RealPython-中文系列教程-十二-
RealPython 中文系列教程(十二)
原文:RealPython
Python heapq 模块:使用堆和优先级队列
堆和优先级队列是鲜为人知但非常有用的数据结构。对于许多涉及在数据集中寻找最佳元素的问题,它们提供了一个易于使用且高效的解决方案。Python heapq模块是标准库的一部分。它实现了所有的低级堆操作,以及堆的一些高级公共用途。
一个优先级队列是一个强大的工具,可以解决各种各样的问题,如编写电子邮件调度程序、在地图上寻找最短路径或合并日志文件。编程充满了优化问题,目标是找到最佳元素。优先级队列和 Python heapq模块中的函数通常可以对此有所帮助。
在本教程中,您将学习:
- 什么是堆和优先级队列以及它们之间的关系
- 使用堆可以解决什么样的问题
- 如何使用 Python
heapq模块解决那些问题
本教程是为那些熟悉列表、字典、集合和生成器并且正在寻找更复杂的数据结构的 python 们准备的。
您可以通过从下面的链接下载源代码来学习本教程中的示例:
获取源代码: 点击此处获取源代码,您将使用在本教程中了解 Python heapq 模块。
什么是堆?
堆是具体的数据结构,而优先级队列是抽象的数据结构。抽象的数据结构决定了接口,而具体的数据结构定义了实现。
堆通常用于实现优先级队列。它们是实现优先级队列抽象数据结构的最流行的具体数据结构。
具体的数据结构也规定了性能保证。性能保证定义了结构的大小和操作花费的时间之间的关系。理解这些保证可以让您预测当输入的大小改变时程序将花费多少时间。
数据结构、堆和优先级队列
抽象数据结构规定了操作和它们之间的关系。例如,优先级队列抽象数据结构支持三种操作:
- is_empty 检查队列是否为空。
- add_element 向队列中添加一个元素。
- pop_element 弹出优先级最高的元素。
优先级队列通常用于优化任务执行,目标是处理优先级最高的任务。任务完成后,它的优先级降低,并返回到队列中。
确定元素的优先级有两种不同的约定:
- 最大的元素具有最高的优先级。
- 最小的元素具有最高的优先级。
这两个约定是等价的,因为您总是可以颠倒有效顺序。例如,如果你的元素由数字组成,那么使用负数将会颠倒约定。
Python heapq模块使用第二种约定,这通常是两种约定中更常见的一种。在这个约定下,最小的元素具有最高的优先级。这听起来可能令人惊讶,但它通常非常有用。在您稍后将看到的真实例子中,这种约定将简化您的代码。
注意:Pythonheapq模块,以及一般的堆数据结构不是设计来允许查找除最小元素之外的任何元素。对于按大小检索任何元素,更好的选择是二叉查找树。
具体数据结构实现抽象数据结构中定义的操作,并进一步指定性能保证。
优先级队列的堆实现保证了推送(添加)和弹出(移除)元素都是对数时间操作。这意味着做 push 和 pop 所需的时间与元素数量的以 2 为底的对数成正比。
对数增长缓慢。以 15 为底的对数大约是 4,而以 1 万亿为底的对数大约是 40。这意味着,如果一个算法在 15 个元素上足够快,那么它在 1 万亿个元素上只会慢 10 倍,而且可能仍然足够快。
在任何关于性能的讨论中,最大的警告是这些抽象的考虑比实际测量一个具体的程序和了解瓶颈在哪里更没有意义。一般的性能保证对于对程序行为做出有用的预测仍然很重要,但是这些预测应该得到证实。
堆的实现
堆将优先级队列实现为完整二叉树。在二叉树中,每个节点最多有两个子节点。在一棵完全二叉树中,除了可能是最深的一层之外,所有层在任何时候都是满的。如果最深层次是不完整的,那么它的节点将尽可能地靠左。
完整性属性意味着树的深度是元素数量的以 2 为底的对数,向上取整。下面是一个完整二叉树的例子:

在这个特殊的例子中,所有级别都是完整的。除了最深的节点之外,每个节点正好有两个子节点。三个级别总共有七个节点。3 是 7 的以 2 为底的对数,向上取整。
基层的单个节点被称为根节点。将树顶端的节点称为根可能看起来很奇怪,但这是编程和计算机科学中的常见约定。
堆中的性能保证取决于元素如何在树中上下渗透。这样做的实际结果是,堆中的比较次数是树大小的以 2 为底的对数。
注意:比较有时涉及到使用.__lt__()调用用户定义的代码。与在堆中进行的其他操作相比,在 Python 中调用用户定义的方法是一个相对较慢的操作,因此这通常会成为瓶颈。
在堆树中,一个节点中的值总是小于它的两个子节点。这被称为堆属性。这与二叉查找树不同,在后者中,只有左边的节点将小于其父节点的值。
推送和弹出的算法都依赖于临时违反堆属性,然后通过比较和替换单个分支上下来修复堆属性。
例如,为了将一个元素推到一个堆上,Python 会将新节点添加到下一个打开的槽中。如果底层未满,则该节点将被添加到底部的下一个空槽中。否则,创建一个新级别,然后将元素添加到新的底层。
添加节点后,Python 会将其与其父节点进行比较。如果违反了堆属性,则交换节点及其父节点,并从父节点重新开始检查。这种情况一直持续到堆属性成立或到达根为止。
类似地,当弹出最小的元素时,Python 知道,由于堆属性,该元素位于树的根。它用最深层的最后一个元素替换该元素,然后检查是否违反了分支的堆属性。
优先级队列的使用
优先级队列,以及作为优先级队列实现的堆,对于需要寻找某种极端元素的程序非常有用。例如,您可以将优先级队列用于以下任何任务:
- 从 hit data 中获取三个最受欢迎的博客帖子
- 寻找从一个地方到另一个地方的最快方法
- 基于到达频率预测哪辆公共汽车将首先到达车站
您可以使用优先级队列的另一个任务是安排电子邮件。想象一下,一个系统有几种电子邮件,每种邮件都需要以一定的频率发送。一种邮件需要每十五分钟发出一次,另一种需要每四十分钟发出一次。
调度程序可以将这两种类型的电子邮件添加到队列中,并带有一个时间戳来指示下一次需要发送电子邮件的时间。然后,调度程序可以查看时间戳最小的元素——表明它是下一个要发送的元素——并计算发送前要休眠多长时间。
当调度程序唤醒时,它将处理相关的电子邮件,将电子邮件从优先级队列中取出,计算下一个时间戳,并将电子邮件放回队列中的正确位置。
Python heapq模块中作为列表的堆
尽管您看到了前面描述的树型堆,但重要的是要记住它是一棵完整的二叉树。完整性意味着除了最后一层,总是可以知道每一层有多少元素。因此,堆可以作为一个列表来实现。这就是 Python heapq模块所做的事情。
有三个规则确定索引k处的元素与其周围元素之间的关系:
- 它的第一个孩子在
2*k + 1。 - 它的第二个孩子在
2*k + 2。 - 它的父节点在
(k - 1) // 2。
注://符号是整数除法运算符。它总是向下舍入到整数。
上面的规则告诉你如何将一个列表可视化为一个完整的二叉树。请记住,元素总是有父元素,但有些元素没有子元素。如果2*k超出了列表的末尾,那么该元素没有任何子元素。如果2*k + 1是一个有效的索引,而2*k + 2不是,那么这个元素只有一个子元素。
heap 属性意味着如果h是一个堆,那么下面的永远不会是False:
h[k] <= h[2*k + 1] and h[k] <= h[2*k + 2]
如果任何索引超出了列表的长度,它可能会引发一个IndexError,但它永远不会是False。
换句话说,一个元素必须总是小于两倍于其索引加 1 和两倍于其索引加 2 的元素。
下面是一个满足堆属性的列表:

箭头从元素k指向元素2*k + 1和2*k + 2。例如,Python 列表中的第一个元素有索引0,所以它的两个箭头指向索引1和2。注意箭头总是从较小的值到较大的值。这是检查列表是否满足堆属性的方法。
基本操作
Python heapq模块实现了对列表的堆操作。与许多其他模块不同,它没有而不是定义一个自定义类。Python heapq模块有直接作用于列表的函数。
通常,就像上面的电子邮件示例一样,元素将从一个空堆开始,一个接一个地插入到一个堆中。然而,如果已经有一个需要成为堆的元素列表,那么 Python heapq模块包含了用于将列表转换成有效堆的heapify()。
下面的代码使用heapify()将a变成堆:
>>> import heapq >>> a = [3, 5, 1, 2, 6, 8, 7] >>> heapq.heapify(a) >>> a [1, 2, 3, 5, 6, 8, 7]你可以检查一下,即使
7在8之后,列表a仍然服从堆属性。比如a[2],也就是3,小于a[2*2 + 2],也就是7。如您所见,
heapify()就地修改了列表,但没有对其进行排序。堆不一定要排序才能满足堆属性。然而,因为每个排序列表都满足堆属性,所以在排序列表上运行heapify()不会改变列表中元素的顺序。Python
heapq模块中的其他基本操作假设列表已经是一个堆。值得注意的是,空列表或长度为 1 的列表总是堆。因为树根是第一个元素,所以不需要专门的函数来非破坏性地读取最小的元素。第一个元素
a[0],永远是最小的元素。为了在保留堆属性的同时弹出最小的元素,Python
heapq模块定义了heappop()。下面是如何使用
heappop()弹出一个元素:
>>> import heapq
>>> a = [1, 2, 3, 5, 6, 8, 7]
>>> heapq.heappop(a)
1
>>> a
[2, 5, 3, 7, 6, 8]
该函数返回第一个元素1,并保留a上的堆属性。比如a[1]是5,a[1*2 + 2]是6。
Python heapq模块还包括heappush(),用于将元素推送到堆中,同时保留堆属性。
以下示例显示了将值推送到堆中:
>>> import heapq >>> a = [2, 5, 3, 7, 6, 8] >>> heapq.heappush(a, 4) >>> a [2, 5, 3, 7, 6, 8, 4] >>> heapq.heappop(a) 2 >>> heapq.heappop(a) 3 >>> heapq.heappop(a) 4将
4推到堆中后,从堆中取出三个元素。因为2和3已经在堆中,并且比4小,所以它们先被弹出。Python
heapq模块还定义了另外两个操作:
heapreplace()相当于heappop()后跟heappush()。heappushpop()相当于heappush()后跟heappop()。这些在一些算法中是有用的,因为它们比分别做这两个操作更有效。
高层操作
由于优先级队列经常用于合并排序后的序列,Python
heapq模块有一个现成的函数merge(),用于使用堆来合并几个可重复项。merge()假设它的输入 iterables 已经排序,并返回一个迭代器,而不是一个列表。作为使用
merge()的一个例子,这里有一个前面描述的电子邮件调度器的实现:import datetime import heapq def email(frequency, details): current = datetime.datetime.now() while True: current += frequency yield current, details fast_email = email(datetime.timedelta(minutes=15), "fast email") slow_email = email(datetime.timedelta(minutes=40), "slow email") unified = heapq.merge(fast_email, slow_email)本例中
merge()的输入是无限发电机。赋给变量unified的返回值也是无限迭代器。这个迭代器将按照未来时间戳的顺序产生要发送的电子邮件。为了调试并确认代码正确合并,您可以打印要发送的前十封电子邮件:
>>> for _ in range(10):
... print(next(element))
(datetime.datetime(2020, 4, 12, 21, 27, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 21, 42, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 21, 52, 20, 305360), 'slow email')
(datetime.datetime(2020, 4, 12, 21, 57, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 12, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 27, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 32, 20, 305360), 'slow email')
(datetime.datetime(2020, 4, 12, 22, 42, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 22, 57, 20, 305358), 'fast email')
(datetime.datetime(2020, 4, 12, 23, 12, 20, 305358), 'fast email')
请注意fast email是如何每隔15分钟安排一次的,slow email是如何每隔40安排一次的,并且电子邮件被适当地交错,以便它们按照时间戳的顺序排列。
不读取所有输入,而是动态工作。即使两个输入都是无限迭代器,打印前十项也会很快完成。
类似地,当用于合并排序后的序列时,比如按时间戳排列的日志文件行,即使日志很大,也会占用合理的内存量。
堆可以解决的问题
正如你在上面看到的,堆对于递增合并排序的序列是很好的。您已经考虑过的堆的两个应用是调度周期性任务和合并日志文件。然而,还有更多的应用。
堆还可以帮助识别顶部的 T2 或底部的 T4。Python heapq模块有实现这种行为的高级函数。
例如,该代码从 2016 年夏季奥运会的女子 100 米决赛中获取时间作为输入,并打印奖牌获得者或前三名:
>>> import heapq >>> results="""\ ... Christania Williams 11.80 ... Marie-Josee Ta Lou 10.86 ... Elaine Thompson 10.71 ... Tori Bowie 10.83 ... Shelly-Ann Fraser-Pryce 10.86 ... English Gardner 10.94 ... Michelle-Lee Ahye 10.92 ... Dafne Schippers 10.90 ... """ >>> top_3 = heapq.nsmallest( ... 3, results.splitlines(), key=lambda x: float(x.split()[-1]) ... ) >>> print("\n".join(top_3)) Elaine Thompson 10.71 Tori Bowie 10.83 Marie-Josee Ta Lou 10.86这段代码使用了 Python
heapq模块中的nsmallest()。nsmallest()返回 iterable 中的最小元素,并接受三个参数:
n表示返回多少个元素。iterable标识要比较的元素或数据集。key是一个决定如何比较元素的可调用函数。在这里,
key函数通过空格分割该行,获取最后一个元素,并将其转换为一个浮点数。这意味着代码将根据运行时间对行进行排序,并返回运行时间最短的三行。这些对应于三个跑得最快的人,这给了你金牌,银牌和铜牌获得者。Python
heapq模块还包括nlargest(),它有类似的参数,返回最大的元素。这将是有用的,如果你想从标枪比赛中获得奖牌,其中的目标是投掷标枪尽可能远。如何识别问题
作为优先级队列的实现,堆是解决极端问题的好工具,比如给定指标的最大值或最小值。
还有其他词语表明堆可能有用:
- 最大的
- 最小的
- 最大的
- 最小的
- 最好的
- 最差的
- 顶端
- 底部
- 最高的
- 最低限度
- 最佳的
每当问题陈述表明您正在寻找一些极端的元素时,就有必要考虑一下优先级队列是否有用。
有时优先级队列将只是解决方案的部分,其余部分将是动态编程的某种变体。这是您将在下一节看到的完整示例的情况。动态编程和优先级队列经常一起使用。
示例:查找路径
下面的例子是 Python
heapq模块的一个真实用例。这个例子将使用一个经典算法,作为它的一部分,需要一个堆。您可以通过单击下面的链接下载示例中使用的源代码:获取源代码: 点击此处获取源代码,您将使用在本教程中了解 Python heapq 模块。
想象一个需要在二维迷宫中导航的机器人。机器人需要从左上角的原点出发,到达右下角的目的地。机器人的记忆中有迷宫的地图,所以它可以在出发前规划出整个路径。
目标是让机器人尽快完成迷宫。
我们的算法是 Dijkstra 算法的变体。在整个算法中,有三种数据结构被保持和更新:
tentative是一张从原点到某个位置的试探性路径图,pos。这条路径被称为暂定,因为它是已知最短的路径,但它可能会被改进。
certain是一组点,对于这些点,tentative映射的路径是确定的最短可能路径。
candidates是一堆有路径的位置。堆的排序键是路径的长度。在每个步骤中,您最多可以执行四个操作:
从
candidates弹出一个候选人。将候选人添加到
certain集合。如果候选人已经是certain集合的成员,则跳过接下来的两个动作。查找到当前候选人的最短已知路径。
对于当前候选的每个近邻,查看遍历候选是否给出比当前
tentative路径更短的路径。如果是,那么用这个新路径更新tentative路径和candidates堆。这些步骤循环运行,直到目的地被添加到
certain集合。当目的地在certain集合中时,您就完成了。该算法的输出是到目的地的tentative路径,现在certain是最短的可能路径。顶层代码
现在您已经理解了算法,是时候编写代码来实现它了。在实现算法本身之前,写一些支持代码是有用的。
首先,你需要导入Python
heapq模块:import heapq您将使用 Python
heapq模块中的函数来维护一个堆,这将帮助您在每次迭代中找到已知路径最短的位置。下一步是将地图定义为代码中的变量:
map = """\ .......X.. .......X.. ....XXXX.. .......... .......... """该地图是一个三重引用字符串,显示机器人可以移动的区域以及任何障碍。
虽然更现实的场景是从文件中读取地图,但出于教学目的,使用这个简单的地图在代码中定义变量更容易。代码可以在任何地图上工作,但是在简单的地图上更容易理解和调试。
该图经过优化,便于代码的人类读者理解。点(
.)足够亮,看起来是空的,但它的优点是显示了允许区域的尺寸。X位置标记机器人无法通过的障碍物。支持代码
第一个函数将把地图转换成更容易用代码解析的形式。
parse_map()获取地图并对其进行分析:def parse_map(map): lines = map.splitlines() origin = 0, 0 destination = len(lines[-1]) - 1, len(lines) - 1 return lines, origin, destination该函数获取一个映射并返回一个包含三个元素的元组:
lines列表origindestination这使得剩余的代码能够处理为计算机设计的数据结构,而不是为人类的视觉扫描能力设计的数据结构。
可以通过
(x, y)坐标来索引lines列表。表达式lines[y][x]返回两个字符之一的位置值:
- 点(
".") 表示该位置为空。- 字母
"X"表示位置是障碍。当你想找到机器人可以占据的位置时,这将是有用的。
函数
is_valid()计算给定的(x, y)位置是否有效:def is_valid(lines, position): x, y = position if not (0 <= y < len(lines) and 0 <= x < len(lines[y])): return False if lines[y][x] == "X": return False return True该函数有两个参数:
lines是把地图看成一列线条。position是要检查的位置,作为指示(x, y)坐标的二元组整数。为了有效,位置必须在地图的边界内,而不是障碍物。
该函数通过检查
lines列表的长度来检查y是否有效。该函数接下来检查x是否有效,确保它在lines[y]内。最后,现在你知道两个坐标都在地图内,代码通过查看这个位置的字符并将字符与"X"进行比较来检查它们是否是障碍。另一个有用的助手是
get_neighbors(),它查找一个位置的所有邻居:def get_neighbors(lines, current): x, y = current for dx in [-1, 0, 1]: for dy in [-1, 0, 1]: if dx == 0 and dy == 0: continue position = x + dx, y + dy if is_valid(lines, position): yield position该函数返回当前位置周围的所有有效位置。
get_neighbors()小心避免将某个位置标识为自己的邻居,但它允许对角邻居。这就是为什么dx和dy中至少有一个不能为零,但是两个都不为零也没关系。最后一个助手函数是
get_shorter_paths(),它寻找更短的路径:def get_shorter_paths(tentative, positions, through): path = tentative[through] + [through] for position in positions: if position in tentative and len(tentative[position]) <= len(path): continue yield position, path
get_shorter_paths()产生以through为最后一步的路径比当前已知路径短的位置。
get_shorter_paths()有三个参数:
tentative是将一个位置映射到最短已知路径的字典。positions是一个可迭代的位置,您要将路径缩短到该位置。through是这样一个位置,通过它也许可以找到一条到positions的更短的路径。假设从
through开始一步就可以到达positions中的所有元素。功能
get_shorter_paths()检查使用through作为最后一步是否会为每个位置创建更好的路径。如果一个位置没有已知的路径,那么任何路径都是较短的。如果有一条已知的路径,那么只有当它的长度更短时,你才会产生新的路径。为了让get_shorter_paths()的 API 更容易使用,yield的一部分也是更短的路径。所有的帮助函数都被写成纯函数,这意味着它们不修改任何数据结构,只返回值。这使得遵循核心算法变得更加容易,核心算法完成所有的数据结构更新。
核心算法代码
概括地说,您正在寻找起点和终点之间的最短路径。
您保留三份数据:
certain是某些职位的设定。candidates是堆候选人。tentative是一个将节点映射到当前最短已知路径的字典。如果您能确定最短的已知路径是最短的可能路径,则位置在
certain中。如果目的地在certain集合中,那么到目的地的最短已知路径无疑是最短的可能路径,并且您可以返回该路径。
candidates的堆由最短已知路径的长度组织,并在 Pythonheapq模块中的函数的帮助下进行管理。在每一步,你看着候选人与最短的已知路径。这是用
heappop()弹出堆的地方。到这个候选者没有更短的路径——所有其他路径都经过candidates中的某个其他节点,并且所有这些路径都更长。正因为如此,目前的候选人可以标上certain。然后查看所有没有被访问过的邻居,如果遍历当前节点是一种改进,那么使用
heappush()将它们添加到candidates堆中。函数
find_path()实现了该算法:1def find_path(map): 2 lines, origin, destination = parse_map(map) 3 tentative = {origin: []} 4 candidates = [(0, origin)] 5 certain = set() 6 while destination not in certain and len(candidates) > 0: 7 _ignored, current = heapq.heappop(candidates) 8 if current in certain: 9 continue 10 certain.add(current) 11 neighbors = set(get_neighbors(lines, current)) - certain 12 shorter = get_shorter_paths(tentative, neighbors, current) 13 for neighbor, path in shorter: 14 tentative[neighbor] = path 15 heapq.heappush(candidates, (len(path), neighbor)) 16 if destination in tentative: 17 return tentative[destination] + [destination] 18 else: 19 raise ValueError("no path")
find_path()接收一个map作为字符串,并返回从原点到目的地的路径作为位置列表。这个函数有点长且复杂,所以让我们一次一点地来看一下:
第 2 行到第 5 行设置了循环将查看和更新的变量。你已经知道了一条从原点到自身的路径,这条路径是空的,长度为 0。
第 6 行定义了循环的终止条件。如果没有
candidates,那么没有路径可以缩短。如果destination在certain,那么到destination的路径不能再短了。第 7 行到第 10 行使用
heappop()得到一个候选者,如果它已经在certain中就跳过这个循环,否则将这个候选者添加到certain。这确保了每个候选项最多被循环处理一次。第 11 行到第 15 行使用
get_neighbors()和get_shorter_paths()寻找到邻近位置的更短路径,并更新tentative字典和candidates堆。第 16 行到第 19 行处理返回正确的结果。如果找到了路径,那么函数将返回它。虽然计算路径而不计算最终位置使得算法的实现更简单,但是返回路径并以为目的地是一个更好的 API。如果找不到路径,则会引发异常。
将函数分解成不同的部分可以让你一次理解一部分。
可视化代码
如果该算法实际上被机器人使用,那么机器人可能会在它应该经过的位置列表中表现得更好。然而,为了使结果对人类来说更好看,可视化他们会更好。
show_path()在地图上绘制路径:def show_path(path, map): lines = map.splitlines() for x, y in path: lines[y] = lines[y][:x] + "@" + lines[y][x + 1 :] return "\n".join(lines) + "\n"该函数将
path和map作为参数。它返回一个新地图,路径由 at 符号("@")指示。运行代码
最后,您需要调用函数。这可以通过 Python 交互式解释器来完成。
以下代码将运行该算法并显示漂亮的输出:
>>> path = find_path(map)
>>> print(show_path(path, map))
@@.....X..
..@....X..
...@XXXX..
....@@@@@.
.........@
首先你得到从find_path()开始的最短路径。然后你把它传递给show_path()来渲染一个标有路径的地图。最后,你print()把地图以标准输出。
路径向右移动一步,然后向右下斜移几步,再向右移几步,最后向右下斜移一步。
恭喜你!您已经使用 Python heapq模块解决了一个问题。
这类寻路问题可以通过动态规划和优先级队列的组合来解决,在工作面试和编程挑战中很常见。例如,2019 年出现的代码包括一个问题,可以用这里描述的技术解决。
结论
你现在知道了什么是堆和优先级队列数据结构,以及它们在解决什么样的问题时有用。您学习了如何使用 Python heapq模块将 Python 列表用作堆。您还学习了如何使用 Python heapq模块中的高级操作,比如merge(),它在内部使用堆。
在本教程中,您已经学会了如何:
- 使用 Python
heapq模块中的低级函数来解决需要堆或优先级队列的问题 - 使用 Python
heapq模块中的高级函数来合并已排序的可迭代对象或查找可迭代对象中最大或最小的元素 - 认识到堆和优先级队列可以帮助解决的问题
- 预测使用堆的代码的性能
凭借您对堆和 Python heapq模块的了解,您现在可以解决许多问题,这些问题的解决方案取决于找到最小或最大的元素。要了解您在本教程中看到的示例,您可以从下面的链接下载源代码:
获取源代码: 点击此处获取源代码,您将使用在本教程中了解 Python heapq 模块。*******
Python 直方图绘制:NumPy、Matplotlib、Pandas 和 Seaborn
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 直方图绘制:NumPy、Matplotlib、Pandas & Seaborn
在本教程中,您将具备制作产品质量、演示就绪的 Python 直方图的能力,并拥有一系列选择和功能。
如果您对 Python 和 statistics 有入门中级知识,那么您可以将本文作为使用 Python 科学堆栈中的库(包括 NumPy、Matplotlib、 Pandas 和 Seaborn)在 Python 中构建和绘制直方图的一站式商店。
直方图是一个很好的工具,可以快速评估几乎所有观众都能直观理解的概率分布。Python 为构建和绘制直方图提供了一些不同的选项。大多数人通过直方图的图形表示来了解直方图,它类似于条形图:
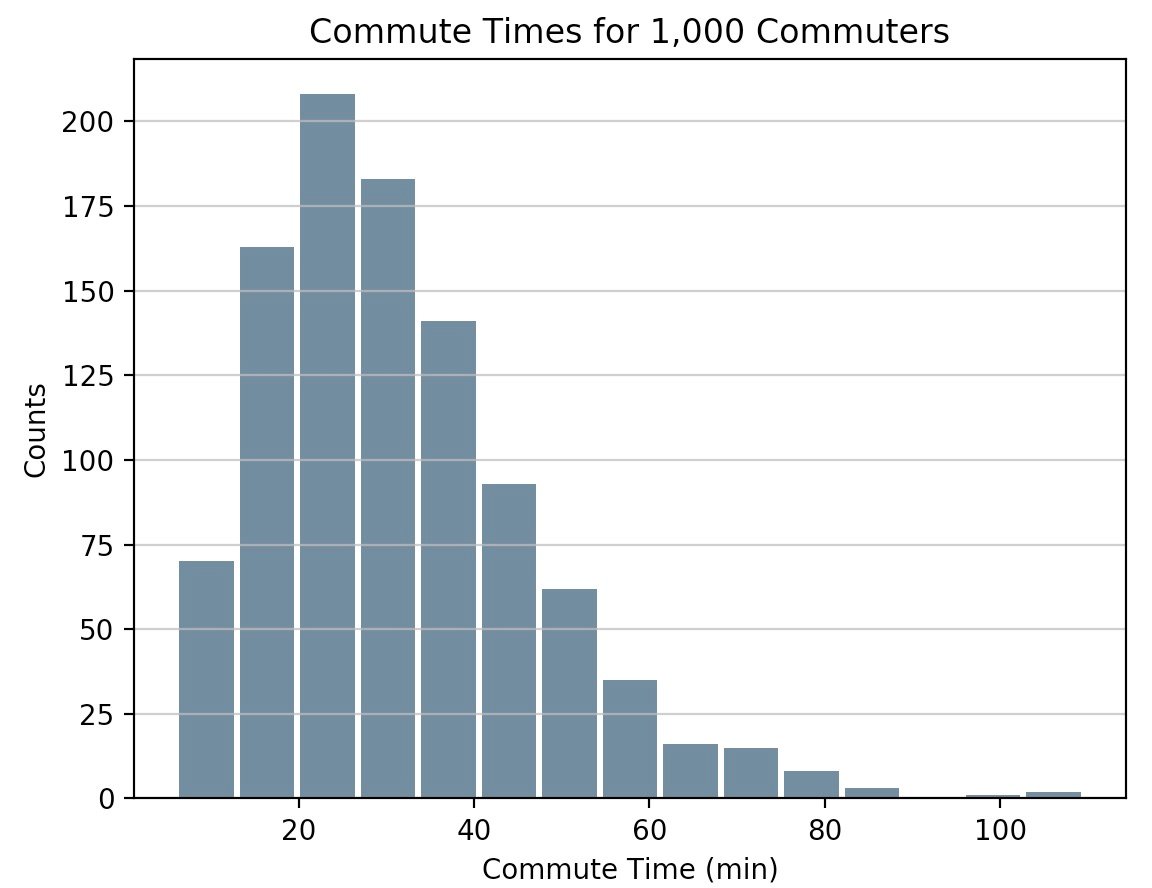
这篇文章将引导你创建类似上面的情节以及更复杂的情节。以下是您将涉及的内容:
- 用纯 Python 构建直方图,不使用第三方库
- 使用 NumPy 构建直方图以汇总底层数据
- 使用 Matplotlib、Pandas 和 Seaborn 绘制结果直方图
免费奖金:时间短?点击这里获得一份免费的两页 Python 直方图备忘单,它总结了本教程中解释的技术。
纯 Python 的直方图
当您准备绘制直方图时,最简单的方法是不要考虑柱,而是报告每个值出现的次数(频率表)。Python 字典非常适合这项任务:
>>> # Need not be sorted, necessarily >>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23) >>> def count_elements(seq) -> dict: ... """Tally elements from `seq`.""" ... hist = {} ... for i in seq: ... hist[i] = hist.get(i, 0) + 1 ... return hist >>> counted = count_elements(a) >>> counted {0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
count_elements()返回一个字典,将序列中的唯一元素作为键,将它们的频率(计数)作为值。在seq的循环中,hist[i] = hist.get(i, 0) + 1说,“对于序列中的每个元素,将它在hist中的对应值增加 1。”事实上,这正是 Python 标准库中的
collections.Counter类所做的,该类的子类化了一个 Python 字典并覆盖了它的.update()方法:
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})
通过测试两者之间的相等性,您可以确认您的手工函数实际上做了与collections.Counter相同的事情:
>>> recounted.items() == counted.items() True技术细节:上面
count_elements()的映射默认为一个更加高度优化的 C 函数,如果它可用的话。在 Python 函数count_elements()中,你可以做的一个微优化是在 for 循环之前声明get = hist.get。这将把一个方法绑定到一个变量,以便在循环中更快地调用。作为理解更复杂的函数的第一步,从头构建简化的函数可能会有所帮助。让我们利用 Python 的输出格式进一步重新发明一个 ASCII 直方图:
def ascii_histogram(seq) -> None: """A horizontal frequency-table/histogram plot.""" counted = count_elements(seq) for k in sorted(counted): print('{0:5d} {1}'.format(k, '+' * counted[k]))该函数创建一个排序频率图,其中计数表示为加号(
+)的计数。在字典上调用sorted()会返回一个排序后的键列表,然后使用counted[k]访问每个键对应的值。要了解这一点,您可以使用 Python 的random模块创建一个稍大的数据集:
>>> # No NumPy ... yet
>>> import random
>>> random.seed(1)
>>> vals = [1, 3, 4, 6, 8, 9, 10]
>>> # Each number in `vals` will occur between 5 and 15 times.
>>> freq = (random.randint(5, 15) for _ in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1 +++++++
3 ++++++++++++++
4 ++++++
6 +++++++++
8 ++++++
9 ++++++++++++
10 ++++++++++++
在这里,您模拟从vals开始拨弦,频率由freq(一个发生器表达式)给出。产生的样本数据重复来自vals的每个值一定的次数,在 5 到 15 之间。
注意 : random.seed() 用于播种或初始化random使用的底层伪随机数发生器( PRNG )。这听起来可能有点矛盾,但这是一种让随机数据具有可重复性和确定性的方法。也就是说,如果你照原样复制这里的代码,你应该得到完全相同的直方图,因为在播种生成器之后第一次调用random.randint()将使用 Mersenne Twister 产生相同的“随机”数据。
从基础开始构建:以 NumPy 为单位的直方图计算
到目前为止,您一直在使用最好称为“频率表”的东西。但是从数学上来说,直方图是区间(区间)到频率的映射。更专业的说,可以用来近似基础变量的概率密度函数( PDF )。
从上面的“频率表”开始,真正的直方图首先“分类”值的范围,然后计算落入每个分类的值的数量。这就是 NumPy 的 histogram()函数所做的事情,它也是你稍后将在 Python 库中看到的其他函数的基础,比如 Matplotlib 和 Pandas。
考虑从拉普拉斯分布中抽取的一个浮点样本。该分布比正态分布具有更宽的尾部,并且具有两个描述性参数(位置和比例):
>>> import numpy as np >>> # `numpy.random` uses its own PRNG. >>> np.random.seed(444) >>> np.set_printoptions(precision=3) >>> d = np.random.laplace(loc=15, scale=3, size=500) >>> d[:5] array([18.406, 18.087, 16.004, 16.221, 7.358])在这种情况下,您处理的是一个连续的分布,单独计算每个浮点数,直到小数点后无数位,并没有多大帮助。相反,您可以对数据进行分类或“分桶”,并对落入每个分类中的观察值进行计数。直方图是每个条柱内值的结果计数:
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])
这个结果可能不是直接直观的。 np.histogram() 默认使用 10 个大小相等的仓,并返回频率计数和相应仓边的元组。它们是边缘,在这种意义上,将会比直方图的成员多一个箱边缘:
>>> hist.size, bin_edges.size (10, 11)技术细节:除了最后一个(最右边的)箱子,其他箱子都是半开的。也就是说,除了最后一个 bin 之外的所有 bin 都是[包含,不包含],最后一个 bin 是[包含,不包含]。
NumPy 如何构造的一个非常简洁的分类如下:
>>> # The leftmost and rightmost bin edges
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10 # NumPy's default
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0\. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23\. ])
上面的例子很有意义:在 23 的峰峰值范围内,10 个等间距的仓意味着宽度为 2.3 的区间。
从那里,该功能委托给 np.bincount() 或 np.searchsorted() 。bincount()本身可以用来有效地构建您在这里开始的“频率表”,区别在于包含了零出现的值:
>>> bcounts = np.bincount(a) >>> hist, _ = np.histogram(a, range=(0, a.max()), bins=a.max() + 1) >>> np.array_equal(hist, bcounts) True >>> # Reproducing `collections.Counter` >>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()])) {0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}注意 :
hist这里实际上使用的是宽度为 1.0 的面元,而不是“离散”计数。因此,这只对计算整数有效,而不是像[3.9, 4.1, 4.15]这样的浮点数。用 Matplotlib 和 Pandas 可视化直方图
现在你已经看到了如何用 Python 从头开始构建直方图,让我们看看其他的 Python 包如何为你完成这项工作。 Matplotlib 通过围绕 NumPy 的
histogram()的通用包装器,提供开箱即用的可视化 Python 直方图的功能:import matplotlib.pyplot as plt # An "interface" to matplotlib.axes.Axes.hist() method n, bins, patches = plt.hist(x=d, bins='auto', color='#0504aa', alpha=0.7, rwidth=0.85) plt.grid(axis='y', alpha=0.75) plt.xlabel('Value') plt.ylabel('Frequency') plt.title('My Very Own Histogram') plt.text(23, 45, r'$\mu=15, b=3$') maxfreq = n.max() # Set a clean upper y-axis limit. plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10)
如前所述,直方图在 x 轴上使用其条边,在 y 轴上使用相应的频率。在上图中,传递
bins='auto'在两个算法之间选择,以估计“理想”的箱数。在高层次上,该算法的目标是选择一个能够生成最忠实的数据表示的条柱宽度。关于这个主题的更多信息,可能会变得非常专业,请查看 Astropy 文档中的选择直方图仓。在 Python 的科学堆栈中,熊猫的
Series.histogram()使用matplotlib.pyplot.hist()绘制输入序列的 Matplotlib 直方图:import pandas as pd # Generate data on commute times. size, scale = 1000, 10 commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5) commutes.plot.hist(grid=True, bins=20, rwidth=0.9, color='#607c8e') plt.title('Commute Times for 1,000 Commuters') plt.xlabel('Counts') plt.ylabel('Commute Time') plt.grid(axis='y', alpha=0.75)
pandas.DataFrame.histogram()类似,但为数据帧中的每列数据生成一个直方图。绘制核密度估计值(KDE)
在本教程中,从统计学的角度来说,您一直在使用样本。无论数据是离散的还是连续的,它都被假定为来自一个总体,该总体具有仅由几个参数描述的真实、精确的分布。
核密度估计(KDE)是一种估计样本中随机变量的概率密度函数(PDF)的方法。KDE 是一种数据平滑的手段。
坚持使用熊猫库,你可以使用
plot.kde()创建和覆盖密度图,它对Series和DataFrame对象都可用。但首先,让我们生成两个不同的数据样本进行比较:
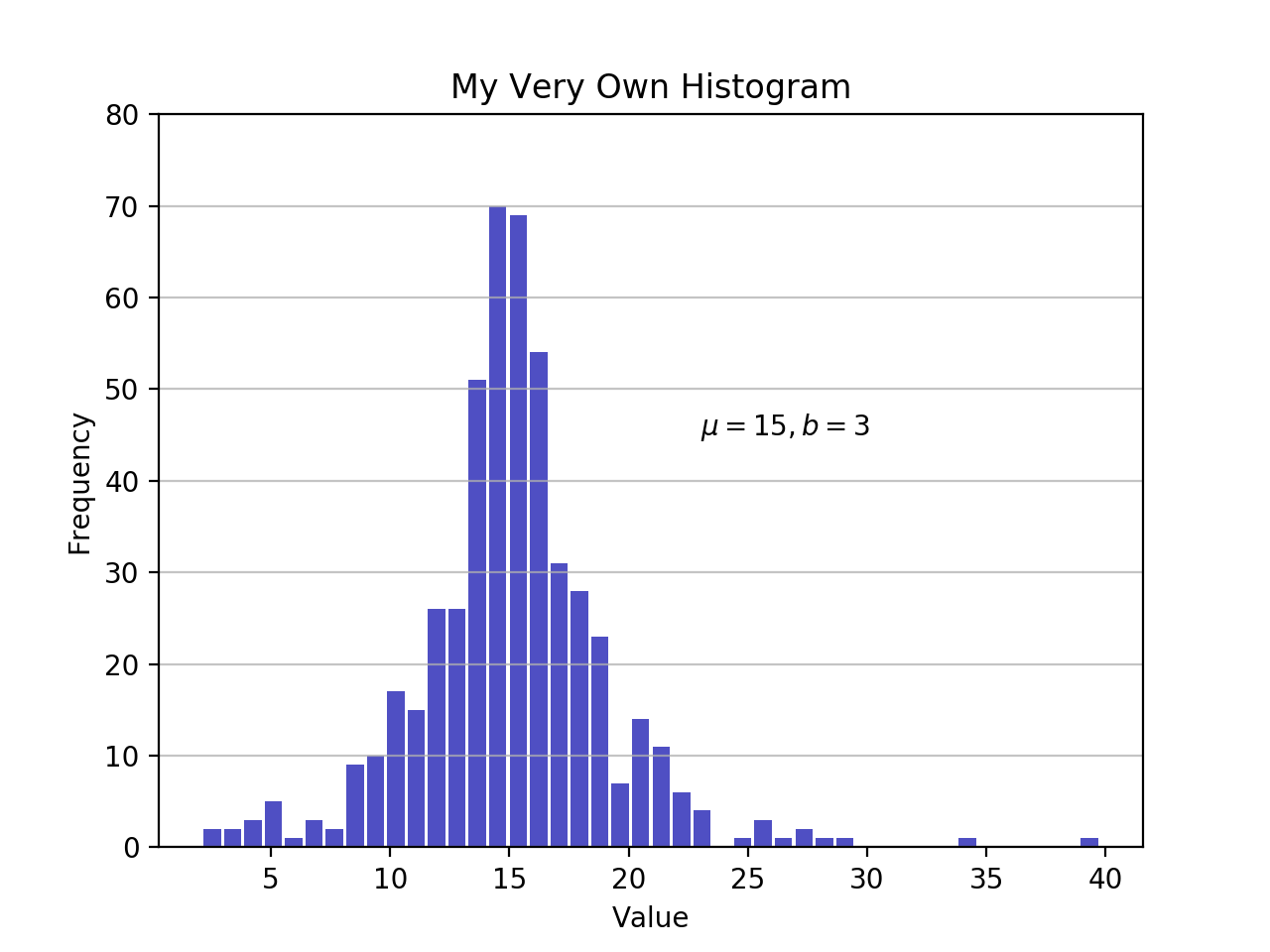
>>> # Sample from two different normal distributions
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=(1000, 2)),
... columns=['a', 'b'])
>>> dist.agg(['min', 'max', 'mean', 'std']).round(decimals=2)
a b
min -1.57 12.46
max 25.32 26.44
mean 10.12 19.94
std 3.94 1.94
现在,要在相同的 Matplotlib 轴上绘制每个直方图:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend=False, title='Histogram: A vs. B')
dist.plot.hist(density=True, ax=ax)
ax.set_ylabel('Probability')
ax.grid(axis='y')
ax.set_facecolor('#d8dcd6')

这些方法利用了 SciPy 的 gaussian_kde() ,从而产生看起来更平滑的 PDF。
如果您仔细观察这个函数,您会发现对于 1000 个数据点的相对较小的样本,它是多么接近“真实”的 PDF。下面,你可以先用scipy.stats.norm()构建“解析”分布。这是一个类实例,封装了统计标准正态分布、其矩和描述函数。它的 PDF 是“精确的”,因为它被精确地定义为norm.pdf(x) = exp(-x**2/2) / sqrt(2*pi)。
在此基础上,您可以从该分布中随机抽取 1000 个数据点,然后尝试使用scipy.stats.gaussian_kde()返回 PDF 的估计值:
from scipy import stats
# An object representing the "frozen" analytical distribution
# Defaults to the standard normal distribution, N~(0, 1)
dist = stats.norm()
# Draw random samples from the population you built above.
# This is just a sample, so the mean and std. deviation should
# be close to (1, 0).
samp = dist.rvs(size=1000)
# `ppf()`: percent point function (inverse of cdf — percentiles).
x = np.linspace(start=stats.norm.ppf(0.01),
stop=stats.norm.ppf(0.99), num=250)
gkde = stats.gaussian_kde(dataset=samp)
# `gkde.evaluate()` estimates the PDF itself.
fig, ax = plt.subplots()
ax.plot(x, dist.pdf(x), linestyle='solid', c='red', lw=3,
alpha=0.8, label='Analytical (True) PDF')
ax.plot(x, gkde.evaluate(x), linestyle='dashed', c='black', lw=2,
label='PDF Estimated via KDE')
ax.legend(loc='best', frameon=False)
ax.set_title('Analytical vs. Estimated PDF')
ax.set_ylabel('Probability')
ax.text(-2., 0.35, r'$f(x) = \frac{\exp(-x^2/2)}{\sqrt{2*\pi}}$',
fontsize=12)

这是一个更大的代码块,所以让我们花点时间来了解几个关键行:
- SciPy 的
stats子包允许您创建表示分析分布的 Python 对象,您可以从中采样以创建实际数据。所以dist = stats.norm()代表一个正常的连续随机变量,你用dist.rvs()从中生成随机数。 - 为了评估分析 PDF 和高斯 KDE,您需要一个分位数数组
x(高于/低于平均值的标准偏差,表示正态分布)。stats.gaussian_kde()表示一个估计的 PDF,在这种情况下,您需要对一个数组进行评估,以产生视觉上有意义的东西。 - 最后一行包含一些 LaTex ,它与 Matplotlib 很好地集成在一起。
与 Seaborn 的别样选择
让我们再加入一个 Python 包。Seaborn 有一个displot()函数,可以一步绘制出单变量分布的直方图和 KDE。使用早期的 NumPy 数组d:
import seaborn as sns
sns.set_style('darkgrid')
sns.distplot(d)

上面的调用产生了一个 KDE。还可以选择为数据拟合特定的分布。这不同于 KDE,它由通用数据的参数估计和指定的分布名称组成:
sns.distplot(d, fit=stats.laplace, kde=False)

同样,请注意细微的差别。在第一种情况下,你估计一些未知的 PDF 在第二种情况下,你需要一个已知的分布,并根据经验数据找出最能描述它的参数。
熊猫里的其他工具
除了它的绘图工具,Pandas 还提供了一个方便的.value_counts()方法来计算 Pandas 的非空值的直方图Series:
>>> import pandas as pd >>> data = np.random.choice(np.arange(10), size=10000, ... p=np.linspace(1, 11, 10) / 60) >>> s = pd.Series(data) >>> s.value_counts() 9 1831 8 1624 7 1423 6 1323 5 1089 4 888 3 770 2 535 1 347 0 170 dtype: int64 >>> s.value_counts(normalize=True).head() 9 0.1831 8 0.1624 7 0.1423 6 0.1323 5 0.1089 dtype: float64在其他地方,
pandas.cut()是将值绑定到任意区间的便捷方式。假设您有一些关于个人年龄的数据,并希望明智地对它们进行分类:
>>> ages = pd.Series(
... [1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = (0, 10, 13, 18, 21, np.inf) # The edges
>>> labels = ('child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype: int64
>>> pd.concat((ages, groups), axis=1).rename(columns={0: 'age', 1: 'group'})
age group
0 1 child
1 1 child
2 3 child
3 5 child
4 8 child
5 10 child
6 12 preteen
7 15 teen
8 18 teen
9 18 teen
10 19 military_age
11 20 military_age
12 25 adult
13 30 adult
14 40 adult
15 51 adult
16 52 adult
令人高兴的是,这两个操作最终都利用了 Cython 代码,这使它们在速度上具有竞争力,同时保持了灵活性。
好吧,那我应该用哪个?
至此,您已经看到了许多用于绘制 Python 直方图的函数和方法可供选择。他们如何比较?简而言之,没有“一刀切”以下是到目前为止您所涉及的函数和方法的回顾,所有这些都与用 Python 分解和表示分布有关:
| 你有/想 | 考虑使用 | 注意事项 |
|---|---|---|
| 包含在列表、元组或集合等数据结构中的简单整数数据,并且您希望在不导入任何第三方库的情况下创建 Python 直方图。 | Python 标准库中的 collections.Counter() 提供了一种从数据容器中获取频率计数的快速而简单的方法。 |
这是一个频率表,所以它不像“真正的”直方图那样使用宁滨的概念。 |
| 大量数据,并且您想要计算表示仓和相应频率的“数学”直方图。 | NumPy 的 np.histogram() 和 np.bincount() 对数值计算直方图值和相应的面元边缘很有用。 |
更多信息,请查看 np.digitize() 。 |
熊猫的Series或DataFrame对象中的表格数据。 |
熊猫法如Series.plot.hist()DataFrame.plot.hist()Series.value_counts()cut(),还有Series.plot.kde()DataFrame.plot.kde()。 |
查看熊猫可视化文档获取灵感。 |
| 从任何数据结构创建高度可定制、微调的图。 | pyplot.hist() 是一个广泛使用的直方图绘制函数,使用np.histogram(),是熊猫绘制函数的基础。 |
Matplotlib,尤其是它的面向对象框架,非常适合微调直方图的细节。这个界面可能需要一点时间来掌握,但最终可以让您非常精确地安排任何可视化。 |
| 预先封装的设计和集成。 | Seaborn 的 distplot() ,用于结合直方图和 KDE 图或绘制分布拟合图。 |
本质上是“包装器周围的包装器”,它在内部利用 Matplotlib 直方图,而 Matplotlib 直方图又利用 NumPy。 |
免费奖金:时间短?点击这里获得一份免费的两页 Python 直方图备忘单,它总结了本教程中解释的技术。
您也可以在真正的 Python 材料页面上找到这篇文章的代码片段,它们都在一个脚本中。
至此,祝你在野外创建直方图好运。希望上面的某个工具能满足你的需求。无论你做什么,只是不要用饼状图。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 直方图绘制:NumPy、Matplotlib、Pandas & Seaborn**
皮托尼斯塔的假日愿望清单
又到了一年中每个人都希望得到最后一分钟礼物的时候了。无论你是 Python 开发者的朋友还是你自己,如果你想得到一些特别的东西,我有一个完美的愿望清单。为了给 Pythonistas 找到最好的礼物,我已经在网上搜遍了,并向我真正的 Python 作者同事进行了投票。
我将这些建议分为五类:
- 好的理由
- 学习资源
- Python swag
- 五金器具
- 小玩意儿
为慈善事业捐款
任何人都能收到的最好的礼物是给予别人的感觉。无论您是想自己捐款还是以他人的名义捐款,这里有一些与 Python 相关的优秀组织可以使用捐款:
-
Python 软件基金会(PSF) :维护 Python 的官方组织,每年举办 Python 大会
-
Django 软件基金会(DSF) :维护 Django(我们最喜欢的网络应用框架)的官方组织
-
PyLadies :致力于帮助更多女性成为 Python 开源社区的参与者和领导者的组织
捐赠你的钱并不是帮助 Python 社区的唯一方法。你也可以作为志愿者贡献你的时间。
Python 学习资源
我认为能给予的最好礼物之一是知识。想好好阅读一下 Python 相关的内容吗?查看最好的 Python 书籍,收集大量的 Python 相关书籍。也许你想要一些更互动的东西?查看在真蟒T5 的课程!
学习 Python 最好的方法之一就是向大师们学习。一张 PyCon 2019 的门票将是最大的学习礼物:三天的课程、演示、编码挑战,以及与 Python 代码梦想者的交流!这将是持续给予的终极礼物。你还会得到一整年都可以用的礼品袋。
蟒蛇贴纸、t 恤和咖啡杯…哦,我的天!
我们是 Pythonistas,为什么不展示一下我们最爱的编程语言呢!我喜欢在我的笔记本电脑上炫耀我对 Python 的热爱。

如果你不喜欢贴纸,那么一件运动衫或 t 恤可能会更好。也别忘了你的旧咖啡杯。它可能也需要升级。

想要有真正 Python 标志的东西吗?他们也为你提供了保障。
硬件
随着技术每天都在进步,每个程序员都需要升级他们的硬件。这可能是因为你的硬盘空间快用完了,键盘磨损了,或者只是想找点乐子。(或者你想要更高级的。每个人都喜欢挑战,对吗?)这是我这一季推荐去看看的硬件。
外部硬盘
无论您有一个庞大的代码库还是运行数百个 Docker 图像,您都可能很快耗尽空间来完成所有工作。好消息是硬盘容量的成本几乎在不断下降!另外,通过 USB 3.0,它几乎与内置硬盘一样快,甚至更快。不到 60 美元就能获得 2 TB 的便携空间!需要更大的吗?对于贵一倍多一点的价格,可以得到 8 TB !如果可以的话,我建议坚持使用希捷和西部数据这样的品牌。
新型机械键盘
作为开发人员,我们在电脑上 99%的时间都在使用键盘。这意味着拥有适合自己的键盘非常重要。不知道买什么?在机械键盘分部的人们创造了一个伟大的机械键盘指南。
推荐键盘就像推荐内衣一样:你永远不知道别人会有什么感觉,所以我强烈建议你看看上面的指南。但是如果你想要我的意见,我使用的并且认为手感最好的键盘是微软 Sculpt Ergo 键盘。

耳机
让我们面对现实吧:没有什么比带着你最喜欢的音乐进入状态,然后埋头研究你的代码库更好的了。那么,为什么不确保你得到一副好的耳机呢?我爱我的 Beyerdynamic DT 770 Pro 耳机,无法想象没有它们的编码。当你买耳机的时候,我推荐使用这个有用的指南,它是由耳机分栏的热心人创建的。

小工具
有新玩具玩总是很有趣,我们 Python 开发者有很多选择。在这里,我们收集了我们最喜欢的使用 Python 的小工具。
树莓派
让我们从一个小馅饼开始——也就是树莓派。您可以用树莓派做很多事情,包括以下内容:
- 自动化你的花园
- 实现家居自动化
- 建造一个老派的游戏中心
- 集群计算
- 这么多!
其起价仅为 35 美元,令人惊讶的是,您将获得一个多核、蓝牙和 WiFi 功能的设备!我强烈建议买一个工具包开始。

开源漫游者
说到树莓派,创建自己的火星科学实验室怎么样!火星探测器的创造者美国宇航局喷气推进实验室(JPL)已经创建了一个使用树莓 Pi 的火星科学实验室探测器的开源副本。
这款车价格不菲(约 2500 美元),不适合心脏不好的人,因为它需要单独购买每个零件,然后组装整个漫游者。不要担心编程的漫游者虽然。这已经是 JPL 用 Python 写的了!如果价格和难度没有吓退你,那么这对于任何想学习机器人技术的人来说都是一份伟大的礼物。

Anki 的 Vector 和 Cozmo 机器人
如果制作自己的机器人似乎有点令人生畏,那么请查看 Vector 和 Cozmo。Vector 是“好机器人”,它可以帮助做很多事情,比如厨房定时器、自拍或告诉你天气将会如何。如果这还不够,还有 Python 软件开发包(SDK) 可以让你完全定制 Vector!
如果你是编程新手,或者想教别人如何给机器人编程,那么 Cozmo 可以满足你。有了完整的 Python SDK 和一个更简单的选项,这个机器人对于初学者和经验丰富的程序员来说是一个很好的选择。

DJI 无人机
有点厌倦了被卡在地上?坐飞机怎么样?DJI 有多种版本的无人机,你可以使用他们的软件手动或自动飞行。如果他们没有您正在寻找的特性,不如检查一下 SDK,自己动手做吧!DJI 有很多无人机可供选择,但我已经盯上了泰洛,因为它更便宜,而且有一个更容易使用的 Python 库。

Pythonic 节日快乐
无论你决定给你或你的 Python 开发者朋友买什么,一定要享受这个假期,继续使用 Python!我现在准备在我的亚马逊购物车上推 checkout,并告诉我的妻子#PythonMadeMeDoIt。***
用 Python 探索 HTTPS
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 中的 HTTPS 和密码学
你有没有想过为什么你可以通过互联网发送你的信用卡信息?你可能已经注意到了浏览器中网址上的https://,但是它是什么,它是如何保证你的信息安全的**?或者,您可能想要创建一个 Python HTTPS 应用程序,但您并不确定这意味着什么。你如何确定你的网络应用是安全的?*
*您可能会惊讶地发现,回答这些问题并不一定要成为安全专家!在本教程中,您将了解到保证互联网通信安全的各种因素。您将看到 Python HTTPS 应用程序如何保护信息安全的具体示例。
在本教程中,您将学习如何:
- 监控和分析网络流量
- 应用密码术保护数据安全
- 描述公钥基础设施(PKI) 的核心概念
- 创建您自己的认证机构
- 构建一个 Python HTTPS 应用
- 识别常见的 Python HTTPS 警告和错误
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
什么是 HTTP?
在深入研究 HTTPS 及其在 Python 中的使用之前,理解它的父代 HTTP 很重要。这个首字母缩写代表超文本传输协议,当你在你最喜欢的网站上冲浪时,它是大多数通信的基础。更具体地说,HTTP 是一个用户代理,比如你的网络浏览器,与一个网络服务器,比如 realpython.com 的通信的方式。下面是 HTTP 通信的简图:
*
此图显示了计算机如何与服务器通信的简化版本。以下是每个步骤的细目分类:
- 你告诉你的浏览器去
http://someserver.com/link。 - 您的设备和服务器建立了一个 TCP 连接。
- 你的浏览器发送一个 HTTP 请求到服务器。
- 服务器接收 HTTP 请求并解析它。
- 服务器用一个 HTTP 响应来响应。
- 您的计算机接收、解析并显示响应。
这个分解抓住了 HTTP 的基础。您向服务器发出请求,服务器返回响应。虽然 HTTP 不需要 TCP,但它需要一个可靠的底层协议。实际上,这几乎总是 TCP over IP(尽管谷歌正试图创造一个替代物】。如果你需要复习,那么看看 Python 中的套接字编程(指南)。
就协议而言,HTTP 是最简单的协议之一。它被设计用来通过互联网发送内容,比如 HTML、视频、图像等等。这是通过 HTTP 请求和响应完成的。HTTP 请求包含以下元素:
- 方法描述了客户端想要执行的动作。静态内容的方法通常是
GET,尽管也有其他可用的方法,比如POST、HEAD和DELETE。 - 路径向服务器指示你想要请求的网页。比如这个页面的路径是
/python-https。 - 版本是几个 HTTP 版本之一,如 1.0、1.1 或 2.0。最常见的大概是 1.1。
- 标题帮助描述服务器的附加信息。
- 主体向服务器提供来自客户端的信息。虽然这个字段不是必需的,但是一些方法通常有一个主体,比如
POST。
这些是您的浏览器用来与服务器通信的工具。服务器用 HTTP 响应来响应。HTTP 响应包含以下元素:
- 版本标识 HTTP 版本,通常与请求的版本相同。
- 状态码表示请求是否成功完成。有不少状态码。
- 状态消息提供了帮助描述状态代码的人类可读消息。
- 头允许服务器用关于请求的附加元数据来响应。这些与请求头的概念相同。
- 正文承载内容。从技术上讲,这是可选的,但通常它包含一个有用的资源。
这些是 HTTP 的构造块。如果您有兴趣了解更多关于 HTTP 的知识,那么您可以查看一个概述页面来更深入地了解该协议。
什么是 HTTPS?
现在您对 HTTP 有了更多的了解,什么是 HTTPS 呢?好消息是,你已经知道了!HTTPS 代表超文本传输协议安全。从根本上说,HTTPS 是与 HTTP 相同的协议,但是增加了通信安全的含义。
HTTPS 没有重写它所基于的任何 HTTP 基础。相反,HTTPS 由通过加密连接发送的常规 HTTP 组成。通常,这种加密连接是由 TLS 或 SSL 提供的,它们是在信息通过网络发送之前加密信息的加密协议。
注意: TLS 和 SSL 是极其相似的协议,尽管 SSL 正在被淘汰,TLS 将取而代之。这些协议的区别超出了本教程的范围。知道 TLS 是 SSL 更新更好的版本就足够了。
那么,为什么要创造这种分离呢?为什么不把复杂性引入 HTTP 协议本身呢?答案是便携性。保护通信安全是一个重要而困难的问题,但是 HTTP 只是需要安全性的众多协议之一。在各种各样的应用中还有数不清的其他例子:
- 电子邮件
- 即时消息
- VoIP(网络电话)
还有其他的!如果这些协议中的每一个都必须创建自己的安全机制,那么世界将变得更加不安全,更加混乱。上述协议经常使用的 TLS 提供了一种保护通信安全的通用方法。
注意:这种协议分离是网络中的一个常见主题,以至于它有了一个名字。 OSI 模型代表了从物理介质一直到页面上呈现的 HTML 的通信!
您将在本教程中学习的几乎所有信息不仅适用于 Python HTTPS 应用程序。您将学习安全通信的基础知识,以及它如何具体应用于 HTTPS。
为什么 HTTPS 很重要?
安全通信对于提供安全的在线环境至关重要。随着世界上越来越多的地方(包括银行和医疗保健网站)走向在线,开发人员创建 Python HTTPS 应用程序变得越来越重要。同样,HTTPS 只是 TLS 或 SSL 上的 HTTP。TLS 旨在防止窃听者窃取隐私。它还可以提供客户端和服务器的身份验证。
在本节中,您将通过执行以下操作来深入探究这些概念:
- 创建一个 Python HTTPS 服务器
- 与您的 Python HTTPS 服务器通信
- 捕捉这些通信
- 分析那些消息
我们开始吧!
创建示例应用程序
假设你是一个叫做秘密松鼠的很酷的 Python 俱乐部的领导者。松鼠是秘密的,需要一个秘密的信息来参加他们的会议。作为领导者,你选择秘密信息,每次会议都会改变。不过,有时候,你很难在会议前与所有成员见面,告诉他们这个秘密消息!你决定建立一个秘密服务器,成员们可以自己看到秘密信息。
注意:本教程中使用的示例代码是而不是为生产设计的。它旨在帮助您学习 HTTP 和 TLS 的基础知识。请勿将此代码用于生产。以下许多例子都有糟糕的安全实践。在本教程中,您将了解 TLS,以及它可以帮助您更加安全的一种方式。
您已经学习了一些关于真实 Python 的教程,并决定使用一些您知道的依赖项:
要安装所有这些依赖项,可以使用 pip :
$ pip install flask uwsgi requests
安装完依赖项后,就可以开始编写应用程序了。在名为server.py的文件中,您创建了一个烧瓶应用程序:
# server.py
from flask import Flask
SECRET_MESSAGE = "fluffy tail"
app = Flask(__name__)
@app.route("/")
def get_secret_message():
return SECRET_MESSAGE
每当有人访问你的服务器的/路径时,这个 Flask 应用程序将显示秘密消息。这样一来,您可以在您的秘密服务器上部署应用程序并运行它:
$ uwsgi --http-socket 127.0.0.1:5683 --mount /=server:app
这个命令使用上面的 Flask 应用程序启动一个服务器。你在一个奇怪的端口上启动它,因为你不想让人们能够找到它,并为自己如此鬼鬼祟祟而沾沾自喜!您可以通过在浏览器中访问http://localhost:5683来确认它正在工作。
因为秘密松鼠中的每个人都知道 Python,所以你决定帮助他们。你写一个名为client.py的脚本来帮助他们获取秘密信息:
# client.py
import os
import requests
def get_secret_message():
url = os.environ["SECRET_URL"]
response = requests.get(url)
print(f"The secret message is: {response.text}")
if __name__ == "__main__":
get_secret_message()
只要设置了SECRET_URL环境变量,这些代码就会打印出秘密消息。在这种情况下,SECRET_URL就是127.0.0.1:5683。所以,你的计划是给每个俱乐部成员的秘密网址,并告诉他们保持它的秘密和安全。
虽然这可能看起来没问题,但请放心,它不是!事实上,即使你把用户名和密码放在这个网站上,它仍然是不安全的。但是即使你的团队设法保证了 URL 的安全,你的秘密信息仍然不安全。为了说明为什么您需要了解一点监控网络流量的知识。为此,您将使用一个名为 Wireshark 的工具。
设置 Wireshark
Wireshark 是一款广泛用于网络和协议分析的工具。这意味着它可以帮助您了解网络连接上发生了什么。安装和设置 Wireshark 对于本教程来说是可选的,但是如果您愿意的话,请随意。下载页面有几个可用的安装程序:
- macOS 10.12 及更高版本
- 64 位 Windows installer
- Windows installer 32 位
如果您使用的是 Windows 或 Mac,那么您应该能够下载适当的安装程序并按照提示进行操作。最后,您应该有一个运行的 Wireshark。
如果你在基于 Debian 的 Linux 环境下,那么安装会有点困难,但是仍然是可能的。您可以使用以下命令安装 Wireshark:
$ sudo add-apt-repository ppa:wireshark-dev/stable
$ sudo apt-get update
$ sudo apt-get install wireshark
$ sudo wireshark
您应该会看到类似这样的屏幕:
随着 Wireshark 的运行,是时候分析一些流量了!
看到你的数据不安全
你当前的客户端和服务器的运行方式是不安全的 T2。HTTP 会将所有内容以明文形式发送给任何人。这意味着,即使有人没有你的SECRET_URL,他们仍然可以看到你做的一切,只要他们可以监控你和服务器之间的任何设备上的流量。
这对你来说应该是比较恐怖的。毕竟,你不希望其他人出现在你的秘密会议上!你可以证明这是真的。首先,如果您的服务器没有运行,请启动它:
$ uwsgi --http-socket 127.0.0.1:5683 --mount /=server:app
这将在端口 5683 上启动您的 Flask 应用程序。接下来,您将在 Wireshark 中开始数据包捕获。此数据包捕获将帮助您查看进出服务器的所有流量。首先在 Wireshark 上选择 Loopback:lo 接口;

您可以看到 Loopback:lo 部分被突出显示。这将指示 Wireshark 监控该端口的流量。您可以做得更好,并指定您想要捕获哪个端口和协议。您可以在捕获过滤器中键入port 5683,在显示过滤器中键入http:
绿色方框表示 Wireshark 对您键入的过滤器满意。现在,您可以通过单击左上角的鳍开始捕获:
单击此按钮将在 Wireshark 中生成一个新窗口:

这个新窗口相当简单,但是底部的信息显示<live capture in progress>,这表明它正在工作。不要担心没有显示,因为这是正常的。为了让 Wireshark 报告任何事情,您的服务器上必须有一些活动。要获取一些数据,请尝试运行您的客户端:
$ SECRET_URL="http://127.0.0.1:5683" python client.py
The secret message is: fluffy tail
在执行了上面的client.py代码后,您现在应该会在 Wireshark 中看到一些条目。如果一切顺利,您将会看到两个条目,如下所示:

这两个条目代表发生的通信的两个部分。第一个是客户端对服务器的请求。当你点击第一个条目时,你会看到大量的信息:
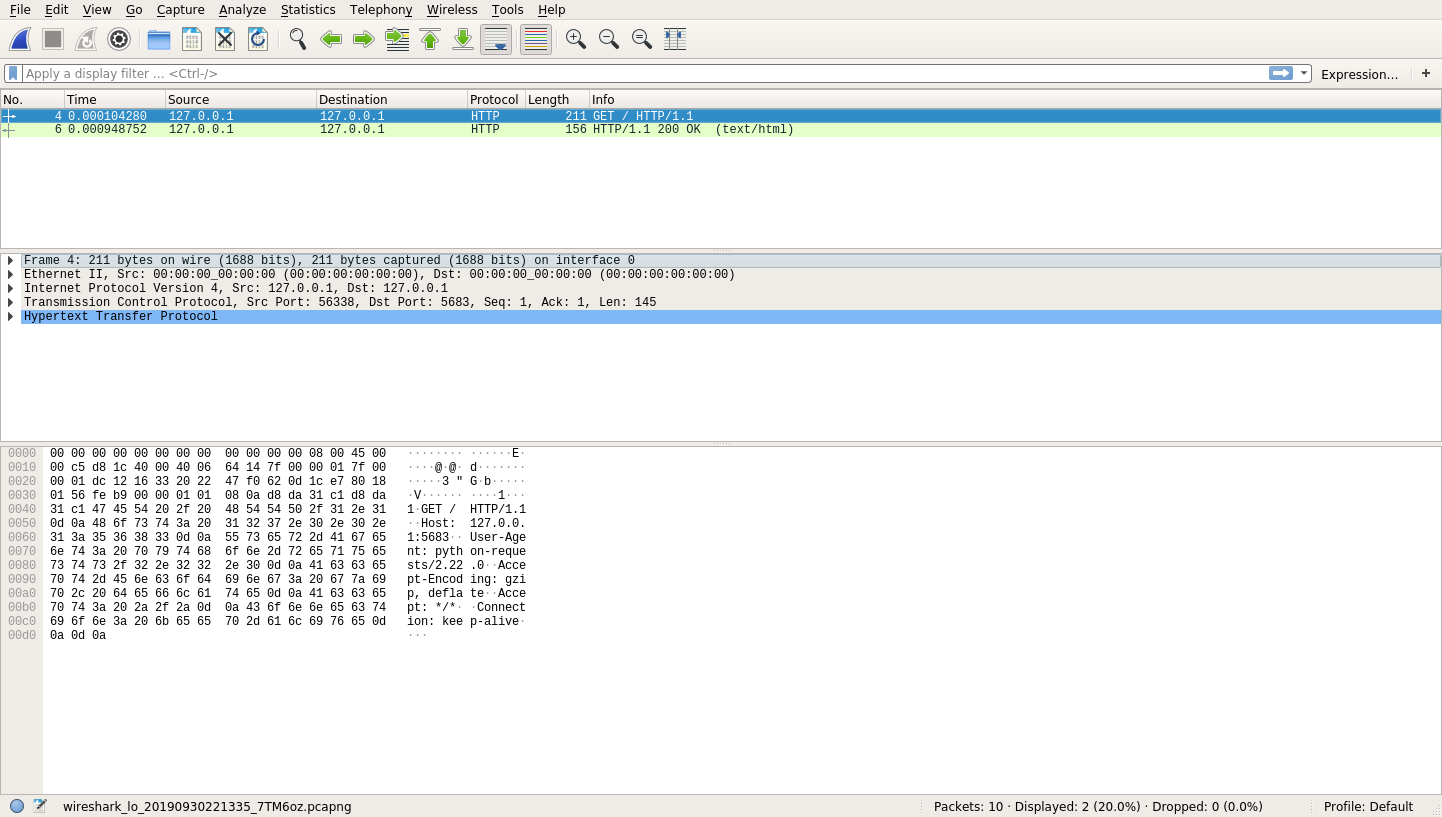
信息量真大!在顶部,仍然有 HTTP 请求和响应。一旦您选择了这些条目中的一个,您将看到中间和底部一行填充了信息。
中间一行提供了 Wireshark 能够为所选请求识别的协议的明细。这种分解允许您探究 HTTP 请求中实际发生了什么。下面是 Wireshark 在中间一行从上到下描述的信息的简要总结:
- 物理层:这一行描述用于发送请求的物理接口。在您的情况下,这可能是环回接口的接口 ID 0 (lo)。
- 以太网信息:这一行显示的是第二层协议,包括源 MAC 地址和目的 MAC 地址。
- IPv4: 这一行显示源和目的 IP 地址(127.0.0.1)。
- TCP: 这一行包括所需的 TCP 握手,以便创建可靠的数据管道。
- HTTP: 这一行显示 HTTP 请求本身的信息。
当您展开超文本传输协议层时,您可以看到构成 HTTP 请求的所有信息:
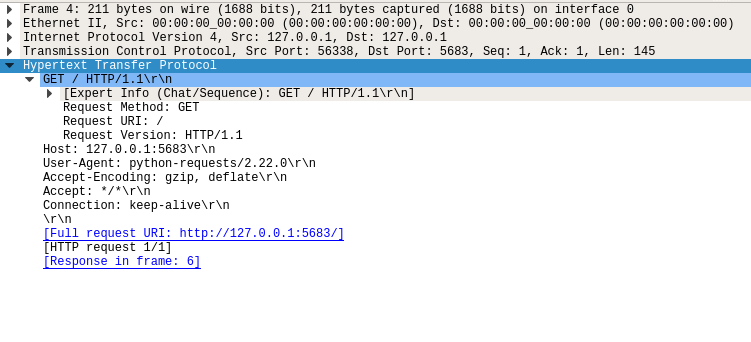
下图显示了脚本的 HTTP 请求:
- 方法:
GET - 路径:
/ - 版本:
1.1 - 表头:
Host: 127.0.0.1:5683``Connection: keep-alive等 - 正文:无正文
您将看到的最后一行是数据的十六进制转储。您可能会注意到,在这个十六进制转储中,您实际上可以看到 HTTP 请求的各个部分。那是因为你的 HTTP 请求是公开发送的。但是回复呢?如果您单击 HTTP 响应,您将看到类似的视图:
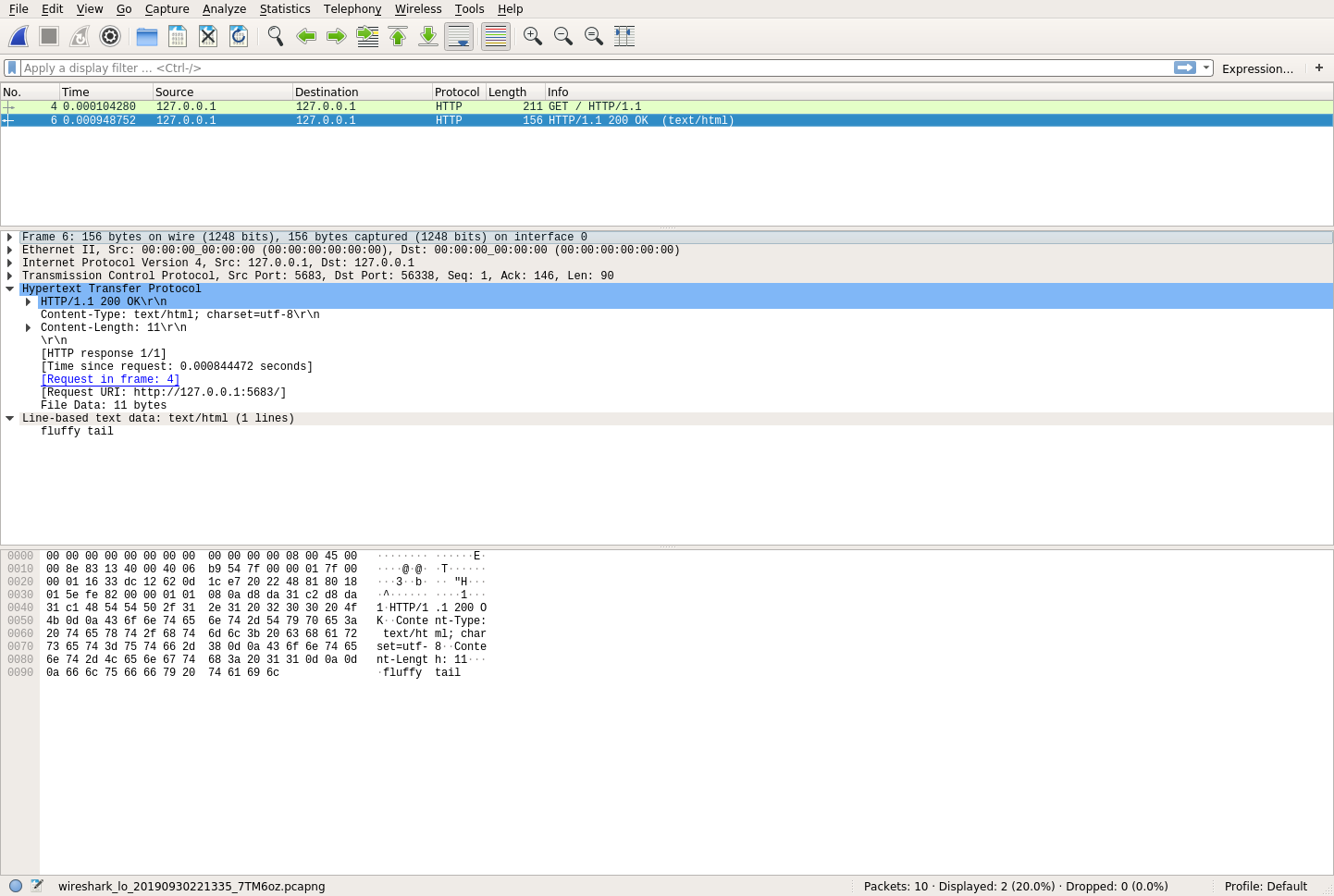
同样,你有相同的三个部分。如果你仔细看十六进制转储,那么你会看到纯文本的秘密消息!这对秘密松鼠来说是个大问题。这意味着任何有一些技术知识的人都可以很容易地看到这种流量,如果他们感兴趣的话。那么,如何解决这个问题呢?答案是密码学。
密码学有什么帮助?
在本节中,您将学习一种保护数据安全的方法,即创建您自己的加密密钥,并在您的服务器和客户端上使用它们。虽然这不是您的最后一步,但它将帮助您为如何构建 Python HTTPS 应用程序打下坚实的基础。
了解密码学基础知识
密码术是一种保护通信免受窃听者或对手攻击的方法。另一种说法是,你获取普通信息,称为明文,并将其转换为加密文本,称为密文。
起初,加密技术可能令人生畏,但是基本概念非常容易理解。事实上,你可能已经练习过密码学了。如果你曾经和你的朋友有过秘密语言,并且在课堂上用它来传递笔记,那么你就练习过密码学。(如果您还没有这样做,请不要担心,您即将这样做。)
不知何故,你需要把字符串 "fluffy tail"转换成不知所云的东西。一种方法是将某些字符映射到不同的字符上。一种有效的方法是将字符在字母表中向后移动一个位置。这样做看起来会像这样:
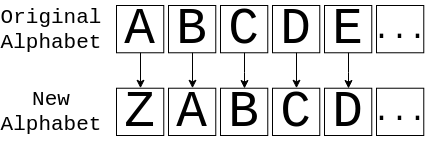
这张图片向你展示了如何从原来的字母表转换到新的字母表,然后再转换回来。所以,如果你有消息ABC,那么你实际上会发送消息ZAB。如果你把这个应用到"fluffy tail",那么假设空间保持不变,你得到ekteex szhk。虽然它并不完美,但对于任何看到它的人来说,它可能看起来像是胡言乱语。
恭喜你!你已经创造了密码学中所谓的密码,它描述了如何将明文转换成密文,以及如何将密文转换成明文。在这种情况下,你的密码是用英语描述的。这种特殊类型的密码被称为替代密码。从根本上来说,这与恩尼格玛机中使用的密码是同一类型的,尽管版本要简单得多。
现在,如果你想给秘密松鼠传递信息,你首先需要告诉它们要移动多少个字母,然后给它们编码的信息。在 Python 中,这可能如下所示:
CIPHER = {"a": "z", "A": "Z", "b": "a"} # And so on
def encrypt(plaintext: str):
return "".join(CIPHER.get(letter, letter) for letter in plaintext)
这里,您已经创建了一个名为encrypt()的函数,它将获取明文并将其转换为密文。想象一下,你有一本字典 CIPHER,里面有所有的字符。同样,你可以创建一个decrypt():
DECIPHER = {v: k for k, v in CIPHER.items()}
def decrypt(ciphertext: str):
return "".join(DECIPHER.get(letter, letter) for letter in ciphertext)
该功能与encrypt()相反。它将密文转换成明文。在这种形式的密码中,用户需要知道一个特殊的密钥来加密和解密消息。对于上面的例子,那个键是1。也就是说,密码指示您应该将每个字母向后移动一个字符。密钥对保密非常重要,因为任何有密钥的人都可以很容易地解密你的信息。
注意:虽然你可以用它来加密,但它还是不够安全。这种密码使用频率分析很快就能破解,而且对秘密松鼠来说太原始了。
在现代,加密技术要先进得多。它依靠复杂的数学理论和计算机科学来保证安全。虽然这些密码背后的数学问题超出了本教程的范围,但是基本概念仍然是相同的。你有一个描述如何将明文转换成密文的密码。
你的替代密码和现代密码之间唯一真正的区别是,现代密码在数学上被证明是无法被窃听者破解的。现在,让我们看看如何使用你的新密码。
在 Python HTTPS 应用程序中使用加密技术
幸运的是,你不必成为数学或计算机科学的专家来使用密码学。Python 还有一个secrets模块,可以帮助你生成加密安全的随机数据。在本教程中,你将学习一个名为 cryptography 的 Python 库。它在 PyPI 上可用,所以您可以用 pip 安装它:
$ pip install cryptography
这将把cryptography安装到你的虚拟环境中。安装了cryptography之后,你现在可以通过使用 Fernet 方法以一种数学上安全的方式加密和解密东西。
回想一下,您的密码中的密钥是1。同样,您需要为 Fernet 创建一个正确工作的密钥:
>>> from cryptography.fernet import Fernet >>> key = Fernet.generate_key() >>> key b'8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM='在这段代码中,您已经导入了
Fernet并生成了一个密钥。密钥只是一堆字节,但是保持密钥的秘密和安全是非常重要的。就像上面的替换例子一样,任何拥有这个密钥的人都可以很容易地解密你的消息。注意:在现实生活中,你会把这把钥匙保管得非常安全。在这些例子中,看到密钥是有帮助的,但是这是不好的做法,尤其是当你把它发布在公共网站上的时候!换句话说,不要使用你在上面看到的那把钥匙来保护你的安全。
这个键的行为与前面的键非常相似。它需要转换成密文,再转换回明文。现在是有趣的部分了!您可以像这样加密邮件:
>>> my_cipher = Fernet(key)
>>> ciphertext = my_cipher.encrypt(b"fluffy tail")
>>> ciphertext
b'gAAAAABdlW033LxsrnmA2P0WzaS-wk1UKXA1IdyDpmHcV6yrE7H_ApmSK8KpCW-6jaODFaeTeDRKJMMsa_526koApx1suJ4_dQ=='
在这段代码中,您创建了一个名为my_cipher的 Fernet 对象,然后您可以用它来加密您的消息。请注意,您的秘密消息"fluffy tail"需要是一个bytes对象才能加密。加密后,您可以看到ciphertext是一个很长的字节流。
多亏了 Fernet,没有密钥就无法操纵或读取这些密文!这种类型的加密要求服务器和客户端都可以访问密钥。当双方要求相同的密钥时,这被称为对称加密。在下一节中,您将看到如何使用这种对称加密来保护您的数据安全。
确保您的数据安全
现在,您已经了解了 Python 中的一些密码学基础知识,您可以将这些知识应用到您的服务器中。创建一个名为symmetric_server.py的新文件:
# symmetric_server.py
import os
from flask import Flask
from cryptography.fernet import Fernet
SECRET_KEY = os.environb[b"SECRET_KEY"]
SECRET_MESSAGE = b"fluffy tail"
app = Flask(__name__)
my_cipher = Fernet(SECRET_KEY)
@app.route("/")
def get_secret_message():
return my_cipher.encrypt(SECRET_MESSAGE)
这段代码结合了您的原始服务器代码和您在上一节中使用的Fernet对象。现在使用 os.environb 将关键点从环境中读取为bytes对象。随着服务器的退出,您现在可以专注于客户端。将以下内容粘贴到symmetric_client.py:
# symmetric_client.py
import os
import requests
from cryptography.fernet import Fernet
SECRET_KEY = os.environb[b"SECRET_KEY"]
my_cipher = Fernet(SECRET_KEY)
def get_secret_message():
response = requests.get("http://127.0.0.1:5683")
decrypted_message = my_cipher.decrypt(response.content)
print(f"The codeword is: {decrypted_message}")
if __name__ == "__main__":
get_secret_message()
同样,这是经过修改的代码,将您的早期客户端与Fernet加密机制结合起来。get_secret_message()执行以下操作:
- 向您的服务器发出请求。
- 从响应中获取原始字节。
- 尝试解密原始字节。
- 打印解密后的消息。
如果您同时运行服务器和客户端,那么您将看到您成功地加密和解密了您的秘密消息:
$ uwsgi --http-socket 127.0.0.1:5683 \
--env SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" \
--mount /=symmetric_server:app
在这个调用中,您再次在端口 5683 上启动服务器。这一次,您传入一个SECRET_KEY,它必须至少是一个 32 长度的 base64 编码字符串。服务器重新启动后,您现在可以查询它:
$ SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" python symmetric_client.py
The secret message is: b'fluffy tail'
呜哇!您可以加密和解密您的邮件。如果您尝试用无效的SECRET_KEY运行这个,那么您将得到一个错误:
$ SECRET_KEY="AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA=" python symmetric_client.py
Traceback (most recent call last):
File ".../cryptography/fernet.py", line 104, in _verify_signature
h.verify(data[-32:])
File ".../cryptography/hazmat/primitives/hmac.py", line 66, in verify
ctx.verify(signature)
File ".../cryptography/hazmat/backends/openssl/hmac.py", line 74, in verify
raise InvalidSignature("Signature did not match digest.")
cryptography.exceptions.InvalidSignature: Signature did not match digest.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "symmetric_client.py", line 16, in <module>
get_secret_message()
File "symmetric_client.py", line 11, in get_secret_message
decrypted_message = my_cipher.decrypt(response.content)
File ".../cryptography/fernet.py", line 75, in decrypt
return self._decrypt_data(data, timestamp, ttl)
File ".../cryptography/fernet.py", line 117, in _decrypt_data
self._verify_signature(data)
File ".../cryptography/fernet.py", line 106, in _verify_signature
raise InvalidToken
cryptography.fernet.InvalidToken
所以,你知道加密和解密是有效的。但是安全吗?嗯,是的,它是。为了证明这一点,您可以回到 Wireshark,使用与以前相同的过滤器开始新的捕获。完成捕获设置后,再次运行客户端代码:
$ SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" python symmetric_client.py
The secret message is: b'fluffy tail'
您又一次成功地发出了 HTTP 请求和响应,您再次在 Wireshark 中看到这些消息。因为秘密消息只在响应中传输,所以您可以单击它来查看数据:
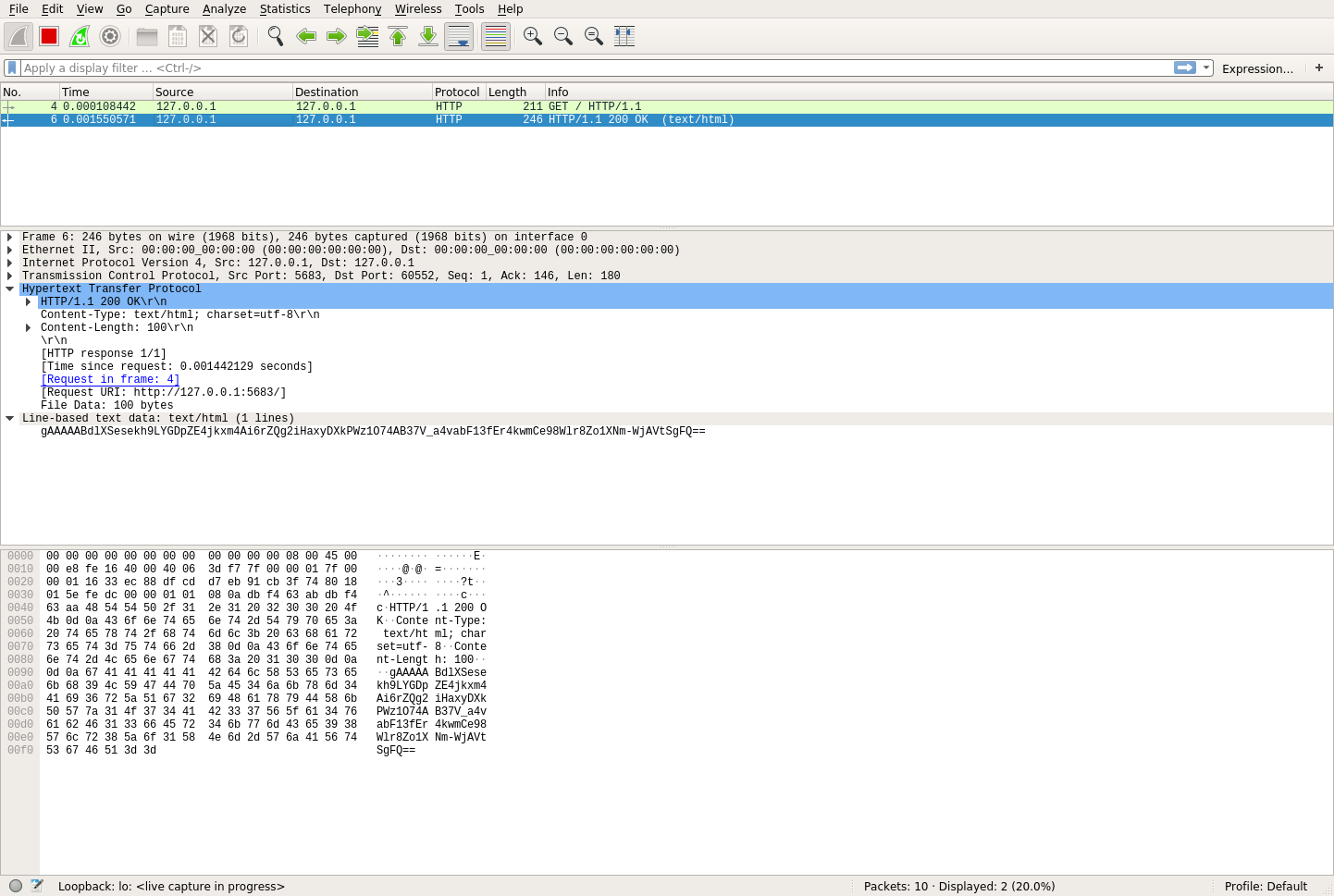
在这张图片的中间一行,您可以看到实际传输的数据:
gAAAAABdlXSesekh9LYGDpZE4jkxm4Ai6rZQg2iHaxyDXkPWz1O74AB37V_a4vabF13fEr4kwmCe98Wlr8Zo1XNm-WjAVtSgFQ==
厉害!这意味着数据是加密的,窃听者不知道消息的实际内容是什么。不仅如此,这还意味着他们可能会花费大量时间试图暴力破解这些数据,而且他们几乎永远不会成功。
您的数据是安全的!但是请等一下,以前在使用 Python HTTPS 应用程序时,您从来不需要了解任何关于键的知识。这是因为 HTTPS 并不专门使用对称加密。事实证明,共享秘密是一个难题。
为了证明这个概念,在浏览器中导航到http://127.0.0.1:5683,您将看到加密的响应文本。这是因为你的浏览器不知道你的秘密密钥。那么 Python HTTPS 应用程序到底是如何工作的呢?这就是不对称加密发挥作用的地方。
密钥是如何共享的?
在上一节中,您了解了如何使用对称加密来保证数据在互联网上传输时的安全。尽管对称加密是安全的,但它并不是 Python HTTPS 应用程序用来保护数据安全的唯一加密技术。对称加密引入了一些不容易解决的基本问题。
注意:记住,对称加密要求您在客户端和服务器之间有一个共享密钥。不幸的是,安全性的发挥取决于您最薄弱的环节,而在对称加密中,薄弱环节尤其具有灾难性。一旦一个人泄露了密钥,那么每个密钥都会被泄露。可以肯定的是,任何安全系统都会在某个时候受到威胁。
那么,你如何改变你的密钥呢?如果您只有一个服务器和一个客户端,那么这可能是一个快速的任务。然而,随着越来越多的客户端和服务器的出现,需要进行越来越多的协调来有效地更改密钥和保护您的秘密。
而且,你每次都要选择一个新的秘密。在上面的例子中,您看到了一个随机生成的密钥。对你来说,试图让人们记住那把钥匙几乎是不可能的。随着客户机和服务器数量的增加,您可能会使用更容易记忆和猜测的密钥。
如果您可以处理密钥的更改,那么您还有一个问题需要解决。你如何分享你的初始密钥?在秘密松鼠的例子中,您通过物理访问每个成员解决了这个问题。你可以亲自给每个成员这个秘密,并告诉他们要保密,但是记住,有人将是最薄弱的环节。
现在,假设您从另一个物理位置向秘密松鼠添加了一个成员。你如何与这个成员分享这个秘密?每次换钥匙的时候你都让他们带飞机去找你吗?如果你能把秘钥放在你的服务器上并自动共享就好了。不幸的是,这将违背加密的全部目的,因为任何人都可以获得密钥!
当然,你可以给每个人一个初始主密钥来获取秘密信息,但是现在你的问题是以前的两倍。如果你头疼,那就别担心!你不是唯一一个。
你需要的是从未交流过的两方共享一个秘密。听起来不可能,对吧?幸运的是,三个名叫拉尔夫·默克、T2、惠特菲尔德·迪菲和 T4 的人会支持你。他们帮助证明了公钥加密,也就是不对称加密是可能的。
注:虽然惠特菲尔德·迪菲和马丁·赫尔曼被广泛认为是第一个发现这一阴谋的人,但在 1997 年,为 GCHQ 工作的三名男子詹姆斯·h·埃利斯、克利福德·考克和马尔科姆·j·威廉森早在七年前就展示了这一能力!
非对称加密允许两个从未交流过的用户共享一个秘密。理解基本原理的最简单的方法之一是使用颜色类比。假设您有以下场景:

在这张图中,你正试图与一只你从未见过的秘密松鼠交流,但间谍可以看到你发送的所有内容。您知道对称加密,并且想要使用它,但是您首先需要共享一个秘密。幸运的是,你们俩都有一把私人钥匙。不幸的是,你不能发送你的私钥,因为间谍会看到它。那你是做什么的?
你需要做的第一件事是和你的搭档就颜色达成一致,比如黄色:

请注意,间谍可以看到共享的颜色,你和秘密松鼠也可以。共享颜色有效地公开。现在,你和秘密松鼠都把你的私人钥匙和共享颜色结合起来:

你的颜色组合成绿色,而秘密松鼠的颜色组合成橙色。你们两个都使用完了共享颜色,现在你们需要彼此共享你们的组合颜色:

你现在有了你的私人钥匙和秘密松鼠的混合颜色。同样,秘密松鼠有他们的私人钥匙和你的组合颜色。你和秘密松鼠很快就把颜色组合起来了。
然而,间谍只有这些混合的颜色。试图找出你的确切的原始颜色是非常困难的,即使给定了最初的共享颜色。间谍将不得不去商店买许多不同的蓝色来尝试。即使这样,也很难知道他们看的是不是正确的绿色。简而言之,你的私钥仍然是私有的。
但是你和秘密松鼠呢?你还是没有组合秘密!这就是你的私钥的来源。如果你把你的私人钥匙和你从秘密松鼠那里得到的混合颜色结合起来,那么你们最终会得到相同的颜色:

