralWidget.setText("<b>Edit > Copy</b> clicked") def pasteContent(self): # Logic for pasting content goes here... self.centralWidget.setText("<b>Edit > Paste</b> clicked") def cutContent(self): # Logic for cutting content goes here... self.centralWidget.setText("<b>Edit > Cut</b> clicked") def helpContent(self): # Logic for launching help goes here... self.centralWidget.setText("<b>Help > Help Content...</b> clicked") def about(self): # Logic for showing an about dialog content goes here... self.centralWidget.setText("<b>Help > About...</b> clicked")这些方法将扮演您的示例应用程序的插槽的角色。每当用户单击相应的菜单选项或工具栏按钮时,它们都会被调用。
一旦有了提供功能的插槽,就需要用动作的
.triggered()信号将它们连接起来。这样,应用程序将执行动作来响应用户事件。要建立这些连接,请转到示例应用程序,并将以下方法添加到Window:class Window(QMainWindow): # Snip... def _connectActions(self): # Connect File actions self.newAction.triggered.connect(self.newFile) self.openAction.triggered.connect(self.openFile) self.saveAction.triggered.connect(self.saveFile) self.exitAction.triggered.connect(self.close) # Connect Edit actions self.copyAction.triggered.connect(self.copyContent) self.pasteAction.triggered.connect(self.pasteContent) self.cutAction.triggered.connect(self.cutContent) # Connect Help actions self.helpContentAction.triggered.connect(self.helpContent) self.aboutAction.triggered.connect(self.about)这个方法将把你所有的动作信号和它们各自的插槽或者回调连接起来。通过这次更新,您的示例应用程序将在您设置为中心小部件的
QLabel对象上显示一条消息,告诉您单击了哪个菜单选项或工具栏按钮。在
exitAction的情况下,你把它的triggered()信号和内置槽QMainWindow.close()连接起来。这样,如果您选择文件→退出,那么您的应用程序将关闭。最后,转到
Window的初始化器,添加对._connectActions()的调用:class Window(QMainWindow): """Main Window.""" def __init__(self, parent=None): # Snip... # self._createContextMenu() self._connectActions()有了这个最后的更新,您可以再次运行应用程序。以下是所有这些变化的工作原理:
如果您单击菜单选项、工具栏按钮或上下文菜单选项,则应用程序窗口中心的标签会显示一条消息,指示所执行的操作。这种功能在学习环境之外不是很有用,但是它让您知道当用户与 GUI 交互时,如何让您的应用程序执行真实的操作。
最后,当您选择文件→退出时,应用程序关闭,因为
exitAction的.triggered()信号连接到内置插槽QMainWindow.close()。作为练习,您可以尝试为查找和替换子菜单中的查找… 和替换… 选项创建自定义插槽,然后将它们的
.triggered()信号连接到这些插槽以激活它们。您还可以试验您在本节中编写的插槽,并尝试用它们做新的事情。动态填充 Python 菜单
在为应用程序创建菜单时,有时您需要用在创建应用程序 GUI 时未知的选项来填充这些菜单。例如,文本编辑器中的打开最近的菜单显示了最近打开的文档列表。您不能在创建应用程序的 GUI 时填充这个菜单,因为每个用户将打开不同的文档,并且没有办法提前知道这些信息。
在这种情况下,您需要动态填充菜单以响应用户操作或应用程序的状态。
QMenu有一个名为.aboutToShow()的信号,你可以连接到一个自定义插槽,在菜单对象显示在屏幕上之前动态填充它。为了继续开发您的示例应用程序,假设您需要在文件下创建一个打开最近的子菜单,并用最近打开的文件或文档动态填充它。为此,您需要运行以下步骤:
- 在文件下创建打开最近的子菜单。
- 编写一个自定义插槽,动态生成填充菜单的操作。
- 将菜单的
.aboutToShow()信号与自定义插槽连接。下面是创建子菜单的代码:
class Window(QMainWindow): # Snip... def _createMenuBar(self): # Snip... fileMenu.addAction(self.openAction) # Adding an Open Recent submenu self.openRecentMenu = fileMenu.addMenu("Open Recent") fileMenu.addAction(self.saveAction) # Snip...在突出显示的行中,您在文件菜单下添加了一个标题为
"Open Recent"的子菜单。这个子菜单还没有菜单选项。您需要动态创建操作来填充它。为此,您可以编写一个方法来动态创建动作,并将它们添加到子菜单中。下面的示例展示了您可以使用的一般逻辑:
from functools import partial # Snip... class Window(QMainWindow): # Snip... def populateOpenRecent(self): # Step 1\. Remove the old options from the menu self.openRecentMenu.clear() # Step 2\. Dynamically create the actions actions = [] filenames = [f"File-{n}" for n in range(5)] for filename in filenames: action = QAction(filename, self) action.triggered.connect(partial(self.openRecentFile, filename)) actions.append(action) # Step 3\. Add the actions to the menu self.openRecentMenu.addActions(actions)在
.populateOpenRecent()中,您首先使用.clear()从菜单中移除旧选项(如果有的话)。然后添加动态创建和连接动作的逻辑。最后,使用.addActions()将动作添加到菜单中。在
for循环中,你用functools.partial()连接.triggered()信号和.openRecentFile(),因为你要把filename作为参数传递给.openRecentFile()。当把一个信号和一个需要额外参数的插槽连接起来时,这是一个非常有用的技术。为了让它工作,您需要从functools导入partial()。注意:本例第二步中的逻辑并没有真正加载最近打开的文件列表。它只是创建了一个由五个假设文件组成的
list,唯一的目的是展示一种实现这种技术的方法。下一步是将
.openRecentMenu的.aboutToShow()信号连接到.populateOpenRecent()。为此,在._connectActions()的末尾添加以下行:class Window(QMainWindow): # Snip... def _connectActions(self): # Snip... self.aboutAction.triggered.connect(self.about) # Connect Open Recent to dynamically populate it self.openRecentMenu.aboutToShow.connect(self.populateOpenRecent)在突出显示的行中,您将
.aboutToShow信号与.populateOpenRecent()相连。这可以确保你的菜单在显示之前就被填充了。现在你需要编码
.openRecentFile()。当您的用户单击任何动态创建的操作时,您的应用程序将调用此方法:class Window(QMainWindow): # Snip... def openRecentFile(self, filename): # Logic for opening a recent file goes here... self.centralWidget.setText(f"<b>{filename}</b> opened")该方法将更新用作示例应用程序中心小部件的
QLabel对象的文本。下面是动态创建的子菜单在实践中的工作方式:
当鼠标指针悬停在打开的最近菜单上时,菜单发出
.aboutToShow()信号。这导致对.populateOpenRecent()的调用,它创建并连接动作。如果您单击一个文件名,那么您会看到中心标签相应地改变以显示一条消息。为菜单和工具栏选项定义键盘快捷键
键盘快捷键是 GUI 应用程序的一个重要特征。键盘快捷键是一种组合键,您可以在键盘上按下它来快速访问应用程序中一些最常用的选项。
以下是键盘快捷键的一些示例:
Ctrl+C将东西复制到剪贴板。Ctrl+V从剪贴板粘贴东西。Ctrl+Z撤销上次操作。Ctrl+O打开文件。Ctrl+S保存文件。在下一节中,您将学习如何在应用程序中添加键盘快捷键,以提高用户的工作效率和体验。
使用按键序列
到目前为止,您已经了解到
QAction是一个用于填充菜单和工具栏的通用类。QAction还提供了一种用户友好的方式来定义菜单选项和工具栏按钮的键盘快捷键。
QAction器物.setShortcut()。该方法将一个QKeySequence对象作为参数,并返回一个键盘快捷键。
QKeySequence提供了几个构造函数。在本教程中,您将了解其中的两种:
QKeySequence(ks, format)以基于字符串的按键序列(ks)和格式(format)作为参数,创建一个QKeySequence对象。
QKeySequence(key)以一个StandardKey常量作为参数,在底层平台上创建一个与该按键序列相匹配的QKeySequence对象。第一个构造函数识别以下字符串:
"Ctrl""Shift""Alt""Meta"您可以通过将这些字符串与字母、标点符号、数字、命名键(
Up、Down、Home)和功能键("Ctrl+S"、"Ctrl+5"、"Alt+Home"、"Alt+F4")组合来创建基于字符串的按键序列。您可以在逗号分隔的列表中传递最多四个基于字符串的键序列。注:关于不同平台上标准快捷方式的完整参考,请参见
QKeySequence文档的标准快捷方式章节。如果您正在开发一个多平台应用程序,并且希望坚持每个平台的标准键盘快捷键,那么第二个构造函数非常方便。例如,
QKeySequence.Copy将返回平台的标准键盘快捷键,用于将对象复制到剪贴板。注:关于 PyQt 提供的标准键的完整参考,请参见 QKeySequence。标准密钥文件。
了解了如何在 PyQt 中为操作定义键盘快捷键的一般背景后,您就可以返回到示例应用程序并添加一些快捷键了。为此,您需要更新
._createActions():from PyQt5.QtGui import QKeySequence # Snip... class Window(QMainWindow): # Snip... def _createActions(self): # File actions # Snip... # Using string-based key sequences self.newAction.setShortcut("Ctrl+N") self.openAction.setShortcut("Ctrl+O") self.saveAction.setShortcut("Ctrl+S") # Edit actions # Snip... # Using standard keys self.copyAction.setShortcut(QKeySequence.Copy) self.pasteAction.setShortcut(QKeySequence.Paste) self.cutAction.setShortcut(QKeySequence.Cut) # Snip...你首先需要导入
QKeySequence。在._createActions()中,前三个突出显示的行使用基于字符串的按键序列创建键盘快捷键。这是一种将键盘快捷键添加到操作中的快捷方式。在第二个突出显示的三行中,您使用QKeySequence来提供标准的键盘快捷键。如果您运行添加了这些内容的示例应用程序,那么您的菜单将如下所示:
您的菜单选项现在会在右侧显示键盘快捷键。如果您按下这些组合键中的任何一个,那么您将执行相应的操作。
使用键盘快捷键
还有另一种方法,你可以将键盘快捷键,或键盘快捷键,添加到应用程序的菜单选项中。
您可能已经注意到,当您为菜单或菜单选项设置文本时,通常会在文本中插入一个&符号(
&)。这样做是为了在菜单或菜单选项的文本中显示时,“与”符号后面的字母会加下划线。例如,如果您在一个文件菜单("&File")的标题中的字母 F 前放置一个&符号,那么当显示菜单标题时, F 将被加下划线。注意:如果你需要在菜单文本上显示一个&符号,那么你需要使用一个双&符号(
&&)来转义这个符号的默认功能。在菜单栏的情况下,使用&符号允许您通过按下
Alt以及菜单标题中带下划线的字母来调用任何菜单。启动菜单后,您可以通过按选项文本中带下划线的字母来访问任何菜单选项。例如,在文件中,您可以通过按字母 E 来访问退出选项。
注意:当您使用&符号来提供键盘快捷键时,请记住您不能在同一个菜单下有两个共享相同访问字母的选项。
如果将 C 设置为复制选项的访问字母,则不能将 C 设置为剪切选项的访问字母。换句话说,在给定的菜单下,访问字母必须是唯一的。
这个特性将允许您为那些喜欢使用键盘来操作您的应用程序的用户提供快速的键盘快捷键。这种技术对于不提供显式键盘快捷键的选项特别有用。
创建菜单和工具栏:最佳实践和技巧
当您使用 Python 和 PyQt 创建菜单和工具栏时,您应该遵循一些通常被认为是 GUI 编程最佳实践的标准。这里有一个快速列表:
按照普遍接受的顺序安排你的菜单。例如,如果你有一个文件菜单,那么它应该是从左到右的第一个菜单。如果你有一个编辑菜单,那么它应该是第二个。帮助应该是最右边的菜单,以此类推。
为你正在开发的应用程序类型填充常用选项。例如,在文本编辑器中,文件菜单通常包括新建、打开、保存、退出等选项。编辑菜单经常包括复制、粘贴、剪切、撤销等选项。
对常用选项使用标准键盘快捷键。比如用
Ctrl``C对复制,Ctrl+V对粘贴,Ctrl+X对剪切等等。使用分隔符来分隔不相关的选项。这些视觉提示将使你的应用程序更容易导航。
在启动附加对话框的选项标题上添加省略号(
...)。比如用另存为… 代替另存为,关于… 代替关于等等。在你的菜单选项中使用&符号(
&)来提供方便的键盘快捷键。比如用"&Open代替"Open",用"&Exit"代替"Exit"。如果你遵循这些原则,那么你的 GUI 应用程序将会为你的用户提供一个熟悉的、吸引人的体验。
在 PyQt 中构建 Python 状态栏
一个状态栏是一个水平面板,通常放置在 GUI 应用程序主窗口的底部。它的主要目的是显示关于应用程序当前状态的信息。状态栏也可以分成几个部分,以显示每个部分的不同信息。
根据 Qt 文档,有三种状态指示器:
临时指示器在短时间内几乎占据了整个状态栏,以显示工具提示文本、菜单项和其他对时间敏感的信息。
正常的指示器占据了状态栏的一部分,显示用户可能希望定期参考的信息,例如文字处理器中的字数。这些可能会被临时指示器暂时隐藏。
永久指示器总是显示在状态栏中,即使临时指示器被激活。它们用于显示关于应用程序当前模式的重要信息,例如当按下 Caps Lock 键时。
您可以使用下列选项之一将状态栏添加到主窗口样式的应用程序中:
在你的
QMainWindow对象上调用.statusBar()。.statusBar()为主窗口创建并返回一个空的状态栏。创建一个
QStatusBar对象,然后用状态栏对象作为参数在主窗口上调用.setStatusBar()。这样,.setStatusBar()会将你的状态栏对象设置为主窗口的状态栏。这里有两种向示例应用程序添加状态栏的可选实现:
# 1\. Using .statusBar() def _createStatusBar(self): self.statusbar = self.statusBar() # 2\. Using .setStatusBar() def _createStatusBar(self): self.statusbar = QStatusBar() self.setStatusBar(self.statusbar)两种实现产生相同的结果。然而,大多数情况下,您将使用第一个实现来创建状态栏。注意,为了让第二个实现工作,您需要从
PyQt5.QtWidgets导入QStatusBar。将上述实现之一添加到应用程序的
Window中,然后在类初始化器中调用._createStatusBar()。有了这些附加功能,当您再次运行您的应用程序时,您将会看到如下窗口:
您的应用程序现在在其主窗口的底部有一个状态栏。状态栏几乎看不见,但是如果你仔细看,你会注意到在窗口的右下角有一个小的虚线三角形。
显示临时状态信息
状态栏的主要用途是向应用程序的用户显示状态信息。要在状态栏中显示临时状态消息,需要使用
QStatusBar.showMessage()。此方法采用以下两个参数:
message以字符串形式保存状态指示消息。timeout保存消息将在状态栏上显示的毫秒数。如果
timeout是0,这是它的缺省值,那么消息会一直留在状态栏上,直到你在状态栏上调用.clearMessage()或.showMessage()。如果你的状态栏上有一条活动消息,你用一条新消息呼叫
.showMessage(),那么这条新消息将会掩盖或替换旧消息。转到您的示例应用程序,将下面一行添加到
._createStatusBar():class Window(QMainWindow): # Snip... def _createStatusBar(self): self.statusbar = self.statusBar() # Adding a temporary message self.statusbar.showMessage("Ready", 3000)
._createStatusBar()中的最后一行会让你的应用程序在状态栏上显示一条Ready消息,持续3000毫秒:
当您运行应用程序时,状态栏会显示消息
Ready。在3000毫秒后,消息消失,状态栏被清除,准备显示新的状态消息。在状态栏中显示永久消息
您还可以在应用程序的状态栏上显示永久消息。永久消息让用户了解应用程序的一般状态。例如,在文本编辑器中,您可能希望显示一条永久消息,其中包含有关当前打开的文件的文本编码的信息。
要在状态栏中添加永久消息,可以使用一个
QLabel对象来保存消息。然后通过调用.addPermanentWidget()将标签添加到状态栏。此方法将给定的小部件永久添加到当前状态栏。小部件的父级设置为状态栏。
.addPermanentWidget()采用以下两个参数:
widget保存你要添加到状态栏的 widget 对象。这个角色上常用的一些小部件有QLabel、、QToolButton、、QProgressBar、。stretch用于计算当状态栏增长和收缩时小工具的合适大小。它默认为0,这意味着小部件将占用最少的空间。请记住,永久的小部件不会被临时消息所掩盖或替代。
.addPermanentWidget()定位状态栏右侧的小工具。注意:你不仅可以使用
.addPermanentWidget()在你的状态栏上显示永久的消息,还可以向用户展示一个进度条来监控给定操作的持续时间。您还可以在状态栏上提供按钮,以允许用户更改属性,如文本编辑器上的文件编码。当你在状态栏上使用这些小部件时,试着坚持使用你正在开发的应用程序类型中最常用的小部件。这样,你的用户会有宾至如归的感觉。
假设您想要将示例应用程序转换为文本编辑器,并且想要向状态栏添加一条消息,显示当前文件的字数信息。为此,您可以创建一个名为
.getWordCount()的方法,然后使用.addPermanentWidget()和一个QLabel对象添加一条永久消息:class Window(QMainWindow): # Snip... def getWordCount(self): # Logic for computing the word count goes here... return 42此方法添加用于计算当前打开的文档中字数的逻辑。现在,您可以将此信息显示为永久消息:
class Window(QMainWindow): # Snip... def _createStatusBar(self): self.statusbar = self.statusBar() # Adding a temporary message self.statusbar.showMessage("Ready", 3000) # Adding a permanent message self.wcLabel = QLabel(f"{self.getWordCount()} Words") self.statusbar.addPermanentWidget(self.wcLabel)在最后两行中,首先创建一个
QLabel对象(wcLabel)来保存关于字数的消息。为了创建消息,您使用一个 f-string ,在其中您插入一个对.getWordCount()的调用来获得字数统计信息。然后使用.addPermanentWidget()将标签添加到状态栏。在这种情况下,您创建了一个作为实例属性的
QLabel对象,因为字数需要根据用户对当前文件的更改进行更新。如果您使用此更新运行应用程序,那么您将在状态栏的右侧看到字数统计信息:
状态栏显示一条消息,通知用户一个假设的当前文件的字数。在状态栏中向用户显示永久信息或其他选项的能力非常有用,可以帮助您极大地改善应用程序的用户体验。
向操作添加帮助提示
当创建 GUI 应用程序时,为用户提供关于应用程序界面上特定功能的帮助提示是很重要的。帮助提示是短消息,为用户提供有关应用程序提供的一些选项的快速指南。
PyQt 操作允许您定义以下几种帮助提示:
状态提示是当用户将鼠标指针悬停在菜单选项或工具栏按钮上时,应用程序在状态栏上显示的帮助提示。默认情况下,状态提示包含一个空字符串。
工具提示是当用户将鼠标指针悬停在工具栏按钮或小部件上时,应用程序显示为浮动消息的帮助提示。默认情况下,工具提示包含标识当前操作的文本。
注意: PyQt 还提供了这是什么帮助提示,您可以在小部件和动作中使用它来显示小部件或动作提供的功能的更丰富的描述。然而,这个主题超出了本教程的范围。
要了解帮助提示是如何工作的,您可以在示例应用程序中添加一些状态提示和工具提示。转到
._createActions()并添加以下代码行:class Window(QMainWindow): # Snip... def _createActions(self): # File actions # Snip... self.saveAction.setShortcut("Ctrl+S") # Adding help tips newTip = "Create a new file" self.newAction.setStatusTip(newTip) self.newAction.setToolTip(newTip) # Edit actions self.copyAction = QAction(QIcon(":edit-copy.svg"), "&Copy", self) # Snip...三个突出显示的行将消息
"Create a new file"设置为新选项的状态和工具提示。如果您现在运行应用程序,那么您会看到新的选项向用户显示了一个简短但描述性的帮助提示:
当您点击文件菜单并将鼠标指针停留在新建上时,您可以看到状态栏左侧显示的帮助提示信息。另一方面,如果你将鼠标指针移动到新的工具栏按钮上,那么你可以在状态栏上看到消息,也可以在鼠标指针旁边看到一个小的浮动框。
通常,向 Python 菜单和工具条添加帮助提示被认为是一种最佳实践。它将使你的 GUI 应用程序更容易被用户浏览和学习。作为最后一个练习,您可以继续向示例应用程序的其余操作添加帮助提示,并在完成后查看它的外观。
结论
菜单、工具栏和状态栏是大多数 GUI 应用的常见且重要的图形组件。您可以使用它们为您的用户提供一种快速访问应用程序选项和功能的方式。它们还能让你的应用看起来更精致、更专业,并为你的用户提供更好的体验。
在本教程中,您已经学会了如何:
- 编程创建菜单、工具栏和状态栏
- 使用 PyQt 动作来填充你的菜单和工具栏
- 使用状态栏提供状态信息
在这个过程中,你已经学习了一些最佳编程实践,当你在 GUI 应用程序中添加和使用菜单、工具栏和状态栏时,这些实践是值得考虑的。
您还编写了一个示例应用程序,其中您将所有知识应用于菜单和工具栏。您可以通过点击下面的方框获得该应用程序的完整源代码和其他资源:
下载示例代码: 单击此处获取代码,您将使用来学习如何使用 Python 和 PyQt 向您的 GUI 应用程序添加菜单、工具栏和状态栏。*************
Python 元类
术语元编程指的是程序了解或操纵自身的潜力。Python 支持一种称为元类的类元编程形式。
元类是一个深奥的 OOP 概念,隐藏在几乎所有 Python 代码的背后。不管你是否意识到,你都在使用它们。在大多数情况下,你不需要意识到这一点。大多数 Python 程序员很少考虑元类。
然而,当需要时,Python 提供了一种并非所有面向对象语言都支持的功能:您可以在幕后定义自定义元类。自定义元类的使用有些争议,正如 Tim Peters(Python 大师,撰写了 Python 的 Zen)所说:
“元类比 99%的用户应该担心的还要神奇。如果你想知道你是否需要他们,你不需要(实际需要他们的人肯定知道他们需要他们,并且不需要关于为什么的解释)。”
— 蒂姆·彼得斯
有些 Python 爱好者(众所周知的 Python 爱好者)认为不应该使用自定义元类。这可能有点过了,但是自定义元类在大多数情况下是不必要的,这可能是真的。如果一个问题不太明显需要它们,那么如果用一种更简单的方式来解决,它可能会更干净,更易读。
尽管如此,理解 Python 元类是值得的,因为它通常会导致对 Python 类内部的更好理解。您永远不知道:有一天,您可能会发现自己处于这样一种情况,您只知道自定义元类是您想要的。
获得通知:不要错过本教程的后续— 点击这里加入真正的 Python 时事通讯你会知道下一期什么时候出来。
旧式与新式课堂
在 Python 领域,类可以是两种类型中的一种。官方术语尚未确定,因此它们被非正式地称为旧式和新式类。
旧式班级
对于旧式的类,类和类型不是一回事。旧式类的实例总是由一个名为
instance的内置类型实现。如果obj是一个旧式类的实例,obj.__class__指定该类,但是type(obj)总是instance。以下示例摘自 Python 2.7:
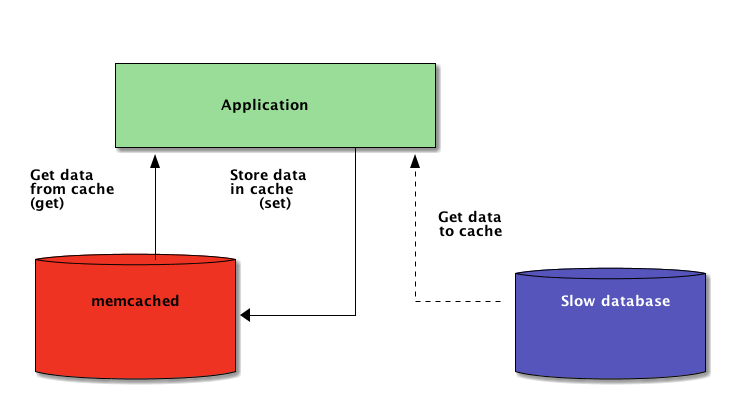
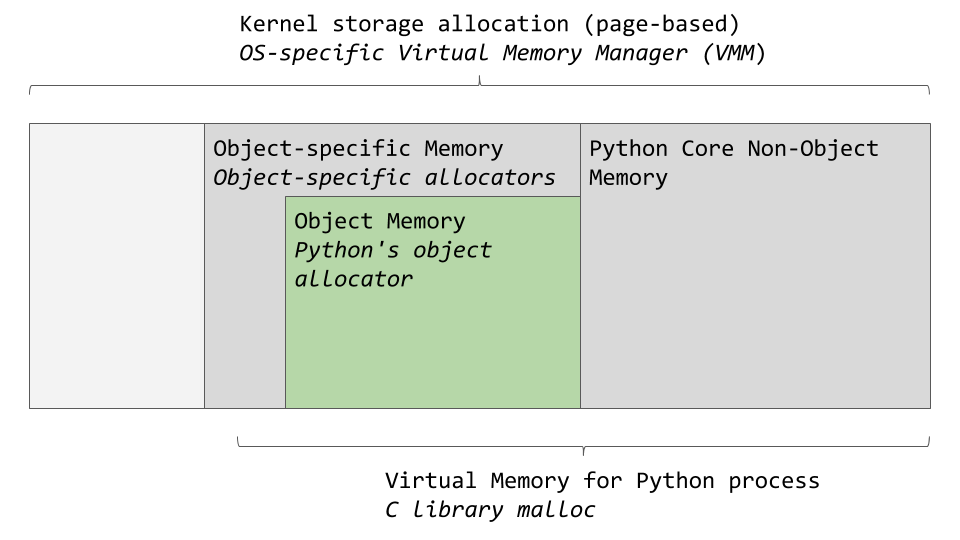
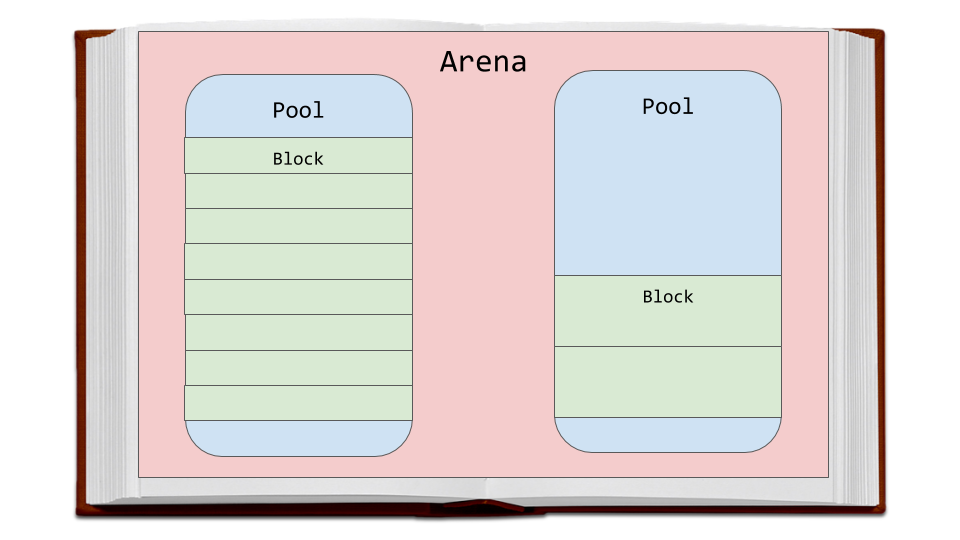
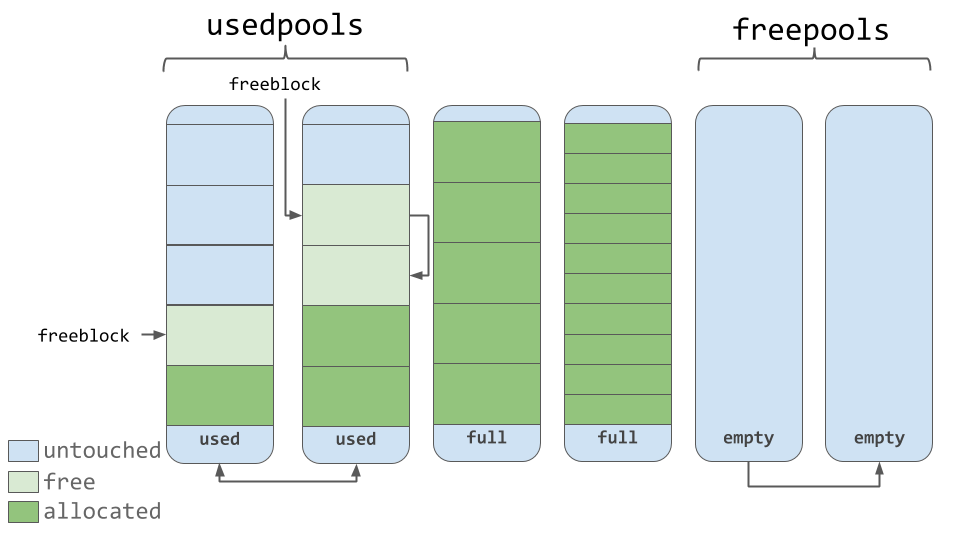
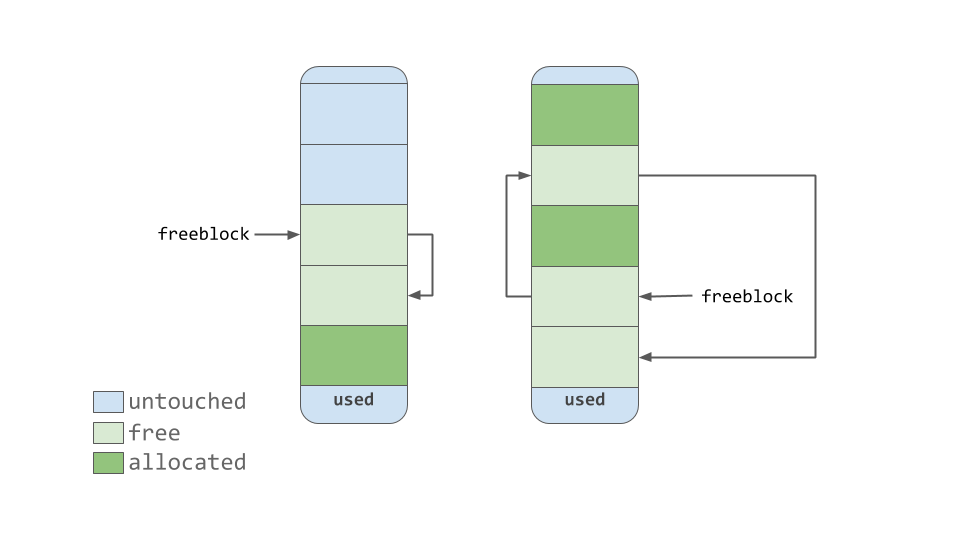
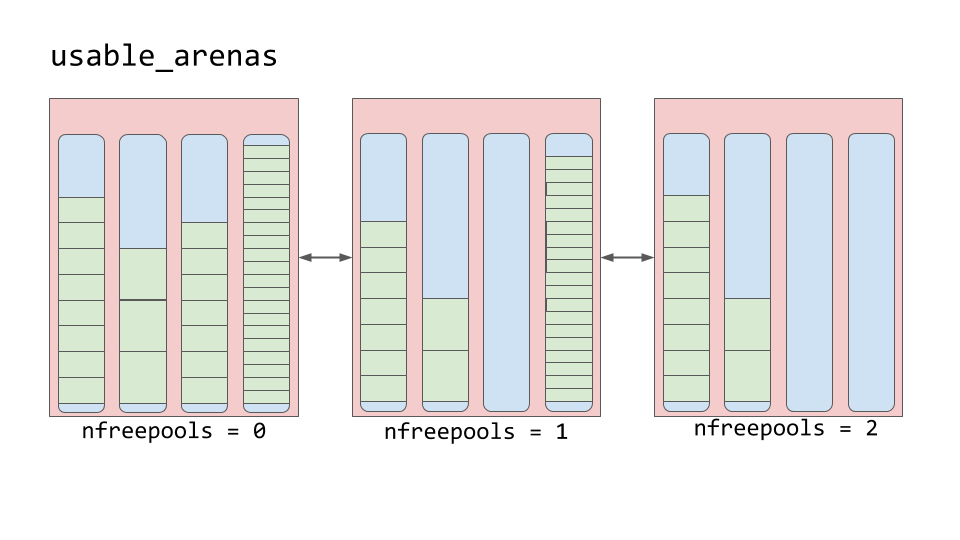
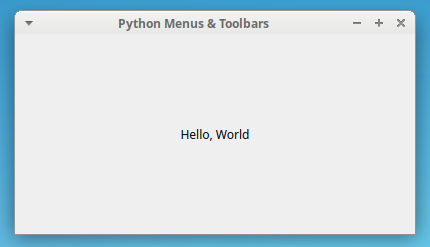
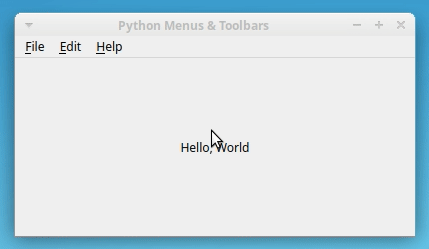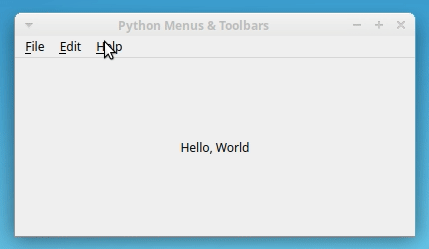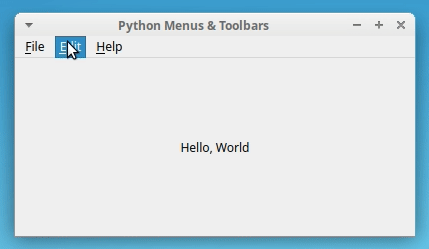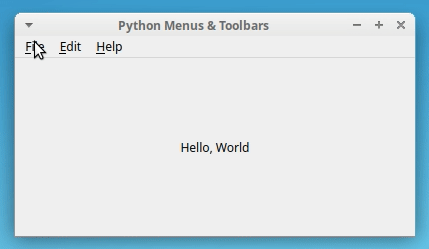


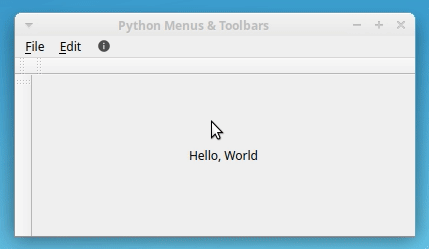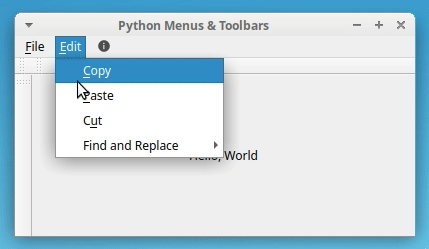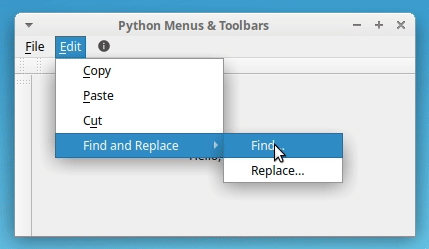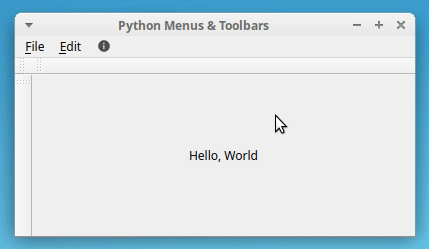









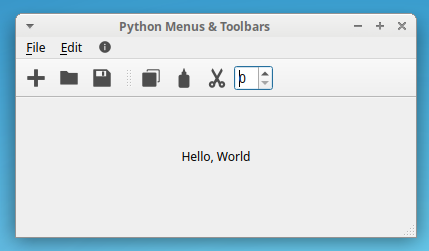



>>> class Foo:
... pass
...
>>> x = Foo()
>>> x.__class__
<class __main__.Foo at 0x000000000535CC48>
>>> type(x)
<type 'instance'>
新型班级
新型类统一了类和类型的概念。如果obj是一个新型类的实例,type(obj)与obj.__class__相同:
>>> class Foo: ... pass >>> obj = Foo() >>> obj.__class__ <class '__main__.Foo'> >>> type(obj) <class '__main__.Foo'> >>> obj.__class__ is type(obj) True
>>> n = 5
>>> d = { 'x' : 1, 'y' : 2 }
>>> class Foo:
... pass
...
>>> x = Foo()
>>> for obj in (n, d, x):
... print(type(obj) is obj.__class__)
...
True
True
True
类型和等级
在 Python 3 中,所有的类都是新型类。因此,在 Python 3 中,互换引用对象的类型和类是合理的。
注意:在 Python 2 中,类默认是旧式的。在 Python 2.2 之前,根本不支持新型类。从 Python 2.2 开始,可以创建它们,但必须显式声明为 new-style。
记住,在 Python 中,一切都是对象。类也是对象。因此,一个类必须有一个类型。一个类的类型是什么?
请考虑以下情况:
>>> class Foo: ... pass ... >>> x = Foo() >>> type(x) <class '__main__.Foo'> >>> type(Foo) <class 'type'>如你所料,
x的类型是类Foo。但是Foo的类型,职业本身,是type。一般来说,任何新型类的类型都是type。你熟悉的内置类的类型也是
type:
>>> for t in int, float, dict, list, tuple:
... print(type(t))
...
<class 'type'>
<class 'type'>
<class 'type'>
<class 'type'>
<class 'type'>
就此而言,type的类型也是type(是的,真的):
>>> type(type) <class 'type'>是一个元类,其中的类是实例。正如普通对象是一个类的实例一样,Python 中的任何新型类,以及 Python 3 中的任何类,都是
type元类的实例。在上述情况下:
x是类Foo的一个实例。Foo是type元类的一个实例。type也是type元类的一个实例,所以它是自身的一个实例。动态定义一个类
当传递一个参数时,内置的
type()函数返回一个对象的类型。对于新型类,这通常与对象的__class__属性相同:
>>> type(3)
<class 'int'>
>>> type(['foo', 'bar', 'baz'])
<class 'list'>
>>> t = (1, 2, 3, 4, 5)
>>> type(t)
<class 'tuple'>
>>> class Foo:
... pass
...
>>> type(Foo())
<class '__main__.Foo'>
也可以用三个参数调用type()—type(<name>, <bases>, <dct>):
<name>指定类名。这成为了类的__name__属性。- 指定该类继承的基类的元组。这成为了类的
__bases__属性。 <dct>指定一个包含类体定义的名称空间字典。这成为了类的__dict__属性。
以这种方式调用type()会创建一个type元类的新实例。换句话说,它动态地创建了一个新类。
在下面的每个例子中,上面的代码片段用type()动态定义了一个类,而下面的代码片段用class语句以通常的方式定义了这个类。在每种情况下,这两个片段在功能上是等效的。
示例 1
在第一个例子中,传递给type()的<bases>和<dct>参数都是空的。没有指定来自任何父类的继承,并且最初在名称空间字典中没有放置任何东西。这是最简单的类定义:
>>> Foo = type('Foo', (), {}) >>> x = Foo() >>> x <__main__.Foo object at 0x04CFAD50>
>>> class Foo:
... pass
...
>>> x = Foo()
>>> x
<__main__.Foo object at 0x0370AD50>
示例 2
这里,<bases>是一个只有一个元素Foo的元组,指定了Bar继承的父类。属性attr最初放在名称空间字典中:
>>> Bar = type('Bar', (Foo,), dict(attr=100)) >>> x = Bar() >>> x.attr 100 >>> x.__class__ <class '__main__.Bar'> >>> x.__class__.__bases__ (<class '__main__.Foo'>,)
>>> class Bar(Foo):
... attr = 100
...
>>> x = Bar()
>>> x.attr
100
>>> x.__class__
<class '__main__.Bar'>
>>> x.__class__.__bases__
(<class '__main__.Foo'>,)
示例 3
这一次,<bases>又空了。两个对象通过<dct>参数放入名称空间字典。第一个是名为attr的属性,第二个是名为attr_val的函数,它成为定义的类的方法:
>>> Foo = type( ... 'Foo', ... (), ... { ... 'attr': 100, ... 'attr_val': lambda x : x.attr ... } ... ) >>> x = Foo() >>> x.attr 100 >>> x.attr_val() 100
>>> class Foo:
... attr = 100
... def attr_val(self):
... return self.attr
...
>>> x = Foo()
>>> x.attr
100
>>> x.attr_val()
100
示例 4
Python 中的 lambda只能定义非常简单的函数。在下面的例子中,一个稍微复杂一点的函数在外部定义,然后在名称空间字典中通过名字f赋给attr_val:
>>> def f(obj): ... print('attr =', obj.attr) ... >>> Foo = type( ... 'Foo', ... (), ... { ... 'attr': 100, ... 'attr_val': f ... } ... ) >>> x = Foo() >>> x.attr 100 >>> x.attr_val() attr = 100
>>> def f(obj):
... print('attr =', obj.attr)
...
>>> class Foo:
... attr = 100
... attr_val = f
...
>>> x = Foo()
>>> x.attr
100
>>> x.attr_val()
attr = 100
自定义元类
再次考虑这个老生常谈的例子:
>>> class Foo: ... pass ... >>> f = Foo()表达式
Foo()创建了类Foo的一个新实例。当解释器遇到Foo()时,会发生以下情况:
调用
Foo的父类的__call__()方法。因为Foo是一个标准的新型类,它的父类是type元类,所以type的__call__()方法被调用。该
__call__()方法依次调用以下内容:
__new__()__init__()如果
Foo没有定义__new__()和__init__(),则默认方法从Foo的祖先继承。但是如果Foo确实定义了这些方法,它们会覆盖那些来自祖先的方法,这允许在实例化Foo时定制行为。在下文中,定义了一个名为
new()的自定义方法,并将其指定为Foo的__new__()方法:
>>> def new(cls):
... x = object.__new__(cls)
... x.attr = 100
... return x
...
>>> Foo.__new__ = new
>>> f = Foo()
>>> f.attr
100
>>> g = Foo()
>>> g.attr
100
这修改了类Foo的实例化行为:每次创建Foo的实例时,默认情况下,它用一个名为attr的属性初始化,该属性的值为100。(像这样的代码更经常出现在__init__()方法中,而不是典型的__new__()。这个例子是为了演示的目的而设计的。)
现在,正如已经重申的,类也是对象。假设您想在创建类似于Foo的类时类似地定制实例化行为。如果您遵循上面的模式,您将再次定义一个自定义方法,并将其指定为类的__new__()方法,而Foo是该类的一个实例。Foo是type元类的一个实例,所以代码看起来像这样:
# Spoiler alert: This doesn't work! >>> def new(cls): ... x = type.__new__(cls) ... x.attr = 100 ... return x ... >>> type.__new__ = new Traceback (most recent call last): File "<pyshell#77>", line 1, in <module> type.__new__ = new TypeError: can't set attributes of built-in/extension type 'type'正如您所看到的,您不能重新分配
type元类的__new__()方法。Python 不允许。这可能是无妨的。是元类,所有新样式的类都是从它派生出来的。不管怎样,你真的不应该再瞎折腾了。但是如果你想定制一个类的实例化,有什么办法呢?
一个可能的解决方案是自定义元类。本质上,你可以定义自己的元类,它从
type派生而来,然后你可以用它来代替type元类。第一步是定义一个从
type派生的元类,如下所示:
>>> class Meta(type):
... def __new__(cls, name, bases, dct):
... x = super().__new__(cls, name, bases, dct)
... x.attr = 100
... return x
...
定义头class Meta(type):指定Meta来源于type。因为type是一个元类,所以Meta也是一个元类。
注意,已经为Meta定义了一个自定义的__new__()方法。直接对type元类这样做是不可能的。__new__()方法执行以下操作:
- 通过
super()委托给父元类(type)的__new__()方法来实际创建一个新类 - 将自定义属性
attr赋值给类,值为100 - 返回新创建的类
现在巫术的另一半:定义一个新类Foo,并指定它的元类是自定义元类Meta,而不是标准元类type。这是使用类定义中的metaclass关键字完成的,如下所示:
>>> class Foo(metaclass=Meta): ... pass ... >>> Foo.attr 100瞧!
Foo已经从Meta元类中自动选取了attr属性。当然,您以类似方式定义的任何其他类也会这样做:
>>> class Bar(metaclass=Meta):
... pass
...
>>> class Qux(metaclass=Meta):
... pass
...
>>> Bar.attr, Qux.attr
(100, 100)
与类作为创建对象的模板一样,元类也作为创建类的模板。元类有时被称为类工厂。
比较以下两个例子:
对象工厂:
>>> class Foo: ... def __init__(self): ... self.attr = 100 ... >>> x = Foo() >>> x.attr 100 >>> y = Foo() >>> y.attr 100 >>> z = Foo() >>> z.attr 100类工厂:
>>> class Meta(type):
... def __init__(
... cls, name, bases, dct
... ):
... cls.attr = 100
...
>>> class X(metaclass=Meta):
... pass
...
>>> X.attr
100
>>> class Y(metaclass=Meta):
... pass
...
>>> Y.attr
100
>>> class Z(metaclass=Meta):
... pass
...
>>> Z.attr
100
这真的有必要吗?
尽管上面的类工厂例子很简单,但它是元类工作的本质。它们允许定制类实例化。
尽管如此,仅仅是给每个新创建的类赋予自定义属性attr就太麻烦了。为此,您真的需要一个元类吗?
在 Python 中,至少有几种其他方法可以有效地完成同样的事情:
简单继承:
>>> class Base: ... attr = 100 ... >>> class X(Base): ... pass ... >>> class Y(Base): ... pass ... >>> class Z(Base): ... pass ... >>> X.attr 100 >>> Y.attr 100 >>> Z.attr 100类装饰器:
>>> def decorator(cls):
... class NewClass(cls):
... attr = 100
... return NewClass
...
>>> @decorator
... class X:
... pass
...
>>> @decorator
... class Y:
... pass
...
>>> @decorator
... class Z:
... pass
...
>>> X.attr
100
>>> Y.attr
100
>>> Z.attr
100
结论
正如 Tim Peters 所建议的,元类很容易成为“寻找问题的解决方案”通常没有必要创建自定义元类。如果手头的问题可以用一种更简单的方式来解决,它可能应该是。尽管如此,理解元类还是有好处的,这样你就能大体理解 Python 类,并能认识到什么时候元类才是真正适合使用的工具。****
使用 gRPC 的 Python 微服务
微服务是一种组织复杂软件系统的方式。你不是把你所有的代码都放在一个 app 里,而是把你的 app 分解成独立部署的微服务,互相通信。本教程将教您如何使用 gRPC(最流行的框架之一)启动和运行 Python 微服务。
很好地实现微服务框架很重要。当您构建一个框架来支持关键应用程序时,您必须确保它是健壮的和对开发人员友好的。在本教程中,您将学习如何做到这一点。这些知识会让你对成长中的公司更有价值。
为了从本教程中获益最大,你应该理解 Python 和 web 应用的基础。如果你想重温这些,请先通读提供的链接。
本教程结束时,你将能够:
- 用 Python 实现通过 gRPC 相互通信的微服务
- 实现中间件来监控微服务
- 单元测试和集成测试你的微服务和中间件
- 使用 Kubernetes 将微服务部署到 Python 生产环境中
您可以通过单击下面的链接下载本教程中使用的所有源代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用了解如何使用 gRPC 创建 Python 微服务。
为什么选择微服务?
假设您在 Online Books For You 工作,这是一家流行的在线销售图书的电子商务网站。该公司有数百名开发人员。每个开发人员都在为一些产品或后端功能编写代码,比如管理用户的购物车、生成推荐、处理支付交易或处理仓库库存。
现在问问你自己,你希望所有的代码都在一个巨大的应用程序中吗?这有多难理解?测试需要多长时间?你如何保持代码和数据库模式的合理性?这肯定会很难,尤其是在业务试图快速发展的时候。
难道你不希望对应于模块化产品特性的代码是模块化的吗?管理购物车的购物车微服务。管理库存的库存微服务。
在下面的章节中,您将会更深入地探究将 Python 代码分离到微服务中的一些原因。
模块化
代码更改通常会选择阻力最小的路径。你心爱的在线图书为你 CEO 想增加一个新的买两本书送一本书的功能。你是被要求尽快启动它的团队的一员。看看当所有代码都在一个应用程序中时会发生什么。
作为您团队中最聪明的工程师,您提到您可以向购物车逻辑添加一些代码,以检查购物车中是否有两本书以上。如果是这样,你可以简单地从购物车总额中减去最便宜的书的价格。没问题——你提出一个拉取请求。
然后你的产品经理说你需要跟踪这个活动对图书销售的影响。这也很简单。因为实现买二送一功能的逻辑在购物车代码中,所以您将在 checkout 流中添加一行来更新交易数据库中的一个新列,以表明该销售是促销的一部分:buy_two_get_one_free_promo = true。完成了。
接下来,您的产品经理会提醒您,该交易仅对每位客户使用一次有效。您需要添加一些逻辑来检查之前的事务是否设置了那个buy_two_get_one_free_promo标志。哦,你需要隐藏主页上的推广横幅,所以你也添加了检查。哦,你还需要发送电子邮件给没有使用过该宣传片的人。把那个也加上。
几年后,事务数据库变得太大,需要用新的共享数据库替换。所有这些参考资料都需要修改。不幸的是,在这一点上,整个代码库都引用了这个数据库。你认为添加所有这些引用实际上有点太容易了。
这就是为什么从长远来看,将所有代码放在一个应用程序中是危险的。有时候有界限是好事。
事务数据库应该只能由事务微服务访问。然后,如果你需要缩放它,它不是那么糟糕。代码的其他部分可以通过隐藏实现细节的抽象 API 与事务进行交互。你可以在一个应用程序中做到这一点——只是不太可能。代码更改通常会选择阻力最小的路径。
灵活性
将 Python 代码拆分成微服务可以给你更多的灵活性。首先,你可以用不同的语言编写你的微服务。通常,一个公司的第一个网络应用程序会用 Ruby 或者 T2 PHP 编写。这并不意味着其他一切都必须如此!
您还可以独立扩展每个微服务。在本教程中,您将使用一个 web 应用程序和一个建议微服务作为运行示例。
你的网络应用很可能会受到 I/O 的限制,从数据库中获取数据,或许从磁盘中加载模板或其他文件。一个推荐微服务可能正在做大量的数字运算,使其受到 CPU 的限制。在不同的硬件上运行这两个 Python 微服务是有意义的。
鲁棒性
如果你所有的代码都在一个应用程序中,那么你必须立刻部署它。这是很大的风险!这意味着对一小部分代码的修改可能会毁掉整个网站。
所有权
当一个单一的代码库被许多人共享时,对于代码的架构通常没有清晰的愿景。在员工来来去去的大公司尤其如此。可能有人对代码应该是什么样子有一个愿景,但是当任何人都可以修改它并且每个人都在快速移动时,很难执行。
微服务的一个好处是团队可以清楚地拥有他们的代码。这使得代码更有可能有一个清晰的愿景,代码也更有条理。它还清楚地表明,当出现问题时,谁负责向代码添加特性或进行更改。
“微”有多小?
微服务应该有多小是工程师们激烈争论的话题之一。以下是我的两点看法:微是用词不当。我们应该只说服务。然而,在本教程中,您将看到用于一致性的微服务。
把微服务做得太小会出问题。首先,它实际上违背了使代码模块化的目的。微服务中的代码应该一起有意义,就像类中的数据和方法一起有意义一样。
用类做类比,考虑 Python 中的file对象。file对象拥有您需要的所有方法。你可以用 .read()和.write() 来代替它,或者你可以用.readlines()来代替它。你不应该需要一个FileReader和一个FileWriter类。也许你熟悉这样做的语言,也许你一直认为这有点麻烦和混乱。
微服务也一样。代码的范围应该是正确的。不要太大,也不要太小。
第二,微服务比单片代码更难测试。如果开发人员想要测试一个跨越许多微服务的特性,那么他们需要在他们的开发环境中启动并运行这些特性。这增加了摩擦。对于一些微服务来说,情况还不算太糟,但如果是几十个,那么这将是一个重大问题。
获得正确的微服务规模是一门艺术。需要注意的一点是每个团队都应该拥有合理数量的微服务。如果你的团队有五个人,但是有二十个微服务,那么这是一个危险信号。另一方面,如果你的团队只开发一个微服务,并且被其他五个团队共享,那么这也可能是一个问题。
不要为了做微服务而把微服务做得越小越好。有些微服务可能比较大。但是要注意单个微服务正在做两件或更多完全不相关的事情。这通常是因为向现有微服务添加不相关的功能是阻力最小的途径,而不是因为它属于那里。
这里有一些方法可以将你假想的网上书店分解成微服务:
- Marketplace 为用户在网站中导航提供逻辑服务。
- 购物车跟踪用户放入购物车的商品和结账流程。
- 交易处理支付处理和发送收据。
- Inventory 提供关于哪些书籍有库存的数据。
- 用户帐户管理用户注册和帐户详情,例如更改他们的密码。
- 评论存储用户输入的图书评分和评论。
这些只是几个例子,并不是详尽的清单。然而,你可以看到它们中的每一个都可能被自己的团队所拥有,并且它们的逻辑是相对独立的。此外,如果 Reviews 微服务部署时出现了导致其崩溃的错误,那么用户仍然可以使用该网站并进行购买,尽管点评无法加载。
微服务与整体服务的权衡
微服务并不总是比将所有代码保存在一个应用程序中的单片要好。一般来说,尤其是在软件开发生命周期的开始,monoliths 会让你走得更快。它们使共享代码和添加功能变得不那么复杂,并且只需部署一个服务就可以让用户快速获得应用。
权衡的结果是,随着复杂性的增长,所有这些事情会逐渐使整体更难开发,部署更慢,并且更脆弱。实现一个整体可能会节省你的时间和精力,但它可能会回来困扰你。
在 Python 中实现微服务可能会在短期内耗费您的时间和精力,但如果做得好,从长远来看,它可以让您更好地扩展。当然,在速度最重要的时候,过早实施微服务可能会降低您的速度。
典型的硅谷创业周期是从一个整体开始,以便在企业找到适合客户的产品时能够快速迭代。等公司有了成功的产品,雇佣了更多的工程师之后,就该开始考虑微服务了。不要过早实施,但也不要等待太久。
要了解更多关于微服务与整体服务的权衡,请观看 Sam Newman 和 Martin Fowler 的精彩讨论,何时使用微服务(以及何时不使用!)。
微服务示例
在本节中,您将为您的在线图书网站定义一些微服务。在本教程中,您将为它们定义一个 API ,并编写 Python 代码将它们实现为微服务。
为了便于管理,您将只定义两个微服务:
- 市场将是一个非常小的网络应用程序,向用户显示图书列表。
- 推荐将是一个微服务,提供用户可能感兴趣的书籍列表。
下图显示了您的用户如何与微服务交互:

您可以看到,用户将通过他们的浏览器与 Marketplace 微服务进行交互,Marketplace 微服务将与推荐微服务进行交互。
思考一下推荐 API。您希望建议请求具有一些特征:
- 用户 ID: 您可以用它来个性化推荐。然而,为了简单起见,本教程中的所有建议都是随机的。
- 图书类别:为了让 API 更有趣,您将添加图书类别,例如推理小说、自助书籍等等。
- Max results: 您不想退回所有库存图书,所以您将为请求添加一个限制。
响应将是一个图书列表。每本书将包含以下数据:
- 图书 ID: 图书的唯一数字 ID。
- 图书标题:可以向用户显示的标题。
一个真实的网站会有更多的数据,但是为了这个例子,你将保持特征的数量有限。
现在,您可以更正式地定义这个 API,使用协议缓冲区的语法:
1syntax = "proto3";
2
3enum BookCategory {
4 MYSTERY = 0;
5 SCIENCE_FICTION = 1;
6 SELF_HELP = 2;
7}
8
9message RecommendationRequest {
10 int32 user_id = 1;
11 BookCategory category = 2;
12 int32 max_results = 3;
13}
14
15message BookRecommendation {
16 int32 id = 1;
17 string title = 2;
18}
19
20message RecommendationResponse {
21 repeated BookRecommendation recommendations = 1;
22}
23
24service Recommendations {
25 rpc Recommend (RecommendationRequest) returns (RecommendationResponse);
26}
这个协议缓冲区文件声明了您的 API。协议缓冲区是 Google 开发的,它提供了一种正式指定 API 的方法。这乍一看可能有点神秘,所以下面是一行一行的分析:
-
第 1 行指定文件使用
proto3语法,而不是旧的proto2版本。 -
第 3 行到第 7 行定义了你的图书类别,每个类别还分配了一个数字 ID。
-
第 9 行到第 13 行定义了您的 API 请求。一个
message包含字段,每一个都是特定的类型。对于user_ID和max_results字段,您使用的是一个 32 位整数int32。您还使用了上面定义为category类型的BookCategory枚举。除了每个字段都有名称之外,还会分配一个数字字段 ID。你可以暂时忽略这个。 -
第 15 到 18 行定义了一个新的类型,您可以用它来推荐一本书。它有一个 32 位的整数 ID 和一个基于字符串的标题。
-
第 20 行到第 22 行定义您的建议微服务响应。注意
repeated关键字,它表明响应实际上有一个BookRecommendation对象的列表。 -
第 24 到 26 行定义了 API 的方法。你可以把它想象成一个类中的函数或方法。它接受一个
RecommendationRequest并返回一个RecommendationResponse。
rpc代表远程过程调用。很快您就会看到,您可以像 Python 中的普通函数一样调用 RPC。但是 RPC 的实现在另一个服务器上执行,这就是为什么它是一个远程过程调用。
为什么是 RPC 和协议缓冲区?
好吧,那么你为什么要使用这种正式语法来定义你的 API 呢?如果要从一个微服务向另一个微服务发出请求,难道就不能发出一个 HTTP 请求得到一个 JSON 响应吗?你可以这么做,但是使用协议缓冲区也有好处。
文档
使用协议缓冲区的第一个好处是,它们为您的 API 提供了一个定义良好且自我记录的模式。如果您使用 JSON,那么您必须记录它包含的字段及其类型。与任何文档一样,您可能会面临文档不准确、不完整或过期的风险。
当您用协议缓冲区语言编写 API 时,您可以从中生成 Python 代码。您的代码永远不会与您的文档不同步。文档是好的,但是自文档代码更好。
验证
第二个好处是,当您从协议缓冲区生成 Python 代码时,您可以免费获得一些基本的验证。例如,生成的代码不会接受错误类型的字段。生成的代码还内置了所有的 RPC 样板文件。
如果您的 API 使用 HTTP 和 JSON,那么您需要编写一点代码来构造请求、发送请求、等待响应、检查状态代码,并解析和验证响应。使用协议缓冲区,您可以生成看起来像普通的函数调用,但实际上是网络请求的代码。
使用 HTTP 和 JSON 框架,比如 Swagger 和 RAML ,你也可以获得同样的好处。关于 Swagger 的一个例子,请查看带有 Flask、Connexion 和 SQLAlchemy 的Python REST API。
那么,是否有理由使用 gRPC 而不是其他替代方案呢?答案还是肯定的。
性能
gRPC 框架通常比使用典型的 HTTP 请求更有效。gRPC 构建在 HTTP/2 之上,它可以以线程安全的方式在一个长期连接上并行发出多个请求。连接设置相对较慢,因此只需设置一次并在多个请求之间共享连接就可以节省时间。gRPC 消息也是二进制的,比 JSON 小。此外,HTTP/2 具有内置的报头压缩。
gRPC 内置了对流式请求和响应的支持。它将比基本的 HTTP 连接更好地管理网络问题,即使在长时间断开连接后也能自动重新连接。它还有拦截器,你将在本教程的后面了解到。你甚至可以对生成的代码实现插件,人们已经这样做了,以输出 Python 类型提示。基本上,你可以免费获得很多很棒的基础设施!
开发者友好型
许多人喜欢 gRPC 胜过 REST 的最有趣的原因可能是,您可以根据函数来定义您的 API,而不是 HTTP 动词和资源。作为一名工程师,你习惯于从函数调用的角度思考,这正是 gRPC APIs 的样子。
将功能映射到 REST API 上通常很困难。你必须决定你的资源是什么,如何构造路径,以及使用哪些动词。通常有多种选择,比如如何嵌套资源,或者是否使用 POST 或其他动词。REST vs gRPC 可能会变成一场关于偏好的辩论。一个并不总是比另一个更好,所以使用最适合你的用例。
严格来说,协议缓冲区是指两个微服务之间发送数据的序列化格式。因此,协议缓冲区类似于 JSON 或 XML,它们是格式化数据的方式。与 JSON 不同,协议缓冲区有严格的模式,通过网络发送时更加紧凑。
另一方面,RPC 基础设施实际上被称为 gRPC ,或者 Google RPC。这更类似于 HTTP。事实上,如上所述,gRPC 是建立在 HTTP/2 之上的。
实施示例
在讨论了协议缓冲区之后,是时候看看它们能做些什么了。术语协议缓冲区很拗口,所以你会看到本教程中常用的简写协议缓冲区。
正如几次提到的,您可以从 protobufs 生成 Python 代码。该工具作为grpcio-tools包的一部分安装。
首先,定义您的初始目录结构:
.
├── protobufs/
│ └── recommendations.proto
|
└── recommendations/
protobufs/目录将包含一个名为recommendations.proto的文件。这个文件的内容就是上面的 protobuf 代码。为了方便起见,您可以通过展开下面的可折叠部分来查看代码:
1syntax = "proto3";
2
3enum BookCategory {
4 MYSTERY = 0;
5 SCIENCE_FICTION = 1;
6 SELF_HELP = 2;
7}
8
9message RecommendationRequest {
10 int32 user_id = 1;
11 BookCategory category = 2;
12 int32 max_results = 3;
13}
14
15message BookRecommendation {
16 int32 id = 1;
17 string title = 2;
18}
19
20message RecommendationResponse {
21 repeated BookRecommendation recommendations = 1;
22}
23
24service Recommendations {
25 rpc Recommend (RecommendationRequest) returns (RecommendationResponse);
26}
您将生成 Python 代码,以便在recommendations/目录中与之交互。首先你必须安装grpcio-tools。创建文件recommendations/requirements.txt,并添加以下内容:
grpcio-tools ~= 1.30
要在本地运行代码,您需要将依赖项安装到一个虚拟环境中。以下命令将在 Windows 上安装依赖项:
C:\ python -m venv venv
C:\ venv\Scripts\activate.bat
(venv) C:\ python -m pip install -r requirements.txt
在 Linux 和 macOS 上,使用以下命令创建虚拟环境并安装依赖项:
$ python3 -m venv venv
$ source venv/bin/activate # Linux/macOS only
(venv) $ python -m pip install -r requirements.txt
现在,要从 protobufs 生成 Python 代码,运行以下代码:
$ cd recommendations
$ python -m grpc_tools.protoc -I ../protobufs --python_out=. \
--grpc_python_out=. ../protobufs/recommendations.proto
这将从.proto文件生成几个 Python 文件。这里有一个细目分类:
python -m grpc_tools.protoc运行 protobuf 编译器,它将从 protobuf 代码生成 Python 代码。-I ../protobufs告诉编译器在哪里找到你的 protobuf 代码导入的文件。您实际上并没有使用 import 特性,但是仍然需要使用-I标志。--python_out=. --grpc_python_out=.告诉编译器将 Python 文件输出到哪里。很快您就会看到,它将生成两个文件,如果您愿意,您可以使用这些选项将每个文件放在一个单独的目录中。../protobufs/recommendations.proto是 protobuf 文件的路径,该文件将用于生成 Python 代码。
如果您查看生成的内容,您会看到两个文件:
$ ls
recommendations_pb2.py recommendations_pb2_grpc.py
这些文件包括 Python 类型和函数,用于与 API 进行交互。编译器将生成调用 RPC 的客户端代码和实现 RPC 的服务器代码。您将首先查看客户端。
RPC 客户端
生成的代码只有主板才会喜欢。也就是说不是很好看的 Python。这是因为它并不真正适合人类阅读。打开 Python shell,查看如何与之交互:
>>> from recommendations_pb2 import BookCategory, RecommendationRequest >>> request = RecommendationRequest( ... user_id=1, category=BookCategory.SCIENCE_FICTION, max_results=3 ... ) >>> request.category 1您可以看到 protobuf 编译器生成了与您的 protobuf 类型相对应的 Python 类型。到目前为止,一切顺利。您还可以看到对字段进行了一些类型检查:
>>> request = RecommendationRequest(
... user_id="oops", category=BookCategory.SCIENCE_FICTION, max_results=3
... )
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'oops' has type str, but expected one of: int, long
这表明,如果将错误的类型传递给 protobuf 字段之一,就会得到一个 TypeError 。
一个重要的注意事项是,proto3中的所有字段都是可选的,因此您需要验证它们是否都已设置。如果不设置,那么对于数值类型,它将默认为零,对于字符串,它将默认为空字符串:
>>> request = RecommendationRequest( ... user_id=1, category=BookCategory.SCIENCE_FICTION ... ) >>> request.max_results 0这里您得到了
0,因为这是未设置的int字段的默认值。虽然 protobufs 会为您进行类型检查,但您仍然需要验证实际值。因此,当您实现您的建议微服务时,您应该验证所有字段都有良好的数据。对于任何服务器来说都是如此,不管您使用 protobufs、JSON 还是其他什么。始终验证输入。
为您生成的
recommendations_pb2.py文件包含类型定义。recommendations_pb2_grpc.py文件包含客户端和服务器的框架。看一下创建客户机所需的导入:
>>> import grpc
>>> from recommendations_pb2_grpc import RecommendationsStub
您导入模块grpc,该模块提供了一些用于建立到远程服务器的连接的功能。然后导入 RPC 客户端存根。它被称为存根,因为客户端本身没有任何功能。它调用远程服务器并将结果传回。
如果你回头看看你的 protobuf 定义,那么你会在最后看到service Recommendations {...}部分。protobuf 编译器获取这个微服务名Recommendations,并在它后面加上Stub,形成客户端名RecommendationsStub。
现在,您可以发出 RPC 请求:
>>> channel = grpc.insecure_channel("localhost:50051") >>> client = RecommendationsStub(channel) >>> request = RecommendationRequest( ... user_id=1, category=BookCategory.SCIENCE_FICTION, max_results=3 ... ) >>> client.Recommend(request) Traceback (most recent call last): ... grpc._channel._InactiveRpcError: <_InactiveRpcError of RPC that terminated with: status = StatusCode.UNAVAILABLE details = "failed to connect to all addresses" ...您在端口
50051上创建一个到您自己的机器localhost的连接。该端口是 gRPC 的标准端口,但是如果您愿意,您可以更改它。现在,您将使用一个不安全的通道,它未经身份验证和加密,但是您将在本教程的后面学习如何使用安全通道。然后将这个通道传递给存根来实例化您的客户机。您现在可以调用您在
Recommendations微服务上定义的Recommend方法。回想一下 protobuf 定义中的第 25 行:rpc Recommend (...) returns (...)。这就是Recommend方法的由来。您将得到一个异常,因为实际上没有微服务在localhost:50051上运行,所以接下来您将实现它!既然已经解决了客户端的问题,接下来我们来看看服务器端。
RPC 服务器
在控制台中测试客户机是一回事,但是在那里实现服务器就有点多了。您可以让您的控制台保持打开,但是您将在一个文件中实现微服务。
从导入和一些数据开始:
1# recommendations/recommendations.py 2from concurrent import futures 3import random 4 5import grpc 6 7from recommendations_pb2 import ( 8 BookCategory, 9 BookRecommendation, 10 RecommendationResponse, 11) 12import recommendations_pb2_grpc 13 14books_by_category = { 15 BookCategory.MYSTERY: [ 16 BookRecommendation(id=1, title="The Maltese Falcon"), 17 BookRecommendation(id=2, title="Murder on the Orient Express"), 18 BookRecommendation(id=3, title="The Hound of the Baskervilles"), 19 ], 20 BookCategory.SCIENCE_FICTION: [ 21 BookRecommendation( 22 id=4, title="The Hitchhiker's Guide to the Galaxy" 23 ), 24 BookRecommendation(id=5, title="Ender's Game"), 25 BookRecommendation(id=6, title="The Dune Chronicles"), 26 ], 27 BookCategory.SELF_HELP: [ 28 BookRecommendation( 29 id=7, title="The 7 Habits of Highly Effective People" 30 ), 31 BookRecommendation( 32 id=8, title="How to Win Friends and Influence People" 33 ), 34 BookRecommendation(id=9, title="Man's Search for Meaning"), 35 ], 36}这段代码导入您的依赖项并创建一些示例数据。这里有一个细目分类:
- 第 2 行导入
futures,因为 gRPC 需要一个线程池。你以后会明白的。- 第 3 行导入
random,因为您将随机选择书籍进行推荐。- 第 14 行创建
books_by_category字典,其中键为图书类别,值为该类别图书的列表。在真正的推荐微服务中,书籍将被存储在数据库中。接下来,您将创建一个实现微服务功能的类:
29class RecommendationService( 30 recommendations_pb2_grpc.RecommendationsServicer 31): 32 def Recommend(self, request, context): 33 if request.category not in books_by_category: 34 context.abort(grpc.StatusCode.NOT_FOUND, "Category not found") 35 36 books_for_category = books_by_category[request.category] 37 num_results = min(request.max_results, len(books_for_category)) 38 books_to_recommend = random.sample( 39 books_for_category, num_results 40 ) 41 42 return RecommendationResponse(recommendations=books_to_recommend)您已经创建了一个包含实现
RecommendRPC 的方法的类。以下是详细情况:
第 29 行定义了
RecommendationService类。这就是你的微服务的实现。请注意,您子类化了RecommendationsServicer。这是您需要做的与 gRPC 集成的一部分。第 32 行在你的类上定义了一个
Recommend()方法。这必须与您在 protobuf 文件中定义的 RPC 同名。它也接受一个RecommendationRequest并返回一个RecommendationResponse,就像在 protobuf 定义中一样。它还需要一个context参数。上下文允许您设置响应的状态代码。第 33 行和第 34 行使用
abort()结束请求,如果您得到一个意外的类别,则将状态代码设置为NOT_FOUND。因为 gRPC 构建在 HTTP/2 之上,所以状态代码类似于标准的 HTTP 状态代码。设置它允许客户端根据它收到的代码采取不同的操作。它还允许中间件(如监控系统)记录有多少请求有错误。第 36 至 40 行从给定的类别中随机挑选一些书籍推荐。请确保将推荐数量限制在
max_results以内。你使用min()来确保你不会要求比实际更多的书,否则random.sample就会出错。第 38 行T3】返回一个
RecommendationResponse对象和你的书籍推荐列表。注意,在错误条件下引发一个异常比像本例中那样使用
abort()更好,但是这样的响应不会正确设置状态码。有一种方法可以解决这个问题,在本教程的后面,当您查看拦截器时,您将会看到这种方法。
RecommendationService类定义了你的微服务实现,但是你仍然需要运行它。这就是serve()的作用:41def serve(): 42 server = grpc.server(futures.ThreadPoolExecutor(max_workers=10)) 43 recommendations_pb2_grpc.add_RecommendationsServicer_to_server( 44 RecommendationService(), server 45 ) 46 server.add_insecure_port("[::]:50051") 47 server.start() 48 server.wait_for_termination() 49 50 51if __name__ == "__main__": 52 serve()
serve()启动网络服务器并使用您的微服务类来处理请求:
- 第 42 行创建一个 gRPC 服务器。您告诉它使用
10线程来服务请求,这对于这个演示来说完全是多余的,但是对于实际的 Python 微服务来说是一个很好的默认设置。- 第 43 行将你的类与服务器关联起来。这就像为请求添加一个处理程序。
- 第 46 行告诉服务器在端口
50051上运行。如前所述,这是 gRPC 的标准端口,但是您可以使用任何您喜欢的端口。- 47 和 48 线调用
server.start()和server.wait_for_termination()启动微服务,等待微服务停止。在这种情况下,停止它的唯一方法是在终端中键入Ctrl+C。在生产环境中,有更好的关闭方法,稍后您将会看到。在不关闭用于测试客户端的终端的情况下,打开一个新的终端并运行以下命令:
$ python recommendations.py这将运行建议微服务,以便您可以在一些实际数据上测试客户端。现在返回到您用来测试客户机的终端,这样您就可以创建通道存根了。如果您让控制台保持打开状态,那么您可以跳过导入,但这里会重复这些内容作为复习:
>>> import grpc
>>> from recommendations_pb2_grpc import RecommendationsStub
>>> channel = grpc.insecure_channel("localhost:50051")
>>> client = RecommendationsStub(channel)
现在您有了一个客户机对象,您可以发出一个请求:
>>> request = RecommendationRequest( ... user_id=1, category=BookCategory.SCIENCE_FICTION, max_results=3) >>> client.Recommend(request) recommendations { id: 6 title: "The Dune Chronicles" } recommendations { id: 4 title: "The Hitchhiker\'s Guide To The Galaxy" } recommendations { id: 5 title: "Ender\'s Game" }有用!你向你的微服务发出 RPC 请求,得到了响应!请注意,您看到的输出可能会有所不同,因为推荐是随机选择的。
现在您已经实现了服务器,您可以实现 Marketplace 微服务并让它调用建议微服务。如果您愿意,现在可以关闭 Python 控制台,但让建议微服务保持运行。
把它绑在一起
为您的 Marketplace 微服务创建一个新的
marketplace/目录,并在其中放入一个marketplace.py文件。您的目录树现在应该如下所示:. ├── marketplace/ │ ├── marketplace.py │ ├── requirements.txt │ └── templates/ │ └── homepage.html | ├── protobufs/ │ └── recommendations.proto | └── recommendations/ ├── recommendations.py ├── recommendations_pb2.py ├── recommendations_pb2_grpc.py └── requirements.txt请注意您的微服务代码
requirements.txt的新marketplace/目录和一个主页。所有这些都将在下面描述。您现在可以为它们创建空文件,以后再填充它们。可以从微服务代码开始。Marketplace 微服务将是一个向用户显示网页的应用程序。它将调用推荐微服务来获取图书推荐,并显示在页面上。
打开
marketplace/marketplace.py文件并添加以下内容:1# marketplace/marketplace.py 2import os 3 4from flask import Flask, render_template 5import grpc 6 7from recommendations_pb2 import BookCategory, RecommendationRequest 8from recommendations_pb2_grpc import RecommendationsStub 9 10app = Flask(__name__) 11 12recommendations_host = os.getenv("RECOMMENDATIONS_HOST", "localhost") 13recommendations_channel = grpc.insecure_channel( 14 f"{recommendations_host}:50051" 15) 16recommendations_client = RecommendationsStub(recommendations_channel) 17 18 19@app.route("/") 20def render_homepage(): 21 recommendations_request = RecommendationRequest( 22 user_id=1, category=BookCategory.MYSTERY, max_results=3 23 ) 24 recommendations_response = recommendations_client.Recommend( 25 recommendations_request 26 ) 27 return render_template( 28 "homepage.html", 29 recommendations=recommendations_response.recommendations, 30 )您设置了 Flask,创建了一个 gRPC 客户机,并添加了一个函数来呈现主页。这里有一个细目分类:
- 第 10 行创建一个 Flask app,为用户呈现网页。
- 第 12 行到第 16 行创建您的 gRPC 通道和存根。
- 第 20 到 30 行创建当用户访问你的应用程序的主页时被调用的
render_homepage()。它返回一个从模板加载的 HTML 页面,带有三个科幻书籍推荐。注意:在本例中,您将 gRPC 通道和存根创建为全局变量。通常全局变量是不允许的,但是在这种情况下,例外是允许的。
gRPC 通道保持与服务器的持久连接,以避免必须重复连接的开销。它可以处理许多同时发生的请求,并将重新建立丢失的连接。但是,如果您在每次请求之前创建一个新的通道,那么 Python 将对它进行垃圾收集,您将无法获得持久连接的大部分好处。
您希望通道保持开放,这样就不需要为每个请求重新连接到建议微服务。您可以将通道隐藏在另一个模块中,但是在这种情况下,因为您只有一个文件,所以您可以通过使用全局变量来简化事情。
打开您的
marketplace/templates/目录中的homepage.html文件,并添加以下 HTML:1<!-- homepage.html --> 2<!doctype html> 3<html lang="en"> 4<head> 5 <title>Online Books For You</title> 6</head> 7<body> 8 <h1>Mystery books you may like</h1> 9 <ul> 10 {% for book in recommendations %} 11 <li>{{ book.title }}</li> 12 {% endfor %} 13 </ul> 14</body>这只是一个演示主页。当你完成后,它会显示一个书籍推荐列表。
要运行这段代码,您需要以下依赖项,您可以将它们添加到
marketplace/requirements.txt:flask ~= 1.1 grpcio-tools ~= 1.30 Jinja2 ~= 2.11 pytest ~= 5.4推荐和市场微服务都有自己的
requirements.txt,但是为了方便起见,在本教程中,您可以为两者使用相同的虚拟环境。运行以下命令来更新您的虚拟环境:$ python -m pip install -r marketplace/requirements.txt既然已经安装了依赖项,那么还需要在
marketplace/目录中为 protobufs 生成代码。为此,请在控制台中运行以下命令:$ cd marketplace $ python -m grpc_tools.protoc -I ../protobufs --python_out=. \ --grpc_python_out=. ../protobufs/recommendations.proto这与您之前运行的命令相同,因此这里没有什么新内容。在
marketplace/和recommendations/目录中有相同的文件可能会感觉奇怪,但是稍后您将看到如何在部署中自动生成这些文件。您通常不会将它们存储在像 Git 这样的版本控制系统中。要运行 Marketplace 微服务,请在控制台中输入以下内容:
$ FLASK_APP=marketplace.py flask run现在,您应该在两个独立的控制台中运行推荐和市场微服务。如果您关闭了建议微服务,请使用以下命令在另一个控制台中重新启动它:
$ cd recommendations $ python recommendations.py这将运行您的 Flask 应用程序,该应用程序默认运行在端口
5000上。继续,在浏览器中打开它并检查它:
您现在有两个微服务在相互对话!但是它们仍然只是在你的开发机器上。接下来,您将学习如何将它们应用到生产环境中。
你可以在运行 Python 微服务的终端输入
Ctrl+C来停止它们。接下来您将在 Docker 中运行这些,这就是它们在生产环境中的运行方式。生产就绪 Python 微服务
此时,您的开发机器上运行着一个 Python 微服务架构,这对于测试来说非常好。在本节中,您将让它在云中运行。
码头工人
Docker 是一项了不起的技术,可以让你将一组进程与同一台机器上的其他进程隔离开来。您可以有两组或更多组进程,它们有自己的文件系统、网络端口等等。你可以把它想象成一个 Python 虚拟环境,但对整个系统来说更安全。
Docker 非常适合部署 Python 微服务,因为您可以打包所有依赖项,并在隔离的环境中运行微服务。当你将你的微服务部署到云中时,它可以和其他微服务运行在同一台机器上,而不会互相影响。这允许更好的资源利用。
本教程不会深入介绍 Docker,因为它需要一整本书来介绍。相反,您只需了解将 Python 微服务部署到云中所需的基础知识。关于 Docker 的更多信息,可以查看 Python Docker 教程。
在开始之前,如果你想在你的机器上继续,那么确保你已经安装了 Docker。可以从官网下载。
您将创建两个 Docker 图像,一个用于市场微服务,另一个用于推荐微服务。映像基本上是一个文件系统加上一些元数据。本质上,你的每个微服务都有一个迷你 Linux 环境。它可以在不影响实际文件系统的情况下写入文件,并在不与其他进程冲突的情况下打开端口。
要创建您的图像,您需要定义一个
Dockerfile。你总是从一个有一些基本东西的基础图像开始。在这种情况下,您的基本映像将包含一个 Python 解释器。然后将文件从开发机器复制到 Docker 映像中。您还可以在 Docker 映像中运行命令。这对于安装依赖项很有用。推荐
Dockerfile您将从创建建议微服务 Docker 映像开始。创建
recommendations/Dockerfile并添加以下内容:1FROM python 2 3RUN mkdir /service 4COPY protobufs/ /service/protobufs/ 5COPY recommendations/ /service/recommendations/ 6WORKDIR /service/recommendations 7RUN python -m pip install --upgrade pip 8RUN python -m pip install -r requirements.txt 9RUN python -m grpc_tools.protoc -I ../protobufs --python_out=. \ 10 --grpc_python_out=. ../protobufs/recommendations.proto 11 12EXPOSE 50051 13ENTRYPOINT [ "python", "recommendations.py" ]下面是一行一行的演练:
第 1 行用一个基本的 Linux 环境加上最新版本的 Python 来初始化你的映像。此时,您的映像具有典型的 Linux 文件系统布局。如果你往里面看,它会有
/bin、/home,以及你所期望的所有基本文件。第 3 行在
/service创建一个新目录来包含你的微服务代码。第 4 行和第 5 行将
protobufs/和recommendations/目录复制到/service中。第 6 行给 Docker 一个
WORKDIR /service/recommendations指令,有点像在图像内部做一个cd。你给 Docker 的任何路径都将相对于这个位置,当你运行一个命令时,它将在这个目录中运行。第 7 行更新
pip以避免关于旧版本的警告。第 8 行告诉 Docker 在图像内部运行
pip install -r requirements.txt。这将把所有的grpcio-tools文件以及您可能添加的任何其他包添加到映像中。请注意,您没有使用虚拟环境,因为这是不必要的。在这个映像中唯一运行的将是你的微服务,所以你不需要进一步隔离它的环境。第 9 行运行
python -m grpc_tools.protoc命令从 protobuf 文件生成 Python 文件。映像中的/service目录现在看起来像这样:/service/ | ├── protobufs/ │ └── recommendations.proto | └── recommendations/ ├── recommendations.py ├── recommendations_pb2.py ├── recommendations_pb2_grpc.py └── requirements.txt`第 12 行告诉 Docker,您将在端口
50051上运行一个微服务,并且您想要在映像之外公开它。第 13 行告诉 Docker 如何运行你的微服务。
现在您可以从您的
Dockerfile生成一个 Docker 图像。从包含所有代码的目录中运行下面的命令——不是在recommendations/目录中,而是在该目录的上一级:$ docker build . -f recommendations/Dockerfile -t recommendations这将为建议微服务构建 Docker 映像。当 Docker 构建图像时,您应该会看到一些输出。现在您可以运行它了:
$ docker run -p 127.0.0.1:50051:50051/tcp recommendations您不会看到任何输出,但是您的推荐微服务现在正在 Docker 容器中运行。当你运行一个图像时,你得到一个容器。您可以多次运行该图像以获得多个容器,但是仍然只有一个图像。
-p 127.0.0.1:50051:50051/tcp选项告诉 Docker 将机器上端口50051上的 TCP 连接转发到容器内的端口50051。这为您提供了在机器上转发不同端口的灵活性。例如,如果您正在运行两个容器,它们都在端口
50051上运行 Python 微服务,那么您将需要在您的主机上使用两个不同的端口。这是因为两个进程不能同时打开同一个端口,除非它们在不同的容器中。市场
Dockerfile接下来,你将建立你的市场形象。创建
marketplace/Dockerfile并添加以下内容:1FROM python 2 3RUN mkdir /service 4COPY protobufs/ /service/protobufs/ 5COPY marketplace/ /service/marketplace/ 6WORKDIR /service/marketplace 7RUN python -m pip install --upgrade pip 8RUN python -m pip install -r requirements.txt 9RUN python -m grpc_tools.protoc -I ../protobufs --python_out=. \ 10 --grpc_python_out=. ../protobufs/recommendations.proto 11 12EXPOSE 5000 13ENV FLASK_APP=marketplace.py 14ENTRYPOINT [ "flask", "run", "--host=0.0.0.0"]这与建议
Dockerfile非常相似,但有几点不同:
- 第 13 行使用
ENV FLASK_APP=marketplace.py设置图像内部的环境变量FLASK_APP。弗拉斯克需要这个来运行。- 第 14 行将
--host=0.0.0.0添加到flask run命令中。如果不添加这个,那么 Flask 将只接受来自本地主机的连接。但是等等,你不是还在
localhost上运行一切吗?不完全是。当您运行 Docker 容器时,默认情况下它与您的主机是隔离的。集装箱内的localhost与集装箱外的localhost不同,即使在同一台机器上。这就是为什么你需要告诉 Flask 接受来自任何地方的连接。去打开一个新的终端。您可以使用以下命令构建您的市场形象:
$ docker build . -f marketplace/Dockerfile -t marketplace这创造了市场形象。现在,您可以使用以下命令在容器中运行它:
$ docker run -p 127.0.0.1:5000:5000/tcp marketplace您不会看到任何输出,但是您的 Marketplace 微服务现在正在运行。
联网
不幸的是,即使你的推荐和市场容器都在运行,如果你现在在浏览器中进入
http://localhost:5000,你会得到一个错误。您可以连接到您的 Marketplace 微服务,但它无法再连接到建议微服务。容器是隔离的。幸运的是,Docker 提供了一个解决方案。您可以创建一个虚拟网络,并将两个容器都添加到其中。您还可以为他们提供 DNS 名称,以便他们可以找到彼此。
下面,您将创建一个名为
microservices的网络,并在其上运行建议微服务。您还将为其指定 DNS 名称recommendations。首先,用Ctrl+C停止当前运行的容器。然后运行以下命令:$ docker network create microservices $ docker run -p 127.0.0.1:50051:50051/tcp --network microservices \ --name recommendations recommendations
docker network create命令创建网络。你只需要这样做一次,然后你可以连接多个容器。然后将‑‑network microservices添加到docker run命令中,以启动这个网络上的容器。‑‑name recommendations选项赋予它 DNS 名称recommendations。在重启 marketplace 容器之前,您需要更改代码。这是因为您在来自
marketplace.py的这一行中硬编码了localhost:50051:recommendations_channel = grpc.insecure_channel("localhost:50051")现在你想连接到
recommendations:50051而不是。但是,您可以从环境变量中加载它,而不是再次硬编码。用下面的两行替换上面的行:recommendations_host = os.getenv("RECOMMENDATIONS_HOST", "localhost") recommendations_channel = grpc.insecure_channel( f"{recommendations_host}:50051" )这将在环境变量
RECOMMENDATIONS_HOST中加载建议微服务的主机名。如果没有设置,那么可以默认为localhost。这允许您直接在机器上或在容器中运行相同的代码。由于更改了代码,您需要重新构建市场映像。然后尝试在您的网络上运行它:
$ docker build . -f marketplace/Dockerfile -t marketplace $ docker run -p 127.0.0.1:5000:5000/tcp --network microservices \ -e RECOMMENDATIONS_HOST=recommendations marketplace这与您之前运行它的方式相似,但是有两个不同之处:
您添加了
‑‑network microservices选项,以便在与您的建议微服务相同的网络上运行它。您没有添加‑‑name选项,因为与推荐微服务不同,不需要查找市场微服务的 IP 地址。-p 127.0.0.1:5000:5000/tcp提供的端口转发就够了,不需要 DNS 名称。您添加了
-e RECOMMENDATIONS_HOST=recommendations,它在容器内部设置环境变量。这就是将建议微服务的主机名传递给代码的方式。此时,您可以在浏览器中再次尝试
localhost:5000,它应该会正确加载。万岁。坞站组成〔t0〕
你可以用 Docker 做到这一切,这很神奇,但是有点繁琐。如果有一个命令可以启动所有的容器,那就太好了。幸好有!它叫做
docker-compose,是 Docker 项目的一部分。您可以在 YAML 文件中声明您的微服务,而不是运行一堆命令来构建映像、创建网络和运行容器:
1version: "3.8" 2services: 3 4 marketplace: 5 build: 6 context: . 7 dockerfile: marketplace/Dockerfile 8 environment: 9 RECOMMENDATIONS_HOST: recommendations 10 image: marketplace 11 networks: 12 - microservices 13 ports: 14 - 5000:5000 15 16 recommendations: 17 build: 18 context: . 19 dockerfile: recommendations/Dockerfile 20 image: recommendations 21 networks: 22 - microservices 23 24networks: 25 microservices:通常,您将它放入一个名为
docker-compose.yaml的文件中。将它放在项目的根目录中:. ├── marketplace/ │ ├── marketplace.py │ ├── requirements.txt │ └── templates/ │ └── homepage.html | ├── protobufs/ │ └── recommendations.proto | ├── recommendations/ │ ├── recommendations.py │ ├── recommendations_pb2.py │ ├── recommendations_pb2_grpc.py │ └── requirements.txt │ └── docker-compose.yaml本教程不会涉及太多语法细节,因为它在其他地方有很好的文档。它实际上只是做了你已经手动做过的同样的事情。然而,现在您只需要运行一个命令来启动您的网络和容器:
$ docker-compose up一旦运行完毕,你应该能够在浏览器中再次打开
localhost:5000,并且一切都应该运行良好。请注意,当
recommendations容器与 Marketplace 微服务在同一个网络中时,您不需要在容器中公开50051,因此您可以删除这一部分。注意:用
docker-compose开发时,如果你更改了任何一个文件,那么运行docker-compose build来重建镜像。如果你运行docker-compose up,它将使用旧的图像,这可能会令人困惑。如果您想在向上移动之前停止
docker-compose进行一些编辑,请按Ctrl+C。测试
为了单元测试你的 Python 微服务,你可以实例化你的微服务类并调用它的方法。这里有一个针对您的
RecommendationService实现的基本示例测试:1# recommendations/recommendations_test.py 2from recommendations import RecommendationService 3 4from recommendations_pb2 import BookCategory, RecommendationRequest 5 6def test_recommendations(): 7 service = RecommendationService() 8 request = RecommendationRequest( 9 user_id=1, category=BookCategory.MYSTERY, max_results=1 10 ) 11 response = service.Recommend(request, None) 12 assert len(response.recommendations) == 1这里有一个细目分类:
- 第 6 行像实例化其他类一样实例化该类,并在其上调用方法。
- 第 11 行为上下文传递
None,只要不使用就行。如果您想测试使用上下文的代码路径,那么您可以模拟它。集成测试包括使用多个未模拟出来的微服务运行自动化测试。所以这有点复杂,但并不难。添加一个
marketplace/marketplace_integration_test.py文件:from urllib.request import urlopen def test_render_homepage(): homepage_html = urlopen("http://localhost:5000").read().decode("utf-8") assert "<title>Online Books For You</title>" in homepage_html assert homepage_html.count("<li>") == 3这会向主页 URL 发出一个 HTTP 请求,并检查它是否返回了一些带有标题和三个
<li>项目符号元素的 HTML。这不是最大的测试,因为如果页面上有更多的内容,它就不太容易维护,但是它证明了一点。只有当建议微服务启动并运行时,此测试才会通过。您甚至可以通过向 Marketplace 微服务发出 HTTP 请求来测试它。那么,如何运行这种类型的测试呢?幸运的是,Docker 的好心人也提供了这样的方法。一旦使用
docker-compose运行 Python 微服务,就可以使用docker-compose exec在其中运行命令。因此,如果您想在marketplace容器中运行您的集成测试,您可以运行以下命令:$ docker-compose build $ docker-compose up $ docker-compose exec marketplace pytest marketplace_integration_test.py这将在
marketplace容器中运行pytest命令。因为您的集成测试连接到localhost,所以您需要在与微服务相同的容器中运行它。部署到 Kubernetes
太好了!现在,您的计算机上运行了几个微服务。您可以快速启动它们,并对它们运行集成测试。但是你需要让他们进入生产环境。为此,您将使用 Kubernetes 。
本教程不会深入讨论 Kubernetes,因为这是一个很大的主题,其他地方有全面的文档和教程。然而,在本节中,您将找到将 Python 微服务部署到云中的 Kubernetes 集群的基础知识。
注意:要将 Docker 映像部署到云提供商,您需要将您的 Docker 映像推送到像 Docker Hub 这样的映像注册中心。
以下示例使用了本教程中的图像,这些图像已经被推送到 Docker Hub。如果你想改变它们,或者如果你想创建自己的微服务,那么你需要在 Docker Hub 上创建一个帐户,这样你就可以推送图像。如果你愿意,你也可以创建一个私人注册中心,或者使用另一个注册中心,比如亚马逊的 ECR。
立方结构〔t0〕
您可以从
kubernetes.yaml中的最小 Kubernetes 配置开始。完整的文件有点长,但它由四个不同的部分组成,所以您将逐个查看它们:1--- 2apiVersion: apps/v1 3kind: Deployment 4metadata: 5 name: marketplace 6 labels: 7 app: marketplace 8spec: 9 replicas: 3 10 selector: 11 matchLabels: 12 app: marketplace 13 template: 14 metadata: 15 labels: 16 app: marketplace 17 spec: 18 containers: 19 - name: marketplace 20 image: hidan/python-microservices-article-marketplace:0.1 21 env: 22 - name: RECOMMENDATIONS_HOST 23 value: recommendations这为市场微服务定义了一个部署。一个部署告诉 Kubernetes 如何部署你的代码。Kubernetes 需要四条主要信息:
- 要部署什么 Docker 映像
- 要部署多少个实例
- 微服务需要什么样的环境变量
- 如何识别你的微服务
你可以告诉 Kubernetes 如何通过使用标签来识别你的微服务。虽然这里没有显示,但是你也可以告诉 Kubernetes 你的微服务需要什么内存和 CPU 资源。您可以在 Kubernetes 文档中找到许多其他选项。
下面是代码中发生的情况:
第 9 行告诉 Kubernetes 为你的微服务创建多少个 pod。一个 pod 基本上是一个隔离的执行环境,就像作为一组容器实现的轻量级虚拟机。设置
replicas: 3为每个微服务提供三个 pod。拥有多台机器可以实现冗余,无需停机即可滚动更新,可以根据需要扩展更多机器,并在一台机器出现故障时进行故障转移。第 20 行是要部署的 Docker 映像。您必须在图像注册表中使用 Docker 图像。要在那里获得您的图像,您必须将其推送到图像注册中心。当你在 Docker Hub 上登录你的账户时,有关于如何做到这一点的说明。
建议微服务的部署非常相似:
24--- 25apiVersion: apps/v1 26kind: Deployment 27metadata: 28 name: recommendations 29 labels: 30 app: recommendations 31spec: 32 replicas: 3 33 selector: 34 matchLabels: 35 app: recommendations 36 template: 37 metadata: 38 labels: 39 app: recommendations 40 spec: 41 containers: 42 - name: recommendations 43 image: hidan/python-microservices-article-recommendations:0.1主要区别是一个用名字
marketplace,一个用recommendations。您还在marketplace部署上设置了RECOMMENDATIONS_HOST环境变量,但是没有在recommendations部署上设置。接下来,为推荐微服务定义一个服务。部署告诉 Kubernetes 如何部署您的代码,而服务告诉它如何将请求路由到它。为了避免与通常用来谈论微服务的术语服务混淆,当提到 Kubernetes 服务时,您会看到这个词被大写。
以下是
recommendations的服务定义:44--- 45apiVersion: v1 46kind: Service 47metadata: 48 name: recommendations 49spec: 50 selector: 51 app: recommendations 52 ports: 53 - protocol: TCP 54 port: 50051 55 targetPort: 50051下面是定义中发生的情况:
第 48 行:当您创建一个服务时,Kubernetes 实际上会在集群中创建一个具有相同
name的 DNS 主机名。因此集群中的任何微服务都可以向recommendations发送请求。Kubernetes 会将此请求转发到您的部署中的一个单元。第 51 行:该行将服务连接到部署。它告诉 Kubernetes 将对
recommendations的请求转发到recommendations部署中的一个 pod。这必须匹配部署的labels中的一个键值对。
marketplace服务是类似的:56--- 57apiVersion: v1 58kind: Service 59metadata: 60 name: marketplace 61spec: 62 type: LoadBalancer 63 selector: 64 app: marketplace 65 ports: 66 - protocol: TCP 67 port: 5000 68 targetPort: 5000除了名称和端口,只有一个区别。您会注意到
type: LoadBalancer只出现在marketplace服务中。这是因为marketplace需要从 Kubernetes 集群外部访问,而recommendations只需要在集群内部访问。注意:在有很多微服务的大型集群中,使用
Ingress服务比使用LoadBalancer服务更常见。如果你在企业环境中开发微服务,那么这可能是一条可行之路。查看 Sandeep Dinesh 的文章 Kubernetes 节点端口 vs 负载平衡器 vs 入口?什么时候该用什么?了解更多信息。
您可以通过展开下面的框来查看完整的文件:
1--- 2apiVersion: apps/v1 3kind: Deployment 4metadata: 5 name: marketplace 6 labels: 7 app: marketplace 8spec: 9 replicas: 3 10 selector: 11 matchLabels: 12 app: marketplace 13 template: 14 metadata: 15 labels: 16 app: marketplace 17 spec: 18 containers: 19 - name: marketplace 20 image: hidan/python-microservices-article-marketplace:0.1 21 env: 22 - name: RECOMMENDATIONS_HOST 23 value: recommendations 24--- 25apiVersion: apps/v1 26kind: Deployment 27metadata: 28 name: recommendations 29 labels: 30 app: recommendations 31spec: 32 replicas: 3 33 selector: 34 matchLabels: 35 app: recommendations 36 template: 37 metadata: 38 labels: 39 app: recommendations 40 spec: 41 containers: 42 - name: recommendations 43 image: hidan/python-microservices-article-recommendations:0.1 44--- 45apiVersion: v1 46kind: Service 47metadata: 48 name: recommendations 49spec: 50 selector: 51 app: recommendations 52 ports: 53 - protocol: TCP 54 port: 50051 55 targetPort: 50051 56--- 57apiVersion: v1 58kind: Service 59metadata: 60 name: marketplace 61spec: 62 type: LoadBalancer 63 selector: 64 app: marketplace 65 ports: 66 - protocol: TCP 67 port: 5000 68 targetPort: 5000现在您已经有了 Kubernetes 配置,下一步是部署它!
部署 Kubernetes
您通常使用云提供商来部署 Kubernetes。有很多云提供商可以选择,包括谷歌 Kubernetes 引擎(GKE) 、亚马逊弹性 Kubernetes 服务(EKS) 、数字海洋。
如果您在自己的公司部署微服务,那么您使用的云提供商可能会由您的基础架构决定。对于这个演示,您将在本地运行 Kubernetes。几乎一切都将和使用云提供商一样。
如果你在 Mac 或 Windows 上运行 Docker Desktop,那么它会附带一个本地 Kubernetes 集群,你可以在 Preferences 菜单中启用它。通过点按系统托盘中的 Docker 图标打开偏好设置,然后找到 Kubernetes 部分并启用它:
如果你运行的是 Linux,那么你可以安装 minikube 。按照起始页上的说明进行设置。
创建集群后,可以使用以下命令部署微服务:
$ kubectl apply -f kubernetes.yaml如果你想尝试在云中部署到 Kubernetes,DigitalOcean 是设置最简单的,并且有一个简单的定价模型。你可以注册账户,然后点击几下就可以创建一个 Kubernetes 集群。如果您更改默认值,只使用一个节点和最便宜的选项,那么在撰写本文时,成本仅为每小时 0.015 美元。
按照 DigitalOcean 提供的说明为
kubectl下载一个配置文件并运行上面的命令。然后你可以点击 DigitalOcean 中的 Kubernetes 按钮来查看你的服务在那里运行。DigitalOcean 将为您的LoadBalancer服务分配一个 IP 地址,因此您可以通过将该 IP 地址复制到浏览器中来访问您的 Marketplace 应用程序。重要提示:当你完成后,销毁你的集群,这样你就不会继续被收费。您还应该转到 Networking 选项卡并销毁负载平衡器,它独立于群集,但也会产生费用。
部署到库伯内特斯。接下来,您将学习如何监控 Python 微服务。
使用拦截器的 Python 微服务监控
一旦你在云中有了一些微服务,你就想要了解它们的运行情况。您希望监控的一些内容包括:
- 每个微服务收到多少请求
- 有多少请求会导致错误,它们会引发什么类型的错误
- 每个请求的延迟
- 异常日志,以便您以后进行调试
在下面几节中,您将了解到实现这一点的几种方法。
为什么不是装修工
有一种方法可以做到这一点,对 Python 开发人员来说最自然的方法是为每个微服务端点添加一个装饰器。然而,在这种情况下,使用 decorators 有几个缺点:
- 新微服务的开发人员必须记住将它们添加到每个方法中。
- 如果你有很多监控,那么你可能会有一堆装饰器。
- 如果你有一个 decorators 的堆栈,那么开发者可能会以错误的顺序堆叠它们。
- 您可以将所有的监控整合到一个装饰器中,但是这样会很麻烦。
这一堆装饰器是你想要避免的:
1class RecommendationService(recommendations_pb2_grpc.RecommendationsServicer): 2 @catch_and_log_exceptions 3 @log_request_counts 4 @log_latency 5 def Recommend(self, request, context): 6 ...在每个方法上都有这一堆装饰器是丑陋和重复的,并且违反了干编程原则:不要重复自己。装饰者也是一个编写挑战,尤其是如果他们接受参数的话。
截击机
有一种使用装饰器的替代方法,您将在本教程中学习:gRPC 有一个拦截器的概念,它提供了类似于装饰器的功能,但方式更简洁。
实现拦截器
不幸的是,gRPC 的 Python 实现为拦截器提供了一个相当复杂的 API。这是因为它的非常灵活。但是,有一个
grpc-interceptor包可以简化它们。为了充分披露,我是作者。将它与
pytest一起添加到您的recommendations/requirements.txt中,您很快就会用到它们:grpc-interceptor ~= 0.12.0 grpcio-tools ~= 1.30 pytest ~= 5.4然后更新您的虚拟环境:
$ python -m pip install recommendations/requirements.txt现在可以用下面的代码创建一个拦截器。您不需要将它添加到您的项目中,因为它只是一个示例:
1from grpc_interceptor import ServerInterceptor 2 3class ErrorLogger(ServerInterceptor): 4 def intercept(self, method, request, context, method_name): 5 try: 6 return method(request, context) 7 except Exception as e: 8 self.log_error(e) 9 raise 10 11 def log_error(self, e: Exception) -> None: 12 # ...每当调用微服务中未处理的异常时,它都会调用
log_error()。例如,您可以通过将异常记录到岗哨来实现这一点,这样当它们发生时,您就可以得到警告和调试信息。要使用这个拦截器,您应该像这样将它传递给
grpc.server():interceptors = [ErrorLogger()] server = grpc.server(futures.ThreadPoolExecutor(max_workers=10), interceptors=interceptors)有了这段代码,Python 微服务的每个请求和响应都将通过拦截器,因此您可以计算它收到了多少请求和错误。
grpc-interceptor还为每个 gRPC 状态代码提供了一个异常和一个名为ExceptionToStatusInterceptor的拦截器。如果微服务引发其中一个异常,那么ExceptionToStatusInterceptor将设置 gRPC 状态代码。这使您可以通过对recommendations/recommendations.py进行以下突出显示的更改来简化您的微服务:1from grpc_interceptor import ExceptionToStatusInterceptor 2from grpc_interceptor.exceptions import NotFound 3 4# ... 5 6class RecommendationService(recommendations_pb2_grpc.RecommendationsServicer): 7 def Recommend(self, request, context): 8 if request.category not in books_by_category: 9 raise NotFound("Category not found") 10 11 books_for_category = books_by_category[request.category] 12 num_results = min(request.max_results, len(books_for_category)) 13 books_to_recommend = random.sample(books_for_category, num_results) 14 15 return RecommendationResponse(recommendations=books_to_recommend) 16 17def serve(): 18 interceptors = [ExceptionToStatusInterceptor()] 19 server = grpc.server( 20 futures.ThreadPoolExecutor(max_workers=10), 21 interceptors=interceptors 22 ) 23 # ...这样可读性更强。您还可以从调用堆栈中的许多函数中抛出异常,而不必传递
context,这样您就可以调用context.abort()。您也不必在您的微服务中自己捕捉异常——拦截器会为您捕捉它。测试拦截器
如果您想编写自己的拦截器,那么您应该测试它们。但是在测试拦截器这样的东西时,过多地模仿是危险的。例如,您可以在测试中调用
.intercept(),并确保它返回您想要的结果,但是这不会测试真实的输入,或者它们甚至根本不会被调用。为了改进测试,您可以运行带有拦截器的 gRPC 微服务。
grpc-interceptor包提供了一个框架来完成这项工作。下面,您将为ErrorLogger拦截器编写一个测试。这只是一个示例,所以您不需要将其添加到项目中。如果您要添加它,那么您应该将它添加到测试文件中。下面是如何为拦截器编写测试的方法:
1from grpc_interceptor.testing import dummy_client, DummyRequest, raises 2 3class MockErrorLogger(ErrorLogger): 4 def __init__(self): 5 self.logged_exception = None 6 7 def log_error(self, e: Exception) -> None: 8 self.logged_exception = e 9 10def test_log_error(): 11 mock = MockErrorLogger() 12 ex = Exception() 13 special_cases = {"error": raises(ex)} 14 15 with dummy_client(special_cases=special_cases, interceptors=[mock]) as client: 16 # Test no exception 17 assert client.Execute(DummyRequest(input="foo")).output == "foo" 18 assert mock.logged_exception is None 19 20 # Test exception 21 with pytest.raises(grpc.RpcError) as e: 22 client.Execute(DummyRequest(input="error")) 23 assert mock.logged_exception is ex这里有一个演练:
第 3 行到第 8 行子类
ErrorLogger模仿出log_error()。你实际上不希望日志副作用发生。你只是想确保它被调用。第 15 到 18 行使用
dummy_client()上下文管理器创建一个连接到真实 gRPC 微服务的客户端。你发送DummyRequest给微服务,它回复DummyResponse。默认情况下,DummyRequest的input回显到DummyResponse的output。但是,你可以传递给dummy_client()一个特殊情况的字典,如果input匹配其中一个,那么它将调用你提供的函数并返回结果。第 21 行到第 23 行:测试
log_error()被调用时出现了预期的异常。raises()返回引发所提供异常的另一个函数。您将input设置为error,这样微服务就会引发一个异常。关于测试的更多信息,你可以阅读用 Pytest 进行有效的 Python 测试和了解 Python 模拟对象库。
在某些情况下,拦截器的替代方案是使用服务网格。它将通过代理发送所有微服务请求和响应,因此代理可以自动记录请求量和错误计数等信息。为了获得准确的错误记录,您的微服务仍然需要正确设置状态代码。所以在某些情况下,您的拦截器可以补充服务网格。一个受欢迎的服务网是 T2 Istio T3。
最佳实践
现在您已经有了一个可以工作的 Python 微服务设置。您可以创建微服务,一起测试它们,将它们部署到 Kubernetes,并用拦截器监控它们。此时,您可以开始创建微服务。但是,您应该记住一些最佳实践,因此您将在本节中学习一些。
Protobuf 组织
通常,您应该将 protobuf 定义与微服务实现分开。客户端几乎可以用任何语言编写,如果你把你的 protobuf 文件捆绑到一个 Python wheel 或者类似的东西中,那么如果有人想要一个 Ruby 或者 Go 客户端,他们将很难得到 protobuf 文件。
即使你所有的代码都是 Python,为什么有人需要为微服务安装包,只是为了给它写一个客户端?
一个解决方案是将 protobuf 文件放在与微服务代码分开的 Git repo 中。许多公司将所有微服务的所有proto buf 文件放在一个单独的 repo 中。这使得更容易找到所有的微服务,在它们之间共享公共的 protobuf 结构,并创建有用的工具。
如果您选择将 protobuf 文件存储在单个 repo 中,那么您需要注意保持 repo 的有序,并且您一定要避免 Python 微服务之间的循环依赖。
Protobuf 版本控制
API 版本控制可能很难。最主要的原因是,如果你改变了一个 API,更新了微服务,那么可能仍然会有客户端使用旧的 API。当客户端运行在客户的机器上时,例如移动客户端或桌面软件,情况尤其如此。
不能轻易强迫人家更新。即使你可以,网络延迟会导致竞争条件,并且你的微服务很可能使用旧的 API 来获得请求。好的 API 应该是向后兼容的或者版本化的。
为了实现向后兼容性,使用 protobufs 版本 3 的 Python 微服务将接受缺少字段的请求。如果你想增加一个新的领域,那也没问题。您可以先部署微服务,它仍然会接受来自旧 API 的请求,而没有新字段。微服务只需要优雅地处理这个问题。
如果你想做更大的改变,那么你需要更新你的 API。Protobufs 允许您将 API 放入一个包名称空间,其中可以包含一个版本号。如果你需要彻底改变 API,那么你可以创建一个新的版本。微服务也可以继续接受旧版本。这允许您推出新的 API 版本,同时逐步淘汰旧版本。
通过遵循这些惯例,你可以避免做出突破性的改变。在公司内部,人们有时认为对 API 进行突破性的修改是可以接受的,因为他们控制了所有的客户。这由您来决定,但请注意,做出突破性的更改需要协调客户端和微服务的部署,这使得回滚变得复杂。
在微服务生命周期的早期,当没有生产客户端时,这是可以接受的。然而,一旦你的微服务对你公司的健康至关重要,养成只做非破坏性改变的习惯是很好的。
原蟾蜍林挺
确保你不会对你的 protobufs 做破坏性改变的一个方法是使用 linter 。比较流行的一个是
buf。您可以将此设置为您的 CI 系统的一部分,这样您就可以检查拉动式请求中的重大变更。类型检查 Protobuf 生成的代码
Mypy 是一个静态类型检查 Python 代码的项目。如果您不熟悉 Python 中的静态类型检查,那么您可以阅读 Python 类型检查来了解它的全部内容。
protoc生成的代码有点粗糙,而且没有类型注释。如果你试着用 Mypy 检查它,那么你会得到很多错误,而且它不会发现真正的错误,比如拼错的字段名。幸运的是,Dropbox 的好心人写了一个插件,让protoc编译器生成类型存根。这些不应与 gRPC 存根混淆。为了使用它,您可以安装
mypy-protobuf包,然后更新命令以生成 protobuf 输出。请注意新的‑‑mypy_out选项:$ python -m grpc_tools.protoc -I ../protobufs --python_out=. \ --grpc_python_out=. --mypy_out=. ../protobufs/recommendations.proto你的大多数错误应该会消失。您可能仍然会得到一个关于
grpc包没有类型信息的错误。你可以安装非官方的 gRPC 类型的存根或者添加以下内容到你的 Mypy 配置中:[mypy-grpc.*] ignore_missing_imports = True您仍然可以获得类型检查的大部分好处,比如捕捉拼写错误的字段。这对于在 bug 进入生产之前捕捉它们非常有帮助。
优雅地关机
在你的开发机器上运行你的微服务时,你可以按
Ctrl+C来停止它。这将导致 Python 解释器引发一个KeyboardInterrupt异常。当 Kubernetes 正在运行你的微服务,需要停止它以推出更新时,它会向你的微服务发送信号。具体来说,它会发出一个
SIGTERM信号,等待三十秒。如果你的微服务到那时还没有退出,它会发送一个SIGKILL信号。您可以并且应该捕获并处理
SIGTERM,这样您就可以完成当前请求的处理,但拒绝新的请求。您可以通过将以下代码放入serve()中来实现这一点:1from signal import signal, SIGTERM 2 3... 4 5def serve(): 6 server = grpc.server(futures.ThreadPoolExecutor(max_workers=10)) 7 ... 8 server.add_insecure_port("[::]:50051") 9 server.start() 10 11 def handle_sigterm(*_): 12 print("Received shutdown signal") 13 all_rpcs_done_event = server.stop(30) 14 all_rpcs_done_event.wait(30) 15 print("Shut down gracefully") 16 17 signal(SIGTERM, handle_sigterm) 18 server.wait_for_termination()这里有一个细目分类:
- 线 1 导入
signal,允许你捕捉和处理来自 Kubernetes 或者几乎任何其他过程的信号。- 第 11 行定义了一个函数来处理
SIGTERM。该函数将在 Python 接收到SIGTERM信号时被调用,Python 将向其传递两个参数。然而,你不需要这些参数,所以用*_来忽略它们。- 第 13 行调用
server.stop(30)优雅地关闭服务器。它将拒绝新的请求,并等待30秒,等待当前请求完成。它立即返回,但是它返回一个可以等待的threading.Event对象。- 第 14 行等待
Event对象,这样 Python 就不会过早退出。- 第 17 行注册你的处理程序。
当您部署新版本的微服务时,Kubernetes 会发送信号关闭现有的微服务。处理这些问题以优雅地关闭将确保请求不会被丢弃。
安全通道
到目前为止,您一直在使用不安全的 gRPC 通道。这意味着几件事:
客户端无法确认它正在向目标服务器发送请求。有人可以创建一个冒名顶替的微服务,并将其注入客户端可能发送请求的某个地方。例如,他们可能能够将微服务注入到负载平衡器将向其发送请求的 pod 中。
服务器无法确认客户端向其发送请求。只要有人可以连接到服务器,他们就可以向它发送任意 gRPC 请求。
流量是未加密的,因此路由流量的任何节点也可以查看它。
本节将描述如何添加 TLS 认证和加密。
注意:这不解决用户认证问题,只解决微服务流程。
您将学习两种设置 TLS 的方法:
- 最简单的方法是,客户端可以验证服务器,但是服务器不验证客户端。
- 更复杂的方式,使用相互 TLS,客户端和服务器互相验证。
在这两种情况下,流量都是加密的。
TLS 基础知识
在深入研究之前,先简要概述一下 TLS:通常,客户端验证服务器。例如,当你访问 Amazon.com 时,你的浏览器会验证这是真的 Amazon.com 而不是冒名顶替者。要做到这一点,客户必须从一个值得信赖的第三方那里得到某种保证,就像只有当你有一个共同的朋友为他们担保时,你才能信任一个新人。
使用 TLS,客户端必须信任一个证书颁发机构(CA) 。CA 将对服务器保存的内容进行签名,这样客户端就可以对其进行验证。这有点像你共同的朋友在纸条上签名,而你认出了他们的笔迹。更多信息,请参见互联网安全如何工作:TLS、SSL 和 CA 。
您的浏览器隐式信任一些 ca,它们通常是 GoDaddy、DigiCert 或 Verisign 等公司。其他公司,如亚马逊,付钱给 CA 为他们签署数字证书,这样你的浏览器就可以信任他们。通常情况下,CA 会在签署证书之前验证亚马逊是否拥有 Amazon.com。这样,冒名顶替者就不会在 Amazon.com 的证书上签名,你的浏览器也会屏蔽这个网站。
对于微服务,你不能真的要求 CA 签署证书,因为你的微服务运行在内部机器上。CA 可能会很乐意签署证书并向您收费,但问题是这不切实际。在这种情况下,您的公司可以充当自己的 CA。如果 gRPC 客户端拥有由您的公司或您(如果您正在做个人项目)签名的证书,它将信任服务器。
服务器认证
以下命令将创建一个可用于签署服务器证书的 CA 证书:
$ openssl req -x509 -nodes -newkey rsa:4096 -keyout ca.key -out ca.pem \ -subj /O=me这将输出两个文件:
ca.key是私钥。ca.pem是一种公共证书。然后,您可以为您的服务器创建一个证书,并用您的 CA 证书对其进行签名:
$ openssl req -nodes -newkey rsa:4096 -keyout server.key -out server.csr \ -subj /CN=recommendations $ openssl x509 -req -in server.csr -CA ca.pem -CAkey ca.key -set_serial 1 \ -out server.pem这将产生三个新文件:
server.key是服务器的私钥。server.csr是一个中间文件。server.pem是服务器的公共证书。注意:这些命令仅用于举例。私钥是而不是加密的。如果您想为您的公司生成证书,请咨询您的安全团队。他们可能有创建、存储和吊销证书的策略,您应该遵循这些策略。
您可以将此添加到推荐微服务
Dockerfile。很难安全地将秘密添加到 Docker 图像中,但有一种方法可以使用最新版本的 Docker 来做到这一点,如下所示:1# syntax = docker/dockerfile:1.0-experimental 2# DOCKER_BUILDKIT=1 docker build . -f recommendations/Dockerfile \ 3# -t recommendations --secret id=ca.key,src=ca.key 4 5FROM python 6 7RUN mkdir /service 8COPY infra/ /service/infra/ 9COPY protobufs/ /service/protobufs/ 10COPY recommendations/ /service/recommendations/ 11COPY ca.pem /service/recommendations/ 12 13WORKDIR /service/recommendations 14RUN python -m pip install --upgrade pip 15RUN python -m pip install -r requirements.txt 16RUN python -m grpc_tools.protoc -I ../protobufs --python_out=. \ 17 --grpc_python_out=. ../protobufs/recommendations.proto 18RUN openssl req -nodes -newkey rsa:4096 -subj /CN=recommendations \ 19 -keyout server.key -out server.csr 20RUN --mount=type=secret,id=ca.key \ 21 openssl x509 -req -in server.csr -CA ca.pem -CAkey /run/secrets/ca.key \ 22 -set_serial 1 -out server.pem 23 24EXPOSE 50051 25ENTRYPOINT [ "python", "recommendations.py" ]新行将突出显示。这里有一个解释:
- 需要第 1 行来启用机密。
- 第 2 行和第 3 行显示了如何构建 Docker 映像的命令。
- 第 11 行将 CA 公共证书复制到镜像中。
- 第 18 行和第 19 行生成新的服务器私有密钥和证书。
- 第 20 到 22 行临时加载 CA 私钥,这样您就可以用它来签署服务器的证书。但是,它不会保留在图像中。
注:关于
‑‑mount=type=secret的更多信息,参见 Docker 文档。将来,这个特性可能会被提升到稳定版本,那时你就不需要在Dockerfile中包含syntax = docker/dockerfile:1.0-experimental评论了。根据版本化策略,实验性语法不会消失,所以你可以无限期地继续使用它。
您的映像现在将包含以下文件:
ca.pemserver.csrserver.keyserver.pem您现在可以更新突出显示的
recommendations.py中的serve():1def serve(): 2 server = grpc.server(futures.ThreadPoolExecutor(max_workers=10)) 3 recommendations_pb2_grpc.add_RecommendationsServicer_to_server( 4 RecommendationService(), server 5 ) 6 7 with open("server.key", "rb") as fp: 8 server_key = fp.read() 9 with open("server.pem", "rb") as fp: 10 server_cert = fp.read() 11 12 creds = grpc.ssl_server_credentials([(server_key, server_cert)]) 13 server.add_secure_port("[::]:443", creds) 14 server.start() 15 server.wait_for_termination()变化如下:
- 第 7 行到第 10 行加载服务器的私钥和证书。
- 第 12 行和第 13 行使用 TLS 运行服务器。它现在只接受 TLS 加密的连接。
您需要更新
marketplace.py来加载 CA 证书。现在,您只需要客户端中的公共证书,如突出显示的那样:1recommendations_host = os.getenv("RECOMMENDATIONS_HOST", "localhost") 2with open("ca.pem", "rb") as fp: 3 ca_cert = fp.read() 4creds = grpc.ssl_channel_credentials(ca_cert) 5recommendations_channel = grpc.secure_channel( 6 f"{recommendations_host}:443", creds 7) 8recommendations_client = RecommendationsStub(recommendations_channel)您还需要将
COPY ca.pem /service/marketplace/添加到市场Dockerfile中。现在可以加密运行客户机和服务器,客户机将验证服务器。为了使运行一切简单明了,您可以使用
docker-compose。然而,在撰写本文时,docker-compose还不支持建造秘密。你将不得不手动建立 Docker 图像,而不是用docker-compose build。但是,您仍然可以运行
docker-compose up。更新docker-compose.yaml文件,删除build部分:1version: "3.8" 2services: 3 4 marketplace: 5 environment: 6 RECOMMENDATIONS_HOST: recommendations 7 # DOCKER_BUILDKIT=1 docker build . -f marketplace/Dockerfile \ 8 # -t marketplace --secret id=ca.key,src=ca.key 9 image: marketplace 10 networks: 11 - microservices 12 ports: 13 - 5000:5000 14 15 recommendations: 16 # DOCKER_BUILDKIT=1 docker build . -f recommendations/Dockerfile \ 17 # -t recommendations --secret id=ca.key,src=ca.key 18 image: recommendations 19 networks: 20 - microservices 21 22networks: 23 microservices:您现在正在加密流量,并验证您是否连接到了正确的服务器。
相互认证
服务器现在证明了它是可信的,但是客户端却不可信。幸运的是,TLS 允许对双方进行验证。更新高亮显示的市场
Dockerfile:1# syntax = docker/dockerfile:1.0-experimental 2# DOCKER_BUILDKIT=1 docker build . -f marketplace/Dockerfile \ 3# -t marketplace --secret id=ca.key,src=ca.key 4 5FROM python 6 7RUN mkdir /service 8COPY protobufs/ /service/protobufs/ 9COPY marketplace/ /service/marketplace/ 10COPY ca.pem /service/marketplace/ 11 12WORKDIR /service/marketplace 13RUN python -m pip install -r requirements.txt 14RUN python -m grpc_tools.protoc -I ../protobufs --python_out=. \ 15 --grpc_python_out=. ../protobufs/recommendations.proto 16RUN openssl req -nodes -newkey rsa:4096 -subj /CN=marketplace \ 17 -keyout client.key -out client.csr 18RUN --mount=type=secret,id=ca.key \ 19 openssl x509 -req -in client.csr -CA ca.pem -CAkey /run/secrets/ca.key \ 20 -set_serial 1 -out client.pem 21 22EXPOSE 5000 23ENV FLASK_APP=marketplace.py 24ENTRYPOINT [ "flask", "run", "--host=0.0.0.0"]这些更改类似于您在上一节中对建议微服务所做的更改。
注意:如果您将私有密钥放在 docker 文件中,那么不要将它们放在公共存储库中。最好是在运行时通过网络从只能通过 VPN 访问的服务器上加载私钥。
更新
recommendations.py中的serve()以验证突出显示的客户端:1def serve(): 2 server = grpc.server(futures.ThreadPoolExecutor(max_workers=10)) 3 recommendations_pb2_grpc.add_RecommendationsServicer_to_server( 4 RecommendationService(), server 5 ) 6 7 with open("server.key", "rb") as fp: 8 server_key = fp.read() 9 with open("server.pem", "rb") as fp: 10 server_cert = fp.read() 11 with open("ca.pem", "rb") as fp: 12 ca_cert = fp.read() 13 14 creds = grpc.ssl_server_credentials( 15 [(server_key, server_cert)], 16 root_certificates=ca_cert, 17 require_client_auth=True, 18 ) 19 server.add_secure_port("[::]:443", creds) 20 server.start() 21 server.wait_for_termination()这将加载 CA 证书并要求客户端验证。
最后,更新
marketplace.py以将其证书发送到服务器,如突出显示的那样:1recommendations_host = os.getenv("RECOMMENDATIONS_HOST", "localhost") 2with open("client.key", "rb") as fp: 3 client_key = fp.read() 4with open("client.pem", "rb") as fp: 5 client_cert = fp.read() 6with open("ca.pem", "rb") as fp: 7 ca_cert = fp.read() 8creds = grpc.ssl_channel_credentials(ca_cert, client_key, client_cert) 9recommendations_channel = grpc.secure_channel( 10 f"{recommendations_host}:443", creds 11) 12recommendations_client = RecommendationsStub(recommendations_channel)这会加载证书并将它们发送到服务器进行验证。
现在,如果您试图用另一个客户端连接到服务器,即使是一个使用 TLS 但具有未知证书的客户端,服务器也会拒绝它,并显示错误
PEER_DID_NOT_RETURN_A_CERTIFICATE。重要提示:虽然以这种方式管理相互 TLS 是可能的,但要做到这一点并不容易。如果您希望只允许某些微服务向其他微服务发出请求,这将变得特别困难。
如果您需要像这样增强安全性,那么最好使用一个服务网格,让它为您管理证书和授权。除了拦截器部分提到的流量监控, Istio 还可以管理相互 TLS 和每个服务的授权。它也更安全,因为它将为您管理机密,并更频繁地重新颁发证书。
这就完成了微服务之间的安全通信。接下来,您将了解如何将 AsyncIO 与微服务结合使用。
AsyncIO and gRPC
官方 gRPC 包中缺少 AsyncIO 支持已经很长时间了,但是最近已经添加了。它仍然处于实验阶段,正在积极开发中,但如果你真的想在你的微服务中尝试 AsyncIO,那么它可能是一个不错的选择。您可以查看 gRPC AsyncIO 文档了解更多详细信息。
还有一个名为
grpclib的第三方包,它实现了对 gRPC 的 AsyncIO 支持,并且已经存在了很长时间。在服务器端使用 AsyncIO 要非常小心。很容易一不小心写了阻塞代码,让你的微服务瘫痪。作为示范,下面是如何使用 AsyncIO 编写建议微服务,去掉所有逻辑:
1import time 2 3import asyncio 4import grpc 5import grpc.experimental.aio 6 7from recommendations_pb2 import ( 8 BookCategory, 9 BookRecommendation, 10 RecommendationResponse, 11) 12import recommendations_pb2_grpc 13 14class AsyncRecommendations(recommendations_pb2_grpc.RecommendationsServicer): 15 async def Recommend(self, request, context): 16 print("Handling request") 17 time.sleep(5) # Oops, blocking! 18 print("Done") 19 return RecommendationResponse(recommendations=[]) 20 21async def main(): 22 grpc.experimental.aio.init_grpc_aio() 23 server = grpc.experimental.aio.server() 24 server.add_insecure_port("[::]:50051") 25 recommendations_pb2_grpc.add_RecommendationsServicer_to_server( 26 AsyncRecommendations(), server 27 ) 28 await server.start() 29 await server.wait_for_termination() 30 31asyncio.run(main())这段代码中有一个错误。在第 17 行,您意外地在一个
async函数中进行了一个阻塞调用,这是一个大禁忌。因为 AsyncIO 服务器是单线程的,这阻塞了整个服务器,所以它一次只能处理一个请求。这比线程服务器差多了。您可以通过发出多个并发请求来证明这一点:
1from concurrent.futures import ThreadPoolExecutor 2 3import grpc 4 5from recommendations_pb2 import BookCategory, RecommendationRequest 6from recommendations_pb2_grpc import RecommendationsStub 7 8request = RecommendationRequest(user_id=1, category=BookCategory.MYSTERY) 9channel = grpc.insecure_channel("localhost:50051") 10client = RecommendationsStub(channel) 11 12executor = ThreadPoolExecutor(max_workers=5) 13a = executor.submit(client.Recommend, request) 14b = executor.submit(client.Recommend, request) 15c = executor.submit(client.Recommend, request) 16d = executor.submit(client.Recommend, request) 17e = executor.submit(client.Recommend, request)这将产生五个并发请求,但是在服务器端,您会看到:
Handling request Done Handling request Done Handling request Done Handling request Done Handling request Done请求是按顺序处理的,这不是您想要的!
在服务器端有 AsyncIO 的用例,但是你必须非常小心不要阻塞。这意味着你不能使用像
requests这样的标准包,甚至不能对其他微服务进行 RPC,除非你使用run_in_executor在另一个线程中运行它们。您还必须小心处理数据库查询。您已经开始使用的许多优秀的 Python 包可能还不支持 AsyncIO,所以要小心检查它们是否支持 AsyncIO。除非您非常需要服务器端的 AsyncIO,否则等到有更多的软件包支持时可能会更安全。阻塞错误可能很难发现。
如果你想了解更多关于 AsyncIO 的知识,那么你可以查看Python 中的异步特性入门和Python 中的异步 IO:完整演练。
结论
微服务是管理复杂系统的一种方式。随着组织的发展,它们成为组织代码的自然方式。了解如何在 Python 中有效地实现微服务,可以让你随着公司的发展而变得更有价值。
在本教程中,您已经学习了:
- 如何用 gRPC 有效实现 Python 微服务
- 如何将微服务部署到 Kubernetes
- 如何将集成测试、拦截器、 TLS 和 AsyncIO 等特性整合到您的微服务中
- 创建 Python 微服务时要遵循哪些最佳实践
现在,您已经准备好将较大的 Python 应用程序分解成较小的微服务,使您的代码更有组织性和可维护性。要回顾您在本教程中学到的所有内容,您可以通过单击下面的链接下载示例的源代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用了解如何使用 gRPC 创建 Python 微服务。**********
Python 的 min()和 max():查找最小和最大值
当你需要在一个可迭代或一系列常规参数中找到最小和最大值时,Python 的内置
min()和max()函数就派上了用场。尽管这些看起来是相当基本的计算,但它们在现实世界的编程中有许多有趣的用例。您将在这里尝试其中的一些用例。在本教程中,您将学习如何:
- 使用 Python 的
min()和max()来查找数据中的最小和最大值- 用单个可迭代或任意数量的常规参数调用
min()和max()- 将
min()和max()与字符串和字典一起使用- 用
key和default参数调整min()和max()的行为- 使用理解和生成器表达式作为
min()和max()的参数一旦你掌握了这些知识,你就可以准备写一堆展示
min()和max()有用性的实例了。最后,您将用纯 Python 编写自己版本的min()和max(),这可以帮助您理解这些函数在内部是如何工作的。免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
为了最大限度地利用本教程,您应该有一些 Python 编程的前期知识,包括像
for循环、函数、列表理解和生成器表达式这样的主题。Python 的
min()和max()函数入门Python 包括几个内置函数,让你的生活更加愉快和富有成效,因为这意味着你不需要重新发明轮子。这些功能的两个例子是
min()和max()。它们大多适用于的可迭代对象,但是你也可以将它们与多个常规参数一起使用。他们的工作是什么?他们负责在他们的输入数据中找到最小和最大的值。无论您使用的是 Python 的
min()还是max(),您都可以使用该函数来实现两种略有不同的行为。每个的标准行为是通过直接比较输入数据返回最小值或最大值。另一种行为是在找到最小和最大值之前,使用单参数函数来修改比较标准。为了探究
min()和max()的标准行为,您可以通过使用单个 iterable 作为参数或者使用两个或更多常规参数来调用每个函数。这就是你马上要做的。用一个可迭代的参数调用
min()和max()内置的
min()和max()有两个不同的签名,允许你用一个 iterable 作为它们的第一个参数或者用两个或更多的常规参数来调用它们。接受单个可迭代参数的签名如下所示:min(iterable, *[, default, key]) -> minimum_value max(iterable, *[, default, key]) -> maximum_value这两个函数都需要一个名为
iterable的参数,并分别返回最小值和最大值。他们还接受两个可选的关键字-唯一的参数:default和key。注意:在上述签名中,星号(
*)表示后面的参数是仅关键字的参数,而方括号([])表示包含的内容是可选的。下面是对
min()和max()的参数的总结:
争吵 描述 需要 iterable接受一个可迭代对象,比如一个列表、元组、字典或字符串 是 default保存输入 iterable 为空时要返回的值 不 key接受单参数函数来自定义比较标准 不 在本教程的后面,您将了解更多关于可选的
default和key参数。现在,只关注iterable参数,这是一个必需的参数,它利用了 Python 中min()和max()的标准行为:


>>> min([3, 5, 9, 1, -5])
-5
>>> min([])
Traceback (most recent call last):
...
ValueError: min() arg is an empty sequence
>>> max([3, 5, 9, 1, -5])
9
>>> max([])
Traceback (most recent call last):
...
ValueError: max() arg is an empty sequence
在这些例子中,你用一个整数列表和一个空列表调用min()和max()。对min()的第一个调用返回输入列表中最小的数字-5。相反,对max()的第一次调用返回列表中最大的数字,即9。如果您将一个空迭代器传递给min()或max(),那么您会得到一个ValueError,因为在空迭代器上没有任何事情可做。
关于min()和max()需要注意的一个重要细节是,输入 iterable 中的所有值必须是可比较的。否则,您会得到一个错误。例如,数值工作正常:
>>> min([3, 5.0, 9, 1.0, -5]) -5 >>> max([3, 5.0, 9, 1.0, -5]) 9这些例子结合了对
min()和max()的调用中的int和float号码。在这两种情况下,您都会得到预期的结果,因为这些数据类型是可比较的。但是,如果把字符串和数字混在一起会怎么样?看看下面的例子:
>>> min([3, "5.0", 9, 1.0, "-5"])
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'str' and 'int'
>>> max([3, "5.0", 9, 1.0, "-5"])
Traceback (most recent call last):
...
TypeError: '>' not supported between instances of 'str' and 'int'
不能用不可比较类型的 iterable 作为参数调用min()或max()。在这个例子中,一个函数试图比较一个数字和一个字符串,这就像比较苹果和橘子一样。最后的结果是你得到了一个TypeError。
使用多个参数调用min()和max()
min()和max()的第二个签名允许您使用任意数量的参数调用它们,前提是您至少使用两个参数。该签名具有以下形式:
min(arg_1, arg_2[, ..., arg_n], *[, key]) -> minimum_value
max(arg_1, arg_2[, ..., arg_n], *[, key]) -> maximum_value
同样,这些函数分别返回最小值和最大值。以下是上述签名中参数的含义:
| 争吵 | 描述 | 需要 |
|---|---|---|
arg_1, arg_2, ..., arg_n |
接受任意数量的常规参数进行比较 | 是(至少两个) |
key |
采用单参数函数来自定义比较标准 | 不 |
这个min()或max()的变体没有default自变量。您必须在调用中提供至少两个参数,函数才能正常工作。因此,不需要一个default值,因为为了找到最小值或最大值,你总是有至少两个值要比较。
要尝试这种替代签名,请运行以下示例:
>>> min(3, 5, 9, 1, -5) -5 >>> max(3, 5, 9, 1, -5) 9可以用两个或多个常规参数调用
min()或max()。同样,您将分别获得输入数据中的最小值或最大值。唯一的条件是参数必须具有可比性。将
min()和max()与字符串和字符串的可重复项一起使用默认情况下,
min()和max()可以处理具有可比性的值。否则,你会得到一个TypeError,你已经知道了。到目前为止,您已经看到了在 iterable 中或者作为多个常规参数使用数值的例子。使用带有数值的
min()和max()可以说是这些函数最常见和最有用的用例。但是,您也可以将函数用于字符串和字符串的可重复项。在这些情况下,字符的字母顺序将决定最终结果。例如,您可以使用
min()和max()在一些文本中查找最小和最大的字母。在此上下文中,最小表示最接近字母表的开头,最大表示最接近字母表的结尾:
>>> min("abcdefghijklmnopqrstuvwxyz")
'a'
>>> max("abcdefghijklmnopqrstuvwxyz")
'z'
>>> min("abcdWXYZ")
'W'
>>> max("abcdWXYZ")
'd'
如前所述,在前两个例子中,min()返回'a',max()返回'z'。然而,在第二对例子中,min()返回'W',而max()返回'd'。为什么?因为在 Python 的默认字符集、 UTF-8 中,大写字母排在小写字母之前。
注意: Python 内部将字符串视为字符的可重复项。因此,用字符串作为参数调用min()或max()就像用单个字符的 iterable 调用函数一样。
使用带有字符串的min()或max()作为参数不仅限于字母。您可以使用包含当前字符集中任何可能字符的字符串。例如,如果您只处理一组 ASCII 字符,那么最小的字符就是最接近 ASCII 表开头的字符。相比之下,最大的字符是最靠近表尾的字符。
对于其他字符集,如 UTF-8,min()和max()的行为类似:
>>> # UTF-8 characters >>> min("abc123ñ") '1' >>> max("abc123ñ") 'ñ'在后台,
min()和max()使用字符的数值来查找输入字符串中的最小和最大字符。例如,在 Unicode 字符表中,大写A的数值小于小写a:
>>> ord("A")
65
>>> ord("a")
97
Python 内置的 ord() 函数接受一个 Unicode 字符,并返回一个表示该字符的 Unicode 码位的整数。在这些例子中,大写"A"的码位低于小写"a"的码位。
这样,当您用两个字母调用min()和max()时,您会得到与这些字母的基本 Unicode 码位顺序相匹配的结果:
>>> min("aA") 'A' >>> max("aA") 'a'是什么让
"A"比"a"小?最简单的答案是字母的 Unicode 码位。可以在键盘上键入的所有字符以及许多其他字符在 Unicode 表中都有自己的代码点。在使用min()和max()时,Python 使用这些代码点来确定最小和最大字符。最后,还可以用字符串的 iterables 或多个字符串参数调用
min()和max()。同样,两个函数都将通过按字母顺序比较字符串来确定它们的返回值:
>>> min(["Hello", "Pythonista", "and", "welcome", "world"])
'Hello'
>>> max(["Hello", "Pythonista", "and", "welcome", "world"])
'world'
为了在一个可迭代的字符串中找到最小或最大的字符串,min()和max()根据首字符的代码点按字母顺序比较所有的字符串。
在第一个例子中,大写的"H"出现在 Unicode 表中的"P"、"a"和"w"之前。所以,min()马上断定"Hello"是最小的字符串。在第二个例子中,小写的"w"出现在所有其他字符串的首字母之后。
注意有两个单词是以"w"、"welcome"和"world"开头的。因此,Python 开始查看每个单词的第二个字母。结果是max()返回"world",因为"o"在"e"之后。
用min()和max() 处理字典
当使用min()和max()处理 Python 字典时,您需要考虑如果您直接使用字典,那么这两个函数都将在键上操作:
>>> prices = { ... "banana": 1.20, ... "pineapple": 0.89, ... "apple": 1.57, ... "grape": 2.45, ... } >>> min(prices) 'apple' >>> max(prices) 'pineapple'在这些例子中,
min()返回prices中按字母顺序最小的键,max()返回最大的键。您可以在输入词典上使用.keys()方法获得相同的结果:
>>> min(prices.keys())
'apple'
>>> max(prices.keys())
'pineapple'
后一个例子和前一个例子之间的唯一区别是,这里的代码更加清晰明了地说明了你在做什么。任何阅读您的代码的人都会很快意识到您想在输入字典中找到最小和最大的键。
另一个常见的需求是在字典中找到最小和最大的值。继续prices的例子,假设你想知道最小和最大价格。在这种情况下,可以使用 .values() 的方法:
>>> min(prices.values()) 0.89 >>> max(prices.values()) 2.45在这些示例中,
min()遍历prices中的所有值,并找到最低价格。类似地,max()遍历prices的值并返回最高价格。最后,您还可以使用输入字典上的
.items()方法来查找最小和最大键-值对:
>>> min(prices.items())
('apple', 1.57)
>>> max(prices.items())
('pineapple', 2.45)
在这种情况下,min()和max()使用 Python 的内部规则来比较元组,找到输入字典中最小和最大的条目。
Python 逐项比较元组。例如,为了确定(x1, x2)是否大于(y1, y2,Python 测试了x1 > y1。如果这个条件是True,那么 Python 断定第一个元组大于第二个元组,而不检查其余的项。相反,如果x1 < y1,那么 Python 会得出第一个元组小于第二个元组的结论。
最后,如果x1 == y1,那么 Python 使用相同的规则比较第二对条目。注意,在这个上下文中,每个元组的第一项来自字典键,因为字典键是惟一的,所以这些项不能相等。所以,Python 永远不会比较第二个值。
用key和default 调整min()和max()的标准行为
到目前为止,您已经了解了min()和max()如何以它们的标准形式工作。在这一节中,您将学习如何通过使用key和default 关键字参数来调整这两个函数的标准行为。
min()或max()的key参数允许您提供一个单参数函数,该函数将应用于输入数据中的每个值。目标是修改用于查找最小值或最大值的比较标准。
作为这个特性如何有用的一个例子,假设您有一个字符串形式的数字列表,并且想要找到最小和最大的数字。如果用min()和max()直接处理列表,那么会得到以下结果:
>>> min(["20", "3", "35", "7"]) '20' >>> max(["20", "3", "35", "7"]) '7'这些可能不是你需要或期待的结果。您获得的最小和最大字符串是基于 Python 的字符串比较规则,而不是基于每个字符串的实际数值。
在这种情况下,解决方案是将内置的
int()函数作为key参数传递给min()和max(),如下例所示:
>>> min(["20", "3", "35", "7"], key=int)
'3'
>>> max(["20", "3", "35", "7"], key=int)
'35'
太好了!现在min()或max()的结果取决于底层字符串的数值。注意,你不需要打电话给int()。您只是传递了没有一对括号的int,因为key需要一个函数对象,或者更准确地说,一个可调用对象。
注意:Python 中的可调用对象包括函数、方法、类,以及任何提供了 .__call__() 特殊方法的类的实例。
第二个仅使用关键字的参数是default,它允许您定制min()或max()的标准行为。请记住,该参数仅在使用单个 iterable 作为参数调用函数时可用。
default的作用是当用空的 iterable 调用min()或max()时,提供一个合适的默认值作为其返回值:
>>> min([], default=42) 42 >>> max([], default=42) 42在这些例子中,输入 iterable 是一个空列表。标准行为是
min()或max()引发一个ValueError来抱怨空序列参数。但是,因为您向default提供了一个值,所以现在两个函数都返回这个值,而不是引发一个异常并中断您的代码。将
min()和max()用于理解和生成器表达式也可以用列表理解或生成器表达式作为参数调用
min()或max()。当您需要在找到最小或最大转换值之前转换输入数据时,此功能非常有用。当您将列表理解输入到
min()或max()中时,结果值将来自转换后的数据,而不是原始数据:
>>> letters = ["A", "B", "C", "X", "Y", "Z"]
>>> min(letters)
'A'
>>> min([letter.lower() for letter in letters]) 'a'
>>> max(letters)
'Z'
>>> max([letter.lower() for letter in letters]) 'z'
对min()的第二次调用将列表理解作为参数。这种理解通过对每个字母应用.lower()方法来转换letters中的原始数据。最终结果是小写的"a",它不存在于原始数据中。关于max()的例子也发生了类似的事情。
注意,在列表理解中使用min()或max()类似于使用key参数。主要区别在于,使用 comprehensions,最终结果是转换后的值,而使用key,结果来自原始数据:
>>> letters = ["A", "B", "C", "X", "Y", "Z"] >>> min([letter.lower() for letter in letters]) 'a' >>> min(letters, key=str.lower) 'A'在这两个例子中,
min()使用.lower()以某种方式修改比较标准。不同之处在于,理解实际上是在进行计算之前转换输入数据,因此结果值来自转换后的数据,而不是原始数据。列表理解在内存中创建一个完整的列表,这通常是一个浪费的操作。如果您的代码中不再需要结果列表,这一点尤其正确,这可能是
min()和max()的情况。因此,使用一个生成器表达式总是更有效。生成器表达式的语法与列表理解的语法几乎相同:
>>> letters = ["A", "B", "C", "X", "Y", "Z"]
>>> min(letters)
'A'
>>> min(letter.lower() for letter in letters) 'a'
>>> max(letters)
'Z'
>>> max(letter.lower() for letter in letters) 'z'
主要的语法差异是生成器表达式使用圆括号而不是方括号([])。因为函数调用已经需要括号,所以您只需要从基于理解的例子中去掉方括号,就可以了。与列表理解不同,生成器表达式按需生成条目,这使得它们的内存效率更高。
将 Python 的min()和max()付诸行动
到目前为止,您已经学习了使用min()和max()在一个可迭代或一系列单个值中寻找最小和最大值的基本知识。您了解了min()和max()如何处理不同的内置 Python 数据类型,比如数字、字符串和字典。您还探索了如何调整这些函数的标准行为,以及如何将它们用于列表理解和生成器表达式。
现在您已经准备好开始编写一些实际的例子,向您展示如何在您自己的代码中使用min()和max()。
删除列表中最小和最大的数字
首先,您将从一个简短的示例开始,了解如何从一个数字列表中删除最小值和最大值。为此,您可以在输入列表上调用.remove()。根据您的需要,您将使用min()或max()来选择您将从底层列表中移除的值:
>>> sample = [4, 5, 7, 6, -12, 4, 42] >>> sample.remove(min(sample)) >>> sample [4, 5, 7, 6, 4, 42] >>> sample.remove(max(sample)) >>> sample [4, 5, 7, 6, 4]在这些示例中,
sample中的最小值和最大值可能是您想要移除的异常值数据点,以便它们不会影响您的进一步分析。这里,min()和max()向.remove()提供参数。构建最小值和最大值列表
现在假设您有一个表示数值矩阵的列表,您需要构建包含输入矩阵中每一行的最小和最大值的列表。为此,您可以使用
min()和max()以及一个列表理解:
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> [min(x) for x in matrix]
[1, 4, 7]
>>> [max(x) for x in matrix]
[3, 6, 9]
第一个理解遍历matrix中的子列表,并使用min()构建一个包含每个子列表中最小值的列表。第二个理解执行类似的任务,但是使用max()来创建一个包含来自matrix中的子列表的最大值的列表。
尽管min()和max()提供了一种快速的方法来处理本节中的例子,但是在处理 Python 中的矩阵时,强烈推荐使用 NumPy 库,因为 NumPy 有专门的优化工具来完成这项工作。
将值剪切到区间边缘
有时,您有一个数值列表,并希望将它们裁剪到给定区间的边缘或界限。例如,如果给定的值大于间隔的上限,那么您需要将其向下转换到该限制。要做这个操作,可以用min()。
等等!为什么是min()?你在处理大额交易,是吗?关键是您需要将每个大值与区间的上限进行比较,然后选择两者中较小的一个。实际上,您将所有大值设置为一个规定的上限:
>>> # Clip values to the largest interval's edge >>> upper = 100 >>> numbers = [42, 78, 200, -230, 25, 142] >>> [min(number, upper) for number in numbers] [42, 78, 100, -230, 25, 100]对
min()的调用将每个数字与区间的上限进行比较。如果目标数大于极限,则min()返回极限。实际效果是,所有大于限制值的值现在都被限制到限制值。在这个例子中,数字200和142被裁剪为100,这是区间的上限。相反,如果你想将小值限制在区间的下限,那么你可以使用
max(),如下例所示:
>>> # Clip values to the smallest interval's edge
>>> lower = 10
>>> numbers = [42, 78, 200, -230, 25, 142]
>>> [max(number, lower) for number in numbers] [42, 78, 200, 10, 25, 142]
对max()的调用将小值限制在区间的下限。为了进行这种裁剪,max()比较当前数字和间隔的限制,以找到最大值。在这个例子中,-230是唯一被截取的数字。
最后,您可以通过组合min()和max()来一次运行这两个操作。以下是如何做到这一点:
>>> # Clipping values to 10 - 100 >>> lower, upper = 10, 100 >>> numbers = [42, 78, 100, -230, 25, 142] >>> [max(min(number, upper), lower) for number in numbers] [42, 78, 100, 10, 25, 100]为了截取所有超出区间限制的值,这种理解结合了
min()和max()。对min()的调用将当前值与区间的上限进行比较,而对max()的调用将结果与下限进行比较。最终结果是,低于或大于相应限制的值被限制在限制本身。这种理解类似于 NumPy 的
clip()函数,它采用一个数组和目标区间的限制,然后将区间外的所有值裁剪到区间的边缘。寻找最近的点
现在假设您有一个元组列表,其中包含表示笛卡尔点的值对。您希望处理所有这些点对,并找出哪一对点之间的距离最小。在这种情况下,您可以执行如下操作:
>>> import math
>>> point_pairs = [
... ((12, 5), (9, 4)),
... ((2, 5), (3, 7)),
... ((4, 11), (15, 2))
... ]
>>> min(point_pairs, key=lambda points: math.dist(*points))
((2, 5), (3, 7))
在本例中,您首先导入 math 来访问 dist() 。该函数返回两个点 p 和 q 之间的欧几里德距离,每个点都以坐标序列的形式给出。这两点必须有相同的维数。
min()函数通过它的key参数发挥它的魔力。在这个例子中,key使用了一个 lambda 函数来计算两点之间的距离。该函数成为min()寻找两点间距离最小的一对点的比较标准。
在这个例子中,您需要一个lambda函数,因为key需要一个单参数函数,而math.dist()需要两个参数。因此,lambda函数接受一个参数points,然后将其解包成两个参数,并输入到math.dist()。
识别便宜和昂贵的产品
现在假设您有一个包含几种产品的名称和价格的字典,并且您想要确定最便宜和最贵的产品。在这种情况下,您可以使用.items()和一个适当的lambda函数作为key参数:
>>> prices = { ... "banana": 1.20, ... "pineapple": 0.89, ... "apple": 1.57, ... "grape": 2.45, ... } >>> min(prices.items(), key=lambda item: item[1]) ('pineapple', 0.89) >>> max(prices.items(), key=lambda item: item[1]) ('grape', 2.45)在这个例子中,
lambda函数将一个键值对作为参数,并返回相应的值,这样min()和max()就有了合适的比较标准。因此,您会在输入数据中获得一个包含最便宜和最贵产品的元组。寻找互质整数
另一个使用
min()解决现实世界问题的有趣例子是,当你需要判断两个数字是否是互质时。换句话说,你需要知道你的数字的唯一公约数是否是1。在这种情况下,您可以编写一个布尔值或谓词函数,如下所示:
>>> def are_coprime(a, b):
... for i in range(2, min(a, b) + 1):
... if a % i == 0 and b % i == 0:
... return False
... return True
...
>>> are_coprime(2, 3)
True
>>> are_coprime(2, 4)
False
在这个代码片段中,您将are_coprime()定义为一个谓词函数,如果输入数字互质,它将返回True。如果这些数字不是互质的,那么函数返回False。
该函数的主要组件是一个for循环,它迭代一个 range 值。要设置这个range对象的上限,您可以使用min()和作为参数的输入数字。同样,您使用min()来设置某个区间的上限。
为代码的不同实现计时
您还可以使用min()来比较您的几个算法,评估它们的执行时间,并确定哪个算法是最高效的。下面的示例使用 timeit.repeat() 来测量两种不同方式构建包含从0到99的数字的平方值的列表的执行时间:
>>> import timeit >>> min( ... timeit.repeat( ... stmt="[i ** 2 for i in range(100)]", ... number=1000, ... repeat=3 ... ) ... ) 0.022141209003166296 >>> min( ... timeit.repeat( ... stmt="list(map(lambda i: i ** 2, range(100)))", ... number=1000, ... repeat=3 ... ) ... ) 0.023857666994445026对
timeit.repeat()的调用将基于字符串的语句运行给定的次数。在这些示例中,该语句重复了三次。对min()的调用从三次重复中返回最小的执行时间。通过结合使用
min()、repeat()和其他 Python 定时器函数,您可以知道哪种算法在执行时间方面是最有效的。上面的例子表明,在构建新列表时,列表理解比内置的map()函数要快一点。《T2》和《T4》中
.__lt__()和.__gt__()的角色探究到目前为止,您已经了解到,内置的
min()和max()函数足够灵活,可以处理各种数据类型的值,比如数字和字符串。这种灵活性背后的秘密是,min()和max()依靠.__lt__()和.__gt__()的特殊方法,拥抱了 Python 的鸭子打字哲学。这些方法是 Python 所谓的丰富比较方法的一部分。具体来说,
.__lt__()和.__gt__()分别支持小于(<)和大于(>)运算符。这里的支持是什么意思?当 Python 在你的代码中发现类似于x < y的东西时,它会在内部做x.__lt__(y)。要点是您可以将
min()和max()与实现.__lt__()和.__gt__()的任何数据类型的值一起使用。这就是为什么这些函数适用于所有 Python 内置数据类型的值:
>>> "__lt__" in dir(int) and "__gt__" in dir(int)
True
>>> "__lt__" in dir(float) and "__gt__" in dir(float)
True
>>> "__lt__" in dir(str) and "__gt__" in dir(str)
True
>>> "__lt__" in dir(list) and "__gt__" in dir(list)
True
>>> "__lt__" in dir(tuple) and "__gt__" in dir(tuple)
True
>>> "__lt__" in dir(dict) and "__gt__" in dir(dict)
True
Python 的内置数据类型实现了.__lt__()和.__gt__()特殊方法。因此,您可以将这些数据类型中的任何一种输入到min()和max()中,唯一的条件是所涉及的数据类型是可比较的。
您还可以使您的自定义类的实例与min()和max()兼容。为了实现这一点,您需要提供自己的.__lt__()和.__gt__()的实现。考虑下面的Person类作为这种兼容性的例子:
# person.py
from datetime import date
class Person:
def __init__(self, name, birth_date):
self.name = name
self.birth_date = date.fromisoformat(birth_date)
def __repr__(self):
return (
f"{type(self).__name__}"
f"({self.name}, {self.birth_date.isoformat()})"
)
def __lt__(self, other): return self.birth_date > other.birth_date
def __gt__(self, other): return self.birth_date < other.birth_date
注意,.__lt__()和.__gt__()的实现需要一个通常名为other的参数。该参数表示基础比较运算中的第二个操作数。例如,在一个类似于x < y的表达式中,你会发现x是self而y是other。
注意:对于小于的和大于的比较操作,您只需要实现.__lt__()或.__gt__()中的一个即可。
在这个例子中,.__lt__()和.__gt__()返回两个人的.birth_date属性的比较结果。这在实践中是如何工作的:
>>> from person import Person >>> jane = Person("Jane Doe", "2004-08-15") >>> john = Person("John Doe", "2001-02-07") >>> jane < john True >>> jane > john False >>> min(jane, john) Person(Jane Doe, 2004-08-15) >>> max(jane, john) Person(John Doe, 2001-02-07)酷!您可以用
min()和max()处理Person对象,因为该类提供了.__lt__()和.__gt__()的实现。对min()的调用返回最年轻的人,对max()的调用返回最老的人。注意:
.__lt__()和.__gt__()方法只支持两个比较操作符<和>。如果你想要一个提供所有比较操作的类,但是你只想写一些特殊的方法,那么你可以使用@functools.total_ordering。如果您有一个定义了.__eq__()和其他丰富的比较方法的类,那么这个装饰器将自动提供其余的比较方法。注意,如果给定的自定义类不提供这些方法,那么它的实例将不支持
min()和max()操作:
>>> class Number:
... def __init__(self, value):
... self.value = value
...
>>> x = Number(21)
>>> y = Number(42)
>>> min(x, y)
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'Number' and 'Number'
>>> max(x, y)
Traceback (most recent call last):
...
TypeError: '>' not supported between instances of 'Number' and 'Number'
因为这个Number类没有提供.__lt__()和.__gt__()的合适实现,min()和max()用一个TypeError来响应。错误消息告诉您当前的类不支持比较操作。
效仿 Python 的min()和max()
至此,您已经了解了 Python 的min()和max()函数是如何工作的。您已经使用它们在几个数字、字符串等中查找最小和最大值。您知道如何使用单个 iterable 作为参数或者使用未定义数量的常规参数来调用这些函数。最后,您已经编写了一系列使用min()和max()解决现实世界问题的实际例子。
虽然 Python 友好地为您提供了min()和max()来查找数据中的最小和最大值,但是从头开始学习如何进行这种计算是一种有益的练习,可以提高您的逻辑思维和编程技能。
在本节中,您将学习如何在数据中查找最小值和最大值。您还将学习如何实现自己版本的min()和max()。
理解min()和max() 背后的代码
作为一个人,要在一个小的数字列表中找到最小值,你通常会检查这些数字,并在头脑中隐式地比较它们。是的,你的大脑太神奇了!然而,计算机并没有那么聪明。他们需要详细的说明来完成任何任务。
你必须告诉你的计算机在成对比较时迭代所有的值。在这个过程中,计算机必须注意每一对中的当前最小值,直到值列表被完全处理。
这种解释可能很难形象化,因此这里有一个 Python 函数来完成这项工作:
>>> def find_min(iterable): ... minimum = iterable[0] ... for value in iterable[1:]: ... if value < minimum: ... minimum = value ... return minimum ... >>> find_min([2, 5, 3, 1, 9, 7]) 1在这个代码片段中,您定义了
find_min()。这个函数假设iterable不为空,并且它的值是任意顺序的。该函数将第一个值视为暂定值
minimum。然后for循环遍历输入数据中的其余元素。条件语句将当前
value与第一次迭代中的暂定minimum进行比较。如果当前的value小于minimum,则条件相应地更新minimum。每次新的迭代将当前的
value与更新的minimum进行比较。当函数到达iterable的末端时,minimum将保存输入数据中的最小值。酷!您已经编写了一个函数,它在一组数字中寻找最小值。现在重温一下
find_min(),想想如何编写一个函数来寻找最大值。对,就是这样!您只需将比较运算符从小于(<)改为大于(>),并可能重命名函数和一些局部变量以防止混淆。您的新函数可能如下所示:
>>> def find_max(iterable):
... maximum = iterable[0]
... for value in iterable[1:]:
... if value > maximum:
... maximum = value
... return maximum
...
>>> find_max([2, 5, 3, 1, 9, 7])
9
请注意,find_max()与find_min()共享其大部分代码。除了命名之外,最重要的区别是find_max()使用大于运算符(>)而不是小于运算符(<)。
作为练习,你可以按照干(不要重复自己)的原则,思考如何避免find_min()和find_max()中的重复代码。通过这种方式,您将准备好使用您的 Python 技能来模拟min()和max()的完整行为,您将很快解决这些问题。
在深入研究之前,您需要了解知识要求。您将在函数中组合一些主题,如条件语句、异常处理、列表理解、带有 for循环的确定迭代,以及 *args 和可选参数。
如果你觉得自己对这些话题并不了解,那么也不用担心。你会边做边学。如果你被卡住了,那么你可以回头查看链接的资源。
规划您的定制min()和max()版本
要编写定制的min()和max()的实现,首先要编写一个助手函数,它能够根据调用中使用的参数找到输入数据中的最小值或最大值。当然,辅助函数将特别依赖于用于比较输入值的操作符。
您的助手函数将具有以下签名:
min_max(*args, operator, key=None, default=None) -> extreme_value
下面是每个参数的作用:
| 争吵 | 描述 | 需要 |
|---|---|---|
*args |
允许您用一个 iterable 或任意数量的常规参数调用函数 | 是 |
operator |
为手边的计算保存适当的比较运算符函数 | 是 |
key |
接受单参数函数,该函数修改函数的比较标准和行为 | 不 |
default |
存储当您使用空的 iterable 调用函数时要返回的默认值 | 不 |
min_max()的主体将通过处理*args来构建一个值列表。拥有一个标准化的值列表将允许您编写所需的算法来查找输入数据中的最小值和最大值。
然后函数需要在计算最小值和最大值之前处理key和default参数,这是min_max()中的最后一步。
有了min_max(),最后一步是在它的基础上定义两个独立的函数。这些函数将使用适当的比较运算符函数来分别找到最小值和最大值。一会儿你会学到更多关于操作函数的知识。
标准化来自*args 的输入数据
为了标准化输入数据,您需要检查用户提供的是单个 iterable 还是任意数量的常规参数。启动你最喜欢的代码编辑器或 IDE ,创建一个名为min_max.py的新 Python 文件。然后向其中添加以下代码:
# min_max.py
def min_max(*args, operator, key=None, default=None):
if len(args) == 1:
try:
values = list(args[0]) # Also check if the object is iterable
except TypeError:
raise TypeError(
f"{type(args[0]).__name__} object is not iterable"
) from None
else:
values = args
在这里,你定义min_max()。该函数的第一部分将输入数据标准化,以便进一步处理。因为用户可以用一个 iterable 或者几个常规参数调用min_max(),所以需要检查args的长度。要进行这项检查,您可以使用内置的 len() 功能。
如果args只有一个值,那么你需要检查这个参数是否是一个可迭代的对象。您使用 list() ,它隐式地进行检查,并将输入的 iterable 转换成一个列表。
如果list()引发了一个TypeError,那么你捕捉它并引发你自己的TypeError来通知用户所提供的对象是不可迭代的,就像min()和max()在它们的标准形式中所做的那样。注意,您使用了from None语法来隐藏原始TypeError的回溯。
当args保存不止一个值时,else分支运行,这处理用户用几个常规参数而不是一个可迭代的值调用函数的情况。
如果这个条件最终没有引发一个TypeError,那么values将保存一个可能为空的值列表。即使结果列表是空的,它现在也是干净的,可以继续寻找它的最小值或最大值。
处理default自变量
为了继续编写min_max(),现在可以处理default参数。继续将以下代码添加到函数的末尾:
# min_max.py
# ...
def min_max(*args, operator, key=None, default=None):
# ...
if not values:
if default is None:
raise ValueError("args is an empty sequence")
return default
在这个代码片段中,您定义了一个条件来检查values是否持有一个空列表。如果是这种情况,那么检查default参数,看看用户是否为它提供了一个值。如果default还是 None ,那么就升起一个ValueError。否则,返回default。当您用空的 iterables 调用min()和max()时,这个行为模拟了它们的标准行为。
处理可选的key功能
现在您需要处理key参数,并根据提供的key准备寻找最小和最大值的数据。继续用下面的代码更新min_max():
# min_max.py
# ...
def min_max(*args, operator, key=None, default=None):
# ...
if key is None:
keys = values
else:
if callable(key):
keys = [key(value) for value in values]
else:
raise TypeError(f"{type(key).__name__} object is not a callable")
您用一个条件来开始这个代码片段,该条件检查用户是否没有提供一个key函数。如果它们没有,那么您可以直接从原始的values创建一个键列表。在计算最小值和最大值时,您将使用这些键作为比较键。
另一方面,如果用户提供了一个key参数,那么你需要确保这个参数实际上是一个函数或者可调用的对象。为此,您使用内置的 callable() 函数,如果它的参数是可调用的,则返回True,否则返回False。
一旦您确定了key是一个可调用的对象,那么您就可以通过将key应用于输入数据中的每个值来构建比较键的列表。
最后,如果key不是一个可调用对象,那么else子句运行,产生一个TypeError,就像min()和max()在类似情况下所做的那样。
寻找最小值和最大值
完成min_max()函数的最后一步是找到输入数据中的最小值和最大值,就像min()和max()一样。继续用下面的代码结束min_max():
# min_max.py
# ...
def min_max(*args, operator, key=None, default=None):
# ...
extreme_key, extreme_value = keys[0], values[0]
for key, value in zip(keys[1:], values[1:]):
if operator(key, extreme_key):
extreme_key = key
extreme_value = value
return extreme_value
将extreme_key和extreme_value 变量分别设置为keys和values中的第一个值。这些变量将为计算最小值和最大值提供初始键和值。
然后使用内置的 zip() 函数一次循环其余的键和值。这个函数将通过组合您的keys和values列表中的值来产生键值元组。
循环内部的条件调用operator将当前的key与存储在extreme_key中的暂定最小或最大密钥进行比较。此时,operator参数将保存来自operator模块的lt()或gt(),这取决于您是否想分别找到最小值或最大值。
比如,当你想在输入数据中寻找最小值时,operator会持有lt()函数。当你想找到最大值的时候,operator会按住gt()。
每次循环迭代将当前的key与暂定的最小或最大键进行比较,并相应地更新extreme_key和extreme_value的值。在循环结束时,这些变量将保存最小或最大键及其相应的值。最后,你只需要返回extreme_value中的值。
编写您的自定义min()和max()函数
有了min_max()助手函数,您可以定义自定义版本的min()和max()。继续将以下函数添加到您的min_max.py文件的末尾:
# min_max.py
from operator import gt, lt
# ...
def custom_min(*args, key=None, default=None):
return min_max(*args, operator=lt, key=key, default=default)
def custom_max(*args, key=None, default=None):
return min_max(*args, operator=gt, key=key, default=default)
在这段代码中,首先从 operator 模块中导入 gt() 和 lt() 。这些函数分别是大于(>)和小于(<)运算符的等效函数。比如布尔表达式x < y等价于函数调用lt(x, y)。您将使用这些函数向您的min_max()提供operator参数。
与min()和max()一样,custom_min()和custom_max()以*args、key和default为参数,分别返回最小值和最大值。为了执行计算,这些函数使用所需的参数和适当的比较函数operator调用min_max()。
在custom_min()中,您使用lt()来查找输入数据中的最小值。在custom_max()中,你使用gt()来获得最大值。
如果您想获得min_max.py文件的全部内容,请点击下面的可折叠部分:
# min_max.py
from operator import gt, lt
def min_max(*args, operator, key=None, default=None):
if len(args) == 1:
try:
values = list(args[0]) # Also check if the object is iterable
except TypeError:
raise TypeError(
f"{type(args[0]).__name__} object is not iterable"
) from None
else:
values = args
if not values:
if default is None:
raise ValueError("args is an empty sequence")
return default
if key is None:
keys = values
else:
if callable(key):
keys = [key(value) for value in values]
else:
raise TypeError(f"{type(key).__name__} object is not a callable")
extreme_key, extreme_value = keys[0], values[0]
for key, value in zip(keys[1:], values[1:]):
if operator(key, extreme_key):
extreme_key = key
extreme_value = value
return extreme_value
def custom_min(*args, key=None, default=None):
return min_max(*args, operator=lt, key=key, default=default)
def custom_max(*args, key=None, default=None):
return min_max(*args, operator=gt, key=key, default=default)
酷!您已经完成了用 Python 编写自己版本的min()和max()的工作。现在去给他们一个尝试吧!
结论
现在你知道如何使用 Python 内置的min()和max()函数在一个可迭代的或者一系列两个或多个常规参数中找到最小的和最大的值。您还了解了min()和max()的一些其他特性,这些特性可以使它们在您的日常编程中有用。
在本教程中,您学习了如何:
- 分别使用 Python 的
min()和max()找到最小的和最大的值 - 用一个可迭代和几个常规参数调用
min()和max() - 将
min()和max()与字符串和字典一起使用 - 用
key和default自定义min()和max()的行为 - 将理解和生成器表达式送入
min()和max()
此外,你已经编写了一些实际的例子,使用min()和max()来处理你在编写代码时可能遇到的现实世界的问题。您还用纯 Python 编写了定制版的min()和max(),这是一个很好的学习练习,可以帮助您理解这些内置函数背后的逻辑。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。**********
Python 中的 Minimax:学习如何输掉 Nim 游戏
游戏很好玩!他们定义明确的规则让你探索不同的策略,寻找必胜的方法。 minimax 算法用于选择游戏中任何一点的最佳走法。您将学习如何用 Python 实现一个可以完美地玩 Nim 游戏的 minimax 播放器。
在本教程中,您将关注极小极大。然而,为了形象化算法如何工作,用一个具体的游戏来工作是很好的。您将学习 Nim 的规则,这是一个规则简单、选择有限的游戏。在例子中使用 Nim 可以让你专注于极小极大原则,而不会迷失在游戏规则中。
随着您学习本教程,您将:
- 了解极大极小算法的原理
- 玩 Nim 的游戏的几个变种
- 实现极大极小算法
- 在与一名迷你游戏玩家的比赛中,输给了尼姆
- 使用阿尔法-贝塔剪枝优化极大极小算法
您可以下载本教程中使用的源代码,以及一个游戏模拟器,在那里您可以通过单击下面的链接与 minimax 对手玩不同的 Nim 变体:
源代码: 点击这里下载免费的源代码,你将使用它来输掉与你的 minimax 玩家的 Nim 游戏。
玩一个 Nim 的简化游戏
尼姆的根源可以追溯到很久以前。虽然历史上一直有人玩这种游戏的变体,但尼姆这个名字是在 1901 年查尔斯·l·波顿发表了尼姆,一种具有完整数学理论的游戏时获得的。
Nim 是两个人的游戏,总是以一个人赢而告终。该游戏由几个放在游戏桌上的计数器组成,玩家轮流移动一个或多个计数器。在本教程的前半部分,您将按照以下规则玩一个简化版的 Nim:
- 共享堆里有几个计数器。
- 两名玩家轮流玩。
*** 在他们的回合中,一名玩家从牌堆中移除个、个或个指示物。* 取得最后一个计数器的玩家输掉游戏。*
*你会把这个游戏称为 Simple-Nim 。稍后,你会学到常规 Nim 的规则。它们并不复杂,但很简单——尼姆更容易理解。
注:现在该上场了!你将从模拟版本开始,所以在你的桌子上清理出一个空间。玩几局简单的 Nim 游戏,了解一下规则。一路上,留意你遇到的任何获胜策略。
您可以使用任何碰巧可用的对象作为计数器,也可以使用记事本来记录当前计数器的数量。十到二十个柜台是一个游戏的好起点。
如果你附近没有对手,你可以暂时和自己打。在本教程结束时,你将会设计出一个你可以与之对战的对手。
为了演示规则,两名玩家——Mindy 和 Maximillian——将玩一个简单的 Nim 游戏,从 12 个计数器开始。明迪先来:
- 明迪拿了两个计数器,剩下十个。
- 马克西米利安拿走一个计数器,剩下九个。
- 明迪拿了三个计数器,剩下六个。
- 马克西米利安拿了两个指示物,剩下四个。
- 明迪拿了三个计数器,剩下一个。
- 马克西米利安拿到最后一个计数器,输掉游戏。
在这场游戏中,马克西米利安占据了最后一个柜台,所以明迪是赢家。
Nim,包括 Simple-Nim,是一个耐人寻味的游戏,因为规则足够简单,游戏完全可以分析。您将使用 Nim 来探索极大极小算法,它能够完美地玩这个游戏。这意味着,如果可能的话,极小极大玩家总是会赢得游戏。
了解 Minimax 算法
游戏已经成为发明和测试人工智能算法的沃土。游戏非常适合这种研究,因为它们有明确定义的规则。最著名的算法之一是极小极大。这个名字描述了一个玩家试图最大化他们的分数,而另一个玩家试图最小化他们的分数。
极大极小可以应用于许多不同的游戏和更一般的决策。在本教程中,你将学习如何教 minimax 玩尼姆。然而,你也可以在其他游戏中使用同样的原则,比如井字游戏和国际象棋。
探索游戏树
回想一下上一节 Mindy 和 Maximillian 玩的游戏。下表显示了游戏的所有步骤:
| 明迪(Minna 的异体)(f.) | 大量 | 姓氏 |
|---|---|---|
| 🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙 | ||
| 🪙🪙 | 🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙 | |
| 🪙🪙🪙🪙🪙🪙🪙🪙🪙 | 🪙 | |
| 🪙🪙🪙 | 🪙🪙🪙🪙🪙🪙 | |
| 🪙🪙🪙🪙 | 🪙🪙 | |
| 🪙🪙🪙 | 🪙 | |
| 🪙 |
这个游戏的表现明确地显示了每个玩家在他们的回合中移除了多少个指示物。然而,表中有一些冗余信息。您可以通过记录筹码堆中的筹码数量以及轮到谁来代表同一个游戏:
| 要移动的玩家 | 大量 |
|---|---|
| 明迪(Minna 的异体)(f.) | 🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙🪙 (12) |
| 姓氏 | 🪙🪙🪙🪙🪙🪙🪙🪙🪙 (10) |
| 明迪(Minna 的异体)(f.) | 🪙🪙🪙🪙🪙🪙🪙🪙 (9) |
| 姓氏 | 🪙🪙🪙🪙🪙 (6) |
| 明迪(Minna 的异体)(f.) | 🪙🪙🪙 (4) |
| 姓氏 | (1) |
虽然每个玩家在他们的回合中移除的指示物的数量没有明确的说明,但是你可以通过比较回合前后的指示物数量来计算。
这种表示更加简洁。然而,你甚至可以完全避开桌子,用一系列数字来表示游戏: 12-10-9-6-4-1 ,明迪开始。你将把这些数字中的每一个称为游戏状态。
你现在有一些符号来谈论不同的游戏。接下来,把你的注意力转向赢得游戏的可能策略。例如,当马克西米利安的筹码堆里还剩六个筹码时,他会赢吗?
研究 Simple-Nim 的一个好处是博弈树不会大得令人望而生畏。游戏树描述了游戏中所有有效的走法。从一堆六个计数器开始,只有十三种可能的不同游戏可以玩:
| 姓氏 | 明迪(Minna 的异体)(f.) | 姓氏 | 明迪(Minna 的异体)(f.) | 姓氏 | 明迪(Minna 的异体)(f.) | 姓氏 |
|---|---|---|---|---|---|---|
| six | three | one | Zero | |||
| 6🪙 | 3🪙 | 2🪙 | 1🪙 | 0 | ||
| six | four | one | Zero | |||
| 6🪙 | 4🪙 | 2🪙 | 1🪙 | 0 | ||
| 6🪙 | 4🪙 | 3🪙 | 1🪙 | 0 | ||
| six | four | three | Two | one | Zero | |
| 6🪙 | 5🪙 | 2🪙 | 1🪙 | 0 | ||
| 6🪙 | 5🪙 | 3🪙 | 1🪙 | 0 | ||
| six | five | three | Two | one | Zero | |
| 6🪙 | 5🪙 | 4🪙 | 1🪙 | 0 | ||
| six | five | four | Two | one | Zero | |
| six | five | four | three | one | Zero | |
| 6🪙 | 5🪙 | 4🪙 | 3🪙 | 2🪙 | 1🪙 | 0 |
表格中的每一列代表一步棋,每一行代表十三种不同游戏中的一种。表格中的数字显示了在玩家行动之前,牌堆中有多少个指示物。粗体行是马克西米连会赢的游戏。
注:从技术上讲,可能的游戏比表中所列的要多一些。例如, 6-3 是一个有效的游戏,其中明蒂拿到最后三个指示物立即输掉游戏。但是在这个分析中,你只会考虑游戏结束时筹码数量减少到一个计数器,一个玩家被迫移除,因为你可以合理地假设一个玩家除非迫不得已,否则不会做出失败的举动。
例如,表格中的第一行代表游戏 6-3-1 ,明蒂获胜,而最后一行代表 6-5-4-3-2-1 ,每个玩家在他们的回合中只取一个计数器。该表显示了所有可能的游戏,但更有见地的表示是显示所有可能结果的游戏树:

在图中,马克西米利安的转弯用较暗的背景表示。彩色的节点是树上的叶子。它们代表游戏已经结束,剩下个零计数器。以红色节点结束的游戏由 Mindy 赢得,以绿色节点结束的游戏由 Maximillian 赢得。
你可以在树上找到和表中一样的十三个游戏。从树的顶部开始,沿着树枝,直到到达标记为 0 的叶子节点。每一关都代表进入一个新的游戏状态。顺着最左边的分支可以找到 6-3-1 游戏,再往最右边下降可以找到 6-5-4-3-2-1 。
马克西米利安赢了十三场比赛中的七场,而明迪赢了另外六场。看起来玩家们应该有几乎均等的机会获胜。尽管如此,马克西米利安有办法确保胜利吗?
找到最佳的下一步棋
把上面的问题重新表述如下:马克西米利安能走一步棋,这样无论明蒂下一步怎么走,他都能赢吗?在上面的树的帮助下,你可以计算出马克西米利安的每一个可能的第一步会发生什么:
- 取三个指示物,在牌堆中留下三个指示物:在这种情况下,明蒂可以取两个指示物,迫使马克西米利安输掉游戏。
- 取两个指示物,留四个指示物在这堆指示物中:在这种情况下,明蒂可以取三个指示物,迫使马克西米利安输掉游戏。
- 拿走一个指示物,留下五个指示物:在这种情况下,明迪没有立即获胜的行动。相反,马克西米利安对明迪的每一个选择都有制胜一招。
如果马克西米利安拿到一个计数器,并在筹码堆中留下五个筹码,他就能确保胜利!
这种论证形成了极小极大算法的基础。你会给两个玩家中的每一个角色,要么是最大化玩家,要么是最小化玩家。当前玩家想要移动以最大化他们的获胜机会,而他们的对手想要用移动来反击以最小化当前玩家的获胜机会。在这个例子中,马克西米利安是最大化玩家,明蒂是最小化玩家。
为了跟踪游戏,画出所有可能移动的树。你已经为 Simple-Nim 从六个计数器开始做了这件事。然后,给树的所有叶节点分配一个极大极小值。在 Simple-Nim 中,这些是剩余零计数器的节点。分数将取决于叶节点所代表的结果。
如果最大化玩家赢了游戏,给叶子一个分数 +1 。类似地,如果最小化玩家赢了游戏,给叶子 -1 打分:
标记为 Max 的行中的叶节点——最大化玩家马克西米利安——标记为 +1 ,而明蒂行中的叶节点标记为 -1 。接下来,让极大极小值在树上冒泡。考虑一个节点,其中所有孩子都被分配了一个分数。如果该节点在一个 Max 行上,那么给它其子节点的最大值。否则,给它它的孩子的最低分。
如果您对树中的所有节点都这样做,那么您将得到下面的树:
因为树的顶端节点 6🪙 的分数为正,所以马克西米利安可以赢得比赛。您可以查看顶层节点的子节点,以找到他的最佳移动。 3🪙 和 4🪙 节点的得分都是 -1 ,代表明蒂获胜。Maximillian 应该保留五个计数器,因为 5🪙 节点是得分为 +1 的顶层节点的唯一子节点。
虽然在为 Nim 优化时只使用了-1 和+1 的最小最大值,但通常可以使用任何范围的数字。例如,在分析像井字游戏这样可能以平局结束的游戏时,您可能希望使用-1、0 和+1。
许多游戏,包括国际象棋,有如此多不同的可能走法,以至于计算整个游戏树是不可行的。在这些情况下,您只需将树绘制到一定深度,并对这个截断树中的叶节点进行评分。由于这些游戏还没有结束,你不能根据游戏的最终结果来给树叶打分。相反,你会根据对当前职位的一些评估来给他们打分。
在下一节中,您将使用 Python 来计算极大极小分数。
在与 Python Minimax 玩家的 Nim 游戏中失败
你已经知道了极大极小算法的步骤。在本节中,您将在 Python 中实现 minimax。您将从直接为 Simple-Nim 游戏定制算法开始。稍后,您将重构您的代码,将算法的核心与游戏规则分离开来,这样您就可以稍后将您的 minimax 代码应用到其他游戏中。
实现 Nim 特定的 Minimax 算法
考虑与上一节相同的例子:轮到马克西米利安,桌上有六个计数器。您将使用极大极小算法来确认 Maximillan 可以赢得这场游戏,并计算他的下一步行动。
不过,首先考虑几个游戏后期情况的例子。假设轮到马克西米利安,他看到了下面的游戏情况:
- 零计数器表示 Mindy 已经使用了最后一个计数器。马克西米利安赢得了比赛。
- 一个计数器没有给 Maximillian 留下任何选择。他拿走了计数器,这样明迪就剩下零个计数器了。使用与上一个要点相同的逻辑,但是玩家的角色颠倒了,你会看到 Mindy 赢得了游戏。
- 两个计数器给了马克西米利安一个选择。他可以选择一个或两个指示物,这将分别给明迪留下一个或零个指示物。从 Mindy 的角度重做前面要点的逻辑。你会注意到,如果马克西米利安拿了一个指示物,他就会留下一个指示物,并赢得游戏。如果他拿了两个指示物,他就剩下零个指示物,明蒂赢得游戏。
请注意,您是如何重用前面要点中的逻辑来确定谁能从特定的游戏位置中胜出的。现在开始用 Python 实现逻辑。创建一个名为minimax_simplenim.py的文件。您将使用state来表示计数器的数量,使用max_turn来记录是否轮到马克西米利安。
第一个规则,对于零计数器,可以实现为条件if测试。如果马克西米利安赢了游戏,你返回1,如果他输了,你返回-1:
# minimax_simplenim.py
def minimax(state, max_turn):
if state == 0:
return 1 if max_turn else -1
# ...
接下来,思考如何处理一个或多个计数器的游戏情况。他们减少到一种或多种状态,有更少的指示物,对手先移动。例如,如果现在轮到马克西米利安,考虑他可能的走法的结果,并选择最佳走法:
# minimax_simplenim.py
def minimax(state, max_turn):
if state == 0:
return 1 if max_turn else -1
possible_new_states = [ state - take for take in (1, 2, 3) if take <= state ] if max_turn: scores = [ minimax(new_state, max_turn=False) for new_state in possible_new_states ] return max(scores)
# ...
你将首先列举可能的新状态,确保玩家不会使用超过可用数量的计数器。你通过再次调用minimax()来计算 Maximillian 可能的移动的分数,注意下一个将轮到 Mindy。因为 Maximillian 是最大化玩家,你将返回他可能得分的最大值。
同样,如果现在轮到 Mindy,考虑她可能的选择。因为-1表示她赢了,所以她会选择得分最低的结果:
# minimax_simplenim.py
def minimax(state, max_turn):
if state == 0:
return 1 if max_turn else -1
possible_new_states = [
state - take for take in (1, 2, 3) if take <= state
]
if max_turn:
scores = [
minimax(new_state, max_turn=False)
for new_state in possible_new_states
]
return max(scores)
else: scores = [ minimax(new_state, max_turn=True) for new_state in possible_new_states ] return min(scores)
minimax()函数不断调用自己,直到到达每局游戏结束。换句话说,minimax()是一个递归函数。
注意:实现一个递归函数是遍历树的一种直观方式,因为探索一棵树的一个分支与探索更大的树是相同的操作。
然而,递归函数有一些问题,特别是对于较大的树。在 Python 中,函数调用有一些开销,调用栈是有限的。
稍后您将看到如何应对这些问题。但是如果你需要优化极大极小算法的速度,极大极小的非递归实现可能是一个更好的选择。
首先确认minimax()按预期工作。打开REPLPython 和导入你的功能:
>>> from minimax_simplenim import minimax >>> minimax(6, max_turn=True) 1 >>> minimax(5, max_turn=False) 1 >>> minimax(4, max_turn=False) -1你首先确认,如果马克西米利安在还剩六个指示物的情况下玩游戏,他可以赢,如
1所示。同样,如果马克西米利安为明迪留下五个筹码,他仍然可以赢。相反,如果他给明迪留了四个柜台,那么她就赢了。为了有效地找到 Maximillian 下一步应该走哪一步,您可以在一个循环中进行相同的计算:
>>> state = 6
>>> for take in (1, 2, 3):
... new_state = state - take
... score = minimax(new_state, max_turn=False)
... print(f"Move from {state} to {new_state}: {score}")
...
Move from 6 to 5: 1
Move from 6 to 4: -1
Move from 6 to 3: -1
寻找最高分,你看到马克西米利安应该拿一个计数器,在桌上留下五个。接下来,更进一步,创建一个可以找到 Maximillian 最佳移动的函数:
# minimax_simplenim.py
# ...
def best_move(state):
for take in (1, 2, 3):
new_state = state - take
score = minimax(new_state, max_turn=False)
if score > 0:
break
return score, new_state
你不断循环,直到找到一个给出正分数的走法——实际上,分数是1。你也可能在三个可能的走法中循环,却找不到获胜的走法。为了表明这一点,您需要返回分数和最佳移动:
>>> best_move(6) (1, 5) >>> best_move(5) (-1, 2)测试你的功能,你确认当面对六个指示物时,马克西米利安可以通过移除一个指示物并为明迪留下五个来赢得游戏。如果桌上有个计数器,那么所有的招式都有
-1分。即使所有的移动都同样糟糕,best_move()建议它检查的最后一个移动:取三个指示物,留下两个。回头看看你的
minimax()和best_move()的代码。两个函数都包含处理 minimax 算法的逻辑和处理 Simple-Nim 规则的逻辑。在下一小节中,您将看到如何将它们分开。重构为一般的极大极小算法
您已经将以下 Simple-Nim 规则编码到您的极大极小算法中:
- 玩家可以在他们的回合中使用一个、两个或三个指示物。
- 玩家不能使用比游戏中剩余数量更多的指示物。
- 当剩下零个计数器时,游戏结束。
- 拿到最后一个计数器的玩家输掉游戏。
此外,您已经使用
max_turn来跟踪 Maximillian 是否是活动玩家。说得更笼统一点,你可以把现在的玩家想成是想把自己的分数最大化的人。为了表明这一点,您将用is_maximizing替换max_turn标志。通过添加两个新函数开始重写代码:
# minimax_simplenim.py # ... def possible_new_states(state): return [state - take for take in (1, 2, 3) if take <= state] def evaluate(state, is_maximizing): if state == 0: return 1 if is_maximizing else -1这两个函数实现了 Simple-Nim 规则。使用
possible_new_states(),你计算可能的下一个状态,同时确保玩家不能使用比棋盘上可用的计数器更多的计数器。你用
evaluate()评估一个游戏位置。如果没有剩余的计数器,那么如果最大化玩家赢了游戏,函数返回1,如果另一个最小化玩家赢了,函数返回-1。如果游戏没有结束,执行将继续到函数结束并隐式返回None。你现在可以重写
minimax()来引用possible_new_states()和evaluate():# minimax_simplenim.py def minimax(state, is_maximizing): if (score := evaluate(state, is_maximizing)) is not None: return score if is_maximizing: scores = [ minimax(new_state, is_maximizing=False) for new_state in possible_new_states(state) ] return max(scores) else: scores = [ minimax(new_state, is_maximizing=True) for new_state in possible_new_states(state) ] return min(scores)记住也要把
max_turn重命名为is_maximizing。只有当剩下零个计数器并且已经决定了赢家的时候,你才能在一个游戏状态中得分。所以你需要检查
score是否为None来决定是继续调用minimax()还是退回游戏评价。您使用一个赋值表达式 (:=)来检查和记忆评估的游戏分数。接下来,观察您的
if…else语句中的块非常相似。这两个模块之间的唯一区别是,您使用哪个函数max()或min()来寻找最佳得分,以及在对minimax()的递归调用中使用什么值作为is_maximizing。这两个都可以直接从is_maximizing的电流值计算出来。因此,您可以将
if…else块折叠成一条语句:# minimax_simplenim.py def minimax(state, is_maximizing): if (score := evaluate(state, is_maximizing)) is not None: return score return (max if is_maximizing else min)( minimax(new_state, is_maximizing=not is_maximizing) for new_state in possible_new_states(state) )您使用一个条件表达式来调用
max()或min()。为了反转is_maximizing的值,您将not is_maximizing传递给对minimax()的递归调用。
minimax()的代码现在非常紧凑。更重要的是,Simple-Nim 的规则没有明确地编码在算法中。相反,它们被封装在possible_new_states()和evaluate()中。通过用
possible_new_states()和is_maximizing代替max_turn来表达best_move(),你完成了重构:# minimax_simplenim.py # ... def best_move(state): for new_state in possible_new_states(state): score = minimax(new_state, is_maximizing=False) if score > 0: break return score, new_state和以前一样,你检查每一步棋的结果,并返回第一个保证赢的棋。
注意:在
best_move()中没有错误处理。特别是,它假设possible_new_states()至少返回一个新的游戏状态。如果没有,那么循环根本不会运行,并且score和new_state将是未定义的。这意味着你应该只用一个有效的游戏状态来调用
best_move()。或者,您可以在best_move()本身内部添加一个额外的检查。在 Python 中,元组是逐元素比较的。您可以利用这一点直接使用
max(),而不是显式检查可能的移动:# minimax_simplenim.py # ... def best_move(state): return max( (minimax(new_state, is_maximizing=False), new_state) for new_state in possible_new_states(state) )如前所述,您考虑并返回一个包含分数和最佳新状态的元组。因为包括
max()在内的比较是在元组中一个元素一个元素地进行的,所以分数必须是元组中的第一个元素。你仍然能够找到最佳的行动:
>>> best_move(6)
(1, 5)
>>> best_move(5)
(-1, 4)
和以前一样,best_move()建议如果你面对六个,你应该选择一个计数器。在失去五个指示物的情况下,你拿多少指示物并不重要,因为无论如何你都要输了。您基于max()的实现最终会在表上留下尽可能多的计数器。
您可以展开下面的框来查看您在本节中实现的完整源代码:
您已经在possible_new_states()和evaluate()中封装了 Simple-Nim 的规则。这些功能由minimax()和best_move()使用:
# minimax_simplenim.py
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None:
return score
return (max if is_maximizing else min)(
minimax(new_state, is_maximizing=not is_maximizing)
for new_state in possible_new_states(state)
)
def best_move(state):
return max(
(minimax(new_state, is_maximizing=False), new_state)
for new_state in possible_new_states(state)
)
def possible_new_states(state):
return [state - take for take in (1, 2, 3) if take <= state]
def evaluate(state, is_maximizing):
if state == 0:
return 1 if is_maximizing else -1
使用best_move()找到给定游戏中的下一步棋。
干得好!您已经为 Simple-Nim 实现了一个极大极小算法。为了挑战它,你应该对你的代码玩几个游戏。从一些指示物开始,轮流自己移除指示物,并使用best_move()选择你的虚拟对手将移除多少指示物。除非你玩一个完美的游戏,否则你会输!
在下一节中,您将为 Nim 的常规规则实现相同的算法。
享受 Nim 变体的乐趣
到目前为止,您已经使用并实现了 Simple-Nim。在这一部分,您将学习 Nim 的最常见规则。这会给你的游戏增加更多的变化。
尼姆——有其固定的规则——仍然是一个简单的游戏。但这也是一个令人惊讶的基础游戏。原来,一个名为公正游戏的游戏家族,本质上都是 Nim 的伪装。
玩 Nim 的常规游戏
是时候拉出 Nim 的常规了。你仍然可以认出这个游戏,但是它允许玩家有更多的选择:
- 有几个堆,每个堆里有若干个计数器。
- 两名玩家轮流玩。
*** 在他们的回合中,一个玩家可以移除任意多的指示物,但是指示物必须来自同一堆。* 取得最后一个计数器的玩家输掉游戏。*
*请注意,在一个回合中移除多少个指示物不再有任何限制。如果一堆包含二十个指示物,那么当前玩家可以拿走所有指示物。
作为一个例子,考虑一个游戏,以分别包含两个、三个和五个计数器的三个筹码开始。看看你的朋友 Mindy 和 Maximillian 在玩这个游戏:
- 明迪从第三堆拿走四个指示物,剩下两个、三个、一个指示物。
- 马克西米利安从第二堆拿走两个指示物,剩下两个、一个、一个指示物。
- 明迪从第一堆拿走一个计数器,剩下一个、一个、一个计数器。
- 马克西米利安没有留下任何有趣的选择,但从第三堆中取出一个计数器,剩下一个、一个和零个计数器。
- 明迪从第二堆中取出一个计数器,剩下一个、零个和零个计数器。
- 马克西米利安拿走最后一个剩余的指示物,输掉了这场游戏。
你可以用表格来表示游戏:
| 要移动的玩家 | 第一堆 | 第二堆 | 三号桩 |
|---|---|---|---|
| 明迪(Minna 的异体)(f.) | 🪙🪙 | 🪙🪙🪙 | 🪙🪙🪙🪙🪙 |
| 姓氏 | 🪙🪙 | 🪙🪙🪙 | 🪙 |
| 明迪(Minna 的异体)(f.) | 🪙🪙 | 🪙 | 🪙 |
| 姓氏 | 🪙 | 🪙 | 🪙 |
| 明迪(Minna 的异体)(f.) | 🪙 | 🪙 | |
| 姓氏 | 🪙 |
就像在 Simple-Nim 游戏中一样,Maximillian 拿到了最后一个计数器,所以 Mindy 赢了。
注意:你应该玩几局 Nim,感受一下新规则是如何改变策略的。尝试不同数量的桩,比如三桩、四桩或五桩。每堆不需要很多计数器。三到九点是一个很好的起点。
考虑如何为这些新规则实现极大极小算法。记住你只需要重新实现possible_new_states()和evaluate()。
让你的代码适应常规 Nim
首先,将minimax_simplenim.py中的代码复制到一个名为minimax_nim.py的新文件中。然后,考虑如何从给定的游戏状态中列出所有可能的移动。比如明迪和马克西米利安,一开始是两个、三个、五个计数器。您可以列出所有可能的后续状态,如下所示:
| 第一桩:🪙🪙 | 第二桩:🪙🪙🪙 | 第三桩:🪙🪙🪙🪙🪙 |
|---|---|---|
| 🪙🪙🪙 | 🪙🪙🪙🪙🪙 | |
| 🪙 | 🪙🪙🪙 | 🪙🪙🪙🪙🪙 |
| 🪙🪙 | 🪙🪙🪙🪙🪙 | |
| 🪙🪙 | 🪙 | 🪙🪙🪙🪙🪙 |
| 🪙🪙 | 🪙🪙 | 🪙🪙🪙🪙🪙 |
| 🪙🪙 | 🪙🪙🪙 | |
| 🪙🪙 | 🪙🪙🪙 | 🪙 |
| 🪙🪙 | 🪙🪙🪙 | 🪙🪙 |
| 🪙🪙 | 🪙🪙🪙 | 🪙🪙🪙 |
| 🪙🪙 | 🪙🪙🪙 | 🪙🪙🪙🪙 |
有十种可能的行动。你可以从第一堆中取出一到两个指示物;第二堆中的一个、两个或三个计数器;或者第三堆中的一个、两个、三个、四个或五个计数器。
在代码中,可以用嵌套循环列出所有可能的新状态。外循环将依次考虑每一堆,内循环将迭代每一堆的不同选择:
# minimax_nim.py
# ...
def possible_new_states(state):
for pile, counters in enumerate(state):
for remain in range(counters):
yield state[:pile] + (remain,) + state[pile + 1 :]
在这里,你用一组数字来表示游戏状态,每个数字代表一堆计数器的数量。比如上面的情况表示为(2, 3, 5)。然后循环遍历每一堆,使用 enumerate() 来跟踪当前堆的索引。
对于每一堆,你使用 range() 列出该堆中可以保留多少个指示物的所有可能选择。你通过复制除当前堆以外的state返回一个新的游戏状态。回想一下,元组可以用方括号([])分割,并用加号(+)连接。
你不用在一个列表中收集可能的走法,而是使用yield一次一个地将它们发送回去。这使得possible_new_states()成为发电机:
>>> from minimax_nim import possible_new_states >>> possible_new_states((2, 3, 5)) <generator object possible_new_states at 0x7f1516ebc660> >>> list(possible_new_states((2, 3, 5))) [(0, 3, 5), (1, 3, 5), (2, 0, 5), (2, 1, 5), (2, 2, 5), (2, 3, 0), (2, 3, 1), (2, 3, 2), (2, 3, 3), (2, 3, 4)]仅仅调用
possible_new_states()返回一个生成器,而不生成可能的新状态。您可以通过将生成器转换为一个列表来查看移动。为了实现常规 Nim 的
evaluate(),您需要考虑两个问题:
- 如何检测游戏结束
- 比赛结束后如何得分
赢得 Nim 的规则与赢得 Simple-Nim 的规则相同,因此您可以像前面一样为游戏评分。当所有的堆都空了,游戏就结束了。另一方面,如果任何一堆仍然包含至少一个计数器,那么游戏还没有结束。您使用
all()来检查所有堆都包含零计数器:# minimax_nim.py # ... def evaluate(state, is_maximizing): if all(counters == 0 for counters in state): return 1 if is_maximizing else -1如果游戏结束,那么如果最大化玩家赢了游戏,你就给游戏打分
1,如果最小化玩家赢了,你就给游戏打分-1。和以前一样,如果游戏还没有结束,并且你还不能评估游戏状态,你隐式地返回None。因为你已经在
possible_new_states()和evaluate()中编码了所有的游戏规则,所以你不需要对minimax()或best_move()做任何改动。您可以展开下面的框来查看常规 Nim 所需的完整源代码:以下代码可以计算常规 Nim 中的下一个最优移动:
# minimax_nim.py def minimax(state, is_maximizing): if (score := evaluate(state, is_maximizing)) is not None: return score return (max if is_maximizing else min)( minimax(new_state, is_maximizing=not is_maximizing) for new_state in possible_new_states(state) ) def best_move(state): return max( (minimax(new_state, is_maximizing=False), new_state) for new_state in possible_new_states(state) ) def possible_new_states(state): for pile, counters in enumerate(state): for remain in range(counters): yield state[:pile] + (remain,) + state[pile + 1 :] def evaluate(state, is_maximizing): if all(counters == 0 for counters in state): return 1 if is_maximizing else -1与
minimax_simplenim.py相比,minimax()和best_move()没有变化。您可以使用您的代码来检查 Mindy 在本节开头的示例中是否选择了一个好的第一步:
>>> from minimax_nim import best_move
>>> best_move((2, 3, 5))
(1, (2, 3, 1))
>>> best_move((2, 3, 1))
(-1, (2, 3, 0))
事实上,从第三堆中取出四个指示物是明迪的最佳选择。在筹码堆中有两个、三个、一个筹码的情况下,没有最优移动,由-1的分数表示。
您已经看到,在更改 Nim 规则时,您可以重用minimax()和best_move()。
尝试 Nim 的其他变体
尼姆有时被称为猜错游戏,因为目标是避免占据最后一个计数器。Nim 的一个流行变体改变了获胜条件。在这个变体中,拿到最后一个计数器的玩家赢得游戏。你会如何改变你的代码来玩这个版本的游戏?
尝试实现 Nim 的非 misre 变体的 minimax 算法。你只需要修改一行代码。
要修改您的代码,使其针对最后一个计数器进行优化,您需要更改评估游戏的方式:
def evaluate(state, is_maximizing):
if all(counters == 0 for counters in state):
return -1 if is_maximizing else 1
现在,如果没有剩余的指示物,最后一个移动的玩家已经赢得了游戏。为了表明这一点,您返回最差的分数:如果您最大化,则返回-1,如果您最小化,则返回1。
Nim 的另一个变体是将所有的计数器放在一堆:
- 有几个计数器,都是从一堆开始。
- 两名玩家轮流玩。
*** 轮到他们时,一名玩家将一堆分成两堆,这样这两堆新的筹码就有了不同的数量的指示物。* 第一个不能分裂任何一堆的玩家输掉游戏。*
*在这个变体中,每次移动都会产生一个新的堆。游戏持续到所有的堆都包含一个或两个指示物,因为那些堆不能被分开。
考虑一个从一堆六个计数器开始的游戏。请注意,有两种可能的开始移动:分裂到五比一或四比二。三-三不是合法的移动,因为两个新牌堆必须有不同数量的指示物。观看 Mindy 和 Maximillian 玩游戏:
- 明迪把这堆分成两堆,分别有四个和两个计数器。
- 马克西米利安将第一堆分成三堆,其中有三个、一个、两个计数器。
- 明迪将第一堆拆分成四堆,分别是两个、一个、一个、两个计数器。
- 马克西米利安不能拆分任何一堆,因为它们都包含一个或两个指示物,所以他输掉了这场游戏。
明蒂赢得了比赛,因为马克西米利安无法采取行动。你将如何实现一个能在这个变体中找到最佳走法的 minimax 版本?
实现 Nim 变体的规则,玩家轮流拆分一堆计数器。你应该思考四个问题:
- 你应该如何表现游戏状态?
- 在一次移动后,你如何列举可能的新状态?
- 你怎么能察觉到游戏结束了呢?
- 你应该如何评价一个游戏的结局?
您需要创建新的possible_new_states()和evaluate()函数。
复制您的minimax_nim.py文件,并将其命名为minimax_nim_split.py。然后您可以修改possible_new_states()和evaluate()来考虑新的规则:
# minimax_nim_split.py
# ...
def possible_new_states(state):
for pile, counters in enumerate(state):
for take in range(1, (counters + 1) // 2):
yield state[:pile] + (counters - take, take) + state[pile + 1 :]
def evaluate(state, is_maximizing):
if all(counters <= 2 for counters in state):
return -1 if is_maximizing else 1
为了列出可能的新状态,依次考虑每一堆。你需要考虑如何拆分一堆计数器。
请注意,拆分是对称的。你不需要把一堆3计数器拆分成(1, 2)和(2, 1)。这意味着您可以迭代大约一半数量的计数器。
更准确地说,你迭代了range(1, (counters + 1) // 2)。这隐含地考虑到您必须将一个堆分成两个具有不同计数器数量的堆。例如,5和6计数器都让take取值1和2。拆分的堆由元组(counters - take, take)表示。
你只评估游戏的最终状态。当所有的堆都包含一个或两个计数器时,游戏就结束了。当游戏结束时,当前玩家已经输了,因为他们不能再移动了。
Nim 还有很多其他的变种。享受实现其中一些的乐趣。
使用 Alpha-Beta 修剪优化 Minimax】
极大极小算法的一个挑战是博弈树可能很大。代表 Simple-Nim 的树中的节点数遵循一个类似 Fibonacci 的公式。例如,代表六个计数器的节点的子节点数量是代表三个、四个和五个计数器的树中节点的总和。
这些数字增长很快,如下表所示:
| Zero | one | Two | three | four | five | six | seven | … | Twenty-five |
|---|---|---|---|---|---|---|---|---|---|
| one | Two | three | six | Twelve | Twenty-two | Forty-one | Seventy-six | Four million four hundred and thirty-four thousand six hundred and ninety |
为了表示一个从 25 个计数器开始的游戏,你需要一个超过 400 万个节点的树。如果你试着计算minimax(25, True),你会注意到这需要几秒钟。
在 Simple-Nim 中,博弈树由许多重复的博弈状态组成。例如,您可以通过四种不同的方式从六个移动到三个计数器: 6-3 、 6-4-3 、 6-5-3 和 6-5-4-3 。所以同样的游戏状态被minimax()重复计算。您可以通过使用缓存来解决这个问题:
from functools import cache
@cache def minimax(state, is_maximizing):
# ...
这将大大加快你的代码,因为 Python 只为每个游戏状态计算一次最小最大值。
注:在常规 Nim 中,有很多等价的游戏状态。比如(2, 2, 3)、(2, 3, 2)、(3, 2, 2)都代表同一个位置。让游戏树变小的一个优化方法是在possible_new_states()中只列出一个对称的位置。你现在不会涉及这个,但是试着自己添加,并在评论中分享你的经验!
另一种提高算法效率的方法是避免不必要地探索子树。在这一部分,你将学习到 alpha-beta 修剪,你可以用它来减少游戏树的大小。
修剪你的游戏树
假设你在玩 Simple-Nim,还有三个计数器。你有两个选择可以考虑——留下一个或者留下两个柜台:
- 如果你留下一个计数器,那么你的对手需要拿走它,你将赢得这场游戏。
- 你不需要计算离开两个指示物的结果,因为你已经找到了赢得游戏的一步棋。
在这个争论中,你不需要考虑是否应该给留两个计数器。你已经修剪了游戏树。
现在回到轮到马克西米利安的例子,桌上有六个计数器。如果您考虑从左到右的分支,并且一旦确定了节点的极大极小值,就停止探索子树,那么您将得到下面的树:
游戏树变得更小。最初的树有 41 个节点,而这个修剪过的版本只需要 17 个节点来代表游戏中的所有移动。
这个过程被称为α-β修剪,因为它使用两个参数,α和β,来跟踪一个分支何时可以被剪切。在下一节中,您将重写minimax()以使用 alpha-beta 修剪。
实施阿尔法-贝塔剪枝
您可以通过重构minimax()函数向代码添加 alpha-beta 修剪。您已经对minimax()进行了重构,使得相同的实现适用于 Nim 的所有变体。在前一小节中,您为 Simple-Nim 修剪了树。然而,您也可以为常规 Nim 实现 alpha-beta 修剪。制作一个minimax_nim.py的副本,命名为alphabeta_nim.py。
你需要一个标准来知道你什么时候可以停止探索。为此,您将添加两个参数,alpha和beta:
alpha将代表确保最大化玩家的最低分数。beta将代表确保最小化玩家的最高得分。
如果beta小于或等于alpha,那么玩家可以停止探索游戏树。最大化将已经找到比玩家通过进一步探索所能找到的更好的选择。
为了实现这个想法,您将从用一个显式的for循环替换您的理解开始。您需要显式循环,这样您就可以摆脱它并有效地修剪树:
# alphabeta_nim.py
from functools import cache
@cache
def minimax(state, is_maximizing):
if (score := evaluate(state, is_maximizing)) is not None:
return score
scores = [] for new_state in possible_new_states(state): scores.append(minimax(new_state, is_maximizing=not is_maximizing)) return (max if is_maximizing else min)(scores)
# ...
这里,在返回最佳分数之前,您在一个名为scores的列表中显式地收集子节点的分数。
接下来,您将添加alpha和beta作为参数。理论上,它们应该分别从负无穷大和正无穷大开始,代表两个玩家可能的最差分数。然而,由于 Nim 中唯一可能的分数是-1和1,您可以使用它们作为起始值。
对于每个 minimax 评估,您更新alpha和beta的值并比较它们。一旦beta变得小于或等于alpha,你就跳出了循环,因为你不需要考虑任何进一步的行动:
# alphabeta_nim.py
from functools import cache
@cache
def minimax(state, is_maximizing, alpha=-1, beta=1):
if (score := evaluate(state, is_maximizing)) is not None:
return score
scores = []
for new_state in possible_new_states(state):
scores.append(
score := minimax(new_state, not is_maximizing, alpha, beta) )
if is_maximizing: alpha = max(alpha, score) else: beta = min(beta, score) if beta <= alpha: break return (max if is_maximizing else min)(scores)
# ...
在递归步骤中,使用赋值表达式(:=)来存储minimax()的返回值并将其添加到分数列表中。
阿尔法-贝塔剪枝只是一种优化。它不会改变极大极小算法的结果。您仍然会看到与前面相同的结果:
>>> from alphabeta_nim import best_move >>> best_move((2, 3, 5)) (1, (2, 3, 1)) >>> best_move((2, 3, 1)) (-1, (2, 3, 0))如果你测量算法执行的时间,那么你会注意到极大极小法使用阿尔法-贝塔剪枝更快,因为它需要探索的博弈树更少。
您可以展开下面的框来查看使用 minimax 和 alpha-beta 剪枝来找到最佳 Nim 移动的完整 Python 代码:
Alpha-beta 修剪在
minimax()中实现:# alphabeta_nim.py from functools import cache @cache def minimax(state, is_maximizing, alpha=-1, beta=1): if (score := evaluate(state, is_maximizing)) is not None: return score scores = [] for new_state in possible_new_states(state): scores.append( score := minimax(new_state, not is_maximizing, alpha, beta) ) if is_maximizing: alpha = max(alpha, score) else: beta = min(beta, score) if beta <= alpha: break return (max if is_maximizing else min)(scores) def best_move(state): return max( (minimax(new_state, is_maximizing=False), new_state) for new_state in possible_new_states(state) ) def possible_new_states(state): for pile, counters in enumerate(state): for remain in range(counters): yield state[:pile] + (remain,) + state[pile + 1 :] def evaluate(state, is_maximizing): if all(counters == 0 for counters in state): return 1 if is_maximizing else -1调用
best_move()从一个给定的游戏状态中找到最优的移动。即使
minimax()现在做阿尔法-贝塔修剪,它仍然依靠evaluate()和possible_new_states()来实现游戏规则。因此,您也可以在 Simple-Nim 上使用新的minimax()实现。结论
干得好!您已经了解了极大极小算法,并看到了如何使用它在 Nim 游戏中找到最佳移动。虽然 Nim 是一个简单的游戏,但 minimax 可以应用于许多其他游戏,如井字游戏和国际象棋。你可以将你探索的原则应用到许多不同的游戏中。
在本教程中,您已经学会了如何:
- 解释极大极小算法的原理
- 玩 Nim 的游戏的几个变种
- 实现极大极小算法
- 输了尼姆对一个极小极大玩家的游戏
- 使用阿尔法-贝塔剪枝优化极大极小算法
想一想如何将极大极小算法应用到你最喜欢的游戏中,以及如何用 Python 实现它。在评论中,让你的程序员同事知道你在与 minimax 的比赛中还输了哪些游戏。
源代码: 点击这里下载免费的源代码,你将使用它来输掉与你的 minimax 玩家的 Nim 游戏。*************
Python mmap:通过内存映射改进了文件 I/O
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python mmap:用内存映射做文件 I/O
Python 的禅有很多智慧可以提供。一个特别有用的想法是“应该有一个——最好只有一个——显而易见的方法去做。”然而,用 Python 做大多数事情有多种方法,而且通常都有很好的理由。比如在 Python 中有多种方式读取一个文件,包括很少使用的
mmap模块。Python 的
mmap提供了内存映射的文件输入和输出(I/O)。它允许你利用底层操作系统的功能来读取文件,就好像它们是一个大的字符串或数组。这可以显著提高需要大量文件 I/O 的代码的性能。在本教程中,您将学习:
- 电脑内存有哪些种类
- 用
mmap可以解决什么问题- 如何使用内存映射来更快地读取大文件
- 如何改变文件的部分而不重写整个文件
- 如何使用
mmap到在多个进程间共享信息免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
了解计算机内存
内存映射是一种使用低级操作系统 API 将文件直接加载到计算机内存中的技术。它可以显著提高程序中的文件 I/O 性能。为了更好地理解内存映射如何提高性能,以及如何以及何时可以使用
mmap模块来利用这些性能优势,首先学习一点关于计算机内存的知识是很有用的。计算机内存是一个大而复杂的话题,但是本教程只关注你需要知道的如何有效地使用
mmap模块。出于本教程的目的,术语存储器指的是随机存取存储器,或 RAM。有几种类型的计算机内存:
- 身体的
- 虚拟的
- 共享的
当您使用内存映射时,每种类型的内存都会发挥作用,所以让我们从较高的层次来回顾一下每种类型的内存。
物理内存
物理内存是理解起来最简单的一种内存,因为它通常是与你的电脑相关的市场营销的一部分。(你可能还记得,当你买电脑时,它宣传的是 8g 内存。)物理内存通常位于连接到计算机主板的卡上。
物理内存是程序运行时可用的易失性内存总量。不应将物理内存与存储混淆,如硬盘或固态硬盘。
虚拟内存
虚拟内存是一种处理内存管理的方式。操作系统使用虚拟内存使你看起来比实际拥有的内存多,这样你就不用担心在任何给定的时间有多少内存可供你的程序使用。在幕后,您的操作系统使用部分非易失性存储(如固态硬盘)来模拟额外的 RAM。
为此,您的操作系统必须维护物理内存和虚拟内存之间的映射。每个操作系统都使用自己的复杂算法,通过一种叫做页表的数据结构将虚拟内存地址映射到物理内存地址。
幸运的是,这种复杂性大部分隐藏在您的程序中。用 Python 编写高性能 I/O 代码不需要理解页表或逻辑到物理的映射。然而,了解一点内存会让你更好地理解计算机和库在为你做什么。
mmap使用虚拟内存,让您看起来好像已经将一个非常大的文件加载到内存中,即使该文件的内容太大而不适合您的物理内存。共享内存
共享内存是操作系统提供的另一种技术,允许多个程序同时访问相同的数据。在使用并发的程序中,共享内存是处理数据的一种非常有效的方式。
Python 的
mmap使用共享内存在多个 Python 进程、线程和并发发生的任务之间高效地共享大量数据。深入挖掘文件 I/O
现在,您已经对不同类型的内存有了一个较高的认识,是时候了解什么是内存映射以及它解决什么问题了。内存映射是执行文件 I/O 的另一种方式,可以提高性能和内存效率。
为了充分理解内存映射的作用,从底层角度考虑常规文件 I/O 是很有用的。当读取文件时,许多事情在幕后发生:
考虑以下执行常规 Python 文件 I/O 的代码:
def regular_io(filename): with open(filename, mode="r", encoding="utf8") as file_obj: text = file_obj.read() print(text)这段代码将整个文件读入物理内存,如果运行时有足够的内存可用的话,然后将它打印到屏幕上。
这种类型的文件 I/O 您可能在 Python 之旅的早期就已经了解过了。代码不是很密集或复杂。然而,在像
read()这样的函数调用的掩盖下发生的事情是非常复杂的。请记住,Python 是一种高级编程语言,所以很多复杂性对程序员来说是隐藏的。系统调用
实际上,对
read()的调用意味着操作系统要做大量复杂的工作。幸运的是,操作系统提供了一种方法,通过系统调用,从你的程序中抽象出每个硬件设备的具体细节。每个操作系统将不同地实现这个功能,但是至少,read()必须执行几次系统调用来从文件中检索数据。所有对物理硬件的访问都必须在一个名为内核空间的受保护环境中进行。系统调用是操作系统提供的 API,允许你的程序从用户空间进入内核空间,在内核空间管理物理硬件的底层细节。
在
read()的情况下,操作系统需要几次系统调用才能与物理存储设备交互并返回数据。同样,你不需要牢牢掌握系统调用和计算机架构的细节来理解内存映射。要记住的最重要的事情是,从计算上来说,系统调用相对昂贵,所以系统调用越少,代码可能执行得越快。
除了系统调用之外,对
read()的调用还包括在数据返回到你的程序之前,在多个数据缓冲区之间进行大量潜在的不必要的数据复制。通常情况下,这一切发生得如此之快,以至于人们察觉不到。但是所有这些层都增加了延迟并且会减慢你的程序。这就是内存映射发挥作用的地方。
内存映射优化
避免这种开销的一种方法是使用一个内存映射文件。您可以将内存映射想象成一个过程,在这个过程中,读写操作跳过上面提到的许多层,将请求的数据直接映射到物理内存中。
内存映射文件 I/O 方法牺牲内存使用来换取速度,这被经典地称为空间-时间权衡。然而,内存映射并不需要比传统方法使用更多的内存。操作系统非常聪明。它将根据请求缓慢地加载数据,类似于 Python 生成器的工作方式。
此外,由于虚拟内存,您可以加载比物理内存更大的文件。然而,当没有足够的物理内存存储文件时,您不会看到内存映射带来的巨大性能提升,因为操作系统将使用较慢的物理存储介质(如固态磁盘)来模拟它缺少的物理内存。
用 Python 的
mmap读取内存映射文件现在,所有这些理论都已过时,您可能会问自己,“我如何使用 Python 的
mmap来创建内存映射文件?”下面是您之前看到的文件 I/O 代码的内存映射等价物:
import mmap def mmap_io(filename): with open(filename, mode="r", encoding="utf8") as file_obj: with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj: text = mmap_obj.read() print(text)这段代码将整个文件作为一个字符串读入内存,并将其打印到屏幕上,就像早期的常规文件 I/O 方法一样。
简而言之,使用
mmap与读取文件的传统方式非常相似,只有一些小的变化:
用
open()打开文件是不够的。您还需要使用mmap.mmap()向操作系统发送信号,表示您希望将文件映射到 RAM 中。你需要确保你和
open()使用的模式和mmap.mmap()兼容。open()的默认模式是读,而mmap.mmap()的默认模式是读和写。所以,在打开文件时,你必须明确。您需要使用
mmap对象而不是由open()返回的标准文件对象来执行所有的读写操作。性能影响
内存映射方法比典型的文件 I/O 稍微复杂一些,因为它需要创建另一个对象。然而,当读取一个只有几兆字节的文件时,这一小小的改变可以带来巨大的性能优势。下面是读著名小说 《堂吉诃德的历史》 的原文对比,大致是 2.4 兆:
>>> import timeit
>>> timeit.repeat(
... "regular_io(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io, filename")
[0.02022400000000002, 0.01988580000000001, 0.020257300000000006]
>>> timeit.repeat(
... "mmap_io(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io, filename")
[0.006156499999999981, 0.004843099999999989, 0.004868600000000001]
这是使用常规文件 I/O 和内存映射文件 I/O 读取整个 2.4 兆字节文件所需的时间。如您所见,内存映射方法大约需要 0.005 秒,而常规方法大约需要 0.02 秒。当读取更大的文件时,这种性能提升甚至会更大。
注意:这些结果是使用 Windows 10 和 Python 3.8 收集的。因为内存映射非常依赖于操作系统的实现,所以您的结果可能会有所不同。
Python 的mmap文件对象提供的 API 与传统文件对象非常相似,除了一个额外的超级能力:Python 的mmap文件对象可以像字符串对象一样被切片!
mmap对象创建
在创建mmap对象的过程中,有一些细微之处值得仔细观察:
mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ)
mmap需要一个文件描述符,它来自一个常规文件对象的fileno()方法。文件描述符是一个内部标识符,通常是一个整数,操作系统用它来跟踪打开的文件。
mmap的第二个参数是length=0。这是存储器映射的字节长度。0是一个特殊的值,表示系统应该创建一个足够大的内存映射来保存整个文件。
access参数告诉操作系统你将如何与映射内存交互。选项有ACCESS_READ、ACCESS_WRITE、ACCESS_COPY和ACCESS_DEFAULT。这些有点类似于内置open()的mode参数:
ACCESS_READ创建一个只读内存映射。ACCESS_DEFAULT默认为可选prot参数中指定的模式,用于内存保护。ACCESS_WRITE和ACCESS_COPY是两种写模式,在下面你会了解到。
文件描述符、length和access参数表示创建一个内存映射文件所需的最低要求,该文件将在 Windows、Linux 和 macOS 等操作系统上工作。上面的代码是跨平台的,这意味着它将通过所有操作系统上的内存映射接口读取文件,而不需要知道代码运行在哪个操作系统上。
另一个有用的参数是offset,这是一种节省内存的技术。这指示mmap从文件中指定的偏移量开始创建一个内存映射。
mmap字符串形式的对象
如前所述,内存映射将文件内容作为字符串透明地加载到内存中。因此,一旦你打开文件,你就可以执行许多与使用字符串相同的操作,比如切片:
import mmap
def mmap_io(filename):
with open(filename, mode="r", encoding="utf8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
print(mmap_obj[10:20])
这段代码将十个字符从mmap_obj打印到屏幕上,并将这十个字符读入物理内存。同样,数据被缓慢地读取。
切片不会提升内部文件位置。所以,如果你在一个片后调用read(),那么你仍然会从文件的开始读取。
搜索内存映射文件
除了切片之外,mmap模块还允许其他类似字符串的行为,比如使用find()和rfind()在文件中搜索特定的文本。例如,有两种方法可以找到文件中第一次出现的" the ":
import mmap
def regular_io_find(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
text = file_obj.read()
print(text.find(" the "))
def mmap_io_find(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
print(mmap_obj.find(b" the "))
这两个函数都在文件中搜索第一次出现的" the ",它们之间的主要区别是第一个函数在字符串对象上使用find(),而第二个函数在内存映射文件对象上使用find()。
注意: mmap操作的是字节,不是字符串。
以下是性能差异:
>>> import timeit >>> timeit.repeat( ... "regular_io_find(filename)", ... repeat=3, ... number=1, ... setup="from __main__ import regular_io_find, filename") [0.01919180000000001, 0.01940510000000001, 0.019157700000000027] >>> timeit.repeat( ... "mmap_io_find(filename)", ... repeat=3, ... number=1, ... setup="from __main__ import mmap_io_find, filename") [0.0009397999999999906, 0.0018005999999999855, 0.000826699999999958]那可是差了好几个数量级啊!同样,您的结果可能会因操作系统而异。
内存映射文件也可以直接和正则表达式一起使用。考虑下面的示例,该示例查找并打印出所有五个字母的单词:
import re import mmap def mmap_io_re(filename): five_letter_word = re.compile(rb"\b[a-zA-Z]{5}\b") with open(filename, mode="r", encoding="utf-8") as file_obj: with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj: for word in five_letter_word.findall(mmap_obj): print(word)这段代码读取整个文件,并打印出其中正好有五个字母的每个单词。请记住,内存映射文件使用字节字符串,因此正则表达式也必须使用字节字符串。
下面是使用常规文件 I/O 的等效代码:
import re def regular_io_re(filename): five_letter_word = re.compile(r"\b[a-zA-Z]{5}\b") with open(filename, mode="r", encoding="utf-8") as file_obj: for word in five_letter_word.findall(file_obj.read()): print(word)这段代码还打印出文件中所有五个字符的单词,但是它使用传统的文件 I/O 机制,而不是内存映射文件。和以前一样,这两种方法的性能不同:
>>> import timeit
>>> timeit.repeat(
... "regular_io_re(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_re, filename")
[0.10474110000000003, 0.10358619999999996, 0.10347820000000002]
>>> timeit.repeat(
... "mmap_io_re(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_re, filename")
[0.0740976000000001, 0.07362639999999998, 0.07380980000000004]
内存映射方法仍然要快一个数量级。
作为文件的内存映射对象
内存映射文件是部分字符串和部分文件,因此mmap也允许您执行常见的文件操作,如seek()、tell()和readline()。这些函数的工作方式与常规的文件对象完全一样。
例如,下面是如何查找文件中的特定位置,然后执行单词搜索:
import mmap
def mmap_io_find_and_seek(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_READ) as mmap_obj:
mmap_obj.seek(10000)
mmap_obj.find(b" the ")
这段代码将寻找文件中的位置10000,然后找到第一次出现" the "的位置。
seek()对内存映射文件的作用与对常规文件的作用完全相同:
def regular_io_find_and_seek(filename):
with open(filename, mode="r", encoding="utf-8") as file_obj:
file_obj.seek(10000)
text = file_obj.read()
text.find(" the ")
这两种方法的代码非常相似。让我们看看他们的表现如何比较:
>>> import timeit >>> timeit.repeat( ... "regular_io_find_and_seek(filename)", ... repeat=3, ... number=1, ... setup="from __main__ import regular_io_find_and_seek, filename") [0.019396099999999916, 0.01936059999999995, 0.019192100000000045] >>> timeit.repeat( ... "mmap_io_find_and_seek(filename)", ... repeat=3, ... number=1, ... setup="from __main__ import mmap_io_find_and_seek, filename") [0.000925100000000012, 0.000788299999999964, 0.0007854999999999945]同样,只需对代码进行一些小的调整,您的内存映射方法就会快得多。
用 Python 的
mmap写内存映射文件内存映射对于读取文件最有用,但是您也可以使用它来写入文件。用于写文件的 API 与常规的文件 I/O 非常相似,除了一些不同之处。
下面是一个将文本写入内存映射文件的示例:
import mmap def mmap_io_write(filename, text): with open(filename, mode="w", encoding="utf-8") as file_obj: with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj: mmap_obj.write(text)这段代码将文本写入内存映射文件。但是,如果在创建
mmap对象时文件是空的,它将引发一个ValueError异常。Python 的
mmap模块不允许空文件的内存映射。这是合理的,因为从概念上讲,一个空的内存映射文件只是一个内存缓冲区,所以不需要内存映射对象。通常,内存映射用于读取或读/写模式。例如,下面的代码演示了如何快速读取文件并只修改其中的一部分:
import mmap def mmap_io_write(filename): with open(filename, mode="r+") as file_obj: with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj: mmap_obj[10:16] = b"python" mmap_obj.flush()该功能将打开一个至少包含 16 个字符的文件,并将字符 10 至 15 更改为
"python"。写入
mmap_obj的更改在磁盘上的文件和内存中都是可见的。官方 Python 文档建议总是调用flush()来保证数据被写回磁盘。写入模式
写操作的语义由
access参数控制。编写内存映射文件和普通文件的一个区别是access参数的选项。有两个选项可以控制如何将数据写入内存映射文件:
ACCESS_WRITE指定直写语义,意味着数据将通过内存写入并持久存储在磁盘上。ACCESS_COPY不将更改写入磁盘,即使flush()被调用。换句话说,
ACCESS_WRITE写入内存和文件,而ACCESS_COPY只写入内存,不写入底层文件。搜索和替换文本
内存映射文件将数据公开为一个字节字符串,但是这个字节字符串与常规字符串相比还有一个重要的优势。内存映射文件数据是一个由个可变字节组成的字符串。这意味着编写在文件中搜索和替换数据的代码要简单和高效得多:
import mmap import os import shutil def regular_io_find_and_replace(filename): with open(filename, "r", encoding="utf-8") as orig_file_obj: with open("tmp.txt", "w", encoding="utf-8") as new_file_obj: orig_text = orig_file_obj.read() new_text = orig_text.replace(" the ", " eht ") new_file_obj.write(new_text) shutil.copyfile("tmp.txt", filename) os.remove("tmp.txt") def mmap_io_find_and_replace(filename): with open(filename, mode="r+", encoding="utf-8") as file_obj: with mmap.mmap(file_obj.fileno(), length=0, access=mmap.ACCESS_WRITE) as mmap_obj: orig_text = mmap_obj.read() new_text = orig_text.replace(b" the ", b" eht ") mmap_obj[:] = new_text mmap_obj.flush()这两个函数都将给定文件中的单词
" the "更改为" eht "。如您所见,内存映射方法大致相同,但是它不需要手动跟踪额外的临时文件来进行适当的替换。在这种情况下,对于这种文件长度,内存映射方法实际上会稍慢一些。因此,对内存映射文件进行完全搜索和替换可能是也可能不是最有效的方法。这可能取决于许多因素,如文件长度、机器的内存速度等。也可能有一些操作系统缓存扭曲了时间。正如您所看到的,常规 IO 方法在每次调用时都会加快速度。
>>> import timeit
>>> timeit.repeat(
... "regular_io_find_and_replace(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import regular_io_find_and_replace, filename")
[0.031016973999996367, 0.019185273000005054, 0.019321329999996806]
>>> timeit.repeat(
... "mmap_io_find_and_replace(filename)",
... repeat=3,
... number=1,
... setup="from __main__ import mmap_io_find_and_replace, filename")
[0.026475408999999672, 0.030173652999998524, 0.029132930999999473]
在这个基本的搜索-替换场景中,内存映射会使代码稍微简洁一些,但并不总是能大幅提高速度。正如他们所说,“你的里程可能会有所不同。”
用 Python 的mmap 在进程间共享数据
到目前为止,您只对磁盘上的数据使用内存映射文件。然而,你也可以创建没有物理存储的匿名内存映射。这可以通过传递-1作为文件描述符来实现:
import mmap
with mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE) as mmap_obj:
mmap_obj[0:100] = b"a" * 100
print(mmap_obj[0:100])
这在 RAM 中创建了一个匿名的内存映射对象,其中包含字母"a"的100个副本。
匿名内存映射对象本质上是内存中特定大小的缓冲区,由参数length指定。缓冲区类似于标准库中的 io.StringIO 或 io.BytesIO 。然而,一个匿名的内存映射对象支持跨多个进程的共享,io.StringIO和io.BytesIO都不允许。
这意味着您可以使用匿名内存映射对象在进程之间交换数据,即使这些进程具有完全独立的内存和堆栈。下面是一个创建匿名内存映射对象来共享可以从两个进程中读写的数据的示例:
import mmap
def sharing_with_mmap():
BUF = mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE)
pid = os.fork()
if pid == 0:
# Child process
BUF[0:100] = b"a" * 100
else:
time.sleep(2)
print(BUF[0:100])
使用这段代码,您创建了一个100字节的内存映射缓冲区,并允许从两个进程中读取和写入该缓冲区。如果您希望节省内存,同时仍能在多个进程间共享大量数据,这种方法会很有用。
使用内存映射共享内存有几个优点:
- 数据不必在进程间复制。
- 操作系统透明地处理内存。
- 数据不必在进程间酸洗,节省了 CPU 时间。
说到酸洗,值得指出的是mmap与更高级、更全功能的 API 如内置multiprocessing模块不兼容。multiprocessing模块需要在进程间传递数据来支持 pickle 协议,而mmap不需要。
您可能会尝试使用multiprocessing而不是os.fork(),如下所示:
from multiprocessing import Process
def modify(buf):
buf[0:100] = b"xy" * 50
if __name__ == "__main__":
BUF = mmap.mmap(-1, length=100, access=mmap.ACCESS_WRITE)
BUF[0:100] = b"a" * 100
p = Process(target=modify, args=(BUF,))
p.start()
p.join()
print(BUF[0:100])
在这里,您试图创建一个新的进程,并将内存映射缓冲区传递给它。这段代码将立即引发一个 TypeError ,因为mmap对象不能被酸洗,这是将数据传递给第二个进程所必需的。因此,要使用内存映射共享数据,您需要坚持使用底层的os.fork()。
如果您使用的是 Python 3.8 或更新版本,那么您可以使用新的 shared_memory模块来更有效地跨 Python 进程共享数据:
from multiprocessing import Process
from multiprocessing import shared_memory
def modify(buf_name):
shm = shared_memory.SharedMemory(buf_name)
shm.buf[0:50] = b"b" * 50
shm.close()
if __name__ == "__main__":
shm = shared_memory.SharedMemory(create=True, size=100)
try:
shm.buf[0:100] = b"a" * 100
proc = Process(target=modify, args=(shm.name,))
proc.start()
proc.join()
print(bytes(shm.buf[:100]))
finally:
shm.close()
shm.unlink()
这个小程序创建了一个100字符列表,并从另一个进程中修改前 50 个字符。
注意,只有缓冲区的名称被传递给第二个进程。然后,第二个进程可以使用该唯一名称检索同一个内存块。这是由mmap供电的shared_memory模块的一个特殊功能。在幕后,shared_memory模块使用每个操作系统独特的 API 为您创建命名的内存映射。
现在您已经知道了新的共享内存 Python 3.8 特性的一些底层实现细节,以及如何直接使用mmap!
结论
内存映射是文件 I/O 的另一种方法,Python 程序可以通过mmap模块使用它。内存映射使用低级操作系统 API 将文件内容直接存储在物理内存中。这种方法通常会提高 I/O 性能,因为它避免了许多昂贵的系统调用,并减少了昂贵的数据缓冲区传输。
在本教程中,您学习了:
- 物理、虚拟和共享内存有什么区别
- 如何优化内存使用与内存映射
- 如何使用 Python 的
mmap模块在你的代码中实现内存映射
mmap API 类似于常规的文件 I/O API,所以测试起来相当简单。在您自己的代码中尝试一下,看看您的程序是否能从内存映射提供的性能改进中受益。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python mmap:用内存映射做文件 I/O*****
了解 Python 模拟对象库
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 使用 Python 模拟对象库 改进您的测试
当您编写健壮的代码时,测试对于验证您的应用程序逻辑是正确的、可靠的和有效的是必不可少的。然而,您的测试的价值取决于它们在多大程度上证明了这些标准。诸如复杂的逻辑和不可预测的依赖关系这样的障碍使得编写有价值的测试变得困难。Python 模拟对象库unittest.mock,可以帮助你克服这些障碍。
本文结束时,你将能够:
- 使用
Mock创建 Python 模拟对象 - 断言你正在按照你的意图使用对象
- 检查存储在 Python 模拟中的使用数据
- 配置 Python 模拟对象的某些方面
- 使用
patch()将你的模型替换成真实的物体 - 避免 Python 模仿中固有的常见问题
您将从了解什么是嘲讽以及它将如何改进您的测试开始。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是嘲讽?
一个模拟对象在一个测试环境中替代并模仿一个真实对象。它是提高测试质量的一个通用且强大的工具。
使用 Python 模拟对象的一个原因是为了在测试过程中控制代码的行为。
例如,如果您的代码向外部服务发出 HTTP 请求,那么您的测试只有在服务的行为符合您的预期时才会可预测地执行。有时,这些外部服务行为的临时变化会导致测试套件中的间歇性故障。
因此,在一个受控的环境中测试您的代码会更好。用模拟对象替换实际的请求将允许您以可预测的方式模拟外部服务中断和成功的响应。
有时候,测试代码库的某些部分是很困难的。这样的区域包括难以满足的except块和if语句。使用 Python 模拟对象可以帮助您控制代码的执行路径以到达这些区域,并提高您的代码覆盖率。
使用模拟对象的另一个原因是为了更好地理解如何在代码中使用它们的真实对应物。Python 模拟对象包含关于其用法的数据,您可以检查这些数据,例如:
- 如果你调用了一个方法
- 您如何调用该方法
- 您调用该方法的频率
理解模拟对象的作用是学习如何使用它的第一步。
现在,您将看到如何使用 Python 模拟对象。
Python 模拟库
Python 模拟对象库是unittest.mock。它提供了一个简单的方法将模拟引入到你的测试中。
注意:标准库包括 Python 3.3 及以后版本中的unittest.mock。如果你使用的是旧版本的 Python,你需要安装库的官方后台。为此,从 PyPI 安装mock:
$ pip install mock
unittest.mock提供了一个名为Mock的类,你可以用它来模仿代码库中的真实对象。Mock提供令人难以置信的灵活性和深刻的数据。这个及其子类将满足您在测试中面临的大多数 Python 模仿需求。
该库还提供了一个名为patch()的函数,它用Mock实例替换代码中的真实对象。您可以使用patch()作为装饰器或上下文管理器,让您控制对象被模仿的范围。一旦指定的作用域退出,patch()将通过用它们原来的对应物替换被模仿的对象来清理你的代码。
最后,unittest.mock为模仿对象中固有的一些问题提供了解决方案。
现在,您已经更好地理解了什么是嘲讽,以及您将用来做这件事的库。让我们深入探讨一下unittest.mock提供了哪些特性和功能。
Mock对象
unittest.mock为模仿对象提供了一个基类,叫做Mock。因为Mock非常灵活,所以Mock的用例实际上是无限的。
首先实例化一个新的Mock实例:
>>> from unittest.mock import Mock >>> mock = Mock() >>> mock <Mock id='4561344720'>现在,您可以用新的
Mock替换代码中的对象。您可以通过将它作为参数传递给函数或重新定义另一个对象来实现这一点:# Pass mock as an argument to do_something() do_something(mock) # Patch the json library json = mock当你在代码中替换一个对象时,
Mock必须看起来像它所替换的真实对象。否则,您的代码将无法使用Mock来代替原始对象。例如,如果您正在模仿
json库,并且您的程序调用了dumps(),那么您的 Python 模仿对象也必须包含dumps()。接下来,您将看到
Mock如何应对这一挑战。惰性属性和方法
一个
Mock必须模拟它替换的任何对象。为了实现这样的灵活性,当你访问属性时,它会创建它的属性:
>>> mock.some_attribute
<Mock name='mock.some_attribute' id='4394778696'>
>>> mock.do_something()
<Mock name='mock.do_something()' id='4394778920'>
由于Mock可以动态创建任意属性,因此适合替换任何对象。
使用前面的一个例子,如果您模仿json库并调用dumps(),Python 模仿对象将创建该方法,以便其接口可以匹配库的接口:
>>> json = Mock() >>> json.dumps() <Mock name='mock.dumps()' id='4392249776'>请注意这个
dumps()模拟版本的两个关键特征:
>>> json = Mock()
>>> json.loads('{"k": "v"}').get('k')
<Mock name='mock.loads().get()' id='4379599424'>
因为每个被模仿的方法的返回值也是一个Mock,所以您可以以多种方式使用您的模仿。
模拟是灵活的,但它们也能提供信息。接下来,您将学习如何使用模拟来更好地理解您的代码。
断言和检验
实例存储你如何使用它们的数据。例如,您可以查看是否调用了一个方法,如何调用该方法,等等。使用这些信息有两种主要方式。
首先,您可以断言您的程序使用了您所期望的对象:
>>> from unittest.mock import Mock >>> # Create a mock object ... json = Mock() >>> json.loads('{"key": "value"}') <Mock name='mock.loads()' id='4550144184'> >>> # You know that you called loads() so you can >>> # make assertions to test that expectation ... json.loads.assert_called() >>> json.loads.assert_called_once() >>> json.loads.assert_called_with('{"key": "value"}') >>> json.loads.assert_called_once_with('{"key": "value"}') >>> json.loads('{"key": "value"}') <Mock name='mock.loads()' id='4550144184'> >>> # If an assertion fails, the mock will raise an AssertionError ... json.loads.assert_called_once() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 795, in assert_called_once raise AssertionError(msg) AssertionError: Expected 'loads' to have been called once. Called 2 times. >>> json.loads.assert_called_once_with('{"key": "value"}') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 824, in assert_called_once_with raise AssertionError(msg) AssertionError: Expected 'loads' to be called once. Called 2 times. >>> json.loads.assert_not_called() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 777, in assert_not_called raise AssertionError(msg) AssertionError: Expected 'loads' to not have been called. Called 2 times.
.assert_called()确保您调用了被模仿的方法,而.assert_called_once()检查您只调用了该方法一次。这两个断言函数都有变体,允许您检查传递给被模仿方法的参数:
.assert_called_with(*args, **kwargs).assert_called_once_with(*args, **kwargs)要传递这些断言,您必须使用传递给实际方法的相同参数来调用模拟方法:
>>> json = Mock()
>>> json.loads(s='{"key": "value"}')
>>> json.loads.assert_called_with('{"key": "value"}')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 814, in assert_called_with
raise AssertionError(_error_message()) from cause
AssertionError: Expected call: loads('{"key": "value"}')
Actual call: loads(s='{"key": "value"}')
>>> json.loads.assert_called_with(s='{"key": "value"}')
json.loads.assert_called_with('{"key": "value"}')提出了一个AssertionError,因为它期望你用位置参数调用 loads() ,但你实际上用关键字参数调用了它。json.loads.assert_called_with(s='{"key": "value"}')这个断言是正确的。
其次,您可以查看特殊属性,以了解您的应用程序如何使用对象:
>>> from unittest.mock import Mock >>> # Create a mock object ... json = Mock() >>> json.loads('{"key": "value"}') <Mock name='mock.loads()' id='4391026640'> >>> # Number of times you called loads(): ... json.loads.call_count 1 >>> # The last loads() call: ... json.loads.call_args call('{"key": "value"}') >>> # List of loads() calls: ... json.loads.call_args_list [call('{"key": "value"}')] >>> # List of calls to json's methods (recursively): ... json.method_calls [call.loads('{"key": "value"}')]您可以使用这些属性编写测试,以确保您的对象如您所愿地运行。
现在,您可以创建模拟并检查它们的使用数据。接下来,您将看到如何定制模拟方法,以便它们在您的测试环境中变得更加有用。
管理模拟的返回值
使用模拟的一个原因是为了在测试过程中控制代码的行为。一种方法是指定函数的返回值。让我们用一个例子来看看这是如何工作的。
首先,创建一个名为
my_calendar.py的文件。添加is_weekday(),这个函数使用 Python 的datetime库来确定今天是否是工作日。最后,编写一个测试,断言该函数按预期工作:from datetime import datetime def is_weekday(): today = datetime.today() # Python's datetime library treats Monday as 0 and Sunday as 6 return (0 <= today.weekday() < 5) # Test if today is a weekday assert is_weekday()因为您正在测试今天是否是工作日,所以结果取决于您运行测试的日期:
$ python my_calendar.py如果该命令没有产生输出,则断言成功。不幸的是,如果您在周末运行该命令,您将得到一个
AssertionError:$ python my_calendar.py Traceback (most recent call last): File "test.py", line 9, in <module> assert is_weekday() AssertionError当编写测试时,确保结果是可预测的是很重要的。您可以使用
Mock来消除测试过程中代码的不确定性。在这种情况下,您可以模仿datetime并将.today()的.return_value设置为您选择的日期:import datetime from unittest.mock import Mock # Save a couple of test days tuesday = datetime.datetime(year=2019, month=1, day=1) saturday = datetime.datetime(year=2019, month=1, day=5) # Mock datetime to control today's date datetime = Mock() def is_weekday(): today = datetime.datetime.today() # Python's datetime library treats Monday as 0 and Sunday as 6 return (0 <= today.weekday() < 5) # Mock .today() to return Tuesday datetime.datetime.today.return_value = tuesday # Test Tuesday is a weekday assert is_weekday() # Mock .today() to return Saturday datetime.datetime.today.return_value = saturday # Test Saturday is not a weekday assert not is_weekday()在这个例子中,
.today()是一个被模仿的方法。通过给模拟的.return_value指定一个特定的日期,您已经消除了不一致性。这样,当你调用.today()时,它会返回你指定的datetime。在第一个测试中,您确保
tuesday是工作日。在第二个测试中,您验证了saturday不是工作日。现在,哪一天运行测试并不重要,因为你已经模仿了datetime,并且控制了对象的行为。延伸阅读:虽然这样嘲讽
datetime是使用Mock的一个很好的实践例子,但是已经有一个很棒的嘲讽datetime的库叫做freezegun。在构建测试时,您可能会遇到这样的情况,仅仅模仿函数的返回值是不够的。这是因为函数通常比简单的单向逻辑流更复杂。
有时,当您不止一次调用函数或者甚至引发异常时,您会希望函数返回不同的值。您可以使用
.side_effect来完成此操作。管理模仿的副作用
您可以通过指定被模仿函数的副作用来控制代码的行为。一个
.side_effect定义了当你调用被模仿的函数时会发生什么。为了测试这是如何工作的,向
my_calendar.py添加一个新函数:import requests def get_holidays(): r = requests.get('http://localhost/api/holidays') if r.status_code == 200: return r.json() return None
get_holidays()向localhost服务器请求一组假期。如果服务器响应成功,get_holidays()将返回一个字典。否则,该方法将返回None。您可以通过设置
requests.get.side_effect来测试get_holidays()将如何响应连接超时。对于这个例子,您只会看到来自
my_calendar.py的相关代码。您将使用 Python 的unittest库构建一个测试用例:import unittest from requests.exceptions import Timeout from unittest.mock import Mock # Mock requests to control its behavior requests = Mock() def get_holidays(): r = requests.get('http://localhost/api/holidays') if r.status_code == 200: return r.json() return None class TestCalendar(unittest.TestCase): def test_get_holidays_timeout(self): # Test a connection timeout requests.get.side_effect = Timeout with self.assertRaises(Timeout): get_holidays() if __name__ == '__main__': unittest.main()鉴于
get()的新副作用,您使用.assertRaises()来验证get_holidays()是否引发了异常。运行此测试以查看测试结果:
$ python my_calendar.py . ------------------------------------------------------- Ran 1 test in 0.000s OK如果您想更动态一点,您可以将
.side_effect设置为一个函数,当您调用您模仿的方法时,Mock将调用该函数。mock 共享.side_effect函数的参数和返回值:import requests import unittest from unittest.mock import Mock # Mock requests to control its behavior requests = Mock() def get_holidays(): r = requests.get('http://localhost/api/holidays') if r.status_code == 200: return r.json() return None class TestCalendar(unittest.TestCase): def log_request(self, url): # Log a fake request for test output purposes print(f'Making a request to {url}.') print('Request received!') # Create a new Mock to imitate a Response response_mock = Mock() response_mock.status_code = 200 response_mock.json.return_value = { '12/25': 'Christmas', '7/4': 'Independence Day', } return response_mock def test_get_holidays_logging(self): # Test a successful, logged request requests.get.side_effect = self.log_request assert get_holidays()['12/25'] == 'Christmas' if __name__ == '__main__': unittest.main()首先,您创建了
.log_request(),它接受一个 URL,使用print()记录一些输出,然后返回一个Mock响应。接下来,您将get()的.side_effect设置为.log_request(),您将在调用get_holidays()时使用它。当您运行测试时,您会看到get()将其参数转发给.log_request(),然后接受返回值并返回它:$ python my_calendar.py Making a request to http://localhost/api/holidays. Request received! . ------------------------------------------------------- Ran 1 test in 0.000s OK太好了!
print()语句记录了正确的值。还有,get_holidays()返回了节假日字典。
.side_effect也可以是 iterable。iterable 必须由返回值、异常或两者的混合组成。每次调用被模仿的方法时,iterable 都会产生下一个值。例如,您可以测试在Timeout返回成功响应后的重试:import unittest from requests.exceptions import Timeout from unittest.mock import Mock # Mock requests to control its behavior requests = Mock() def get_holidays(): r = requests.get('http://localhost/api/holidays') if r.status_code == 200: return r.json() return None class TestCalendar(unittest.TestCase): def test_get_holidays_retry(self): # Create a new Mock to imitate a Response response_mock = Mock() response_mock.status_code = 200 response_mock.json.return_value = { '12/25': 'Christmas', '7/4': 'Independence Day', } # Set the side effect of .get() requests.get.side_effect = [Timeout, response_mock] # Test that the first request raises a Timeout with self.assertRaises(Timeout): get_holidays() # Now retry, expecting a successful response assert get_holidays()['12/25'] == 'Christmas' # Finally, assert .get() was called twice assert requests.get.call_count == 2 if __name__ == '__main__': unittest.main()第一次调用
get_holidays(),get()引出一个Timeout。第二次,该方法返回一个有效的假日字典。这些副作用符合它们在传递给.side_effect的列表中出现的顺序。您可以直接在
Mock上设置.return_value和.side_effect。但是,因为 Python 模拟对象需要灵活地创建其属性,所以有一种更好的方法来配置这些和其他设置。配置您的模拟
您可以配置一个
Mock来设置对象的一些行为。一些可配置的成员包括.side_effect、.return_value和.name。当您创建一个或者当您使用.configure_mock()时,您配置一个Mock。您可以在初始化对象时通过指定某些属性来配置
Mock:
>>> mock = Mock(side_effect=Exception)
>>> mock()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 939, in __call__
return _mock_self._mock_call(*args, **kwargs)
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 995, in _mock_call
raise effect
Exception
>>> mock = Mock(name='Real Python Mock')
>>> mock
<Mock name='Real Python Mock' id='4434041432'>
>>> mock = Mock(return_value=True)
>>> mock()
True
虽然.side_effect和.return_value可以在Mock实例本身上设置,但其他属性如.name只能通过.__init__()或.configure_mock()设置。如果您尝试在实例上设置Mock的.name,您将得到不同的结果:
>>> mock = Mock(name='Real Python Mock') >>> mock.name <Mock name='Real Python Mock.name' id='4434041544'> >>> mock = Mock() >>> mock.name = 'Real Python Mock' >>> mock.name 'Real Python Mock'
.name是对象使用的常用属性。因此,Mock不允许您像使用.return_value或.side_effect那样在实例上设置值。如果您访问mock.name,您将创建一个.name属性,而不是配置您的模拟。您可以使用
.configure_mock()配置现有的Mock:
>>> mock = Mock()
>>> mock.configure_mock(return_value=True)
>>> mock()
True
通过将字典解包到.configure_mock()或Mock.__init__(),您甚至可以配置 Python 模拟对象的属性。使用Mock配置,您可以简化前面的例子:
# Verbose, old Mock
response_mock = Mock()
response_mock.json.return_value = {
'12/25': 'Christmas',
'7/4': 'Independence Day',
}
# Shiny, new .configure_mock()
holidays = {'12/25': 'Christmas', '7/4': 'Independence Day'}
response_mock = Mock(**{'json.return_value': holidays})
现在,您可以创建和配置 Python 模拟对象。您还可以使用模拟来控制您的应用程序的行为。到目前为止,您已经使用 mocks 作为函数的参数,或者在测试的同一个模块中修补对象。
接下来,您将学习如何在其他模块中用模拟对象替换真实对象。
patch()
unittest.mock提供了一个强大的模仿对象的机制,叫做 patch() ,它在给定的模块中查找一个对象,并用一个Mock替换那个对象。
通常,您使用patch()作为装饰器或上下文管理器来提供一个模仿目标对象的范围。
patch()当装潢师
如果你想在整个测试函数期间模仿一个对象,你可以使用patch()作为函数的装饰者。
要了解这是如何工作的,通过将逻辑和测试放入单独的文件来重新组织您的my_calendar.py文件:
import requests
from datetime import datetime
def is_weekday():
today = datetime.today()
# Python's datetime library treats Monday as 0 and Sunday as 6
return (0 <= today.weekday() < 5)
def get_holidays():
r = requests.get('http://localhost/api/holidays')
if r.status_code == 200:
return r.json()
return None
这些函数现在位于它们自己的文件中,与它们的测试分开。接下来,您将在名为tests.py的文件中重新创建您的测试。
到目前为止,您已经在对象所在的文件中对它们进行了猴子修补。猴子补丁是在运行时用一个对象替换另一个对象。现在,您将使用patch()来替换my_calendar.py中的对象:
import unittest
from my_calendar import get_holidays
from requests.exceptions import Timeout
from unittest.mock import patch
class TestCalendar(unittest.TestCase):
@patch('my_calendar.requests') def test_get_holidays_timeout(self, mock_requests):
mock_requests.get.side_effect = Timeout
with self.assertRaises(Timeout):
get_holidays()
mock_requests.get.assert_called_once()
if __name__ == '__main__':
unittest.main()
最初,您在本地范围内创建了一个Mock并修补了requests。现在,你需要从tests.py进入my_calendar.py的requests图书馆。
对于这种情况,您使用了patch()作为装饰器,并传递了目标对象的路径。目标路径是由模块名和对象组成的'my_calendar.requests'。
您还为测试函数定义了一个新参数。patch()使用此参数将被模仿的对象传递到您的测试中。从那里,您可以根据需要修改 mock 或做出断言。
您可以执行这个测试模块来确保它按预期工作:
$ python tests.py
.
-------------------------------------------------------
Ran 1 test in 0.001s
OK
技术细节: patch()返回 MagicMock 的一个实例,是Mock的子类。MagicMock很有用,因为它为你实现了大部分魔法方法,比如.__len__()、.__str__()和.__iter__(),并且有合理的默认值。
在这个例子中,使用patch()作为装饰器效果很好。在某些情况下,使用patch()作为上下文管理器更易读、更有效或更容易。
patch()作为上下文管理器
有时,你会想要使用patch()作为上下文管理器而不是装饰器。您可能更喜欢上下文管理器的一些原因包括:
- 您只想在测试范围的一部分模拟一个对象。
- 您已经使用了太多的装饰器或参数,这会损害测试的可读性。
要将patch()用作上下文管理器,可以使用 Python 的with语句:
import unittest
from my_calendar import get_holidays
from requests.exceptions import Timeout
from unittest.mock import patch
class TestCalendar(unittest.TestCase):
def test_get_holidays_timeout(self):
with patch('my_calendar.requests') as mock_requests: mock_requests.get.side_effect = Timeout
with self.assertRaises(Timeout):
get_holidays()
mock_requests.get.assert_called_once()
if __name__ == '__main__':
unittest.main()
当测试退出with语句时,patch()用原始对象替换被模仿的对象。
到目前为止,您已经模拟了完整的对象,但有时您只想模拟对象的一部分。
修补对象的属性
假设您只想模仿一个对象的一个方法,而不是整个对象。你可以使用 patch.object() 来完成。
比如,.test_get_holidays_timeout()真的只需要模仿requests.get(),将其.side_effect设置为Timeout:
import unittest
from my_calendar import requests, get_holidays
from unittest.mock import patch
class TestCalendar(unittest.TestCase):
@patch.object(requests, 'get', side_effect=requests.exceptions.Timeout) def test_get_holidays_timeout(self, mock_requests):
with self.assertRaises(requests.exceptions.Timeout):
get_holidays()
if __name__ == '__main__':
unittest.main()
在这个例子中,你只模仿了get(),而不是所有的requests。其他所有属性保持不变。
object()采用与patch()相同的配置参数。但是不是传递目标的路径,而是提供目标对象本身作为第一个参数。第二个参数是您试图模仿的目标对象的属性。你也可以像使用patch()一样使用object()作为上下文管理器。
延伸阅读:除了对象和属性,还可以用 patch.dict() 的patch()字典。
学习如何使用patch()对于模仿其他模块中的对象至关重要。然而,有时目标对象的路径并不明显。
哪里打补丁
知道在哪里告诉patch()寻找你想要嘲笑的对象是很重要的,因为如果你选择了错误的目标位置,patch()的结果可能是你意想不到的。
假设你在用patch()嘲讽my_calendar.py中的is_weekday():
>>> import my_calendar >>> from unittest.mock import patch >>> with patch('my_calendar.is_weekday'): ... my_calendar.is_weekday() ... <MagicMock name='is_weekday()' id='4336501256'>首先,你导入
my_calendar.py。然后你修补is_weekday(),用一个Mock替换它。太好了!这是预期的工作。现在,让我们稍微修改一下这个例子,直接导入函数:
>>> from my_calendar import is_weekday
>>> from unittest.mock import patch
>>> with patch('my_calendar.is_weekday'):
... is_weekday()
...
False
注意:根据您阅读本教程的日期,您的控制台输出可能会显示True或False。重要的是,输出不是像以前一样的Mock。
注意,即使您传递给patch()的目标位置没有改变,调用is_weekday()的结果也是不同的。这种差异是由于导入函数的方式发生了变化。
将实函数绑定到局部范围。因此,即使您稍后patch()该函数,您也会忽略模仿,因为您已经有了对未模仿函数的本地引用。
一个好的经验法则就是patch()被仰望的物体。
在第一个例子中,模仿'my_calendar.is_weekday()'是可行的,因为您在my_calendar模块中查找函数。在第二个例子中,您有一个对is_weekday()的本地引用。因为您使用了在局部范围内找到的函数,所以您应该模仿局部函数:
>>> from unittest.mock import patch >>> from my_calendar import is_weekday >>> with patch('__main__.is_weekday'): ... is_weekday() ... <MagicMock name='is_weekday()' id='4502362992'>现在,你牢牢掌握了
patch()的力量。你已经看到了如何patch()对象和属性,以及在哪里修补它们。接下来,您将看到对象模仿中固有的一些常见问题以及
unittest.mock提供的解决方案。常见嘲讽问题
模仿对象会给你的测试带来几个问题。有些问题是嘲讽固有的,有些问题是
unittest.mock特有的。请记住,本教程中没有提到嘲讽的其他问题。这里讨论的问题彼此相似,因为它们引起的问题基本上是相同的。在每种情况下,测试断言都是不相关的。虽然每个模仿的意图是有效的,但模仿本身却是无效的。
对象接口的变化和拼写错误
类和函数定义一直在变化。当一个对象的接口改变时,任何依赖于该对象的
Mock的测试都可能变得无关紧要。例如,您重命名了一个方法,但是忘记了一个测试模拟了这个方法并调用了
.assert_not_called()。变化之后,.assert_not_called()依然是True。但是这个断言没有用,因为这个方法已经不存在了。不相关的测试听起来可能不重要,但是如果它们是您唯一的测试,并且您认为它们工作正常,那么这种情况对您的应用程序来说可能是灾难性的。
一个特定于
Mock的问题是拼写错误会破坏测试。回想一下,当您访问一个Mock的成员时,它会创建自己的接口。因此,如果您拼错了属性的名称,就会无意中创建新属性。如果你调用
.asert_called()而不是.assert_called(),你的测试将不会产生AssertionError。这是因为您已经在 Python 模拟对象上创建了一个名为.asert_called()的新方法,而不是评估一个实际的断言。技术细节:有趣的是,
assret是assert的特殊拼错。如果您试图访问一个以assret(或assert)开头的属性,Mock将自动引发一个AttributeError。当您在自己的代码库中模仿对象时,会出现这些问题。当您模仿与外部代码库交互的对象时,会出现一个不同的问题。
外部依赖关系的变化
再想象一下,您的代码向外部 API 发出请求。在这种情况下,外部依赖是 API,它容易在未经您同意的情况下被更改。
一方面,单元测试测试代码的独立组件。因此,模拟发出请求的代码有助于您在受控条件下测试隔离的组件。然而,这也带来了一个潜在的问题。
如果一个外部依赖改变了它的接口,你的 Python 模拟对象将变得无效。如果发生这种情况(并且接口变化是破坏性的),您的测试将会通过,因为您的模拟对象已经屏蔽了这种变化,但是您的生产代码将会失败。
不幸的是,这不是一个
unittest.mock提供解决方案的问题。嘲笑外部依赖时,你必须运用判断力。所有这三个问题都可能导致测试无关性和潜在的代价高昂的问题,因为它们威胁到您的模拟的完整性。给你一些处理这些问题的工具。
使用规范避免常见问题
如前所述,如果您更改了一个类或函数定义,或者拼错了 Python 模拟对象的属性,那么您的测试就会出现问题。
出现这些问题是因为当您访问属性和方法时,
Mock会创建它们。这些问题的答案是防止Mock创建与您试图模仿的对象不一致的属性。当配置一个
Mock时,您可以将一个对象规范传递给spec参数。spec参数接受一个名称列表或另一个对象,并定义 mock 的接口。如果您试图访问一个不属于规范的属性,Mock将引发一个AttributeError:
>>> from unittest.mock import Mock
>>> calendar = Mock(spec=['is_weekday', 'get_holidays'])
>>> calendar.is_weekday()
<Mock name='mock.is_weekday()' id='4569015856'>
>>> calendar.create_event()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'create_event'
这里,您已经指定了calendar具有名为.is_weekday()和.get_holidays()的方法。当你访问.is_weekday()时,它返回一个Mock。当您访问.create_event()时,一个与规范不匹配的方法Mock会引发一个AttributeError。
如果用对象配置Mock,规格的工作方式相同:
>>> import my_calendar >>> from unittest.mock import Mock >>> calendar = Mock(spec=my_calendar) >>> calendar.is_weekday() <Mock name='mock.is_weekday()' id='4569435216'> >>> calendar.create_event() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__ raise AttributeError("Mock object has no attribute %r" % name) AttributeError: Mock object has no attribute 'create_event'
.is_weekday()对calendar可用,因为您配置了calendar来匹配my_calendar模块的接口。此外,
unittest.mock提供了自动指定Mock实例的接口的便利方法。实现自动规格的一种方法是
create_autospec:
>>> import my_calendar
>>> from unittest.mock import create_autospec
>>> calendar = create_autospec(my_calendar)
>>> calendar.is_weekday()
<MagicMock name='mock.is_weekday()' id='4579049424'>
>>> calendar.create_event()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__
raise AttributeError("Mock object has no attribute %r" % name)
AttributeError: Mock object has no attribute 'create_event'
像以前一样,calendar是一个Mock实例,它的接口匹配my_calendar。如果您正在使用patch(),您可以向autospec参数发送一个参数来获得相同的结果:
>>> import my_calendar >>> from unittest.mock import patch >>> with patch('__main__.my_calendar', autospec=True) as calendar: ... calendar.is_weekday() ... calendar.create_event() ... <MagicMock name='my_calendar.is_weekday()' id='4579094312'> Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/unittest/mock.py", line 582, in __getattr__ raise AttributeError("Mock object has no attribute %r" % name) AttributeError: Mock object has no attribute 'create_event'结论
你已经学到了很多关于使用
unittest.mock模仿物体的知识!现在,您能够:
- 在你的测试中使用
Mock来模仿物体- 检查使用数据以了解如何使用对象
- 定制模拟对象的返回值和副作用
- 整个代码库中的对象
- 查看和避免使用 Python 模拟对象的问题
您已经建立了理解的基础,这将帮助您构建更好的测试。您可以使用模拟来深入了解您的代码,否则您将无法获得这些信息。
我留给你最后一个免责声明。当心过度使用模仿对象!
很容易利用 Python 模拟对象的强大功能,并且模拟得如此之多,以至于实际上降低了测试的价值。
如果你有兴趣了解更多关于
unittest.mock的信息,我鼓励你阅读它优秀的文档。立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 使用 Python 模拟对象库 改进您的测试******
Python 模块和包——简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 模块和包:简介
本文探索了 Python 模块和 Python 包,这两种机制促进了模块化编程。
模块化编程指的是将一个庞大、笨拙的编程任务分解成独立、更小、更易管理的子任务或模块的过程。然后,可以像构建模块一样将各个模块拼凑在一起,创建一个更大的应用程序。
在大型应用程序中,模块化代码有几个优点:
简单性:一个模块通常专注于问题的一个相对较小的部分,而不是关注手头的整个问题。如果你在一个模块上工作,你将会有一个更小的问题域去思考。这使得开发更容易,更不容易出错。
可维护性:模块通常被设计成在不同的问题域之间强制执行逻辑边界。如果以最小化相互依赖性的方式编写模块,那么对单个模块的修改对程序的其他部分产生影响的可能性就会降低。(您甚至可以在不了解模块之外的应用程序的情况下对模块进行更改。)这使得一个由许多程序员组成的团队在一个大型应用程序上协作工作变得更加可行。
可重用性:在单个模块中定义的功能可以很容易地被应用程序的其他部分重用(通过适当定义的接口)。这消除了复制代码的需要。
作用域:模块通常定义一个单独的 命名空间 ,这有助于避免程序不同区域的标识符之间的冲突。(Python 的禅的信条之一是名称空间是一个非常棒的想法——让我们做更多这样的事情吧!)
函数、模块和包都是 Python 中促进代码模块化的构造。
免费 PDF 下载: Python 3 备忘单
Python 模块:概述
在 Python 中,实际上有三种不同的方式来定义模块:
- 一个模块可以用 Python 本身编写。
- 一个模块可以用 C 编写,在运行时动态加载,像
re( 正则表达式 )模块。- 一个内置的模块本质上包含在解释器中,就像
itertools模块一样。一个模块的内容在所有三种情况下都以相同的方式被访问:用
import语句。这里,重点将主要放在用 Python 编写的模块上。用 Python 编写的模块最酷的一点是它们非常容易构建。您所需要做的就是创建一个包含合法 Python 代码的文件,然后给这个文件起一个扩展名为
.py的名字。就是这样!不需要特殊的语法或巫术。例如,假设您创建了一个名为
mod.py的文件,其中包含以下内容:mod . pyT3】
s = "If Comrade Napoleon says it, it must be right." a = [100, 200, 300] def foo(arg): print(f'arg = {arg}') class Foo: pass在
mod.py中定义了几个对象:
s(一个字符串)a(一个列表)foo()(一种功能)Foo(一类)假设
mod.py在一个合适的位置,稍后您将了解到更多,这些对象可以通过导入模块来访问,如下所示:
>>> import mod
>>> print(mod.s)
If Comrade Napoleon says it, it must be right.
>>> mod.a
[100, 200, 300]
>>> mod.foo(['quux', 'corge', 'grault'])
arg = ['quux', 'corge', 'grault']
>>> x = mod.Foo()
>>> x
<mod.Foo object at 0x03C181F0>
模块搜索路径
继续上面的例子,让我们看看 Python 执行语句时会发生什么:
import mod
当解释器执行上述import语句时,它在从以下来源汇编的目录的列表中搜索mod.py:
- 运行输入脚本的目录或当前目录(如果解释器交互运行)
- 包含在
PYTHONPATH环境变量中的目录列表,如果设置了的话。(PYTHONPATH的格式依赖于操作系统,但应该模仿PATH环境变量。) - 安装 Python 时配置的依赖于安装的目录列表
结果搜索路径可在 Python 变量sys.path中访问,该变量从名为sys的模块中获得:
>>> import sys >>> sys.path ['', 'C:\\Users\\john\\Documents\\Python\\doc', 'C:\\Python36\\Lib\\idlelib', 'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib', 'C:\\Python36', 'C:\\Python36\\lib\\site-packages']注意:
sys.path的确切内容取决于安装。上述内容在您的计算机上看起来几乎肯定会略有不同。因此,要确保找到您的模块,您需要执行以下操作之一:
- 将
mod.py放入输入脚本所在的目录或者当前目录,如果是交互的话- 在启动解释器之前,修改
PYTHONPATH环境变量以包含mod.py所在的目录
- 或:将
mod.py放入已经包含在PYTHONPATH变量中的一个目录中- 将
mod.py放在一个依赖于安装的目录中,根据操作系统的不同,您可能有也可能没有写权限实际上还有一个额外的选项:您可以将模块文件放在您选择的任何目录中,然后在运行时修改
sys.path,使其包含该目录。例如,在这种情况下,您可以将mod.py放在目录C:\Users\john中,然后发出以下语句:
>>> sys.path.append(r'C:\Users\john')
>>> sys.path
['', 'C:\\Users\\john\\Documents\\Python\\doc', 'C:\\Python36\\Lib\\idlelib',
'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib',
'C:\\Python36', 'C:\\Python36\\lib\\site-packages', 'C:\\Users\\john']
>>> import mod
一旦模块被导入,您可以使用模块的__file__属性来确定它被发现的位置:
>>> import mod >>> mod.__file__ 'C:\\Users\\john\\mod.py' >>> import re >>> re.__file__ 'C:\\Python36\\lib\\re.py'
__file__的目录部分应该是sys.path中的一个目录。
import语句模块的内容通过
import语句提供给调用者。import语句有许多不同的形式,如下所示。
import <module_name>最简单的形式是上面已经显示的形式:
import <module_name>注意这个并不使模块内容直接可被调用者访问。每个模块都有自己的私有符号表,作为模块中定义的所有对象的全局符号表。因此,正如已经提到的,一个模块创建了一个单独的名称空间。
语句
import <module_name>只将<module_name>放在调用者的符号表中。在模块中定义的对象保留在模块的私有符号表中。从调用者那里,模块中的对象只有在通过点符号以
<module_name>为前缀时才是可访问的,如下所示。在下面的
import语句之后,mod被放入局部符号表。因此,mod在呼叫者的当地语境中有意义:
>>> import mod
>>> mod
<module 'mod' from 'C:\\Users\\john\\Documents\\Python\\doc\\mod.py'>
但是s和foo保留在模块的私有符号表中,在本地上下文中没有意义:
>>> s NameError: name 's' is not defined >>> foo('quux') NameError: name 'foo' is not defined要在本地上下文中访问,模块中定义的对象名必须以
mod为前缀:
>>> mod.s
'If Comrade Napoleon says it, it must be right.'
>>> mod.foo('quux')
arg = quux
几个逗号分隔的模块可以在单个import语句中指定:
import <module_name>[, <module_name> ...]
from <module_name> import <name(s)>
另一种形式的import语句允许将模块中的单个对象直接导入调用者的符号表:
from <module_name> import <name(s)>
在执行上述语句之后,<name(s)>可以在调用者的环境中被引用,而没有前缀<module_name>:
>>> from mod import s, foo >>> s 'If Comrade Napoleon says it, it must be right.' >>> foo('quux') arg = quux >>> from mod import Foo >>> x = Foo() >>> x <mod.Foo object at 0x02E3AD50>因为这种形式的
import将对象名直接放入调用者的符号表中,任何已经存在的同名对象将被覆盖:
>>> a = ['foo', 'bar', 'baz']
>>> a
['foo', 'bar', 'baz']
>>> from mod import a
>>> a
[100, 200, 300]
甚至有可能一下子不加选择地从一个模块中取出所有内容:
from <module_name> import *
这将把来自<module_name>的所有对象的名称放到本地符号表中,除了任何以下划线(_)字符开头的对象。
例如:
>>> from mod import * >>> s 'If Comrade Napoleon says it, it must be right.' >>> a [100, 200, 300] >>> foo <function foo at 0x03B449C0> >>> Foo <class 'mod.Foo'>这在大规模生产代码中不一定被推荐。这有点危险,因为你正在把名字一起输入到本地符号表中。除非你对它们都很了解,并且确信不会有冲突,否则你很有可能无意中覆盖了一个已有的名字。然而,当您只是在使用交互式解释器进行测试或发现时,这种语法非常方便,因为它可以让您快速访问模块提供的所有内容,而无需大量键入。
from <module_name> import <name> as <alt_name>也可以
import单个对象,但用备用名输入到本地符号表中:from <module_name> import <name> as <alt_name>[, <name> as <alt_name> …]这使得可以将名称直接放入局部符号表,但避免与先前存在的名称冲突:
>>> s = 'foo'
>>> a = ['foo', 'bar', 'baz']
>>> from mod import s as string, a as alist
>>> s
'foo'
>>> string
'If Comrade Napoleon says it, it must be right.'
>>> a
['foo', 'bar', 'baz']
>>> alist
[100, 200, 300]
import <module_name> as <alt_name>
您也可以用另一个名称导入整个模块:
import <module_name> as <alt_name>
>>> import mod as my_module >>> my_module.a [100, 200, 300] >>> my_module.foo('qux') arg = qux模块内容可以从函数定义中导入。在这种情况下,
import不会发生,直到函数被调用:
>>> def bar():
... from mod import foo
... foo('corge')
...
>>> bar()
arg = corge
然而, Python 3 不允许在函数内部使用不加选择的import *语法:
>>> def bar(): ... from mod import * ... SyntaxError: import * only allowed at module level最后,带有
except ImportError子句的try语句可用于防止不成功的import尝试:
>>> try:
... # Non-existent module
... import baz
... except ImportError:
... print('Module not found')
...
Module not found
>>> try: ... # Existing module, but non-existent object ... from mod import baz ... except ImportError: ... print('Object not found in module') ... Object not found in module
dir()功能内置函数
dir()返回名称空间中已定义名称的列表。如果没有参数,它会在当前的本地符号表中产生一个按字母顺序排序的名称列表:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> qux = [1, 2, 3, 4, 5]
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'qux']
>>> class Bar():
... pass
...
>>> x = Bar()
>>> dir()
['Bar', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'qux', 'x']
注意上面对dir()的第一次调用是如何列出几个名称的,这些名称是自动定义的,并且在解释器启动时已经存在于名称空间中。随着新名称的定义(qux、Bar、x),它们会出现在后续的dir()调用中。
这对于确定 import 语句向名称空间添加了什么非常有用:
>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__'] >>> import mod >>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'mod'] >>> mod.s 'If Comrade Napoleon says it, it must be right.' >>> mod.foo([1, 2, 3]) arg = [1, 2, 3] >>> from mod import a, Foo >>> dir() ['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'mod'] >>> a [100, 200, 300] >>> x = Foo() >>> x <mod.Foo object at 0x002EAD50> >>> from mod import s as string >>> dir() ['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'mod', 'string', 'x'] >>> string 'If Comrade Napoleon says it, it must be right.'当给定一个作为模块名称的参数时,
dir()列出模块中定义的名称:
>>> import mod
>>> dir(mod)
['Foo', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__',
'__name__', '__package__', '__spec__', 'a', 'foo', 's']
>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__'] >>> from mod import * >>> dir() ['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'foo', 's']将模块作为脚本执行
任何包含一个模块的
.py文件本质上也是一个 Python 脚本,没有任何理由它不能像这样执行。这里又是上面定义的
mod.py:mod . pyT3】
s = "If Comrade Napoleon says it, it must be right." a = [100, 200, 300] def foo(arg): print(f'arg = {arg}') class Foo: pass这可以作为脚本运行:
C:\Users\john\Documents>python mod.py C:\Users\john\Documents>没有错误,所以它显然是有效的。当然,这不是很有趣。正如所写的,只有定义了对象。T2 不会对它们做任何事情,也不会产生任何输出。
让我们修改上面的 Python 模块,使它在作为脚本运行时生成一些输出:
mod . pyT3】
s = "If Comrade Napoleon says it, it must be right." a = [100, 200, 300] def foo(arg): print(f'arg = {arg}') class Foo: pass print(s) print(a) foo('quux') x = Foo() print(x)现在应该更有趣一点了:
C:\Users\john\Documents>python mod.py If Comrade Napoleon says it, it must be right. [100, 200, 300] arg = quux <__main__.Foo object at 0x02F101D0>不幸的是,现在它在作为模块导入时也会生成输出:
>>> import mod
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<mod.Foo object at 0x0169AD50>
这可能不是你想要的。模块在导入时通常不会生成输出。
如果您能够区分文件何时作为模块加载,何时作为独立脚本运行,这不是很好吗?
有求必应。
当一个.py文件作为模块导入时,Python 将特殊的 dunder 变量 __name__ 设置为模块的名称。然而,如果一个文件作为独立脚本运行,__name__被(创造性地)设置为字符串'__main__'。利用这一事实,您可以在运行时辨别出哪种情况,并相应地改变行为:
mod . pyT3】
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
if (__name__ == '__main__'):
print('Executing as standalone script')
print(s)
print(a)
foo('quux')
x = Foo()
print(x)
现在,如果您作为脚本运行,您会得到输出:
C:\Users\john\Documents>python mod.py
Executing as standalone script
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<__main__.Foo object at 0x03450690>
但是如果您作为模块导入,您不会:
>>> import mod >>> mod.foo('grault') arg = grault模块通常被设计为能够作为独立脚本运行,以测试模块中包含的功能。这被称为 单元测试。例如,假设您创建了一个包含阶乘函数的模块
fact.py,如下所示:fact.py
def fact(n): return 1 if n == 1 else n * fact(n-1) if (__name__ == '__main__'): import sys if len(sys.argv) > 1: print(fact(int(sys.argv[1])))该文件可以作为一个模块,导入的
fact()函数:
>>> from fact import fact
>>> fact(6)
720
但是也可以通过在命令行上传递一个整数参数来独立运行,以便进行测试:
C:\Users\john\Documents>python fact.py 6
720
重新加载模块
出于效率的原因,一个模块在每个解释器会话中只加载一次。这对于函数和类定义来说很好,它们通常构成了模块的大部分内容。但是模块也可以包含可执行语句,通常用于初始化。请注意,这些语句只会在第一次导入模块时执行。
考虑下面的文件mod.py:
mod . pyT3】
a = [100, 200, 300]
print('a =', a)
>>> import mod a = [100, 200, 300] >>> import mod >>> import mod >>> mod.a [100, 200, 300]在后续导入中不执行
print()语句。(就此而言,赋值语句也不是,但正如最后显示的mod.a值所示,这无关紧要。一旦任务完成,它就生效了。)如果您对一个模块进行了更改,并且需要重新加载它,您需要重新启动解释器或者使用模块
importlib中的一个名为reload()的函数:
>>> import mod
a = [100, 200, 300]
>>> import mod
>>> import importlib
>>> importlib.reload(mod)
a = [100, 200, 300]
<module 'mod' from 'C:\\Users\\john\\Documents\\Python\\doc\\mod.py'>
Python 包
假设您开发了一个包含许多模块的非常大的应用程序。随着模块数量的增长,如果将它们放在一个位置,就很难跟踪所有的模块。如果它们具有相似的名称或功能,尤其如此。您可能希望有一种方法来对它们进行分组和组织。
包允许使用点符号对模块名称空间进行层次化构造。同样,模块有助于避免全局变量名之间的冲突,包有助于避免模块名之间的冲突。
创建一个包非常简单,因为它利用了操作系统固有的层次文件结构。考虑以下安排:

这里有一个名为pkg的目录,包含两个模块mod1.py和mod2.py。这些模块的内容包括:
mod1.py
def foo():
print('[mod1] foo()')
class Foo:
pass
mod2.py
def bar():
print('[mod2] bar()')
class Bar:
pass
给定这种结构,如果pkg目录位于可以找到它的位置(在sys.path中包含的一个目录中),您可以引用带有点符号 ( pkg.mod1,pkg.mod2)的两个模块,并用您已经熟悉的语法导入它们:
import <module_name>[, <module_name> ...]
>>> import pkg.mod1, pkg.mod2 >>> pkg.mod1.foo() [mod1] foo() >>> x = pkg.mod2.Bar() >>> x <pkg.mod2.Bar object at 0x033F7290>from <module_name> import <name(s)>
>>> from pkg.mod1 import foo
>>> foo()
[mod1] foo()
from <module_name> import <name> as <alt_name>
>>> from pkg.mod2 import Bar as Qux >>> x = Qux() >>> x <pkg.mod2.Bar object at 0x036DFFD0>您也可以使用这些语句导入模块:
from <package_name> import <modules_name>[, <module_name> ...] from <package_name> import <module_name> as <alt_name>
>>> from pkg import mod1
>>> mod1.foo()
[mod1] foo()
>>> from pkg import mod2 as quux
>>> quux.bar()
[mod2] bar()
从技术上讲,您也可以导入包:
>>> import pkg >>> pkg <module 'pkg' (namespace)>但这无济于事。虽然严格来说,这是一个语法正确的 Python 语句,但它并没有做多少有用的事情。特别是,它不会将
pkg中的任何模块放入本地名称空间:
>>> pkg.mod1
Traceback (most recent call last):
File "<pyshell#34>", line 1, in <module>
pkg.mod1
AttributeError: module 'pkg' has no attribute 'mod1'
>>> pkg.mod1.foo()
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
pkg.mod1.foo()
AttributeError: module 'pkg' has no attribute 'mod1'
>>> pkg.mod2.Bar()
Traceback (most recent call last):
File "<pyshell#36>", line 1, in <module>
pkg.mod2.Bar()
AttributeError: module 'pkg' has no attribute 'mod2'
要实际导入模块或它们的内容,您需要使用上面显示的表单之一。
包初始化
如果包目录中有一个名为__init__.py的文件,当导入包或包中的一个模块时,它会被调用。这可用于执行包初始化代码,例如包级数据的初始化。
例如,考虑下面的__init__.py文件:
init。pyT3】
print(f'Invoking __init__.py for {__name__}')
A = ['quux', 'corge', 'grault']
让我们将这个文件添加到上面示例中的pkg目录中:
现在,当包被导入时,全局列表A被初始化:
>>> import pkg Invoking __init__.py for pkg >>> pkg.A ['quux', 'corge', 'grault']包中的模块可以通过依次导入来访问全局变量:
mod1.py
def foo(): from pkg import A print('[mod1] foo() / A = ', A) class Foo: pass
>>> from pkg import mod1
Invoking __init__.py for pkg
>>> mod1.foo()
[mod1] foo() / A = ['quux', 'corge', 'grault']
__init__.py也可用于实现从包中自动导入模块。例如,前面您看到语句import pkg只将名字pkg放在调用者的本地符号表中,没有导入任何模块。但是如果pkg目录中的__init__.py包含以下内容:
init。pyT3】
print(f'Invoking __init__.py for {__name__}')
import pkg.mod1, pkg.mod2
然后当您执行import pkg时,模块mod1和mod2被自动导入:
>>> import pkg Invoking __init__.py for pkg >>> pkg.mod1.foo() [mod1] foo() >>> pkg.mod2.bar() [mod2] bar()注意:很多 Python 文档都指出,当创建一个包时,
__init__.py文件必须存在于包目录中。这曾经是真的。过去,__init__.py的出现对 Python 来说意味着一个包正在被定义。该文件可以包含初始化代码,甚至可以是空的,但是它必须有存在。从 Python 3.3 开始,隐式名称空间包被引入。这些允许创建一个没有任何
__init__.py文件的包。当然,如果需要包初始化,它可以仍然存在。但是不再需要了。从包中导入
*出于以下讨论的目的,前面定义的包被扩展为包含一些附加模块:
现在在
pkg目录中定义了四个模块。它们的内容如下所示:mod1.py
def foo(): print('[mod1] foo()') class Foo: passmod2.py
def bar(): print('[mod2] bar()') class Bar: passmod3.py
def baz(): print('[mod3] baz()') class Baz: passmod4.py
def qux(): print('[mod4] qux()') class Qux: pass(很有想象力,不是吗?)
您已经看到,当
import *用于模块,时,模块中的所有对象都被导入到本地符号表中,除了那些名称以下划线开头的对象,一如既往:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg.mod3 import *
>>> dir()
['Baz', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'baz']
>>> baz()
[mod3] baz()
>>> Baz
<class 'pkg.mod3.Baz'>
一个包的类似陈述如下:
from <package_name> import *
那有什么用?
>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__'] >>> from pkg import * >>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__']嗯。不多。您可能期望(假设您有任何期望)Python 会深入到包目录中,找到它能找到的所有模块,并导入它们。但是正如你所看到的,默认情况下并不是这样。
相反,Python 遵循这样的约定:如果包目录中的
__init__.py文件包含一个名为__all__的列表,那么当遇到语句from <package_name> import *时,它被认为是应该导入的模块列表。对于本例,假设您在
pkg目录中创建了一个__init__.py,如下所示:pkg/init。pyT3】
__all__ = [ 'mod1', 'mod2', 'mod3', 'mod4' ]现在
from pkg import *导入所有四个模块:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'mod1', 'mod2', 'mod3', 'mod4']
>>> mod2.bar()
[mod2] bar()
>>> mod4.Qux
<class 'pkg.mod4.Qux'>
使用import *仍然不被认为是很好的形式,对于包比对于模块更是如此。但是这个工具至少给了包的创建者一些控制,当指定了import *时会发生什么。(事实上,它提供了完全不允许它的能力,简单地拒绝定义__all__。正如您所看到的,包的默认行为是不导入任何东西。)
顺便说一下,__all__也可以在模块中定义,其目的相同:控制用import *导入的内容。例如,将mod1.py修改如下:
pkg/mod1.py
__all__ = ['foo']
def foo():
print('[mod1] foo()')
class Foo:
pass
现在来自pkg.mod1的import *语句将只导入包含在__all__中的内容:
>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__'] >>> from pkg.mod1 import * >>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'foo'] >>> foo() [mod1] foo() >>> Foo Traceback (most recent call last): File "<pyshell#37>", line 1, in <module> Foo NameError: name 'Foo' is not defined
foo()(函数)现在在本地名称空间中定义,但是Foo(类)没有,因为后者不在__all__中。总之,
__all__被包和模块用来控制当import *被指定时导入什么。但是默认行为不同:
- 对于一个包,当没有定义
__all__时,import *不导入任何东西。- 对于一个模块,当没有定义
__all__时,import *会导入所有内容(除了——你猜对了——以下划线开头的名字)。子包
包可以包含任意深度的嵌套子包。例如,让我们对示例包目录进行如下修改:
四个模块(
mod1.py、mod2.py、mod3.py和mod4.py)的定义如前。但是现在,它们没有被集中到pkg目录中,而是被分成两个子包目录,sub_pkg1和sub_pkg2。导入仍然与前面所示的一样。语法是相似的,但是额外的点符号被用来分隔包名和子包名:
>>> import pkg.sub_pkg1.mod1
>>> pkg.sub_pkg1.mod1.foo()
[mod1] foo()
>>> from pkg.sub_pkg1 import mod2
>>> mod2.bar()
[mod2] bar()
>>> from pkg.sub_pkg2.mod3 import baz
>>> baz()
[mod3] baz()
>>> from pkg.sub_pkg2.mod4 import qux as grault
>>> grault()
[mod4] qux()
此外,一个子包中的模块可以引用一个兄弟子包中的对象(如果兄弟子包包含您需要的一些功能)。例如,假设您想从模块mod3中导入并执行函数foo()(在模块mod1中定义)。您可以使用绝对导入:
pkg/sub _ _ pkg 2/mod 3 . pyT3】
def baz():
print('[mod3] baz()')
class Baz:
pass
from pkg.sub_pkg1.mod1 import foo
foo()
>>> from pkg.sub_pkg2 import mod3 [mod1] foo() >>> mod3.foo() [mod1] foo()或者你可以使用一个相对导入,这里
..指的是上一级的包。从mod3.py内部,也就是在sub_pkg2子包中,
..评估为父包(pkg),并且..sub_pkg1评估为父包的子包sub_pkg1。pkg/sub _ _ pkg 2/mod 3 . pyT3】
def baz(): print('[mod3] baz()') class Baz: pass from .. import sub_pkg1 print(sub_pkg1) from ..sub_pkg1.mod1 import foo foo()
>>> from pkg.sub_pkg2 import mod3
<module 'pkg.sub_pkg1' (namespace)>
[mod1] foo()
结论
在本教程中,您学习了以下主题:
- 如何创建一个 Python 模块
- Python 解释器搜索模块的位置
- 如何使用
import语句访问模块中定义的对象 - 如何创建可作为独立脚本执行的模块
- 如何将模块组织成包和子包
- 如何控制包的初始化
免费 PDF 下载: Python 3 备忘单
这有望让您更好地理解如何获得 Python 中许多第三方和内置模块的可用功能。
此外,如果你正在开发自己的应用程序,创建自己的模块和包将帮助你组织和模块化你的代码,这使得编码、维护和调试更容易。
如果您想了解更多信息,请在Python.org查阅以下文档:
快乐的蟒蛇!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 模块和包:简介*****
Python 模运算实践:如何使用%运算符
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 模:使用%运算符
Python 支持多种多样的算术运算符,当您在代码中处理数字时,可以使用这些运算符。其中一个运算符是模运算符 ( %),它返回两个数相除的余数。
在本教程中,您将学习:
- 模在数学中是如何工作的
- 如何对不同的数字类型使用 Python 模运算符
- Python 如何计算模运算的结果
- 如何在你的类中覆盖
.__mod__()来使用模运算符 - 如何使用 Python 模运算符解决现实世界的问题
Python 的模操作符有时会被忽略。但是很好地理解这个操作符将为您的 Python 工具箱提供一个无价的工具。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
数学中的模数
术语模来自一个叫做模运算的数学分支。模运算在一个有固定数字集合的循环数字线上处理整数运算。在该数字线上执行的所有算术运算将在达到某个称为模数的数字时回绕。
模运算中模的一个经典例子是十二小时时钟。十二小时制的时钟有一组固定的值,从 1 到 12。当在 12 小时制的时钟上计数时,您计数到模数 12,然后返回到 1。十二小时的时钟可以归类为“模 12”,有时缩写为“mod 12”
当您想要将一个数字与模数进行比较,并获得限制在模数范围内的等效数字时,可以使用模运算符。
例如,假设您想确定上午 8:00 后 9 个小时是什么时间。在 12 小时制的时钟上,您不能简单地将 9 加 8,因为您会得到 17。您需要得到结果 17,并使用mod在 12 小时的上下文中获得它的等值:
8 o'clock + 9 = 17 o'clock
17 mod 12 = 5
17 mod 12返回5。这意味着上午 8:00 之后的 9 个小时是下午 5:00。您通过将数字17应用于mod 12上下文来确定这一点。
现在,如果你想一想,17和5在mod 12上下文中是等价的。如果你在 5 点和 17 点看时针,它会在同样的位置。模运算有一个等式来描述这种关系:
a ≡ b (mod n)
这个等式读作“a和b同余模n”这意味着a和b在mod n中是等价的,因为它们除以n后有相同的余数。在上式中,n是a和b的模数。使用之前的值17和5,等式将如下所示:
17 ≡ 5 (mod 12)
上面写着"17和5同余模12"17和5被12除时,余数5相同。所以在mod 12中,数字17和5是等价的。
您可以使用除法来确认这一点:
17 / 12 = 1 R 5
5 / 12 = 0 R 5
这两种运算都有相同的余数5,所以它们的模12是等价的。
现在,对于 Python 操作符来说,这似乎是一个很大的数学问题,但是有了这些知识,您就可以在本教程后面的例子中使用模操作符了。在下一节中,您将看到对数值类型int和float使用 Python 模操作符的基础。
Python 模运算符基础知识
像其他算术运算符一样,模运算符可以与数字类型 int 和 float 一起使用。稍后您将会看到,它也可以用于其他类型,如math.fmod()decimal.Decimal,以及您自己的类。
带int的模运算符
大多数情况下,您将对整数使用模运算符。模运算符在用于两个正整数时,将返回标准欧几里德除法的余数:
>>> 15 % 4 3 >>> 17 % 12 5 >>> 240 % 13 6 >>> 10 % 16 10小心点!就像除法运算符(
/)一样,如果您尝试使用除数为0的模运算符,Python 将返回一个ZeroDivisionError:
>>> 22 % 0
ZeroDivisionError: integer division or modulo by zero
接下来,我们将看看如何使用带float的模操作符。
带float的模运算符
与int类似,与float一起使用的模运算符将返回除法的余数,但作为一个float值:
>>> 12.5 % 5.5 1.5 >>> 17.0 % 12.0 5.0将
float与模运算符一起使用的另一种方法是使用math.fmod()对float值执行模运算:
>>> import math
>>> math.fmod(12.5, 5.5)
1.5
>>> math.fmod(8.5, 2.5)
1.0
由于math.fmod()计算模运算结果的方式,官方 Python 文档建议在处理float值时使用math.fmod() 而不是 Python 模运算符。如果您使用负操作数,那么您可能会在math.fmod(x, y)和x % y之间看到不同的结果。在下一节中,您将更详细地探索对负操作数使用模运算符。
就像其他算术运算符一样,模运算符和math.fmod()在处理浮点运算时可能会遇到舍入和精度问题:
>>> 13.3 % 1.1 0.09999999999999964 >>> import math >>> math.fmod(13.3, 1.1) 0.09999999999999964如果保持浮点精度对您的应用程序很重要,那么您可以使用带
decimal.Decimal的模操作符。在本教程的后面,你会看到这个。带负操作数的模运算符
到目前为止,您看到的所有模运算都使用两个正操作数并返回可预测的结果。当引入负操作数时,事情变得更加复杂。
事实证明,计算机确定带有负操作数的模运算结果的方式留下了模糊性,即余数应该采用被除数(被除的数)还是除数(被除数)的符号。不同的编程语言对此有不同的处理方式。
例如,在 JavaScript 中,余数将带有被除数的符号:
8 % -3 = 2本例中的余数
2为正,因为它采用被除数8的符号。在 Python 和其他语言中,余数将改为除数的符号:8 % -3 = -1这里你可以看到余数
-1,取除数-3的符号。你可能想知道为什么 JavaScript 中的余数是
2而 Python 中的余数是-1。这与不同的语言如何决定模运算的结果有关。余数带有被除数符号的语言使用以下等式来确定余数:r = a - (n * trunc(a/n))这个等式有三个变量:
r是余数。a是股息。n是除数。这个等式中的
trunc()意味着它使用了截断除法,它总是将负数四舍五入为零。为更清楚起见,请参见下面使用8作为被除数和-3作为除数的模运算步骤:r = 8 - (-3 * trunc(8/-3)) r = 8 - (-3 * trunc(-2.666666666667)) r = 8 - (-3 * -2) # Rounded toward 0 r = 8 - 6 r = 2这里你可以看到像 JavaScript 这样的语言是如何得到剩余部分
2的。Python 和其他语言中,余数采用除数的符号,使用以下等式:r = a - (n * floor(a/n))此等式中的
floor()表示使用楼层划分。对于正数,底除法将返回与截断除法相同的结果。但是,如果是负数,floor division 会将结果向下舍入,远离零:r = 8 - (-3 * floor(8/-3)) r = 8 - (-3 * floor(-2.666666666667)) r = 8 - (-3 * -3) # Rounded away from 0 r = 8 - 9 r = -1这里可以看到结果是
-1。既然您已经理解了剩余部分的不同之处,那么您可能会想,如果您只使用 Python,为什么这很重要。事实证明,Python 中的模运算并不完全相同。虽然与
int和float类型一起使用的模将采用除数的符号,但其他类型不会。当您比较
8.0 % -3.0和math.fmod(8.0, -3.0)的结果时,可以看到一个这样的例子:
>>> 8.0 % -3
-1.0
>>> import math
>>> math.fmod(8.0, -3.0)
2.0
math.fmod()使用截断除法得到被除数的符号,而float使用除数的符号。在本教程的后面,您将看到另一种使用被除数符号的 Python 类型,decimal.Decimal。
模运算符divmod()和
Python 有内置函数 divmod() ,内部使用模运算符。divmod()接受两个参数,并使用所提供的参数返回一个元组,该元组包含取底和取模的结果。
下面是一个将divmod()与37和5一起使用的例子:
>>> divmod(37, 5) (7, 2) >>> 37 // 5 7 >>> 37 % 5 2可以看到
divmod(37, 5)返回了元组(7, 2)。7是37和5分楼层的结果。2是37对5取模的结果。下面是第二个参数是负数的例子。如前所述,当模运算符与
int一起使用时,余数将采用除数的符号:
>>> divmod(37, -5)
(-8, -3)
>>> 37 // -5
-8
>>> 37 % -5
-3 # Result has the sign of the divisor
既然您已经有机会看到了在几种场景中使用的模运算符,那么看看 Python 如何确定模运算符与其他算术运算符一起使用时的优先级是很重要的。
模运算符优先级
像其他 Python 操作符一样,模操作符有特定的规则,这些规则决定了它在计算表达式时的优先级。模运算符(%)与乘法(*)、除法(/)和除法(//)运算符具有相同的优先级。
看看下面这个模运算符优先级的例子:
>>> 4 * 10 % 12 - 9 -5乘法和模操作符具有相同的优先级,所以 Python 将从左到右计算它们。以上操作的步骤如下:
4 * 10被求值,产生40 % 12 - 9。40 % 12被求值,产生4 - 9。4 - 9被求值,产生-5。如果您想要覆盖其他运算符的优先级,那么您可以使用括号将您想要首先计算的运算括起来:
>>> 4 * 10 % (12 - 9)
1
在这个例子中,首先计算(12 - 9),然后是4 * 10,最后是40 % 3,等于1。
实践中的 Python 模运算符
现在您已经了解了 Python 模操作符的基础知识,接下来您将看到一些使用它来解决实际编程问题的例子。有时,很难确定何时在代码中使用模运算符。下面的例子将让你了解它的许多用法。
如何检查一个数是偶数还是奇数
在这一节中,您将看到如何使用模运算符来确定一个数字是偶数还是奇数。使用模数为2的模操作符,你可以检查任何一个数是否能被2整除。如果它能被整除,那么它就是一个偶数。
看一下is_even(),它检查num参数是否为偶数:
def is_even(num):
return num % 2 == 0
如果num是偶数,这里的num % 2将等于0,如果num是奇数,这里的1将等于0。检查0将根据num是否为偶数返回一个True或False的布尔值。
检查奇数是非常相似的。要检查奇数,可以反转等式检查:
def is_odd(num):
return num % 2 != 0
如果num % 2不等于0,这个函数将返回True,这意味着有一个余数证明num是奇数。现在,您可能想知道是否可以使用以下函数来确定num是否为奇数:
def is_odd(num):
return num % 2 == 1
这个问题的答案是肯定的和否。从技术上讲,这个函数将与 Python 计算整数模的方式一起工作。也就是说,您应该避免将模运算的结果与1进行比较,因为 Python 中并非所有的模运算都会返回相同的余数。
你可以在下面的例子中看到原因:
>>> -3 % 2 1 >>> 3 % -2 -1在第二个例子中,余数取负除数的符号并返回
-1。在这种情况下,布尔校验3 % -2 == 1将返回False。但是,如果你用
0来比较模运算,那么哪个操作数是负的就无所谓了。当它是偶数时,结果总是True:
>>> -2 % 2
0
>>> 2 % -2
0
如果您坚持将 Python 模运算与0进行比较,那么在代码中检查偶数和奇数或任何其他倍数应该没有任何问题。
在下一节中,您将了解如何在循环中使用模操作符来控制程序的流程。
如何在循环中以特定间隔运行代码
使用 Python 模操作符,您可以在循环中以特定的间隔运行代码。这是通过用循环的当前索引和模数执行模运算来完成的。模数决定了特定于间隔的代码在循环中运行的频率。
这里有一个例子:
def split_names_into_rows(name_list, modulus=3):
for index, name in enumerate(name_list, start=1):
print(f"{name:-^15} ", end="")
if index % modulus == 0:
print()
print()
这段代码定义了split_names_into_rows(),它有两个参数。name_list是一个列表中的名字应该被分成行。modulus为运算设置一个模数,有效地确定每行应该有多少个名字。split_names_into_rows()将在name_list上循环,并在达到modulus值后开始新的一行。
在更详细地分析该功能之前,先看一下它的运行情况:
>>> names = ["Picard", "Riker", "Troi", "Crusher", "Worf", "Data", "La Forge"] >>> split_names_into_rows(names) ----Picard----- -----Riker----- -----Troi------ ----Crusher---- -----Worf------ -----Data------ ---La Forge----如您所见,姓名列表被分成三行,每行最多三个姓名。
modulus默认为3,但您可以指定任意数字:
>>> split_names_into_rows(names, modulus=4)
----Picard----- -----Riker----- -----Troi------ ----Crusher----
-----Worf------ -----Data------ ---La Forge----
>>> split_names_into_rows(names, modulus=2)
----Picard----- -----Riker-----
-----Troi------ ----Crusher----
-----Worf------ -----Data------
---La Forge----
>>> split_names_into_rows(names, modulus=1)
----Picard-----
-----Riker-----
-----Troi------
----Crusher----
-----Worf------
-----Data------
---La Forge----
现在您已经看到了运行中的代码,您可以分解它在做什么了。首先,它使用 enumerate() 来迭代name_list,将列表中的当前项分配给name,并将一个计数值分配给index。您可以看到enumerate()的可选start参数被设置为1。这意味着index计数将从1而不是0开始:
for index, name in enumerate(name_list, start=1):
接下来,在循环内部,该函数调用 print() 将name输出到当前行。print()的end参数是一个空的字符串 ( ""),所以它不会在字符串末尾输出换行符。一个 f 字符串被传递给print(),T5 使用 Python 提供的字符串输出格式化语法:
print(f"{name:-^15} ", end="")
在不涉及太多细节的情况下,:-^15语法告诉print()做以下事情:
- 至少输出
15个字符,即使字符串短于 15 个字符。 - 将字符串居中对齐。
- 用连字符(
-)填充字符串右边或左边的任何空格。
现在名称已经打印到行中,看一下split_names_into_rows()的主要部分:
if index % modulus == 0:
print()
这段代码获取当前迭代index,并使用模运算符,将其与modulus进行比较。如果结果等于0,那么它可以运行特定于间隔的代码。在这种情况下,该函数调用print()来添加一个新行,这将开始一个新行。
上面的代码只是一个例子。使用模式index % modulus == 0允许你在循环中以特定的间隔运行不同的代码。在下一节中,您将进一步理解这个概念,看看循环迭代。
如何创建循环迭代
循环迭代描述了一种迭代类型,一旦到达某一点就会重置。通常,这种类型的迭代用于将迭代的索引限制在某个范围内。
您可以使用模运算符来创建循环迭代。看一个使用 turtle库绘制形状的例子:
import turtle
import random
def draw_with_cyclic_iteration():
colors = ["green", "cyan", "orange", "purple", "red", "yellow", "white"]
turtle.bgcolor("gray8") # Hex: #333333
turtle.pendown()
turtle.pencolor(random.choice(colors)) # First color is random
i = 0 # Initial index
while True:
i = (i + 1) % 6 # Update the index
turtle.pensize(i) # Set pensize to i
turtle.forward(225)
turtle.right(170)
# Pick a random color
if i == 0:
turtle.pencolor(random.choice(colors))
上面的代码使用了一个无限循环来绘制一个重复的星形。每六次迭代后,它会改变钢笔的颜色。笔的大小随着每次迭代而增加,直到i被重置回0。如果您运行该代码,那么您应该会得到类似如下的内容:

该代码的重要部分强调如下:
import turtle
import random
def draw_with_cyclic_iteration():
colors = ["green", "cyan", "orange", "purple", "red", "yellow", "white"]
turtle.bgcolor("gray8") # Hex: #333333
turtle.pendown()
turtle.pencolor(random.choice(colors))
i = 0 # Initial index
while True: i = (i + 1) % 6 # Update the index turtle.pensize(i) # Set pensize to i turtle.forward(225) turtle.right(170) # Pick a random color if i == 0: turtle.pencolor(random.choice(colors))
每次循环时,i根据(i + 1) % 6的结果更新。这个新的i值用于在每次迭代中增加.pensize。一旦i到达5,(i + 1) % 6将等于0,i将重置回0。
您可以查看下面的迭代步骤以获得更多的说明:
i = 0 : (0 + 1) % 6 = 1
i = 1 : (1 + 1) % 6 = 2
i = 2 : (2 + 1) % 6 = 3
i = 3 : (3 + 1) % 6 = 4
i = 4 : (4 + 1) % 6 = 5
i = 5 : (5 + 1) % 6 = 0 # Reset
当i复位回0时,.pencolor变成新的随机颜色,如下图所示:
if i == 0:
turtle.pencolor(random.choice(colors))
本节中的代码使用6作为模数,但是您可以将其设置为任意数字,以调整在重置值i之前循环迭代的次数。
如何转换单位
在这一节中,您将看到如何使用模运算符来转换单位。以下示例采用较小的单位,并在不使用小数的情况下将其转换为较大的单位。模运算符用于确定当较小的单位不能被较大的单位整除时可能存在的任何余数。
在第一个示例中,您将把英寸转换为英尺。模运算符用于获得没有被平均分为英尺的剩余英寸。地板除法运算符(//)用于向下舍入总英尺数:
def convert_inches_to_feet(total_inches):
inches = total_inches % 12
feet = total_inches // 12
print(f"{total_inches} inches = {feet} feet and {inches} inches")
下面是一个正在使用的函数示例:
>>> convert_inches_to_feet(450) 450 inches = 37 feet and 6 inches正如您在输出中看到的,
450 % 12返回6,这是没有被平均分成英尺的剩余英寸。450 // 12的结果是37,这是英寸被等分的总英尺数。在下一个例子中,你可以更进一步。
convert_minutes_to_days()取一个整数total_mins,表示分钟数,并输出以天、小时和分钟为单位的时间段:def convert_minutes_to_days(total_mins): days = total_mins // 1440 extra_minutes = total_mins % 1440 hours = extra_minutes // 60 minutes = extra_minutes % 60 print(f"{total_mins} = {days} days, {hours} hours, and {minutes} minutes")细分来看,您可以看到该函数执行以下操作:
- 用
total_mins // 1440确定可整除的天数,其中1440是一天中的分钟数- 用
total_mins % 1440计算剩余的extra_minutes- 使用
extra_minutes得到可整除的hours和任何多余的minutes你可以在下面看到它是如何工作的:
>>> convert_minutes_to_days(1503)
1503 = 1 days, 1 hours, and 3 minutes
>>> convert_minutes_to_days(3456)
3456 = 2 days, 9 hours, and 36 minutes
>>> convert_minutes_to_days(35000)
35000 = 24 days, 7 hours, and 20 minutes
虽然上面的例子只处理将英寸转换为英尺,将分钟转换为天,但是您可以使用任何类型的单位和模运算符将较小的单位转换为较大的单位。
注意:上面的两个例子都可以修改成使用divmod()来使代码更加简洁。如果您还记得的话,divmod()使用所提供的参数返回一个包含地板除法和模运算结果的元组。
下面,地板除法和模数运算符已被替换为divmod():
def convert_inches_to_feet_updated(total_inches):
feet, inches = divmod(total_inches, 12) print(f"{total_inches} inches = {feet} feet and {inches} inches")
可以看到,divmod(total_inches, 12)返回一个元组,这个元组被解包到feet和inches中。
如果您尝试这个更新的函数,那么您将收到与以前相同的结果:
>>> convert_inches_to_feet(450) 450 inches = 37 feet and 6 inches >>> convert_inches_to_feet_updated(450) 450 inches = 37 feet and 6 inches您会得到相同的结果,但是现在代码更简洁了。您也可以更新
convert_minutes_to_days():def convert_minutes_to_days_updated(total_mins): days, extra_minutes = divmod(total_mins, 1440) hours, minutes = divmod(extra_minutes, 60) print(f"{total_mins} = {days} days, {hours} hours, and {minutes} minutes")使用
divmod(),该函数比以前的版本更容易阅读,并返回相同的结果:
>>> convert_minutes_to_days(1503)
1503 = 1 days, 1 hours, and 3 minutes
>>> convert_minutes_to_days_updated(1503)
1503 = 1 days, 1 hours, and 3 minutes
使用divmod()并非在所有情况下都是必要的,但它在这里是有意义的,因为单位转换计算同时使用底除法和模。
现在您已经看到了如何使用模操作符来转换单位,在下一节中,您将看到如何使用模操作符来检查质数。
如何判断一个数是否是质数
在下一个例子中,您将了解如何使用 Python 模运算符来检查一个数字是否是质数**。质数是任何只包含两个因子的数,1和它本身。质数的一些例子有2、3、5、7、23、29、59、83和97。*
*下面的代码是使用模运算符确定一个数的素性的实现:
def check_prime_number(num):
if num < 2:
print(f"{num} must be greater than or equal to 2 to be prime.")
return
factors = [(1, num)]
i = 2
while i * i <= num:
if num % i == 0:
factors.append((i, num//i))
i += 1
if len(factors) > 1:
print(f"{num} is not prime. It has the following factors: {factors}")
else:
print(f"{num} is a prime number")
这段代码定义了check_prime_number(),它接受参数num并检查它是否是一个质数。如果是,则显示一条消息,说明num是一个质数。如果它不是一个质数,那么将显示一条消息,其中包含该数的所有因子。
注意:上面的代码不是检查质数的最有效的方法。如果你有兴趣深入挖掘,那么看看厄拉多塞的筛子和阿特金的筛子,它们是寻找素数的更高效算法的例子。
在您更仔细地研究这个函数之前,下面是使用一些不同数字得到的结果:
>>> check_prime_number(44) 44 is not prime. It has the following factors: [(1, 44), (2, 22), (4, 11)] >>> check_prime_number(53) 53 is a prime number >>> check_prime_number(115) 115 is not prime. It has the following factors: [(1, 115), (5, 23)] >>> check_prime_number(997) 997 is a prime number深入研究代码,您会发现它从检查
num是否小于2开始。质数只能大于等于2。如果num小于2,则该功能不需要继续。它会print()发出信息和return:if num < 2: print(f"{num} must be greater than or equal to 2 to be prime.") return如果
num大于2,则该函数检查num是否为质数。为了检查这一点,该函数对2和num的平方根之间的所有数字进行迭代,以查看是否有任何数字被均匀地分为num。如果其中一个数被整除,那么已经找到了一个因子,num不可能是质数。下面是该函数的主要部分:
factors = [(1, num)] i = 2 while i * i <= num: if num % i == 0: factors.append((i, num//i)) i += 1这里要解开的东西很多,我们一步一步来。
首先,用初始因子
(1, num)创建一个factors列表。该列表将用于存储发现的任何其他因素:factors = [(1, num)]接下来,从
2开始,代码增加i,直到它达到num的平方根。在每次迭代中,它将num与i进行比较,看它是否能被整除。代码只需要检查到并包括num的平方根,因为它不会包含任何高于此的因子:i = 2 while i * i <= num: if num % i == 0: factors.append((i, num//i)) i += 1该函数不是试图确定
num的平方根,而是使用一个while循环来查看i * i <= num是否。只要i * i <= num,循环还没有到达num的平方根。在
while循环中,模运算符检查num是否能被i整除:factors = [(1, num)] i = 2 # Start the initial index at 2 while i * i <= num: if num % i == 0: factors.append((i, num//i)) i += 1如果
num能被i整除,那么i就是num的一个因子,一个因子元组被添加到factors列表中。一旦
while循环完成,代码会检查是否发现了任何其他因素:if len(factors) > 1: print(f"{num} is not prime. It has the following factors: {factors}") else: print(f"{num} is a prime number")如果不止一个元组存在于
factors列表中,那么num不可能是质数。对于非质数,会打印出因数。对于质数,该函数打印一条消息,说明num是质数。如何实现密码
Python 模运算符可用于创建密码。密码是一种算法,用于对通常为文本的输入进行加密和解密。在这一部分,你将看到两种密码,T4 凯撒密码和维根奈尔密码。
凯撒密码
你将看到的第一个密码是凯撒密码,以朱利叶斯·凯撒命名,他用它来秘密传递信息。这是一种替代密码,它使用字母替代来加密一串文本。
凯撒密码的工作原理是将一个要加密的字母在字母表中向左或向右移动一定的位置。在那个位置的任何一个字母都被用作加密字符。这个相同的移位值应用于字符串中的所有字符。
例如,如果移位是
5,那么A将向上移位五个字母成为F,B将成为G,以此类推。下面你可以看到文本REALPYTHON的加密过程,移位5:
得到的密码是
WJFQUDYMTS。解密密码是通过反转移位来完成的。加密和解密过程都可以用下面的表达式来描述,其中
char_index是字符在字母表中的索引:encrypted_char_index = (char_index + shift) % 26 decrypted_char_index = (char_index - shift) % 26这种密码使用模运算符来确保当移动一个字母时,如果到达字母表的末尾,索引将会绕回。现在您已经知道了这个密码是如何工作的,让我们来看一个实现:
import string def caesar_cipher(text, shift, decrypt=False): if not text.isascii() or not text.isalpha(): raise ValueError("Text must be ASCII and contain no numbers.") lowercase = string.ascii_lowercase uppercase = string.ascii_uppercase result = "" if decrypt: shift = shift * -1 for char in text: if char.islower(): index = lowercase.index(char) result += lowercase[(index + shift) % 26] else: index = uppercase.index(char) result += uppercase[(index + shift) % 26] return result这段代码定义了一个名为
caesar_cipher()的函数,它有两个必需参数和一个可选参数:
text是要加密或解密的文本。shift是每个字母要移位的位数。decrypt是一个布尔值,用于设置text是否应该被解密。
decrypt被包括在内,以便可以使用一个函数来处理加密和解密。该实现只能处理字母字符,因此该函数首先检查text是否是 ASCII 编码中的字母字符:def caesar_cipher(text, shift, decrypt=False): if not text.isascii() or not text.isalpha(): raise ValueError("Text must be ASCII and contain no numbers.")然后,该函数定义三个变量来存储
lowercaseASCII 字符、uppercaseASCII 字符以及加密或解密的结果:lowercase = string.ascii_lowercase # "abcdefghijklmnopqrstuvwxyz" uppercase = string.ascii_uppercase # "ABCDEFGHIJKLMNOPQRSTUVWXYZ" result = ""接下来,如果该函数正被用于解密
text,那么它将shift乘以-1以使其向后移位:if decrypt: shift = shift * -1最后,
caesar_cipher()循环遍历text中的单个字符,并对每个char执行以下动作:
- 检查
char是小写还是大写。- 获取
lowercase或uppercaseASCII 列表中char的index。- 给这个
index加一个shift来确定要使用的密码字符的索引。- 使用
% 26确保移位会回到字母表的开始。- 将密码字符附加到
result字符串。在循环完成对
text值的迭代后,返回result:for char in text: if char.islower(): index = lowercase.index(char) result += lowercase[(index + shift) % 26] else: index = uppercase.index(char) result += uppercase[(index + shift) % 26] return result下面是完整的代码:
import string def caesar_cipher(text, shift, decrypt=False): if not text.isascii() or not text.isalpha(): raise ValueError("Text must be ASCII and contain no numbers.") lowercase = string.ascii_lowercase uppercase = string.ascii_uppercase result = "" if decrypt: shift = shift * -1 for char in text: if char.islower(): index = lowercase.index(char) result += lowercase[(index + shift) % 26] else: index = uppercase.index(char) result += uppercase[(index + shift) % 26] return result现在运行 Python REPL 中的代码,使用文本
meetMeAtOurHideOutAtTwo和移位10:

>>> caesar_cipher("meetMeAtOurHideOutAtTwo", 10)
woodWoKdYebRsnoYedKdDgy
加密的结果是woodWoKdYebRsnoYedKdDgy。使用这个加密文本,您可以运行解密来获得原始文本:
>>> caesar_cipher("woodWoKdYebRsnoYedKdDgy", 10, decrypt=True) meetMeAtOurHideOutAtTwo凯撒密码是一个有趣的密码学入门游戏。虽然凯撒密码很少单独使用,但它是更复杂的替代密码的基础。在下一节中,您将看到凯撒密码的一个后代,Vigenère 密码。
维根涅尔密码
维根奈尔密码是一种多字母替换密码。为了执行加密,它对输入文本的每个字母使用不同的凯撒密码。Vigenère 密码使用关键字来确定应该使用哪个凯撒密码来查找密码字母。
您可以在下图中看到加密过程的示例。在这个例子中,使用关键字
MODULO对输入文本REALPYTHON进行加密:
对于输入文本的每个字母
REALPYTHON,来自关键字MODULO的一个字母用于确定应该选择哪个凯撒密码列。如果关键字比输入文本短,如MODULO的情况,那么关键字的字母会重复,直到输入文本的所有字母都被加密。下面是 Vigenère 密码的实现。正如您将看到的,模运算符在函数中使用了两次:
import string def vigenere_cipher(text, key, decrypt=False): if not text.isascii() or not text.isalpha() or not text.isupper(): raise ValueError("Text must be uppercase ASCII without numbers.") uppercase = string.ascii_uppercase # "ABCDEFGHIJKLMNOPQRSTUVWXYZ" results = "" for i, char in enumerate(text): current_key = key[i % len(key)] char_index = uppercase.index(char) key_index = uppercase.index(current_key) if decrypt: index = char_index - key_index + 26 else: index = char_index + key_index results += uppercase[index % 26] return results您可能已经注意到
vigenere_cipher()的签名与上一节中的caesar_cipher()非常相似:def vigenere_cipher(text, key, decrypt=False): if not text.isascii() or not text.isalpha() or not text.isupper(): raise ValueError("Text must be uppercase ASCII without numbers.") uppercase = string.ascii_uppercase results = ""主要的区别在于,
vigenere_cipher()采用的是key参数,而不是shift参数,它是加密和解密过程中使用的关键字。另一个区别是增加了text.isupper()。基于这个实现,vigenere_cipher()只能接受全大写的输入文本。像
caesar_cipher()一样,vigenere_cipher()遍历输入文本的每个字母来加密或解密它:for i, char in enumerate(text): current_key = key[i % len(key)]在上面的代码中,您可以看到该函数第一次使用模运算符:
current_key = key[i % len(key)]这里,基于从
i % len(key)返回的索引来确定current_key值。这个索引用于从key字符串中选择一个字母,比如从MODULO中选择M。模运算符允许您使用任何长度的关键字,而不管要加密的
text的长度。一旦当前被加密字符的索引i等于关键字的长度,它将从关键字的开头重新开始。对于输入文本的每个字母,有几个步骤决定如何加密或解密它:
- 根据
uppercase内char的索引确定char_index。- 根据
uppercase内current_key的索引确定key_index。- 使用
char_index和key_index获取加密或解密字符的索引。看看下面代码中的这些步骤:
char_index = uppercase.index(char) key_index = uppercase.index(current_key) if decrypt: index = char_index - key_index + 26 else: index = char_index + key_index您可以看到解密和加密的索引是以不同的方式计算的。这就是为什么在这个函数中使用
decrypt的原因。这样,您可以使用该函数进行加密和解密。确定了
index之后,您会发现该函数对模运算符的第二种用法:results += uppercase[index % 26]
index % 26确保字符的index不超过25,从而确保它保持在字母表内。有了这个索引,从uppercase中选择加密或解密的字符并附加到results。这是完整的密码,又是维根涅尔密码:
import string def vigenere_cipher(text, key, decrypt=False): if not text.isascii() or not text.isalpha() or not text.isupper(): raise ValueError("Text must be uppercase ASCII without numbers.") uppercase = string.ascii_uppercase # "ABCDEFGHIJKLMNOPQRSTUVWXYZ" results = "" for i, char in enumerate(text): current_key = key[i % len(key)] char_index = uppercase.index(char) key_index = uppercase.index(current_key) if decrypt: index = char_index - key_index + 26 else: index = char_index + key_index results += uppercase[index % 26] return results现在,在 Python REPL 中运行它:

>>> vigenere_cipher(text="REALPYTHON", key="MODULO")
DSDFAMFVRH
>>> encrypted = vigenere_cipher(text="REALPYTHON", key="MODULO")
>>> print(encrypted)
DSDFAMFVRH
>>> vigenere_cipher(encrypted, "MODULO", decrypt=True)
REALPYTHON
不错!您现在有了一个用于加密文本字符串的 Vigenère 密码。
Python 模运算符高级用法
在这最后一节中,您将通过使用decimal.Decimal将您的模运算符知识提升到下一个层次。您还将看到如何将.__mod__()添加到您的自定义类中,以便它们可以与模操作符一起使用。
使用 Python 模运算符与decimal.Decimal
在本教程的前面,您看到了如何将模运算符用于数字类型,如int和float以及math.fmod()。您也可以使用来自decimal模块的 Decimal 模运算符。当您想要对浮点算术运算的精度进行离散控制时,可以使用decimal.Decimal。
下面是一些使用整数和模操作符的例子:
>>> import decimal >>> decimal.Decimal(15) % decimal.Decimal(4) Decimal('3') >>> decimal.Decimal(240) % decimal.Decimal(13) Decimal('6')下面是一些与
decimal.Decimal和模运算符一起使用的浮点数:
>>> decimal.Decimal("12.5") % decimal.Decimal("5.5")
Decimal('1.5')
>>> decimal.Decimal("13.3") % decimal.Decimal("1.1")
Decimal('0.1')
所有使用decimal.Decimal的模运算都返回与其他数值类型相同的结果,除非其中一个操作数为负。与int和float不同,但与math.fmod()一样,decimal.Decimal使用结果的红利符号。
看看下面的例子,将使用模运算符的结果与标准的int和float值以及decimal.Decimal值进行比较:
>>> -17 % 3 1 # Sign of the divisor >>> decimal.Decimal(-17) % decimal.Decimal(3) Decimal(-2) # Sign of the dividend >>> 17 % -3 -1 # Sign of the divisor >>> decimal.Decimal(17) % decimal.Decimal(-3) Decimal("2") # Sign of dividend >>> -13.3 % 1.1 1.0000000000000004 # Sign of the divisor >>> decimal.Decimal("-13.3") % decimal.Decimal("1.1") Decimal("-0.1") # Sign of the dividend与
math.fmod(),decimal.Decimal相比,符号相同,但精度不同:
>>> decimal.Decimal("-13.3") % decimal.Decimal("1.1")
Decimal("-0.1")
>>> math.fmod(-13.3, 1.1)
-0.09999999999999964
从上面的例子可以看出,使用decimal.Decimal和模操作符与使用其他数值类型类似。你只需要记住当处理负操作数时,它是如何决定结果的符号的。
在下一节中,您将看到如何在您的类中覆盖模操作符来定制它的行为。
对自定义类使用 Python 模操作符
Python 数据模型允许你覆盖 Python 对象中的内置方法来定制它的行为。在这一节中,您将看到如何覆盖.__mod__(),以便您可以在自己的类中使用模操作符。
对于这个例子,您将使用一个Student类。这门课将记录学生学习的时间。下面是初始的Student类:
class Student:
def __init__(self, name):
self.name = name
self.study_sessions = []
def add_study_sessions(self, sessions):
self.study_sessions += sessions
Student类用一个name参数初始化,并以一个空列表study_sessions开始,它将保存一个整数列表,表示每个会话学习的分钟数。还有.add_study_sessions(),它接受一个sessions参数,该参数应该是要添加到study_sessions的学习会话列表。
现在,如果您还记得上面的转换单位部分,convert_minutes_to_day()使用 Python 模操作符将total_mins转换为日、小时和分钟。现在,您将实现该方法的一个修改版本,以了解如何使用带有模运算符的自定义类:
def total_study_time_in_hours(student, total_mins):
hours = total_mins // 60
minutes = total_mins % 60
print(f"{student.name} studied {hours} hours and {minutes} minutes")
您可以使用这个函数和Student类来显示一个Student已经学习的总时间。结合上面的Student类,代码将如下所示:
class Student:
def __init__(self, name):
self.name = name
self.study_sessions = []
def add_study_sessions(self, sessions):
self.study_sessions += sessions
def total_study_time_in_hours(student, total_mins):
hours = total_mins // 60
minutes = total_mins % 60
print(f"{student.name} studied {hours} hours and {minutes} minutes")
如果在 Python REPL 中加载此模块,则可以像这样使用它:
>>> jane = Student("Jane") >>> jane.add_study_sessions([120, 30, 56, 260, 130, 25, 75]) >>> total_mins = sum(jane.study_sessions) >>> total_study_time_in_hours(jane, total_mins) Jane studied 11 hours and 36 minutes上面的代码打印出学习的总时间
jane。这个版本的代码可以工作,但是在调用total_study_time_in_hours()之前,需要对study_sessions求和以得到total_mins的额外步骤。下面是如何修改
Student类来简化代码:class Student: def __init__(self, name): self.name = name self.study_sessions = [] def add_study_sessions(self, sessions): self.study_sessions += sessions def __mod__(self, other): return sum(self.study_sessions) % other def __floordiv__(self, other): return sum(self.study_sessions) // other通过覆盖
.__mod__()和.__floordiv__(),您可以使用带有模操作符的Student实例。计算study_sessions的sum()也包含在Student类中。通过这些修改,您可以在
total_study_time_in_hours()中直接使用Student实例。由于不再需要total_mins,您可以将其移除:def total_study_time_in_hours(student): hours = student // 60 minutes = student % 60 print(f"{student.name} studied {hours} hours and {minutes} minutes")以下是修改后的完整代码:
class Student: def __init__(self, name): self.name = name self.study_sessions = [] def add_study_sessions(self, sessions): self.study_sessions += sessions def __mod__(self, other): return sum(self.study_sessions) % other def __floordiv__(self, other): return sum(self.study_sessions) // other def total_study_time_in_hours(student): hours = student // 60 minutes = student % 60 print(f"{student.name} studied {hours} hours and {minutes} minutes")现在,调用 Python REPL 中的代码,可以看到它简洁多了:
>>> jane = Student("Jane")
>>> jane.add_study_sessions([120, 30, 56, 260, 130, 25, 75])
>>> total_study_time_in_hours(jane)
Jane studied 11 hours and 36 minutes
通过覆盖.__mod__(),您允许您的定制类表现得更像 Python 的内置数值类型。
结论
乍一看,Python 模运算符可能不会引起您的注意。然而,正如你所看到的,这个卑微的经营者有这么多。从检查偶数到用密码加密文本,您已经看到了模运算符的许多不同用途。
在本教程中,您已经学会了如何:
- 将模运算符与
int、float、math.fmod()、divmod()和decimal.Decimal一起使用 - 计算模运算的结果
- 使用模运算符解决现实世界的问题
- 在你自己的类中覆盖
.__mod__(),使用模操作符
根据您在本教程中获得的知识,您现在可以开始在自己的代码中成功地使用模运算符了。快乐的蟒蛇!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 模:使用%运算符********
Python 中的模字符串格式
如果你用 Python 3 编写现代 Python 代码,你可能想用 Python f-strings 格式化你的字符串。然而,如果您正在使用旧的 Python 代码库,您很可能会遇到用于字符串格式化的字符串模操作符。
如果您正在阅读或编写 Python 2 代码,熟悉这种技术会有所帮助。因为该语法在 Python 3 中仍然有效,所以您甚至可以看到开发人员在现代 Python 代码库中使用它。
在本教程中,您将学习如何:
- 使用模运算符(
%) 进行字符串格式化 - 将值转换成特定类型,然后将它们插入到字符串中
- 指定格式化值占据的水平间距
- 使用转换标志微调显示
- 使用字典映射而不是元组指定值
如果你熟悉 C 、Perl 或者 Java 的 printf() 函数族,那么你会发现这些在 Python 中并不存在。然而,printf()和字符串模操作符之间有很多相似之处,所以如果你熟悉printf(),那么下面的很多内容你都会觉得熟悉。
另一方面,如果你不熟悉printf(),不要担心!掌握 Python 中的模字符串格式不需要任何关于printf()的先验知识。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
在 Python 中使用模运算符进行字符串格式化
您可能已经对数字使用过模运算符(% ) ,在这种情况下,它会计算除法的余数:
>>> 11 % 3 2对于字符串操作数,模运算符有一个完全不同的功能:字符串格式化。
注意:这两种操作并不十分相似。它们只有相同的名字,因为它们由相同的符号(
%)表示。字符串模运算符的语法如下:
<format_string> % <values>在
%操作符的左边,<format_string>是一个包含一个或多个转换说明符的字符串。右侧的<values>插入到<format_string>中,代替转换说明符。得到的格式化字符串是表达式的值。从一个例子开始,在这个例子中,您调用
print()来使用字符串模运算符显示一个格式化的字符串:
>>> print("%d %s cost $%.2f" % (6, "bananas", 1.74))
6 bananas cost $1.74
除了表示字符串模运算本身,%字符还表示格式字符串中转换说明符的开始——在本例中,有三个:%d、%s和%.2f。
在输出中,Python 将每个项目从值元组转换为字符串值,并将其插入到格式字符串中,以代替相应的转换说明符:
- 元组中的第一项是
6,一个代替格式字符串中的%d的数值。 - 下一项是字符串值
"bananas",替换%s。 - 最后一项是浮点值
1.74,代替%.2f。
结果字符串是6 bananas cost $1.74,如下图所示:
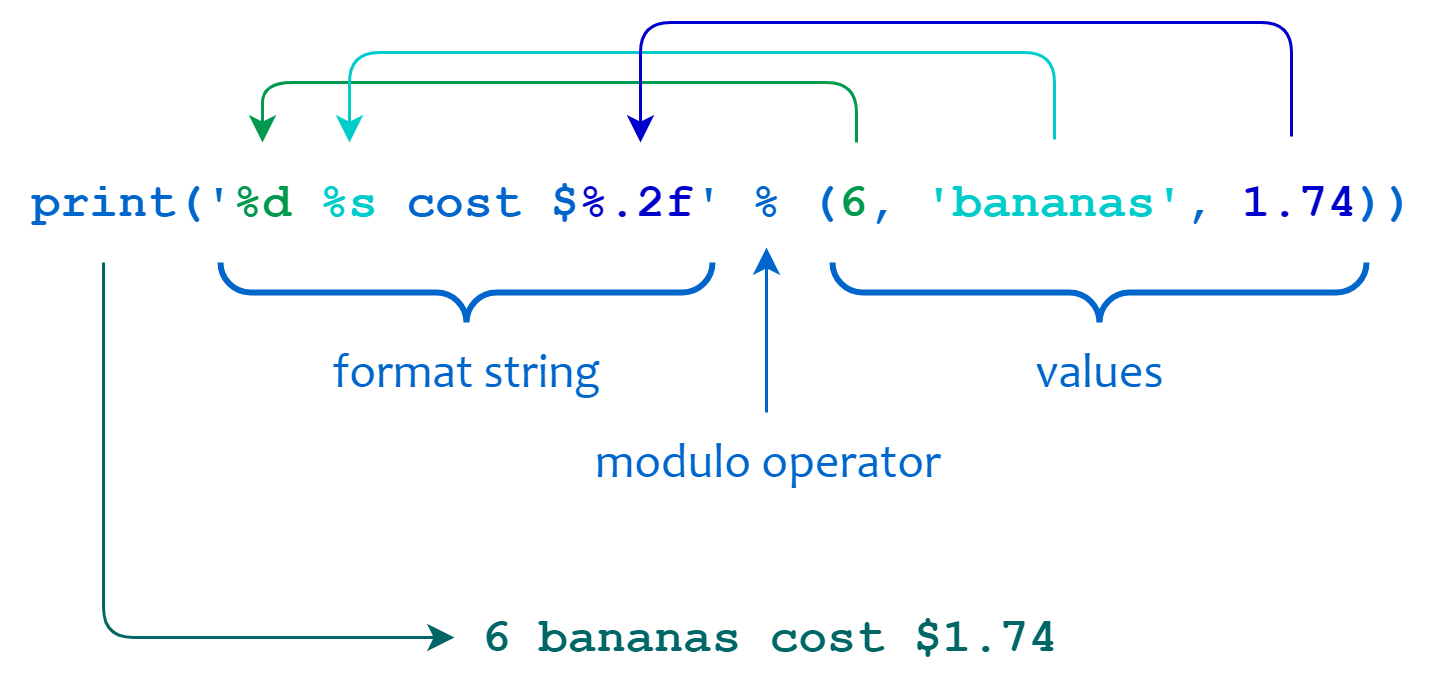
如果有多个值要插入,那么它们必须包含在一个元组中,如上所示。如果只有一个值,那么可以不加括号单独写:
>>> print("Hello, my name is %s." % "Graham") Hello, my name is Graham.还要注意,字符串模运算不仅仅用于打印。您也可以格式化值并将它们分配给另一个字符串变量:
>>> welcome_sentence = "Hello, my name is %s." % "Graham"
>>> welcome_sentence
'Hello, my name is Graham.'
如果您熟悉 C 编程语言中与printf()相关的函数,那么您可能会注意到上面显示的模字符串格式语法让人想起了sprintf()。如果你不是,那么不要担心!
了解转换说明符
转换说明符的不同组件出现在格式字符串中,并决定 Python 将值插入格式字符串时如何格式化这些值。
转换说明符以一个%字符开始,可以由几个按一定顺序排列的组件组成:
%[<flags>][<width>][.<precision>]<type>
需要%字符和<type>组件。方括号中显示的其余组件是可选的。
下表总结了转换说明符的每个组件的作用:
| 成分 | 意义 |
|---|---|
% |
引入转换说明符 |
<flags> |
指示一个或多个对格式进行更精细控制的标志 |
<width> |
指定格式化结果的最小宽度 |
.<precision> |
确定浮点或字符串输出的长度和精度 |
<type> |
指示要执行的转换类型 |
请继续阅读,了解更多关于这些如何工作的细节。
使用转换类型转换数值
转换说明符的最后一个组件<type>,是除了介绍性的%字符之外唯一必需的组件:
%[<flags>][<width>][.<precision>]<type>T3】
在将值插入格式字符串之前,它确定 Python 应用于相应值的转换类型。下表列出了可能的转换类型:
<type> |
转换类型 |
|---|---|
d、i、u |
小数整数 |
x,X |
十六进制整数 |
o |
八进制整数 |
f,F |
浮点型 |
e,E |
E 符号 |
g,G |
浮点或 E 符号 |
c |
单字符 |
s、r、a |
字符串 |
% |
单个'%'字符 |
在接下来的小节中,您将看到如何使用这些转换类型。
整数转换类型
d、i、u、x、X、o转换类型对应整数值。
d、i和u功能等同。它们都将相应的参数转换为十进制整数的字符串表示形式:
>>> "%d, %i, %u" % (42, 42, 42) '42, 42, 42' >>> "%d, %i, %u" % (-42, -42, -42) '-42, -42, -42'该值可以是正数,也可以是负数。如果是负数,那么结果值将以减号(
-)开始。转换类型
x和X转换为十六进制整数值的字符串表示形式,o转换为八进制整数值的字符串表示形式:
>>> "%x, %X" % (252, 252)
'fc, FC'
>>> "%o" % 16
'20'
使用小写x产生小写输出,使用大写X产生大写输出。
注意:大写O不是有效的转换类型。
您可以通过使用转换标志获得对结果格式的额外控制,您将在下一节中了解更多关于的内容。
浮点转换类型
转换类型f和F转换成浮点数的字符串表示,而e和E产生一个表示 E(科学)符号的字符串:
>>> "%f, %F" % (3.14159, 3.14) '3.141590, 3.140000' >>> "%e, %E" % (1000.0, 1000.0) '1.000000e+03, 1.000000E+03'使用小写
f和e产生小写输出,大写F和E产生大写输出。在某些情况下,浮点运算可以产生一个实质上无穷大的值。这样的数字在 Python 中的字符串表示是
inf。浮点运算产生的值也可能无法用数字表示。Python 用特殊的浮点值
nan来表示这一点。当使用字符串模运算符转换这些值时,转换类型字符控制结果输出的大小写。
f和e产生小写字符串,而F和E产生大写字符串:
>>> x = float("NaN")
>>> "%f, %e, %F, %E" % (x, x, x, x)
'nan, nan, NAN, NAN'
>>> y = float("Inf")
>>> "%f, %e, %F, %E" % (y, y, y, y)
'inf, inf, INF, INF'
这些转换类型的小写和大写版本之间的唯一区别是,它们分别产生小写和大写字符串输出。这种差异甚至延伸到浮点数的 E 记法输出中e和E的大小写。
根据指数的大小和您为.<precision>组件指定的值,g和G转换类型在浮点或 E 符号输出之间进行选择:
>>> "%g" % 3.14 '3.14' >>> "%g" % 0.00000003 '3e-08' >>> "%G" % 0.00000003 '3E-08'如果指数小于
-4或不小于.<precision>,则输出与e或E相同。否则,与f或F相同。在本教程的后面,你将会学到更多关于.<precision>组件的知识。注:你可以把这些转换类型看成是做出合理的选择。如果有问题的值合理地适合它,它们将产生浮点输出,否则产生 E 符号。
与其他浮点转换类型类似,
g产生小写输出,G产生大写输出。字符转换类型
c转换类型插入单个字符。相应的值可以是整数或单个字符串:
>>> "%c" % 97
'a'
>>> "%c" % "y"
'y'
如果您提供一个整数,那么 Python 会将其翻译成相应的可打印字符。这种转换类型也支持转换成 Unicode 字符:
>>> "%c" % 8721 '∑'您可以使用
%c并传递 ASCII 或 Unicode 字符的代码点,以便在您的字符串中很好地呈现它。
>>> "%s" % "Café ☕️"
'Café ☕️'
>>> "%r" % "Café ☕️"
"'Café ☕️'"
>>> "%a" % "Café ☕️"
"'Caf\\xe9 \\u2615\\ufe0f'"
当您使用%a时,Python 将 Unicode 字符转换成它们的 ASCII 表示。
很快您就会看到,您可以使用<width>和.<precision>转换说明符组件来控制字符串输出的对齐和填充。
文字百分比字符(%% )
要在输出中插入一个百分比字符(%),可以在格式字符串中指定两个连续的百分比字符(%%)。第一个百分比字符引入一个转换说明符,第二个百分比字符指定转换类型为%。
这种格式会在输出中产生一个百分比字符(%):
>>> "Get %d%% off on %s today only!" % (30, "bananas") 'Get 30% off on bananas today only!'此代码示例中的子字符串
%d%%表示两种相互跟随的转换类型:
%d表示十进制整数转换类型。%%代表文字百分比字符,呈现为%。注意,
%%转换类型不消耗字符串模操作符(30, "bananas")右边显示的两个<values>中的任何一个。如果您需要在字符串中呈现一个文字百分比字符,您可以将这种转换类型视为一种转义百分比字符的方法。使用宽度和精度水平对齐数据
<width>和.<precision>组件位于转换说明符的中间:
%[<flags>][<width>][.<precision>]T2】您可以单独使用它们,也可以相互结合使用。它们通过更改字符串填充或 Python 显示的值的总长度来确定格式化值占用的水平空间。
<width>组件您可以通过使用
<width>组件来确定输出字段的最小宽度。如果输出比<width>短,那么默认情况下,它在一个<width>字符宽的字段中右对齐,并在左边用 ASCII 空格字符填充:
>>> "%5s" % "foo"
' foo'
>>> "%3d" % 4
' 4'
第一个字符串"foo",长度为三个字符。因为您使用5作为<width>转换说明符组件,所以 Python 在添加"foo"之前添加了两个空白字符,以构建一个总长度为五个字符的字符串。
在第二个例子中,您使用一位数的数字4作为输入值,并请求三个字符的字符串宽度。因此,Python 在插入字符串表示形式4之前再次添加了两个空白字符,以构建总长度为三个字符的最终字符串。
您可以修改对齐方式以及 Python 应该使用的填充字符。在下面的转换标志一节中,你会学到更多关于如何做的内容。
如果输出长度大于<width>,则<width>无效:
>>> "%2d" % 1234 '1234' >>> "%d" % 1234 '1234' >>> "%2s" % "foobar" 'foobar' >>> "%s" % "foobar" 'foobar'这些例子中的每一个都指定了字段宽度
2。但是因为您要求 Python 格式化的值的长度超过两个字符,所以结果与您根本没有指定<width>时是一样的。
.<precision>组件
.<precision>转换说明符组件影响浮点转换类型和字符转换类型。对于浮点转换类型
f、F、e和E,.<precision>决定小数点后的位数:
>>> "%.2f" % 123.456789
'123.46'
>>> "%.2e" % 123.456789
'1.23e+02'
对于浮点转换类型g和G,.<precision>决定小数点前后的有效位数:
>>> "%.2g" % 123.456789 '1.2e+02'用
s、r和a字符转换类型格式化的字符串值被截断到由.<precision>组件指定的长度:
>>> "%.4s" % "foobar"
'foob'
在这个例子中,您的输入值"foobar"的长度是 6 个字符,但是您已经将.<precision>设置为4。因此 Python 只显示输入字符串的前四个字符。
你可能还会看到<width>和.<precision>一起使用:
>>> "%8.2f" % 123.45678 ' 123.46' >>> "%8.3s" % "foobar" ' foo'您可以使用星号(
*)作为占位符来指定<width>和.<precision>。如果这样做,Python 会从<values>元组中的项目中为它们取值:
>>> "%*d" % (10, 123)
' 123'
>>> "%.*d" % (10, 123)
'0000000123'
>>> "%*.*d" % (10, 5, 123)
' 00123'
当你的<width>值是一个常量时,你可能不需要使用这个。在上例中使用占位符和直接添加值之间没有任何功能差异:
>>> "%10d" % 123 ' 123' >>> "%.10d" % 123 '0000000123' >>> "%10.5d" % 123 ' 00123'当您使用变量指定宽度或精度时,使用占位符星号会变得更有趣:
>>> for i in range(3):
... w = int(input("Enter width: "))
... print("[%*s]" % (w, "foo"))
...
Enter width: 2
[foo]
Enter width: 4
[ foo]
Enter width: 8
[ foo]
使用这种语法,您可以在运行时确定宽度和精度,这意味着它们可能会随着执行的不同而变化。
使用转换标志微调输出
您可以在第一个%字符后指定可选的转换标志:
%[<flags>]T2】
这些允许您更详细地控制某些转换类型的显示。转换说明符的<flags>组件可以包括下表中显示的任何字符:
| 性格;角色;字母 | 控制 |
|---|---|
# |
整数和浮点值的小数点或小数点显示 |
0 |
短于指定字段宽度的值的填充 |
- |
比指定字段宽度短的值的对齐 |
+ |
数值前导符号的显示 |
' '(空格) |
数值前导符号的显示 |
下面几节更详细地解释了转换标志是如何操作的。
哈希标志(# )
#标志使基本信息包含在八进制和十六进制转换类型的格式化输出中。对于o转换类型,该标志添加一个前导"0o"。对于x和X转换类型,增加一个前导"0x"或"0X":
>>> "%#o" % 16 '0o20' >>> "%#x" % 16, "%#X" % 16 ('0x10', '0X10')对于十进制转换类型
d、i和u,忽略#标志。对于浮点值,
#标志强制输出总是包含小数点。通常,如果小数点后没有任何数字,浮点值将不包含小数点。此标志强制包含小数点:
>>> "%.0f" % 123
'123'
>>> "%#.0f" % 123
'123.'
>>> "%.0e" % 123
'1e+02'
>>> "%#.0e" % 123
'1.e+02'
通过使用#标志强制包含小数点也适用于以 E 表示法显示的值,如示例代码片段所示。
零标志(0 )
当格式化数值短于指定的字段宽度时,默认行为是在值的左侧用 ASCII 空格字符填充字段。0标志导致用"0"字符填充:
>>> "%05d" % 123 '00123' >>> "%08.2f" % 1.2 '00001.20'
0标志可用于所有的数字转换类型:d、i、u、x、X、o、f、F、e、E、g和G。连字符减号标志(
-)当格式化值短于指定的字段宽度时,它通常在字段中右对齐。连字符减号(
-)标志使值在指定字段中左对齐:
>>> "%-5d" % 123
'123 '
>>> "%-8.2f" % 123.3
'123.30 '
>>> "%-*s" % (10, "foo")
'foo '
您可以对字符串转换类型s、a和r以及所有数字转换类型使用-标志。对于数字类型,如果0和-都存在,那么0被忽略。
加号标志(+ )
默认情况下,正数值没有前导符号字符。+标志在数字输出的左侧添加一个加号(+):
>>> "%+d" % 3 '+3' >>> "%+5d" % 3 ' +3' >>> "%5d" % 3 ' 3'在比较最后两个输出时,您可能会注意到 Python 在计算输出的宽度时考虑了您使用该标志添加的
+字符。此标志不影响负数值,它总是有一个前导减号(
-)。与加号字符一样,Python 在计算输出宽度时也会考虑减号字符。空格字符标志(
' ')空格字符标志(
' ')在正数值前添加一个空格字符:
>>> "% d" % 3
' 3'
就像+标志一样,这个标志也不影响负数值,它总是有一个前导减号(-):
>>> "% d" % 3 ' 3' >>> "% d" % -3 '-3' >>> "%d" % -3 '-3'使用
+标志或空格字符标志可以帮助您一致地对齐正值和负值的混合。通过字典映射指定值
您可以将插入到格式字符串中的
<values>指定为字典,而不是元组。在这种情况下,每个转换说明符必须包含紧跟在%字符后面的括号中的字典键之一:
>>> "%d %s cost $%.2f" % (6, "bananas", 1.74)
'6 bananas cost $1.74'
>>> data = {"quantity": 6, "item": "bananas", "price": 1.74} >>> template = "%(quantity)d %(item)s cost $%(price).2f" >>> template % data
'6 bananas cost $1.74'
通过使用这种技术,您可以按任意顺序指定插入的值:
>>> data = {"quantity": 6, "item": "bananas", "price": 1.74} >>> ad_1 = "%(quantity)d %(item)s cost $%(price).2f" >>> ad_1 % data '6 bananas cost $1.74' >>> ad_2 = "You'll pay $%(price).2f for %(item)s, if you buy %(quantity)d" >>> ad_2 % data "You'll pay $1.74 for bananas, if you buy 6"上面显示的所有转换说明符组件——
<flags>、<width>、.<precision>和<type>——仍然以与使用元组输入值时相同的方式工作。当您将<values>指定为词典时,您可以使用其中任何一个:
>>> "Quantity: %(quantity)03d" % data
'Quantity: 006'
>>> "Item: %(item).5s" % data
'Item: banan'
在上面的示例代码片段中,您在第一个示例中使用了结合了<width>的0标志,在第二个示例中使用了值为5的.<precision>。
注意:如果通过字典映射指定<values>,那么就不能用星号占位符(*)来指定<width>或者.<precision>。
如果您只想定义一次数据,并且可能会在不同的输出中切换显示顺序,则通过字典映射指定输入值特别有用。
结论
至此,您已经了解了很多关于字符串模操作符的知识。这是 Python 中一种比较老的字符串格式化方法。因为这种技术仍然有效,并且在 Python 2 中被广泛使用,所以理解这种语法的基础是有帮助的。
在本教程中,您已经学会了如何:
- 使用模运算符(
%) 进行字符串格式化 - 将值转换成特定类型,然后将它们插入到字符串中
- 指定格式化值占据的水平间距
- 使用转换标志微调显示
- 使用字典映射而不是元组指定值
尽管 string modulo 操作符功能多样,Python 提供了更好的格式化字符串数据的新方法:string .format()方法和格式化的字符串文字,通常称为 f-string 。******
在 Python 类中提供多个构造函数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深你的理解: 在你的 Python 类中提供多个构造器
有时,您需要编写一个 Python 类,提供多种方法来构造对象。换句话说,你想要一个实现了多个构造函数的类。当您需要使用不同类型或数量的参数创建实例时,这种类型的类非常方便。拥有提供多个构造函数的工具将帮助您编写灵活的类,以适应不断变化的需求。
在 Python 中,有几种技术和工具可以用来构造类,包括通过可选参数模拟多个构造函数,通过类方法定制实例创建,以及使用 decorators 进行特殊调度。如果您想了解这些技术和工具,那么本教程就是为您准备的。
在本教程中,您将学习如何:
- 使用可选参数和类型检查模拟多个构造函数
- 使用内置的
@classmethod装饰器编写多个构造函数 - 使用
@singledispatchmethod装饰器重载你的类构造函数
您还将看到 Python 如何在内部构造一个常规类的实例,以及一些标准库类如何提供多个构造函数。
为了从本教程中获得最大收益,你应该具备面向对象编程的基础知识,并了解如何用@classmethod定义类方法。你也应该有在 Python 中使用装饰器的经验。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
在 Python 中实例化类
Python 用易于创建和使用的类支持面向对象编程。Python 类提供了强大的特性,可以帮助你编写更好的软件。类就像是对象的蓝图,也称为实例。用同样的方式,你可以从一个蓝图中构建几个房子,你也可以从一个类中构建几个实例。
要在 Python 中定义一个类,需要使用 class 关键字,后跟类名:
>>> # Define a Person class >>> class Person: ... def __init__(self, name): ... self.name = name ...Python 有一套丰富的特殊方法,你可以在你的类中使用。Python 隐式调用特殊方法来自动执行实例上的各种操作。有一些特殊的方法可以使你的对象可迭代,为你的对象提供合适的字符串表示,初始化实例属性,等等。
一个相当常见的特殊方法是
.__init__()。这个方法提供了 Python 中所谓的实例初始化器。这个方法的工作是在实例化一个给定的类时,用适当的值初始化实例属性。在
Person中,.__init__()方法的第一个参数被称为self。此参数保存当前对象或实例,它在方法调用中隐式传递。Python 中的每个实例方法都有这个参数。.__init__()的第二个参数叫做name,它将把人名作为一个字符串保存。注意:使用
self来命名当前对象在 Python 中是一个相当强的约定,但不是必需的。然而,使用另一个名字会让你的 Python 开发伙伴感到惊讶。一旦定义了一个类,就可以开始用实例化它。换句话说,您可以开始创建该类的对象。为此,您将使用熟悉的语法。只需使用一对括号(
())调用该类,这与您调用任何 Python 函数的语法相同:
>>> # Instantiating Person
>>> john = Person("John Doe")
>>> john.name
'John Doe'
在 Python 中,类名提供了其他语言如 C++ 和 Java 调用类构造函数的内容。调用一个类,就像使用Person一样,触发 Python 的类实例化过程,该过程在内部分两步运行:
- 创建目标类的一个新实例。
- 用合适的实例属性值初始化实例。
继续上面的例子,作为参数传递给Person的值在内部传递给.__init__(),然后分配给实例属性.name。这样,您就用有效数据初始化了 person 实例john,您可以通过访问.name来确认这些数据。成功!John Doe的确是他的名字。
注意:当你调用这个类来创建一个新的实例时,你需要提供.__init__()需要的尽可能多的参数,这样这个方法就可以初始化所有需要初始值的实例属性。
现在您已经理解了对象初始化机制,您已经准备好学习 Python 在实例化过程的这一点之前做了什么。下面我们来挖掘另一种特殊的方法,叫做 .__new__() 。这个方法负责在 Python 中创建新的实例。
注意:.__new__()特殊方法在 Python 中经常被称为类构造函数。然而,它的工作实际上是从类蓝图创建新的对象,所以你可以更准确地称它为实例创建者或对象创建者。
特殊方法.__new__()将底层类作为它的第一个参数,并返回一个新对象。这个对象通常是输入类的一个实例,但是在某些情况下,它可以是不同类的一个实例。
如果.__new__()返回的对象是当前类的一个实例,那么这个实例会立即传递给.__init__()进行初始化。这两个步骤在您调用类时运行。
Python 的 object 类提供了.__new__()和.__init__()的基础或默认实现。与.__init__()不同,您很少需要在自定义类中覆盖.__new__()。大多数时候,您可以放心地依赖它的默认实现。
总结一下到目前为止您所学到的内容,Python 的实例化过程从您用适当的参数调用一个类开始。然后,该过程分两步进行:用.__new__()方法创建对象,用.__init__()方法初始化对象。
既然您已经了解了 Python 的这种内部行为,那么您就可以开始在您的类中提供多个构造函数了。换句话说,您将提供多种方法来构造给定 Python 类的对象。
定义多个类构造函数
有时你想写一个类,允许你使用不同数据类型的参数甚至不同数量的参数来构造对象。实现这一点的一种方法是在手边的类中提供多个构造函数。每个构造函数都允许您使用一组不同的参数创建该类的实例。
一些编程语言,如 C++ 、 C# 和 Java ,支持所谓的函数或方法重载。这个特性允许您提供多个类构造函数,因为它允许您创建多个具有相同名称和不同实现的函数或方法。
方法重载意味着根据你调用方法的方式,语言会选择合适的实现来运行。因此,您的方法可以根据调用的上下文执行不同的任务。
不幸的是,Python 不直接支持函数重载。Python 类将方法名保存在名为 .__dict__ 的内部字典中,该字典保存类的名称空间。像任何 Python 字典一样,.__dict__不能有重复的键,所以在给定的类中不能有多个同名的方法。如果您尝试这样做,那么 Python 将只记住手头方法的最后一个实现:
# greet.py
class Greeter:
def say_hello(self):
print("Hello, World")
def say_hello(self):
print("Hello, Pythonista")
在这个例子中,您用两个方法创建了一个 Python 类Greeter。这两种方法名称相同,但实现略有不同。
要了解当两个方法同名时会发生什么,请将您的类保存到工作目录中的一个greet.py文件中,并在一个交互会话中运行以下代码:
>>> from greet import Greeter >>> greeter = Greeter() >>> greeter.say_hello() Hello, Pythonista >>> Greeter.__dict__ mappingproxy({..., 'say_hello': <function Greeter.say_hello at...>, ...})在这个例子中,您在
greeter上调用.say_hello(),它是Greeter类的一个实例。您在屏幕上看到的是Hello, Pythonista而不是Hello, World,这证实了该方法的第二个实现优先于第一个实现。最后一行代码检查了
.__dict__的内容,发现方法名say_hello在类名称空间中只出现了一次。这与 Python 中字典的工作方式是一致的。Python 模块和交互式会话中的函数也会发生类似的情况。几个同名函数的最后一个实现优先于其余的实现:
>>> def say_hello():
... print("Hello, World")
...
>>> def say_hello():
... print("Hello, Pythonista")
...
>>> say_hello()
Hello Pythonista
您在同一个解释器会话中定义了两个同名函数say_hello()。但是,第二个定义会覆盖第一个定义。当你调用函数时,你得到Hello, Pythonista,它确认最后一个函数定义生效。
一些编程语言用来提供多种方法调用方法或函数的另一种技术是多重分派。
使用这种技术,您可以编写同一个方法或函数的几种不同的实现,并根据调用中使用的参数的类型或其他特征来动态调度所需的实现。您可以使用来自标准库的几个工具将这项技术引入到您的 Python 代码中。
Python 是一种相当灵活且功能丰富的语言,它提供了多种方法来实现多个构造函数,并使您的类更加灵活。
在下一节中,您将通过传递可选参数并通过检查参数类型来确定实例初始化器中的不同行为,从而模拟多个构造函数。
在你的类中模拟多个构造函数
在 Python 类中模拟多个构造函数的一个非常有用的技术是使用默认参数值为.__init__()提供可选参数。这样,您可以用不同的方式调用类构造函数,每次都能获得不同的行为。
另一个策略是检查.__init__()的参数的数据类型,根据您在调用中传递的具体数据类型提供不同的行为。这种技术允许您在一个类中模拟多个构造函数。
在本节中,您将学习如何通过为.__init__()方法的参数提供适当的默认值以及检查该方法参数的数据类型来模拟多种构造对象的方法。这两种方法都只需要一个.__init__()的实现。
使用.__init__()中的可选参数值
模拟多个构造函数的一种优雅而巧妙的方式是用可选参数实现一个.__init__()方法。您可以通过指定适当的默认参数值来做到这一点。
注意:你也可以在你的函数和方法中使用未定义数量的位置参数或者未定义数量的关键字参数来提供可选参数。查看定义函数时使用 Python 可选参数以获得关于这些选项的更多细节。
为此,假设您需要编写一个名为CumulativePowerFactory的工厂类。这个类将使用一串数字作为输入,创建计算特定幂的可调用对象。您还需要您的类来跟踪连续幂的总和。最后,您的类应该接受一个参数,该参数包含幂和的初始值。
继续在当前目录下创建一个power.py文件。然后输入下面的代码来实现CumulativePowerFactory:
# power.py
class CumulativePowerFactory:
def __init__(self, exponent=2, *, start=0):
self._exponent = exponent
self.total = start
def __call__(self, base):
power = base ** self._exponent
self.total += power
return power
CumulativePowerFactory的初始化器有两个可选参数,exponent和start。第一个参数包含您将用来计算一系列幂的指数。默认为2,这是计算能力时常用的值。
exponent后的星号或星号(*)表示start是一个关键字参数。要将值传递给仅包含关键字的参数,需要显式使用参数的名称。换句话说,要将arg设置为value,需要显式键入arg=value。
start参数保存初始值以计算幂的累积和。它默认为0,这是在没有预先计算值来初始化累计功率和的情况下的合适值。
特殊方法 .__call__() 将CumulativePowerFactory的实例转化为可调用的对象。换句话说,你可以像调用任何常规函数一样调用CumulativePowerFactory的实例。
在.__call__()里面,你首先计算base的幂提升到exponent。然后将结果值加到.total的当前值上。最后,你返回计算出的功率。
为了给CumulativePowerFactory一个尝试,在包含power.py的目录中打开一个 Python 交互会话并运行下面的代码:
>>> from power import CumulativePowerFactory >>> square = CumulativePowerFactory() >>> square(21) 441 >>> square(42) 1764 >>> square.total 2205 >>> cube = CumulativePowerFactory(exponent=3) >>> cube(21) 9261 >>> cube(42) 74088 >>> cube.total 83349 >>> initialized_cube = CumulativePowerFactory(3, start=2205) >>> initialized_cube(21) 9261 >>> initialized_cube(42) 74088 >>> initialized_cube.total 85554这些例子展示了
CumulativePowerFactory如何模拟多个构造函数。例如,第一个构造函数没有参数。它允许您创建计算2次方的类实例,这是exponent参数的默认值。.total实例属性保存你所计算的幂的累积和。第二个例子展示了一个构造函数,它将
exponent作为一个参数,并返回一个计算多维数据集的可调用实例。在这种情况下,.total的工作方式与第一个例子相同。第三个例子展示了
CumulativePowerFactory似乎有另一个构造函数,允许您通过提供exponent和start参数来创建实例。现在.total以2205的值开始,它初始化幂的和。在类中实现
.__init__()时使用可选参数是创建模拟多个构造函数的类的一种简洁而巧妙的技术。检查
.__init__()中的参数类型模拟多个构造函数的另一种方法是编写一个
.__init__()方法,它根据参数类型表现不同。在 Python 中检查一个变量的类型,一般依靠内置的isinstance()函数。如果一个对象是一个给定类的实例,这个函数返回True,否则返回False:
>>> isinstance(42, int)
True
>>> isinstance(42, float)
False
>>> isinstance(42, (list, int))
True
>>> isinstance(42, list | int) # Python >= 3.10
True
isinstance()的第一个参数是您想要类型检查的对象。第二个参数是引用的类或数据类型。您还可以将一个类型的元组传递给该参数。如果您运行的是 Python 3.10 或更高版本,那么您也可以使用新的联合语法和管道符号(|)。
现在假设您想继续处理您的Person类,并且您需要该类也接受这个人的出生日期。您的代码将出生日期表示为一个 date 对象,但是为了方便起见,您的用户也可以选择以给定格式的字符串形式提供出生日期。在这种情况下,您可以执行如下操作:
>>> from datetime import date >>> class Person: ... def __init__(self, name, birth_date): ... self.name = name ... if isinstance(birth_date, date): ... self.birth_date = birth_date ... elif isinstance(birth_date, str): ... self.birth_date = date.fromisoformat(birth_date) ... >>> jane = Person("Jane Doe", "2000-11-29") >>> jane.birth_date datetime.date(2000, 11, 29) >>> john = Person("John Doe", date(1998, 5, 15)) >>> john.birth_date datetime.date(1998, 5, 15)在
.__init__()中,首先定义通常的.name属性。条件语句的if子句检查所提供的出生日期是否是一个date对象。如果是这样,那么您定义.birth_date来存储手头的数据。
elif子句检查birth_date参数是否属于str类型。如果是这样,那么将.birth_date设置为从提供的字符串构建的date对象。注意,birth_date参数应该是一个带有日期的字符串,格式为 ISO , YYYY-MM-DD 。就是这样!现在您有了一个
.__init__()方法,它模拟了一个具有多个构造函数的类。一个构造函数接受date类型的参数。另一个构造函数接受字符串类型的参数。注意:如果您运行的是 Python 3.10 或更高版本,那么您也可以使用结构化模式匹配语法来实现本节中的技术。
上面例子中的技术有一个缺点,就是扩展性不好。如果您有多个参数可以接受不同数据类型的值,那么您的实现很快就会变成一场噩梦。因此,这种技术被认为是 Python 中的反模式。
注意: PEP 443 声明“……目前 Python 代码的一种常见反模式是检查接收到的参数的类型,以便决定如何处理对象。”根据同一份文件,这种编码模式是“脆弱的,不可扩展的”。
PEP 443 因此引入了单分派 通用函数来帮助你尽可能避免使用这种编码反模式。您将在章节中了解更多关于这个特性的内容,该章节提供了带有
@singledispatchmethod的多个类构造器。例如,如果用户为
birth_date输入一个 Unix 时间值,会发生什么?查看以下代码片段:
>>> linda = Person("Linda Smith", 1011222000)
>>> linda.birth_date
Traceback (most recent call last):
...
AttributeError: 'Person' object has no attribute 'birth_date'
当您访问.birth_date时,您会得到一个 AttributeError ,因为您的条件语句没有考虑不同日期格式的分支。
要解决这个问题,您可以继续添加elif子句来涵盖用户可以传递的所有可能的日期格式。您还可以添加一个else子句来捕捉不支持的日期格式:
>>> from datetime import date >>> class Person: ... def __init__(self, name, birth_date): ... self.name = name ... if isinstance(birth_date, date): ... self.birth_date = birth_date ... elif isinstance(birth_date, str): ... self.birth_date = date.fromisoformat(birth_date) ... else: ... raise ValueError(f"unsupported date format: {birth_date}") ... >>> linda = Person("Linda Smith", 1011222000) Traceback (most recent call last): ... ValueError: unsupported date format: 1011222000在这个例子中,如果
birth_date的值不是一个date对象或者包含有效 ISO 日期的字符串,那么else子句就会运行。这样,例外情况就不会悄无声息地通过。用 Python 中的
@classmethod提供多个构造函数在 Python 中提供多个构造函数的一个强大技术是使用
@classmethod。这个装饰器允许你把一个常规方法变成一个类方法。与常规方法不同,类方法不将当前实例
self作为参数。相反,它们接受类本身,通常作为cls参数传入。使用cls来命名这个参数是 Python 社区中一个流行的约定。下面是定义类方法的基本语法:
>>> class DemoClass:
... @classmethod
... def class_method(cls):
... print(f"A class method from {cls.__name__}!")
...
>>> DemoClass.class_method()
A class method from DemoClass!
>>> demo = DemoClass()
>>> demo.class_method()
A class method from DemoClass!
DemoClass使用 Python 内置的@classmethod装饰器定义一个类方法。.class_method()的第一个论点持有类本身。通过这个参数,您可以从类内部访问该类。在这个例子中,您访问了.__name__属性,它将底层类的名称存储为一个字符串。
值得注意的是,您可以使用类或手边的类的具体实例来访问类方法。无论您如何调用.class_method(),它都会接收DemoClass作为它的第一个参数。您可以使用类方法作为构造函数的最终原因是,您不需要实例来调用类方法。
使用@classmethod可以向给定的类中添加任意多的显式构造函数。这是实现多个构造函数的一种流行的 Pythonic 方式。你也可以在 Python 中将这种类型的构造函数称为替代构造函数,正如雷蒙德·赫廷格在他的 PyCon 演讲 Python 的类开发工具包中所做的那样。
现在,如何使用类方法来定制 Python 的实例化过程呢?您将控制两个步骤:对象创建和初始化,而不是微调.__init__()和对象初始化。通过下面的例子,你将学会如何做到这一点。
从直径构造一个圆
要用@classmethod创建你的第一个类构造器,假设你正在编写一个几何相关的应用程序,需要一个Circle类。最初,您按如下方式定义您的类:
# circle.py
import math
class Circle:
def __init__(self, radius):
self.radius = radius
def area(self):
return math.pi * self.radius ** 2
def perimeter(self):
return 2 * math.pi * self.radius
def __repr__(self):
return f"{self.__class__.__name__}(radius={self.radius})"
Circle的初始化器将一个半径值作为参数,并将其存储在一个名为.radius的实例属性中。然后这个类使用 Python 的 math 模块实现计算圆的面积和周长的方法。特殊方法 .__repr__() 为您的类返回一个合适的字符串表示。
继续在您的工作目录中创建circle.py文件。然后打开 Python 解释器,运行下面的代码来测试Circle:
>>> from circle import Circle >>> circle = Circle(42) >>> circle Circle(radius=42) >>> circle.area() 5541.769440932395 >>> circle.perimeter() 263.89378290154264酷!你的类工作正常!现在说你也想用直径实例化
Circle。您可以做一些类似于Circle(diameter / 2)的事情,但这并不十分 Pythonic 化或直观。最好有一个替代的构造函数,直接使用它们的直径来创建圆。继续将下面的类方法添加到
.__init__()之后的Circle:# circle.py import math class Circle: def __init__(self, radius): self.radius = radius @classmethod def from_diameter(cls, diameter): return cls(radius=diameter / 2) # ...在这里,您将
.from_diameter()定义为一个类方法。它的第一个参数接收对包含它的类Circle的引用。第二个参数包含您想要创建的特定圆的直径。在该方法中,首先使用输入值
diameter计算半径。然后通过调用半径为diameter参数的cls来实例化Circle。这样,您可以完全控制使用直径作为参数来创建和初始化
Circle的实例。注意:在上面的例子中,你似乎可以通过调用
Circle本身而不是cls来达到相同的结果。然而,如果你的类是子类,这可能会导致错误。当这些子类用.from_diameter()初始化时,它们将调用Circle而不是自己。对
cls参数的调用自动运行 Python 实例化一个类所需的对象创建和初始化步骤。最后,.from_diameter()将新实例返回给调用者。注意:Python 社区中一个流行的惯例是使用
from介词来命名作为类方法创建的构造函数。以下是如何使用全新的构造函数通过直径来创建圆:
>>> from circle import Circle
>>> Circle.from_diameter(84)
Circle(radius=42.0)
>>> circle.area()
5541.769440932395
>>> circle.perimeter()
263.89378290154264
对Circle上的.from_diameter()的调用返回该类的一个新实例。为了构造该实例,该方法使用直径而不是半径。注意,Circle的其余功能和以前一样。
像上面例子中那样使用@classmethod是在类中提供显式多个构造函数的最常见方式。使用这种技术,您可以选择为您提供的每个备选构造函数选择正确的名称,这可以使您的代码更具可读性和可维护性。
从笛卡尔坐标构建一个极点
对于一个使用类方法提供多个构造函数的更详细的例子,假设您有一个在数学相关的应用程序中表示一个极坐标点的类。你需要一种方法使你的类更加灵活,这样你也可以使用笛卡尔坐标构造新的实例。
下面是如何编写一个构造函数来满足这一要求:
# point.py
import math
class PolarPoint:
def __init__(self, distance, angle):
self.distance = distance
self.angle = angle
@classmethod
def from_cartesian(cls, x, y):
distance = math.dist((0, 0), (x, y))
angle = math.degrees(math.atan2(y, x))
return cls(distance, angle)
def __repr__(self):
return (
f"{self.__class__.__name__}"
f"(distance={self.distance:.1f}, angle={self.angle:.1f})"
)
在这个例子中,.from_cartesian()接受两个参数,分别代表给定点的x和y笛卡尔坐标。然后该方法计算所需的distance和angle来构造相应的PolarPoint对象。最后,.from_cartesian()返回该类的一个新实例。
下面是该类使用两种坐标系的工作方式:
>>> from point import PolarPoint >>> # With polar coordinates >>> PolarPoint(13, 22.6) PolarPoint(distance=13.0, angle=22.6) >>> # With cartesian coordinates >>> PolarPoint.from_cartesian(x=12, y=5) PolarPoint(distance=13.0, angle=22.6)在这些例子中,您使用标准的实例化过程和您的替代构造函数
.from_cartesian(),使用概念上不同的初始化参数来创建PolarPoint实例。探索现有 Python 类中的多个构造函数
使用
@classmethod装饰器在一个类中提供多个构造函数是 Python 中相当流行的技术。有几个内置和标准库类的例子使用这种技术来提供多个可选的构造函数。在本节中,您将了解这些类中最著名的三个例子:
dict、datetime.date和pathlib.Path。从关键字构建字典
字典是 Python 中的一种基本数据类型。它们存在于每一段 Python 代码中,无论是显式的还是隐式的。它们也是语言本身的基石,因为 CPython 实现的重要部分依赖于它们。
在 Python 中,有几种方法可以定义字典实例。您可以使用字典文字,它由花括号(
{})中的键值对组成。例如,您也可以使用关键字参数或双项元组序列显式调用dict()。这个流行的类还实现了一个名为
.fromkeys()的替代构造函数。这个类方法有一个iterable键和一个可选的value。value参数默认为None,并作为结果字典中所有键的值。现在,
.fromkeys()如何在您的代码中发挥作用?假设您正在经营一家动物收容所,您需要构建一个小应用程序来跟踪目前有多少动物生活在您的收容所中。你的应用程序使用字典来存储动物的库存。因为您已经知道您能够在庇护所中安置哪些物种,所以您可以动态地创建初始库存字典,如下面的代码片段所示:
>>> allowed_animals = ["dog", "cat", "python", "turtle"]
>>> animal_inventory = dict.fromkeys(allowed_animals, 0)
>>> animal_inventory
{'dog': 0, 'cat': 0, 'python': 0, 'turtle': 0}
在这个例子中,您使用.fromkeys()构建了一个初始字典,它从allowed_animals获取键。通过将这个值作为第二个参数提供给.fromkeys(),将每只动物的初始库存设置为0。
正如您已经了解到的,value默认为None,在某些情况下,这可能是您的字典的键的合适的初始值。然而,在上面的例子中,0是一个方便的值,因为您正在处理每个物种的个体数量。
注意:大多数情况下, collections 模块中的 Counter 类是一个更适合处理库存问题的工具,就像上面的例子一样。然而,Counter并没有提供一个合适的.fromkeys()实现来防止类似Counter.fromkeys("mississippi", 0)的歧义。
标准库中的其他映射也有一个名为.fromkeys()的构造函数。OrderedDictdefaultdictUserDict就是这种情况。例如,UserDict的源代码提供了.fromkeys()的如下实现:
@classmethod
def fromkeys(cls, iterable, value=None):
d = cls()
for key in iterable:
d[key] = value
return d
这里,.fromkeys()将一个iterable和一个value作为自变量。该方法通过调用cls创建一个新的字典。然后它遍历iterable中的键并将每个值设置为value,默认为None,和往常一样。最后,该方法返回新创建的字典。
创建datetime.date个对象
标准库中的datetime.date类是另一个利用多个构造函数的类。这个类提供了几个可选的构造函数,比如 .today() 、 .fromtimestamp() 、 .fromordinal() 、。它们都允许您使用概念上不同的参数来构造datetime.date对象。
下面是一些如何使用这些构造函数来创建datetime.date对象的例子:
>>> from datetime import date >>> from time import time >>> # Standard constructor >>> date(2022, 1, 13) datetime.date(2022, 1, 13) >>> date.today() datetime.date(2022, 1, 13) >>> date.fromtimestamp(1642110000) datetime.date(2022, 1, 13) >>> date.fromtimestamp(time()) datetime.date(2022, 1, 13) >>> date.fromordinal(738168) datetime.date(2022, 1, 13) >>> date.fromisoformat("2022-01-13") datetime.date(2022, 1, 13)第一个示例使用标准类构造函数作为引用。第二个例子展示了如何使用
.today()从当天的日期构建一个date对象。其余的例子展示了
datetime.date如何使用几个类方法来提供多个构造函数。这种构造函数的多样性使得实例化过程非常灵活和强大,涵盖了广泛的用例。它还通过描述性的方法名称提高了代码的可读性。寻找回家的路
Python 的标准库中的
pathlib模块提供了方便和现代的工具,用于优雅地处理代码中的系统路径。如果你从未使用过这个模块,那么看看 Python 3 的 pathlib 模块:驯服文件系统。
pathlib中最方便的工具是它的Path类。这个类允许你以跨平台的方式处理你的系统路径。Path是另一个提供多个构造函数的标准类库。例如,您会发现Path.home(),它从您的主目录创建一个路径对象:
- 视窗
** Linux + macOS****>>>
>>> from pathlib import Path >>> Path.home() WindowsPath('C:/Users/username')
>>> from pathlib import Path
>>> Path.home()
PosixPath('/home/username')
.home()构造函数返回一个代表用户主目录的新路径对象。当您在 Python 应用程序和项目中处理配置文件时,这个可选的构造函数会很有用。
最后,Path还提供了一个名为 .cwd() 的构造函数。该方法从当前工作目录创建一个 path 对象。来吧,试一试!
为多个构造函数提供@singledispatchmethod
您将学习的最后一项技术被称为单分派 通用函数。使用这种技术,您可以向类中添加多个构造函数,并根据它们的第一个参数的类型有选择地运行它们。
单分派通用函数由对不同数据类型实现相同操作的多个函数组成。底层的分派算法根据单个参数的类型决定运行哪个实现。这就是一词的由来。
从 Python 3.8 开始,您可以使用 @singledispatch 或 @singledispatchmethod 装饰器分别将一个函数或一个方法转化为一个单分派泛型函数。 PEP 443 说明你可以在 functools 模块中找到这些装饰者。
在常规函数中,Python 根据函数第一个参数的类型选择要调度的实现。在方法中,目标参数是紧跟在self之后的第一个参数。
单一分派方法的演示示例
要将单分派方法技术应用于给定的类,您需要定义一个基本方法实现并用@singledispatchmethod修饰它。然后,您可以编写替代实现,并使用基方法的名称加上.register来修饰它们。
下面的示例展示了基本语法:
# demo.py
from functools import singledispatchmethod
class DemoClass:
@singledispatchmethod
def generic_method(self, arg):
print(f"Do something with argument of type: {type(arg).__name__}")
@generic_method.register
def _(self, arg: int):
print("Implementation for an int argument...")
@generic_method.register(str)
def _(self, arg):
print("Implementation for a str argument...")
在DemoClass中,首先定义一个名为generic_method()的基础方法,并用@singledispatchmethod修饰它。然后定义两个可选的generic_method()实现,并用@generic_method.register修饰它们。
在本例中,您使用一个下划线(_)作为占位符名称来命名替代实现。在实际代码中,您应该使用描述性名称,前提是它们不同于基方法名称generic_method()。当使用描述性名称时,考虑添加一个前导下划线来将替代方法标记为非公共,并防止最终用户直接调用。
你可以使用类型注释来定义目标参数的类型。您还可以显式地将目标参数的类型传递给.register()装饰器。如果您需要定义一个方法来处理几个类型,那么您可以堆叠对.register()的多个调用,每个调用都有所需的类型。
您的类是这样工作的:
>>> from demo import DemoClass >>> demo = DemoClass() >>> demo.generic_method(42) Implementation for an int argument... >>> demo.generic_method("Hello, World!") Implementation for a str argument... >>> demo.generic_method([1, 2, 3]) Do something with argument of type: list如果使用一个整数作为参数调用
.generic_method(),那么 Python 将运行对应于int类型的实现。同样,当您使用字符串调用方法时,Python 会调度字符串实现。最后,如果您使用未注册的数据类型(比如列表)调用.generic_method(),那么 Python 将运行该方法的基本实现。您还可以使用这种技术来重载
.__init__(),这将允许您为此方法提供多个实现,因此,您的类将有多个构造函数。单一分派方法的真实示例
作为使用
@singledispatchmethod的一个更现实的例子,假设您需要继续向您的Person类添加特性。这一次,您需要提供一种方法,根据一个人的出生日期来计算他的大概年龄。为了给Person添加这个特性,您可以使用一个助手类来处理与出生日期和年龄相关的所有信息。继续在您的工作目录中创建一个名为
person.py的文件。然后向其中添加以下代码:1# person.py 2 3from datetime import date 4from functools import singledispatchmethod 5 6class BirthInfo: 7 @singledispatchmethod 8 def __init__(self, birth_date): 9 raise ValueError(f"unsupported date format: {birth_date}") 10 11 @__init__.register(date) 12 def _from_date(self, birth_date): 13 self.date = birth_date 14 15 @__init__.register(str) 16 def _from_isoformat(self, birth_date): 17 self.date = date.fromisoformat(birth_date) 18 19 @__init__.register(int) 20 @__init__.register(float) 21 def _from_timestamp(self, birth_date): 22 self.date = date.fromtimestamp(birth_date) 23 24 def age(self): 25 return date.today().year - self.date.year下面是这段代码的工作原理:
第 3 行从
datetime导入date,这样你以后可以将任何输入的日期转换成一个date对象。第 4 行导入
@singledispatchmethod来定义重载方法。第 6 行将
BirthInfo定义为一个普通的 Python 类。第 7 到 9 行使用
@singledispatchmethod将类初始化器定义为单分派泛型方法。这是该方法的基本实现,它为不支持的日期格式引发一个ValueError。第 11 到 13 行注册了直接处理
date对象的.__init__()的实现。第 15 到 17 行定义了
.__init__()的实现,它处理以 ISO 格式的字符串形式出现的日期。第 19 行到第 22 行注册了一个实现,它处理从纪元开始以秒为单位的 Unix 时间日期。这一次,您通过将
.register装饰器与int和float类型堆叠起来,注册了重载方法的两个实例。第 24 到 25 行提供了一种计算给定人员年龄的常规方法。注意,
age()的实现并不完全准确,因为它在计算年龄时没有考虑一年中的月和日。age()方法只是丰富示例的一个额外特性。现在你可以在你的
Person类中使用组合来利用新的BirthInfo类。继续用下面的代码更新Person:# person.py # ... class Person: def __init__(self, name, birth_date): self.name = name self._birth_info = BirthInfo(birth_date) @property def age(self): return self._birth_info.age() @property def birth_date(self): return self._birth_info.date在这次更新中,
Person有一个新的非公共属性叫做._birth_info,它是BirthInfo的一个实例。这个实例用输入参数birth_date初始化。BirthInfo的重载初始化器会根据用户的出生日期初始化._birth_info。然后,您将
age()定义为一个属性,以提供一个计算属性,返回这个人当前的大概年龄。对Person的最后一个添加是birth_date()属性,它将这个人的出生日期作为一个date对象返回。要试用您的
Person和BirthInfo类,请打开一个交互式会话并运行以下代码:
>>> from person import Person
>>> john = Person("John Doe", date(1998, 5, 15))
>>> john.age
24
>>> john.birth_date
datetime.date(1998, 5, 15)
>>> jane = Person("Jane Doe", "2000-11-29")
>>> jane.age
22
>>> jane.birth_date
datetime.date(2000, 11, 29)
>>> linda = Person("Linda Smith", 1011222000)
>>> linda.age
20
>>> linda.birth_date
datetime.date(2002, 1, 17)
>>> david = Person("David Smith", {"year": 2000, "month": 7, "day": 25})
Traceback (most recent call last):
...
ValueError: unsupported date format: {'year': 2000, 'month': 7, 'day': 25}
您可以使用不同的日期格式实例化Person。BirthDate的内部实例自动将输入的日期转换成 date 对象。如果用不支持的日期格式(比如字典)实例化Person,那么就会得到一个ValueError。
注意,BirthDate.__init__()负责为您处理输入的出生日期。不需要使用显式的替代构造函数来处理不同类型的输入。您可以使用标准构造函数实例化该类。
单分派方法技术的主要限制是它依赖于单个参数,即self之后的第一个参数。如果您需要使用多个参数来分派适当的实现,那么可以查看一些现有的第三方库,例如 multipledispatch 和 multimethod 。
结论
用多个构造函数编写 Python 类可以让你的代码更加通用灵活,覆盖广泛的用例。多个构造函数是一个强大的功能,它允许您根据需要使用不同类型的参数、不同数量的参数或两者来构建基础类的实例。
在本教程中,您学习了如何:
- 使用可选参数和类型检查模拟多个构造函数
- 使用内置的
@classmethod装饰器编写多个构造函数 - 使用
@singledispatchmethod装饰器重载你的类构造函数
您还了解了 Python 如何在内部构造给定类的实例,以及一些标准库类如何提供多个构造函数。
有了这些知识,现在您可以用多个构造函数来丰富您的类,用几种方法来处理 Python 中的实例化过程。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深你的理解: 在你的 Python 类中提供多个构造器********
Python 和 MySQL 数据库:实用介绍
MySQL 是当今市场上最流行的数据库管理系统(DBMS)之一。在今年的 DB-Engines 排名中,它仅次于 Oracle DBMS 位列第二。由于大多数软件应用程序需要以某种形式与数据进行交互,像 Python 这样的编程语言提供了存储和访问这些数据源的工具。
使用本教程中讨论的技术,您将能够有效地集成 MySQL 数据库和 Python 应用程序。您将为电影分级系统开发一个小型 MySQL 数据库,并学习如何直接从 Python 代码中查询它。
本教程结束时,你将能够:
- 确定 MySQL 的独特功能
- 将您的应用程序连接到 MySQL 数据库
- 查询数据库获取所需数据
- 处理访问数据库时发生的异常
- 在构建数据库应用程序时使用最佳实践
为了从本教程中获得最大收益,您应该具备 Python 概念的工作知识,如 for循环、函数、异常处理,以及使用 pip 安装 Python 包。您还应该对关系数据库管理系统和 SQL 查询有一个基本的了解,比如SELECT、DROP、CREATE和JOIN。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
将 MySQL 与其他 SQL 数据库进行比较
SQL 代表结构化查询语言,是一种广泛用于管理关系数据库的编程语言。您可能听说过不同风格的基于 SQL 的 DBMSs。最流行的有 MySQL 、 PostgreSQL 、 SQLite 、 SQL Server 。所有这些数据库都符合 SQL 标准,但符合程度各不相同。
自 1995 年成立以来,MySQL 一直是开源的,并迅速成为 SQL 解决方案的市场领导者。MySQL 也是 Oracle 生态系统的一部分。虽然它的核心功能是完全免费的,但也有一些付费的附加功能。目前,所有主要的科技公司都在使用 MySQL,包括谷歌、LinkedIn、优步、网飞、Twitter 等。
除了大型开源社区的支持,MySQL 的成功还有许多其他原因:
-
易于安装: MySQL 的设计是用户友好的。建立一个 MySQL 数据库非常简单,一些广泛可用的第三方工具,如 phpMyAdmin ,进一步简化了设置过程。MySQL 适用于所有主流操作系统,包括 Windows、macOS、Linux 和 Solaris。
-
速度: MySQL 以其极快的数据库解决方案而闻名。它占用的空间相对较小,并且从长远来看非常具有可伸缩性。
-
用户权限和安全性: MySQL 附带了一个脚本,允许您设置密码安全级别、分配管理员密码以及添加和删除用户帐户权限。此脚本完成了虚拟主机用户管理门户的管理过程。其他 DBMSs,如 PostgreSQL,使用更复杂的配置文件。
虽然 MySQL 以其速度和易用性而闻名,但你可以通过 PostgreSQL 获得更多的高级特性。此外,MySQL 并不完全符合 SQL,并且有一定的功能限制,比如不支持FULL JOIN子句。
在 MySQL 中,您可能还会面临一些并发读写的问题。如果您的软件有许多用户同时向其写入数据,那么 PostgreSQL 可能是更合适的选择。
注:要在现实环境中更深入地比较 MySQL 和 PostgreSQL,请查看为什么优步工程公司从 Postgres 转向 MySQL 。
SQL Server 也是一种非常流行的 DBMS,以其可靠性、效率和安全性而闻名。这是公司的首选,尤其是在银行领域,他们经常处理大量的流量工作负载。这是一个商业解决方案,也是与 Windows 服务最兼容的系统之一。
2010 年,当甲骨文收购太阳微系统和 MySQL 时,许多人担心 MySQL 的未来。当时,甲骨文是 MySQL 最大的竞争对手。开发者担心这是甲骨文的恶意收购,目的是摧毁 MySQL。
以 MySQL 的原作者 Michael Widenius 为首的几位开发人员创建了 MySQL 代码库的一个分支,奠定了 MariaDB 的基础。目的是保护对 MySQL 的访问,并让它永远免费。
到目前为止,MariaDB 仍然完全被 GPL 许可,完全处于公共领域。另一方面,MySQL 的一些特性只有付费许可才能使用。另外,MariaDB 提供了几个 MySQL 服务器不支持的非常有用的特性,比如分布式 SQL 和列存储。你可以在 MariaDB 的网站上找到更多 MySQL 和 MariaDB 的区别。
MySQL 使用与标准 SQL 非常相似的语法。然而,官方文档中提到了一些显著的差异。
安装 MySQL 服务器和 MySQL 连接器/Python
现在,要开始学习本教程,您需要设置两件事情:一个 MySQL 服务器和一个 MySQL 连接器。MySQL 服务器将提供处理您的数据库所需的所有服务。一旦服务器启动并运行,您就可以使用 MySQL Connector/Python 将您的 Python 应用程序与其连接起来。
安装 MySQL 服务器
官方文档详细介绍了下载和安装 MySQL 服务器的推荐方法。你会找到所有流行操作系统的说明,包括 Windows 、 macOS 、 Solaris 、 Linux 等等。
对于 Windows,最好的方法是下载 MySQL 安装程序,让它负责整个过程。安装管理器还可以帮助您配置 MySQL 服务器的安全设置。在 Accounts and Roles 页面上,您需要为 root (admin)帐户输入一个密码,还可以选择添加具有不同权限的其他用户:

虽然您必须在安装过程中为 root 帐户指定凭据,但您可以在以后修改这些设置。
注意:记住主机名、用户名和密码,因为稍后需要它们来建立与 MySQL 服务器的连接。
虽然本教程只需要 MySQL 服务器,但是您也可以使用这些安装程序设置其他有用的工具,如 MySQL Workbench 。如果你不想在你的操作系统中直接安装 MySQL,那么用 Docker 在 Linux 上部署 MySQL 是一个方便的选择。
安装 MySQL 连接器/Python
数据库驱动是一个软件,它允许应用程序连接数据库系统并与之交互。像 Python 这样的编程语言需要一个特殊的驱动程序,才能与特定供应商的数据库对话。
这些驱动程序通常作为第三方模块获得。 Python 数据库 API (DB-API)定义了所有 Python 数据库驱动必须遵守的标准接口。这些细节记录在 PEP 249 中。所有的 Python 数据库驱动,比如 sqlite 的 sqlite3 ,PostgreSQL 的 psycopg ,MySQL 的 MySQL Connector/Python 都遵循这些实现规则。
注意: MySQL 的官方文档使用了术语连接器而不是驱动。从技术上讲,连接器只与连接到数据库相关联,而不与数据库交互。然而,该术语通常用于整个数据库访问模块,包括连接器和驱动程序。
为了与文档保持一致,只要提到 MySQL,您就会看到术语连接器。
许多流行的编程语言都有自己的数据库 API。例如,Java 有 Java 数据库连接(JDBC) API。如果你需要将一个 Java 应用程序连接到一个 MySQL 数据库,那么你需要使用 MySQL JDBC 连接器,它遵循 JDBC API。
类似地,在 Python 中,您需要安装一个 Python MySQL 连接器来与 MySQL 数据库交互。许多软件包遵循 DB-API 标准,但其中最流行的是 MySQL Connector/Python 。可以用 pip 得到:
$ pip install mysql-connector-python
pip将连接器作为第三方模块安装在当前活动的虚拟环境中。建议您为项目以及所有依赖项设置一个隔离虚拟环境。
要测试安装是否成功,请在 Python 终端上键入以下命令:
>>> import mysql.connector如果上面的代码执行时没有错误,那么
mysql.connector就安装好了,可以使用了。如果您遇到任何错误,那么请确保您处于正确的虚拟环境中,并且使用了正确的 Python 解释器。确保你正在安装正确的
mysql-connector-python包,这是一个纯 Python 实现。小心类似的名字,但现在贬值的连接器,如mysql-connector。与 MySQL 服务器建立连接
MySQL 是一个基于服务器的数据库管理系统。一台服务器可能包含多个数据库。要与数据库交互,必须首先与服务器建立连接。与基于 MySQL 的数据库交互的 Python 程序的一般工作流程如下:
- 连接到 MySQL 服务器。
- 创建新的数据库。
- 连接到新创建的或现有的数据库。
- 执行 SQL 查询并获取结果。
- 如果对表进行了任何更改,请通知数据库。
- 关闭与 MySQL 服务器的连接。
这是一个通用的工作流程,可能因具体应用而异。但是不管应用程序是什么,第一步是将数据库与应用程序连接起来。
建立连接
与 MySQL 服务器交互的第一步是建立连接。为此,您需要来自
mysql.connector模块的connect()。该函数接受host、user、password等参数,并返回一个MySQLConnection对象。您可以从用户那里接收这些凭证作为输入,并将它们传递给connect():from getpass import getpass from mysql.connector import connect, Error try: with connect( host="localhost", user=input("Enter username: "), password=getpass("Enter password: "), ) as connection: print(connection) except Error as e: print(e)上面的代码使用输入的登录凭证建立与 MySQL 服务器的连接。作为回报,您得到一个
MySQLConnection对象,它存储在connection变量中。从现在开始,你将使用这个变量来访问你的 MySQL 服务器。在上面的代码中有几件重要的事情需要注意:
您应该始终处理在建立到 MySQL 服务器的连接时可能出现的异常。这就是为什么您使用
try…except块来捕捉和打印您可能遇到的任何异常。在访问完数据库后,您应该总是关闭连接。不使用打开的连接会导致一些意外错误和性能问题。上面的代码利用了使用
with的上下文管理器,它抽象出了连接清理过程。你应该永远不要在 Python 脚本中直接硬编码你的登录凭证,也就是你的用户名和密码。这对于部署来说是一个糟糕的做法,并且给带来了严重的安全威胁。上面的代码提示用户输入登录凭证。它使用内置的
getpass模块隐藏密码。虽然这比硬编码要好,但是还有其他更安全的方法来存储敏感信息,比如使用环境变量。现在您已经在您的程序和 MySQL 服务器之间建立了一个连接,但是您仍然需要创建一个新的数据库或者连接到服务器内部的一个现有数据库。
创建新数据库
在上一节中,您建立了与 MySQL 服务器的连接。要创建新的数据库,您需要执行一条 SQL 语句:
CREATE DATABASE books_db;上面的语句将创建一个名为
books_db的新数据库。注意:在 MySQL 中,必须在语句末尾加上分号(
;),表示查询的终止。然而,MySQL Connector/Python 会自动在查询的末尾附加一个分号,所以不需要在 Python 代码中使用它。要在 Python 中执行 SQL 查询,您需要使用一个光标,它抽象出对数据库记录的访问。MySQL Connector/Python 为你提供了
MySQLCursor类,实例化了可以在 Python 中执行 MySQL 查询的对象。MySQLCursor类的一个实例也被称为cursor。
cursor对象利用一个MySQLConnection对象与你的 MySQL 服务器交互。要创建一个cursor,使用connection变量的.cursor()方法:cursor = connection.cursor()上面的代码给出了一个
MySQLCursor类的实例。需要执行的查询以字符串格式发送给
cursor.execute()。在这个特殊的场合,您将把CREATE DATABASE查询发送给cursor.execute():from getpass import getpass from mysql.connector import connect, Error try: with connect( host="localhost", user=input("Enter username: "), password=getpass("Enter password: "), ) as connection: create_db_query = "CREATE DATABASE online_movie_rating" with connection.cursor() as cursor: cursor.execute(create_db_query) except Error as e: print(e)在执行了上面的代码之后,您将在 MySQL 服务器中拥有一个名为
online_movie_rating的新数据库。
CREATE DATABASE查询作为字符串存储在create_db_query变量中,然后传递给cursor.execute()执行。代码使用带有cursor对象的上下文管理器来处理清理过程。如果您的服务器中已经存在同名的数据库,您可能会收到一条错误消息。要确认这一点,您可以显示服务器中所有数据库的名称。使用前面的同一个
MySQLConnection对象,执行SHOW DATABASES语句:
>>> show_db_query = "SHOW DATABASES"
>>> with connection.cursor() as cursor:
... cursor.execute(show_db_query)
... for db in cursor:
... print(db)
...
('information_schema',)
('mysql',)
('online_movie_rating',)
('performance_schema',)
('sys',)
上面的代码打印了【MySQL 服务器中当前所有数据库的名称。SHOW DATABASES命令还输出一些不是在服务器上创建的数据库,比如 information_schema 、 performance_schema 等等。这些数据库由 MySQL 服务器自动生成,并提供对各种数据库元数据和 MySQL 服务器设置的访问。
通过执行 CREATE DATABASE语句,您在这个部分中创建了一个新的数据库。在下一节中,您将看到如何连接到一个已经存在的数据库。
连接到现有数据库
在上一节中,您创建了一个名为online_movie_rating的新数据库。然而,你仍然没有连接到它。在许多情况下,您已经有了一个 MySQL 数据库,并希望将其与 Python 应用程序连接起来。
您可以通过发送一个名为database的额外参数,使用之前使用的相同的connect()函数来实现这一点:
from getpass import getpass
from mysql.connector import connect, Error
try:
with connect(
host="localhost",
user=input("Enter username: "),
password=getpass("Enter password: "),
database="online_movie_rating", ) as connection:
print(connection)
except Error as e:
print(e)
上面的代码与您之前使用的连接脚本非常相似。这里唯一的变化是一个额外的database参数,其中数据库的名称被传递给connect()。一旦您执行了这个脚本,您将连接到online_movie_rating数据库。
创建、修改和删除表格
在本节中,您将学习如何使用 Python 执行一些基本的 DDL 查询,如CREATE、DROP和ALTER。您将快速浏览一下将在本教程的剩余部分使用的 MySQL 数据库。您还将创建数据库所需的所有表,并学习稍后如何对这些表进行修改。
定义数据库模式
首先,您可以为在线电影分级系统创建一个数据库模式。该数据库将由三个表组成:
movies包含关于电影的一般信息,具有以下属性:idtitlerelease_yeargenrecollection_in_mil
reviewers包含发布评论或评级的人的信息,具有以下属性:idfirst_namelast_name
ratings包含已发布的评级信息,具有以下属性:movie_id(外键)reviewer_id(外键)rating
一个真实世界的电影分级系统,比如 IMDb ,需要存储一堆其他属性,比如电子邮件、电影演员名单等等。如果需要,可以向该数据库添加更多的表和属性。但是这三个表足以满足本教程的目的。
下图描述了数据库模式:

这个数据库中的表是相互关联的。movies和reviewers将具有多对多的关系,因为一部电影可以由多个评论者评论,而一个评论者可以评论多部电影。ratings工作台连接movies工作台和reviewers工作台。
使用CREATE TABLE语句创建表格
现在,要在 MySQL 中创建一个新表,需要使用 CREATE TABLE语句。以下 MySQL 查询将为您的online_movie_rating数据库创建movies表:
CREATE TABLE movies( id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(100), release_year YEAR(4), genre VARCHAR(100), collection_in_mil INT );
如果您以前看过 SQL 语句,那么上面的大多数查询可能是有意义的。但是在 MySQL 语法中有一些差异,您应该知道。
例如,MySQL 有各种各样的数据类型供您阅读,包括YEAR、INT、BIGINT等等。此外,当插入新记录时必须自动增加列值时,MySQL 使用AUTO_INCREMENT关键字。
要创建一个新表,您需要将这个查询传递给cursor.execute(),它接受一个 MySQL 查询并在连接的 MySQL 数据库上执行该查询:
create_movies_table_query = """
CREATE TABLE movies(
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(100),
release_year YEAR(4),
genre VARCHAR(100),
collection_in_mil INT
)
"""
with connection.cursor() as cursor:
cursor.execute(create_movies_table_query)
connection.commit()
现在数据库中有了movies表。您将create_movies_table_query传递给cursor.execute(),后者执行所需的执行。
注意:connection变量指的是连接到数据库时返回的MySQLConnection对象。
另外,注意代码末尾的 connection.commit() 语句。默认情况下,MySQL 连接器不会自动提交事务。在 MySQL 中,事务中提到的修改只有在最后使用COMMIT命令时才会发生。每次事务处理后都要调用此方法来执行实际表中的更改。
正如您对movies表所做的那样,执行以下脚本来创建reviewers表:
create_reviewers_table_query = """
CREATE TABLE reviewers (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(100),
last_name VARCHAR(100)
)
"""
with connection.cursor() as cursor:
cursor.execute(create_reviewers_table_query)
connection.commit()
如果需要,您可以添加关于审阅者的更多信息,例如他们的电子邮件 ID 或人口统计信息。但是现在first_name和last_name将为你的目的服务。
最后,您可以使用以下脚本创建ratings表:
create_ratings_table_query = """
CREATE TABLE ratings (
movie_id INT,
reviewer_id INT,
rating DECIMAL(2,1),
FOREIGN KEY(movie_id) REFERENCES movies(id),
FOREIGN KEY(reviewer_id) REFERENCES reviewers(id),
PRIMARY KEY(movie_id, reviewer_id)
)
"""
with connection.cursor() as cursor:
cursor.execute(create_ratings_table_query)
connection.commit()
与标准 SQL 相比,MySQL 中外键关系的实现略有不同,并且受限于。在 MySQL 中,外键约束中的父节点和子节点必须使用相同的存储引擎。
存储引擎是数据库管理系统用来执行 SQL 操作的底层软件组件。在 MySQL 中,存储引擎有两种不同的风格:
-
事务存储引擎是事务安全的,允许您使用
rollback等简单命令回滚事务。很多流行的 MySQL 引擎,包括 InnoDB 和 NDB 都属于这一类。 -
非事务性存储引擎依靠精心编制的手动代码来撤销提交给数据库的语句。 MyISAM 、 MEMORY 和许多其他 MySQL 引擎都是非事务性的。
InnoDB 是默认的、最流行的存储引擎。它通过支持外键约束来帮助维护数据完整性。这意味着外键上的任何 CRUD 操作都会被检查,以确保它不会导致不同表之间的不一致。
另外,请注意,ratings表使用列movie_id和reviewer_id,两者都是外键,共同作为主键。这一步骤确保了审查者不能对同一部电影进行两次评级。
您可以选择在多次执行中重复使用同一个游标。在这种情况下,所有的执行将变成一个原子事务,而不是多个独立的事务。例如,您可以用一个游标执行所有的CREATE TABLE语句,然后只提交一次事务:
with connection.cursor() as cursor:
cursor.execute(create_movies_table_query)
cursor.execute(create_reviewers_table_query)
cursor.execute(create_ratings_table_query)
connection.commit()
上面的代码将首先执行所有三个CREATE语句。然后,它会向提交您的事务的 MySQL 服务器发送一个COMMIT命令。您还可以使用 .rollback() 向 MySQL 服务器发送ROLLBACK命令,并从事务中删除所有数据更改。
使用DESCRIBE语句显示表模式
现在,您已经创建了所有三个表,您可以使用以下 SQL 语句查看它们的模式:
DESCRIBE <table_name>;
要从cursor对象获得一些结果,需要使用 cursor.fetchall() 。该方法从最后执行的语句中获取所有行。假设在connection变量中已经有了MySQLConnection对象,您可以打印出cursor.fetchall()获取的所有结果:
>>> show_table_query = "DESCRIBE movies" >>> with connection.cursor() as cursor: ... cursor.execute(show_table_query) ... # Fetch rows from last executed query ... result = cursor.fetchall() ... for row in result: ... print(row) ... ('id', 'int(11)', 'NO', 'PRI', None, 'auto_increment') ('title', 'varchar(100)', 'YES', '', None, '') ('release_year', 'year(4)', 'YES', '', None, '') ('genre', 'varchar(100)', 'YES', '', None, '') ('collection_in_mil', 'int(11)', 'YES', '', None, '')一旦执行了上面的代码,您应该会收到一个包含关于
movies表中所有列的信息的表。对于每一列,您将收到详细信息,如该列的数据类型、该列是否是主键等等。使用
ALTER语句修改表模式在
movies表中,有一个名为collection_in_mil的列,其中包含一部电影的票房收入(以百万美元计)。您可以编写以下 MySQL 语句,将collection_in_mil属性的数据类型从INT修改为DECIMAL:ALTER TABLE movies MODIFY COLUMN collection_in_mil DECIMAL(4,1);
DECIMAL(4,1)表示十进制数,最多可以有4位,其中1为小数,如120.1、3.4、38.0等。在执行了ALTER TABLE语句之后,您可以使用DESCRIBE显示更新后的表模式:
>>> alter_table_query = """
... ALTER TABLE movies
... MODIFY COLUMN collection_in_mil DECIMAL(4,1)
... """
>>> show_table_query = "DESCRIBE movies"
>>> with connection.cursor() as cursor:
... cursor.execute(alter_table_query)
... cursor.execute(show_table_query)
... # Fetch rows from last executed query
... result = cursor.fetchall()
... print("Movie Table Schema after alteration:")
... for row in result:
... print(row)
...
Movie Table Schema after alteration
('id', 'int(11)', 'NO', 'PRI', None, 'auto_increment')
('title', 'varchar(100)', 'YES', '', None, '')
('release_year', 'year(4)', 'YES', '', None, '')
('genre', 'varchar(100)', 'YES', '', None, '')
('collection_in_mil', 'decimal(4,1)', 'YES', '', None, '')
如输出所示,collection_in_mil属性现在属于类型DECIMAL(4,1)。还要注意,在上面的代码中,你调用了cursor.execute()两次。但是cursor.fetchall()只从最后执行的查询中获取行,这就是show_table_query。
使用DROP语句删除表格
要删除一个表,需要在 MySQL 中执行 DROP TABLE语句。删除表格是一个不可逆的过程。如果您执行下面的代码,那么您将需要再次调用CREATE TABLE查询,以便在接下来的部分中使用ratings表。
要删除ratings表,发送drop_table_query到cursor.execute():
drop_table_query = "DROP TABLE ratings"
with connection.cursor() as cursor:
cursor.execute(drop_table_query)
如果您执行上面的代码,您将成功地删除了ratings表。
在表格中插入记录
在上一节中,您在数据库中创建了三个表:movies、reviewers和ratings。现在您需要用数据填充这些表。本节将介绍在 MySQL Connector for Python 中插入记录的两种不同方法。
第一种方法是.execute(),当记录数量很少并且记录可以被硬编码时效果很好。第二种方法是.executemany(),这种方法更受欢迎,也更适合真实世界的场景。
使用.execute()
第一种方法使用您一直使用的相同的cursor.execute()方法。你把 INSERT INTO查询写成一个字符串,传递给cursor.execute()。您可以使用此方法将数据插入到movies表中。
作为参考,movies表有五个属性:
idtitlerelease_yeargenrecollection_in_mil
您不需要为id添加数据,因为AUTO_INCREMENT会自动为您计算id。以下脚本将记录插入到movies表中:
insert_movies_query = """
INSERT INTO movies (title, release_year, genre, collection_in_mil)
VALUES
("Forrest Gump", 1994, "Drama", 330.2),
("3 Idiots", 2009, "Drama", 2.4),
("Eternal Sunshine of the Spotless Mind", 2004, "Drama", 34.5),
("Good Will Hunting", 1997, "Drama", 138.1),
("Skyfall", 2012, "Action", 304.6),
("Gladiator", 2000, "Action", 188.7),
("Black", 2005, "Drama", 3.0),
("Titanic", 1997, "Romance", 659.2),
("The Shawshank Redemption", 1994, "Drama",28.4),
("Udaan", 2010, "Drama", 1.5),
("Home Alone", 1990, "Comedy", 286.9),
("Casablanca", 1942, "Romance", 1.0),
("Avengers: Endgame", 2019, "Action", 858.8),
("Night of the Living Dead", 1968, "Horror", 2.5),
("The Godfather", 1972, "Crime", 135.6),
("Haider", 2014, "Action", 4.2),
("Inception", 2010, "Adventure", 293.7),
("Evil", 2003, "Horror", 1.3),
("Toy Story 4", 2019, "Animation", 434.9),
("Air Force One", 1997, "Drama", 138.1),
("The Dark Knight", 2008, "Action",535.4),
("Bhaag Milkha Bhaag", 2013, "Sport", 4.1),
("The Lion King", 1994, "Animation", 423.6),
("Pulp Fiction", 1994, "Crime", 108.8),
("Kai Po Che", 2013, "Sport", 6.0),
("Beasts of No Nation", 2015, "War", 1.4),
("Andadhun", 2018, "Thriller", 2.9),
("The Silence of the Lambs", 1991, "Crime", 68.2),
("Deadpool", 2016, "Action", 363.6),
("Drishyam", 2015, "Mystery", 3.0)
"""
with connection.cursor() as cursor:
cursor.execute(insert_movies_query)
connection.commit()
movies表现在装载了 30 条记录。代码最后调用connection.commit()。在对表进行任何修改之后,调用.commit()是非常重要的。
使用.executemany()
当记录的数量相当少,并且您可以将这些记录直接写入代码时,前一种方法更合适。但这很少是真的。您通常将这些数据存储在其他文件中,或者这些数据将由不同的脚本生成,并需要添加到 MySQL 数据库中。
这就是 .executemany() 派上用场的地方。它接受两个参数:
- 一个查询,包含需要插入的记录的占位符
- 一个列表,包含您希望插入的所有记录
以下示例为reviewers表格插入记录:
insert_reviewers_query = """
INSERT INTO reviewers
(first_name, last_name)
VALUES ( %s, %s )
"""
reviewers_records = [
("Chaitanya", "Baweja"),
("Mary", "Cooper"),
("John", "Wayne"),
("Thomas", "Stoneman"),
("Penny", "Hofstadter"),
("Mitchell", "Marsh"),
("Wyatt", "Skaggs"),
("Andre", "Veiga"),
("Sheldon", "Cooper"),
("Kimbra", "Masters"),
("Kat", "Dennings"),
("Bruce", "Wayne"),
("Domingo", "Cortes"),
("Rajesh", "Koothrappali"),
("Ben", "Glocker"),
("Mahinder", "Dhoni"),
("Akbar", "Khan"),
("Howard", "Wolowitz"),
("Pinkie", "Petit"),
("Gurkaran", "Singh"),
("Amy", "Farah Fowler"),
("Marlon", "Crafford"),
]
with connection.cursor() as cursor:
cursor.executemany(insert_reviewers_query, reviewers_records) connection.commit()
在上面的脚本中,您将查询和记录列表作为参数传递给.executemany()。这些记录可能是从文件或用户那里获取的,并存储在reviewers_records列表中。
代码使用%s作为必须插入到insert_reviewers_query中的两个字符串的占位符。占位符充当格式说明符,帮助在字符串中为变量保留一个位置。然后,在执行过程中,将指定的变量添加到该点。
您可以类似地使用.executemany()在ratings表中插入记录:
insert_ratings_query = """
INSERT INTO ratings
(rating, movie_id, reviewer_id)
VALUES ( %s, %s, %s)
"""
ratings_records = [
(6.4, 17, 5), (5.6, 19, 1), (6.3, 22, 14), (5.1, 21, 17),
(5.0, 5, 5), (6.5, 21, 5), (8.5, 30, 13), (9.7, 6, 4),
(8.5, 24, 12), (9.9, 14, 9), (8.7, 26, 14), (9.9, 6, 10),
(5.1, 30, 6), (5.4, 18, 16), (6.2, 6, 20), (7.3, 21, 19),
(8.1, 17, 18), (5.0, 7, 2), (9.8, 23, 3), (8.0, 22, 9),
(8.5, 11, 13), (5.0, 5, 11), (5.7, 8, 2), (7.6, 25, 19),
(5.2, 18, 15), (9.7, 13, 3), (5.8, 18, 8), (5.8, 30, 15),
(8.4, 21, 18), (6.2, 23, 16), (7.0, 10, 18), (9.5, 30, 20),
(8.9, 3, 19), (6.4, 12, 2), (7.8, 12, 22), (9.9, 15, 13),
(7.5, 20, 17), (9.0, 25, 6), (8.5, 23, 2), (5.3, 30, 17),
(6.4, 5, 10), (8.1, 5, 21), (5.7, 22, 1), (6.3, 28, 4),
(9.8, 13, 1)
]
with connection.cursor() as cursor:
cursor.executemany(insert_ratings_query, ratings_records)
connection.commit()
这三个表现在都填充了数据。你现在有一个全功能的在线电影分级数据库。下一步是理解如何与这个数据库交互。
从数据库中读取记录
到目前为止,您一直在构建您的数据库。现在是时候对它执行一些查询,并从这个数据集中找到一些有趣的属性。在本节中,您将学习如何使用 SELECT语句从数据库表中读取记录。
使用SELECT语句读取记录
要检索记录,您需要向cursor.execute()发送一个SELECT查询。然后使用cursor.fetchall()以行或记录列表的形式提取检索到的表。
尝试编写一个 MySQL 查询,从movies表中选择所有记录,并将其发送到.execute():
>>> select_movies_query = "SELECT * FROM movies LIMIT 5" >>> with connection.cursor() as cursor: ... cursor.execute(select_movies_query) ... result = cursor.fetchall() ... for row in result: ... print(row) ... (1, 'Forrest Gump', 1994, 'Drama', Decimal('330.2')) (2, '3 Idiots', 2009, 'Drama', Decimal('2.4')) (3, 'Eternal Sunshine of the Spotless Mind', 2004, 'Drama', Decimal('34.5')) (4, 'Good Will Hunting', 1997, 'Drama', Decimal('138.1')) (5, 'Skyfall', 2012, 'Action', Decimal('304.6'))
result变量保存使用.fetchall()返回的记录。这是一个元组的列表,代表表中的单个记录。在上面的查询中,您使用
LIMIT子句来约束从SELECT语句接收的行数。当处理大量数据时,开发人员经常使用LIMIT来执行分页。在 MySQL 中,
LIMIT子句接受一个或两个非负数值参数。使用一个参数时,指定要返回的最大行数。因为您的查询包括LIMIT 5,所以只获取第一个5记录。当使用这两个参数时,您还可以指定要返回的第一行的偏移量:SELECT * FROM movies LIMIT 2,5;第一个参数指定偏移量
2,第二个参数将返回的行数限制为5。上述查询将返回第 3 行到第 7 行。您还可以查询选定的列:
>>> select_movies_query = "SELECT title, release_year FROM movies LIMIT 5"
>>> with connection.cursor() as cursor:
... cursor.execute(select_movies_query)
... for row in cursor.fetchall():
... print(row)
...
('Forrest Gump', 1994)
('3 Idiots', 2009)
('Eternal Sunshine of the Spotless Mind', 2004)
('Good Will Hunting', 1997)
('Skyfall', 2012)
现在,代码只输出两个指定列的值:title和release_year。
使用WHERE子句过滤结果
您可以使用WHERE子句根据特定标准过滤表记录。例如,要检索票房收入超过 3 亿美元的所有电影,可以运行以下查询:
SELECT title, collection_in_mil FROM movies WHERE collection_in_mil > 300;
您还可以在最后一个查询中使用 ORDER BY子句将结果从最高收入者到最低收入者排序:
>>> select_movies_query = """ ... SELECT title, collection_in_mil ... FROM movies ... WHERE collection_in_mil > 300 ... ORDER BY collection_in_mil DESC ... """ >>> with connection.cursor() as cursor: ... cursor.execute(select_movies_query) ... for movie in cursor.fetchall(): ... print(movie) ... ('Avengers: Endgame', Decimal('858.8')) ('Titanic', Decimal('659.2')) ('The Dark Knight', Decimal('535.4')) ('Toy Story 4', Decimal('434.9')) ('The Lion King', Decimal('423.6')) ('Deadpool', Decimal('363.6')) ('Forrest Gump', Decimal('330.2')) ('Skyfall', Decimal('304.6'))MySQL 提供了过多的字符串格式化操作,比如用于连接字符串的
CONCAT。通常,网站会显示电影名称和上映年份,以避免混淆。若要检索票房收入最高的五部电影的标题及其上映年份,可以编写以下查询:
>>> select_movies_query = """
... SELECT CONCAT(title, " (", release_year, ")"),
... collection_in_mil
... FROM movies
... ORDER BY collection_in_mil DESC
... LIMIT 5
... """
>>> with connection.cursor() as cursor:
... cursor.execute(select_movies_query)
... for movie in cursor.fetchall():
... print(movie)
...
('Avengers: Endgame (2019)', Decimal('858.8'))
('Titanic (1997)', Decimal('659.2'))
('The Dark Knight (2008)', Decimal('535.4'))
('Toy Story 4 (2019)', Decimal('434.9'))
('The Lion King (1994)', Decimal('423.6'))
如果不想使用LIMIT子句,也不需要获取所有记录,那么cursor对象也有 .fetchone() 和 .fetchmany() 方法:
.fetchone()以元组的形式检索结果的下一行,如果没有更多行可用,则检索None。.fetchmany()从结果中检索下一组行,作为元组列表。它有一个size参数,默认为1,可以用来指定需要获取的行数。如果没有更多的行可用,则该方法返回一个空列表。
再次尝试检索五部票房最高的电影的名称及其上映年份,但这次使用.fetchmany():
>>> select_movies_query = """ ... SELECT CONCAT(title, " (", release_year, ")"), ... collection_in_mil ... FROM movies ... ORDER BY collection_in_mil DESC ... """ >>> with connection.cursor() as cursor: ... cursor.execute(select_movies_query) ... for movie in cursor.fetchmany(size=5): ... print(movie) ... cursor.fetchall() ... ('Avengers: Endgame (2019)', Decimal('858.8')) ('Titanic (1997)', Decimal('659.2')) ('The Dark Knight (2008)', Decimal('535.4')) ('Toy Story 4 (2019)', Decimal('434.9')) ('The Lion King (1994)', Decimal('423.6'))带有
.fetchmany()的输出类似于使用LIMIT子句时得到的结果。你可能已经注意到了结尾附加的cursor.fetchall()呼叫。您这样做是为了清除所有未被.fetchmany()读取的剩余结果。在同一连接上执行任何其他语句之前,有必要清除所有未读结果。否则,将引发一个
InternalError: Unread result found异常。使用
JOIN语句处理多个表如果您发现上一节中的查询非常简单,不要担心。您可以使用上一节中的相同方法使您的
SELECT查询尽可能复杂。让我们看一些稍微复杂一点的
JOIN查询。如果您想找出数据库中评分最高的前五部电影的名称,则可以运行以下查询:
>>> select_movies_query = """
... SELECT title, AVG(rating) as average_rating
... FROM ratings
... INNER JOIN movies
... ON movies.id = ratings.movie_id
... GROUP BY movie_id
... ORDER BY average_rating DESC
... LIMIT 5
... """
>>> with connection.cursor() as cursor:
... cursor.execute(select_movies_query)
... for movie in cursor.fetchall():
... print(movie)
...
('Night of the Living Dead', Decimal('9.90000'))
('The Godfather', Decimal('9.90000'))
('Avengers: Endgame', Decimal('9.75000'))
('Eternal Sunshine of the Spotless Mind', Decimal('8.90000'))
('Beasts of No Nation', Decimal('8.70000'))
如上图,活死人之夜和教父并列为你online_movie_rating数据库中评分最高的电影。
若要查找给出最高评级的审阅者的姓名,请编写以下查询:
>>> select_movies_query = """ ... SELECT CONCAT(first_name, " ", last_name), COUNT(*) as num ... FROM reviewers ... INNER JOIN ratings ... ON reviewers.id = ratings.reviewer_id ... GROUP BY reviewer_id ... ORDER BY num DESC ... LIMIT 1 ... """ >>> with connection.cursor() as cursor: ... cursor.execute(select_movies_query) ... for movie in cursor.fetchall(): ... print(movie) ... ('Mary Cooper', 4)
Mary Cooper是此数据库中最频繁的审阅者。如上所述,不管查询有多复杂,因为它最终是由 MySQL 服务器处理的。您执行查询的过程将始终保持不变:将查询传递给cursor.execute(),并使用.fetchall()获取结果。更新和删除数据库中的记录
在本节中,您将更新和删除数据库中的记录。这两种操作都可以在表中的单个记录或多个记录上执行。您将使用
WHERE子句选择需要修改的行。
UPDATE命令您数据库中的一名评审员
Amy Farah Fowler,现在已经与Sheldon Cooper结婚。她的姓现在已经改成了Cooper,所以你需要相应地更新你的数据库。为了更新记录,MySQL 使用了UPDATE语句:update_query = """ UPDATE reviewers SET last_name = "Cooper" WHERE first_name = "Amy" """ with connection.cursor() as cursor: cursor.execute(update_query) connection.commit()代码将更新查询传递给
cursor.execute(),然后.commit()将所需的更改传递给reviewers表。注意:在
UPDATE查询中,WHERE子句帮助指定需要更新的记录。如果你不使用WHERE,那么所有的记录都会被更新!假设您需要提供一个允许审阅者修改评级的选项。评审者将提供三个值,
movie_id、reviewer_id和新的rating。代码将在执行指定的修改后显示记录。假设
movie_id = 18、reviewer_id = 15和新的rating = 5.0,您可以使用下面的 MySQL 查询来执行所需的修改:UPDATE ratings SET rating = 5.0 WHERE movie_id = 18 AND reviewer_id = 15; SELECT * FROM ratings WHERE movie_id = 18 AND reviewer_id = 15;上述查询首先更新评级,然后显示它。您可以创建一个完整的 Python 脚本来建立与数据库的连接,并允许审阅者修改评级:
from getpass import getpass from mysql.connector import connect, Error movie_id = input("Enter movie id: ") reviewer_id = input("Enter reviewer id: ") new_rating = input("Enter new rating: ") update_query = """ UPDATE ratings SET rating = "%s" WHERE movie_id = "%s" AND reviewer_id = "%s"; SELECT * FROM ratings WHERE movie_id = "%s" AND reviewer_id = "%s" """ % ( new_rating, movie_id, reviewer_id, movie_id, reviewer_id, ) try: with connect( host="localhost", user=input("Enter username: "), password=getpass("Enter password: "), database="online_movie_rating", ) as connection: with connection.cursor() as cursor: for result in cursor.execute(update_query, multi=True): if result.with_rows: print(result.fetchall()) connection.commit() except Error as e: print(e)将该代码保存到名为
modify_ratings.py的文件中。上面的代码使用%s占位符将接收到的输入插入到update_query字符串中。在本教程中,您第一次在一个字符串中有多个查询。要将多个查询传递给单个cursor.execute(),您需要设置方法的multi参数到True。如果
multi是True,那么cursor.execute()返回一个迭代器。迭代器中的每一项都对应于一个执行查询中传递的语句的cursor对象。上面的代码在这个迭代器上运行一个for循环,然后在每个cursor对象上调用.fetchall()。注意:在所有光标对象上运行
.fetchall()很重要。要在同一个连接上执行新语句,必须确保没有以前执行的未读结果。如果有未读的结果,那么你会收到一个异常。如果在操作中没有获取结果集,那么
.fetchall()会引发一个异常。为了避免这种错误,在上面的代码中使用了cursor.with_rows属性,该属性指示最近执行的操作是否产生了行。虽然这段代码应该可以解决你的问题,但是在当前状态下,
WHERE子句是网络黑客的主要目标。它很容易受到所谓的 SQL 注入攻击,这可以让恶意行为者破坏或滥用你的数据库。警告:不要在你的数据库上尝试以下输入!它们会损坏您的表,您需要重新创建它。
例如,如果用户发送
movie_id=18、reviewer_id=15和新的rating=5.0作为输入,则输出如下:$ python modify_ratings.py Enter movie id: 18 Enter reviewer id: 15 Enter new rating: 5.0 Enter username: <user_name> Enter password: [(18, 15, Decimal('5.0'))]带
movie_id=18和reviewer_id=15的rating已改为5.0。但是如果你是黑客,你可能会在输入中发送一个隐藏命令:$ python modify_ratings.py Enter movie id: 18 Enter reviewer id: 15"; UPDATE reviewers SET last_name = "A Enter new rating: 5.0 Enter username: <user_name> Enter password: [(18, 15, Decimal('5.0'))]同样,输出显示指定的
rating已经更改为5.0。什么变了?黑客在进入
reviewer_id的时候偷偷进入了更新查询。更新查询update reviewers set last_name = "A将reviewers表中所有记录的last_name更改为"A"。如果您打印出reviewers表格,您可以看到这一变化:
>>> select_query = """
... SELECT first_name, last_name
... FROM reviewers
... """
>>> with connection.cursor() as cursor:
... cursor.execute(select_query)
... for reviewer in cursor.fetchall():
... print(reviewer)
...
('Chaitanya', 'A')
('Mary', 'A')
('John', 'A')
('Thomas', 'A')
('Penny', 'A')
('Mitchell', 'A')
('Wyatt', 'A')
('Andre', 'A')
('Sheldon', 'A')
('Kimbra', 'A')
('Kat', 'A')
('Bruce', 'A')
('Domingo', 'A')
('Rajesh', 'A')
('Ben', 'A')
('Mahinder', 'A')
('Akbar', 'A')
('Howard', 'A')
('Pinkie', 'A')
('Gurkaran', 'A')
('Amy', 'A')
('Marlon', 'A')
上面的代码显示了reviewers表中所有记录的first_name和last_name。SQL 注入攻击通过将所有记录的last_name更改为"A"来破坏该表。
有一种快速解决方法可以防止这种攻击。不要将用户提供的查询值直接添加到查询字符串中。相反,更新modify_ratings.py脚本,将这些查询值作为参数发送给.execute():
from getpass import getpass
from mysql.connector import connect, Error
movie_id = input("Enter movie id: ")
reviewer_id = input("Enter reviewer id: ")
new_rating = input("Enter new rating: ")
update_query = """
UPDATE
ratings
SET
rating = %s WHERE
movie_id = %s AND reviewer_id = %s;
SELECT *
FROM ratings
WHERE
movie_id = %s AND reviewer_id = %s """
val_tuple = (
new_rating, movie_id, reviewer_id, movie_id, reviewer_id, )
try:
with connect(
host="localhost",
user=input("Enter username: "),
password=getpass("Enter password: "),
database="online_movie_rating",
) as connection:
with connection.cursor() as cursor:
for result in cursor.execute(update_query, val_tuple, multi=True): if result.with_rows:
print(result.fetchall())
connection.commit()
except Error as e:
print(e)
注意,%s占位符不再在字符串引号中。传递给占位符的字符串可能包含一些特殊字符。如果需要,底层库可以正确地对这些进行转义。
cursor.execute()确保作为参数接收的元组中的值是所需的数据类型。如果用户试图偷偷输入一些有问题的字符,那么代码将引发一个异常:
$ python modify_ratings.py
Enter movie id: 18
Enter reviewer id: 15"; UPDATE reviewers SET last_name = "A
Enter new rating: 5.0
Enter username: <user_name>
Enter password:
1292 (22007): Truncated incorrect DOUBLE value: '15";
UPDATE reviewers SET last_name = "A'
如果在用户输入中发现任何不需要的字符,将引发异常。每当在查询中包含用户输入时,都应该使用这种方法。还有其他方法可以防止 SQL 注入袭击 T2。
DELETE命令
删除记录与更新记录非常相似。你使用 DELETE语句来删除选中的记录。
注意:删除是一个不可逆的过程。如果不使用WHERE子句,那么指定表中的所有记录都将被删除。您需要再次运行INSERT INTO查询来取回被删除的记录。
建议您首先使用相同的过滤器运行一个SELECT查询,以确保您删除的是正确的记录。例如,要删除reviewer_id = 2给出的所有评级,您应该首先运行相应的SELECT查询:
>>> select_movies_query = """ ... SELECT reviewer_id, movie_id FROM ratings ... WHERE reviewer_id = 2 ... """ >>> with connection.cursor() as cursor: ... cursor.execute(select_movies_query) ... for movie in cursor.fetchall(): ... print(movie) ... (2, 7) (2, 8) (2, 12) (2, 23)上面的代码片段输出了
ratings表中记录的reviewer_id和movie_id,其中reviewer_id = 2。一旦您确认这些是您需要删除的记录,您就可以使用相同的过滤器运行一个DELETE查询:delete_query = "DELETE FROM ratings WHERE reviewer_id = 2" with connection.cursor() as cursor: cursor.execute(delete_query) connection.commit()在这个查询中,您将从
ratings表中删除由带有reviewer_id = 2的评审者给出的所有评分。Python 和 MySQL 的其他连接方式
在本教程中,您看到了 MySQL Connector/Python,这是官方推荐的从 Python 应用程序与 MySQL 数据库交互的方法。还有另外两种流行的连接器:
mysqlclient 是一个库,它是官方连接器的竞争对手,并且正在积极地更新新特性。因为它的核心是用 C 写的,所以比纯 Python 官方连接器有更好的性能。一个很大的缺点是设置和安装相当困难,尤其是在 Windows 上。
MySQLdb 是一款仍在商业应用中使用的传统软件。它是用 C 写的,比 MySQL Connector/Python 快,但只适用于 Python 2。
这些连接器充当程序和 MySQL 数据库之间的接口,您可以通过它们发送 SQL 查询。但是许多开发人员更喜欢使用面向对象的范例而不是 SQL 查询来操作数据。
对象关系映射 (ORM)是一种允许你直接使用面向对象语言从数据库中查询和操作数据的技术。ORM 库封装了操纵数据所需的代码,这消除了使用哪怕一丁点 SQL 的需要。以下是基于 SQL 的数据库中最流行的 Python ORMs:
SQLAlchemy 是一种便于 Python 和其他 SQL 数据库之间通信的 ORM。您可以为不同的数据库创建不同的引擎,如 MySQL、PostgreSQL、SQLite 等等。SQLAlchemy 通常与 pandas 库一起使用来提供完整的数据处理功能。
peewee 是一个轻量级的快速 ORM,可以快速设置。当您与数据库的交互仅限于提取少量记录时,这非常有用。例如,如果您需要将 MySQL 数据库中的选定记录复制到 CSV 文件中,那么 peewee 可能是您的最佳选择。
Django ORM 是 Django 最强大的特性之一,与 Django web 框架一起提供。它可以与 SQLite、PostgreSQL 和 MySQL 等各种数据库进行交互。许多基于 Django 的应用程序使用 Django ORM 进行数据建模和基本查询,但通常会切换到 SQLAlchemy 来处理更复杂的需求。
您可能会发现这些方法中的一种更适合您的应用程序。如果您不确定使用哪一个,那么最好使用官方推荐的 MySQL Connector/Python,您在本教程中已经看到了。
结论
在本教程中,您了解了如何使用 MySQL Connector/Python 将 MySQL 数据库与 Python 应用程序集成在一起。您还看到了 MySQL 数据库区别于其他 SQL 数据库的一些独特特性。
在这个过程中,您了解了一些编程最佳实践,在数据库应用程序中建立连接、创建表以及插入和更新记录时,这些实践是值得考虑的。您还为在线电影分级系统开发了一个示例 MySQL 数据库,并直接从 Python 应用程序与它进行交互。
在本教程中,您学习了如何:
- 将您的 Python 应用程序与一个 MySQL 数据库连接
- 将数据从 MySQL 数据库导入到 Python 进行进一步分析
- 从您的 Python 应用程序中执行 SQL 查询
- 访问数据库时处理异常
- 防止 SQL 注入攻击你的应用
如果你感兴趣,Python 也有其他 DBMSs 的连接器,比如 MongoDB 和 PostgreSQL 。更多信息,请查看 Python 数据库教程。********
用 namedtuple 编写 Pythonic 式的干净代码
Python 的
collections模块提供了一个名为namedtuple()的工厂函数,专门用来让你在处理元组的时候代码更加python 化。使用namedtuple(),您可以创建不可变的序列类型,允许您使用描述性的字段名和点符号而不是模糊的整数索引来访问它们的值。如果您有一些使用 Python 的经验,那么您应该知道编写 Python 代码是 Python 开发人员的核心技能。在本教程中,您将使用
namedtuple提升该技能。在本教程中,您将学习如何:
- 使用
namedtuple()创建namedtuple类- 识别并利用的酷功能
namedtuple的- 使用
namedtuple实例编写python 代码- 决定是使用
namedtuple还是类似的数据结构- 子类 a
namedtuple提供新特性为了从本教程中获得最大收益,您需要对与编写 Python 可读代码相关的 Python 哲学有一个大致的了解。您还需要了解使用的基本知识:
如果在开始本教程之前,您还没有掌握所有必需的知识,那也没关系!可以根据需要停下来复习一下以上资源。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
使用
namedtuple编写 Pythonic 代码Python 的
namedtuple()是collections中可用的一个工厂函数。它允许你用命名字段创建tuple子类。您可以使用点符号和字段名来访问给定命名元组中的值,就像在obj.attr中一样。Python 的
namedtuple是为了提高代码可读性而创建的,它提供了一种使用描述性字段名称而不是整数索引来访问值的方法,在大多数情况下,整数索引不提供任何关于值是什么的上下文。这个特性也使得代码更干净,更易于维护。相比之下,对常规元组中的值使用索引可能会令人讨厌、难以阅读并且容易出错。如果 tuple 有很多字段,并且是在远离使用它的地方构造的,这一点尤其正确。
注意:在本教程中,你会发现不同的术语用来指代 Python 的
namedtuple,它的工厂函数,以及它的实例。为了避免混淆,这里总结了在整个教程中如何使用每个术语:
学期 意义 namedtuple()工厂功能 namedtuple、namedtuple类namedtuple()返回的元组子类namedtuple实例,命名元组特定 namedtuple类的实例你会发现这些术语在整个教程中都有相应的含义。
除了命名元组的这个主要特性之外,您会发现它们:
- 是不可变的数据结构吗
- 具有一致的哈希值
- 可以作为字典键
- 可以存储在组中
- 根据类型和字段名创建一个有用的文档串
- 提供一个有用的字符串表示,以
name=value格式打印元组内容- 支持分度
- 提供附加的方法和属性,如
._make(),_asdict(),._fields等等- 与常规元组向后兼容吗
- 有个与常规元组相似的内存消耗
一般来说,只要需要类似元组的对象,就可以使用
namedtuple实例。命名元组的优势在于,它们提供了一种使用字段名和点符号来访问其值的方法。这将使您的代码更加 Pythonic 化。通过对
namedtuple及其一般特性的简要介绍,您可以更深入地在代码中创建和使用它们。使用
namedtuple()创建类似元组的类您使用一个
namedtuple()来创建一个不可变的和带有字段名称的类似元组的数据结构。在关于namedtuple的教程中,一个常见的例子是创建一个类来表示一个数学点。根据问题的不同,您可能希望使用不可变的数据结构来表示给定点。以下是使用常规元组创建二维点的方法:
>>> # Create a 2D point as a tuple
>>> point = (2, 4)
>>> point
(2, 4)
>>> # Access coordinate x
>>> point[0]
2
>>> # Access coordinate y
>>> point[1]
4
>>> # Try to update a coordinate value
>>> point[0] = 3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
这里,您使用常规的tuple创建了一个不可变的二维point。这段代码是有效的:你有一个有两个坐标的point,你不能修改其中任何一个坐标。但是,这段代码可读吗?你能预先告诉我0和1指数是什么意思吗?为了避免这些歧义,你可以像这样使用一个namedtuple:
>>> from collections import namedtuple >>> # Create a namedtuple type, Point >>> Point = namedtuple("Point", "x y") >>> issubclass(Point, tuple) True >>> # Instantiate the new type >>> point = Point(2, 4) >>> point Point(x=2, y=4) >>> # Dot notation to access coordinates >>> point.x 2 >>> point.y 4 >>> # Indexing to access coordinates >>> point[0] 2 >>> point[1] 4 >>> # Named tuples are immutable >>> point.x = 100 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute现在您有了一个带有两个适当命名的字段的
point,x和y。默认情况下,point提供了用户友好的描述性字符串表示(Point(x=2, y=4))。它允许您使用点符号来访问坐标,这是方便的、可读的和明确的。您还可以使用索引来访问每个坐标的值。注意:需要注意的是,虽然元组和命名元组是不可变的,但是它们存储的值不一定是不可变的。
创建保存可变值的元组或命名元组是完全合法的:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name children")
>>> john = Person("John Doe", ["Timmy", "Jimmy"])
>>> john
Person(name='John Doe', children=['Timmy', 'Jimmy'])
>>> id(john.children)
139695902374144
>>> john.children.append("Tina")
>>> john
Person(name='John Doe', children=['Timmy', 'Jimmy', 'Tina'])
>>> id(john.children)
139695902374144
>>> hash(john)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
您可以创建包含可变对象的命名元组。您可以修改底层元组中的可变对象。然而,这并不意味着您正在修改元组本身。元组将继续保存相同的内存引用。
最后,具有可变值的元组或命名元组不是可散列的,正如你在上面的例子中看到的。
最后,由于namedtuple类是tuple的子类,它们也是不可变的。所以如果你试图改变一个坐标的值,你会得到一个AttributeError。
向namedtuple() 提供所需的参数
正如您之前所了解的,namedtuple()是一个工厂函数,而不是一个典型的数据结构。要创建一个新的namedtuple,您需要向函数提供两个位置参数:
typename为namedtuple()返回的namedtuple提供类名。您需要将一个带有有效 Python 标识符的字符串传递给这个参数。field_names提供了用于访问元组中的值的字段名称。您可以使用以下方式提供字段名称:- 一个可迭代的字符串,比如
["field1", "field2", ..., "fieldN"] - 每个字段名由空格分隔的字符串,例如
"field1 field2 ... fieldN" - 每个字段名用逗号分隔的字符串,例如
"field1, field2, ..., fieldN"
- 一个可迭代的字符串,比如
为了说明如何提供field_names,以下是创建点的不同方法:
>>> from collections import namedtuple >>> # A list of strings for the field names >>> Point = namedtuple("Point", ["x", "y"]) >>> Point <class '__main__.Point'> >>> Point(2, 4) Point(x=2, y=4) >>> # A string with comma-separated field names >>> Point = namedtuple("Point", "x, y") >>> Point <class '__main__.Point'> >>> Point(4, 8) Point(x=4, y=8) >>> # A generator expression for the field names >>> Point = namedtuple("Point", (field for field in "xy")) >>> Point <class '__main__.Point'> >>> Point(8, 16) Point(x=8, y=16)在这些例子中,首先使用字段名的
list创建Point。然后,使用带有逗号分隔的字段名的字符串。最后,使用一个生成器表达式。在这个例子中,最后一个选项可能看起来有些多余。然而,它旨在说明该过程的灵活性。注意:如果你使用一个 iterable 来提供字段名,那么你应该使用一个类似序列的 iterable,因为字段的顺序对于产生可靠的结果很重要。
例如,使用
set可以工作,但可能会产生意想不到的结果:
>>> from collections import namedtuple
>>> Point = namedtuple("Point", {"x", "y"})
>>> Point(2, 4)
Point(y=2, x=4)
当您使用一个无序的 iterable 向一个namedtuple提供字段时,您可能会得到意想不到的结果。在上面的例子中,坐标名称被交换了,这可能不适合您的用例。
您可以使用任何有效的 Python 标识符作为字段名称,除了:
- 以下划线(
_)开头的名称 - Python
keywords
如果您提供的字段名违反了这些条件中的任何一个,那么您会得到一个ValueError:
>>> from collections import namedtuple >>> Point = namedtuple("Point", ["x", "_y"]) Traceback (most recent call last): ... ValueError: Field names cannot start with an underscore: '_y'在这个例子中,第二个字段名以和下划线开头,所以您得到一个
ValueError告诉您字段名不能以那个字符开头。这是为了避免与namedtuple方法和属性的名称冲突。在
typename的例子中,当你看上面的例子时会产生一个问题:为什么我需要提供typename参数?答案是你需要一个由namedtuple()返回的类的名字。这类似于为现有类创建别名:
>>> from collections import namedtuple
>>> Point1 = namedtuple("Point", "x y")
>>> Point1
<class '__main__.Point'>
>>> class Point:
... def __init__(self, x, y):
... self.x = x
... self.y = y
...
>>> Point2 = Point
>>> Point2
<class '__main__.Point'>
在第一个例子中,您使用namedtuple()创建了Point。然后你把这个新类型分配给全局 变量 Point1。在第二个例子中,您创建了一个名为Point的常规 Python 类,然后将该类分配给Point2。在这两种情况下,类名都是Point。Point1和Point2是当前类的别名。
最后,您还可以使用关键字参数或提供现有字典来创建命名元组,如下所示:
>>> from collections import namedtuple >>> Point = namedtuple("Point", "x y") >>> Point(x=2, y=4) Point(x=2, y=4) >>> Point(**{"x": 4, "y": 8}) Point(x=4, y=8)在第一个例子中,您使用关键字参数来创建一个
Point对象。在第二个例子中,您使用了一个字典,它的键与Point的字段相匹配。在这种情况下,你需要执行一个字典解包。使用可选参数
namedtuple()与除了两个必需的参数外,
namedtuple()工厂函数还接受以下可选参数:
renamedefaultsmodule如果您将
rename设置为True,那么所有无效的字段名将自动替换为位置名。假设您的公司有一个用 Python 编写的旧数据库应用程序,用来管理与公司一起旅行的乘客的数据。要求您更新系统,您开始创建命名元组来存储从数据库中读取的数据。
应用程序提供了一个名为
get_column_names()的函数,该函数返回一个包含列名的字符串列表,您认为可以使用该函数创建一个namedtuple类。您最终会得到以下代码:# passenger.py from collections import namedtuple from database import get_column_names Passenger = namedtuple("Passenger", get_column_names())然而,当您运行代码时,您会得到如下所示的异常回溯:
Traceback (most recent call last): ... ValueError: Type names and field names cannot be a keyword: 'class'这告诉您,
class列名不是您的namedtuple类的有效字段名称。为了防止这种情况,你决定使用rename:# passenger.py # ... Passenger = namedtuple("Passenger", get_column_names(), rename=True)这导致
namedtuple()自动用位置名称替换无效名称。现在假设您从数据库中检索一行并创建第一个Passenger实例,如下所示:
>>> from passenger import Passenger
>>> from database import get_passenger_by_id
>>> Passenger(get_passenger_by_id("1234"))
Passenger(_0=1234, name='john', _2='Business', _3='John Doe')
在这种情况下,get_passenger_by_id()是您的假设应用程序中的另一个可用函数。它检索元组中给定乘客的数据。最终结果是您新创建的乘客有三个位置字段名称,只有name反映了原始的列名称。当您深入数据库时,您会发现“乘客”表包含以下列:
| 圆柱 | 商店 | 被替换了? | 理由 |
|---|---|---|---|
_id |
每位乘客的唯一标识符 | 是 | 它以下划线开头。 |
name |
每位乘客的简称 | 不 | 这是一个有效的 Python 标识符。 |
class |
乘客旅行的等级 | 是 | 这是一个 Python 关键字。 |
name |
乘客的全名 | 是 | 重复了。 |
在基于控制之外的值创建命名元组的情况下,rename选项应该设置为True,这样无效字段就可以用有效的位置名重命名。
namedtuple()的第二个可选参数是defaults。该参数默认为 None ,这意味着这些字段没有默认值。您可以将defaults设置为可迭代的值。在这种情况下,namedtuple()将defaults iterable 中的值分配给最右边的字段:
>>> from collections import namedtuple >>> Developer = namedtuple( ... "Developer", ... "name level language", ... defaults=["Junior", "Python"] ... ) >>> Developer("John") Developer(name='John', level='Junior', language='Python')在这个例子中,
level和language字段具有默认值。这使它们成为可选参数。因为您没有为name定义默认值,所以您需要在创建namedtuple实例时提供一个值。因此,没有默认值的参数是必需的。请注意,默认值应用于最右边的字段。
namedtuple()的最后一个参数是module。如果您为这个参数提供了一个有效的模块名,那么结果namedtuple的.__module__属性将被设置为这个值。此属性保存定义给定函数或可调用函数的模块的名称:
>>> from collections import namedtuple
>>> Point = namedtuple("Point", "x y", module="custom")
>>> Point
<class 'custom.Point'>
>>> Point.__module__
'custom'
在这个例子中,当你在Point上访问.__module__时,你得到的结果是'custom'。这表明您的Point类是在您的custom模块中定义的。
在 Python 3.6 中将module参数添加到namedtuple()的动机是为了使命名元组能够通过不同的 Python 实现支持酸洗。
探索namedtuple类的附加特性
除了继承自tuple的方法,如.count()和.index(),namedtuple类还提供了三个额外的方法和两个属性。为了防止与自定义字段的名称冲突,这些属性和方法的名称以下划线开头。在本节中,您将了解这些方法和属性以及它们是如何工作的。
从 Iterables 创建namedtuple实例
您可以使用 ._make() 来创建命名元组实例。该方法采用 iterable 值,并返回一个新的命名元组:
>>> from collections import namedtuple >>> Person = namedtuple("Person", "name age height") >>> Person._make(["Jane", 25, 1.75]) Person(name='Jane', age=25, height=1.75)这里,首先使用
namedtuple()创建一个Person类。然后调用._make(),并在namedtuple中列出每个字段的值。注意,._make()是一个类方法,它作为另一个类构造函数工作,并返回一个新的命名元组实例。最后,
._make()期望一个单独的 iterable 作为参数,在上面的例子中是一个list。另一方面,namedtuple构造函数可以接受位置参数或关键字参数,正如您已经了解的那样。将
namedtuple个实例转换成字典您可以使用
._asdict()将现有的命名元组实例转换为字典。该方法返回一个使用字段名作为键的新字典。结果字典的键与原始namedtuple中的字段顺序相同:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> jane._asdict()
{'name': 'Jane', 'age': 25, 'height': 1.75}
当您在一个命名元组上调用._asdict()时,您会得到一个新的dict对象,它将字段名映射到它们在原始命名元组中对应的值。
自从 Python 3.8 ,._asdict()回归了常规字典。在此之前,它返回了一个 OrderedDict 对象:
Python 3.7.9 (default, Jan 14 2021, 11:41:20) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from collections import namedtuple >>> Person = namedtuple("Person", "name age height") >>> jane = Person("Jane", 25, 1.75) >>> jane._asdict() OrderedDict([('name', 'Jane'), ('age', 25), ('height', 1.75)])Python 3.8 更新了
._asdict()返回常规字典,因为在 Python 3.6 及以上版本中字典会记住它们的键的插入顺序。请注意,结果字典中键的顺序等同于原始命名元组中字段的顺序。替换现有
namedtuple实例中的字段最后一个方法是
._replace()。该方法采用形式为field=value的关键字参数,并返回一个新的namedtuple实例来更新所选字段的值:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> # After Jane's birthday
>>> jane = jane._replace(age=26)
>>> jane
Person(name='Jane', age=26, height=1.75)
在本例中,您在 Jane 生日后更新她的年龄。尽管._replace()的名字可能意味着该方法修改了现有的命名元组,但实际上并不是这样。这是因为namedtuple实例是不可变的,所以._replace()不会就地更新jane。
探索附加的namedtuple属性
命名元组还有两个附加属性: ._fields 和 ._field_defaults 。第一个属性包含一组列出字段名称的字符串。第二个属性包含一个字典,该字典将字段名映射到它们各自的默认值(如果有的话)。
对于._fields,您可以用它来自省您的namedtuple类和实例。您也可以从现有类别创建新类别:
>>> from collections import namedtuple >>> Person = namedtuple("Person", "name age height") >>> ExtendedPerson = namedtuple( ... "ExtendedPerson", ... [*Person._fields, "weight"] ... ) >>> jane = ExtendedPerson("Jane", 26, 1.75, 67) >>> jane ExtendedPerson(name='Jane', age=26, height=1.75, weight=67) >>> jane.weight 67在本例中,您创建了一个名为
ExtendedPerson的新namedtuple,它带有一个新字段weight。这种新型号扩展了你的旧型号Person。为此,您在Person访问._fields,并将其与一个附加字段weight一起解包到一个新列表中。您还可以使用 Python 的
zip()使用._fields迭代给定namedtuple实例中的字段和值:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height weight")
>>> jane = Person("Jane", 26, 1.75, 67)
>>> for field, value in zip(jane._fields, jane):
... print(field, "->", value)
...
name -> Jane
age -> 26
height -> 1.75
weight -> 67
在这个例子中,zip()产生了形式为(field, value)的元组。这样,您可以访问底层命名元组中字段-值对的两个元素。另一种同时迭代字段和值的方法是使用._asdict().items()。来吧,试一试!
使用._field_defaults,您可以自省namedtuple类和实例,找出哪些字段提供默认值。拥有默认值使您的字段成为可选字段。例如,假设您的Person类应该包含一个额外的字段来保存这个人居住的国家。因为您主要与来自加拿大的人一起工作,所以您为country字段设置适当的默认值,如下所示:
>>> from collections import namedtuple >>> Person = namedtuple( ... "Person", ... "name age height weight country", ... defaults=["Canada"] ... ) >>> Person._field_defaults {'country': 'Canada'}通过快速查询
._field_defaults,您可以找出给定namedtuple中的哪些字段提供默认值。在这个例子中,您团队中的任何其他程序员都可以看到您的Person类提供了"Canada"作为country的便利默认值。如果您的
namedtuple没有提供默认值,那么.field_defaults保存一个空字典:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height weight country")
>>> Person._field_defaults
{}
如果你不给namedtuple()提供一个默认值列表,那么它依赖于defaults的默认值,也就是 None 。在这种情况下,._field_defaults保存一个空字典。
用namedtuple 编写 Pythonic 代码
可以说,命名元组的基本用例是帮助您编写更多 Pythonic 代码。创建工厂函数是为了让你写可读的、明确的、干净的和可维护的代码。
在这一节中,您将编写一系列实用的示例,帮助您发现使用命名元组而不是常规元组的好机会,从而使您的代码更加 Pythonic 化。
使用字段名代替索引
假设您正在创建一个绘画应用程序,您需要根据用户的选择定义要使用的笔属性。您已经将笔的属性编码在一个元组中:
>>> pen = (2, "Solid", True) >>> if pen[0] == 2 and pen[1] == "Solid" and pen[2]: ... print("Standard pen selected") ... Standard pen selected这行代码定义了一个包含三个值的元组。你能说出每个值的含义吗?也许你能猜到第二个值和线条样式有关,但是
2和True是什么意思呢?您可以添加一个很好的注释来为
pen提供一些上下文,在这种情况下,您将会得到类似这样的结果:
>>> # Tuple containing: line weight, line style, and beveled edges
>>> pen = (2, "Solid", True)
酷!现在您知道了元组中每个值的含义。然而,如果你或另一个程序员使用的pen与这个定义相去甚远呢?他们不得不回到定义中去,仅仅是为了记住每个值的含义。
这里有一个使用namedtuple的pen的替代实现:
>>> from collections import namedtuple >>> Pen = namedtuple("Pen", "width style beveled") >>> pen = Pen(2, "Solid", True) >>> if pen.width == 2 and pen.style == "Solid" and pen.beveled: ... print("Standard pen selected") ... Standard pen selected现在你的代码清楚地表明
2代表钢笔的宽度,"Solid"是线条样式,等等。任何阅读您的代码的人都可以看到并理解这一点。您的新实现pen有两行额外的代码。这是在可读性和可维护性方面产生巨大成功的少量工作。从函数中返回多个命名值
可以使用命名元组的另一种情况是当您需要从给定的函数中返回多个值时。在这种情况下,使用命名元组可以使您的代码更具可读性,因为返回值还将为其内容提供一些上下文。
例如,Python 提供了一个名为
divmod()的内置函数,该函数将两个数字作为参数,并返回一个元组,该元组具有从输入数字的整数除法得到的商和余数:
>>> divmod(8, 4)
(2, 0)
为了记住每个数字的含义,你可能需要阅读divmod()的文档,因为数字本身并没有提供关于它们各自含义的太多信息。函数名也没多大帮助。
下面是一个函数,它使用一个namedtuple来阐明divmod()返回的每个数字的含义:
>>> from collections import namedtuple >>> def custom_divmod(a, b): ... DivMod = namedtuple("DivMod", "quotient remainder") ... return DivMod(*divmod(a, b)) ... >>> custom_divmod(8, 4) DivMod(quotient=2, remainder=0)在本例中,您为每个返回值添加了上下文,因此任何程序员在阅读您的代码时都可以立即理解每个数字的含义。
减少函数的参数数量
减少函数可以接受的参数数量被认为是最佳编程实践。这使得你的函数的签名更加简洁,并且优化了你的测试过程,因为减少了参数的数量和它们之间可能的组合。
同样,您应该考虑使用命名元组来处理这个用例。假设您正在编写一个管理客户信息的应用程序。该应用程序使用一个数据库来存储客户的数据。为了处理数据和更新数据库,您已经创建了几个函数。你的一个高层函数是
create_user(),看起来是这样的:def create_user(db, username, client_name, plan): db.add_user(username) db.complete_user_profile(username, client_name, plan)这个函数有四个参数。第一个参数
db代表您正在使用的数据库。其余的论点与给定的客户密切相关。这是一个使用命名元组将参数数量减少到create_user()的好机会:User = namedtuple("User", "username client_name plan") user = User("john", "John Doe", "Premium") def create_user(db, user): db.add_user(user.username) db.complete_user_profile( user.username, user.client_name, user.plan )现在
create_user()只需要两个参数:db和user。在函数内部,使用方便的描述性字段名为db.add_user()和db.complete_user_profile()提供参数。你的高级功能create_user(),更侧重于user。测试也更容易,因为您只需要为每个测试提供两个参数。从文件和数据库中读取表格数据
命名元组的一个非常常见的用例是使用它们来存储数据库记录。您可以使用列名作为字段名来定义
namedtuple类,并将数据从数据库的行中检索到命名元组。你也可以对 CSV 文件做类似的事情。例如,假设您有一个包含公司员工数据的 CSV 文件,您希望将该数据读入一个合适的数据结构,以便进一步处理。您的 CSV 文件如下所示:
name,job,email "Linda","Technical Lead","linda@example.com" "Joe","Senior Web Developer","joe@example.com" "Lara","Project Manager","lara@example.com" "David","Data Analyst","david@example.com" "Jane","Senior Python Developer","jane@example.com"您正在考虑使用 Python 的
csv模块及其DictReader来处理文件,但是您有一个额外的需求——您需要将数据存储到一个不可变的轻量级数据结构中。在这种情况下,namedtuple可能是个不错的选择:
>>> import csv
>>> from collections import namedtuple
>>> with open("employees.csv", "r") as csv_file:
... reader = csv.reader(csv_file)
... Employee = namedtuple("Employee", next(reader), rename=True)
... for row in reader:
... employee = Employee(*row)
... print(employee.name, employee.job, employee.email)
...
Linda Technical Lead linda@example.com
Joe Senior Web Developer joe@example.com
Lara Project Manager lara@example.com
David Data Analyst david@example.com
Jane Senior Python Developer jane@example.com
在这个例子中,首先在一个 with语句中打开employees.csv文件。然后使用 csv.reader() 来获取 CSV 文件中各行的迭代器。使用namedtuple(),您创建了一个新的Employee类。对 next() 的调用从reader中检索第一行数据,其中包含 CSV 文件头。这个标题为您的namedtuple提供了字段名称。
注意:当您基于不受您控制的字段名创建namedtuple时,您应该将.rename设置为True。这样,您可以防止无效字段名称的问题,这在您处理数据库表和查询、CSV 文件或任何其他类型的表格数据时是一种常见的情况。
最后, for循环从 CSV 文件中的每个row创建一个Employee实例,然后将雇员列表打印到屏幕上。
使用namedtuple vs 其他数据结构
到目前为止,您已经学习了如何创建命名元组,以使您的代码更具可读性、更显式和更具 Pythonic 性。您还编写了一些示例,帮助您发现在代码中使用命名元组的机会。
在这一节中,您将大致了解一下namedtuple类和其他 Python 数据结构(如字典、数据类和类型化的命名元组)之间的异同。您将比较命名元组与其他数据结构的以下特征:
- 可读性
- 易变性
- 内存使用
- 表演
这样,您就可以更好地为您的特定用例选择正确的数据结构。
namedtuple vs 字典
字典是 Python 中的基本数据结构。语言本身是围绕着字典建立的,所以它们无处不在。因为它们如此普遍和有用,你可能在你的代码中经常使用它们。但是字典和命名元组有多大区别呢?
就可读性而言,你大概可以说字典和命名元组一样可读。尽管它们没有提供通过点符号访问属性的方法,但是字典式的键查找非常易读和简单:
>>> from collections import namedtuple >>> jane = {"name": "Jane", "age": 25, "height": 1.75} >>> jane["age"] 25 >>> # Equivalent named tuple >>> Person = namedtuple("Person", "name age height") >>> jane = Person("Jane", 25, 1.75) >>> jane.age 25在这两个例子中,您已经完全理解了代码及其意图。不过,命名元组定义需要两行额外的代码:一行用于导入工厂函数,另一行用于定义
namedtuple类Person。这两种数据结构的一个很大的区别是字典是可变的,而命名元组是不可变的。这意味着您可以就地修改字典,但是您不能修改命名元组:
>>> from collections import namedtuple
>>> jane = {"name": "Jane", "age": 25, "height": 1.75}
>>> jane["age"] = 26
>>> jane["age"]
26
>>> jane["weight"] = 67
>>> jane
{'name': 'Jane', 'age': 26, 'height': 1.75, 'weight': 67}
>>> # Equivalent named tuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> jane.age = 26
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
>>> jane.weight = 67
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Person' object has no attribute 'weight'
您可以在字典中更新现有键的值,但不能在命名元组中做类似的事情。可以向现有字典添加新的键-值对,但不能向现有的命名元组添加字段-值对。
注意:在命名元组中,可以使用._replace()来更新给定字段的值,但是该方法创建并返回一个新的命名元组实例,而不是就地更新底层实例。
一般来说,如果您需要一个不可变的数据结构来正确地解决一个给定的问题,那么可以考虑使用一个命名元组来代替字典,这样就可以满足您的需求。
关于内存使用,命名元组是一种非常轻量级的数据结构。启动您的代码编辑器或 IDE 并创建以下脚本:
# namedtuple_dict_memory.py
from collections import namedtuple
from pympler import asizeof
Point = namedtuple("Point", "x y z")
point = Point(1, 2, 3)
namedtuple_size = asizeof.asizeof(point)
dict_size = asizeof.asizeof(point._asdict())
gain = 100 - namedtuple_size / dict_size * 100
print(f"namedtuple: {namedtuple_size} bytes ({gain:.2f}% smaller)")
print(f"dict: {dict_size} bytes")
这个小脚本使用来自 Pympler 的asizeof.asizeof()来获取一个命名元组及其等价字典的内存占用。
注意: Pympler 是一个监控和分析 Python 对象内存行为的工具。
$ pip install pympler
在您运行这个命令之后,Pympler 将在您的 Python 环境中可用,因此您可以运行上面的脚本。
如果您从命令行运行脚本,那么您将得到以下输出:
$ python namedtuple_dict_memory.py
namedtuple: 160 bytes (67.74% smaller)
dict: 496 bytes
该输出证实了命名元组比等效的字典消耗更少的内存。因此,如果内存消耗对您来说是一个限制,那么您应该考虑使用命名元组而不是字典。
注意:在比较命名元组和字典时,最终的内存消耗差异将取决于值的数量及其类型。不同的值,你会得到不同的结果。
最后,您需要了解命名元组和字典在操作性能方面有多么不同。为此,您将测试成员资格和属性访问操作。回到代码编辑器,创建以下脚本:
# namedtuple_dict_time.py
from collections import namedtuple
from time import perf_counter
def average_time(structure, test_func):
time_measurements = []
for _ in range(1_000_000):
start = perf_counter()
test_func(structure)
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_dict(dictionary):
"x" in dictionary
"missing_key" in dictionary
2 in dictionary.values()
"missing_value" in dictionary.values()
dictionary["y"]
def time_namedtuple(named_tuple):
"x" in named_tuple._fields
"missing_field" in named_tuple._fields
2 in named_tuple
"missing_value" in named_tuple
named_tuple.y
Point = namedtuple("Point", "x y z")
point = Point(x=1, y=2, z=3)
namedtuple_time = average_time(point, time_namedtuple)
dict_time = average_time(point._asdict(), time_dict)
gain = dict_time / namedtuple_time
print(f"namedtuple: {namedtuple_time:.2f} ns ({gain:.2f}x faster)")
print(f"dict: {dict_time:.2f} ns")
这个脚本对字典和命名元组的常见操作进行计时,比如成员测试和属性访问。在当前系统上运行该脚本会显示类似于以下内容的输出:
$ namedtuple_dict_time.py
namedtuple: 527.26 ns (1.36x faster)
dict: 717.71 ns
该输出显示,对命名元组的操作比对字典的类似操作稍快。
namedtuple vs 数据类
Python 3.7 带来了一个很酷的新特性:数据类。根据 PEP 557 的说法,数据类类似于命名元组,但是它们是可变的:
数据类可以被认为是“带有默认值的可变命名元组”(来源)
然而,更准确地说,数据类就像带有类型提示的可变命名元组。“默认值”部分根本没有区别,因为命名元组的字段也可以有默认值。所以,乍一看,主要的区别是可变性和类型提示。
要创建一个数据类,需要从 dataclasses 导入 dataclass() 装饰器。然后,您可以使用常规的类定义语法来定义数据类:
>>> from dataclasses import dataclass >>> @dataclass ... class Person: ... name: str ... age: int ... height: float ... weight: float ... country: str = "Canada" ... >>> jane = Person("Jane", 25, 1.75, 67) >>> jane Person(name='Jane', age=25, height=1.75, weight=67, country='Canada') >>> jane.name 'Jane' >>> jane.name = "Jane Doe" >>> jane.name 'Jane Doe'就可读性而言,数据类和命名元组之间没有显著差异。它们提供了相似的字符串表示,您可以使用点符号来访问它们的属性。
可变性——根据定义,数据类是可变的,因此您可以在需要时更改它们的属性值。然而,他们有一张王牌。您可以将
dataclass()装饰器的frozen参数设置为True,并使它们不可变:
>>> from dataclasses import dataclass
>>> @dataclass(frozen=True)
... class Person:
... name: str
... age: int
... height: float
... weight: float
... country: str = "Canada"
...
>>> jane = Person("Jane", 25, 1.75, 67)
>>> jane.name = "Jane Doe"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 4, in __setattr__
dataclasses.FrozenInstanceError: cannot assign to field 'name'
如果您在对dataclass()的调用中将frozen设置为True,那么您就使数据类不可变。在这种情况下,当您尝试更新 Jane 的名字时,您会得到一个 FrozenInstanceError 。
命名元组和数据类之间的另一个微妙区别是,后者在默认情况下是不可迭代的。坚持以 Jane 为例,尝试迭代她的数据:
>>> for field in jane: ... print(field) ... Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'Person' object is not iterable如果您试图迭代一个基本的数据类,那么您会得到一个
TypeError。这是普通班常见的。幸运的是,有办法解决这个问题。例如,您可以向Person添加一个.__iter__()特殊方法,如下所示:
>>> from dataclasses import astuple, dataclass
>>> @dataclass
... class Person:
... name: str
... age: int
... height: float
... weight: float
... country: str = "Canada"
... def __iter__(self):
... return iter(astuple(self))
...
>>> for field in Person("Jane", 25, 1.75, 67):
... print(field)
...
Jane
25
1.75
67
Canada
这里,你先从dataclasses导入 astuple() 。这个函数将数据类转换成一个元组。然后将结果元组传递给 iter() ,这样就可以构建并从.__iter__()返回一个迭代器。有了这个添加,您就可以开始迭代 Jane 的数据了。
关于内存消耗,命名元组比数据类更轻量级。您可以通过创建并运行一个类似于上一节中看到的小脚本来确认这一点。要查看完整的脚本,请展开下面的框。
下面的脚本比较了namedtuple和它的等价数据类之间的内存使用情况:
# namedtuple_dataclass_memory.py
from collections import namedtuple
from dataclasses import dataclass
from pympler import asizeof
PointNamedTuple = namedtuple("PointNamedTuple", "x y z")
@dataclass
class PointDataClass:
x: int
y: int
z: int
namedtuple_memory = asizeof.asizeof(PointNamedTuple(x=1, y=2, z=3))
dataclass_memory = asizeof.asizeof(PointDataClass(x=1, y=2, z=3))
gain = 100 - namedtuple_memory / dataclass_memory * 100
print(f"namedtuple: {namedtuple_memory} bytes ({gain:.2f}% smaller)")
print(f"data class: {dataclass_memory} bytes")
在这个脚本中,您创建了一个命名元组和一个包含相似数据的数据类。然后比较它们的内存占用。
以下是运行脚本的结果:
$ python namedtuple_dataclass_memory.py
namedtuple: 160 bytes (61.54% smaller)
data class: 416 bytes
与namedtuple类不同,数据类保留一个基于实例的 .__dict__ 来存储可写的实例属性。这有助于更大的内存占用。
接下来,您可以展开下面的部分来查看一个代码示例,该示例比较了namedtuple类和数据类在属性访问方面的性能。
以下脚本比较了命名元组及其等效数据类的属性访问性能:
# namedtuple_dataclass_time.py
from collections import namedtuple
from dataclasses import dataclass
from time import perf_counter
def average_time(structure, test_func):
time_measurements = []
for _ in range(1_000_000):
start = perf_counter()
test_func(structure)
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_structure(structure):
structure.x
structure.y
structure.z
PointNamedTuple = namedtuple("PointNamedTuple", "x y z", defaults=[3])
@dataclass
class PointDataClass:
x: int
y: int
z: int
namedtuple_time = average_time(PointNamedTuple(x=1, y=2, z=3), time_structure)
dataclass_time = average_time(PointDataClass(x=1, y=2, z=3), time_structure)
gain = dataclass_time / namedtuple_time
print(f"namedtuple: {namedtuple_time:.2f} ns ({gain:.2f}x faster)")
print(f"data class: {dataclass_time:.2f} ns")
这里,您对属性访问操作进行计时,因为这几乎是命名元组和数据类之间唯一常见的操作。您也可以对成员操作进行计时,但是您必须访问数据类的属性。
在性能方面,结果如下:
$ python namedtuple_dataclass_time.py
namedtuple: 274.32 ns (1.08x faster)
data class: 295.37 ns
性能差异很小,所以在属性访问操作方面,可以说这两种数据结构具有相同的性能。
namedtuplevstyping.NamedTupleT2】
Python 3.5 引入了一个名为 typing 的临时模块来支持函数类型注释或者类型提示。本模块提供 NamedTuple ,是namedtuple的打字版本。使用NamedTuple,您可以创建带有类型提示的namedtuple类。接下来是Person的例子,您可以创建一个等价的类型化命名元组,如下所示:
>>> from typing import NamedTuple >>> class Person(NamedTuple): ... name: str ... age: int ... height: float ... weight: float ... country: str = "Canada" ... >>> issubclass(Person, tuple) True >>> jane = Person("Jane", 25, 1.75, 67) >>> jane.name 'Jane' >>> jane.name = "Jane Doe" Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute使用
NamedTuple,您可以通过点符号创建支持类型提示和属性访问的元组子类。由于生成的类是 tuple 子类,所以它也是不可变的。在上面的例子中需要注意的一个微妙的细节是
NamedTuple子类看起来比命名元组更像数据类。当谈到内存消耗时,
namedtuple和NamedTuple实例使用相同数量的内存。您可以展开下面的框来查看比较两者内存使用情况的脚本。这里有一个脚本比较了一个
namedtuple和它的对等typing.NamedTuple的内存使用情况:# typed_namedtuple_memory.py from collections import namedtuple from typing import NamedTuple from pympler import asizeof PointNamedTuple = namedtuple("PointNamedTuple", "x y z") class PointTypedNamedTuple(NamedTuple): x: int y: int z: int namedtuple_memory = asizeof.asizeof(PointNamedTuple(x=1, y=2, z=3)) typed_namedtuple_memory = asizeof.asizeof( PointTypedNamedTuple(x=1, y=2, z=3) ) print(f"namedtuple: {namedtuple_memory} bytes") print(f"typing.NamedTuple: {typed_namedtuple_memory} bytes")在这个脚本中,您创建了一个命名元组和一个等效的类型化
NamedTuple实例。然后比较两个实例的内存使用情况。这一次,比较内存使用情况的脚本产生以下输出:
$ python typed_namedtuple_memory.py namedtuple: 160 bytes typing.NamedTuple: 160 bytes在这种情况下,两个实例消耗相同数量的内存,所以这次没有赢家。
由于
namedtuple类和NamedTuple子类都是tuple的子类,所以它们有很多共同点。在这种情况下,您可以对字段和值的成员资格测试进行计时。您还可以使用点符号对属性访问进行计时。展开下面的方框,查看比较namedtuple和NamedTuple性能的脚本。以下脚本比较了
namedtuple和typing.NamedTuple的性能:# typed_namedtuple_time.py from collections import namedtuple from time import perf_counter from typing import NamedTuple def average_time(structure, test_func): time_measurements = [] for _ in range(1_000_000): start = perf_counter() test_func(structure) end = perf_counter() time_measurements.append(end - start) return sum(time_measurements) / len(time_measurements) * int(1e9) def time_structure(structure): "x" in structure._fields "missing_field" in structure._fields 2 in structure "missing_value" in structure structure.y PointNamedTuple = namedtuple("PointNamedTuple", "x y z") class PointTypedNamedTuple(NamedTuple): x: int y: int z: int namedtuple_time = average_time(PointNamedTuple(x=1, y=2, z=3), time_structure) typed_namedtuple_time = average_time( PointTypedNamedTuple(x=1, y=2, z=3), time_structure ) print(f"namedtuple: {namedtuple_time:.2f} ns") print(f"typing.NamedTuple: {typed_namedtuple_time:.2f} ns")在这个脚本中,首先创建一个命名元组,然后创建一个具有类似内容的类型化命名元组。然后比较两种数据结构上常见操作的性能。
结果如下:
$ python typed_namedtuple_time.py namedtuple: 503.34 ns typing.NamedTuple: 509.91 ns在这种情况下,可以说这两种数据结构在性能方面表现几乎相同。除此之外,使用
NamedTuple创建命名元组可以使代码更加明确,因为您可以向字段添加类型信息。您还可以提供默认值,添加新功能,并为您的类型化命名元组编写文档字符串。在本节中,您已经学习了很多关于
namedtuple和其他类似的数据结构和类的知识。下面的表格总结了namedtuple与本节介绍的数据结构的比较:
dict数据类 NamedTuple可读性 类似的 平等的 平等的 不变性 不 默认为否,如果使用 @dataclass(frozen=True)则为是是 内存使用量 高等级的;级别较高的;较重要的 高等级的;级别较高的;较重要的 平等的 性能 慢的 类似的 类似的 可迭代性 是 默认为否,如果提供 .__iter__()则为是是 有了这个总结,您将能够选择最适合您当前需求的数据结构。此外,您应该考虑数据类和
NamedTuple允许您添加类型提示,这是当前 Python 代码中非常需要的特性。子类化
namedtuple类因为
namedtuple类是常规的 Python 类,所以如果需要提供额外的功能、文档字符串、用户友好的字符串表示等等,可以对它们进行子类化。例如,将一个人的年龄存储在一个对象中并不被认为是最佳实践。因此,您可能希望存储出生日期,并在需要时计算年龄:
>>> from collections import namedtuple
>>> from datetime import date
>>> BasePerson = namedtuple(
... "BasePerson",
... "name birthdate country",
... defaults=["Canada"]
... )
>>> class Person(BasePerson):
... """A namedtuple subclass to hold a person's data."""
... __slots__ = ()
... def __repr__(self):
... return f"Name: {self.name}, age: {self.age} years old."
... @property
... def age(self):
... return (date.today() - self.birthdate).days // 365
...
>>> Person.__doc__
"A namedtuple subclass to hold a person's data."
>>> jane = Person("Jane", date(1996, 3, 5))
>>> jane.age
25
>>> jane
Name: Jane, age: 25 years old.
Person继承自BasePerson,是一个namedtuple类。在子类定义中,首先添加一个 docstring 来描述该类的功能。然后将 __slots__ 设置为空元组,这样可以防止自动创建基于实例的.__dict__。这让你的BasePerson子类内存保持高效。
您还可以添加一个自定义的 .__repr__() 来为该类提供一个漂亮的字符串表示。最后,添加一个属性,使用 datetime 计算这个人的年龄。
测量创作时间:tuple vs namedtuple
到目前为止,您已经根据几个特性将namedtuple类与其他数据结构进行了比较。在这一节中,您将大致了解常规元组和命名元组在创建时间方面的比较。
假设您有一个动态创建大量元组的应用程序。您决定使用命名元组来提高代码的 Pythonic 性和可维护性。一旦您更新了所有的代码库以使用命名元组,您运行应用程序并注意到一些性能问题。经过一些测试后,您得出结论,这些问题可能与动态创建命名元组有关。
下面是一个脚本,它测量动态创建几个元组和命名元组所需的平均时间:
# tuple_namedtuple_time.py
from collections import namedtuple
from time import perf_counter
def average_time(test_func):
time_measurements = []
for _ in range(1_000):
start = perf_counter()
test_func()
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_tuple():
tuple([1] * 1000)
fields = [f"a{n}" for n in range(1000)]
TestNamedTuple = namedtuple("TestNamedTuple", fields)
def time_namedtuple():
TestNamedTuple(*([1] * 1000))
namedtuple_time = average_time(time_namedtuple)
tuple_time = average_time(time_tuple)
gain = namedtuple_time / tuple_time
print(f"tuple: {tuple_time:.2f} ns ({gain:.2f}x faster)")
print(f"namedtuple: {namedtuple_time:.2f} ns")
在这个脚本中,您将计算创建几个元组及其等价的命名元组所需的平均时间。如果您从命令行运行该脚本,那么您将得到类似如下的输出:
$ python tuple_namedtuple_time.py
tuple: 7075.82 ns (3.36x faster)
namedtuple: 23773.67 ns
当您查看这个输出时,可以看到动态创建tuple对象比创建相似的命名元组要快得多。在某些情况下,例如使用大型数据库,创建命名元组所需的额外时间会严重影响应用程序的性能,因此如果您的代码动态创建了大量元组,请注意这一点。
结论
编写Python代码是 Python 开发领域的一项热门技能。Python 代码是可读的、明确的、干净的、可维护的,并且利用了 Python 习惯用法和最佳实践。在本教程中,您了解了如何创建namedtuple类和实例,以及它们如何帮助您提高 Python 代码的质量。
在本教程中,您学习了:
- 如何创建和使用
namedtuple类和实例 - 如何利用酷
namedtuple功能 - 何时使用
namedtuple实例编写python 代码 - 何时使用一个
namedtuple而不是一个类似的数据结构 - 如何向子类的
namedtuple添加新功能
有了这些知识,您可以大大提高现有和未来代码的质量。如果您经常使用元组,那么只要有意义,就考虑将它们转换成命名元组。这样做将使您的代码更具可读性和 Pythonic 性。*********
Python 中的名称空间和范围
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 在 Python 中导航名称空间和范围
本教程涵盖了 Python 名称空间,这种结构用于组织在 Python 程序中分配给对象的符号名称。
本系列之前的教程已经强调了 Python 中 对象 的重要性。对象无处不在!事实上,Python 程序创建或操作的所有东西都是对象。
一个赋值语句创建一个符号名,你可以用它来引用一个对象。语句x = 'foo'创建了一个符号名x,它引用了字符串对象'foo'。
在任何复杂的程序中,你都会创建成百上千个这样的名字,每个名字都指向一个特定的对象。Python 如何跟踪所有这些名称,使它们不会互相干扰?
在本教程中,您将学习:
- Python 如何在名称空间中组织符号名称和对象
- 当 Python 创建一个新的名称空间时
- 名称空间是如何实现的
- 变量作用域如何决定符号名的可见性
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 中的名称空间
名称空间是当前定义的符号名称以及每个名称引用的对象信息的集合。您可以将名称空间想象成一个字典,其中的键是对象名,值是对象本身。每个键值对都将一个名称映射到其对应的对象。
名称空间是一个非常棒的想法——让我们多做一些吧!
——蟒蛇的禅,作者蒂姆·皮特斯
正如 Tim Peters 所说,名称空间不仅仅是伟大的。它们很棒,Python 广泛使用它们。在 Python 程序中,有四种类型的名称空间:
- 内置的
- 全球的
- 封闭
- 当地的
这些具有不同的寿命。Python 执行程序时,会根据需要创建名称空间,并在不再需要时删除它们。通常,在任何给定时间都会存在许多名称空间。
内置名称空间
内置名称空间包含所有 Python 内置对象的名称。当 Python 运行时,这些都是可用的。您可以使用以下命令列出内置名称空间中的对象:
>>> dir(__builtins__) ['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException','BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']您将在这里看到一些您可能在以前的教程中见过的对象—例如,
StopIteration异常,内置函数,如max()和len(),以及对象类型,如int和str。Python 解释器在启动时创建内置名称空间。这个名称空间一直存在,直到解释器终止。
全局名称空间
全局名称空间包含在主程序级别定义的任何名称。Python 在主程序体启动时创建全局名称空间,并且它一直存在,直到解释器终止。
严格地说,这可能不是唯一存在的全局名称空间。解释器还为程序用
import语句加载的任何模块创建一个全局名称空间。要进一步了解 Python 中的主要函数和模块,请参阅以下资源:在本系列的后续教程中,您将更详细地探索这些模块。目前,当您看到术语全局名称空间时,请考虑属于主程序的名称空间。
本地和封闭名称空间
正如您在上一篇关于函数的教程中所学的,每当函数执行时,解释器都会创建一个新的名称空间。该名称空间是函数的本地名称,并且在函数终止之前一直存在。
只有在主程序的层次上,函数才不是彼此独立存在的。您也可以在另一个中定义一个函数:
1>>> def f(): 2... print('Start f()')
3...
4... def g(): 5... print('Start g()')
6... print('End g()')
7... return 8...
9... g() 10...
11... print('End f()')
12... return 13...
14
15>>> f() 16Start f()
17Start g()
18End g()
19End f()
在这个例子中,函数g()被定义在f()的主体中。下面是这段代码中发生的情况:
- 第 1 到 12 行定义
f(),包含功能的。 - 第 4 行到第 7 行定义
g(),其中包含功能。 - 在第 15 行,主程序调用
f()。 - 在9 号线,
f()呼叫g()。
当主程序调用f()时,Python 为f()创建一个新的名称空间。类似地,当f()调用g()时,g()获得自己独立的名称空间。为g()创建的名称空间是本地名称空间,为f()创建的名称空间是封闭名称空间。
这些名称空间中的每一个都保持存在,直到其各自的功能终止。当名称空间的函数终止时,Python 可能不会立即回收为这些名称空间分配的内存,但是对它们包含的对象的所有引用都不再有效。
可变范围
多个不同名称空间的存在意味着在 Python 程序运行时,特定名称的几个不同实例可以同时存在。只要每个实例在不同的名称空间中,它们都是单独维护的,不会互相干扰。
但是这就产生了一个问题:假设您在代码中引用了名称x,并且x存在于几个名称空间中。Python 怎么知道你说的是哪个?
答案在于范围的概念。名字的范围是该名字有意义的程序区域。解释器在运行时根据名字定义出现的位置和代码中名字被引用的位置来确定这一点。
延伸阅读:参见维基百科关于计算机编程中的作用域的页面了解编程语言中变量作用域的详细讨论。
如果你更喜欢钻研视频课程,那就去看看探索 Python 中的作用域和闭包或者用 Python 基础:作用域回到基础。
回到上面的问题,如果您的代码引用了名称x,那么 Python 将在下面的名称空间中按照所示的顺序搜索x:
- 局部:如果你在一个函数中引用
x,那么解释器首先在该函数局部的最内层作用域中搜索它。 - 封闭:如果
x不在局部范围内,但是出现在驻留在另一个函数内的函数中,那么解释器在封闭函数的范围内搜索。 - 全局:如果上面的搜索都没有结果,那么解释器接下来在全局范围内查找。
- 内置:如果在别的地方找不到
x,那么解释器就尝试内置作用域。
这就是 Python 文献中通常所说的 LEGB 规则(尽管这个术语实际上并没有出现在 Python 文档中)。解释器从里到外搜索一个名字,在 l ocal、 e nclosing、 g lobal、最后是 b 内置范围中查找:

如果解释器在这些位置都找不到这个名字,Python 就会抛出一个 NameError异常。
例子
下面是 LEGB 规则的几个例子。在每种情况下,最里面的封闭函数g()试图向控制台显示名为x的变量的值。注意每个例子是如何根据范围为x打印不同的值的。
示例 1:单一定义
在第一个例子中,x只在一个位置定义。它在f()和g()之外,所以驻留在全局范围内:
1>>> x = 'global' 2 3>>> def f(): 4... 5... def g(): 6... print(x) 7... 8... g() 9... 10 11>>> f() 12global第 6 行的
print()语句只能引用一个可能的x。它显示了在全局名称空间中定义的x对象,也就是字符串'global'。示例 2:双重定义
在下一个例子中,
x的定义出现在两个地方,一个在f()之外,一个在f()之内,但是在g()之外:
1>>> x = 'global' 2
3>>> def f():
4... x = 'enclosing' 5...
6... def g():
7... print(x) 8...
9... g()
10...
11
12>>> f()
13enclosing
和前面的例子一样,g()指的是x。但这一次,它有两个定义可供选择:
- 第 1 行在全局范围内定义
x。 - 第 4 行在封闭范围内再次定义了
x。
根据 LEGB 规则,解释器在查看全局范围之前从封闭范围中找到值。所以第七行的语句显示的是'enclosing'而不是'global'。
示例 3:三重定义
接下来是x在这里、那里和任何地方被定义的情况。一个定义在f()之外,另一个定义在f()之内,但在g()之外,第三个定义在g()之内:
1>>> x = 'global' 2 3>>> def f(): 4... x = 'enclosing' 5... 6... def g(): 7... x = 'local' 8... print(x) 9... 10... g() 11... 12 13>>> f() 14local现在,第 8 行的语句必须区分三种不同的可能性:
- 第 1 行在全局范围内定义
x。- 第 4 行在封闭范围内再次定义了
x。- 第 7 行在
g()的局部范围内第三次定义了x。这里,LEGB 规则规定
g()首先看到自己本地定义的值x。所以print()语句显示'local'。示例 4:无定义
最后,我们有一个例子,其中
g()试图打印x的值,但是x在任何地方都没有定义。那根本行不通:
1>>> def f():
2...
3... def g():
4... print(x) 5...
6... g()
7...
8
9>>> f()
10Traceback (most recent call last):
11 File "<stdin>", line 1, in <module>
12 File "<stdin>", line 6, in f
13 File "<stdin>", line 4, in g
14NameError: name 'x' is not defined
这一次,Python 没有在任何名称空间中找到x,所以第 4 行的语句生成了一个NameError异常。
Python 名称空间词典
在本教程的前面,当第一次引入名称空间时,我们鼓励您将名称空间看作一个字典,其中的键是对象名,值是对象本身。事实上,对于全局和局部命名空间来说,这正是它们的意义所在!Python 确实将这些名称空间实现为字典。
注意:内置名称空间的行为不像字典。Python 将其实现为一个模块。
Python 提供了名为globals()和locals()的内置函数,允许您访问全局和本地名称空间字典。
globals()功能
内置函数globals()返回对当前全局名称空间字典的引用。您可以使用它来访问全局名称空间中的对象。下面是主程序启动时的一个示例:
>>> type(globals()) <class 'dict'> >>> globals() {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>}如您所见,解释器已经在
globals()中放入了几个条目。根据您的 Python 版本和操作系统,它在您的环境中可能会有所不同。不过应该差不多。现在看看在全局范围内定义变量时会发生什么:
>>> x = 'foo'
>>> globals()
{'__name__': '__main__', '__doc__': None, '__package__': None,
'__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None,
'__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>,
'x': 'foo'}
在赋值语句x = 'foo'之后,一个新的条目出现在全局名称空间字典中。字典键是对象的名称x,字典值是对象的值'foo'。
您通常会以通常的方式访问这个对象,通过引用它的符号名x。但是您也可以通过全局名称空间字典间接访问它:
1>>> x 2'foo' 3>>> globals()['x'] 4'foo' 5 6>>> x is globals()['x'] 7True第六行的上的
is比较确认这些实际上是同一物体。您也可以使用
globals()函数在全局名称空间中创建和修改条目:
1>>> globals()['y'] = 100 2
3>>> globals()
4{'__name__': '__main__', '__doc__': None, '__package__': None,
5'__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None,
6'__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>,
7'x': 'foo', 'y': 100} 8
9>>> y
10100 11
12>>> globals()['y'] = 3.14159 13
14>>> y 153.14159
第 1 行的语句与赋值语句y = 100具有同等效力。第 12 行上的语句等同于y = 3.14159。
当简单的赋值语句就可以在全局范围内创建和修改对象时,这种方式有点偏离常规。但是它是有效的,它很好地解释了这个概念。
locals()功能
Python 也提供了相应的内置函数,名为locals()。它类似于globals(),但是访问本地名称空间中的对象:
>>> def f(x, y): ... s = 'foo' ... print(locals()) ... >>> f(10, 0.5) {'s': 'foo', 'y': 0.5, 'x': 10}当在
f()中调用时,locals()返回一个表示函数的本地名称空间的字典。注意,除了本地定义的变量s,本地名称空间还包括函数参数x和y,因为它们对于f()也是本地的。如果您在主程序中的函数外部调用
locals(),那么它的行为与globals()相同。深度潜水:
globals()和locals()之间的细微差别了解一下
globals()和locals()之间的一个小区别是很有用的。
globals()返回包含全局名称空间的字典的实际引用。这意味着如果您调用globals(),保存返回值,并随后定义额外的变量,那么这些新变量将出现在保存的返回值所指向的字典中:`1>>> g = globals() 2>>> g 3{'__name__': '__main__', '__doc__': None, '__package__': None, 4'__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, 5'__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 6'g': {...}} 7 8>>> x = 'foo' 9>>> y = 29 10>>> g 11{'__name__': '__main__', '__doc__': None, '__package__': None, 12'__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, 13'__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 14'g': {...}, 'x': 'foo', 'y': 29}`这里,
g是对全局名称空间字典的引用。在第 8 行和第 9 行的赋值语句之后,x和y出现在g指向的字典中。另一方面,
locals()返回的字典是本地名称空间的当前副本,而不是对它的引用。对本地名称空间的进一步添加不会影响之前从locals()返回的值,直到您再次调用它。此外,您不能使用来自locals()的返回值来修改实际本地名称空间中的对象:`1>>> def f(): 2... s = 'foo' 3... loc = locals() 4... print(loc) 5... 6... x = 20 7... print(loc) 8... 9... loc['s'] = 'bar' 10... print(s) 11... 12 13>>> f() 14{'s': 'foo'} 15{'s': 'foo'} 16foo`在这个例子中,
loc指向来自locals()的返回值,它是本地名称空间的副本。第 6 行第行的语句x = 20将x添加到本地名称空间,但不会将添加到loc指向的副本。类似地,第 9 行上的语句修改了loc指向的副本中键's'的值,但这对实际本地名称空间中的s的值没有影响。这是一个微妙的区别,但如果你不记得它,它可能会给你带来麻烦。
修改超出范围的变量
在本系列的早些时候,在关于用户定义的 Python 函数的教程中,您了解到 Python 中的参数传递有点像按值传递,有点像按引用传递。有时,函数可以通过更改相应的参数来修改其在调用环境中的参数,有时则不能:
- 不可变的参数永远不能被函数修改。
- 一个可变的参数不能被大规模地重新定义,但是它可以被适当地修改。
注:关于修改函数参数的更多信息,请参见 Pascal 中的按值传递 vs 按引用传递和 Python 中的按值传递 vs 按引用传递。
当函数试图修改其局部范围之外的变量时,也存在类似的情况。一个函数根本不能在它的局部范围之外修改一个不可变的对象:
1>>> x = 20
2>>> def f():
3... x = 40 4... print(x)
5...
6
7>>> f()
840
9>>> x
1020
当f()执行行 3 上的赋值x = 40时,它创建一个新的本地引用到一个值为40的整数对象。此时,f()失去了对全局名称空间中名为x的对象的引用。所以赋值语句不会影响全局对象。
注意当f()在行 4 执行print(x)时,显示40,它自己的局部x的值。但是f()终止后,全局范围内的x仍然是20。
如果函数在适当的位置修改了可变类型的对象,那么它可以在局部范围之外修改该对象:
>>> my_list = ['foo', 'bar', 'baz'] >>> def f(): ... my_list[1] = 'quux' ... >>> f() >>> my_list ['foo', 'quux', 'baz']在这种情况下,
my_list是一个列表,列表是可变的。f()可以在my_list内进行修改,即使它不在本地范围内。但是如果
f()试图完全重新分配my_list,那么它将创建一个新的本地对象,而不会修改全局my_list:
>>> my_list = ['foo', 'bar', 'baz']
>>> def f():
... my_list = ['qux', 'quux'] ...
>>> f()
>>> my_list
['foo', 'bar', 'baz']
这类似于当f()试图修改可变函数参数时发生的情况。
global声明
如果您确实需要从f()内部修改全局范围内的值,该怎么办?在 Python 中使用global声明可以做到这一点:
>>> x = 20 >>> def f(): ... global x ... x = 40 ... print(x) ... >>> f() 40 >>> x 40
global x语句表明当f()执行时,对名字x的引用将指向全局名称空间中的x。这意味着赋值x = 40不会创建新的引用。而是在全局范围内给x赋一个新值:
The global Declaration 正如您已经看到的,
globals()返回对全局名称空间字典的引用。如果您愿意,可以不使用global语句,而是使用globals()来完成同样的事情:

>>> x = 20
>>> def f():
... globals()['x'] = 40 ... print(x)
...
>>> f()
40
>>> x 40
没有太多的理由这样做,因为global声明可以说使意图更加清晰。但它确实为globals()如何工作提供了另一个例证。
如果函数启动时在global声明中指定的名字在全局范围内不存在,那么global语句和赋值的组合将创建它:
1>>> y 2Traceback (most recent call last): 3 File "<pyshell#79>", line 1, in <module> 4 y 5NameError: name 'y' is not defined 6 7>>> def g(): 8... global y 9... y = 20 10... 11 12>>> g() 13>>> y 1420在这种情况下,当
g()启动时,全局范围内没有名为y的对象,但是g()在的第 8 行用global y语句创建了一个对象。您也可以在单个
global声明中指定几个逗号分隔的名称:
1>>> x, y, z = 10, 20, 30
2
3>>> def f():
4... global x, y, z
5...
这里,x、y、z都是通过第 4 行的单个global语句声明引用全局范围内的对象。
在global声明中指定的名称不能出现在global语句之前的函数中:
1>>> def f(): 2... print(x) 3... global x 4... 5 File "<stdin>", line 3 6SyntaxError: name 'x' is used prior to global declaration第 3 行上的
global x语句的目的是使对x的引用指向全局范围内的一个对象。但是行 2** 的print()声明是指x到global声明之前。这引发了一个SyntaxError异常。**
nonlocal声明嵌套函数定义也存在类似的情况。
global声明允许函数在全局范围内访问和修改对象。如果被封闭的函数需要修改封闭范围内的对象怎么办?考虑这个例子:
1>>> def f():
2... x = 20
3...
4... def g():
5... x = 40 6...
7... g()
8... print(x)
9...
10
11>>> f()
1220
在这种情况下,x的第一个定义是在封闭范围内,而不是在全局范围内。正如g()不能在全局范围内直接修改变量一样,它也不能在封闭函数的范围内修改x。在行 5 赋值x = 40后,包围范围内的x保留20。
global关键词不是这种情况的解决方案:
>>> def f(): ... x = 20 ... ... def g(): ... global x ... x = 40 ... ... g() ... print(x) ... >>> f() 20因为
x在封闭函数的范围内,而不是全局范围内,所以global关键字在这里不起作用。g()终止后,包围范围内的x仍然是20。事实上,在这个例子中,
global x语句不仅不能在封闭范围内提供对x的访问,而且还在全局范围内创建了一个名为x的对象,其值为40:
>>> def f():
... x = 20
...
... def g():
... global x
... x = 40
...
... g()
... print(x)
...
>>> f()
20
>>> x 40
要从g()内部修改封闭范围内的x,需要类似的关键字 nonlocal 。在nonlocal关键字后指定的名称指最近的封闭范围内的变量:
1>>> def f(): 2... x = 20 3... 4... def g(): 5... nonlocal x 6... x = 40 7... 8... g() 9... print(x) 10... 11 12>>> f() 1340在行 5 的
nonlocal x语句后,当g()指x时,指最近的包围范围内的x,其定义在行 2 的f()中:
The nonlocal Declaration 第 9 行的
f()末尾的print()语句确认对g()的调用已经将封闭范围内的x的值更改为40。最佳实践
尽管 Python 提供了
global和nonlocal关键字,但使用它们并不总是明智的。当一个函数在局部范围之外修改数据时,无论是使用
global还是nonlocal关键字,或者直接修改一个可变类型,这都是一种副作用,类似于函数修改它的一个参数。广泛修改全局变量通常被认为是不明智的,不仅在 Python 中如此,在其他编程语言中也是如此。和许多事情一样,这在某种程度上是风格和偏好的问题。有时候,明智地使用全局变量修改可以降低程序的复杂性。
在 Python 中,使用
global关键字至少可以清楚地表明函数正在修改一个全局变量。在许多语言中,函数可以通过赋值来修改全局变量,而不用以任何方式声明它。这使得跟踪全局数据被修改的位置变得非常困难。总而言之,在局部范围之外修改变量通常是不必要的。几乎总有更好的方法,通常是函数返回值。
结论
Python 程序使用或作用的几乎所有东西都是对象。即使是很短的程序也会创建许多不同的对象。在一个更复杂的程序中,它们可能会数以千计。Python 必须跟踪所有这些对象和它们的名字,它用名称空间来做这件事。
在本教程中,您学习了:
- Python 中有哪些不同的名称空间
- 当 Python 创建一个新的名称空间时
- Python 使用什么结构来实现名称空间
- 名称空间如何在 Python 程序中定义范围
许多编程技术利用了 Python 中每个函数都有自己的名称空间这一事实。在本系列接下来的两篇教程中,您将探索其中的两种技术:函数式编程和递归。
« Regular Expressions: Regexes in Python (Part 2)Namespaces and Scope in PythonFunctional Programming in Python: When and How to Use It »
立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 在 Python 中导航名称空间和范围******
Python 新闻:2021 年 4 月有什么新消息
如果你和 Python 开发人员相处的时间足够长,你最终会听到有人谈论 Python 社区有多棒。如果你想了解 2021 年 4 月的 Python 社区中发生的事情,那么你来对了地方来获取你的新闻**!*
*从改善用户体验的更好的错误消息到社区驱动的推迟 CPython 变更的努力,2021 年 4 月是一个充满故事的月份,这些故事提醒我们 Python 因其社区而变得更好。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
由于有远见的赞助商,PSF 正在招人
2021 年 2 月,谷歌成为 Python 软件基金会(PSF) 第一个有远见的赞助商。此后不久,彭博工程公司也成为了一个有远见的赞助商。
有远见的赞助商是最高级别的赞助商,提供大量资金支持 PSF 计划。来自谷歌和彭博的赞助正在帮助 PSF 雇佣两名新的全职员工。
CPython 常驻开发人员
多亏了谷歌的赞助基金,PSF 已经宣布计划雇佣一名常驻开发者。根据 PSF 的公告,常驻开发者将“解决积压问题,进行分析研究以了解项目的志愿者时间和资金,调查项目优先级及其未来任务,并开始处理这些优先级。”
该全职职位的资助期限为一年,截止日期为2021 年 5 月 16 日开始接受简历提交。然而,这个职位似乎只对现有的核心开发人员开放。
雇佣一名全职员工来支持 CPython 开发对于 PSF 和 Python 社区来说是一个巨大的进步。这个决定是受 Django Fellowship Program 的启发,该项目雇佣有偿承包商来处理行政和社区管理任务。
Python 打包项目经理
彭博的捐款资助了一个 Python 包装项目经理的职位。根据 PSF 的公告,项目经理将“监督改进和增加的功能,这将使所有 Python 用户受益,同时引导 PyPI 发展成为可持续的服务。”
申请截止日期为2021 年 5 月 18 日。想了解更多关于这个职位的信息,请查看 Python 职位公告栏。
你可以阅读更多关于彭博支持 Python 的决定,以及他们为什么对 Python 打包生态系统特别感兴趣的博客文章通过“左移”支持 Python 社区
Python 3.10 将改进错误消息
2021 年 4 月 9 日,Python 核心开发者 Pablo Galindo ,他也是 Python 3.10 和 3.11 的发布经理,在推特上向 Python 教育者提出了一个问题:
Python 教育者和用户:最近我一直致力于改进 CPython 中的语法错误消息。什么错误(目前只有个语法错误😅)你或你的学生感到困惑的信息?你认为我们应该改进哪些?🤔(请努力帮助更多的人🙏).(来源
这条推文得到了很多关注,包括要求改进关于赋值(
=)和比较(==)操作符、缩进错误和缺少冒号的错误消息。在某些情况下,加林多指出他已经改进了人们提到的错误!例如,在一个标题为 bpo-42997:改善缺失的错误消息:在套件之前,Galindo 改善了缺失冒号的错误消息。在 Python 3.10 中,如果您忘记在定义函数的后键入冒号(
:,您将会看到这个新的和改进的消息:

>>> # Python 3.10a7
>>> def f()
File "<stdin>", line 1
def f()
^
SyntaxError: expected ':'
对比一下 Python 3.9 中的错误消息:
>>> # Python 3.9.4 >>> def f() File "<stdin>", line 1 def f() ^ SyntaxError: invalid syntax这是一个很小的变化,但是指出解释器需要一个冒号,而不仅仅是告诉用户他们的语法是无效的更有帮助,而且不仅仅是对初学者。有其他语言经验但不熟悉 Python 语法的开发人员也会喜欢更友好的消息传递。
标题为 bpo-43797:改进无效比较的语法错误的 PR 中介绍了改进的无效比较错误消息。在 Python 3.10 中,如果您不小心在
if语句中键入了赋值运算符而不是比较运算符,您将会看到以下消息:
>>> # Python 3.10a7
>>> a = 1
>>> b = 2
>>> if a = b:
File "<stdin>", line 1
if a = b:
^^^^^
SyntaxError: invalid syntax. Maybe you meant '==' or ':=' instead of '='?
这是对 Python 3.9 中现有消息的重大改进:
>>> # Python 3.9.4 >>> a = 1 >>> b = 2 >>> if a = b: File "<stdin>", line 1 if a = b: ^ SyntaxError: invalid syntax除了更好的
SyntaxError消息外,AttributeError,NameError,IndentationError消息也得到了改进。Galindo 在 4 月 14 日的推文中分享了一个例子,展示了如果你输入了错误的属性名称,Python 3.10 将如何建议现有的属性:
>>> # Python 3.10a7
>>> import collections
>>> collections.namedtoplo
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'collections' has no attribute 'namedtoplo'. Did you mean: 'namedtuple'?
一些用户对搜索现有姓名的费用表示关切。以下是加林多的回应:
它只发生在显示未被捕获的异常时,所以它发生在解释器将要结束时,所以它不会影响运行时。即使在这种情况下,它也有许多限制(如字符串的长度或候选项的数量)来保持成本最小。(来源)
总的来说,改进的错误消息对 Python 的用户体验是一个很大的改进。有关错误消息改进的完整列表,请查看 Python 文档中的Python 3.10 新特性页面。
PEP 563、PEP 649 和 Python 类型注释的未来
PEP 484 早在 2014 年就引入了类型提示。类型提示允许您在函数参数、类属性和变量上指定类型,稍后可以使用像 Mypy 这样的工具静态类型检查。
例如,下面的代码定义了函数add(),它将两个整数、x和y相加:
def add(x: int, y: int) -> int:
return x + y
类型提示指定两个参数x和y应该是类型int并且函数返回一个int值。
当前如何评估类型提示
目前,类型提示必须是有效的 Python 表达式,因为它们在函数定义时间被求值。一旦类型提示被评估,它们就作为字符串存储在对象的.__annotations__属性中:
>>> def add(x: int, y: int) -> int: ... return x + y ... >>> add.__annotations__ {'x': 'int', 'y': 'int', 'return': 'int'}您通常可以使用
typing模块中的get_type_hints()来检索实际的类型对象:
>>> import typing
>>> typing.get_type_hints(add)
{'x': <class 'int'>, 'y': <class 'int'>, 'return': <class 'int'>}
为实现运行时类型检查的工具提供一些基本支持。Python 作为一种动态类型语言,如果没有第三方工具,可能永远不会支持真正的运行时类型检查。
在函数定义时计算类型提示有一些缺点。例如,必须定义类型的名称。否则,Python 会抛出一个NameError:
>>> def add(x: Number, y: Number) -> Number: ... return x + y ... Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'Number' is not defined您可以通过使用类似于
typing.Union的东西定义一个类型别名来创建一个允许int和float值的Number别名,从而避免这种情况:
>>> from typing import Union
>>> Number = Union[int, float]
>>> def add(x: Number, y: Number) -> Number:
... return x + y
...
>>> # No NameError is raised!
但是,有一种情况,当您需要从类本身的方法中返回一个类的实例时,您不能在使用类型别名之前定义它:
class Point:
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
@classmethod
def origin(cls) -> Point: # Point type is still undefined
return cls(0, 0)
在名字被定义之前使用它被称为前向引用。为了避免这种情况,PEP 484 要求使用字符串作为类型名:
class Point:
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
@classmethod def origin(cls) -> "Point":
return cls(0, 0)
对字符串的求值被延迟,直到模块完全加载。
在函数定义时计算类型注释的另一个缺点是,它会在导入类型化模块时增加计算开销。
PEP 563 建议改进什么类型注释
2017 年 9 月, PEP 563 提出从在函数定义时评估注释改为在内置__annotations__字典中以字符串形式保存注释。这有效地解决了前向引用问题,并消除了导入类型化模块的计算开销。
从 Python 3.7 开始,您可以通过从__future__导入annotations来访问这个新行为。这允许你使用一个Number类型的提示,即使它还没有被定义:
>>> from __future__ import annotations >>> def add(x: Number, y: Number) -> Number: ... return x + y ... >>> # No NameError is raised! >>> add.__annotations__ {'x': 'Number', 'y': 'Number', 'return': 'Number'}为了评估类型提示,您需要调用
get_type_hints()。换句话说,类型提示的评估被推迟到调用get_type_hints()或其他函数,比如eval()。最初,计划是逐步引入这一新行为,并最终将其作为 Python 4 中的默认行为。然而,该决定是在 2020 年 Python 语言峰会后做出的,将于 2021 年 10 月发布。
关于这种新行为将如何影响 Python 用户,PEP 563 做出如下声明:
静态类型检查器看不到行为上的差异,而运行时使用注释的工具将不得不执行延迟的评估。(来源)
换句话说,工具不能再期望为它们评估类型提示,并且需要更新它们的代码来根据需要显式地评估注释。
随着 PEP 563 被接受并计划改变默认行为,像 FastAPI 和 pydantic 这样在运行时使用注释的项目开始支持 PEP。
为什么项目难以实施 PEP 563
2021 年 4 月 15 日,pydantic 的所有者和核心贡献者 Samuel Colvin 在 pydantic 的 GitHub 知识库上为撰写了一期文章,解释了“试图评估那些字符串以获得真正的注释对象是多么困难,也许不可能总是正确的。”
Colvin 列出了 22 个 pydantic 问题,强调了维护人员在尝试实现 PEP 563 时遇到的困难。他这样解释实施如此艰难的原因:
原因很复杂,但基本上
typing.get_type_hints()并不总是有效,我们介绍的试图修复它的众多方法也是如此。即使typing.get_type_hints()没有错误,它仍然会比当前的语义慢很多。(来源在 bugs.python.org 搜索“get _ type _ hints”发现了许多未解决的问题,似乎证实了科尔文的说法,即
typing.get_type_hints()并不是在每种情况下都能正确工作。作为一个解决方案,Colvin 指出了 PEP 649 ,它是由 Python 核心开发者 Larry Hastings 在 2021 年 1 月编写的。PEP 649 提出了注释的延期评估,而不是 PEP 563 的延期评估。
简而言之,PEP 649 推迟类型提示的评估,直到访问了
.__annotations__属性。这解决了 PEP 563 提出的两个问题,同时也解决了 pydantic 和 FastAPI 等项目遇到的问题。Colvin 在 pydantic 的 GitHub 知识库上发表了他对 PEP 649 的支持,在 4 月 15 日的一条消息中也表达了他对 PEP 649 的支持python-dev 邮件列表上。
Python 用户和核心开发者如何达成友好的解决方案
在 Colvin 表达了他对 python-dev 的担忧之后,核心开发人员开始与他讨论如何解决这个问题。
当一个用户请求指导委员会接受 PEP 649 并避免破坏 pydantic 时,核心开发人员 Paul Ganssle 回应指出这些不是唯一的选择,并建议在 Python 3.11 发布之前保持 PEP 563 可选:
我应该指出,“接受 PEP 649”和“打破 pydantic”不是这里唯一的选择。将打破 pydantic 的是 PEP 563 弃用期的结束,而不是实现 PEP 649 的失败。
其他可行的选择包括:
- 在我们就这个问题的解决方案达成一致之前,不要加入 PEP 563。
- 永远离开 PEP 563 选择加入。
- 弃用 PEP 563,回到原状。
…假设这是一个真正的问题(部分基于 attrs 花了多长时间才获得对 PEP 563 的支持…如果 PEP 563 也在其他几个地方悄悄破坏工作,我不会感到惊讶),我的投票是让 PEP 563 至少在 3.11 之前选择加入,而不是试图匆忙完成对 PEP 649 的讨论和实施。(来源)
就连 Pablo Galindo 也对 Colvin 最初的 pydantic 问题发表了意见,他表示希望 Colvin 能够早点通知核心团队,同时也确认团队正在认真对待 Colvin 的反馈:
作为 Python 3.10 的发布经理,我很难过这里提到的第一个问题…可以追溯到 2018 年,但我们听到了所有这些问题,以及它们如何影响 pydantic 严重危险地接近 beta 冻结。…
无论如何,对我们来说,确保我们所有的用户群都被考虑在内是一件非常严肃的事情,所以你可以确信我们在讨论整体问题时会考虑到这一点。(来源
Python 核心开发者和指导委员会成员 Carol Willing 也在 Colvin 的问题上发帖,以证实他的担忧,并向所有人保证可以达成解决方案:
让我先声明,我是 pydantic 和 FastAPI 的一个非常满意的用户,我非常感谢维护者和他们周围的社区所做的工作和贡献。…
我很乐观,我们可以找到 pydantic / FastAPI 和 Python 的双赢。我认为,如果我们不试图过早地将解决办法两极分化为“要么全有,要么全无”或“接受或拒绝 649”,这是可能的。为了实现这一点,我们需要通过“什么是可能的”来看待这个问题,权衡利弊,并朝着“好但可能不理想”的解决方案努力。(来源)
最后,在 4 月 20 日,就在 Colvin 提醒 Python 核心开发者 pydantic 面临的问题的五天后,指导委员会宣布将推迟 PEP 563 的采用,直到 Python 3.11:
指导委员会已经仔细考虑了这个问题,以及许多建议的替代方案和解决方案,我们已经决定,在这一点上,我们不能冒险破坏 PEP 563 的兼容性。我们需要回滚使字符串化注释成为默认注释的更改,至少在 3.10 中是这样。(巴勃罗已经在做这个了。)
明确一点,我们并不是还原 PEP 563 本身。未来的导入将继续像 Python 3.7 以来那样工作。在 Python 3.11 之前,我们不会将 PEP 563 基于字符串的注释作为默认注释。这将让我们有时间找到一个适合所有人的解决方案。(来源)
指导委员会的决定受到了 Colvin 的欢迎,并受到了 pydantic 和 FastAPI 用户的欢迎。这一决定也赢得了 Python 开发者吉多·范·罗苏姆的赞扬,他对指导委员会表示赞赏:
你有所罗门的智慧。回滚使 PEP 563 成为默认行为的代码是 3.10 唯一明智的解决方案。(来源)
最终,pydantic 维护人员避免了一个严重的头痛问题,Python 核心开发人员也是如此。正如 Galindo 所指出的,重要的是,在实现 PEP 时遇到问题的维护人员要尽快联系核心开发人员,以避免混乱的局面,并确保及时满足需求。
看起来科尔文已经把这个反馈记在心里了。他在听到指导委员会的决定后对加林多的答复中说:
这对我来说是一次非常积极的经历,我对与 python-dev 社区的交流更加积极。
在未来,我会参与到发布过程中,把它当成我的一部分(非常小的一部分),而不是发生在我身上的事情。(来源)
项目维护人员是 Python 发布过程的一部分,而不是受制于匿名开发人员突发奇想的无助的旁观者,这种想法对每个人来说都是很重要的。
作为 Python 用户,我们的反馈有助于帮助 Python 核心开发者和指导委员会做出决策。即使我们可能不同意做出的每一个决定,科尔文的经历证明了指导委员会听取我们的意见。
Python 的下一步是什么?
4 月,Python 出现了一些激动人心的新发展。在真实 Python 展会上,我们对 Python 的未来感到兴奋,迫不及待地想看看在5 月会有什么新的东西等着我们。
来自的 Python 新闻4 月你最喜欢的一条是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!******
Python 新闻:2022 年 4 月有什么新消息
【2022 年 4 月见证了 PyCon US 大会在盐湖城的回归。在会议期间,Python 开发者参加了一年一度的语言峰会,而 Anaconda 宣布了 PyScript ,一种直接在 HTML 中编写 Python 的方法。本月早些时候,Python 软件基金会(PSF)迎来了新的执行董事。
继续阅读,深入了解上个月最大的 Python 新闻!
PyScript:浏览器中的 Python
在他的主题演讲中,Anaconda 首席执行官王蒙杰公布了 PyScript 项目。PyScript 允许你直接在 HTML 中编写 Python,并在你的浏览器中运行。考虑下面的例子:
<html> <head> <link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" /> <script defer src="https://pyscript.net/alpha/pyscript.js"></script> </head> <body> <py-script> print('Hello, World!') </py-script> </body> </html>注意
<py-script>标签,它可以包含任何有效的 Python 代码。在这种情况下,这是传统的Hello, World!问候。这是功能代码。你可以把上面的代码块复制到一个文件里,比如
hello.html,把那个文件保存到你的电脑里。然后您可以在浏览器中打开它,例如使用Ctrl+O或Cmd+O并选择hello.html。或者,您可以在 PyScript 演示页面上立即测试一个类似的示例。PyScript 提供定制的 HTML 标签,包括上面看到的
<py-script>。还有其他几个标签,其中许多仍在开发中。然而,这里有几个立即有用的:
<py-env>列出了应该在环境中可用的包。<py-repl>创建一个工作的 Python REPL 来与环境交互。下面这个稍微复杂一点的示例展示了如何使用这些功能:
<html> <head> <link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" /> <script defer src="https://pyscript.net/alpha/pyscript.js"></script> <py-env> - numpy </py-env> </head> <body> <h1 id="title">Magic Squares - Loading ...</h1> <py-script> import numpy as np # Initialize a magic square magic = np.array([[6, 7, 2], [1, 5, 9], [8, 3, 4]]) # Update title to indicate that the page has finished loading pyscript.write("title", "Magic Squares") </py-script> <py-repl id="magic-repl" auto-generate="true"> magic.sum(axis=0) </py-repl> </body> </html>在这个例子中,您声明您想要在您的环境中使用
numpy。然后导入numpy,创建一个代表魔方的数组,并更新页面上的标题以表明页面加载完成。 REPL 将用代码填充,您可以在用 HTML 指定的网页上交互运行这些代码。典型的会话如下所示:
请注意,
pyscript.write()可以与文档对象模型(DOM) 交互,并更新命名的 HTML 元素的内容。此外,在 REPL 中编写的代码可以使用在早期代码中初始化的变量。PyScript 通过在 Pyodide 的基础上进行构建,使这一切成为可能。Pyodide 提供了编译成 WebAssembly 的 CPython,这样它就可以在浏览器中运行或者与 Node.js 一起运行。此外,Pyodide 方便了从 Python 调用 JavaScript,PyScript 利用这一点来包装 JavaScript 库,如 D3 。
注意:趁 PyScript 还是全新的,深入了解它,抢先一步吧!在网络浏览器中先看一下 PyScript:Python会引导你进行这一探索。
PyScript 仍然处于实验阶段,但是这个新框架的可能性非常令人兴奋。我们期待着继续关注 PyScript 的发展。
PyCon US 2022
PyCon US 大会是 Python 社区最大的年度聚会。自 2003 年以来,这种事情每年都会发生,但在前两年,由于新冠肺炎疫情,这个会议变成了虚拟的。
从 4 月 27 日到 5 月 3 日,大约 1800 人参加了盐湖城的 PyCon。虽然会议回到了面对面的活动,但疫情的影响是显而易见的:出席人数比 2019 年下降了,强有力的健康和安全指导方针已经到位,并提供了在线选项。
与任何 PyCon 会议一样,会谈涵盖了广泛的主题,质量很高。所有的谈话都被记录了下来,一旦后期处理完成,将会发布在 Youtube 频道上。今年有五个主题演讲:
- 关于类型和复杂性
- 萨拉·伊桑关于黑洞成像的文章
- 王蒙杰宣布 PyScript
- 托马斯·伍特斯和巴勃罗·加林多·萨尔加多关于 Python 3.11 和指导委员会的工作
- 娜奥米·塞德尔关于建立一个伟大的社区
此外, Georgi Ker 、 Reuven Lerner 、 Anthony Shaw 和 Lorena Mesa 参加了关于 Python 中多样性和包容性的小组讨论:
会议在盐宫会议中心举行。由于有充足的空间和长长的走廊,会场提供了许多与赞助商和其他与会者见面的机会。今年,我们在 Real Python 有了自己的展台,很高兴见到我们的许多读者和成员。
虽然今年的 PyCon US 大门已经关闭,但下一届的规划已经开始。它还将于 2023 年 4 月 19 日至 4 月 27 日在盐湖城举办。
Python 语言峰会 2022
Python 语言峰会是一年一度的会议,Python 开发者可以在会上分享信息,讨论与 CPython 和其他实现相关的挑战。这种语言的重要事件通常发生在 PyCon 会议期间。
今年的语言峰会讨论了诸如全局解释器锁(GIL) 的未来、 faster-cpython 和 Cinder 项目的优化,以及解析 f 字符串方式的可能变化等话题。
我们期待着更多地了解语言峰会上提出的话题。和早些年一样,PSF 将在他们的博客上总结讨论。今年, Alex Waygood 将在一系列即将发布的博客文章中报道峰会上的演讲。
PSF 新任执行董事
去年年底, Ewa Jodlowska 在 Python 软件基金会(PSF) 任职约十年后,卸任执行董事。
4 月 7 日,PSF 宣布 Deb Nicholson 将担任 PSF 执行董事。Nicholson 拥有来自其他开源和非营利组织的丰富经验,包括开源倡议、 OpenHatch 和本地 Boston Python 用户组。
我们在 Real Python 欢迎 Deb Nicholson,并且很高兴看到 PSF 的继续发展。
Python 的下一步是什么
这个月,Python 新闻一直被 PyCon US 的兴奋和能够再次参加面对面会议的喜悦所主导。随着世界慢慢恢复正常,越来越多的用户组、聚会和会议将会回到面对面的状态。有你期待的会议吗?
四月份你最喜欢的 Python 新闻是什么?请在评论中告诉我们。快乐的蟒蛇!*
Python 新闻:2021 年 8 月有什么新消息
暑假结束了,又回到了学校。虽然对我们许多人来说,这是一个休闲的时代,脱离了虚拟世界,但 Python 的维护者和贡献者在同一时期一直忙于工作。就在 2021 年 8 月的,Python 社区看到了三个新的 Python 版本,带来了一些重要的安全修复、优化和全新的特性。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 3.10 差不多准备好了
8 月 3 日,Python 3.10.0 的首个预览版终于出来了。
几个月来,Python 社区一直屏住呼吸,期待着他们最喜欢的语言的下一个小版本。Python 3.10.0 将包含大量令人兴奋的新特性和改进。有些甚至引发了一点的争议,但这通常是开创性的变化。
如果你迫不及待地想在 Python 3.10.0 于 10 月 4 日正式发布之前进行一次测试,那么你可以抓住上个月初发布的候选版本。最终版本将只包括错误修复,不会增加额外的功能,所以预览版是相当完整的。
您可以通过几种不同的方式访问预览版:
- 您可以通过 web 浏览器导航到官方的 Python 3.10.0rc1 下载页面,并获取要编译的源代码或适用于您的操作系统的 Python 安装程序。
- 或者,您可以在 pyenv 的帮助下,与其他 Python 解释器一起运行候选版本。
- 最后,您可以通过在一个 Docker 容器中运行解释器来尝试最新的 Python 版本,而无需安装它。
最具革命性的即将到来的变化,值得在这里简单提一下,是在语言的语法中增加了与匹配的结构模式。模式匹配是一些函数式编程语言中的强大构造,比如 Scala,它可以让你的代码更加简洁可靠。在某些情况下,它还会让你模仿
switch语句,Python 因为没有而被批评。但这只是皮毛而已!还会有很多其他的改进,所以请继续关注未来的真正的 Python 教程,它将为你分解 Python 3.10 中的大多数新特性。
Python 3.9 和 3.8 变得更安全
Python 3.9.7 和 Python 3.8.12 都是 8 月 30 日发布的。
尽管 Python 3.10 将很快成为该语言的最新版本,并将提供一些前沿特性,但它要得到第三方库供应商的广泛支持还需要一段时间。因此,大多数商业使用 Python 的公司可能会坚持使用稍旧的版本,因为旧版本更稳定,更经得起考验。
Python 3.9.7 现在是你应该考虑安装的最新稳定版。这个版本包括几十个安全和漏洞修复以及小的优化和改进。Python 3.9 将被支持到大约 2025 年 10 月。
Python 3.8.12 是遗留 Python 3.8 系列的第二个纯安全补丁。与此同时,尽管没有定期的维护版本,它仍将支持到 2024 年 10 月。
PyCharm 2021.2.1 变得更快更好
在 8 月 27 日的一篇博客文章中,JetBrains 宣布发布 PyCharm 2021.2.1,这是他们为 Python 开发者开发的非常受欢迎的 IDE 的最新版本。
随着 Python 3.10 的出现,为 Python 生态系统中的软件开发人员提供工具的公司必须为这个新的 Python 版本将带来的巨大变化做好准备。 PyCharm 现在为 Python 3.10 中引入的新语法结构提供支持,比如结构模式匹配和联合类型。
除了无数的错误修复,以及性能和可用性的改进,PyCharm 中另一个有趣的创新是从 Python 的内置
venv模块转移到用于虚拟环境创建的virtualenv库。这一小小的改变通过利用缓存以及链接到目录而不是复制目录来显著提高速度。如果您是 PyCharm 的新手,那么您会喜欢 IDE 中改进的特性训练器插件。它是最近增加的,通过互动课程教你如何使用图形用户界面。现在,它有新的课程致力于直接从 IDE 中使用 Git 存储库。
2021 年 Django 开发者调查正式启动
8 月 4 日,Django 软件基金会(DSF) 宣布他们已经开始收集来自世界各地 Django 开发者的意见,以更好地了解社区如何使用他们的 web 框架和相关工具。在与 JetBrains 的合作中,这项调查的目标是收集知识,以帮助他们选择正确的发展方向。
该调查现已结束,但它花了大约 10 分钟完成,并且主要由多项选择题组成。希望很多 Django 用户有机会分享你的宝贵反馈。
调查结果将被汇总、匿名并向公众公开。要了解结果何时出来,你可以在社交媒体上关注 Django 软件基金会和 T2 的 JetBrains。
Python 有一个打包项目经理
8 月 18 日,Python 软件基金会(PSF) 宣布Shamika Mohan已经接受了一个新的职位,担任包装项目经理。
在上个月的新闻中,你了解到 PSF 雇佣了 ukasz Langa 作为第一个全职的 CPython 常驻开发者。由于赞助商的持续支持,这家非营利组织得以聘用另一名全职员工,并签订了一份有保障的两年合同。
Shamika 将负责从 Python 社区收集关于打包生态系统中的挑战和正在进行的项目和计划的反馈,重点是改进 Python 包索引(PyPI) 。这是个好消息,考虑到 Python 中打包工具的前景一直是支离破碎的,没有遵循一个特定的标准。
恭喜你,沙米卡👏
PyCon US 2022 正在寻找志愿者
8 月 30 日,PyCon 美国组织者宣布他们开始寻找愿意为明年的会议贡献时间和知识的志愿者。
在 PyCon 通常有很多机会作为志愿者工作。然而,目前 PSF 特别感兴趣的是为负责提案征集流程的委员会招募成员。它涉及三个广泛的任务,在这个谷歌文档中有更详细的描述。
Python 的下一步是什么?
8 月,Python 出现了一些令人兴奋的发展。在真实 Python 展会上,我们对 Python 的未来感到兴奋,迫不及待地想看看在9 月会有什么新东西等着我们。
来自8 月的 Python 新闻你最喜欢的片段是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!**
Python 新闻:2022 年 8 月有什么新消息
在【2022 年 8 月,Python 向 3.11 发布,熊猫推出增强提案,各种包见证了新发布,Python 在 TIOBE 指数顶端扩大了领先优势, PyPI 与恶意软件战斗。
请继续阅读,了解 2022 年 8 月 Python 世界发生的更多细节!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
Python 有 pep,NumPy 有 nep,熊猫现在有 pdep
首个熊猫增强提案(PDEP)于 2022 年 8 月 3 日提交,标题为目的和方针。增强提议对于 Python 社区来说并不新鲜。Python 从 2000 年就有了 PEPs ,NumPy 在 2017 年又有了 NEPs 。
第一个 PDEP 遵循 pep 和 nep 的传统, PDEP-1 是对增强提案本身背后的想法的介绍。
简而言之,PDEPs 旨在帮助对 pandas 的重大变更的提议过程,例如将模块从主 pandas 存储库移动到一个分支存储库。PDP 不是为了快速解决问题,而是为了涉及更广泛社区的主要任务,并且通常是一些重要的权衡。
解决复杂的问题不太适合基于线程的媒体,比如 GitHub issues 。如果任何人都可以在任何时候回应,即使最初的想法是好的,讨论也很难保持专注。
GitHub 问题线程不仅会给核心开发人员带来噪音,也会给贡献者和最终用户带来噪音。此外,他们可能会因为没有提供合适的讨论媒介而埋没好的但复杂的想法。撰稿人 h-vetinari 在 2019 年 GitHub 一期中提出了这个话题:
API 含义越复杂,在 GitHub 注释中讨论就越困难(因为通常要同时考虑的事情太多,或者注释/线程长得离谱,或者两者兼而有之)。这并不意味着给定的变化没有价值,只是它(可能)太难以线程格式讨论。(来源)
h-vetinari 三年前提出的 GitHub 问题现在已经随着 PDEP-1 的拉请求而结束。这可能会为 PDEP 生命周期的未来奠定一个蓝图。当某人制造了一个问题时,PDEPs 可能会开始。如果问题被认为是重要的和有价值的,那么提出这个问题的人可能会被指示创建一个 PDEP。
这种向 PDEPs 的转移意味着通常用于向熊猫传达更大变化的路线图将慢慢向 PDEPs 迁移。
你对移动到 PDEPs 有什么感觉?请在评论中分享你的想法!
Python 生态系统庆祝新发布
Python 社区在整个八月都没有休息,尽管这通常是一个度假的月份。像往常一样,Python 生态系统中已经发布了大量版本。从 CPython 到 CircuitPython,有许多新特性可供您开始尝试。请继续阅读精选的版本和里程碑。
cpython〔t0〕
CPython 团队仍在为 2022 年 10 月发布 Python 3.11 做准备。如果您有兴趣了解更多关于 3.11 版本的信息,请查看一些深入探究 3.11 新特性的真实 Python 教程,例如异常组、
tomllib,以及更好的错误消息。8 月,Python 3.11.0rc1(一个候选版本)发布了:
[Image source](https://twitter.com/pyblogsal/status/1556687421928083457) 如果您想帮助 Python 社区,那么可以通过运行您的代码和包来测试这个新的候选版本。除了上面提到的弃用,大部分东西应该还能工作,你也有望注意到一个不错的速度提升。
如果你想要一个指南,那么看看真正的 Python 教程如何安装 Python 的预发布版本!
如果你在 3.11 候选版本中发现了你认为可能是 bug 的东西,检查一下发布板看看它是否正在被讨论。如果你真的认为你发现了一个别人没有发现的 bug,开一期新的!
为了准备 Python 3.11 的发布, NumPy 已经领先一步,发布了 3.11 的轮子:
[Image source](https://twitter.com/HenrySchreiner3/status/1558993585198059522?t=Led4H_qk2PEwcHxKE3bhlA&s=19) 这对于许多依赖 NumPy 的其他软件包来说是个好消息,如果没有 NumPy 3.11 轮子,它们将无法开始移植到 3.11。
虽然 3.11 可能会风靡一时,但 3.10 并没有被遗忘。本月,新的维护版本发布了:
[Image source](https://twitter.com/pyblogsal/status/1554481408386686977?t=ABlM9ANvphT7AucVljcHhQ&s=19) 除非很方便,否则不需要从 3.10.x 升级到 3.10.6。也就是说,升级不应该破坏 3.10.x 上的现有代码,除非无意中引入了回归,但这不太可能。
请在下面的评论中告诉我们你对新版本的看法!你最感兴趣的功能是什么?
姜戈
同样在 2022 年 8 月, Django 4.1 发布,为基于类的视图提供异步处理程序、异步 ORM 接口、模型约束验证、表单呈现可访问性改进等等。
Django 的核心开发者詹姆斯·贝内特在发布后不久发表了一篇的博客文章,以促进对异步 Python 用于 web 开发的理解。这篇文章精彩地概述了
asyncio模块是如何产生的,强调了协程从生成器到asyncio的演变。在一个巧妙的标题为“一切与厨房异步”的章节中,Bennet 警告人们不要对所有事情都使用异步。
事件循环适用于某些应用程序,但不适用于其他应用程序。要了解更多关于异步 Python 的优秀应用程序,请查看关于异步 IO 和并发的真实 Python 教程。
阅读文档
[Image source](https://twitter.com/readthedocs/status/1559575996558221312?t=0uCB1K1PuwV8KOHqj9LXnA&s=19) 一个不起眼的需求文件会导致 Python 生态系统中最著名的包之一。
阅读文档将有助于您创建文档并将其分发给用户。它不仅开发了一个软件包来自动创建你的在线文档,而且还免费托管你的文档。read Docs 每月提供超过 5500 万页的文档,相当于整整 40TB 的带宽。
要了解最新的阅读文档,请查看其博客。此外,Read Docs 正在为其优秀文档项目库收集条目——查看一下,为您的文档寻找一些灵感。
电路表面
8 月,CircuitPython 发布了 CircuitPython 8.0.0 的测试版。CircuitPython 的 8.0.0 版本计划引入新的 WiFi 工作流程,使通过 WiFi 使用您的评估板更容易,提供与代码编辑器的更好集成,等等。
CircuitPython 是针对微控制器的 Python 版本,是 MicroPython 的初学者友好分支。一些最知名的 DIY 微控制器设计师创建支持 CircuitPython 和 MicroPython 的电路板,包括 Raspberry Pi 、 Arduino 和 Adafruit ,后者也是 CircuitPython 的主要赞助商。
要了解更多关于 CircuitPython 版本和相关新闻的信息,请查看 Adafruit 的配套博客文章。
同样在 8 月,Adafruit 庆祝了 2022 年 CircuitPython 日,这些记录现在已经上传到了 T2 的 YouTube 上。去看看!
Python 在 TIOBE 索引顶部扩展了 Lead
8 月份的 TIOBE 编程社区指数显示 Python 又获得了 2%的市场份额,继续保持有史以来最高的市场份额:
Python 似乎势不可挡。(来源)
自从 TIOBE 在 2001 年开始排名以来,C 和 Java 一直不分上下。
然而,值得注意的是,TIOBE 索引是基于该语言的网页在不同搜索中的排名。所以 TIOBE 的排名不是关于 T2 最好的或者最受欢迎的语言。它主要显示了该语言在互联网上的排名。尽管如此,Python 还是赢了!
PyPI 对抗恶意软件攻击
8 月,一些 PyPI 用户遭遇了首个已知的针对 PyPI 的网络钓鱼活动:
[Image source](https://twitter.com/pypi/status/1562442188285308929) 用户报告收到一封电子邮件,要求他们验证他们的包,以防止从 PyPI 中删除。该消息包含重定向到 PyPI 登录页面的虚假版本的链接。
如果您将您的用户名和密码插入这个虚假的登录页面,您的凭据将被发送给网络钓鱼活动背后的人。然后,他们将使用帐户凭证登录到真正的 PyPI,篡改您上传的软件包,并可能锁定您。
注意: PyPI 不会从 PyPI 中删除软件包,除非它们违反了使用条款或者是有害的软件包,比如恶意软件。因此,任何这种效果的交流都应该立即引起人们的注意。
到目前为止,攻击者设法获得的任何凭证都被用来上传用户包的恶意软件感染版本。因此,下次有人下载最新版本的受损软件包时,他们的计算机就会感染该恶意软件。
PyPI 已经公布了假冒站点的地址为
sites[dot]google[dot]com/view/pypivalidate,凭证信息发送到linkedopports[dot]com。使用这些恶意地址,PyPI 已经发现了各种各样的受损包。任何受损的包裹都已被及时清理并暂时冻结。当 PyPI 恢复对合法所有者的访问时,软件包被冻结以锁定攻击者,并确保用户可以继续下载软件包而不用担心恶意软件。
此外,使用
linkedopports[dot]com模式,PyPI 发现了许多域名仿冒包。PyPI 中的域名仿冒涉及上传一个恶意软件包,其名称与一个流行的包非常相似。例如,当下载一个带有python -m pip install requests的包时,你可能会把requests误打成reqyests。一个域名抢注者可能会上传一个叫做reqyests的恶意软件包来感染那些打错字的人。本月早些时候, Snyk ,一个开发者安全平台,发现各种上传到 PyPI 的小软件包带有恶意软件,从 Windows 用户那里窃取 Discord 和 Roblox 凭证。这些包使用 PyInstaller 到混淆其中包含的恶意代码。
因此,即使最近采用了双因素认证 (2FA),这也表明在安全方面没有灵丹妙药。你应该始终意识到,当使用
pip时,你是在从互联网上下载代码来在你的机器上运行。尽最大努力确保软件包是合法的,例如,您可以检查软件包的自述文件,以确定它是真实的:
- 它有文档吗?
- 它周围有社区吗?
- 源代码是公开的吗?
- 套餐有没有带联系方式的网站?
这些只是合法软件包可能具有的一些指标,但正如前面提到的,没有灵丹妙药,当您在现代互联世界中导航时,您需要保持头脑清醒!
这个月, TalkPython 及时地发布了一个播客片段,其中有 PyPI 维护者和 PSF 主管达斯汀·英格拉姆,他们聊到了 Python 打包、PyPI、安全性以及最近向 2FA 的转移。
你在 PyPI 遇到过恶意软件或者可疑的包吗?联系 security@pypi.org 了解所有细节。记住,PyPI 是一个由赞助商和用户资助的开源平台。他们不赚取任何利润,他们需要社区的支持来保证每个人的安全。
Python 的下一步是什么
八月的 Python 世界,你最激动的是什么?我们错过了什么吗?你会尝试任何新版本吗?你对熊猫搬到 PDEPs 有什么想法吗?如何看待最近围绕 PyPI 的安全问题?请在评论中告诉我们!
快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。***
Python 新闻:2021 年 12 月有什么新消息
2021 年 12 月的年,第四届 Python 指导委员会选举产生,一如既往地由新老成员组成。Python 生命周期的发布周期一直在旋转,随着新的版本 Python 3.10 和即将发布的 Python 3.11 的发布。与此同时,流行的 Python 3.6 也到了生命周期的尽头,将不再被支持。
在这一连串的活动中,来自各地的开发人员通过解决一年一度的降临代码谜题在假期中获得了一些乐趣。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 指导委员会选举
吉多·范·罗苏姆是 Python 的创造者。很长一段时间,他也是语言的【BDFL】仁慈的终身独裁者,负责监督所有被实施的变革。
2018 年夏天,Guido 辞去了BDFL 的职务,并要求社区提出一种新的语言治理模式。在一些讨论之后,社区决定选举一个指导委员会来指导 Python 的开发。
新的指导委员会定期选举,或多或少与 Python 的每个版本相一致。因此,这些术语通常由将在该术语期间发布的相应 Python 版本来标记。Python 3.11 任期的最近一次选举于 12 月上半月举行,最终结果于 12 月 17 日公布。
自第一届指导委员会于 2019 年 1 月选举产生以来,以下成员已任职:
- 巴里华沙(3.8,3.9,3.10)
- 布雷特·卡农 (3.8,3.9,3.10)
- 卡罗尔·威林 (3.8,3.9,3.10)
- 古多·凡·rossum(3.8)
- 尼克·科格兰 (3.8)
- 巴勃罗·加林多·萨尔加多 (3.10)
- 托马斯伍特斯 (3.9,3.10)
- 维克多·斯坦纳 (3.9)
对于 Python 3.11 任期选举,有十个合格的候选人。投票期从 2021 年 12 月 1 日持续至 15 日。总共有 67 名 Python 核心开发人员投了票。
获得最多票数的五个人,也就是新指导委员会的成员是:
- 布雷特·卡农
- 格雷戈里·史密斯
- 巴勃罗·加林多·萨尔加多
- 彼得·维多利亚
- 托马斯·伍特斯
布雷特、巴勃罗和托马斯是理事会的返回成员,而格雷戈里和彼得将担任他们的第一个任期。
指导委员会在让每个人都有发言权的同时,还承担着指导机构群体的重要工作。去年春天围绕推迟评估注解的讨论是一个很好的例子,说明了理事会如何通过寻求共识来发挥领导作用。
我们在 Real Python 感谢指导委员会为语言和社区所做的工作,我们祝愿委员会在新的任期一切顺利。
新的 Python 版本
Python 的最新版本, Python 3.10 ,是在 2021 年 10 月发布的。它的第一个维护版本 Python 3.10.1 于 12 月 6 日发布。像往常一样,这个小版本包括许多小的 错误修复以及对文档和测试的更新。
Python 的下一个版本 Python 3.11 将于 2022 年 10 月发布。然而,核心开发团队已经为新特性和改进工作了好几个月。如果您有兴趣预览即将推出的产品,可以下载并安装最新的预发布版本。
即使 Python 3.11 的正式发布已经过去了好几个月,所谓的 alpha 版本已经可以供你使用了。12 月 8 日, Python 3.11.0a3 ,第三个 alpha 版本公开。您可以尝试体验一下改进的错误报告和更快的执行速度。
就其本质而言,alpha 版本是不稳定的,可能包含许多错误。因此,在生产或其他重要的脚本中,您永远不应该依赖 Python alpha 版本。但是,如果您很想尝试新的特性和改进,可以考虑尝试一下新的预发布版本。
Python 3.6 的生命周期结束
在发布周期的另一边,你会发现 Python 3.6,它在 2021 年 12 月 23 日达到了它的寿命终止日期。在 Python 3.6 中,你得到了许多流行的新特性,包括如下:
- 数字文字中的下划线
- f 弦
- 变量注释
- 使用保证元素排序的更高效的字典
- 对 Python 的异步特性的许多改进
然而,Python 3.6 现在已经超过五年了。Python 3.6 不会有任何新的维护版本,即使发现了严重的安全问题。虽然您的 Python 3.6 仍将继续工作,但您应该确保升级任何仍运行 Python 3.6 或更旧版本的重要系统。
由于 f 字符串、类型注释和异步等特性的流行,Python 3.6 多年来一直是许多库支持的最低版本。然而,像 NumPy 和 Django 这样的流行库已经将 Python 3.8 列为他们最新版本的最低要求。获得对依赖项的适当支持是保持 Python 版本合理更新的另一个原因。
PyPI Stats 是一个了解不同 Python 包和 Python 版本使用的好网站。您可以在他们的网页上或通过
pypistats命令行工具访问统计数据:$ pypistats python_minor __all__ -m 2021-12 | category | percent | downloads | | :------- | ------: | -------------: | | 3.7 | 41.15% | 5,002,371,969 | | 3.8 | 21.56% | 2,621,179,853 | | 3.6 | 14.98% | 1,821,281,479 | | 3.9 | 7.93% | 964,495,785 | | 2.7 | 7.13% | 866,934,431 | | null | 4.03% | 490,065,646 | | 3.10 | 1.46% | 177,027,749 | | 3.5 | 1.23% | 149,063,639 | | 3.4 | 0.51% | 62,069,015 | | 3.11 | 0.00% | 536,407 | | 3.3 | 0.00% | 24,849 | | 3.2 | 0.00% | 4,131 | | 2.6 | 0.00% | 3,683 | | 2.8 | 0.00% | 123 | | 3.1 | 0.00% | 73 | | 4.11 | 0.00% | 26 | | Total | | 12,155,058,858 | Date range: 2021-12-01 - 2021-12-31这份概览显示,2021 年 12 月 PyPI 上大约 15%的下载是针对 Python 3.6 的。总的来说,几乎四分之一的下载是针对现在已经过时的 Python 版本的,包括 Python 2。参见It ' s Time to Stop use Python 3.6作者 Itamar Turner-Trauring 关于让您的 Python 保持最新的更深入讨论。
代码的出现
Advent of Code 是一个在线降临节日历,从 12 月 1 日到 25 日,每天都会发布新的编程谜题。上个月,来自世界各地的程序员连续第七年聚集在一起进行友好比赛。Code 2021的问世成为迄今为止最受欢迎的版本,有超过 20 万的参与者。
每年,一个精彩的故事伴随着谜题。今年,你需要通过找回掉在海底的圣诞老人的雪橇钥匙来拯救圣诞节。在你寻找钥匙的过程中,你要和一只巨型乌贼玩宾果游戏,惊叹灯笼鱼的产卵能力,帮助一群片脚类动物找到它们的家洞穴,并解决许多其他令人兴奋的谜题。
即使你错过了每个谜题解开时所有令人兴奋的事情,你仍然可以回去解决所有这些谜题,以及追溯到 2015 年的早期版本。杰西·范·艾尔特伦做了一个分析将《代码 2021》的出现与过去几年进行比较。
类似地,耶鲁安·海曼斯做了一个非官方调查代码参与者的降临。调查表明,Python 是解决降临代码难题最受欢迎的语言,超过 40%的受访者使用它。
在 Real Python ,我们为我们的社区举办了一场私人排行榜比赛,非常有趣。我们要感谢《降临代码》的创作者 Eric Wastl ,感谢他多年来为该项目付出的所有努力,并祝贺他在 2021 年 12 月达到了 500,000 总用户和 10,000,000 总星级的里程碑。
如果你想自己尝试这些谜题,看看我们的指南。竞赛程序员手册是解决这类难题的综合资源,包含许多有用技术和算法的信息。
Python 的下一步是什么?
2021 年对于 Python 来说是很棒的一年,Python 3.10 的发布是其中的亮点之一。在真实的 Python ,我们期待着 2022 年和 Python 3.11 的进一步发展,由新的指导委员会指导,由核心开发团队和来自世界各地的其他志愿者实施。
十二月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!**
Python 新闻:2022 年 2 月有什么新消息
在 2022 年 2 月的,另一个 Python 3.11 的预览版可供早期采用者测试和分享他们的反馈。不久之后,Python 指导委员会宣布 Python 3.11 也将在标准库中包含一个 TOML 解析器。另外, GitHub Issues 即将成为 Python 的官方 bug 追踪系统。
其他新闻, PyCon US 2022 分享了其会议日程。Python 软件基金会(PSF)想雇佣两名合同开发者来改进 Python 包索引(PyPI)。苹果终于从 macOS 中移除 Python 2.7 。
让我们深入了解过去一个月最大的 Python 新闻!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
Python 3.11 Alpha 5 发布
虽然 Python 3.11 的最终版本计划在【2022 年 10 月发布,这仍然是几个月前的事,但你已经可以看到即将到来的事情了。根据 PEP 664 中描述的开发和发布时间表,Python 3.11 现在正处于其发布周期的 alpha 阶段,这意味着收集来自像您这样的用户的早期反馈。2 月初,7 个计划中的 alpha 版本中的第 5 个 3.11.0a5 开始测试。
要试用 Python 的 alpha 版本,你可以从 Docker Hub 获取相应的 Docker 映像,用 pyenv 安装一个替代的 Python 解释器,或者使用编译器工具构建 CPython 源代码。源代码方法允许你从 GitHub 中克隆出 CPython 的仓库,并且不需要等待 alpha 版本就可以检查出一个最新的快照。
注意:开发中的特性可能会不稳定和有问题,它们可能会被修改或从最终版本中删除,恕不另行通知。因此,您不应该在生产环境中使用预览版本!
如果您想探索 Python 3.11 中一些最激动人心的特性,那么请确保您可以运行解释器的 alpha 版本。您将在下面找到下载并运行 Python 3.11.0a5 的命令:
$ docker pull python:3.11.0a5-slim $ docker run -it --rm python:3.11.0a5-slim Python 3.11.0a5 (main, Feb 25 2022, 20:02:52) [GCC 10.2.1 20210110] on linux Type "help", "copyright", "credits" or "license" for more information.


