
RealPython-中文系列教程-十-
RealPython 中文系列教程(十)
原文:RealPython
Python 中的条件语句
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的条件语句(if/elif/else)
从本系列前面的教程中,您现在已经掌握了相当多的 Python 代码。到目前为止,您所看到的一切都是由顺序执行组成的,其中语句总是按照指定的顺序一个接一个地执行。
但世界往往比这更复杂。通常,程序需要跳过一些语句,重复执行一系列语句,或者在不同的语句集之间进行选择。
这就是控制结构的用武之地。控制结构指导程序中语句的执行顺序(称为程序的控制流)。
这里是你将在本教程中学到的:你将遇到你的第一个 Python 控制结构,if语句。
在现实世界中,我们通常必须评估周围的信息,然后根据我们的观察选择一种或另一种行动方案:
如果天气好的话,我就去割草。(言下之意,如果天气不好,那我就不割草了。)
在 Python 程序中,if语句是你如何执行这种决策的。它允许根据表达式的值有条件地执行一条或一组语句。
本教程的大纲如下:
- 首先,您将快速浏览一下最简单形式的
if语句。 - 接下来,使用
if语句作为模型,您将看到为什么控制结构需要某种机制来将语句分组到复合语句或块中。您将学习如何在 Python 中实现这一点。 - 最后,您将把它们联系在一起,并学习如何编写复杂的决策代码。
准备好了吗?开始了。
参加测验:通过我们的交互式“Python 条件语句”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
if语句简介
我们将从最基本类型的if语句开始。最简单的形式是这样的:
if <expr>:
<statement>
在上面显示的表单中:
<expr>是一个在布尔上下文中计算的表达式,如 Python 教程中的运算符和表达式中的逻辑运算符一节所述。<statement>是有效的 Python 语句,必须缩进。(你很快就会明白为什么。)
如果<expr>为真(评估为“真”值),则执行<statement>。如果<expr>为假,那么<statement>被跳过并且不被执行。
请注意,<expr>后面的冒号(:)是必需的。一些编程语言要求<expr>用括号括起来,但是 Python 不需要。
以下是这种类型的if语句的几个例子:
>>> x = 0 >>> y = 5 >>> if x < y: # Truthy ... print('yes') ... yes >>> if y < x: # Falsy ... print('yes') ... >>> if x: # Falsy ... print('yes') ... >>> if y: # Truthy ... print('yes') ... yes >>> if x or y: # Truthy ... print('yes') ... yes >>> if x and y: # Falsy ... print('yes') ... >>> if 'aul' in 'grault': # Truthy ... print('yes') ... yes >>> if 'quux' in ['foo', 'bar', 'baz']: # Falsy ... print('yes') ...注意:如果你在 REPL 会话中交互地尝试这些例子,你会发现,当你在输入
print('yes')语句后点击Enter时,什么都不会发生。因为这是一个多行语句,你需要第二次点击
Enter来告诉解释器你已经完成了。在从脚本文件执行的代码中,这个额外的换行符是不必要的。分组语句:缩进和块
到目前为止,一切顺利。
但是,假设您想要评估一个条件,然后如果它为真,则执行多项操作:
如果天气好,我会:
- 修剪草坪
- 给花园除草
- 带狗去散步
(如果天气不好,我就不会做这些事情。)
在上面显示的所有例子中,每个
if <expr>:后面只有一个<statement>。需要有某种方法来说“如果<expr>是真的,做以下所有的事情。”大多数编程语言通常采用的方法是定义一个语法装置,将多个语句组合成一个复合语句或块。一个块在语法上被认为是一个单一的实体。当它是一个
if语句的目标,并且<expr>为真时,那么块中的所有语句都被执行。如果<expr>是假的,那么它们都不是。几乎所有的编程语言都提供了定义块的能力,但是它们提供的方式不尽相同。我们来看看 Python 是怎么做的。
Python:这都是关于缩进的
Python 遵循一个被称为越位规则的惯例,这个术语是由英国计算机科学家彼得·j·兰丁创造的。(该术语取自足协足球中的越位法。)遵循越位规则的语言通过缩进来定义块。Python 是相对较小的一组场外规则语言中的一种。
回想一下之前关于 Python 程序结构的教程,缩进在 Python 程序中有特殊的意义。现在你知道为什么了:缩进是用来定义复合语句或者块的。在 Python 程序中,缩进到同一级别的连续语句被视为同一块的一部分。
因此,Python 中的复合
if语句如下所示:1if <expr>: 2 <statement> 3 <statement> 4 ... 5 <statement> 6<following_statement>这里,匹配缩进级别的所有语句(第 2 行到第 5 行)都被认为是同一个块的一部分。如果
<expr>为真,则执行整个块;如果<expr>为假,则跳过整个块。无论哪种方式,执行都是从<following_statement>(第 6 行)开始的。
Python Compound if Statement 请注意,没有表示块结束的标记。更确切地说,块的结尾是由一个比块本身的行缩进量小的行来表示的。
注意:在 Python 文档中,由缩进定义的一组语句通常被称为套件。本教程系列交替使用术语块和套件。
考虑这个脚本文件
foo.py:1if 'foo' in ['bar', 'baz', 'qux']: 2 print('Expression was true') 3 print('Executing statement in suite') 4 print('...') 5 print('Done.') 6print('After conditional')运行
foo.py产生以下输出:C:\Users\john\Documents>python foo.py After conditional第 2 行到第 5 行的四个
print()语句缩进到相同的级别。它们构成了条件为真时将被执行的块。但它是假的,所以块中的所有语句都被跳过。到达复合if语句的末尾后(无论是否执行第 2 到 5 行的块中的语句),执行将继续到具有较小缩进级别的第一条语句:第 6 行的print()语句。块可以嵌套到任意深度。每个缩进定义一个新块,每个突出结束前一个块。由此产生的结构是直截了当的、一致的和直观的。
下面是一个更复杂的脚本文件,名为
blocks.py:# Does line execute? Yes No # --- -- if 'foo' in ['foo', 'bar', 'baz']: # x print('Outer condition is true') # x if 10 > 20: # x print('Inner condition 1') # x print('Between inner conditions') # x if 10 < 20: # x print('Inner condition 2') # x print('End of outer condition') # x print('After outer condition') # x运行该脚本时生成的输出如下所示:
C:\Users\john\Documents>python blocks.py Outer condition is true Between inner conditions Inner condition 2 End of outer condition After outer condition注意:如果您想知道,在 REPL 会话中输入多行语句时,越位规则是需要额外换行符的原因。否则,解释器无法知道已经进入了该块的最后一条语句。
其他语言是做什么的?
也许你很好奇有哪些选择。在不遵守越位规则的语言中,如何定义块?
大多数编程语言使用的策略是指定特殊的标记来标记一个块的开始和结束。例如,在 Perl 中,块是用成对的花括号(
{})定义的,如下所示:# (This is Perl, not Python) if (<expr>) { <statement>; <statement>; ... <statement>; } <following_statement>;C/C++、 Java 以及一大堆其他语言都是这样使用花括号的。
Compound if Statement in C/C++, Perl, and Java 其他语言,比如 Algol 和 Pascal,用关键字
begin和end来括住块。哪个更好?
情人眼里出西施。总的来说,程序员倾向于强烈地感受到他们是如何做事的。关于越位规则优点的辩论可能会相当激烈。
有利的一面是:
- Python 对缩进的使用是干净、简洁和一致的。
- 在不使用越界规则的编程语言中,代码的缩进完全独立于块定义和代码函数。有可能编写的代码缩进的方式与代码执行的方式并不匹配,因此当一个人浏览它时会产生错误的印象。这种错误在 Python 中几乎是不可能犯的。
- 使用缩进来定义块迫使您维护您可能无论如何都应该使用的代码格式标准。
消极的一面是:
- 许多程序员不喜欢被迫以某种方式做事。他们往往对什么好看什么不好看有强烈的看法,他们不喜欢被硬塞给一个特定的选择。
- 一些编辑器在缩进行的左边混合插入空格和制表符,这使得 Python 解释器很难确定缩进级别。另一方面,经常可以配置编辑器不这样做。不管用什么语言,在源代码中混合使用制表符和空格通常是不可取的。
不管你喜不喜欢,如果你在用 Python 编程,你就会被越位规则所困。Python 中的所有控件结构都使用它,您将在以后的几个教程中看到。
值得一提的是,许多习惯于使用更传统的块定义方式的程序员最初对 Python 的方式感到畏惧,但现在已经习惯了,甚至越来越喜欢它。
else和elif条款现在您知道了如何使用
if语句有条件地执行一条语句或几条语句的块。是时候找出你还能做什么了。有时,您希望评估一个条件,如果条件为真,则采用一条路径,如果条件不为真,则指定另一条路径。这是通过一个
else子句实现的:if <expr>: <statement(s)> else: <statement(s)>如果
<expr>为真,则执行第一套,跳过第二套。如果<expr>为假,则跳过第一套,执行第二套。无论哪种方式,在第二个 suite 之后,执行将继续。如上所述,这两个套件都是由缩进定义的。在本例中,
x小于50,因此执行第一个套件(第 4 行到第 5 行),跳过第二个套件(第 7 行到第 8 行):


1>>> x = 20
2
3>>> if x < 50:
4... print('(first suite)')
5... print('x is small')
6... else:
7... print('(second suite)')
8... print('x is large')
9...
10(first suite)
11x is small
另一方面,这里的x大于50,所以第一个套件被忽略,第二个套件被执行:
1>>> x = 120 2>>> 3>>> if x < 50: 4... print('(first suite)') 5... print('x is small') 6... else: 7... print('(second suite)') 8... print('x is large') 9... 10(second suite) 11x is large还有基于几种选择的分支执行的语法。为此,使用一个或多个
elif(简称 else if )子句。Python 依次评估每个<expr>,并执行对应于第一个为真的套件。如果没有一个表达式为真,并且指定了一个else子句,则执行其套件:if <expr>: <statement(s)> elif <expr>: <statement(s)> elif <expr>: <statement(s)> ... else: <statement(s)>可以指定任意数量的
elif子句。else子句是可选的。如果存在,只能有一个,并且必须在最后指定:
>>> name = 'Joe'
>>> if name == 'Fred':
... print('Hello Fred')
... elif name == 'Xander':
... print('Hello Xander')
... elif name == 'Joe':
... print('Hello Joe')
... elif name == 'Arnold':
... print('Hello Arnold')
... else:
... print("I don't know who you are!")
...
Hello Joe
最多执行一个指定的代码块。如果没有包含一个else子句,并且所有条件都为假,那么不会执行任何块。
注意:使用一个冗长的if / elif / else系列可能会有点不雅,尤其是当动作是像print()这样简单的语句时。在许多情况下,可能有更好的方法来完成同样的事情。
下面是使用dict.get()方法的上述示例的一个可能的替代方法:
>>> names = { ... 'Fred': 'Hello Fred', ... 'Xander': 'Hello Xander', ... 'Joe': 'Hello Joe', ... 'Arnold': 'Hello Arnold' ... } >>> print(names.get('Joe', "I don't know who you are!")) Hello Joe >>> print(names.get('Rick', "I don't know who you are!")) I don't know who you are!回想一下 Python 字典的教程,
dict.get()方法在字典中搜索指定的键,如果找到就返回相关的值,如果没有找到就返回给定的默认值。带有
elif子句的if语句使用短路评估,类似于您看到的and和or操作符。一旦发现其中一个表达式为真并且执行了它的块,就不会测试其余的表达式。下面演示了这一点:
>>> var # Not defined
Traceback (most recent call last):
File "<pyshell#58>", line 1, in <module>
var
NameError: name 'var' is not defined
>>> if 'a' in 'bar':
... print('foo')
... elif 1/0:
... print("This won't happen")
... elif var:
... print("This won't either")
...
foo
第二个表达式包含被零除,第三个引用未定义的变量 var。这两种情况都会引发错误,但都不会被计算,因为指定的第一个条件为真。
单行if语句
习惯上把if <expr>写在一行上,把<statement>缩进下一行,就像这样:
if <expr>:
<statement>
但是允许在一行上写完整的if语句。以下内容在功能上等同于上面的示例:
if <expr>: <statement>
同一行甚至可以有多个<statement>,用分号隔开:
if <expr>: <statement_1>; <statement_2>; ...; <statement_n>
但这意味着什么呢?有两种可能的解释:
-
如果
<expr>为真,则执行<statement_1>。然后,无条件执行
<statement_2> ... <statement_n>,不管<expr>是否为真。 -
如果
<expr>为真,则执行所有的<statement_1> ... <statement_n>。否则,不要执行其中任何一个。
Python 采取的是后一种解读。分隔<statements>的分号比<expr>后面的冒号具有更高的优先级——在计算机行话中,分号被认为比冒号绑定得更紧密。因此,<statements>被视为一个套件,要么全部执行,要么都不执行:
>>> if 'f' in 'foo': print('1'); print('2'); print('3') ... 1 2 3 >>> if 'z' in 'foo': print('1'); print('2'); print('3') ...可以在同一行指定多个语句作为一个
elif或else子句:
>>> x = 2
>>> if x == 1: print('foo'); print('bar'); print('baz')
... elif x == 2: print('qux'); print('quux')
... else: print('corge'); print('grault')
...
qux
quux
>>> x = 3
>>> if x == 1: print('foo'); print('bar'); print('baz')
... elif x == 2: print('qux'); print('quux')
... else: print('corge'); print('grault')
...
corge
grault
虽然所有这些都可行,解释器也允许,但通常不鼓励这样做,因为这会导致可读性差,特别是对于复杂的if语句。 PEP 8 特别推荐反对。
和往常一样,这在某种程度上是一个品味问题。乍看之下,大多数人会觉得下面的例子比上面的例子更吸引人,也更容易理解:
>>> x = 3 >>> if x == 1: ... print('foo') ... print('bar') ... print('baz') ... elif x == 2: ... print('qux') ... print('quux') ... else: ... print('corge') ... print('grault') ... corge grault但是,如果一个
if语句足够简单,把它放在一行可能是合理的。像这样的事情可能不会引起任何人太多的愤怒:debugging = True # Set to True to turn debugging on. . . . if debugging: print('About to call function foo()') foo()条件表达式(Python 的三元运算符)
Python 支持一个额外的决策实体,称为条件表达式。(在 Python 文档的不同地方,它也被称为条件运算符或三元运算符。)2005 年,Guido 提议将条件表达式添加到 PEP 308 语言中,并对此开了绿灯。
最简单的形式是,条件表达式的语法如下:
<expr1> if <conditional_expr> else <expr2>这不同于上面列出的
if语句形式,因为它不是一个控制结构来指导程序执行的流程。它更像是一个定义表达式的运算符。在上面的例子中,首先计算<conditional_expr>。如果为真,表达式的计算结果为<expr1>。如果为 false,表达式的计算结果为<expr2>。注意这个不明显的顺序:首先计算中间的表达式,然后基于这个结果,返回末端的一个表达式。以下是一些例子,希望有助于澄清:
>>> raining = False
>>> print("Let's go to the", 'beach' if not raining else 'library')
Let's go to the beach
>>> raining = True
>>> print("Let's go to the", 'beach' if not raining else 'library')
Let's go to the library
>>> age = 12
>>> s = 'minor' if age < 21 else 'adult'
>>> s
'minor'
>>> 'yes' if ('qux' in ['foo', 'bar', 'baz']) else 'no'
'no'
注意: Python 的条件表达式类似于许多其他语言使用的<conditional_expr> ? <expr1> : <expr2>语法——C、Perl 和 Java 等等。事实上,?:操作符在这些语言中通常被称为三元操作符,这可能是 Python 的条件表达式有时被称为 Python 三元操作符的原因。
你可以在 PEP 308 中看到,<conditional_expr> ? <expr1> : <expr2>语法曾被考虑用于 Python,但最终被上面显示的语法所取代。
条件表达式的一个常见用途是选择变量赋值。例如,假设您想找出两个数字中较大的一个。当然,有一个内置的函数, max() ,你可以使用它来做这件事。但是假设您想从头开始编写自己的代码。
您可以使用带有else子句的标准if语句:
>>> if a > b: ... m = a ... else: ... m = b ...但是条件表达式更短,也更具可读性:
>>> m = a if a > b else b
请记住,条件表达式在语法上的行为类似于表达式。它可以用作较长表达式的一部分。条件表达式的优先级比几乎所有其他操作符都低,所以需要用括号将它单独分组。
在下面的例子中,+操作符比条件表达式绑定得更紧密,所以首先计算1 + x和y + 2,然后计算条件表达式。第二种情况中的括号是不必要的,不会改变结果:
>>> x = y = 40 >>> z = 1 + x if x > y else y + 2 >>> z 42 >>> z = (1 + x) if x > y else (y + 2) >>> z 42如果希望首先计算条件表达式,需要用分组括号将它括起来。在下一个示例中,首先计算
(x if x > y else y)。结果是y,也就是40,所以z被赋值1 + 40 + 2=43:
>>> x = y = 40
>>> z = 1 + (x if x > y else y) + 2
>>> z
43
如果您使用条件表达式作为更大表达式的一部分,那么使用分组括号进行说明可能是个好主意,即使它们并不需要。
条件表达式也像复合逻辑表达式一样使用短路求值。如果不需要,条件表达式的某些部分不会被计算。
在表达式<expr1> if <conditional_expr> else <expr2>中:
- 如果
<conditional_expr>为真,则返回<expr1>并且不评估<expr2>。 - 如果
<conditional_expr>为假,则返回<expr2>并且不评估<expr1>。
和以前一样,您可以通过使用会引起错误的术语来验证这一点:
>>> 'foo' if True else 1/0 'foo' >>> 1/0 if False else 'bar' 'bar'在这两种情况下,
1/0项都不会被计算,所以不会引发异常。条件表达式也可以链接在一起,作为一种可选的
if/elif/else结构,如下所示:
>>> s = ('foo' if (x == 1) else
... 'bar' if (x == 2) else
... 'baz' if (x == 3) else
... 'qux' if (x == 4) else
... 'quux'
... )
>>> s
'baz'
不清楚这是否比相应的if / elif / else语句有任何显著的优势,但它是语法正确的 Python。
Python pass语句
偶尔,您可能会发现您想要编写一个所谓的代码存根:一个占位符,您最终将在其中放置尚未实现的代码块。
在使用标记分隔符定义代码块的语言中,比如 Perl 和 C 中的花括号,空分隔符可以用来定义代码存根。例如,以下是合法的 Perl 或 C 代码:
# This is not Python
if (x)
{
}
这里,空花括号定义了一个空块。Perl 或者 C 会对表达式x求值,然后即使是真的,也不动声色的什么都不做。
因为 Python 使用缩进而不是分隔符,所以不可能指定空块。如果你用if <expr>:引入一个if语句,那么在它后面必须有一些东西,要么在同一行,要么缩进到下一行。
考虑这个脚本foo.py:
if True:
print('foo')
如果你试着运行foo.py,你会得到这个:
C:\Users\john\Documents\Python\doc>python foo.py
File "foo.py", line 3
print('foo')
^
IndentationError: expected an indented block
Python pass语句解决了这个问题。它根本不会改变程序的行为。它是一个占位符,在语法上需要一个语句,但您实际上不想做任何事情的任何情况下,它都可以让解释器满意:
if True:
pass
print('foo')
现在foo.py运行无误:
C:\Users\john\Documents\Python\doc>python foo.py
foo
结论
完成本教程后,您将开始编写超越简单顺序执行的 Python 代码:
- 向您介绍了控制结构的概念。这些复合语句改变了程序控制流——程序语句的执行顺序。
- 您学习了如何将单个语句组合成一个块或组。
- 您遇到了您的第一个控制结构,即
if语句,这使得有条件地执行基于程序数据评估的语句或块成为可能。
所有这些概念对于开发更复杂的 Python 代码都至关重要。
接下来的两个教程将介绍两个新的控制结构: while 语句和 for 语句。这些结构有助于迭代,重复执行一个语句或语句块。
参加测验:通过我们的交互式“Python 条件语句”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Python Program StructureConditional Statements in PythonPython "while" Loops »
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的条件语句(if/elif/else)*****
Python 常量:提高代码的可维护性
在编程中,术语常量指的是代表在程序执行期间不变的值的名称。常量是编程中的一个基本概念,Python 开发人员在很多情况下都会用到它们。然而,Python 没有定义常量的专用语法。实际上,Python 常量只是从不改变的变量。
为了防止程序员重新分配一个应该包含常量的名称,Python 社区采用了一种命名约定:使用大写字母。对于每一个 Pythonista 来说,知道什么是常量,以及为什么和什么时候使用它们是很重要的。
在本教程中,您将学习如何:
- 在 Python 中正确地定义常数
- 识别一些内置常数
- 使用常量来提高代码的可读性、可重用性、可维护性和可维护性
- 应用不同的方法组织和管理项目中的常量
- 在 Python 中使用几种技术使常量成为严格常量
通过学习定义和使用常量,您将极大地提高代码的可读性、可维护性和可重用性。
为了最大限度地从本教程中学习,您将需要 Python 变量、函数、模块、包和名称空间的基础知识。你还需要知道 Python 中面向对象编程的基础知识。
示例代码: 点击此处下载示例代码,向您展示如何在 Python 中使用常量。
理解常数和变量
变量和常数是计算机编程中两个历史性的基本概念。大多数编程语言都使用这些概念来操作数据,并以一种有效且符合逻辑的方式工作。
变量和常量可能会出现在每个项目、应用程序、库或您编写的其他代码中。问题是:实际中变量和常数是什么?
是什么变量
在数学中,变量被定义为一个符号,指的是可以随时间变化的值或量。在编程中,变量也是通常与包含值、对象或数据的内存地址相关联的符号或名称。与数学一样,编程变量的内容可以在定义它的代码执行期间改变。
变量通常有一个描述性的名字,这个名字以某种方式与目标值或对象相关联。这个目标值可以是任何数据类型。因此,您可以使用变量来表示数字、字符串、序列、自定义对象等等。
您可以对变量执行两个主要操作:
- 访问它的值
- 给分配一个新值
在大多数编程语言中,您可以通过在代码中引用变量名来访问与变量关联的值。为了给一个给定的变量赋值,您将使用一个赋值语句,它通常由变量名、赋值操作符和期望值组成。
在实践中,您会发现许多可以表示为变量的数量、数据和对象的例子。一些例子包括温度、速度、时间和长度。其他可以作为变量处理的数据例子包括一个网络应用的注册用户数量,一个视频游戏的活跃角色数量,以及一个跑步者跑了多少英里。
是什么常数
数学也有常数的概念。这个术语指的是永远不会改变的值或量。在编程中,常量是指与在程序执行过程中从不改变的值相关联的名称。
就像变量一样,编程常量由两部分组成:一个名称和一个关联值。该名称将清楚地描述常数是什么。值是常数本身的具体表达。
与变量一样,与给定常数关联的值可以是任何数据类型。因此,您可以定义整数常量、浮点常量、字符常量、字符串常量等等。
在你定义了一个常量之后,它只允许你对它执行一个操作。您只能访问常量的值,但不能随时间改变它。这不同于变量,变量允许你访问它的值,也可以重新赋值。
您将使用常量来表示不会改变的值。在你的日常编程中,你会发现很多这样的价值观。一些例子包括光速、一小时的分钟数和项目根文件夹的名称。
为什么使用常数
在大多数编程语言中,当您在凌晨两点编码时,常量可以防止您在代码的某个地方意外更改它们的值,从而导致无法预料和难以调试的错误。常量还可以帮助您使代码更具可读性和可维护性。
在代码中使用常量而不是直接使用它们的值的一些优点包括:
| 优势 | 描述 |
|---|---|
| 提高可读性 | 在整个程序中代表给定值的描述性名称总是比基本值本身更易读、更明确。例如,一个名为MAX_SPEED的常数比具体的速度值本身更容易阅读和理解。 |
| 明确传达意图 | 大多数人会假设3.14可能指的是π常数。然而,使用Pi、pi或PI名称会比直接使用值更清楚地传达您的意图。这种做法将允许其他开发人员快速准确地理解您的代码。 |
| 更好的可维护性 | 常数使您能够在整个代码中使用相同的名称来标识相同的值。如果您需要更新常量的值,那么您不必更改该值的每个实例。你只需要在一个地方改变这个值:常量定义。这提高了代码的可维护性。 |
| 降低出错风险 | 在整个程序中表示给定值的常数比该值的几个显式实例更不容易出错。假设您根据目标计算对 Pi 使用不同的精度级别。您已经明确使用了每个计算所需精度的值。如果您需要更改一组计算的精度,那么替换这些值很容易出错,因为您最终可能会更改错误的值。为不同的精度级别创建不同的常量并在一个地方更改代码更安全。 |
| 减少调试需求 | 常量在程序的生命周期内保持不变。因为它们总是有相同的值,所以它们不会导致错误和缺陷。这个特性在小型项目中可能不是必需的,但是在有多个开发人员的大型项目中可能是至关重要的。开发人员不必花时间调试任何常量的当前值。 |
| 线程安全的数据存储 | 常量只能访问,不能写入。这个特性使它们成为线程安全的对象,这意味着几个线程可以同时使用一个常量,而没有破坏或丢失底层数据的风险。 |
正如您在本表中所了解到的,常量是编程中的一个重要概念,这是有道理的。它们可以让您的生活更加愉快,让您的代码更加可靠、可维护和可读。那么,什么时候应该使用常量呢?
当使用常量时
生活,尤其是科学,充满了不变的价值观的例子。一些例子包括:
- 3.141592653589793 :用 π 表示的常数,英文拼写为 Pi ,表示圆的周长与其直径的比值
- 2.718281828459045 :用 e 表示的常数,称为欧拉数,与自然对数和复利密切相关
- 3600 秒:一小时中的秒数,在大多数应用中被认为是恒定的,尽管有时会添加闰秒来解释地球自转速度的变化
- -273.15 :以摄氏度表示绝对零度的常数,相当于开尔文温标上的 0 开尔文
以上例子都是人们在生活和科学中常用的常量值。在编程中,您会经常发现自己在处理这些和许多其他类似的值,您可以将它们视为常量。
总之,用一个常量来表示一个量、数量、对象、参数或任何其他在生命周期中保持不变的数据。
在 Python 中定义自己的常量
到目前为止,您已经了解了常量在生活、科学和编程中的一般概念。现在是时候学习 Python 如何处理常量了。首先,你应该知道 Python 没有定义常量的专用语法。
换句话说,Python 没有严格意义上的常量。它只有变量,主要是因为它的动态性质。因此,要在 Python 中拥有一个常量,您需要定义一个永远不会改变的变量,并通过避免对变量本身进行赋值操作来坚持这种行为。
注意:在这一节,你将关注于定义你自己的常数。然而,Python 中内置了一些常量。稍后你会了解到他们。
那么,Python 开发人员如何知道一个给定的变量代表一个常量呢?Python 社区已经决定使用一个强大的命名约定来区分变量和常量。继续阅读,了解更多!
用户定义的常数
要告诉其他程序员给定的值应该被视为常量,您必须使用一个被广泛接受的常量标识符或名称的命名约定。如 PEP 8 的常量部分所述,你应该用大写字母写名字,并用下划线分隔单词。
以下是用户定义 Python 常量的几个例子:
PI = 3.14
MAX_SPEED = 300
DEFAULT_COLOR = "\033[1;34m"
WIDTH = 20
API_TOKEN = "593086396372"
BASE_URL = "https://api.example.com"
DEFAULT_TIMEOUT = 5
ALLOWED_BUILTINS = ("sum", "max", "min", "abs")
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
...
]
请注意,您已经像创建变量一样创建了这些常量。您已经使用了一个描述性的名称、赋值操作符(=)和常量的具体值。
通过只使用大写字母,你在传达这样一种信息,即当前的名字应该被视为一个常量——或者更准确地说,是一个永不改变的变量。因此,其他 Python 开发人员会知道这一点,并且希望不会对手头的变量执行任何赋值操作。
注意:同样,Python 不支持常量或不可重新分配的名称。使用大写字母只是一种约定,并不妨碍开发人员给你的常量赋新值。因此,任何从事代码工作的程序员都需要小心,永远不要编写改变常量值的代码。记住这条规则,因为你也需要遵守它。
因为 Python 常量只是变量,所以两者都遵循相似的命名规则,唯一的区别是常量只使用大写字母。按照这个想法,常量的名称可以:
- 长度不限
- 由大写字母(
A–Z)组成 - 包括数字(
0–9),但不作为第一个字符 - 使用下划线字符(
_)来分隔单词或作为它们的第一个字符
使用大写字母使你的常量从变量中脱颖而出。通过这种方式,其他开发人员将清楚地认识到他们的目的。
作为一般的命名建议,在定义常数时避免缩写名称。常量名称的目的是阐明常量值的含义,以便您以后可以重用它。这个目标需要描述性的名称。避免使用单字母名称、不常见的缩写和通用名称,如NUMBER或MAGNITUDE。
推荐的做法是在任何 import 语句之后的任何.py文件的顶部定义常数。这样,阅读您的代码的人将立即知道常量的用途和预期的处理。
模块级数据常量
模块级数据名是以双下划线开始和结束的特殊名称。一些例子包括诸如__all__、__author__和__version__的名字。在 Python 项目中,这些名称通常被视为常量。
注:在 Python 中,一个 dunder 名字是一个有特殊含义的名字。它以双下划线开始和结束,单词 dunder 是ddouble在 score 下的组合词。
根据 Python 的编码风格指南, PEP 8 ,模块级数据名称应该出现在模块的 docstring 之后,任何import语句之前,除了__future__ imports。
下面是一个示例模块,其中包括一组 dunder 名称:
# greeting.py
"""This module defines some module-level dunder names."""
from __future__ import barry_as_FLUFL
__all__ = ["greet"]
__author__ = "Real Python"
__version__ = "0.1.0"
import sys
def greet(name="World"):
print(f"Hello, {name}!")
print(f"Greetings from version: {__version__}!")
print(f"Yours, {__author__}!")
在这个例子中,__all__预先定义了当您在代码中使用from module import * import 构造时 Python 将导入的名称列表。在这种情况下,用通配符导入的人导入greeting将只是取回greet()函数。他们将无法访问__author__、__version__以及__all__上未列出的其他名称。
注意:from module import *构造允许您一次性导入给定模块中定义的所有名称。属性将导入的名字限制在底层列表中。
Python 社区强烈不鼓励这种import构造,通常被称为通配符导入,因为它会使您当前的名称空间中塞满您可能不会在代码中使用的名称。
相反,__author__和__version__只对代码的作者和用户有意义,而对代码的逻辑本身没有意义。这些名称应该被视为常量,因为在程序执行期间,不允许任何代码更改作者或版本。
注意,greet()函数确实访问了数据名称,但并没有改变它们。下面是greet()在实践中的工作方式:
>>> from greeting import * >>> greet() Hello, World! Greetings from version: 0.1.0! Yours, Real Python!一般来说,没有硬性规定阻止你定义自己的模块级数据名。然而,Python 文档强烈警告不要使用除了那些被社区普遍接受和使用的名字之外的名字。核心开发人员将来可能会在没有任何警告的情况下向该语言引入新的数据名称。
将常量付诸实施
到目前为止,您已经了解了常量及其在编程中的作用和重要性。您还了解到 Python 不支持严格常量。这就是为什么你可以把常数看成是永远不变的变量。
在接下来的几节中,您将编写一些例子来说明常量在日常编码工作中的价值。
替换幻数以提高可读性
在编程中,术语幻数指的是直接出现在你的代码中,没有任何解释的任何数字。它是一个突如其来的值,使你的代码变得神秘而难以理解。幻数也使得程序可读性更差,更难维护和更新。
例如,假设您有以下函数:
def compute_net_salary(hours): return hours * 35 * (1 - (0.04 + 0.1))你能预先告诉我这个计算中每个数字的含义吗?大概不会。这个函数中的不同数字是幻数,因为你不能从数字本身可靠地推断出它们的含义。
查看此函数的以下重构版本:
HOURLY_SALARY = 35 SOCIAL_SECURITY_TAX_RATE = 0.04 FEDERAL_TAX_RATE = 0.10 def compute_net_salary(hours): return ( hours * HOURLY_SALARY * (1 - (SOCIAL_SECURITY_TAX_RATE + FEDERAL_TAX_RATE)) )有了这些小的更新,你的函数现在读起来很有魅力。您和其他任何阅读您的代码的开发人员肯定能知道这个函数是做什么的,因为您已经用适当命名的常数替换了原来的幻数。每个常数的名称都清楚地解释了其对应的含义。
每当你发现自己在使用一个神奇的数字时,花点时间用一个常数来代替它。这个常量的名称必须是描述性的,并且清楚地解释目标幻数的含义。这种做法会自动提高代码的可读性。
重用可维护性对象
常量的另一个日常使用案例是当一个给定值在代码的不同部分重复出现时。如果您在代码中每个需要的地方插入具体的值,那么如果您出于任何原因需要更改该值,您将会遇到麻烦。在这种情况下,您需要更改每个地方的值。
一次在多个地方更改目标值容易出错。即使您依赖于编辑器的查找和替换特性,您也可以留下一些值的未更改实例,这可能会导致以后出现意外的错误和奇怪的行为。
为了防止这些恼人的问题,您可以用一个正确命名的常数来替换该值。这将允许您设置一次该值,并根据需要在任意多个位置重复该值。如果你需要改变常量的值,那么你只需要在一个地方改变它:常量定义。
例如,假设您正在编写一个
Circle类,您需要一些方法来计算圆的面积、周长等等。在几分钟的编码之后,您最终得到了下面的类:# circle.py class Circle: def __init__(self, radius): self.radius = radius def area(self): return 3.14 * self.radius**2 def perimeter(self): return 2 * 3.14 * self.radius def projected_volume(self): return 4/3 * 3.14 * self.radius**3 def __repr__(self): return f"{self.__class__.__name__}(radius={self.radius})"这个例子揭示了圆周率的近似值(
3.14)是如何在你的Circle类的几个方法中被写成一个幻数的。为什么这种做法是一个问题?比如你需要提高圆周率的精度。然后,您将不得不在至少三个不同的地方手动更改该值,这既繁琐又容易出错,使得您的代码难以维护。注:一般不需要自己定义 Pi。Python 附带了一些内置常量,包括 Pi。稍后你会看到如何利用它。
使用一个命名的常量来存储 Pi 的值是解决这些问题的一个很好的方法。下面是上述代码的增强版本:
# circle.py PI = 3.14 class Circle: def __init__(self, radius): self.radius = radius def area(self): return PI * self.radius**2 def perimeter(self): return 2 * PI * self.radius def projected_volume(self): return 4/3 * PI * self.radius**3 def __repr__(self): return f"{self.__class__.__name__}(radius={self.radius})"这个版本的
Circle用全局常数PI代替幻数。与原始代码相比,这段代码有几个优点。如果你需要增加圆周率的精度,那么你只需要更新文件开头的PI常量的值。这一更新将立即反映在代码的其余部分,而不需要您进行任何额外的操作。注意:常量不应该在代码执行期间改变。但是,在开发过程中,您可以根据需要更改和调整您的常数。在您的
Circle类中更新 Pi 的精度是一个很好的例子,说明了为什么您可能需要在代码开发期间更改常量的值。另一个好处是,现在你的代码可读性更强,更容易理解。常数的名称不言自明,反映了公认的数学术语。
一次声明一个常量,然后多次重用它,就像您在上面的例子中所做的那样,这代表了一个显著的可维护性改进。如果您必须更新常量的值,那么您将在一个地方更新它,而不是在多个地方,这意味着更少的工作和错误风险。
提供默认参数值
使用命名常量为函数、方法和类提供默认参数值是 Python 中的另一种常见做法。在 Python 标准库中有很多这种实践的例子。
例如,
zipfile模块提供了创建、读取、写入、追加和列出 ZIP 文件的工具。这个模块最相关的类是ZipFile。有了ZipFile,你可以高效快速地操作你的 ZIP 文件。
ZipFile的类构造函数接受一个名为compression的参数,它允许你在一些可用的数据压缩方法中进行选择。这个参数是可选的,并且将ZIP_STORED作为其默认值,这意味着默认情况下ZipFile不会压缩输入数据。在这个例子中,
ZIP_STORED是在zipfile中定义的常数。该常数保存未压缩数据的数值。例如,您还会发现其他压缩方法,这些方法由命名的常数表示,如用于 Deflate 压缩算法的ZIP_DEFLATED。
ZipFile类构造函数中的compression参数是一个很好的例子,当您的参数只能接受有限数量的有效值时,可以使用常量来提供默认的参数值。常量作为默认参数值很方便的另一个例子是当您有几个带有循环参数的函数时。假设您正在开发一个连接到本地 SQLite 数据库的应用程序。您的应用程序使用以下一组函数来管理数据库:
import sqlite3 from sqlite3 import Error def create_database(db_path): # Code to create the initial database goes here... def create_connection(db_path): # Code to create a database connection goes here... def backup_database(db_path): # Code to back up the database goes here...这些函数对 SQLite 数据库执行不同的操作。注意,所有的函数都共享
db_path参数。在开发应用程序时,您决定为函数提供一个默认的数据库路径,以便可以快速测试它们。在这种情况下,您可以直接使用路径作为
db_path参数的默认值。但是,最好使用命名常量来提供默认的数据库路径:
import sqlite3 from sqlite3 import Error DEFAULT_DB_PATH = "/path/to/database.sqlite" def create_database(db_path=DEFAULT_DB_PATH): # Code to create the initial database goes here... def create_connection(db_path=DEFAULT_DB_PATH): # Code to create a database connection goes here... def backup_database(db_path=DEFAULT_DB_PATH): # Code to back up the database goes here...这个小小的更新使您能够在开发过程中针对一个示例数据库快速测试您的应用程序。它还提高了代码的可维护性,因为您可以在应用程序的未来版本中出现的其他数据库相关函数中重用该常量。
最后,您会发现一些情况,您希望将具有特定行为的对象传递给类、方法或函数。这种实践通常被称为 duck typing ,是 Python 中的一个基本原则。现在假设您的代码将负责提供所需对象的标准实现。如果你的用户想要一个自定义对象,那么他们应该自己提供。
在这种情况下,您可以使用一个常数来定义默认对象,然后将该常数作为默认参数值传递给目标类、方法或函数。看看下面这个假想的
FileReader类的例子:# file_handler.py from readers import DEFAULT_READER class FileHandler: def __init__(self, file, reader=DEFAULT_READER): self._file = file self._reader = reader def read(self): self._reader.read(self._file) # FileHandler implementation goes here...这个类提供了一种操作不同类型文件的方法。
.read()方法使用注入的reader对象根据其特定格式读取输入的file。下面是一个 reader 类的玩具实现:
# readers.py class _DefaultReader: def read(self, file): with open(file, mode="r", encoding="utf-8") as file_obj: for line in file_obj: print(line) DEFAULT_READER = _DefaultReader()本例中的
.read()方法获取一个文件的路径,打开它,并将其内容逐行打印到屏幕上。这个类将扮演默认读者的角色。最后一步是创建一个常量DEFAULT_READER,用来存储默认阅读器的实例。就是这样!您有一个处理输入文件的类,还有一个提供默认阅读器的助手类。您的用户也可以编写自定义阅读器。例如,他们可以为 CSV 和 JSON 文件编写代码阅读器。一旦他们编写了一个给定的阅读器,他们可以将它传递给
FileHandler类构造函数,并使用产生的实例来处理使用阅读器的目标文件格式的文件。在真实项目中处理您的常量
既然您已经知道了如何在 Python 中创建常量,那么是时候学习如何在实际项目中处理和组织它们了。为此,您可以使用几种方法或策略。例如,您可以将常数放入:
- 与使用它们的代码相同的文件
- 用于项目范围常量的专用模块
- 一个配置文件
- 一些环境变量
在接下来的几节中,您将编写一些实际的例子来演示上述适当管理常量的策略。
将常量与相关代码放在一起
组织和管理常量的第一个也可能是最自然的策略是将它们和使用它们的代码一起定义。使用这种方法,您将在包含相关代码的模块顶部定义常数。
例如,假设您正在创建一个自定义模块来执行计算,您需要使用数学常数,如圆周率、欧拉数等。在这种情况下,您可以这样做:
# calculations.py """This module implements custom calculations.""" # Imports go here... import numpy as np # Constants go here... PI = 3.141592653589793 EULER_NUMBER = 2.718281828459045 TAU = 6.283185307179586 # Your custom calculations start here... def circular_land_area(radius): return PI * radius**2 def future_value(present_value, interest_rate, years): return present_value * EULER_NUMBER ** (interest_rate * years) # ...在这个例子中,您在使用它们的代码所在的同一个模块中定义您的常量。
注意:如果你想明确地表明一个常量应该只在它的包含模块中使用,那么你可以在它的名字前面加上一个下划线(
_)。比如可以做_PI = 3.141592653589793这样的事情。这个前导下划线将这个名字标记为非公共,这意味着用户的代码不应该直接使用这个名字。对于仅与给定项目中的单个模块相关的窄范围常量,将常量与使用它们的代码放在一起是一种快速而合适的策略。在这种情况下,您可能不会在包含模块本身之外使用常量。
为常量创建专用模块
组织和管理常量的另一个常见策略是创建一个专用模块来存放它们。这种策略适用于在给定项目的许多模块甚至包中使用的常量。
这种策略的中心思想是为常量创建一个直观且唯一的名称空间。要将此策略应用于您的计算示例,您可以创建包含以下文件的 Python 包:
calc/ ├── __init__.py ├── calculations.py └── constants.py
__init__.py文件将把calc/目录变成一个 Python 包。然后您可以将以下内容添加到您的constants.py文件中:# constants.py """This module defines project-level constants.""" PI = 3.141592653589793 EULER_NUMBER = 2.718281828459045 TAU = 6.283185307179586一旦您将这段代码添加到
constants.py,那么您就可以在需要使用任何常量时导入模块:# calculations.py """This module implements custom calculations.""" # Imports go here... import numpy as np from . import constants # Your custom calculations start here... def circular_land_area(radius): return constants.PI * radius**2 def future_value(present_value, interest_rate, years): return present_value * constants.EULER_NUMBER ** (interest_rate * years) # ...注意,您使用相对导入直接从
calc包中导入constants模块。然后,使用完全限定名来访问计算中所需的任何常数。这种练习可以改善你的意图交流。现在完全清楚了,PI和EULER_NUMBER在您的项目中是常量,因为有了constants前缀。要使用你的
calculations模块,你可以这样做:
>>> from calc import calculations
>>> calculations.circular_land_area(100)
31415.926535897932
>>> from calc.calculations import circular_land_area
>>> circular_land_area(100)
31415.926535897932
现在你的calculations模块存在于calc包中。这意味着如果你想使用calculations中的功能,那么你需要从calc中导入calculations。您也可以像在上面的第二个例子中一样,通过引用包和模块来直接导入函数。
在配置文件中存储常数
现在假设您想更进一步,将一个给定项目的常量外部化。您可能需要在项目的源代码中保留所有的常量。为此,您可以使用外部配置文件。
以下是如何将常数移动到配置文件中的示例:
; constants.ini [CONSTANTS] PI=3.141592653589793 EULER_NUMBER=2.718281828459045 TAU=6.283185307179586
该文件使用 INI 文件格式。您可以使用标准库中的configparser模块读取这种类型的文件。
现在回到calculations.py并更新它,如下所示:
# calculations.py
"""This module implements custom calculations."""
# Imports go here...
from configparser import ConfigParser
import numpy as np
constants = ConfigParser() constants.read("path/to/constants.ini")
# Your custom calculations start here...
def circular_land_area(radius):
return float(constants.get("CONSTANTS", "PI")) * radius**2
def future_value(present_value, interest_rate, years):
return (
present_value * float(constants.get( "CONSTANTS", "EULER_NUMBER" ))) ** (interest_rate * years)
# ...
在本例中,您的代码首先读取配置文件,并将结果ConfigParser对象存储在全局变量constants中。您也可以将这个变量命名为CONSTANTS,并将其作为常量全局使用。然后更新计算,从配置对象本身读取常数。
注意,ConfigParser对象将配置参数存储为字符串,因此需要使用内置的float()函数将值转换为数字。
例如,当你创建一个图形用户界面(GUI)应用程序并需要设置一些参数来定义加载和显示 GUI 时应用程序窗口的形状和大小时,这种策略可能是有益的。
将常量作为环境变量处理
另一个处理常量的有用策略是,如果你在 Windows 上,将它们定义为系统变量,如果你在 macOS 或 Linux 上,将它们定义为环境变量。
这种方法通常用于在不同的环境中配置部署。您还可以将环境变量用于暗示安全风险的常量,并且不应该直接提交给源代码。这些常量类型的示例包括身份验证凭证、API 访问令牌等。
注意:在使用敏感信息的环境变量时,你应该小心,因为它们可能会意外地暴露在日志或子进程中。所有的云提供商都提供某种更安全的秘密管理。
要使用这种策略,首先必须将常量导出为操作系统中的环境或系统变量。至少有两种方法可以做到这一点:
- 手动导出当前 shell 会话中的常量
- 将常量添加到 shell 的配置文件中
第一种技术非常快速和实用。您可以使用它对您的代码运行一些快速测试。例如,假设您需要导出一个 API 令牌作为系统或环境变量。在这种情况下,您只需运行以下命令:
- 视窗
** Linux + macOS*
C:\> set API_TOKEN="593086396372"
$ export API_TOKEN="593086396372"
这种技术的主要缺点是,您的常量只能从定义它们的命令行会话中访问。一个好得多的方法是让操作系统在您启动命令行窗口时加载这些常量。
如果你在 Windows 上,那么查看你的 Python 编码环境在 Windows 上:设置指南中的配置环境变量部分,学习如何创建系统变量。遵循本指南中的说明,添加一个值为593086396372的API_TOKEN系统变量。
如果您使用的是 Linux 或 macOS,那么您可以转到您的主文件夹并打开您的 shell 的配置文件。打开该文件后,在文件末尾添加下面一行:
# .bashrc
export API_TOKEN="593086396372"
# .zshrc
export API_TOKEN="593086396372"
每当您启动终端或命令行窗口时,Linux 和 macOS 都会自动加载相应的 shell 配置文件。这样,您可以确保API_TOKEN变量在您的系统中始终可用。
一旦为 Python 常量定义了所需的环境变量,就需要将它们加载到代码中。为此,可以使用 Python 的 os 模块中的 environ 字典。environ的键和值是分别代表环境变量及其值的字符串。
您的API_TOKEN常量现在出现在environ字典中。因此,您可以用两行代码从那里读取它:
>>> import os >>> os.environ["API_TOKEN"] '593086396372'使用环境变量存储常数,并使用
os.environ字典将它们读入代码,这是配置常数的有效方法,这些常数依赖于应用程序部署的环境。这在使用云时特别有用,所以将这种技术放在您的 Python 工具包中。探索 Python 中的其他常量
除了用户定义的常量之外,Python 还定义了几个可以被视为常量的内部名称。其中一些名称是严格的常量,这意味着一旦解释器运行,就不能更改它们。此例为
__debug__常数为例。在接下来的几节中,您将了解一些内部 Python 名称,您可以考虑并应该在代码中将其视为常量。首先,您将回顾一些内置常量和常量值。
内置常数
根据 Python 文档,“少量常量存在于内置名称空间中”( Source )。文档中列出的前两个常量是
True和False,它们是 Python 布尔值。这两个值也是int的实例。True的值为1,而False的值为0:
>>> True
True
>>> False
False
>>> isinstance(True, int)
True
>>> isinstance(False, int)
True
>>> int(True)
1
>>> int(False)
0
>>> True = 42
...
SyntaxError: cannot assign to True
>>> True is True
True
>>> False is False
True
请注意,True和False名称是严格的常量。换句话说,它们不能被重新分配。如果你试图重新分配它们,那么你会得到一个 SyntaxError 。这两个值在 Python 中也是单例对象,这意味着每个值只有一个实例。这就是为什么在上面最后的例子中,标识运算符 ( is)返回True。
另一个重要且常见的常量值是 None ,这是 Python 中的空值。当您想要表达可空性的想法时,这个常量值就派上了用场。与True和False一样,None也是一个不能被重新分配的单例严格常量对象:
>>> None is None True >>> None = 42 ... SyntaxError: cannot assign to None
None作为函数、方法和类构造函数中的默认参数值非常有用。它通常用于表示变量为空。在内部,Python 使用None作为没有显式return语句的函数的隐式返回值。省略号文字(
...)是 Python 中的另一个常量值。这个特殊值与Ellipsis相同,是types.EllipsisType类型的唯一实例:
>>> Ellipsis
Ellipsis
>>> ...
Ellipsis
>>> ... is Ellipsis
True
您可以使用Ellipsis作为未写代码的占位符。你也可以用它来代替 pass 语句。在类型提示中,...文字传达了一个具有统一类型的未知长度数据集合的思想:
>>> def do_something(): ... ... # TODO: Implement this function later ... >>> class CustomException(Exception): ... ... >>> raise CustomException("some error message") Traceback (most recent call last): ... CustomException: some error message >>> # A tuple of integer values >>> numbers: tuple[int, ...]在许多情况下,
Ellipsis常量值可以派上用场,并帮助您使代码更具可读性,因为它在语义上等同于英文省略号标点符号(…)。另一个有趣且可能有用的内置常量是
__debug__,正如您在本节开始时已经了解到的。Python 的__debug__是一个布尔常量,默认为True。它是一个严格的常量,因为一旦解释器运行,就不能改变它的值:
>>> __debug__
True
>>> __debug__ = False
...
SyntaxError: cannot assign to __debug__
__debug__常数与 assert 语句密切相关。简而言之,如果__debug__是True,那么你所有的assert语句都会运行。如果__debug__是False,那么您的assert语句将被禁用,根本不会运行。这个特性可以稍微提高生产代码的性能。
注意:尽管__debug__也有一个 dunder 名称,但它是一个严格的常量,因为一旦解释器运行,你就不能改变它的值。相比之下,下一节中的内部数据名称应被视为常量,但不是严格的常量。您可以在代码执行期间更改它们的值。然而,这种做法可能很棘手,需要高深的知识。
要将__debug__的值更改为False,您必须使用 -O 或 -OO 命令行选项在优化模式下运行 Python,这提供了两个级别的字节码优化。这两个级别都生成不包含断言的优化 Python 字节码。
内部数据名称
Python 也有一组广泛的内部数据名称,您可以将其视为常量。因为有几个这样的特殊名称,所以在本教程中,您将只学习 __name__ 和 __file__ 。
注意:要更深入地了解 Python 中的其他 dunder 名称以及它们对该语言的意义,请查看关于 Python 的数据模型的官方文档。
__name__属性与您如何运行一段给定的代码密切相关。当导入一个模块时,Python 在内部将__name__设置为一个字符串,该字符串包含您正在导入的模块的名称。
启动您的代码编辑器并创建以下示例模块:
# sample_name.py
print(f"The type of __name__ is: {type(__name__)}")
print(f"The value of __name__ is: {__name__}")
准备好该文件后,返回命令行窗口并运行以下命令:
$ python -c "import sample_name"
The type of __name__ is: <class 'str'>
The value of __name__ is: sample_name
使用-c开关,您可以在命令行执行一小段 Python 代码。在这个例子中,您导入了sample_name模块,该模块将一些消息打印到屏幕上。第一条消息告诉你__name__的类型是 str ,或者字符串。第二条消息显示__name__被设置为sample_name,这是您刚刚导入的模块的名称。
或者,如果您将sample_name.py和作为脚本运行,那么 Python 会将 __name__设置为"__main__" 字符串。要确认这一事实,请继续运行以下命令:
$ python sample_name.py
The type of __name__ is: <class 'str'>
The value of __name__ is: __main__
注意现在__name__保存了"__main__"字符串。这种行为表明您已经将该文件作为可执行的 Python 程序直接运行。
__file__属性将包含 Python 当前导入或执行的文件的路径。当需要获取模块本身的路径时,可以在给定的模块内部使用__file__。
作为__file__如何工作的示例,继续创建以下模块:
# sample_file.py
print(f"The type of __file__ is: {type(__file__)}")
print(f"The value of __file__ is: {__file__}")
如果您在 Python 代码中导入了sample_file模块,那么__file__将在您的文件系统中存储其包含模块的路径。通过运行以下命令来检查这一点:
$ python -c "import sample_file"
The type of __file__ is: <class 'str'>
The value of __file__ is: /path/to/sample_file.py
同样,如果您将sample_file.py作为一个 Python 可执行程序运行,那么您将得到与之前相同的输出:
$ python sample_file.py
The type of __file__ is: <class 'str'>
The value of __file__ is: /path/to/sample_file.py
简而言之,Python 将__file__设置为包含使用或访问该属性的模块的路径。
有用的字符串和数学常数
你会在标准库中找到许多有用的常数。其中一些与一些特定的模块、函数和类紧密相连。其他的更通用,您可以在各种场景中使用它们。你可以分别在 math 和 string 模块中找到的一些数学和字符串相关的常量就是这种情况。
math模块提供以下常量:
>>> import math >>> # Euler's number (e) >>> math.e 2.718281828459045 >>> # Pi (π) >>> math.pi 3.141592653589793 >>> # Infinite (∞) >>> math.inf inf >>> # Not a number (NaN) >>> math.nan nan >>> # Tau (τ) >>> math.tau 6.283185307179586每当你编写与数学相关的代码,甚至只是使用它们来执行特定计算的代码时,这些常量都会派上用场,就像你在重用对象以实现可维护性一节中的
Circle类一样。这里有一个使用
math.pi代替自定义PI常量的Circle的更新实现:# circle.py import math class Circle: def __init__(self, radius): self.radius = radius def area(self): return math.pi * self.radius**2 def perimeter(self): return 2 * math.pi * self.radius def projected_volume(self): return 4/3 * math.pi * self.radius**3 def __repr__(self): return f"{self.__class__.__name__}(radius={self.radius})"这个更新版本的
Circle比您的原始版本更易读,因为它提供了更多关于 Pi 常数来源的上下文,清楚地表明它是一个数学相关的常数。
math.pi常量还有一个优点,如果您使用的是旧版本的 Python,那么您将获得 32 位版本的 Pi。相比之下,如果您在现代版本的 Python 中使用Circle,那么您将得到 64 位版本的 Pi。因此,您的程序将自适应其具体的执行环境。
string模块还定义了几个有用的字符串常量。下表显示了每个常量的名称和值:
名字 价值 ascii_lowercaseabcdefghijklmnopqrstuvwxyz ascii_uppercaseABCDEFGHIJKLMNOPQRSTUVWXYZ ascii_lettersABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz digits0123456789 hexdigits0123456789abcdefABCDEF octdigits01234567 punctuation!"#$%&'()*+,-./:;<=>?@[]^_`{|}~ whitespace空格字符、横纵制表符、换行、回车、换页的组合 printabledigits、ascii_letters、punctuation和whitespace的组合这些与字符串相关的常量在很多情况下都会派上用场。当你进行大量的字符串处理、使用正则表达式、处理自然语言等等时,你可以使用它们。
类型注释常量
从 Python 3.8 开始,
typing模块包含了一个Final类,允许你对常量进行类型注释。如果你在定义你的常量时使用这个类,那么你将告诉静态类型检查器像 mypy 你的常量不应该被重新分配。这样,类型检查器可以帮助您检测对常数的未授权赋值。下面是一些使用
Final定义常数的例子:from typing import Final MAX_SPEED: Final[int] = 300 DEFAULT_COLOR: Final[str] = "\033[1;34m" ALLOWED_BUILTINS: Final[tuple[str, ...]] = ("sum", "max", "min", "abs") # Later in your code... MAX_SPEED = 450 # Cannot assign to final name "MAX_SPEED" mypy(error)
Final类代表了一个特殊的类型构造,它指示类型检查器在代码中的某个地方重新分配名字时报告一个错误。注意,即使您得到了类型检查器的错误报告,Python 也确实改变了MAX_SPEED的值。因此,Final并不能防止运行时意外的常量重新分配。在 Python 中定义严格常量
到目前为止,您已经学习了很多关于编程和 Python 常量的知识。您现在知道 Python 不支持严格常量。只是有变数而已。因此,Python 社区采用了使用大写字母来表示给定变量实际上是常数的命名约定。
所以,在 Python 中,你没有常量。相反,你有永不改变的变量。如果您与不同级别的许多程序员一起处理一个大型 Python 项目,这可能是一个问题。在这种情况下,最好有一种机制来保证严格常数——在程序启动后没有人可以更改的常数。
因为 Python 是一种非常灵活的编程语言,所以您可以找到几种方法来实现使常量不变的目标。在接下来的几节中,您将了解其中的一些方法。它们都意味着创建一个自定义类,并将其用作常数的命名空间。
为什么应该使用类作为常数的命名空间?在 Python 中,任何名字都可以被随意反弹。在模块级别,您没有适当的工具来防止这种情况发生。所以,你需要使用一个类,因为类比模块提供了更多的定制工具。
在接下来的几节中,您将了解使用类作为严格常量的命名空间的几种不同方式。
.__slots__属性Python 类允许你定义一个名为
.__slots__的特殊类属性。该属性将保存一系列名称,这些名称将作为实例属性。您将无法向具有
.__slots__属性的类添加新的实例属性,因为.__slots__阻止创建实例.__dict__属性。此外,没有.__dict__属性意味着在内存消耗方面的优化。使用
.__slots__,您可以创建一个类,作为只读常量的名称空间:
>>> class ConstantsNamespace:
... __slots__ = ()
... PI = 3.141592653589793
... EULER_NUMBER = 2.718281828459045
...
>>> constants = ConstantsNamespace()
>>> constants.PI
3.141592653589793
>>> constants.EULER_NUMBER
2.718281828459045
>>> constants.PI = 3.14
Traceback (most recent call last):
...
AttributeError: 'ConstantsNamespace' object attribute 'PI' is read-only
在这个例子中,您定义了ConstantsNamespace。该类的.__slots__属性包含一个空的元组,这意味着该类的实例将没有属性。然后将常量定义为类属性。
下一步是实例化该类,以创建一个变量来保存包含所有常数的名称空间。请注意,您可以快速访问特殊名称空间中的任何常量,但不能给它赋值。如果你尝试去做,你会得到一个AttributeError。
使用这种技术,您可以保证团队中的其他人不能更改您的常量的值。您已经实现了严格常数的预期行为。
@property装饰者
你也可以利用 @property 装饰器来创建一个类,作为你的常量的命名空间。为此,您只需将常量定义为属性,而无需为它们提供 setter 方法:
>>> class ConstantsNamespace: ... @property ... def PI(self): ... return 3.141592653589793 ... @property ... def EULER_NUMBER(self): ... return 2.718281828459045 ... >>> constants = ConstantsNamespace() >>> constants.PI 3.141592653589793 >>> constants.EULER_NUMBER 2.718281828459045 >>> constants.PI = 3.14 Traceback (most recent call last): ... AttributeError: can't set attribute 'PI'因为您没有为
PI和EULER_NUMBER属性提供 setter 方法,所以它们是只读属性。这意味着你只能访问它们的值。不可能给任何一个赋予新的值。如果你尝试去做,你会得到一个AttributeError。
namedtuple()工厂功能Python 的
collections模块提供了一个工厂函数叫做namedtuple()。这个函数允许您创建元组子类,允许使用命名字段和点符号来访问它们的项目,就像在tuple_obj.attribute中一样。像常规元组一样,命名元组实例是不可变的,这意味着您不能在适当的位置修改现有的命名元组对象。不可变听起来适合于创建一个作为严格常量的命名空间的类。
以下是如何做到这一点:
>>> from collections import namedtuple
>>> ConstantsNamespace = namedtuple(
... "ConstantsNamespace", ["PI", "EULER_NUMBER"]
... )
>>> constants = ConstantsNamespace(3.141592653589793, 2.718281828459045)
>>> constants.PI
3.141592653589793
>>> constants.EULER_NUMBER
2.718281828459045
>>> constants.PI = 3.14
Traceback (most recent call last):
...
AttributeError: can't set attribute
在这个例子中,您的常量在底层命名元组ConstantsNamespace中扮演字段的角色。一旦创建了命名元组实例constants,就可以通过使用点符号来访问常量,就像在constants.PI中一样。
因为元组是不可变的,所以没有办法修改任何字段的值。因此,您的constants命名的元组对象是一个完全成熟的严格常量名称空间。
@dataclass装饰者
数据类顾名思义,主要包含数据的类。他们也可以有方法,但这不是他们的主要目标。要创建一个数据类,需要使用 dataclasses 模块中的 @dataclass 装饰器。
如何使用这种类型的类来创建严格常量的命名空间?@dataclass装饰器接受一个frozen参数,允许您将数据类标记为不可变的。如果它是不可变的,那么一旦创建了给定数据类的实例,就没有办法修改它的实例属性。
下面是如何使用数据类创建包含常量的命名空间:
>>> from dataclasses import dataclass >>> @dataclass(frozen=True) ... class ConstantsNamespace: ... PI = 3.141592653589793 ... EULER_NUMBER = 2.718281828459045 ... >>> constants = ConstantsNamespace() >>> constants.PI 3.141592653589793 >>> constants.EULER_NUMBER 2.718281828459045 >>> constants.PI = 3.14 Traceback (most recent call last): ... dataclasses.FrozenInstanceError: cannot assign to field 'PI'在这个例子中,首先导入
@dataclass装饰器。然后使用这个装饰器将ConstantsNamespace转换成一个数据类。为了使数据类不可变,您将frozen参数设置为True。最后,用常量作为类属性定义ConstantsNamespace。您可以创建该类的一个实例,并将其用作您的常量命名空间。同样,您可以访问所有常量,但不能修改它们的值,因为数据类是冻结的。
.__setattr__()特殊方法Python 类让你定义一个叫做
.__setattr__()的特殊方法。该方法允许您自定义属性赋值过程,因为 Python 会在每次属性赋值时自动调用该方法。实际上,您可以覆盖
.__setattr__()来防止所有的属性重新分配,并使您的属性不可变。下面是如何重写此方法来创建一个类,作为常数的命名空间:
>>> class ConstantsNamespace:
... PI = 3.141592653589793
... EULER_NUMBER = 2.718281828459045
... def __setattr__(self, name, value):
... raise AttributeError(f"can't reassign constant '{name}'")
...
>>> constants = ConstantsNamespace()
>>> constants.PI
3.141592653589793
>>> constants.EULER_NUMBER
2.718281828459045
>>> constants.PI = 3.14
Traceback (most recent call last):
...
AttributeError: can't reassign constant 'PI'
您的自定义实现.__setattr__()不在类的属性上执行任何赋值操作。当您试图设置任何属性时,它只会引发一个AttributeError。这种实现使得属性不可变。同样,您的ConstantsNamespace表现为常量的名称空间。
结论
现在你知道什么是常量,以及为什么和什么时候在你的代码中使用它们。你也知道 Python 没有严格的常量。Python 社区使用大写字母作为命名约定来传达变量应该作为常量使用。这种命名约定有助于防止其他开发人员更改应该是常量的变量。
常量在编程中无处不在,Python 开发人员也在使用它们。所以,学习在 Python 中定义和使用常量是你需要掌握的一项重要技能。
在本教程中,您学习了如何:
- 在代码中定义 Python 常量
- 识别并理解一些内置常数
- 用常量提高代码的可读性、可重用性和可维护性
- 使用不同的策略来组织和管理现实项目中的常量
- 应用各种技术使你的 Python 常量严格恒定
了解了什么是常量,为什么它们很重要,以及何时使用它们,您就可以立即开始改进代码的可读性、可维护性和可重用性了。来吧,试一试!
示例代码: 点击此处下载示例代码,向您展示如何在 Python 中使用常量。***************
用 Python、PyQt 和 SQLite 构建联系簿
构建项目可以说是学习编程的更容易接近和有效的方法之一。真正的项目需要你运用不同的编码技巧。他们还鼓励你研究在开发过程中解决问题时出现的主题。在本教程中,您将使用 Python、PyQt 和 SQLite 创建一个通讯录应用程序。
在本教程中,您将学习如何:
- 使用 Python 和 PyQt 为您的通讯录应用程序创建一个图形用户界面(GUI)
- 使用 PyQt 的 SQL 支持将应用程序连接到 SQLite 数据库
- 使用 PyQt 的模型视图架构管理联系人数据
在这个项目结束时,你将有一个功能的通讯录应用程序,允许你存储和管理你的联系信息。
要获得该应用程序的完整源代码以及本教程中每个步骤的代码,请单击下面的链接:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
演示:用 Python 编写的通讯录
通讯录是一种有用且广泛使用的应用程序。他们无处不在。你的手机和电脑上可能有一本通讯录。使用通讯录,您可以存储和管理家庭成员、朋友、同事等的联系信息。
在本教程中,您将使用 Python、 SQLite 和 PyQt 编写一个通讯录 GUI 应用程序。这是一个演示,演示了按照本教程中的步骤操作后,通讯录的外观和工作方式:
https://player.vimeo.com/video/500503701?background=1
您的通讯录将为此类应用程序提供所需的最少功能。您可以显示、创建、更新和删除联系人列表中的信息。
项目概述
要构建您的通讯录应用程序,您需要将代码组织成模块和包,并为您的项目提供一致的结构。在本教程中,您将使用以下目录和文件结构:
rpcontacts_project/
│
├── rpcontacts/
│ ├── __init__.py
│ ├── views.py
│ ├── database.py
│ ├── main.py
│ └── model.py
│
├── requirements.txt
├── README.md
└── rpcontacts.py
以下是项目目录内容的简要总结:
rpcontacts_project/是项目的根目录。它将包含以下文件:requirements.txt提供了该项目的需求列表。README.md提供项目的一般信息。rpcontacts.py提供了运行应用程序的入口点脚本。
rpcontacts/是提供应用主包的子目录。它提供了以下模块:__init__.pyviews.pydatabase.pymain.pymodel.py
在本教程中,您将一步一步地介绍这些文件。每个文件的名称表明了它在应用程序中的作用。例如,views.py将包含生成窗口和对话框 GUI 的代码,database.py将包含处理数据库的代码,main.py将托管应用程序本身。最后,model.py将实现模型来管理应用程序数据库中的数据。
一般来说,应用程序会有一个主窗口来显示、添加、删除和更新联系人。它还会有一个对话框来添加新的联系人到数据库中。
先决条件
为了从这个项目中获得最大的收益,一些以前使用 Python 和 PyQt 进行 GUI 编程的知识会有所帮助。在这方面,您需要了解如何:
- 用 PyQt 和 Python 创建 GUI 应用程序
- 用 PyQt 构建和布局 GUI
- 用 Python 和 PyQt 管理 SQL 数据库
- 使用 SQLite 数据库
要复习这些主题,您可以查看以下资源:
- Python 和 PyQt:构建 GUI 桌面计算器
- Python 和 PyQt:创建菜单、工具栏和状态栏
- PyQt 布局:创建专业外观的 GUI 应用程序
- 用 PyQt 处理 SQL 数据库:基础知识
- Python SQL 库简介
- 使用 Python、SQLite 和 SQLAlchemy 进行数据管理
在开始本教程之前,如果您不是这些领域的专家,请不要担心。你将通过参与真实项目的过程来学习。如果你被卡住了,那就花点时间复习上面链接的资源。然后回到代码上。
您将在本教程中构建的通讯录应用程序只有一个外部依赖项:PyQt。
注意:在本教程中,您将使用 PyQt 版本 5.15.2 来构建您的通讯录应用程序。该项目需要 5.15.2 版才能在 macOS Big Sur 上运行。
PyQt 6.0 版本于 2021 年 1 月 4 日发布。这是绑定到 Qt 版本 6 的库的第一个版本。然而,本教程中的项目还没有经过 PyQt 6.0 的测试。
如果您觉得有必要使用这个新版本的 PyQt 来运行项目,那么就试一试吧。作为提示,您应该使用pip install PyQt6,然后更新导入以使用PyQt6而不是PyQt5。
为了遵循开发过程中的最佳实践,您可以从创建一个虚拟环境开始,然后使用pip安装 PyQt 。一旦安装了 PyQt,就可以开始编码了!
步骤 1:用 PyQt 创建通讯录的框架应用
在第一步中,您将创建一个最小但功能强大的 PyQt GUI 应用程序,为您开始构建通讯录提供基础。您还将创建所需的最小项目结构,包括项目的主包和运行应用程序的入口点脚本。
您将在本节中添加到通讯录项目的所有代码和文件都收集在source_code_step_1/目录下。您可以通过单击下面的链接下载它们:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
在本节结束时,您将能够第一次为您的通讯录运行框架 GUI 应用程序。
构建通讯录项目
要开始编写应用程序,请创建一个名为rpcontacts_project/的新目录。这将是项目的根目录。现在在rpcontacts_project/中创建一个名为rpcontacts/的新子目录。这个子目录将保存应用程序的主包。最后,在根目录中启动您的代码编辑器或 IDE 。
为了将一个目录变成一个包,Python 需要一个__init__.py模块来初始化这个包。在rpcontacts/中创建该文件,并向其中添加以下代码:
# -*- coding: utf-8 -*-
"""This module provides the rpcontacts package."""
