RealPython-中文系列教程-十九-
RealPython 中文系列教程(十九)
原文:RealPython
如何在 Python 中替换字符串
如果你正在寻找在 Python 中删除或替换全部或部分字符串的方法,那么本教程就是为你准备的。你将获得一个虚构的聊天室脚本,并使用 .replace()方法和 re.sub()函数对其进行净化。
在 Python 中,.replace()方法和re.sub()函数通常用于通过移除字符串或子字符串或替换它们来清理文本。在本教程中,您将扮演一家公司的开发人员,该公司通过一对一的文本聊天提供技术支持。你的任务是创建一个脚本来净化聊天,删除任何的个人数据,并用表情符号替换任何脏话。
你只会得到一份非常简短的聊天记录:
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
尽管这份文字记录很短,但它是代理一直在进行的典型聊天类型。它有用户标识符、 ISO 时间戳和消息。
在这种情况下,客户johndoe提交了投诉,公司的政策是整理和简化记录,然后将其传递给独立评估。净化信息是你的工作!
示例代码: 点击这里下载免费的示例代码,您将使用它来替换 Python 中的字符串。
你要做的第一件事就是注意任何脏话。
如何移除或替换 Python 字符串或子字符串
在 Python 中替换字符串最基本的方法是使用.replace() string 方法:
>>> "Fake Python".replace("Fake", "Real") 'Real Python'如您所见,您可以将
.replace()链接到任何字符串上,并为该方法提供两个参数。第一个是要替换的字符串,第二个是替换。注意:虽然 Python shell 显示了
.replace()的结果,但是字符串本身保持不变。通过将字符串赋给变量,可以更清楚地看到这一点:
>>> name = "Fake Python"
>>> name.replace("Fake", "Real")
'Real Python'
>>> name
'Fake Python'
>>> name = name.replace("Fake", "Real")
'Real Python'
>>> name
'Real Python'
请注意,当您简单地调用.replace()时,name的值不会改变。但是当你把name.replace()的结果赋给name变量的时候,'Fake Python'就变成了'Real Python'。
现在是时候将这些知识应用到文字记录中了:
>>> transcript = """\ ... [support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with? ... [johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT ... [support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock? ... [johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!""" >>> transcript.replace("BLASTED", "😤") [support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with? [johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY 😤 ACCOUNT [support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock? [johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right! ```py 将脚本加载为一个[三重引用字符串](https://realpython.com/python-data-types/#triple-quoted-strings),然后对其中一个脏话使用`.replace()`方法就可以了。但是还有另一个不会被取代的脏话,因为在 Python 中,字符串需要与*完全匹配*:
>>> "Fake Python".replace("fake", "Real")
'Fake Python'
```py
如您所见,即使一个字母的大小写不匹配,它也会阻止任何替换。这意味着如果你使用的是`.replace()`方法,你将需要不同次数的调用它。在这种情况下,您可以继续另一个对`.replace()`的呼叫:
>>>
transcript.replace("BLASTED", "😤").replace("Blast", "😤")
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY 😤 ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : 😤! You're right!
成功!但是你可能会想,对于像通用转录消毒剂这样的东西来说,这不是最好的方法。你会想要有一个替换列表,而不是每次都必须键入`.replace()`。
[*Remove ads*](/account/join/)
## 设置多个替换规则
您还需要对文字稿进行一些替换,以使其成为独立审查可接受的格式:
* 缩短或删除时间戳
* 将用户名替换为*代理*和*客户端*
现在你开始有更多的字符串需要替换,链接`.replace()`会变得重复。一个想法是保存一个元组的 T2 列表,每个元组中有两个条目。这两项对应于您需要传递给`.replace()`方法的参数——要替换的字符串和替换字符串:
transcript_multiple_replace.py
REPLACEMENTS = [
("BLASTED", "😤"),
("Blast", "😤"),
("2022-08-24T", ""),
("+00:00", ""),
("[support_tom]", "Agent "),
("[johndoe]", "Client"),
]
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
for old, new in REPLACEMENTS:
transcript = transcript.replace(old, new)
print(transcript)
在这个版本的清理脚本中,您创建了一个替换元组列表,这为您提供了一个快速添加替换的方法。如果有大量替换,您甚至可以从外部 [CSV 文件](https://realpython.com/python-csv/)中创建这个元组列表。
然后迭代替换元组列表。在每次迭代中,对字符串调用`.replace()`,用从每个替换元组中解包的`old`和`new`变量填充参数。
**注意:**在这种情况下,`for`循环中的解包在功能上与使用索引相同:
for replacement in replacements:
new_transcript = new_transcript.replace(replacement[0], replacement[1])
如果您对解包感到困惑,那么查看 Python 列表和元组教程中关于解包的[部分。](https://realpython.com/python-lists-tuples/#tuple-assignment-packing-and-unpacking)
这样,您就大大提高了脚本的整体可读性。如果需要,还可以更容易地添加替换。运行这个脚本显示了一个更加清晰的脚本:
$ python transcript_multiple_replace.py
Agent 10:02:23 : What can I help you with?
Client 10:03:15 : I CAN'T CONNECT TO MY 😤 ACCOUNT
Agent 10:03:30 : Are you sure it's not your caps lock?
Client 10:04:03 : 😤! You're right!
这是一份非常干净的成绩单。也许这就是你所需要的。但是如果你内心的自动机不开心,可能是因为仍然有一些事情困扰着你:
* 如果有另一种使用 *-ing* 或不同大小写的变体,如 *BLAst* ,替换脏话将不起作用。
* 从时间戳中删除日期目前仅适用于 2022 年 8 月 24 日。
* 移除完整的时间戳将涉及到为每一个可能的时间建立替换对——这不是你太热衷于做的事情。
* 在*代理*后添加空格来排列你的列是可行的,但不是很通用。
如果这些是您关心的问题,那么您可能希望将注意力转向正则表达式。
## 利用`re.sub()`制定复杂的规则
每当你想做一些稍微复杂一些或者需要一些[通配符](https://en.wikipedia.org/wiki/Wildcard_character)的替换时,你通常会想把注意力转向[正则表达式](https://realpython.com/regex-python/),也称为**正则表达式**。
Regex 是一种小型语言,由定义模式的字符组成。这些模式或正则表达式通常用于在*查找*和*查找和替换*操作中搜索字符串。许多编程语言都支持正则表达式,它被广泛使用。Regex 甚至会给你[超能力](https://xkcd.com/208/)。
在 Python 中,利用正则表达式意味着使用`re`模块的 [`sub()`函数](https://docs.python.org/3/library/re.html#re.sub)并构建自己的正则表达式模式:
transcript_regex.py
import re
REGEX_REPLACEMENTS = [
(r"blast\w", "😤"),
(r" [-T:+\d]{25}", ""),
(r"[support\w]", "Agent "),
(r"[johndoe]", "Client"),
]
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
for old, new in REGEX_REPLACEMENTS:
transcript = re.sub(old, new, transcript, flags=re.IGNORECASE)
print(transcript)
虽然您可以将`sub()`函数与`.replace()`方法混合使用,但是本例只使用了`sub()`,所以您可以看到它是如何使用的。您会注意到,现在只需使用一个替换元组就可以替换脏话的所有变体。类似地,对于完整的时间戳,您只使用一个正则表达式:
$ python transcript_regex.py
Agent : What can I help you with?
Client : I CAN'T CONNECT TO MY 😤 ACCOUNT
Agent : Are you sure it's not your caps lock?
Client : 😤! You're right!
现在你的成绩单已经完全清理干净了,所有的噪音都被去除了!那是怎么发生的?这就是 regex 的魔力。
**的第一个正则表达式模式**,`"blast\w*"`,利用了`\w` [特殊字符](https://www.regular-expressions.info/characters.html),它将匹配[字母数字字符](https://en.wikipedia.org/wiki/Alphanumericals)和下划线。直接在`*` [后面加上量词](https://www.regular-expressions.info/refrepeat.html)将匹配`\w`的零个或多个字符。
第一个模式的另一个重要部分是,`re.IGNORECASE`标志使它不区分大小写。所以现在,任何包含`blast`的子串,无论大小写,都会被匹配和替换。
**注:**`"blast\w*"`模式相当宽泛,也会将`fibroblast`修改为`fibro😤`。它也不能识别这个词的礼貌用法。刚好符合人物。也就是说,你想要审查的典型脏话并不真的有礼貌的替代含义!
**第二个正则表达式模式**使用[字符集](https://www.regular-expressions.info/charclass.html)和量词来替换时间戳。你经常一起使用字符集和量词。例如,`[abc]`的正则表达式模式将匹配一个字符`a`、`b`或`c`。在匹配`a`、`b`或`c`的零个或多个字符的**之后直接加上一个`*`。**
尽管有更多的量词。如果您使用`[abc]{10}`,它将精确匹配`a`、`b`或`c`的任意顺序和任意组合的十个字符。还要注意重复字符是多余的,所以`[aa]`相当于`[a]`。
对于时间戳,您使用一个扩展字符集`[-T:+\d]`来匹配您可能在时间戳中找到的所有可能字符。与量词`{25}`配对,这将匹配任何可能的时间戳,至少到 10,000 年。
**注意:**特殊字符`\d`,匹配任何数字字符。
时间戳正则表达式模式允许您以时间戳格式选择任何可能的日期。鉴于《纽约时报》对于这些抄本的独立审查员来说并不重要,您可以用一个空字符串来替换它们。可以编写一个更高级的正则表达式,在删除日期的同时保留时间信息。
第三个正则表达式模式用于选择任何以关键字`"support"`开头的用户字符串。请注意,您[对](https://en.wikipedia.org/wiki/Escape_character) ( `\`)方括号(`[`)进行了转义,因为否则该关键字将被解释为字符集。
最后,**最后一个正则表达式模式**选择客户端用户名字符串并用`"Client"`替换它。
**注意:**虽然深入了解这些正则表达式模式的细节会很有趣,但本教程不是关于正则表达式的。通读 [Python 正则表达式教程](https://realpython.com/regex-python/)可以获得关于这个主题的很好的入门。此外,您可以利用神奇的 [RegExr](https://regexr.com/) 网站,因为 regex 很复杂,所有级别的 regex 向导都依赖于像 RegExr 这样方便的工具。
RegExr 特别好,因为您可以复制和粘贴 regex 模式,它会通过解释为您分解它们。
使用 regex,您可以大幅减少必须写出的替换数量。也就是说,您可能仍然需要想出许多模式。鉴于 regex 不是可读性最好的语言,拥有大量模式很快就会变得难以维护。
幸运的是,`re.sub()`有一个巧妙的技巧,允许您对替换的工作方式有更多的控制,并且它提供了一个更易维护的架构。
[*Remove ads*](/account/join/)
## 使用带有`re.sub()`的回调来获得更多控制
Python 和`sub()`的一个锦囊妙计是,你可以传入一个[回调函数](https://en.wikipedia.org/wiki/Callback_(computer_programming)),而不是替换字符串。这使您可以完全控制如何匹配和替换。
为了开始构建这个版本的脚本清理脚本,您将使用一个基本的 regex 模式来看看如何使用带有`sub()`的回调:
```py
# transcript_regex_callback.py
import re
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
def sanitize_message(match):
print(match)
re.sub(r"[-T:+\d]{25}", sanitize_message, transcript)
您使用的 regex 模式将匹配时间戳,并且您不是提供替换字符串,而是传入对sanitize_message()函数的引用。现在,当sub()找到一个匹配时,它将调用sanitize_message(),使用一个匹配对象作为参数。
由于sanitize_message()只是打印它作为参数接收的对象,当运行它时,您会看到匹配对象被打印到控制台:
$ python transcript_regex_callback.py
<re.Match object; span=(15, 40), match='2022-08-24T10:02:23+00:00'>
<re.Match object; span=(79, 104), match='2022-08-24T10:03:15+00:00'>
<re.Match object; span=(159, 184), match='2022-08-24T10:03:30+00:00'>
<re.Match object; span=(235, 260), match='2022-08-24T10:04:03+00:00'>
一个匹配对象是re模块的构件之一。更基本的re.match()函数返回一个匹配对象。sub()不返回任何匹配对象,而是在后台使用它们。
因为您在回调中获得了这个 match 对象,所以您可以使用其中包含的任何信息来构建替换字符串。一旦构建好了,就返回新的字符串,sub()将用返回的字符串替换匹配的字符串。
将回调应用到脚本
在您的脚本清理脚本中,您将利用 match 对象的.groups()方法来返回两个捕获组的内容,然后您可以在它自己的函数中清理每个部分或者丢弃它:
# transcript_regex_callback.py
import re
ENTRY_PATTERN = (
r"\[(.+)\] " # User string, discarding square brackets
r"[-T:+\d]{25} " # Time stamp
r": " # Separator
r"(.+)" # Message
)
BAD_WORDS = ["blast", "dash", "beezlebub"]
CLIENTS = ["johndoe", "janedoe"]
def censor_bad_words(message):
for word in BAD_WORDS:
message = re.sub(rf"{word}\w*", "😤", message, flags=re.IGNORECASE)
return message
def censor_users(user):
if user.startswith("support"):
return "Agent"
elif user in CLIENTS:
return "Client"
else:
raise ValueError(f"unknown client: '{user}'")
def sanitize_message(match):
user, message = match.groups()
return f"{censor_users(user):<6} : {censor_bad_words(message)}"
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
print(re.sub(ENTRY_PATTERN, sanitize_message, transcript))
```py
不需要有很多不同的正则表达式,你可以有一个匹配整行的顶级正则表达式,用括号(`()`)把它分成捕获组。捕获组对实际的匹配过程没有影响,但它们会影响由匹配产生的匹配对象:
* `\[(.+)\]`匹配方括号中的任何字符序列。捕获组挑选出用户名字符串,例如`johndoe`。
* `[-T:+\d]{25}`匹配您在上一节中探索的时间戳。因为您不会在最终的脚本中使用时间戳,所以不会用括号来捕获它。
* `:`匹配一个字面冒号。冒号用作消息元数据和消息本身之间的分隔符。
* `(.+)`匹配任何字符序列,直到行尾,这将是消息。
通过调用`.groups()`方法,捕获组的内容将作为 match 对象中的单独项可用,该方法返回匹配字符串的元组。
**注意:**条目正则表达式定义使用 Python 的隐式字符串连接:
ENTRY_PATTERN = (
r"[(.+)] " # User string, discarding square brackets
r"[-T:+\d]{25} " # Time stamp
r": " # Separator
r"(.+)" # Message
)
从功能上来说,这与将所有内容写成一个字符串是一样的:`r"\[(.+)\] [-T:+\d]{25} : (.+)"`。将较长的正则表达式模式组织在单独的行上,可以将它分成块,这不仅使它更易读,而且还允许您插入注释。
这两个组是用户字符串和消息。`.groups()`方法将它们作为一组字符串返回。在`sanitize_message()`函数中,首先使用解包将两个字符串赋给变量:
def sanitize_message(match):
user, message = match.groups() return f"{censor_users(user):<6} : {censor_bad_words(message)}"
请注意这种体系结构如何在顶层允许非常广泛和包容的正则表达式,然后让您在替换回调中用更精确的正则表达式补充它。
`sanitize_message()`函数使用两个函数来清除用户名和不良单词。它还使用 [f 弦](https://realpython.com/python-f-strings/)来调整消息。注意`censor_bad_words()`如何使用动态创建的正则表达式,而`censor_users()`依赖于更基本的字符串处理。
这看起来像是一个很好的净化脚本的第一个原型!输出非常干净:
$ python transcript_regex_callback.py
Agent : What can I help you with?
Client : I CAN'T CONNECT TO MY 😤 ACCOUNT
Agent : Are you sure it's not your caps lock?
Client : 😤! You're right!
不错!使用带有回调的`sub()`可以让您更加灵活地混合和匹配不同的方法,并动态构建正则表达式。当你的老板或客户不可避免地改变他们对你的要求时,这种结构也给你最大的发展空间!
[*Remove ads*](/account/join/)
## 结论
在本教程中,您已经学习了如何在 Python 中替换字符串。一路走来,您已经从使用基本的 Python `.replace()` string 方法发展到使用带有`re.sub()`的回调来实现绝对控制。您还研究了一些正则表达式模式,并将它们分解成更好的架构来管理替换脚本。
有了所有这些知识,您已经成功地清理了一份聊天记录,现在可以进行独立审查了。不仅如此,您的脚本还有很大的发展空间。
**示例代码:** [点击这里下载免费的示例代码](https://realpython.com/bonus/replace-string-python-code/),您将使用它来替换 Python 中的字符串。***
# rethink Flask——一个由 Flask 和 RethinkDB 支持的简单待办事项列表
> 原文:<https://realpython.com/rethink-flask-a-simple-todo-list-powered-by-flask-and-rethinkdb/>
在对基本的 [Flask](http://flask.pocoo.org/) 和 [RethinkDB](http://www.rethinkdb.com/) 模板的多次请求之后,我决定继续写一篇博文。这是那个帖子。
> BTW:我们总是欢迎请求。如果你想让我们写点什么,或者做点什么,请发邮件给我们。
今天我们将创建一个*简单的*待办事项列表,您可以根据自己的需要进行修改。在开始之前,我强烈建议通读一下[这篇](http://www.rethinkdb.com/docs/rethinkdb-vs-mongodb/)文章,它详细介绍了 RethinkDB 与其他一些 NoSQL 数据库的不同之处。
## 设置重新思考数据库
### 安装重新思考数据库
导航[此处](http://www.rethinkdb.com/docs/install/)并下载适合您系统的软件包。我用的是自制软件,花了将近 20 分钟来下载和安装这个版本:
==> Installing rethinkdb
==> Downloading http://download.rethinkdb.com/dist/rethinkdb- 1.11.2.tgz
######################################################################## 100.0%
==> ./configure --prefix=/usr/local/Cellar/rethinkdb/1.11.2 -- fetch v8 --fetch protobuf
==> make
==> make install-osx
==> Caveats
To have launchd start rethinkdb at login:
ln -sfv /usr/local/opt/rethinkdb/*.plist ~/Library/LaunchAgents
Then to load rethinkdb now:
launchctl load ~/Library/LaunchAgents/homebrew.mxcl.rethinkdb.plist
==> Summary
🍺 /usr/local/Cellar/rethinkdb/1.11.2: 174 files, 29M, built in 19.7 minutes
[*Remove ads*](/account/join/)
### 全局安装 Python 驱动程序*
$ sudo pip install rethinkdb
> **注意:**我全局安装了 Rethink(在 virtualenv 之外),因为我可能会在许多项目中使用相同的版本,使用许多不同的语言。在本教程的后面,我们将在 virtualenv 中安装。
### 测试您的设置
首先,让我们用以下命令启动服务器:
$ rethinkdb
如果全部安装正确,您应该会看到类似以下内容:
info: Creating directory /Users/michaelherman/rethinkdb_data
info: Creating a default database for your convenience. (This is because you ran 'rethinkdb' without 'create', 'serve', or '--join', and the directory '/Users/michaelherman/rethinkdb_data' did not already exist.)
info: Running rethinkdb 1.11.2 (CLANG 4.2 (clang-425.0.28))...
info: Running on Darwin 12.4.0 x86_64
info: Loading data from directory /Users/michaelherman/rethinkdb_data
info: Listening for intracluster connections on port 29015
info: Listening for client driver connections on port 28015
info: Listening for administrative HTTP connections on port 8080
info: Listening on addresses: 127.0.0.1, ::1
info: To fully expose RethinkDB on the network, bind to all addresses
info: by running rethinkdb with the --bind all command line option.
info: Server ready
然后测试连接。在终端中打开一个新窗口,输入以下命令:
>>>
$ python
import rethinkdb
rethinkdb.connect('localhost', 28015).repl()
您应该看到:
>>>
<rethinkdb.net.Connection object at 0x101122410>
退出 Python shell,但让 RethinkDB 服务器在另一个终端窗口中运行。
## 建立一个基本的烧瓶项目
### 创建一个目录来存储您的项目
$ mkdir flask-rethink
$ cd flask-rethink
### 设置并[激活一个虚拟](https://realpython.com/python-virtual-environments-a-primer/)
$ virtualenv --no-site-packages env
$ source env/bin/activate
### 安装烧瓶和烧瓶-WTF
$ pip install flask
$ pip install flask-wtf
[*Remove ads*](/account/join/)
### 创建一个 Pip 需求文件*
$ pip freeze > requirements.txt
### 下载烧瓶样板文件
在[的模板目录中找到这个](https://github.com/mjhea0/flask-rethink)回购。您的项目结构现在应该如下所示:
├── app
│ ├── init.py
│ ├── forms.py
│ ├── models.py
│ ├── templates
│ │ ├── base.html
│ │ └── index.html
│ └── views.py
├── readme.md
├── requirements.txt
└── run.py
### 运行应用程序
$ python run.py
导航到 [http://localhost:5000/](http://localhost:5000/) ,您应该看到:
[](https://files.realpython.com/media/flask-rethink-main.a26c1da16d65.png)
先不要尝试提交任何东西,因为我们需要先建立一个数据库。让我们重新思考一下。
## 重新思考数据库配置
### 安装重新思考数据库
$ pip install rethinkdb
### 将以下代码添加到“views . py”
rethink imports
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
rethink config
RDB_HOST = 'localhost'
RDB_PORT = 28015
TODO_DB = 'todo'
db setup; only run once
def dbSetup():
connection = r.connect(host=RDB_HOST, port=RDB_PORT)
try:
r.db_create(TODO_DB).run(connection)
r.db(TODO_DB).table_create('todos').run(connection)
print 'Database setup completed'
except RqlRuntimeError:
print 'Database already exists.'
finally:
connection.close()
dbSetup()
open connection before each request
@app.before_request
def before_request():
try:
g.rdb_conn = r.connect(host=RDB_HOST, port=RDB_PORT, db=TODO_DB)
except RqlDriverError:
abort(503, "Database connection could be established.")
close the connection after each request
@app.teardown_request
def teardown_request(exception):
try:
g.rdb_conn.close()
except AttributeError:
pass
查看注释,了解每个函数的简要说明。
### 再次启动您的服务器
您应该会在终端中看到以下警报:
Database setup completed
> 如果您看到这个错误`rethinkdb.errors.RqlDriverError: Could not connect to localhost:28015.`,您的 RethinkDB 服务器没有运行。打开一个新的终端窗口并运行`$ rethinkdb`。
所以,我们创建了一个名为“todo”的新数据库,其中有一个名为“todos”的表。
您可以在 RethinkDB 管理中验证这一点。导航到 [http://localhost:8080/](http://localhost:8080/) 。管理员应该加载。如果您单击“Tables ”,您应该会看到我们创建的数据库和表:
[](https://files.realpython.com/media/flask-rethink-admin.a3996f26af7b.png)[*Remove ads*](/account/join/)
### 显示待办事项
有了数据库设置,让我们添加代码来显示待办事项。更新“views.py”中的`index()`函数:
@app.route("/")
def index():
form = TaskForm()
selection = list(r.table('todos').run(g.rdb_conn))
return render_template('index.html', form=form, tasks=selection)
这里,我们选择“todos”表,提取 JSON 中的所有数据,并将整个表传递给模板。
### 手动添加数据
在查看任何待办事项之前,我们需要先添加一些待办事项。让我们检查一下外壳,然后手动添加它们。
>>>
$ python
import rethinkdb
conn = rethinkdb.connect(db='todo')
rethinkdb.table('todos').insert({'name':'sail to the moon'}).run(conn)
{u'errors': 0, u'deleted': 0, u'generated_keys': [u'c5562325-c5a1-4a78-8232-c0de4f500aff'], u'unchanged': 0, u'skipped': 0, u'replaced': 0, u'inserted': 1}
rethinkdb.table('todos').insert({'name':'jump in the ocean'}).run(conn)
{u'errors': 0, u'deleted': 0, u'generated_keys': [u'0a3e3658-4513-48cb-bc68-5af247269ee4'], u'unchanged': 0, u'skipped': 0, u'replaced': 0, u'inserted': 1}
rethinkdb.table('todos').insert({'name':'think of another todo'}).run(conn)
因此,我们连接到数据库,然后在数据库的表中输入三个新对象。查看 API [文档](http://www.rethinkdb.com/api/python/)了解更多信息。
启动服务器。您现在应该看到三个任务:
[](https://files.realpython.com/media/flask-rethink-tasks.1cbdfdfea433.png)
### 最终确定表格
再次更新`index()`函数,从表单中提取数据并将其添加到数据库中:
@app.route('/', methods = ['GET', 'POST'])
def index():
form = TaskForm()
if form.validate_on_submit():
r.table('todos').insert({"name":form.label.data}).run(g.rdb_conn)
return redirect(url_for('index'))
selection = list(r.table('todos').run(g.rdb_conn))
return render_template('index.html', form = form, tasks = selection)
测试一下。添加一些 todos。发疯吧。
## 结论和挑战
目前的应用程序是功能性的,但我们还可以做更多的事情。让这款应用更上一层楼。
这里有一些想法:
1. 添加用户登录。
2. 创建一个更健壮的表单,可以为每个待办事项添加截止日期,然后在将待办事项呈现到 DOM 之前按该日期对其进行排序。
3. 添加功能和[单元测试](https://realpython.com/python-testing/)。
4. 添加为每个任务创建子任务的功能。
5. 通读 API 参考[文档](http://www.rethinkdb.com/api/python/)。玩转各种方法。
6. 将应用模块化。
7. 重构代码。向 RethinkDB 展示您的新代码。
你还想看什么?有兴趣看第二部分吗?与 [MongoDB](https://realpython.com/introduction-to-mongodb-and-python/) 相比,你觉得 RethinkDB 怎么样?下面分享一下你的想法。
你可以从[回购](https://github.com/mjhea0/flask-rethink)中抓取所有代码。干杯!***
# Python 中的反向字符串:reversed()、Slicing 等等
> 原文:<https://realpython.com/reverse-string-python/>
当你经常在代码中使用 Python 字符串时,你可能需要以**逆序**处理它们。Python 包含了一些方便的工具和技术,可以在这些情况下帮到你。有了它们,您将能够快速有效地构建现有字符串的反向副本。
了解这些在 Python 中反转字符串的工具和技术将有助于您提高作为 Python 开发人员的熟练程度。
**在本教程中,您将学习如何:**
* 通过**切片**快速构建反向字符串
* 使用`reversed()`和`.join()`创建现有字符串的**反向副本**
* 使用**迭代**和**递归**手动反转现有字符串
* 对字符串执行**反向迭代**
* **使用`sorted()`将**的字符串反向排序
为了充分利用本教程,您应该了解[琴弦](https://realpython.com/python-strings/)、 [`for`](https://realpython.com/python-for-loop/) 和 [`while`](https://realpython.com/python-while-loop/) 循环以及[递归](https://realpython.com/python-thinking-recursively/)的基础知识。
**免费下载:** [从《Python 基础:Python 3 实用入门》中获取一个示例章节](https://realpython.com/bonus/python-basics-sample-download/),看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
## 使用核心 Python 工具反转字符串
在某些特定的情况下,使用 Python [字符串](https://realpython.com/python-strings/)以**逆序**工作可能是一个需求。例如,假设您有一个字符串`"ABCDEF"`,您想要一个快速的方法来反转它以得到`"FEDCBA"`。您可以使用哪些 Python 工具来提供帮助?
在 Python 中,字符串是不可变的,所以在适当的位置反转给定的字符串是不可能的。你需要创建目标字符串的反向**副本**来满足需求。
Python 提供了两种简单的方法来反转字符串。因为字符串是序列,所以它们是**可索引**、**可切片**和**可迭代**。这些特性允许您使用[切片](https://docs.python.org/dev/whatsnew/2.3.html#extended-slices)以逆序直接生成给定字符串的副本。第二种选择是使用内置函数 [`reversed()`](https://docs.python.org/dev/library/functions.html#reversed) 创建一个迭代器,以逆序生成输入字符串的字符。
[*Remove ads*](/account/join/)
### 切片反转琴弦
切片是一种有用的技术,它允许你使用不同的整数索引组合从给定的序列中提取项目,这些整数索引被称为 T2 偏移量。在对字符串进行切片时,这些偏移量定义了切片中第一个字符的索引、停止切片的字符的索引以及一个值,该值定义了在每次迭代中要跳过多少个字符。
要分割字符串,可以使用以下语法:
```py
a_string[start:stop:step]
你的偏移量是start、stop和step。该表达式通过step提取从start到stop − 1的所有字符。一会儿你们会更深入地了解这一切意味着什么。
所有偏移都是可选的,它们具有以下默认值:
| 抵消 | 缺省值 |
|---|---|
start |
0 |
stop |
len(a_string) |
step |
1 |
这里,start表示切片中第一个字符的索引,而stop保存停止切片操作的索引。第三个偏移量step,允许您决定切片在每次迭代中跳过多少个字符。
注:当指数大于等于stop时,切片操作结束。这意味着它永远不会在最终切片中包含该索引处的项目(如果有)。
step偏移量允许您微调如何从字符串中提取所需字符,同时跳过其他字符:
>>> letters = "AaBbCcDd" >>> # Get all characters relying on default offsets >>> letters[::] 'AaBbCcDd' >>> letters[:] 'AaBbCcDd' >>> # Get every other character from 0 to the end >>> letters[::2] 'ABCD' >>> # Get every other character from 1 to the end >>> letters[1::2] 'abcd'这里,您首先对
letters进行切片,而不提供显式的偏移值,以获得原始字符串的完整副本。为此,还可以使用省略第二个冒号(:)的切片。当step等于2时,切片从目标字符串中获取每隔一个字符。您可以尝试不同的偏移来更好地理解切片是如何工作的。为什么切片和第三个偏移量与 Python 中的反转字符串相关?答案在于
step如何处理负值。如果您给step提供一个负值,那么切片向后运行,意味着从右到左。例如,如果您将
step设置为等于-1,那么您可以构建一个以逆序检索所有字符的切片:
>>> letters = "ABCDEF"
>>> letters[::-1]
'FEDCBA'
>>> letters
'ABCDEF'
这个切片返回从字符串右端(索引等于len(letters) - 1)到字符串左端(索引为0)的所有字符。当你使用这个技巧时,你会得到一个原字符串逆序的副本,而不会影响letters的原内容。
创建现有字符串的反向副本的另一种技术是使用 slice() 。这个内置函数的签名如下:
slice(start, stop, step)
该函数接受三个参数,与切片操作符中的偏移量具有相同的含义,并返回一个表示调用range(start, stop, step)产生的一组索引的切片对象。
您可以使用slice()来模拟切片[::-1]并快速反转您的字符串。继续运行下面对方括号内的slice()的调用:
>>> letters = "ABCDEF" >>> letters[slice(None, None, -1)] 'FEDCBA'将
None传递给slice()的前两个参数,告诉函数您想要依赖它的内部默认行为,这与没有start和stop值的标准切片是一样的。换句话说,将None传递给start和stop意味着您想要从底层序列的左端到右端的切片。用
.join()和reversed()反转琴弦第二种也可能是最巧妙的反转字符串的方法是将
reversed()和str.join()一起使用。如果你传递一个字符串给reversed(),你会得到一个迭代器,它以相反的顺序产生字符:
>>> greeting = reversed("Hello, World!")
>>> next(greeting)
'!'
>>> next(greeting)
'd'
>>> next(greeting)
'l'
当您使用greeting作为参数调用next()时,您从原始字符串的右端获取每个字符。
关于reversed()需要注意的重要一点是,结果迭代器直接从原始字符串产生字符。换句话说,它不会创建一个新的反向字符串,而是从现有字符串反向读取字符。这种行为在内存消耗方面是相当有效的,在某些环境和情况下,比如迭代,这是一个基本的优势。
您可以使用通过直接调用reversed()获得的迭代器作为.join()的参数:
>>> "".join(reversed("Hello, World!")) '!dlroW ,olleH'在这个单行表达式中,您将调用
reversed()的结果作为参数直接传递给.join()。因此,您会得到原始输入字符串的反向副本。这种reversed()和.join()的组合是换弦的绝佳选择。手工生成反向字符串
到目前为止,您已经了解了快速反转字符串的核心 Python 工具和技术。大多数时候,他们会是你要走的路。但是,在编码过程中的某些时候,您可能需要手动反转字符串。
在本节中,您将学习如何使用显式循环和递归来反转字符串。最后一种技术是借助 Python 的
reduce()函数使用函数式编程方法。在循环中反转字符串
您将用来反转字符串的第一个技术涉及到一个
for循环和连接操作符(+)。使用两个字符串作为操作数,该运算符返回一个新字符串,该新字符串是通过连接原始字符串而得到的。整个操作被称为串联。注意:使用
.join()是在 Python 中连接字符串的推荐方法。它干净、高效,而且蟒蛇。下面是一个函数,它获取一个字符串,并使用串联在循环中反转它:
>>> def reversed_string(text):
... result = ""
... for char in text:
... result = char + result
... return result
...
>>> reversed_string("Hello, World!")
'!dlroW ,olleH'
在每次迭代中,循环从text中取出一个后续字符char,并将其与result的当前内容连接起来。注意,result最初保存一个空字符串("")。新的中间字符串然后被重新分配给result。在循环结束时,result保存一个新字符串,作为原始字符串的反向副本。
注意:由于 Python 字符串是不可变的数据类型,您应该记住本节中的例子使用了一种浪费的技术。他们依赖于创建连续的中间字符串,只是为了在下一次迭代中丢弃它们。
如果你喜欢使用一个 while循环,那么你可以这样做来构建一个给定字符串的反向副本:
>>> def reversed_string(text): ... result = "" ... index = len(text) - 1 ... while index >= 0: ... result += text[index] ... index -= 1 ... return result ... >>> reversed_string("Hello, World!") '!dlroW ,olleH'这里,首先使用
len()计算输入字符串中最后一个字符的index。循环从index向下迭代到0。在每次迭代中,使用增加赋值操作符(+=)创建一个中间字符串,将result的内容与来自text的相应字符连接起来。同样,最终结果是通过反转输入字符串得到的新字符串。用递归反转字符串
你也可以使用递归来反转字符串。递归是函数在自己的体内调用自己。为了防止无限递归,你应该提供一个基础用例,它不需要再次调用函数就能产生结果。第二个组件是递归用例,它启动递归循环并执行大部分计算。
下面是如何定义一个递归函数来返回给定字符串的反向副本:
>>> def reversed_string(text):
... if len(text) == 1:
... return text
... return reversed_string(text[1:]) + text[:1]
...
>>> reversed_string("Hello, World!")
'!dlroW ,olleH'
在这个例子中,您首先检查基本情况。如果输入字符串只有一个字符,就将该字符串返回给调用者。
最后一个语句是递归情况,调用reversed_string()本身。该调用使用输入字符串的片段text[1:]作为参数。这片包含了text中的所有角色,除了第一个。下一步是将递归调用的结果与包含第一个字符text的单字符字符串text[:1]相加。
在上面的例子中需要注意的一个重要问题是,如果您将一个长字符串作为参数传递给reversed_string(),那么您将得到一个RecursionError:
>>> very_long_greeting = "Hello, World!" * 1_000 >>> reversed_string(very_long_greeting) Traceback (most recent call last): ... RecursionError: maximum recursion depth exceeded while calling a Python object达到 Python 的默认递归限制是您应该在代码中考虑的一个重要问题。但是,如果您真的需要使用递归,那么您仍然可以选择手动设置递归限制。
从
sys调用getrecursionlimit()可以检查你当前 Python 解释器的递归极限。默认情况下,这个值通常是1000。您可以在同一个模块sys中使用setrecursionlimit()来调整这个限制。使用这些函数,您可以配置 Python 环境,以便您的递归解决方案可以工作。来吧,试一试!使用
reduce()反转字符串如果你喜欢使用函数式编程方法,你可以使用
reduce()从functools来反转字符串。Python 的reduce()将一个折叠或归约函数和一个 iterable 作为参数。然后,它将提供的函数应用于输入 iterable 中的项,并返回一个累积值。以下是如何利用
reduce()来反转字符串:
>>> from functools import reduce
>>> def reversed_string(text):
... return reduce(lambda a, b: b + a, text)
...
>>> reversed_string("Hello, World!")
'!dlroW ,olleH'
在这个例子中, lambda 函数获取两个字符串,并以相反的顺序将它们连接起来。对reduce()的调用将lambda应用到循环中的text,并构建原始字符串的反向副本。
反向遍历字符串
有时,您可能希望以相反的顺序遍历现有的字符串,这种技术通常被称为反向迭代。根据您的具体需要,您可以使用以下选项之一对字符串进行反向迭代:
reversed()内置函数[::-1]切片操作符
逆向迭代可以说是这些工具最常见的用例,所以在接下来的几节中,您将学习如何在迭代环境中使用它们。
reversed()内置函数
以相反的顺序遍历一个字符串的可读性最好的方法是使用reversed()。当您使用这个函数和.join()一起创建反向字符串时,您已经了解了这个函数。
然而,reversed()的主要意图和用例是支持 Python iterables 上的反向迭代。使用字符串作为参数,reversed()返回一个迭代器,该迭代器以相反的顺序从输入字符串中产生字符。
下面是如何用reversed()以相反的顺序遍历一个字符串:
>>> greeting = "Hello, World!" >>> for char in reversed(greeting): ... print(char) ... ! d l r o W , o l l e H >>> reversed(greeting) <reversed object at 0x7f17aa89e070>这个例子中的
for循环可读性很强。reversed()的名字清楚地表达了它的意图,并传达了该函数不会对输入数据产生任何副作用。由于reversed()返回一个迭代器,这个循环在内存使用方面也是高效的。
[::-1]切片操作符,对字符串执行反向迭代的第二种方法是使用您在前面的
a_string[::-1]示例中看到的扩展切片语法。尽管这种方法不利于提高内存效率和可读性,但它仍然提供了一种快速迭代现有字符串的反向副本的方法:
>>> greeting = "Hello, World!"
>>> for char in greeting[::-1]:
... print(char)
...
!
d
l
r
o
W
,
o
l
l
e
H
>>> greeting[::-1]
'!dlroW ,olleH'
在这个例子中,您对greeting应用切片操作符来创建它的反向副本。然后,您使用新的反向字符串来填充循环。在这种情况下,您正在迭代一个新的反向字符串,因此这种解决方案比使用reversed()的内存效率低。
创建自定义可逆字符串
如果你曾经尝试过用反转一个 Python 列表,那么你会知道列表有一个叫做.reverse()的简便方法,可以在适当的位置反转底层列表。因为字符串在 Python 中是不可变的,所以它们没有提供类似的方法。
然而,您仍然可以用模仿list.reverse()的.reverse()方法创建一个定制的 string 子类。你可以这样做:
>>> from collections import UserString >>> class ReversibleString(UserString): ... def reverse(self): ... self.data = self.data[::-1] ...
ReversibleString继承自UserString,是collections模块的一个类。UserString是包装str的内置数据类型。它是专门为创建str的子类而设计的。当您需要创建带有额外功能的自定义字符串类时,UserString非常方便。
UserString提供与常规字符串相同的功能。它还添加了一个名为.data的公共属性,用于保存和访问包装的字符串对象。在
ReversibleString内部,你创建了.reverse()。该方法反转.data中的包装字符串,并将结果重新分配给.data。从外部来看,调用.reverse()的工作原理就像将字符串反转到位。然而,它实际做的是创建一个新的字符串,以相反的顺序包含原始数据。下面是
ReversibleString在实践中的工作方式:
>>> text = ReversibleString("Hello, World!")
>>> text
'Hello, World!'
>>> # Reverse the string in place
>>> text.reverse()
>>> text
'!dlroW ,olleH'
当您在text上调用.reverse()时,该方法的行为就好像您正在对底层字符串进行就地变异。然而,您实际上是在创建一个新的字符串,并将它赋回包装后的字符串。注意text现在以相反的顺序保存原始字符串。
因为UserString提供了和它的超类str相同的功能,你可以使用reversed()来执行逆向迭代:
>>> text = ReversibleString("Hello, World!") >>> # Support reverse iteration out of the box >>> for char in reversed(text): ... print(char) ... ! d l r o W , o l l e H >>> text "Hello, World!"在这里,您用
text作为参数调用reversed(),以进入一个for循环。这个调用按预期工作并返回相应的迭代器,因为UserString从str继承了所需的行为。注意调用reversed()不会影响原来的字符串。逆序排序 Python 字符串
您将学习的最后一个主题是如何对字符串中的字符进行逆序排序。当您处理没有特定顺序的字符串,并且需要按相反的字母顺序对它们进行排序时,这非常方便。
处理这个问题,可以用
sorted()。这个内置函数返回一个列表,该列表按顺序包含输入 iterable 的所有项目。除了输入 iterable,sorted()还接受一个reverse关键字参数。如果希望输入 iterable 按降序排序,可以将该参数设置为True:
>>> vowels = "eauoi"
>>> # Sort in ascending order
>>> sorted(vowels)
['a', 'e', 'i', 'o', 'u']
>>> # Sort in descending order
>>> sorted(vowels, reverse=True)
['u', 'o', 'i', 'e', 'a']
当您使用一个字符串作为参数调用sorted()并且将reverse设置为True时,您会得到一个列表,其中包含以逆序或降序排列的输入字符串的字符。因为sorted()返回了一个list对象,所以你需要一种方法把这个列表变回一个字符串。同样,您可以像在前面几节中一样使用.join():
>>> vowels = "eauoi" >>> "".join(sorted(vowels, reverse=True)) 'uoiea'在这个代码片段中,您在一个空字符串上调用
.join(),它扮演一个分隔符的角色。对.join()的参数是以vowels作为参数调用sorted()并将reverse设置为True的结果。您还可以利用
sorted()以排序和反转的顺序遍历一个字符串:
>>> for vowel in sorted(vowels, reverse=True):
... print(vowel)
...
...
u
o
i
e
a
sorted()的reverse参数允许你以降序排列可重复项,包括字符串。所以,如果你需要一个字符串的字符按照相反的字母顺序排序,那么sorted()就是为你准备的。
结论
以逆序反转和处理字符串可能是编程中的常见任务。Python 提供了一套工具和技术,可以帮助您快速高效地执行字符串反转。在本教程中,您了解了这些工具和技术,以及如何在字符串处理挑战中利用它们。
在本教程中,您学习了如何:
- 通过切片快速构建反向字符串
- 使用
reversed()和.join()创建现有字符串的反向副本 - 使用迭代和递归手工创建反向字符串
- 以相反的顺序在你的琴弦上循环
- 使用
sorted()对字符串进行降序排序
尽管这个主题本身可能没有很多令人兴奋的用例,但了解如何反转字符串在编写入门级职位的面试代码时会很有用。您还会发现,掌握反转字符串的不同方式可以帮助您真正理解 Python 中字符串的不变性,这是该语言的一个显著特征。*****
如何运行您的 Python 脚本
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 运行 Python 脚本
作为 Python 开发人员,您需要掌握的最重要的技能之一是能够运行 Python 脚本和代码。这将是你知道你的代码是否如你计划的那样工作的唯一方法。这甚至是知道你的代码是否工作的唯一方法!
这个循序渐进的教程将根据您的环境、平台、需求和程序员的技能,引导您通过一系列方式来运行 Python 脚本。
您将有机会通过使用来学习如何运行 Python 脚本
- 操作系统命令行或终端
- Python 交互模式
- 您最喜欢的 IDE 或文本编辑器
- 系统的文件管理器,双击脚本图标
这样,您将获得所需的知识和技能,使您的开发周期更加高效和灵活。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
参加测验:通过我们的交互式“如何运行您的 Python 脚本”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
脚本与模块
在计算技术中,脚本一词用来指包含命令逻辑序列的文件或批处理文件。这通常是一个简单的程序,存储在一个纯文本文件中。
脚本总是由某种解释器处理,解释器负责按顺序执行每个命令。
打算由用户直接执行的包含 Python 代码的纯文本文件通常被称为脚本,这是一个非正式术语,意思是顶层程序文件。
另一方面,包含 Python 代码的纯文本文件被称为模块,该代码被设计为从另一个 Python 文件导入并使用。
所以,模块和脚本的主要区别在于,模块是为了导入,而脚本是为了直接执行。
无论是哪种情况,重要的是知道如何运行您编写到模块和脚本中的 Python 代码。
Python 解释器是什么?
Python 是一种优秀的编程语言,允许你在广泛的领域中高效工作。
Python 也是一个叫做解释器的软件。解释器是运行 Python 代码和脚本所需的程序。从技术上讲,解释器是一层软件,它在你的程序和你的计算机硬件之间工作,使你的代码运行。
根据您使用的 Python 实现,解释器可以是:
无论解释器采用什么形式,你写的代码总是由这个程序运行。因此,能够运行 Python 脚本的首要条件是在您的系统上正确安装解释器。
解释器能够以两种不同的方式运行 Python 代码:
- 作为脚本或模块
- 作为在交互式会话中键入的一段代码
如何交互式运行 Python 代码
一种广泛使用的运行 Python 代码的方式是通过交互式会话。要启动 Python 交互式会话,只需打开命令行或终端,然后根据您的 Python 安装键入python或python3,然后点击 Enter 。
下面是一个在 Linux 上如何做到这一点的例子:
$ python3
Python 3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
交互模式的标准提示是>>>,所以只要你看到这些字符,你就知道你已经进入了。
现在,您可以随心所欲地编写和运行 Python 代码,唯一的缺点是当您关闭会话时,您的代码将会消失。
当您以交互方式工作时,您键入的每个表达式和语句都会被立即计算和执行:
>>> print('Hello World!') Hello World! >>> 2 + 5 7 >>> print('Welcome to Real Python!') Welcome to Real Python!交互式会话将允许您测试您编写的每一段代码,这使它成为一个非常棒的开发工具,也是一个试验语言和动态测试 Python 代码的绝佳场所。
要退出交互模式,您可以使用以下选项之一:
quit()或exit(),内置函数- Windows 上的
Ctrl+Z和Enter组合键,或者类 Unix 系统上的Ctrl+D注意:使用 Python 时要记住的第一条经验法则是,如果你对一段 Python 代码的作用有疑问,那么就启动一个交互式会话,尝试一下看看会发生什么。
如果您从未使用过命令行或终端,那么您可以尝试这样做:
在 Windows 上,命令行通常被称为命令提示符或 MS-DOS 控制台,它是一个名为
cmd.exe的程序。该程序的路径会因系统版本的不同而有很大差异。快速访问它的方法是按下
Win+R组合键,这将把你带到运行对话框。一旦你到了那里,输入cmd并按下Enter。在 GNU/Linux(和其他 Unixes)上,有几个应用程序可以让您访问系统命令行。一些最流行的是 xterm、Gnome 终端和 Konsole。这些工具运行 shell 或终端,如 Bash、ksh、csh 等等。
在这种情况下,到这些应用程序的路径要多得多,并且取决于发行版,甚至取决于您使用的桌面环境。所以,你需要阅读你的系统文档。
在 Mac OS X 上,您可以从应用程序→实用程序→终端访问系统终端。
解释器如何运行 Python 脚本?
当您尝试运行 Python 脚本时,一个多步骤的过程开始了。在此过程中,口译员将:
按顺序处理脚本语句
将源代码编译成称为字节码的中间格式
这个字节码是将代码翻译成独立于平台的低级语言。其目的是优化代码执行。所以,下一次解释器运行你的代码时,它会绕过这个编译步骤。
严格来说,这种代码优化只针对模块(导入的文件),不针对可执行脚本。
发送要执行的代码
此时,一种称为 Python 虚拟机(PVM)的东西开始发挥作用。PVM 是 Python 的运行时引擎。这是一个循环,它遍历字节码中的指令,一个接一个地运行它们。
PVM 不是 Python 的一个独立组件。它只是你安装在机器上的 Python 系统的一部分。从技术上讲,PVM 是 Python 解释器的最后一步。
运行 Python 脚本的整个过程被称为 Python 执行模型。
注意:Python 执行模型的这个描述对应的是语言的核心实现,也就是 CPython。由于这不是一个语言要求,它可能会受到未来的变化。
如何使用命令行运行 Python 脚本
Python 交互式会话将允许您编写许多行代码,但是一旦您关闭会话,您将丢失您所编写的所有内容。这就是为什么编写 Python 程序的通常方式是使用纯文本文件。按照惯例,这些文件将使用
.py扩展名。(在 Windows 系统上,扩展名也可以是.pyw。)Python 代码文件可以用任何纯文本编辑器创建。如果你是 Python 编程新手,可以试试 Sublime Text ,这是一个功能强大且易于使用的编辑器,但是你可以使用任何你喜欢的编辑器。
为了继续学习本教程,您需要创建一个测试脚本。打开您最喜欢的文本编辑器,编写以下代码:
1#!/usr/bin/env python3 2 3print('Hello World!')用名称
hello.py将文件保存在您的工作目录中。准备好测试脚本后,您可以继续阅读。使用
python命令要使用
python命令运行 Python 脚本,您需要打开一个命令行,键入单词python,或者如果您有两个版本,键入python3,后跟脚本的路径,如下所示:$ python3 hello.py Hello World!如果一切正常,按下
Enter后,你会在屏幕上看到短语Hello World!。就是这样!您刚刚运行了您的第一个 Python 脚本!如果这不能正常工作,也许你需要检查你的系统
PATH,你的 Python 安装,你创建hello.py脚本的方式,你保存它的地方,等等。这是运行 Python 脚本的最基本和最实用的方法。
重定向输出
有时保存脚本的输出供以后分析会很有用。你可以这样做:
$ python3 hello.py > output.txt这个操作将脚本的输出重定向到
output.txt,而不是标准的系统输出(stdout)。这个过程通常被称为流重定向,在 Windows 和类 Unix 系统上都可用。如果
output.txt不存在,那么它是自动创建的。另一方面,如果文件已经存在,那么它的内容将被新的输出替换。最后,如果你想把连续执行的输出加到
output.txt的末尾,那么你必须用两个尖括号(>>而不是一个,就像这样:$ python3 hello.py >> output.txt现在,输出将被附加到
output.txt的末尾。使用
-m选项运行模块Python 提供了一系列命令行选项,您可以根据自己的需要来使用。例如,如果你想运行一个 Python 模块,你可以使用命令
python -m <module-name>。
-m选项在sys.path中搜索模块名,并以__main__的身份运行其内容:$ python3 -m hello Hello World!注意:
module-name需要是模块对象的名称,而不是字符串。使用脚本文件名
在最新版本的 Windows 上,只需在命令提示符下输入包含代码的文件名,就可以运行 Python 脚本:
C:\devspace> hello.py Hello World!这是可能的,因为 Windows 使用系统注册表和文件关联来确定使用哪个程序来运行特定文件。
在类似 Unix 的系统上,比如 GNU/Linux,您可以实现类似的东西。您只需添加第一行文本
#!/usr/bin/env python,就像您对hello.py所做的那样。对于 Python 来说,这是一个简单的注释,但是对于操作系统来说,这一行表示必须使用什么程序来运行文件。
这一行以
#!字符组合开始,通常称为哈希邦或舍邦,并继续到解释器的路径。有两种方法可以指定解释器的路径:
#!/usr/bin/python: 书写绝对路径#!/usr/bin/env python: 使用操作系统env命令,通过搜索PATH环境变量定位并执行 Python如果您记住不是所有的类 Unix 系统都将解释器放在同一个地方,那么最后一个选项是有用的。
最后,要执行这样的脚本,您需要为它分配执行权限,然后在命令行输入文件名。
下面是一个如何做到这一点的示例:
$ # Assign execution permissions $ chmod +x hello.py $ # Run the script by using its filename $ ./hello.py Hello World!有了执行权限和适当配置的 shebang 行,您只需在命令行输入文件名就可以运行该脚本。
最后,您需要注意,如果您的脚本不在您当前的工作目录中,您将不得不使用文件路径来使这个方法正确工作。
如何交互式运行 Python 脚本
也可以从交互式会话中运行 Python 脚本和模块。这个选项为您提供了多种可能性。
利用
import当您导入一个模块时,真正发生的是您加载它的内容供以后访问和使用。这个过程有趣的地方在于
import运行代码作为它的最后一步。当模块只包含类、函数、变量和常量定义时,您可能不会意识到代码实际上在运行,但是当模块包含对函数、方法或其他生成可见结果的语句的调用时,您将会看到它的执行。
这为您提供了另一个运行 Python 脚本的选项:
>>> import hello
Hello World!
您必须注意,这个选项在每个会话中只起一次作用。在第一个import之后,连续的import执行什么都不做,即使你修改了模块的内容。这是因为import操作成本很高,因此只运行一次。这里有一个例子:
>>> import hello # Do nothing >>> import hello # Do nothing again这两个
import操作什么都不做,因为 Python 知道hello已经被导入了。这种方法的工作有一些要求:
- 包含 Python 代码的文件必须位于您当前的工作目录中。
- 该文件必须位于 Python 模块搜索路径(PMSP) 中,Python 会在这里查找您导入的模块和包。
要了解您当前的 PMSP 中有什么,您可以运行以下代码:
>>> import sys
>>> for path in sys.path:
... print(path)
...
/usr/lib/python36.zip
/usr/lib/python3.6
/usr/lib/python3.6/lib-dynload
/usr/local/lib/python3.6/dist-packages
/usr/lib/python3/dist-packages
运行这段代码,您将获得 Python 在其中搜索您导入的模块的目录和.zip文件的列表。
使用importlib和imp
在 Python 标准库中可以找到 importlib ,这是一个提供import_module()的模块。
使用import_module(),您可以模拟一个import操作,并因此执行任何模块或脚本。看一下这个例子:
>>> import importlib >>> importlib.import_module('hello') Hello World! <module 'hello' from '/home/username/hello.py'>一旦你第一次导入了一个模块,你将不能继续使用
import来运行它。在这种情况下,您可以使用importlib.reload(),这将强制解释器再次重新导入模块,就像下面的代码一样:
>>> import hello # First import
Hello World!
>>> import hello # Second import, which does nothing
>>> import importlib
>>> importlib.reload(hello)
Hello World!
<module 'hello' from '/home/username/hello.py'>
这里需要注意的重要一点是,reload()的参数必须是模块对象的名称,而不是字符串:
>>> importlib.reload('hello') Traceback (most recent call last): ... TypeError: reload() argument must be a module如果你使用一个字符串作为参数,那么
reload()将引发一个TypeError异常。注意:为了节省空间,前面代码的输出被缩写为(
...)。当您正在修改一个模块,并且想要测试您的更改是否有效,而又不离开当前的交互会话时,这个功能就派上了用场。
最后,如果您使用的是 Python 2.x,那么您将拥有
imp,这是一个提供名为reload()的函数的模块。imp.reload()的工作原理与importlib.reload()类似。这里有一个例子:
>>> import hello # First import
Hello World!
>>> import hello # Second import, which does nothing
>>> import imp
>>> imp.reload(hello)
Hello World!
<module 'hello' from '/home/username/hello.py'>
在 Python 2.x 中,reload()是一个内置函数。在 2.6 和 2.7 版本中,它也被包含在imp中,以帮助过渡到 3.x。
注意: imp自该语言 3.4 版本起已被弃用。imp方案正等待有利于importlib的否决。
使用runpy.run_module()和runpy.run_path()
标准库包括一个名为 runpy 的模块。在这个模块中,你可以找到run_module(),这是一个可以让你不用先导入模块就可以运行模块的功能。这个函数返回被执行模块的globals字典。
这里有一个你如何使用它的例子:
>>> runpy.run_module(mod_name='hello') Hello World! {'__name__': 'hello', ... '_': None}}使用标准的
import机制定位模块,然后在新的模块命名空间上执行。
run_module()的第一个参数必须是带有模块绝对名称的字符串(不带.py扩展名)。另一方面,
runpy还提供了run_path(),这将允许您通过提供模块在文件系统中的位置来运行模块:
>>> import runpy
>>> runpy.run_path(path_name='hello.py')
Hello World!
{'__name__': '<run_path>',
...
'_': None}}
像run_module(),run_path()返回被执行模块的globals字典。
path_name参数必须是一个字符串,可以引用以下内容:
- Python 源文件的位置
- 编译后的字节码文件的位置
sys.path中有效条目的值,包含一个__main__模块(__main__.py文件)
黑客exec()
到目前为止,您已经看到了运行 Python 脚本最常用的方法。在本节中,您将看到如何通过使用 exec() 来实现这一点,这是一个支持 Python 代码动态执行的内置函数。
exec()提供了运行脚本的另一种方式:
>>> exec(open('hello.py').read()) 'Hello World!'该语句打开
hello.py,读取其内容,并发送给exec(),最后运行代码。上面的例子有点离谱。这只是一个“黑客”,它向您展示了 Python 是多么的通用和灵活。
使用
execfile()(仅限 Python 2.x】如果您喜欢使用 Python 2.x,可以使用一个名为
execfile()的内置函数,它能够运行 Python 脚本。
execfile()的第一个参数必须是一个字符串,包含您要运行的文件的路径。这里有一个例子:
>>> execfile('hello.py')
Hello World!
这里,hello.py被解析和评估为一系列 Python 语句。
如何从 IDE 或文本编辑器运行 Python 脚本
当开发更大更复杂的应用时,建议您使用集成开发环境(IDE)或高级文本编辑器。
这些程序中的大多数都提供了从环境内部运行脚本的可能性。它们通常包含一个运行或构建命令,这通常可以从工具栏或主菜单中获得。
Python 的标准发行版包括作为默认 IDE 的 IDLE ,你可以用它来编写、调试、修改和运行你的模块和脚本。
其他 ide 如 Eclipse-PyDev、PyCharm、Eric 和 NetBeans 也允许您从环境内部运行 Python 脚本。
像 Sublime Text 和 Visual Studio Code 这样的高级文本编辑器也允许你运行你的脚本。
为了掌握如何从您喜欢的 IDE 或编辑器中运行 Python 脚本的细节,您可以看一下它的文档。
如何从文件管理器运行 Python 脚本
通过双击文件管理器中的图标来运行脚本是运行 Python 脚本的另一种可能方式。这个选项可能不会在开发阶段广泛使用,但是当您发布代码用于生产时可能会用到。
为了能够双击运行您的脚本,您必须满足一些取决于您的操作系统的条件。
例如,Windows 将扩展名.py和.pyw分别与程序python.exe和pythonw.exe相关联。这允许您通过双击脚本来运行它们。
当您有一个带有命令行界面的脚本时,您很可能只能在屏幕上看到一个黑色的闪烁窗口。为了避免这种恼人的情况,您可以在脚本末尾添加类似于input('Press Enter to Continue...')的语句。这样,程序会停止,直到你按下 Enter 。
不过,这种技巧也有缺点。例如,如果您的脚本有任何错误,执行将在到达input()语句之前中止,您仍然无法看到结果。
在类似 Unix 的系统上,您可以通过在文件管理器中双击脚本来运行它们。要实现这一点,您的脚本必须有执行权限,并且您需要使用您已经看到的 shebang 技巧。同样,对于命令行界面脚本,您可能在屏幕上看不到任何结果。
因为通过双击执行脚本有一些限制,并且取决于许多因素(例如操作系统、文件管理器、执行权限、文件关联),所以建议您将它视为已经调试好并准备投入生产的脚本的一个可行选项。
结论
通过阅读本教程,您已经掌握了在各种情况和开发环境下以多种方式运行 Python 脚本和代码所需的知识和技能。
您现在可以从运行 Python 脚本了
- 操作系统命令行或终端
- Python 交互模式
- 您最喜欢的 IDE 或文本编辑器
- 系统的文件管理器,双击脚本图标
这些技能将使你的开发过程更快,更有效率和灵活性。
参加测验:通过我们的交互式“如何运行您的 Python 脚本”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 运行 Python 脚本*********
支持一个烧瓶项目
让我们构建一个命令行实用程序来快速生成 Flask 样板结构。
模仿 Flask-Skeleton 项目,这个工具将自动执行一些重复的任务,这样你就可以快速启动一个 Flask 项目,并使用你喜欢的结构、扩展和配置,一步一步地:
- 建立基本结构
- 添加自定义配置文件
- 利用 Bower 管理前端依赖关系
- 创建虚拟环境
- 初始化 Git
一旦完成,您将拥有一个强大的脚手架脚本,您可以(并且应该)定制它来满足您自己的开发需求。
更新:
- 08/01/2016:升级到 Python 版本 3.5.1 。
快速入门
首先,我们需要一个基本的 Flask 应用程序。为了简单起见,我们将使用真正的 Python 样板烧瓶结构,因此只需将其克隆下来以设置基本结构:
$ mkdir flask-scaffold
$ cd flask-scaffold
$ git clone https://github.com/realpython/flask-skeleton skeleton
$ rm -rf skeleton/.git
$ rm skeleton/.gitignore
$ mkdir templates
$ pyvenv-3.5 env
$ source env/bin/activate
本文利用了 Python 3.5 然而,最终的脚本与 Python 2 和 3 都兼容。
第一项任务–结构
在根目录下保存一个新的 Python 文件为 flask_skeleton.py 。该文件将用于驱动整个脚手架实用程序。在您最喜欢的文本编辑器中打开它,并添加以下代码:
# -*- coding: utf-8 -*-
import sys
import os
import argparse
import shutil
# Globals #
cwd = os.getcwd()
script_dir = os.path.dirname(os.path.realpath(__file__))
def main(argv):
# Arguments #
parser = argparse.ArgumentParser(description='Scaffold a Flask Skeleton.')
parser.add_argument('appname', help='The application name')
parser.add_argument('-s', '--skeleton', help='The skeleton folder to use.')
args = parser.parse_args()
# Variables #
appname = args.appname
fullpath = os.path.join(cwd, appname)
skeleton_dir = args.skeleton
# Tasks #
# Copy files and folders
shutil.copytree(os.path.join(script_dir, skeleton_dir), fullpath)
if __name__ == '__main__':
main(sys.argv)
这里,我们使用 argparse 为新项目获取一个appname,然后复制框架目录(通过 shutil ),其中包含项目样板文件,以快速重新创建项目结构。
shutil.copytree()方法( source )用于递归地将源目录复制到目标目录(只要目标目录还不存在)。
测试一下:
$ python flask_skeleton.py new_project -s skeleton
这应该将真正的 Python 样板 Flask 结构(源)复制到一个名为“new_project”(目标)的新目录中。成功了吗?如果是这样,删除新项目,因为还有很多工作要做:
$ rm -rf new_project
处理多个骨架
如果你需要一个带有 MongoDB 数据库或支付蓝图的应用程序呢?所有的应用程序都有特定的需求,你显然不能为它们创建一个框架,但也许有某些功能在大多数时候是需要的。例如,大约 50%的时间你可能需要一个 NoSQL 数据库。您可以向根添加一个新的框架来实现这一点。然后,当您运行 scaffold 命令时,只需指定包含您希望制作副本的框架应用程序的目录的名称。
第二项任务–配置
我们现在需要为每个骨架生成一个定制的 config.py 文件。这个脚本将为我们做到这一点;让代码做重复性的工作!首先,在模板文件夹中添加一个名为 config.jinja2 的文件:
# config.jinja2
import os
basedir = os.path.abspath(os.path.dirname(__file__))
class BaseConfig(object):
"""Base configuration."""
SECRET_KEY = '{{ secret_key }}'
DEBUG = False
BCRYPT_LOG_ROUNDS = 13
WTF_CSRF_ENABLED = True
DEBUG_TB_ENABLED = False
DEBUG_TB_INTERCEPT_REDIRECTS = False
class DevelopmentConfig(BaseConfig):
"""Development configuration."""
DEBUG = True
BCRYPT_LOG_ROUNDS = 13
WTF_CSRF_ENABLED = False
SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(basedir, 'dev.sqlite')
DEBUG_TB_ENABLED = True
class TestingConfig(BaseConfig):
"""Testing configuration."""
DEBUG = True
TESTING = True
BCRYPT_LOG_ROUNDS = 13
WTF_CSRF_ENABLED = False
SQLALCHEMY_DATABASE_URI = 'sqlite:///'
DEBUG_TB_ENABLED = False
class ProductionConfig(BaseConfig):
"""Production configuration."""
SECRET_KEY = '{{ secret_key }}'
DEBUG = False
SQLALCHEMY_DATABASE_URI = 'postgresql://localhost/example'
DEBUG_TB_ENABLED = False
在支架脚本的开始,flask_skeleton.py,就在 main()函数之前,我们需要初始化Jinja2,以便正确地呈现配置。
# Jinja2 environment
template_loader = jinja2.FileSystemLoader(searchpath=os.path.join(script_dir, "templates"))
template_env = jinja2.Environment(loader=template_loader)
确保也添加导入:
import jinja2
安装:
$ pip install jinja2
$ pip freeze > requirements.txt
回头看看模板 config.jinja2 ,我们有一个变量需要定义——{{ secret_key }}。为此,我们可以使用编解码器模块。
向flask_skeleton.py的进口添加:
import codecs
将以下代码添加到main()函数的底部:
# Create config.py
secret_key = codecs.encode(os.urandom(32), 'hex').decode('utf-8')
template = template_env.get_template('config.jinja2')
template_var = {
'secret_key': secret_key,
}
with open(os.path.join(fullpath, 'project', 'config.py'), 'w') as fd:
fd.write(template.render(template_var))
如果管理几个骨架,需要几个配置模板怎么办?
简单:您只需检查哪个框架作为参数传递,并使用适当的配置模板。请记住,os.path.join(fullpath, 'project', 'config.py')必须代表您的配置在您的框架中应该存储的路径。如果每个框架都不同,那么您应该将存储配置文件的文件夹指定为一个附加的 argparse 参数。
准备测试了吗?
$ python flask_skeleton.py new_project -s skeleton
确保 config.py 文件存在于“new_project/project”文件夹中,然后删除新项目:rm -rf new_project
第三项任务–凉亭
没错:我们将使用 bower 来下载和管理静态库。要向 scaffold 脚本添加 bower 支持,首先要添加另一个参数:
parser.add_argument('-b', '--bower', help='Install dependencies via bower')
为了处理 bower 的运行,在 scaffold 脚本的 config 部分下面添加以下代码:
# Add bower dependencies
if args.bower:
bower = args.bower.split(',')
bower_exe = which('bower')
if bower_exe:
os.chdir(os.path.join(fullpath, 'project', 'client', 'static'))
for dependency in bower:
output, error = subprocess.Popen(
[bower_exe, 'install', dependency],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
).communicate()
# print(output)
if error:
print("An error occurred with Bower")
print(error)
else:
print("Could not find bower. Ignoring.")
不要忘记在 flask_skeleton.py - import subprocess的导入部分添加子流程模块。
你注意到which()法(来源)了吗?这实际上使用了 unix/linux which 工具来指示可执行文件在文件系统中的安装位置。因此,在上面的代码中,我们检查是否安装了bower。如果您想知道这是如何工作的,请在 Python 3 解释器中测试一下:
>>> import shutil >>> shutil.which('bower') '/usr/local/bin/bower'不幸的是,这个方法
which()对于 Python 3.3 来说是新的,所以,如果你使用 Python 2,那么你需要安装一个单独的包——shutilwhich:$ pip install shutilwhich $ pip freeze > requirements.txt更新导入:
if sys.version_info < (3, 0): from shutilwhich import which else: from shutil import which最后,请注意下面几行代码:
output, error = subprocess.Popen( [bower_exe, 'install', dependency], stdout=subprocess.PIPE, stderr=subprocess.PIPE ).communicate() # print(output) if error: print("An error occurred with Bower") print(error)从查看官方的子流程文档开始。简单地说,它用于调用外部 shell 命令。在上面的代码中,我们只是捕获了来自 stdout 和 stderr 的输出。
如果您想知道输出是什么,取消对 print 语句
# print(output)的注释,然后运行您的代码…在测试之前,这段代码假设在您的框架文件夹中,有一个包含“静态”文件夹的“项目”文件夹。经典烧瓶应用。在命令行上,您现在可以安装多个依赖项,如下所示:
$ python flask_skeleton.py new_project -s skeleton -b 'angular, jquery, bootstrap'第四项任务——虚拟人
由于虚拟环境是任何 Flask (err,Python)应用程序最重要的部分之一,使用 scaffold 脚本创建 virtualenv 将非常有用。像往常一样,首先添加参数:
parser.add_argument('-v', '--virtualenv', action='store_true')然后在 bower 部分下面添加以下代码:
# Add a virtualenv virtualenv = args.virtualenv if virtualenv: virtualenv_exe = which('pyvenv') if virtualenv_exe: output, error = subprocess.Popen( [virtualenv_exe, os.path.join(fullpath, 'env')], stdout=subprocess.PIPE, stderr=subprocess.PIPE ).communicate() if error: with open('virtualenv_error.log', 'w') as fd: fd.write(error.decode('utf-8')) print("An error occurred with virtualenv") sys.exit(2) venv_bin = os.path.join(fullpath, 'env/bin') output, error = subprocess.Popen( [ os.path.join(venv_bin, 'pip'), 'install', '-r', os.path.join(fullpath, 'requirements.txt') ], stdout=subprocess.PIPE, stderr=subprocess.PIPE ).communicate() if error: with open('pip_error.log', 'w') as fd: fd.write(error.decode('utf-8')) sys.exit(2) else: print("Could not find virtualenv executable. Ignoring")这个代码片段假设在根目录下的“skeleton”文件夹中有一个 requirements.txt 文件。如果是这样,它将创建一个 virtualenv,然后安装依赖项。
第 5 个任务–Git Init
注意到模式了吗?添加参数:
parser.add_argument('-g', '--git', action='store_true')然后在 virtualenv 的任务下添加代码:
# Git init if args.git: output, error = subprocess.Popen( ['git', 'init', fullpath], stdout=subprocess.PIPE, stderr=subprocess.PIPE ).communicate() if error: with open('git_error.log', 'w') as fd: fd.write(error.decode('utf-8')) print("Error with git init") sys.exit(2) shutil.copyfile( os.path.join(script_dir, 'templates', '.gitignore'), os.path.join(fullpath, '.gitignore') )现在在模板文件夹中添加一个。gitignore 文件,然后添加您想要忽略的文件和文件夹。如果需要,从 Github 获取示例。再次测试。
求和并确认
最后,让我们在创建应用程序之前添加一个漂亮的摘要,然后在执行脚本之前要求用户确认…
总结
将名为 brief.jinja2 的文件添加到“templates”文件夹中:
Welcome! The following settings will be used to create your application: Python Version: {{ pyversion }} Project Name: {{ appname }} Project Path: {{ path }} Virtualenv: {% if virtualenv %}Enabled{% else %}Disabled{% endif %} Skeleton: {{ skeleton }} Git: {% if git %}Yes{% else %}{{ disabled }}No{% endif %} Bower: {% if bower %}Enabled{% else %}Disabled{% endif %} {% if bower %}Bower Dependencies: {% for dependency in bower %}{{ dependency }}{% endfor %}{% endif %}现在我们只需要捕捉每个用户提供的参数,然后呈现模板。首先,将导入-
import platform-添加到导入部分,然后在 flask_skeleton.py 脚本的“变量”部分下添加以下代码:# Summary # def generate_brief(template_var): template = template_env.get_template('brief.jinja2') return template.render(template_var) template_var = { 'pyversion': platform.python_version(), 'appname': appname, 'bower': args.bower, 'virtualenv': args.virtualenv, 'skeleton': args.skeleton, 'path': fullpath, 'git': args.git } print(generate_brief(template_var))测试一下:
$ python flask_skeleton.py new_project -s skeleton -b 'angular, jquery, bootstrap' -g -v您应该会看到类似这样的内容:
Welcome! The following settings will be used to create your application: Python Version: 3.5.1 Project Name: new_project Project Path: /Users/michael/repos/realpython/flask-scaffold/new_project Virtualenv: Enabled Skeleton: skeleton Git: Yes Bower: Enabled Bower Dependencies: angular, jquery, bootstrap不错!
重构
现在我们需要稍微重构脚本,首先检查错误。我建议从 refactor 标签中抓取代码,然后比较 diff ,因为有一些小的更新。
在继续之前,确保你使用了来自 refactor 标签的更新脚本。
确认
现在让我们通过更新
if __name__ == '__main__':来添加用户确认功能:if __name__ == '__main__': arguments = get_arguments(sys.argv) print(generate_brief(arguments)) if sys.version_info < (3, 0): input = raw_input proceed = input("\nProceed (yes/no)? ") valid = ["yes", "y", "no", "n"] while True: if proceed.lower() in valid: if proceed.lower() == "yes" or proceed.lower() == "y": main(arguments) print("Done!") break else: print("Goodbye!") break else: print("Please respond with 'yes' or 'no' (or 'y' or 'n').") proceed = input("\nProceed (yes/no)? ")这应该相当简单。
快跑!
如果您使用 Linux 或 Mac,您可以使这个脚本更容易运行。只需将以下别名添加到任一中。巴沙尔或。zshrc ,定制它以匹配您的目录结构:
alias flaskcli="python /Users/michael/repos/realpython/flask-scaffold/flask_skeleton.py"注意:如果你同时安装了 Python 2.7 和 Python 3.5,你必须指定你想要使用的版本——要么是
python要么是python3。删除新项目(如有必要)-
rm -rf new_project-然后最后一次测试脚本以确认:$ flaskcli new_project -s skeleton -b 'angular, jquery, bootstrap' -g -v结论
你怎么想呢?我们错过了什么吗?为了进一步定制您的 scaffold 脚本,您还会向
argparse添加哪些参数?下面评论!从回购中抓取最终代码。
这是 Depado 和 Real Python 的人们之间的合作作品。由德里克·卡尼编辑。****
使用 Python 的情感分析对电影评论进行分类
情感分析是一个强大的工具,可以让计算机理解一篇文章潜在的主观基调。这是人类很难做到的,正如你所想象的,对计算机来说也不总是那么容易。但是有了合适的工具和 Python,你可以使用情感分析来更好地理解一篇文章的情感。
你为什么要这么做?情绪分析有很多用途,例如通过使用社交媒体数据或汇总评论来了解股票交易者对某家公司的看法,这将在本教程结束时完成。
在本教程中,您将学习:
- 如何使用自然语言处理技术
- 如何利用机器学习确定文本的情感
- 如何使用 spaCy 来构建一个 NLP 管道,该管道将输入到情感分析分类器中
本教程非常适合希望获得以项目为中心的指导,使用 spaCy 构建情感分析管道的机器学习初学者。
你应该熟悉基本的机器学习技术比如二进制分类以及它们背后的概念,比如训练循环、数据批次、权重和偏差。如果你不熟悉机器学习,那么你可以通过学习逻辑回归来启动你的旅程。
准备好之后,您可以通过从下面的链接下载源代码来学习本教程中的示例:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习自然语言处理中的情感分析。
使用自然语言处理对文本数据进行预处理和清理
任何情感分析工作流程都是从加载数据开始的。但是一旦数据加载完毕,你会怎么做呢?在你可以用它做任何有趣的事情之前,你需要通过一个自然语言处理管道来处理它。
必要的步骤包括(但不限于)以下内容:
- 标记句子将文本分解成句子、单词或其他单元
- 删除停用词如“如果”、“但是”、“或者”等
- 通过将一个单词的所有形式压缩成一种形式来使单词规范化
- 通过将文本转化为数字表示供分类器使用,对文本进行矢量化
所有这些步骤都是为了减少任何人类可读文本中固有的噪声,并提高分类器结果的准确性。有很多很棒的工具可以帮助你,比如自然语言工具包、 TextBlob 和 spaCy 。对于本教程,您将使用 spaCy。
注意: spaCy 是一个非常强大的工具,具有许多特性。要深入了解这些特性,请查看使用 spaCy 的自然语言处理。
在继续之前,请确保您已经安装了 spaCy 及其英文版:
$ pip install spacy==2.3.5 $ python -m spacy download en_core_web_sm第一个命令安装 spaCy,第二个命令使用 spaCy 下载其英语语言模型。spaCy 支持许多不同的语言,这些语言在 spaCy 网站上列出。
警告:本教程仅适用于 spaCy 2。并且与 spaCy 3.0 不兼容。为了获得最佳体验,请安装上面指定的版本。
接下来,您将学习如何使用 spaCy 来帮助完成之前学习过的预处理步骤,从标记化开始。
标记化
标记化是将大块文本分解成小块的过程。spaCy 附带了一个默认的处理管道,从标记化开始,使这个过程变得很容易。在 spaCy 中,您可以进行句子标记化或单词标记化:
- 单词标记化将文本分解成单个单词。
- 句子标记化将文本分解成单独的句子。
在本教程中,您将使用单词标记化将文本分成单个单词。首先,将文本加载到 spaCy 中,spaCy 会为您完成标记化工作:
>>> import spacy
>>> text = """
... Dave watched as the forest burned up on the hill,
... only a few miles from his house. The car had
... been hastily packed and Marta was inside trying to round
... up the last of the pets. "Where could she be?" he wondered
... as he continued to wait for Marta to appear with the pets.
... """
>>> nlp = spacy.load("en_core_web_sm")
>>> doc = nlp(text)
>>> token_list = [token for token in doc]
>>> token_list
[
, Dave, watched, as, the, forest, burned, up, on, the, hill, ,,
, only, a, few, miles, from, his, house, ., The, car, had,
, been, hastily, packed, and, Marta, was, inside, trying, to, round,
, up, the, last, of, the, pets, ., ", Where, could, she, be, ?, ", he, wondered,
, as, he, continued, to, wait, for, Marta, to, appear, with, the, pets, .,
]
在这段代码中,您设置了一些要标记的示例文本,加载 spaCy 的英语模型,然后通过将文本传递到nlp构造函数中来标记文本。这个模型包括一个您可以定制的默认处理管道,您将在项目部分的后面看到。
之后,生成一个令牌列表并打印出来。您可能已经注意到,“单词标记化”是一个稍微容易引起误解的术语,因为捕获的标记包括标点符号和其他非单词字符串。
令牌是 spaCy 中一种重要的容器类型,具有非常丰富的特性。在下一节中,您将学习如何使用这些特性之一来过滤掉停用词。
移除停止字
停用词是在人类交流中可能很重要,但对机器价值不大的词。spaCy 提供了一个默认的停用词列表,您可以自定义该列表。现在,您将看到如何使用令牌属性来删除停用词:
>>> filtered_tokens = [token for token in doc if not token.is_stop] >>> filtered_tokens [ , Dave, watched, forest, burned, hill, ,, , miles, house, ., car, , hastily, packed, Marta, inside, trying, round, , pets, ., ", ?, ", wondered, , continued, wait, Marta, appear, pets, ., ]在一行 Python 代码中,使用
.is_stoptoken 属性从标记化的文本中过滤出停用词。您注意到这个输出和标记文本后得到的输出之间有什么不同?去掉停用词后,标记列表会更短,帮助您理解标记的上下文也更少。
标准化单词
规范化比记号化稍微复杂一点。它需要将一个单词的所有形式浓缩成一个单词的单一表示。例如,“观看”、“观看”和“手表”都可以规范化为“手表”有两种主要的标准化方法:
- 堵塞物
- 词汇化
使用词干,一个单词在其词干处被切断,这是该单词的最小单位,从中可以创建后代单词。你刚刚看到了一个例子,上面是“手表”词干处理只是使用普通的词尾来截断字符串,所以它会漏掉“feel”和“felt”之间的关系。
词汇化试图解决这个问题。这个过程使用了一种数据结构,将一个单词的所有形式与其最简单的形式联系起来,即词条。因为词汇化通常比词干化更强大,所以它是 spaCy 提供的唯一规范化策略。
幸运的是,您不需要任何额外的代码来做到这一点。当你调用
nlp()的时候,它会自动发生——还有许多其他活动,比如词性标注和命名实体识别。您可以利用.lemma_属性来检查每个令牌的引理:
>>> lemmas = [
... f"Token: {token}, lemma: {token.lemma_}"
... for token in filtered_tokens
... ]
>>> lemmas
['Token: \n, lemma: \n', 'Token: Dave, lemma: Dave',
'Token: watched, lemma: watch', 'Token: forest, lemma: forest',
# ...
]
您在这里所做的只是通过遍历过滤后的记号列表生成一个可读的记号和词条列表,利用.lemma_属性来检查词条。这个例子只显示了前几个记号和引理。你的输出会更长。
注意:注意.lemma_属性上的下划线。那不是错别字。spaCy 中的惯例是获取属性的人类可读版本。
下一步是以机器能够理解的方式来表示每个令牌。这叫做矢量化。
向量化文本
矢量化是将令牌转换为向量或数值数组的过程,在 NLP 环境中,该数值数组是唯一的,并代表令牌的各种特征。向量被用于寻找单词相似性、对文本进行分类以及执行其他 NLP 操作。
这个特殊的表示是一个密集数组,其中数组中的每个空间都有定义的值。这与早期使用稀疏数组的方法相反,在这些方法中,大部分空间是空的。
像其他步骤一样,矢量化是通过nlp()调用自动完成的。因为您已经有了一个令牌对象列表,所以您可以获得其中一个令牌的向量表示,如下所示:
>>> filtered_tokens[1].vector array([ 1.8371646 , 1.4529226 , -1.6147211 , 0.678362 , -0.6594443 , 1.6417935 , 0.5796405 , 2.3021278 , -0.13260496, 0.5750932 , 1.5654886 , -0.6938864 , -0.59607106, -1.5377437 , 1.9425622 , -2.4552505 , 1.2321601 , 1.0434952 , -1.5102385 , -0.5787632 , 0.12055647, 3.6501784 , 2.6160972 , -0.5710199 , -1.5221789 , 0.00629176, 0.22760668, -1.922073 , -1.6252862 , -4.226225 , -3.495663 , -3.312053 , 0.81387717, -0.00677544, -0.11603224, 1.4620426 , 3.0751472 , 0.35958546, -0.22527039, -2.743926 , 1.269633 , 4.606786 , 0.34034157, -2.1272311 , 1.2619178 , -4.209798 , 5.452852 , 1.6940253 , -2.5972986 , 0.95049495, -1.910578 , -2.374927 , -1.4227567 , -2.2528825 , -1.799806 , 1.607501 , 2.9914255 , 2.8065152 , -1.2510269 , -0.54964066, -0.49980402, -1.3882618 , -0.470479 , -2.9670253 , 1.7884955 , 4.5282774 , -1.2602427 , -0.14885521, 1.0419178 , -0.08892632, -1.138275 , 2.242618 , 1.5077229 , -1.5030195 , 2.528098 , -1.6761329 , 0.16694719, 2.123961 , 0.02546412, 0.38754445, 0.8911977 , -0.07678384, -2.0690763 , -1.1211847 , 1.4821006 , 1.1989193 , 2.1933236 , 0.5296372 , 3.0646474 , -1.7223308 , -1.3634219 , -0.47471118, -1.7648507 , 3.565178 , -2.394205 , -1.3800384 ], dtype=float32)在这里,您在
filtered_tokens列表中的第二个标记上使用了.vector属性,在这组示例中是单词Dave。注意:如果您对
.vector属性得到不同的结果,不要担心。这可能是因为您正在使用不同版本的en_core_web_sm模型,或者可能是 spaCy 本身。现在您已经了解了 spaCy 中一些典型的文本预处理步骤,您将学习如何对文本进行分类。
使用机器学习分类器预测情感
你的文本现在被处理成你的计算机可以理解的形式,所以你可以开始根据它的情感对它进行分类。您将涉及三个主题,这些主题将让您对文本数据的机器学习分类有一个大致的了解:
- 有哪些机器学习工具,它们是如何使用的
- 分类如何工作
- 如何使用 spaCy 进行文本分类
首先,您将了解一些可用于进行机器学习分类的工具。
机器学习工具
Python 中有许多工具可用于解决分类问题。以下是一些比较受欢迎的:
这个列表并不是包罗万象的,但是这些是 Python 中更广泛使用的机器学习框架。它们是庞大而强大的框架,需要花费大量时间才能真正掌握和理解。
TensorFlow 由 Google 开发,是最流行的机器学习框架之一。您主要使用它来实现您自己的机器学习算法,而不是使用现有的算法。它是相当低级的,这给了用户很大的权力,但它伴随着陡峭的学习曲线。
PyTorch 是脸书对 TensorFlow 的回应,并实现了许多相同的目标。然而,它是为了让 Python 程序员更熟悉而构建的,并且凭借其自身的优势已经成为一个非常受欢迎的框架。因为它们有相似的用例,如果你正在考虑学习一个框架,比较 TensorFlow 和 PyTorch 是一个有用的练习。
scikit-learn 与 TensorFlow 和 PyTorch 形成对比。它是更高层次的,允许你使用现成的机器学习算法,而不是构建自己的算法。它在可定制性方面的不足,在易用性方面得到了充分的弥补,允许您只需几行代码就可以快速训练分类器。
幸运的是,spaCy 提供了一个相当简单的内置文本分类器,稍后您将会了解到。然而,首先,理解任何分类问题的一般工作流程是很重要的。
分类如何工作
不要担心——在这一部分,你不会深入到线性代数、向量空间或其他深奥的概念中,这些概念通常会推动机器学习。相反,您将获得对分类问题中常见的工作流和约束的实际介绍。
一旦有了矢量化数据,分类的基本工作流程如下所示:
- 将您的数据分成训练集和评估集。
- 选择模型架构。
- 使用训练数据来训练您的模型。
- 使用测试数据来评估模型的性能。
- 对新数据使用您的训练模型来生成预测,在这种情况下,预测值将是介于-1.0 和 1.0 之间的数字。
这个列表并不详尽,为了提高准确性,还可以做一些额外的步骤和变化。例如,机器学习实践者经常将他们的数据集分成三组:
- 培养
- 确认
- 试验
训练集顾名思义就是用来训练你的模型。验证集用于帮助调整您的模型的超参数,这可以带来更好的性能。
注意:超参数控制模型的训练过程和结构,可以包括学习率和批量大小等内容。但是,哪些超参数可用在很大程度上取决于您选择使用的模型。
测试集是一个数据集,它整合了各种各样的数据,以准确判断模型的性能。测试集通常用于比较多个模型,包括不同训练阶段的相同模型。
既然你已经学习了分类的一般流程,是时候用 spaCy 把它付诸行动了。
如何使用 spaCy 进行文本分类
您已经了解了 spaCy 如何使用
nlp()构造函数为您做大量的文本预处理工作。这真的很有帮助,因为训练分类模型需要许多有用的例子。此外,spaCy 还提供了一个管道功能,当您调用
nlp()时,这个管道功能为发生在引擎盖下的许多魔法提供了动力。默认管道是在一个 JSON 文件中定义的,该文件与您正在使用的任何一个预先存在的模型相关联(对于本教程来说是en_core_web_sm),但是如果您愿意,您也可以从头构建一个。注意:要了解更多关于创建自己的语言处理管道的信息,请查看 spaCy 管道文档。
这和分类有什么关系?spaCy 提供的内置管道组件之一叫做
textcat(T1 的缩写),它使你能够为你的文本数据分配类别(或标签,并将其用作神经网络的训练数据。这个过程将生成一个训练好的模型,然后你可以用它来预测一段给定文本的情感。要利用该工具,您需要执行以下步骤:
- 将
textcat组件添加到现有管道中。- 向
textcat组件添加有效标签。- 加载、洗牌和分割数据。
- 训练模型,评估每个训练循环。
- 使用训练好的模型来预测非训练数据的情感。
- 或者,保存已训练的模型。
注意:你可以在空间文档示例中看到这些步骤的实现。这是在 spaCy 中对文本进行分类的主要方法,因此您会注意到项目代码大量来自这个示例。
在下一节中,您将学习如何通过构建自己的项目将所有这些部分组合在一起:一个电影评论情感分析器。
构建自己的 NLP 情感分析器
从前面的章节中,您可能已经注意到了构建情感分析管道的四个主要阶段:
- 加载数据
- 预处理
- 训练分类器
- 分类数据
为了构建一个现实生活中的情感分析器,您将完成组成这些阶段的每个步骤。你将使用由安德鲁·马斯编辑的大型电影评论数据集来训练和测试你的情感分析器。准备好之后,继续下一部分加载数据。
加载和预处理数据
如果您还没有,请下载并提取大型电影评论数据集。花几分钟时间四处探索,看看它的结构,并对一些数据进行采样。这将告诉你如何加载数据。对于这一部分,你将使用 spaCy 的
textcat例子作为粗略的指南。您可以(也应该)将加载阶段分解成具体的步骤来帮助规划您的编码。这里有一个例子:
- 从文件和目录结构中加载文本和标签。
- 打乱数据。
- 将数据分成训练集和测试集。
- 返回两组数据。
这个过程是比较自成体系的,所以至少应该是自己的功能。在考虑该函数将执行的操作时,您可能已经想到了一些可能的参数。
因为您正在分割数据,控制这些分割的大小的能力可能是有用的,所以
split是一个很好的包含参数。您可能还希望用一个limit参数来限制您处理的文档总量。您可以打开您最喜欢的编辑器并添加这个函数签名:def load_training_data( data_directory: str = "aclImdb/train", split: float = 0.8, limit: int = 0 ) -> tuple:有了这个签名,你就可以利用 Python 3 的类型注释来明确你的函数需要什么类型以及它将返回什么。
此处的参数允许您定义存储数据的目录以及训练数据与测试数据的比率。一个好的开始比例是 80%的数据用于训练数据,20%的数据用于测试数据。除非另有说明,所有这些代码和下面的代码都应该在同一个文件中。
接下来,您需要遍历该数据集中的所有文件,并将它们加载到一个列表中:
import os def load_training_data( data_directory: str = "aclImdb/train", split: float = 0.8, limit: int = 0 ) -> tuple: # Load from files reviews = [] for label in ["pos", "neg"]: labeled_directory = f"{data_directory}/{label}" for review in os.listdir(labeled_directory): if review.endswith(".txt"): with open(f"{labeled_directory}/{review}") as f: text = f.read() text = text.replace("<br />", "\n\n") if text.strip(): spacy_label = { "cats": { "pos": "pos" == label, "neg": "neg" == label } } reviews.append((text, spacy_label))虽然这看起来很复杂,但是您正在做的是构建数据的目录结构,查找并打开文本文件,然后将一个内容元组和一个标签字典追加到
reviews列表中。标签字典结构是 spaCy 模型在训练循环中需要的一种格式,您很快就会看到这一点。
注意:在本教程和您的 Python 之旅中,您将成为读写文件的。这是一项需要掌握的基本技能,所以在学习本教程时,请务必复习一下。
因为此时您已经打开了每个评论,所以用换行符替换文本中的
<br />HTML 标签并使用.strip()删除所有前导和尾随空格是一个好主意。对于这个项目,您不会立即从训练数据中删除停用词,因为它可能会改变句子或短语的含义,从而降低分类器的预测能力。这在一定程度上取决于您使用的停用词表。
加载完文件后,你想打乱它们。这有助于消除加载训练数据的顺序中任何可能的偏差。由于
random模块使这一点在一行中很容易做到,您还将看到如何分割混洗的数据:import os import random def load_training_data( data_directory: str = "aclImdb/train", split: float = 0.8, limit: int = 0 ) -> tuple: # Load from files reviews = [] for label in ["pos", "neg"]: labeled_directory = f"{data_directory}/{label}" for review in os.listdir(labeled_directory): if review.endswith(".txt"): with open(f"{labeled_directory}/{review}") as f: text = f.read() text = text.replace("<br />", "\n\n") if text.strip(): spacy_label = { "cats": { "pos": "pos" == label, "neg": "neg" == label} } reviews.append((text, spacy_label)) random.shuffle(reviews) if limit: reviews = reviews[:limit] split = int(len(reviews) * split) return reviews[:split], reviews[split:]在这里,您通过调用
random.shuffle()来混洗数据。然后,您可以选择使用某种数学方法截断和拆分数据,将拆分转换为定义拆分边界的多个项目。最后,您使用列表片返回reviews列表的两个部分。以下是一个示例输出,为了简洁起见,进行了截断:
( 'When tradition dictates that an artist must pass (...)', {'cats': {'pos': True, 'neg': False}} )要了解更多关于
random如何工作的信息,请看一下用 Python 生成随机数据(指南)。注意:spaCy 的制造商也发布了一个名为
thinc的包,除了其他功能外,它还包括对大型数据集的简化访问,包括您在这个项目中使用的 IMDB review 数据集。你可以在 GitHub 上找到项目。如果您对其进行研究,请查看他们如何处理 IMDB 数据集的加载,并了解他们的代码与您自己的代码之间存在哪些重叠。
既然您已经构建了数据加载器并做了一些简单的预处理,那么是时候构建空间管道和分类器训练循环了。
训练您的分类器
将 spaCy 管道放在一起,可以让您快速构建和训练一个用于分类文本数据的卷积神经网络 (CNN)。当你在这里使用它进行情感分析时,只要你给它提供训练数据和标签,它就足够通用于任何种类的文本分类任务。
在项目的这一部分,您将负责三个步骤:
- 修改基础空间管线以包含
textcat组件- 构建一个训练循环来训练
textcat组件- 在给定数量的训练循环后评估模型训练的进度
首先,您将把
textcat添加到默认的空间管道中。修改空间管道以包括
textcat对于第一部分,您将加载与本教程开始时的例子中相同的管道,然后添加
textcat组件(如果它还不存在的话)。之后,您将把数据使用的标签("pos"表示正数,"neg"表示负数)添加到textcat。完成后,您就可以开始构建培训循环了:import os import random import spacy def train_model( training_data: list, test_data: list, iterations: int = 20 ) -> None: # Build pipeline nlp = spacy.load("en_core_web_sm") if "textcat" not in nlp.pipe_names: textcat = nlp.create_pipe( "textcat", config={"architecture": "simple_cnn"} ) nlp.add_pipe(textcat, last=True)如果你已经看过 spaCy 文档的
textcat例子,那么这个应该看起来很熟悉。首先,加载内置的en_core_web_sm管道,然后检查.pipe_names属性,查看textcat组件是否已经可用。如果不是,那么您创建带有
.create_pipe()的组件(也称为管道,并传入一个配置字典。在TextCategorizer文档中描述了一些你可以使用的选项。最后,使用
.add_pipe()将组件添加到管道中,使用last参数表示该组件应该添加到管道的末尾。接下来,您将处理存在
textcat组件的情况,然后添加标签作为文本的类别:import os import random import spacy def train_model( training_data: list, test_data: list, iterations: int = 20 ) -> None: # Build pipeline nlp = spacy.load("en_core_web_sm") if "textcat" not in nlp.pipe_names: textcat = nlp.create_pipe( "textcat", config={"architecture": "simple_cnn"} ) nlp.add_pipe(textcat, last=True) else: textcat = nlp.get_pipe("textcat") textcat.add_label("pos") textcat.add_label("neg")如果组件出现在加载的管道中,那么您只需使用
.get_pipe()将它赋给一个变量,这样您就可以对它进行操作。对于这个项目,你要做的就是从你的数据中添加标签,这样textcat就知道要寻找什么了。你会和.add_label()一起这么做。您已经创建了管道,并为标签准备了
textcat组件,它将用于训练。现在是时候编写训练循环了,它将允许textcat对电影评论进行分类。建立你的训练循环来训练
textcat为了开始训练循环,您将首先设置您的管道只训练
textcat组件,使用 spaCy 的minibatch()和compounding()实用程序为它生成批数据,然后遍历它们并更新您的模型。一个批次只是你的数据的一个子集。批处理数据可以减少训练过程中的内存占用,并更快地更新超参数。
注意:混合批量大小是一项相对较新的技术,应该有助于加快培训。你可以在 spaCy 的培训提示中了解更多关于混合批量的信息。
下面是上述训练循环的实现:
1import os 2import random 3import spacy 4from spacy.util import minibatch, compounding 5 6def train_model( 7 training_data: list, 8 test_data: list, 9 iterations: int = 20 10) -> None: 11 # Build pipeline 12 nlp = spacy.load("en_core_web_sm") 13 if "textcat" not in nlp.pipe_names: 14 textcat = nlp.create_pipe( 15 "textcat", config={"architecture": "simple_cnn"} 16 ) 17 nlp.add_pipe(textcat, last=True) 18 else: 19 textcat = nlp.get_pipe("textcat") 20 21 textcat.add_label("pos") 22 textcat.add_label("neg") 23 24 # Train only textcat 25 training_excluded_pipes = [ 26 pipe for pipe in nlp.pipe_names if pipe != "textcat" 27 ]在第 25 到 27 行,您创建了管道中除了
textcat组件之外的所有组件的列表。然后,使用nlp.disable()上下文管理器为上下文管理器范围内的所有代码禁用这些组件。现在您已经准备好添加代码来开始训练了:
import os import random import spacy from spacy.util import minibatch, compounding def train_model( training_data: list, test_data: list, iterations: int = 20 ) -> None: # Build pipeline nlp = spacy.load("en_core_web_sm") if "textcat" not in nlp.pipe_names: textcat = nlp.create_pipe( "textcat", config={"architecture": "simple_cnn"} ) nlp.add_pipe(textcat, last=True) else: textcat = nlp.get_pipe("textcat") textcat.add_label("pos") textcat.add_label("neg") # Train only textcat training_excluded_pipes = [ pipe for pipe in nlp.pipe_names if pipe != "textcat" ] with nlp.disable_pipes(training_excluded_pipes): optimizer = nlp.begin_training() # Training loop print("Beginning training") batch_sizes = compounding( 4.0, 32.0, 1.001 ) # A generator that yields infinite series of input numbers这里,您调用
nlp.begin_training(),它返回初始优化器函数。这是nlp.update()将用来更新底层模型的权重。然后使用
compounding()实用程序创建一个生成器,给你一个无限系列的batch_sizes,供minibatch()实用程序稍后使用。现在,您将开始对批量数据进行训练:
import os import random import spacy from spacy.util import minibatch, compounding def train_model( training_data: list, test_data: list, iterations: int = 20 ) -> None: # Build pipeline nlp = spacy.load("en_core_web_sm") if "textcat" not in nlp.pipe_names: textcat = nlp.create_pipe( "textcat", config={"architecture": "simple_cnn"} ) nlp.add_pipe(textcat, last=True) else: textcat = nlp.get_pipe("textcat") textcat.add_label("pos") textcat.add_label("neg") # Train only textcat training_excluded_pipes = [ pipe for pipe in nlp.pipe_names if pipe != "textcat" ] with nlp.disable_pipes(training_excluded_pipes): optimizer = nlp.begin_training() # Training loop print("Beginning training") batch_sizes = compounding( 4.0, 32.0, 1.001 ) # A generator that yields infinite series of input numbers for i in range(iterations): loss = {} random.shuffle(training_data) batches = minibatch(training_data, size=batch_sizes) for batch in batches: text, labels = zip(*batch) nlp.update( text, labels, drop=0.2, sgd=optimizer, losses=loss )现在,对于在
train_model()签名中指定的每个迭代,您创建一个名为loss的空字典,它将由nlp.update()更新和使用。您还可以利用minibatch()打乱训练数据,并将其分成不同大小的批次。对于每一批,你分离文本和标签,然后输入它们,空的
loss字典,和optimizer到nlp.update()。这将对每个示例进行实际的训练。
dropout参数告诉nlp.update()该批训练数据中要跳过的比例。这样做是为了让模型更难意外地记住训练数据,而没有提出一个可概括的模型。这需要一些时间,所以定期评估你的模型是很重要的。您将使用从训练集中保留的数据来完成这项工作,该训练集也称为维持集。
评估模型训练的进度
因为你要做许多评估,每个评估都有许多计算,所以写一个单独的
evaluate_model()函数是有意义的。在这个函数中,您将针对未完成的模型运行测试集中的文档,以获得模型的预测,然后将它们与该数据的正确标签进行比较。使用该信息,您将计算以下值:
真阳性是您的模型正确预测为阳性的文档。对于这个项目,这映射到积极的情绪,但在二元分类任务中推广到你试图识别的类别。
假阳性是您的模型错误地预测为阳性但实际上是阴性的文档。
真否定是您的模型正确预测为否定的文档。
假阴性是您的模型错误地预测为阴性但实际上为阳性的文档。
因为您的模型将为每个标签返回一个介于 0 和 1 之间的分数,所以您将基于该分数确定一个肯定或否定的结果。根据上述四个统计数据,您将计算精度和召回率,这是分类模型性能的常用度量:
Precision 是真阳性与您的模型标记为阳性的所有项目的比率(真和假阳性)。精度为 1.0 意味着您的模型标记为正面的每个评论都属于正面类。
召回是真阳性与所有实际上阳性的评论的比率,或者是真阳性的数量除以真阳性和假阴性的总数。
F 值是另一个流行的准确性指标,尤其是在 NLP 领域。解释它可能需要自己的文章,但是您将在代码中看到计算。与精确度和召回率一样,分数范围从 0 到 1,1 表示最高性能,0 表示最低性能。
对于
evaluate_model(),您需要传入管道的tokenizer组件、textcat组件和您的测试数据集:def evaluate_model( tokenizer, textcat, test_data: list ) -> dict: reviews, labels = zip(*test_data) reviews = (tokenizer(review) for review in reviews) true_positives = 0 false_positives = 1e-8 # Can't be 0 because of presence in denominator true_negatives = 0 false_negatives = 1e-8 for i, review in enumerate(textcat.pipe(reviews)): true_label = labels[i] for predicted_label, score in review.cats.items(): # Every cats dictionary includes both labels. You can get all # the info you need with just the pos label. if ( predicted_label == "neg" ): continue if score >= 0.5 and true_label["pos"]: true_positives += 1 elif score >= 0.5 and true_label["neg"]: false_positives += 1 elif score < 0.5 and true_label["neg"]: true_negatives += 1 elif score < 0.5 and true_label["pos"]: false_negatives += 1 precision = true_positives / (true_positives + false_positives) recall = true_positives / (true_positives + false_negatives) if precision + recall == 0: f_score = 0 else: f_score = 2 * (precision * recall) / (precision + recall) return {"precision": precision, "recall": recall, "f-score": f_score}在这个函数中,您将评论和它们的标签分开,然后使用一个生成器表达式来标记您的每个评估评论,准备将它们传递给
textcat。生成器表达式是 spaCy 文档中推荐的一个很好的技巧,它允许你遍历你的标记化评论,而不用把它们都保存在内存中。然后使用
score和true_label来确定真或假阳性以及真或假阴性。然后,您使用这些来计算精确度、召回率和 f 值。现在剩下的就是给evaluate_model()打电话了:def train_model(training_data: list, test_data: list, iterations: int = 20): # Previously seen code omitted for brevity. # Training loop print("Beginning training") print("Loss\tPrecision\tRecall\tF-score") batch_sizes = compounding( 4.0, 32.0, 1.001 ) # A generator that yields infinite series of input numbers for i in range(iterations): loss = {} random.shuffle(training_data) batches = minibatch(training_data, size=batch_sizes) for batch in batches: text, labels = zip(*batch) nlp.update( text, labels, drop=0.2, sgd=optimizer, losses=loss ) with textcat.model.use_params(optimizer.averages): evaluation_results = evaluate_model( tokenizer=nlp.tokenizer, textcat=textcat, test_data=test_data ) print( f"{loss['textcat']}\t{evaluation_results['precision']}" f"\t{evaluation_results['recall']}" f"\t{evaluation_results['f-score']}" )这里您添加了一个打印语句来帮助组织来自
evaluate_model()的输出,然后用.use_params()上下文管理器调用它,以便在当前状态下使用模型。然后你给evaluate_model()打电话并打印结果。训练过程完成后,最好保存刚刚训练的模型,以便在不训练新模型的情况下再次使用它。在您的训练循环之后,添加此代码以将训练好的模型保存到位于您的工作目录中名为
model_artifacts的目录中:# Save model with nlp.use_params(optimizer.averages): nlp.to_disk("model_artifacts")这个代码片段将您的模型保存到一个名为
model_artifacts的目录中,这样您就可以在不重新训练模型的情况下进行调整。最终的训练函数应该是这样的:def train_model( training_data: list, test_data: list, iterations: int = 20 ) -> None: # Build pipeline nlp = spacy.load("en_core_web_sm") if "textcat" not in nlp.pipe_names: textcat = nlp.create_pipe( "textcat", config={"architecture": "simple_cnn"} ) nlp.add_pipe(textcat, last=True) else: textcat = nlp.get_pipe("textcat") textcat.add_label("pos") textcat.add_label("neg") # Train only textcat training_excluded_pipes = [ pipe for pipe in nlp.pipe_names if pipe != "textcat" ] with nlp.disable_pipes(training_excluded_pipes): optimizer = nlp.begin_training() # Training loop print("Beginning training") print("Loss\tPrecision\tRecall\tF-score") batch_sizes = compounding( 4.0, 32.0, 1.001 ) # A generator that yields infinite series of input numbers for i in range(iterations): print(f"Training iteration {i}") loss = {} random.shuffle(training_data) batches = minibatch(training_data, size=batch_sizes) for batch in batches: text, labels = zip(*batch) nlp.update(text, labels, drop=0.2, sgd=optimizer, losses=loss) with textcat.model.use_params(optimizer.averages): evaluation_results = evaluate_model( tokenizer=nlp.tokenizer, textcat=textcat, test_data=test_data ) print( f"{loss['textcat']}\t{evaluation_results['precision']}" f"\t{evaluation_results['recall']}" f"\t{evaluation_results['f-score']}" ) # Save model with nlp.use_params(optimizer.averages): nlp.to_disk("model_artifacts")在本节中,您学习了如何训练模型并在训练时评估其性能。然后,您构建了一个根据输入数据训练分类模型的函数。
对评论进行分类
现在你有了一个训练好的模型,是时候用一个真实的评论来测试它了。出于这个项目的目的,您将硬编码一个评论,但是您当然应该尝试通过从其他来源读取评论来扩展这个项目,例如文件或评论聚合器的 API。
这个新功能的第一步是加载之前保存的模型。虽然您可以使用内存中的模型,但是加载保存的模型工件允许您有选择地完全跳过训练,稍后您将看到这一点。下面是
test_model()签名以及加载您保存的模型的代码:def test_model(input_data: str=TEST_REVIEW): # Load saved trained model loaded_model = spacy.load("model_artifacts")在这段代码中,您定义了
test_model(),它包含了input_data参数。然后加载之前保存的模型。您正在处理的 IMDB 数据包括训练数据目录中的一个
unsup目录,其中包含您可以用来测试您的模型的未标记的评论。这里有一篇这样的评论。您应该将它(或您选择的另一个)保存在文件顶部的一个TEST_REVIEW常量中:import os import random import spacy from spacy.util import minibatch, compounding TEST_REVIEW = """ Transcendently beautiful in moments outside the office, it seems almost sitcom-like in those scenes. When Toni Colette walks out and ponders life silently, it's gorgeous.<br /><br />The movie doesn't seem to decide whether it's slapstick, farce, magical realism, or drama, but the best of it doesn't matter. (The worst is sort of tedious - like Office Space with less humor.) """接下来,您将把这个检查传递到您的模型中以生成一个预测,为显示做准备,然后向用户显示它:
def test_model(input_data: str = TEST_REVIEW): # Load saved trained model loaded_model = spacy.load("model_artifacts") # Generate prediction parsed_text = loaded_model(input_data) # Determine prediction to return if parsed_text.cats["pos"] > parsed_text.cats["neg"]: prediction = "Positive" score = parsed_text.cats["pos"] else: prediction = "Negative" score = parsed_text.cats["neg"] print( f"Review text: {input_data}\nPredicted sentiment: {prediction}" f"\tScore: {score}" )在这段代码中,您将您的
input_data传递到您的loaded_model,这将在parsed_text变量的cats属性中生成一个预测。然后你检查每种情绪的分数,并将最高的分数保存在prediction变量中。然后,您将该情绪的分数保存到
score变量中。这将更容易创建人类可读的输出,这是该函数的最后一行。现在,您已经编写了
load_data()、train_model()、evaluate_model()和test_model()函数。这意味着是时候把它们放在一起,训练你的第一个模型了。连接管道
到目前为止,您已经构建了许多独立的函数,这些函数合在一起将加载数据,并训练、评估、保存和测试 Python 中的情感分析分类器。
让这些函数可用还有最后一步,那就是在脚本运行时调用它们。您将使用
if __name__ == "__main__":习语来完成这个任务:if __name__ == "__main__": train, test = load_training_data(limit=2500) train_model(train, test) print("Testing model") test_model()在这里,您使用您在加载和预处理数据部分编写的函数加载您的训练数据,并限制用于
2500总计的评论数量。然后你使用你在训练你的分类器中写的train_model()函数训练模型,一旦完成,你调用test_model()来测试你的模型的性能。注意:根据训练示例的数量,训练可能需要十分钟或更长时间,具体取决于您的系统。您可以减少训练集的大小以缩短训练时间,但是您可能会有模型不太准确的风险。
你的模型预测了什么?你同意这个结果吗?如果在加载数据时增加或减少
limit参数会发生什么?您的分数甚至您的预测可能会有所不同,但是您应该期望您的输出是这样的:$ python pipeline.py Training model Beginning training Loss Precision Recall F-score 11.293997120810673 0.7816593886121546 0.7584745762390477 0.7698924730851658 1.979159922178951 0.8083333332996527 0.8220338982702527 0.8151260503859189 [...] 0.000415042785704145 0.7926829267970453 0.8262711864056664 0.8091286306718204 Testing model Review text: Transcendently beautiful in moments outside the office, it seems almost sitcom-like in those scenes. When Toni Colette walks out and ponders life silently, it's gorgeous.<br /><br />The movie doesn't seem to decide whether it's slapstick, farce, magical realism, or drama, but the best of it doesn't matter. (The worst is sort of tedious - like Office Space with less humor.) Predicted sentiment: Positive Score: 0.8773064017295837当您的模型训练时,您将看到丢失、精度和召回的度量以及每个训练迭代的 F 分数。你应该会看到损失普遍减少。精确度、召回率和 F 值都会反弹,但理想情况下它们会增加。然后你会看到考试复习,情绪预测,以及那个预测的分数——越高越好。
您现在已经使用 spaCy 的自然语言处理技术和神经网络训练了您的第一个情感分析机器学习模型!这里有两个图表显示了模型在二十次训练迭代中的表现。第一个图表显示了损失在训练过程中的变化:
虽然上图显示了一段时间内的损失,但下图绘制了同一训练期间的精确度、召回率和 F 分数:
在这些图表中,您可以看到损失开始很高,但在训练迭代中下降很快。在最初的几次训练迭代之后,精确度、召回率和 F 值相当稳定。你能做些什么来改善这些价值观呢?