现在,你和秘密松鼠有着相同的秘密颜色。您现在已经成功地与一个完全陌生的人共享了一个安全的秘密。这与公钥加密的工作原理惊人地一致。这一系列事件的另一个常见名称是 Diffie-Hellman 密钥交换。密钥交换由以下部分组成:
- 私钥是例子中你的私有颜色。
- 公钥是您共享的组合色。
私钥是你一直保密的东西,而公钥可以和任何人共享。这些概念直接映射到 Python HTTPS 应用程序的真实世界。现在,服务器和客户机有了一个共享的秘密,您可以使用以前的 pal 对称加密来加密所有进一步的消息!
注意:公钥加密也依赖于一些数学来进行颜色混合。关于 Diffie-Hellman 密钥交换的维基百科页面有很好的解释,但是深入的解释超出了本教程的范围。
当您通过安全网站(如本网站)进行通信时,您的浏览器和服务器会使用相同的原则建立安全通信:
- 您的浏览器向服务器请求信息。
- 您的浏览器和服务器交换公钥。
- 您的浏览器和服务器生成一个共享私钥。
- 您的浏览器和服务器通过对称加密使用这个共享密钥加密和解密消息。
幸运的是,您不需要实现这些细节。有许多内置的和第三方的库可以帮助您保持客户端和服务器通信的安全。
现实世界中的 HTTPS 是什么样的?
鉴于所有这些关于加密的信息,让我们缩小一点,谈谈 Python HTTPS 应用程序在现实世界中是如何工作的。加密只是故事的一半。访问安全网站时,需要两个主要组件:
- 加密将明文转换成密文,再转换回来。
- 认证验证一个人或一件事是他们所说的那个人或事。
您已经广泛听说了加密是如何工作的,但是身份验证呢?要理解现实世界中的认证,您需要了解公钥基础设施。PKI 在安全生态系统中引入了另一个重要的概念,称为证书。
证书就像互联网的护照。像计算机世界中的大多数东西一样,它们只是文件中的大块数据。一般来说,证书包括以下信息:
- 颁发给:标识谁拥有证书
- 颁发者:标识证书的颁发者
- 有效期:标识证书有效的时间范围
就像护照一样,证书只有在由某个权威机构生成并认可的情况下才真正有用。让你的浏览器知道你在互联网上访问的每个网站的每一个证书是不切实际的。相反,PKI 依赖于一个被称为认证机构(CA) 的概念。
证书颁发机构负责颁发证书。它们被认为是 PKI 中可信任的第三方(TTP)。本质上,这些实体充当证书的有效机构。假设你想去另一个国家,你有一本护照,上面有你所有的信息。外国的移民官员如何知道你的护照包含有效信息?
如果你要自己填写所有信息并签字,那么你要去的每个国家的每个移民官员都需要亲自了解你,并能够证明那里的信息确实是正确的。
另一种处理方式是将你的所有信息发送给一个可信的第三方(TTP) 。TTP 会对你提供的信息进行彻底的调查,核实你的说法,然后在你的护照上签字。这被证明是更实际的,因为移民官员只需要知道可信任的第三方。
TTP 场景是证书在实践中的处理方式。这个过程大概是这样的:
- 创建证书签名请求(CSR): 这就像填写签证信息一样。
- 将 CSR 发送给可信任的第三方(TTP): 这就像将您的信息发送到签证申请办公室。
- 核实您的信息:TTP 需要核实您提供的信息。例如,请看亚马逊如何验证所有权。
- 生成公钥:TTP 签署您的 CSR。这就相当于 TTP 签了你的签证。
- 发布验证过的公钥:这相当于你在邮件中收到了你的签证。
请注意,CSR 以加密方式与您的私钥绑定在一起。因此,所有三种信息——公钥、私钥和证书颁发机构——都以某种方式相关联。这就创建了所谓的信任链,所以你现在有了一个可以用来验证你的身份的有效证书。
大多数情况下,这只是网站所有者的责任。网站所有者将遵循所有这些步骤。在此过程结束时,他们的证书会显示以下内容:
从时间
A到时间B根据Y我是X
这句话是一个证书真正告诉你的全部。变量可以按如下方式填写:
- A 是有效的开始日期和时间。
- B 是有效的结束日期和时间。
- X 是服务器的名称。
- Y 是认证机构的名称。
从根本上说,这就是证书所描述的全部内容。换句话说,有证书并不一定意味着你就是你所说的那个人,只是你得到了Y到同意你就是你所说的那个人。这就是可信第三方的“可信”部分的用武之地。
TTP 需要在客户机和服务器之间共享,以便每个人都对 HTTPS 握手感到满意。您的浏览器附带了许多自动安装的证书颁发机构。要查看它们,请执行以下步骤:
- Chrome: 进入设置>高级>隐私和安全>管理证书>权限。
- 火狐:进入设置>首选项>隐私&安全>查看证书>权限。
这涵盖了在现实世界中创建 Python HTTPS 应用程序所需的基础设施。在下一节中,您将把这些概念应用到您自己的代码中。您将通过最常见的例子,并成为自己的秘密松鼠认证机构!
Python HTTPS 应用程序看起来像什么?
现在,您已经了解了创建 Python HTTPS 应用程序所需的基本部分,是时候将所有部分逐一整合到您之前的应用程序中了。这将确保服务器和客户端之间的通信是安全的。
在您自己的机器上建立整个 PKI 基础设施是可能的,这正是您将在本节中要做的。没有听起来那么难,放心吧!成为一个真正的证书颁发机构比采取下面的步骤要困难得多,但是你将读到的或多或少都是运行你自己的 CA 所需要的。
成为认证机构
认证中心只不过是一对非常重要的公钥和私钥。要成为一个 CA,您只需要生成一个公钥和私钥对。
注意:成为公众使用的 CA 是一个非常艰难的过程,尽管有许多公司都遵循这一过程。然而,在本教程结束时,你将不再是那些公司中的一员!
您的初始公钥和私钥对将是一个自签名证书。你正在生成初始的秘密,所以如果你真的要成为一个 CA,那么这个私钥的安全是非常重要的。如果有人可以访问 CA 的公钥和私钥对,那么他们可以生成一个完全有效的证书,除了停止信任您的 CA 之外,您无法检测到这个问题。
有了这个警告,您可以立即生成证书。首先,您需要生成一个私钥。将以下内容粘贴到名为pki_helpers.py的文件中:
1# pki_helpers.py
2from cryptography.hazmat.backends import default_backend
3from cryptography.hazmat.primitives import serialization
4from cryptography.hazmat.primitives.asymmetric import rsa
5
6def generate_private_key(filename: str, passphrase: str):
7 private_key = rsa.generate_private_key(
8 public_exponent=65537, key_size=2048, backend=default_backend()
9 )
10
11 utf8_pass = passphrase.encode("utf-8")
12 algorithm = serialization.BestAvailableEncryption(utf8_pass)
13
14 with open(filename, "wb") as keyfile:
15 keyfile.write(
16 private_key.private_bytes(
17 encoding=serialization.Encoding.PEM,
18 format=serialization.PrivateFormat.TraditionalOpenSSL,
19 encryption_algorithm=algorithm,
20 )
21 )
22
23 return private_key
generate_private_key()使用 RSA 生成私钥。下面是代码的细目分类:
- 第 2 行到第 4 行导入函数工作所需的库。
- 第 7 行到第 9 行使用 RSA 生成一个私钥。幻数
65537和2048只是两个可能的值。你可以阅读更多关于为什么或者只是相信这些数字是有用的。 - 第 11 行到第 12 行设置用于您的私钥的加密算法。
- 第 14 到 21 行在指定的
filename把你的私钥写到磁盘上。该文件使用提供的密码加密。
成为您自己的 CA 的下一步是生成一个自签名公钥。您可以绕过证书签名请求(CSR ),立即构建公钥。将以下内容粘贴到pki_helpers.py:
1# pki_helpers.py
2from datetime import datetime, timedelta
3from cryptography import x509
4from cryptography.x509.oid import NameOID
5from cryptography.hazmat.primitives import hashes
6
7def generate_public_key(private_key, filename, **kwargs):
8 subject = x509.Name(
9 [
10 x509.NameAttribute(NameOID.COUNTRY_NAME, kwargs["country"]),
11 x509.NameAttribute(
12 NameOID.STATE_OR_PROVINCE_NAME, kwargs["state"]
13 ),
14 x509.NameAttribute(NameOID.LOCALITY_NAME, kwargs["locality"]),
15 x509.NameAttribute(NameOID.ORGANIZATION_NAME, kwargs["org"]),
16 x509.NameAttribute(NameOID.COMMON_NAME, kwargs["hostname"]),
17 ]
18 )
19
20 # Because this is self signed, the issuer is always the subject
21 issuer = subject
22
23 # This certificate is valid from now until 30 days
24 valid_from = datetime.utcnow()
25 valid_to = valid_from + timedelta(days=30)
26
27 # Used to build the certificate
28 builder = (
29 x509.CertificateBuilder()
30 .subject_name(subject)
31 .issuer_name(issuer)
32 .public_key(private_key.public_key())
33 .serial_number(x509.random_serial_number())
34 .not_valid_before(valid_from)
35 .not_valid_after(valid_to)
36 .add_extension(x509.BasicConstraints(ca=True,
37 path_length=None), critical=True)
38 )
39
40 # Sign the certificate with the private key
41 public_key = builder.sign(
42 private_key, hashes.SHA256(), default_backend()
43 )
44
45 with open(filename, "wb") as certfile:
46 certfile.write(public_key.public_bytes(serialization.Encoding.PEM))
47
48 return public_key
这里有一个新函数generate_public_key(),它将生成一个自签名的公钥。下面是这段代码的工作原理:
- 第 2 行到第 5 行是函数工作所需的导入。
- 第 8 行到第 18 行建立关于证书主题的信息。
- 第 21 行使用相同的颁发者和主题,因为这是一个自签名证书。
- 第 24 到 25 行表示该公钥有效的时间范围。在这种情况下,是 30 天。
- 第 28 到 38 行将所有需要的信息添加到一个公钥生成器对象中,然后需要对其进行签名。
- 第 41 到 43 行用私钥签署公钥。
- 第 45 到 46 行将公钥写出到
filename。
使用这两个函数,您可以在 Python 中非常快速地生成您的私钥和公钥对:
>>> from pki_helpers import generate_private_key, generate_public_key >>> private_key = generate_private_key("ca-private-key.pem", "secret_password") >>> private_key <cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7ffbb292bf90> >>> generate_public_key( ... private_key, ... filename="ca-public-key.pem", ... country="US", ... state="Maryland", ... locality="Baltimore", ... org="My CA Company", ... hostname="my-ca.com", ... ) <Certificate(subject=<Name(C=US,ST=Maryland,L=Baltimore,O=My CA Company,CN=logan-ca.com)>, ...)>从
pki_helpers导入您的助手函数后,您首先生成您的私钥并将其保存到文件ca-private-key.pem。然后,您将这个私钥传递给generate_public_key()来生成您的公钥。在您的目录中,现在应该有两个文件:$ ls ca* ca-private-key.pem ca-public-key.pem恭喜你!您现在有能力成为证书颁发机构。
信任您的服务器
您的服务器变得可信的第一步是生成一个证书签名请求(CSR) 。在现实世界中,CSR 将被发送到实际的认证机构,如 Verisign 或让我们加密。在本例中,您将使用刚刚创建的 CA。
将生成 CSR 的代码从上面粘贴到
pki_helpers.py文件中:1# pki_helpers.py 2def generate_csr(private_key, filename, **kwargs): 3 subject = x509.Name( 4 [ 5 x509.NameAttribute(NameOID.COUNTRY_NAME, kwargs["country"]), 6 x509.NameAttribute( 7 NameOID.STATE_OR_PROVINCE_NAME, kwargs["state"] 8 ), 9 x509.NameAttribute(NameOID.LOCALITY_NAME, kwargs["locality"]), 10 x509.NameAttribute(NameOID.ORGANIZATION_NAME, kwargs["org"]), 11 x509.NameAttribute(NameOID.COMMON_NAME, kwargs["hostname"]), 12 ] 13 ) 14 15 # Generate any alternative dns names 16 alt_names = [] 17 for name in kwargs.get("alt_names", []): 18 alt_names.append(x509.DNSName(name)) 19 san = x509.SubjectAlternativeName(alt_names) 20 21 builder = ( 22 x509.CertificateSigningRequestBuilder() 23 .subject_name(subject) 24 .add_extension(san, critical=False) 25 ) 26 27 csr = builder.sign(private_key, hashes.SHA256(), default_backend()) 28 29 with open(filename, "wb") as csrfile: 30 csrfile.write(csr.public_bytes(serialization.Encoding.PEM)) 31 32 return csr在很大程度上,这段代码与您生成原始公钥的方式相同。主要区别概述如下:
- 第 16 行到第 19 行设置备用 DNS 名称,这些名称对您的证书有效。
- 第 21 行到第 25 行生成一个不同的构建器对象,但基本原理和以前一样。你正在为你的企业社会责任建立所有必要的属性。
- 第 27 行用私钥给你的 CSR 签名。
- 第 29 到 30 行以 PEM 格式将您的 CSR 写入磁盘。
您会注意到,为了创建 CSR,您首先需要一个私钥。幸运的是,您可以使用与创建 CA 私钥时相同的
generate_private_key()。使用上述函数和前面定义的方法,您可以执行以下操作:
>>> from pki_helpers import generate_csr, generate_private_key
>>> server_private_key = generate_private_key(
... "server-private-key.pem", "serverpassword"
... )
>>> server_private_key
<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7f6adafa3050>
>>> generate_csr(
... server_private_key,
... filename="server-csr.pem",
... country="US",
... state="Maryland",
... locality="Baltimore",
... org="My Company",
... alt_names=["localhost"],
... hostname="my-site.com",
... )
<cryptography.hazmat.backends.openssl.x509._CertificateSigningRequest object at 0x7f6ad5372210>
在控制台中运行这些步骤后,您应该得到两个新文件:
server-private-key.pem: 你服务器的私钥server-csr.pem: 您的服务器的 CSR
您可以从控制台查看新的 CSR 和私钥:
$ ls server*.pem
server-csr.pem server-private-key.pem
有了这两个文档,您现在可以开始签名您的密钥了。通常,这一步会进行大量的验证。在现实世界中,CA 会确保您拥有my-site.com,并要求您以各种方式证明这一点。
因为在这种情况下您是 CA,所以您可以放弃这个麻烦,创建您自己的经过验证的公钥。为此,您将向您的pki_helpers.py文件添加另一个函数:
1# pki_helpers.py
2def sign_csr(csr, ca_public_key, ca_private_key, new_filename):
3 valid_from = datetime.utcnow()
4 valid_until = valid_from + timedelta(days=30)
5
6 builder = (
7 x509.CertificateBuilder()
8 .subject_name(csr.subject) 9 .issuer_name(ca_public_key.subject) 10 .public_key(csr.public_key()) 11 .serial_number(x509.random_serial_number())
12 .not_valid_before(valid_from)
13 .not_valid_after(valid_until)
14 )
15
16 for extension in csr.extensions: 17 builder = builder.add_extension(extension.value, extension.critical) 18
19 public_key = builder.sign(
20 private_key=ca_private_key, 21 algorithm=hashes.SHA256(),
22 backend=default_backend(),
23 )
24
25 with open(new_filename, "wb") as keyfile:
26 keyfile.write(public_key.public_bytes(serialization.Encoding.PEM))
这段代码看起来与来自generate_ca.py文件的generate_public_key()非常相似。事实上,它们几乎一模一样。主要区别如下:
- 第 8 行到第 9 行基于 CSR 的主题名称,而发布者基于证书颁发机构。
- 10 号线这次从 CSR 获取公钥。在
builder定义的末尾,generate_public_key()中指定这是一个 CA 的行已经被删除。 - 第 16 到 17 行复制 CSR 上设置的任何扩展。
- 第 20 行用 CA 的私钥签署公钥。
下一步是启动 Python 控制台并使用sign_csr()。您需要加载您的 CSR 和 CA 的私钥和公钥。首先加载您的 CSR:
>>> from cryptography import x509 >>> from cryptography.hazmat.backends import default_backend >>> csr_file = open("server-csr.pem", "rb") >>> csr = x509.load_pem_x509_csr(csr_file.read(), default_backend()) >>> csr <cryptography.hazmat.backends.openssl.x509._CertificateSigningRequest object at 0x7f68ae289150>在这段代码中,你将打开你的
server-csr.pem文件,并使用x509.load_pem_x509_csr()创建你的csr对象。接下来,您需要加载 CA 的公钥:
>>> ca_public_key_file = open("ca-public-key.pem", "rb")
>>> ca_public_key = x509.load_pem_x509_certificate(
... ca_public_key_file.read(), default_backend()
... )
>>> ca_public_key
<Certificate(subject=<Name(C=US,ST=Maryland,L=Baltimore,O=My CA Company,CN=logan-ca.com)>, ...)>
你又一次创建了一个可以被sign_csr()使用的ca_public_key对象。“T2”号有方便的“T3”帮忙。最后一步是加载 CA 的私钥:
>>> from getpass import getpass >>> from cryptography.hazmat.primitives import serialization >>> ca_private_key_file = open("ca-private-key.pem", "rb") >>> ca_private_key = serialization.load_pem_private_key( ... ca_private_key_file.read(), ... getpass().encode("utf-8"), ... default_backend(), ... ) Password: >>> private_key <cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7f68a85ade50>这段代码将加载您的私钥。回想一下,您的私钥是使用您指定的密码加密的。有了这三个组件,您现在可以签署您的 CSR 并生成一个经过验证的公钥:
>>> from pki_helpers import sign_csr
>>> sign_csr(csr, ca_public_key, ca_private_key, "server-public-key.pem")
运行此命令后,您的目录中应该有三个服务器密钥文件:
$ ls server*.pem
server-csr.pem server-private-key.pem server-public-key.pem
咻!那是相当多的工作。好消息是,现在您已经有了您的私有和公共密钥对,您不需要修改任何服务器代码就可以开始使用它。
使用原始的server.py文件,运行以下命令来启动全新的 Python HTTPS 应用程序:
$ uwsgi \
--master \
--https localhost:5683,\
logan-site.com-public-key.pem,\
logan-site.com-private-key.pem \
--mount /=server:app
恭喜你!现在,您有了一个支持 Python HTTPS 的服务器,它使用您自己的私有-公共密钥对运行,并由您自己的认证机构进行了签名!
注意:Python HTTPS 认证等式还有另外一面,那就是客户端。也可以为客户端证书设置证书验证。这需要更多的工作,在企业之外并不常见。然而,客户端身份验证可能是一个非常强大的工具。
现在,剩下要做的就是查询您的服务器。首先,您需要对client.py代码进行一些修改:
# client.py
import os
import requests
def get_secret_message():
response = requests.get("https://localhost:5683")
print(f"The secret message is {response.text}")
if __name__ == "__main__":
get_secret_message()
与之前代码的唯一变化是从http到https。如果您尝试运行这段代码,您将会遇到一个错误:
$ python client.py
...
requests.exceptions.SSLError: \
HTTPSConnectionPool(host='localhost', port=5683): \
Max retries exceeded with url: / (Caused by \
SSLError(SSLCertVerificationError(1, \
'[SSL: CERTIFICATE_VERIFY_FAILED] \
certificate verify failed: unable to get local issuer \
certificate (_ssl.c:1076)')))
这是一个非常讨厌的错误信息!这里重要的部分是消息certificate verify failed: unable to get local issuer。这些话你现在应该比较熟悉了。本质上,它是在说:
localhost:5683 给了我一个证书。我检查了它给我的证书的颁发者,根据我所知道的所有证书颁发机构,该颁发者不在其中。
如果您尝试使用浏览器导航到您的网站,您会收到类似的消息:
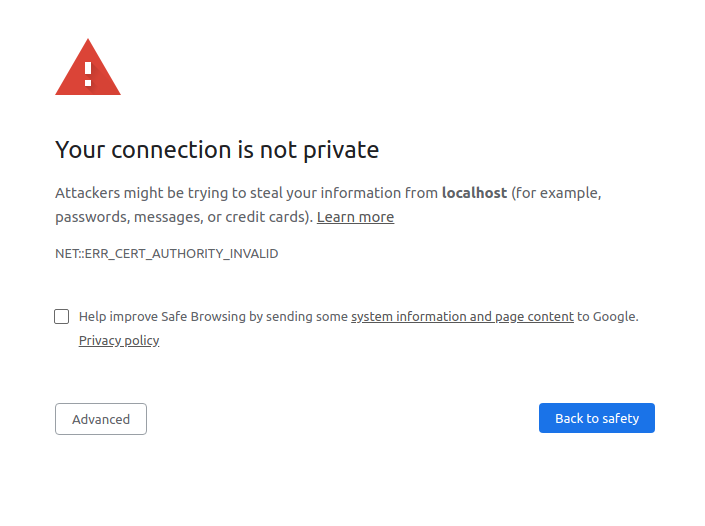
如果您想避免此消息,那么您必须告诉requests您的证书颁发机构!您需要做的就是将请求指向您之前生成的ca-public-key.pem文件:
# client.py
def get_secret_message():
response = requests.get("http://localhost:5683", verify="ca-public-key.pem")
print(f"The secret message is {response.text}")
完成后,您应该能够成功运行以下内容:
$ python client.py
The secret message is fluffy tail
不错!您已经创建了一个功能完整的 Python HTTPS 服务器,并成功查询了它。你和秘密松鼠现在有消息,你可以愉快和安全地来回交易!
结论
在本教程中,你已经了解了当今互联网上安全通信的一些核心基础。现在您已经理解了这些构件,您将成为一名更好、更安全的开发人员。
通过本教程,您已经了解了几个主题:
- 密码系统
- HTTPS 和 TLS
- 公钥基础设施
- 证书
如果这些信息让你感兴趣,那么你很幸运!你仅仅触及了每一层中所有细微差别的表面。安全世界在不断发展,新技术和漏洞也在不断被发现。如果你还有问题,请在下面的评论区或在 Twitter 上联系我们。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 中的 HTTPS 和密码学***********
Python IDEs 和代码编辑器(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 寻找完美的 Python 代码编辑器
使用 IDLE 或 Python Shell 编写 Python 对于简单的事情来说是很棒的,但是这些工具很快会将大型编程项目变成令人沮丧的绝望之地。使用 IDE,或者仅仅是一个好的专用代码编辑器,会让编码变得有趣——但是哪一个最适合你呢?
不要害怕,亲爱的读者!我们在这里帮助你解释和揭开无数可供选择的秘密。我们无法选择最适合您和您的流程的方法,但是我们可以解释每种方法的优缺点,并帮助您做出明智的决定。
为了使事情变得简单,我们将把我们的列表分成两大类工具:一类是专门为 Python 开发构建的,另一类是为可以用于 Python 的一般开发构建的。我们将为每个问题说出一些为什么和为什么不。最后,这些选项都不是相互排斥的,所以您可以自己尝试一下,代价很小。
但是首先…
什么是 ide 和代码编辑器?
IDE(或集成开发环境)是专用于软件开发的程序。顾名思义,ide 集成了几个专门为软件开发设计的工具。这些工具通常包括:
- 为处理代码而设计的编辑器(例如,带有语法突出显示和自动完成功能)
- 构建、执行和调试工具
- 某种形式的源代码管理
大多数 ide 支持许多不同的编程语言,并包含更多的特性。因此,它们可能很大,下载和安装需要时间。您可能还需要高级知识来正确使用它们。
相比之下,专用代码编辑器可以像文本编辑器一样简单,具有语法突出显示和代码格式化功能。大多数好的代码编辑器可以执行代码并控制一个调试器。最好的软件也与源代码控制系统交互。与 IDE 相比,一个好的专用代码编辑器通常更小、更快,但是功能不丰富。
良好的 Python 编码环境的要求
那么在编码环境中我们真正需要的是什么呢?功能列表因应用而异,但有一组核心功能可以简化编码:
- 保存并重新加载代码文件
如果一个 IDE 或编辑器不允许你保存你的工作,并在你离开时以同样的状态重新打开一切,那它就不是一个好的 IDE。 - 在环境中运行代码
同样,如果你不得不退出编辑器来运行你的 Python 代码,那么它也不过是一个简单的文本编辑器。 - 调试支持
能够在代码运行时逐句通过代码是所有 ide 和大多数优秀代码编辑器的核心特性。 - 语法突出显示
能够快速发现代码中的关键词、变量和符号使得阅读和理解代码更加容易。 - 自动代码格式化
任何称职的编辑器或 IDE 都会识别出while或for语句末尾的冒号,并知道下一行应该缩进。
当然,您可能还需要许多其他特性,比如源代码控制、扩展模型、构建和测试工具、语言帮助等等。但是上面的列表是我认为一个好的编辑环境应该支持的“核心特性”。
记住这些特性,让我们来看看一些可以用于 Python 开发的通用工具。
支持 Python 的通用编辑器和 IDEs】
Eclipse + PyDev
类别: IDE
网站:www.eclipse.org
Python 工具: PyDev,www.pydev.org
如果你在开源社区呆过一段时间,你应该听说过 Eclipse。适用于 Linux、Windows 和 OS X 的 Eclipse 是 Java 开发的事实上的开源 IDE。它有一个丰富的扩展和附加组件市场,这使得 Eclipse 对于广泛的开发活动非常有用。
PyDev 就是这样一个扩展,它支持 Python 调试、代码完成和交互式 Python 控制台。将 PyDev 安装到 Eclipse 很容易:从 Eclipse 中选择 Help,Eclipse Marketplace,然后搜索 PyDev。如有必要,单击 Install 并重启 Eclipse。
优点:如果你已经安装了 Eclipse,添加 PyDev 会更快更容易。对于有经验的 Eclipse 开发人员来说,PyDev 非常容易使用。
缺点:如果你刚刚开始使用 Python,或者一般的软件开发,Eclipse 可能会很难处理。还记得我说过 ide 比较大,需要更多的知识才能正确使用吗?Eclipse 就是所有这些和一袋(微型)芯片。
崇高的文字
类别:代码编辑
网站:http://www.sublimetext.com
Sublime Text 是由一个梦想拥有更好的文本编辑器的 Google 工程师编写的,是一个非常受欢迎的代码编辑器。所有平台都支持 Sublime Text,它内置了对 Python 代码编辑的支持和一组丰富的扩展(称为包),这些扩展扩展了语法和编辑功能。
安装额外的 Python 包可能很棘手:所有 Sublime 文本包都是用 Python 本身编写的,安装社区包通常需要你直接在 Sublime 文本中执行 Python 脚本。
优点: Sublime Text 在社区中有很多追随者。作为一个代码编辑器,单独来说,Sublime Text 很快,很小,并且得到很好的支持。
缺点: Sublime Text 不是免费的,虽然你可以无限期使用评估版。安装扩展可能很棘手,并且没有从编辑器中执行或调试代码的直接支持。
为了充分利用您的 Sublime Text 设置,请阅读我们的 Python + Sublime Text 设置指南,并考虑我们的深度视频课程,该课程将向您展示如何使用 Sublime Text 3 创建有效的 Python 开发设置。
Atom
类别:代码编辑
网站:https://atom.io/
Atom 可在所有平台上使用,被宣传为“21 世纪可破解的文本编辑器”。凭借时尚的界面、文件系统浏览器和扩展市场,开源 Atom 是使用 Electron 构建的,这是一个使用 JavaScript 、 HTML 和 CSS 创建桌面应用程序的框架。Python 语言支持由一个扩展提供,该扩展可以在 Atom 运行时安装。
优点:多亏了 Electron,它在所有平台上都有广泛的支持。Atom 很小,所以下载和加载速度很快。
缺点:构建和调试支持不是内置的,而是社区提供的附加组件。因为 Atom 是基于 Electron 构建的,所以它总是在 JavaScript 进程中运行,而不是作为原生应用程序。
GNU Emacs
类别:代码编辑
网站:https://www.gnu.org/software/emacs/
早在 iPhone vs Android 大战之前,在 Linux vs Windows 大战之前,甚至在 PC vs Mac 大战之前,就有了编辑器大战,GNU Emacs 作为参战方之一。GNU Emacs 被宣传为“可扩展、可定制、自我文档化的实时显示编辑器”,它几乎和 UNIX 一样存在了很长时间,并拥有狂热的追随者。
GNU Emacs 总是免费的,在每个平台上都可用(以某种形式),它使用一种强大的 Lisp 编程语言进行定制,并且存在各种用于 Python 开发的定制脚本。
优点:你知道 Emacs,你用 Emacs,你爱 Emacs。Lisp 是第二语言,你知道它给你的力量意味着你可以做任何事情。
缺点:定制就是将 Lisp 代码编写(或者复制/粘贴)到各种脚本文件中。如果还没有提供,您可能需要学习 Lisp 来弄清楚如何去做。
另外,你知道 Emacs 会是一个很棒的操作系统,只要它有一个好的文本编辑器…
请务必参考我们的 Python + Emacs 设置指南来充分利用这个设置。
Vi / Vim
类别:代码编辑
网站:https://www.vim.org/
文本编辑器战争的另一方是 VI(又名 VIM)。几乎每个 UNIX 系统和 Mac OS X 系统都默认包含 VI,它拥有同样狂热的追随者。
VI 和 VIM 是模态编辑器,将文件的查看和编辑分开。VIM 包含了对原始 VI 的许多改进,包括可扩展性模型和就地代码构建。VIMScripts 可用于各种 Python 开发任务。
优点:你知道 VI,你用 VI,你爱 VI。VIMScripts 不会吓到你,你知道你可以随心所欲地使用它。
缺点:像 Emacs 一样,您不习惯寻找或编写自己的脚本来支持 Python 开发,并且您不确定模态编辑器应该如何工作。
另外,你知道 VI 将是一个伟大的文本编辑器,只要它有一个像样的操作系统。
如果你打算使用这种组合,请查看我们的 Python + VIM 设置指南,其中包含提示和插件推荐。
Visual Studio
类别: IDE
网站:https://www.visualstudio.com/vs/
Python 工具:Visual Studio 的 Python 工具,又名 PTVS
Visual Studio 由微软构建,是一个全功能的 IDE,在许多方面可以与 Eclipse 相媲美。VS 仅适用于 Windows 和 Mac OS,有免费(社区)和付费(专业和企业)两个版本。Visual Studio 支持各种平台的开发,并自带扩展市场。
Visual Studio 的 Python 工具(又名 PTVS)支持 Visual Studio 中的 Python 编码,以及 Python 的智能感知、调试和其他工具。
优点:如果您已经为其他开发活动安装了 Visual Studio,那么添加 PTVS 会更快更容易。
缺点: Visual Studio 对于 Python 来说是一个很大的下载量。此外,如果您使用的是 Linux,那么您就不走运了:该平台没有 Visual Studio 安装程序。
Visual Studio 代码
类别:代码编辑
网站:https://code.visualstudio.com/
Python 工具:https://marketplace.visualstudio.com/items?itemName=ms-python.python
不要与完整的 Visual Studio 混淆,Visual Studio Code(又名 VS Code)是一个适用于 Linux、Mac OS X 和 Windows 平台的全功能代码编辑器。小巧轻便,但功能齐全,VS 代码是开源的,可扩展的,并且几乎可以为任何任务进行配置。和 Atom 一样,VS 代码也是建立在电子之上的,所以它也有同样的优缺点。
在 VS 代码中安装 Python 支持非常容易:只需点击一下按钮就可以进入市场。搜索 Python,单击安装,并在必要时重启。VS 代码会自动识别你的 Python 安装和库。
优点:多亏了 electronic,VS 代码可以在每个平台上使用,尽管占地面积很小,但功能却惊人地全面,而且是开源的。
缺点:电子意味着 VS 代码不是原生 app。另外,有些人可能有原则性的理由不使用微软的资源。
请务必参考我们的教程使用 Visual Studio 代码进行 Python 开发,以及的配套视频课程,以充分利用这一设置。如果你使用的是 Windows,那么请查看你的 Python 编码环境:设置指南中的设置 VS 代码部分。
特定于 Python 的编辑器和 ide
PyCharm
类别:IDE
T3】网站:T5】https://www.jetbrains.com/pycharm/
Python 最好的(也是唯一的)全功能专用 ide 之一是 PyCharm 。PyCharm 有付费(专业版)和免费开源(社区版)两种版本,可以在 Windows、Mac OS X 和 Linux 平台上快速轻松地安装。
开箱即用,PyCharm 直接支持 Python 开发。你可以打开一个新文件,开始写代码。您可以在 PyCharm 中直接运行和调试 Python,它支持源代码控制和项目。
优点:这是事实上的 Python IDE 环境,有大量的支持和支持社区。它开箱即可编辑、运行和调试 Python。
缺点: PyCharm 加载速度可能会很慢,现有项目的默认设置可能需要调整。
Spyder
类别:IDE
T3】网站:T5】https://github.com/spyder-ide/spyder
Spyder 是一个开源 Python IDE,针对数据科学工作流进行了优化。Spyder 包含在 Anaconda 包管理器发行版中,所以根据您的设置,您可能已经在您的机器上安装了 spyder。
Spyder 的有趣之处在于,它的目标受众是使用 Python 的数据科学家。你会注意到这一点。例如,Spyder 与常见的 Python 数据科学库集成得很好,如 SciPy 、 NumPy 和 Matplotlib 。
Spyder 具有您可能期望的大多数“通用 IDE 特性”,例如具有强大语法高亮显示的代码编辑器、Python 代码完成,甚至是集成的文档浏览器。
我在其他 Python 编辑环境中没有见过的一个特殊特性是 Spyder 的“变量浏览器”,它允许您在 ide 中使用基于表格的布局显示数据。就我个人而言,我通常不需要这个,但它看起来很整洁。如果您经常使用 Python 进行数据科学工作,您可能会爱上这个独特的功能。IPython/Jupyter 集成也很好。
总的来说,我认为 Spyder 比其他 ide 更基本。我更喜欢把它看作一个特殊用途的工具,而不是我每天用来作为主要编辑环境的东西。这个 Python IDE 的好处在于它可以在 Windows、macOS 和 Linux 上免费获得,并且是完全开源的软件。
优点:你是一名使用 Anaconda Python 发行版的数据科学家。
缺点:更有经验的 Python 开发人员可能会发现 Spyder 过于基础,无法在日常工作中使用,因此会选择更完整的 IDE 或定制的编辑器解决方案。
汤妮
类别:IDE
T3】网站:T5】http://thonny.org/
Thonny 是 Python IDE 家族的新成员,被宣传为初学者的 IDE。Thonny 由爱沙尼亚塔尔图大学计算机科学研究所编写和维护,可用于所有主要平台,网站上有安装说明。
默认情况下,Thonny 安装了自己的 Python 捆绑版本,因此您不需要安装任何其他新的东西。更有经验的用户可能需要调整这个设置,以便找到并使用已经安装的库。
优点:你是 Python 的初级用户,想要一个现成的 IDE。
反对意见:更有经验的 Python 开发者会发现 Thonny 对于大多数应用来说太基础了,内置解释器是需要解决的,而不是与之一起使用的。此外,作为一种新工具,您可能会发现一些问题无法立即解决。
如果您有兴趣使用 Thonny 作为您的 Python 编辑器,请务必阅读我们关于 Thonny 的专门文章,这篇文章更深入地向您展示了其他特性。
哪个 Python IDE 适合你?
只有你能决定,但这里有一些基本的建议:
- 新的 Python 开发人员应该尝试尽可能少定制的解决方案。越少妨碍越好。
- 如果您将文本编辑器用于其他任务(如网页或文档),请寻找代码编辑器解决方案。
- 如果您已经在开发其他软件,您可能会发现将 Python 功能添加到现有工具集更容易。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 寻找完美的 Python 代码编辑器***
Python IDLE 入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 从 Python 闲置开始
如果你最近下载了 Python 到你的电脑上,那么你可能已经注意到你的电脑上有一个名为 IDLE 的新程序。你可能想知道,“这个程序在我的电脑上做什么?我没有下载那个!”虽然您可能没有自己下载过这个程序,但 IDLE 是与每个 Python 安装捆绑在一起的。它可以帮助您立即开始学习这门语言。在本教程中,您将学习如何在 Python IDLE 中工作,以及一些您可以在 Python 之旅中使用的很酷的技巧!
在本教程中,您将学习:
- Python IDLE 是什么
- 如何使用 IDLE 直接与 Python 交互
- 如何用 IDLE 编辑、执行和调试 Python 文件
- 如何根据自己的喜好定制 Python IDLE
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 空闲是什么?
每一个 Python 安装都带有一个集成开发和学习环境,你会看到它被缩短为 IDLE 甚至 IDE。这是一类帮助你更有效地编写代码的应用程序。虽然有许多ide供您选择,但是 Python IDLE 非常精简,这使得它成为初学程序员的完美工具。
Python IDLE 包含在 Windows 和 Mac 上的 Python 安装中。如果您是 Linux 用户,那么您应该能够使用您的包管理器找到并下载 Python IDLE。一旦你安装了它,你就可以使用 Python IDLE 作为交互式解释器或者文件编辑器。
交互式解释器
试验 Python 代码的最好地方是在交互式解释器,也称为外壳。外壳是一个基本的读取-评估-打印循环(REPL) 。它读取一条 Python 语句,评估该语句的结果,然后将结果打印在屏幕上。然后,它循环返回以读取下一条语句。
Python shell 是试验小代码片段的绝佳场所。您可以通过计算机上的终端或命令行应用程序来访问它。您可以使用 Python IDLE 简化工作流程,当您打开 Python shell 时,它会立即启动。
一个文件编辑器
每个程序员都需要能够编辑和保存文本文件。Python 程序是扩展名为.py的文件,包含多行 Python 代码。Python IDLE 使您能够轻松地创建和编辑这些文件。
Python IDLE 还提供了几个你将在专业 ide 中看到的有用特性,比如基本语法高亮、代码完成和自动缩进。专业 ide 是更健壮的软件,它们有一个陡峭的学习曲线。如果您刚刚开始您的 Python 编程之旅,那么 Python IDLE 是一个很好的选择!
如何使用 Python IDLE Shell
shell 是 Python IDLE 的默认操作模式。当你点击图标打开程序时,你首先看到的是外壳:
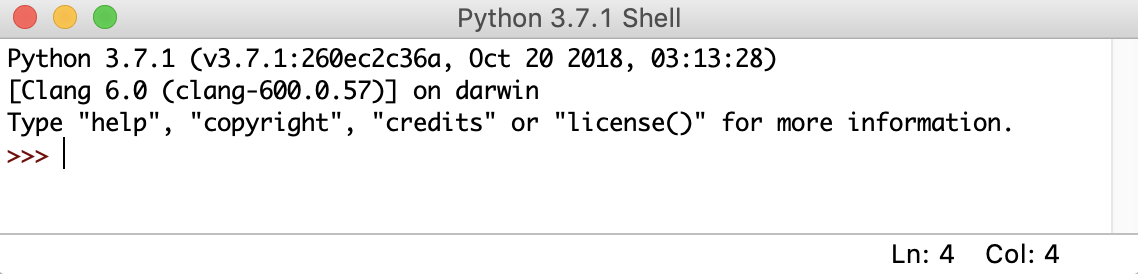
这是一个空白的 Python 解释器窗口。您可以使用它立即开始与 Python 交互。您可以用一小段代码来测试它:
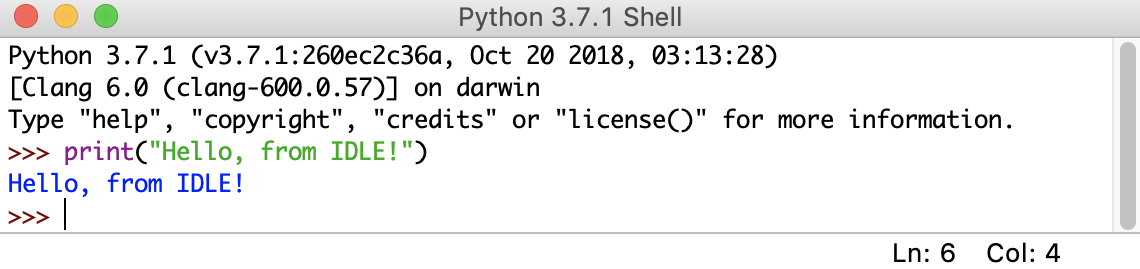
这里,您使用了 print() 将字符串"Hello, from IDLE!"输出到您的屏幕。这是与 Python IDLE 交互的最基本方式。您一次输入一个命令,Python 会响应每个命令的结果。
接下来,看看菜单栏。您将看到使用 shell 的几个选项:
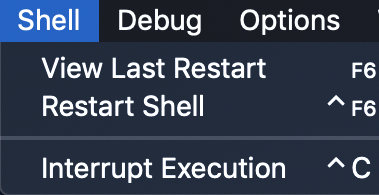
您可以从该菜单重新启动 shell。如果您选择该选项,那么您将清除 shell 的状态。它将表现得好像您已经启动了一个新的 Python IDLE 实例。外壳将会忘记以前状态的所有内容:
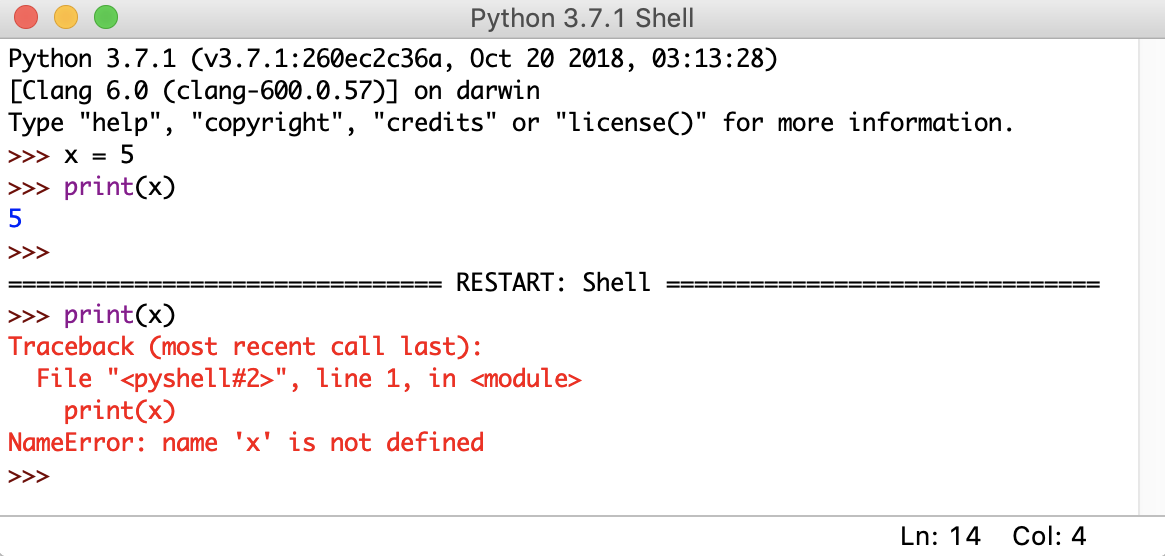
在上图中,首先声明一个变量,x = 5。当您调用print(x)时,shell 显示正确的输出,这是数字5。但是,当您重启 shell 并尝试再次调用print(x)时,您可以看到 shell 打印了一个 traceback 。这是一条错误消息,说明变量x未定义。shell 已经忘记了重启之前发生的所有事情。
您也可以从这个菜单中断 shell 的执行。这将在中断时停止 shell 中正在运行的任何程序或语句。看看当您向 shell 发送键盘中断时会发生什么:
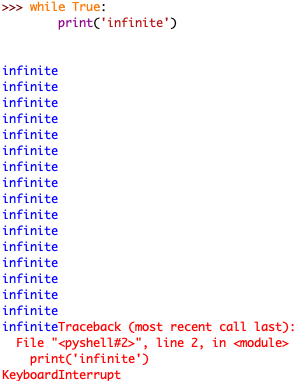
窗口底部以红色文本显示一条KeyboardInterrupt错误信息。程序接收到中断并已停止执行。
如何使用 Python 文件
Python IDLE 提供了一个成熟的文件编辑器,让您能够在这个程序中编写和执行 Python 程序。内置的文件编辑器还包括几个功能,如代码完成和自动缩进,这将加快您的编码工作流程。首先,我们来看看如何在 Python IDLE 中编写和执行程序。
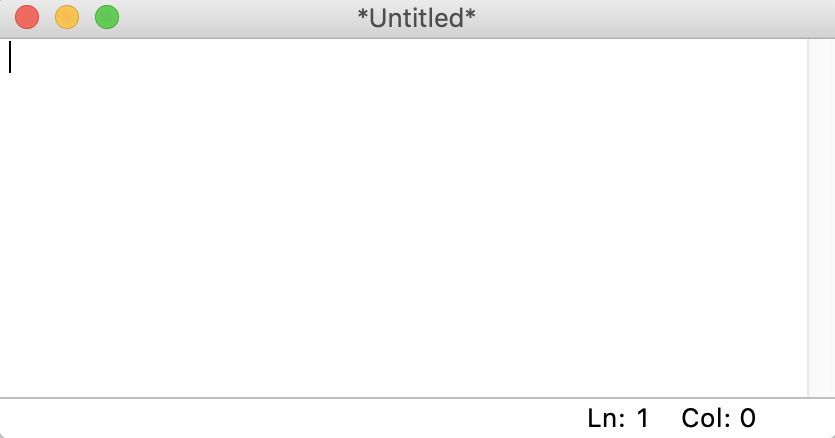
打开文件
要启动一个新的 Python 文件,从菜单栏中选择文件→新文件。这将在编辑器中打开一个空白文件,如下所示:
从这个窗口中,您可以编写一个全新的 Python 文件。您也可以通过选择菜单栏中的文件→打开… 来打开现有的 Python 文件。这将打开您操作系统的文件浏览器。然后,可以找到想要打开的 Python 文件。
如果您对阅读 Python 模块的源代码感兴趣,那么您可以选择文件→路径浏览器。这将允许您查看 Python IDLE 可以看到的模块。当你双击其中一个,文件编辑器就会打开,你就可以阅读它了。
该窗口的内容将与您调用sys.path时返回的路径相同。如果您知道想要查看的特定模块的名称,那么您可以选择文件→模块浏览器,并在出现的框中输入模块的名称。
编辑文件
一旦你在 Python IDLE 中打开了一个文件,你就可以对它进行修改。当您准备好编辑文件时,您会看到类似这样的内容:
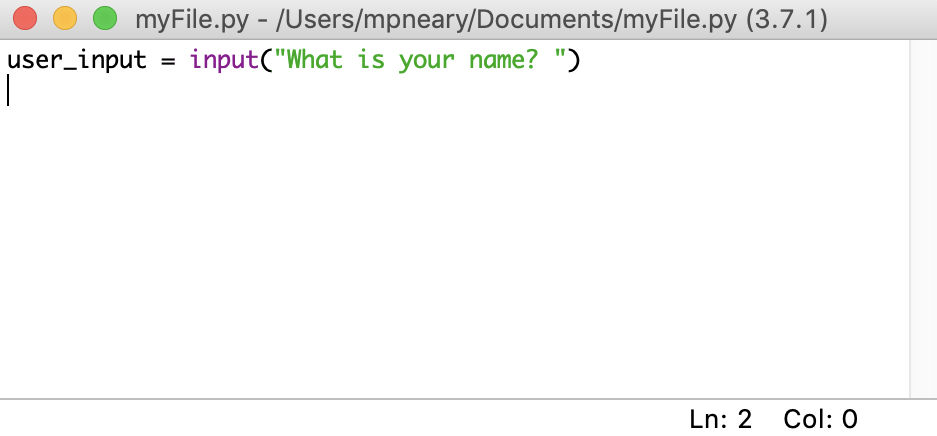
文件的内容显示在打开的窗口中。窗口顶部的栏包含三条重要信息:
- 您正在编辑的文件的名称
- 您可以在电脑上找到该文件的文件夹的完整路径
- IDLE 正在使用的 Python 版本
在上图中,您正在编辑文件myFile.py,它位于Documents文件夹中。Python 版本是 3.7.1,你可以在括号里看到。
窗口右下角还有两个数字:
- Ln: 显示光标所在的行号。
- Col: 显示光标所在的列号。
看到这些数字很有用,这样您可以更快地找到错误。它们还能帮助你确保你保持在一定的线宽内。
此窗口中有一些视觉提示,可以帮助您记住保存您的工作。如果你仔细观察,你会发现 Python IDLE 使用星号让你知道你的文件有未保存的修改:
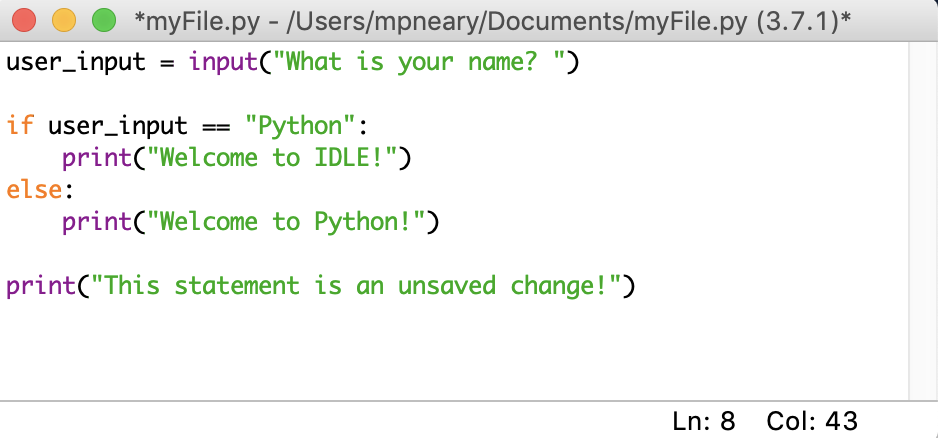
显示在空闲窗口顶部的文件名被星号包围。这意味着编辑器中有未保存的更改。您可以使用系统的标准键盘快捷键保存这些更改,也可以从菜单栏中选择文件→保存。请确保使用扩展名.py保存文件,以便启用语法高亮显示。
执行文件
当你想执行一个你在空闲状态下创建的文件时,你应该首先确保它被保存。请记住,您可以通过查看文件编辑器窗口顶部文件名周围的星号来查看您的文件是否被正确保存。不过,如果你忘记了也不用担心!当你试图执行一个未保存的文件时,Python IDLE 会提醒你保存。
要在空闲状态下执行文件,只需按键盘上的 F5 键。您也可以从菜单栏中选择运行→运行模块。这两个选项都将重启 Python 解释器,然后运行您用新的解释器编写的代码。这个过程与您在终端中运行python3 -i [filename]是一样的。
当你的代码执行完毕,解释器将知道你的代码的一切,包括任何全局变量、函数和类。这使得 Python IDLE 成为在出现问题时检查数据的好地方。如果你需要中断程序的执行,你可以在运行代码的解释器中按 Ctrl + C 。
如何改进你的工作流程
现在您已经了解了如何在 Python IDLE 中编写、编辑和执行文件,是时候加快您的工作流程了!Python IDLE 编辑器提供了一些您将在大多数专业 ide 中看到的特性,来帮助您更快地编码。这些特性包括自动缩进、代码完成和调用提示以及代码上下文。
自动缩进
当 IDLE 需要开始一个新的块时,它会自动缩进你的代码。这通常发生在您键入冒号(:)之后。当您在冒号后按回车键时,光标将自动移动一定数量的空格,并开始一个新的代码块。
您可以在设置中配置光标将移动多少个空格,但默认是标准的四个空格。Python 的开发人员就编写良好的 Python 代码的标准风格达成了一致,这包括缩进、空白等规则。这种标准风格被形式化了,现在被称为 PEP 8 。要了解更多信息,请查看如何用 PEP 8 编写漂亮的 Python 代码。
代码完成和呼叫提示
当你为一个大项目或者一个复杂的问题编写代码时,你可能会花费大量的时间来输入你需要的所有代码。代码完成通过尝试为您完成代码来帮助您节省键入时间。Python IDLE 具有基本的代码完成功能。它只能自动补全函数和类名。要在编辑器中使用自动完成功能,只需在一系列文本后按 tab 键。
Python IDLE 还会提供呼叫提示。一个调用提示就像是对代码某一部分的提示,帮助你记住那个元素需要什么。键入左括号开始函数调用后,如果几秒钟内没有键入任何内容,将会出现调用提示。例如,如果您不太记得如何添加到一个列表,那么您可以在左括号后暂停以调出呼叫提示:

呼叫提示将显示为弹出提示,提醒您如何添加到列表中。像这样的调用技巧在您编写代码时提供了有用的信息。
代码上下文
代码上下文功能是 Python 空闲文件编辑器的一个简洁的特性。它将向你展示一个函数、类、循环或其他结构的范围。当您滚动浏览一个很长的文件,并需要在编辑器中查看代码时跟踪您的位置时,这尤其有用。
要打开它,在菜单栏中选择选项→代码上下文。您会看到编辑器窗口顶部出现一个灰色栏:
当你向下滚动你的代码时,包含每一行代码的上下文将停留在这个灰色条内。这意味着你在上图中看到的print()函数是主函数的一部分。当您到达超出此函数范围的一行时,条形将会消失。
如何在空闲状态下调试
一个 bug 是你程序中的一个意外问题。它们可以以多种形式出现,其中一些比另一些更难修复。有些 bug 非常棘手,你不能通过通读你的程序来发现它们。幸运的是,Python IDLE 提供了一些基本工具,可以帮助你轻松调试你的程序!
解释器调试模式
如果您想用内置调试器运行您的代码,那么您需要打开这个特性。为此,从 Python 空闲菜单栏中选择调试→调试器。在解释器中,您应该看到[DEBUG ON]出现在提示符(>>>)之前,这意味着解释器已经准备好并正在等待。
执行 Python 文件时,将出现调试器窗口:
在此窗口中,您可以在代码执行时检查局部变量和全局变量的值。这使您能够深入了解代码运行时数据是如何被操作的。
您也可以单击以下按钮来浏览代码:
- Go: 按下此键,执行前进到下一个断点。您将在下一节了解这些内容。
- 步骤:按此执行当前行,转到下一行。
- Over: 如果当前代码行包含一个函数调用,那么按下此键以跳过该函数。换句话说,执行那个函数,转到下一行,但是在执行函数的时候不要暂停(除非有断点)。
- Out: 如果当前行代码在一个函数中,则按此键可以从该函数的中跳出。换句话说,继续执行这个函数,直到返回。
一定要小心,因为没有反向按钮!在程序的执行过程中,您只能及时向前移动。
您还会在“调试”窗口中看到四个复选框:
- 全局:您的程序的全局信息
- Locals: 您的程序在执行过程中的本地信息
- 栈:执行过程中运行的函数
- 来源:你的文件在空闲时编辑
当您选择其中之一时,您将在调试窗口中看到相关信息。
断点
一个断点是一行代码,当你运行你的代码时,你把它标识为解释器应该暂停的地方。它们只有在调试模式开启时才能工作,所以确保你已经先这样做了。
要设置断点,右键单击要暂停的代码行。这将以黄色突出显示代码行,作为设置断点的可视指示。您可以在代码中设置任意数量的断点。要撤销断点,再次右键单击同一行并选择清除断点。
一旦你设置了断点并打开了调试模式,你就可以像平常一样运行你的代码了。调试器窗口将弹出,您可以开始手动单步调试您的代码。
错误和异常
当您在解释器中看到报告给您的错误时,Python IDLE 允许您从菜单栏直接跳转到有问题的文件或行。您只需用光标高亮显示报告的行号或文件名,并从菜单栏中选择调试→转到文件/行。这将打开有问题的文件,并把您带到包含错误的那一行。无论调试模式是否开启,该功能都起作用。
Python IDLE 还提供了一个叫做堆栈查看器的工具。你可以在菜单栏的调试选项下进入。这个工具将向您展示 Python IDLE 在运行代码时遇到的最后一个错误或异常的堆栈上出现的错误的回溯。当发生意外或有趣的错误时,您可能会发现查看堆栈很有帮助。否则,这个特性可能很难解析,并且可能对您没有用处,除非您正在编写非常复杂的代码。
如何定制 Python IDLE
有很多方法可以让 Python IDLE 拥有适合自己的视觉风格。默认的外观基于 Python 徽标中的颜色。如果你不喜欢任何东西的样子,那么你几乎总是可以改变它。
要访问定制窗口,从菜单栏中选择选项→配置空闲。要预览您想要进行的更改的结果,请按下应用。当你定制完 Python IDLE 后,按 OK 保存你所有的修改。如果您不想保存您的更改,只需按下取消。
您可以自定义 Python IDLE 的 5 个区域:
- 字体/标签
- 突出
- 键
- 一般
- 扩展ˌ扩张
现在,让我们来逐一了解一下。
字体/标签
第一个选项卡允许您更改字体颜色、字体大小和字体样式。根据您的操作系统,您可以将字体更改为几乎任何您喜欢的样式。字体设置窗口如下所示:
您可以使用滚动窗口选择您喜欢的字体。(建议你选择 Courier New 这样的定宽字体。)选择一个足够大的字体,让你看得更清楚。您也可以点击粗体旁边的复选框来切换是否所有文本都以粗体显示。
此窗口还允许您更改每个缩进级别使用的空格数。默认情况下,这将被设置为四个空格的 PEP 8 标准。您可以更改这一点,使代码的宽度根据您的喜好或多或少地展开。
亮点
第二个定制选项卡将允许您更改突出显示。语法突出显示是任何 IDE 的一个重要特性,它可以突出显示您正在使用的语言的语法。这有助于您直观地区分不同的 Python 结构和代码中使用的数据。
Python IDLE 允许您完全自定义 Python 代码的外观。它预装了三种不同的亮点主题:
- 无聊的日子
- 无所事事的夜晚
- 闲置新闻
您可以从这些预安装的主题中进行选择,或者在此窗口中创建您自己的自定义主题:
不幸的是,IDLE 不允许你从一个文件中安装自定义主题。你必须从这个窗口创建自定义主题。为此,您可以简单地开始改变不同项目的颜色。选择一个项目,然后按为选择颜色。你将被带到一个颜色选择器,在那里你可以选择你想要使用的确切颜色。
然后,系统会提示您将该主题保存为新的自定义主题,您可以输入自己选择的名称。如果愿意,您可以继续更改不同项目的颜色。记得按下应用来查看您的行动变化!
按键
第三个定制选项卡允许您将不同的按键映射到动作,也称为键盘快捷键。无论何时使用 IDE,这些都是生产力的重要组成部分。你可以自己想出键盘快捷键,也可以使用 IDLE 自带的快捷键。预安装的快捷方式是一个很好的起点:
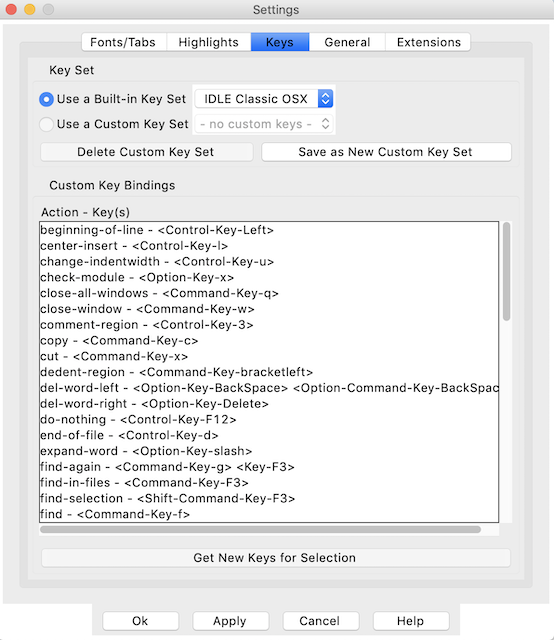
键盘快捷键按动作的字母顺序列出。它们以动作-快捷方式的格式列出,其中动作是当你按下快捷方式中的组合键时会发生的事情。如果您想使用内置的键集,请选择与您的操作系统相匹配的映射。请密切注意不同的键,并确保您的键盘有它们!
创建自己的快捷方式
键盘快捷键的定制与语法高亮颜色的定制非常相似。遗憾的是,IDLE 不允许您从文件中安装自定义键盘快捷键。您必须从键选项卡创建一组自定义快捷键。
从列表中选择一对,按下获取新的选择键。将弹出一个新窗口:
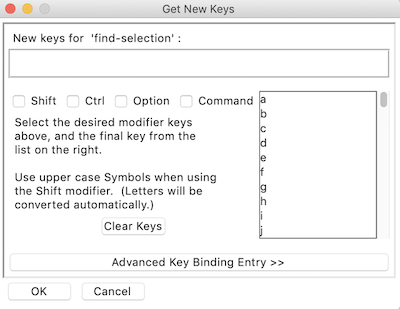
在这里,您可以使用复选框和滚动菜单来选择要用于该快捷键的组合键。您可以选择高级键绑定条目> > 手动输入命令。请注意,这不会拾取您按下的键。您必须逐字键入您在快捷键列表中看到的命令。
常规
“定制”窗口的第四个选项卡是进行小的常规更改的地方。“常规设置”选项卡如下所示:
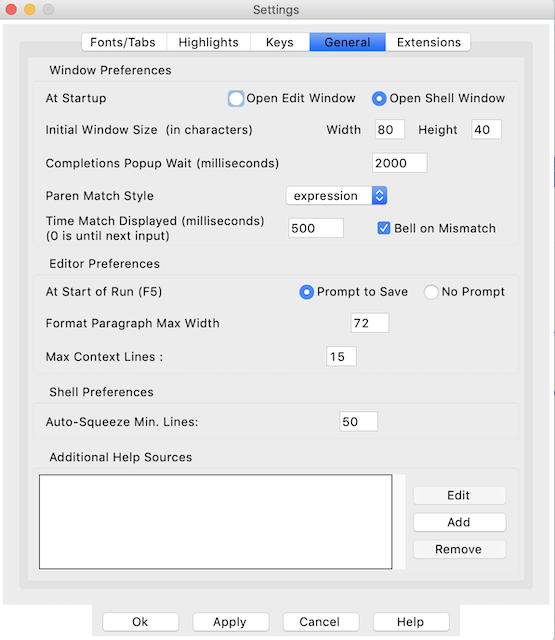
在这里,您可以自定义窗口大小,以及启动 Python IDLE 时是先打开 shell 还是先打开文件编辑器。这个窗口中的大部分东西改变起来并不令人兴奋,所以你可能不需要摆弄它们。
扩展
定制窗口的第五个选项卡允许您向 Python IDLE 添加扩展。扩展允许你在编辑器和解释器窗口中添加新的、令人敬畏的特性。您可以从互联网上下载它们,并将其安装到 Python IDLE 中。
要查看安装了哪些扩展,选择选项→配置空闲- >扩展。互联网上有许多扩展可供你阅读更多。找到自己喜欢的,添加到 Python IDLE!
结论
在本教程中,您已经学习了使用 IDLE 编写 Python 程序的所有基础知识。你知道什么是 Python IDLE,以及如何使用它直接与 Python 交互。您还了解了如何处理 Python 文件,以及如何根据自己的喜好定制 Python IDLE。
你已经学会了如何:
- 使用 Python 空闲 shell
- 使用 Python IDLE 作为文件编辑器
- 利用帮助您更快编码的功能改进您的工作流程
- 调试代码并查看错误和异常
- 根据您的喜好定制 Python IDLE
现在,您拥有了一个新工具,它将让您高效地编写 Pythonic 代码,并为您节省无数时间。编程快乐!
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 从 Python 闲置开始*****
Python 导入:高级技术和技巧
在 Python 中,你使用 import 关键字使一个模块中的代码在另一个模块中可用。Python 中的导入对于有效地构建代码非常重要。正确使用导入将使您更有效率,允许您在保持项目可维护性的同时重用代码。
本教程将全面概述 Python 的import语句及其工作原理。导入系统是强大的,你将学会如何驾驭这种力量。虽然您将涉及 Python 导入系统背后的许多概念,但本教程主要是示例驱动的。您将从几个代码示例中学习。
在本教程中,您将学习如何:
- 使用模块、包和命名空间包
- 在你的包中处理资源和数据文件
- 运行时动态导入模块和
- 定制 Python 的导入系统
在整个教程中,您将看到如何使用 Python 导入机制来最有效地工作的例子。虽然教程中显示了所有代码,但是您也可以通过单击下面的框来下载它:
获取源代码: 点击此处获取源代码,您将在本教程中使用来了解 Python 导入系统。
基础 Python import
Python 代码被组织到模块和包中。本节将解释它们之间的区别以及如何使用它们。
在本教程的后面,您将看到 Python 的导入系统的一些高级和鲜为人知的用法。然而,让我们从基础开始:导入模块和包。
模块
Python.org 词汇表对模块的定义如下:
作为 Python 代码的组织单位的对象。模块有一个包含任意 Python 对象的名称空间。模块通过导入过程加载到 Python 中。(来源)
实际上,一个模块通常对应一个包含 Python 代码的.py文件。
模块的真正强大之处在于它们可以被导入并在其他代码中重用。考虑下面的例子:
>>> import math >>> math.pi 3.141592653589793在第一行
import math,您导入math模块中的代码,并使其可供使用。在第二行,您访问math模块中的pi变量。math是 Python 的标准库的一部分,这意味着当你运行 Python 时,它总是可以被导入。注意你写的是
math.pi而不仅仅是简单的pi。除了作为一个模块,math还作为一个 名称空间 将模块的所有属性保存在一起。名称空间有助于保持代码的可读性和组织性。用蒂姆·彼得斯的话说:名称空间是一个非常棒的想法——让我们多做一些吧!(来源)
您可以使用
dir()列出名称空间的内容:
>>> import math
>>> dir()
['__annotations__', '__builtins__', ..., 'math']
>>> dir(math)
['__doc__', ..., 'nan', 'pi', 'pow', ...]
使用不带任何参数的dir()显示了全局名称空间中的内容。要查看math名称空间的内容,可以使用dir(math)。
你已经看到了import最直接的用法。但是,还有其他方法可以使用它,允许您导入模块的特定部分,并在导入时重命名模块。
以下代码仅从math模块导入pi变量:
>>> from math import pi >>> pi 3.141592653589793 >>> math.pi NameError: name 'math' is not defined请注意,这将把
pi放在全局名称空间中,而不是放在math名称空间中。您也可以在导入模块和属性时给它们重新命名:
>>> import math as m
>>> m.pi
3.141592653589793
>>> from math import pi as PI
>>> PI
3.141592653589793
关于导入模块的语法的更多细节,请查看 Python 模块和包——简介。
包装
您可以使用一个包来进一步组织您的模块。Python.org 词汇表将包定义如下:
一个 Python 模块,可以包含子模块或递归子包。从技术上讲,包是一个带有
__path__属性的 Python 模块。(来源)
注意,包仍然是一个模块。作为一个用户,你通常不需要担心你是导入一个模块还是一个包。
实际上,一个包通常对应于一个包含 Python 文件和其他目录的文件目录。要自己创建一个 Python 包,需要创建一个目录和一个名为__init__.py 的文件。当被视为一个模块时,__init__.py文件包含了包的内容。可以留空。
注意:没有__init__.py文件的目录仍然被 Python 视为包。然而,这些不会是常规的包,而是被称为名称空间包的东西。稍后你会学到更多关于他们的知识。
通常,当您导入一个包时,子模块和子包不会被导入。但是,如果您愿意,您可以使用__init__.py来包含任何或者所有的子模块和子包。为了展示这种行为的几个例子,您将创建一个用几种不同的语言说 Hello world 的包。该软件包将包含以下目录和文件:
world/
│
├── africa/
│ ├── __init__.py
│ └── zimbabwe.py
│
├── europe/
│ ├── __init__.py
│ ├── greece.py
│ ├── norway.py
│ └── spain.py
│
└── __init__.py
每个国家文件打印出的问候,而__init__.py文件有选择地导入一些子包和子模块。这些文件的确切内容如下:
# world/africa/__init__.py (Empty file)
# world/africa/zimbabwe.py
print("Shona: Mhoroyi vhanu vese")
print("Ndebele: Sabona mhlaba")
# world/europe/__init__.py
from . import greece
from . import norway
# world/europe/greece.py
print("Greek: Γειά σας Κόσμε")
# world/europe/norway.py
print("Norwegian: Hei verden")
# world/europe/spain.py
print("Castellano: Hola mundo")
# world/__init__.py
from . import africa
注意world/__init__.py只导入africa而不导入europe。同样,world/africa/__init__.py不导入任何东西,而world/europe/__init__.py导入greece和norway但不导入spain。每个国家模块在导入时都会打印一个问候语。
让我们在交互提示符下使用world包,以便更好地理解子包和子模块的行为:
>>> import world >>> world <module 'world' from 'world/__init__.py'> >>> # The africa subpackage has been automatically imported >>> world.africa <module 'world.africa' from 'world/africa/__init__.py'> >>> # The europe subpackage has not been imported >>> world.europe AttributeError: module 'world' has no attribute 'europe'当
europe被导入时,europe.greece和europe.norway模块也被导入。您可以看到这一点,因为国家模块在导入时会打印一条问候语:
>>> # Import europe explicitly
>>> from world import europe
Greek: Γειά σας Κόσμε
Norwegian: Hei verden
>>> # The greece submodule has been automatically imported
>>> europe.greece
<module 'world.europe.greece' from 'world/europe/greece.py'>
>>> # Because world is imported, europe is also found in the world namespace
>>> world.europe.norway
<module 'world.europe.norway' from 'world/europe/norway.py'>
>>> # The spain submodule has not been imported
>>> europe.spain
AttributeError: module 'world.europe' has no attribute 'spain'
>>> # Import spain explicitly inside the world namespace
>>> import world.europe.spain
Castellano: Hola mundo
>>> # Note that spain is also available directly inside the europe namespace
>>> europe.spain
<module 'world.europe.spain' from 'world/europe/spain.py'>
>>> # Importing norway doesn't do the import again (no output), but adds
>>> # norway to the global namespace
>>> from world.europe import norway
>>> norway
<module 'world.europe.norway' from 'world/europe/norway.py'>
world/africa/__init__.py文件是空的。这意味着导入world.africa包创建了名称空间,但是没有其他影响:
>>> # Even though africa has been imported, zimbabwe has not >>> world.africa.zimbabwe AttributeError: module 'world.africa' has no attribute 'zimbabwe' >>> # Import zimbabwe explicitly into the global namespace >>> from world.africa import zimbabwe Shona: Mhoroyi vhanu vese Ndebele: Sabona mhlaba >>> # The zimbabwe submodule is now available >>> zimbabwe <module 'world.africa.zimbabwe' from 'world/africa/zimbabwe.py'> >>> # Note that zimbabwe can also be reached through the africa subpackage >>> world.africa.zimbabwe <module 'world.africa.zimbabwe' from 'world/africa/zimbabwe.py'>记住,导入一个模块会加载内容并创建一个包含内容的名称空间。最后几个例子表明,同一个模块可能是不同名称空间的一部分。
技术细节:模块名称空间被实现为一个 Python 字典,并且在
.__dict__属性中可用:
>>> import math
>>> math.__dict__["pi"]
3.141592653589793
你很少需要直接和.__dict__互动。
同样,Python 的全局名称空间也是一个字典。可以通过globals()访问。
在一个__init__.py文件中导入子包和子模块以使它们更容易被用户使用是很常见的。你可以在流行的 requests套餐中看到这种的一个例子。
绝对和相对进口
回想一下前面例子中的源代码world/__init__.py:
from . import africa
你已经见过from math import pi等from...import语句,但是from . import africa中的点(.)是什么意思呢?
圆点表示当前包,该语句是一个相对导入的例子。可以理解为“从当前包中,导入子包africa”
有一个等价的 absolute import 语句,在其中显式命名当前包:
from world import africa
事实上,world中的所有导入都可以用类似的绝对导入显式完成。
相对导入必须采用from...import的形式,并且导入位置必须以点开始。
PEP 8 风格指南一般推荐使用绝对进口。但是,相对导入是组织包层次结构的一种替代方法。有关更多信息,请参见 Python 中的绝对与相对导入。
Python 的导入路径
Python 如何找到它导入的模块和包?稍后您将看到关于 Python 导入系统的更多细节。现在,只知道 Python 在它的 导入路径 中寻找模块和包。这是在其中搜索要导入的模块的位置列表。
注意:当你输入import something的时候,Python 会在搜索导入路径之前寻找something几个不同的地方。
特别是,它会在模块缓存中查看something是否已经被导入,并且会在内置模块中进行搜索。
在后面的章节中,您将了解更多关于 Python 导入机制的内容。
您可以通过打印sys.path来检查 Python 的导入路径。概括地说,该列表将包含三种不同的位置:
- 当前脚本的目录(如果没有脚本,则为当前目录,例如 Python 交互运行时)
PYTHONPATH环境变量的内容- 其他依赖于安装的目录
通常,Python 会从位置列表的开头开始,在每个位置寻找给定的模块,直到第一个匹配。因为脚本目录或当前目录总是在这个列表的第一位,所以您可以通过组织目录并注意从哪个目录运行 Python 来确保您的脚本找到您自制的模块和包。
然而,你也应该小心不要创建那些遮蔽了或者隐藏了其他重要模块的模块。例如,假设您定义了下面的math模块:
# math.py
def double(number):
return 2 * number
使用该模块可以像预期的那样工作:
>>> import math >>> math.double(3.14) 6.28但是这个模块也隐藏了标准库中包含的
math模块。不幸的是,这意味着我们之前查找π值的例子不再有效:
>>> import math
>>> math.pi
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'math' has no attribute 'pi'
>>> math
<module 'math' from 'math.py'>
问题是 Python 现在在你的新math模块中搜索pi,而不是在标准库中搜索math模块。
为了避免这类问题,您应该小心使用模块和包的名称。特别是,顶级模块和包的名称应该是唯一的。如果math被定义为一个包内的子模块,那么它不会遮蔽内置模块。
示例:构建您的导入
虽然可以通过使用当前目录以及操纵PYTHONPATH甚至sys.path来组织您的导入,但是这个过程通常是不规则的,并且容易出错。要查看典型示例,请考虑以下应用:
structure/
│
├── files.py
└── structure.py
该应用程序将通过创建目录和空文件来重新创建给定的文件结构。structure.py文件包含主脚本,files.py是一个库模块,有一些处理文件的函数。下面是应用程序输出的一个例子,在这种情况下是在structure目录下运行的:
$ python structure.py .
Create file: /home/gahjelle/structure/001/structure.py
Create file: /home/gahjelle/structure/001/files.py
Create file: /home/gahjelle/structure/001/__pycache__/files.cpython-38.pyc
这两个源代码文件以及自动创建的.pyc文件在名为001的新目录中重新创建。
现在看一下源代码。应用程序的主要功能在structure.py中定义:
1# structure/structure.py
2
3# Standard library imports
4import pathlib
5import sys
6
7# Local imports
8import files
9
10def main():
11 # Read path from command line
12 try:
13 root = pathlib.Path(sys.argv[1]).resolve()
14 except IndexError:
15 print("Need one argument: the root of the original file tree")
16 raise SystemExit()
17
18 # Re-create the file structure
19 new_root = files.unique_path(pathlib.Path.cwd(), "{:03d}")
20 for path in root.rglob("*"):
21 if path.is_file() and new_root not in path.parents:
22 rel_path = path.relative_to(root)
23 files.add_empty_file(new_root / rel_path)
24
25if __name__ == "__main__":
26 main()
在的第 12 到 16 行,您从命令行读取一个根路径。在上面的例子中,你使用了一个点,这意味着当前的目录。该路径将被用作您将重新创建的文件层次结构的root。
实际工作发生在19 到 23 行。首先,创建一个惟一的路径new_root,它将成为新文件层次结构的根。然后循环遍历原始root下的所有路径,并在新的文件层次结构中将它们重新创建为空文件。
对于这样的路径操作,标准库中的pathlib非常有用。关于如何使用它的更多细节,请查看 Python 3 的pathlib模块:驯服文件系统。
在第 26 行,你调用main()。稍后你会学到更多关于线 25 的if测试。现在,您应该知道特殊变量__name__在脚本中有值__main__,但是它在导入的模块中获得模块的名称。关于__name__的更多信息,请查看在 Python 中定义主函数和如果 name == " main 在 Python 中做什么?。
请注意,您在第 8 行的处导入了files。该库模块包含两个实用功能:
# structure/files.py
def unique_path(directory, name_pattern):
"""Find a path name that does not already exist"""
counter = 0
while True:
counter += 1
path = directory / name_pattern.format(counter)
if not path.exists():
return path
def add_empty_file(path):
"""Create an empty file at the given path"""
print(f"Create file: {path}")
path.parent.mkdir(parents=True, exist_ok=True)
path.touch()
unique_path() 使用计数器找到一条不存在的路径。在应用程序中,您使用它来找到一个唯一的子目录,用作重新创建的文件层次结构的new_root。接下来,add_empty_file()确保在使用 .touch() 创建一个空文件之前创建了所有必要的目录。
再看一下files的导入:
7# Local imports
8import files
看起来挺无辜的。但是,随着项目的增长,这条线会让你有些头疼。即使您从structure项目导入files,导入也是绝对:它不是以点开始的。这意味着必须在导入路径中找到files才能进行导入。
幸运的是,包含当前脚本的目录总是在 Python 的导入路径中,所以现在这样做很好。然而,如果你的项目获得了一些动力,那么它可能会被用在其他方面。
例如,有人可能想要将脚本导入到一个 Jupyter 笔记本中,并从那里运行它。或者他们可能想在另一个项目中重用files库。他们甚至可能用 PyInstaller 创建一个可执行文件来更容易地分发它。不幸的是,这些场景中的任何一个都可能导致files的导入出现问题。
要查看示例,您可以遵循 PyInstaller 指南并为您的应用程序创建一个入口点。在应用程序目录之外添加一个额外的目录:
structure/
│
├── structure/
│ ├── files.py
│ └── structure.py
│
└── cli.py
在外层目录中,创建入口点脚本,cli.py:
# cli.py
from structure.structure import main
if __name__ == "__main__":
main()
这个脚本将从您的原始脚本导入main()并运行它。注意由于在structure.py的线 25 上的if测试,当structure被导入时main()没有运行。这意味着您需要显式运行main()。
理论上,这应该类似于直接运行应用程序:
$ python cli.py structure
Traceback (most recent call last):
File "cli.py", line 1, in <module>
from structure.structure import main
File "/home/gahjelle/structure/structure/structure.py", line 8, in <module>
import files
ModuleNotFoundError: No module named 'files'
为什么没用?突然,files的导入引发了一个错误。
问题是通过用cli.py启动应用程序,你已经改变了当前脚本的位置,这反过来改变了导入路径。files已经不在导入路径上,所以绝对不能导入。
一个可能的解决方案是更改 Python 的导入路径:
7# Local imports
8sys.path.insert(0, str(pathlib.Path(__file__).parent))
9import files
这是因为导入路径包括了包含structure.py和files.py的文件夹。这种方法的问题是,您的导入路径会变得非常混乱,难以理解。
实际上,您正在重新创建早期 Python 版本的一个特性,称为隐式相对导入。这些被 PEP 328 从语言中删除,理由如下:
在 Python 2.4 和更早的版本中,如果你正在读取一个位于包内的模块,不清楚
import foo是指顶层模块还是包内的另一个模块。随着 Python 的库的扩展,越来越多的现有包内部模块突然不小心遮蔽了标准库模块。在包内这是一个特别困难的问题,因为没有办法指定哪个模块是指哪个模块。(来源)
另一个解决方案是使用相对导入。按如下方式更改structure.py中的导入:
7# Local imports
8from . import files
现在,您可以通过入口点脚本启动您的应用程序:
$ python cli.py structure
Create file: /home/gahjelle/structure/001/structure.py
Create file: /home/gahjelle/structure/001/files.py
Create file: /home/gahjelle/structure/001/__pycache__/structure.cpython-38.pyc
Create file: /home/gahjelle/structure/001/__pycache__/files.cpython-38.pyc
遗憾的是,您不能再直接调用该应用程序:
$ python structure.py .
Traceback (most recent call last):
File "structure.py", line 8, in <module>
from . import files
ImportError: cannot import name 'files' from '__main__' (structure.py)
问题是相对导入在脚本中的解析与导入模块不同。当然,您可以在直接运行脚本之前返回并恢复绝对导入,或者您甚至可以做一些try...except技巧来绝对或相对导入文件,这取决于什么有效。
甚至有一个官方认可的黑客来让相对导入在脚本中工作。不幸的是,这也迫使你在大多数情况下改变sys.path。引用雷蒙德·赫廷格的话:
一定有更好的办法!(来源)
事实上,一个更好——也更稳定——的解决方案是配合 Python 的导入和打包系统,使用pip 将您的项目作为本地包安装。
创建并安装一个本地包
当您从 PyPI 安装一个包时,您环境中的所有脚本都可以使用这个包。但是,您也可以从本地计算机安装软件包,它们也可以以同样的方式获得。
创建一个本地包并不涉及太多的开销。首先,在外层的structure目录中创建最小的 setup.cfg 和 setup.py 文件:
# setup.cfg
[metadata]
name = local_structure
version = 0.1.0
[options]
packages = structure
# setup.py
import setuptools
setuptools.setup()
理论上,name和version可以是你喜欢的任何东西。然而,pip在引用你的包时会用到它们,所以你应该选择可识别的值,并且不要和你使用的其他包冲突。
一个技巧是给所有这样的本地包一个公共的前缀,比如local_或者你的用户名。packages应该列出包含你的源代码的目录。然后您可以使用pip在本地安装包:
$ python -m pip install -e .
此命令将把软件包安装到您的系统中。structure将在 Python 的导入路径中找到,这意味着您可以在任何地方使用它,而不必担心脚本目录、相对导入或其他复杂性。-e选项代表可编辑,这很重要,因为它允许你改变你的包的源代码,而不需要重新安装。
注意:这种设置文件在您自己处理项目时非常有用。但是,如果您计划与他人共享代码,那么您应该在安装文件中添加更多的信息。
关于安装文件的更多细节,请查看如何将开源 Python 包发布到 PyPI 。
现在structure已经安装在您的系统上,您可以使用下面的导入语句:
7# Local imports
8from structure import files
无论您最终如何调用您的应用程序,这都会起作用。
提示:在自己的代码中,要有意识地将脚本和库分开。这里有一个很好的经验法则:
- 一个脚本将要运行。
- 一个库将被导入。
您可能有既想自己运行又想从其他脚本导入的代码。在这种情况下,通常值得重构您的代码,以便将公共部分拆分成一个库模块。
虽然将脚本和库分开是个好主意,但是所有 Python 文件都可以执行和导入。在后面的部分中,您将了解更多关于如何创建模块来很好地处理这两者。
名称空间包
Python 模块和包与文件和目录密切相关。这使得 Python 不同于许多其他编程语言,在其他编程语言中,包仅仅充当名称空间,而不强制执行源代码的组织方式。示例见 PEP 402 中的讨论。
命名空间包从版本 3.3 开始在 Python 中可用。这些不太依赖于底层的文件层次结构。特别是,名称空间包可以跨多个目录拆分。如果您的目录包含一个.py文件,但没有__init__.py,则会自动创建一个名称空间包。详见 PEP 420 。
注意:准确的说,隐式命名空间包是在 Python 3.3 中引入的。在 Python 的早期版本中,您可以用几种不同的不兼容方式在中手动创建名称空间包。PEP 420 统一并简化了这些早期的方法。
为了更好地理解命名空间包为什么有用,让我们试着实现一个。作为一个激励性的例子,您将再次尝试在工厂方法模式及其在 Python 中的实现中解决的问题:给定一个Song对象,您想要将它转换成几个字符串表示中的一个。换句话说,你希望序列化 Song对象。
更具体地说,您希望实现类似这样的代码:
>>> song = Song(song_id="1", title="The Same River", artist="Riverside") >>> song.serialize() '{"id": "1", "title": "The Same River", "artist": "Riverside"}'让我们假设您很幸运,遇到了需要序列化的几种格式的第三方实现,它被组织成一个名称空间包:
third_party/ │ └── serializers/ ├── json.py └── xml.py文件
json.py包含可以将对象序列化为 JSON 格式的代码:# third_party/serializers/json.py import json class JsonSerializer: def __init__(self): self._current_object = None def start_object(self, object_name, object_id): self._current_object = dict(id=object_id) def add_property(self, name, value): self._current_object[name] = value def __str__(self): return json.dumps(self._current_object)这个序列化器接口有点受限,但它足以演示名称空间包是如何工作的。
文件
xml.py包含一个类似的XmlSerializer,它可以将一个对象转换成 XML :# third_party/serializers/xml.py import xml.etree.ElementTree as et class XmlSerializer: def __init__(self): self._element = None def start_object(self, object_name, object_id): self._element = et.Element(object_name, attrib={"id": object_id}) def add_property(self, name, value): prop = et.SubElement(self._element, name) prop.text = value def __str__(self): return et.tostring(self._element, encoding="unicode")注意,这两个类都用
.start_object()、.add_property()和.__str__()方法实现了相同的接口。然后创建一个可以使用这些序列化器的
Song类:# song.py class Song: def __init__(self, song_id, title, artist): self.song_id = song_id self.title = title self.artist = artist def serialize(self, serializer): serializer.start_object("song", self.song_id) serializer.add_property("title", self.title) serializer.add_property("artist", self.artist) return str(serializer)一个
Song由它的 ID、标题和艺术家定义。注意.serialize()不需要知道它转换成哪种格式,因为它使用了前面定义的公共接口。假设您已经安装了第三方
serializers包,您可以如下使用它:
>>> from serializers.json import JsonSerializer
>>> from serializers.xml import XmlSerializer
>>> from song import Song
>>> song = Song(song_id="1", title="The Same River", artist="Riverside")
>>> song.serialize(JsonSerializer())
'{"id": "1", "title": "The Same River", "artist": "Riverside"}'
>>> song.serialize(XmlSerializer())
'<song id="1"><title>The Same River</title><artist>Riverside</artist></song>'
通过向.serialize()提供不同的序列化对象,您可以获得歌曲的不同表示。
注意:当你自己运行代码时,你可能会得到一个ModuleNotFoundError或者一个ImportError。这是因为serializers不在你的 Python 导入路径中。您很快就会看到如何解决这个问题。
到目前为止,一切顺利。然而,现在您意识到您还需要将您的歌曲转换成一种 YAML 表示,这在第三方库中是不支持的。进入名称空间包的魔力:您可以将自己的YamlSerializer添加到serializers包中,而不需要接触第三方库。
首先,在本地文件系统上创建一个名为serializers的目录。目录的名称必须与您正在定制的名称空间包的名称相匹配,这一点很重要:
local/
│
└── serializers/
└── yaml.py
在yaml.py文件中,您定义了自己的YamlSerializer。你把这个基于 PyYAML包,它必须从 PyPI 安装:
$ python -m pip install PyYAML
由于 YAML 和 JSON 是非常相似的格式,您可以重用JsonSerializer的大部分实现:
# local/serializers/yaml.py
import yaml
from serializers.json import JsonSerializer
class YamlSerializer(JsonSerializer):
def __str__(self):
return yaml.dump(self._current_object)
注意,YamlSerializer是基于JsonSerializer的,后者是从serializers本身导入的。由于json和yaml都是同一个名称空间包的一部分,您甚至可以使用一个相对导入:from .json import JsonSerializer。
继续上面的例子,您现在也可以将歌曲转换为 YAML:
>>> from serializers.yaml import YamlSerializer >>> song.serialize(YamlSerializer()) "artist: Riverside\nid: '1'\ntitle: The Same River\n"就像常规的模块和包一样,命名空间包必须位于 Python 导入路径中。如果您遵循前面的例子,那么您可能会遇到 Python 找不到
serializers的问题。在实际代码中,您将使用pip来安装第三方库,因此它将自动位于您的路径中。注意:在原始示例中,串行器的选择更加动态。稍后您将看到如何以正确的工厂方法模式使用名称空间包。
您还应该确保您的本地库像普通包一样可用。如上所述,可以通过从正确的目录运行 Python 或者使用
pip安装本地库来实现。在这个例子中,您正在测试如何将一个假冒的第三方包与您的本地包集成在一起。如果
third_party是一个真实的包,那么您可以使用pip从 PyPI 下载它。因为这是不可能的,你可以通过在本地安装third_party来模拟它,就像你在前面的structure例子中所做的那样。或者,您可以修改导入路径。将
third_party和local目录放在同一个文件夹中,然后定制 Python 路径,如下所示:
>>> import sys
>>> sys.path.extend(["third_party", "local"])
>>> from serializers import json, xml, yaml
>>> json
<module 'serializers.json' from 'third_party/serializers/json.py'>
>>> yaml
<module 'serializers.yaml' from 'local/serializers/yaml.py'>
现在,您可以使用所有序列化程序,而不用担心它们是在第三方包中定义的还是在本地定义的。
进口款式指南
Python 风格指南 PEP 8 ,有一些关于导入的建议。和 Python 一样,保持代码的可读性和可维护性是一个重要的考虑因素。以下是如何设计导入样式的一些通用规则:
- 将导入放在文件的顶部。
- 将导入写在单独的行上。
- 将导入组织成组:首先是标准库导入,然后是第三方导入,最后是本地应用程序或库导入。
- 在每个组中按字母顺序排列导入。
- 比起相对进口,更喜欢绝对进口。
- 避免像
from module import *这样的通配符导入。
isort 和 reorder-python-imports 是让你的进口货风格一致的好工具。
下面是一个在真正的 Python 提要阅读器包中的导入部分的例子:
# Standard library imports
import sys
from typing import Dict, List
# Third party imports
import feedparser
import html2text
# Reader imports
from reader import URL
注意这种分组是如何使这个模块的依赖关系变得清晰的:feedparser和html2text需要安装在系统上。您通常可以假设标准库是可用的。将导入从包中分离出来,可以让您对代码的内部依赖关系有所了解。
在有些情况下,稍微变通一下这些规则是有道理的。您已经看到了相对导入可以作为组织包层次结构的替代方法。稍后,您将看到在某些情况下,如何将导入转移到函数定义中,以打破导入循环。
资源进口
有时你会有依赖于数据文件或其他资源的代码。在小脚本中,这不是问题——您可以指定数据文件的路径并继续!
但是,如果资源文件对您的包很重要,并且您想将您的包分发给其他用户,那么将会出现一些挑战:
-
您无法控制资源的路径,因为这取决于您的用户的设置以及软件包的分发和安装方式。您可以尝试根据您的包的
__file__或__path__属性来找出资源路径,但是这可能并不总是像预期的那样工作。 -
您的包可能驻留在一个 ZIP 文件或一个旧的
.egg文件中,在这种情况下,资源甚至不会是用户系统上的一个物理文件。
已经有几种尝试来解决这些挑战,包括 setuptools.pkg_resources 。然而,随着在 Python 3.7 的标准库中引入了importlib.resources,现在有了一种处理资源文件的标准方式。
importlib.resources简介
importlib.resources 授予对包内资源的访问权。在这个上下文中,资源是位于可导入包中的任何文件。该文件可能对应于也可能不对应于文件系统上的物理文件。
这有几个好处。通过重用导入系统,您可以获得一种更一致的方式来处理包内的文件。它还使您更容易访问其他包中的资源文件。文档很好地总结了这一点:
如果您可以导入包,则可以访问该包中的资源。(来源)
importlib.resources成为 Python 3.7 中标准库的一部分。然而,在旧版本的 Python 中,一个反向端口可以作为importlib_resources 使用。要使用背面端口,请从 PyPI 安装:
$ python -m pip install importlib_resources
反向端口与 Python 2.7 以及 Python 3.4 和更高版本兼容。
使用importlib.resources时有一个要求:你的资源文件必须在一个常规包中可用。不支持命名空间包。实际上,这意味着文件必须在包含一个__init__.py文件的目录中。
作为第一个例子,假设您在一个包中有个资源,如下所示:
books/
│
├── __init__.py
├── alice_in_wonderland.png
└── alice_in_wonderland.txt
__init__.py只是将books指定为常规包所必需的空文件。
然后,您可以使用open_text()和open_binary()分别打开文本和二进制文件:
>>> from importlib import resources >>> with resources.open_text("books", "alice_in_wonderland.txt") as fid: ... alice = fid.readlines() ... >>> print("".join(alice[:7])) CHAPTER I. Down the Rabbit-Hole Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, 'and what is the use of a book,' thought Alice 'without pictures or conversations?' >>> with resources.open_binary("books", "alice_in_wonderland.png") as fid: ... cover = fid.read() ... >>> cover[:8] # PNG file signature b'\x89PNG\r\n\x1a\n'
open_text()和open_binary()相当于内置的open(),其中mode参数分别设置为rt和rb。直接读取文本或二进制文件的方便函数还有read_text()和read_binary()。更多信息参见官方文档。注意:要无缝地回退到在旧的 Python 版本上使用 backport,您可以如下导入
importlib.resources:try: from importlib import resources except ImportError: import importlib_resources as resources更多信息参见本教程的提示和技巧章节。
本节的其余部分将展示一些在实践中使用资源文件的详细示例。
示例:使用数据文件
作为使用数据文件的一个更完整的例子,您将看到如何实现一个基于联合国人口数据的测验程序。首先,创建一个
data包,从联合国网页下载WPP2019_TotalPopulationBySex.csv:data/ │ ├── __init__.py └── WPP2019_TotalPopulationBySex.csv打开 CSV 文件并查看数据:
LocID,Location,VarID,Variant,Time,PopMale,PopFemale,PopTotal,PopDensity 4,Afghanistan,2,Medium,1950,4099.243,3652.874,7752.117,11.874 4,Afghanistan,2,Medium,1951,4134.756,3705.395,7840.151,12.009 4,Afghanistan,2,Medium,1952,4174.45,3761.546,7935.996,12.156 4,Afghanistan,2,Medium,1953,4218.336,3821.348,8039.684,12.315 ...每一行包含一个国家某一年和某一变量的人口,这表明预测使用的是哪一种情景。该文件包含了到 2100 年的人口预测。
以下函数读取该文件,并挑选出给定
year和variant的每个国家的总人口:import csv from importlib import resources def read_population_file(year, variant="Medium"): population = {} print(f"Reading population data for {year}, {variant} scenario") with resources.open_text( "data", "WPP2019_TotalPopulationBySex.csv" ) as fid: rows = csv.DictReader(fid) # Read data, filter the correct year for row in rows: if row["Time"] == year and row["Variant"] == variant: pop = round(float(row["PopTotal"]) * 1000) population[row["Location"]] = pop return population突出显示的行显示了如何使用
importlib.resources打开数据文件。有关使用 CSV 文件的更多信息,请查看在 Python 中读写 CSV 文件。上面的函数返回一个包含人口数量的字典:
>>> population = read_population_file("2020")
Reading population data for 2020, Medium scenario
>>> population["Norway"]
5421242
使用这个人口字典,您可以做许多有趣的事情,包括分析和可视化。在这里,您将创建一个问答游戏,要求用户识别集合中哪个国家人口最多。玩这个游戏会是这样的:
$ python population_quiz.py
Question 1:
1\. Tunisia
2\. Djibouti
3\. Belize
Which country has the largest population? 1 Yes, Tunisia is most populous (11,818,618)
Question 2:
1\. Mozambique
2\. Ghana
3\. Hungary
Which country has the largest population? 2 No, Mozambique (31,255,435) is more populous than Ghana (31,072,945)
...
实现的细节已经超出了本教程的主题,所以这里不再讨论。但是,您可以展开下面的部分来查看完整的源代码。
人口测验由两个函数组成,一个函数像上面一样读取人口数据,另一个函数运行实际测验:
1# population_quiz.py
2
3import csv
4import random
5
6try:
7 from importlib import resources
8except ImportError:
9 import importlib_resources as resources
10
11def read_population_file(year, variant="Medium"):
12 """Read population data for the given year and variant"""
13 population = {}
14
15 print(f"Reading population data for {year}, {variant} scenario")
16 with resources.open_text(
17 "data", "WPP2019_TotalPopulationBySex.csv"
18 ) as fid:
19 rows = csv.DictReader(fid)
20
21 # Read data, filter the correct year
22 for row in rows:
23 if (
24 int(row["LocID"]) < 900
25 and row["Time"] == year
26 and row["Variant"] == variant
27 ):
28 pop = round(float(row["PopTotal"]) * 1000)
29 population[row["Location"]] = pop
30
31 return population
32
33def run_quiz(population, num_questions, num_countries):
34 """Run a quiz about the population of countries"""
35 num_correct = 0
36 for q_num in range(num_questions):
37 print(f"\n\nQuestion {q_num + 1}:")
38 countries = random.sample(population.keys(), num_countries)
39 print("\n".join(f"{i}. {a}" for i, a in enumerate(countries, start=1)))
40
41 # Get user input
42 while True:
43 guess_str = input("\nWhich country has the largest population? ")
44 try:
45 guess_idx = int(guess_str) - 1
46 guess = countries[guess_idx]
47 except (ValueError, IndexError):
48 print(f"Please answer between 1 and {num_countries}")
49 else:
50 break
51
52 # Check the answer
53 correct = max(countries, key=lambda k: population[k])
54 if guess == correct:
55 num_correct += 1
56 print(f"Yes, {guess} is most populous ({population[guess]:,})")
57 else:
58 print(
59 f"No, {correct} ({population[correct]:,}) is more populous "
60 f"than {guess} ({population[guess]:,})"
61 )
62
63 return num_correct
64
65def main():
66 """Read population data and run quiz"""
67 population = read_population_file("2020")
68 num_correct = run_quiz(population, num_questions=10, num_countries=3)
69 print(f"\nYou answered {num_correct} questions correctly")
70
71if __name__ == "__main__":
72 main()
请注意,在行 24 上,您还要检查LocID是否小于900。具有900及以上的LocID的位置不是适当的国家,而是像World、Asia等的集合。
示例:向 Tkinter GUIs 添加图标
在构建图形用户界面(GUI)时,您通常需要包含图标之类的资源文件。下面的例子展示了如何使用importlib.resources实现这一点。最终的应用程序看起来很简单,但它会有一个自定义图标,以及一个关于再见按钮的插图:
这个例子使用了 Tkinter ,这是一个在标准库中可用的 GUI 包。它基于最初为 Tcl 编程语言开发的 Tk 窗口系统。Python 还有许多其他的 GUI 包。如果你用的是不同的,那么你应该能够使用类似这里介绍的想法给你的应用添加图标。
在 Tkinter 中,图像由 PhotoImage类处理。要创建一个PhotoImage,需要传递一个图像文件的路径。
请记住,在分发您的包时,您甚至不能保证资源文件将作为物理文件存在于文件系统中。importlib.resources通过提供path()来解决这个问题。这个函数将返回一个路径到资源文件,如果需要的话创建一个临时文件。
为了确保所有临时文件都被正确清理,您应该使用关键字with将path()用作上下文管理器:
>>> from importlib import resources >>> with resources.path("hello_gui.gui_resources", "logo.png") as path: ... print(path) ... /home/gahjelle/hello_gui/gui_resources/logo.png对于完整的示例,假设您有以下文件层次结构:
hello_gui/ │ ├── gui_resources/ │ ├── __init__.py │ ├── hand.png │ └── logo.png │ └── __main__.py如果您想亲自尝试这个示例,那么您可以通过单击下面的链接下载这些文件以及本教程中使用的其余源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用来了解 Python 导入系统。
代码存储在一个特殊名称为
__main__.py的文件中。此名称表明该文件是包的入口点。拥有一个__main__.py文件可以让你的包用python -m执行:$ python -m hello_gui关于使用
-m调用包的更多信息,请参见如何将开源 Python 包发布到 PyPI 。GUI 在一个名为
Hello的类中定义。注意,您使用importlib.resources来获取图像文件的路径:1# hello_gui/__main__.py 2 3import tkinter as tk 4from tkinter import ttk 5 6try: 7 from importlib import resources 8except ImportError: 9 import importlib_resources as resources 10 11class Hello(tk.Tk): 12 def __init__(self, *args, **kwargs): 13 super().__init__(*args, **kwargs) 14 self.wm_title("Hello") 15 16 # Read image, store a reference to it, and set it as an icon 17 with resources.path("hello_gui.gui_resources", "logo.png") as path: 18 self._icon = tk.PhotoImage(file=path) 19 self.iconphoto(True, self._icon) 20 21 # Read image, create a button, and store a reference to the image 22 with resources.path("hello_gui.gui_resources", "hand.png") as path: 23 hand = tk.PhotoImage(file=path) 24 button = ttk.Button( 25 self, 26 image=hand, 27 text="Goodbye", 28 command=self.quit, 29 compound=tk.LEFT, # Add the image to the left of the text 30 ) 31 button._image = hand 32 button.pack(side=tk.TOP, padx=10, pady=10) 33 34if __name__ == "__main__": 35 hello = Hello() 36 hello.mainloop()如果你想了解更多关于用 Tkinter 构建 GUI 的知识,那么请查看用 Tkinter 进行 Python GUI 编程的。官方文档也有一个不错的资源列表,TkDocs 上的教程是另一个展示如何在其他语言中使用 Tk 的很好的资源。
注意:在 Tkinter 中处理图像时,困惑和沮丧的一个来源是您必须确保图像没有被垃圾收集。由于 Python 和 Tk 交互的方式,Python 中的垃圾收集器(至少在 CPython 中)不会注册图像被
.iconphoto()和Button使用。为了确保图像被保留,您应该手动添加对它们的引用。你可以在上面代码的第 18 行和第 31 行中看到这样的例子。
动态导入
Python 的定义特性之一是它是一种非常动态的语言。尽管有时这是个坏主意,但在 Python 程序运行时,你可以对它做很多事情,包括给类添加属性、重定义方法或更改模块的 docstring 。例如,您可以更改
print(),使其不做任何事情:
>>> print("Hello dynamic world!")
Hello dynamic world!
>>> # Redefine the built-in print()
>>> print = lambda *args, **kwargs: None
>>> print("Hush, everybody!")
>>> # Nothing is printed
从技术上讲,你没有重新定义print()。相反,你定义了另一个 print()的,它隐藏了内置的那个。要返回使用原来的print(),你可以用del print删除你的自定义。如果您愿意,您可以隐藏任何内置于解释器中的 Python 对象。
注意:在上面的例子中,你使用 lambda 函数重新定义了print()。您也可以使用普通的函数定义:
>>> def print(*args, **kwargs): ... pass要了解 lambda 函数的更多信息,请参见如何使用 Python Lambda 函数。
在本节中,您将学习如何在 Python 中进行动态导入。有了它们,在程序运行之前,您不必决定导入什么。
使用
importlib到目前为止,您已经使用 Python 的
import关键字显式地导入了模块和包。然而,整个导入机制在importlib包中是可用的,这允许您更动态地进行导入。以下脚本要求用户输入模块的名称,导入该模块,并打印其 docstring:# docreader.py import importlib module_name = input("Name of module? ") module = importlib.import_module(module_name) print(module.__doc__)
import_module()返回一个可以绑定到任何变量的模块对象。然后,您可以将该变量视为定期导入的模块。您可以像这样使用脚本:$ python docreader.py Name of module? math This module is always available. It provides access to the mathematical functions defined by the C standard. $ python docreader.py Name of module? csv CSV parsing and writing. This module provides classes that assist in the reading and writing of Comma Separated Value (CSV) files, and implements the interface described by PEP 305\. Although many CSV files are simple to parse, the format is not formally defined by a stable specification and is subtle enough that parsing lines of a CSV file with something like line.split(",") is bound to fail. The module supports three basic APIs: reading, writing, and registration of dialects. [...]在每种情况下,模块都是由
import_module()动态导入的。示例:带有名称空间包的工厂方法
回想一下前面的序列化器示例。通过将
serializers实现为名称空间包,您可以添加定制的序列化程序。在之前教程的原始示例中,序列化器是通过序列化器工厂提供的。使用importlib,可以做类似的事情。将以下代码添加到本地
serializers名称空间包中:# local/serializers/factory.py import importlib def get_serializer(format): try: module = importlib.import_module(f"serializers.{format}") serializer = getattr(module, f"{format.title()}Serializer") except (ImportError, AttributeError): raise ValueError(f"Unknown format {format!r}") from None return serializer() def serialize(serializable, format): serializer = get_serializer(format) serializable.serialize(serializer) return str(serializer)
get_serializer()工厂可以基于format参数动态地创建序列化器,然后serialize()可以将序列化器应用于任何实现了.serialize()方法的对象。工厂对包含单个序列化程序的模块和类的命名做了一些强有力的假设。在下一节的中,您将了解一个允许更多灵活性的插件架构。
现在,您可以重新创建前面的示例,如下所示:
>>> from serializers import factory
>>> from song import Song
>>> song = Song(song_id="1", title="The Same River", artist="Riverside")
>>> factory.serialize(song, "json")
'{"id": "1", "title": "The Same River", "artist": "Riverside"}'
>>> factory.serialize(song, "yaml")
"artist: Riverside, id: '1', title: The Same River\n"
>>> factory.serialize(song, "toml")
ValueError: Unknown format 'toml'
在这种情况下,您不再需要显式导入每个序列化程序。相反,您可以用字符串指定序列化程序的名称。该字符串甚至可以由用户在运行时选择。
注意:在一个普通的包中,你可能已经在一个__init__.py文件中实现了get_serializer()和serialize()。这将允许您简单地导入serializers,然后调用serializers.serialize()。
然而,名称空间包不允许使用__init__.py,所以您需要在一个单独的模块中实现这些函数。
最后一个例子表明,如果您试图序列化为尚未实现的格式,也会得到一个适当的错误消息。
例子:一个插件包
让我们看另一个使用动态导入的例子。你可以使用下面的模块在你的代码中建立一个灵活的插件架构。这类似于前面的例子,在这个例子中,您可以通过添加新的模块来插入不同格式的序列化程序。
一个有效使用插件的应用是 Glue 探索可视化工具。Glue 可以开箱读取许多不同的数据格式。然而,如果您的数据格式不受支持,那么您可以编写自己的定制数据加载器。
您可以通过添加一个函数来实现这一点,您可以装饰该函数并将其放置在一个特殊的位置,以便 Glue 可以轻松找到它。你不需要修改 Glue 源代码的任何部分。参见文档了解所有细节。
您可以建立一个类似的插件架构,并在自己的项目中使用。在该架构中,有两个级别:
- 插件包是一个 Python 包对应的相关插件的集合。
- 插件是 Python 模块中可用的自定义行为。
公开插件架构的plugins模块有以下功能:
# plugins.py
def register(func):
"""Decorator for registering a new plugin"""
def names(package):
"""List all plugins in one package"""
def get(package, plugin):
"""Get a given plugin"""
def call(package, plugin, *args, **kwargs):
"""Call the given plugin"""
def _import(package, plugin):
"""Import the given plugin file from a package"""
def _import_all(package):
"""Import all plugins in a package"""
def names_factory(package):
"""Create a names() function for one package"""
def get_factory(package):
"""Create a get() function for one package"""
def call_factory(package):
"""Create a call() function for one package"""
工厂函数用于方便地向插件包添加功能。您将很快看到一些如何使用它们的例子。
查看这段代码的所有细节超出了本教程的范围。如果您感兴趣,那么您可以通过展开下面的部分来查看实现。
以下代码显示了上述plugins.py的实现:
# plugins.py
import functools
import importlib
from collections import namedtuple
from importlib import resources
# Basic structure for storing information about one plugin
Plugin = namedtuple("Plugin", ("name", "func"))
# Dictionary with information about all registered plugins
_PLUGINS = {}
def register(func):
"""Decorator for registering a new plugin"""
package, _, plugin = func.__module__.rpartition(".")
pkg_info = _PLUGINS.setdefault(package, {})
pkg_info[plugin] = Plugin(name=plugin, func=func)
return func
def names(package):
"""List all plugins in one package"""
_import_all(package)
return sorted(_PLUGINS[package])
def get(package, plugin):
"""Get a given plugin"""
_import(package, plugin)
return _PLUGINS[package][plugin].func
def call(package, plugin, *args, **kwargs):
"""Call the given plugin"""
plugin_func = get(package, plugin)
return plugin_func(*args, **kwargs)
def _import(package, plugin):
"""Import the given plugin file from a package"""
importlib.import_module(f"{package}.{plugin}")
def _import_all(package):
"""Import all plugins in a package"""
files = resources.contents(package)
plugins = [f[:-3] for f in files if f.endswith(".py") and f[0] != "_"]
for plugin in plugins:
_import(package, plugin)
def names_factory(package):
"""Create a names() function for one package"""
return functools.partial(names, package)
def get_factory(package):
"""Create a get() function for one package"""
return functools.partial(get, package)
def call_factory(package):
"""Create a call() function for one package"""
return functools.partial(call, package)
这个实现有点简单。特别是,它不做任何显式的错误处理。查看 PyPlugs 项目以获得更完整的实现。
可以看到_import()使用importlib.import_module()动态加载插件。此外,_import_all()使用importlib.resources.contents()列出给定软件包中所有可用的插件。
让我们看一些如何使用插件的例子。第一个例子是一个greeter包,你可以用它给你的应用程序添加许多不同的问候。对于这个例子来说,一个完整的插件架构无疑是多余的,但是它展示了插件是如何工作的。
假设您有以下greeter包:
greeter/
│
├── __init__.py
├── hello.py
├── howdy.py
└── yo.py
每个greeter模块定义了一个接受一个name参数的函数。注意它们是如何使用@register装饰器注册为插件的:
# greeter/hello.py
import plugins
@plugins.register
def greet(name):
print(f"Hello {name}, how are you today?")
# greeter/howdy.py
import plugins
@plugins.register
def greet(name):
print(f"Howdy good {name}, honored to meet you!")
# greeter/yo.py
import plugins
@plugins.register
def greet(name):
print(f"Yo {name}, good times!")
要了解更多关于 decorator 及其用法的信息,请查看 Python Decorators 的初级读本。
注意:为了简化插件的发现和导入,每个插件的名字都是基于包含它的模块的名字而不是函数名。这限制了每个文件只能有一个插件。
要完成将greeter设置为插件包,你可以使用plugins中的工厂函数给greeter包本身添加功能:
# greeter/__init__.py
import plugins
greetings = plugins.names_factory(__package__)
greet = plugins.call_factory(__package__)
您现在可以如下使用greetings()和greet():
>>> import greeter >>> greeter.greetings() ['hello', 'howdy', 'yo'] >>> greeter.greet(plugin="howdy", name="Guido") Howdy good Guido, honored to meet you!注意
greetings()会自动发现包中所有可用的插件。您还可以更动态地选择调用哪个插件。在下面的例子中,你随机选择一个插件。但是,您也可以根据配置文件或用户输入来选择插件:
>>> import greeter
>>> import random
>>> greeting = random.choice(greeter.greetings())
>>> greeter.greet(greeting, name="Frida")
Hello Frida, how are you today?
>>> greeting = random.choice(greeter.greetings())
>>> greeter.greet(greeting, name="Frida")
Yo Frida, good times!
要发现和调用不同的插件,您需要导入它们。让我们快速看一下plugins是如何处理进口的。主要工作在plugins.py内部的以下两个函数中完成:
import importlib
import pathlib
from importlib import resources
def _import(package, plugin):
"""Import the given plugin file from a package"""
importlib.import_module(f"{package}.{plugin}")
def _import_all(package):
"""Import all plugins in a package"""
files = resources.contents(package)
plugins = [f[:-3] for f in files if f.endswith(".py") and f[0] != "_"]
for plugin in plugins:
_import(package, plugin)
看起来似乎很简单。它使用importlib来导入一个模块。但是后台也发生了一些事情:
- Python 的导入系统确保每个插件只导入一次。
- 每个插件模块内部定义的装饰器注册每个导入的插件。
- 在一个完整的实现中,还会有一些错误处理来处理丢失的插件。
发现软件包中的所有插件。它是这样工作的:
contents()fromimportlib.resources列出了一个包中的所有文件。- 过滤结果以找到潜在的插件。
- 每个不以下划线开头的 Python 文件都会被导入。
- 发现并注册任何文件中的插件。
让我们以序列化器名称空间包的最终版本来结束这一节。一个突出的问题是,get_serializer()工厂对序列化类的命名做了强有力的假设。您可以使用插件使其更加灵活。
首先,添加一行注册每个序列化程序的代码。下面是一个在yaml序列化器中如何实现的例子:
# local/serializers/yaml.py
import plugins import yaml
from serializers.json import JsonSerializer
@plugins.register class YamlSerializer(JsonSerializer):
def __str__(self):
return yaml.dump(self._current_object)
接下来,更新get_serializers()以使用plugins:
# local/serializers/factory.py
import plugins
get_serializer = plugins.call_factory(__package__)
def serialize(serializable, format):
serializer = get_serializer(format)
serializable.serialize(serializer)
return str(serializer)
您使用call_factory()实现get_serializer(),因为这将自动实例化每个序列化程序。通过这种重构,序列化器的工作方式与前面的一样。但是,在命名序列化程序类时,您有更大的灵活性。
有关使用插件的更多信息,请查看 PyPI 上的 PyPlugs 和来自 PyCon 2019 的插件:为您的应用添加灵活性演示。
Python 导入系统
您已经看到了许多利用 Python 导入系统的方法。在这一节中,您将了解更多关于导入模块和包时幕后发生的事情。
与 Python 的大多数部分一样,导入系统可以定制。您将看到几种改变导入系统的方法,包括从 PyPI 自动下载缺失的包,以及像导入模块一样导入数据文件。
导入内部零件
官方文档中描述了 Python 导入系统的细节。在高层次上,当您导入一个模块(或者包)时,会发生三件事情。该模块是:
- 搜索
- 装载的;子弹上膛的
- 绑定到命名空间
对于通常的导入——用import语句完成的导入——所有三个步骤都是自动进行的。然而,当您使用importlib时,只有前两步是自动的。您需要自己将模块绑定到变量或名称空间。
例如,以下导入和重命名math.pi的方法大致相同:
>>> from math import pi as PI >>> PI 3.141592653589793 >>> import importlib >>> _tmp = importlib.import_module("math") >>> PI = _tmp.pi >>> del _tmp >>> PI 3.141592653589793当然,在普通代码中,您应该更喜欢前者。
需要注意的一点是,即使只从一个模块中导入一个属性,也会加载并执行整个模块。模块的其余内容并没有绑定到当前的名称空间。证明这一点的一个方法是看看所谓的模块缓存:
>>> from math import pi
>>> pi
3.141592653589793
>>> import sys
>>> sys.modules["math"].cos(pi)
-1.0
sys.modules充当模块缓存。它包含对所有已导入模块的引用。
模块缓存在 Python 导入系统中起着非常重要的作用。Python 在执行导入时首先会在sys.modules中寻找模块。如果一个模块已经可用,那么它不会被再次加载。
这是一个很好的优化,但也是必要的。如果模块在每次导入时都被重新加载,那么在某些情况下可能会导致不一致,比如在脚本运行时底层源代码发生了变化。
回想一下您之前看到的导入路径。它实际上告诉 Python 在哪里搜索模块。但是,如果 Python 在模块缓存中找到了一个模块,那么它就不会费心搜索模块的导入路径。
示例:作为模块的单件
在面向对象编程中, singleton 是一个最多有一个实例的类。虽然在 Python 中实现单例是可能的,但是单例的大多数良好应用可以由模块来处理。您可以相信模块缓存只能实例化一个类一次。
举个例子,让我们回到你之前看到的联合国人口数据。下面的模块定义了一个包装人口数据的类:
# population.py
import csv
from importlib import resources
import matplotlib.pyplot as plt
class _Population:
def __init__(self):
"""Read the population file"""
self.data = {}
self.variant = "Medium"
print(f"Reading population data for {self.variant} scenario")
with resources.open_text(
"data", "WPP2019_TotalPopulationBySex.csv"
) as fid:
rows = csv.DictReader(fid)
# Read data, filter the correct variant
for row in rows:
if int(row["LocID"]) >= 900 or row["Variant"] != self.variant:
continue
country = self.data.setdefault(row["Location"], {})
population = float(row["PopTotal"]) * 1000
country[int(row["Time"])] = round(population)
def get_country(self, country):
"""Get population data for one country"""
data = self.data[country]
years, population = zip(*data.items())
return years, population
def plot_country(self, country):
"""Plot data for one country, population in millions"""
years, population = self.get_country(country)
plt.plot(years, [p / 1e6 for p in population], label=country)
def order_countries(self, year):
"""Sort countries by population in decreasing order"""
countries = {c: self.data[c][year] for c in self.data}
return sorted(countries, key=lambda c: countries[c], reverse=True)
# Instantiate the Singleton
data = _Population()
从磁盘读取数据需要一些时间。因为您不希望数据文件发生变化,所以在加载模块时实例化该类。类名以下划线开头,以向用户表明他们不应该使用它。
您可以使用population.data singleton 创建一个 Matplotlib 图表,显示人口最多的国家的人口预测:
>>> import matplotlib.pyplot as plt >>> import population Reading population data for Medium scenario >>> # Pick out five most populous countries in 2050 >>> for country in population.data.order_countries(2050)[:5]: ... population.data.plot_country(country) ... >>> plt.legend() >>> plt.xlabel("Year") >>> plt.ylabel("Population [Millions]") >>> plt.title("UN Population Projections") >>> plt.show()这将创建如下所示的图表:
注意,在导入时加载数据是一种反模式。理想情况下,你希望你的进口产品尽可能没有副作用。更好的方法是在需要时延迟加载数据。您可以使用属性非常优雅地做到这一点。展开以下部分查看示例。
第一次读取人口数据时,
population的惰性实现将人口数据存储在._data中。.data属性处理数据的缓存:# population.py import csv from importlib import resources import matplotlib.pyplot as plt class _Population: def __init__(self): """Prepare to read the population file""" self._data = {} self.variant = "Medium" @property def data(self): """Read data from disk""" if self._data: # Data has already been read, return it directly return self._data # Read data and store it in self._data print(f"Reading population data for {self.variant} scenario") with resources.open_text( "data", "WPP2019_TotalPopulationBySex.csv" ) as fid: rows = csv.DictReader(fid) # Read data, filter the correct variant for row in rows: if int(row["LocID"]) >= 900 or row["Variant"] != self.variant: continue country = self._data.setdefault(row["Location"], {}) population = float(row["PopTotal"]) * 1000 country[int(row["Time"])] = round(population) return self._data def get_country(self, country): """Get population data for one country""" country = self.data[country] years, population = zip(*country.items()) return years, population def plot_country(self, country): """Plot data for one country, population in millions""" years, population = self.get_country(country) plt.plot(years, [p / 1e6 for p in population], label=country) def order_countries(self, year): """Sort countries by population in decreasing order""" countries = {c: self.data[c][year] for c in self.data} return sorted(countries, key=lambda c: countries[c], reverse=True) # Instantiate the singleton data = _Population()现在数据不会在导入时加载。相反,它将在您第一次访问
_Population.data字典时被导入。关于属性的更多信息和描述符的更一般的概念,参见 Python 描述符:简介。重新加载模块
当您在交互式解释器中工作时,模块缓存可能会有点令人沮丧。在你改变一个模块之后,重新加载它并不是一件小事。例如,看一下下面的模块:
# number.py answer = 24作为测试和调试该模块的一部分,您可以在 Python 控制台中导入它:
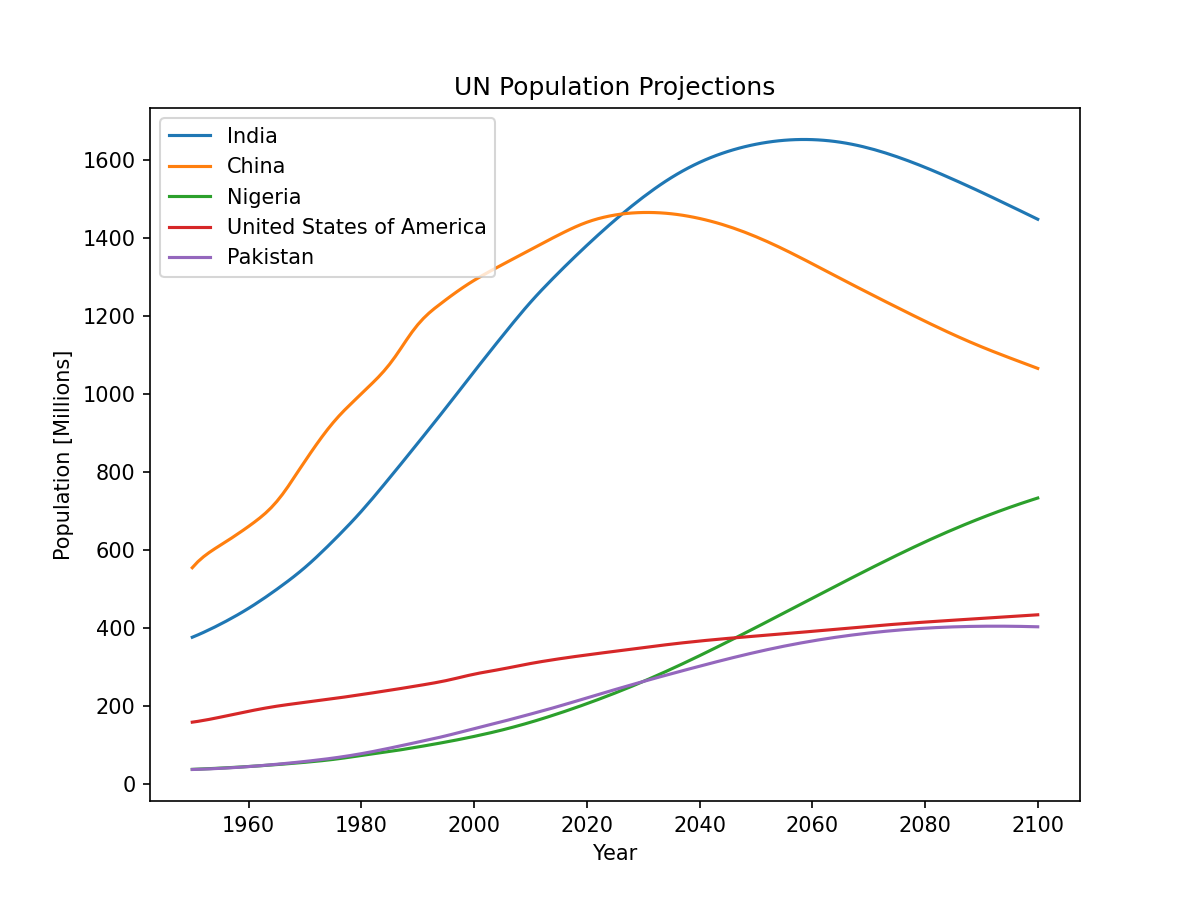
>>> import number
>>> number.answer
24
假设您意识到您的代码中有一个 bug,所以您在编辑器中更新了number.py文件:
# number.py
answer = 42
返回到控制台,导入更新的模块以查看修复的效果:
>>> import number >>> number.answer 24为什么答案还是
24?模块缓存正在发挥它的(现在令人沮丧的)魔力:因为 Python 早些时候导入了number,所以它认为没有理由再次加载模块,即使您只是更改了它。对此最直接的解决方案是退出 Python 控制台并重新启动它。这也迫使 Python 清除其模块缓存:
>>> import number
>>> number.answer
42
然而,重启解释器并不总是可行的。你可能在一个更复杂的会话中,花了你很长时间来设置。如果是这种情况,那么你可以用 importlib.reload() 来重新加载一个模块来代替:
>>> import number >>> number.answer 24 >>> # Update number.py in your editor >>> import importlib >>> importlib.reload(number) <module 'number' from 'number.py'> >>> number.answer 42注意,
reload()需要一个模块对象,而不是像import_module()那样需要一个字符串。另外,请注意reload()有一些警告。特别是,当模块重新加载时,引用模块内对象的变量不会重新绑定到新对象。详见文档。发现者和装载者
您之前已经看到创建与标准库同名的模块会产生问题。例如,如果在 Python 的导入路径中有一个名为
math.py的文件,那么您将无法从标准库中导入math。然而,情况并非总是如此。用以下内容创建一个名为
time.py的文件:# time.py print("Now's the time!")接下来,打开 Python 解释器并导入这个新模块:
>>> import time
>>> # Nothing is printed
>>> time.ctime()
'Mon Jun 15 14:26:12 2020'
>>> time.tzname
('CET', 'CEST')
奇怪的事情发生了。Python 好像没有导入你的新time模块。而是从标准库中导入了 time模块。为什么标准库模块的行为不一致?您可以通过检查模块获得提示:
>>> import math >>> math <module 'math' from '.../python/lib/python3.8/lib-dynload/math.cpython.so'> >>> import time >>> time <module 'time' (built-in)>您可以看到
math是从一个文件导入的,而time是某种内置模块。似乎内置模块不会被本地模块遮蔽。注意:内置模块编译成 Python 解释器。通常,它们是基础模块,如
builtins、sys和time。内置哪些模块取决于您的 Python 解释器,但是您可以在sys.builtin_module_names中找到它们的名称。让我们更深入地研究 Python 的导入系统。这也将展示为什么内置模块不会被本地模块遮蔽。导入模块时涉及几个步骤:
Python 检查模块是否在模块缓存中可用。如果
sys.modules包含模块名,那么模块已经可用,导入过程结束。Python 使用几个查找器开始查找模块。查找器将使用给定的策略搜索模块。默认的查找器可以导入内置模块、冻结模块和导入路径上的模块。
Python 使用加载器加载模块。Python 使用哪个加载器由定位模块的查找器决定,并在一个叫做模块规范的东西中指定。
您可以通过实现自己的查找器来扩展 Python 导入系统,如果有必要,还可以实现自己的加载器。稍后您将看到一个更有用的 finder 示例。现在,您将学习如何对导入系统进行基本的(也可能是愚蠢的)定制。
sys.meta_path控制在导入过程中调用哪些查找器:
>>> import sys
>>> sys.meta_path
[<class '_frozen_importlib.BuiltinImporter'>,
<class '_frozen_importlib.FrozenImporter'>,
<class '_frozen_importlib_external.PathFinder'>]
首先,请注意,这回答了前面的问题:内置模块不会被本地模块隐藏,因为内置查找器在查找本地模块的导入路径查找器之前被调用。第二,注意你可以根据自己的喜好定制sys.meta_path。
要快速弄乱您的 Python 会话,您可以删除所有查找器:
>>> import sys >>> sys.meta_path.clear() >>> sys.meta_path [] >>> import math Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'math' >>> import importlib # Autoimported at start-up, still in the module cache >>> importlib <module 'importlib' from '.../python/lib/python3.8/importlib/__init__.py'>由于没有查找器,Python 无法找到或导入新模块。然而,Python 仍然可以导入已经在模块缓存中的模块,因为它在调用任何查找器之前会在那里查找。
在上面的例子中,在您清除查找器列表之前,
importlib已经被加载。如果您真的想让您的 Python 会话完全不可用,那么您也可以清除模块缓存,sys.modules。下面是一个稍微有用的例子。您将编写一个 finder,向控制台打印一条消息,标识正在导入的模块。该示例显示了如何添加您自己的查找器,尽管它实际上并不试图查找模块:
1# debug_importer.py 2 3import sys 4 5class DebugFinder: 6 @classmethod 7 def find_spec(cls, name, path, target=None): 8 print(f"Importing {name!r}") 9 return None 10 11sys.meta_path.insert(0, DebugFinder)所有的查找器必须实现一个
.find_spec()类方法,它应该尝试查找一个给定的模块。有三种方式可以终止.find_spec():
- 如果不知道如何找到并加载模块,通过返回
None- 通过返回指定如何加载模块的模块规范
- 通过升高
ModuleNotFoundError来表示该模块不能被导入
DebugFinder将一条消息打印到控制台,然后显式返回None来指示其他发现程序应该弄清楚如何实际导入该模块。注意:由于 Python 隐式从任何没有显式
return的函数或方法返回None,所以可以省去第 9 行。然而,在这种情况下,最好包含return None来表明DebugFinder没有找到模块。通过在查找器列表中首先插入
DebugFinder,您将获得所有正在导入的模块的运行列表:
>>> import debug_importer
>>> import csv
Importing 'csv'
Importing 're'
Importing 'enum'
Importing 'sre_compile'
Importing '_sre'
Importing 'sre_parse'
Importing 'sre_constants'
Importing 'copyreg'
Importing '_csv'
例如,您可以看到导入csv触发了csv所依赖的其他几个模块的导入。请注意,Python 解释器的详细选项python -v给出了相同的信息以及更多的信息。
再举一个例子,假设你正在寻求消除世界上的正则表达式。(现在,为什么会想要这样的东西?正则表达式很棒!)您可以实现下面的查找器,它禁止使用 re正则表达式模块:
# ban_importer.py
import sys
BANNED_MODULES = {"re"}
class BanFinder:
@classmethod
def find_spec(cls, name, path, target=None):
if name in BANNED_MODULES:
raise ModuleNotFoundError(f"{name!r} is banned")
sys.meta_path.insert(0, BanFinder)
引发一个ModuleNotFoundError确保查找器列表中后面的查找器都不会被执行。这有效地阻止了您在 Python 中使用正则表达式:
>>> import ban_importer >>> import csv Traceback (most recent call last): File "<stdin>", line 1, in <module> File ".../python/lib/python3.8/csv.py", line 6, in <module> import re File "ban_importer.py", line 11, in find_spec raise ModuleNotFoundError(f"{name!r} is banned") ModuleNotFoundError: 're' is banned即使您只导入了
csv,该模块也在后台导入了re,因此会出现一个错误。示例:从 PyPI 自动安装
因为 Python 导入系统已经非常强大和有用了,所以除了以有用的方式扩展它之外,还有很多方法可以搞乱它。但是,下面的示例在某些情况下会很有用。
Python 包索引 (PyPI)是你寻找第三方模块和包的一站式奶酪店。它也是
pip下载软件包的地方。在其他的 Real Python 教程中,你可能已经看到了使用
python -m pip install来安装你需要的第三方模块和软件包的说明以及例子。让 Python 自动为您安装缺失的模块不是很棒吗?警告:在大多数情况下,让 Python 自动安装模块真的不会很棒。例如,在大多数生产环境中,您希望保持对环境的控制。此外,文档警告不要这样使用
pip。为了避免弄乱 Python 安装,您应该只在不介意删除或重新安装的环境中使用这段代码。
以下查找器尝试使用
pip安装模块:# pip_importer.py from importlib import util import subprocess import sys class PipFinder: @classmethod def find_spec(cls, name, path, target=None): print(f"Module {name!r} not installed. Attempting to pip install") cmd = f"{sys.executable} -m pip install {name}" try: subprocess.run(cmd.split(), check=True) except subprocess.CalledProcessError: return None return util.find_spec(name) sys.meta_path.append(PipFinder)与您之前看到的查找器相比,这个稍微复杂一些。通过将这个查找器放在查找器列表的最后,您知道如果您调用
PipFinder,那么在您的系统上将找不到该模块。因此,.find_spec()的工作只是做pip install。如果安装成功,那么模块规范将被创建并返回。尝试使用
parse库而不用自己安装:
>>> import pip_importer
>>> import parse
Module 'parse' not installed. Attempting to pip install
Collecting parse
Downloading parse-1.15.0.tar.gz (29 kB)
Building wheels for collected packages: parse
Building wheel for parse (setup.py) ... done
Successfully built parse
Installing collected packages: parse
Successfully installed parse-1.15.0
>>> pattern = "my name is {name}"
>>> parse.parse(pattern, "My name is Geir Arne")
<Result () {'name': 'Geir Arne'}>
正常情况下,import parse会引发一个ModuleNotFoundError,但是在这种情况下,parse被安装并导入。
虽然PipFinder看似可行,但这种方法存在一些挑战。一个主要问题是模块的导入名称并不总是对应于它在 PyPI 上的名称。比如 真正的 Python feed 阅读器在 PyPI 上被称为realpython-reader,但导入名却简单的叫reader。
使用PipFinder来导入和安装reader最终会安装错误的包:
>>> import pip_importer >>> import reader Module 'reader' not installed. Attempting to pip install Collecting reader Downloading reader-1.2-py3-none-any.whl (68 kB) ...这可能会给你的项目带来灾难性的后果。
自动安装非常有用的一种情况是当你在云中运行 Python,对环境的控制更加有限,比如当你在谷歌实验室运行 Jupyter 风格的笔记本时。Colab 笔记本环境非常适合进行协作式数据探索。
一个典型的笔记本会安装许多数据科学包,包括 NumPy 、 Pandas 和 Matplotlib ,并且你可以用
pip添加新的包。但是您也可以激活自动安装:
由于
pip_importer在 Colab 服务器上本地不可用,代码被复制到笔记本的第一个单元格中。示例:导入数据文件
本节的最后一个例子是受 Aleksey Bilogur 的伟大博客文章的启发:用 Python 导入几乎任何东西:模块加载器和查找器简介。你已经看到了如何使用
importlib.resources导入数据文件。在这里,您将实现一个可以直接导入 CSV 文件的定制加载器。早些时候,您处理了一个包含人口数据的巨大 CSV 文件。为了使定制加载器示例更易于管理,考虑下面这个更小的
employees.csv文件:name,department,birthday month John Smith,Accounting,November Erica Meyers,IT,March第一行是一个标题,命名了三个字段,接下来的两行数据各包含一个雇员的信息。有关使用 CSV 文件的更多信息,请查看在 Python 中读取和写入 CSV 文件。
本节的目标是编写一个允许您直接导入 CSV 文件的 finder 和 loader,以便您可以编写如下代码:
>>> import csv_importer
>>> import employees
>>> employees.name
('John Smith', 'Erica Meyers')
>>> for row in employees.data:
... print(row["department"])
...
Accounting
IT
>>> for name, month in zip(employees.name, employees.birthday_month):
... print(f"{name} is born in {month}")
...
John Smith is born in November
Erica Meyers is born in March
>>> employees.__file__
'employees.csv'
查找器的工作将是搜索和识别 CSV 文件。加载器的工作是导入 CSV 数据。通常,您可以在一个公共类中实现查找器和相应的加载器。这就是你在这里要采取的方法:
1# csv_importer.py
2
3import csv
4import pathlib
5import re
6import sys
7from importlib.machinery import ModuleSpec
8
9class CsvImporter():
10 def __init__(self, csv_path):
11 """Store path to CSV file"""
12 self.csv_path = csv_path
13
14 @classmethod
15 def find_spec(cls, name, path, target=None):
16 """Look for CSV file"""
17 package, _, module_name = name.rpartition(".")
18 csv_file_name = f"{module_name}.csv"
19 directories = sys.path if path is None else path
20 for directory in directories:
21 csv_path = pathlib.Path(directory) / csv_file_name
22 if csv_path.exists():
23 return ModuleSpec(name, cls(csv_path))
24
25 def create_module(self, spec):
26 """Returning None uses the standard machinery for creating modules"""
27 return None
28
29 def exec_module(self, module):
30 """Executing the module means reading the CSV file"""
31 # Read CSV data and store as a list of rows
32 with self.csv_path.open() as fid:
33 rows = csv.DictReader(fid)
34 data = list(rows)
35 fieldnames = tuple(_identifier(f) for f in rows.fieldnames)
36
37 # Create a dict with each field
38 values = zip(*(row.values() for row in data))
39 fields = dict(zip(fieldnames, values))
40
41 # Add the data to the module
42 module.__dict__.update(fields)
43 module.__dict__["data"] = data
44 module.__dict__["fieldnames"] = fieldnames
45 module.__file__ = str(self.csv_path)
46
47 def __repr__(self):
48 """Nice representation of the class"""
49 return f"{self.__class__.__name__}({str(self.csv_path)!r})"
50
51def _identifier(var_str):
52 """Create a valid identifier from a string
53
54 See https://stackoverflow.com/a/3305731
55 """
56 return re.sub(r"\W|^(?=\d)", "_", var_str)
57
58# Add the CSV importer at the end of the list of finders
59sys.meta_path.append(CsvImporter)
这个例子中有相当多的代码!幸运的是,大部分工作是在.find_spec()和.exec_module()中完成的。让我们更详细地看看它们。
正如您前面看到的,.find_spec()负责查找模块。在本例中,您正在寻找 CSV 文件,因此您创建了一个带有.csv后缀的文件名。name包含导入的模块的全名。比如你用from data import employees,那么name就是data.employees。在这种情况下,文件名将是employees.csv。
对于顶级导入,path将是None。在这种情况下,您将在完整的导入路径中查找 CSV 文件,该路径将包括当前的工作目录。如果你在一个包中导入一个 CSV 文件,那么path将被设置为这个包的路径。如果找到匹配的 CSV 文件,则返回模块规范。这个模块规范告诉 Python 使用CsvImporter加载模块。
CSV 数据由.exec_module()加载。您可以使用标准库中的csv.DictReader来进行文件的实际解析。像 Python 中的大多数东西一样,模块由字典支持。通过将 CSV 数据添加到module.__dict__,您可以将它作为模块的属性使用。
例如,将fieldnames添加到模块字典的第行第 44 上,允许您列出 CSV 文件中的字段名,如下所示:
>>> employees.fieldnames ('name', 'department', 'birthday_month')通常,CSV 字段名称可以包含空格和 Python 属性名称中不允许的其他字符。在将字段作为属性添加到模块之前,您需要使用正则表达式来净化字段名称。这在从线 51 开始的
_identifier()中完成。您可以在上面的
birthday_month字段名称中看到这种效果的示例。如果您查看原始的 CSV 文件,那么您会看到文件头用空格而不是下划线表示birthday month。通过将这个
CsvImporter与 Python 导入系统挂钩,您可以免费获得相当多的功能。例如,模块缓存将确保数据文件只加载一次。导入技巧和窍门
为了完善本教程,您将看到一些关于如何处理不时出现的某些情况的提示。您将看到如何处理丢失的包、循环导入,甚至是存储在 ZIP 文件中的包。
跨 Python 版本处理包
有时,您需要处理根据 Python 版本而具有不同名称的包。您已经看到了一个这样的例子:
importlib.resources从 Python 3.7 开始才可用。在早期版本的 Python 中,需要安装并使用importlib_resources来代替。只要包的不同版本是兼容的,您可以通过用
as重命名包来处理这个问题:try: from importlib import resources except ImportError: import importlib_resources as resources在剩下的代码中,你可以引用
resources,而不用担心你使用的是importlib.resources还是importlib_resources。通常,使用
try...except语句来决定使用哪个版本是最简单的。另一个选择是检查 Python 解释器的版本。但是,如果您需要更新版本号,这可能会增加一些维护成本。您可以将前面的示例重写如下:
import sys if sys.version_info >= (3, 7): from importlib import resources else: import importlib_resources as resources这将在 Python 3.7 和更新版本上使用
importlib.resources,而在旧版本的 Python 上回退到importlib_resources。查看flake8-2020项目,获得关于如何检查哪个 Python 版本正在运行的可靠建议。处理丢失的包:使用替代方案
下面的用例与前面的例子密切相关。假设有一个兼容的包的重新实现。重新实现得到了更好的优化,所以如果它可用的话,您可以使用它。然而,原始包更容易获得,也提供了可接受的性能。
一个这样的例子是
quicktions,它是标准库中fractions的优化版本。您可以像前面处理不同的包名一样处理这些首选项:try: from quicktions import Fraction except ImportError: from fractions import Fraction如果可用,将使用
quicktions,如果不可用,将返回到fractions。另一个类似的例子是 UltraJSON 包,一个超快的 JSON 编码器和解码器,可以用来替代标准库中的
json:try: import ujson as json except ImportError: import json将
ujson重命名为json,就不用担心实际导入的是哪个包了。处理丢失的包:使用模拟代替
第三个相关的例子是添加一个包,它提供了一个很好的特性,而这个特性对你的应用程序来说并不是绝对必要的。同样,这可以通过向您的导入添加
try...except来解决。额外的挑战是,如果可选软件包不可用,您将如何替换它。举个具体的例子,假设您正在使用 Colorama 在控制台中添加彩色文本。Colorama 主要由打印时添加颜色的特殊字符串常量组成:
>>> import colorama
>>> colorama.init(autoreset=True)
>>> from colorama import Back, Fore
>>> Fore.RED
'\x1b[31m'
>>> print(f"{Fore.RED}Hello Color!")
Hello Color!
>>> print(f"{Back.RED}Hello Color!")
Hello Color!
不幸的是,颜色没有在上面的例子中呈现。在您的终端中,它看起来像这样:
在你开始使用 Colorama 颜色之前,你应该打电话给colorama.init()。将autoreset设置为True意味着颜色指令将在字符串结束时自动重置。如果你想一次只给一条线上色,这是一个很有用的设置。
如果你想让所有的输出都是蓝色的,那么你可以让autoreset成为False,并在脚本的开头添加Fore.BLUE。有以下几种颜色可供选择:
>>> from colorama import Fore >>> sorted(c for c in dir(Fore) if not c.startswith("_")) ['BLACK', 'BLUE', 'CYAN', 'GREEN', 'LIGHTBLACK_EX', 'LIGHTBLUE_EX', 'LIGHTCYAN_EX', 'LIGHTGREEN_EX', 'LIGHTMAGENTA_EX', 'LIGHTRED_EX', 'LIGHTWHITE_EX', 'LIGHTYELLOW_EX', 'MAGENTA', 'RED', 'RESET', 'WHITE', 'YELLOW']您还可以使用
colorama.Style来控制文本的样式。您可以在DIM、NORMAL和BRIGHT之间进行选择。最后,
colorama.Cursor提供了控制光标位置的代码。您可以使用它来显示正在运行的脚本的进度或状态。以下示例显示从10开始的倒计时:# countdown.py import colorama from colorama import Cursor, Fore import time colorama.init(autoreset=True) countdown = [f"{Fore.BLUE}{n}" for n in range(10, 0, -1)] countdown.append(f"{Fore.RED}Lift off!") print(f"{Fore.GREEN}Countdown starting:\n") for count in countdown: time.sleep(1) print(f"{Cursor.UP(1)}{count} ")请注意计数器如何保持不变,而不是像通常那样打印在单独的行上:
让我们回到手头的任务上来。对于许多应用程序来说,在控制台输出中添加颜色很酷,但并不重要。为了避免给你的应用程序添加另一个依赖项,你应该只在系统上有 Colorama 时才使用它,如果没有就不要破坏应用程序。
为此,你可以从测试及其对模仿的使用中获得灵感。模拟可以代替另一个对象,同时允许您控制它的行为。这里有一个嘲弄 Colorama 的天真尝试:
>>> from unittest.mock import Mock
>>> colorama = Mock()
>>> colorama.init(autoreset=True)
<Mock name='mock.init()' id='139887544431728'>
>>> Fore = Mock()
>>> Fore.RED
<Mock name='mock.RED' id='139887542331320'>
>>> print(f"{Fore.RED}Hello Color!")
<Mock name='mock.RED' id='139887542331320'>Hello Color!
这并不十分有效,因为Fore.RED是由一个字符串表示的,这会打乱您的输出。相反,您希望创建一个始终呈现为空字符串的对象。
可以改变Mock对象上.__str__()的返回值。然而,在这种情况下,编写自己的模拟更方便:
# optional_color.py
try:
from colorama import init, Back, Cursor, Fore, Style
except ImportError:
from collections import UserString
class ColoramaMock(UserString):
def __call__(self, *args, **kwargs):
return self
def __getattr__(self, key):
return self
init = ColoramaMock("")
Back = Cursor = Fore = Style = ColoramaMock("")
ColoramaMock("")是一个空字符串,当它被调用时也将返回空字符串。这有效地给了我们一个 Colorama 的重新实现,只是没有颜色。
最后一个技巧是.__getattr__()返回它自己,这样所有的颜色、样式和光标移动都是Back、Fore、Style和Cursor的属性。
optional_color模块旨在替代 Colorama,因此您可以使用搜索和替换来更新倒计时示例:
# countdown.py
import optional_color from optional_color import Cursor, Fore import time
optional_color.init(autoreset=True) countdown = [f"{Fore.BLUE}{n}" for n in range(10, 0, -1)]
countdown.append(f"{Fore.RED}Lift off!")
print(f"{Fore.GREEN}Countdown starting:\n")
for count in countdown:
time.sleep(1)
print(f"{Cursor.UP(1)}{count} ")
如果您在 Colorama 不可用的系统上运行这个脚本,它仍然可以工作,但是看起来可能不太好:
安装 Colorama 后,您应该会看到与前面相同的结果。
将脚本作为模块导入
脚本和库模块之间的一个区别是脚本通常做一些事情,而库提供功能。脚本和库都存在于常规的 Python 文件中,就 Python 而言,它们之间没有区别。
相反,区别在于如何使用文件:是用python file.py执行还是用另一个脚本中的import file导入?
有时你会有一个既作为脚本又作为库的模块。你可以尝试将你的模块重构到两个不同的文件中。
标准库中的一个例子是 json包。您通常将它作为一个库使用,但是它也捆绑了一个可以美化 JSON 文件的脚本。假设你有下面的 colors.json文件:
{"colors": [{"color": "blue", "category": "hue", "type": "primary", "code": {"rgba": [0,0,255,1], "hex": "#00F"}}, {"color": "yellow", "category": "hue", "type": "primary", "code": {"rgba": [255,255,0,1], "hex": "#FF0"}}]}
由于 JSON 通常是机器只读的,所以许多 JSON 文件的格式都不可读。事实上,JSON 文件由一行很长的文本组成是很常见的。
json.tool是一个使用json库以更易读的方式格式化 JSON 的脚本:
$ python -m json.tool colors.json --sort-keys
{
"colors": [
{
"category": "hue",
"code": {
"hex": "#00F",
"rgba": [
0,
0,
255,
1
]
},
"color": "blue",
"type": "primary"
},
{
"category": "hue",
"code": {
"hex": "#FF0",
"rgba": [
255,
255,
0,
1
]
},
"color": "yellow",
"type": "primary"
}
]
}
现在,掌握 JSON 文件的结构变得简单多了。您可以使用--sort-keys选项按字母顺序对键进行排序。
虽然将脚本和库分开是一个很好的做法,但是 Python 有一个习语,可以将一个模块同时视为脚本和库。正如前面提到的,特殊的__name__模块变量的值是在运行时根据模块是导入还是作为脚本运行来设置的。
让我们来测试一下!创建以下文件:
# name.py
print(__name__)
如果您运行这个文件,那么您会看到__name__被设置为特殊值__main__:
$ python name.py
__main__
但是,如果导入模块,那么__name__被设置为模块的名称:
>>> import name name这种行为在以下模式中得到利用:
def main(): ... if __name__ == "__main__": main()让我们用这个更大的例子。为了让保持年轻,下面的脚本将用
24替换任何“老”的年龄(25或以上):1# feel_young.py 2 3def make_young(text): 4 words = [replace_by_age(w) for w in text.split()] 5 return " ".join(words) 6 7def replace_by_age(word, new_age=24, age_range=(25, 120)): 8 if word.isdigit() and int(word) in range(*age_range): 9 return str(new_age) 10 return word 11 12if __name__ == "__main__": 13 text = input("Tell me something: ") 14 print(make_young(text))您可以将此作为脚本运行,它会以交互方式使您键入的年龄更年轻:
$ python feel_young.py Tell me something: Forever young - Bob is 79 years old Forever young - Bob is 24 years old您也可以将模块用作可导入的库。第 12 行上的
if测试确保在导入库时没有副作用。仅定义了功能make_young()和replace_by_age()。例如,您可以按如下方式使用该库:
>>> from feel_young import make_young
>>> headline = "Twice As Many 100-Year-Olds"
>>> make_young(headline)
'Twice As Many 24-Year-Olds'
如果没有if测试的保护,导入会触发交互input()并使feel_young很难用作库。
从 ZIP 文件运行 Python 脚本
Python 的一个稍微模糊的特性是它可以运行打包成 ZIP 文件的脚本。这样做的主要优点是,您可以将完整的包作为单个文件分发。
但是,请注意,这仍然需要在系统上安装 Python。如果你想把你的 Python 应用程序作为一个独立的可执行文件发布,那么请看使用 PyInstaller 轻松发布 Python 应用程序。
如果你给 Python 解释器一个 ZIP 文件,那么它会在 ZIP 存档中寻找一个名为__main__.py的文件,解压并运行它。作为一个基本示例,创建下面的__main__.py文件:
# __main__.py
print(f"Hello from {__file__}")
这将在您运行它时打印一条消息:
$ python __main__.py
Hello from __main__.py
现在将它添加到 ZIP 存档中。您也许可以在命令行上做到这一点:
$ zip hello.zip __main__.py
adding: __main__.py (stored 0%)
在 Windows 上,您可以使用点并点击。在文件浏览器中选择文件,然后右键选择发送到→压缩文件夹。
由于__main__不是一个非常具有描述性的名称,您将 ZIP 文件命名为hello.zip。现在可以用 Python 直接调用它:
$ python hello.zip
Hello from hello.zip/__main__.py
请注意,您的脚本知道它位于hello.zip中。此外,您的 ZIP 文件的根被添加到 Python 的导入路径中,以便您的脚本可以导入同一 ZIP 文件中的其他模块。
回想一下之前的例子,在这个例子中,您基于人口数据创建了一个测验。可以将整个应用程序作为一个单独的 ZIP 文件分发。importlib.resources将确保在需要时从 ZIP 存档中提取数据文件。
该应用程序由以下文件组成:
population_quiz/
│
├── data/
│ ├── __init__.py
│ └── WPP2019_TotalPopulationBySex.csv
│
└── population_quiz.py
您可以像上面一样将它们添加到一个 ZIP 文件中。然而,Python 附带了一个名为 zipapp 的工具,它简化了将应用程序打包成 ZIP 存档的过程。您可以按如下方式使用它:
$ python -m zipapp population_quiz -m population_quiz:main
这个命令主要做两件事:它创建一个入口点并打包应用程序。
请记住,您需要一个__main__.py文件作为 ZIP 存档中的入口点。如果你给-m选项提供了你的应用程序应该如何启动的信息,那么zipapp会为你创建这个文件。在本例中,生成的__main__.py如下所示:
# -*- coding: utf-8 -*-
import population_quiz
population_quiz.main()
这个__main__.py和population_quiz目录的内容一起打包到一个名为population_quiz.pyz的 ZIP 存档中。.pyz后缀表示这是一个打包到 ZIP 存档中的 Python 文件。
注意:默认情况下,zipapp不压缩任何文件。它只将它们打包成一个文件。您可以通过添加-c选项来告诉zipapp压缩文件。
但是,该功能仅在 Python 3.7 和更高版本中可用。更多信息参见zipapp 文档。
在 Windows 上,.pyz文件应该已经注册为 Python 文件。在 Mac 和 Linux 上,您可以通过使用-p解释器选项并指定使用哪个解释器来让zipapp创建可执行文件:
$ python -m zipapp population_quiz -m population_quiz:main \
> -p "/usr/bin/env python"
-p选项增加了一个shebang(#!),告诉操作系统如何运行文件。此外,它使.pyz文件成为可执行文件,这样你只需输入文件名就可以运行该文件:
$ ./population_quiz.pyz
Reading population data for 2020, Medium scenario
Question 1:
1\. Timor-Leste
2\. Viet Nam
3\. Bermuda
Which country has the largest population?
注意文件名前面的./。这是在 Mac 和 Linux 上运行当前目录中的可执行文件的典型技巧。如果你将文件移动到你的 PATH 上的一个目录,或者如果你使用的是 Windows,那么你应该只能使用文件名:population_quiz.pyz。
注意:在 Python 3.6 和更早的版本中,前面的命令将会失败,并显示一条消息说它在data目录中找不到人口数据资源。这是由于zipimport 中的限制。
一种解决方法是提供population_quiz.pyz的绝对路径。在 Mac 和 Linux 上,您可以通过以下技巧来实现这一点:
$ `pwd`/population_quiz.pyz
pwd命令扩展到当前目录的路径。
让我们通过查看使用importlib.resources的良好效果来结束这一部分。请记住,您使用了以下代码来打开数据文件:
from importlib import resources
with resources.open_text("data", "WPP2019_TotalPopulationBySex.csv") as fid:
...
打开数据文件的一种更常见的方法是根据您的模块的__file__属性来定位它们:
import pathlib
DATA_DIR = pathlib.Path(__file__).parent / "data"
with open(DATA_DIR / "WPP2019_TotalPopulationBySex.csv") as fid:
...
这种方法通常很有效。然而,当您的应用程序被打包成一个 ZIP 文件时,它就分崩离析了:
$ python population_quiz.pyz
Reading population data for 2020, Medium scenario
Traceback (most recent call last):
...
NotADirectoryError: 'population_quiz.pyz/data/WPP2019_TotalPopulationBySex.csv'
您的数据文件在 ZIP 存档中,因此open()无法打开它。另一方面,importlib.resources会在打开之前将您的数据提取到一个临时文件中。
处理循环导入
当两个或多个模块相互导入时,就会发生循环导入。更具体地说,假设模块yin使用import yang,模块yang类似地导入yin。
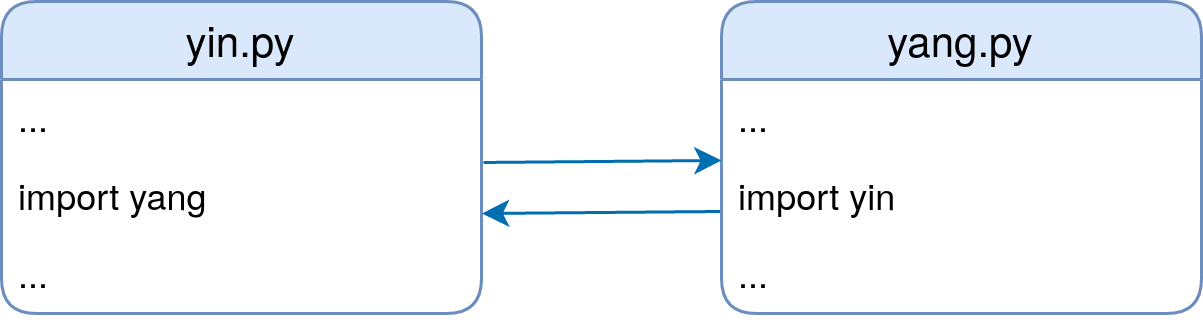
Python 的导入系统在某种程度上是为处理导入周期而设计的。例如,下面的代码虽然不是很有用,但运行良好:
# yin.py
print(f"Hello from yin")
import yang
print(f"Goodbye from yin")
# yang.py
print(f"Hello from yang")
import yin
print(f"Goodbye from yang")
试图在交互式解释器中导入yin也会导入yang:
>>> import yin Hello from yin Hello from yang Goodbye from yang Goodbye from yin注意,
yang是在yin的导入中间导入的,准确的说是在yin源代码中的import yang语句处。这不会以无休止的递归结束的原因是我们的老朋友模块缓存。当您键入
import yin时,对yin的引用甚至在yin被加载之前就被添加到模块缓存中。当yang稍后试图导入yin时,它只是使用模块缓存中的引用。你也可以让模块做一些稍微有用的事情。如果您在模块中定义了属性和函数,那么它仍然可以工作:
# yin.py print(f"Hello from yin") import yang number = 42 def combine(): return number + yang.number print(f"Goodbye from yin") # yang.py print(f"Hello from yang") import yin number = 24 def combine(): return number + yin.number print(f"Goodbye from yang")导入
yin的工作方式与之前相同:
>>> import yin
Hello from yin
Hello from yang
Goodbye from yang
Goodbye from yin
当您在导入时实际使用另一个模块,而不仅仅是定义稍后将使用另一个模块的函数时,与递归导入相关的问题就开始出现了。在yang.py中增加一行:
# yin.py
print(f"Hello from yin")
import yang
number = 42
def combine():
return number + yang.number
print(f"Goodbye from yin")
# yang.py
print(f"Hello from yang")
import yin
number = 24
def combine():
return number + yin.number
print(f"yin and yang combined is {combine()}") print(f"Goodbye from yang")
现在 Python 被导入弄糊涂了:
>>> import yin Hello from yin Hello from yang Traceback (most recent call last): ... File ".../yang.py", line 8, in combine return number + yin.number AttributeError: module 'yin' has no attribute 'number'该错误消息起初可能看起来有点令人费解。回头看源代码,可以确认
number是在yin模块中定义的。问题是在
yang被导入时number没有在yin中定义。因此,yin.number被用于对combine()的调用。更令人困惑的是,导入
yang将不会有问题:
>>> import yang
Hello from yang
Hello from yin
Goodbye from yin
yin and yang combined is 66
Goodbye from yang
当yang调用combine()时,yin被完全导入,yin.number被很好地定义。最后,由于您之前看到的模块缓存,import yin可能会工作,如果您先做一些其他的导入:
>>> import yang Hello from yang Hello from yin Goodbye from yin yin and yang combined is 66 Goodbye from yang >>> yin Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'yin' is not defined >>> import yin >>> yin.combine() 66那么,你如何才能避免陷入周期性进口的困境和困惑呢?让两个或更多的模块相互导入通常是可以改进模块设计的标志。
通常,修复循环导入最容易的时间是在实现它们之前的。如果你在你的建筑草图中看到循环,仔细看看试图打破循环。
不过,有些时候引入进口周期是合理的。正如您在上面看到的,只要您的模块只定义属性、函数、类等等,这就不是问题。第二个技巧——也是很好的设计实践——是在导入时保持模块不受副作用的影响。
如果你真的需要有导入周期和副作用的模块,还有另一种方法:在函数内部本地导入。
注意,在下面的代码中,
import yang是在combine()内部完成的。这有两个后果。首先,yang只能在combine()功能中使用。更重要的是,在yin完全导入后,直到您调用combine()时,导入才会发生:# yin.py print(f"Hello from yin") number = 42 def combine(): import yang return number + yang.number print(f"Goodbye from yin") # yang.py print(f"Hello from yang") import yin number = 24 def combine(): return number + yin.number print(f"yin and yang combined is {combine()}") print(f"Goodbye from yang")现在没有导入和使用
yin的问题:
>>> import yin
Hello from yin
Goodbye from yin
>>> yin.combine()
Hello from yang
yin and yang combined is 66
Goodbye from yang
66
请注意,yang实际上直到您调用combine()时才被导入。关于周期性进口的另一个视角,请参见弗雷德里克·伦德的经典笔记。
配置文件导入
当导入几个模块和包时,需要考虑的一个问题是这会增加脚本的启动时间。根据您的应用,这可能很重要,也可能不重要。
自从 Python 3.7 发布以来,你已经有了一个快速了解导入包和模块需要多少时间的方法。Python 3.7 支持-X importtime命令行选项,该选项测量并打印每个模块导入所需的时间:
$ python -X importtime -c "import datetime"
import time: self [us] | cumulative | imported package
...
import time: 87 | 87 | time
import time: 180 | 180 | math
import time: 234 | 234 | _datetime
import time: 820 | 1320 | datetime
cumulative列显示了每个包的累积导入时间(以微秒计)。您可以这样阅读清单:Python 花费了1320微秒来完全导入datetime,这涉及到导入time、math,以及 C 实现_datetime。
self列显示了仅导入给定模块所花费的时间,不包括任何递归导入。可以看到time用了87微秒导入,math用了180,_datetime用了234,而datetime本身的导入用了820微秒。总而言之,这加起来累积时间为1320微秒(在舍入误差内)。
看看 Colorama 部分的countdown.py例子:
$ python3.7 -X importtime countdown.py
import time: self [us] | cumulative | imported package
...
import time: 644 | 7368 | colorama.ansitowin32
import time: 310 | 11969 | colorama.initialise
import time: 333 | 12301 | colorama
import time: 297 | 12598 | optional_color
import time: 119 | 119 | time
在这个例子中,导入optional_color花费了将近 0.013 秒。大部分时间花在导入 Colorama 及其依赖项上。self列显示不包括嵌套导入的导入时间。
举个极端的例子,考虑一下早期中的 population单例。因为加载的是大数据文件,导入速度极慢。为了测试这一点,您可以使用-c选项将import population作为脚本运行:
$ python3.7 -X importtime -c "import population"
import time: self [us] | cumulative | imported package
...
import time: 4933 | 322111 | matplotlib.pyplot
import time: 1474 | 1474 | typing
import time: 420 | 1894 | importlib.resources
Reading population data for Medium scenario
import time: 1593774 | 1921024 | population
在这种情况下,导入population几乎需要 2 秒,其中大约 1.6 秒花在模块本身,主要用于加载数据文件。
-X importtime是优化您的导入的绝佳工具。如果你需要对你的代码进行更一般的监控和优化,那么看看 Python 定时器函数:三种监控你的代码的方法。
结论
在本教程中,您已经了解了 Python 导入系统。像 Python 中的许多东西一样,对于导入模块和包之类的基本任务,使用它相当简单。同时,导入系统非常复杂、灵活且可扩展。您已经学习了几个与导入相关的技巧,可以在自己的代码中加以利用。
在本教程中,您已经学会了如何:
- 创建名称空间包
- 导入资源和数据文件
- 决定在运行时动态导入什么
- 扩展 Python 的导入系统
- 处理包的不同版本
在整个教程中,您已经看到了许多进一步信息的链接。Python 导入系统最权威的来源是官方文档:
通过遵循本教程中的示例,您可以将 Python 导入的知识派上用场。单击下面的链接访问源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用来了解 Python 导入系统。**********
Python 的“in”和“not in”操作符:检查成员资格
Python 的 in 和 not in 运算符允许您快速确定一个给定值是否是值集合的一部分。这种类型的检查在编程中很常见,在 Python 中通常被称为成员测试。因此,这些算子被称为隶属算子。
在本教程中,您将学习如何:
- 使用
in和not in操作符执行成员测试 - 使用不同数据类型的
in和not in - 与
operator.contains()、一起工作,相当于in操作员的功能 - 在你的自己的班级中为
in和not in提供支持
为了充分利用本教程,您将需要 Python 的基础知识,包括内置数据类型,如列表、元组、范围、字符串、集合和字典。您还需要了解 Python 生成器、综合和类。
源代码: 点击这里下载免费的源代码,你将使用它们用in和not in在 Python 中执行成员测试。
Python 成员测试入门
有时,您需要找出一个值是否存在于一个值集合中。换句话说,您需要检查给定的值是否是值集合的成员。这种检查通常被称为会员资格测试。
可以说,执行这种检查的自然方式是迭代这些值,并将它们与目标值进行比较。你可以借助一个 for循环和一个条件语句来完成这个任务。
考虑下面的is_member()函数:
>>> def is_member(value, iterable): ... for item in iterable: ... if value is item or value == item: ... return True ... return False ...这个函数有两个参数,目标值
value和一组值,通常称为iterable。循环在iterable上迭代,同时条件语句检查目标value是否等于当前值。注意,该条件使用is检查对象标识,或者使用相等运算符(==)检查值相等。这些测试略有不同,但互为补充。如果条件为真,那么函数返回
True,退出循环。这种提前返回短路的循环操作。如果循环结束而没有任何匹配,那么函数返回False:
>>> is_member(5, [2, 3, 5, 9, 7])
True
>>> is_member(8, [2, 3, 5, 9, 7])
False
对is_member()的第一次调用返回True,因为目标值5是当前列表[2, 3, 5, 9, 7]的成员。对该函数的第二次调用返回False,因为8不在输入值列表中。
像上面这样的成员资格测试在编程中是如此普遍和有用,以至于 Python 有专门的操作符来执行这些类型的检查。您可以通过下表了解隶属运算符:
| 操作员 | 描述 | 句法 |
|---|---|---|
T2in |
如果目标值是值集合中的,则返回True。否则返回False。 |
value in collection |
T2not in |
如果目标值是给定值集合中的而不是,则返回True。否则返回False。 |
value not in collection |
与布尔运算符一样,Python 通过使用普通的英语单词而不是潜在的混淆符号作为运算符来提高可读性。
注意:当in 关键字在for循环语法中作为成员操作符时,不要将它与in关键字混淆。它们有完全不同的含义。in操作符检查一个值是否在一个值集合中,而for循环中的in关键字表示您想要从中提取的 iterable。
和其他很多运算符一样,in和not in都是二元运算符。这意味着你可以通过连接两个操作数来创建表达式。在这种情况下,它们是:
- 左操作数:要在值集合中查找的目标值
- 右操作数:可以找到目标值的值的集合
成员资格测试的语法如下所示:
value in collection
value not in collection
在这些表达式中,value可以是任何 Python 对象。同时,collection可以是能够保存值集合的任何数据类型,包括列表、元组、字符串、集合和字典。它也可以是实现.__contains__()方法的类,或者是明确支持成员测试或迭代的用户定义的类。
如果您正确使用了in和not in操作符,那么您用它们构建的表达式将总是计算出一个布尔值。换句话说,这些表达式将总是返回True或False。另一方面,如果你试图在不支持成员测试的东西中找到一个值,那么你将得到一个 TypeError 。稍后,您将了解更多关于支持成员测试的 Python 数据类型。
因为成员运算符总是计算为布尔值,Python 将它们视为布尔运算符,就像 and 、 or 和 not 运算符一样。
现在您已经知道了什么是成员资格操作符,是时候学习它们如何工作的基础知识了。
Python 的in操作符
为了更好地理解in操作符,您将从编写一些小的演示示例开始,这些示例确定给定值是否在列表中:
>>> 5 in [2, 3, 5, 9, 7] True >>> 8 in [2, 3, 5, 9, 7] False第一个表达式返回
True,因为5出现在数字列表中。第二个表达式返回False,因为8不在列表中。根据
in操作符文档,类似value in collection的表达式相当于下面的代码:any(value is item or value == item for item in collection)包装在对
any()的调用中的生成器表达式构建了一个布尔值列表,该列表是通过检查目标value是否具有相同的身份或者是否等于collection中的当前item而得到的。对any()的调用检查是否有任何一个结果布尔值为True,在这种情况下,函数返回True。如果所有的值都是False,那么any()返回False。Python 的
not in操作符
not in成员操作符做的正好相反。使用这个操作符,您可以检查给定值是否不在值集合中:
>>> 5 not in [2, 3, 5, 9, 7]
False
>>> 8 not in [2, 3, 5, 9, 7]
True
在第一个例子中,您得到了False,因为5在[2, 3, 5, 9, 7]中。在第二个例子中,您得到了True,因为8不在值列表中。这种消极的逻辑看起来像绕口令。为了避免混淆,请记住您正在尝试确定值是否是给定值集合的而不是部分。
注意:not value in collection构造与value not in collection构造的工作原理相同。然而,前一种结构更难阅读。因此,你应该使用not in作为单个运算符,而不是使用not来否定in的结果。
通过对成员操作符如何工作的快速概述,您已经准备好进入下一个层次,学习in和not in如何处理不同的内置数据类型。
使用不同 Python 类型的in和not in
所有内置的序列——比如列表、元组、 range 对象和字符串——都支持使用in和not in操作符进行成员测试。像集合和字典这样的集合也支持这些测试。默认情况下,字典上的成员操作检查字典是否有给定的键。但是,字典也有显式的方法,允许您对键、值和键值对使用成员操作符。
在接下来的几节中,您将了解对不同的内置数据类型使用in和not in的一些特殊之处。您将从列表、元组和range对象开始。
列表、元组和范围
到目前为止,您已经编写了一些使用in和not in操作符来确定一个给定值是否存在于一个现有的值列表中的例子。对于这些例子,你已经明确地使用了list对象。因此,您已经熟悉了成员资格测试如何处理列表。
对于元组,成员运算符的工作方式与列表相同:
>>> 5 in (2, 3, 5, 9, 7) True >>> 5 not in (2, 3, 5, 9, 7) False这里没有惊喜。这两个例子的工作方式都与以列表为中心的例子相同。在第一个例子中,
in操作符返回True,因为目标值5在元组中。在第二个示例中,not in返回相反的结果。对于列表和元组,成员操作符使用一个搜索算法,该算法迭代底层集合中的项目。因此,随着 iterable 变长,搜索时间也成正比增加。使用大 O 符号,你会说对这些数据类型的成员操作具有的时间复杂度为 O(n) 。
如果您对
range对象使用in和not in操作符,那么您会得到类似的结果:
>>> 5 in range(10)
True
>>> 5 not in range(10)
False
>>> 5 in range(0, 10, 2)
False
>>> 5 not in range(0, 10, 2)
True
当涉及到range对象时,使用成员测试乍一看似乎是不必要的。大多数情况下,您会事先知道结果范围内的值。但是,如果您使用的range()带有在运行时确定的偏移量呢?
注意:创建range对象时,最多可以传递三个参数给range()。这些论点是start、stop和step。它们定义了开始范围的次数,范围必须停止生成值的次数,以及生成值之间的步长。这三个参数通常被称为偏移。
考虑以下示例,这些示例使用随机数来确定运行时的偏移量:
>>> from random import randint >>> 50 in range(0, 100, randint(1, 10)) False >>> 50 in range(0, 100, randint(1, 10)) False >>> 50 in range(0, 100, randint(1, 10)) True >>> 50 in range(0, 100, randint(1, 10)) True在您的机器上,您可能会得到不同的结果,因为您正在使用随机范围偏移。在这些具体示例中,
step是唯一变化的偏移量。在实际代码中,start和stop偏移量也可以有不同的值。对于
range对象,成员测试背后的算法使用表达式(value - start) % step) == 0计算给定值的存在,这取决于用来创建当前范围的偏移量。这使得成员测试在操作range对象时非常有效。在这种情况下,你会说他们的时间复杂度是 O(1) 。注意:列表、元组和
range对象有一个.index()方法,返回给定值在底层序列中第一次出现的索引。此方法对于在序列中定位值非常有用。有些人可能认为他们可以使用方法来确定一个值是否在一个序列中。但是,如果值不在序列中,那么
.index()会引发一个ValueError:
>>> (2, 3, 5, 9, 7).index(8)
Traceback (most recent call last):
...
ValueError: tuple.index(x): x not in tuple
您可能不想通过引发异常来判断一个值是否在一个序列中,因此您应该使用成员操作符而不是.index()来达到这个目的。
请记住,成员测试中的目标值可以是任何类型。测试将检查该值是否在目标集合中。例如,假设您有一个假想的应用程序,其中用户使用用户名和密码进行身份验证。你可以有这样的东西:
# users.py
username = input("Username: ")
password = input("Password: ")
users = [("john", "secret"), ("jane", "secret"), ("linda", "secret")]
if (username, password) in users:
print(f"Hi {username}, you're logged in!")
else:
print("Wrong username or password")
这是一个幼稚的例子。不太可能有人会这样处理他们的用户和密码。但是该示例显示目标值可以是任何数据类型。在这种情况下,您使用一个字符串元组来表示给定用户的用户名和密码。
下面是代码在实践中的工作方式:
$ python users.py
Username: john
Password: secret
Hi john, you're logged in!
$ python users.py
Username: tina
Password: secret
Wrong username or password
在第一个例子中,用户名和密码是正确的,因为它们在users列表中。在第二个示例中,用户名不属于任何注册用户,因此身份验证失败。
在这些例子中,重要的是要注意数据在登录元组中的存储顺序是至关重要的,因为在元组比较中像("john", "secret")这样的东西不等于("secret", "john"),即使它们有相同的条目。
在本节中,您已经探索了一些示例,这些示例展示了带有常见 Python 内置序列的成员运算符的核心行为。然而,还有一个内置序列。是的,弦乐!在下一节中,您将了解在 Python 中成员运算符如何处理这种数据类型。
字符串
Python 字符串是每个 Python 开发者工具箱中的基本工具。像元组、列表和范围一样,字符串也是序列,因为它们的项或字符是顺序存储在内存中的。
当需要判断目标字符串中是否存在给定的字符时,可以对字符串使用in和not in操作符。例如,假设您使用字符串来设置和管理给定资源的用户权限:
>>> class User: ... def __init__(self, username, permissions): ... self.username = username ... self.permissions = permissions ... >>> admin = User("admin", "wrx") >>> john = User("john", "rx") >>> def has_permission(user, permission): ... return permission in user.permissions ... >>> has_permission(admin, "w") True >>> has_permission(john, "w") False
User类有两个参数,一个用户名和一组权限。为了提供权限,您使用一个字符串,其中w表示用户拥有写权限,r表示用户拥有读权限,x表示执行权限。注意,这些字母与您在 Unix 风格的文件系统权限中找到的字母相同。
has_permission()中的成员测试检查当前user是否有给定的permission,相应地返回True或False。为此,in操作符搜索权限字符串来查找单个字符。在这个例子中,您想知道用户是否有写权限。但是,您的权限系统有一个隐藏的问题。如果用空字符串调用函数会发生什么?这是你的答案:
>>> has_permission(john, "")
True
因为空字符串总是被认为是任何其他字符串的子字符串,所以类似于"" in user.permissions的表达式将返回True。根据谁有权访问您的用户权限,这种成员资格测试行为可能意味着您的系统存在安全漏洞。
您还可以使用成员运算符来确定一个字符串是否包含一个子字符串:
>>> greeting = "Hi, welcome to Real Python!" >>> "Hi" in greeting True >>> "Hi" not in greeting False >>> "Hello" in greeting False >>> "Hello" not in greeting True对于字符串数据类型,如果
substring是string的一部分,类似于substring in string的表达式就是True。否则,表情就是False。注意:与列表、元组和
range对象等其他序列不同,字符串提供了一个.find()方法,您可以在现有字符串中搜索给定的子字符串时使用这个方法。例如,您可以这样做:
>>> greeting.find("Python")
20
>>> greeting.find("Hello")
-1
如果子串存在于底层字符串中,那么.find()返回子串在字符串中开始的索引。如果目标字符串不包含子字符串,那么结果是得到-1。因此,像string.find(substring) >= 0这样的表达式相当于一个substring in string测试。
然而,成员测试可读性更强,也更明确,这使得它在这种情况下更可取。
在字符串上使用成员资格测试时要记住的重要一点是,字符串比较是区分大小写的:
>>> "PYTHON" in greeting False这个成员测试返回
False,因为字符串比较是区分大小写的,大写的"PYTHON"在greeting中不存在。要解决这种区分大小写的问题,您可以使用.upper()或.lower()方法来规范化所有字符串:
>>> "PYTHON".lower() in greeting.lower()
True
在这个例子中,您使用.lower()将目标子字符串和原始字符串转换成小写字母。这种转换在隐式字符串比较中不区分大小写。
发电机
生成器函数和生成器表达式创建内存高效的迭代器,称为生成器迭代器。为了提高内存效率,这些迭代器按需生成条目,而不需要在内存中保存完整的值序列。
实际上,生成器函数是一个函数,它在函数体中使用了 yield 语句。例如,假设您需要一个生成器函数,它接受一组数字并返回一个迭代器,该迭代器从原始数据中生成平方值。在这种情况下,您可以这样做:
>>> def squares_of(values): ... for value in values: ... yield value ** 2 ... >>> squares = squares_of([1, 2, 3, 4]) >>> next(squares) 1 >>> next(squares) 4 >>> next(squares) 9 >>> next(squares) 16 >>> next(squares) Traceback (most recent call last): ... StopIteration这个函数返回一个生成器迭代器,根据需要生成平方数。可以使用内置的
next()函数从迭代器中检索连续值。当生成器迭代器被完全消耗完时,它会引发一个StopIteration异常,告知不再有剩余的值。您可以在生成器函数上使用成员操作符,如
squares_of():
>>> 4 in squares_of([1, 2, 3, 4])
True
>>> 9 in squares_of([1, 2, 3, 4])
True
>>> 5 in squares_of([1, 2, 3, 4])
False
当您将in操作符与生成器迭代器一起使用时,它将按预期工作,如果值出现在迭代器中,则返回True,否则返回False。
然而,在检查生成器的成员资格时,需要注意一些事情。一个生成器迭代器将只产生每个项目一次。如果你消耗了所有的条目,那么迭代器将被耗尽,你将无法再次迭代它。如果您只使用生成器迭代器中的一些项,那么您只能迭代剩余的项。
当您在生成器迭代器上使用in或not in时,操作符将在搜索目标值时消耗它。如果值存在,那么操作符将消耗所有值,直到目标值。其余的值在生成器迭代器中仍然可用:
>>> squares = squares_of([1, 2, 3, 4]) >>> 4 in squares True >>> next(squares) 9 >>> next(squares) 16 >>> next(squares) Traceback (most recent call last): ... StopIteration在这个例子中,
4在生成器迭代器中,因为它是2的平方。因此,in返回True。当你使用next()从square中检索一个值时,你得到9,它是3的平方。该结果确认您不再能够访问前两个值。您可以继续调用next(),直到当生成器迭代器用尽时,您得到一个StopIteration异常。同样,如果值不在生成器迭代器中,那么操作符将完全消耗迭代器,您将无法访问它的任何值:
>>> squares = squares_of([1, 2, 3, 4])
>>> 5 in squares
False
>>> next(squares)
Traceback (most recent call last):
...
StopIteration
在这个例子中,in操作符完全消耗了squares,返回了False,因为目标值不在输入数据中。因为生成器迭代器现在已经用完了,所以用squares作为参数调用next()会引发StopIteration。
还可以使用生成器表达式创建生成器迭代器。这些表达式使用与列表理解相同的语法,但是用圆括号(())代替了方括号([])。您可以将in和not in操作符用于生成器表达式的结果:
>>> squares = (value ** 2 for value in [1, 2, 3, 4]) >>> squares <generator object <genexpr> at 0x1056f20a0> >>> 4 in squares True >>> next(squares) 9 >>> next(squares) 16 >>> next(squares) Traceback (most recent call last): ... StopIteration
squares变量现在保存由生成器表达式产生的迭代器。这个迭代器从输入的数字列表中产生平方值。来自生成器表达式的生成器迭代器与来自生成器函数的生成器迭代器工作方式相同。因此,当您在成员资格测试中使用它们时,同样的规则也适用。当您在生成器迭代器中使用
in和not in操作符时,会出现另一个关键问题。当您使用无限迭代器时,这个问题可能会出现。下面的函数返回一个产生无限整数的迭代器:
>>> def infinite_integers():
... number = 0
... while True:
... yield number
... number += 1
...
>>> integers = infinite_integers()
>>> integers
<generator object infinite_integers at 0x1057e8c80>
>>> next(integers)
0
>>> next(integers)
1
>>> next(integers)
2
>>> next(integers)
3
>>> next(integers)
infinite_integers()函数返回一个生成器迭代器,存储在integers中。这个迭代器按需产生值,但是记住,将会有无限个值。因此,在这个迭代器中使用成员操作符不是一个好主意。为什么?好吧,如果目标值不在生成器迭代器中,那么你会遇到一个无限循环,这将使你的执行挂起。
字典和集合
Python 的成员操作符也可以处理字典和集合。如果您直接在字典上使用in或not in操作符,那么它将检查字典是否有给定的键。你也可以使用 .keys() 的方法来做这个检查,它更明确地表达了你的意图。
您还可以检查给定值或键值对是否在字典中。要做这些检查,可以分别使用 .values() 和 .items() 方法:
>>> likes = {"color": "blue", "fruit": "apple", "pet": "dog"} >>> "fruit" in likes True >>> "hobby" in likes False >>> "blue" in likes False >>> "fruit" in likes.keys() True >>> "hobby" in likes.keys() False >>> "blue" in likes.keys() False >>> "dog" in likes.values() True >>> "drawing" in likes.values() False >>> ("color", "blue") in likes.items() True >>> ("hobby", "drawing") in likes.items() False在这些例子中,您直接在您的
likes字典上使用in操作符来检查"fruit"、"hobby"和"blue"键是否在字典中。注意,即使"blue"是likes中的一个值,测试也返回False,因为它只考虑键。接下来,使用
.keys()方法得到相同的结果。在这种情况下,显式的方法名称会让阅读您代码的其他程序员更清楚您的意图。要检查像
"dog"或"drawing"这样的值是否出现在likes中,您可以使用.values()方法,该方法返回一个带有底层字典中的值的视图对象。类似地,要检查一个键值对是否包含在likes中,可以使用.items()。请注意,目标键-值对必须是两项元组,键和值按此顺序排列。如果使用的是集合,那么成员运算符就像处理列表或元组一样工作:
>>> fruits = {"apple", "banana", "cherry", "orange"}
>>> "banana" in fruits
True
>>> "banana" not in fruits
False
>>> "grape" in fruits
False
>>> "grape" not in fruits
True
这些例子表明,您还可以通过使用成员运算符in和not in来检查一个给定值是否包含在一个集合中。
现在您已经知道了in和not in操作符是如何处理不同的内置数据类型的,是时候通过几个例子将这些操作符付诸实践了。
将 Python 的in和not in操作符付诸实施
用in和not in进行成员测试是编程中非常常见的操作。您将在许多现有的 Python 代码库中找到这类测试,并且也将在您的代码中使用它们。
在接下来的小节中,您将学习如何用成员测试替换基于 or 操作符的布尔表达式。因为成员测试在您的代码中很常见,所以您还将学习如何使这些测试更有效。
替换连锁的or操作符
使用成员测试来用几个or操作符替换一个复合布尔表达式是一种有用的技术,它允许您简化代码并使其更具可读性。
要了解这项技术的实际应用,假设您需要编写一个函数,该函数将颜色名称作为一个字符串,并确定它是否是一种原色。为了解决这个问题,您将使用 RGB(红、绿、蓝)颜色模型:
>>> def is_primary_color(color): ... color = color.lower() ... return color == "red" or color == "green" or color == "blue" ... >>> is_primary_color("yellow") False >>> is_primary_color("green") True在
is_primary_color()中,您使用一个复合布尔表达式,该表达式使用or操作符来检查输入颜色是红色、绿色还是蓝色。即使该功能如预期的那样工作,情况可能会令人困惑,难以阅读和理解。好消息是你可以用一个简洁易读的成员测试来代替上面的条件:
>>> def is_primary_color(color):
... primary_colors = {"red", "green", "blue"}
... return color.lower() in primary_colors ...
>>> is_primary_color("yellow")
False
>>> is_primary_color("green")
True
现在,您的函数使用in操作符来检查输入颜色是红色、绿色还是蓝色。将一组原色分配给一个适当命名的变量,如primary_colors,也有助于提高代码的可读性。最后的检查现在很清楚了。任何阅读您的代码的人都会立即理解您正试图根据 RGB 颜色模型来确定输入颜色是否是原色。
如果你再看一下这个例子,你会注意到原色已经被存储在一个集合中。为什么?你会在下一节找到你的答案。
编写高效的成员测试
Python 使用一种叫做哈希表的数据结构来实现字典和集合。哈希表有一个显著的特性:在数据结构中寻找任何给定的值需要大约相同的时间,不管表中有多少个值。使用大 O 符号,你会说哈希表中的值查找的时间复杂度为 O(1) ,这使得它们非常快。
现在,哈希表的这个特性与字典和集合上的成员测试有什么关系呢?事实证明,in和not in操作符在操作这些类型时工作非常快。这个细节允许您通过在成员测试中优先使用字典和集合而不是列表和其他序列来优化代码的性能。
要了解集合的效率比列表高多少,请继续创建以下脚本:
# performance.py
from timeit import timeit
a_list = list(range(100_000))
a_set = set(range(100_000))
list_time = timeit("-1 in a_list", number=1, globals=globals())
set_time = timeit("-1 in a_set", number=1, globals=globals())
print(f"Sets are {(list_time / set_time):.2f} times faster than Lists")
这个脚本创建了一个包含十万个值的整数列表和一个包含相同数量元素的集合。然后,脚本计算确定数字-1是否在列表和集合中所需的时间。你预先知道-1不会出现在列表或集合中。因此,在得到最终结果之前,成员操作符必须检查所有的值。
正如您已经知道的,当in操作符在一个列表中搜索一个值时,它使用一个时间复杂度为 O(n) 的算法。另一方面,当in操作符在集合中搜索一个值时,它使用哈希表查找算法,该算法的时间复杂度为 O(1) 。这一事实可以在性能方面产生很大的差异。
使用以下命令从命令行运行您的脚本:
$ python performance.py
Sets are 1563.33 times faster than Lists
尽管您的命令输出可能略有不同,但在这个特定的成员测试中,当您使用集合而不是列表时,它仍然会显示出显著的性能差异。有了列表,处理时间将与值的数量成正比。有了集合,对于任何数量的值,时间都差不多。
该性能测试表明,当您的代码对大型值集合进行成员资格检查时,您应该尽可能使用集合而不是列表。当您的代码在执行过程中执行几个成员测试时,您也将受益于 set。
但是,请注意,仅仅为了执行一些成员测试而将现有列表转换为集合并不是一个好主意。记住把链表转换成集合是一个时间复杂度为 O(n) 的操作。
使用operator.contains()进行成员资格测试
in操作符在 operator 模块中有一个等价的函数,它来自标准库。这个功能叫做 contains() 。它有两个参数——一组值和一个目标值。如果输入集合包含目标值,则返回True:
>>> from operator import contains >>> contains([2, 3, 5, 9, 7], 5) True >>> contains([2, 3, 5, 9, 7], 8) False
contains()的第一个参数是值的集合,第二个参数是目标值。请注意,参数的顺序不同于常规的成员资格操作,在常规操作中,目标值排在第一位。当您使用
map()或filter()等工具来处理代码中的可重复项时,这个函数就派上了用场。例如,假设你有一堆笛卡尔坐标点作为元组存储在一个列表中。您想要创建一个只包含不在坐标轴上的点的新列表。使用filter()功能,您可以得出以下解决方案:
>>> points = [
... (1, 3),
... (5, 0),
... (3, 7),
... (0, 6),
... (8, 3),
... (2, 0),
... ]
>>> list(filter(lambda point: not contains(point, 0), points))
[(1, 3), (3, 7), (8, 3)]
在这个例子中,您使用filter()来检索不包含0坐标的点。为此,在 lambda 函数中使用contains()。因为filter()返回一个迭代器,所以您将所有内容都包装在对list()的调用中,将迭代器转换成一个点列表。
尽管上面例子中的结构可以工作,但它相当复杂,因为它意味着导入contains(),在它上面创建一个lambda函数,并调用几个函数。您可以直接使用contains()或not in操作符使用列表理解得到相同的结果:
>>> [point for point in points if not contains(point, 0)] [(1, 3), (3, 7), (8, 3)] >>> [point for point in points if 0 not in point] [(1, 3), (3, 7), (8, 3)]上面的列表理解比前一个例子中对应的
filter()调用更短,并且更具可读性。它们也不太复杂,因为你不需要创建一个lambda函数或者调用list(),所以你减少了知识需求。支持用户定义类中的成员测试
提供一个
.__contains__()方法是在您自己的类中支持成员测试的最显式和首选的方式。当你在成员测试中使用你的类的一个实例作为右操作数时,Python 会自动调用这个特殊方法。您可能只向作为值集合的类添加一个
.__contains__()方法。这样,类的用户将能够确定给定值是否存储在类的特定实例中。举例来说,假设您需要创建一个最小的堆栈数据结构来存储遵循 LIFO(后进先出)原则的值。定制数据结构的一个要求是支持成员测试。因此,您最终编写了下面的类:
# stack.py class Stack: def __init__(self): self.items = [] def push(self, item): self.items.append(item) def pop(self): return self.items.pop() def __contains__(self, item): return item in self.items您的
Stack类支持堆栈数据结构的两个核心功能。你可以将一个值推到栈顶,从栈顶弹出一个值。请注意,您的数据结构使用了一个list对象来存储和操作实际数据。您的类也支持使用
in和not in操作符的成员测试。为此,该类实现了一个依赖于in操作符本身的.__contains__()方法。要测试您的类,请继续运行以下代码:
>>> from stack import Stack
>>> stack = Stack()
>>> stack.push(1)
>>> stack.push(2)
>>> stack.push(3)
>>> 2 in stack
True
>>> 42 in stack
False
>>> 42 not in stack
True
您的类完全支持in和not in操作符。干得好!现在,您知道了如何在自己的类中支持成员测试。
注意,如果一个给定的类有一个.__contains__()方法,那么这个类不必是可迭代的,成员操作符也能工作。在上面的例子中,Stack是不可迭代的,操作符仍然工作,因为它们从.__contains__()方法中检索结果。
除了提供一个.__contains__()方法,至少还有两种方法支持用户定义类中的成员测试。如果你的类有一个 .__iter__() 或者一个 .__getitem__() 方法,那么in和not in操作符也可以工作。
考虑下面这个Stack的替代版本:
# stack.py
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __iter__(self): yield from self.items
这个.__iter__()特殊方法使得你的类是可迭代的,这足以让成员测试工作。来吧,试一试!
支持成员测试的另一种方法是实现一个.__getitem__()方法,该方法在类中使用从零开始的整数索引来处理索引操作:
# stack.py
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __getitem__(self, index): return self.items[index]
当您对底层对象执行索引操作时,Python 会自动调用.__getitem__()方法。在本例中,当您执行stack[0]时,您将获得Stack实例中的第一项。Python 利用.__getitem__()让成员操作符正常工作。
结论
现在您知道了如何使用 Python 的 in 和 not in 操作符来执行成员测试。这种类型的测试允许您检查给定的值是否存在于值集合中,这是编程中非常常见的操作。
在本教程中,您已经学会了如何:
- 使用 Python 的
in和not in操作符运行成员测试 - 使用具有不同数据类型的
in和not in运算符 - 与
operator.contains()、一起工作,相当于in操作员的功能 - 支持自己班级中的
in和not in
有了这些知识,您就可以在代码中使用 Python 的in和not in操作符进行成员测试了。
源代码: 点击这里下载免费的源代码,你将使用它们用in和not in在 Python 中执行成员测试。*****
Python 中的基本输入、输出和字符串格式
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中的阅读输入和写作输出
对于一个有用的程序,它通常需要通过从用户那里获得输入数据并向用户显示结果数据来与外界进行通信。在本教程中,您将了解 Python 的输入和输出。
输入可以由用户直接通过键盘输入,也可以来自外部资源,如文件或数据库。输出可以直接显示到控制台或 IDE,通过图形用户界面(GUI)显示到屏幕,或者再次显示到外部源。
在本介绍性系列的之前的教程中,您将:
- 比较了编程语言用来实现确定迭代的不同范例
- 了解了 iterables 和 iterators,这两个概念构成了 Python 中明确迭代的基础
- 将它们联系在一起,学习 Python 的 for loops
本教程结束时,你将知道如何:
- 通过内置功能
input()从键盘上接受用户输入 - 用内置函数
print()显示输出到控制台 - 使用 Python f-strings 格式化字符串数据
事不宜迟,我们开始吧!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
从键盘读取输入
程序经常需要从用户那里获取数据,通常是通过键盘输入的方式。在 Python 中实现这一点的一种方法是使用 input() :
input([<prompt>])从键盘上读取一行。(文档
input()功能暂停程序执行,以允许用户从键盘键入一行输入。一旦用户按下 Enter 键,所有键入的字符被读取并作为字符串返回:
>>> user_input = input() foo bar baz >>> user_input 'foo bar baz'请注意,您的返回字符串不包括用户按下
Enter键时生成的换行符。如果包含可选的
<prompt>参数,那么input()会将其显示为一个提示,以便用户知道应该输入什么:
>>> name = input("What is your name? ")
What is your name? Winston Smith
>>> name
'Winston Smith'
input()总是返回一个字符串。如果你想要一个数字类型,那么你需要用内置的int()、float()或complex()函数将字符串转换成合适的类型:
1>>> number = input("Enter a number: ") 2Enter a number: 50 3>>> print(number + 100) 4Traceback (most recent call last): 5 File "<stdin>", line 1, in <module> 6TypeError: must be str, not int 7 8>>> number = int(input("Enter a number: ")) 9Enter a number: 50 10>>> print(number + 100) 11150在上面的例子中,第 3 行的表达式
number + 100是无效的,因为number是一个字符串,而100是一个整数。为了避免出现这种错误,第 8 行在收集用户输入后立即将number转换成一个整数。这样,第 10 行的计算number + 100有两个整数要相加。正因为如此,对print()的调用成功。Python 版本注意:如果您发现自己正在使用 Python 2.x 代码,您可能会发现 Python 版本 2 和 3 的输入函数略有不同。
Python 2 中的
raw_input()从键盘读取输入并返回。如上所述,Python 2 中的raw_input()的行为就像 Python 3 中的input()。但是 Python 2 也有一个函数叫做
input()。在 Python 2 中,input()从键盘读取输入,将其作为 Python 表达式进行解析和求值,并返回结果值。Python 3 没有提供一个函数来完成 Python 2 的
input()所做的事情。您可以用表达式eval(input())模仿 Python 3 中的效果。但是,这是一个安全风险,因为它允许用户运行任意的、潜在的恶意代码。有关
eval()及其潜在安全风险的更多信息,请查看 Python eval():动态评估表达式。使用
input(),你可以从你的用户那里收集数据。但是如果你想向他们展示你的程序计算出的任何结果呢?接下来,您将学习如何在控制台中向用户显示输出。将输出写入控制台
除了从用户那里获取数据,程序通常还需要将数据返回给用户。用 Python 中的
print()可以将程序数据显示到控制台。要向控制台显示对象,请将它们作为逗号分隔的参数列表传递给
print()。
print(<obj>, ..., <obj>)向控制台显示每个
<obj>的字符串表示。(文档)默认情况下,
print()用一个空格分隔对象,并在输出的末尾附加一个新行:
>>> first_name = "Winston"
>>> last_name = "Smith"
>>> print("Name:", first_name, last_name)
Name: Winston Smith
您可以指定任何类型的对象作为print()的参数。如果一个对象不是一个字符串,那么print()在显示它之前将它转换成一个合适的字符串表示:
>>> example_list = [1, 2, 3] >>> type(example_list) <class 'list'> >>> example_int = -12 >>> type(example_int) <class 'int'> >>> example_dict = {"foo": 1, "bar": 2} >>> type(example_dict) <class 'dict'> >>> type(len) <class 'builtin_function_or_method'> >>> print(example_list, example_int, example_dict, len) [1, 2, 3] -12 {'foo': 1, 'bar': 2} <built-in function len>如你所见,甚至像列表、字典和函数这样的复杂类型也可以用
print()显示到控制台。具有高级功能的打印
print()接受一些额外的参数,对输出的格式提供适度的控制。每一个都是一种特殊类型的论点,叫做关键词论点。在这个介绍性系列的后面,您将会遇到一个关于函数和参数传递的教程,这样您就可以了解更多关于关键字参数的知识。不过,现在你需要知道的是:
- 关键字参数的形式为
<keyword>=<value>。- 传递给
print()的任何关键字参数必须出现在末尾,在要显示的对象列表之后。在下面几节中,您将看到这些关键字参数如何影响由
print()产生的控制台输出。分离打印值
添加关键字参数
sep=<str>会导致 Python 通过而不是默认的单个空格: 来分隔对象
>>> print("foo", 42, "bar")
foo 42 bar
>>> print("foo", 42, "bar", sep="/")
foo/42/bar
>>> print("foo", 42, "bar", sep="...")
foo...42...bar
>>> d = {"foo": 1, "bar": 2, "baz": 3}
>>> for k, v in d.items():
... print(k, v, sep=" -> ")
...
foo -> 1
bar -> 2
baz -> 3
要将对象挤在一起,中间没有任何空间,请指定一个空字符串("")作为分隔符:
>>> print("foo", 42, "bar", sep="") foo42bar您可以使用
sep关键字指定任意字符串作为分隔符。控制换行符
关键字参数
end=<str>导致输出由<str>终止,而不是由默认换行符终止:
>>> if True:
... print("foo", end="/")
... print(42, end="/")
... print("bar")
...
foo/42/bar
例如,如果您在一个循环中显示值,您可以使用end使值显示在一行上,而不是单独的行上:
>>> for number in range(10): ... print(number) ... 0 1 2 3 4 5 6 7 8 9 >>> for number in range(10): ... print(number, end=(" " if number < 9 else "\n")) ... 0 1 2 3 4 5 6 7 8 9您可以使用
end关键字将任何字符串指定为输出终止符。将输出发送到流
print()接受两个额外的关键字参数,这两个参数都会影响函数处理输出流的方式:
file=<stream>: 默认情况下,print()将其输出发送到一个名为sys.stdout的默认流,这个流通常相当于控制台。file=<stream>参数使print()将输出发送到由<stream>指定的替代流。
flush=True: 通常,print()缓冲其输出,只间歇地写入输出流。flush=True指定 Python 在每次调用print()时强制刷新输出流。为了完整起见,这里给出了这两个关键字参数。在学习旅程的这个阶段,您可能不需要太关心输出流。
使用格式化字符串
虽然您可以深入了解 Python
print()函数,但它提供的控制台输出格式充其量只是初步的。您可以选择如何分离打印的对象,并指定打印行末尾的内容。大概就是这样。在许多情况下,您需要更精确地控制要显示的数据的外观。Python 提供了几种格式化输出字符串数据的方法。在本节中,您将看到一个使用 Python f-strings 格式化字符串的例子。
注意:****f-string 语法是字符串格式化的现代方法之一。要进行深入讨论,您可能需要查看这些教程:
在 Python 中的格式化字符串输出的教程中,您还将更详细地了解字符串格式化的两种方法,f-strings 和
str.format(),该教程在本介绍性系列教程的后面。在本节中,您将使用 f 字符串来格式化您的输出。假设您编写了一些要求用户输入姓名和年龄的代码:
>>> name = input("What is your name? ")
What is your name? Winston
>>> age = int(input("How old are you? "))
How old are you? 24
>>> print(name)
Winston
>>> print(age)
24
您已经成功地从您的用户那里收集了数据,并且您还可以将其显示回他们的控制台。要创建格式良好的输出消息,可以使用 f 字符串语法:
>>> f"Hello, {name}. You are {age}." Hello, Winston. You are 24.string 允许你把变量名放在花括号(
{})中,把它们的值注入到你正在构建的字符串中。你所需要做的就是在字符串的开头加上字母f或者F。接下来,假设您想告诉您的用户 50 年后他们的年龄。Python f-strings 允许您在没有太多开销的情况下做到这一点!您可以在花括号之间添加任何 Python 表达式,Python 将首先计算它的值,然后将其注入到您的 f 字符串中:
>>> f"Hello, {name}. In 50 years, you'll be {age + 50}."
Hello, Winston. In 50 years, you'll be 74.
您已经将50添加到从用户处收集的age的值中,并在前面使用int()将其转换为整数。整个计算发生在 f 弦的第二对花括号里。相当酷!
注意:如果你想了解更多关于使用这种方便的字符串格式化技术,那么你可以更深入地阅读关于 Python 3 的 f-Strings 的指南。
Python f-strings 可以说是在 Python 中格式化字符串的最方便的方式。如果你只想学习一种方法,最好坚持使用 Python 的 f 字符串。然而,这种语法从 Python 3.6 开始才可用,所以如果您需要使用 Python 的旧版本,那么您将不得不使用不同的语法,例如str.format()方法或字符串模运算符。
Python 输入和输出:结论
在本教程中,您学习了 Python 中的输入和输出,以及 Python 程序如何与用户通信。您还研究了一些参数,您可以使用这些参数向输入提示添加消息,或者定制 Python 如何向用户显示输出。
你已经学会了如何:
- 通过内置功能
input()从键盘上接受用户输入 - 用内置函数
print()显示输出到控制台 - 使用 Python f-strings 格式化字符串数据
在这个介绍性系列的下一篇教程中,您将学习另一种字符串格式化技术,并且将更深入地使用 f 字符串。
« Python "for" Loops (Definite Iteration)Basic Input and Output in PythonPython String Formatting Techniques »
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中的阅读输入和写作输出**
在 Python 中实现接口
接口在软件工程中起着重要的作用。随着应用程序的增长,对代码库的更新和更改变得更加难以管理。通常情况下,您最终会得到看起来非常相似但不相关的类,这可能会导致一些混淆。在本教程中,您将看到如何使用一个 Python 接口来帮助确定应该使用什么类来解决当前的问题。
在本教程中,你将能够:
- 了解接口如何工作以及 Python 接口创建的注意事项
- 理解在像 Python 这样的动态语言中接口是多么有用
- 实现一个非正式的 Python 接口
- 使用
abc.ABCMeta和@abc.abstractmethod实现一个正式的 Python 接口
Python 中的接口处理方式不同于大多数其他语言,它们的设计复杂度也各不相同。在本教程结束时,您将对 Python 数据模型的某些方面有更好的理解,以及 Python 中的接口与 Java、C++和 Go 等语言中的接口的比较。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 接口概述
在高层次上,接口充当设计类的蓝图。像类一样,接口定义方法。与类不同,这些方法是抽象的。一个抽象方法是接口简单定义的方法。它没有实现这些方法。这是由类来完成的,然后实现接口,并赋予接口的抽象方法具体的含义。
与像 Java 、Go 和 C++ 这样的语言相比,Python 的界面设计方法有些不同。这些语言都有一个interface关键字,而 Python 没有。Python 在另一个方面进一步偏离了其他语言。它不需要实现接口的类来定义接口的所有抽象方法。
非正式接口
在某些情况下,您可能不需要正式 Python 接口的严格规则。Python 的动态特性允许你实现一个非正式接口。非正式的 Python 接口是一个定义了可以被覆盖的方法的类,但是没有严格的执行。
在下面的例子中,您将从一个数据工程师的角度出发,他需要从各种不同的非结构化文件类型中提取文本,比如 pdf 和电子邮件。您将创建一个非正式的接口,它定义了在PdfParser和EmlParser具体类中的方法:
class InformalParserInterface:
def load_data_source(self, path: str, file_name: str) -> str:
"""Load in the file for extracting text."""
pass
def extract_text(self, full_file_name: str) -> dict:
"""Extract text from the currently loaded file."""
pass
InformalParserInterface定义了两种方法.load_data_source()和.extract_text()。这些方法已定义但未实现。一旦你创建了从InformalParserInterface继承的具体类,这个实现就会发生。
如您所见,InformalParserInterface看起来和标准 Python 类一样。你依靠鸭打字来通知用户这是一个接口,应该相应地使用。
注:没听说过鸭打字?这个术语说,如果你有一个看起来像鸭子,走路像鸭子,叫声像鸭子的物体,那么它一定是鸭子!要了解更多,请查看鸭子打字。
记住 duck 类型,定义两个实现InformalParserInterface的类。要使用您的接口,您必须创建一个具体的类。一个具体类是接口的子类,提供接口方法的实现。您将创建两个具体的类来实现您的接口。第一个是PdfParser,您将使用它来解析来自 PDF 文件的文本:
class PdfParser(InformalParserInterface):
"""Extract text from a PDF"""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides InformalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides InformalParserInterface.extract_text()"""
pass
InformalParserInterface的具体实现现在允许你从 PDF 文件中提取文本。
第二个具体的类是EmlParser,您将使用它来解析来自电子邮件的文本:
class EmlParser(InformalParserInterface):
"""Extract text from an email"""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides InformalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override InformalParserInterface.extract_text()
"""
pass
InformalParserInterface的具体实现现在允许你从电子邮件文件中提取文本。
到目前为止,您已经定义了InformalPythonInterface的两个具体实现。然而,请注意EmlParser未能正确定义.extract_text()。如果您要检查EmlParser是否实现了InformalParserInterface,那么您会得到以下结果:
>>> # Check if both PdfParser and EmlParser implement InformalParserInterface >>> issubclass(PdfParser, InformalParserInterface) True >>> issubclass(EmlParser, InformalParserInterface) True这将返回
True,这造成了一点问题,因为它违反了接口的定义!现在检查
PdfParser和EmlParser的方法解析顺序(MRO) 。这将告诉您正在讨论的类的超类,以及它们在执行方法时被搜索的顺序。你可以通过使用邓德方法cls.__mro__来查看一个类的 MRO:
>>> PdfParser.__mro__
(__main__.PdfParser, __main__.InformalParserInterface, object)
>>> EmlParser.__mro__
(__main__.EmlParser, __main__.InformalParserInterface, object)
这种非正式的接口对于只有少数开发人员开发源代码的小项目来说很好。然而,随着项目越来越大,团队越来越多,这可能导致开发人员花费无数时间在代码库中寻找难以发现的逻辑错误!
使用元类
理想情况下,当实现类没有定义接口的所有抽象方法时,您会希望issubclass(EmlParser, InformalParserInterface)返回False。为此,您将创建一个名为ParserMeta的元类。您将覆盖两个 dunder 方法:
.__instancecheck__().__subclasscheck__()
在下面的代码块中,您创建了一个名为UpdatedInformalParserInterface的类,它从ParserMeta元类构建而来:
class ParserMeta(type):
"""A Parser metaclass that will be used for parser class creation.
"""
def __instancecheck__(cls, instance):
return cls.__subclasscheck__(type(instance))
def __subclasscheck__(cls, subclass):
return (hasattr(subclass, 'load_data_source') and
callable(subclass.load_data_source) and
hasattr(subclass, 'extract_text') and
callable(subclass.extract_text))
class UpdatedInformalParserInterface(metaclass=ParserMeta):
"""This interface is used for concrete classes to inherit from.
There is no need to define the ParserMeta methods as any class
as they are implicitly made available via .__subclasscheck__().
"""
pass
现在已经创建了ParserMeta和UpdatedInformalParserInterface,您可以创建您的具体实现了。
首先,创建一个名为PdfParserNew的解析 pdf 的新类:
class PdfParserNew:
"""Extract text from a PDF."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides UpdatedInformalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides UpdatedInformalParserInterface.extract_text()"""
pass
这里,PdfParserNew覆盖了.load_data_source()和.extract_text(),所以issubclass(PdfParserNew, UpdatedInformalParserInterface)应该返回True。
在下一个代码块中,您有了一个名为EmlParserNew的电子邮件解析器的新实现:
class EmlParserNew:
"""Extract text from an email."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides UpdatedInformalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override UpdatedInformalParserInterface.extract_text()
"""
pass
在这里,您有一个用于创建UpdatedInformalParserInterface的元类。通过使用元类,您不需要显式定义子类。相反,子类必须定义所需的方法。如果没有,那么issubclass(EmlParserNew, UpdatedInformalParserInterface)将返回False。
在您的具体类上运行issubclass()将产生以下结果:
>>> issubclass(PdfParserNew, UpdatedInformalParserInterface) True >>> issubclass(EmlParserNew, UpdatedInformalParserInterface) False正如所料,
EmlParserNew不是UpdatedInformalParserInterface的子类,因为.extract_text()没有在EmlParserNew中定义。现在,让我们来看看 MRO:
>>> PdfParserNew.__mro__
(<class '__main__.PdfParserNew'>, <class 'object'>)
如您所见,UpdatedInformalParserInterface是PdfParserNew的超类,但是它没有出现在 MRO 中。这种不寻常的行为是由于UpdatedInformalParserInterface是PdfParserNew的虚拟基类造成的。
使用虚拟基类
在前面的例子中,issubclass(EmlParserNew, UpdatedInformalParserInterface)返回了True,即使UpdatedInformalParserInterface没有出现在EmlParserNew MRO 中。那是因为UpdatedInformalParserInterface是EmlParserNew的一个虚拟基类。
这些子类和标准子类之间的关键区别在于,虚拟基类使用.__subclasscheck__() dunder 方法来隐式检查一个类是否是超类的虚拟子类。此外,虚拟基类不会出现在子类 MRO 中。
看一下这个代码块:
class PersonMeta(type):
"""A person metaclass"""
def __instancecheck__(cls, instance):
return cls.__subclasscheck__(type(instance))
def __subclasscheck__(cls, subclass):
return (hasattr(subclass, 'name') and
callable(subclass.name) and
hasattr(subclass, 'age') and
callable(subclass.age))
class PersonSuper:
"""A person superclass"""
def name(self) -> str:
pass
def age(self) -> int:
pass
class Person(metaclass=PersonMeta):
"""Person interface built from PersonMeta metaclass."""
pass
这里,您有了创建虚拟基类的设置:
- 元类
PersonMeta - 基类
PersonSuper - Python 接口
Person
现在创建虚拟基类的设置已经完成,您将定义两个具体的类,Employee和Friend。Employee类继承自PersonSuper,而Friend隐式继承自Person:
# Inheriting subclasses
class Employee(PersonSuper):
"""Inherits from PersonSuper
PersonSuper will appear in Employee.__mro__
"""
pass
class Friend:
"""Built implicitly from Person
Friend is a virtual subclass of Person since
both required methods exist.
Person not in Friend.__mro__
"""
def name(self):
pass
def age(self):
pass
虽然Friend没有显式继承Person,但是它实现了.name()和.age(),所以Person成为了Friend的虚拟基类。当你运行issubclass(Friend, Person)时,它应该返回True,这意味着Friend是Person的子类。
下面的 UML 图显示了当您在Friend类上调用issubclass()时会发生什么:
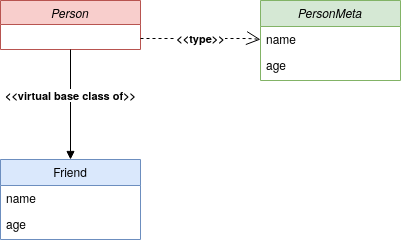
看一看PersonMeta,您会注意到还有另一个名为.__instancecheck__()的 dunder 方法。该方法用于检查是否从Person接口创建了Friend的实例。当你使用isinstance(Friend, Person)时,你的代码将调用.__instancecheck__()。
正式接口
非正式接口对于代码基数小、程序员数量有限的项目非常有用。然而,非正式接口对于大型应用程序来说是错误的。为了创建一个正式的 Python 接口,你将需要 Python 的abc模块中的一些工具。
使用abc.ABCMeta
为了强制抽象方法的子类实例化,您将利用 Python 的内置模块 abc 中的ABCMeta。回到您的UpdatedInformalParserInterface接口,您创建了自己的元类ParserMeta,用被覆盖的 dunder 方法.__instancecheck__()和.__subclasscheck__()。
您将使用abc.ABCMeta作为元类,而不是创建自己的元类。然后,您将覆盖.__subclasshook__()来代替.__instancecheck__()和.__subclasscheck__(),因为它创建了这些 dunder 方法的更可靠的实现。
使用.__subclasshook__()
下面是使用abc.ABCMeta作为元类的FormalParserInterface的实现:
import abc
class FormalParserInterface(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass):
return (hasattr(subclass, 'load_data_source') and
callable(subclass.load_data_source) and
hasattr(subclass, 'extract_text') and
callable(subclass.extract_text))
class PdfParserNew:
"""Extract text from a PDF."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text(self, full_file_path: str) -> dict:
"""Overrides FormalParserInterface.extract_text()"""
pass
class EmlParserNew:
"""Extract text from an email."""
def load_data_source(self, path: str, file_name: str) -> str:
"""Overrides FormalParserInterface.load_data_source()"""
pass
def extract_text_from_email(self, full_file_path: str) -> dict:
"""A method defined only in EmlParser.
Does not override FormalParserInterface.extract_text()
"""
pass
如果在PdfParserNew和EmlParserNew上运行issubclass(),那么issubclass()将分别返回True和False。
使用abc注册一个虚拟子类
一旦导入了abc模块,就可以通过使用.register()元方法直接注册一个虚拟子类。在下一个例子中,您将接口Double注册为内置__float__类的虚拟基类:
class Double(metaclass=abc.ABCMeta):
"""Double precision floating point number."""
pass
Double.register(float)
你可以看看使用.register()的效果:
>>> issubclass(float, Double) True >>> isinstance(1.2345, Double) True通过使用
.register()元方法,您已经成功地将Double注册为float的虚拟子类。一旦你注册了
Double,你就可以用它作为类装饰器来将装饰类设置为虚拟子类:@Double.register class Double64: """A 64-bit double-precision floating-point number.""" pass print(issubclass(Double64, Double)) # Truedecorator register 方法帮助您创建自定义虚拟类继承的层次结构。
通过注册使用子类检测
当你组合
.__subclasshook__()和.register()时,你必须小心,因为.__subclasshook__()优先于虚拟子类注册。为了确保注册的虚拟子类被考虑在内,您必须将NotImplemented添加到.__subclasshook__()dunder 方法中。FormalParserInterface将更新为以下内容:class FormalParserInterface(metaclass=abc.ABCMeta): @classmethod def __subclasshook__(cls, subclass): return (hasattr(subclass, 'load_data_source') and callable(subclass.load_data_source) and hasattr(subclass, 'extract_text') and callable(subclass.extract_text) or NotImplemented) class PdfParserNew: """Extract text from a PDF.""" def load_data_source(self, path: str, file_name: str) -> str: """Overrides FormalParserInterface.load_data_source()""" pass def extract_text(self, full_file_path: str) -> dict: """Overrides FormalParserInterface.extract_text()""" pass @FormalParserInterface.register class EmlParserNew: """Extract text from an email.""" def load_data_source(self, path: str, file_name: str) -> str: """Overrides FormalParserInterface.load_data_source()""" pass def extract_text_from_email(self, full_file_path: str) -> dict: """A method defined only in EmlParser. Does not override FormalParserInterface.extract_text() """ pass print(issubclass(PdfParserNew, FormalParserInterface)) # True print(issubclass(EmlParserNew, FormalParserInterface)) # True因为您已经使用了注册,所以您可以看到
EmlParserNew被视为FormalParserInterface接口的虚拟子类。这不是你想要的,因为EmlParserNew不会覆盖.extract_text()。请谨慎注册虚拟子类!使用抽象方法声明
抽象方法是由 Python 接口声明的方法,但它可能没有有用的实现。抽象方法必须由实现相关接口的具体类重写。
要在 Python 中创建抽象方法,需要在接口的方法中添加
@abc.abstractmethoddecorator。在下一个例子中,您更新了FormalParserInterface以包含抽象方法.load_data_source()和.extract_text():class FormalParserInterface(metaclass=abc.ABCMeta): @classmethod def __subclasshook__(cls, subclass): return (hasattr(subclass, 'load_data_source') and callable(subclass.load_data_source) and hasattr(subclass, 'extract_text') and callable(subclass.extract_text) or NotImplemented) @abc.abstractmethod def load_data_source(self, path: str, file_name: str): """Load in the data set""" raise NotImplementedError @abc.abstractmethod def extract_text(self, full_file_path: str): """Extract text from the data set""" raise NotImplementedError class PdfParserNew(FormalParserInterface): """Extract text from a PDF.""" def load_data_source(self, path: str, file_name: str) -> str: """Overrides FormalParserInterface.load_data_source()""" pass def extract_text(self, full_file_path: str) -> dict: """Overrides FormalParserInterface.extract_text()""" pass class EmlParserNew(FormalParserInterface): """Extract text from an email.""" def load_data_source(self, path: str, file_name: str) -> str: """Overrides FormalParserInterface.load_data_source()""" pass def extract_text_from_email(self, full_file_path: str) -> dict: """A method defined only in EmlParser. Does not override FormalParserInterface.extract_text() """ pass在上面的例子中,您最终创建了一个正式的接口,当抽象方法没有被覆盖时,它会引发错误。因为
PdfParserNew正确地覆盖了FormalParserInterface抽象方法,所以PdfParserNew实例pdf_parser不会引发任何错误。但是,EmlParserNew会引发一个错误:
>>> pdf_parser = PdfParserNew()
>>> eml_parser = EmlParserNew()
Traceback (most recent call last):
File "real_python_interfaces.py", line 53, in <module>
eml_interface = EmlParserNew()
TypeError: Can't instantiate abstract class EmlParserNew with abstract methods extract_text
如您所见, traceback 消息告诉您还没有覆盖所有的抽象方法。这是您在构建正式 Python 接口时所期望的行为。
其他语言界面
接口出现在许多编程语言中,并且它们的实现因语言而异。在接下来的几节中,您将比较 Python 与 Java、C++和 Go 中的接口。
Java
与 Python 不同, Java 包含一个interface关键字。按照文件解析器的例子,用 Java 声明一个接口,如下所示:
public interface FileParserInterface { // Static fields, and abstract methods go here ... public void loadDataSource(); public void extractText(); }
现在您将创建两个具体的类,PdfParser和EmlParser,来实现FileParserInterface。为此,您必须在类定义中使用implements关键字,如下所示:
public class EmlParser implements FileParserInterface { public void loadDataSource() { // Code to load the data set } public void extractText() { // Code to extract the text } }
继续您的文件解析示例,一个全功能的 Java 接口应该是这样的:
import java.util.*; import java.io.*; public class FileParser { public static void main(String[] args) throws IOException { // The main entry point } public interface FileParserInterface { HashMap<String, ArrayList<String>> file_contents = null; public void loadDataSource(); public void extractText(); } public class PdfParser implements FileParserInterface { public void loadDataSource() { // Code to load the data set } public void extractText() { // Code to extract the text } } public class EmlParser implements FileParserInterface { public void loadDataSource() { // Code to load the data set } public void extractText() { // Code to extract the text } } }
如您所见,Python 接口在创建过程中比 Java 接口提供了更多的灵活性。
C++
像 Python 一样,C++使用抽象基类来创建接口。在 C++中定义接口时,使用关键字virtual来描述应该在具体类中覆盖的方法:
class FileParserInterface { public: virtual void loadDataSource(std::string path, std::string file_name); virtual void extractText(std::string full_file_name); };
当您想要实现接口时,您将给出具体的类名,后跟一个冒号(:),然后是接口的名称。下面的示例演示了 C++接口的实现:
class PdfParser : FileParserInterface { public: void loadDataSource(std::string path, std::string file_name); void extractText(std::string full_file_name); }; class EmlParser : FileParserInterface { public: void loadDataSource(std::string path, std::string file_name); void extractText(std::string full_file_name); };
Python 接口和 C++接口有一些相似之处,因为它们都利用抽象基类来模拟接口。
转到
虽然 Go 的语法让人想起 Python,但是 Go 编程语言包含了一个interface关键字,就像 Java 一样。让我们在 Go 中创建fileParserInterface:
type fileParserInterface interface { loadDataSet(path string, filename string) extractText(full_file_path string) }
Python 和 Go 的一个很大的区别就是 Go 没有类。更确切地说,Go 类似于 C ,因为它使用struct关键字来创建结构。一个结构类似于一个类,因为一个结构包含数据和方法。然而,与类不同的是,所有的数据和方法都是公开访问的。Go 中的具体结构将用于实现fileParserInterface。
下面是 Go 如何使用接口的一个例子:
package main type fileParserInterface interface { loadDataSet(path string, filename string) extractText(full_file_path string) } type pdfParser struct { // Data goes here ... } type emlParser struct { // Data goes here ... } func (p pdfParser) loadDataSet() { // Method definition ... } func (p pdfParser) extractText() { // Method definition ... } func (e emlParser) loadDataSet() { // Method definition ... } func (e emlParser) extractText() { // Method definition ... } func main() { // Main entrypoint }
与 Python 接口不同,Go 接口是使用 structs 和显式关键字interface创建的。
结论
当你创建接口时,Python 提供了很大的灵活性。非正式的 Python 接口对于小型项目非常有用,在这些项目中,您不太可能对方法的返回类型感到困惑。随着项目的增长,对正式 Python 接口的需求变得更加重要,因为推断返回类型变得更加困难。这确保了实现接口的具体类覆盖了抽象方法。
现在你可以:
- 理解接口如何工作以及创建 Python 接口的注意事项
- 理解像 Python 这样的动态语言中接口的用途
- 用 Python 实现正式和非正式的接口
- 将 Python 接口与 Java、C++和 Go 等语言中的接口进行比较
既然您已经熟悉了如何创建 Python 接口,那么在您的下一个项目中添加一个 Python 接口来看看它的实际用途吧!*****
Python 实践问题:解析 CSV 文件
原文:https://realpython.com/python-interview-problem-parsing-csv-files/
你是一名开发人员,在即将到来的面试之前,你在寻找一些使用逗号分隔值(CSV)文件的练习吗?本教程将引导您完成一系列 Python CSV 实践问题,帮助您做好准备。
本教程面向中级 Python 开发人员。它假设一个Python 的基础知识和处理 CSV 文件。和其他练习题教程一样,这里列出的每个问题都有问题描述。您将首先看到问题陈述,然后有机会开发您自己的解决方案。
在本教程中,您将探索:
- 编写使用 CSV 文件的代码
- 用 pytest 做测试驱动开发
- 讨论您的解决方案和可能的改进
- 内置 CSV 模块和熊猫之间的权衡
通过单击下面的链接,您可以获得本教程中遇到的每个问题的单元测试失败的框架代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用来练习解析 CSV 文件。
Python CSV 解析:足球比分
你的第一个问题是关于英超联赛的排名。解决这个不需要什么专门的足球知识,Python 就行!
当你解决问题时,试着为每一点功能编写更多的单元测试,然后编写功能以通过测试。这就是所谓的测试驱动开发,这是一个展示你的编码和测试能力的好方法!
问题描述
对于这一轮的问题,坚持标准库csv模块。稍后你会用熊猫再拍一次。这是你的第一个问题:
找出最小目标差值
编写一个程序,在命令行上输入文件名并处理 CSV 文件的内容。内容将是英格兰超级联赛赛季末的足球排名。你的程序应该确定那个赛季哪个队的净胜球最少。
CSV 文件的第一行是列标题,随后的每一行显示一个团队的数据:
`Team,Games,Wins,Losses,Draws,Goals For,Goals Against Arsenal,38,26,9,3,79,36`标有
Goals For和Goals Against的栏包含该赛季各队的总进球数。(所以阿森纳进了 79 个球,对他们进了 36 个球。)写个程序读取文件,然后打印出
Goals For和Goals Against相差最小的队伍名称。用 pytest 创建单元测试来测试你的程序。
框架代码中提供了一个单元测试,用于测试您稍后将看到的问题陈述。您可以在编写解决方案时添加更多内容。还有两个 pytest 夹具给定:
# test_football_v1.py
import pytest
import football_v1 as fb
@pytest.fixture
def mock_csv_data():
return [
"Team,Games,Wins,Losses,Draws,Goals For,Goals Against",
"Liverpool FC, 38, 32, 3, 3, 85, 33",
"Norwich City FC, 38, 5, 27, 6, 26, 75",
]
@pytest.fixture
def mock_csv_file(tmp_path, mock_csv_data):
datafile = tmp_path / "football.csv"
datafile.write_text("\n".join(mock_csv_data))
return str(datafile)
第一个 fixture 提供了一个由字符串组成的列表,这些字符串模仿真实的 CSV 数据,第二个 fixture 提供了一个由测试数据支持的文件名。字符串列表中的每个字符串代表测试文件中的一行。
注意:此处的解决方案将有一组非详尽的测试,仅证明基本功能。对于一个真实的系统,你可能想要一个更完整的测试套件,可能利用参数化。
请记住,所提供的装置只是一个开始。在设计解决方案的每个部分时,添加使用它们的单元测试!
问题解决方案
这里讨论一下 Real Python 团队达成的解决方案,以及团队是如何达成的。
注意:记住,在您准备好查看每个 Python 练习问题的答案之前,不要打开下面折叠的部分!
乐谱解析的怎么样了?你准备好看到真正的 Python 团队给出的答案了吗?
在解决这个问题的过程中,该团队通过编写并多次重写代码,提出了几个解决方案。在面试中,你通常只有一次机会。在实时编码的情况下,您可以使用一种技术来解决这个问题,那就是花一点时间来讨论您现在可以使用的其他实现选项。
解决方案 1
您将研究这个问题的两种不同的解决方案。您将看到的第一个解决方案运行良好,但仍有改进的空间。您将在这里使用测试驱动开发(TDD)模型,因此您不会首先查看完整的解决方案,而只是查看解决方案的整体计划。
将解决方案分成几个部分允许您在编写代码之前为每个部分编写单元测试。这是该解决方案的大致轮廓:
- 在生成器中读取并解析 CSV 文件的每一行。
- 计算给定线的队名和分数差。
- 求最小分数差。
让我们从第一部分开始,一次一行地读取和解析文件。您将首先为该操作构建测试。
读取并解析
给定问题的描述,您提前知道列是什么,所以您不需要输出中的第一行标签。您还知道每一行数据都有七个字段,因此您可以测试您的解析函数是否返回一个行列表,每一行都有七个条目:
# test_football_v1.py
import pytest
import football_v1 as fb
# ...
def test_parse_next_line(mock_csv_data):
all_lines = [line for line in fb.parse_next_line(mock_csv_data)]
assert len(all_lines) == 2
for line in all_lines:
assert len(line) == 7
您可以看到这个测试使用了您的第一个 pytest fixture,它提供了一个 CSV 行列表。这个测试利用了 CSV 模块可以解析一个列表对象或者一个文件对象的事实。这对于您的测试来说非常方便,因为您还不必担心管理文件对象。
测试使用一个列表理解来读取从parse_next_line()开始的所有行,这将是一个生成器。然后,它断言列表中的几个属性:
- 列表中有两个条目。
- 每个条目本身是一个包含七个项目的列表。
现在您有了一个测试,您可以运行它来确认它是否运行以及它是否如预期的那样失败:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 1 item
test_football_v1.py F [100%]
=================================== FAILURES ===================================
_______________________________ test_parse_next_line ___________________________
mock_csv_data = ['Team,Games,Wins,Losses,Draws,Goals For,Goals Against', ....
def test_parse_next_line(mock_csv_data ):
> all_lines = [line for line in fb.parse_next_line(mock_csv_data)]
E AttributeError: module 'football_v1' has no attribute 'parse_next_line'
test_football_csv.py:30: AttributeError
=========================== short test summary info ============================
FAILED test_football_v1.py::test_parse_next_line - AttributeError: module 'fo...
============================== 1 failed in 0.02s ===============================
测试失败是因为parse_next_line()是未定义的,考虑到您还没有编写它,这是有意义的。当你知道测试会失败时运行测试会给你信心,当测试最终通过时,你所做的改变就是修复它们的原因。
注意:上面的 pytest 输出假设您有一个名为football_v1.py的文件,但是它不包含函数parse_next_line()。如果你没有这个文件,你可能会得到一个错误提示ModuleNotFoundError: No module named 'football_v1'。
接下来你要写缺失的parse_next_line()。这个函数将是一个生成器,返回文件中每一行的解析版本。您需要添加一些代码来跳过标题:
# football_v1.py
import csv
def parse_next_line(csv_file):
for line in csv.DictReader(csv_file):
yield line
该函数首先创建一个csv.DictReader(),它是 CSV 文件的迭代器。DictReader使用标题行作为它创建的字典的关键字。文件的每一行都用这些键和相应的值构建了一个字典。这个字典是用来创建您的生成器的。
现在用您的单元测试来尝试一下:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 1 item
test_football_v1.py . [100%]
============================== 1 passed in 0.01s ===============================
太棒了。您的第一个功能块正在工作。您知道您添加的代码是使测试通过的原因。现在你可以进入下一步,计算给定线的分数差。
计算微分
该函数将获取由parse_next_line()解析的值列表,并计算分数差Goals For - Goals Against。这就是那些具有少量代表性数据的测试装置将会有所帮助的地方。您可以手动计算测试数据中两条线的差异,得到利物浦足球俱乐部的差异为 52,诺里奇城足球俱乐部的差异为 49。
这个测试将使用您刚刚完成的生成器函数从测试数据中提取每一行:
# test_football_v1.py
import pytest
import football_v1 as fb
# ...
def test_get_score_difference(mock_csv_data):
reader = fb.parse_next_line(mock_csv_data)
assert fb.get_name_and_diff(next(reader)) == ("Liverpool FC", 52)
assert fb.get_name_and_diff(next(reader)) == ("Norwich City FC", 49)
首先创建刚刚测试过的生成器,然后使用next()遍历两行测试数据。 assert语句测试每个手工计算的值是否正确。
和以前一样,一旦有了测试,就可以运行它以确保它失败:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 2 items
test_football_v1.py .F [100%]
=================================== FAILURES ===================================
__________________________ test_get_score_difference ___________________________
mock_csv_data = ['Team,Games,Wins,Losses,Draws,Goals For,Goals Against', ...
def test_get_score_difference(mock_csv_data):
reader = fb.parse_next_line(mock_csv_data)
> team, diff = fb.get_name_and_diff(next(reader))
E AttributeError: module 'football_v1' has no attribute 'get_name_and ...
test_football_v1.py:38: AttributeError
=========================== short test summary info ============================
FAILED test_football_v1.py::test_get_score_difference - AttributeError: modul...
========================= 1 failed, 1 passed in 0.03s ==========================
现在测试已经就绪,看看get_name_and_diff()的实现。由于DictReader为您将 CSV 值放入字典中,您可以从每个字典中检索团队名称并计算目标差异:
# football_v1.py
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], diff
您可以把它写成一行程序,但是把它分成几个清晰的字段可能会提高可读性。它还可以使调试这段代码变得更容易。如果你在面试中现场编码,这些都是很好的提点。表明你对可读性有所考虑会有所不同。
现在您已经实现了这个功能,您可以重新运行您的测试:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 2 items
test_football_v1.py .F [100%]
=================================== FAILURES ===================================
__________________________ test_get_score_difference ___________________________
mock_csv_data = ['Team,Games,Wins,Losses,Draws,Goals For,Goals Against', ...
def test_get_score_difference(mock_csv_data):
reader = fb.parse_next_line(mock_csv_data)
assert fb.get_name_and_diff(next(reader)) == ("Liverpool FC", 52)
> assert fb.get_name_and_diff(next(reader)) == ("Norwich City FC", 49)
E AssertionError: assert ('Norwich City FC', -49) == ('Norwich City FC'...
E At index 1 diff: -49 != 49
E Use -v to get the full diff
test_football_v1.py:40: AssertionError
=========================== short test summary info ============================
FAILED test_football_v1.py::test_get_score_difference - AssertionError: asser...
========================= 1 failed, 1 passed in 0.07s ==========================
哎呦!这是不对的。该函数返回的差值不应为负。还好你写了测试!
您可以通过在返回值上使用 abs() 来更正:
# football_v1.py
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
你可以在函数的最后一行看到它现在调用了abs(diff),所以你不会得到负数的结果。现在用您的测试来尝试这个版本,看看它是否通过:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 2 items
test_football_v1.py .. [100%]
============================== 2 passed in 0.01s ===============================
那好多了。如果你想找到净胜球差距最小的球队,你就需要差距的绝对值。
查找最小值
对于您的最后一块拼图,您需要一个函数,它使用您的生成器获取 CSV 文件的每一行,并使用您的函数返回每一行的球队名称和得分差异,然后找到这些差异的最小值。对此的测试是框架代码中给出的总体测试:
# test_football_v1.py
import pytest
import football_v1 as fb
# ...
def test_get_min_score(mock_csv_file):
assert fb.get_min_score_difference(mock_csv_file) == (
"Norwich City FC",
49,
)
您再次使用提供的 pytest fixtures,但是这一次您使用mock_csv_file fixture 来获取一个文件的文件名,该文件包含您到目前为止一直在使用的相同的测试数据集。该测试调用您的最终函数,并断言您手动计算的正确答案:诺维奇城队以 49 球的比分差距最小。
至此,您已经看到在被测试的函数实现之前测试失败了,所以您可以跳过这一步,直接跳到您的解决方案:
# football_v1.py
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_file:
min_diff = 10000
min_team = None
for line in parse_next_line(csv_file):
team, diff = get_name_and_diff(line)
if diff < min_diff:
min_diff = diff
min_team = team
return min_team, min_diff
该函数使用上下文管理器打开给定的 CSV 文件进行读取。然后它设置min_diff和min_team变量,您将使用它们来跟踪您在遍历列表时找到的最小值。你在10000开始最小差异,这对于足球比分似乎是安全的。
然后,该函数遍历每一行,获取团队名称和差异,并找到差异的最小值。
当您针对测试运行此代码时,它会通过:
$ pytest test_football_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 3 items
test_football_v1.py ... [100%]
============================== 3 passed in 0.03s ===============================
恭喜你!您已经找到了所述问题的解决方案!
一旦你做到了这一点,尤其是在面试的情况下,是时候检查你的解决方案,看看你是否能找出让代码更可读、更健壮或更 T2 的变化。这是您将在下一部分中执行的操作。
解决方案 2:重构解决方案 1
从整体上看一下你对这个问题的第一个解决方案:
# football_v1.py
import csv
def parse_next_line(csv_file):
for line in csv.DictReader(csv_file):
yield line
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_file:
min_diff = 10000
min_team = None
for line in parse_next_line(csv_file):
team, diff = get_name_and_diff(line)
if diff < min_diff:
min_diff = diff
min_team = team
return min_team, min_diff
从整体上看这段代码,有一些事情需要注意。其中之一是get_name_and_diff()并没有做那么多。它只从字典中取出三个字段并减去。第一个函数parse_next_line()也相当短,似乎可以将这两个函数结合起来,让生成器只返回球队名称和分数差。
您可以将这两个函数重构为一个名为get_next_name_and_diff()的新函数。如果你跟随本教程,现在是一个很好的时机将football_v1.py复制到football_v2.py并对测试文件做类似的操作。坚持您的 TDD 过程,您将重用您的第一个解决方案的测试:
# test_football_v2.py
import pytest
import football_v2 as fb
# ...
def test_get_min_score(mock_csv_file):
assert fb.get_min_score_difference(mock_csv_file) == (
"Norwich City FC",
49,
)
def test_get_score_difference(mock_csv_data):
reader = fb.get_next_name_and_diff(mock_csv_data) assert next(reader) == ("Liverpool FC", 52) assert next(reader) == ("Norwich City FC", 49) with pytest.raises(StopIteration): next(reader)
第一个测试test_get_min_score()保持不变,因为它测试的是最高级别的功能,这是不变的。
其他两个测试函数合并成一个函数,将返回的项目数和返回值的测试合并成一个测试。它借助 Python 内置的next()直接使用从get_next_name_and_diff()返回的生成器。
下面是将这两个非测试函数放在一起时的样子:
# football_v2.py
import csv
def get_next_name_and_diff(csv_file):
for team_stats in csv.DictReader(csv_file):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
yield team_stats["Team"], abs(diff)
这个函数看起来确实像前面的函数挤在一起。它使用csv.DictReader(),而不是产生从每一行创建的字典,只产生团队名称和计算的差异。
虽然就可读性而言,这并不是一个巨大的改进,但它将允许您在剩余的函数中做一些其他的简化。
剩下的功能get_min_score_difference(),也有一定的改进空间。手动遍历列表以找到最小值是标准库提供的功能。幸运的是,这是顶级功能,所以您的测试不需要更改。
如上所述,您可以使用 min() 从标准库中找到列表或 iterable 中的最小项。“或可迭代”部分很重要。您的get_next_name_and_diff()生成器符合可迭代条件,因此min()将运行生成器并找到最小结果。
一个问题是get_next_name_and_diff()产生了(team_name, score_differential)个元组,并且您想要最小化差值。为了方便这个用例,min()有一个关键字参数,key。您可以提供一个函数,或者在您的情况下提供一个 lambda ,来指示它将使用哪些值来搜索最小值:
# football_v2.py
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min(get_next_name_and_diff(csv_data), key=lambda item: item[1])
这种变化将代码压缩成一个更小、更 Pythonic 化的函数。用于key的λ允许min()找到分数差的最小值。对新代码运行 pytest 表明,它仍然解决了上述问题:
$ pytest test_football_v2.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 3 items
test_football_v2.py ... [100%]
============================== 3 passed in 0.01s ===============================
以这种方式花时间检查和重构代码在日常编码中是一个很好的实践,但在面试环境中可能实用,也可能不实用。即使你觉得在面试中没有时间或精力来完全重构你的解决方案,花一点时间向面试官展示你的想法也是值得的。
当你在面试时,花一分钟指出,“这些功能很小——我可以合并它们,”或者,“如果我推动这个显式循环,那么我可以使用min()功能”,这将向面试官展示你知道这些事情。没有人在第一次尝试时就能得出最优解。
面试中另一个值得讨论的话题是边角案例。解决方案能处理坏的数据线吗?像这样的主题有助于很好的测试,并且可以在早期发现很多问题。有时候在面试中讨论这些问题就足够了,有时候回去重构你的测试和代码来处理这些问题是值得的。
你可能还想讨论问题的定义。特别是这个问题有一个不明确的规范。如果两个队有相同的差距,解决方案应该是什么?您在这里看到的解决方案选择了第一个,但也有可能返回全部,或者最后一个,或者其他一些决定。
这种类型的模糊性在实际项目中很常见,因此认识到这一点并将其作为一个主题提出来可能表明您正在思考超越代码解决方案的问题。
既然您已经使用 Python csv模块解决了一个问题,那么就用一个类似的问题再试一次。
Python CSV 解析:天气数据
你的第二个问题看起来和第一个很相似。使用类似的结构来解决它可能是个好主意。一旦你完成了这个问题的解决方案,你将会读到一些重构重用代码的想法,所以在工作中要记住这一点。
问题描述
这个问题涉及到解析 CSV 文件中的天气数据:
最高平均温度
编写一个程序,在命令行上输入文件名并处理 CSV 文件的内容。内容将是一个月的天气数据,每行一天。
您的程序应该确定哪一天的平均温度最高,其中平均温度是当天最高温度和最低温度的平均值。这通常不是计算平均温度的方法,但在这个演示中是可行的。
CSV 文件的第一行是列标题:
`Day,MaxT,MinT,AvDP,1HrP TPcn,PDir,AvSp,Dir,MxS,SkyC,MxR,Mn,R AvSLP 1,88,59,74,53.8,0,280,9.6,270,17,1.6,93,23,1004.5`日期、最高温度和最低温度是前三列。
用 pytest 编写单元测试来测试你的程序。
与足球比分问题一样,框架代码中提供了测试问题陈述的单元测试:
# test_weather_v1.py
import pytest
import weather_v1 as wthr
@pytest.fixture
def mock_csv_data():
return [
"Day,MxT,MnT,AvT,AvDP,1HrP TPcn,PDir,AvSp,Dir,MxS,SkyC,MxR,Mn,R AvSLP",
"1,88,59,74,53.8,0,280,9.6,270,17,1.6,93,23,1004.5",
"2,79,63,71,46.5,0,330,8.7,340,23,3.3,70,28,1004.5",
]
@pytest.fixture
def mock_csv_file(tmp_path, mock_csv_data):
datafile = tmp_path / "weather.csv"
datafile.write_text("\n".join(mock_csv_data))
return str(datafile)
再次注意,给出了两个装置。第一个提供模拟真实 CSV 数据的字符串列表,第二个提供由测试数据支持的文件名。字符串列表中的每个字符串代表测试文件中的一行。
请记住,所提供的装置只是一个开始。在设计解决方案的每个部分时添加测试!
问题解决方案
这里讨论一下真正的 Python 团队达成了什么。
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
您将在这里看到的解决方案与前面的解决方案非常相似。您看到了上面略有不同的一组测试数据。这两个测试函数基本上与足球解决方案相同:
# test_weather_v1.py
import pytest
import weather_v1 as wthr
# ...
def test_get_max_avg(mock_csv_file):
assert wthr.get_max_avg(mock_csv_file) == (1, 73.5)
def test_get_next_day_and_avg(mock_csv_data):
reader = wthr.get_next_day_and_avg(mock_csv_data)
assert next(reader) == (1, 73.5)
assert next(reader) == (2, 71)
with pytest.raises(StopIteration):
next(reader)
虽然这些测试是好的,但是当你更多地思考问题并在你的解决方案中发现 bug 时,添加新的测试也是好的。这里有一些新的测试,涵盖了你在上一个问题结束时想到的一些极限情况:
# test_weather_v1.py
import pytest
import weather_v1 as wthr
# ...
def test_no_lines():
no_data = []
for _ in wthr.get_next_day_and_avg(no_data):
assert False
def test_trailing_blank_lines(mock_csv_data):
mock_csv_data.append("")
all_lines = [x for x in wthr.get_next_day_and_avg(mock_csv_data)]
assert len(all_lines) == 2
for line in all_lines:
assert len(line) == 2
def test_mid_blank_lines(mock_csv_data):
mock_csv_data.insert(1, "")
all_lines = [x for x in wthr.get_next_day_and_avg(mock_csv_data)]
assert len(all_lines) == 2
for line in all_lines:
assert len(line) == 2
这些测试包括传入空文件的情况,以及 CSV 文件中间或结尾有空行的情况。文件的第一行有坏数据的情况更有挑战性。如果第一行不包含标签,数据是否仍然满足问题的要求?真正的 Python 解决方案假定这是无效的,并且不对其进行测试。
对于这个问题,代码本身不需要做太大的改动。和以前一样,如果你正在你的机器上处理这些解决方案,现在是复制football_v2.py到weather_v1.py的好时机。
如果您从足球解决方案开始,那么生成器函数被重命名为get_next_day_and_avg(),调用它的函数现在是get_max_avg():
# weather_v1.py
import csv
def get_next_day_and_avg(csv_file):
for day_stats in csv.DictReader(csv_file):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
yield day_number, avg
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(get_next_day_and_avg(csv_file), key=lambda item: item[1])
在这种情况下,你稍微改变一下get_next_day_and_avg()。您现在得到的是一个代表天数并计算平均温度的整数,而不是团队名称和分数差。
调用get_next_day_and_avg()的函数已经改为使用 max() 而不是min(),但仍然保持相同的结构。
针对这段代码运行新的测试显示了使用标准库中的工具的优势:
$ pytest test_weather_v1.py
============================= test session starts ==============================
platform linux -- Python 3.7.1, pytest-6.2.1, py-1.10.0, pluggy-0.13.1
rootdir: /home/jima/coding/realPython/articles/jima-csv
collected 5 items
test_weather_v1.py ..... [100%]
============================== 5 passed in 0.05s ===============================
新函数通过了您添加的新空行测试。那个人会帮你处理那些案子。您的测试运行没有错误,您有一个伟大的解决方案!
在面试中,讨论你的解决方案的性能可能是好的。对于这里的框架代码提供的小数据文件,速度和内存使用方面的性能并不重要。但是如果天气数据是上个世纪的每日报告呢?这个解决方案会遇到内存问题吗?有没有办法通过重新设计解决方案来解决这些问题?
到目前为止,这两种解决方案具有相似的结构。在下一节中,您将看到重构这些解决方案,以及如何在它们之间共享代码。
Python CSV 解析:重构
到目前为止,您看到的两个问题非常相似,解决它们的程序也非常相似。一个有趣的面试问题可能是要求你重构这两个解决方案,找到一种共享代码的方法,使它们更易于维护。
问题描述
这个问题和前面两个有点不同。对于本节,从前面的问题中提取解决方案,并对它们进行重构,以重用常见的代码和结构。在现实世界中,这些解决方案足够小,以至于这里的重构工作可能不值得,但它确实是一个很好的思考练习。
问题解决方案
这是真正的 Python 团队完成的重构。
注意:记住,在你准备好查看这个 Python 练习题的答案之前,不要打开下面折叠的部分!
从查看这两个问题的解决方案代码开始。不算测试,足球解决方案有两个函数长:
# football_v2.py
import csv
def get_next_name_and_diff(csv_file):
for team_stats in csv.DictReader(csv_file):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
yield team_stats["Team"], abs(diff)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min(get_next_name_and_diff(csv_data), key=lambda item: item[1])
类似地,平均温度解由两个函数组成。相似的结构指出了需要重构的领域:
# weather_v1.py
import csv
def get_next_day_and_avg(csv_file):
for day_stats in csv.DictReader(csv_file):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
yield day_number, avg
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(get_next_day_and_avg(csv_file), key=lambda item: item[1])
在比较代码时,有时使用diff工具来比较每个代码的文本是很有用的。不过,您可能需要从文件中删除额外的代码来获得准确的图片。在这种情况下,文件字符串被删除。当你diff这两个解决方案时,你会发现它们非常相似:
--- football_v2.py 2021-02-09 19:22:05.653628190 -0700 +++ weather_v1.py 2021-02-09 19:22:16.769811115 -0700 @@ -1,9 +1,10 @@ -def get_next_name_and_diff(csv_file): - for team_stats in csv.DictReader(csv_file): - diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"]) - yield team_stats["Team"], abs(diff) +def get_next_day_and_avg(csv_file): + for day_stats in csv.DictReader(csv_file): + day_number = int(day_stats["Day"]) + avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2 + yield day_number, avg -def get_min_score_difference(filename): - with open(filename, "r", newline="") as csv_data: - return min(get_next_name_and_diff(csv_data), key=lambda item: item[1]) +def get_max_avg(filename): + with open(filename, "r", newline="") as csv_file: + return max(get_next_day_and_avg(csv_file), key=lambda item: item[1])
除了函数和变量的名称,还有两个主要区别:
- 足球解得出
Goals For和Goals Against的差值,而天气解得出MxT和MnT的平均值。 - 足球解决方案找到结果的
min(),而天气解决方案使用max()。
第二个区别可能不值得讨论,所以让我们从第一个开始。
这两个发生器功能在结构上是相同的。不同的部分通常可以描述为“获取一行数据并从中返回两个值”,这听起来像一个函数定义。
如果你重新编写足球解决方案来实现这个功能,它会让程序变得更长:
# football_v3.py
import csv
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_next_name_and_diff(csv_file):
for team_stats in csv.DictReader(csv_file):
yield get_name_and_diff(team_stats)
虽然这段代码比较长,但它提出了一些有趣的观点,值得在采访中讨论。有时候当你重构时,让代码更易读会导致代码更长。这里的情况可能不是这样,因为很难说将这个函数分离出来会使代码更具可读性。
然而,还有另外一点。有时为了重构代码,您必须降低代码的可读性或简洁性,以使公共部分可见。这绝对是你要去的地方。
最后,这是一个讨论单一责任原则的机会。在高层次上,单一责任原则声明您希望代码的每一部分,一个类,一个方法,或者一个函数,只做一件事情或者只有一个责任。在上面的重构中,您将从每行数据中提取值的职责从负责迭代csv.DictReader()的函数中抽出。
如果你回头看看你在上面足球问题的解决方案 1 和解决方案 2 之间所做的重构,你会看到最初的重构将parse_next_line()和get_name_and_diff()合并成了一个函数。在这个重构中,你把它们拉了回来!乍一看,这似乎是矛盾的,因此值得更仔细地研究。
在第一次重构中,合并两个功能很容易被称为违反单一责任原则。在这种情况下,在拥有两个只能一起工作的小函数和将它们合并成一个仍然很小的函数之间有一个可读性权衡。在这种情况下,合并它们似乎使代码更具可读性,尽管这是主观的。
在这种情况下,您出于不同的原因将这两个功能分开。这里的分裂不是最终目标,而是通往你目标的一步。通过将功能一分为二,您能够在两个解决方案之间隔离和共享公共代码。
对于这样一个小例子,这种分割可能是不合理的。然而,正如您将在下面看到的,它允许您有更多的机会共享代码。这种技术将一个功能块从一个函数中提取出来,放入一个独立的函数中,通常被称为提取方法技术。一些ide 和代码编辑器提供工具来帮助你完成这个操作。
此时,您还没有获得任何东西,下一步将使代码稍微复杂一些。你将把get_name_and_diff()传递给生成器。乍一看,这似乎违反直觉,但它将允许您重用生成器结构:
# football_v4.py
import csv
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_next_name_and_diff(csv_file, func):
for team_stats in csv.DictReader(csv_file):
yield func(team_stats)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min( get_next_name_and_diff(csv_data, get_name_and_diff), key=lambda item: item[1], )
这看起来像是一种浪费,但是有时候重构是一个将解决方案分解成小块以隔离不同部分的过程。尝试对天气解决方案进行同样的更改:
# weather_v2.py
import csv
def get_day_and_avg(day_stats):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
return day_number, avg
def get_next_day_and_avg(csv_file, func):
for day_stats in csv.DictReader(csv_file):
yield func(day_stats)
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(
get_next_day_and_avg(csv_file, get_day_and_avg),
key=lambda item: item[1],
)
这使得两个解决方案看起来更加相似,更重要的是,突出了两者之间的不同之处。现在,两种解决方案之间的差异主要包含在传入的函数中:
--- football_v4.py 2021-02-20 16:05:53.775322250 -0700 +++ weather_v2.py 2021-02-20 16:06:04.771459061 -0700 @@ -1,19 +1,20 @@ import csv -def get_name_and_diff(team_stats): - diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"]) - return team_stats["Team"], abs(diff) +def get_day_and_avg(day_stats): + day_number = int(day_stats["Day"]) + avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2 + return day_number, avg -def get_next_name_and_diff(csv_file, func): - for team_stats in csv.DictReader(csv_file): - yield func(team_stats) +def get_next_day_and_avg(csv_file, func): + for day_stats in csv.DictReader(csv_file): + yield func(day_stats) -def get_min_score_difference(filename): - with open(filename, "r", newline="") as csv_data: - return min( - get_next_name_and_diff(csv_data, get_name_and_diff), +def get_max_avg(filename): + with open(filename, "r", newline="") as csv_file: + return max( + get_next_day_and_avg(csv_file, get_day_and_avg), key=lambda item: item[1], )
一旦到了这一步,您可以将生成器函数重命名为更通用的名称。您还可以将它移动到自己的模块中,这样您就可以在两个解决方案中重用该代码:
# csv_parser.py
import csv
def get_next_result(csv_file, func):
for stats in csv.DictReader(csv_file):
yield func(stats)
现在您可以重构每个解决方案来使用这个公共代码。这是足球解决方案的重构版本:
# football_final.py
import csv_reader
def get_name_and_diff(team_stats):
diff = int(team_stats["Goals For"]) - int(team_stats["Goals Against"])
return team_stats["Team"], abs(diff)
def get_min_score_difference(filename):
with open(filename, "r", newline="") as csv_data:
return min(
csv_reader.get_next_result(csv_data, get_name_and_diff),
key=lambda item: item[1],
)
天气解决方案的最终版本虽然相似,但在问题需要的地方有所不同:
# weather_final.py
import csv_parser
def get_name_and_avg(day_stats):
day_number = int(day_stats["Day"])
avg = (int(day_stats["MxT"]) + int(day_stats["MnT"])) / 2
return day_number, avg
def get_max_avg(filename):
with open(filename, "r", newline="") as csv_file:
return max(
csv_parser.get_next_result(csv_file, get_name_and_avg),
key=lambda item: item[1],
)
您编写的单元测试可以被拆分,这样它们可以分别测试每个模块。
虽然这种特殊的重构导致了更少的代码,但是思考一下——并且在面试的情况下,讨论一下——这是否是一个好主意是有好处的。对于这一组特殊的解决方案,它可能不是。这里共享的代码大约有十行,而这些行只使用了两次。此外,这两个问题总体上相当不相关,这使得组合解决方案有点不太明智。
然而,如果你必须做四十个符合这个模型的操作,那么这种类型的重构可能是有益的。或者,如果你分享的生成器函数很复杂,很难得到正确的结果,那么它也将是一个更大的胜利。
这些都是面试时讨论的好话题。然而,对于像这样的问题集,您可能想讨论处理 CSV 文件时最常用的包:pandas。你现在会看到的。
Python CSV 解析:熊猫
到目前为止,您在解决方案中使用了标准库中的csv.DictReader类,这对于这些相对较小的问题来说效果很好。
对于更大的问题, pandas 包可以以极好的速度提供很好的结果。你的最后一个挑战是用熊猫重写上面的足球程序。
问题描述
这是本教程的最后一个问题。对于这个问题,你将使用熊猫重写足球问题的解决方案。pandas 解决方案看起来可能与只使用标准库的解决方案不同。
问题解决方案
这里讨论了团队达成的解决方案以及他们是如何达成的。
注意:记住,在您准备好查看每个 Python 练习问题的答案之前,不要打开下面折叠的部分!
这个 pandas 解决方案的结构不同于标准库解决方案。不使用生成器,而是使用 pandas 来解析文件并创建一个数据帧。
由于这种差异,您的测试看起来相似,但略有不同:
# test_football_pandas.py
import pytest
import football_pandas as fb
@pytest.fixture
def mock_csv_file(tmp_path):
mock_csv_data = [
"Team,Games,Wins,Losses,Draws,Goals For,Goals Against",
"Liverpool FC, 38, 32, 3, 3, 85, 33",
"Norwich City FC, 38, 5, 27, 6, 26, 75",
]
datafile = tmp_path / "football.csv"
datafile.write_text("\n".join(mock_csv_data))
return str(datafile)
def test_read_data(mock_csv_file):
df = fb.read_data(mock_csv_file)
rows, cols = df.shape
assert rows == 2
# The dataframe df has all seven of the cols in the original dataset plus
# the goal_difference col added in read_data().
assert cols == 8
def test_score_difference(mock_csv_file):
df = fb.read_data(mock_csv_file)
assert df.team_name[0] == "Liverpool FC"
assert df.goal_difference[0] == 52
assert df.team_name[1] == "Norwich City FC"
assert df.goal_difference[1] == 49
def test_get_min_diff(mock_csv_file):
df = fb.read_data(mock_csv_file)
diff = fb.get_min_difference(df)
assert diff == 49
def test_get_team_name(mock_csv_file):
df = fb.read_data(mock_csv_file)
assert fb.get_team(df, 49) == "Norwich City FC"
assert fb.get_team(df, 52) == "Liverpool FC"
def test_get_min_score(mock_csv_file):
assert fb.get_min_score_difference(mock_csv_file) == (
"Norwich City FC",
49,
)
这些测试包括三个动作:
- 读取文件并创建数据帧
- 求最小微分
- 找到与最小值相对应的队名
这些测试与第一个问题中的测试非常相似,所以与其详细检查测试,不如关注解决方案代码,看看它是如何工作的。您将从一个名为read_data()的函数开始创建数据帧:
1# football_pandas.py
2import pandas as pd
3
4def read_data(csv_file):
5 return (
6 pd.read_csv(csv_file)
7 .rename(
8 columns={
9 "Team": "team_name",
10 "Goals For": "goals",
11 "Goals Against": "goals_allowed",
12 }
13 )
14 .assign(goal_difference=lambda df: abs(df.goals - df.goals_allowed))
15 )
哇!这是一行函数的一堆代码。像这样将方法调用链接在一起被称为使用流畅接口,这在处理 pandas 时相当常见。一个数据帧上的每个方法返回一个DataFrame对象,所以你可以将方法调用链接在一起。
理解这样的代码的关键是,如果它跨越多行,从左到右、从上到下地理解它。
在这种情况下,从第 6 行的 pd.read_csv() 开始,它读取 CSV 文件并返回初始的DataFrame对象。
第 7 行的下一步是在返回的数据帧上调用 .rename() 。这将把数据帧的列重命名为将作为属性工作的名称。你关心的三个栏目改名为team_name、goals、goals_allowed。一会儿你会看到如何访问它们。
从.rename()返回的值是一个新的 DataFrame,在第 14 行,您调用它的 .assign() 来添加一个新列。该列将被称为goal_difference,并且您提供一个 lambda 函数来为每一行计算它。同样,.assign()返回它被调用的DataFrame对象,该对象用于该函数的返回值。
注意: pandas 为您将在这个解决方案中使用的每个列名提供了属性。这产生了良好的、可读的结果。然而,它确实有一个潜在的陷阱。
如果属性名与 pandas 中的 DataFrame 方法冲突,命名冲突可能会导致意外的行为。如果您有疑问,您可以随时使用 .loc[] 来访问列值。
您的解决方案中的下一个函数展示了一些神奇熊猫可以提供的功能。利用 pandas 将整个列作为一个对象进行寻址并在其上调用方法的能力。在这个实例中,您调用 .min() 来查找该列的最小值:
# football_pandas.py
def get_min_difference(parsed_data):
return parsed_data.goal_difference.min()
熊猫提供了几个类似于.min()的功能,可以让你快速有效地操纵行和列。
你的解决方案的下一部分是找到与最小分数差相对应的队名。get_team()再次使用流畅的编程风格将单个数据帧上的多个调用链接在一起:
# football_pandas.py
def get_team(parsed_data, min_score_difference):
return (
parsed_data.query(f"goal_difference == {min_score_difference}")
.reset_index()
.loc[0, "team_name"]
)
在这个函数中,您调用 .query() ,指定您想要的行中的goal_difference列等于您之前找到的最小值。从.query()返回的值是一个新的 DataFrame,具有相同的列,但只有那些匹配查询的行。
由于 pandas 管理查询索引的一些内部机制,需要下一个调用 .reset_index() ,以便于访问这个新数据帧的第一行。一旦索引被重置,您调用.loc[]来获取行0和team_name列,这将从第一行返回匹配最小分数差的球队名称。
最后,您需要一个函数将所有这些放在一起,并返回球队名称和最小差异。和这个问题的其他解决方案一样,这个函数叫做get_min_score_difference():
# football_pandas.py
def get_min_score_difference(csv_file):
df = read_data(csv_file)
min_diff = get_min_difference(df)
team = get_team(df, min_diff)
return team, min_diff
这个函数使用前面的三个函数将团队名称和最小差异放在一起。
这就完成了你的熊猫版足球节目。它看起来不同于其他两种解决方案:
# football_pandas.py
import pandas as pd
def read_data(csv_file):
return (
pd.read_csv(csv_file)
.rename(
columns={
"Team": "team_name",
"Goals For": "goals",
"Goals Against": "goals_allowed",
}
)
.assign(goal_difference=lambda df: abs(df.goals - df.goals_allowed))
)
def get_min_difference(parsed_data):
return parsed_data.goal_difference.min()
def get_team(parsed_data, min_score_difference):
return (
parsed_data.query(f"goal_difference == {min_score_difference}")
.reset_index()
.loc[0, "team_name"]
)
def get_min_score_difference(csv_file):
df = read_data(csv_file)
min_diff = get_min_difference(df)
team = get_team(df, min_diff)
return team, min_diff
既然你已经看到了一个基于熊猫的解决方案,思考一下这个解决方案比你看到的其他解决方案更好或更差是一个好主意。这种类型的讨论可以在面试中提出来。
这里的 pandas 解决方案比标准库版本稍长,但是如果目标是这样的话,当然可以缩短。对于像这样的小问题来说,熊猫可能有点小题大做了。然而,对于更大、更复杂的问题,花费额外的时间和复杂性引入 pandas 可以节省大量的编码工作,并且比直接使用 CSV 库更快地提供解决方案。
这里要讨论的另一个角度是,你正在进行的项目是否有或被允许有外部依赖性。在一些项目中,引入熊猫这样的额外项目可能需要大量的政治或技术工作。在这种情况下,标准库解决方案会更好。
结论
这一套 Python CSV 解析练习题到此结束!您已经练习了如何将 Python 技能应用于 CSV 文件,并且还花了一些时间来思考可以在面试中讨论的折衷方案。然后,您查看了重构解决方案,既从单个问题的角度,也从两个解决方案中重构公共代码的角度。
除了解决这些问题,你还学了:
- 用
csv.DictReader()类编写代码 - 利用熊猫解决 CSV 问题
- 在面试中讨论你的解决方案
- 谈论设计决策和权衡
现在,您已经准备好面对 Python CSV 解析问题,并在采访中讨论它了!如果您有任何问题或者对其他 Python 实践问题有任何建议,请随时在下面的评论区联系我们。祝你面试好运!
请记住,您可以通过单击下面的链接下载这些问题的框架代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用来练习解析 CSV 文件。***
Python 3 简介
Python 是一种高级解释脚本语言,由荷兰国家数学和计算机科学研究所的吉多·范·罗苏姆在 20 世纪 80 年代后期开发。最初的版本于 1991 年在 alt.sources 新闻组上发布,1.0 版本于 1994 年发布。
Python 2.0 发布于 2000 年,2.x 版本是直到 2008 年 12 月的主流版本。当时,开发团队决定发布 3.0 版本,其中包含一些相对较小但重要的更改,这些更改与 2.x 版本不向后兼容。Python 2 和 3 非常相似,Python 3 的一些特性被反向移植到了 Python 2。但总的来说,他们仍然不太兼容。
Python 2 和 3 都继续得到维护和开发,并定期发布更新。在撰写本文时,最新的可用版本是 2.7.15 和 3.6.5。然而,官方已经为 Python 2 确定了 2020 年 1 月 1 日的生命周期结束日期,在此之后,将不再保留该日期。如果你是 Python 的新手,建议你关注 Python 3,就像本教程一样。
Python 仍然由研究所的核心开发团队维护,Guido 仍然负责,他被 Python 社区授予了 BDFL(仁慈的终身独裁者)的称号。顺便说一句,Python 这个名字不是来源于蛇,而是来源于英国喜剧团蒙蒂·派森的飞行马戏团,圭多是这个马戏团的粉丝,大概现在仍然是。在 Python 文档中很容易找到对 Monty Python 草图和电影的引用。
免费 PDF 下载: Python 3 备忘单
为什么选择 Python?
如果你要写程序,有几十种常用语言可供选择。为什么选择 Python?下面是一些使 Python 成为吸引人的选择的特性。
Python 流行
Python 在过去几年里越来越受欢迎。2018 年栈溢出开发者调查将 Python 列为今年第七大最受欢迎和第一大最受欢迎的技术。全球的世界级软件开发公司每天都在使用 Python。
根据 Dice 的研究,根据编程语言指数的受欢迎程度,Python 也是最热门的技能之一,是世界上最受欢迎的编程语言。
由于 Python 作为编程语言的流行和广泛使用,Python 开发者受到追捧,待遇优厚。如果你想深入了解 Python 薪资统计和工作机会,你可以点击这里。
Python 被解读
许多语言都是编译的,这意味着你创建的源代码在运行之前需要被翻译成机器代码,即你的计算机处理器的语言。用解释语言编写的程序被直接传递给直接运行它们的解释器。
这使得开发周期更快,因为您只需输入代码并运行它,没有中间的编译步骤。
解释语言的一个潜在缺点是执行速度。编译成计算机处理器的本地语言的程序往往比解释程序运行得更快。对于一些计算特别密集的应用程序,如图形处理或密集的数字处理,这可能是限制性的。
然而,在实践中,对于大多数程序来说,执行速度的差异是以毫秒或者最多以秒来衡量的,并且对于人类用户来说是不可察觉的。对于大多数应用程序来说,用解释型语言编码的便利性通常是值得的。
延伸阅读:参见这个维基百科页面阅读更多关于解释语言和编译语言之间的差异。
Python 是免费的
Python 解释器是在 OSI 批准的开源许可下开发的,可以自由安装、使用和分发,甚至用于商业目的。
该解释器的一个版本几乎适用于任何平台,包括各种风格的 Unix、Windows、macOS、智能手机和平板电脑,以及你可能听说过的任何其他平台。一个版本甚至为剩下的六个使用 OS/2 的人而存在。
Python 是可移植的
因为 Python 代码是被解释的,而不是被编译成本机指令,所以为一个平台编写的代码可以在任何其他安装了 Python 解释器的平台上运行。(任何解释语言都是如此,不仅仅是 Python。)
Python 很简单
就编程语言而言,Python 相对来说比较整洁,开发人员有意让它保持这样。
从语言中关键字或保留字的数量可以粗略估计语言的复杂性。这些词是编译器或解释器保留的特殊含义,因为它们指定了语言的特定内置功能。
Python 3 有 33 个关键词,Python 2 有 31 个。相比之下,C++有 62 个,Java 有 53 个,Visual Basic 有超过 120 个,尽管后面这些例子可能会因实现或方言而有所不同。
Python 代码结构简单干净,易学易读。事实上,正如您将看到的,语言定义强制实施易于阅读的代码结构。
但事情没那么简单
尽管语法简单,Python 支持大多数在高级语言中预期的结构,包括复杂的动态数据类型、结构化和函数式编程,以及面向对象编程。
此外,还有一个非常丰富的类库和函数库,它提供的功能远远超出了语言内置的功能,比如数据库操作或 GUI 编程。
Python 完成了许多编程语言没有完成的事情:语言本身设计简单,但是就你可以用它完成的事情而言,它是非常通用的。
结论
本节概述了 Python 编程语言,包括:
- Python 的发展简史
- 您可能选择 Python 作为您的语言选择的一些原因
Python 是一个很好的选择,无论你是一个希望学习基础知识的初级程序员,还是一个设计大型应用程序的有经验的程序员,或者介于两者之间。Python 的基础很容易掌握,但是它的功能非常强大。
继续下一节,了解如何在您的计算机上获取和安装 Python。
Introduction to PythonInstalling Python »**
通过 Python 的 IP Address 模块学习 IP 地址概念
Python 的 ipaddress 模块是 Python 标准库中一颗不被看好的宝石。你不必是一个成熟的网络工程师,也可以在野外接触到 IP 地址。 IP 地址和网络在软件开发和基础设施中无处不在。它们是计算机如何相互寻址的基础。
边做边学是掌握 IP 地址的有效方法。通过将 IP 地址作为 Python 对象来查看和操作,ipaddress模块允许您这样做。在本教程中,您将通过使用 Python 的ipaddress模块的一些特性来更好地掌握 IP 地址。
在本教程中,您将学习:
- IP 地址在理论上和 Python 代码中是如何工作的
- IP 网络如何表示 IP 地址组,以及如何检查两者之间的关系
- Python 的
ipaddress模块如何巧妙运用经典设计模式让你事半功倍
要跟进,您只需要 Python 3.3 或更高版本,因为在那个版本中ipaddress被添加到了 Python 标准库中。本教程中的例子是使用 Python 3.8 生成的。
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
理论和实践中的 IP 地址
如果你只记得一个关于 IP 地址的概念,那么记住这个:IP 地址是一个整数。这条信息将帮助您更好地理解 IP 地址的功能以及如何将它们表示为 Python 对象。
在开始编写任何 Python 代码之前,看看这个概念在数学上是如何具体化的会很有帮助。如果你在这里只是为了一些如何使用ipaddress模块的例子,那么你可以跳到下一节,关于使用模块本身。
IP 地址的机制
你在上面看到 IP 地址可以归结为一个整数。更全面的定义是, IPv4 地址是一个 32 位整数,用于表示网络上的主机。术语主机有时用作地址的同义词。
由此得出有 2 个 32 可能的 IPv4 地址,从 0 到 4,294,967,295(其中上限为 2 32 - 1)。但这是给人类的教程,不是给机器人的。没人想 ping IP 地址0xdc0e0925。
更常见的表示 IPv4 地址的方式是使用四点符号,它由四个点分隔的十进制整数组成:
220.14.9.37
不过,地址220.14.9.37代表什么样的底层整数并不明显。按照公式,您可以将 IP 地址220.14.9.37分成四个八位字节组成部分:
>>> ( ... 220 * (256 ** 3) + ... 14 * (256 ** 2) + ... 9 * (256 ** 1) + ... 37 * (256 ** 0) ... ) 3691907365如上图,地址
220.14.9.37代表整数 3,691,907,365。每个八位字节是一个字节,或者是一个从 0 到 255 的数字。考虑到这一点,您可以推断出最大的 IPv4 地址是255.255.255.255(或者十六进制的FF.FF.FF.FF),而最小的是0.0.0.0。接下来,您将看到 Python 的
ipaddress模块如何为您进行这种计算,允许您使用人类可读的形式,并让地址运算在看不见的地方发生。Python
ipaddress模块要继续操作,您可以在命令行中获取计算机的外部 IP 地址:
$ curl -sS ifconfig.me/ip 220.14.9.37这将从站点 ifconfig.me 请求您的 IP 地址,该地址可用于显示有关您的连接和网络的一系列详细信息。
注意:出于技术正确性的考虑,这很可能不是你电脑自己的公共 IP 地址。如果你的连接位于一个终端路由器之后,那么最好把它看作一个“代理”IP,通过它你可以到达互联网。
现在打开一个 Python REPL。您可以使用
IPv4Address类来构建封装地址的 Python 对象:
>>> from ipaddress import IPv4Address
>>> addr = IPv4Address("220.14.9.37")
>>> addr
IPv4Address('220.14.9.37')
向IPv4Address构造函数传递一个像"220.14.9.37"这样的str是最常见的方法。但是,该类也可以接受其他类型:
>>> IPv4Address(3691907365) # From an int IPv4Address('220.14.9.37') >>> IPv4Address(b"\xdc\x0e\t%") # From bytes (packed form) IPv4Address('220.14.9.37')虽然从人类可读的
str开始构建可能是更常见的方式,但是如果您使用类似于 TCP 包数据的东西,您可能会看到bytes输入。上述转换在其他方向也是可能的:
>>> int(addr)
3691907365
>>> addr.packed
b'\xdc\x0e\t%'
除了允许不同 Python 类型的往返输入和输出,IPv4Address的实例也是可散列的。这意味着您可以将它们用作映射数据类型中的键,例如字典:
>>> hash(IPv4Address("220.14.9.37")) 4035855712965130587 >>> num_connections = { ... IPv4Address("220.14.9.37"): 2, ... IPv4Address("100.201.0.4"): 16, ... IPv4Address("8.240.12.2"): 4, ... }最重要的是,
IPv4Address还实现了方法,允许使用底层整数进行比较:
>>> IPv4Address("220.14.9.37") > IPv4Address("8.240.12.2")
True
>>> addrs = (
... IPv4Address("220.14.9.37"),
... IPv4Address("8.240.12.2"),
... IPv4Address("100.201.0.4"),
... )
>>> for a in sorted(addrs):
... print(a)
...
8.240.12.2
100.201.0.4
220.14.9.37
您可以使用任何标准的比较运算符来比较地址对象的整数值。
注:本教程重点介绍互联网协议第 4 版(IPv4)地址。还有 IPv6 地址,是 128 位而不是 32 位,用2001:0:3238:dfe1:63::fefb之类更 headier 的形式表示。因为地址的算法基本相同,所以本教程从等式中去掉一个变量,集中讨论 IPv4 地址。
ipaddress模块具有更灵活的工厂函数、 ip_address() ,它接受代表 IPv4 或 IPv6 地址的参数,并尽最大努力分别返回IPv4Address或IPv6Address实例。
在本教程中,您将切入正题,直接用IPv4Address构建地址对象。
正如你在上面看到的,IPv4Address的构造函数本身是简短的。当你开始把地址组合成组或网络时,事情就变得更有趣了。
IP 网络和接口
一个网络是一组 IP 地址。网络被描述和显示为连续的地址范围。例如,网络可以由地址192.4.2.0到192.4.2.255组成,一个包含 256 个地址的网络。
您可以通过 IP 地址的上限和下限来识别网络,但是如何用更简洁的约定来显示呢?这就是 CIDR 记谱法的由来。
CIDR 符号
使用网络地址加上 无类域间路由(CIDR)符号 中的前缀来定义网络:
>>> from ipaddress import IPv4Network >>> net = IPv4Network("192.4.2.0/24") >>> net.num_addresses 256CIDR 符号将网络表示为
<network_address>/<prefix>。路由前缀(或前缀长度,或仅仅是前缀),在这种情况下是 24,是用于回答诸如某个地址是否是网络的一部分或网络中有多少地址等问题的前导位计数。(此处前导位是指二进制中从整数左边数起的第一个 N 位。)您可以使用
.prefixlen属性找到路由前缀:
>>> net.prefixlen
24
让我们直接看一个例子。地址192.4.2.12是否在网络192.4.2.0/24中?这种情况下的答案是肯定的,因为192.4.2.12的前 24 位是前三个八位字节(192.4.2)。有了/24前缀,你可以简单地砍掉最后一个八位字节,然后看到192.4.2.xxx部分匹配。
如图所示,/24前缀被翻译成网络掩码,顾名思义,它被用来屏蔽被比较地址中的位:
>>> net.netmask IPv4Address('255.255.255.0')您比较前导位来确定一个地址是否是网络的一部分。如果前导位匹配,则该地址是网络的一部分:
11000000 00000100 00000010 00001100 # 192.4.2.12 # Host IP address 11000000 00000100 00000010 00000000 # 192.4.2.0 # Network address | ^ 24th bit (stop here!) |_________________________| | These bits match以上,
192.4.2.12的最后 8 位被屏蔽(用0),在比较中被忽略。Python 的ipaddress再一次为您节省了数学体操,并支持惯用的成员测试:
>>> net = IPv4Network("192.4.2.0/24")
>>> IPv4Address("192.4.2.12") in net
True
>>> IPv4Address("192.4.20.2") in net
False
这是通过操作符重载来实现的,其中IPv4Network定义了__contains__()来允许使用in操作符进行成员测试。
在 CIDR 符号192.4.2.0/24中,192.4.2.0部分是网络地址,用于标识网络:
>>> net.network_address IPv4Address('192.4.2.0')正如您在上面看到的,当对主机 IP 地址应用掩码时,网络地址
192.4.2.0可以被视为预期的结果:11000000 00000100 00000010 00001100 # Host IP address 11111111 11111111 11111111 00000000 # Netmask, 255.255.255.0 or /24 11000000 00000100 00000010 00000000 # Result (compared to network address)当你这样想的时候,你可以看到前缀
/24实际上是如何翻译成真正的IPv4Address:
>>> net.prefixlen
24
>>> net.netmask
IPv4Address('255.255.255.0') # 11111111 11111111 11111111 00000000
事实上,如果您感兴趣,您可以直接从两个地址构造一个IPv4Network:
>>> IPv4Network("192.4.2.0/255.255.255.0") IPv4Network('192.4.2.0/24')上图中,
192.4.2.0是网络地址,而255.255.255.0是网络掩码。网络中的另一端是其最终地址,或称 广播地址 ,它是一个可用于与其网络中所有主机通信的单一地址:
>>> net.broadcast_address
IPv4Address('192.4.2.255')
关于网络掩码,还有一点值得一提。您最常看到的前缀长度是 8 的倍数:
| 前缀长度 | 地址数量 | 网络掩码 |
|---|---|---|
| eight | Sixteen million seven hundred and seventy-seven thousand two hundred and sixteen | 255.0.0.0 |
| Sixteen | Sixty-five thousand five hundred and thirty-six | 255.255.0.0 |
| Twenty-four | Two hundred and fifty-six | 255.255.255.0 |
| Thirty-two | one | 255.255.255.255 |
但是,0 到 32 之间的任何整数都是有效的,尽管不太常见:
>>> net = IPv4Network("100.64.0.0/10") >>> net.num_addresses 4194304 >>> net.netmask IPv4Address('255.192.0.0')在这一节中,您看到了如何构建一个
IPv4Network实例,并测试其中是否有某个 IP 地址。在下一节中,您将学习如何在网络中循环访问地址。通过网络循环
IPv4Network类支持迭代,这意味着您可以在一个for循环中迭代它的单个地址:
>>> net = IPv4Network("192.4.2.0/28")
>>> for addr in net:
... print(addr)
...
192.4.2.0
192.4.2.1
192.4.2.2
...
192.4.2.13
192.4.2.14
192.4.2.15
类似地,net.hosts()返回一个生成器,它将产生上面显示的地址,不包括网络和广播地址:
>>> h = net.hosts() >>> type(h) <class 'generator'> >>> next(h) IPv4Address('192.4.2.1') >>> next(h) IPv4Address('192.4.2.2')在下一节中,您将深入了解一个与网络密切相关的概念:子网。
子网
子网是 IP 网络的细分:
>>> small_net = IPv4Network("192.0.2.0/28")
>>> big_net = IPv4Network("192.0.0.0/16")
>>> small_net.subnet_of(big_net)
True
>>> big_net.supernet_of(small_net)
True
以上,small_net只包含 16 个地址,足够你和你身边的几个小隔间使用。相反,big_net包含 65,536 个地址。
实现子网划分的常见方法是将网络的前缀长度增加 1。让我们举一个维基百科的例子:
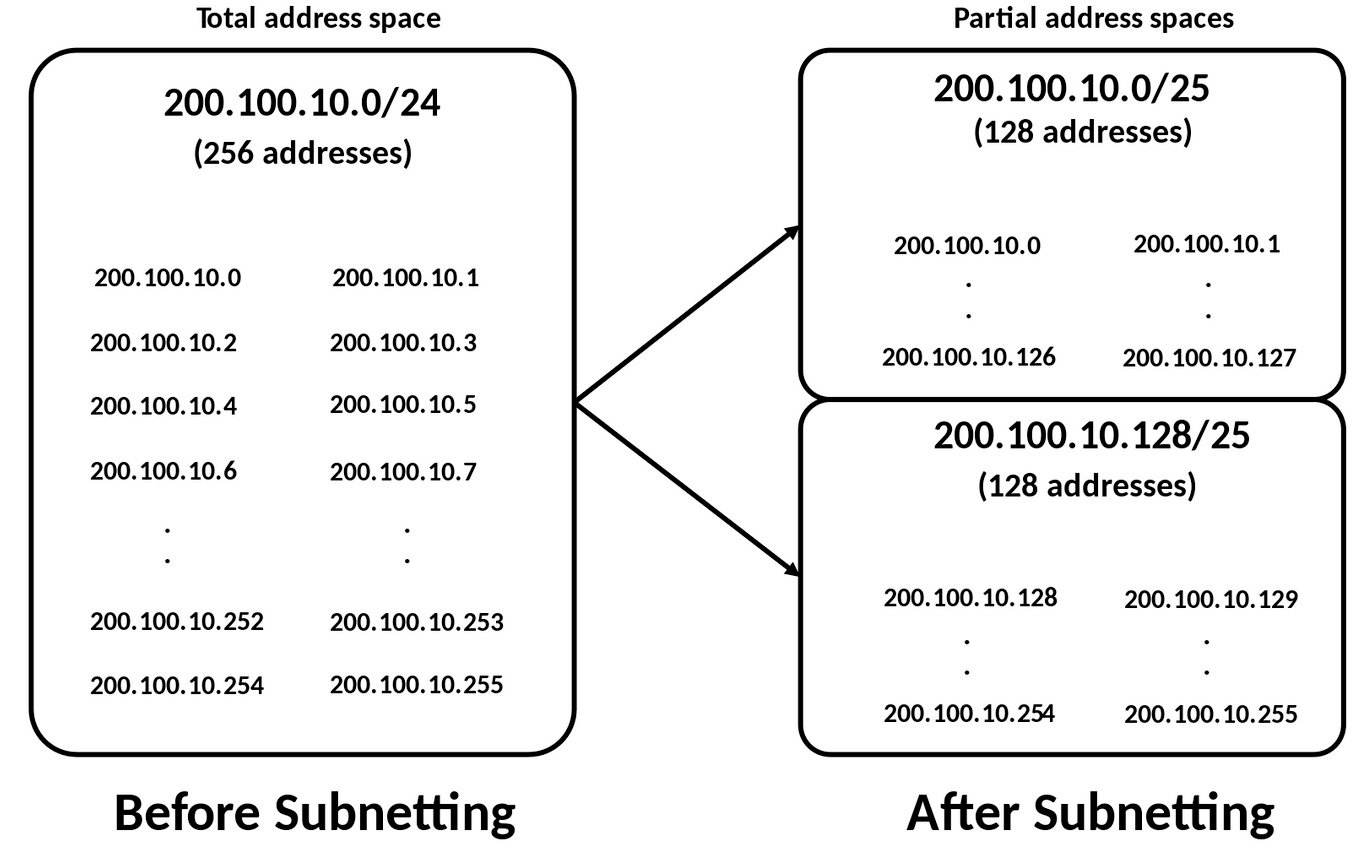
这个例子从一个/24网络开始:
net = IPv4Network("200.100.10.0/24")
通过将前缀长度从 24 增加到 25 来划分子网,需要移动位来将网络分成更小的部分。这在数学上有点复杂。幸运的是,IPv4Network使它变得很容易,因为.subnets()在子网上返回一个迭代器:
>>> for sn in net.subnets(): ... print(sn) ... 200.100.10.0/25 200.100.10.128/25你也可以告诉
.subnets()新的前缀应该是什么。更高的前缀意味着更多更小的子网:
>>> for sn in net.subnets(new_prefix=28):
... print(sn)
...
200.100.10.0/28
200.100.10.16/28
200.100.10.32/28
...
200.100.10.208/28
200.100.10.224/28
200.100.10.240/28
除了地址和网络,接下来您将看到ipaddress模块的第三个核心部分。
主机接口
最后但同样重要的是,Python 的ipaddress模块导出了一个用于表示主机接口的IPv4Interface类。主机接口是一种以简洁的形式描述主机 IP 地址及其所在网络的方式:
>>> from ipaddress import IPv4Interface >>> ifc = IPv4Interface("192.168.1.6/24") >>> ifc.ip # The host IP address IPv4Address('192.168.1.6') >>> ifc.network # Network in which the host IP resides IPv4Network('192.168.1.0/24')以上,
192.168.1.6/24表示“网络192.168.1.0/24中的 IP 地址192.168.1.6注:在计算机网络环境中,接口也可以指网络接口,最常见的是网络接口卡(NIC)。如果您曾经使用过
ifconfig工具(*nix)或ipconfig(Windows),那么您可能会知道您的工具的名称,如eth0、en0或ens3。这两种类型的接口是不相关的。换句话说,IP 地址本身并不能告诉你该地址位于哪个(哪些)网络中,网络地址是一组 IP 地址而不是单个地址。
IPv4Interface提供了一种通过 CIDR 符号同时表示单个主机 IP 地址及其网络的方法。特殊地址范围
既然您已经对 IP 地址和网络有了大致的了解,那么知道并非所有的 IP 地址都是平等的(有些是特殊的)也很重要。
互联网数字地址分配机构(IANA)与互联网工程任务组(IETF)共同监督不同地址范围的分配。IANA 的 IPv4 专用地址注册中心是一个非常重要的表,它规定了某些地址范围应该具有特殊的含义。
一个常见的例子是私有地址。专用 IP 地址用于网络上不需要连接到公共互联网的设备之间的内部通信。以下范围仅供私人使用:
范围 地址数量 网络地址 广播地址 10.0.0.0/8Sixteen million seven hundred and seventy-seven thousand two hundred and sixteen 10.0.0.010.255.255.255172.16.0.0/12One million forty-eight thousand five hundred and seventy-six 172.16.0.0172.31.255.255192.168.0.0/16Sixty-five thousand five hundred and thirty-six 192.168.0.0192.168.255.255一个随机选择的例子是
10.243.156.214。那么,你怎么知道这个地址是私人的呢?您可以确认它落在10.0.0.0/8范围内:
>>> IPv4Address("10.243.156.214") in IPv4Network("10.0.0.0/8")
True
第二种特殊地址类型是链路本地地址,它只能从给定的子网内到达。一个例子是亚马逊时间同步服务,它可用于链接本地 IP 169.254.169.123上的 AWS EC2 实例。如果您的 EC2 实例位于一个虚拟私有云 (VPC),那么您不需要互联网连接来告诉您的实例现在是什么时间。块 169.254.0.0/16 保留给本地链路地址:
>>> timesync_addr = IPv4Address("169.254.169.123") >>> timesync_addr.is_link_local True从上面可以看出,确认
10.243.156.214是私有地址的一种方法是测试它是否位于10.0.0.0/8范围内。但是 Python 的ipaddress模块也提供了一组属性,用于测试地址是否为特殊类型:
>>> IPv4Address("10.243.156.214").is_private
True
>>> IPv4Address("127.0.0.1").is_loopback
True
>>> [i for i in dir(IPv4Address) if i.startswith("is_")] # "is_X" properties
['is_global',
'is_link_local',
'is_loopback',
'is_multicast',
'is_private',
'is_reserved',
'is_unspecified']
关于.is_private有一点需要注意,它使用了比上表所示的三个 IANA 范围更广泛的私有网络定义。Python 的ipaddress模块还集成了其他分配给私有网络的地址:
这不是一个详尽的列表,但它涵盖了最常见的情况。
引擎盖下的 Python ipaddress模块
除了其记录的 API 之外,ipaddress模块及其 IPv4Address 类的 CPython 源代码提供了一些很好的见解,让你知道如何使用一个叫做组合的模式来为你自己的代码提供一个惯用的 API。
作文的核心作用
ipaddress模块利用了一种叫做组合 的面向对象模式。它的IPv4Address类是一个复合,包装了一个普通的 Python 整数。毕竟,IP 地址基本上是整数。
注意:公平地说,ipaddress模块也使用了健康剂量的继承,主要是为了减少代码重复。
每个IPv4Address实例都有一个准私有的._ip属性,它本身就是一个int。该类的许多其他属性和方法都是由该属性的值驱动的:
>>> addr = IPv4Address("220.14.9.37") >>> addr._ip 3691907365
._ip属性实际上负责产生int(addr)。这个调用链是int(my_addr)调用my_addr.__int__(),而IPv4Address只实现为my_addr._ip:
如果你问 CPython 的开发者,他们可能会告诉你
._ip是一个实现细节。虽然在 Python 中没有什么是真正私有的,但是前导下划线表示._ip是准私有的,不是公共ipaddressAPI 的一部分,并且可能会在没有通知的情况下发生变化。这就是为什么用int(addr)提取底层整数更稳定的原因。尽管如此,是底层的
._ip赋予了IPv4Address和IPv4Network类魔力。扩展
IPv4Address您可以通过扩展IP v4 地址类来展示底层
._ip整数的威力:from ipaddress import IPv4Address class MyIPv4(IPv4Address): def __and__(self, other: IPv4Address): if not isinstance(other, (int, IPv4Address)): raise NotImplementedError return self.__class__(int(self) & int(other))添加
.__and__()允许您使用二进制 AND (&)运算符。现在,您可以直接将网络掩码应用到主机 IP:
>>> addr = MyIPv4("100.127.40.32")
>>> mask = MyIPv4("255.192.0.0") # A /10 prefix
>>> addr & mask
MyIPv4('100.64.0.0')
>>> addr & 0xffc00000 # Hex literal for 255.192.0.0
MyIPv4('100.64.0.0')
上面,.__and__()允许你直接使用另一个IPv4Address或一个int作为蒙版。因为MyIPv4是IPv4Address的子类,在那种情况下isinstance()检查将返回True。
除了运算符重载之外,您还可以添加全新的属性:
1import re
2from ipaddress import IPv4Address
3
4class MyIPv4(IPv4Address):
5 @property
6 def binary_repr(self, sep=".") -> str:
7 """Represent IPv4 as 4 blocks of 8 bits."""
8 return sep.join(f"{i:08b}" for i in self.packed) 9
10 @classmethod
11 def from_binary_repr(cls, binary_repr: str):
12 """Construct IPv4 from binary representation."""
13 # Remove anything that's not a 0 or 1
14 i = int(re.sub(r"[^01]", "", binary_repr), 2) 15 return cls(i)
在.binary_repr ( 第 8 行)中,使用.packed将 IP 地址转换成字节数组,然后将其格式化为二进制形式的字符串表示。
在.from_binary_repr中,对线 14 上int(re.sub(r"[^01]", "", binary_repr), 2)的调用有两部分:
- 它从输入字符串中删除除 0 和 1 之外的任何内容。
- 它用
int(<string>, 2)解析结果,假设基数为 2。
使用.binary_repr()和.from_binary_repr()允许您转换和构造二进制记数法中 1 和 0 的str:
>>> MyIPv4("220.14.9.37").binary_repr '11011100.00001110.00001001.00100101' >>> MyIPv4("255.255.0.0").binary_repr # A /16 netmask '11111111.11111111.00000000.00000000' >>> MyIPv4.from_binary_repr("11011100 00001110 00001001 00100101") MyIPv4('220.14.9.37')这些只是展示利用 IP-as-integer 模式如何帮助您用少量额外代码扩展
IPv4Address功能的几种方式。结论
在本教程中,您看到了 Python 的
ipaddress模块如何允许您使用常见的 Python 结构处理 IP 地址和网络。以下是你可以吸取的一些要点:
- IP 地址从根本上来说是一个整数,这是你如何用地址做手工运算以及如何使用组合设计来自
ipaddress的 Python 类的基础。
***ipaddress模块利用操作符重载来允许你推断地址和网络之间的关系。*ipaddress模块使用组合,您可以根据需要扩展该功能以增加行为。**和往常一样,如果你想更深入,那么阅读模块源代码是一个很好的方法。
延伸阅读
以下是一些深入的资源,您可以查看以了解更多关于
ipaddress模块的信息:Python!=' Is Not 'is not ':在 Python 中比较对象
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 比较 Python 对象的正确方式:“is”vs = = "
Python 标识操作符(
is)和等式操作符(==)之间有细微的区别。当您使用 Python 的is操作符比较数字时,您的代码可以运行得很好,直到它突然不。你可能在哪里听说过 Pythonis操作符比==操作符快,或者你可能觉得它看起来更像Python。然而,重要的是要记住,这些操作符的行为并不完全相同。
==操作符比较两个对象的值或相等性,而 Pythonis操作符检查两个变量是否指向内存中的同一个对象。在绝大多数情况下,这意味着你应该使用等号运算符==和!=,除非你比较None。在本教程中,您将学习:
- 对象相等和对象相同有什么区别
- 何时使用等式和等式运算符来比较对象
- 这些 Python 操作者在幕后做什么
- 为什么使用
is和is not比较值会导致意外行为- 如何编写一个自定义
__eq__()类方法来定义等式运算符行为Python 中途站:本教程是一个快速和实用的方法来找到你需要的信息,所以你会很快回到你的项目!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
用 Python 比较身份是和不是运算符
Python 的
is和is not操作符比较两个对象的身份。在 CPython 中,这是他们的内存地址。Python 中的一切都是一个对象,每个对象都存储在一个特定的内存位置。Python 的is和is not操作符检查两个变量是否指向内存中的同一个对象。注意:记住,具有相同值的对象通常存储在不同的内存地址。
您可以使用
id()来检查对象的身份:
>>> help(id)
Help on built-in function id in module builtins:
id(obj, /)
Return the identity of an object.
This is guaranteed to be unique among simultaneously existing objects.
(CPython uses the object's memory address.)
>>> id(id)
2570892442576
最后一行显示了存储内置函数id本身的内存地址。
在一些常见的情况下,具有相同值的对象默认具有相同的 id。例如,数字-5 到 256 在 CPython 中被拘留。每个数字都存储在内存中一个单一的固定位置,这为常用的整数节省了内存。
你可以用sys.intern()到实习生的琴弦来演奏。此函数允许您比较它们的内存地址,而不是逐字符比较字符串:
>>> from sys import intern >>> a = 'hello world' >>> b = 'hello world' >>> a is b False >>> id(a) 1603648396784 >>> id(b) 1603648426160 >>> a = intern(a) >>> b = intern(b) >>> a is b True >>> id(a) 1603648396784 >>> id(b) 1603648396784变量
a和b最初指向内存中两个不同的对象,如它们不同的 id 所示。当你对它们进行实习时,你要确保a和b指向内存中的同一个对象。任何带有值'hello world'的新字符串现在都将在新的内存位置创建,但是当你实习这个新字符串时,你要确保它与你实习的第一个'hello world'指向相同的内存地址。注意:即使一个对象的内存地址在任何给定的时间都是唯一的,它也会在相同代码的运行之间发生变化,并且依赖于 CPython 的版本和运行它的机器。
其他默认被拘留的对象有
None、True、False和简单字符串。请记住,大多数时候,具有相同值的不同对象将存储在不同的内存地址。这意味着您不应该使用 Pythonis操作符来比较值。当只有一些整数被保留时
在幕后,Python 实习生使用常用值(例如,整数-5 到 256)的对象来节省内存。下面的代码向您展示了为什么只有一些整数有固定的内存地址:
>>> a = 256
>>> b = 256
>>> a is b
True
>>> id(a)
1638894624
>>> id(b)
1638894624
>>> a = 257
>>> b = 257
>>> a is b
False
>>> id(a)
2570926051952
>>> id(b)
2570926051984
最初,a和b指向内存中同一个被拘留的对象,但是当它们的值超出公共整数(范围从-5 到 256)的范围时,它们被存储在不同的内存地址。
当多个变量指向同一个对象时
当您使用赋值操作符(=)使一个变量等于另一个变量时,您使这些变量指向内存中的同一个对象。这可能会导致可变对象的意外行为:
>>> a = [1, 2, 3] >>> b = a >>> a [1, 2, 3] >>> b [1, 2, 3] >>> a.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4] >>> id(a) 2570926056520 >>> id(b) 2570926056520刚刚发生了什么?您向
a添加了一个新元素,但是现在b也包含了这个元素!嗯,在b = a的那一行,你设置b指向和a相同的内存地址,这样两个变量现在指向同一个对象。如果你定义这些列表彼此独立,那么它们被存储在不同的内存地址并独立运行:
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> a is b
False
>>> id(a)
2356388925576
>>> id(b)
2356388952648
因为a和b现在指的是内存中不同的对象,改变一个不会影响另一个。
用 Python == and 比较等式!=运算符
回想一下,具有相同值的对象通常存储在单独的内存地址。如果你想检查两个对象是否有相同的值,使用相等操作符==和!=,不管它们存储在内存的什么地方。绝大多数情况下,这是你想做的。
当对象副本相等但不相同时
在下面的例子中,您将b设置为a的副本(T1 是一个可变对象,比如一个列表或者一个字典)。这两个变量将具有相同的值,但每个变量将存储在不同的内存地址:
>>> a = [1, 2, 3] >>> b = a.copy() >>> a [1, 2, 3] >>> b [1, 2, 3] >>> a == b True >>> a is b False >>> id(a) 2570926058312 >>> id(b) 2570926057736
a和b现在存储在不同的内存地址,所以a is b不再返回True。然而,a == b返回True,因为两个对象具有相同的值。等式比较是如何工作的
等式运算符
==的魔力发生在==符号左边的对象的__eq__()类方法中。注意:除非右边的对象是左边对象的子类,否则就是这种情况。更多信息,请查看官方文档。
这是一个神奇的类方法,每当这个类的一个实例与另一个对象进行比较时,就会调用这个方法。如果这个方法没有实现,那么
==默认比较两个对象的内存地址。作为一个练习,创建一个从
str继承的SillyString类,并实现__eq__()来比较这个字符串的长度是否与另一个对象的长度相同:class SillyString(str): # This method gets called when using == on the object def __eq__(self, other): print(f'comparing {self} to {other}') # Return True if self and other have the same length return len(self) == len(other)现在,SillyString
'hello world'应该等于 string'world hello',甚至等于任何其他具有相同长度的对象:
>>> # Compare two strings
>>> 'hello world' == 'world hello'
False
>>> # Compare a string with a SillyString
>>> 'hello world' == SillyString('world hello')
comparing world hello to hello world
True
>>> # Compare a SillyString with a list
>>> SillyString('hello world') == [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
comparing hello world to [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
True
当然,对于一个行为类似于字符串的对象来说,这是愚蠢的行为,但是它确实说明了当您使用==比较两个对象时会发生什么。除非实现了特定的__ne__()类方法,否则!=操作符会给出相反的响应。
上面的例子也清楚地向您展示了为什么使用 Python is操作符来与None进行比较,而不是使用==操作符是一个好的实践。它不仅因为比较内存地址而更快,而且因为不依赖于任何__eq__()类方法的逻辑而更安全。
比较 Python 比较运算符
作为一个经验法则,你应该总是使用等式运算符==和!=,除了当你和None比较的时候:
-
使用 Python 的
==和!=操作符来比较对象的相等性。这里,你通常比较两个对象的值。如果你想比较两个对象是否有相同的内容,并且不关心它们在内存中的存储位置,这就是你需要的。 -
当你想要比较对象身份时,使用 Python
is和is not操作符。这里,您比较的是两个变量是否指向内存中的同一个对象。这些运算符的主要用例是当您与None进行比较时。通过内存地址与None进行比较比使用类方法更快也更安全。
具有相同值的变量通常存储在不同的内存地址。这意味着您应该使用==和!=来比较它们的值,只有当您想要检查两个变量是否指向同一个内存地址时,才使用 Python 的is和is not操作符。
结论
在本教程中,您已经了解到==和!= 比较两个对象的值,而 Python is和is not操作符比较两个变量是否引用内存中的同一个对象。如果您记住这一区别,那么您应该能够防止代码中的意外行为。
如果你想了解更多关于对象实习和 Python is操作符的精彩世界,那么看看为什么在 Python 中几乎不应该使用“is”。您还可以看看如何使用sys.intern()来优化内存使用和字符串的比较时间,尽管 Python 可能已经在幕后自动为您处理了这一点。
既然您已经了解了等式和等式操作符的功能,那么您可以尝试编写自己的__eq__()类方法,这些方法定义了在使用==操作符时如何比较这个类的实例。去应用这些 Python 比较运算符的新知识吧!
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 比较 Python 对象的正确方式:“is”vs = = "***
例如,Python 3 中的 Itertools
它被称为“宝石”“几乎是有史以来最酷的东西”,如果你还没有听说过它,那么你就错过了 Python 3 标准库最棒的角落之一:itertools。
有一些很好的资源可以用来学习itertools模块中有哪些功能。T2 的医生们本身就是一个很好的起点。这个岗位也是。
然而,关于itertools,仅仅知道它包含的函数的定义是不够的。真正的力量在于组合这些函数来创建快速、内存高效且美观的代码。
这篇文章采用了不同的方法。不是一次向你介绍一个函数,你将构建实际的例子来鼓励你“迭代地思考”一般来说,示例将从简单开始,并逐渐增加复杂性。
一个警告:这篇文章很长,面向中高级 Python 程序员。在开始之前,您应该对使用 Python 3 中的迭代器和生成器、多重赋值和元组解包有信心。如果你不是,或者你需要温习你的知识,在继续阅读之前,考虑检查以下内容:
- Python 迭代器:一步一步的介绍
- Python 生成器简介
- 第六章 Python 技巧:丹·巴德的书
- 多重赋值和元组解包提高 Python 代码可读性
免费奖励: 点击这里获取我们的 itertools 备忘单,它总结了本教程中演示的技术。
都准备好了吗?让我们以一个问题开始任何美好的旅程。
什么是Itertools,为什么要用?
根据 itertools文档的说法,它是一个“模块[它]实现了许多迭代器构建块,灵感来自 APL、Haskell 和 SML 的构造……它们一起形成了一个‘迭代器代数’,使得用纯 Python 简洁高效地构建专门的工具成为可能。”
不严格地说,这意味着itertools中的函数“操作”迭代器来产生更复杂的迭代器。例如,考虑一下内置的zip()函数,它接受任意数量的 iterables 作为参数,并返回一个遍历其对应元素元组的迭代器:
>>> list(zip([1, 2, 3], ['a', 'b', 'c'])) [(1, 'a'), (2, 'b'), (3, 'c')]
zip()到底是如何工作的?与所有列表一样,
[1, 2, 3]和['a', 'b', 'c']是可迭代的,这意味着它们可以一次返回一个元素。从技术上讲,任何实现了.__iter__()或.__getitem__()方法的 Python 对象都是可迭代的。(更详细的解释见 Python 3 文档词汇表。)当在可迭代对象上调用
iter()内置函数时,返回该可迭代对象的迭代器对象:
>>> iter([1, 2, 3, 4])
<list_iterator object at 0x7fa80af0d898>
本质上,zip()函数的工作方式是对它的每个参数调用iter(),然后用next()推进由iter()返回的每个迭代器,并将结果聚合成元组。 zip() 返回的迭代器对这些元组进行迭代。
map()内置函数是另一种“迭代器操作符”,其最简单的形式是将单参数函数应用于可迭代的每个元素,一次一个元素:
>>> list(map(len, ['abc', 'de', 'fghi'])) [3, 2, 4]
map()函数的工作方式是在第二个参数上调用iter(),用next()推进这个迭代器,直到迭代器用完,并在每一步将传递给第一个参数的函数应用于next()返回的值。在上面的例子中,对['abc', 'de', 'fghi']的每个元素调用len()来返回列表中每个字符串长度的迭代器。由于迭代器是可迭代的,您可以组合
zip()和map()来产生一个迭代器,遍历多个可迭代的元素组合。例如,下面对两个列表的相应元素求和:
>>> list(map(sum, zip([1, 2, 3], [4, 5, 6])))
[5, 7, 9]
这就是itertools中的函数形成“迭代器代数”的含义itertools最好被看作是一个构建块的集合,这些构建块可以组合起来形成专门的“数据管道”,就像上面的例子一样。
历史注:在 Python 2 中,内置的
zip()和map()函数不返回迭代器,而是返回一个列表。要返回一个迭代器,必须使用itertools的izip()和imap()函数。在 Python 3 中,izip()和imap()已经从itertools中移除了,取而代之的是zip()和map()内置。所以,在某种程度上,如果你曾经在 Python 3 中使用过zip()或者map(),你就已经在使用itertools!
这种“迭代器代数”有用的主要原因有两个:提高内存效率(通过惰性求值)和更快的执行时间。要了解这一点,请考虑以下问题:
给定一个值列表
inputs和一个正整数n,写一个函数将inputs分成长度为n的组。为了简单起见,假设输入列表的长度可以被n整除。比如说inputs = [1, 2, 3, 4, 5, 6]和n = 2,你的函数应该返回[(1, 2), (3, 4), (5, 6)]。
采用一种天真的方法,您可能会写出这样的内容:
def naive_grouper(inputs, n):
num_groups = len(inputs) // n
return [tuple(inputs[i*n:(i+1)*n]) for i in range(num_groups)]
当您测试它时,您会看到它按预期工作:
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> naive_grouper(nums, 2) [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]当你试图传递给它一个有 1 亿个元素的列表时会发生什么?你将需要大量的可用内存!即使您有足够的可用内存,您的程序也会挂起一段时间,直到输出列表被填充。
要了解这一点,请将以下内容存储在一个名为
naive.py的脚本中:def naive_grouper(inputs, n): num_groups = len(inputs) // n return [tuple(inputs[i*n:(i+1)*n]) for i in range(num_groups)] for _ in naive_grouper(range(100000000), 10): pass从控制台,您可以使用
time命令(在 UNIX 系统上)来测量内存使用和 CPU 用户时间。在执行以下命令之前,确保至少有 5GB 的空闲内存:$ time -f "Memory used (kB): %M\nUser time (seconds): %U" python3 naive.py Memory used (kB): 4551872 User time (seconds): 11.04注意:在 Ubuntu 上,你可能需要运行
/usr/bin/time而不是time来运行上面的例子。
naive_grouper()中的list和tuple实现需要大约 4.5GB 的内存来处理range(100000000)。使用迭代器极大地改善了这种情况。请考虑以下情况:def better_grouper(inputs, n): iters = [iter(inputs)] * n return zip(*iters)这个小函数里有很多东西,所以让我们用一个具体的例子来分解它。表达式
[iters(inputs)] * n创建了一个对同一迭代器的n引用的列表:
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> iters = [iter(nums)] * 2
>>> list(id(itr) for itr in iters) # IDs are the same.
[139949748267160, 139949748267160]
接下来,zip(*iters)返回一个迭代器,遍历iters中每个迭代器的对应元素对。当第一个元素1取自“第一个”迭代器时,“第二个”迭代器现在从2开始,因为它只是对“第一个”迭代器的引用,因此已经前进了一步。所以,zip()产生的第一个元组是(1, 2)。
此时,iters中的“两个”迭代器都从3开始,所以当zip()从“第一个”迭代器中拉取3时,它从“第二个”迭代器中获取4产生元组(3, 4)。这个过程一直持续到zip()最终产生(9, 10)并且iters中的“两个”迭代器都用完为止:
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> list(better_grouper(nums, 2)) [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]由于几个原因,
better_grouper()函数更好。首先,在没有引用内置的len()的情况下,better_grouper()可以将任何 iterable 作为参数(甚至是无限迭代器)。第二,通过返回一个迭代器而不是一个列表,better_grouper()可以毫无困难地处理大量的可迭代对象,并且使用更少的内存。将以下内容存储在名为
better.py的文件中,并使用time从控制台再次运行:def better_grouper(inputs, n): iters = [iter(inputs)] * n return zip(*iters) for _ in better_grouper(range(100000000), 10): pass$ time -f "Memory used (kB): %M\nUser time (seconds): %U" python3 better.py Memory used (kB): 7224 User time (seconds): 2.48这比在不到四分之一的时间内使用的
naive.py内存少了 630 倍!现在你已经看到了什么是
itertools(“迭代器代数”)以及为什么要使用它(提高内存效率和更快的执行时间),让我们来看看如何用itertools让better_grouper()更上一层楼。
grouper食谱
better_grouper()的问题是它不能处理传递给第二个参数的值不是第一个参数中 iterable 长度的一个因素的情况:
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(better_grouper(nums, 4))
[(1, 2, 3, 4), (5, 6, 7, 8)]
分组输出中缺少元素 9 和 10。发生这种情况是因为一旦传递给它的最短的 iterable 用尽,zip()就停止聚集元素。返回包含 9 和 10 的第三个组更有意义。
为此,可以使用itertools.zip_longest()。这个函数接受任意数量的 iterables 作为参数和一个默认为None的fillvalue关键字参数。了解zip()和zip_longest()之间区别的最简单方法是查看一些示例输出:
>>> import itertools as it >>> x = [1, 2, 3, 4, 5] >>> y = ['a', 'b', 'c'] >>> list(zip(x, y)) [(1, 'a'), (2, 'b'), (3, 'c')] >>> list(it.zip_longest(x, y)) [(1, 'a'), (2, 'b'), (3, 'c'), (4, None), (5, None)]考虑到这一点,将
better_grouper()中的zip()替换为zip_longest():import itertools as it def grouper(inputs, n, fillvalue=None): iters = [iter(inputs)] * n return it.zip_longest(*iters, fillvalue=fillvalue)现在你得到了一个更好的结果:
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> print(list(grouper(nums, 4)))
[(1, 2, 3, 4), (5, 6, 7, 8), (9, 10, None, None)]
grouper()功能可以在itertools文档的食谱部分中找到。这些食谱是如何利用itertools为你带来优势的绝佳灵感来源。
注意:从这一点开始,import itertools as it行将不再包含在示例的开头。代码示例中的所有itertools方法都以it.开头,暗示了模块导入。
如果你在运行本教程中的一个例子时得到一个NameError: name 'itertools' is not defined或NameError: name 'it' is not defined异常,你需要首先导入itertools模块。
你呢,蛮力?
这里有一个常见的面试式问题:
你有三张 20 美元的钞票,五张 10 美元的钞票,两张 5 美元的钞票和五张 1 美元的钞票。一张 100 美元的钞票有多少种找零方法?
对于这个问题,你只需开始列出从你的钱包中选择一张钞票的方法,检查这些方法中是否有一张可以兑换 100 美元,然后列出从你的钱包中选择两张钞票的方法,再次检查,等等。
但是你是一个程序员,所以你自然想自动化这个过程。
首先,列出你钱包里的账单:
bills = [20, 20, 20, 10, 10, 10, 10, 10, 5, 5, 1, 1, 1, 1, 1]
从一组 n 事物中选择一个 k 事物称为一个 组合 ,itertools背对着这里。itertools.combinations()函数接受两个参数——一个可迭代的inputs和一个正整数n——并生成一个迭代器,遍历inputs中所有n元素组合的元组。
例如,要列出钱包中三张钞票的组合,只需:
>>> list(it.combinations(bills, 3)) [(20, 20, 20), (20, 20, 10), (20, 20, 10), ... ]为了解决这个问题,您可以循环从 1 到
len(bills)的正整数,然后检查每个大小的哪些组合总计为 100 美元:
>>> makes_100 = []
>>> for n in range(1, len(bills) + 1):
... for combination in it.combinations(bills, n):
... if sum(combination) == 100:
... makes_100.append(combination)
如果你打印出makes_100,你会注意到有很多重复的组合。这很有意义,因为你可以用三张 20 美元和四张 10 美元的钞票兑换 100 美元,但combinations()只能用你钱包里的前四张 10 美元钞票来兑换;第一、第三、第四和第五张十元钞票;第一、第二、第四和第五张十元钞票;诸如此类。
要删除makes_100中的重复项,您可以将其转换为set:
>>> set(makes_100) {(20, 20, 10, 10, 10, 10, 10, 5, 1, 1, 1, 1, 1), (20, 20, 10, 10, 10, 10, 10, 5, 5), (20, 20, 20, 10, 10, 10, 5, 1, 1, 1, 1, 1), (20, 20, 20, 10, 10, 10, 5, 5), (20, 20, 20, 10, 10, 10, 10)}所以,用你钱包里的钞票兑换 100 美元有五种方法。
这是同一个问题的变体:
用任何数量的 50 美元、20 美元、10 美元、5 美元和 1 美元钞票兑换 100 美元钞票有多少种方法?
在这种情况下,您没有预设的账单集合,因此您需要一种方法来使用任意数量的账单生成所有可能的组合。为此,您将需要
itertools.combinations_with_replacement()函数。它就像
combinations()一样工作,接受一个可迭代的inputs和一个正整数n,并返回一个遍历n的迭代器——来自inputs的元素元组。不同的是combinations_with_replacement()允许元素在它返回的元组中重复。例如:
>>> list(it.combinations_with_replacement([1, 2], 2))
[(1, 1), (1, 2), (2, 2)]
与combinations()相比:
>>> list(it.combinations([1, 2], 2)) [(1, 2)]下面是修改后的问题的解决方案:
>>> bills = [50, 20, 10, 5, 1]
>>> make_100 = []
>>> for n in range(1, 101):
... for combination in it.combinations_with_replacement(bills, n):
... if sum(combination) == 100:
... makes_100.append(combination)
在这种情况下,您不需要删除任何副本,因为combinations_with_replacement()不会产生任何副本:
>>> len(makes_100) 343如果您运行上面的解决方案,您可能会注意到需要一段时间才能显示输出。那是因为它必须处理 96,560,645 个组合!
另一个“强力”
itertools函数是permutations(),它接受一个可迭代的元素,并产生其元素的所有可能的排列:
>>> list(it.permutations(['a', 'b', 'c']))
[('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'),
('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')]
任何三个元素的可迭代将有六种排列,更长的可迭代的排列数量增长极快。事实上,长度为 n 的可迭代函数有 n!排列,其中