__version__ = "0.1.0"
这个文件告诉 Pythonrpcontacts是一个包。文件中的代码在您导入包或它的一些模块时运行。
你不需要在一个__init__.py文件中放入任何代码来初始化这个包。一个空的__init__.py文件将完成这项工作。然而,在这种情况下,您定义了一个名为__version__的模块级常量来保存应用程序的版本号。
创建应用程序的主窗口
现在是时候创建你的通讯录的主窗口了。为此,在您的rpcontacts包中创建一个名为views.py的模块。然后将以下代码添加到模块中并保存它:
# -*- coding: utf-8 -*-
"""This module provides views to manage the contacts table."""
from PyQt5.QtWidgets import (
QHBoxLayout,
QMainWindow,
QWidget,
)
class Window(QMainWindow):
"""Main Window."""
def __init__(self, parent=None):
"""Initializer."""
super().__init__(parent)
self.setWindowTitle("RP Contacts")
self.resize(550, 250)
self.centralWidget = QWidget()
self.setCentralWidget(self.centralWidget)
self.layout = QHBoxLayout()
self.centralWidget.setLayout(self.layout)
首先,从PyQt5.QtWidgets导入所需的类。然后你创建Window。这个类继承了 QMainWindow 并提供了生成应用程序主窗口的代码。在初始化器方法中,您将窗口的标题设置为"RP Contacts",将窗口大小调整为250像素的550,使用 QWidget 定义并设置中心小部件,最后使用水平框布局为中心小部件定义一个布局。
编码和运行应用程序
既然您已经有了一个通讯录的主窗口,那么是时候使用 QApplication 编写代码来创建一个功能性的 PyQt 应用程序了。为此,在您的rpcontacts包中创建一个名为main.py的新模块,并向其中添加以下代码:
# -*- coding: utf-8 -*-
# rpcontacts/main.py
"""This module provides RP Contacts application."""
import sys
from PyQt5.QtWidgets import QApplication
from .views import Window
def main():
"""RP Contacts main function."""
# Create the application
app = QApplication(sys.argv)
# Create the main window
win = Window()
win.show()
# Run the event loop
sys.exit(app.exec())
在这个模块中,您导入 sys 来访问 exit() ,这允许您在用户关闭主窗口时干净地退出应用程序。然后你从PyQt5.QtWidgets导入QApplication,从views导入Window。最后一步是将 main() 定义为应用程序的主函数。
在main()中,你实例化了QApplication和Window。然后在Window上调用.show(),最后使用 .exec() 运行应用程序的主循环,或者事件循环。
现在向上移动到项目根目录rpcontacts_project/并创建一个名为rpcontacts.py的文件。这个文件提供了运行应用程序的入口点脚本。将以下代码添加到文件中并保存:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# rpcontacts_project/rpcontacts.py
"""This module provides RP Contacts entry point script."""
from rpcontacts.main import main
if __name__ == "__main__":
main()
这个文件从你的main.py模块导入main()。然后实现传统的条件语句,如果用户以 Python 脚本的形式运行该模块,则该语句调用main()。现在,通过在 Python 环境中运行命令python rpcontacts.py来启动应用程序。您将在屏幕上看到以下窗口:

就是这样!您已经创建了一个最小但功能强大的 PyQt GUI 应用程序,可以用它作为构建通讯录的起点。此时,您的项目应该具有以下结构:
./rpcontacts_project/
│
├── rpcontacts/
│ ├── __init__.py
│ ├── views.py
│ └── main.py
│
└── rpcontacts.py
在本节中,您已经使用 Python 模块和包创建了通讯录项目所需的最小结构。您已经构建了应用程序的主窗口,并将样板代码放在一起创建了一个 PyQt GUI 应用程序。您还第一次运行了该应用程序。接下来,您将开始向 GUI 添加特性。
步骤 2:用 Python 构建通讯录的 GUI
现在您已经构建了通讯录应用程序的框架,您可以开始编写主窗口的 GUI 了。在本节结束时,您将完成使用 Python 和 PyQt 创建通讯录 GUI 的必要步骤。GUI 将如下所示:

在窗口的中央,您有一个表格视图来显示您的联系人列表。在表单的右侧,有三个按钮:
- 添加 向列表中添加新的联系人
- 删除 从列表中删除选中的联系人
- 清除全部 从列表中删除所有联系人
您将在本节中添加或修改的所有代码和文件都收集在source_code_step_2/目录下。您可以通过单击下面的链接下载它们:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
回到views.py模块,更新Window的代码,生成上面的 GUI:
1# -*- coding: utf-8 -*-
2# rpcontacts/views.py
3
4"""This module provides views to manage the contacts table."""
5
6from PyQt5.QtWidgets import (
7 QAbstractItemView, 8 QHBoxLayout,
9 QMainWindow,
10 QPushButton, 11 QTableView, 12 QVBoxLayout, 13 QWidget,
14)
15
16class Window(QMainWindow):
17 """Main Window."""
18 def __init__(self, parent=None):
19 """Initializer."""
20 # Snip...
21
22 self.setupUI()
23 24 def setupUI(self): 25 """Setup the main window's GUI."""
26 # Create the table view widget
27 self.table = QTableView()
28 self.table.setSelectionBehavior(QAbstractItemView.SelectRows)
29 self.table.resizeColumnsToContents()
30 # Create buttons
31 self.addButton = QPushButton("Add...")
32 self.deleteButton = QPushButton("Delete")
33 self.clearAllButton = QPushButton("Clear All")
34 # Lay out the GUI
35 layout = QVBoxLayout()
36 layout.addWidget(self.addButton)
37 layout.addWidget(self.deleteButton)
38 layout.addStretch()
39 layout.addWidget(self.clearAllButton)
40 self.layout.addWidget(self.table)
41 self.layout.addLayout(layout)
首先导入一些额外的 PyQt 类,以便在 GUI 中使用。以下是一些比较相关的例子:
QPushButton创建添加,删除,清除所有按钮QTableView提供显示联系人列表的表格视图QAbstractItemView提供访问表格视图选择行为策略
在这段代码中,对Window的第一个添加是在__init__()结束时对.setupUI()的调用。当您运行应用程序时,这个调用生成主窗口的 GUI。
下面是.setupUI()中代码的作用:
- 第 27 行创建一个
QTableView实例来显示联系人列表。 - 第 28 行将
.selectionBehavior属性设置为QAbstractItemView.SelectRows。这确保了当用户单击表格视图的任何单元格时,整个行都会被选中。表格视图中的行保存与联系人列表中的单个联系人相关的所有信息。 - 第 31 行到第 33 行向 GUI 添加三个按钮:添加、删除、全部清除。这些按钮还不执行任何操作。
- 第 35 到 41 行为 GUI 中的所有小部件创建并设置一个一致的布局。
有了这些对Window的补充,您可以再次运行应用程序。您屏幕上的窗口将与您在本节开始时看到的窗口相似。
注意:上述代码和本教程中其余代码示例中的行号是为了便于解释。它们与最终模块或脚本中的行顺序不匹配。
在本节中,您已经运行了创建通讯录主窗口的 GUI 所需的所有步骤。现在,您已经准备好开始处理您的应用程序将如何管理和存储您的联系人数据。
第三步:建立通讯录数据库
此时,您已经创建了一个 PyQt 应用程序及其主窗口的 GUI 来构建您的通讯录项目。在本节中,您将编写代码来定义应用程序如何连接到联系人数据库。为了完成这一步,您将使用 SQLite 来处理数据库,并且 PyQt 的 SQL 支持将应用程序连接到数据库,并处理您的联系数据。
您将在本节中添加或修改的源代码和文件存储在source_code_step_3/目录下。您可以通过单击下面的链接下载它们:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
首先,返回到rpcontacts/目录中的main.py,更新代码以创建到数据库的连接:
# -*- coding: utf-8 -*-
# rpcontacts/main.py
"""This module provides RP Contacts application."""
import sys
from PyQt5.QtWidgets import QApplication
from .database import createConnection from .views import Window
def main():
"""RP Contacts main function."""
# Create the application
app = QApplication(sys.argv)
# Connect to the database before creating any window
if not createConnection("contacts.sqlite"): sys.exit(1) # Create the main window if the connection succeeded
win = Window()
win.show()
# Run the event loop
sys.exit(app.exec_())
在这种情况下,首先从database.py导入createConnection()。该函数将包含创建和打开到联系人数据库的连接的代码。您将在下一部分创建database.py并编写createConnection()。
在main()中,第一个突出显示的行试图使用createConnection()创建到数据库的连接。如果由于某种原因,应用程序不能创建一个连接,那么调用sys.exit(1)将关闭应用程序而不创建一个图形元素,并指示出现了一个错误。
您必须以这种方式处理连接,因为应用程序依赖于数据库才能正常工作。如果你没有一个功能性的连接,那么你的应用程序根本就不能工作。
这种做法允许您处理错误,并在出现问题时干净地关闭应用程序。您还能够向用户显示应用程序在尝试连接数据库时遇到的错误的相关信息。
有了这些补充,是时候深入研究createConnection()的代码了。
用 PyQt 和 SQLite 连接数据库
将您的通讯录应用程序连接到其关联的数据库是开发应用程序的基本步骤。为此,您将编写一个名为createConnection()的函数,它将创建并打开一个到数据库的连接。如果连接成功,那么函数将返回 True。否则,它将提供有关连接失败原因的信息。
回到rpcontacts/目录,并在其中创建一个名为database.py的新模块。然后将以下代码添加到该模块中:
1# -*- coding: utf-8 -*-
2# rpcontacts/database.py
3
4"""This module provides a database connection."""
5
6from PyQt5.QtWidgets import QMessageBox
7from PyQt5.QtSql import QSqlDatabase
8
9def createConnection(databaseName):
10 """Create and open a database connection."""
11 connection = QSqlDatabase.addDatabase("QSQLITE")
12 connection.setDatabaseName(databaseName)
13
14 if not connection.open():
15 QMessageBox.warning(
16 None,
17 "RP Contact",
18 f"Database Error: {connection.lastError().text()}",
19 )
20 return False
21
22 return True
在这里,首先导入一些必需的 PyQt 类。然后你定义createConnection()。这个函数有一个参数: databaseName 保存文件系统中物理 SQLite 数据库文件的名称或路径。
下面是createConnection()中代码的作用:
- 第 11 行使用
QSQLITE驱动程序创建数据库连接。 - 第 12 行设置数据库的文件名或路径。
- 第 14 行试图打开连接。如果在调用
.open()的过程中出现问题,那么if代码块会显示一条错误消息,然后返回False来表明连接尝试失败。 - 如果连接尝试成功,第 22 行返回
True。
您已经编码了createConnection()。现在您可以编写代码在数据库中创建contacts表。
创建contacts表格
有了创建和打开数据库连接的函数,您可以继续编写一个助手函数来创建contacts表。您将使用此表来存储有关联系人的信息。
下面是实现_createContactsTable()的代码:
# -*- coding: utf-8 -*-
# rpcontacts/database.py
# Snip...
from PyQt5.QtSql import QSqlDatabase, QSqlQuery
def _createContactsTable():
"""Create the contacts table in the database."""
createTableQuery = QSqlQuery()
return createTableQuery.exec(
"""
CREATE TABLE IF NOT EXISTS contacts (
id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE NOT NULL,
name VARCHAR(40) NOT NULL,
job VARCHAR(50),
email VARCHAR(40) NOT NULL
)
"""
)
def createConnection(databaseName):
# Snip...
_createContactsTable() return True
在这里,首先添加一个新的导入。你导入 QSqlQuery 来执行和操作 SQL 语句。
在_createContactsTable()中,您创建了一个QSqlQuery实例。然后,使用基于字符串的 SQL CREATE TABLE语句作为参数,对查询对象调用.exec()。该语句在数据库中创建一个名为contacts的新表。该表包含以下列:
| 圆柱 | 内容 |
|---|---|
id |
一个带有表的主键的整数 |
name |
带有联系人姓名的字符串 |
job |
包含联系人职务的字符串 |
email |
联系人电子邮件的字符串 |
您数据库中的contacts表将存储您联系人的相关信息。
完成编码database.py的最后一步是从createConnection()内部添加对_createContactsTable()的调用,就在最后一个 return语句之前。这确保了应用程序在对数据库进行任何操作之前创建了contacts表。
一旦创建了contacts表,就可以在数据库上运行一些测试,并为进一步的测试添加一些样本数据。
测试通讯录的数据库
到目前为止,您已经完成了处理到通讯录数据库的连接所需的代码。在本节中,您将执行一些测试来确保代码和数据库本身正常工作。您还将向数据库添加一些示例数据,以便在本教程的后面部分执行进一步的测试。
现在打开一个终端或命令行,移动到项目的根目录rpcontacts_project/。在那里,启动一个 Python 交互会话,并输入以下代码:
>>> from rpcontacts.database import createConnection >>> # Create a connection >>> createConnection("contacts.sqlite") True >>> # Confirm that contacts table exists >>> from PyQt5.QtSql import QSqlDatabase >>> db = QSqlDatabase.database() >>> db.tables() ['contacts', 'sqlite_sequence']这里,首先从
database.py模块导入createConnection()。然后调用这个函数创建并打开一个到联系人数据库的连接。数据库文件名是contacts.sqlite。因为这个文件不存在于项目的根目录中,所以 SQLite 会为您创建它。您可以通过查看您当前的目录来检查这一点。接下来,您确认数据库包含一个名为
contacts的表。为此,您在QSqlDatabase上调用.database()。这个类方法返回一个指向当前数据库连接的指针。有了这个对连接的引用,您可以调用.tables()来获取数据库中的表列表。注意,列表中的第一个表是contacts,所以现在您可以确定一切都运行良好。现在您可以准备一个 SQL 查询来将样本数据插入到
contacts表中:
>>> # Prepare a query to insert sample data
>>> from PyQt5.QtSql import QSqlQuery
>>> insertDataQuery = QSqlQuery()
>>> insertDataQuery.prepare(
... """
... INSERT INTO contacts (
... name,
... job,
... email
... )
... VALUES (?, ?, ?)
... """
... )
True
上面的查询允许您将特定的值插入到name、job和email属性中,并将这些值保存到数据库中。下面是如何做到这一点的示例:
>>> # Sample data >>> data = [ ... ("Linda", "Technical Lead", "linda@example.com"), ... ("Joe", "Senior Web Developer", "joe@example.com"), ... ("Lara", "Project Manager", "lara@example.com"), ... ("David", "Data Analyst", "david@example.com"), ... ("Jane", "Senior Python Developer", "jane@example.com"), ... ] >>> # Insert sample data >>> for name, job, email in data: ... insertDataQuery.addBindValue(name) ... insertDataQuery.addBindValue(job) ... insertDataQuery.addBindValue(email) ... insertDataQuery.exec() ... True True True True True在这段代码中,首先定义
data来保存一组人的联系信息。接下来,您使用一个for循环通过调用.addBindValue()来插入数据。然后在查询对象上调用.exec()来有效地在数据库上运行 SQL 查询。因为对
.exec()的所有调用都返回True,所以可以断定数据已经成功地插入到数据库中。如果要确认这一点,请运行以下代码:
>>> query = QSqlQuery()
>>> query.exec("SELECT name, job, email FROM contacts")
True
>>> while query.next():
... print(query.value(0), query.value(1), query.value(2))
...
Linda Technical Lead linda@example.com
Joe Senior Web Developer joe@example.com
Lara Project Manager lara@example.com
David Data Analyst david@example.com
Jane Senior Python Developer jane@example.com
就是这样!你的数据库工作正常!现在,您已经有了一些用来测试应用程序的样本数据,您可以专注于如何在您的通讯录主窗口中加载和显示联系人信息。
步骤 4:显示和更新现有联系人
要在应用程序的主窗口中显示您的联系人数据,您可以使用QTableView。这个类是 PyQt 的模型-视图架构的一部分,提供了一种健壮有效的方式来显示来自 PyQt 模型对象的项目。
您将在本节中添加或修改的文件和代码存储在source_code_step_4/目录下。要下载它们,请单击下面的链接:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
完成此步骤后,您的通讯录将如下所示:

主窗口中的表格视图对象提供了允许您快速修改和更新联系人信息所需的功能。
例如,要更新联系人的姓名,您可以双击包含姓名的单元格,更新姓名,然后按 Enter 将更改自动保存到数据库。但是在这样做之前,您需要创建一个模型并将其连接到表视图。
创建处理联系数据的模型
PyQt 提供了一组丰富的类,用于处理 SQL 数据库。对于您的通讯录应用程序,您将使用 QSqlTableModel ,它为单个数据库表提供了一个可编辑的数据模型。它非常适合这项工作,因为您的数据库只有一个表contacts。
回到代码编辑器,在rpcontacts/目录下创建一个名为model.py的新模块。将以下代码添加到文件中并保存:
1# -*- coding: utf-8 -*-
2# rpcontacts/model.py
3
4"""This module provides a model to manage the contacts table."""
5
6from PyQt5.QtCore import Qt
7from PyQt5.QtSql import QSqlTableModel
8
9class ContactsModel:
10 def __init__(self):
11 self.model = self._createModel()
12
13 @staticmethod
14 def _createModel():
15 """Create and set up the model."""
16 tableModel = QSqlTableModel()
17 tableModel.setTable("contacts")
18 tableModel.setEditStrategy(QSqlTableModel.OnFieldChange)
19 tableModel.select()
20 headers = ("ID", "Name", "Job", "Email")
21 for columnIndex, header in enumerate(headers):
22 tableModel.setHeaderData(columnIndex, Qt.Horizontal, header)
23 return tableModel
在这段代码中,首先进行一些必需的导入,然后创建ContactsModel。在类初始化器中,定义一个名为.model的实例属性来保存数据模型。
接下来,添加一个静态方法来创建和设置模型对象。下面是._createModel()中的代码所做的事情:
- 第 16 行创建了一个名为
tableModel的QSqlTableModel()实例。 - 第 17 行将模型对象与数据库中的
contacts表相关联。 - 第 18 行将模型的
.editStrategy属性设置为QSqlTableModel.OnFieldChange。这样,您可以确保模型上的更改立即保存到数据库中。 - 第 19 行通过调用
.select()将表格加载到模型中。 - 第 20 到 22 行为
contacts表格的列定义和设置用户友好的标题。 - 第 23 行返回新创建的模型。
此时,您已经准备好使用您的数据模型了。现在您需要将表视图小部件连接到模型,这样您就可以向您的用户提供联系信息。
将模型连接到视图
要在通讯录的主窗口中显示联系人数据,您需要将表格视图与数据模型连接起来。要执行这个连接,您需要在表视图对象上调用.setModel(),并将模型作为参数传递:
# -*- coding: utf-8 -*-
# rpcontacts/views.py
# Snip...
from .model import ContactsModel
class Window(QMainWindow):
"""Main Window."""
def __init__(self, parent=None):
# Snip...
self.contactsModel = ContactsModel() self.setupUI()
def setupUI(self):
"""Setup the main window's GUI."""
# Create the table view widget
self.table = QTableView()
self.table.setModel(self.contactsModel.model) self.table.setSelectionBehavior(QAbstractItemView.SelectRows)
# Snip...
在这段代码中,首先从model.py导入ContactsModel。该类提供了管理联系人数据库中数据的模型。
在Window的初始化器中,你创建了一个ContactsModel的实例。然后在.setupUI()中,调用.table上的.setModel()来连接模型和表格视图。如果您在这次更新后运行应用程序,那么您将得到您在步骤 4 开始时看到的窗口。
显示和更新联系人
PyQt 的模型视图架构提供了一种健壮且用户友好的方式来创建管理数据库的 GUI 应用程序。模型与数据库中的数据通信并访问数据。模型中的任何变化都会立即更新数据库。视图负责向用户显示数据,并提供可编辑的小部件,允许用户直接在视图中修改数据。
如果用户通过视图修改数据,则视图会在内部与模型通信并更新模型,从而将更改保存到物理数据库:

在本例中,您双击乔的职务字段。这使您可以访问一个可编辑的小部件,允许您修改单元格中的值。然后你把工作描述从Senior Web Developer更新到Web Developer。当您点击 Enter 时,表格视图将变更传递给模型,模型立即将变更保存到数据库中。
要确认更改已成功保存到数据库中,您可以关闭应用程序并再次运行它。表格视图应该反映您的更新。
步骤 5:创建新联系人
在这一步,您的通讯录应用程序提供了加载、显示和更新联系人信息的功能。尽管您可以修改和更新联系人信息,但您不能在列表中添加或移除联系人。
您将在本节中添加或修改的所有文件和代码都收集在source_code_step_5/目录中。要下载它们,请单击下面的链接:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
在本节中,您将提供向数据库添加新联系人所需的功能,使用弹出对话框输入新信息。第一步是创建添加联系人对话框。
创建添加联系人对话框
对话框是可以用来与用户交流的小窗口。在本节中,您将编写通讯录的添加联系人对话框,以允许您的用户向他们当前的联系人列表添加新的联系人。
要编写添加联系人对话框,您需要子类化 QDialog 。这个类为你的 GUI 应用程序提供了一个构建对话框的蓝图。
现在打开views.py模块,像这样更新导入部分:
# -*- coding: utf-8 -*-
# rpcontacts/views.py
# Snip...
from PyQt5.QtCore import Qt from PyQt5.QtWidgets import (
QAbstractItemView,
QDialog, QDialogButtonBox, QFormLayout, QHBoxLayout,
QLineEdit, QMainWindow,
QMessageBox, QPushButton,
QTableView,
QVBoxLayout,
QWidget,
)
上面代码中突出显示的行导入了构建添加联系人对话框所需的类。将这些类放在您的名称空间中,在views.py的末尾添加以下类:
1# -*- coding: utf-8 -*-
2# rpcontacts/views.py
3
4# Snip...
5class AddDialog(QDialog):
6 """Add Contact dialog."""
7 def __init__(self, parent=None):
8 """Initializer."""
9 super().__init__(parent=parent)
10 self.setWindowTitle("Add Contact")
11 self.layout = QVBoxLayout()
12 self.setLayout(self.layout)
13 self.data = None
14
15 self.setupUI()
16
17 def setupUI(self):
18 """Setup the Add Contact dialog's GUI."""
19 # Create line edits for data fields
20 self.nameField = QLineEdit()
21 self.nameField.setObjectName("Name")
22 self.jobField = QLineEdit()
23 self.jobField.setObjectName("Job")
24 self.emailField = QLineEdit()
25 self.emailField.setObjectName("Email")
26 # Lay out the data fields
27 layout = QFormLayout()
28 layout.addRow("Name:", self.nameField)
29 layout.addRow("Job:", self.jobField)
30 layout.addRow("Email:", self.emailField)
31 self.layout.addLayout(layout)
32 # Add standard buttons to the dialog and connect them
33 self.buttonsBox = QDialogButtonBox(self)
34 self.buttonsBox.setOrientation(Qt.Horizontal)
35 self.buttonsBox.setStandardButtons(
36 QDialogButtonBox.Ok | QDialogButtonBox.Cancel
37 )
38 self.buttonsBox.accepted.connect(self.accept)
39 self.buttonsBox.rejected.connect(self.reject)
40 self.layout.addWidget(self.buttonsBox)
这段代码中发生了很多事情。这里有一个总结:
- 第 5 行定义了一个新类从
QDialog继承了。 - 第 7 到 15 行定义了类初始化器。在这种情况下,最相关的添加是
.data,它是一个实例属性,您将使用它来保存用户提供的数据。
在.setupUI()中,您定义了对话框的 GUI:
- 第 20 行到第 25 行添加三个
QLineEdit对象:name、job、email。您将使用这些行编辑来获取用户输入的要添加的联系人的姓名、工作描述和电子邮件。它们代表数据库中相应的字段。 - 第 27 行到第 30 行创建一个
QFormLayout实例,它在一个表单中排列行编辑。这个布局管理器还为每个行编辑或字段提供用户友好的标签。 - 第 33 行到第 37 行添加一个
QDialogButtonBox对象,提供两个标准按钮: OK 和取消。确定按钮接受用户输入,而取消按钮拒绝用户输入。 - 线 38 和 39 分别将对话框的内置
.accepted()和.rejected()信号与.accept()和reject()插槽相连。在这种情况下,您将依赖对话框内置的.reject()插槽,它关闭对话框而不处理输入。除此之外,你只需要对.accept()槽进行编码。
为了给对话框的.accept()槽编码,你需要考虑任何用户输入都需要验证来确保它的正确性和安全性。当你使用 SQL 数据库时尤其如此,因为存在 SQL 注入攻击 T4 的风险。
在本例中,您将添加一个最小验证规则,以确保用户为对话框中的每个输入字段提供数据。然而,添加您自己的更健壮的验证规则将是一个很好的练习。
事不宜迟,回到AddDialog并为其.accept()插槽添加以下代码:
1# -*- coding: utf-8 -*-
2# rpcontacts/views.py
3
4# Snip...
5class AddDialog(QDialog):
6 def __init__(self, parent=None):
7 # Snip...
8
9 def setupUI(self):
10 # Snip...
11
12 def accept(self): 13 """Accept the data provided through the dialog."""
14 self.data = []
15 for field in (self.nameField, self.jobField, self.emailField):
16 if not field.text():
17 QMessageBox.critical(
18 self,
19 "Error!",
20 f"You must provide a contact's {field.objectName()}",
21 )
22 self.data = None # Reset .data
23 return
24
25 self.data.append(field.text())
26
27 if not self.data:
28 return
29
30 super().accept()
.accept()中的代码执行以下操作:
- 第 14 行将
.data初始化为空列表([])。该列表将存储用户的输入数据。 - 第 15 行定义了一个
for循环,迭代对话框中的三行编辑或字段。 - 第 16 到 23 行定义了一个条件语句,检查用户是否为对话框中的每个字段提供了数据。如果没有,则对话框会显示一条错误消息,警告用户缺少数据。
- 第 25 行将用户对每个字段的输入添加到
.data。 - 第 30 行调用超类的
.accept()槽来提供用户点击 OK 后关闭对话框的标准行为。
有了这段代码,您就可以在通讯录的主窗口中添加一个新的位置了。该插槽将启动该对话框,如果用户提供有效的输入,那么该插槽将使用该模型将新添加的联系人保存到数据库中。
启动添加联系人对话框
现在你已经编写了添加联系人对话框,是时候给Window添加一个新的槽了,这样你就可以通过点击添加来启动对话框,并在用户点击 OK 时处理用户的输入。
转到Window的定义,添加以下代码:
1# -*- coding: utf-8 -*-
2# rpcontacts/views.py
3
4# Snip...
5class Window(QMainWindow):
6 # Snip...
7
8 def setupUI(self):
9 # Snip...
10 self.addButton = QPushButton("Add...")
11 self.addButton.clicked.connect(self.openAddDialog) 12 # Snip...
13
14 def openAddDialog(self): 15 """Open the Add Contact dialog."""
16 dialog = AddDialog(self) 17 if dialog.exec() == QDialog.Accepted: 18 self.contactsModel.addContact(dialog.data) 19 self.table.resizeColumnsToContents()
下面是上面代码中发生的事情的总结:
- 线 11 将添加按钮的
.clicked()信号连接到新创建的插槽.openAddDialog()。这样,点击按钮将自动调用插槽。 - 第 14 行定义了
.openAddDialog()槽。 - 第 16 行创建一个
AddDialog的实例。 - 第 17 到 19 行定义了一个条件语句来检查对话是否被接受。如果是这样,那么第 14 行用对话框的
.data属性作为参数调用数据模型上的.addContact()。if代码块中的最后一条语句调整表格视图的大小,以适应其更新内容的大小。
现在您已经有了启动添加联系人对话框并处理其数据的方法,您需要在您的数据模型中提供.addContact()的代码。这是下一节的主题。
在模型中处理添加对话框的数据
在本节中,您将向您的数据模型ContactsModel添加一个名为.addContact()的方法。在您的代码编辑器中打开model.py,转到ContactsModel的定义,并添加以下代码:
1# -*- coding: utf-8 -*-
2# rpcontacts/model.py
3
4# Snip...
5class ContactsModel:
6 # Snip...
7
8 def addContact(self, data): 9 """Add a contact to the database."""
10 rows = self.model.rowCount() 11 self.model.insertRows(rows, 1) 12 for column, field in enumerate(data): 13 self.model.setData(self.model.index(rows, column + 1), field) 14 self.model.submitAll() 15 self.model.select()
在.addContact()中,代码执行以下操作:
- 第 10 行获取数据模型中的当前行数。
- 第 11 行在数据模型的末尾插入一个新行。
- 第 12 行和第 13 行运行一个
for循环,将data中的每一项插入到数据模型中相应的单元格中。为此,第 9 行调用模型上的.setData(),将单元格的索引和当前数据field作为参数。 - 第 14 行通过调用模型上的
.submitAll()向数据库提交变更。 - 第 15 行将数据从数据库重新加载到模型中。
如果您使用这些新增功能运行应用程序,您将获得以下行为:

现在,当您点击添加时,屏幕上会出现添加联系人对话框。您可以使用该对话框提供新联系人所需的信息,并通过点击 OK 将该联系人添加到数据库中。
步骤 6:删除现有联系人
您将添加到通讯录应用程序的最后一个特性是使用 GUI 从数据库中删除联系人的能力。
同样,您可以在source_code_step_6/目录下找到本节中添加或修改的所有文件和代码。您可以通过单击下面的链接下载它们:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
在本节中,您将首先添加一次删除一个联系人的功能。然后,您将添加代码从数据库中删除所有联系人。
删除选定的联系人
要从联系人数据库中删除单个联系人,您需要在通讯录主窗口的表格视图中选择所需的联系人。一旦选择了联系人,就可以点击删除来对数据库执行操作。
转到model.py模块,添加以下代码以在ContactsModel中实现.deleteContact():
# -*- coding: utf-8 -*-
# rpcontacts/model.py
# Snip...
class ContactsModel:
# Snip...
def deleteContact(self, row): """Remove a contact from the database."""
self.model.removeRow(row) self.model.submitAll() self.model.select()
这个方法有三行代码。第一行删除选中的row。第二行将更改提交给数据库。最后,第三行将数据重新加载到模型中。
接下来,返回到views.py模块,在Window中的删除按钮后面添加代码:
# -*- coding: utf-8 -*-
# rpcontacts/views.py
# Snip...
class Window(QMainWindow):
# Snip...
def setupUI(self):
"""Setup the main window's GUI."""
# Snip...
self.deleteButton = QPushButton("Delete")
self.deleteButton.clicked.connect(self.deleteContact) # Snip...
def deleteContact(self): """Delete the selected contact from the database."""
row = self.table.currentIndex().row() if row < 0: return
messageBox = QMessageBox.warning( self, "Warning!",
"Do you want to remove the selected contact?", QMessageBox.Ok | QMessageBox.Cancel, )
if messageBox == QMessageBox.Ok: self.contactsModel.deleteContact(row)
在第一个突出显示的行中,您将删除按钮的.clicked()信号连接到.deleteContact()插槽。每当用户点击按钮时,这个连接就会触发对.deleteContact()的调用。
在.deleteContact()中,首先获取表格视图中当前选中行的索引。if语句检查索引是否小于0,这意味着在表视图中没有联系人。如果是,则该方法立即返回,而不执行任何进一步的动作。
则该方法显示警告消息,确认用户想要删除所选联系人。如果用户接受操作,那么.deleteContact(row)被调用。在这种情况下,row表示表中当前选中行的索引。
完成这些添加后,您可以再次运行该应用程序以获得以下行为:

现在,当您从表格视图中选择一个联系人并单击删除时,您会看到一条警告消息。如果您点击消息对话框的 OK 按钮,那么应用程序将从数据库中删除选定的联系人,并相应地更新表格视图。
清除联系人数据库
要从数据库中删除所有联系人,首先要向ContactsModel添加一个名为.clearContacts()的方法。打开你的model.py模块,在类的末尾添加下面的方法:
1# -*- coding: utf-8 -*-
2# rpcontacts/model.py
3
4# Snip...
5class ContactsModel:
6 # Snip...
7
8 def clearContacts(self): 9 """Remove all contacts in the database."""
10 self.model.setEditStrategy(QSqlTableModel.OnManualSubmit) 11 self.model.removeRows(0, self.model.rowCount()) 12 self.model.submitAll() 13 self.model.setEditStrategy(QSqlTableModel.OnFieldChange) 14 self.model.select()
下面是每行代码的作用:
- 第 10 行将数据模型的
.editStrategy属性设置为QSqlTableModel.OnManualSubmit。这允许您缓存所有的更改,直到您稍后调用.submitAll()。您需要这样做,因为您要同时更改几行。 - 第 11 行从模型中删除所有行。
- 第 12 行保存对数据库的更改。
- 第 13 行将模型的
.editStrategy属性重置为其初始值QSqlTableModel.OnFieldChange。如果您不将该属性重置为其原始值,那么您将无法直接在表格视图中更新联系人。 - 第 14 行将数据重新载入模型。
一旦你编写了.clearContacts(),你可以回到views.py文件,用下面的代码更新Window:
# -*- coding: utf-8 -*-
# rpcontacts/views.py
# Snip...
class Window(QMainWindow):
# Snip...
def setupUI(self):
"""Setup the main window's GUI."""
# Snip...
self.clearAllButton = QPushButton("Clear All")
self.clearAllButton.clicked.connect(self.clearContacts) # Snip...
def clearContacts(self): """Remove all contacts from the database."""
messageBox = QMessageBox.warning( self, "Warning!", "Do you want to remove all your contacts?", QMessageBox.Ok | QMessageBox.Cancel, )
if messageBox == QMessageBox.Ok: self.contactsModel.clearContacts()
这段代码中第一个突出显示的行将清除所有按钮的.clicked()信号连接到下面的.clearContacts()插槽。
在.clearContacts()中,首先创建一个消息对话框messageBox,要求用户确认移除操作。如果用户通过点击 OK 来确认操作,那么.clearContacts()将在模型上被调用以从数据库中删除所有联系人:

就是这样!有了这最后一段代码,您的通讯录应用程序就完成了。该应用程序提供的功能允许您的用户显示、添加、更新和删除数据库中的联系人。
结论
用 Python、PyQt 和 SQLite 构建一个通讯录 GUI 应用程序对于您来说是一个很好的练习,可以扩展您使用这些工具的技能,对于一般的开发人员来说也是如此。像这样的编码项目允许你应用你已经拥有的知识和技能,并且每当你遇到一个新的编程问题时,也推动你去研究和学习新的主题。
在本教程中,您学习了如何:
- 使用 PyQt 为通讯录应用程序构建 GUI
- 使用 PyQt 的 SQL 支持将应用程序连接到 SQLite 数据库
- 使用 PyQt 的模型-视图架构来处理应用程序的数据库
您可以通过单击下面的链接下载通讯录应用程序的完整源代码以及完成本教程中每个步骤的代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Python、PyQt 和 SQLite 构建通讯录。
接下来的步骤
至此,您已经完成了一个功能完整的通讯录项目。该应用程序提供了最少的功能,但它是一个很好的起点,可以继续添加功能,并将您的 Python 和 PyQt 技能提升到一个新的水平。以下是一些你可以实施的下一步想法:
-
添加新的数据字段:添加新的数据字段来存储更多关于你的联系人的信息会很棒。例如,您可以添加联系人的照片、电话号码、网页、Twitter 账号等。为此,您可能需要创建新的表并设置它们之间的关系。PyQt 提供了
QSqlRelationalTableModel,为单个表定义了一个可编辑的数据模型,并提供外键支持。 -
提供搜索功能:让用户能够在数据库中搜索联系人,这无疑是这类应用程序的必备功能。要实现它,可以用 PyQt 的
QSqlQuery和QSqlQueryModel。 -
添加备份功能:提供一种备份联系信息的方式是另一个有趣的功能。用户的计算机可能会出现问题,并丢失数据。您可以提供将数据上传到云服务或将数据备份到外部磁盘的选项。
这些只是一些关于如何继续向您的通讯录添加功能的想法。接受挑战,在此基础上创造出令人惊叹的东西!*********
与 Python 的持续集成:简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 与 Python 的持续集成
当你自己写代码时,唯一优先考虑的是让它工作。然而,在一个专业软件开发团队中工作会带来很多挑战。其中一个挑战是协调许多人在同一代码上工作。
专业团队如何在保证每个人都协调一致、不出任何纰漏的情况下,每天做出几十个改动?进入持续集成!
在本教程中,您将:
- 了解持续集成背后的核心概念
- 了解持续集成的好处
- 建立一个基本的持续集成系统
- 创建一个简单的 Python 示例,并将其连接到持续集成系统
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
什么是持续集成?
持续集成(CI)是指经常自动地、尽可能早地构建和测试对代码所做的每个更改。多产的开发人员和作者 Martin Fowler 将 CI 定义如下:
“持续集成是一种软件开发实践,团队成员经常集成他们的工作,通常每个人至少每天集成一次——导致每天多次集成。每个集成都由自动化构建(包括测试)来验证,以尽快检测集成错误。”(来源)
让我们打开这个。
编程是迭代的。源代码存在于团队所有成员共享的存储库中。如果你想开发那个产品,你必须得到一个拷贝。您将进行更改,测试它们,并将它们集成回主回购中。冲洗并重复。
不久前,这些集成规模很大,而且相隔几周(或几个月),导致头痛、浪费时间和损失金钱。有了经验,开发人员开始做一些小的改动,并更频繁地集成它们。这减少了引入冲突的机会,您稍后需要解决这些冲突。
每次集成之后,您都需要构建源代码。构建意味着将您的高级代码转换成您的计算机知道如何运行的格式。最后,系统地测试结果,以确保您的更改不会引入错误。
我为什么要在乎?
在个人层面上,持续集成实际上是关于你和你的同事如何度过你的时间。
使用 CI,您将花费更少的时间:
- 担心每次修改时都会引入一个 bug
- 修复别人造成的混乱,这样你就可以集成你的代码
- 确保代码可以在每台机器、操作系统和浏览器上运行
相反,你会花更多的时间:
- 解决有趣的问题
- 与您的团队一起编写出色的代码
- 共同创造令人惊叹的产品,为用户提供价值
听起来怎么样?
在团队层面上,它允许一个更好的工程文化,在那里你尽早地并且经常地交付价值。合作是被鼓励的,错误会更快地被发现。持续集成将:
- 让你和你的团队更快
- 给你信心,你正在建立稳定的软件,更少的错误
- 确保您的产品可以在其他机器上运行,而不仅仅是您的笔记本电脑
- 消除大量繁琐的开销,让您专注于重要的事情
- 减少解决冲突所花费的时间(当不同的人修改相同的代码时)
核心概念
为了有效地进行持续集成,您需要理解几个关键的想法和实践。此外,当您谈论 CI 时,可能会有一些您不熟悉但经常使用的单词和短语。本章将向你介绍这些概念以及伴随它们而来的术语。
单一来源储存库
如果你和其他人合作开发一个代码库,通常会有一个共享的源代码库。从事该项目的每个开发人员都会创建一个本地副本并进行更改。一旦他们对变更感到满意,他们就将它们合并回中央存储库。
使用 Git 这样的版本控制系统(VCS)来为您处理这个工作流已经成为一种标准。团队通常使用外部服务来托管他们的源代码并处理所有移动部分。最受欢迎的是 GitHub、BitBucket 和 GitLab。
Git 允许您创建一个存储库的多个分支。每个分支都是源代码的独立副本,可以在不影响其他分支的情况下进行修改。这是一个重要的特性,大多数团队都有一个代表项目当前状态的主线分支(通常称为主分支)。
如果您想要添加或修改代码,您应该创建一个主分支的副本,并在新的开发分支中工作。完成后,将这些更改合并回主分支。

版本控制不仅仅包含代码。文档和测试脚本通常与源代码一起存储。一些程序寻找用于配置其参数和初始设置的外部文件。其他应用程序需要数据库模式。所有这些文件都应该放入您的存储库中。
如果您从未使用过 Git 或需要复习,请查看我们的面向 Python 开发人员的 Git 和 GitHub 介绍。
自动化构建
如前所述,构建代码意味着获取原始源代码,以及执行代码所需的一切,并将其转换为计算机可以直接运行的格式。Python 是一种解释语言,所以它的“构建”主要围绕测试执行而不是编译。
在每一个小的改变之后手动运行这些步骤是乏味的,并且从你试图做的实际问题解决中花费宝贵的时间和注意力。持续集成的很大一部分是自动化该过程,并将其转移到看不见的地方(和想不到的地方)。
这对 Python 意味着什么?想想你写的一段更复杂的代码。如果您使用的库、包或框架不是 Python 标准库附带的(想想您需要用pip或conda安装的任何东西),Python 需要知道这一点,所以当程序发现它不识别的命令时,它知道去哪里找。
您将那些包的列表存储在requirements.txt或 Pipfile 中。这些是代码的依赖,是成功构建的必要条件。
你会经常听到“打破构建”这个短语。当您中断构建时,这意味着您引入了一个导致最终产品不可用的变更。别担心。每个人都会遇到这种情况,即使是久经沙场的高级开发人员。您希望避免这种情况,主要是因为它会妨碍其他人工作。
CI 的全部意义在于让每个人都在一个已知的稳定基础上工作。如果他们克隆了一个破坏了构建的存储库,他们将使用一个破坏了的代码版本,并且不能引入或者测试他们的变更。当您中断构建时,首要任务是修复它,以便每个人都可以继续工作。

当构建自动化时,鼓励您频繁提交,通常是每天多次。它允许人们快速发现变化,并注意到两个开发人员之间是否有冲突。如果有许多小的变化而不是一些大的更新,那么定位错误的来源就容易多了。这也会鼓励你把工作分成更小的块,这样更容易跟踪和测试。
自动化测试
因为每个人每天都要提交多次变更,所以知道您的变更没有破坏代码中的任何东西或者引入 bug 是很重要的。在许多公司中,测试现在是每个开发人员的责任。如果你写代码,你应该写测试。最起码,你应该用单元测试覆盖每一个新功能。
自动运行测试,提交每一个变更,这是一个捕捉 bug 的好方法。失败的测试会自动导致构建失败。它会把你的注意力吸引到测试揭示的问题上,失败的构建会让你修复你引入的 bug。测试不能保证你的代码没有错误,但是它可以防止很多粗心的修改。
自动化测试执行让您安心,因为您知道服务器会在您每次提交时测试您的代码,即使您忘记在本地测试。
使用外部持续集成服务
如果某样东西在你的电脑上能用,它会在每台电脑上都能用吗?大概不会。这是一个老生常谈的借口,也是开发人员之间的一种内部玩笑,他们说,“嗯,它在我的机器上工作了!”让代码在本地工作并不是你的责任。
为了解决这个问题,大多数公司使用外部服务来处理集成,就像使用 GitHub 托管源代码库一样。外部服务拥有构建代码和运行测试的服务器。它们充当您的存储库的监视器,并且如果他们的变更破坏了构建,阻止任何人合并到主分支。
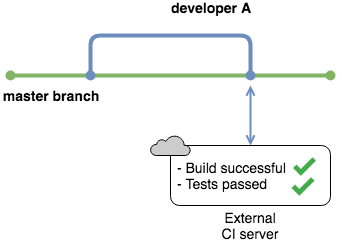
有很多这样的服务,有不同的功能和价格。大多数都有一个免费层,这样您就可以试验您的一个存储库。在本教程后面的示例中,您将使用一个名为 CircleCI 的服务。
在试运行环境中测试
生产环境是软件最终运行的地方。即使在成功地构建和测试了应用程序之后,您也不能确定您的代码是否能在目标计算机上运行。这就是团队在模拟生产环境的环境中部署最终产品的原因。一旦确定一切正常,应用程序就部署到生产环境中了。
注意:这一步与应用程序代码比与库代码更相关。您编写的任何 Python 库仍然需要在构建服务器上进行测试,以确保它们可以在不同于本地计算机的环境中工作。
您将听到人们使用开发环境、试运行环境或测试环境等术语来谈论生产环境的这个克隆。开发环境通常使用 DEV 这样的缩写,生产环境通常使用 PROD 这样的缩写。
开发环境应该尽可能地复制生产条件。这种设置通常被称为开发/生产奇偶校验。让本地计算机上的环境尽可能与开发和生产环境相似,以便在部署应用程序时最大限度地减少异常。

我们提到这一点是为了向您介绍词汇表,但是持续地将软件部署到开发和生产是一个完全不同的主题。不出所料,这个过程被称为持续部署(CD)。您可以在本文的后续步骤部分找到更多相关资源。
轮到你了!
最好的学习方法是边做边学。您现在已经理解了持续集成的所有基本实践,所以是时候动手创建使用 CI 所必需的整个步骤链了。这个链通常被称为 CI 管道。
这是一个实践教程,所以启动你的编辑器,准备好阅读这些步骤吧!
我们假设您了解 Python 和 Git 的基础知识。我们将使用 Github 作为我们的托管服务,使用 CircleCI 作为我们的外部持续集成服务。如果您没有这些服务的帐户,请继续注册。这两个都有免费层!
问题定义
请记住,您在这里的重点是为您的功能带添加一个新工具,即持续集成。对于这个例子,Python 代码本身很简单。您希望将大部分时间用于内部化构建管道的步骤,而不是编写复杂的代码。
假设您的团队正在开发一个简单的计算器应用程序。你的任务是编写一个基本数学函数库:加、减、乘、除。您并不关心实际的应用程序,因为那是您的同行使用您的库中的函数开发的。
创建回购
登录您的 GitHub 帐户,创建一个新的存储库,并将其命名为 CalculatorLibrary 。添加自述文件和。gitignore,然后将存储库克隆到您的本地机器上。如果你在这个过程中需要更多的帮助,看看 GitHub 的演练关于创建一个新的仓库。
建立工作环境
为了让其他人(和 CI 服务器)复制您的工作条件,您需要设置一个环境。在 repo 之外的某个地方创建一个虚拟环境并激活它:
$ # Create virtual environment
$ python3 -m venv calculator
$ # Activate virtual environment (Mac and Linux)
$ . calculator/bin/activate
前面的命令适用于 macOS 和 Linux。如果您是 Windows 用户,请查看官方文档中的平台表。这将创建一个包含 Python 安装的目录,并告诉解释器使用它。现在我们可以安装软件包了,因为它不会影响系统的默认 Python 安装。
写一个简单的 Python 例子
在存储库的顶层目录中创建一个名为calculator.py的新文件,并复制以下代码:
"""
Calculator library containing basic math operations.
"""
def add(first_term, second_term):
return first_term + second_term
def subtract(first_term, second_term):
return first_term - second_term
这是一个简单的例子,包含了我们将要编写的四个函数中的两个。一旦我们启动并运行了 CI 管道,您将添加剩下的两个功能。
继续并提交这些更改:
$ # Make sure you are in the correct directory
$ cd CalculatorLibrary
$ git add calculator.py
$ git commit -m "Add functions for addition and subtraction"
您的 CalculatorLibrary 文件夹现在应该包含以下文件:
CalculatorLibrary/
|
├── .git
├── .gitignore
├── README.md
└── calculator.py
很好,您已经完成了所需功能的一部分。下一步是添加测试,以确保您的代码按照预期的方式工作。
编写单元测试
您将分两步测试您的代码。
第一步涉及林挺——运行一个名为 linter 的程序,分析代码中的潜在错误。 flake8 常用来检查你的代码是否符合标准的 Python 编码风格。林挺确保你的代码对于 Python 社区的其他人来说是易读的。
第二步是单元测试。单元测试旨在检查代码的单个功能或单元。Python 附带了一个标准的单元测试库,但是其他库也存在并且非常流行。本例使用 pytest 。
与测试密切相关的一个标准实践是计算代码覆盖率。代码覆盖率是测试“覆盖”的源代码的百分比。pytest有一个扩展pytest-cov,可以帮助你理解你的代码覆盖率。
这些是外部依赖项,您需要安装它们:
$ pip install flake8 pytest pytest-cov
这些是您将使用的唯一外部软件包。确保将这些依赖关系存储在一个requirements.txt文件中,以便其他人可以复制您的环境:
$ pip freeze > requirements.txt
要运行 linter,请执行以下命令:
$ flake8 --statistics
./calculator.py:3:1: E302 expected 2 blank lines, found 1
./calculator.py:6:1: E302 expected 2 blank lines, found 1
2 E302 expected 2 blank lines, found 1
--statistics选项给你一个特定错误发生次数的概览。这里我们有两个 PEP 8 违规,因为flake8期望在函数定义前有两个空行,而不是一个。继续在每个函数定义前添加一个空行。再次运行flake8,检查错误信息是否不再出现。
现在是编写测试的时候了。在存储库的顶层目录中创建一个名为test_calculator.py的文件,并复制以下代码:
"""
Unit tests for the calculator library
"""
import calculator
class TestCalculator:
def test_addition(self):
assert 4 == calculator.add(2, 2)
def test_subtraction(self):
assert 2 == calculator.subtract(4, 2)
这些测试确保我们的代码按预期运行。这还不够广泛,因为您还没有测试代码的潜在误用,但是现在保持简单。
以下命令运行您的测试:
$ pytest -v --cov
collected 2 items
test_calculator.py::TestCalculator::test_addition PASSED [50%]
test_calculator.py::TestCalculator::test_subtraction PASSED [100%]
---------- coverage: platform darwin, python 3.6.6-final-0 -----------
Name Stmts Miss Cover
---------------------------------------------------------------------
calculator.py 4 0 100%
test_calculator.py 6 0 100%
/Users/kristijan.ivancic/code/learn/__init__.py 0 0 100%
---------------------------------------------------------------------
TOTAL 10 0 100%
pytest擅长测试发现。因为您有一个前缀为test的文件,pytest知道它将包含单元测试以便运行。同样的原则也适用于文件中的类名和方法名。
-v标志给你一个更好的输出,告诉你哪些测试通过了,哪些测试失败了。在我们的案例中,两个测试都通过了。--cov标志确保pytest-cov运行,并给你一份calculator.py的代码覆盖报告。
你已经完成了准备工作。提交测试文件,并将所有这些更改推送到主分支:
$ git add test_calculator.py
$ git commit -m "Add unit tests for calculator"
$ git push
在本节结束时,您的 CalculatorLibrary 文件夹应该包含以下文件:
CalculatorLibrary/
|
├── .git
├── .gitignore
├── README.md
├── calculator.py
├── requirements.txt
└── test_calculator.py
太好了,你的两个功能都经过测试,工作正常。
连接到 CircleCI
最后,您已经准备好建立您的持续集成管道了!
CircleCI 需要知道如何运行您的构建,并希望该信息以特定的格式提供。它要求 repo 中有一个.circleci文件夹,其中有一个配置文件。配置文件包含构建服务器需要执行的所有步骤的指令。CircleCI 希望这个文件被称为config.yml。
一个.yml文件使用一种数据序列化语言, YAML ,它有自己的规范。YAML 的目标是让人类可读,并能很好地与现代编程语言一起完成日常任务。
在 YAML 文件中,有三种基本方式来表示数据:
- 映射(键值对)
- 序列(列表)
- 标量(字符串或数字)
读起来很简单:
- 缩进可以用于结构。
- 冒号分隔键值对。
- 破折号用于创建列表。
在您的 repo 中创建.circleci文件夹和一个包含以下内容的config.yml文件:
# Python CircleCI 2.0 configuration file version: 2 jobs: build: docker: - image: circleci/python:3.7 working_directory: ~/repo steps: # Step 1: obtain repo from GitHub - checkout # Step 2: create virtual env and install dependencies - run: name: install dependencies command: | python3 -m venv venv . venv/bin/activate pip install -r requirements.txt # Step 3: run linter and tests - run: name: run tests command: | . venv/bin/activate flake8 --exclude=venv* --statistics pytest -v --cov=calculator
其中一些单词和概念可能对你来说不熟悉。比如什么是 Docker,什么是 images?让我们回到过去一点。
还记得程序员面临的问题吗?有些东西在他们的笔记本电脑上可以用,但在别的地方不行。以前,开发人员常常创建一个程序,隔离计算机的一部分物理资源(内存、硬盘驱动器等),并将它们变成一个虚拟机。
虚拟机自己伪装成一台完整的计算机。它甚至会有自己的操作系统。在该操作系统上,您部署您的应用程序或安装您的库并测试它。
虚拟机占用了大量的资源,这激发了容器的发明。这个想法类似于海运集装箱。在集装箱发明之前,制造商必须以多种尺寸、包装和方式(卡车、火车、轮船)运输货物。
通过标准化集装箱,这些货物可以在不同的运输方式之间转移,而无需任何修改。同样的想法也适用于软件容器。
容器是一个轻量级的代码单元及其运行时依赖项,以一种标准化的方式打包,因此它们可以快速插入并在 Linux 操作系统上运行。您不需要像创建虚拟机那样创建一个完整的虚拟操作系统。
容器只复制它们工作所需的操作系统的一部分。这减小了它们的尺寸,并大大提高了它们的性能。
Docker 是目前领先的容器平台,它甚至能够在 Windows 和 macOS 上运行 Linux 容器。要创建 Docker 容器,您需要一个 Docker 映像。图像为容器提供蓝图,就像类为对象提供蓝图一样。你可以在他们的入门指南中阅读更多关于 Docker 的内容。
CircleCI 为几种编程语言维护了预构建的 Docker 映像。在上面的配置文件中,您指定了一个已经安装了 Python 的 Linux 映像。这个图像将会创造一个容器,在这个容器中其他的事情都会发生。
让我们依次看看配置文件的每一行:
-
version: 每个config.yml都以 CircleCI 版本号开头,用于发布关于重大变更的警告。 -
jobs: 作业代表构建的一次执行,由一组步骤定义。如果你只有一份工作,那一定叫build。 -
build: 如前所述,build是你工作的名称。您可以有多个作业,在这种情况下,它们需要有唯一的名称。 -
docker: 一个作业的各个步骤发生在一个叫做执行器的环境中。CircleCI 中常见的执行者是一个 Docker 容器。这是一个云托管的执行环境,但也有其他选择,比如 macOS 环境。 -
image:Docker 镜像是一个用来创建运行 Docker 容器的文件。我们使用预装了 Python 3.7 的映像。 -
working_directory: 您的存储库必须在构建服务器上的某个地方被检出。工作目录代表存储库的文件路径。 -
steps: 这个键标志着构建服务器要执行的一系列步骤的开始。 -
checkout: 服务器需要做的第一步是将源代码签出到工作目录。这是通过一个叫做checkout的特殊步骤来完成的。 -
run: 命令行程序或命令的执行是在command键内完成的。实际的 shell 命令将嵌套在。 -
name:circle ci 用户界面以可扩展部分的形式向您展示每个构建步骤。该部分的标题取自与name键相关联的值。 -
command: 该键代表通过 shell 运行的命令。|符号指定接下来是一组命令,每行一个,就像您在 shell/bash 脚本中看到的一样。
您可以阅读 CircleCI 配置参考文档了解更多信息。
我们的管道非常简单,由 3 个步骤组成:
- 签出存储库
- 在虚拟环境中安装依赖关系
- 在虚拟环境中运行 linter 和测试
我们现在有了启动管道所需的一切。登录你的 CircleCI 账户,点击添加项目。找到你的计算器库回购,点击设置项目。选择 Python 作为您的语言。因为我们已经有了一个config.yml,我们可以跳过接下来的步骤,点击开始构建。
CircleCI 将带您进入工作的执行仪表板。如果你正确地遵循所有的步骤,你应该看到你的工作成功。
您的 CalculatorLibrary 文件夹的最终版本应该如下所示:
CalculatorRepository/
|
├── .circleci
├── .git
├── .gitignore
├── README.md
├── calculator.py
├── requirements.txt
└── test_calculator.py
恭喜你!您已经创建了您的第一个持续集成管道。现在,每次推送到主分支,都会触发一个作业。点击 CircleCI 侧边栏中的 Jobs ,可以看到你当前和过去的工作列表。
进行更改
是时候把乘法加入我们的计算器库中了。
这一次,我们将首先添加一个单元测试,而不编写函数。如果没有代码,测试将会失败,CircleCI 作业也会失败。将以下代码添加到您的test_calculator.py的末尾:
def test_multiplication(self):
assert 100 == calculator.multiply(10, 10)
将代码推送到主分支,并在 CircleCI 中看到作业失败。这表明持续集成是有效的,如果你犯了错误,它会保护你。
现在将代码添加到calculator.py中,这将使测试通过:
def multiply(first_term, second_term):
return first_term * second_term
确保乘法函数和前一个函数之间有两个空格,否则您的代码将无法通过 linter 检查。
这次工作应该会成功。这种先写一个失败的测试,然后添加代码通过测试的工作流程被称为测试驱动开发 (TDD)。这是一个很好的工作方式,因为它让你提前考虑你的代码结构。
现在你自己试试。为除法函数添加一个测试,看到它失败,然后编写函数使测试通过。
通知
当处理具有大量移动部件的大型应用程序时,持续集成工作可能需要一段时间才能运行。大多数团队都建立了一个通知程序,让他们知道自己的工作是否失败。他们可以在等待作业运行的同时继续工作。
最受欢迎的选项有:
- 为每个失败的构建发送电子邮件
- 向松弛通道发送故障通知
- 在每个人都能看到的仪表板上显示故障
默认情况下,CircleCI 应该在作业失败时向您发送电子邮件。
接下来的步骤
您已经理解了持续集成的基础,并练习了为一个简单的 Python 程序设置管道。这是您作为开发人员的旅程中向前迈出的一大步。你可能会问自己,“现在怎么办?”
为了简单起见,本教程跳过了一些大的主题。通过花些时间更深入地研究每一个主题,你可以极大地提高你的技能。这里有一些你可以进一步研究的话题。
Git 工作流程
除了您在这里使用的东西之外,还有更多的东西可以利用。每个开发团队都有一个适合他们特定需求的工作流程。其中大多数包括分支策略和所谓的同行评审。他们在与master分支分开的分支上进行更改。当你想用master合并那些变更时,在你被允许合并之前,其他开发人员必须首先查看你的变更并批准它们。
注:如果你想了解更多关于团队使用的不同工作流,看看 GitHub 和 BitBucket 上的教程。
如果你想提高你的 Git 技能,我们有一篇文章叫做Python 开发者的高级 Git 技巧。
依赖性管理和虚拟环境
除了virtualenv,还有其他流行的包和环境管理器。其中一些只处理虚拟环境,而一些同时处理包安装和环境管理。其中之一是康达:
“Conda 是一个开源的软件包管理系统和环境管理系统,可以在 Windows、macOS 和 Linux 上运行。Conda 快速安装、运行和更新软件包及其依赖项。Conda 可以在本地计算机上轻松创建、保存、加载和切换环境。它是为 Python 程序设计的,但它可以为任何语言打包和分发软件。”(来源)
另一个选择是 Pipenv ,一个在应用程序开发人员中越来越受欢迎的年轻竞争者。Pipenv 将pip和virtualenv组合成一个工具,并使用Pipfile代替requirements.txt。pip 文件提供了确定性的环境和更高的安全性。这个介绍并没有做到公正,所以请查看 Pipenv:新 Python 打包工具指南。
测试
用pytest进行简单的单元测试只是冰山一角。外面有一整个世界等着你去探索!软件可以在许多层面上进行测试,包括集成测试、验收测试、回归测试等等。为了让你的 Python 代码测试知识更上一层楼,请前往Python 测试入门。
包装
在本教程中,您开始构建一个函数库,供其他开发人员在他们的项目中使用。您需要将这个库打包成一种易于分发和安装的格式,例如使用pip。
创建一个可安装包需要不同的布局和一些额外的文件,如__init__.py和setup.py。阅读 Python 应用程序布局:参考了解更多关于构建代码的信息。
要了解如何将您的存储库变成可安装的 Python 包,请阅读由 Python 打包权威撰写的打包 Python 项目。
持续集成
在本教程中,您使用了一个简单的 Python 代码示例,涵盖了 CI 的所有基础知识。CI 管道的最后一步通常是创建一个可部署工件。一个工件代表一个完成的、打包的工作单元,可以随时部署给用户或者包含在复杂的产品中。
例如,要将您的计算器库变成一个可部署的工件,您应该将它组织成一个可安装的包。最后,您将在 CircleCI 中添加一个步骤来打包库,并将工件存储在其他进程可以获取的地方。
对于更复杂的应用程序,您可以创建一个工作流来安排多个 CI 作业并将其连接到一次执行中。请随意浏览 CircleCI 文档。
连续部署
您可以将持续部署视为 CI 的扩展。一旦您的代码被测试并构建到可部署的工件中,它就被部署到生产中,这意味着动态应用程序会随着您的更改而更新。其中一个目标是最小化交付时间,即从编写一行新代码到提交给用户之间的时间。
注意:为了增加一点混乱,缩写 CD 不是唯一的。它也可以意味着连续交付,这与连续部署几乎相同,但是在集成和部署之间有一个手动验证步骤。你可以在任何时候集成你的代码,但是你必须按下一个按钮才能把它发布到正在运行的应用程序中。
大多数公司同时使用 CI/CD,因此值得您花时间了解更多关于连续交付/部署的信息。
持续集成服务概述
您已经使用了 CircleCI,这是最流行的持续集成服务之一。然而,这是一个有很多强有力竞争者的大市场。CI 产品分为两个基本类别:远程和自托管服务。
Jenkins 是最受欢迎的自托管解决方案。它是开源的、灵活的,社区开发了很多扩展。
在远程服务方面,有许多流行的选项,如 TravisCI 、 CodeShip 和 Semaphore 。大企业往往有他们的定制解决方案,他们把它们作为服务来卖,比如 AWS CodePipeline 、微软 Team Foundation Server ,甲骨文的 Hudson 。
您选择哪个选项取决于您和您的团队需要的平台和功能。如需更详细的细分,请查看 G2Crowd 的最佳 CI 软件。
结论
借助本教程中的知识,您现在可以回答以下问题:
- 什么是持续集成?
- 为什么持续集成很重要?
- 持续集成的核心实践是什么?
- 如何为我的 Python 项目设置持续集成?
你已经获得了编程的超能力!理解持续集成的哲学和实践将使你成为任何团队中有价值的一员。太棒了。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 与 Python 的持续集成******
Python 的计数器:计算对象的 python 方式
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 的计数器计数
一次计数几个重复的对象是编程中常见的问题。Python 提供了一系列工具和技术来解决这个问题。然而,Python 的 Counter 从 collections 提供了一个干净、高效、Python 式的解决方案。
这个字典子类提供了开箱即用的高效计数能力。作为 Python 开发人员,理解Counter以及如何有效地使用它是一项方便的技能。
在本教程中,您将学习如何:
- 一次数几个重复的物体
- 用 Python 的
Counter创建计数器 - 检索计数器中最常见的对象
- 更新对象计数
- 使用
Counter来帮助进一步计算
您还将学习使用Counter作为多集的基础知识,这是 Python 中该类的一个附加特性。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 中的计数对象
有时,您需要对给定数据源中的对象进行计数,以了解它们出现的频率。换句话说,你需要确定它们的频率。例如,您可能想知道特定项目在值列表或值序列中出现的频率。当你的清单很短的时候,计算清单可以简单快捷。然而,当你有一个很长的清单时,计数会更有挑战性。
为了计数对象,通常使用一个计数器,它是一个初始值为零的整数变量。然后递增计数器,以反映给定对象在输入数据源中出现的次数。
当计算单个对象的出现次数时,可以使用单个计数器。但是,当您需要对几个不同的对象进行计数时,您必须创建与您拥有的唯一对象一样多的计数器。
要一次计算几个不同的对象,可以使用 Python 字典。字典键将存储您想要计数的对象。字典值将保存给定对象的重复次数,或者该对象的计数。
例如,要使用字典对序列中的对象进行计数,可以循环遍历序列,检查当前对象是否不在字典中以初始化计数器(键-值对),然后相应地增加其计数。
下面是一个计算单词“Mississippi”中的字母的例子:
>>> word = "mississippi" >>> counter = {} >>> for letter in word: ... if letter not in counter: ... counter[letter] = 0 ... counter[letter] += 1 ... >>> counter {'m': 1, 'i': 4, 's': 4, 'p': 2}
for循环迭代word中的字母。在每次迭代中,条件语句检查手头的字母是否已经是您用作counter的字典中的一个键。如果是,它用字母创建一个新的密钥,并将其计数初始化为零。最后一步是将计数加 1。当您访问counter时,您会看到字母作为键工作,而值作为计数。注意:当你用 Python 字典计算几个重复的对象时,记住它们必须是可散列的,因为它们将作为字典键。成为可散列的意味着你的对象必须有一个在其生命周期中永不改变的散列值。在 Python 中,不可变的对象也是可散列的。
用字典计数对象的另一种方法是使用
dict.get(),用0作为缺省值:
>>> word = "mississippi"
>>> counter = {}
>>> for letter in word:
... counter[letter] = counter.get(letter, 0) + 1
...
>>> counter
{'m': 1, 'i': 4, 's': 4, 'p': 2}
当您以这种方式调用.get()时,您将获得给定letter的当前计数,或者如果字母丢失,则获得0(默认)。然后将计数增加1,并将其存储在字典中相应的letter下。
您也可以从 collections 中使用 defaultdict 来计数一个循环内的对象:
>>> from collections import defaultdict >>> word = "mississippi" >>> counter = defaultdict(int) >>> for letter in word: ... counter[letter] += 1 ... >>> counter defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})这个解决方案更简洁,可读性更好。首先使用带有
int()的defaultdict初始化counter作为默认工厂函数。这样,当您访问底层defaultdict中不存在的键时,字典会自动创建这个键,并用工厂函数返回的值初始化它。在这个例子中,因为你使用
int()作为工厂函数,初始值是0,这是无参数调用int()的结果。与编程中的许多其他常见任务一样,Python 提供了一种更好的方法来处理计数问题。在
collections中,你会发现一个专门设计的类,可以一次计算几个不同的物体。这个班就顺手叫Counter。Python 的
Counter入门
Counter是dict的一个子类,专门用于计算 Python 中可散列对象的数量。它是一个将对象存储为键并作为值计数的字典。为了用Counter计数,你通常提供一个可散列对象的序列或可迭代作为类的构造函数的参数。
Counter在内部遍历输入序列,计算给定对象出现的次数,并将对象存储为键,将计数存储为值。在下一节中,您将了解构造计数器的不同方法。构建计数器
创建
Counter实例有几种方法。但是,如果你的目标是一次计数几个对象,那么你需要使用一个序列或 iterable 来初始化计数器。例如,下面是如何使用Counter重写密西西比的例子:
>>> from collections import Counter
>>> # Use a string as an argument
>>> Counter("mississippi")
Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
>>> # Use a list as an argument
>>> Counter(list("mississippi"))
Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
Counter遍历"mississippi"并生成一个字典,将字母作为关键字,将它们的频率作为值。在第一个例子中,您使用一个字符串作为Counter的参数。您还可以使用列表、元组或任何包含重复对象的 iterables,如第二个示例所示。
注:Counter中的,经过高度优化的 C 函数提供计数功能。如果这个函数由于某种原因不可用,那么这个类使用一个等效的但是效率较低的 Python 函数。
创建Counter实例还有其他方法。然而,它们并不严格意味着计数。例如,您可以使用包含键和计数的字典,如下所示:
>>> from collections import Counter >>> Counter({"i": 4, "s": 4, "p": 2, "m": 1}) Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})计数器现在有了一组初始的键计数对。当您需要提供现有对象组的初始计数时,这种创建
Counter实例的方式非常有用。当您呼叫类别的建构函式时,也可以使用关键字引数来产生类似的结果:
>>> from collections import Counter
>>> Counter(i=4, s=4, p=2, m=1)
Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
同样,您可以使用这种方法为键和计数对创建一个具有特定初始状态的Counter对象。
在实践中,如果你使用Counter从头开始计数,那么你不需要初始化计数,因为它们默认为 0。另一种可能是将计数初始化为1。在这种情况下,您可以这样做:
>>> from collections import Counter >>> Counter(set("mississippi")) Counter({'p': 1, 's': 1, 'm': 1, 'i': 1})Python 设置存储唯一的对象,因此本例中对
set()的调用抛出了重复的字母。在此之后,您将得到原始 iterable 中每个字母的一个实例。
Counter继承了普通词典的接口。但是,它没有提供一个.fromkeys()的工作实现来防止歧义,比如Counter.fromkeys("mississippi", 2)。在这个特定的例子中,每个字母都有一个默认的计数2,不管它在输入 iterable 中的当前出现次数。对于可以存储在计数器的键和值中的对象没有任何限制。键可以存储可散列对象,而值可以存储任何对象。但是,要作为计数器工作,这些值应该是表示计数的整数。
下面是一个保存负数和零计数的
Counter实例的例子:
>>> from collections import Counter
>>> inventory = Counter(
... apple=10,
... orange=15,
... banana=0,
... tomato=-15
... )
在这个例子中,你可能会问,“为什么我有-15西红柿?”嗯,这可能是一个内部惯例,表明你有一个客户的15西红柿订单,而你目前的库存中没有。谁知道呢?Counter允许你这样做,你可能会发现这个特性的一些用例。
更新对象计数
一旦有了一个Counter实例,就可以使用.update()用新的对象和计数来更新它。由Counter提供的 .update() 实现将现有的计数加在一起,而不是像它的dict对应物那样替换值。它还会在必要时创建新的键计数对。
您可以使用.update()将 iterables 和计数映射作为参数。如果使用 iterable,方法会计算其项数,并相应地更新计数器:
>>> from collections import Counter >>> letters = Counter({"i": 4, "s": 4, "p": 2, "m": 1}) >>> letters.update("missouri") >>> letters Counter({'i': 6, 's': 6, 'p': 2, 'm': 2, 'o': 1, 'u': 1, 'r': 1})现在你有了
i的6实例、s的6实例,等等。您还拥有一些新的键计数对,例如'o': 1、'u': 1和'r': 1。请注意,iterable 需要是一个项目序列,而不是一个(key, count)对序列。注意:正如您已经知道的,您可以在计数器中存储的值(计数)没有限制。
使用整数以外的对象进行计数会破坏常见的计数器功能:
>>> from collections import Counter
>>> letters = Counter({"i": "4", "s": "4", "p": "2", "m": "1"})
>>> letters.update("missouri")
Traceback (most recent call last):
...