结论
恭喜你用 Python 构建了你的第一个情感分析模型!你觉得这个项目怎么样?你不仅构建了一个有用的数据分析工具,还掌握了许多自然语言处理和机器学习的基本概念。
在本教程中,您学习了如何:
- 使用自然语言处理技术
- 使用机器学习分类器来确定处理后的文本数据的情感
- 使用 spaCy 构建您自己的 NLP 管道
你现在有了基本的工具包来构建更多的模型来回答你可能有的任何研究问题。如果您想回顾一下您所学的内容,那么您可以从下面的链接下载并试验本教程中使用的代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习自然语言处理中的情感分析。
这个项目你还能做什么?以下是一些建议。
情绪分析和 Python 的后续步骤
这是一个核心项目,根据您的兴趣,您可以围绕它构建许多功能。这里有一些想法可以让你开始扩展这个项目:
在
load_data()期间,数据加载过程将每个检查加载到内存中。你能通过使用生成器函数来提高内存效率吗?重写您的代码以在预处理或数据加载过程中删除停止字。模式性能如何变化?您能把这种预处理合并到管道组件中吗?
使用点击等工具生成交互式命令行界面。
将你的模型部署到像 AWS 这样的云平台上,并为其连接一个 API。这可以构成基于网络的工具的基础。
探索
textcat管道组件的配置参数,并试验不同的配置。探索不同的方式传递新的评论以生成预测。
将选项参数化,如保存和加载已训练模型的位置,是否跳过训练或训练新模型,等等。
这个项目使用大型电影评论数据集,由安德鲁·马斯维护。感谢 Andrew 让这个精选的数据集被广泛使用。*******
设置简单的 OCR 服务器
以下是博比·格雷森,一位 Ahalogy 的软件开发人员和真正的 Python 之间的合作片段。
为什么要用 Python 做 OCR?
OCR (光学字符识别)已经成为一种常见的 Python 工具。随着像宇宙魔方和 Ocrad 这样的库的出现,越来越多的开发者正在构建以新颖有趣的方式使用 OCR 的库和机器人。一个简单的例子是一个基本的 OCR 工具,用于从屏幕截图中提取文本,这样您就不必稍后重新键入文本。
开始步骤
我们将从开发 Flask 后端层开始,为 OCR 引擎的结果服务。从那里,您可以点击终端,并以适合您的方式将结果提供给最终用户。本教程将详细介绍所有这些内容。我们还将添加一些后端代码来生成 HTML 表单,以及前端代码来消费 API 。本教程将不会涉及这一点,但是您可以访问代码。
我们开始吧。
首先,我们必须安装一些依赖项。一如既往,配置您的环境是 90%的乐趣。
这篇文章已经在 Ubuntu 版本上进行了测试,但它应该也适用于 12.x 和 13.x 版本。如果你运行的是 OSX,你可以使用 VirtualBox 、 Docker (查看Docker 文件以及安装指南)或 DigitalOcean 上的 droplet(推荐!)来创造适当的环境。
下载依赖关系
我们需要宇宙魔方及其所有的依赖项,包括莱普尼卡,以及其他一些支持这两个包的包,以便开始健全性检查。
注意:您也可以使用 _run.sh shell 脚本来快速安装依赖项以及 Leptonica 和 Tesseract。如果你走这条路,跳到网络服务器时间!一节。但是如果您以前没有这样做过,请考虑手工构建这些库(出于学习目的)。
$ sudo apt-get update $ sudo apt-get install autoconf automake libtool $ sudo apt-get install libpng12-dev $ sudo apt-get install libjpeg62-dev $ sudo apt-get install g++ $ sudo apt-get install libtiff4-dev $ sudo apt-get install libopencv-dev libtesseract-dev $ sudo apt-get install git $ sudo apt-get install cmake $ sudo apt-get install build-essential $ sudo apt-get install libleptonica-dev $ sudo apt-get install liblog4cplus-dev $ sudo apt-get install libcurl3-dev $ sudo apt-get install python2.7-dev $ sudo apt-get install tk8.5 tcl8.5 tk8.5-dev tcl8.5-dev $ sudo apt-get build-dep python-imaging --fix-missing发生什么事了?
简单地说,
sudo apt-get update是“确保我们有最新的包列表”的缩写。然后我们抓取了一些允许我们摆弄图像的库——比如libtiff、libpng等等。除此之外,我们使用我们选择的编程语言Python 2.7,以及与所有这些部分交互的python-imaging库。说到图像,如果我们想在以编程方式将图像放入之前摆弄(编辑)它们,我们还需要 ImageMagick 。
$ sudo apt-get install imagemagick建造莱普尼卡和宇宙魔方
同样,如果您运行了 shell 脚本,那么它们已经安装好了,所以请继续执行 Web 服务器时间!章节
百日咳〔t0〕
现在,终于轮到莱普妮卡了!
$ wget http://www.leptonica.org/source/leptonica-1.70.tar.gz $ tar -zxvf leptonica-1.70.tar.gz $ cd leptonica-1.70/ $ ./autobuild $ ./configure $ make $ sudo make install $ sudo ldconfig如果这是你第一次玩 tar ,下面是发生的事情:
- 获取 Leptonica 的二进制文件(通过
wget)- 拉开 tarball
cd放入新解压的目录- 运行
autobuild和configurebash 脚本来设置应用程序- 使用
make来构建它- 构建完成后用
make安装- 用
ldconfig创建必要的链接嘣!现在我们有了莱普尼卡。去宇宙魔方!
宇宙魔方
现在下载并构建宇宙魔方…
$ cd .. $ wget https://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.02.tar.gz $ tar -zxvf tesseract-ocr-3.02.02.tar.gz $ cd tesseract-ocr/ $ ./autogen.sh $ ./configure $ make $ sudo make install $ sudo ldconfig这里的过程几乎完全模仿了莱普尼卡的过程。所以为了保持干燥,请参阅 Leptonica 的解释以获取更多信息。
环境变量
我们需要设置一个环境变量来获取我们的宇宙魔方数据:
$ export TESSDATA_PREFIX=/usr/local/share/宇宙魔方包
最后,让我们看看相关的 Tesseract 英语语言包:
$ cd .. $ wget https://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.eng.tar.gz $ tar -xf tesseract-ocr-3.02.eng.tar.gz $ sudo cp -r tesseract-ocr/tessdata $TESSDATA_PREFIX嘣!我们现在有了宇宙魔方。我们可以使用 CLI 来测试。如果你想玩,请随意阅读文档。然而,我们需要一个 Python 包装器来真正实现我们的最终目标。所以下一步是建立一个 Flask 服务器和一个接受 POST 请求的基本 API:
- 接受图像 URL
- 对图像运行字符识别
网络服务器时间!
现在,开始有趣的事情。首先,我们需要构建一种通过 Python 与 Tesseract 交互的方法。我们可以使用
popen,但这感觉是错误的/不和谐的。相反,我们可以使用一个非常简单但功能强大的 Python 包来包装 Tesseract - pytesseract 。想快速上手?运行 _app.sh shell 脚本。或者您可以通过抓取样板代码/结构这里然后运行以下命令来手动设置应用程序:
$ wget https://github.com/rhgraysonii/ocr_tutorial/archive/v0.tar.gz $ tar -xf v0.tar.gz $ mv ocr_tutorial-0/* ../home/ $ cd ../home $ sudo apt-get install python-virtualenv $ virtualenv env $ source env/bin/activate $ pip install -r requirements.txt注意:Flask 样板(由 Real Python 维护)是一个很棒的库,可以让一个简单的 Python 服务器运行。我们为我们的基本应用程序定制了这个。查看烧瓶样本库了解更多信息。
让我们做一个 OCR 引擎
现在,我们需要使用 pytesseract 创建一个类来接收和读取图像。在“flask_server”目录中创建一个名为 ocr.py 的新文件,并添加以下代码:
import pytesseract import requests from PIL import Image from PIL import ImageFilter from StringIO import StringIO def process_image(url): image = _get_image(url) image.filter(ImageFilter.SHARPEN) return pytesseract.image_to_string(image) def _get_image(url): return Image.open(StringIO(requests.get(url).content))精彩!
因此,在我们的主要方法
process_image()中,我们锐化图像来锐化文本。太棒了。一个可以玩的工作模块。
可选:为您的新 OCR 引擎构建 CLI 工具
制作一个 CLI 是一个很好的概念验证,也是做了这么多配置后的一个有趣的喘息。所以让我们试着做一个。在“flask_server”中创建一个名为 cli.py 的新文件,然后添加以下代码:
import sys import requests import pytesseract from PIL import Image from StringIO import StringIO def get_image(url): return Image.open(StringIO(requests.get(url).content)) if __name__ == '__main__': """Tool to test the raw output of pytesseract with a given input URL""" sys.stdout.write(""" ===OOOO=====CCCCC===RRRRRR=====\n ==OO==OO===CC=======RR===RR====\n ==OO==OO===CC=======RR===RR====\n ==OO==OO===CC=======RRRRRR=====\n ==OO==OO===CC=======RR==RR=====\n ==OO==OO===CC=======RR== RR====\n ===OOOO=====CCCCC===RR====RR===\n\n """) sys.stdout.write("A simple OCR utility\n") url = raw_input("What is the url of the image you would like to analyze?\n") image = get_image(url) sys.stdout.write("The raw output from tesseract with no processing is:\n\n") sys.stdout.write("-----------------BEGIN-----------------\n") sys.stdout.write(pytesseract.image_to_string(image) + "\n") sys.stdout.write("------------------END------------------\n")这真的很简单。我们逐行查看引擎输出的文本,并将其输出到 STDOUT。用几个图片 URL 来测试一下(
python flask_server/cli.py),或者玩一玩自己的 ascii 艺术。回到服务器
现在我们有了引擎,我们需要给自己一些输出!向 app.py 添加以下路线处理程序和查看功能:
@app.route('/v{}/ocr'.format(_VERSION), methods=["POST"]) def ocr(): try: url = request.json['image_url'] if 'jpg' in url: output = process_image(url) return jsonify({"output": output}) else: return jsonify({"error": "only .jpg files, please"}) except: return jsonify( {"error": "Did you mean to send: {'image_url': 'some_jpeg_url'}"} )确保更新导入:
import os import logging from logging import Formatter, FileHandler from flask import Flask, request, jsonify from ocr import process_image另外,添加 API 版本号:
_VERSION = 1 # API version现在,如你所见,我们只是添加了引擎的
process_image()方法的 JSON 响应,使用来自 PIL 的Image将它传递到一个文件对象中进行安装。是的,就目前而言,这个功能只适用于。jpg 图片。注意:你不会安装
PIL本身;这从Pillow开始,允许我们做同样的事情。这是因为 PIL 图书馆曾经被分叉,变成了Pillow。社区对这件事有强烈的意见。咨询谷歌的洞察力-和戏剧。我们来测试一下!
运行您的应用程序:
$ cd ../home/flask_server/ $ python app.py然后在另一个终端选项卡运行中:
$ curl -X POST http://localhost:5000/v1/ocr -d '{"image_url": "some_url"}' -H "Content-Type: application/json"示例
$ curl -X POST http://localhost:5000/v1/ocr -d '{"image_url": "https://realpython.cimg/blog_images/ocr/ocr.jpg"}' -H "Content-Type: application/json" { "output": "ABCDE\nFGH I J\nKLMNO\nPQRST" }前端
随着后端 API 和 OCR 引擎的完成,我们现在可以添加一个基本的前端来使用 API,并通过 AJAX 和 jQuery 将结果添加到 DOM 中。同样,这不在本教程的讨论范围内,但是您可以从库中获取代码。
用一些示例图像来测试这一点:
结论和后续步骤
希望你喜欢这个教程。从库中获取这里的最终代码。哦——如果你觉得这个代码/教程有用,请启动回购。干杯!
黑客快乐!****
为全栈 Python 开发设置 Sublime Text 3
原文:https://realpython.com/setting-up-sublime-text-3-for-full-stack-python-development/
Sublime Text 3 (ST3)是一个轻量级的跨平台代码编辑器,以其速度快、易于使用和强大的社区支持而闻名。这是一个开箱即用的令人难以置信的编辑器,但真正的力量来自于使用包控制和创建自定义设置来增强其功能的能力。
在本文中,我们将了解如何为全栈 Python 开发(从前到后)设置 Sublime Text,使用自定义主题和包增强基本功能,并使用许多使 ST3 如此强大的命令、特性和关键字快捷方式。
注意:本教程假设您使用的是 Mac,并且对终端很熟悉。如果您使用的是 Windows 或 Linux,许多命令会有所不同,但是您应该能够使用 Google 根据本教程中的信息快速找到答案。
在我们开始之前,让我们来解释一下我所说的“全栈”到底是什么意思
在当今 HTML5 和移动开发的世界中,JavaScript 无处不在。到处都是。Python 加上一个框架如 Django 或 Flask 是不够的。要真正开发一个端到端的网站,你必须熟悉 JavaScript(以及各种 JavaScript 框架)、REST APIs、响应式设计,当然还有 HTML 和 CSS 等等。
让我们面对现实吧:作为一名程序员,你和其他工匠一样。如果你想成为最好的你,那么你需要你的工具是锋利的。您的开发环境必须设置为全栈开发——这正是我们现在要做的。
免费奖励: 5 个崇高的文本调整,以提高您的 Python 生产力,这是一个免费的电子邮件类,向您展示如何优化您的 Python +崇高的开发设置,以实现最高效率。
特征
让我们先来看看 Sublime Text 3 的几个默认特性:
分割布局允许你在不同的分割屏幕上排列你的文件。这在您进行测试驱动开发(Python 代码在一个屏幕上,测试脚本在另一个屏幕上)或在前端工作(HTML 在一个屏幕上,CSS 和/或 JavaScript 在另一个屏幕上)时非常有用。T3
T5
类似 Chrome 的标签页让浏览和编辑几个文件变得更加简单。
自动加载最后一个会话重新打开上次关闭编辑器时打开的所有文件和文件夹。我让 ST3 一直开着,各种项目都开着,所以如果我重启电脑,它会马上打开文件和文件夹。
代码片段让你能够用一个关键词创建普通的代码片段,从而提高你的工作效率。有许多默认的代码片段。要自己尝试一个,打开一个新文件,输入
lorem,按Tab。你应该得到一段 lorem ipsum 文本。同样,如果你在一个 Python 文件中输入defs,然后按下Tab,它将设置一个通用函数。定制崇高文本 3
下载 ST3 后,你可以自定义它。
安装
subl命令行工具就像 TextMate 有
mate命令一样,Sublime Text 有一个名为subl的命令行工具,允许你从终端打开一个文件,或者整个目录的文件和文件夹。要激活该命令,创建一个到
subl二进制文件的符号链接:$ sudo ln -s /Applications/Sublime\ Text.app/Contents/SharedSupport/bin/subl /usr/bin/subl通过打开 Sublime 确保链接正常工作:
$ subl如果这不起作用,您可能需要将
/bin添加到您的路径中:$ echo "export PATH=~/bin:$PATH" >> ~/.profile然后重复第一步。
注:如果你仍然有困难,请查看这篇文章寻求帮助。你也可以阅读关于在 Windows 和 Linux 中创建符号链接的内容。
现在,您可以使用以下命令打开文件或目录:
# Open the current directory. $ subl . # Open a directory called tests. $ subl ~/Documents/test # Open a file called text.txt. $ subl test.txt如果路径中有空格,必须用双引号将整个路径括起来:
$ subl "~/Documents/test/my test file.txt"要查看所有命令,请打开帮助文件:
$ subl --help安装包装控制
为了开始利用各种包来扩展 Sublime 的功能,您需要手动安装名为 Package Control 的包管理器。一旦您安装了它,您可以使用它来安装,删除和升级所有其他 ST3 软件包。
- 要安装,复制崇高文本 3 的 Python 代码找到这里。点击查看>显示控制台打开 ST3 控制台。将代码粘贴到控制台中。按下
Enter。重启 ST3。- 你现在可以使用快捷键
Cmd+Shift+P来安装软件包。开始输入install,直到Package Control: Install Package出现。按下Enter并搜索可用的软件包。以下是一些其他相关命令:
List Packages显示您所有已安装的软件包。Remove Package删除特定的包。Upgrade Package升级特定的软件包。- 升级您所有已安装的软件包。
查看官方文档查看更多命令。
创建自定义设置文件
您可以使用基于 JSON 的设置文件完全配置 Sublime Text,因此很容易将您的自定义设置传输或同步到另一个系统。首先,我们需要创建自定义设置。最好为所有环境创建一个基础文件以及特定语言的设置文件。
要设置基本文件,请单击升华文本>首选项>设置-用户。向文件中添加一个空的 JSON 对象,并添加您的设置,如下所示:
{ // base settings "auto_complete": false, "sublimelinter": false, "tab_size": 2, "word_wrap": true }
- 对于特定语言设置,单击升华文本>首选项>设置-更多>语法特定-用户。然后使用以下格式保存文件:language . sublime-settings。对于 Python 特定的设置,将文件保存为 Python.sublime-settings 。
- 显然,您可以根据自己的喜好配置设置。然而,我强烈推荐从我的基础和 Python 特有的设置开始,然后做你认为合适的改变。
- 可选:您可以使用 Dropbox 同步所有设置。只需将您的设置文件上传到 Dropbox 中,并从那里加载它们以同步您所有机器上的 Sublime 环境。
- 一个很好的设置参考可以在崇高文本非官方文件中找到。
主题
ST3 还让你选择改变整体主题,以更好地适应你的个性。自己设计。或者,如果你不喜欢艺术,你可以通过 Package Control 下载 Sublime 社区设计的各种自定义主题中的一个。在安装主题之前,请查看 ColorSublime 预览主题。
安装主题后,确保通过崇高文本>首选项>设置-用户更新您的基本设置:
{ "theme": "Flatland Dark.sublime-theme", "color_scheme": "Packages/Theme - Flatland/Flatland Dark.tmTheme" }包装
除了打包的主题之外,我还利用下面的包来加速我的工作流。
侧边增强功能
SideBarEnhancements 扩展了侧边栏中菜单选项的数量,加快了您的整体工作流程。像新文件和副本这样的选项是必不可少的,应该是 ST3 开箱即用的一部分。单单是删除选项就让它值得下载。这个特性只是将文件发送到回收站,这看起来似乎微不足道,但如果你删除了一个没有它的文件,那么就很难恢复,除非你使用的是版本控制系统。
立即下载!
蟒蛇
Anaconda 是最终的 Python 包。它为 ST3 添加了许多类似 IDE 的功能,包括:
- 自动补全默认工作,但是有许多配置选项。
- 代码林挺 使用 PyLint 或 PyFlakes 与 PEP 8。我个人使用一个不同的林挺包,我将很快解释,所以我在用户定义的 Anaconda 设置文件Anaconda . Sublime-Settings中完全禁用林挺,通过文件菜单:Sublime>Preferences>Package Settings>Anaconda>Settings-User:
{"anaconda_linting": false}- McCabe 代码复杂性检查器在特定文件中运行 McCabe 复杂性检查器工具。如果你不熟悉什么是复杂性,一定要访问上面的链接。
- Goto Definitions 查找并显示整个项目中任何变量、函数或类的定义。
- 查找用法快速搜索变量、函数或类在特定文件中的使用位置。
- 显示文档显示函数或类的文档串(当然,如果有定义的话)。
你可以在这里查看所有的功能或者在 ST3 套装设置的自述文件中:崇高文本>偏好设置>套装设置>蟒蛇>自述。
注意: SublimeCodeIntel 是另一个流行的软件包,它有许多与 Anaconda 相同的特性。我建议把它们都测试出来。
Djaneiro
Djaneiro 支持 Django 模板和关键词高亮显示,并为 Sublime 文本提供有用的代码片段(制表符补全)。snippet 系统是一个不可思议的省时工具。对于模板、模型、表单和视图,只需几次击键就可以创建通用的 Django 块。查看官方文档以查看片段列表。
我个人最喜欢的是模板:
var创建{{ }},tag创建{% %}。要求文本
requirementstxt 为您的 requirements.txt 文件提供自动补全和语法高亮显示以及一个不错的版本管理系统。
" T0 "级曲速调管风琴曲终人曲速调管风琴曲终人曲速调管风琴曲终人曲速调管风琴曲终人曲速调管风琴曲曲
SublimeLinter 是一个 ST3 棉绒的框架。包装本身不包括任何实际的棉绒;这些必须通过软件包控制使用SublimeLinter-[linter _ name]命名语法单独安装。你可以在这里查看官方贴吧。还有许多第三方棉绒,可以在包装控制中查看。点击查看安装说明。
对于 Python 林挺,我推荐使用 SublimeLinter-pyflakes 和 SublimeLinter-pep8 。
我也用 SublimeLinter-jshint 、 SublimeLinter-pyyaml 、 SublimeLinter-csslint 、 SublimeLinter-html-tidy 、 SublimeLinter-json 。
注意:这些 linters 大部分都有相关的依赖项,所以请在安装前阅读安装说明。
您可以在自定义的SublimeLinter . Sublime-Settings文件: Sublime Text >首选项>包设置> SublimeLinter >设置-用户中自定义每一条 linter。例如,我忽略了以下 PEP 8 错误和警告:
"pep8": { "@disable": false, "args": [], "excludes": [], "ignore": "E501,C0301,W0142,W0402,R0201,E1101,E1102,C0103,R0901,R0903,R0904,C1001,W0223,W0232,W0201,E1103,R0801,C0111", "max-line-length": 100, "select": "" },GitGutter
GitGutter 在 ST3 的 Gutter 区域显示小图标,指示自上次提交以来是否有行被插入、修改或删除。
注意:如果你想要支持许多分布式版本控制系统(Git、SVN、Bazaar 和 Mercurial),请查看 Modific 。
FTPSync
将你的项目与你的远程文件同步。只需打开文件进行下载(如果远程文件比本地文件新),并在每次保存时上传到远程服务器。这是保持本地和远程同步的好方法。您需要确保通过点击升华文本>首选项>包设置> FTPSync >设置 FTPSync 来添加至少一个远程连接。
示例设置:
{ "primary": { host: "ftp.mywebsite.com", username: "johnsmith", password: "secretpassword", path: "/www/", upload_on_save: true, tls: true } }我个人将密码设置为
null,因为我不想在那个文件中看到它。FTPSync 只是在每次保存后询问我的密码。高级新文件
AdvancedNewFile 用于在 ST3 内创建一个新的文件夹或文件,仅使用键绑定。
只需通过适当的键绑定调出 AdvancedNewFile 输入。然后,在输入字段中输入路径和文件名。按下
Enter,文件将被创建。此外,如果指定的目录尚不存在,将会创建它们。默认情况下,当您输入路径信息时,状态栏中将显示正在创建的文件的路径。有关其用法的更详细解释,请查看 GitHub 上的文档。请务必阅读制表符补全和预定义别名。
我替换了普通的
Cmd+N命令,通过向键绑定-用户文件添加以下代码来创建一个带有 AdvancedNewFile 的新文件:崇高文本>首选项>包设置>高级 NewFile >键绑定-用户:[ { "keys": ["cmd+n"], "command": "advanced_new_file_new"} ]你也可以设置一个默认目录开始:崇高文本>偏好设置>包设置>高级新文件>设置-用户
{"default_initial": "/Users/michaelherman/Documents/repos"}现在,当我创建一个新文件时,
/Users/michaelherman/Documents/repos字符串首先被自动插入,因为 99%的时间我都将所有脚本存储在该目录中。埃米特
Emmet ,原名 Zen Coding,使用简单的缩写生成 HTML 或 CSS 代码片段。
例如,如果在一个 HTML 文件中键入一个 bang,
!,并按下Tab,那么就会生成 HTML5 doctype 和一些基本的标签:<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> </body> </html>降价预览
降价预览用于预览和建立降价文件。
要使用,打开包管理器并键入
Markdown Preview来显示可用的命令:
- 降价预览:Python 降价:在浏览器中预览
- Markdown 预览:Python Markdown:在 Sublime 文本中导出 HTML
- 降价预览:Python 降价:复制到剪贴板
- 降价预览:GitHub 风格的降价:在浏览器中预览
- Markdown 预览:GitHub 风格的 Markdown:以崇高的文本导出 HTML
- 降价预览:GitHub 风格的降价:复制到剪贴板
- 降价预览:打开降价备忘单
转换后,输出文件将在每次后续保存时更新。
键盘快捷键
- Goto things
Cmd+P用于快速查找和打开文件。只需在项目中键入部分路径和文件名,就可以轻松打开该文件。这对于在大型 Django 项目中快速打开文件非常有用。- 转到行号
Ctrl+G带你到激活文件中的特定行号。- Goto 符号
Cmd+R列出了一个文件中的所有函数和类,以便于查找。只需开始输入您想要的。- 转到行首
Cmd+Left和转到行尾Cmd+Right帮助您在行内导航。- 删除当前行
Ctrl+Shift+K删除当前行。- 多重编辑是迄今为止我最喜欢的快捷方式:
- 选择一个单词,然后按
Cmd+D选择下一个相同的单词。然后再按Cmd+D再次选择下一个相同的单词,以此类推。- 按
Cmd+Left Button在你点击的任何地方创建一个用于编辑的光标。- 块选择
Option+Left Button用于选择一个文本块。它非常适合在格式化 CSV 文件时删除空白。注:更多快捷方式,看看这篇文章。
自定义命令
用 Python 编写自己的定制命令和键绑定很容易。我目前使用的工作流程是:
通过文件菜单(Sublime>Preferences>Browse Packages)将 Python 文件添加到您的/Sublime Text 3/Packages/User目录,然后打开用户目录,即可安装这些文件。要完成设置,从键绑定-用户文件(升华文本>首选项>包设置>高级新文件>键绑定-用户)绑定它们。
[ // Copy file name { "keys": ["cmd+shift+c"], "command": "copy_path_to_clipboard" }, // Close all other tabs { "keys": ["cmd+alt+w"], "command": "close_tabs" } ]额外资源
免费奖励: ,这是一个免费课程,向您展示如何优化您的 Python 开发设置。
结论
我希望这篇文章对您有所帮助,并且您能够根据您的个人偏好将上面的一些包和自定义设置与您自己的结合起来,以改进您的工作流。
如果你有任何问题或建议,请在下面的评论中告诉我。最后,查看这个 repo 中的 dotfiles 文件夹,查看我创建的所有资源。干杯!*****
SimPy:用 Python 模拟真实世界的流程
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 SimPy 用 Python 模拟真实世界的流程
现实世界充满了系统,像机场和高速公路,经常经历拥堵和延误。当这些系统没有得到优化时,它们的低效率会导致无数不满意的客户和数小时的时间浪费。在本教程中,你将学习如何使用 Python 的
simpy框架来创建虚拟模拟,帮助你解决类似的问题。在本教程中,您将学习如何:
- 使用模拟来模拟真实世界的流程
- 创建一种逐步算法来近似一个复杂的系统
- 用
simpy设计并用 Python 运行一个真实世界的模拟在本教程中,您将为本地电影院创建一个模拟。您的目标是为经理提供一个脚本,以帮助找到员工的最佳数量。您可以通过单击下面的链接下载该脚本的源代码:
下载代码: 单击此处下载代码,您将使用在本教程中了解 SimPy。
什么是模拟
一个模拟是一个真实世界系统的代表。人们可以使用这个系统的数学或计算模型来研究它是如何工作的,或者当它的部分被改变时会发生什么。模拟用于机场、餐馆、机械、政府机构和许多其他系统,在这些系统中,不良的资源分配会导致拥堵、客户不满和严重的运输延误。
一个系统可以是任何事情发生的环境。现实世界系统的例子包括洗车场、银行、制造厂、机场、邮局、呼叫中心等等。这些系统有代理,它们内部经历过程。例如:
- 洗车处会让汽车经过清洗过程。
- 机场会让乘客通过安检程序。
- 呼叫中心会让客户经历与电话销售人员交谈的过程。
下表总结了这种关系:
系统 代理人 过程 洗车处 汽车 洗涤 机场 乘客 安全检查 呼叫中心 顾客 与电话销售人员交谈 理解代理在一个系统中经历的过程是后勤规划的一个重要组成部分,特别是对于大规模的组织。例如,如果当天没有足够的工作人员,机场可以看到乘客在安检处的等待时间飙升。类似地,如果没有正确的路由,时间敏感的邮件可能会延迟几天(甚至几周)。
这些拥堵情况会对时间和金钱产生现实后果,因此能够预先对这些过程建模是很重要的。这让您知道系统可能在哪里遇到问题,以及应该如何提前分配资源,以尽可能最有效的方式解决这些问题。
模拟如何工作
在 Python 中,可以使用
simpy框架进行事件模拟。首先,快速浏览一下 Python 中模拟的流程是如何运行的。下面是一个安全检查点系统模拟的代码片段。以下三行代码设置环境,传递所有必要的函数,并运行模拟:# Set up the environment env = simpy.Environment() # Assume you've defined checkpoint_run() beforehand env.process(checkpoint_run(env, num_booths, check_time, passenger_arrival)) # Let's go! env.run(until=10)上面的第一行代码建立了环境。你可以通过将
simpy.Environment()赋值给期望的变量来实现。这里简单命名为env。这告诉simpy创建一个名为env的环境对象,该对象将管理模拟时间,并在每个后续的时间步骤中移动模拟。一旦你建立了你的环境,你将传递所有的变量作为你的参数。这些都是你可以改变的,以观察系统对变化的反应。对于这个安全检查点系统,您使用以下参数:
env: 环境对象对事件进行调度和处理num_booths:ID 检查亭的数量check_time:检查一个乘客的身份证所需要的时间长度passenger_arrival: 乘客到达队列的速度然后,是时候运行模拟了!您可以通过调用
env.run()并指定您希望模拟运行多长时间来实现。该模拟以分钟为单位运行,因此该示例代码将运行 10 分钟的实时模拟。注意:别急!你不需要等 10 分钟就能完成模拟。因为模拟给你一个虚拟的实时过程,这 10 分钟在电脑上只需几秒钟就能过去。
概括来说,以下是在 Python 中运行模拟的三个步骤:
- 建立环境。
- 在参数中传递。
- 运行模拟。
但是在引擎盖下还有更多事情要做!您需要了解如何选择这些参数,并且您必须定义在模拟运行时将调用的所有函数。
我们开始吧!
simpy如何入门在 Python 中创建模拟之前,您应该检查一下列表中的一些待办事项。你需要做的第一件事是确保你对 Python 基础有扎实的理解。特别是,您需要很好地掌握类和生成器。
注意:如果你需要更新这些主题,那么看看Python 面向对象编程(OOP)简介和Python 生成器简介。这些是模拟过程中至关重要的部分,因此在继续之前,您需要理解它们。
接下来您要做的是安装所需的包。您将使用的主要框架是
simpy。这是创建、管理和运行模拟的核心包。可以用pip安装:$ python3 -m pip install simpy您还需要一些内置的 Python 模块。您将使用
statistics模块计算平均等待时间,使用random模块生成随机数。这些是 Python 标准库的一部分,所以您不需要安装任何新的东西。最后,您需要选择运行模拟的方式。通常,您可以选择两个选项之一:
- 交互式运行:使用一个 Jupyter 笔记本,其中每个代码块将包含自己的类或函数定义。输出将显示在笔记本的底部。
- 在 shell 中运行:将您的模拟保存为
.py文件,并告诉 Python 在您的终端中运行它。输出将直接打印到控制台。选择你最喜欢的方法!结局应该是一样的。
在本教程中,您会看到对名为
simulate.py的独立文件的引用。当您浏览本教程时,代码块将引用simulate.py来帮助您跟踪所有的部分是如何组合在一起的。作为参考,你可以通过下面的链接获得simulate.py的完整代码:下载代码: 单击此处下载代码,您将使用在本教程中了解 SimPy。
请随意保存文件
simulate.py并在您最喜欢的编辑器中跟随!如何用
simpy包模拟在
simpy中运行模拟的第一步是选择要建模的流程。模拟就是创建一个虚拟环境来反映真实世界的系统。本着同样的精神,您将为您的模拟“模拟”一种情况!想象一下,你被当地一家小电影院雇用来帮助经理。由于等待时间长,这家影院的评价一直很差。这位经理既关心成本,也关心顾客的满意度,他只能养得起这么多的员工。
经理特别担心一旦这些大片开始上映,会出现什么样的混乱:影院周围排起了长队,员工们工作到了极限,愤怒的观众错过了开场镜头……这绝对是应该避免的情况!
在检查评论后,经理能够确定给定的电影院观众愿意从他们到达到他们坐下最多花 10 分钟。换句话说,在电影院过夜的平均等待时间需要在 10 分钟或更少。经理请求您帮助找出一个解决方案,使客户等待时间低于 10 分钟的要求。
头脑风暴模拟算法
在您编写一行代码之前,重要的是您首先要弄清楚您的过程在现实生活中是如何运行的。这是为了确保,当你把它传递给机器时,这个过程准确地反映了客户将真正体验到的东西。你可以这样思考一个电影观众写出你的算法的步骤:
- 到达剧院,排队,等着买票。
- 从售票处买一张票。
- 排队等候检票。
- 得到引座员检查过的票。
- 选择是否排队进入小卖部:
- 如果他们排队,然后他们购买食物。
- 如果他们没有排队,然后他们跳到最后一步。
- 去找他们的座位。
对于在影院票房购票的观众来说,这是一个循序渐进的迭代过程。您已经可以看到这个过程的哪些部分是可以控制的。你可以通过增加售票处的收银员来影响顾客的等待时间。
过程中也有一些部分是无法控制的,比如第一步。你无法控制会有多少顾客到来,或者他们到来的速度有多快。你可以猜测,但你不能简单地选择一个数字,因为那不能很好地反映现实。对于这个参数,你能做的最好的事情是使用可用的数据来确定一个合适的到达时间。
注意:使用历史数据可以确保您找到的解决方案将准确反映您在现实生活中可以预期看到的情况。
考虑到这些事情,是时候构建您的模拟了!
设置环境
在开始构建您的模拟之前,您需要确保您的开发环境被正确配置。你要做的第一件事就是导入必要的包。您可以通过在文件顶部声明
import语句来做到这一点:import simpy import random import statistics这些是您将用来为剧院经理构建脚本的主要库。请记住,目标是找到平均等待时间少于 10 分钟的最佳员工数量。为此,您需要收集每位电影观众到达座位所用的时间长度。下一步是声明一个保存这些时间的列表:
wait_times = []这个列表将包含每个电影观众从到达电影院到坐到座位上所花费的总时间。您在文件的最顶端声明这个列表,这样您就可以在以后定义的任何函数中使用它。
创建环境:类定义
您想要构建的模拟的第一部分是系统的蓝图。这将是事情发生的整体环境,人或物体从一个地方移动到另一个地方。记住,环境可以是许多不同系统中的一个,比如银行、洗车场或安全检查站。在这种情况下,环境是一个电影院,所以这将是您的类的名称:
class Theater(object): def __init__(self): # More to come!现在是时候思考一下电影院的各个部分了。当然,还有剧院本身,也就是你所说的环境。稍后,您将使用一个
simpy函数显式地将剧院声明为实际的environment。现在,将其简称为env,并将其添加到类定义中:class Theater(object): def __init__(self, env): self.env = env好吧,剧院里还会有什么?你可以通过思考你之前设计的模拟算法来解决这个问题。当观众到达时,他们需要在票房排队,收银员会等着帮他们。现在你已经发现了关于剧院环境的两件事:
- 还有收银员。
- 电影观众可以从他们那里买票。
收银员是影院提供给顾客的一种资源,他们帮助观众完成购票的 T2 流程。现在,你不知道模拟剧场里有多少收银员。事实上,这正是你想要解决的问题。等待时间是如何变化的,取决于某个晚上工作的收银员的数量?
你可以继续调用这个未知变量
num_cashiers。这个变量的确切值可以在以后解决。现在,只要知道它是剧院环境中不可或缺的一部分。将其添加到类定义中:class Theater(object): def __init__(self, env, num_cashiers): self.env = env self.cashier = simpy.Resource(env, num_cashiers)在这里,您将新参数
num_cashiers添加到您的__init__()定义中。然后,您创建一个资源self.cashier,并使用simpy.Resource()来声明在任何给定时间这个环境中可以有多少个资源。注:
simpy、资源中的是环境(env)中数量有限的部分。使用其中一个需要时间,而且一次只能使用这么多(num_cashiers)。你还需要再走一步。收银员不会为自己买票,对吧?他们会帮助观众的!同样,您知道购买机票的过程需要一定的时间。但是需要多少时间呢?
假设你已经向经理索要了剧院的历史数据,比如员工绩效评估或购票收据。根据这些数据,您已经了解到在售票处出票平均需要 1 到 2 分钟。你如何让
simpy模仿这种行为?它只需要一行代码:yield self.env.timeout(random.randint(1, 3))
env.timeout()告知simpy在经过一定时间后触发事件。在这种情况下,事件是购买了一张票。这需要的时间可能是一分钟、两分钟或三分钟。你希望每个电影观众在收银台花费不同的时间。为此,您可以使用
random.randint()在给定的高低值之间选择一个随机数。然后,对于每个电影观众,模拟将等待选定的时间。让我们用一个简洁的函数将它包装起来,并将其添加到类定义中:
class Theater(object): def __init__(self, env, num_cashiers): self.env = env self.cashier = simpy.Resource(env, num_cashiers) def purchase_ticket(self, moviegoer): yield self.env.timeout(random.randint(1, 3))在
purchase_ticket()中启动事件的是moviegoer,因此它们必须作为必需的参数传递。注意:你将在下一节看到观众实际上是如何购票的!
就是这样!您已经选择了一个有时间限制的资源,定义了它的相关流程,并在您的类定义中对此进行了编码。对于本教程,您还需要声明两个资源:
- 检票员
- 卖食物的服务员
在检查了经理发送过来的数据后,您确定服务器需要 1 到 5 分钟来完成一个订单。此外,引座员检票速度非常快,平均 3 秒钟!
您需要将这些资源添加到您的类中,并定义相应的函数
check_ticket()和sell_food()。你能想出代码应该是什么样子吗?当你有了一个想法,你可以展开下面的代码块来检查你的理解:class Theater(object): def __init__(self, env, num_cashiers, num_servers, num_ushers): self.env = env self.cashier = simpy.Resource(env, num_cashiers) self.server = simpy.Resource(env, num_servers) self.usher = simpy.Resource(env, num_ushers) def purchase_ticket(self, moviegoer): yield self.env.timeout(random.randint(1, 3)) def check_ticket(self, moviegoer): yield self.env.timeout(3 / 60) def sell_food(self, moviegoer): yield self.env.timeout(random.randint(1, 5))仔细看看新的资源和功能。注意它们是如何遵循如上所述的格式的。
sell_food()使用random.randint()生成一个介于 1 到 5 分钟之间的随机数,代表观众下单并收到食物所需的时间。
check_ticket()的延时有点不同,因为引座员只需要 3 秒钟。因为simpy以分钟为单位,所以这个值需要作为一分钟的一部分,或者说3 / 60来传递。在环境中移动:功能定义
好了,你已经通过定义一个类建立了环境。你有资源和流程。现在你需要一个
moviegoer来使用它们。当一个moviegoer到达剧院时,他们将请求一个资源,等待其流程完成,然后离开。您将创建一个名为go_to_movies()的函数来跟踪这一点:def go_to_movies(env, moviegoer, theater): # Moviegoer arrives at the theater arrival_time = env.now有三个参数传递给该函数:
env:moviegoer会被环境控制,所以你会把这个作为第一个参数传递。moviegoer: 这个变量跟踪每个人在系统中的移动。theater: 此参数允许您访问您在总体类定义中定义的流程。您还声明了一个变量
arrival_time来保存每个moviegoer到达剧院的时间。您可以使用simpy呼叫env.now来获得该时间。您将希望来自您的
theater的每个流程在go_to_movies()中有相应的请求。例如,类中的第一个进程是purchase_ticket(),它使用了一个cashier资源。moviegoer将需要向cashier资源发出请求,以帮助他们完成purchase_ticket()流程。下面的表格总结了这一点:
theater中的过程go_to_movies()中的请求purchase_ticket()请求一个 cashiercheck_ticket()请求一个 ushersell_food()请求一个 server收银台是一个共享资源,这意味着许多电影观众将使用同一个收银台。然而,一个收银员一次只能帮助一个观众,所以你需要在你的代码中包含一些等待行为。这是如何工作的:
def go_to_movies(env, moviegoer, theater): # Moviegoer arrives at the theater arrival_time = env.now with theater.cashier.request() as request: yield request yield env.process(theater.purchase_ticket(moviegoer))下面是这段代码的工作原理:
theater.cashier.request():moviegoer生成使用cashier的请求。yield request:moviegoer等待一个cashier变为可用,如果所有的都在使用中。要了解更多关于yield关键字的信息,请查看如何在 Python 中使用生成器和 yield。yield env.process():moviegoer使用可用的cashier完成给定的过程。在这种情况下,就是通过呼叫theater.purchase_ticket()来购买机票。使用资源后,必须释放该资源以供下一个代理使用。你可以用
release()显式地做到这一点,但是在上面的代码中,你用一个with语句来代替。此快捷方式告诉模拟在流程完成后自动释放资源。换句话说,一旦买了票,moviegoer就会离开,收银员就会自动准备带下一位顾客。当收银员有空的时候,
moviegoer会花一些时间去买他们的票。env.process()告诉模拟转到Theater实例,并在这个moviegoer上运行purchase_ticket()流程。moviegoer将重复此请求、使用、释放周期,以检查其车票:def go_to_movies(env, moviegoer, theater): # Moviegoer arrives at the theater arrival_time = env.now with theater.cashier.request() as request: yield request yield env.process(theater.purchase_ticket(moviegoer)) with theater.usher.request() as request: yield request yield env.process(theater.check_ticket(moviegoer))这里,代码的结构是相同的。
然后,还有从小卖部购买食物的可选步骤。你无法知道电影观众是否会想买零食和饮料。处理这种不确定性的一种方法是在函数中引入一点随机性。
每个人
moviegoer要么想要么不想买食物,你可以把它们存储为布尔值True或False。然后,使用random模块让模拟随机决定该特定的moviegoer是否会前往特许摊位:def go_to_movies(env, moviegoer, theater): # Moviegoer arrives at the theater arrival_time = env.now with theater.cashier.request() as request: yield request yield env.process(theater.purchase_ticket(moviegoer)) with theater.usher.request() as request: yield request yield env.process(theater.check_ticket(moviegoer)) if random.choice([True, False]): with theater.server.request() as request: yield request yield env.process(theater.sell_food(moviegoer))这个条件语句将返回两个结果之一:
True:moviegoer将请求服务器并点餐。False:moviegoer会去找座位,不买任何零食。现在,请记住这个模拟的目标是确定收银员、迎宾员和服务员的数量,以便将等待时间控制在 10 分钟以内。要做到这一点,你需要知道任何给定的
moviegoer到达座位需要多长时间。您在函数开始时使用env.now来跟踪arrival_time,并在每个moviegoer完成所有流程并进入剧院时再次使用:def go_to_movies(env, moviegoer, theater): # Moviegoer arrives at the theater arrival_time = env.now with theater.cashier.request() as request: yield request yield env.process(theater.purchase_ticket(moviegoer)) with theater.usher.request() as request: yield request yield env.process(theater.check_ticket(moviegoer)) if random.choice([True, False]): with theater.server.request() as request: yield request yield env.process(theater.sell_food(moviegoer)) # Moviegoer heads into the theater wait_times.append(env.now - arrival_time)您使用
env.now来获取moviegoer完成所有流程并到达座位的时间。你从这个出发时间中减去观众的arrival_time,并将得到的时差添加到你的等待列表中wait_times。注意:你可以像
departure_time一样将出发时间存储在一个单独的变量中,但这会使你的代码非常重复,这违反了 D.R.Y .原则。这个
moviegoer准备看一些预告!使事情发生:函数定义
现在,您需要定义一个函数来运行模拟。将负责创建一个剧院的实例,并生成电影观众,直到模拟停止。这个函数应该做的第一件事是创建一个剧院的实例:
def run_theater(env, num_cashiers, num_servers, num_ushers): theater = Theater(env, num_cashiers, num_servers, num_ushers)因为这是主过程,所以你需要传递所有你已经声明的未知数:
num_cashiersnum_serversnum_ushers这些都是模拟需要创建和控制环境的变量,所以通过它们是绝对重要的。然后,定义一个变量
theater,并告诉模拟用一定数量的收银员、服务员和招待员来设置剧院。您可能还想从一些在电影院等候的电影观众开始您的模拟。门一开,大概就有几个人准备走了!经理说,预计票房一开门,就会有大约 3 名观众排队买票。您可以让模拟继续进行,并像这样穿过这个初始组:
def run_theater(env, num_cashiers, num_servers, num_ushers): theater = Theater(env, num_cashiers, num_servers, num_ushers) for moviegoer in range(3): env.process(go_to_movies(env, moviegoer, theater))你使用
range()来填充 3 个观影者。然后,您使用env.process()告诉模拟准备移动他们通过剧院。其余的观众将在他们自己的时间里赶到电影院。因此,只要模拟在运行,该功能就应该不断向剧院发送新客户。你不知道新的电影观众要多久才能到达电影院,所以你决定查看过去的数据。使用票房的时间戳收据,你了解到电影观众倾向于平均每 12 秒到达电影院。现在您所要做的就是告诉函数在生成一个新人之前等待这么长时间:
def run_theater(env, num_cashiers, num_servers, num_ushers): theater = Theater(env, num_cashiers, num_servers, num_ushers) for moviegoer in range(3): env.process(go_to_movies(env, moviegoer, theater)) while True: yield env.timeout(0.20) # Wait a bit before generating a new person # Almost done!...请注意,您使用十进制数字
0.20来表示 12 秒。要得到这个数,你只需将 12 秒除以 60 秒,60 秒就是一分钟的秒数。等待之后,函数应该将
moviegoer加 1,生成下一个人。发生器函数就是你用来初始化前三个电影观众的函数:def run_theater(env, num_cashiers, num_servers, num_ushers): theater = Theater(env, num_cashiers, num_servers, num_ushers) for moviegoer in range(3): env.process(go_to_movies(env, moviegoer, theater)) while True: yield env.timeout(0.20) # Wait a bit before generating a new person moviegoer += 1 env.process(go_to_movies(env, moviegoer, theater))就是这样!当您调用此函数时,模拟将生成 3 个电影观众,并开始用
go_to_movies()移动他们通过电影院。之后,新的观影者将间隔 12 秒到达影院,并在自己的时间内穿过影院。计算等待时间:功能定义
此时,您应该有一个列表
wait_times,其中包含每个电影观众到达座位所花费的总时间。现在,您需要定义一个函数来帮助计算 amoviegoer从到达到完成检票的平均时间。get_average_wait_time()无非如此:def get_average_wait_time(wait_times): average_wait = statistics.mean(wait_times)这个函数将您的
wait_times列表作为一个参数,并使用statistics.mean()来计算平均等待时间。因为您正在创建一个将由电影院管理器使用的脚本,所以您将希望确保用户能够容易地阅读输出。为此,您可以添加一个名为
calculate_wait_time()的函数:def calculate_wait_time(arrival_times, departure_times): average_wait = statistics.mean(wait_times) # Pretty print the results minutes, frac_minutes = divmod(average_wait, 1) seconds = frac_minutes * 60 return round(minutes), round(seconds)函数的最后一部分使用
divmod()以分钟和秒为单位返回结果,因此管理人员可以很容易地理解程序的输出。选择参数:用户输入功能定义
在构建这些函数时,您会遇到一些尚未明确定义的变量:
num_cashiersnum_serversnum_ushers这些变量是你可以通过改变来观察模拟如何变化的参数。如果一部卖座电影有顾客在街区周围排队,应该有多少收银员在工作?如果人们在票房上飞来飞去,却在让步上停滞不前怎么办?什么值的
num_servers将有助于缓解流量?注:这就是模拟的妙处。它允许你尝试这些事情,这样你就可以在现实生活中做出最好的决定。
无论是谁使用您的模拟,都需要能够更改这些参数的值来尝试不同的场景。为此,您将创建一个助手函数来从用户那里获取这些值:
def get_user_input(): num_cashiers = input("Input # of cashiers working: ") num_servers = input("Input # of servers working: ") num_ushers = input("Input # of ushers working: ") params = [num_cashiers, num_servers, num_ushers] if all(str(i).isdigit() for i in params): # Check input is valid params = [int(x) for x in params] else: print( "Could not parse input. The simulation will use default values:", "\n1 cashier, 1 server, 1 usher.", ) params = [1, 1, 1] return params这个函数简单地调用 Python 的
input()函数从用户那里检索数据。因为用户输入冒着混乱的风险,所以您可以包含一个if/else子句来捕捉任何无效的内容。如果用户输入了错误的数据,那么模拟将以默认值运行。完成设置:主功能定义
您想要创建的最后一个函数是
main()。这将确保当您在命令行上执行脚本时,脚本以正确的顺序运行。你可以在中阅读更多关于main()的内容,在 Python 中定义主函数。你的main()应该是这样的:def main(): # Setup random.seed(42) num_cashiers, num_servers, num_ushers = get_user_input() # Run the simulation env = simpy.Environment() env.process(run_theater(env, num_cashiers, num_servers, num_ushers)) env.run(until=90) # View the results mins, secs = get_average_wait_time(wait_times) print( "Running simulation...", f"\nThe average wait time is {mins} minutes and {secs} seconds.", )下面是
main()的工作原理:
- 通过声明一个随机种子来设置您的环境。这将确保您的输出看起来像你在本教程中看到的。
- 查询你的程序的用户的一些输入。
- 创建环境,并将其保存为变量
env,这将在每个时间步中移动模拟。- 告诉
simpy运行流程run_theater(),这将创建影院环境,并生成电影观众在其中穿行。- 确定您希望模拟运行多长时间。作为默认值,模拟设置为运行 90 分钟。
- 将
get_average_wait_time()的输出存储在两个变量mins和secs中。- 使用
print()向用户显示结果。至此,设置完成!
如何运行模拟
只需几行代码,您就可以看到模拟变得栩栩如生。但是首先,这里有一个到目前为止您已经定义的函数和类的概述:
Theater: 这个类定义作为你想要模拟的环境的蓝图。它决定了关于该环境的一些信息,比如哪些资源是可用的,以及哪些进程与它们相关联。
go_to_movies(): 这个函数明确地请求使用一个资源,通过相关的过程,然后把它释放给下一个电影观众。
run_theater(): 该功能控制模拟。它使用Theater类蓝图来创建一个剧院的实例,然后调用go_to_movies()来生成并在剧院中移动人们。
get_average_wait_time(): 该函数计算moviegoer通过电影院所花费的平均时间。
calculate_wait_time(): 该功能确保最终输出易于用户阅读。
get_user_input(): 该功能允许用户定义一些参数,比如有多少收银员可用。
main(): 这个函数确保你的脚本在命令行中正常运行。现在,您只需要两行代码来调用您的主函数:
if __name__ == '__main__': main()这样,您的脚本就可以运行了!打开您的终端,导航到您存储
simulate.py的位置,并运行以下命令:$ python simulate.py Input # of cashiers working:系统将提示您选择模拟所需的参数。下面是使用默认参数时的输出:
$ python simulate.py Input # of cashiers working: 1 Input # of servers working: 1 Input # of ushers working: 1 Running simulation... The average wait time is 42 minutes and 53 seconds.哇哦。等待的时间太长了!
何时改变现状
请记住,您的目标是向经理提出一个解决方案,说明他需要多少员工才能将等待时间控制在 10 分钟以内。为此,您将希望试验一下您的参数,看看哪些数字提供了最佳解决方案。
首先,尝试一些完全疯狂的事情,最大限度地利用资源!假设有 100 名收银员、100 名服务员和 100 名引座员在这个剧院工作。当然,这是不可能的,但是使用高得惊人的数字会很快告诉你系统的极限是什么。立即尝试:
$ python simulate.py Input # of cashiers working: 100 Input # of servers working: 100 Input # of ushers working: 100 Running simulation... The average wait time is 3 minutes and 29 seconds.即使您用尽了资源,也只能将等待时间减少到 3.5 分钟。现在试着改变数字,看看你是否能像经理要求的那样,把等待时间减少到 10 分钟。你想出了什么解决办法?您可以展开下面的代码块来查看一个可能的解决方案:
$ python simulate.py Input # of cashiers working: 9 Input # of servers working: 6 Input # of ushers working: 1 Running simulation... The average wait time is 9 minutes and 60 seconds.在这一点上,你可以向经理展示你的结果,并提出帮助改善剧院的建议。例如,为了降低成本,他可能想在剧院前面安装 10 个售票亭,而不是每晚都有 10 个收银员。
结论
在本教程中,您已经学习了如何使用
simpy框架在 Python 中构建和运行模拟。您已经开始理解系统是如何让代理经历过程的,以及如何创建这些系统的虚拟表示来加强它们对拥塞和延迟的防御。虽然模拟的类型可以不同,但总体执行是相同的!你将能够把你在这里学到的东西应用到各种不同的场景中。现在你可以:
- 头脑风暴一步一步模拟算法
- 用
simpy用 Python 创建一个虚拟环境- 定义代表代理和进程的函数
- 更改模拟的参数,以找到最佳解决方案
你可以用
simpy做很多事情,所以不要让你的探索就此停止。将你所学到的应用到新的场景中。您的解决方案可以帮助人们节省宝贵的时间和金钱,所以深入了解一下,看看您还可以优化哪些流程!您可以通过单击下面的链接下载您在本教程中构建的脚本的源代码:下载代码: 单击此处下载代码,您将使用在本教程中了解 SimPy。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 SimPy 用 Python 模拟真实世界的流程*****
用 Python 构建站点连通性检查器
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 构建站点连通性检查器
用 Python 构建站点连通性检查器是一个提高技能的有趣项目。在这个项目中,您将整合与处理 HTTP 请求,创建命令行界面(CLI) ,以及使用通用 Python 项目布局实践组织应用程序代码相关的知识。
通过构建这个项目,您将了解 Python 的异步特性如何帮助您高效地处理多个 HTTP 请求。
在本教程中,您将学习如何:
- 使用 Python 的
argparse创建命令行界面(CLI)- 使用标准库中 Python 的
http.client检查网站是否在线- 对多个网站实施同步检查
- 使用第三方库
aiohttp检查网站是否在线- 对多个网站实施异步检查
为了充分利用这个项目,您需要了解处理 HTTP 请求和使用
argparse创建 CLI 的基本知识。你还应该熟悉asyncio模块以及async和await关键字。但是不用担心!整个教程中的主题将以循序渐进的方式进行介绍,以便您可以在学习过程中掌握它们。此外,您可以通过单击下面的链接下载该项目的完整源代码和其他资源:
获取源代码: 点击此处获取源代码,您将使用来构建您的站点连接检查器应用程序。
演示:站点连接检查器
在这个循序渐进的项目中,您将构建一个应用程序来检查一个或多个网站在给定时刻是否在线。该应用程序将在命令行中获取一个目标 URL 列表,并检查它们的连通性,同步或异步。以下视频展示了该应用程序的工作原理:***
***https://player.vimeo.com/video/688288790?background=1
您的站点连接检查器可以在命令行中接受一个或多个 URL。然后,它创建一个目标 URL 的内部列表,并通过发出 HTTP 请求和处理相应的响应来检查它们的连通性。
使用
-a或--asynchronous选项使应用程序异步执行连接性检查,这可能会降低执行时间,尤其是当您处理一长串网站时。项目概述
您的网站连接检查器应用程序将通过最小的命令行界面(CLI) 提供一些选项。以下是这些选项的摘要:
-u或--urls允许您在评论行提供一个或多个目标 URL。-f或--input-file允许您提供一个包含要检查的 URL 列表的文件。-a或--asynchronous允许您异步运行连通性检查。默认情况下,您的应用程序将同步运行连通性检查。换句话说,应用程序将一个接一个地执行检查。
使用
-a或--asynchronous选项,您可以修改这种行为,并让应用程序同时运行连通性检查。为此,您将利用 Python 的异步特性和第三方库aiohttp。运行异步检查可以使您的网站连通性检查更快、更有效,尤其是当您有一长串 URL 要检查时。
在内部,您的应用程序将使用标准库
http.client模块来创建到目标网站的连接。一旦建立了连接,就可以向网站发出 HTTP 请求,希望网站能够给出适当的响应。如果请求成功,那么您将知道该站点在线。否则,你会知道该网站是离线的。为了在屏幕上显示每次连接检查的结果,您将为应用程序提供一个格式良好的输出,这将使应用程序对您的用户有吸引力。
先决条件
您将在本教程中构建的项目需要熟悉一般 Python 编程。此外,还需要具备以下主题的基本知识:
- 在 Python 中处理异常
- 使用文件、
with语句和pathlib模块- 用标准库或第三方工具处理 HTTP 请求
- 使用
argparse模块创建 CLI 应用程序- 使用 Python 的异步特性
了解第三方库
aiohttp的基础知识也是有利条件,但不是必要条件。但是,如果你还没有掌握所有这些知识,那也没关系!你可以通过尝试这个项目学到更多东西。如果遇到困难,您可以随时停下来查看此处链接的资源。有了这个网站连通性检查项目和先决条件的简短概述,您就差不多准备好开始 Pythoning 化并在编码时享受乐趣了。但是首先,您需要创建一个合适的工作环境,并设置您的项目布局。
步骤 1:在 Python 中设置站点连通性检查器项目
在本节中,您将准备开始编写站点连通性检查器应用程序。您将从为项目创建一个 Python 虚拟环境开始。该环境将允许您将项目及其依赖项与其他项目和您的系统 Python 安装隔离开来。
下一步是通过创建所有需要的文件和目录结构来设置项目的布局。
要下载第一步的代码,请点击以下链接并导航至
source_code_step_1/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的站点连接检查器应用程序。
设置开发环境
在你开始为一个新项目编码之前,你应该做一些准备。在 Python 中,通常从为项目创建一个虚拟环境开始。虚拟环境提供了一个独立的 Python 解释器和一个安装项目依赖项的空间。
首先,创建项目的根目录,名为
rpchecker_project/。然后转到该目录,在系统的命令行或终端上运行以下命令:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> venv\Scripts\activate (venv) PS>$ python -m venv venv $ source venv/bin/activate (venv) $第一个命令在项目的根目录中创建一个名为
venv的全功能 Python 虚拟环境,而第二个命令激活该环境。现在运行下面的命令来安装项目对标准 Python 包管理器pip的依赖项:(venv) $ python -m pip install aiohttp使用这个命令,您可以将
aiohttp安装到您的虚拟环境中。您将使用这个第三方库和 Python 的async特性来处理站点连通性检查器应用程序中的异步 HTTP 请求。酷!您有了一个工作的 Python 虚拟环境,其中包含了开始构建项目所需的所有依赖项。现在,您可以创建项目布局,按照 Python 最佳实践来组织代码。
组织您的站点连通性检查项目
Python 在构建应用程序时具有惊人的灵活性,因此您可能会发现不同项目的结构大相径庭。然而,小型的可安装 Python 项目通常有一个单独的包,它通常以项目本身命名。
遵循本练习,您可以使用以下目录结构组织站点连通性检查器应用程序:
rpchecker_project/ │ ├── rpchecker/ │ ├── __init__.py │ ├── __main__.py │ ├── checker.py │ └── cli.py │ ├── README.md └── requirements.txt您可以为此项目及其主包使用任何名称。在本教程中,该项目将被命名为
rpchecker,作为真实 Python (rp)和checker的组合,指出了 app 的主要功能。
README.md文件将包含项目的描述以及安装和运行应用程序的说明。向您的项目添加一个README.md文件是编程中的最佳实践,尤其是如果您计划将项目作为开源解决方案发布的话。要了解更多关于编写好的README.md文件的信息,请查看如何为你的 GitHub 项目编写一个好的自述文件。
requirements.txt文件将保存项目的外部依赖列表。在这种情况下,您只需要aiohttp库,因为您将使用的其他工具和模块都可以在 Python 标准库中找到。您可以使用这个文件,通过使用标准的包管理器pip,为您的应用程序自动重现合适的 Python 虚拟环境。注意:在本教程中,您不会向
README.md和requirements.txt文件添加内容。要体验它们的内容,请下载本教程中提供的额外资料,并查看相应的文件。在
rpchecker/目录中,您将拥有以下文件:
__init__.py启用rpchecker/作为 Python 包。__main__.py作为应用程序的入口脚本。checker.py提供了应用的核心功能。cli.py包含了应用程序的命令行界面。现在,继续将所有这些文件创建为空文件。你可以通过使用你最喜欢的代码编辑器或者 IDE 来实现。一旦你完成创建项目的布局,然后你就可以开始编写应用程序的主要功能:检查一个网站是否在线。
第二步:用 Python 检查网站的连通性
此时,您应该有一个合适的 Python 虚拟环境,其中安装了项目的依赖项。您还应该有一个项目目录,其中包含您将在本教程中使用的所有文件。是时候开始编码了!
在进入真正有趣的内容之前,继续将应用程序的版本号添加到您的
rpchecker包中的__init__.py模块:# __init__.py __version__ = "0.1.0"
__version__模块级常量保存项目的当前版本号。因为您正在创建一个全新的应用程序,所以初始版本被设置为0.1.0。有了这个最小的设置,您就可以开始实现连通性检查功能了。要下载此步骤的代码,请单击以下链接并查看
source_code_step_2/文件夹:获取源代码: 点击此处获取源代码,您将使用来构建您的站点连接检查器应用程序。
实施连通性检查功能
有几个 Python 工具和库可用于检查网站在给定时间是否在线。例如,一个流行的选项是
requests第三方库,它允许您使用人类可读的 API 来执行 HTTP 请求。然而,使用
requests的缺点是安装一个外部库只是为了使用它的一小部分功能。在 Python 标准库中找到合适的工具会更有效。快速浏览一下标准库,您会发现
urllib包,它提供了几个处理 HTTP 请求的模块。例如,要检查网站是否在线,您可以使用urllib.request模块中的urlopen()功能:
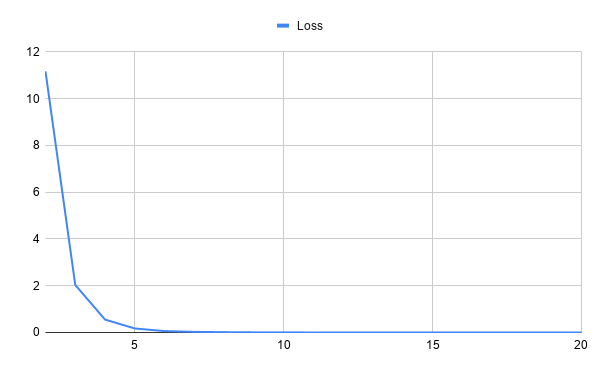
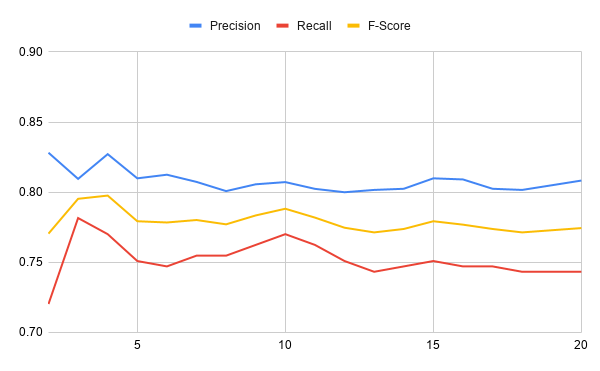


 T5
T5
>>> from urllib.request import urlopen
>>> response = urlopen("https://python.org")
>>> response.read()
b'<!doctype html>\n<!--[if lt IE 7]>
...
urlopen()函数获取一个 URL 并打开它,以字符串或 Request 对象的形式返回其内容。但是你只需要检查网站是否在线,所以下载整个页面是一种浪费。你需要更有效的方法。
有没有一种工具可以让您对 HTTP 请求进行低级别的控制?这就是 http.client 模块的用武之地。这个模块提供了 HTTPConnection 类,代表一个到给定 HTTP 服务器的连接。
HTTPConnection有一个 .request() 方法,允许您使用不同的 HTTP 方法执行 HTTP 请求。对于这个项目,您可以使用 HEAD HTTP 方法来请求只包含目标网站的头的响应。此选项将减少要下载的数据量,从而提高连通性检查应用程序的效率。
至此,您对要使用的工具有了一个清晰的概念。现在你可以做一些快速测试。继续在 Python 交互式会话中运行以下代码:
>>> from http.client import HTTPConnection >>> connection = HTTPConnection("pypi.org", port=80, timeout=10) >>> connection.request("HEAD", "/") >>> response = connection.getresponse() >>> response.getheaders() [('Server', 'Varnish'), ..., ('X-Permitted-Cross-Domain-Policies', 'none')]在本例中,首先创建一个针对
pypi.org网站的HTTPConnection实例。该连接使用端口80,这是默认的 HTTP 端口。最后,timeout参数提供了连接尝试超时前等待的秒数。然后使用
.request()在站点的根路径"/"上执行一个HEAD请求。为了从服务器获得实际的响应,您在connection对象上调用.getresponse()。最后,通过调用.getheaders()来检查响应的头部。您的网站连接检查器只需要创建一个连接并发出一个
HEAD请求。如果请求成功,则目标网站在线。否则,该网站处于脱机状态。在后一种情况下,向用户显示一条错误消息是合适的。现在在代码编辑器中打开
checker.py文件。然后向其中添加以下代码:1# checker.py 2 3from http.client import HTTPConnection 4from urllib.parse import urlparse 5 6def site_is_online(url, timeout=2): 7 """Return True if the target URL is online. 8 9 Raise an exception otherwise. 10 """ 11 error = Exception("unknown error") 12 parser = urlparse(url) 13 host = parser.netloc or parser.path.split("/")[0] 14 for port in (80, 443): 15 connection = HTTPConnection(host=host, port=port, timeout=timeout) 16 try: 17 connection.request("HEAD", "/") 18 return True 19 except Exception as e: 20 error = e 21 finally: 22 connection.close() 23 raise error下面是这段代码的逐行分解:
三号线 从
http.client进口HTTPConnection。您将使用该类建立与目标网站的连接并处理 HTTP 请求。4 号线从
urllib.parse进口urlparse()。这个函数将帮助您解析目标 URL。第 6 行定义了
site_is_online(),它带有一个url和一个timeout参数。url参数将保存一个表示网站 URL 的字符串。同时,timeout将保持连接尝试超时前等待的秒数。第 11 行定义了一个通用的
Exception实例作为占位符。第 12 行定义了一个
parser变量,包含使用urlparse()解析目标 URL 的结果。第 13 行使用
or操作符从目标 URL 中提取主机名。第 14 行通过 HTTP 和 HTTPS 端口开始一个
for循环。这样,您可以检查网站是否在任一端口上可用。第 15 行使用
host、port和timeout作为参数创建一个HTTPConnection实例。第 16 到 22 行定义了一个
try…except…finally语句。try块试图通过调用.request()向目标网站发出HEAD请求。如果请求成功,那么函数返回T6。如果出现异常,那么except模块在error中保存一个对该异常的引用。finally模块关闭连接以释放获取的资源。第 23 行如果循环结束而没有成功的请求,则引发存储在
error中的异常。如果目标网站在线,您的
site_is_online()函数将返回True。否则,它会引发一个异常,指出遇到的问题。后一种行为很方便,因为当站点不在线时,您需要显示一条信息性的错误消息。现在是时候尝试你的新功能了。运行第一次连通性检查
要尝试您的
site_is_online()功能,请继续并返回您的互动会话。然后运行以下代码:
>>> from rpchecker.checker import site_is_online
>>> site_is_online("python.org")
True
>>> site_is_online("non-existing-site.org")
Traceback (most recent call last):
...
socket.gaierror: [Errno -2] Name or service not known
在这个代码片段中,首先从checker模块导入site_is_online()。然后你调用带有"python.org"作为参数的函数。因为函数返回True,所以你知道目标站点在线。
在最后一个例子中,您使用一个不存在的网站作为目标 URL 来调用site_is_online()。在这种情况下,该函数会引发一个异常,您可以稍后捕获并处理该异常,以便向用户显示一条错误消息。
太好了!您已经实现了应用程序检查网站连通性的主要功能。现在,您可以通过设置项目的 CLI 来继续您的项目。
步骤 3:创建您的网站连接检查器的 CLI
到目前为止,您已经有了一个工作函数,它允许您通过使用标准库中的http.client模块执行 HTTP 请求来检查给定网站是否在线。在这一步结束时,您将拥有一个最小的 CLI,允许您从命令行运行网站连通性检查器应用程序。
CLI 将包括在命令行获取 URL 列表和从文本文件加载 URL 列表的选项。该应用程序还将显示连通性检查结果,并显示一条用户友好的消息。
要创建应用程序的 CLI,您将使用 Python 标准库中的argparse。该模块允许您构建用户友好的 CLI,而无需安装任何外部依赖项,如 Click 或 Typer 。
首先,您将编写使用argparse所需的样板代码。您还将编写从命令行读取 URL 的选项。
单击下面的链接下载此步骤的代码,以便您可以跟随项目。您将在source_code_step_3/文件夹中找到您需要的内容:
获取源代码: 点击此处获取源代码,您将使用来构建您的站点连接检查器应用程序。
在命令行解析网站 URLs】
要用argparse构建应用程序的 CLI,您需要创建一个 ArgumentParser 实例,这样您就可以解析命令行中提供的参数。一旦你有了一个参数解析器,你就可以开始向你的应用程序的命令行界面添加参数和选项。
现在在代码编辑器中打开cli.py文件。然后添加以下代码:
# cli.py
import argparse
def read_user_cli_args():
"""Handle the CLI arguments and options."""
parser = argparse.ArgumentParser(
prog="rpchecker", description="check the availability of websites"
)
parser.add_argument(
"-u",
"--urls",
metavar="URLs",
nargs="+",
type=str,
default=[],
help="enter one or more website URLs",
)
return parser.parse_args()
在这个代码片段中,您创建了read_user_cli_args()来将与参数解析器相关的功能保存在一个地方。要构建解析器对象,需要使用两个参数:
prog定义了程序的名称。description为应用提供了合适的描述。当您使用--help选项调用应用程序时,将显示此描述。
创建参数解析器后,使用 .add_argument() 添加第一个命令行参数。该参数将允许用户在命令行输入一个或多个 URL。它将使用-u和--urls开关。
.add_argument()的其余参数如下:
metavar为用法或帮助消息中的参数设置名称。nargs告诉argparse在-u或--urls开关后接受一系列命令行参数。type设置命令行参数的数据类型,即本参数中的str。default默认情况下将命令行参数设置为空列表。help为用户提供了帮助信息。
最后,您的函数返回对解析器对象调用 .parse_args() 的结果。该方法返回一个包含已解析参数的 Namespace 对象。
从文件中加载网址
在站点连通性检查器中实现的另一个有价值的选项是从本地机器上的文本文件中加载 URL 列表的能力。为此,您可以添加带有-f和--input-file标志的第二个命令行参数。
继续使用以下代码更新read_user_cli_args():
# cli.py
# ...
def read_user_cli_args():
# ...
parser.add_argument( "-f",
"--input-file",
metavar="FILE",
type=str,
default="",
help="read URLs from a file",
)
return parser.parse_args()
要创建这个新的命令行参数,可以使用.add_argument()和上一节中几乎相同的参数。在这种情况下,您没有使用nargs参数,因为您希望应用程序在命令行只接受一个输入文件。
显示检查结果
通过命令行与用户交互的每个应用程序的基本组件是应用程序的输出。您的应用程序需要向用户显示其操作的结果。该功能对于确保愉快的用户体验至关重要。
您的站点连通性检查器不需要非常复杂的输出。它只需要通知用户关于被检查网站的当前状态。为了实现这个功能,您将编写一个名为display_check_result()的函数。
现在回到cli.py文件,在末尾添加函数:
# cli.py
# ...
def display_check_result(result, url, error=""):
"""Display the result of a connectivity check."""
print(f'The status of "{url}" is:', end=" ")
if result:
print('"Online!" 👍')
else:
print(f'"Offline?" 👎 \n Error: "{error}"')
```py
这个函数接受连通性检查结果、检查的 URL 和一个可选的错误消息。[条件语句](https://realpython.com/python-conditional-statements/)测试查看`result`是否为真,在这种情况下,一条`"Online!"`消息被[打印](https://realpython.com/python-print/)到屏幕上。如果`result`为假,那么`else`子句打印`"Offline?"`以及一个关于刚刚发生的实际问题的错误报告。
就是这样!您的网站连接检查器有一个命令行界面,允许用户与应用程序进行交互。现在是时候将所有东西放在应用程序的入口点脚本中了。
## 第四步:把所有东西放在应用程序的主脚本中
到目前为止,您的站点连通性检查器项目具有检查给定网站是否在线的功能。它还有一个 CLI,您可以使用 Python 标准库中的`argparse`模块快速构建。在这一步中,您将编写[粘合代码](https://en.wikipedia.org/wiki/Glue_code)——这些代码将把所有这些组件结合在一起,使您的应用程序作为一个成熟的命令行应用程序工作。
首先,您将从设置应用程序的主脚本或[入口点](https://en.wikipedia.org/wiki/Entry_point)脚本开始。该脚本将包含 [`main()`](https://realpython.com/python-main-function/) 函数和一些高级代码,这些代码将帮助您将[前端的 CLI](https://en.wikipedia.org/wiki/Frontend_and_backend)与后端的连通性检查功能连接起来。
要下载该步骤的代码,请单击下面的链接,然后查看`source_code_step_4/`文件夹:
**获取源代码:** [点击此处获取源代码,您将使用](https://realpython.com/bonus/site-connectivity-checker-python-project-code/)来构建您的站点连接检查器应用程序。
### 创建应用程序的入口点脚本
构建网站连通性检查器应用程序的下一步是用合适的`main()`函数定义入口点脚本。为此,您将使用位于`rpchecker`包中的 [`__main__.py`](https://docs.python.org/3/library/__main__.html#module-__main__) 文件。在 Python 包中包含一个`__main__.py`文件使您能够使用命令`python -m <package_name>`将包作为可执行程序运行。
要开始用代码填充`__main__.py`,请在代码编辑器中打开文件。然后添加以下内容:
1# main.py
2
3import sys
4
5from rpchecker.cli import read_user_cli_args
6
7def main():
8 """Run RP Checker."""
9 user_args = read_user_cli_args()
10 urls = _get_websites_urls(user_args)
11 if not urls:
12 print("Error: no URLs to check", file=sys.stderr)
13 sys.exit(1)
14 _synchronous_check(urls)
从`cli`模块导入`read_user_cli_args()`后,定义应用的`main()`功能。在`main()`中,您会发现几行代码还没有运行。在您提供了缺少的功能后,下面是这段代码应该做的事情:
* **第 9 行**调用`read_user_cli_args()`来解析命令行参数。产生的`Namespace`对象然后被存储在`user_args`局部[变量](https://realpython.com/python-variables/)中。
* **第 10 行**通过调用一个名为`_get_websites_urls()`的**辅助函数**来组合一个目标 URL 列表。一会儿你就要编写这个函数了。
* **第 11 行**定义了一个`if`语句来检查 URL 列表是否为空。如果是这种情况,那么`if`块向用户打印一条错误消息并退出应用程序。
* **第 14 行**调用一个名为`_synchronous_check()`的函数,该函数将目标 URL 列表作为参数,并对每个 URL 进行连通性检查。顾名思义,这个函数将同步运行连通性检查,或者一个接一个地运行。同样,您将在一会儿编写这个函数。
有了`main()`,你可以开始编码缺失的部分,使其正确工作。在接下来的部分中,您将实现`_get_websites_urls()`和`_synchronous_check()`。一旦它们准备就绪,您就可以首次运行您的网站连通性检查器应用程序了。
[*Remove ads*](/account/join/)
### 建立目标网站 URL 列表
你的网站连通性检查应用程序将能够在每次执行时检查多个 URL。用户将通过在命令行列出 URL、在文本文件中提供 URL 或者两者都提供来将 URL 输入应用程序。为了创建目标 URL 的内部列表,应用程序将首先处理命令行中提供的 URL。然后它会从一个文件中添加额外的 URL,如果有的话。
下面是完成这些任务并返回目标 URL 列表的代码,该列表结合了两个源、命令行和一个可选的文本文件:
1# main.py
2
3import pathlib 4import sys
5
6from rpchecker.cli import read_user_cli_args
7
8def main():
9 # ...
10
11def _get_websites_urls(user_args): 12 urls = user_args.urls
13 if user_args.input_file:
14 urls += _read_urls_from_file(user_args.input_file)
15 return urls
16
17def _read_urls_from_file(file): 18 file_path = pathlib.Path(file)
19 if file_path.is_file():
20 with file_path.open() as urls_file:
21 urls = [url.strip() for url in urls_file]
22 if urls:
23 return urls
24 print(f"Error: empty input file, {file}", file=sys.stderr)
25 else:
26 print("Error: input file not found", file=sys.stderr)
27 return []
该代码片段中的第一个更新是导入`pathlib`来管理可选 URL 文件的路径。第二个更新是添加了`_get_websites_urls()`辅助函数,它执行以下操作:
* **第 12 行**定义了`urls`,它最初存储命令行提供的 URL 列表。注意,如果用户没有提供任何 URL,那么`urls`将存储一个空列表。
* **第 13 行**定义了一个条件,检查用户是否提供了一个 URL 文件。如果是这样的话,`if`块会用`user_args.input_file`命令行参数中提供的文件来增加调用`_read_urls_from_file()`所得到的目标 URL 列表。
* 第 15 行返回 URL 的结果列表。
同时,`_read_urls_from_file()`运行以下动作:
* **第 18 行**将`file`实参变为 [`pathlib.Path`](https://docs.python.org/3/library/pathlib.html#pathlib.Path) 对象,以便于进一步处理。
* **第 19 行**定义了一个条件语句,检查当前文件是否是本地文件系统中的一个实际文件。为了执行这个检查,条件调用`Path`对象上的 [`.is_file()`](https://docs.python.org/3/library/pathlib.html#pathlib.Path.is_file) 。然后`if`块打开文件,并使用 list comprehension 读取其内容。这种理解去除了文件中每一行任何可能的前导和结尾空格,以防止以后出现处理错误。
* 第 22 行定义了一个嵌套的条件来检查是否已经收集了任何 URL。如果是,那么第 23 行返回 URL 的结果列表。否则,第 24 行打印一条错误消息,通知读者输入文件是空的。
第 25 到 26 行的`else`子句打印一条错误消息,指出输入文件不存在。如果函数运行时没有返回有效的 URL 列表,它将返回一个空列表。
哇!太多了,但是你坚持到了最后!现在你可以继续进行`__main__.py`的最后部分了。换句话说,您可以实现`_synchronous_check()`功能,以便应用程序可以在多个网站上执行连通性检查。
### 检查多个网站的连接性
要对多个网站运行连通性检查,您需要遍历目标 URL 列表,进行检查,并显示相应的结果。这就是下面的`_synchronous_check()`函数的作用:
1# main.py
2
3import pathlib
4import sys
5
6from rpchecker.checker import site_is_online 7from rpchecker.cli import display_check_result, read_user_cli_args 8
9# ...
10
11def _synchronous_check(urls): 12 for url in urls:
13 error = ""
14 try:
15 result = site_is_online(url)
16 except Exception as e:
17 result = False
18 error = str(e)
19 display_check_result(result, url, error)
20
21if name == "main": 22 main()
在这段代码中,首先通过添加`site_is_online()`和`display_check_result()`来更新您的导入。然后定义`_synchronous_check()`,它接受一个 URL 列表作为参数。该函数的主体是这样工作的:
* **第 12 行**开始一个`for`循环,遍历目标 URL。
* **第 13 行**定义并初始化`error`,它将保存应用程序没有从目标网站得到响应时显示的消息。
* **第 14 行到第 18 行**定义了一个`try` … `except`语句,该语句捕捉连通性检查期间可能发生的任何异常。这些检查运行在第 15 行,该行使用目标 URL 作为参数调用`site_is_online()`。然后,如果出现连接问题,第 17 行和第 18 行更新`result`和`error`变量。
* **第 19 行**最后用适当的参数调用`display_check_result()`,将连通性检查结果显示到屏幕上。
为了包装`__main__.py`文件,您添加典型的 Python [`if __name__ == "__main__":`](https://realpython.com/if-name-main-python/) 样板代码。当模块[作为脚本](https://realpython.com/run-python-scripts/)或可执行程序运行时,这个片段调用`main()`。有了这些更新,您的应用程序现在可以进行测试飞行了!