为了客观地看待这个问题,这里有一个表格,列出了从 n = 1 到 n = 10 的这些数字:
| n | n! |
|---|---|
| Two | Two |
| three | six |
| four | Twenty-four |
| five | One hundred and twenty |
| six | Seven hundred and twenty |
| seven | Five thousand and forty |
| eight | Forty thousand three hundred and twenty |
| nine | Three hundred and sixty-two thousand eight hundred and eighty |
| Ten | Three million six hundred and twenty-eight thousand eight hundred |
仅仅几个输入产生大量结果的现象被称为组合爆炸,在使用combinations()、combinations_with_replacement()和permutations()时要记住这一点。
通常最好避免暴力算法,尽管有时你可能需要使用一个(例如,如果算法的正确性很关键,或者每一个可能的结果必须被考虑)。这样的话,itertools有你罩着。
章节摘要
在本节中,您遇到了三个itertools函数:combinations()、combinations_with_replacement()和permutations()。
在继续之前,让我们回顾一下这些函数:
itertools.combinations例子
combinations(iterable, n)返回 iterable 中元素的连续 n 长度组合。
>>> combinations([1, 2, 3], 2) (1, 2), (1, 3), (2, 3)
itertools.combinations_with_replacement例子
combinations_with_replacement(iterable, n)返回 iterable 中元素的连续 n 长度组合,允许单个元素连续重复。
>>> combinations_with_replacement([1, 2], 2)
(1, 1), (1, 2), (2, 2)
itertools.permutations例子
permutations(iterable, n=None)返回 iterable 中元素的连续 n 长度排列。
>>> permutations('abc') ('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'), ('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')数字序列
使用
itertools,可以很容易地在无限序列上生成迭代器。在本节中,您将探索数字序列,但是这里看到的工具和技术绝不仅限于数字。偶数和奇数
对于第一个例子,您将在偶数和奇数整数上创建一对迭代器,而不用显式地做任何算术。在开始之前,让我们看一个使用发电机的算术解决方案:
>>> def evens():
... """Generate even integers, starting with 0."""
... n = 0
... while True:
... yield n
... n += 2
...
>>> evens = evens()
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> def odds():
... """Generate odd integers, starting with 1."""
... n = 1
... while True:
... yield n
... n += 2
...
>>> odds = odds()
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]
这非常简单,但是使用itertools你可以更简洁地完成这项工作。您需要的函数是itertools.count(),它确实像它听起来的那样:它计数,默认情况下从数字 0 开始。
>>> counter = it.count() >>> list(next(counter) for _ in range(5)) [0, 1, 2, 3, 4]您可以通过设置
start关键字参数(默认为 0)从您喜欢的任何数字开始计数。您甚至可以设置一个step关键字参数来确定从count()返回的数字之间的间隔——默认为 1。使用
count(),偶数和奇数整数上的迭代器变成了文字一行程序:
>>> evens = it.count(step=2)
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> odds = it.count(start=1, step=2)
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]
从 Python 3.1 开始,count()函数也接受非整数参数:
>>> count_with_floats = it.count(start=0.5, step=0.75) >>> list(next(count_with_floats) for _ in range(5)) [0.5, 1.25, 2.0, 2.75, 3.5]你甚至可以给它传递负数:
>>> negative_count = it.count(start=-1, step=-0.5)
>>> list(next(negative_count) for _ in range(5))
[-1, -1.5, -2.0, -2.5, -3.0]
在某些方面,count()类似于内置的range()函数,但是count()总是返回一个无限序列。你可能想知道无限序列有什么用,因为它不可能完全迭代。这是一个有效的问题,我承认我第一次接触无限迭代器时,我也不太明白这一点。
让我意识到无限迭代器威力的例子如下,它模拟了内置函数的行为:
>>> list(zip(it.count(), ['a', 'b', 'c'])) [(0, 'a'), (1, 'b'), (2, 'c')]这是一个简单的例子,但是请想一想:您刚刚枚举了一个没有
for循环并且事先不知道列表长度的列表。递归关系
递归关系是用递归公式描述数列的一种方式。最著名的递归关系之一是描述斐波那契数列的递归关系。
斐波那契数列就是数列
0, 1, 1, 2, 3, 5, 8, 13, ...。它从 0 和 1 开始,序列中的每个后续数字都是前两个数字的和。这个数列中的数字被称为斐波那契数列。在数学符号中,描述第 n 个斐波那契数的递归关系如下:
注意:如果你搜索 Google,你会发现这些数字在 Python 中的大量实现。你可以在真正的 Python 上的用 Python 递归思考一文中找到一个递归函数来产生它们。
常见的是使用生成器生成斐波纳契数列:
def fibs(): a, b = 0, 1 while True: yield a a, b = b, a + b描述斐波那契数列的递归关系被称为二阶递归关系,因为要计算数列中的下一个数,你需要回顾它后面的两个数。
通常,二阶递归关系具有以下形式:
这里, P 、 Q 、 R 为常数。要生成序列,您需要两个初始值。对于斐波那契数列, P = Q = 1, R = 0,初始值为 0 和 1。
如你所料,一阶递归关系具有以下形式:
有无数的数列可以用一阶和二阶递推关系来描述。例如,正整数可以描述为一阶递推关系,P=Q*= 1,初始值为 1。对于偶数,取 P = 1、 Q = 2,初始值为 0。
在本节中,您将构造函数来生成任何序列的,其值可以用一阶或二阶递归关系来描述。
一阶递归关系
您已经看到了
count()如何生成非负整数、偶整数和奇整数的序列。你也可以用它来生成序列 3n = 0,3,6,9,12,… 和 4n = 0,4,8,12,16,… 。count_by_three = it.count(step=3) count_by_four = it.count(step=4)事实上,
count()可以产生任意倍数的序列。这些序列可以用一阶递推关系来描述。例如,要生成某个数的倍数序列 n ,只需取 P = 1, Q = n ,初始值为 0。一阶递归关系的另一个简单例子是常数序列 n,n,n,n,n… ,其中 n 是您想要的任何值。对于该序列,用初始值 n 设置 P = 1 和 Q = 0。
itertools提供了一种简单的方法来实现这个序列,通过repeat()函数:all_ones = it.repeat(1) # 1, 1, 1, 1, ... all_twos = it.repeat(2) # 2, 2, 2, 2, ...如果需要有限的重复值序列,可以通过将正整数作为第二个参数传递来设置停止点:
five_ones = it.repeat(1, 5) # 1, 1, 1, 1, 1 three_fours = it.repeat(4, 3) # 4, 4, 4可能不太明显的是,交替的 1 和-1 的序列
1, -1, 1, -1, 1, -1, ...也可以用一阶递归关系来描述。就取 P = -1, Q = 0,初始值 1。有一种简单的方法可以用
itertools.cycle()函数生成这个序列。该函数将一个可迭代的inputs作为参数,并返回一个对inputs中的值的无限迭代器,一旦到达inputs的末尾,该迭代器将返回到开始处。因此,要产生 1 和-1 的交替序列,您可以这样做:alternating_ones = it.cycle([1, -1]) # 1, -1, 1, -1, 1, -1, ...不过,这一部分的目标是生成一个函数,它可以生成任何一阶递归关系——只需传递给它 P 、 Q 和一个初始值。一种方法是使用
itertools.accumulate()。
accumulate()函数接受两个参数——一个可迭代的inputs和一个二元函数func(也就是说,一个函数正好有两个输入)——并返回一个迭代器,遍历将func应用于inputs元素的累积结果。它大致相当于以下生成器:def accumulate(inputs, func): itr = iter(inputs) prev = next(itr) for cur in itr: yield prev prev = func(prev, cur)例如:



>>> import operator
>>> list(it.accumulate([1, 2, 3, 4, 5], operator.add))
[1, 3, 6, 10, 15]
由accumulate()返回的迭代器中的第一个值总是输入序列中的第一个值。在上面的例子中,这是 1,即[1, 2, 3, 4, 5]中的第一个值。
输出迭代器中的下一个值是输入序列的前两个元素之和:add(1, 2) = 3。为了产生下一个值,accumulate()取add(1, 2)的结果,并将其与输入序列中的第三个值相加:
add(3, 3) = add(add(1, 2), 3) = 6
accumulate()产生的第四个值是add(add(add(1, 2), 3), 4) = 10,以此类推。
accumulate()的第二个参数默认为operator.add(),所以前面的例子可以简化为:
>>> list(it.accumulate([1, 2, 3, 4, 5])) [1, 3, 6, 10, 15]传递内置的
min()到accumulate()将跟踪运行最小值:
>>> list(it.accumulate([9, 21, 17, 5, 11, 12, 2, 6], min))
[9, 9, 9, 5, 5, 5, 2, 2]
更复杂的函数可以通过lambda表达式传递给accumulate():
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: (x + y) / 2)) [1, 1.5, 2.25, 3.125, 4.0625]传递给
accumulate()的二元函数中参数的顺序很重要。第一个参数总是先前累加的结果,第二个参数总是输入 iterable 的下一个元素。例如,考虑以下表达式输出的差异:
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: x - y))
[1, -1, -4, -8, -13]
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: y - x))
[1, 1, 2, 2, 3]
为了建模递归关系,您可以忽略传递给accumulate()的二元函数的第二个参数。即给定值p、q、s、lambda x, _: p*s + q将返回sᵢ=psᵢ₋₁+q定义的递归关系中x之后的值。
为了让accumulate()迭代得到的递归关系,您需要向它传递一个具有正确初始值的无限序列。序列中其余的值是什么并不重要,只要初始值是递推关系的初始值就行。您可以使用repeat()来完成此操作:
def first_order(p, q, initial_val):
"""Return sequence defined by s(n) = p * s(n-1) + q."""
return it.accumulate(it.repeat(initial_val), lambda s, _: p*s + q)
使用first_order(),您可以从上面构建序列,如下所示:
>>> evens = first_order(p=1, q=2, initial_val=0)
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> odds = first_order(p=1, q=2, initial_val=1)
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]
>>> count_by_threes = first_order(p=1, q=3, initial_val=0)
>>> list(next(count_by_threes) for _ in range(5))
[0, 3, 6, 9, 12]
>>> count_by_fours = first_order(p=1, q=4, initial_val=0)
>>> list(next(count_by_fours) for _ in range(5))
[0, 4, 8, 12, 16]
>>> all_ones = first_order(p=1, q=0, initial_val=1)
>>> list(next(all_ones) for _ in range(5))
[1, 1, 1, 1, 1]
>>> all_twos = first_order(p=1, q=0, initial_val=2)
>>> list(next(all_twos) for _ in range(5))
[2, 2, 2, 2, 2]
>>> alternating_ones = first_order(p=-1, 0, initial_val=1)
>>> list(next(alternating_ones) for _ in range(5))
[1, -1, 1, -1, 1]
二阶递推关系
生成由二阶递归关系描述的序列,如斐波那契序列,可以使用与一阶递归关系类似的技术来实现。
这里的区别是,你需要创建一个元组的中间序列,它跟踪序列的前两个元素,然后将这些元组中的每一个map()到它们的第一个组件,以获得最终的序列。
它看起来是这样的:
def second_order(p, q, r, initial_values):
"""Return sequence defined by s(n) = p * s(n-1) + q * s(n-2) + r."""
intermediate = it.accumulate(
it.repeat(initial_values),
lambda s, _: (s[1], p*s[1] + q*s[0] + r)
)
return map(lambda x: x[0], intermediate)
使用second_order(),您可以生成如下斐波纳契数列:
>>> fibs = second_order(p=1, q=1, r=0, initial_values=(0, 1))
>>> list(next(fibs) for _ in range(8))
[0, 1, 1, 2, 3, 5, 8, 13]
通过改变p、q和r的值,可以很容易地生成其他序列。例如,可以如下生成佩尔数和卢卡斯数:
pell = second_order(p=2, q=1, r=0, initial_values=(0, 1))
>>> list(next(pell) for _ in range(6))
[0, 1, 2, 5, 12, 29]
>>> lucas = second_order(p=1, q=1, r=0, initial_values=(2, 1))
>>> list(next(lucas) for _ in range(6))
[2, 1, 3, 4, 7, 11]
您甚至可以生成交替的斐波那契数列:
>>> alt_fibs = second_order(p=-1, q=1, r=0, initial_values=(-1, 1))
>>> list(next(alt_fibs) for _ in range(6))
[-1, 1, -2, 3, -5, 8]
如果你像我一样是一个超级数学呆子,这真的很酷,但是退一步来比较一下本节开头的second_order()和fibs()生成器。哪个更容易理解?
这是宝贵的一课。accumulate()函数是工具箱中的一个强大工具,但是有时使用它可能意味着牺牲清晰性和可读性。
章节摘要
在本节中,您看到了几个itertools函数。现在让我们来回顾一下。
itertools.count例子
count(start=0, step=1)返回一个计数对象。
__next__()方法返回连续的值。
>>> count() 0, 1, 2, 3, 4, ... >>> count(start=1, step=2) 1, 3, 5, 7, 9, ...
itertools.repeat例子
repeat(object, times=1)创建一个迭代器,按照指定的次数返回对象。如果未指定,则无休止地返回对象。
>>> repeat(2)
2, 2, 2, 2, 2 ...
>>> repeat(2, 5) # Stops after 5 repititions.
2, 2, 2, 2, 2
itertools.cycle例子
cycle(iterable)从 iterable 中返回元素,直到用完为止。然后无限重复这个序列。
>>> cycle(['a', 'b', 'c']) a, b, c, a, b, c, a, ...
itertools accumulate例子
accumulate(iterable, func=operator.add)返回一系列累加和(或其他二元函数结果)。
>>> accumulate([1, 2, 3])
1, 3, 6
好吧,让我们从数学中休息一下,玩玩牌。
分发一副纸牌
假设您正在构建一个扑克应用程序。你需要一副纸牌。您可以首先定义一个等级列表(a、k、q、j、10、9 等)和一个花色列表(红心、方块、梅花和黑桃):
ranks = ['A', 'K', 'Q', 'J', '10', '9', '8', '7', '6', '5', '4', '3', '2']
suits = ['H', 'D', 'C', 'S']
你可以把一张牌表示成一个元组,它的第一个元素是一个等级,第二个元素是一个花色。一副牌就是这些元组的集合。这副牌应该表现得像真的一样,所以定义一个生成器是有意义的,它一次生成一张牌,一旦所有的牌都发完了,它就会耗尽。
实现这一点的一种方法是编写一个生成器,在ranks和suits上嵌套for循环:
def cards():
"""Return a generator that yields playing cards."""
for rank in ranks:
for suit in suits:
yield rank, suit
您可以用一个生成器表达式更简洁地写出来:
cards = ((rank, suit) for rank in ranks for suit in suits)
然而,有些人可能会认为这实际上比更显式的嵌套for循环更难理解。
它有助于从数学的角度来看待嵌套的for循环——也就是说,作为两个或更多可迭代的笛卡尔乘积。在数学中,两个集合 A 和 B 的笛卡尔积是形式为 (a,b) 的所有元组的集合,其中 a 是 A 的元素, b 是 B 的元素。
这里有一个 Python iterables 的例子:A = [1, 2]和B = ['a', 'b']的笛卡尔乘积是[(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')]。
itertools.product()功能正是针对这种情况。它接受任意数量的 iterables 作为参数,并返回笛卡尔积中元组的迭代器:
it.product([1, 2], ['a', 'b']) # (1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')
product()函数绝不仅限于两个可迭代的。您可以传递任意多的数据,它们甚至不必都是相同的大小!看看你能否预测出product([1, 2, 3], ['a', 'b'], ['c'])是什么,然后通过在解释器中运行它来检查你的工作。
警告:
product()函数是另一种“暴力”函数,如果你不小心的话,可能会导致组合爆炸。
使用product(),您可以在一行中重写cards:
cards = it.product(ranks, suits)
这一切都很好,但任何有价值的扑克应用程序最好从洗牌开始:
import random
def shuffle(deck):
"""Return iterator over shuffled deck."""
deck = list(deck)
random.shuffle(deck)
return iter(tuple(deck))
cards = shuffle(cards)
注意:
random.shuffle()函数使用 Fisher-Yates 混洗在 O(n) time 中将一个列表(或任何可变序列)混洗到位。这个算法非常适合混洗cards,因为它产生了一个无偏的排列——也就是说,所有可迭代的排列都同样有可能被random.shuffle()返回。也就是说,你可能注意到
shuffle()通过调用list(deck)在内存中创建了一个输入deck的副本。虽然这似乎违背了本文的精神,但作者不知道如何在不复制的情况下改变迭代器。
出于对用户的礼貌,你应该给他们一个动手的机会。如果你想象卡片整齐地堆放在一张桌子上,你让用户挑选一个数字 n ,然后从堆叠的顶部移除前 n 张卡片,并将它们移动到底部。
如果你对切片略知一二,你可以这样完成:
def cut(deck, n):
"""Return an iterator over a deck of cards cut at index `n`."""
if n < 0:
raise ValueError('`n` must be a non-negative integer')
deck = list(deck)
return iter(deck[n:] + deck[:n])
cards = cut(cards, 26) # Cut the deck in half.
cut()函数首先将deck转换成一个列表,这样您就可以对其进行切片以进行切割。为了保证你的切片行为符合预期,你必须检查n是否为非负。如果不是,你最好抛出一个异常,这样就不会发生什么疯狂的事情。
切牌非常简单:切牌的顶部是deck[:n],底部是剩余的牌,或deck[n:]。要构建新的甲板,把上面的“一半”移到下面,你只需要把它附加到下面:deck[n:] + deck[:n]。
cut()函数非常简单,但是有几个问题。对列表进行切片时,会复制原始列表,并返回包含选定元素的新列表。对于只有 52 张卡片的卡片组,空间复杂度的增加微不足道,但是您可以使用itertools减少内存开销。为此,您需要三个函数:itertools.tee()、itertools.islice()和itertools.chain()。
让我们来看看这些函数是如何工作的。
tee()函数可以用来从一个 iterable 创建任意数量的独立迭代器。它有两个参数:第一个是可迭代的inputs,第二个是要返回的inputs上独立迭代器的数量n(默认情况下,n设置为 2)。迭代器在长度为n的元组中返回。
>>> iterator1, iterator2 = it.tee([1, 2, 3, 4, 5], 2) >>> list(iterator1) [1, 2, 3, 4, 5] >>> list(iterator1) # iterator1 is now exhausted. [] >>> list(iterator2) # iterator2 works independently of iterator1 [1, 2, 3, 4, 5].虽然
tee()对于创建独立迭代器很有用,但是了解一点它是如何工作的也很重要。当你调用tee()来创建 n 个独立迭代器时,每个迭代器本质上都是在用自己的 FIFO 队列工作。当从一个迭代器中提取一个值时,该值被附加到其他迭代器的队列中。因此,如果一个迭代器在其他迭代器之前用尽,那么剩余的迭代器将在内存中保存整个 iterable 的副本。(你可以在
itertools文档中找到一个模拟tee()的 Python 函数。)因此,
tee()应该小心使用。如果您在处理由tee()返回的另一个迭代器之前用尽了迭代器的大部分,那么您最好将输入迭代器转换为list或tuple。
islice()函数的工作方式与分割列表或元组非常相似。您向它传递一个 iterable、一个开始点和一个停止点,就像对一个列表进行切片一样,返回的切片在停止点之前的索引处停止。您也可以选择包含一个步长值。当然,这里最大的不同是islice()返回一个迭代器。
>>> # Slice from index 2 to 4
>>> list(it.islice('ABCDEFG', 2, 5))
['C' 'D' 'E']
>>> # Slice from beginning to index 4, in steps of 2
>>> list(it.islice([1, 2, 3, 4, 5], 0, 5, 2))
[1, 3, 5]
>>> # Slice from index 3 to the end
>>> list(it.islice(range(10), 3, None))
[3, 4, 5, 6, 7, 8, 9]
>>> # Slice from beginning to index 3
>>> list(it.islice('ABCDE', 4))
['A', 'B', 'C', 'D']
上面的最后两个例子对于截断 iterables 很有用。你可以用这个来代替在cut()中使用的列表切片来选择牌组的“顶”和“底”。作为一个额外的好处,islice()不接受负的开始/停止位置指数和步长值,所以如果n是负的,你就不需要抛出异常。
你需要的最后一个函数是chain()。该函数将任意数量的 iterables 作为参数,并将它们“链接”在一起。例如:
>>> list(it.chain('ABC', 'DEF')) ['A' 'B' 'C' 'D' 'E' 'F'] >>> list(it.chain([1, 2], [3, 4, 5, 6], [7, 8, 9])) [1, 2, 3, 4, 5, 6, 7, 8, 9]现在您的武器库中已经有了一些额外的火力,您可以重新编写
cut()函数来切割这副牌,而无需在内存中制作完整的副本cards:def cut(deck, n): """Return an iterator over a deck of cards cut at index `n`.""" deck1, deck2 = it.tee(deck, 2) top = it.islice(deck1, n) bottom = it.islice(deck2, n, None) return it.chain(bottom, top) cards = cut(cards, 26)既然你已经洗完牌并切牌了,是时候发牌了。您可以编写一个函数
deal(),它将一副牌、手牌数量和手牌大小作为参数,并返回一个包含指定手牌数量的元组。你不需要任何新的
itertools函数来编写这个函数。在继续阅读之前,看看你自己能想出什么。这里有一个解决方案:
def deal(deck, num_hands=1, hand_size=5): iters = [iter(deck)] * hand_size return tuple(zip(*(tuple(it.islice(itr, num_hands)) for itr in iters)))首先创建一个对
deck上的迭代器的hand_size引用列表。然后遍历这个列表,在每一步删除num_hands卡片,并将它们存储在元组中。接下来,你把这些元组组合起来,模拟一次给每个玩家发一张牌。这产生了
num_hands个元组,每个元组包含hand_size张卡片。最后,将双手打包成一个元组,一次性返回它们。这个实现将
num_hands的默认值设置为1,将hand_size的默认值设置为5——也许您正在制作一个“五张牌抽奖”应用程序。下面是使用该函数的方法,以及一些示例输出:
>>> p1_hand, p2_hand, p3_hand = deal(cards, num_hands=3)
>>> p1_hand
(('A', 'S'), ('5', 'S'), ('7', 'H'), ('9', 'H'), ('5', 'H'))
>>> p2_hand
(('10', 'H'), ('2', 'D'), ('2', 'S'), ('J', 'C'), ('9', 'C'))
>>> p3_hand
(('2', 'C'), ('Q', 'S'), ('6', 'C'), ('Q', 'H'), ('A', 'C'))
你认为cards现在发了三手五张牌是什么状态?
>>> len(tuple(cards)) 37发出的十五张牌是从
cards迭代器中消耗掉的,这正是你想要的。这样,随着游戏的继续,cards迭代器的状态反映了游戏中牌组的状态。章节摘要
让我们回顾一下您在本节中看到的
itertools函数。
itertools.product例子
product(*iterables, repeat=1)输入项的笛卡尔乘积。相当于嵌套的 for 循环。
>>> product([1, 2], ['a', 'b'])
(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')
itertools.tee例子
tee(iterable, n=2)从单个输入 iterable 创建任意数量的独立迭代器。
>>> iter1, iter2 = it.tee(['a', 'b', 'c'], 2) >>> list(iter1) ['a', 'b', 'c'] >>> list(iter2) ['a', 'b', 'c']
itertools.islice例子
islice(iterable, stop)islice(iterable, start, stop, step=1)返回一个迭代器,其
__next__()方法从 iterable 中返回选定的值。像列表中的slice()一样工作,但是返回一个迭代器。
>>> islice([1, 2, 3, 4], 3)
1, 2, 3
>>> islice([1, 2, 3, 4], 1, 2)
2, 3
itertools.chain例子
chain(*iterables)返回一个链对象,它的
__next__()方法返回第一个 iterable 中的元素,直到用完为止,然后返回下一个 iterable 中的元素,直到用完所有 iterable。
>>> chain('abc', [1, 2, 3]) 'a', 'b', 'c', 1, 2, 3中场休息:拉平一列列表
在前面的例子中,您使用了
chain()将一个迭代器固定在另一个迭代器的末尾。chain()函数有一个类方法.from_iterable(),它接受一个单独的 iterable 作为参数。iterable 的元素本身必须是 iterable 的,所以实际效果是chain.from_iterable()简化了它的参数:
>>> list(it.chain.from_iterable([[1, 2, 3], [4, 5, 6]]))
[1, 2, 3, 4, 5, 6]
没有理由认为chain.from_iterable()的参数必须是有限的。您可以模仿cycle()的行为,例如:
>>> cycle = it.chain.from_iterable(it.repeat('abc'))
>>> list(it.islice(cycle, 8))
['a', 'b', 'c', 'a', 'b', 'c', 'a', 'b']
当您需要在已经“分块”的数据上构建迭代器时,chain.from_iterable()函数非常有用
在下一节中,您将看到如何使用itertools对大型数据集进行一些数据分析。但是你坚持了这么久应该休息一下。为什么不喝点水放松一下呢?甚至可能玩一会儿《星际迷航:第 n 次迭代》。
回来了?太好了!我们来做一些数据分析。
解析 S&P500
在这个例子中,您将第一次体验到使用itertools操作大型数据集——特别是 S & P500 指数的历史每日价格数据。有这个数据的 CSV 文件SP500.csv可以在这里找到(来源:雅虎财经)。你要解决的问题是:
确定 S&P500 历史上的最大日收益、日损失(百分比变化)和最长的连续上涨。
为了对你正在处理的事情有个感觉,这里是SP500.csv的前十行:
$ head -n 10 SP500.csv
Date,Open,High,Low,Close,Adj Close,Volume
1950-01-03,16.660000,16.660000,16.660000,16.660000,16.660000,1260000
1950-01-04,16.850000,16.850000,16.850000,16.850000,16.850000,1890000
1950-01-05,16.930000,16.930000,16.930000,16.930000,16.930000,2550000
1950-01-06,16.980000,16.980000,16.980000,16.980000,16.980000,2010000
1950-01-09,17.080000,17.080000,17.080000,17.080000,17.080000,2520000
1950-01-10,17.030001,17.030001,17.030001,17.030001,17.030001,2160000
1950-01-11,17.090000,17.090000,17.090000,17.090000,17.090000,2630000
1950-01-12,16.760000,16.760000,16.760000,16.760000,16.760000,2970000
1950-01-13,16.670000,16.670000,16.670000,16.670000,16.670000,3330000
如你所见,早期的数据是有限的。以后的数据会有所改善,总体来说,对于这个例子来说已经足够了。
解决这个问题的策略如下:
- 从 CSV 文件中读取数据,并使用“Adj Close”列将其转换为每日百分比变化序列
gains。 - 找出
gains序列的最大值和最小值,以及它们出现的日期。(请注意,这些值可能是在多个日期获得的;在这种情况下,最近的日期就足够了。) - 将
gains转换为gains中连续正值元组的序列growth_streaks。然后确定growth_streaks中最长元组的长度以及条纹的起止日期。(在growth_streaks中,可能不止一个元组达到了最大长度;在这种情况下,具有最近开始和结束日期的元组就足够了。)
两个值 x 和 y 之间的百分比变化由以下公式给出:

对于分析中的每一步,都需要比较与日期相关的值。为了便于比较,可以从 collections模块中子类化 namedtuple对象:
from collections import namedtuple
class DataPoint(namedtuple('DataPoint', ['date', 'value'])):
__slots__ = ()
def __le__(self, other):
return self.value <= other.value
def __lt__(self, other):
return self.value < other.value
def __gt__(self, other):
return self.value > other.value
DataPoint类有两个属性:date(一个 datetime.datetime 实例)和value。实现了 .__le__() 、 .__lt__() 和 .__gt__() dunder 方法,从而可以使用<=、<和>布尔比较器来比较两个DataPoint对象的值。这也允许使用DataPoint参数调用 max()和min() 内置函数。
注:如果你对
namedtuple不熟悉,那就去看看这个优秀的资源。DataPoint的namedtuple实现只是构建这种数据结构的许多方法之一。例如,在 Python 3.7 中,您可以将DataPoint实现为一个数据类。查看我们的数据类终极指南了解更多信息。
以下代码将数据从SP500.csv读取到一组DataPoint对象中:
import csv
from datetime import datetime
def read_prices(csvfile, _strptime=datetime.strptime):
with open(csvfile) as infile:
reader = csv.DictReader(infile)
for row in reader:
yield DataPoint(date=_strptime(row['Date'], '%Y-%m-%d').date(),
value=float(row['Adj Close']))
prices = tuple(read_prices('SP500.csv'))
read_prices()发生器打开SP500.csv,用 csv.DictReader() 对象读取每一行。DictReader()将每一行作为 OrderedDict 返回,其键是 CSV 文件标题行中的列名。
对于每一行,read_prices()产生一个包含“Date”和“Adj Close”列中的值的DataPoint对象。最后,数据点的完整序列作为tuple提交到内存中,并存储在prices 变量中。
接下来,prices需要转换为每日百分比变化序列:
gains = tuple(DataPoint(day.date, 100*(day.value/prev_day.value - 1.))
for day, prev_day in zip(prices[1:], prices))
选择将数据存储在tuple中是有意的。尽管您可以将gains指向一个迭代器,但是您将需要对数据进行两次迭代来找到最小值和最大值。
如果使用tee()创建两个独立的迭代器,用尽一个迭代器来寻找最大值将为第二个迭代器创建一个内存中所有数据的副本。通过预先创建一个tuple,与tee()相比,你不会在空间复杂度方面损失任何东西,你甚至可能获得一点点速度。
注意:这个例子着重于利用
itertools来分析 S & P500 数据。那些打算处理大量时间序列金融数据的人可能也想看看熊猫图书馆,它非常适合这样的任务。
最大增益和损耗
要确定任何一天的最大收益,你可以这样做:
max_gain = DataPoint(None, 0)
for data_point in gains:
max_gain = max(data_point, max_gain)
print(max_gain) # DataPoint(date='2008-10-28', value=11.58)
您可以使用 functools.reduce()函数来简化for循环。该函数接受一个二元函数func和一个可迭代函数inputs作为参数,并通过对可迭代函数中的对象对累积应用func将inputs减少到一个值。
例如,functools.reduce(operator.add, [1, 2, 3, 4, 5])将返回总和1 + 2 + 3 + 4 + 5 = 15。您可以认为 reduce() 的工作方式与accumulate()非常相似,除了它只返回新序列中的最终值。
使用reduce(),您可以在上面的例子中完全摆脱for循环:
import functools as ft
max_gain = ft.reduce(max, gains)
print(max_gain) # DataPoint(date='2008-10-28', value=11.58)
上面的解决方案是可行的,但是它不等同于你之前的for循环。你知道为什么吗?假设您的 CSV 文件中的数据记录了每天的损失。max_gain的值会是多少?
在for循环中,你首先设置max_gain = DataPoint(None, 0),所以如果没有增益,最后的max_gain值将是这个空的DataPoint对象。然而,reduce()解决方案带来的损失最小。这不是您想要的,并且可能会引入一个难以发现的错误。
这就是itertools可以帮你的地方。itertools.filterfalse()函数有两个参数:一个返回True或False的函数(称为谓词)和一个可迭代的inputs。它返回一个迭代器,遍历谓词返回了False的inputs中的元素。
这里有一个简单的例子:
>>> only_positives = it.filterfalse(lambda x: x <= 0, [0, 1, -1, 2, -2])
>>> list(only_positives)
[1, 2]
您可以使用filterfalse()来过滤掉gains中的负值或零值,这样reduce()只对正值起作用:
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= 0, gains))
如果永远没有收获会怎么样?请考虑以下情况:
>>> ft.reduce(max, it.filterfalse(lambda x: x <= 0, [-1, -2, -3]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: reduce() of empty sequence with no initial value
嗯,那不是你想要的!但是,这是有意义的,因为由filterflase()返回的迭代器是空的。您可以通过用try...except包装对reduce()的调用来处理TypeError,但是有更好的方法。
reduce()函数接受可选的第三个参数作为初始值。将0传递给第三个参数会得到预期的行为:
>>> ft.reduce(max, it.filterfalse(lambda x: x <= 0, [-1, -2, -3]), 0) 0将此应用于 S&P500 的例子:
zdp = DataPoint(None, 0) # zero DataPoint max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= 0, diffs), zdp)太好了!你已经让它正常工作了!现在,找到最大损失很容易:
max_loss = ft.reduce(min, it.filterfalse(lambda p: p > 0, gains), zdp) print(max_loss) # DataPoint(date='2018-02-08', value=-20.47)最长增长线
找到 S&P500 历史上最长的增长轨迹相当于找到
gains序列中最大数量的连续正数据点。itertools.takewhile()和itertools.dropwhile()功能非常适合这种情况。
takewhile()函数将一个谓词和一个可迭代的inputs作为参数,并返回一个遍历inputs的迭代器,该迭代器在谓词为其返回False的元素的第一个实例处停止:it.takewhile(lambda x: x < 3, [0, 1, 2, 3, 4]) # 0, 1, 2
dropwhile()函数的作用正好相反。它从谓词返回False的第一个元素开始返回一个迭代器:it.dropwhile(lambda x: x < 3, [0, 1, 2, 3, 4]) # 3, 4在下面的生成器函数中,
takewhile()和dropwhile()被组合以产生序列的连续正元素的元组:def consecutive_positives(sequence, zero=0): def _consecutives(): for itr in it.repeat(iter(sequence)): yield tuple(it.takewhile(lambda p: p > zero, it.dropwhile(lambda p: p <= zero, itr))) return it.takewhile(lambda t: len(t), _consecutives())
consecutive_positives()函数工作是因为repeat()不断返回一个指针到一个sequence参数上的迭代器,它在每次迭代中被调用yield语句中的tuple()所部分消耗。您可以使用
consecutive_positives()来获得一个生成器,该生成器在gains中生成连续正数据点的元组:growth_streaks = consecutive_positives(gains, zero=DataPoint(None, 0))现在,您可以使用
reduce()来提取最长的生长条纹:longest_streak = ft.reduce(lambda x, y: x if len(x) > len(y) else y, growth_streaks)综上所述,下面是一个完整的脚本,它将从
SP500.csv文件中读取数据,并打印出最大收益/损失和最长增长曲线:from collections import namedtuple import csv from datetime import datetime import itertools as it import functools as ft class DataPoint(namedtuple('DataPoint', ['date', 'value'])): __slots__ = () def __le__(self, other): return self.value <= other.value def __lt__(self, other): return self.value < other.value def __gt__(self, other): return self.value > other.value def consecutive_positives(sequence, zero=0): def _consecutives(): for itr in it.repeat(iter(sequence)): yield tuple(it.takewhile(lambda p: p > zero, it.dropwhile(lambda p: p <= zero, itr))) return it.takewhile(lambda t: len(t), _consecutives()) def read_prices(csvfile, _strptime=datetime.strptime): with open(csvfile) as infile: reader = csv.DictReader(infile) for row in reader: yield DataPoint(date=_strptime(row['Date'], '%Y-%m-%d').date(), value=float(row['Adj Close'])) # Read prices and calculate daily percent change. prices = tuple(read_prices('SP500.csv')) gains = tuple(DataPoint(day.date, 100*(day.value/prev_day.value - 1.)) for day, prev_day in zip(prices[1:], prices)) # Find maximum daily gain/loss. zdp = DataPoint(None, 0) # zero DataPoint max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= zdp, gains)) max_loss = ft.reduce(min, it.filterfalse(lambda p: p > zdp, gains), zdp) # Find longest growth streak. growth_streaks = consecutive_positives(gains, zero=DataPoint(None, 0)) longest_streak = ft.reduce(lambda x, y: x if len(x) > len(y) else y, growth_streaks) # Display results. print('Max gain: {1:.2f}% on {0}'.format(*max_gain)) print('Max loss: {1:.2f}% on {0}'.format(*max_loss)) print('Longest growth streak: {num_days} days ({first} to {last})'.format( num_days=len(longest_streak), first=longest_streak[0].date, last=longest_streak[-1].date ))运行上述脚本会产生以下输出:
Max gain: 11.58% on 2008-10-13 Max loss: -20.47% on 1987-10-19 Longest growth streak: 14 days (1971-03-26 to 1971-04-15)章节摘要
在这一节中,您讨论了很多内容,但是您只看到了
itertools中的几个函数。现在让我们来回顾一下。
itertools.filterfalse例子
filterfalse(pred, iterable)返回那些
pred(item)为假的序列项。如果pred是None,则返回为假的项目。
>>> filterfalse(bool, [1, 0, 1, 0, 0])
0, 0, 0
itertools.takewhile例子
takewhile(pred, iterable)只要每个条目的
pred计算结果为真,就从 iterable 返回连续的条目。
>>> takewhile(bool, [1, 1, 1, 0, 0]) 1, 1, 1
itertools.dropwhile例子
dropwhile(pred, iterable)当
pred(item)为真时,从 iterable 中删除项目。然后,返回每个元素,直到 iterable 用尽。
>>> dropwhile(bool, [1, 1, 1, 0, 0, 1, 1, 0])
0, 0, 1, 1, 0
你真的开始掌握整个事情了!社区游泳队想委托你做一个小项目。
根据游泳运动员数据建立接力队
在本例中,您将从 CSV 文件中读取数据,该文件包含社区游泳队在一个赛季中所有游泳比赛的游泳赛事时间。目标是决定哪些运动员应该在下个赛季参加每个泳姿的接力赛。
每个泳姿都应该有一个“A”和一个“B”接力队,每个队有四名游泳运动员。“A”组应该包括四名游出最好成绩的运动员,“B”组应该包括下四名游出最好成绩的运动员。
这个例子的数据可以在这里找到。如果您想继续,将它下载到您当前的工作目录并保存为swimmers.csv。
以下是swimmers.csv的前 10 行:
$ head -n 10 swimmers.csv
Event,Name,Stroke,Time1,Time2,Time3
0,Emma,freestyle,00:50:313667,00:50:875398,00:50:646837
0,Emma,backstroke,00:56:720191,00:56:431243,00:56:941068
0,Emma,butterfly,00:41:927947,00:42:062812,00:42:007531
0,Emma,breaststroke,00:59:825463,00:59:397469,00:59:385919
0,Olivia,freestyle,00:45:566228,00:46:066985,00:46:044389
0,Olivia,backstroke,00:53:984872,00:54:575110,00:54:932723
0,Olivia,butterfly,01:12:548582,01:12:722369,01:13:105429
0,Olivia,breaststroke,00:49:230921,00:49:604561,00:49:120964
0,Sophia,freestyle,00:55:209625,00:54:790225,00:55:351528
每行三个时间代表三个不同秒表记录的时间,以MM:SS:mmmmmm格式给出(分、秒、微秒)。一个事件的可接受时间是这三个时间的中值,而不是的平均值。
让我们从创建namedtuple对象的子类Event开始,就像我们在 SP500 的例子中所做的一样:
from collections import namedtuple
class Event(namedtuple('Event', ['stroke', 'name', 'time'])):
__slots__ = ()
def __lt__(self, other):
return self.time < other.time
属性.stroke存储事件中游泳运动员的名字,.name存储游泳运动员的名字,.time记录事件被接受的时间。.__lt__() dunder 方法将允许在一系列Event对象上调用min()。
要将数据从 CSV 读入一个由Event对象组成的元组,可以使用csv.DictReader对象:
import csv
import datetime
import statistics
def read_events(csvfile, _strptime=datetime.datetime.strptime):
def _median(times):
return statistics.median((_strptime(time, '%M:%S:%f').time()
for time in row['Times']))
fieldnames = ['Event', 'Name', 'Stroke']
with open(csvfile) as infile:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')
next(reader) # skip header
for row in reader:
yield Event(row['Stroke'], row['Name'], _median(row['Times']))
events = tuple(read_events('swimmers.csv'))
read_events()生成器将swimmers.csv文件中的每一行读入下面一行中的OrderedDict对象:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')
通过将'Times'字段分配给restkey,CSV 文件中每一行的“时间 1”、“时间 2”和“时间 3”列将被存储在由csv.DictReader返回的OrderedDict的'Times'键的列表中。
例如,文件的第一行(不包括标题行)被读入以下对象:
OrderedDict([('Event', '0'),
('Name', 'Emma'),
('Stroke', 'freestyle'),
('Times', ['00:50:313667', '00:50:875398', '00:50:646837'])])
接下来,read_events()产生一个由_median()函数返回的带有泳姿、游泳者姓名和中值时间的Event对象(作为 datetime.time对象),该函数调用该行中时间列表上的 statistics.median() 。
由于时间列表中的每一项都被csv.DictReader()读取为一个字符串,_median()使用 datetime.datetime.strptime()类方法从每个字符串中实例化一个时间对象。
最后,创建一组Event对象:
events = tuple(read_events('swimmers.csv'))
events的前五个元素是这样的:
>>> events[:5] (Event(stroke='freestyle', name='Emma', time=datetime.time(0, 0, 50, 646837)), Event(stroke='backstroke', name='Emma', time=datetime.time(0, 0, 56, 720191)), Event(stroke='butterfly', name='Emma', time=datetime.time(0, 0, 42, 7531)), Event(stroke='breaststroke', name='Emma', time=datetime.time(0, 0, 59, 397469)), Event(stroke='freestyle', name='Olivia', time=datetime.time(0, 0, 46, 44389)))现在你已经把数据存入了内存,你会怎么处理它呢?攻击计划如下:
- 按笔划将事件分组。
- 对于每个冲程:
- 按游泳运动员的名字分组,并确定每个运动员的最佳时间。
- 按最佳时间给游泳者排序。
- 前四名运动员组成 A 队,后四名运动员组成 B 队。
itertools.groupby()函数使得在一个 iterable 中分组对象变得轻而易举。它需要一个可迭代的inputs和一个key来分组,并返回一个包含迭代器的对象,迭代器遍历由键分组的inputs的元素。这里有一个简单的
groupby()例子:
>>> data = [{'name': 'Alan', 'age': 34},
... {'name': 'Catherine', 'age': 34},
... {'name': 'Betsy', 'age': 29},
... {'name': 'David', 'age': 33}]
...
>>> grouped_data = it.groupby(data, key=lambda x: x['age'])
>>> for key, grp in grouped_data:
... print('{}: {}'.format(key, list(grp)))
...
34: [{'name': 'Alan', 'age': 34}, {'name': 'Betsy', 'age': 34}]
29: [{'name': 'Catherine', 'age': 29}]
33: [{'name': 'David', 'age': 33}]
如果没有指定键,groupby()默认为按“标识”分组,即聚合 iterable 中相同的元素:
>>> for key, grp in it.groupby([1, 1, 2, 2, 2, 3]: ... print('{}: {}'.format(key, list(grp))) ... 1: [1, 1] 2: [2, 2, 2] 3: [3]从返回的迭代器与一个键相关联的意义上来说,
groupby()返回的对象有点像字典。但是,与字典不同,它不允许您通过键名访问它的值:>>> grouped_data[1] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'itertools.groupby' object is not subscriptable事实上,
groupby()返回元组的迭代器,元组的第一个组件是键,第二个组件是分组数据的迭代器:
>>> grouped_data = it.groupby([1, 1, 2, 2, 2, 3])
>>> list(grouped_data)
[(1, <itertools._grouper object at 0x7ff3056130b8>),
(2, <itertools._grouper object at 0x7ff3056130f0>),
(3, <itertools._grouper object at 0x7ff305613128>)]
关于groupby()要记住的一件事是,它没有你想象的那么聪明。当groupby()遍历数据时,它聚合元素,直到遇到具有不同键的元素,这时它开始一个新的组:
>>> grouped_data = it.groupby([1, 2, 1, 2, 3, 2]) >>> for key, grp in grouped_data: ... print('{}: {}'.format(key, list(grp))) ... 1: [1] 2: [2] 1: [1] 2: [2] 3: [3] 2: [2]与 SQL
GROUP BY命令相比,SQLGROUP BY命令对元素进行分组,而不考虑它们出现的顺序。当使用
groupby()时,您需要根据您想要分组的关键字对数据进行排序。否则,你可能会得到意想不到的结果。这很常见,因此编写一个实用函数来解决这个问题会有所帮助:def sort_and_group(iterable, key=None): """Group sorted `iterable` on `key`.""" return it.groupby(sorted(iterable, key=key), key=key)回到游泳者的例子,您需要做的第一件事是创建一个 for 循环,该循环遍历按笔画分组的
events元组中的数据:for stroke, evts in sort_and_group(events, key=lambda evt: evt.stroke):接下来,您需要在上面的
for循环中按照游泳者的名字对evts迭代器进行分组:events_by_name = sort_and_group(evts, key=lambda evt: evt.name)要计算
events_by_name中每个游泳者的最佳时间,您可以调用该游泳者组中事件的min()。(这是因为您在Events类中实现了.__lt__()邓德方法。)best_times = (min(evt) for _, evt in events_by_name)请注意,
best_times生成器生成包含每个游泳者最佳划水时间的Event对象。为了建立接力队,你需要按时间对best_times进行排序,并将结果分成四组。要汇总结果,您可以使用的grouper()配方部分的grouper()函数,并使用islice()获取前两组。sorted_by_time = sorted(best_times, key=lambda evt: evt.time) teams = zip(('A', 'B'), it.islice(grouper(sorted_by_time, 4), 2))现在,
teams是一个迭代器,正好遍历两个元组,这两个元组代表笔画的“A”和“B”组。每个元组的第一个组件是字母“A”或“B ”,第二个组件是包含队中游泳者的Event对象的迭代器。您现在可以打印结果:for team, swimmers in teams: print('{stroke} {team}: {names}'.format( stroke=stroke.capitalize(), team=team, names=', '.join(swimmer.name for swimmer in swimmers) ))以下是完整的脚本:
from collections import namedtuple import csv import datetime import itertools as it import statistics class Event(namedtuple('Event', ['stroke', 'name', 'time'])): __slots__ = () def __lt__(self, other): return self.time < other.time def sort_and_group(iterable, key=None): return it.groupby(sorted(iterable, key=key), key=key) def grouper(iterable, n, fillvalue=None): iters = [iter(iterable)] * n return it.zip_longest(*iters, fillvalue=fillvalue) def read_events(csvfile, _strptime=datetime.datetime.strptime): def _median(times): return statistics.median((_strptime(time, '%M:%S:%f').time() for time in row['Times'])) fieldnames = ['Event', 'Name', 'Stroke'] with open(csvfile) as infile: reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times') next(reader) # Skip header. for row in reader: yield Event(row['Stroke'], row['Name'], _median(row['Times'])) events = tuple(read_events('swimmers.csv')) for stroke, evts in sort_and_group(events, key=lambda evt: evt.stroke): events_by_name = sort_and_group(evts, key=lambda evt: evt.name) best_times = (min(evt) for _, evt in events_by_name) sorted_by_time = sorted(best_times, key=lambda evt: evt.time) teams = zip(('A', 'B'), it.islice(grouper(sorted_by_time, 4), 2)) for team, swimmers in teams: print('{stroke} {team}: {names}'.format( stroke=stroke.capitalize(), team=team, names=', '.join(swimmer.name for swimmer in swimmers) ))如果您运行上面的代码,您将得到以下输出:
Backstroke A: Sophia, Grace, Penelope, Addison Backstroke B: Elizabeth, Audrey, Emily, Aria Breaststroke A: Samantha, Avery, Layla, Zoe Breaststroke B: Lillian, Aria, Ava, Alexa Butterfly A: Audrey, Leah, Layla, Samantha Butterfly B: Alexa, Zoey, Emma, Madison Freestyle A: Aubrey, Emma, Olivia, Evelyn Freestyle B: Elizabeth, Zoe, Addison, Madison何去何从
如果你已经做到了这一步,祝贺你!我希望你旅途愉快。
itertools是 Python 标准库中一个强大的模块,也是您工具箱中的一个必备工具。有了它,你可以编写更快、更节省内存、更简单、更易读的代码(尽管情况并不总是如此,正如你在二阶递归关系一节中看到的)。不过,如果有什么不同的话,
itertools是对迭代器和懒惰求值的力量的一个证明。尽管您已经看到了许多技术,但本文只是触及了皮毛。所以我想这意味着你的旅程才刚刚开始。
免费奖励: 点击这里获取我们的 itertools 备忘单,它总结了本教程中演示的技术。
其实这篇文章跳过了两个
itertools函数:starmap()和compress()。根据我的经验,这是两个很少使用的itertools函数,但是我强烈建议您阅读他们的文档,用您自己的用例进行实验!这里有几个地方你可以找到更多
itertools的例子(感谢布拉德·所罗门的这些好建议):最后,关于构造迭代器的更多工具,请看一下 more-itertools 。
你有什么最喜欢的
itertools食谱/用例吗?我们很乐意在评论中听到他们的消息!我们要感谢我们的读者 Putcher 和 Samir Aghayev 指出了这篇文章最初版本中的几个错误。***********
在 Python 中使用 JSON 数据
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 处理 JSON 数据
自从诞生以来, JSON 已经迅速成为事实上的信息交换标准。很有可能你在这里是因为你需要把一些数据从这里传输到那里。也许你正在通过一个 API 收集信息,或者将你的数据存储在一个文档数据库中。无论如何,您已经深陷 JSON,您必须使用 Python 才能摆脱困境。
幸运的是,这是一个非常普通的任务,而且——和大多数普通任务一样——Python 让它变得非常简单。别害怕,蟒蛇和蟒蛇们。这次会轻而易举!
所以,我们用 JSON 来存储和交换数据?是的,你猜对了!它只不过是社区用来传递数据的标准化格式。请记住,JSON 不是这类工作的唯一可用格式,但是 XML 和 YAML 可能是唯一值得一提的格式。
免费 PDF 下载: Python 3 备忘单
JSON 的(非常)简史
不足为奇的是,JavaSscriptOobjectNrotation 的灵感来自于处理对象字面语法的 JavaScript 编程语言的子集。他们有一个漂亮的网站来解释整个事情。不过不要担心:JSON 早已成为语言不可知论者,并作为自己的标准而存在,所以我们可以出于讨论的目的而避开 JavaScript。
最终,整个社区都采用了 JSON,因为它易于人类和机器创建和理解。
看,是 JSON!
准备好。我将向您展示一些真实的 JSON——就像您在野外看到的一样。没关系:JSON 应该是任何使用过 C 风格语言的人都可读的,而 Python 是一种 C 风格语言…所以那就是你!
{ "firstName": "Jane", "lastName": "Doe", "hobbies": ["running", "sky diving", "singing"], "age": 35, "children": [ { "firstName": "Alice", "age": 6 }, { "firstName": "Bob", "age": 8 } ] }如您所见,JSON 支持基本类型,如字符串和数字,以及嵌套列表和对象。
等等,那看起来像一本 Python 字典!我知道,对吧?在这一点上,它几乎是通用的对象符号,但我不认为 UON 能很好地脱口而出。欢迎在评论中讨论替代方案。
咻!你在第一次遭遇野生 JSON 时幸存了下来。现在你只需要学会如何驯服它。
Python 原生支持 JSON!
Python 自带了一个名为
json的内置包,用于编码和解码 JSON 数据。把这个小家伙放在你档案的最上面:
import json一点词汇
对 JSON 进行编码的过程通常被称为序列化。这个术语指的是将数据转换成一个字节序列(因此成为序列)以便存储或通过网络传输。你可能也听说过术语编组,但那是一个完全不同的讨论。自然地,反序列化是解码已经以 JSON 标准存储或交付的数据的相反过程。
哎呀!这听起来很专业。肯定。但实际上,我们在这里谈论的都是读和写。可以这样想:编码是为了将数据写入磁盘,而解码是为了将数据读入内存。
正在序列化 JSON
计算机处理大量信息后会发生什么?它需要进行数据转储。相应地,
json库公开了将数据写入文件的dump()方法。还有一个用于写入 Python 字符串的dumps()方法(读作“dump-s”)。简单的 Python 对象根据一种相当直观的转换被翻译成 JSON。
计算机编程语言 JSON dictobjectlist,tuplearraystrstringint、long、floatnumberTruetrueFalsefalseNonenull一个简单的序列化例子
假设您正在内存中处理一个 Python 对象,看起来有点像这样:
data = { "president": { "name": "Zaphod Beeblebrox", "species": "Betelgeusian" } }将这些信息保存到磁盘上是非常重要的,因此您的任务是将其写入文件。
使用 Python 的上下文管理器,您可以创建一个名为
data_file.json的文件,并以写模式打开它。(JSON 文件通常以扩展名.json结尾。)with open("data_file.json", "w") as write_file: json.dump(data, write_file)注意
dump()有两个位置参数:(1)要序列化的数据对象,以及(2)字节将被写入的类似文件的对象。或者,如果您倾向于在程序中继续使用这种序列化的 JSON 数据,您可以将它写入一个本机 Python
str对象。json_string = json.dumps(data)请注意,类似文件的对象不存在,因为您实际上没有写入磁盘。除此之外,
dumps()就跟dump()一样。万岁!你生了一些小 JSON,你准备把它放回野外,让它长得又大又壮。
一些有用的关键字参数
请记住,JSON 是为了让人们容易阅读,但是如果把所有的语法都挤在一起,可读的语法是不够的。另外,你可能有一种不同于我的编程风格,当代码被格式化成你喜欢的格式时,你可能更容易阅读它。
注意:
dump()和dumps()方法使用相同的关键字参数。大多数人想要改变的第一个选项是空白。您可以使用
indent关键字参数来指定嵌套结构的缩进大小。通过使用我们在上面定义的data,并在控制台中运行以下命令,来亲自检查一下不同之处:
>>> json.dumps(data)
>>> json.dumps(data, indent=4)
另一个格式化选项是separators关键字参数。默认情况下,这是一个 2 元组的分隔符字符串(", ", ": "),但是 compact JSON 的一个常见替代字符串是(",", ":")。再次查看示例 JSON,看看这些分隔符在哪里发挥作用。
还有其他的,比如sort_keys,但是我不知道那个是做什么的。如果你好奇的话,你可以在文档中找到完整的列表。
反序列化 JSON
太好了,看起来你已经为自己捕获了一些野生 JSON!现在是时候让它成形了。在json库中,您会发现用于将 JSON 编码的数据转换成 Python 对象的load()和loads()。
就像序列化一样,反序列化也有一个简单的转换表,不过您可能已经猜到它是什么样子了。
| JSON | 计算机编程语言 |
|---|---|
object |
dict |
array |
list |
string |
str |
number(整数) |
int |
number(真实) |
float |
true |
True |
false |
False |
null |
None |
从技术上讲,这种转换并不是序列化表的完美逆过程。这基本上意味着,如果你现在对一个对象进行编码,然后再解码,你可能得不到完全相同的对象。我想象这有点像传送:在这里分解我的分子,然后在那里把它们重新组合起来。我还是原来的我吗?
在现实中,这可能更像是让一个朋友把一些东西翻译成日语,另一个朋友把它翻译回英语。不管怎样,最简单的例子是对一个 tuple 进行编码,并在解码后得到一个list,就像这样:
>>> blackjack_hand = (8, "Q") >>> encoded_hand = json.dumps(blackjack_hand) >>> decoded_hand = json.loads(encoded_hand) >>> blackjack_hand == decoded_hand False >>> type(blackjack_hand) <class 'tuple'> >>> type(decoded_hand) <class 'list'> >>> blackjack_hand == tuple(decoded_hand) True一个简单的反序列化示例
这一次,假设您已经在磁盘上存储了一些数据,您希望在内存中操作这些数据。您仍将使用上下文管理器,但这次您将以读取模式打开现有的
data_file.json。with open("data_file.json", "r") as read_file: data = json.load(read_file)这里的事情非常简单,但是请记住,这个方法的结果可以从转换表中返回任何允许的数据类型。这只有在你加载以前没有见过的数据时才重要。在大多数情况下,根对象将是一个
dict或一个list。如果您已经从另一个程序获取了 JSON 数据,或者以其他方式获得了 Python 中的一串 JSON 格式的数据,那么您可以很容易地用
loads()对其进行反序列化,它自然地从一个字符串中加载:json_string = """ { "researcher": { "name": "Ford Prefect", "species": "Betelgeusian", "relatives": [ { "name": "Zaphod Beeblebrox", "species": "Betelgeusian" } ] } } """ data = json.loads(json_string)瞧啊。你驯服了野 JSON,现在它在你的控制之下。但是你用这种力量做什么取决于你自己。你可以喂养它,培养它,甚至教它一些技巧。我不是不信任你…但是要控制好它,好吗?
一个真实世界的例子
对于您的介绍性示例,您将使用 JSONPlaceholder ,这是一个用于实践目的的假 JSON 数据源。
首先创建一个名为
scratch.py的脚本文件,或者你想要的任何东西。我真的不能阻止你。您需要向 JSONPlaceholder 服务发出一个 API 请求,所以只需使用
requests包来完成繁重的工作。将这些导入添加到文件的顶部:import json import requests现在,你将会处理一份待办事项清单,因为就像…你知道,这是一种通过仪式或其他什么。
继续向 JSONPlaceholder API 请求
/todos端点。如果您不熟悉requests,实际上有一个方便的json()方法可以为您完成所有工作,但是您可以练习使用json库来反序列化响应对象的text属性。它应该是这样的:response = requests.get("https://jsonplaceholder.typicode.com/todos") todos = json.loads(response.text)你不相信这有用吗?好吧,在交互模式下运行文件,自己测试一下。同时,检查一下
todos的类型。如果你想冒险,看看列表中的前 10 个项目。
>>> todos == response.json()
True
>>> type(todos)
<class 'list'>
>>> todos[:10]
...
我不会骗你,但我很高兴你是个怀疑论者。
什么是交互模式?啊,我还以为你不会问呢!你知道你总是在编辑器和终端之间跳来跳去吗?嗯,我们这些狡猾的 python 爱好者在运行脚本时使用了
-i交互标志。这是测试代码的一个很棒的小技巧,因为它运行脚本,然后打开一个交互式命令提示符,可以访问脚本中的所有数据!
好了,该行动了。您可以通过在浏览器中访问端点来查看数据的结构,但是这里有一个示例 TODO:
{ "userId": 1, "id": 1, "title": "delectus aut autem", "completed": false }
有多个用户,每个用户都有一个惟一的userId,每个任务都有一个布尔completed属性。您能确定哪些用户完成了最多的任务吗?
# Map of userId to number of complete TODOs for that user
todos_by_user = {}
# Increment complete TODOs count for each user.
for todo in todos:
if todo["completed"]:
try:
# Increment the existing user's count.
todos_by_user[todo["userId"]] += 1
except KeyError:
# This user has not been seen. Set their count to 1.
todos_by_user[todo["userId"]] = 1
# Create a sorted list of (userId, num_complete) pairs.
top_users = sorted(todos_by_user.items(),
key=lambda x: x[1], reverse=True)
# Get the maximum number of complete TODOs.
max_complete = top_users[0][1]
# Create a list of all users who have completed
# the maximum number of TODOs.
users = []
for user, num_complete in top_users:
if num_complete < max_complete:
break
users.append(str(user))
max_users = " and ".join(users)
是的,是的,您的实现更好,但关键是,您现在可以像操作普通 Python 对象一样操作 JSON 数据!
我不知道您是怎么想的,但是当我再次以交互方式运行该脚本时,我会得到以下结果:
>>> s = "s" if len(users) > 1 else "" >>> print(f"user{s} {max_users} completed {max_complete} TODOs") users 5 and 10 completed 12 TODOs这很酷,但你是来学习 JSON 的。对于您的最后一个任务,您将创建一个 JSON 文件,其中包含每个完成了最多待办事项的用户的已完成待办事项。
您所需要做的就是过滤
todos并将结果列表写入一个文件。出于原创的考虑,可以调用输出文件filtered_data_file.json。有很多方法可以做到这一点,但这里有一个:# Define a function to filter out completed TODOs # of users with max completed TODOS. def keep(todo): is_complete = todo["completed"] has_max_count = str(todo["userId"]) in users return is_complete and has_max_count # Write filtered TODOs to file. with open("filtered_data_file.json", "w") as data_file: filtered_todos = list(filter(keep, todos)) json.dump(filtered_todos, data_file, indent=2)太好了,你已经去掉了所有你不需要的数据,把好的东西保存到了一个全新的文件中!再次运行脚本并检查
filtered_data_file.json以验证一切正常。当您运行它时,它将与scratch.py在同一个目录中。既然你已经走了这么远,我打赌你一定感觉很棒,对吧?不要骄傲自大:谦逊是一种美德。不过,我倾向于同意你的观点。到目前为止,这是一帆风顺的,但你可能要为这最后一段旅程做好准备。
编码和解码自定义 Python 对象
当我们试图从你正在开发的地下城&龙应用中序列化
Elf类时会发生什么?class Elf: def __init__(self, level, ability_scores=None): self.level = level self.ability_scores = { "str": 11, "dex": 12, "con": 10, "int": 16, "wis": 14, "cha": 13 } if ability_scores is None else ability_scores self.hp = 10 + self.ability_scores["con"]不足为奇的是,Python 抱怨说
Elf不是可序列化的(如果你曾经试图告诉一个小精灵,你就会知道这一点):
>>> elf = Elf(level=4)
>>> json.dumps(elf)
TypeError: Object of type 'Elf' is not JSON serializable
虽然json模块可以处理大多数内置的 Python 类型,但是它并不理解默认情况下如何编码定制的数据类型。这就像试图把一个方钉装进一个圆孔——你需要一个电锯和父母的监督。
简化数据结构
现在,问题是如何处理更复杂的数据结构。嗯,您可以尝试手工编码和解码 JSON,但是有一个稍微聪明一点的解决方案可以帮您节省一些工作。您可以插入一个中间步骤,而不是直接从定制数据类型转换到 JSON。
你所需要做的就是用json已经理解的内置类型来表示你的数据。本质上,您将更复杂的对象转换成更简单的表示,然后由json模块转换成 JSON。这就像数学中的传递性:如果 A = B and B = C,那么 A = C
要掌握这一点,你需要一个复杂的对象来玩。您可以使用任何您喜欢的自定义类,但是 Python 有一个名为complex的内置类型,用于表示复数,默认情况下它是不可序列化的。因此,为了这些例子,你的复杂对象将是一个complex对象。困惑了吗?
>>> z = 3 + 8j >>> type(z) <class 'complex'> >>> json.dumps(z) TypeError: Object of type 'complex' is not JSON serializable复数从何而来?你看,当一个实数和一个虚数非常相爱时,它们加在一起产生一个数,这个数(名正言顺地)叫做 复数 。
当使用自定义类型时,一个很好的问题是重新创建这个对象所需的最少信息量是多少?在复数的情况下,你只需要知道实部和虚部,这两部分都可以作为属性在
complex对象上访问:
>>> z.real
3.0
>>> z.imag
8.0
将相同的数字传递给complex构造函数足以满足__eq__比较运算符:
>>> complex(3, 8) == z True将自定义数据类型分解成基本组件对于序列化和反序列化过程都至关重要。
编码自定义类型
要将一个定制对象翻译成 JSON,您需要做的就是为
dump()方法的default参数提供一个编码函数。json模块将在任何非本地可序列化的对象上调用这个函数。这里有一个简单的解码函数,你可以用来练习:def encode_complex(z): if isinstance(z, complex): return (z.real, z.imag) else: type_name = z.__class__.__name__ raise TypeError(f"Object of type '{type_name}' is not JSON serializable")请注意,如果您没有得到所期望的那种对象,那么您应该抛出一个
TypeError。这样,您就避免了意外序列化任何精灵。现在您可以自己尝试编码复杂的对象了!
>>> json.dumps(9 + 5j, default=encode_complex)
'[9.0, 5.0]'
>>> json.dumps(elf, default=encode_complex)
TypeError: Object of type 'Elf' is not JSON serializable
为什么我们把复数编码成一个
tuple?好问题!这当然不是唯一的选择,也不一定是最好的选择。事实上,如果您以后想要解码该对象,这不是一个很好的表示,您很快就会看到这一点。
另一种常见的方法是子类化标准的JSONEncoder并覆盖它的default()方法:
class ComplexEncoder(json.JSONEncoder):
def default(self, z):
if isinstance(z, complex):
return (z.real, z.imag)
else:
return super().default(z)
您可以简单地让基类处理它,而不是自己引发TypeError。您可以通过cls参数直接在dump()方法中使用它,或者通过创建一个编码器实例并调用它的encode()方法来使用它:
>>> json.dumps(2 + 5j, cls=ComplexEncoder) '[2.0, 5.0]' >>> encoder = ComplexEncoder() >>> encoder.encode(3 + 6j) '[3.0, 6.0]'解码自定义类型
虽然复数的实部和虚部是绝对必要的,但它们实际上并不足以重建物体。当您尝试用
ComplexEncoder对一个复数进行编码,然后对结果进行解码时,就会发生这种情况:
>>> complex_json = json.dumps(4 + 17j, cls=ComplexEncoder)
>>> json.loads(complex_json)
[4.0, 17.0]
您得到的只是一个列表,如果您还想要那个复杂的对象,您必须将值传递给一个complex构造函数。回忆一下我们关于传送的讨论。缺少的是元数据,或者关于你正在编码的数据类型的信息。
我想你真正应该问自己的问题是重建这个物体所需的必要的和足够的的最小信息量是多少?
在 JSON 标准中,json模块期望所有的自定义类型都表示为objects。为了多样化,这次您可以创建一个名为complex_data.json的 JSON 文件,并添加下面的object来表示一个复数:
{ "__complex__": true, "real": 42, "imag": 36 }
看到聪明的地方了吗?那个"__complex__"键就是我们刚刚谈到的元数据。关联值是多少并不重要。要让这个小技巧发挥作用,您需要做的就是验证密钥是否存在:
def decode_complex(dct):
if "__complex__" in dct:
return complex(dct["real"], dct["imag"])
return dct
如果"__complex__"不在字典中,你可以返回对象,让默认的解码器处理它。
每次load()方法试图解析object时,您都有机会在默认解码器处理数据之前进行调解。您可以通过将解码函数传递给object_hook参数来实现这一点。
现在玩和以前一样的游戏:
>>> with open("complex_data.json") as complex_data: ... data = complex_data.read() ... z = json.loads(data, object_hook=decode_complex) ... >>> type(z) <class 'complex'>虽然
object_hook可能感觉像是dump()方法的default参数的对应物,但是这种类比实际上是从这里开始和结束的。这也不仅仅适用于一个对象。尝试将这个复数列表放入
complex_data.json并再次运行脚本:[ { "__complex__":true, "real":42, "imag":36 }, { "__complex__":true, "real":64, "imag":11 } ]如果一切顺利,您将获得一个
complex对象列表:
>>> with open("complex_data.json") as complex_data:
... data = complex_data.read()
... numbers = json.loads(data, object_hook=decode_complex)
...
>>> numbers
[(42+36j), (64+11j)]
您也可以尝试子类化JSONDecoder并覆盖object_hook,但是最好尽可能坚持使用轻量级解决方案。
全部完成!
恭喜你,现在你可以运用 JSON 的强大力量来满足你所有的邪恶的 Python 需求了。
虽然您在这里使用的示例肯定是人为的并且过于简单,但是它们展示了一个您可以应用于更一般任务的工作流:
- 导入的
json包。 - 用
load()或loads()读取数据。 - 处理数据。
- 用
dump()或dumps()写入更改的数据。
一旦数据被加载到内存中,您将如何处理它取决于您的用例。一般来说,你的目标是从一个来源收集数据,提取有用的信息,并将这些信息传递下去或记录下来。
今天你进行了一次旅行:你捕获并驯服了一些野生 JSON,并及时赶回来吃晚饭!作为一个额外的奖励,学习json包将使学习 pickle 和 marshal 变得轻而易举。
祝你在未来的 Pythonic 努力中好运!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 处理 JSON 数据******
用 Python 和 Keras 实现实用的文本分类
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 和 Keras 学习文本分类
想象一下你可以知道网上人们的心情。也许你对它的整体不感兴趣,但前提是人们今天在你最喜欢的社交媒体平台上开心。在本教程之后,你将具备这样做的能力。在这样做的同时,你将掌握(深度)神经网络的当前进展,以及它们如何应用于文本。
用机器学习从文本中读取情绪被称为情感分析,是文本分类中比较突出的用例之一。这属于非常活跃的研究领域自然语言处理(NLP) 。文本分类的其他常见用例包括检测垃圾邮件、自动标记客户查询以及将文本分类到定义的主题中。那么你如何做到这一点呢?
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
选择一个数据集
在开始之前,我们先来看看我们有哪些数据。继续从 UCI 机器学习知识库下载来自情感标签句子数据集的数据集。
顺便说一下,当你想尝试一些算法时,这个存储库是机器学习数据集的一个很好的来源。这个数据集包括来自 IMDb、亚马逊和 Yelp 的标签评论。每篇评论的负面情绪得分为 0,正面情绪得分为 1。
将文件夹解压到一个data文件夹中,然后加载带有熊猫的数据:
import pandas as pd
filepath_dict = {'yelp': 'data/sentiment_analysis/yelp_labelled.txt',
'amazon': 'data/sentiment_analysis/amazon_cells_labelled.txt',
'imdb': 'data/sentiment_analysis/imdb_labelled.txt'}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source # Add another column filled with the source name
df_list.append(df)
df = pd.concat(df_list)
print(df.iloc[0])
结果将如下所示:
sentence Wow... Loved this place.
label 1
source yelp
Name: 0, dtype: object
这看起来差不多是对的。有了这个数据集,你就能够训练一个模型来预测一个句子的情感。花一点时间思考一下你将如何预测这些数据。
一种方法是统计每个单词在每个句子中的出现频率,并将这一统计结果与数据集中的所有单词联系起来。你可以从获取数据开始,用所有句子中的所有单词创建一个词汇表。在 NLP 中,文本集合也被称为语料库。
本例中的词汇表是在我们的文本中出现的单词列表,其中每个单词都有自己的索引。这使你能够为一个句子创建一个向量。然后,你将得到你想要矢量化的句子,并计算词汇中的每一个出现次数。得到的向量将是词汇表的长度和词汇表中每个单词的计数。
得到的向量也被称为特征向量。在特征向量中,每个维度可以是数字或分类特征,例如建筑物的高度、股票的价格,或者在我们的情况下,词汇表中的单词计数。这些特征向量是数据科学和机器学习中至关重要的一部分,因为你想要训练的模型取决于它们。
让我们快速说明这一点。想象你有以下两句话:
>>> sentences = ['John likes ice cream', 'John hates chocolate.']接下来,你可以使用 scikit-learn 库提供的
CountVectorizer对句子进行矢量化。它获取每个句子的单词,并创建一个包含句子中所有独特单词的词汇表。然后,该词汇表可用于创建单词计数的特征向量:
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vectorizer = CountVectorizer(min_df=0, lowercase=False)
>>> vectorizer.fit(sentences)
>>> vectorizer.vocabulary_
{'John': 0, 'chocolate': 1, 'cream': 2, 'hates': 3, 'ice': 4, 'likes': 5}
这个词汇表也是每个单词的索引。现在,您可以根据之前的词汇,获取每个句子中出现的单词。词汇表由句子中的所有五个单词组成,每个单词代表词汇表中的一个单词。当你用CountVectorizer转换前两个句子时,你将得到一个代表句子中每个单词数量的向量:
>>> vectorizer.transform(sentences).toarray() array([[1, 0, 1, 0, 1, 1], [1, 1, 0, 1, 0, 0]])现在,您可以看到基于前面的词汇得到的每个句子的特征向量。例如,如果你看一下第一项,你可以看到两个向量都有一个
1。这意味着两个句子都有一个John出现,在词汇表中排在第一位。这被认为是一个单词包(BOW) 模型,这是 NLP 中从文本中创建向量的一种常用方法。每个文档都表示为一个向量。现在,您可以将这些向量用作机器学习模型的特征向量。这将引导我们进入下一部分,定义基线模型。
定义基线模型
当您使用机器学习时,一个重要的步骤是定义基线模型。这通常涉及一个简单的模型,然后用来与您想要测试的更高级的模型进行比较。在这种情况下,您将使用基线模型将其与涉及(深度)神经网络的更高级的方法进行比较,这是本教程的主要内容。
首先,您将将数据分成一个训练和测试集,这将允许您评估准确性,并查看您的模型是否概括良好。这意味着模型是否能够在以前没有见过的数据上表现良好。这是一种查看模型是否过度拟合的方法。
过拟合是指模型在训练数据上训练得太好。您希望避免过度拟合,因为这将意味着模型大部分只是记住了训练数据。这将解释训练数据的高精度,但是测试数据的低精度。
我们从 Yelp 数据集开始,这个数据集是从我们的连接数据集中提取的。从那里,我们把句子和标签。
.values返回一个 NumPy 数组,而不是一个熊猫系列对象,后者在这个上下文中更容易处理:
>>> from sklearn.model_selection import train_test_split
>>> df_yelp = df[df['source'] == 'yelp']
>>> sentences = df_yelp['sentence'].values
>>> y = df_yelp['label'].values
>>> sentences_train, sentences_test, y_train, y_test = train_test_split(
... sentences, y, test_size=0.25, random_state=1000)
这里,我们将再次使用之前的 BOW 模型对句子进行矢量化。您可以再次使用CountVectorizer来完成该任务。由于在训练期间您可能没有可用的测试数据,因此您可以仅使用训练数据来创建词汇表。使用这个词汇表,您可以为训练和测试集的每个句子创建特征向量:
>>> from sklearn.feature_extraction.text import CountVectorizer >>> vectorizer = CountVectorizer() >>> vectorizer.fit(sentences_train) >>> X_train = vectorizer.transform(sentences_train) >>> X_test = vectorizer.transform(sentences_test) >>> X_train <750x2505 sparse matrix of type '<class 'numpy.int64'>' with 7368 stored elements in Compressed Sparse Row format>您可以看到,得到的特征向量有 750 个样本,这是我们在训练-测试拆分后的训练样本数。每个样本有 2505 个维度,这是词汇表的大小。同样,你可以看到我们得到了一个稀疏矩阵。这是一种为只有几个非零元素的矩阵优化的数据类型,它只跟踪非零元素,从而减少了内存负载。
CountVectorizer执行标记化,将句子分成一组标记,就像你之前在词汇表中看到的那样。此外,它还删除了标点符号和特殊字符,并可以对每个单词进行其他预处理。如果您愿意,您可以使用来自 NLTK 库中的定制标记器和CountVectorizer,或者使用您可以探索的任意数量的定制来提高您的模型的性能。注意:这里我们放弃使用
CountVectorizer()的许多附加参数,例如添加 ngrams ,因为我们的目标是首先建立一个简单的基线模型。令牌模式本身默认为token_pattern=’(?u)\b\w\w+\b’,这是一个 regex 模式,表示“一个单词是由单词边界包围的 2 个或更多的 Unicode 单词字符。”。我们将使用的分类模型是逻辑回归,这是一个简单而强大的线性模型,从数学上讲,实际上是基于输入特征向量的 0 和 1 之间的一种回归形式。通过指定临界值(默认为 0.5),回归模型用于分类。您可以再次使用 scikit-learn 库,它提供了
LogisticRegression分类器:
>>> from sklearn.linear_model import LogisticRegression
>>> classifier = LogisticRegression()
>>> classifier.fit(X_train, y_train)
>>> score = classifier.score(X_test, y_test)
>>> print("Accuracy:", score)
Accuracy: 0.796
您可以看到逻辑回归达到了令人印象深刻的 79.6%,但让我们看看这个模型在我们拥有的其他数据集上的表现如何。在这个脚本中,我们对我们拥有的每个数据集执行并评估整个过程:
for source in df['source'].unique():
df_source = df[df['source'] == source]
sentences = df_source['sentence'].values
y = df_source['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print('Accuracy for {} data: {:.4f}'.format(source, score))
结果如下:
Accuracy for yelp data: 0.7960
Accuracy for amazon data: 0.7960
Accuracy for imdb data: 0.7487
太好了!你可以看到这个相当简单的模型达到了相当好的精度。看看我们是否能超越这种模式将会很有趣。在下一部分中,我们将熟悉(深度)神经网络以及如何将它们应用于文本分类。
(深度)神经网络初级读本
你可能经历过一些与人工智能和深度学习相关的兴奋和恐惧。你可能无意中发现了一些令人困惑的文章或有关即将到来的奇点的 TED 演讲,或者你可能看到了后空翻机器人,你想知道在森林里生活到底是否合理。
在一个轻松的话题上,人工智能研究人员都同意,当人工智能超过人类水平的表现时,他们彼此不同意。根据这张纸我们应该还有一些时间。
所以你可能已经好奇神经网络是如何工作的。如果你已经熟悉神经网络,请随意跳到涉及 Keras 的部分。此外,如果你想更深入地研究数学,我强烈推荐伊恩·古德费勒写的精彩的深度学习书籍。你可以免费在线阅读整本书。在这一节中,您将对神经网络及其内部工作原理有一个概述,稍后您将看到如何将神经网络与出色的 Keras 库一起使用。
在这篇文章中,你不必担心奇点,但(深度)神经网络在 AI 的最新发展中起着至关重要的作用。这一切都始于 2012 年 Geoffrey Hinton 和他的团队发表的一篇著名的论文,这篇论文在著名的 ImageNet 挑战赛中胜过了之前所有的模特。
挑战可以被认为是计算机视觉中的世界杯,它涉及到根据给定的标签对一大组图像进行分类。Geoffrey Hinton 和他的团队通过使用卷积神经网络(CNN) 成功击败了之前的模型,我们也将在本教程中介绍。
从那以后,神经网络进入了几个领域,包括分类、回归甚至生成模型。最流行的领域包括计算机视觉、语音识别和自然语言处理(NLP)。
神经网络,或有时被称为人工神经网络(ANN)或前馈神经网络,是由人脑中的神经网络模糊启发的计算网络。它们由神经元(也称为节点)组成,如下图所示连接在一起。
首先有一层输入神经元,输入特征向量,然后值被前馈到一个隐藏层。在每一个连接处,你向前馈送值,同时该值被乘以权重,并且偏差被添加到该值。这发生在每一个连接中,最终您会到达一个具有一个或多个输出节点的输出层。
如果您想要有一个二进制分类,您可以使用一个节点,但是如果您有多个类别,您应该为每个类别使用多个节点:

您可以拥有任意多的隐藏层。事实上,具有一个以上隐藏层的神经网络被认为是深度神经网络。别担心:我不会在这里深入到关于神经网络的数学深度。但是如果你想对其中的数学有一个直观的理解,你可以看看格兰特·桑德森的 YouTube 播放列表。从一层到下一层的公式是这个简短的等式:

让我们慢慢解开这里发生了什么。你看,我们这里只处理两层。具有节点a的层作为具有节点o的层的输入。为了计算每个输出节点的值,我们必须将每个输入节点乘以一个权重w并加上一个偏差b。
所有这些必须相加并传递给函数f。该功能被认为是激活功能,根据层或问题可以使用各种不同的功能。通常使用整流线性单元(ReLU) 用于隐藏层,使用 sigmoid 函数用于二进制分类问题的输出层,或者使用 softmax 函数用于多类分类问题的输出层。
您可能已经想知道权重是如何计算的,这显然是神经网络最重要的部分,但也是最困难的部分。该算法首先用随机值初始化权重,然后用一种叫做反向传播的方法训练权重。
这是通过使用优化方法(也称为优化器)完成的,如梯度下降,以减少计算输出和期望输出(也称为目标输出)之间的误差。这个误差是由一个损失函数决定的,我们希望通过优化器最小化它的损失。整个过程太广泛了,无法在这里涵盖,但我会再次参考 Grant Sanderson 播放列表和我之前提到的 Ian Goodfellow 的深度学习书籍。
你要知道的是,你可以使用的优化方法有很多种,但是目前最常用的优化器叫做 Adam 在各种问题中都有不错的表现。
您也可以使用不同的损失函数,但在本教程中,您将只需要交叉熵损失函数,或者更具体地说,用于二进制分类问题的二进制交叉熵。一定要尝试各种可用的方法和工具。一些研究人员甚至在最近的一篇文章中声称,对最佳执行方法的选择近乎炼金术。原因是许多方法没有得到很好的解释,并且包含了大量的调整和测试。
介绍 Keras
Keras 是由Fran ois Chollet开发的深度学习和神经网络 API,能够运行在 Tensorflow (谷歌) Theano 或 CNTK (微软)之上。引用 Franç ois Chollet 的精彩著作用 Python 进行深度学习:
Keras 是一个模型级的库,为开发深度学习模型提供了高级别的构建模块。它不处理张量操作和微分等低级操作。相反,它依靠一个专门的、优化良好的张量库来完成这项工作,充当 Keras 的后端引擎
这是一个开始尝试神经网络的好方法,而不必自己实现每一层和每一部分。例如 Tensorflow 是一个很棒的机器学习库,但是你必须实现许多样板代码来运行一个模型。
安装 Keras
在安装 Keras 之前,您需要 Tensorflow、Theano 或 CNTK。在本教程中,我们将使用 Tensorflow,所以请查看他们的安装指南这里,但是请随意使用任何最适合您的框架。Keras 可以通过以下命令使用 PyPI 进行安装:
$ pip install keras
您可以通过打开 Keras 配置文件来选择您想要的后端,您可以在这里找到:
$HOME/.keras/keras.json
如果你是 Windows 用户,你得把$HOME换成%USERPROFILE%。配置文件应该如下所示:
{ "image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow" }
假设您已经在机器上安装了后端,您可以将这里的backend字段更改为"theano"、"tensorflow"或"cntk"。更多细节请查看 Keras 后端文档。
您可能会注意到,我们在配置文件中使用了float32数据。之所以这样,是因为神经网络在 GPU 中的使用频率很高,计算瓶颈是内存。通过使用 32 位,我们能够减少内存负载,并且在此过程中不会丢失太多信息。
您的第一款 Keras 车型
现在你终于准备好试验 Keras 了。Keras 支持两种主要类型的模型。您将在本教程中看到使用的顺序模型 API 和功能 API ,它们可以完成顺序模型的所有工作,但也可以用于具有复杂网络架构的高级模型。
顺序模型是层的线性堆栈,您可以在其中使用 Keras 中的大量可用层。最常见的层是密集层,这是一个常规的密集连接的神经网络层,具有您已经熟悉的所有权重和偏差。
让我们看看是否可以对我们之前的逻辑回归模型进行一些改进。您可以使用在前面的例子中构建的X_train和X_test数组。
在我们建立模型之前,我们需要知道特征向量的输入维数。这仅发生在第一层,因为随后的层可以进行自动形状推断。为了构建顺序模型,可以按如下顺序逐个添加层:
>>> from keras.models import Sequential >>> from keras import layers >>> input_dim = X_train.shape[1] # Number of features >>> model = Sequential() >>> model.add(layers.Dense(10, input_dim=input_dim, activation='relu')) >>> model.add(layers.Dense(1, activation='sigmoid')) Using TensorFlow backend.在开始训练模型之前,您需要配置学习过程。这是通过
.compile()方法完成的。这个方法指定了优化器和损失函数。此外,您可以添加一个稍后可用于评估的指标列表,但它们不会影响培训。在这种情况下,我们希望使用二进制交叉熵和 Adam 优化器,您可以在前面提到的初级读本中看到。Keras 还包括一个方便的
.summary()函数,用于给出模型和可用于训练的参数数量的概述:
>>> model.compile(loss='binary_crossentropy',
... optimizer='adam',
... metrics=['accuracy'])
>>> model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 10) 25060
_________________________________________________________________
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 25,071
Trainable params: 25,071
Non-trainable params: 0
_________________________________________________________________
您可能会注意到,第一层有 25060 个参数,第二层有 11 个参数。这些是从哪里来的?
每个特征向量有 2505 个维度,然后我们有 10 个节点。我们需要每个特征维度和每个节点的权重,这说明了2505 * 10 = 25050参数,然后我们为每个节点增加了另外 10 倍的偏差,这就得到 25060 个参数。在最后一个节点中,我们有另外 10 个权重和一个偏差,这样我们就有了 11 个参数。这两层总共有 25071 个参数。
整洁!你就快到了。现在是使用.fit()功能开始训练的时候了。
由于神经网络中的训练是一个迭代过程,训练不会在完成后就停止。您必须指定您希望模型训练的迭代次数。那些完成的迭代通常被称为时期。我们希望运行它 100 个时期,以便能够看到在每个时期之后训练损失和准确性是如何变化的。
您选择的另一个参数是批量。批量大小决定了我们希望在一个时期中使用多少样本,这意味着在一次向前/向后传递中使用多少样本。这提高了计算的速度,因为它需要更少的历元来运行,但它也需要更多的内存,并且模型可能随着更大的批量而降级。因为我们有一个小的训练集,我们可以把它留给一个小的批量:
>>> history = model.fit(X_train, y_train, ... epochs=100, ... verbose=False, ... validation_data=(X_test, y_test), ... batch_size=10)现在你可以用
.evaluate()的方法来衡量模型的精度。对于训练数据和测试数据,您都可以这样做。我们期望训练数据比测试数据具有更高的准确性。你训练一个神经网络的时间越长,它越有可能开始过度拟合。请注意,如果您重新运行
.fit()方法,您将从之前训练中计算出的重量开始。再次开始训练模型之前,请务必致电clear_session():
>>> from keras.backend import clear_session
>>> clear_session()
现在让我们评估模型的准确性:
>>> loss, accuracy = model.evaluate(X_train, y_train, verbose=False) >>> print("Training Accuracy: {:.4f}".format(accuracy)) >>> loss, accuracy = model.evaluate(X_test, y_test, verbose=False) >>> print("Testing Accuracy: {:.4f}".format(accuracy)) Training Accuracy: 1.0000 Testing Accuracy: 0.7754您已经可以看到该模型过度拟合,因为它达到了训练集的 100%准确性。但是这是意料之中的,因为对于这个模型来说,历元的数量相当大。然而,测试集的准确性已经超过了我们以前用 BOW 模型进行的逻辑回归,这是我们进步的一大步。
为了让您的生活更轻松,您可以使用这个小助手功能来可视化基于历史回调的训练和测试数据的损失和准确性。这个自动应用于每个 Keras 模型的回调记录了损失和可以添加到
.fit()方法中的额外的指标。在这种情况下,我们只对准确性感兴趣。该辅助函数使用了 matplotlib 绘图库:import matplotlib.pyplot as plt plt.style.use('ggplot') def plot_history(history): acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] x = range(1, len(acc) + 1) plt.figure(figsize=(12, 5)) plt.subplot(1, 2, 1) plt.plot(x, acc, 'b', label='Training acc') plt.plot(x, val_acc, 'r', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.subplot(1, 2, 2) plt.plot(x, loss, 'b', label='Training loss') plt.plot(x, val_loss, 'r', label='Validation loss') plt.title('Training and validation loss') plt.legend()要使用这个函数,只需用收集到的精度和损失在
history字典中调用plot_history():
>>> plot_history(history)

你可以看到,自从训练集达到 100%的准确率以来,我们已经训练了我们的模型太长时间。观察模型何时开始过度拟合的一个好方法是验证数据的丢失何时开始再次上升。这往往是停止模型的好时机。在本次培训中,您可以看到大约 20-40 个时期。
注意:训练神经网络时,应该使用单独的测试和验证集。您通常会做的是选择具有最高验证准确性的模型,然后用测试集测试该模型。
这可以确保您不会过度拟合模型。使用验证集来选择最佳模型是一种形式的数据泄露(或“作弊”)来从数百个模型中挑选出产生最佳测试分数的结果。当模型中使用了训练数据集之外的信息时,就会发生数据泄漏。
在这种情况下,我们的测试和验证集是相同的,因为我们有一个较小的样本量。正如我们之前讨论过的,当你拥有大量样本时,(深度)神经网络表现最佳。在下一部分中,您将看到将单词表示为向量的不同方式。这是一种非常令人兴奋和强大的处理单词的方式,您将看到如何将单词表示为密集向量。
什么是单词嵌入?
文本被视为序列数据的一种形式,类似于天气数据或金融数据中的时序数据。在前面的 BOW 模型中,您已经看到了如何将整个单词序列表示为单个特征向量。现在你将看到如何用向量来表示每个单词。对文本进行矢量化有多种方法,例如:
- 由每个单词作为向量表示的单词
- 由每个字符作为向量表示的字符
- 用向量表示的单词/字符的 N 元语法(N 元语法是文本中多个连续单词/字符的重叠组)
在本教程中,您将看到如何将单词表示为向量,这是在神经网络中使用文本的常见方式。将单词表示为向量的两种可能方式是一键编码和单词嵌入。
一键编码
将单词表示为向量的第一种方法是创建一个所谓的 one-hot 编码,这可以简单地通过为语料库中的每个单词取一个词汇长度的向量来完成。
这样,对于每个单词,假设它在词汇表中有一个点,你就有了一个向量,除了该单词的对应点被设置为 1 之外,其他地方都是 0。正如你可能想象的那样,这可能成为每个单词的一个相当大的向量,并且它不提供任何额外的信息,如单词之间的关系。
假设您有一个城市列表,如下例所示:
>>> cities = ['London', 'Berlin', 'Berlin', 'New York', 'London'] >>> cities ['London', 'Berlin', 'Berlin', 'New York', 'London']您可以使用 scikit-learn 和
LabelEncoder将城市列表编码成分类整数值,如下所示:
>>> from sklearn.preprocessing import LabelEncoder
>>> encoder = LabelEncoder()
>>> city_labels = encoder.fit_transform(cities)
>>> city_labels
array([1, 0, 0, 2, 1])
使用这个表示,您可以使用 scikit-learn 提供的OneHotEncoder将我们之前得到的分类值编码成一个一键编码的数字数组。OneHotEncoder期望每个分类值都在单独的行中,因此您需要调整数组的形状,然后您可以应用编码器:
>>> from sklearn.preprocessing import OneHotEncoder >>> encoder = OneHotEncoder(sparse=False) >>> city_labels = city_labels.reshape((5, 1)) >>> encoder.fit_transform(city_labels) array([[0., 1., 0.], [1., 0., 0.], [1., 0., 0.], [0., 0., 1.], [0., 1., 0.]])您可以看到分类整数值表示数组的位置,即
1和剩余的0。当您有一个无法用数值表示的分类特征,但您仍然希望能够在机器学习中使用它时,通常会使用这种方法。这种编码的一个用例当然是文本中的单词,但它主要用于类别。例如,这些类别可以是城市、部门或其他类别。单词嵌入
这种方法将单词表示为密集单词向量(也称为单词嵌入),与硬编码的一键编码不同,这种方法是经过训练的。这意味着单词嵌入在更少的维度中收集更多的信息。
请注意,单词嵌入不像人类那样理解文本,而是映射语料库中使用的语言的统计结构。他们的目标是将语义映射到几何空间。这个几何空间然后被称为嵌入空间。
这将在嵌入空间上映射语义相似的单词,如数字或颜色。如果嵌入很好地捕捉了单词之间的关系,像向量算术这样的事情应该成为可能。这一研究领域的一个著名例子是绘制国王-男人+女人=王后的能力。
怎么能得到这样的文字嵌入呢?你有两个选择。一种方法是在训练神经网络的过程中训练你的单词嵌入。另一种方法是使用预训练的单词嵌入,您可以直接在模型中使用。在那里,你可以选择在训练期间保持这些单词嵌入不变,或者你也训练它们。
现在您需要将数据标记成单词 embeddings 可以使用的格式。Keras 为文本预处理和序列预处理提供了一些方便的方法,你可以用它们来准备你的文本。
您可以从使用
Tokenizer实用程序类开始,它可以将文本语料库矢量化为整数列表。每个整数映射到对整个语料库进行编码的字典中的一个值,字典中的键就是词汇项本身。可以添加参数num_words,负责设置词汇量的大小。最常见的num_words词汇将被保留。我有从前面的例子中准备的测试和训练数据:
>>> from keras.preprocessing.text import Tokenizer
>>> tokenizer = Tokenizer(num_words=5000)
>>> tokenizer.fit_on_texts(sentences_train)
>>> X_train = tokenizer.texts_to_sequences(sentences_train)
>>> X_test = tokenizer.texts_to_sequences(sentences_test)
>>> vocab_size = len(tokenizer.word_index) + 1 # Adding 1 because of reserved 0 index
>>> print(sentences_train[2])
>>> print(X_train[2])
Of all the dishes, the salmon was the best, but all were great.
[11, 43, 1, 171, 1, 283, 3, 1, 47, 26, 43, 24, 22]
索引是在文本中最常见的单词之后排序的,您可以通过单词the的索引1看到这一点。值得注意的是,索引0是保留的,没有分配给任何单词。这个零索引用于填充,我稍后会介绍。
未知单词(不在词汇表中的单词)在 Keras 中用word_count + 1表示,因为它们也可以保存一些信息。通过查看Tokenizer对象的word_index字典,可以看到每个单词的索引:
>>> for word in ['the', 'all', 'happy', 'sad']: ... print('{}: {}'.format(word, tokenizer.word_index[word])) the: 1 all: 43 happy: 320 sad: 450注:密切注意该技术与 scikit-learn 的
CountVectorizer生产的X_train的区别。使用
CountVectorizer,我们有单词计数的堆叠向量,并且每个向量都是相同的长度(总语料库词汇的大小)。使用 Tokenizer,得到的向量等于每个文本的长度,数字不表示计数,而是对应于字典tokenizer.word_index中的单词值。我们面临的一个问题是,在大多数情况下,每个文本序列都有不同的单词长度。为了解决这个问题,你可以使用
pad_sequence(),它简单地用零填充单词序列。默认情况下,它会在前面加上零,但我们想在后面加上零。通常情况下,无论是预先添加还是附加零都没有关系。此外,您可能希望添加一个
maxlen参数来指定序列应该有多长。这将删除超过该数字的序列。在下面的代码中,您可以看到如何用 Keras 填充序列:
>>> from keras.preprocessing.sequence import pad_sequences
>>> maxlen = 100
>>> X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
>>> X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
>>> print(X_train[0, :])
[ 1 10 3 282 739 25 8 208 30 64 459 230 13 1 124 5 231 8
58 5 67 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
第一个值表示词汇表中的索引,您已经从前面的示例中了解到了这一点。您还可以看到,得到的特征向量主要包含零,因为您有一个相当短的句子。在下一部分中,您将看到如何在 Keras 中使用单词嵌入。
Keras 嵌入层
注意,在这一点上,我们的数据仍然是硬编码的。我们没有告诉 Keras 通过连续的任务学习新的嵌入空间。现在,您可以使用 Keras 的嵌入层,它获取之前计算的整数,并将它们映射到嵌入的密集向量。您将需要以下参数:
input_dim: 词汇量的大小output_dim: 密集向量的大小input_length:序列的长度
有了Embedding层,我们现在有几个选项。一种方法是将嵌入层的输出插入到一个Dense层。为了做到这一点,你必须在它们之间添加一个Flatten层,为Dense层准备顺序输入:
from keras.models import Sequential
from keras import layers
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
结果将如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_8 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
flatten_3 (Flatten) (None, 5000) 0
_________________________________________________________________
dense_13 (Dense) (None, 10) 50010
_________________________________________________________________
dense_14 (Dense) (None, 1) 11
=================================================================
Total params: 137,371
Trainable params: 137,371
Non-trainable params: 0
_________________________________________________________________
您现在可以看到,我们有 87350 个新参数需要训练。这个数字来自于vocab_size乘以embedding_dim。嵌入层的这些权重用随机权重初始化,然后在训练期间通过反向传播进行调整。这个模型将单词按照它们在句子中的顺序作为输入向量。您可以通过以下方式训练它:
history = model.fit(X_train, y_train,
epochs=20,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果将如下所示:
Training Accuracy: 0.5100
Testing Accuracy: 0.4600

正如您在性能中看到的那样,这通常不是处理顺序数据的非常可靠的方式。当处理顺序数据时,您希望关注查看本地和顺序信息而不是绝对位置信息的方法。
另一种处理嵌入的方法是在嵌入后使用MaxPooling1D / AveragePooling1D或GlobalMaxPooling1D / GlobalAveragePooling1D层。你可以把合并图层看作是对引入的特征向量进行下采样(一种减小尺寸的方法)的一种方式。
在最大池的情况下,对于每个特征尺寸,取池中所有特征的最大值。在平均池的情况下,您取平均值,但最大池似乎更常用,因为它突出了大值。
全局最大/平均池取所有特性的最大值/平均值,而在其他情况下,您必须定义池大小。Keras 也有自己的层,可以添加到顺序模型中:
from keras.models import Sequential
from keras import layers
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
结果将如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_9 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_5 (Glob (None, 50) 0
_________________________________________________________________
dense_15 (Dense) (None, 10) 510
_________________________________________________________________
dense_16 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 87,871
Non-trainable params: 0
_________________________________________________________________
培训程序不变:
history = model.fit(X_train, y_train,
epochs=50,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果将如下所示:
Training Accuracy: 1.0000
Testing Accuracy: 0.8050

你已经可以看到我们的模型有了一些改进。接下来,您将看到我们如何使用预训练的单词嵌入,以及它们是否有助于我们的模型。
使用预训练的单词嵌入
我们刚刚看到了一个联合学习单词嵌入的例子,它被整合到我们想要解决的更大的模型中。
一种替代方案是使用预计算的嵌入空间,该嵌入空间利用了大得多的语料库。通过简单地在大型文本语料库上训练它们,可以预先计算单词嵌入。其中最流行的方法是谷歌开发的 Word2Vec 和斯坦福 NLP 小组开发的 GloVe (单词表示的全局向量)。
请注意,这些是目标相同的不同方法。Word2Vec 通过使用神经网络来实现这一点,GloVe 通过使用共生矩阵和矩阵分解来实现这一点。在这两种情况下,你都在处理降维,但 Word2Vec 更准确,GloVe 计算更快。
在本教程中,您将看到如何使用斯坦福大学 NLP 小组的 GloVe 单词嵌入,因为它们的大小比 Google 提供的 Word2Vec 单词嵌入更易于管理。继续从这里 ( glove.6B.zip,822 MB)下载 6B(训练有素的 60 亿字)单词嵌入。
你还可以在主 GloVe 页面上找到其他单词嵌入。你可以在这里找到谷歌预训练的 Word2Vec 嵌入。如果你想训练你自己的单词嵌入,你可以通过使用 Word2Vec 进行计算的 gensim Python 包来有效地完成。关于如何做到这一点的更多细节在这里。
既然我们已经介绍了您,您可以开始在您的模型中使用嵌入这个词了。你可以在下一个例子中看到如何加载嵌入矩阵。文件中的每一行都以单词开始,后面是特定单词的嵌入向量。
这是一个有 400000 行的大文件,每行代表一个单词,后跟一个作为浮点流的向量。例如,下面是第一行的前 50 个字符:
$ head -n 1 data/glove_word_embeddings/glove.6B.50d.txt | cut -c-50
the 0.418 0.24968 -0.41242 0.1217 0.34527 -0.04445
因为你不需要所有的单词,你可以只关注我们词汇表中的单词。由于我们的词汇表中只有有限数量的单词,我们可以跳过预训练单词嵌入中的 40000 个单词中的大部分:
import numpy as np
def create_embedding_matrix(filepath, word_index, embedding_dim):
vocab_size = len(word_index) + 1 # Adding again 1 because of reserved 0 index
embedding_matrix = np.zeros((vocab_size, embedding_dim))
with open(filepath) as f:
for line in f:
word, *vector = line.split()
if word in word_index:
idx = word_index[word]
embedding_matrix[idx] = np.array(
vector, dtype=np.float32)[:embedding_dim]
return embedding_matrix
您现在可以使用此函数来检索嵌入矩阵:
>>> embedding_dim = 50 >>> embedding_matrix = create_embedding_matrix( ... 'data/glove_word_embeddings/glove.6B.50d.txt', ... tokenizer.word_index, embedding_dim)精彩!现在,您可以在训练中使用嵌入矩阵了。让我们继续使用以前的具有全局最大池的网络,看看我们是否可以改进这个模型。当您使用预训练的单词嵌入时,您可以选择允许嵌入在训练期间更新,或者只使用得到的嵌入向量。
首先,让我们快速看一下有多少嵌入向量是非零的:
>>> nonzero_elements = np.count_nonzero(np.count_nonzero(embedding_matrix, axis=1))
>>> nonzero_elements / vocab_size
0.9507727532913566
这意味着预训练模型覆盖了 95.1%的词汇,这很好地覆盖了我们的词汇。让我们来看看使用GlobalMaxPool1D层时的性能:
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix],
input_length=maxlen,
trainable=False))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
结果将如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_10 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_6 (Glob (None, 50) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 510
_________________________________________________________________
dense_18 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 521
Non-trainable params: 87,350
_________________________________________________________________
history = model.fit(X_train, y_train,
epochs=50,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果将如下所示:
Training Accuracy: 0.7500
Testing Accuracy: 0.6950

因为单词嵌入没有被额外训练,所以预期它会更低。但是现在让我们看看,如果我们允许使用trainable=True来训练嵌入,这是如何执行的:
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix],
input_length=maxlen,
trainable=True))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
结果将如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_11 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_7 (Glob (None, 50) 0
_________________________________________________________________
dense_19 (Dense) (None, 10) 510
_________________________________________________________________
dense_20 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 87,871
Non-trainable params: 0
_________________________________________________________________
history = model.fit(X_train, y_train,
epochs=50,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果将如下所示:
Training Accuracy: 1.0000
Testing Accuracy: 0.8250

你可以看到允许嵌入被训练是最有效的。当处理大型训练集时,它可以提高训练过程的速度。对我们来说,这似乎有所帮助,但帮助不大。这不一定是因为预训练的单词嵌入。
现在是时候专注于更先进的神经网络模型,看看是否有可能提升该模型,并使其领先于以前的模型。
卷积神经网络(CNN)
卷积神经网络也称为 convnets 是近年来机器学习领域最令人兴奋的发展之一。
他们通过能够从图像中提取特征并将其用于神经网络,彻底改变了图像分类和计算机视觉。使它们在图像处理中有用的特性也使它们便于序列处理。你可以把 CNN 想象成一个专门的神经网络,能够检测特定的模式。
如果它只是另一个神经网络,那么它与你之前所学的有什么区别呢?
CNN 有隐藏层,称为卷积层。当你想到图像时,计算机必须处理一个二维数字矩阵,因此你需要某种方法来检测这个矩阵中的特征。这些卷积层能够检测边缘、角落和其他种类的纹理,这使它们成为如此特殊的工具。卷积层由多个滤波器组成,这些滤波器在图像上滑动,能够检测特定的特征。
这是技术的核心,卷积的数学过程。随着每个卷积层,网络能够检测更复杂的模式。在 Chris Olah 的特征可视化中,你可以很好地直觉这些特征看起来像什么。
当你处理像文本这样的顺序数据时,你处理的是一维卷积,但是概念和应用程序是一样的。你仍然需要在序列中挑选模式,随着卷积层的增加,这些模式变得更加复杂。
在下图中,您可以看到这种卷积是如何工作的。它首先获取一个具有过滤器内核大小的输入特征补丁。有了这个补丁,你就可以得到滤镜的乘法权重的点积。一维 convnet 对于平移是不变的,这意味着某些序列可以在不同的位置被识别。这对文本中的某些模式很有帮助:

现在让我们看看如何在 Keras 中使用这个网络。Keras 再次提供了各种卷积层,你可以使用这个任务。你需要的层是Conv1D层。这一层又有各种参数可供选择。您现在感兴趣的是过滤器的数量、内核大小和激活函数。你可以在Embedding层和GlobalMaxPool1D层之间添加这一层:
embedding_dim = 100
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
model.add(layers.Conv1D(128, 5, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
结果将如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_13 (Embedding) (None, 100, 100) 174700
_________________________________________________________________
conv1d_2 (Conv1D) (None, 96, 128) 64128
_________________________________________________________________
global_max_pooling1d_9 (Glob (None, 128) 0
_________________________________________________________________
dense_23 (Dense) (None, 10) 1290
_________________________________________________________________
dense_24 (Dense) (None, 1) 11
=================================================================
Total params: 240,129
Trainable params: 240,129
Non-trainable params: 0
_________________________________________________________________
history = model.fit(X_train, y_train,
epochs=10,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
结果将如下所示:
Training Accuracy: 1.0000
Testing Accuracy: 0.7700