TypeError: can only concatenate str (not "int") to str
在这个例子中,字母计数是字符串而不是整数值。这中断了.update(),导致了TypeError。
使用.update()的第二种方法是提供另一个计数器或计数映射作为参数。在这种情况下,您可以这样做:
>>> from collections import Counter >>> sales = Counter(apple=25, orange=15, banana=12) >>> # Use a counter >>> monday_sales = Counter(apple=10, orange=8, banana=3) >>> sales.update(monday_sales) >>> sales Counter({'apple': 35, 'orange': 23, 'banana': 15}) >>> # Use a dictionary of counts >>> tuesday_sales = {"apple": 4, "orange": 7, "tomato": 4} >>> sales.update(tuesday_sales) >>> sales Counter({'apple': 39, 'orange': 30, 'banana': 15, 'tomato': 4})在第一个示例中,您使用另一个计数器
monday_sales来更新现有的计数器sales。注意.update()是如何将两个计数器的计数相加的。注意:你也可以把
.update()和关键字参数一起使用。例如,做类似于sales.update(apple=10, orange=8, banana=3)的事情和上面例子中的sales.update(monday_sales)是一样的。接下来,使用包含项目和计数的常规字典。在这种情况下,
.update()添加现有键的计数,并创建缺失的键计数对。访问计数器的内容
正如你已经知道的,
Counter和dict的界面几乎一样。您可以使用计数器执行与标准字典几乎相同的操作。例如,您可以使用类似字典的键访问([key])来访问它们的值。您还可以使用常用的技术和方法迭代键、值和项:
>>> from collections import Counter
>>> letters = Counter("mississippi")
>>> letters["p"]
2
>>> letters["s"]
4
>>> for letter in letters:
... print(letter, letters[letter])
...
m 1
i 4
s 4
p 2
>>> for letter in letters.keys():
... print(letter, letters[letter])
...
m 1
i 4
s 4
p 2
>>> for count in letters.values():
... print(count)
...
1
4
4
2
>>> for letter, count in letters.items():
... print(letter, count)
...
m 1
i 4
s 4
p 2
在这些例子中,您使用熟悉的字典接口访问并迭代计数器的键(字母)和值(计数),该接口包括诸如.keys()、.values()和.items()之类的方法。
注意:如果你想深入了解如何迭代字典,那么看看如何用 Python 迭代字典。
关于Counter需要注意的最后一点是,如果你试图访问一个丢失的键,那么你得到的是零而不是一个 KeyError :
>>> from collections import Counter >>> letters = Counter("mississippi") >>> letters["a"] 0由于字母
"a"没有出现在字符串"mississippi"中,当您试图访问该字母的计数时,计数器返回0。寻找最常见的物体
如果你需要根据一组物体出现的频率或者次数来列出它们,那么你可以使用
.most_common()。这个方法返回一个按对象当前计数排序的列表(object, count)。计数相等的对象按照它们第一次出现的顺序排列。如果您提供一个整数
n作为.most_common()的参数,那么您将得到n最常见的对象。如果省略n或将其设为None,则.most_common()返回计数器中的所有对象:
>>> from collections import Counter
>>> sales = Counter(banana=15, tomato=4, apple=39, orange=30)
>>> # The most common object
>>> sales.most_common(1)
[('apple', 39)]
>>> # The two most common objects
>>> sales.most_common(2)
[('apple', 39), ('orange', 30)]
>>> # All objects sorted by count
>>> sales.most_common()
[('apple', 39), ('orange', 30), ('banana', 15), ('tomato', 4)]
>>> sales.most_common(None)
[('apple', 39), ('orange', 30), ('banana', 15), ('tomato', 4)]
>>> sales.most_common(20)
[('apple', 39), ('orange', 30), ('banana', 15), ('tomato', 4)]
在这些例子中,您使用.most_common()来检索sales中最频繁出现的对象。不带参数或带 None ,该方法返回所有对象。如果.most_common()的参数大于当前计数器的长度,那么您将再次获得所有对象。
你也可以通过对.most_common()的结果进行切片得到最不常见的对象:
>>> from collections import Counter >>> sales = Counter(banana=15, tomato=4, apple=39, orange=30) >>> # All objects in reverse order >>> sales.most_common()[::-1] [('tomato', 4), ('banana', 15), ('orange', 30), ('apple', 39)] >>> # The two least-common objects >>> sales.most_common()[:-3:-1] [('tomato', 4), ('banana', 15)]第一次切片,
[::-1],根据各自的计数以相反的顺序返回sales中的所有对象。切片[:-3:-1]从.most_common()的结果中提取最后两个对象。通过更改切片操作符中的第二个偏移值,可以调整最不常用对象的数量。例如,要获得三个最不常用的对象,可以将-3改为-4,依此类推。注:查看反向 Python 列表:Beyond。reverse()和 reversed() 获得使用切片语法的实际例子。
如果你想让
.most_common()正常工作,那么确保你的计数器中的值是可排序的。这一点需要记住,因为如上所述,您可以在计数器中存储任何数据类型。将
Counter付诸行动到目前为止,您已经学习了在代码中创建和使用
Counter对象的基础知识。您现在知道如何计算每个对象在给定序列或 iterable 中出现的次数。您还知道如何:
- 用初始值创建计数器
- 更新现有计数器
- 获取给定计数器中最频繁出现的对象
在接下来的部分中,您将编写一些实际的例子,这样您就可以更好地了解 Python 的
Counter有多有用。对文本文件中的字母进行计数
假设您有一个包含一些文本的文件。你需要计算每个字母在文本中出现的次数。例如,假设您有一个名为
pyzen.txt的文件,其内容如下:The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!是的,这是Python 的禅,一系列指导原则定义了 Python 设计背后的核心哲学。为了统计每个字母在这个文本中出现的次数,你可以利用
Counter和编写一个函数,如下所示:1# letters.py 2 3from collections import Counter 4 5def count_letters(filename): 6 letter_counter = Counter() 7 with open(filename) as file: 8 for line in file: 9 line_letters = [ 10 char for char in line.lower() if char.isalpha() 11 ] 12 letter_counter.update(Counter(line_letters)) 13 return letter_counter下面是这段代码的工作原理:
- 第 5 行定义
count_letters()。该函数将基于字符串的文件路径作为参数。- 第 6 行创建一个空计数器,用于计算目标文本中的字母数。
- 第 7 行 打开输入文件进行读取并在文件内容上创建一个迭代器。
- 第 8 行开始一个循环,逐行遍历文件内容。
- 第 9 到 11 行定义了一个列表理解,使用
.isalpha()从当前行中排除非字母字符。在过滤字母之前,理解小写字母,以防止出现单独的小写和大写计数。- 第 12 行调用字母计数器上的
.update()来更新每个字母的计数。要使用
count_letters(),您可以这样做:
>>> from letters import count_letters
>>> letter_counter = count_letters("pyzen.txt")
>>> for letter, count in letter_counter.items():
... print(letter, "->", count)
...
t -> 79
h -> 31
e -> 92
z -> 1
...
k -> 2
v -> 5
w -> 4
>>> for letter, count in letter_counter.most_common(5):
... print(letter, "->", count)
...
e -> 92
t -> 79
i -> 53
a -> 53
s -> 46
太好了!您的代码计算给定文本文件中每个字母的出现频率。语言学家经常用字母频率进行语言识别。例如,在英语中,对平均字母频率的研究表明,五个最常见的字母是“e”、“t”、“a”、“o”和“I”。哇!这几乎与您的结果相符!
用 ASCII 条形图绘制分类数据
统计是另一个可以使用Counter的字段。例如,当您处理分类数据时,您可能想要创建条形图来可视化每个类别的观察数量。条形图对于绘制这种类型的数据特别方便。
现在假设您想创建一个函数,允许您在终端上创建 ASCII 条形图。为此,您可以使用以下代码:
# bar_chart.py
from collections import Counter
def print_ascii_bar_chart(data, symbol="#"):
counter = Counter(data).most_common()
chart = {category: symbol * frequency for category, frequency in counter}
max_len = max(len(category) for category in chart)
for category, frequency in chart.items():
padding = (max_len - len(category)) * " "
print(f"{category}{padding} |{frequency}")
在这个例子中,print_ascii_bar_chart()获取一些分类data,计算每个唯一类别在数据中出现的次数(frequency,并生成一个反映该频率的 ASCII 条形图。
以下是使用该功能的方法:
>>> from bar_chart import print_ascii_bar_chart >>> letters = "mississippimississippimississippimississippi" >>> print_ascii_bar_chart(letters) i |################ s |################ p |######## m |#### >>> from collections import Counter >>> sales = Counter(banana=15, tomato=4, apple=39, orange=30) >>> print_ascii_bar_chart(sales, symbol="+") apple |+++++++++++++++++++++++++++++++++++++++ orange |++++++++++++++++++++++++++++++ banana |+++++++++++++++ tomato |++++对
print_ascii_bar_chart()的第一次调用绘制了输入字符串中每个字母的频率。第二个调用绘制每个水果的销售额。在这种情况下,您使用计数器作为输入。另外,请注意,您可以使用symbol来更改条形的字符。注意:在上面的例子中,
print_ascii_bar_chart()在绘制图表时并没有将frequency的值归一化。如果你使用高frequency值的数据,那么你的屏幕会看起来像一堆符号。创建条形图时,使用水平条可以为类别标签留出足够的空间。条形图的另一个有用的特性是可以根据频率对数据进行排序。在本例中,您使用
.most_common()对数据进行排序。使用 Matplotlib 绘制分类数据
很高兴知道如何使用 Python 从头开始创建 ASCII 条形图。然而,在 Python 生态系统中,您可以找到一些绘制数据的工具。其中一个工具是 Matplotlib。
Matplotlib 是一个第三方库,用于在 Python 中创建静态、动画和交互式可视化。您可以照常使用
pip从 PyPI 安装库:$ python -m pip install matplotlib这个命令在您的 Python 环境中安装 Matplotlib。一旦你安装了这个库,你就可以用它来创建你的条形图等等。下面是如何用 Matplotlib 创建一个最小的条形图:
>>> from collections import Counter
>>> import matplotlib.pyplot as plt
>>> sales = Counter(banana=15, tomato=4, apple=39, orange=30).most_common()
>>> x, y = zip(*sales)
>>> x
('apple', 'orange', 'banana', 'tomato')
>>> y
(39, 30, 15, 4)
>>> plt.bar(x, y)
<BarContainer object of 4 artists>
>>> plt.show()
在这里,你先做所需的进口。然后创建一个包含水果销售的初始数据的计数器,并使用.most_common()对数据进行排序。
你用 zip() 把sales的内容解压成两个变量:
x持有一份水果清单。y持有每果对应的售出单位。
然后你用 plt.bar() 创建一个条形图。当您运行 plt.show() 时,您会在屏幕上看到如下窗口:

在此图表中,横轴显示每种独特水果的名称。同时,纵轴表示每个水果售出的单位数。
寻找样本的模式
在统计学中,模式是数据样本中出现频率最高的值。例如,如果您有样本[2, 1, 2, 2, 3, 5, 3],那么模式就是2,因为它出现得最频繁。
在某些情况下,模式不是唯一的值。考虑样本[2, 1, 2, 2, 3, 5, 3, 3]。这里有两种模式,2和3,因为两者出现的次数相同。
您将经常使用模式来描述分类数据。例如,当您需要知道数据中最常见的类别时,该模式非常有用。
要找到 Python 的模式,需要计算样本中每个值出现的次数。然后你必须找到最频繁的值。换句话说,就是出现次数最多的值。这听起来像是你可以使用Counter和.most_common()来做的事情。
注: Python 在标准库中的 statistics 模块提供了计算多个统计量的函数,包括单峰和多峰样本的模式。下面的例子只是为了展示Counter有多有用。
这是一个计算样本模式的函数:
# mode.py
from collections import Counter
def mode(data):
counter = Counter(data)
_, top_count = counter.most_common(1)[0]
return [point for point, count in counter.items() if count == top_count]
在mode()中,首先计算每个观察值在输入data中出现的次数。然后你用.most_common(1)得到最常见的观察频率。因为.most_common()以(point, count)的形式返回元组列表,所以您需要检索索引0处的元组,这是列表中最常见的。然后将元组解包成两个变量:
_掌握着最普通的物体。使用下划线命名变量意味着您不需要在代码中使用该变量,但是您需要它作为占位符。top_count保存着data中最常见物体的频率。
列表理解将每个对象的count与最常见的一个对象的计数top_count进行比较。这允许您识别给定样品中的多种模式。
要使用此功能,您可以执行以下操作:
>>> from collections import Counter >>> from mode import mode >>> # Single mode, numerical data >>> mode([2, 1, 2, 2, 3, 5, 3]) [2] >>> # Multiple modes, numerical data >>> mode([2, 1, 2, 2, 3, 5, 3, 3]) [2, 3] >>> # Single mode, categorical data >>> data = [ ... "apple", ... "orange", ... "apple", ... "apple", ... "orange", ... "banana", ... "banana", ... "banana", ... "apple", ... ] >>> mode(data) ['apple'] >>> # Multiple modes, categorical data >>> mode(Counter(apple=4, orange=4, banana=2)) ['apple', 'orange']你的
mode()管用!它找到数值和分类数据的模式。它也适用于单模和多模样品。大多数情况下,您的数据会以一系列值的形式出现。然而,最后一个例子表明,您也可以使用计数器来提供输入数据。按类型计数文件
另一个涉及到
Counter的有趣例子是统计给定目录中的文件,按照文件扩展名或文件类型对它们进行分组。为此,你可以利用pathlib:
>>> import pathlib
>>> from collections import Counter
>>> entries = pathlib.Path("Pictures/").iterdir()
>>> extensions = [entry.suffix for entry in entries if entry.is_file()]
['.gif', '.png', '.jpeg', '.png', '.png', ..., '.png']
>>> Counter(extensions)
Counter({'.png': 50, '.jpg': 11, '.gif': 10, '.jpeg': 9, '.mp4': 9})
在这个例子中,首先使用 Path.iterdir() 在给定目录中的条目上创建一个迭代器。然后使用 list comprehension 构建一个包含目标目录中所有文件扩展名( .suffix )的列表。最后,使用文件扩展名作为分组标准来计算文件的数量。
如果你在你的计算机上运行这个代码,那么你会得到一个不同的输出,这取决于你的Pictures/目录的内容,如果它存在的话。因此,您可能需要使用另一个输入目录来运行这段代码。
使用Counter实例作为多重集
在数学中,多重集代表一个集的变体,允许其元素的多个实例。给定元素的实例数量被称为其多重性。因此,您可以有一个类似{1,1,2,3,3,3,4,4}的多重集,但是集合版本将被限制为{1,2,3,4}。
就像在数学中一样,常规的 Python 集合只允许唯一的元素:
>>> # A Python set >>> {1, 1, 2, 3, 3, 3, 4, 4} {1, 2, 3, 4}当您创建这样的集合时,Python 会删除每个数字的所有重复实例。因此,您将得到一个只包含唯一元素的集合。
Python 用
Counter支持多重集的概念。Counter实例中的键是惟一的,所以它们相当于一个集合。计数包含每个元素的多重性或实例数:
>>> from collections import Counter
>>> # A Python multiset
>>> multiset = Counter([1, 1, 2, 3, 3, 3, 4, 4])
>>> multiset
Counter({3: 3, 1: 2, 4: 2, 2: 1})
>>> # The keys are equivalent to a set
>>> multiset.keys() == {1, 2, 3, 4}
True
这里,首先使用Counter创建一个多重集。这些键相当于您在上面的示例中看到的集合。这些值包含集合中每个元素的多重性。
实现了一系列多重集特性,可以用来解决一些问题。编程中多集的一个常见用例是购物车,因为根据客户的需求,它可以包含每种产品的多个实例:
>>> from collections import Counter >>> prices = {"course": 97.99, "book": 54.99, "wallpaper": 4.99} >>> cart = Counter(course=1, book=3, wallpaper=2) >>> for product, units in cart.items(): ... subtotal = units * prices[product] ... price = prices[product] ... print(f"{product:9}: ${price:7.2f} × {units} = ${subtotal:7.2f}") ... course : $ 97.99 × 1 = $ 97.99 book : $ 54.99 × 3 = $ 164.97 wallpaper: $ 4.99 × 2 = $ 9.98在这个例子中,您使用一个
Counter对象作为一个多重集来创建一个购物车。计数器提供有关客户订单的信息,其中包括几个学习资源。for循环遍历计数器,计算每个product的subtotal,然后将打印到屏幕上。为了巩固您使用
Counter对象作为多重集的知识,您可以展开下面的方框并完成练习。完成后,展开解决方案框来比较您的结果。作为练习,您可以修改上面的示例来计算在结帐时要支付的总金额。
这里有一个可能的解决方案:
>>> from collections import Counter
>>> prices = {"course": 97.99, "book": 54.99, "wallpaper": 4.99}
>>> cart = Counter(course=1, book=3, wallpaper=2)
>>> total = 0.0
>>> for product, units in cart.items():
... subtotal = units * prices[product]
... price = prices[product]
... print(f"{product:9}: ${price:7.2f} × {units} = ${subtotal:7.2f}")
... total += subtotal ...
course : $ 97.99 × 1 = $ 97.99
book : $ 54.99 × 3 = $ 164.97
wallpaper: $ 4.99 × 2 = $ 9.98
>>> total
272.94
在第一个突出显示的行中,您添加了一个新变量来保存您订购的所有产品的总成本。在第二个突出显示的行中,您使用一个增强赋值来累加total中的每个subtotal。
现在您已经了解了什么是多重集以及 Python 如何实现它们,您可以看看Counter提供的一些多重集特性。
从计数器中恢复元素
你将要学习的Counter的第一个多重集特性是 .elements() 。这个方法返回一个多集合(Counter实例)中元素的迭代器,重复每个元素,重复次数等于它的计数:
>>> from collections import Counter >>> for letter in Counter("mississippi").elements(): ... print(letter) ... m i i i i s s s s p p在计数器上调用
.elements()的净效果是恢复您用来创建计数器本身的原始数据。该方法按照元素在基础计数器中首次出现的顺序返回元素(在本例中为字母)。自从 Python 3.7 ,Counter记住其键的插入顺序作为从dict继承的特性。注意:正如你已经知道的,你可以创建带有零和负计数的计数器。如果一个元素的计数小于 1,那么
.elements()忽略它。源代码文件中
.elements()的 docstring 提供了一个有趣的例子,使用这种方法从一个数的质因数计算出该数。由于一个给定的质因数可能出现不止一次,你可能会得到一个多重集。例如,您可以将数字 1836 表示为其质因数的乘积,如下所示:1836 = 2×2×3×3×3×17 = 22×33×171
您可以将此表达式写成像{2,2,3,3,3,17}这样的多重集。使用 Python 的
Counter,你将拥有Counter({2: 2, 3: 3, 17: 1})。一旦有了这个计数器,就可以使用它的质因数来计算原始数:
>>> from collections import Counter
>>> # Prime factors of 1836
>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})
>>> product = 1
>>> for factor in prime_factors.elements():
... product *= factor
...
>>> product
1836
该循环迭代prime_factors中的元素,并将它们相乘以计算原始数1836。如果您使用的是 Python 3.8 或更高版本,那么您可以从 math 中使用 prod() 来获得类似的结果。此函数计算输入 iterable 中所有元素的乘积:
>>> import math >>> from collections import Counter >>> prime_factors = Counter({2: 2, 3: 3, 17: 1}) >>> math.prod(prime_factors.elements()) 1836在这个例子中,对
.elements()的调用恢复了质因数。然后math.prod()从它们中一次性计算出1836,这样可以省去编写循环和一些中间变量。使用
.elements()提供了一种恢复原始输入数据的方法。它唯一的缺点是,在大多数情况下,输入项的顺序与输出项的顺序不匹配:
>>> from collections import Counter
>>> "".join(Counter("mississippi").elements())
'miiiisssspp'
在这个例子中,得到的字符串没有拼写出原来的单词mississippi。但是,就字母而言,它有相同的内容。
减去元素的多重性
有时,您需要减去多重集或计数器中元素的多重性(计数)。那样的话,可以用.subtract()。顾名思义,该方法从目标计数器的计数中减去 iterable 或 mapping 中提供的计数。
假设你有一个当前水果库存的多重集,你需要保持它的更新。然后,您可以运行以下一些操作:
>>> from collections import Counter >>> inventory = Counter(apple=39, orange=30, banana=15) >>> # Use a counter >>> wastage = Counter(apple=6, orange=5, banana=8) >>> inventory.subtract(wastage) >>> inventory Counter({'apple': 33, 'orange': 25, 'banana': 7}) >>> # Use a mapping of counts >>> order_1 = {"apple": 12, "orange": 12} >>> inventory.subtract(order_1) >>> inventory Counter({'apple': 21, 'orange': 13, 'banana': 7}) >>> # Use an iterable >>> order_2 = ["apple", "apple", "apple", "apple", "banana", "banana"] >>> inventory.subtract(order_2) >>> inventory Counter({'apple': 17, 'orange': 13, 'banana': 5})这里,您使用几种方式向
.subtract()提供输入数据。在所有情况下,通过减去输入数据中提供的计数来更新每个唯一对象的计数。你可以把.subtract()想象成.update()的翻版。用元素的多重性做算术
使用
.subtract()和.update(),可以通过加减相应的元素计数来组合计数器。或者,Python 提供了元素计数的加法(+)和减法(-)操作符,以及交集(&)和并集(|)操作符。交集运算符返回相应计数的最小值,而并集运算符返回计数的最大值。以下是所有这些运算符如何工作的几个示例:
>>> from collections import Counter
>>> # Fruit sold per day
>>> sales_day1 = Counter(apple=4, orange=9, banana=4)
>>> sales_day2 = Counter(apple=10, orange=8, banana=6)
>>> # Total sales
>>> sales_day1 + sales_day2
Counter({'orange': 17, 'apple': 14, 'banana': 10})
>>> # Sales increment
>>> sales_day2 - sales_day1
Counter({'apple': 6, 'banana': 2})
>>> # Minimum sales
>>> sales_day1 & sales_day2
Counter({'orange': 8, 'apple': 4, 'banana': 4})
>>> # Maximum sales
>>> sales_day1 | sales_day2
Counter({'apple': 10, 'orange': 9, 'banana': 6})
这里,首先使用加法运算符(+)将两个计数器相加。得到的计数器包含相同的键(元素),而它们各自的值(多重性)保存两个相关计数器的计数之和。
第二个例子展示了减法运算符(-)的工作原理。请注意,负数和零计数会导致结果计数器中不包括键计数对。所以,你在输出中看不到orange,因为 8 - 9 = -1。
交集运算符(&)从两个计数器中提取计数较低的对象,而并集运算符(|)从两个相关计数器中返回计数较高的对象。
注意:关于Counter如何处理算术运算的更多细节,请查看类文档。
Counter还支持一些一元运算。例如,您可以分别使用加号(+)和减号(-)获得正计数和负计数的项目:
>>> from collections import Counter >>> counter = Counter(a=2, b=-4, c=0) >>> +counter Counter({'a': 2}) >>> -counter Counter({'b': 4})当您在现有计数器上使用加号(
+)作为一元运算符时,您将获得计数大于零的所有对象。另一方面,如果您使用减号(-),您将获得具有负计数的对象。请注意,在这两种情况下,结果都不包括计数等于零的对象。结论
在 Python 中需要统计几个重复的对象时,可以使用
collections中的Counter。这个类提供了一种有效的 Pythonic 方式来计数,而不需要使用涉及循环和嵌套数据结构的传统技术。这可以让你的代码更干净、更快。在本教程中,您学习了如何:
- 使用不同的 Python 工具计数几个重复的对象
- 用 Python 的
Counter创建快速高效的计数器- 检索特定计数器中最常见的对象
- 更新和操作对象计数
- 使用
Counter来帮助进一步计算您还了解了使用
Counter实例作为多重集的基本知识。有了这些知识,您将能够快速计算代码中的对象数,并使用多重集执行数学运算。立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 的计数器计数******
用 Python 读写 CSV 文件
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 读写 CSV 文件
让我们面对现实吧:你需要通过不仅仅是键盘和控制台来将信息输入和输出你的程序。通过文本文件交换信息是程序间共享信息的常见方式。交换数据最流行的格式之一是 CSV 格式。但是怎么用呢?
让我们弄清楚一件事:您不必(也不会)从头构建自己的 CSV 解析器。有几个完全可以接受的库可供您使用。Python
csv库将适用于大多数情况。如果您的工作需要大量数据或数值分析,那么pandas库也有 CSV 解析功能,它应该可以处理剩下的事情。在本文中,您将学习如何使用 Python 从文本文件中读取、处理和解析 CSV。您将看到 CSV 文件是如何工作的,学习 Python 内置的非常重要的
csv库,并使用pandas库查看 CSV 解析是如何工作的。所以让我们开始吧!
免费下载: 从《Python 基础:Python 3 实用入门》中获取一个示例章节,看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
参加测验:通过我们的交互式“用 Python 读写 CSV 文件”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
什么是 CSV 文件?
CSV 文件(逗号分隔值文件)是一种纯文本文件,它使用特定的结构来排列表格数据。因为它是一个纯文本文件,所以它只能包含实际的文本数据——换句话说,可打印的 ASCII 或 Unicode 字符。
CSV 文件的结构由它的名称给出。通常,CSV 文件使用逗号分隔每个特定的数据值。这个结构看起来是这样的:
column 1 name,column 2 name, column 3 name first row data 1,first row data 2,first row data 3 second row data 1,second row data 2,second row data 3 ...注意每段数据是如何被逗号分隔的。通常,第一行标识每条数据,换句话说,就是数据列的名称。其后的每一行都是实际数据,仅受文件大小的限制。
一般来说,分隔符称为分隔符,逗号不是唯一使用的分隔符。其他流行的分隔符包括制表符(
\t)、冒号(:)和分号(;)字符。正确解析 CSV 文件需要我们知道使用了哪个分隔符。CSV 文件从哪里来?
CSV 文件通常由处理大量数据的程序创建。它们是从电子表格和数据库导出数据以及在其他程序中导入或使用数据的便捷方式。例如,您可以将数据挖掘程序的结果导出到 CSV 文件,然后将其导入到电子表格中以分析数据、为演示文稿生成图表或准备发布报告。
CSV 文件很容易以编程方式处理。任何支持文本文件输入和字符串操作的语言(比如 Python)都可以直接处理 CSV 文件。
用 Python 内置的 CSV 库解析 CSV 文件
csv库提供了读取和写入 CSV 文件的功能。它设计用于 Excel 生成的 CSV 文件,可以很容易地适应各种 CSV 格式。csv库包含从 CSV 文件读取、写入和处理数据的对象和其他代码。用
csv读取 CSV 文件使用
reader对象读取 CSV 文件。CSV 文件通过 Python 内置的open()函数作为文本文件打开,该函数返回一个 file 对象。这然后被传递给reader,它做繁重的工作。下面是
employee_birthday.txt文件:name,department,birthday month John Smith,Accounting,November Erica Meyers,IT,March下面是阅读它的代码:
import csv with open('employee_birthday.txt') as csv_file: csv_reader = csv.reader(csv_file, delimiter=',') line_count = 0 for row in csv_reader: if line_count == 0: print(f'Column names are {", ".join(row)}') line_count += 1 else: print(f'\t{row[0]} works in the {row[1]} department, and was born in {row[2]}.') line_count += 1 print(f'Processed {line_count} lines.')这会产生以下输出:
Column names are name, department, birthday month John Smith works in the Accounting department, and was born in November. Erica Meyers works in the IT department, and was born in March. Processed 3 lines.由
reader返回的每一行都是一个由String元素组成的列表,其中包含了通过删除分隔符找到的数据。返回的第一行包含列名,这是以特殊方式处理的。用
csv将 CSV 文件读入字典不需要处理单个
String元素的列表,您也可以将 CSV 数据直接读入字典(技术上来说,是一个有序字典)。再次,我们的输入文件,
employee_birthday.txt如下:name,department,birthday month John Smith,Accounting,November Erica Meyers,IT,March下面是这次作为字典读入的代码:
import csv with open('employee_birthday.txt', mode='r') as csv_file: csv_reader = csv.DictReader(csv_file) line_count = 0 for row in csv_reader: if line_count == 0: print(f'Column names are {", ".join(row)}') line_count += 1 print(f'\t{row["name"]} works in the {row["department"]} department, and was born in {row["birthday month"]}.') line_count += 1 print(f'Processed {line_count} lines.')这将产生与之前相同的输出:
Column names are name, department, birthday month John Smith works in the Accounting department, and was born in November. Erica Meyers works in the IT department, and was born in March. Processed 3 lines.字典键是从哪里来的?假设 CSV 文件的第一行包含用于构建字典的键。如果您的 CSV 文件中没有这些,您应该通过将可选参数
fieldnames设置为包含它们的列表来指定您自己的键。可选 Python CSV
reader参数
reader对象可以通过指定附加参数来处理不同样式的 CSV 文件,其中一些如下所示:
delimiter指定用于分隔每个字段的字符。默认为逗号(',')。
quotechar指定用于包围包含分隔符的字段的字符。默认为双引号(' " ')。
escapechar指定在不使用引号的情况下,用于转义分隔符的字符。默认情况下没有转义字符。这些参数值得更多的解释。假设您正在使用下面的
employee_addresses.txt文件:name,address,date joined john smith,1132 Anywhere Lane Hoboken NJ, 07030,Jan 4 erica meyers,1234 Smith Lane Hoboken NJ, 07030,March 2这个 CSV 文件包含三个字段:
name、address和date joined,用逗号分隔。问题是address字段的数据还包含一个逗号来表示邮政编码。有三种不同的方法来处理这种情况:
使用不同的分隔符
这样,逗号可以安全地用在数据本身中。使用可选参数delimiter来指定新的分隔符。用引号将数据括起来
在带引号的字符串中,您选择的分隔符的特殊性质会被忽略。因此,您可以用可选参数quotechar指定用于引用的字符。只要这个字符没有出现在数据中,就没有问题。转义数据中的分隔符
转义字符的作用就像在格式字符串中一样,使被转义字符的解释无效(在本例中是分隔符)。如果使用转义字符,必须使用可选参数escapechar指定。用
csv编写 CSV 文件您还可以使用
writer对象和.write_row()方法写入 CSV 文件:import csv with open('employee_file.csv', mode='w') as employee_file: employee_writer = csv.writer(employee_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL) employee_writer.writerow(['John Smith', 'Accounting', 'November']) employee_writer.writerow(['Erica Meyers', 'IT', 'March'])可选参数
quotechar告诉writer在写入时使用哪个字符来引用字段。然而,是否使用引用由quoting可选参数决定:
- 如果
quoting被设置为csv.QUOTE_MINIMAL,那么.writerow()将引用包含delimiter或quotechar的字段。这是默认情况。- 如果
quoting被设置为csv.QUOTE_ALL,那么.writerow()将引用所有字段。- 如果
quoting设置为csv.QUOTE_NONNUMERIC,那么.writerow()将引用所有包含文本数据的字段,并将所有数值字段转换为float数据类型。- 如果
quoting被设置为csv.QUOTE_NONE,那么.writerow()将转义分隔符而不是引用它们。在这种情况下,您还必须为可选参数escapechar提供一个值。以纯文本形式读回该文件显示,该文件是按如下方式创建的:
John Smith,Accounting,November Erica Meyers,IT,March用
csv从字典写入 CSV 文件既然您可以将我们的数据读入字典,那么您也应该能够将它从字典中写出来,这才是公平的:
import csv with open('employee_file2.csv', mode='w') as csv_file: fieldnames = ['emp_name', 'dept', 'birth_month'] writer = csv.DictWriter(csv_file, fieldnames=fieldnames) writer.writeheader() writer.writerow({'emp_name': 'John Smith', 'dept': 'Accounting', 'birth_month': 'November'}) writer.writerow({'emp_name': 'Erica Meyers', 'dept': 'IT', 'birth_month': 'March'})与
DictReader不同的是,编写字典时需要fieldnames参数。仔细想想,这是有道理的:没有一个fieldnames列表,DictWriter就不知道使用哪个键从字典中检索值。它还使用fieldnames中的键写出第一行作为列名。上面的代码生成以下输出文件:
emp_name,dept,birth_month John Smith,Accounting,November Erica Meyers,IT,March使用
pandas库解析 CSV 文件当然,Python CSV 库并不是唯一的游戏。在
pandas中也可以读取 CSV 文件。如果你有很多数据要分析,强烈推荐。
pandas是一个开源的 Python 库,提供高性能的数据分析工具和易于使用的数据结构。pandas可用于所有 Python 安装,但它是 Anaconda 发行版的关键部分,在 Jupyter 笔记本中非常好地工作,以共享数据、代码、分析结果、可视化和叙述性文本。在
Anaconda中安装pandas及其依赖项很容易:$ conda install pandas对于其他 Python 安装,使用
pip/pipenv:$ pip install pandas我们不会深究
pandas如何工作或如何使用它的细节。关于使用pandas读取和分析大型数据集的深入讨论,请查看 Shantnu Tiwari 的关于在 pandas 中使用大型 Excel 文件的精彩文章。用
pandas读取 CSV 文件为了展示
pandasCSV 功能的一些威力,我创建了一个稍微复杂一点的文件来阅读,名为hrdata.csv。它包含公司员工的数据:Name,Hire Date,Salary,Sick Days remaining Graham Chapman,03/15/14,50000.00,10 John Cleese,06/01/15,65000.00,8 Eric Idle,05/12/14,45000.00,10 Terry Jones,11/01/13,70000.00,3 Terry Gilliam,08/12/14,48000.00,7 Michael Palin,05/23/13,66000.00,8将 CSV 读取为
pandasDataFrame既快速又简单:import pandas df = pandas.read_csv('hrdata.csv') print(df)就是这样:三行代码,其中只有一行在做实际的工作。
pandas.read_csv()打开、分析并读取提供的 CSV 文件,并将数据存储在数据帧中。打印DataFrame会产生以下输出:Name Hire Date Salary Sick Days remaining 0 Graham Chapman 03/15/14 50000.0 10 1 John Cleese 06/01/15 65000.0 8 2 Eric Idle 05/12/14 45000.0 10 3 Terry Jones 11/01/13 70000.0 3 4 Terry Gilliam 08/12/14 48000.0 7 5 Michael Palin 05/23/13 66000.0 8这里有几点不值一提:
- 首先,
pandas识别出 CSV 的第一行包含列名,并自动使用它们。我称之为善。- 然而,
pandas在DataFrame中也使用从零开始的整数索引。那是因为我们没有告诉它我们的索引应该是什么。- 此外,如果您查看我们的列的数据类型,您会看到
pandas已经正确地将Salary和Sick Days remaining列转换为数字,但是Hire Date列仍然是一个String。这在交互模式下很容易确认:
```py
>>> print(type(df['Hire Date'][0]))
<class 'str'>`
```
让我们一次解决一个问题。要使用不同的列作为DataFrame索引,添加index_col可选参数:
import pandas
df = pandas.read_csv('hrdata.csv', index_col='Name')
print(df)
现在Name字段是我们的DataFrame索引:
Hire Date Salary Sick Days remaining
Name
Graham Chapman 03/15/14 50000.0 10
John Cleese 06/01/15 65000.0 8
Eric Idle 05/12/14 45000.0 10
Terry Jones 11/01/13 70000.0 3
Terry Gilliam 08/12/14 48000.0 7
Michael Palin 05/23/13 66000.0 8
接下来,让我们修复Hire Date字段的数据类型。您可以使用可选参数parse_dates强制pandas将数据作为日期读取,该参数被定义为列名列表,以作为日期处理:
import pandas
df = pandas.read_csv('hrdata.csv', index_col='Name', parse_dates=['Hire Date'])
print(df)
请注意输出中的差异:
Hire Date Salary Sick Days remaining
Name
Graham Chapman 2014-03-15 50000.0 10
John Cleese 2015-06-01 65000.0 8
Eric Idle 2014-05-12 45000.0 10
Terry Jones 2013-11-01 70000.0 3
Terry Gilliam 2014-08-12 48000.0 7
Michael Palin 2013-05-23 66000.0 8
日期现在已正确格式化,这在交互模式下很容易确认:
>>> print(type(df['Hire Date'][0])) <class 'pandas._libs.tslibs.timestamps.Timestamp'>如果您的 CSV 文件在第一行没有列名,您可以使用
names可选参数来提供列名列表。如果您想覆盖第一行中提供的列名,也可以使用这个方法。在这种情况下,您还必须使用可选参数header=0告诉pandas.read_csv()忽略现有的列名:import pandas df = pandas.read_csv('hrdata.csv', index_col='Employee', parse_dates=['Hired'], header=0, names=['Employee', 'Hired','Salary', 'Sick Days']) print(df)注意,由于列名发生了变化,在可选参数
index_col和parse_dates中指定的列也必须发生变化。这会产生以下输出:Hired Salary Sick Days Employee Graham Chapman 2014-03-15 50000.0 10 John Cleese 2015-06-01 65000.0 8 Eric Idle 2014-05-12 45000.0 10 Terry Jones 2013-11-01 70000.0 3 Terry Gilliam 2014-08-12 48000.0 7 Michael Palin 2013-05-23 66000.0 8用
pandas编写 CSV 文件当然,如果你不能再次把你的数据从
pandas中取出来,对你没有太大的好处。将DataFrame写入 CSV 文件就像读入一样简单。让我们将带有新列名的数据写入一个新的 CSV 文件:import pandas df = pandas.read_csv('hrdata.csv', index_col='Employee', parse_dates=['Hired'], header=0, names=['Employee', 'Hired', 'Salary', 'Sick Days']) df.to_csv('hrdata_modified.csv')这段代码与上面的读取代码的唯一区别是,
print(df)调用被替换为df.to_csv(),提供了文件名。新的 CSV 文件如下所示:Employee,Hired,Salary,Sick Days Graham Chapman,2014-03-15,50000.0,10 John Cleese,2015-06-01,65000.0,8 Eric Idle,2014-05-12,45000.0,10 Terry Jones,2013-11-01,70000.0,3 Terry Gilliam,2014-08-12,48000.0,7 Michael Palin,2013-05-23,66000.0,8结论
如果你理解了阅读 CSV 文件的基础,那么当你需要处理导入数据时,你就不会手足无措。基本的
csvPython 库可以轻松处理大多数 CSV 读取、处理和编写任务。如果您有大量数据要读取和处理,那么pandas库也提供了快速简单的 CSV 处理功能。参加测验:通过我们的交互式“用 Python 读写 CSV 文件”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
还有其他解析文本文件的方法吗?当然啦!像 ANTLR 、 PLY 、 PlyPlus 这样的库都可以处理重型解析,如果简单的
String操纵不行,总有正则表达式。但是那些是其他文章的主题…
免费下载: 从《Python 基础:Python 3 实用入门》中获取一个示例章节,看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 读写 CSV 文件*****
用 Dash 开发 Python 中的数据可视化接口
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的数据可视化接口带破折号
在过去,创建分析性 web 应用程序是经验丰富的开发人员的任务,需要多种编程语言和框架的知识。现在不再是这样了。如今,你可以使用纯 Python 制作数据可视化界面。一个流行的工具是破折号。
Dash 使数据科学家能够在交互式 web 应用程序中展示他们的成果。你不需要成为网页开发的专家。一个下午的时间,你就可以构建并部署一个 Dash 应用,与他人分享。
在本教程中,您将学习如何:
- 创建一个 Dash 应用程序
- 使用 Dash 核心组件和 HTML 组件
- 定制 Dash 应用程序的风格
- 使用回调构建交互式应用
- 在 Heroku 上部署您的应用程序
您可以通过单击下面的链接下载您将在本教程中制作的示例应用程序的源代码、数据和资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Dash 在 Python 中创建数据可视化接口。
Dash 是什么?
Dash 是一个用于构建数据可视化界面的开源框架。它于 2017 年作为 Python 库发布,现已发展到包括 R 和 Julia 的实现。Dash 帮助数据科学家构建分析 web 应用程序,而不需要高级 web 开发知识。
三项技术构成了 Dash 的核心:
- Flask 提供网络服务器功能。
- React.js 渲染网页的用户界面。
- Plotly.js 生成应用程序中使用的图表。
但是你不必担心让所有这些技术一起工作。达什会帮你做的。你只需要写 Python,R,或者 Julia,再撒上一点 CSS。
总部位于加拿大的公司 Plotly 建立了 Dash 并支持其发展。你可能从与它同名的流行图形库中知道这家公司。Plotly(该公司)开源了 Dash,并在麻省理工学院许可下发布,所以你可以免费使用 Dash。
Plotly 还提供 Dash 的商业伙伴,名为 Dash Enterprise 。这项付费服务为公司提供支持服务,例如托管、部署和处理 Dash 应用程序上的身份验证。但这些功能不属于 Dash 的开源生态系统。
Dash 将帮助您快速构建仪表板。如果您习惯于使用 Python 分析数据或构建数据可视化,那么 Dash 将是您工具箱中一个有用的补充。这里有几个你可以用 Dash 做的例子:
这只是一个微小的样本。如果你想看看其他有趣的用例,那么去查看一下 Dash 应用程序库。
注意:你不需要 web 开发的高级知识来学习这个教程,但是熟悉一些 HTML 和 CSS 不会有坏处。
本教程的其余部分假设您了解以下主题的基础知识:
- Python 图形库,如 Plotly、 Bokeh 或 Matplotlib
- HTML 和 HTML 文件的结构
- CSS 和样式表
如果您对这些要求感到满意,并且想在您的下一个项目中学习如何使用 Dash,那么请继续下面的部分!
Python 中的 Dash 入门
在本教程中,您将经历使用 Dash 构建仪表板的端到端过程。如果您按照示例进行操作,那么您将从本地机器上的一个基本仪表板变成部署在 Heroku 上的一个风格化的仪表板。
为了构建仪表板,您将使用 2015 年至 2018 年间美国鳄梨的销售和价格的数据集。这个数据集是由贾斯汀·基金斯利用来自哈斯鳄梨委员会的数据汇编而成。
如何设置您的本地环境
为了开发你的应用,你需要一个新的目录来存储你的代码和数据,以及一个干净的 Python 3 虚拟环境。要创建这些版本,请遵循以下说明,选择与您的操作系统相匹配的版本。
如果您使用的是 Windows ,那么打开命令提示符并执行这些命令:
c:\> mkdir avocado_analytics && cd avocado_analytics c:\> c:\path\to\python\launcher\python -m venv venv c:\> venv\Scripts\activate.bat第一个命令为您的项目创建一个目录,并将您的当前位置移动到那里。第二个命令在该位置创建一个虚拟环境。最后一个命令激活虚拟环境。确保用 Python 3 启动器的路径替换第二个命令中的路径。
如果你使用的是 macOS(苹果操作系统)或 Linux(T2 操作系统),那么在终端上遵循以下步骤:
$ mkdir avocado_analytics && cd avocado_analytics $ python3 -m venv venv $ source venv/bin/activate前两个命令执行以下操作:
- 创建一个名为
avocado_analytics的目录- 将您的当前位置移动到
avocado_analytics目录- 在该目录中创建一个名为
venv的干净的虚拟环境最后一个命令激活您刚刚创建的虚拟环境。
接下来,您需要安装所需的库。你可以在你的虚拟环境中使用
pip来实现。按如下方式安装库:(venv) $ python -m pip install dash==1.13.3 pandas==1.0.5这个命令将在你的虚拟环境中安装 Dash 和熊猫。您将使用这些包的特定版本来确保您拥有与本教程中使用的环境相同的环境。除了 Dash 之外,pandas 还将帮助你处理阅读和争论你将在应用程序中使用的数据。
最后,您需要一些数据输入到您的仪表板中。您可以通过单击下面的链接下载本教程中的数据和代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Dash 在 Python 中创建数据可视化接口。
将数据保存为项目根目录下的
avocado.csv。到目前为止,您应该已经有了一个虚拟环境,其中包含所需的库和项目根文件夹中的数据。您的项目结构应该如下所示:avocado_analytics/ | ├── venv/ | └── avocado.csv你可以走了!接下来,您将构建您的第一个 Dash 应用程序。
如何构建 Dash 应用程序
出于开发目的,将构建 Dash 应用程序的过程分为两步是很有用的:
- 使用应用程序的布局定义应用程序的外观。
- 使用回调来确定你的应用程序的哪些部分是交互式的,以及它们对什么做出反应。
在这一节中,您将学习布局,在后面的一节中,您将学习如何使您的仪表板交互。首先,设置初始化应用程序所需的一切,然后定义应用程序的布局。
初始化您的 Dash 应用程序
在项目的根目录下创建一个名为
app.py的空文件,然后查看本节中app.py的代码。为了让你更容易复制完整的代码,你会在本节末尾找到app.py的全部内容。下面是
app.py的前几行:1import dash 2import dash_core_components as dcc 3import dash_html_components as html 4import pandas as pd 5 6data = pd.read_csv("avocado.csv") 7data = data.query("type == 'conventional' and region == 'Albany'") 8data["Date"] = pd.to_datetime(data["Date"], format="%Y-%m-%d") 9data.sort_values("Date", inplace=True) 10 11app = dash.Dash(__name__)在第 1 到 4 行,您导入所需的库:
dash、dash_core_components、dash_html_components和pandas。每个库都为您的应用程序提供了一个构建块:
dash帮助你初始化你的应用程序。dash_core_components允许您创建交互式组件,如图表、下拉列表或日期范围。dash_html_components让你访问 HTML 标签。pandas帮助你阅读和组织数据。在第 6 到 9 行,您读取数据并对其进行预处理,以便在仪表板中使用。您过滤了一些数据,因为您的仪表板的当前版本不是交互式的,否则绘制的值没有意义。
在第 11 行,您创建了一个
Dash类的实例。如果你以前用过 Flask ,那么初始化Dash类可能看起来很熟悉。在 Flask 中,通常使用Flask(__name__)初始化 WSGI 应用程序。同样,对于一个 Dash 应用,你使用Dash(__name__)。定义 Dash 应用程序的布局
接下来,您将定义应用程序的
layout属性。这个属性决定了你的应用程序的外观。在这种情况下,您将使用一个标题,标题下有一段描述和两个图表。你可以这样定义它:13app.layout = html.Div( 14 children=[ 15 html.H1(children="Avocado Analytics",), 16 html.P( 17 children="Analyze the behavior of avocado prices" 18 " and the number of avocados sold in the US" 19 " between 2015 and 2018", 20 ), 21 dcc.Graph( 22 figure={ 23 "data": [ 24 { 25 "x": data["Date"], 26 "y": data["AveragePrice"], 27 "type": "lines", 28 }, 29 ], 30 "layout": {"title": "Average Price of Avocados"}, 31 }, 32 ), 33 dcc.Graph( 34 figure={ 35 "data": [ 36 { 37 "x": data["Date"], 38 "y": data["Total Volume"], 39 "type": "lines", 40 }, 41 ], 42 "layout": {"title": "Avocados Sold"}, 43 }, 44 ), 45 ] 46)这段代码定义了
app对象的layout属性。该属性使用由 Dash 组件组成的树结构来确定应用程序的外观。Dash 组件预先打包在 Python 库中。有的装的时候自带 Dash。其余的你要单独安装。几乎每个应用程序中都有两组组件:
- Dash HTML Components 为你提供 HTML 元素的 Python 包装器。例如,您可以使用此库来创建段落、标题或列表等元素。
- Dash Core Components 为您提供了创建交互式用户界面的 Python 抽象。您可以使用它来创建交互式元素,如图形、滑块或下拉列表。
在第 13 到 20 行,您可以看到实际的 Dash HTML 组件。首先定义父组件,一个
html.Div。然后再添加两个元素,一个标题(html.H1)和一个段落(html.P),作为它的子元素。这些组件相当于
div、h1和pHTML 标签。您可以使用组件的参数来修改标签的属性或内容。例如,要指定在div标签中包含什么,可以在html.Div中使用children参数。组件中还有其他参数,如
style、className或id,它们引用 HTML 标签的属性。在下一节中,您将看到如何使用这些属性来设计您的仪表板。第 13 到 20 行显示的布局部分将被转换成下面的 HTML 代码:
<div> <h1>Avocado Analytics</h1> <p> Analyze the behavior of avocado prices and the number of avocados sold in the US between 2015 and 2018 </p> <!-- Rest of the app --> </div>当您在浏览器中打开应用程序时,会呈现此 HTML 代码。它遵循与 Python 代码相同的结构,带有一个包含一个
h1和一个p元素的div标签。在布局代码片段的第 21 到 24 行,您可以看到来自 Dash Core Components 的 graph 组件。
app.layout中有两个dcc.Graph组件。第一个是研究期间鳄梨的平均价格,第二个是同一时期在美国销售的鳄梨数量。在幕后,Dash 使用 Plotly.js 来生成图形。
dcc.Graph组件期望一个图形对象或一个 Python 字典包含绘图的数据和布局。在这种情况下,您提供了后者。最后,这两行代码帮助您运行应用程序:
48if __name__ == "__main__": 49 app.run_server(debug=True)第 48 和 49 行使得使用 Flask 的内置服务器在本地运行 Dash 应用程序成为可能。来自
app.run_server的debug=True参数启用应用程序中的热重装选项。这意味着当您对应用程序进行更改时,它会自动重新加载,而无需您重新启动服务器。最后,这里是完整版的
app.py。您可以将这段代码复制到您之前创建的空的app.py中。import dash import dash_core_components as dcc import dash_html_components as html import pandas as pd data = pd.read_csv("avocado.csv") data = data.query("type == 'conventional' and region == 'Albany'") data["Date"] = pd.to_datetime(data["Date"], format="%Y-%m-%d") data.sort_values("Date", inplace=True) app = dash.Dash(__name__) app.layout = html.Div( children=[ html.H1(children="Avocado Analytics",), html.P( children="Analyze the behavior of avocado prices" " and the number of avocados sold in the US" " between 2015 and 2018", ), dcc.Graph( figure={ "data": [ { "x": data["Date"], "y": data["AveragePrice"], "type": "lines", }, ], "layout": {"title": "Average Price of Avocados"}, }, ), dcc.Graph( figure={ "data": [ { "x": data["Date"], "y": data["Total Volume"], "type": "lines", }, ], "layout": {"title": "Avocados Sold"}, }, ), ] ) if __name__ == "__main__": app.run_server(debug=True)这是一个基本仪表板的代码。它包括您在本节前面回顾的所有代码片段。
现在是运行应用程序的时候了。在项目的根目录和项目的虚拟环境中打开一个终端。运行
python app.py,然后使用您喜欢的浏览器转到http://localhost:8050。它还活着!您的仪表板应该如下所示:
好消息是您现在有了一个工作版本的仪表板。坏消息是,在向其他人展示之前,还有一些工作要做。仪表板在视觉上并不令人满意,您仍然需要为它添加一些交互性。
但是不要担心,您将在接下来的章节中学习如何解决这些问题。
设计您的 Dash 应用程序
Dash 为您定制应用程序的外观提供了很大的灵活性。您可以使用自己的 CSS 或 JavaScript 文件,设置一个 favicon (显示在网络浏览器上的小图标),嵌入图像,以及其他高级选项。
在本节中,您将学习如何将自定义样式应用于组件,然后您将样式化您在上一节中构建的仪表板。
如何将自定义样式应用到组件中
可以通过两种方式设置组件的样式:
- 使用单个组件的
style参数- 提供外部 CSS 文件
使用
style参数定制您的仪表板非常简单。该参数采用一个 Python 字典,其中的键值对由 CSS 属性的名称和要设置的值组成。注意:在
style参数中指定 CSS 属性时,应该使用 mixedCase 语法,而不是用连字符分隔的单词。例如,要改变一个元素的背景颜色,你应该使用backgroundColor而不是background-color。如果你想改变
app.py中H1元素的大小和颜色,那么你可以如下设置元素的style参数:html.H1( children="Avocado Analytics", style={"fontSize": "48px", "color": "red"}, ),在这里,您向
style提供一个字典,其中包含您想要为它们设置的属性和值。在这种情况下,指定的样式是红色标题,字体大小为 48 像素。使用
style参数的缺点是,随着代码库的增长,它不能很好地伸缩。如果您的仪表板有多个您希望看起来相同的组件,那么您将会重复很多代码。相反,您可以使用自定义 CSS 文件。如果你想要包含你自己的本地 CSS 或者 JavaScript 文件,那么你需要在你的项目的根目录下创建一个名为
assets/的文件夹,并保存你想要添加的文件。默认情况下,Dash 会自动为assets/中包含的任何文件提供服务。这也适用于添加一个 favicon 或嵌入图像,你很快就会看到。然后,您可以使用组件的
className或id参数通过 CSS 调整它们的样式。这些参数在转换成 HTML 标签时与class和id属性相对应。如果您想调整
app.py中H1元素的字体大小和文本颜色,那么您可以使用如下的className参数:html.H1( children="Avocado Analytics", className="header-title", ),设置
className参数将为H1元素定义 class 属性。然后你可以在assets文件夹中使用一个 CSS 文件来指定你想要的外观:.header-title { font-size: 48px; color: red; }你使用一个类选择器来格式化你的 CSS 文件中的标题。该选择器将调整标题格式。您也可以通过设置
className="header-title"将它与其他需要共享格式的元素一起使用。接下来,您将设计仪表板的样式。
如何改善您仪表板的外观
您刚刚介绍了 Dash 中造型的基础知识。现在,您将学习如何定制您的仪表板的外观。您将做出以下改进:
- 向页面添加网站图标和标题
- 更改仪表板的字体系列
- 使用外部 CSS 文件来设置仪表板组件的样式
您将从学习如何在应用程序中使用外部资产开始。这将允许您添加一个 favicon、一个自定义字体系列和一个 CSS 样式表。然后,您将学习如何使用
className参数将定制样式应用到您的 Dash 组件。向您的应用添加外部资产
在项目的根目录下创建一个名为
assets/的文件夹。从 Twemoji 开源项目中下载一个 favicon ,在assets/中另存为favicon.ico。最后,在assets/中创建一个名为style.css的 CSS 文件和下面可折叠部分中的代码。body { font-family: "Lato", sans-serif; margin: 0; background-color: #F7F7F7; } .header { background-color: #222222; height: 256px; display: flex; flex-direction: column; justify-content: center; } .header-emoji { font-size: 48px; margin: 0 auto; text-align: center; } .header-title { color: #FFFFFF; font-size: 48px; font-weight: bold; text-align: center; margin: 0 auto; } .header-description { color: #CFCFCF; margin: 4px auto; text-align: center; max-width: 384px; } .wrapper { margin-right: auto; margin-left: auto; max-width: 1024px; padding-right: 10px; padding-left: 10px; margin-top: 32px; } .card { margin-bottom: 24px; box-shadow: 0 4px 6px 0 rgba(0, 0, 0, 0.18); }
assets/文件包含您将应用于应用程序布局中组件的样式。现在,您的项目结构应该如下所示:avocado_analytics/ │ ├── assets/ │ ├── favicon.ico │ └── style.css │ ├── venv/ │ ├── app.py └── avocado.csv一旦启动服务器,Dash 将自动提供位于
assets/的文件。您在assets/中包含了两个文件:favicon.ico和style.css。对于设置默认的 favicon,您不必采取任何额外的步骤。为了使用您在style.css中定义的样式,您需要使用 Dash 组件中的className参数。需要一些改变。您将包含一个外部样式表,向您的仪表板添加一个标题,并使用
style.css文件对组件进行样式化。查看下面的更改。然后,在这一节的最后一部分,你会找到更新版app.py的完整代码。以下是如何包含外部样式表并将标题添加到仪表板的方法:
11external_stylesheets = [ 12 { 13 "href": "https://fonts.googleapis.com/css2?" 14 "family=Lato:wght@400;700&display=swap", 15 "rel": "stylesheet", 16 }, 17] 18app = dash.Dash(__name__, external_stylesheets=external_stylesheets) 19app.title = "Avocado Analytics: Understand Your Avocados!"在第 11 行到第 18 行,您指定了一个外部 CSS 文件,一个想要加载到应用程序中的字体系列。外部文件被添加到应用程序的
head标签中,并在应用程序的body加载之前加载。使用external_stylesheets参数添加外部 CSS 文件,或者使用external_scripts添加外部 JavaScript 文件,比如 Google Analytics。在第 19 行,您设置了应用程序的标题。这是当你分享你的网站时,出现在你的网页浏览器的标题栏,谷歌的搜索结果,以及社交媒体卡片上的文字。
定制组件的样式
要使用
style.css中的样式,您需要使用 Dash 组件中的className参数。下面的代码将一个带有相应类选择器的className添加到组成仪表板标题的每个组件中:21app.layout = html.Div( 22 children=[ 23 html.Div( 24 children=[ 25 html.P(children="🥑", className="header-emoji"), 26 html.H1( 27 children="Avocado Analytics", className="header-title" 28 ), 29 html.P( 30 children="Analyze the behavior of avocado prices" 31 " and the number of avocados sold in the US" 32 " between 2015 and 2018", 33 className="header-description", 34 ), 35 ], 36 className="header", 37 ), ```py 在第 21 行到第 37 行,您可以看到仪表板的初始版本有两个变化: 1. 有一个新的段落元素,鳄梨表情符号将作为标志。 2. 每个组件中都有一个`className`参数。这些类名应该匹配`style.css`中的一个类选择器,它将定义每个组件的外观。 例如,分配给以`"Analyze the behavior of avocado prices"`开始的段落组件的`header-description`类在`style.css`中有一个对应的选择器:29.header-description { 30 color: #CFCFCF; 31 margin: 4px auto; 32 text-align: center; 33 max-width: 384px; 34}
`style.css`的第 29 到 34 行定义了`header-description`类选择器的格式。这些将改变任何带有`className="header-description"`的组件的颜色、边距、对齐和最大宽度。所有组件在 CSS 文件中都有相应的类选择器。 另一个显著的变化是在图表中。这是价格图表的新代码:38html.Div(
39 children=[
40 html.Div(
41 children=dcc.Graph(
42 id="price-chart",
43 config={"displayModeBar": False},
44 figure={
45 "data": [
46 {
47 "x": data["Date"],
48 "y": data["AveragePrice"],
49 "type": "lines",
50 "hovertemplate": "\(%{y:.2f}" 51 "<extra></extra>", 52 }, 53 ], 54 "layout": { 55 "title": { 56 "text": "Average Price of Avocados", 57 "x": 0.05, 58 "xanchor": "left", 59 }, 60 "xaxis": {"fixedrange": True}, 61 "yaxis": { 62 "tickprefix": "\)",
63 "fixedrange": True,
64 },
65 "colorway": ["#17B897"],
66 },
67 },
68 ),
69 className="card",
70 ),在这段代码中,您为图表的参数`config`和`figure`定义了一个`className`和一些定制。变化如下: * **第 43 行**:移除默认情况下 Plotly 显示的浮动条。 * **第 50 行和第 51 行:**您设置了悬停模板,以便当用户悬停在数据点上时,它显示以美元为单位的价格。它将显示为`$2.5`,而不是`2.5`。 * **第 54 行到第 66 行:**您在图形的布局部分调整轴、图形的颜色和标题格式。 * **第 69 行:**你用一个`"card"`类将图包装在一个`html.Div`中。这将给图形一个白色背景,并在其下方添加一个小阴影。 销售和成交量图表也有类似的调整。你可以在下面的可折叠部分看到更新的`app.py`的完整代码。import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pddata = pd.read_csv("avocado.csv")
data = data.query("type == 'conventional' and region == 'Albany'")
data["Date"] = pd.to_datetime(data["Date"], format="%Y-%m-%d")
data.sort_values("Date", inplace=True)external_stylesheets = [
{
"href": "https://fonts.googleapis.com/css2?"
"family=Lato:wght@400;700&display=swap",
"rel": "stylesheet",
},
]
app = dash.Dash(name, external_stylesheets=external_stylesheets)
app.title = "Avocado Analytics: Understand Your Avocados!"app.layout = html.Div(
children=[
html.Div(
children=[
html.P(children="🥑", className="header-emoji"),
html.H1(
children="Avocado Analytics", className="header-title"
),
html.P(
children="Analyze the behavior of avocado prices"
" and the number of avocados sold in the US"
" between 2015 and 2018",
className="header-description",
),
],
className="header",
),
html.Div(
children=[
html.Div(
children=dcc.Graph(
id="price-chart",
config={"displayModeBar": False},
figure={
"data": [
{
"x": data["Date"],
"y": data["AveragePrice"],
"type": "lines",
"hovertemplate": "\(%{y:.2f}" "<extra></extra>", }, ], "layout": { "title": { "text": "Average Price of Avocados", "x": 0.05, "xanchor": "left", }, "xaxis": {"fixedrange": True}, "yaxis": { "tickprefix": "\)",
"fixedrange": True,
},
"colorway": ["#17B897"],
},
},
),
className="card",
),
html.Div(
children=dcc.Graph(
id="volume-chart",
config={"displayModeBar": False},
figure={
"data": [
{
"x": data["Date"],
"y": data["Total Volume"],
"type": "lines",
},
],
"layout": {
"title": {
"text": "Avocados Sold",
"x": 0.05,
"xanchor": "left",
},
"xaxis": {"fixedrange": True},
"yaxis": {"fixedrange": True},
"colorway": ["#E12D39"],
},
},
),
className="card",
),
],
className="wrapper",
),
]
)if name == "main":
app.run_server(debug=True)这是`app.py`的更新版本。它对代码进行了必要的修改,添加了一个 favicon 和一个页面标题,更新了字体系列,并使用了一个外部 CSS 文件。经过这些更改后,您的仪表板应该如下所示: [](https://files.realpython.com/media/styling_small.c3b8362982f1.jpg) 在下一节中,您将学习如何向仪表板添加交互式组件。 [*Remove ads*](/account/join/) ## 使用回调功能为您的 Dash 应用添加交互性 在本节中,您将学习如何向您的仪表板添加交互式元素。 Dash 的交互性基于一种[反应式编程](https://en.wikipedia.org/wiki/Reactive_programming)范式。这意味着您可以将组件与您想要更新的应用程序元素相链接。如果用户与输入组件(如下拉列表或范围滑块)进行交互,那么输出(如图表)将自动对输入的变化做出反应。 现在,让我们使您的仪表板具有交互性。这个新版本的仪表板将允许用户与以下过滤器进行交互: * 地区 * 鳄梨的种类 * 日期范围 首先在下面的可折叠部分用新版本替换您的本地`app.py`。import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pd
import numpy as np
from dash.dependencies import Output, Inputdata = pd.read_csv("avocado.csv")
data["Date"] = pd.to_datetime(data["Date"], format="%Y-%m-%d")
data.sort_values("Date", inplace=True)external_stylesheets = [
{
"href": "https://fonts.googleapis.com/css2?"