### 从命令行运行连通性检查
您已经编写了大量代码,却没有机会看到它们的运行。您已经编写了站点连通性检查器的 CLI 及其入口点脚本。现在是时候尝试一下您的应用程序了。在此之前,请确保您已经下载了本步骤开始时提到的奖励材料,尤其是`sample-urls.txt`文件。
现在回到命令行,执行以下命令:
$ python -m rpchecker -h
python -m rpchecker -h
usage: rpchecker [-h] [-u URLs [URLs ...]] [-f FILE] [-a]
check the availability of web sites
options:
-h, --help show this help message and exit
-u URLs [URLs ...], --urls URLs [URLs ...]
enter one or more website URLs
-f FILE, --input-file FILE
read URLs from a file
$ python -m rpchecker -u python.org pypi.org peps.python.org
The status of "python.org" is: "Online!" 👍
The status of "pypi.org" is: "Online!" 👍
The status of "peps.python.org" is: "Online!" 👍
$ python -m rpchecker --urls non-existing-site.org
The status of "non-existing-site.org" is: "Offline?" 👎
Error: "[Errno -2] Name or service not known"
$ cat sample-urls.txt
python.org
pypi.org
docs.python.org
peps.python.org
$ python -m rpchecker -f sample-urls.txt
The status of "python.org" is: "Online!" 👍
The status of "pypi.org" is: "Online!" 👍
The status of "docs.python.org" is: "Online!" 👍
The status of "peps.python.org" is: "Online!" 👍
你的网站连接检查工作很棒!当你用`-h`或`--help`选项运行`rpchecker`时,你会得到一条解释如何使用该应用的使用信息。
应用程序可以从命令行或文本文件中获取几个 URL,并检查它们的连通性。如果在检查过程中出现错误,屏幕上会显示一条消息,告诉您是什么导致了错误。
继续尝试一些其他的网址和功能。例如,尝试使用`-u`和`-f`开关将命令行中的 URL 与文件中的 URL 结合起来。此外,检查当您提供一个空的或不存在的 URL 文件时会发生什么。
酷!你的网站连通性检查应用程序工作得很好,很流畅,不是吗?然而,它有一个隐藏的问题。当您使用一个很长的目标 URL 列表运行应用程序时,执行时间可能会很长,因为所有的连接性检查都是同步运行的。
要解决这个问题并提高应用程序的性能,您可以实现异步连接检查。这就是你在下一节要做的。
[*Remove ads*](/account/join/)
## 步骤 5:异步检查网站的连通性
通过异步编程对多个网站同时执行连接性检查,可以提高应用程序的整体性能。为此,您可以利用 Python 的异步特性和第三方库`aiohttp`,它们已经安装在您项目的虚拟环境中。
Python 支持使用`asyncio`模块、 [`async`和`await`](https://realpython.com/python-keywords/#asynchronous-programming-keywords-async-await) 关键字进行异步编程。在下面几节中,您将编写所需的代码,使您的应用程序使用这些工具异步运行连通性检查。
要下载这最后一步的代码,请单击以下链接并查看`source_code_step_5/`文件夹:
**获取源代码:** [点击此处获取源代码,您将使用](https://realpython.com/bonus/site-connectivity-checker-python-project-code/)来构建您的站点连接检查器应用程序。
### 实施异步连接检查功能
让您的网站连通性检查器同时工作的第一步是编写一个`async`函数,允许您在给定的网站上执行一次连通性检查。这将是您的`site_is_online()`函数的异步等价物。
回到`checker.py`文件,添加以下代码:
1# checker.py
2
3import asyncio 4from http.client import HTTPConnection
5from urllib.parse import urlparse
6
7import aiohttp 8# ...
9
10async def site_is_online_async(url, timeout=2): 11 """Return True if the target URL is online.
12
13 Raise an exception otherwise.
14 """
15 error = Exception("unknown error")
16 parser = urlparse(url)
17 host = parser.netloc or parser.path.split("/")[0]
18 for scheme in ("http", "https"):
19 target_url = scheme + "😕/" + host
20 async with aiohttp.ClientSession() as session:
21 try:
22 await session.head(target_url, timeout=timeout)
23 return True
24 except asyncio.exceptions.TimeoutError:
25 error = Exception("timed out")
26 except Exception as e:
27 error = e
28 raise error
在这个更新中,首先添加所需的导入,`asyncio`和`aiohttp`。然后在第 10 行定义`site_is_online_async()`。这是一个`async`函数,它有两个参数:要检查的 URL 和请求超时前的秒数。该函数的主体执行以下操作:
* 第 15 行定义了一个通用的`Exception`实例作为占位符。
* **第 16 行**定义了一个`parser`变量,包含使用`urlparse()`解析目标 URL 的结果。
* **第 17 行**使用 [`or`操作符](https://realpython.com/python-or-operator/)从目标 URL 中提取主机名。
* **第 18 行**定义了一个通过 HTTP 和 HTTPS 方案的`for`循环。这将允许您检查网站是否可用。
* **第 19 行**使用当前方案和主机名构建一个 URL。
* **第 20 行**定义了一个 [`async with`语句](https://realpython.com/async-io-python/)来处理一个 [`aiohttp.ClientSession`](https://docs.aiohttp.org/en/stable/client_reference.html) 实例。这个类是使用`aiohttp`进行 HTTP 请求的推荐接口。
* **第 21 到 27 行**定义了一个`try` … `except`语句。`try`块通过调用`session`对象上的`.head()`来执行并等待对目标网站的`HEAD`请求。如果请求成功,那么函数返回`True`。第一个`except`子句捕获`TimeoutError`异常并将`error`设置为一个新的`Exception`实例。第二个`except`子句捕捉任何其他异常,并相应地更新`error`变量。
* **第 28 行**如果循环没有成功请求就结束,则引发存储在`error`中的异常。
`site_is_online_async()`的实现与`site_is_online()`的实现类似。如果目标网站在线,它返回`True`。否则,它会引发一个异常,指出遇到的问题。
这些函数之间的主要区别在于,`site_is_online_async()`使用第三方库`aiohttp`异步执行 HTTP 请求。当你有一长串网站需要查看时,这种方法可以帮助你优化应用程序的性能。
有了这个函数,您就可以使用一个新选项来更新您的应用程序的 CLI,该选项允许您异步运行连接性检查。
### 将异步选项添加到应用程序的 CLI
现在,您需要向站点连通性检查器应用程序的 CLI 添加一个选项。这个新选项将告诉应用程序异步运行检查。该选项可以只是一个[布尔](https://realpython.com/python-boolean/)标志。要实现这种类型的选项,可以使用`.add_argument()`的`action`参数。
现在继续用下面的代码更新`cli.py`文件上的`read_user_cli_args()`:
cli.py
...
def read_user_cli_args():
"""Handles the CLI user interactions."""
# ...
parser.add_argument( "-a",
"--asynchronous",
action="store_true", help="run the connectivity check asynchronously",
)
return parser.parse_args()
...
对`parser`对象上的`.add_argument()`的调用向应用程序的 CLI 添加了一个新的`-a`或`--asynchronous`选项。`action`参数被设置为`"store_true"`,这告诉`argparse``-a`和`--asynchronous`是布尔标志,当在命令行提供时将存储`True`。
有了这个新选项,是时候编写异步检查多个网站连通性的逻辑了。
[*Remove ads*](/account/join/)
### 异步检查多个网站的连通性
为了异步检查多个网站的连通性,您将编写一个`async`函数,该函数调用并等待来自`checker`模块的`site_is_online_async()`。回到`__main__.py`文件,向其中添加以下代码:
1# main.py
2import asyncio
3import pathlib
4import sys
5
6from rpchecker.checker import site_is_online, site_is_online_async 7from rpchecker.cli import display_check_result, read_user_cli_args
8# ...
9
10async def _asynchronous_check(urls): 11 async def _check(url):
12 error = ""
13 try:
14 result = await site_is_online_async(url)
15 except Exception as e:
16 result = False
17 error = str(e)
18 display_check_result(result, url, error)
19
20 await asyncio.gather(*(_check(url) for url in urls))
21
22def _synchronous_check(urls):
23 # ...
在这段代码中,首先更新您的导入来访问`site_is_online_async()`。然后使用`async`关键字将第 10 行的`_asynchronous_check()`定义为异步函数。这个函数获取一个 URL 列表,并异步检查它们的连通性。它是这样做的:
* **第 11 行**定义了一个名为`_check()`的[内部](https://realpython.com/inner-functions-what-are-they-good-for/) `async`函数。该函数允许您重用检查单个 URL 连通性的代码。
* **第 12 行**定义并初始化一个占位符`error`变量,该变量将在稍后对`display_check_result()`的调用中使用。
* **第 13 行到第 17 行**定义了一个`try` … `except`语句来完成连通性检查。`try`块使用目标 URL 作为参数调用并等待`site_is_online_async()`。如果呼叫成功,那么`result`会变成`True`。如果调用引发异常,那么`result`将会是`False`,而`error`将会保存产生的错误消息。
* **第 18 行**使用`result`、`url`和`error`作为参数调用`display_check_result()`。该呼叫显示关于网站可用性的信息。
* **第 20 行**调用并等待来自`asyncio`模块的 [`gather()`](https://docs.python.org/3/library/operator.html#operator.itemgetter) 函数。该函数同时运行一个由[个可奖励对象](https://docs.python.org/3/library/asyncio-task.html#asyncio-awaitables)组成的列表,如果所有可奖励对象都成功完成,则返回一个结果值的汇总列表。为了提供一个合适的对象列表,您使用一个[生成器表达式](https://realpython.com/introduction-to-python-generators/#building-generators-with-generator-expressions),它为每个目标 URL 调用`_check()`。
好吧!您几乎已经准备好尝试站点连通性检查器应用程序的异步功能了。在此之前,您需要注意最后一个细节:更新`main()`函数来集成这个新特性。
### 向应用程序的主代码添加异步检查
为了给应用程序的`main()`函数添加异步功能,您将使用一个条件语句来检查用户是否在命令行提供了`-a`或`--asynchronous`标志。该条件将允许您根据用户的输入使用正确的工具运行连通性检查。
继续并再次打开`__main__.py`文件。然后更新`main()`,如下面的代码片段所示:
1# main.py
2# ...
3
4def main():
5 """Run RP Checker."""
6 user_args = read_user_cli_args()
7 urls = _get_websites_urls(user_args)
8 if not urls:
9 print("Error: no URLs to check", file=sys.stderr)
10 sys.exit(1)
11
12 if user_args.asynchronous: 13 asyncio.run(_asynchronous_check(urls))
14 else:
15 _synchronous_check(urls)
16
17# ...
第 12 到 15 行的条件语句检查用户是否在命令行提供了`-a`或`--asynchronous`标志。如果是这种情况,`main()`使用`asyncio.run()`异步运行连通性检查。否则,它使用`_synchronous_check()`同步运行检查。
就是这样!您现在可以在实践中测试网站连接检查器的这一新功能。回到命令行,运行以下命令:
$ python -m rpchecker -h
usage: rpchecker [-h] [-u URLs [URLs ...]] [-f FILE] [-a]
check the availability of web sites
options:
-h, --help show this help message and exit
-u URLs [URLs ...], --urls URLs [URLs ...]
enter one or more website URLs
-f FILE, --input-file FILE
read URLs from a file
-a, --asynchronous run the connectivity check asynchronously
$ # Synchronous execution $ python -m rpchecker -u python.org pypi.org docs.python.org
The status of "python.org" is: "Online!" 👍
The status of "pypi.org" is: "Online!" 👍
The status of "docs.python.org" is: "Online!" 👍
$ # Asynchronous execution $ python -m rpchecker -u python.org pypi.org docs.python.org -a
The status of "pypi.org" is: "Online!" 👍
The status of "docs.python.org" is: "Online!" 👍
The status of "python.org" is: "Online!" 👍
第一个命令显示您的应用程序现在有了一个新的`-a`或`--asynchronous`选项,它将异步运行连通性检查。
第二个命令让`rpchecker`同步运行连通性检查,就像您在上一节中所做的那样。这是因为您没有提供`-a`或`--asynchronous`标志。请注意,URL 的检查顺序与它们在命令行中输入的顺序相同。
最后,在第三个命令中,您在行尾使用了`-a`标志。该标志使`rpchecker`同时运行连通性检查。现在,检查结果的显示顺序不同于 URL 的输入顺序,而是按照目标网站的响应顺序。
作为练习,您可以尝试使用一长串目标 URL 运行站点连通性检查应用程序,并比较应用程序同步和异步运行检查时的执行时间。
## 结论
您已经用 Python 构建了一个功能站点连通性检查器应用程序。现在你知道了处理给定网站的 HTTP 请求的基本知识。您还学习了如何为您的应用程序创建一个最小但功能强大的**命令行界面(CLI)** ,以及如何组织一个真实的 Python 项目。此外,您已经尝试了 Python 的异步特性。
**在本教程中,您学习了如何:**
* 用 **`argparse`** 在 Python 中创建命令行界面(CLI)
* 使用 Python 的 **`http.client`** 检查网站是否在线
* 在多个网站上运行**同步**检查
* 使用 **`aiohttp`** 检查网站是否在线
* 异步检查多个网站**的连通性**
有了这个基础,您就可以通过创建更复杂的命令行应用程序来继续提升您的技能。您还可以更好地准备继续学习 Python 中的 HTTP 请求。
要查看您为构建应用所做的工作,您可以下载下面的完整源代码:
**获取源代码:** [点击此处获取源代码,您将使用](https://realpython.com/bonus/site-connectivity-checker-python-project-code/)来构建您的站点连接检查器应用程序。
[*Remove ads*](/account/join/)
## 接下来的步骤
现在,您已经完成了站点连通性检查器应用程序的构建,您可以进一步实现一些附加功能。自己添加新特性会推动您学习新的、令人兴奋的编码概念和主题。
以下是一些关于新功能的想法:
* **定时支持:**测量每个目标网站的响应时间。
* **检查安排支持:**安排多轮连接检查,以防某些网站离线。
要实现这些特性,您可以利用 Python 的 [`time`](https://realpython.com/python-timer/) 模块,它将允许您测量代码的执行时间。
一旦你实现了这些新特性,你就可以换个方式,投入到其他更酷、更复杂的项目中。以下是您继续学习 Python 和构建项目的一些很好的后续步骤:
* [用 Python 构建掷骰子应用程序](https://realpython.com/python-dice-roll/):在这个循序渐进的项目中,您将使用 Python 构建一个最小化的基于文本的用户界面的掷骰子模拟器应用程序。该应用程序将模拟多达六个骰子的滚动。每个独立的骰子将有六个面。
* [外面下雨了?使用 Python](https://realpython.com/build-a-python-weather-app-cli/) 构建天气 CLI 应用程序:在本教程中,您将编写一个格式良好的 Python CLI 应用程序,显示您提供名称的任何城市的当前天气信息。
* [为命令行构建一个 Python 目录树生成器](https://realpython.com/directory-tree-generator-python/):在这个分步项目中,您将为您的命令行创建一个 Python 目录树生成器应用程序。您将使用`argparse`编写命令行界面,并使用 [`pathlib`](https://realpython.com/python-pathlib/) 遍历文件系统。
* [用 Python 和 Typer](https://realpython.com/python-typer-cli/) 构建命令行待办事项应用:在这个循序渐进的项目中,你将使用 Python 和 [Typer](https://typer.tiangolo.com/) 为你的命令行创建一个待办事项应用。当您构建这个应用程序时,您将学习 Typer 的基础知识,这是一个用于构建命令行界面(CLI)的现代通用库。
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: [**构建站点连通性检查器**](/courses/python-site-connectivity-checker/)*****************
# 对 Python 字典进行排序:值、键等等
> 原文:<https://realpython.com/sort-python-dictionary/>
您已经有了一个[字典](https://realpython.com/python-dicts/),但是您想要对键值对进行排序。也许你已经尝试过将字典传递给`sorted()` [函数](https://realpython.com/defining-your-own-python-function/),但是没有得到你期望的结果。在本教程中,如果您想用 Python 对字典进行排序,您将了解您需要知道的一切。
**在本教程中,您将**:
* 复习如何使用 **`sorted()`** 功能
* 学习如何让字典**视图**到**迭代**
* 了解字典在排序过程中是如何被转换成列表的
* 了解如何指定一个**排序键**来按照值、键或嵌套属性对字典进行排序
* 审查字典**的理解**和`dict()` **的构造**来重建你的字典
* 为您的**键值数据**考虑替代的**数据结构**
在这个过程中,您还将使用`timeit`模块对代码进行计时,并通过比较不同的键-值数据排序方法获得切实的结果。你还会考虑[一个排序字典是否真的是你的最佳选择](#judging-whether-you-want-to-use-a-sorted-dictionary),因为它不是一个特别常见的模式。
为了充分利用本教程,您应该了解字典、列表、元组和函数。有了这些知识,在本教程结束时,您将能够对字典进行排序。一些高阶函数,比如[λ](https://realpython.com/python-lambda/)函数,也会派上用场,但不是必需的。
**免费下载:** [点击这里下载代码](https://realpython.com/bonus/sort-python-dictionary-code/),您将在本教程中使用它对键-值对进行排序。
首先,在尝试用 Python 对字典进行排序之前,您将学习一些基础知识。
## 在 Python 中重新发现字典顺序
在 Python 3.6 之前,字典本来就**无序**。Python 字典是[散列表](https://realpython.com/python-hash-table/)的一个实现,散列表传统上是一种无序的数据结构。
作为 Python 3.6 中[紧凑字典](https://docs.python.org/3/whatsnew/3.6.html#whatsnew36-compactdict)实现的一个副作用,字典开始保留[插入顺序](https://mail.python.org/pipermail/python-dev/2016-September/146327.html)。从 3.7 开始,插入顺序已经由 [*保证为*](https://realpython.com/python37-new-features/#the-order-of-dictionaries-is-guaranteed) 。
如果你想在压缩字典之前保持一个有序的字典作为数据结构,那么你可以使用 [`collections`模块](https://realpython.com/python-collections-module/)中的 [`OrderedDict`](https://realpython.com/python-ordereddict/) 。类似于现代的压缩字典,它也保持插入顺序,但是这两种类型的字典都不会自己排序。
存储有序键值对数据的另一种方法是将这些对存储为元组列表。正如您将在教程的后面看到的[,使用元组列表可能是您的数据的最佳选择。](#judging-whether-you-want-to-use-a-sorted-dictionary)
在对字典进行排序时,需要理解的一个要点是,即使它们保持插入顺序,它们也不会被视为一个[序列](https://docs.python.org/3/library/stdtypes.html#sequence-types-list-tuple-range)。字典就像键值对的[集合](https://realpython.com/python-sets/),集合是无序的。
字典也没有太多的重新排序功能。它们不像列表,你可以在任何位置插入元素。在下一节中,您将进一步探索这种限制的后果。
[*Remove ads*](/account/join/)
## 理解字典排序的真正含义
因为字典没有太多的重新排序功能,所以在对字典进行排序时,很少会**就地**完成。事实上,没有方法可以显式地移动字典中的条目。
如果您想对字典进行就地排序,那么您必须使用`del`关键字从字典中删除一个条目,然后再添加它。删除然后再次添加实际上将键-值对移动到末尾。
`OrderedDict`类有一个[特定的方法](https://docs.python.org/3/library/collections.html#collections.OrderedDict.move_to_end)来将一个项目移动到末尾或开始,这可能使`OrderedDict`更适合保存一个排序的字典。然而,至少可以说,它仍然不是很常见,也不是很有性能。
对字典进行排序的典型方法是获取一个字典**视图**,对其进行排序,然后将结果列表转换回字典。所以你可以有效地从字典到列表,再回到字典。根据您的用例,您可能不需要将列表转换回字典。
**注意:**排序字典不是一种很常见的模式。在教程的后面,你会探索更多关于这个话题[的内容。](#judging-whether-you-want-to-use-a-sorted-dictionary)
有了这些准备工作,您将在下一部分开始对字典进行排序。
## Python 中的字典排序
在本节中,您将把字典排序的组件放在一起,以便最终掌握字典排序的最常用方法:
>>>
```py
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"}
>>> # Sort by key
>>> dict(sorted(people.items()))
{1: 'Jill', 2: 'Jack', 3: 'Jim', 4: 'Jane'}
>>> # Sort by value
>>> dict(sorted(people.items(), key=lambda item: item[1]))
{2: 'Jack', 4: 'Jane', 1: 'Jill', 3: 'Jim'}
如果您不理解上面的片段,请不要担心,您将在接下来的部分中一步一步地回顾它。在这个过程中,您将学习如何使用带有排序键的sorted()函数、lambda函数和字典构造函数。
使用sorted()功能
您将用来对字典进行排序的关键函数是内置的 sorted() 函数。该函数将一个可迭代的作为主参数,并带有两个可选的仅关键字参数——一个key函数和一个reverse布尔值。
为了孤立地说明sorted()函数的行为,检查它在数字的列表上的使用:
>>> numbers = [5, 3, 4, 3, 6, 7, 3, 2, 3, 4, 1] >>> sorted(numbers) [1, 2, 3, 3, 3, 3, 4, 4, 5, 6, 7]如您所见,
sorted()函数接受一个 iterable,对类似数字的可比元素进行排序,排序顺序为升序,并返回一个新列表。对于字符串,它按照字母顺序排序:
>>> words = ["aa", "ab", "ac", "ba", "cb", "ca"]
>>> sorted(words)
['aa', 'ab', 'ac', 'ba', 'ca', 'cb']
按数字或字母顺序排序是最常见的元素排序方式,但也许您需要更多的控制。
假设您想要对上一个示例中每个单词的第二个字符进行排序。为了定制sorted()函数用来排序元素的内容,您可以将一个回调函数传递给key参数。
回调函数是作为参数传递给另一个函数的函数。对于sorted(),您传递给它一个充当排序键的函数。然后sorted()函数将回调每个元素的排序键。
在下面的示例中,作为键传递的函数接受一个字符串,并将返回该字符串的第二个字符:
>>> def select_second_character(word): ... return word[1] ... >>> sorted(words, key=select_second_character) ['aa', 'ba', 'ca', 'ab', 'cb', 'ac']
sorted()函数将wordsiterable 的每个元素传递给key函数,并使用返回值进行比较。使用键意味着sorted()函数将比较第二个字母,而不是直接比较整个字符串。在教程的后面的中,当你使用参数按照值或嵌套元素对字典进行排序时,会有更多关于参数
key的例子和解释。如果你再看一下最后一次排序的结果,你可能会注意到
sorted()函数的稳定性。这三个元素,aa、ba和ca,当按它们的第二个字符排序时是等价的。因为它们相等,sorted()函数保留了它们的原始顺序。Python 保证了这种稳定性。注意:每个列表也有一个
.sort()方法,与sorted()函数的签名相同。主要区别在于,.sort()方法对列表就地排序。相反,sorted()函数返回一个新的列表,不修改原来的列表。你也可以通过
reverse=True向排序函数或方法返回相反的顺序。或者,您可以使用reversed()函数在排序后反转 iterable:
>>> list(reversed([3, 2, 1]))
[1, 2, 3]
如果您想更深入地了解 Python 中的排序机制,并学习如何对字典以外的数据类型进行排序,那么请查看关于如何使用sorted()和.sort()T3的教程
那么,字典怎么样?实际上,您可以将字典直接输入到sorted()函数中:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"} >>> sorted(people) [1, 2, 3, 4]但是将字典直接传递给
sorted()函数的默认行为是获取字典的个键,对它们进行排序,并返回一个键的列表,只有。这可能不是你想要的行为!为了保存字典中的所有信息,您需要熟悉字典视图。从字典中获取键、值或两者
如果您想在对字典进行排序时保留字典中的所有信息,典型的第一步是调用字典上的
.items()方法。在字典上调用.items()将提供一个表示键值对的元组的 iterable:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"}
>>> people.items()
dict_items([(3, 'Jim'), (2, 'Jack'), (4, 'Jane'), (1, 'Jill')])
.items()方法返回一个只读的字典视图对象,作为进入字典的窗口。这个视图不是副本或列表——它是一个只读的可迭代的,它实际上链接到生成它的字典:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"} >>> view = people.items() >>> people[2] = "Elvis" >>> view dict_items([(3, 'Jim'), (2, 'Elvis'), (4, 'Jane'), (1, 'Jill')])您会注意到对字典的任何更新也会反映在视图中,因为它们是链接的。视图代表了一种轻量级的方式来迭代字典,而不需要首先生成列表。
注意:您可以使用
.values()只获得值的视图,使用.keys()只获得键的视图。至关重要的是,您可以对字典视图使用
sorted()函数。您调用.items()方法,并将结果用作sorted()函数的参数。使用.items()保留字典中的所有信息:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"}
>>> sorted(people.items())
[(1, 'Jill'), (2, 'Jack'), (3, 'Jim'), (4, 'Jane')]
这个例子产生一个元组的排序列表,每个元组代表字典的一个键值对。
如果您想最终得到一个按值排序的字典,那么还有两个问题。默认行为似乎仍然是按键而不是值排序。另一个问题是,你最终得到的是元组的列表,而不是字典。首先,您将了解如何按值排序。
理解 Python 如何排序元组
当在字典上使用.items()方法并将其输入到sorted()函数中时,您传递的是元组的 iterable,而sorted()函数直接比较整个元组。
在比较元组时,Python 的行为很像是按字母顺序对字符串进行排序。也就是说,它按字典顺序对它们进行排序。
字典式排序是指如果你有两个元组,(1, 2, 4)和(1, 2, 3),那么你从比较每个元组的第一项开始。第一项在两种情况下都是1,这是相等的。第二个元素2在两种情况下也是相同的。第三要素分别是4和3。由于3小于4,您已经发现哪个项目比另一个项目少*。
因此,为了按字典顺序排列元组(1, 2, 4)和(1, 2, 3),您可以将它们的顺序切换为(1, 2, 3)和(1, 2, 4)。
由于 Python 对元组的字典排序行为,使用带有sorted()函数的.items()方法将总是按键排序,除非您使用额外的东西。
使用key参数和λ函数
例如,如果您想按值排序,那么您必须指定一个排序键。排序关键字是提取可比值的一种方式。例如,如果您有一堆书,那么您可以使用作者的姓氏作为排序关键字。使用sorted()函数,您可以通过传递回调函数作为key参数来指定排序键。
注意:key参数与字典键无关!
要查看实际的排序键,请看这个例子,它类似于您在介绍sorted()函数的部分看到的例子:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"} >>> # Sort key >>> def value_getter(item): ... return item[1] ... >>> sorted(people.items(), key=value_getter) [(2, 'Jack'), (4, 'Jane'), (1, 'Jill'), (3, 'Jim')] >>> # Or with a lambda function >>> sorted(people.items(), key=lambda item: item[1]) [(2, 'Jack'), (4, 'Jane'), (1, 'Jill'), (3, 'Jim')]在这个例子中,您尝试了两种传递
key参数的方法。key参数接受一个回调函数。该函数可以是一个普通的函数标识符或一个λ函数。示例中的 lambda 函数与value_getter()函数完全等价。注意: Lambda 函数也称为匿名函数,因为它们没有名字。Lambda 函数是在代码中只使用一次的标准函数。
Lambda 函数除了让事情变得更紧凑,消除了单独定义函数的需要之外,没有带来任何好处。它们很好地将事物包含在同一行中:
# With a normal function def value_getter(item): return item[1] sorted(people.items(), key=value_getter) # With a lambda function sorted(people.items(), key=lambda item: item[1])对于示例中的基本 getter 函数,lambdas 可以派上用场。但是 lambdas 会使您的代码对于任何更复杂的东西来说可读性更差,所以要小心使用它们。
Lambdas 也只能包含一个表达式,使得任何多行语句如
if语句或for循环都被禁止。例如,你可以通过使用理解和if表达式来解决这个问题,但是这可能会导致冗长而晦涩的一行程序。
key回调函数将接收它正在排序的 iterable 的每个元素。回调函数的工作是返回可以比较的东西,比如一个数字或者一个字符串。在这个例子中,您将函数命名为value_getter(),因为它所做的只是从一个键值元组中获取值。因为带有元组的
sorted()的默认行为是按字典顺序排序,所以key参数允许您从它比较的元素中选择一个值。在下一节中,您将进一步学习排序键,并使用它们按嵌套值进行排序。
使用排序关键字选择嵌套值
您还可以更进一步,使用排序键选择可能存在或不存在的嵌套值,如果不存在,则返回默认值:
data = { 193: {"name": "John", "age": 30, "skills": {"python": 8, "js": 7}}, 209: {"name": "Bill", "age": 15, "skills": {"python": 6}}, 746: {"name": "Jane", "age": 58, "skills": {"js": 2, "python": 5}}, 109: {"name": "Jill", "age": 83, "skills": {"java": 10}}, 984: {"name": "Jack", "age": 28, "skills": {"c": 8, "assembly": 7}}, 765: {"name": "Penelope", "age": 76, "skills": {"python": 8, "go": 5}}, 598: {"name": "Sylvia", "age": 62, "skills": {"bash": 8, "java": 7}}, 483: {"name": "Anna", "age": 24, "skills": {"js": 10}}, 277: {"name": "Beatriz", "age": 26, "skills": {"python": 2, "js": 4}}, } def get_relevant_skills(item): """Get the sum of Python and JavaScript skill""" skills = item[1]["skills"] # Return default value that is equivalent to no skill return skills.get("python", 0) + skills.get("js", 0) print(sorted(data.items(), key=get_relevant_skills, reverse=True))在本例中,您有一个带有数字键的字典和一个作为值的嵌套字典。您希望按照组合的 Python 和 JavaScript 技能、在
skills子字典中找到的属性进行排序。让综合技能排序变得棘手的部分原因是
python和js键并不存在于所有人的skills字典中。skills字典也是嵌套的。您使用.get()来读取密钥,并提供0作为缺省值,用于缺少的技能。您还使用了
reverse参数,因为您希望顶级 Python 技能首先出现。注意:在这个例子中没有使用 lambda 函数。虽然这是可能的,但它会产生一长串潜在的加密代码:
sorted( data.items(), key=lambda item: ( item[1]["skills"].get("python", 0) + item[1]["skills"].get("js", 0) ), reverse=True, )一个 lambda 函数只能包含一个表达式,所以要在嵌套的
skills子字典中重复完整的查找。这大大增加了线路长度。lambda 函数还需要多个链接的方括号(
[])索引,这使得阅读起来更加困难。在这个例子中使用 lambda 只节省了几行代码,性能差异可以忽略不计。因此,在这些情况下,使用普通函数通常更有意义。您已经成功地使用了一个高阶函数作为排序键来按值对字典视图进行排序。那是困难的部分。现在只剩下一个问题需要解决——将
sorted()生成的列表转换回字典。转换回字典
使用默认行为
sorted()要解决的唯一问题是它返回一个列表,而不是一个字典。有几种方法可以将元组列表转换回字典。您可以用一个
for循环迭代结果,并在每次迭代中填充一个字典:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"}
>>> sorted_people = sorted(people.items(), key=lambda item: item[1])
>>> sorted_people_dict = {}
>>> for key, value in sorted_people:
... sorted_people_dict[key] = value
...
>>> sorted_people_dict
{2: 'Jack', 4: 'Jane', 1: 'Jill', 3: 'Jim'}
这种方法让您在决定如何构建词典时拥有绝对的控制权和灵活性。不过,这个方法输入起来可能会很长。如果您对构造字典没有任何特殊要求,那么您可能希望使用字典构造器:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"} >>> sorted_people = sorted(people.items(), key=lambda item: item[1]) >>> dict(sorted_people) {2: 'Jack', 4: 'Jane', 1: 'Jill', 3: 'Jim'}那个好看又小巧!你也可以使用字典理解,但是这只在你想要改变字典的形状或者交换键和值的时候才有意义。在下面的理解中,您交换了键和值:
>>> {
... value: key ... for key, value in sorted(people.items(), key=lambda item: item[1]) ... }
...
{'Jack': 2, 'Jane': 4, 'Jill': 1, 'Jim': 3}
根据你或你的团队对理解的熟悉程度,这可能比仅仅使用一个普通的for循环可读性差。
恭喜你,你已经得到了你的分类词典!你现在可以根据你喜欢的任何标准对它进行分类。
现在您可以对字典进行排序了,您可能想知道使用排序的字典是否会对性能产生影响,或者对于键值数据是否有替代的数据结构。
考虑战略和性能问题
在这一节中,您将快速浏览一些性能调整、策略考虑以及关于如何使用键值数据的问题。
注意:如果你决定去订购集合,检查一下分类容器包,其中包括一个 SortedDict 。
您将利用 timeit 模块来获取一些指标。重要的是要记住,要对性能做出任何可靠的结论,您需要在各种硬件上进行测试,并使用各种类型和大小的样本。
最后,请注意,您不会详细讨论如何使用timeit。为此,请查看关于 Python 定时器的教程。不过,您将有一些示例可以使用。
使用特殊的 Getter 函数来提高性能和可读性
您可能已经注意到,到目前为止,您使用的大多数排序键功能都没有发挥多大作用。这个函数所做的就是从一个元组中获取一个值。创建 getter 函数是一种非常常见的模式,Python 有一种特殊的方法来创建比常规函数更快获取值的特殊函数。
itemgetter() 函数可以产生高效版本的 getter 函数。
您传递给itemgetter()一个参数,它通常是您想要选择的键或索引位置。然后,itemgetter()函数将返回一个 getter 对象,您可以像调用函数一样调用它。
没错,就是返回函数的函数。使用itemgetter()函数是使用高阶函数的另一个例子。
来自itemgetter()的 getter 对象将在传递给它的项目上调用.__getitem__()方法。当某个东西调用.__getitem__()时,它需要传入要获取什么的键或索引。用于.__getitem__()的参数与传递给itemgetter()的参数相同:
>>> item = ("name", "Guido") >>> from operator import itemgetter >>> getter = itemgetter(0) >>> getter(item) 'name' >>> getter = itemgetter(1) >>> getter(item) 'Guido'在这个例子中,我们从一个 tuple 开始,类似于作为字典视图的一部分得到的 tuple。
您通过将
0作为参数传递给itemgetter()来创建第一个 getter。当结果 getter 接收到元组时,它返回元组中的第一项——索引0处的值。如果你用一个参数1调用itemgetter(),那么它会得到索引位置1的值。您可以使用这个 itemgetter 作为
sorted()函数的键:
>>> from operator import itemgetter
>>> fruit_inventory = [
... ("banana", 5), ("orange", 15), ("apple", 3), ("kiwi", 0)
... ]
>>> # Sort by key
>>> sorted(fruit_inventory, key=itemgetter(0))
[('apple', 3), ('banana', 5), ('kiwi', 0), ('orange', 15)]
>>> # Sort by value
>>> sorted(fruit_inventory, key=itemgetter(1))
[('kiwi', 0), ('apple', 3), ('banana', 5), ('orange', 15)]
>>> sorted(fruit_inventory, key=itemgetter(2))
Traceback (most recent call last):
File "<input>", line 1, in <module>
sorted(fruit_inventory, key=itemgetter(2))
IndexError: tuple index out of range
在这个例子中,首先使用带有0的itemgetter()作为参数。因为它对来自fruit_inventory变量的每个元组进行操作,所以它从每个元组中获取第一个元素。然后这个例子演示了用1作为参数初始化一个itemgetter,它选择了元组中的第二项。
最后,这个例子展示了如果您将itemgetter()和2一起用作参数会发生什么。因为这些元组只有两个索引位置,所以试图获取索引为2的第三个元素会导致一个IndexError。
您可以使用由itemgetter()产生的函数来代替您到目前为止一直使用的 getter 函数:
>>> people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"} >>> from operator import itemgetter >>> sorted(people.items(), key=itemgetter(1)) [(2, 'Jack'), (4, 'Jane'), (1, 'Jill'), (3, 'Jim')]
itemgetter()函数产生的函数与前面章节中的value_getter()函数具有完全相同的效果。你想使用itemgetter()的函数的主要原因是因为它更有效。在下一节中,您将开始给出一些数字,说明它的效率究竟有多高。使用
itemgetter()和测量性能因此,您最终得到了一个行为类似于前面章节中的原始
value_getter()的函数,除了从itemgetter()返回的版本更有效。您可以使用timeit模块来比较它们的性能:# compare_lambda_vs_getter.py from timeit import timeit dict_to_order = { 1: "requests", 2: "pip", 3: "jinja", 4: "setuptools", 5: "pandas", 6: "numpy", 7: "black", 8: "pillow", 9: "pyparsing", 10: "boto3", 11: "botocore", 12: "urllib3", 13: "s3transfer", 14: "six", 15: "python-dateutil", 16: "pyyaml", 17: "idna", 18: "certifi", 19: "typing-extensions", 20: "charset-normalizer", 21: "awscli", 22: "wheel", 23: "rsa", } sorted_with_lambda = "sorted(dict_to_order.items(), key=lambda item: item[1])" sorted_with_itemgetter = "sorted(dict_to_order.items(), key=itemgetter(1))" sorted_with_lambda_time = timeit(stmt=sorted_with_lambda, globals=globals()) sorted_with_itemgetter_time = timeit( stmt=sorted_with_itemgetter, setup="from operator import itemgetter", globals=globals(), ) print( f"""\ {sorted_with_lambda_time=:.2f} seconds {sorted_with_itemgetter_time=:.2f} seconds itemgetter is {( sorted_with_lambda_time / sorted_with_itemgetter_time ):.2f} times faster""" )这段代码使用
timeit模块来比较来自itemgetter()的函数和 lambda 函数的排序过程。从 shell 中运行这个脚本应该会得到与下面类似的结果:
$ python compare_lambda_vs_getter.py sorted_with_lambda_time=1.81 seconds sorted_with_itemgetter_time=1.29 seconds itemgetter is 1.41 times faster大约 40%的节约意义重大!
请记住,在对代码执行进行计时时,系统之间的时间可能会有很大差异。也就是说,在这种情况下,比率应该在系统间相对稳定。
从这个测试的结果可以看出,从性能的角度来看,使用
itemgetter()更好。另外,它是 Python 标准库的一部分,所以使用它是免费的。注意:在这个测试中,使用 lambda 和普通函数作为排序关键字的区别可以忽略不计。
要不要比较一下这里没有涉及到的一些操作的性能?请务必在评论中分享结果!
现在,您可以从字典排序中获得更多的性能,但是值得后退一步,考虑使用排序的字典作为您的首选数据结构是否是最佳选择。毕竟,排序字典不是一种非常常见的模式。
接下来,你会问自己一些问题,关于你想用你的排序字典做什么,以及它是否是你的用例的最佳数据结构。
判断是否要使用分类词典
如果您正在考虑创建一个排序的键值数据结构,那么您可能需要考虑一些事情。
如果您要将数据添加到字典中,并且希望数据保持有序,那么您最好使用元组列表或字典列表这样的结构:
# Dictionary people = {3: "Jim", 2: "Jack", 4: "Jane", 1: "Jill"} # List of tuples people = [ (3, "Jim"), (2, "Jack"), (4, "Jane"), (1, "Jill") ] # List of dictionaries people = [ {"id": 3, "name": "Jim"}, {"id": 2, "name": "Jack"}, {"id": 4, "name": "Jane"}, {"id": 1, "name": "Jill"}, ]字典列表是最普遍的模式,因为它的跨语言兼容性,被称为语言互操作性。
例如,如果您创建了一个 HTTP REST API ,那么语言互操作性尤其重要。让你的数据在互联网上可用很可能意味着在 JSON 中序列化它。
如果有人使用 JavaScript 来消费 REST API 中的 JSON 数据,那么等价的数据结构就是一个对象。有趣的是,JavaScript 对象是没有顺序的*,所以顺序会被打乱!
这种混乱的行为对许多语言来说都是真实的,对象甚至在 JSON 规范中被定义为一种无序的数据结构。因此,如果您在序列化到 JSON 之前仔细订购了字典,那么当它进入大多数其他环境时,这就无关紧要了。
注意:标记一个有序的键值对序列可能不仅仅与将 Python 字典序列化为 JSON 相关。想象一下,你的团队中有人习惯了其他语言。有序字典对他们来说可能是一个陌生的概念,所以您可能需要明确您已经创建了一个有序的数据结构。
在 Python 中明确拥有有序字典的一种方式是使用恰当命名的
OrderedDict。另一个选择是,如果不需要,就不要担心数据的排序。包括每个对象的
id、priority或其他等价属性足以表达顺序。如果由于某种原因,排序混淆了,那么总会有一种明确的方法来排序:people = { 3: {"priority": 2, "name": "Jim"}, 2: {"priority": 4, "name": "Jack"}, 4: {"priority": 1, "name": "Jane"}, 1: {"priority": 2, "name": "Jill"} }例如,对于一个
priority属性,很明显Jane应该排在第一位。明确你想要的顺序很好地符合了古老的 Python 格言显式比隐式好,来自 Python 的禅。但是,使用字典列表和字典词典在性能上有什么权衡呢?在下一节中,您将开始获得关于这个问题的一些数据。
比较不同数据结构的性能
如果性能是一个考虑因素—例如,也许您将使用大型数据集—那么您应该仔细考虑您将使用字典做什么。
在接下来的几节中,您将寻求回答的两个主要问题是:
- 你会排序一次,然后进行大量的查找吗?
- 你会进行多次排序而很少查找吗?
一旦您决定了您的数据结构将遵循什么样的使用模式,那么您就可以使用
timeit模块来测试性能。这些测量值会随着被测数据的确切形状和大小而有很大变化。在这个例子中,您将比较字典的字典和字典的列表,看看它们在性能方面有什么不同。您将使用以下示例数据对排序操作和查找操作进行计时:
# samples.py dictionary_of_dictionaries = { 1: {"first_name": "Dorthea", "last_name": "Emmanuele", "age": 29}, 2: {"first_name": "Evelina", "last_name": "Ferras", "age": 91}, 3: {"first_name": "Frederica", "last_name": "Livesay", "age": 99}, 4: {"first_name": "Murray", "last_name": "Linning", "age": 36}, 5: {"first_name": "Annette", "last_name": "Garioch", "age": 93}, 6: {"first_name": "Rozamond", "last_name": "Todd", "age": 36}, 7: {"first_name": "Tiffi", "last_name": "Varian", "age": 28}, 8: {"first_name": "Noland", "last_name": "Cowterd", "age": 51}, 9: {"first_name": "Dyana", "last_name": "Fallows", "age": 100}, 10: {"first_name": "Diahann", "last_name": "Cutchey", "age": 44}, 11: {"first_name": "Georgianne", "last_name": "Steinor", "age": 32}, 12: {"first_name": "Sabina", "last_name": "Lourens", "age": 31}, 13: {"first_name": "Lynde", "last_name": "Colbeck", "age": 35}, 14: {"first_name": "Abdul", "last_name": "Crisall", "age": 84}, 15: {"first_name": "Quintus", "last_name": "Brando", "age": 95}, 16: {"first_name": "Rowena", "last_name": "Geraud", "age": 21}, 17: {"first_name": "Maurice", "last_name": "MacAindreis", "age": 83}, 18: {"first_name": "Pall", "last_name": "O'Cullinane", "age": 79}, 19: {"first_name": "Kermie", "last_name": "Willshere", "age": 20}, 20: {"first_name": "Holli", "last_name": "Tattoo", "age": 88} } list_of_dictionaries = [ {"id": 1, "first_name": "Dorthea", "last_name": "Emmanuele", "age": 29}, {"id": 2, "first_name": "Evelina", "last_name": "Ferras", "age": 91}, {"id": 3, "first_name": "Frederica", "last_name": "Livesay", "age": 99}, {"id": 4, "first_name": "Murray", "last_name": "Linning", "age": 36}, {"id": 5, "first_name": "Annette", "last_name": "Garioch", "age": 93}, {"id": 6, "first_name": "Rozamond", "last_name": "Todd", "age": 36}, {"id": 7, "first_name": "Tiffi", "last_name": "Varian", "age": 28}, {"id": 8, "first_name": "Noland", "last_name": "Cowterd", "age": 51}, {"id": 9, "first_name": "Dyana", "last_name": "Fallows", "age": 100}, {"id": 10, "first_name": "Diahann", "last_name": "Cutchey", "age": 44}, {"id": 11, "first_name": "Georgianne", "last_name": "Steinor", "age": 32}, {"id": 12, "first_name": "Sabina", "last_name": "Lourens", "age": 31}, {"id": 13, "first_name": "Lynde", "last_name": "Colbeck", "age": 35}, {"id": 14, "first_name": "Abdul", "last_name": "Crisall", "age": 84}, {"id": 15, "first_name": "Quintus", "last_name": "Brando", "age": 95}, {"id": 16, "first_name": "Rowena", "last_name": "Geraud", "age": 21}, {"id": 17, "first_name": "Maurice", "last_name": "MacAindreis", "age": 83}, {"id": 18, "first_name": "Pall", "last_name": "O'Cullinane", "age": 79}, {"id": 19, "first_name": "Kermie", "last_name": "Willshere", "age": 20}, {"id": 20, "first_name": "Holli", "last_name": "Tattoo", "age": 88} ]每个数据结构都有相同的信息,除了一个是字典的字典结构,另一个是字典的列表。首先,您将获得对这两种数据结构进行排序的一些性能指标。
比较排序的性能
在下面的代码中,您将使用
timeit来比较通过age属性对两个数据结构进行排序所花费的时间:# compare_sorting_dict_vs_list.py from timeit import timeit from samples import dictionary_of_dictionaries, list_of_dictionaries sorting_list = "sorted(list_of_dictionaries, key=lambda item:item['age'])" sorting_dict = """ dict( sorted( dictionary_of_dictionaries.items(), key=lambda item: item[1]['age'] ) ) """ sorting_list_time = timeit(stmt=sorting_list, globals=globals()) sorting_dict_time = timeit(stmt=sorting_dict, globals=globals()) print( f"""\ {sorting_list_time=:.2f} seconds {sorting_dict_time=:.2f} seconds list is {(sorting_dict_time/sorting_list_time):.2f} times faster""" )这段代码导入样本数据结构,用于对
age属性进行排序。看起来你好像没有使用来自samples的导入,但是这些样本必须在全局名称空间中,这样timeit上下文才能访问它们。在命令行上运行这个测试的代码应该会为您提供一些有趣的结果:
$ python compare_sorting_dict_vs_list.py sorting_list_time=1.15 seconds sorting_dict_time=2.26 seconds list is 1.95 times faster对列表进行排序的速度几乎是对字典视图进行排序然后创建新的排序字典的速度的两倍。因此,如果您计划非常有规律地对数据进行排序,那么元组列表可能比字典更适合您。
注意:从这样的单一数据集无法得出多少可靠的结论。此外,对于不同大小或形状的数据,结果可能会有很大差异。
这些例子是让你接触
timeit模块的一种方式,并开始了解如何以及为什么你可能会使用它。这将为您提供一些测试数据结构所必需的工具,帮助您决定为您的键值对选择哪种数据结构。如果您需要额外的性能,那么就继续为您的特定数据结构计时。也就是说,当心过早优化!
与列表相比,对字典进行排序的主要开销之一是在排序后重建字典。如果您去掉了外部的
dict()构造函数,那么您将大大减少执行时间。在下一节中,您将看到在字典和字典列表中查找值所花费的时间。
比较查找的性能
但是,如果您计划使用字典对数据进行一次排序,并且主要使用字典进行查找,那么字典肯定比列表更有意义:
# compare_lookup_dict_vs_list.py from timeit import timeit from samples import dictionary_of_dictionaries, list_of_dictionaries lookups = [15, 18, 19, 16, 6, 12, 5, 3, 9, 20, 2, 10, 13, 17, 4, 14, 11, 7, 8] list_setup = """ def get_key_from_list(key): for item in list_of_dictionaries: if item["id"] == key: return item """ lookup_list = """ for key in lookups: get_key_from_list(key) """ lookup_dict = """ for key in lookups: dictionary_of_dictionaries[key] """ lookup_list_time = timeit(stmt=lookup_list, setup=list_setup, globals=globals()) lookup_dict_time = timeit(stmt=lookup_dict, globals=globals()) print( f"""\ {lookup_list_time=:.2f} seconds {lookup_dict_time=:.2f} seconds dict is {(lookup_list_time / lookup_dict_time):.2f} times faster""" )这段代码对列表和字典进行了一系列的查找。您会注意到,对于这个列表,您必须编写一个特殊的函数来进行查找。进行列表查找的函数涉及到逐个检查所有列表元素,直到找到目标元素,这并不理想。
从命令行运行这个比较脚本应该会产生一个结果,显示字典查找明显更快:
$ python compare_lookup_dict_vs_list.py lookup_list_time=6.73 seconds lookup_dict_time=0.38 seconds dict is 17.83 times faster快了将近十八倍!那是一大堆。因此,您肯定希望权衡字典查找的高速和数据结构的慢速排序。请记住,这个比率在不同的系统之间可能会有很大的差异,更不用说不同大小的字典或列表可能带来的差异了。
不过,无论你如何分割,字典查找肯定会更快。也就是说,如果你只是在做查找,那么你可以用一个普通的未排序的字典来做。在这种情况下,为什么需要一个分类词典呢?在评论中留下你的用例吧!
注意:您可以尝试优化列表查找,例如通过实现二分搜索法算法来减少列表查找的时间。然而,只有在列表很大的情况下,好处才会变得明显。
对于这里测试的列表大小,使用带有
bisect模块的二分搜索法要比常规的for循环慢得多。现在您应该对存储键值数据的两种方法之间的一些权衡有了一个相对较好的想法。您可以得出的结论是,大多数时候,如果您想要一个排序的数据结构,那么您可能应该避开字典,主要是出于语言互操作性的原因。
也就是说,给格兰特·詹克斯的前面提到的排序词典一个尝试。它使用一些巧妙的策略来规避典型的性能缺陷。
对于排序的键值数据结构,你有什么有趣的或者高性能的实现吗?在评论中分享它们,以及你的排序字典的用例!
结论
您已经从对字典进行排序的最基本方法发展到了一些考虑对键-值对进行排序的高级方法。
在本教程中,您已经:
- 复习了
sorted()功能- 发现的字典视图
- 了解字典在排序过程中如何转换为列表
- 指定的排序关键字按值、关键字或嵌套属性对字典进行排序
- 使用字典的理解和
dict()的构造器来重建你的字典- 考虑一个排序的字典是否是你的键值数据的正确的数据结构
现在,您不仅可以根据您可能想到的任何标准对词典进行排序,还可以判断排序后的词典是否是您的最佳选择。
在下面的评论中分享你的排序字典用例以及性能比较!
免费下载: 点击这里下载代码,您将在本教程中使用它对键-值对进行排序。*********
Python 中的排序算法
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中排序算法介绍
排序是一个基本的构建模块,许多其他算法都是基于它构建的。它与你在整个编程生涯中会看到的几个令人兴奋的想法有关。理解 Python 中排序算法的幕后工作方式是实现解决现实问题的正确高效算法的基本步骤。
在本教程中,您将学习:
- Python 中不同的排序算法如何工作,以及它们在不同环境下如何比较
- Python 的内置排序功能如何在幕后工作
- 不同的计算机科学概念,如递归和分治如何应用于排序
- 如何用大 O 记法和 Python 的
timeit模块来衡量一个算法的效率在本教程结束时,你将从理论和实践的角度理解排序算法。更重要的是,你将对不同的算法设计技术有更深的理解,这些技术可以应用到你工作的其他领域。我们开始吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 中排序算法的重要性
排序是计算机科学中研究得最透彻的算法之一。有几十种不同的排序实现和应用程序可以用来提高代码的效率和效果。
您可以使用排序来解决各种问题:
搜索:如果对列表进行排序,那么在列表中搜索一个项目会快得多。
选择:使用排序的数据,根据条目与其他条目的关系从列表中选择条目更容易。例如,当值按升序或降序排列时,找到第 k 第T5】个最大值或最小值,或者找到列表的中值就容易得多。
Duplicates: 在对列表进行排序时,可以非常快速地找到列表中的重复值。
分布:分析列表上项目的频率分布,如果对列表进行排序,速度非常快。例如,使用排序列表,查找出现频率最高或最低的元素相对简单。
从商业应用到学术研究,以及介于两者之间的任何领域,有无数种方法可以让你利用排序来节省时间和精力。
Python 内置的排序算法
Python 语言,像许多其他高级编程语言一样,提供了使用
sorted()对开箱即用的数据进行排序的能力。下面是一个对整数数组进行排序的示例:
>>> array = [8, 2, 6, 4, 5]
>>> sorted(array)
[2, 4, 5, 6, 8]
您可以使用sorted()对任何列表进行排序,只要列表中的值具有可比性。
注意:要更深入地了解 Python 内置的排序功能是如何工作的,请查看如何在 Python 中使用 sorted()和 sort()和用 Python 排序数据。
时间复杂性的意义
本教程涵盖了两种不同的方法来测量排序算法的运行时间:
- 从实用的角度来看,您将使用
timeit模块测量实现的运行时间。 - 从更理论的角度来看,您将使用 大 O 符号 来测量算法的运行时复杂度。
为您的代码计时
在比较 Python 中的两种排序算法时,查看每种算法运行的时间总是有帮助的。每个算法花费的具体时间将部分由您的硬件决定,但是您仍然可以使用执行之间的比例时间来帮助您决定哪个实现更节省时间。
在这一节中,您将关注一种使用timeit模块来测量运行排序算法所花费的实际时间的实用方法。关于在 Python 中计时代码执行的不同方法的更多信息,请查看 Python 计时器函数:监控代码的三种方法。
这里有一个函数,你可以用它来为你的算法计时:
1from random import randint
2from timeit import repeat
3
4def run_sorting_algorithm(algorithm, array):
5 # Set up the context and prepare the call to the specified
6 # algorithm using the supplied array. Only import the
7 # algorithm function if it's not the built-in `sorted()`.
8 setup_code = f"from __main__ import {algorithm}" \
9 if algorithm != "sorted" else ""
10
11 stmt = f"{algorithm}({array})"
12
13 # Execute the code ten different times and return the time
14 # in seconds that each execution took
15 times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
16
17 # Finally, display the name of the algorithm and the
18 # minimum time it took to run
19 print(f"Algorithm: {algorithm}. Minimum execution time: {min(times)}")
在这个例子中,run_sorting_algorithm()接收算法的名称和需要排序的输入数组。以下是对其工作原理的逐行解释:
-
第 8 行使用 Python 的 f 字符串的魔力导入算法的名称。这是为了让
timeit.repeat()知道从哪里调用算法。请注意,这只对于本教程中使用的自定义实现是必要的。如果指定的算法是内置的sorted(),则不会导入任何内容。 -
第 11 行用提供的数组准备对算法的调用。这是将要执行和计时的语句。
-
第 15 行用设置代码和语句调用
timeit.repeat()。这将调用指定的排序算法十次,返回每次执行所用的秒数。 -
第 19 行标识返回的最短时间,并将其与算法名称一起打印出来。
注意:一个常见的误解是,你应该找到算法每次运行的平均时间,而不是选择单个最短时间。时间测量是噪声,因为系统同时运行其他进程。最短的时间总是最少的噪音,使其成为算法真实运行时间的最佳表示。
下面是一个如何使用run_sorting_algorithm()来确定使用sorted()对一万个整数值的数组进行排序所需时间的例子:
21ARRAY_LENGTH = 10000
22
23if __name__ == "__main__":
24 # Generate an array of `ARRAY_LENGTH` items consisting
25 # of random integer values between 0 and 999
26 array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
27
28 # Call the function using the name of the sorting algorithm
29 # and the array you just created
30 run_sorting_algorithm(algorithm="sorted", array=array)
如果您将上面的代码保存在一个sorting.py文件中,那么您可以从终端运行它并查看它的输出:
$ python sorting.py
Algorithm: sorted. Minimum execution time: 0.010945824000000007
请记住,每个实验的时间(以秒为单位)部分取决于您使用的硬件,因此在运行代码时,您可能会看到略有不同的结果。
注:你可以在官方 Python 文档中了解更多关于timeit模块的内容。
用大 O 符号测量效率
一个算法运行的具体时间不足以得到它的 、时间复杂度 的全貌。要解决这个问题,可以使用大 O(读作“大 oh”)符号。大 O 通常用于比较不同的实现,并决定哪一个是最有效的,跳过不必要的细节,专注于算法运行时最重要的内容。
运行不同算法所需的时间(以秒计)会受到几个不相关因素的影响,包括处理器速度或可用内存。另一方面,Big O 提供了一个平台,用与硬件无关的术语来表达运行时的复杂性。使用大 O,您可以根据算法的运行时相对于输入大小的增长速度来表示复杂性,尤其是当输入增长到任意大时。
假设 n 是算法输入的大小,大 O 符号表示 n 和算法寻找解的步骤数之间的关系。大 O 用一个大写字母“O”后跟括号内的这个关系。例如, O(n) 表示执行与输入大小成比例的多个步骤的算法。
虽然本教程不会深入大 O 符号的细节,但这里有五个不同算法的运行时复杂性的例子:
| 大 O | 复杂性 | 描述 |
|---|---|---|
| O(1) | 常数 | 无论输入的大小如何,运行时都是恒定的。在散列表中寻找元素是可以在常数时间中执行的操作的一个例子。 |
| O(n) | 线性的 | 运行时随着输入的大小线性增长。检查列表中每一项的条件的函数就是一个 O(n) 算法的例子。 |
| O(n 2 ) | 二次的 | 运行时间是输入大小的二次函数。在列表中查找重复值的简单实现是二次算法的一个例子,其中每个项目都要检查两次。 |
| O(2 n ) | 指数的 | 运行时随着输入的大小呈指数增长。这些算法被认为效率极低。指数算法的一个例子是三色问题。 |
| O(对数 n) | 对数的 | 运行时呈线性增长,而输入的大小呈指数增长。例如,如果处理一千个元素需要一秒钟,那么处理一万个元素需要两秒钟,处理十万个元素需要三秒钟,以此类推。二分搜索法是对数运行时算法的一个例子。 |
本教程涵盖了所讨论的每种排序算法的运行时复杂性。它还包括如何在每个特定情况下确定运行时间的简要说明。这会让你更好地理解如何开始使用大 O 来分类其他算法。
注:为了更深入的了解大 O,结合 Python 中的几个实际例子,查看大 O 记法和算法分析结合 Python 例子。
Python 中的冒泡排序算法
冒泡排序是最直接的排序算法之一。它的名字来源于算法的工作方式:随着每一次新的传递,列表中最大的元素向正确的位置“冒泡”。
冒泡排序包括多次遍历一个列表,逐个比较元素,并交换相邻的无序项。
在 Python 中实现冒泡排序
下面是一个用 Python 实现的冒泡排序算法:
1def bubble_sort(array):
2 n = len(array)
3
4 for i in range(n):
5 # Create a flag that will allow the function to
6 # terminate early if there's nothing left to sort
7 already_sorted = True
8
9 # Start looking at each item of the list one by one,
10 # comparing it with its adjacent value. With each
11 # iteration, the portion of the array that you look at
12 # shrinks because the remaining items have already been
13 # sorted.
14 for j in range(n - i - 1):
15 if array[j] > array[j + 1]:
16 # If the item you're looking at is greater than its
17 # adjacent value, then swap them
18 array[j], array[j + 1] = array[j + 1], array[j]
19
20 # Since you had to swap two elements,
21 # set the `already_sorted` flag to `False` so the
22 # algorithm doesn't finish prematurely
23 already_sorted = False
24
25 # If there were no swaps during the last iteration,
26 # the array is already sorted, and you can terminate
27 if already_sorted:
28 break
29
30 return array
因为这个实现以升序对数组进行排序,所以每一步都将最大的元素“冒泡”到数组的末尾。这意味着每次迭代比前一次迭代需要更少的步骤,因为数组的连续更大部分被排序。
第 4 行和第 10 行中的循环决定了算法遍历列表的方式。注意j最初是如何从列表中的第一个元素移动到最后一个元素之前的元素的。在第二次迭代中,j一直运行到最后两个项目,然后是最后三个项目,依此类推。在每次迭代结束时,列表的末尾部分将被排序。
随着循环的进行,行 15 将每个元素与其相邻的值进行比较,行 18 如果它们的顺序不正确就交换它们。这确保了函数末尾的排序列表。
注意:上面代码的第行第 13、23 和 27 行中的already_sorted标志是对算法的优化,在全功能的冒泡排序实现中不需要。但是,如果在循环结束之前列表已经全部排序,它允许函数保存不必要的步骤。
作为一个练习,您可以删除这个标志的使用,并比较两种实现的运行时。
为了正确分析算法是如何工作的,考虑一个值为[8, 2, 6, 4, 5]的列表。假设你从上面使用bubble_sort()。下图展示了算法每次迭代时数组的样子:
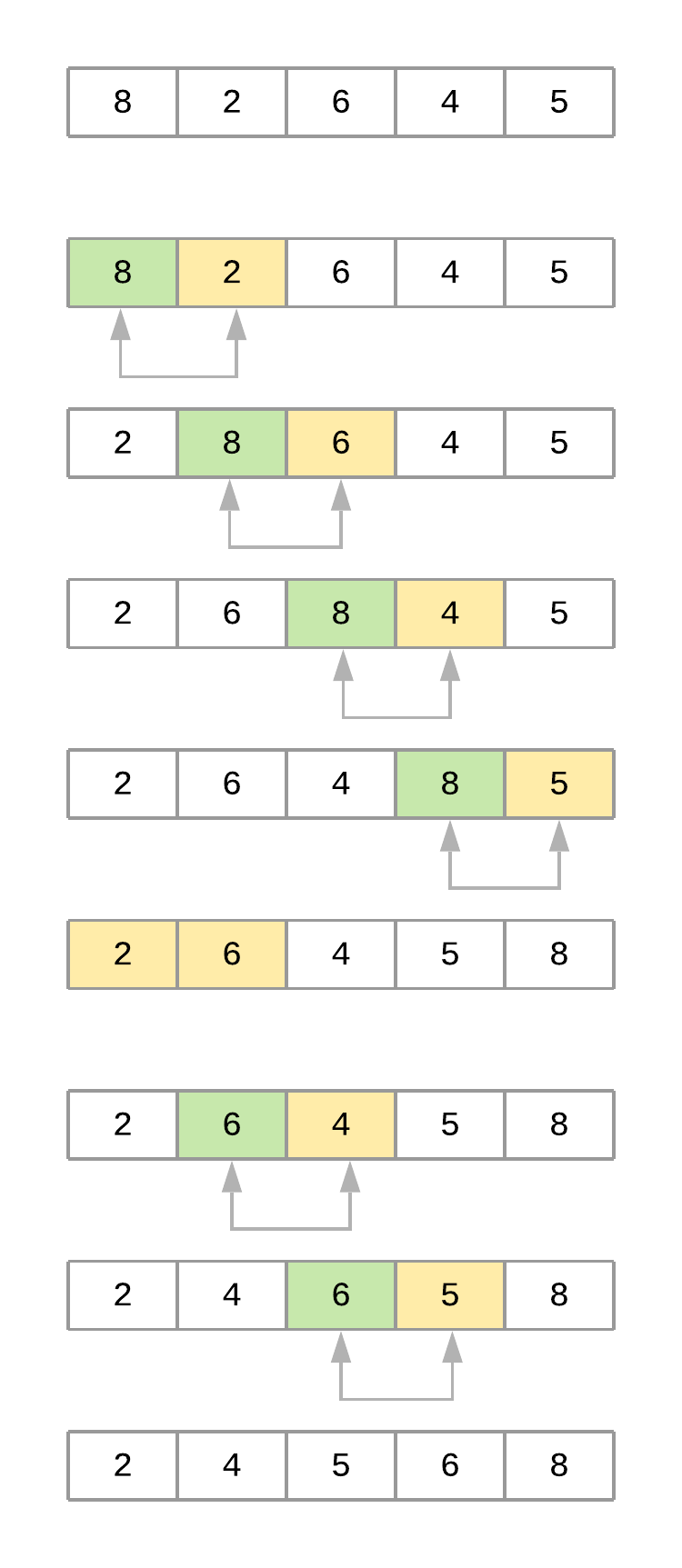
现在,随着算法的进展,让我们一步一步地看看阵列发生了什么:
-
代码首先将第一个元素
8与其相邻的元素2进行比较。由于8 > 2,值被交换,导致如下顺序:[2, 8, 6, 4, 5]。 -
然后,该算法将第二个元素
8与其相邻元素6进行比较。由于8 > 6,值被交换,导致如下顺序:[2, 6, 8, 4, 5]。 -
接下来,该算法将第三个元素
8与其相邻元素4进行比较。自从8 > 4以来,它也交换了值,产生了下面的顺序:[2, 6, 4, 8, 5]。 -
最后,该算法将第四个元素
8与其相邻元素5进行比较,并交换它们,得到[2, 6, 4, 5, 8]。此时,算法完成了对列表的第一次遍历(i = 0)。注意值8是如何从初始位置上升到列表末尾的正确位置的。 -
第二遍(
i = 1)考虑到列表的最后一个元素已经被定位,并关注剩余的四个元素[2, 6, 4, 5]。在这一过程结束时,值6找到了它的正确位置。第三次遍历列表定位值5,依此类推,直到列表被排序。
测量冒泡排序的运行时间复杂度
您的冒泡排序实现由两个嵌套的 for循环组成,其中算法执行 n - 1 比较,然后是 n - 2 比较,依此类推,直到完成最终比较。这样总共有(n-1)+(n-2)+(n-3)+…+2+1 = n(n-1)/2个比较,也可以写成 n 2 - n 。
您之前已经了解到,Big O 关注的是运行时相对于输入大小的增长情况。这意味着,为了将上述等式转化为算法的大 O 复杂度,您需要移除常数,因为它们不会随着输入大小而改变。
这样做将符号简化为 n 2 - n 。由于 n 2 比 n 增长得快得多,所以最后一项也可以去掉,留下平均和最坏情况复杂度为O(n2)的冒泡排序。
在算法接收到一个已经排序的数组的情况下——假设实现包括前面解释的already_sorted标志优化——运行时复杂性将下降到更好的 O(n) ,因为算法不需要访问任何元素超过一次。
那么, O(n) 就是冒泡排序的最佳运行时复杂度。但是请记住,最好的情况是一个例外,在比较不同的算法时,您应该关注平均情况。
计时你的冒泡排序实现
使用本教程前面的run_sorting_algorithm(),下面是冒泡排序处理一个包含一万个条目的数组所需的时间。第 8 行替换了算法的名称,其他内容保持不变:
1if __name__ == "__main__":
2 # Generate an array of `ARRAY_LENGTH` items consisting
3 # of random integer values between 0 and 999
4 array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
5
6 # Call the function using the name of the sorting algorithm
7 # and the array you just created
8 run_sorting_algorithm(algorithm="bubble_sort", array=array)
您现在可以运行脚本来获取bubble_sort的执行时间:
$ python sorting.py
Algorithm: bubble_sort. Minimum execution time: 73.21720498399998
对包含一万个元素的数组进行排序花费了73秒。这代表了run_sorting_algorithm()运行的十次重复中最快的一次。多次执行这个脚本会产生类似的结果。
注意:单次执行冒泡排序需要73秒,但是算法使用timeit.repeat()运行了十次。这意味着,假设你有相似的硬件特征,你应该预期你的代码需要大约73 * 10 = 730秒来运行。速度较慢的机器可能需要更长的时间才能完成。
分析冒泡排序的优缺点
冒泡排序算法的主要优点是它的简单性。实现和理解都很简单。这可能是大多数计算机科学课程引入使用冒泡排序的主题的主要原因。
正如你之前看到的,冒泡排序的缺点是慢,运行时复杂度为 O(n 2 ) 。不幸的是,这排除了它作为排序大型数组的实际候选。
Python 中的插入排序算法
像冒泡排序一样,插入排序算法易于实现和理解。但与冒泡排序不同,它通过将每个项目与列表的其余部分进行比较,并将其插入到正确的位置,来一次一个元素地构建排序列表。这种“插入”过程给了算法它的名字。
解释插入排序的一个很好的类比是你排序一副卡片的方式。想象你手里拿着一组卡片,你想把它们按顺序排列。你首先要一步一步地将一张卡片与其余的卡片进行比较,直到你找到它的正确位置。这时,你将卡片插入正确的位置,并重新开始一张新卡片,重复直到你手中的所有卡片都被分类。
在 Python 中实现插入排序
插入排序算法的工作方式与卡片组的例子完全一样。下面是 Python 中的实现:
1def insertion_sort(array):
2 # Loop from the second element of the array until
3 # the last element
4 for i in range(1, len(array)):
5 # This is the element we want to position in its
6 # correct place
7 key_item = array[i]
8
9 # Initialize the variable that will be used to
10 # find the correct position of the element referenced
11 # by `key_item`
12 j = i - 1
13
14 # Run through the list of items (the left
15 # portion of the array) and find the correct position
16 # of the element referenced by `key_item`. Do this only
17 # if `key_item` is smaller than its adjacent values.
18 while j >= 0 and array[j] > key_item:
19 # Shift the value one position to the left
20 # and reposition j to point to the next element
21 # (from right to left)
22 array[j + 1] = array[j]
23 j -= 1
24
25 # When you finish shifting the elements, you can position
26 # `key_item` in its correct location
27 array[j + 1] = key_item
28
29 return array
与冒泡排序不同,插入排序的这种实现通过将较小的项目推到左边来构造排序列表。让我们一行一行地分解insertion_sort():
-
第 4 行建立了一个循环,该循环决定了函数在每次迭代中定位的
key_item。注意,循环从列表中的第二项开始,一直到最后一项。 -
第 7 行用函数试图放置的项目初始化
key_item。 -
第 12 行初始化一个变量,该变量将连续指向
key item左侧的每个元素。这些是将与key_item连续比较的元素。 -
第 18 行使用一个
while循环将key_item与其左边的每个值进行比较,移动元素以腾出空间来放置key_item。 -
第 27 行在算法将所有较大的值向右移动后,将
key_item定位在其正确的位置。
下图展示了对数组[8, 2, 6, 4, 5]排序时算法的不同迭代:
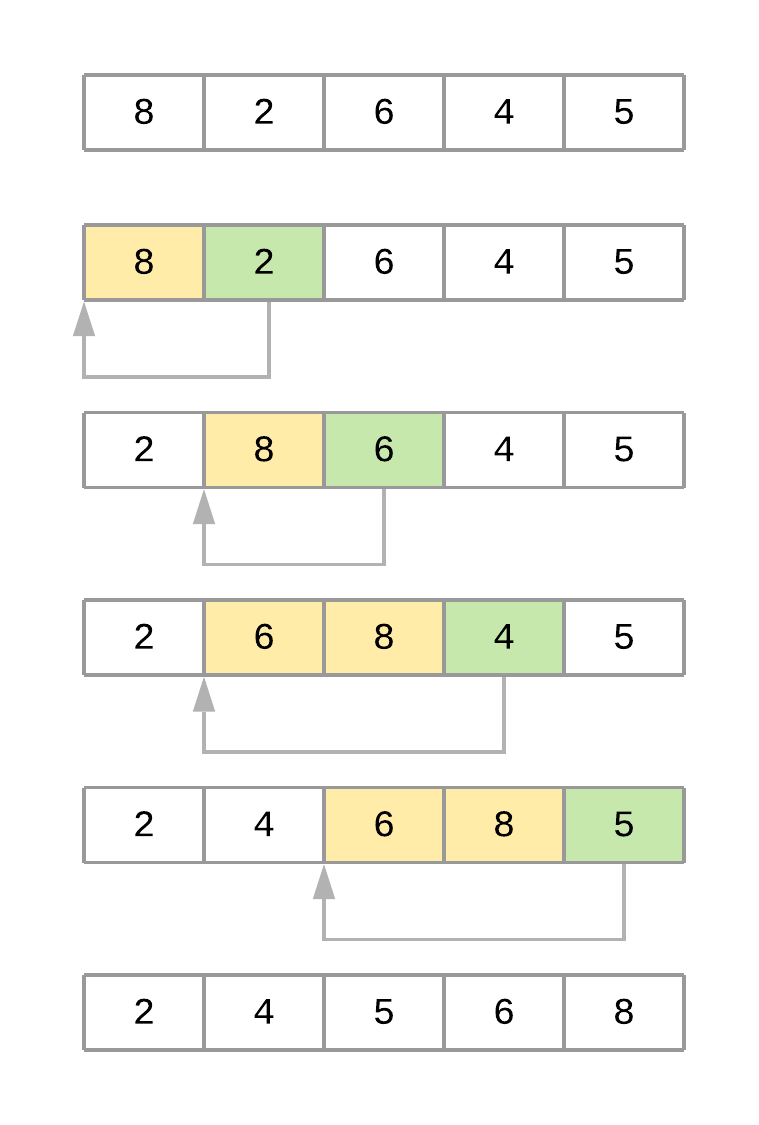
下面是对数组排序时算法步骤的总结:
-
该算法从
key_item = 2开始,遍历其左侧的子阵列,找到它的正确位置。在这种情况下,子阵列是[8]。 -
从
2 < 8开始,算法将元素8向右移动一个位置。此时得到的数组是[8, 8, 6, 4, 5]。 -
由于子数组中不再有元素,
key_item现在被放置在新的位置,最后一个数组是[2, 8, 6, 4, 5]。 -
第二遍从
key_item = 6开始,穿过位于其左侧的子阵列,在本例中为[2, 8]。 -
从
6 < 8开始,算法向右移动 8。此时得到的数组是[2, 8, 8, 4, 5]。 -
由于
6 > 2,算法不需要一直遍历子阵列,所以定位key_item,完成第二遍。这时,合成的数组是[2, 6, 8, 4, 5]。 -
第三次遍历列表将元素
4放在正确的位置,第四次遍历将元素5放在正确的位置,使数组保持排序。
测量插入排序的运行时间复杂度
与冒泡排序实现类似,插入排序算法有两个遍历列表的嵌套循环。内部循环非常有效,因为它只遍历列表,直到找到元素的正确位置。也就是说,该算法在平均情况下仍有一个 O(n 2 ) 的运行时复杂度。
最坏的情况发生在所提供的数组以相反的顺序排序时。在这种情况下,内部循环必须执行每个比较,以将每个元素放在正确的位置。这仍然会给你一个 O(n 2 ) 的运行时复杂度。
最好的情况发生在所提供的数组已经排序的时候。这里,从不执行内部循环,导致运行时复杂性为 O(n) ,就像冒泡排序的最佳情况一样。
尽管冒泡排序和插入排序具有相同的运行时复杂性,但实际上,插入排序比冒泡排序有效得多。如果您查看这两种算法的实现,那么您可以看到插入排序是如何减少比较来对列表进行排序的。
为插入排序实现计时
为了证明插入排序比冒泡排序更高效的论断,可以对插入排序算法计时,并与冒泡排序的结果进行比较。为此,您只需用插入排序实现的名称替换对run_sorting_algorithm()的调用:
1if __name__ == "__main__":
2 # Generate an array of `ARRAY_LENGTH` items consisting
3 # of random integer values between 0 and 999
4 array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
5
6 # Call the function using the name of the sorting algorithm
7 # and the array we just created
8 run_sorting_algorithm(algorithm="insertion_sort", array=array)
您可以像以前一样执行脚本:
$ python sorting.py
Algorithm: insertion_sort. Minimum execution time: 56.71029764299999
注意插入排序实现如何比冒泡排序实现少花大约17秒来排序相同的数组。尽管它们都是 O(n 2 ) 算法,插入排序更有效。
分析插入排序的优缺点
就像冒泡排序一样,插入排序算法实现起来非常简单。尽管插入排序是一种 O(n 2 ) 算法,但它在实践中也比其他二次实现(如冒泡排序)高效得多。
还有更强大的算法,包括合并排序和快速排序,但这些实现是递归的,在处理小列表时通常无法胜过插入排序。如果列表足够小以提供更快的整体实现,一些快速排序实现甚至在内部使用插入排序。 Timsort 也在内部使用插入排序对输入数组的小部分进行排序。
也就是说,插入排序对于大型数组并不实用,这为可以以更有效的方式扩展的算法打开了大门。
Python 中的归并排序算法
归并排序是一种非常高效的排序算法。它基于分治方法,这是一种用于解决复杂问题的强大算法技术。
要正确理解分而治之,首先要理解递归的概念。递归包括将一个问题分解成更小的子问题,直到它们小到可以管理。在编程中,递归通常由一个函数调用自己来表示。
注:本教程不深入探讨递归。为了更好地理解递归是如何工作的,并看到它在 Python 中的实际应用,请查看 Python 中的递归思维和 Python 中的递归:介绍。
分治算法通常遵循相同的结构:
- 原始输入被分成几个部分,每个部分代表一个子问题,它与原始输入相似,但更简单。
- 每个子问题都是递归求解的。
- 所有子问题的解决方案被组合成一个单一的整体解决方案。
在合并排序的情况下,分治法将输入值集分成两个大小相等的部分,对每一半递归排序,最后将这两个排序部分合并成一个排序列表。
在 Python 中实现合并排序
合并排序算法的实现需要两个不同的部分:
- 递归地将输入分成两半的函数
- 合并两半的函数,产生一个排序的数组
下面是合并两个不同数组的代码:
1def merge(left, right):
2 # If the first array is empty, then nothing needs
3 # to be merged, and you can return the second array as the result
4 if len(left) == 0:
5 return right
6
7 # If the second array is empty, then nothing needs
8 # to be merged, and you can return the first array as the result
9 if len(right) == 0:
10 return left
11
12 result = []
13 index_left = index_right = 0
14
15 # Now go through both arrays until all the elements
16 # make it into the resultant array
17 while len(result) < len(left) + len(right):
18 # The elements need to be sorted to add them to the
19 # resultant array, so you need to decide whether to get
20 # the next element from the first or the second array
21 if left[index_left] <= right[index_right]:
22 result.append(left[index_left])
23 index_left += 1
24 else:
25 result.append(right[index_right])
26 index_right += 1
27
28 # If you reach the end of either array, then you can
29 # add the remaining elements from the other array to
30 # the result and break the loop
31 if index_right == len(right):
32 result += left[index_left:]
33 break
34
35 if index_left == len(left):
36 result += right[index_right:]
37 break
38
39 return result
merge()接收需要合并在一起的两个不同的排序数组。实现这一点的过程非常简单:
-
第 4 行和第 9 行检查数组是否为空。如果其中一个是,那么没有什么要合并的,所以函数返回另一个数组。
-
第 17 行开始一个
while循环,每当结果包含来自两个提供的数组的所有元素时结束。目标是查看两个数组,并组合它们的条目以产生一个排序列表。 -
第 21 行比较两个数组开头的元素,选择较小的值,将附加到结果数组的末尾。
-
第 31 行和第 35 行如果任何一个数组中的所有元素都已被使用,则将剩余的元素添加到结果中。
有了上面的函数,唯一缺少的是递归地将输入数组分成两半并使用merge()产生最终结果的函数:
41def merge_sort(array):
42 # If the input array contains fewer than two elements,
43 # then return it as the result of the function
44 if len(array) < 2:
45 return array
46
47 midpoint = len(array) // 2
48
49 # Sort the array by recursively splitting the input
50 # into two equal halves, sorting each half and merging them
51 # together into the final result
52 return merge(
53 left=merge_sort(array[:midpoint]),
54 right=merge_sort(array[midpoint:]))
下面是代码的简要总结:
-
第 44 行作为递归的停止条件。如果输入数组包含的元素少于两个,则函数返回该数组。请注意,接收单个项目或空数组可能会触发这种情况。在这两种情况下,都没有什么需要排序的,所以函数应该返回。
-
第 47 行计算数组的中点。
-
第 52 行调用
merge(),将排序后的两半作为数组传递。
注意这个函数如何递归地调用自己**,每次都将数组减半。每次迭代都要处理一个不断缩小的数组,直到只剩下不到两个元素,这意味着没有什么可排序的了。此时,merge()接管,合并两半并产生一个排序列表。*
*看一看 merge sort 对数组[8, 2, 6, 4, 5]进行排序的步骤表示:
该图使用黄色箭头表示在每个递归级别将数组减半。绿色箭头表示将每个子阵列合并在一起。这些步骤可以总结如下:
-
用
[8, 2, 6, 4, 5]对merge_sort()的第一次调用将midpoint定义为2。midpoint用于将输入数组分成array[:2]和array[2:],分别产生[8, 2]和[6, 4, 5]。然后对每一半递归调用merge_sort()来分别对它们进行排序。 -
用
[8, 2]对merge_sort()的调用产生[8]和[2]。对这两半中的每一半重复该过程。 -
用
[8]调用merge_sort()会返回[8],因为这是唯一的元素。用[2]调用merge_sort()也会发生同样的情况。 -
此时,该函数开始使用
merge()将子数组合并在一起,从[8]和[2]作为输入数组开始,产生[2, 8]作为结果。 -
另一方面,
[6, 4, 5]被递归分解并使用相同的过程合并,产生结果[4, 5, 6]。 -
最后一步,
[2, 8]和[4, 5, 6]与merge()合并在一起,产生最终结果:[2, 4, 5, 6, 8]。
衡量合并排序的复杂度
要分析合并排序的复杂性,可以分别看一下它的两个步骤:
-
merge()有线性运行时。它接收两个组合长度最多为 n (原始输入数组的长度)的数组,并通过查看每个元素最多一次来组合这两个数组。这导致运行时复杂度为 O(n) 。 -
第二步递归分割输入数组,并为每一半调用
merge()。由于数组被减半直到只剩下一个元素,因此该函数执行的减半操作的总数为 log 2 n 。由于每半年调用一次merge(),我们得到总运行时间为O(n log2n)。
有趣的是, O(n log 2 n) 是排序算法能够实现的最佳可能最坏情况运行时间。
为合并排序实现计时
为了比较合并排序与前两个实现的速度,您可以使用与之前相同的机制,并替换第 8 行中的算法名称:
1if __name__ == "__main__":
2 # Generate an array of `ARRAY_LENGTH` items consisting
3 # of random integer values between 0 and 999
4 array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
5
6 # Call the function using the name of the sorting algorithm
7 # and the array you just created
8 run_sorting_algorithm(algorithm="merge_sort", array=array)
您可以执行脚本来获得merge_sort的执行时间:
$ python sorting.py
Algorithm: merge_sort. Minimum execution time: 0.6195857160000173
与冒泡排序和插入排序相比,合并排序的实现速度非常快,对一万个元素的数组进行排序不到一秒钟!
分析合并排序的优缺点
得益于其运行时复杂度为 O(n log 2 n) ,合并排序是一个非常有效的算法,可以随着输入数组的大小增长而很好地扩展。将 并行化 也很简单,因为它将输入数组分成块,如果需要的话,这些块可以并行分布和处理。
也就是说,对于小列表,递归的时间开销使得冒泡排序和插入排序等算法更快。例如,运行一个包含 10 个元素的实验会产生以下时间:
Algorithm: bubble_sort. Minimum execution time: 0.000018774999999998654
Algorithm: insertion_sort. Minimum execution time: 0.000029786000000000395
Algorithm: merge_sort. Minimum execution time: 0.00016983000000000276
对十元素列表进行排序时,冒泡排序和插入排序都优于合并排序。
合并排序的另一个缺点是,它在递归调用自身时会创建数组的副本。它还在merge()中创建了一个新的列表来排序并返回两个输入部分。这使得合并排序比冒泡排序和插入排序使用更多的内存,冒泡排序和插入排序都能够就地对列表进行排序。
由于这种限制,您可能不希望在内存受限的硬件中使用合并排序来对大型列表进行排序。
Python 中的快速排序算法
就像 merge sort 一样, Quicksort 算法应用分而治之的原则,将输入数组分成两个列表,第一个包含小项,第二个包含大项。然后,该算法递归地对两个列表进行排序,直到结果列表被完全排序。
划分输入列表被称为划分列表。Quicksort 首先选择一个pivot元素并围绕pivot划分列表,将每个较小的元素放入一个low数组,将每个较大的元素放入一个high数组。
将low列表中的每个元素放在pivot的左边,将high列表中的每个元素放在右边,将pivot精确地定位在最终排序列表中它需要的位置。这意味着该函数现在可以递归地对low和high应用相同的过程,直到整个列表被排序。
在 Python 中实现快速排序
下面是 Quicksort 的一个相当简洁的实现:
1from random import randint
2
3def quicksort(array):
4 # If the input array contains fewer than two elements,
5 # then return it as the result of the function
6 if len(array) < 2:
7 return array
8
9 low, same, high = [], [], []
10
11 # Select your `pivot` element randomly
12 pivot = array[randint(0, len(array) - 1)]
13
14 for item in array:
15 # Elements that are smaller than the `pivot` go to
16 # the `low` list. Elements that are larger than
17 # `pivot` go to the `high` list. Elements that are
18 # equal to `pivot` go to the `same` list.
19 if item < pivot:
20 low.append(item)
21 elif item == pivot:
22 same.append(item)
23 elif item > pivot:
24 high.append(item)
25
26 # The final result combines the sorted `low` list
27 # with the `same` list and the sorted `high` list
28 return quicksort(low) + same + quicksort(high)
下面是代码的摘要:
-
第 6 行如果数组包含的元素少于两个,则停止递归函数。
-
第 12 行从列表中随机选择
pivot元素,并继续划分列表。 -
第 19 行和第 20 行将小于
pivot的所有元素放入名为low的列表中。 -
第 21 行和第 22 行将等于
pivot的每个元素放入名为same的列表中。 -
第 23 行和第 24 行将大于
pivot的所有元素放入名为high的列表中。 -
第 28 行递归排序
low和high列表,并将它们与same列表的内容组合在一起。
下面是 Quicksort 对数组[8, 2, 6, 4, 5]进行排序的步骤说明:
黄线表示将数组划分为三个列表:low、same和high。绿线代表排序和把这些列表放回一起。以下是对这些步骤的简要说明:
-
随机选择
pivot元素。在这个例子中,pivot就是6。 -
第一遍划分输入数组,使得
low包含[2, 4, 5],same包含[6],high包含[8]。 -
然后以
low作为输入递归调用quicksort()。这将随机选择一个pivot,并将数组分成[2]作为low、[4]作为same和[5]作为high。 -
该过程继续,但是在这一点上,
low和high都有少于两个项目。这结束了递归,函数将数组放回一起。将排序后的low和high添加到same列表的任一侧产生[2, 4, 5]。 -
另一方面,包含
[8]的high列表少于两个元素,因此算法返回排序后的low数组,现在是[2, 4, 5]。将其与same([6])和high([8])合并产生最终的排序列表。
选择pivot元素
为什么上面的实现随机选择了pivot元素?一致地选择输入列表的第一个或最后一个元素不是一样的吗?
由于快速排序算法的工作方式,递归级别的数量取决于pivot在每个分区中的结束位置。在最好的情况下,算法始终选择中值元素作为pivot。这将使每个生成的子问题正好是前一个问题的一半大小,导致最多 log 2 n 级。
另一方面,如果算法始终选择数组的最小或最大元素作为pivot,那么生成的分区将尽可能不相等,导致 n-1 递归级别。这将是快速排序最糟糕的情况。
如你所见,Quicksort 的效率往往取决于pivot的选择。如果输入数组是未排序的,那么使用第一个或最后一个元素作为pivot将与随机元素一样工作。但是,如果输入数组已经排序或几乎排序,使用第一个或最后一个元素作为pivot可能会导致最坏的情况。随机选择pivot使得快速排序更有可能选择更接近中间值的值,从而更快地完成。
选择pivot的另一个选项是找到数组的中值,并强制算法使用它作为pivot。这可以在 O(n) 时间内完成。虽然这个过程稍微复杂一点,但是使用中间值作为快速排序的pivot可以保证你会得到最好的大 O 场景。
衡量快速排序的复杂程度
使用快速排序,输入列表以线性时间划分, O(n) ,并且这个过程平均递归重复 log 2 n 次。这就导致了最后的复杂度为O(n log2n)。
也就是说,记住关于选择pivot如何影响算法运行时间的讨论。当所选的pivot接近数组的中值时,会出现 O(n) 的最佳情况,当pivot是数组的最小或最大值时,会出现 O(n 2 ) 的情况。
理论上,如果算法首先专注于找到中值,然后将其用作pivot元素,那么最坏情况的复杂度将下降到 O(n log 2 n) 。可以在线性时间内找到数组的中值,使用它作为pivot保证代码的快速排序部分将在 O(n log 2 n) 内执行。
通过使用中间值作为pivot,最终得到最终运行时间 O(n) + O(n log 2 n) 。你可以将其简化为 O(n log 2 n) ,因为对数部分比线性部分增长得更快。
注意:虽然在快速排序的最坏情况下实现 O(n log 2 n) 是可能的,但是这种方法在实践中很少使用。列表必须非常大,以使实现比简单的随机选择pivot更快。
随机选择pivot使得最坏的情况不太可能发生。这使得随机选择对于算法的大多数实现来说已经足够好了。
为您的快速排序实施计时
到目前为止,您已经熟悉了算法运行时的计时过程。只需更改第 8 行中的算法名称:
1if __name__ == "__main__":
2 # Generate an array of `ARRAY_LENGTH` items consisting
3 # of random integer values between 0 and 999
4 array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
5
6 # Call the function using the name of the sorting algorithm
7 # and the array you just created
8 run_sorting_algorithm(algorithm="quicksort", array=array)
您可以像以前一样执行脚本:
$ python sorting.py
Algorithm: quicksort. Minimum execution time: 0.11675417600002902
快速排序不仅在不到一秒钟内完成,而且比合并排序快得多(0.11秒对0.61秒)。将由ARRAY_LENGTH指定的元素数量从10,000增加到1,000,000并再次运行脚本,合并排序在97秒内完成,而快速排序只需10秒。
分析快速排序的优势和劣势
名副其实,Quicksort 非常快。尽管理论上最坏的情况是 O(n 2 ) ,但在实践中,快速排序的良好实现胜过大多数其他排序实现。同样,就像合并排序一样,快速排序对于并行化来说很简单。
Quicksort 的一个主要缺点是不能保证它能达到平均的运行时复杂度。尽管最坏的情况很少发生,但某些应用不能承受性能下降的风险,因此它们选择保持在 O(n log 2 n) 范围内的算法,而不管输入如何。
就像合并排序一样,快速排序也是以牺牲内存空间来换取速度。这可能成为对较大列表排序的限制。
一个对十个元素列表进行排序的快速实验会产生以下结果:
Algorithm: bubble_sort. Minimum execution time: 0.0000909000000000014
Algorithm: insertion_sort. Minimum execution time: 0.00006681900000000268
Algorithm: quicksort. Minimum execution time: 0.0001319930000000004
结果表明,当列表足够小时,快速排序也要付出递归的代价,比插入排序和冒泡排序需要更长的时间来完成。
Python 中的 Timsort 算法
Timsort 算法被认为是一种混合排序算法,因为它采用了插入排序和合并排序的两全其美的组合。Timsort 对 Python 社区来说很亲近,因为它是由 Tim Peters 在 2002 年创建的,被用作 Python 语言的标准排序算法。
Timsort 的主要特点是它利用了大多数真实数据集中已经排序的元素。这些被称为自然运行。然后,该算法遍历列表,将元素收集到游程中,并将它们合并到一个单独的排序列表中。
用 Python 实现 Timsort
在本节中,您将创建一个演示 Timsort 算法所有部分的基本 Python 实现。如果你有兴趣,你也可以看看 Timsort 的原始 C 实现。
实现 Timsort 的第一步是修改前面的insertion_sort()的实现:
1def insertion_sort(array, left=0, right=None): 2 if right is None: 3 right = len(array) - 1 4
5 # Loop from the element indicated by
6 # `left` until the element indicated by `right`
7 for i in range(left + 1, right + 1): 8 # This is the element we want to position in its
9 # correct place
10 key_item = array[i]
11
12 # Initialize the variable that will be used to
13 # find the correct position of the element referenced
14 # by `key_item`
15 j = i - 1
16
17 # Run through the list of items (the left
18 # portion of the array) and find the correct position
19 # of the element referenced by `key_item`. Do this only
20 # if the `key_item` is smaller than its adjacent values.
21 while j >= left and array[j] > key_item: 22 # Shift the value one position to the left
23 # and reposition `j` to point to the next element
24 # (from right to left)
25 array[j + 1] = array[j]
26 j -= 1
27
28 # When you finish shifting the elements, position
29 # the `key_item` in its correct location
30 array[j + 1] = key_item
31
32 return array
这个修改后的实现增加了两个参数,left和right,它们指示数组的哪一部分应该被排序。这允许 Timsort 算法就地对数组的一部分进行排序。修改函数而不是创建一个新函数意味着它可以在插入排序和时间排序中重用。
现在看一下 Timsort 的实现:
1def timsort(array):
2 min_run = 32
3 n = len(array)
4
5 # Start by slicing and sorting small portions of the
6 # input array. The size of these slices is defined by
7 # your `min_run` size.
8 for i in range(0, n, min_run):
9 insertion_sort(array, i, min((i + min_run - 1), n - 1))
10
11 # Now you can start merging the sorted slices.
12 # Start from `min_run`, doubling the size on
13 # each iteration until you surpass the length of
14 # the array.
15 size = min_run
16 while size < n:
17 # Determine the arrays that will
18 # be merged together
19 for start in range(0, n, size * 2):
20 # Compute the `midpoint` (where the first array ends
21 # and the second starts) and the `endpoint` (where
22 # the second array ends)
23 midpoint = start + size - 1
24 end = min((start + size * 2 - 1), (n-1))
25
26 # Merge the two subarrays.
27 # The `left` array should go from `start` to
28 # `midpoint + 1`, while the `right` array should
29 # go from `midpoint + 1` to `end + 1`.
30 merged_array = merge(
31 left=array[start:midpoint + 1],
32 right=array[midpoint + 1:end + 1])
33
34 # Finally, put the merged array back into
35 # your array
36 array[start:start + len(merged_array)] = merged_array
37
38 # Each iteration should double the size of your arrays
39 size *= 2
40
41 return array
尽管实现比前面的算法要复杂一些,但我们可以用下面的方式快速总结一下:
-
第 8 行和第 9 行创建数组的小片段或游程,并使用插入排序对它们进行排序。您之前已经了解到插入排序在小列表上速度很快,Timsort 利用了这一点。Timsort 使用
insertion_sort()中新引入的left和right参数对列表进行排序,而不必像 merge sort 和 Quicksort 那样创建新的数组。 -
线 16 合并这些较小的游程,每个游程最初的大小为
32。随着每次迭代,游程的大小加倍,并且算法继续合并这些较大的游程,直到剩下单个排序的游程。
注意,与合并排序不同,Timsort 合并先前排序的子数组。这样做可以减少生成排序列表所需的比较总数。当使用不同的数组运行实验时,这种优于合并排序的优势将变得明显。
最后,第二行定义min_run = 32。这里使用32作为值有两个原因:
-
使用插入排序对小数组进行排序非常快,
min_run有一个小值就是利用了这个特性。用一个太大的值初始化min_run将会违背使用插入排序的目的,并且会使算法变慢。 -
合并两个平衡的列表比合并大小不相称的列表更有效。当合并算法创建的所有不同运行时,选择一个 2 的幂的
min_run值可以确保更好的性能。
结合以上两个条件,为min_run提供了几种选择。本教程中的实现使用min_run = 32作为可能性之一。
注意:在实践中,Timsort 做一些稍微复杂一点的事情来计算min_run。它在 32 和 64 之间选择一个值,这样列表的长度除以min_run正好是 2 的幂。如果不可能,它会选择一个接近但严格小于 2 的幂的值。
如果你很好奇,可以阅读计算民润板块下关于如何挑选min_run 的完整分析。
测量时间排序的大复杂度
平均来说,Timsort 的复杂度是O(n log2n),就像归并排序和快速排序一样。对数部分来自于将运行的大小加倍以执行每个线性合并操作。
然而,Timsort 在已经排序或接近排序的列表上表现得非常好,导致了最好的情况 O(n) 。在这种情况下,Timsort 明显优于 merge sort,并且符合 Quicksort 的最佳情况。但是 Timsort 最差的情况也是 O(n log 2 n) ,超过了 Quicksort 的 O(n 2 ) 。
为您的 Timsort 实现计时
您可以使用run_sorting_algorithm()来查看 Timsort 如何对一万个元素的数组进行排序:
1if __name__ == "__main__":
2 # Generate an array of `ARRAY_LENGTH` items consisting
3 # of random integer values between 0 and 999
4 array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
5
6 # Call the function using the name of the sorting algorithm
7 # and the array you just created
8 run_sorting_algorithm(algorithm="timsort", array=array)
现在执行脚本以获得timsort的执行时间:
$ python sorting.py
Algorithm: timsort. Minimum execution time: 0.5121690789999998
在0.51秒,这个 Timsort 实现比 merge sort 快了整整0.1秒,即 17 %,尽管它比不上 Quicksort 的0.11。这也比插入排序快了可笑的 11000 %!