你可以看到,80%的准确率似乎是一个很难克服的障碍,CNN 可能没有很好的装备。这种平稳状态的原因可能是:
- 没有足够的训练样本
- 你掌握的数据不能很好地概括
- 忽略了对超参数的调整
CNN 在大型训练集中工作得最好,在那里它们能够找到像逻辑回归这样的简单模型不能找到的概括。
超参数优化
深度学习和使用神经网络的一个关键步骤是超参数优化。
正如您在我们目前使用的模型中看到的,即使是更简单的模型,您也有大量的参数需要调整和选择。这些参数被称为超参数。这是机器学习中最耗时的部分,遗憾的是,没有万能的解决方案。
当你看一看在 Kaggle 上的比赛,这是与其他数据科学家竞争的最大场所之一,你可以看到许多获胜的团队和模型都经历了大量的调整和试验,直到他们达到巅峰。因此,当情况变得困难并且达到稳定水平时,不要气馁,而是要考虑如何优化模型或数据。
超参数优化的一种流行方法是网格搜索。这个方法的作用是获取参数列表,并使用找到的每个参数组合运行模型。这是最彻底的方法,但也是计算量最大的方法。另一种常见的方法,随机搜索,您将在这里看到它的实际应用,它只是采用参数的随机组合。
为了用 Keras 应用随机搜索,你将需要使用 KerasClassifier ,它作为 scikit-learn API 的包装器。有了这个包装器,你就可以使用 scikit 提供的各种工具,比如交叉验证。您需要的类是 RandomizedSearchCV ,它实现了带有交叉验证的随机搜索。交叉验证是一种验证模型的方法,它将整个数据集分成多个测试和训练数据集。
有各种类型的交叉验证。一种类型是 k 倍交叉验证,您将在本例中看到。在这种类型中,数据集被划分为 k 个大小相等的集合,其中一个集合用于测试,其余的分区用于训练。这使您能够运行 k 次不同的运行,其中每个分区被用作一个测试集。因此, k 越高,模型评估越准确,但是每个测试集越小。
KerasClassifier的第一步是创建一个 Keras 模型的函数。我们将使用之前的模型,但我们将允许为超参数优化设置各种参数:
def create_model(num_filters, kernel_size, vocab_size, embedding_dim, maxlen):
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
model.add(layers.Conv1D(num_filters, kernel_size, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
接下来,您需要定义要在培训中使用的参数网格。它由一个字典组成,每个参数的名称与前面的函数相同。网格上的空格数是3 * 3 * 1 * 1 * 1,其中每个数字都是给定参数的不同选项数。
您可以看到这可能很快变得计算昂贵,但幸运的是网格搜索和随机搜索都是令人尴尬的并行,并且这些类带有一个n_jobs参数,允许您并行测试网格空间。使用以下字典初始化参数网格:
param_grid = dict(num_filters=[32, 64, 128],
kernel_size=[3, 5, 7],
vocab_size=[5000],
embedding_dim=[50],
maxlen=[100])
现在,您已经准备好开始运行随机搜索。在这个例子中,我们迭代每个数据集,然后您希望以与前面相同的方式预处理数据。然后,您获取前面的函数,并将其添加到包含纪元数量的KerasClassifier包装器类中。
然后,产生的实例和参数网格被用作RandomSearchCV类中的估计器。此外,您可以选择 k-folds 交叉验证中的折叠数,在本例中为 4。在前面的例子中,您已经看到了这个代码片段中的大部分代码。除了RandomSearchCV和KerasClassifier,我还添加了一小段处理评估的代码:
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import RandomizedSearchCV
# Main settings
epochs = 20
embedding_dim = 50
maxlen = 100
output_file = 'data/output.txt'
# Run grid search for each source (yelp, amazon, imdb)
for source, frame in df.groupby('source'):
print('Running grid search for data set :', source)
sentences = df['sentence'].values
y = df['label'].values
# Train-test split
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
# Tokenize words
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(sentences_train)
X_train = tokenizer.texts_to_sequences(sentences_train)
X_test = tokenizer.texts_to_sequences(sentences_test)
# Adding 1 because of reserved 0 index
vocab_size = len(tokenizer.word_index) + 1
# Pad sequences with zeros
X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
# Parameter grid for grid search
param_grid = dict(num_filters=[32, 64, 128],
kernel_size=[3, 5, 7],
vocab_size=[vocab_size],
embedding_dim=[embedding_dim],
maxlen=[maxlen])
model = KerasClassifier(build_fn=create_model,
epochs=epochs, batch_size=10,
verbose=False)
grid = RandomizedSearchCV(estimator=model, param_distributions=param_grid,
cv=4, verbose=1, n_iter=5)
grid_result = grid.fit(X_train, y_train)
# Evaluate testing set
test_accuracy = grid.score(X_test, y_test)
# Save and evaluate results
prompt = input(f'finished {source}; write to file and proceed? [y/n]')
if prompt.lower() not in {'y', 'true', 'yes'}:
break
with open(output_file, 'a') as f:
s = ('Running {} data set\nBest Accuracy : '
'{:.4f}\n{}\nTest Accuracy : {:.4f}\n\n')
output_string = s.format(
source,
grid_result.best_score_,
grid_result.best_params_,
test_accuracy)
print(output_string)
f.write(output_string)
这需要一段时间,这是一个出去呼吸新鲜空气甚至徒步旅行的绝佳机会,这取决于你要跑多少个模型。让我们看看我们得到了什么:
Running amazon data set
Best Accuracy : 0.8122
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Test Accuracy : 0.8457
Running imdb data set
Best Accuracy : 0.8161
{'vocab_size': 4603, 'num_filters': 128, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Test Accuracy : 0.8210
Running yelp data set
Best Accuracy : 0.8127
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 7, 'embedding_dim': 50}
Test Accuracy : 0.8384
有意思!由于某种原因,测试精度高于训练精度,这可能是因为在交叉验证过程中分数有很大的差异。我们可以看到,我们仍然无法突破可怕的 80%,这似乎是给定大小的数据的自然限制。请记住,我们有一个小数据集,卷积神经网络往往表现最好的大数据集。
CV 的另一种方法是嵌套交叉验证(此处显示为),在超参数也需要优化时使用。使用这种方法是因为产生的非嵌套 CV 模型偏向数据集,这可能导致过于乐观的分数。你看,当我们在前面的例子中进行超参数优化时,我们为特定的训练集选择了最佳的超参数,但这并不意味着这些超参数概括了最佳的。
结论
现在你知道了:你已经学会了如何使用 Keras 进行文本分类,我们已经从使用逻辑回归的单词袋模型发展到越来越先进的卷积神经网络方法。
现在你应该熟悉单词嵌入,为什么它们有用,以及如何在训练中使用预训练的单词嵌入。您还学习了如何使用神经网络,以及如何使用超参数优化来提高模型的性能。
我们在这里没有涉及的一个大话题是递归神经网络,更具体地说是 LSTM 和 GRU 。这些都是处理序列数据(如文本或时间序列)的强大而流行的工具。其他有趣的发展目前在使用注意力的神经网络方面,这正在积极的研究中,并且似乎是有希望的下一步,因为 LSTM 倾向于计算繁重。
现在,您已经了解了自然语言处理中的一个重要基础,可以用它来进行各种文本分类。情感分析是这方面最突出的例子,但这还包括许多其他应用,例如:
- 电子邮件中的垃圾邮件检测
- 文本的自动标记
- 具有预定义主题的新闻文章的分类
你可以使用这些知识和你在这个教程中的高级项目中训练的模型,通过 Kibana 和 Elasticsearch 对 twitter 的连续数据流进行情感分析。你也可以将情感分析或文本分类与语音识别结合起来,就像在这个方便的教程中使用 Python 中的 speech recognition 库一样。
延伸阅读
如果您想更深入地了解本文中的各种主题,可以看看这些链接:
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 和 Keras 学习文本分类*********
Python KeyError 异常以及如何处理它们
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python KeyError 异常及如何处理
Python 的KeyError异常是初学者经常遇到的异常。了解为什么会引发一个KeyError,以及一些防止它停止你的程序的解决方案,是提高 Python 程序员水平的基本步骤。
本教程结束时,你会知道:
- 一条蟒蛇通常意味着什么
- 在标准库中还有什么地方可以看到一个
KeyError - 看到一个
KeyError怎么处理
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
什么是 Python KeyError通常指的是
Python KeyError 异常是当你试图访问一个不在字典 ( dict)中的键时引发的。
Python 的官方文档称,当访问映射键但在映射中找不到时,会引发KeyError。映射是将一组值映射到另一组值的数据结构。Python 中最常见的映射是字典。
Python KeyError是一种 LookupError 异常,表示在检索您正在寻找的密钥时出现了问题。当你看到一个KeyError时,语义是找不到要找的钥匙。
在下面的例子中,你可以看到一个用三个人的年龄定义的字典(ages)。当您试图访问一个不在字典中的键时,会引发一个KeyError:
>>> ages = {'Jim': 30, 'Pam': 28, 'Kevin': 33} >>> ages['Michael'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Michael'这里,试图访问
ages字典中的键'Michael'会导致一个KeyError被引发。在追溯的底部,您可以获得相关信息:
- 一个
KeyError被提出的事实- 找不到的钥匙是
'Michael'倒数第二行告诉您哪一行引发了异常。当您从文件中执行 Python 代码时,这些信息会更有帮助。
注意:当一个异常在 Python 中出现时,它是通过一个回溯来完成的。回溯为您提供了所有相关信息,以便您能够确定异常出现的原因以及导致异常的原因。
学习如何阅读 Python traceback 并理解它告诉你什么对于提高 Python 程序员来说至关重要。要了解更多关于 Python 回溯的信息,请查看了解 Python 回溯
在下面的程序中,可以看到再次定义的
ages字典。这一次,系统会提示您提供要检索年龄的人的姓名:1# ages.py 2 3ages = {'Jim': 30, 'Pam': 28, 'Kevin': 33} 4person = input('Get age for: ') 5print(f'{person} is {ages[person]} years old.')该代码将采用您在提示符下提供的姓名,并尝试检索该人的年龄。您在提示符下输入的任何内容都将被用作第 4 行的
ages字典的关键字。重复上面失败的例子,我们得到另一个回溯,这次是关于文件中产生
KeyError的行的信息:$ python ages.py Get age for: Michael Traceback (most recent call last): File "ages.py", line 4, in <module> print(f'{person} is {ages[person]} years old.') KeyError: 'Michael'当你给出一个不在字典中的键时,程序会失败。这里,回溯的最后几行指出了问题所在。
File "ages.py", line 4, in <module>告诉您哪个文件的哪一行引发了结果KeyError异常。然后您会看到这一行。最后,KeyError异常提供了丢失的密钥。所以你可以看到
KeyErrortraceback 的最后一行本身并没有给你足够的信息,但是它之前的几行可以让你更好地理解哪里出错了。注意:和上面的例子一样,本教程中的大多数例子都使用了在 Python 3.6 中引入的 f 字符串。
在标准库中,你还能在哪里看到 Python
KeyError大多数情况下,Python
KeyError被引发是因为在字典或字典子类中找不到键(比如os.environ)。在极少数情况下,如果在 ZIP 存档中找不到某个项目,您可能还会在 Python 的标准库中的其他地方看到它,例如在
zipfile模块中。然而,这些地方保留了 PythonKeyError的相同语义,即没有找到请求的键。在下面的例子中,您可以看到使用
zipfile.ZipFile类提取关于使用.getinfo()的 ZIP 存档的信息:
>>> from zipfile import ZipFile
>>> zip_file = ZipFile('the_zip_file.zip')
>>> zip_file.getinfo('something')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/path/to/python/installation/zipfile.py", line 1304, in getinfo
'There is no item named %r in the archive' % name)
KeyError: "There is no item named 'something' in the archive"
这看起来不太像字典键查找。相反,是对zipfile.ZipFile.getinfo()的调用引发了异常。
回溯看起来也有一点不同,它给出了比丢失的键更多的信息:KeyError: "There is no item named 'something' in the archive"。
这里要注意的最后一点是,引发KeyError的代码行不在您的代码中。它在zipfile代码中,但是回溯的前几行指出了代码中的哪几行导致了问题。
当你需要在自己的代码中提出一个 Python KeyError
有时候您在自己的代码中引发一个 Python KeyError异常是有意义的。这可以通过使用raise 关键字并调用KeyError异常来完成:
raise KeyError(message)
通常,message将是丢失的键。然而,就像在zipfile包的情况下,您可以选择提供更多的信息来帮助下一个开发者更好地理解哪里出错了。
如果您决定在自己的代码中使用 Python KeyError,只需确保您的用例与异常背后的语义相匹配。它应该表示找不到正在寻找的密钥。
当你看到一条 Python KeyError时如何处理它
当你遇到一个KeyError时,有几个标准的处理方法。根据您的使用情况,这些解决方案中的一些可能比其他的更好。最终目标是阻止意外的KeyError异常被引发。
通常的解决方案:.get()
如果在您自己的代码中由于字典键查找失败而引发了KeyError,您可以使用.get()返回在指定键中找到的值或默认值。
与前面的年龄检索示例非常相似,下面的示例展示了使用提示符下提供的键从字典中获取年龄的更好方法:
1# ages.py
2
3ages = {'Jim': 30, 'Pam': 28, 'Kevin': 33}
4person = input('Get age for: ')
5age = ages.get(person) 6
7if age:
8 print(f'{person} is {age} years old.')
9else:
10 print(f"{person}'s age is unknown.")
在这里,第 5 行显示了如何使用.get()从ages获得年龄值。这将导致age 变量具有在字典中为所提供的键找到的年龄值或默认值,在本例中为 None 。
这一次,您将不会得到引发的KeyError异常,因为使用了更安全的.get()方法来获取年龄,而不是尝试直接访问密钥:
$ python ages.py
Get age for: Michael
Michael's age is unknown.
在上面的执行示例中,当提供了一个错误的键时,不再引发KeyError。键'Michael'在字典中找不到,但是通过使用.get(),我们得到一个返回的None,而不是一个提升的KeyError。
age变量要么是在字典中找到的人的年龄,要么是默认值(默认为None)。您还可以通过传递第二个参数在.get()调用中指定一个不同的默认值。
这是上例中的第 5 行,使用.get()指定了不同的默认年龄:
age = ages.get(person, 0)
这里,不是'Michael'返回None,而是返回0,因为没有找到键,现在返回的默认值是0。
罕见的解决方案:检查键
有时候,您需要确定字典中是否存在某个键。在这些情况下,使用.get()可能不会给你正确的信息。从对.get()的调用中返回一个None可能意味着没有找到键,或者在字典中找到的键的值实际上是None。
对于字典或类似字典的对象,可以使用in操作符来确定一个键是否在映射中。该操作符将返回一个布尔 ( True或False)值,指示是否在字典中找到了该键。
在这个例子中,您将从调用 API 的获得一个response字典。该响应可能在响应中定义了一个error键值,这将表明该响应处于错误状态:
1# parse_api_response.py
2...
3# Assuming you got a `response` from calling an API that might
4# have an error key in the `response` if something went wrong
5
6if 'error' in response: 7 ... # Parse the error state
8else:
9 ... # Parse the success state
这里,检查error键是否存在于response中并从该键获得默认值是有区别的。这是一种罕见的情况,你真正要找的是这个键是否在字典中,而不是这个键的值是什么。
一般解法:try except
对于任何异常,您都可以使用try except块来隔离潜在的引发异常的代码,并提供备份解决方案。
您可以在与前面类似的示例中使用try except块,但是这一次提供了一个默认的要打印的消息,如果在正常情况下引发了一个KeyError:
1# ages.py
2
3ages = {'Jim': 30, 'Pam': 28, 'Kevin': 33}
4person = input('Get age for: ')
5
6try:
7 print(f'{person} is {ages[person]} years old.')
8except KeyError:
9 print(f"{person}'s age is unknown.")
在这里,您可以在打印人名和年龄的try块中看到正常情况。备份实例在except块中,如果在正常情况下KeyError被引发,那么备份实例将打印不同的消息。
对于其他可能不支持.get()或in操作符的地方来说,try except阻塞解决方案也是一个很好的解决方案。如果KeyError是从另一个人的代码中产生的,这也是最好的解决方案。
这里是一个再次使用zipfile包的例子。这一次,try except块为我们提供了一种阻止KeyError异常停止程序的方法:
>>> from zipfile import ZipFile >>> zip = ZipFile('the_zip_file.zip') >>> try: ... zip.getinfo('something') ... except KeyError: ... print('Can not find "something"') ... Can not find "something"因为
ZipFile类不像字典那样提供.get(),所以您需要使用tryexcept解决方案。在这个例子中,您不需要提前知道哪些值可以传递给.getinfo()。结论
您现在知道了 Python 的
KeyError异常可能出现的一些常见地方,以及可以用来防止它们停止您的程序的一些很好的解决方案。现在,下次你看到一个
KeyError被提出来,你就知道这很可能只是一个不好的字典键查找。通过查看回溯的最后几行,您还可以找到确定错误来源所需的所有信息。如果问题是在您自己的代码中查找字典键,那么您可以从直接在字典上访问键切换到使用带有默认返回值的更安全的
.get()方法。如果问题不是来自您自己的代码,那么使用tryexcept块是您控制代码流的最佳选择。例外不一定是可怕的。一旦你知道如何理解回溯中提供给你的信息和异常的根本原因,那么你就可以使用这些解决方案来使你的程序流程更加可预测。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python KeyError 异常及如何处理***
Python 关键词:简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 中的关键词
每种编程语言都有特殊的保留字,或关键字,它们有特定的含义和使用限制。Python 也不例外。Python 关键字是任何 Python 程序的基本构件。
在本文中,您将找到对所有 Python 关键字的基本介绍,以及有助于了解每个关键字的更多信息的其他资源。
本文结束时,你将能够:
- 识别 Python 关键字
- 了解每个关键词的用途
- 使用
keyword模块以编程方式使用关键字来处理免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 关键词
Python 关键字是特殊的保留字,具有特定的含义和用途,除了这些特定的用途之外,不能用于任何其他用途。这些关键字总是可用的——您永远不必将它们导入到您的代码中。
Python 关键字不同于 Python 的内置函数和类型。内置函数和类型也总是可用的,但是它们在使用时没有关键字那么严格。
一个你不能用 Python 关键字做的事情的例子是给它们赋值。如果你尝试,那么你会得到一个
SyntaxError。如果你试图给一个内置函数或类型赋值,你不会得到一个SyntaxError,但这仍然不是一个好主意。关于关键字可能被误用的更深入的解释,请查看 Python 中的无效语法:语法错误的常见原因。截至 Python 3.8,Python 中有三十五个关键字。下面是本文其余部分相关章节的链接:
| T2
False| T2await| T2else| T2import| T2pass|
| T2None| T2break| T2except| T2in| T2raise|
| T2True| T2class| T2finally| T2is| T2return|
| T2and| T2continue| T2for| T2lambda| T2try|
| T2as| T2def| T2from| T2nonlocal| T2while|
| T2assert| T2del| T2global| T2not| T2with|
| T2async| T2elif| T2if| T2or| T2yield|你可以使用这些链接跳转到你想阅读的关键词,或者你可以继续阅读一个导游。
注意:两个关键词除了它们最初的用例之外,还有额外的用途。
else关键字也是与循环一起使用的,以及与try和exceptT10 一起使用的。as关键字也与with关键字一起使用。如何识别 Python 关键词
随着时间的推移,Python 关键字列表已经发生了变化。例如,直到 Python 3.7 才添加了关键字
await和async。另外,exec在 Python 2.7 中都是关键字,但在 Python 3+中已经变成了内置函数,不再出现在关键字列表中。在下面几节中,您将学习几种方法来知道或找出哪些单词是 Python 中的关键字。
使用带有语法高亮显示的 IDE
外面有很多好的 Python IDEs。它们都会突出显示关键字,以区别于代码中的其他单词。这将帮助您在编程时快速识别 Python 关键字,从而避免错误地使用它们。
使用 REPL 中的代码来检查关键字
在 Python REPL 中,有多种方法可以识别有效的 Python 关键字并了解更多。
注意:本文中的代码示例使用 Python 3.8 ,除非另有说明。
您可以使用
help()获得可用关键字列表:
>>> help("keywords")
Here is a list of the Python keywords. Enter any keyword to get more help.
False class from or
None continue global pass
True def if raise
and del import return
as elif in try
assert else is while
async except lambda with
await finally nonlocal yield
break for not
接下来,如上面的输出所示,您可以通过传入您需要更多信息的特定关键字来再次使用help()。例如,您可以使用pass关键字来实现这一点:
>>> help("pass") The "pass" statement ******************** pass_stmt ::= "pass" "pass" is a null operation — when it is executed, nothing happens. It is useful as a placeholder when a statement is required syntactically, but no code needs to be executed, for example: def f(arg): pass # a function that does nothing (yet) class C: pass # a class with no methods (yet)Python 还提供了一个
keyword模块,用于以编程方式处理 Python 关键字。Python 中的keyword模块为处理关键字提供了两个有用的成员:
kwlist为您正在运行的 Python 版本提供了所有 Python 关键字的列表。iskeyword()提供了一种简便的方法来确定一个字符串是否也是一个关键字。要获得您正在运行的 Python 版本中所有关键字的列表,并快速确定定义了多少个关键字,请使用
keyword.kwlist:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'async', ...
>>> len(keyword.kwlist)
35
如果您需要更多地了解某个关键字,或者需要以编程的方式使用关键字,那么 Python 为您提供了这种文档和工具。
找一个SyntaxError
最后,另一个表明你正在使用的单词实际上是一个关键字的指标是,当你试图给它赋值,用它命名一个函数,或者用它做其他不允许的事情时,你是否得到了一个SyntaxError。这个有点难发现,但这是 Python 让你知道你在错误地使用关键字的一种方式。
Python 关键字及其用法
以下部分根据 Python 关键字的用法对其进行分组。例如,第一组是所有用作值的关键字,第二组是用作运算符的关键字。这些分组将帮助您更好地理解如何使用关键字,并提供一种很好的方式来组织 Python 关键字的长列表。
以下章节中使用的一些术语可能对您来说是新的。这里对它们进行了定义,您应该在继续之前了解它们的含义:
-
真值是指一个值的布尔求值。值的真值表示该值是真值还是假值。
-
真值表示在布尔上下文中评估为真的任何值。要确定一个值是否为真,将其作为参数传递给
bool()。如果它返回True,那么这个值就是 the。真值的例子有非空字符串、任何不是0的数字、非空列表等等。 -
Falsy 表示在布尔上下文中评估为假的任何值。要确定一个值是否为 falsy,将其作为参数传递给
bool()。如果它返回False,那么值就是 falsy。虚假值的例子有""、0、[]、{}和set()。
有关这些术语和概念的更多信息,请查看 Python 中的运算符和表达式。
数值关键词:True、False、None、
有三个 Python 关键字用作值。这些值是单值值,可以反复使用,并且总是引用完全相同的对象。您很可能会经常看到和使用这些值。
True和False关键词
True 关键字在 Python 代码中用作布尔真值。Python 关键字 False 类似于True关键字,但是具有相反的布尔值 false。在其他编程语言中,你会看到这些关键字被写成小写(true和false),但是在 Python 中它们总是被写成大写。
Python 关键字True和False可以分配给变量并直接进行比较:
>>> x = True >>> x is True True >>> y = False >>> y is False TruePython 中的大多数值在传递给
bool()时将计算为True。Python 中只有几个值在传递给bool():0、""、[]和{}时会计算为False。向bool()传递一个值表示该值的真值,或者等价的布尔值。通过将值传递给bool(),您可以将值的真实性与True或False进行比较:
>>> x = "this is a truthy value"
>>> x is True
False
>>> bool(x) is True
True
>>> y = "" # This is falsy
>>> y is False
False
>>> bool(y) is False
True
请注意,使用 is 将真值直接与True或False进行比较不起作用。只有当你想知道一个值实际上是*True还是False时,你才应该直接将这个值与True或False进行比较。
当编写基于值的真实性的条件语句时,您应该而不是直接与True或False进行比较。您可以依靠 Python 来为您进行条件的真实性检查:
>>> x = "this is a truthy value" >>> if x is True: # Don't do this ... print("x is True") ... >>> if x: # Do this ... print("x is truthy") ... x is truthy在 Python 中,一般不需要将值转换成显式的
True或False。Python 将隐式地为您确定值的真实性。
None关键词Python 关键字
None表示没有值。在其他编程语言中,None被表示为null、nil、none、undef或undefined。
None也是一个函数返回的默认值,如果它没有return语句:
>>> def func():
... print("hello")
...
>>> x = func()
hello
>>> print(x)
None
要更深入地了解这个非常重要和有用的 Python 关键字,请查看 Python: Understanding Python 的 NoneType 对象中的 Null。
操作员关键词:and、or、not、in、is、
几个 Python 关键字被用作运算符。在其他编程语言中,这些操作符使用类似于&、|和!的符号。这些的 Python 运算符都是关键字:
| 数学运算符 | 其他语言 | Python 关键字 |
|---|---|---|
| 还有,∧ | && |
and |
| 或者,∨ | || |
or |
| 不是, | ! |
not |
| 包含,∈ | in |
|
| 身份 | === |
is |
Python 代码是为了可读性而设计的。这就是为什么在其他编程语言中使用符号的许多操作符在 Python 中是关键字。
and关键词
Python 关键字 and 用于确定左右操作数是真还是假。如果两个操作数都是真的,那么结果将是真的。如果一个是假的,那么结果将是假的:
<expr1> and <expr2>
注意,and语句的结果不一定是True或False。这是因为and的古怪行为。与其将操作数评估为布尔值,and不如简单地返回<expr1>,如果为 falsy,否则返回<expr2>。一条and语句的结果可以传递给bool()以获得显式的True或False值,或者它们可以在一条条件if语句中使用。
如果您想定义一个与and表达式做同样事情的表达式,但是不使用and关键字,那么您可以使用 Python 三元运算符:
left if not left else right
上述语句将产生与left and right相同的结果。
因为and如果为 falsy 则返回第一个操作数,否则返回最后一个操作数,所以也可以在赋值中使用and:
x = y and z
如果 y 是 falsy,那么这将导致x被赋予y的值。否则,x将被赋予z的值。然而,这导致了混乱的代码。一个更详细、更清晰的替代方案是:
x = y if not y else z
这段代码比较长,但是它更清楚地表明了您想要完成的任务。
or关键词
Python 的 or 关键字用于判断是否至少有一个操作数是真的。如果第一个操作数为真,则or语句返回该操作数,否则返回第二个操作数:
<expr1> or <expr2>
就像关键字and一样,or不会将其操作数转换为布尔值。相反,它依赖于他们的真实性来决定结果。
如果您想在不使用or的情况下编写类似于or的表达式,那么您可以使用三元表达式:
left if left else right
该表达式将产生与left or right相同的结果。为了利用这种行为,您有时也会看到在赋值中使用or。通常不鼓励这种做法,而支持更明确的赋值。
为了更深入地了解or,你可以阅读关于如何使用 Python or操作符。
not关键词
Python 的 not 关键字用于获取变量的相反布尔值:
>>> val = "" # Truthiness value is `False` >>> not val True >>> val = 5 # Truthiness value is `True` >>> not val False
not关键字用于条件语句或其他布尔表达式中,以翻转布尔含义或结果。与and****or不同,not会确定显式布尔值,True或False,然后返回相反的。如果您想在不使用
not的情况下获得相同的行为,那么您可以使用以下三元表达式:True if bool(<expr>) is False else False该语句将返回与
not <expr>相同的结果。
in关键词Python 的
in关键字是一个强大的遏制检查,或者说隶属运算符。给定要查找的元素和要搜索的容器或序列,in将返回True或False,指示是否在容器中找到了该元素:<element> in <container>使用
in关键字的一个很好的例子是检查字符串中的特定字母:
>>> name = "Chad"
>>> "c" in name
False
>>> "C" in name
True
in关键字适用于所有类型的容器:列表、字典、集合、字符串以及任何定义了__contains__()或者可以被迭代的东西。
is关键词
Python 的 is 关键字是一个身份检查。这与检查相等性的==操作符不同。有时两个事物可以被认为是相等的,但在内存中不是完全相同的对象。is关键字确定两个对象是否是完全相同的对象:
<obj1> is <obj2>
如果<obj1>和<obj2>在内存中是完全相同的对象,它将返回True,否则它将返回False。
大多数时候你会看到is用来检查一个对象是否是None。由于None是单例的,只能存在None的一个实例,所以所有的None值都是内存中完全相同的对象。
如果这些概念对你来说是新的,那么你可以通过查看 Python 来获得更深入的解释!=' Is Not 'is not ':在 Python 中比较对象。为了更深入地了解is是如何工作的,请查看 Python 中的操作符和表达式。
控制流关键字:if、elif、else、
三个 Python 关键字用于控制流:if、elif和else。这些 Python 关键字允许您使用条件逻辑,并在特定条件下执行代码。这些关键字非常常见——它们几乎会出现在你用 Python 看到或编写的每个程序中。
if关键词
if 关键字用于开始一个条件语句。一个if语句允许你写一个代码块,只有当if后面的表达式是真的时才被执行。
if语句的语法以行首的关键字if开始,后面是一个有效的表达式,将对其真值进行评估:
if <expr>:
<statements>
语句是大多数程序的重要组成部分。有关if语句的更多信息,请查看 Python 中的条件语句。
if关键字的另一个用途是作为 Python 的三元运算符的一部分:
<var> = <expr1> if <expr2> else <expr3>
这是下面的一行if...else语句:
if <expr2>:
<var> = <expr1>
else:
<var> = <expr3>
如果您的表达式是不复杂的语句,那么使用三元表达式提供了一个很好的方法来稍微简化您的代码。一旦条件变得有点复杂,依靠标准的if语句通常会更好。
elif关键词
elif 语句的外观和功能与if语句相似,但有两个主要区别:
- 使用
elif仅在一个if语句或另一个elif之后有效。 - 您可以根据需要使用任意多的
elif语句。
在其他编程语言中,elif要么是else if(两个独立的单词),要么是elseif(两个单词混合在一起)。当你看到 Python 中的elif时,想想else if:
if <expr1>:
<statements>
elif <expr2>:
<statements>
elif <expr3>:
<statements>
Python 没有 switch语句。获得其他编程语言用switch语句提供的相同功能的一种方法是使用if和elif。关于在 Python 中再现switch语句的其他方法,请查看 Python 中的仿真 switch/case 语句。
else关键词
else 语句,结合 Python 关键字if和elif,表示只有当其他条件块if和elif都为假时才应该执行的代码块:
if <expr>:
<statements>
else:
<statements>
请注意,else语句没有采用条件表达式。对于 Python 程序员来说,了解 elif和else关键词及其正确用法至关重要。它们和if一起构成了任何 Python 程序中最常用的组件。
迭代关键词:for、while、break、continue、else、
循环和迭代是非常重要的编程概念。几个 Python 关键字用于创建和处理循环。这些,就像上面用于条件的 Python 关键字一样,将会在你遇到的每个 Python 程序中使用和看到。理解它们以及它们的正确用法将有助于您提高 Python 程序员的水平。
for关键词
Python 中最常见的循环是for循环。它由前面解释的 Python 关键字 for 和 in 组合而成。for循环的基本语法如下:
for <element> in <container>:
<statements>
一个常见的例子是循环播放数字 1 到 5,并将它们打印到屏幕上:
>>> for num in range(1, 6): ... print(num) ... 1 2 3 4 5在其他编程语言中,
for循环的语法看起来会有些不同。您经常需要指定变量、继续的条件以及增加变量的方式(for (int i = 0; i < 5; i++))。在 Python 中,
for循环就像其他编程语言中的 for-each 循环。给定要迭代的对象,它将每次迭代的值赋给变量:
>>> people = ["Kevin", "Creed", "Jim"]
>>> for person in people:
... print(f"{person} was in The Office.")
...
Kevin was in The Office.
Creed was in The Office.
Jim was in The Office.
在这个例子中,我们从人名列表(容器)开始。for循环从行首的for关键字开始,接着是为列表中的每个元素赋值的变量,然后是in关键字,最后是容器(people)。
Python 的for循环是任何 Python 程序的另一个主要成分。要了解更多关于for循环的信息,请查看Python“for”循环(有限迭代)。
while关键词
Python 的 while循环使用关键字 while ,工作方式类似于其他编程语言中的while循环。只要跟在while关键字后面的条件是真的,跟在while语句后面的代码块就会不断重复执行:
while <expr>:
<statements>
注意:对于下面的无限循环示例,如果您决定在自己的机器上尝试,请准备好使用 Ctrl + C 来停止该进程。
在 Python 中指定无限循环最简单的方法是使用while关键字和一个总是真实的表达式:
>>> while True: ... print("working...") ...关于无限循环的更多例子,请查看 Python 中的套接字编程(指南)。要了解更多关于
while循环的信息,请查看Python“while”循环(无限迭代)。
break关键词如果你需要提前退出一个循环,那么你可以使用
break关键字。这个关键字在for和while循环中都有效:for <element> in <container>: if <expr>: break使用
break关键字的一个例子是,如果你对一列数字中的整数求和,当总数超过给定值时,你想退出:
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> total_sum = 0
>>> for num in nums:
... total_sum += num
... if total_sum > 10:
... break
...
>>> total_sum
15
Python 关键字break和continue在处理循环时都是有用的工具。要深入讨论它们的用法,请查看Python“while”循环(无限迭代)。如果您想探索break关键字的另一个用例,那么您可以学习如何在 Python 中模拟 do-while 循环。
continue关键词
Python 还有一个 continue 关键字,用于当你想跳到下一个循环迭代时。与大多数其他编程语言一样,continue关键字允许您停止执行当前的循环迭代,并继续下一次迭代:
for <element> in <container>:
if <expr>:
continue
continue关键字也适用于while循环。如果在一个循环中到达了continue关键字,那么当前的迭代停止,并开始循环的下一次迭代。
与循环一起使用的else关键字
除了将else关键字用于条件if语句之外,您还可以将它用作循环的一部分。当与循环一起使用时, else 关键字指定如果循环正常退出时应该运行的代码,这意味着没有提前调用break来退出循环。
将else与for循环一起使用的语法如下所示:
for <element> in <container>:
<statements>
else:
<statements>
这非常类似于在if语句中使用else。使用带有while循环的else看起来很相似:
while <expr>:
<statements>
else:
<statements>
Python 标准文档中有一节是关于使用break和else的,还有一个for循环,你真应该去看看。它用一个很好的例子来说明else块的用处。
它显示的任务是在数字 2 到 9 之间循环寻找质数。有一种方法可以做到这一点,那就是使用带有标志变量的标准for循环:
>>> for n in range(2, 10): ... prime = True ... for x in range(2, n): ... if n % x == 0: ... prime = False ... print(f"{n} is not prime") ... break ... if prime: ... print(f"{n} is prime!") ... 2 is prime! 3 is prime! 4 is not prime 5 is prime! 6 is not prime 7 is prime! 8 is not prime 9 is not prime您可以使用
prime标志来指示循环是如何退出的。如果它正常退出,那么prime标志保持True。如果用break退出,那么prime标志将被设置为False。一旦在内部的for循环之外,你可以检查这个标志来确定prime是否是True,如果是,打印出这个数字是质数。
else块提供了更简单的语法。如果您发现自己必须在一个循环中设置一个标志,那么可以将下一个示例视为一种潜在的简化代码的方法:
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0:
... print(f"{n} is not prime")
... break
... else:
... print(f"{n} is prime!")
...
2 is prime!
3 is prime!
4 is not prime
5 is prime!
6 is not prime
7 is prime!
8 is not prime
9 is not prime
在这个例子中,使用else块唯一需要做的事情就是删除prime标志,并用else块替换最后的if语句。这最终会产生与前面示例相同的结果,只是代码更清晰。
有时候在循环中使用else关键字看起来有点奇怪,但是一旦你明白它可以让你避免在循环中使用标志,它就会成为一个强大的工具。
结构关键词:def、class、with、as、pass、lambda、
为了定义函数和类或者使用上下文管理器,您将需要使用本节中的一个 Python 关键字。它们是 Python 语言的重要组成部分,了解何时使用它们将有助于您成为更好的 Python 程序员。
def关键词
Python 的关键字 def 用于定义一个类的函数或方法。这相当于 JavaScript 和 PHP 中的function。用def定义函数的基本语法如下:
def <function>(<params>):
<body>
在任何 Python 程序中,函数和方法都是非常有用的结构。要了解更多关于定义它们的细节,请查看定义自己的 Python 函数。
class关键词
要在 Python 中定义一个类,可以使用class关键字。用 class 定义类的一般语法如下:
class MyClass(<extends>):
<body>
类是面向对象编程中的强大工具,您应该了解它们以及如何定义它们。要了解更多,请查看 Python 3 中的面向对象编程(OOP)。
with关键词
在 Python 中,上下文管理器是一个非常有用的结构。每个上下文管理器在您指定的语句之前和之后执行特定的代码。要使用一个,你使用 with 关键字:
with <context manager> as <var>:
<statements>
使用with为您提供了一种方法来定义要在上下文管理器的范围内执行的代码。最基本的例子是当你在 Python 中使用文件 I/O 时。
如果你想打开一个文件,对该文件做些什么,然后确保该文件被正确关闭,那么你可以使用上下文管理器。考虑这个例子,其中names.txt包含一个名字列表,每行一个名字:
>>> with open("names.txt") as input_file: ... for name in input_file: ... print(name.strip()) ... Jim Pam Cece Philip由
open()提供并由with关键字启动的文件 I/O 上下文管理器打开文件进行读取,将打开的文件指针分配给input_file,然后执行您在with块中指定的任何代码。然后,在块被执行后,文件指针关闭。即使with块中的代码引发了异常,文件指针仍然会关闭。关于使用
with和上下文管理器的一个很好的例子,请查看 Python 定时器函数:监控代码的三种方法。
as关键字与with一起使用如果你想访问传递给
with的表达式或上下文管理器的结果,你需要用as给它起别名。您可能还见过用于别名导入和异常的as,这没有什么不同。别名在with块中可用:with <expr> as <alias>: <statements>大多数时候,你会看到这两个 Python 关键字,
with和as一起使用。
pass关键词由于 Python 没有块指示符来指定块的结束,所以使用了
pass关键字来指定该块故意留空。这相当于不操作,或者不操作。以下是使用pass指定块为空白的几个例子:def my_function(): pass class MyClass: pass if True: pass关于
pass的更多信息,请查看pass 语句:如何在 Python 中不做任何事情。
lambda关键词
lambda关键字用于定义一个没有名字,只有一条语句,返回结果的函数。用lambda定义的函数称为λ函数:lambda <args>: <statement>一个计算参数的
lambda函数的基本例子是这样的:p10 = lambda x: x**10这相当于用
def定义一个函数:def p10(x): return x**10
lambda函数的一个常见用途是为另一个函数指定不同的行为。例如,假设您想按整数值对字符串列表进行排序。sorted()的默认行为是将字符串按字母顺序排序。但是使用sorted(),你可以指定列表应该按照哪个键排序。lambda 函数提供了一种很好的方式来实现这一点:
>>> ids = ["id1", "id2", "id30", "id3", "id20", "id10"]
>>> sorted(ids)
['id1', 'id10', 'id2', 'id20', 'id3', 'id30']
>>> sorted(ids, key=lambda x: int(x[2:]))
['id1', 'id2', 'id3', 'id10', 'id20', 'id30']
此示例在将字符串转换为整数后,不是根据字母顺序,而是根据最后一个字符的数字顺序对列表进行排序。如果没有lambda,你将不得不定义一个函数,给它一个名字,然后把它传递给sorted()。lambda使这段代码更干净。
作为比较,这是上面的例子在没有使用lambda的情况下看起来的样子:
>>> def sort_by_int(x): ... return int(x[2:]) ... >>> ids = ["id1", "id2", "id30", "id3", "id20", "id10"] >>> sorted(ids, key=sort_by_int) ['id1', 'id2', 'id3', 'id10', 'id20', 'id30']这段代码产生与
lambda示例相同的结果,但是您需要在使用它之前定义函数。关于
lambda的更多信息,请查看如何使用 Python Lambda 函数。返回关键词:
return、yield、有两个 Python 关键字用于指定从函数或方法返回什么:
return和yield。理解何时何地使用return对于成为一名更好的 Python 程序员至关重要。yield关键字是 Python 的一个更高级的特性,但它也是理解的一个有用工具。
return关键词Python 的
return关键字只作为用def定义的函数的一部分有效。当 Python 遇到这个关键字时,它将在该点退出函数,并返回在return关键字之后的任何结果:def <function>(): return <expr>如果没有给定表达式,默认情况下,
return将返回None:
>>> def return_none():
... return
...
>>> return_none()
>>> r = return_none()
>>> print(r)
None
但是,大多数情况下,您希望返回表达式或特定值的结果:
>>> def plus_1(num): ... return num + 1 ... >>> plus_1(9) 10 >>> r = plus_1(9) >>> print(r) 10你甚至可以在一个函数中多次使用
return关键字。这允许您在函数中有多个出口点。当您希望有多个 return 语句时,一个经典的例子是下面的计算阶乘的递归解决方案:def factorial(n): if n == 1: return 1 else: return n * factorial(n - 1)在上面的阶乘函数中,有两种情况下你会想从函数中返回。第一种是基本情况,当数字为
1时,第二种是常规情况,当您想要将当前数字乘以下一个数字的阶乘值时。要了解更多关于关键字
return的信息,请查看定义你自己的 Python 函数。
yield关键词Python 的
yield关键字有点像return关键字,因为它指定了从函数返回什么。然而,当一个函数有一个yield语句时,返回的是一个生成器。然后可以将生成器传递给 Python 的内置next()来获取函数返回的下一个值。当你用
yield语句调用一个函数时,Python 会执行这个函数,直到它到达第一个yield关键字,然后返回一个生成器。这些被称为生成器函数:def <function>(): yield <expr>最简单的例子是返回相同值集的生成器函数:
>>> def family():
... yield "Pam"
... yield "Jim"
... yield "Cece"
... yield "Philip"
...
>>> names = family()
>>> names
<generator object family at 0x7f47a43577d8>
>>> next(names)
'Pam'
>>> next(names)
'Jim'
>>> next(names)
'Cece'
>>> next(names)
'Philip'
>>> next(names)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
一旦StopIteration异常被引发,生成器就完成返回值。为了再次浏览这些名字,您需要再次调用family()并获得一个新的生成器。大多数情况下,一个生成器函数会作为一个for循环的一部分被调用,它会为您执行next()调用。
关于yield关键字和使用生成器和生成器函数的更多信息,请查看如何在 Python 中使用生成器和屈服和 Python 生成器 101 。
导入关键词:import、from、as、
对于那些不像 Python 关键字和内置的工具,还不能用于您的 Python 程序,您需要将它们导入到您的程序中。Python 的标准库中有许多有用的模块,只需要导入即可。在 PyPI 中还有许多其他有用的库和工具,一旦你把它们安装到你的环境中,你就需要把它们导入到你的程序中。
以下是用于将模块导入程序的三个 Python 关键字的简要描述。有关这些关键字的更多信息,请查看 Python 模块和包——简介和 Python 导入:高级技术和技巧。
import关键词
Python 的import关键字用于导入或包含在 Python 程序中使用的模块。基本用法语法如下所示:
import <module>
该语句运行后,<module>将可供您的程序使用。
例如,如果你想使用标准库中collections模块中的 Counter 类,那么你可以使用下面的代码:
>>> import collections >>> collections.Counter() Counter()以这种方式导入
collections使得整个collections模块,包括Counter类,对您的程序可用。通过使用模块名,您可以访问该模块中所有可用的工具。要访问Counter,您需要从模块collections.Counter中引用它。
from关键词
from关键字与import一起使用,从模块中导入特定的内容:from <module> import <thing>这将把
<module>中的<thing>导入到你的程序中。这两个 Python 关键字,from和import,一起使用。如果您想使用标准库中
collections模块中的Counter,那么您可以专门导入它:
>>> from collections import Counter
>>> Counter()
Counter()
像这样导入Counter使得Counter类可用,但是来自collections模块的其他任何东西都不可用。Counter现已可用,无需从collections模块引用。
as关键词
as 关键字用于别名一个导入的模块或工具。它与 Python 关键字import和from一起使用,以更改正在导入的东西的名称:
import <module> as <alias>
from <module> import <thing> as <alias>
对于名字很长或者有一个常用导入别名的模块,as有助于创建别名。
如果您想从 collections 模块导入Counter类,但将其命名为不同的名称,您可以通过使用as来为其起别名:
>>> from collections import Counter as C >>> C() Counter()现在
Counter可以在你的程序中使用了,但是它被C引用了。as进口别名更常见的用法是用于 NumPy 或 Pandas 包装。这些通常使用标准别名导入:import numpy as np import pandas as pd这是从一个模块中导入所有内容的一个更好的选择,它允许您缩短正在导入的模块的名称。
异常处理关键字:
try、except、raise、finally、else、assert、任何 Python 程序最常见的一个方面就是异常的引发和捕获。因为这是所有 Python 代码的一个基本方面,所以有几个 Python 关键字可以帮助您使代码的这一部分清晰简洁。
下面几节将介绍这些 Python 关键字及其基本用法。关于这些关键词的更深入的教程,请查看 Python 异常:简介。
try关键词任何异常处理块都以 Python 的
try关键字开始。这在大多数其他具有异常处理的编程语言中是相同的。
try块中的代码可能会引发异常。其他几个 Python 关键字与try相关联,用于定义如果出现不同的异常或在不同的情况下应该做什么。这些是except、else和finally:try: <statements> <except|else|finally>: <statements>一个
try块是无效的,除非它在整个try语句中至少有一个用于异常处理的 Python 关键字。如果您想要计算并返回每加仑汽油的英里数(
mpg),给定行驶的英里数和使用的加仑数,那么您可以编写如下函数:def mpg(miles, gallons): return miles / gallons您可能看到的第一个问题是,如果将
gallons参数作为0传入,您的代码可能会引发一个ZeroDivisionError。try关键字允许您修改上面的代码来适当地处理这种情况:def mpg(miles, gallons): try: mpg = miles / gallons except ZeroDivisionError: mpg = None return mpg现在如果
gallons = 0,那么mpg()不会引发异常,而是返回None。这可能更好,或者您可能决定要引发不同类型的异常或以不同的方式处理这种情况。您将在下面看到该示例的扩展版本,以说明用于异常处理的其他关键字。
except关键词Python 的
except关键字与try一起使用,定义当出现特定异常时做什么。你可以用一个try拥有一个或多个except区块。基本用法如下:try: <statements> except <exception>: <statements>以前面的
mpg()为例,如果有人传递了不能与/操作符一起工作的类型,您也可以做一些特定的事情。在前面的例子中已经定义了mpg(),现在试着用字符串而不是数字来调用它:
>>> mpg("lots", "many")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in mpg
TypeError: unsupported operand type(s) for /: 'str' and 'str'
您也可以修改mpg()并使用多个except块来处理这种情况:
def mpg(miles, gallons):
try:
mpg = miles / gallons
except ZeroDivisionError:
mpg = None
except TypeError as ex:
print("you need to provide numbers")
raise ex
return mpg
在这里,您修改mpg()以仅在将有用的提醒打印到屏幕上之后引发TypeError异常。
请注意,except关键字也可以与as关键字结合使用。这与as的其他用法效果相同,给引发的异常一个别名,这样您就可以在except块中使用它。
尽管在语法上是允许的,但是尽量不要使用except语句作为隐式的捕获。更好的做法是总是明确地捕捉的某个东西,即使它只是Exception:
try:
1 / 0
except: # Don't do this
pass
try:
1 / 0
except Exception: # This is better
pass
try:
1 / 0
except ZeroDivisionError: # This is best
pass
如果你真的想捕捉大范围的异常,那么指定父类Exception。这是一个更明确的总括,它不会捕捉你可能不想捕捉的异常,如RuntimeError或KeyboardInterrupt。
raise关键词
raise 关键字引发了一个异常。如果您发现您需要引发一个异常,那么您可以使用raise,后跟要引发的异常:
raise <exception>
在前面的mpg()示例中,您使用了raise。当您捕捉到TypeError时,您会在屏幕上显示一条消息后再次引发该异常。
finally关键词
Python 的 finally 关键字有助于指定无论在try、except或else块中发生什么都应该运行的代码。要使用finally,将其作为try块的一部分,并指定无论如何都要运行的语句:
try:
<statements>
finally:
<statements>
使用前面的例子,指定无论发生什么情况,您都想知道函数是用什么参数调用的,这可能是有帮助的。您可以修改mpg()来包含一个finally块来实现这个功能:
def mpg(miles, gallons):
try:
mpg = miles / gallons
except ZeroDivisionError:
mpg = None
except TypeError as ex:
print("you need to provide numbers")
raise ex
finally:
print(f"mpg({miles}, {gallons})")
return mpg
现在,无论如何调用mpg()或者结果是什么,都要打印用户提供的参数:
>>> mpg(10, 1) mpg(10, 1) 10.0 >>> mpg("lots", "many") you need to provide numbers mpg(lots, many) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 8, in mpg File "<stdin>", line 3, in mpg TypeError: unsupported operand type(s) for /: 'str' and 'str'关键字
finally可能是异常处理代码中非常有用的一部分。
else关键字与try和exceptT3 一起使用您已经了解到
else关键字可以与if关键字和 Python 中的循环一起使用,但是它还有一个用途。它可以与try和exceptPython 关键字结合使用。只有当您同时使用至少一个except模块时,您才能以这种方式使用else:try: <statements> except <exception>: <statements> else: <statements>在这种情况下,
else块中的代码仅在try块中出现异常而非时执行。换句话说,如果try块成功执行了所有代码,那么else块代码将被执行。在
mpg()的例子中,假设您想要确保无论传入什么数字组合,结果mpg总是作为float返回。你可以这样做的方法之一是使用一个else块。如果mpg的try块计算成功,那么在返回之前将结果转换成else块中的float:def mpg(miles, gallons): try: mpg = miles / gallons except ZeroDivisionError: mpg = None except TypeError as ex: print("you need to provide numbers") raise ex else: mpg = float(mpg) if mpg is not None else mpg finally: print(f"mpg({miles}, {gallons})") return mpg现在,调用
mpg()的结果,如果成功,将总是一个float。关于使用
else块作为try和except块的一部分的更多信息,请查看 Python 异常:简介。
assert关键词Python 中的
assert关键字用于指定一个assert语句,或者一个关于表达式的断言。如果表达式(<expr>)为真,一个assert语句将导致一个 no-op,如果表达式为假,它将引发一个AssertionError。要定义断言,使用assert后跟一个表达式:assert <expr>一般来说,
assert语句会被用来确定某件需要为真的事情。但是,您不应该依赖它们,因为根据 Python 程序的执行方式,它们可以被忽略。异步编程关键词:
async、await、异步编程是一个复杂的话题。定义了两个 Python 关键字来帮助提高异步代码的可读性和整洁性:
async和await。下面几节将介绍这两个异步关键字及其基本语法,但它们不会深入异步编程。要了解更多关于异步编程的知识,请查看Python 中的异步 IO:完整演练和Python 中的异步特性入门。
async关键词
async关键字与def一起使用,定义一个异步函数,或协程。语法就像定义一个函数,只是在开头添加了async:async def <function>(<params>): <statements>您可以通过在函数的常规定义前添加关键字
async来使函数异步。
await关键词Python 的
await关键字在异步函数中用于指定函数中的一个点,在这个点上,控制权被交还给事件循环,以供其他函数运行。您可以通过将await关键字放在任何async函数的调用之前来使用它:await <some async function call> # OR <var> = await <some async function call>使用
await时,可以调用异步函数并忽略结果,也可以在函数最终返回时将结果存储在一个变量中。变量处理关键字:
del、global、nonlocal、三个 Python 关键字用于处理变量。
del关键字比global和nonlocal关键字更常用。但是知道并理解这三个关键词仍然是有帮助的,这样你就可以确定何时以及如何使用它们。
del关键词
del在 Python 中用于取消设置变量或名称。您可以在变量名上使用它,但更常见的用途是从列表或字典中移除索引。要取消设置一个变量,使用del,后跟您想要取消设置的变量:del <variable>让我们假设您想要清理一个从 API 响应中得到的字典,方法是扔掉您知道不会使用的键。您可以使用关键字
del来实现:
>>> del response["headers"]
>>> del response["errors"]
这将从字典response中删除"headers"和"errors"键。
global关键词
如果你需要修改一个没有在函数中定义但是在全局范围中定义的变量,那么你需要使用 global 关键字。这是通过在函数中指定需要从全局范围将哪些变量拉入函数来实现的:
global <variable>
一个基本的例子是用函数调用增加一个全局变量。你可以用关键字global来实现:
>>> x = 0 >>> def inc(): ... global x ... x += 1 ... >>> inc() >>> x 1 >>> inc() >>> x 2这通常不被认为是好的做法,但是它确实有它的用处。要了解更多关于
global关键字的信息,请查看Python Scope&LEGB 规则:解析代码中的名称。
nonlocal关键词
nonlocal关键字与global相似,它允许您修改不同范围的变量。有了global,你从中提取的范围就是全局范围。对于nonlocal,您从中提取的作用域是父作用域。语法类似于global:nonlocal <variable>这个关键字不常使用,但有时会很方便。关于作用域和
nonlocal关键字的更多信息,请查看 Python 作用域&LEGB 规则:解析代码中的名称。弃用的 Python 关键字
有时,Python 关键字会成为一个内置函数。
exec都是这种情况。在 2.7 版本中,这些曾经是 Python 关键字,但后来被改为内置函数。前
当
print "Hello, World"请注意,它看起来像许多其他关键字语句,关键字后跟参数。
现在
print()完成的。要将某些内容打印到屏幕上,现在可以使用以下语法:print("Hello, World")关于打印的更多信息,请查看 Python print()函数的指南。
前
exec关键词在 Python 2.7 中,
exec关键字将 Python 代码作为字符串执行。这是使用以下语法完成的:exec "<statements>"您可以在 Python 3+中获得相同的行为,只是使用了内置的
exec()。例如,如果您想在 Python 代码中执行"x = 12 * 7",那么您可以执行以下操作:
>>> exec("x = 12 * 7")
>>> x == 84
True
关于exec()及其用途的更多信息,请查看如何运行您的 Python 脚本和 Python 的 exec():执行动态生成的代码。
结论
Python 关键字是任何 Python 程序的基本构件。理解它们的正确用法是提高您的 Python 技能和知识的关键。
在整篇文章中,您看到了一些巩固您对 Python 关键字的理解并帮助您编写更高效和可读性更好的代码的东西。
在这篇文章中,你已经了解到:
- 3.8 版本中的 Python 关键字及其基本用法
- 几个资源帮助你加深对许多关键词的理解
- 如何使用 Python 的
keyword模块以编程的方式处理关键字
如果你理解了这些关键词中的大部分,并能自如地使用它们,那么你可能会有兴趣了解更多关于 Python 的语法以及使用这些关键词的语句是如何被指定和构造的。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 探索 Python 中的关键词************
Python 参数和 kwargs:去神秘化
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python args 和 kwargs:揭秘
有时候,当你查看 Python 中的函数定义时,你可能会发现它带有两个奇怪的参数: *args 和 **kwargs 。如果你想知道这些特殊的变量是什么,或者为什么你的 IDE 在 main() 中定义它们,那么这篇文章就是为你准备的。您将学习如何在 Python 中使用 args 和 kwargs 来增加函数的灵活性。
到文章结束,你就知道:
*args和**kwargs到底是什么意思- 如何在函数定义中使用
*args和**kwargs - 如何使用单个星号(
*)解包可重复项 - 如何使用两个星号(
**)解包字典
本文假设你已经知道如何定义 Python 函数和使用 T2 列表和字典。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
向函数传递多个参数
*args 和 **kwargs 允许您向一个函数传递多个参数或关键字参数。考虑下面的例子。这是一个简单的函数,它接受两个参数并返回它们的和:
def my_sum(a, b):
return a + b
这个函数工作正常,但是它仅限于两个参数。如果您需要对不同数量的参数求和,而传递的参数的具体数量只能在运行时确定,该怎么办?创建一个函数,不管传递给它的整数有多少,它都可以对所有整数求和,这不是很好吗?
在函数定义中使用 Python args 变量
有几种方法可以将不同数量的参数传递给函数。对于有收藏经验的人来说,第一种方式通常是最直观的。你只需将所有参数的列表或集合传递给你的函数。所以对于my_sum(),你可以传递一个需要相加的所有整数的列表:
# sum_integers_list.py
def my_sum(my_integers):
result = 0
for x in my_integers:
result += x
return result
list_of_integers = [1, 2, 3]
print(my_sum(list_of_integers))
这个实现是可行的,但是无论何时调用这个函数,都需要创建一个参数列表来传递给它。这可能不太方便,尤其是如果您事先不知道应该进入列表的所有值。
这就是*args真正有用的地方,因为它允许您传递不同数量的位置参数。举以下例子:
# sum_integers_args.py
def my_sum(*args):
result = 0
# Iterating over the Python args tuple
for x in args:
result += x
return result
print(my_sum(1, 2, 3))
在本例中,您不再向my_sum()传递列表。相反,你要传递三个不同的位置参数。my_sum()获取输入中提供的所有参数,并将它们打包到一个名为args的可迭代对象中。
注意 args只是一个名字。你不需要使用args这个名字。你可以选择任何你喜欢的名字,比如integers:
# sum_integers_args_2.py
def my_sum(*integers):
result = 0
for x in integers:
result += x
return result
print(my_sum(1, 2, 3))
即使您将 iterable 对象作为integers而不是args传递,该函数仍然有效。这里重要的是你使用拆包操作员 ( *)。
请记住,使用解包操作符*得到的可迭代对象是,不是list,而是tuple 。一个tuple和一个list相似,它们都支持切片和迭代。然而,元组至少在一个方面非常不同:列表是可变的,而元组不是。要对此进行测试,请运行以下代码。这个脚本试图改变一个列表的值:
# change_list.py
my_list = [1, 2, 3]
my_list[0] = 9
print(my_list)
位于列表第一个索引处的值应更新为9。如果您执行这个脚本,您将看到列表确实被修改了:
$ python change_list.py
[9, 2, 3]
第一个值不再是0,而是更新后的值9。现在,试着对一个元组做同样的事情:
# change_tuple.py
my_tuple = (1, 2, 3)
my_tuple[0] = 9
print(my_tuple)
在这里,您可以看到相同的值,除了它们作为一个元组保存在一起。如果您尝试执行这个脚本,您将看到 Python 解释器返回一个错误:
$ python change_tuple.py
Traceback (most recent call last):
File "change_tuple.py", line 3, in <module>
my_tuple[0] = 9
TypeError: 'tuple' object does not support item assignment
这是因为 tuple 是一个不可变的对象,它的值在赋值后不能改变。在处理元组和*args时,请记住这一点。
在函数定义中使用 Python kwargs 变量
好了,现在你已经明白了*args是干什么的,但是**kwargs呢?**kwargs的工作方式与*args相似,但是它不接受位置参数,而是接受关键字(或名为的)参数。举以下例子:
# concatenate.py
def concatenate(**kwargs):
result = ""
# Iterating over the Python kwargs dictionary
for arg in kwargs.values():
result += arg
return result
print(concatenate(a="Real", b="Python", c="Is", d="Great", e="!"))
当您执行上面的脚本时,concatenate()将遍历 Python kwargs 字典并连接它找到的所有值:
$ python concatenate.py
RealPythonIsGreat!
和args一样,kwargs只是一个名字,想怎么改就怎么改。同样,这里重要的是使用拆包操作符 ( **)。
所以,前面的例子可以写成这样:
# concatenate_2.py
def concatenate(**words):
result = ""
for arg in words.values():
result += arg
return result
print(concatenate(a="Real", b="Python", c="Is", d="Great", e="!"))
注意,在上面的例子中,iterable 对象是一个标准的dict。如果您遍历字典并想要返回它的值,如示例所示,那么您必须使用.values()。
事实上,如果您忘记使用这个方法,您会发现自己正在遍历 Python kwargs 字典的键,如下例所示:
# concatenate_keys.py
def concatenate(**kwargs):
result = ""
# Iterating over the keys of the Python kwargs dictionary
for arg in kwargs:
result += arg
return result
print(concatenate(a="Real", b="Python", c="Is", d="Great", e="!"))
现在,如果您尝试执行这个示例,您会注意到以下输出:
$ python concatenate_keys.py
abcde
如您所见,如果您不指定.values(),您的函数将迭代您的 Python kwargs 字典的键,返回错误的结果。
函数中的参数排序
既然您已经了解了*args和**kwargs的用途,那么您就可以开始编写接受不同数量输入参数的函数了。但是,如果您想创建一个函数,同时接受可变数量的位置和命名参数,该怎么办呢?
在这种情况下,你必须记住订单计数。正如非默认参数必须在默认参数之前一样,*args必须在**kwargs之前。
概括地说,参数的正确顺序是:
- 标准参数
*args论据**kwargs论据
例如,这个函数定义是正确的:
# correct_function_definition.py
def my_function(a, b, *args, **kwargs):
pass
*args变量适当地列在**kwargs之前。但是如果你试图改变参数的顺序呢?例如,考虑以下函数:
# wrong_function_definition.py
def my_function(a, b, **kwargs, *args):
pass
现在,在函数定义中,**kwargs在*args之前。如果您尝试运行这个例子,您将从解释器收到一个错误:
$ python wrong_function_definition.py
File "wrong_function_definition.py", line 2
def my_function(a, b, **kwargs, *args):
^
SyntaxError: invalid syntax
在这种情况下,由于*args在**kwargs之后,Python 解释器抛出一个 SyntaxError 。
带星号的拆包符:* & **
现在,您可以使用*args和**kwargs来定义接受不同数量输入参数的 Python 函数。让我们更深入地了解一下开箱操作员。
Python 2 中引入了单星和双星号解包操作符。在 3.5 版本中,由于 PEP 448 ,它们变得更加强大。简而言之,解包操作符是从 Python 中的 iterable 对象解包值的操作符。单星号操作符*可以用在 Python 提供的任何 iterable 上,而双星号操作符**只能用在字典上。
让我们从一个例子开始:
# print_list.py
my_list = [1, 2, 3]
print(my_list)
这段代码定义了一个列表,然后将它打印到标准输出中:
$ python print_list.py
[1, 2, 3]
请注意列表是如何打印的,以及相应的括号和逗号。
现在,尝试将解包操作符*添加到列表名称的前面:
# print_unpacked_list.py
my_list = [1, 2, 3]
print(*my_list)
这里,*操作符告诉print()首先解包列表。
在这种情况下,输出不再是列表本身,而是列表的内容:
$ python print_unpacked_list.py
1 2 3
你能看出这次执行和print_list.py的区别吗?print()没有使用列表,而是使用了三个独立的参数作为输入。
您会注意到的另一件事是,在print_unpacked_list.py中,您使用解包操作符*来调用函数,而不是在函数定义中。在这种情况下,print()接受列表中的所有项目,就像它们是单个参数一样。
您也可以使用这个方法来调用您自己的函数,但是如果您的函数需要特定数量的参数,那么您解包的 iterable 必须具有相同数量的参数。
要测试此行为,请考虑以下脚本:
# unpacking_call.py
def my_sum(a, b, c):
print(a + b + c)
my_list = [1, 2, 3]
my_sum(*my_list)
这里,my_sum()明确声明a、b和c是必需参数。
如果您运行这个脚本,您将得到my_list中三个数字的总和:
$ python unpacking_call.py
6
my_list中的 3 个元素与my_sum()中所需的参数完全匹配。
现在看看下面的脚本,其中my_list有 4 个参数,而不是 3 个:
# wrong_unpacking_call.py
def my_sum(a, b, c):
print(a + b + c)
my_list = [1, 2, 3, 4]
my_sum(*my_list)
在这个例子中,my_sum()仍然只需要三个参数,但是*操作符从列表中得到 4 个条目。如果您尝试执行这个脚本,您将会看到 Python 解释器无法运行它:
$ python wrong_unpacking_call.py
Traceback (most recent call last):
File "wrong_unpacking_call.py", line 6, in <module>
my_sum(*my_list)
TypeError: my_sum() takes 3 positional arguments but 4 were given
当您使用*操作符解包一个列表并将参数传递给一个函数时,就好像您在单独传递每个参数一样。这意味着您可以使用多个解包操作符从几个列表中获取值,并将它们全部传递给一个函数。
要测试此行为,请考虑以下示例:
# sum_integers_args_3.py
def my_sum(*args):
result = 0
for x in args:
result += x
return result
list1 = [1, 2, 3]
list2 = [4, 5]
list3 = [6, 7, 8, 9]
print(my_sum(*list1, *list2, *list3))
如果您运行这个例子,所有三个列表都将被解包。每个单独的项目被传递到my_sum(),产生以下输出:
$ python sum_integers_args_3.py
45
解包操作符还有其他方便的用途。例如,假设您需要将一个列表分成三个不同的部分。输出应该显示第一个值、最后一个值以及两者之间的所有值。使用解包操作符,只需一行代码就可以完成:
# extract_list_body.py
my_list = [1, 2, 3, 4, 5, 6]
a, *b, c = my_list
print(a)
print(b)
print(c)
本例中my_list包含 6 项。第一个变量分配给a,最后一个分配给c,所有其他值都被打包到一个新的列表b中。如果您运行脚本,print()将向您显示,您的三个变量具有您所期望的值:
$ python extract_list_body.py
1
[2, 3, 4, 5]
6
使用解包操作符*可以做的另一件有趣的事情是拆分任何可迭代对象的项目。如果您需要合并两个列表,这可能非常有用,例如:
# merging_lists.py
my_first_list = [1, 2, 3]
my_second_list = [4, 5, 6]
my_merged_list = [*my_first_list, *my_second_list]
print(my_merged_list)
解包操作符*被加在my_first_list和my_second_list的前面。
如果您运行这个脚本,您会看到结果是一个合并的列表:
$ python merging_lists.py
[1, 2, 3, 4, 5, 6]
您甚至可以使用解包操作符**合并两个不同的字典:
# merging_dicts.py
my_first_dict = {"A": 1, "B": 2}
my_second_dict = {"C": 3, "D": 4}
my_merged_dict = {**my_first_dict, **my_second_dict}
print(my_merged_dict)
这里,要合并的 iterables 是my_first_dict和my_second_dict。
执行这段代码会输出一个合并的字典:
$ python merging_dicts.py
{'A': 1, 'B': 2, 'C': 3, 'D': 4}
记住*操作符作用于任何可迭代对象。它也可以用来打开管柱:
# string_to_list.py
a = [*"RealPython"]
print(a)
在 Python 中,字符串是可迭代的对象,所以*会将其解包,并将所有单个值放在一个列表a中:
$ python string_to_list.py
['R', 'e', 'a', 'l', 'P', 'y', 't', 'h', 'o', 'n']
前面的例子看起来很棒,但是当你使用这些操作符时,记住第七条规则很重要,Tim Peters 的Python 的禅宗:可读性很重要。
要了解原因,请考虑以下示例:
# mysterious_statement.py
*a, = "RealPython"
print(a)
有一个解包操作符*,后面跟着一个变量、一个逗号和一个赋值。一条线装了这么多东西!实际上,这段代码与前面的例子没有什么不同。它只接受字符串RealPython并将所有条目分配给新列表a,这要感谢拆包操作符*。
a后面的逗号起了作用。将解包操作符用于变量赋值时,Python 要求结果变量要么是列表,要么是元组。通过后面的逗号,您定义了一个只有一个命名变量a的元组,这个变量就是列表['R', 'e', 'a', 'l', 'P', 'y', 't', 'h', 'o', 'n']。
您永远看不到 Python 在这个操作中创建的元组,因为您将元组解包与解包操作符*结合使用。
如果在赋值的左边命名第二个变量,Python 会将字符串的最后一个字符赋给第二个变量,同时收集列表中所有剩余的字符a:
>>> *a, b = "RealPython" >>> b "n" >>> type(b) <class 'str'> >>> a ["R", "e", "a", "l", "P", "y", "t", "h", o"] >>> type(a) <class 'list'>如果您以前使用过元组解包,那么当您对第二个命名变量使用该操作时,结果可能会更熟悉,如上所示。但是,如果您想将可变长度 iterable 的所有项解包到一个变量
a中,那么您需要添加逗号(,) ,而不需要命名第二个变量。然后 Python 会将所有项目解包到第一个命名变量中,这是一个列表。虽然这是一个巧妙的技巧,但许多 python 爱好者并不认为这段代码可读性很强。因此,最好少用这种结构。
结论
您现在可以使用
*args和**kwargs在函数中接受可变数量的参数。您还了解了更多关于解包操作符的知识。你已经学会了:
*args和**kwargs到底是什么意思- 如何在函数定义中使用
*args和**kwargs- 如何使用单个星号(
*)解包可重复项- 如何使用两个星号(
**)解包字典如果你还有问题,不要犹豫,在下面的评论区联系我们!要了解 Python 中星号用法的更多信息,请看一下 Trey Hunner 关于这个主题的文章。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python args 和 kwargs:揭秘**
如何使用 Python Lambda 函数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 如何使用 Python Lambda 函数
Python 和其他语言,如 Java、C#、甚至 C++都在语法中添加了 lambda 函数,而 LISP 或 ML 语言家族、Haskell、OCaml 和 F#等语言则使用 lambdas 作为核心概念。
Python lambdas 是小型的匿名函数,其语法比常规 Python 函数更严格,但也更简洁。
到本文结束时,你会知道:
- Python lambdas 是如何产生的
- lambdas 与常规函数对象相比如何
- 如何编写 lambda 函数
- Python 标准库中的哪些函数利用了 lambdas
- 何时使用或避免 Python lambda 函数
注释:你会看到一些使用
lambda的代码示例,它们似乎明显忽略了 Python 风格的最佳实践。这只是为了说明 lambda 演算的概念或者突出 Pythonlambda的能力。随着文章的深入,这些有问题的例子将与更好的方法或替代方案进行对比。
本教程主要面向中级到有经验的 Python 程序员,但对编程和 lambda 演算感兴趣的任何好奇者也可以阅读。
本教程中包含的所有例子都已经用 Python 3.7 测试过了。
参加测验:通过我们的交互式“Python Lambda 函数”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
λ演算
Python 和其他编程语言中的 Lambda 表达式源于 lambda 演算,这是阿隆佐·邱奇发明的一种计算模型。您将发现 lambda 演算是何时引入的,以及为什么它是最终出现在 Python 生态系统中的一个基本概念。
历史
20 世纪 30 年代,阿隆佐·邱奇形式化了λ演算,一种基于纯抽象的语言。Lambda 函数也被称为 lambda 抽象,直接引用阿隆佐·邱奇最初创造的抽象模型。
Lambda 演算可以编码任何计算。它是图灵完成,但是与一个图灵机的概念相反,它是纯粹的,不保持任何状态。
函数式语言起源于数理逻辑和 lambda 演算,而命令式编程语言则采用了 Alan Turing 发明的基于状态的计算模型。两种计算模型,lambda 演算和图灵机,可以相互转换。这种等价被称为丘奇-图灵假设。
函数式语言直接继承了 lambda 演算哲学,采用强调抽象、数据转换、组合和纯度(无状态和无副作用)的声明式编程方法。函数式语言的例子包括 Haskell 、 Lisp 或 Erlang 。
相比之下,图灵机导致了命令式编程的出现,比如 Fortran 语言的、 C 语言的或 Python 语言的。
命令式风格包括用语句编程,用详细的指令一步一步地驱动程序流程。这种方法促进了变异,并且需要管理状态。
两个家族中的分离呈现出一些细微差别,因为一些函数式语言包含命令式特性,如 OCaml ,而函数式特性已经渗透到命令式语言家族中,特别是在 Java 或 Python 中引入了 lambda 函数。
Python 本质上不是函数式语言,但是它很早就采用了一些函数式概念。1994 年 1 月,语言中增加了
map()filter()reduce()``lambda运算符。第一个例子
这里有几个例子让你对一些 Python 代码感兴趣,函数风格。
>>> def identity(x):
... return x
identity()接受一个参数x并在调用时返回它。
相反,如果您使用 Python lambda 构造,您会得到以下结果:
>>> lambda x: x在上面的示例中,表达式由以下部分组成:
- 关键词:
lambda- 一个绑定变量:
x- 一体:
x注意:在本文的上下文中,绑定变量是 lambda 函数的参数。
相比之下,自由变量没有被绑定,可以在表达式体中被引用。自由变量可以是常量,也可以是在函数的封闭范围中定义的变量。
您可以编写一个稍微复杂一点的示例,一个将
1添加到参数的函数,如下所示:
>>> lambda x: x + 1
您可以将上述函数应用于参数,方法是用括号将函数及其参数括起来:
>>> (lambda x: x + 1)(2) 3归约是一种计算表达式值的λ演算策略。在当前示例中,它包括用参数
2替换绑定变量x:(lambda x: x + 1)(2) = lambda 2: 2 + 1 = 2 + 1 = 3因为 lambda 函数是一个表达式,所以它可以被命名。因此,您可以编写如下代码:
>>> add_one = lambda x: x + 1
>>> add_one(2)
3
上面的 lambda 函数相当于这样写:
def add_one(x):
return x + 1
这些函数都有一个参数。你可能已经注意到,在 lambdas 的定义中,参数没有括号。在 Python lambdas 中,多参数函数(采用多个参数的函数)通过列出参数并用逗号(,)分隔,但不用括号括起来来表示:
>>> full_name = lambda first, last: f'Full name: {first.title()} {last.title()}' >>> full_name('guido', 'van rossum') 'Full name: Guido Van Rossum'分配给
full_name的 lambda 函数接受两个参数,并返回一个字符串,对两个参数first和last进行插值。正如所料,lambda 的定义列出了不带括号的参数,而调用函数完全像普通的 Python 函数一样,用括号将参数括起来。匿名函数
根据编程语言类型和区域性,下列术语可以互换使用:
- 匿名函数
- λ函数
- λ表达式
- λ抽象
- λ形式
- 函数文字
在本节之后的文章中,您将主要看到术语 lambda function 。
从字面上看,匿名函数是没有名字的函数。在 Python 中,用
lambda关键字创建一个匿名函数。更宽泛地说,它可能被赋予名称,也可能没有。考虑一个用lambda定义的双参数匿名函数,但没有绑定到变量。lambda 没有给定名称:
>>> lambda x, y: x + y
上面的函数定义了一个 lambda 表达式,它接受两个参数并返回它们的和。
除了向您提供 Python 非常适合这种形式的反馈之外,它没有任何实际用途。您可以调用 Python 解释器中的函数:
>>> _(1, 2) 3上面的例子利用了通过下划线(
_)提供的交互式解释器特性。有关更多详细信息,请参见下面的注释。您不能在 Python 模块中编写类似的代码。将解释器中的
_视为您利用的副作用。在 Python 模块中,可以给 lambda 指定一个名称,或者将 lambda 传递给一个函数。在本文的后面,您将使用这两种方法。注意:在交互式解释器中,单下划线(
_)被绑定到最后一个被求值的表达式。在上面的例子中,
_指向 lambda 函数。关于 Python 中这个特殊字符用法的更多细节,请查看 Python 中下划线的含义。JavaScript 等其他语言中使用的另一种模式是立即执行 Python lambda 函数。这就是所谓的立即调用函数表达式(life,读作“iffy”)。这里有一个例子:
>>> (lambda x, y: x + y)(2, 3)
5
上面的 lambda 函数被定义,然后用两个参数(2和3)立即调用。它返回值5,这是参数的总和。
本教程中的几个例子使用这种格式来突出 lambda 函数的匿名性,并避免将 Python 中的lambda作为定义函数的一种更简短的方式。
Python 不鼓励使用直接调用的 lambda 表达式。它只是由可调用的 lambda 表达式产生的,不像普通函数的主体。
Lambda 函数经常与高阶函数一起使用,后者将一个或多个函数作为参数,或者返回一个或多个函数。
通过将函数(normal 或 lambda)作为参数,lambda 函数可以是高阶函数,如下例所示:
>>> high_ord_func = lambda x, func: x + func(x) >>> high_ord_func(2, lambda x: x * x) 6 >>> high_ord_func(2, lambda x: x + 3) 7Python 将高阶函数公开为内置函数或标准库中的函数。例如
map()、filter()、functools.reduce(),以及、sort()、sorted()、、、max()、等关键功能。在lambda 表达式的适当使用中,您将使用 Lambda 函数和 Python 高阶函数。Python Lambda 和正则函数
这段引用自 Python 设计和历史常见问题解答的话似乎为关于在 Python 中使用 lambda 函数的总体预期定下了基调:
与其他语言中添加功能的 lambda 形式不同,如果你懒得定义函数,Python lambdas 只是一种速记符号。(来源)
然而,不要让这种说法阻止你使用 Python 的
lambda。乍一看,你可能会认为 lambda 函数是一个带有某种语法糖的函数,它缩短了定义或调用函数的代码。以下部分强调了普通 Python 函数和 lambda 函数之间的共性和细微差别。功能
此时,您可能想知道绑定到变量的 lambda 函数与只有一行
return的常规函数的根本区别:在表面之下,几乎什么都没有。让我们验证一下 Python 如何看待用单个返回语句构建的函数和作为表达式(lambda)构建的函数。
dis模块公开了用于分析 Python 编译器生成的 Python 字节码的函数:
>>> import dis
>>> add = lambda x, y: x + y
>>> type(add)
<class 'function'>
>>> dis.dis(add)
1 0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 RETURN_VALUE
>>> add
<function <lambda> at 0x7f30c6ce9ea0>
您可以看到dis()公开了 Python 字节码的可读版本,允许检查 Python 解释器在执行程序时将使用的低级指令。
现在用一个常规的函数对象来看它:
>>> import dis >>> def add(x, y): return x + y >>> type(add) <class 'function'> >>> dis.dis(add) 1 0 LOAD_FAST 0 (x) 2 LOAD_FAST 1 (y) 4 BINARY_ADD 6 RETURN_VALUE >>> add <function add at 0x7f30c6ce9f28>Python 解释的字节码对于这两个函数是相同的。但是您可能会注意到命名是不同的:对于用
def定义的函数,函数名是add,而 Python lambda 函数被视为lambda。追溯
在上一节中您看到,在 lambda 函数的上下文中,Python 没有提供函数的名称,而只是提供了
<lambda>。当异常发生时,这可能是一个需要考虑的限制,一个回溯只显示<lambda>:
>>> div_zero = lambda x: x / 0
>>> div_zero(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda> ZeroDivisionError: division by zero
执行 lambda 函数时引发的异常的回溯仅将导致异常的函数标识为<lambda>。
下面是一个普通函数引发的相同异常:
>>> def div_zero(x): return x / 0 >>> div_zero(2) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 1, in div_zero ZeroDivisionError: division by zeronormal 函数会导致类似的错误,但会导致更精确的回溯,因为它给出了函数名
div_zero。语法
正如您在前面几节中看到的,lambda 形式呈现了与普通函数的语法区别。特别是,lambda 函数具有以下特征:
- 它只能包含表达式,不能在其主体中包含语句。
- 它被写成一行执行代码。
- 它不支持类型批注。
- 可以立即调用(IIFE)。
没有报表
lambda 函数不能包含任何语句。在 lambda 函数中,像
return、pass、assert或raise这样的语句会引发一个SyntaxError异常。下面是一个将assert添加到 lambda 主体的例子:
>>> (lambda x: assert x == 2)(2)
File "<input>", line 1
(lambda x: assert x == 2)(2)
^
SyntaxError: invalid syntax
这个虚构的例子旨在assert参数x的值为2。但是,解释器在解析代码时识别出了一个SyntaxError,该代码包含了lambda主体中的语句assert。
单一表达式
与普通函数相比,Python lambda 函数是一个单一的表达式。尽管在lambda的主体中,您可以使用括号或多行字符串将表达式扩展到几行,但它仍然是一个表达式:
>>> (lambda x: ... (x % 2 and 'odd' or 'even'))(3) 'odd'上面的例子在 lambda 参数为奇数时返回字符串
'odd',在参数为偶数时返回'even'。它跨两行,因为它包含在一组括号中,但它仍然是一个表达式。类型注释
如果您已经开始采用类型提示,这在 Python 中是可用的,那么您有另一个更喜欢普通函数而不是 Python lambda 函数的好理由。查看 Python 类型检查(指南)了解更多关于 Python 类型提示和类型检查的信息。在 lambda 函数中,以下内容没有等效项:
def full_name(first: str, last: str) -> str: return f'{first.title()} {last.title()}'任何带有
full_name()的类型错误都可以被类似mypy或pyre的工具捕获,而带有等效 lambda 函数的SyntaxError则在运行时引发:
>>> lambda first: str, last: str: first.title() + " " + last.title() -> str
File "<stdin>", line 1
lambda first: str, last: str: first.title() + " " + last.title() -> str
SyntaxError: invalid syntax
就像试图在 lambda 中包含一个语句一样,添加类型注释会在运行时立即导致一个SyntaxError。
人生
您已经看到了几个立即调用函数执行的例子:
>>> (lambda x: x * x)(3) 9在 Python 解释器之外,这个特性在实践中可能不会用到。这是 lambda 函数被定义为可调用的直接结果。例如,这允许您将 Python lambda 表达式的定义传递给高阶函数,如
map()、filter()或functools.reduce(),或者传递给一个关键函数。参数
像用
def定义的普通函数对象一样,Python lambda 表达式支持传递参数的所有不同方式。这包括:
- 位置参数
- 命名参数(有时称为关键字参数)
- 变量参数列表(通常称为 varargs
- 关键字参数的可变列表
- 仅关键字参数
以下示例说明了向 lambda 表达式传递参数的可选方法:
>>> (lambda x, y, z: x + y + z)(1, 2, 3)
6
>>> (lambda x, y, z=3: x + y + z)(1, 2)
6
>>> (lambda x, y, z=3: x + y + z)(1, y=2)
6
>>> (lambda *args: sum(args))(1,2,3)
6
>>> (lambda **kwargs: sum(kwargs.values()))(one=1, two=2, three=3)
6
>>> (lambda x, *, y=0, z=0: x + y + z)(1, y=2, z=3)
6
装修工
在 Python 中,装饰器是一种模式的实现,允许向函数或类添加行为。它通常用函数前面的@decorator语法来表示。这里有一个人为的例子:
def some_decorator(f):
def wraps(*args):
print(f"Calling function '{f.__name__}'")
return f(args)
return wraps
@some_decorator
def decorated_function(x):
print(f"With argument '{x}'")
在上面的例子中,some_decorator()是一个向decorated_function()添加行为的函数,因此调用decorated_function("Python")会产生以下输出:
Calling function 'decorated_function'
With argument 'Python'
decorated_function()只打印With argument 'Python',但是装饰者添加了一个额外的行为,也打印Calling function 'decorated_function'。
装饰器可以应用于 lambda。尽管不可能用@decorator语法来修饰 lambda,但修饰器只是一个函数,所以它可以调用 lambda 函数:
1# Defining a decorator
2def trace(f):
3 def wrap(*args, **kwargs):
4 print(f"[TRACE] func: {f.__name__}, args: {args}, kwargs: {kwargs}")
5 return f(*args, **kwargs)
6
7 return wrap
8
9# Applying decorator to a function
10@trace
11def add_two(x): 12 return x + 2
13
14# Calling the decorated function
15add_two(3) 16
17# Applying decorator to a lambda
18print((trace(lambda x: x ** 2))(3))
在第 11 行用@trace修饰的add_two(),在第 15 行用参数3调用。相比之下,在第 18 行,lambda 函数立即被包含并嵌入到对装饰器trace()的调用中。当您执行上面的代码时,您将获得以下内容:
[TRACE] func: add_two, args: (3,), kwargs: {}
[TRACE] func: <lambda>, args: (3,), kwargs: {}
9
正如您已经看到的,lambda 函数的名称显示为<lambda>,而add_two显然是普通函数的名称。
以这种方式修饰 lambda 函数对于调试非常有用,可能是为了调试在高阶函数或关键函数的上下文中使用的 lambda 函数的行为。让我们看一个关于map()的例子:
list(map(trace(lambda x: x*2), range(3)))
map()的第一个参数是一个将其参数乘以2的 lambda。这个 lambda 是用trace()装饰的。执行时,上面的示例输出以下内容:
[TRACE] Calling <lambda> with args (0,) and kwargs {}
[TRACE] Calling <lambda> with args (1,) and kwargs {}
[TRACE] Calling <lambda> with args (2,) and kwargs {}
[0, 2, 4]
结果[0, 2, 4]是将range(3)的各个元素相乘得到的一个列表。现在,考虑将range(3)等同于列表[0, 1, 2]。
你将在地图中接触到map()的更多细节。
lambda 也可以作为装饰器,但不推荐这样做。如果你发现自己需要这样做,请参考 PEP 8,编程建议。
关于 Python decorator 的更多信息,请查看 Python decorator 的初级读本。
关闭
一个闭包是一个函数,在这个函数中使用的每个自由变量,除了参数之外的所有东西,都被绑定到一个在这个函数的封闭范围中定义的特定值。实际上,闭包定义了它们运行的环境,因此可以从任何地方调用。
lambdas 和闭包的概念没有必然的联系,尽管 lambda 函数可以是闭包,就像普通函数也可以是闭包一样。有些语言有特殊的闭包或 lambda 结构(例如,Groovy 用一个匿名代码块作为闭包对象),或者 lambda 表达式(例如,Java Lambda 表达式有一个有限的闭包选项)。
下面是一个用普通 Python 函数构造的闭包:
1def outer_func(x):
2 y = 4
3 def inner_func(z):
4 print(f"x = {x}, y = {y}, z = {z}")
5 return x + y + z 6 return inner_func
7
8for i in range(3):
9 closure = outer_func(i) 10 print(f"closure({i+5}) = {closure(i+5)}")
outer_func()返回inner_func(),这是一个嵌套函数,它计算三个参数的和:
x作为参数传递给outer_func()。y是outer_func()的局部变量。z是传递给inner_func()的一个自变量。
为了测试outer_func()和inner_func()的行为,在 for循环中调用了outer_func()三次,输出如下:
x = 0, y = 4, z = 5
closure(5) = 9
x = 1, y = 4, z = 6
closure(6) = 11
x = 2, y = 4, z = 7
closure(7) = 13
在代码的第 9 行,调用outer_func()返回的inner_func()被绑定到名字closure。在第 5 行,inner_func()捕获了x和y,因为它可以访问它的嵌入环境,因此在调用闭包时,它能够对两个自由变量x和y进行操作。
类似地,一个lambda也可以是一个闭包。以下是 Python lambda 函数的相同示例:
1def outer_func(x):
2 y = 4
3 return lambda z: x + y + z 4
5for i in range(3):
6 closure = outer_func(i) 7 print(f"closure({i+5}) = {closure(i+5)}")
当您执行上面的代码时,您将获得以下输出:
closure(5) = 9
closure(6) = 11
closure(7) = 13
在第 6 行,outer_func()返回一个 lambda 并将它赋给变量closure。在第 3 行,lambda 函数的主体引用了x和y。变量y在定义时可用,而x是在运行时调用outer_func()时定义的。
在这种情况下,正常函数和 lambda 的行为类似。在下一节中,您将看到 lambda 的行为由于其评估时间(定义时间与运行时间)而具有欺骗性的情况。
评估时间
在一些涉及循环的情况下,Python lambda 函数作为闭包的行为可能是违反直觉的。它需要理解自由变量何时在 lambda 的上下文中被绑定。以下示例展示了使用常规函数与使用 Python lambda 的区别。
首先使用常规函数测试场景:
1>>> def wrap(n): 2... def f(): 3... print(n) 4... return f 5... 6>>> numbers = 'one', 'two', 'three' 7>>> funcs = [] 8>>> for n in numbers: 9... funcs.append(wrap(n)) 10... 11>>> for f in funcs: 12... f() 13... 14one 15two 16three在一个普通函数中,当函数被添加到列表:
funcs.append(wrap(n))中时,n在定义时被求值,在第 9 行。现在,使用 lambda 函数实现相同的逻辑,观察意外的行为:
1>>> numbers = 'one', 'two', 'three'
2>>> funcs = []
3>>> for n in numbers:
4... funcs.append(lambda: print(n))
5...
6>>> for f in funcs:
7... f()
8...
9three
10three
11three
出现意外结果是因为自由变量n在执行 lambda 表达式时被绑定。第 4 行的 Python lambda 函数是一个闭包,它捕获了运行时绑定的自由变量n。在运行时,当调用第 7 行的函数f时,n的值是three。
为了解决这个问题,您可以在定义时为 free 变量赋值,如下所示:
1>>> numbers = 'one', 'two', 'three' 2>>> funcs = [] 3>>> for n in numbers: 4... funcs.append(lambda n=n: print(n)) 5... 6>>> for f in funcs: 7... f() 8... 9one 10two 11threePython lambda 函数在参数方面的行为类似于普通函数。因此,可以用默认值初始化 lambda 参数:参数
n将外部的n作为默认值。Python lambda 函数可以写成lambda x=n: print(x)的形式,结果也是一样的。Python lambda 函数在第 7 行没有任何参数的情况下被调用,它使用在定义时设置的默认值
n。测试 Lambdas
Python lambdas 可以像常规函数一样进行测试。可以同时使用
unittest和doctest。T2
unittest
unittest模块像处理常规函数一样处理 Python lambda 函数:import unittest addtwo = lambda x: x + 2 class LambdaTest(unittest.TestCase): def test_add_two(self): self.assertEqual(addtwo(2), 4) def test_add_two_point_two(self): self.assertEqual(addtwo(2.2), 4.2) def test_add_three(self): # Should fail self.assertEqual(addtwo(3), 6) if __name__ == '__main__': unittest.main(verbosity=2)
LambdaTest用三种测试方法定义了一个测试用例,每种方法都为作为 lambda 函数实现的addtwo()运用了一个测试场景。包含LambdaTest的 Python 文件lambda_unittest.py的执行产生如下结果:$ python lambda_unittest.py test_add_three (__main__.LambdaTest) ... FAIL test_add_two (__main__.LambdaTest) ... ok test_add_two_point_two (__main__.LambdaTest) ... ok ====================================================================== FAIL: test_add_three (__main__.LambdaTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "lambda_unittest.py", line 18, in test_add_three self.assertEqual(addtwo(3), 6) AssertionError: 5 != 6 ---------------------------------------------------------------------- Ran 3 tests in 0.001s FAILED (failures=1)正如预期的那样,我们对
test_add_three有两个成功的测试用例,一个失败:结果是5,但是预期的结果是6。这个失败是由于测试用例中的一个故意的错误。将预期结果从6更改为5将满足LambdaTest的所有测试。T2
doctest
doctest模块从docstring中提取交互式 Python 代码来执行测试。尽管 Python lambda 函数的语法不支持典型的docstring,但是可以将一个字符串赋给一个已命名 lambda 的__doc__元素:addtwo = lambda x: x + 2 addtwo.__doc__ = """Add 2 to a number. >>> addtwo(2) 4 >>> addtwo(2.2) 4.2 >>> addtwo(3) # Should fail 6 """ if __name__ == '__main__': import doctest doctest.testmod(verbose=True)lambda
addtwo()的文档注释中的doctest描述了与上一节相同的测试用例。当您通过
doctest.testmod()执行测试时,您会得到以下结果:$ python lambda_doctest.py Trying: addtwo(2) Expecting: 4 ok Trying: addtwo(2.2) Expecting: 4.2 ok Trying: addtwo(3) # Should fail Expecting: 6 ********************************************************************** File "lambda_doctest.py", line 16, in __main__.addtwo Failed example: addtwo(3) # Should fail Expected: 6 Got: 5 1 items had no tests: __main__ ********************************************************************** 1 items had failures: 1 of 3 in __main__.addtwo 3 tests in 2 items. 2 passed and 1 failed. ***Test Failed*** 1 failures.失败的测试与上一节中单元测试的执行中所解释的失败相同。
您可以通过给
__doc__赋值来给 Python lambda 添加一个docstring来记录 lambda 函数。尽管可能,Python 语法比 lambda 函数更适合普通函数的docstring。要全面了解 Python 中的单元测试,您可能想参考Python 测试入门。
λ表达式滥用
本文中的几个例子,如果是在专业 Python 代码的上下文中编写的,将被视为滥用。
如果你发现自己试图克服 lambda 表达式不支持的东西,这可能是一个普通函数更适合的迹象。上一节中 lambda 表达式的
docstring就是一个很好的例子。试图克服 Python lambda 函数不支持语句的事实是另一个危险信号。接下来的部分举例说明了一些应该避免使用 lambda 的例子。这些示例可能是在 Python lambda 的上下文中,代码表现出以下模式的情况:
- 它不遵循 Python 风格指南(PEP 8)
- 很繁琐,很难读懂。
- 这是以难以阅读为代价的不必要的聪明。
引发异常
试图在 Python lambda 中引发异常应该让你三思。有一些聪明的方法可以做到这一点,但即使像下面这样的事情也最好避免:
>>> def throw(ex): raise ex
>>> (lambda: throw(Exception('Something bad happened')))()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
File "<stdin>", line 1, in throw
Exception: Something bad happened
因为 Python lambda 主体中的语句在语法上是不正确的,所以上例中的解决方法是用专用函数throw()抽象语句调用。应该避免使用这种类型的变通方法。如果您遇到这种类型的代码,您应该考虑重构代码以使用常规函数。
隐晦的风格
与任何编程语言一样,您会发现 Python 代码由于其使用的风格而难以阅读。Lambda 函数由于其简洁性,有助于编写难以阅读的代码。
以下 lambda 示例包含几个错误的样式选择:
>>> (lambda _: list(map(lambda _: _ // 2, _)))([1,2,3,4,5,6,7,8,9,10]) [0, 1, 1, 2, 2, 3, 3, 4, 4, 5]下划线(
_)指的是不需要显式引用的变量。但是在这个例子中,三个_指的是不同的变量。对这个 lambda 代码的初始升级可以是命名变量:
>>> (lambda some_list: list(map(lambda n: n // 2,
some_list)))([1,2,3,4,5,6,7,8,9,10])
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]
诚然,它仍然很难阅读。通过仍然利用lambda,一个常规函数将大大提高代码的可读性,将逻辑分散在几行代码和函数调用中:
>>> def div_items(some_list): div_by_two = lambda n: n // 2 return map(div_by_two, some_list) >>> list(div_items([1,2,3,4,5,6,7,8,9,10]))) [0, 1, 1, 2, 2, 3, 3, 4, 4, 5]这仍然不是最佳的,但是向您展示了一种使代码,尤其是 Python lambda 函数更具可读性的可能途径。在中,你将学会用列表理解或生成器表达式替换
map()和lambda。这将极大地提高代码的可读性。Python 类
您可以但不应该将类方法编写为 Python lambda 函数。下面的例子是完全合法的 Python 代码,但是展示了依赖于
lambda的非常规 Python 代码。例如,它没有将__str__作为常规函数来实现,而是使用了一个lambda。类似地,brand和year是属性也用 lambda 函数实现,而不是常规函数或装饰器:class Car: """Car with methods as lambda functions.""" def __init__(self, brand, year): self.brand = brand self.year = year brand = property(lambda self: getattr(self, '_brand'), lambda self, value: setattr(self, '_brand', value)) year = property(lambda self: getattr(self, '_year'), lambda self, value: setattr(self, '_year', value)) __str__ = lambda self: f'{self.brand} {self.year}' # 1: error E731 honk = lambda self: print('Honk!') # 2: error E731运行一个类似
flake8的工具,一个样式向导执行工具,将为__str__和honk显示以下错误:E731 do not assign a lambda expression, use a def虽然
flake8没有指出 Python lambda 函数在属性中的用法问题,但是它们很难阅读,并且容易出错,因为使用了多个字符串,如'_brand'和'_year'。
__str__的正确实施预计如下:def __str__(self): return f'{self.brand} {self.year}'
brand将被写成如下:@property def brand(self): return self._brand @brand.setter def brand(self, value): self._brand = value一般来说,在用 Python 编写的代码环境中,正则函数比 lambda 表达式更受欢迎。尽管如此,还是有受益于 lambda 语法的情况,您将在下一节中看到。
λ表达式的适当使用
Python 中的 Lambdas 往往是争议的主题。Python 中反对 lambdas 的一些论点是:
- 可读性问题
- 强加一种功能性思维方式
- 带有关键字
lambda的复杂语法尽管存在激烈的争论,质疑这个特性在 Python 中的存在,但是 lambda 函数的属性有时为 Python 语言和开发人员提供了价值。
以下示例说明了在 Python 代码中使用 lambda 函数不仅合适,而且受到鼓励的场景。
经典函数构造
Lambda 函数通常与内置函数
map()filter()以及functools.reduce()一起使用,暴露在模块functools中。以下三个示例分别说明了如何使用带有 lambda 表达式的函数:
>>> list(map(lambda x: x.upper(), ['cat', 'dog', 'cow']))
['CAT', 'DOG', 'COW']
>>> list(filter(lambda x: 'o' in x, ['cat', 'dog', 'cow']))
['dog', 'cow']
>>> from functools import reduce
>>> reduce(lambda acc, x: f'{acc} | {x}', ['cat', 'dog', 'cow'])
'cat | dog | cow'
您可能需要阅读类似上面例子的代码,尽管有更多相关的数据。因此,识别这些结构非常重要。然而,这些构造有被认为更 Pythonic 化的等价替代。在 Lambdas 的替代方案中,您将学习如何将高阶函数及其伴随的 Lambdas 转换成其他更惯用的形式。
关键功能
Python 中的关键函数是高阶函数,采用参数key作为命名参数。key接收一个可以是lambda的函数。该函数直接影响由关键函数本身驱动的算法。以下是一些关键功能:
sort(): 列表法sorted()、min()、max(): 内置函数nlargest()和nsmallest():堆队列算法模块中的heapq
假设您想要对表示为字符串的 id 列表进行排序。每个 ID 是字符串id和一个数字的串联。默认情况下,使用内置函数sorted()对这个列表进行排序,使用字典顺序,因为列表中的元素是字符串。
为了影响排序的执行,您可以为命名参数key分配一个 lambda,这样排序将使用与 ID 相关联的数字:
>>> ids = ['id1', 'id2', 'id30', 'id3', 'id22', 'id100'] >>> print(sorted(ids)) # Lexicographic sort ['id1', 'id100', 'id2', 'id22', 'id3', 'id30'] >>> sorted_ids = sorted(ids, key=lambda x: int(x[2:])) # Integer sort >>> print(sorted_ids) ['id1', 'id2', 'id3', 'id22', 'id30', 'id100']用户界面框架
像 Tkinter 、 wxPython 或者。带有 IronPython 的. NET Windows 窗体利用 lambda 函数来映射动作以响应 UI 事件。
下面简单的 Tkinter 程序演示了分配给反转按钮命令的
lambda的用法:import tkinter as tk import sys window = tk.Tk() window.grid_columnconfigure(0, weight=1) window.title("Lambda") window.geometry("300x100") label = tk.Label(window, text="Lambda Calculus") label.grid(column=0, row=0) button = tk.Button( window, text="Reverse", command=lambda: label.configure(text=label.cget("text")[::-1]), ) button.grid(column=0, row=1) window.mainloop()点击按钮 Reverse 触发一个事件,触发 lambda 函数,将标签从 Lambda Calculus 更改为 suluclaC adbmaL *:
上的 wxPython 和 IronPython。NET 平台也有类似的处理事件的方法。注意
lambda是处理触发事件的一种方式,但是一个函数也可以用于同样的目的。当需要的代码量非常少时,使用lambda会变得独立且不那么冗长。要探索 wxPython,请查看如何使用 wxPython 构建 Python GUI 应用程序。
Python 解释器
当您在交互式解释器中使用 Python 代码时,Python lambda 函数通常是一个福音。创建一个快速的一行函数来探索一些在解释器之外永远不会出现的代码片段是很容易的。解释器里写的 lambdas,为了快速发现,就像你用后可以扔掉的废纸。
timeit本着与 Python 解释器中的实验相同的精神,模块
timeit提供了计时小代码片段的函数。timeit.timeit()尤其可以直接调用,在字符串中传递一些 Python 代码。这里有一个例子:
>>> from timeit import timeit
>>> timeit("factorial(999)", "from math import factorial", number=10)
0.0013087529951008037
当语句作为字符串传递时,timeit()需要完整的上下文。在上面的例子中,这是由第二个参数提供的,它设置了主函数需要计时的环境。否则会引发一个NameError异常。
另一种方法是使用一个lambda:
>>> from math import factorial >>> timeit(lambda: factorial(999), number=10) 0.0012704220062005334这种解决方案更干净,可读性更好,在解释器中输入更快。尽管
lambda版本的执行时间稍短,但再次执行函数可能会显示出string版本的优势。setup的执行时间不包括在总的执行时间内,不会对结果产生任何影响。猴子打补丁
对于测试来说,有时需要依赖可重复的结果,即使在给定软件的正常执行过程中,相应的结果可能会有所不同,甚至完全是随机的。
假设你想测试一个函数,它在运行时处理随机值。但是,在测试执行期间,您需要以可重复的方式断言可预测的值。下面的例子展示了如何使用
lambda函数,monkey patching 可以帮助您:from contextlib import contextmanager import secrets def gen_token(): """Generate a random token.""" return f'TOKEN_{secrets.token_hex(8)}' @contextmanager def mock_token(): """Context manager to monkey patch the secrets.token_hex function during testing. """ default_token_hex = secrets.token_hex secrets.token_hex = lambda _: 'feedfacecafebeef' yield secrets.token_hex = default_token_hex def test_gen_key(): """Test the random token.""" with mock_token(): assert gen_token() == f"TOKEN_{'feedfacecafebeef'}" test_gen_key()上下文管理器有助于隔离从标准库(在本例中为
secrets)对函数进行猴子修补的操作。分配给secrets.token_hex()的 lambda 函数通过返回一个静态值来替代默认行为。这允许以可预测的方式测试依赖于
token_hex()的任何功能。在退出上下文管理器之前,token_hex()的默认行为被重新建立,以消除任何意外的副作用,这些副作用会影响可能依赖于token_hex()的默认行为的其他测试领域。像
unittest和pytest这样的单元测试框架将这个概念带到了更高的复杂程度。用
pytest,仍然使用一个lambda函数,同样的例子变得更加优雅简洁:import secrets def gen_token(): return f'TOKEN_{secrets.token_hex(8)}' def test_gen_key(monkeypatch): monkeypatch.setattr('secrets.token_hex', lambda _: 'feedfacecafebeef') assert gen_token() == f"TOKEN_{'feedfacecafebeef'}"使用 pytest
monkeypatchfixture ,secrets.token_hex()被一个 lambda 覆盖,该 lambda 将返回一个确定值feedfacecafebeef,允许验证测试。pytestmonkeypatch夹具允许您控制覆盖的范围。在上面的例子中,在后续测试中调用secrets.token_hex(),不使用猴子补丁,将执行这个函数的正常实现。执行
pytest测试得到以下结果:$ pytest test_token.py -v ============================= test session starts ============================== platform linux -- Python 3.7.2, pytest-4.3.0, py-1.8.0, pluggy-0.9.0 cachedir: .pytest_cache rootdir: /home/andre/AB/tools/bpython, inifile: collected 1 item test_token.py::test_gen_key PASSED [100%] =========================== 1 passed in 0.01 seconds ===========================测试通过,因为我们验证了
gen_token()已经执行,并且结果是测试上下文中的预期结果。兰姆达斯的替代品
虽然有很好的理由使用
lambda,但也有不赞成使用它的例子。那么有哪些选择呢?像
map()、filter()和functools.reduce()这样的高阶函数可以通过轻微的创造性转换成更优雅的形式,特别是使用列表理解或生成器表达式。要了解更多关于列表理解的内容,请查看在 Python 中何时使用列表理解。要了解关于生成器表达式的更多信息,请查看如何在 Python 中使用生成器和 yield。
地图
内置函数
map()将一个函数作为第一个参数,并将其应用于第二个参数的每个元素,这是一个可迭代的。可迭代的例子有字符串、列表和元组。有关可迭代和迭代器的更多信息,请查看可迭代和迭代器。
map()返回转换后的集合对应的迭代器。例如,如果您想将一个字符串列表转换成一个每个字符串都大写的新列表,您可以使用map(),如下所示:
>>> list(map(lambda x: x.capitalize(), ['cat', 'dog', 'cow']))
['Cat', 'Dog', 'Cow']
您需要调用list()将map()返回的迭代器转换成可以在 Python shell 解释器中显示的扩展列表。
使用列表理解消除了定义和调用 lambda 函数的需要:
>>> [x.capitalize() for x in ['cat', 'dog', 'cow']] ['Cat', 'Dog', 'Cow']过滤器
内置函数
filter(),另一个经典的函数构造,可以转换成列表理解。它将一个谓词作为第一个参数,将一个 iterable 作为第二个参数。它构建一个迭代器,包含满足谓词函数的初始集合的所有元素。下面是一个过滤给定整数列表中所有偶数的示例:
>>> even = lambda x: x%2 == 0
>>> list(filter(even, range(11)))
[0, 2, 4, 6, 8, 10]
注意,filter()返回一个迭代器,因此需要调用内置类型list,它构造一个给定迭代器的列表。
利用列表理解结构的实现给出了以下内容:
>>> [x for x in range(11) if x%2 == 0] [0, 2, 4, 6, 8, 10]减少
从 Python 3 开始,
reduce()从内置函数变成了functools模块函数。作为map()和filter(),它的前两个参数分别是一个函数和一个可迭代函数。它也可以接受一个初始化式作为第三个参数,作为结果累加器的初始值。对于 iterable 的每个元素,reduce()应用函数并累加 iterable 用尽时返回的结果。要将
reduce()应用于一组对,并计算每对的第一项的总和,您可以这样写:
>>> import functools
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> functools.reduce(lambda acc, pair: acc + pair[0], pairs, 0)
6
使用生成器表达式作为示例中sum()的参数的更惯用的方法如下:
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')] >>> sum(x[0] for x in pairs) 6一个稍微不同但可能更简洁的解决方案消除了显式访问对的第一个元素的需要,而是使用解包:
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> sum(x for x, _ in pairs)
6
使用下划线(_)是 Python 的惯例,表示可以忽略该对中的第二个值。
sum()采用唯一参数,因此生成器表达式不需要放在括号中。
兰达斯到底是不是蟒蛇?
PEP 8 ,这是 Python 代码的风格指南,内容如下:
始终使用 def 语句,而不是将 lambda 表达式直接绑定到标识符的赋值语句。(来源)
这强烈反对使用绑定到标识符的 lambda,主要是在应该使用函数并且有更多好处的地方。PEP 8 没有提到lambda的其他用法。正如您在前面几节中看到的,lambda 函数肯定有很好的用途,尽管它们是有限的。
回答这个问题的一个可能的方法是,如果没有更好的 python 语言,那么 lambda 函数就是完美的 python 语言。我不打算定义“Pythonic”的含义,而是留给您最适合您的思维方式以及您个人或您团队的编码风格的定义。
在 Python lambda、的狭窄范围之外,如何用 PEP 8 编写漂亮的 Python 代码是一个很好的资源,你可能想查看一下 Python 中的代码风格。
结论
您现在知道如何使用 Python lambda函数,并且可以:
- 编写 Python lambdas 并使用匿名函数
- 明智地在 lambdas 或普通 Python 函数之间做出选择
- 避免过度使用兰姆达斯
- 将 lambdas 与高阶函数或 Python 键函数一起使用
如果你对数学情有独钟,你可能会在探索λ微积分的迷人世界中找到一些乐趣。
蟒蛇羊肉就像盐一样。在你的肉、火腿和鸡蛋中加一点会增加味道,但是太多会破坏菜肴。
参加测验:通过我们的交互式“Python Lambda 函数”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
注:以 Monty Python 命名的 Python 编程语言,更喜欢用spamham``eggs作为元合成变量,而不是传统的foo``bar``baz。
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 如何使用 Python Lambda 函数***********
LBYL vs EAFP:防止或处理 Python 中的错误
处理错误和异常情况是编程中的常见要求。你可以在错误发生前阻止错误,或者在错误发生后处理错误。一般来说,你会有两种与这些策略相匹配的编码风格:三思而后行 (LBYL),和请求原谅比请求许可容易 (EAFP)。在本教程中,您将深入探讨 Python 中 LBYL vs EAFP 的相关问题和注意事项。
通过学习 Python 的 LBYL 和 EAFP 编码风格,您将能够决定在处理代码中的错误时使用哪种策略和编码风格。
在本教程中,您将学习如何:
- 在你的 Python 代码中使用 LBYL 和 EAFP 风格
- 了解 LBYL vs EAFP 的利弊和利弊
- 决定何时使用 LBYL 或 EAFP
为了充分利用本教程,您应该熟悉条件语句和 try … except 语句是如何工作的。这两条语句是在 Python 中实现 LBYL 和 EAFP 编码风格的构建块。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
错误和异常情况:预防还是处理?
处理错误和异常情况是计算机编程的基本部分。错误和异常无处不在,如果您想要健壮和可靠的代码,您需要学习如何管理它们。
在处理错误和异常时,您至少可以遵循两种通用策略:
- 防止错误或异常情况发生
- 处理发生后的错误或异常情况
从历史上看,在错误发生之前防止错误一直是编程中最常见的策略或方法。这种方法通常依赖于条件语句,在许多编程语言中也被称为if语句。
当编程语言开始提供异常处理机制,如 Java 和 C++ 中的try … catch语句,以及 Python 中的 try … except 语句时,在错误和异常发生后进行处理就出现了。然而,在 Java 和 C++中,处理异常可能是一个代价很高的操作,所以这些语言倾向于防止错误,而不是处理错误。
注:一优化即将到来 Python 3.11 是零成本异常。这意味着当没有异常出现时,try语句的开销将几乎被消除。
其他编程语言如 C 和 Go 甚至没有异常处理机制。例如,Go 程序员习惯于使用条件语句来防止错误,如下例所示:
func SomeFunc(arg int) error { result, err := DoSomething(arg) if err != nil { // Handle the error here... log.Print(err) return err } return nil }
这个假设的 Go 函数调用DoSomething()并将它的返回值存储在result和err中。err变量将保存函数执行过程中出现的任何错误。如果没有错误发生,那么err将包含nil,这是 Go 中的空值。
然后,if语句检查错误是否不同于nil,在这种情况下,函数继续处理错误。这种模式很常见,你会在大多数围棋程序中反复看到。
当没有出现异常时,Python 的异常处理机制非常有效。因此,在 Python 中,使用该语言的异常处理语法来处理错误和异常情况是很常见的,有时也是被鼓励的。这种做法经常让来自其他编程语言的人感到惊讶。
这对您来说意味着 Python 足够灵活和高效,您可以选择正确的策略来处理代码中的错误和异常情况。你既可以用条件语句防止错误,也可以用语句try … except处理错误。
Pythonistas 通常使用以下术语来确定这两种处理错误和异常情况的策略:
| 战略 | 术语 |
|---|---|
| 防止错误发生 | 三思而后行( LBYL ) |
| 错误发生后的处理 | 请求原谅比请求允许容易( EAFP ) |
在接下来的章节中,您将了解这两种策略,在 Python 和其他编程语言中也被称为编码风格。
具有昂贵的异常处理机制的编程语言倾向于依赖于在错误发生之前检查可能的错误。这些语言通常喜欢 LBYL 风格。相比之下,Python 在处理错误和异常情况时更有可能依赖其异常处理机制。
简要介绍了处理错误和异常的策略后,您就可以更深入地研究 Python 的 LBYL 和 EAFP 编码风格,并探索如何在代码中使用它们。
“三思而后行”(LBYL)风格
LBYL,或三思而后行,是指你首先检查某件事是否会成功,然后只有在你知道它会成功的情况下才继续进行。Python 文档将这种编码风格定义为:
三思而后行。这种编码风格在进行调用或查找之前显式测试前置条件。这种风格与 EAFP 的方法形成了鲜明的对比,其特点是出现了许多
if语句。(来源)
为了理解 LBYL 的本质,您将使用一个经典的例子来处理字典中丢失的键。
假设您有一个包含一些数据的字典,并且您想要逐个键地处理该字典。你预先知道字典可能包括一些特定的关键字。您还知道有些键可能不存在。你如何处理丢失的键而不被破解你的代码呢?
你会有几种方法来解决这个问题。首先,考虑如何使用条件语句来解决这个问题:
if "possible_key" in data_dict:
value = data_dict["possible_key"]
else:
# Handle missing keys here...
在这个例子中,首先检查目标字典data_dict中是否存在"possible_key"。如果是这种情况,那么您访问密钥并将其内容分配给value。这样,您就防止了一个KeyError异常,并且您的代码不会中断。如果"possible_key"不在场,那么你在else条款中处理这个问题。
这种解决问题的方法被称为 LBYL,因为它依赖于在执行期望的动作之前检查先决条件。LBYL 是一种传统的编程风格,在这种风格下,你要确保一段代码在运行之前能够正常工作。如果你坚持这种风格,那么你将会在你的代码中有很多if语句。
这种做法并不是解决 Python 中缺少键问题的唯一或最常见的方法。您还可以使用 EAFP 编码风格,接下来您将了解这一点。
“请求原谅比请求允许容易”(EAFP)风格
Grace Murray Hopper ,一位对计算机编程做出杰出贡献的美国计算机科学家先驱,提供了一条宝贵的建议和智慧,她说:
请求原谅比获得许可更容易。(来源)
EAFP,或者说请求原谅比请求允许更容易,是这个建议应用于编程的具体表达。它建议你马上去做你期望的工作。如果它不起作用并且发生了异常,那么只需捕捉异常并适当地处理它。
根据 Python 的官方术语表, EAFP 编码风格有如下定义:
请求原谅比请求允许容易。这种常见的 Python 编码风格假设存在有效的键或属性,并在假设证明为假时捕捉异常。这种干净快速的风格的特点是存在许多
try和except语句。这种技术与许多其他语言中常见的 LBYL 风格形成对比,比如 C. ( 来源)
在 Python 中,EAFP 编码风格非常流行和普遍。它有时比 LBYL 风格更受推荐。
这种受欢迎程度至少有两个激励因素:
- Python 中的异常处理快速而高效。
- 对潜在问题的必要检查通常是语言本身的一部分。
正如官方定义所说,EAFP 编码风格的特点是使用try … except语句来捕捉和处理代码执行过程中可能出现的错误和异常情况。
下面是如何使用 EAFP 风格重写上一节中关于处理丢失键的示例:
try:
value = data_dict["possible_key"]
except KeyError:
# Handle missing keys here...
在这个变体中,在使用它之前,您不检查密钥是否存在。相反,您可以继续尝试访问所需的密钥。如果由于某种原因,这个键不存在,那么您只需捕获except子句中的KeyError并适当地处理它。
这种风格与 LBYL 风格形成对比。它不是一直检查先决条件,而是立即运行所需的操作,并期望操作成功。
蟒蛇之路:LBYL 还是 EAFP?
Python 更适合 EAFP 还是 LBYL?这几种风格哪一种更有 Pythonic 风格?嗯,看起来 Python 开发者一般倾向于 EAFP 而不是 LBYL。这种行为基于几个原因,稍后您将对此进行探讨。
然而,事实仍然是 Python 作为一种语言,对于这两种编码风格没有明确的偏好。Python 的创始人吉多·范·罗苏姆也说过:
[……]我不同意 EAFP 比 LBYL 好,或者 Python“普遍推荐”的立场。(来源)
正如生活中的许多其他事情一样,最初问题的答案是:视情况而定!如果眼前的问题表明 EAFP 是最好的方法,那就去做吧。另一方面,如果最佳解决方案意味着使用 LBYL,那么使用它时不要认为违反了 Pythonic 规则。
换句话说,你应该对在你的代码中使用 LBYL 或者 EAFP 持开放态度。根据您的具体问题,这两种风格都可能是正确的解决方案。
可以帮助你决定使用哪种风格的是回答这个问题:在这种情况下,什么更方便,防止错误发生还是在错误发生后处理它们?想好答案,做出选择。在接下来的部分,你将探索 LBYL 和 EAFP 的利弊,这可以帮助你做出这个决定。
Python 中的 LBYL 和 EAFP 编码风格
为了更深入地探究何时使用 Python 的 LBYL 或 EAFP 编码风格,您将使用一些相关的比较标准来比较这两种风格:
- 支票数量
- 可读性和清晰性
- 竞争条件风险
- 代码性能
在下面的小节中,您将使用上面的标准来发现 LBYL 和 EAFP 编码风格如何影响您的代码,以及哪种风格适合您的特定用例。
避免不必要的重复检查
EAFP 相对于 LBYL 的优势之一是,前者通常可以帮助您避免不必要的重复检查。例如,假设您需要一个函数,它将正数数字作为字符串,并将它们转换为整数值。您可以使用 LBYL 编写这个函数,如下例所示:
>>> def to_integer(value): ... if value.isdigit(): ... return int(value) ... return None ... >>> to_integer("42") 42 >>> to_integer("one") is None True在这个函数中,首先检查
value是否包含可以转换成数字的内容。为了进行检查,您使用内置的 str 类中的.isdigit()方法。如果输入字符串中的所有字符都是数字,这个方法返回True。否则返回False。酷!这个功能听起来是正确的选择。如果您尝试了该功能,那么您会得出结论,它按照您的计划工作。如果输入包含数字,则返回一个整数;如果输入包含至少一个非数字字符,则返回
None。然而,在这个函数中有一些隐藏的重复。你能发现它吗?对int()的调用在内部执行所有需要的检查,将输入字符串转换为实际的整数。因为检查已经是
int()的一部分,用.isdigit()测试输入字符串会重复已经存在的检查。为了避免这种不必要的重复和相应的开销,您可以使用 EAFP 风格,做如下事情:
>>> def to_integer(value):
... try:
... return int(value)
... except ValueError:
... return None
...
>>> to_integer("42")
42
>>> to_integer("one") is None
True
这个实现完全消除了您之前看到的隐藏重复。它还有其他优点,您将在本教程的后面部分探索,比如提高可读性和性能。
提高可读性和清晰度
要发现使用 LBYL 或 EAFP 如何影响代码的可读性和清晰性,假设您需要一个将两个数相除的函数。该函数必须能够检测其第二个参数分母是否等于0,以避免ZeroDivisionError异常。如果分母是0,那么函数将返回一个默认值,该值可以在调用中作为可选参数提供。
下面是使用 LBYL 编码风格的该函数的实现:
>>> def divide(a, b, default=None): ... if b == 0: # Exceptional situation ... print("zero division detected") # Error handling ... return default ... return a / b # Most common situation ... >>> divide(8, 2) 4.0 >>> divide(8, 0) zero division detected >>> divide(8, 0, default=0) zero division detected 0
divide()函数使用一个if语句来检查除法中的分母是否等于0。如果是这种情况,那么函数将一条消息打印到屏幕上,并返回存储在default中的值,该值最初被设置为None。否则,该函数将两个数相除并返回结果。上面的
divide()实现的问题是,它将异常情况放在了前面和中心,影响了代码的可读性,并使函数不清晰和难以理解。最后,这个函数是关于计算两个数的除法,而不是确保分母不是
0。因此,在这种情况下,LBYL 风格会分散开发人员的注意力,将他们的注意力吸引到异常情况上,而不是主流情况上。现在考虑如果你使用 EAFP 编码风格编写这个函数会是什么样子:
>>> def divide(a, b, default=None):
... try:
... return a / b # Most common situation
... except ZeroDivisionError: # Exceptional situation
... print("zero division detected") # Error handling
... return default
...
>>> divide(8, 2)
4.0
>>> divide(8, 0)
zero division detected
>>> divide(8, 0, default=0)
zero division detected
0
在这个新的divide()实现中,函数的主要计算在try子句中处于前端和中心,而异常情况在后台的except子句中被捕获和处理。
当您开始阅读这个实现时,您会立即注意到这个函数是关于计算两个数的除法的。您还会意识到,在异常情况下,第二个参数可以等于0,生成一个ZeroDivisionError异常,这个异常在except代码块中得到很好的处理。
避免竞态条件
当不同的程序、进程或线程同时访问给定的计算资源时,就会出现竞争条件。在这种情况下,程序、进程或线程竞相访问所需的资源。
出现竞争条件的另一种情况是给定的一组指令以不正确的顺序被处理。竞争条件会导致底层系统出现不可预测的问题。它们通常很难检测和调试。
Python 的词汇表页面直接提到了 LBYL 编码风格引入了竞态条件的风险:
在多线程环境中,LBYL 方法可能会在“寻找”和“跳跃”之间引入竞争条件。例如,如果另一个线程在测试之后、查找之前从
mapping中移除了key,那么代码if key in mapping: return mapping[key]可能会失败。这个问题可以通过锁或使用 EAFP 方法来解决。(来源)
竞争条件的风险不仅适用于多线程环境,也适用于 Python 编程中的其他常见情况。
例如,假设您已经设置了一个到正在使用的数据库的连接。现在,为了防止可能损坏数据库的问题,您需要检查连接是否处于活动状态:
connection = create_connection(db, host, user, password)
# Later in your code...
if connection.is_active():
# Update your database here...
connection.commit()
else:
# Handle the connection error here...
如果数据库主机在调用.is_active()和执行if代码块之间变得不可用,那么您的代码将会失败,因为主机不可用。
为了防止这种失败的风险,您可以使用 EAFP 编码风格,做一些类似这样的事情:
connection = create_connection(db, host, user, password)
# Later in your code...
try:
# Update your database here...
connection.commit()
except ConnectionError:
# Handle the connection error here...
这段代码继续尝试更新数据库,而不检查连接是否是活动的,这消除了检查和实际操作之间发生竞争的风险。如果出现ConnectionError,那么except代码块会适当地处理错误。这种方法会产生更健壮、更可靠的代码,将您从难以调试的竞争环境中解救出来。
提高代码的性能
在使用 LBYL 或 EAFP 时,性能是一个重要的考虑因素。如果您来自一种具有昂贵的异常处理过程的编程语言,那么这种担心是完全可以理解的。
然而,大多数 Python 实现都努力让异常处理成为一种廉价的操作。所以,当你写 Python 代码的时候,你不应该担心异常的代价。在许多情况下,异常比条件语句更快。
根据经验,如果您的代码处理许多错误和异常情况,那么 LBYL 可以更高效,因为检查许多条件比处理许多异常的成本更低。
相比之下,如果你的代码只面临一些错误,那么 EAFP 可能是最有效的策略。在这些情况下,EAFP 会比 LBYL 快,因为你不会处理很多异常。您只需执行所需的操作,而无需一直检查先决条件的额外开销。
作为使用 LBYL 或 EAFP 如何影响代码性能的一个例子,假设您需要创建一个函数来测量给定文本中字符的频率。所以,你最终写下了:
>>> def char_frequency_lbyl(text): ... counter = {} ... for char in text: ... if char in counter: ... counter[char] += 1 ... else: ... counter[char] = 1 ... return counter ...该函数将一段文本作为参数,并返回一个以字符为键的字典。每个对应的值代表该字符在文本中出现的次数。
注意:在本教程的提高代码性能部分,您会发现一个补充本部分的例子。
为了构建这个字典,
for循环遍历输入文本中的每个字符。在每次迭代中,条件语句检查当前字符是否已经在counter字典中。如果是这种情况,那么if代码块将字符的计数增加1。另一方面,如果该字符还不在
counter中,那么else代码块将该字符添加为一个键,并将其计数或频率设置为初始值1。最后,函数返回counter字典。如果您使用一些示例文本调用您的函数,那么您将得到如下所示的结果:
>>> sample_text = """
... Lorem ipsum dolor sit amet consectetur adipisicing elit. Maxime
... mollitia, molestiae quas vel sint commodi repudiandae consequuntur
... voluptatum laborum numquam blanditiis harum quisquam eius sed odit
... fugiat iusto fuga praesentium optio, eaque rerum! Provident similique
... accusantium nemo autem. Veritatis obcaecati tenetur iure eius earum
... ut molestias architecto voluptate aliquam nihil, eveniet aliquid
... culpa officia aut! Impedit sit sunt quaerat, odit, tenetur error,
... harum nesciunt ipsum debitis quas aliquid.
... """
>>> char_frequency_lbyl(sample_text)
{'\n': 9, 'L': 1, 'o': 24, 'r': 22, ..., 'V': 1, 'I': 1}
以sample_text作为参数调用char_frequency_lbyl()会返回一个包含字符计数对的字典。
如果你稍微思考一下寻找文本中字符频率的问题,那么你会意识到你需要考虑的字符数量是有限的。现在想想这个事实会如何影响你的解决方案。拥有有限数量的字符意味着你要做很多不必要的检查,看看当前字符是否已经在计数器中。
注意: Python 在 collections 模块中有一个专门的Counter类,用来处理计数对象的问题。查看 Python 的计数器:Python 计数对象的方式以获得更多细节。
一旦函数处理了一些文本,那么当您执行检查时,目标字符很可能已经在counter中了。最终,所有这些不必要的检查都会增加代码的性能成本。如果您正在处理大块文本,这一点尤其正确。
如何在代码中避免这种额外的开销?这时候 EAFP 就派上用场了。回到您的交互式会话,编写以下函数:
>>> def char_frequency_eafp(text): ... counter = {} ... for char in text: ... try: ... counter[char] += 1 ... except KeyError: ... counter[char] = 1 ... return counter ... >>> char_frequency_eafp(sample_text) {'\n': 9, 'L': 1, 'o': 24, 'r': 22, ..., 'V': 1, 'I': 1}这个函数的作用与前面例子中的
char_frequency_lbyl()相同。然而,这一次,该函数使用 EAFP 编码风格。现在,您可以对这两个函数运行一个快速的
timeit性能测试,以了解哪一个更快:
>>> import timeit
>>> sample_text *= 100
>>> eafp_time = min(
... timeit.repeat(
... stmt="char_frequency_eafp(sample_text)",
... number=1000,
... repeat=5,
... globals=globals(),
... )
... )
>>> lbyl_time = min(
... timeit.repeat(
... stmt="char_frequency_lbyl(sample_text)",
... number=1000,
... repeat=5,
... globals=globals(),
... )
... )
>>> print(f"LBYL is {lbyl_time / eafp_time:.3f} times slower than EAFP")
LBYL is 1.211 times slower than EAFP
在这个例子中,函数之间的性能差异很小。你可能会说这两种功能的表现是一样的。然而,随着文本大小的增长,函数之间的性能差异也成比例地增长,EAFP 实现最终比 LBYL 实现的效率略高。
从这个性能测试中得出的结论是,您需要事先考虑您要处理哪种问题。
你输入的数据大部分是正确的还是有效的?你只是在处理一些错误吗?就时间而言,你的先决条件代价大吗?如果你对这些问题的答案是是,那么请向 EAFP 倾斜。相比之下,如果你的数据很糟糕,你预计会发生很多错误,你的前提条件很轻,那么支持 LBYL。
总结:LBYL 对 EAFP
哇!您已经了解了很多关于 Python 的 LBYL 和 EAFP 编码风格。现在你知道这些风格是什么,它们的权衡是什么。要总结本节的主要主题和要点,请查看下表:
| 标准 | LBYL | EAFP |
|---|---|---|
| 支票数量 | 重复通常由 Python 提供的检查 | 仅运行一次 Python 提供的检查 |
| 可读性和清晰性 | 可读性和清晰性较差,因为异常情况似乎比目标操作本身更重要 | 增强了可读性,因为目标操作位于前端和中心,而异常情况被置于后台 |
| 竞争条件风险 | 意味着检查和目标操作之间存在竞争条件的风险 | 防止竞争情况的风险,因为操作运行时不做任何检查 |
| 代码性能 | 当检查几乎总是成功时性能较差,而当检查几乎总是失败时性能较好 | 当检查几乎总是成功时,性能较好;当检查几乎总是失败时,性能较差 |
既然您已经深入比较了 LBYL 和 EAFP,那么是时候了解两种编码风格的一些常见问题以及如何在您的代码中避免它们了。连同上表中总结的主题,这些问题可以帮助您决定在给定的情况下使用哪种风格。
LBYL 和 EAFP 的常见问题
当你使用 LBYL 风格编写代码时,你必须意识到你可能忽略了某些需要检查的条件。为了澄清这一点,回到将字符串值转换为整数的示例:
>>> value = "42" >>> if value.isdigit(): ... number = int(value) ... else: ... number = 0 ... >>> number 42显然,
.isdigit()支票满足了你的所有需求。但是,如果您必须处理一个表示负数的字符串,该怎么办呢?.isdigit()对你有用吗?使用有效的负数作为字符串运行上面的示例,并检查会发生什么情况:
>>> value = "-42"
>>> if value.isdigit():
... number = int(value)
... else:
... number = 0
...
>>> number
0
现在你得到的是0而不是预期的-42数。刚刚发生了什么?嗯,.isdigit()只检查从0到9的数字。它不检查负数。这种行为使得您的检查对于您的新需求来说是不完整的。你在检查前提条件时忽略了负数。
您也可以考虑使用.isnumeric(),但是这个方法也不会返回带有负值的True:
>>> value = "-42" >>> if value.isnumeric(): ... number = int(value) ... else: ... number = 0 ... >>> number 0这张支票不能满足你的需要。你需要尝试一些不同的东西。现在考虑如何防止在这个例子中遗漏必要检查的风险。是的,你可以使用 EAFP 编码风格:
>>> value = "-42"
>>> try:
... number = int(value)
... except ValueError:
... number = 0
...
>>> number
-42
酷!现在,您的代码按预期工作。它转换正值和负值。为什么?因为默认情况下,将字符串转换为整数所需的所有条件都隐式包含在对int()的调用中。
到目前为止,看起来 EAFP 是你所有问题的答案。然而,事实并非总是如此。这种风格也有它的缺点。特别是,不能运行有副作用的代码。
考虑以下示例,该示例将问候消息写入文本文件:
moments = ["morning", "afternoon", "evening"]
index = 3
with open("hello.txt", mode="w", encoding="utf-8") as hello:
try:
hello.write("Good\n") hello.write(f"{moments[index]}!") except IndexError:
pass
在本例中,您有一个表示一天中不同时刻的字符串列表。然后你用 with语句以写模式"w"打开hello.txt 文件。
try代码块包括对 .write() 的两次调用。第一个将问候语的开始部分写入目标文件。第二个调用通过从列表中检索一个时刻并将其写入文件来完成问候。
在第二次调用.write()期间,except语句捕获任何IndexError,后者执行索引操作以获得适当的参数。如果索引超出范围,就像示例中那样,那么您会得到一个IndexError,而except块会消除错误。然而,对.write()的第一次调用已经将"Good\n"写入了hello.txt文件,这最终导致了一种不期望的状态。
这种副作用在某些情况下可能很难恢复,所以您最好避免这样做。要解决此问题,您可以这样做:
moments = ["morning", "afternoon", "evening"]
index = 3
with open("hello.txt", mode="w", encoding="utf-8") as hello:
try:
moment = f"{moments[index]}!" except IndexError:
pass
else:
hello.write("Good\n") hello.write(moment)
这一次,try代码块只运行索引,也就是可以引发一个IndexError的操作。如果出现这样的错误,那么您只需在except代码块中忽略它,让文件为空。如果索引成功,那么在else代码块中向文件写入完整的问候。
继续用index = 0和index = 3测试这两个代码片段,看看你的hello.txt文件会发生什么。
当你在except语句中使用一个宽泛的异常类时,EAFP 的第二个陷阱就出现了。例如,如果您正在处理一段可能引发几种异常类型的代码,那么您可能会考虑在except语句中使用Exception类,或者更糟,根本不使用异常类。
为什么这种做法是一个问题?嗯, Exception 类是几乎所有 Python 内置异常的父类。所以,你几乎可以捕捉到代码中的任何东西。结论是,您不会清楚地知道在给定的时刻您正在处理哪个错误或异常。
在实践中,避免做这样的事情:
try:
do_something()
except Exception:
pass
显然,您的do_something()函数可以引发多种类型的异常。在所有情况下,您只需消除错误并继续执行您的程序。消除所有的错误,包括未知的错误,可能会导致以后意想不到的错误,这违反了 Python 的法则中的一个基本原则:错误永远不应该被忽略。
为了避免将来的麻烦,尽可能使用具体的异常。使用那些您有意识地期望代码引发的异常。记住你可以有几个except分支。例如,假设您已经测试了do_something()函数,并且您希望它引发ValueError和IndexError异常。在这种情况下,您可以这样做:
try:
do_something()
except ValueError:
# Handle the ValueError here...
except IndexError:
# Handle the IndexError here...
在这个例子中,拥有多个except分支允许您适当地处理每个预期的异常。这种构造还有一个优点,就是使您的代码更容易调试。为什么?因为如果do_something()引发意外异常,您的代码将立即失败。这样,您可以防止未知错误无声无息地传递。
EAFP vs LBYL 举例
到目前为止,您已经了解了什么是 LBYL 和 EAFP,它们是如何工作的,以及这两种编码风格的优缺点。在这一节中,您将更深入地了解何时使用这种或那种样式。为此,您将编写一些实际的例子。
在开始举例之前,这里有一个何时使用 LBYL 或 EAFP 的总结:
| 将 LBYL 用于 | 将 EAFP 用于 |
|---|---|
| 可能失败的操作 | 不太可能失败的操作 |
| 不可撤销的手术,以及可能有副作用的手术 | 输入和输出(IO)操作,主要是硬盘和网络操作 |
| 可以提前快速预防的常见异常情况 | 可以快速回滚的数据库操作 |
有了这个总结,您就可以开始使用 LBYL 和 EAFP 编写一些实际的例子,展示这两种编码风格在现实编程中的优缺点。
处理过多的错误或异常情况
如果你预计你的代码会遇到大量的错误和异常情况,那么考虑使用 LBYL 而不是 EAFP。在这种情况下,LBYL 会更安全,可能会有更好的表现。
例如,假设您想编写一个函数来计算一段文本中单词的频率。要做到这一点,你计划使用字典。键将保存单词,值将存储它们的计数或频率。
因为自然语言有太多可能的单词需要考虑,所以你的代码将会处理许多KeyError异常。尽管如此,您还是决定使用 EAFP 编码风格。您最终会得到以下函数:
>>> def word_frequency_eafp(text): ... counter = {} ... for word in text.split(): ... try: ... counter[word] += 1 ... except KeyError: ... counter[word] = 1 ... return counter ... >>> sample_text = """ ... Lorem ipsum dolor sit amet consectetur adipisicing elit. Maxime ... mollitia, molestiae quas vel sint commodi repudiandae consequuntur ... voluptatum laborum numquam blanditiis harum quisquam eius sed odit ... fugiat iusto fuga praesentium optio, eaque rerum! Provident similique ... accusantium nemo autem. Veritatis obcaecati tenetur iure eius earum ... ut molestias architecto voluptate aliquam nihil, eveniet aliquid ... culpa officia aut! Impedit sit sunt quaerat, odit, tenetur error, ... harum nesciunt ipsum debitis quas aliquid. ... """ >>> word_frequency_eafp(sample_text) {'Lorem': 1, 'ipsum': 2, 'dolor': 1, ..., 'aliquid.': 1}这个函数创建一个
counter字典来存储单词和它们的计数。for循环遍历输入文本中的单词。在try块中,您试图通过将1加到当前单词的上一个值来更新当前单词的计数。如果目标单词在counter中不作为关键字存在,那么这个操作会引发一个KeyError。
except语句捕获KeyError异常,并用值1初始化counter中丢失的键——一个单词。当您使用一些示例文本调用函数时,您会得到一个字典,其中单词作为键,计数作为值。就是这样!你解决了问题!
你的函数看起来不错!你用的是 EAFP 风格,而且很有效。但是,该函数可能比 LBYL 函数慢:
>>> def word_frequency_lbyl(text):
... counter = {}
... for word in text.split():
... if word in counter:
... counter[word] += 1
... else:
... counter[word] = 1
... return counter
...
>>> word_frequency_lbyl(sample_text)
{'Lorem': 1, 'ipsum': 2, 'dolor': 1, ..., 'aliquid.': 1}
在这个变体中,您使用一个条件语句来预先检查当前单词是否已经存在于counter字典中。如果是这种情况,那么您将计数增加1。否则,创建相应的键并将其值初始化为1。当您对示例文本运行该函数时,您会得到相同的字数对字典。
这个基于 LBYL 的实现与基于 EAFP 的实现获得相同的结果。但是,它可以有更好的性能。要确认这种可能性,请继续运行以下性能测试:
>>> import timeit >>> lbyl_time = min( ... timeit.repeat( ... stmt="word_frequency_lbyl(sample_text)", ... number=1000, ... repeat=5, ... globals=globals(), ... ) ... ) >>> eafp_time = min( ... timeit.repeat( ... stmt="word_frequency_eafp(sample_text)", ... number=1000, ... repeat=5, ... globals=globals(), ... ) ... ) >>> print(f"EAFP is {eafp_time / lbyl_time:.3f} times slower than LBYL") EAFP is 2.117 times slower than LBYLEAFP 并不总是你所有问题的最佳解决方案。在这个例子中,EAFP 比 LBYL 慢两倍多。
所以,如果错误和异常情况在你的代码中很常见,那就选择 LBYL 而不是 EAFP。许多条件语句可能比许多异常更快,因为在 Python 中检查条件仍然比处理异常成本更低。
检查对象的类型和属性
在 Python 中,检查对象的类型被广泛认为是一种反模式,应该尽可能避免。一些 Python 核心开发人员明确地将这种实践称为反模式,他们说:
[…]目前,Python 代码的一种常见反模式是检查接收到的参数的类型,以决定如何处理对象。
【这种编码模式是】“脆弱且对扩展封闭”(来源)。
使用类型检查反模式至少会影响 Python 编码的两个核心原则:
Python 通常依赖于对象的行为,而不是类型。例如,您应该有一个使用
.append()方法的函数。相反,你不应该有一个期待一个list参数的函数。为什么?因为将函数的行为绑定到参数的类型会牺牲鸭类型。考虑以下函数:
def add_users(username, users): if isinstance(users, list): users.append(username)这个功能工作正常。它接受用户名和用户列表,并将新用户名添加到列表的末尾。然而,这个函数没有利用 duck 类型,因为它依赖于其参数的类型,而不是所需的行为,后者有一个
.append()方法。例如,如果您决定使用一个
collections.deque()对象来存储您的users列表,那么如果您想让您的代码继续工作,您就必须修改这个函数。为了避免用类型检查牺牲鸭式键入,您可以使用 EAFP 编码风格:
def add_user(username, users): try: users.append(username) except AttributeError: pass
add_user()的实现不依赖于users的类型,而是依赖于它的.append()行为。有了这个新的实现,您可以立即开始使用一个deque对象来存储您的用户列表,或者您可以继续使用一个list对象。你不需要修改函数来保持你的代码工作。Python 通常通过直接调用对象的方法和访问对象的属性来与对象进行交互,而无需事先检查对象的类型。在这些情况下,EAFP 编码风格是正确的选择。
影响多态性和 duck 类型的一个实践是,在代码中访问一个对象之前,检查它是否具有某些属性。考虑下面的例子:
def get_user_roles(user): if hasattr(user, "roles"): return user.roles return None在这个例子中,
get_user_roles()使用 LBYL 编码风格来检查user对象是否有一个.roles属性。如果是这样,那么函数返回.roles的内容。否则,函数返回None。不用通过使用内置的
hasattr()函数来检查user是否有一个.roles属性,您应该直接用 EAFP 风格访问该属性:def get_user_roles(user): try: return user.roles except AttributeError: return None
get_user_roles()的这个变体更加明确、直接和简单。它比基于 LBYL 的变体更具 Pythonic 风格。最后,它也可以更有效,因为它不是通过调用hasattr()不断检查前提条件。使用文件和目录
管理文件系统上的文件和目录有时是 Python 应用程序和项目中的一项需求。当涉及到处理文件和目录时,很多事情都可能出错。
例如,假设您需要打开文件系统中的一个给定文件。如果你使用 LBYL 编码风格,那么你可以得到这样一段代码:
from pathlib import Path file_path = Path("/path/to/file.txt") if file_path.exists(): with file_path.open() as file: print(file.read()) else: print("file not found")如果您针对文件系统中的一个文件运行这段代码,那么您将在屏幕上打印出该文件的内容。所以,这段代码有效。然而,它有一个隐藏的问题。如果由于某种原因,您的文件在检查文件是否存在和尝试打开它之间被删除,那么文件打开操作将失败并出现错误,您的代码将崩溃。
你如何避免这种竞争情况?你可以使用 EAFP 编码风格,如下面的代码所示:
from pathlib import Path file_path = Path("/path/to/file.txt") try: with file_path.open() as file: print(file.read()) except IOError as e: print("file not found")你不是检查你是否能打开文件,而是试图打开它。如果这行得通,那就太好了!如果它不起作用,那么您可以捕获错误并适当地处理它。请注意,您不再冒陷入竞争状态的风险。你现在安全了。
结论
现在你知道 Python 有三思而后行 (LBYL)和请求原谅比请求许可更容易 (EAFP)的编码风格,这是处理代码中的错误和异常情况的一般策略。您还了解了这些编码风格是什么,以及如何在代码中使用它们。
在本教程中,您已经学习了:
- Python 的 LBYL 和 EAFP 编码风格的基础
- Python 中 LBYL vs EAFP 的利弊和利弊
- 决定何时使用 LBYL 或 EAFP 的关键
有了关于 Python 的 LBYL 和 EAFP 编码风格的知识,您现在就能够决定在处理代码中的错误和异常情况时使用哪种策略。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。*******
Python 中的列表和元组
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python 中的列表和元组
列表和元组可以说是 Python 最通用、最有用的数据类型。几乎在每一个重要的 Python 程序中都可以找到它们。
在本教程中,您将学到以下内容:您将了解列表和元组的重要特征。您将学习如何定义它们以及如何操作它们。完成后,您应该对在 Python 程序中何时以及如何使用这些对象类型有了很好的感觉。
参加测验:通过我们的交互式“Python 列表和元组”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
Python 列表
简而言之,列表是任意对象的集合,有点类似于许多其他编程语言中的数组,但是更加灵活。在 Python 中,通过将逗号分隔的对象序列放在方括号(
[])中来定义列表,如下所示:
>>> a = ['foo', 'bar', 'baz', 'qux']
>>> print(a)
['foo', 'bar', 'baz', 'qux']
>>> a
['foo', 'bar', 'baz', 'qux']
Python 列表的重要特征如下:
- 列表是有序的。
- 列表可以包含任意对象。
- 列表元素可以通过索引来访问。
- 列表可以嵌套到任意深度。
- 列表是可变的。
- 列表是动态的。
下面将更详细地研究这些特性。
列表已排序
列表不仅仅是对象的集合。它是对象的有序集合。定义列表时指定元素的顺序是该列表的固有特征,并在该列表的生存期内保持不变。(在下一个字典教程中,您将看到一个无序的 Python 数据类型。)
具有不同顺序的相同元素的列表是不同的:
>>> a = ['foo', 'bar', 'baz', 'qux'] >>> b = ['baz', 'qux', 'bar', 'foo'] >>> a == b False >>> a is b False >>> [1, 2, 3, 4] == [4, 1, 3, 2] False列表可以包含任意对象
列表可以包含任何种类的对象。列表的元素可以都是相同的类型:
>>> a = [2, 4, 6, 8]
>>> a
[2, 4, 6, 8]
或者元素可以是不同的类型:
>>> a = [21.42, 'foobar', 3, 4, 'bark', False, 3.14159] >>> a [21.42, 'foobar', 3, 4, 'bark', False, 3.14159]列表甚至可以包含复杂的对象,如函数、类和模块,您将在接下来的教程中了解这些内容:
>>> int
<class 'int'>
>>> len
<built-in function len>
>>> def foo():
... pass
...
>>> foo
<function foo at 0x035B9030>
>>> import math
>>> math
<module 'math' (built-in)>
>>> a = [int, len, foo, math]
>>> a
[<class 'int'>, <built-in function len>, <function foo at 0x02CA2618>,
<module 'math' (built-in)>]
列表可以包含任意数量的对象,从零到计算机内存允许的数量:
>>> a = [] >>> a [] >>> a = [ 'foo' ] >>> a ['foo'] >>> a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ... 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, ... 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, ... 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, ... 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100] >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100](只有一个对象的列表有时被称为单例列表。)
列表对象不必是唯一的。给定对象可以在列表中出现多次:
>>> a = ['bark', 'meow', 'woof', 'bark', 'cheep', 'bark']
>>> a
['bark', 'meow', 'woof', 'bark', 'cheep', 'bark']
列表元素可以通过索引来访问
列表中的单个元素可以使用方括号中的索引来访问。这完全类似于访问字符串中的单个字符。列表索引和字符串一样,是从零开始的。
考虑以下列表:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
a中元素的索引如下所示:
List Indices 下面是访问
a的一些元素的 Python 代码:

>>> a[0]
'foo'
>>> a[2]
'baz'
>>> a[5]
'corge'
几乎所有关于字符串索引的工作都类似于列表。例如,负列表索引从列表末尾开始计数:
>>> a[-1] 'corge' >>> a[-2] 'quux' >>> a[-5] 'bar'切片也可以。如果
a是一个列表,表达式a[m:n]返回从索引m到索引n的a部分,但不包括索引【】:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a[2:5]
['baz', 'qux', 'quux']
字符串切片的其他特性同样适用于列表切片:
-
可以指定正索引和负索引:
>>> a[-5:-2] ['bar', 'baz', 'qux'] >>> a[1:4] ['bar', 'baz', 'qux'] >>> a[-5:-2] == a[1:4] True`>>> print(a[:4], a[0:4]) ['foo', 'bar', 'baz', 'qux'] ['foo', 'bar', 'baz', 'qux'] >>> print(a[2:], a[2:len(a)]) ['baz', 'qux', 'quux', 'corge'] ['baz', 'qux', 'quux', 'corge'] >>> a[:4] + a[4:] ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a[:4] + a[4:] == a True` -
您可以指定步幅,可以是正的,也可以是负的:
>>> a[0:6:2] ['foo', 'baz', 'quux'] >>> a[1:6:2] ['bar', 'qux', 'corge'] >>> a[6:0:-2] ['corge', 'qux', 'bar']`>>> a[::-1] ['corge', 'quux', 'qux', 'baz', 'bar', 'foo']` -
[:]语法适用于列表。但是,这个操作如何处理列表和如何处理字符串之间有一个重要的区别。如果
s是一个字符串,s[:]返回对同一对象的引用:>>> s = 'foobar' >>> s[:] 'foobar' >>> s[:] is s True`相反,如果
a是一个列表,a[:]返回一个新对象,它是a的副本:>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a[:] ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a[:] is a False`
几个 Python 运算符和内置函数也可以以类似于字符串的方式用于列表:
-
in和not in操作符:>>> a ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> 'qux' in a True >>> 'thud' not in a True`>>> a ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a + ['grault', 'garply'] ['foo', 'bar', 'baz', 'qux', 'quux', 'corge', 'grault', 'garply'] >>> a * 2 ['foo', 'bar', 'baz', 'qux', 'quux', 'corge', 'foo', 'bar', 'baz', 'qux', 'quux', 'corge']` -
len()、min()、max()功能:>>> a ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> len(a) 6 >>> min(a) 'bar' >>> max(a) 'qux'`
>>> ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'][2]
'baz'
>>> ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'][::-1]
['corge', 'quux', 'qux', 'baz', 'bar', 'foo']
>>> 'quux' in ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
True
>>> ['foo', 'bar', 'baz'] + ['qux', 'quux', 'corge']
['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> len(['foo', 'bar', 'baz', 'qux', 'quux', 'corge'][::-1])
6
就此而言,您可以对字符串文字做同样的事情:
>>> 'If Comrade Napoleon says it, it must be right.'[::-1] '.thgir eb tsum ti ,ti syas noelopaN edarmoC fI'列表可以嵌套
您已经看到列表中的元素可以是任何类型的对象。这包括另一份名单。一个列表可以包含子列表,子列表又可以包含子列表本身,依此类推,直到任意深度。
考虑这个(公认是人为的)例子:
>>> x = ['a', ['bb', ['ccc', 'ddd'], 'ee', 'ff'], 'g', ['hh', 'ii'], 'j']
>>> x
['a', ['bb', ['ccc', 'ddd'], 'ee', 'ff'], 'g', ['hh', 'ii'], 'j']
x引用的对象结构如下图所示:
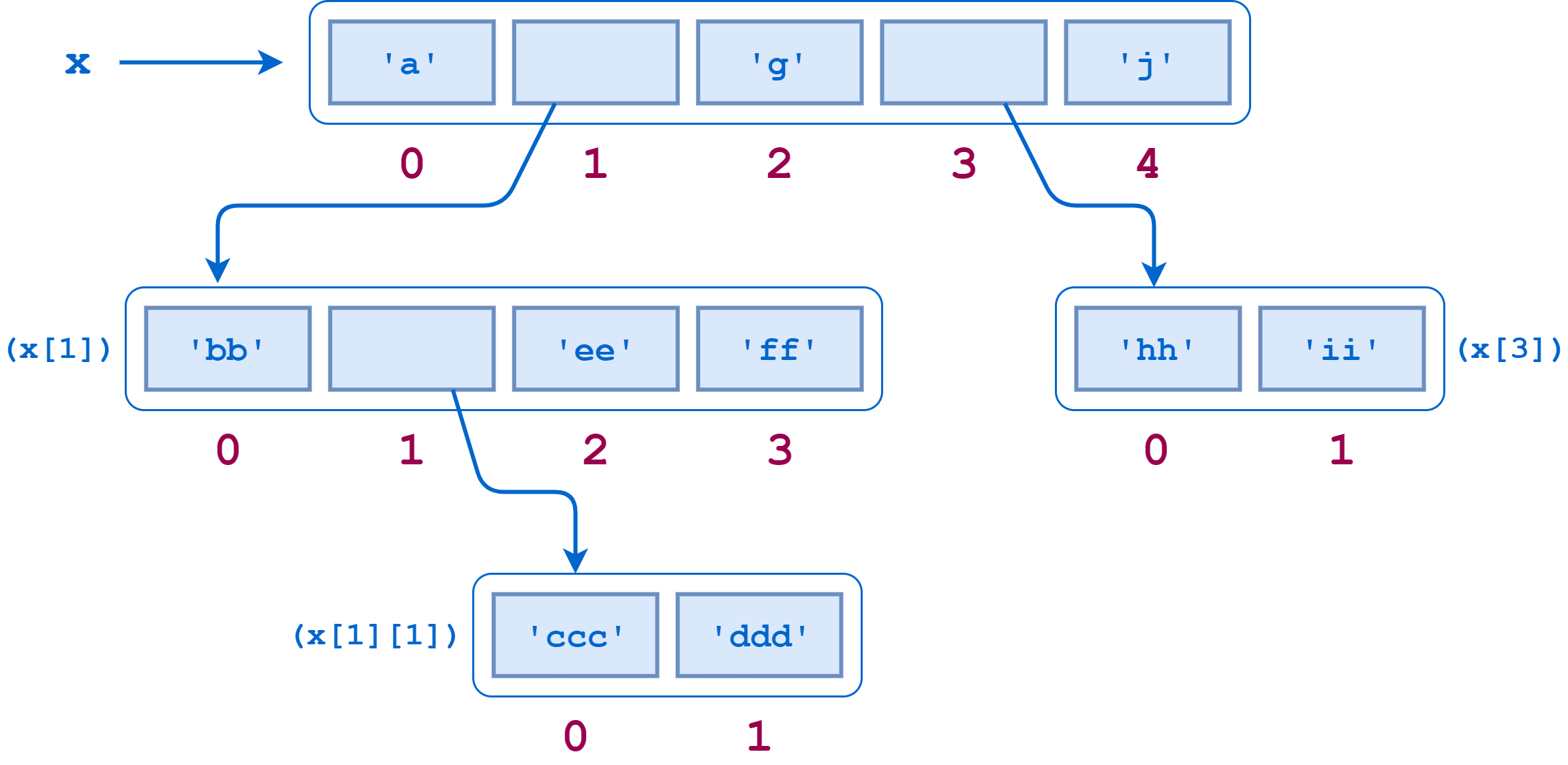
x[0]、x[2]和x[4]是字符串,每个都是一个字符长:
>>> print(x[0], x[2], x[4]) a g j但是
x[1]和x[3]是子列表:
>>> x[1]
['bb', ['ccc', 'ddd'], 'ee', 'ff']
>>> x[3]
['hh', 'ii']
要访问子列表中的项目,只需附加一个额外的索引:
>>> x[1] ['bb', ['ccc', 'ddd'], 'ee', 'ff'] >>> x[1][0] 'bb' >>> x[1][1] ['ccc', 'ddd'] >>> x[1][2] 'ee' >>> x[1][3] 'ff' >>> x[3] ['hh', 'ii'] >>> print(x[3][0], x[3][1]) hh ii
x[1][1]是另一个子列表,所以再添加一个索引就可以访问它的元素:
>>> x[1][1]
['ccc', 'ddd']
>>> print(x[1][1][0], x[1][1][1])
ccc ddd
用这种方式嵌套列表的深度和复杂度没有限制,除非你的计算机内存不够大。
所有关于索引和切片的常用语法也适用于子列表:
>>> x[1][1][-1] 'ddd' >>> x[1][1:3] [['ccc', 'ddd'], 'ee'] >>> x[3][::-1] ['ii', 'hh']然而,要注意操作符和函数只适用于你指定的层次上的列表,而不是递归。考虑当您使用
len()查询x的长度时会发生什么:
>>> x
['a', ['bb', ['ccc', 'ddd'], 'ee', 'ff'], 'g', ['hh', 'ii'], 'j']
>>> len(x)
5
>>> x[0]
'a'
>>> x[1]
['bb', ['ccc', 'ddd'], 'ee', 'ff']
>>> x[2]
'g'
>>> x[3]
['hh', 'ii']
>>> x[4]
'j'
只有五个元素——三个字符串和两个子列表。子列表中的单个元素不计入x的长度。
使用in操作符时,您会遇到类似的情况:
>>> 'ddd' in x False >>> 'ddd' in x[1] False >>> 'ddd' in x[1][1] True
'ddd'不是x或x[1]中的元素之一。它只是子列表x[1][1]中的一个直接元素。子列表中的单个元素不能算作父列表中的元素。列表是可变的
到目前为止,您遇到的大多数数据类型都是原子类型。例如,整数或浮点对象是不能再进一步分解的基本单元。这些类型是不可变的,这意味着它们一旦被赋值就不能被改变。想改变一个整数的值没有太大意义。如果你想要一个不同的整数,你只需要分配一个不同的。
相比之下,字符串类型是一种复合类型。字符串可以简化为更小的部分,即组成字符。考虑改变字符串中的字符可能是有意义的。但是你不能。在 Python 中,字符串也是不可变的。
列表是您遇到的第一个可变数据类型。一旦创建了列表,就可以随意添加、删除、移动和移动元素。Python 提供了多种修改列表的方法。
修改单个列表值
列表中的单个值可以通过索引和简单赋值来替换:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a
['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a[2] = 10
>>> a[-1] = 20
>>> a
['foo', 'bar', 10, 'qux', 'quux', 20]
您可能还记得教程中的字符串和 Python 中的字符数据,您不能用字符串来做这件事:
>>> s = 'foobarbaz' >>> s[2] = 'x' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment使用
del命令可以删除列表项:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> del a[3]
>>> a
['foo', 'bar', 'baz', 'quux', 'corge']
修改多个列表值
如果你想一次改变一个列表中几个连续的元素怎么办?Python 允许使用切片赋值来实现这一点,其语法如下:
a[m:n] = <iterable>
现在,再次把 iterable 看作一个列表。该赋值用<iterable>替换a的指定片:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a[1:4] ['bar', 'baz', 'qux'] >>> a[1:4] = [1.1, 2.2, 3.3, 4.4, 5.5] >>> a ['foo', 1.1, 2.2, 3.3, 4.4, 5.5, 'quux', 'corge'] >>> a[1:6] [1.1, 2.2, 3.3, 4.4, 5.5] >>> a[1:6] = ['Bark!'] >>> a ['foo', 'Bark!', 'quux', 'corge']插入的元素数不必等于替换的元素数。Python 只是根据需要增加或缩小列表。
您可以插入多个元素来代替单个元素,只需使用仅表示一个元素的切片即可:
>>> a = [1, 2, 3]
>>> a[1:2] = [2.1, 2.2, 2.3]
>>> a
[1, 2.1, 2.2, 2.3, 3]
请注意,这不同于用列表替换单个元素:
>>> a = [1, 2, 3] >>> a[1] = [2.1, 2.2, 2.3] >>> a [1, [2.1, 2.2, 2.3], 3]您也可以在列表中插入元素,而不删除任何内容。只需在所需的索引处指定一个形式为
[n:n](零长度切片)的切片:
>>> a = [1, 2, 7, 8]
>>> a[2:2] = [3, 4, 5, 6]
>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
通过将适当的片分配给空列表,可以删除列表中间的多个元素。您也可以对同一个切片使用del语句:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a[1:5] = [] >>> a ['foo', 'corge'] >>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> del a[1:5] >>> a ['foo', 'corge']将项目添加到列表中
使用
+串联运算符或+=增强赋值运算符,可以将附加项添加到列表的开头或结尾:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a += ['grault', 'garply']
>>> a
['foo', 'bar', 'baz', 'qux', 'quux', 'corge', 'grault', 'garply']
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a = [10, 20] + a
>>> a
[10, 20, 'foo', 'bar', 'baz', 'qux', 'quux', 'corge']
请注意,一个列表必须与另一个列表连接在一起,因此如果您只想添加一个元素,则需要将其指定为单一列表:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a += 20 Traceback (most recent call last): File "<pyshell#58>", line 1, in <module> a += 20 TypeError: 'int' object is not iterable >>> a += [20] >>> a ['foo', 'bar', 'baz', 'qux', 'quux', 'corge', 20]注意:从技术上讲,说一个列表必须与另一个列表连接是不正确的。更准确地说,列表必须与可迭代的对象连接在一起。当然,列表是可迭代的,所以可以将一个列表与另一个列表连接起来。
字符串也是可迭代的。但是请注意当您将一个字符串连接到一个列表时会发生什么:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux']
>>> a += 'corge'
>>> a
['foo', 'bar', 'baz', 'qux', 'quux', 'c', 'o', 'r', 'g', 'e']
这个结果可能不太符合你的预期。当遍历一个字符串时,结果是其组成字符的列表。在上面的例子中,连接到列表a上的是字符串'corge'中的字符列表。
如果你真的想把单个字符串'corge'添加到列表的末尾,你需要把它指定为一个单例列表:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux'] >>> a += ['corge'] >>> a ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']如果这看起来很神秘,不要太担心。在关于明确迭代的教程中,您将了解到可迭代的来龙去脉。
修改列表的方法
最后,Python 提供了几个可以用来修改列表的内置方法。这些方法的详细信息如下。
注意:你在上一个教程中看到的字符串方法并没有直接修改目标字符串。这是因为字符串是不可变的。相反,字符串方法返回一个新的字符串对象,该对象按照方法的指示进行修改。它们保持原来的目标字符串不变:
>>> s = 'foobar'
>>> t = s.upper()
>>> print(s, t)
foobar FOOBAR
列表方法不同。因为列表是可变的,所以这里显示的列表方法就地修改目标列表。
a.append(<obj>)
将对象追加到列表中。
a.append(<obj>) 将对象<obj>追加到列表a的末尾:
>>> a = ['a', 'b'] >>> a.append(123) >>> a ['a', 'b', 123]记住,列表方法就地修改目标列表。它们不会返回新的列表:
>>> a = ['a', 'b']
>>> x = a.append(123)
>>> print(x)
None
>>> a
['a', 'b', 123]
请记住,当使用+操作符连接一个列表时,如果目标操作数是可迭代的,那么它的元素将被分开并单独追加到列表中:
>>> a = ['a', 'b'] >>> a + [1, 2, 3] ['a', 'b', 1, 2, 3]
.append()方法不是那样工作的!如果用.append()将一个 iterable 追加到一个列表中,它将作为单个对象添加:
>>> a = ['a', 'b']
>>> a.append([1, 2, 3])
>>> a
['a', 'b', [1, 2, 3]]
因此,使用.append(),您可以将一个字符串作为单个实体追加:
>>> a = ['a', 'b'] >>> a.append('foo') >>> a ['a', 'b', 'foo']
a.extend(<iterable>)用 iterable 中的对象扩展列表。
是的,这大概就是你想的那样。
.extend()也添加到列表的末尾,但是参数应该是可迭代的。<iterable>中的项目是单独添加的:
>>> a = ['a', 'b']
>>> a.extend([1, 2, 3])
>>> a
['a', 'b', 1, 2, 3]
换句话说,.extend()的行为类似于+操作符。更准确地说,因为它就地修改了列表,所以它的行为类似于+=操作符:
>>> a = ['a', 'b'] >>> a += [1, 2, 3] >>> a ['a', 'b', 1, 2, 3]
a.insert(<index>, <obj>)将对象插入列表。
a.insert(<index>, <obj>)在指定的<index>处将对象<obj>插入到列表a中。在方法调用之后,a[<index>]是<obj>,剩余的列表元素被推到右边:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a.insert(3, 3.14159)
>>> a[3]
3.14159
>>> a
['foo', 'bar', 'baz', 3.14159, 'qux', 'quux', 'corge']
a.remove(<obj>)
从列表中移除对象。
a.remove(<obj>)从列表a中删除对象<obj>。如果<obj>不在a中,则会引发一个异常:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a.remove('baz') >>> a ['foo', 'bar', 'qux', 'quux', 'corge'] >>> a.remove('Bark!') Traceback (most recent call last): File "<pyshell#13>", line 1, in <module> a.remove('Bark!') ValueError: list.remove(x): x not in list
a.pop(index=-1)从列表中移除元素。
该方法与
.remove()在两个方面不同:
- 您指定要移除的项目的索引,而不是对象本身。
- 该方法返回值:被移除的项。
a.pop()删除列表中的最后一项:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a.pop()
'corge'
>>> a
['foo', 'bar', 'baz', 'qux', 'quux']
>>> a.pop()
'quux'
>>> a
['foo', 'bar', 'baz', 'qux']
如果指定了可选的<index>参数,则移除并返回该索引处的项目。<index>可能是负数,如字符串和列表索引:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a.pop(1) 'bar' >>> a ['foo', 'baz', 'qux', 'quux', 'corge'] >>> a.pop(-3) 'qux' >>> a ['foo', 'baz', 'quux', 'corge']
<index>默认为-1,所以a.pop(-1)相当于a.pop()。列表是动态的
本教程从 Python 列表的六个定义特征开始。最后一点是列表是动态的。在上面的章节中,您已经看到了许多这样的例子。当项目添加到列表中时,它会根据需要增长:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge']
>>> a[2:2] = [1, 2, 3]
>>> a += [3.14159]
>>> a
['foo', 'bar', 1, 2, 3, 'baz', 'qux', 'quux', 'corge', 3.14159]
类似地,列表会缩小以适应项目的移除:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> a[2:3] = [] >>> del a[0] >>> a ['bar', 'qux', 'quux', 'corge']python 元组
Python 提供了另一种类型,即有序的对象集合,称为元组。
发音因你问的人而异。有些人把它发音为“too-ple”(与“Mott the Hoople”押韵),其他人则发音为“tup-ple”(与“supple”押韵)。我倾向于后者,因为它可能与“五重”、“六重”、“八重”等等起源相同,而且我认识的每个人都把后者发音为与“柔软”押韵。
定义和使用元组
元组在所有方面都与列表相同,除了以下属性:
- 元组是通过将元素括在圆括号(
())而不是方括号([])中来定义的。- 元组是不可变的。
下面是一个简短的示例,展示了元组定义、索引和切片:
>>> t = ('foo', 'bar', 'baz', 'qux', 'quux', 'corge')
>>> t
('foo', 'bar', 'baz', 'qux', 'quux', 'corge')
>>> t[0]
'foo'
>>> t[-1]
'corge'
>>> t[1::2]
('bar', 'qux', 'corge')
不要害怕!我们最喜欢的字符串和列表反转机制也适用于元组:
>>> t[::-1] ('corge', 'quux', 'qux', 'baz', 'bar', 'foo')注意:即使元组是用括号定义的,你还是要用方括号对元组进行索引和切片,就像对字符串和列表一样。
你所了解的关于列表的一切——它们是有序的,它们可以包含任意对象,它们可以被索引和切片,它们可以被嵌套——对元组也是如此。但是它们不能被修改:
>>> t = ('foo', 'bar', 'baz', 'qux', 'quux', 'corge')
>>> t[2] = 'Bark!'
Traceback (most recent call last):
File "<pyshell#65>", line 1, in <module>
t[2] = 'Bark!'
TypeError: 'tuple' object does not support item assignment
为什么要用元组而不是列表?
-
当操作一个元组时,程序的执行速度比操作等价列表时要快。(当列表或元组很小时,这可能不会被注意到。)
-
有时候你不希望数据被修改。如果集合中的值在程序的生命周期中保持不变,使用元组而不是列表可以防止意外修改。
-
您将很快遇到另一种 Python 数据类型,称为 dictionary,它需要一个不可变类型的值作为其组件之一。元组可以用于此目的,而列表则不能。
在 Python REPL 会话中,您可以同时显示多个对象的值,方法是在>>>提示符下直接输入这些值,用逗号分隔:
>>> a = 'foo' >>> b = 42 >>> a, 3.14159, b ('foo', 3.14159, 42)Python 在括号中显示响应,因为它隐式地将输入解释为元组。
关于元组定义,有一个特性您应该知道。当定义一个空元组,或者一个有两个或更多元素的元组时,没有歧义。Python 知道您正在定义一个元组:
>>> t = ()
>>> type(t)
<class 'tuple'>
>>> t = (1, 2) >>> type(t) <class 'tuple'> >>> t = (1, 2, 3, 4, 5) >>> type(t) <class 'tuple'>但是当你试图用一个条目定义一个元组时会发生什么呢:
>>> t = (2)
>>> type(t)
<class 'int'>
Doh!由于圆括号也用于定义表达式中的运算符优先级,Python 将表达式(2)简单地作为整数2进行计算,并创建一个int对象。要告诉 Python 您确实想要定义一个单例元组,请在右括号前包含一个尾随逗号(,):
>>> t = (2,) >>> type(t) <class 'tuple'> >>> t[0] 2 >>> t[-1] 2你可能不需要经常定义一个单元组,但是必须有一种方法。
当您显示单元组时,Python 包含了逗号,以提醒您这是一个元组:
>>> print(t)
(2,)
元组分配、打包和解包
正如您在上面已经看到的,包含几个项目的文字元组可以分配给单个对象:
>>> t = ('foo', 'bar', 'baz', 'qux')当这种情况发生时,就好像元组中的项目已经被“打包”到对象中:
Tuple Packing
>>> t
('foo', 'bar', 'baz', 'qux')
>>> t[0]
'foo'
>>> t[-1]
'qux'
如果该“打包”对象随后被分配给新的元组,则各个项被“解包”到元组中的对象中:

>>> (s1, s2, s3, s4) = t >>> s1 'foo' >>> s2 'bar' >>> s3 'baz' >>> s4 'qux'解包时,左侧变量的数量必须与元组中值的数量相匹配:
>>> (s1, s2, s3) = t
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
(s1, s2, s3) = t
ValueError: too many values to unpack (expected 3)
>>> (s1, s2, s3, s4, s5) = t
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
(s1, s2, s3, s4, s5) = t
ValueError: not enough values to unpack (expected 5, got 4)
打包和解包可以合并到一个语句中进行复合赋值:
>>> (s1, s2, s3, s4) = ('foo', 'bar', 'baz', 'qux') >>> s1 'foo' >>> s2 'bar' >>> s3 'baz' >>> s4 'qux'同样,赋值左边元组中元素的数量必须等于右边的数量:
>>> (s1, s2, s3, s4, s5) = ('foo', 'bar', 'baz', 'qux')
Traceback (most recent call last):
File "<pyshell#63>", line 1, in <module>
(s1, s2, s3, s4, s5) = ('foo', 'bar', 'baz', 'qux')
ValueError: not enough values to unpack (expected 5, got 4)
在像这样的赋值和少数其他情况下,Python 允许省略通常用于表示元组的括号:
>>> t = 1, 2, 3 >>> t (1, 2, 3) >>> x1, x2, x3 = t >>> x1, x2, x3 (1, 2, 3) >>> x1, x2, x3 = 4, 5, 6 >>> x1, x2, x3 (4, 5, 6) >>> t = 2, >>> t (2,)无论是否包含括号都是一样的,所以如果您对是否需要它们有任何疑问,请继续包含它们。
元组赋值考虑到了一点奇怪的 Python 习惯。在编程时,您经常需要交换两个变量的值。在大多数编程语言中,有必要在交换发生时将其中一个值存储在临时变量中,如下所示:
>>> a = 'foo'
>>> b = 'bar'
>>> a, b
('foo', 'bar')
>>># We need to define a temp variable to accomplish the swap.
>>> temp = a
>>> a = b
>>> b = temp
>>> a, b
('bar', 'foo')
在 Python 中,交换可以通过一个元组赋值来完成:
>>> a = 'foo' >>> b = 'bar' >>> a, b ('foo', 'bar') >>># Magic time! >>> a, b = b, a >>> a, b ('bar', 'foo')任何曾经不得不使用临时变量交换值的人都知道,能够在 Python 中这样做是现代技术成就的顶峰。再也没有比这更好的了。
结论
本教程涵盖了 Python 列表和元组的基本属性,以及如何操作它们。您将在 Python 编程中广泛使用这些工具。
列表的主要特征之一是它是有序的。列表中元素的顺序是该列表的固有属性,不会改变,除非列表本身被修改。(元组也是一样,当然除了不能修改。)
下一篇教程将向您介绍 Python 字典:一种无序的复合数据类型。请继续阅读!
参加测验:通过我们的交互式“Python 列表和元组”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Strings in PythonLists and Tuples in PythonDictionaries in Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python 中的列表和元组*********
Python 日志记录:源代码漫游
Python
logging包是一个轻量级但可扩展的包,用于更好地跟踪您自己的代码做了什么。使用它比仅仅用多余的print()调用使代码杂乱无章要灵活得多。然而,Python 的
logging包在某些地方可能很复杂。处理程序、记录器、级别、名称空间、过滤器:跟踪所有这些部分以及它们如何交互并不容易。在你对
logging的理解中,一个解决细节的方法是查看它的 CPython 源代码。logging背后的 Python 代码简洁且模块化,通读它可以帮助你获得那个啊哈时刻。本文旨在补充日志记录 HOWTO 文档以及 Python 中的日志记录,这是一个关于如何使用该包的演练。
在本文结束时,你会熟悉下面的:
logging级别及其工作方式logging中线程安全与进程安全的对比- 从面向对象的角度看
logging的设计- 在库和应用程序中登录
- 使用
logging的最佳实践和设计模式在很大程度上,我们将逐行深入 Python 的
logging包中的核心模块,以便构建一幅它是如何布局的画面。免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
如何跟进
因为
logging源代码是本文的核心,所以您可以假设任何代码块或链接都基于 Python 3.7 CPython 存储库中的特定提交,即提交d730719。您可以在 CPython 源代码的Lib/目录中找到logging包本身。在
logging包中,大部分繁重的工作发生在logging/__init__.py中,这是您在这里花费时间最多的文件:cpython/ │ ├── Lib/ │ ├── logging/ │ │ ├── __init__.py │ │ ├── config.py │ │ └── handlers.py │ ├── ... ├── Modules/ ├── Include/ ... ... [truncated]就这样,让我们开始吧。
准备工作
在我们进入重量级之前,
__init__.py的前一百行介绍了一些微妙但重要的概念。预备#1:等级只是一个
int!像
logging.INFO或logging.DEBUG这样的对象可能看起来有点不透明。这些内部变量是什么,它们是如何定义的?事实上,Python 的
logging中的大写常量只是整数,形成了一个类似枚举的数值级别集合:CRITICAL = 50 FATAL = CRITICAL ERROR = 40 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0为什么不直接用琴弦
"INFO"或者"DEBUG"?级别是int常量,允许简单、明确地比较一个级别和另一个级别。它们被命名也是为了赋予它们语义。说一条消息的严重性为 50 可能不会马上清楚,但是说它的级别为CRITICAL会让您知道您的程序中有一个闪烁的红灯。现在,从技术上来说,你可以在一些地方只通过一个级别的
str形式,比如logger.setLevel("DEBUG")。在内部,这将调用_checkLevel(),它最终对相应的int进行dict查找:_nameToLevel = { 'CRITICAL': CRITICAL, 'FATAL': FATAL, 'ERROR': ERROR, 'WARN': WARNING, 'WARNING': WARNING, 'INFO': INFO, 'DEBUG': DEBUG, 'NOTSET': NOTSET, } def _checkLevel(level): if isinstance(level, int): rv = level elif str(level) == level: if level not in _nameToLevel: raise ValueError("Unknown level: %r" % level) rv = _nameToLevel[level] else: raise TypeError("Level not an integer or a valid string: %r" % level) return rv你更喜欢哪个?我对此没有太多的看法,但值得注意的是,
logging的医生一直使用logging.DEBUG的形式,而不是"DEBUG"或10。此外,传递str表单在 Python 2 中不是一个选项,一些logging方法如logger.isEnabledFor()将只接受int,而不是它的str表亲。预备#2:日志是线程安全的,但不是进程安全的
往下几行,你会发现下面的短代码块,它对整个包来说是非常关键的:
import threading _lock = threading.RLock() def _acquireLock(): if _lock: _lock.acquire() def _releaseLock(): if _lock: _lock.release()
_lock对象是一个重入锁,它位于logging/__init__.py模块的全局名称空间中。它使得整个logging包中的几乎每个对象和操作都是线程安全的,使得线程能够在没有竞争条件威胁的情况下进行读写操作。您可以在模块源代码中看到,_acquireLock()和_releaseLock()对于模块及其类来说是无处不在的。但是,这里有些东西没有考虑到:过程安全呢?简单的回答是
logging模块是而不是进程安全的。这并不是logging的固有错误——一般来说,如果没有程序员的积极努力,两个进程无法写入同一个文件。这意味着在使用像涉及多重处理的
logging.FileHandler这样的类之前,你要小心。如果两个进程想要同时读写同一个底层文件,那么在长时间运行的例程中,您可能会遇到一个令人讨厌的 bug。如果你想绕过这个限制,在官方的伐木食谱中有一个详细的食谱。因为这需要相当多的设置,一个替代方案是让每个进程根据其进程 ID 记录到一个单独的文件中,您可以使用
os.getpid()来获取该文件。包架构:日志的 MRO
现在我们已经介绍了一些初步的设置代码,让我们从更高的层面来看看
logging是如何布局的。logging包使用了健康剂量的 OOP 和遗传。下面是包中一些最重要的类的方法解析顺序(MRO)的局部视图:object │ ├── LogRecord ├── Filterer │ ├── Logger │ │ └── RootLogger │ └── Handler │ ├── StreamHandler │ └── NullHandler ├── Filter └── Manager上面的树形图没有涵盖模块中的所有类,只是那些最值得强调的类。
注意:你可以使用 dunder 属性
logging.StreamHandler.__mro__来查看继承链。MRO 的权威指南可以在 Python 2 文档中找到,尽管它也适用于 Python 3。这一连串的类通常是混乱的来源之一,因为有很多正在进行中,而且都是术语。
Filter对Filterer?Logger对Handler?跟踪每一件事都很有挑战性,更不用说想象它们是如何组合在一起的了。一张图片胜过千言万语,所以这里有一个场景图,其中一个日志记录器和两个处理程序一起编写一个级别为logging.INFO的日志消息:
Flow of logging objects (Image: Real Python) 在 Python 代码中,上面的所有内容看起来都像这样:
import logging import sys logger = logging.getLogger("pylog") logger.setLevel(logging.DEBUG) h1 = logging.FileHandler(filename="/tmp/records.log") h1.setLevel(logging.INFO) h2 = logging.StreamHandler(sys.stderr) h2.setLevel(logging.ERROR) logger.addHandler(h1) logger.addHandler(h2) logger.info("testing %d.. %d.. %d..", 1, 2, 3)在日志记录指南中有一个更详细的流程图。上面显示的是一个简化的场景。
您的代码只定义了一个
Logger实例logger,以及两个Handler实例h1和h2。当您调用
logger.info("testing %d.. %d.. %d..", 1, 2, 3)时,logger对象充当过滤器,因为它也有一个关联的level。只有当消息级别足够严重时,记录器才会对消息做任何事情。因为记录器具有级别DEBUG,并且消息携带更高的INFO级别,所以它获得继续前进的许可。在内部,
logger调用logger.makeRecord()将消息字符串"testing %d.. %d.. %d.."及其参数(1, 2, 3)放入一个真正的LogRecord的类实例中,该实例只是消息及其元数据的容器。
logger对象四处寻找它的处理程序(Handler的实例),这些处理程序可能直接绑定到logger本身或者它的父对象(这个概念我们稍后会谈到)。在本例中,它找到了两个处理程序:
- 一个级别为
INFO,在/tmp/records.log将日志数据转储到一个文件中- 一个写至
sys.stderr但仅当输入消息处于级别ERROR或更高时此时,又一轮测试开始了。因为
LogRecord和它的消息只携带级别INFO,所以记录被写入处理程序 1(绿色箭头),而不是处理程序 2 的stderr流(红色箭头)。对于处理程序来说,将LogRecord写到它们的流中被称为发射 it,这是在它们的.emit()中捕获的。接下来,让我们从上面进一步解剖一切。
LogRecord类什么是
LogRecord?当您记录一个消息时,LogRecord类的一个实例就是您发送来记录的对象。它是由一个Logger实例为您创建的,封装了该事件的所有相关信息。在内部,它只不过是包含记录属性的dict的包装器。一个Logger实例向零个或多个Handler实例发送一个LogRecord实例。
LogRecord包含一些元数据,如下所示:
- 一个名字
- Unix 时间戳形式的创建时间
- 消息本身
- 关于哪个函数进行了日志记录调用的信息
下面是它所携带的元数据,您可以通过使用
pdb模块单步执行logging.error()调用来反思它:
>>> import logging
>>> import pdb
>>> def f(x):
... logging.error("bad vibes")
... return x / 0
...
>>> pdb.run("f(1)")
在单步执行了一些更高级别的函数之后,您在第 1517 行结束了:
(Pdb) l
1514 exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
1515 elif not isinstance(exc_info, tuple):
1516 exc_info = sys.exc_info()
1517 record = self.makeRecord(self.name, level, fn, lno, msg, args,
1518 exc_info, func, extra, sinfo)
1519 -> self.handle(record)
1520
1521 def handle(self, record):
1522 """
1523 Call the handlers for the specified record.
1524
(Pdb) from pprint import pprint
(Pdb) pprint(vars(record))
{'args': (),
'created': 1550671851.660067,
'exc_info': None,
'exc_text': None,
'filename': '<stdin>',
'funcName': 'f',
'levelname': 'ERROR',
'levelno': 40,
'lineno': 2,
'module': '<stdin>',
'msecs': 660.067081451416,
'msg': 'bad vibes',
'name': 'root',
'pathname': '<stdin>',
'process': 2360,
'processName': 'MainProcess',
'relativeCreated': 295145.5490589142,
'stack_info': None,
'thread': 4372293056,
'threadName': 'MainThread'}
在内部,一个LogRecord包含一个以某种方式使用的元数据宝库。
你很少需要直接与LogRecord打交道,因为Logger和Handler会为你做这件事。知道什么信息被包装在一个LogRecord中仍然是值得,因为当您看到记录的日志消息时,所有有用的信息,如时间戳,都来自这里。
注意:在LogRecord类下面,你还会发现setLogRecordFactory()、getLogRecordFactory()和makeLogRecord()、工厂函数。除非你想用一个定制类代替LogRecord来封装日志消息和它们的元数据,否则你不需要这些。
Logger和Handler类
Logger和Handler类都是logging如何工作的核心,它们彼此频繁交互。一个Logger、一个Handler和一个LogRecord都有一个.level与之相关联。
Logger获取LogRecord并将其传递给Handler,但前提是LogRecord的有效电平等于或高于Logger的有效电平。这同样适用于LogRecord对Handler测试。这被称为基于级别的过滤,其Logger和Handler实现方式略有不同。
换句话说,在您记录的消息到达任何地方之前,应用了(至少)两步测试。为了完全从记录器传递到处理程序,然后记录到结束流(可能是sys.stdout,一个文件,或者通过 SMTP 的一封电子邮件),一个LogRecord的级别必须至少与记录器和处理程序的的一样高。
PEP 282 描述了其工作原理:
每个
Logger对象跟踪它感兴趣的日志级别(或阈值),并丢弃低于该级别的日志请求。(来源)
那么对于Logger和Handler,这种基于级别的过滤实际发生在哪里呢?
对于Logger类,合理的第一个假设是记录器会将其.level属性与LogRecord的级别进行比较,并在那里完成。然而,它比那稍微更复杂一些。
基于级别的日志过滤发生在.isEnabledFor()中,它依次调用.getEffectiveLevel()。总是使用logger.getEffectiveLevel()而不仅仅是咨询logger.level。原因与层次名称空间中的Logger对象的组织有关。(稍后您会看到更多相关内容。)
默认情况下,Logger实例的级别为0 ( NOTSET)。然而,记录器也有父记录器,其中一个是根记录器,它充当所有其他记录器的父记录器。一个Logger将在它的层次结构中向上走,并获得它相对于其父节点的有效级别(如果没有找到其他父节点,最终可能是root)。
这里是发生的地方在Logger类中:
class Logger(Filterer):
# ...
def getEffectiveLevel(self):
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
try:
return self._cache[level]
except KeyError:
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
相应的,这里有一个调用你上面看到的源代码的例子:
>>> import logging >>> logger = logging.getLogger("app") >>> logger.level # No! 0 >>> logger.getEffectiveLevel() 30 >>> logger.parent <RootLogger root (WARNING)> >>> logger.parent.level 30要点如下:不要依赖
.level。如果您没有在您的logger对象上显式地设置一个级别,并且由于某种原因您依赖于.level,那么您的日志记录设置可能会与您预期的有所不同。那
Handler呢?对于处理程序来说,级别间的比较更简单,尽管它实际上发生在来自Logger类的.callHandlers()中的:class Logger(Filterer): # ... def callHandlers(self, record): c = self found = 0 while c: for hdlr in c.handlers: found = found + 1 if record.levelno >= hdlr.level: hdlr.handle(record)对于一个给定的
LogRecord实例(在上面的源代码中被命名为record),一个记录器检查它的每个注册的处理程序,并快速检查那个Handler实例的.level属性。如果LogRecord的.levelno大于或等于处理程序的,则记录才会被传递。logging中的 docstring 将此称为“有条件地发出指定的日志记录。”对于一个
Handler子类实例来说,最重要的属性是它的.stream属性。这是日志写入的最终目的地,可以是任何类似文件的对象。这里有一个关于io.StringIO的例子,它是一个用于文本 I/O 的内存流(缓冲区)首先,设置一个级别为
DEBUG的Logger实例。您会看到,默认情况下,它没有直接的处理程序:
>>> import io
>>> import logging
>>> logger = logging.getLogger("abc")
>>> logger.setLevel(logging.DEBUG)
>>> print(logger.handlers)
[]
接下来,你可以子类化logging.StreamHandler来使.flush()调用一个无操作。我们想要刷新sys.stderr或者sys.stdout,但是在这个例子中不是内存缓冲区:
class IOHandler(logging.StreamHandler):
def flush(self):
pass # No-op
现在,声明 buffer 对象本身,并将其作为自定义处理程序的.stream绑定,级别为INFO,然后将该处理程序绑定到记录器中:
>>> stream = io.StringIO() >>> h = IOHandler(stream) >>> h.setLevel(logging.INFO) >>> logger.addHandler(h) >>> logger.debug("extraneous info") >>> logger.warning("you've been warned") >>> logger.critical("SOS") >>> try: ... print(stream.getvalue()) ... finally: ... stream.close() ... you've been warned SOS这最后一块是基于级别的过滤的另一个例子。
等级为
DEBUG、WARNING和CRITICAL的三条消息通过链传递。起初,看起来好像他们哪儿也不去,但有两个人去了。他们三个都从logger(有等级DEBUG)走出大门。然而,其中只有两个被处理程序发出,因为它有一个更高的级别
INFO,它超过了DEBUG。最后,您以一个str的形式获得缓冲区的全部内容,并关闭缓冲区以显式释放系统资源。
Filter和Filterer类上面,我们问了这个问题,“基于级别的过滤发生在哪里?”在回答这个问题时,很容易被
Filter和Filterer类分散注意力。矛盾的是,Logger和Handler实例的基于级别的过滤在没有Filter或Filterer类帮助的情况下发生。
Filter和Filterer旨在让您在默认的基于级别的过滤之上添加额外的基于函数的过滤器。我喜欢把它想象成点菜过滤。
Filterer是Logger和Handler的基类,因为这两个类都有资格接收您指定的额外自定义过滤器。你用logger.addFilter()或handler.addFilter()给它们添加Filter的实例,这就是下面方法中的self.filters所指的:class Filterer(object): # ... def filter(self, record): rv = True for f in self.filters: if hasattr(f, 'filter'): result = f.filter(record) else: result = f(record) if not result: rv = False break return rv给定一个
record(它是一个LogRecord实例),.filter()返回True或False,这取决于该记录是否从该类的过滤器中获得许可。这是。
handle()依次为Logger和Handler类:class Logger(Filterer): # ... def handle(self, record): if (not self.disabled) and self.filter(record): self.callHandlers(record) # ... class Handler(Filterer): # ... def handle(self, record): rv = self.filter(record) if rv: self.acquire() try: self.emit(record) finally: self.release() return rv默认情况下,
Logger和Handler都没有额外的过滤器,但是这里有一个简单的例子来说明如何添加过滤器:
>>> import logging
>>> logger = logging.getLogger("rp")
>>> logger.setLevel(logging.INFO)
>>> logger.addHandler(logging.StreamHandler())
>>> logger.filters # Initially empty
[]
>>> class ShortMsgFilter(logging.Filter):
... """Only allow records that contain long messages (> 25 chars)."""
... def filter(self, record):
... msg = record.msg
... if isinstance(msg, str):
... return len(msg) > 25
... return False
...
>>> logger.addFilter(ShortMsgFilter())
>>> logger.filters
[<__main__.ShortMsgFilter object at 0x10c28b208>]
>>> logger.info("Reeeeaaaaallllllly long message") # Length: 31
Reeeeaaaaallllllly long message
>>> logger.info("Done") # Length: <25, no output
上面,您定义了一个类ShortMsgFilter并覆盖了它的.filter()。在.addHandler()中,你也可以只传递一个可调用的,比如一个函数或者λ或者一个定义.__call__()的类。
Manager类
还有一个值得一提的logging幕后演员:Manager班。最重要的不是Manager类,而是它的一个实例,这个实例充当了越来越多的记录器层次结构的容器,这些记录器是跨包定义的。在下一节中,您将看到这个类的单个实例是如何将模块粘合在一起并允许其各个部分相互通信的。
最重要的根日志记录器
说到Logger实例,有一个很突出。它被称为 root logger:
class RootLogger(Logger):
def __init__(self, level):
Logger.__init__(self, "root", level)
# ...
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
这段代码块的最后三行是logging包使用的巧妙技巧之一。以下是几点:
-
根日志记录器只是一个简单的 Python 对象,标识符为
root。它的等级为logging.WARNING,T2 为"root"。就RootLogger这个职业而言,这个独特的名字就是它的特别之处。 -
root对象又变成了Logger类的类属性。这意味着Logger的所有实例,以及Logger类本身,都有一个作为根日志记录器的.root属性。这是在logging包中实施的类似单例模式的另一个例子。 -
一个
Manager实例被设置为Logger的.manager类属性。这最终在logging.getLogger("name")中发挥作用。.manager负责搜索名为"name"的现有记录器,如果它们不存在就创建它们。
记录器层级
在 logger 名称空间中,一切都是root的子元素,我指的是一切。这包括您自己指定的记录器以及您从第三方库中导入的记录器。
还记得之前我们的logger实例的.getEffectiveLevel()是 30 ( WARNING)吗,尽管我们没有明确地设置它?这是因为根记录器位于层次结构的顶端,如果任何嵌套记录器的空级别为NOTSET,那么它的级别就是一个后备级别:
>>> root = logging.getLogger() # Or getLogger("") >>> root <RootLogger root (WARNING)> >>> root.parent is None True >>> root.root is root # Self-referential True >>> root is logging.root True >>> root.getEffectiveLevel() 30同样的逻辑也适用于搜索记录器的处理程序。这种搜索实际上是对一个日志记录者的父树的逆序搜索。
多处理器设计
logger 层次结构在理论上看起来很简洁,但是在实践中它有多大益处呢?
让我们暂时停止探索
logging代码,开始编写我们自己的迷你应用程序——一个利用 logger 层次结构的应用程序,减少样板代码,并在项目代码库增长时保持可伸缩性。以下是项目结构:
project/ │ └── project/ ├── __init__.py ├── utils.py └── base.py不用担心应用程序在
utils.py和base.py中的主要功能。这里我们更关注的是project/中模块之间的logging对象的交互。在这种情况下,假设您想要设计一个多向日志记录设置:
每个模块获得一个带有多个处理程序的
logger。一些处理程序在不同模块中的不同
logger实例之间共享。这些处理程序只关心基于级别的过滤,而不关心日志记录来自哪个模块。有一个用于DEBUG消息的处理器,一个用于INFO,一个用于WARNING,等等。每个
logger还被绑定到一个额外的处理程序,该处理程序只接收来自那个单独的logger的LogRecord实例。您可以称之为基于模块的文件处理程序。从视觉上看,我们的目标应该是这样的:
A multipronged logging design (Image: Real Python) 这两个松石色的对象是
Logger的实例,用logging.getLogger(__name__)为包中的每个模块建立。其他一切都是 T2 的例子。这种设计背后的想法是,它被整齐地划分。您可以方便地查看来自单个记录器的消息,或者查看来自任何记录器或模块的特定级别或更高级别的消息。
logger 层次结构的属性使它适合于设置这种多向 logger-handler 布局。那是什么意思?以下是 Django 文档中的简要解释:
为什么等级制度很重要?因为记录器可以被设置为将它们的日志调用传播给它们的父母。这样,您可以在记录器树的根处定义一组处理程序,并在记录器的子树中捕获所有日志调用。在
project名称空间中定义的日志处理程序将捕获在project.interesting和project.interesting.stuff记录器上发出的所有日志消息。(来源)术语 propagate 指的是一个伐木工人如何沿着它的父母链向上寻找管理者。默认情况下,
Logger实例的.propagate属性为True:
>>> logger = logging.getLogger(__name__)
>>> logger.propagate
True
在.callHandlers()中,如果propagate是True,每个连续的父节点被重新分配给局部变量c,直到层次结构被用尽:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None
else: c = c.parent
这意味着:因为包的__init__.py模块中的__name__ dunder 变量仅仅是包的名称,所以那里的记录器成为同一包中其他模块中存在的任何记录器的父级。
以下是用logging.getLogger(__name__)赋值给logger后得到的.name属性:
| 组件 | .name属性 |
|---|---|
project/__init__.py |
'project' |
project/utils.py |
'project.utils' |
project/base.py |
'project.base' |
因为'project.utils'和'project.base'记录器是'project'的子进程,它们不仅会锁定自己的直接处理程序,还会锁定任何附加到'project'的处理程序。
让我们来构建模块。首先出现的是__init__.py:
# __init__.py
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
levels = ("DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL")
for level in levels:
handler = logging.FileHandler(f"/tmp/level-{level.lower()}.log")
handler.setLevel(getattr(logging, level))
logger.addHandler(handler)
def add_module_handler(logger, level=logging.DEBUG):
handler = logging.FileHandler(
f"/tmp/module-{logger.name.replace('.', '-')}.log"
)
handler.setLevel(level)
logger.addHandler(handler)
该模块在project包导入时导入。您为DEBUG到CRITICAL中的每一级添加一个处理程序,然后将其附加到层次结构顶部的一个日志记录器。
您还定义了一个实用函数,它向记录器添加了一个FileHandler,其中处理程序的filename对应于定义记录器的模块名称。(这假设记录器是用__name__定义的。)
然后您可以在base.py和utils.py中添加一些最小的样板文件记录器设置。请注意,您只需要从__init__.py添加一个带有add_module_handler()的额外处理器。您不需要担心面向级别的处理程序,因为它们已经被添加到名为'project'的父记录器中:
# base.py
import logging
from project import add_module_handler
logger = logging.getLogger(__name__)
add_module_handler(logger)
def func1():
logger.debug("debug called from base.func1()")
logger.critical("critical called from base.func1()")
这里是utils.py:
# utils.py
import logging
from project import add_module_handler
logger = logging.getLogger(__name__)
add_module_handler(logger)
def func2():
logger.debug("debug called from utils.func2()")
logger.critical("critical called from utils.func2()")
让我们通过一个新的 Python 会话来看看所有这些是如何协同工作的:
>>> from pprint import pprint >>> import project >>> from project import base, utils >>> project.logger <Logger project (DEBUG)> >>> base.logger, utils.logger (<Logger project.base (DEBUG)>, <Logger project.utils (DEBUG)>) >>> base.logger.handlers [<FileHandler /tmp/module-project-base.log (DEBUG)>] >>> pprint(base.logger.parent.handlers) [<FileHandler /tmp/level-debug.log (DEBUG)>, <FileHandler /tmp/level-info.log (INFO)>, <FileHandler /tmp/level-warning.log (WARNING)>, <FileHandler /tmp/level-error.log (ERROR)>, <FileHandler /tmp/level-critical.log (CRITICAL)>] >>> base.func1() >>> utils.func2()您将在生成的日志文件中看到我们的过滤系统按预期工作。面向模块的处理程序将一个记录器指向一个特定的文件,而面向级别的处理程序将多个记录器指向一个不同的文件:
$ cat /tmp/level-debug.log debug called from base.func1() critical called from base.func1() debug called from utils.func2() critical called from utils.func2() $ cat /tmp/level-critical.log critical called from base.func1() critical called from utils.func2() $ cat /tmp/module-project-base.log debug called from base.func1() critical called from base.func1() $ cat /tmp/module-project-utils.log debug called from utils.func2() critical called from utils.func2()值得一提的一个缺点是,这种设计引入了很多冗余。一个
LogRecord实例可以访问不少于六个文件。这也是一个不可忽略的文件 I/O 量,可能会在性能关键型应用程序中增加。现在你已经看到了一个实际的例子,让我们换个话题,深入研究一下
logging中一个可能的混淆来源。“为什么我的日志消息不在任何地方?”困境
logging有两种容易出错的常见情况:
- 你记录了一条看似无处可去的消息,但你不知道为什么。
- 一条日志消息非但没有被压制,反而出现在了一个你意想不到的地方。
每一个都有一两个与之相关的原因。
你记录了一条看似无处可去的消息,但你不知道为什么。
不要忘记,没有为其设置自定义级别的记录器的有效级别是
WARNING,因为记录器将沿着它的层次结构向上,直到它找到具有它自己的WARNING级别的根记录器:
>>> import logging
>>> logger = logging.getLogger("xyz")
>>> logger.debug("mind numbing info here")
>>> logger.critical("storm is coming")
storm is coming
由于这个缺省值,.debug()调用无处可去。
日志消息非但没有被压制,反而出现在了你意想不到的地方。
当您在上面定义您的logger时,您没有向它添加任何处理程序。那么,它为什么要写控制台呢?
原因是logging 偷偷使用一个名为lastResort的处理程序,如果找不到其他处理程序,该处理程序将向sys.stderr写入数据:
class _StderrHandler(StreamHandler):
# ...
@property
def stream(self):
return sys.stderr
_defaultLastResort = _StderrHandler(WARNING)
lastResort = _defaultLastResort
当记录器去寻找它的处理程序时,这就发生了:
class Logger(Filterer):
# ...
def callHandlers(self, record):
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level: lastResort.handle(record)
如果记录器放弃了对处理程序(它自己的直接处理程序和父记录器的属性)的搜索,那么它会选择并使用lastResort处理程序。
还有一个更微妙的细节值得了解。本节主要讨论了实例方法(类定义的方法),而不是同名的logging包的模块级函数。
如果您使用函数,比如logging.info()而不是logger.info(),那么内部会发生一些稍微不同的事情。该函数调用logging.basicConfig(),这增加了一个写入sys.stderr的StreamHandler。最终,行为实际上是相同的:
>>> import logging >>> root = logging.getLogger("") >>> root.handlers [] >>> root.hasHandlers() False >>> logging.basicConfig() >>> root.handlers [<StreamHandler <stderr> (NOTSET)>] >>> root.hasHandlers() True利用惰性格式化
是时候换个角度,仔细看看消息本身是如何与数据结合在一起的。虽然它已经被
str.format()和 f-strings 所取代,但你可能已经使用 Python 的百分比格式来做类似这样的事情:
>>> print("To iterate is %s, to recurse %s" % ("human", "divine"))
To iterate is human, to recurse divine
因此,您可能会尝试在logging通话中做同样的事情:
>>> # Bad! Check out a more efficient alternative below. >>> logging.warning("To iterate is %s, to recurse %s" % ("human", "divine")) WARNING:root:To iterate is human, to recurse divine这使用整个格式字符串及其参数作为
logging.warning()的msg参数。以下是推荐的备选方案,直接来自
logging文档:
>>> # Better: formatting doesn't occur until it really needs to.
>>> logging.warning("To iterate is %s, to recurse %s", "human", "divine")
WARNING:root:To iterate is human, to recurse divine
看起来有点怪,对吧?这似乎违背了百分比样式的字符串格式化的惯例,但是这是一个更有效的函数调用,因为格式化字符串是被懒惰地格式化的而不是贪婪地格式化*。这是它的意思。
***Logger.warning()的方法签名如下所示:
def warning(self, msg, *args, **kwargs)
这同样适用于其他方法,如.debug()。当你调用warning("To iterate is %s, to recurse %s", "human", "divine")时,"human"和"divine"都作为*args被捕获,在方法体的范围内,args等于("human", "divine")。
与上面的第一个呼叫相比:
logging.warning("To iterate is %s, to recurse %s" % ("human", "divine"))
在这种形式中,括号中的所有内容立即合并到"To iterate is human, to recurse divine"中,并作为msg传递,而args是一个空元组。
为什么这很重要?重复的日志记录调用会稍微降低运行时性能,但是logging包会尽最大努力来控制它。通过不立即合并格式字符串和它的参数,logging延迟了字符串的格式化,直到Handler请求了LogRecord。
这发生在 LogRecord.getMessage() 中,因此只有在logging认为LogRecord实际上将被传递给一个处理程序之后,它才成为其完全合并的自我。
这就是说,logging包在正确的地方做了一些非常精细的性能优化。这可能看起来像是细枝末节,但是如果你在一个循环中一百万次调用同一个logging.debug(),并且args是函数调用,那么logging字符串格式化的懒惰本质会有所不同。
在对msg和args进行任何合并之前,Logger实例将检查它的.isEnabledFor(),看看是否应该首先进行合并。
函数与方法
在logging/__init__.py的底部是模块级的函数,这些函数在logging的公共 API 中被提前公布。你已经看到了Logger方法,比如.debug()、.info()和.warning()。顶层函数是同名对应方法的包装器,但是它们有两个重要的特性:
-
它们总是从根日志记录器中调用它们对应的方法,
root。 -
在调用根日志记录器方法之前,如果
root没有任何处理程序,它们会不带参数地调用logging.basicConfig()。正如您前面看到的,正是这个调用为根日志记录器设置了一个sys.stdout处理程序。
举例来说,这里有 logging.error() :
def error(msg, *args, **kwargs):
if len(root.handlers) == 0:
basicConfig()
root.error(msg, *args, **kwargs)
你会发现logging.debug()、logging.info()和其他人也有同样的模式。追踪命令链很有趣。最终,你会到达同一个地方,这就是内部Logger._log()被调用的地方。
对debug()、info()、warning()以及其他基于级别的函数的调用都路由到这里。_log()主要有两个目的:
-
调用
self.makeRecord(): 从传递给它的msg和其他参数中创建一个LogRecord实例。 -
调用
self.handle(): 这决定了对记录的实际处理。它被送到哪里?它会出现在那里还是被过滤掉?
在一张图中显示了整个过程:

也可以用pdb追踪调用栈。
>>> import logging >>> import pdb >>> pdb.run('logging.warning("%s-%s", "uh", "oh")') > <string>(1)<module>() (Pdb) s --Call-- > lib/python3.7/logging/__init__.py(1971)warning() -> def warning(msg, *args, **kwargs): (Pdb) s > lib/python3.7/logging/__init__.py(1977)warning() -> if len(root.handlers) == 0: (Pdb) unt > lib/python3.7/logging/__init__.py(1978)warning() -> basicConfig() (Pdb) unt > lib/python3.7/logging/__init__.py(1979)warning() -> root.warning(msg, *args, **kwargs) (Pdb) s --Call-- > lib/python3.7/logging/__init__.py(1385)warning() -> def warning(self, msg, *args, **kwargs): (Pdb) l 1380 logger.info("Houston, we have a %s", "interesting problem", exc_info=1) 1381 """ 1382 if self.isEnabledFor(INFO): 1383 self._log(INFO, msg, args, **kwargs) 1384 1385 -> def warning(self, msg, *args, **kwargs): 1386 """ 1387 Log 'msg % args' with severity 'WARNING'. 1388 1389 To pass exception information, use the keyword argument exc_info with 1390 a true value, e.g. (Pdb) s > lib/python3.7/logging/__init__.py(1394)warning() -> if self.isEnabledFor(WARNING): (Pdb) unt > lib/python3.7/logging/__init__.py(1395)warning() -> self._log(WARNING, msg, args, **kwargs) (Pdb) s --Call-- > lib/python3.7/logging/__init__.py(1496)_log() -> def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False): (Pdb) s > lib/python3.7/logging/__init__.py(1501)_log() -> sinfo = None (Pdb) unt 1517 > lib/python3.7/logging/__init__.py(1517)_log() -> record = self.makeRecord(self.name, level, fn, lno, msg, args, (Pdb) s > lib/python3.7/logging/__init__.py(1518)_log() -> exc_info, func, extra, sinfo) (Pdb) s --Call-- > lib/python3.7/logging/__init__.py(1481)makeRecord() -> def makeRecord(self, name, level, fn, lno, msg, args, exc_info, (Pdb) p name 'root' (Pdb) p level 30 (Pdb) p msg '%s-%s' (Pdb) p args ('uh', 'oh') (Pdb) up > lib/python3.7/logging/__init__.py(1518)_log() -> exc_info, func, extra, sinfo) (Pdb) unt > lib/python3.7/logging/__init__.py(1519)_log() -> self.handle(record) (Pdb) n WARNING:root:uh-oh
getLogger()到底是做什么的?隐藏在这部分源代码中的还有顶层的
getLogger(),它包装了Logger.manager.getLogger():def getLogger(name=None): if name: return Logger.manager.getLogger(name) else: return root这是实施单一日志记录器设计的入口点:
如果你指定了一个
name,那么底层的.getLogger()会在字符串name上进行dict查找。这归结为在logging.Manager的loggerDict中的查找。这是一个所有已注册记录器的字典,包括当您在引用其父记录器之前引用层次结构中较低位置的记录器时生成的中间PlaceHolder实例。否则,返回
root。只有一个root——上面讨论的RootLogger的实例。这个特性是一个可以让您窥视所有已注册的记录器的技巧背后的东西:
>>> import logging
>>> logging.Logger.manager.loggerDict
{}
>>> from pprint import pprint
>>> import asyncio
>>> pprint(logging.Logger.manager.loggerDict)
{'asyncio': <Logger asyncio (WARNING)>,
'concurrent': <logging.PlaceHolder object at 0x10d153710>,
'concurrent.futures': <Logger concurrent.futures (WARNING)>}
哇,等一下。这里发生了什么事?看起来像是由于另一个库的导入而对logging包内部做了一些改变,这正是所发生的事情。
首先,回想一下Logger.manager是一个类属性,其中Manager的一个实例被附加到了Logger类上。manager被设计用来跟踪和管理Logger的所有单例实例。这些都装在.loggerDict里。
现在,当您最初导入logging时,这个字典是空的。但是在导入asyncio之后,同一个字典被三个记录器填充。这是一个模块就地设置另一个模块的属性的例子。果然,在asyncio/log.py里面,你会发现以下内容:
import logging
logger = logging.getLogger(__package__) # "asyncio"
键-值对是在Logger.getLogger()中设置的,这样manager就可以监管记录器的整个名称空间。这意味着对象asyncio.log.logger在属于logging包的日志字典中注册。类似的事情也发生在由asyncio导入的concurrent.futures包中。
您可以在等价测试中看到单例设计的威力:
>>> obj1 = logging.getLogger("asyncio") >>> obj2 = logging.Logger.manager.loggerDict["asyncio"] >>> obj1 is obj2 True这个比较说明了(掩盖了一些细节)什么是
getLogger()最终要做的。库 vs 应用程序日志:什么是
NullHandler?这将我们带到了
logging/__init__.py源代码的最后一百行左右,这里定义了NullHandler。以下是其最辉煌的定义:class NullHandler(Handler): def handle(self, record): pass def emit(self, record): pass def createLock(self): self.lock = None
NullHandler是关于在库中登录和在应用程序中登录的区别。让我们看看这是什么意思。一个库是一个可扩展的、通用的 Python 包,供其他用户安装和设置。它是由开发者构建的,明确的目的是分发给用户。例子包括流行的开源项目,如 NumPy 、
dateutil和cryptography。一个应用(或 app,或程序)是为更具体的目的和更小的用户群(可能只有一个用户)设计的。它是一个或一组由用户高度定制的程序,用来做一组有限的事情。一个应用程序的例子是位于网页后面的 Django 应用程序。应用程序通常使用(
import)库和它们包含的工具。说到日志记录,在库中和应用程序中有不同的最佳实践。
这就是
NullHandler适合的地方。它基本上是一个什么都不做的存根类。如果你正在编写一个 Python 库,你真的需要在你的包的
__init__.py中做这个简单的设置:# Place this in your library's uppermost `__init__.py` # Nothing else! import logging logging.getLogger(__name__).addHandler(NullHandler())这有两个重要的目的。
首先,默认情况下,用
logger = logging.getLogger(__name__)声明的库记录器(没有任何进一步的配置)将记录到sys.stderr,即使这不是最终用户想要的。这可以被描述为一种选择退出的方法,在这种方法中,如果库的最终用户不想登录控制台,他们必须进入并禁用登录。常识告诉我们应该使用选择加入的方法:默认情况下不要发出任何日志消息,让库的最终用户决定是否要进一步配置库的记录器并为它们添加处理程序。这是由
logging包的作者 Vinay Sajip 用更直白的措辞表达的哲学:默认情况下,使用
logging的第三方库不应该输出日志输出,因为使用它的应用程序的开发人员/用户可能不需要这些输出。(来源)这就让库用户而不是库开发人员来逐步调用诸如
logger.addHandler()或logger.setLevel()这样的方法。
NullHandler存在的第二个原因更加古老。在 Python 2.7 和更早的版本中,试图从一个没有设置处理程序的记录器中记录一个LogRecord,会导致产生一个警告。添加无操作类NullHandler将避免这一点。下面是在上面的行
logging.getLogger(__name__).addHandler(NullHandler())中具体发生的事情:
Python 获得(创建)与您的包同名的
Logger实例。如果你在__init__.py中设计calculus包,那么__name__将等于'calculus'。一个
NullHandler实例被附加到这个记录器上。这意味着 Python 不会默认使用lastResort处理程序。请记住,在包的任何其他
.py模块中创建的任何记录器都将是记录器层次结构中该记录器的子级,因为该处理程序也属于它们,所以它们不需要使用lastResort处理程序,也不会默认记录到标准错误(stderr)。举个简单的例子,假设您的库具有以下结构:
calculus/ │ ├── __init__.py └── integration.py在
integration.py中,作为库开发者,你可以自由地做以下事情:# calculus/integration.py import logging logger = logging.getLogger(__name__) def func(x): logger.warning("Look!") # Do stuff return None现在,一个用户通过
pip install calculus从 PyPI 安装你的库。他们在一些应用程序代码中使用from calculus.integration import func。这个用户可以像任何其他 Python 对象一样,随心所欲地操作和配置库中的logger对象。异常情况下日志记录做什么
您可能需要警惕的一件事是对
logging的调用可能会引发异常。如果您有一个logging.error()调用,它的目的是为您提供一些更详细的调试信息,但是这个调用本身由于某种原因引发了一个异常,这将是最大的讽刺,对吗?聪明的是,如果
logging包遇到一个与日志本身有关的异常,那么它会打印回溯,但不会引发异常本身。这里有一个处理常见输入错误的例子:向只需要一个参数的格式字符串传递两个参数。重要的区别在于,您在下面看到的是而不是一个被引发的异常,而是一个被美化的内部异常的打印回溯,它本身是被抑制的:
>>> logging.critical("This %s has too many arguments", "msg", "other")
--- Logging error ---
Traceback (most recent call last):
File "lib/python3.7/logging/__init__.py", line 1034, in emit
msg = self.format(record)
File "lib/python3.7/logging/__init__.py", line 880, in format
return fmt.format(record)
File "lib/python3.7/logging/__init__.py", line 619, in format
record.message = record.getMessage()
File "lib/python3.7/logging/__init__.py", line 380, in getMessage
msg = msg % self.args
TypeError: not all arguments converted during string formatting
Call stack:
File "<stdin>", line 1, in <module>
Message: 'This %s has too many arguments'
Arguments: ('msg', 'other')
这让您的程序优雅地继续其实际的程序流。基本原理是,你不希望一个未被捕获的异常来自于一个logging调用本身,并阻止一个程序在它的轨道上死亡。
回溯可能会很混乱,但这一条信息丰富且相对简单。能够抑制与logging相关的异常的是Handler.handleError()。当处理程序调用.emit()时,这是它试图记录记录的方法,如果出现问题,它会退回到.handleError()。下面是StreamHandler类的.emit()的实现:
def emit(self, record):
try:
msg = self.format(record)
stream = self.stream
stream.write(msg + self.terminator)
self.flush()
except Exception:
self.handleError(record)
任何与格式化和写入相关的异常都被捕获,而不是被引发,handleError优雅地将回溯写到sys.stderr。
记录 Python 回溯
说到异常和它们的回溯,当你的程序遇到异常但应该记录异常并继续执行时,该怎么办呢?
让我们通过几种方法来实现这一点。
这是一个虚构的彩票模拟器的例子,它使用了非 Pythonic 代码。你正在开发一个在线彩票游戏,用户可以对他们的幸运数字下注:
import random
class Lottery(object):
def __init__(self, n):
self.n = n
def make_tickets(self):
for i in range(self.n):
yield i
def draw(self):
pool = self.make_tickets()
random.shuffle(pool)
return next(pool)
在前端应用程序的后面是下面的关键代码。你要确保你跟踪任何由网站引起的错误,这些错误可能会让用户损失金钱。第一种(次优)方法是使用logging.error()并记录异常实例本身的str形式:
try:
lucky_number = int(input("Enter your ticket number: "))
drawn = Lottery(n=20).draw()
if lucky_number == drawn:
print("Winner chicken dinner!")
except Exception as e:
# NOTE: See below for a better way to do this.
logging.error("Could not draw ticket: %s", e)
这只会得到实际的异常消息,而不是回溯。您检查了网站服务器上的日志,发现了这条神秘的消息:
ERROR:root:Could not draw ticket: object of type 'generator' has no len()
嗯。作为应用程序开发人员,您遇到了一个严重的问题,结果一个用户被骗了。但是也许这个异常消息本身并没有提供太多的信息。看到导致这个异常的回溯的血统不是很好吗?
正确的解决方案是使用logging.exception(),它记录级别为ERROR的消息,并显示异常回溯。将上面最后两行替换为:
except Exception:
logging.exception("Could not draw ticket")
现在,您对正在发生的事情有了更好的了解:
ERROR:root:Could not draw ticket Traceback (most recent call last): File "<stdin>", line 3, in <module> File "<stdin>", line 9, in draw File "lib/python3.7/random.py", line 275, in shuffle for i in reversed(range(1, len(x))): TypeError: object of type 'generator' has no len()使用
exception()让你不必自己引用异常,因为logging用sys.exc_info()把它拉进来。这让事情变得更清楚,问题源于
random.shuffle(),它需要知道它正在洗牌的对象的长度。因为我们的Lottery类将一个生成器传递给了shuffle(),所以它在池被洗牌之前被挂起并上升,更不用说生成一张中奖票了。在大型、成熟的应用程序中,当涉及到深度、多库回溯时,您会发现
logging.exception()甚至更有用,并且您不能使用像pdb这样的实时调试器来介入它们。
logging.Logger.exception()以及logging.exception()的代码只有一行:def exception(self, msg, *args, exc_info=True, **kwargs): self.error(msg, *args, exc_info=exc_info, **kwargs)即
logging.exception()只是用exc_info=True调用logging.error(),否则默认为False。如果您想记录一个异常回溯,但级别不同于logging.ERROR,只需用exc_info=True调用那个函数或方法。请记住,
exception()应该只在异常处理程序的上下文中调用,在except块内部:for i in data: try: result = my_longwinded_nested_function(i) except ValueError: # We are in the context of exception handler now. # If it's unclear exactly *why* we couldn't process # `i`, then log the traceback and move on rather than # ditching completely. logger.exception("Could not process %s", i) continue请谨慎使用这种模式,而不要将其作为抑制任何异常的手段。当您调试一个很长的函数调用堆栈时,这是非常有用的,否则您会看到一个模糊的、不清楚的、难以跟踪的错误。
结论
拍拍自己的背,因为您刚刚浏览了将近 2000 行密集的源代码。您现在可以更好地处理
logging包了!请记住,本教程远未涵盖
logging包中的所有类。甚至有更多的机械把所有东西粘在一起。如果你想了解更多,那么你可以看看Formatter课程和单独的模块logging/config.py和logging/handlers.py。*************在 Python 中登录
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 登录 Python
日志是程序员工具箱中非常有用的工具。它可以帮助您更好地理解程序的流程,并发现您在开发时可能没有想到的场景。
日志为开发人员提供了一双额外的眼睛,时刻关注着应用程序正在经历的流程。它们可以存储信息,比如哪个用户或 IP 访问了应用程序。如果发生错误,它们可以告诉您程序在到达发生错误的代码行之前的状态,从而提供比堆栈跟踪更多的信息。
通过从正确的位置记录有用的数据,您不仅可以轻松地调试错误,还可以使用这些数据来分析应用程序的性能,以规划扩展或查看使用模式来规划营销。
Python 提供了一个日志系统作为其标准库的一部分,因此您可以快速地将日志添加到您的应用程序中。在本文中,您将了解为什么使用这个模块是向您的应用程序添加日志记录的最佳方式,以及如何快速入门,并且您将了解一些可用的高级特性。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
日志模块
Python 中的日志模块是一个随时可用的强大模块,旨在满足初学者以及企业团队的需求。大多数第三方 Python 库都使用它,因此您可以将日志消息与这些库中的日志消息集成在一起,为您的应用程序生成一个同构日志。
向 Python 程序添加日志记录就像这样简单:
import logging导入日志模块后,您可以使用一个叫做“日志记录器”的东西来记录您想要查看的消息。默认情况下,有 5 个标准级别来表示事件的严重性。每个都有相应的方法,可用于记录该严重级别的事件。定义的级别(按严重性递增顺序排列)如下:
- 调试
- 信息
- 警告
- 错误
- 批评的
日志模块为您提供了一个默认的日志记录器,允许您无需做太多配置就可以开始使用。每个级别对应的方法都可以调用,如下例所示:
import logging logging.debug('This is a debug message') logging.info('This is an info message') logging.warning('This is a warning message') logging.error('This is an error message') logging.critical('This is a critical message')上述程序的输出如下所示:
WARNING:root:This is a warning message ERROR:root:This is an error message CRITICAL:root:This is a critical message输出显示了每条消息前的严重性级别以及
root,这是日志记录模块为其默认日志记录器指定的名称。(日志程序将在后面的章节中详细讨论。)这种格式显示由冒号(:)分隔的级别、名称和消息,是默认的输出格式,可以配置为包括时间戳、行号和其他细节。请注意,
debug()和info()消息没有被记录。这是因为,默认情况下,日志模块记录严重级别为WARNING或更高的消息。如果您愿意,可以通过配置日志模块来记录所有级别的事件来改变这种情况。您还可以通过更改配置来定义自己的严重性级别,但通常不建议这样做,因为这会与您可能正在使用的一些第三方库的日志混淆。基本配置
您可以使用
basicConfig(**kwargs)的方法来配置日志记录:“您会注意到日志模块打破了 PEP8 styleguide,使用了
camelCase命名约定。这是因为它采用了 Log4j,一个 Java 中的日志记录实用程序。这是软件包中的一个已知问题,但在决定将其添加到标准库中时,它已经被用户采用,更改它以满足 PEP8 要求会导致向后兼容性问题。”(来源)
basicConfig()的一些常用参数如下:
level:root logger 将被设置为指定的严重级别。filename:指定文件。filemode:如果给定了filename,则以此模式打开文件。默认是a,意思是追加。format:这是日志消息的格式。通过使用
level参数,您可以设置想要记录的日志消息的级别。这可以通过传递类中可用的一个常数来实现,这将允许记录该级别或更高级别的所有日志调用。这里有一个例子:import logging logging.basicConfig(level=logging.DEBUG) logging.debug('This will get logged')DEBUG:root:This will get logged所有在
DEBUG级别或以上的事件都将被记录。类似地,对于记录到文件而不是控制台,可以使用
filename和filemode,并且您可以使用format来决定消息的格式。下面的示例显示了所有三种方法的用法:import logging logging.basicConfig(filename='app.log', filemode='w', format='%(name)s - %(levelname)s - %(message)s') logging.warning('This will get logged to a file')root - ERROR - This will get logged to a file该消息看起来像这样,但是将被写入一个名为
app.log的文件,而不是控制台。filemode 设置为w,这意味着每次调用basicConfig()时,日志文件以“写模式”打开,程序每次运行都会重写文件。filemode 的默认配置是a,它是 append。您可以通过使用更多的参数来定制根日志记录器,这些参数可以在这里找到。
需要注意的是,调用
basicConfig()来配置根日志记录器只有在之前没有配置根日志记录器的情况下才有效。基本上这个函数只能调用一次。
debug()、info()、warning()、error()、critical()如果之前没有调用过basicConfig(),也会自动调用basicConfig()而不带参数。这意味着在第一次调用上述函数之一后,您不能再配置根日志记录器,因为它们会在内部调用basicConfig()函数。
basicConfig()中的默认设置是设置记录器以下列格式写入控制台:ERROR:root:This is an error message格式化输出
虽然您可以将程序中任何可以表示为字符串的变量作为消息传递给日志,但是有一些基本元素已经是
LogRecord的一部分,可以很容易地添加到输出格式中。如果您想记录进程 ID 以及级别和消息,您可以这样做:import logging logging.basicConfig(format='%(process)d-%(levelname)s-%(message)s') logging.warning('This is a Warning')18472-WARNING-This is a Warning
format可以任意排列带有LogRecord属性的字符串。可用属性的完整列表可以在这里找到。这是另一个您可以添加日期和时间信息的示例:
import logging logging.basicConfig(format='%(asctime)s - %(message)s', level=logging.INFO) logging.info('Admin logged in')2018-07-11 20:12:06,288 - Admin logged in
%(asctime)s添加LogRecord的创建时间。可以使用datefmt属性更改格式,该属性使用与 datetime 模块中的格式化函数相同的格式化语言,例如time.strftime():import logging logging.basicConfig(format='%(asctime)s - %(message)s', datefmt='%d-%b-%y %H:%M:%S') logging.warning('Admin logged out')12-Jul-18 20:53:19 - Admin logged out你可以在这里找到指南。
记录变量数据
在大多数情况下,您会希望在日志中包含来自应用程序的动态信息。您已经看到,日志记录方法将一个字符串作为参数,在单独的一行中用可变数据格式化一个字符串并将其传递给 log 方法似乎是很自然的。但这实际上可以通过使用消息的格式字符串并附加变量数据作为参数来直接完成。这里有一个例子:
import logging name = 'John' logging.error('%s raised an error', name)ERROR:root:John raised an error传递给该方法的参数将作为变量数据包含在消息中。
虽然您可以使用任何格式样式,但 Python 3.6 中引入的 f-strings 是一种格式化字符串的绝佳方式,因为它们有助于保持格式简短易读:
import logging name = 'John' logging.error(f'{name} raised an error')ERROR:root:John raised an error捕获堆栈跟踪
日志模块还允许您捕获应用程序中的完整堆栈跟踪。如果将
exc_info参数作为True传递,则可以捕获异常信息,日志记录函数调用如下:import logging a = 5 b = 0 try: c = a / b except Exception as e: logging.error("Exception occurred", exc_info=True)ERROR:root:Exception occurred Traceback (most recent call last): File "exceptions.py", line 6, in <module> c = a / b ZeroDivisionError: division by zero [Finished in 0.2s]如果
exc_info没有设置为True,上述程序的输出不会告诉我们任何关于异常的信息,在现实世界中,这可能不像ZeroDivisionError那么简单。想象一下,试图在一个复杂的代码库中调试一个错误,而日志只显示以下内容:ERROR:root:Exception occurred这里有一个小提示:如果您从一个异常处理程序进行日志记录,请使用
logging.exception()方法,该方法记录一条级别为ERROR的消息,并将异常信息添加到消息中。更简单的说,叫logging.exception()就像叫logging.error(exc_info=True)。但是因为这个方法总是转储异常信息,所以应该只从异常处理程序中调用它。看一下这个例子:import logging a = 5 b = 0 try: c = a / b except Exception as e: logging.exception("Exception occurred")ERROR:root:Exception occurred Traceback (most recent call last): File "exceptions.py", line 6, in <module> c = a / b ZeroDivisionError: division by zero [Finished in 0.2s]使用
logging.exception()将显示ERROR级别的日志。如果您不希望这样,您可以调用从debug()到critical()的任何其他日志记录方法,并将exc_info参数作为True传递。类别和功能
到目前为止,我们已经看到了名为
root的默认记录器,每当像这样直接调用它的函数时,它都会被日志模块使用:logging.debug()。你可以(也应该)通过创建一个Logger类的对象来定义你自己的日志记录器,尤其是当你的应用程序有多个模块的时候。让我们看看模块中的一些类和函数。日志模块中定义的最常用的类如下:
Logger: 这个类的对象将在应用程序代码中直接调用函数。
LogRecord: 记录器自动创建LogRecord对象,这些对象包含与正在记录的事件相关的所有信息,比如记录器的名称、函数、行号、消息等等。
Handler: 处理程序将LogRecord发送到所需的输出目的地,如控制台或文件。Handler是StreamHandler、FileHandler、SMTPHandler、HTTPHandler等子类的基础。这些子类将日志输出发送到相应的目的地,比如sys.stdout或磁盘文件。
Formatter: 这是通过指定一个列出输出应该包含的属性的字符串格式来指定输出格式的地方。其中,我们主要处理的是
Logger类的对象,它们是使用模块级函数logging.getLogger(name)实例化的。用同一个name多次调用getLogger()将返回一个对同一个Logger对象的引用,这样我们就不用把日志对象传递到每个需要的地方。这里有一个例子:import logging logger = logging.getLogger('example_logger') logger.warning('This is a warning')This is a warning这将创建一个名为
example_logger的定制日志记录器,但是与根日志记录器不同,定制日志记录器的名称不是默认输出格式的一部分,必须添加到配置中。将其配置为显示记录器名称的格式将会产生如下输出:WARNING:example_logger:This is a warning同样,与根日志记录器不同,定制日志记录器不能使用
basicConfig()进行配置。您必须使用处理程序和格式化程序来配置它:“建议我们使用模块级记录器,通过将名称参数
__name__传递给getLogger()来创建一个记录器对象,因为记录器本身的名称会告诉我们从哪里记录事件。__name__是 Python 中一个特殊的内置变量,它计算当前模块的名称(来源)使用处理程序
当您想要配置自己的日志记录程序,并在生成日志时将日志发送到多个地方时,处理程序就会出现。处理程序将日志消息发送到已配置的目的地,如标准输出流或文件,或者通过 HTTP 或 SMTP 发送到您的电子邮件。
您创建的记录器可以有多个处理程序,这意味着您可以将其设置为保存到日志文件中,也可以通过电子邮件发送。
与记录器一样,您也可以在处理程序中设置严重级别。如果您希望为同一个日志程序设置多个处理程序,但希望每个处理程序具有不同的严重级别,这将非常有用。例如,您可能希望将级别为
WARNING及以上的日志记录到控制台,但是级别为ERROR及以上的所有内容也应该保存到文件中。这里有一个程序可以做到这一点:# logging_example.py import logging # Create a custom logger logger = logging.getLogger(__name__) # Create handlers c_handler = logging.StreamHandler() f_handler = logging.FileHandler('file.log') c_handler.setLevel(logging.WARNING) f_handler.setLevel(logging.ERROR) # Create formatters and add it to handlers c_format = logging.Formatter('%(name)s - %(levelname)s - %(message)s') f_format = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') c_handler.setFormatter(c_format) f_handler.setFormatter(f_format) # Add handlers to the logger logger.addHandler(c_handler) logger.addHandler(f_handler) logger.warning('This is a warning') logger.error('This is an error')__main__ - WARNING - This is a warning __main__ - ERROR - This is an error这里,
logger.warning()创建了一个保存所有事件信息的LogRecord,并将其传递给它拥有的所有处理程序:c_handler和f_handler。
c_handler是一个带WARNING电平的StreamHandler,从LogRecord获取信息,生成指定格式的输出,并打印到控制台。f_handler是一个带有级别ERROR的FileHandler,它忽略这个LogRecord,因为它的级别是WARNING。当
logger.error()被调用时,c_handler的行为与之前完全一样,f_handler得到一个ERROR级别的LogRecord,因此它继续生成一个类似于c_handler的输出,但它不是将输出打印到控制台,而是以如下格式将其写入指定文件:2018-08-03 16:12:21,723 - __main__ - ERROR - This is an error对应于
__name__变量的记录器的名称被记录为__main__,这是 Python 分配给开始执行的模块的名称。如果这个文件是由其他模块导入的,那么__name__变量将对应于它的名字 logging_example 。下面是它的样子:# run.py import logging_examplelogging_example - WARNING - This is a warning logging_example - ERROR - This is an error其他配置方法
您可以使用模块和类函数,或者通过创建一个配置文件或一个字典并分别使用
fileConfig()或dictConfig()加载,如上所示配置日志记录。如果您想在正在运行的应用程序中更改日志记录配置,这些选项非常有用。下面是一个文件配置示例:
[loggers] keys=root,sampleLogger [handlers] keys=consoleHandler [formatters] keys=sampleFormatter [logger_root] level=DEBUG handlers=consoleHandler [logger_sampleLogger] level=DEBUG handlers=consoleHandler qualname=sampleLogger propagate=0 [handler_consoleHandler] class=StreamHandler level=DEBUG formatter=sampleFormatter args=(sys.stdout,) [formatter_sampleFormatter] format=%(asctime)s - %(name)s - %(levelname)s - %(message)s在上面的文件中,有两个记录器、一个处理程序和一个格式化程序。在定义它们的名称后,通过在它们的名称前添加单词 logger、handler 和 formatter 来配置它们,用下划线分隔。
要加载这个配置文件,您必须使用
fileConfig():import logging import logging.config logging.config.fileConfig(fname='file.conf', disable_existing_loggers=False) # Get the logger specified in the file logger = logging.getLogger(__name__) logger.debug('This is a debug message')2018-07-13 13:57:45,467 - __main__ - DEBUG - This is a debug message配置文件的路径作为参数传递给
fileConfig()方法,而disable_existing_loggers参数用于保持或禁用调用函数时出现的记录器。如未提及,默认为True。下面是字典方法的 YAML 格式的相同配置:
version: 1 formatters: simple: format: '%(asctime)s - %(name)s - %(levelname)s - %(message)s' handlers: console: class: logging.StreamHandler level: DEBUG formatter: simple stream: ext://sys.stdout loggers: sampleLogger: level: DEBUG handlers: [console] propagate: no root: level: DEBUG handlers: [console]下面的例子展示了如何从
yaml文件加载配置:import logging import logging.config import yaml with open('config.yaml', 'r') as f: config = yaml.safe_load(f.read()) logging.config.dictConfig(config) logger = logging.getLogger(__name__) logger.debug('This is a debug message')2018-07-13 14:05:03,766 - __main__ - DEBUG - This is a debug message保持冷静,阅读日志
日志模块被认为是非常灵活的。它的设计非常实用,并且应该适合您的开箱即用的用例。您可以将基本的日志记录添加到一个小项目中,或者如果您正在处理一个大项目,您甚至可以创建自己的定制日志级别、处理程序类等等。
如果您还没有在应用程序中使用日志记录,现在是开始使用的好时机。如果做得正确,日志记录肯定会消除开发过程中的许多摩擦,并帮助您找到将应用程序提升到下一个级别的机会。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 登录 Python***
在 Python 中定义主函数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 在 Python 中定义主要函数
许多编程语言都有一个特殊的功能,当操作系统开始运行程序时,这个功能会自动执行。这个函数通常被称为
main(),根据语言标准,它必须有一个特定的返回类型和参数。另一方面,Python 解释器从文件顶部开始执行脚本,没有 Python 自动执行的特定函数。然而,为程序的执行定义一个起点对于理解程序如何工作是有用的。Python 程序员想出了几个约定来定义这个起点。
到本文结束时,你会明白:
- 什么是特殊的
__name__变量,Python 如何定义它- 为什么要在 Python 中使用
main()- 在 Python 中定义
main()有什么约定- 将什么代码放入您的
main()中的最佳实践是什么免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
一个基本的 Python main()
在某些 Python 脚本中,您可能会看到类似于以下示例的函数定义和条件语句:
def main(): print("Hello World!") if __name__ == "__main__": main()在这段代码中,有一个名为
main()的函数,当 Python 解释器执行它时,它打印出短语Hello World!。还有一个条件(或if)语句检查__name__的值,并将其与字符串"__main__"进行比较。当if语句评估为True时,Python 解释器执行main()。你可以在 Python 的条件语句中阅读更多关于条件语句的内容。这种代码模式在 Python 文件中很常见,你希望作为脚本执行,而在另一个模块中导入。为了帮助理解这段代码将如何执行,您应该首先理解 Python 解释器如何根据代码如何执行来设置
__name__。Python 中的执行模式
有两种主要方法可以指示 Python 解释器执行或使用代码:
- 您可以使用命令行将 Python 文件作为脚本来执行。
- 您可以将代码从一个 Python 文件导入到另一个文件或交互式解释器中。
你可以在如何运行你的 Python 脚本中读到更多关于这些方法的内容。无论您使用哪种方式运行代码,Python 都定义了一个名为
__name__的特殊变量,该变量包含一个字符串,其值取决于代码的使用方式。我们将使用这个保存为
execution_methods.py的示例文件,探索代码的行为如何根据上下文而变化:print("This is my file to test Python's execution methods.") print("The variable __name__ tells me which context this file is running in.") print("The value of __name__ is:", repr(__name__))在这个文件中,有三个对
print()的调用被定义。前两个打印一些介绍性短语。第三个print()将首先打印短语The value of __name__ is,然后它将使用 Python 的内置repr()打印__name__变量的表示。在 Python 中,
repr()显示对象的可打印表示。这个例子使用了repr()来强调__name__的值是一个字符串。你可以在 Python 文档中阅读更多关于repr()的内容。您将看到贯穿本文的词语文件、模块和脚本。实际上,他们之间没有太大的区别。然而,在强调一段代码的目的时,在含义上有细微的差别:
文件:通常,Python 文件是任何包含代码的文件。大多数 Python 文件都有扩展名
.py。脚本:Python 脚本是您打算从命令行执行以完成任务的文件。
模块:Python 模块是您打算从另一个模块或脚本中,或者从交互式解释器中导入的文件。你可以在 Python 模块和包——简介中阅读更多关于模块的内容。
在如何运行您的 Python 脚本中也讨论了这种区别。
从命令行执行
在这种方法中,您希望从命令行执行 Python 脚本。
当您执行脚本时,您将无法以交互方式定义 Python 解释器正在执行的代码。对于本文的目的来说,如何从命令行执行 Python 的细节并不重要,但是您可以展开下面的框来阅读更多关于 Windows、Linux 和 macOS 上命令行之间的差异。
根据操作系统的不同,从命令行告诉计算机执行代码的方式会略有不同。
在 Linux 和 macOS 上,命令行通常如下例所示:
eleanor@realpython:~/Documents$美元符号(
$)之前的部分可能看起来不同,这取决于您的用户名和电脑名称。您输入的命令将在$之后。在 Linux 或 macOS 上,Python 3 可执行文件的名称是python3,所以您应该通过在$后面键入python3 script_name.py来运行 Python 脚本。在 Windows 上,命令提示符通常如下例所示:
C:\Users\Eleanor\Documents>
>之前的部分可能看起来不同,这取决于您的用户名。您输入的命令将在>之后。在 Windows 上,Python 3 可执行文件的名字通常是python,所以您应该通过在>后面键入python script_name.py来运行 Python 脚本。无论您使用什么操作系统,您在本文中使用的 Python 脚本的输出都是相同的,因此本文只显示 Linux 和 macOS 风格的输入,输入行将从
$开始。现在您应该从命令行执行
execution_methods.py脚本,如下所示:$ python3 execution_methods.py This is my file to test Python's execution methods. The variable __name__ tells me which context this file is running in. The value of __name__ is: '__main__'在本例中,您可以看到
__name__的值为'__main__',其中引号(')告诉您该值为字符串类型。记住,在 Python 中,用单引号(
')和双引号(")定义的字符串没有区别。你可以阅读更多关于在 Python 的基本数据类型中定义字符串的内容。如果您在脚本中包含一个 shebang 行并直接执行它(
./execution_methods.py),或者使用 IPython 或 Jupyter 笔记本中的%run魔法,您会发现相同的输出。通过在命令中添加
-m参数,您还可以看到从包中执行的 Python 脚本。大多数情况下,当你使用pip:python3 -m pip install package_name时,你会看到这个推荐。添加
-m参数运行包的__main__.py模块中的代码。你可以在How to Publish a Open-Source Python Package to PyPI中找到更多关于__main__.py文件的信息。在所有这三种情况下,
__name__都有相同的值:字符串'__main__'。技术细节:Python 文档明确定义了
__name__何时拥有值'__main__':当从标准输入、脚本或交互式提示中读取时,模块的
__name__被设置为等于'__main__'。(来源
__name__与__doc__、__package__和其他属性一起存储在模块的全局名称空间中。你可以在 Python 数据模型文档中读到更多关于这些属性的内容,尤其是模块和包,在 Python 导入文档中。导入模块或交互式解释器
现在让我们看看 Python 解释器执行代码的第二种方式:导入。当你在开发一个模块或脚本时,你很可能想要利用别人已经构建好的模块,你可以用
import关键字来实现。在导入过程中,Python 会执行指定模块中定义的语句(但只在第一次导入模块时)。为了演示导入
execution_methods.py文件的结果,启动交互式 Python 解释器,然后导入execution_methods.py文件:
>>> import execution_methods
This is my file to test Python's execution methods.
The variable __name__ tells me which context this file is running in.
The value of __name__ is: 'execution_methods'
在这段代码输出中,您可以看到 Python 解释器执行了对 print() 的三次调用。输出的前两行与您在命令行上将该文件作为脚本执行时完全相同,因为前两行都没有变量。但是,第三个print()的输出存在差异。
当 Python 解释器导入代码时,__name__的值被设置为与正在导入的模块的名称相同。您可以在上面的第三行输出中看到这一点。__name__的值为'execution_methods',这是 Python 从中导入的.py文件的名称。
请注意,如果您在没有退出 Python 的情况下再次import该模块,将不会有输出。
注意:关于 Python 中导入如何工作的更多信息,请查看 Python 导入:高级技术和技巧以及Python 中的绝对与相对导入。
Python 主函数的最佳实践
既然您已经看到了 Python 处理不同执行模式的不同之处,那么了解一些可以使用的最佳实践是很有用的。每当您想要编写可以作为脚本和在另一个模块或交互式会话中导入运行的代码时,这些都适用。
您将了解四种最佳实践,以确保您的代码可以服务于双重目的:
- 将大部分代码放入函数或类中。
- 使用
__name__来控制代码的执行。 - 创建一个名为
main()的函数来包含您想要运行的代码。 - 从
main()调用其他函数。
将大部分代码放入函数或类
请记住,Python 解释器在导入模块时会执行模块中的所有代码。有时,您编写的代码会有您希望用户控制的副作用,例如:
- 运行需要很长时间的计算
- 写入磁盘上的文件
- 打印会扰乱用户终端的信息
在这些情况下,您希望用户控制触发代码的执行,而不是让 Python 解释器在导入您的模块时执行代码。
因此,最佳实践是将大多数代码包含在一个函数或一个类中。这是因为当 Python 解释器遇到 def或class关键字时,它只存储那些定义供以后使用,并不实际执行它们,直到你告诉它这样做。
将下面的代码保存到一个名为best_practices.py的文件中来演示这个想法:
1from time import sleep
2
3print("This is my file to demonstrate best practices.")
4
5def process_data(data):
6 print("Beginning data processing...")
7 modified_data = data + " that has been modified"
8 sleep(3)
9 print("Data processing finished.")
10 return modified_data
在这段代码中,首先从 time模块中导入 sleep() 。
暂停解释器,无论你给定多少秒作为一个参数,它将产生一个函数,这个函数需要很长时间来运行。接下来,使用print()打印一个句子,描述这段代码的用途。
然后,定义一个名为process_data()的函数,它做五件事:
- 打印一些输出,告诉用户数据处理正在开始
- 修改输入数据
- 使用
sleep()暂停执行三秒钟 - 打印一些输出,告诉用户处理已经完成
- 返回修改后的数据
在命令行上执行最佳实践文件
现在,当您在命令行上将这个文件作为脚本执行时,会发生什么呢?
Python 解释器将执行函数定义之外的from time import sleep和print()行,然后创建名为process_data()的函数定义。然后,脚本将退出,不再做任何事情,因为脚本没有任何执行process_data()的代码。
下面的代码块显示了将该文件作为脚本运行的结果:
$ python3 best_practices.py
This is my file to demonstrate best practices.
我们在这里看到的输出是第一个print()的结果。注意,从time导入并定义process_data()不会产生输出。具体来说,在process_data()定义内的print()调用的输出不会被打印出来!
在另一个模块或交互式解释器中导入最佳实践文件
当您在交互式会话(或另一个模块)中导入此文件时,Python 解释器将执行与将文件作为脚本执行时完全相同的步骤。
一旦 Python 解释器导入了文件,您就可以使用在您导入的模块中定义的任何变量、类或函数。为了演示这一点,我们将使用交互式 Python 解释器。启动交互式解释器,然后键入import best_practices:
>>> import best_practices This is my file to demonstrate best practices.导入
best_practices.py文件的唯一输出来自在process_data()之外定义的第一个print()调用。从time导入并定义process_data()不会产生输出,就像从命令行执行代码一样。使用
if __name__ == "__main__"来控制代码的执行如果您希望在从命令行运行脚本时执行
process_data(),而不是在 Python 解释器导入文件时执行,该怎么办?您可以使用
if __name__ == "__main__"习语来确定执行上下文,并且只有当__name__等于"__main__"时,才有条件运行process_data()。将下面的代码添加到您的best_practices.py文件的底部:11if __name__ == "__main__": 12 data = "My data read from the Web" 13 print(data) 14 modified_data = process_data(data) 15 print(modified_data)在这段代码中,您添加了一个条件语句来检查
__name__的值。当__name__等于字符串"__main__"时,该条件将评估为True。记住,变量__name__的特殊值"__main__"意味着 Python 解释器正在执行你的脚本,而不是导入它。在条件块中,您添加了四行代码(第 12、13、14 和 15 行):
- 第 12 行和第 13 行:您正在创建一个变量
data,它存储您从 Web 上获取的数据并打印出来。- 第 14 行:你在处理数据。
- 第 15 行:您正在打印修改后的数据。
现在,从命令行运行您的
best_practices.py脚本,看看输出将如何变化:$ python3 best_practices.py This is my file to demonstrate best practices. My data read from the Web Beginning data processing... Data processing finished. My data read from the Web that has been modified首先,输出显示了在
process_data()之外print()调用的结果。之后,打印出
data的值。这是因为当 Python 解释器将文件作为脚本执行时,变量__name__的值为"__main__",所以条件语句的值为True。接下来,您的脚本调用
process_data()并传入data进行修改。当process_data()执行时,它在输出中打印一些状态信息。最后,打印出modified_data的值。现在,您应该检查当您从交互式解释器(或另一个模块)导入
best_practices.py文件时发生了什么。下面的示例演示了这种情况:
>>> import best_practices
This is my file to demonstrate best practices.
请注意,您将获得与在文件末尾添加条件语句之前相同的行为!这是因为__name__变量有值"best_practices",所以 Python 不执行块内的代码,包括process_data(),因为条件语句求值为False。
创建一个名为 main()的函数来包含您想要运行的代码
现在,您可以编写 Python 代码,这些代码可以作为脚本从命令行运行,并且在导入时不会产生不必要的副作用。接下来,您将学习如何编写代码,使其他 Python 程序员能够轻松理解您的意思。
很多语言,比如 C 、 C++ 、 Java 等,都定义了一个必须被调用的特殊函数main(),操作系统在执行编译好的程序时自动调用这个函数。这个函数通常被称为入口点,因为它是执行进入程序的地方。
相比之下,Python 没有作为脚本入口点的特殊函数。实际上,您可以给 Python 脚本中的入口点函数起任何您想要的名字!
尽管 Python 没有给名为main()的函数赋予任何意义,但最佳实践是将入口点函数命名为main() 。这样,任何阅读您的脚本的其他程序员都会立即知道这个函数是完成脚本主要任务的代码的起点。
此外,main()应该包含 Python 解释器执行文件时想要运行的任何代码。这比直接将代码放入条件块要好,因为如果用户导入您的模块,他们可以重用main()。
更改best_practices.py文件,使其看起来像下面的代码:
1from time import sleep
2
3print("This is my file to demonstrate best practices.")
4
5def process_data(data):
6 print("Beginning data processing...")
7 modified_data = data + " that has been modified"
8 sleep(3)
9 print("Data processing finished.")
10 return modified_data
11
12def main():
13 data = "My data read from the Web"
14 print(data)
15 modified_data = process_data(data)
16 print(modified_data)
17
18if __name__ == "__main__":
19 main()
在这个例子中,您添加了main()的定义,它包含了之前在条件块中的代码。然后,您更改了条件块,使其执行main()。如果您将此代码作为脚本运行或导入,您将获得与上一节相同的输出。
从 main() 调用其他函数
Python 中另一个常见的做法是让main()执行其他函数,而不是将完成任务的代码包含在main()中。当您可以将整个任务由几个可以独立执行的更小的子任务组成时,这尤其有用。
例如,您可能有一个执行以下操作的脚本:
- 从可能是数据库、磁盘上的文件或 web API 的源中读取数据文件
- 处理数据
- 将处理过的数据写入另一个位置
如果您在单独的功能中实现这些子任务中的每一个,那么您(或另一个用户)很容易重用其中的一些步骤,而忽略那些您不想要的步骤。然后可以在main()中创建一个默认的工作流,两全其美。
是否将这种实践应用到您的代码中是您自己的判断。将工作分成几个功能使得重用更容易,但是增加了其他人试图解释你的代码的难度,因为他们必须跟随程序流中的几个跳跃。
修改您的best_practices.py文件,使其看起来像下面的代码:
1from time import sleep
2
3print("This is my file to demonstrate best practices.")
4
5def process_data(data):
6 print("Beginning data processing...")
7 modified_data = data + " that has been modified"
8 sleep(3)
9 print("Data processing finished.")
10 return modified_data
11
12def read_data_from_web():
13 print("Reading data from the Web")
14 data = "Data from the web"
15 return data
16
17def write_data_to_database(data):
18 print("Writing data to a database")
19 print(data)
20
21def main():
22 data = read_data_from_web()
23 modified_data = process_data(data)
24 write_data_to_database(modified_data)
25
26if __name__ == "__main__":
27 main()
在这个示例代码中,文件的前 10 行与之前的内容相同。第 12 行的第二个函数定义创建并返回一些样本数据,第 17 行的第三个函数定义模拟将修改后的数据写入数据库。
第 21 行定义了main()。在本例中,您修改了main(),使其依次调用数据读取、数据处理和数据写入函数。
首先,从read_data_from_web()创建data。这个data被传递给process_data(),T3 返回modified_data。最后将modified_data传入write_data_to_database()。
脚本的最后两行是条件块,它检查__name__并在if语句为True时运行main()。
现在,您可以从命令行运行整个处理管道,如下所示:
$ python3 best_practices.py
This is my file to demonstrate best practices.
Reading data from the Web
Beginning data processing...
Data processing finished.
Writing processed data to a database
Data from the web that has been modified
在这个执行的输出中,您可以看到 Python 解释器执行了main(),它执行了read_data_from_web()、process_data()和write_data_to_database()。但是,您也可以导入best_practices.py文件,并对不同的输入数据源重复使用process_data(),如下所示:
>>> import best_practices as bp This is my file to demonstrate best practices. >>> data = "Data from a file" >>> modified_data = bp.process_data(data) Beginning data processing... Data processing finished. >>> bp.write_data_to_database(modified_data) Writing processed data to a database Data from a file that has been modified在这个例子中,您导入了
best_practices并将这个代码的名称缩短为bp。导入过程导致 Python 解释器执行
best_practices.py文件中的所有代码行,因此输出显示了解释文件用途的代码行。然后,您将文件中的数据存储在
data中,而不是从 Web 上读取数据。然后,您重用了best_practices.py文件中的process_data()和write_data_to_database()。在这种情况下,您利用了重用代码的优势,而不是在main()中定义所有的逻辑。Python 主函数最佳实践总结
这里是你刚刚看到的关于 Python 中的
main()的四个关键最佳实践:
将需要长时间运行或对计算机有其他影响的代码放在函数或类中,这样您就可以精确地控制代码的执行时间。
使用不同的值
__name__来确定上下文,并用条件语句改变代码的行为。您应该将您的入口点函数命名为
main(),以便传达该函数的意图,尽管 Python 并没有赋予名为main()的函数任何特殊的意义。如果您想重用代码中的功能,请在
main()之外的函数中定义逻辑,并在main()内调用这些函数。结论
恭喜你!您现在知道了如何创建 Python
main()函数。您学到了以下内容:
了解变量
__name__的值对于编写具有可执行脚本和可导入模块双重用途的代码非常重要。
__name__根据您执行 Python 文件的方式呈现不同的值。__name__将等于:
"__main__"从命令行或用python -m执行文件时(执行一个包的__main__.py文件)- 模块的名称(如果正在导入模块)
当您想要开发可重用代码时,Python 程序员已经开发了一套好的实践。
现在您已经准备好编写一些令人敬畏的 Python
main()函数代码了!立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 在 Python 中定义主要函数******


 浙公网安备 33010602011771号
浙公网安备 33010602011771号