"family=Lato:wght@400;700&display=swap",
"rel": "stylesheet",
},
]
app = dash.Dash(name, external_stylesheets=external_stylesheets)
app.title = "Avocado Analytics: Understand Your Avocados!"app.layout = html.Div(
children=[
html.Div(
children=[
html.P(children="🥑", className="header-emoji"),
html.H1(
children="Avocado Analytics", className="header-title"
),
html.P(
children="Analyze the behavior of avocado prices"
" and the number of avocados sold in the US"
" between 2015 and 2018",
className="header-description",
),
],
className="header",
),
html.Div(
children=[
html.Div(
children=[
html.Div(children="Region", className="menu-title"),
dcc.Dropdown(
id="region-filter",
options=[
{"label": region, "value": region}
for region in np.sort(data.region.unique())
],
value="Albany",
clearable=False,
className="dropdown",
),
]
),
html.Div(
children=[
html.Div(children="Type", className="menu-title"),
dcc.Dropdown(
id="type-filter",
options=[
{"label": avocado_type, "value": avocado_type}
for avocado_type in data.type.unique()
],
value="organic",
clearable=False,
searchable=False,
className="dropdown",
),
],
),
html.Div(
children=[
html.Div(
children="Date Range",
className="menu-title"
),
dcc.DatePickerRange(
id="date-range",
min_date_allowed=data.Date.min().date(),
max_date_allowed=data.Date.max().date(),
start_date=data.Date.min().date(),
end_date=data.Date.max().date(),
),
]
),
],
className="menu",
),
html.Div(
children=[
html.Div(
children=dcc.Graph(
id="price-chart", config={"displayModeBar": False},
),
className="card",
),
html.Div(
children=dcc.Graph(
id="volume-chart", config={"displayModeBar": False},
),
className="card",
),
],
className="wrapper",
),
]
)@app.callback(
[Output("price-chart", "figure"), Output("volume-chart", "figure")],
[
Input("region-filter", "value"),
Input("type-filter", "value"),
Input("date-range", "start_date"),
Input("date-range", "end_date"),
],
)
def update_charts(region, avocado_type, start_date, end_date):
mask = (
(data.region == region)
& (data.type == avocado_type)
& (data.Date >= start_date)
& (data.Date <= end_date)
)
filtered_data = data.loc[mask, :]
price_chart_figure = {
"data": [
{
"x": filtered_data["Date"],
"y": filtered_data["AveragePrice"],
"type": "lines",
"hovertemplate": "\(%{y:.2f}<extra></extra>", }, ], "layout": { "title": { "text": "Average Price of Avocados", "x": 0.05, "xanchor": "left", }, "xaxis": {"fixedrange": True}, "yaxis": {"tickprefix": "\)", "fixedrange": True},
"colorway": ["#17B897"],
},
}volume_chart_figure = { "data": [ { "x": filtered_data["Date"], "y": filtered_data["Total Volume"], "type": "lines", }, ], "layout": { "title": {"text": "Avocados Sold", "x": 0.05, "xanchor": "left"}, "xaxis": {"fixedrange": True}, "yaxis": {"fixedrange": True}, "colorway": ["#E12D39"], }, } return price_chart_figure, volume_chart_figureif name == "main":
app.run_server(debug=True)接下来,用下面可折叠部分中的代码替换`style.css`。body { font-family: "Lato", sans-serif; margin: 0; background-color: #F7F7F7; } .header { background-color: #222222; height: 288px; padding: 16px 0 0 0; } .header-emoji { font-size: 48px; margin: 0 auto; text-align: center; } .header-title { color: #FFFFFF; font-size: 48px; font-weight: bold; text-align: center; margin: 0 auto; } .header-description { color: #CFCFCF; margin: 4px auto; text-align: center; max-width: 384px; } .wrapper { margin-right: auto; margin-left: auto; max-width: 1024px; padding-right: 10px; padding-left: 10px; margin-top: 32px; } .card { margin-bottom: 24px; box-shadow: 0 4px 6px 0 rgba(0, 0, 0, 0.18); } .menu { height: 112px; width: 912px; display: flex; justify-content: space-evenly; padding-top: 24px; margin: -80px auto 0 auto; background-color: #FFFFFF; box-shadow: 0 4px 6px 0 rgba(0, 0, 0, 0.18); } .Select-control { width: 256px; height: 48px; } .Select--single > .Select-control .Select-value, .Select-placeholder { line-height: 48px; } .Select--multi .Select-value-label { line-height: 32px; } .menu-title { margin-bottom: 6px; font-weight: bold; color: #079A82; }
现在,您已经准备好开始向您的应用程序添加交互式组件了! ### 如何创建交互式组件 首先,您将学习如何创建用户可以与之交互的组件。为此,你将在你的图表上方加入一个新的`html.Div`。它将包括两个下拉框和一个日期范围选择器,用户可以使用它来过滤数据和更新图表。 下面是它在`app.py`中的样子:24html.Div(
25 children=[
26 html.Div(
27 children=[
28 html.Div(children="Region", className="menu-title"),
29 dcc.Dropdown(
30 id="region-filter",
31 options=[
32 {"label": region, "value": region}
33 for region in np.sort(data.region.unique())
34 ],
35 value="Albany",
36 clearable=False,
37 className="dropdown",
38 ),
39 ]
40 ),
41 html.Div(
42 children=[
43 html.Div(children="Type", className="menu-title"),
44 dcc.Dropdown(
45 id="type-filter",
46 options=[
47 {"label": avocado_type, "value": avocado_type}
48 for avocado_type in data.type.unique()
49 ],
50 value="organic",
51 clearable=False,
52 searchable=False,
53 className="dropdown",
54 ),
55 ],
56 ),
57 html.Div(
58 children=[
59 html.Div(
60 children="Date Range",
61 className="menu-title"
62 ),
63 dcc.DatePickerRange(
64 id="date-range",
65 min_date_allowed=data.Date.min().date(),
66 max_date_allowed=data.Date.max().date(),
67 start_date=data.Date.min().date(),
68 end_date=data.Date.max().date(),
69 ),
70 ]
71 ),
72 ],
73 className="menu",
74),在第 24 到 74 行,您在您的图形顶部定义了一个由两个下拉列表和一个日期范围选择器组成的`html.Div`。它将作为用户用来与数据交互的菜单: [](https://files.realpython.com/media/dropdowns_and_daterange.4028753a720e.png) 菜单中的第一个组件是区域下拉列表。下面是该组件的代码:41html.Div(
42 children=[
43 html.Div(children="Region", className="menu-title"),
44 dcc.Dropdown(
45 id="region-filter",
46 options=[
47 {"label": region, "value": region}
48 for region in np.sort(data.region.unique())
49 ],
50 value="Albany",
51 clearable=False,
52 className="dropdown",
53 ),
54 ]
55),在第 41 到 55 行,您定义了用户将用来按地区过滤数据的下拉列表。除了标题,它还有一个`dcc.Dropdown`的成分。以下是每个参数的含义: * **`id`** 是这个元素的标识符。 * **`options`** 是选择下拉菜单时显示的选项。它需要一个带有标签和值的字典。 * **`value`** 是页面加载时的默认值。 * **`clearable`** 如果设置为`True`,允许用户将该字段留空。 * **`className`** 是用于应用样式的类选择器。 类型和日期范围选择器遵循与区域下拉列表相同的结构。请自行检查。 接下来,看看`dcc.Graphs`组件:90html.Div(
91 children=[
92 html.Div(
93 children=dcc.Graph(
94 id="price-chart", config={"displayModeBar": False},
95 ),
96 className="card",
97 ),
98 html.Div(
99 children=dcc.Graph(
100 id="volume-chart", config={"displayModeBar": False},
101 ),
102 className="card",
103 ),
104 ],
105 className="wrapper",
106),在第 90 到 106 行,您定义了`dcc.Graph`组件。您可能已经注意到,与以前版本的仪表板相比,组件缺少了`figure`参数。这是因为`figure`参数现在将由[回调函数](https://en.wikipedia.org/wiki/Callback_(computer_programming))使用用户使用区域、类型和日期范围选择器设置的输入来生成。 [*Remove ads*](/account/join/) ### 如何定义回调 您已经定义了用户将如何与您的应用程序交互。现在,您需要让您的应用程序对用户交互做出反应。为此,您将使用**回调函数。** Dash 的回调函数是带有`app.callback` [修饰符](https://realpython.com/primer-on-python-decorators/)的常规 Python 函数。在 Dash 中,当输入改变时,会触发一个回调函数。该函数执行一些预定的操作,如过滤数据集,并将输出返回给应用程序。本质上,回调链接了应用程序中的输入和输出。 下面是用于更新图形的回调函数:111@app.callback(
112 [Output("price-chart", "figure"), Output("volume-chart", "figure")],
113 [
114 Input("region-filter", "value"),
115 Input("type-filter", "value"),
116 Input("date-range", "start_date"),
117 Input("date-range", "end_date"),
118 ],
119)
120def update_charts(region, avocado_type, start_date, end_date):
121 mask = (
122 (data.region == region)
123 & (data.type == avocado_type)
124 & (data.Date >= start_date)
125 & (data.Date <= end_date)
126 )
127 filtered_data = data.loc[mask, :]
128 price_chart_figure = {
129 "data": [
130 {
131 "x": filtered_data["Date"],
132 "y": filtered_data["AveragePrice"],
133 "type": "lines",
134 "hovertemplate": "\(%{y:.2f}<extra></extra>", 135 }, 136 ], 137 "layout": { 138 "title": { 139 "text": "Average Price of Avocados", 140 "x": 0.05, 141 "xanchor": "left", 142 }, 143 "xaxis": {"fixedrange": True}, 144 "yaxis": {"tickprefix": "\)", "fixedrange": True},
145 "colorway": ["#17B897"],
146 },
147 }
148
149 volume_chart_figure = {
150 "data": [
151 {
152 "x": filtered_data["Date"],
153 "y": filtered_data["Total Volume"],
154 "type": "lines",
155 },
156 ],
157 "layout": {
158 "title": {
159 "text": "Avocados Sold",
160 "x": 0.05,
161 "xanchor": "left"
162 },
163 "xaxis": {"fixedrange": True},
164 "yaxis": {"fixedrange": True},
165 "colorway": ["#E12D39"],
166 },
167 }
168 return price_chart_figure, volume_chart_figure在第 111 到 119 行,您在`app.callback`装饰器中定义了输入和输出。 首先,使用`Output`对象定义输出。这些对象有两个参数: 1. 当函数执行时,他们将修改的元素的标识符 2. 要修改的元素的属性 例如,`Output("price-chart", "figure")`将更新`"price-chart"`元素的`figure`属性。 然后使用`Input`对象定义输入。他们还提出了两个论点: 1. 他们将监视更改的元素的标识符 2. 被监视元素的属性,当发生更改时,它们应该采用该属性 因此,`Input("region-filter", "value")`将观察`"region-filter"`元素的变化,如果元素发生变化,将获取其`value`属性。 **注:**这里讨论的`Input`对象是从`dash.dependencies`导入的。注意不要把它和来自`dash_core_components`的组件混淆。这些对象不可互换,并且有不同的用途。 在第 120 行,您定义了当输入改变时将应用的函数。这里需要注意的一点是,函数的参数将与提供给回调的`Input`对象的顺序相对应。函数中参数的名称和输入对象中指定的值之间没有明确的关系。 最后,在第 121 到 164 行,您定义了函数体。在这种情况下,该函数接受输入(地区、鳄梨类型和日期范围),过滤数据,并为价格和交易量图表生成图形对象。 仅此而已!如果您已经遵循了这一点,那么您的仪表板应该是这样的: [https://player.vimeo.com/video/489978858?background=1](https://player.vimeo.com/video/489978858?background=1) 好样的。这是您的仪表板的最终版本。除了让它看起来很漂亮,你还让它具有了互动性。唯一缺少的一步是将它公之于众,这样你就可以与他人分享。 ## 将您的 Dash 应用程序部署到 Heroku 您已经完成了应用程序的构建,并且拥有了一个漂亮的、完全交互式的仪表板。现在您将学习如何部署它。 Dash 应用程序是 Flask 应用程序,因此两者共享相同的[部署选项](https://flask.palletsprojects.com/en/1.1.x/deploying/)。在本节中,您将在 Heroku 上部署您的应用程序。 在开始之前,确保你已经安装了 [Heroku 命令行界面(CLI)](https://devcenter.heroku.com/articles/heroku-cli) 和 [Git](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) 。您可以通过在命令提示符(Windows)或终端(macOS、Linux)上运行以下命令来验证您的系统中是否存在这两者:$ git --version
git version 2.21.1 (Apple Git-122.3)
$ heroku --version
heroku/7.42.2 darwin-x64 node-v12.16.2根据您的操作系统和您安装的版本,输出可能会有一些变化,但是您应该不会得到错误。 我们开始吧! 首先,您需要在`app.py`中做一个小小的改变。在第 18 行初始化应用程序后,添加一个名为`server`的新的[变量](https://realpython.com/python-variables/):18app = dash.Dash(name, external_stylesheets=external_stylesheets)
19server = app.server使用一个 [WSGI 服务器](https://www.python.org/dev/peps/pep-3333/)来运行你的应用程序,这个添加是必要的。不建议在生产中使用 Flask 的内置服务器,因为它不能处理太多的流量。 接下来,在项目的根目录下,创建一个名为`runtime.txt`的文件,在这里您将为 Heroku 应用程序指定一个 Python 版本:python-3.8.6
当你部署你的应用程序时,Heroku 会自动检测出它是一个 Python 应用程序,并使用正确的`buildpack`。如果您还提供了一个`runtime.txt`,那么它将确定您的应用程序将使用的 Python 版本。 接下来,在项目的根目录下创建一个`requirements.txt`文件,您将在其中复制在 web 服务器上设置 Dash 应用程序所需的库:dash1.13.3
pandas1.0.5
gunicorn==20.0.4你可能注意到了,`requirements.txt`里有个包你到现在都没见过:`gunicorn`。Gunicorn 是一个 WSGI [HTTP](https://realpython.com/python-https/#what-is-http) 服务器,经常用于将 Flask 应用程序部署到产品中。您将使用它来部署您的仪表板。 现在创建一个名为`Procfile`的文件,内容如下:web: gunicorn app:server
这个文件告诉 Heroku 应用程序应该执行什么命令来启动你的应用程序。在这种情况下,它为您的仪表板启动一个`gunicorn`服务器。 接下来,您需要初始化一个 [Git](https://realpython.com/python-git-github-intro/) 存储库。为此,转到项目的根目录并执行以下命令:$ git init
这将在`avocado_analytics/`中启动一个`Git`存储库。它将开始跟踪您对该目录中的文件所做的所有更改。 但是,有些文件是您不希望使用 Git 跟踪的。例如,您通常想要删除 Python 编译的文件、虚拟环境文件夹的内容或元数据文件,如`.DS_Store`。 为了避免跟踪不必要的文件,在根目录中创建一个名为`.gitignore`的文件。然后在里面复制以下内容:venv
*.pyc
.DS_Store # Only if you are using macOS这将确保您的存储库不会跟踪不必要的文件。现在提交您的项目文件:$ git add .
$ git commit -m 'Add dashboard files'在最后一步之前,确保你已经准备好了一切。您的项目结构应该如下所示:avocado_analytics/
│
├── assets/
│ ├── favicon.ico
│ └── style.css
│
├── venv/
│
├── app.py
├── avocado.csv
├── Procfile
├── requirements.txt
└── runtime.txt最后,您需要在 Heroku 中创建一个应用程序,使用 Git 将您的代码推送到那里,并在 Heroku 的一个免费服务器选项中启动应用程序。您可以通过运行以下命令来实现这一点:$ heroku create APP-NAME # Choose a name for your app
$ git push heroku master
$ heroku ps:scale web=1第一个命令将在 Heroku 上创建一个新的应用程序和一个关联的 Git 存储库。第二个会将更改推送到那个存储库,第三个会在 Heroku 的一个免费服务器选项中启动你的应用程序。 就是这样!您已经构建并部署了您的仪表板。现在你只需要访问它,与你的朋友分享。要访问您的应用程序,请在您的浏览器中复制`https://APP-NAME.herokuapp.com/`,并用您在上一步中定义的名称替换`APP-NAME`。 如果你很好奇,可以看看一个[示例应用](https://avocado-analytics.herokuapp.com/)。 [*Remove ads*](/account/join/) ## 结论 恭喜你!您刚刚使用 Dash 构建、定制并部署了您的第一个仪表板。你从一个简单的仪表板变成了一个部署在 Heroku 上的完全交互式的仪表板。 有了这些知识,您就可以使用 Dash 来构建分析应用程序,并与他人共享。随着越来越多的公司更加重视数据的使用,知道如何使用 Dash 将增加你在工作场所的影响。过去只有专家才能完成的任务,现在一个下午就能完成。 **在本教程中,您已经学习了:** * 如何**使用 Dash 创建仪表板** * 如何**定制【Dash 应用程序的样式** * 如何使用 Dash 组件使您的应用程序**具有交互性** * 什么是**回调**以及如何使用它们来创建交互式应用程序 * 如何在 Heroku 上部署您的应用程序 现在,您已经准备好开发新的 Dash 应用程序了。找到一个数据集,想到一些令人兴奋的可视化,并建立另一个仪表板! 您可以通过单击下面的链接下载您在本教程中制作的示例应用程序的源代码、数据和资源: **获取源代码:** [点击此处获取源代码,您将在本教程中使用](https://realpython.com/bonus/dash-code/)了解如何使用 Dash 在 Python 中创建数据可视化接口。 *立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:[**Python 中的数据可视化接口带破折号**](/courses/data-viz-with-dash/)********* # Python 3.7+中的数据类(指南) > 原文:<https://realpython.com/python-data-classes/> *立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: [**在 Python 中使用数据类**](/courses/python-data-classes/) Python 3.7 中一个令人兴奋的新特性是数据类。数据类通常主要包含数据,尽管实际上没有任何限制。它是使用新的`@dataclass`装饰器创建的,如下所示: ```py from dataclasses import dataclass @dataclass class DataClassCard: rank: str suit: str注意:这段代码,以及本教程中的所有其他例子,将只在 Python 3.7 和更高版本中工作。
数据类带有已经实现的基本功能。例如,您可以立即实例化、打印和比较数据类实例:
>>> queen_of_hearts = DataClassCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
DataClassCard(rank='Q', suit='Hearts')
>>> queen_of_hearts == DataClassCard('Q', 'Hearts')
True
与普通班级相比。最小的常规类应该是这样的:
class RegularCard:
def __init__(self, rank, suit):
self.rank = rank
self.suit = suit
虽然没有更多的代码要写,但是您已经可以看到样板文件之痛的迹象:rank和suit都重复了三次,只是为了初始化一个对象。此外,如果您尝试使用这个普通的类,您会注意到对象的表示不是非常具有描述性,并且由于某种原因,红心皇后与红心皇后不同:
>>> queen_of_hearts = RegularCard('Q', 'Hearts') >>> queen_of_hearts.rank 'Q' >>> queen_of_hearts <__main__.RegularCard object at 0x7fb6eee35d30> >>> queen_of_hearts == RegularCard('Q', 'Hearts') False似乎数据类正在幕后帮助我们。默认情况下,数据类实现了一个
.__repr__()方法来提供良好的字符串表示,还实现了一个.__eq__()方法来进行基本的对象比较。为了让RegularCard类模仿上面的数据类,您还需要添加这些方法:class RegularCard def __init__(self, rank, suit): self.rank = rank self.suit = suit def __repr__(self): return (f'{self.__class__.__name__}' f'(rank={self.rank!r}, suit={self.suit!r})') def __eq__(self, other): if other.__class__ is not self.__class__: return NotImplemented return (self.rank, self.suit) == (other.rank, other.suit)在本教程中,您将确切了解数据类提供了哪些便利。除了漂亮的表示和比较,您还会看到:
- 如何向数据类字段添加默认值
- 数据类如何允许对象排序
- 如何表示不可变数据
- 数据类如何处理继承
我们将很快深入研究数据类的这些特性。然而,你可能会想你以前已经见过类似的东西了。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
数据类的替代方案
对于简单的数据结构,你可能已经使用过、
tuple或dict、。您可以用以下任何一种方式代表红心皇后牌:
>>> queen_of_hearts_tuple = ('Q', 'Hearts')
>>> queen_of_hearts_dict = {'rank': 'Q', 'suit': 'Hearts'}
它工作了。然而,作为一名程序员,这给你带来了很多责任:
- 你需要记住的是
queen_of_hearts_...变量代表一张牌。 - 对于
tuple版本,你需要记住属性的顺序。编写('Spades', 'A')会搞乱你的程序,但可能不会给你一个容易理解的错误信息。 - 如果您使用
dict版本,您必须确保属性的名称是一致的。例如{'value': 'A', 'suit': 'Spades'}将无法按预期工作。
此外,使用这些结构并不理想:
>>> queen_of_hearts_tuple[0] # No named access 'Q' >>> queen_of_hearts_dict['suit'] # Would be nicer with .suit 'Hearts'更好的选择是
namedtuple。它长期以来被用来创建可读的小型数据结构。事实上,我们可以像这样使用namedtuple重新创建上面的数据类示例:from collections import namedtuple NamedTupleCard = namedtuple('NamedTupleCard', ['rank', 'suit'])
NamedTupleCard的这个定义将给出与我们的DataClassCard示例完全相同的输出:
>>> queen_of_hearts = NamedTupleCard('Q', 'Hearts')
>>> queen_of_hearts.rank
'Q'
>>> queen_of_hearts
NamedTupleCard(rank='Q', suit='Hearts')
>>> queen_of_hearts == NamedTupleCard('Q', 'Hearts')
True
那么,为什么还要麻烦数据类呢?首先,数据类提供了比你目前所见更多的特性。同时,namedtuple还有一些其他不一定可取的特性。按照设计,一个namedtuple是一个常规元组。这可以从比较中看出,例如:
>>> queen_of_hearts == ('Q', 'Hearts') True虽然这看起来是件好事,但是缺乏对自身类型的了解可能会导致微妙且难以发现的错误,尤其是因为它还会乐于比较两个不同的
namedtuple类:
>>> Person = namedtuple('Person', ['first_initial', 'last_name']
>>> ace_of_spades = NamedTupleCard('A', 'Spades')
>>> ace_of_spades == Person('A', 'Spades')
True
namedtuple也有一些限制。例如,很难向namedtuple中的一些字段添加默认值。一个namedtuple本质上也是不可改变的。也就是说,namedtuple的值永远不会改变。在某些应用程序中,这是一个很棒的功能,但在其他设置中,如果有更多的灵活性就更好了:
>>> card = NamedTupleCard('7', 'Diamonds') >>> card.rank = '9' AttributeError: can't set attribute数据类不会取代
namedtuple的所有用途。例如,如果您需要您的数据结构表现得像一个元组,那么命名元组是一个很好的选择!另一个选择,也是数据类的灵感之一,是
attrs项目。安装了attrs(pip install attrs)后,可以编写如下的卡类:import attr @attr.s class AttrsCard: rank = attr.ib() suit = attr.ib()这可以以与前面的
DataClassCard和NamedTupleCard示例完全相同的方式使用。attrs项目很棒,支持一些数据类不支持的特性,包括转换器和验证器。此外,attrs已经存在了一段时间,在 Python 2.7 以及 Python 3.4 和更高版本中都得到了支持。然而,由于attrs不是标准库的一部分,它给你的项目增加了一个外部依赖项。通过数据类,类似的功能将随处可见。除了
tuple、dict、namedtuple、attrs之外,还有很多其他类似的项目,包括typing.NamedTuple、namedlist、attrdict、plumber、fields。虽然数据类是一个很好的新选择,但是仍然有旧的变体更适合的用例。例如,如果您需要与期望元组的特定 API 兼容,或者需要数据类中不支持的功能。基本数据类别
让我们回到数据类。例如,我们将创建一个
Position类,它将使用名称以及纬度和经度来表示地理位置:from dataclasses import dataclass @dataclass class Position: name: str lon: float lat: float使它成为数据类的是类定义上面的
@dataclass装饰符。在class Position:行下面,您只需简单地列出您想要包含在数据类中的字段。用于字段的:符号使用了 Python 3.6 中的一个新特性,叫做变量注释。我们将很快谈论更多关于这个符号以及为什么我们指定像str和float这样的数据类型。您只需要这几行代码。新类已经可以使用了:
>>> pos = Position('Oslo', 10.8, 59.9)
>>> print(pos)
Position(name='Oslo', lon=10.8, lat=59.9)
>>> pos.lat
59.9
>>> print(f'{pos.name} is at {pos.lat}°N, {pos.lon}°E')
Oslo is at 59.9°N, 10.8°E
您也可以像创建命名元组一样创建数据类。以下(几乎)等同于上面Position的定义:
from dataclasses import make_dataclass
Position = make_dataclass('Position', ['name', 'lat', 'lon'])
数据类是一个常规的 Python 类。它与众不同的唯一一点是,它为您实现了基本的数据模型方法,如.__init__()、.__repr__()和.__eq__()。
默认值
向数据类的字段添加默认值很容易:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
这与您在常规类的.__init__()方法的定义中指定默认值完全一样:
>>> Position('Null Island') Position(name='Null Island', lon=0.0, lat=0.0) >>> Position('Greenwich', lat=51.8) Position(name='Greenwich', lon=0.0, lat=51.8) >>> Position('Vancouver', -123.1, 49.3) Position(name='Vancouver', lon=-123.1, lat=49.3)稍后你会了解到
default_factory,它给出了一种提供更复杂默认值的方法。类型提示
到目前为止,我们还没有对数据类支持开箱即用的输入这一事实大惊小怪。您可能已经注意到我们用类型提示定义了字段:
name: str表示name应该是一个文本字符串 (str类型)。事实上,在定义数据类中的字段时,添加某种类型的提示是强制性的。如果没有类型提示,字段将不会是数据类的一部分。但是,如果您不想向您的数据类添加显式类型,请使用
typing.Any:from dataclasses import dataclass from typing import Any @dataclass class WithoutExplicitTypes: name: Any value: Any = 42虽然在使用数据类时需要以某种形式添加类型提示,但这些类型在运行时并不是强制的。以下代码运行时没有任何问题:
>>> Position(3.14, 'pi day', 2018)
Position(name=3.14, lon='pi day', lat=2018)
Python 中的类型通常是这样工作的: Python 现在是并且将永远是一种动态类型语言。为了实际捕捉类型错误,可以在源代码上运行像 Mypy 这样的类型检查器。
添加方法
你已经知道数据类只是一个普通的类。这意味着您可以自由地将自己的方法添加到数据类中。作为一个例子,让我们沿着地球表面计算一个位置和另一个位置之间的距离。一种方法是使用哈弗辛公式:
您可以向数据类添加一个.distance_to()方法,就像处理普通类一样:
from dataclasses import dataclass
from math import asin, cos, radians, sin, sqrt
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
def distance_to(self, other):
r = 6371 # Earth radius in kilometers
lam_1, lam_2 = radians(self.lon), radians(other.lon)
phi_1, phi_2 = radians(self.lat), radians(other.lat)
h = (sin((phi_2 - phi_1) / 2)**2
+ cos(phi_1) * cos(phi_2) * sin((lam_2 - lam_1) / 2)**2)
return 2 * r * asin(sqrt(h))
它的工作方式如您所料:
>>> oslo = Position('Oslo', 10.8, 59.9) >>> vancouver = Position('Vancouver', -123.1, 49.3) >>> oslo.distance_to(vancouver) 7181.7841229421165更灵活的数据类别
到目前为止,您已经看到了 data 类的一些基本特性:它为您提供了一些方便的方法,您仍然可以添加默认值和其他方法。现在您将了解一些更高级的特性,比如
@dataclass装饰器和field()函数的参数。当创建数据类时,它们一起给你更多的控制。让我们回到您在本教程开始时看到的扑克牌示例,并添加一个包含一副扑克牌的类:
from dataclasses import dataclass from typing import List @dataclass class PlayingCard: rank: str suit: str @dataclass class Deck: cards: List[PlayingCard]可以像这样创建一个只包含两张卡片的简单卡片组:
>>> queen_of_hearts = PlayingCard('Q', 'Hearts')
>>> ace_of_spades = PlayingCard('A', 'Spades')
>>> two_cards = Deck([queen_of_hearts, ace_of_spades])
Deck(cards=[PlayingCard(rank='Q', suit='Hearts'),
PlayingCard(rank='A', suit='Spades')])
高级默认值
假设您想给Deck一个默认值。例如,如果Deck()创建一副由 52 张扑克牌组成的普通(法国)牌,那将会很方便。首先,指定不同的军衔和服装。然后,添加一个函数make_french_deck(),它创建一个PlayingCard实例的列表:
RANKS = '2 3 4 5 6 7 8 9 10 J Q K A'.split()
SUITS = '♣ ♢ ♡ ♠'.split()
def make_french_deck():
return [PlayingCard(r, s) for s in SUITS for r in RANKS]
有趣的是,这四种不同的套装是用它们的 Unicode 符号指定的。
注意:上面,我们在源代码中直接使用了类似
♠的 Unicode 字形。我们可以这样做,因为默认情况下 Python 支持在 UTF-8 中编写源代码。关于如何在您的系统上输入这些内容,请参考本页的 Unicode 输入。您也可以使用\N命名字符转义符(如\N{BLACK SPADE SUIT})或\uUnicode 转义符(如\u2660)为套装输入 Unicode 符号。
为了简化以后卡片的比较,等级和套装也按照通常的顺序排列。
>>> make_french_deck() [PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ... PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')]理论上,您现在可以使用这个函数为
Deck.cards指定一个默认值:from dataclasses import dataclass from typing import List @dataclass class Deck: # Will NOT work cards: List[PlayingCard] = make_french_deck()不要这样!这引入了 Python 中最常见的反模式之一:使用可变默认参数。问题是
Deck的所有实例将使用相同的列表对象作为.cards属性的默认值。这意味着,比方说,如果从一个Deck中移除一张卡片,那么它也会从所有其他Deck的实例中消失。实际上,数据类试图阻止你这样做,上面的代码会引发一个ValueError。相反,数据类使用一种叫做
default_factory的东西来处理可变的默认值。要使用default_factory(以及数据类的许多其他很酷的特性),您需要使用field()说明符:from dataclasses import dataclass, field from typing import List @dataclass class Deck: cards: List[PlayingCard] = field(default_factory=make_french_deck)
default_factory的参数可以是任何可调用的零参数。现在很容易创建一副完整的扑克牌:
>>> Deck()
Deck(cards=[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ...
PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')])
field()说明符用于单独定制数据类的每个字段。稍后您将看到其他一些示例。作为参考,以下是field()支持的参数:
default:该字段的默认值default_factory:返回字段初始值的函数init:在.__init__()方法中使用字段?(默认为True。)repr:使用对象的repr中的字段?(默认为True。)compare:在比较中包含该字段?(默认为True。)hash:计算hash()时包含该字段?(默认使用与compare相同的。)metadata:关于字段信息的映射
在Position示例中,您看到了如何通过编写lat: float = 0.0来添加简单的默认值。然而,如果您还想定制这个字段,例如在repr中隐藏它,您需要使用default参数:lat: float = field(default=0.0, repr=False)。您不能同时指定default和default_factory。
数据类本身不使用metadata参数,但是您(或第三方包)可以使用它将信息附加到字段中。在Position示例中,您可以指定纬度和经度应该以度为单位:
from dataclasses import dataclass, field
@dataclass
class Position:
name: str
lon: float = field(default=0.0, metadata={'unit': 'degrees'})
lat: float = field(default=0.0, metadata={'unit': 'degrees'})
可以使用fields()函数检索元数据(以及关于字段的其他信息)(注意复数 s ):
>>> from dataclasses import fields >>> fields(Position) (Field(name='name',type=<class 'str'>,...,metadata={}), Field(name='lon',type=<class 'float'>,...,metadata={'unit': 'degrees'}), Field(name='lat',type=<class 'float'>,...,metadata={'unit': 'degrees'})) >>> lat_unit = fields(Position)[2].metadata['unit'] >>> lat_unit 'degrees'你需要代理吗?
回想一下,我们可以凭空创造卡片组:
>>> Deck()
Deck(cards=[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ...
PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')])
虽然这种对Deck的表示是显式的和可读的,但它也非常冗长。在上面的输出中,我已经删除了 52 张卡片中的 48 张。在一个 80 列的显示器上,仅仅打印完整的Deck就要占用 22 行!让我们添加一个更简洁的表示。一般来说,一个 Python 对象有两种不同的字符串表示:
-
repr(obj)由obj.__repr__()定义,应该返回一个对开发者友好的obj的表示。如果可能的话,这应该是可以重新创建obj的代码。数据类就是这样做的。 -
str(obj)由obj.__str__()定义,应该返回一个用户友好的obj表示。数据类没有实现.__str__()方法,所以 Python 将退回到.__repr__()方法。
让我们实现一个PlayingCard的用户友好表示:
from dataclasses import dataclass
@dataclass
class PlayingCard:
rank: str
suit: str
def __str__(self):
return f'{self.suit}{self.rank}'
卡片现在看起来漂亮多了,但是这副牌还是和以前一样冗长:
>>> ace_of_spades = PlayingCard('A', '♠') >>> ace_of_spades PlayingCard(rank='A', suit='♠') >>> print(ace_of_spades) ♠A >>> print(Deck()) Deck(cards=[PlayingCard(rank='2', suit='♣'), PlayingCard(rank='3', suit='♣'), ... PlayingCard(rank='K', suit='♠'), PlayingCard(rank='A', suit='♠')])为了说明添加自己的
.__repr__()方法也是可能的,我们将违反它应该返回可以重新创建对象的代码的原则。实用性终究胜过纯粹性。下面的代码添加了一个更简洁的Deck表示:from dataclasses import dataclass, field from typing import List @dataclass class Deck: cards: List[PlayingCard] = field(default_factory=make_french_deck) def __repr__(self): cards = ', '.join(f'{c!s}' for c in self.cards) return f'{self.__class__.__name__}({cards})'注意
{c!s}格式字符串中的!s说明符。这意味着我们明确地想要使用每个PlayingCard的str()表示。有了新的.__repr__(),对Deck的描绘更加赏心悦目:
>>> Deck()
Deck(♣2, ♣3, ♣4, ♣5, ♣6, ♣7, ♣8, ♣9, ♣10, ♣J, ♣Q, ♣K, ♣A,
♢2, ♢3, ♢4, ♢5, ♢6, ♢7, ♢8, ♢9, ♢10, ♢J, ♢Q, ♢K, ♢A,
♡2, ♡3, ♡4, ♡5, ♡6, ♡7, ♡8, ♡9, ♡10, ♡J, ♡Q, ♡K, ♡A,
♠2, ♠3, ♠4, ♠5, ♠6, ♠7, ♠8, ♠9, ♠10, ♠J, ♠Q, ♠K, ♠A)
这是一个更好的甲板代表。然而,这是有代价的。您不再能够通过执行其表示来重新创建牌组。通常,用.__str__()实现相同的表示会更好。
比较卡片
在许多纸牌游戏中,纸牌是互相比较的。例如,在典型的取牌游戏中,最高的牌取牌。正如当前实现的那样,PlayingCard类不支持这种比较:
>>> queen_of_hearts = PlayingCard('Q', '♡') >>> ace_of_spades = PlayingCard('A', '♠') >>> ace_of_spades > queen_of_hearts TypeError: '>' not supported between instances of 'Card' and 'Card'然而,这(看起来)很容易纠正:
from dataclasses import dataclass @dataclass(order=True) class PlayingCard: rank: str suit: str def __str__(self): return f'{self.suit}{self.rank}'装饰器有两种形式。到目前为止,您已经看到了没有任何括号和参数的简单形式。然而,您也可以给圆括号中的
@dataclass()装饰器提供参数。支持以下参数:
init:添加.__init__()方法?(默认为True。)repr:添加.__repr__()方法?(默认为True。)eq:添加.__eq__()方法?(默认为True。)order:添加订购方式?(默认为False。)unsafe_hash:强制添加一个.__hash__()方法?(默认为False。)frozen:如果True,赋值给字段引发异常。(默认为False。)参见原 PEP 了解更多关于各参数的信息。设置
order=True后,可以比较PlayingCard的实例:
>>> queen_of_hearts = PlayingCard('Q', '♡')
>>> ace_of_spades = PlayingCard('A', '♠')
>>> ace_of_spades > queen_of_hearts
False
但是这两张卡有什么不同呢?您没有指定应该如何排序,而且出于某种原因,Python 似乎认为皇后比 a 高…
事实证明,数据类比较对象就好像它们是其字段的元组一样。换句话说,皇后比 a 高,因为在字母表中'Q'排在'A'之后:
>>> ('A', '♠') > ('Q', '♡') False这对我们来说并不奏效。相反,我们需要定义某种使用
RANKS和SUITS顺序的排序索引。大概是这样的:
>>> RANKS = '2 3 4 5 6 7 8 9 10 J Q K A'.split()
>>> SUITS = '♣ ♢ ♡ ♠'.split()
>>> card = PlayingCard('Q', '♡')
>>> RANKS.index(card.rank) * len(SUITS) + SUITS.index(card.suit)
42
为了让PlayingCard使用这个排序索引进行比较,我们需要向类中添加一个字段.sort_index。然而,该字段应根据其他字段.rank和.suit自动计算。这正是特殊方法.__post_init__()的目的。它允许在调用常规的.__init__()方法后进行特殊处理:
from dataclasses import dataclass, field
RANKS = '2 3 4 5 6 7 8 9 10 J Q K A'.split()
SUITS = '♣ ♢ ♡ ♠'.split()
@dataclass(order=True)
class PlayingCard:
sort_index: int = field(init=False, repr=False)
rank: str
suit: str
def __post_init__(self):
self.sort_index = (RANKS.index(self.rank) * len(SUITS)
+ SUITS.index(self.suit))
def __str__(self):
return f'{self.suit}{self.rank}'
请注意,.sort_index是作为该类的第一个字段添加的。这样,首先使用.sort_index进行比较,只有当出现平局时才使用其他字段。使用field(),您还必须指定.sort_index不应该作为参数包含在.__init__()方法中(因为它是从.rank和.suit字段中计算出来的)。为了避免用户对这个实现细节感到困惑,从类的repr中移除.sort_index可能也是一个好主意。
最后,ace 很高:
>>> queen_of_hearts = PlayingCard('Q', '♡') >>> ace_of_spades = PlayingCard('A', '♠') >>> ace_of_spades > queen_of_hearts True现在,您可以轻松创建一个已排序的卡片组:
>>> Deck(sorted(make_french_deck()))
Deck(♣2, ♢2, ♡2, ♠2, ♣3, ♢3, ♡3, ♠3, ♣4, ♢4, ♡4, ♠4, ♣5,
♢5, ♡5, ♠5, ♣6, ♢6, ♡6, ♠6, ♣7, ♢7, ♡7, ♠7, ♣8, ♢8,
♡8, ♠8, ♣9, ♢9, ♡9, ♠9, ♣10, ♢10, ♡10, ♠10, ♣J, ♢J, ♡J,
♠J, ♣Q, ♢Q, ♡Q, ♠Q, ♣K, ♢K, ♡K, ♠K, ♣A, ♢A, ♡A, ♠A)
或者,如果你不在乎排序,这是你随机抽取 10 张牌的方法:
>>> from random import sample >>> Deck(sample(make_french_deck(), k=10)) Deck(♢2, ♡A, ♢10, ♣2, ♢3, ♠3, ♢A, ♠8, ♠9, ♠2)当然,你不需要
order=True来做这个…不可变数据类
您之前看到的
namedtuple的一个定义特性是是不可变的。也就是说,其字段的值可能永远不会改变。对于许多类型的数据类来说,这是一个好主意!为了使数据类不可变,在创建时设置frozen=True。例如,下面是您之前看到的的Position类的不可变版本:from dataclasses import dataclass @dataclass(frozen=True) class Position: name: str lon: float = 0.0 lat: float = 0.0在冻结的数据类中,不能在创建后为字段赋值:
>>> pos = Position('Oslo', 10.8, 59.9)
>>> pos.name
'Oslo'
>>> pos.name = 'Stockholm'
dataclasses.FrozenInstanceError: cannot assign to field 'name'
请注意,如果您的数据类包含可变字段,这些字段仍然可能会发生变化。这适用于 Python 中的所有嵌套数据结构(更多信息请参见本视频):
from dataclasses import dataclass
from typing import List
@dataclass(frozen=True)
class ImmutableCard:
rank: str
suit: str
@dataclass(frozen=True)
class ImmutableDeck:
cards: List[ImmutableCard]
尽管ImmutableCard和ImmutableDeck都是不可变的,但是包含cards的列表却不是。因此,您仍然可以更改这副牌中的牌:
>>> queen_of_hearts = ImmutableCard('Q', '♡') >>> ace_of_spades = ImmutableCard('A', '♠') >>> deck = ImmutableDeck([queen_of_hearts, ace_of_spades]) >>> deck ImmutableDeck(cards=[ImmutableCard(rank='Q', suit='♡'), ImmutableCard(rank='A', suit='♠')]) >>> deck.cards[0] = ImmutableCard('7', '♢') >>> deck ImmutableDeck(cards=[ImmutableCard(rank='7', suit='♢'), ImmutableCard(rank='A', suit='♠')])为了避免这种情况,请确保不可变数据类的所有字段都使用不可变类型(但请记住,类型在运行时是不强制的)。应该使用元组而不是列表来实现
ImmutableDeck。继承
你可以很自由地子类化数据类。例如,我们将使用一个
country字段来扩展我们的Position示例,并使用它来记录大写字母:from dataclasses import dataclass @dataclass class Position: name: str lon: float lat: float @dataclass class Capital(Position): country: str在这个简单的例子中,一切顺利:
>>> Capital('Oslo', 10.8, 59.9, 'Norway')
Capital(name='Oslo', lon=10.8, lat=59.9, country='Norway')
Capital的country字段添加在Position的三个原始字段之后。如果基类中的任何字段都有默认值,事情会变得稍微复杂一些:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
@dataclass
class Capital(Position):
country: str # Does NOT work
这段代码会立即崩溃,并出现一个TypeError抱怨“非默认参数‘country’跟在默认参数后面。”问题是我们新的country字段没有默认值,而lon和lat字段有默认值。数据类将尝试用下面的签名编写一个.__init__()方法:
def __init__(name: str, lon: float = 0.0, lat: float = 0.0, country: str):
...
但是,这不是有效的 Python。如果一个参数有默认值,所有后续参数也必须有默认值。换句话说,如果基类中的字段有默认值,那么子类中添加的所有新字段也必须有默认值。
另一件需要注意的事情是字段在子类中是如何排序的。从基类开始,字段按照第一次定义的顺序排序。如果一个字段在子类中被重新定义,它的顺序不会改变。例如,如果将Position和Capital定义如下:
from dataclasses import dataclass
@dataclass
class Position:
name: str
lon: float = 0.0
lat: float = 0.0
@dataclass
class Capital(Position):
country: str = 'Unknown'
lat: float = 40.0
那么Capital中字段的顺序仍然是name、lon、lat、country。但是lat的默认值会是40.0。
>>> Capital('Madrid', country='Spain') Capital(name='Madrid', lon=0.0, lat=40.0, country='Spain')优化数据类
我要用几句关于槽的话来结束这个教程。插槽可以用来使类更快,使用更少的内存。数据类没有处理插槽的显式语法,但是创建插槽的正常方式也适用于数据类。(他们真的只是普通班!)
from dataclasses import dataclass @dataclass class SimplePosition: name: str lon: float lat: float @dataclass class SlotPosition: __slots__ = ['name', 'lon', 'lat'] name: str lon: float lat: float本质上,槽是使用
.__slots__来定义的,列出一个类中的变量。不存在于.__slots__中的变量或属性可能无法定义。此外,插槽类可能没有默认值。添加这些限制的好处是可以进行某些优化。例如,插槽类占用更少的内存,可以使用 Pympler 来测量:
>>> from pympler import asizeof
>>> simple = SimplePosition('London', -0.1, 51.5)
>>> slot = SlotPosition('Madrid', -3.7, 40.4)
>>> asizeof.asizesof(simple, slot)
(440, 248)
类似地,插槽类通常使用起来更快。以下示例使用标准库中的 timeit 来测量 slots 数据类和常规数据类的属性访问速度。
>>> from timeit import timeit >>> timeit('slot.name', setup="slot=SlotPosition('Oslo', 10.8, 59.9)", globals=globals()) 0.05882283499886398 >>> timeit('simple.name', setup="simple=SimplePosition('Oslo', 10.8, 59.9)", globals=globals()) 0.09207444800267695在这个特殊的例子中,slot 类大约快了 35%。
结论和进一步阅读
数据类是 Python 3.7 的新特性之一。使用数据类,您不必编写样板代码来获得对象的正确初始化、表示和比较。
您已经看到了如何定义自己的数据类,以及:
- 如何向数据类中的字段添加默认值
- 如何自定义数据类对象的排序
- 如何使用不可变数据类
- 继承如何为数据类工作
如果你想深入了解数据类的所有细节,看看 PEP 557 以及最初的 GitHub repo 中的讨论。
此外,Raymond Hettinger 的 PyCon 2018 talk Dataclasses:结束所有代码生成器的代码生成器非常值得一看。
如果您还没有 Python 3.7,那么 Python 3.6 还有一个数据类反向移植。现在,向前迈进,编写更少的代码!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 在 Python 中使用数据类******
用 Pandas 和 NumPy 清理 Pythonic 数据
原文:https://realpython.com/python-data-cleaning-numpy-pandas/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用熊猫和 NumPy 进行数据清洗
数据科学家花费大量时间清理数据集,并将它们转换成他们可以使用的形式。事实上,许多数据科学家认为,获取和清理数据的初始步骤构成了 80%的工作。
因此,如果您刚刚进入这个领域或者计划进入这个领域,能够处理杂乱的数据是很重要的,无论这意味着丢失的值、不一致的格式、畸形的记录还是无意义的异常值。
在本教程中,我们将利用 Python 的 Pandas 和 NumPy 库来清理数据。
我们将讨论以下内容:
- 删除
DataFrame中不必要的列- 改变一个
DataFrame的索引- 使用
.str()方法清洁色谱柱- 使用
DataFrame.applymap()函数逐个元素地清理整个数据集- 将列重命名为更容易识别的标签集
- 跳过 CSV 文件中不必要的行
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
以下是我们将使用的数据集:
- BL-Flickr-Images-book . csv–包含大英图书馆书籍信息的 CSV 文件
- university _ towns . txt–包含美国各州大学城名称的文本文件
- Olympics . csv–总结所有国家参加夏季和冬季奥运会的 CSV 文件
您可以从 Real Python 的 GitHub 仓库下载数据集,以便了解这里的示例。
注意:我推荐使用 Jupyter 笔记本来跟进。
本教程假设对 Pandas 和 NumPy 库有基本的了解,包括 Panda 的主力
Series和DataFrame对象,可以应用于这些对象的常用方法,以及熟悉 NumPy 的NaN值。让我们导入所需的模块并开始吧!
>>> import pandas as pd
>>> import numpy as np
在DataFrame中拖放列
通常,您会发现并非数据集中的所有数据类别都对您有用。例如,您可能有一个包含学生信息(姓名、年级、标准、父母姓名和地址)的数据集,但您希望专注于分析学生的成绩。
在这种情况下,地址或父母的名字对你来说并不重要。保留这些不需要的类别会占用不必要的空间,还可能会影响运行时间。
Pandas 提供了一种简便的方法,通过 drop() 功能从DataFrame中删除不需要的列或行。让我们看一个简单的例子,我们从一个DataFrame中删除了一些列。
首先,让我们从 CSV 文件“BL-Flickr-Images-Book.csv”中创建一个 DataFrame 。在下面的例子中,我们传递了一个到pd.read_csv的相对路径,这意味着所有的数据集都在我们当前工作目录中一个名为Datasets的文件夹中:
>>> df = pd.read_csv('Datasets/BL-Flickr-Images-Book.csv') >>> df.head() Identifier Edition Statement Place of Publication \ 0 206 NaN London 1 216 NaN London; Virtue & Yorston 2 218 NaN London 3 472 NaN London 4 480 A new edition, revised, etc. London Date of Publication Publisher \ 0 1879 [1878] S. Tinsley & Co. 1 1868 Virtue & Co. 2 1869 Bradbury, Evans & Co. 3 1851 James Darling 4 1857 Wertheim & Macintosh Title Author \ 0 Walter Forbes. [A novel.] By A. A A. A. 1 All for Greed. [A novel. The dedication signed... A., A. A. 2 Love the Avenger. By the author of “All for Gr... A., A. A. 3 Welsh Sketches, chiefly ecclesiastical, to the... A., E. S. 4 [The World in which I live, and my place in it... A., E. S. Contributors Corporate Author \ 0 FORBES, Walter. NaN 1 BLAZE DE BURY, Marie Pauline Rose - Baroness NaN 2 BLAZE DE BURY, Marie Pauline Rose - Baroness NaN 3 Appleyard, Ernest Silvanus. NaN 4 BROOME, John Henry. NaN Corporate Contributors Former owner Engraver Issuance type \ 0 NaN NaN NaN monographic 1 NaN NaN NaN monographic 2 NaN NaN NaN monographic 3 NaN NaN NaN monographic 4 NaN NaN NaN monographic Flickr URL \ 0 http://www.flickr.com/photos/britishlibrary/ta... 1 http://www.flickr.com/photos/britishlibrary/ta... 2 http://www.flickr.com/photos/britishlibrary/ta... 3 http://www.flickr.com/photos/britishlibrary/ta... 4 http://www.flickr.com/photos/britishlibrary/ta... Shelfmarks 0 British Library HMNTS 12641.b.30. 1 British Library HMNTS 12626.cc.2. 2 British Library HMNTS 12625.dd.1. 3 British Library HMNTS 10369.bbb.15. 4 British Library HMNTS 9007.d.28.当我们使用
head()方法查看前五个条目时,我们可以看到一些列提供了对图书馆有帮助的辅助信息,但并没有很好地描述书籍本身:Edition Statement、Corporate Author、Corporate Contributors、Former owner、Engraver、Issuance type和Shelfmarks。我们可以通过以下方式删除这些列:
>>> to_drop = ['Edition Statement',
... 'Corporate Author',
... 'Corporate Contributors',
... 'Former owner',
... 'Engraver',
... 'Contributors',
... 'Issuance type',
... 'Shelfmarks']
>>> df.drop(to_drop, inplace=True, axis=1)
上面,我们定义了一个列表,其中包含了我们想要删除的所有列的名称。接下来,我们调用对象上的drop()函数,将inplace参数作为True传入,将axis参数作为1传入。这告诉 Pandas 我们希望直接在我们的对象中进行更改,并且它应该在对象的列中寻找要删除的值。
当我们再次检查DataFrame时,我们会看到不需要的列已经被删除:
>>> df.head() Identifier Place of Publication Date of Publication \ 0 206 London 1879 [1878] 1 216 London; Virtue & Yorston 1868 2 218 London 1869 3 472 London 1851 4 480 London 1857 Publisher Title \ 0 S. Tinsley & Co. Walter Forbes. [A novel.] By A. A 1 Virtue & Co. All for Greed. [A novel. The dedication signed... 2 Bradbury, Evans & Co. Love the Avenger. By the author of “All for Gr... 3 James Darling Welsh Sketches, chiefly ecclesiastical, to the... 4 Wertheim & Macintosh [The World in which I live, and my place in it... Author Flickr URL 0 A. A. http://www.flickr.com/photos/britishlibrary/ta... 1 A., A. A. http://www.flickr.com/photos/britishlibrary/ta... 2 A., A. A. http://www.flickr.com/photos/britishlibrary/ta... 3 A., E. S. http://www.flickr.com/photos/britishlibrary/ta... 4 A., E. S. http://www.flickr.com/photos/britishlibrary/ta...或者,我们也可以通过将列直接传递给
columns参数来删除列,而不是单独指定要删除的标签和熊猫应该在哪个轴上寻找标签:
>>> df.drop(columns=to_drop, inplace=True)
这种语法更直观,可读性更强。我们要做的事情很明显。
如果您事先知道想要保留哪些列,另一个选项是将它们传递给pd.read_csv的usecols参数。
改变一个DataFrame的索引
Pandas Index扩展了 NumPy 数组的功能,允许更多的切片和标记。在许多情况下,使用数据的唯一值标识字段作为索引是很有帮助的。
例如,在上一节使用的数据集中,可以预计当图书管理员搜索记录时,他们可能会输入一本书的唯一标识符(Identifier列中的值):
>>> df['Identifier'].is_unique True让我们使用
set_index用这个列替换现有的索引:
>>> df = df.set_index('Identifier')
>>> df.head()
Place of Publication Date of Publication \
206 London 1879 [1878]
216 London; Virtue & Yorston 1868
218 London 1869
472 London 1851
480 London 1857
Publisher \
206 S. Tinsley & Co.
216 Virtue & Co.
218 Bradbury, Evans & Co.
472 James Darling
480 Wertheim & Macintosh
Title Author \
206 Walter Forbes. [A novel.] By A. A A. A.
216 All for Greed. [A novel. The dedication signed... A., A. A.
218 Love the Avenger. By the author of “All for Gr... A., A. A.
472 Welsh Sketches, chiefly ecclesiastical, to the... A., E. S.
480 [The World in which I live, and my place in it... A., E. S.
Flickr URL
206 http://www.flickr.com/photos/britishlibrary/ta...
216 http://www.flickr.com/photos/britishlibrary/ta...
218 http://www.flickr.com/photos/britishlibrary/ta...
472 http://www.flickr.com/photos/britishlibrary/ta...
480 http://www.flickr.com/photos/britishlibrary/ta...
技术细节:与 SQL 中的主键不同,Pandas Index不保证唯一性,尽管许多索引和合并操作会注意到运行时的加速。
我们可以用loc[]直接访问每条记录。虽然loc[]可能没有名字那么直观,但它允许我们做基于标签的索引,这是对行或记录的标签,而不考虑其位置:
>>> df.loc[206] Place of Publication London Date of Publication 1879 [1878] Publisher S. Tinsley & Co. Title Walter Forbes. [A novel.] By A. A Author A. A. Flickr URL http://www.flickr.com/photos/britishlibrary/ta... Name: 206, dtype: object换句话说,206 是索引的第一个标签。要通过位置访问它,我们可以使用
df.iloc[0],它执行基于位置的索引。技术细节 :
.loc[]在技术上是一个类实例,并且有一些特殊的语法,这些语法并不完全符合大多数普通的 Python 实例方法。以前,我们的索引是一个 RangeIndex:从
0开始的整数,类似于 Python 的内置range。通过将一个列名传递给set_index,我们将索引更改为Identifier中的值。您可能已经注意到,我们将变量重新分配给了由带有
df = df.set_index(...)的方法返回的对象。这是因为,默认情况下,该方法返回我们的对象的修改副本,并不直接对对象进行更改。我们可以通过设置inplace参数来避免这种情况:df.set_index('Identifier', inplace=True)整理数据中的字段
到目前为止,我们已经删除了不必要的列,并将
DataFrame的索引改为更合理的。在这一节中,我们将清理特定的列,并将它们转换为统一的格式,以便更好地理解数据集并增强一致性。特别是,我们将清洁Date of Publication和Place of Publication。经检查,目前所有的数据类型都是
objectdtype ,这大致类似于原生 Python 中的str。它封装了任何不能作为数字或分类数据的字段。这是有意义的,因为我们处理的数据最初是一堆杂乱的字符串:
>>> df.get_dtype_counts()
object 6
强制使用数字值有意义的一个字段是出版日期,这样我们可以在以后进行计算:
>>> df.loc[1905:, 'Date of Publication'].head(10) Identifier 1905 1888 1929 1839, 38-54 2836 [1897?] 2854 1865 2956 1860-63 2957 1873 3017 1866 3131 1899 4598 1814 4884 1820 Name: Date of Publication, dtype: object一本书只能有一个出版日期。因此,我们需要做到以下几点:
- 删除方括号中的多余日期:1879 [1878]
- 将日期范围转换为它们的“开始日期”,如果有的话:1860-63;1839, 38-54
- 完全去掉我们不确定的日期,用 NumPy 的
NaN:【1897?]- 将字符串
nan转换为 NumPy 的NaN值综合这些模式,我们实际上可以利用一个正则表达式来提取出版年份:
regex = r'^(\d{4})'
上面的正则表达式旨在查找字符串开头的任意四位数字,这就满足了我们的情况。上面是一个原始字符串(意思是反斜杠不再是转义字符),这是正则表达式的标准做法。
\d代表任意数字,{4}重复这个规则四次。^字符匹配一个字符串的开头,圆括号表示一个捕获组,这向 Pandas 发出信号,表明我们想要提取正则表达式的这一部分。(我们希望^避免[开始串的情况。)
让我们看看在数据集上运行这个正则表达式会发生什么:
>>> extr = df['Date of Publication'].str.extract(r'^(\d{4})', expand=False) >>> extr.head() Identifier 206 1879 216 1868 218 1869 472 1851 480 1857 Name: Date of Publication, dtype: object延伸阅读:不熟悉 regex?你可以在 regex101.com查看上面的表达式,用正则表达式:Python 中的正则表达式学习所有关于正则表达式的知识。
从技术上讲,这个列仍然有
objectdtype,但是我们可以很容易地用pd.to_numeric得到它的数字版本:
>>> df['Date of Publication'] = pd.to_numeric(extr)
>>> df['Date of Publication'].dtype
dtype('float64')
这导致大约十分之一的值丢失,对于现在能够对剩余的有效值进行计算来说,这是一个很小的代价:
>>> df['Date of Publication'].isnull().sum() / len(df) 0.11717147339205986太好了!就这么定了!
将
str方法与 NumPy 结合起来清洗色谱柱以上,你可能注意到了
df['Date of Publication'].str的用法。这个属性是在 Pandas 中访问快速的字符串操作的一种方式,这些操作很大程度上模仿了原生 Python 字符串或编译后的正则表达式的操作,如.split()、、和.capitalize()。为了清理
Place of Publication字段,我们可以将 Pandasstr方法与 NumPy 的np.where函数结合起来,该函数基本上是 Excel 的IF()宏的矢量化形式。它具有以下语法:
>>> np.where(condition, then, else)
这里,condition或者是一个类数组对象,或者是一个布尔掩码。then是在condition评估为True时使用的值,而else是在其他情况下使用的值。
本质上,.where()获取用于condition的对象中的每个元素,检查该特定元素在条件的上下文中是否评估为True,并返回包含then或else的ndarray,这取决于哪一个适用。
它可以嵌套在一个复合 if-then 语句中,允许我们基于多个条件计算值:
>>> np.where(condition1, x1, np.where(condition2, x2, np.where(condition3, x3, ...)))我们将利用这两个函数来清理
Place of Publication,因为这个列有 string 对象。以下是该专栏的内容:
>>> df['Place of Publication'].head(10)
Identifier
206 London
216 London; Virtue & Yorston
218 London
472 London
480 London
481 London
519 London
667 pp. 40\. G. Bryan & Co: Oxford, 1898
874 London]
1143 London
Name: Place of Publication, dtype: object
我们看到,对于某些行,发布位置被其他不必要的信息所包围。如果我们要查看更多的值,我们会发现只有一些发布地点为“London”或“Oxford”的行是这种情况。
让我们来看看两个具体条目:
>>> df.loc[4157862] Place of Publication Newcastle-upon-Tyne Date of Publication 1867 Publisher T. Fordyce Title Local Records; or, Historical Register of rema... Author T. Fordyce Flickr URL http://www.flickr.com/photos/britishlibrary/ta... Name: 4157862, dtype: object >>> df.loc[4159587] Place of Publication Newcastle upon Tyne Date of Publication 1834 Publisher Mackenzie & Dent Title An historical, topographical and descriptive v... Author E. (Eneas) Mackenzie Flickr URL http://www.flickr.com/photos/britishlibrary/ta... Name: 4159587, dtype: object这两本书是在同一个地方出版的,但是一本在地名上有连字符,而另一本没有。
为了在一次扫描中清理这个列,我们可以使用
str.contains()来获得一个布尔掩码。我们按照以下步骤清洗色谱柱:
>>> pub = df['Place of Publication']
>>> london = pub.str.contains('London')
>>> london[:5]
Identifier
206 True
216 True
218 True
472 True
480 True
Name: Place of Publication, dtype: bool
>>> oxford = pub.str.contains('Oxford')
我们将它们与np.where结合起来:
df['Place of Publication'] = np.where(london, 'London', np.where(oxford, 'Oxford', pub.str.replace('-', ' '))) >>> df['Place of Publication'].head() Identifier 206 London 216 London 218 London 472 London 480 London Name: Place of Publication, dtype: object这里,
np.where函数在一个嵌套结构中被调用,其中condition是用str.contains()获得的布尔值的Series。contains()方法的工作方式类似于内置的in关键字,用于查找 iterable 中实体(或字符串中的子字符串)的出现。要使用的替换是一个表示我们想要的发布地点的字符串。我们还将连字符替换为带有
str.replace()的空格,并重新分配给我们的DataFrame中的列。尽管这个数据集中有更多的脏数据,我们现在只讨论这两列。
让我们来看看前五个条目,它们看起来比我们开始时清晰得多:
>>> df.head()
Place of Publication Date of Publication Publisher \
206 London 1879 S. Tinsley & Co.
216 London 1868 Virtue & Co.
218 London 1869 Bradbury, Evans & Co.
472 London 1851 James Darling
480 London 1857 Wertheim & Macintosh
Title Author \
206 Walter Forbes. [A novel.] By A. A AA
216 All for Greed. [A novel. The dedication signed... A. A A.
218 Love the Avenger. By the author of “All for Gr... A. A A.
472 Welsh Sketches, chiefly ecclesiastical, to the... E. S A.
480 [The World in which I live, and my place in it... E. S A.
Flickr URL
206 http://www.flickr.com/photos/britishlibrary/ta...
216 http://www.flickr.com/photos/britishlibrary/ta...
218 http://www.flickr.com/photos/britishlibrary/ta...
472 http://www.flickr.com/photos/britishlibrary/ta...
480 http://www.flickr.com/photos/britishlibrary/ta...
注意:在这一点上,Place of Publication将是转换为 Categorical dtype 的一个很好的候选,因为我们可以用整数对相当小的唯一的一组城市进行编码。(一个分类的内存使用量与分类的数量加上数据的长度成正比;对象数据类型是一个常数乘以数据的长度。)
使用applymap函数清理整个数据集
在某些情况下,您会看到“污垢”并不局限于某一列,而是更加分散。
在某些情况下,将定制函数应用于数据帧的每个单元格或元素会很有帮助。Pandas .applymap()方法类似于内置的 map()函数,只是将一个函数应用于DataFrame中的所有元素。
让我们看一个例子。我们将从“university_towns.txt”文件中创建一个DataFrame:
$ head Datasets/univerisity_towns.txt
Alabama[edit]
Auburn (Auburn University)[1]
Florence (University of North Alabama)
Jacksonville (Jacksonville State University)[2]
Livingston (University of West Alabama)[2]
Montevallo (University of Montevallo)[2]
Troy (Troy University)[2]
Tuscaloosa (University of Alabama, Stillman College, Shelton State)[3][4]
Tuskegee (Tuskegee University)[5]
Alaska[edit]
我们看到,我们有周期性的州名,后面跟着该州的大学城:StateA TownA1 TownA2 StateB TownB1 TownB2...。如果我们观察状态名在文件中的书写方式,我们会发现所有的状态名中都有“[edit]”子字符串。
我们可以通过创建一个由(state, city)元组组成的列表并将该列表包装在一个DataFrame中来利用这种模式:
>>> university_towns = [] >>> with open('Datasets/university_towns.txt') as file: ... for line in file: ... if '[edit]' in line: ... # Remember this `state` until the next is found ... state = line ... else: ... # Otherwise, we have a city; keep `state` as last-seen ... university_towns.append((state, line)) >>> university_towns[:5] [('Alabama[edit]\n', 'Auburn (Auburn University)[1]\n'), ('Alabama[edit]\n', 'Florence (University of North Alabama)\n'), ('Alabama[edit]\n', 'Jacksonville (Jacksonville State University)[2]\n'), ('Alabama[edit]\n', 'Livingston (University of West Alabama)[2]\n'), ('Alabama[edit]\n', 'Montevallo (University of Montevallo)[2]\n')]我们可以将这个列表包装在一个 DataFrame 中,并将列设置为“State”和“RegionName”。Pandas 将获取列表中的每个元素,并将
State设置为左边的值,将RegionName设置为右边的值。生成的数据帧如下所示:
>>> towns_df = pd.DataFrame(university_towns,
... columns=['State', 'RegionName'])
>>> towns_df.head()
State RegionName
0 Alabama[edit]\n Auburn (Auburn University)[1]\n
1 Alabama[edit]\n Florence (University of North Alabama)\n
2 Alabama[edit]\n Jacksonville (Jacksonville State University)[2]\n
3 Alabama[edit]\n Livingston (University of West Alabama)[2]\n
4 Alabama[edit]\n Montevallo (University of Montevallo)[2]\n
虽然我们可以在上面的 for 循环中清理这些字符串,但 Pandas 让它变得很容易。我们只需要州名和镇名,其他的都可以去掉。虽然我们可以在这里再次使用 Pandas 的.str()方法,但是我们也可以使用applymap()将一个 Python callable 映射到 DataFrame 的每个元素。
我们一直在使用术语元素,但是它到底是什么意思呢?考虑以下“玩具”数据帧:
0 1 0 Mock Dataset 1 Python Pandas 2 Real Python 3 NumPy Clean在这个例子中,每个单元格(' Mock ',' Dataset ',' Python ',' Pandas '等)。)是一个元素。因此,
applymap()将独立地对其中的每一个应用一个函数。让我们来定义这个函数:
>>> def get_citystate(item):
... if ' (' in item:
... return item[:item.find(' (')]
... elif '[' in item:
... return item[:item.find('[')]
... else:
... return item
Pandas 的.applymap()只有一个参数,它是应该应用于每个元素的函数(可调用的):
>>> towns_df = towns_df.applymap(get_citystate)首先,我们定义一个 Python 函数,它将来自
DataFrame的一个元素作为它的参数。在函数内部,执行检查以确定元素中是否有(或[。根据检查结果,函数会相应地返回值。最后,在我们的对象上调用
applymap()函数。现在数据框架更加整洁了:
>>> towns_df.head()
State RegionName
0 Alabama Auburn
1 Alabama Florence
2 Alabama Jacksonville
3 Alabama Livingston
4 Alabama Montevallo
applymap()方法从 DataFrame 中取出每个元素,将其传递给函数,原始值被返回值替换。就这么简单!
技术细节:虽然它是一个方便且通用的方法,但是.applymap对于较大的数据集来说有很长的运行时间,因为它将一个可调用的 Python 映射到每个单独的元素。在某些情况下,利用 Cython 或 NumPY(反过来,用 C 进行调用)进行矢量化操作会更有效。
重命名列和跳过行
通常,您将使用的数据集要么具有不容易理解的列名,要么在前几行和/或最后几行中具有不重要的信息,如数据集中术语的定义或脚注。
在这种情况下,我们希望重命名列并跳过某些行,这样我们就可以使用正确和合理的标签深入到必要的信息。
为了演示我们如何去做,让我们先看一下“olympics.csv”数据集的前五行:
$ head -n 5 Datasets/olympics.csv
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
,? Summer,01 !,02 !,03 !,Total,? Winter,01 !,02 !,03 !,Total,? Games,01 !,02 !,03 !,Combined total
Afghanistan (AFG),13,0,0,2,2,0,0,0,0,0,13,0,0,2,2
Algeria (ALG),12,5,2,8,15,3,0,0,0,0,15,5,2,8,15
Argentina (ARG),23,18,24,28,70,18,0,0,0,0,41,18,24,28,70
现在,我们将把它读入熊猫数据帧:
>>> olympics_df = pd.read_csv('Datasets/olympics.csv') >>> olympics_df.head() 0 1 2 3 4 5 6 7 8 \ 0 NaN ? Summer 01 ! 02 ! 03 ! Total ? Winter 01 ! 02 ! 1 Afghanistan (AFG) 13 0 0 2 2 0 0 0 2 Algeria (ALG) 12 5 2 8 15 3 0 0 3 Argentina (ARG) 23 18 24 28 70 18 0 0 4 Armenia (ARM) 5 1 2 9 12 6 0 0 9 10 11 12 13 14 15 0 03 ! Total ? Games 01 ! 02 ! 03 ! Combined total 1 0 0 13 0 0 2 2 2 0 0 15 5 2 8 15 3 0 0 41 18 24 28 70 4 0 0 11 1 2 9 12这真的很乱!这些列是索引为 0 的整数的字符串形式。本应是我们标题的行(即用于设置列名的行)位于
olympics_df.iloc[0]。这是因为我们的 CSV 文件以 0,1,2,…,15 开头。此外,如果我们转到数据集的源,我们会看到上面的
NaN应该是类似于“国家”的东西,? Summer应该代表“夏季运动会”,01 !应该是“黄金”,等等。因此,我们需要做两件事:
- 跳过一行,将标题设置为第一行(索引为 0)
- 重命名列
我们可以通过向
read_csv()函数传递一些参数,在读取 CSV 文件时跳过行并设置标题。这个函数需要 很多 的可选参数,但是在这种情况下我们只需要一个(
header)来删除第 0 行:
>>> olympics_df = pd.read_csv('Datasets/olympics.csv', header=1)
>>> olympics_df.head()
Unnamed: 0 ? Summer 01 ! 02 ! 03 ! Total ? Winter \
0 Afghanistan (AFG) 13 0 0 2 2 0
1 Algeria (ALG) 12 5 2 8 15 3
2 Argentina (ARG) 23 18 24 28 70 18
3 Armenia (ARM) 5 1 2 9 12 6
4 Australasia (ANZ) [ANZ] 2 3 4 5 12 0
01 !.1 02 !.1 03 !.1 Total.1 ? Games 01 !.2 02 !.2 03 !.2 \
0 0 0 0 0 13 0 0 2
1 0 0 0 0 15 5 2 8
2 0 0 0 0 41 18 24 28
3 0 0 0 0 11 1 2 9
4 0 0 0 0 2 3 4 5
Combined total
0 2
1 15
2 70
3 12
4 12
现在,我们已经将正确的行设置为标题,并删除了所有不必要的行。请注意熊猫如何将包含国家名称的列的名称从NaN更改为Unnamed: 0。
为了重命名列,我们将利用 DataFrame 的rename()方法,该方法允许您基于映射(在本例中为dict)重新标记轴。
让我们首先定义一个字典,将当前的列名(作为键)映射到更有用的列名(字典的值):
>>> new_names = {'Unnamed: 0': 'Country', ... '? Summer': 'Summer Olympics', ... '01 !': 'Gold', ... '02 !': 'Silver', ... '03 !': 'Bronze', ... '? Winter': 'Winter Olympics', ... '01 !.1': 'Gold.1', ... '02 !.1': 'Silver.1', ... '03 !.1': 'Bronze.1', ... '? Games': '# Games', ... '01 !.2': 'Gold.2', ... '02 !.2': 'Silver.2', ... '03 !.2': 'Bronze.2'}我们在对象上调用
rename()函数:
>>> olympics_df.rename(columns=new_names, inplace=True)
将就地设置为True指定我们的更改直接作用于对象。让我们看看这是否属实:
>>> olympics_df.head() Country Summer Olympics Gold Silver Bronze Total \ 0 Afghanistan (AFG) 13 0 0 2 2 1 Algeria (ALG) 12 5 2 8 15 2 Argentina (ARG) 23 18 24 28 70 3 Armenia (ARM) 5 1 2 9 12 4 Australasia (ANZ) [ANZ] 2 3 4 5 12 Winter Olympics Gold.1 Silver.1 Bronze.1 Total.1 # Games Gold.2 \ 0 0 0 0 0 0 13 0 1 3 0 0 0 0 15 5 2 18 0 0 0 0 41 18 3 6 0 0 0 0 11 1 4 0 0 0 0 0 2 3 Silver.2 Bronze.2 Combined total 0 0 2 2 1 2 8 15 2 24 28 70 3 2 9 12 4 4 5 12Python 数据清理:概述和资源
在本教程中,您学习了如何使用
drop()函数从数据集中删除不必要的信息,以及如何为数据集设置索引,以便可以轻松引用其中的项目。此外,您还学习了如何使用
.str()访问器清理object字段,以及如何使用applymap()方法清理整个数据集。最后,我们探索了如何跳过 CSV 文件中的行并使用rename()方法重命名列。了解数据清理非常重要,因为它是数据科学的一大部分。现在,您已经对如何利用 Pandas 和 NumPy 清理数据集有了基本的了解!