现在尝试使用这四种算法对一个已经排序的列表进行排序,看看会发生什么。您可以按如下方式修改您的__main__部分:
1if __name__ == "__main__":
2 # Generate a sorted array of ARRAY_LENGTH items
3 array = [i for i in range(ARRAY_LENGTH)]
4
5 # Call each of the functions
6 run_sorting_algorithm(algorithm="insertion_sort", array=array)
7 run_sorting_algorithm(algorithm="merge_sort", array=array)
8 run_sorting_algorithm(algorithm="quicksort", array=array)
9 run_sorting_algorithm(algorithm="timsort", array=array)
如果您现在执行脚本,那么所有算法都将运行并输出它们相应的执行时间:
Algorithm: insertion_sort. Minimum execution time: 53.5485634999991
Algorithm: merge_sort. Minimum execution time: 0.372304601
Algorithm: quicksort. Minimum execution time: 0.24626494199999982
Algorithm: timsort. Minimum execution time: 0.23350277099999994
这一次,Timsort 比 merge sort 快了 37 %,比 Quicksort 快了 5 %,展示了它利用已排序运行的能力。
注意 Timsort 是如何受益于两种算法的,这两种算法在单独使用时要慢得多。Timsort 的天才之处在于将这些算法结合起来,发挥它们的优势,以实现令人印象深刻的结果。
分析 Timsort 的优势和劣势
Timsort 的主要缺点是复杂。尽管实现了原始算法的一个非常简化的版本,它仍然需要更多的代码,因为它依赖于insertion_sort()和merge()。
Timsort 的一个优点是,不管输入数组的结构如何,它都能够以 O(n log 2 n) 的方式可预测地执行。相比之下,快速排序可以降低到 O(n 2 ) 。Timsort 对于小数组也非常快,因为该算法变成了单插入排序。
在现实世界中,对已经有某种预先存在的顺序的数组进行排序是很常见的,Timsort 是一个很好的选择。它的适应性使它成为排序任意长度数组的绝佳选择。
结论
排序是任何 Pythonista 工具箱中的基本工具。了解 Python 中不同的排序算法以及如何最大化它们的潜力,您就可以实现更快、更高效的应用和程序了!
在本教程中,您学习了:
- Python 内置的
sort()如何在幕后工作 - 什么是大 O 记法以及如何用它来比较不同算法的效率
- 如何测量运行代码所花费的实际时间
- 如何用 Python 实现五种不同的排序算法
- 使用不同算法的利弊是什么
您还学习了不同的技术,如递归、分治和随机化。这些是解决一长串不同算法的基本构件,在你继续研究的过程中,它们会一次又一次地出现。
使用本教程中的代码,创建新的实验,并进一步探索这些算法。更好的是,尝试用 Python 实现其他排序算法。这个列表很庞大,但是 选择排序 、 堆排序 和 树排序 是三个很好的开始选项。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中排序算法介绍************
开始为 Python 做贡献:您的第一步
如果你想让开始为开源贡献,那么 Python 是一个很好的开始项目。你不仅会在最大的项目之一留下你的印记,而且你还会成为充满活力和热情的社区的一员。开源项目依赖于像你这样的志愿者的贡献来成长和发展,所以你将对开源软件的未来产生真正的影响。
最重要的是,为开源做贡献是学习和培养技能的好方法,所以如果你觉得自己不是专家,也不用担心。也许有一种方式非常适合你,即使你还不知道。一切从你的第一份贡献开始!
本教程结束时,你会知道:
- 你如何以符合你的技能和兴趣的方式做出贡献
- 你可以使用哪些资源和工具来帮助你自信地做出贡献
- 你可以在第一篇文章的中找到修改建议
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
如何做出贡献
根据你的兴趣和技能,你可以以多种不同的方式做出贡献。例如,如果您想为 CPython 做贡献,您可以:
但是如果你想在其他领域有所贡献,你可以:
- 为 Python 开发者指南编写文档
- 翻译文档
- 使用你的前端技能改进 Python 的官方网站
您还可以帮助审查来自其他贡献者的拉请求。核心开发者手头有很多工作,所以如果你能帮助推进一些问题,那么你将帮助 Python 变得更快。
如何获得您需要的资源
当你开始为一个开源项目做贡献时,可能会一下子吸收很多信息。
为了帮助你浏览这一切,你的第一站应该是 Python 开发者指南。这是一个所有贡献者和核心开发者都依赖的超级重要的资源,因为它涵盖了从如何评估潜在贡献到如何处理问题跟踪的所有内容。(如果你对本指南有所贡献,那么你将能够对 Python 的贡献产生重大影响。)
一旦你开始做贡献,熟悉一些工具会很有用:
-
GitHub: Python 贡献者通过 GitHub 相互协作,让你托管代码,做版本控制,给出反馈,等等。要了解如何使用这个工具的更多信息,请查看针对 Python 开发者的Git 和 GitHub 简介以及 Python 的官方 Git Bootcamp 和备忘单。
-
如果你想贡献文档,那么学习如何使用这种标记语言会很有帮助。Python 开发者指南有一本关于 reStructuredText 的初级读本来帮助你开始。(有趣的事实:reStructuredText 比 Markdown 存在的时间还要长!)
-
Sphinx: 您将使用 Sphinx 来构建 Python 的文档。要了解更多信息,您可以查看 Mariatta Wijaya 的演讲介绍 Sphinx 文档和重构文本和 Eric Holscher 的演讲用 Sphinx 记录您的项目&阅读文档。
虽然你不需要有使用 C 编程语言的经验来为 Python 做贡献,但是它可以开辟一些新的贡献方式。以下是一些资源,您可以查看以了解更多信息:
为了感受贡献 Python 的人际方面是如何工作的,你也可以看看 Brett Canon 的py cascade talk设定对开源参与的期望。这是关于对彼此设定合理的期望,这样我们就可以让开源让每个参与进来的人都感到愉快。
如何挑选你的第一期
如果您看到 Python 中有您认为应该改进的地方,那么欢迎您提出建议。但是对于你的第一次投稿,从一个已经被其他人标记的问题开始会更容易。
如果你想为 Python 开发者指南或 Python 的官方网站投稿,那么你可以查看 GitHub 上列出的问题:
如果你想为 CPython 做贡献,这是大多数人说“Python”的意思,那么你需要在 Python 的 bug tracker 上创建一个帐户,这个帐户叫做 BPO ,因为它位于bugs.python.org。您可以通过进入左侧菜单中的用户→注册将自己注册为用户。
默认视图中的信息可能很难理解,因为它显示了用户提出的问题以及核心开发人员提出的问题,这些问题可能已经得到了解决。幸运的是,你可以过滤这个列表来找到你想要的东西。
要过滤列表,首先登录,然后进入左侧菜单中的您的查询→编辑。你会得到一个查询的列表,你可以在或省略:
下面是一个例子,如果您编辑您的查询,只留下简单的文档问题,您会看到什么:
现在您已经过滤了列表,只留下了简单的文档问题,您看到的只是适合初学者的文档问题。
如果您想处理文档之外的内容,也可以尝试其他一些查询来帮助您找到感兴趣的问题:
| 询问 | 问题的类型 |
|---|---|
| 简单任务 | 被标记为适合初学者的问题 |
| 没有回复的报告 | 已报告但未讨论的问题 |
| 未读 | 已报告但未阅读的问题 |
| 最近创建的 | 最近报告的问题 |
| 50 期最新 | 最近更新的前五十个问题 |
一旦你决定了你的第一篇文章要写哪个问题,最好查看一下评论看看:
- 关于是否应该解决这个问题以及如何解决这个问题,仍有一些讨论在进行中
- 有人已经在研究这个问题了
你也可以检查最新版本的代码和文档,看看问题是否已经解决,但还没有被核心开发人员关闭。
注意:你可以在官方文档中了解更多关于如何使用问题跟踪器对问题进行分类。
一旦您确定了要从哪个问题开始,您可以对该问题发表评论:
- 说你会继续努力
- 让其他人知道您计划何时提交您的拉动请求
如果你清楚地传达了你的计划,那么其他贡献者将会知道其他人已经在处理这个问题了,并且能够将他们的精力集中在解决其他问题上。
如何提交您的第一篇投稿
请务必查看 Python 关于拉请求的生命周期的官方文档。它将带你通过提交拉请求的一步一步的机制,给你关于做好提交的提示,等等。
由于大多数核心开发人员都是志愿者,您可能不会马上得到回复,但是您可以做一些事情来加快这个过程:
- 清楚地解释你解决的问题以及你是如何解决的:这将有助于评审者快速上手,并获得他们需要的信息接受你的拉取请求。
- 在每个拉式请求中只解决一个问题:如果你在做贡献时注意到另一个问题,那么你可以在第二个拉式请求中解决它。
为开源做贡献是关于协作的,所以交流是非常重要的。要了解更多,请查看开源指南关于提交投稿时有效沟通的说法。
当你提交了你的第一个拉取请求后,放松并庆祝吧!你已经在通往一些很酷的地方的旅途上迈出了第一大步。
下一步是什么?
如果你决定更多地参与其中,那么你可以探索一些机会。也许你想:
- 努力成为核心开发人员
- 求师友
- 加入分流团队
- 加入一个特定项目的工作组
- 成为 Python 软件基金会的会员
Python 的世界里发生了很多事情,所以环顾四周,看看有什么让你着迷。让我们友好相处,共同创造美好的未来。
结论:开始为 Python 做贡献
祝贺您迈出了为 Python 做贡献的第一步!如果你冒险开始,那么你一定会在对一个重要的开源项目产生影响的同时学到很多东西。
在本教程中,您学习了:
- 你如何以符合你的技能和兴趣的方式为 Python 做出贡献
- 你可以使用哪些资源和工具来帮助你自信地做出贡献
- 你可以在第一篇文章的中找到修改建议
核心开发团队中的每个人都是从一个贡献开始的,那么为什么不试一试呢?在这个过程中,你一定会学到一些东西!**
Python 中存储和访问大量图像的三种方式
为什么您想了解更多关于在 Python 中存储和访问图像的不同方法?如果你正在用颜色分割一些图像或者用 OpenCV 逐个检测人脸,那么你不需要担心这个问题。即使你正在使用 Python 图像库(PIL) 来绘制几百张照片,你仍然不需要。将图像作为.png或.jpg文件存储在磁盘上既合适又合适。
然而,给定任务所需的图像数量越来越多。卷积神经网络(也称为 convnets 或 CNN)等算法可以处理大量图像数据集,甚至可以从中学习。如果你感兴趣,你可以阅读更多关于 convnets 如何用于自拍排名或 T2 情绪分析的内容。
ImageNet 是一个著名的公共图像数据库,它由超过 1400 万张图像组成。
想想把它们全部加载到内存中进行训练要花多长时间,分批加载,可能是几百次,也可能是几千次。继续读下去,你会相信这需要相当长的时间——至少足够你离开电脑做许多其他事情,而你希望你在谷歌或英伟达工作。
在本教程中,您将了解到:
- 将图像作为
.png文件存储在磁盘上 - 在 lightning 内存映射数据库中存储图像(LMDB)
- 以分层数据格式存储图像(HDF5)
您还将探索以下内容:
- 为什么替代存储方法值得考虑
- 当你读写单个图像时,性能有什么不同
- 当你读写多张图片时,性能有何不同
- 这三种方法在磁盘使用方面有何不同
如果没有一种存储方法,不要担心:对于本文,您所需要的只是相当扎实的 Python 基础和对图像的基本理解(它们实际上是由多维数组数字组成的)和相对内存,比如 10MB 和 10GB 之间的区别。
我们开始吧!
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
设置
您将需要一个图像数据集来进行实验,以及几个 Python 包。
要使用的数据集
我们将使用加拿大高级研究所的图像数据集,更好的说法是 CIFAR-10 ,它由 60,000 张 32x32 像素的彩色图像组成,属于不同的对象类别,如狗、猫和飞机。相对而言,CIFAR 不是一个非常大的数据集,但是如果我们使用完整的tinyi images 数据集,那么您将需要大约 400GB 的可用磁盘空间,这可能是一个限制因素。
本技术报告第三章中描述的数据集的功劳归于 Alex Krizhevsky、Vinod Nair 和 Geoffrey Hinton。
如果您想了解本文中的代码示例,您可以在这里下载 CIFAR-10,选择 Python 版本。您将牺牲 163MB 的磁盘空间:

当你下载并解压文件夹时,你会发现这些文件不是人类可读的图像文件。它们实际上已经被序列化并使用 cPickle 批量保存。
虽然在本文中我们不会考虑 pickle 或cPickle,但除了提取 CIFAR 数据集之外,值得一提的是 Python pickle模块的关键优势是能够序列化任何 Python 对象,而无需您进行任何额外的代码或转换。它还有一个潜在的严重缺点,即存在安全风险,并且在处理大量数据时处理不好。
以下代码对五个批处理文件中的每一个进行解拾取,并将所有图像加载到一个 NumPy 数组中:
import numpy as np
import pickle
from pathlib import Path
# Path to the unzipped CIFAR data
data_dir = Path("data/cifar-10-batches-py/")
# Unpickle function provided by the CIFAR hosts
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# Each image is flattened, with channels in order of R, G, B
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# Reconstruct the original image
images.append(np.dstack((im_channels)))
# Save the label
labels.append(batch_data[b"labels"][i])
print("Loaded CIFAR-10 training set:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")
所有的图像现在都在 RAM 中的images 变量中,它们相应的元数据在labels中,并准备好供你操作。接下来,您可以安装将用于这三种方法的 Python 包。
注意:最后一个代码块使用了 f 字符串。你可以在 Python 3 的 f-Strings:一个改进的字符串格式化语法(指南)中读到更多关于它们的内容。
在磁盘上存储图像的设置
您需要将您的环境设置为从磁盘保存和访问这些图像的默认方法。本文假设您的系统上安装了 Python 3.x,并将使用Pillow进行图像操作:
$ pip install Pillow
或者,如果您愿意,可以使用 Anaconda 来安装它:
$ conda install -c conda-forge pillow
注意: PIL是 Python 映像库的原始版本,不再维护,与 Python 3.x 不兼容,如果您之前已经安装了PIL,请确保在安装Pillow之前卸载它,因为它们不能共存。
现在,您已经准备好从磁盘存储和读取图像了。
LMDB 入门
LMDB ,有时被称为“闪电数据库”,代表闪电内存映射数据库,因为它速度快,并且使用内存映射文件。它是一个键值存储,而不是关系数据库。
在实现方面,LMDB 是一个 B+树,这基本上意味着它是一个存储在内存中的树状图形结构,其中每个键值元素都是一个节点,节点可以有许多子节点。同一级别上的节点相互链接,以便快速遍历。
关键的是,B+树的关键组件被设置为对应于主机操作系统的页面大小,从而在访问数据库中的任何键值对时最大化效率。由于 LMDB 高性能在很大程度上依赖于这一点,因此 LMDB 效率也依赖于底层文件系统及其实施。
LMDB 高效的另一个关键原因是它是内存映射的。这意味着它返回指向键和值的内存地址的直接指针,而不需要像大多数其他数据库那样复制内存中的任何内容。
那些想深入了解 B+树的内部实现细节的人可以查看这篇关于 B+树的文章,然后用体验一下节点插入的可视化。
如果你对 B+树不感兴趣,不用担心。为了使用 LMDB,你不需要了解太多它们的内部实现。我们将为 LMDB C 库使用 Python 绑定,它可以通过 pip 安装:
$ pip install lmdb
您还可以选择通过 Anaconda 进行安装:
$ conda install -c conda-forge python-lmdb
检查一下你能不能从 Python shell 中import lmdb,你就可以开始了。
HDF5 入门
HDF5 代表分层数据格式,一种称为 HDF4 或 HDF5 的文件格式。我们不需要担心 HDF4,因为 HDF5 是当前维护的版本。
有趣的是,HDF 起源于国家超级计算应用中心,作为一种可移植的、紧凑的科学数据格式。如果你想知道它是否被广泛使用,看看美国宇航局关于 HDF5 的简介,来自他们的地球数据项目。
HDF 文件由两种类型的对象组成:
- 资料组
- 组
数据集是多维数组,组由数据集或其他组组成。任何大小和类型的多维数组都可以存储为数据集,但是数据集内的维度和类型必须一致。每个数据集必须包含一个同质的 N 维数组。也就是说,因为组和数据集可能是嵌套的,所以您仍然可以获得您可能需要的异构性:
$ pip install h5py
与其他库一样,您也可以通过 Anaconda 安装:
$ conda install -c conda-forge h5py
如果你能从 Python shell 中import h5py,那么一切都设置好了。
存储单幅图像
现在,您已经对这些方法有了大致的了解,让我们直接进入主题,看看我们关心的基本任务的定量比较:读写文件需要多长时间,以及将使用多少磁盘内存。这也将作为方法如何工作的基本介绍,以及如何使用它们的代码示例。
当我提到“文件”时,我通常是指很多文件。但是,进行区分很重要,因为有些方法可能针对不同的操作和文件数量进行了优化。
出于实验的目的,我们可以比较不同数量的文件之间的性能,从单个图像到 100,000 个图像,相差 10 倍。由于我们的五批 CIFAR-10 加起来有 50,000 张图像,因此我们可以使用每张图像两次,得到 100,000 张图像。
为了准备实验,您需要为每个方法创建一个文件夹,其中包含所有数据库文件或图像,并将这些目录的路径保存在变量中:
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")
Path不会自动为您创建文件夹,除非您特别要求它:
disk_dir.mkdir(parents=True, exist_ok=True)
lmdb_dir.mkdir(parents=True, exist_ok=True)
hdf5_dir.mkdir(parents=True, exist_ok=True)
现在,您可以继续运行实际的实验,使用代码示例说明如何使用这三种不同的方法执行基本任务。我们可以使用包含在 Python 标准库中的timeit模块来帮助计时实验。
虽然本文的主要目的不是学习不同 Python 包的 API,但是理解它们是如何实现的是很有帮助的。我们将在所有用于进行存储实验的代码旁边讨论一般原则。
存储到磁盘
我们这个实验的输入是一个单独的图像image,当前在内存中是一个 NumPy 数组。你想先把它保存到磁盘上作为一个.png图像,并用一个唯一的图像 ID image_id来命名它。这可以使用您之前安装的Pillow包来完成:
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" Stores a single image as a .png file on disk.
Parameters:
---------------
image image array, (32, 32, 3) to be stored
image_id integer unique ID for image
label image label
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])
这保存了图像。在所有真实的应用程序中,您还会关心附加到图像的元数据,在我们的示例数据集中是图像标签。当您将图像储存到磁盘时,有几个选项可用于存储元数据。
一种解决方案是将标签编码到图像名称中。这具有不需要任何额外文件的优点。
然而,它也有一个很大的缺点,那就是每当你对标签做任何事情时,都要强迫你处理所有的文件。将标签存储在一个单独的文件中允许您单独处理标签,而不必加载图像。上面,我已经为这个实验将标签存储在一个单独的.csv文件中。
现在让我们继续对 LMDB 做同样的工作。
存储到 LMDB
首先,LMDB 是一个键值存储系统,其中每个条目都保存为一个字节数组,所以在我们的例子中,键将是每个图像的唯一标识符,值将是图像本身。键和值都应该是字符串,所以通常的用法是将值序列化为一个字符串,然后在读回它时取消序列化。
您可以使用pickle进行序列化。任何 Python 对象都可以序列化,因此您还可以在数据库中包含图像元数据。当我们从磁盘加载数据集时,这样可以省去将元数据附加到图像数据的麻烦。
您可以为图像及其元数据创建一个基本的 Python 类:
class CIFAR_Image:
def __init__(self, image, label):
# Dimensions of image for reconstruction - not really necessary
# for this dataset, but some datasets may include images of
# varying sizes
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" Returns the image as a numpy array. """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)
其次,因为 LMDB 是内存映射的,所以新数据库需要知道它们预计会用完多少内存。在我们的例子中,这相对简单,但是在其他例子中,这可能是一个巨大的痛苦,您将在后面的部分中更深入地看到这一点。LMDB 称这个变量为map_size。
最后,在transactions中执行 LMDB 的读写操作。你可以把它们想象成类似于传统的数据库,由一组对数据库的操作组成。这可能看起来已经比磁盘版本复杂得多,但是坚持下去,继续阅读!
记住这三点,让我们看看将单个图像保存到 LMDB 的代码:
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" Stores a single image to a LMDB.
Parameters:
---------------
image image array, (32, 32, 3) to be stored
image_id integer unique ID for image
label image label
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()
注意:计算每个键值对将占用的确切字节数是个好主意。
对于不同大小的图像数据集,这将是一个近似值,但是您可以使用sys.getsizeof()来获得一个合理的近似值。请记住,sys.getsizeof(CIFAR_Image)将只返回一个类定义的大小,这是 1056,不是实例化对象的大小。
该函数也不能完全计算嵌套项目、列表或包含对其他对象的引用的对象。
或者,你可以使用 pympler 通过确定一个对象的精确大小来节省一些计算。
您现在可以将图像保存到 LMDB 了。最后,我们来看看最后一种方法,HDF5。
使用 HDF5 存储
请记住,一个 HDF5 文件可以包含多个数据集。在这个相当简单的例子中,您可以创建两个数据集,一个用于图像,一个用于元数据:
import h5py
def store_single_hdf5(image, image_id, label):
""" Stores a single image to an HDF5 file.
Parameters:
---------------
image image array, (32, 32, 3) to be stored
image_id integer unique ID for image
label image label
"""
# Create a new HDF5 file
file = h5py.File(hdf5_dir / f"{image_id}.h5", "w")
# Create a dataset in the file
dataset = file.create_dataset(
"image", np.shape(image), h5py.h5t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h5py.h5t.STD_U8BE, data=label
)
file.close()
h5py.h5t.STD_U8BE指定将存储在数据集中的数据类型,在本例中是无符号的 8 位整数。你可以在这里看到 HDF 预定义数据类型的完整列表。
注意:数据类型的选择会强烈影响 HDF5 的运行时和存储要求,所以最好选择你的最低要求。
现在我们已经回顾了保存单个图像的三种方法,让我们继续下一步。
存储单幅图像的实验
现在,您可以将保存单幅图像的所有三个函数放入字典中,稍后在计时实验中可以调用:
_store_single_funcs = dict(
disk=store_single_disk, lmdb=store_single_lmdb, hdf5=store_single_hdf5
)
最后,进行定时实验的一切都准备好了。让我们尝试保存来自 CIFAR 的第一个图像及其相应的标签,并以三种不同的方式存储它:
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"Method: {method}, Time usage: {t}")
注意:当你在玩 LMDB 的时候,你可能会看到一个MapFullError: mdb_txn_commit: MDB_MAP_FULL: Environment mapsize limit reached错误。需要注意的是,LMDB 不会而不是覆盖预先存在的值,即使它们有相同的键。
这有助于加快写入时间,但也意味着如果你在同一个 LMDB 文件中不止一次地存储一张图片,那么你将用完地图的大小。如果您运行存储功能,请确保首先删除任何预先存在的 LMDB 文件。
请记住,我们感兴趣的是以秒为单位显示的运行时间,以及内存使用情况:
| 方法 | 保存单个图像+元 | 记忆 |
|---|---|---|
| 唱片 | 1.915 毫秒 | 8 K |
| IMDB(IMDB) | 1.203 毫秒 | 32 K |
| HDF5 | 8.243 毫秒 | 8 K |
这里有两个要点:
- 所有的方法都非常快。
- 就磁盘使用而言,LMDB 使用的更多。
显然,尽管 LMDB 在性能上略有领先,但我们还没有说服任何人为什么不把图像存储在磁盘上。毕竟,它是人类可读的格式,您可以从任何文件系统浏览器打开和查看它们!好了,是时候看看更多的图片了…
存储许多图像
您已经看到了使用各种存储方法保存单个图像的代码,所以现在我们需要调整代码来保存多个图像,然后运行定时实验。
调整许多图像的代码
将多个图像保存为.png文件就像多次调用store_single_method()一样简单。但这对于 LMDB 或 HDF5 来说是不正确的,因为你不希望每个图像有不同的数据库文件。相反,您希望将所有图像放入一个或多个文件中。
您需要稍微修改一下代码,创建三个新的函数来接受多个图像,store_many_disk()、store_many_lmdb()和store_many_hdf5:
store_many_disk(images, labels):
""" Stores an array of images to disk
Parameters:
---------------
images images array, (N, 32, 32, 3) to be stored
labels labels array, (N, 1) to be stored
"""
num_images = len(images)
# Save all the images one by one
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# Save all the labels to the csv file
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
# This typically would be more than just one value per row
writer.writerow([label])
def store_many_lmdb(images, labels):
""" Stores an array of images to LMDB.
Parameters:
---------------
images images array, (N, 32, 32, 3) to be stored
labels labels array, (N, 1) to be stored
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# Create a new LMDB DB for all the images
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# Same as before — but let's write all the images in a single transaction
with env.begin(write=True) as txn:
for i in range(num_images):
# All key-value pairs need to be Strings
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()
def store_many_hdf5(images, labels):
""" Stores an array of images to HDF5.
Parameters:
---------------
images images array, (N, 32, 32, 3) to be stored
labels labels array, (N, 1) to be stored
"""
num_images = len(images)
# Create a new HDF5 file
file = h5py.File(hdf5_dir / f"{num_images}_many.h5", "w")
# Create a dataset in the file
dataset = file.create_dataset(
"images", np.shape(images), h5py.h5t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h5py.h5t.STD_U8BE, data=labels
)
file.close()
因此,您可以将多个文件存储到磁盘,image files 方法被修改为遍历列表中的每个图像。对于 LMDB,也需要一个循环,因为我们为每个图像及其元数据创建了一个CIFAR_Image对象。
HDF5 方法的调整最小。事实上,几乎没有任何调整!除了外部限制或数据集大小之外,HFD5 文件对文件大小没有任何限制,因此所有图像都被填充到一个数据集中,就像以前一样。
接下来,您需要通过增加数据集的大小来为实验准备数据集。
准备数据集
在再次运行实验之前,让我们首先将数据集的大小加倍,这样我们可以用多达 100,000 张图像进行测试:
cutoffs = [10, 100, 1000, 10000, 100000]
# Let's double our images so that we have 100,000
images = np.concatenate((images, images), axis=0)
labels = np.concatenate((labels, labels), axis=0)
# Make sure you actually have 100,000 images and labels
print(np.shape(images))
print(np.shape(labels))
既然有了足够多的图像,就该做实验了。
存储多幅图像的实验
正如您阅读许多图像一样,您可以使用store_many_创建一个处理所有功能的字典,并运行实验:
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time
print(f"Method: {method}, Time usage: {t}")
如果您自己跟随并运行代码,您需要暂停片刻,等待 111,110 个图像以三种不同的格式分别存储到您的磁盘上三次。您还需要告别大约 2 GB 的磁盘空间。
现在是关键时刻了!所有这些存储需要多长时间?一张图胜过千言万语:

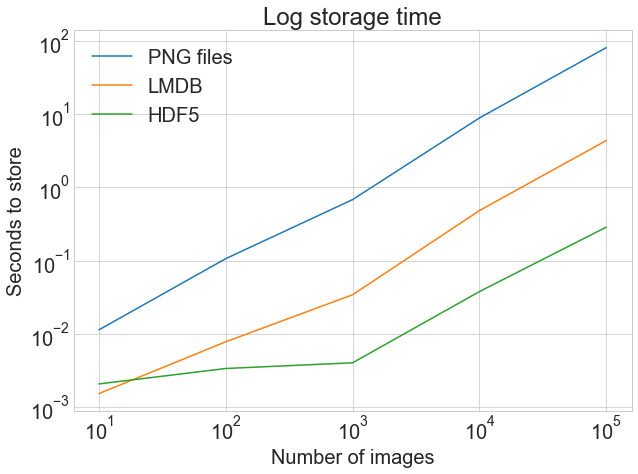
第一张图显示了正常的、未调整的存储时间,突出了存储到.png文件和 LMDB 或 HDF5 之间的巨大差异。
第二张图显示了计时的log,突出显示了 HDF5 开始时比 LMDB 慢,但由于图像量较大,它略微领先。
虽然具体结果可能因您的机器而异,但这也是 LMDB 和 HDF5 值得考虑的原因。下面是生成上图的代码:
import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" Displays a single plot with multiple datasets and matching legends.
Parameters:
--------------
x_range list of lists containing x data
y_data list of lists containing y values
legend_labels list of string legend labels
x_label x axis label
y_label y axis label
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"Error: number of data sets does not match number of labels."
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)
现在让我们继续把图像读出来。
读取单个图像
首先,让我们考虑对于这三种方法中的每一种,将单个图像读回数组的情况。
从磁盘读取
在这三种方法中,由于序列化步骤,LMDB 在从内存中读回图像文件时需要做的工作最多。让我们来看一下这些函数,它们为三种存储格式中的每一种读取单个图像。
首先,从一个.png和.csv文件中读取一个图像及其元数据:
def read_single_disk(image_id):
""" Stores a single image to disk.
Parameters:
---------------
image_id integer unique ID for image
Returns:
----------
image image array, (32, 32, 3) to be stored
label associated meta data, int label
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, label
阅读 LMDB 的作品
接下来,通过打开环境并启动读取事务,从 LMDB 读取相同的映像和元:
1def read_single_lmdb(image_id):
2 """ Stores a single image to LMDB.
3 Parameters:
4 ---------------
5 image_id integer unique ID for image
6
7 Returns:
8 ----------
9 image image array, (32, 32, 3) to be stored
10 label associated meta data, int label
11 """
12 # Open the LMDB environment
13 env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
14
15 # Start a new read transaction
16 with env.begin() as txn:
17 # Encode the key the same way as we stored it
18 data = txn.get(f"{image_id:08}".encode("ascii"))
19 # Remember it's a CIFAR_Image object that is loaded
20 cifar_image = pickle.loads(data)
21 # Retrieve the relevant bits
22 image = cifar_image.get_image()
23 label = cifar_image.label
24 env.close()
25
26 return image, label
关于上面的代码片段,有几点需要注意:
- 第 13 行:
readonly=True标志指定在事务完成之前不允许对 LMDB 文件进行写操作。在数据库行话中,这相当于获取一个读锁。 - 第 20 行:要检索 CIFAR_Image 对象,您需要颠倒我们在编写它时处理它的步骤。这就是对象的
get_image()有用的地方。
这就完成了从 LMDB 读取图像的工作。最后,您可能想对 HDF5 做同样的事情。
从 HDF5 读取
从 HDF5 读取看起来与写入过程非常相似。以下是打开和读取 HDF5 文件并解析相同图像和元的代码:
def read_single_hdf5(image_id):
""" Stores a single image to HDF5.
Parameters:
---------------
image_id integer unique ID for image
Returns:
----------
image image array, (32, 32, 3) to be stored
label associated meta data, int label
"""
# Open the HDF5 file
file = h5py.File(hdf5_dir / f"{image_id}.h5", "r+")
image = np.array(file["/image"]).astype("uint8")
label = int(np.array(file["/meta"]).astype("uint8"))
return image, label
请注意,您可以通过使用前面带有正斜杠/的数据集名称索引file对象来访问文件中的各种数据集。和前面一样,您可以创建一个包含所有读取函数的字典:
_read_single_funcs = dict(
disk=read_single_disk, lmdb=read_single_lmdb, hdf5=read_single_hdf5
)
有了这本字典,你就可以做实验了。
读取单个图像的实验
您可能认为在中读取单个图像的实验会有一些微不足道的结果,但下面是实验代码:
from timeit import timeit
read_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_single_funcs[method](0)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
read_single_timings[method] = t
print(f"Method: {method}, Time usage: {t}")
以下是阅读单幅图像的实验结果:
| 方法 | 读取单个图像+元 |
|---|---|
| 唱片 | 1.61970 毫秒 |
| IMDB(IMDB) | 4.52063 毫秒 |
| HDF5 | 1.98036 毫秒 |
直接从磁盘读取.png和.csv文件稍微快一些,但是这三种方法的执行速度都很快。我们接下来要做的实验要有趣得多。
读取许多图像
现在,您可以调整代码来一次读取许多图像。这可能是您最常执行的操作,因此运行时性能至关重要。
调整许多图像的代码
扩展上面的函数,可以用read_many_创建函数,用于接下来的实验。像以前一样,在读取不同数量的图像时比较性能是很有趣的,下面的代码中重复了这些内容以供参考:
def read_many_disk(num_images):
""" Reads image from disk.
Parameters:
---------------
num_images number of images to read
Returns:
----------
images images array, (N, 32, 32, 3) to be stored
labels associated meta data, int label (N, 1)
"""
images, labels = [], []
# Loop over all IDs and read each image in one by one
for image_id in range(num_images):
images.append(np.array(Image.open(disk_dir / f"{image_id}.png")))
with open(disk_dir / f"{num_images}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for row in reader:
labels.append(int(row[0]))
return images, labels
def read_many_lmdb(num_images):
""" Reads image from LMDB.
Parameters:
---------------
num_images number of images to read
Returns:
----------
images images array, (N, 32, 32, 3) to be stored
labels associated meta data, int label (N, 1)
"""
images, labels = [], []
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), readonly=True)
# Start a new read transaction
with env.begin() as txn:
# Read all images in one single transaction, with one lock
# We could split this up into multiple transactions if needed
for image_id in range(num_images):
data = txn.get(f"{image_id:08}".encode("ascii"))
# Remember that it's a CIFAR_Image object
# that is stored as the value
cifar_image = pickle.loads(data)
# Retrieve the relevant bits
images.append(cifar_image.get_image())
labels.append(cifar_image.label)
env.close()
return images, labels
def read_many_hdf5(num_images):
""" Reads image from HDF5.
Parameters:
---------------
num_images number of images to read
Returns:
----------
images images array, (N, 32, 32, 3) to be stored
labels associated meta data, int label (N, 1)
"""
images, labels = [], []
# Open the HDF5 file
file = h5py.File(hdf5_dir / f"{num_images}_many.h5", "r+")
images = np.array(file["/images"]).astype("uint8")
labels = np.array(file["/meta"]).astype("uint8")
return images, labels
_read_many_funcs = dict(
disk=read_many_disk, lmdb=read_many_lmdb, hdf5=read_many_hdf5
)
有了存储在字典中的阅读函数和写作函数,您就可以开始实验了。
读取多幅图像的实验
现在,您可以运行实验来读出许多图像:
from timeit import timeit
read_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_many_funcs[method](num_images)",
setup="num_images=cutoff",
number=1,
globals=globals(),
)
read_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time
print(f"Method: {method}, No. images: {cutoff}, Time usage: {t}")
正如我们之前所做的,您可以绘制读取实验结果的图表:


上图显示了正常的、未调整的读取时间,显示了从.png文件读取与 LMDB 或 HDF5 之间的巨大差异。
相比之下,底部的图表显示了计时的log,突出显示了较少图像的相对差异。也就是说,我们可以看到 HDF5 是如何落后的,但随着图像数量的增加,它始终比 LMDB 快一点点。
使用与写时序相同的绘图函数,我们得到如下结果:
disk_x_r = read_many_timings["disk"]
lmdb_x_r = read_many_timings["lmdb"]
hdf5_x_r = read_many_timings["hdf5"]
plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to read",
"Read time",
log=False,
)
plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to read",
"Log read time",
log=True,
)
在实践中,写时间通常没有读时间重要。想象一下,你正在训练一个关于图像的深度神经网络,而你的整个图像数据集一次只有一半适合 RAM。训练网络的每个时期都需要整个数据集,模型需要几百个时期才能收敛。实际上,您将在每个时期将数据集的一半读入内存。
人们有几个小技巧,比如训练伪纪元来使这个稍微好一点,但是你明白了。
现在,再看一下上面的图表。一个 40 秒和 4 秒的读取时间之间的差别就像等待你的模型训练 6 个小时或 40 分钟之间的差别!
如果我们在同一个图表上查看读取和写入时间,我们会看到以下内容:
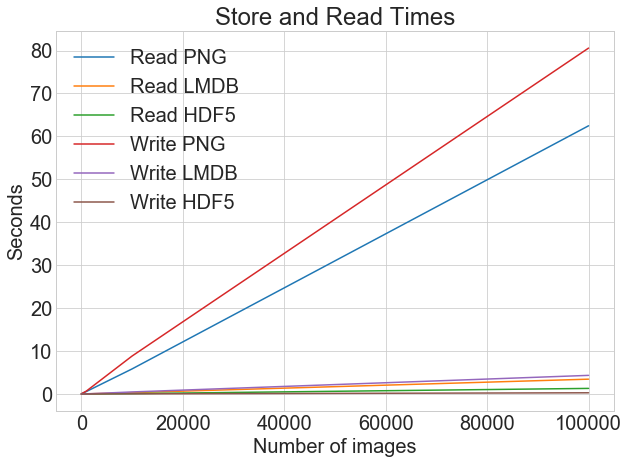
您可以使用相同的绘图功能在单个图形上绘制所有读取和写入时序:
plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r, disk_x, lmdb_x, hdf5_x],
[
"Read PNG",
"Read LMDB",
"Read HDF5",
"Write PNG",
"Write LMDB",
"Write HDF5",
],
"Number of images",
"Seconds",
"Log Store and Read Times",
log=False,
)
当你将图像存储为.png文件时,写和读的时间有很大的不同。然而,对于 LMDB 和 HDF5,差异就不那么明显了。总的来说,即使读取时间比写入时间更重要,使用 LMDB 或 HDF5 存储图像也有很强的说服力。
现在,您已经了解了 LMDB 和 HDF5 的性能优势,让我们来看看另一个关键指标:磁盘使用率。
考虑磁盘使用情况
速度不是您可能感兴趣的唯一性能指标。我们已经在处理非常大的数据集,所以磁盘空间也是一个非常有效和相关的问题。
假设您有一个 3TB 的图像数据集。与我们的 CIFAR 示例不同,假设您已经在磁盘的某个地方保存了它们,那么通过使用另一种存储方法,您实际上是在制作它们的副本,该副本也必须被存储。这样做将在使用图像时给你带来巨大的性能优势,但是你需要确保你有足够的磁盘空间。
各种存储方法使用多少磁盘空间?以下是每种方法用于每种数量图像的磁盘空间:
我使用 Linux du -h -c folder_name/*命令来计算我的系统上的磁盘使用情况。由于四舍五入的原因,这种方法有一些固有的近似性,但下面是一般的比较:
# Memory used in KB
disk_mem = [24, 204, 2004, 20032, 200296]
lmdb_mem = [60, 420, 4000, 39000, 393000]
hdf5_mem = [36, 304, 2900, 29000, 293000]
X = [disk_mem, lmdb_mem, hdf5_mem]
ind = np.arange(3)
width = 0.35
plt.subplots(figsize=(8, 10))
plots = [plt.bar(ind, [row[0] for row in X], width)]
for i in range(1, len(cutoffs)):
plots.append(
plt.bar(
ind, [row[i] for row in X], width, bottom=[row[i - 1] for row in X]
)
)
plt.ylabel("Memory in KB")
plt.title("Disk memory used by method")
plt.xticks(ind, ("PNG", "LMDB", "HDF5"))
plt.yticks(np.arange(0, 400000, 100000))
plt.legend(
[plot[0] for plot in plots], ("10", "100", "1,000", "10,000", "100,000")
)
plt.show()
与使用普通.png图像存储相比,HDF5 和 LMDB 占用更多的磁盘空间。值得注意的是,LMDB 和 HDF5 的磁盘使用和性能高度依赖于各种因素,包括操作系统,更重要的是,您存储的数据大小。
LMDB 通过缓存和利用操作系统页面大小来提高效率。你不需要理解它的内部工作原理,但是请注意,对于较大的图像,你最终会使用 LMDB 更多的磁盘,因为图像不适合 LMDB 的叶页面,树中的常规存储位置,相反你会有许多溢出页面。上图中的 LMDB 棒线将脱离图表。
与您可能使用的普通图像相比,我们的 32x32x3 像素图像相对较小,并且可以实现最佳的 LMDB 性能。
虽然我们不会在这里进行实验性探索,但根据我自己对 256x256x3 或 512x512x3 像素图像的经验,HDF5 通常在磁盘使用方面比 LMDB 略高。这是进入最后一节的一个很好的过渡,这一节定性地讨论了这两种方法之间的差异。
讨论
LMDB 和 HDF5 还有其他值得了解的显著特性,简单讨论一下对这两种方法的批评也很重要。如果您想了解更多信息,讨论中包含了几个链接。
并行访问
我们在上面的实验中没有测试的一个关键比较是并发读取和写入。通常,对于如此大的数据集,您可能希望通过并行化来加快操作速度。
在大多数情况下,你不会对同时阅读同一幅图像的不同部分感兴趣,但是你会想要一次阅读多幅图像。根据并发性的定义,以.png文件的形式存储到磁盘实际上允许完全并发。只要图像名称不同,就可以从不同的线程中一次读取多个图像,或者一次写入多个文件。
LMDB 怎么样?在 LMDB 环境中,一次可以有多个读者,但只能有一个编写器,并且编写器不会阻止读者。你可以在 LMDB 科技网站上了解更多信息。
多个应用程序可以同时访问同一个 LMDB 数据库,来自同一个进程的多个线程也可以并发访问 LMDB 进行读取。这允许更快的读取时间:如果您将所有的 CIFAR 分成 10 个集合,那么您可以设置 10 个进程来读取一个集合中的每一个,这将把加载时间除以 10。
HDF5 还提供并行 I/O,支持并发读写。然而,在实现中,持有写锁,并且访问是顺序的,除非您有并行文件系统。
如果您正在开发这样一个系统,有两个主要的选择,这将在 HDF 并行 IO 小组撰写的本文中进行更深入的讨论。这可能会变得非常复杂,最简单的选择是智能地将数据集分成多个 HDF5 文件,这样每个进程可以独立于其他文件处理一个.h5文件。
文档
如果你谷歌lmdb,至少在英国,第三个搜索结果是 IMDb,互联网电影数据库。那不是你要找的!
实际上,LMDB 的 Python 绑定有一个主要的文档来源,它位于Read Docs LMDB。虽然 Python 包甚至还没有达到版本> 0.94,但它已经被广泛使用并且被认为是稳定的。
至于 LMDB 技术本身,在 LMDB 科技网站有更详细的文档,感觉有点像二年级学微积分,除非你从他们的入门页面开始。
对于 HDF5,在 h5py docs 网站上有非常清晰的文档,还有一篇由 Christopher Lovell 撰写的很有帮助的博客文章,它很好地概述了如何使用h5py软件包。O'Reilly 的书、 Python 和 HDF5 也是入门的好方法。
虽然没有像初学者可能会欣赏的那样记录在案,但 LMDB 和 HDF5 都有庞大的用户社区,所以更深入的谷歌搜索通常会产生有用的结果。
更加严格地审视实施情况
存储系统中没有乌托邦,LMDB 和 HDF5 都有陷阱。
了解 LMDB 的一个关键点是,新数据是在不覆盖或移动现有数据的情况下写入的。这是一个设计决策,允许您在我们的实验中看到的极快的读取,并且还保证了数据的完整性和可靠性,而不需要额外保留事务日志。
但是,请记住,在写入新数据库之前,您需要为内存分配定义map_size参数。这就是 LMDB 可能成为麻烦的地方。假设你已经创建了一个 LMDB 数据库,一切都很好。您已经耐心地等待将庞大的数据集打包到 LMDB 中。
然后,稍后,您记得需要添加新数据。即使使用您在map_size上指定的缓冲区,您也很容易看到lmdb.MapFullError错误。除非你想用更新后的map_size重写整个数据库,否则你必须把新数据存储在一个单独的 LMDB 文件中。即使一个事务可以跨越多个 LMDB 文件,拥有多个文件仍然是一件痛苦的事情。
此外,一些系统对一次可以申请多少内存有限制。在我自己使用高性能计算(HPC)系统的经验中,这被证明是非常令人沮丧的,并且经常使我更喜欢 HDF5 而不是 LMDB。
对于 LMDB 和 HDF5,一次只能将请求的项目读入内存。使用 LMDB,键-单元对被逐个读入内存,而使用 HDF5,dataset对象可以像 Python 数组一样被访问,带有索引dataset[i]、范围、dataset[i:j]和其他拼接dataset[i:j:interval]。
由于系统的优化方式以及操作系统的不同,访问项目的顺序会影响性能。
根据我的经验,对于 LMDB 来说,按键顺序访问项目(键-值对按键的字母数字顺序保存在内存中)可能会获得更好的性能,而对于 HDF5 来说,访问大范围比使用以下方法逐个读取数据集的每个元素性能更好:
# Slightly slower
for i in range(len(dataset)):
# Read the ith value in the dataset, one at a time
do_something_with(dataset[i])
# This is better
data = dataset[:]
for d in data:
do_something_with(d)
如果你正在考虑选择一种文件存储格式来编写你的软件,那就不能不提 Cyrille Rossant 关于 HDF5 缺陷的远离 HDF5 ,以及 Konrad Hinsen 关于 HDF5 和数据管理未来的的回应,这表明在他自己的使用案例中,一些缺陷可以通过许多较小的数据集而不是几个巨大的数据集来避免。请注意,相对较小的数据集仍有几 GB 大小。
与其他库的集成
如果你正在处理非常大的数据集,很有可能你会对它们做一些有意义的事情。值得考虑深度学习库以及与 LMDB 和 HDF5 的集成。
首先,所有的库都支持从磁盘读取图片作为.png文件,只要你把它们转换成期望格式的 NumPy 数组。这适用于所有的方法,我们在上面已经看到,以数组的形式读取图像是相对简单的。
下面是几个最受欢迎的深度学习库及其 LMDB 和 HDF5 集成:
-
Caffe 有一个稳定的、得到良好支持的 LMDB 集成,它透明地处理读取步骤。LMDB 层也可以轻松替换为 HDF5 数据库。
-
Keras 使用 HDF5 格式保存和恢复模型。这意味着张量流也可以。
-
TensorFlow 内置类
LMDBDataset,提供从 LMDB 文件读入输入数据的接口,可以批量生成迭代器和张量。tensor flow不是有一个内置的 HDF5 类,但是可以编写一个继承自Dataset类的类。我个人使用了一个定制类,它是基于我构建 HDF5 文件的方式为最佳读访问而设计的。 -
Theano 本身并不支持任何特定的文件格式或数据库,但如前所述,可以使用任何东西,只要它作为 N 维数组读入。
虽然还不够全面,但这有望让您对一些关键深度学习库的 LMDB/HDF5 集成有所了解。
关于用 Python 存储图像的几点个人见解
在我自己分析 TB 级医疗图像的日常工作中,我同时使用了 LMDB 和 HDF5,并且了解到,对于任何存储方法,深谋远虑是至关重要的。
通常,需要使用 k-fold 交叉验证来训练模型,这涉及将整个数据集分成 k 个集合(k 通常为 10),并且训练 k 个模型,每个模型使用不同的 k 个集合作为测试集合。这确保了模型不会过度拟合数据集,或者换句话说,不会对看不见的数据做出好的预测。
制作 k 集的标准方法是将数据集中表示的每种类型的数据的相等表示放入每个 k 集中。因此,将每个 k 集保存到单独的 HDF5 数据集中可以最大限度地提高效率。有时,单个 k-set 不能一次加载到内存中,因此即使是数据集中的数据排序也需要一些预先考虑。
对于 LMDB,我同样会在创建数据库之前提前做好计划。在存储图像之前,有几个值得问的好问题:
- 我如何保存图像,以便大部分读取是连续的?
- 什么是好钥匙?
- 我如何计算一个好的
map_size,预测数据集中潜在的未来变化? - 单笔交易可以有多大,交易应该如何细分?
不管存储方法如何,当您处理大型影像数据集时,一点点规划就能帮上大忙。
结论
你已经坚持到最后了!你现在已经对一个大的主题有了一个鸟瞰。
在本文中,您已经了解了在 Python 中存储和访问大量图像的三种方法,并且可能有机会使用其中的一些方法。这篇文章的所有代码都在 Jupyter 笔记本这里或者 Python 脚本这里。风险自负,因为几 GB 的磁盘空间将被汽车、船等小方块图像所取代。
您已经看到了各种存储方法如何极大地影响读写时间的证据,以及本文中考虑的三种方法的优缺点。虽然将图像存储为.png文件可能是最直观的,但考虑 HDF5 或 LMDB 等方法会带来很大的性能优势。
欢迎在评论区讨论本文未涉及的优秀存储方法,如 LevelDB 、羽毛、 TileDB 、獾、 BoltDB ,或其他。没有完美的存储方法,最好的方法取决于你具体的数据集和用例。
延伸阅读
以下是与本文中涉及的三种方法相关的一些参考资料:
您可能还会欣赏 Lim、Young 和 Patton 的“用于深度神经网络可扩展训练的图像存储系统分析”。该论文涵盖了与本文类似的实验,但是规模更大,考虑了冷缓存和热缓存以及其他因素。**********
Django RESTful API 的测试驱动开发
原文:https://realpython.com/test-driven-development-of-a-django-restful-api/
这篇文章介绍了使用 Django 和 Django REST 框架开发基于 CRUD 的 RESTful API 的过程,Django REST 框架用于快速构建基于 Django 模型的 RESTful API。
该应用程序使用:
- python 3 . 6 . 0 版
- Django v1.11.0
- Django REST 框架 v3.6.2
- Postgres v9.6.1
- Psycopg2 v2.7.1
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
注意:查看第三个真实 Python 课程,获得关于 Django REST 框架的更深入的教程。
目标
本教程结束时,您将能够…
- 讨论使用 Django REST 框架引导 RESTful API 开发的好处
- 使用序列化程序验证模型查询集
- 欣赏 Django REST 框架的可浏览 API 特性,获得一个更干净、文档更完整的 API 版本
- 实践测试驱动的开发
为什么选择 Django REST 框架?
Django REST Framework(REST Framework)提供了许多开箱即用的强大特性,这些特性与惯用的 Django 非常匹配,包括:
- 可浏览的 API :用一个人友好的 HTML 输出来记录你的 API,提供一个漂亮的类似表单的界面,使用标准的 HTTP 方法向资源提交数据并从中获取数据。
- 身份验证支持 : REST 框架对各种身份验证协议以及权限和节流策略提供了丰富的支持,这些策略可以基于每个视图进行配置。
- 序列化器(serializer):序列化器是一种验证模型查询集/实例并将其转换为可以轻松呈现为 JSON 和 XML 的原生 Python 数据类型的优雅方式。
- 节流:节流是决定一个请求是否被授权的方式,可以和不同的权限集成。它通常用于对单个用户的 API 请求进行速率限制。
此外,该文档易于阅读,并且充满了示例。如果你正在构建一个 RESTful 的 API,在你的 API 端点和你的模型之间有一对一的关系,那么 REST 框架是一个不错的选择。
Django 项目设置
创建并激活虚拟设备:
$ mkdir django-puppy-store
$ cd django-puppy-store
$ python3.6 -m venv env
$ source env/bin/activate
安装 Django 并建立一个新项目:
(env)$ pip install django==1.11.0
(env)$ django-admin startproject puppy_store
您当前的项目结构应该如下所示:
└── puppy_store
├── manage.py
└── puppy_store
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
Django 应用和 REST 框架设置
首先创建puppies应用程序,然后在你的虚拟机中安装 REST 框架:
(env)$ cd puppy_store
(env)$ python manage.py startapp puppies
(env)$ pip install djangorestframework==3.6.2
现在我们需要配置 Django 项目来利用 REST 框架。
首先,将puppies app 和rest_framework添加到puppy _ store/puppy _ store/settings . py内的INSTALLED_APPS部分:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'puppies',
'rest_framework'
]
接下来,在单个字典中定义 REST 框架的全局设置,同样是在 settings.py 文件中:
REST_FRAMEWORK = {
# Use Django's standard `django.contrib.auth` permissions,
# or allow read-only access for unauthenticated users.
'DEFAULT_PERMISSION_CLASSES': [],
'TEST_REQUEST_DEFAULT_FORMAT': 'json'
}
这允许无限制地访问 API,并将所有请求的默认测试格式设置为 JSON。
注意:不受限制的访问对于本地开发来说很好,但是在生产环境中,您可能需要限制对某些端点的访问。一定要更新这个。查看文档了解更多信息。
您当前的项目结构看起来应该是这样的:
└── puppy_store
├── manage.py
├── puppies
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
└── puppy_store
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
数据库和模型设置
让我们设置 Postgres 数据库,并对其应用所有的迁移。
注意:您可以随意将 Postgres 替换为您选择的关系数据库!
一旦您的系统上有了一个正常工作的 Postgres 服务器,打开 Postgres 交互式 shell 并创建数据库:
$ psql # CREATE DATABASE puppy_store_drf; CREATE DATABASE # \q
安装 psycopg2 以便我们可以通过 Python 与 Postgres 服务器进行交互:
(env)$ pip install psycopg2==2.7.1
更新 settings.py 中的数据库配置,添加适当的用户名和密码:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'puppy_store_drf',
'USER': '<your-user>',
'PASSWORD': '<your-password>',
'HOST': '127.0.0.1',
'PORT': '5432'
}
}
接下来,在django-puppy-store/puppy _ store/puppy/models . py中定义一个具有一些基本属性的小狗模型:
from django.db import models
class Puppy(models.Model):
"""
Puppy Model
Defines the attributes of a puppy
"""
name = models.CharField(max_length=255)
age = models.IntegerField()
breed = models.CharField(max_length=255)
color = models.CharField(max_length=255)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
def get_breed(self):
return self.name + ' belongs to ' + self.breed + ' breed.'
def __repr__(self):
return self.name + ' is added.'
现在应用迁移:
(env)$ python manage.py makemigrations
(env)$ python manage.py migrate
健全性检查
再次跳转到psql并验证puppies_puppy已经创建:
$ psql # \c puppy_store_drf You are now connected to database "puppy_store_drf". puppy_store_drf=# \dt List of relations Schema | Name | Type | Owner --------+----------------------------+-------+----------------
public | auth_group | table | michael.herman public | auth_group_permissions | table | michael.herman public | auth_permission | table | michael.herman public | auth_user | table | michael.herman public | auth_user_groups | table | michael.herman public | auth_user_user_permissions | table | michael.herman public | django_admin_log | table | michael.herman public | django_content_type | table | michael.herman public | django_migrations | table | michael.herman public | django_session | table | michael.herman public | puppies_puppy | table | michael.herman (11 rows)
注意:如果您想查看实际的表细节,可以运行
\d+ puppies_puppy。
在继续之前,让我们为小狗模型写一个快速单元测试。
将以下代码添加到名为 test_models.py 的新文件中,该文件位于“django-puppy-store/puppy _ store/puppy”内名为“tests”的新文件夹中:
from django.test import TestCase
from ..models import Puppy
class PuppyTest(TestCase):
""" Test module for Puppy model """
def setUp(self):
Puppy.objects.create(
name='Casper', age=3, breed='Bull Dog', color='Black')
Puppy.objects.create(
name='Muffin', age=1, breed='Gradane', color='Brown')
def test_puppy_breed(self):
puppy_casper = Puppy.objects.get(name='Casper')
puppy_muffin = Puppy.objects.get(name='Muffin')
self.assertEqual(
puppy_casper.get_breed(), "Casper belongs to Bull Dog breed.")
self.assertEqual(
puppy_muffin.get_breed(), "Muffin belongs to Gradane breed.")
在上面的测试中,我们通过来自django.test.TestCase的setUp()方法向 puppy 表中添加了虚拟条目,并断言get_breed()方法返回了正确的字符串。
添加一个 init。py 文件到“tests”并从“django-puppy-store/puppy _ store/puppy”中删除 tests.py 文件。
让我们运行第一个测试:
(env)$ python manage.py test
Creating test database for alias 'default'...
.
----------------------------------------------------------------------
Ran 1 test in 0.007s
OK
Destroying test database for alias 'default'...
太好了!我们的第一个单元测试已经通过了!
串行器
在继续创建实际的 API 之前,让我们为 Puppy 模型定义一个序列化器,它验证模型查询集并生成 Pythonic 数据类型。
将以下代码片段添加到django-puppy-store/puppy _ store/puppy/serializer . py:
from rest_framework import serializers
from .models import Puppy
class PuppySerializer(serializers.ModelSerializer):
class Meta:
model = Puppy
fields = ('name', 'age', 'breed', 'color', 'created_at', 'updated_at')
在上面的代码片段中,我们为我们的小狗模型定义了一个ModelSerializer,验证了所有提到的字段。简而言之,如果你的 API 端点和你的模型之间有一对一的关系——如果你正在创建一个 RESTful API,你可能应该这样做——那么你可以使用一个 ModelSerializer 来创建一个序列化器。
有了我们的数据库,我们现在可以开始构建 RESTful API 了…
RESTful 结构
在 RESTful API 中,端点(URL)定义了 API 的结构,以及最终用户如何使用 HTTP 方法(GET、POST、PUT、DELETE)从我们的应用程序中访问数据。端点应该围绕集合和元素进行逻辑组织,两者都是资源。
在我们的例子中,我们有一个单独的资源,puppies,所以我们将使用下面的 URL-/puppies/和/puppies/<id>,分别用于集合和元素:
| 端点 | HTTP 方法 | CRUD 方法 | 结果 |
|---|---|---|---|
puppies |
得到 | 阅读 | 得到所有小狗 |
puppies/:id |
得到 | 阅读 | 养一只小狗 |
puppies |
邮政 | 创造 | 添加一只小狗 |
puppies/:id |
放 | 更新 | 更新一只小狗 |
puppies/:id |
删除 | 删除 | 删除一只小狗 |
路线和测试(TDD)
我们将采用测试优先的方法,而不是彻底的测试驱动的方法,其中我们将经历以下过程:
- 添加一个单元测试,代码足够失败
- 然后更新代码,使其通过测试。
一旦测试通过,重新开始新的测试。
首先创建一个新文件,django-puppy-store/puppy _ store/puppy/tests/test _ views . py,保存我们的视图的所有测试,并为我们的应用程序创建一个新的测试客户端:
import json
from rest_framework import status
from django.test import TestCase, Client
from django.urls import reverse
from ..models import Puppy
from ..serializers import PuppySerializer
# initialize the APIClient app
client = Client()
在开始所有的 API 路由之前,让我们首先创建一个所有返回空响应的视图函数的框架,并将它们映射到文件django-puppy-store/puppy _ store/puppy/views . py中相应的 URL:
from rest_framework.decorators import api_view
from rest_framework.response import Response
from rest_framework import status
from .models import Puppy
from .serializers import PuppySerializer
@api_view(['GET', 'DELETE', 'PUT'])
def get_delete_update_puppy(request, pk):
try:
puppy = Puppy.objects.get(pk=pk)
except Puppy.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
# get details of a single puppy
if request.method == 'GET':
return Response({})
# delete a single puppy
elif request.method == 'DELETE':
return Response({})
# update details of a single puppy
elif request.method == 'PUT':
return Response({})
@api_view(['GET', 'POST'])
def get_post_puppies(request):
# get all puppies
if request.method == 'GET':
return Response({})
# insert a new record for a puppy
elif request.method == 'POST':
return Response({})
创建各自的 URL 以匹配django-puppy-store/puppy _ store/puppy/URLs . py中的视图:
from django.conf.urls import url
from . import views
urlpatterns = [
url(
r'^api/v1/puppies/(?P<pk>[0-9]+)$',
views.get_delete_update_puppy,
name='get_delete_update_puppy'
),
url(
r'^api/v1/puppies/$',
views.get_post_puppies,
name='get_post_puppies'
)
]
更新django-puppy-store/puppy _ store/puppy _ store/URLs . py同样:
from django.conf.urls import include, url
from django.contrib import admin
urlpatterns = [
url(r'^', include('puppies.urls')),
url(
r'^api-auth/',
include('rest_framework.urls', namespace='rest_framework')
),
url(r'^admin/', admin.site.urls),
]
可浏览的 API
现在,所有的路由都与视图函数连接起来了,让我们打开 REST 框架的可浏览 API 接口,验证所有的 URL 是否都按预期工作。
首先,启动开发服务器:
(env)$ python manage.py runserver
确保注释掉我们的settings.py文件的REST_FRAMEWORK部分中的所有属性,以绕过登录。现在参观http://localhost:8000/api/v1/puppies
您将看到 API 响应的交互式 HTML 布局。同样,我们可以测试其他网址,并验证所有网址都工作得非常好。
让我们从每条路线的单元测试开始。
路线
获取全部
从验证提取的记录的测试开始:
class GetAllPuppiesTest(TestCase):
""" Test module for GET all puppies API """
def setUp(self):
Puppy.objects.create(
name='Casper', age=3, breed='Bull Dog', color='Black')
Puppy.objects.create(
name='Muffin', age=1, breed='Gradane', color='Brown')
Puppy.objects.create(
name='Rambo', age=2, breed='Labrador', color='Black')
Puppy.objects.create(
name='Ricky', age=6, breed='Labrador', color='Brown')
def test_get_all_puppies(self):
# get API response
response = client.get(reverse('get_post_puppies'))
# get data from db
puppies = Puppy.objects.all()
serializer = PuppySerializer(puppies, many=True)
self.assertEqual(response.data, serializer.data)
self.assertEqual(response.status_code, status.HTTP_200_OK)
运行测试。您应该会看到以下错误:
self.assertEqual(response.data, serializer.data)
AssertionError: {} != [OrderedDict([('name', 'Casper'), ('age',[687 chars])])]
更新视图以通过测试。
@api_view(['GET', 'POST'])
def get_post_puppies(request):
# get all puppies
if request.method == 'GET':
puppies = Puppy.objects.all()
serializer = PuppySerializer(puppies, many=True)
return Response(serializer.data)
# insert a new record for a puppy
elif request.method == 'POST':
return Response({})
在这里,我们获得小狗的所有记录,并使用PuppySerializer验证每个记录。
运行测试以确保它们全部通过:
Ran 2 tests in 0.072s
OK
获得单身
获取一只小狗涉及两个测试案例:
- 获得有效的小狗-例如,小狗存在
- 得到无效的小狗-例如,小狗不存在
添加测试:
class GetSinglePuppyTest(TestCase):
""" Test module for GET single puppy API """
def setUp(self):
self.casper = Puppy.objects.create(
name='Casper', age=3, breed='Bull Dog', color='Black')
self.muffin = Puppy.objects.create(
name='Muffin', age=1, breed='Gradane', color='Brown')
self.rambo = Puppy.objects.create(
name='Rambo', age=2, breed='Labrador', color='Black')
self.ricky = Puppy.objects.create(
name='Ricky', age=6, breed='Labrador', color='Brown')
def test_get_valid_single_puppy(self):
response = client.get(
reverse('get_delete_update_puppy', kwargs={'pk': self.rambo.pk}))
puppy = Puppy.objects.get(pk=self.rambo.pk)
serializer = PuppySerializer(puppy)
self.assertEqual(response.data, serializer.data)
self.assertEqual(response.status_code, status.HTTP_200_OK)
def test_get_invalid_single_puppy(self):
response = client.get(
reverse('get_delete_update_puppy', kwargs={'pk': 30}))
self.assertEqual(response.status_code, status.HTTP_404_NOT_FOUND)
进行测试。您应该会看到以下错误:
self.assertEqual(response.data, serializer.data)
AssertionError: {} != {'name': 'Rambo', 'age': 2, 'breed': 'Labr[109 chars]26Z'}
更新视图:
@api_view(['GET', 'UPDATE', 'DELETE'])
def get_delete_update_puppy(request, pk):
try:
puppy = Puppy.objects.get(pk=pk)
except Puppy.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
# get details of a single puppy
if request.method == 'GET':
serializer = PuppySerializer(puppy)
return Response(serializer.data)
在上面的代码片段中,我们用一个 ID 得到了小狗。运行测试以确保它们都通过。
帖子
插入新记录也涉及两种情况:
- 插入有效的小狗
- 插入一只残疾小狗
首先,为它编写测试:
class CreateNewPuppyTest(TestCase):
""" Test module for inserting a new puppy """
def setUp(self):
self.valid_payload = {
'name': 'Muffin',
'age': 4,
'breed': 'Pamerion',
'color': 'White'
}
self.invalid_payload = {
'name': '',
'age': 4,
'breed': 'Pamerion',
'color': 'White'
}
def test_create_valid_puppy(self):
response = client.post(
reverse('get_post_puppies'),
data=json.dumps(self.valid_payload),
content_type='application/json'
)
self.assertEqual(response.status_code, status.HTTP_201_CREATED)
def test_create_invalid_puppy(self):
response = client.post(
reverse('get_post_puppies'),
data=json.dumps(self.invalid_payload),
content_type='application/json'
)
self.assertEqual(response.status_code, status.HTTP_400_BAD_REQUEST)
进行测试。您应该会看到两个失败:
self.assertEqual(response.status_code, status.HTTP_400_BAD_REQUEST)
AssertionError: 200 != 400
self.assertEqual(response.status_code, status.HTTP_201_CREATED)
AssertionError: 200 != 201
同样,更新视图以通过测试:
@api_view(['GET', 'POST'])
def get_post_puppies(request):
# get all puppies
if request.method == 'GET':
puppies = Puppy.objects.all()
serializer = PuppySerializer(puppies, many=True)
return Response(serializer.data)
# insert a new record for a puppy
if request.method == 'POST':
data = {
'name': request.data.get('name'),
'age': int(request.data.get('age')),
'breed': request.data.get('breed'),
'color': request.data.get('color')
}
serializer = PuppySerializer(data=data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
在这里,我们通过在插入数据库之前序列化和验证请求数据来插入新记录。
再次运行测试以确保它们通过。
您也可以使用可浏览的 API 来测试这一点。再次启动开发服务器,并导航到http://localhost:8000/API/v1/puppies/。然后,在 POST 表单中,提交以下内容作为application/json:
{ "name": "Muffin", "age": 4, "breed": "Pamerion", "color": "White" }
一定要得到全部,也要得到单个工作。
放
从更新记录的测试开始。与添加记录类似,我们也需要测试有效和无效的更新:
class UpdateSinglePuppyTest(TestCase):
""" Test module for updating an existing puppy record """
def setUp(self):
self.casper = Puppy.objects.create(
name='Casper', age=3, breed='Bull Dog', color='Black')
self.muffin = Puppy.objects.create(
name='Muffy', age=1, breed='Gradane', color='Brown')
self.valid_payload = {
'name': 'Muffy',
'age': 2,
'breed': 'Labrador',
'color': 'Black'
}
self.invalid_payload = {
'name': '',
'age': 4,
'breed': 'Pamerion',
'color': 'White'
}
def test_valid_update_puppy(self):
response = client.put(
reverse('get_delete_update_puppy', kwargs={'pk': self.muffin.pk}),
data=json.dumps(self.valid_payload),
content_type='application/json'
)
self.assertEqual(response.status_code, status.HTTP_204_NO_CONTENT)
def test_invalid_update_puppy(self):
response = client.put(
reverse('get_delete_update_puppy', kwargs={'pk': self.muffin.pk}),
data=json.dumps(self.invalid_payload),
content_type='application/json')
self.assertEqual(response.status_code, status.HTTP_400_BAD_REQUEST)
进行测试。
self.assertEqual(response.status_code, status.HTTP_400_BAD_REQUEST)
AssertionError: 405 != 400
self.assertEqual(response.status_code, status.HTTP_204_NO_CONTENT)
AssertionError: 405 != 204
更新视图:
@api_view(['GET', 'DELETE', 'PUT'])
def get_delete_update_puppy(request, pk):
try:
puppy = Puppy.objects.get(pk=pk)
except Puppy.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
# get details of a single puppy
if request.method == 'GET':
serializer = PuppySerializer(puppy)
return Response(serializer.data)
# update details of a single puppy
if request.method == 'PUT':
serializer = PuppySerializer(puppy, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_204_NO_CONTENT)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
# delete a single puppy
elif request.method == 'DELETE':
return Response({})
在上面的代码片段中,类似于插入,我们序列化并验证请求数据,然后做出适当的响应。
再次运行测试以确保所有测试都通过。
删除
要删除单个记录,需要 ID:
class DeleteSinglePuppyTest(TestCase):
""" Test module for deleting an existing puppy record """
def setUp(self):
self.casper = Puppy.objects.create(
name='Casper', age=3, breed='Bull Dog', color='Black')
self.muffin = Puppy.objects.create(
name='Muffy', age=1, breed='Gradane', color='Brown')
def test_valid_delete_puppy(self):
response = client.delete(
reverse('get_delete_update_puppy', kwargs={'pk': self.muffin.pk}))
self.assertEqual(response.status_code, status.HTTP_204_NO_CONTENT)
def test_invalid_delete_puppy(self):
response = client.delete(
reverse('get_delete_update_puppy', kwargs={'pk': 30}))
self.assertEqual(response.status_code, status.HTTP_404_NOT_FOUND)
进行测试。您应该看到:
self.assertEqual(response.status_code, status.HTTP_204_NO_CONTENT)
AssertionError: 200 != 204
更新视图:
@api_view(['GET', 'DELETE', 'PUT'])
def get_delete_update_puppy(request, pk):
try:
puppy = Puppy.objects.get(pk=pk)
except Puppy.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
# get details of a single puppy
if request.method == 'GET':
serializer = PuppySerializer(puppy)
return Response(serializer.data)
# update details of a single puppy
if request.method == 'PUT':
serializer = PuppySerializer(puppy, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_204_NO_CONTENT)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
# delete a single puppy
if request.method == 'DELETE':
puppy.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
再次运行测试。确保他们都通过。确保在可浏览的 API 中测试更新和删除功能!
结论和后续步骤
在本教程中,我们通过测试优先的方法,使用 Django REST 框架完成了创建 RESTful API 的过程。
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
下一步是什么?为了使我们的 RESTful API 健壮和安全,我们可以为生产环境实现权限和节流,以允许基于认证凭证和速率限制的受限访问,从而避免任何类型的 DDoS 攻击。此外,不要忘记防止可浏览 API 在生产环境中被访问。
欢迎在下面的评论中分享你的评论、问题或建议。完整的代码可以在 django-puppy-store 存储库中找到。******
Django 中的测试(第 1 部分)——最佳实践和例子
原文:https://realpython.com/testing-in-django-part-1-best-practices-and-examples/
测试至关重要。没有正确地测试你的代码,你将永远不知道代码是否如它应该的那样工作,无论是现在还是将来当代码库改变时。无数的时间可能被浪费在修复由代码库变更引起的问题上。更糟糕的是,您可能根本不知道有问题,直到您的最终用户抱怨它,这显然不是您想要发现代码中断的方式。
测试到位将有助于确保如果一个特定的函数出错,你会知道它。测试也使得调试代码中断变得更加容易,节省了时间和金钱。
在过去,由于没有根据旧的代码库正确地测试新的特性,我真的丢了很多工作。不要让这种事发生在你身上。认真对待测试。你会对你的代码更有信心,你的雇主也会对你更有信心。它本质上是一份保险单。
测试有助于你构建好的代码,发现错误,写文档。
在本帖中,我们将首先看一个包括最佳实践的简介,然后看几个例子。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
Django 测试简介
测试类型
单元测试和集成测试是两种主要的测试类型:
- 单元测试是测试一个特定功能的独立测试。
- 与此同时,集成测试是更大的测试,关注用户行为和测试整个应用程序。换句话说,集成测试结合了不同的代码功能,以确保它们的行为正确。
关注单元测试。写很多这样的。与集成测试相比,这些测试更容易编写和调试,您拥有的越多,您需要的集成测试就越少。单元测试应该很快。我们将研究一些加速测试的技术。
也就是说,集成测试有时仍然是必要的,即使你已经覆盖了单元测试,因为集成测试可以帮助捕捉代码回归。
通常,测试会导致成功(预期结果)、失败(意外结果)或错误。您不仅需要测试预期的结果,还需要测试代码处理意外结果的能力。
最佳实践
- 如果它能断裂,就应该进行测试。这包括模型、视图、表单、模板、验证器等等。
- 每个测试通常应该只测试一个功能。
- 保持简单。您不希望必须在其他测试之上编写测试。
- 无论何时从 repo 中拉出或推出代码,都要运行测试,并在进入生产环境之前运行测试。
- 升级到 Django 的新版本时:
- 本地升级,
- 运行您的测试套件,
- 修复 bug,
- 推到回购和暂存,然后
- 在交付代码之前,在 staging 中再次测试。
结构
构建适合您的项目的测试。我倾向于将每个应用程序的所有测试放在 tests.py 文件中,并根据我测试的内容对测试进行分组——例如,模型、视图、表单等。
您还可以完全绕过(删除)tests.py 文件,并在每个应用程序中以这种方式构建您的测试:
└── app_name
└── tests
├── __init__.py
├── test_forms.py
├── test_models.py
└── test_views.py
最后,您可以创建一个单独的测试文件夹,它镜像整个项目结构,在每个应用程序文件夹中放置一个 tests.py 文件。
较大的项目应该使用后一种结构。如果你知道你的小项目最终会扩展成更大的项目,最好也使用后两种结构中的一种。我倾向于第一种和第三种结构,因为我发现为每个应用程序设计测试更容易,因为它们都可以在一个脚本中查看。
第三方软件包
使用以下包和库来帮助编写和运行您的测试套件:
- django-webtest :让编写符合最终用户体验的功能测试和断言变得更加容易。将这些测试与 Selenium 测试结合起来,以全面覆盖模板和视图。
- 覆盖率:用于测量测试的有效性,显示你的代码库被测试覆盖的百分比。如果您刚刚开始设置单元测试,覆盖率可以帮助提供应该测试什么的建议。覆盖率也可以用来将测试变成一场游戏:例如,我每天都试图增加测试所覆盖的代码的百分比。
- django-discover-runner :如果你以不同的方式组织测试,帮助定位测试(例如,在 tests.py 之外)。因此,如果您将测试组织到单独的文件夹中,就像上面的例子一样,您可以使用 discover-runner 来定位测试。
- factory_boy 、model _ mummy、 mock :都是用来代替fixture或 ORM 填充测试所需的数据。fixtures 和 ORM 都很慢,并且需要在模型改变时进行更新。
示例
在这个基本示例中,我们将测试:
- 模特,
- 观点,
- 表单,以及
- API。
点击下载 Github repo 继续跟进。
设置
安装覆盖范围并将其添加到您的 INSTALLED_APPS:
$ pip install coverage==3.6
跑步覆盖范围:
$ coverage run manage.py test whatever -v 2
使用详细级别 2,
-v 2,以获得更多详细信息。您也可以使用这个命令:coverage run manage.py test -v 2一次性测试您的整个 Django 项目。
构建您的报告以查看测试应该从哪里开始:
$ coverage html
打开django 15/html cov/index . html查看您的报告结果。滚动到报告的底部。您可以跳过 virtualenv 文件夹中的所有行。不要测试任何内置的 Python 函数或库,因为它们已经被测试过了。您可以将 virtualenv 移出文件夹,以便在运行报告后使其更加清晰。
让我们从测试模型开始。
测试模型
在覆盖率报告中,单击“whatever/models”链接。您应该会看到这个屏幕:

从本质上说,这个报告表明我们应该测试一个条目的标题。简单。
打开 tests.py 并添加以下代码:
from django.test import TestCase
from whatever.models import Whatever
from django.utils import timezone
from django.core.urlresolvers import reverse
from whatever.forms import WhateverForm
# models test
class WhateverTest(TestCase):
def create_whatever(self, title="only a test", body="yes, this is only a test"):
return Whatever.objects.create(title=title, body=body, created_at=timezone.now())
def test_whatever_creation(self):
w = self.create_whatever()
self.assertTrue(isinstance(w, Whatever))
self.assertEqual(w.__unicode__(), w.title)
这是怎么回事?我们实际上创建了一个Whatever对象,并测试创建的标题是否与预期的标题匹配——它确实匹配。
注意:确保您的函数名称以
test_开头,这不仅是一个常见的约定,也是为了让 django-discover-runner 能够定位测试。此外,为您添加到模型中的所有方法编写测试。
重新运行覆盖率:
$ coverage run manage.py test whatever -v 2
您应该会看到以下结果,表明测试已经通过:
test_whatever_creation (whatever.tests.WhateverTest) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.002s
OK
然后,如果您再次查看覆盖率报告,模型现在应该是 100%。
测试视图
测试视图有时会很困难。我通常使用单元测试来检查状态代码,使用 Selenium Webdriver 来测试 AJAX、Javascript 等。
将以下代码添加到 tests.py 中的 WhateverTest 类中:
# views (uses reverse)
def test_whatever_list_view(self):
w = self.create_whatever()
url = reverse("whatever.views.whatever")
resp = self.client.get(url)
self.assertEqual(resp.status_code, 200)
self.assertIn(w.title, resp.content)
这里,我们从客户端获取 URL,将结果存储在变量resp中,然后测试我们的断言。首先,我们测试响应代码是否为 200,然后我们测试实际的响应。您应该会得到以下结果:
test_whatever_creation (whatever.tests.WhateverTest) ... ok
test_whatever_list_view (whatever.tests.WhateverTest) ... ok
----------------------------------------------------------------------
Ran 2 tests in 0.052s
OK
再次运行您的报告。您现在应该会看到一个“whatever/views”的链接,显示以下结果:
您也可以编写测试来确保某些东西失败。例如,如果用户需要登录来创建一个新的对象,测试将会成功,即使它实际上无法创建对象。
让我们来看一个快速硒测试:
# views (uses selenium)
import unittest
from selenium import webdriver
class TestSignup(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
def test_signup_fire(self):
self.driver.get("http://localhost:8000/add/")
self.driver.find_element_by_id('id_title').send_keys("test title")
self.driver.find_element_by_id('id_body').send_keys("test body")
self.driver.find_element_by_id('submit').click()
self.assertIn("http://localhost:8000/", self.driver.current_url)
def tearDown(self):
self.driver.quit
if __name__ == '__main__':
unittest.main()
安装 selenium:
$ pip install selenium==2.33.0
进行测试。Firefox 应该加载(如果你安装了的话)并运行测试。然后,我们断言在提交时加载了正确的页面。您还可以检查以确保新对象已添加到数据库中。
测试表格
添加以下方法:
def test_valid_form(self):
w = Whatever.objects.create(title='Foo', body='Bar')
data = {'title': w.title, 'body': w.body,}
form = WhateverForm(data=data)
self.assertTrue(form.is_valid())
def test_invalid_form(self):
w = Whatever.objects.create(title='Foo', body='')
data = {'title': w.title, 'body': w.body,}
form = WhateverForm(data=data)
self.assertFalse(form.is_valid())
注意我们是如何从 JSON 生成表单数据的。这是一个固定装置。
您现在应该已经通过了 5 项测试:
test_signup_fire (whatever.tests.TestSignup) ... ok
test_invalid_form (whatever.tests.WhateverTest) ... ok
test_valid_form (whatever.tests.WhateverTest) ... ok
test_whatever_creation (whatever.tests.WhateverTest) ... ok
test_whatever_list_view (whatever.tests.WhateverTest) ... ok
----------------------------------------------------------------------
Ran 5 tests in 12.753s
OK
您还可以编写测试,根据表单本身的验证器来断言是否显示某个错误消息。
测试 API
首先,你可以从这个网址访问 API:http://localhost:8000/API/whatever/?format=json 。这是一个简单的设置,所以测试也相当简单。
安装 lxml 和解除 xml:
$ pip install lxml==3.2.3
$ pip install defusedxml==0.4.1
添加以下测试案例:
from tastypie.test import ResourceTestCase
class EntryResourceTest(ResourceTestCase):
def test_get_api_json(self):
resp = self.api_client.get('/api/whatever/', format='json')
self.assertValidJSONResponse(resp)
def test_get_api_xml(self):
resp = self.api_client.get('/api/whatever/', format='xml')
self.assertValidXMLResponse(resp)
我们只是断言我们在每种情况下都会得到响应。
下次
在下一个教程中,我们将会看到一个更复杂的例子,以及使用 model _ mommy 来生成测试数据。同样,您可以从回购中获取代码。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
有什么要补充的吗?请在下方留言评论。****
在 Django 测试(第二部分)-模型妈咪 vs Django 测试夹具
原文:https://realpython.com/testing-in-django-part-2-model-mommy-vs-django-testing-fixtures/
在上一篇帖子中,我向您介绍了 Django 中的测试,我们讨论了最佳实践和一些例子。这一次,我将向您展示一个更复杂的例子,并向您介绍用于创建样本数据的模型妈妈。
你为什么要在乎?
在上一篇文章中,我说过,“工厂男孩、模特妈咪、模拟都是用来代替夹具或 ORM 来填充测试所需的数据。fixtures 和 ORM 都很慢,并且需要在模型改变时进行更新。”
总而言之,Django 测试夹具是有问题的,因为它们:
- 必须在每次模型/模式改变时更新,
- 非常非常慢。和
- 有时硬编码数据会导致您的测试在将来失败。
因此,通过使用 Model Mommy,您可以创建加载速度更快并且随着时间的推移更容易维护的装置。
Django 测试夹具
让我们从上一篇文章中测试模型的例子开始:
class WhateverTest(TestCase):
def create_whatever(self, title="only a test", body="yes, this is only a test"):
return Whatever.objects.create(
title=title, body=body, created_at=timezone.now())
def test_whatever_creation(self):
w = self.create_whatever()
self.assertTrue(isinstance(w, Whatever))
self.assertEqual(w.__unicode__(), w.title)
这里我们简单地创建了一个Whatever()对象,并断言创建的标题与预期的标题相匹配。
如果您从 repo 下载了项目,启动服务器并运行测试:
$ coverage run manage.py test whatever -v 2
您将看到上述测试通过:
test_whatever_creation (whatever.tests.WhateverTest) ... ok
现在,不必每次都为每个属性创建一个新的实例(无聊!),我们可以用模型妈咪来精简流程。
模特妈咪
安装:
$ pip install model_mommy
还记得我们的模特长什么样吗?
class Whatever(models.Model):
title = models.CharField(max_length=200)
body = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
def __unicode__(self):
return self.title
现在,我们可以用更简单的方式重写上面的测试:
from model_mommy import mommy
class WhateverTestMommy(TestCase):
def test_whatever_creation_mommy(self):
what = mommy.make(Whatever)
self.assertTrue(isinstance(what, Whatever))
self.assertEqual(what.__unicode__(), what.title)
运行它。通过了吗?
有多简单?不需要传入参数。
新型号
让我们看一个更复杂的例子。
设置
创建新应用程序:
$ python manage.py startapp whatevs
将 app 添加到 settings.py 文件中的Installed_Apps
创建模型:
from django.db import models
from django.contrib.auth.models import User
from django.contrib import admin
class Forum(models.Model):
title = models.CharField(max_length=100)
def __unicode__(self):
return self.title
class Post(models.Model):
title = models.CharField(max_length=100)
created = models.DateTimeField(auto_now_add=True)
creator = models.ForeignKey(User, blank=True, null=True)
forum = models.ForeignKey(Forum)
body = models.TextField(max_length=10000)
def __unicode__(self):
return unicode(self.creator) + " - " + self.title
同步数据库。
我们的覆盖报告是什么样的?
测试
添加测试:
from model_mommy import mommy
from django.test import TestCase
from whatevs.models import Forum, Thread
class WhateverTestMommy(TestCase):
def test_forum_creation_mommy(self):
new_forum = mommy.make('whatevs.Forum')
new_thread = mommy.make('whatevs.Thread')
self.assertTrue(isinstance(new_forum, Forum))
self.assertTrue(isinstance(new_thread, Thread))
self.assertEqual(new_forum.__unicode__(), new_forum.title)
self.assertEqual(
new_thread.__unicode__(),
(str(new_thread.forum) + " - " + str(new_thread.title)))
重新运行您的测试(应该会通过),然后创建覆盖率报告:
$ coverage run manage.py test whatevs -v 2
$ coverage html
嗯?
想尝试使用 JSON 装置运行上述测试,看看如何使用 Django 测试装置设置测试吗?
我不确定下一个教程我们会有什么,所以让我知道你想看什么。抢码这里。有问题一定要在下面评论。干杯!**
用模拟服务器测试外部 API
原文:https://realpython.com/testing-third-party-apis-with-mock-servers/
尽管如此有用,外部 API 测试起来还是很痛苦。当您遇到一个实际的 API 时,您的测试会受到外部服务器的支配,这会导致以下棘手问题:
- 请求-响应周期可能需要几秒钟。起初,这可能看起来不多,但随着每次测试的进行,时间会越来越长。想象一下,在测试整个应用程序时,调用一个 API 10 次、50 次甚至 100 次。
- API 可以设置速率限制。
- API 服务器可能无法访问。可能服务器停机维护了?也许它因为一个错误而失败了,开发团队正在努力让它再次正常工作>您真的希望测试的成功依赖于您无法控制的服务器的健康吗?
你的测试不应该评估一个 API 服务器是否正在运行;他们应该测试你的代码是否按预期运行。
在之前的教程中,我们介绍了模拟对象的概念,演示了如何使用它们来测试与外部 API 交互的代码。本教程建立在相同的主题上,但是在这里我们将带你实际构建一个模拟服务器,而不是模拟 API。有了模拟服务器,您可以执行端到端的测试。您可以使用您的应用程序,并从模拟服务器实时获得实际的反馈。
当您完成下面的示例时,您将已经编写了一个基本的模拟服务器和两个测试——一个使用真正的 API 服务器,另一个使用模拟服务器。这两个测试将访问相同的服务,一个检索用户列表的 API。
注意:本教程使用 Python 3 . 5 . 1 版。
开始使用
从上一篇文章的第一步开始。或者从库中抓取代码。在继续之前,确保测试通过:
$ nosetests --verbosity=2 project
test_todos.test_request_response ... ok
----------------------------------------------------------------------
Ran 1 test in 1.029s
OK
测试模拟 API
设置完成后,您就可以对模拟服务器进行编程了。编写描述该行为的测试:
project/tests/test _ mock _ server . py
# Third-party imports...
from nose.tools import assert_true
import requests
def test_request_response():
url = 'http://localhost:{port}/users'.format(port=mock_server_port)
# Send a request to the mock API server and store the response.
response = requests.get(url)
# Confirm that the request-response cycle completed successfully.
assert_true(response.ok)
注意,它开始看起来几乎与真正的 API 测试一样。URL 已经更改,现在指向模拟服务器将运行的本地主机上的 API 端点。
下面是如何用 Python 创建一个模拟服务器:
project/tests/test _ mock _ server . py
# Standard library imports...
from http.server import BaseHTTPRequestHandler, HTTPServer
import socket
from threading import Thread
# Third-party imports...
from nose.tools import assert_true
import requests
class MockServerRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
# Process an HTTP GET request and return a response with an HTTP 200 status.
self.send_response(requests.codes.ok)
self.end_headers()
return
def get_free_port():
s = socket.socket(socket.AF_INET, type=socket.SOCK_STREAM)
s.bind(('localhost', 0))
address, port = s.getsockname()
s.close()
return port
class TestMockServer(object):
@classmethod
def setup_class(cls):
# Configure mock server.
cls.mock_server_port = get_free_port()
cls.mock_server = HTTPServer(('localhost', cls.mock_server_port), MockServerRequestHandler)
# Start running mock server in a separate thread.
# Daemon threads automatically shut down when the main process exits.
cls.mock_server_thread = Thread(target=cls.mock_server.serve_forever)
cls.mock_server_thread.setDaemon(True)
cls.mock_server_thread.start()
def test_request_response(self):
url = 'http://localhost:{port}/users'.format(port=self.mock_server_port)
# Send a request to the mock API server and store the response.
response = requests.get(url)
# Confirm that the request-response cycle completed successfully.
print(response)
assert_true(response.ok)
首先创建一个BaseHTTPRequestHandler的子类。这个类捕获请求并构造返回的响应。覆盖do_GET()函数,为 HTTP GET 请求创建响应。在这种情况下,只需返回一个 OK 状态。接下来,编写一个函数来获取可供模拟服务器使用的端口号。
下一个代码块实际上配置了服务器。注意代码是如何实例化一个HTTPServer实例并传递给它一个端口号和一个处理程序的。接下来创建一个线程,这样服务器就可以异步运行,并且你的主程序线程可以与之通信。让线程成为守护进程,当主程序退出时,守护进程告诉线程停止。最后,启动线程永远为模拟服务器服务(直到测试完成)。
创建一个测试类,并将测试函数移动到其中。您必须添加一个额外的方法来确保在任何测试运行之前启动模拟服务器。注意,这个新代码位于一个特殊的类级函数setup_class()中。
运行测试并观察它们是否通过:
$ nosetests --verbosity=2 project
测试符合 API 的服务
您可能希望在代码中调用多个 API 端点。在设计应用程序时,您可能会创建服务函数来向 API 发送请求,然后以某种方式处理响应。也许您会将响应数据存储在数据库中。或者将数据传递给用户界面。
重构您的代码,将硬编码的 API 基 URL 提取到一个常量中。将该变量添加到一个 constants.py 文件中:
project/constants.py
BASE_URL = 'http://jsonplaceholder.typicode.com'
接下来,将从 API 检索用户的逻辑封装到一个函数中。请注意如何通过将 URL 路径连接到基础来创建新的 URL。
project/services.py
# Standard library imports...
from urllib.parse import urljoin
# Third-party imports...
import requests
# Local imports...
from project.constants import BASE_URL
USERS_URL = urljoin(BASE_URL, 'users')
def get_users():
response = requests.get(USERS_URL)
if response.ok:
return response
else:
return None
将模拟服务器代码从特性文件移动到一个新的 Python 文件中,这样就可以很容易地重用它。向请求处理程序添加条件逻辑,以检查 HTTP 请求的目标是哪个 API 端点。通过添加一些简单的头信息和基本的响应负载来增强响应。服务器创建和启动代码可以封装在一个方便的方法start_mock_server()中。
项目/测试/模拟. py
# Standard library imports...
from http.server import BaseHTTPRequestHandler, HTTPServer
import json
import re
import socket
from threading import Thread
# Third-party imports...
import requests
class MockServerRequestHandler(BaseHTTPRequestHandler):
USERS_PATTERN = re.compile(r'/users')
def do_GET(self):
if re.search(self.USERS_PATTERN, self.path):
# Add response status code.
self.send_response(requests.codes.ok)
# Add response headers.
self.send_header('Content-Type', 'application/json; charset=utf-8')
self.end_headers()
# Add response content.
response_content = json.dumps([])
self.wfile.write(response_content.encode('utf-8'))
return
def get_free_port():
s = socket.socket(socket.AF_INET, type=socket.SOCK_STREAM)
s.bind(('localhost', 0))
address, port = s.getsockname()
s.close()
return port
def start_mock_server(port):
mock_server = HTTPServer(('localhost', port), MockServerRequestHandler)
mock_server_thread = Thread(target=mock_server.serve_forever)
mock_server_thread.setDaemon(True)
mock_server_thread.start()
完成对逻辑的更改后,更改测试以使用新的服务函数。更新测试以检查从服务器传回的增加的信息。
project/tests/test _ real _ server . py
# Third-party imports...
from nose.tools import assert_dict_contains_subset, assert_is_instance, assert_true
# Local imports...
from project.services import get_users
def test_request_response():
response = get_users()
assert_dict_contains_subset({'Content-Type': 'application/json; charset=utf-8'}, response.headers)
assert_true(response.ok)
assert_is_instance(response.json(), list)
project/tests/test _ mock _ server . py
# Third-party imports...
from unittest.mock import patch
from nose.tools import assert_dict_contains_subset, assert_list_equal, assert_true
# Local imports...
from project.services import get_users
from project.tests.mocks import get_free_port, start_mock_server
class TestMockServer(object):
@classmethod
def setup_class(cls):
cls.mock_server_port = get_free_port()
start_mock_server(cls.mock_server_port)
def test_request_response(self):
mock_users_url = 'http://localhost:{port}/users'.format(port=self.mock_server_port)
# Patch USERS_URL so that the service uses the mock server URL instead of the real URL.
with patch.dict('project.services.__dict__', {'USERS_URL': mock_users_url}):
response = get_users()
assert_dict_contains_subset({'Content-Type': 'application/json; charset=utf-8'}, response.headers)
assert_true(response.ok)
assert_list_equal(response.json(), [])
注意在 test_mock_server.py 代码中使用了一项新技术。response = get_users()行用来自模拟库的patch.dict()函数包装。
这个语句是做什么的?