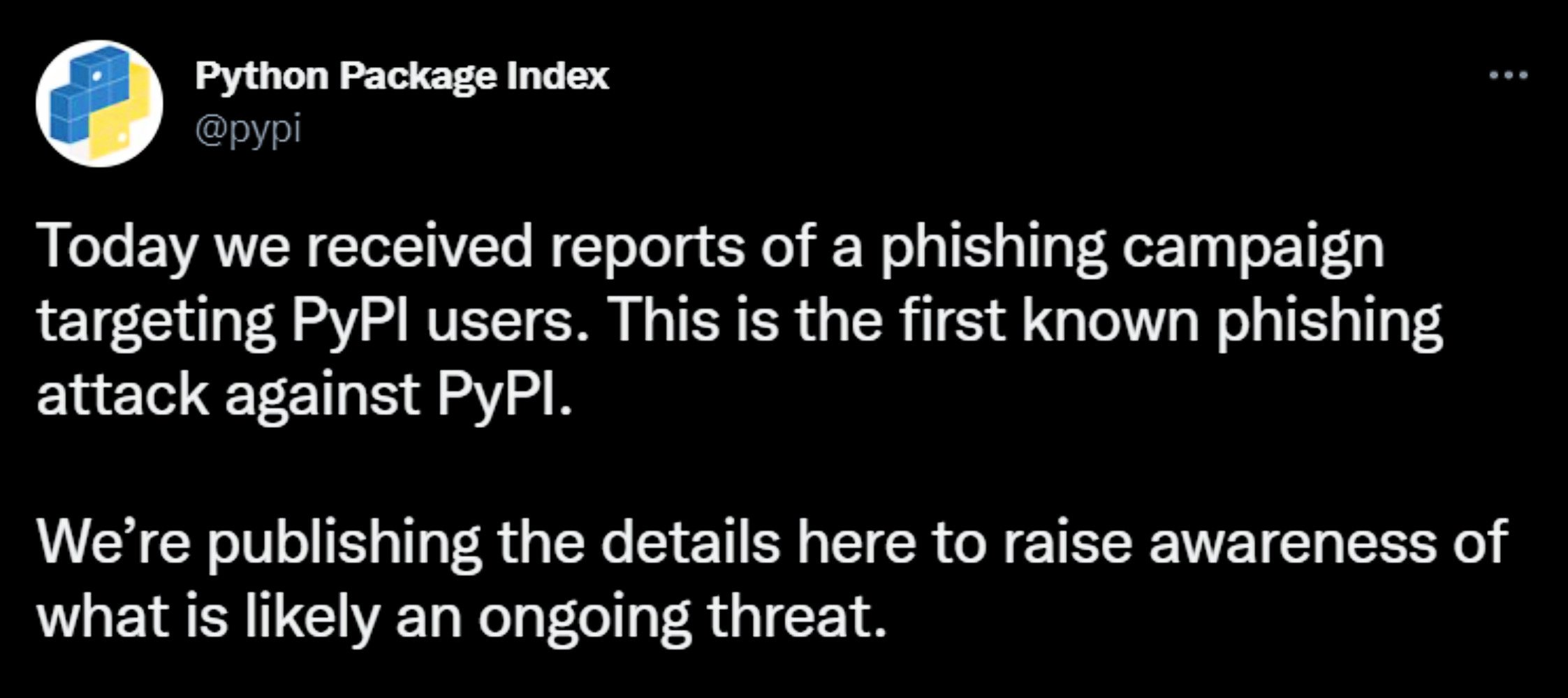
```py
$ pyenv update
$ pyenv install 3.11.0a5
$ pyenv local 3.11.0a5
$ python
Python 3.11.0a5 (main, Mar 1 2022, 10:05:02) [GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
$ git clone git@github.com:python/cpython.git
$ cd cpython/
$ git checkout v3.11.0a5
$ ./configure
$ make
$ ./python
Python 3.11.0a5 (tags/v3.11.0a5:c4e4b91557, Mar 1 2022, 17:48:56) [GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
那么,关于这个 alpha 版本的大肆宣传是什么呢?有几个大大小小的改进,但是现在,让我们把重点放在 Python 3.11 的一些亮点上!
PEP 657:回溯中的错误位置
Python 3.10 已经大大改进了它的错误信息。通过查明根本原因、提供上下文,甚至提出修复建议,错误消息变得更加人性化,对 Python 初学者更有帮助。Python 3.11 将错误消息传递向前推进了一步,以改善调试体验,并为代码分析工具提供一个 API。
有时,一行代码可能包含多条指令或一个复杂的表达式,这在早期的 Python 版本中很难调试:
$ cat test.py
x, y, z = 1, 2, 0
w = x / y / z
$ python3.10 test.py
Traceback (most recent call last):
File "/home/realpython/test.py", line 2, in <module>
w = x / y / z
ZeroDivisionError: float division by zero
$ python3.11a5 test.py
File "/home/realpython/test.py", line 2, in <module>
w = x / y / z
~~~~~~^~~
ZeroDivisionError: float division by zero
这里,其中一个变量会导致零除法误差。Python 3.10 告诉你问题所在,但没有指明罪魁祸首。在 Python 3.11 中,回溯将包括视觉反馈关于一行中引发异常的确切位置。您还将有一种编程方式来获取工具的相同信息。
注意,这些增强的回溯对于在 Python REPL 中动态评估的代码不起作用,因为回溯需要预编译的字节码来跟踪源代码行:
Python 3.11.0a5 (main, Mar 1 2022, 10:05:02) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> x, y, z = 1, 2, 0 >>> w = x / y / z Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: float division by zero有关回溯中错误位置的更多信息,请参见 PEP 657 。
PEP 654:异常组和
except*Python 3.11 将引入一个新的异常类型,称为异常组,它允许将几个异常合并到一个容器中。异常组的主要目的是简化并发代码中的错误处理,特别是异步 IO ,这在传统上是冗长而混乱的。但是还有其他用例,比如对数据验证期间出现的多个异常进行分组。
因为异常组将是一个标准异常,所以您仍然可以使用常规的
try…except子句来处理它。与此同时,将会有一个新的except*语法,用于挑选一个例外组的特定成员,同时重新增加你目前不想处理的其他成员。如果您用except*捕获到一个常规异常,那么 Python 会为您将它捆绑到一个临时异常组中。注意:不要混淆
except*和*args,它们看起来很相似,但由于星的位置不同而有不同的含义。这里有一个有点人为的例外组的例子:
>>> try:
... raise ExceptionGroup(
... "Validation exceptions", (
... ValueError("Invalid email"),
... TypeError("Age must be a number"),
... KeyError("No such country code"),
... )
... )
... except* (ValueError, TypeError) as subgroup:
... print(subgroup.exceptions)
... except* KeyError as subgroup:
... print(subgroup.exceptions)
...
(ValueError('Invalid email'), TypeError('Age must be a number'))
(KeyError('No such country code'),)
与常规的except子句不同,新语法except*在找到匹配的异常类型时不会停止,而是继续向前匹配。这使您可以一次处理多个异常。另一个区别是,您最终得到一个过滤异常的子组,您可以通过.exceptions属性访问它。
异常组也将有很好的分层回溯:
+ Exception Group Traceback (most recent call last):
| File "/home/realpython/test.py", line 2, in <module>
| raise ExceptionGroup(
| ^^^^^^^^^^^^^^^^^^^^^
| ExceptionGroup: Validation exceptions
+-+---------------- 1 ----------------
| ValueError: Invalid email
+---------------- 2 ----------------
| TypeError: Age must be a number
+---------------- 3 ----------------
| KeyError: 'No such country code'
+------------------------------------
有关异常组和except*的更多信息,参见 PEP 654 。
PEP 673:自身类型
尽管 Python 3.11 Alpha 5 的发布说明提到了这个新特性,但在存储库历史中标记发布点之前,它实际上并没有被合并到主分支中。如果您想体验一下Self类型,那么使用 CPython 主分支中的最新提交。
简而言之,你可以使用Self作为类型提示,比如用注释一个方法,该方法返回定义它的类的一个实例。Python 中有很多返回self的特殊方法。除此之外,实现流畅接口或带有交叉引用的数据结构,如树或链表,也将受益于这种新的类型提示。
下面是一个更具体的例子,说明了Self的用处。特别是,由于循环引用的问题,你不能用你正在定义的类来注释一个属性或方法:
>>> from dataclasses import dataclass >>> @dataclass ... class TreeNode: ... parent: TreeNode ... Traceback (most recent call last): File "<stdin>", line 2, in <module> File "<stdin>", line 3, in TreeNode NameError: name 'TreeNode' is not defined到目前为止,此错误有两种解决方法:
- 使用类似于
"TreeNode"的字符串文字,这是大多数类型检查器能够识别的- 以基类为界限定义一个类型变量
这两种方法都有一个共同的缺点,即当类名改变时,必须更新代码。在 Python 3.11 中,您将有另一种更优雅、更有意义且独立于名称的方式来传达相同的意图:
Python 3.11.0a5+ (heads/main:b35603532b, Mar 3 2022, 19:32:06) [GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from dataclasses import dataclass
>>> from typing import Self >>> @dataclass
... class TreeNode:
... parent: Self
...
>>> TreeNode.__annotations__
{'parent': typing.Self}
有关Self类型的更多信息,请参见 PEP 673 。
PEP 646:可变泛型
同样,尽管 Python 3.11 Alpha 5 发行说明突出了可变泛型,但在本文发表时,它们仍处于非常早期的开发阶段。相关代码甚至还没有合并到 CPython 存储库的主分支中。也就是说,如果您坚持要动手,那么可以查看位于分叉库中的实现草案。
注意:这段代码在外部类型检查工具和代码编辑器赶上它之前是没有用的,因为 Python 解释器在运行时会忽略类型提示。
泛型类型,或简称为泛型,有助于实现更好的类型安全性。它们是指定用其他类型参数化的类型的一种方式,其他类型可能是像int或str这样的具体类型:
fruits: set[str] = {"apple", "banana", "orange"}
这样的声明将集合元素的类型限制为字符串,这样类型检查器会将任何添加其他类型的尝试视为错误。您还可以用抽象符号表示这些类型的占位符来表示通用参数。在这种情况下,您已经能够在早期的 Python 版本中用TypeVar定义一个定制的类型变量,就像这样:
from typing import TypeVar
T = TypeVar("T", int, float, str)
def add(a: T, b: T) -> T:
return a + b
这将强制使用相同类型的参数调用add(),T,这些参数必须是int,float或str。类型检查器会拒绝用两个不兼容的类型调用add()的尝试。
现在,Python 3.11 将以TypeVarTuple的形式提供可变泛型,其目标是在科学库中找到的非常具体的用例,如 NumPy ,并处理多维数组。使用可变泛型,您可以通过用一个变量数量的占位符类型来参数化数组的类型,从而定义数组的形状:
from typing import Generic, TypeVarTuple
Ts = TypeVarTuple("Ts")
class DatabaseTable(Generic[*Ts]):
def insert(self, row: tuple[*Ts]) -> None:
...
users: DatabaseTable[int, str, str] = DatabaseTable()
users.insert((1, "Joe", "Doe"))
users.insert((2, "Jane", "Doe"))
roles: DatabaseTable[str, str] = DatabaseTable()
users.insert(("a2099b0f-c614-4d8d-a195-0330b919ff7b", "user"))
users.insert(("ea35ce1f-2a0f-48bc-bf4a-c555a6a63c4f", "admin"))
有关可变泛型的更多信息,请参见 PEP 646 。
性能优化
Python 3.11 会变得明显更快。您可以通过使用新旧解释器在终端中运行一小段代码来亲身体验这种差异。这里有一个计算斐波那契数列的第 35 个元素的快速基准,特意用递归来实现,以模拟计算机的一个挑战性任务:
$ SETUP='fib = lambda n: 1 if n < 2 else fib(n - 1) + fib(n - 2)'
$ python3.10 -m timeit -s "$SETUP" 'fib(35)'
1 loop, best of 5: 3.16 sec per loop
$ python3.11a5 -m timeit -s "$SETUP" 'fib(35)'
1 loop, best of 5: 1.96 sec per loop
如您所见,Python 3.10 完成计算需要三秒多一点,而 Python 3.11 Alpha 5 不到两秒。这是一个巨大的性能提升!当然,这种差异会根据手头的任务而有所不同,一般来说,你应该预料到的数字不会那么令人印象深刻。
有关性能优化的更多信息,请参见 GitHub 上的 faster-cpython 项目。
TOML 即将迎来 Python 3.11
在计划于 2022 年 5 月发布的 Python 3.11 Beta 1 中的特性冻结之前,新特性会不断被讨论和添加到 Python 的开发分支中。指导委员会最近接受了 PEP 680 ,这证明了 Python 的标准库中需要一个 TOML 解析器,因为 PEP 517 的向基于pyproject.toml的新构建系统移动。以前,打包工具必须捆绑一个库来从这个文件中读取项目元数据。
实现将基于现有的 tomli 库,该库得到了积极的维护和良好的测试。许多流行的工具已经在使用它,这将使得在那些情况下的切换更加平滑。但是,内置模块将被命名为 tomllib 。
注意:该特性仍处于早期开发阶段,在 Python 3.11 Alpha 5 版本中不可用。
有了这个附加功能,Python 将获得开箱即用地读取 XML 、 JSON 和 TOML 的能力。不过,可惜的是不会有任何内置的对 YAML 的支持。注意,当前的计划只包括一个 TOML 解析器,没有相应的序列化器。以这种格式写入数据仍然需要安装和导入外部库。
迁移到 GitHub 的 Python 问题
你有没有发现 Python 3.11 Alpha 5 的 bug,想知道去哪里报错?你现在可以在 Python 的 Bug Tracker (BPO) 中报告 Bug,托管在 Roundup 上。继 2017 年 2 月 CPython 知识库迁移之后,Roundup 是 Python 基础设施中尚未迁移到 GitHub 的最后剩余部分之一。然而,随着迁移工作的加速,这种情况很快就会改变。
下面是当前 Python 的 bug 追踪器的样子:
二月中旬, CPython 常驻开发者ukasz Langa 在官方 Python 社区论坛上宣布,指导委员会要求他接管关于 bug 追踪器迁移的项目管理。他还概述了路线图,并要求在测试期间提供反馈,强调 BPO 将继续保持只读模式。新的问题最终只会通过 GitHub 产生。
如果你想了解这一决定背后的基本原理,请前往 PEP 581 。简而言之, Python 软件基金会(PSF) 下的所有其他项目已经使用 GitHub 问题进行 bug 跟踪。除此之外,GitHub 是众所周知的,并得到了积极的维护,它有许多当前 bug 跟踪系统所缺少的有趣特性。
计划是在 4 月下旬 PyCon US 2022 之前,将所有现有门票从 BPO 迁移到 GitHub。
PyCon 美国 2022 日程公布
由于疫情的原因,在连续两年的虚拟 PyCon US 活动之后, PyCon US 2022 似乎最终将亲自举行,这是许多 PyConistas 一直期待的。除非有一些意想不到的进展,否则会议将首次在犹他州盐湖城举行。同时,将有一个在线流媒体选项。
二月下旬,组织者分享了关于敲定会议日程的消息,该日程概述了充满教程、研讨会、讲座等的紧张的一周:
| 日期 | 事件 | 描述 |
|---|---|---|
| 4 月 27 日至 28 日 | 教程 | 由经验丰富的讲师指导的实践课程 |
| 4 月 28 日 | 主办研讨会 | 通常展示由会议发起人开发的工具和解决方案 |
| 4 月 28 日 | 教育峰会 | 针对教师和教育工作者的联合讨论集中在通过 Python 开发编码素养上 |
| 4 月 29 日 | 维护者峰会 | 围绕如何维护和发展项目和社区的最佳实践的讨论 |
| 4 月 30 日 | 为不同的初学者辅导短跑 | 关于如何成为完全初学者的开源项目贡献者的实践课程 |
| 4 月 30 日 | 皮拉迪斯拍卖会 | 有现场竞价机会的慈善拍卖 |
| 4 月 29 日至 5 月 1 日 | 会议会谈 | 五个同步演示轨道,以及开放空间,赞助商,闪电谈话,海报,晚餐,等等 |
| 5 月 1 日 | 招聘会 | 在赞助商的展位上直接申请工作的机会 |
| 5 月 2 日至 3 日 | 短距离赛跑 | 小组练习,研究与 Python 相关的各种开源项目 |
请注意,教程的名额有限,很快就会满员,每节课需要 150 美元的报名费。皮拉迪斯拍卖也有 35 美元的报名费和可选的 15 美元捐款。
你今年会参加在盐湖城举行的 PyCon US 吗?在下面的评论区让大家知道。真正的 Python 团队将在那里等着你,准备好击掌并提供酷礼品!
PSF 雇佣来改善 PyPI
Python 软件基金会(PSF)宣布,他们正在寻求雇佣两名合同开发者**来帮助在 Python 包索引(PyPI) 中构建新功能,这是 Python 包的官方存储库。这个决定是在对 Python 社区进行了一些调查之后做出的,这些调查确定了 PyPI 目前缺少的关键用户需求。*
*最受欢迎的特性是 PyPI 中的组织账户,这是两家承包商将要设计、开发和部署的。目标是允许在 PyPI 中设置一个组织帐户,邀请其他用户加入组织,将这些用户分组到团队中,以及管理多个项目的所有权和权限。这将是向公司提供的有偿服务。
其中一个承包商角色将关注后端,另一个处理前端。这两个职位都是远程友好的,合同工作预计将于 2022 年 4 月初开始。每个角色的预算高达 9.8 万美元,约 560 小时,每周工作 35 小时。
查看评估标准了解更多信息。
Python 2.7 从 macOS 中移除
从技术上讲,这是一月份的新闻,但在这里值得一提,因为这是一个历史性的时刻。
这不仅是一个主要的安全风险,T2 英国网络安全局(NCSC)已经警告过了,也给 macOS 用户带来了不便。他们经常会不小心将包安装到他们遗留的系统级解释器中,而不是期望的虚拟环境。最终,当苹果在 macOS Monterey 12.3 Beta 5 的发行说明中悄悄提到从 macOS 中移除 Python 2.7 时,谣言被证明是真的。
然而,有趣的是,他们决定在操作系统发布周期的中期,通过 macOS 更新的测试版做出如此重大的改变。
Python 的下一步是什么?
二月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。******
Python 新闻:2022 年 1 月有什么新消息
在 2022 年 1 月的,代码格式化程序布莱克看到了它的第一个非测试版本,并发布了一个新的稳定性政策。 IPython ,强大的交互式 Python shell,标志着版本 8.0** 的发布,这是其三年来的第一个主要版本发布。此外, PEP 665 ,旨在通过指定锁文件的格式使可复制的安装更容易,被拒绝。最后但同样重要的是,Python 中一个 15 年前的内存泄漏 bug 被修复。**
让我们深入了解过去一个月最大的 Python 新闻故事!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
不再黑贝塔
固执己见的代码格式器 Black 的开发者现在有足够的信心称最新版本是稳定的。此次发布首次将 Black 带出测试版:
代码格式可能是开发人员之间大量冲突的根源。这就是为什么代码格式化程序,或者说 linters ,有助于执行风格约定,以保持整个代码库的一致性。Linters 建议更改,而代码格式化程序重写您的代码:
这使您的代码库更加一致,有助于及早发现错误,并使代码更容易扫描。
YAPF 是格式化程序的一个例子。默认情况下,它带有 PEP 8 风格指南,但它并不固执己见,给你很多对其配置的控制。
Black 走得更远:它带有 PEP 8 兼容风格,但总的来说,它是不可配置的。不允许配置背后的想法是,通过放弃对风格的控制,您可以解放您的大脑,专注于实际的代码。许多人认为这种限制给了他们更多的自由去成为有创造力的程序员。但是当然,并不是所有人都喜欢放弃这种控制权!
像布莱克这样固执己见的格式化者的一个重要特征是,他们让你的差异更具信息性。如果你曾经向你的版本控制系统提交过清理或格式化的提交,你可能已经无意中污染了你的 diff。
使用可配置的格式化程序,或者不使用格式化程序,在项目中途更改或实施样式会使功能代码的更改难以跟踪。这是因为差异会带来风格上的变化和功能上的代码变化,这可能需要很长时间才能理清。
但是,如果您在整个项目中使用黑色,那么您可以确信您的 diff 将只显示功能性的代码更改。
随着 Black 的第一个稳定发布,一个新的稳定政策也随之而来,它旨在明确你可以从 Black 的稳定发布中期待什么。
稳定性策略主要关注如何处理格式更改。Python 在不断发展,偶尔 Black 对自己的风格做一点小小的改变也是有意义的。稳定性政策将阻止 Black 在给定的日历年内进行此类更改。
稳定性策略保证,在给定的一月中,任何用黑色格式化的代码将在该年的十二月中产生完全相同的输出,而不管黑色的任何内部变化。黑色的版本号也与年份相关联,因此版本 22 对应于 2022 年期间的黑色。当 2023 年到来时,布莱克将发布第 23 版。如果有任何样式的改变,它们将会在 23 版中应用,而不是之前。
黑色已经相当受欢迎,这个新的稳定版本可能会增加它的采用。
IPython 8.0 的发布
在 IPython 7.0 发布三年后,本月发布了 IPython 8.0。这个新版本反映了大量的协作努力,包含了 250 多个拉取请求。主要亮点是默认的黑色格式、改进的回溯和改进的建议。
IPython 是由费尔南多·佩雷斯在 21 世纪初创建的,据说是在他拖延大学学业的时候。IPython 的核心是一个交互式 shell,可以用来替代 Python 的默认 REPL。它包括诸如语法高亮、自动建议和代码完成等便利功能:

IPython 被用作 Jupyter Notebook 的 Python 内核,这是一个以类似文档的格式显示代码执行的程序。科学家和教育工作者经常使用它以更广为人知的格式显示 Python 代码,包括优雅的输出或富文本格式:

有关 Jupyter 功能的更多信息,请查看Jupyter 笔记本简介。
从开发人员的角度来看,开发最新版本的最重要的工作之一是关注代码库的精简。这一努力得到了回报,将代码库从 348 个文件的 37,500 行代码减少到 294 个文件的 36,100 行代码!
该版本还发布了一个关于经验教训的总结,其中包含了一些给开发者的智慧之言。
PEP 665 -被拒绝
PEP 665 本月被指导委员会否决。这个有点争议的 PEP 旨在使 Python 的可复制安装更加容易。
大多数包管理器都有一个锁文件。Python 生态系统中的一个这样的文件是 poetry.lock文件,你可以在诗歌中找到它。 Pipenv 也有自己的锁文件。
你可以把一个锁文件想象成一个更加详细的 requirements.txt 文件。它更详细地介绍了用于安装的确切文件、版本甚至安装程序。锁定文件有助于跨环境、大型团队或用户群进行可重复的设置。PEP 665 旨在标准化锁文件格式。
关于更详细的讨论,请查看 PEP 作者、Python 核心开发者 Brett Cannon 的真实 Python 播客第 93 集。这个播客是在 PEP 被否决之前录制的。
根据批评者的说法,这个 PEP 有所欠缺,因为它要求所有的包都作为轮分发,并且留下了一些关于如何准确处理列表(源代码分发)包的疑问。有关轮子和目录的更多详细信息,请查看什么是 Python 轮子,为什么要关注?
在播客中,Brett Cannon 将 Python 称为“世界的粘合代码”,这要归功于 Python 能够整合来自其他语言的库,如 C、Go 和 Rust。当安装一个依赖于其他语言的包时,Python 有很多工作要做,以确保一切设置正确。这项工作并不总是成功的,这给 Python 社区带来了一些挫折。
编写 PEP 665 是为了解决安装的棘手问题,以及在不同系统上安装略有不同的缺陷。虽然它被否决了,但在这个问题上仍有许多工作要做。一些相关的 pep 有:
我们在 Real Python 要特别感谢 Brett Cannon,他也是 PEP 621 和 PEP 650 的作者,感谢他在这一领域的持续努力。
至少现在,Python 不会标准化一个锁文件格式,而像 poem 和 Pipenv 这样的工具将继续拥有它们自己的版本。
你想看看标准化的锁文件吗?您在复制安装时遇到过问题吗?我们很想在下面的评论中听到你的意见!
十五岁的 Bug,修复!
维克多·斯丁纳表现出非凡的坚韧,他将一个15 岁的臭虫标记为“已修复”。
这个 bug 是由 Ben Sizer 在 2007 年提出的,显示 Python 在退出时有一个内存泄漏。也就是说,Python 不会释放它已经使用的所有内存。就像当处理文件时你应该如何关闭文件对象一样,程序应该在不再需要内存时释放内存。
由于这是各种程序相对常见的问题,操作系统通常会在应用程序退出后自行清理。自动清理意味着这个内存泄漏错误的影响相对较小,不会影响大多数用户。然而,对于启动许多 Python 子进程的程序来说,这是一个问题,正如错误报告中发布的演示 C 程序所示:
#include <Python.h> int main(int argc, char *argv[]) { Py_Initialize(); Py_Finalize(); Py_Initialize(); Py_Finalize(); Py_Initialize(); Py_Finalize(); Py_Initialize(); Py_Finalize(); Py_Initialize(); Py_Finalize(); Py_Initialize(); Py_Finalize(); Py_Initialize(); Py_Finalize(); }
这个程序多次启动和结束 Python,导致越来越多的未释放引用,这代表了内存泄漏。要了解更多关于内存和内存管理的知识,请查看 Python 中的内存管理。
这些泄密范围很广,来自几个不同的来源。经过了无数次的修改和十五年(!)将 bug 减少到值得将其标记为“已修复”的程度仍然有一些内存泄漏,但现在已经足够好了。谢谢你,维克多·斯坦纳!
Python 的下一步是什么?
一月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!**
Python 新闻:2021 年 7 月有什么新消息
【2021 年 7 月对于 Python 社区来说,这是激动人心的一个月!Python 软件基金会雇佣了有史以来第一个 CPython 常驻开发人员——一个致力于 CPython 开发的全职带薪职位。来自 CPython 开发团队的其他消息中,回溯和错误消息得到了一些急需的关注。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
CPython 有一个全职的常驻开发人员
在我们六月的新闻综述中,我们特别报道了 Python 软件基金会宣布他们正在招聘一名常驻 CPython 开发人员。7 月,PSF 的计划取得了成果,聘用了 ukasz Langa。
作为 CPython 核心开发人员和 Python 社区的活跃成员,ukasz 可能为真正的 Python 读者所熟悉。在 Real Python 播客的第 7 集,茹卡斯加入主持人克里斯·贝利谈论黑色代码格式化程序的起源,他作为 Python 3.8 和 3.9 的 Python 发布经理的经历,以及他如何将 Python 与他对音乐的兴趣融合在一起。
作为第一个 CPython 常驻开发人员,ukasz 负责:
- 处理拉取请求和问题积压
- 进行分析研究以了解 CPython 的志愿者时间和资金
- 调查项目优先级及其未来任务
- 处理项目优先级
在关于他的新角色的声明中,他描述了他对 PSF 招聘公告的反应:
当 PSF 第一次宣布常驻开发者职位时,我立刻对 Python 充满了难以置信的希望。我认为对于这个项目来说,这是一个具有变革潜力的角色。简而言之,我认为常驻开发人员(DIR)的使命是加速其他所有人的开发体验。这不仅包括核心开发团队,而且最重要的是提交 pull 请求和在 tracker 上创建问题的驱动贡献者。(来源)
在他的个人网站上,ukasz 每周在一系列周报告中记录他的工作。在工作的第一周,他完成了 14 个问题和 54 个拉动式请求(PRs),审查了 9 个 PRs,并编写了 6 个自己的 PRs。
“不过不要对这些数字太过兴奋,”祖卡斯在他的第一份周报中写道。“按照 CPython 的开发方式,许多变化都是从main分支开始的,然后再移植到【Python】3.10,通常还会移植到 3.9。所以有些变化是三倍的。”
每周报告提供的透明度令人耳目一新,并提供了一个独特的角色幕后的外观。未来的申请人将会有一个极好的资源来帮助他们了解这份工作需要什么,什么地方做得好,哪里可以改进。
祖卡斯在 7 月写了两份周报:
- 【2021 年每周报告,7 月 12 日至 18 日
- 【2021 年每周报告,7 月 19 日至 25 日
这个系列一直持续到八月。每份报告都包括一个亮点部分,展示了一周内 ukasz 应对的几个最有趣的挑战。这一节尤其值得一读,因为它深入探讨了语言特性和错误修复。
祝贺 ukasz 成为第一位常驻 CPython 开发人员!真正的 Python 很高兴看到他在任期内取得的成就,并为 PSF 成功创造并填补了这一角色而欣喜若狂。
Python 3.11 获得增强的错误报告
Python 3.10 的发布指日可待,正如我们在 5 月报道的那样,新的解释器将对错误消息进行一些改进。Python 3.11 继续致力于改进错误。
对,没错!尽管 Python 3.10 要到 10 月才会发布,但是 Python 3.11 的工作已经在进行了!
回溯中的细粒度错误位置
Python 3.10 和 3.11 的发布经理 Pablo Galindo 于 2021 年 7 月 16 日在的推特上分享了他和他的团队已经完成了 PEP 657 的实现。PEP 增加了对“回溯中细粒度错误位置”的支持,对于新的和有经验的 Python 开发人员来说,这是一次重要的用户体验升级。
有趣的事实: A PEP 是一个 Python 增强提议,并且是主要的方法,在其中提议的 Python 语言特性被记录并在整个核心 Python 开发团队中共享。你可以通过阅读 PEP 1 来了解更多关于 PEP 的信息——第一个 PEP!
为了说明新的错误位置报告有多细粒度,考虑下面的代码片段,它将值1赋给名为x的嵌套字典中的键"d":
x["a"]["b"]["c"]["d"] = 1
在 Python 3.10 之前的任何 Python 3 版本中,如果键"a"、"b"或"c"的任何一个值是None,那么执行上面的代码片段会引发一个TypeError,告诉您不能下标 a NoneType:
Traceback (most recent call last):
File "test.py", line 2, in <module>
x['a']['b']['c']['d'] = 1
TypeError: 'NoneType' object is not subscriptable
这个误差是准确的,但不是有用的。哪个值是None?是在x["a"]、x["b"]还是x["c"]的值?找到错误的确切位置需要进行更多的调试,并且可能会很昂贵和耗时。
在 Python 3.11 中,相同的代码片段会产生一个回溯,其中包含一些有用的注释,指向None值的确切位置:
Traceback (most recent call last):
File "test.py", line 2, in <module>
x['a']['b']['c']['d'] = 1
~~~~~~~~~~~^^^^^
TypeError: 'NoneType' object is not subscriptable
脱字符指向NoneType的确切位置。元凶是x["c"]!不再猜测,不再调试。错误消息本身为您提供了查找错误原因所需的所有信息。
Python 社区热烈欢迎这一变化。在撰写本文时,Pablo 的推文已经获得了超过 4000 个赞,评论中充满了 Python 开发人员表达他们的感谢。
一些开发人员设法找到了目前不支持的边缘案例——至少在当前的实现中不支持。例如, Will McGugan 想知道新的位置报告对于亚洲字符和表情符号是否会像预期的那样工作。这条推特帖子证实了缺乏支持。
这种改变也是有代价的。正如在 PEP 中提到的,实现需要“向每个字节码指令添加新数据”
有趣的事实:你经常听到 Python 被称为一种解释语言,但这并不是 100%准确。事实上,Python 代码被编译成一种叫做字节码的低级语言。CPython 解释的是编译器生成的字节码指令,而不是您的 Python 代码。
要了解更多关于 CPython 如何工作的信息,请点击 Real Python 查看您的 CPython 源代码指南。
添加字节码指令的最终结果是标准库的.pyc文件增加了 22%。这听起来是一个显著的增长,但它仅相当于大约 6MB,负责 PEP 的团队认为:
这是一个非常容易接受的数字,因为开销的数量级非常小,尤其是考虑到现代计算机的存储大小和内存容量…
我们知道这些信息的额外成本对于一些用户来说可能是不可接受的,所以我们提出了一种选择退出机制,它将导致生成的代码对象没有额外的信息,同时也允许 pyc [sic]文件不包括额外的信息。(来源)
退出机制由一个新的PYTHONDEBUGRANGES环境变量和一个新的命令行选项组成。
你可以阅读 PEP 657 了解更多关于新错误位置报告的信息。你可以在Python 3.11 新特性文档中找到更多关于这个特性的例子。
改进了循环导入的错误消息
CPython 常驻开发人员 ukasz Langa 在他 7 月 19-26 日的每周报告中称,Python 3.11 中增加了一个改进的循环导入错误消息。
考虑以下封装结构:
a
├── b
│ ├── c.py
│ └── __init__.py
└── __init__.py
在a/b/__init__.py中有下面一行代码:
import a.b.c
c.py文件包含这行代码:
import a.b
这导致了一种情况,即包b依赖于模块c,即使模块c也依赖于包b。在 Python 3.10 之前的 Python 版本中,此结构会生成一条含糊的错误消息:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/private/tmp/cpymain/a/b/__init__.py", line 1, in <module>
import a.b.c
File "/private/tmp/cpymain/a/b/c.py", line 3, in <module>
a.b
AttributeError: module 'a' has no attribute 'b'
像这样的消息让无数 Python 开发人员感到沮丧!
多亏了来自 CPython 开发者 Filipe lains 的 pull 请求,新的错误信息更加清晰:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/private/tmp/cpymain/a/b/__init__.py", line 1, in <module>
import a.b.c
^^^^^^^^^^^^
File "/private/tmp/cpymain/a/b/c.py", line 3, in <module>
a.b
^^^
AttributeError: cannot access submodule 'b' of module 'a'
(most likely due to a circular import)
有没有其他的插入语有可能节省这么多的头部抨击?
在撰写本文时,还不清楚这一变化是否已经被移植到 Python 3.10。您可能需要再等待一个发布周期才能看到新的错误消息。
Python 的下一步是什么?
7 月,Python 出现了一些令人兴奋的发展。在真实 Python 展会上,我们对 Python 的未来感到兴奋,迫不及待地想看看在8 月会有什么新东西等着我们。
你最喜欢的来自7 月的 Python 新闻是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!**
Python 新闻:2022 年 7 月有什么新消息
在 2022 年 7 月的,Python 触及了星星,在处理来自詹姆斯·韦伯太空望远镜的数据中发挥了关键作用。经过两年的虚拟会议,欧洲 Python 2022** 在爱尔兰都柏林举行。 Anaconda 迎来了它的十岁生日, Flask 在 GitHub 上实现了一个重大的里程碑。**
Python 3.11 的两个新预发布版本发布,3.11.0b5 代表最终测试版。同时, Python 包索引(PyPI) 为关键项目的维护者引入了双重认证要求。最后,RStudio 改变了它的名字,并为 Python 发布了Shiny。
号外号外!阅读上个月所有令人兴奋的 Python 新闻!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
Python 去太空
嗯,也许更准确的说法是 Python 把太空带到了地球。詹姆斯·韦伯太空望远镜(JWST) 成为全球头条新闻,当时美国国家航空航天局和美国总统乔·拜登公布了它的第一批图像。全画廊视觉上非常壮观,在科学上具有开创性,因为它充满了迄今为止宇宙最深的红外图像。
Python 使得这项工作成为可能。正如都柏林高级研究院研究员、中红外仪器【MIRI】软件开发者帕特里克·卡瓦纳博士在 EuroPython 2022 的演讲中所说:
90%或者更多的分析工具、模拟器等等都是用 Python 开发的,并且使用 Python。(来源)
例如, JWST 科学校准管道运行在 Python 上,带有一些用于提高速度的 C 插件。韦伯的图像被处理为数字阵列,太空望远镜科学研究所的数据科学家依靠 SciPy 和 Jupyter 笔记本,以及该研究所自己的 AstroConda 频道。
如果你想尝试处理天文数据,那么你很幸运!韦伯的数据是免费提供的,你可以通过三个步骤准备离开这个世界:
现在你差不多准备好玩了。但是在发射之前,你需要从芭芭拉·a·米库尔斯基太空望远镜档案馆下载原始数据。有大量的数据,要得到你想要的可能很复杂。幸运的是,AstroExploring 有一个如何做的博客和视频来帮你。
要了解更多关于 Python 在这个新领域中的作用,请查看播客【Python 与我对话】中的 Python 和詹姆斯·韦伯太空望远镜。一定要在下面的评论里分享你的天文发现!
都柏林举办 2022 年欧洲 Python 大会
就像在4 月和5 月与 PyCon US 2022 一样,Python 社区又在一起了,感觉真好!本月,最大的聚会是 7 月 11 日至 17 日在爱尔兰都柏林举行的欧洲 Python 2022 。
大会举办了许多激动人心的活动,包括初学者日-简陋数据工作坊、 Django Girls 和 Trans*Code 。诸如此类的事件打开了 Python 社区的大门,使得编码对所有人来说更受欢迎和更容易理解。非常感谢 EuroPython 将包容性放在了首位!
当几个程序员兴奋地聚在一起时,EuroPython 还提供了一个功能齐全的远程选项来确保每个人,无论远近,都在礼堂里有一个座位。远程持票者可以积极参与闪电对话、Q &答问环节,并与特邀发言人进行分组讨论。
现场与会者和远程与会者都可以参加涵盖各种主题的讲座。即使你没有买票,你仍然可以在网上观看所有的场次。
蟒蛇和烧瓶庆祝里程碑
7 月 11 日,蟒蛇满十岁! Anaconda 是一个开源分发系统,它特别面向数据科学和机器学习。
注:如果你想入门 Anaconda 和机器学习,那么就来看看这个设置指南。
Pythonistas 还可以感谢 Anaconda 开发了包括 pandas 、 Dask 、 Bokeh 以及最近的 PyScript 在内的库。
要了解 Anaconda 的第一个十年及其未来计划,请查看 10 年数据科学创新:Anaconda 对开源 Python 社区的承诺。Anaconda 团队注意到 Python 正在以比任何其他编程语言更快的速度取得进展,Anaconda 拥有超过 3000 万用户,该团队致力于全面扩展对数据素养的访问。我们 Real Python 为这些努力喝彩!
但是 Anaconda 并不是唯一有理由庆祝的人——Flask 在这个月开始时没有任何未决问题或 GitHub 上的拉请求:
祝贺大卫·洛德和整个团队取得这一巨大成就!
Flask 是一个用于 web 开发的流行库。库维护人员不断地响应用户的需求并做出改进,因此清除队列是一项相当大的成就。如果你想在你自己的 web 开发中利用 Flask 的力量,你可以通过跟随 Real Python 的 Flask by Example 学习路径来学习。
为 Anaconda 的下一个十年和 Flask 的持续流行和维护干杯!
Python 3.11 最终测试版发布
2022 年 10 月大新闻来了, Python 3.11 终于要放归野外了!但是现在,Python 社区可以享受修补测试版的乐趣。
7 月 11 日, Python 3.11.0b4 问世,终于:
Python 3.10/3.11 发布经理兼 Python 核心开发者 Pablo Galindo Salgado 称这是一个诅咒版,因为一些屏蔽者要求修改发布时间表。特别是,过去的测试版存在稳定性问题,所以这个版本在它的继任者 Python 3.11.0b5 预计发布的后两天发布。
最初,有人预测 Python 3.11 的正式发布可能会推迟到 2022 年 12 月,但看起来开发者们已经回到了 10 月发布的轨道上。7 月 26 日标志着 Python 3.11.0b5 的发布:
这些推文强调了每个测试版投入的时间和精力。那么为什么要为他们费心呢?简而言之,测试阶段对 Python 的健康至关重要。
在 alpha 阶段,新的功能正在被添加,但是 beta 阶段伴随着功能冻结。这是开发人员、库维护人员和程序员用他们的代码进行测试,并在重要的日子到来之前报告任何错误或意外行为的最佳时机:

所以,现在是时候试一试了。如果你还没有,你可以在这里下载 Python 3.11.0b5。然后尝试它闪亮的新特性,像更好的错误消息、任务和异常组,以及支持用tomllib 读取 TOML。在下面的评论中分享你的发现和阻碍。
PyPI 要求双因素认证
Python 健康的另一个关键是确保所有第三方库安全可靠。这就是为什么 PyPI 致力于确保关键库的开发者使用双因素认证(2FA) 。这将成为未来几个月的一项要求。
虽然最终目标是让尽可能多的库维护者和所有者使用 2FA,但是第一个主要的推动力是让所有关键库的维护者都参与进来。以下是 critical 在此上下文中的含义:
项目资格是基于下载量的:任何在前 6 个月下载量前 1%的项目都被指定为关键项目(以及 PyPI 自己的依赖项)。(来源)
超过 3500 个项目符合这一标准,谷歌开源安全团队正在向所有合格的维护者提供两个免费的 Titan 安全密钥。
但是即使你没有维护一个关键的库,你也可以选择加入并要求你的维护者和所有者伙伴使用 2FA。
您可以在 PyPI 2FA 仪表板上跟踪该计划的进展。截至 7 月 31 日,8000 多名关键维护人员中约有 2000 名采用了 2FA:
如果你在 PyPI 上维护一个库,不管是否重要,你都应该启用 2FA 来保护自己和他人!
RStudio 更名并发布 Shiny for Python
RStudio 公司通过为数据科学、科学研究和技术交流提供开源软件而声名鹊起。现在它采用了一个新名字: Posit !这意味着:
Posit 是一个真实的词,意思是提出一个想法供讨论。数据科学家每天花大量时间提出主张,然后用数据进行评估。当考虑公司的新名字时,我们希望它既能反映我们社区从事的工作(测试假设!)以及建立更高层次的知识和理解的科学愿望。(来源)
这篇博客文章继续指出,尽管 RStudio 的努力主要与 R 编程语言有关,但该公司的使命“有意超越‘数据科学的 R’”。"
这包括继续致力于开发 Python 工具。7 月底,alpha 发布了一个这样的工具。 Shiny for Python 为构建 web 应用程序提供了一个可接近的、灵活的、高性能的仪表板。
因为它仍处于 alpha 阶段,所以你不应该在生产中依赖它的应用程序,但你绝对可以尝试一下,看看它能做什么。您可以通过将它安装在您的计算机上或在您的网络浏览器中试用来开始使用。
Python 的下一步是什么
这个月在 Python 的世界里,你最激动的是什么?
你参加了 2022 年欧洲蟒蛇展吗?你是否摆弄过来自太空最深处的数据?通过要求 2FA,您是否使您的库更加安全?你正在测试 Python 3.11 的最新测试版吗?你是如何庆祝《蟒蛇》和《烧瓶》的成功的?请在评论中告诉我们!
快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。**
Python 新闻:2021 年 6 月有什么新消息
如果你想了解 2021 年 6 月的 Python 世界中发生的事情,那么你来对地方了,可以得到你的新闻**!*
*六月是变化的一个月。Python 软件基金会(PSF) 的执行董事 Ewa Jodlowska 在任职十年后宣布离职,PSF 董事会获得三名新董事。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Ewa Jodlowska 卸任 PSF 执行董事
6 月 16 日,Python 软件基金会(PSF) 宣布执行董事 Ewa Jodlowska 已经决定在 2021 年底离开基金会。
即使你没有听说过埃娃,你无疑已经被她的作品所影响。作为执行董事,Ewa 负责确保 PSF 实现其使命“促进、保护和发展 Python 编程语言,并支持和促进 Python 程序员多元化和国际化社区的发展。”
PSF 负责管理和维护python.org网站以及 Python 包索引。PSF 还支持和资助一些组织的活动和研讨会,如 Django Girls 和 PyLadies 以及世界各地的其他 Python 会议和聚会。
除了管理社区外展,PSF 还支持和资助 Python 软件开发。这包括组织、资助和支持 CPython sprints。正如您将在本文后面的中了解到的那样,PSF 的资金和支持不仅仅是对核心 Python 语言的支持。PSF 还通过各种资助和财政赞助项目来帮助 Python 库。
作为执行董事,Ewa 参与了 PSF 的所有项目。她的领导能力和奉献精神帮助 PSF 和 Python 语言达到了令人难以置信的高度,她的工作对世界各地的 Python 开发人员产生了积极的影响。现在 Ewa 即将卸任,PSF 董事会将开始寻找新的执行董事。关注 PSF 博客和推特账户的更新和即将到来的工作列表。
如果你想了解更多关于 Ewa 和她为 PSF 所做的工作,请查看 Real Python 的 s 社区对 Ewa Jodlowska 的采访。
PSF 宣布董事会选举结果
在 PSF 的其他新闻中,六月见证了董事会三位新董事的选举!
新董事是:
- 乔安娜·南杰凯
- 德博拉·阿泽维多
- 塔尼亚·阿拉德
祝贺新导演和所有被提名的人!
PSF 董事是志愿者,他们帮助监督和管理 PSF 的业务和事务,包括任命官员和确定委员会和工作组的预算。他们充当大使,代表 Python 社区的许多不同利益和目标。
你可以在视频作为 Python 软件基金会主任的生活中了解更多关于 PSF 主任的工作。
Jazzband 接受 PSF 财政赞助计划
你曾经使用过 django-debug-toolbar 来调试你的 Django 应用或者 pip-tools 来管理你的 Python 项目的依赖吗?如果是这样,那么您已经直接从 Jazzband 所做的工作中受益,这些工作确保了优秀的 Python 包继续得到维护和支持。
Jazzband 的使命是帮助开源项目——特别是那些只有少数维护人员的项目——摆脱维护开源软件的压力。他们通过培养“合作编码”来做到这一点,这有助于保持项目的活力并降低贡献者的障碍。Jazzband 阵容中目前有五十五个项目。
2021 年 6 月 4 日,Jazzband 创始人 Jannis Leidel 宣布 Jazzband 已经被 PSF 财政赞助计划接受。
财政担保人获得 501(c)(3)免税地位,并帮助处理后台事务,如会计、现金流、保险和法律支持。作为财政赞助者,Jazzband 现在可以接受个人和企业用户的捐赠。
如果你想给 Jazzband 捐款,你可以通过 PSF 捐款页面进行。
如果您是 Python 包的新手,并且想了解更多关于在您自己的代码中使用开源库的知识,那么您可以从什么是 Pip 中开始了解包管理器。新蟒蛇指南。如果您对发布和维护自己的 Python 包感兴趣,请查看如何将开源 Python 包发布到 PyPI 。
微软正在雇人帮助提升 Python 的速度
微软宣布了一个新的高级软件工程师的角色,致力于加速 Python。这个职位是由 Python 开发者吉多·范·罗苏姆在 Twitter 上宣布的。
招聘启事将该角色的主要职责描述为“执行与显著提高开源 CPython 解释器中实现的 Python 编程语言的运行时性能相关的任务。”该职位是远程友好的,并向美国以外的新兵开放。
欲了解更多信息,请查看官方职位列表。
PyCon US 2021 视频录像现已发布
在上个月的新闻综合报道中,我们报道了一年一度的 PyCon US 会议。今年虚拟会议的所有视频记录,包括演讲和教程,现在都可以在 PyConUS YouTube 频道上看到!
我们特别兴奋的是真正的 Python 的自己的 Geir Arne Hjelle 的关于 Python 装饰者的教程,这是对他的文章Python 装饰者入门的精彩补充。
Python 的下一步是什么?
六月对于 Python 来说是一个多事之秋!在真实 Python 展会上,我们对 Python 的未来感到兴奋,迫不及待地想看看 7 月的会有什么新的东西等着我们。
来自6 月的 Python 新闻你最喜欢的片段是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!****
Python 新闻:2022 年 6 月有什么新消息
2022 年 6 月为 Python 社区带来了一系列激动人心的消息!PSF 收到了一笔资金,用于一个专注于安全的新角色,并为董事会的四个席位举行了选举。两个重要的开发者调查的结果已经公布,Python 和一些流行包的新版本已经问世。
PEP 691 被接受,扩展了 Python 打包索引的简单 API。随着 Python 3.12 变更页面的上线,您现在可以点击刷新,第一时间了解明年主要 Python 版本中即将推出的特性和反对意见。
随着夏季的全面展开,Python 社区中也出现了更多面对面的聚会,其他聚会还在继续。
让我们深入了解过去一个月最大的 Python 新闻!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
Python 软件基金会有消息
Python 软件基金会(PSF) 是 Python 背后的组织。它旨在“促进、保护和发展 Python 编程语言,并支持和促进一个多样化和国际化的 Python 程序员社区的发展”(来源)。
如果你以前没有听说过 PSF,一定要去看看 PSF 博客,在这篇新闻文章中你会看到它的几次链接。
PSF 选举新的董事会董事
填补 PSF 董事会四个席位的选举于六月下半月举行。PSF 董事会席位的任期为三年,董事有资格连任。要在这次选举中投票,你必须是有投票权的注册 PSF 成员。
今年有很多被提名人,而的席位被获得最多票数的四名被提名人占据:
如果你对在 PSF 董事会任职意味着什么以及董事的职责是什么感到好奇,那么你可以看一个视频,其中三名董事会成员描述了作为 Python 软件基金会董事的 T2 的生活。
祝贺新的和回归的董事会董事,非常感谢所有其他被提名者继续参与 Python 社区。
PSF 发布 2021 年年报
本月,PSF 也发布了其 2021 年年度报告。去年是 Python 软件基金会成立二十周年,也是 Python 本身成立三十周年:

该报告重点介绍了四名团队成员如何在 2021 年以新的角色加入 PSF。Python 打包和 CPython 本身通过打包项目经理和常驻开发人员的专门角色得到了强有力的支持。活动资助再次启动,重点是在线活动。PSF 还组织了 PyCon US 2021,作为一项完全在线的活动。
如果你想了解更多,你可以在线阅读完整的报告。
OpenSSF 资助 Python 生态系统的安全角色
遗憾的是,这已经不是第一次了,PyPI 上还发现了另一组恶意软件包。因为 Python 在世界范围内被如此庞大的社区所使用,这样的攻击可能会产生危险而深远的后果。在上面链接的新闻文章中,你会看到这些软件包旨在揭露程序员的秘密。
因此,开源安全基金会(OpenSSF) 决定资助 PSF 中的一个新角色,这是一个好消息。
担任该角色的人将有机会积极影响更广泛的 Python 生态系统中的当前安全状态,因为他们“为 Python、Python 包索引(PyPI)和 Python 生态系统的其余部分提供了安全专业知识”( Source )。
这笔赠款还将用于完成对 Python 生态系统中关键开源基础设施的安全审计,如 PyPI 和 CPython 源代码本身。有一个专门的角色和资金将有望大大提高 Python 的大型全球社区的安全性。
调查结果出来了!
也许您过去参加过开发者调查,或者您喜欢浏览结果以了解社区的发展方向。6 月,两项重要的开发商调查结果公布。
Python 开发者调查
本月初,PSF 宣布了第五次年度 Python 开发者调查的结果,这是 PSF 和 JetBrains 的一次合作。
你可以在专用网页上以可视化方式查看一些调查结果,或者你可以打开你的数据分析指关节,看看你能在的原始数据中找到什么。
调查中首次包含了关于 Python 打包的明确问题:

以微弱优势,诗歌是最受欢迎的依赖管理工具,此外还有 Pipenv 和 pip-tools 。
注意:有些问题允许有多个答案,这就是总分可能大于 100%的原因。
在关于 Python 打包的部分,您还可以看到 pip 和 venv 是最流行的打包相关工具,大多数开发人员将他们的项目依赖记录在一个requirements.txt文件中。
Python 开发者主要将他们的包发布到 PyPI,尽管 37%的受访者表示他们将包发布到私有的 Python 包索引。随着 PEP 691 接受,以后会不会有一部分转移到 JSON 中托管包信息?
虽然调查结果没有什么大的惊喜,但是这些数据帮助了 Python 核心开发人员、打包项目经理和其他人的工作。
接下来,看看更广泛的开发人员社区的状态!
StackOverflow 的开发者调查
今年的 StackOverflow 开发者调查在五月进行,超过七万名开发者参与。他们分享了关于最喜欢的工具、教育背景、喜欢和不喜欢等等的观点!
Python 也得到了更广泛的开发人员社区的喜爱:
Rust […]与 Python 并列为最受欢迎的技术,TypeScript 紧随其后。(来源)
Python 也几乎和 HTML/CSS、JavaScript 并列成为最受初学编程的新人欢迎的语言。但是 Python 生态系统中的包呢?
因为 Python 在学习编码的人群中很受欢迎,所以像 NumPy 和 pandas 这样的包在新手中也比专业开发人员更受欢迎。
就 web 框架而言,开发人员喜欢 FastAPI ,并且对学习它和使用 FastAPI 构建 web API很感兴趣。
在开发者调查结果中,你有没有发现其他特别有趣的东西?如果你有,请在下面的评论中分享你的发现。
Python 生态系统发布新版本
几乎每个月都有几个著名的 Python 包,甚至 Python 本身的新版本发布。他们通常会添加新功能、修复错误、纠正安全问题等等。2022 年 6 月也不例外。现在,您可以测试、使用和享受几个新版本。继续阅读,了解更多信息!
Python 3.11.0b3 加急
Python 3.11 之前的测试版(3.11.0b2)与 pytest 有不兼容的地方。由于 Python 3.11 中编译器和 AST 节点的变化,pytest默认重写的 AST 节点最终无效。
为了避免要求用户修改他们的测试套件,Python 3.11 发布团队决定创建这个额外的测试版,来解决这个问题。这个决定将 3.11 的测试版总数从四个增加到五个。
注意: Python 3.11 仍在开发中,将为该语言带来许多新的有趣的特性,例如更好的错误消息、任务和异常组,以及 TOML 支持。
你可以在 6 月 1 日宣布加急发布的博客页面上阅读更多关于 3.11.0b3 的细节。
Python 3.10.5 维护
6 月初,发布团队还公布了 Python 3.10 的第五个维护版本,Python 3.10.5:
这个版本包含了超过 230 个错误修正和文档变更,所以你肯定想更新:)( Source )
如果您仍在使用任何早期版本,请获取您的更新以充分享受 Python 3.10 中的所有新特性,而不会遇到已经报告并解决的问题。
Django 4.0.5 错误修复和 4.1 Beta 1
Django 在 6 月发布了 Django 4.0.5 的 bugfix 版本,修复了 4.0.4 中出现的几个 bug。
本月晚些时候,Django 项目宣布了一个令人兴奋的更新,发布了 Django 4.1 beta 1。这一版本意味着 Django 4.1 的所有主要新功能现在都被锁定,“从现在到 4.1 最终版之间,只有新功能中的错误和 Django 早期版本的退化才会被修复”(来源)。
如果你渴望看到 Django 4.1 的许多新特性,那么你现在可以安装 Django 4.1 beta 1 并试用它们!确保向 Django 团队报告你发现的任何错误,帮助他们修复在开发阶段遗留的问题。
请求 2.28.0 和 2.28.1
Requests 本月还发布了两个新版本。除了一些改进和错误修复,该项目还根据 GitHub PR 6091 中的建议,在 2.28.0 中放弃了对 Python 2.7 和 Python 3.6 的支持。这意味着新版本的请求不再支持任何版本的 Python 2.x。
月底带来了另一个版本 2.28.1 ,它在iter_content中添加了速度优化,并过渡到yield from。
Python 3.12 变更页面上线
描述 Python 3.12 新特性的页面上线了。在撰写本文时,还没有列出任何新特性,但是您可以浏览将在下一个 Python 版本中生效的反对意见列表。
讨论了很长时间的一个有趣的奇怪现象将进一步产生一个可见的错误:
目前,Python 接受后面紧跟关键字的数字文字,例如
0in x、1or x、0if 1else 2。它允许像[0x1for x in y](可以解释为[0x1 for x in y]或[0x1f or x in y])这样令人困惑和模棱两可的表达。如果数字文字后面紧跟关键字and、else、for、if、in、is和or之一,则会发出语法警告。在未来的版本中,它将被更改为语法错误。
如果您使用较旧的 Python 解释器运行这些代码示例之一,那么您不会看到任何警告。在 3.11 中,它引发了一个 DeprecationWarning ,你只有在开发模式下运行 Python 时才能看到:
$ python -X dev
一旦在开发模式下启动了 Python 3.11,就可以运行示例来查看DeprecationWarning:
>>> [0x1for x in (1, 2)] <stdin>:1: DeprecationWarning: invalid hexadecimal literal [31]在 3.12 中,无声的
DeprecationWarning将会变成无声的SyntaxWarning,在你玩这种恶作剧的时候给你提个醒。正如前面提到的,核心开发者计划在以后的版本中把这个SyntaxWarning改成SyntaxError。“Python 中的新特性”页面会不断更新,直到 Python 版本发布。你能找到其他有趣的弃用或改变吗?如果有你想讨论的,请在下面留言!
PEP 691 为 Python 包索引带来了一个基于 JSON 的简单 API
PEP 691 引入了基于 JSON 的 简单 API 允许 Python 包索引使用 JSON 代替 HTML。
这个 PEP 代表了对简单 API 的一个改变,它是 Python 包索引的一个接口。这个 API 主要由安装程序和解析程序使用,比如
pip,当获取关于要安装的包的信息时。注意: PyPI 还有一个 JSON API ,它提供关于托管在 PyPI 上的项目的信息。这个 API 和通过 PEP 691 添加的基于 JSON 的简单 API 没有任何关系。
基于 JSON 的简单 API 主要是作为现有的基于 HTML 的简单 API 的一个更加机器友好的替代,因此避免引入新的功能。
例如,基于 HTML 的简单 API 上的包的发布将需要具有关于包含在 HTML 链接元素中的文件的所有信息:
<a href="https://files.pythonhosted.org/packages/7a/93/551e43aefa86a6f57e1852d60568024e12a20f5f9bf316a37fc869c0c274/barbican-14.0.0.tar.gz#sha256=1a034410189d045974bf70b703ecdce17c1a7b6a14814541e05ba5cb34f6e419" data-requires-python=">=3.6"> barbican-14.0.0.tar.gz </a>通过基于 JSON 的简单 API 提供的相同信息更容易解析:
{ "filename": "barbican-14.0.0.tar.gz", "hashes": { "sha256": "1a034410189d045974bf70b703ecdce17c1a7b6a14814541e05ba5cb34f6e419" }, "requires-python": ">=3.6", "url": "https://files.pythonhosted.org/packages/7a/93/551e43aefa86a6f57e1852d60568024e12a20f5f9bf316a37fc869c0c274/barbican-14.0.0.tar.gz", "yanked": false }您可能还会发现,与基于 HTML 的简单 API 相比,实际上有一个新特性。通过将
"hashes"编码为一个 JSON 对象,基于 JSON 的简单 API 允许您为每个文件包含多个哈希。这对于基于 HTML 的简单 API 的 URL 查询参数是不可能的。如果您是 Python 的最终用户,那么这个变化很可能对您没有任何影响。如果您是自定义 Python 打包索引的维护者,那么添加基于 JSON 的简单 API 会给您提供三种选择:
- 什么都不做,继续使用简单的 API 提供包信息,使用
text/html作为内容类型。- 决定用 HTML 或 JSON 提供包信息,使用两种新引入的内容类型之一:
- JSON:T0】
- HTML:
application/vnd.pypi.simple.v1+html- 实现两个并通过内容协商决定将哪个版本发送给你的用户。
简而言之,PEP 691 严格来说是对由来已久的 PEP 503 -简单存储库 API 及其附加物的补充。PyPI 不会放弃 HTML 支持,你仍然可以使用静态服务器来托管你的定制包索引。
注意:如果你的静态服务器是 GitHub pages,你必须坚持提供 HTML,因为在撰写本文时,GitHub 不支持定制内容类型,只有
application/vnd.pypi.simple.v1+html可以回退到受支持的text/html。如果您正在托管一个私有 Python 包索引,并且不想麻烦地实现 HTML 响应,那么现在可以使用新的基于 JSON 的简单 API 来实现。然而,PEP 的主要好处可能还是在未来:
这给了我们完全的权限来有效地冻结 HTML API,不再添加新的特性,同时我们开始向 JSON API 添加新的特性,使我们不必担心如何将我们想要添加的东西编码到 HTML 中。(来源)
在当前基于 HTML 的简单 API 中,有什么特性是您非常缺少的,并且希望在基于 JSON 的 API 中实现吗?如果你有想法或建议,请在下面留下评论。
Python 社区再次聚首
像大多数社区一样,当人们可以见面和交谈时,Python 社区受益,包括离线!如果你想认识你所在地区的其他使用 Python 的人,那么看看 PyCon 日历。
还要记住的是,COVID 疫情并没有结束。保持安全,尊重他人,尤其是你国家的卫生保健工作者。
全球各地都有面对面的 Python 聚会
PyCon US 已经结束了,但是在夏季及以后还有许多其他的 Python 社区会议在进行。六月份,至少有三场官方宣布的现场 Python 会议召开了:
- 6 月 2 日至 5 日,佛罗伦萨意大利文化节
- 6 月 20 日至 22 日,巴塞尔地质公园
- 6 月 28 日至 29 日在特拉维夫举行的以色列动漫展
面对面的会议提供了一个很好的机会,可以结识其他志同道合的人,就共同的项目和兴趣进行交流。如果你认为你已经准备好负责任地与人交往,那么看看 PyCon 日历了解一下你附近的 Python 会议和聚会。
《欧洲科学》的门票开始发售
如果你住在欧洲,并且在科学领域使用 Python,你可能会有兴趣参加今年的 EuroSciPy 。会议将于 8 月 29 日至 9 月 2 日在瑞士巴塞尔举行。
为期五天的活动将聚集 80 名演讲者,您可以从 24 个研讨会中进行选择:
或者你可以选择完全退出研讨会,转而参加走廊赛道——由你决定!
第十四届欧洲科学中的 Python 大会门票现已开始购买。
网上提供的 PyCon US 教程录音
来自 PyCon US 2022 的教程录像已登陆 PyCon YouTube 页面:
除非你有一个时间转换器,否则你不可能参加 PyCon 的所有教程,即使你足够幸运亲自去那里。看看这些录像,并在评论中分享哪些是你觉得最有趣的,哪些是你建议其他人观看的。
杂项新闻
像往常一样,在 Python 的世界里发生了更多的事情。在最后一部分,你可以读到一些在网上成为新闻的故事。
Anaconda 收购 PythonAnywhere
软件开发和咨询公司 Anaconda,Inc. ,因其广泛使用的 Anaconda Python 发行版而闻名,收购了基于云的 Python 开发和托管环境 PythonAnywhere 。
根据 Anaconda 的新闻页面,PythonAnywhere 将“继续作为一个独立的产品发展,因为 Anaconda 和 PythonAnywhere 共同努力简化 Python 用户的工作负载和应用程序的开发和托管”(来源)。
这两个平台的用户可能很快就会受益于这两个产品之间更好的集成。
GitHub 关闭了 Atom 文本编辑器
自 2014 年问世以来, Atom 文本编辑器一直是广受欢迎的文本编辑器。由于 Atom 受欢迎程度的下降以及内部对其他工具和服务的重新关注,GitHub 决定停止该项目的任何开发,并在 12 月 15 日存档 Atom 组织的所有存储库。
GitHub 官方宣布的这一决定包括一个段落,以表彰 Atom 对当今文本编辑器世界的影响:
这是一次艰难的告别。值得一提的是,Atom 已经成为电子框架的基础,为成千上万个应用的创建铺平了道路,包括微软 Visual Studio 代码、Slack 和我们自己的 GitHub 桌面。(来源)
目前的 Atom 用户将有六个月的时间转向使用不同的产品。如果你曾经使用过 Atom,并且你正在寻求切换到一个不同的代码编辑器,使用 Visual Studio 代码进行 Python 开发可能会感觉很熟悉。
Python 的下一步是什么?
那么,六月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?你会自己设置包索引,实验服 JSON 吗?如何看待提升 Python 生态系统的安全性?2022 年有没有参加 Python 大会的打算?请在评论中告诉我们!
快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。*****
Python 新闻:2021 年 3 月有什么新消息
Python 在很多方面都是一种动态语言:它不仅不是像 C 或 C++那样的静态语言,而且还在不断发展。如果你想了解 2021 年 3 月在的巨蟒世界里发生的事情,那么你来对地方了,来获取你的新闻!
2021 年 3 月标志着 Python 语言的核心发生了显著的变化,增加了结构模式匹配,现在可以在 Python 3.10.0 的最新 alpha 版本中测试。
除了语言本身的变化,对于 Python 来说,三月是一个充满激动人心的历史性时刻的月份。这种语言庆祝了它的 30 岁生日,并成为第一批登陆另一个星球的开源技术之一。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 岁了
虽然 Python 的实际出生日期是1991 年 2 月 20 日,也就是0 . 9 . 0 版发布的时间,但是三月是一个值得庆祝的好月份。今年 3 月是 Python 软件基金会成立于 2001 年 3 月 6 日的20 周年。
在过去的三十年里,Python 已经发生了很大的变化,无论是作为一门语言还是作为一个组织。从 Python 2 到 Python 3 的过渡花了十年才完成。决策的组织模式也发生了变化:该语言的创造者吉多·范·罗苏姆曾是掌舵人,但 2018 年成立了一个五人指导委员会,以规划 Python 的未来。
生日快乐,巨蟒!为🥂的更多岁月干杯
结构模式匹配来到 Python 3.10.0
Python 3.10.0 是 Python 的下一个次要版本,预计将于 2021 年 10 月 4 日发布。此次更新将为核心语法带来一大新增:结构模式匹配,这是在 PEP 634 中提出的。你可以说结构模式匹配给 Python 增加了一种
switch语句,但这并不完全准确。模式匹配做得更多。举个例子,来自 PEP 635 。假设您需要检查对象
x是否是一个包含套接字连接的主机和端口信息的元组,以及可选的模式,比如 HTTP 或 HTTPS。您可以使用一个if…elif…else块来编写这样的代码:if isinstance(x, tuple) and len(x) == 2: host, port = x mode = "http" elif isinstance(x, tuple) and len(x) == 3: host, port, mode = x else: # Etc…Python 新的结构模式匹配允许你使用一个
match语句来更清晰地写这个:match x: case host, port: mode = "http" case host, port, mode: pass # Etc…
match语句检查对象的形状是否匹配其中一种情况,并将数据从对象绑定到case表达式中的变量名。不是每个人都对模式匹配感到兴奋,这个特性受到了核心开发团队和更广泛的社区的批评。在接受公告中,指导委员会承认这些问题,同时也表示支持该提案:
我们承认模式匹配对 Python 来说是一个很大的改变,在整个社区达成共识几乎是不可能的。不同的人对语义和语法的不同方面有所保留或关注(指导委员会也是如此)。尽管如此,经过深思熟虑,……我们相信,PEP 634 等规范中规定的模式匹配将是对 Python 语言的一大补充。(来源)
尽管意见不一,模式匹配是即将到来的下一个 Python 版本。你可以通过阅读 PEP 636 中的教程来了解更多关于模式匹配的工作原理。
巨蟒登陆火星
2 月 18 日,毅力号火星车经过 7 个月的旅程在火星着陆。(从技术上来说,这是一个 2 月的新闻项目,但它太酷了,我们不得不将其纳入本月!)
坚持不懈带来了大量的新仪器和科学实验,这将为科学家们提供迄今为止对火星的最佳观察。毅力依赖于一系列开源软件和现成的硬件,这使它成为迄今为止最容易实现的火星漫游项目。
Python 是依靠毅力生存的开源技术之一。它在火星车上被用来处理着陆过程中拍摄的图像和视频。
毅力号携带的最令人兴奋的实验之一是别出心裁的火星直升机,这是一架小型无人机,用于在稀薄的火星大气中测试飞行。Python 是飞控软件的开发需求之一,称为F’。
2020 年 Python 开发者调查结果在
由 JetBrains 和 Python 软件基金会进行的 2020 Python 开发者调查的结果出来了,与去年的调查相比,他们显示了一些有趣的变化。
2020 年,94%的受访者报告主要使用 Python 3,高于 2019 年的 90%和 2017 年的 75%。有趣的是,Python 2 仍然在计算机图形和游戏开发领域的大多数受访者中使用。
Flask 和 Django 继续主导 web 框架,分别拥有 46%和 43%的采用率。新人 FastAPI 以 12%的采用率成为第三大最受欢迎的 web 框架——考虑到 2020 年是该框架首次出现在选项列表中,这是一个令人难以置信的壮举。
在“你目前的 Python 开发使用的主要编辑器是什么?”这个问题上,Visual Studio Code 获得了超过 5%的回答份额这使得微软的 IDE 占据了 29%的份额,进一步缩小了 Visual Studio 代码和 PyCharm 之间的差距,后者仍以 33%的份额高居榜首。
查看调查结果,了解更多关于 Python 及其生态系统的统计数据。
Django 3.2 的新特性
Django 3.2 将于 2021 年 4 月发布,随之而来的是一系列令人印象深刻的新特性。
一个主要的更新增加了对函数索引的支持,它允许你索引表达式和数据库函数,比如索引小写文本或涉及一个或多个数据库列的数学公式。
函数索引是在
Model类的Meta.indexes选项中创建的。这里有一个改编自官方发布说明的例子:from django.db import models from django.db.models import F, Index, Value class MyModel(models.Model): height = models.IntegerField() weight = models.IntegerField() class Meta: indexes = [ Index( F("height") / (F("weight") + Value(5)), name="calc_idx", ), ]这将创建一个名为
calc_idx的函数索引,该索引对一个表达式进行索引,该表达式将height字段除以weight字段,然后加上5。Django 3.2 中的另一个与索引相关的变化是支持覆盖索引的 PostgreSQL。一个覆盖索引允许您在一个索引中存储多个列。这使得只包含索引字段的查询能够得到满足,而不需要额外的表查找。换句话说,您的查询可以快得多!
另一个值得注意的变化是添加了管理站点装饰者,简化了自定义显示 T2 和动作功能 T4 的创建。
要获得 Django 3.2 中新特性的完整列表,请查看官方发布说明。 Real Python 贡献者 Haki Benita 也有一篇有用的概述文章,通过更多的上下文和几个例子带你了解一些即将推出的特性。
PEP 621 到达最终状态
早在 2016 年, PEP 518 引入了
pyproject.toml文件作为指定项目构建需求的标准化地方。以前,您只能在setup.py文件中指定元数据。这导致了一些问题,因为执行setup.py和读取构建依赖关系需要安装一些构建依赖关系。在过去的几年里越来越受欢迎,现在不仅仅用于存储构建需求。像
black自动套用格式器这样的项目使用pyproject.toml来存储包配置。PEP 621 于 2020 年 11 月被临时接受,并于 2021 年 3 月 1 日被标记为最终版本,它规定了如何在
pyproject.toml文件中写入项目的核心元数据。从表面上看,这似乎是一个不太重要的 PEP,但它代表了一个远离setup.py文件的持续运动,并指向 Python 打包生态系统的改进。PyPI 现在是 GitHub 秘密扫描集成商
Python 包索引,或 PyPI ,是下载所有组成 Python 丰富生态系统的包的地方。在
pypi.org网站和files.pythonhosted.org网站之间,PyPI 每月产生超过20Pb的流量。超过 20,000 太字节!有这么多的人和组织依赖 PyPI,保证索引的安全是最重要的。这个月,PyPI 成为了官方的 GitHub 秘密扫描集成商。GitHub 现在会检查每一个提交给公共库的泄露的 PyPI API 令牌,如果发现任何漏洞,会禁用库并通知其所有者。
Python 的下一步是什么?
Python 继续以越来越大的势头发展。随着越来越多的用户转向这种语言来完成越来越多的任务,Python 及其生态系统将会继续发展,这是很自然的。在真实 Python 展会上,我们对 Python 的未来感到兴奋,迫不及待地想看看在4 月会有什么新的东西等着我们。
来自三月的 Python 新闻你最喜欢的片段是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!**
Python 新闻:2022 年 3 月有什么新消息
在 2022 年 3 月的中, Python 3.11.0a6 预发布版本可供您测试,因此您可以了解 Python 的最新特性。这个版本是 Python 进入测试阶段(计划于 2022 年 5 月 5 日)之前计划的七个 alpha 版本中的第六个。
pep 们现在有了一个时尚现代的新家。此外,PEP 594 也已经被接受,它处理从 Python 标准库中移除废电池的问题。关于 Python 事件,2022 年欧洲 Python 大会(CFP)举行了提案征集活动,目前正在出售大会门票。
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
让我们深入了解过去一个月最激动人心的 Python 新闻!
Python 发布了几个新版本
几乎每个月都会发布几个 Python 版本。他们通常会添加新功能,修复漏洞,纠正安全问题,等等。2022 年 3 月也不例外。现在,您可以测试、使用和享受几个新版本。继续阅读,了解更多信息!
Python 3.11.0a6 发布
Python 的第六个 alpha 版本于 3 月 7 日发布。由于一些内部问题,一周的延迟之后, Python 3.11.0a6 在这里给你试驾。Python 3.11 拥有几个新特性和变化:
要了解更多关于这些功能的基础知识,请查看 Python 新闻:2022 年 2 月有什么新消息?。此外,如果你想提前了解细粒度错误位置如何改善你的编码和调试体验,请查看 Python 3.11 预览版:更好的错误消息。
要尝试 Python 3.11 将会带来的最令人兴奋的特性,并跟上该语言的发展,请安装新的解释器。请随意选择您最喜欢的安装程序:
$ docker pull python:3.11.0a6-slim $ docker run -it --rm python:3.11.0a6-slim$ pyenv update $ pyenv install 3.11.0a6 $ pyenv local 3.11.0a6 $ python$ git clone git@github.com:python/cpython.git $ cd cpython/ $ git checkout v3.11.0a6 $ ./configure $ make $ ./python试试看!走自己的路,亲手探索 Python 3.11 酷炫的新特性!
其他 Python 版本
本月,其他几个 Python 版本已经问世。Python 3.10.3 、 3.9.11 、 3.8.13 和 3.7.13 现已推出多项安全修正,使其更加健壮可靠。
三月还迎来了两个最后时刻的 Python 版本, 3.10.4 和 3.9.12 。它们在常规时间表之外发布,以快速修复导致 Python 不再基于 Red Hat Enterprise Linux 6:
[Image source](https://twitter.com/llanga/status/1506967216692121601?t=AaDx5TBUVAj1s-ReVva3NQ&s=19) 尽管这个操作系统相当旧,但它仍然支持相当大的生产工作负载,包括 Python 基础设施中的一些服务,如
manylinux2010映像。此图基于 CentOS 6,CentOS 6 也受到该问题的影响。因为这些都是最新的版本,所以他们只是在各自之前的版本上添加了一些错误修复和安全更正。
Python 为 PEPs 发布了一个新网站
Python 增强提案,俗称 PEPs,现在有了一个全新的家,在【peps.python.org】有一个专用的 URL。这个新网站展现了它最好的一面,闪亮的主题看起来干净而现代:
[Image source](https://peps.python.org/) 如果你把你的浏览器指向这个地址,那么你将登陆到 PEP 0,这是所有 PEP 的索引。在那里,你会找到所有按照类别和编号精心组织的 pep。
该网站还包括关于 pep 本身的便利信息。您将找到 PEP 类型及其当前状态。PEP 的状态很方便,因为它允许您快速了解给定的 PEP 是被接受还是被拒绝,或者是否处于另一个阶段。
去看看这个新的 PEPs 网站吧。你不会后悔的!
废电池将从标准库中移除
Python 以拥有一个标准库而闻名,其中包含大量有用的模块和包。由于其广泛的标准库,Python 通常被称为包含电池的语言,这是 Python 成功故事的重要基石。随着时间的推移,这些电池中的一些已经不再有用或方便。然而,它们仍然存在,膨胀了标准库。
Python 的标准库已经被设计糟糕的模块、不必要的重复和不必要的特性填满了。
为了应对这种趋势,Python 指导委员会接受了 PEP 594 :
[Image source](https://twitter.com/pganssle/status/1503378905968881666?t=0D8AbVYBTCjLzqE0vXe6Tg&s=19) PEP 的主要目标是从标准库中移除失效电池。换句话说,PEP 提出了一个模块的列表,这些模块将在未来的 Python 版本中从标准库中移除。候选模块将包括以下模块:
- 支持旧的文件格式,例如与准将和孙相关的文件格式
- 支持早就被取代的 API 和操作系统,比如 macOS 9
- 没有当前的维护者
- 都是设计很差而且几乎不可能修好的,比如
sgi- 暗示安全隐患,如
crypt和spwd- 在图书馆外有更好的选择
该 PEP 还有其他具体目标,包括:
- 将核心开发团队从维护未使用的代码中解放出来
- 将用户引向第三方生态系统中通常可用的更好的解决方案
- 降低对存储能力有限的平台的要求
移除这些失效电池的建议日程包括从 Python 3.11 开始发布一个
DeprecationWarning,最终在 Python 3.13 中彻底移除它们。建议您检查您的项目,看看它们是否使用了这些废电池,并找到合适的替代品。MyPy 实验性地支持了
match的说法Python 3.10 引入了
match和case语句,将结构模式匹配引入到语言中。这个特性被证明是 Python 中最有争议的特性之一。它使您的程序能够从复杂的数据类型中提取信息,对数据结构进行分支,并基于不同形式的数据应用特定的操作。通常,像 code linters 和 formatters 这样的工具在采用目标语言的语法变化时会有一个自然的延迟。这就是 MyPy 的情况,它为 Python 提供了一个可选但流行的静态类型检查器。
好消息是,MyPy 在 3 月 11 日发布了版本 0.940 。这个新版本有实验性的对类型检查
match和case语句的支持。现在就可以试用了!继续在 Python 虚拟环境中安装 MyPy:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> venv\Scripts\activate (venv) PS> python -m pip install mypy$ python -m venv venv $ source venv/bin/activate (venv) $ python -m pip install mypy前两个命令在当前目录中创建和激活一个全新的虚拟环境。第三个命令安装 MyPy 的最新版本,应该是 0.940 或更高版本。
现在创建一个名为
try_mypy.py的 Python 文件。一旦你在你最喜欢的文本编辑器中打开了文件,然后复制并粘贴 MyPy 0.940 发布文章中的代码示例:# try_mypy.py def empty_value(x: int | str) -> str: match x: case str(): # Type of "x" is "str" here return '""' case int(): # Type of "x" is "int" here return "0" # No error about missing return statement (unreachable)该函数接受一个
x参数,该参数可以是一个字符串或一个整数数字。如果x是str类型,则match…case语句返回一个空字符串,如果x是int类型,则返回"0"。如果您对这个文件运行mypy命令,那么您将得到以下结果:$ python -m mypy try_mypy.py Success: no issues found in 1 source file酷!现在,MyPy 可以检测到
x是类型str还是类型int,而不会发出错误报告。MyPy 可以正确解析match…case语句,并抑制"missing return statement"错误报告。查看发行说明,了解关于这个实验性特性的当前限制的更多信息。
欧洲蟒蛇 2022 宣布其 CFP 和门票销售
在 Zoom、Matrix 和 Discord 上进行了两年的远程活动后,EuroPython 承诺在 2022 年举办一次面对面的会议。它也将虚拟地提供给那些不能去都柏林旅行的人:
[Image source](https://ep2022.europython.eu/) 会议将于 7 月 11 日至 17 日举行!它将举办以下活动:
- 两天研讨会/辅导(7 月 11 日至 12 日,周一至周二)
- 三个会议日(7 月 13 日至 15 日,周三至周五)
- 冲刺周末(7 月 16-17 日,周六-周日)
会议将在都柏林的 CCD 召开:
[Image source](https://www.google.com/maps/place/The+Convention+Centre+Dublin/@53.3482207,-6.2524556,14z/data=!4m5!3m4!1s0x0:0x25faa23c18a1e358!8m2!3d53.3478621!4d-6.2395809?hl=en) 欧洲 Python 2022 团队于 3 月 8 日开启了提案征集 (CFP)。在此次 CFP 上,EuroPython 正在寻找关于 Python 各个方面的建议,包括:
- 编程从初级到高级
- 应用程序和框架
- 将 Python 引入您的组织的经验
毫无疑问,这次欧洲 Python 大会将是一次令人惊叹的会议,有许多有趣的演讲和活动,肯定会为世界 Python 社区贡献大量的知识。
CFP 于 4 月 3 日星期日关闭。你发送你的提议了吗?请在评论中告诉我们!
你想作为志愿者为会议做贡献吗?这是你的机会。欧洲 Python 由 Python 社区的志愿者组织和运营。所以,新面孔总是受欢迎的!
反过来,你会有一个安全的空间来分享你的想法和工作。你将塑造会议,确保它是为社区和社区的。当然,在这个过程中你也会得到很多乐趣!如果你有兴趣加入其中一个团队,请发送电子邮件至志愿者@europython.eu。
最后,EuroPython 2022 战队也在 3 月 17 日开启了售票。如果你还没有买到票,那就大胆尝试吧。你需要经济资助吗?嗯,EuroPython 2022 也可以帮你做到这一点。查看他们的财政援助页面了解更多信息。
Python 的下一步是什么?
那么,三月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?你打算试试 Python 3.11.0a6 吗?如何看待从标准库中移除废电池?您计划参加 2022 年欧洲 Python 大会吗?请在评论中告诉我们!
快乐的蟒蛇!******
Python 新闻:2021 年 5 月有什么新消息
如果你想了解 2021 年 5 月的 Python 世界中发生的事情,那么你来对地方了,可以得到你的新闻**!*
*五月是重大事件发生的一个月。托盘项目 T1 是流行框架如 T2 烧瓶 T3 和 T4 点击 T5 的所在地,发布了所有六个核心项目的新的主要版本。Python 软件基金会(PSF) 主办了 PyCon US 2021,这是一次虚拟会议,提供了真实的现场体验。
让我们深入了解过去一个月最大的 Python 新闻!
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
微软成为 PSF 第三个有远见的赞助商
在上个月的新闻综述中,我们报道了谷歌和彭博工程公司是如何成为 PSF 的首批两个有远见的赞助商的。四月底,PSF 也宣布微软增加了对远见者的支持。
微软正在向 Python 打包工作组提供财政支持:
作为我们对 PSF 的 15 万美元财政赞助的一部分,我们将把我们的资金集中到包装工作组,以帮助进一步改善 PyPI 和包装生态系统的开发成本。由于最近披露的安全漏洞,可信供应链对我们和 Python 社区来说是一个关键问题,我们很高兴能为长期改进做出贡献。(来源)
除了有远见的赞助商身份,微软还有五名 Python 核心开发人员兼职为 Python 做贡献:布雷特·坎农、史蒂夫·道尔、吉多·范·罗苏姆、埃里克·斯诺和巴里·华沙。
关于微软对 Python 和 PSF 支持的更多信息,请查看其官方声明。
查看 Steve Dower 的账户,了解微软对 Python 的立场在这些年是如何变化的。你也可以在的真实 Python 播客上听 Brett Cannon 分享他在微软使用 Python 的经历。
托盘发布所有核心项目的新的主要版本
经过 Pallets 团队及其众多开源贡献者两年的辛勤工作,终于发布了所有六个核心项目的新的主要版本:
所有六个项目都放弃了对 Python 2 和 Python 3.5 的支持,使得 Python 3.6 成为支持的最低版本。删除了以前不赞成使用的代码,并添加了一些新的不赞成使用的代码。
影响所有六个项目的一些主要变化包括:
除了上面列出的大范围变化,单个项目还有几个吸引人的新特性。
Flask 获得原生
asyncio支持根据 2020 年 Python 开发者调查,Flask 是最流行的 Python web 框架。Flask 2.0 的原生支持肯定会让该框架的支持者高兴。
您可以将从路由到错误处理程序到请求前和请求后功能的所有东西都放入协程中,这意味着您可以使用
async def和await来定义视图:@app.route("/get-data") async def get_data(): data = await async_db_query(...) return jsonify(data)在这个取自 Flask docs 的示例代码片段中,定义了一个名为
get_data()的异步视图。它进行异步数据库查询,然后以 JSON 格式返回数据。Flask 的支持并非没有警告。Flask 仍然是一个 Web 服务器网关接口(WSGI) 应用程序,并且和任何其他 WSGI 框架一样受到相同的限制。Flask 的文档描述了这些限制:
异步函数需要事件循环才能运行。Flask 作为一个 WSGI 应用程序,使用一个 worker 来处理一个请求/响应周期。当一个请求进入一个异步视图时,Flask 将在一个线程中启动一个事件循环,在那里运行视图函数,然后返回结果。
即使对于异步视图,每个请求仍然会占用一个工作线程。好处是您可以在一个视图中运行异步代码,例如进行多个并发数据库查询、对外部 API 的 HTTP 请求等。但是,您的应用程序一次可以处理的请求数量将保持不变。(来源)
如果你是异步编程的新手,看看 Python 中的异步 IO:一个完整的演练。你也可以从 Flask 2.0 中的文章 Async 中获得 Flask 新的
asyncio支持,这篇文章是 PyCoder 的每周时事通讯中的特色。除了原生的
asyncio支持,Flask 2.0 还为常见的 HTTP 方法增加了一些新的路由装饰器。例如,在 Flask 1.x 中,您使用@app.route()视图装饰器声明了一个支持POST方法的路由:@app.route("/submit-form", methods=["POST"]) def submit_form(): return handle_form_data(request.form)在 Flask 2.0 中,您可以使用
@app.post()视图装饰器来缩短这段代码:@app.post("/submit-form") def submit_form(): return handle_form_data(request.form)这是一个很小的变化,但是可读性有了很大的提高!
你可以在官方 changelog 中找到 Flask 2.0 的所有改动。
Jinja 获得改进的异步环境
在 Jinja 2.x 中的支持需要一个补丁系统以及一些开发者需要记住的警告。原因之一是 Jinja 2.x 支持 Python 2.7 和 Python 3.5。
现在所有的托盘项目都只支持 Python 3.6+,修补系统被移除,为使用 Jinja 3.0 的项目提供更自然的
asyncio体验。你可以在官方 changelog 中找到 Jinja 3.0 的所有改动。
点击得到一个检修过的外壳标签完成系统
为应用程序构建优秀的命令行界面 (CLI)可能是一件苦差事。 Click 项目通过其友好的 API 帮助减轻了这一负担。
shell 用户期望从 CLI 获得的特性之一是制表符补全,当用户键入几个字符并按下
Tab时,它会提示命令名、选项名和选项值。Click 一直支持 shell tab 补全,但是实现起来很混乱,正如 Pallets 维护者 David Lord 在 2020 年 3 月的一期 GitHub 上指出的:
我一直在尝试审查[一个 pull 请求],它增加了基于类型的完成,这让我意识到完成是多么的混乱,无论是在 Click 中还是在 shells 如何实现和记录它们的系统中。…
我们不得不重新实现 shell 应该做的事情,比如转义特殊字符、添加空格(目录除外)、排序等等。如果用户想要提供他们自己的完成,他们也必须记住这样做。
我们没有理由只返回完成。我们已经支持返回描述,大概我们可以扩展更多。如果 Click 可以向完成脚本指示它应该使用 Bash 或 ZSH 提供的其他函数,这不是很酷吗?(来源)
到 2020 年 10 月,Click 的 shell tab 补全系统已经全面检修,内置了对 Bash 、 Zsh 和 fish 的支持。该系统是可扩展的。您可以添加对其他 shells 的支持,并且可以在多个级别上定制完成建议。
新的完成系统现在在 Click 8.0 中可用,对于希望在用户最喜欢的 shell 中为用户提供友好的 CLI 体验的项目来说,这是一个巨大的胜利。
你可以在官方的变更日志上找到 Click 8.0 以上的完整变更列表。
PyCon US 2021 连接世界各地的 Pythonistas】
对于美国的皮托尼斯塔来说,晚春总是令人兴奋的时刻。PyCon US 是致力于 Python 的最大年度大会,传统上在四月或五月举行。
今年的 PyCon US 与以往的会议略有不同。最初定于在宾夕法尼亚州匹兹堡举行的 PyCon US 2021 因新冠肺炎疫情而转变为仅在线活动。
感觉像真的一样的虚拟会议
PyCon US 2020 也是虚拟的,但最后一刻过渡到网上会议让组织者几乎没有时间准备一次真正的 PyCon 体验。今年,PSF 有充足的时间来计划,它提供了一个令人难以置信的参与活动,真实地反映了过去 PyCon US 会议的精神。
虽然谈话是预先录制的,但视频是按时间表播放的,而不是按需提供的。每个讲座都有一个与之相关的聊天室,演讲者可以与参与者互动并回答问题。
大会还设有一个虚拟展厅,将 Pythonistas 与 Python 世界的各种组织联系起来,包括微软、谷歌、彭博、和更多的。
然而,PyCon 2021 最吸引人的部分是执行良好的开放空间和休息区。开放空间是类似 meetup 的小型活动,允许与会者围绕共同的兴趣进行会面和互动。Python 作者、业余无线电爱好者、社区组织者等等都有开放的空间。
会议休息区包括虚拟桌子,让有限数量的人参加视频会议。任何人都可以抢一把空椅子,参与到谈话中,即使谈话已经开始了。休息室给了 PyCon 一种真正独特的氛围,具有你在面对面会议中所期望的所有自发性,有效地实现了虚拟的走廊轨道,这是 PyCon US 的标志之一。
将 PyCon US 搬到网上使得全球更多的 Pythonistas 可以参加会议。Python 爱好者不再有旅行和住宿费用的负担,只需支付入场费,就可以在自己舒适的家中加入 PyCon。
如果你错过了 2021 年的 PyCon US,你很快就可以在 YouTube 上观看这场演讲。在撰写本文时,这些视频仍在后期制作中,但应该会在未来几周内推出。
Python 的未来集中在性能上
PyCon US 的目标之一是将 Python 核心开发者和 Python 用户聚集在一起,讨论该语言的现状和未来愿景。每年的 Python 语言峰会都会聚集 Python 实现的维护者,比如 CPython 、pypypy和 Jython ,分享信息,解决问题。
今年的语言峰会有几个激动人心的演讲。 Dino Viehland 谈到了 Instagram 在其内部以性能为导向的项目 Cinder 中对 CPython 的改进,包括对异步 I/O 的几项增强。
Python 的创造者吉多·范·罗苏姆提出了让 CPython 更快的计划。Van Rossum 的目标是在 Python 3.11 之前将 CPython 的速度翻倍。提升的性能将主要惠及运行 CPU 密集型纯 Python 代码或使用 Python 内置工具和网站的用户。
今年 Python 语言峰会的另一个令人兴奋的特点是,PSF 给了真正的 Python 自己的 T2 一个机会,在一系列博客文章中报道峰会的演讲和讨论。你可以在 PSF 博客上找到她所有关于语言峰会的文章。
Python 的下一步是什么?
五月对于 Python 来说是一个多事之秋。在 Real Python 展会上,我们对 Python 的未来感到兴奋,迫不及待地想看看在6 月会有什么新东西等着我们。
你最喜欢的 Python 新闻来自5 月的哪一条?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!*****
Python 新闻:2022 年 5 月有什么新消息
2022 年 5 月日是今年 PyCon US 活动的最后几天。就在 PyCon 大会之前, Python 语言峰会聚集了 Python 核心开发者、triagers 和特别嘉宾。其中一些与会者正是本月发布两个重要 Python 版本的人。
五月的第三个星期四是全球无障碍意识日。这一天旨在提高人们对如何打造包容性数字产品的认识。
继续阅读,深入了解上个月的 Python 新闻!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
PyCon 美国视频
2022 年 4 月一些最大的 Python 新闻发生在盐湖城的 PyCon 期间。如果你想赶上会谈,那么你可以前往 PyCon US YouTube 频道,并开始观看活动的视频记录。五月底,PyCon 团队开始上传所有视频:
[Image source](https://twitter.com/pycon/status/1528803453526499331) PyCon US YouTube 频道是一个非常宝贵的资源,在那里你可以找到各种主题的视频,包括 Python 古怪现象解释、让数据类为你工作和理解属性。
注:就在美国国家航空航天局爱因斯坦研究员兼观测天文学家萨拉·伊桑博士在美国皮肯大会上做主题演讲的几天后,一张黑洞的突破性图像发布了。这一重大成就代表了她和团队其他成员两年多的辛勤工作!
如果你想了解 Python 社区如何帮助事件视界望远镜合作团队的研究,那么看看Issa oun 博士在 PyCon US 2022 上的主题演讲。
真正的 Python 团队第一次在 PyCon 大会上有了展台。如果这还不够令人兴奋的话,真正的 Python 团队的两位成员也发表了演讲。盖尔·阿恩·Hjelle在大会第三天的闪电谈话中谈到了阅读 PEPs 。作为今年 PyCon US 西班牙赛道的一部分, Andres Pineda 谈到了 RxPy 的反应式编程。
语言峰会报道
就在 PyCon 大会之前,Python 核心开发者、triagers 和特别嘉宾齐聚一堂,参加了 Python 语言峰会。在这次独家活动中,与会者讨论了 Python 编程语言的未来方向。五月,他们在官方 Python 软件基金会博客上发布了 2022 Python 语言峰会的广泛摘要。
正如您将在下一节中了解到的,Python 3.11 的改进之一是更快的 CPython。但是要知道如何让 Python 更快,你需要知道 Python 目前有多慢。在 Python 语言峰会上, Mark Shannon 和他的团队分享了他们对 CPython 性能改进的见解。马克还鼓励社区共享代码,以便在用于监控改进的基准中获得更多的多样性。
Python 3.11 测试版
随着 Python 3.11 的第一个测试版本的发布,五月标志着 Python 发布时间表的一个重要里程碑。从现在开始,Python 3.11 将不会添加新的特性或 API。如果你正在维护一个第三方 Python 项目,或者如果你计划发布一个支持 Python 3.11 新特性的包,这对你来说是个好消息:
- PEP 657 :在回溯中包含细粒度的错误位置
- PEP 654 :异常组和 except*
- PEP 673 :自身类型
- PEP 646 :可变泛型
- PEP 680 : tomllib:支持在标准库中解析 TOML
- PEP 675 :任意文字字符串类型
- PEP 655 :将单个类型的直接项目标记为必需的或潜在缺失的
- bpo-46752 :向 asyncio 介绍任务组
- 更快的 CPython :让 Python 3.11 比 Python 3.10 快 10-60%
如果你想更深入地了解 Python 3.11 带来的一些新特性,那么看看 Python 3.11 预览版:更好的错误消息、 Python 3.11 预览版:任务和异常组和 Python 3.11 预览版:TOML 和 tomllib 。
Python 3.9.13 最终正式发布
根据 PEP 596 中发布日历的规定, Python 3.9 的第十三版是最终的常规维护版。这意味着从现在开始, Python 3.9 将只接受安全修复。
Python 3.9 的最后一个定期维护版本也是当前常驻 CPython 开发人员的一个里程碑。ukasz 是 Python 3.8 和 3.9 的发布经理,所以这是他的最后一个常规版本:
[Image source](https://twitter.com/llanga/status/1526613566773657601?t=qECZ2uhAove0ZuPz_gGMzg&s=19) 如果你想了解更多关于 ukasz 的知识,那么看看真正的 Python 播客的第 82 集。在本播客中,ukasz 讲述了他作为常驻开发人员的第一个月,以及他如何帮助其他 Python 开发人员推进他们的贡献。
强烈建议将您正在使用的 Python 版本更新到最新的安全更新,以最大限度地减少代码库中的漏洞。你可以在官方 Python 网站下载 Python 3.9.13,并阅读发行说明中的所有变更。
全球无障碍宣传日
自 2012 年起,每年五月的第三个星期四标志着一年一度的全球无障碍意识日(GAAD) 。 GAAD 的目的是提高人们对如何打造包容性数字产品的认识。我们鼓励世界各地的开发者组织和参与活动,为的数字无障碍带来光明:
每个用户都应该获得一流的网络数字体验。残障人士必须能够体验基于网络的服务、内容和其他数字产品,并获得与非残障人士相同的成功结果。(来源)
GAAD 是由 Joe Devon 于 2011 年 11 月在他的博客文章【T2 挑战:易访问性技术需要成为开发者的主流】中发起的。现在。:
对一些人来说,一个无障碍的互联网确实让世界变得不同。虽然我是一名后端程序员,但我仍然为自己所知甚少而感到羞愧。你呢?(来源)
博文发布后不久,来自多伦多的无障碍专家 Jennison Asuncion 联系了 Joe Devon。Jennison 和 Joe 联手发起了第一个全球无障碍意识日。
查看 GAAD 网站的活动页面,了解社区这些年是如何庆祝全球意识日的。例如,今年, GitHub 博客强调了该公司为使其产品更具包容性所做的工作。
注: 真正的 Python 社区的成员和创造者 Joel Dodson 目前正在开发一套可访问的命令行实用程序。他分享了关于如何改进 Python 代码使其更易访问的评论:
对我们 Python 程序员来说,重要的是要想到你那些可能失明的 Python 程序员同事。一般来说,代码的结构显然很重要。但是结构不良的代码对盲人开发者的影响要糟糕得多。
你可以做的一个练习是向你自己或你的队友大声朗读你的部分代码。这样你可能会注意到,例如,你应该为你的变量或函数选择更具描述性的名字。
如果你想创建更具可读性的 Python 代码,那么看看如何用 PEP 8 编写漂亮的 Python 代码。
当然,让网络更易访问不能局限在某一天!例如,Kent Connects 正在提供一个名为“无障碍之夏”的免费网络研讨会系列。要注册课程,请查看他们的活动页面。
Python 的下一步是什么
那么,五月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?你对最近的 Python 发布感到兴奋吗?你参加过全球无障碍意识日活动吗?或者您有自己的关于可访问性的笔记想要分享吗?请在评论中告诉我们!
快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。**
Python 新闻:2022 年 11 月有什么新消息
Python 世界从未停止旋转!在 10 月发布 Python 3.11 之后,Python 发布团队已经开始发布 Python 3.12 的第一个 alpha 版本。尽管尝试新鲜事物的兴奋不应该分散你在编码时的谨慎。最近,研究人员在 PyPI 上发现了更多的恶意包,律师提出了使用 GitHub Copilot 生成代码时违反许可的担忧。
让我们深入了解过去一个月最大的 Python 新闻!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
Python 3.12 Alpha 发布
十月最有新闻价值的事件之一是 Python 3.11 的发布。当我们中的许多人正在探索 Python 3.11 的酷新特性时,其他人已经在为下一个版本努力工作了。
随着 Python 3.12 发布时间表步入正轨,Python 发布团队在 11 月中旬发布了 Python 3.12 alpha 2 。核心团队仍然处于开发周期的早期,但是到目前为止,的新特性列表看起来令人兴奋。
以下是 Python 3.12 的一些新特性:
- 更多改进的错误信息
- 支持 Linux
perfprofiler- 旧函数、类和模块的弃用
虽然 Python 3.11 已经改进了错误消息,但是下一个特性版本将会提供更好的修复错误的建议。例如,当您忘记导入一个模块或导入语句顺序错误时,检查它会做什么:









>>> sys.version_info
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'sys' is not defined. Did you forget to import 'sys'?
>>> import pi from math
File "<stdin>", line 1
import pi from math
^^^^^^^^^^^^^^^^^^^
SyntaxError: Did you mean to use 'from ... import ...' instead?
尤其是在学习 Python 的时候,建设性的错误消息可以为您指出改进代码的正确方向。此外,如果您是一名经验丰富的 Python 开发人员,那么即将发布的 Python 版本将为您的代码改进做好准备:

Linux perf profiler 使您能够分析应用程序的性能。在 Python 3.12 之前,您已经可以使用perf来获取关于您的 Python 代码的信息。然而,你只能看到用 C 编程语言写的名字和过程。有了perf 的 Python 3.12 支持,你将能够研究 Python 调用栈并在perf的输出中暴露 Python 函数。
新的 Python 版本也继续从标准库中移除了的电池,理由如下:
回到 Python 的早期,解释器附带了一大套有用的模块。这通常被称为“包含电池”的哲学,是 Python 成功故事的基石之一。[然而],任何额外的模块都会增加 Python 核心开发团队的维护成本。团队的资源有限,维护成本的降低为其他改进腾出了开发时间。(来源)
紧随其后,Python 3.12 将从 Unicode 中移除wstr,弃用distutils模块。完整的细节,可以访问 Python 的 changelog 。
如果您想试用 Python 3.12 的 alpha 版本,那么请查看关于如何安装 Python 预发布版本的真正的 Python 指南。
PyPI 上的恶意软件包
在从 Python 标准库中移除废电池的基本原理中,您可以找到这样一段话:
如今,Python 拥有丰富而充满活力的第三方包生态系统。从 PyPI 安装包或者使用许多 Python 或 Linux 发行版中的一个是非常标准的。(来源)
Python 生态系统变得越大,对麻烦制造者就越有吸引力。在八月的 Python 新闻中,我们报道了攻击者向 PyPI 上传恶意软件包以窃取用户信息的事件。
攻击者使用域名仿冒来欺骗开发者下载恶意软件。PyPI 中的域名仿冒涉及到上传一个恶意软件包,其名称与另一个流行的包相似。例如,当下载一个带有python -m pip install colorama的包时,你可能会不小心打错了附加字母s,把colorama错打成了colorsama。一个域名抢注者可能会上传一个叫做colorsama的恶意软件包来感染那些打错字的人。
在他们关于当前事件的博客文章中,安全公司 Phylum 总结了恶意代码是如何进入你的机器的:
恶意代码是包的
setup.py【or】__init__.py中隐藏的__import__语句。无论如何,它包含了一个 Base64 编码的字符串。[…]解码后,Base64 编码的字符串包含一个 Python 脚本,该脚本被写入一个临时文件并被执行。(来源)
在执行时,临时文件试图下载恶意软件,该恶意软件将试图从您系统上的 cookies 中抓取数据。虽然据报道事故的数量很少,但仔细检查您系统上安装的任何第三方软件包仍然是一个好主意。
GitHub 副驾驶的湍流
微软在今年夏天公开发布了 GitHub Copilot。发布声明以这句话开头:
在 GitHub,构建让开发者满意的技术是我们使命的一部分。(来源)。
但 GitHub Copilot 是否符合这一使命是一些争论的主题。
GitHub Copilot 使您能够以思维的速度与 Python 一起飞行。一旦它被激活,你就可以在你的代码中写一个注释,GitHub Copilot 会尝试生成与你的注释意图相匹配的代码。微软声称代码建议源自公开可用的源代码,例如公开的 GitHub 库。
在对 GitHub Copilot 提起的集体诉讼中, Matthew Butterick 声称微软侵犯了 GitHub 上托管的开源软件的许可证:
微软显然是通过无视底层开源许可证的条件和其他法律要求,从他人的作品中获利。[……]这起诉讼构成了一场全行业辩论中的关键一章,这场辩论涉及在未经创作者许可的情况下使用数据训练人工智能工具的道德问题,以及什么构成了知识产权的合理使用。尽管微软提出了相反的抗议,但它没有权利将在开源许可下提供的源代码视为公共领域。(来源)
如果你想了解更多关于集体诉讼的信息,那就去查看一下 GitHub Copilot 诉讼网站。该网站包含联系人、法律文件和关于该案件的持续更新。
尽管 GitHub Copilot 的飞行目前可能有点粗糙,但微软继续在他们的人工智能工具中实现新功能。在未来的版本中,你将能够通过与 GitHub Copilot 对话来使用你的声音编码。
你对 GitHub Copilot 有什么看法?你是期待用你的声音来编码,还是会提高你的声音来表达关心?在下面的评论里让真正的 Python 社区知道吧!
新闻片段
除了上面的 Python 新闻,这里还有一些新闻片段:
-
降临代号: 每年一样的程序!一年一度的降临节又回来了。这是一本由 25 个编程难题组成的降临节日历,每年 12 月出版。它是由 Eric Wastl 创建的,在 Python 社区中赢得了许多粉丝。如果你想了解更多关于这个有趣的传统,那么看看我们真正的 Python 教程代码降临:用 Python 解决你的难题。
-
乳齿象上的 Python 人:如果你正在考虑退出 Twitter,但你仍然想与其他 Python 开发者保持联系,那么看看塞缪尔·科尔文的 Python 人要点。你会注意到许多条目还包含了乳齿象简介的链接。如果你对这个社交网络平台很好奇,那么看看 Python 播客专题mastocon for Python Devs的 Talk。
-
Python 的历史:本月,吉多·范·罗苏姆的导师,兰伯特·梅尔滕斯,分享了一些关于Python起源的故事。您将了解 Python 的历史,并深入了解 Python 是如何成为如此受欢迎的编程语言的。处于这一发展前沿的当然是范·罗森,他最近在莱克斯·弗里德曼播客上接受了长达三小时的采访。
在 Python 的世界里总是有很多事情发生!
Python 的下一步是什么?
Python 一直在发展,这令人兴奋,但也可能伴随着成长的烦恼。我们赞扬核心开发人员为改进 Python 所做的不懈努力,以及社区为记录该语言的历史、保持跨平台连接和保护每个人的安全所做的努力。
来自11 月的 Python 新闻你最喜欢的片段是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。**
Python 新闻:2021 年 10 月有什么新消息
作为全球志愿者所做的伟大工作的高潮, Python 3.10 的发布主宰了 2021 年 10 月Python 社区的新闻周期。在这个版本推出新特性的同时,Python 在 TIOBE 编程社区指数中被评为本月最佳编程语言。
通过参与 Python 开发者调查和回答 PyCon US 2022 提案征集,您还有一些支持社区的新机会。
让我们深入了解过去一个月最大的 Python 新闻!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 3.10 版本
Python 的新版本现在每年发布。我们可以期待核心开发者在每年十月和我们其他人分享一个可爱的糖果袋。随着 Python 3.10 于 10 月 4 日推出测试版,每个人都有一些令人兴奋的东西可以期待。
Python 的每个版本都有一个发布经理,他负责协调所有的变更,并构建和准备用于分发的文件。Python 3.10 和 3.11 的发布经理是 Pablo Galindo Salgado 。在 Python 的第一次尝试中,他构建并在 YouTube 上发布了 Python 。
Python 3.10 亮点
新版本包括对语言的许多改进。我们最喜欢的是改进的错误消息,简化的类型联合的语法,以及结构模式匹配。
改进的错误消息将使您的生活更加轻松,无论您是新的 Python 开发人员还是有经验的开发人员。特别是,当你的代码不是有效的 Python 时,你得到的反馈在 Python 3.10 中比在以前的版本中更有针对性和可操作性。例如,考虑下面的代码,其中第一行末尾没有右括号:
news = ["errors", "types", "patterns"
print(", ".join(news))
在 Python 3.9 和更早版本中,如果您尝试运行此代码,将会看到以下内容:
File "errors.py", line 2
print(", ".join(news))
^
SyntaxError: invalid syntax
这个解释不是很有见地。更糟糕的是,报告的行号是错误的。实际的错误发生在第 1 行,而不是错误消息所说的第 2 行。Python 3.9 中引入的新解析器,允许更好的反馈:
File "errors.py", line 1
news = ["errors", "types", "patterns"
^
SyntaxError: '[' was never closed
行号没错,附带的解释切中要害。这将允许您直接进入,修复错误,并继续编码!
类型联合的简化语法允许你使用类型提示,通常不需要任何额外的导入。你可以使用类型提示来注释你的代码,从你的编辑器中获得更多的支持,并且更早地发现错误。
typing 模块是向 Python 添加静态类型的核心。然而,在最近几个版本中,越来越多的工具已经从typing转移到内置功能。在 Python 3.10 中,允许使用管道操作符(|)来指定类型联合,而不是从typing导入Union。以下代码片段显示了新语法的示例:
def mean(numbers: list[float | int]) -> float | None:
return sum(numbers) / len(numbers) if numbers else None
number的注释指定它应该是一个由float和int对象组成的列表。以前,你可能会把它写成List[Union[float, int]]。类似地,返回值的注释float | None是类型联合的一个特例,也可以写成Optional[float]。新的语法意味着你可以注释很多代码,甚至不需要导入typing。
结构模式匹配是一种处理数据结构的强大方法,你可能从函数式语言如 Elixir、Scala 和 Haskell 中了解到这一点。我们在三月和八月的新闻简报中预览了这个功能。
当您需要操作列表、字典、数据类或其他结构时,结构模式匹配处于最佳状态。下面的例子实现了一个递归函数,它对一组数字求和。它让您快速了解新语法:
def sum(numbers, accumulator=0):
match numbers:
case []:
return accumulator
case [head, *tail]:
return sum(tail, accumulator + head)
这段代码使用accumulator来跟踪运行总数。您将numbers匹配到两个不同的案例。
在第一种情况下,numbers是一个空列表。因为你不需要在你的 sum 上增加更多,所以你可以返回accumulator。第二种情况说明了当列表中至少有一个元素时该怎么做:命名第一个元素为head,命名列表的其余元素为tail。您将head添加到您的运行总数中,然后递归调用sum()获得剩余的元素。
您可以使用if语句实现相同的算法。然而,新的语法打开了一个更加功能化的思考 Python 代码的方式,这可能是一个有趣的探索前进的途径。
在我们的专用教程中,深入了解这些改进的细节,以及 Python 3.10 中的所有其他新特性。
YouTube 上的现场 Python 3.10 发布会
通常,新 Python 版本的实际发布是在闭门造车的情况下进行的。虽然提前宣布了,但是下载新版本的链接往往会突然出现。
今年不一样了!发布经理 Pablo Galindo Salgado 和来自 Python Discord 的Leon sandy邀请所有人参加在 YouTube 上直播的发布会。尽管互联网经历了糟糕的一天,但直播效果很好,我们都可以看到 Pablo 运行他的神奇脚本,让 Python 在全世界可用。
除了 Pablo 和 Leon,其他几位核心贡献者也参加了聚会:
- ukasz Langa展示了对打字系统的更新。
- Brandt Bucher 推出结构模式匹配。
- Carol Willing 主持了一场关于 Python 社区的讨论。
- Irit Katriel 向展示了如何为 CPython 的发展做出贡献。
该流仍然可用。如果您有兴趣获得一个独特的外观,并了解发布新版本的 Python 需要什么,请查看它。
Python 在 TIOBE 的第一名
TIOBE 编程社区指数是编程语言受欢迎程度的指标。它基于搜索引擎的结果,已经被追踪了 20 多年。
在 10 月份的排名中,Python 首次登上榜首。事实上,这是第一次一种不叫 Java 或 C 的语言登上了索引的榜首。
虽然这只是一个指数,但结果证实 Python 是一种非常受欢迎的编程语言,仍然有很多人对它感兴趣,在线上有很多可供开发人员使用的资源。
2021 年 Python 开发者调查
一年一度的 Python 开发者调查已经开始。这项调查对于理解社区如何使用 Python 语言和支持它的生态系统非常重要。来自早些年的结果给了我们很多启示。这些结果对于社区的许多部分规划如何使用他们有限的资源是重要的输入。
如果您有时间贡献您的答案,您可以通过打开调查来完成。问题相当多样,但是你可以计划在大约十到十五分钟内完成。今年,有几个新问题将有助于驻地开发商和包装项目经理的工作。
PyCon US 2022:征集提案
PyCon US 2022 的准备工作进展顺利。会议将于明年 4 月 27 日(T3)至 5 月 5 日(T5)在 T2 盐湖城举行。和往常一样,会议将包括两天的指导研讨会,三天的演讲和其他演示,以及四天的 sprints,在这里你可以和社区中的其他 Python 程序员一起工作。
如果你想参加 PyCon,看看征集提案。提交提案的截止日期是 2021 年 12 月 20 日。您可以参与四种类型的演示:
- 会谈通常持续 30 分钟,在主要会议期间举行,从 4 月 29 日到 5 月 1 日。
- Charlas 是用西班牙语进行的演讲。4 月 29 日星期五将会有一场查尔斯的演唱会。
- 教程是在会议的前两天(4 月 27 日和 4 月 28 日)进行的三小时研讨会。
- 在 4 月 29 日至 5 月 1 日的主要会议期间,在会议厅展示海报。
PyCon 鼓励任何人提交提案,不管你的经验水平如何。前往 PyCon 的提交页面了解更多信息。
浏览器中的 Visual Studio 代码
Visual Studio 代码编辑器是许多 Python 开发者的最爱。作为10 月发布的一部分,编辑器可以在完全运行于你的浏览器的零安装版本中获得。
您可以通过导航到 vscode.dev 来打开 web 的 VS 代码。一旦你到了那里,你就可以在支持的浏览器上打开文件,甚至是目录,然后开始工作。还有一些不支持的功能,包括终端和调试器。尽管如此,你将会有一个很好的编辑体验,你已经习惯了桌面版本的大部分功能和扩展。
网络编辑器让你可以即时访问存储在 GitHub 或 Azure 中的代码。您可以导航到一个存储库,然后在 URL 前面添加vscode.dev,在编辑器中打开它。例如,您可以通过输入vscode.dev/github.com/realpython/reader作为您的 URL 在github.com/realpython/reader打开存储库。这类似于——但不完全相同——当你在 GitHub 中查看一个库时,按下 . 来启动一个编辑器。
Python 的下一步是什么?
随着 Python 语言新版本的发布,10 月对 Python 来说永远是一个激动人心的月份。在真实的 Python ,我们期待着深入挖掘 Python 3.10,我们迫不及待地想看看在11 月会有什么新东西等着我们。
来自10 月的 Python 新闻你最喜欢的片段是什么?我们错过了什么值得注意的吗?请在评论中告诉我们,我们可能会在下个月的 Python 新闻综述中介绍您。
快乐的蟒蛇!***
Python 新闻:2022 年 10 月有什么新消息
和往常一样,今年十月对于 Python 社区来说是一个多事之秋。它带来了最终的 Python 3.11 版本,流行的 Python 库的下一个主要版本的几个测试版本,以及 Python 社区中一些令人兴奋的发展。
这里快速回顾一下 2022 年 10 月发生的最有趣的事情。
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。
Python 3.11 版本
到目前为止,本月最令人兴奋的事件是 Python 3.11 的发布,盖过了其他一些有趣的新闻。几年前,一年一度的 Python 发布会选择了 10 月,这为 Python 提供了一个稳定且可预测的发布周期。
Python 3.11 的发布日期原计划是 10 月 3 日。不幸的是,由于大约一个月前意料之外的问题阻碍了之前的候选版本,所以它被推迟了。全世界不得不再等三个星期,直到 10 月 24 日,才能最终见证下一个重要的 Python 版本:
**
这个版本包含了许多新功能,并承诺显著的性能改进,这一努力将在未来的版本中继续,以实现更好的结果。Python 3.11 的新特性一文概述了该语言自上一版本以来的变化。 Python 3.11 changelog 提供了更多细节,链接到各个 GitHub 问题及其相应的代码提交。
简而言之,这些可以说是 Python 3.11 中最有价值的新特性:
要深入了解 Python 3.11 并亲身体验,请前往我们关于新特性的专用教程或视频课程,在那里您可以通过代码示例了解最重要的语言改进。
尽管 Python 3.11 刚刚发布,但公司和云服务提供商开始在生产中大规模使用它还需要一段时间。升级运行时环境总是有风险的,可能会导致停机、数据丢失或其他不可预见的问题。这正是为什么美国陆军拒绝升级关键任务设备上的老式软件。
同时,值得一提的是,一些主要的 Python 库,尤其是数据科学领域的库,在正式发布之前就开始支持 Python 3.11 并进行彻底的测试。这确保了用户可以安全地切换到 Python 3.11,并开始利用新的语言特性,而不必等待他们的包依赖关系跟上。
Python 3.11 中你最喜欢的新特性是什么?
来自 Python 生态系统的更新
Python 生态系统每个月都会发布新的版本。pytest 7.2.0 版本现已发布, SQLAlchemy 2.0 终于发布了测试版。T4 网络图书馆也发布了下一个主要版本的测试版。
pytest 7.2.0
10 月下旬,开源社区发布了一个新的次要版本 pytest ,这是 Python 中最广泛使用的测试库之一。这个版本带来了一些生活质量的改善。
最值得注意的是,pytest 将不再识别为 nose 编写的单元测试,这曾经是另一个流行的测试库。因为它的开发在几年前就停止了,而且随着 pytest 的发展,pytest-nose 兼容层的维护变得越来越昂贵,所以 pytest 的开发人员决定放弃它。
因此,您应该停止在 pytest 中基于类的单元测试中使用.setup()和.teardown()方法。虽然它们将继续在弃用计划下工作,但不再推荐使用它们。pytest 自带的设置和拆卸方法的名称略有不同,但在其他方面应该是相同的。
此外,pytest 将识别一个替代的配置文件pytest.ini,它现在可能隐藏在类 Unix 操作系统中。这意味着可以选择以前导点开始文件名:
# .pytest.ini [pytest] python_functions = should_*
另一个值得注意的变化是,testpaths配置选项将使用 Python 的glob模块支持 Unix 风格的路径名模式扩展:
[pytest] testpaths = src/*/unit_tests src/*/integration_tests src/*/system_tests **/tests
星号(*)匹配任意数量的字符,而双星号(**)递归匹配目录。这个特性在大型存储库中会变得特别方便,称为 monorepo ,它包括遵循相同目录结构的多个项目。
要了解这个新 pytest 版本的更多信息,请查看官方网站上的完整变更日志。还有更多您可能感兴趣的改进、错误修复和更新。
SQLAlchemy 2.0 测试版
10 月份发布了 SQLAlchemy 2.0 的预览版,标志着期待已久的与遗留接口的分离和向使用现代 Python 模式的转变。从这个新版本的每日下载量来看,人们的兴趣超出了预期。一周后,一个包含几个错误修复的后续版本发布了。
多年来, SQLAlchemy 一直是一个非常受欢迎的框架,它提供了低级抽象和高级对象关系映射器(ORM ),用于以一致的方式在 Python 和各种关系数据库之间移动数据。同时,它公开了特定类型的数据库特有的行为。该框架有助于自动化重复的 SQL 样板语句,这在大多数应用程序中是不可避免的。
SQLAlchemy 2.0 的完整特性和架构在过渡版 1.4 系列中已经存在很长时间了,它在新旧界面之间架起了一座桥梁。任何使用该框架当前稳定版本的人都可以启用 SQLAlchemy 2.0 弃用模式,以便在最终切换到下一代 SQLAlchemy 之前获得关于各种不兼容和问题的通知。
那么,SQLAlchemy 2.0 测试版有哪些重大变化呢?
第一个也是最重要的变化是放弃对 Python 2 的支持,同时从代码库中清除一些旧的 cruft ,使得框架更容易维护。SQLAlchemy 将只在 Python 3.7 或更高版本上运行,并将利用现代句法结构,如上下文管理器来管理其资源。
另一个值得注意的改进是在 SQLAlchemy 的经典阻塞查询 API 之上添加了一个异步层。与 Python 的异步 IO 的集成将使框架能够在异步 web 应用程序中运行,这在以前无法从 SQLAlchemy 中受益,除非 SQLAlchemy 被包装在线程池中。这也应该向那些以前因为其阻塞特性而没有考虑过它的人展示这个框架。
编译后的 SQL 语句的新的缓存机制将使代码运行得更快。它将允许核心引擎的进一步改进,这在以前由于有限的执行时间是不可能的。
最后但同样重要的是,该框架将引入新的统一 API来缩小以更冗长和明确的编码风格实现相同目标的替代方法。这个想法是,程序员应该总是知道他们在做什么,为什么要这么做,而不是与底层 SQL 隔离开来。长期以来被弃用但仍在使用的传统接口将被移除。
官方文档提供了关于将您的代码迁移到下一代 SQLAlchemy 的详细说明。请记住,SQLAlchemy 2.0 仍在开发中,还没有准备好投入生产,所以不要贸然升级!
NetworkX 3.0 测试版
上个月宣布了另一个测试版。NetworkX 是一个流行的数据科学库,用于创建和分析 Python 中的图形和网络,它有了一个新的主要版本。 NetworkX 3.0 Beta 的发布是一项意义重大的任务,通过仔细删除旧代码来解决多年的技术债务。作为副作用,库的核心不再依赖于任何第三方包。
精简和现代化该库的代码将降低新贡献者参与的门槛,并将提高其性能。此外,NetworkX 3.0 将与其他流行的科学库更紧密地集成,如 NumPy 、 Matplotlib 、 pandas 和 SciPy 。以前在 NetworkX 中实现的算法现在将受益于这些集成。
Python 社区集锦
Python 社区上个月很忙。PyCon US 2023 现已接受提案, Python 开发者调查 2022 现已开放,新的 Python 发布经理已经任命。此外,阿尔·斯威加特也发布了一本新书。
PyCon US 2023:征集提案
最大的年度 Python 大会的筹备工作已经开始,来自世界各地的 Python 爱好者都热切期待着这一盛事。就像今年早些时候的会议一样, PyCon US 2023 将回到盐湖城,并且将按照健康和安全指南的要求,在现场和网上举行。明年的大会将于 4 月 19 日至 27 日举行,届时将庆祝美国皮肯节二十周年:

在 PyCon,任何人都可以发表演讲或以其他方式积极参与会议,无论其经验水平如何。您可以从以下演示类型中选择提交您的提案:
- 传统的会议会谈,通常长达 30 分钟,在主要会议期间举行,从 4 月 21 日到 23 日
- 在会议的前两天,即 4 月 21 日和 22 日,用西班牙语进行的演讲
- 教程:研讨会时间为 4 月 19 日和 4 月 20 日,在主会议前两天的上午或下午,每次大约三个小时
- 海报:在 4 月 21 日和 22 日的展馆开放时间以及 4 月 23 日的招聘会期间,在海报板上展示主题
个人提交的截止日期为2022 年 12 月 9 日。
要了解最新消息,你可以阅读 PyCon US 博客或在 Twitter 上关注PyCon US了解重要公告。如果你打算参加,那么一定要看看 Real Python 的 PyCon US guide ,了解如何从会议中获得最大收益。
我们将在明年 4 月到那里,所以一定要在 Real Python 的展台前停下来和我们握手。与此同时,你可以通过阅读我们对 PyCon US 2019 和 PyCon US 2022 的总结来领略一下即将到来的事情。
2022 年 Python 开发者调查
连续第六年, Python 软件基金会(PSF) 正在进行官方的 Python 开发者调查,以深入了解 Python 社区并了解其发展。具体来说,该调查有助于收集关于 Python 语言及其生态系统的状态的反馈,以及像您这样的人是如何使用它们的。如果你有兴趣,可以回顾一下去年的业绩。
该调查具有适应性,因此问题的确切数量及其范围将取决于您之前的选择。但是,填写时间不会超过 10 到 15 分钟:
这些问题涉及各种各样的主题,从您的角色和经验,到软件开发实践,到您的组织使用哪些工具和库以及使用的频率。大多数问题是选择题,有些是互斥的,只有少数要求你用自己的话写一个简短的回答。
注意:就像前几年一样,PSF 与 JetBrains 合作处理技术方面的问题,如主持调查和人们的反应。JetBrains 是一个流行的 Python IDEpy charm的幕后公司。
如果你有几分钟的空闲时间,那么考虑贡献你的答案。他们真的很重要!请注意,今年将有礼品卡抽奖,因此请确保在调查结束时输入您的电子邮件地址以参加抽奖!
新的 Python 发布管理器
由同一个人管理两个连续的 Python 版本是一个非官方的规则。最近两次发布由 Pablo Galindo Salgado 负责,他是 Python 指导委员会的核心 CPython 开发者,他率先提出了向公众直播发布过程的新颖想法。Python 3.11 版本在 YouTube上发布,现在仍然可以观看:
戴上有趣的帽子已经成为那些 Python 发布会的关键部分。我们希望这个传统能继续下去!
然而,连续两年之后,是时候改变了。谢谢你,帕布罗!Python 3.12(T0)和 3.13(T3)的发布将由上图中的托马斯·伍特斯(T5)负责,他是 Python 指导委员会中另一位经验丰富的核心开发者。此外,他还是 Python 软件基金会(PSF) 董事会成员。
Thomas 已经尝试在 3.11 发布之后发布 Python 3.12 的第一个 alpha 版本。你可以从 GitHub 上相应的 v3.12.0a1 标签中抓取它的新鲜源代码。或者,如果你想试一试,你可以通过 Docker 或 pyenv 安装 Python 3.12 alpha 1 。然而,要注意的是,这仍然是一个非常早期的预览版本,不包括实质性的变化。
托马斯,祝你在新岗位上好运!我们对 Python 3.12 将带来的新特性和改进很好奇。
阿尔·斯威加特的免费新书
Al Sweigart 是一位多产的技术作家,有几本关于 Python 的书,包括一些流行的书籍,如 用 Python 自动化枯燥的东西,你可以在亚马逊上找到。与此同时,作者慷慨地在他的网站上以电子形式免费提供他所有的书。
他的新书《Python 编程练习》 委婉地解释了 ,通过解决 42 个代码挑战,采取实用的方法向初学者教授 Python:

如果您陷入了 Python 之旅,那么这些编程练习可能是帮助您继续前进的完美资源。顺便说一下,书中练习的数量不是任意的。数字 42 是程序员之间的一个内部玩笑,他们倾向于将它用作数字的占位符值,就像单词 foobar 表示字符串一样。
最后,如果你在 PyCon US 遇见了这本书的作者,那么不要犹豫,和他聊聊吧!艾尔是一个非常平易近人和友好的人,他肯定会有兴趣与你交谈。
Python 的下一步是什么?
10 月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?你是准备升级到 Python 3.11,还是对你来说还太早?你参加过 2022 年 Python 开发者调查吗?你打算参加明年的 PyCon 美国会议吗?请在评论中告诉我们!
快乐的蟒蛇!
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。*****
Python 新闻:2022 年 9 月有什么新消息
在 2022 年 9 月的中, Python 3.11.0rc2 发布候选版本可供您测试并掌握 Python 的最新特性。该版本是 Python 3.11.0 最终发布之前的最后一个预览版,计划于 2022 年 10 月 24 日发布。
Python 最新的 bugfix 版本,包括 3.10.7,已经引入了突破性的更改来应对一个安全漏洞,该漏洞会影响str到int的转换,并可能使您面临 DDoS 攻击。
像往常一样,Python 生态系统庆祝了许多基础包、库和框架的新版本的发布。
让我们深入了解过去一个月最激动人心的 Python 新闻!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。
Python 3.11.0rc2 发布
每个月,Python 都会从其不同的开发分支发布几个版本。新版本通常会添加新功能、修复错误、纠正安全漏洞等等。2022 年 9 月发布了几个新版本,供 Python 程序员测试、使用和享受。最值得注意的是 Python 最近的 3.11 候选版本。
Python 3.11.0rc2 于 2022 年 9 月 12 日星期一发布。这是 Python 3.11.0 最终发布之前的最后一个预览版:
在发布候选阶段中,只允许修改 bug 的变更。在这个候选版本和最终版本之间,即使有代码变更,也是非常少的。如发布帖中所列,与 3.10 相比,3.11 系列的新特性包括以下内容:
- PEP 657–在回溯中包含细粒度的错误位置
- PEP 654–异常组和
except* - PEP 680–
tomllib:支持解析标准库中的 TOML - PEP 673–
Self型 - PEP 646–可变泛型
- PEP 675–任意文字字符串类型
- PEP 655–将单个
TypedDict项目标记为必需或潜在缺失 - PEP 681–数据类转换
Python 3.11 还带来了一些其他令人兴奋的更新。 gh-90908 向asyncio引入任务组, gh-34627 允许在正则表达式中使用原子分组((?>…))和所有格量词(*+, ++, ?+, {m,n}+)。
另外,Python 3.11 将提供更快的性能:
更快的 CPython 项目已经产生了一些令人兴奋的结果。Python 3.11 比 Python 3.10 快 10-60%。平均而言,我们在标准基准测试套件上测量到 1.22 倍的加速。详见更快的 CPython】。(来源)
要深入了解 Python 3.11 的一些很酷的新特性,请根据您的具体需求和兴趣查看以下资源:
此列表中的前三个教程是帮助您使用 Python 3.11 的系列文章的一部分。
如果你想安装这个新版本并尝试它的一些最令人兴奋的特性,那么请查看名为的真正的 Python 指南——如何安装 Python 的预发布版本?
Python 3.11.0 发布推迟到 10 月 24 日
由于上一个候选版本 3.11.0rc2 推迟了一周,Python 核心开发团队推迟了 Python 3.11.0 的最终发布。现在正式发布的时间是定于2022 年 10 月 24 日星期一。
这个最终版本最初定于 2022 年 10 月 3 日星期一发布。所以,我们还得再等三周才能在我们的电脑上欢迎 Python 3.11.0。
根据 3.11 生命周期注释,这个版本将在大约十八个月内大约每两个月接收一次 bugfix 更新。
Python 引入了一个突破性的改变来修复一个漏洞
Python 版本 3.10.7 、 3.9.14 、 3.8.14 和 3.7.14 现已发布。Python 3.10,最新的稳定版本,如期发布了第七个 bugfix 版本。该决定旨在解决由于str到int转换的算法复杂性而导致的允许拒绝服务( DoS )攻击的漏洞。
CVE 平台在其 CVE-2020-10735 报告中注册了这一公开披露的网络安全漏洞。最初的漏洞描述指出:
在 Python 中发现了一个缺陷。在使用非二进制基数的具有二次时间复杂度的算法中,当使用
int("text")时,系统可能需要 50 毫秒来解析具有 100,000 个数字的int字符串,而对于 1,000,000 个数字则需要 5 秒(二进制基数为 2、4、8、16 和 32 的float、decimal、int.from_bytes()和int()不受影响)。此漏洞对系统可用性的威胁最大。(来源)
同时,Python 文档中的Python 3.10 新特性页面对该问题的描述如下:
在 2(二进制)、4、8(八进制)、16(十六进制)或 32(如十进制)之外的基数中,在
int和str之间转换时,如果字符串形式的位数超过限制,则会引发ValueError,以避免因算法复杂性而导致的潜在拒绝服务攻击。(来源)
此更改将破坏对超过给定位数的数字运行此类转换的现有代码。现在,默认的位数限制是 4300 位。这里有一个简短的例子,通过在 Python 3.10.6 和 3.10.7 中运行str到int的转换,揭示了突破性的变化:
>>> # Python 3.10.6 >>> int("2" * 5432) 222222222222222222222222222222222222222222222222222222222222222... >>> # Python 3.10.7 >>> int("2" * 5432) Traceback (most recent call last): ... ValueError: Exceeds the limit (4300) for integer string conversion: value has 5432 digits; use sys.set_int_max_str_digits() to increase the limit.这个对
int()的调用在 Python 3.10.6 中运行良好,在 Python 3.10.7 中引发了一个ValueError。注意 Python 仍然可以处理大整数。只有在整数和字符串之间进行转换时,才会引发该错误。这种新行为可能会破坏不止一个代码库,所以如果您的代码经常处理这种转换,请密切关注。幸运的是,当您希望某个操作超过允许的位数时,您可以增加它。为此,您可以使用以下方法之一:
PYTHONINTMAXSTRDIGITS环境变量-X int_max_str_digits命令行标志set_int_max_str_digits()功能来自sys模块如果您希望您的代码超过这个值,请查看文档以获得关于更改默认限制的更多细节。
最后,3.9.14、3.8.14 和 3.7.14 安全版本也解决了所描述的问题,以及一些不太紧急的安全改进和修复。因此,如果您在生产代码中使用这些 Python 系列中的任何一个,强烈建议升级您的安装。
Python 生态系统中的新版本
全球 Python 社区从未停止推动 Python 生态系统走向未来。像往常一样,您会发现来自不同库、框架和项目的大量新版本。姜戈、熊猫、 TensorFlow 和 Matplotlib 是 9 月份新发布列表中最引人注目的几个项目。
Django Bugfix 版本 4.1.1
2022 年 9 月 5 日, Django 发布了其 4.1.1 bugfix 版本。这个版本修复了 Django 4.1 的几个倒退。要获得完整的修复列表,请查看这个版本的发行说明。
像往常一样,你可以从 Django 的下载页面下载发布的包。或者,您可以通过在命令行或终端上运行
pip install Django,直接从 Python 包索引 PyPI 安装 Django 。熊猫 1.5.0 发布
Python 的另一个重量级软件——熊猫库——于 9 月 19 日发布了新版本。熊猫 1.5.0 现已推出,增加了几个增强和错误修复。
一些最相关的增强包括:
- 熊猫开发团队现在支持
pandas-stubs,它为熊猫 API 提供了类型存根。这些类型存根允许你使用 mypy 和 Pyright 对你的熊猫代码进行类型检查。DataFrame交换 API 协议现在可以使用了。该协议的目的是实现不同类型数据帧之间的数据交换。它允许你将一种类型的数据帧转换成另一种类型。Styler类现在有了一个新的.concat()方法,它允许添加定制的页脚行来可视化数据上的附加计算。查看这个熊猫版本的发行说明以获得新特性、错误修复等的完整列表。
TensorFlow 2.10 发布
TensorFlow 2.10 于 2022 年 9 月 6 日发布!这个版本在 Keras 深度学习 Python API 中包含了几个新的用户友好特性。您会发现有助于开发 transformer 风格模型的特性。您还将拥有确定性和无状态的 Keras 初始化器,使 Keras 能够支持新的特性,例如使用 DTensor 进行多客户端模型训练。
该版本还对 Keras optimizers API 进行了更新。这种改变应该不会影响太多用户,但是您应该检查文档来验证您在工作流中使用的任何 API 是否已经改变。
你还会发现新的工具帮助你加载音频数据,并从 WAV 文件目录中生成音频分类数据集。有了这些新工具,您可以生成带标签的
tf.data.Dataset对象,您可以用它们来构建和训练自动语音识别 (ASR)模型。有关 TensorFlow 2.10 中新功能和改进的完整列表,请查看发布帖子,tensor flow 2.10 中的新功能?
Matplotlib 3.6.0 发布
Matplotlib 的最新版本带来了几个很酷的新功能,可以帮助您从数据中创建更好的绘图。最显著的改进涉及到该库的许多方面,包括:
- 图形和轴的创建和管理
- 绘图方法
- 颜色和色彩映射表
- 标题、记号和标签
- 传说
- 标记
- 字体和文本
- 3D 轴
- 交互式工具
该版本还包括特定于平台的更改,这些更改改进了 Matplotlib 在 macOS 和 Windows 平台上行为的几个方面。
同样,如果您想要新功能和增强功能的详细列表,请查看Matplotlib 3 . 6 . 0 新特性(2022 年 9 月 15 日)中的发行说明。
如果你想建立和锻炼你的 Matplotlib 肌肉,你可以画出 Mandelbrot 集合或者使用
plt.scatter()可视化你的数据。如果你想用一行代码定制你的图表,那么看看真正的 Python 播客:第 125 集来学习如何使用样式表。Python 的下一步是什么?
那么,9 月份你最喜欢的 Python 新闻是什么?我们错过了什么值得注意的吗?你打算试试 Python 3.11.0rc2 吗?如何看待 Python 3.10.7 中围绕
str到int转换的突破性变化?请在评论中告诉我们!快乐的蟒蛇!
立即加入: ,你将永远不会错过另一个 Python 教程、课程更新或帖子。**
情感分析:使用 Python 的 NLTK 库的第一步
一旦你理解了 Python 的基础,让自己熟悉它最流行的包不仅会提高你对这门语言的掌握,还会迅速增加你的通用性。在本教程中,您将学习自然语言工具包(NLTK)处理和分析文本的惊人能力,从基本的功能到由机器学习驱动的情感分析!
情感分析可以帮助你确定对某个特定话题的积极参与和消极参与的比例。您可以分析文本主体,如评论、推文和产品评论,以从您的受众那里获得洞察力。在本教程中,您将了解 NLTK 处理文本数据的重要特性,以及可以用来对数据执行情感分析的不同方法。
本教程结束时,您将能够:
- 拆分和过滤文本数据以备分析
- 分析词频
- 用不同的方法找出的一致和的搭配
- 使用 NLTK 的内置分类器执行快速情感分析
- 为自定义分类定义特征
- 使用并比较用于 NLTK 情感分析的分类器
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
NLTK 入门
NLTK 库包含各种实用程序,允许您有效地操作和分析语言数据。在它的高级特性中有文本分类器,你可以使用它进行多种分类,包括情感分析。
情感分析是利用算法将相关文本的各种样本分类为整体的正面和负面类别的实践。使用 NLTK,您可以通过强大的内置机器学习操作来使用这些算法,以从语言数据中获得洞察力。
安装和导入
您将从安装一些先决条件开始,包括 NLTK 本身以及贯穿本教程所需的特定资源。
首先,使用
pip安装 NLTK:$ python3 -m pip install nltk虽然这将安装 NLTK 模块,但是您仍然需要获得一些额外的资源。其中一些是文本样本,另一些是某些 NLTK 函数需要的数据模型。
要获得您需要的资源,请使用
nltk.download():import nltk nltk.download()NLTK 将显示一个下载管理器,显示所有可用的和已安装的资源。以下是您在本教程中需要下载的内容:
names: 马克·坎特罗威茨编撰的常用英文名列表stopwords: 非常常见的单词列表,如冠词、代词、介词和连词state_union: 不同美国总统的国情咨文演讲样本,由凯瑟琳·阿伦斯编译twitter_samples: 发布到推特上的社交媒体短语列表movie_reviews: 两千条影评按庞博和莉莲·李分类averaged_perceptron_tagger: 一种数据模型,NLTK 使用它将单词分类到它们的词性vader_lexicon:NLTK 在执行情感分析时引用的单词和行话的评分列表,由 C.J .休顿和 Eric Gilbert 创建punkt:Jan Strunk 创建的一个数据模型,NLTK 使用它将全文拆分成单词列表注意:在本教程中,你会发现许多关于文集及其复数形式文集的参考资料。语料库是大量相关文本样本的集合。在 NLTK 的上下文中,使用用于自然语言处理(NLP) 的特征来编译语料库,例如特定特征的类别和数字分数。
直接从控制台下载特定资源的一种快速方法是将一个列表传递给
nltk.download():
>>> import nltk
>>> nltk.download([
... "names",
... "stopwords",
... "state_union",
... "twitter_samples",
... "movie_reviews",
... "averaged_perceptron_tagger",
... "vader_lexicon",
... "punkt",
... ])
[nltk_data] Downloading package names to /home/user/nltk_data...
[nltk_data] Unzipping corpora/names.zip.
[nltk_data] Downloading package stopwords to /home/user/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Downloading package state_union to
[nltk_data] /home/user/nltk_data...
[nltk_data] Unzipping corpora/state_union.zip.
[nltk_data] Downloading package twitter_samples to
[nltk_data] /home/user/nltk_data...
[nltk_data] Unzipping corpora/twitter_samples.zip.
[nltk_data] Downloading package movie_reviews to
[nltk_data] /home/user/nltk_data...
[nltk_data] Unzipping corpora/movie_reviews.zip.
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /home/user/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
[nltk_data] Downloading package vader_lexicon to
[nltk_data] /home/user/nltk_data...
[nltk_data] Downloading package punkt to /home/user/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
True
这将告诉 NLTK 根据标识符来查找和下载每个资源。
如果 NLTK 需要您尚未安装的额外资源,您将会看到一个有用的LookupError,其中包含下载该资源的详细信息和说明:
>>> import nltk >>> w = nltk.corpus.shakespeare.words() ... LookupError: ********************************************************************** Resource shakespeare not found. Please use the NLTK Downloader to obtain the resource: >>> import nltk >>> nltk.download('shakespeare') ...
LookupError指定哪个资源是所请求的操作所必需的,以及使用其标识符下载它的指令。编译数据
NLTK 提供了许多函数,您可以使用很少的参数或不使用参数来调用这些函数,这些函数将帮助您在接触它的机器学习功能之前对文本进行有意义的分析。NLTK 的许多实用程序有助于为更高级的分析准备数据。
很快,你将学习频率分布,一致性和搭配。但首先,你需要一些数据。
首先加载您之前下载的国情咨文:
words = [w for w in nltk.corpus.state_union.words() if w.isalpha()]注意,您使用语料库的
.words()方法构建了一个单词列表,但是您使用str.isalpha()仅包含由字母组成的单词。否则,你的单词表可能会以仅仅是标点符号的“单词”结束。看看你的清单。你会注意到很多像“of”、“a”、“the”之类的小词。这些常用词被称为停用词,它们会对你的分析产生负面影响,因为它们在文本中出现得太频繁了。幸运的是,有一种简便的方法可以过滤掉它们。
NLTK 提供了一个小型的停用词语料库,您可以将它加载到一个列表中:
stopwords = nltk.corpus.stopwords.words("english")确保将
english指定为所需语言,因为该语料库包含各种语言的停用词。现在,您可以从原始单词列表中删除停用单词:
words = [w for w in words if w.lower() not in stopwords]因为
stopwords列表中的所有单词都是小写的,而原始列表中的单词可能不是,所以使用str.lower()来说明任何差异。否则,你的列表中可能会出现混合大小写或大写的停用词。虽然您将在本教程中使用 NLTK 提供的语料库,但是也可以从任何来源构建您自己的文本语料库。建立一个语料库可以像加载一些纯文本一样简单,也可以像对每个句子进行标记和分类一样复杂。参考 NLTK 的文档,了解更多关于如何使用语料库阅读器的信息。
对于一些快速分析来说,创建一个语料库可能是多余的。如果你需要的只是一个单词表,有更简单的方法来实现这个目标。除了 Python 自己的字符串操作方法之外,NLTK 还提供了
nltk.word_tokenize(),一个将原始文本分割成单个单词的函数。虽然标记化本身是一个更大的主题(并且很可能是创建自定义语料库时要采取的步骤之一),但是这个标记化器非常好地提供了简单的单词列表。要使用它,用您想要分割的原始文本调用
word_tokenize():
>>> from pprint import pprint
>>> text = """
... For some quick analysis, creating a corpus could be overkill.
... If all you need is a word list,
... there are simpler ways to achieve that goal."""
>>> pprint(nltk.word_tokenize(text), width=79, compact=True)
['For', 'some', 'quick', 'analysis', ',', 'creating', 'a', 'corpus', 'could',
'be', 'overkill', '.', 'If', 'all', 'you', 'need', 'is', 'a', 'word', 'list',
',', 'there', 'are', 'simpler', 'ways', 'to', 'achieve', 'that', 'goal', '.']
现在你有一个可行的单词表了!记住标点符号会被算作单个单词,所以后面用str.isalpha()过滤掉。
创建频率分布
现在你已经为频率分布做好准备了。频率分布本质上是一个表格,它告诉你每个单词在给定文本中出现的次数。在 NLTK 中,频率分布是一种特定的对象类型,作为一个名为FreqDist的独特类来实现。这个类为词频分析提供了有用的操作。
要用 NLTK 构建频率分布,用单词列表构建nltk.FreqDist类:
words: list[str] = nltk.word_tokenize(text)
fd = nltk.FreqDist(words)
这将创建一个类似于 Python 字典的频率分布对象,但是增加了一些特性。
注意:你在上面的words: list[str] = ...中看到的泛型类型提示是 Python 3.9 中的一个新特性!
构建完对象后,您可以使用类似于.most_common()和.tabulate()的方法开始可视化信息:
>>> fd.most_common(3) [('must', 1568), ('people', 1291), ('world', 1128)] >>> fd.tabulate(3) must people world 1568 1291 1128这些方法允许您快速确定样品中的常用词。使用
.most_common(),您可以获得包含每个单词的元组列表,以及它在您的文本中出现的次数。您可以使用.tabulate()以更易读的格式获得相同的信息。除了这两种方法,您还可以使用频率分布来查询特定的单词。您还可以将它们用作迭代器,对 word 属性执行一些自定义分析。
例如,要发现大小写的差异,您可以查询同一个单词的不同变体:
>>> fd["America"]
1076
>>> fd["america"] # Note this doesn't result in a KeyError
0
>>> fd["AMERICA"]
3
这些返回值指示每个单词按照给定的精确值出现的次数。
因为频率分布对象是可迭代的,你可以在列表理解中使用它们来创建初始分布的子集。您可以将这些子集集中在对您自己的分析有用的属性上。
尝试创建一个新的频率分布,它基于最初的频率分布,但将所有单词规范化为小写:
lower_fd = nltk.FreqDist([w.lower() for w in fd])
现在,无论大小写如何,您都可以更准确地表达单词的用法了。
想想这些可能性:你可以创建单词的频率分布,以一个特定的字母开始,或一个特定的长度,或包含某些字母。你的想象力是极限!
提取索引和搭配
在 NLP 的上下文中,索引是单词位置及其上下文的集合。您可以使用索引来查找:
- 一个单词出现多少次
- 每次出现的位置
- 每个事件周围有哪些单词
在 NLTK 中,可以通过调用.concordance()来实现这一点。要使用它,您需要一个nltk.Text类的实例,它也可以用一个单词列表来构造。
在调用.concordance()之前,从原始的语料库文本构建一个新的单词列表,这样所有的上下文,甚至停用的单词都将存在:
>>> text = nltk.Text(nltk.corpus.state_union.words()) >>> text.concordance("america", lines=5) Displaying 5 of 1079 matches: would want us to do . That is what America will do . So much blood has already ay , the entire world is looking to America for enlightened leadership to peace beyond any shadow of a doubt , that America will continue the fight for freedom to make complete victory certain , America will never become a party to any pl nly in law and in justice . Here in America , we have labored long and hard to注意
.concordance()已经忽略了大小写,允许您按照出现的顺序查看一个单词的所有大小写变体的上下文。还要注意,这个函数不会显示文本中每个单词的位置。此外,由于
.concordance()只将信息打印到控制台,它对于数据操作来说并不理想。要获得一个有用的列表,该列表还将为您提供每个事件的位置信息,请使用.concordance_list():
>>> concordance_list = text.concordance_list("america", lines=2)
>>> for entry in concordance_list:
... print(entry.line)
...
would want us to do . That is what America will do . So much blood has already
ay , the entire world is looking to America for enlightened leadership to peace
.concordance_list()给出了一个ConcordanceLine对象的列表,其中包含了每个单词出现的位置信息以及一些值得探索的属性。该列表也按出现的顺序排序。
类本身还有一些其他有趣的特性。其中一个是.vocab(),值得一提,因为它为给定的文本创建了一个频率分布。
再次访问nltk.word_tokenize(),看看您可以多快地创建一个定制的nltk.Text实例和一个伴随的频率分布:
>>> words: list[str] = nltk.word_tokenize( ... """Beautiful is better than ugly. ... Explicit is better than implicit. ... Simple is better than complex.""" ... ) >>> text = nltk.Text(words) >>> fd = text.vocab() # Equivalent to fd = nltk.FreqDist(words) >>> fd.tabulate(3) is better than 3 3 3
.vocab()本质上是从nltk.Text的实例创建频率分布的快捷方式。这样,你就不必单独调用实例化一个新的nltk.FreqDist对象。NLTK 的另一个强大特性是它能够通过简单的函数调用快速找到搭配。搭配是在给定文本中经常一起出现的一系列单词。例如,在国情咨文语料库中,你会发现联合和州这两个词经常出现在一起。这两个词一起出现是一种搭配。
搭配可以由两个或更多的单词组成。NLTK 提供了处理几种搭配类型的类:
- 二元组:频繁出现的两个词的组合
- 三元组:频繁出现的三字组合
- 四字格:频繁出现的四字组合
NLTK 为您提供了特定的类来查找文本中的搭配。按照您到目前为止看到的模式,这些类也是由单词列表构建的:
words = [w for w in nltk.corpus.state_union.words() if w.isalpha()] finder = nltk.collocations.TrigramCollocationFinder.from_words(words)
TrigramCollocationFinder实例将专门搜索三元模型。您可能已经猜到,NLTK 也有分别用于二元模型和四元模型的BigramCollocationFinder和QuadgramCollocationFinder类。所有这些类都有许多实用程序来提供所有已识别搭配的信息。他们最有用的工具之一是
ngram_fd属性。该属性保存为每个搭配而不是为单个单词构建的频率分布。使用
ngram_fd,您可以在提供的文本中找到最常见的搭配:
>>> finder.ngram_fd.most_common(2)
[(('the', 'United', 'States'), 294), (('the', 'American', 'people'), 185)]
>>> finder.ngram_fd.tabulate(2)
('the', 'United', 'States') ('the', 'American', 'people')
294 185
您甚至不必创建频率分布,因为它已经是 collocation finder 实例的一个属性。
现在,您已经了解了 NLTK 的一些最有用的工具,是时候投入情感分析了!
使用 NLTK 预先训练的情感分析器
NLTK 已经有了一个内置的、预训练的情感分析器,名为 VADER(ValenceAwareDictionary 和 sEentimentReasoner)。
由于 VADER 经过预训练,您可以比许多其他分析仪更快地获得结果。然而,VADER 最适合社交媒体中使用的语言,比如含有俚语和缩写的短句。当评价较长的结构化句子时,它不太准确,但它通常是一个很好的切入点。
要使用 VADER,首先创建一个nltk.sentiment.SentimentIntensityAnalyzer的实例,然后在一个原始的字符串上使用.polarity_scores():
>>> from nltk.sentiment import SentimentIntensityAnalyzer >>> sia = SentimentIntensityAnalyzer() >>> sia.polarity_scores("Wow, NLTK is really powerful!") {'neg': 0.0, 'neu': 0.295, 'pos': 0.705, 'compound': 0.8012}你会得到一本不同分数的字典。负的、中性的和正的分数是相关的:它们加起来都是 1,不能是负的。复合得分的计算方式不同。它不仅仅是一个平均值,它的范围可以从-1 到 1。
现在,您将使用两个不同的语料库对真实数据进行测试。首先,将
twitter_samples语料库加载到一个字符串列表中,替换成不活动的 URL,以避免意外点击:tweets = [t.replace("://", "//") for t in nltk.corpus.twitter_samples.strings()]注意,您使用了不同的语料库方法
.strings(),而不是.words()。这会给你一个字符串形式的原始 tweets 列表。不同的语料库有不同的特性,所以你可能需要使用 Python 的
help(),就像在help(nltk.corpus.tweet_samples)中一样,或者查阅 NLTK 的文档来学习如何使用给定的语料库。现在使用您的
SentimentIntensityAnalyzer实例的.polarity_scores()函数对 tweets 进行分类:from random import shuffle def is_positive(tweet: str) -> bool: """True if tweet has positive compound sentiment, False otherwise.""" return sia.polarity_scores(tweet)["compound"] > 0 shuffle(tweets) for tweet in tweets[:10]: print(">", is_positive(tweet), tweet)在这种情况下,
is_positive()仅使用复合得分的正性来进行呼叫。你可以选择 VADER 分数的任意组合来根据你的需要调整分类。现在来看看第二部文集
movie_reviews。顾名思义,这是一个影评集。这部文集的特别之处在于它已经被分类了。因此,你可以用它来判断你在给相似文本评分时所选择的算法的准确性。请记住,VADER 可能更擅长给推特评分,而不是给长篇电影评论评分。为了获得更好的结果,您将设置 VADER 来评价评论中的单个句子,而不是整个文本。
由于 VADER 的评级需要原始数据,你不能像以前那样使用
.words()。相反,列出语料库使用的文件 id,您可以稍后使用它们来引用单个评论:positive_review_ids = nltk.corpus.movie_reviews.fileids(categories=["pos"]) negative_review_ids = nltk.corpus.movie_reviews.fileids(categories=["neg"]) all_review_ids = positive_review_ids + negative_review_ids存在于大多数(如果不是全部)语料库中。在
movie_reviews的情况下,每个文件对应一个单独的审查。还要注意,您可以通过指定类别来过滤文件 id 列表。这种分类是这个语料库和其他同类型语料库特有的特征。接下来,重新定义
is_positive()来处理整个评审。您需要使用其文件 ID 获得该特定评论,然后在评级前将其分成句子:from statistics import mean def is_positive(review_id: str) -> bool: """True if the average of all sentence compound scores is positive.""" text = nltk.corpus.movie_reviews.raw(review_id) scores = [ sia.polarity_scores(sentence)["compound"] for sentence in nltk.sent_tokenize(text) ] return mean(scores) > 0
.raw()是另一种存在于大多数语料库中的方法。通过指定一个文件 ID 或文件 ID 列表,您可以从语料库中获取特定的数据。在这里,您获得一条评论,然后使用nltk.sent_tokenize()从评论中获得一个句子列表。最后,is_positive()计算所有句子的平均复合得分,并将正面结果与正面评论相关联。你可以借此机会对所有评论进行评分,看看 VADER 在这个设置中有多准确:
>>> shuffle(all_review_ids)
>>> correct = 0
>>> for review_id in all_review_ids:
... if is_positive(review_id):
... if review_id in positive_review_ids:
... correct += 1
... else:
... if review_id in negative_review_ids:
... correct += 1
...
>>> print(F"{correct / len(all_review_ids):.2%} correct")
64.00% correct
在对所有评论进行评级后,你可以看到只有 64%被 VADER 使用is_positive()中定义的逻辑正确分类。
64%的准确率并不算高,但这是一个开始。稍微调整一下is_positive(),看看你是否能提高精确度。
在下一节中,您将构建一个自定义分类器,该分类器允许您使用额外的特征进行分类,并最终将其准确度提高到可接受的水平。
定制 NLTK 的情感分析
NLTK 提供了一些内置的分类器,适用于各种类型的分析,包括情感分析。诀窍是找出数据集的哪些属性在将每一段数据分类到您想要的类别中是有用的。
在机器学习的世界中,这些数据属性被称为特征,当您处理数据时,必须揭示和选择这些特征。虽然本教程不会深入探究特征选择和特征工程,但是您将能够看到它们对分类器准确性的影响。
选择有用的功能
既然你已经学会了如何使用频率分布,为什么不把它们作为一个额外特性的起点呢?
通过使用movie_reviews语料库中预定义的类别,您可以创建正面和负面词汇集,然后确定哪些词汇在每个集合中出现频率最高。首先排除不需要的单词并建立初始类别组:
1unwanted = nltk.corpus.stopwords.words("english")
2unwanted.extend([w.lower() for w in nltk.corpus.names.words()])
3
4def skip_unwanted(pos_tuple):
5 word, tag = pos_tuple
6 if not word.isalpha() or word in unwanted:
7 return False
8 if tag.startswith("NN"):
9 return False
10 return True
11
12positive_words = [word for word, tag in filter(
13 skip_unwanted,
14 nltk.pos_tag(nltk.corpus.movie_reviews.words(categories=["pos"]))
15)]
16negative_words = [word for word, tag in filter(
17 skip_unwanted,
18 nltk.pos_tag(nltk.corpus.movie_reviews.words(categories=["neg"]))
19)]
这一次,您还将来自names语料库的单词添加到第 2 行的unwanted列表中,因为电影评论可能有许多演员的名字,这不应该是您的特征集的一部分。注意第 14 行和第 18 行的pos_tag(),它根据词类来标记单词。
在过滤你的单词列表之前调用pos_tag() 是很重要的,这样 NLTK 可以更准确地标记所有的单词。根据 NLTK 的默认标签集,在第 4 行定义的skip_unwanted()使用这些标签来排除名词。
现在您已经准备好为您的定制特征创建频率分布了。由于许多单词同时出现在正集合和负集合中,因此首先要找到公共集合,这样就可以将它从分布对象中移除:
positive_fd = nltk.FreqDist(positive_words)
negative_fd = nltk.FreqDist(negative_words)
common_set = set(positive_fd).intersection(negative_fd)
for word in common_set:
del positive_fd[word]
del negative_fd[word]
top_100_positive = {word for word, count in positive_fd.most_common(100)}
top_100_negative = {word for word, count in negative_fd.most_common(100)}
一旦在每个频率分布对象中有了唯一的正面和负面单词,您就可以最终从每个分布中最常见的单词构建集合。每组中的单词量是你可以调整的,以确定它对情感分析的影响。
这是可以从数据中提取的特征的一个例子,它还远非完美。仔细观察这些集合,你会注意到一些不常见的名字和单词,它们不一定是正面或负面的。此外,到目前为止,您已经学习的其他 NLTK 工具对于构建更多功能非常有用。一种可能是利用带有积极意义的搭配,比如 bigram“竖起大拇指!”
以下是如何设置正负二元模型查找器的方法:
unwanted = nltk.corpus.stopwords.words("english")
unwanted.extend([w.lower() for w in nltk.corpus.names.words()])
positive_bigram_finder = nltk.collocations.BigramCollocationFinder.from_words([
w for w in nltk.corpus.movie_reviews.words(categories=["pos"])
if w.isalpha() and w not in unwanted
])
negative_bigram_finder = nltk.collocations.BigramCollocationFinder.from_words([
w for w in nltk.corpus.movie_reviews.words(categories=["neg"])
if w.isalpha() and w not in unwanted
])
剩下的就看你自己了!尝试不同的功能组合,想办法使用负 VADER 分数,创建比率,完善频率分布。可能性是无限的!
训练和使用分类器
新的特征集准备就绪后,训练分类器的第一个先决条件是定义一个从给定数据中提取特征的函数。
既然你在寻找积极的电影评论,那就把注意力放在积极的特征上,包括 VADER 评分:
def extract_features(text):
features = dict()
wordcount = 0
compound_scores = list()
positive_scores = list()
for sentence in nltk.sent_tokenize(text):
for word in nltk.word_tokenize(sentence):
if word.lower() in top_100_positive:
wordcount += 1
compound_scores.append(sia.polarity_scores(sentence)["compound"])
positive_scores.append(sia.polarity_scores(sentence)["pos"])
# Adding 1 to the final compound score to always have positive numbers
# since some classifiers you'll use later don't work with negative numbers.
features["mean_compound"] = mean(compound_scores) + 1
features["mean_positive"] = mean(positive_scores)
features["wordcount"] = wordcount
return features
extract_features()应该返回一个字典,它将为每段文本创建三个特征:
- 平均复合得分
- 平均正面分数
- 文本中所有正面评论中前 100 个单词中的单词量
为了训练和评估分类器,您需要为要分析的每个文本建立一个特征列表:
features = [
(extract_features(nltk.corpus.movie_reviews.raw(review)), "pos")
for review in nltk.corpus.movie_reviews.fileids(categories=["pos"])
]
features.extend([
(extract_features(nltk.corpus.movie_reviews.raw(review)), "neg")
for review in nltk.corpus.movie_reviews.fileids(categories=["neg"])
])
这个特性列表中的每一项都需要是一个元组,它的第一项是由extract_features返回的字典,第二项是文本的预定义类别。在最初用一些已经被分类的数据(比如movie_reviews语料库)训练分类器之后,您将能够对新数据进行分类。
训练分类器包括分割特征集,以便一部分用于训练,另一部分用于评估,然后调用.train():
>>> # Use 1/4 of the set for training >>> train_count = len(features) // 4 >>> shuffle(features) >>> classifier = nltk.NaiveBayesClassifier.train(features[:train_count]) >>> classifier.show_most_informative_features(10) Most Informative Features wordcount = 2 pos : neg = 4.1 : 1.0 wordcount = 3 pos : neg = 3.8 : 1.0 wordcount = 0 neg : pos = 1.6 : 1.0 wordcount = 1 pos : neg = 1.5 : 1.0 >>> nltk.classify.accuracy(classifier, features[train_count:]) 0.668因为你在重组特性列表,每次运行都会给你不同的结果。事实上,调整列表以避免在列表的第一个季度意外地将相似的分类评论分组是很重要的。
增加一个单一的特征略微提高了 VADER 的初始准确度,从 64%提高到 67%。更多的功能可能会有所帮助,只要它们真正表明一篇评论有多正面。您可以使用
classifier.show_most_informative_features()来确定哪些特征最能代表特定的属性。要对新数据进行分类,在某处找到一个电影评论,并将其传递给
classifier.classify()。你也可以用extract_features()告诉你到底是怎么评分的:
>>> new_review = ...
>>> classifier.classify(new_review)
>>> extract_features(new_review)
这是正确的吗?根据来自extract_features()的评分输出,您可以改进什么?
特征工程是提高给定算法准确性的重要部分,但不是全部。另一个策略是使用和比较不同的分类器。
比较附加分类器
NLTK 提供了一个类,可以使用流行的机器学习框架 scikit-learn 中的大多数分类器。
scikit-learn 提供的许多分类器都可以快速实例化,因为它们的缺省值通常都很好。在这一节中,您将学习如何将它们集成到 NLTK 中来对语言数据进行分类。
安装和导入 scikit-learn
像 NLTK 一样,scikit-learn 是第三方 Python 库,所以您必须用pip安装它:
$ python3 -m pip install scikit-learn
安装 scikit-learn 之后,您将能够直接在 NLTK 中使用它的分类器。
以下分类器是您可以使用的所有分类器的子集。这些将在 NLTK 中用于情感分析:
from sklearn.naive_bayes import (
BernoulliNB,
ComplementNB,
MultinomialNB,
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
导入这些分类器后,首先必须实例化每个分类器。谢天谢地,所有这些都有很好的默认值,不需要太多的调整。
为了帮助评估准确性,有一个分类器名称及其实例的映射是很有帮助的:
classifiers = {
"BernoulliNB": BernoulliNB(),
"ComplementNB": ComplementNB(),
"MultinomialNB": MultinomialNB(),
"KNeighborsClassifier": KNeighborsClassifier(),
"DecisionTreeClassifier": DecisionTreeClassifier(),
"RandomForestClassifier": RandomForestClassifier(),
"LogisticRegression": LogisticRegression(),
"MLPClassifier": MLPClassifier(max_iter=1000),
"AdaBoostClassifier": AdaBoostClassifier(),
}
现在,您可以使用这些实例进行训练和准确性评估。
通过 NLTK 使用 scikit-learn 分类器
因为 NLTK 允许您将 scikit-learn 分类器直接集成到它自己的分类器类中,所以训练和分类过程将使用您已经看到的相同方法,.train()和.classify()。
您还可以利用之前通过extract_features()构建的同一个features列表。为了提醒你,下面是你如何建立features名单的:
features = [
(extract_features(nltk.corpus.movie_reviews.raw(review)), "pos")
for review in nltk.corpus.movie_reviews.fileids(categories=["pos"])
]
features.extend([
(extract_features(nltk.corpus.movie_reviews.raw(review)), "neg")
for review in nltk.corpus.movie_reviews.fileids(categories=["neg"])
])
features列表包含元组,其第一项是由extract_features()给出的一组特征,其第二项是来自movie_reviews语料库中预分类数据的分类标签。
由于列表的前半部分只包含正面评论,因此首先对其进行洗牌,然后遍历所有分类器来训练和评估每个分类器:
>>> # Use 1/4 of the set for training >>> train_count = len(features) // 4 >>> shuffle(features) >>> for name, sklearn_classifier in classifiers.items(): ... classifier = nltk.classify.SklearnClassifier(sklearn_classifier) ... classifier.train(features[:train_count]) ... accuracy = nltk.classify.accuracy(classifier, features[train_count:]) ... print(F"{accuracy:.2%} - {name}") ... 67.00% - BernoulliNB 66.80% - ComplementNB 66.33% - MultinomialNB 69.07% - KNeighborsClassifier 62.73% - DecisionTreeClassifier 66.60% - RandomForestClassifier 72.20% - LogisticRegression 73.13% - MLPClassifier 69.40% - AdaBoostClassifier对于每个 scikit-learn 分类器,调用
nltk.classify.SklearnClassifier来创建一个可用的 NLTK 分类器,可以像您之前看到的那样使用nltk.NaiveBayesClassifier及其其他内置分类器对其进行训练和评估。.train()和.accuracy()方法应该接收相同特性列表的不同部分。现在,在添加第二个功能之前,您已经达到了超过 73%的准确率!虽然这并不意味着当你设计新特性时,
MLPClassifier将继续是最好的,但是拥有额外的分类算法显然是有利的。结论
您现在已经熟悉了 NTLK 的特性,它允许您将文本处理成可以过滤和操作的对象,这允许您分析文本数据以获得关于其属性的信息。您还可以使用不同的分类器对数据进行情感分析,并了解受众对内容的反应。
在本教程中,您学习了如何:
- 拆分和过滤文本数据以备分析
- 分析词频
- 用不同的方法找出的一致和的搭配
- 使用 NLTK 内置的 VADER 进行快速情绪分析
- 为自定义分类定义特征
- 使用和比较 scikit-learn 中的分类器,用于 NLTK 中的情感分析
有了这些工具,您就可以开始在自己的项目中使用 NLTK 了。为了获得一些灵感,看看一个情绪分析可视化工具,或者尝试在一个 Python web 应用程序中增加文本处理,同时了解其他流行的包!******


 浙公网安备 33010602011771号
浙公网安备 33010602011771号