请查看下面的链接,找到对您的 Python 数据科学之旅有所帮助的其他资源:
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用熊猫和 NumPy 进行数据清洗******
什么是数据工程,它适合你吗?
大数据。云数据。AI 训练数据和个人识别数据。数据无处不在,并且每天都在增长。软件工程已经发展到包括数据工程(一个直接关注数据传输、转换和存储的分支学科)是有意义的。
也许你已经看过大数据的招聘信息,并对处理 Pb 级数据的前景感兴趣。也许你很好奇生成性对抗网络是如何从底层数据中创造出逼真的图像的。也许你从未听说过数据工程,但对开发人员如何处理当今大多数应用程序所需的大量数据感兴趣。
无论你属于哪一类,这篇介绍性文章都适合你。你将对这个领域有一个大致的了解,包括什么是数据工程以及它需要什么样的工作。
在这篇文章中,你将了解到:
- 数据工程领域的当前状态是什么
- 数据工程在行业中是如何使用的
- 数据工程师的各种客户是谁
- 什么是数据工程领域的一部分,什么不是
- 如何决定你是否想将数据工程作为一门学科来学习
首先,你要回答这个领域最紧迫的问题之一:数据工程师到底是做什么的?
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
数据工程师是做什么的?
数据工程是一个非常广泛的学科,有多个头衔。在许多组织中,它甚至可能没有特定的标题。因此,最好首先确定数据工程的目标,然后讨论什么样的工作会带来期望的结果。
数据工程的最终目标是提供有组织的、一致的数据流,以实现数据驱动的工作,例如:
- 训练机器学习模型
- 进行探索性数据分析
- 用外部数据填充应用程序中的字段
这种数据流可以通过多种方式实现,并且所需的特定工具集、技术和技能在团队、组织和期望的结果之间会有很大的不同。然而,一种常见的模式是数据流水线。这是一个由独立程序组成的系统,这些程序对输入或收集的数据进行各种操作。
数据管道通常分布在多个服务器上:
此图是一个简化的数据管道示例,让您对可能遇到的架构有一个非常基本的了解。你会看到更复杂的表现形式。
数据可以来自任何来源:
- 物联网设备
- 车辆遥测技术
- 房地产数据馈送
- web 应用程序上的正常用户活动
- 你能想到的任何其他收集或测量工具
根据这些来源的性质,传入的数据将在实时流中进行处理,或者在批处理中以某种规则的节奏进行处理。
数据通过的管道是数据工程师的责任。数据工程团队负责设计、构建、维护、扩展,通常还负责支持数据管道的基础设施。他们还可能负责传入的数据,或者更常见的是负责数据模型以及数据最终是如何存储的。
如果您将数据管道视为一种应用程序,那么数据工程开始看起来像任何其他软件工程学科。
许多团队也在朝着建立数据平台的方向前进。在许多组织中,仅有一个管道将传入数据保存到某个地方的 SQL 数据库是不够的。大型组织有多个团队,他们需要对不同类型的数据进行不同级别的访问。
例如,人工智能(AI) 团队可能需要标注和拆分清洗过的数据的方法。商业智能(BI) 团队可能需要轻松访问来聚合数据和构建数据可视化。数据科学团队可能需要数据库级别的访问权限来正确地探索数据。
如果你熟悉 web 开发,那么你可能会发现这种结构类似于模型-视图-控制器(MVC)设计模式。使用 MVC,数据工程师负责模型,AI 或 BI 团队处理视图,所有团队在控制器上协作。对于拥有依赖数据访问的多样化团队的组织来说,构建满足所有这些需求的数据平台正成为首要任务。
现在,您已经了解了一些数据工程师的工作,以及他们与所服务的客户之间的关系,进一步了解这些客户以及数据工程师对他们的责任将会很有帮助。
数据工程师的职责是什么?
依赖数据工程师的客户就像数据工程团队本身的技能和产出一样多种多样。无论你从事什么领域,你的客户永远决定你解决什么问题,你如何解决问题。
在本节中,您将从数据需求的角度了解数据工程团队的一些常见客户:
- 数据科学和人工智能团队
- 商业智能或分析团队
- 产品团队
在这些团队有效工作之前,必须满足某些需求。特别是,数据必须:
- 可靠地路由到更广泛的系统中
- 规范化为合理的数据模型
- 清理以填补重要缺口
- 向所有相关成员公开
Monica Rogarty 的优秀文章人工智能需求层次对这些需求进行了更全面的描述。作为一名数据工程师,您有责任满足客户的数据需求。但是,您将使用各种方法来适应他们各自的工作流。
数据流
要对系统中的数据做任何事情,您必须首先确保数据能够可靠地流入和通过系统。输入几乎可以是您能想到的任何类型的数据,包括:
- JSON 或 XML 数据的实时流
- 每小时更新一批视频
- 每月抽血数据
- 每周批量标记的图像
- 来自部署传感器的遥测
数据工程师通常负责消费这些数据,设计一个系统,该系统可以将来自一个或多个来源的数据作为输入,转换这些数据,然后为客户存储这些数据。这些系统通常被称为 ETL 管道,分别代表提取、转换、加载。
数据流责任主要属于提取步骤。但是数据工程师的职责并不仅限于将数据导入管道。他们必须确保管道足够健壮,以应对意外或畸形的数据、离线的源和致命的错误。正常运行时间非常重要,尤其是在使用实时数据或时间敏感型数据时。
无论你的客户是谁,你维护数据流的责任都是一致的。但是,有些客户可能比其他客户要求更高,尤其是当客户是一个依赖于实时更新数据的应用程序时。
数据标准化和建模
流入系统的数据是巨大的。然而,在某些时候,数据需要符合某种架构标准。规范化数据包括使用户更容易访问数据的任务。这包括但不限于以下步骤:
- 删除重复项(重复数据删除)
- 修复冲突数据
- 使数据符合指定的数据模型
这些过程可能发生在不同的阶段。例如,假设您在一个大型组织中工作,有数据科学家和 BI 团队,他们都依赖于您的数据。您可以将非结构化数据存储在数据湖中,供您的数据科学客户用于探索性数据分析。您还可以将规范化的数据存储在一个关系数据库或一个更专门构建的数据仓库中,供 BI 团队在其报告中使用。
您可能有更多或更少的客户团队,或者可能有一个使用您的数据的应用程序。下图显示了先前管道示例的修改版本,突出显示了某些团队可能访问数据的不同阶段:
在此图中,您可以看到一个假设的数据管道,以及您经常会发现不同客户团队工作的各个阶段。
如果您的客户是一个产品团队,那么一个架构良好的数据模型是至关重要的。一个深思熟虑的数据模型可能是一个缓慢的、几乎没有响应的应用程序和一个运行起来好像已经知道用户想要访问什么数据的应用程序之间的区别。这类决策通常是产品和数据工程团队合作的结果。
数据规范化和建模通常是 ETL 的转换步骤的一部分,但它们不是这一类别中的唯一部分。另一个常见的转型步骤是数据清理。
数据清理
数据清理与数据标准化齐头并进。有些人甚至认为数据规范化是数据清理的一个子集。但是,虽然数据规范化主要关注于使不同的数据符合某种数据模型,但数据清理包括许多使数据更加统一和完整的操作,包括:
- 将相同的数据转换为单一类型(例如,强制整数字段中的字符串成为整数
- 确保日期格式一致
- 如果可能,填写缺失的字段
- 将字段的值约束到指定的范围
- 删除损坏或不可用的数据
数据清理可以纳入上图中的重复数据消除和统一数据模型步骤。但实际上,这些步骤中的每一步都非常庞大,可以包含任意数量的阶段和单独的过程。
您采取的清理数据的具体操作将高度依赖于输入、数据模型和期望的结果。然而,干净数据的重要性是不变的:
- 数据科学家需要它来执行精确的分析。
- 机器学习工程师需要它来建立精确的、可推广的模型。
- 商业智能团队需要 it 为企业提供准确的报告和预测。
- 产品团队需要它来确保他们的产品不会崩溃或者给用户错误的信息。
数据清理的责任落在许多不同的肩上,取决于整个组织及其优先级。作为一名数据工程师,您应该努力尽可能地实现自动化清理,并对传入和存储的数据进行定期抽查。您的客户团队和领导层可以提供关于什么构成符合其目的的干净数据的见解。
数据可访问性
数据可访问性没有得到像数据规范化和清理那样多的关注,但它可以说是以客户为中心的数据工程团队更重要的职责之一。
数据可访问性是指数据对于客户来说访问和理解的难易程度。这一点根据客户的不同而有不同的定义:
- 数据科学团队可能只需要可以用某种查询语言访问的数据。
- 分析团队可能更喜欢按某种指标分组的数据,可通过基本查询或报告界面访问。
- 考虑到产品性能和可靠性,产品团队通常希望数据可以通过快速、简单的查询获得,并且不会经常改变。
因为较大的组织为这些团队和其他团队提供相同的数据,所以许多组织已经开始为不同的团队开发自己的内部平台。这方面一个非常成熟的例子是打车服务优步,它分享了其令人印象深刻的大数据平台的许多细节。
事实上,许多数据工程师发现自己正在成为平台工程师,这表明了数据工程技能对数据驱动型企业的持续重要性。因为数据可访问性与数据的存储方式密切相关,所以它是 ETL 的 load 步骤的主要组成部分,它指的是如何存储数据以备后用。
现在,您已经遇到了一些常见的数据工程客户,并了解了他们的需求,是时候更仔细地看看您可以开发哪些技能来帮助满足这些需求了。
有哪些常见的数据工程技能?
数据工程技能在很大程度上与你从事软件工程所需的技能相同。然而,有几个领域是数据工程师更关注的。在本节中,您将了解几项重要的技能:
- 一般编程概念
- 数据库
- 分布式系统和云工程
在让你成为一名全面发展的数据工程师的过程中,上述每一项都将发挥至关重要的作用。
通用编程技巧
数据工程是软件工程的一个专门化,所以软件工程的基础在这个列表的顶部是有意义的。与其他软件工程专业一样,数据工程师应该理解设计概念,如 DRY(不要重复)、面向对象编程、数据结构和算法。
和其他专业一样,也有少数偏爱的语言。在撰写本文时,你在数据工程工作描述中最常看到的是 Python、Scala 和 Java 。是什么让这些语言如此受欢迎?
Python 受欢迎有几个原因。其中最大的一个是它的普遍性。从很多方面来看,Python 是世界上最流行的三种编程语言之一。例如,它在 2020 年 11 月的 TIOBE 社区指数中排名第二,在 Stack Overflow 的 2020 开发者调查中排名第三。
它也被机器学习和人工智能团队广泛使用。紧密合作的团队经常需要能够用同一种语言交流,而 Python 仍然是这个领域的通用语言。
Python 流行的另一个更有针对性的原因是它在编排工具中的使用,如 Apache Airflow 和流行工具的可用库,如 Apache Spark 。如果一个组织使用这样的工具,那么了解他们使用的语言是很重要的。
Scala 也很受欢迎,和 Python 一样,这部分是由于使用它的工具的流行,尤其是 Apache Spark。Scala 是一种运行在 Java 虚拟机(JVM)上的函数式语言,这使得它能够与 Java 无缝地结合使用。
Java 在数据工程中并不那么受欢迎,但是你仍然会在一些工作描述中看到它。这部分是因为它在企业软件栈中的普遍性,部分是因为它与 Scala 的互操作性。随着 Scala 被用于 Apache Spark,一些团队也使用 Java 是有道理的。
除了一般的编程技能之外,熟悉数据库技术也是必不可少的。
数据库技术
如果您要移动数据,那么您将会大量使用数据库。非常宽泛地说,您可以将数据库技术分为两类:SQL 和 NoSQL。
SQL 数据库是关系数据库管理系统 (RDBMS),它对关系进行建模,并通过使用结构化查询语言或 SQL 进行交互。这些通常用于对由关系定义的数据进行建模,例如客户订单数据。
注意:如果你想学习更多关于 SQL 的知识,以及如何用 Python 与 SQL 数据库进行交互,那么请查看Python SQL 库简介。
NoSQL 通常意味着“其他一切”这些数据库通常存储非关系数据,如下所示:
- 键值存储,如 Redis 或 AWS 的 DynamoDB
- 像 MongoDB 或 Elasticsearch 这样的文档商店
- 图形数据库,如 Neo4j
- 其他不太常见的数据存储
虽然不要求您了解所有数据库技术的来龙去脉,但是您应该了解这些不同系统的优缺点,并能够快速学习其中的一两种。
数据工程师工作的系统越来越多地位于云上,数据管道通常分布在多个服务器或集群上,无论是否在私有云上。因此,未来的数据工程师应该了解分布式系统和云工程。
分布式系统和云工程
诸如 ETL 管道之类的数据工程技术的主要优势之一是,它们有助于实现分布式系统。一种常见的模式是让管道的独立部分运行在单独的服务器上,由像 RabbitMQ 或 Apache Kafka 这样的消息队列来编排。
了解如何设计这些系统,它们的好处和风险是什么,以及何时应该使用它们是非常重要的。
这些系统需要许多服务器,地理上分散的团队经常需要访问它们包含的数据。Amazon Web Services、Google Cloud 和 Microsoft Azure 等私有云提供商是构建和部署分布式系统的非常流行的工具。
对云提供商的主要产品以及一些更流行的分布式消息传递工具的基本了解将有助于您找到第一份数据工程工作。你可以在工作中更深入地学习这些工具。
到目前为止,您已经了解了很多关于什么是数据工程的知识。但是因为这个学科没有标准的定义,而且因为有很多相关的学科,你也应该知道什么是数据工程而不是。
什么不是数据工程?
许多领域与数据工程密切相关,您的客户通常是这些领域的成员。了解你的客户很重要,所以你应该了解这些领域以及它们与数据工程的区别。
以下是一些与数据工程密切相关的领域:
- 数据科学
- 商业智能
- 机器学习工程
在本节中,您将从数据科学开始,更仔细地了解这些领域。
数据科学
如果说数据工程是由如何移动和组织海量数据决定的,那么数据科学则是由如何处理这些数据决定的。
数据科学家通常会查询、探索并尝试从数据集中获得见解。他们可能编写用于特定数据集的一次性脚本,而数据工程师倾向于使用软件工程最佳实践创建可重用的程序。
数据科学家使用统计工具,如 k 均值聚类和回归以及机器学习技术。他们经常使用 R 或 Python,并试图从数据中获得洞察力和预测,以指导企业各个层面的决策。
注:你想探索数据科学吗?看看以下任何一种学习途径:
数据科学家通常来自科学或统计背景,他们的工作风格反映了这一点。他们从事一个项目,回答一个特定的研究问题,而数据工程团队专注于构建可扩展的、可重用的、快速的内部产品。
数据科学家回答研究问题的一个很好的例子可以在生物技术和健康技术公司找到,在那里,数据科学家探索药物相互作用、副作用、疾病结果等数据。
商业智能
商业智能类似于数据科学,但有一些重要的区别。数据科学侧重于预测和做出未来预测,而商业智能侧重于提供业务当前状态的视图。
这两个组都由数据工程团队提供服务,甚至可能来自同一个数据池。然而,商业智能关注的是分析业务绩效并从数据中生成报告。然后,这些报告帮助管理层在业务层面做出决策。
像数据科学家一样,商业智能团队依靠数据工程师来构建工具,使他们能够分析和报告与其关注领域相关的数据。
机器学习工程
机器学习工程师是你会经常接触到的另一个群体。你可能和他们做类似的工作,或者你甚至可能被嵌入到一个机器学习工程师的团队中。
像数据工程师一样,机器学习工程师更专注于构建可重用的软件,许多人都有计算机科学背景。然而,他们不太专注于构建应用程序,而是更专注于构建机器学习模型或设计用于模型的新算法。
注:如果你对机器学习领域感兴趣,那就去看看用 Python 进行机器学习的学习路径吧。
机器学习工程师建立的模型经常被产品团队用于面向客户的产品中。你作为数据工程师提供的数据将用于训练他们的模型,使你的工作成为任何与你合作的机器学习团队的能力的基础。
例如,机器学习工程师可能为您公司的产品开发新的推荐算法,而数据工程师将提供用于训练和测试该算法的数据。
需要理解的一件重要事情是,您在这里看到的字段通常并不清晰。具有数据科学、BI 或机器学习背景的人可能会在某个组织中从事数据工程工作,作为一名数据工程师,您可能会被要求协助这些团队的工作。
你可能会发现自己某一天重新构建了一个数据模型,另一天构建了一个数据标签工具,然后优化了一个内部深度学习框架。好的数据工程师灵活、好奇,并且愿意尝试新事物。
结论
这就完成了你对数据工程领域的介绍,这是对有计算机科学和技术背景或兴趣的人最需要的学科之一!
在本教程中,您学习了:
- 数据工程师做什么
- 谁是数据工程师的客户
- 哪些技能是数据工程中常见的
- 什么数据工程不是
现在你可以决定是否要深入了解这个令人兴奋的领域。你对数据工程感兴趣吗?你有兴趣更深入地探索它吗?请在评论中告诉我们!****
通用 Python 数据结构(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 栈和队列:选择理想的数据结构
数据结构是构建程序的基础结构。每种数据结构都提供了一种特定的组织数据的方式,因此可以根据您的使用情况有效地访问数据。Python 在其标准库中附带了一组广泛的数据结构。
然而,Python 的命名约定并不像其他语言那样清晰。在 Java 中,列表不仅仅是一个
list——它或者是一个LinkedList或者是一个ArrayList。在 Python 中并非如此。即使是有经验的 Python 开发人员有时也会怀疑内置的list类型是作为链表还是动态数组实现的。在本教程中,您将学习:
- Python 标准库中内置了哪些常见的抽象数据类型
- 最常见的抽象数据类型如何映射到 Python 的命名方案
- 如何在各种算法中把抽象数据类型实际运用
注:本教程改编自 Python 招数:书 中“Python 中常见的数据结构”一章。如果你喜欢下面的内容,那么一定要看看这本书的其余部分。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
字典、地图和哈希表
在 Python 中,字典(或简称为字典)是一个中心数据结构。字典存储任意数量的对象,每个对象都由唯一的字典键标识。
字典也经常被称为映射、哈希表、查找表,或者关联数组。它们允许高效地查找、插入和删除与给定键相关联的任何对象。
电话簿是字典对象的真实模拟。它们允许您快速检索与给定键(人名)相关的信息(电话号码)。你可以或多或少地直接跳到一个名字,并查找相关信息,而不必从头到尾阅读电话簿来查找某人的号码。
当涉及到如何组织信息以允许快速查找时,这个类比就有些站不住脚了。但是基本的性能特征保持不变。字典允许您快速找到与给定关键字相关的信息。
字典是计算机科学中最重要和最常用的数据结构之一。那么,Python 是如何处理字典的呢?让我们浏览一下核心 Python 和 Python 标准库中可用的字典实现。
dict:您的首选词典因为字典非常重要,Python 提供了一个健壮的字典实现,它直接内置在核心语言中:
dict数据类型。Python 还提供了一些有用的语法糖,用于在程序中使用字典。例如,花括号({ })字典表达式语法和字典理解允许您方便地定义新的字典对象:

>>> phonebook = {
... "bob": 7387,
... "alice": 3719,
... "jack": 7052,
... }
>>> squares = {x: x * x for x in range(6)}
>>> phonebook["alice"]
3719
>>> squares
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
对于哪些对象可以用作有效的键有一些限制。
Python 的字典是通过关键字索引的,关键字可以是任何哈希类型。一个 hashable 对象有一个哈希值,这个哈希值在它的生命周期内不会改变(见__hash__),它可以和其他对象进行比较(见__eq__)。被比较为相等的可散列对象必须具有相同的散列值。
不可变类型像字符串和数字是可散列的,并且作为字典键工作得很好。你也可以使用 tuple对象作为字典键,只要它们本身只包含可散列类型。
对于大多数用例,Python 的内置字典实现将完成您需要的一切。字典是高度优化的,是语言的许多部分的基础。例如,类属性和堆栈框架中的变量都存储在字典内部。
Python 字典基于一个经过良好测试和微调的哈希表实现,它提供了您所期望的性能特征: O (1)一般情况下查找、插入、更新和删除操作的时间复杂度。
没有理由不使用 Python 中包含的标准dict实现。然而,存在专门的第三方字典实现,例如跳过列表或基于 B 树的字典。
除了普通的dict对象,Python 的标准库还包括许多专门的字典实现。这些专门的字典都基于内置的字典类(并共享其性能特征),但也包括一些额外的便利特性。
让我们来看看它们。
collections.OrderedDict:记住按键的插入顺序
Python 包含一个专门的dict子类,它会记住添加到其中的键的插入顺序: collections.OrderedDict 。
注意: OrderedDict不是核心语言的内置部分,必须从标准库中的collections模块导入。
虽然在 CPython 3.6 和更高版本中,标准的dict实例保留了键的插入顺序,但这只是 CPython 实现的一个副作用,直到 Python 3.7 才在语言规范中定义。因此,如果键的顺序对算法的工作很重要,那么最好通过显式地使用OrderedDict类来清楚地表达这一点:
>>> import collections >>> d = collections.OrderedDict(one=1, two=2, three=3) >>> d OrderedDict([('one', 1), ('two', 2), ('three', 3)]) >>> d["four"] = 4 >>> d OrderedDict([('one', 1), ('two', 2), ('three', 3), ('four', 4)]) >>> d.keys() odict_keys(['one', 'two', 'three', 'four'])在 Python 3.8 之前,不能使用
reversed()逆序迭代字典条目。只有OrderedDict实例提供该功能。即使在 Python 3.8 中,dict和OrderedDict对象也不完全相同。OrderedDict实例有一个普通dict实例没有的.move_to_end()方法,以及一个比普通dict实例更加可定制的.popitem()方法。
collections.defaultdict:返回缺失键的默认值
defaultdict类是另一个字典子类,在其构造函数中接受一个 callable,如果找不到请求的键,将使用其返回值。与在常规字典中使用
get()或捕捉KeyError异常相比,这可以节省您的一些输入,并使您的意图更加清晰:
>>> from collections import defaultdict
>>> dd = defaultdict(list)
>>> # Accessing a missing key creates it and
>>> # initializes it using the default factory,
>>> # i.e. list() in this example:
>>> dd["dogs"].append("Rufus")
>>> dd["dogs"].append("Kathrin")
>>> dd["dogs"].append("Mr Sniffles")
>>> dd["dogs"]
['Rufus', 'Kathrin', 'Mr Sniffles']
collections.ChainMap:将多个字典作为单个映射进行搜索
collections.ChainMap 数据结构将多个字典组合成一个映射。查找逐个搜索底层映射,直到找到一个键。插入、更新和删除仅影响添加到链中的第一个映射:
>>> from collections import ChainMap >>> dict1 = {"one": 1, "two": 2} >>> dict2 = {"three": 3, "four": 4} >>> chain = ChainMap(dict1, dict2) >>> chain ChainMap({'one': 1, 'two': 2}, {'three': 3, 'four': 4}) >>> # ChainMap searches each collection in the chain >>> # from left to right until it finds the key (or fails): >>> chain["three"] 3 >>> chain["one"] 1 >>> chain["missing"] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'missing'
types.MappingProxyType:用于制作只读字典的包装器
MappingProxyType是一个标准字典的包装器,它提供了对包装字典数据的只读视图。这个类是在 Python 3.3 中添加的,可以用来创建不可变的字典代理版本。例如,如果你想从一个类或模块返回一个携带内部状态的字典,同时阻止对这个对象的写访问,那么
MappingProxyType会很有帮助。使用MappingProxyType允许您设置这些限制,而不必首先创建字典的完整副本:
>>> from types import MappingProxyType
>>> writable = {"one": 1, "two": 2}
>>> read_only = MappingProxyType(writable)
>>> # The proxy is read-only:
>>> read_only["one"]
1
>>> read_only["one"] = 23
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> # Updates to the original are reflected in the proxy:
>>> writable["one"] = 42
>>> read_only
mappingproxy({'one': 42, 'two': 2})
Python 中的字典:摘要
本教程中列出的所有 Python 字典实现都是内置于 Python 标准库中的有效实现。
如果您正在寻找在程序中使用哪种映射类型的一般建议,我会向您推荐内置的dict数据类型。它是一个通用的、优化的哈希表实现,直接内置于核心语言中。
我建议您使用这里列出的其他数据类型,除非您有超出dict所提供的特殊需求。
所有的实现都是有效的选择,但是如果你的代码大部分时间都依赖于标准的 Python 字典,那么你的代码将会更加清晰和易于维护。
数组数据结构
一个数组是大多数编程语言中可用的基本数据结构,它在不同的算法中有广泛的用途。
在本节中,您将了解 Python 中的数组实现,这些实现只使用 Python 标准库中包含的核心语言特性或功能。您将看到每种方法的优点和缺点,因此您可以决定哪种实现适合您的用例。
但是在我们开始之前,让我们先了解一些基础知识。数组是如何工作的,它们有什么用途?数组由固定大小的数据记录组成,允许根据索引有效地定位每个元素:
因为数组将信息存储在相邻的内存块中,所以它们被认为是连续的数据结构(例如,相对于像链表这样的链接的数据结构)。
数组数据结构的真实类比是停车场。你可以把停车场看作一个整体,把它当作一个单独的对象,但是在停车场内部,有一些停车位,它们由一个唯一的数字索引。停车点是车辆的容器——每个停车点可以是空的,也可以停放汽车、摩托车或其他车辆。
但并不是所有的停车场都一样。一些停车场可能仅限于一种类型的车辆。例如,一个房车停车场不允许自行车停在上面。受限停车场对应于一个类型的数组数据结构,它只允许存储相同数据类型的元素。
就性能而言,根据元素的索引查找数组中包含的元素非常快。对于这种情况,适当的阵列实现保证了恒定的 O (1)访问时间。
Python 在其标准库中包含了几个类似数组的数据结构,每个结构都有略微不同的特征。让我们来看看。
list:可变动态数组
列表是核心 Python 语言的一部分。尽管名字如此,Python 的列表在幕后被实现为动态数组。
这意味着列表允许添加或删除元素,并且列表将通过分配或释放内存来自动调整保存这些元素的后备存储。
Python 列表可以保存任意元素——Python 中的一切都是对象,包括函数。因此,您可以混合和匹配不同种类的数据类型,并将它们全部存储在一个列表中。
这可能是一个强大的功能,但缺点是同时支持多种数据类型意味着数据通常不太紧凑。因此,整个结构占据了更多的空间:
>>> arr = ["one", "two", "three"] >>> arr[0] 'one' >>> # Lists have a nice repr: >>> arr ['one', 'two', 'three'] >>> # Lists are mutable: >>> arr[1] = "hello" >>> arr ['one', 'hello', 'three'] >>> del arr[1] >>> arr ['one', 'three'] >>> # Lists can hold arbitrary data types: >>> arr.append(23) >>> arr ['one', 'three', 23]
tuple:不可变容器就像列表一样,元组是 Python 核心语言的一部分。然而,与列表不同,Python 的
tuple对象是不可变的。这意味着不能动态地添加或删除元素——元组中的所有元素都必须在创建时定义。元组是另一种可以保存任意数据类型元素的数据结构。拥有这种灵活性是非常强大的,但是同样,这也意味着数据没有在类型化数组中那么紧密:
>>> arr = ("one", "two", "three")
>>> arr[0]
'one'
>>> # Tuples have a nice repr:
>>> arr
('one', 'two', 'three')
>>> # Tuples are immutable:
>>> arr[1] = "hello"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> del arr[1]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object doesn't support item deletion
>>> # Tuples can hold arbitrary data types:
>>> # (Adding elements creates a copy of the tuple)
>>> arr + (23,)
('one', 'two', 'three', 23)
array.array:基本类型数组
Python 的array模块为基本的 C 风格数据类型(如字节、32 位整数、浮点数等)提供了节省空间的存储。
用 array.array 类创建的数组是可变的,其行为类似于列表,除了一个重要的区别:它们是被限制为单一数据类型的类型化数组。
由于这个限制,array.array具有许多元素的对象比列表和元组更有空间效率。存储在其中的元素被紧密打包,如果您需要存储许多相同类型的元素,这可能会很有用。
此外,数组支持许多与常规列表相同的方法,并且您可以将它们作为一种替代方法来使用,而无需对应用程序代码进行其他更改。
>>> import array >>> arr = array.array("f", (1.0, 1.5, 2.0, 2.5)) >>> arr[1] 1.5 >>> # Arrays have a nice repr: >>> arr array('f', [1.0, 1.5, 2.0, 2.5]) >>> # Arrays are mutable: >>> arr[1] = 23.0 >>> arr array('f', [1.0, 23.0, 2.0, 2.5]) >>> del arr[1] >>> arr array('f', [1.0, 2.0, 2.5]) >>> arr.append(42.0) >>> arr array('f', [1.0, 2.0, 2.5, 42.0]) >>> # Arrays are "typed": >>> arr[1] = "hello" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
str:不可变的 Unicode 字符数组Python 3.x 使用
str对象将文本数据存储为 Unicode 字符的不可变序列。实际上,这意味着str是一个不可变的字符数组。奇怪的是,它也是一个递归数据结构——字符串中的每个字符本身都是一个长度为 1 的str对象。字符串对象是空间高效的,因为它们被紧密地打包,并且它们专门用于一种数据类型。如果你存储的是 Unicode 文本,那么你应该使用一个字符串。
因为字符串在 Python 中是不可变的,所以修改字符串需要创建一个修改后的副本。与可变字符串最接近的等效方式是在列表中存储单个字符:
>>> arr = "abcd"
>>> arr[1]
'b'
>>> arr
'abcd'
>>> # Strings are immutable:
>>> arr[1] = "e"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
>>> del arr[1]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object doesn't support item deletion
>>> # Strings can be unpacked into a list to
>>> # get a mutable representation:
>>> list("abcd")
['a', 'b', 'c', 'd']
>>> "".join(list("abcd"))
'abcd'
>>> # Strings are recursive data structures:
>>> type("abc")
"<class 'str'>"
>>> type("abc"[0])
"<class 'str'>"
bytes:不可变的单字节数组
bytes 对象是不可变的单字节序列,或者 0 ≤ x ≤ 255 范围内的整数。从概念上讲,bytes对象类似于str对象,你也可以把它们看作不可变的字节数组。
像字符串一样,bytes有自己的文字语法来创建对象,并且空间效率高。bytes对象是不可变的,但与字符串不同,有一个专用的可变字节数组数据类型,称为bytearray,它们可以被解压到:
>>> arr = bytes((0, 1, 2, 3)) >>> arr[1] 1 >>> # Bytes literals have their own syntax: >>> arr b'\x00\x01\x02\x03' >>> arr = b"\x00\x01\x02\x03" >>> # Only valid `bytes` are allowed: >>> bytes((0, 300)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: bytes must be in range(0, 256) >>> # Bytes are immutable: >>> arr[1] = 23 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'bytes' object does not support item assignment >>> del arr[1] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'bytes' object doesn't support item deletion
bytearray:单字节可变数组
bytearray类型是一个可变的整数序列,范围为 0 ≤ x ≤ 255。bytearray对象与bytes对象密切相关,主要区别在于bytearray可以自由修改——您可以覆盖元素、删除现有元素或添加新元素。bytearray物体会相应地增大和缩小。一个
bytearray可以被转换回不可变的bytes对象,但是这涉及到完全复制存储的数据——一个花费 O ( n )时间的缓慢操作:
>>> arr = bytearray((0, 1, 2, 3))
>>> arr[1]
1
>>> # The bytearray repr:
>>> arr
bytearray(b'\x00\x01\x02\x03')
>>> # Bytearrays are mutable:
>>> arr[1] = 23
>>> arr
bytearray(b'\x00\x17\x02\x03')
>>> arr[1]
23
>>> # Bytearrays can grow and shrink in size:
>>> del arr[1]
>>> arr
bytearray(b'\x00\x02\x03')
>>> arr.append(42)
>>> arr
bytearray(b'\x00\x02\x03*')
>>> # Bytearrays can only hold `bytes`
>>> # (integers in the range 0 <= x <= 255)
>>> arr[1] = "hello"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object cannot be interpreted as an integer
>>> arr[1] = 300
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: byte must be in range(0, 256)
>>> # Bytearrays can be converted back into bytes objects:
>>> # (This will copy the data)
>>> bytes(arr)
b'\x00\x02\x03*'
Python 中的数组:摘要
在 Python 中实现数组时,有许多内置的数据结构可供选择。在本节中,您已经关注了标准库中包含的核心语言特性和数据结构。
如果你愿意超越 Python 标准库,那么像 NumPy 和 pandas 这样的第三方包为科学计算和数据科学提供了广泛的快速数组实现。
如果您想将自己局限于 Python 中包含的数组数据结构,那么这里有一些指导原则:
-
如果您需要存储任意对象,可能是混合数据类型,那么使用
list或tuple,这取决于您是否想要一个不可变的数据结构。 -
如果您有数字(整数或浮点)数据,并且紧密封装和性能很重要,那么尝试一下
array.array。 -
如果您有表示为 Unicode 字符的文本数据,那么使用 Python 的内置
str。如果你需要一个可变的类似字符串的数据结构,那么使用字符的list。 -
如果您想要存储一个连续的字节块,那么使用不可变的
bytes类型,或者如果您需要可变的数据结构,使用bytearray。
在大多数情况下,我喜欢从简单的list开始。如果性能或存储空间成为一个问题,我将稍后专门讨论。很多时候,使用像list这样的通用数组数据结构,可以给你最快的开发速度和最大的编程便利。
我发现这通常在开始时比从一开始就试图挤出最后一滴表现要重要得多。
记录、结构和数据传输对象
与数组相比,记录数据结构提供了固定数量的字段。每个字段可以有一个名称,也可以有不同的类型。
在本节中,您将看到如何仅使用标准库中的内置数据类型和类在 Python 中实现记录、结构和普通的旧数据对象。
注意:我在这里不严格地使用记录的定义。例如,我还将讨论像 Python 的内置tuple这样的类型,它们在严格意义上可能被认为是记录,也可能不被认为是记录,因为它们不提供命名字段。
Python 提供了几种数据类型,可用于实现记录、结构和数据传输对象。在本节中,您将快速了解每个实现及其独特的特征。最后,你会发现一个总结和一个决策指南,可以帮助你做出自己的选择。
注:本教程改编自 Python 招数:书 中“Python 中常见的数据结构”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
好吧,让我们开始吧!
dict:简单数据对象
正如前面提到的和,Python 字典存储任意数量的对象,每个对象由一个惟一的键标识。字典通常也被称为映射或关联数组,允许高效地查找、插入和删除与给定键相关的任何对象。
在 Python 中使用字典作为记录数据类型或数据对象是可能的。Python 中的字典很容易创建,因为它们以字典文字的形式在语言中内置了自己的语法糖。该词典语法简洁,打字十分方便。
使用字典创建的数据对象是可变的,而且几乎没有防止字段名拼写错误的保护措施,因为字段可以随时自由添加和删除。这两个属性都会引入令人惊讶的错误,并且总是要在便利性和错误恢复能力之间进行权衡:
>>> car1 = { ... "color": "red", ... "mileage": 3812.4, ... "automatic": True, ... } >>> car2 = { ... "color": "blue", ... "mileage": 40231, ... "automatic": False, ... } >>> # Dicts have a nice repr: >>> car2 {'color': 'blue', 'automatic': False, 'mileage': 40231} >>> # Get mileage: >>> car2["mileage"] 40231 >>> # Dicts are mutable: >>> car2["mileage"] = 12 >>> car2["windshield"] = "broken" >>> car2 {'windshield': 'broken', 'color': 'blue', 'automatic': False, 'mileage': 12} >>> # No protection against wrong field names, >>> # or missing/extra fields: >>> car3 = { ... "colr": "green", ... "automatic": False, ... "windshield": "broken", ... }
tuple:不可变的对象组Python 的元组是对任意对象进行分组的直接数据结构。元组是不可变的——它们一旦被创建就不能被修改。
就性能而言,在 CPython 中,元组占用的内存比列表略少,而且它们的构建速度也更快。
正如您在下面的字节码反汇编中看到的,构造一个元组常量只需要一个
LOAD_CONST操作码,而构造一个具有相同内容的列表对象需要更多的操作:
>>> import dis
>>> dis.dis(compile("(23, 'a', 'b', 'c')", "", "eval"))
0 LOAD_CONST 4 ((23, "a", "b", "c"))
3 RETURN_VALUE
>>> dis.dis(compile("[23, 'a', 'b', 'c']", "", "eval"))
0 LOAD_CONST 0 (23)
3 LOAD_CONST 1 ('a')
6 LOAD_CONST 2 ('b')
9 LOAD_CONST 3 ('c')
12 BUILD_LIST 4
15 RETURN_VALUE
然而,你不应该过分强调这些差异。在实践中,性能差异通常可以忽略不计,试图通过从列表切换到元组来挤出程序的额外性能可能是错误的方法。
普通元组的一个潜在缺点是,存储在其中的数据只能通过整数索引访问才能取出。不能给存储在元组中的单个属性命名。这可能会影响代码的可读性。
此外,一个元组总是一个特别的结构:很难确保两个元组中存储了相同数量的字段和相同的属性。
这很容易引入疏忽的错误,比如混淆了字段顺序。因此,我建议您尽可能减少存储在元组中的字段数量:
>>> # Fields: color, mileage, automatic >>> car1 = ("red", 3812.4, True) >>> car2 = ("blue", 40231.0, False) >>> # Tuple instances have a nice repr: >>> car1 ('red', 3812.4, True) >>> car2 ('blue', 40231.0, False) >>> # Get mileage: >>> car2[1] 40231.0 >>> # Tuples are immutable: >>> car2[1] = 12 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> # No protection against missing or extra fields >>> # or a wrong order: >>> car3 = (3431.5, "green", True, "silver")编写自定义类:更多工作,更多控制
类允许您为数据对象定义可重用的蓝图,以确保每个对象提供相同的字段集。
使用常规 Python 类作为记录数据类型是可行的,但是也需要手工操作才能获得其他实现的便利特性。例如,向
__init__构造函数添加新字段是冗长且耗时的。此外,从自定义类实例化的对象的默认字符串表示也没什么帮助。为了解决这个问题,你可能需要添加你自己的
__repr__方法,这通常也是相当冗长的,每次你添加一个新的字段时都必须更新。存储在类上的字段是可变的,新字段可以自由添加,您可能喜欢也可能不喜欢。使用
@property装饰器可以提供更多的访问控制并创建只读字段,但是这又需要编写更多的粘合代码。每当您想使用方法向记录对象添加业务逻辑和行为时,编写自定义类是一个很好的选择。然而,这意味着这些对象在技术上不再是普通的数据对象:
>>> class Car:
... def __init__(self, color, mileage, automatic):
... self.color = color
... self.mileage = mileage
... self.automatic = automatic
...
>>> car1 = Car("red", 3812.4, True)
>>> car2 = Car("blue", 40231.0, False)
>>> # Get the mileage:
>>> car2.mileage
40231.0
>>> # Classes are mutable:
>>> car2.mileage = 12
>>> car2.windshield = "broken"
>>> # String representation is not very useful
>>> # (must add a manually written __repr__ method):
>>> car1
<Car object at 0x1081e69e8>
dataclasses.dataclass : Python 3.7+数据类
数据类在 Python 3.7 及以上版本中可用。它们为从头定义自己的数据存储类提供了一个很好的选择。
通过编写一个数据类而不是普通的 Python 类,您的对象实例获得了一些现成的有用特性,这将为您节省一些键入和手动实现工作:
- 定义实例变量的语法更短,因为您不需要实现
.__init__()方法。 - 数据类的实例通过自动生成的
.__repr__()方法自动获得好看的字符串表示。 - 实例变量接受类型注释,使您的数据类在一定程度上是自文档化的。请记住,类型注释只是一些提示,如果没有单独的类型检查工具,这些提示是不会生效的。
数据类通常是使用@dataclass 装饰器创建的,您将在下面的代码示例中看到:
>>> from dataclasses import dataclass >>> @dataclass ... class Car: ... color: str ... mileage: float ... automatic: bool ... >>> car1 = Car("red", 3812.4, True) >>> # Instances have a nice repr: >>> car1 Car(color='red', mileage=3812.4, automatic=True) >>> # Accessing fields: >>> car1.mileage 3812.4 >>> # Fields are mutable: >>> car1.mileage = 12 >>> car1.windshield = "broken" >>> # Type annotations are not enforced without >>> # a separate type checking tool like mypy: >>> Car("red", "NOT_A_FLOAT", 99) Car(color='red', mileage='NOT_A_FLOAT', automatic=99)要了解更多关于 Python 数据类的信息,请查看Python 3.7中数据类的终极指南。
collections.namedtuple:方便的数据对象Python 2.6+中可用的
namedtuple类提供了内置tuple数据类型的扩展。类似于定义一个定制类,使用namedtuple允许您为您的记录定义可重用的蓝图,确保使用正确的字段名称。对象是不可变的,就像正则元组一样。这意味着在创建了
namedtuple实例之后,您不能添加新字段或修改现有字段。除此之外,
namedtuple物体是,嗯。。。命名元组。存储在其中的每个对象都可以通过唯一的标识符来访问。这使您不必记住整数索引或求助于变通方法,如定义整数常量作为索引的助记符。对象在内部被实现为常规的 Python 类。就内存使用而言,它们也比常规类更好,内存效率与常规元组一样高:
>>> from collections import namedtuple
>>> from sys import getsizeof
>>> p1 = namedtuple("Point", "x y z")(1, 2, 3)
>>> p2 = (1, 2, 3)
>>> getsizeof(p1)
64
>>> getsizeof(p2)
64
对象是清理代码的一种简单方法,通过为数据实施更好的结构,使代码更具可读性。
我发现,从特定的数据类型(如具有固定格式的字典)到namedtuple对象有助于我更清楚地表达代码的意图。通常当我应用这种重构时,我会神奇地为我面临的问题想出一个更好的解决方案。
在常规(非结构化)元组和字典上使用namedtuple对象也可以让你的同事的生活变得更轻松,至少在某种程度上,这是通过让正在传递的数据自文档化来实现的:
>>> from collections import namedtuple >>> Car = namedtuple("Car" , "color mileage automatic") >>> car1 = Car("red", 3812.4, True) >>> # Instances have a nice repr: >>> car1 Car(color="red", mileage=3812.4, automatic=True) >>> # Accessing fields: >>> car1.mileage 3812.4 >>> # Fields are immtuable: >>> car1.mileage = 12 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute >>> car1.windshield = "broken" Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Car' object has no attribute 'windshield'
typing.NamedTuple:改进的命名元组Python 3.6 中新增,
typing.NamedTuple是collections模块中namedtuple类的弟弟。它与namedtuple非常相似,主要区别是定义新记录类型的更新语法和增加对类型提示的支持。请注意,如果没有像 mypy 这样的独立类型检查工具,类型注释是不会生效的。但是,即使没有工具支持,它们也可以为其他程序员提供有用的提示(或者,如果类型提示过时,就会变得非常混乱):
>>> from typing import NamedTuple
>>> class Car(NamedTuple):
... color: str
... mileage: float
... automatic: bool
>>> car1 = Car("red", 3812.4, True)
>>> # Instances have a nice repr:
>>> car1
Car(color='red', mileage=3812.4, automatic=True)
>>> # Accessing fields:
>>> car1.mileage
3812.4
>>> # Fields are immutable:
>>> car1.mileage = 12
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
>>> car1.windshield = "broken"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Car' object has no attribute 'windshield'
>>> # Type annotations are not enforced without
>>> # a separate type checking tool like mypy:
>>> Car("red", "NOT_A_FLOAT", 99)
Car(color='red', mileage='NOT_A_FLOAT', automatic=99)
struct.Struct:序列化的 C 结构
struct.Struct 类在 Python 值和序列化为 Python bytes对象的 C 结构之间进行转换。例如,它可以用于处理存储在文件中或来自网络连接的二进制数据。
使用基于格式字符串的迷你语言来定义结构,这允许你定义各种 C 数据类型的排列,如char、int和long以及它们的unsigned变体。
序列化结构很少用于表示纯粹在 Python 代码中处理的数据对象。它们主要是作为一种数据交换格式,而不是一种仅由 Python 代码使用的在内存中保存数据的方式。
在某些情况下,将原始数据打包到结构中可能比将其保存在其他数据类型中使用更少的内存。然而,在大多数情况下,这将是一个非常高级的(可能是不必要的)优化:
>>> from struct import Struct >>> MyStruct = Struct("i?f") >>> data = MyStruct.pack(23, False, 42.0) >>> # All you get is a blob of data: >>> data b'\x17\x00\x00\x00\x00\x00\x00\x00\x00\x00(B' >>> # Data blobs can be unpacked again: >>> MyStruct.unpack(data) (23, False, 42.0)
types.SimpleNamespace:花式属性访问这里还有一个用 Python 实现数据对象的稍微晦涩的选择:
types.SimpleNamespace。这个类是在 Python 3.3 中添加的,提供了对其名称空间的属性访问。这意味着
SimpleNamespace实例将它们所有的键作为类属性公开。您可以使用obj.key点状属性访问,而不是常规字典使用的obj['key']方括号索引语法。默认情况下,所有实例都包含一个有意义的__repr__。顾名思义,
SimpleNamespace简单!它基本上是一个允许属性访问和良好打印的字典。可以自由添加、修改和删除属性:
>>> from types import SimpleNamespace
>>> car1 = SimpleNamespace(color="red", mileage=3812.4, automatic=True)
>>> # The default repr:
>>> car1
namespace(automatic=True, color='red', mileage=3812.4)
>>> # Instances support attribute access and are mutable:
>>> car1.mileage = 12
>>> car1.windshield = "broken"
>>> del car1.automatic
>>> car1
namespace(color='red', mileage=12, windshield='broken')
Python 中的记录、结构和数据对象:摘要
如您所见,实现记录或数据对象有很多不同的选择。Python 中的数据对象应该使用哪种类型?通常,您的决定将取决于您的用例:
-
如果只有几个字段,那么如果字段顺序容易记忆或者字段名是多余的,那么使用普通元组对象可能是没问题的。比如,想象三维空间中的一个
(x, y, z)点。 -
如果需要不可变的字段,那么普通元组、
collections.namedtuple和typing.NamedTuple都是不错的选择。 -
如果您需要锁定字段名以避免输入错误,那么
collections.namedtuple和typing.NamedTuple就是您的朋友。 -
如果您想保持简单,那么一个普通的字典对象可能是一个不错的选择,因为它的语法非常类似于 JSON 。
-
如果您需要完全控制您的数据结构,那么是时候用
@propertysetter 和 getter编写一个自定义类了。 -
如果你需要给对象添加行为(方法),那么你应该从头开始写一个自定义类,或者使用
dataclass装饰器,或者通过扩展collections.namedtuple或typing.NamedTuple。 -
如果您需要将数据紧密打包以将其序列化到磁盘或通过网络发送,那么是时候阅读一下
struct.Struct了,因为这是一个很好的用例!
如果您正在寻找一个安全的默认选择,那么我对在 Python 中实现普通记录、结构或数据对象的一般建议是在 Python 2.x 中使用collections.namedtuple,在 Python 3 中使用它的兄弟typing.NamedTuple。
集合和多重集合
在这一节中,您将看到如何使用标准库中的内置数据类型和类在 Python 中实现可变和不可变的 set 和 multiset (bag)数据结构。
一个集合是不允许重复元素的无序对象集合。通常,集合用于快速测试集合中的成员资格值,从集合中插入或删除新值,以及计算两个集合的并集或交集。
在一个适当的 set 实现中,成员资格测试应该在快速的 O (1)时间内运行。并、交、差、子集运算平均要花 O ( n )时间。Python 标准库中包含的 set 实现遵循这些性能特征。
就像字典一样,集合在 Python 中得到了特殊处理,并且有一些语法上的好处,使得它们易于创建。例如,花括号集合表达式语法和集合理解允许您方便地定义新的集合实例:
vowels = {"a", "e", "i", "o", "u"}
squares = {x * x for x in range(10)}
但是要小心:创建空集需要调用set()构造函数。使用空的花括号({})是不明确的,会创建一个空的字典。
Python 及其标准库提供了几个 set 实现。让我们来看看它们。
set:您的定位设置
set 类型是 Python 中内置的 set 实现。它是可变的,允许动态插入和删除元素。
Python 的集合由dict数据类型支持,并共享相同的性能特征。任何可散列的对象都可以存储在一个集合中:
>>> vowels = {"a", "e", "i", "o", "u"} >>> "e" in vowels True >>> letters = set("alice") >>> letters.intersection(vowels) {'a', 'e', 'i'} >>> vowels.add("x") >>> vowels {'i', 'a', 'u', 'o', 'x', 'e'} >>> len(vowels) 6
frozenset:不可变集合
frozenset类实现了set的不可变版本,该版本在被构造后不能被更改。对象是静态的,只允许对其元素进行查询操作,不允许插入或删除。因为
frozenset对象是静态的和可散列的,它们可以用作字典键或另一个集合的元素,这是常规(可变)set对象所不能做到的:
>>> vowels = frozenset({"a", "e", "i", "o", "u"})
>>> vowels.add("p")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
>>> # Frozensets are hashable and can
>>> # be used as dictionary keys:
>>> d = { frozenset({1, 2, 3}): "hello" }
>>> d[frozenset({1, 2, 3})]
'hello'
collections.Counter:多重集
Python 标准库中的 collections.Counter 类实现了一个多重集合或包类型,允许集合中的元素出现不止一次。
如果您不仅需要跟踪某个元素是否是集合的一部分,还需要跟踪它在集合中被包含的次数,这将非常有用:
>>> from collections import Counter >>> inventory = Counter() >>> loot = {"sword": 1, "bread": 3} >>> inventory.update(loot) >>> inventory Counter({'bread': 3, 'sword': 1}) >>> more_loot = {"sword": 1, "apple": 1} >>> inventory.update(more_loot) >>> inventory Counter({'bread': 3, 'sword': 2, 'apple': 1})对
Counter类的一个警告是,在计算一个Counter对象中的元素数量时,你要小心。调用len()返回多重集中唯一元素的数量,而元素的总数可以使用sum()来检索:
>>> len(inventory)
3 # Unique elements
>>> sum(inventory.values())
6 # Total no. of elements
Python 中的集合和多重集合:摘要
集合是 Python 及其标准库包含的另一种有用且常用的数据结构。以下是决定使用哪种方法的一些指导原则:
- 如果需要可变集合,那么使用内置的
set类型。 - 如果你需要可以用作字典或设置键的可散列对象,那么使用
frozenset。 - 如果你需要一个多重集,或者包,数据结构,那么使用
collections.Counter。
堆栈(后进先出法)
一个栈是支持快速后进/先出 (LIFO)插入和删除语义的对象集合。与列表或数组不同,堆栈通常不允许对它们包含的对象进行随机访问。插入和删除操作通常也被称为推送和弹出。
栈数据结构的一个有用的现实类比是一堆盘子。新的盘子被放在盘子堆的最上面,因为这些盘子很珍贵也很重,所以只有最上面的盘子可以被移动。换句话说,堆叠的最后一个盘子必须是第一个取出的(LIFO)。为了够到堆叠中较低的板,最上面的板必须一个接一个地移开。
就性能而言,一个合适的栈实现预计会花费 O (1)的时间用于插入和删除操作。
堆栈在算法中有广泛的用途。例如,它们被用于语言解析和运行时内存管理,后者依赖于一个调用栈。使用堆栈的一个简短而漂亮的算法是在树或图数据结构上的深度优先搜索 (DFS)。
Python 附带了几个堆栈实现,每个实现都有略微不同的特征。让我们来看看他们,比较他们的特点。
list:简单的内置堆栈
Python 内置的list类型使得一个体面的栈数据结构,因为它支持在摊销O(1)时间内的推送和弹出操作。
Python 的列表在内部被实现为动态数组,这意味着当添加或删除元素时,它们偶尔需要为存储在其中的元素调整存储空间。列表过度分配了它的后备存储器,因此不是每次推送或弹出都需要调整大小。结果,你得到了这些操作的分摊的 O (1)时间复杂度。
不利的一面是,这使得它们的性能不如基于链表的实现所提供的稳定的 O (1)插入和删除(您将在下面的collections.deque中看到)。另一方面,链表确实提供了对栈上元素的快速随机访问,这是一个额外的好处。
当使用列表作为堆栈时,有一个重要的性能警告需要注意:为了获得插入和删除的分摊的 O (1)性能,必须使用append()方法将新的项目添加到列表的末端,并使用pop()再次从末端移除。为了获得最佳性能,基于 Python 列表的栈应该向更高的索引增长,向更低的索引收缩。
从前面添加和移除要慢得多,需要 O ( n )的时间,因为现有的元素必须四处移动才能为新元素腾出空间。这是一个您应该尽可能避免的性能反模式:
>>> s = [] >>> s.append("eat") >>> s.append("sleep") >>> s.append("code") >>> s ['eat', 'sleep', 'code'] >>> s.pop() 'code' >>> s.pop() 'sleep' >>> s.pop() 'eat' >>> s.pop() Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: pop from empty list
collections.deque:快速和稳定的堆栈
deque类实现了一个双端队列,支持在 O (1)时间(非摊销)内从两端添加和移除元素。因为 deques 同样支持从两端添加和删除元素,所以它们既可以用作队列,也可以用作堆栈。Python 的
deque对象被实现为双向链表,这使得它们在插入和删除元素时具有出色且一致的性能,但在随机访问堆栈中间的元素时,性能却很差 O ( n )。总的来说,
collections.deque是一个很好的选择如果你正在 Python 的标准库中寻找一个栈数据结构,它具有链表实现的性能特征:
>>> from collections import deque
>>> s = deque()
>>> s.append("eat")
>>> s.append("sleep")
>>> s.append("code")
>>> s
deque(['eat', 'sleep', 'code'])
>>> s.pop()
'code'
>>> s.pop()
'sleep'
>>> s.pop()
'eat'
>>> s.pop()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: pop from an empty deque
queue.LifoQueue:并行计算的锁定语义
Python 标准库中的 LifoQueue 栈实现是同步的,并提供锁定语义来支持多个并发生产者和消费者。
除了LifoQueue之外,queue模块还包含其他几个类,它们实现了对并行计算有用的多生产者、多消费者队列。
根据您的用例,锁定语义可能是有帮助的,或者它们可能只是招致不必要的开销。在这种情况下,最好使用一个list或一个deque作为通用堆栈:
>>> from queue import LifoQueue >>> s = LifoQueue() >>> s.put("eat") >>> s.put("sleep") >>> s.put("code") >>> s <queue.LifoQueue object at 0x108298dd8> >>> s.get() 'code' >>> s.get() 'sleep' >>> s.get() 'eat' >>> s.get_nowait() queue.Empty >>> s.get() # Blocks/waits forever...Python 中的堆栈实现:概要
如您所见,Python 附带了堆栈数据结构的几种实现。它们都有稍微不同的特征以及性能和使用权衡。
如果您不寻求并行处理支持(或者如果您不想手动处理锁定和解锁),那么您可以选择内置的
list类型或collections.deque。区别在于幕后使用的数据结构和整体易用性。
list由一个动态数组支持,这使得它非常适合快速随机访问,但需要在添加或删除元素时偶尔调整大小。列表过度分配了它的后备存储,所以不是每次推送或弹出都需要调整大小,并且你得到了这些操作的分摊的 O (1)时间复杂度。但是您需要注意的是,只能使用
append()和pop()来插入和移除项目。否则,性能会下降到 O ( n )。
collections.deque以双向链表为后盾,优化了两端的追加和删除,并为这些操作提供了一致的 O (1)性能。不仅其性能更稳定,而且deque类也更易于使用,因为您不必担心从错误的一端添加或删除项目。总之,
collections.deque是在 Python 中实现堆栈(LIFO 队列)的绝佳选择。队列(先进先出)
在本节中,您将看到如何仅使用 Python 标准库中的内置数据类型和类来实现一个先进/先出 (FIFO)队列数据结构。
一个队列是支持插入和删除的快速 FIFO 语义的对象集合。插入和删除操作有时被称为入队和出列。与列表或数组不同,队列通常不允许对它们包含的对象进行随机访问。
这里有一个 FIFO 队列的真实类比:
想象一下 PyCon 注册的第一天,一队 Pythonistas 在等着领取他们的会议徽章。当新人进入会场,排队领取胸卡时,他们在队伍的后面排队。开发人员收到他们的徽章和会议礼品包,然后在队列的前面离开队伍(出列)。
记住队列数据结构特征的另一种方法是把它想象成一个管道。你把乒乓球放在一端,它们会移动到另一端,然后你把它们移走。当球在队列中(一根实心金属管)时,你不能够到它们。与队列中的球进行交互的唯一方法是在管道的后面添加新的球(入队)或者在前面移除它们(出列)。
队列类似于堆栈。两者的区别在于如何移除物品。用一个队列,你移除最近添加最少的项目(FIFO),但是用一个堆栈,你移除最近添加最多的项目(LIFO)。
就性能而言,一个合适的队列实现预计会花费 O (1)的时间来执行插入和删除操作。这是对队列执行的两个主要操作,在正确的实现中,它们应该很快。
队列在算法中有广泛的应用,通常有助于解决调度和并行编程问题。使用队列的一个简短而漂亮的算法是在树或图数据结构上的广度优先搜索 (BFS)。
调度算法经常在内部使用优先级队列。这些是专门的队列。一个优先级队列检索优先级最高的元素,而不是按照插入时间检索下一个元素。单个元素的优先级由队列根据应用于它们的键的顺序来决定。
然而,常规队列不会对其携带的项目进行重新排序。就像在管道的例子中,你取出你放入的东西,并且完全按照那个顺序。
Python 附带了几个队列实现,每个实现都有稍微不同的特征。我们来复习一下。
list:非常慢的队列有可能使用常规的
list作为队列,但是从性能角度来看这并不理想。为此目的,列表非常慢,因为在开头插入或删除一个元素需要将所有其他元素移动一位,需要 O ( n )时间。因此,我而不是建议在 Python 中使用
list作为临时队列,除非你只处理少量元素:
>>> q = []
>>> q.append("eat")
>>> q.append("sleep")
>>> q.append("code")
>>> q
['eat', 'sleep', 'code']
>>> # Careful: This is slow!
>>> q.pop(0)
'eat'
collections.deque:快速和健壮的队列
deque类实现了一个双端队列,支持在 O (1)时间内(非摊销)从两端添加和移除元素。因为 deques 同样支持从两端添加和删除元素,所以它们既可以用作队列,也可以用作堆栈。
Python 的deque对象被实现为双向链表。这使得它们在插入和删除元素时具有出色且一致的性能,但在随机访问堆栈中间的元素时,性能却很差。
因此,如果您在 Python 的标准库中寻找队列数据结构,collections.deque是一个很好的默认选择:
>>> from collections import deque >>> q = deque() >>> q.append("eat") >>> q.append("sleep") >>> q.append("code") >>> q deque(['eat', 'sleep', 'code']) >>> q.popleft() 'eat' >>> q.popleft() 'sleep' >>> q.popleft() 'code' >>> q.popleft() Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: pop from an empty deque
queue.Queue:并行计算的锁定语义Python 标准库中的
queue.Queue实现是同步的,并提供锁定语义来支持多个并发的生产者和消费者。模块包含了其他几个实现多生产者、多消费者队列的类,这对于并行计算非常有用。
根据您的用例,锁定语义可能会有所帮助,也可能会带来不必要的开销。在这种情况下,最好使用
collections.deque作为通用队列:
>>> from queue import Queue
>>> q = Queue()
>>> q.put("eat")
>>> q.put("sleep")
>>> q.put("code")
>>> q
<queue.Queue object at 0x1070f5b38>
>>> q.get()
'eat'
>>> q.get()
'sleep'
>>> q.get()
'code'
>>> q.get_nowait()
queue.Empty
>>> q.get() # Blocks/waits forever...
multiprocessing.Queue:共享作业队列
multiprocessing.Queue 是一个共享的作业队列实现,允许多个并发工作器并行处理排队的项目。基于进程的并行化在 CPython 中很流行,这是因为全局解释器锁 (GIL)阻止了在单个解释器进程上的某些形式的并行执行。
作为一个专门用于在进程间共享数据的队列实现,multiprocessing.Queue使得在多个进程间分配工作变得容易,从而绕过 GIL 限制。这种类型的队列可以跨进程边界存储和传输任何可拾取的对象:
>>> from multiprocessing import Queue >>> q = Queue() >>> q.put("eat") >>> q.put("sleep") >>> q.put("code") >>> q <multiprocessing.queues.Queue object at 0x1081c12b0> >>> q.get() 'eat' >>> q.get() 'sleep' >>> q.get() 'code' >>> q.get() # Blocks/waits forever...Python 中的队列:摘要
Python 包括几个队列实现,作为核心语言及其标准库的一部分。
对象可以用作队列,但由于性能较慢,通常不建议这样做。
如果您不寻求并行处理支持,那么由
collections.deque提供的实现是在 Python 中实现 FIFO 队列数据结构的一个极好的默认选择。它提供了良好队列实现的性能特征,也可以用作堆栈(LIFO 队列)。优先队列
一个优先级队列是一个容器数据结构,它管理一组具有全序关键字的记录,以提供对该组中具有最小或最大关键字的记录的快速访问。
您可以将优先级队列视为修改后的队列。它不是根据插入时间检索下一个元素,而是检索优先级最高的元素。单个元素的优先级由应用于它们的键的顺序决定。
优先级队列通常用于处理调度问题。例如,您可以使用它们来优先处理更紧急的任务。
考虑操作系统任务调度程序的工作:
理想情况下,系统中优先级较高的任务(比如玩实时游戏)应该优先于优先级较低的任务(比如在后台下载更新)。通过将未决任务组织在以任务紧急程度为关键字的优先级队列中,任务计划程序可以快速选择优先级最高的任务,并允许它们首先运行。
在本节中,您将看到一些选项,说明如何使用内置数据结构或 Python 标准库中包含的数据结构在 Python 中实现优先级队列。每种实现都有自己的优点和缺点,但在我看来,对于大多数常见的场景,都有一个明显的赢家。让我们找出是哪一个。
list:手动排序队列你可以使用一个排序的
list来快速识别和删除最小或最大的元素。缺点是向列表中插入新元素是一个缓慢的 O ( n )操作。虽然可以使用标准库中的
bisect.insort在 O (log n )时间内找到插入点,但这总是由缓慢的插入步骤决定。通过追加列表和重新排序来维持顺序也至少需要 O ( n log n )的时间。另一个缺点是,当插入新元素时,您必须手动重新排序列表。错过这一步很容易引入 bug,负担永远在你这个开发者身上。
这意味着排序列表仅在插入很少时适合作为优先级队列:
>>> q = []
>>> q.append((2, "code"))
>>> q.append((1, "eat"))
>>> q.append((3, "sleep"))
>>> # Remember to re-sort every time a new element is inserted,
>>> # or use bisect.insort()
>>> q.sort(reverse=True)
>>> while q:
... next_item = q.pop()
... print(next_item)
...
(1, 'eat')
(2, 'code')
(3, 'sleep')
heapq:基于列表的二进制堆
heapq 是一个通常由普通list支持的二进制堆实现,支持在 O (log n )时间内插入和提取最小元素。
对于用 Python 实现优先级队列的来说,这个模块是个不错的选择。由于heapq在技术上只提供了一个最小堆实现,必须采取额外的步骤来确保排序稳定性和其他实际优先级队列通常期望的特性:
>>> import heapq >>> q = [] >>> heapq.heappush(q, (2, "code")) >>> heapq.heappush(q, (1, "eat")) >>> heapq.heappush(q, (3, "sleep")) >>> while q: ... next_item = heapq.heappop(q) ... print(next_item) ... (1, 'eat') (2, 'code') (3, 'sleep')
queue.PriorityQueue:漂亮的优先队列
queue.PriorityQueue内部使用heapq,具有相同的时间和空间复杂度。不同之处在于PriorityQueue是同步的,并提供锁定语义来支持多个并发的生产者和消费者。根据您的用例,这可能是有帮助的,或者可能只是稍微减慢您的程序。无论如何,你可能更喜欢由
PriorityQueue提供的基于类的接口,而不是由heapq提供的基于函数的接口:
>>> from queue import PriorityQueue
>>> q = PriorityQueue()
>>> q.put((2, "code"))
>>> q.put((1, "eat"))
>>> q.put((3, "sleep"))
>>> while not q.empty():
... next_item = q.get()
... print(next_item)
...
(1, 'eat')
(2, 'code')
(3, 'sleep')
Python 中的优先级队列:摘要
Python 包括几个优先级队列实现,可供您使用。
queue.PriorityQueue 凭借一个漂亮的面向对象的界面和一个清楚表明其意图的名字脱颖而出。应该是你的首选。
如果你想避免queue.PriorityQueue的锁定开销,那么直接使用 heapq 模块也是一个不错的选择。
结论:Python 数据结构
这就结束了您对 Python 中常见数据结构的探索。有了这里学到的知识,您就可以实现适合您的特定算法或用例的高效数据结构了。
在本教程中,您已经学习了:
- Python 标准库中内置了哪些常见的抽象数据类型
- 最常见的抽象数据类型如何映射到 Python 的命名方案
- 如何在各种算法中把抽象数据类型实际运用
如果你喜欢在这个例子中从 Python 技巧中学到的东西,那么一定要看看这本书的其余部分。
如果你有兴趣温习你的一般数据结构知识,那么我强烈推荐史蒂文·s·斯基纳的《算法设计手册》。它在教您基本的(和更高级的)数据结构和向您展示如何在代码中实现它们之间取得了很好的平衡。史蒂夫的书对本教程的写作有很大的帮助。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 栈和队列:选择理想的数据结构*********
Python 中的基本数据类型
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的基本数据类型
现在你知道了如何与 Python 解释器交互并执行 Python 代码。是时候深入研究 Python 语言了。首先讨论 Python 内置的基本数据类型。
以下是你将在本教程中学到的内容:
- 您将了解 Python 中内置的几种基本的数字、字符串和布尔类型。本教程结束时,您将熟悉这些类型的对象的外观,以及如何表示它们。
- 您还将大致了解 Python 的内置函数。这些是预先写好的代码块,你可以调用它们来做有用的事情。你已经看到了内置的
print()函数,但是还有很多其他的。
免费 PDF 下载: Python 3 备忘单
参加测验:通过我们的交互式“Python 中的基本数据类型”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
整数
在 Python 3 中,整数值的长度实际上没有限制。当然,它会受到系统内存容量的限制,但除此之外,任何整数都可以是您需要的长度:
>>> print(123123123123123123123123123123123123123123123123 + 1) 123123123123123123123123123123123123123123123124Python 将不带任何前缀的十进制数字序列解释为十进制数:
>>> print(10)
10
以下字符串可以添加到整数值的前面,以表示基数不是 10:
| 前缀 | 解释 | 基础 |
|---|---|---|
0b(零+小写字母'b' ) |
||
0B(零+大写字母'B') |
二进制的 | Two |
0o(零+小写字母'o' ) |
||
0O(零+大写字母'O') |
八进制的 | eight |
0x(零+小写字母'x' ) |
||
0X(零+大写字母'X') |
十六进制的 | Sixteen |
例如:
>>> print(0o10) 8 >>> print(0x10) 16 >>> print(0b10) 2有关非十进制整数值的更多信息,请参见下面的维基百科网站:二进制、八进制和十六进制。
Python 整数的底层类型被称为
int,与用于指定它的基数无关:
>>> type(10)
<class 'int'>
>>> type(0o10)
<class 'int'>
>>> type(0x10)
<class 'int'>
注意:这是一个很好的时机来说明,如果你想在 REPL 会话中显示一个值,你不需要使用print()函数。只需在>>>提示符下输入值,然后点击 Enter 就会显示出来:
>>> 10 10 >>> 0x10 16 >>> 0b10 2本系列教程中的许多例子都将使用这个特性。
请注意,这在脚本文件中不起作用。在脚本文件中,一个值单独出现在一行不会有任何作用。
浮点数
Python 中的
float类型指定一个浮点数。float数值用小数点指定。可选地,后跟正整数或负整数的字符e或E可以被附加以指定科学符号:
>>> 4.2
4.2
>>> type(4.2)
<class 'float'>
>>> 4.