记住,您将requests.get()功能从特性逻辑移到了get_users()服务功能。在内部,get_users()使用USERS_URL变量调用requests.get()。patch.dict()功能临时替换USERS_URL变量的值。事实上,它只在with语句的范围内这样做。在代码运行之后,USERS_URL变量被恢复到它的原始值。这段代码修补了URL 以使用模拟服务器地址。
运行测试并观察它们是否通过。
$ nosetests --verbosity=2
test_mock_server.TestMockServer.test_request_response ... 127.0.0.1 - - [05/Jul/2016 20:45:30] "GET /users HTTP/1.1" 200 -
ok
test_real_server.test_request_response ... ok
test_todos.test_request_response ... ok
----------------------------------------------------------------------
Ran 3 tests in 0.871s
OK
跳过触及真正 API 的测试
我们在本教程开始时描述了测试模拟服务器而不是真实服务器的优点,然而,您的代码目前测试两者。如何配置测试来忽略真实的服务器?Python 的“unittest”库提供了几个允许你跳过测试的函数。您可以使用条件跳过函数' skipIf '和一个环境变量来打开和关闭真正的服务器测试。在下面的例子中,我们传递了一个应该被忽略的标记名:
$ export SKIP_TAGS=real
project/constants.py
# Standard-library imports...
import os
BASE_URL = 'http://jsonplaceholder.typicode.com'
SKIP_TAGS = os.getenv('SKIP_TAGS', '').split()
project/tests/test _ real _ server . py
# Standard library imports...
from unittest import skipIf
# Third-party imports...
from nose.tools import assert_dict_contains_subset, assert_is_instance, assert_true
# Local imports...
from project.constants import SKIP_TAGS
from project.services import get_users
@skipIf('real' in SKIP_TAGS, 'Skipping tests that hit the real API server.')
def test_request_response():
response = get_users()
assert_dict_contains_subset({'Content-Type': 'application/json; charset=utf-8'}, response.headers)
assert_true(response.ok)
assert_is_instance(response.json(), list)
运行测试并注意真实的服务器测试是如何被忽略的:
$ nosetests --verbosity=2 project
test_mock_server.TestMockServer.test_request_response ... 127.0.0.1 - - [05/Jul/2016 20:52:18] "GET /users HTTP/1.1" 200 -
ok
test_real_server.test_request_response ... SKIP: Skipping tests that hit the real API server.
test_todos.test_request_response ... ok
----------------------------------------------------------------------
Ran 3 tests in 1.196s
OK (SKIP=1)
接下来的步骤
既然您已经创建了一个模拟服务器来测试您的外部 API 调用,那么您可以将这些知识应用到您自己的项目中。以这里创建的简单测试为基础。扩展处理程序的功能,以更接近地模拟真实 API 的行为。
尝试以下练习来升级:
- 如果以未知路径发送请求,则返回状态为 HTTP 404(未找到)的响应。
- 如果使用不允许的方法(POST、DELETE、UPDATE)发送请求,则返回状态为 HTTP 405(不允许的方法)的响应。
- 将有效请求的实际用户数据返回给
/users。 - 编写测试来捕捉这些场景。
从回购中抓取代码。**
在 Python 中模仿外部 API
原文:https://realpython.com/testing-third-party-apis-with-mocks/
下面的教程演示了如何使用 Python 模拟对象来测试外部 API 的使用。
与第三方应用程序集成是扩展产品功能的好方法。
然而,附加值也伴随着障碍。您不拥有外部库,这意味着您无法控制托管它的服务器、组成其逻辑的代码或在它和您的应用程序之间传输的数据。在这些问题之上,用户通过与库的交互不断地操纵数据。
如果你想用第三方 API 增强你的应用程序的实用性,那么你需要确信这两个系统会很好的运行。您需要测试这两个应用程序以可预测的方式接口,并且您需要您的测试在一个受控的环境中执行。
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
乍一看,您似乎对第三方应用程序没有任何控制权。他们中的许多人不提供测试服务器。您不能测试实时数据,即使您可以,测试也会返回不可靠的结果,因为数据是通过使用更新的。此外,您永远不希望您的自动化测试连接到外部服务器。如果发布代码依赖于您的测试是否通过,那么他们那边的错误可能会导致您的开发停止。幸运的是,有一种方法可以在受控环境中测试第三方 API 的实现,而不需要实际连接到外部数据源。解决方案是使用所谓的模仿来伪造外部代码的功能。
mock 是一个假对象,您构建它的目的是让它看起来和行为起来像真实的数据。您将它与实际对象交换,并欺骗系统,使其认为模拟是真实的交易。使用模拟让我想起了一个经典的电影比喻,主人公抓住一个亲信,穿上制服,步入行进中的敌人行列。没有人注意到这个冒名顶替者,每个人都继续前进——一切照旧。
第三方认证,比如 OAuth,是在你的应用中模仿的一个很好的选择。OAuth 要求您的应用程序与外部服务器通信,它涉及真实的用户数据,并且您的应用程序依赖于它的成功来访问它的 API。模拟认证允许您作为授权用户测试您的系统,而不必经历实际的凭证交换过程。在这种情况下,您不想测试您的系统是否成功地对用户进行了身份验证;你想测试你的应用程序的功能在通过认证后的表现。
注意:本教程使用 Python 3 . 5 . 1 版。
第一步
首先建立一个新的开发环境来保存您的项目代码。创建一个新的虚拟环境,然后安装以下库:
$ pip install nose requests
以下是您正在安装的每个库的快速概要,以防您从未遇到过它们:
- 模拟库通过用模拟对象替换部分系统来测试 Python 代码。注意:如果您使用的是 Python 3.3 或更高版本,
mock库是unittest的一部分。如果您使用的是旧版本,请安装 backport mock 库。 - nose 库扩展了内置的 Python
unittest模块,使得测试更加容易。你可以使用unittest或者其他第三方库比如 pytest 来达到同样的效果,但是我更喜欢 nose 的断言方法。 - 请求库极大地简化了 Python 中的 HTTP 调用。
在本教程中,您将与一个为测试而构建的假在线 API 进行通信- JSON 占位符。在您编写任何测试之前,您需要知道 API 会带来什么。
首先,您应该期望当您向您的目标 API 发送请求时,它实际上会返回一个响应。通过用 cURL 调用端点来确认这个假设:
$ curl -X GET 'http://jsonplaceholder.typicode.com/todos'
这个调用应该返回一个 JSON 序列化的 todo 项目列表。注意响应中 todo 数据的结构。您应该会看到带有关键字userId、id、title和completed的对象列表。现在,您准备进行第二个假设——您知道预期的数据是什么样的。API 端点处于活动状态并正常工作。您可以通过从命令行调用它来证明这一点。现在,编写一个 nose 测试,这样你就可以确认未来服务器的寿命。保持简单。您应该只关心服务器是否返回 OK 响应。
项目/测试/测试 _todos.py
# Third-party imports...
from nose.tools import assert_true
import requests
def test_request_response():
# Send a request to the API server and store the response.
response = requests.get('http://jsonplaceholder.typicode.com/todos')
# Confirm that the request-response cycle completed successfully.
assert_true(response.ok)
运行测试并观察其通过:
$ nosetests --verbosity=2 project
test_todos.test_request_response ... ok
----------------------------------------------------------------------
Ran 1 test in 9.270s
OK
将代码重构为服务
在整个应用程序中,您很可能会多次调用外部 API。此外,这些 API 调用可能会涉及比简单的 HTTP 请求更多的逻辑,比如数据处理、错误处理和过滤。您应该从您的测试中提取代码,并将它重构为一个封装了所有预期逻辑的服务函数。
重写您的测试以引用服务函数并测试新的逻辑。
项目/测试/测试 _todos.py
# Third-party imports...
from nose.tools import assert_is_not_none
# Local imports...
from project.services import get_todos
def test_request_response():
# Call the service, which will send a request to the server.
response = get_todos()
# If the request is sent successfully, then I expect a response to be returned.
assert_is_not_none(response)
运行测试并观察其失败,然后编写最少的代码使其通过:
project/services.py
# Standard library imports...
try:
from urllib.parse import urljoin
except ImportError:
from urlparse import urljoin
# Third-party imports...
import requests
# Local imports...
from project.constants import BASE_URL
TODOS_URL = urljoin(BASE_URL, 'todos')
def get_todos():
response = requests.get(TODOS_URL)
if response.ok:
return response
else:
return None
project/constants.py
BASE_URL = 'http://jsonplaceholder.typicode.com'
您编写的第一个测试期望返回一个状态为 OK 的响应。您将编程逻辑重构为一个服务函数,当对服务器的请求成功时,该服务函数会返回响应本身。如果请求失败,则返回一个 None 值。测试现在包括一个断言来确认函数不返回None。
注意我是如何指示您创建一个constants.py文件,然后用一个BASE_URL填充它的。服务函数扩展了BASE_URL来创建TODOS_URL,由于所有的 API 端点都使用相同的基础,您可以继续创建新的端点,而不必重写代码。将BASE_URL放在一个单独的文件中允许您在一个地方编辑它,如果多个模块引用该代码,这将很方便。
运行测试,看着它通过。
$ nosetests --verbosity=2 project
test_todos.test_request_response ... ok
----------------------------------------------------------------------
Ran 1 test in 1.475s
OK
你的第一次嘲弄
代码按预期运行。你知道这一点,因为你有一个通过测试。不幸的是,您有一个问题-您的服务功能仍然是直接访问外部服务器。当您调用get_todos()时,您的代码正在向 API 端点发出请求,并返回一个依赖于该服务器活动的结果。在这里,我将演示如何通过用一个返回相同数据的假请求来交换真实请求,从而将您的编程逻辑与实际的外部库分离。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest.mock import Mock, patch
# Third-party imports...
from nose.tools import assert_is_not_none
# Local imports...
from project.services import get_todos
@patch('project.services.requests.get')
def test_getting_todos(mock_get):
# Configure the mock to return a response with an OK status code.
mock_get.return_value.ok = True
# Call the service, which will send a request to the server.
response = get_todos()
# If the request is sent successfully, then I expect a response to be returned.
assert_is_not_none(response)
请注意,我根本没有更改服务函数。我编辑的唯一一部分代码是测试本身。首先,我从mock库中导入了patch()函数。接下来,我用作为装饰器的patch()函数修改了测试函数,传入了对project.services.requests.get的引用。在函数本身中,我传入了一个参数mock_get,然后在测试函数体中,我添加了一行来设置mock_get.return_value.ok = True。
太好了。那么当测试运行时,实际上会发生什么呢?在我深入研究之前,您需要了解一些关于requests库的工作方式。当您调用requests.get()函数时,它在后台发出一个 HTTP 请求,然后以Response对象的形式返回一个 HTTP 响应。get()函数本身与外部服务器通信,这就是为什么您需要将它作为目标。还记得主人公穿着制服与敌人交换位置的画面吗?你需要让这个模拟看起来和行为起来像requests.get()函数。
当测试函数运行时,它找到声明了requests库的模块project.services,并用一个 mock 替换目标函数requests.get()。测试还告诉 mock 按照服务功能期望的方式进行操作。如果你看一下get_todos(),你会发现函数的成功取决于if response.ok:返回True。这就是生产线mock_get.return_value.ok = True正在做的事情。当在 mock 上调用ok属性时,它将像实际对象一样返回True。get_todos()函数将返回响应,也就是 mock,测试将通过,因为 mock 不是None。
运行测试以查看它是否通过。
$ nosetests --verbosity=2 project
其他方式打补丁
使用装饰器只是用模仿来修补函数的几种方法之一。在下一个例子中,我使用上下文管理器在代码块中显式地修补一个函数。 with语句为代码块中任何代码使用的函数打补丁。当代码块结束时,原始函数被恢复。with语句和装饰器实现了相同的目标:两种方法都修补了project.services.request.get。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest.mock import patch
# Third-party imports...
from nose.tools import assert_is_not_none
# Local imports...
from project.services import get_todos
def test_getting_todos():
with patch('project.services.requests.get') as mock_get:
# Configure the mock to return a response with an OK status code.
mock_get.return_value.ok = True
# Call the service, which will send a request to the server.
response = get_todos()
# If the request is sent successfully, then I expect a response to be returned.
assert_is_not_none(response)
运行测试以查看它们是否仍然通过。
修补函数的另一种方法是使用修补程序。在这里,我确定要修补的源代码,然后显式地开始使用 mock。直到我明确地告诉系统停止使用 mock,修补才会停止。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest.mock import patch
# Third-party imports...
from nose.tools import assert_is_not_none
# Local imports...
from project.services import get_todos
def test_getting_todos():
mock_get_patcher = patch('project.services.requests.get')
# Start patching `requests.get`.
mock_get = mock_get_patcher.start()
# Configure the mock to return a response with an OK status code.
mock_get.return_value.ok = True
# Call the service, which will send a request to the server.
response = get_todos()
# Stop patching `requests.get`.
mock_get_patcher.stop()
# If the request is sent successfully, then I expect a response to be returned.
assert_is_not_none(response)
再次运行测试以获得相同的成功结果。
既然您已经看到了用 mock 修补函数的三种方法,那么您应该在什么时候使用每种方法呢?简短的回答是:这完全取决于你。每种打补丁的方法都是完全有效的。也就是说,我发现特定的编码模式与以下修补方法配合得特别好。
- 当你的测试函数体中的所有代码都使用模仿时,使用装饰器。
- 当你的测试函数中的一些代码使用了模拟代码,而其他代码引用了实际的函数时,使用上下文管理器。
- 当你需要在多个测试中明确地开始和停止模仿一个函数时,使用一个补丁(例如,一个测试类中的
setUp()和tearDown()函数)。
我在本教程中使用了这些方法中的每一种,并且我将在第一次介绍它们时重点介绍每一种方法。
嘲讽完整服务行为
在前面的例子中,您实现了一个基本的模拟,并测试了一个简单的断言——函数get_todos()是否返回了None。get_todos()函数调用外部 API 并接收响应。如果调用成功,该函数将返回一个响应对象,其中包含一个 JSON 序列化的 todos 列表。如果请求失败,get_todos()返回None。在下面的例子中,我演示了如何模拟get_todos()的全部功能。在本教程的开始,您使用 cURL 对服务器进行的第一次调用返回了一个 JSON 序列化的字典列表,它表示 todo 项。这个例子将向您展示如何模拟数据。
记住@patch()是如何工作的:你给它提供一个到你想要模仿的函数的路径。找到了函数,patch()创建了一个Mock对象,真正的函数被暂时替换成了 mock。当测试调用get_todos()时,该函数使用mock_get的方式与使用真实的get()方法的方式相同。这意味着它像函数一样调用mock_get,并期望它返回一个响应对象。
在这种情况下,响应对象是一个requests库Response对象,它有几个属性和方法。在前面的例子中,您伪造了其中一个属性ok。Response对象还有一个json()函数,它将其 JSON 序列化的字符串内容转换成 Python 数据类型(例如list或dict)。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest.mock import Mock, patch
# Third-party imports...
from nose.tools import assert_is_none, assert_list_equal
# Local imports...
from project.services import get_todos
@patch('project.services.requests.get')
def test_getting_todos_when_response_is_ok(mock_get):
todos = [{
'userId': 1,
'id': 1,
'title': 'Make the bed',
'completed': False
}]
# Configure the mock to return a response with an OK status code. Also, the mock should have
# a `json()` method that returns a list of todos.
mock_get.return_value = Mock(ok=True)
mock_get.return_value.json.return_value = todos
# Call the service, which will send a request to the server.
response = get_todos()
# If the request is sent successfully, then I expect a response to be returned.
assert_list_equal(response.json(), todos)
@patch('project.services.requests.get')
def test_getting_todos_when_response_is_not_ok(mock_get):
# Configure the mock to not return a response with an OK status code.
mock_get.return_value.ok = False
# Call the service, which will send a request to the server.
response = get_todos()
# If the response contains an error, I should get no todos.
assert_is_none(response)
我在前面的例子中提到,当您运行用 mock 修补的get_todos()函数时,该函数返回一个 mock 对象“response”。您可能已经注意到了一个模式:每当return_value被添加到一个 mock 时,该 mock 被修改为作为一个函数运行,并且默认情况下它返回另一个 mock 对象。在这个例子中,我通过显式声明Mock对象mock_get.return_value = Mock(ok=True)使这一点更加清楚。mock_get()镜像requests.get(),而requests.get()返回Response,而mock_get()返回Mock。Response对象有一个ok属性,所以您向Mock添加了一个ok属性。
Response对象也有一个json()函数,所以我给Mock添加了json,并给它附加了一个return_value,因为它会像函数一样被调用。json()函数返回一个 todo 对象列表。注意,测试现在包括了一个检查response.json()值的断言。您希望确保get_todos()函数返回 todos 列表,就像实际的服务器一样。最后,为了完善对get_todos()的测试,我添加了一个失败测试。
运行测试并观察它们是否通过。
$ nosetests --verbosity=2 project
test_todos.test_getting_todos_when_response_is_not_ok ... ok
test_todos.test_getting_todos_when_response_is_ok ... ok
----------------------------------------------------------------------
Ran 2 tests in 0.285s
OK
模拟集成功能
我给你看的例子相当简单,在下一个例子中,我会增加复杂性。想象一个场景,您创建一个新的服务函数,调用get_todos(),然后过滤这些结果,只返回已经完成的待办事项。非要再嘲讽一下requests.get()吗?不,在这种情况下你可以直接模仿get_todos()函数!请记住,当您模仿一个函数时,您是在用模仿对象替换实际对象,您只需要担心服务函数如何与模仿对象交互。在get_todos()的例子中,您知道它没有参数,它返回一个带有json()函数的响应,该函数返回一个 todo 对象列表。你不关心引擎盖下发生了什么;您只需要关心get_todos() mock 返回您期望真正的get_todos()函数返回的内容。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest.mock import Mock, patch
# Third-party imports...
from nose.tools import assert_list_equal, assert_true
# Local imports...
from project.services import get_uncompleted_todos
@patch('project.services.get_todos')
def test_getting_uncompleted_todos_when_todos_is_not_none(mock_get_todos):
todo1 = {
'userId': 1,
'id': 1,
'title': 'Make the bed',
'completed': False
}
todo2 = {
'userId': 1,
'id': 2,
'title': 'Walk the dog',
'completed': True
}
# Configure mock to return a response with a JSON-serialized list of todos.
mock_get_todos.return_value = Mock()
mock_get_todos.return_value.json.return_value = [todo1, todo2]
# Call the service, which will get a list of todos filtered on completed.
uncompleted_todos = get_uncompleted_todos()
# Confirm that the mock was called.
assert_true(mock_get_todos.called)
# Confirm that the expected filtered list of todos was returned.
assert_list_equal(uncompleted_todos, [todo1])
@patch('project.services.get_todos')
def test_getting_uncompleted_todos_when_todos_is_none(mock_get_todos):
# Configure mock to return None.
mock_get_todos.return_value = None
# Call the service, which will return an empty list.
uncompleted_todos = get_uncompleted_todos()
# Confirm that the mock was called.
assert_true(mock_get_todos.called)
# Confirm that an empty list was returned.
assert_list_equal(uncompleted_todos, [])
请注意,现在我正在修补测试函数,以查找并使用模拟替换project.services.get_todos。mock 函数应该返回一个具有json()函数的对象。当被调用时,json()函数应该返回一个 todo 对象列表。我还添加了一个断言来确认get_todos()函数确实被调用了。这有助于确定当服务函数访问实际的 API 时,真正的get_todos()函数将会执行。这里,我还包含了一个测试来验证如果get_todos()返回None,那么get_uncompleted_todos()函数将返回一个空列表。我再次确认调用了get_todos()函数。
编写测试,运行它们以查看它们是否失败,然后编写必要的代码使它们通过。
project/services.py
def get_uncompleted_todos():
response = get_todos()
if response is None:
return []
else:
todos = response.json()
return [todo for todo in todos if todo.get('completed') == False]
测试现在通过了。
重构测试以使用类
您可能已经注意到,有些测试似乎属于同一个组。您有两个测试碰到了get_todos()函数。你的另外两个测试重点是get_uncompleted_todos()。每当我开始注意到测试之间的趋势和相似之处,我就将它们重构为一个测试类。这种重构实现了几个目标:
- 将常见的测试函数移动到一个类中,可以让您更容易地将它们作为一个组一起测试。您可以告诉 nose 以一系列函数为目标,但是以单个类为目标更容易。
- 常见的测试功能通常需要相似的步骤来创建和销毁每个测试所使用的数据。这些步骤可以分别封装在
setup_class()和teardown_class()函数中,以便在适当的阶段执行代码。 - 您可以在类上创建实用函数,以重用测试函数中重复的逻辑。想象一下,必须在每个函数中单独调用相同的数据创建逻辑。多痛苦啊!
注意,我使用了补丁技术来模拟测试类中的目标函数。正如我前面提到的,这种修补方法非常适合创建跨越多个函数的模拟。当测试完成时,teardown_class()方法中的代码显式地恢复原始代码。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest.mock import Mock, patch
# Third-party imports...
from nose.tools import assert_is_none, assert_list_equal, assert_true
# Local imports...
from project.services import get_todos, get_uncompleted_todos
class TestTodos(object):
@classmethod
def setup_class(cls):
cls.mock_get_patcher = patch('project.services.requests.get')
cls.mock_get = cls.mock_get_patcher.start()
@classmethod
def teardown_class(cls):
cls.mock_get_patcher.stop()
def test_getting_todos_when_response_is_ok(self):
# Configure the mock to return a response with an OK status code.
self.mock_get.return_value.ok = True
todos = [{
'userId': 1,
'id': 1,
'title': 'Make the bed',
'completed': False
}]
self.mock_get.return_value = Mock()
self.mock_get.return_value.json.return_value = todos
# Call the service, which will send a request to the server.
response = get_todos()
# If the request is sent successfully, then I expect a response to be returned.
assert_list_equal(response.json(), todos)
def test_getting_todos_when_response_is_not_ok(self):
# Configure the mock to not return a response with an OK status code.
self.mock_get.return_value.ok = False
# Call the service, which will send a request to the server.
response = get_todos()
# If the response contains an error, I should get no todos.
assert_is_none(response)
class TestUncompletedTodos(object):
@classmethod
def setup_class(cls):
cls.mock_get_todos_patcher = patch('project.services.get_todos')
cls.mock_get_todos = cls.mock_get_todos_patcher.start()
@classmethod
def teardown_class(cls):
cls.mock_get_todos_patcher.stop()
def test_getting_uncompleted_todos_when_todos_is_not_none(self):
todo1 = {
'userId': 1,
'id': 1,
'title': 'Make the bed',
'completed': False
}
todo2 = {
'userId': 2,
'id': 2,
'title': 'Walk the dog',
'completed': True
}
# Configure mock to return a response with a JSON-serialized list of todos.
self.mock_get_todos.return_value = Mock()
self.mock_get_todos.return_value.json.return_value = [todo1, todo2]
# Call the service, which will get a list of todos filtered on completed.
uncompleted_todos = get_uncompleted_todos()
# Confirm that the mock was called.
assert_true(self.mock_get_todos.called)
# Confirm that the expected filtered list of todos was returned.
assert_list_equal(uncompleted_todos, [todo1])
def test_getting_uncompleted_todos_when_todos_is_none(self):
# Configure mock to return None.
self.mock_get_todos.return_value = None
# Call the service, which will return an empty list.
uncompleted_todos = get_uncompleted_todos()
# Confirm that the mock was called.
assert_true(self.mock_get_todos.called)
# Confirm that an empty list was returned.
assert_list_equal(uncompleted_todos, [])
进行测试。一切都会过去的,因为你没有引入任何新的逻辑。你只是移动了代码。
$ nosetests --verbosity=2 project
test_todos.TestTodos.test_getting_todos_when_response_is_not_ok ... ok
test_todos.TestTodos.test_getting_todos_when_response_is_ok ... ok
test_todos.TestUncompletedTodos.test_getting_uncompleted_todos_when_todos_is_none ... ok
test_todos.TestUncompletedTodos.test_getting_uncompleted_todos_when_todos_is_not_none ... ok
----------------------------------------------------------------------
Ran 4 tests in 0.300s
OK
测试 API 数据的更新
在本教程中,我一直在演示如何模拟第三方 API 返回的数据。这个模拟数据基于一个假设,即真实数据和你伪造的数据使用相同的数据契约。您的第一步是调用实际的 API 并记录返回的数据。您可以相当自信地认为,在您研究这些示例的短时间内,数据的结构没有发生变化,但是,您不应该确信数据会永远保持不变。任何好的外部库都会定期更新。虽然开发人员的目标是使新代码向后兼容,但最终会有代码被弃用的时候。
可以想象,完全依赖假数据是很危险的。因为您是在不与实际服务器通信的情况下测试代码,所以您很容易对测试的强度过于自信。当需要将您的应用程序与真实数据结合使用时,一切都会崩溃。应该使用以下策略来确认您期望从服务器获得的数据与您正在测试的数据相匹配。这里的目标是比较数据结构(如对象中的键)而不是实际数据。
注意我是如何使用上下文管理器修补技术的。在这里,你需要调用真正的服务器和你需要分别模拟它。
项目/测试/测试 _todos.py
def test_integration_contract():
# Call the service to hit the actual API.
actual = get_todos()
actual_keys = actual.json().pop().keys()
# Call the service to hit the mocked API.
with patch('project.services.requests.get') as mock_get:
mock_get.return_value.ok = True
mock_get.return_value.json.return_value = [{
'userId': 1,
'id': 1,
'title': 'Make the bed',
'completed': False
}]
mocked = get_todos()
mocked_keys = mocked.json().pop().keys()
# An object from the actual API and an object from the mocked API should have
# the same data structure.
assert_list_equal(list(actual_keys), list(mocked_keys))
你的测试应该会通过。您模拟的数据结构与实际 API 中的数据结构相匹配。
有条件测试场景
现在您有了一个测试来比较实际的数据契约和模拟的数据契约,您需要知道何时运行它。击中真实服务器的测试不应该是自动化的,因为失败不一定意味着您的代码是坏的。由于十几个您无法控制的原因,您可能无法在测试套件执行时连接到真实的服务器。与自动化测试分开运行这个测试,但是也要相当频繁地运行它。有选择地跳过测试的一种方法是使用环境变量作为开关。在下面的例子中,所有的测试都会运行,除非环境变量SKIP_REAL被设置为True。当SKIP_REAL变量被打开时,任何带有@skipIf(SKIP_REAL)装饰器的测试都将被跳过。
项目/测试/测试 _todos.py
# Standard library imports...
from unittest import skipIf
# Local imports...
from project.constants import SKIP_REAL
@skipIf(SKIP_REAL, 'Skipping tests that hit the real API server.')
def test_integration_contract():
# Call the service to hit the actual API.
actual = get_todos()
actual_keys = actual.json().pop().keys()
# Call the service to hit the mocked API.
with patch('project.services.requests.get') as mock_get:
mock_get.return_value.ok = True
mock_get.return_value.json.return_value = [{
'userId': 1,
'id': 1,
'title': 'Make the bed',
'completed': False
}]
mocked = get_todos()
mocked_keys = mocked.json().pop().keys()
# An object from the actual API and an object from the mocked API should have
# the same data structure.
assert_list_equal(list(actual_keys), list(mocked_keys))
project/constants.py
# Standard-library imports...
import os
BASE_URL = 'http://jsonplaceholder.typicode.com'
SKIP_REAL = os.getenv('SKIP_REAL', False)
$ export SKIP_REAL=True
运行测试并注意输出。一个测试被忽略,控制台显示消息“跳过命中实际 API 服务器的测试”太棒了。
$ nosetests --verbosity=2 project
test_todos.TestTodos.test_getting_todos_when_response_is_not_ok ... ok
test_todos.TestTodos.test_getting_todos_when_response_is_ok ... ok
test_todos.TestUncompletedTodos.test_getting_uncompleted_todos_when_todos_is_none ... ok
test_todos.TestUncompletedTodos.test_getting_uncompleted_todos_when_todos_is_not_none ... ok
test_todos.test_integration_contract ... SKIP: Skipping tests that hit the real API server.
----------------------------------------------------------------------
Ran 5 tests in 0.240s
OK (SKIP=1)
接下来的步骤
至此,您已经看到了如何使用 mocks 测试您的应用程序与第三方 API 的集成。既然您已经知道了如何解决这个问题,那么您可以继续练习为 JSON 占位符中的其他 API 端点编写服务函数(例如,帖子、评论、用户)。
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
通过将你的应用程序连接到一个真实的外部库,如谷歌、脸书或 Evernote,进一步提高你的技能,看看你是否能编写使用模拟的测试。继续编写干净可靠的代码,并关注下一篇教程,它将描述如何使用模拟服务器将测试提升到一个新的水平!
从回购中抓取代码。****
最小可行测试套件
在上一篇帖子中,我们详细介绍了如何在用户注册期间验证电子邮件地址。
这次,我们将添加单元和集成测试(耶!)添加到我们使用烧瓶测试扩展的应用程序中,涵盖了最重要的特性。这种类型的测试被称为最小可行测试(或基于风险的测试),旨在围绕应用程序的特性测试高风险功能。
你错过了第一个邮件吗?从项目回购中抓取代码,快速上手。
单元和集成测试–已定义
对于那些测试新手来说,测试你的应用程序是至关重要的,因为“未经测试的应用程序很难改进现有的代码,未经测试的应用程序的开发人员往往会变得相当偏执。如果一个应用程序有自动化测试,你可以安全地进行修改,并立即知道是否有任何问题”(来源)。
单元测试本质上是测试孤立的代码单元——即单个函数——以确保实际输出与预期输出相同。在许多情况下,由于您经常需要进行外部 API 调用或接触数据库,单元测试可能会严重依赖于模仿假数据。通过模拟测试,它们可能运行得更快,但也可能效率更低,更难维护。因此,除非万不得已,否则我们不会使用模拟;相反,我们将根据需要读写数据库。
请记住,当一个数据库在一个特定的测试中被触及时,从技术上来说,它是一个集成测试,因为测试本身并没有被隔离到一个特定的单元。此外,如果您通过 Flask 应用程序运行您的测试,使用测试助手 test client ,它们也被认为是集成测试。
开始使用
通常很难决定如何开始测试应用程序。这个问题的一个解决方案是从终端用户功能的角度来考虑你的应用:
- 未注册用户必须注册才能访问该应用程序。
- 用户注册后,一封确认电子邮件会发送给用户,他们被认为是“未确认”用户。
- 未经确认的用户可以登录,但他们会立即被重定向到一个页面,提醒他们在访问应用程序之前通过电子邮件确认他们的帐户。
- 确认后,用户可以完全访问该网站,在那里他们可以查看主页,在个人资料页面上更新他们的密码,并注销。
如开始所述,我们将编写足够的测试来覆盖这个主要功能。测试很难;我们非常清楚这一点,所以如果你只是热衷于编写一些测试,那么测试什么是最重要的。这与通过 coverage.py 进行的覆盖测试(我们将在本系列的下一篇文章中详细介绍)一起,将使构建一个健壮的测试套件变得更加容易。
设置
激活 virtualenv,然后确保设置了以下环境变量:
$ export APP_SETTINGS="project.config.DevelopmentConfig"
$ export APP_MAIL_USERNAME="foo"
$ export APP_MAIL_PASSWORD="bar"
然后运行当前的测试套件:
$ python manage.py test
test_app_is_development (test_config.TestDevelopmentConfig) ... ok
test_app_is_production (test_config.TestProductionConfig) ... ok
test_app_is_testing (test_config.TestTestingConfig) ... ok
----------------------------------------------------------------------
Ran 3 tests in 0.003s
OK
这些测试只是测试配置和环境变量。它们应该相当简单。
为了扩展套件,我们需要从一个有组织的结构开始,以保持一切整洁。由于应用程序已经围绕蓝图构建,让我们对测试套件做同样的事情。因此,在“测试”目录中创建两个新的测试文件——test _ main . py和test _ user . py——并在每个文件中添加以下代码:
import unittest
from flask.ext.login import current_user
from project.util import BaseTestCase
#
# Tests go here
#
if __name__ == '__main__':
unittest.main()
注意:你也可以围绕测试类型来组织你的测试——单元、集成、功能等..
第 1 部分–主要蓝图
查看 views.py 文件中的代码(在“project/main”文件夹中),以及最终用户工作流,我们可以看到我们只需要测试主路由/需要用户登录。所以将下面的代码添加到 test_main.py 中:
def test_main_route_requires_login(self):
# Ensure main route requires a logged in user.
response = self.client.get('/', follow_redirects=True)
self.assertTrue(response.status_code == 200)
self.assertTemplateUsed('user/login.html')
这里,我们断言响应状态代码是200,并且使用了正确的模板。运行测试套件。所有 4 项测试都应该通过。
第 2 部分–用户蓝图
在这个蓝图中还有更多的东西要做,所以需要的测试要密集得多。本质上,我们需要测试视图,因此,我们将相应地分解我们的测试套件。别担心,我会指导你的。让我们创建两个类来确保我们的测试在逻辑上是分开的。
将以下代码添加到 test_user.py 中,这样我们就可以开始测试所需的许多功能。
class TestUserForms(BaseTestCase):
pass
class TestUserViews(BaseTestCase):
pass
表格
拥有一个用户注册是一个基于登录的程序的核心概念,没有它,我们就有了一扇“打开的门”去解决问题。这必须按设计运行。因此,按照用户工作流程,让我们从注册表单开始。将这段代码添加到TestUserForms()类中。
def test_validate_success_register_form(self):
# Ensure correct data validates.
form = RegisterForm(
email='new@test.test',
password='example', confirm='example')
self.assertTrue(form.validate())
def test_validate_invalid_password_format(self):
# Ensure incorrect data does not validate.
form = RegisterForm(
email='new@test.test',
password='example', confirm='')
self.assertFalse(form.validate())
def test_validate_email_already_registered(self):
# Ensure user can't register when a duplicate email is used
form = RegisterForm(
email='test@user.com',
password='just_a_test_user',
confirm='just_a_test_user'
)
self.assertFalse(form.validate())
在这些测试中,我们确保表单根据输入的数据通过或未通过验证。将它与“项目/用户”文件夹中的 forms.py 文件进行比较。在最后一个测试中,我们只是从 util.py 文件中的BaseTestCase方法注册了同一个用户。
当我们测试表单时,让我们继续测试登录表单:
def test_validate_success_login_form(self):
# Ensure correct data validates.
form = LoginForm(email='test@user.com', password='just_a_test_user')
self.assertTrue(form.validate())
def test_validate_invalid_email_format(self):
# Ensure invalid email format throws error.
form = LoginForm(email='unknown', password='example')
self.assertFalse(form.validate())
最后,让我们测试一下更改密码表单:
def test_validate_success_change_password_form(self):
# Ensure correct data validates.
form = ChangePasswordForm(password='update', confirm='update')
self.assertTrue(form.validate())
def test_validate_invalid_change_password(self):
# Ensure passwords must match.
form = ChangePasswordForm(password='update', confirm='unknown')
self.assertFalse(form.validate())
def test_validate_invalid_change_password_format(self):
# Ensure invalid email format throws error.
form = ChangePasswordForm(password='123', confirm='123')
self.assertFalse(form.validate())
确保添加所需的导入:
from project.user.forms import RegisterForm, \
LoginForm, ChangePasswordForm
然后运行测试!
$ python manage.py test
test_app_is_development (test_config.TestDevelopmentConfig) ... ok
test_app_is_production (test_config.TestProductionConfig) ... ok
test_app_is_testing (test_config.TestTestingConfig) ... ok
test_main_route_requires_login (test_main.TestMainViews) ... ok
test_validate_email_already_registered (test_user.TestUserForms) ... ok
test_validate_invalid_change_password (test_user.TestUserForms) ... ok
test_validate_invalid_change_password_format (test_user.TestUserForms) ... ok
test_validate_invalid_email_format (test_user.TestUserForms) ... ok
test_validate_invalid_password_format (test_user.TestUserForms) ... ok
test_validate_success_change_password_form (test_user.TestUserForms) ... ok
test_validate_success_login_form (test_user.TestUserForms) ... ok
test_validate_success_register_form (test_user.TestUserForms) ... ok
----------------------------------------------------------------------
Ran 12 tests in 1.656s
对于表单测试,我们基本上只是实例化表单并调用 validate 函数,该函数将触发所有验证,包括我们的自定义验证,并返回一个布尔值,指示表单数据是否确实有效。
测试完表单后,让我们继续查看视图…
视图
登录和查看档案是安全的关键部分,所以我们要确保这是彻底的测试。
login:
def test_correct_login(self):
# Ensure login behaves correctly with correct credentials.
with self.client:
response = self.client.post(
'/login',
data=dict(email="test@user.com", password="just_a_test_user"),
follow_redirects=True
)
self.assertTrue(response.status_code == 200)
self.assertTrue(current_user.email == "test@user.com")
self.assertTrue(current_user.is_active())
self.assertTrue(current_user.is_authenticated())
self.assertTemplateUsed('main/index.html')
def test_incorrect_login(self):
# Ensure login behaves correctly with incorrect credentials.
with self.client:
response = self.client.post(
'/login',
data=dict(email="not@correct.com", password="incorrect"),
follow_redirects=True
)
self.assertTrue(response.status_code == 200)
self.assertIn(b'Invalid email and/or password.', response.data)
self.assertFalse(current_user.is_active())
self.assertFalse(current_user.is_authenticated())
self.assertTemplateUsed('user/login.html')
profile:
def test_profile_route_requires_login(self):
# Ensure profile route requires logged in user.
self.client.get('/profile', follow_redirects=True)
self.assertTemplateUsed('user/login.html')
添加所需的导入:
from project import db
from project.models import User
register和resend_confirmation:
在编写测试来覆盖register和resend_confirmation视图之前,先看一下代码。注意我们是如何利用 email.py 文件中的send_email()函数来发送确认邮件的。我们真的想发送这封邮件吗,还是应该用一个模仿库来伪造它?即使我们发送了邮件,如果不使用 Selenium 在浏览器中调出实际的收件箱,也很难断言实际的邮件出现在虚拟收件箱中。因此,让我们模拟发送电子邮件,我们将在后续文章中处理。
confirm/<token>:
def test_confirm_token_route_requires_login(self):
# Ensure confirm/<token> route requires logged in user.
self.client.get('/confirm/blah', follow_redirects=True)
self.assertTemplateUsed('user/login.html')
像最后两个视图一样,这个视图的其余部分可能会被嘲笑,因为需要生成一个确认令牌。然而,我们可以使用 token.py 文件中的实用函数生成一个令牌,generate_confirmation_token():
def test_confirm_token_route_valid_token(self):
# Ensure user can confirm account with valid token.
with self.client:
self.client.post('/login', data=dict(
email='test@user.com', password='just_a_test_user'
), follow_redirects=True)
token = generate_confirmation_token('test@user.com')
response = self.client.get('/confirm/'+token, follow_redirects=True)
self.assertIn(b'You have confirmed your account. Thanks!', response.data)
self.assertTemplateUsed('main/index.html')
user = User.query.filter_by(email='test@user.com').first_or_404()
self.assertIsInstance(user.confirmed_on, datetime.datetime)
self.assertTrue(user.confirmed)
def test_confirm_token_route_invalid_token(self):
# Ensure user cannot confirm account with invalid token.
token = generate_confirmation_token('test@test1.com')
with self.client:
self.client.post('/login', data=dict(
email='test@user.com', password='just_a_test_user'
), follow_redirects=True)
response = self.client.get('/confirm/'+token, follow_redirects=True)
self.assertIn(
b'The confirmation link is invalid or has expired.',
response.data
)
添加导入:
import datetime
from project.token import generate_confirmation_token, confirm_token
然后进行测试。一个应该失败:
Ran 18 tests in 4.666s
FAILED (failures=1)
本次测试失败:test_confirm_token_route_invalid_token()。为什么?因为视图中有一个错误:
@user_blueprint.route('/confirm/<token>')
@login_required
def confirm_email(token):
try:
email = confirm_token(token)
except:
flash('The confirmation link is invalid or has expired.', 'danger')
user = User.query.filter_by(email=email).first_or_404()
if user.confirmed:
flash('Account already confirmed. Please login.', 'success')
else:
user.confirmed = True
user.confirmed_on = datetime.datetime.now()
db.session.add(user)
db.session.commit()
flash('You have confirmed your account. Thanks!', 'success')
return redirect(url_for('main.home'))
怎么了?
现在,flash调用——例如,flash('The confirmation link is invalid or has expired.', 'danger')——不会导致函数退出,所以即使令牌无效,它也会进入 if/else 并确认用户。这就是你写测试的原因。
让我们重写函数:
@user_blueprint.route('/confirm/<token>')
@login_required
def confirm_email(token):
if current_user.confirmed:
flash('Account already confirmed. Please login.', 'success')
return redirect(url_for('main.home'))
email = confirm_token(token)
user = User.query.filter_by(email=current_user.email).first_or_404()
if user.email == email:
user.confirmed = True
user.confirmed_on = datetime.datetime.now()
db.session.add(user)
db.session.commit()
flash('You have confirmed your account. Thanks!', 'success')
else:
flash('The confirmation link is invalid or has expired.', 'danger')
return redirect(url_for('main.home'))
再次运行测试。18 个都应该通过。
如果令牌过期会发生什么?写一个测试。
def test_confirm_token_route_expired_token(self):
# Ensure user cannot confirm account with expired token.
user = User(email='test@test1.com', password='test1', confirmed=False)
db.session.add(user)
db.session.commit()
token = generate_confirmation_token('test@test1.com')
self.assertFalse(confirm_token(token, -1))
再次运行测试:
$ python manage.py test
test_app_is_development (test_config.TestDevelopmentConfig) ... ok
test_app_is_production (test_config.TestProductionConfig) ... ok
test_app_is_testing (test_config.TestTestingConfig) ... ok
test_main_route_requires_login (test_main.TestMainViews) ... ok
test_validate_email_already_registered (test_user.TestUserForms) ... ok
test_validate_invalid_change_password (test_user.TestUserForms) ... ok
test_validate_invalid_change_password_format (test_user.TestUserForms) ... ok
test_validate_invalid_email_format (test_user.TestUserForms) ... ok
test_validate_invalid_password_format (test_user.TestUserForms) ... ok
test_validate_success_change_password_form (test_user.TestUserForms) ... ok
test_validate_success_login_form (test_user.TestUserForms) ... ok
test_validate_success_register_form (test_user.TestUserForms) ... ok
test_confirm_token_route_expired_token (test_user.TestUserViews) ... ok
test_confirm_token_route_invalid_token (test_user.TestUserViews) ... ok
test_confirm_token_route_requires_login (test_user.TestUserViews) ... ok
test_confirm_token_route_valid_token (test_user.TestUserViews) ... ok
test_correct_login (test_user.TestUserViews) ... ok
test_incorrect_login (test_user.TestUserViews) ... ok
test_profile_route_requires_login (test_user.TestUserViews) ... ok
----------------------------------------------------------------------
Ran 19 tests in 5.306s
OK
反射
这可能是停下来反思的好时机,尤其是因为我们关注的是最小测试。还记得我们的核心特征吗?
- 未注册用户必须注册才能访问该应用程序。
- 用户注册后,会发送一封确认邮件——他们被认为是“未确认”用户。
- 未经确认的用户可以登录,但他们会立即被重定向到一个页面,提醒他们在访问应用程序之前通过电子邮件确认他们的帐户。
- 确认后,用户可以完全访问该网站,在那里他们可以查看主页,在个人资料页面上更新他们的密码,并注销。
我们是否涵盖了所有这些内容?让我们看看:
“未注册用户必须注册才能访问应用程序”:
test_main_route_requires_logintest_validate_email_already_registeredtest_validate_invalid_email_formattest_validate_invalid_password_formattest_validate_success_register_form
“用户注册后,会发送一封确认电子邮件,他们被视为‘未确认’用户”
并且:
“未经确认的用户可以登录,但他们会立即被重定向到一个页面,提醒他们在访问应用程序之前通过电子邮件确认帐户”:
test_validate_success_login_formtest_confirm_token_route_expired_tokentest_confirm_token_route_invalid_tokentest_confirm_token_route_requires_logintest_confirm_token_route_valid_tokentest_correct_logintest_incorrect_logintest_profile_route_requires_login
“确认后,用户可以完全访问该网站,在那里他们可以查看主页,在个人资料页面上更新密码,并注销”:
test_validate_invalid_change_passwordtest_validate_invalid_change_password_formattest_validate_success_change_password_form
在上面的测试中,我们直接测试了表单,然后还为视图创建了测试(这使用了很多与表单测试相同的代码)。这种方法的利弊是什么?当我们进行覆盖测试时,我们会解决这个问题。
下次
这个帖子到此为止。在接下来的几篇文章中,我们将-
- 模拟
user蓝图中的以下全部或部分功能,以完成单元/集成测试-register()和resend_confirmation() - 通过 coverage.py 添加覆盖测试,以帮助确保我们的代码库得到充分的测试。
- 通过使用 Selenium 添加功能测试来扩展测试套件。
测试愉快!***
模型-视图-控制器(MVC)解释-用乐高
原文:https://realpython.com/the-model-view-controller-mvc-paradigm-summarized-with-legos/
为了演示使用 模型-视图-控制器 模式(或 MVC )构建的 web 应用程序在实践中是如何工作的,让我们沿着记忆之路走一趟…
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
乐高积木!
你十岁了,坐在你家客厅的地板上,你面前是一大桶乐高积木。有各种不同形状和大小的乐高玩具。一些蓝色的,高的,长的。就像拖拉机拖车。有些是红色的,几乎是立方体形状。有些是黄色的-大而宽的平面,像玻璃片。有了这些不同类型的乐高玩具,很难说你能建造出什么。
但是惊喜,惊喜,已经有请求了。你哥哥跑过来说,“嘿!给我造一艘飞船!”
“好吧,”你想,“这可能真的很酷!”它是一艘宇宙飞船。
所以你开始工作。你开始拿出你认为你会需要的乐高玩具。有些大,有些小。宇宙飞船的外部用不同的颜色,引擎用不同的颜色。哦,还有不同颜色的爆能枪。(你必须有爆破枪!)
现在你已经把所有的积木都准备好了,是时候组装飞船了。经过几个小时的艰苦工作,现在你面前有一艘宇宙飞船!
你跑去找你哥给他看成品。“哇,干得好!”他说。“哼,”他想,“我几个小时前就要求过了,什么也没做,现在就有了。我希望每件事都那么简单。”
如果我告诉你构建一个 web 应用程序就像用乐高积木搭建一样,会怎么样?
这一切都始于一个请求……
在乐高玩具的例子中,是你的哥哥让你去做一些东西。在 web 应用程序的情况下,用户输入一个 URL,请求查看某个页面。
所以你哥哥就是用户。
请求到达控制器 …
有了乐高,你就是控制器。
控制器负责抓取所有必要的构建模块并根据需要组织它们。
这些积木被称为模型……
不同类型的乐高是模型。你有各种不同的尺寸和形状,你抓住你需要的来建造飞船。在 web 应用程序中,模型帮助控制器从数据库中检索它需要的所有信息。
所以请求进来了…
控制器(您)接收请求。
它去模型(乐高)取回必要的物品。
现在生产最终产品的一切准备就绪。
最终产品被称为视图……
宇宙飞船是风景。它是最终产品,最终显示给提出请求的人(你的兄弟)。
在 web 应用程序中,视图是用户在浏览器中看到的最终页面。
总结…
用乐高积木搭建时:
- 你哥哥请求你建造一艘宇宙飞船。
- 你收到请求。
- 你取回并组织所有你需要建造宇宙飞船的乐高玩具。
- 你用乐高建造宇宙飞船,然后把完成的宇宙飞船还给你的兄弟。
在网络应用中:
- 用户通过输入 URL 请求查看页面。
- 控制器接收该请求。
- 它使用模型来检索所有必要的数据,对其进行组织,并将其发送给…
- 查看,然后使用该数据来渲染最终的网页,并在用户的浏览器中呈现给用户。
从更技术性的角度来看
总结了 MVC 的功能之后,让我们更深入一点,看看在更高的技术层面上一切是如何运作的。
当您在浏览器中键入 URL 以访问 web 应用程序时,您正在请求查看应用程序中的某个页面。但是应用程序如何知道显示/呈现哪个页面呢?
当构建一个 web 应用程序时,你定义了所谓的路线。路由本质上是与不同页面相关联的 URL 模式。因此,当有人输入一个 URL 时,在后台,应用程序会尝试将该 URL 与这些预定义的路由之一进行匹配。
所以,其实真的有四个主要部件在发挥作用:路线、车型、视图、控制器。
路线
每条路线都与一个控制器相关联——更具体地说,是控制器内的某个功能,称为控制器动作。因此,当您输入一个 URL 时,应用程序会尝试查找匹配的路由,如果成功,它会调用该路由的相关控制器操作。
让我们看一个基本的烧瓶路线作为例子:
@app.route('/')
def main_page():
pass
这里我们建立与main_page()视图功能相关的/路线。
型号和控制器
在控制器动作中,通常会发生两件主要的事情:模型用于从数据库中检索所有必要的数据;并且该数据被传递给呈现所请求页面的视图。通过模型检索的数据通常被添加到一个数据结构中(比如一个列表或字典),该结构就是发送给视图的内容。
回到我们的烧瓶例子:
@app.route('/')
def main_page():
"""Searches the database for entries, then displays them."""
db = get_db()
cur = db.execute('select * from entries order by id desc')
entries = cur.fetchall()
return render_template('index.html', entries=entries)
现在,在视图函数中,我们从数据库中获取数据并执行一些基本逻辑。这将返回一个列表,我们将它赋给变量entries,该变量可以在index.html模板中访问。
视图
最后,在视图中,数据结构被访问,其中包含的信息被用来呈现用户最终在浏览器中看到的页面的 HTML 内容。
同样,回到我们的 Flask 应用程序,我们可以循环通过entries,使用 Jinja 语法显示每一个:
{% for entry in entries %}
<li>
<h2>{{ entry.title }}</h2>
<div>{{ entry.text|safe }}</div>
</li>
{% else %}
<li><em>No entries yet. Add some!</em></li>
{% endfor %}
总结
因此,MVC 请求过程的更详细的技术总结如下:
- 用户通过输入 URL 请求查看页面。
- 应用程序将 URL 与预定义的路线进行匹配。
- 调用与路线相关的控制器动作。
- 控制器动作使用模型从数据库中检索所有必要的数据,将数据放在一个数组中,并加载一个视图,沿着数据结构传递。
- 视图访问数据结构并使用它来呈现请求的页面,然后在用户的浏览器中呈现给用户。
这是亚历克斯·科尔曼(Alex Coleman)的一篇客座博文,他是一名编码教师和咨询网站开发人员。**
最邪恶的 Python 反模式
原文:https://realpython.com/the-most-diabolical-python-antipattern/
以下是《强大的 Python的作者 Aaron Maxwell 的客座博文。
有很多方法可以写出糟糕的代码。但是在 Python 中,有一个特别重要。
我们筋疲力尽,但仍欢欣鼓舞。在另外两个工程师尝试了三天来修复一个神秘的 Unicode bug,但都徒劳无功后,我终于在仅仅一天的工作后隔离了原因。十分钟后,我们找到了候选人。
悲剧在于,我们本可以跳过七天,直接进入十分钟。但是我已经超越了我自己…
这是笑点。下面这段代码是 Python 开发人员可以编写的最具自我破坏性的东西之一:
try:
do_something()
except:
pass
有相当于同一事物的变体——例如说except Exception:或except Exception as e:。它们都造成了同样的巨大危害:无声无息地隐藏错误条件,否则这些错误条件可以被快速检测和调度。
为什么我认为这是当今 Python 世界中最邪恶的反模式?
- 人们这样做是因为他们预计那里会发生特定的错误。然而,捕捉
Exception隐藏了所有的错误……甚至那些完全出乎意料的错误。 - 当 bug 最终被发现时——因为它已经出现在产品中,这太频繁了——您可能很少或根本不知道它在代码库中的什么地方出了问题。甚至在 try 块中发现错误都要花费你一段令人沮丧的时间。
- 一旦您意识到错误发生在那里,由于缺少关键信息,您的故障诊断就会受到很大的阻碍。什么是错误/异常类?涉及什么调用或数据结构?错误源自哪一行代码,在哪个文件中?
- 你正在丢弃堆栈跟踪——一个字面上无价的信息体,它可以决定在几天内还是在分钟内排除一个错误。是的,几分钟。稍后将详细介绍。
- 最糟糕的是,这很容易伤害在代码库工作的工程师的士气、快乐甚至自尊。当错误抬头时,故障排除人员可以花几个小时去了解根本原因。他们认为自己是个糟糕的程序员,因为要花很长时间才能搞清楚。他们不是;通过静默捕捉异常而产生的错误本质上很难识别、排查和修复。
在我近十年用 Python 编写应用程序的经历中,无论是个人还是作为团队的一员,这种模式都是开发人员生产力和应用程序可靠性的最大消耗……特别是从长期来看。如果你认为你有更坏的人选,我很想听听。
为什么我们要这样对待自己?
当然,没有人故意写代码来给你的开发伙伴增加压力,破坏应用程序的可靠性。我们这样做是因为在正常操作中,try 块中的代码有时会以某种特定的方式失败。乐观地说,尝试然后捕捉异常是处理这种情况的一种优秀且完全 Pythonic 化的方式。
不知不觉中,捕捉异常,然后静静地继续,似乎并不是一个可怕的想法。但是一旦你保存了这个文件,你就已经设置了你的代码来产生最糟糕的错误:
- 在开发过程中可以逃避检测,并被推出到实际生产系统中的错误。
- 在您意识到 bug 一直在发生之前,bug 可以在产品代码中存在几分钟、几小时、几天或几周。
- 难以排除的错误。
- 即使知道被抑制的异常是在哪里出现的,也很难修复的错误。
注意,我并不是说永远不要捕捉异常。有有好的理由来捕捉异常,然后继续——只是没有默默地。一个很好的例子是一个任务关键的过程,你只是不想永远下去。这里,一个聪明的模式是注入捕获异常的 try 子句,记录严重性为logging.ERROR或更高的全栈跟踪,并继续。
解决方案
那么,如果我们不想捕捉异常,我们该怎么做呢?有两个选择。
在大多数情况下,最好的选择是捕捉一个更具体的异常。大概是这样的:
try:
do_something()
# Catch some very specific exception - KeyError, ValueError, etc.
except ValueError:
pass
这是你应该尝试的第一件事。这需要对调用的代码有一点了解,所以您知道它可能会引发什么类型的错误。当你第一次写代码时,这比清理别人的代码更容易做好。
如果某个代码路径必须广泛地捕捉所有异常——例如,某个长期运行的持久化进程的顶层循环——那么每个被捕捉的异常必须将全栈跟踪连同时间戳一起写入日志或文件。如果你使用的是 Python 的logging模块,这非常简单——每个 logger 对象都有一个名为 exception 的方法,接受一个消息字符串。如果在 except 块中调用它,被捕获的异常将自动被完整记录,包括跟踪。
import logging
def get_number():
return int('foo')
try:
x = get_number()
except Exception as ex:
logging.exception('Caught an error')
日志将包含错误消息,后面是跨几行的格式化的堆栈跟踪:
ERROR:root:Caught an error
Traceback (most recent call last):
File "example-logging-exception.py", line 8, in <module>
x = get_number()
File "example-logging-exception.py", line 5, in get_number
return int('foo')
ValueError: invalid literal for int() with base 10: 'foo'
非常容易。
如果您的应用程序以其他方式记录日志——不使用logging模块——会怎么样?假设您不想重构您的应用程序来这样做,您可以只获取和格式化与异常相关联的回溯。这在 Python 3 中是最简单的:
# The Python 3 version. It's a little less work.
import traceback
def log_traceback(ex):
tb_lines = traceback.format_exception(ex.__class__, ex, ex.__traceback__)
tb_text = ''.join(tb_lines)
# I'll let you implement the ExceptionLogger class,
# and the timestamping.
exception_logger.log(tb_text)
try:
x = get_number()
except Exception as ex:
log_traceback(ex)
在 Python 2 中,您必须做稍微多一点的工作,因为异常对象没有附加它们的回溯。您可以通过调用 except 块中的sys.exc_info()来实现这一点:
import sys
import traceback
def log_traceback(ex, ex_traceback):
tb_lines = traceback.format_exception(ex.__class__, ex, ex_traceback)
tb_text = ''.join(tb_lines)
exception_logger.log(tb_text)
try:
x = get_number()
except Exception as ex:
# Here, I don't really care about the first two values.
# I just want the traceback.
_, _, ex_traceback = sys.exc_info()
log_traceback(ex, ex_traceback)
事实证明,您可以定义一个既适用于 Python 2 又适用于 Python 3 的回溯记录函数:
import traceback
def log_traceback(ex, ex_traceback=None):
if ex_traceback is None:
ex_traceback = ex.__traceback__
tb_lines = [ line.rstrip('\n') for line in
traceback.format_exception(ex.__class__, ex, ex_traceback)]
exception_logger.log(tb_lines)
你现在能做什么
“好吧,亚伦,你说服了我。我为我过去所做的一切哭泣和悲伤。我该如何赎罪?”我很高兴你问了。这里有一些你可以从今天开始的练习。
在你的编码指南中明确禁止它
如果您的团队进行代码审查,您可能有一个编码指南文档。如果没有,很容易开始-这可以像创建一个新的维基页面一样简单,你的第一个条目可以是这个。只需添加以下两条准则:
- 如果某个代码路径必须广泛地捕捉所有异常——例如,某个长期运行的持久化进程的顶层循环——那么每个这样捕捉到的异常必须将完整堆栈跟踪连同时间戳一起写入日志或文件。不仅仅是异常类型和消息,还有完整的堆栈跟踪。
- 对于所有其他 except 子句——实际上应该是绝大多数——捕获的异常类型必须尽可能具体。类似于 KeyError ,或者 ConnectionTimeout 等。
为除条款之外的现有天桥创建车票
以上将有助于防止新问题进入你的代码库。现有的过宽抓地力如何?简单:在你的 bug 跟踪系统中制作一个标签或问题来修复它。这是一个简单的行动步骤,大大增加了问题被解决和不被遗忘的机会。说真的,你现在就可以做这件事。
我建议您为每个存储库或应用程序创建一个标签,通过代码进行审计,找到每个捕获异常的地方。(你可以通过搜索“except:”和“except Exception”的代码库来找到它们。)对于每一次出现,要么将其转换为捕捉一个非常具体的异常类型;或者,如果不清楚应该是什么,可以修改 except 块来记录完整的堆栈跟踪。
或者,审计开发人员可以为任何特定的 try/except 块创建额外的票证。如果您觉得异常类可以做得更具体,但是对代码的这一部分不够了解,无法确定,那么这是一件好事。在这种情况下,您需要编写代码来记录完整的堆栈跟踪;创建一个单独的票证以进行进一步调查;然后分配给更清楚的人。如果你发现自己花了超过五分钟思考一个特定的 try/except 块,我建议你这样做,然后继续下一个。
教育你的团队成员
你定期举行工程会议吗?每周、每两周还是每月?在下一次培训中,花五分钟时间解释这个反模式、它对团队生产力的影响以及简单的解决方案。
更好的办法是,事先去找你的技术主管或工程经理,告诉他们这件事。这将更容易说服他们,因为他们至少和你一样关心团队的生产力。把这篇文章的链接发给他们。见鬼,如果你不得不,我会帮忙的-让他们和我通电话,我会说服他们。
你可以在你的社区中接触到更多的人。你会去当地的 Python 聚会吗?他们会进行闪电式会谈吗,或者你能在下一次会议上协商五到十五分钟的发言时间吗?通过传播这一崇高的事业来服务你的工程师同事。
为什么要记录完整的堆栈跟踪?
以上几次,我反复强调记录完整的堆栈跟踪,而不仅仅是异常对象的消息。如果这看起来像是更多的工作,那是因为它可能是:跟踪中的换行符会扰乱日志系统的格式,您可能不得不修改 traceback 模块,等等。仅仅记录消息本身还不够吗?
不,不是的。精心制作的异常消息只告诉您 except 子句在哪里——在哪个文件中,在哪一行代码中。它通常不会缩小范围,但是让我们假设最好的情况。只记录消息比什么都不记录要好,但不幸的是,它不能告诉您任何关于错误来源的信息。一般来说,它可以在一个完全不同的文件或模块中,而且通常不太容易猜到。
除此之外,团队开发的实际应用程序往往有多个代码路径可以调用异常引发块。也许只有当 Foo 类的方法 bar 被调用时才会出现错误,但函数 bar()不会被调用。只记录消息不会帮助您区分这两者。
我所知道的最好的战争故事是在一个大约 50 人的中型工程团队中工作时得到的。我是一个相对较新的人,四个多月来,我被一个 unicode bug 困扰着,这个 bug 经常会吵醒那些随叫随到的人。异常被捕获,消息被记录,但是没有记录其他信息。另外两名高级工程师各自研究了几天,然后放弃了,说他们搞不明白。
这些也是令人生畏的聪明工程师。最后,出于无奈,他们试着传给我。利用他们大量的笔记,我立即着手重现这个问题,得到一个堆栈跟踪。六个小时后,我终于明白了。一旦我有了那个该死的堆栈跟踪,你能猜到我花了多长时间来修复吗?
十分钟。没错。一旦我们有了堆栈跟踪,修复就很明显了。如果我们从一开始就记录堆栈跟踪,就可以节省工程师一周的时间。还记得上面我说的堆栈跟踪可以在几天内解决一个 bug 和几分钟内解决一个 bug 的区别吗?我没开玩笑。
(有趣的是,从中也有好的一面。正是这样的经历让我开始写更多关于 Python 的东西,以及我们作为工程师如何更有效地使用这种语言。)**
终极烧瓶前端–第 2 部分
原文:https://realpython.com/the-ultimate-flask-front-end-part-2/
欢迎来到第 2 部分!同样,这也是我们要讨论的内容:让我们看看小而强大的 JavaScript UI 库 ReactJS 在构建一个基本的 web 应用程序时的表现。
这款应用由 Python 3 和后端的 Flask 框架以及前端的 React 提供支持。另外我们会用到 gulp.js (任务运行器) bower (前端包管理器) Browserify (JavaScript 依赖捆绑器)。
- 第 1 部分–入门
- 第 2 部分——开发动态搜索工具(当前)
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
更新:
- 05/22/2016:升级至 React 最新版本(v 15.0.1 )。
反应–第二轮
Hello World 很棒,但是让我们创建一个更有趣的东西——一个动态搜索工具。这个组件用于根据用户输入过滤出一个条目列表。
将以下代码添加到project/static/scripts/jsx/main . js中:
var DynamicSearch = React.createClass({ // sets initial state getInitialState: function(){ return { searchString: '' }; }, // sets state, triggers render method handleChange: function(event){ // grab value form input box this.setState({searchString:event.target.value}); console.log("scope updated!"); }, render: function() { var countries = this.props.items; var searchString = this.state.searchString.trim().toLowerCase(); // filter countries list by value from input box if(searchString.length > 0){ countries = countries.filter(function(country){ return country.name.toLowerCase().match( searchString ); }); } return ( <div> <input type="text" value={this.state.searchString} onChange={this.handleChange} placeholder="Search!" /> <ul> { countries.map(function(country){ return <li>{country.name} </li> }) } </ul> </div> ) } }); // list of countries, defined with JavaScript object literals var countries = [ {"name": "Sweden"}, {"name": "China"}, {"name": "Peru"}, {"name": "Czech Republic"}, {"name": "Bolivia"}, {"name": "Latvia"}, {"name": "Samoa"}, {"name": "Armenia"}, {"name": "Greenland"}, {"name": "Cuba"}, {"name": "Western Sahara"}, {"name": "Ethiopia"}, {"name": "Malaysia"}, {"name": "Argentina"}, {"name": "Uganda"}, {"name": "Chile"}, {"name": "Aruba"}, {"name": "Japan"}, {"name": "Trinidad and Tobago"}, {"name": "Italy"}, {"name": "Cambodia"}, {"name": "Iceland"}, {"name": "Dominican Republic"}, {"name": "Turkey"}, {"name": "Spain"}, {"name": "Poland"}, {"name": "Haiti"} ]; ReactDOM.render( <DynamicSearch items={ countries } />, document.getElementById('main') );
到底怎么回事?
我们创建了一个名为DynamicSearch的组件,当输入框中的值改变时,它会更新 DOM。这是如何工作的?当在输入框中添加或删除一个值时,调用handleChange()函数,然后通过setState()更新状态。这个方法然后调用render()函数来重新呈现组件。
这里的关键要点是,状态变化只发生在组件内部。
测试一下:
//jsfiddle.net/mjhea0/2qn7ktq3/embedded/result,html/
由于我们将 JSX 代码添加到了一个外部文件中,我们需要在浏览器之外用 Gulp 触发从 JSX 到普通 JavaScript 的转换。
一饮而尽
Gulp 是一个强大的任务运行器/构建工具,可用于自动化转换过程。我们还将使用它来监视我们代码的变更(project/static/scripts/jsx/main . js),并基于这些变更自动创建新的构建。
初始化
和 bower 一样,可以用 npm 安装 gulp。全局安装,然后添加到 package.json 文件:
$ npm install -g gulp
$ npm install --save-dev gulp
在项目的根目录下添加一个 gulpfile.js :
// requirements var gulp = require('gulp'); // tasks gulp.task('default', function() { console.log("hello!"); });
这个文件告诉 gulp 运行哪些任务,以及以什么顺序运行它们。您可以看到我们的default任务将字符串hello!记录到控制台。你可以通过运行gulp来运行这个任务。您应该会看到类似这样的内容:
$ gulp
[08:54:47] Using gulpfile ~/gulpfile.js
[08:54:47] Starting 'default'...
hello!
[08:54:47] Finished 'default' after 148 μs
我们需要安装以下 gulp 插件:
为此,只需更新 package.json 文件:
{ "name": "ultimate-flask-front-end", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "repository": { "type": "git", "url": "git+https://github.com/realpython/ultimate-flask-front-end.git" }, "author": "", "license": "ISC", "bugs": { "url": "https://github.com/realpython/ultimate-flask-front-end/issues" }, "homepage": "https://github.com/realpython/ultimate-flask-front-end#readme", "devDependencies": { "bower": "^1.7.9", "del": "^2.2.0", "gulp": "^3.9.1", "gulp-browser": "^2.1.4", "gulp-size": "^2.1.0", "reactify": "^1.1.1" } }
然后运行npm install安装插件。
您可以在“node_modules”目录中看到这些已安装的插件。确保将该目录包含在您的中。gitignore 文件。
最后更新 gulpfile.js :
// requirements var gulp = require('gulp'); var gulpBrowser = require("gulp-browser"); var reactify = require('reactify'); var del = require('del'); var size = require('gulp-size'); // tasks gulp.task('transform', function () { // add task }); gulp.task('del', function () { // add task }); gulp.task('default', function() { console.log("hello!"); });
任务
现在让我们添加一些任务,从transform开始,处理从 JSX 到 JavaScript 的转换过程。
第一个任务—transform
gulp.task('transform', function () { var stream = gulp.src('./project/static/scripts/jsx/*.js') .pipe(gulpBrowser.browserify({transform: ['reactify']})) .pipe(gulp.dest('./project/static/scripts/js/')) .pipe(size()); return stream; });
task()函数有两个参数——任务名和一个匿名函数:
- 定义源目录,
- 将 JSX 文件通过浏览器传输到 JSX 转换器
- 指定目标目录,并且
- 计算创建的文件的大小。
Gulp 利用管道来传输数据进行处理。在抓取源文件( main.js )之后,该文件被“输送”到browserify()函数进行转换/绑定。然后,这些经过转换和捆绑的代码将与size()函数一起被“输送”到目标目录。
对管道和溪流感到好奇?查看这个优秀的资源。
准备好快速测试了吗?更新index.html:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>Flask React</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- styles -->
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='bower_components/bootstrap/dist/css/bootstrap.min.css') }}">
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/style.css') }}">
</head>
<body>
<div class="container">
<h1>Flask React</h1>
<br>
<div id="main"></div>
</div>
<!-- scripts -->
<script src="{{ url_for('static', filename='bower_components/react/react.min.js') }}"></script>
<script src="{{ url_for('static', filename='bower_components/react/react-dom.min.js') }}"></script>
<script src="{{ url_for('static', filename='scripts/js/main.js') }}"></script>
</body>
</html>
然后更新default任务:
gulp.task('default', function () { gulp.start('transform'); });
测试:
$ gulp
[08:58:39] Using gulpfile /gulpfile.js
[08:58:39] Starting 'default'...
[08:58:39] Starting 'transform'...
[08:58:39] Finished 'default' after 12 ms
[08:58:40] all files 1.99 kB
[08:58:40] Finished 'transform' after 181 ms
你注意到倒数第二行了吗?这是size()函数的结果。换句话说,新创建的 JavaScript 文件(转换后),project/static/scripts/js/main . js,大小为 1.99 kB。
启动 Flask 服务器,导航到 http://localhost:5000/ 。你应该可以在搜索框中看到所有的国家。测试功能。此外,如果您在 Chrome Developer Tools 中打开 JavaScript 控制台,您会看到每次范围发生变化时都会记录的字符串scope updated!——它来自于DynamicSearch组件中的handleChange()函数。
第二个任务—clean*
gulp.task('del', function () { return del(['./project/static/scripts/js']); });
当这个任务运行时,我们获取源目录——transform任务的结果——然后运行del()函数来删除目录及其内容。这是一个好主意,在每一个新的构建之前运行它,以确保你的开始是全新的和干净的。
尝试运行gulp del。这应该会删除“项目/静态/脚本/js”。让我们将它添加到我们的default任务中,以便它在转换之前自动运行:
gulp.task('default', ['del'], function () { gulp.start('transform'); });
在继续之前,请务必对此进行测试。
第三个任务—watch
最后,最后一次更新default任务,添加在任何发生变化时自动重新运行transform任务的能力。“项目/静态/脚本/jsx”目录下的 js 文件:
gulp.task('default', ['del'], function () { gulp.start('transform'); gulp.watch('./project/static/scripts/jsx/*.js', ['transform']); });
打开一个新的终端窗口,导航到项目根目录,运行gulp生成一个新的构建并激活watcher功能。在另一个窗口中运行sh run.sh来运行 Flask 服务器。您的应用程序应该正在运行。现在如果你注释掉项目/static/scripts/jsx/main.js 文件中的所有代码,这将触发transform函数。刷新浏览器以查看更改。完成后,请确保恢复更改。
想更进一步吗?查看一下 Livereload 插件。
结论
下面是给project/static/CSS/style . CSS添加一些自定义样式后的最终结果:
请务必查看官方文档以及优秀的教程以获得更多关于 React 的信息。
从回购中抓取代码。如果你想更深入地研究 Flask,看看如何用它从头开始构建一个完整的 web 应用程序,一定要看看这个视频系列:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
如果您有任何问题或发现任何错误,请在下面评论。还有,你还想看什么?如果人们感兴趣,我们可以增加第三部分。下面评论。**
终极烧瓶前端
让我们看看小而强大的 JavaScript UI 库 ReactJS 在构建一个基本的 web 应用程序时的表现。这款应用由 Python 3 和后端的烧瓶框架和前端的反应提供支持。另外我们会用到 gulp.js (任务运行器) bower (前端包管理器) Browserify (JavaScript 依赖捆绑器)。
- 第 1 部分–入门(当前)
- 第 2 部分——开发动态搜索工具
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
更新:
- 05/22/2016:升级至 React 最新版本(v 15.0.1 )。
反应解释
React 是一个库,不是框架。与客户端 MVC 框架不同,如 Backbone、Ember 和 AngularJS,它对您的技术堆栈没有任何假设,因此您可以轻松地将其集成到新的或遗留的代码库中。它通常用于管理应用程序 UI 的特定区域,而不是整个 UI 的 T2。
React 唯一关心的是用户界面(MVC 中的“V”),它是由模块化视图组件的层次结构定义的,这些组件将静态标记与动态 JavaScript 耦合在一起。如果你熟悉 Angular,这些组件类似于指令。组件使用一种称为 JSX 的类似 XML 的语法,该语法向下转换为普通的 JavaScript。
因为组件是按层次顺序定义的,所以当状态改变时,不必重新呈现整个 DOM。取而代之的是,它使用一个虚拟 DOM 来在状态改变后以惊人的速度重新渲染单个组件!
请务必阅读入门指南和优秀的我们为什么要构建 React?官方博客文章反应文档。
项目设置
先说我们知道的:烧瓶。
从库下载样板代码,提取文件,创建然后激活一个 virtualenv,并安装需求:
$ pip install -r requirements.txt
最后,让我们运行应用程序,开始表演:
$ sh run.sh
反应–第一轮
让我们来看看一个简单的组件。
组件:从静止到反应
我们将把这个 JSX 脚本添加到我们的hello.html中。花一分钟去看看。
<script type="text/jsx"> /*** @jsx React.DOM */ var realPython = React.createClass({ render: function() { return (<h2>Greetings, from Real Python!</h2>); } }); ReactDOM.render( React.createElement(realPython, null), document.getElementById('content') ); </script>
到底怎么回事?
- 我们通过调用
createClass()创建了一个组件,然后将它分配给变量realPython。React.createClass()采用单个参数,一个对象。 - 在这个对象中,我们添加了一个
render()函数,它在被调用时声明性地更新 DOM。 - 接下来是 JSX 的返回值
<h2>Greetings, from Real Python!</h2>,它表示将被添加到 DOM 中的实际的 HTML 元素。 - 最后,
ReactDOM.render()实例化realPython组件,并用content的ID选择器将标记注入 DOM 元素。
更多信息请参考官方文件。
转变
下一步是什么?好吧,我们需要将 JSX“转换”或转换成普通的 JavaScript。这很简单。更新hello.html喜欢这样:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>Flask React</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- styles -->
</head>
<body>
<div class="container">
<h1>Flask React</h1>
<br>
<div id="content"></div>
</div>
<!-- scripts -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/15.1.0/react.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/15.1.0/react-dom.min.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.13.3/JSXTransformer.js"></script>
<script type="text/jsx"> /*** @jsx React.DOM */ var realPython = React.createClass({ render: function() { return (<h2>Greetings, from Real Python!</h2>); } }); ReactDOM.render( React.createElement(realPython, null), document.getElementById('content') ); </script>
</body>
</html>
在这里,我们将helloWorld组件和以下脚本一起添加到模板中
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/15.1.0/react.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/15.1.0/react-dom.min.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.13.3/JSXTransformer.js"></script>
-后者,JSXTransformer.js,用type="text/jsx"搜索<script>标签,然后在浏览器中将 JSX 语法“转换”成普通的 JavaScript。请注意,该工具已弃用,并已被我们稍后将设置的 Browserify 所取代。
注意我们没有添加 jQuery,因为它是 React 所需要的而不是。
就是这样。运行 Flask development server 并在浏览器中查看结果,网址为http://localhost:5000/hello。
鲍尔
不要使用 CDN 中预先构建的 JavaScript 文件,让我们使用 bower 来更好地( IMHO ) 管理这些依赖关系。Bower 是一个强大的前端依赖包管理器——即 jQuery、Bootstrap、React、Angular、Backbone。
在继续之前,确保您已经安装了节点和 npm 。
初始化
安装带 npm 的 bower:
$ npm install -g bower
npm 是另一个用来管理节点模块的包管理器。与 PyPI/pip 不同,npm 的默认行为是在本地级别安装依赖项。标志用于覆盖全局安装 bower 的行为,因为您可能会在许多项目中使用 bower。
鲍尔森*
Bower 使用一个名为 bower.json 的文件来定义项目依赖关系,这类似于一个 requirements.txt 文件。运行以下命令以交互方式创建该文件:
$ bower init
暂时接受默认值。一旦完成,您的 bower.json 文件应该看起来像这样:
{ "name": "ultimate-flask-front-end", "homepage": "https://github.com/realpython/ultimate-flask-front-end", "authors": [ "Michael Herman michael@realpython.com" ], "description": "", "main": "", "license": "MIT", "ignore": [ "**/.*", "node_modules", "bower_components", "test", "tests" ] }
关于 bower.json 和
init命令的更多信息,请查看官方文档。
npm
像 bower.json 文件一样,npm 利用一个类似的文件,名为 package.json 来定义特定于项目的依赖关系。您也可以交互式地创建它:
$ npm init
再次接受默认值:
{ "name": "ultimate-flask-front-end", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "repository": { "type": "git", "url": "git+https://github.com/realpython/ultimate-flask-front-end.git" }, "author": "", "license": "ISC", "bugs": { "url": "https://github.com/realpython/ultimate-flask-front-end/issues" }, "homepage": "https://github.com/realpython/ultimate-flask-front-end#readme" }
现在,让我们将 bower 添加到 npm 依赖文件中:
$ npm install --save-dev bower
配置
和 bower.json 文件一起,我们可以在一个名为的文件中定义配置设置。鲍尔维奇。现在在项目根目录下创建文件。您的项目结构现在应该如下所示:
├── .bowerrc
├── .gitignore
├── bower.json
├── package.json
├── project
│ ├── app.py
│ ├── static
│ │ └── css
│ │ └── style.css
│ └── templates
│ ├── hello.html
│ └── index.html
├── requirements.txt
└── run.sh
bower 的标准行为是在项目根目录下名为“bower_components”的目录中安装包。我们需要覆盖这个行为,因为 Flask 需要访问静态目录中的包。因此,将以下 JSON 添加到文件中,以便 bower 自动将文件安装到正确的目录中:
{ "directory": "./project/static/bower_components" }
安装
让我们安装 Bootstrap 和 React。这可以通过两种方式之一实现:
- 对每个包运行
bower install <package_name> --save(--save标志将依赖项(名称和版本)添加到 bower.json 文件中。). - 用每个依赖项(同样是名称和版本)直接更新 bower.json 文件,然后运行
bower install从该文件安装所有依赖项。
因为我们(呃, I )已经知道了版本,所以让我们使用第二种方法。更新 bower.json 文件如下:
{ "name": "ultimate-flask-front-end", "homepage": "https://github.com/realpython/ultimate-flask-front-end", "authors": [ "Michael Herman michael@realpython.com" ], "description": "", "main": "", "license": "MIT", "ignore": [ "**/.*", "node_modules", "bower_components", "test", "tests" ], "dependencies": { "bootstrap": "^3.3.6", "react": "^15.1.0" } }
然后运行bower install:
$ bower install
bower cached https://github.com/twbs/bootstrap.git#3.3.6
bower validate 3.3.6 against https://github.com/twbs/bootstrap.git#^3.3.6
bower cached https://github.com/facebook/react-bower.git#15.1.0
bower validate 15.1.0 against https://github.com/facebook/react-bower.git#^15.1.0
bower cached https://github.com/jquery/jquery-dist.git#2.2.4
bower validate 2.2.4 against https://github.com/jquery/jquery-dist.git#1.9.1 - 2
bower install react#15.1.0
bower install bootstrap#3.3.6
bower install jquery#2.2.4
react#15.1.0 project/static/bower_components/react
bootstrap#3.3.6 project/static/bower_components/bootstrap
└── jquery#2.2.4
jquery#2.2.4 project/static/bower_components/jquery
您现在应该看到“project/static/bower _ components”目录。
现在,在克隆了 repo 之后,您可以使用 pip、npm 和 bower 获取所有必需的依赖项:
$ pip install -r requirements.txt
$ npm install
$ bower install
测试
更新hello.html中的 React 脚本:
<script src="{{ url_for('static', filename='bower_components/react/react.min.js') }}"></script>
<script src="{{ url_for('static', filename='bower_components/react/react-dom.min.js') }}"></script>
测试应用程序,以确保它仍然工作。
接下来的步骤
设置好工具后,我们将在第二部分的中回过头来反应并开发一个更健壮的应用程序。如果您想了解如何从头开始设置一个完整的 Python + Flask web 应用程序,请务必观看此视频系列:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。***
用 Python 中的 AI 播放器构建井字游戏引擎
当你还是个孩子的时候,你会学着玩井字游戏,有些人称之为十字游戏。直到你进入青少年时期,这个游戏仍然充满乐趣和挑战。然后,你学习编程,发现为这个双人游戏的虚拟版本编码的乐趣。作为一个成年人,你可能仍然会欣赏用 Python 创造一个拥有人工智能(AI) 的对手的游戏的简单性。
通过完成这个详细的一步一步的冒险,你将建立一个可扩展的游戏引擎和一个无与伦比的电脑玩家,它使用最小最大算法来玩井字游戏。一路上,您将深入了解不可变的类设计、通用插件架构和现代 Python 代码实践和模式。
在本教程中,您将学习如何:
- 用井字游戏引擎创建一个可重用的 Python 库
- 遵循 Pythonic 代码风格对井字游戏的域进行建模
- 实现人工播放器,包括一个基于 minimax 算法的播放器
- 为有人类玩家的游戏构建一个基于文本的控制台前端
- 探索性能优化的策略
单击下面的链接下载该项目的完整源代码:
源代码: 点击此处下载免费源代码,您将使用它用 Python 构建井字游戏引擎和 AI 播放器。
演示:Python 中的井字游戏 AI 播放器
在本教程结束时,你将拥有一个高度可重用和可扩展的 Python 库,以及一个用于井字游戏的抽象游戏引擎。它将封装通用游戏规则和计算机玩家,包括一个由于基本人工智能支持而永远不会输的游戏。此外,您将创建一个示例控制台前端,它构建在您的库之上,并实现一个在终端上运行的基于文本的交互式井字游戏。
这是两个玩家之间的真实游戏:
https://player.vimeo.com/video/747651381?background=1
一般来说,你可以从人类玩家、随机移动的虚拟电脑玩家和坚持最优策略的智能电脑玩家中混合选择玩家。您还可以指定哪个玩家应该先走一步,增加他们获胜或平手的机会。
稍后,你将能够为不同的平台改编你的通用井字游戏库,比如一个窗口桌面环境或者一个网络浏览器。虽然在本教程中您将只遵循构建控制台应用程序的说明,但是您可以在支持材料中找到 Tkinter 和 PyScript 前端示例。
注意:这些前端不在这里讨论,因为实现它们需要相当熟悉 Python 中的线程、 asyncio 和队列,这超出了本教程的范围。但是您可以自己随意研究和使用示例代码。
Tkinter 前端是同一款游戏的精简版本,在另一个单独的教程中有所描述,该教程仅作为桌面环境中的库演示:
https://player.vimeo.com/video/747651753?background=1
与原版不同的是,它看起来不那么流畅,也不允许你轻松重启游戏。然而,它增加了与电脑或其他玩家对战的选项。
PyScript 前端允许您或您的朋友在 web 浏览器中玩游戏,即使他们的计算机上没有安装 Python,这是一个显著的优势:
https://player.vimeo.com/video/747651357?background=1
如果你富有冒险精神,并且知道一点 PyScript 或 JavaScript,那么你可以通过增加与另一个玩家在线游戏的能力来扩展这个前端。为了方便通信,您需要使用 WebSocket 协议实现一个远程 web 服务器。看一看另一个教程中的一个工作中的 WebSocket 客户端和服务器示例,了解一下它是如何工作的。
值得注意的是,本节演示的三个前端中的每一个都只是为同一个 Python 库实现了不同的表示层,它提供了底层的游戏逻辑和玩家。由于清晰的关注点分离和您将在本教程中实践的其他编程原则,它们之间没有不必要的冗余或代码重复。
项目概述
您将要构建的项目由两个高级组件组成,如下图所示:
第一个组件是一个抽象的井字游戏 Python 库,它不知道以图形形式向用户呈现游戏的可能方式。而是包含了游戏的核心逻辑和两个人造玩家。然而,该库不能独立存在,所以您还将创建一个示例前端来收集来自键盘的用户输入,并使用纯文本在控制台中可视化游戏。
您将从实现井字游戏库的底层细节开始,然后使用这些细节以自下而上的方式实现更高级别的游戏前端。完成本教程后,完整的文件结构将如下所示:
tic-tac-toe/
│
├── frontends/
│ │
│ └── console/
│ ├── __init__.py
│ ├── __main__.py
│ ├── args.py
│ ├── cli.py
│ ├── players.py
│ └── renderers.py
│
└── library/
│
├── src/
│ │
│ └── tic_tac_toe/
│ │
│ ├── game/
│ │ ├── __init__.py
│ │ ├── engine.py
│ │ ├── players.py
│ │ └── renderers.py
│ │
│ ├── logic/
│ │ ├── __init__.py
│ │ ├── exceptions.py
│ │ ├── minimax.py
│ │ ├── models.py
│ │ └── validators.py
│ │
│ └── __init__.py
│
└── pyproject.toml
frontends/文件夹是为了存放一个或多个具体的游戏实现,比如你的基于文本的控制台,而library/是游戏库的主文件夹。您可以将这两个顶层文件夹视为相关但独立的项目。
注意,您的控制台前端包含了__main__.py文件,使它成为一个可运行的 Python 包,您将能够使用 Python 的-m选项从命令行调用它。假设您在下载了本教程中将要编写的完整源代码后,将当前工作目录更改为frontends/,您可以使用以下命令启动游戏:
(venv) $ python -m console
记住 Python 必须能够在模块搜索路径上找到你的前端所依赖的井字库。确保这一点的最佳实践是创建并激活一个共享的虚拟环境,并安装带有 pip 的库。您可以在支持材料的自述文件中找到有关如何操作的详细说明。
井字游戏库是一个名为tic_tac_toe的 Python 包,由两个子包组成:
tic_tac_toe.game:设计成前端可延伸的脚手架tic_tac_toe.logic:井字游戏的积木
您将很快深入了解每一个问题。 pyproject.toml 文件包含构建和打包库所需的元数据。要将下载的库或您将在本教程中构建的完成代码安装到活动的虚拟环境中,请尝试以下命令:
(venv) $ python -m pip install --editable library/
在开发过程中,您可以使用带有-e或--editable标志的pip来挂载库的源代码,而不是在您的虚拟环境中构建的包,从而制作一个可编辑安装。这将避免您在对库进行更改以在前端反映这些更改后必须重复安装。
好吧,那就是你要建的!但是在开始之前,请检查一下先决条件。
先决条件
这是一个高级教程,涉及广泛的 Python 概念,为了顺利地继续学习,您应该熟悉这些概念。请使用以下资源来熟悉或回忆一些重要的主题:
您将要构建的项目完全依赖于 Python 的标准库,没有外部依赖性。也就是说,你至少需要 Python 3.10 或更高版本来利用本教程中的最新语法和特性。如果你目前使用的是旧的 Python 版本,那么你可以用pyenv 或安装并管理多个 Python 版本,在 Docker 中尝试最新的 Python 版本。
最后,你应该知道你将要实现的游戏规则。经典的井字游戏是在一个三乘三的格子或方块上进行的,每个玩家在一个空格子中放置他们的标记,一个 X 或一个 O。第一个将三个标记水平、垂直或对角排成一行的玩家赢得游戏。
步骤 1:模拟井字游戏领域
在这一步中,您将识别组成井字游戏的各个部分,并使用面向对象的方法来实现它们。通过用不可变对象对游戏的域建模,你将得到模块化的可组合代码,这些代码更容易测试、维护、调试和推理,还有其他一些优点。
首先,打开您选择的代码编辑器,例如 Visual Studio 代码或 PyCharm ,并创建一个名为tic-tac-toe的新项目,它也将成为您的项目文件夹的名称。如今,大多数代码编辑器会给你自动为你的项目创建一个虚拟环境的选项,所以继续吧,照着做。如果您的没有,那么从命令行手动创建虚拟环境:
$ cd tic-tac-toe/
$ python3 -m venv venv/
这将在tic-tac-toe/下创建一个名为venv/的文件夹。除非您计划继续在当前命令行会话中工作,否则不必激活新的虚拟环境。
接下来,在新项目中搭建文件和文件夹的基本结构,记住在src/子文件夹中的 Python 包中使用下划线(_)而不是破折号(-):
tic-tac-toe/
│
├── frontends/
│ │
│ └── console/
│ ├── __init__.py
│ └── __main__.py
│
└── library/
│
├── src/
│ │
│ └── tic_tac_toe/
│ │
│ ├── game/
│ │ └── __init__.py
│ │
│ ├── logic/
│ │ └── __init__.py
│ │
│ └── __init__.py
│
└── pyproject.toml
此时,上面文件树中的所有文件都应该是空的。在学习本教程的过程中,您将陆续用内容填充它们,并添加更多的文件。首先编辑位于src/子文件夹旁边的pyproject.toml文件。您可以将这个相当简单的井字游戏库打包配置粘贴到其中:
# pyproject.toml [build-system] requires = ["setuptools>=64.0.0", "wheel"] build-backend = "setuptools.build_meta" [project] name = "tic-tac-toe" version = "1.0.0"
您指定所需的构建工具,Python 将在必要时下载并安装这些工具,以及项目的一些元数据。将pyproject.toml文件添加到库中可以让您将它作为 Python 包构建并安装到您的活动虚拟环境中。
注意:pyproject.toml文件是一个标准的配置文件,使用 TOML 格式来指定 Python 项目的最低构建系统需求。这个概念是在 PEP 518 中引入的,现在是在 Python 中添加打包元数据和配置的推荐方式。您将需要它来将井字游戏库安装到您的虚拟环境中。
打开终端窗口,发出以下命令激活您的虚拟环境(如果您还没有激活),并使用可编辑模式安装井字游戏库:
$ source venv/bin/activate
(venv) $ python -m pip install --editable library/
即使你的库中还没有 Python 代码,现在用--editable标志安装它将允许 Python 解释器导入你将直接从你的项目中添加的函数和类。否则,每当您对源代码进行更改并想要测试它时,您都必须记得再次构建并安装库到您的虚拟环境中。
现在您已经有了项目的总体结构,您可以开始实现一些代码了。到这一步结束时,您将拥有井字游戏的所有必要部分,包括游戏逻辑和状态验证,因此您将准备好将它们组合到一个抽象的游戏引擎中。
列举玩家的分数
游戏开始时,每位井字游戏玩家都会被分配到两个符号中的一个,要么是十字(X) 要么是零(O) ,他们用这些符号来标记游戏板上的位置。因为只有两个符号属于一组固定的离散值,所以可以在枚举类型或枚举中定义它们。使用枚举比常量更可取,因为它们具有增强的类型安全性、公共命名空间和对其成员的编程访问。
在tic_tac_toe.logic包中创建一个名为models的新 Python 模块:
tic-tac-toe/
│
└── library/
│
├── src/
│ │
│ └── tic_tac_toe/
│ │
│ ├── game/
│ │ └── __init__.py
│ │
│ ├── logic/
│ │ ├── __init__.py
│ │ └── models.py │ │
│ └── __init__.py
│
└── pyproject.toml
在本步骤的剩余部分,您将使用这个文件来定义井字游戏域模型对象。
现在,从 Python 的标准库中导入 enum 模块,并在您的模型中定义一个新的数据类型:
# tic_tac_toe/logic/models.py
import enum
class Mark(enum.Enum):
CROSS = "X"
NAUGHT = "O"
Mark类的两个单例实例,枚举成员Mark.CROSS和Mark.NAUGHT,代表玩家的符号。默认情况下,不能将 Python 枚举的成员与其值进行比较。例如,比较Mark.CROSS == "X"会得到False。这是为了避免混淆在不同地方定义的相同值和不相关的语义。
然而,有时根据字符串而不是枚举成员来考虑玩家标记可能更方便。为了实现这一点,将Mark定义为str和enum.Enum类型的 mixin 类:
# tic_tac_toe/logic/models.py
import enum
class Mark(str, enum.Enum):
CROSS = "X"
NAUGHT = "O"
这被称为派生枚举,其成员可以与混合类型的实例进行比较。在这种情况下,您现在可以将Mark.NAUGHT和Mark.CROSS与字符串值进行比较。
注意:在撰写本教程时,Python 3.10 是最新的版本,但是如果您正在使用更新的版本,那么您可以直接扩展 enum.StrEnum ,它被添加到 Python 3.11 的标准库中:
import enum
class Mark(enum.StrEnum):
CROSS = "X"
NAUGHT = "O"
enum.StrEnum的成员也是字符串,这意味着你可以在任何需要常规字符串的地方使用它们。
一旦你给第一个玩家分配了一个给定的标记,第二个玩家必须被分配唯一剩下的未分配的标记。因为枚举是被美化的类,你可以自由地将普通的方法和属性放入其中。例如,您可以定义一个将返回另一个成员的Mark成员的属性:
# tic_tac_toe/logic/models.py
import enum
class Mark(str, enum.Enum):
CROSS = "X"
NAUGHT = "O"
@property def other(self) -> "Mark": return Mark.CROSS if self is Mark.NAUGHT else Mark.NAUGHT
属性的主体是一行代码,它使用一个条件表达式来确定正确的标记。您的酒店签名中的返回类型周围的引号是强制的,以进行向前声明,并避免由于未解析的名称而导致的错误。毕竟你声称返回一个Mark,这个还没有完全定义。
注意:或者,您可以将注释的评估推迟到它们被定义之后:
# tic_tac_toe/logic/models.py
from __future__ import annotations
import enum
class Mark(str, enum.Enum):
CROSS = "X"
NAUGHT = "O"
@property
def other(self) -> Mark: return Mark.CROSS if self is Mark.NAUGHT else Mark.NAUGHT
添加一个特殊的__future__导入,它必须出现在文件的开头,启用类型提示的惰性计算。稍后您将使用这种模式来避免导入交叉引用模块时的循环引用问题。
在 Python 3.11 中,你也可以使用一个通用的 typing.Self 类型来避免类型提示中的前向声明。
为了展示一些使用Mark枚举的实际例子,展开下面的可折叠部分:
在继续之前,请确保在模块搜索路径上可以访问该库,例如,将其安装到活动的虚拟环境中,如前面的项目概述中所示:
>>> from tic_tac_toe.logic.models import Mark >>> # Refer to a mark by its symbolic name literal >>> Mark.CROSS <Mark.CROSS: 'X'> >>> Mark.NAUGHT <Mark.NAUGHT: 'O'> >>> # Refer to a mark by its symbolic name (string) >>> Mark["CROSS"] <Mark.CROSS: 'X'> >>> Mark["NAUGHT"] <Mark.NAUGHT: 'O'> >>> # Refer to a mark by its value >>> Mark("X") <Mark.CROSS: 'X'> >>> Mark("O") <Mark.NAUGHT: 'O'> >>> # Get the other mark >>> Mark("X").other <Mark.NAUGHT: 'O'> >>> Mark("O").other <Mark.CROSS: 'X'> >>> # Get a mark's name >>> Mark("X").name 'CROSS' >>> # Get a mark's value >>> Mark("X").value 'X' >>> # Compare a mark to a string >>> Mark("X") == "X" True >>> Mark("X") == "O" False >>> # Use the mark as if it was a string >>> isinstance(Mark.CROSS, str) True >>> Mark.CROSS.lower() 'x' >>> # Iterate over the available marks >>> for mark in Mark: ... print(mark) ... Mark.CROSS Mark.NAUGHT在本教程的后面,您将使用其中的一些技术。
您现在有一种方法来表示玩家将在棋盘上留下的可用标记,以推进游戏。接下来,您将实现一个抽象的游戏板,并为这些标记定义好位置。
代表单元格的正方形网格
虽然有些人用不同的人数或不同大小的格子玩井字游戏,但你会坚持最基本和最经典的规则。回想一下,在经典的井字游戏中,游戏的棋盘是由一个 3×3 的单元格网格表示的。每个单元格可以是空的,也可以标有叉号或零号。
因为您用单个字符表示标记,所以您可以使用与单元格对应的一串精确的九个字符**来实现网格。单元格可以是空的,在这种情况下,您可以用空格字符(
" ")填充它,或者它可以包含玩家的标记。在本教程中,您将通过从上到下连接行来按照行主顺序存储网格。**例如,用这样的表示法,你可以用下面的字符串来表达在之前演示的三个游戏:
"XXOXO O ""OXXXXOOOX""OOOXXOXX "为了更好地可视化它们,您可以在一个交互式 Python 解释器会话中快速启动并运行这个简短的函数:
>>> def preview(cells):
... print(cells[:3], cells[3:6], cells[6:], sep="\n")
>>> preview("XXOXO O ")
XXO
XO
O
>>> preview("OXXXXOOOX")
OXX
XXO
OOX
>>> preview("OOOXXOXX ")
OOO
XXO
XX
该函数将一串单元格作为参数,并以用切片操作符从输入字符串中分割出的三个独立行的形式打印到屏幕上。
虽然使用字符串来表示单元格网格非常简单,但在验证其形状和内容方面却有所欠缺。除此之外,普通字符串不能提供您可能感兴趣的额外的、特定于网格的属性。出于这些原因,您将在包装在属性中的字符串之上创建一个新的Grid数据类型:
# tic_tac_toe/logic/models.py
import enum
from dataclasses import dataclass
# ...
@dataclass(frozen=True) class Grid:
cells: str = " " * 9
您将Grid定义为一个冻结数据类,使其实例不可变,这样一旦您创建了一个网格对象,您就不能改变它的单元格。起初这听起来可能有局限性,而且很浪费,因为您将被迫创建许多Grid类的实例,而不仅仅是重用一个对象。然而,不可变对象的好处,包括容错和提高代码可读性,远远超过了现代计算机的成本。
默认情况下,当您没有为.cells属性指定任何值时,它会假设一个正好有九个空格的字符串来反映一个空网格。但是,您仍然可以用错误的单元格值初始化网格,最终导致程序崩溃。您可以通过允许您的对象仅在处于有效状态时存在来防止这种情况。否则,按照快速失效和永远有效的域模型原则,它们根本不会被创建。
数据类控制对象初始化,但是它们也允许你运行一个后初始化钩子来设置派生属性,例如基于其他字段的值。您将利用这种机制来执行单元格验证,并在实例化网格对象之前潜在地丢弃无效字符串:
# tic_tac_toe/logic/models.py
import enum
import re from dataclasses import dataclass
# ...
@dataclass(frozen=True)
class Grid:
cells: str = " " * 9
def __post_init__(self) -> None: if not re.match(r"^[\sXO]{9}$", self.cells): raise ValueError("Must contain 9 cells of: X, O, or space")
您的特殊的.__post_init__()方法使用一个正则表达式来检查.cells属性的给定值是否正好是九个字符长,并且只包含预期的字符——即"X"、"O"或" "。还有其他方法来验证字符串,但是正则表达式非常简洁,并且将与您稍后添加的验证规则保持一致。
注:网格只负责验证一串单元格的语法正确性,并不理解游戏的更高层规则。一旦获得了额外的上下文,您将在其他地方实现特定单元格组合语义的验证。
此时,您可以向您的Grid类添加一些额外属性,这将在确定游戏状态时变得很方便:
# tic_tac_toe/logic/models.py
import enum
import re
from dataclasses import dataclass
from functools import cached_property
# ...
@dataclass(frozen=True)
class Grid:
cells: str = " " * 9
def __post_init__(self) -> None:
if not re.match(r"^[\sXO]{9}$", self.cells):
raise ValueError("Must contain 9 cells of: X, O, or space")
@cached_property def x_count(self) -> int: return self.cells.count("X")
@cached_property def o_count(self) -> int: return self.cells.count("O")
@cached_property def empty_count(self) -> int: return self.cells.count(" ")
这三个属性分别返回交叉、空和空单元格的当前数量。因为你的数据类是不可变的,它的状态永远不会改变,所以你可以在来自functools模块的@cached_property装饰器的帮助下缓存计算出的属性值。这将确保它们的代码最多运行一次,无论您访问这些属性多少次,例如在验证期间。
为了展示一些使用Grid类的实际例子,展开下面的可折叠部分:
在继续之前,请确保在模块搜索路径上可以访问该库,例如,将其安装到活动的虚拟环境中,如前面的项目概述中所示:
>>> from tic_tac_toe.logic.models import Grid >>> # Create an empty grid >>> Grid() Grid(cells=' ') >>> # Create a grid of a particular cell combination >>> Grid("XXOXO O ") Grid(cells='XXOXO O ') >>> # Don't create a grid with too few cells >>> Grid("XO") Traceback (most recent call last): ... ValueError: Must contain 9 cells of: X, O, or space >>> # Don't create a grid with invalid characters >>> Grid("XXOxO O ") Traceback (most recent call last): ... ValueError: Must contain 9 cells of: X, O, or space >>> # Get the count of Xs, Os, and empty cells >>> grid = Grid("OXXXXOOOX") >>> grid.x_count 5 >>> grid.o_count 4 >>> grid.empty_count 0现在你知道如何使用
Grid类了。使用 Python 代码,您模拟了一个 3×3 的单元格网格,其中可以包含玩家标记的特定组合。现在,是时候对玩家的移动进行建模,以便人工智能可以评估和选择最佳选项。
拍摄玩家移动的快照
代表玩家在井字游戏中移动的对象应该主要回答以下两个问题:
- 玩家标记:玩家放置了什么标记?