4.0
>>> .2
0.2
>>> .4e7
4000000.0
>>> type(.4e7)
<class 'float'>
>>> 4.2e-4
0.00042
深潜:浮点表示
下面是关于 Python 如何在内部表示浮点数的更深入的信息。您可以在 Python 中轻松使用浮点数,而不必理解到这种程度,所以如果这看起来过于复杂,也不用担心。这里提供了一些信息,以防你感到好奇。
根据 IEEE 754 标准,几乎所有平台都将 Python
float值表示为 64 位“双精度”值。在这种情况下,一个浮点数可以拥有的最大值大约是 1.8 ⨉ 10 308 。Python 将通过字符串inf指示一个大于该数字的数字:`>>> 1.79e308 1.79e+308 >>> 1.8e308 inf`非零数字最接近零的值大约是 5.0 ⨉ 10 -324 。任何比这更接近零的东西实际上都是零:
`>>> 5e-324 5e-324 >>> 1e-325 0.0`浮点数在内部表示为二进制(基数为 2)分数。大多数十进制分数不能精确地表示为二进制分数,因此在大多数情况下,浮点数的内部表示是实际值的近似值。实际上,实际值和表示值之间的差异非常小,通常不会造成重大问题。
延伸阅读:有关 Python 中浮点表示法的更多信息以及相关的潜在缺陷,请参见 Python 文档中的浮点运算:问题和限制。
复数
复数指定为<real part>+<imaginary part>j。例如:
>>> 2+3j (2+3j) >>> type(2+3j) <class 'complex'>字符串
字符串是字符数据的序列。Python 中的字符串类型称为
str。字符串可以用单引号或双引号分隔。开始分隔符和匹配的结束分隔符之间的所有字符都是字符串的一部分:
>>> print("I am a string.")
I am a string.
>>> type("I am a string.")
<class 'str'>
>>> print('I am too.')
I am too.
>>> type('I am too.')
<class 'str'>
Python 中的字符串可以包含任意多的字符。唯一的限制是你的机器的内存资源。字符串也可以是空的:
>>> '' ''如果您想包含一个引号字符作为字符串本身的一部分呢?你的第一反应可能是尝试这样的事情:
>>> print('This string contains a single quote (') character.')
SyntaxError: invalid syntax
如你所见,这并不奏效。本例中的字符串以单引号开始,因此 Python 假设下一个单引号,即括号中的单引号,是字符串的一部分,是结束分隔符。最后一个单引号是个迷,导致了所示的语法错误。
如果您想在字符串中包含任何一种类型的引号字符,最简单的方法是用另一种类型来分隔字符串。如果字符串包含单引号,请用双引号将其分隔开,反之亦然:
>>> print("This string contains a single quote (') character.") This string contains a single quote (') character. >>> print('This string contains a double quote (") character.') This string contains a double quote (") character.字符串中的转义序列
有时,您希望 Python 以不同的方式解释字符串中的字符或字符序列。这可能以两种方式之一发生:
- 您可能希望取消某些字符通常在字符串中给出的特殊解释。
- 您可能希望对字符串中通常按字面理解的字符进行特殊解释。
您可以使用反斜杠(
\)字符来完成此操作。字符串中的反斜杠字符表示它后面的一个或多个字符应该被特殊处理。(这被称为转义序列,因为反斜杠导致后续字符序列“转义”其通常含义。)让我们看看这是如何工作的。
抑制特殊字符含义
您已经看到了当您试图在字符串中包含引号字符时可能会遇到的问题。如果字符串由单引号分隔,则不能直接指定单引号字符作为字符串的一部分,因为对于该字符串,单引号有特殊的含义,它终止字符串:
>>> print('This string contains a single quote (') character.')
SyntaxError: invalid syntax
在字符串中的引号字符前面指定一个反斜杠会“转义”它,并导致 Python 取消其通常的特殊含义。然后,它被简单地解释为文字单引号字符:
>>> print('This string contains a single quote (\') character.') This string contains a single quote (') character.这同样适用于由双引号分隔的字符串:
>>> print("This string contains a double quote (\") character.")
This string contains a double quote (") character.
以下是转义序列表,这些转义序列会导致 Python 禁止对字符串中的字符进行通常的特殊解释:
| 转义
序列 | 反斜杠后的
字符的通常解释 | “逃”的解释 |
| --- | --- | --- |
| \' | 用单引号开始分隔符终止字符串 | 文字单引号(')字符 |
| \" | 用双引号开始分隔符终止字符串 | 文字双引号(")字符 |
| \<newline> | 终止输入线 | 换行被忽略 |
| \\ | 引入转义序列 | 文字反斜杠(\)字符 |
通常,换行符终止行输入。所以在字符串中间按下 Enter 会让 Python 认为它是不完整的:
>>> print('a SyntaxError: EOL while scanning string literal要将一个字符串拆分成多行,请在每个换行符前加一个反斜杠,换行符将被忽略:
>>> print('a\
... b\
... c')
abc
要在字符串中包含文字反斜杠,请用反斜杠对其进行转义:
>>> print('foo\\bar') foo\bar对字符应用特殊含义
接下来,假设您需要创建一个包含制表符的字符串。一些文本编辑器可能允许您直接在代码中插入制表符。但是许多程序员认为这是一种糟糕的做法,原因有几个:
- 计算机可以区分制表符和一系列空格字符,但你不能。对于阅读代码的人来说,制表符和空格字符在视觉上是无法区分的。
- 一些文本编辑器被配置为通过将制表符扩展到适当的空格数来自动消除制表符。
- 一些 Python REPL 环境不会在代码中插入制表符。
在 Python(以及几乎所有其他常见的计算机语言)中,制表符可以由转义序列
\t指定:
>>> print('foo\tbar')
foo bar
转义序列\t导致t字符失去其通常的含义,即字面上的t。相反,该组合被解释为制表符。
以下是导致 Python 应用特殊含义而不是字面解释的转义序列列表:
| 换码顺序 | “逃”的解释 |
|---|---|
\a |
ASCII 字符(BEL) |
\b |
ASCII 退格(BS)字符 |
\f |
ASCII 换页符(FF)字符 |
\n |
ASCII 换行(LF)字符 |
\N{<name>} |
具有给定<name>的 Unicode 数据库中的字符 |
\r |
ASCII 回车(CR)字符 |
\t |
ASCII 水平制表符(TAB)字符 |
\uxxxx |
带 16 位十六进制值的 Unicode 字符xxxx |
\Uxxxxxxxx |
具有 32 位十六进制值的 Unicode 字符xxxxxxxx |
\v |
ASCII 垂直制表符(VT)字符 |
\ooo |
具有八进制值的字符ooo |
\xhh |
带十六进制值的字符hh |
示例:
>>> print("a\tb") a b >>> print("a\141\x61") aaa >>> print("a\nb") a b >>> print('\u2192 \N{rightwards arrow}') → →这种类型的转义序列通常用于插入不易从键盘生成或者不易阅读或打印的字符。
原始字符串
原始字符串文字的前面是
r或R,这表示相关字符串中的转义序列不被翻译。反斜杠字符留在字符串中:
>>> print('foo\nbar')
foo
bar
>>> print(r'foo\nbar')
foo\nbar
>>> print('foo\\bar')
foo\bar
>>> print(R'foo\\bar')
foo\\bar
三重引号字符串
在 Python 中还有另一种分隔字符串的方法。三重引号字符串由三个单引号或三个双引号组成的匹配组分隔。转义序列在三重引号字符串中仍然有效,但是单引号、双引号和换行符可以在不转义它们的情况下包含在内。这为创建包含单引号和双引号的字符串提供了一种便捷的方法:
>>> print('''This string has a single (') and a double (") quote.''') This string has a single (') and a double (") quote.因为可以包含换行符而不用转义它们,所以这也允许多行字符串:
>>> print("""This is a
string that spans
across several lines""")
This is a
string that spans
across several lines
在即将到来的 Python 程序结构教程中,您将看到如何使用三重引号字符串向 Python 代码添加解释性注释。
布尔类型、布尔上下文和“真实性”
Python 3 提供了一种布尔数据类型。布尔类型的对象可能有两个值,True或False:
>>> type(True) <class 'bool'> >>> type(False) <class 'bool'>正如您将在接下来的教程中看到的,Python 中的表达式通常在布尔上下文中计算,这意味着它们被解释为代表真或假。在布尔上下文中为真的值有时被称为“真”,而在布尔上下文中为假的值被称为“假”(你也可能看到“falsy”拼成“falsey”)
布尔类型对象的“真”是不言而喻的:等于
True的布尔对象是真(true),等于False的布尔对象是假(false)。但是非布尔对象也可以在布尔上下文中进行评估,并确定为真或假。在接下来的关于 Python 中的运算符和表达式的教程中,当您遇到逻辑运算符时,您将会学到更多关于在布尔上下文中计算对象的知识。
内置函数
Python 解释器支持许多内置的函数:从 Python 3.6 开始有 68 个函数。在接下来的讨论中,当它们出现在上下文中时,您将会涉及其中的许多内容。
现在,接下来是一个简短的概述,只是为了给大家一个可用的感觉。更多细节参见关于内置函数的 Python 文档。以下许多描述涉及到将在未来教程中讨论的主题和概念。
数学
功能 描述 T2 abs()返回一个数字的绝对值 divmod()返回整数除法的商和余数 T2 max()返回 iterable 中给定参数或项目的最大值 T2 min()返回 iterable 中最小的给定参数或项 pow()对一个数字进行幂运算 round()对浮点值进行舍入 sum()对 iterable 的各项求和 类型转换
功能 描述 ascii()返回包含对象的可打印表示形式的字符串 bin()将整数转换为二进制字符串 bool()将参数转换为布尔值 chr()返回由整数参数给出的字符的字符串表示形式 complex()返回由参数构造的复数 float()返回由数字或字符串构造的浮点对象 hex()将整数转换为十六进制字符串 int()返回由数字或字符串构造的整数对象 oct()将整数转换为八进制字符串 ord()返回字符的整数表示形式 repr()返回包含对象的可打印表示形式的字符串 str()返回对象的字符串版本 type()返回对象的类型或创建新的类型对象 可迭代程序和迭代器
功能 描述 T2 all()如果 iterable 的所有元素都为真,则返回 TrueT2 any()如果 iterable 的任何元素为真,则返回 TrueT2 enumerate()从 iterable 返回包含索引和值的元组列表 T2 filter()从 iterable 中筛选元素 iter()返回迭代器对象 T2 len()返回对象的长度 T2 map()将函数应用于 iterable 的每一项 next()从迭代器中检索下一项 range()生成一系列整数值 reversed()返回反向迭代器 slice()返回一个 slice对象T2 sorted()从 iterable 返回一个排序列表 T2 zip()创建一个迭代器,从可迭代对象中聚合元素 复合数据类型
功能 描述 bytearray()创建并返回一个 bytearray类的对象bytes()创建并返回一个 bytes对象(类似于bytearray,但不可变)dict()创建一个 dict对象frozenset()创建一个 frozenset对象list()创建一个 list对象object()创建新的无特征对象 set()创建一个 set对象tuple()创建一个 tuple对象类、属性和继承
功能 描述 classmethod()返回函数的类方法 delattr()从对象中删除属性 getattr()返回对象的命名属性的值 hasattr()如果对象具有给定的属性,则返回 Trueisinstance()确定对象是否是给定类的实例 issubclass()确定一个类是否是给定类的子类 property()返回类的属性值 setattr()设置对象的命名属性的值 T2 super()返回一个代理对象,该对象将方法调用委托给父类或同级类 输入/输出
功能 描述 format()将值转换为格式化的表示形式 input()从控制台读取输入 open()打开一个文件并返回一个 file 对象 print()打印到文本流或控制台 变量、引用和范围
功能 描述 dir()返回当前本地范围内的名称列表或对象属性列表 globals()返回表示当前全局符号表的字典 id()返回对象的标识 locals()更新并返回表示当前本地符号表的字典 vars()返回模块、类或对象的 __dict__属性杂项
功能 描述 callable()如果对象显示为可调用,则返回 Truecompile()将源代码编译成代码或 AST 对象 T2 eval()计算 Python 表达式 exec()实现 Python 代码的动态执行 hash()返回对象的哈希值 help()调用内置帮助系统 memoryview()返回一个内存视图对象 staticmethod()返回函数的静态方法 __import__()由 import语句调用结论
在本教程中,您了解了 Python 提供的内置数据类型和函数。
到目前为止给出的例子都只处理和显示常量值。在大多数程序中,您通常会希望创建在程序执行时值会发生变化的对象。
进入下一个教程,学习 Python 变量。
参加测验:通过我们的交互式“Python 中的基本数据类型”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Interacting with PythonBasic Data Types in PythonVariables in Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的基本数据类型******
用 Python 和 DVC 实现数据版本控制
机器学习和数据科学带来了一系列不同于传统软件工程的问题。版本控制系统帮助开发人员管理源代码的变更。但是数据版本控制,管理对模型和数据集的变更,还没有很好地建立起来。
要跟踪你用于实验的所有数据和你制作的模型并不容易。准确地重现你或其他人做过的实验是一个挑战。许多团队正在积极开发工具和框架来解决这些问题。
在本教程中,您将学习如何:
- 使用一个叫做 DVC 的工具来应对这些挑战
- 跟踪和版本化您的数据集和模型
- 队友之间共用一台单机开发电脑
- 创建可重复的机器学习实验
本教程包括几个数据版本控制技术的例子。要继续学习,您可以通过单击下面的链接获得包含示例代码的存储库:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解 DVC 的数据版本控制。
什么是数据版本控制?
在标准软件工程中,许多人需要在一个共享的代码库上工作,并处理同一代码的多个版本。这可能很快导致混乱和代价高昂的错误。
为了解决这个问题,开发人员使用版本控制系统,比如 Git ,帮助团队成员保持组织性。
在版本控制系统中,有一个代表项目当前官方状态的中央代码库。开发人员可以复制该项目,进行一些更改,并要求他们的新版本成为正式版本。然后,他们的代码在部署到生产环境之前会经过审查和测试。
在传统的开发项目中,这些快速的反馈循环每天会发生很多次。但商业数据科学和机器学习中很大程度上缺乏类似的约定和标准。数据版本控制是一套工具和过程,试图使版本控制过程适应数据世界。
拥有允许人们快速工作并继续完成其他人没有完成的工作的系统将会提高交付成果的速度和质量。它将使人们能够透明地管理数据,有效地进行实验,并与其他人合作。
注意:一个实验在这个上下文中意味着要么训练一个模型,要么在数据集上运行操作以从中学习一些东西。
一个帮助研究人员管理他们的数据和模型并运行可重复实验的工具是 DVC ,它代表数据版本控制。
什么是 DVC?
DVC 是用 Python 编写的命令行工具。它模仿 Git 命令和工作流,以确保用户可以快速地将它整合到他们的常规 Git 实践中。如果你以前没有使用过 Git,那么一定要看看给 Python 开发者的 Git 和 GitHub 介绍。如果你对 Git 很熟悉,但是想让你的技能更上一层楼,那么看看针对 Python 开发者的高级 Git 技巧。
DVC 注定要和吉特并肩作战。事实上,
git和dvc命令经常会被一前一后地使用。当 Git 被用来存储和版本化代码时,DVC 对数据和模型文件做同样的事情。Git 可以在本地存储代码,也可以在托管服务上存储代码,比如 GitHub、T2、T4、GitLab 和 T5。同样,DVC 使用远程存储库来存储您的所有数据和模型。这是真理的唯一来源,可以在整个团队中共享。您可以获得远程存储库的本地副本,修改文件,然后上传您的更改以与团队成员共享。
远程存储库可以在您工作的同一台计算机上,也可以在云中。DVC 支持大多数主要的云提供商,包括 AWS 、 GCP 和 Azure 。但是你可以在任何服务器上建立一个 DVC 远程存储库,并将其连接到你的笔记本电脑上。有保护措施来防止成员破坏或删除远程数据。
当您在远程存储库中存储数据和模型时,会创建一个
.dvc文件。一个.dvc文件是一个小的文本文件,它指向远程存储中的实际数据文件。
.dvc文件是轻量级的,应该和你的代码一起存储在 GitHub 中。当您下载一个 Git 存储库时,您还会获得.dvc文件。然后,您可以使用这些文件来获取与该存储库相关联的数据。大型数据和模型文件放在你的 DVC 远程存储器中,指向你的数据的小型.dvc文件放在 GitHub 中。了解 DVC 的最好方法是使用它,所以让我们开始吧。您将通过几个例子来探索最重要的特性。在开始之前,您需要设置一个工作环境,然后获取一些数据。
设置您的工作环境
在本教程中,您将通过练习处理图像数据的示例来学习如何使用 DVC。您将处理大量图像文件,并训练一个机器学习模型来识别图像包含的内容。
要完成这些示例,您需要在系统上安装 Python 和 Git。您可以按照 Python 3 安装和设置指南在您的系统上安装 Python。要安装 Git,可以通读安装 Git 。
由于 DVC 是一个命令行工具,您需要熟悉操作系统的命令行。如果你是 Windows 用户,看看在 Windows 上运行 DVC 的。
要准备工作区,您需要采取以下步骤:
- 创建并激活一个虚拟环境。
- 安装 DVC 及其必备的 Python 库。
- 派生并克隆一个包含所有代码的 GitHub 库。
- 下载一个免费的数据集用于示例。
您可以使用任何您想要的包和环境管理器。本教程使用 conda 是因为它对数据科学和机器学习工具有很大的支持。要创建并激活虚拟环境,请打开您选择的命令行界面,并键入以下命令:
$ conda create --name dvc python=3.8.2 -y
create命令创建一个新的虚拟环境。--name开关为该环境命名,在本例中为dvc。python参数允许您选择想要安装在环境中的 Python 版本。最后,-y开关自动同意安装 Python 需要的所有必要的包,而不需要您回应任何提示。安装好一切后,激活环境:
$ conda activate dvc现在,您拥有了一个独立于操作系统 Python 安装的 Python 环境。这给了你一个干净的石板,防止你不小心弄乱了你的默认 Python 版本。
在本教程中,您还将使用一些外部库:
dvc是本教程的主角。scikit-learn是一个机器学习库,可以让你训练模型。scikit-image是一个图像处理库,您将使用它来准备训练数据。pandas是一个用于数据分析的库,它以类似表格的结构组织数据。numpy是一个数值计算库,增加了对多维数据的支持,比如图像。其中一些只能通过 conda-forge 获得,所以您需要将它添加到您的配置中,并使用
conda install来安装所有的库:$ conda config --add channels conda-forge $ conda install dvc scikit-learn scikit-image pandas numpy或者,您可以使用
pip安装程序:$ python -m pip install dvc scikit-learn scikit-image pandas numpy现在,您已经拥有了运行代码所需的所有 Python 库。
本教程附带了一个现成的存储库,其中包含目录结构和代码,可以让您快速体验 DVC。您可以通过单击下面的链接获得该存储库:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解 DVC 的数据版本控制。
您需要将存储库分支到您自己的 GitHub 帐户。在资源库的 GitHub 页面上,点击屏幕右上角的叉,在弹出的窗口中选择你的私人账户。GitHub 将在你的帐户下创建一个库的分叉副本。
使用
git clone命令将分叉的存储库克隆到您的计算机上,并将您的命令行放在存储库文件夹中:$ git clone https://github.com/YourUsername/data-version-control $ cd data-version-control不要忘记用您实际的用户名替换上面命令中的
YourUsername。现在,您的计算机上应该有一个存储库的克隆。下面是存储库的文件夹结构:
data-version-control/ | ├── data/ │ ├── prepared/ │ └── raw/ | ├── metrics/ ├── model/ └── src/ ├── evaluate.py ├── prepare.py └── train.py您的存储库中有六个文件夹:
src/为源代码。data/是针对所有版本的数据集。data/raw/是针对从外部来源获得的数据。data/prepared/是对数据进行内部修改。model/是用于机器学习的模型。data/metrics/用于跟踪您的模型的性能指标。
src/文件夹包含三个 Python 文件:
prepare.py包含为训练准备数据的代码。train.py包含用于训练机器学习模型的代码。evaluate.py包含用于评估机器学习模型结果的代码。准备工作的最后一步是获取一个可用于练习 DVC 的示例数据集。图像非常适合本教程,因为管理大量的大文件是 DVC 的强项,所以您可以很好地了解 DVC 最强大的功能。您将使用来自 fastai 的 Imagenette 数据集。
Imagenette 是 ImageNet 数据集的子集,在许多机器学习论文中经常被用作基准数据集。ImageNet 太大了,不能在笔记本电脑上用作示例,所以您将使用较小的 ImageNet 数据集。进入 Imagenette GitHub 页面,点击
README中的 160 px 下载。这将下载压缩到 TAR 档案中的数据集。Mac 用户可以通过连按 Finder 中的归档来提取文件。Linux 用户可以用
tar命令解包。Windows 用户需要安装一个解压 TAR 文件的工具,比如 7-zip 。数据集是以一种特殊的方式构建的。它有两个主要文件夹:
train/包括用于训练模型的图像。val/包括用于验证模型的图像。注意:验证通常发生在模型正在训练的时候,因此研究人员可以快速了解模型的表现如何。由于本教程并不关注性能指标,所以在完成训练后,您将使用验证集来测试您的模型。
Imagenette 是一个分类数据集,这意味着每个图像都有一个描述图像内容的相关类。为了解决分类问题,您需要训练一个模型,该模型可以准确地确定图像的类别。它需要查看图像,并正确识别正在显示的内容。
train/和val/文件夹被进一步分成多个文件夹。每个文件夹都有一个代表 10 个可能类别之一的代码,并且该数据集中的每个图像都属于 10 个类别之一:
- 滕奇
- 獚
- 盒式磁带录音机
- 链锯
- 教堂
- 圆号
- 垃圾车
- 气泵
- 高尔夫球
- 降落伞
为了简单和快速,您将只使用十个类中的两个来训练模型,高尔夫球和降落伞。经过训练后,模型会接受任何图像,并告诉你这是高尔夫球的图像还是降落伞的图像。这种一个模型在两种对象之间做决定的问题,叫做二元分类。
复制
train/和val/文件夹,并将它们放入您的新存储库的data/raw/文件夹中。您的存储库结构现在应该如下所示:data-version-control/ | ├── data/ │ ├── prepared/ │ └── raw/ │ ├── train/ │ │ ├── n01440764/ │ │ ├── n02102040/ │ │ ├── n02979186/ │ │ ├── n03000684/ │ │ ├── n03028079/ │ │ ├── n03394916/ │ │ ├── n03417042/ │ │ ├── n03425413/ │ │ ├── n03445777/ │ │ └── n03888257/ | | │ └── val/ │ ├── n01440764/ │ ├── n02102040/ │ ├── n02979186/ │ ├── n03000684/ │ ├── n03028079/ │ ├── n03394916/ │ ├── n03417042/ │ ├── n03425413/ │ ├── n03445777/ │ └── n03888257/ | ├── metrics/ ├── model/ └── src/ ├── evaluate.py ├── prepare.py └── train.py或者,您可以使用
curl命令获取数据:$ curl https://s3.amazonaws.com/fast-ai-imageclas/imagenette2-160.tgz \ -O imagenette2-160.tgz反斜杠()允许您将一个命令分成多行,以提高可读性。上面的命令将下载 TAR 归档文件。
然后,您可以提取数据集并将其移动到数据文件夹:
$ tar -xzvf imagenette2-160.tgz $ mv imagenette2-160/train data/raw/train $ mv imagenette2-160/val data/raw/val最后,删除归档文件和解压缩的文件夹:
$ rm -rf imagenette2-160 $ rm imagenette2-160.tgz太好了!你已经完成了设置,并准备开始与 DVC 玩。
练习基本的 DVC 工作流程
你下载的数据集足以开始练习 DVC 基础。在这一节中,您将看到 DVC 如何与 Git 协同工作来管理您的代码和数据。
首先,为您的第一个实验创建一个分支:
$ git checkout -b "first_experiment"
git checkout改变你当前的分支,-b开关告诉 Git 这个分支不存在,应该创建。接下来,您需要初始化 DVC。确保您位于存储库的顶层文件夹中,然后运行
dvc init:$ dvc init这将创建一个保存配置信息的
.dvc文件夹,就像 Git 的.git文件夹一样。原则上,您不需要打开那个文件夹,但是您可以在本教程中浏览一下,这样您就可以了解在这个引擎盖下发生了什么。注意: DVC 最近开始收集匿名化的使用分析,因此作者可以更好地了解 DVC 是如何被使用的。这有助于他们改进工具。您可以通过将分析配置选项设置为
false来关闭它:$ dvc config core.analytics falseGit 让您能够将本地代码推送到远程存储库,这样您就有了与其他开发人员共享的真实信息来源。其他人可以检查您的代码并在本地处理它,而不用担心会破坏其他人的代码。DVC 也是如此。
您需要某种远程存储来存储由 DVC 控制的数据和模型文件。这可以像系统中的另一个文件夹一样简单。在系统中的某个地方,在
data-version-control/存储库之外创建一个文件夹,并将其命名为dvc_remote。现在回到您的
data-version-control/存储库,告诉 DVC 远程存储在您系统的什么位置:$ dvc remote add -d remote_storage path/to/your/dvc_remoteDVC 现在知道在哪里备份你的数据和模型。
dvc remote add将位置存储到您的远程存储器,并将其命名为remote_storage。如果你愿意,你可以选择另一个名字。-d开关告诉 DVC 这是你默认的远程存储器。您可以添加多个存储位置,并在它们之间切换。您可以随时检查您的存储库的远程是什么。在存储库的
.dvc文件夹中有一个名为config的文件,它存储了关于存储库的配置信息:[core] analytics = false remote = remote_storage ['remote "remote_storage"'] url = /path/to/your/remote_storage
remote = remote_storage将您的remote_storage文件夹设置为默认文件夹,['remote "remote_storage"']定义您遥控器的配置。url指向你系统上的文件夹。如果您的远程存储是一个云存储系统,那么url变量将被设置为一个 web URL。DVC 支持许多基于云的存储系统,如 AWS S3 桶、谷歌云存储和微软 Azure Blob 存储。你可以在 DVC 官方文档中找到更多关于 dvc 远程添加命令的信息。
您的存储库现在已经初始化,可以开始工作了。您将涉及三个基本操作:
- 跟踪文件
- 上传文件
- 下载文件
你要遵循的基本经验是,小文件去 GitHub,大文件去 DVC 远程存储。
跟踪文件
Git 和 DVC 都使用
add命令开始跟踪文件。这将文件置于它们各自的控制之下。将
train/和val/文件夹添加到 DVC 控件:$ dvc add data/raw/train $ dvc add data/raw/val图像被视为大文件,尤其是当它们被收集到包含数百或数千个文件的数据集中时。命令将这两个文件夹添加到 DVC 的控制下。以下是 DVC 在幕后做的事情:
- 将你的
train/和val/文件夹添加到.gitignore- 创建两个扩展名为
.dvc、train.dvc和val.dvc的文件- 将
train/和val/文件夹复制到暂存区这个过程有点复杂,需要更详细的解释。
.gitignore是一个文本文件,包含 Git 应该忽略或不跟踪的文件列表。当一个文件被列在.gitignore中时,它对git命令是不可见的。通过将train/和val/文件夹添加到.gitignore,DVC 确保你不会不小心将大数据文件上传到 GitHub。你在一节中了解了
.dvc文件什么是 DVC?它们是小文本文件,将 DVC 指向你远程存储的数据。记住经验法则:大的数据文件和文件夹进入 DVC 远程存储,但是小的.dvc文件进入 GitHub。当你回到你的工作中,从 GitHub 中检查出所有的代码,你也会得到.dvc文件,你可以用它来获得你的大数据文件。最后,DVC 将数据文件复制到临时区域。暂存区被称为高速缓存。当您用
dvc init初始化 DVC 时,它会在您的存储库中创建一个.dvc文件夹。在那个文件夹中,它创建了缓存文件夹,.dvc/cache。当你运行dvc add时,所有的文件都被复制到.dvc/cache。这提出了两个问题:
- 复制文件不浪费很多空间吗?
- 你能把缓存放在别的地方吗?
两个问题的答案都是肯定的。您将在共享开发机器一节中解决这两个问题。
以下是执行任何命令之前存储库的样子:
The Starting State of a Repository DVC 控制的所有东西都在左边(绿色),Git 控制的所有东西都在右边(蓝色)。本地存储库有一个包含 Python 代码的
code.py文件和一个包含训练数据的train/文件夹。这是您的存储库将会发生的事情的简化版本。当你运行
dvc add train/时,包含大文件的文件夹在 DVC 控制下,而小的.dvc和.gitignore文件在 Git 控制下。train/文件夹也进入暂存区或缓存:
Adding Large Files and Folders to DVC Control 一旦大的图像文件被置于 DVC 控制之下,您就可以用
git add将所有的代码和小文件添加到 Git 控制之下:$ git add --all
--all开关将 Git 可见的所有文件添加到登台区。现在,所有文件都在各自版本控制系统的控制之下:
Adding Small Files to Git Control 概括地说,大的图像文件受 DVC 控制,小的文件受 Git 控制。如果有人想参与您的项目并使用
train/和val/数据,那么他们首先需要下载您的 Git 存储库。然后他们可以使用.dvc文件来获取数据。但是在人们可以获得你的存储库和数据之前,你需要把你的文件上传到远程存储器。
上传文件
要将文件上传到 GitHub,首先需要创建存储库当前状态的快照。当您使用
git add将所有修改过的文件添加到暂存区时,使用commit命令创建一个快照:$ git commit -m "First commit with setup and DVC files"
-m开关意味着后面的引用文本是一个提交消息解释做了什么。该命令将单个跟踪的更改转化为存储库状态的完整快照。DVC 也有一个
commit命令,但是它不做与git commit相同的事情。DVC 不需要整个存储库的快照。一旦被dvc add追踪到,它就可以上传单个文件。当一个已经被跟踪的文件改变时,使用
dvc commit。如果您对数据进行本地更改,那么您应该在将数据上传到远程之前将更改提交到缓存中。自从添加数据以来,您没有更改过数据,因此您可以跳过提交步骤。注意:由于 DVC 的这一部分不同于 Git,您可能想在 DVC 官方文档中阅读更多关于
add和commit命令的内容。要将文件从缓存上传到遥控器,请使用
push命令:$ dvc pushDVC 将浏览你所有的存储库文件夹来寻找
.dvc文件。如上所述,这些文件将告诉 DVC 需要备份哪些数据,DVC 会将它们从缓存拷贝到远程存储:
Uploading Large Files to DVC Remote Storage 您的数据现在安全地存储在远离存储库的位置。最后,将 Git 控制下的文件推送到 GitHub:
$ git push --set-upstream origin first_experimentGitHub 不知道你在本地创建的新分支,所以第一个
push需要使用--set-upstream选项。origin是你的主版本代码所在的地方。在这种情况下,它意味着 GitHub。您的代码和其他小文件现在安全地存储在 GitHub 中:
Uploading small files to GitHub 干得好!您的所有文件都已备份到远程存储中。
下载文件
要了解如何下载文件,首先需要从存储库中删除一些文件。
一旦你用
dvc add添加了你的数据,并用dvc push推送,它就被备份并且安全了。如果想节省空间,可以删除实际数据。只要所有的文件都被 DVC 跟踪,并且他们的.dvc文件都在你的存储库中,你就可以很快地取回数据。您可以删除整个
val/文件夹,但要确保.dvc文件不会被删除:$ rm -rf data/raw/val这将从您的存储库中删除
data/raw/val/文件夹,但是该文件夹仍然安全地存储在您的缓存和远程存储中。你可以随时取回它。要从缓存中取回数据,使用
dvc checkout命令:$ dvc checkout data/raw/val.dvc您的
data/raw/val/文件夹已恢复。如果您想让 DVC 搜索您的整个存储库并检查出所有丢失的东西,那么使用dvc checkout而不需要额外的参数。当您在新机器上克隆 GitHub 存储库时,缓存将是空的。
fetch命令将远程存储器的内容获取到缓存中:$ dvc fetch data/raw/val.dvc或者您可以只使用
dvc fetch来获取存储库中所有 DVC 文件的数据。一旦数据在您的缓存中,使用dvc checkout将其签出到存储库。你可以用一个命令dvc pull执行fetch和checkout:$ dvc pull
dvc pull执行dvc fetch,然后执行dvc checkout。它将您的数据从远程设备复制到缓存,然后一次性复制到您的存储库中。这些命令大致模仿了 Git 的功能,因为 Git 也有fetch、checkout和pull命令:
Getting Your Data Back From the Remote 请记住,您首先需要从 Git 获取
.dvc文件,只有这样,您才能调用 DVC 命令,如fetch和checkout来获取您的数据。如果.dvc文件不在您的存储库中,那么 DVC 将不知道您想要获取和检出什么数据。您现在已经学习了 DVC 和 Git 的基本工作流程。每当您添加更多数据或更改一些代码时,您可以使用
add、commit和push来保持所有内容的版本控制和安全备份。对于许多人来说,这种基本的工作流程足以满足他们的日常需求。本教程的其余部分集中在一些特定的用例上,比如多人共享计算机和创建可复制的管道。为了探索 DVC 如何处理这些问题,你需要一些运行机器学习实验的代码。
建立机器学习模型
使用 Imagenette 数据集,您将训练一个模型来区分高尔夫球和降落伞的图像。
您将遵循三个主要步骤:
- 为培训准备数据。
- 训练你的机器学习模型。
- 评估模型的性能。
如前所述,这些步骤对应于
src/文件夹中的三个 Python 文件:
prepare.pytrain.pyevaluate.py以下小节将解释每个文件的作用。将显示整个文件的内容,并解释每一行的作用。
准备数据
由于数据存储在多个文件夹中,Python 需要搜索所有文件夹来找到图像。文件夹名称决定了标签的内容。这对计算机来说可能不难,但对人类来说就不太直观了。
为了使数据更容易使用,您将创建一个 CSV 文件,它将包含一个用于训练的所有图像及其标签的列表。CSV 文件将有两列,一列是包含单个图像完整路径的
filename列,另一列是包含实际标签字符串的label列,如"golf ball"或"parachute"。每行代表一幅图像。这是 CSV 外观的预览图:
filename, label full/path/to/data-version-control/raw/n03445777/n03445777_5768.JPEG,golf ball full/path/to/data-version-control/raw/n03445777/n03445777_5768,golf ball full/path/to/data-version-control/raw/n03445777/n03445777_11967.JPEG,golf ball ...您需要两个 CSV 文件:
train.csv将包含用于训练的图片列表。test.csv将包含一个用于测试的图片列表。您可以通过运行
prepare.py脚本来创建 CSV 文件,它有三个主要步骤:
- 将文件夹名称如
n03445777/映射到标签名称如golf ball。- 获取标签为
golf ball和parachute的文件列表。- 将
filelist-label对保存为 CSV 文件。以下是您将用于准备步骤的源代码:
1# prepare.py 2from pathlib import Path 3 4import pandas as pd 5 6FOLDERS_TO_LABELS = { 7 "n03445777": "golf ball", 8 "n03888257": "parachute" 9 } 10 11def get_files_and_labels(source_path): 12 images = [] 13 labels = [] 14 for image_path in source_path.rglob("*/*.JPEG"): 15 filename = image_path.absolute() 16 folder = image_path.parent.name 17 if folder in FOLDERS_TO_LABELS: 18 images.append(filename) 19 label = FOLDERS_TO_LABELS[folder] 20 labels.append(label) 21 return images, labels 22 23def save_as_csv(filenames, labels, destination): 24 data_dictionary = {"filename": filenames, "label": labels} 25 data_frame = pd.DataFrame(data_dictionary) 26 data_frame.to_csv(destination) 27 28def main(repo_path): 29 data_path = repo_path / "data" 30 train_path = data_path / "raw/train" 31 test_path = data_path / "raw/val" 32 train_files, train_labels = get_files_and_labels(train_path) 33 test_files, test_labels = get_files_and_labels(test_path) 34 prepared = data_path / "prepared" 35 save_as_csv(train_files, train_labels, prepared / "train.csv") 36 save_as_csv(test_files, test_labels, prepared / "test.csv") 37 38if __name__ == "__main__": 39 repo_path = Path(__file__).parent.parent 40 main(repo_path)要运行本教程,您不必理解代码中发生的所有事情。如果您感到好奇,以下是对代码功能的高级解释:
第 6 行:包含高尔夫球和降落伞图像的文件夹的名称被映射到名为
FOLDERS_TO_LABELS的字典中的标签"golf ball"和"parachute"。第 11 到 21 行:
get_files_and_labels()接受一个指向data/raw/文件夹的Path。该功能在所有文件夹和子文件夹中循环查找以.jpeg扩展名结尾的文件。标签被分配给那些文件夹在FOLDERS_TO_LABELS中被表示为关键字的文件。文件名和标签作为列表返回。第 23 到 26 行:
save_as_csv()接受文件列表、标签列表和目的地Path。文件名和标签被格式化为熊猫数据帧,并在目的地保存为 CSV 文件。第 28 到 36 行:
main()驱动脚本的功能。它运行get_files_and_labels()来查找data/raw/train/和data/raw/val/文件夹中的所有图像。文件名和它们匹配的标签将作为两个 CSV 文件保存在data/prepared/文件夹中,train.csv和test.csv。第 38 到 40 行:当你从命令行运行
prepare.py时,脚本的主作用域被执行并调用main()。所有路径操作都是使用
pathlib模块完成的。如果你不熟悉这些操作,那么看看用 Python 处理文件的。在命令行中运行
prepare.py脚本:$ python src/prepare.py当脚本完成时,您的
data/prepared/文件夹中会有train.csv和test.csv文件。您需要将这些文件添加到 DVC,并将相应的.dvc文件添加到 GitHub:$ dvc add data/prepared/train.csv data/prepared/test.csv $ git add --all $ git commit -m "Created train and test CSV files"太好了!现在,您有了一个用于训练和测试机器学习模型的文件列表。下一步是加载图像并使用它们来运行训练。
训练模型
为了训练这个模型,你将使用一种叫做监督学习的方法。这种方法包括向模型显示一幅图像,并让它猜测图像显示的内容。然后,你给它看正确的标签。如果它猜错了,那么它会自我纠正。对于数据集中的每个图像和标签,您都要多次执行此操作。
解释每个模型如何工作超出了本教程的范围。幸运的是,scikit-learn 有大量现成的模型可以解决各种问题。每个模型都可以通过调用一些标准方法来训练。
使用
train.py文件,您将执行六个步骤:
- 阅读告诉 Python 图像位置的 CSV 文件。
- 将训练图像加载到内存中。
- 将类别标签载入内存。
- 对图像进行预处理,以便用于训练。
- 训练机器学习模型对图像进行分类。
- 将机器学习模型保存到您的磁盘。
以下是您将在培训步骤中使用的源代码:
1# train.py 2from joblib import dump 3from pathlib import Path 4 5import numpy as np 6import pandas as pd 7from skimage.io import imread_collection 8from skimage.transform import resize 9from sklearn.linear_model import SGDClassifier 10 11def load_images(data_frame, column_name): 12 filelist = data_frame[column_name].to_list() 13 image_list = imread_collection(filelist) 14 return image_list 15 16def load_labels(data_frame, column_name): 17 label_list = data_frame[column_name].to_list() 18 return label_list 19 20def preprocess(image): 21 resized = resize(image, (100, 100, 3)) 22 reshaped = resized.reshape((1, 30000)) 23 return reshape 24 25def load_data(data_path): 26 df = pd.read_csv(data_path) 27 labels = load_labels(data_frame=df, column_name="label") 28 raw_images = load_images(data_frame=df, column_name="filename") 29 processed_images = [preprocess(image) for image in raw_images] 30 data = np.concatenate(processed_images, axis=0) 31 return data, labels 32 33def main(repo_path): 34 train_csv_path = repo_path / "data/prepared/train.csv" 35 train_data, labels = load_data(train_csv_path) 36 sgd = SGDClassifier(max_iter=10) 37 trained_model = sgd.fit(train_data, labels) 38 dump(trained_model, repo_path / "model/model.joblib") 39 40if __name__ == "__main__": 41 repo_path = Path(__file__).parent.parent 42 main(repo_path)下面是代码的作用:
第 11 到 14 行:
load_images()接受一个 DataFrame,它代表在prepare.py中生成的一个 CSV 文件和包含图像文件名的列的名称。然后,该函数加载并返回图像,作为一个由 NumPy 数组组成的列表。第 16 到 18 行:
load_labels()接受与load_images()相同的数据帧和包含标签的列名。该函数读取并返回对应于每个图像的标签列表。第 20 行到第 23 行:
preprocess()接受一个表示单个图像的 NumPy 数组,调整它的大小,并将其重新整形为一行数据。第 25 到 31 行:
load_data()接受Path到train.csv的文件。该函数加载图像和标签,对它们进行预处理,并将它们堆叠到一个二维 NumPy 数组中,因为您将使用的 scikit-learn 分类器期望数据采用这种格式。数据数组和标签被返回给调用者。第 33 到 38 行:
main()将数据加载到内存中,并定义一个名为 SGDClassifier 的示例分类器。使用训练数据训练分类器,并保存在model/文件夹中。scikit-learn 推荐使用joblib模块来完成这项工作。第 40 到 42 行:当
train.py被执行时,脚本的主要作用域运行main()。现在在命令行中运行
train.py脚本:$ python src/train.py运行代码可能需要几分钟时间,这取决于您的计算机有多强。执行这段代码时,您可能会得到一个警告:
ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.这意味着 scikit-learn 认为您可以增加
max_iter并获得更好的结果。您将在下面的某一节中做到这一点,但本教程的目标是让您的实验运行得更快,而不是达到最高的精度。当脚本完成时,您将有一个经过训练的机器学习模型保存在名为
model.joblib的model/文件夹中。这是实验中最重要的文件。需要将它添加到 DVC,并将相应的.dvc文件提交到 GitHub:$ dvc add model/model.joblib $ git add --all $ git commit -m "Trained an SGD classifier"干得好!你已经训练了一个机器学习模型来区分两类图像。下一步是确定模型在测试图像上的表现有多准确,这是模型在训练期间没有看到的。
评估模型
评估会带来一点回报,因为你的努力最终会得到一些反馈。在这个过程的最后,你会有一些硬数字来告诉你这个模型做得有多好。
下面是您将用于评估步骤的源代码:
1# evaluate.py 2from joblib import load 3import json 4from pathlib import Path 5 6from sklearn.metrics import accuracy_score 7 8from train import load_data 9 10def main(repo_path): 11 test_csv_path = repo_path / "data/prepared/test.csv" 12 test_data, labels = load_data(test_csv_path) 13 model = load(repo_path / "model/model.joblib") 14 predictions = model.predict(test_data) 15 accuracy = accuracy_score(labels, predictions) 16 metrics = {"accuracy": accuracy} 17 accuracy_path = repo_path / "metrics/accuracy.json" 18 accuracy_path.write_text(json.dumps(metrics)) 19 20if __name__ == "__main__": 21 repo_path = Path(__file__).parent.parent 22 main(repo_path)下面是代码的作用:
第 10 到 14 行:
main()根据测试数据评估训练好的模型。该函数加载测试图像,加载模型,并预测哪些图像对应于哪些标签。第 15 行到第 18 行:将模型生成的预测与来自
test.csv的实际标签进行比较,并将准确性作为 JSON 文件保存在metrics/文件夹中。准确度表示正确分类的图像的比率。之所以选择 JSON 格式,是因为 DVC 可以用它来比较不同实验之间的指标,这一点您将在创建可再现的管道一节中学习。第 20 到 22 行:当
evaluate.py被执行时,脚本的主要作用域运行main()。在命令行中运行
evaluate.py脚本:$ python src/evaluate.py您的模型现在已经被评估了,度量标准被安全地存储在一个
accuracy.json文件中。每当你改变你的模型或者使用一个不同的模型,你可以通过比较它和这个值来看它是否有所改进。在这种情况下,您的 JSON 文件只包含一个对象,即您的模型的准确性:
{ "accuracy": 0.670595690747782 }如果您将
accuracy变量乘以 100,您将得到正确分类的百分比。在这种情况下,该模型对 67.06%的测试图像进行了正确分类。JSON 文件非常小,将它保存在 GitHub 中非常有用,这样您可以快速检查每个实验的执行情况:
$ git add --all $ git commit -m "Evaluate the SGD model accuracy"干得好!评估完成后,您就可以深入了解 DVC 的一些高级功能和流程了。
版本数据集和模型
可再生数据科学的核心是能够拍摄用于构建模型的所有事物的快照。每次运行实验时,您都想确切地知道什么输入进入了系统,什么输出被创建。
在本节中,您将尝试一个更复杂的工作流来对您的实验进行版本控制。您还将打开一个
.dvc文件并查看其内部。首先,将您对
first_experiment分支所做的所有更改推送到您的 GitHub 和 DVC 远程存储器:$ git push $ dvc push您的代码和模型现在备份在远程存储上。
训练一个模型或完成一个实验是一个项目的里程碑。你应该有办法找到并回到这个特定的点。
标记提交
一种常见的做法是使用标记来标记您的 Git 历史中的某个重要点。既然您已经完成了一项实验并制作了一个新模型,那么就创建一个标记,向您自己和他人表明您已经有了一个现成的模型:
$ git tag -a sgd-classifier -m "SGDClassifier with accuracy 67.06%"
-a开关用于注释您的标签。你可以把它变得简单或复杂。一些团队用版本号对他们训练的模型进行版本化,像v1.0、v1.3等等。其他人使用日期和训练模型的团队成员的首字母。您和您的团队决定如何跟踪您的模型。-m开关允许您向标签添加消息字符串,就像提交一样。Git 标签不是通过常规提交来推送的,所以它们必须被单独推送至 GitHub 或您使用的任何平台上的存储库的源位置。使用
--tags开关将所有标签从本地存储库推送到远程存储库:$ git push origin --tags如果您使用 GitHub,那么您可以通过存储库的 Releases 选项卡访问标签。
您可以随时查看当前存储库中的所有标签:
$ git tagDVC 工作流严重依赖于有效的 Git 实践。标记特定的提交标志着项目的重要里程碑。另一种让工作流更加有序和透明的方法是使用分支。
为每个实验创建一个 Git 分支
到目前为止,您已经完成了
first_experiment分支上的所有工作。复杂的问题或长期项目通常需要运行许多实验。一个好主意是为每个实验创建一个新的分支。在您的第一个实验中,您将模型的最大迭代次数设置为
10。您可以尝试将该数字设置得更高,看看是否能改善结果。创建一个新的分支,并将其命名为sgd-100-iterations:$ git checkout -b "sgd-100-iterations"当您创建一个新的分支时,您在先前分支中的所有
.dvc文件都将出现在新分支中,就像其他文件和文件夹一样。更新
train.py中的代码,使SGDClassifier模型具有参数max_iter=100:# train.py def main(repo_path): train_csv_path = repo_path / "data/prepared/train.csv" train_data, labels = load_data(train_csv_path) sgd = SGDClassifier(max_iter=100) trained_model = sgd.fit(train_data, labels) dump(trained_model, repo_path / "model/model.joblib")这是你唯一能做的改变。通过运行
train.py和evaluate.py重新运行培训和评估:$ python src/train.py $ python src/evaluate.py您现在应该有一个新的
model.joblib文件和一个新的accuracy.json文件。由于训练过程已经更改了
model.joblib文件,您需要将它提交到 DVC 缓存:$ dvc commitDVC 将抛出一个提示,询问您是否确定要进行更改。按下
Y,然后按下Enter。记住,
dvc commit的工作方式与git commit不同,它用于更新一个已经跟踪的文件。这不会删除以前的模型,但会创建一个新的模型。添加并提交您对 Git 所做的更改:
$ git add --all $ git commit -m "Change SGD max_iter to 100"标记您的新实验:
$ git tag -a sgd-100-iter -m "Trained an SGD Classifier for 100 iterations" $ git push origin --tags将代码更改推送到 GitHub,将 DVC 更改推送到您的远程存储器:
$ git push --set-upstream origin sgd-100-iter $ dvc push通过从 GitHub 检查代码,然后从 DVC 检查数据和模型,您可以在分支之间跳转。例如,您可以检查
first_example分支并获得相关的数据和模型:$ git checkout first_experiment $ dvc checkout非常好。现在您有了多个实验,并且它们的结果被版本化和存储,您可以通过 Git 和 DVC 检查内容来访问它们。
查看 DVC 档案
您已经创建并提交了一些
.dvc文件到 GitHub,但是文件里面有什么呢?打开模型data-version-control/model/model.joblib.dvc的当前.dvc文件。以下是内容示例:md5: 62bdac455a6574ed68a1744da1505745 outs: - md5: 96652bd680f9b8bd7c223488ac97f151 path: model.joblib cache: true metric: false persist: false内容可能会令人困惑。DVC 的档案是 YAML 的档案。信息存储在键值对和列表中。第一个是 md5 密钥,后面是一串看似随机的字符。
MD5 是众所周知的哈希函数。哈希处理任意大小的文件,并使用其内容产生固定长度的字符串,称为哈希或校验和。在这种情况下,长度是 32 个字符。不管文件的原始大小是多少,MD5 总是计算 32 个字符的散列。
两个完全相同的文件将产生相同的哈希。但是,如果其中一个文件中有一个比特发生了变化,那么散列将会完全不同。DVC 使用 MD5 的这些属性来实现两个重要目标:
- 通过查看文件的哈希值来跟踪哪些文件发生了更改
- 查看两个大文件何时相同,以便只有一个副本可以存储在缓存或远程存储中
在您正在查看的示例
.dvc文件中,有两个md5值。第一个描述了.dvc文件本身,第二个描述了model.joblib文件。path是模型的文件路径,相对于您的工作目录,cache是一个布尔值,它决定 DVC 是否应该缓存模型。您将在后面的章节中看到其他一些字段,但是您可以在官方文档中了解关于
.dvc文件格式的所有信息。如果只有你一个人使用运行实验的计算机,你刚刚学习的工作流程就足够了。但是许多团队不得不共享强大的机器来完成他们的工作。
共享一台开发机
在许多学术和工作环境中,计算繁重的工作不是在个人笔记本电脑上完成的,因为它们的功能不足以处理大量数据或密集处理。相反,团队使用云计算机或内部工作站。多个用户经常在一台机器上工作。
当多个用户处理相同的数据时,您不希望在用户和存储库中散布相同数据的多个副本。为了节省空间,DVC 允许您设置共享缓存。当您用
dvc init初始化 DVC 存储库时,默认情况下,DVC 会将缓存放在存储库的.dvc/cache文件夹中。您可以更改默认值以指向计算机上其他地方。在计算机上的某个位置创建一个新文件夹。把它叫做
shared_cache,告诉 DVC 把那个文件夹作为缓存:$ dvc cache dir path/to/shared_cache现在每次运行
dvc add或者dvc commit,数据都会备份到那个文件夹里。当您使用dvc fetch从远程存储获取数据时,它将进入共享缓存,而dvc checkout将把它带到您的工作存储库。如果您一直在学习本教程中的例子,那么您所有的文件都将在您的存储库的
.dvc/cache文件夹中。执行上述命令后,将数据从默认缓存移动到新的共享缓存:$ mv .dvc/cache/* path/to/shared_cache该计算机上的所有用户现在都可以将其存储库缓存指向共享缓存:
Multiple Users Can Share a Single Cache 太好了。现在,您有了一个共享缓存,所有其他用户都可以共享它们的存储库。如果您的操作系统(OS)不允许任何人使用共享缓存,那么请确保您系统上的所有权限都设置正确。你可以在 DVC 文档中找到关于建立共享系统的更多细节。
如果您检查您的存储库的
.dvc/config文件,那么您会看到一个新的部分出现:[cache] dir = /path/to/shared_cache这允许您仔细检查数据备份的位置。
但是这如何帮助你节省空间呢?DVC 可以使用链接,而不是在本地存储库、共享缓存、和机器上的所有其他存储库中复制相同的数据。链接是操作系统的一个特征。
如果你有一个文件,比如一张图片,那么你可以创建一个到那个文件的链接。该链接看起来就像系统中的另一个文件,但它不包含数据。它只引用系统中其他地方的实际文件,比如快捷方式。有许多类型的链接,像参考链接、符号链接和硬链接。每种都有不同的属性。
默认情况下,DVC 将尝试使用参考链接,但它们并非在所有电脑上都可用。如果你的操作系统不支持引用链接,DVC 将默认创建副本。你可以在 DVC 文档中了解更多关于文件链接类型的信息。
您可以通过更改
cache.type配置选项来更改缓存的默认行为:$ dvc config cache.type symlink你可以用
reflink、hardlink或者copies来代替symlink。研究每种类型的链接,并选择最适合您正在使用的操作系统的选项。记住,您可以通过阅读.dvc/config文件来检查您的 DVC 存储库当前是如何配置的:[cache] dir = /path/to/shared_cache type = symlink如果您对
cache.type进行了更改,它不会立即生效。你需要告诉 DVC 查看链接,而不是文件副本:$ dvc checkout --relink开关将告诉 DVC 检查缓存类型并重新链接 DVC 当前跟踪的所有文件。
如果您的存储库或缓存中有没有被使用的模型或数据文件,那么您可以通过使用
dvc gc清理您的存储库来节省额外的空间。gc代表垃圾收集,将从缓存中移除任何未使用的文件和目录。重要提示:小心任何删除数据的命令!
通过查阅删除文件命令的官方文档,如
gc和remove,确保你理解所有的细微差别。现在,您可以与您的团队共享一台开发机器了。要探索的下一个特性是创建管道。
创建可复制管道
以下是迄今为止您为训练机器学习模型所做的步骤的回顾:
- 获取数据
- 准备数据
- 跑步训练
- 评估训练运行
您手动提取数据并将其添加到远程存储。你现在可以用
dvc checkout或者dvc pull得到它。其他步骤通过运行各种 Python 文件来执行。这些可以被链接到一个叫做 DVC 流水线的单一执行中,只需要一个命令。创建一个新的分支,并将其命名为
sgd-pipeline:$ git checkout -b sgd-pipeline您将使用这个分支作为 DVC 管道重新运行实验。流水线由多个阶段组成,使用
dvc run命令执行。每个阶段有三个组成部分:
- 输入
- 输出
- 命令
DVC 使用术语依赖作为输入,使用输出作为输出。该命令可以是您通常在命令行中运行的任何内容,包括 Python 文件。您可以在运行另一个实验时练习创建阶段管道。三个 Python 文件中的每一个,
prepare.py、train.py和evaluate.py都将由管道中的一个阶段来表示。注意:你将通过创建管道来复制你用
prepare.py、train.py和evaluate.py创建的所有文件。管道会自动将新创建的文件添加到 DVC 控制中,就像你输入了
dvc add一样。由于你已经手动添加了很多文件到 DVC 控制,如果你试图用管道创建相同的文件,DVC 会感到困惑。为了避免这种情况,首先使用
dvc remove删除 CSV 文件、模型和指标:$ dvc remove data/prepared/train.csv.dvc \ data/prepared/test.csv.dvc \ model/model.joblib.dvc --outs这将删除
.dvc文件和.dvc文件指向的相关数据。现在,您应该有一张白纸,使用 DVC 管道重新创建这些文件。首先,你将运行
prepare.py作为 DVC 管道阶段。这个命令是dvc run,它需要知道依赖项、输出和命令:
- 依赖:
prepare.py和data/raw中的数据- 输出:
train.csv和test.csv- 命令:
python prepare.py使用
dvc run命令将prepare.py作为 DVC 流水线阶段执行:1$ dvc run -n prepare \ 2 -d src/prepare.py -d data/raw \ 3 -o data/prepared/train.csv -o data/prepared/test.csv \ 4 python src/prepare.py所有这些都是一个单一的命令。第一行启动
dvc run命令并接受几个选项:
-n开关为舞台命名。-d开关将依赖关系传递给命令。-o开关定义了命令的输出。该命令的主要参数是将要执行的 Python 命令,
python src/prepare.py。简单地说,上面的dvc run命令给了 DVC 以下信息:
- 第 1 行:你要运行一个流水线阶段,称之为
prepare。- 第二行:管道需要
prepare.py文件和data/raw文件夹。- 第 3 行:流水线会产生
train.csv和test.csv文件。- 第 4 行:要执行的命令是
python src/prepare.py。一旦你创建了舞台,DVC 将创建两个文件,
dvc.yaml和dvc.lock。打开看看里面。这是您将在
dvc.yaml中看到的示例:stages: prepare: cmd: python src/prepare.py deps: - data/raw - src/prepare.py outs: - data/prepared/test.csv - data/prepared/train.csv都是你放在
dvc run命令里的信息。顶层元素stages下嵌套了多个元素,每个阶段一个。目前,你只有一个阶段,prepare。当你链接更多的时候,它们会出现在这个文件中。从技术上讲,您不必在命令行中键入dvc run命令——您可以在这里创建您的所有阶段。每个
dvc.yaml都有一个对应的dvc.lock文件,也是 YAML 格式。里面的信息是相似的,除了所有依赖项和输出的 MD5 散列之外:prepare: cmd: python src/prepare.py deps: - path: data/raw md5: a8a5252d9b14ab2c1be283822a86981a.dir - path: src/prepare.py md5: 0e29f075d51efc6d280851d66f8943fe outs: - path: data/prepared/test.csv md5: d4a8cdf527c2c58d8cc4464c48f2b5c5 - path: data/prepared/train.csv md5: 50cbdb38dbf0121a6314c4ad9ff786fe添加 MD5 哈希允许 DVC 跟踪所有的依赖和输出,并检测这些文件是否有任何变化。例如,如果一个依赖文件改变了,那么它将有一个不同的散列值,DVC 将知道它需要用新的依赖重新运行那个阶段。因此,
train.csv、test.csv和model.joblib没有单独的.dvc文件,所有的东西都在.lock文件中被跟踪。太好了—您已经自动化了管道的第一阶段,这可以可视化为流程图:
The First Stage of the Pipeline 您将在接下来的阶段中使用此阶段生成的 CSV 文件。
下一步是培训。依赖关系是
train.py文件本身和data/prepared中的train.csv文件。唯一的输出是model.joblib文件。要用train.py创建一个流水线阶段,用dvc run执行它,指定正确的依赖项和输出:$ dvc run -n train \ -d src/train.py -d data/prepared/train.csv \ -o model/model.joblib \ python src/train.py这将创建管道的第二阶段,并将其记录在
dvc.yml和dvc.lock文件中。这是管道新状态的可视化:
The Second Stage of the Pipeline 搞定两个,还剩一个!最后一个阶段是评估。依赖项是前一阶段生成的
evaluate.py文件和模型文件。输出是度量文件accuracy.json。用dvc run执行evaluate.py:$ dvc run -n evaluate \ -d src/evaluate.py -d model/model.joblib \ -M metrics/accuracy.json \ python src/evaluate.py请注意,您使用了
-M开关,而不是-o。DVC 对指标的处理不同于其他输出。当您运行这个命令时,它会生成accuracy.json文件,但是 DVC 会知道这是一个用来衡量模型性能的指标。您可以使用
dvc show命令让 DVC 向您展示它知道的所有指标:$ dvc metrics show metrics/accuracy.json: accuracy: 0.6996197718631179您已经完成了管道的最后一个阶段,如下所示:
The Full Pipeline 现在,您可以在一幅图像中看到整个工作流程。别忘了给你的新分支贴上标签,把所有的改变都推送到 GitHub 和 DVC:
$ git add --all $ git commit -m "Rerun SGD as pipeline" $ dvc commit $ git push --set-upstream origin sgd-pipeline $ git tag -a sgd-pipeline -m "Trained SGD as DVC pipeline." $ git push origin --tags $ dvc push这将为新的 DVC 管道版本化和存储您的代码、模型和数据。
现在是最精彩的部分!
对于训练,您将使用一个随机森林分类器,这是一个不同的模型,可用于分类。它比 SGD 分类器更复杂,可能会产生更好的结果。首先创建并检出一个新分支,并将其命名为
random_forest:$ git checkout -b "random_forest"管道的强大之处在于,无论何时你做了任何改变,它都能以最小的麻烦重现。修改你的
train.py,使用RandomForestClassifier代替SGDClassifier:# train.py from joblib import dump from pathlib import Path import numpy as np import pandas as pd from skimage.io import imread_collection from skimage.transform import resize from sklearn.ensemble import RandomForestClassifier # ... def main(path_to_repo): train_csv_path = repo_path / "data/prepared/train.csv" train_data, labels = load_data(train_csv_path) rf = RandomForestClassifier() trained_model = rf.fit(train_data, labels) dump(trained_model, repo_path / "model/model.joblib")唯一改变的代码行是导入
RandomForestClassifier而不是SGDClassifier,创建分类器的一个实例,并调用它的fit()方法。其他一切都保持不变。自从您的
train.py文件改变后,它的 MD5 散列也改变了。DVC 将意识到需要复制管道阶段中的一个。您可以使用dvc status命令检查发生了什么变化:$ dvc status train: changed deps: modified: src/train.py这将显示管道每个阶段的所有已更改的依赖关系。因为模型中的变化也会影响度量,所以您想要重现整个链。您可以使用
dvc repro命令复制任何 DVC 管线文件:$ dvc repro evaluate就是这样!当您运行
repro命令时,DVC 会检查整个管道的所有依赖项,以确定发生了什么变化以及哪些命令需要再次执行。想想这意味着什么。你可以从一个分支跳到另一个分支,用一个简单的命令复制任何实验!最后,将您的随机森林分类器代码推送到 GitHub,将模型推送到 DVC:
$ git add --all $ git commit -m "Train Random Forrest classifier" $ dvc commit $ git push --set-upstream origin random-forest $ git tag -a random-forest -m "Random Forest classifier with 80.99% accuracy." $ git push origin --tags $ dvc push现在您可以跨多个分支和标签比较指标。
使用
-T开关调用dvc metrics show,显示多个标签的指标:$ dvc metrics show -T sgd-pipeline: metrics/accuracy.json: accuracy: 0.6996197718631179 forest: metrics/accuracy.json: accuracy: 0.8098859315589354厉害!这为您提供了一种快速跟踪存储库中表现最好的实验的方法。
当你六个月后回到这个项目,不记得细节时,你可以用
dvc metrics show -T检查哪个设置是最成功的,并用dvc repro重现!任何想复制你作品的人都可以这样做。他们只需要采取三个步骤:
- 运行
git clone或git checkout获取代码和.dvc文件。- 用
dvc checkout获取训练数据。- 用
dvc repro evaluate再现整个工作流程。如果他们可以编写一个脚本来获取数据并为其创建一个管道阶段,那么他们甚至不需要步骤 2。
干得好!您运行了多个实验,并安全地版本化和备份了数据和模型。更重要的是,您可以通过获取必要的代码和数据并执行一个
dvc repro命令来快速重现每个实验。接下来的步骤
祝贺您完成教程!您已经学习了如何在日常工作中使用数据版本控制。如果您想更深入地优化您的工作流程或了解更多关于 DVC 的信息,本节将提供一些建议。
记住在正确的时间运行所有的 DVC 和 Git 命令可能是一个挑战,尤其是在您刚刚开始的时候。DVC 提供了将两者更紧密地结合在一起的可能性。使用 Git 挂钩,您可以在运行某些 Git 命令时自动执行 DVC 命令。在官方文档中阅读更多关于为 DVC 安装 Git 挂钩的信息。
Git 和 GitHub 允许您跟踪特定存储库的变更历史。您可以看到谁在何时更新了什么。您可以创建拉式请求来更新数据。像这样的模式在 DVC 也是可能的。看看 DVC 文档中关于数据注册中心的章节。
DVC 甚至有一个 Python API ,这意味着你可以在你的 Python 代码中调用 DVC 命令来访问存储在 DVC 库中的数据或模型。
尽管本教程提供了 DVC 的可能性的广泛概述,但不可能在一个文档中涵盖所有内容。你可以通过查看官方用户指南、命令参考和互动教程来详细探索 DVC。
结论
您现在知道如何使用 DVC 来解决数据科学家多年来一直在努力解决的问题了!对于您运行的每个实验,您可以对您使用的数据和您训练的模型进行版本化。您可以与其他团队成员共享训练机器,而不必担心丢失数据或耗尽磁盘空间。你的实验是可重复的,任何人都可以重复你所做的。
在本教程中,您已经学会了如何:
- 在类似于 Git 的工作流中使用 DVC ,带有
add、commit和push命令- 与其他团队成员共享开发机器,并通过符号链接节省空间
- 创建可以用
dvc repro复制的实验管道如果您想重现上面看到的示例,请务必点击以下链接下载源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解 DVC 的数据版本控制。
练习这些技巧,你会自动开始这个过程。这将让你把所有的注意力放在运行酷实验上。祝你好运!**********
Python 中使用散景的交互式数据可视化
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用散景在 Python 中交互数据可视化
Bokeh 为自己是一个交互式数据可视化库而自豪。
与 Python 可视化领域流行的 Matplotlib 和 Seaborn 不同,Bokeh 使用 HTML 和 JavaScript 呈现图形。这使得它成为构建基于 web 的仪表板和应用程序的绝佳候选。然而,对于探索和理解您的数据,或者为项目或报告创建漂亮的自定义图表,它是一个同样强大的工具。
使用真实数据集上的大量示例,本教程的目标是让您开始使用散景。
您将学习如何:
- 使用散景将您的数据转换成可视化效果
- 定制和组织您的可视化效果
- 为您的可视化添加交互性
所以让我们开始吧。您可以从 Real Python GitHub repo 下载示例和代码片段。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
从数据到可视化
使用散景构建可视化效果包括以下步骤:
- 准备数据
- 确定可视化将在哪里呈现
- 设置图形
- 连接到并绘制数据
- 组织布局
- 预览并保存您创建的漂亮数据
让我们更详细地探索每一步。
准备数据
任何好的数据可视化都始于——你猜对了——数据。如果你需要快速复习用 Python 处理数据,一定要看看关于这个主题的越来越多的优秀的真正的 Python 教程。
这一步通常涉及到数据处理库,如 Pandas 和 Numpy ,并采取必要的步骤将其转换成最适合您想要的可视化的形式。
确定可视化将在何处呈现
在这一步,您将确定如何生成并最终查看可视化效果。在本教程中,您将了解散景提供的两个常见选项:生成静态 HTML 文件和在 Jupyter 笔记本中内联渲染您的可视化效果。
设置图
从这里,您将组装您的图形,为您的可视化准备画布。在这一步中,您可以自定义从标题到刻度线的所有内容。您还可以设置一套工具,支持用户与可视化进行各种交互。
连接并提取您的数据
接下来,您将使用 Bokeh 的众多渲染器来为您的数据赋予形状。在这里,您可以使用许多可用的标记和形状选项灵活地从头开始绘制数据,所有这些选项都可以轻松定制。这种功能让您在表示数据时拥有难以置信的创作自由。
此外,Bokeh 还有一些内置功能,用于构建类似于堆积条形图的东西,以及大量用于创建更高级可视化效果的示例,如网络图和地图。
组织布局
如果你需要一个以上的数字来表达你的数据,散景可以满足你。Bokeh 不仅提供了标准的网格布局选项,还可以让您轻松地用几行代码将可视化内容组织成选项卡式布局。
此外,您的地块可以快速链接在一起,因此对一个地块的选择将反映在其他地块的任何组合上。
预览并保存您创建的漂亮数据
最后,是时候看看你创造了什么。
无论您是在浏览器中还是在笔记本中查看可视化效果,您都将能够探索您的可视化效果,检查您的自定义设置,并体验添加的任何交互。
如果你喜欢你所看到的,你可以将你的可视化保存到一个图像文件中。否则,您可以根据需要重新访问上述步骤,将您的数据愿景变为现实。
就是这样!这六个步骤是一个整洁、灵活的模板的组成部分,可用于将您的数据从表格带到大屏幕上:
"""Bokeh Visualization Template This template is a general outline for turning your data into a visualization using Bokeh. """ # Data handling import pandas as pd import numpy as np # Bokeh libraries from bokeh.io import output_file, output_notebook from bokeh.plotting import figure, show from bokeh.models import ColumnDataSource from bokeh.layouts import row, column, gridplot from bokeh.models.widgets import Tabs, Panel # Prepare the data # Determine where the visualization will be rendered output_file('filename.html') # Render to static HTML, or output_notebook() # Render inline in a Jupyter Notebook # Set up the figure(s) fig = figure() # Instantiate a figure() object # Connect to and draw the data # Organize the layout # Preview and save show(fig) # See what I made, and save if I like it上面预览了在每个步骤中发现的一些常见代码片段,当您浏览教程的其余部分时,您将看到如何填写其余部分!