- Mark 的位置:放在哪里?
然而,为了有一个完整的画面,一个人还必须在行动之前了解游戏的状态。毕竟,这可能是一个好的或坏的举措,取决于当前的情况。你可能还会发现手边有游戏的结果状态很方便,这样你就可以给它打分了。通过模拟那个动作,你将能够把它与其他可能的动作进行比较。
注意:如果不知道游戏的一些细节,比如起始玩家的标记,移动对象就不能验证自己,因为它不知道这些细节。在负责管理游戏状态的类中,您将检查给定的移动是否有效,并验证特定的网格单元组合。
基于这些想法,您可以向您的模型添加另一个不可变的数据类:
# tic_tac_toe/logic/models.py # ... class Mark(str, enum.Enum): ... @dataclass(frozen=True) class Grid: ... @dataclass(frozen=True) class Move: mark: Mark cell_index: int before_state: "GameState" after_state: "GameState"暂时请忽略
GameState类的两个前向声明。在下一节中,您将使用类型提示作为临时占位符来定义该类。您的新类严格来说是一个数据传输对象(DTO) ,其主要目的是传送数据,因为它不通过方法或动态计算的属性提供任何行为。
Move类的对象由标识移动玩家的标记、单元格字符串中从零开始的数字索引以及移动前后的两种状态组成。将实例化
Move类,用值填充,并由缺失的GameState类操作。没有它,您自己将无法正确创建移动对象。现在是时候解决这个问题了!确定游戏状态
井字游戏可能处于几种状态之一,包括三种可能的结果:
- 比赛还没开始。
- 游戏还在继续。
- 比赛以平局结束。
- 游戏已经结束,玩家 X 赢了。
- 游戏结束,玩家 O 赢了。
您可以根据两个参数来确定井字游戏的当前状态:
- 网格中单元格的组合
- 首发球员的标志
如果不知道是谁开始游戏,你就无法判断现在轮到谁了,也无法判断给定的走法是否有效。最终,你无法正确评估情况,以便人工智能可以做出正确的决定。
要解决这个问题,首先将游戏状态指定为另一个不可变的数据类,由单元格网格和开始玩家的标记组成:
# tic_tac_toe/logic/models.py # ... class Mark(str, enum.Enum): ... @dataclass(frozen=True) class Grid: ... @dataclass(frozen=True) class Move: ... @dataclass(frozen=True) class GameState: grid: Grid starting_mark: Mark = Mark("X")按照惯例,用十字标记单元格的玩家开始游戏,因此开始玩家标记的默认值为
Mark("X")。但是,您可以根据自己的喜好,通过在运行时提供不同的值来更改它。现在,添加一个缓存属性,返回应该进行下一步的玩家的标记:
# tic_tac_toe/logic/models.py # ... @dataclass(frozen=True) class GameState: grid: Grid starting_mark: Mark = Mark("X") @cached_property def current_mark(self) -> Mark: if self.grid.x_count == self.grid.o_count: return self.starting_mark else: return self.starting_mark.other当格子是空的或者当两个玩家标记了相同数量的格子时,当前玩家的标记将与开始玩家的标记相同。在实践中,你只需要检查后一个条件,因为一个空白网格意味着两个玩家在网格中的分数都是零。要确定其他玩家的标记,您可以利用您在
Mark枚举中的.other属性。接下来,您将添加一些属性来评估游戏的当前状态。例如,当网格是空白的,或者正好包含九个空单元格时,您可以判断游戏尚未开始:
# tic_tac_toe/logic/models.py # ... @dataclass(frozen=True) class GameState: # ... @cached_property def current_mark(self) -> Mark: ... @cached_property def game_not_started(self) -> bool: return self.grid.empty_count == 9这就是网格属性派上用场的地方。相反,当出现明显的赢家或平局时,你可以断定游戏已经结束:
# tic_tac_toe/logic/models.py # ... @dataclass(frozen=True) class GameState: # ... @cached_property def current_mark(self) -> Mark: ... @cached_property def game_not_started(self) -> bool: ... @cached_property def game_over(self) -> bool: return self.winner is not None or self.tie稍后您将实现的
.winner属性将返回一个Mark实例或None,而.tie属性将是一个布尔值。一个平局是当两个玩家都没有赢,这意味着没有赢家,所有的方格都被填满,留下零个空白单元格:# tic_tac_toe/logic/models.py # ... @dataclass(frozen=True) class GameState: # ... @cached_property def current_mark(self) -> Mark: ... @cached_property def game_not_started(self) -> bool: ... @cached_property def game_over(self) -> bool: ... @cached_property def tie(self) -> bool: return self.winner is None and self.grid.empty_count == 0
.game_over和.tie属性都依赖于它们委托给的.winner属性。不过,找到一个赢家要稍微困难一些。例如,您可以尝试使用正则表达式将当前单元格网格与预定义的获胜模式集合进行匹配:# tic_tac_toe/logic/models.py # ... WINNING_PATTERNS = ( "???......", "...???...", "......???", "?..?..?..", ".?..?..?.", "..?..?..?", "?...?...?", "..?.?.?..", ) class Mark(str, enum.Enum): ... class Grid: ... class Move: ... @dataclass(frozen=True) class GameState: # ... @cached_property def current_mark(self) -> Mark: ... @cached_property def game_not_started(self) -> bool: ... @cached_property def game_over(self) -> bool: ... @cached_property def tie(self) -> bool: ... @cached_property def winner(self) -> Mark | None: for pattern in WINNING_PATTERNS: for mark in Mark: if re.match(pattern.replace("?", mark), self.grid.cells): return mark return None两位玩家各有八种获胜模式,您可以使用类似正则表达式的模板来定义这些模式。模板包含具体玩家标记的问号占位符。迭代这些模板,用两个玩家的标记替换问号,为每个模式合成两个正则表达式。当单元格匹配获胜图案时,您返回相应的标记。否则,你返回
None。知道获胜者是一回事,但您可能还想知道匹配的获胜单元格以便在视觉上区分它们。在这种情况下,您可以添加一个类似的属性,它使用一个列表理解来返回获胜单元格的整数索引列表:
# tic_tac_toe/logic/models.py # ... WINNING_PATTERNS = ( "???......", "...???...", "......???", "?..?..?..", ".?..?..?.", "..?..?..?", "?...?...?", "..?.?.?..", ) class Mark(str, enum.Enum): ... class Grid: ... class Move: ... @dataclass(frozen=True) class GameState: # ... @cached_property def current_mark(self) -> Mark: ... @cached_property def game_not_started(self) -> bool: ... @cached_property def game_over(self) -> bool: ... @cached_property def tie(self) -> bool: ... @cached_property def winner(self) -> Mark | None: ... @cached_property def winning_cells(self) -> list[int]: for pattern in WINNING_PATTERNS: for mark in Mark: if re.match(pattern.replace("?", mark), self.grid.cells): return [ match.start() for match in re.finditer(r"\?", pattern) ] return []你可能会担心在
.winner和.winnning_cells之间有一点代码重复,这违反了不要重复自己(干)的原则,但是没关系。Python 的禅说实用性胜过纯粹性,事实上,提取公分母在这里提供不了什么价值,反而会降低代码的可读性。注意:当一个重复的代码片段至少有三个实例时,开始考虑重构你的代码通常是有意义的。您很有可能需要更多地重用同一段代码。
你的
GameState开始看起来不错了。它可以正确地识别所有可能的游戏状态,但它缺乏适当的验证,这使得它容易出现运行时错误。在接下来的几节中,您将通过编纂和实施一些井字游戏规则来纠正这种情况。引入单独的验证层
与网格一样,当提供的单元格组合和开始玩家的标记没有意义时,创建
GameState类的实例应该会失败。例如,目前可以创建一个无效的游戏状态,它不能反映真正的游戏性。你可以自己测试一下。在之前安装库的虚拟环境中启动一个交互式 Python 解释器会话,然后运行以下代码:
>>> from tic_tac_toe.logic.models import GameState, Grid
>>> GameState(Grid("XXXXXXXXX"))
GameState(grid=Grid(cells='XXXXXXXXX'), starting_mark=<Mark.CROSS: 'X'>)
在这里,您使用一个网格初始化一个新的游戏状态,这个网格包含一个语法上正确的字符串和正确的字符和长度。然而,这样的单元格组合在语义上是不正确的,因为不允许一个玩家用他们的标记填满整个格子。
因为验证游戏状态相对来说比较复杂,所以在域模型中实现它会违反单责任原则,并使您的代码可读性更差。验证属于您的体系结构中的一个单独的层,因此您应该将域模型及其验证逻辑保存在两个不同的 Python 模块中,而不要混合它们的代码。继续在您的项目中创建两个新文件:
tic-tac-toe/
│
└── library/
│
├── src/
│ │
│ └── tic_tac_toe/
│ │
│ ├── game/
│ │ └── __init__.py
│ │
│ ├── logic/
│ │ ├── __init__.py
│ │ ├── exceptions.py │ │ ├── models.py
│ │ └── validators.py │ │
│ └── __init__.py
│
└── pyproject.toml
您将在validators.py中存储各种辅助函数,并在exceptions.py文件中存储一些异常类,以便将游戏状态验证与模型分离。
为了提高代码的一致性,您可以提取之前在__post_init__()方法中定义的网格验证,将其移动到新创建的 Python 模块中,并将其包装在一个新函数中:
# tic_tac_toe/logic/validators.py
import re
from tic_tac_toe.logic.models import Grid
def validate_grid(grid: Grid) -> None:
if not re.match(r"^[\sXO]{9}$", grid.cells):
raise ValueError("Must contain 9 cells of: X, O, or space")
注意,您用grid.cells替换了self.cells,因为您现在通过函数的参数引用了一个网格实例。
如果您正在使用 PyCharm,那么它可能已经开始突出显示对tic_tac_toe的未解析引用,这在 Python 模块和包的搜索路径上是不存在的。PyCharm 似乎不能正确识别可编辑的安装,但是您可以通过右键单击您的src/文件夹并在项目视图中将它标记为所谓的源根目录来解决这个问题:
https://player.vimeo.com/video/749562307?background=1
您可以根据需要将任意多个文件夹标记为源根目录。这样做将把它们的绝对路径附加到 PyCharm 管理的 PYTHONPATH 环境变量中。然而,这不会影响 PyCharm 之外的环境,所以通过系统终端运行脚本不会从标记这些文件夹中受益。相反,您可以激活安装了库的虚拟环境来导入它的代码。
在提取了网格验证逻辑之后,您应该通过将验证委托给适当的抽象来更新您的Grid模型中的相应部分:
# tic_tac_toe/logic/models.py import enum import re from dataclasses import dataclass from functools import cached_property +from tic_tac_toe.logic.validators import validate_grid
# ... @dataclass(frozen=True) class Grid: cells: str = " " * 9 def __post_init__(self) -> None: - if not re.match(r"^[\sXO]{9}$", self.cells): - raise ValueError("Must contain 9 cells of: X, O, or space") + validate_grid(self)
@cached_property def x_count(self) -> int: return self.cells.count("X") @cached_property def o_count(self) -> int: return self.cells.count("O") @cached_property def empty_count(self) -> int: return self.cells.count(" ") # ...
您导入新的 helper 函数,并在您的网格的后初始化钩子中调用它,它现在使用更高级的词汇表来传达它的意图。以前,一些底层的细节,比如正则表达式的使用,会泄露到你的模型中,而且现在还不清楚.__post_init__()方法是做什么的。
不幸的是,这种变化现在在你的模型层和验证层之间产生了臭名昭著的循环引用问题,它们相互依赖对方的位。当您尝试导入Grid时,您会得到以下错误:
Traceback (most recent call last):
...
ImportError: cannot import name 'Grid' from partially initialized module
'tic_tac_toe.logic.models' (most likely due to a circular import)
(.../tic_tac_toe/logic/models.py)
那是因为 Python 是从上到下读取源代码的。一旦遇到 import 语句,它就会跳到导入的文件并开始读取。然而,在这种情况下,导入的validators模块想要导入models模块,该模块还没有被完全处理。当您开始使用类型提示时,这是 Python 中一个非常常见的问题。
您需要导入models的唯一原因是验证函数中的类型提示。您可以通过用引号("Grid")将类型提示括起来,像前面一样进行前向声明,从而摆脱 import 语句。然而,这次你将追随一个不同的习语。您可以将注释的延期求值与一个特殊的 TYPE_CHECKING 常量结合起来:
# tic_tac_toe/logic/validators.py +from __future__ import annotations
+from typing import TYPE_CHECKING
+if TYPE_CHECKING: + from tic_tac_toe.logic.models import Grid
import re -from tic_tac_toe.logic.models import Grid def validate_grid(grid: Grid) -> None: if not re.match(r"^[\sXO]{9}$", grid.cells): raise ValueError("Must contain 9 cells of: X, O, or space")
你有条件的导入Grid。TYPE_CHECKING常量在运行时为假,但第三方工具,如 mypy ,在执行静态类型检查时会假装为真,以允许导入语句运行。但是,因为您不再在运行时导入所需的类型,所以现在您必须使用前向声明或者利用from __future__ import annotations,这将隐式地将注释转换为字符串文字。
注意:__future__导入最初是为了让从 Python 2 到 Python 3 的迁移更加无缝。今天,您可以使用它来启用未来版本中计划的各种语言特性。一旦某个特性成为标准 Python 发行版的一部分,并且您不需要支持旧语言版本,您就可以移除该导入。
所有这些准备就绪后,您终于准备好约束游戏状态以遵守井字游戏规则了。接下来,您将向新的validators模块添加一些GameState验证函数。
丢弃不正确的游戏状态
为了拒绝无效的游戏状态,您将在您的GameState类中实现一个熟悉的后初始化钩子,将处理委托给另一个函数:
# tic_tac_toe/logic/models.py
import enum
import re
from dataclasses import dataclass
from functools import cached_property
from tic_tac_toe.logic.validators import validate_game_state, validate_grid
# ...
@dataclass(frozen=True)
class GameState:
grid: Grid
starting_mark: Mark = Mark("X")
def __post_init__(self) -> None: validate_game_state(self)
# ...
验证函数validate_game_state()接收游戏状态的实例,该实例又包含单元格网格和开始玩家。您将使用这些信息,但是首先,您将通过在您的validators模块中进一步委托状态位来将验证分成几个更小且更集中的阶段:
# tic_tac_toe/logic/validators.py
from __future__ import annotations
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from tic_tac_toe.logic.models import GameState, Grid
import re
def validate_grid(grid: Grid) -> None:
...
def validate_game_state(game_state: GameState) -> None:
validate_number_of_marks(game_state.grid) validate_starting_mark(game_state.grid, game_state.starting_mark) validate_winner( game_state.grid, game_state.starting_mark, game_state.winner )
您的新助手函数通过调用几个后续函数充当游戏状态验证的入口点,稍后您将定义这些函数。
为了防止在网格中出现玩家标记数量不正确的游戏状态,例如您之前偶然发现的游戏状态,您必须考虑零号与十字号的比例:
# tic_tac_toe/logic/validators.py
from __future__ import annotations
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from tic_tac_toe.logic.models import GameState, Grid
import re
from tic_tac_toe.logic.exceptions import InvalidGameState
def validate_grid(grid: Grid) -> None:
...
def validate_game_state(game_state: GameState) -> None:
...
def validate_number_of_marks(grid: Grid) -> None:
if abs(grid.x_count - grid.o_count) > 1: raise InvalidGameState("Wrong number of Xs and Os")
在任何时候,一个玩家留下的分数必须等于或大于另一个玩家留下的分数。最初,没有标记,所以 x 和 o 的数量等于零。当第一个玩家移动时,他们将比对手多一个标记。但是,一旦另一个玩家开始第一步,这个比例又变平了,以此类推。
要发出无效状态的信号,需要引发在另一个模块中定义的自定义异常:
# tic_tac_toe/logic/exceptions.py
class InvalidGameState(Exception):
"""Raised when the game state is invalid."""
习惯上,让空类扩展 Python 中内置的Exception类型,而不在其中指定任何方法或属性。这样的类仅仅因为它们的名字而存在,它们传达了足够的关于运行时发生的错误的信息。请注意,如果您使用 docstring ,则不需要使用 pass语句或省略文字(... ) 作为类体占位符,它们可以提供额外的文档。
另一个游戏状态不一致与格子上剩余的标记数量有关,与开始玩家的标记有关,这可能是错误的:
# tic_tac_toe/logic/validators.py
from __future__ import annotations
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from tic_tac_toe.logic.models import GameState, Grid
import re
from tic_tac_toe.logic.exceptions import InvalidGameState
def validate_grid(grid: Grid) -> None:
...
def validate_game_state(game_state: GameState) -> None:
...
def validate_number_of_marks(grid: Grid) -> None:
...
def validate_starting_mark(grid: Grid, starting_mark: Mark) -> None:
if grid.x_count > grid.o_count: if starting_mark != "X": raise InvalidGameState("Wrong starting mark") elif grid.o_count > grid.x_count: if starting_mark != "O": raise InvalidGameState("Wrong starting mark")
在格子上留下更多标记的玩家保证是首发玩家。如果不是,那么你知道一定是哪里出了问题。因为您将Mark定义为从str派生的 enum,所以您可以直接将开始玩家的标记与字符串文字进行比较。
最后,赢家只能有一个,根据谁开始游戏,格子上剩下的 Xs 和 Os 的比例会有所不同:
# tic_tac_toe/logic/validators.py
from __future__ import annotations
from typing import TYPE_CHECKING
if TYPE_CHECKING:
from tic_tac_toe.logic.models import GameState, Grid, Mark
import re
from tic_tac_toe.logic.exceptions import InvalidGameState
def validate_grid(grid: Grid) -> None:
...
def validate_game_state(game_state: GameState) -> None:
...
def validate_number_of_marks(grid: Grid) -> None:
...
def validate_starting_mark(grid: Grid, starting_mark: Mark) -> None:
...
def validate_winner(
grid: Grid, starting_mark: Mark, winner: Mark | None ) -> None:
if winner == "X": if starting_mark == "X": if grid.x_count <= grid.o_count: raise InvalidGameState("Wrong number of Xs") else: if grid.x_count != grid.o_count: raise InvalidGameState("Wrong number of Xs") elif winner == "O": if starting_mark == "O": if grid.o_count <= grid.x_count: raise InvalidGameState("Wrong number of Os") else: if grid.o_count != grid.x_count: raise InvalidGameState("Wrong number of Os")
先发球员有优势,所以当他们赢了,他们会比对手留下更多的分数。相反,第二个玩家处于劣势,所以他们只能通过做出与开始玩家相同数量的移动来赢得游戏。
您几乎已经完成了用 Python 代码封装井字游戏规则的工作,但是还缺少一个更重要的部分。在下一节中,您将编写代码,通过模拟玩家的移动来系统地产生新的游戏状态。
通过产生新的游戏状态来模拟动作
您将添加到您的GameState类的最后一个属性是一个可能移动的固定列表,您可以通过用当前玩家的标记填充网格中剩余的空白单元格来找到它:
# tic_tac_toe/logic/models.py
# ...
@dataclass(frozen=True)
class GameState:
# ...
@cached_property def possible_moves(self) -> list[Move]: moves = [] if not self.game_over: for match in re.finditer(r"\s", self.grid.cells): moves.append(self.make_move_to(match.start())) return moves
如果游戏结束了,那么你会返回一个空的移动列表。否则,使用正则表达式确定空单元格的位置,然后移动到每个单元格。移动会创建一个新的Move对象,你可以在不改变游戏状态的情况下将它添加到列表中。
这就是如何构造一个Move对象:
# tic_tac_toe/logic/models.py
import enum
import re
from dataclasses import dataclass
from functools import cached_property
from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.validators import validate_game_state, validate_grid
# ...
@dataclass(frozen=True)
class GameState:
# ...
def make_move_to(self, index: int) -> Move: if self.grid.cells[index] != " ": raise InvalidMove("Cell is not empty") return Move( mark=self.current_mark, cell_index=index, before_state=self, after_state=GameState( Grid( self.grid.cells[:index] + self.current_mark + self.grid.cells[index + 1:] ), self.starting_mark, ), )
如果目标单元格已经被你或你的对手的标记占据,则不允许移动,在这种情况下,你会引发一个InvalidMove异常。另一方面,如果单元格是空的,那么在合成下面的状态时,对当前玩家的标记、目标单元格的索引和当前游戏状态进行快照。
不要忘记定义您导入的新异常类型:
# tic_tac_toe/logic/exceptions.py
class InvalidGameState(Exception):
"""Raised when the game state is invalid."""
class InvalidMove(Exception):
"""Raised when the move is invalid."""
就是这样!您刚刚获得了井字游戏的一个非常坚实的域模型,您可以用它来构建各种前端的交互式游戏。该模型封装了游戏规则,并强制执行其约束。
在继续之前,请确保在模块搜索路径上可以访问该库,例如,将其安装到活动的虚拟环境中,如前面的项目概述中所示:
>>> from tic_tac_toe.logic.models import GameState, Grid, Mark >>> game_state = GameState(Grid()) >>> game_state.game_not_started True >>> game_state.game_over False >>> game_state.tie False >>> game_state.winner is None True >>> game_state.winning_cells [] >>> game_state = GameState(Grid("XOXOXOXXO"), starting_mark=Mark("X")) >>> game_state.starting_mark <Mark.CROSS: 'X'> >>> game_state.current_mark <Mark.NAUGHT: 'O'> >>> game_state.winner <Mark.CROSS: 'X'> >>> game_state.winning_cells [2, 4, 6] >>> game_state = GameState(Grid("XXOXOX O")) >>> game_state.possible_moves [ Move( mark=<Mark.NAUGHT: 'O'>, cell_index=6, before_state=GameState(...), after_state=GameState(...) ), Move( mark=<Mark.NAUGHT: 'O'>, cell_index=7, before_state=GameState(...), after_state=GameState(...) ) ]现在您知道了各种
GameState属性是如何工作的,以及如何将它们与其他领域模型对象结合起来。在下一部分,您将构建一个抽象的游戏引擎和您的第一个虚拟玩家。
第二步:搭建一个通用的井字游戏引擎
此时,您应该已经为井字游戏库定义了所有的域模型。现在,是时候构建一个游戏引擎了,它将利用这些模型类来促进井字游戏。
现在继续在
tic_tac_toe.game包中创建另外三个 Python 模块:tic-tac-toe/ │ └── library/ │ ├── src/ │ │ │ └── tic_tac_toe/ │ │ │ ├── game/ │ │ ├── __init__.py │ │ ├── engine.py │ │ ├── players.py │ │ └── renderers.py │ │ │ ├── logic/ │ │ ├── __init__.py │ │ ├── exceptions.py │ │ ├── models.py │ │ └── validators.py │ │ │ └── __init__.py │ └── pyproject.toml
engine模块是虚拟游戏的核心,在这里你可以实现游戏的主循环。您将在players和renderers模块中定义游戏引擎使用的抽象接口,以及一个示例计算机播放器。到这一步结束时,您就可以为井字游戏库编写一个有形的前端了。拉动玩家的移动来驱动游戏
最起码,玩井字游戏,你需要有两个玩家,一些可以利用的东西和一套要遵守的规则。幸运的是,您可以将这些元素表示为不可变的数据类,这利用了您的库中现有的域模型。首先,您将在
engine模块中创建TicTacToe类:# tic_tac_toe/game/engine.py from dataclasses import dataclass from tic_tac_toe.game.players import Player from tic_tac_toe.game.renderers import Renderer @dataclass(frozen=True) class TicTacToe: player1: Player player2: Player renderer: Renderer
Player和Renderer都将在下面的章节中作为 Python 的抽象基类来实现,这些抽象基类只描述你的游戏引擎的高级接口。然而,它们最终会被具体的类所取代,其中一些可能来自外部定义的前端。玩家将知道该做什么,渲染器将负责可视化网格。要玩这个游戏,你必须决定哪个玩家应该使第一个移动,或者你可以假设默认的那个,就是有十字的玩家。你也应该从一个空白格子和一个初始游戏状态开始:
# tic_tac_toe/game/engine.py from dataclasses import dataclass from tic_tac_toe.game.players import Player from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Grid, Mark @dataclass(frozen=True) class TicTacToe: player1: Player player2: Player renderer: Renderer def play(self, starting_mark: Mark = Mark("X")) -> None: game_state = GameState(Grid(), starting_mark) while True: self.renderer.render(game_state) if game_state.game_over: break player = self.get_current_player(game_state) try: game_state = player.make_move(game_state) except InvalidMove: pass引擎请求渲染器更新视图,然后使用拉策略通过要求两个玩家轮流移动来推进游戏。这些步骤在无限循环中重复,直到游戏结束。
仅知道当前玩家的标记,可以是 X 或 O,但不知道分配了这些标记的特定玩家对象。因此,您需要使用这个辅助方法将当前标记映射到一个玩家对象:
# tic_tac_toe/game/engine.py from dataclasses import dataclass from tic_tac_toe.game.players import Player from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Grid, Mark @dataclass(frozen=True) class TicTacToe: player1: Player player2: Player renderer: Renderer def play(self, starting_mark: Mark = Mark("X")) -> None: game_state = GameState(Grid(), starting_mark) while True: self.renderer.render(game_state) if game_state.game_over: break player = self.get_current_player(game_state) try: game_state = player.make_move(game_state) except InvalidMove: pass def get_current_player(self, game_state: GameState) -> Player: if game_state.current_mark is self.player1.mark: return self.player1 else: return self.player2在这里,您使用 Python 的
is操作符通过标识来比较枚举成员。如果由游戏状态决定的当前玩家的标记与分配给第一个玩家的标记相同,那么该玩家应该进行下一步。提供给
TicTacToe对象的两个玩家应该有相反的标记。否则,你就不能在不违反游戏规则的情况下玩这个游戏。因此,在实例化TicTacToe类时验证玩家的标记是合理的:# tic_tac_toe/game/engine.py from dataclasses import dataclass from tic_tac_toe.game.players import Player from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Grid, Mark from tic_tac_toe.logic.validators import validate_players @dataclass(frozen=True) class TicTacToe: player1: Player player2: Player renderer: Renderer def __post_init__(self): validate_players(self.player1, self.player2) def play(self, starting_mark: Mark = Mark("X")) -> None: game_state = GameState(Grid(), starting_mark) while True: self.renderer.render(game_state) if game_state.game_over: break player = self.get_current_player(game_state) try: game_state = player.make_move(game_state) except InvalidMove: pass def get_current_player(self, game_state: GameState) -> Player: if game_state.current_mark is self.player1.mark: return self.player1 else: return self.player2您在数据类中添加一个后初始化挂钩,并调用另一个必须添加到
validators模块中的验证函数:# tic_tac_toe/logic/validators.py from __future__ import annotations from typing import TYPE_CHECKING if TYPE_CHECKING: from tic_tac_toe.game.players import Player from tic_tac_toe.logic.models import GameState, Grid, Mark import re from tic_tac_toe.logic.exceptions import InvalidGameState def validate_grid(grid: Grid) -> None: ... def validate_game_state(game_state: GameState) -> None: ... def validate_number_of_marks(grid: Grid) -> None: ... def validate_starting_mark(grid: Grid, starting_mark: Mark) -> None: ... def validate_winner( grid: Grid, starting_mark: Mark, winner: Mark | None ) -> None: ... def validate_players(player1: Player, player2: Player) -> None: if player1.mark is player2.mark: raise ValueError("Players must use different marks")您再次使用身份比较来检查两个玩家的标记,并在两个玩家使用相同标记时阻止游戏开始。
还有一件事可能会出错。因为由玩家,包括人类玩家来决定他们的行动,他们的选择可能是无效的。目前,你的
TicTacToe类捕捉到了InvalidMove异常,但是除了忽略这样的移动并要求玩家做出不同的选择之外,并没有做任何有用的事情。让前端处理错误可能会有所帮助,例如,显示一条合适的消息:# tic_tac_toe/game/engine.py from dataclasses import dataclass from typing import Callable, TypeAlias from tic_tac_toe.game.players import Player from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Grid, Mark from tic_tac_toe.logic.validators import validate_players ErrorHandler: TypeAlias = Callable[[Exception], None] @dataclass(frozen=True) class TicTacToe: player1: Player player2: Player renderer: Renderer error_handler: ErrorHandler | None = None def __post_init__(self): validate_players(self.player1, self.player2) def play(self, starting_mark: Mark = Mark("X")) -> None: game_state = GameState(Grid(), starting_mark) while True: self.renderer.render(game_state) if game_state.game_over: break player = self.get_current_player(game_state) try: game_state = player.make_move(game_state) except InvalidMove as ex: if self.error_handler: self.error_handler(ex) def get_current_player(self, game_state: GameState) -> Player: if game_state.current_mark is self.player1.mark: return self.player1 else: return self.player2为了让前端决定如何处理一个无效的移动,您通过引入一个可选的
.error_handler回调,在您的类中公开一个钩子,该回调将接收异常。您使用一个类型别名来定义回调的类型,使其类型声明更加简洁。在无效移动的情况下,TicTacToe游戏将触发这个回调,只要您提供错误处理程序。实现了一个抽象的井字游戏引擎后,您可以继续编写一个虚拟玩家。您将定义一个通用的播放器接口,并用一个随机移动的示例计算机播放器来实现它。
让计算机随机选择一步棋
首先,定义一个抽象的
Player,它将是具体玩家要扩展的基类:# tic_tac_toe/game/players.py import abc from tic_tac_toe.logic.models import Mark class Player(metaclass=abc.ABCMeta): def __init__(self, mark: Mark) -> None: self.mark = mark一个抽象类是你不能实例化的,因为它的对象不会独立存在。它唯一的目的是为具体的子类提供框架。在 Python 中,通过将类的元类设置为
abc.ABCMeta或者扩展abc.ABC祖先,可以将类标记为抽象的。注意:使用
metaclass参数而不是扩展基类稍微灵活一些,因为它不会影响你的继承层次。这在像 Python 这样支持多重继承的语言中不太重要。无论如何,作为一个经验法则,只要有可能,你应该支持合成而不是继承。玩家得到一个他们将在游戏中使用的
Mark实例。给定某个游戏状态,玩家还公开一个公共方法来移动:# tic_tac_toe/game/players.py import abc from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Mark, Move class Player(metaclass=abc.ABCMeta): def __init__(self, mark: Mark) -> None: self.mark = mark def make_move(self, game_state: GameState) -> GameState: if self.mark is game_state.current_mark: if move := self.get_move(game_state): return move.after_state raise InvalidMove("No more possible moves") else: raise InvalidMove("It's the other player's turn") @abc.abstractmethod def get_move(self, game_state: GameState) -> Move | None: """Return the current player's move in the given game state."""请注意 public
.make_move()方法是如何定义移动的通用算法的,但是移动的单个步骤被委托给一个抽象方法,您必须在具体的子类中实现它。这样的设计在面向对象编程中被称为模板方法模式。走一步棋需要检查是否轮到给定的玩家,以及该步棋是否存在。
.get_move()方法返回None来表示不能再移动,抽象的Player类使用 Walrus 操作符(:=) 来简化调用代码。为了让游戏感觉更自然,你可以引入一个短暂的延迟,让电脑玩家在选择下一步棋之前等待。否则,计算机会立即行动,不像人类玩家。您可以定义另一个稍微更具体的抽象基类来表示计算机玩家:
# tic_tac_toe/game/players.py import abc import time from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Mark, Move class Player(metaclass=abc.ABCMeta): ... class ComputerPlayer(Player, metaclass=abc.ABCMeta): def __init__(self, mark: Mark, delay_seconds: float = 0.25) -> None: super().__init__(mark) self.delay_seconds = delay_seconds def get_move(self, game_state: GameState) -> Move | None: time.sleep(self.delay_seconds) return self.get_computer_move(game_state) @abc.abstractmethod def get_computer_move(self, game_state: GameState) -> Move | None: """Return the computer's move in the given game state."""
ComputerPlayer通过向其实例添加一个额外的成员.delay_seconds来扩展Player,默认情况下这等于 250 毫秒。它还实现了.get_move()方法来模拟一定的等待时间,然后调用另一个特定于电脑玩家的抽象方法。拥有一个抽象的计算机播放器数据类型可以实现一个统一的接口,你只需要几行代码就可以很方便地满足它。例如,您可以通过以下方式实现计算机玩家随机选择移动:
# tic_tac_toe/game/players.py import abc import random import time from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Mark, Move class Player(metaclass=abc.ABCMeta): ... class ComputerPlayer(Player, metaclass=abc.ABCMeta): ... class RandomComputerPlayer(ComputerPlayer): def get_computer_move(self, game_state: GameState) -> Move | None: try: return random.choice(game_state.possible_moves) except IndexError: return None你使用
choice()从可能的移动列表中选择一个随机元素。如果在给定的游戏状态下没有更多的移动,那么你会因为一个空列表而得到一个IndexError,所以你捕捉它并返回None。你现在有了两个抽象基类,
Player和ComputerPlayer,以及一个具体的RandomComputerPlayer,你将能够在你的游戏中使用它们。在将这些类付诸实践之前,等式中唯一剩下的元素是抽象渲染器,接下来将对其进行定义。制作一个抽象的井字格渲染器
给予井字游戏网格一个可视化的形式完全取决于前端,所以您将只在您的库中定义一个抽象接口:
# tic_tac_toe/game/renderers.py import abc from tic_tac_toe.logic.models import GameState class Renderer(metaclass=abc.ABCMeta): @abc.abstractmethod def render(self, game_state: GameState) -> None: """Render the current game state."""这可以作为一个常规函数来实现,因为渲染器只公开一个操作,而通过一个参数来获得整个状态。然而,具体的子类可能需要维护一个额外的状态,比如应用程序的窗口,所以拥有一个类在某些时候可能会派上用场。
好了,你有了具有健壮的领域模型的井字游戏库、封装游戏规则的引擎、模拟移动的机制,甚至还有一个具体的计算机玩家。在下一节中,您将把所有的部分组合在一起,构建一个游戏前端,让您最终看到一些动作!
第三步:为主机构建游戏前端
到目前为止,您一直在开发一个抽象的井字游戏引擎库,它为游戏提供了构建模块。在本节中,您将通过编写一个依赖于该库的独立项目来实现它。这将是一个在基于文本的控制台上运行的基本游戏。
用 ANSI 转义码渲染网格
任何游戏前端最重要的方面是通过图形界面向玩家提供视觉反馈。因为在这个例子中,您被限制在基于文本的控制台上,所以您将利用 ANSI 转义码来控制诸如文本格式或位置之类的事情。
在你的控制台前端创建
renderers模块,并定义一个具体的类来扩展井字游戏的抽象渲染器:# frontends/console/renderers.py from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.models import GameState class ConsoleRenderer(Renderer): def render(self, game_state: GameState) -> None: clear_screen()如果您使用的是 Visual Studio 代码,并且它不能解析导入,请尝试关闭并重新打开编辑器。
ConsoleRenderer类覆盖了.render(),这是唯一一个负责可视化游戏当前状态的抽象方法。在这种情况下,首先使用一个助手函数清除屏幕内容,可以在类下面定义这个函数:# frontends/console/renderers.py from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.models import GameState class ConsoleRenderer(Renderer): def render(self, game_state: GameState) -> None: clear_screen() def clear_screen() -> None: print("\033c", end="")字符串文字
"\033"代表一个不可打印的Esc字符,它开始一个特殊的代码序列。后面的字母c编码了清除屏幕的命令。注意print()函数会自动用换行符结束文本。为了避免添加不必要的空行,您必须通过设置end参数来禁用它。当有赢家时,你会想用闪烁的文本来区分他们的中奖标记。您可以定义另一个助手函数,使用相关的 ANSI 转义码对闪烁文本进行编码:
# frontends/console/renderers.py from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.models import GameState class ConsoleRenderer(Renderer): def render(self, game_state: GameState) -> None: clear_screen() def clear_screen() -> None: print("\033c", end="") def blink(text: str) -> str: return f"\033[5m{text}\033[0m"在这里,您用开始和结束 ANSI 转义码将提供的文本包装在 Python 的 f 字符串中。
为了呈现填充有玩家标记的井字游戏网格,您将格式化一个多行模板字符串,并使用
textwrap模块来移除缩进:# frontends/console/renderers.py import textwrap from typing import Iterable from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.models import GameState class ConsoleRenderer(Renderer): def render(self, game_state: GameState) -> None: clear_screen() print_solid(game_state.grid.cells) def clear_screen() -> None: print("\033c", end="") def blink(text: str) -> str: return f"\033[5m{text}\033[0m" def print_solid(cells: Iterable[str]) -> None: print( textwrap.dedent( """\ A B C ------------ 1 ┆ {0} │ {1} │ {2} ┆ ───┼───┼─── 2 ┆ {3} │ {4} │ {5} ┆ ───┼───┼─── 3 ┆ {6} │ {7} │ {8} """ ).format(*cells) )
print_solid()函数获取一系列单元格,并在左上角用附加装订线打印出来。它包含由字母索引的编号行和列。例如,部分填充的井字游戏网格在屏幕上可能是这样的:A B C ------------ 1 ┆ X │ O │ X ┆ ───┼───┼─── 2 ┆ O │ O │ ┆ ───┼───┼─── 3 ┆ │ X │装订线将使玩家更容易指定他们想要放置标记的目标单元格的坐标。
如果有一个赢家,你会想要闪烁他们的一些单元格,并打印一条消息,说明谁赢得了游戏。否则,您将打印一个实心的单元格网格,并选择性地通知玩家在出现平局的情况下没有赢家:
# frontends/console/renderers.py import textwrap from typing import Iterable from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.models import GameState class ConsoleRenderer(Renderer): def render(self, game_state: GameState) -> None: clear_screen() if game_state.winner: print_blinking(game_state.grid.cells, game_state.winning_cells) print(f"{game_state.winner} wins \N{party popper}") else: print_solid(game_state.grid.cells) if game_state.tie: print("No one wins this time \N{neutral face}") def clear_screen() -> None: print("\033c", end="") def blink(text: str) -> str: return f"\033[5m{text}\033[0m" def print_solid(cells: Iterable[str]) -> None: print( textwrap.dedent( """\ A B C ------------ 1 ┆ {0} │ {1} │ {2} ┆ ───┼───┼─── 2 ┆ {3} │ {4} │ {5} ┆ ───┼───┼─── 3 ┆ {6} │ {7} │ {8} """ ).format(*cells) )您的消息包含 Unicode 字符的姓名别名的特殊语法,包括表情符号,以便使输出看起来更加丰富多彩和令人兴奋。例如,
"\N{party popper}"将呈现🎉表情符号。注意,您还调用了另一个助手函数print_blinking(),现在您必须定义它:# frontends/console/renderers.py import textwrap from typing import Iterable from tic_tac_toe.game.renderers import Renderer from tic_tac_toe.logic.models import GameState class ConsoleRenderer(Renderer): def render(self, game_state: GameState) -> None: clear_screen() if game_state.winner: print_blinking(game_state.grid.cells, game_state.winning_cells) print(f"{game_state.winner} wins \N{party popper}") else: print_solid(game_state.grid.cells) if game_state.tie: print("No one wins this time \N{neutral face}") def clear_screen() -> None: print("\033c", end="") def blink(text: str) -> str: return f"\033[5m{text}\033[0m" def print_blinking(cells: Iterable[str], positions: Iterable[int]) -> None: mutable_cells = list(cells) for position in positions: mutable_cells[position] = blink(mutable_cells[position]) print_solid(mutable_cells) def print_solid(cells: Iterable[str]) -> None: print( textwrap.dedent( """\ A B C ------------ 1 ┆ {0} │ {1} │ {2} ┆ ───┼───┼─── 2 ┆ {3} │ {4} │ {5} ┆ ───┼───┼─── 3 ┆ {6} │ {7} │ {8} """ ).format(*cells) )这个新函数接受单元格序列和那些应该使用闪烁文本呈现的单元格的数字位置。然后,它制作单元格的可变副本,用闪烁的 ANSI 转义码覆盖指定的单元格,并将呈现委托给
print_solid()。此时,您可以使用井字游戏库中内置的两个计算机播放器来测试您的自定义渲染器。将以下代码保存在位于
frontends/文件夹中名为play.py的文件中:# frontends/play.py from tic_tac_toe.game.engine import TicTacToe from tic_tac_toe.game.players import RandomComputerPlayer from tic_tac_toe.logic.models import Mark from console.renderers import ConsoleRenderer player1 = RandomComputerPlayer(Mark("X")) player2 = RandomComputerPlayer(Mark("O")) TicTacToe(player1, player2, ConsoleRenderer()).play()当你运行这个脚本时,你会看到两个虚拟玩家随机移动,每次都会导致不同的结果:
https://player.vimeo.com/video/757513281?background=1
Random Moves of Two Computer Players 虽然看他们的游戏很有趣,但是没有任何互动性。你现在要改变这种情况,让人类玩家来决定如何行动。
创建一个交互式控制台播放器
在这一部分结束时,除了你刚刚看到的两个电脑玩家之外,你还可以在一个人和一个电脑玩家或者两个人玩家之间玩井字游戏。人类玩家将使用键盘界面来指定他们的移动。
您可以在您的控制台前端定义一个新的具体播放器类,它将实现库中指定的抽象
.get_move()方法。创建前端的players模块,并填充以下内容:# frontends/console/players.py from tic_tac_toe.game.players import Player from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Move class ConsolePlayer(Player): def get_move(self, game_state: GameState) -> Move | None: while not game_state.game_over: try: index = grid_to_index(input(f"{self.mark}'s move: ").strip()) except ValueError: print("Please provide coordinates in the form of A1 or 1A") else: try: return game_state.make_move_to(index) except InvalidMove: print("That cell is already occupied.") return None如果游戏已经结束,那么你返回
None来表明没有移动是可能的。否则,你会一直向玩家要求一个有效的移动,直到他们提供一个有效的移动并开始移动。因为人类玩家键入像A1或C3这样的单元格坐标,所以您必须借助grid_to_index()函数将这样的文本转换成数字索引:# frontends/console/players.py import re from tic_tac_toe.game.players import Player from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.models import GameState, Move class ConsolePlayer(Player): def get_move(self, game_state: GameState) -> Move | None: while not game_state.game_over: try: index = grid_to_index(input(f"{self.mark}'s move: ").strip()) except ValueError: print("Please provide coordinates in the form of A1 or 1A") else: try: return game_state.make_move_to(index) except InvalidMove: print("That cell is already occupied.") return None def grid_to_index(grid: str) -> int: if re.match(r"[abcABC][123]", grid): col, row = grid elif re.match(r"[123][abcABC]", grid): row, col = grid else: raise ValueError("Invalid grid coordinates") return 3 * (int(row) - 1) + (ord(col.upper()) - ord("A"))该函数使用正则表达式提取数字行和数字列,以便您可以在单元格的平面序列中计算相应的索引。
您现在可以通过导入和实例化
ConsolePlayer来修改您的测试脚本:# frontends/play.py from tic_tac_toe.game.engine import TicTacToe from tic_tac_toe.game.players import RandomComputerPlayer from tic_tac_toe.logic.models import Mark from console.players import ConsolePlayer from console.renderers import ConsoleRenderer player1 = ConsolePlayer(Mark("X")) player2 = RandomComputerPlayer(Mark("O")) TicTacToe(player1, player2, ConsoleRenderer()).play()运行这个脚本将允许你在电脑上扮演 X。不幸的是,没有方便的方法来改变玩家或规定谁应该开始游戏,因为这些信息被嵌入到代码中。接下来,您将添加一个命令行界面来解决这个问题。
添加命令行界面(CLI)
您几乎已经完成了井字游戏前端的构建。然而,是时候添加最后的润色了,通过使用
argparse模块实现一个有用的命令行界面,把它变成一个可玩的游戏。这样,你就可以在运行游戏之前选择玩家类型和开始标记。控制台前端的入口点是特殊的
__main__.py模块,它通过python命令使包含的包可以运行。因为按照的惯例会将最少的包装代码放入其中,所以您将通过将处理委托给从另一个模块导入的函数来保持模块的轻量级:# frontends/console/__main__.py from .cli import main main()这使得在
cli.py中定义的代码在许多地方更加可重用,并且更容易单独测试。下面是代码可能的样子:# frontends/console/cli.py from tic_tac_toe.game.engine import TicTacToe from .args import parse_args from .renderers import ConsoleRenderer def main() -> None: player1, player2, starting_mark = parse_args() TicTacToe(player1, player2, ConsoleRenderer()).play(starting_mark)您导入游戏引擎、新的控制台渲染器和一个助手函数
parse_argse(),该函数将能够读取命令行参数,并基于它们返回两个玩家对象和开始玩家的标记。要实现参数的解析,您可以从将可用的播放器类型定义为一个 Python 字典开始,该字典将像 human 这样的日常名字与扩展抽象
Player的具体类相关联:# frontends/console/args.py from tic_tac_toe.game.players import RandomComputerPlayer from .players import ConsolePlayer PLAYER_CLASSES = { "human": ConsolePlayer, "random": RandomComputerPlayer, }这将使得将来添加更多的播放器类型变得更加简单。接下来,您可以编写一个函数,使用
argparse模块从命令行获取预期的参数:# frontends/console/args.py import argparse from tic_tac_toe.game.players import Player, RandomComputerPlayer from tic_tac_toe.logic.models import Mark from .players import ConsolePlayer PLAYER_CLASSES = { "human": ConsolePlayer, "random": RandomComputerPlayer, } def parse_args() -> tuple[Player, Player, Mark]: parser = argparse.ArgumentParser() parser.add_argument( "-X", dest="player_x", choices=PLAYER_CLASSES.keys(), default="human", ) parser.add_argument( "-O", dest="player_o", choices=PLAYER_CLASSES.keys(), default="random", ) parser.add_argument( "--starting", dest="starting_mark", choices=Mark, type=Mark, default="X", ) args = parser.parse_args()上面的代码转化为以下三个可选参数,它们都有默认值:
争吵 缺省值 描述 -Xhuman将 X 分配给指定的玩家 -Orandom将 O 分配给指定的玩家 --startingX决定开始玩家的标记 此时,该函数解析这些参数,并将它们的值作为字符串存储在一个特殊的名称空间对象中,分别位于属性
.player_x、.player_o和.starting_mark下。但是,该函数应该返回由自定义数据类型组成的元组,而不是字符串。为了使函数体符合其签名,可以使用字典将用户提供的字符串映射到相应的类:# frontends/console/args.py import argparse from tic_tac_toe.game.players import Player, RandomComputerPlayer from tic_tac_toe.logic.models import Mark from .players import ConsolePlayer PLAYER_CLASSES = { "human": ConsolePlayer, "random": RandomComputerPlayer, } def parse_args() -> tuple[Player, Player, Mark]: parser = argparse.ArgumentParser() parser.add_argument( "-X", dest="player_x", choices=PLAYER_CLASSES.keys(), default="human", ) parser.add_argument( "-O", dest="player_o", choices=PLAYER_CLASSES.keys(), default="random", ) parser.add_argument( "--starting", dest="starting_mark", choices=Mark, type=Mark, default="X", ) args = parser.parse_args() player1 = PLAYER_CLASSES[args.player_x](Mark("X")) player2 = PLAYER_CLASSES[args.player_o](Mark("O")) if args.starting_mark == "O": player1, player2 = player2, player1 return player1, player2, args.starting_mark您将用户提供的名称转换为具体的播放器类。如果开始玩家的标记不同于默认标记,那么在从函数返回之前,你交换这两个玩家。
为了使代码更简洁、更有表现力,您可以用名为 tuple 的类型化的来替换泛型 tuple:
# frontends/console/args.py import argparse from typing import NamedTuple from tic_tac_toe.game.players import Player, RandomComputerPlayer from tic_tac_toe.logic.models import Mark from .players import ConsolePlayer PLAYER_CLASSES = { "human": ConsolePlayer, "random": RandomComputerPlayer, } class Args(NamedTuple): player1: Player player2: Player starting_mark: Mark def parse_args() -> Args: parser = argparse.ArgumentParser() parser.add_argument( "-X", dest="player_x", choices=PLAYER_CLASSES.keys(), default="human", ) parser.add_argument( "-O", dest="player_o", choices=PLAYER_CLASSES.keys(), default="random", ) parser.add_argument( "--starting", dest="starting_mark", choices=Mark, type=Mark, default="X", ) args = parser.parse_args() player1 = PLAYER_CLASSES[args.player_x](Mark("X")) player2 = PLAYER_CLASSES[args.player_o](Mark("O")) if args.starting_mark == "O": player1, player2 = player2, player1 return Args(player1, player2, args.starting_mark)首先,您定义了一个
typing.NamedTuple子类,它正好包含三个命名和类型化的元素。然后返回命名元组的实例,而不是泛型元组。这样做为您提供了额外的类型安全性,以及通过名称和索引对元组元素的访问。要与另一个人对战,您可以使用以下参数运行您的控制台前端:
(venv) $ cd frontends/ (venv) $ python -m console -X human -O human如果你想在电脑上试试运气,那么用随机替换
-X或-O选项的值,这是目前唯一可用的电脑播放器类型。不幸的是,与随机行动的玩家对战并不是特别有挑战性。下一步,你将实现一个更高级的计算机播放器,利用极小极大算法,这使得计算机几乎不可战胜。第四步:给计算机配备人工智能
你已经达到了本教程的最后一步,这涉及到创建另一个计算机播放器,这一个配备了基本的人工智能。具体来说,它将使用表面下的极小最大算法,在任何回合制零和游戏中的每种可能情况下做出最佳移动,如井字游戏。
注意:掌握极大极小算法的细节并不是本教程的重点。但是,如果你想了解更多,那么看看 Python 中的Minimax:Learn How to lost the Game of Nim,它使用了一个更简单的游戏 Nim 作为例子。
在实现算法之前,你必须发明一种评估游戏分数的方法,这将成为选择最佳行动背后的决定因素。你可以通过引入一个数值的绝对尺度来表示两个玩家的表现。
评估已完成游戏的分数
为了简单起见,我们将考虑一个游戏成品的静态评估。游戏有三种可能的结果,您可以指定任意数值,例如:
- 玩家输:
-1- 玩家平局:
0- 玩家获胜:
1你将评估其分数的主角玩家被称为最大化玩家,因为他们试图最大化游戏的总分数。因此,从他们的角度来看,更大的价值应该对应更好的结果。另一方面,最小化玩家是他们的对手,他试图尽可能降低分数。毕竟,当你的玩家输了,他们就赢了,而平局对双方来说可能是好的也可能是坏的。
一旦你决定了最大化和最小化玩家,规模保持绝对,这意味着你不需要在评估对手的移动时翻转符号。
通过将以下方法添加到井字游戏库中的
GameState模型,您可以用 Python 代码来表示这个数值范围:# tic_tac_toe/logic/models.py import enum import re from dataclasses import dataclass from functools import cached_property from tic_tac_toe.logic.exceptions import InvalidMove, UnknownGameScore from tic_tac_toe.logic.validators import validate_game_state, validate_grid # ... @dataclass(frozen=True) class GameState: # ... def make_move_to(self, index: int) -> Move: ... def evaluate_score(self, mark: Mark) -> int: if self.game_over: if self.tie: return 0 if self.winner is mark: return 1 else: return -1 raise UnknownGameScore("Game is not over yet")因为这是一个静态的评价,你只能在游戏结束的时候才能确定分数。否则,您会引发一个
UnknownGameScore异常,您必须将它添加到库中的exceptions模块中:# tic_tac_toe/logic/exceptions.py class InvalidGameState(Exception): """Raised when the game state is invalid.""" class InvalidMove(Exception): """Raised when the move is invalid.""" class UnknownGameScore(Exception): """Raised when the game score is unknown."""当你想做出一个明智的决定来选择一步棋时,知道一个已完成游戏的分数并没有多大帮助。然而,这是在最坏的情况下,找到赢得比赛的最佳可能顺序的第一步。接下来,您将使用极大极小算法来计算任何游戏状态下的分数。
用最小最大算法传播分数
当你有几个动作可以选择时,你应该选择一个可以增加你预期分数的动作。与此同时,你要避免那些有可能使游戏比分向有利于你的对手的方向移动。极大极小算法可以通过使用
min()和max()函数来最小化对手的最大收益,同时最大化你的最小收益。如果这听起来很复杂,那么看看下面井字游戏的可视化图形。
当你把所有可能的博弈状态想象成一棵博弈树时,选择最佳走法归结为从当前节点开始,在这样一个加权图中寻找最优路径。minimax 算法通过在游戏树中冒泡来传播静态评估的叶节点的分数,这些节点对应于已完成的游戏。根据轮到谁,最小或最大分数在每一步都被传播。
您可以使用井字游戏中最后三个回合的具体例子来形象化这个过程。下面,你会发现井字游戏树中的一小段显示了最大化玩家 X 的可能移动,其回合以绿色表示:
Tic-Tac-Toe Game Tree With Propagated Scores 极大极小算法从递归地探索树开始向前看,找到所有可能的游戏结果。一旦找到它们,它就计算它们的分数,并回溯到起始节点。如果最大化玩家的回合导致下一个位置,那么算法选择该级别的最高分。否则,它会选择最低分,假设对手永远不会出错。
在上面的博弈树中,最左边的分支导致最大化玩家立即获胜,因此连接边具有最高的权重。选择中间的分支也可能导致胜利,但是极大极小算法悲观地指出了最坏的情况,那就是平局。最后,右边的分支几乎肯定代表一个失败的举动。
在井字游戏库中创建一个新的
minimax模块,并使用以下圆滑的 Python 表达式实现该算法:# tic_tac_toe/logic/minimax.py from tic_tac_toe.logic.models import Mark, Move def minimax( move: Move, maximizer: Mark, choose_highest_score: bool = False ) -> int: if move.after_state.game_over: return move.after_state.evaluate_score(maximizer) return (max if choose_highest_score else min)( minimax(next_move, maximizer, not choose_highest_score) for next_move in move.after_state.possible_moves )
minimax()函数返回与作为参数传递的移动相关的分数,用于指示最大化玩家。如果游戏已经结束,那么你通过执行网格的静态评估来计算分数。否则,你可以选择最大或最小的分数,你可以通过递归找到当前位置所有可能的移动。注意:
minimax模块在项目目录树中的位置有些主观,因为它在其他地方定义时也能很好地工作。然而,有人可能会说它在逻辑上属于游戏的逻辑层,因为它只依赖于域模型。只要您在虚拟环境中对井字游戏库进行了可编辑的安装,您就能够在交互式 Python 解释器会话中测试您的新功能:
>>> from tic_tac_toe.logic.minimax import minimax
>>> from tic_tac_toe.logic.models import GameState, Grid, Mark
>>> def preview(cells):
... print(cells[:3], cells[3:6], cells[6:], sep="\n")
>>> game_state = GameState(Grid("XXO O X O"), starting_mark=Mark("X"))
>>> for move in game_state.possible_moves:
... print("Score:", minimax(move, maximizer=Mark("X")))
... preview(move.after_state.grid.cells)
... print("-" * 10)
Score: 1
XXO
XO
X O
----------
Score: 0
XXO
OX
X O
----------
Score: -1
XXO
O
XXO
----------
计算出的分数与你之前看到的游戏树中的边权重相对应。找到最好的移动只是选择一个最高得分的问题。请注意,在游戏树中,有时会有多种选择来赢得游戏结果。
在下一节中,您将创建另一个具体的计算机播放器,它将利用 minimax 算法,然后您将在您的控制台前端使用它。
做一个不可战胜的迷你电脑玩家
极大极小算法计算与特定移动相关的分数。要找到给定游戏状态下的最佳走法,您可以根据分数对所有可能的走法进行排序,并选择具有最高值的走法。通过这样做,您将使用人工智能和 Python 创建一个无与伦比的井字游戏玩家。
继续在井字游戏库的minimax模块中定义以下函数:
# tic_tac_toe/logic/minimax.py
from functools import partial
from tic_tac_toe.logic.models import GameState, Mark, Move
def find_best_move(game_state: GameState) -> Move | None:
maximizer: Mark = game_state.current_mark bound_minimax = partial(minimax, maximizer=maximizer) return max(game_state.possible_moves, key=bound_minimax)
def minimax(
move: Move, maximizer: Mark, choose_highest_score: bool = False
) -> int:
...
find_best_move()函数获取一些游戏状态,并返回当前玩家的最佳走法或None以指示不可能有更多走法。注意使用了一个分部函数来冻结maximizer参数的值,这个值在minimax()调用中不会改变。这允许您使用bound_minimax()函数作为排序键,该函数只需要一个参数。
注意: Python 的functools.partial()是一个工厂,通过用具体值预先填充一个或多个原始函数的参数,产生一个参数更少的新函数。与编写代码时手动定义这样一个包装函数不同,工厂可以在运行时动态地这样做,并提供更简洁的语法。
接下来,在井字游戏库的players模块中添加一个新的电脑玩家。该玩家将使用您刚刚创建的find_best_move()辅助函数:
# tic_tac_toe/game/players.py
import abc
import random
import time
from tic_tac_toe.logic.exceptions import InvalidMove
from tic_tac_toe.logic.minimax import find_best_move from tic_tac_toe.logic.models import GameState, Mark, Move
class Player(metaclass=abc.ABCMeta):
...
class ComputerPlayer(Player, metaclass=abc.ABCMeta):
...
class RandomComputerPlayer(ComputerPlayer):
def get_computer_move(self, game_state: GameState) -> Move | None:
try:
return random.choice(game_state.possible_moves)
except IndexError:
return None
class MinimaxComputerPlayer(ComputerPlayer):
def get_computer_move(self, game_state: GameState) -> Move | None: return find_best_move(game_state)
这个电脑玩家会一直尝试用 AI 和 Python 寻找最佳的井字棋走法。然而,为了使游戏更难预测并减少计算量,您可以让它在运行昂贵的 minimax 算法之前随机选择第一步。你已经在上面定义的RandomComputerPlayer中实现了选择随机移动的逻辑。现在,将公共逻辑提取到一个可重用的组件中会有所帮助。
继续修改随机和最小最大计算机播放器的代码:
# tic_tac_toe/game/players.py import abc -import random import time from tic_tac_toe.logic.exceptions import InvalidMove from tic_tac_toe.logic.minimax import find_best_move from tic_tac_toe.logic.models import GameState, Mark, Move class Player(metaclass=abc.ABCMeta): ... class ComputerPlayer(Player, metaclass=abc.ABCMeta): ... class RandomComputerPlayer(ComputerPlayer): def get_computer_move(self, game_state: GameState) -> Move | None: - try: - return random.choice(game_state.possible_moves) - except IndexError: - return None + return game_state.make_random_move()
class MinimaxComputerPlayer(ComputerPlayer): def get_computer_move(self, game_state: GameState) -> Move | None: - return find_best_move(game_state) + if game_state.game_not_started: + return game_state.make_random_move() + else: + return find_best_move(game_state)
您在两个类中都调用了游戏状态的.make_random_move()方法。您需要使用 Python 的 random 模块定义这个新方法来选择一个可能的移动:
# tic_tac_toe/logic/models.py
import enum
import random import re
from dataclasses import dataclass
from functools import cached_property
from tic_tac_toe.logic.exceptions import InvalidMove
from tic_tac_toe.logic.validators import validate_game_state, validate_grid
# ...
@dataclass(frozen=True)
class GameState:
# ...
@cached_property
def possible_moves(self) -> list[Move]:
...
def make_random_move(self) -> Move | None: try: return random.choice(self.possible_moves) except IndexError: return None
def make_move_to(self, index: int) -> Move:
...
def evaluate_score(self, mark: Mark) -> int:
...
最后一步是在你的前端使用新的电脑播放器。打开控制台前端项目中的args模块,导入MinimaxComputerPlayer:
# frontends/console/args.py
import argparse
from typing import NamedTuple
from tic_tac_toe.game.players import (
Player, RandomComputerPlayer, MinimaxComputerPlayer, ) from tic_tac_toe.logic.models import Mark
from .players import ConsolePlayer
PLAYER_CLASSES = {
"human": ConsolePlayer,
"random": RandomComputerPlayer,
"minimax": MinimaxComputerPlayer, }
class Args(NamedTuple):
player1: Player
player2: Player
starting_mark: Mark
def parse_args() -> Args:
parser = argparse.ArgumentParser()
parser.add_argument(
"-X",
dest="player_x",
choices=PLAYER_CLASSES.keys(),
default="human",
)
parser.add_argument(
"-O",
dest="player_o",
choices=PLAYER_CLASSES.keys(),
default="minimax", )
# ...
你将新玩家类型添加到名称映射中,并使用最小最大电脑玩家作为人类玩家的默认对手。
好的,现在你有三种球员可以选择。你可以通过选择不同的玩家来测试他们彼此之间的机会,从而对你的主机前端进行终极测试。例如,您可以选择两个 minimax 电脑玩家:
(venv) $ cd frontends/
(venv) $ python -m console -X minimax -O minimax
在这种情况下,你应该预料到游戏总是以平局结束,因为双方都使用最优策略。
当你要求至少一个最小最大玩家的时候,你可能会注意到一件事,那就是游戏的性能很差,尤其是在游戏开始的时候。这是因为构建整个游戏树,即使是像井字游戏这样相对基础的游戏,也是非常昂贵的。在接下来的步骤中,您将探索一些性能优化的可能性。
恭喜你!你已经到达了这个漫长旅程的终点。不要忘记支持材料,其中包含了教程中没有涉及的额外代码。这些材料包括另外两个前端和一些表演技巧,这使得 minimax 玩家可以立即行动。您可以通过单击下面的链接下载此代码:
源代码: 点击此处下载免费源代码,您将使用它用 Python 构建井字游戏引擎和 AI 播放器。
结论
您非常出色地完成了这个详细的分步指南!你已经用游戏的核心逻辑和两个人工的电脑玩家建立了一个前端不可知的井字游戏库,其中包括一个利用极小极大算法的无敌玩家。您还创建了一个示例前端,它在基于文本的控制台中呈现游戏,并接受来自人类玩家的输入。
一路走来,您遵循了良好的编程实践,包括带有函数范式元素的面向对象设计,并利用了 Python 语言中最新的增强功能。
在本教程中,您已经学会了如何:
- 用井字游戏引擎创建一个可重用的 Python 库
- 遵循 Pythonic 代码风格对井字游戏的域进行建模
- 实现人工播放器,包括一个基于 minimax 算法的播放器
- 为有人类玩家的游戏构建一个基于文本的控制台前端
- 探索性能优化的策略
如果您还没有这样做,请单击下面的链接下载您在本教程中构建的项目的完整源代码和一些附加代码:
源代码: 点击此处下载免费源代码,您将使用它用 Python 构建井字游戏引擎和 AI 播放器。
接下来的步骤
拥有一个带有游戏核心逻辑和人工智能的通用 Python 井字游戏库,可以让你专注于构建可以利用不同图形界面的替代前端。在本教程中,您已经为井字游戏构建了一个基于文本的控制台前端,而支持材料包含了其他表示层的示例。也许你会想为的 Jupyter 笔记本或使用 Kivy 或其他 Python 框架的手机制作一个。
一个需要改进的重要领域是源于极小极大算法的蛮力本质的性能瓶颈,该算法检查所有可能的游戏状态。有几种方法可以减少计算量并加快处理速度:
- 试探法:你可以在指定的级别停下来,用试探法估计一个粗略的分数,而不是探索树的整个深度。值得注意的是,这有时可能会给出次优的结果。
- 缓存:你可以预先计算整个游戏树,这是一次性的工作,需要大量的资源。稍后,你可以将查找表(LUT) 加载到内存中,并立即获得每一个可能的游戏状态的分数。
- 阿尔法-贝塔剪枝:当用极大极小算法探索博弈树时,可能会将博弈树中相当一部分节点视为糟糕的选择而不予考虑。你可以对极大极小算法稍加修改,这就是所谓的阿尔法-贝塔剪枝技术。简而言之,它跟踪已经可用的更好的选择,而不进入保证提供更差选择的分支。
你对井字游戏库的使用或扩展有其他想法吗?在下面的评论中分享吧!************
用 Python 和 Tkinter 构建一个井字游戏
玩电脑游戏是放松或挑战自我的好方法。有些人甚至做得很专业。制作自己的电脑游戏既有趣又有教育意义。在本教程中,您将使用 Python 和 Tkinter 构建一个经典的井字游戏。
在这个项目中,你将经历创建你自己的游戏所需的思考过程。您还将学习如何整合您的各种编程技能和知识,以开发一个功能和有趣的电脑游戏。
在本教程中,您将学习如何:
- 使用 Python 编程经典井字游戏的逻辑
- 使用 Tkinter 工具包创建游戏的图形用户界面(GUI)
- 将游戏的逻辑和图形用户界面整合到一个全功能的电脑游戏
如前所述,您将使用 Python 标准库中的 Tkinter GUI 框架来创建您的游戏界面。您还将使用模型-视图-控制器模式和面向对象的方法来组织您的代码。关于这些概念的更多信息,请查看先决条件中的链接。
要下载该项目的完整源代码,请单击下面框中的链接:
获取源代码: 单击此处获取您将用来构建井字游戏的源代码。
演示:Python 中的井字游戏
在这个循序渐进的项目中,您将使用 Python 构建一个井字游戏。您将使用来自 Python 标准库的 Tkinter 工具包来创建游戏的 GUI。在下面的演示视频中,一旦你完成了本教程,你将对你的游戏如何工作有一个大致的了解:
https://player.vimeo.com/video/717834507?background=1
您的井字游戏将有一个界面,再现经典的三乘三游戏板。玩家将在共享设备上轮流移动。窗口顶部的游戏显示屏将显示下一个出场的玩家的名字。
如果玩家赢了,游戏显示屏将显示带有玩家姓名或标记的获胜消息( X 或 O )。同时,获胜的细胞组合将在板上突出显示。
最后,游戏的文件菜单会有选项来重置游戏,如果你想再玩一次或者当你玩完后退出游戏。
如果这听起来对你来说是一个有趣的项目,那么继续读下去开始吧!
项目概述
这个项目的目标是用 Python 创建一个井字游戏。对于游戏界面,您将使用 Tkinter GUI 工具包,它在标准 Python 安装中作为包含的电池提供。
井字游戏是两个人玩的。一个玩家玩 X ,另一个玩家玩 O 。玩家轮流在一个 3×3 的格子上做标记。如果给定的玩家在一行中得到水平、垂直或对角的三个标记,则该玩家赢得游戏。当所有的格子都被标记时,如果没有人连续得到三个,游戏将被打平。
记住这些规则,您需要将以下游戏组件放在一起:
- 游戏的棋盘,你将使用一个名为
TicTacToeBoard的类来构建它 - 游戏的逻辑,你将使用一个名为
TicTacToeGame的类来管理它
游戏板将作为模型-视图-控制器设计中的视图和控制器的混合体。要构建电路板,您将使用 Tkinter 窗口,可以通过实例化 tkinter.Tk 类来创建该窗口。该窗口有两个主要部分:
- 顶部显示:显示游戏状态信息
- 单元格网格:表示以前的移动和可用的空间或单元格
您将使用一个 tkinter.Label 小部件创建游戏显示,它允许您显示文本和图像。
对于单元格网格,您将使用一系列排列在网格中的 tkinter.Button 小部件。当玩家点击这些按钮中的一个时,游戏逻辑将运行以处理玩家的移动并确定是否有赢家。在这种情况下,游戏逻辑将作为模型工作,它将管理游戏的数据、逻辑和规则。
现在你对如何构建井字游戏有了一个大致的概念,你应该检查一些知识前提,让你从本教程中获得最大的收益。
先决条件
要完成这个井字游戏项目,您应该熟悉或至少熟悉以下资源中涵盖的概念和主题:
- 使用 Tkinter 的 Python GUI 编程
- Python 3 中的面向对象编程(OOP)
- Python“for”循环(确定迭代)
- 在 Python 中何时使用列表理解
- 模型-视图-控制器(MVC)解释-用乐高
- Python 中的字典
- 如何在 Python 中迭代字典
- Python 中的主要函数
- 用 namedtuple 编写 Pythonic 式的干净代码
如果在开始本教程之前,您还没有掌握所有建议的知识,那也没关系。你将通过实践来学习,所以去试一试吧!如果遇到困难,您可以随时停下来查看此处链接的资源。
第一步:用 Tkinter 设置井字游戏板
首先,您将从创建游戏板开始。在这样做之前,您需要决定如何组织井字游戏的代码。因为这个项目相当小,所以最初可以将所有代码保存在一个单独的.py文件中。这样,运行代码和执行游戏将会更加简单。
开始启动你最喜欢的代码编辑器或 IDE 。然后在当前工作目录下创建一个tic_tac_toe.py文件:
# tic_tac_toe.py
"""A tic-tac-toe game built with Python and Tkinter."""
在本教程中,您将逐步向该文件添加代码,所以请保持它的开放性和接近性。如果您想获得这个井字游戏项目的完整代码,那么您可以单击下面的可折叠部分并从中复制代码:
"""A tic-tac-toe game built with Python and Tkinter."""
import tkinter as tk
from itertools import cycle
from tkinter import font
from typing import NamedTuple
class Player(NamedTuple):
label: str
color: str
class Move(NamedTuple):
row: int
col: int
label: str = ""
BOARD_SIZE = 3
DEFAULT_PLAYERS = (
Player(label="X", color="blue"),
Player(label="O", color="green"),
)
class TicTacToeGame:
def __init__(self, players=DEFAULT_PLAYERS, board_size=BOARD_SIZE):
self._players = cycle(players)
self.board_size = board_size
self.current_player = next(self._players)
self.winner_combo = []
self._current_moves = []
self._has_winner = False
self._winning_combos = []
self._setup_board()
def _setup_board(self):
self._current_moves = [
[Move(row, col) for col in range(self.board_size)]
for row in range(self.board_size)
]
self._winning_combos = self._get_winning_combos()
def _get_winning_combos(self):
rows = [
[(move.row, move.col) for move in row]
for row in self._current_moves
]
columns = [list(col) for col in zip(*rows)]
first_diagonal = [row[i] for i, row in enumerate(rows)]
second_diagonal = [col[j] for j, col in enumerate(reversed(columns))]
return rows + columns + [first_diagonal, second_diagonal]
def toggle_player(self):
"""Return a toggled player."""
self.current_player = next(self._players)
def is_valid_move(self, move):
"""Return True if move is valid, and False otherwise."""
row, col = move.row, move.col
move_was_not_played = self._current_moves[row][col].label == ""
no_winner = not self._has_winner
return no_winner and move_was_not_played
def process_move(self, move):
"""Process the current move and check if it's a win."""
row, col = move.row, move.col
self._current_moves[row][col] = move
for combo in self._winning_combos:
results = set(self._current_moves[n][m].label for n, m in combo)
is_win = (len(results) == 1) and ("" not in results)
if is_win:
self._has_winner = True
self.winner_combo = combo
break
def has_winner(self):
"""Return True if the game has a winner, and False otherwise."""
return self._has_winner
def is_tied(self):
"""Return True if the game is tied, and False otherwise."""
no_winner = not self._has_winner
played_moves = (
move.label for row in self._current_moves for move in row
)
return no_winner and all(played_moves)
def reset_game(self):
"""Reset the game state to play again."""
for row, row_content in enumerate(self._current_moves):
for col, _ in enumerate(row_content):
row_content[col] = Move(row, col)
self._has_winner = False
self.winner_combo = []
class TicTacToeBoard(tk.Tk):
def __init__(self, game):
super().__init__()
self.title("Tic-Tac-Toe Game")
self._cells = {}
self._game = game
self._create_menu()
self._create_board_display()
self._create_board_grid()
def _create_menu(self):
menu_bar = tk.Menu(master=self)
self.config(menu=menu_bar)
file_menu = tk.Menu(master=menu_bar)
file_menu.add_command(label="Play Again", command=self.reset_board)
file_menu.add_separator()
file_menu.add_command(label="Exit", command=quit)
menu_bar.add_cascade(label="File", menu=file_menu)
def _create_board_display(self):
display_frame = tk.Frame(master=self)
display_frame.pack(fill=tk.X)
self.display = tk.Label(
master=display_frame,
text="Ready?",
font=font.Font(size=28, weight="bold"),
)
self.display.pack()
def _create_board_grid(self):
grid_frame = tk.Frame(master=self)
grid_frame.pack()
for row in range(self._game.board_size):
self.rowconfigure(row, weight=1, minsize=50)
self.columnconfigure(row, weight=1, minsize=75)
for col in range(self._game.board_size):
button = tk.Button(
master=grid_frame,
text="",
font=font.Font(size=36, weight="bold"),
fg="black",
width=3,
height=2,
highlightbackground="lightblue",
)
self._cells[button] = (row, col)
button.bind("<ButtonPress-1>", self.play)
button.grid(row=row, column=col, padx=5, pady=5, sticky="nsew")
def play(self, event):
"""Handle a player's move."""
clicked_btn = event.widget
row, col = self._cells[clicked_btn]
move = Move(row, col, self._game.current_player.label)
if self._game.is_valid_move(move):
self._update_button(clicked_btn)
self._game.process_move(move)
if self._game.is_tied():
self._update_display(msg="Tied game!", color="red")
elif self._game.has_winner():
self._highlight_cells()
msg = f'Player "{self._game.current_player.label}" won!'
color = self._game.current_player.color
self._update_display(msg, color)
else:
self._game.toggle_player()
msg = f"{self._game.current_player.label}'s turn"
self._update_display(msg)
def _update_button(self, clicked_btn):
clicked_btn.config(text=self._game.current_player.label)
clicked_btn.config(fg=self._game.current_player.color)
def _update_display(self, msg, color="black"):
self.display["text"] = msg
self.display["fg"] = color
def _highlight_cells(self):
for button, coordinates in self._cells.items():
if coordinates in self._game.winner_combo:
button.config(highlightbackground="red")
def reset_board(self):
"""Reset the game's board to play again."""
self._game.reset_game()
self._update_display(msg="Ready?")
for button in self._cells.keys():
button.config(highlightbackground="lightblue")
button.config(text="")
button.config(fg="black")
def main():
"""Create the game's board and run its main loop."""
game = TicTacToeGame()
board = TicTacToeBoard(game)
board.mainloop()
if __name__ == "__main__":
main()
拥有完整的源代码可以让你在浏览教程`的时候检查你的进度。
或者,您也可以通过单击下面框中的链接从 GitHub 下载游戏源代码:
获取源代码: 单击此处获取您将用来构建井字游戏的源代码。
现在你已经知道了游戏的最终代码是什么样子,是时候确保你有适合这个项目的 Tkinter 版本了。然后,您将继续创建您的游戏板。
确保正确的 Tkinter 版本
为了完成这个项目,您将使用标准的 Python 安装。不需要创建虚拟环境,因为不需要外部依赖。你唯一需要的包是 Tkinter ,它带有 Python 标准库。
但是,您需要确保安装了正确的 Tkinter 版本。您的 Tkinter 应该大于或等于 8.6。否则,你的游戏就没用了。
您可以通过启动 Python 交互式会话并运行以下代码来检查您当前的 Tkinter 版本:
>>> import tkinter >>> tkinter.TkVersion 8.6如果这段代码没有显示您的 Tkinter 安装的版本高于或等于 8.6,那么您需要修复它。
在 Ubuntu Linux 上,您可能需要使用系统的软件包管理器
apt来安装python3-tk软件包。这是因为 Ubuntu 通常不会在默认的 Python 安装中包含 Tkinter。正确安装 Tkinter 后,您需要检查它的当前版本。如果 Tkinter 版本低于 8.6,那么你必须安装一个更新的 Python 版本,要么从官方的下载页面下载,要么使用像 pyenv 或 Docker 这样的工具。
在 macOS 和 Windows 上,一个直接的选择是从下载页面安装大于或等于 3.9.8 的 Python 版本。
一旦你确定你有正确的 Tkinter 版本,你就可以回到你的代码编辑器并开始写代码。您将从表示井字游戏棋盘的 Python 类开始。
创建一个类来代表游戏板
要构建井字游戏的棋盘,您将使用
Tk类,它允许您创建 Tkinter 应用程序的主窗口。然后,您将在顶部框架上添加一个显示,并在主窗口的其余部分添加一个单元格网格。继续导入所需的对象并定义电路板类别:
# tic_tac_toe.py import tkinter as tk from tkinter import font class TicTacToeBoard(tk.Tk): def __init__(self): super().__init__() self.title("Tic-Tac-Toe Game") self._cells = {}在这个代码片段中,首先将
tkinter作为tk导入,将模块的名称带到当前的名称空间。在代码中使用 Tkinter 时,使用tk缩写是一种常见的做法。然后你直接从
tkinter导入font模块。在本教程的后面,你将使用这个模块来调整游戏显示的字体。
TicTacToeBoard类从Tk继承了,这使得它成为一个成熟的 GUI 窗口。这个窗口将代表游戏板。在.__init__()中,首先调用超类的.__init__()方法来正确初始化父类。为此,您可以使用内置的 super() 函数。
Tk的.title属性定义了显示在窗口标题栏上的文本。在本例中,您将标题设置为"Tic-Tac-Toe Game"字符串。
._cells非公共属性保存一个最初为空的字典。这个字典将游戏板上的按钮或单元格映射到它们在网格上对应的坐标——行和列。这些坐标将是整数数字,反映给定按钮将出现的行和列。要继续游戏板,您现在需要创建一个显示,您可以在其中提供有关游戏状态和结果的信息。对于这个显示,您将使用一个
Frame小部件作为显示面板,并使用一个Label小部件来显示所需的信息。注意:本教程中代码示例的行号是为了便于解释。大多数情况下,它们不会与你最终脚本中的行号相匹配。
现在继续将下面的方法添加到您的
TicTacToeBoard类中:1# tic_tac_toe.py 2# ... 3 4class TicTacToeBoard(tk.Tk): 5 # ... 6 7 def _create_board_display(self): 8 display_frame = tk.Frame(master=self) 9 display_frame.pack(fill=tk.X) 10 self.display = tk.Label( 11 master=display_frame, 12 text="Ready?", 13 font=font.Font(size=28, weight="bold"), 14 ) 15 self.display.pack()下面是这个方法的逐行分解:
第 8 行创建一个
Frame对象来保存游戏显示。请注意,master参数被设置为self,这意味着游戏的主窗口将是该框架的父窗口。第 9 行使用
.pack()几何管理器将框架对象放置在主窗口的顶部边框上。通过将fill参数设置为tk.X,可以确保当用户调整窗口大小时,框架将填满它的整个宽度。第 10 到 14 行创建一个
Label对象。这个标签需要存在于框架对象中,所以您将它的参数master设置为实际的框架。标签最初会显示文字"Ready?",表示游戏准备就绪,玩家可以开始新的比赛。最后,将标签的字体大小改为28像素,并将其加粗。15 号线使用
.pack()几何图形管理器将显示标签打包在框架内。酷!您已经有了游戏显示。现在,您可以创建单元格网格。一个经典的井字游戏有一个 3×3 的格子。
这里有一个使用
Button对象创建单元格网格的方法:1# tic_tac_toe.py 2# ... 3 4class TicTacToeBoard(tk.Tk): 5 # ... 6 7 def _create_board_grid(self): 8 grid_frame = tk.Frame(master=self) 9 grid_frame.pack() 10 for row in range(3): 11 self.rowconfigure(row, weight=1, minsize=50) 12 self.columnconfigure(row, weight=1, minsize=75) 13 for col in range(3): 14 button = tk.Button( 15 master=grid_frame, 16 text="", 17 font=font.Font(size=36, weight="bold"), 18 fg="black", 19 width=3, 20 height=2, 21 highlightbackground="lightblue", 22 ) 23 self._cells[button] = (row, col) 24 button.grid( 25 row=row, 26 column=col, 27 padx=5, 28 pady=5, 29 sticky="nsew" 30 )哇!这个方法做的很多!下面是对每一行的解释:
第 8 行创建一个
Frame对象来保存游戏的格子。您将master参数设置为self,这再次意味着游戏的主窗口将是这个 frame 对象的父窗口。第 9 行使用
.pack()几何管理器将框架对象放置在主窗口上。这个框架将占据游戏显示下面的区域,一直到窗口的底部。第 10 行开始一个从
0到2的循环。这些数字代表网格中每个单元格的行坐标。现在,您将在网格上拥有3行。但是,稍后您将更改这个幻数,并提供使用不同网格大小的选项,比如 4x 4。第 11 行和第 12 行配置网格上每个单元格的宽度和最小尺寸。
第 13 行在三个列坐标上循环。同样,您使用三列,但是您将在以后更改这个数字,以提供更大的灵活性并消除幻数。
第 14 到 22 行为网格上的每个单元格创建一个
Button对象。注意,您设置了几个属性,包括master、text、font等等。第 23 行将每个新按钮添加到
._cells字典中。按钮作为按键工作,它们的坐标——表示为(row, col)——作为值工作。第 24 到 30 行最后使用
.grid()几何管理器将每个按钮添加到主窗口。现在你已经实现了
._create_board_display()和._create_board_grid(),你可以从类初始化器中调用它们。继续将下面两行添加到您的TicTacToeBoard类中的.__init__():# tic_tac_toe.py # ... class TicTacToeBoard(tk.Tk): def __init__(self): super().__init__() self.title("Tic-Tac-Toe Game") self._cells = {} self._create_board_display() self._create_board_grid()这两条线通过添加显示和单元格网格将游戏板放在一起。是不是很酷?
有了这些更新,你几乎可以运行你的应用程序,看看你的井字游戏会是什么样子。你只需要多写几行样板代码。您需要实例化
TicTacToeBoard并调用它的.mainloop()方法来启动您的 Tkinter 应用程序。继续将下面这段代码添加到您的
tic_tac_toe.py文件的末尾:# tic_tac_toe.py # ... def main(): """Create the game's board and run its main loop.""" board = TicTacToeBoard() board.mainloop() if __name__ == "__main__": main()这段代码为你的游戏定义了一个
main()函数。在这个函数中,首先实例化TicTacToeBoard,然后通过调用.mainloop()运行它的主循环。
if __name__ == "__main__":结构是 Python 应用程序中的常见模式。它允许您控制代码的执行。在这种情况下,只有将.py文件作为可执行程序运行,而不是作为可导入模块运行,才会调用main()。就是这样!你现在可以第一次运行你的游戏了。当然,游戏还不能玩,但是棋盘已经准备好了。要运行游戏,请在命令行上执行以下命令:
$ python tic_tac_toe.py一旦您运行了这个命令,您将在屏幕上看到以下窗口:
酷!你的井字游戏开始看起来像真的了。现在你需要让这个窗口响应玩家在棋盘上的动作。
第二步:在 Python 中设置井字游戏逻辑
至此,您已经使用 Tkinter 构建了一个合适的井字游戏棋盘。现在你需要考虑如何处理游戏的逻辑。该逻辑将由处理玩家移动并确定该玩家是否赢得游戏的代码组成。
在实现井字游戏的逻辑时,有几个想法是关键。首先,你需要一个有效的代表玩家和他们的移动。你还需要一个更高级别的类来代表游戏本身。在本节中,您将为这三个逻辑概念定义类。
您可以通过单击下面的链接并导航到
source_code_step_2/文件夹来下载此步骤的源代码:获取源代码: 单击此处获取您将用来构建井字游戏的源代码。
为玩家和他们的动作定义职业
在第一轮中,您将定义类来表示游戏板上的玩家和他们的移动。这些课程将非常简单。他们所需要的只是各自的一些属性。他们甚至不需要有什么方法。
您可以使用一些工具来构建满足这些需求的类。例如,您可以使用一个名为 tuple 的数据类或。在本教程中,您将为这两个类使用一个命名元组,因为这种类提供了您所需要的一切。
不是使用来自
collections模块的经典namedtuple,而是使用来自typing的NamedTuple类,作为在类中提供初始类型提示信息的一种方式。回到代码编辑器,在
tic_tac_toe.py文件的开头添加以下代码:1# tic_tac_toe.py 2 3import tkinter as tk 4from tkinter import font 5from typing import NamedTuple 6 7class Player(NamedTuple): 8 label: str 9 color: str 10 11class Move(NamedTuple): 12 row: int 13 col: int 14 label: str = "" 15 16# ...下面是这段代码的分解:
五号线从
typing进口NamedTuple。第 7 到 9 行定义了
Player类。.label属性将存储经典玩家标志, X 和 O 。.color属性将保存一个带有 Tkinter 颜色的字符串。您将使用这种颜色来识别游戏板上的目标玩家。第 11 到 14 行定义了
Move类。.row和.col属性将保存标识移动目标单元格的坐标。.label属性将持有标识玩家的符号, X 或 O 。注意,.label默认为空弦,"",表示这个具体的招式还没有打出。有了这两个类,现在可以定义用来表示游戏逻辑的类了。
创建一个类来表示游戏逻辑
在本节中,您将定义一个类来管理游戏的逻辑。这个类将负责处理移动,寻找赢家,切换玩家,并执行一些其他任务。回到您的
tic_tac_toe.py文件,在您的TicTacToeBoard类之前添加下面的类:# tic_tac_toe.py import tkinter as tk from itertools import cycle from tkinter import font # ... class TicTacToeGame: def __init__(self, players=DEFAULT_PLAYERS, board_size=BOARD_SIZE): self._players = cycle(players) self.board_size = board_size self.current_player = next(self._players) self.winner_combo = [] self._current_moves = [] self._has_winner = False self._winning_combos = [] self._setup_board() class TicTacToeBoard(tk.Tk): # ...这里,你先从
itertools模块中导入cycle()。然后定义TicTacToeGame,它的初始化器有两个参数,players和board_size。players参数将保存两个Player对象的元组,代表玩家 X 和 O 。这个参数默认为DEFAULT_PLAYERS,一个您稍后将定义的常量。
board_size参数将保存一个代表游戏棋盘大小的数字。在经典的井字游戏中,这个大小应该是3。在您的类中,参数默认为BOARD_SIZE,这是您很快将定义的另一个常数。在
.__init__()中,您定义了以下实例属性:
属性 描述 ._playersplayers的输入元组上的循环迭代器.board_size电路板尺寸 .current_player当前玩家 .winner_combo定义赢家的单元格组合 ._current_moves给定游戏中玩家的移动列表 ._has_winner一个用于确定游戏是否有赢家的布尔变量 ._winning_combos包含定义获胜的单元格组合的列表 属性从
itertools模块中调用cycle()。该函数将 iterable 作为参数,并返回一个迭代器,该迭代器从输入 iterable 中循环产生项目。在这种情况下,cycle()的参数是通过players参数传入的默认玩家元组。在学习本教程的过程中,您将了解上表中所有属性的更多信息。关于
.__init__()中的最后一行,它调用._setup_board(),这是一个方法,稍后您也将定义它。现在继续在
Move类下面定义以下常量:# tic_tac_toe.py # ... class Move(NamedTuple): # ... BOARD_SIZE = 3 DEFAULT_PLAYERS = ( Player(label="X", color="blue"), Player(label="O", color="green"), ) class TicTacToeGame: # ...正如您已经了解到的,
BOARD_SIZE掌握着井字游戏棋盘的大小。通常这个尺寸是3。所以,你会在黑板上看到一个 3x 3 的格子。另一方面,
DEFAULT_PLAYERS定义了一个两项元组。每个物品代表游戏中的一个玩家。每个玩家的.label和.color属性被设置为合适的值。玩家 X 会是蓝色,玩家 O 会是绿色。设置抽象游戏板
管理游戏每时每刻的状态是游戏逻辑中的一个基本步骤。你需要跟踪棋盘上的每个动作。为此,您将使用
._current_moves属性,每当玩家移动时,您将更新该属性。您还需要确定棋盘上的哪些单元格组合决定了胜局。您将把这些组合存储在
._winning_combos属性中。下面是
._setup_board()方法,它计算._current_moves和._winning_combos的初始值:# tic_tac_toe.py # ... class TicTacToeGame: # ... def _setup_board(self): self._current_moves = [ [Move(row, col) for col in range(self.board_size)] for row in range(self.board_size) ] self._winning_combos = self._get_winning_combos()在
._setup_board()中,您使用一个列表理解来为._current_moves提供一个初始的值列表。理解创建了一个列表列表。每个内部列表将包含空的Move对象。空移动存储其包含单元格的坐标和一个空字符串作为初始玩家的标签。这个方法的最后一行调用
._get_winning_combos(),并将其返回值赋给._winning_combos。您将在下一节中实现这个新方法。找出获胜的组合
在经典的井字游戏棋盘上,你会有八种可能的获胜组合。它们本质上是棋盘的行、列和对角线。下图显示了这些获奖组合:
如何使用 Python 代码获得所有这些组合的坐标?有几种方法可以做这件事。在下面的代码中,您将使用四种列表理解来获得所有可能的获胜组合:
# tic_tac_toe.py # ... class TicTacToeGame: # ... def _get_winning_combos(self): rows = [ [(move.row, move.col) for move in row] for row in self._current_moves ] columns = [list(col) for col in zip(*rows)] first_diagonal = [row[i] for i, row in enumerate(rows)] second_diagonal = [col[j] for j, col in enumerate(reversed(columns))] return rows + columns + [first_diagonal, second_diagonal]这个方法的主要输入是
._current_moves属性。默认情况下,该属性将保存一个包含三个子列表的列表。每个子列表代表网格上的一行,其中有三个Move对象。第一种理解是遍历网格上的行,获得每个单元格的坐标,并构建一个坐标子列表。每个坐标子列表代表一个获胜的组合。第二种理解是创建包含网格列中每个单元格坐标的子列表。
第三和第四个理解使用类似的方法来获得棋盘对角线上每个单元格的坐标。最后,该方法返回包含井字游戏棋盘上所有可能获胜组合的列表列表。
有了游戏板的初始设置,您就可以开始考虑处理玩家的移动了。
第三步:根据游戏的逻辑处理玩家的行动
在这个井字游戏中,你将主要处理一种事件:玩家的移动。翻译成 Tkinter 术语,玩家的移动只是在选定的单元格上单击,它由一个按钮小部件表示。
玩家的每一个动作都会触发
TicTacToeGame类上的一堆操作。这些操作包括:
- 验证移动
- 寻找赢家
- 检查平局的比赛
- 切换玩家的下一步行动
在接下来的部分中,您将编写代码来处理您的
TicTacToeGame类中的所有这些操作。要从 GitHub 下载该步骤的源代码,请单击下面的链接并导航到
source_code_step_3/文件夹:获取源代码: 单击此处获取您将用来构建井字游戏的源代码。
验证玩家的移动
每次玩家点击井字游戏棋盘上的给定单元格时,您都需要验证该移动。问题是:如何定义有效的移动?好吧,至少有两个条件能让这一招有效。玩家只能在以下情况下玩游戏:
- 这个游戏没有赢家。
- 所选的棋还没有下过。
继续将以下方法添加到
TicTacToeGame的末尾:1# tic_tac_toe.py 2# ... 3 4class TicTacToeGame: 5 # ... 6 7 def is_valid_move(self, move): 8 """Return True if move is valid, and False otherwise.""" 9 row, col = move.row, move.col 10 move_was_not_played = self._current_moves[row][col].label == "" 11 no_winner = not self._has_winner 12 return no_winner and move_was_not_played
.is_valid_move()方法接受一个Move对象作为参数。下面是该方法的其余部分:
第 9 行从输入的
move中获取.row和.col坐标。第 10 行检查当前坐标
[row][col]处的移动是否仍保留一个空字符串作为其标签。如果之前没有玩家输入过move,则该条件为True。第 11 行检查游戏是否还没有赢家。
该方法返回一个布尔值,该值是通过检查游戏是否没有赢家以及当前棋步是否还没有下完而得到的。
处理玩家的移动以找到赢家
现在是时候让你决定一个玩家在最后一步棋后是否赢得了游戏。作为游戏设计师,这可能是你最关心的问题。当然,你会有许多不同的方法来找出一个给定的玩家是否赢得了游戏。
在这个项目中,您将使用以下想法来确定获胜者:
- 游戏板上的每个单元格都有一个关联的
Move对象。- 每一个
Move对象都有一个.label属性,用于识别进行移动的玩家。为了找出最后一个玩家是否赢得了游戏,您将检查该玩家的标签是否出现在给定获胜组合中包含的所有可能的移动中。
继续将以下方法添加到您的
TicTacToeGame类中:1# tic_tac_toe.py 2# ... 3 4class TicTacToeGame: 5 # ... 6 7 def process_move(self, move): 8 """Process the current move and check if it's a win.""" 9 row, col = move.row, move.col 10 self._current_moves[row][col] = move 11 for combo in self._winning_combos: 12 results = set( 13 self._current_moves[n][m].label 14 for n, m in combo 15 ) 16 is_win = (len(results) == 1) and ("" not in results) 17 if is_win: 18 self._has_winner = True 19 self.winner_combo = combo 20 break下面是这种新方法的逐行分解:
第 7 行定义了
process_move(),它以一个Move对象作为参数。第 9 行从输入的
move中获取.row和.col坐标。第 10 行将输入
move分配给当前移动列表中[row][col]处的项目。第 11 行开始在获胜的组合上循环。
第 12 行到第 15 行运行一个生成器表达式,从当前获胜组合的移动中检索所有标签。然后结果被转换成一个
set对象。第 16 行定义了一个布尔表达式,检查当前的移动是否决定了胜利。结果存储在
is_win中。第 17 行检查
is_win的内容。如果变量保持True,那么._has_winner被设置为True并且.winner_combo被设置为当前组合。然后循环中断,功能终止。在第 12 至 16 行,有几点和想法需要澄清。为了更好地理解第 12 行到第 15 行,假设与当前获胜组合的单元格相关联的移动中的所有标签都持有一个 X 。在这种情况下,生成器表达式将产生三个 X 标签。
当你用几个 X 的实例来填充内置的
set()函数时,你会得到一个只有一个 X 实例的集合。集合不允许重复值。所以,如果
results中的集合包含一个不同于空字符串的值,那么你就有一个赢家。在这个例子中,获胜者将是带有 X 标签的玩家。第 16 行检查这两个条件。为了总结寻找井字游戏赢家的主题,继续在您的
TicTacToeGame类的末尾添加以下方法:# tic_tac_toe.py # ... class TicTacToeGame: # ... def has_winner(self): """Return True if the game has a winner, and False otherwise.""" return self._has_winner每当您需要检查当前匹配是否有赢家时,该方法返回存储在
._has_winner中的布尔值。在本教程的后面,您将使用这个方法。检查平局游戏
在井字游戏中,如果玩家在所有单元格上玩,但没有赢家,那么游戏就平手了。因此,在宣布比赛平局之前,您需要检查两个条件:
- 所有可能的方法都用过了。
- 这场比赛没有赢家。
继续在
TicTacToeGame的末尾添加以下方法来检查这些条件:# tic_tac_toe.py # ... class TicTacToeGame: # ... def is_tied(self): """Return True if the game is tied, and False otherwise.""" no_winner = not self._has_winner played_moves = ( move.label for row in self._current_moves for move in row ) return no_winner and all(played_moves)在
.is_tied()里面,你首先检查游戏是否还没有赢家。然后你用内置的all()函数检查._current_moves中的所有招式是否都有不同于空串的标号。如果是这样,那么所有可能的单元格都已经打过了。如果两个条件都为真,那么比赛就平手了。在回合之间切换玩家
每当一个玩家进行有效的移动时,您需要切换当前玩家,以便另一个玩家可以进行下一步移动。为了提供这个功能,继续将下面的方法添加到您的
TicTacToeGame类中:# tic_tac_toe.py # ... class TicTacToeGame: # ... def toggle_player(self): """Return a toggled player.""" self.current_player = next(self._players)因为
._players拥有一个迭代器,循环遍历两个默认玩家,所以只要需要,就可以在这个迭代器上调用next()来获取下一个玩家。这种切换机制将允许下一个玩家轮到他们并继续游戏。步骤 4:处理玩家在游戏棋盘上的移动
在这一点上,你能够在游戏逻辑上处理玩家的移动。现在你要把这个逻辑和游戏板本身联系起来。您还需要编写代码来使棋盘对玩家的移动做出响应。
首先,继续将游戏逻辑注入游戏板。为此,如下面的代码所示更新
TicTacToeBoard类:# tic_tac_toe.py # ... class TicTacToeGame: # ... class TicTacToeBoard(tk.Tk): def __init__(self, game): super().__init__() self.title("Tic-Tac-Toe Game") self._cells = {} self._game = game self._create_board_display() self._create_board_grid() # ... def _create_board_grid(self): grid_frame = tk.Frame(master=self) grid_frame.pack() for row in range(self._game.board_size): self.rowconfigure(row, weight=1, minsize=50) self.columnconfigure(row, weight=1, minsize=75) for col in range(self._game.board_size): # ...在这个代码片段中,首先向
TicTacToeBoard初始化器添加一个game参数。然后将这个参数分配给一个实例属性._game,这将使您能够从游戏面板上完全访问游戏逻辑。第二个更新是使用
._game.board_size来设置电路板尺寸,而不是使用一个幻数。此更新还使您能够使用不同的电路板尺寸。例如,您可以创建一个四乘四的棋盘网格,这可能是一种令人兴奋的体验。有了这些更新,你就可以在
TicTacToeBoard职业中处理玩家的移动了。通常,您可以通过单击下面的链接并导航到
source_code_step_4/文件夹来下载该步骤的源代码:获取源代码: 单击此处获取您将用来构建井字游戏的源代码。
处理玩家的移动事件
Tk类上的.mainloop()方法运行所谓的应用程序的主循环或事件循环。这是一个无限循环,所有 GUI 事件都在其中发生。在这个循环中,您可以处理应用程序用户界面上的事件。事件是 GUI 上的用户操作,如按键、鼠标移动或鼠标单击。当井字游戏中的玩家单击单元格时,游戏的事件循环中会发生一个单击事件。您可以通过在您的
TicTacToeBoard类上提供一个适当的处理方法来处理这个事件。为此,请回到代码编辑器,在类的末尾添加下面的.play()方法:1# tic_tac_toe.py 2# ... 3 4class TicTacToeBoard(tk.Tk): 5 # ... 6 7 def play(self, event): 8 """Handle a player's move.""" 9 clicked_btn = event.widget 10 row, col = self._cells[clicked_btn] 11 move = Move(row, col, self._game.current_player.label) 12 if self._game.is_valid_move(move): 13 self._update_button(clicked_btn) 14 self._game.process_move(move) 15 if self._game.is_tied(): 16 self._update_display(msg="Tied game!", color="red") 17 elif self._game.has_winner(): 18 self._highlight_cells() 19 msg = f'Player "{self._game.current_player.label}" won!' 20 color = self._game.current_player.color 21 self._update_display(msg, color) 22 else: 23 self._game.toggle_player() 24 msg = f"{self._game.current_player.label}'s turn" 25 self._update_display(msg)这种方法是井字游戏的基础,因为它将几乎所有的游戏逻辑和 GUI 行为放在了一起。下面是这种方法的一个总结:
第 7 行定义了
play(),它以一个 Tkinter 事件对象作为参数。第 9 行检索触发当前事件的小部件。这个小部件将是棋盘网格上的一个按钮。
第 10 行将按钮的坐标解包成两个局部变量
row和col。第 11 行使用
row、col和当前玩家的.label属性作为参数创建一个新的Move对象。第 12 行开始一个条件语句,检查玩家的移动是否有效。如果移动有效,那么运行
if代码块。否则,不会发生进一步的动作。第 13 行通过调用
._update_button()方法更新被点击的按钮。您将在下一节的中编写这个方法。简而言之,该方法更新按钮的文本以反映当前播放器的标签和颜色。第 14 行使用当前移动作为参数调用
._game对象上的.process_move()。第 15 行检查比赛是否平局。如果是这种情况,那么游戏显示会相应地更新。
第 17 行检查当前玩家是否已经赢得游戏。然后第 18 行突出显示获胜的单元格,第 19 到 21 行更新游戏显示以确认获胜者。
如果比赛不分胜负,没有赢家,第 22 行就会运行。在这种情况下,第 23 到 25 行切换玩家的下一步棋,并更新显示以指出下一个将玩的玩家。
你就快到了!通过一些更新和添加,您的井字游戏将为其首次比赛做好准备。
下一步是将游戏板上的每个按钮连接到
.play()方法。为此,返回到._create_board_grid()方法并更新它,如下面的代码所示:# tic_tac_toe.py # ... class TicTacToeBoard(tk.Tk): # ... def _create_board_grid(self): grid_frame = tk.Frame(master=self) grid_frame.pack() for row in range(self._game.board_size): self.rowconfigure(row, weight=1, minsize=50) self.columnconfigure(row, weight=1, minsize=75) for col in range(self._game.board_size): # ... self._cells[button] = (row, col) button.bind("<ButtonPress-1>", self.play) # ...高亮显示的行用
.play()方法绑定游戏板上每个按钮的点击事件。这样,每当玩家单击一个给定的按钮时,该方法将运行以处理移动并更新游戏状态。更新游戏板以反映游戏状态
要完成处理游戏板上玩家移动的代码,您需要编写三个助手方法。这些方法将完成以下操作:
- 更新单击的按钮
- 更新游戏显示
- 突出显示获奖单元格
要开始,继续将
._update_button()添加到TicTacToeBoard:# tic_tac_toe.py # ... class TicTacToeBoard(tk.Tk): # ... def _update_button(self, clicked_btn): clicked_btn.config(text=self._game.current_player.label) clicked_btn.config(fg=self._game.current_player.color)在这段代码中,
._update_button()在被点击的按钮上调用.config(),将其.text属性设置为当前玩家的标签。该方法还将文本前景色fg设置为当前玩家的颜色。下一个要添加的助手方法是
._update_display():# tic_tac_toe.py # ... class TicTacToeBoard(tk.Tk): # ... def _update_display(self, msg, color="black"): self.display["text"] = msg self.display["fg"] = color在这个方法中,不是使用
.config()来调整游戏显示的文本和颜色,而是使用字典风格的下标符号。使用这种类型的符号是 Tkinter 为访问小部件的属性提供的另一个选项。最后,您需要一个助手方法,以便在给定玩家做出获胜的一步时突出显示获胜的单元格:
# tic_tac_toe.py # ... class TicTacToeBoard(tk.Tk): # ... def _highlight_cells(self): for button, coordinates in self._cells.items(): if coordinates in self._game.winner_combo: button.config(highlightbackground="red")
._highlight_cells()中的循环遍历._cells字典中的条目。该字典将按钮映射到它们在棋盘网格上的行和列坐标。如果当前坐标在一个获胜的单元格组合中,那么按钮的背景色设置为"red",突出显示棋盘上的单元格组合。有了这最后一个辅助方法,您的井字游戏就可以开始第一场比赛了!
第一次玩井字游戏
要完成井字游戏的逻辑和用户界面的整合,您需要更新游戏的
main()功能。到目前为止,您只有一个TicTacToeBoard对象。您需要创建一个TicTacToeGame对象,并将其传递给TicTacToeBoard更新的构造函数。回到
main()并更新它,如下面的代码所示:# tic_tac_toe.py # ... def main(): """Create the game's board and run its main loop.""" game = TicTacToeGame() board = TicTacToeBoard(game) board.mainloop()在这段代码中,第一个突出显示的行创建了一个
TicTacToeGame的实例,您将使用它来处理游戏逻辑。第二行突出显示的代码将新实例传递给TicTacToeBoard类构造函数,后者将游戏逻辑注入游戏板。有了这些更新,你现在可以运行你的游戏了。为此,启动一个终端窗口并导航到包含您的
tic_tac_toe.py文件的目录。然后运行以下命令:$ python tic_tac_toe.py一旦这个命令运行,你游戏的主窗口就会出现在你的屏幕上。来吧,试一试!它会有这样的行为:
https://player.vimeo.com/video/717495498?background=1
哇!你的游戏项目到目前为止看起来很惊艳!它允许两个玩家共享他们的鼠标,玩经典的井字游戏。游戏的图形用户界面看起来不错,总的来说,游戏运行正常。
在接下来的部分中,您将编写代码来允许玩家重新启动游戏并再次游戏。你还可以选择退出游戏。
第五步:提供重新游戏的选项并退出游戏
在本节中,您将为井字游戏提供一个主菜单。这个菜单将有一个重新开始游戏的选项,这样玩家可以开始另一场比赛。一旦玩家结束游戏,它还会有一个退出游戏的选项。
主菜单通常是许多 GUI 应用程序的基本组件。因此,学习如何在 Tkinter 中创建它们是一个很好的练习,可以提高你在游戏开发本身之外的 GUI 相关技能。
这是一个例子,说明构建自己的游戏是一种强大的学习体验,因为它允许您整合知识和技能,以便以后在其他非游戏项目中使用。
这一步的完整源代码可以下载。只需点击下面的链接并导航至
source_code_step_5/文件夹:获取源代码: 单击此处获取您将用来构建井字游戏的源代码。
构建游戏的主菜单
要向 Tkinter 应用程序添加主菜单,可以使用
tkinter.Menu类。这个类允许你在你的 Tkinter 窗口上创建一个菜单栏。它还允许您在菜单栏中添加下拉菜单。下面是创建主菜单并将其添加到井字游戏中的代码:
1# tic_tac_toe.py 2# ... 3 4class TicTacToeBoard(tk.Tk): 5 def __init__(self, game): 6 # ... 7 8 def _create_menu(self): 9 menu_bar = tk.Menu(master=self) 10 self.config(menu=menu_bar) 11 file_menu = tk.Menu(master=menu_bar) 12 file_menu.add_command( 13 label="Play Again", 14 command=self.reset_board 15 ) 16 file_menu.add_separator() 17 file_menu.add_command(label="Exit", command=quit) 18 menu_bar.add_cascade(label="File", menu=file_menu)下面是这段代码逐行执行的操作:
第 8 行定义了一个名为
._create_menu()的助手方法来处理单个位置的菜单创建。第 9 行创建一个
Menu的实例,它将作为菜单栏工作。Line 10 将菜单栏对象设置为当前 Tkinter 窗口的主菜单。
第 11 行创建了
Menu的另一个实例来提供一个文件菜单。注意,类构造函数中的master参数被设置为菜单栏对象。第 12 到 15 行使用
.add_command()方法向文件菜单添加一个新的菜单选项。这个新选项将有标签"Play Again"。当用户点击这个选项时,应用程序将运行您通过command参数提供的.reset_board()方法。您将在下一节中编写这个方法。第 16 行使用
.add_separator()方法添加一个菜单分隔符。当您需要在给定的下拉菜单中分隔相关命令组时,分隔符非常有用。第 17 行向文件菜单添加一个退出命令。该命令将通过调用
quit()函数使游戏退出。第 18 行最后通过调用带有适当参数的
.add_cascade()将文件菜单添加到菜单栏。要将主菜单添加到游戏的主窗口中,您需要从
TicTacToeBoard的初始化器中调用._create_menu()。因此,继续将下面一行添加到该类的.__init__()方法中:# tic_tac_toe.py # ... class TicTacToeBoard(tk.Tk): def __init__(self, game): super().__init__() self.title("Tic-Tac-Toe Game") self._cells = {} self._game = game self._create_menu() self._create_board_display() self._create_board_grid() # ...随着这个最后的更新,你的游戏的主菜单几乎可以使用了。但是,在使用它之前,您必须实现
.reset_board()方法。这就是你在接下来的部分要做的,为了让玩家可以再次玩。执行再次播放选项
要重置游戏板并允许玩家再次游戏,您需要向两个类添加代码,
TicTacToeGame和TicTacToeBoard。在游戏逻辑类中,您需要重置
._current_moves属性来保存最初为空的Move对象列表。您还需要将._has_winner和.winner_combo复位到它们的初始状态。另一方面,在游戏棋盘类中,您需要将棋盘显示和单元格重置为初始状态。回到代码编辑器中的
TicTacToeGame,在类的末尾添加下面的方法:# tic_tac_toe.py # ... class TicTacToeGame(tk.Tk): # ... def reset_game(self): """Reset the game state to play again.""" for row, row_content in enumerate(self._current_moves): for col, _ in enumerate(row_content): row_content[col] = Move(row, col) self._has_winner = False self.winner_combo = []
.reset_game()中的for循环将所有当前移动设置为一个空的Move对象。空移动的主要特征是它的.label属性保存空字符串""。在更新当前移动之后,这些方法将
._has_winner设置为False并将.winner_combo设置为空列表。这三个重置确保游戏的抽象表示准备好开始新的比赛。请注意,在为新的比赛准备游戏时,
reset_game()不会将玩家重置回 X 。通常情况下,上一场比赛的获胜者会在下一场比赛中第一个出场。所以,这里不需要重置播放器。一旦在游戏逻辑中提供了所需的新功能,就可以更新游戏板的功能了。继续将以下方法添加到
TicTacToeBoard的末尾:1# tic_tac_toe.py 2# ... 3 4class TicTacToeBoard(tk.Tk): 5 # ... 6 7 def reset_board(self): 8 """Reset the game's board to play again.""" 9 self._game.reset_game() 10 self._update_display(msg="Ready?") 11 for button in self._cells.keys(): 12 button.config(highlightbackground="lightblue") 13 button.config(text="") 14 button.config(fg="black")该
.reset_board()方法的工作原理如下:
第 9 行调用
.reset_game()来重置棋盘的抽象表示。第 10 行更新板显示以保存初始文本
"Ready?"。第 11 行在棋盘格子上的按钮上开始一个循环。
第 12 到 14 行将每个按钮的
highlightbackground、text、fg属性恢复到初始状态。就是这样!有了这最后一个功能,您的井字游戏项目就完成了。来吧,试一试!
结论
在这个循序渐进的项目中,您已经使用 Python 和 Tkinter 创建了一个经典的井字游戏。Python 标准库中提供了这个 GUI 框架。它可以在 Windows、Linux 和 macOS 上运行,所以你的游戏在这三个平台上都可以很好地运行。那很酷!
在本教程中,您学习了如何:
- 使用 Python 实现经典井字游戏的逻辑
- 使用 Python 标准库中的 Tkinter 构建游戏的棋盘或 GUI
- 连接游戏的逻辑和 GUI,使游戏正常运行
这些知识为您创建新的更复杂的游戏和 GUI 项目提供了基础,这将帮助您将 Python 技能提升到一个新的水平。
接下来的步骤
您在本教程中实现的井字游戏相当简单。然而,你可以用几种不同的有趣的方式来扩展它。让这个游戏项目更上一层楼的一些想法包括允许你的用户:
- 使用不同尺寸的游戏板
- 与电脑对战
你还能想出什么其他的主意来扩展这个项目?要有创意,要有乐趣!
现在你已经完成了这个项目,这里有一些额外的好项目可以继续用 Python 构建你自己的游戏:
制作你的第一个 Python 游戏:石头、剪刀、布!:在本教程中,你将从头开始学习用 Python 编程石头剪刀布。您将学习如何接受用户输入,让计算机选择一个随机动作,确定获胜者,以及将您的代码拆分成多个函数。
PyGame:Python 游戏编程入门:在这个循序渐进的教程中,你将学习如何使用 py Game。这个库允许你用 Python 创建游戏和丰富的多媒体程序。您将学习如何在屏幕上绘制项目,实现碰撞检测,处理用户输入,等等!
用 Python 和 Pygame 构建一个小行星游戏:这篇文章将向你展示如何在 PyGame 中创建一个游戏!
Arcade:Python 游戏框架入门:这篇文章是一个很好的后续,因为它向您展示了另一个 Python 游戏框架,允许您创建更复杂的游戏。
用街机在 Python 中构建平台游戏:在这个循序渐进的教程中,你将使用街机库在 Python 中构建一个平台游戏。您将学习设计关卡、获取资源和实现高级功能的技术。
用 Python 中的 AI 玩家构建井字游戏引擎:在这个循序渐进的教程中,你将使用井字游戏规则和两个计算机玩家构建一个 Python 通用游戏引擎,包括一个使用 minimax 算法的无敌 AI 玩家。*********
使用 Flask 的基于令牌的认证
原文:https://realpython.com/token-based-authentication-with-flask/
本教程采用测试优先的方法,使用 JSON Web 令牌(jwt)在 Flask 应用程序中实现基于令牌的认证。
更新:
- 08/04/2017 :为 PyBites 挑战赛重构路线处理程序。
目标
本教程结束时,您将能够…
- 讨论使用 jwt 与会话和 cookies 进行身份验证的优势
- 用 JWTs 实现用户认证
- 必要时将用户令牌列入黑名单
- 编写测试来创建和验证 jwt 和用户认证
- 实践测试驱动的开发
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
简介
JSON Web 令牌(或 JWTs)提供了一种从客户端向服务器传输信息的方式,这是一种安全的无状态的方式。
在服务器上,jwt 是通过使用秘密密钥对用户信息进行签名而生成的,然后安全地存储在客户机上。这种形式的身份验证与现代的单页面应用程序配合得很好。有关这方面的更多信息,以及使用 JWTs 与会话和基于 cookie 的身份验证的优缺点,请查看以下文章:
- 饼干 vs 代币:权威指南
- 令牌认证与 cookie
- 在 Flask 中会话是如何工作的?
注意:请记住,由于 JWT 是由签名的,而不是加密的,它不应该包含像用户密码这样的敏感信息。
开始使用
理论够了,开始实现一些代码吧!
项目设置
首先克隆项目样板文件,然后创建一个新的分支:
$ git clone https://github.com/realpython/flask-jwt-auth.git $ cd flask-jwt-auth $ git checkout tags/1.0.0 -b jwt-auth创建并激活 virtualenv 并安装依赖项:
$ python3.6 -m venv env $ source env/bin/activate (env)$ pip install -r requirements.txt这是可选的,但是创建一个新的 Github 存储库并更新 remote 是个好主意:
(env)$ git remote set-url origin <newurl>数据库设置
让我们设置 Postgres。
注意:如果你在苹果电脑上,看看的 Postgres 应用。
一旦本地 Postgres 服务器运行,从
psql创建两个新的数据库,它们与您的项目名称同名:(env)$ psql # create database flask_jwt_auth; CREATE DATABASE # create database flask_jwt_auth_test; CREATE DATABASE # \q注意:根据您的 Postgres 版本,上述创建数据库的命令可能会有一些变化。检查 Postgres 文档中的正确命令。
在应用数据库迁移之前,我们需要更新位于 project/server/config.py 中的配置文件。简单更新一下
database_name:database_name = 'flask_jwt_auth'在终端中设置环境变量:
(env)$ export APP_SETTINGS="project.server.config.DevelopmentConfig"更新project/tests/test _ _ config . py中的以下测试:
class TestDevelopmentConfig(TestCase): def create_app(self): app.config.from_object('project.server.config.DevelopmentConfig') return app def test_app_is_development(self): self.assertTrue(app.config['DEBUG'] is True) self.assertFalse(current_app is None) self.assertTrue( app.config['SQLALCHEMY_DATABASE_URI'] == 'postgresql://postgres:@localhost/flask_jwt_auth' ) class TestTestingConfig(TestCase): def create_app(self): app.config.from_object('project.server.config.TestingConfig') return app def test_app_is_testing(self): self.assertTrue(app.config['DEBUG']) self.assertTrue( app.config['SQLALCHEMY_DATABASE_URI'] == 'postgresql://postgres:@localhost/flask_jwt_auth_test' )运行它们以确保它们仍然通过:
(env)$ python manage.py test您应该看到:
test_app_is_development (test__config.TestDevelopmentConfig) ... ok test_app_is_production (test__config.TestProductionConfig) ... ok test_app_is_testing (test__config.TestTestingConfig) ... ok ---------------------------------------------------------------------- Ran 3 tests in 0.007s OK迁移
在“服务器”目录中添加一个 models.py 文件:
# project/server/models.py import datetime from project.server import app, db, bcrypt class User(db.Model): """ User Model for storing user related details """ __tablename__ = "users" id = db.Column(db.Integer, primary_key=True, autoincrement=True) email = db.Column(db.String(255), unique=True, nullable=False) password = db.Column(db.String(255), nullable=False) registered_on = db.Column(db.DateTime, nullable=False) admin = db.Column(db.Boolean, nullable=False, default=False) def __init__(self, email, password, admin=False): self.email = email self.password = bcrypt.generate_password_hash( password, app.config.get('BCRYPT_LOG_ROUNDS') ).decode() self.registered_on = datetime.datetime.now() self.admin = admin在上面的代码片段中,我们定义了一个基本的用户模型,它使用 Flask-Bcrypt 扩展来散列密码。
安装 psycopg2 连接到 Postgres:
(env)$ pip install psycopg2==2.6.2 (env)$ pip freeze > requirements.txt在 manage.py 内更改-
from project.server import app, db到
from project.server import app, db, models应用迁移:
(env)$ python manage.py create_db (env)$ python manage.py db init (env)$ python manage.py db migrate健全性检查
成功了吗?
(env)$ psql # \c flask_jwt_auth You are now connected to database "flask_jwt_auth" as user "michael.herman". # \d List of relations Schema | Name | Type | Owner --------+-----------------+----------+---------- public | alembic_version | table | postgres public | users | table | postgres public | users_id_seq | sequence | postgres (3 rows)JWT 设置
身份验证工作流的工作方式如下:
- 客户端提供电子邮件和密码,发送给服务器
- 然后,服务器验证电子邮件和密码是否正确,并使用一个身份验证令牌进行响应
- 客户端存储令牌,并将其与所有后续请求一起发送给 API
- 服务器解码令牌并验证它
这个循环重复进行,直到令牌过期或被撤销。在后一种情况下,服务器会发出一个新的令牌。
令牌本身分为三个部分:
- 页眉
- 有效载荷
- 签名
我们将更深入地研究有效负载,但是如果您有兴趣,您可以从 JSON Web Tokens 的文章中阅读关于每个部分的更多内容。
要在我们的应用程序中使用 JSON Web 令牌,请安装 PyJWT 包:
(env)$ pip install pyjwt==1.4.2 (env)$ pip freeze > requirements.txt编码令牌
将下面的方法添加到项目/服务器/模型. py 中的
User()类中:def encode_auth_token(self, user_id): """ Generates the Auth Token :return: string """ try: payload = { 'exp': datetime.datetime.utcnow() + datetime.timedelta(days=0, seconds=5), 'iat': datetime.datetime.utcnow(), 'sub': user_id } return jwt.encode( payload, app.config.get('SECRET_KEY'), algorithm='HS256' ) except Exception as e: return e不要忘记添加导入:
import jwt因此,给定一个用户 id,这个方法从有效负载和在 config.py 文件中设置的密钥创建并返回一个令牌。负载是我们添加关于令牌的元数据和关于用户的信息的地方。这些信息通常被称为 JWT 声称的。我们利用以下“声明”:
exp:令牌到期日期iat:令牌生成的时间sub:令牌的主题(它标识的用户)秘密密钥必须是随机的,并且只能在服务器端访问。使用 Python 解释器生成密钥:


>>> import os
>>> os.urandom(24)
b"\xf9'\xe4p(\xa9\x12\x1a!\x94\x8d\x1c\x99l\xc7\xb7e\xc7c\x86\x02MJ\xa0"
将密钥设置为环境变量:
(env)$ export SECRET_KEY="\xf9'\xe4p(\xa9\x12\x1a!\x94\x8d\x1c\x99l\xc7\xb7e\xc7c\x86\x02MJ\xa0"
将此键添加到项目/服务器/配置文件中BaseConfig()类内的SECRET_KEY:
SECRET_KEY = os.getenv('SECRET_KEY', 'my_precious')
更新project/tests/test _ _ config . py中的测试,以确保变量设置正确:
def test_app_is_development(self):
self.assertFalse(app.config['SECRET_KEY'] is 'my_precious')
self.assertTrue(app.config['DEBUG'] is True)
self.assertFalse(current_app is None)
self.assertTrue(
app.config['SQLALCHEMY_DATABASE_URI'] == 'postgresql://postgres:@localhost/flask_jwt_auth'
)
class TestTestingConfig(TestCase):
def create_app(self):
app.config.from_object('project.server.config.TestingConfig')
return app
def test_app_is_testing(self):
self.assertFalse(app.config['SECRET_KEY'] is 'my_precious')
self.assertTrue(app.config['DEBUG'])
self.assertTrue(
app.config['SQLALCHEMY_DATABASE_URI'] == 'postgresql://postgres:@localhost/flask_jwt_auth_test'
)
在继续之前,让我们为用户模型编写一个快速的单元测试。将以下代码添加到“项目/测试”中名为 test_user_model.py 的新文件中:
# project/tests/test_user_model.py
import unittest
from project.server import db
from project.server.models import User
from project.tests.base import BaseTestCase
class TestUserModel(BaseTestCase):
def test_encode_auth_token(self):
user = User(
email='test@test.com',
password='test'
)
db.session.add(user)
db.session.commit()
auth_token = user.encode_auth_token(user.id)
self.assertTrue(isinstance(auth_token, bytes))
if __name__ == '__main__':
unittest.main()
进行测试。他们都应该通过。
解码令牌
类似地,要解码一个令牌,将下面的方法添加到User()类中:
@staticmethod
def decode_auth_token(auth_token):
"""
Decodes the auth token
:param auth_token:
:return: integer|string
"""
try:
payload = jwt.decode(auth_token, app.config.get('SECRET_KEY'))
return payload['sub']
except jwt.ExpiredSignatureError:
return 'Signature expired. Please log in again.'
except jwt.InvalidTokenError:
return 'Invalid token. Please log in again.'
我们需要对每个 API 请求的 auth 令牌进行解码,并验证其签名,以确保用户的真实性。为了验证auth_token,我们使用了与编码令牌相同的SECRET_KEY。
如果auth_token有效,我们从有效载荷的sub索引中获取用户 id。如果无效,可能有两种例外情况:
- 过期签名:当令牌过期后被使用时,它抛出一个
ExpiredSignatureError异常。这意味着有效载荷的exp字段中指定的时间已经过期。 - 无效令牌:当提供的令牌不正确或格式不正确时,就会引发一个
InvalidTokenError异常。
注意:我们使用了一个静态方法,因为它与类的实例无关。
向 test_user_model.py 添加一个测试:
def test_decode_auth_token(self):
user = User(
email='test@test.com',
password='test'
)
db.session.add(user)
db.session.commit()
auth_token = user.encode_auth_token(user.id)
self.assertTrue(isinstance(auth_token, bytes))
self.assertTrue(User.decode_auth_token(auth_token) == 1)
确保在继续之前通过测试。
注意:我们稍后将通过将无效令牌列入黑名单来处理它们。
路线设置
现在,我们可以使用测试优先的方法来配置授权路由:
/auth/register/auth/login/auth/logout/auth/user
首先在“项目/服务器”中创建一个名为“auth”的新文件夹。然后,在“auth”内添加两个文件, init。py 和视图。最后,将以下代码添加到 views.py :
# project/server/auth/views.py
from flask import Blueprint, request, make_response, jsonify
from flask.views import MethodView
from project.server import bcrypt, db
from project.server.models import User
auth_blueprint = Blueprint('auth', __name__)
要在应用程序中注册新的蓝图,请将以下内容添加到项目/服务器/init 的底部。py :
from project.server.auth.views import auth_blueprint
app.register_blueprint(auth_blueprint)
现在,在“project/tests”中添加一个名为 test_auth.py 的新文件来保存我们对这个蓝图的所有测试:
# project/tests/test_auth.py
import unittest
from project.server import db
from project.server.models import User
from project.tests.base import BaseTestCase
class TestAuthBlueprint(BaseTestCase):
pass
if __name__ == '__main__':
unittest.main()
注册路线
从一个测试开始:
def test_registration(self):
""" Test for user registration """
with self.client:
response = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'success')
self.assertTrue(data['message'] == 'Successfully registered.')
self.assertTrue(data['auth_token'])
self.assertTrue(response.content_type == 'application/json')
self.assertEqual(response.status_code, 201)
确保添加导入:
import json
进行测试。您应该会看到以下错误:
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
现在,让我们编写通过测试的代码。将以下内容添加到project/server/auth/views . py中:
class RegisterAPI(MethodView):
"""
User Registration Resource
"""
def post(self):
# get the post data
post_data = request.get_json()
# check if user already exists
user = User.query.filter_by(email=post_data.get('email')).first()
if not user:
try:
user = User(
email=post_data.get('email'),
password=post_data.get('password')
)
# insert the user
db.session.add(user)
db.session.commit()
# generate the auth token
auth_token = user.encode_auth_token(user.id)
responseObject = {
'status': 'success',
'message': 'Successfully registered.',
'auth_token': auth_token.decode()
}
return make_response(jsonify(responseObject)), 201
except Exception as e:
responseObject = {
'status': 'fail',
'message': 'Some error occurred. Please try again.'
}
return make_response(jsonify(responseObject)), 401
else:
responseObject = {
'status': 'fail',
'message': 'User already exists. Please Log in.',
}
return make_response(jsonify(responseObject)), 202
# define the API resources
registration_view = RegisterAPI.as_view('register_api')
# add Rules for API Endpoints
auth_blueprint.add_url_rule(
'/auth/register',
view_func=registration_view,
methods=['POST']
)
这里,我们注册了一个新用户,并为进一步的请求生成了一个新的 auth token,我们将它发送回客户端。
运行测试以确保它们全部通过:
Ran 6 tests in 0.132s
OK
接下来,让我们再添加一个测试,以确保在用户已经存在的情况下注册失败:
def test_registered_with_already_registered_user(self):
""" Test registration with already registered email"""
user = User(
email='joe@gmail.com',
password='test'
)
db.session.add(user)
db.session.commit()
with self.client:
response = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'fail')
self.assertTrue(
data['message'] == 'User already exists. Please Log in.')
self.assertTrue(response.content_type == 'application/json')
self.assertEqual(response.status_code, 202)
在进入下一条路线之前,再次进行测试。一切都会过去。
登录路线
再次,从一个测试开始。为了验证登录 API,让我们测试两种情况:
- 注册用户登录
- 非注册用户登录
注册用户登录
def test_registered_user_login(self):
""" Test for login of registered-user login """
with self.client:
# user registration
resp_register = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json',
)
data_register = json.loads(resp_register.data.decode())
self.assertTrue(data_register['status'] == 'success')
self.assertTrue(
data_register['message'] == 'Successfully registered.'
)
self.assertTrue(data_register['auth_token'])
self.assertTrue(resp_register.content_type == 'application/json')
self.assertEqual(resp_register.status_code, 201)
# registered user login
response = self.client.post(
'/auth/login',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'success')
self.assertTrue(data['message'] == 'Successfully logged in.')
self.assertTrue(data['auth_token'])
self.assertTrue(response.content_type == 'application/json')
self.assertEqual(response.status_code, 200)
在这个测试用例中,注册用户试图登录,正如所料,我们的应用程序应该允许这样做。
进行测试。他们应该失败。现在编写代码:
class LoginAPI(MethodView):
"""
User Login Resource
"""
def post(self):
# get the post data
post_data = request.get_json()
try:
# fetch the user data
user = User.query.filter_by(
email=post_data.get('email')
).first()
auth_token = user.encode_auth_token(user.id)
if auth_token:
responseObject = {
'status': 'success',
'message': 'Successfully logged in.',
'auth_token': auth_token.decode()
}
return make_response(jsonify(responseObject)), 200
except Exception as e:
print(e)
responseObject = {
'status': 'fail',
'message': 'Try again'
}
return make_response(jsonify(responseObject)), 500
不要忘记将类转换成视图函数:
# define the API resources
registration_view = RegisterAPI.as_view('register_api')
login_view = LoginAPI.as_view('login_api')
# add Rules for API Endpoints
auth_blueprint.add_url_rule(
'/auth/register',
view_func=registration_view,
methods=['POST']
)
auth_blueprint.add_url_rule(
'/auth/login',
view_func=login_view,
methods=['POST']
)
再次运行测试。他们通过了吗?他们应该。在所有测试通过之前,不要继续前进。
非注册用户登录
添加测试:
def test_non_registered_user_login(self):
""" Test for login of non-registered user """
with self.client:
response = self.client.post(
'/auth/login',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'fail')
self.assertTrue(data['message'] == 'User does not exist.')
self.assertTrue(response.content_type == 'application/json')
self.assertEqual(response.status_code, 404)
在这种情况下,一个未注册的用户试图登录,正如所料,我们的应用程序不应该允许这样做。
运行测试,然后更新代码:
class LoginAPI(MethodView):
"""
User Login Resource
"""
def post(self):
# get the post data
post_data = request.get_json()
try:
# fetch the user data
user = User.query.filter_by(
email=post_data.get('email')
).first()
if user and bcrypt.check_password_hash(
user.password, post_data.get('password')
):
auth_token = user.encode_auth_token(user.id)
if auth_token:
responseObject = {
'status': 'success',
'message': 'Successfully logged in.',
'auth_token': auth_token.decode()
}
return make_response(jsonify(responseObject)), 200
else:
responseObject = {
'status': 'fail',
'message': 'User does not exist.'
}
return make_response(jsonify(responseObject)), 404
except Exception as e:
print(e)
responseObject = {
'status': 'fail',
'message': 'Try again'
}
return make_response(jsonify(responseObject)), 500
我们改变了什么?测试通过了吗?邮件正确但密码不正确怎么办?会发生什么?为此写一个测试!
用户状态路线
为了获得当前登录用户的用户详细信息,auth 令牌必须与请求一起在报头中发送。
从一个测试开始:
def test_user_status(self):
""" Test for user status """
with self.client:
resp_register = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
response = self.client.get(
'/auth/status',
headers=dict(
Authorization='Bearer ' + json.loads(
resp_register.data.decode()
)['auth_token']
)
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'success')
self.assertTrue(data['data'] is not None)
self.assertTrue(data['data']['email'] == 'joe@gmail.com')
self.assertTrue(data['data']['admin'] is 'true' or 'false')
self.assertEqual(response.status_code, 200)
测试应该会失败。现在,在处理程序类中,我们应该:
- 提取身份验证令牌并检查其有效性
- 从有效负载中获取用户 id 并获得用户详细信息(当然,如果令牌有效的话)
class UserAPI(MethodView):
"""
User Resource
"""
def get(self):
# get the auth token
auth_header = request.headers.get('Authorization')
if auth_header:
auth_token = auth_header.split(" ")[1]
else:
auth_token = ''
if auth_token:
resp = User.decode_auth_token(auth_token)
if not isinstance(resp, str):
user = User.query.filter_by(id=resp).first()
responseObject = {
'status': 'success',
'data': {
'user_id': user.id,
'email': user.email,
'admin': user.admin,
'registered_on': user.registered_on
}
}
return make_response(jsonify(responseObject)), 200
responseObject = {
'status': 'fail',
'message': resp
}
return make_response(jsonify(responseObject)), 401
else:
responseObject = {
'status': 'fail',
'message': 'Provide a valid auth token.'
}
return make_response(jsonify(responseObject)), 401
因此,如果令牌有效且未过期,我们将从令牌的有效负载中获取用户 id,然后使用它从数据库中获取用户数据。
注意:我们仍然需要检查令牌是否被列入黑名单。我们很快就会谈到这一点。
确保添加:
user_view = UserAPI.as_view('user_api')
并且:
auth_blueprint.add_url_rule(
'/auth/status',
view_func=user_view,
methods=['GET']
)
测试应该通过:
Ran 10 tests in 0.240s
OK
还有一条路要走!
注销路由测试
测试有效注销:
def test_valid_logout(self):
""" Test for logout before token expires """
with self.client:
# user registration
resp_register = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json',
)
data_register = json.loads(resp_register.data.decode())
self.assertTrue(data_register['status'] == 'success')
self.assertTrue(
data_register['message'] == 'Successfully registered.')
self.assertTrue(data_register['auth_token'])
self.assertTrue(resp_register.content_type == 'application/json')
self.assertEqual(resp_register.status_code, 201)
# user login
resp_login = self.client.post(
'/auth/login',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data_login = json.loads(resp_login.data.decode())
self.assertTrue(data_login['status'] == 'success')
self.assertTrue(data_login['message'] == 'Successfully logged in.')
self.assertTrue(data_login['auth_token'])
self.assertTrue(resp_login.content_type == 'application/json')
self.assertEqual(resp_login.status_code, 200)
# valid token logout
response = self.client.post(
'/auth/logout',
headers=dict(
Authorization='Bearer ' + json.loads(
resp_login.data.decode()
)['auth_token']
)
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'success')
self.assertTrue(data['message'] == 'Successfully logged out.')
self.assertEqual(response.status_code, 200)
在第一个测试中,我们注册了一个新用户,让他们登录,然后尝试在令牌过期之前让他们注销。
测试无效注销:
def test_invalid_logout(self):
""" Testing logout after the token expires """
with self.client:
# user registration
resp_register = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json',
)
data_register = json.loads(resp_register.data.decode())
self.assertTrue(data_register['status'] == 'success')
self.assertTrue(
data_register['message'] == 'Successfully registered.')
self.assertTrue(data_register['auth_token'])
self.assertTrue(resp_register.content_type == 'application/json')
self.assertEqual(resp_register.status_code, 201)
# user login
resp_login = self.client.post(
'/auth/login',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data_login = json.loads(resp_login.data.decode())
self.assertTrue(data_login['status'] == 'success')
self.assertTrue(data_login['message'] == 'Successfully logged in.')
self.assertTrue(data_login['auth_token'])
self.assertTrue(resp_login.content_type == 'application/json')
self.assertEqual(resp_login.status_code, 200)
# invalid token logout
time.sleep(6)
response = self.client.post(
'/auth/logout',
headers=dict(
Authorization='Bearer ' + json.loads(
resp_login.data.decode()
)['auth_token']
)
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'fail')
self.assertTrue(
data['message'] == 'Signature expired. Please log in again.')
self.assertEqual(response.status_code, 401)
像上一个测试一样,我们注册一个用户,让他们登录,然后尝试让他们注销。在这种情况下,令牌无效,因为它已经过期。
添加导入:
import time
现在,代码必须:
- 验证身份验证令牌
- 将令牌列入黑名单(当然,如果有效的话)
在编写路由处理程序之前,让我们为黑名单令牌创建一个新模型…
黑名单
将以下代码添加到项目/服务器/模型. py 中:
class BlacklistToken(db.Model):
"""
Token Model for storing JWT tokens
"""
__tablename__ = 'blacklist_tokens'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
token = db.Column(db.String(500), unique=True, nullable=False)
blacklisted_on = db.Column(db.DateTime, nullable=False)
def __init__(self, token):
self.token = token
self.blacklisted_on = datetime.datetime.now()
def __repr__(self):
return '<id: token: {}'.format(self.token)
然后创建并应用迁移。完成后,您的数据库应该包含以下表格:
Schema | Name | Type | Owner --------+-------------------------+----------+----------
public | alembic_version | table | postgres public | blacklist_tokens | table | postgres public | blacklist_tokens_id_seq | sequence | postgres public | users | table | postgres public | users_id_seq | sequence | postgres (5 rows)
这样,我们可以添加注销处理程序…
注销路由处理程序
更新视图:
class LogoutAPI(MethodView):
"""
Logout Resource
"""
def post(self):
# get auth token
auth_header = request.headers.get('Authorization')
if auth_header:
auth_token = auth_header.split(" ")[1]
else:
auth_token = ''
if auth_token:
resp = User.decode_auth_token(auth_token)
if not isinstance(resp, str):
# mark the token as blacklisted
blacklist_token = BlacklistToken(token=auth_token)
try:
# insert the token
db.session.add(blacklist_token)
db.session.commit()
responseObject = {
'status': 'success',
'message': 'Successfully logged out.'
}
return make_response(jsonify(responseObject)), 200
except Exception as e:
responseObject = {
'status': 'fail',
'message': e
}
return make_response(jsonify(responseObject)), 200
else:
responseObject = {
'status': 'fail',
'message': resp
}
return make_response(jsonify(responseObject)), 401
else:
responseObject = {
'status': 'fail',
'message': 'Provide a valid auth token.'
}
return make_response(jsonify(responseObject)), 403
# define the API resources
registration_view = RegisterAPI.as_view('register_api')
login_view = LoginAPI.as_view('login_api')
user_view = UserAPI.as_view('user_api')
logout_view = LogoutAPI.as_view('logout_api')
# add Rules for API Endpoints
auth_blueprint.add_url_rule(
'/auth/register',
view_func=registration_view,
methods=['POST']
)
auth_blueprint.add_url_rule(
'/auth/login',
view_func=login_view,
methods=['POST']
)
auth_blueprint.add_url_rule(
'/auth/status',
view_func=user_view,
methods=['GET']
)
auth_blueprint.add_url_rule(
'/auth/logout',
view_func=logout_view,
methods=['POST']
)
更新导入:
from project.server.models import User, BlacklistToken
当用户注销时,令牌不再有效,因此我们将其添加到黑名单中。
注意:通常,较大的应用程序有办法不时更新列入黑名单的令牌,以便系统不会用完有效令牌。
运行测试:
Ran 12 tests in 6.418s
OK
重构
最后,我们需要确保令牌没有被列入黑名单,就在令牌被解码之后- decode_auth_token() -在注销和用户状态路由中。
首先,让我们为注销路由编写一个测试:
def test_valid_blacklisted_token_logout(self):
""" Test for logout after a valid token gets blacklisted """
with self.client:
# user registration
resp_register = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json',
)
data_register = json.loads(resp_register.data.decode())
self.assertTrue(data_register['status'] == 'success')
self.assertTrue(
data_register['message'] == 'Successfully registered.')
self.assertTrue(data_register['auth_token'])
self.assertTrue(resp_register.content_type == 'application/json')
self.assertEqual(resp_register.status_code, 201)
# user login
resp_login = self.client.post(
'/auth/login',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
data_login = json.loads(resp_login.data.decode())
self.assertTrue(data_login['status'] == 'success')
self.assertTrue(data_login['message'] == 'Successfully logged in.')
self.assertTrue(data_login['auth_token'])
self.assertTrue(resp_login.content_type == 'application/json')
self.assertEqual(resp_login.status_code, 200)
# blacklist a valid token
blacklist_token = BlacklistToken(
token=json.loads(resp_login.data.decode())['auth_token'])
db.session.add(blacklist_token)
db.session.commit()
# blacklisted valid token logout
response = self.client.post(
'/auth/logout',
headers=dict(
Authorization='Bearer ' + json.loads(
resp_login.data.decode()
)['auth_token']
)
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'fail')
self.assertTrue(data['message'] == 'Token blacklisted. Please log in again.')
self.assertEqual(response.status_code, 401)
在这个测试中,我们在注销路由命中之前将令牌列入黑名单,这使得我们的有效令牌不可用。
更新导入:
from project.server.models import User, BlacklistToken
测试应该会失败,并出现以下异常:
psycopg2.IntegrityError: duplicate key value violates unique constraint "blacklist_tokens_token_key"
DETAIL: Key (token)=(eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE0ODUyMDgyOTUsImlhdCI6MTQ4NTIwODI5MCwic3ViIjoxfQ.D9annoyh-VwpI5RY3blaSBX4pzK5UJi1H9dmKg2DeLQ) already exists.
现在更新decode_auth_token函数,以便在解码后立即处理已经列入黑名单的令牌,并使用适当的消息进行响应。
@staticmethod
def decode_auth_token(auth_token):
"""
Validates the auth token
:param auth_token:
:return: integer|string
"""
try:
payload = jwt.decode(auth_token, app.config.get('SECRET_KEY'))
is_blacklisted_token = BlacklistToken.check_blacklist(auth_token)
if is_blacklisted_token:
return 'Token blacklisted. Please log in again.'
else:
return payload['sub']
except jwt.ExpiredSignatureError:
return 'Signature expired. Please log in again.'
except jwt.InvalidTokenError:
return 'Invalid token. Please log in again.'
最后,将check_blacklist()函数添加到BlacklistToken类中的项目/服务器/模型. py 中:
@staticmethod
def check_blacklist(auth_token):
# check whether auth token has been blacklisted
res = BlacklistToken.query.filter_by(token=str(auth_token)).first()
if res:
return True
else:
return False
在运行测试之前,更新test_decode_auth_token将 bytes 对象转换成一个字符串:
def test_decode_auth_token(self):
user = User(
email='test@test.com',
password='test'
)
db.session.add(user)
db.session.commit()
auth_token = user.encode_auth_token(user.id)
self.assertTrue(isinstance(auth_token, bytes))
self.assertTrue(User.decode_auth_token(
auth_token.decode("utf-8") ) == 1)
运行测试:
Ran 13 tests in 9.557s
OK
以类似的方式,为用户状态路由再添加一个测试。
def test_valid_blacklisted_token_user(self):
""" Test for user status with a blacklisted valid token """
with self.client:
resp_register = self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json'
)
# blacklist a valid token
blacklist_token = BlacklistToken(
token=json.loads(resp_register.data.decode())['auth_token'])
db.session.add(blacklist_token)
db.session.commit()
response = self.client.get(
'/auth/status',
headers=dict(
Authorization='Bearer ' + json.loads(
resp_register.data.decode()
)['auth_token']
)
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'fail')
self.assertTrue(data['message'] == 'Token blacklisted. Please log in again.')
self.assertEqual(response.status_code, 401)
与上一个测试类似,我们在用户状态路由命中之前将令牌列入黑名单。
最后一次运行测试:
Ran 14 tests in 10.206s
OK
代码气味
最后看一下 test_auth.py 。注意到重复的代码了吗?例如:
self.client.post(
'/auth/register',
data=json.dumps(dict(
email='joe@gmail.com',
password='123456'
)),
content_type='application/json',
)
这种情况出现了八次。要修复此问题,请在文件顶部添加以下助手:
def register_user(self, email, password):
return self.client.post(
'/auth/register',
data=json.dumps(dict(
email=email,
password=password
)),
content_type='application/json',
)
现在,在任何需要注册用户的地方,您都可以呼叫助手:
register_user(self, 'joe@gmail.com', '123456')
登录一个用户怎么样?自己重构它。还能重构什么?下面评论。
重构
对于 PyBites 挑战,让我们重构一些代码来纠正添加到 GitHub repo 中的一个问题。首先向 test_auth.py 添加以下测试:
def test_user_status_malformed_bearer_token(self):
""" Test for user status with malformed bearer token"""
with self.client:
resp_register = register_user(self, 'joe@gmail.com', '123456')
response = self.client.get(
'/auth/status',
headers=dict(
Authorization='Bearer' + json.loads(
resp_register.data.decode()
)['auth_token']
)
)
data = json.loads(response.data.decode())
self.assertTrue(data['status'] == 'fail')
self.assertTrue(data['message'] == 'Bearer token malformed.')
self.assertEqual(response.status_code, 401)
本质上,如果Authorization头的格式不正确,就会抛出一个错误——例如,Bearer和令牌值之间没有空格。运行测试以确保它们失败,然后更新project/server/auth/views . py中的UserAPI类:
class UserAPI(MethodView):
"""
User Resource
"""
def get(self):
# get the auth token
auth_header = request.headers.get('Authorization')
if auth_header:
try:
auth_token = auth_header.split(" ")[1]
except IndexError:
responseObject = {
'status': 'fail',
'message': 'Bearer token malformed.'
}
return make_response(jsonify(responseObject)), 401
else:
auth_token = ''
if auth_token:
resp = User.decode_auth_token(auth_token)
if not isinstance(resp, str):
user = User.query.filter_by(id=resp).first()
responseObject = {
'status': 'success',
'data': {
'user_id': user.id,
'email': user.email,
'admin': user.admin,
'registered_on': user.registered_on
}
}
return make_response(jsonify(responseObject)), 200
responseObject = {
'status': 'fail',
'message': resp
}
return make_response(jsonify(responseObject)), 401
else:
responseObject = {
'status': 'fail',
'message': 'Provide a valid auth token.'
}
return make_response(jsonify(responseObject)), 401
最后一次测试。
结论
在本教程中,我们经历了使用 JSON Web 令牌向 Flask 应用程序添加身份验证的过程。回到本教程开头的目标。你能把每一个都付诸行动吗?你学到了什么?
下一步是什么?客户端怎么样?查看使用 Angular 的基于令牌的认证,将 Angular 添加到组合中。
要了解如何使用 Flask 从头构建一个完整的 web 应用程序,请查看我们的视频系列:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
欢迎在下面的评论中分享你的评论、问题或建议。完整的代码可以在 flask-jwt-auth 存储库中找到。
干杯!********
顶级 Python 游戏引擎
和很多人一样,也许你刚开始学编码的时候想写视频游戏。但是那些游戏和你玩过的游戏一样吗?可能你刚开始的时候没有 Python,没有 Python 游戏可供你学习,也没有游戏引擎可言。没有真正的指导或框架来帮助你,你在其他游戏中体验到的高级图形和声音可能仍然遥不可及。
现在,有了 Python,以及大量优秀的 Python 游戏引擎。这种强大的组合使得制作优秀的电脑游戏比过去容易得多。在本教程中,您将探索其中的几个游戏引擎,了解开始制作您自己的 Python 视频游戏所需的东西!
本文结束时,你将:
- 了解几款流行的 Python 游戏引擎的优劣
- 看看这些游戏引擎的运行
- 理解他们如何比较和独立游戏引擎
- 了解其他可用的 Python 游戏引擎
为了从本教程中获得最大收益,您应该精通 Python 编程,包括面向对象编程。理解基本的游戏概念是有帮助的,但不是必需的。
准备好开始了吗?单击下面的链接下载您将创建的所有游戏的源代码:
获取源代码: 点击此处获取您将使用试用 Python 游戏引擎的源代码。
Python 游戏引擎概述
Python 的游戏引擎通常采用 Python 库的形式,可以通过多种方式安装。大多数在 PyPI 上有,可以和 pip 一起安装。但是,有一些只在 GitHub、GitLab 或其他代码共享位置上可用,它们可能需要其他安装步骤。本文将涵盖所有讨论过的引擎的安装方法。
Python 是一种通用编程语言,除了编写计算机游戏之外,它还用于各种任务。相比之下,有许多不同的单机游戏引擎是专门为编写游戏而定制的。其中包括:
这些独立游戏引擎在几个关键方面不同于 Python 游戏引擎:
- 语言支持:像 C++、C#和 JavaScript 这样的语言在独立游戏引擎中编写的游戏中很受欢迎,因为引擎本身通常是用这些语言编写的。很少有独立引擎支持 Python。
- 专有脚本支持:另外,很多单机游戏引擎都维护和支持自己的脚本语言,可能不像 Python。比如 Unity 原生使用 C#,Unreal 用 C++效果最好。
- 平台支持:很多现代单机游戏引擎都可以不费吹灰之力制作出适用于多种平台的游戏,包括移动和专用游戏系统。相比之下,将 Python 游戏移植到各种平台,尤其是移动平台,可能是一项艰巨的任务。
- 许可选项:根据所使用的引擎,使用独立游戏引擎编写的游戏可能会有不同的许可选项和限制。
那么为什么要用 Python 来写游戏呢?一句话,Python。使用单机游戏引擎往往需要你学习一门新的编程或脚本语言。Python 游戏引擎利用您现有的 Python 知识,缩短学习曲线,让您快速前进。
有许多游戏引擎可用于 Python 环境。您将在此了解的所有引擎都具有以下标准:
- 它们是相对受欢迎的引擎,或者它们涵盖了游戏中通常不被涉及的方面。
- 它们目前被维护着。
- 他们有很好的文件可用。
对于每种引擎,您将了解到:
- 安装方法
- 基本概念,以及引擎做出的假设
- 主要特性和功能
- 两个游戏实现,为了便于比较
在适当的地方,你应该在一个虚拟环境中安装这些游戏引擎。本教程中游戏的完整源代码可以从下面的链接下载,并将在整篇文章中引用:
获取源代码: 点击此处获取您将使用试用 Python 游戏引擎的源代码。
下载完源代码后,您就可以开始了。
Pygame
当人们想到 Python 游戏引擎时,许多人的第一个想法是 Pygame 。事实上,在 Real Python 网站上已经有了关于 Pygame 的很棒的初级读本。
作为停滞不前的 PySDL 库的替代品,Pygame 包装并扩展了 SDL 库,它代表简单直接媒体层。SDL 提供对系统底层多媒体硬件组件的跨平台访问,如声音、视频、鼠标、键盘和操纵杆。SDL 和 Pygame 的跨平台特性意味着你可以为每一个支持它们的平台编写游戏和丰富的多媒体 Python 程序!
Pygame 安装
PyPI 上有 Pygame,所以在创建并激活一个虚拟环境后,您可以使用适当的pip命令来安装它:
(venv) $ python -m pip install pygame
完成后,您可以通过运行库附带的示例来验证安装:
(venv) $ python -m pygame.examples.aliens
现在你已经安装了 Pygame,你可以马上开始使用它。如果您在安装过程中遇到问题,那么入门指南概述了一些已知问题和所有平台的可能解决方案。
基本概念
Pygame 被组织成几个不同的模块,这些模块提供了对计算机图形、声音和输入硬件的抽象访问。Pygame 还定义了许多类,这些类封装了与硬件无关的概念。例如,在Surface对象上绘图,其矩形界限由其Rect对象定义。
每个游戏都利用一个游戏循环来控制游戏的进行。这个循环随着游戏的进行不断迭代。Pygame 提供了实现游戏循环的方法和函数,但是它没有自动提供。游戏作者应该实现游戏循环的功能。
游戏循环的每次迭代被称为一个帧。每一帧,游戏执行四个重要动作:
-
处理用户输入。使用事件模型处理 Pygame 中的用户输入。鼠标和键盘输入会生成事件,这些事件可以被读取和处理,也可以被忽略。Pygame 本身不提供任何事件处理程序。
-
更新游戏对象的状态。游戏对象可以使用任何 Pygame 数据结构或特殊的 Pygame 类来表示。诸如精灵、图像、字体和颜色等对象可以在 Python 中创建和扩展,以提供尽可能多的状态信息。
-
更新显示和音频输出。 Pygame 提供了对显示器和声音硬件的抽象访问。
display、mixer和music模块允许游戏作者在游戏设计和实现中具有灵活性。 -
保持游戏速度。 Pygame 的
time模块允许游戏作者控制游戏速度。通过确保每一帧在指定的时间限制内完成,游戏作者可以确保游戏在不同的硬件上类似地运行。
你可以在一个基本的例子中看到这些概念的结合。
基本应用
这个基本的 Pygame 程序在屏幕上绘制一些形状和一些文本:
此示例的代码可以在下面的可下载资料中找到:
1"""
2Basic "Hello, World!" program in Pygame
3
4This program is designed to demonstrate the basic capabilities
5of Pygame. It will:
6- Create a game window
7- Fill the background with white
8- Draw some basic shapes in different colors
9- Draw some text in a specified size and color
10- Allow you to close the window
11"""
12
13# Import and initialize the pygame library
14import pygame
15
16pygame.init()
17
18# Set the width and height of the output window, in pixels
19WIDTH = 800
20HEIGHT = 600
21
22# Set up the drawing window
23screen = pygame.display.set_mode([WIDTH, HEIGHT])
24
25# Run until the user asks to quit
26running = True
27while running:
28
29 # Did the user click the window close button?
30 for event in pygame.event.get():
31 if event.type == pygame.QUIT:
32 running = False
33
34 # Fill the background with white
35 screen.fill((255, 255, 255))
36
37 # Draw a blue circle with a radius of 50 in the center of the screen
38 pygame.draw.circle(screen, (0, 0, 255), (WIDTH // 2, HEIGHT // 2), 50)
39
40 # Draw a red-outlined square in the top-left corner of the screen
41 red_square = pygame.Rect((50, 50), (100, 100))
42 pygame.draw.rect(screen, (200, 0, 0), red_square, 1)
43
44 # Draw an orange caption along the bottom in 60-point font
45 text_font = pygame.font.SysFont("any_font", 60)
46 text_block = text_font.render(
47 "Hello, World! From Pygame", False, (200, 100, 0)
48 )
49 screen.blit(text_block, (50, HEIGHT - 50))
50
51 # Flip the display
52 pygame.display.flip()
53
54# Done! Time to quit.
55pygame.quit()
尽管它的期望很低,但即使是这个基本的 Pygame 程序也需要一个游戏循环和事件处理程序。游戏循环从线 27 开始,由running变量控制。将该变量设置为False将结束程序。
事件处理从第 30 行的开始,伴随着事件循环。使用pygame.event.get()从队列中检索事件,并在每次循环迭代中一次处理一个事件。在这种情况下,唯一被处理的事件是pygame.QUIT事件,它是在用户关闭游戏窗口时生成的。当这个事件被处理时,你设置running = False,这将最终结束游戏循环和程序。
Pygame 提供了各种绘制基本形状的方法,比如圆形和矩形。在该示例中,在第 38 条的线上画了一个蓝色圆圈,在第 41 和 42 条的线上画了一个红色方块。请注意,绘制矩形需要您首先创建一个Rect对象。
在屏幕上绘制文本稍微复杂一些。首先,在第 45 行上,选择一种字体并创建一个font对象。在第 46 到 48 行上使用该字体,调用.render()方法。这将创建一个包含以指定字体和颜色呈现的文本的Surface对象。最后,使用行 49 上的.blit()方法将Surface复制到屏幕上。
游戏循环的结束发生在线 52 处,此时先前绘制的所有内容都显示在显示器上。没有这一行,什么都不会显示。
要运行此代码,请使用以下命令:
(venv) $ python pygame/pygame_basic.py
您应该会看到一个窗口,上面显示的图像。恭喜你!您刚刚运行了您的第一个 Pygame 程序!
高级应用程序
当然,Pygame 是为用 Python 写游戏而设计的。为了探究一个实际的 Pygame 游戏的功能和需求,您将通过以下细节来检查一个用 Pygame 编写的游戏:
- 玩家是屏幕上的一个精灵,通过移动鼠标来控制。
- 每隔一段时间,硬币就会一个接一个地出现在屏幕上。
- 当玩家移动每枚硬币时,硬币消失,玩家获得 10 分。
- 随着游戏的进行,硬币会更快地加入。
- 当屏幕上出现十个以上的硬币时,游戏结束。
完成后,游戏看起来会像这样:
这个游戏的完整代码可以在下面的下载资料中找到:
1"""
2Complete Game in Pygame
3
4This game demonstrates some of the more advanced features of
5Pygame, including:
6- Using sprites to render complex graphics
7- Handling user mouse input
8- Basic sound output
9"""
10
11# Import and initialize the pygame library
12import pygame
13
14# To randomize coin placement
15from random import randint
16
17# To find your assets
18from pathlib import Path
19
20# For type hinting
21from typing import Tuple
22
23# Set the width and height of the output window, in pixels
24WIDTH = 800
25HEIGHT = 600
26
27# How quickly do you generate coins? Time is in milliseconds
28coin_countdown = 2500
29coin_interval = 100
30
31# How many coins can be on the screen before you end?
32COIN_COUNT = 10
33
34# Define the Player sprite
35class Player(pygame.sprite.Sprite):
36 def __init__(self):
37 """Initialize the player sprite"""
38 super(Player, self).__init__()
39
40 # Get the image to draw for the player
41 player_image = str(
42 Path.cwd() / "pygame" / "images" / "alien_green_stand.png"
43 )
44 # Load the image, preserve alpha channel for transparency
45 self.surf = pygame.image.load(player_image).convert_alpha()
46 # Save the rect so you can move it
47 self.rect = self.surf.get_rect()
48
49 def update(self, pos: Tuple):
50 """Update the position of the player
51
52 Arguments:
53 pos {Tuple} -- the (X,Y) position to move the player
54 """
55 self.rect.center = pos
56
57# Define the Coin sprite
58class Coin(pygame.sprite.Sprite):
59 def __init__(self):
60 """Initialize the coin sprite"""
61 super(Coin, self).__init__()
62
63 # Get the image to draw for the coin
64 coin_image = str(Path.cwd() / "pygame" / "images" / "coin_gold.png")
65
66 # Load the image, preserve alpha channel for transparency
67 self.surf = pygame.image.load(coin_image).convert_alpha()
68
69 # The starting position is randomly generated
70 self.rect = self.surf.get_rect(
71 center=(
72 randint(10, WIDTH - 10),
73 randint(10, HEIGHT - 10),
74 )
75 )
76
77# Initialize the Pygame engine
78pygame.init()
79
80# Set up the drawing window
81screen = pygame.display.set_mode(size=[WIDTH, HEIGHT])
82
83# Hide the mouse cursor
84pygame.mouse.set_visible(False)
85
86# Set up the clock for a decent frame rate
87clock = pygame.time.Clock()
88
89# Create a custom event for adding a new coin
90ADDCOIN = pygame.USEREVENT + 1
91pygame.time.set_timer(ADDCOIN, coin_countdown)
92
93# Set up the coin_list
94coin_list = pygame.sprite.Group()
95
96# Initialize the score
97score = 0
98
99# Set up the coin pickup sound
100coin_pickup_sound = pygame.mixer.Sound(
101 str(Path.cwd() / "pygame" / "sounds" / "coin_pickup.wav")
102)
103
104# Create a player sprite and set its initial position
105player = Player()
106player.update(pygame.mouse.get_pos())
107
108# Run until you get to an end condition
109running = True
110while running:
111
112 # Did the user click the window close button?
113 for event in pygame.event.get():
114 if event.type == pygame.QUIT:
115 running = False
116
117 # Should you add a new coin?
118 elif event.type == ADDCOIN:
119 # Create a new coin and add it to the coin_list
120 new_coin = Coin()
121 coin_list.add(new_coin)
122
123 # Speed things up if fewer than three coins are on-screen
124 if len(coin_list) < 3:
125 coin_countdown -= coin_interval
126 # Need to have some interval
127 if coin_countdown < 100:
128 coin_countdown = 100
129
130 # Stop the previous timer by setting the interval to 0
131 pygame.time.set_timer(ADDCOIN, 0)
132
133 # Start a new timer
134 pygame.time.set_timer(ADDCOIN, coin_countdown)
135
136 # Update the player position
137 player.update(pygame.mouse.get_pos())
138
139 # Check if the player has collided with a coin, removing the coin if so
140 coins_collected = pygame.sprite.spritecollide(
141 sprite=player, group=coin_list, dokill=True
142 )
143 for coin in coins_collected:
144 # Each coin is worth 10 points
145 score += 10
146 # Play the coin collected sound
147 coin_pickup_sound.play()
148
149 # Are there too many coins on the screen?
150 if len(coin_list) >= COIN_COUNT:
151 # This counts as an end condition, so you end your game loop
152 running = False
153
154 # To render the screen, first fill the background with pink
155 screen.fill((255, 170, 164))
156
157 # Draw the coins next
158 for coin in coin_list:
159 screen.blit(coin.surf, coin.rect)
160
161 # Then draw the player
162 screen.blit(player.surf, player.rect)
163
164 # Finally, draw the score at the bottom left
165 score_font = pygame.font.SysFont("any_font", 36)
166 score_block = score_font.render(f"Score: {score}", False, (0, 0, 0))
167 screen.blit(score_block, (50, HEIGHT - 50))
168
169 # Flip the display to make everything appear
170 pygame.display.flip()
171
172 # Ensure you maintain a 30 frames per second rate
173 clock.tick(30)
174
175# Done! Print the final score
176print(f"Game over! Final score: {score}")
177
178# Make the mouse visible again
179pygame.mouse.set_visible(True)
180
181# Quit the game
182pygame.quit()
Pygame 中的精灵提供了一些基本的功能,但是它们被设计成子类而不是独立使用。Pygame 精灵默认没有关联的图片,也不能自己定位。
为了正确地抽取和管理玩家和屏幕上的硬币,在第 35 到 55 行的上创建了一个Player类,在第 58 到 75 行的上创建了一个Coin类。当每个 sprite 对象被创建时,它首先定位并加载它将显示的图像,保存在self.surf中。属性在屏幕上定位和移动精灵。
定期向屏幕添加硬币是通过计时器完成的。在 Pygame 中,每当定时器到期时都会触发事件,游戏创建者可以将自己的事件定义为整数常量。在线 90 上定义ADDCOIN事件,定时器在线 91 上coin_countdown毫秒后触发事件。
由于ADDCOIN是一个事件,它需要在一个事件循环中处理,这发生在的第 118 到 134 行。该事件创建一个新的Coin对象,并将其添加到现有的coin_list中。检查屏幕上的硬币数量。如果少于三个,则coin_countdown减少。最后,前一个计时器停止,新的计时器开始计时。
当玩家移动时,它们会与硬币碰撞,一边碰撞一边收集硬币。这将自动从coin_list中移除每个收集的硬币。这也会更新乐谱并播放声音。
玩家移动发生在线 137 。在行 140 到 142 检查与屏幕上硬币的碰撞。dokill=True参数自动从coin_list中取出硬币。最后,第 143 到 147 行更新分数并为收集到的每枚硬币播放声音。
当用户关闭窗口,或者当屏幕上出现十个以上的硬币时,游戏结束。在行 150 到 152 上检查十个以上的硬币。
因为 Pygame 精灵没有内置的图像知识,他们也不知道如何在屏幕上画自己。游戏作者需要清空屏幕,按照正确的顺序画出所有的精灵,画出屏幕上的分数,然后.flip()显示器让一切出现。这一切都发生在第 155 到 170 行。
Pygame 是一个非常强大和完善的库,但是它也有缺点。Pygame 让游戏作者工作来得到他们的结果。由游戏作者来实现基本的精灵行为,并实现游戏循环和基本事件处理程序等关键的游戏要求。接下来,您将看到其他游戏引擎如何提供类似的结果,同时减少您必须做的工作量。
Pygame Zero
Pygame 在许多方面做得很好,但在其他方面却显而易见。对于游戏写作初学者来说,更好的选择可以在 Pygame Zero 找到。Pygame Zero 专为教育而设计,由一套简单的原则指导,旨在为年轻和刚入门的程序员提供完美的服务:
- 使其可访问:一切都是为初级程序员设计的。
- 保守一点:支持通用平台,避免实验特性。
- 工作就是了:确保一切正常,不要大惊小怪。
- 最小化运行成本:如果某些东西可能会失败,那就尽早失败。
- 错误明显:没有什么比不知道为什么会出错更糟糕的了。
- 做好文档:一个框架只有和它的文档一样好。
- 最小化突破性的改变:升级不需要重写你的游戏。
Pygame Zero 的文档对于初级程序员来说非常容易理解,它包括一个完整的逐步教程。此外,Pygame Zero 团队认识到许多初学编程的人是从 Scratch 开始编码的,所以他们给提供了一个教程,演示如何将 Scratch 程序迁移到 Pygame Zero。
Pygame 零安装
Pygame Zero 在 PyPI 上可用,您可以像在 Windows、macOS 或 Linux 上安装任何其他 Python 库一样安装它:
(venv) $ python -m pip install pgzero
Pygame Zero,顾名思义,是建立在 Pygame 之上的,所以这一步也是将 Pygame 作为依赖库安装。Pygame Zero 默认安装在 Raspberry Pi 平台上,在 Raspbian Jessie 或更高版本上。
基本概念
Pygame Zero 自动化了许多程序员在 Pygame 中必须手动完成的事情。默认情况下,Pygame Zero 为游戏创建者提供:
- 一个游戏循环,所以没必要写
- 处理绘图、更新和输入处理的事件模型
- 统一的图像、文本和声音处理
- 一个可用的精灵类和用户精灵的动画方法
由于这些规定,一个基本的 Pygame Zero 程序可能会非常短:
1"""
2Basic "Hello, World!" program in Pygame Zero
3
4This program is designed to demonstrate the basic capabilities
5of Pygame Zero. It will:
6- Create a game window
7- Fill the background with white
8- Draw some basic shapes in different colors
9- Draw some text in a specified size and color
10"""
11
12# Import pgzrun allows the program to run in Python IDLE
13import pgzrun
14
15# Set the width and height of your output window, in pixels
16WIDTH = 800
17HEIGHT = 600
18
19def draw():
20 """Draw is called once per frame to render everything on the screen"""
21
22 # Clear the screen first
23 screen.clear()
24
25 # Set the background color to white
26 screen.fill("white")
27
28 # Draw a blue circle with a radius of 50 in the center of the screen
29 screen.draw.filled_circle(
30 (WIDTH // 2, HEIGHT // 2), 50, "blue"
31 )
32
33 # Draw a red-outlined square in the top-left corner of the screen
34 red_square = Rect((50, 50), (100, 100))
35 screen.draw.rect(red_square, (200, 0, 0))
36
37 # Draw an orange caption along the bottom in 60-point font
38 screen.draw.text(
39 "Hello, World! From Pygame Zero!",
40 (100, HEIGHT - 50),
41 fontsize=60,
42 color="orange",
43 )
44
45# Run the program
46pgzrun.go()
Pygame Zero 识别出第 16 行和第 17 行上的常量WIDTH和HEIGHT指的是窗口的大小,并自动使用这些尺寸来创建窗口。另外,Pygame Zero 提供了一个内置的游戏循环,并且每帧调用一次行 19 到 43 上定义的draw()函数来渲染屏幕。
因为 Pygame Zero 基于 Pygame,所以继承了一些形状绘制代码。你可以看到在第 29 行上画圆和在第 34 到 35 行上画正方形的相似之处:
然而,文本绘制现在是对第 38 到 43 行的单个函数调用,而不是三个独立的函数。
Pygame Zero 还提供了基本的窗口处理代码,因此您可以通过单击适当的关闭按钮来关闭窗口,而不需要事件处理程序。
您可以在可下载的资料中找到演示 Pygame Zero 的一些基本功能的代码:
获取源代码: 点击此处获取您将使用试用 Python 游戏引擎的源代码。
运行 Pygame Zero 程序是从命令行使用以下命令完成的:
(venv) $ python pygame_zero/pygame_zero_basic.py
运行此命令将启动您的 Pygame Zero 游戏。您应该会看到一个窗口,显示基本形状和您的 Pygame Zero 问候语。
精灵和图像
精灵在 Pygame Zero 中被称为演员,他们有一些需要解释的特征:
- Pygame Zero 提供了
Actor类。每个Actor至少有一个图像和一个位置。 - Pygame Zero 程序中使用的所有图像必须位于名为img/`的子文件夹中,并且只能使用小写字母、数字和下划线命名。
- 仅使用图像的基本名称引用图像。例如,如果你的图像被称为
alien.png,你在你的程序中引用它为"alien"。
由于 Pygame Zero 的这些内置特性,在屏幕上绘制精灵只需要很少的代码:
1alien = Actor("alien")
2alien.pos = 100, 56
3
4WIDTH = 500
5HEIGHT = alien.height + 20
6
7def draw():
8 screen.clear()
9 alien.draw()
现在,您将逐行分解这个小示例:
- 第 1 行创建新的
Actor对象,给它一个要绘制的图像的名称。 - 线 2 设置
Actor的初始 x 和 y 位置。 - 第 4 行和第 5 行设置 Pygame 零窗口的大小。注意
HEIGHT是基于 sprite 的.height属性的。该值来自用于创建精灵的图像的高度。 - 第 9 行通过调用
Actor对象上的.draw()来绘制精灵。这将在屏幕上由.pos提供的位置绘制精灵图像。
接下来,您将在更高级的游戏中使用这些技术。
高级应用程序
为了演示游戏引擎之间的区别,您将再次访问您在 Pygame 部分看到的相同的高级游戏,现在使用 Pygame Zero 编写。提醒一下,这个游戏的关键细节是:
- 玩家是屏幕上的一个精灵,通过移动鼠标来控制。
- 每隔一段时间,硬币就会一个接一个地出现在屏幕上。
- 当玩家移动每枚硬币时,硬币消失,玩家获得 10 分。
- 随着游戏的进行,硬币会更快地加入。
- 当屏幕上出现十个以上的硬币时,游戏结束。
这个游戏的外观和行为应该与之前演示的 Pygame 版本一致,只有窗口标题栏暴露了 Pygame 零原点:
您可以在下面的下载资料中找到该示例的完整代码:
1"""
2Complete game in Pygame Zero
3
4This game demonstrates some of the more advanced features of
5Pygame Zero, including:
6- Using sprites to render complex graphics
7- Handling user input
8- Sound output
9
10"""
11
12# Import pgzrun allows the program to run in Python IDLE
13import pgzrun
14
15# For type-hinting support
16from typing import Tuple
17
18# To randomize coin placement
19from random import randint
20
21# Set the width and height of your output window, in pixels
22WIDTH = 800
23HEIGHT = 600
24
25# Set up the player
26player = Actor("alien_green_stand")
27player_position = WIDTH // 2, HEIGHT // 2
28player.center = player_position
29
30# Set up the coins to collect
31COIN_COUNT = 10
32coin_list = list()
33
34# Set up a timer to create new coins
35coin_countdown = 2.5
36coin_interval = 0.1
37
38# Score is initially zero
39score = 0
40
41def add_coin():
42 """Adds a new coin to playfield, then
43 schedules the next coin to be added
44 """
45 global coin_countdown
46
47 # Create a new coin Actor at a random location
48 new_coin = Actor(
49 "coin_gold", (randint(10, WIDTH - 10), randint(10, HEIGHT - 10))
50 )
51
52 # Add it to the global coin list
53 coin_list.append(new_coin)
54
55 # Decrease the time between coin appearances if there are
56 # fewer than three coins on the screen.
57 if len(coin_list) < 3:
58 coin_countdown -= coin_interval
59
60 # Make sure you don't go too quickly
61 if coin_countdown < 0.1:
62 coin_countdown = 0.1
63
64 # Schedule the next coin addition
65 clock.schedule(add_coin, coin_countdown)
66
67def on_mouse_move(pos: Tuple):
68 """Called whenever the mouse changes position
69
70 Arguments:
71 pos {Tuple} -- The current position of the mouse
72 """
73 global player_position
74
75 # Set the player to the mouse position
76 player_position = pos
77
78 # Ensure the player doesn't move off the screen
79 if player_position[0] < 0:
80 player_position[0] = 0
81 if player_position[0] > WIDTH:
82 player_position[0] = WIDTH
83
84 if player_position[1] < 0:
85 player_position[1] = 0
86 if player_position[1] > HEIGHT:
87 player_position[1] = HEIGHT
88
89def update(delta_time: float):
90 """Called every frame to update game objects
91
92 Arguments:
93 delta_time {float} -- Time since the last frame
94 """
95 global score
96
97 # Update the player position
98 player.center = player_position
99
100 # Check if the player has collided with a coin
101 # First, set up a list of coins to remove
102 coin_remove_list = []
103
104 # Check each coin in the list for a collision
105 for coin in coin_list:
106 if player.colliderect(coin):
107 sounds.coin_pickup.play()
108 coin_remove_list.append(coin)
109 score += 10
110
111 # Remove any coins with which you collided
112 for coin in coin_remove_list:
113 coin_list.remove(coin)
114
115 # The game is over when there are too many coins on the screen
116 if len(coin_list) >= COIN_COUNT:
117 # Stop making new coins
118 clock.unschedule(add_coin)
119
120 # Print the final score and exit the game
121 print(f"Game over! Final score: {score}")
122 exit()
123
124def draw():
125 """Render everything on the screen once per frame"""
126
127 # Clear the screen first
128 screen.clear()
129
130 # Set the background color to pink
131 screen.fill("pink")
132
133 # Draw the remaining coins
134 for coin in coin_list:
135 coin.draw()
136
137 # Draw the player
138 player.draw()
139
140 # Draw the current score at the bottom
141 screen.draw.text(
142 f"Score: {score}",
143 (50, HEIGHT - 50),
144 fontsize=48,
145 color="black",
146 )
147
148# Schedule the first coin to appear
149clock.schedule(add_coin, coin_countdown)
150
151# Run the program
152pgzrun.go()
创建玩家Actor是在的第 26 到 28 行完成的。初始位置是屏幕的中心。
clock.schedule()方法处理定期创建硬币。该方法需要调用一个函数,并在调用该函数之前确定延迟的秒数。
第 41 到 65 行定义了将要被调度的add_coin()功能。它在第 48 到 50 行的随机位置创建一个新硬币Actor,并将其添加到可见硬币的全局列表中。
随着游戏的进行,硬币应该会越来越快地出现,但不能太快。间隔管理在线 57 至 62 完成。因为clock.schedule()只会触发一次,所以你在线路 65 上安排了另一次呼叫。
鼠标移动在第 67 到 87 行的事件处理程序中处理。鼠标位置被捕获并存储在线 76** 的一个全局变量中。第 79 行到第 87 行确保该位置不会离开屏幕。**
将玩家位置存储在一个global变量中是一种便利,它简化了代码,并允许您专注于 Pygame Zero 的功能。在更完整的游戏中,你的设计选择可能会有所不同。
第 89 到 122 行定义的update()函数被 Pygame Zero 每帧调用一次。你用它来移动Actor物体并更新你所有游戏物体的状态。玩家Actor的位置被更新以在线 98 上跟踪鼠标。
与硬币的碰撞在线 102 到 113 上处理。如果玩家撞上了一枚硬币,那么硬币会被加到coin_remove_list上,分数会增加,并且会发出声音。当所有的碰撞都被处理后,你取出添加到行 112 到 113 的coin_remove_list中的硬币。
处理完硬币碰撞后,检查屏幕上的行 116 处是否还有过多硬币。如果是这样,游戏就结束了,所以你停止创造新的硬币,打印最后的分数,在第 118 到 122 行结束游戏。
当然,这一切的更新都需要体现在屏幕上。第 124 到 146 行上的draw()函数在每帧update()之后被调用一次。在清空屏幕并在行 128 和 131** 处填充背景色后,玩家Actor和所有硬币被绘制在行 134 至 138 处。当前分数是在第 141 至 146 行上绘制的最后一项。**
Pygame Zero 实现使用了 152 行代码来交付与 182 行 Pygame 代码相同的游戏。虽然这些行数是可比的,但 Pygame Zero 版本无疑比 Pygame 版本更干净、更模块化,并且可能更容易理解和编码。
当然,写游戏总会多一种方式。
街机
Arcade 是一个现代的 Python 框架,用于制作具有引人注目的图形和声音的游戏。通过面向对象的设计, Arcade 为游戏作者提供了一套现代的工具来打造出色的 Python 游戏体验。
Arcade 由美国爱荷华州辛普森学院的 Paul Craven 教授设计,建立在 T2 的 pyglet 窗口和多媒体图书馆之上。它提供了一系列改进、现代化和增强功能,与 Pygame 和 Pygame Zero 相比毫不逊色:
- 支持现代 OpenGL 图形
- 支持 Python 3 类型提示
- 支持基于帧的动画精灵
- 整合了一致的命令、函数和参数名称
- 鼓励游戏逻辑与显示代码的分离
- 需要较少的样板代码
- 提供维护良好的最新文档,包括几个教程和完整的 Python 游戏示例
- 内置了自顶向下和平台游戏的物理引擎
Arcade 处于不断的开发中,在社区中得到很好的支持,并且有一个对问题、错误报告和潜在修复非常敏感的作者。
街机安装
要安装 Arcade 及其依赖项,使用相应的 pip 命令:
(venv) $ python -m pip install arcade
基于您的平台的完整安装说明可用于 Windows 、 macOS 和 Linux 。如果你愿意,你甚至可以直接从源安装arcade。
基本概念
Arcade 中的一切都发生在一个由用户定义大小的窗口中。坐标系假设原点(0, 0)位于屏幕的左下角,随着你向上移动,y 坐标增加。这和其他很多游戏引擎不同,把(0, 0)放在左上角,增加了 y 坐标下移。
本质上,Arcade 是一个面向对象的库。虽然程序化地编写 Arcade 应用程序是可能的,但是当您创建完全面向对象的代码时,它的真正威力才会显现出来。
Arcade 和 Pygame Zero 一样,提供了内置的游戏循环和定义良好的事件模型,所以你最终得到的是非常干净易读的游戏代码。也像 Pygame Zero 一样,Arcade 提供了一个强大的 sprite 类来帮助渲染、定位和碰撞检测。此外,街机精灵可以通过提供多个图像来制作动画。
下面列出的基本 Arcade 应用程序的代码在教程的源代码中作为arcade_basic.py提供:
1"""
2Basic "Hello, World!" program in Arcade
3
4This program is designed to demonstrate the basic capabilities
5of Arcade. It will:
6- Create a game window
7- Fill the background with white
8- Draw some basic shapes in different colors
9- Draw some text in a specified size and color
10"""
11
12# Import arcade allows the program to run in Python IDLE
13import arcade
14
15# Set the width and height of your output window, in pixels
16WIDTH = 800
17HEIGHT = 600
18
19# Classes
20class ArcadeBasic(arcade.Window):
21 """Main game window"""
22
23 def __init__(self, width: int, height: int, title: str):
24 """Initialize the window to a specific size
25
26 Arguments:
27 width {int} -- Width of the window
28 height {int} -- Height of the window
29 title {str} -- Title for the window
30 """
31
32 # Call the parent class constructor
33 super().__init__(width, height, title)
34
35 # Set the background window
36 arcade.set_background_color(color=arcade.color.WHITE)
37
38 def on_draw(self):
39 """Called once per frame to render everything on the screen"""
40
41 # Start rendering
42 arcade.start_render()
43
44 # Draw a blue circle with a radius of 50 in the center of the screen
45 arcade.draw_circle_filled(
46 center_x=WIDTH // 2,
47 center_y=HEIGHT // 2,
48 radius=50,
49 color=arcade.color.BLUE,
50 num_segments=50,
51 )
52
53 # Draw a red-outlined square in the top-left corner of the screen
54 arcade.draw_lrtb_rectangle_outline(
55 left=50,
56 top=HEIGHT - 50,
57 bottom=HEIGHT - 100,
58 right=100,
59 color=arcade.color.RED,
60 border_width=3,
61 )
62
63 # Draw an orange caption along the bottom in 60-point font
64 arcade.draw_text(
65 text="Hello, World! From Arcade!",
66 start_x=100,
67 start_y=50,
68 font_size=28,
69 color=arcade.color.ORANGE,
70 )
71
72# Run the program
73if __name__ == "__main__":
74 arcade_game = ArcadeBasic(WIDTH, HEIGHT, "Arcade Basic Game")
75 arcade.run()
要运行此代码,请使用以下命令:
(venv) $ python arcade/arcade_basic.py
该程序在屏幕上绘制一些形状和一些文本,如前面显示的基本示例所示:
如上所述,街机程序可以写成完全面向对象的代码。这个arcade.Window类被设计成你的游戏的子类,如第 20 行所示。在线 33 上调用super().__init()确保游戏窗口被正确设置。
Arcade 每帧调用一次行 38 到 70 上定义的.on_draw()事件处理程序,将所有内容渲染到屏幕上。这个方法从调用.start_render()开始,它告诉 Arcade 准备窗口进行绘制。这相当于 Pygame 绘制步骤结束时需要的pygame.flip()调用。
Arcade 中的每个基本形状绘制方法都以draw_*开始,并且需要一条线来完成。Arcade 内置了对众多形状的绘图支持。
Arcade 在arcade.color包中装载了数百种命名的颜色,但你也可以使用 RGB 或 RGBA 元组自由选择自己的颜色。
高级应用程序
为了展示 Arcade 与其他游戏引擎的不同,您将看到以前的相同游戏,现在在 Arcade 中实现。提醒一下,以下是游戏的关键细节:
- 玩家是屏幕上的一个精灵,通过移动鼠标来控制。
- 每隔一段时间,硬币就会一个接一个地出现在屏幕上。
- 当玩家移动每枚硬币时,硬币消失,玩家获得 10 分。
- 随着游戏的进行,硬币会更快地加入。
- 当屏幕上出现十个以上的硬币时,游戏结束。
同样,游戏的行为应该与前面的示例相同:
下面列出的完整街机游戏代码在可下载资料中以arcade_game.py的形式提供:
1"""
2Complete game in Arcade
3
4This game demonstrates some of the more advanced features of
5Arcade, including:
6- Using sprites to render complex graphics
7- Handling user input
8- Sound output
9"""
10
11# Import arcade allows the program to run in Python IDLE
12import arcade
13
14# To randomize coin placement
15from random import randint
16
17# To locate your assets
18from pathlib import Path
19
20# Set the width and height of your game window, in pixels
21WIDTH = 800
22HEIGHT = 600
23
24# Set the game window title
25TITLE = "Arcade Sample Game"
26
27# Location of your assets
28ASSETS_PATH = Path.cwd() / "assets"
29
30# How many coins must be on the screen before the game is over?
31COIN_COUNT = 10
32
33# How much is each coin worth?
34COIN_VALUE = 10
35
36# Classes
37class ArcadeGame(arcade.Window):
38 """The Arcade Game class"""
39
40 def __init__(self, width: float, height: float, title: str):
41 """Create the main game window
42
43 Arguments:
44 width {float} -- Width of the game window
45 height {float} -- Height of the game window
46 title {str} -- Title for the game window
47 """
48
49 # Call the super class init method
50 super().__init__(width, height, title)
51
52 # Set up a timer to create new coins
53 self.coin_countdown = 2.5
54 self.coin_interval = 0.1
55
56 # Score is initially zero
57 self.score = 0
58
59 # Set up empty sprite lists
60 self.coins = arcade.SpriteList()
61
62 # Don't show the mouse cursor
63 self.set_mouse_visible(False)
64
65 def setup(self):
66 """Get the game ready to play"""
67
68 # Set the background color
69 arcade.set_background_color(color=arcade.color.PINK)
70
71 # Set up the player
72 sprite_image = ASSETS_PATH / "images" / "alien_green_stand.png"
73 self.player = arcade.Sprite(
74 filename=sprite_image, center_x=WIDTH // 2, center_y=HEIGHT // 2
75 )
76
77 # Spawn a new coin
78 arcade.schedule(
79 function_pointer=self.add_coin, interval=self.coin_countdown
80 )
81
82 # Load your coin collision sound
83 self.coin_pickup_sound = arcade.load_sound(
84 ASSETS_PATH / "sounds" / "coin_pickup.wav"
85 )
86
87 def add_coin(self, dt: float):
88 """Add a new coin to the screen, reschedule the timer if necessary
89
90 Arguments:
91 dt {float} -- Time since last call (unused)
92 """
93
94 # Create a new coin
95 coin_image = ASSETS_PATH / "images" / "coin_gold.png"
96 new_coin = arcade.Sprite(
97 filename=coin_image,
98 center_x=randint(20, WIDTH - 20),
99 center_y=randint(20, HEIGHT - 20),
100 )
101
102 # Add the coin to the current list of coins
103 self.coins.append(new_coin)
104
105 # Decrease the time between coin appearances, but only if there are
106 # fewer than three coins on the screen.
107 if len(self.coins) < 3:
108 self.coin_countdown -= self.coin_interval
109
110 # Make sure you don't go too quickly
111 if self.coin_countdown < 0.1:
112 self.coin_countdown = 0.1
113
114 # Stop the previously scheduled call
115 arcade.unschedule(function_pointer=self.add_coin)
116
117 # Schedule the next coin addition
118 arcade.schedule(
119 function_pointer=self.add_coin, interval=self.coin_countdown
120 )
121
122 def on_mouse_motion(self, x: float, y: float, dx: float, dy: float):
123 """Processed when the mouse moves
124
125 Arguments:
126 x {float} -- X Position of the mouse
127 y {float} -- Y Position of the mouse
128 dx {float} -- Change in x position since last move
129 dy {float} -- Change in y position since last move
130 """
131
132 # Ensure the player doesn't move off-screen
133 self.player.center_x = arcade.clamp(x, 0, WIDTH)
134 self.player.center_y = arcade.clamp(y, 0, HEIGHT)
135
136 def on_update(self, delta_time: float):
137 """Update all the game objects
138
139 Arguments:
140 delta_time {float} -- How many seconds since the last frame?
141 """
142
143 # Check if you've picked up a coin
144 coins_hit = arcade.check_for_collision_with_list(
145 sprite=self.player, sprite_list=self.coins
146 )
147
148 for coin in coins_hit:
149 # Add the coin score to your score
150 self.score += COIN_VALUE
151
152 # Play the coin sound
153 arcade.play_sound(self.coin_pickup_sound)
154
155 # Remove the coin
156 coin.remove_from_sprite_lists()
157
158 # Are there more coins than allowed on the screen?
159 if len(self.coins) > COIN_COUNT:
160 # Stop adding coins
161 arcade.unschedule(function_pointer=self.add_coin)
162
163 # Show the mouse cursor
164 self.set_mouse_visible(True)
165
166 # Print the final score and exit the game
167 print(f"Game over! Final score: {self.score}")
168 exit()
169
170 def on_draw(self):
171 """Draw everything"""
172
173 # Start the rendering pass
174 arcade.start_render()
175
176 # Draw the coins
177 self.coins.draw()
178
179 # Draw the player
180 self.player.draw()
181
182 # Draw the score in the lower-left corner
183 arcade.draw_text(
184 text=f"Score: {self.score}",
185 start_x=50,
186 start_y=50,
187 font_size=32,
188 color=arcade.color.BLACK,
189 )
190
191if __name__ == "__main__":
192 arcade_game = ArcadeGame(WIDTH, HEIGHT, TITLE)
193 arcade_game.setup()
194 arcade.run()
Arcade 的面向对象特性允许您通过将游戏的初始化与每个不同级别的初始化分开来快速实现不同的级别。游戏在第 40 到 63 行的.__init__()方法中初始化,而关卡在第 65 到 85 行使用单独的.setup()方法设置和重启。这是一个很好的模式,即使是像这样只有一个关卡的游戏。
精灵是通过创建一个类arcade.Sprite的对象,并提供一个图像的路径来定义的。Arcade 支持 pathlib 路径,这使得在第 72 到 75 行上创建玩家精灵变得更加容易。
创建新硬币是在第 78 行到第 80 行的上处理的,它们每隔一段时间调用arcade.schedule()来调用self.add_coin()方法。
在第 87 到 120 行定义的.add_coin()方法在一个随机的位置创建一个新的硬币精灵,并将其添加到一个列表中,以简化绘图以及以后的碰撞处理。
要使用鼠标移动玩家,您需要在第 122 行到第 134 行的上实现.on_mouse_motion()方法。arcade.clamp()方法确保玩家的中心坐标不会离开屏幕。
检查玩家和硬币之间的碰撞是在行 144 到 156 的.on_update()方法中处理的。方法返回列表中所有与指定精灵冲突的精灵的列表。代码遍历列表,增加分数并播放声音效果,然后将每个硬币移出游戏。
.on_update()方法还检查在行 159 到 168 上是否有太多的硬币。如果是,游戏结束。
这个 Arcade 实现和 Pygame Zero 代码一样易读和结构良好,尽管它用了超过 27%的代码,写了 194 行。较长的代码可能是值得的,因为 Arcade 提供了更多这里没有展示的功能,例如:
- 动画精灵
- 几个内置的物理引擎
- 支持第三方游戏地图
- 更新的粒子和着色器系统
来自 Python Zero 的新游戏作者会发现 Arcade 在结构上类似,但提供了更强大和更广泛的功能。
adventure lib〔t0〕
当然,并不是每个游戏都需要一个彩色的玩家在屏幕上移动,躲避障碍,杀死坏人。像 Zork 这样的经典电脑游戏展示了好故事的力量,同时还提供了很好的游戏体验。制作这些基于文本的游戏,也被称为互动小说,在任何语言中都很难。对 Python 程序员来说幸运的是,有 adventurelib:
adventurelib 提供了编写基于文本的冒险游戏的基本功能,目的是让青少年也能轻松完成。(来源)
然而,这不仅仅是针对青少年的!adventurelib 非常适合那些想编写基于文本的游戏而不需要编写自然语言解析器的人。
adventurelib 由 Pygame Zero 背后的人创建,它处理更高级的计算机科学主题,例如状态管理、业务逻辑、命名和引用以及集合操作等等。这使它成为教育工作者、家长和导师帮助年轻人通过游戏学习计算机科学的伟大的下一步。这对拓展你自己的游戏编码技能也很有帮助。
adventurelib 安装
PyPI 上有 adventurelib,可以使用适当的pip命令进行安装:
(venv) $ python -m pip install adventurelib
adventurelib 是一个单独的文件,所以也可以从 GitHub repo 中下载,保存在和你的游戏相同的文件夹中,直接使用。
基本概念
为了学习 adventurelib 的基础知识,您将看到一个有三个房间的小游戏和一把打开下面最后一个房间的门的钥匙。该示例游戏的代码在adventurelib_basic.py的可下载资料中提供:
1"""
2Basic "Hello, World!" program in adventurelib
3
4This program is designed to demonstrate the basic capabilities
5of adventurelib. It will:
6- Create a basic three-room world
7- Add a single inventory item
8- Require that inventory item to move to the final room
9"""
10
11# Import the library contents
12import adventurelib as adv
13
14# Define your rooms
15bedroom = adv.Room(
16 """
17You are in your bedroom. The bed is unmade, but otherwise
18it's clean. Your dresser is in the corner, and a desk is
19under the window.
20"""
21)
22
23living_room = adv.Room(
24 """
25The living room stands bright and empty. The TV is off,
26and the sun shines brightly through the curtains.
27"""
28)
29
30front_porch = adv.Room(
31 """
32The creaky boards of your front porch welcome you as an
33old friend. Your front door mat reads 'Welcome'.
34"""
35)
36
37# Define the connections between the rooms
38bedroom.south = living_room
39living_room.east = front_porch
40
41# Define a constraint to move from the bedroom to the living room
42# If the door between the living room and front porch door is locked,
43# you can't exit
44living_room.locked = {"east": True}
45
46# None of the other rooms have any locked doors
47bedroom.locked = dict()
48front_porch.locked = dict()
49
50# Set the starting room as the current room
51current_room = bedroom
52
53# Define functions to use items
54def unlock_living_room(current_room):
55
56 if current_room == living_room:
57 print("You unlock the door.")
58 current_room.locked["east"] = False
59 else:
60 print("There is nothing to unlock here.")
61
62# Create your items
63key = adv.Item("a front door key", "key")
64key.use_item = unlock_living_room
65
66# Create empty Bags for room contents
67bedroom.contents = adv.Bag()
68living_room.contents = adv.Bag()
69front_porch.contents = adv.Bag()
70
71# Put the key in the bedroom
72bedroom.contents.add(key)
73
74# Set up your current empty inventory
75inventory = adv.Bag()
76
77# Define your movement commands
78@adv.when("go DIRECTION")
79@adv.when("north", direction="north")
80@adv.when("south", direction="south")
81@adv.when("east", direction="east")
82@adv.when("west", direction="west")
83@adv.when("n", direction="north")
84@adv.when("s", direction="south")
85@adv.when("e", direction="east")
86@adv.when("w", direction="west")
87def go(direction: str):
88 """Processes your moving direction
89
90 Arguments:
91 direction {str} -- which direction does the player want to move
92 """
93
94 # What is your current room?
95 global current_room
96
97 # Is there an exit in that direction?
98 next_room = current_room.exit(direction)
99 if next_room:
100 # Is the door locked?
101 if direction in current_room.locked and current_room.locked[direction]:
102 print(f"You can't go {direction} --- the door is locked.")
103 else:
104 current_room = next_room
105 print(f"You go {direction}.")
106 look()
107
108 # No exit that way
109 else:
110 print(f"You can't go {direction}.")
111
112# How do you look at the room?
113@adv.when("look")
114def look():
115 """Looks at the current room"""
116
117 # Describe the room
118 adv.say(current_room)
119
120 # List the contents
121 for item in current_room.contents:
122 print(f"There is {item} here.")
123
124 # List the exits
125 print(f"The following exits are present: {current_room.exits()}")
126
127# How do you look at items?
128@adv.when("look at ITEM")
129@adv.when("inspect ITEM")
130def look_at(item: str):
131
132 # Check if the item is in your inventory or not
133 obj = inventory.find(item)
134 if not obj:
135 print(f"You don't have {item}.")
136 else:
137 print(f"It's an {obj}.")
138
139# How do you pick up items?
140@adv.when("take ITEM")
141@adv.when("get ITEM")
142@adv.when("pickup ITEM")
143def get(item: str):
144 """Get the item if it exists
145
146 Arguments:
147 item {str} -- The name of the item to get
148 """
149 global current_room
150
151 obj = current_room.contents.take(item)
152 if not obj:
153 print(f"There is no {item} here.")
154 else:
155 print(f"You now have {item}.")
156 inventory.add(obj)
157
158# How do you use an item?
159@adv.when("unlock door", item="key")
160@adv.when("use ITEM")
161def use(item: str):
162 """Use an item, consumes it if used
163
164 Arguments:
165 item {str} -- Which item to use
166 """
167
168 # First, do you have the item?
169 obj = inventory.take(item)
170 if not obj:
171 print(f"You don't have {item}")
172
173 # Try to use the item
174 else:
175 obj.use_item(current_room)
176
177if __name__ == "__main__":
178 # Look at the starting room
179 look()
180
181 adv.start()
要运行此代码,请使用以下命令:
(venv) $ python adventurelib/adventurelib_basic.py
基于文本的游戏严重依赖于解析用户输入来驱动游戏前进。adventurelib 将玩家键入的文本定义为一个命令,并提供@when() 装饰器来定义命令。
命令的一个很好的例子是在行 113 到 125 上定义的look命令。@when("look")装饰器将文本look添加到有效命令列表中,并将其连接到look()函数。每当玩家键入look,adventurelib 就会调用look()函数。
玩家输入的命令不区分大小写。玩家可以键入look、LOOK、Look,甚至lOOk,adventurelib 会找到正确的命令。
多个命令可以使用相同的功能,如第 78 到 110 行的go()功能所示。这个功能由九个独立的命令装饰,允许玩家以几种不同的方式在游戏世界中移动。在下面的游戏示例中,命令south、east和north都被使用,但是每一个都导致相同的函数被调用:
有时候玩家输入的命令是针对某个特定的物品的。例如,玩家可能想看某个特定的东西或者朝某个特定的方向走。游戏设计者可以通过在@when()装饰器中指定大写单词来捕获额外的命令上下文。这些被视为变量名,玩家在它们的位置键入的文本就是值。
这可以在第 128 到 137 行的look_at()功能中看到。这个函数定义了一个名为item的字符串参数。在定义look at和inspect命令的@when()装饰器中,单词ITEM充当命令后面任何文本的占位符。然后,该文本作为item参数传递给look_at()函数。比如玩家输入look at book,那么参数item就会得到值"book"。
基于文本的游戏的优势依赖于其文本的描述性。虽然您可以并且应该使用print()函数,但是为了响应用户命令而打印多行文本会给跨多行文本和确定换行符带来困难。adventurelib 通过say()函数减轻了这一负担,该函数可以很好地处理三重引用的多行字符串。
您可以在look()功能中的线 118 上看到say()功能正在运行。每当玩家输入look时,say()功能就会向控制台输出当前房间的描述。
当然,你的命令需要出现的地方。adventurelib 提供了Room类来定义游戏世界的不同区域。通过提供房间的描述来创建房间,并且可以使用.north、.south、.east和.west属性将它们连接到其他房间。您还可以定义应用于整个Room类或单个对象的自定义属性。
这个游戏中的三个房间是在15 到 35 线创建的。Room()构造函数接受字符串形式的描述,或者在本例中,接受多行字符串形式的描述。一旦你创建了房间,然后你在第 38 到 39 行上连接它们。将bedroom.south设置为living_room意味着living_room.north将成为bedroom。adventurelib 足够智能,可以自动建立这种连接。
您还可以在线 44 上创建一个约束,以指示起居室和前廊之间的一扇锁着的门。打开这扇门需要玩家找到一个物品。
基于文本的游戏通常以必须收集的物品为特色,以打开游戏的新领域或解决某些谜题。物品也可以代表玩家可以与之互动的非玩家角色。adventurelib 提供了Item类来通过名字和别名定义可收集的物品和非玩家角色。例如,别名key是指前门钥匙:
在第 63 行,你定义了用于打开客厅和前廊之间的门的key。Item()构造函数接受一个或多个字符串。第一个是项目的默认名称或全名,在打印项目名称时使用。所有其他名称都被用作别名,因此玩家不必键入项目的全名。
这个key不仅仅有名字和别名。它还有一个预期用途,在行 64 中定义。key.use_item是指当玩家试图通过输入"use key"来使用该物品时将被调用的功能。该功能在行 159 至 175 定义的use()命令处理器中调用。
物品的集合,例如玩家的物品清单或房间地面上的物品,可以存储在一个Bag对象中。您可以向包中添加物品,从包中取出物品,以及检查包中的物品。Bag对象在 Python 中是可迭代的,所以你也可以使用in来测试包里是否有东西,并在for循环中遍历包里的内容。
四个不同的Bag对象被定义在行 67 到 75 上。三个房间中的每一个都有一个Bag来存放房间中的物品,玩家也有一个Bag来存放他们拾取的inventory物品。key项目被放置在bedroom的起始位置。
物品通过行 140 到 156 定义的get()功能添加到玩家的物品清单中。当玩家输入get key时,你试图在行 151 上take()房间contents包中的物品。如果key被归还,它也会从房间的contents中移除。然后将key添加到玩家的inventory中的行 156 处。
高级应用程序
当然,adventurelib 还有更多内容。为了展示它的其他功能,您将使用下面的背景故事来创建一个更复杂的文本冒险:
- 你住在一个安静的小村庄里。
- 最近,你的邻居开始抱怨丢失的牲畜。
- 作为夜间巡逻队的一员,你注意到一个破损的栅栏和一条离开它的痕迹。
- 你决定去调查,只带了一把练习用的木剑。
这个游戏有几个方面需要描述和定义:
- 你安静的小村庄
- 这条小路远离田野
- 附近的一个村庄,在那里你可以买到更好的武器
- 一条通往能为你的武器附魔的巫师的小路
- 一个洞穴,里面有一个拿走你牲畜的巨人
有几个项目需要收集,如武器和食物,以及与角色互动。你还需要一个基本的战斗系统来让你与巨人战斗并赢得比赛。
这个游戏的所有代码都列在下面,可以在下载的资料中找到:
获取源代码: 点击此处获取您将使用试用 Python 游戏引擎的源代码。
为了让事情有条理,你把你的游戏分成不同的文件:
adventurelib_game_rooms.py定义房间和区域。adventurelib_game_items.py定义项目及其属性。adventurelib_game_characters.py定义您可以与之互动的角色。- 把所有东西放在一起,添加命令,然后开始游戏。
1"""
2Complete game written in adventurelib
3
4This program is designed to demonstrate the capabilities
5of adventurelib. It will:
6- Create a large world in which to wander
7- Contain several inventory items
8- Set contexts for moving from one area to another
9- Require some puzzle-solving skills
10"""
11
12# Import the library contents
13# from adventurelib import *
14import adventurelib as adv
15
16# Import your rooms, which imports your items and characters
17import adventurelib_game_rooms
18
19import adventurelib_game_items
20
21# For your battle sequence
22from random import randint
23
24# To allow you to exit the game
25import sys
26
27# Set the first room
28current_room = adventurelib_game_rooms.home
29current_room.visited = False
30
31# How many HP do you have?
32hit_points = 20
33
34# How many HP does the giant have?
35giant_hit_points = 50
36
37# Your current inventory
38inventory = adv.Bag()
39
40# Some basic item commands
41@adv.when("inventory")
42@adv.when("inv")
43@adv.when("i")
44def list_inventory():
45 if inventory:
46 print("You have the following items:")
47 for item in inventory:
48 print(f" - {item.description}")
49 else:
50 print("You have nothing in your inventory.")
51
52@adv.when("look at ITEM")
53def look_at(item: str):
54 """Prints a short description of an item if it is either:
55 1\. in the current room, or
56 2\. in our inventory
57
58 Arguments:
59 item {str} -- the item to look at
60 """
61
62 global inventory, current_room
63
64 # Check if the item is in the room
65 obj = current_room.items.find(item)
66 if not obj:
67 # Check if the item is in your inventory
68 obj = inventory.find(item)
69 if not obj:
70 print(f"I can't find {item} anywhere.")
71 else:
72 print(f"You have {item}.")
73 else:
74 print(f"You see {item}.")
75
76@adv.when("describe ITEM")
77def describe(item: str):
78 """Prints a description of an item if it is either:
79 1\. in the current room, or
80 2\. in your inventory
81
82 Arguments:
83 item {str} -- the item to look at
84 """
85
86 global inventory, current_room
87
88 # Check if the item is in the room
89 obj = current_room.items.find(item)
90 if not obj:
91 # Check if the item is in your inventory
92 obj = inventory.find(item)
93 if not obj:
94 print(f"I can't find {item} anywhere.")
95 else:
96 print(f"You have {obj.description}.")
97 else:
98 print(f"You see {obj.description}.")
99
100@adv.when("take ITEM")
101@adv.when("get ITEM")
102@adv.when("pickup ITEM")
103@adv.when("pick up ITEM")
104@adv.when("grab ITEM")
105def take_item(item: str):
106 global current_room
107
108 obj = current_room.items.take(item)
109 if not obj:
110 print(f"I don't see {item} here.")
111 else:
112 print(f"You now have {obj.description}.")
113 inventory.add(obj)
114
115@adv.when("eat ITEM")
116def eat(item: str):
117 global inventory
118
119 # Make sure you have the thing first
120 obj = inventory.find(item)
121
122 # Do you have this thing?
123 if not obj:
124 print(f"You don't have {item}.")
125
126 # Is it edible?
127 elif obj.edible:
128 print(f"You savor every bite of {obj.description}.")
129 inventory.take(item)
130
131 else:
132 print(f"How do you propose we eat {obj.description}?")
133
134@adv.when("wear ITEM")
135@adv.when("put on ITEM")
136def wear(item: str):
137 global inventory
138
139 # Make sure you have the thing first
140 obj = inventory.find(item)
141
142 # Do you have this thing?
143 if not obj:
144 print(f"You don't have {item}.")
145
146 # Is it wearable?
147 elif obj.wearable:
148 print(f"The {obj.description} makes a wonderful fashion statement!")
149
150 else:
151 print(
152 f"""This is no time for avant garde fashion choices!
153 Wear a {obj.description}? Really?"""
154 )
155
156# Some character-specific commands
157@adv.when("talk to CHARACTER")
158def talk_to(character: str):
159 global current_room
160
161 char = current_room.characters.find(character)
162
163 # Is the character there?
164 if not char:
165 print(f"Sorry, I can't find {character}.")
166
167 # It's a character who is there
168 else:
169 # Set the context, and start the encounter
170 adv.set_context(char.context)
171 adv.say(char.greeting)
172
173@adv.when("yes", context="elder")
174def yes_elder():
175 global current_room
176
177 adv.say(
178 """
179 It is not often one of our number leaves, and rarer still if they leave
180 to defend our Home. Go with our blessing, and our hope for a successful
181 journey and speedy return. To help, we bestow three gifts.
182
183 The first is one of knowledge. There is a blacksmith in one of the
184 neighboring villages. You may find help there.
185
186 Second, seek a wizard who lives as a hermit, who may be persuaded to
187 give aid. Be wary, though! The wizard does not give away his aid for
188 free. As he tests you, remember always where you started your journey.
189
190 Lastly, we don't know what dangers you may face. We are peaceful people,
191 but do not wish you to go into the world undefended. Take this meager
192 offering, and use it well!
193 """
194 )
195 inventory.add(adventurelib_game_items.wooden_sword)
196 current_room.locked_exits["south"] = False
197
198@adv.when("thank you", context="elder")
199@adv.when("thanks", context="elder")
200def thank_elder():
201 adv.say("It is we who should thank you. Go with our love and hopes!")
202
203@adv.when("yes", context="blacksmith")
204def yes_blacksmith():
205 global current_room
206
207 adv.say(
208 """
209 I can see you've not a lot of money. Usually, everything here
210 if pretty expensive, but I just might have something...
211
212 There's this steel sword here, if you want it. Don't worry --- it
213 doesn't cost anything! It was dropped off for repair a few weeks
214 ago, but the person never came back for it. It's clean, sharp,
215 well-oiled, and will do a lot more damage than that
216 fancy sword-shaped club you've got. I need it gone to clear some room.
217
218 If you want, we could trade even up --- the wooden sword for the
219 steel one. I can use yours for fire-starter. Deal?
220 """
221 )
222 adv.set_context("blacksmith.trade")
223
224@adv.when("yes", context="blacksmith.trade")
225def trade_swords_yes():
226 print("Great!")
227 inventory.take("wooden sword")
228 inventory.add(adventurelib_game_items.steel_sword)
229
230@adv.when("no", context="blacksmith.trade")
231def trade_swords_no():
232 print("Well, that's all I have within your budget. Good luck!")
233 adv.set_context(None)
234
235@adv.when("yes", context="wizard")
236def yes_wizard():
237 global current_room
238
239 adv.say(
240 """
241 I can make your weapon more powerful than it is, but only if
242 you can answer my riddle:
243
244 What has one head...
245 One foot...
246 But four legs?
247 """
248 )
249
250 adv.set_context("wizard.riddle")
251
252@adv.when("bed", context="wizard.riddle")
253@adv.when("a bed", context="wizard.riddle")
254def answer_riddle():
255 adv.say("You are smarter than you believe yourself to be! Behold!")
256
257 obj = inventory.find("sword")
258 obj.bonus = 2
259 obj.description += ", which glows with eldritch light"
260
261 adv.set_context(None)
262 current_room.locked_exits["west"] = False
263
264@adv.when("fight CHARACTER", context="giant")
265def fight_giant(character: str):
266
267 global giant_hit_points, hit_points
268
269 sword = inventory.find("sword")
270
271 # The player gets a swing
272 player_attack = randint(1, sword.damage + 1) + sword.bonus
273 print(f"You swing your {sword}, doing {player_attack} damage!")
274 giant_hit_points -= player_attack
275
276 # Is the giant dead?
277 if giant_hit_points <= 0:
278 end_game(victory=True)
279
280 print_giant_condition()
281 print()
282
283 # Then the giant tries
284 giant_attack = randint(0, 5)
285 if giant_attack == 0:
286 print("The giant's arm whistles harmlessly over your head!")
287 else:
288 print(
289 f"""
290 The giant swings his mighty fist,
291 and does {giant_attack} damage!
292 """
293 )
294 hit_points -= giant_attack
295
296 # Is the player dead?
297 if hit_points <= 0:
298 end_game(victory=False)
299
300 print_player_condition()
301 print()
302
303def print_giant_condition():
304
305 if giant_hit_points < 10:
306 print("The giant staggers, his eyes unfocused.")
307 elif giant_hit_points < 20:
308 print("The giant's steps become more unsteady.")
309 elif giant_hit_points < 30:
310 print("The giant sweats and wipes the blood from his brow.")
311 elif giant_hit_points < 40:
312 print("The giant snorts and grits his teeth against the pain.")
313 else:
314 print("The giant smiles and readies himself for the attack.")
315
316def print_player_condition():
317
318 if hit_points < 4:
319 print("Your eyes lose focus on the giant as you sway unsteadily.")
320 elif hit_points < 8:
321 print(
322 """
323 Your footing becomes less steady
324 as you swing your sword sloppily.
325 """
326 )
327 elif hit_points < 12:
328 print(
329 """
330 Blood mixes with sweat on your face
331 as you wipe it from your eyes.
332 """
333 )
334 elif hit_points < 16:
335 print("You bite down as the pain begins to make itself felt.")
336 else:
337 print("You charge into the fray valiantly!")
338
339def end_game(victory: bool):
340 if victory:
341 adv.say(
342 """
343 The giant falls to his knees as the last of his strength flees
344 his body. He takes one final swing at you, which you dodge easily.
345 His momentum carries him forward, and he lands face down in the dirt.
346 His final breath escapes his lips as he succumbs to your attack.
347
348 You are victorious! Your name will be sung for generations!
349 """
350 )
351
352 else:
353 adv.say(
354 """
355 The giant's mighty fist connects with your head, and the last
356 sound you hear are the bones in your neck crunching. You spin
357 and tumble down, your sword clattering to the floor
358 as the giant laughs.
359 Your eyes see the giant step towards you, his mighty foot
360 raised to crash down on you.
361 Oblivion takes over before you experience anything else...
362
363 You have been defeated! The giant is free to ravage your town!
364 """
365 )
366
367 sys.exit()
368
369@adv.when("flee", context="giant")
370def flee():
371 adv.say(
372 """
373 As you turn to run, the giant reaches out and catches your tunic.
374 He lifts you off the ground, grabbing your dangling sword-arm
375 as he does so. A quick twist, and your sword tumbles to the ground.
376 Still holding you, he reaches his hand to your throat and squeezes,
377 cutting off your air supply.
378
379 The last sight you see before blackness takes you are
380 the rotten teeth of the evil grin as the giant laughs
381 at your puny attempt to stop him...
382
383 You have been defeated! The giant is free to ravage your town!
384 """
385 )
386
387 sys.exit()
388
389@adv.when("goodbye")
390@adv.when("bye")
391@adv.when("adios")
392@adv.when("later")
393def goodbye():
394
395 # Are you fighting the giant?
396 if adv.get_context() == "giant":
397 # Not so fast!
398 print("The giant steps in front of you, blocking your exit!")
399
400 else:
401 # Close the current context
402 adv.set_context(None)
403 print("Fare thee well, traveler!")
404
405# Define some basic commands
406@adv.when("look")
407def look():
408 """Print the description of the current room.
409 If you've already visited it, print a short description.
410 """
411 global current_room
412
413 if not current_room.visited:
414 adv.say(current_room)
415 current_room.visited = True
416 else:
417 print(current_room.short_desc)
418
419 # Are there any items here?
420 for item in current_room.items:
421 print(f"There is {item.description} here.")
422
423@adv.when("describe")
424def describe_room():
425 """Print the full description of the room."""
426 adv.say(current_room)
427
428 # Are there any items here?
429 for item in current_room.items:
430 print(f"There is {item.description} here.")
431
432# Define your movement commands
433@adv.when("go DIRECTION")
434@adv.when("north", direction="north")
435@adv.when("south", direction="south")
436@adv.when("east", direction="east")
437@adv.when("west", direction="west")
438@adv.when("n", direction="north")
439@adv.when("s", direction="south")
440@adv.when("e", direction="east")
441@adv.when("w", direction="west")
442def go(direction: str):
443 """Processes your moving direction
444
445 Arguments:
446 direction {str} -- which direction does the player want to move
447 """
448
449 # What is your current room?
450 global current_room
451
452 # Is there an exit in that direction?
453 next_room = current_room.exit(direction)
454 if next_room:
455 # Is the door locked?
456 if (
457 direction in current_room.locked_exits
458 and current_room.locked_exits[direction]
459 ):
460 print(f"You can't go {direction} --- the door is locked.")
461 else:
462 # Clear the context if necessary
463 current_context = adv.get_context()
464 if current_context == "giant":
465 adv.say(
466 """Your way is currently blocked.
467 Or have you forgotten the giant you are fighting?"""
468 )
469 else:
470 if current_context:
471 print("Fare thee well, traveler!")
472 adv.set_context(None)
473
474 current_room = next_room
475 print(f"You go {direction}.")
476 look()
477
478 # No exit that way
479 else:
480 print(f"You can't go {direction}.")
481
482# Define a prompt
483def prompt():
484 global current_room
485
486 # Get possible exits
487 exits_string = get_exits(current_room)
488
489 # Are you in battle?
490 if adv.get_context() == "giant":
491 prompt_string = f"HP: {hit_points} > "
492 else:
493 prompt_string = f"({current_room.title}) > "
494
495 return f"""({exits_string}) {prompt_string}"""
496
497def no_command_matches(command: str):
498 if adv.get_context() == "wizard.riddle":
499 adv.say("That is not the correct answer. Begone!")
500 adv.set_context(None)
501 current_room.locked_exits["west"] = False
502 else:
503 print(f"What do you mean by '{command}'?")
504
505def get_exits(room):
506 exits = room.exits()
507
508 exits_string = ""
509 for exit in exits:
510 exits_string += f"{exit[0].upper()}|"
511
512 return exits_string[:-1]
513
514# Start the game
515if __name__ == "__main__":
516 # No context is normal
517 adv.set_context(None)
518
519 # Set the prompt
520 adv.prompt = prompt
521
522 # What happens with unknown commands
523 adv.no_command_matches = no_command_matches
524
525 # Look at your starting room
526 look()
527
528 # Start the game
529 adv.start()
1"""
2Rooms for the adventurelib game
3"""
4
5# Import the library contents
6import adventurelib as adv
7
8# Import your items as well
9import adventurelib_game_items
10
11# And your characters
12import adventurelib_game_characters
13
14# Create a subclass of Rooms to track some custom properties
15class GameArea(adv.Room):
16 def __init__(self, description: str):
17
18 super().__init__(description)
19
20 # All areas can have locked exits
21 self.locked_exits = {
22 "north": False,
23 "south": False,
24 "east": False,
25 "west": False,
26 }
27 # All areas can have items in them
28 self.items = adv.Bag()
29
30 # All areas can have characters in them
31 self.characters = adv.Bag()
32
33 # All areas may have been visited already
34 # If so, you can print a shorter description
35 self.visited = False
36
37 # Which means each area needs a shorter description
38 self.short_desc = ""
39
40 # Each area also has a very short title for the prompt
41 self.title = ""
42
43# Your home
44home = GameArea(
45 """
46You wake as the sun streams in through the single
47window into your small room. You lie on your feather bed which
48hugs the north wall, while the remains of last night's
49fire smolders in the center of the room.
50
51Remembering last night's discussion with the council, you
52throw back your blanket and rise from your comfortable
53bed. Cold water awaits you as you splash away the night's
54sleep, grab an apple to eat, and prepare for the day.
55"""
56)
57home.title = "Home"
58home.short_desc = "This is your home."
59
60# Hamlet
61hamlet = GameArea(
62 """
63From the center of your small hamlet, you can see every other
64home. It doesn't really even have an official name --- folks
65around here just call it Home.
66
67The council awaits you as you approach. Elder Barron beckons you
68as you exit your home.
69"""
70)
71hamlet.title = "Hamlet"
72hamlet.short_desc = "You are in the hamlet."
73
74# Fork in road
75fork = GameArea(
76 """
77As you leave your hamlet, you think about how unprepared you
78really are. Your lack of experience and pitiful equipment
79are certainly no match for whatever has been stealing
80the villages livestock.
81
82As you travel, you come across a fork in the path. The path of
83the livestock thief continues east. However, you know
84the village of Dunhaven lies to the west, where you may
85get some additional help.
86"""
87)
88fork.title = "Fork in road"
89fork.short_desc = "You are at a fork in the road."
90
91# Village of Dunhaven
92village = GameArea(
93 """
94A short trek up the well-worn path brings you the village
95of Dunhaven. Larger than your humble Home, Dunhaven sits at
96the end of a supply route from the capitol. As such, it has
97amenities and capabilities not found in the smaller farming
98communities.
99
100As you approach, you hear the clang-clang of hammer on anvil,
101and inhale the unmistakable smell of the coal-fed fire of a
102blacksmith shop to your south.
103"""
104)
105village.title = "Village of Dunhaven"
106village.short_desc = "You are in the village of Dunhaven."
107
108# Blacksmith shop
109blacksmith_shop = GameArea(
110 """
111As you approach the blacksmith, the sounds of the hammer become
112clearer and clearer. Passing the front door, you head towards
113the sound of the blacksmith, and find her busy at the furnace.
114"""
115)
116blacksmith_shop.title = "Blacksmith Shop"
117blacksmith_shop.short_desc = "You are in the blacksmith shop."
118
119# Side path away from fork
120side_path = GameArea(
121 """
122The path leads away from the fork to Dunhaven. Fresh tracks of
123something big, dragging something behind it, lead away to the south.
124"""
125)
126side_path.title = "Side path"
127side_path.short_desc = "You are standing on a side path."
128
129# Wizard's Hut
130wizard_hut = GameArea(
131 """
132The path opens into a shaded glen. A small stream wanders down the
133hills to the east and past an unassuming hut. In front of the hut,
134the local wizard Trent sits smoking a long clay pipe.
135"""
136)
137wizard_hut.title = "Wizard's Hut"
138wizard_hut.short_desc = "You are at the wizard's hut."
139
140# Cave mouth
141cave_mouth = GameArea(
142 """
143The path from Trent's hut follows the stream for a while before
144turning south away from the water. The trees begin closing overhead,
145blocking the sun and lending a chill to the air as you continue.
146
147The path finally terminates at the opening of a large cave. The
148tracks you have been following mix and mingle with others, both
149coming and going, but all the same. Whatever has been stealing
150your neighbor's livestock lives here, and comes and goes frequently.
151"""
152)
153cave_mouth.title = "Cave Mouth"
154cave_mouth.short_desc = "You are at the mouth of large cave."
155
156# Cave of the Giant
157giant_cave = GameArea(
158 """
159You take a few tentative steps into the cave. It feels much warmer
160and more humid than the cold sunless forest air outside. A steady
161drip of water from the rocks is the only sound for a while.
162
163You begin to make out a faint light ahead. You hug the wall and
164press on, as the light becomes brighter. You finally enter a
165chamber at least 20 meters across, with a fire blazing in the center.
166Cages line one wall, some empty, but others containing cows and
167sheep stolen from you neighbors. Opposite them are piles of the bones
168of the creatures unlucky enough to have already been devoured.
169
170As you look around, you become aware of another presence in the room.
171"""
172)
173giant_cave.title = "Cave of the Giant"
174giant_cave.short_desc = "You are in the giant's cave."
175
176# Set up the paths between areas
177home.south = hamlet
178hamlet.south = fork
179fork.west = village
180fork.east = side_path
181village.south = blacksmith_shop
182side_path.south = wizard_hut
183wizard_hut.west = cave_mouth
184cave_mouth.south = giant_cave
185
186# Lock some exits, since you can't leave until something else happens
187hamlet.locked_exits["south"] = True
188wizard_hut.locked_exits["west"] = True
189
190# Place items in different areas
191# These are just for flavor
192home.items.add(adventurelib_game_items.apple)
193fork.items.add(adventurelib_game_items.cloak)
194cave_mouth.items.add(adventurelib_game_items.slug)
195
196# Place characters where they should be
197hamlet.characters.add(adventurelib_game_characters.elder_barron)
198blacksmith_shop.characters.add(adventurelib_game_characters.blacksmith)
199wizard_hut.characters.add(adventurelib_game_characters.wizard_trent)
200giant_cave.characters.add(adventurelib_game_characters.giant)
1"""
2Items for the adventurelib Game
3"""
4
5# Import the adventurelib library
6import adventurelib as adv
7
8# All items have some basic properties
9adv.Item.color = "undistinguished"
10adv.Item.description = "a generic thing"
11adv.Item.edible = False
12adv.Item.wearable = False
13
14# Create your "flavor" items
15apple = adv.Item("small red apple", "apple")
16apple.color = "red"
17apple.description = "a small ripe red apple"
18apple.edible = True
19apple.wearable = False
20
21cloak = adv.Item("wool cloak", "cloak")
22cloak.color = "grey tweed"
23cloak.description = (
24 "a grey tweed cloak, heavy enough to keep the wind and rain at bay"
25)
26cloak.edible = False
27cloak.wearable = True
28
29slug = adv.Item("slimy brown slug", "slug")
30slug.color = "slimy brown"
31slug.description = "a fat, slimy, brown slug"
32slug.edible = True
33slug.wearable = False
34
35# Create the real items you need
36wooden_sword = adv.Item("wooden sword", "sword")
37wooden_sword.color = "brown"
38wooden_sword.description = (
39 "a small wooden practice sword, not even sharp enough to cut milk"
40)
41wooden_sword.edible = False
42wooden_sword.wearable = False
43wooden_sword.damage = 4
44wooden_sword.bonus = 0
45
46steel_sword = adv.Item("steel sword", "sword")
47steel_sword.color = "steely grey"
48steel_sword.description = (
49 "a finely made steel sword, honed to a razor edge, ready for blood"
50)
51steel_sword.edible = False
52steel_sword.wearable = False
53steel_sword.damage = 10
54steel_sword.bonus = 0
1"""
2Characters for the adventurelib Game
3"""
4
5# Import the adventurelib library
6import adventurelib as adv
7
8# All characters have some properties
9adv.Item.greeting = ""
10adv.Item.context = ""
11
12# Your characters
13elder_barron = adv.Item("Elder Barron", "elder", "barron")
14elder_barron.description = """Elder Barron, a tall distinguished member
15of the community. His steely grey hair and stiff beard inspire confidence."""
16elder_barron.greeting = (
17 "I have some information for you. Would you like to hear it?"
18)
19elder_barron.context = "elder"
20
21blacksmith = adv.Item("Alanna Smith", "Alanna", "blacksmith", "smith")
22blacksmith.description = """Alanna the blacksmith stands just 1.5m tall,
23and her strength lies in her arms and heart"""
24blacksmith.greeting = (
25 "Oh, hi! I've got some stuff for sale. Do you want to see it?"
26)
27blacksmith.context = "blacksmith"
28
29wizard_trent = adv.Item("Trent the Wizard", "Trent", "wizard")
30wizard_trent.description = """Trent's wizardly studies have apparently
31aged him past his years, but they have also preserved his life longer than
32expected."""
33wizard_trent.greeting = (
34 "It's been a long time since I've had a visitor? Do you seek wisdom?"
35)
36wizard_trent.context = "wizard"
37
38giant = adv.Item("hungry giant", "giant")
39giant.description = """Almost four meters of hulking brutish strength
40stands before you, his breath rank with rotten meat, his mangy hair
41tangled and matted"""
42giant.greeting = "Argh! Who dares invade my home? Prepare to defend yourself!"
43giant.context = "giant"
你可以用下面的命令开始这个游戏:
(venv) $ python adventurelib/adventurelib_game.py
在定义了背景故事之后,你绘制了不同的游戏区域和玩家在它们之间移动的路径:
每个区域都有与其相关联的各种属性,包括:
- 该区域中的项目和角色
- 一些出口被锁上了
- 标题、简短描述和较长描述
- 玩家是否到过这个区域的指示
为了确保每个区域都有自己的属性实例,您在第 15 到 41 行的adventurelib_game_rooms.py中创建了一个名为GameArea的Room的子类。每个房间中的物品保存在一个名为items的Bag对象中,而角色存储在characters中,在的第 28 行和第 31 行中定义。现在您可以创建GameArea对象,描述它们,并用独特的项目和角色填充它们,这些都在第 9 行和第 12 行中导入。
一些游戏道具是完成游戏所必需的,而其他的只是为了增加趣味。风味项目被识别并放置在行 192 到 194 上,随后是行 197 到 200 上的字符。
你所有的游戏物品都在adventurelib_game_items.py中被定义为Item()类型的对象。游戏物品有定义它们的属性,但是因为你使用了Item基类,一些基本的通用属性被添加到第 9 到 12 行的类中。创建项目时会用到这些属性。例如,apple对象创建于第 15 到 19 行,并在创建时定义每个通用属性。
但是,某些项目具有该项目独有的特定属性。例如,wooden_sword和steel_sword物品需要属性来追踪它们造成的伤害和它们携带的魔法奖励。在43 至 44 线和 53 至 54 线追加。
与角色互动有助于推动游戏故事向前发展,并经常给玩家一个探索的理由。adventurelib 中的角色被创建为Item对象,并且在adventurelib_game_characters.py中定义了该游戏的角色。
每个角色,就像每个物品一样,都有与之相关的通用属性,比如长描述和玩家第一次遇到它时使用的问候语。这些属性在的第 9 行和第 10 行声明,并且在创建角色时为每个角色定义。
当然,如果你有角色,那么玩家与他们交谈和互动是有意义的。知道什么时候你在和一个角色互动,什么时候你和一个角色在同一个游戏区域通常是个好主意。
这是通过使用一个叫做上下文的 adventurelib 概念来完成的。上下文允许您针对不同的情况打开不同的命令。它们还允许某些命令有不同的行为,并跟踪玩家可能采取的行动的附加信息。
当游戏开始时,没有背景设定。随着玩家的前进,他们首先遇到了老巴伦。当玩家输入"talk to elder"时,上下文被设置为elder.context,在本例中是elder。
老巴伦的问候以一个是或否的问题结束。如果玩家输入"yes",那么adventurelib_game.py中行 173 上的命令处理程序被触发,定义为@when("yes", context="elder"),如下图所示:

稍后,当玩家与铁匠交谈时,第二层的上下文被添加,以反映他们正在进行一场可能的武器交易。第 203 到 233 行定义了与铁匠的讨论,包括提供武器交易。在第 222 行上定义了一个新的上下文,这允许以多种方式优雅地使用同一个"yes"命令。
您还可以在命令处理程序中检查上下文。例如,玩家不能简单地通过结束对话来离开与巨人的战斗。在行 389 到 403 定义的"goodbye"命令处理程序检查玩家是否在"giant"上下文中,这是当他们开始与巨人战斗时进入的。如果是这样,他们不允许停止谈话——这是一场殊死搏斗!
你也可以问玩家一些需要具体答案的问题。当玩家与巫师特伦特交谈时,他们被要求解答一个谜语。不正确的答案将结束互动。虽然正确答案由第 252 到 262 行上的命令处理程序处理,但几乎无限的错误答案中有一个与任何处理程序都不匹配。
没有匹配的命令由行 497 到 503 上的no_command_matches()函数处理。通过检查第行 498 上的wizard.riddle上下文,您可以利用这一点来处理向导谜语的错误答案。任何不正确的答案将导致向导结束对话。通过将adventurelib.no_command_matches设置为您的新函数,您可以在行 523 上将它连接到 adventurelib。
您可以通过编写一个返回新提示的函数来自定义显示给播放器的提示。您的新提示定义在第 483 到 495 行的上,并连接到第 520 行的上的 adventurelib。
当然,你还可以添加更多。创建一个完整的文本冒险游戏是具有挑战性的,adventurelib 确保主要的挑战在于用文字画一幅画。
Ren'Py
纯文本冒险的现代后代是视觉小说,它突出了游戏的讲故事方面,限制了玩家的互动,同时添加了视觉和声音来增强体验。视觉小说是游戏世界的图画小说——现代的、创新的、极具吸引力的创作和消费。
Ren'Py 是一款基于 Pygame 的工具,专为创作视觉小说而设计。Ren'Py 的名字来自日语,意为浪漫爱情,它为制作引人入胜的视觉小说提供了工具和框架。
公平地说,Ren'Py 严格来说并不是一个你可以使用的 Python 库。Ren'Py 游戏是使用 Ren'Py Launcher 创建的,它带有完整的 Ren'Py SDK。这个启动器也有一个游戏编辑器,虽然你可以在你选择的编辑器中编辑你的游戏。Ren'Py 还拥有自己的游戏创作脚本语言。然而,Ren'Py 基于 Pygame,并且可以使用 Python 进行扩展,这保证了它在这里的出现。
Ren'Py 装置
如前所述,Ren'Py 不仅需要 SDK,还需要 Ren'Py 启动器。这些都打包在一个单元里,你需要下载。
知道下载哪个包以及如何安装取决于您的平台。Ren'Py 为 Windows、macOS 和 Linux 用户提供安装程序和说明:
**Windows 用户应该下载提供的可执行文件,然后运行它来安装 SDK 和 Ren'Py Launcher。
Linux 用户应该将提供的 tarball 下载到一个方便的位置,然后使用bunzip2展开它。
macOS 用户应该下载提供的 DMG 文件,双击该文件将其打开,并将内容复制到一个方便的位置。
软件包安装完成后,您可以导航到包含 SDK 的文件夹,然后运行 Ren'Py 启动器。Windows 用户要用renpy.exe,macOS 和 Linux 用户要运行renpy.sh。这将首次启动 Ren'Py 启动器:
在这里,您将开始新的 Ren'Py 项目,处理现有项目,并设置 Ren'Py 的整体首选项。
基本概念
Ren'Py 游戏在 Ren'Py 启动器中作为新项目启动。创建一个将会为一个游戏建立正确的文件和文件夹结构。项目建立后,您可以使用自己的编辑器编写游戏,尽管运行游戏需要 Ren'Py 启动器:
任我行游戏包含在名为脚本的文件中。不要把 Ren'Py 脚本当成 shell 脚本。它们更类似于戏剧或电视节目的脚本。瑞文脚本的扩展名为.rpy,是用瑞文语言编写的。您的游戏可以包含任意多的脚本,这些脚本都存储在项目文件夹的game/子文件夹中。
创建新的 Ren'Py 项目时,会创建以下脚本供您使用和更新:
gui.rpy,它定义了游戏中使用的所有 UI 元素的外观options.rpy,它定义了可改变的选项来定制你的游戏screens.rpy,定义了用于对话、菜单和其他游戏输出的样式- 这是你开始编写游戏的地方
要运行本教程下载资料中的示例游戏,您将使用以下过程:
- 启动 Ren'Py 发射器。
- 点击首选项,然后点击项目目录。
- 将项目目录更改为您下载的存储库中的
renpy文件夹。 - 点击返回返回到主启动页面。
您会在左侧的项目列表中看到basic_game和giant_quest_game。选择您希望运行的项目,然后点击启动项目。
对于这个例子,您将只修改basic_game的script.rpy文件。这个游戏的完整代码可以在下载的资料中找到,也可以在下面找到:
1# The script of the game goes in this file.
2
3# Declare characters used by this game. The color argument colorizes the
4# name of the character.
5
6define kevin = Character("Kevin", color="#c8ffc8")
7define mom = Character("Mom", color="#c8ffff")
8define me = Character("Me", color="#c8c8ff")
9
10# The game starts here.
11
12label start:
13
14 # Some basic narration to start the game
15
16 "You hear your alarm going off, and your mother calling to you."
17
18 mom "It's time to wake up. If I can hear your alarm,
19 you can hear it to - let's go!"
20
21 "Reluctantly you open your eyes."
22
23 # Show a background.
24
25 scene bedroom day
26
27 # This shows the basic narration
28
29 "You awaken in your bedroom after a good night's rest.
30 Laying there sleepily, your eyes wander to the clock on your phone."
31
32 me "Yoinks! I'm gonna be late!"
33
34 "You leap out of bed and quickly put on some clothes.
35 Grabbing your book bag, you sprint for the door to the living room."
36
37 scene hallway day
38
39 "Your brother is waiting for you in the hall."
40
41 show kevin normal
42
43 kevin "Let's go, loser! We're gonna be late!"
44
45 mom "Got everything, honey?"
46
47 menu:
48 "Yes, I've got everything.":
49 jump follow_kevin
50
51 "Wait, I forgot my phone!":
52 jump check_room
53
54label check_room:
55
56 me "Wait! My phone!"
57
58 kevin "Whatever. See you outside!"
59
60 "You sprint back to your room to get your phone."
61
62 scene bedroom day
63
64 "You grab the phone from the nightstand and sprint back to the hall."
65
66 scene hallway day
67
68 "True to his word, Kevin is already outside."
69
70 jump outside
71
72label follow_kevin:
73
74 kevin "Then let's go!"
75
76 "You follow Kevin out to the street."
77
78label outside:
79
80 scene street
81
82 show kevin normal
83
84 kevin "About time you got here. Let's Go!"
85
86 # This ends the game
87 return
标签定义你的故事的切入点,通常用于开始新的场景,并提供贯穿整个故事的替代路径。所有 Ren'Py 游戏都从第label start:行开始运行,这可以出现在你选择的任何脚本中。你可以在script.rpy的第 12 行看到这个。
您还可以使用标签来定义背景图像,设置场景之间的过渡,以及控制角色的外观。在该示例中,第二个场景从第行第 54 开始,第label check_room:行开始。
一行中用双引号括起来的文本称为 say 语句。一行中的单个字符串被视为叙述。两个字符串被视为对话,首先识别一个字符,然后提供他们正在说的台词。
在游戏开始时,旁白出现在第 16 行的处,设定场景。对话在第 18 行提供,当你妈妈叫你的时候。
你可以通过在故事中简单地命名来定义角色。但是,您也可以在脚本的顶部定义字符。你可以在的第 6 到第 8 行中看到这一点,这里定义了你、你的兄弟凯文和你的妈妈。define语句将三个变量初始化为Characters,给它们一个显示名称,后跟一个用于显示名称的文本颜色。
当然,这是一部视觉小说,所以伦比有办法处理图像是有道理的。像 Pygame Zero 一样,Ren'Py 要求游戏中使用的所有图像和声音都保存在特定的文件夹中。图像在gaimg/文件夹中,声音在game/audio/文件夹中。在游戏脚本中,你通过文件名来引用它们,没有任何文件扩展名。
第 25 行展示了这一点,当你睁开眼睛,第一次看到你的卧室。scene关键字清除屏幕,然后显示bedroom day.png图像。Ren'Py 支持 JPG、WEBP 和 PNG 图像格式。
您也可以使用show关键字和相同的图像命名约定在屏幕上显示字符。第 41 行显示了你弟弟凯文的照片,存储为kevin normal.png。
当然,如果你不能做出决定来影响结果,这就不是一场游戏。在 Ren'Py 中,玩家从游戏过程中出现的菜单中做出选择。游戏通过跳转到预定义的标签、改变角色图像、播放声音或采取其他必要的动作来做出反应。
这个例子中的一个基本选择显示在第 47 到 52 行中,这时你意识到你忘记带手机了。在一个更完整的故事中,这个选择可能会在以后产生后果。
当然,你可以用 Ren'Py 做更多的事情。您可以控制场景之间的转换,让角色以特定的方式进入和离开场景,并为您的游戏添加声音和音乐。Ren'Py 还支持编写更复杂的 Python 代码,包括使用 Python 数据类型和直接调用 Python 函数。现在让我们在一个更高级的应用程序中仔细看看这些功能。
高级应用程序
为了展示 Ren'Py 的深度,您将实现与 adventurelib 相同的游戏。提醒一下,这是游戏的基本设计:
- 你住在一个安静的小村庄里。
- 最近,你的邻居开始抱怨丢失的牲畜。
- 作为夜间巡逻队的一员,你注意到一个破损的栅栏和一条离开它的痕迹。
- 你决定去调查,只带了一把练习用的木剑。
这个游戏有几个需要定义和提供图像的区域。例如,您将需要图像和定义,用于您的安静小村庄、远离田野的小径、附近可以购买更好武器的村庄、通向可以为您的武器附魔的巫师的小路,以及包含一直在掠夺您牲畜的巨人的洞穴。
也有一些字符来定义和提供图像。你需要一个能给你更好武器的铁匠,一个能给你武器附魔的巫师,还有一个你需要打败的巨人。
对于本例,您将创建四个单独的脚本:
script.rpy,这是游戏开始的地方town.rpy,其中包含了附近村庄的故事path.rpy,其中包含了村庄之间的道路giant.rpy,其中包含了巨人战斗的逻辑
你可以单独练习创建向导遭遇战。
这个游戏的完整代码可以在renpy_sample/giant_quest/的下载资料中找到,也可以在下面找到:
1#
2# Complete game in Ren'Py
3#
4# This game demonstrates some of the more advanced features of
5# Ren'Py, including:
6# - Multiple sprites
7# - Handling user input
8# - Selecting alternate outcomes
9# - Tracking score and inventory
10#
11
12## Declare characters used by this game. The color argument colorizes the
13## name of the character.
14define player = Character("Me", color="#c8ffff")
15define smith = Character("Miranda, village blacksmith", color="#99ff9c")
16define wizard = Character("Endeavor, cryptic wizard", color="#f4d3ff")
17define giant = Character("Maull, terrifying giant", color="#ff8c8c")
18
19## Images used in the game
20# Backgrounds
21image starting path = "BG10a_1280.jpg"
22image crossroads = "BG19a01_1280.jpg"
23
24# Items
25image wooden sword = "SwordWood.png"
26image steel sword = "Sword.png"
27image enchanted sword = "SwordT2.png"
28
29## Default settings
30# What is the current weapon?
31default current_weapon = "wooden sword"
32
33# What is the weapon damage?
34# These change when the weapon is upgraded or enchanted
35default base_damage = 4
36default multiplier = 1
37default additional = 0
38
39# Did they cross the bridge to town?
40default cross_bridge = False
41
42# You need this for the giant battle later
43
44init python:
45 from random import randint
46
47# The game starts here.
48
49label start:
50
51 # Show the initial background.
52
53 scene starting path
54 with fade
55
56 # Begin narration
57
58 "Growing up in a small hamlet was boring, but reliable and safe.
59 At least, it was until the neighbors began complaining of missing
60 livestock. That's when the evening patrols began."
61
62 "While on patrol just before dawn, your group noticed broken fence
63 around a cattle paddock. Beyond the broken fence,
64 a crude trail had been blazed to a road leading away from town."
65
66 # Show the current weapon
67 show expression current_weapon at left
68 with moveinleft
69
70 "After reporting back to the town council, it was decided that you
71 should follow the tracks to discover the fate of the livestock.
72 You picked up your only weapon, a simple wooden practice sword,
73 and set off."
74
75 scene crossroads
76 with fade
77
78 show expression current_weapon at left
79
80 "Following the path, you come to a bridge across the river."
81
82 "Crossing the bridge will take you to the county seat,
83 where you may hear some news or get supplies.
84 The tracks, however, continue straight on the path."
85
86 menu optional_name:
87 "Which direction will you travel?"
88
89 "Cross the bridge":
90 $ cross_bridge = True
91 jump town
92 "Continue on the path":
93 jump path
94
95 "Your quest is ended!"
96
97 return
1##
2## Code for the interactions in town
3##
4
5## Backgrounds
6image distant town = "4_road_a.jpg"
7image within town = "3_blacksmith_a.jpg"
8
9# Characters
10image blacksmith greeting = "blacksmith1.png"
11image blacksmith confused = "blacksmith2.png"
12image blacksmith happy = "blacksmith3.png"
13image blacksmith shocked = "blacksmith4.png"
14
15label town:
16
17 scene distant town
18 with fade
19
20 show expression current_weapon at left
21
22 "Crossing the bridge, you stride away from the river along a
23 well worn path. The way is pleasant, and you find yourself humming
24 a tune as you break into a small clearing."
25
26 "From here, you can make out the county seat of Fetheron.
27 You feel confident you can find help for your quest here."
28
29 scene within town
30 with fade
31
32 show expression current_weapon at left
33
34 "As you enter town, you immediately begin seeking the local blacksmith.
35 After asking one of the townsfolk, you find the smithy on the far
36 south end of town. You approach the smithy,
37 smelling the smoke of the furnace long before you hear
38 the pounding of hammer on steel."
39
40 player "Hello! Is the smith in?"
41
42 smith "Who wants to know?"
43
44 show blacksmith greeting
45
46 "The blacksmith appears from her bellows.
47 She greets you with a warm smile."
48
49 smith "Oh, hello! You're from the next town over, right?"
50
51 menu:
52 "Yes, from the other side of the river.":
53 show blacksmith happy
54
55 smith "I thought I recognized you. Nice to see you!"
56
57 "Look, I don't have time for pleasantries, can we get to business?":
58 show blacksmith shocked
59
60 smith "Hey, just trying to make conversation"
61
62 smith "So, what can I do for you?"
63
64 player "I need a better weapon than this wooden thing."
65
66 show blacksmith confused
67
68 smith "Are you going to be doing something dangerous?"
69
70 player "Have you heard about the missing livestock in town?"
71
72 smith "Of course. Everyone has. What do you know about it?"
73
74 player "Well, I'm tracking whatever took them from our town."
75
76 smith "Oh, I see. So you want something better to fight with!"
77
78 player "Exactly! Can you help?"
79
80 smith "I've got just the thing. Been working on it for a while,
81 but didn't know what to do with it. Now I know."
82
83 "Miranda walks back past the furnace to a small rack.
84 On it, a gleaming steel sword rests.
85 She picks it up and walks back to you."
86
87 smith "Will this do?"
88
89 menu:
90 "It's perfect!":
91 show blacksmith happy
92
93 smith "Wonderful! Give me the wooden one -
94 I can use it in the furnace!"
95
96 $ current_weapon = "steel sword"
97 $ base_damage = 6
98 $ multiplier = 2
99
100 "Is that piece of junk it?":
101 show blacksmith confused
102
103 smith "I worked on this for weeks.
104 If you don't want it, then don't take it."
105
106 # Show the current weapon
107 show expression current_weapon at left
108
109 smith "Anything else?"
110
111 player "Nope, that's all."
112
113 smith "Alright. Good luck!"
114
115 scene distant town
116 with fade
117
118 show expression current_weapon at left
119
120 "You make your way back through town.
121 Glancing back at the town, you wonder if
122 you can keep them safe too."
123
124 jump path
1##
2## Code for the interactions in town
3##
4
5## Backgrounds
6image path = "1_forest_a.jpg"
7image wizard hut = "BG600a_1280.jpg"
8
9# Characters
10image wizard greeting = "wizard1.png"
11image wizard happy = "wizard2.png"
12image wizard confused = "wizard3.png"
13image wizard shocked = "wizard4.png"
14
15label path:
16
17 scene path
18 with fade
19
20 show expression current_weapon at left
21
22 "You pick up the tracks as you follow the path through the woods."
23
24 jump giant_battle
1##
2## Code for the giant battle
3##
4
5## Backgrounds
6image forest = "forest_hill_night.jpg"
7
8# Characters
9image giant greeting = "giant1.png"
10image giant unhappy = "giant2.png"
11image giant angry = "giant3.png"
12image giant hurt = "giant4.png"
13
14# Text of the giant encounter
15label giant_battle:
16
17 scene forest
18 with fade
19
20 show expression current_weapon at left
21
22 "As you follow the tracks down the path, night falls.
23 You hear sounds in the distance:
24 cows, goats, sheep. You've found the livestock!"
25
26 show giant greeting
27
28 "As you approach the clearing and see your villages livestock,
29 a giant appears."
30
31 giant "Who are you?"
32
33 player "I've come to get our livestock back."
34
35 giant "You and which army, little ... whatever you are?"
36
37 show giant unhappy
38
39 "The giant bears down on you - the battle is joined!"
40
41python:
42
43 def show_giant_condition(giant_hp):
44 if giant_hp < 10:
45 renpy.say(None, "The giant staggers, his eyes unfocused.")
46 elif giant_hp < 20:
47 renpy.say(None, "The giant's steps become more unsteady.")
48 elif giant_hp < 30:
49 renpy.say(
50 None, "The giant sweats and wipes the blood from his brow."
51 )
52 elif giant_hp < 40:
53 renpy.say(
54 None,
55 "The giant snorts and grits his teeth against the pain.",
56 )
57 else:
58 renpy.say(
59 None,
60 "The giant smiles and readies himself for the attack.",
61 )
62
63 def show_player_condition(player_hp):
64 if player_hp < 4:
65 renpy.say(
66 None,
67 "Your eyes lose focus on the giant as you sway unsteadily.",
68 )
69 elif player_hp < 8:
70 renpy.say(
71 None,
72 "Your footing becomes less steady as you swing your sword sloppily.",
73 )
74 elif player_hp < 12:
75 renpy.say(
76 None,
77 "Blood mixes with sweat on your face as you wipe it from your eyes.",
78 )
79 elif player_hp < 16:
80 renpy.say(
81 None,
82 "You bite down as the pain begins to make itself felt.",
83 )
84 else:
85 renpy.say(None, "You charge into the fray valiantly!")
86
87 def fight_giant():
88
89 # Default values
90 giant_hp = 50
91 player_hp = 20
92 giant_damage = 4
93
94 battle_over = False
95 player_wins = False
96
97 # Keep swinging until something happens
98 while not battle_over:
99
100 renpy.say(
101 None,
102 "You have {0} hit points. Do you want to fight or flee?".format(
103 player_hp
104 ),
105 interact=False,
106 )
107 battle_over = renpy.display_menu(
108 [("Fight!", False), ("Flee!", True)]
109 )
110
111 if battle_over:
112 player_wins = False
113 break
114
115 # The player gets a swing
116 player_attack = (
117 randint(1, base_damage + 1) * multiplier + additional
118 )
119 renpy.say(
120 None,
121 "You swing your {0}, doing {1} damage!".format(
122 current_weapon, player_attack
123 ),
124 )
125 giant_hp -= player_attack
126
127 # Is the giant dead?
128 if giant_hp <= 0:
129 battle_over = True
130 player_wins = True
131 break
132
133 show_giant_condition(giant_hp)
134
135 # Then the giant tries
136 giant_attack = randint(0, giant_damage)
137 if giant_attack == 0:
138 renpy.say(
139 None,
140 "The giant's arm whistles harmlessly over your head!",
141 )
142 else:
143 renpy.say(
144 None,
145 "The giant swings his mighty fist, and does {0} damage!".format(
146 giant_attack
147 ),
148 )
149 player_hp -= giant_attack
150
151 # Is the player dead?
152 if player_hp <= 0:
153 battle_over = True
154 player_wins = False
155
156 show_player_condition(player_hp)
157
158 # Return who died
159 return player_wins
160
161 # fight_giant returns True if the player wins.
162 if fight_giant():
163 renpy.jump("player_wins")
164 else:
165 renpy.jump("giant_wins")
166
167label player_wins:
168
169 "The giant's eyes glaze over as he falls heavily to the ground.
170 The earth shakes as his bulk lands face down,
171 and his death rattle fills the air."
172
173 hide giant
174
175 "You are victorious! The land is safe from the giant!"
176
177 return
178
179label giant_wins:
180
181 "The giant takes one last swing, knocking you down.
182 Your vision clouds, and you see the ground rising to meet you.
183 As you slowly lose consciousness, your last vision is
184 the smiling figure of the giant as he advances on you."
185
186 "You have lost!"
187
188 return
和前面的例子一样,在脚本从script.rpy的第 14 到 17 行的开始之前,您定义了Character()对象。
您还可以定义背景或人物image对象以备后用。第 21 行到第 27 行定义了几个你稍后会用到的图像,既可以用作背景,也可以作为项目显示。使用此语法,您可以为图像指定更短、更具描述性的内部名称。稍后,您将看到它们是如何显示的。
你还需要追踪装备武器的能力。这是在第 31 到 37 行的中完成的,使用的是default变量值,你将在稍后的大型战役中用到。
为了表明哪种武器被激活,你把图像显示为一个表达式。人物表情是显示在游戏窗口角落的小图像,用来显示各种各样的信息。在这个游戏中,你先在第 67 行和第 68 行的处使用一个表达式来显示武器。
show命令记录了许多修饰符。with moveinleft修改器使current_weapon图像从左边滑动到屏幕上。此外,重要的是要记住,每次scene改变,整个屏幕都被清除,要求你再次显示当前的武器。你可以在第 75 到 78 行看到。
当你在town.rpy进入城镇时,你遇到铁匠,他向你打招呼:
铁匠为你提供升级武器的机会。如果你选择这样做,那么你就更新了current_weapon和武器属性的值。这在第 93 到 98 行完成。
以$字符开头的行被 Ren'Py 解释为 Python 语句,允许您根据需要编写任意的 Python 代码。更新current_weapon和武器统计是使用第 96 到 98 行的三个 Python 语句完成的,这些语句改变了您在script.rpy顶部定义的default变量的值。
您还可以使用一个python:部分定义一大块 Python 代码,如从行 41 开始的giant.rpy所示。
第 43 到 61 行包含了一个助手功能,根据巨人剩余的生命值来显示巨人的状况。它使用renpy.say()方法将叙述输出回主窗口。在第 63 到 85 行中可以看到一个类似的显示玩家状态的助手功能。
战斗由 87 到 159 线上的fight_giant()控制。游戏循环在线 98** 上实现,并由battle_over变量控制。玩家选择战斗或逃跑是使用renpy.display_menu()方法显示的。**
如果玩家战斗,那么在线 116 到 118 上造成随机数量的伤害,并且调整巨人的生命值。如果巨人还活着,那么他们会在的第 136 到 149 行以类似的方式攻击。注意巨人有机会失手,而玩家总是命中。战斗持续到玩家或巨人的生命值为零或者玩家逃跑:
需要注意的是,这段代码与您在 adventurelib 战斗中使用的代码非常相似。这展示了如何将完整的 Python 代码放到你的 Ren'Py 游戏中,而不需要将其翻译成 Ren'Py 脚本。
除了你在这里尝试过的,还有很多值得尝试的。查阅 Ren'Py 文档了解更多完整细节。
其他著名的 Python 游戏引擎
这五个引擎只是众多不同 Python 游戏引擎中的一小部分。还有其他几十种方法,这里有一些值得注意:
-
芥末 2D 由 Pygame Zero 的团队开发。这是一个建立在 moderngl 基础上的现代框架,可以自动渲染,为动画效果提供协同程序,内置粒子效果,并使用事件驱动模型玩游戏。
-
cocos2d 是一个为跨平台游戏编码而设计的框架。可悲的是,cocos2d-python 从 2017 年开始就没有更新过。
-
熊猫 3D 是一个用于创建 3D 游戏和 3D 渲染的开源框架。Panda 3D 可跨平台移植,支持多种资产类型,开箱即可与众多第三方库连接,并提供内置的管道分析。
-
Ursina 建立在熊猫 3D 的基础上,提供了一个专用的游戏开发引擎,简化了熊猫 3D 的许多方面。在撰写本文时,Ursina 得到了很好的支持和很好的文档,正在积极开发中。
-
purchased ybear 被宣传为教育图书馆。它拥有一个场景管理系统,基于帧的动画精灵,可以暂停,进入门槛低。文档很少,但是帮助只是 GitHub 讨论的一部分。
每天都有新的 Python 游戏引擎诞生。如果你找到了一个适合你的需求,但这里没有提到的,请在评论中赞美它!
游戏资产的来源
通常,创建游戏资产是游戏作者面临的最大问题。大型视频游戏公司雇佣艺术家、动画师和音乐家团队来设计游戏的外观和声音。有编码背景的单人游戏开发者可能会发现游戏开发的这一方面令人望而生畏。幸运的是,游戏资产有许多不同的来源。以下是在本教程中为游戏定位资产的一些重要因素:
-
OpenGameArt.org 为 2D 和 3D 游戏提供了各种各样的游戏艺术、音乐、背景、图标和其他资源。艺术家和音乐家列出了可供下载的资产,您可以下载并在游戏中使用这些资产。大多数资产都是免费的,许可条款可能适用于其中的许多资产。
-
Kenney.nl 拥有一系列免费和付费的资产,其中许多在别处是找不到的。捐款总是受欢迎的,以支持免费资产,这些资产都被授权用于商业游戏。
-
Itch.io 是一个面向专注于独立游戏开发的数字创作者的市场。在这里,你可以找到任何用途的数字资产,包括免费和付费的,还有完整的游戏。个人创作者在这里控制他们自己的内容,所以你总是直接与有才华的个人一起工作。
第三方提供的大多数资产都带有许可条款,规定了资产的正确和允许使用。作为这些资产的用户,您有责任阅读、理解并遵守资产所有者定义的许可条款。如果您对这些条款有任何疑问或疑虑,请咨询法律专业人士寻求帮助。
本文引用的游戏中使用的所有资产都符合各自的许可要求。
结论
恭喜你,伟大的游戏设计现在触手可及!多亏了 Python 和一系列高性能的 Python 游戏引擎,你可以比以前更容易地创作出高质量的电脑游戏。在本教程中,您已经探索了几个这样的游戏引擎,学习了开始制作自己的 Python 视频游戏所需的信息!
到目前为止,您已经看到了一些顶级 Python 游戏引擎的运行,并且您已经:
- 探究了几种流行的 Python 游戏引擎的优缺点
- 体验了他们如何将与单机游戏引擎进行比较
- 了解其他可用的 Python 游戏引擎
如果你想查看本教程中游戏的代码,你可以点击下面的链接:
获取源代码: 点击此处获取您将使用试用 Python 游戏引擎的源代码。
现在你可以根据你的目的选择最好的 Python 游戏引擎。你还在等什么?出去写些游戏吧!*************
使用 Python 进行传统人脸检测
原文:https://realpython.com/traditional-face-detection-python/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 进行传统人脸检测
计算机视觉是一个令人兴奋且不断发展的领域。有很多有趣的问题需要解决!其中之一是人脸检测:计算机识别照片中包含人脸,并告诉你其位置的能力。在本文中,您将学习使用 Python 进行人脸检测。
为了检测图像中的任何对象,有必要了解图像在计算机内部是如何表示的,以及该对象在视觉上与任何其他对象有何不同。
一旦完成,扫描图像和寻找这些视觉线索的过程需要自动化和优化。所有这些步骤结合在一起形成了一个快速可靠的计算机视觉算法。
在本教程中,你将学习:
- 什么是人脸检测
- 计算机如何理解图像中的特征
- 如何快速分析许多不同的特征以做出决策
- 如何使用最小的 Python 解决方案来检测图像中的人脸
免费奖励: ,向您展示真实世界 Python 计算机视觉技术的实用代码示例。
什么是人脸检测?
人脸检测是一种能够在数字图像中识别人脸的计算机视觉技术。这对人类来说非常容易,但计算机需要精确的指令。这些图像可能包含许多不是人脸的物体,比如建筑物、汽车、动物等等。
它不同于其他涉及人脸的计算机视觉技术,如面部识别、分析和跟踪。
面部识别包括识别图像中的面部属于人 X 而不是人 Y 。它通常用于生物识别目的,比如解锁你的智能手机。
面部分析试图通过人们的面部特征来了解他们的一些事情,比如确定他们的年龄、性别或他们表现出的情绪。
面部跟踪主要出现在视频分析中,试图逐帧跟踪面部及其特征(眼睛、鼻子和嘴唇)。最受欢迎的应用程序是 Snapchat 等移动应用程序中的各种滤镜。
所有这些问题都有不同的技术解决方案。本教程将重点介绍第一个挑战的传统解决方案:人脸检测。
计算机是如何“看见”图像的?
图像的最小元素称为像素,或图片元素。基本上就是图中的一个点。图像包含按行和列排列的多个像素。
你会经常看到用图像分辨率表示的行数和列数。例如,超高清电视的分辨率为 3840x2160,即宽 3840 像素,高 2160 像素。
但是计算机不理解像素是彩色的点。它只懂数字。为了将颜色转换成数字,计算机使用各种颜色模型。
在彩色图像中,像素通常用 RGB 颜色模型表示。RGB 代表RedGreenBlue。每个像素都是这三种颜色的混合。RGB 非常擅长通过组合不同数量的红色、绿色和蓝色来模拟人类感知的所有颜色。
由于计算机只理解数字,每个像素由三个数字表示,对应于该像素中存在的红色、绿色和蓝色的数量。您可以在 OpenCV + Python 中使用色彩空间了解更多关于图像分割中的色彩空间。
在灰度(黑白)图像中,每个像素都是一个数字,代表它携带的光量或强度。在许多应用中,亮度范围从0(黑色)到255(白色)。在0和255之间的一切都是各种深浅不同的灰色。
如果每个灰度像素都是一个数字,那么图像只不过是一个数字矩阵(或表格):

在彩色图像中,有三个这样的矩阵代表红色、绿色和蓝色通道。
什么是特性?
特征是图像中与解决某个问题相关的一条信息。它可以是简单的单个像素值,也可以是更复杂的边缘、拐角和形状。您可以将多个简单特征组合成一个复杂特征。
对图像应用某些操作产生的信息也可以被认为是特征。计算机视觉和图像处理有大量有用的特征和特征提取操作。
基本上,图像的任何固有或衍生属性都可以用作解决任务的特征。
准备工作
要运行代码示例,您需要设置一个安装了所有必需库的环境。最简单的办法就是用 conda 。
您将需要三个库:
scikit-imagescikit-learnopencv
要在conda中创建环境,请在您的 shell 中运行以下命令:
$ conda create --name face-detection python=3.7
$ source activate face-detection
(face-detection)$ conda install scikit-learn
(face-detection)$ conda install -c conda-forge scikit-image
(face-detection)$ conda install -c menpo opencv3
如果您在正确安装 OpenCV 和运行示例时遇到问题,请尝试参考他们的安装指南或关于 OpenCV 教程、资源和指南的文章。
现在,您已经拥有了练习本教程中所学内容所需的所有软件包。
Viola-Jones 物体检测框架
这种算法是以 2001 年提出该方法的两位计算机视觉研究人员的名字命名的:保罗·维奥拉和迈克尔·琼斯。
他们开发了一个通用对象检测框架,能够实时提供有竞争力的对象检测率。它可以用来解决各种检测问题,但主要的动机来自人脸检测。
Viola-Jones 算法有 4 个主要步骤,您将在接下来的章节中了解每个步骤的更多信息:
- 选择类哈尔特征
- 创造一个完整的形象
- 跑步 AdaBoost 训练
- 创建分类器级联
给定一幅图像,该算法查看许多更小的子区域,并通过在每个子区域中寻找特定特征来尝试找到一张脸。它需要检查许多不同的位置和比例,因为一幅图像可能包含许多不同大小的脸。Viola 和 Jones 使用类似 Haar 的特征来检测人脸。
类哈尔特征
所有人的面孔都有一些相似之处。例如,如果你看一张显示一个人面部的照片,你会发现眼睛区域比鼻梁要暗。脸颊也比眼睛区域更亮。我们可以使用这些属性来帮助我们理解图像是否包含人脸。
找出哪个区域更亮或更暗的简单方法是将两个区域的像素值相加并进行比较。较暗区域中像素值的总和将小于较亮区域中像素值的总和。这可以通过使用类似 Haar 的特征来实现。
Haar-like 特征通过获取图像的矩形部分并将该矩形分成多个部分来表示。它们通常被视为黑白相邻的矩形:
在此图像中,您可以看到 4 种基本类型的 Haar-like 特征:
- 带有两个矩形的水平特征
- 带有两个矩形的垂直特征
- 带有三个矩形的垂直特征
- 具有四个矩形的对角线特征
前两个例子对于检测边缘是有用的。第三个检测线条,第四个适合寻找对角线特征。但是它们是如何工作的呢?
特征的值计算为一个数字:黑色区域的像素值之和减去白色区域的像素值之和。对于像墙这样的均匀区域,这个数字接近于零,不会给你任何有意义的信息。
为了有用,一个 Haar-like 特征需要给你一个大的数字,这意味着黑色和白色矩形中的面积是非常不同的。有一些已知的特征可以很好地检测人脸:

在这个例子中,眼睛区域比下面的区域暗。您可以使用此属性来查找图像的哪些区域对特定功能有强烈的响应(大量):

这个例子在应用于鼻梁时给出了强烈的反应。您可以结合这些特征来理解图像区域是否包含人脸。
如上所述,Viola-Jones 算法在图像的许多子区域中计算了许多这些特征。这很快在计算上变得昂贵:使用计算机有限的资源要花费大量的时间。
为了解决这个问题,Viola 和 Jones 使用了积分图像。
积分图像
积分图像(也称为总面积表)是数据结构和用于获得该数据结构的算法的名称。它被用作计算图像或图像的矩形部分中的像素值之和的快速有效的方法。
在积分图像中,每个点的值是上方和左侧所有像素的总和,包括目标像素:
积分图像可以在原始图像上的单次通过中计算。这将矩形内像素亮度的求和减少到只有三个四个数的运算,而与矩形大小无关:
矩形 ABCD 中的像素之和可以从点 A 、 B 、 C 和 D 的值导出,使用公式 D - B - C + A 。更容易直观地理解这个公式:
你会注意到,减去 B 和 C 意味着用 A 定义的面积已经被减去两次,所以我们需要再把它加回来。
现在你有一个简单的方法来计算两个矩形的像素值之和的差。这对于类似 Haar 的特性来说是完美的!
但是你如何决定使用这些特征中的哪一个,以什么样的尺寸在图像中寻找人脸呢?这是通过一种叫做 boosting 的机器学习算法来解决的。具体来说,您将了解 AdaBoost,这是自适应增强的缩写。
AdaBoost
Boosting 基于以下问题:“一组弱学习者能创造出一个单独的强学习者吗?”弱学习器(或弱分类器)被定义为仅比随机猜测略好的分类器。
在人脸检测中,这意味着弱学习者可以将图像的子区域分类为人脸或非人脸,仅略好于随机猜测。一个强有力的学习者更善于从非人脸中识别人脸。
提升的能力来自于将许多(数千个)弱分类器组合成单个强分类器。在 Viola-Jones 算法中,每个 Haar-like 特征代表一个弱学习者。为了决定进入最终分类器的特征的类型和大小,AdaBoost 检查您提供给它的所有分类器的性能。
要计算分类器的性能,需要对用于训练的所有图像的所有子区域进行评估。一些次区域将在分类器中产生强响应。这些将被分类为阳性,这意味着分类器认为它包含人脸。
在分类者看来,没有产生强烈反应的分区不包含人脸。它们将被归类为阴性。
表现良好的分类器被赋予更高的重要性或权重。最终结果是一个强分类器,也称为增强分类器,它包含性能最好的弱分类器。
该算法被称为自适应,因为随着训练的进行,它会更加强调那些被错误分类的图像。在这些硬例子中表现较好的弱分类器比其他分类器具有更强的权重。
让我们看一个例子:
假设您要使用一组弱分类器对下图中的蓝色和橙色圆圈进行分类:
您使用的第一个分类器捕获了一些蓝色的圆圈,但错过了其他的。在下一次迭代中,您将更加重视遗漏的示例:
第二个能够正确分类这些例子的分类器将获得更高的权重。请记住,如果弱分类器表现更好,它将获得更高的权重,从而更有可能被包括在最终的强分类器中:
现在你已经成功地捕捉到了所有的蓝色圆圈,但是错误地捕捉到了一些橙色的圆圈。这些错误分类的橙色圆圈在下一次迭代中被赋予更大的重要性:
最终的分类器设法正确地捕捉那些橙色圆圈:
要创建一个强分类器,您需要组合所有三个分类器来正确分类所有示例:
Viola 和 Jones 使用这一过程的一种变体,评估了数十万个专门在图像中寻找人脸的分类器。但是,在每幅图像的每个区域运行所有这些分类器在计算上是昂贵的,所以他们创建了一个叫做分类器级联的东西。
级联分类器
瀑布的定义是一系列一个接一个的瀑布。在计算机科学中,类似的概念被用来用简单的单元解决复杂的问题。这里的问题是减少每个图像的计算量。
为了解决这个问题,Viola 和 Jones 将他们的强分类器(由数千个弱分类器组成)变成了一个级联,其中每个弱分类器代表一个阶段。级联的工作是快速丢弃非人脸,避免浪费宝贵的时间和计算。
当图像子区域进入级联时,它由第一级评估。如果该阶段将子区域评估为正,这意味着它认为它是一张脸,则该阶段的输出是可能是。
如果一个子区域得到一个也许是,它将被发送到级联的下一级。如果那个给了正面评价,那么那就是另一个也许是,图像被发送到第三阶段:
重复这个过程,直到图像通过级联的所有阶段。如果所有分类器都认可该图像,则该图像最终被分类为人脸,并作为检测结果呈现给用户。
然而,如果第一阶段给出否定的评价,则该图像由于不包含人脸而被立即丢弃。如果它通过了第一阶段,但没有通过第二阶段,它也被丢弃。基本上,图像可以在分类器的任何阶段被丢弃:
这种设计使得非人脸很快被丢弃,节省了大量的时间和计算资源。因为每个分类器代表一张人脸的一个特征,所以一个肯定的检测基本上是说,“是的,这个子区域包含了人脸的所有特征。”但是一旦缺少一个特征,它就拒绝整个次区域。
为了有效地实现这一点,将性能最好的分类器放在级联的早期是很重要的。在 Viola-Jones 算法中,眼睛和鼻梁分类器是性能最好的弱分类器的例子。
既然你已经理解了算法的工作原理,那么是时候用 Python 来使用它检测人脸了。
使用维奥拉-琼斯分类器
从头开始训练 Viola-Jones 分类器可能需要很长时间。幸运的是,OpenCV 提供了一个预先训练好的 Viola-Jones 分类器!您将使用它来查看运行中的算法。
首先,找到并下载一张你想扫描人脸的图像。这里有一个例子:

导入 OpenCV 并将图像加载到内存中:
import cv2 as cv
# Read image from your local file system
original_image = cv.imread('path/to/your-image.jpg')
# Convert color image to grayscale for Viola-Jones
grayscale_image = cv.cvtColor(original_image, cv.COLOR_BGR2GRAY)
接下来,您需要加载 Viola-Jones 分类器。如果您从源代码安装 OpenCV,它将位于您安装 OpenCV 库的文件夹中。
根据版本的不同,确切的路径可能会有所不同,但文件夹名称将是haarcascades,并且它将包含多个文件。你需要的那个叫haarcascade_frontalface_alt.xml。
如果出于某种原因,您安装的 OpenCV 没有获得预训练的分类器,您可以从 OpenCV GitHub repo 中获得它:
# Load the classifier and create a cascade object for face detection
face_cascade = cv.CascadeClassifier('path/to/haarcascade_frontalface_alt.xml')
face_cascade对象有一个方法detectMultiScale(),它接收一个图像作为参数,并在图像上运行分类器级联。术语多尺度表示该算法以多种尺度查看图像的子区域,以检测不同大小的面部:
detected_faces = face_cascade.detectMultiScale(grayscale_image)
变量 detected_faces现在包含目标图像的所有检测。为了可视化检测,您需要迭代所有检测,并在检测到的人脸上绘制矩形。
OpenCV 的rectangle()在图像上绘制矩形,它需要知道左上角和右下角的像素坐标。坐标表示图像中像素的行和列。
幸运的是,检测结果被保存为像素坐标。每个检测由其左上角坐标以及包含检测到的面部的矩形的宽度和高度来定义。
增加行的宽度和列的高度将得到图像的右下角:
for (column, row, width, height) in detected_faces:
cv.rectangle(
original_image,
(column, row),
(column + width, row + height),
(0, 255, 0),
2
)
rectangle()接受以下论点:
- 原始图像
- 检测左上角点的坐标
- 检测点右下角的坐标
- 矩形的颜色(定义红色、绿色和蓝色数量的元组(
0-255)) - 矩形线条的粗细
最后,您需要显示图像:
cv.imshow('Image', original_image)
cv.waitKey(0)
cv.destroyAllWindows()
imshow()显示图像。waitKey()等待击键。否则,imshow()会显示图像并立即关闭窗口。传递0作为参数,告诉它无限期等待。最后,当你按下一个键时,destroyAllWindows()关闭窗口。
结果如下:

就是这样!现在,Python 中已经有了一个现成的人脸检测器。
如果你真的想自己训练分类器,scikit-image在他们的网站上提供了一个附带代码的教程。
延伸阅读
Viola-Jones 算法是一项惊人的成就。尽管它在许多用例中仍然表现出色,但它已经使用了将近 20 年。还存在其他算法,它们使用不同的功能
一个例子使用支持向量机(SVM)和称为梯度方向直方图(HOG)的特征。在 Python 数据科学手册中可以找到一个例子。
大多数当前最先进的人脸检测和识别方法都使用深度学习,我们将在后续文章中介绍这一点。
对于最先进的计算机视觉研究,看看最近关于 arXiv 的计算机视觉和模式识别的科学文章。
如果你对机器学习感兴趣,但想切换到计算机视觉以外的东西,请使用 Python 和 Keras 查看实用文本分类。
结论
干得好!你现在能够在图像中找到人脸。
在本教程中,您已经学习了如何用类似 Haar 的特征来表示图像中的区域。使用积分图像可以非常快速地计算这些特征。
您已经了解了 AdaBoost 如何从成千上万个可用特征中找到性能最佳的 Haar-like 特征,并将其转化为一系列弱分类器。
最后,您已经学习了如何创建一系列弱分类器,能够快速可靠地区分人脸和非人脸。
这些步骤说明了计算机视觉的许多重要元素:
- 寻找有用的功能
- 将它们结合起来解决复杂的问题
- 平衡性能和管理计算资源
这些想法一般适用于对象检测,并将帮助您解决许多现实世界的挑战。祝你好运!
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 进行传统人脸检测******
使用 scikit-learn 的 train_test_split()拆分数据集
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 scikit 拆分数据集-learn 和 train_test_split()
受监督的机器学习的一个关键方面是模型评估和验证。当您评估模型的预测性能时,评估过程必须公正,这一点非常重要。使用数据科学库 scikit-learn 中的 train_test_split() ,您可以将数据集分割成子集,从而最大限度地减少评估和验证过程中的潜在偏差。
在本教程中,您将学习:
- 为什么在监督机器学习中需要分割数据集
- 您需要数据集的哪些子集来对您的模型进行无偏评估
- 如何使用
train_test_split()拆分你的数据 - 如何将
train_test_split()和预测方法结合起来
此外,您将从 sklearn.model_selection 获得相关工具的信息。
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
数据拆分的重要性
监督机器学习是关于创建模型,该模型将给定输入(独立变量,或预测器)精确映射到给定输出(因变量,或响应)。
如何衡量模型的精度取决于您试图解决的问题的类型。在回归分析中,通常使用决定系数、均方根误差、平均绝对误差或类似的量。对于分类问题,你经常应用准确度、精度、召回、 F1 分数,以及相关指标。
衡量精度的可接受数值因字段而异。你可以从吉姆、 Quora 的统计和许多其他资源中找到详细的解释。
最重要的是要明白,你通常需要无偏评估来正确使用这些度量,评估你的模型的预测性能,并验证模型。
这意味着您无法使用用于训练的相同数据来评估模型的预测性能。你需要用模型以前没有见过的新数据评估模型。您可以通过在使用数据集之前对其进行拆分来实现这一点。
培训、验证和测试集
分割数据集对于无偏评估预测性能至关重要。在大多数情况下,将数据集随机分成三个子集就足够了:
-
验证集用于超参数调整期间的无偏模型评估。例如,当您想要找到神经网络中神经元的最佳数量或支持向量机的最佳核时,您可以尝试不同的值。对于每个考虑的超参数设置,用训练集拟合模型,并用验证集评估其性能。
-
最终模型的无偏评估需要测试集。你不应该用它来拟合或验证。
在不太复杂的情况下,当您不必调优超参数时,只使用训练集和测试集也是可以的。
欠配合和过配合
分割数据集对于检测您的模型是否存在两个非常常见的问题也很重要,这两个问题分别称为欠拟合和过拟合:
-
欠拟合通常是模型无法封装数据间关系的结果。例如,当试图用线性模型表示非线性关系时,就会发生这种情况。训练不足的模型在训练集和测试集上都可能表现不佳。
-
过拟合通常发生在模型具有过度复杂的结构,并学习数据和噪声之间的现有关系时。这种模型通常具有较差的泛化能力。尽管它们可以很好地处理训练数据,但对于看不见的(测试)数据,它们通常表现不佳。
你可以在 Python 的线性回归中找到更详细的欠拟合和过拟合解释。
使用train_test_split() 的前提条件
现在,您已经了解了分割数据集以执行无偏模型评估并识别欠拟合或过拟合的必要性,您可以开始学习如何分割您自己的数据集了。
你将使用 0.23.1 版本的 scikit-learn ,或者 sklearn 。它有许多用于数据科学和机器学习的包,但对于本教程,您将重点关注 model_selection 包,特别是函数 train_test_split() 。
可以用 pip install 安装sklearn :
$ python -m pip install -U "scikit-learn==0.23.1"
如果你使用 Anaconda ,那么你可能已经安装了它。但是,如果你想使用一个的新鲜环境,确保你有指定的版本,或者使用 Miniconda ,那么你可以用conda install从 Anaconda Cloud 安装sklearn:
$ conda install -c anaconda scikit-learn=0.23
你还需要 NumPy ,但你不必单独安装它。如果你还没有安装它,你应该把它和sklearn放在一起。如果你想更新你的 NumPy 知识,那么看看官方文档或者看看 Look Ma,No For-Loops:Array Programming With NumPy。
train_test_split()的应用
需要导入 train_test_split()和 NumPy 才能使用,所以可以从 import 语句开始:
>>> import numpy as np >>> from sklearn.model_selection import train_test_split现在,您已经导入了这两个数据,您可以使用它们将数据分为定型集和测试集。您将通过一个函数调用同时分离输入和输出。
使用
train_test_split(),您需要提供想要分割的序列以及任何可选的参数。它返回一个列表的 NumPy 数组,其他序列,或者稀疏矩阵如果合适的话:sklearn.model_selection.train_test_split(*arrays, **options) -> list
arrays是列表的序列、 NumPy 数组、 pandas DataFrames ,或者类似的数组状对象,它们保存着你想要分割的数据。所有这些对象一起构成数据集,并且必须具有相同的长度。在受监督的机器学习应用程序中,您通常会处理两个这样的序列:
- 带有输入(
x)的二维数组- 带有输出(
y)的一维数组
options是可选的关键字参数,您可以使用它们来获得想要的行为:
train_size是定义训练集大小的数字。如果您提供一个float,那么它必须在0.0和1.0之间,并且将定义用于测试的数据集的份额。如果您提供一个int,那么它将代表训练样本的总数。默认值为None。
test_size是定义测试集大小的数字。和train_size很像。你应该提供train_size或test_size。如果两者都没有给出,那么将用于测试的数据集的默认份额是0.25,或者 25%。
random_state是分割时控制随机化的对象。它可以是一个int,也可以是一个RandomState的实例。默认值为None。
shuffle是布尔对象(默认为True)决定在应用分割之前是否洗牌。
stratify是一个类似数组的对象,如果不是None,则决定如何使用分层拆分。现在是时候尝试数据拆分了!您将从创建一个简单的数据集开始。数据集将包含二维数组
x中的输入和一维数组y中的输出:
>>> x = np.arange(1, 25).reshape(12, 2)
>>> y = np.array([0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0])
>>> x
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10],
[11, 12],
[13, 14],
[15, 16],
[17, 18],
[19, 20],
[21, 22],
[23, 24]])
>>> y
array([0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0])
为了得到你的数据,你使用 arange() ,这对于根据数值范围生成数组是非常方便的。你也可以使用 .reshape() 来修改arange()返回的数组的形状,得到一个二维的数据结构。
您可以通过一次函数调用分割输入和输出数据集:
>>> x_train, x_test, y_train, y_test = train_test_split(x, y) >>> x_train array([[15, 16], [21, 22], [11, 12], [17, 18], [13, 14], [ 9, 10], [ 1, 2], [ 3, 4], [19, 20]]) >>> x_test array([[ 5, 6], [ 7, 8], [23, 24]]) >>> y_train array([1, 1, 0, 1, 0, 1, 0, 1, 0]) >>> y_test array([1, 0, 0])给定两个序列,如这里的
x和y,train_test_split()执行分割并按以下顺序返回四个序列(在本例中为 NumPy 数组):
x_train: 第一序列的训练部分(x)x_test: 第一序列的测试部分(x)y_train: 第二序列的训练部分(y)y_test: 第二序列的测试部分(y)您可能会得到与您在这里看到的不同的结果。这是因为数据集分割在默认情况下是随机的。每次运行该函数时,结果都会不同。然而,这通常不是你想要的。
有时,为了使您的测试具有可重复性,您需要对每个函数调用进行随机分割,并得到相同的输出。你可以用参数
random_state来实现。random_state的值并不重要,它可以是任何非负整数。你可以使用一个numpy.random.RandomState的实例来代替,但是这是一个更复杂的方法。在前面的示例中,您使用了一个包含 12 个观察值(行)的数据集,得到了一个包含 9 行的训练样本和一个包含 3 行的测试样本。这是因为您没有指定所需的训练集和测试集的大小。默认情况下,25%的样本被分配给测试集。对于许多应用程序来说,这个比率通常是不错的,但是它并不总是您所需要的。
通常,您会想要明确地定义测试(或训练)集的大小,有时您甚至会想要试验不同的值。您可以通过参数
train_size或test_size来实现。修改代码,以便您可以选择测试集的大小并获得可重现的结果:
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=4, random_state=4
... )
>>> x_train
array([[17, 18],
[ 5, 6],
[23, 24],
[ 1, 2],
[ 3, 4],
[11, 12],
[15, 16],
[21, 22]])
>>> x_test
array([[ 7, 8],
[ 9, 10],
[13, 14],
[19, 20]])
>>> y_train
array([1, 1, 0, 0, 1, 0, 1, 1])
>>> y_test
array([0, 1, 0, 0])
有了这个改变,你会得到与以前不同的结果。之前,您有一个包含九个项目的训练集和一个包含三个项目的测试集。现在,由于参数test_size=4,训练集有八个项目,测试集有四个项目。用test_size=0.33你会得到同样的结果,因为 12 的 33%大约是 4。
最后两个例子还有一个非常重要的区别:现在每次运行这个函数都会得到相同的结果。这是因为你已经用random_state=4修复了随机数生成器。
下图显示了调用train_test_split()时的情况:
数据集的样本被随机打乱,然后根据您定义的大小分成训练集和测试集。
你可以看到y有六个 0 和六个 1。然而,测试集的四个项目中有三个零。如果你想通过训练集和测试集(大概)保持y值的比例,那就通过stratify=y。这将实现分层分割:
>>> x_train, x_test, y_train, y_test = train_test_split( ... x, y, test_size=0.33, random_state=4, stratify=y ... ) >>> x_train array([[21, 22], [ 1, 2], [15, 16], [13, 14], [17, 18], [19, 20], [23, 24], [ 3, 4]]) >>> x_test array([[11, 12], [ 7, 8], [ 5, 6], [ 9, 10]]) >>> y_train array([1, 0, 1, 0, 1, 0, 0, 1]) >>> y_test array([0, 0, 1, 1])现在
y_train和y_test具有与原始y数组相同的 0 和 1 的比率。在某些情况下,分层分割是可取的,例如当您对一个不平衡数据集进行分类时,该数据集在属于不同类的样本数量上有显著差异。
最后,您可以使用
shuffle=False关闭数据混排和随机分割:
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=0.33, shuffle=False
... )
>>> x_train
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10],
[11, 12],
[13, 14],
[15, 16]])
>>> x_test
array([[17, 18],
[19, 20],
[21, 22],
[23, 24]])
>>> y_train
array([0, 1, 1, 0, 1, 0, 0, 1])
>>> y_test
array([1, 0, 1, 0])
现在,您有了一个拆分,原始x和y数组中的前三分之二样本被分配给训练集,后三分之一被分配给测试集。没有洗牌。没有随机性。
用train_test_split()监督机器学习
现在是时候看看train_test_split()在解决监督学习问题时的表现了。在看一个更大的问题之前,您将从一个可以用线性回归解决的小回归问题开始。您还将看到,您也可以使用train_test_split()进行分类。
线性回归的极简例子
在这个例子中,您将应用到目前为止所学的知识来解决一个小的回归问题。您将学习如何创建数据集,将它们分成训练和测试子集,并使用它们进行线性回归。
和往常一样,您将从导入必要的包、函数或类开始。你需要 NumPy、 LinearRegression 和train_test_split():
>>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> from sklearn.model_selection import train_test_split现在您已经导入了您需要的所有东西,您可以创建两个小数组,
x和y,来表示观察值,然后像以前一样将它们分成训练集和测试集:
>>> x = np.arange(20).reshape(-1, 1)
>>> y = np.array([5, 12, 11, 19, 30, 29, 23, 40, 51, 54, 74,
... 62, 68, 73, 89, 84, 89, 101, 99, 106])
>>> x
array([[ 0],
[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[ 7],
[ 8],
[ 9],
[10],
[11],
[12],
[13],
[14],
[15],
[16],
[17],
[18],
[19]])
>>> y
array([ 5, 12, 11, 19, 30, 29, 23, 40, 51, 54, 74, 62, 68,
73, 89, 84, 89, 101, 99, 106])
>>> x_train, x_test, y_train, y_test = train_test_split(
... x, y, test_size=8, random_state=0
... )
您的数据集有二十个观察值,即x - y对。您指定了参数test_size=8,因此数据集被分为一个包含 12 个观察值的训练集和一个包含 8 个观察值的测试集。
现在,您可以使用训练集来拟合模型:
>>> model = LinearRegression().fit(x_train, y_train) >>> model.intercept_ 3.1617195496417523 >>> model.coef_ array([5.53121801])
LinearRegression创建代表模型的对象,而.fit()训练或拟合模型并返回它。对于线性回归,拟合模型意味着确定回归线的最佳截距(model.intercept_)和斜率(model.coef_)值。尽管您可以使用
x_train和y_train来检查拟合度,但这不是最佳实践。对模型预测性能的无偏估计基于测试数据:
>>> model.score(x_train, y_train)
0.9868175024574795
>>> model.score(x_test, y_test)
0.9465896927715023
.score() 返回通过数据的决定系数,或 R 。它的最大值是1。 R 值越高,拟合度越好。在这种情况下,训练数据会产生稍高的系数。然而,用测试数据计算的 R 是对模型预测性能的无偏测量。
这是它在图表上的样子:
绿点代表用于训练的x - y对。黑线称为估计回归线,由模型拟合的结果定义:截距和斜率。所以,它只反映了绿点的位置。
白点代表测试集。您可以使用它们来估计模型(回归线)的性能,而数据不用于定型。
回归示例
现在,您已经准备好分割更大的数据集来解决回归问题。您将使用一个著名的波士顿房价数据集,它包含在sklearn中。该数据集有 506 个样本、13 个输入变量和作为输出的房屋值。可以用 load_boston() 检索。
首先,导入train_test_split()和load_boston():
>>> from sklearn.datasets import load_boston >>> from sklearn.model_selection import train_test_split现在您已经导入了两个函数,您可以获取要处理的数据了:
>>> x, y = load_boston(return_X_y=True)
如您所见,带有参数return_X_y=True的load_boston()返回一个带有两个 NumPy 数组的元组:
- 带有输入的二维数组
- 具有输出的一维数组
下一步是像以前一样分割数据:
>>> x_train, x_test, y_train, y_test = train_test_split( ... x, y, test_size=0.4, random_state=0 ... )现在您有了训练集和测试集。训练数据在
x_train和y_train中,测试数据在x_test和y_test中。当您处理较大的数据集时,通常以比率的形式传递训练或测试大小会更方便。
test_size=0.4表示大约 40%的样本将被分配给测试数据,剩余的 60%将被分配给训练数据。最后,您可以使用训练集(
x_train和y_train)来拟合模型,并使用测试集(x_test和y_test)来对模型进行无偏见的评估。在本例中,您将应用三种众所周知的回归算法来创建适合您的数据的模型:
- 用
LinearRegression()进行线性回归- 渐变助推与
GradientBoostingRegressor()- 随机森林同
RandomForestRegressor()这个过程与前面的例子非常相似:
- 导入你需要的类。
- 使用这些类创建模型实例。
- 使用训练集将模型实例与
.fit()拟合。- 使用测试集对
.score()的模型进行评估。以下是遵循上述所有三种回归算法步骤的代码:
>>> from sklearn.linear_model import LinearRegression
>>> model = LinearRegression().fit(x_train, y_train)
>>> model.score(x_train, y_train)
0.7668160223286261
>>> model.score(x_test, y_test)
0.6882607142538016
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> model = GradientBoostingRegressor(random_state=0).fit(x_train, y_train)
>>> model.score(x_train, y_train)
0.9859065238883613
>>> model.score(x_test, y_test)
0.8530127436482149
>>> from sklearn.ensemble import RandomForestRegressor
>>> model = RandomForestRegressor(random_state=0).fit(x_train, y_train)
>>> model.score(x_train, y_train)
0.9811695664860354
>>> model.score(x_test, y_test)
0.8325867908704008
您已经使用训练和测试数据集来拟合三个模型并评估它们的性能。用.score()获得的精度测量值是决定系数。它可以用训练集或测试集来计算。然而,正如您已经了解到的,测试集获得的分数代表了对性能的无偏估计。
正如文档中提到的,您可以向LinearRegression()、GradientBoostingRegressor()和RandomForestRegressor()提供可选参数。GradientBoostingRegressor()和RandomForestRegressor()使用random_state参数的原因与train_test_split()相同:处理算法中的随机性并确保可再现性。
对于某些方法,您可能还需要特征缩放。在这种情况下,您应该让定标器适合训练数据,并使用它们来转换测试数据。
分类示例
你可以使用train_test_split()来解决分类问题,就像你做回归分析一样。在机器学习中,分类问题涉及训练模型来对输入值应用标签或进行分类,并将数据集分类。
在 Python 中的逻辑回归教程中,你会发现一个手写识别任务的例子。该示例提供了将数据分为训练集和测试集的另一个示例,以避免评估过程中的偏差。
其他验证功能
软件包 sklearn.model_selection 提供了许多与模型选择和验证相关的功能,包括以下内容:
- 交叉验证
- 学习曲线
- 超参数调谐
交叉验证是一套技术,它结合了预测性能的测量,以获得更准确的模型估计。
广泛使用的交叉验证方法之一是k——折叠交叉验证。在其中,你将你的数据集分成大小相等的 k (通常是五个或十个)子集,或者说折叠,然后执行 k 次训练和测试过程。每次,您使用不同的折叠作为测试集,所有剩余的折叠作为训练集。这提供了预测性能的 k 个度量,然后您可以分析它们的平均值和标准偏差。
您可以使用 KFold 、 StratifiedKFold 、 LeaveOneOut 以及sklearn.model_selection中的其他一些类和函数来实现交叉验证。
学习曲线,有时称为训练曲线,显示了训练和验证集的预测分数如何取决于训练样本的数量。您可以使用 learning_curve() 来获得这种依赖关系,它可以帮助您找到训练集的最佳大小,选择超参数,比较模型,等等。
超参数调优,也叫超参数优化,是确定一组最佳超参数来定义你的机器学习模型的过程。sklearn.model_selection为此提供了几个选项,包括GridSearchCVRandomizedSearchCVvalidation_curve()等。分割数据对于超参数调整也很重要。
结论
你现在知道为什么以及如何从sklearn中使用 train_test_split() 了。您已经了解到,为了对机器学习模型的预测性能进行无偏估计,您应该使用尚未用于模型拟合的数据。这就是为什么您需要将数据集分为训练、测试和某些情况下的验证子集。
在本教程中,您已经学会了如何:
- 使用
train_test_split()获得训练集和测试集 - 用参数
train_size和test_size控制子集的大小 - 用
random_state参数确定你劈叉的随机性 - 用
stratify参数获得分层分裂 - 使用
train_test_split()作为监督机器学习程序的一部分
您还看到了sklearn.model_selection模块提供了几个其他的模型验证工具,包括交叉验证、学习曲线和超参数调整。
如果你有任何问题或意见,请写在下面的评论区。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 scikit 拆分数据集-learn 和 train_test_split()**


 浙公网安备 33010602011771号
浙公网安备 33010602011771号