生成您的第一个数字
在散景中有多种方式输出你的视觉效果。在本教程中,您将看到这两个选项:
output_file('filename.html')将把可视化结果写入一个静态 HTML 文件。output_notebook()将直接在 Jupyter 笔记本上呈现你的可视化。值得注意的是,这两个函数实际上都不会向您显示可视化效果。直到调用
show()才会发生这种情况。然而,它们将确保当调用show()时,可视化出现在您想要的地方。通过在同一次执行中同时调用
output_file()和output_notebook(),可视化将同时呈现到静态 HTML 文件和笔记本中。然而,如果出于某种原因你在同一次执行中运行了多个output_file()命令,那么只有最后一个会被用于渲染。这是一个很好的机会,让你第一次看到使用
output_file()的默认散景:# Bokeh Libraries from bokeh.io import output_file from bokeh.plotting import figure, show # The figure will be rendered in a static HTML file called output_file_test.html output_file('output_file_test.html', title='Empty Bokeh Figure') # Set up a generic figure() object fig = figure() # See what it looks like show(fig)
正如你所看到的,一个新的浏览器窗口打开了,有一个名为空散景图的标签和一个空图。没有显示的是在当前工作目录中生成的名为 output_file_test.html 的文件。
如果您要用
output_notebook()代替output_file()运行相同的代码片段,假设您有一个 Jupyter 笔记本启动并准备运行,您将得到以下内容:# Bokeh Libraries from bokeh.io import output_notebook from bokeh.plotting import figure, show # The figure will be right in my Jupyter Notebook output_notebook() # Set up a generic figure() object fig = figure() # See what it looks like show(fig)
如您所见,结果是相同的,只是在不同的位置进行了渲染。
关于
output_file()和output_notebook()的更多信息可以在散景官方文档中找到。注意:有时,当连续渲染多个可视化效果时,你会发现每次执行都没有清除过去的渲染。如果您遇到这种情况,请在执行之间导入并运行以下内容:
# Import reset_output (only needed once) from bokeh.plotting import reset_output # Use reset_output() between subsequent show() calls, as needed reset_output()在继续之前,你可能已经注意到默认的散景图预装了一个工具栏。这是对开箱即用的散景互动元素的重要预览。你将在本教程末尾的添加交互部分找到更多关于工具栏以及如何配置它的信息。
为数据准备好数据
现在,您已经知道如何在浏览器或 Jupyter 笔记本中创建和查看普通散景图像,是时候了解如何配置
figure()对象了。
figure()对象不仅是数据可视化的基础,也是解锁所有可用于数据可视化的 Bokeh 工具的对象。散景图形是散景绘图对象的子类,它提供了许多参数,使您可以配置图形的美学元素。为了向您展示可用的定制选项,让我们创建一个有史以来最丑的图形:
# Bokeh Libraries from bokeh.io import output_notebook from bokeh.plotting import figure, show # The figure will be rendered inline in my Jupyter Notebook output_notebook() # Example figure fig = figure(background_fill_color='gray', background_fill_alpha=0.5, border_fill_color='blue', border_fill_alpha=0.25, plot_height=300, plot_width=500, h_symmetry=True, x_axis_label='X Label', x_axis_type='datetime', x_axis_location='above', x_range=('2018-01-01', '2018-06-30'), y_axis_label='Y Label', y_axis_type='linear', y_axis_location='left', y_range=(0, 100), title='Example Figure', title_location='right', toolbar_location='below', tools='save') # See what it looks like show(fig)
一旦实例化了
figure()对象,您仍然可以在事后配置它。假设你想去掉网格线:# Remove the gridlines from the figure() object fig.grid.grid_line_color = None # See what it looks like show(fig)网格线属性可以通过图形的
grid属性来访问。在这种情况下,将grid_line_color设置为None可以有效地完全删除网格线。关于图形属性的更多细节可以在绘图类文档的文件夹下找到。
注意:如果您正在使用具有自动完成功能的笔记本电脑或 IDE,该功能绝对是您的好朋友!有了这么多可定制的元素,它对发现可用选项非常有帮助:
否则,用关键字散景和你想做的事情做一个快速的网络搜索,通常会给你指出正确的方向。
这里还有很多我可以接触到的,但不要觉得你错过了。随着教程的进展,我将确保引入不同的图形调整。以下是该主题的一些其他有用链接:
以下是一些值得一试的特定定制选项:
- 文本属性 涵盖了所有与改变字体样式、大小、颜色等相关的属性。
- TickFormatters 是内置对象,专门用于使用类似 Python 的字符串格式化语法来格式化轴。
有时,直到你的图形中实际上有一些可视化的数据时,才知道你的图形需要如何定制,所以接下来你将学习如何实现这一点。
用字形绘制数据
一个空的图形并不令人兴奋,所以让我们看看字形:散景可视化的构建块。字形是一种用于表示数据的矢量化图形形状或标记,如圆形或方形。更多例子可以在散景图库中找到。在你创建了你的图形之后,你就可以访问一组可配置的字形方法。
让我们从一个非常基本的例子开始,在 x-y 坐标网格上画一些点:
# Bokeh Libraries from bokeh.io import output_file from bokeh.plotting import figure, show # My x-y coordinate data x = [1, 2, 1] y = [1, 1, 2] # Output the visualization directly in the notebook output_file('first_glyphs.html', title='First Glyphs') # Create a figure with no toolbar and axis ranges of [0,3] fig = figure(title='My Coordinates', plot_height=300, plot_width=300, x_range=(0, 3), y_range=(0, 3), toolbar_location=None) # Draw the coordinates as circles fig.circle(x=x, y=y, color='green', size=10, alpha=0.5) # Show plot show(fig)
一旦您的图形被实例化,您就可以看到如何使用定制的
circle字形来绘制 x-y 坐标数据。以下是几类字形:
标记包括圆形、菱形、正方形和三角形等形状,对于创建散点图和气泡图等可视化效果非常有效。
线条包括单线、阶跃和多线形状,可用于构建折线图。
条形图/矩形形状可用于创建传统或堆积条形图(
hbar)和柱形图(vbar)以及瀑布图或甘特图。关于上面以及其他符号的信息可以在散景的参考指南中找到。
这些字形可以根据需要进行组合,以满足您的可视化需求。比方说,我想创建一个可视化程序,显示我在制作本教程时每天写了多少单词,并用累计字数的趋势线覆盖:
import numpy as np # Bokeh libraries from bokeh.io import output_notebook from bokeh.plotting import figure, show # My word count data day_num = np.linspace(1, 10, 10) daily_words = [450, 628, 488, 210, 287, 791, 508, 639, 397, 943] cumulative_words = np.cumsum(daily_words) # Output the visualization directly in the notebook output_notebook() # Create a figure with a datetime type x-axis fig = figure(title='My Tutorial Progress', plot_height=400, plot_width=700, x_axis_label='Day Number', y_axis_label='Words Written', x_minor_ticks=2, y_range=(0, 6000), toolbar_location=None) # The daily words will be represented as vertical bars (columns) fig.vbar(x=day_num, bottom=0, top=daily_words, color='blue', width=0.75, legend='Daily') # The cumulative sum will be a trend line fig.line(x=day_num, y=cumulative_words, color='gray', line_width=1, legend='Cumulative') # Put the legend in the upper left corner fig.legend.location = 'top_left' # Let's check it out show(fig)
要合并图上的列和行,只需使用同一个
figure()对象创建它们。此外,您可以在上面看到如何通过为每个字形设置
legend属性来无缝地创建图例。然后通过将'top_left'分配给fig.legend.location将图例移动到绘图的左上角。你可以查看更多关于造型传奇的信息。预告:在教程的后面,当我们开始挖掘可视化的交互元素时,它们会再次出现。
关于数据的快速旁白
每当您探索一个新的可视化库时,从您熟悉的领域中的一些数据开始是一个好主意。散景的美妙之处在于,你的任何想法都有可能实现。这只是你想如何利用可用的工具来做到这一点的问题。
其余的例子将使用来自 Kaggle 的公开可用数据,该数据具有关于国家篮球协会(NBA) 2017-18 赛季的的信息,具体来说:
- 2017-18 _ player box score . CSV:球员统计的逐场快照
- 2017-18 _ teamboxscore . CSV:球队统计的逐场快照
- 2017-18 _ 积分榜. csv :每日球队积分榜及排名
这些数据与我的工作无关,但我热爱篮球,喜欢思考如何可视化与篮球相关的不断增长的数据。
如果你没有来自学校或工作的数据可以使用,想想你感兴趣的东西,并试图找到一些与此相关的数据。这将大大有助于使学习和创作过程更快、更愉快!
为了跟随教程中的例子,你可以从上面的链接下载数据集,并使用以下命令将它们读入到熊猫
DataFrame中:import pandas as pd # Read the csv files player_stats = pd.read_csv('2017-18_playerBoxScore.csv', parse_dates=['gmDate']) team_stats = pd.read_csv('2017-18_teamBoxScore.csv', parse_dates=['gmDate']) standings = pd.read_csv('2017-18_standings.csv', parse_dates=['stDate'])这段代码从三个 CSV 文件中读取数据,并自动将日期列解释为
datetime对象。现在是时候获取一些真实的数据了。
使用
ColumnDataSource对象上面的例子使用了 Python 列表和 Numpy 数组来表示数据,Bokeh 很好地处理了这些数据类型。然而,当谈到 Python 中的数据时,你很可能会遇到 Python 字典和 Pandas DataFrames ,尤其是当你从文件或外部数据源读入数据时。
Bokeh 能够很好地处理这些更复杂的数据结构,甚至有内置的功能来处理它们,即
ColumnDataSource。您可能会问自己,“当散景可以直接与其他数据类型交互时,为什么还要使用
ColumnDataSource”首先,不管你是直接引用列表、数组、字典还是数据帧,Bokeh 都会在幕后把它变成一个
ColumnDataSource。更重要的是,ColumnDataSource使得实现散景的交互式启示更加容易。
ColumnDataSource是将数据传递给用于可视化的字形的基础。它的主要功能是将名称映射到数据的列。这使您在构建可视化时更容易引用数据元素。这也使得散景在构建可视化效果时更容易做到这一点。
ColumnDataSource可以解释三种类型的数据对象:
Python
dict:键是与各自的值序列(列表、数组等)相关联的名称。熊猫
DataFrame:DataFrame的栏目成为ColumnDataSource的参照名。熊猫
groupby:ColumnDataSource的列引用调用groupby.describe()看到的列。让我们从 2017-18 赛季卫冕冠军金州勇士队和挑战者休斯顿火箭队之间争夺 NBA 西部第一名的比赛开始。这两个队每天的胜负记录存储在一个名为
west_top_2的数据帧中:
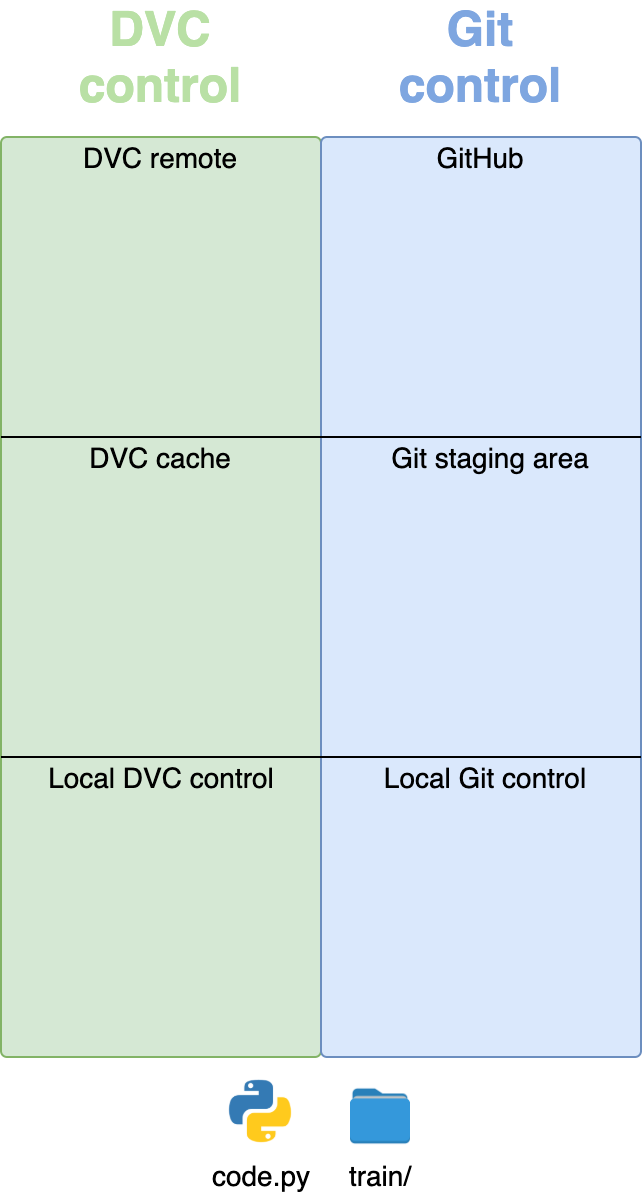
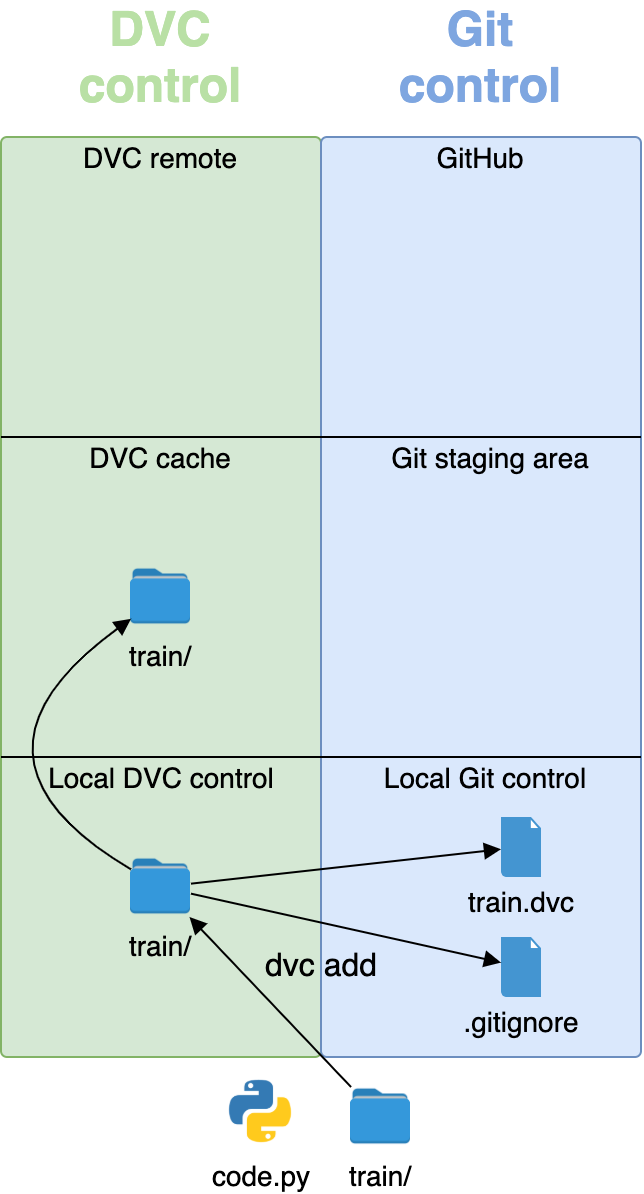
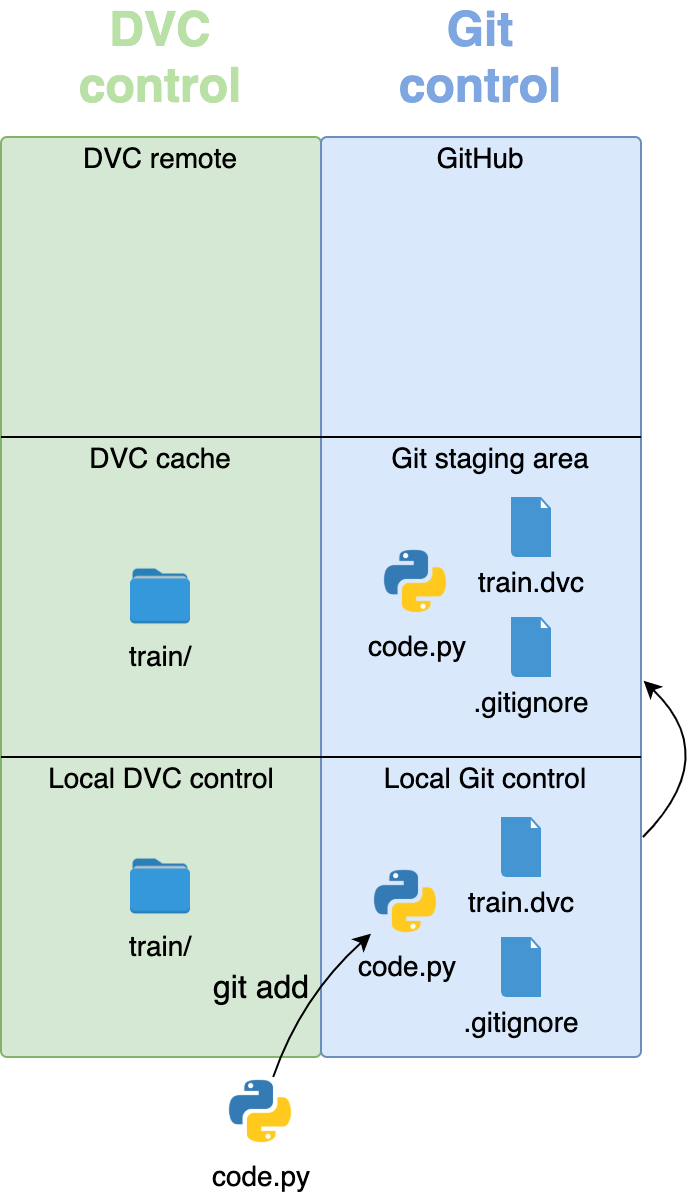
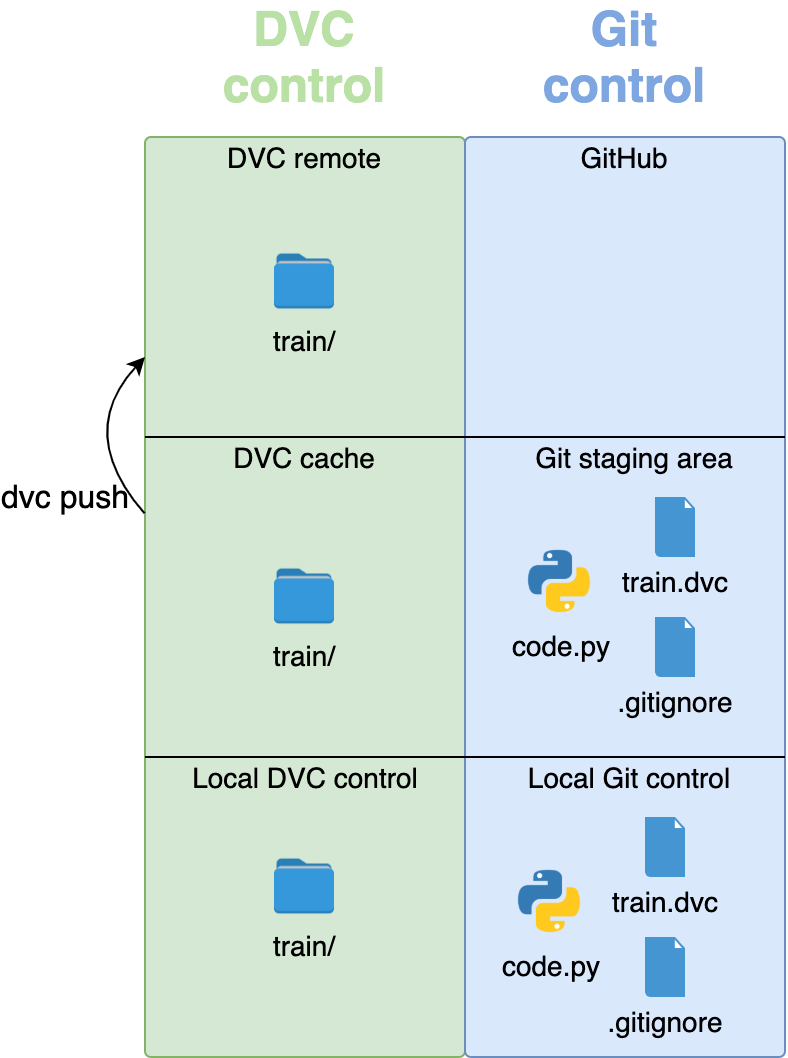
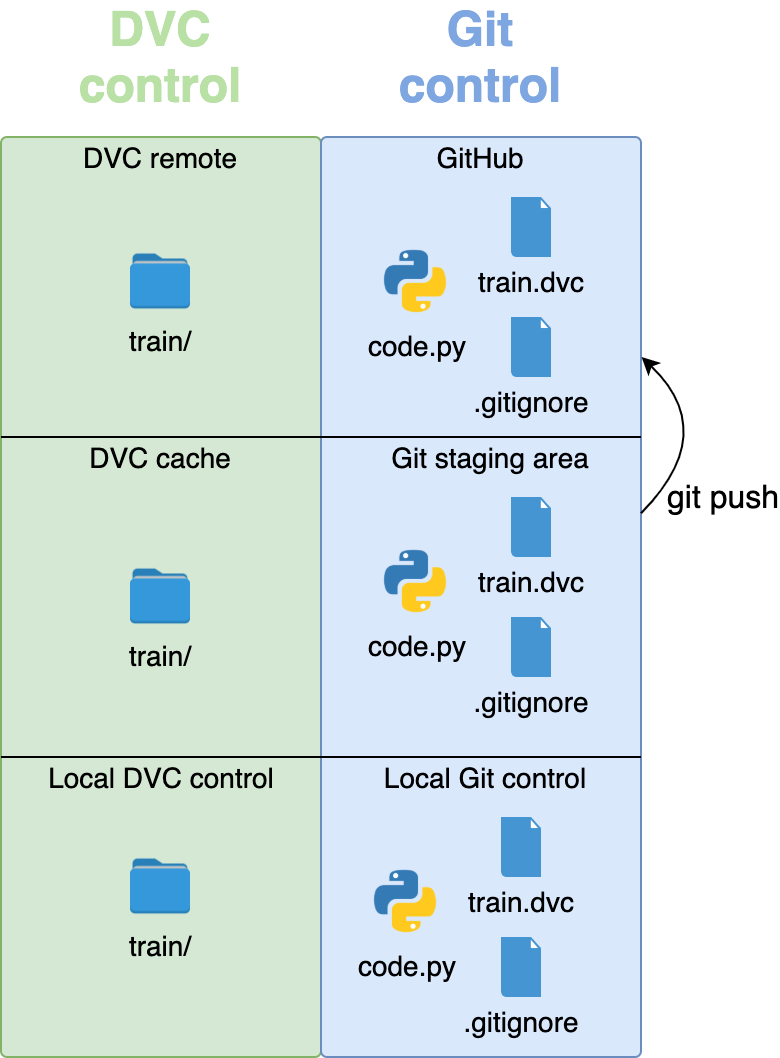
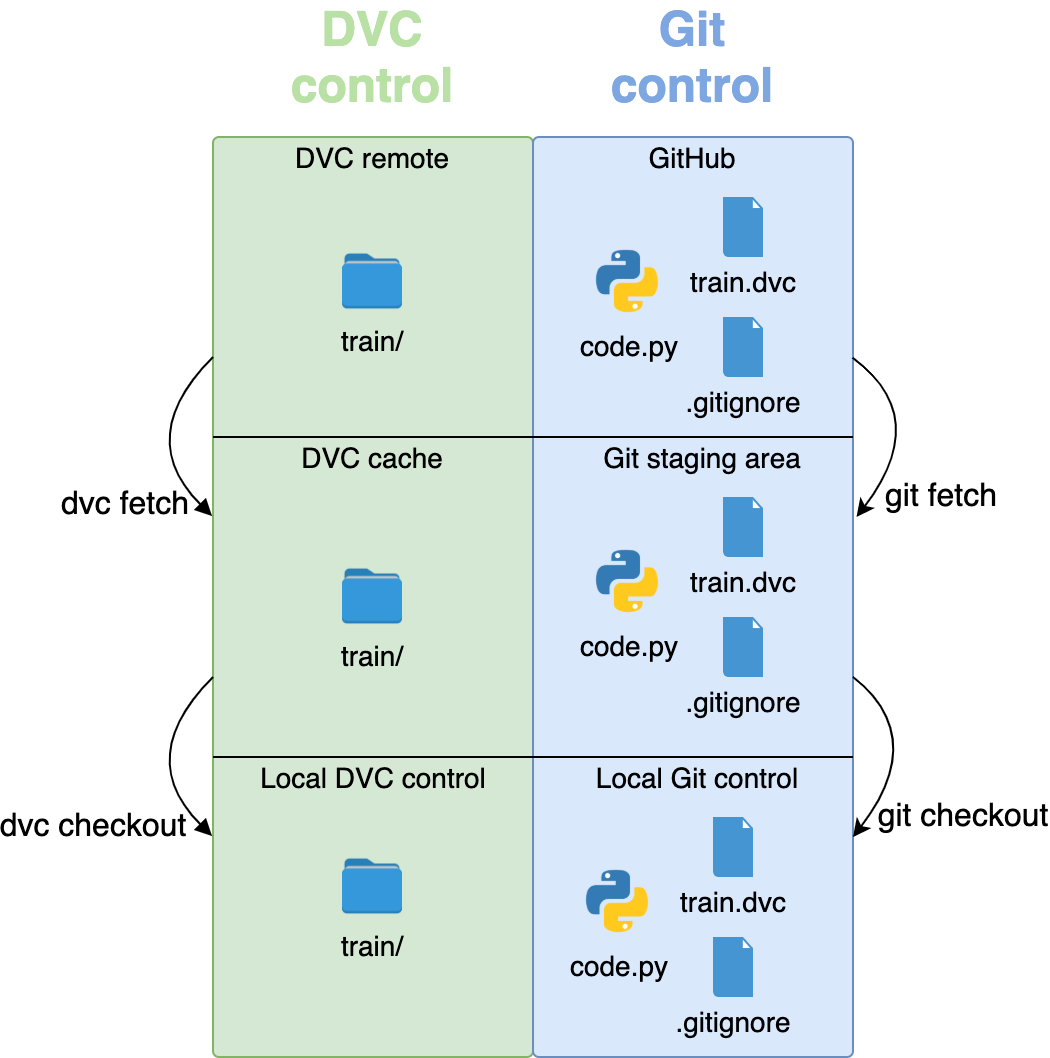
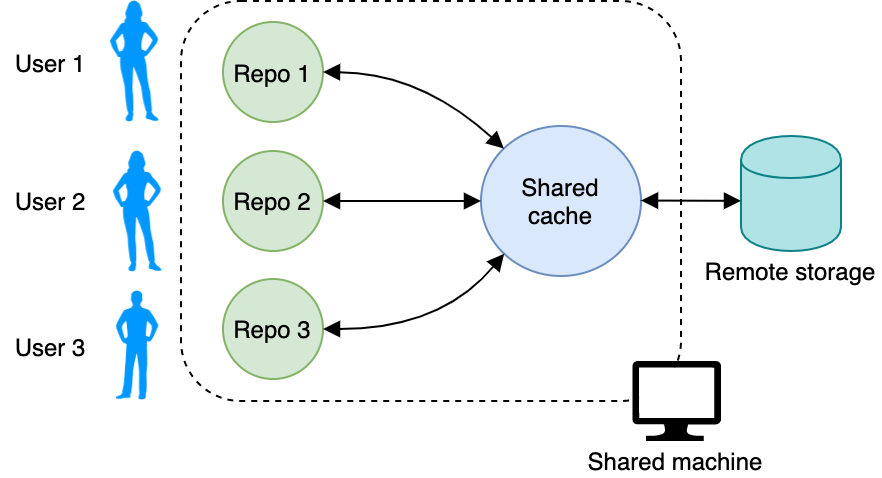
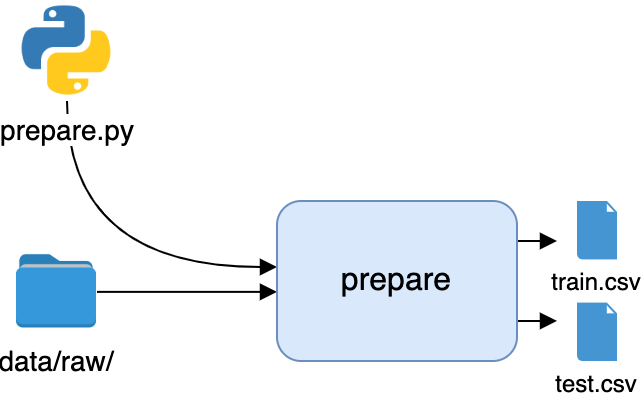
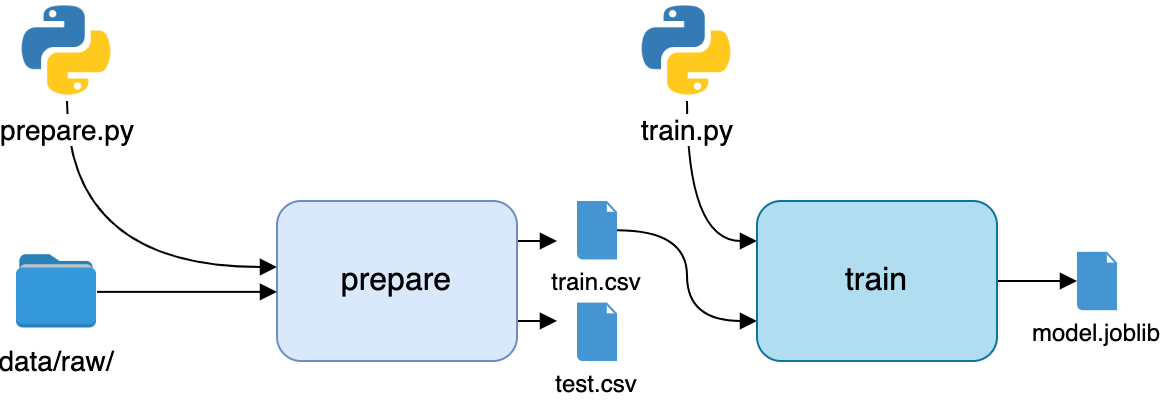
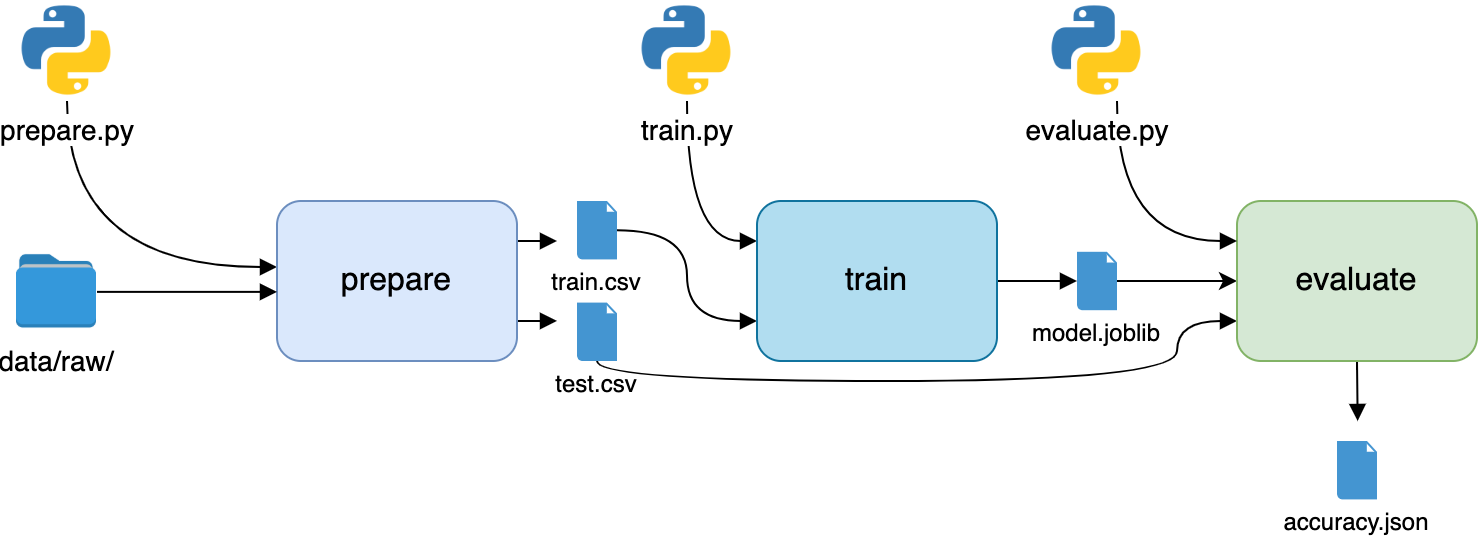
>>> west_top_2 = (standings[(standings['teamAbbr'] == 'HOU') | (standings['teamAbbr'] == 'GS')]
... .loc[:, ['stDate', 'teamAbbr', 'gameWon']]
... .sort_values(['teamAbbr','stDate']))
>>> west_top_2.head()
stDate teamAbbr gameWon
9 2017-10-17 GS 0
39 2017-10-18 GS 0
69 2017-10-19 GS 0
99 2017-10-20 GS 1
129 2017-10-21 GS 1
从这里,您可以将这个DataFrame加载到两个ColumnDataSource对象中,并可视化比赛:
# Bokeh libraries
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource
# Output to file
output_file('west-top-2-standings-race.html',
title='Western Conference Top 2 Teams Wins Race')
# Isolate the data for the Rockets and Warriors
rockets_data = west_top_2[west_top_2['teamAbbr'] == 'HOU']
warriors_data = west_top_2[west_top_2['teamAbbr'] == 'GS']
# Create a ColumnDataSource object for each team
rockets_cds = ColumnDataSource(rockets_data)
warriors_cds = ColumnDataSource(warriors_data)
# Create and configure the figure
fig = figure(x_axis_type='datetime',
plot_height=300, plot_width=600,
title='Western Conference Top 2 Teams Wins Race, 2017-18',
x_axis_label='Date', y_axis_label='Wins',
toolbar_location=None)
# Render the race as step lines
fig.step('stDate', 'gameWon',
color='#CE1141', legend='Rockets',
source=rockets_cds)
fig.step('stDate', 'gameWon',
color='#006BB6', legend='Warriors',
source=warriors_cds)
# Move the legend to the upper left corner
fig.legend.location = 'top_left'
# Show the plot
show(fig)
注意在创建两条线时如何引用各自的ColumnDataSource对象。您只需将原始列名作为输入参数传递,并通过source属性指定使用哪个ColumnDataSource。
可视化显示了整个赛季的紧张比赛,勇士队在赛季中期建立了一个相当大的缓冲。然而,赛季后期的一点下滑让火箭赶上并最终超过卫冕冠军,成为西部联盟的头号种子。
注意:在散景中,您可以通过名称、十六进制值或 RGB 颜色代码来指定颜色。
对于上面的可视化,为代表两个团队的相应线条指定了颜色。不要使用 CSS 颜色名称,如火箭队的'red'和勇士队的'blue',你可能想通过使用十六进制颜色代码形式的官方团队颜色来添加一个漂亮的视觉效果。或者,你可以使用代表 RGB 颜色代码的元组:(206, 17, 65)代表火箭,(0, 107, 182)代表勇士。
散景提供了一个有用的 CSS 颜色名称列表,按照它们的色调分类。另外,htmlcolorcodes.com 的是一个寻找 CSS、十六进制和 RGB 颜色代码的好网站。
ColumnDataSource对象可以做的不仅仅是作为引用DataFrame列的简单方法。ColumnDataSource对象有三个内置过滤器,可用于使用CDSView对象创建数据视图:
GroupFilter根据分类引用值从ColumnDataSource中选择行IndexFilter通过整数索引列表过滤ColumnDataSourceBooleanFilter允许您使用一列boolean值,并选择True行
在前面的例子中,创建了两个ColumnDataSource对象,分别来自west_top_2数据帧的一个子集。下一个例子将使用一个创建数据视图的GroupFilter,基于所有的west_top_2,从一个ColumnDataSource重新创建相同的输出:
# Bokeh libraries
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, CDSView, GroupFilter
# Output to file
output_file('west-top-2-standings-race.html',
title='Western Conference Top 2 Teams Wins Race')
# Create a ColumnDataSource
west_cds = ColumnDataSource(west_top_2)
# Create views for each team
rockets_view = CDSView(source=west_cds,
filters=[GroupFilter(column_name='teamAbbr', group='HOU')])
warriors_view = CDSView(source=west_cds,
filters=[GroupFilter(column_name='teamAbbr', group='GS')])
# Create and configure the figure
west_fig = figure(x_axis_type='datetime',
plot_height=300, plot_width=600,
title='Western Conference Top 2 Teams Wins Race, 2017-18',
x_axis_label='Date', y_axis_label='Wins',
toolbar_location=None)
# Render the race as step lines
west_fig.step('stDate', 'gameWon',
source=west_cds, view=rockets_view,
color='#CE1141', legend='Rockets')
west_fig.step('stDate', 'gameWon',
source=west_cds, view=warriors_view,
color='#006BB6', legend='Warriors')
# Move the legend to the upper left corner
west_fig.legend.location = 'top_left'
# Show the plot
show(west_fig)
注意列表中的GroupFilter是如何传递给CDSView的。这允许您将多个过滤器组合在一起,根据需要从ColumnDataSource中分离出您需要的数据。
有关集成数据源的信息,请查看 ColumnDataSource上的散景用户指南帖子和其他可用的源对象。
西部联盟最终是一场激动人心的比赛,但如果你想看看东部联盟是否同样紧张。不仅如此,您还想在一个可视化视图中查看它们。这是一个完美的下一个话题:布局。
用布局组织多个可视化
东部联盟排名下降到大西洋赛区的两个对手:波士顿凯尔特人队和多伦多猛龙队。在复制用于创建west_top_2的步骤之前,让我们用上面学到的知识再一次测试一下ColumnDataSource。
在本例中,您将看到如何将整个数据帧输入到一个ColumnDataSource中,并创建视图来隔离相关数据:
# Bokeh libraries
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, CDSView, GroupFilter
# Output to file
output_file('east-top-2-standings-race.html',
title='Eastern Conference Top 2 Teams Wins Race')
# Create a ColumnDataSource
standings_cds = ColumnDataSource(standings)
# Create views for each team
celtics_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='BOS')])
raptors_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='TOR')])
# Create and configure the figure
east_fig = figure(x_axis_type='datetime',
plot_height=300, plot_width=600,
title='Eastern Conference Top 2 Teams Wins Race, 2017-18',
x_axis_label='Date', y_axis_label='Wins',
toolbar_location=None)
# Render the race as step lines
east_fig.step('stDate', 'gameWon',
color='#007A33', legend='Celtics',
source=standings_cds, view=celtics_view)
east_fig.step('stDate', 'gameWon',
color='#CE1141', legend='Raptors',
source=standings_cds, view=raptors_view)
# Move the legend to the upper left corner
east_fig.legend.location = 'top_left'
# Show the plot
show(east_fig)
ColumnDataSource能够毫不费力地将相关数据隔离在一个 5040 乘 39 的DataFrame内,在此过程中节省了几行熊猫代码。
从视觉效果来看,你可以看到东部联盟的比赛并不轻松。在凯尔特人咆哮着冲出大门后,猛龙一路追上了他们的分区对手,并以五连胜结束了常规赛。
我们的两个可视化已经准备好了,是时候把它们放在一起了。
与 Matplotlib 的subplot 功能类似,Bokeh 在其bokeh.layouts模块中提供了column、row和gridplot功能。这些功能通常可以归类为布局。
用法非常简单。如果要将两个可视化效果放在垂直配置中,可以通过以下方式实现:
# Bokeh library
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.layouts import column
# Output to file
output_file('east-west-top-2-standings-race.html',
title='Conference Top 2 Teams Wins Race')
# Plot the two visualizations in a vertical configuration
show(column(west_fig, east_fig))
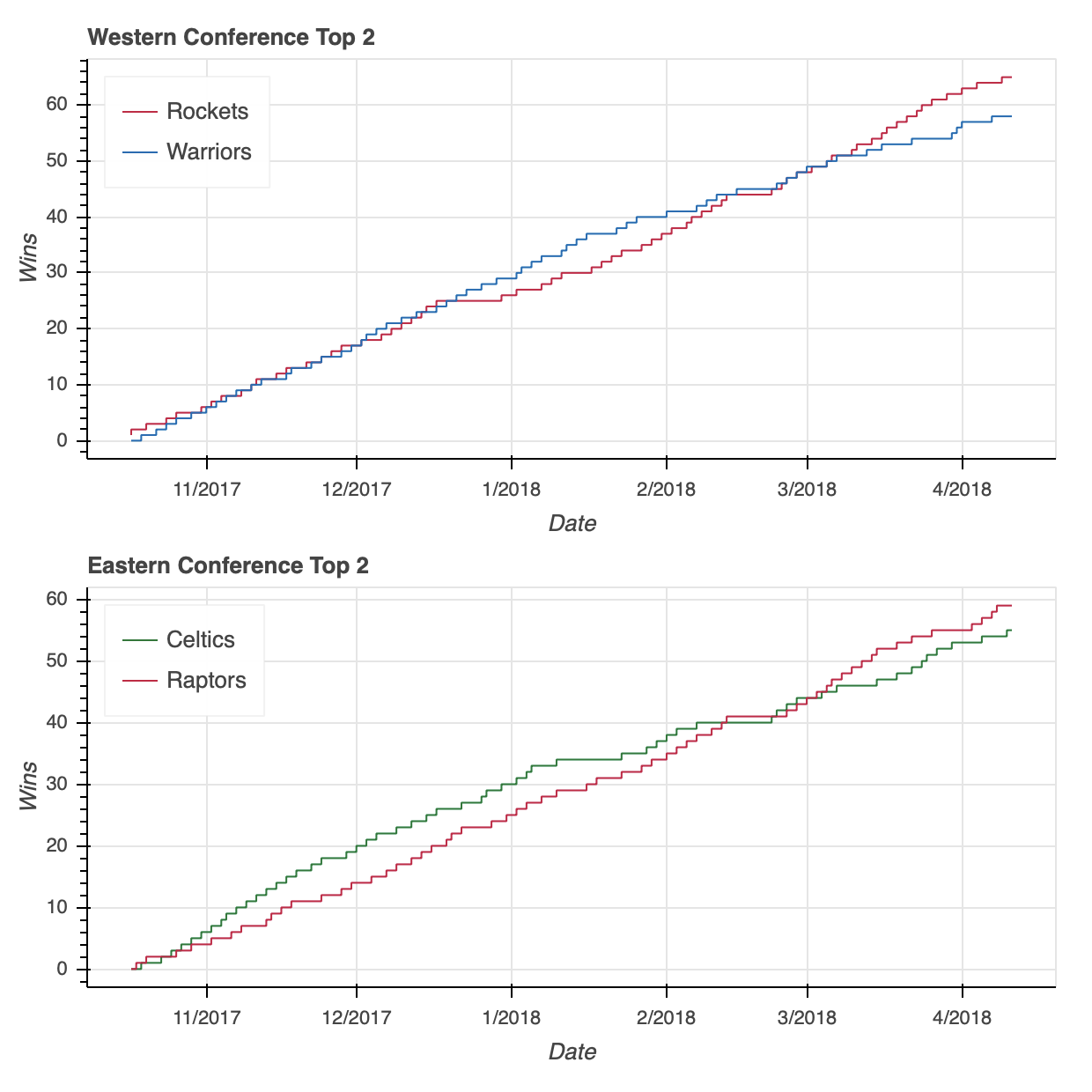
我将为您节省两行代码,但是请放心,将上面代码片段中的column替换为row将类似地在水平配置中配置两个图。
注意:如果您在阅读教程的过程中正在尝试代码片段,我想绕个弯来解决您在下面的例子中访问west_fig和east_fig时可能会看到的一个错误。这样做时,您可能会收到如下错误:
WARNING:bokeh.core.validation.check:W-1004 (BOTH_CHILD_AND_ROOT): Models should not be a document root...
这是散景的验证模块的许多错误之一,其中w-1004特别警告在新布局中重复使用west_fig和east_fig。
为了避免在测试示例时出现这种错误,请在说明每个布局的代码片段前面加上以下内容:
# Bokeh libraries
from bokeh.plotting import figure, show
from bokeh.models import ColumnDataSource, CDSView, GroupFilter
# Create a ColumnDataSource
standings_cds = ColumnDataSource(standings)
# Create the views for each team
celtics_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='BOS')])
raptors_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='TOR')])
rockets_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='HOU')])
warriors_view = CDSView(source=standings_cds,
filters=[GroupFilter(column_name='teamAbbr',
group='GS')])
# Create and configure the figure
east_fig = figure(x_axis_type='datetime',
plot_height=300,
x_axis_label='Date',
y_axis_label='Wins',
toolbar_location=None)
west_fig = figure(x_axis_type='datetime',
plot_height=300,
x_axis_label='Date',
y_axis_label='Wins',
toolbar_location=None)
# Configure the figures for each conference
east_fig.step('stDate', 'gameWon',
color='#007A33', legend='Celtics',
source=standings_cds, view=celtics_view)
east_fig.step('stDate', 'gameWon',
color='#CE1141', legend='Raptors',
source=standings_cds, view=raptors_view)
west_fig.step('stDate', 'gameWon', color='#CE1141', legend='Rockets',
source=standings_cds, view=rockets_view)
west_fig.step('stDate', 'gameWon', color='#006BB6', legend='Warriors',
source=standings_cds, view=warriors_view)
# Move the legend to the upper left corner
east_fig.legend.location = 'top_left'
west_fig.legend.location = 'top_left'
# Layout code snippet goes here!
这样做将更新相关组件以呈现可视化,确保不需要警告。
不要用column或row,你可以用一个gridplot来代替。
gridplot的一个关键区别是它会自动合并所有子图形的工具栏。上面的两个可视化没有工具栏,但如果有,那么当使用column或row时,每个图形都有自己的工具栏。这样,它也有了自己的toolbar_location属性,见下面设置为'right'。
从语法上来说,您还会注意到下面的gridplot的不同之处在于,它不是被传递一个元组作为输入,而是需要一个列表列表,其中每个子列表代表网格中的一行:
# Bokeh libraries
from bokeh.io import output_file
from bokeh.layouts import gridplot
# Output to file
output_file('east-west-top-2-gridplot.html',
title='Conference Top 2 Teams Wins Race')
# Reduce the width of both figures
east_fig.plot_width = west_fig.plot_width = 300
# Edit the titles
east_fig.title.text = 'Eastern Conference'
west_fig.title.text = 'Western Conference'
# Configure the gridplot
east_west_gridplot = gridplot([[west_fig, east_fig]],
toolbar_location='right')
# Plot the two visualizations in a horizontal configuration
show(east_west_gridplot)
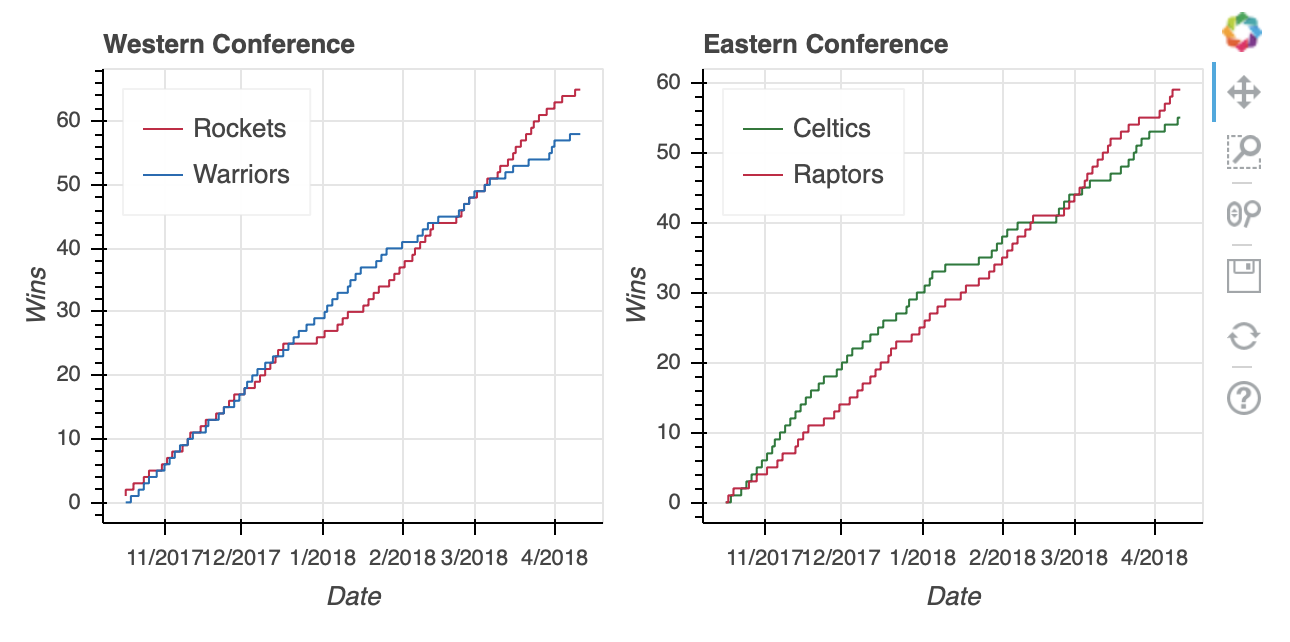
最后,gridplot允许传递被解释为空白支线剧情的None值。因此,如果您想为两个额外的图留一个占位符,您可以这样做:
# Bokeh libraries
from bokeh.io import output_file
from bokeh.layouts import gridplot
# Output to file
output_file('east-west-top-2-gridplot.html',
title='Conference Top 2 Teams Wins Race')
# Reduce the width of both figures
east_fig.plot_width = west_fig.plot_width = 300
# Edit the titles
east_fig.title.text = 'Eastern Conference'
west_fig.title.text = 'Western Conference'
# Plot the two visualizations with placeholders
east_west_gridplot = gridplot([[west_fig, None], [None, east_fig]],
toolbar_location='right')
# Plot the two visualizations in a horizontal configuration
show(east_west_gridplot)
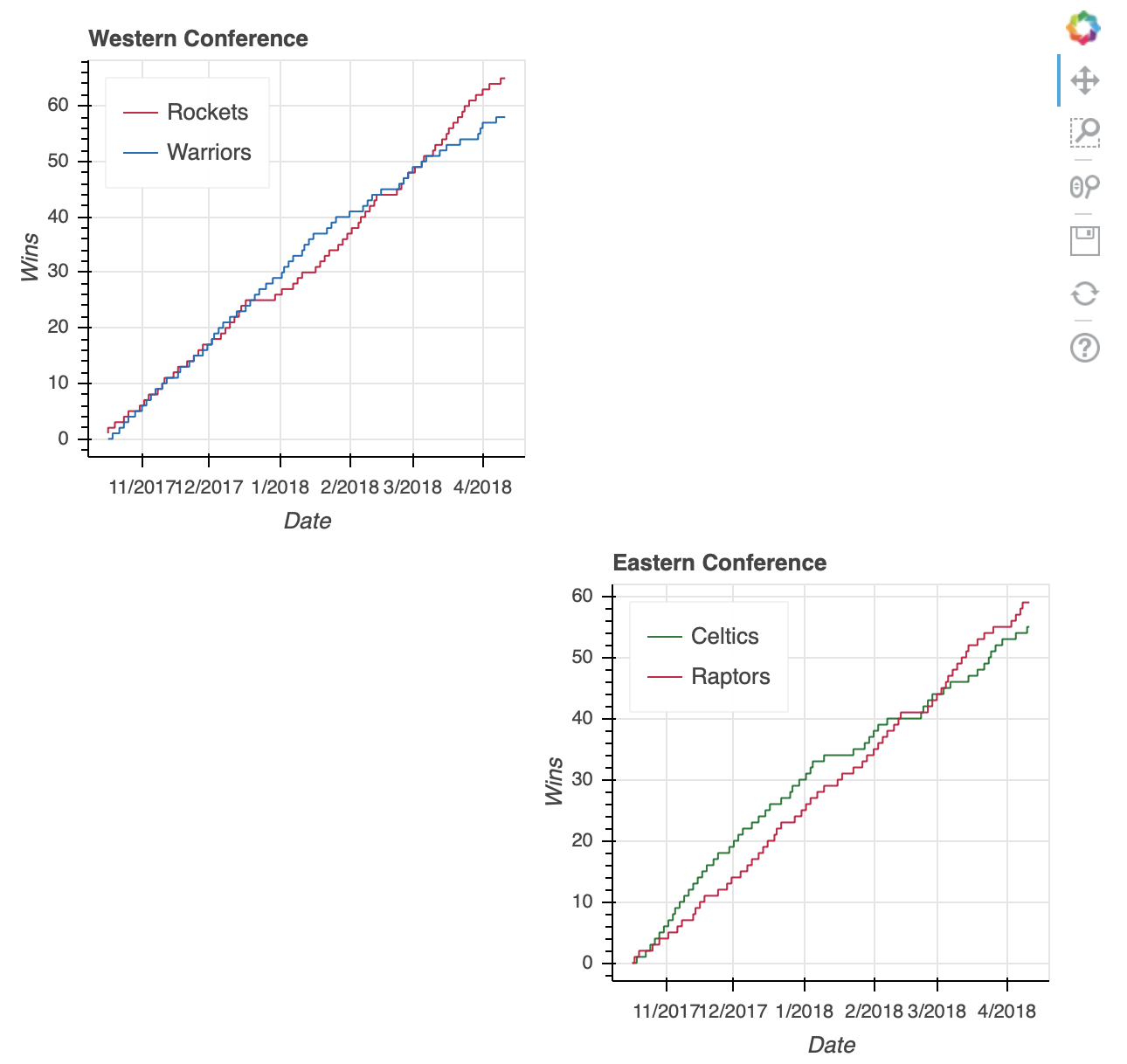
如果您更愿意在两种可视化效果之间切换,而不必将它们压缩到彼此相邻或重叠,选项卡式布局是一个不错的选择。
选项卡式布局由两个散景小部件功能组成:bokeh.models.widgets子模块中的Tab()和Panel()。像使用gridplot()一样,制作选项卡式布局非常简单:
# Bokeh Library
from bokeh.io import output_file
from bokeh.models.widgets import Tabs, Panel
# Output to file
output_file('east-west-top-2-tabbed_layout.html',
title='Conference Top 2 Teams Wins Race')
# Increase the plot widths
east_fig.plot_width = west_fig.plot_width = 800
# Create two panels, one for each conference
east_panel = Panel(child=east_fig, title='Eastern Conference')
west_panel = Panel(child=west_fig, title='Western Conference')
# Assign the panels to Tabs
tabs = Tabs(tabs=[west_panel, east_panel])
# Show the tabbed layout
show(tabs)
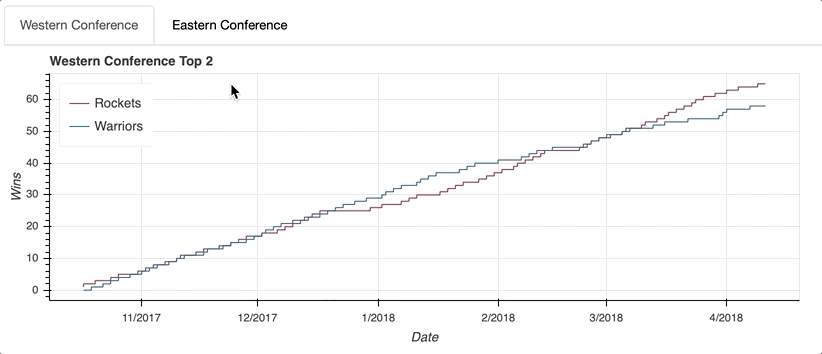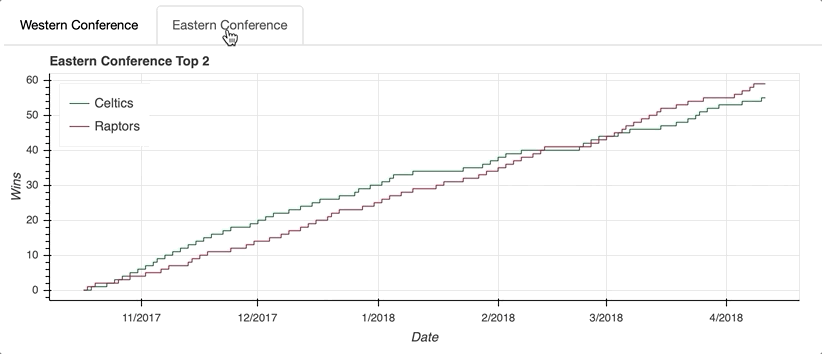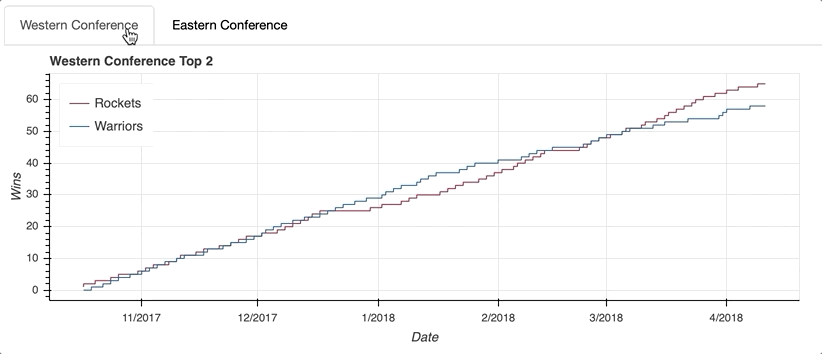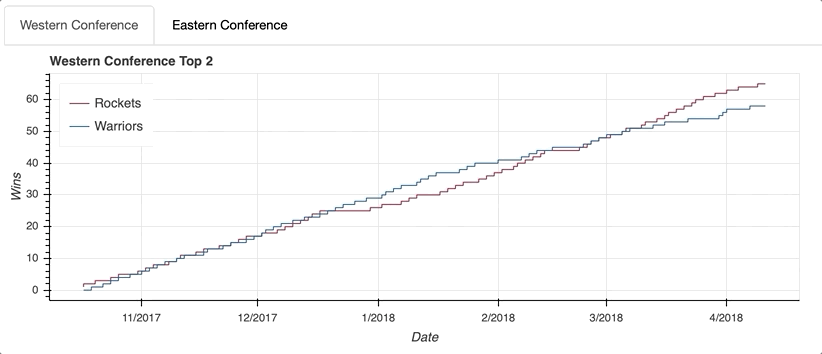
第一步是为每个选项卡创建一个Panel()。这听起来可能有点混乱,但是可以把Tabs()函数看作是组织用Panel()创建的各个选项卡的机制。
每个Panel()接受一个孩子作为输入,这个孩子可以是一个单独的figure()或者一个布局。(记住,布局是column、row或gridplot的通称。)一旦你的面板组装好了,它们就可以作为输入传递给列表中的Tabs()。
既然你已经了解了如何访问、绘制和组织你的数据,是时候进入散景的真正魔力了:交互!一如既往,查看散景的用户指南,了解更多关于布局的信息。
添加交互
让散景与众不同的特性是它能够在可视化中轻松实现交互性。Bokeh 甚至将自己描述为一个交互式可视化库:
Bokeh 是一个交互式可视化库,面向现代 web 浏览器进行演示。(来源)
在这一节中,我们将讨论增加交互性的五种方法:
- 配置工具栏
- 选择数据点
- 添加悬停动作
- 链接轴和选择
- 使用图例高亮显示数据
实现这些交互式元素为探索数据提供了可能性,这是静态可视化本身无法做到的。
配置工具栏
正如你在生成你的第一个数字时所看到的,默认的散景figure()带有一个开箱即用的工具栏。默认工具栏包含以下工具(从左到右):
- 平底锅
- 方框缩放
- 滚轮缩放
- 救援
- 重置
- 链接到 散景配置绘图工具的用户指南
- 链接到 散景主页
当实例化一个figure()对象时,可以通过传递toolbar_location=None来移除工具栏,或者通过传递'above'、'below'、'left'或'right'中的任意一个来重新定位工具栏。
此外,工具栏可以配置为包含您需要的任何工具组合。Bokeh 提供五大类 18 种特定工具:
- 平移/拖动 :
box_select、box_zoom、lasso_select、pan、xpan、ypan、resize_select - 点击/轻击 :
poly_select,tap - 滚动/捏合 :
wheel_zoom,xwheel_zoom,ywheel_zoom - 动作 :
undo,redo,reset,save - 检查员 :
crosshair,hover
要研究工具,一定要访问指定工具的。否则,它们将在本文涉及的各种交互中进行说明。
选择数据点
实现选择行为就像在声明字形时添加一些特定的关键字一样简单。
下一个示例将创建一个散点图,将球员的三分球尝试总数与三分球尝试次数的百分比相关联(对于至少有 100 次三分球尝试的球员)。
数据可以从player_stats数据帧中汇总:
# Find players who took at least 1 three-point shot during the season
three_takers = player_stats[player_stats['play3PA'] > 0]
# Clean up the player names, placing them in a single column
three_takers['name'] = [f'{p["playFNm"]} {p["playLNm"]}'
for _, p in three_takers.iterrows()]
# Aggregate the total three-point attempts and makes for each player
three_takers = (three_takers.groupby('name')
.sum()
.loc[:,['play3PA', 'play3PM']]
.sort_values('play3PA', ascending=False))
# Filter out anyone who didn't take at least 100 three-point shots
three_takers = three_takers[three_takers['play3PA'] >= 100].reset_index()
# Add a column with a calculated three-point percentage (made/attempted)
three_takers['pct3PM'] = three_takers['play3PM'] / three_takers['play3PA']
下面是结果DataFrame的一个例子:
>>> three_takers.sample(5) name play3PA play3PM pct3PM 229 Corey Brewer 110 31 0.281818 78 Marc Gasol 320 109 0.340625 126 Raymond Felton 230 81 0.352174 127 Kristaps Porziņģis 229 90 0.393013 66 Josh Richardson 336 127 0.377976假设您想要在分布中选择一组玩家,并在这样做时将代表未选择玩家的符号的颜色静音:
# Bokeh Libraries from bokeh.plotting import figure, show from bokeh.io import output_file from bokeh.models import ColumnDataSource, NumeralTickFormatter # Output to file output_file('three-point-att-vs-pct.html', title='Three-Point Attempts vs. Percentage') # Store the data in a ColumnDataSource three_takers_cds = ColumnDataSource(three_takers) # Specify the selection tools to be made available select_tools = ['box_select', 'lasso_select', 'poly_select', 'tap', 'reset'] # Create the figure fig = figure(plot_height=400, plot_width=600, x_axis_label='Three-Point Shots Attempted', y_axis_label='Percentage Made', title='3PT Shots Attempted vs. Percentage Made (min. 100 3PA), 2017-18', toolbar_location='below', tools=select_tools) # Format the y-axis tick labels as percentages fig.yaxis[0].formatter = NumeralTickFormatter(format='00.0%') # Add square representing each player fig.square(x='play3PA', y='pct3PM', source=three_takers_cds, color='royalblue', selection_color='deepskyblue', nonselection_color='lightgray', nonselection_alpha=0.3) # Visualize show(fig)首先,指定要提供的选择工具。在上面的例子中,
'box_select'、'lasso_select'、'poly_select'和'tap'(加上一个重置按钮)在一个名为select_tools的列表中被指定。当图形被实例化时,工具栏被定位到图中的'below',列表被传递到tools以使上面选择的工具可用。每个玩家最初由一个皇家蓝色方形符号表示,但当选择一个玩家或一组玩家时,会设置以下配置:
- 将选定的玩家转到
deepskyblue- 将所有未被选中的玩家的符号更改为带有
0.3不透明度的lightgray颜色就是这样!只需快速添加一些内容,现在的可视化效果如下所示:
关于选择后可以做什么的更多信息,请查看已选择和未选择的字形。
添加悬停动作
因此,我实现了选择散点图中感兴趣的特定玩家数据点的功能,但如果您想快速查看一个字形代表哪些玩家呢?一种选择是使用散景的
HoverTool()在光标穿过带有字形的路径时显示工具提示。您需要做的只是将以下内容添加到上面的代码片段中:# Bokeh Library from bokeh.models import HoverTool # Format the tooltip tooltips = [ ('Player','@name'), ('Three-Pointers Made', '@play3PM'), ('Three-Pointers Attempted', '@play3PA'), ('Three-Point Percentage','@pct3PM{00.0%}'), ] # Add the HoverTool to the figure fig.add_tools(HoverTool(tooltips=tooltips)) # Visualize show(fig)
HoverTool()与你在上面看到的选择工具略有不同,因为它有属性,特别是tooltips。首先,您可以通过创建包含对
ColumnDataSource的描述和引用的元组列表来配置格式化的工具提示。这个列表作为输入传递给HoverTool(),然后使用add_tools()简单地添加到图形中。事情是这样的:
注意工具栏上增加了悬停按钮,可以切换开关。
如果你想进一步强调玩家的悬停,散景可以通过悬停检查来实现。下面是添加了工具提示的代码片段的略微修改版本:
# Format the tooltip tooltips = [ ('Player','@name'), ('Three-Pointers Made', '@play3PM'), ('Three-Pointers Attempted', '@play3PA'), ('Three-Point Percentage','@pct3PM{00.0%}'), ] # Configure a renderer to be used upon hover hover_glyph = fig.circle(x='play3PA', y='pct3PM', source=three_takers_cds, size=15, alpha=0, hover_fill_color='black', hover_alpha=0.5) # Add the HoverTool to the figure fig.add_tools(HoverTool(tooltips=tooltips, renderers=[hover_glyph])) # Visualize show(fig)这是通过创建一个全新的字形来完成的,在这种情况下是圆形而不是方形,并将其分配给
hover_glyph。请注意,初始不透明度设置为零,因此在光标接触到它之前,它是不可见的。通过将hover_alpha和hover_fill_color一起设置为0.5来捕捉悬停时出现的属性。现在,当您将鼠标悬停在各种标记上时,您会看到一个黑色小圆圈出现在原始方块上:
要进一步了解
HoverTool()的功能,请参见悬停工具和悬停检查指南。链接轴和选择
链接是同步布局中不同可视化元素的过程。例如,您可能想要链接多个图的轴,以确保如果您放大一个图,它会反映在另一个图上。我们来看看是怎么做的。
对于这个例子,可视化将能够平移到球队赛程的不同部分,并检查各种比赛统计数据。每个统计数据都将在一个两两的
gridplot()中用它自己的图来表示。可以从
team_stats数据框架中收集数据,选择费城 76 人队作为感兴趣的球队:# Isolate relevant data phi_gm_stats = (team_stats[(team_stats['teamAbbr'] == 'PHI') & (team_stats['seasTyp'] == 'Regular')] .loc[:, ['gmDate', 'teamPTS', 'teamTRB', 'teamAST', 'teamTO', 'opptPTS',]] .sort_values('gmDate')) # Add game number phi_gm_stats['game_num'] = range(1, len(phi_gm_stats)+1) # Derive a win_loss column win_loss = [] for _, row in phi_gm_stats.iterrows(): # If the 76ers score more points, it's a win if row['teamPTS'] > row['opptPTS']: win_loss.append('W') else: win_loss.append('L') # Add the win_loss data to the DataFrame phi_gm_stats['winLoss'] = win_loss以下是 76 人队前 5 场比赛的结果:
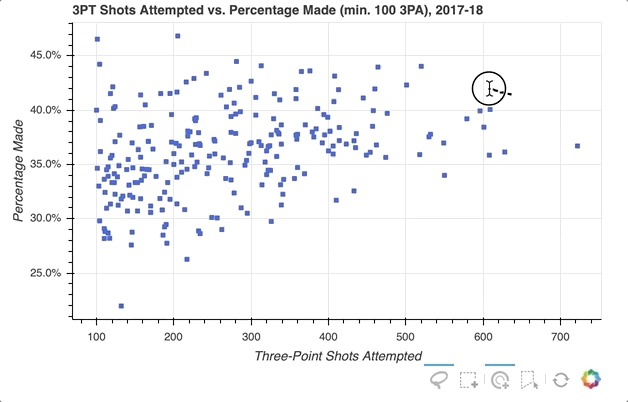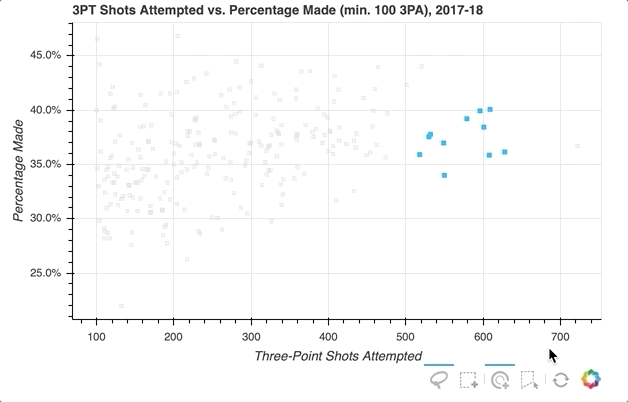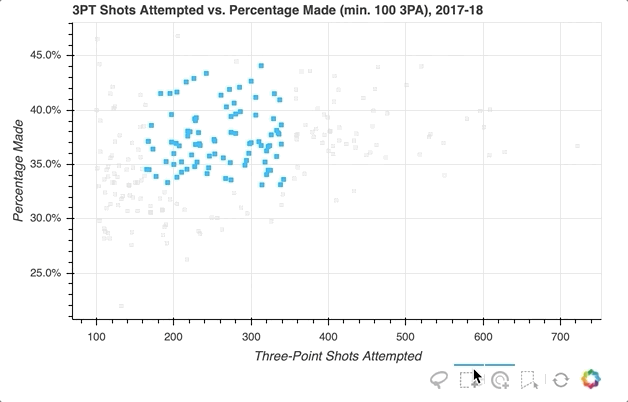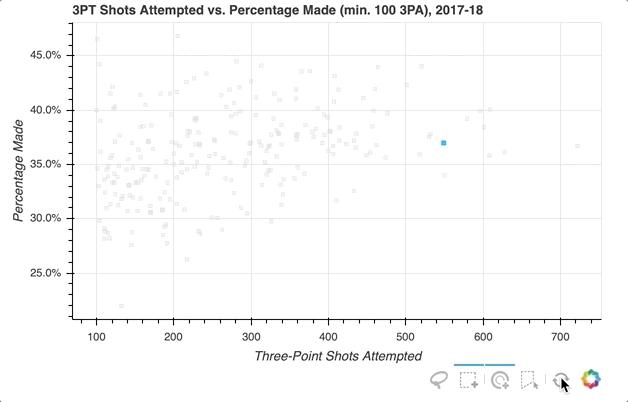
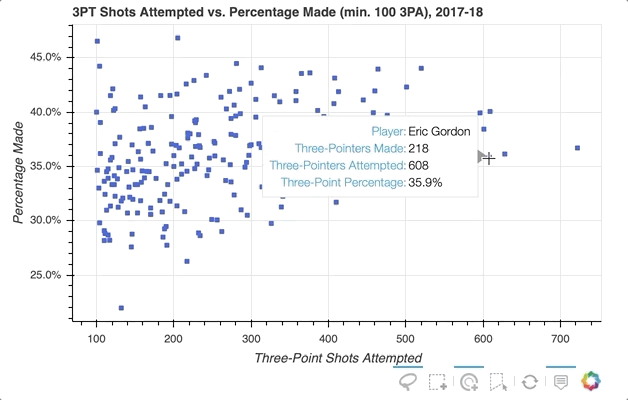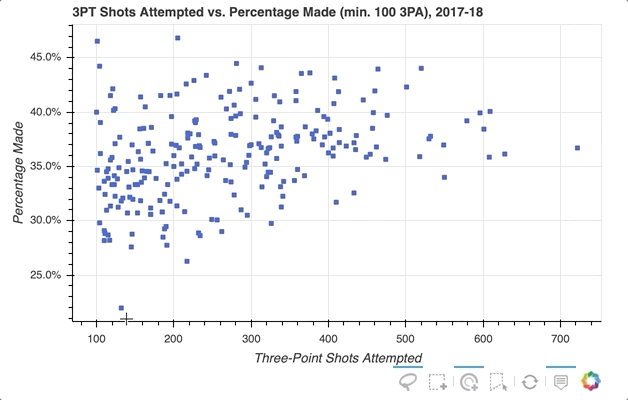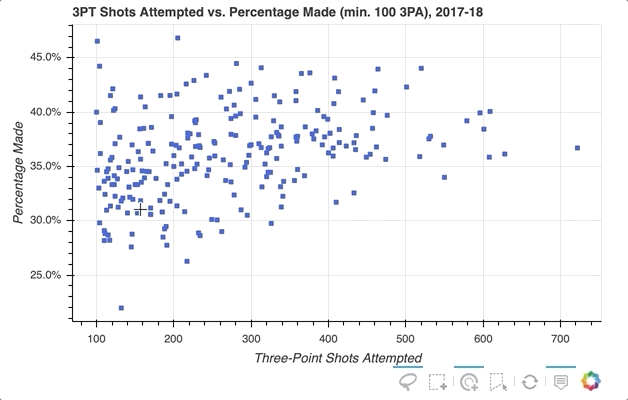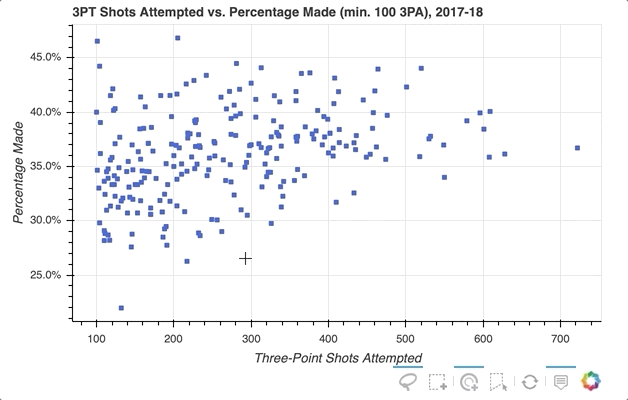
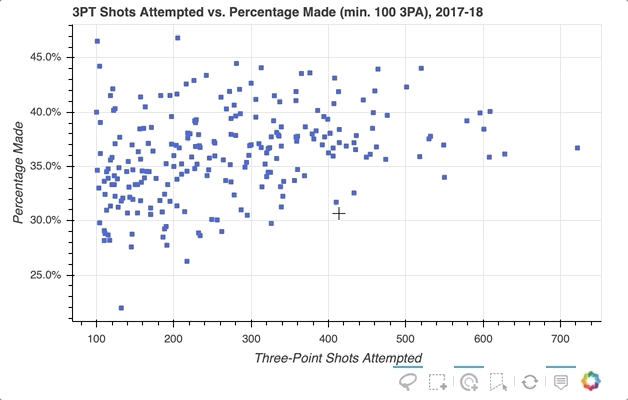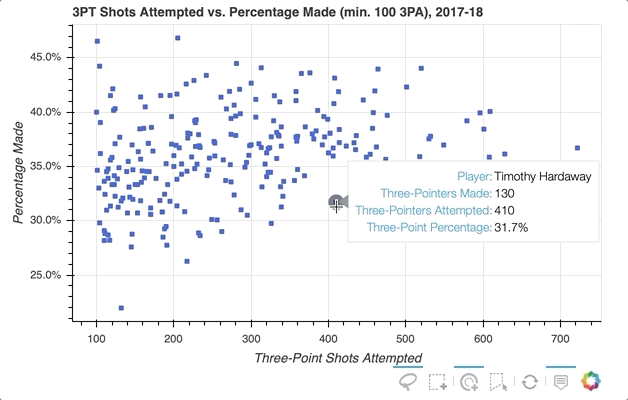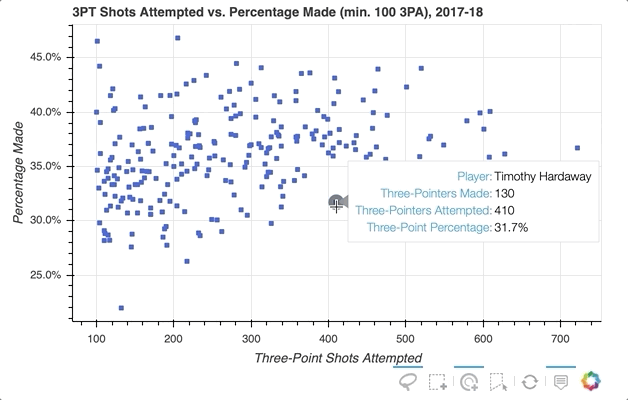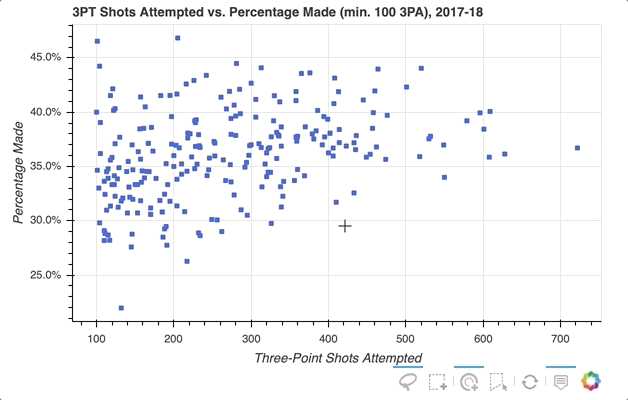
>>> phi_gm_stats.head()
gmDate teamPTS teamTRB teamAST teamTO opptPTS game_num winLoss
10 2017-10-18 115 48 25 17 120 1 L
39 2017-10-20 92 47 20 17 102 2 L
52 2017-10-21 94 41 18 20 128 3 L
80 2017-10-23 97 49 25 21 86 4 W
113 2017-10-25 104 43 29 16 105 5 L
首先导入必要的散景库,指定输出参数,并将数据读入ColumnDataSource:
# Bokeh Libraries
from bokeh.plotting import figure, show
from bokeh.io import output_file
from bokeh.models import ColumnDataSource, CategoricalColorMapper, Div
from bokeh.layouts import gridplot, column
# Output to file
output_file('phi-gm-linked-stats.html',
title='76ers Game Log')
# Store the data in a ColumnDataSource
gm_stats_cds = ColumnDataSource(phi_gm_stats)
每场比赛由一列表示,如果结果是赢,将显示为绿色,如果结果是输,将显示为红色。为此,可以使用散景的CategoricalColorMapper将数据值映射到指定的颜色:
# Create a CategoricalColorMapper that assigns a color to wins and losses
win_loss_mapper = CategoricalColorMapper(factors = ['W', 'L'],
palette=['green', 'red'])
对于这个用例,指定要映射的分类数据值的列表被传递给factors,带有预期颜色的列表被传递给palette。有关CategoricalColorMapper的更多信息,请参见 Bokeh 用户指南中处理分类数据的颜色部分。
在二乘二gridplot中有四个数据可以可视化:得分、助攻、篮板和失误。在创建这四个图并配置它们各自的图表时,属性中有很多冗余。因此,为了简化代码,可以使用一个for循环:
# Create a dict with the stat name and its corresponding column in the data
stat_names = {'Points': 'teamPTS',
'Assists': 'teamAST',
'Rebounds': 'teamTRB',
'Turnovers': 'teamTO',}
# The figure for each stat will be held in this dict
stat_figs = {}
# For each stat in the dict
for stat_label, stat_col in stat_names.items():
# Create a figure
fig = figure(y_axis_label=stat_label,
plot_height=200, plot_width=400,
x_range=(1, 10), tools=['xpan', 'reset', 'save'])
# Configure vbar
fig.vbar(x='game_num', top=stat_col, source=gm_stats_cds, width=0.9,
color=dict(field='winLoss', transform=win_loss_mapper))
# Add the figure to stat_figs dict
stat_figs[stat_label] = fig
如您所见,唯一需要调整的参数是图中的y-axis-label和将在vbar中指示top的数据。这些值可以很容易地存储在一个dict中,通过迭代该值来创建每个 stat 的数字。
你也可以在vbar字形的配置中看到CategoricalColorMapper的实现。向color属性传递一个dict,其中包含要映射的ColumnDataSource中的字段和上面创建的CategoricalColorMapper的名称。
初始视图将只显示 76 人赛季的前 10 场比赛,因此需要有一种方法来水平平移,以浏览赛季的其余比赛。因此,将工具栏配置为具有一个xpan工具,允许在整个绘图中平移,而不必担心视图沿垂直轴意外倾斜。
现在图形已经创建,可以参照上面创建的dict中的图形来设置gridplot:
# Create layout
grid = gridplot([[stat_figs['Points'], stat_figs['Assists']],
[stat_figs['Rebounds'], stat_figs['Turnovers']]])
连接四个图的轴就像设置每个图形的x_range彼此相等一样简单:
# Link together the x-axes
stat_figs['Points'].x_range = \
stat_figs['Assists'].x_range = \
stat_figs['Rebounds'].x_range = \
stat_figs['Turnovers'].x_range
要将标题栏添加到可视化中,您可以尝试在 points 图形上这样做,但是它会被限制在该图形的空间内。因此,一个很好的技巧是使用 Bokeh 解释 HTML 的能力来插入包含标题信息的Div元素。一旦创建完成,只需在column布局中将它与gridplot()组合起来:
# Add a title for the entire visualization using Div
html = """<h3>Philadelphia 76ers Game Log</h3>
<b><i>2017-18 Regular Season</i>
<br>
</b><i>Wins in green, losses in red</i>
"""
sup_title = Div(text=html)
# Visualize
show(column(sup_title, grid))
将所有部分放在一起会产生以下结果:
同样,您可以轻松实现链接选择,其中一个绘图上的选择将反映在其他绘图上。
为了了解这一点,下一个可视化将包含两个散点图:一个显示 76 人的两分与三分投篮命中率,另一个显示 76 人在每场比赛中的球队得分与对手得分。
目标是能够选择左侧散点图上的数据点,并能够快速识别右侧散点图上的相应数据点是赢还是输。
该可视化的数据框架与第一个示例中的数据框架非常相似:
# Isolate relevant data
phi_gm_stats_2 = (team_stats[(team_stats['teamAbbr'] == 'PHI') &
(team_stats['seasTyp'] == 'Regular')]
.loc[:, ['gmDate',
'team2P%',
'team3P%',
'teamPTS',
'opptPTS']]
.sort_values('gmDate'))
# Add game number
phi_gm_stats_2['game_num'] = range(1, len(phi_gm_stats_2) + 1)
# Derive a win_loss column
win_loss = []
for _, row in phi_gm_stats_2.iterrows():
# If the 76ers score more points, it's a win
if row['teamPTS'] > row['opptPTS']:
win_loss.append('W')
else:
win_loss.append('L')
# Add the win_loss data to the DataFrame
phi_gm_stats_2['winLoss'] = win_loss
数据看起来是这样的:
>>> phi_gm_stats_2.head() gmDate team2P% team3P% teamPTS opptPTS game_num winLoss 10 2017-10-18 0.4746 0.4286 115 120 1 L 39 2017-10-20 0.4167 0.3125 92 102 2 L 52 2017-10-21 0.4138 0.3333 94 128 3 L 80 2017-10-23 0.5098 0.3750 97 86 4 W 113 2017-10-25 0.5082 0.3333 104 105 5 L创建可视化的代码如下:
# Bokeh Libraries from bokeh.plotting import figure, show from bokeh.io import output_file from bokeh.models import ColumnDataSource, CategoricalColorMapper, NumeralTickFormatter from bokeh.layouts import gridplot # Output inline in the notebook output_file('phi-gm-linked-selections.html', title='76ers Percentages vs. Win-Loss') # Store the data in a ColumnDataSource gm_stats_cds = ColumnDataSource(phi_gm_stats_2) # Create a CategoricalColorMapper that assigns specific colors to wins and losses win_loss_mapper = CategoricalColorMapper(factors = ['W', 'L'], palette=['Green', 'Red']) # Specify the tools toolList = ['lasso_select', 'tap', 'reset', 'save'] # Create a figure relating the percentages pctFig = figure(title='2PT FG % vs 3PT FG %, 2017-18 Regular Season', plot_height=400, plot_width=400, tools=toolList, x_axis_label='2PT FG%', y_axis_label='3PT FG%') # Draw with circle markers pctFig.circle(x='team2P%', y='team3P%', source=gm_stats_cds, size=12, color='black') # Format the y-axis tick labels as percenages pctFig.xaxis[0].formatter = NumeralTickFormatter(format='00.0%') pctFig.yaxis[0].formatter = NumeralTickFormatter(format='00.0%') # Create a figure relating the totals totFig = figure(title='Team Points vs Opponent Points, 2017-18 Regular Season', plot_height=400, plot_width=400, tools=toolList, x_axis_label='Team Points', y_axis_label='Opponent Points') # Draw with square markers totFig.square(x='teamPTS', y='opptPTS', source=gm_stats_cds, size=10, color=dict(field='winLoss', transform=win_loss_mapper)) # Create layout grid = gridplot([[pctFig, totFig]]) # Visualize show(grid)这很好地说明了使用
ColumnDataSource的威力。只要字形渲染器(在这种情况下,百分比的circle字形和赢输的square字形)共享同一个ColumnDataSource,那么默认情况下选择将被链接。下面是它的实际效果,您可以看到在任一图形上所做的选择都会反映在另一个图形上:
通过在左散点图的右上象限中选择数据点的随机样本,那些对应于高两分和三分投篮命中率的数据点,右散点图上的数据点被突出显示。
类似地,在右侧散点图上选择对应于损失的数据点倾向于更靠近左下方,在左侧散点图上投篮命中率更低。
有关链接图的所有详细信息可以在散景用户指南的链接图中找到。
使用图例突出显示数据
这就把我们带到了本教程的最后一个交互例子:交互图例。
在用字形绘制数据部分,您看到了在创建绘图时实现图例是多么容易。有了图例,添加交互性只是分配一个
click_policy的问题。使用一行代码,您就可以使用图例快速地向hide或mute数据添加功能。在这个例子中,你会看到两个相同的散点图,比较勒布朗詹姆斯和凯文·杜兰特每场比赛的得分和篮板。唯一的区别将是一个使用一个
hide作为它的click_policy,而另一个使用mute。第一步是配置输出和设置数据,从
player_stats数据帧为每个玩家创建一个视图:# Bokeh Libraries from bokeh.plotting import figure, show from bokeh.io import output_file from bokeh.models import ColumnDataSource, CDSView, GroupFilter from bokeh.layouts import row # Output inline in the notebook output_file('lebron-vs-durant.html', title='LeBron James vs. Kevin Durant') # Store the data in a ColumnDataSource player_gm_stats = ColumnDataSource(player_stats) # Create a view for each player lebron_filters = [GroupFilter(column_name='playFNm', group='LeBron'), GroupFilter(column_name='playLNm', group='James')] lebron_view = CDSView(source=player_gm_stats, filters=lebron_filters) durant_filters = [GroupFilter(column_name='playFNm', group='Kevin'), GroupFilter(column_name='playLNm', group='Durant')] durant_view = CDSView(source=player_gm_stats, filters=durant_filters)在创建图形之前,可以将图形、标记和数据的公共参数合并到字典中并重复使用。这不仅在下一步中节省了冗余,而且提供了一种简单的方法来在以后需要时调整这些参数:
# Consolidate the common keyword arguments in dicts common_figure_kwargs = { 'plot_width': 400, 'x_axis_label': 'Points', 'toolbar_location': None, } common_circle_kwargs = { 'x': 'playPTS', 'y': 'playTRB', 'source': player_gm_stats, 'size': 12, 'alpha': 0.7, } common_lebron_kwargs = { 'view': lebron_view, 'color': '#002859', 'legend': 'LeBron James' } common_durant_kwargs = { 'view': durant_view, 'color': '#FFC324', 'legend': 'Kevin Durant' }既然已经设置了各种属性,就可以用更简洁的方式构建两个散点图:
# Create the two figures and draw the data hide_fig = figure(**common_figure_kwargs, title='Click Legend to HIDE Data', y_axis_label='Rebounds') hide_fig.circle(**common_circle_kwargs, **common_lebron_kwargs) hide_fig.circle(**common_circle_kwargs, **common_durant_kwargs) mute_fig = figure(**common_figure_kwargs, title='Click Legend to MUTE Data') mute_fig.circle(**common_circle_kwargs, **common_lebron_kwargs, muted_alpha=0.1) mute_fig.circle(**common_circle_kwargs, **common_durant_kwargs, muted_alpha=0.1)注意
mute_fig有一个额外的参数叫做muted_alpha。当mute用作click_policy时,该参数控制标记的不透明度。最后,设置每个图形的
click_policy,它们以水平配置显示:# Add interactivity to the legend hide_fig.legend.click_policy = 'hide' mute_fig.legend.click_policy = 'mute' # Visualize show(row(hide_fig, mute_fig))
一旦图例就位,您所要做的就是将
hide或mute分配给图形的click_policy属性。这将自动把你的基本图例变成一个交互式图例。还要注意,特别是对于
mute,muted_alpha的附加属性是在勒布朗·詹姆斯和凯文·杜兰特各自的circle字形中设置的。这决定了图例交互驱动的视觉效果。关于散景互动的更多信息,在散景用户指南中添加互动是一个很好的开始。
总结和后续步骤
恭喜你!您已经完成了本教程的学习。
现在,您应该有了一套很好的工具,可以开始使用散景将您的数据转化为漂亮的交互式可视化效果。您可以从 Real Python GitHub repo 下载示例和代码片段。
您学习了如何:
- 配置您的脚本以呈现静态 HTML 文件或 Jupyter 笔记本
- 实例化并定制
figure()对象- 使用字形构建可视化
- 使用
ColumnDataSource访问和过滤您的数据- 在网格和选项卡布局中组织多个图
- 添加不同形式的交互,包括选择、悬停动作、链接和交互图例
为了探索更多的散景功能,官方的散景用户指南是深入探讨一些更高级主题的绝佳场所。我还建议去散景画廊看看大量的例子和灵感。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用散景在 Python 中交互数据可视化*********
使用 Python datetime 处理日期和时间
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 的 datetime 模块
处理日期和时间是编程中最大的挑战之一。在处理时区、夏令时和不同的书面日期格式之间,很难记住您所指的日期和时间。幸运的是,内置的 Python
datetime模块可以帮助您管理复杂的日期和时间。在本教程中,您将学习:
- 为什么用日期和时间编程如此具有挑战性
- Python
datetime模块中有哪些函数- 如何以特定格式打印或读取日期和时间
- 如何用日期和时间做算术
此外,您将开发一个简洁的应用程序来倒数到下一次 PyCon US 的剩余时间!
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
我们开始吧!
用日期和时间编程
如果您曾经开发过需要跨几个地理区域记录时间的软件,那么您可能会理解为什么用时间编程会如此痛苦。最根本的脱节是计算机程序更喜欢完全有序和有规律的事件,但大多数人使用和指代时间的方式是非常不规则的。
注意:如果你想了解更多为什么时间会如此复杂,那么网络上有很多很好的资源。这里有几个好的起点:
- 电脑爱好者:时间的问题&时区
- 使用时区:你希望不需要知道的一切
- 时间数据编程的复杂性
这种不规则性的一个很好的例子就是 夏令时 。在美国和加拿大,时钟在三月的第二个星期天拨快一小时,在十一月的第一个星期天拨慢一小时。然而,这只是自 2007 年以来的情况。在 2007 年之前,时钟在 4 月的第一个星期天向前拨,在 10 月的最后一个星期天向后拨。
当你考虑到 时区 时,事情变得更加复杂。理想情况下,时区的边界应该完全沿着经度线。然而,由于历史和政治原因,时区线很少是直的。通常,相距很远的区域位于同一时区,而相邻的区域位于不同的时区。有些时区的有着非常时髦的形状。
计算机如何计算时间
几乎所有的计算机都从一个叫做 Unix 纪元 的瞬间开始计时。这发生在 1970 年 1 月 1 日 00:00:00 UTC。UTC 代表 协调世界时 ,是指经度 0°的时间。UTC 通常也被称为格林威治标准时间,或 GMT。UTC 不根据夏令时进行调整,所以它始终保持每天 24 小时。
根据定义,Unix 时间以与 UTC 相同的速率流逝,因此 UTC 中的一秒对应于 Unix 时间中的一秒。通过计算自 Unix 纪元以来的秒数,通常可以计算出自 1970 年 1 月 1 日以来任何给定时刻的 UTC 日期和时间,但 闰秒 除外。闰秒偶尔会添加到 UTC 中,以解释地球自转变慢的原因,但不会添加到 Unix 时间中。
注意:有一个关于 Unix 时间的有趣错误。由于许多较老的操作系统是 32 位的,所以它们将 Unix 时间存储在 32 位有符号整数中。
这意味着在 2038 年 1 月 19 日 03:14:07,整数将溢出,导致所谓的年 2038 问题,或 Y2038。与 Y2K 问题类似,2038 年也需要修正,以避免对关键系统造成灾难性后果。
几乎所有的编程语言,包括 Python ,都包含了 Unix 时间的概念。Python 的标准库包括一个名为
time的模块,它可以打印自 Unix 纪元以来的秒数:
>>> import time
>>> time.time()
1579718137.550164
在这个例子中,您导入 time模块中的并执行 time() 来打印 Unix 时间,或者从 epoch 开始的秒数(不包括闰秒)。
除了 Unix 时间,计算机还需要一种向用户传达时间信息的方式。正如您在上一个例子中看到的,Unix 时间对于人来说几乎是不可能解析的。相反,Unix 时间通常被转换为 UTC,然后可以使用时区偏移量将其转换为本地时间。
互联网数字地址分配机构(IANA) 维护着一个包含所有时区偏移量的数据库。IANA 还发布定期更新,包括时区偏移的任何变化。该数据库通常包含在您的操作系统中,尽管某些应用程序可能包含更新的副本。
该数据库包含所有指定时区的副本,以及它们与 UTC 相差多少小时和分钟。因此,在冬季,当夏令时无效时,美国东部时区的时差为-05:00,即比 UTC 时间晚 5 个小时。其他地区有不同的偏移量,可能不是整数小时。例如,尼泊尔的 UTC 时差为+05:45,即比 UTC 时差 5 小时 45 分。
如何报告标准日期
Unix 时间是计算机计算时间的方式,但是对于人类来说,通过计算任意日期的秒数来确定时间是非常低效的。相反,我们按照年、月、日等等来工作。但是即使有了这些约定,另一层复杂性源于不同的语言和文化有不同的书写日期的方式。
例如,在美国,日期通常以月开始,然后是日,最后是年。这意味着 2020 年 1 月 31 日写成 01-31-2020 。这与日期的长形式书面版本非常匹配。
然而,欧洲的大部分地区和许多其他地区都是以日开始写日期,然后是月,然后是年。这意味着 2020 年 1 月 31 日写成 31-01-2020 。当跨文化交流时,这些差异会引起各种各样的困惑。
为了帮助避免沟通错误,国际标准化组织(ISO)开发了【ISO 8601】。本标准规定,所有日期都应该按照从最重要到最不重要的顺序书写。这意味着格式是年、月、日、小时、分钟和秒:
YYYY-MM-DD HH:MM:SS
在这个例子中,YYYY代表四位数的年份,MM和DD是两位数的月和日,必要时可以从零开始。之后,HH、MM和SS表示两位数的小时、分钟和秒,必要时以零开始。
这种格式的优点是可以清楚地表示日期。如果日期是有效的月份号,那么写为DD-MM-YYYY或MM-DD-YYYY的日期可能会被误解。稍后在你会看到一点点你如何在 Python datetime中使用 ISO 8601 格式。
时间应该如何存储在你的程序中
大多数与时间打交道的开发人员都听过将本地时间转换为 UTC 并存储该值以供以后参考的建议。在许多情况下,尤其是当您存储过去的日期时,这些信息足以进行任何必要的运算。
但是,如果程序的用户以当地时间输入未来的日期,就会出现问题。时区和夏令时规则变化相当频繁,正如您之前看到的 2007 年美国和加拿大夏令时的变化。如果用户所在位置的时区规则在他们输入的未来日期之前发生了变化,那么 UTC 将不会提供足够的信息来转换回正确的当地时间。
注意:有许多优秀的资源可以帮助您确定在应用程序中存储时间数据的适当方式。这里有几个地方可以开始:
- 夏令时和时区最佳实践
- 存储 UTC 不是灵丹妙药
- 如何为未来事件保存日期时间
- 中使用日期时间的编码最佳实践。NET 框架
在这种情况下,您需要存储用户输入的本地时间,包括时区,以及用户保存时间时有效的 IANA 时区数据库的版本。这样,您总是能够将本地时间转换为 UTC。然而,这种方法并不总是允许您将 UTC 转换为正确的本地时间。
使用 Python datetime模块
如您所见,在编程中处理日期和时间可能很复杂。幸运的是,现在你很少需要从头实现复杂的特性,因为有很多开源库可以帮助你。Python 就是这种情况,它在标准库中包括三个独立的模块来处理日期和时间:
在本教程中,你将重点使用 Python datetime 模块。datetime的主要目的是降低访问与日期、时间和时区相关的对象属性的复杂性。由于这些对象非常有用,calendar也从datetime返回类的实例。
time 不如datetime强大,使用起来更复杂。time中的许多函数返回一个特殊的 struct_time 实例。这个对象有一个名为 tuple 的接口,用于访问存储的数据,使其类似于datetime的一个实例。然而,它并不支持datetime的所有特性,尤其是对时间值执行算术运算的能力。
datetime提供了三个类,组成了大多数人都会使用的高级接口:
datetime.date是一个理想化的日期,假设公历无限延伸到未来和过去。这个对象将year、month和day存储为属性。datetime.time是一个理想化的时间,假设每天有 86,400 秒,没有闰秒。这个对象存储了hour、minute、second、microsecond和tzinfo(时区信息)。datetime.datetime是一个date和一个time的组合。它具有这两个类的所有属性。
创建 Python datetime实例
在datetime中代表日期和时间的三个类有相似的 初始值设定项 。它们可以通过为每个属性传递关键字参数来实例化,比如year、date或hour。您可以尝试下面的代码来了解每个对象是如何创建的:
>>> from datetime import date, time, datetime >>> date(year=2020, month=1, day=31) datetime.date(2020, 1, 31) >>> time(hour=13, minute=14, second=31) datetime.time(13, 14, 31) >>> datetime(year=2020, month=1, day=31, hour=13, minute=14, second=31) datetime.datetime(2020, 1, 31, 13, 14, 31)在这段代码中,您从
datetime和导入三个主要类,通过向构造函数传递参数来实例化它们中的每一个。您可以看到这段代码有些冗长,如果您没有所需的信息作为整数,这些技术就不能用于创建datetime实例。幸运的是,
datetime提供了其他几种创建datetime实例的方便方法。这些方法不要求您使用整数来指定每个属性,而是允许您使用一些其他信息:
date.today()用当前本地日期创建一个datetime.date实例。datetime.now()用当前的本地日期和时间创建一个datetime.datetime实例。datetime.combine()将datetime.date和datetime.time的实例组合成一个datetime.datetime实例。当您事先不知道需要向基本初始化器传递什么信息时,这三种创建
datetime实例的方法很有帮助。您可以尝试这段代码,看看替代的初始化器是如何工作的:
>>> from datetime import date, time, datetime
>>> today = date.today()
>>> today
datetime.date(2020, 1, 24)
>>> now = datetime.now()
>>> now
datetime.datetime(2020, 1, 24, 14, 4, 57, 10015)
>>> current_time = time(now.hour, now.minute, now.second)
>>> datetime.combine(today, current_time)
datetime.datetime(2020, 1, 24, 14, 4, 57)
在这段代码中,您使用date.today()、datetime.now()和datetime.combine()来创建date、datetime和time对象的实例。每个实例存储在不同的变量中:
today是一个只有年、月和日的date实例。now是具有年、月、日、小时、分钟、秒和微秒的datetime实例。current_time是一个time实例,它的小时、分钟和秒设置为与now相同的值。
在最后一行,您将today中的日期信息与current_time中的时间信息结合起来,产生一个新的datetime实例。
警告: datetime还提供了datetime.utcnow(),在当前 UTC 返回一个datetime的实例。然而,Python 文档建议不要使用这种方法,因为它在结果实例中不包含任何时区信息。
当在datetime实例之间做算术或比较时,使用datetime.utcnow()可能会产生一些令人惊讶的结果。在后面的章节中,您将看到如何为datetime实例分配时区信息。
使用字符串创建 Python datetime实例
创建date实例的另一种方法是使用 .fromisoformat() 。要使用这个方法,您需要提供一个带有 ISO 8601 格式日期的字符串,您之前已经了解了和。例如,您可以提供一个指定了年、月和日的字符串:
2020-01-31
根据 ISO 8601 格式,此字符串表示日期 2020 年 1 月 31 日。您可以用下面的例子创建一个date实例:
>>> from datetime import date >>> date.fromisoformat("2020-01-31") datetime.date(2020, 1, 31)在这段代码中,您使用
date.fromisoformat()为 2020 年 1 月 31 日创建一个date实例。这种方法非常有用,因为它是基于 ISO 8601 标准的。但是,如果您有一个表示日期和时间的字符串,但不是 ISO 8601 格式的,该怎么办呢?幸运的是,Python
datetime提供了一个名为.strptime()的方法来处理这种情况。这个方法使用一种特殊的小型语言来告诉 Python 字符串的哪些部分与datetime属性相关联。要使用
.strptime()从一个字符串构造一个datetime,您必须使用迷你语言的格式化代码告诉 Python 字符串的每个部分代表什么。你可以试试这个例子,看看.strptime()是如何运作的:
1>>> date_string = "01-31-2020 14:45:37"
2>>> format_string = "%m-%d-%Y %H:%M:%S"
在的第 1 行,您创建了date_string,它表示 2020 年 1 月 31 日下午 2:45:37 的日期和时间。在的第 2 行,您创建了format_string,它使用迷你语言来指定如何将date_string的各个部分转化为datetime属性。
在format_string中,您包括几个格式代码和所有的破折号(-)、冒号(:)和空格,就像它们在date_string中出现的一样。要处理date_string中的日期和时间,需要包含以下格式代码:
| 成分 | 密码 | 价值 |
|---|---|---|
| 年份(四位数整数) | %Y |
Two thousand and twenty |
| 月份(以零填充的小数形式) | %m |
01 |
| 日期(以零填充的小数形式) | %d |
Thirty-one |
| 小时(以 24 小时制零填充十进制表示) | %H |
Fourteen |
| 分钟(以零填充的小数形式) | %M |
Forty-five |
| 秒(以零填充的小数形式) | %S |
Thirty-seven |
迷你语言中所有选项的完整列表超出了本教程的范围,但是你可以在网上找到一些好的参考资料,包括 Python 的文档和一个名为 strftime.org的网站。
既然已经定义了date_string和format_string,您可以使用它们来创建一个datetime实例。这里有一个.strptime()如何工作的例子:
3>>> from datetime import datetime 4>>> datetime.strptime(date_string, format_string) 5datetime.datetime(2020, 1, 31, 14, 45, 37)在这段代码中,您在第 3 行的上导入
datetime,并在第 4 行的上使用带有date_string和format_string的datetime.strptime()。最后,第 5 行显示了由.strptime()创建的datetime实例中的属性值。您可以看到它们与上表中显示的值相匹配。注意:创建
datetime实例有更高级的方法,但是它们涉及到使用必须安装的第三方库。一个特别简洁的库叫做dateparser,它允许你提供自然语言的字符串输入。输入甚至支持多种语言:
1>>> import dateparser
2>>> dateparser.parse("yesterday")
3datetime.datetime(2020, 3, 13, 14, 39, 1, 350918)
4>>> dateparser.parse("morgen")
5datetime.datetime(2020, 3, 15, 14, 39, 7, 314754)
在这段代码中,您使用dateparser通过传递两个不同的时间字符串表示来创建两个datetime实例。在第 1 行,你导入dateparser。然后,在第 2 行的上,您使用带有参数"yesterday"的.parse()来创建一个过去 24 小时的datetime实例。写这篇文章时,这是 2020 年 3 月 13 日,下午 2 点 39 分。
在的第 3 行,你用.parse()和参数"morgen"。 Morgen 在德语中是明天的意思,所以dateparser在未来 24 小时创建一个datetime实例。在撰写本文时,这是 3 月 15 日下午 2 点 39 分。
开始你的 PyCon 倒计时
现在你已经有足够的信息开始为明年的 PyCon US 倒计时钟工作了!PyCon US 2021 将于 2021 年 5 月 12 日在宾夕法尼亚州匹兹堡开幕。随着 2020 年的活动被取消,许多蟒蛇对明年的聚会格外兴奋。这是记录你需要等待多长时间的好方法,同时还能提升你的datetime技能!
首先,创建一个名为pyconcd.py的文件,并添加以下代码:
# pyconcd.py
from datetime import datetime
PYCON_DATE = datetime(year=2021, month=5, day=12, hour=8)
countdown = PYCON_DATE - datetime.now()
print(f"Countdown to PyCon US 2021: {countdown}")
在这段代码中,您从datetime导入datetime并定义一个常量PYCON_DATE,它存储下一个 PyCon US 的日期。你不希望 PyCon 的日期改变,所以你用大写字母命名变量,以表明它是一个常数。
接下来,计算datetime.now(),即当前时间和PYCON_DATE之间的差值。取两个datetime实例之间的差返回一个 datetime.timedelta 实例。
timedelta实例表示两个datetime实例之间的时间变化。名称中的 delta 是对希腊字母 delta 的引用,在科学和工程中用来表示变化。稍后你会学到更多关于如何使用timedelta进行更一般的算术运算的。
最后,截至 2020 年 4 月 9 日晚上 9:30 之前的打印输出是:
Countdown to PyCon US 2021: 397 days, 10:35:32.139350
距离 PyCon US 2021 只有 397 天了!这个输出有点笨拙,所以稍后您将看到如何改进格式。如果您在不同的日子运行这个脚本,您将得到不同的输出。如果您在 2021 年 5 月 12 日上午 8:00 运行该脚本,您将获得负剩余时间!
使用时区
如前所述,存储日期所在的时区是确保代码正确的一个重要方面。Python datetime提供了tzinfo,这是一个抽象基类,允许datetime.datetime和datetime.time包含时区信息,包括夏令时的概念。
然而,datetime没有提供与 IANA 时区数据库交互的直接方式。Python datetime.tzinfo文档推荐使用名为dateutil的第三方包。可以用 pip 安装dateutil:
$ python -m pip install python-dateutil
请注意,您从 PyPI 安装的包的名称python-dateutil不同于您用来导入包的名称,后者只是dateutil。
使用dateutil将时区添加到 Python datetime
dateutil如此有用的一个原因是它包括一个到 IANA 时区数据库的接口。这消除了为您的datetime实例分配时区的麻烦。试试这个例子,看看如何设置一个datetime实例,使其符合您的本地时区:
>>> from dateutil import tz >>> from datetime import datetime >>> now = datetime.now(tz=tz.tzlocal()) >>> now datetime.datetime(2020, 1, 26, 0, 55, 3, 372824, tzinfo=tzlocal()) >>> now.tzname() 'Eastern Standard Time'在这个例子中,您从
dateutil导入tz,从datetime导入datetime。然后使用.now()创建一个设置为当前时间的datetime实例。您还将关键字
tz传递给.now(),并将tz设置为等于tz.tzlocal()。在dateutil中,tz.tzlocal()返回datetime.tzinfo的一个具体实例。这意味着它可以表示datetime需要的所有必要的时区偏移和夏令时信息。您还可以使用
.tzname()打印时区名称,它会打印'Eastern Standard Time'。这是 Windows 的输出,但是在 macOS 或 Linux 上,如果您在美国东部时区的冬天,您的输出可能是'EST'。您也可以创建与您的计算机报告的时区不同的时区。为此,您将使用
tz.gettz()并传递您感兴趣的时区的官方 IANA 名称。这里有一个如何使用tz.gettz()的例子:
>>> from dateutil import tz
>>> from datetime import datetime
>>> London_tz = tz.gettz("Europe/London")
>>> now = datetime.now(tz=London_tz)
>>> now
datetime.datetime(2020, 1, 26, 6, 14, 53, 513460, tzinfo=tzfile('GB-Eire'))
>>> now.tzname()
'GMT'
在本例中,您使用tz.gettz()检索英国伦敦的时区信息,并将其存储在London_tz中。然后检索当前时间,将时区设置为London_tz。
在 Windows 上,这给了属性tzinfo值tzfile('GB-Eire')。在 macOS 或 Linux 上,tzinfo属性看起来类似于tzfile('/usr/share/zoneinfo/Europe/London),但是根据dateutil从哪里提取时区数据,它可能会略有不同。
您还使用tzname()打印时区的名称,现在是'GMT',意思是格林威治标准时间。这个输出在 Windows、macOS 和 Linux 上是相同的。
在前面的章节中,您了解到不应该使用.utcnow()在当前的 UTC 创建一个datetime实例。现在您知道了如何使用dateutil.tz向datetime实例提供时区。这里有一个修改自 Python 文档中的建议的例子:
>>> from dateutil import tz >>> from datetime import datetime >>> datetime.now(tz=tz.UTC) datetime.datetime(2020, 3, 14, 19, 1, 20, 228415, tzinfo=tzutc())在这段代码中,您使用
tz.UTC将datetime.now()的时区设置为 UTC 时区。相比使用utcnow(),推荐使用这种方法,因为utcnow()返回一个朴素datetime实例,而这里演示的方法返回一个感知datetime实例。接下来,您将绕一小段路来了解天真的与清醒的
datetime实例。如果你已经知道了这一切,那么你可以跳过来用时区信息改进你的 PyCon 倒计时。比较幼稚和有意识的 Python
datetime实例Python
datetime实例支持两种类型的操作,简单操作和感知操作。它们之间的基本区别是简单实例不包含时区信息,而感知实例包含时区信息。更正式地说,引用 Python 文档:一个有意识的物体代表了一个不可解释的特定时刻。简单对象不包含足够的信息来明确地定位自己相对于其他日期/时间对象的位置。(来源)
这是使用 Python
datetime的一个重要区别。一个感知的datetime实例可以明确地将其自身与其他感知的datetime实例进行比较,并且在算术运算中使用时将总是返回正确的时间间隔。天真的
datetime相反,实例可能是模棱两可的。这种模糊性的一个例子与夏令时有关。实行夏令时的地区在春季将时钟向前拨一小时,在秋季将时钟向后拨一小时。这通常发生在当地时间凌晨 2:00。在春天,从凌晨 2:00 到 2:59 的时间从不发生,在秋天,从凌晨 1:00 到 1:59 的时间发生两次!实际上,这些时区与 UTC 的时差在一年中会发生变化。IANA 跟踪这些变化,并将它们编入计算机上安装的不同数据库文件中。使用像
dateutil这样的库,它在幕后使用 IANA 数据库,是确保您的代码正确处理时间算术的一个好方法。注意:在 Python 中,naive 和 aware
datetime实例的区别是由tzinfo属性决定的。一个 awaredatetime实例的tzinfo属性等同于datetime.tzinfo抽象基类的一个子类。Python 3.8 及以下版本提供了
tzinfo的一个具体实现,称为timezone。然而,timezone仅限于表示 UTC 的固定偏移量,一年中不会改变,所以当您需要考虑夏令时之类的变化时,它就没什么用了。Python 3.9 包含了一个名为
zoneinfo的新模块,它提供了跟踪 IANA 数据库的tzinfo的具体实现,因此它包含了像夏令时这样的变化。然而,在 Python 3.9 被广泛使用之前,如果你需要支持多个 Python 版本,依靠dateutil可能是有意义的。
dateutil还提供了您之前使用的tz模块中tzinfo的几个具体实现。你可以查看dateutil.tz文档了解更多信息。这并不意味着您总是需要使用 aware
datetime实例。但是,如果你在相互比较时间,尤其是在比较世界不同地区的时间时,感知实例是至关重要的。提高你的 PyCon 倒计时
既然您已经知道了如何向 Python
datetime实例添加时区信息,那么您就可以改进您的 PyCon 倒计时代码了。之前,您使用了标准的datetime构造函数来传递 PyCon 将启动的年、月、日和小时。您可以更新您的代码来使用dateutil.parser模块,它为创建datetime实例提供了一个更自然的界面:# pyconcd.py from dateutil import parser, tz from datetime import datetime PYCON_DATE = parser.parse("May 12, 2021 8:00 AM") PYCON_DATE = PYCON_DATE.replace(tzinfo=tz.gettz("America/New_York")) now = datetime.now(tz=tz.tzlocal()) countdown = PYCON_DATE - now print(f"Countdown to PyCon US 2021: {countdown}")在这段代码中,您从
dateutil导入parser和tz,从datetime导入datetime。接下来,使用parser.parse()从字符串中读取下一个 PyCon US 的日期。这比普通的datetime构造函数可读性更好。
parser.parse()返回一个简单的datetime实例,所以您使用.replace()将tzinfo更改为America/New_York时区。PyCon US 2021 将在美国东部时区宾夕法尼亚州的匹兹堡举行。该时区的标准名称是America/New_York,因为纽约市是该时区最大的城市。
PYCON_DATE是一个 awaredatetime实例,其时区设置为美国东部时间。由于 5 月 12 日是夏令时生效后,时区名称为'EDT',或'Eastern Daylight Time'。接下来,创建
now来表示当前时刻,并将其作为您的本地时区。最后,找到PYCON_DATE和now之间的timedelta,并打印结果。如果您所在的地区没有根据夏令时调整时钟,那么您可能会看到 PyCon 改变一小时之前的剩余小时数。用 Python
datetime做算术Python
datetime实例支持几种类型的算法。正如您之前看到的,这依赖于使用timedelta实例来表示时间间隔。timedelta非常有用,因为它内置于 Python 标准库中。这里有一个如何使用timedelta的例子:
>>> from datetime import datetime, timedelta
>>> now = datetime.now()
>>> now
datetime.datetime(2020, 1, 26, 9, 37, 46, 380905)
>>> tomorrow = timedelta(days=+1)
>>> now + tomorrow
datetime.datetime(2020, 1, 27, 9, 37, 46, 380905)
在这段代码中,您创建了存储当前时间的now和存储+1天的timedelta的tomorrow。接下来,添加now和tomorrow来产生未来某一天的datetime实例。请注意,使用简单的datetime实例,就像您在这里一样,意味着datetime的day属性增加 1,并且不考虑任何重复或跳过的时间间隔。
timedelta实例也支持负值作为参数的输入:
>>> yesterday = timedelta(days=-1) >>> now + yesterday datetime.datetime(2020, 1, 25, 9, 37, 46, 380905)在这个例子中,您提供了
-1作为timedelta的输入,所以当您添加now和yesterday时,结果是在days属性中减少 1。实例支持加法和减法以及所有参数的正整数和负整数。你甚至可以提供正反两面的观点。例如,您可能想加上三天,减去四小时:
>>> delta = timedelta(days=+3, hours=-4)
>>> now + delta
datetime.datetime(2020, 1, 29, 5, 37, 46, 380905)
在本例中,您加上三天,减去四小时,因此新的datetime是 1 月 29 日上午 5:37。timedelta在这种方式下非常有用,但是它有一定的局限性,因为它不能加减大于一天的时间间隔,比如一个月或一年。幸运的是,dateutil提供了一个更强大的替代品叫做 relativedelta 。
relativedelta的基本语法和timedelta非常相似。您可以提供产生任意数量的年、月、日、小时、秒或微秒变化的关键字参数。您可以用这段代码重现第一个timedelta示例:
>>> from dateutil.relativedelta import relativedelta >>> tomorrow = relativedelta(days=+1) >>> now + tomorrow datetime.datetime(2020, 1, 27, 9, 37, 46, 380905)在这个例子中,你用
relativedelta而不是timedelta来寻找明天对应的datetime。现在你可以试着给now加上五年一个月零三天,同时减去四小时三十分钟:
>>> delta = relativedelta(years=+5, months=+1, days=+3, hours=-4, minutes=-30)
>>> now + delta
datetime.datetime(2025, 3, 1, 5, 7, 46, 380905)
请注意,在此示例中,日期结束于 2025 年 3 月 1 日。这是因为给now加三天就是 1 月 29 日,再加一个月就是 2 月 29 日,这一天只存在于闰年。因为 2025 年不是闰年,所以日期会滚动到下个月。
您还可以使用relativedelta来计算两个datetime实例之间的差异。在前面,您使用了减法运算符来查找两个 Python 实例datetime、PYCON_DATE和now之间的差异。使用relativedelta,您需要将两个datetime实例作为参数传递,而不是使用减法运算符:
>>> now datetime.datetime(2020, 1, 26, 9, 37, 46, 380905) >>> tomorrow = datetime(2020, 1, 27, 9, 37, 46, 380905) >>> relativedelta(now, tomorrow) relativedelta(days=-1)在这个例子中,您通过将
days字段加 1 来为tomorrow创建一个新的datetime实例。然后,使用relativedelta并传递now和tomorrow作为两个参数。dateutil然后取这两个datetime实例之间的差,并将结果作为relativedelta实例返回。在这种情况下,差异是-1天,因为now发生在tomorrow之前。物体还有无数其他用途。您可以使用它们来查找复杂的日历信息,例如下一年的 10 月 13 日是星期五,或者当月的最后一个星期五是几号。您甚至可以使用它们来替换一个
datetime实例的属性,并创建一个datetime,例如,在未来一周的上午 10:00。你可以在dateutil文档中了解所有这些其他用途。完成你的 PyCon 倒计时
你现在已经有足够的工具来完成你的 PyCon 2021 倒计时钟,并且提供了一个很好的界面来使用。在本节中,您将使用
relativedelta来计算离 PyCon 还有多长时间,开发一个函数来以漂亮的格式打印剩余时间,并向用户显示 PyCon 的日期。在您的 PyCon 倒计时中使用
relativedelta首先,用
relativedelta代替普通的减法运算符。使用减法运算符,您的timedelta对象无法计算大于一天的时间间隔。但是,relativedelta允许您显示剩余的年、月和日:1# pyconcd.py 2 3from dateutil import parser, tz 4from dateutil.relativedelta import relativedelta 5from datetime import datetime 6 7PYCON_DATE = parser.parse("May 12, 2021 8:00 AM") 8PYCON_DATE = PYCON_DATE.replace(tzinfo=tz.gettz("America/New_York")) 9now = datetime.now(tz=tz.tzlocal()) 10 11countdown = relativedelta(PYCON_DATE, now) 12print(f"Countdown to PyCon US 2021: {countdown}")您在这段代码中所做的唯一更改是用
countdown = relativedelta(PYCON_DATE, now)替换第 11 行的。这个脚本的输出应该告诉您 PyCon US 2021 将在大约一年零一个月后发生,这取决于您何时运行该脚本。然而,输出并不是很漂亮,因为它看起来像是
relativedelta()的签名。您可以通过用下面的代码替换前面代码中的第 11 行来构建一些更漂亮的输出:11def time_amount(time_unit: str, countdown: relativedelta) -> str: 12 t = getattr(countdown, time_unit) 13 return f"{t} {time_unit}" if t != 0 else "" 14 15countdown = relativedelta(PYCON_DATE, now) 16time_units = ["years", "months", "days", "hours", "minutes", "seconds"] 17output = (t for tu in time_units if (t := time_amount(tu, countdown))) 18print("Countdown to PyCon US 2021:", ", ".join(output))这段代码需要 Python 3.8,因为它使用了新的 海象运算符 。通过使用传统的
for循环代替第 17 行,可以让这个脚本在旧版本的 Python 上工作。在这段代码中,您定义了带有两个参数的
time_amount(),时间单位和应该从中检索时间单位的relativedelta实例。如果时间量不等于零,那么time_amount()返回一个带有时间量和时间单位的字符串。否则,它返回一个空字符串。你在第 17 行的理解中使用
time_amount()。那一行创建了一个 生成器 来存储从time_amount()返回的非空字符串。它使用 walrus 运算符将time_amount()的返回值赋给t,并且只有在True时才包含t。最后,行 18 使用发生器上的
.join()打印最终输出。接下来,您将看到在脚本的输出中包含 PyCon 日期。在 PyCon 倒计时中显示 PyCon 日期
在前面的中,您学习了如何使用
.strptime()创建datetime实例。这个方法使用 Python 中一种特殊的小型语言来指定日期字符串的格式。Python
datetime有一个额外的方法叫做.strftime(),它允许你将一个datetime实例格式化为一个字符串。从某种意义上说,这是使用.strptime()解析的逆向操作。你可以通过记住.strptime()中的p代表解析,而.strftime()中的f代表格式来区分这两种方法。在您的 PyCon 倒计时中,您可以使用
.strftime()来打印输出,让用户知道 PyCon US 将开始的日期。记住,你可以在strftime.org上找到你想要使用的格式化代码。现在将这段代码添加到 PyCon 倒计时脚本的第 18 行的处:18pycon_date_str = PYCON_DATE.strftime("%A, %B %d, %Y at %H:%M %p %Z") 19print(f"PyCon US 2021 will start on:", pycon_date_str) 20print("Countdown to PyCon US 2021:", ", ".join(output))在这段代码中,第 18 行使用
.strftime()创建一个表示 PyCon US 2021 开始日期的字符串。输出包括工作日、月、日、年、小时、分钟、上午或下午以及时区:Wednesday, May 12, 2021 at 08:00 AM EDT在第行第 19 处,您打印这个字符串,让用户看到一些解释文本。最后一行打印离 PyCon 开始日期的剩余时间。接下来,您将完成您的脚本,以便其他人可以更容易地重用它。
完成您的 PyCon 倒计时
你需要采取的最后一步是遵循 Python 最佳实践,将产生输出的代码放入
main()函数中。应用所有这些更改后,您可以签出完整的最终代码:1# pyconcd.py 2 3from dateutil import parser, tz 4from dateutil.relativedelta import relativedelta 5from datetime import datetime 6 7PYCON_DATE = parser.parse("May 12, 2021 8:00 AM") 8PYCON_DATE = PYCON_DATE.replace(tzinfo=tz.gettz("America/New_York")) 9 10def time_amount(time_unit: str, countdown: relativedelta) -> str: 11 t = getattr(countdown, time_unit) 12 return f"{t} {time_unit}" if t != 0 else "" 13 14def main(): 15 now = datetime.now(tz=tz.tzlocal()) 16 countdown = relativedelta(PYCON_DATE, now) 17 time_units = ["years", "months", "days", "hours", "minutes", "seconds"] 18 output = (t for tu in time_units if (t := time_amount(tu, countdown))) 19 pycon_date_str = PYCON_DATE.strftime("%A, %B %d, %Y at %H:%M %p %Z") 20 print(f"PyCon US 2021 will start on:", pycon_date_str) 21 print("Countdown to PyCon US 2021:", ", ".join(output)) 22 23if __name__ == "__main__": 24 main()在这段代码中,您将
print()和用于生成器的代码移动到main()中。在的第 23 行,你使用保护子句来确保main()只在这个文件作为脚本执行时运行。这允许其他人导入您的代码并重用PYCON_DATE,例如,如果他们愿意的话。现在,您可以随意修改这个脚本。一个简单的做法是允许用户通过传递一个命令行参数来改变与
now相关的时区。你也可以把PYCON_DATE改成离家更近的,比如说 PyCon Africa 或者europhon。要对 PyCon 更加兴奋,请在 PyCon US 2019 和查看真实 Python,了解如何充分利用 PyCon !
Python 的替代品
datetime和dateutil当您处理日期和时间时,Python
datetime和dateutil是强大的库组合。在 Python 文档中甚至推荐使用dateutil。然而,还有许多其他库可以用来处理 Python 中的日期和时间。其中一些依赖于datetime和dateutil,而另一些则是完全独立的替代品:
- pytz 提供类似
dateutil的时区信息。它使用了与标准datetime.tzinfo稍有不同的接口,所以如果你决定使用它,请注意潜在的问题。- 箭头 为
datetime提供了插播替换。它的灵感来自于moment.js,所以如果你是 web 开发出身,那么这可能是一个更熟悉的界面。- 摆 为
datetime提供了另一个插播替代。它包括一个时区接口和一个改进的timedelta实现。- Maya 提供了与
datetime类似的界面。它依赖于 Pendulum 的部分解析库。- dateparser 提供了从人类可读的文本中生成
datetime实例的接口。它很灵活,支持多种语言。此外,如果您大量使用 NumPy 、 Pandas 或其他数据科学软件包,那么有几个选项可能对您有用:
- NumPy 提供了与内置 Python
datetime库类似的 API,但是 NumPy 版本可以在数组中使用。- 熊猫 通过使用 NumPy
datetime模块为数据帧中的时序数据提供支持,通常是基于时间的事件的顺序值。- cftime 支持除公历以外的日历,以及其他符合气候和预测(CF)惯例的时间单位。它被
xarray包用来提供时序支持。延伸阅读
因为用时间编程可能非常复杂,所以网上有很多资源可以帮助你了解更多。幸运的是,这是许多使用每种编程语言的人都考虑过的问题,因此您通常可以找到信息或工具来帮助解决您可能遇到的任何问题。以下是一些精选的文章和视频,我发现它们对撰写本教程很有帮助:
- 夏令时和时区最佳实践
- 存储 UTC 不是灵丹妙药
- 如何为未来事件保存日期时间
- 中使用日期时间的编码最佳实践。NET 框架
- 电脑爱好者:时间的问题&时区
- 时间数据编程的复杂性
另外,Paul Ganssle 是 CPython 的核心贡献者,也是目前
dateutil的维护者。他的文章和视频对 Python 用户来说是一个很好的资源:结论
在本教程中,您学习了关于日期和时间的编程,以及为什么它经常导致错误和混乱。您还了解了 Python
datetime和dateutil模块,以及如何在代码中处理时区。现在你可以:
- 在你的程序中以一种良好的、经得起未来考验的格式存储日期
- 用格式化字符串创建 Python
datetime实例- 用
dateutil将时区信息添加到datetime实例中- 使用
relativedelta对datetime实例执行算术运算最后,您创建了一个脚本,该脚本倒数到下一次 PyCon US 的剩余时间,这样您就可以为最大的 Python 聚会感到兴奋了。日期和时间可能很棘手,但是有了这些 Python 工具,您就可以解决最棘手的问题了!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 的 datetime 模块*********
查找并修复 Python 中的代码错误:用 IDLE 调试
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 基础知识:查找并修复代码 bug
每个人都会犯错——即使是经验丰富的专业开发人员!Python 的交互式解释器 IDLE 非常擅长捕捉语法错误和运行时错误,但是还有第三种类型的错误,你可能已经经历过了。逻辑错误发生在一个原本有效的程序没有做预期的事情的时候。逻辑错误导致被称为bug的意外行为。去除 bug 叫做调试。
一个调试器是一个帮助你追踪 bug 并理解它们为什么会发生的工具。知道如何找到并修复代码中的 bug 是一项你将在整个编码生涯中使用的技能!
在本教程中,您将:
- 了解如何使用 IDLE 的调试控制窗口
- 练习在有问题的函数上调试
- 学习调试代码的替代方法
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“查找并修复代码 bug”一章。
该书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互,因此在整个教程中,您将会看到对 IDLE 内置调试工具的引用。但是,您应该能够将相同的概念应用到您选择的调试器中。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
使用调试控制窗口
IDLE 调试器的主界面是调试控制窗口,或简称为调试窗口。您可以通过从交互窗口的菜单中选择调试→调试器来打开调试窗口。继续并打开调试窗口。
注意:如果你的菜单栏中没有调试菜单,那么一定要点击它使交互窗口成为焦点。
每当调试窗口打开时,交互式窗口会在提示符旁边显示
[DEBUG ON],表示调试器已打开。现在打开一个新的编辑器窗口,在屏幕上排列这三个窗口,这样你就可以同时看到它们。在本节中,您将了解如何组织调试窗口,如何使用调试器一次一行地单步调试代码,以及如何设置断点来帮助加快调试过程。
调试控制窗口:概述
要了解调试器如何工作,您可以从编写一个没有任何错误的简单程序开始。在编辑器窗口中键入以下内容:
1for i in range(1, 4): 2 j = i * 2 3 print(f"i is {i} and j is {j}")保存文件,然后保持调试窗口打开并按下
F5。你会注意到执行并没有走多远。调试窗口将如下所示:
请注意,窗口顶部的堆栈面板包含以下消息:
> '__main__'.<module>(), line 1: for i in range(1, 4):这告诉你线 1 (包含代码
for i in range(1, 4):)是关于要运行但还没开始。消息的'__main__'.module()部分指的是这样一个事实,即你当前在程序的主要部分,而不是,例如,在到达主要代码块之前在一个函数定义中。堆栈面板下面是一个局部面板,列出了一些看起来很奇怪的东西,比如
__annotations__、__builtins__、__doc__等等。这些是你现在可以忽略的内部系统变量T4。当你的程序运行时,你会在这个窗口中看到代码中声明的变量,这样你就可以跟踪它们的值。调试窗口的左上角有五个按钮:前进、步进、越过、退出、退出。这些按钮控制调试器如何遍历代码。
在接下来的部分中,您将从步骤开始,探究这些按钮的作用。
步进按钮
继续点击调试窗口左上角的步骤。调试窗口略有变化,如下所示:
这里有两个不同点需要注意。首先,“堆栈”面板中的消息更改为:
> '__main__'.<module>(), line 2: j = i * 2:此时,代码的行 1 已经运行,调试器在执行行 2 之前已经停止。
要注意的第二个变化是新变量
i,它在“局部变量”面板中被赋值为1。那是因为第一行代码中的for循环创建了变量i,并给它赋值1。继续点击步骤按钮,一行一行地浏览你的代码,并观察调试器窗口中发生了什么。当你到达第
print(f"i is {i} and j is {j}")行时,你可以看到显示在交互窗口中的输出,一次一片。更重要的是,当你逐步通过
for循环时,你可以跟踪i和j的增长值。当您试图定位程序中的错误来源时,您可以想象这个特性是多么的有用。了解每一行代码中每个变量的值可以帮助您查明哪里出错了。断点和继续按钮
通常,您可能知道 bug 一定在代码的特定部分,但是您可能不知道确切的位置。不要整天点击步骤按钮,你可以设置一个断点,告诉调试器连续运行所有代码,直到它到达断点。
断点告诉调试器什么时候暂停代码执行,这样你就可以看看程序的当前状态。他们实际上并不破坏任何东西。
要设置断点,右键单击(
Ctrl-在 Mac 上单击)编辑器窗口中您想要暂停的代码行,然后选择设置断点。IDLE 用黄色突出显示该行,表示已经设置了断点。要删除断点,右键单击带有断点的行并选择清除断点。继续按下调试窗口顶部的退出,暂时关闭调试器。这不会关闭窗口,您会希望让它保持打开状态,因为您稍后会再次使用它。
用
print()语句在代码行上设置一个断点。编辑器窗口现在应该如下所示:
保存并运行文件。就像之前一样,调试窗口的堆栈面板指示调试器已经启动,正在等待执行行 1 。点击 Go ,观察调试窗口中会发生什么:
堆栈面板现在显示以下消息,表明它正在等待执行行 3 :
> '__main__'.<module>(), line 3: print(f"i is {i} and j is {j}")如果您查看“局部变量”面板,那么您会看到变量
i和j分别具有值1和2。通过点击 Go ,你告诉调试器连续运行你的代码,直到它到达一个断点或者程序的结尾。再次按下 Go 。调试窗口现在看起来像这样:
你看到什么改变了吗?堆栈面板中显示与之前相同的消息,表明调试器正在等待再次执行行 3 。然而,变量
i和j的值现在是2和4。交互式窗口还显示第一次通过循环运行带有print()的行的输出。每次你按下 Go 按钮,调试器就会连续运行代码,直到到达下一个断点。由于您在行的第 3 处设置了断点,这是在
for循环内,调试器每次遍历循环时都会在这一行停止。第三次按下 Go 。现在
i和j具有值3和6。你认为再按一次 Go 会发生什么?由于for循环只迭代三次,当你再次按 Go 时,程序将结束运行。完了,完了
Over 按钮有点像是 Step 和 Go 的组合。它单步执行一个函数或循环。换句话说,如果您要使用调试器单步执行一个函数,那么您仍然可以运行该函数的代码,而不必单步执行它的每一行。点击上的按钮可以直接看到运行该功能的结果。
同样,如果你已经在一个函数或循环中,那么 Out 按钮执行函数或循环体内的剩余代码,然后暂停。
在下一节中,您将看到一些有问题的代码,并学习如何用 IDLE 来修复它。
压扁一些虫子
既然您已经习惯了使用调试控制窗口,让我们来看看一个有问题的程序。
下面的代码定义了一个函数
add_underscores(),它将一个字符串对象word作为参数,并返回一个新字符串,该字符串包含一个word的副本,每个字符都用下划线包围。比如add_underscores("python")应该返回"_p_y_t_h_o_n_"。下面是有问题的代码:
def add_underscores(word): new_word = "_" for i in range(len(word)): new_word = word[i] + "_" return new_word phrase = "hello" print(add_underscores(phrase))在编辑器窗口中输入这段代码,然后保存文件,按
F5运行程序。预期的输出是_h_e_l_l_o_,但是您看到的却是o_,或者是字母"o"后跟一个下划线。如果您已经发现了代码的问题所在,不要只是修复它。本节的重点是学习如何使用 IDLE 的调试器来识别问题。
如果看不出问题出在哪里,不要着急!在本节结束时,您将会找到它,并且能够识别您遇到的其他代码中的类似问题。
注意:调试可能会很困难,也很耗时,而且错误可能很微妙,很难识别。
虽然这一节着眼于一个相对基本的 bug,但是用于检查代码和发现 bug 的方法对于更复杂的问题是相同的。
调试就是解决问题,随着你越来越有经验,你会开发出自己的方法。在本节中,您将学习一个简单的四步法来帮助您开始:
- 猜猜哪一段代码可能包含 bug。
- 设置一个断点,通过一次一行地遍历有问题的部分来检查代码,同时跟踪重要的变量。
- 确定有错误的代码行(如果有的话),并进行更改以解决问题。
- 根据需要重复步骤 1–3,直到代码按预期运行。
第一步:猜测 Bug 在哪里
第一步是识别可能包含 bug 的代码部分。一开始,您可能无法确定错误的确切位置,但是您通常可以合理地猜测代码的哪个部分有错误。
注意,程序被分成两个不同的部分:一个函数定义(在这里定义了
add_underscores())和一个主代码块,它定义了一个值为"hello"的变量phrase,然后打印调用add_underscores(phrase)的结果。看主要部分:
phrase = "hello" print(add_underscores(phrase))你认为问题会在这里吗?看起来不像是吧?这两行代码的一切看起来都很好。所以,问题一定出在函数定义上:
def add_underscores(word): new_word = "_" for i in range(len(word)): new_word = word[i] + "_" return new_word函数中的第一行代码创建了一个值为
"_"的变量new_word。你们都很好,所以可以断定问题出在for循环的某个地方。步骤 2:设置断点并检查代码
既然您已经确定了 bug 的位置,那么就在
for循环的开始处设置一个断点,这样您就可以通过调试窗口准确地跟踪出代码内部发生了什么:
打开调试窗口并运行该文件。执行仍然停留在它看到的第一行,也就是函数定义。
按 Go 运行代码,直到遇到断点。调试窗口现在将如下所示:
此时,代码在进入
add_underscores()函数中的for循环之前暂停。注意,两个局部变量word和new_word显示在“局部变量”面板中。目前,word的值为"hello",而new_word的值为"_",与预期一致。点击步一次,进入
for循环。调试窗口发生变化,一个值为0的新变量i显示在“局部变量”面板中:
i是在for循环中使用的计数器,你可以用它来跟踪你当前正在查看的for循环的迭代。再次点击步骤。如果您查看“局部变量”面板,您会看到变量
new_word的值为"h_":
这不对。最初,
new_word有值"_",在for循环的第二次迭代中,它现在应该有值"_h_"。如果你点击步骤几次,那么你会看到new_word被设置为e_,然后是l_,以此类推。步骤 3:识别错误并尝试修复它
此时您可以得出的结论是,在
for循环的每次迭代中,new_word都被字符串中的下一个字符"hello"和尾随下划线覆盖。由于在for循环中只有一行代码,您知道问题一定出在下面的代码上:new_word = word[i] + "_"仔细看这条线。它告诉 Python 获取下一个字符
word,在它的末尾加上一个下划线,并将这个新字符串赋给变量new_word。这正是你在for循环中看到的行为!要解决这个问题,您需要告诉 Python 将字符串
word[i] + "_"连接到现有的值new_word。在调试窗口中按退出,但暂时不要关闭窗口。打开编辑器窗口,将for循环中的代码行改为:new_word = new_word + word[i] + "_"步骤 4:重复步骤 1 到 3,直到 Bug 消失
保存对程序的新更改,然后再次运行。在调试窗口中,按 Go 执行代码直到断点。
注意:如果您在上一步中关闭了调试器而没有点击退出,那么当您重新打开调试窗口时,您可能会看到以下错误:
You can only toggle the debugger when idle当你完成一个调试会话时,一定要点击 Go 或 Quit ,而不是仅仅关闭调试器,否则你可能很难重新打开它。要消除这个错误,您必须关闭并重新打开 IDLE。
程序在进入
add_underscores()中的for循环之前暂停。重复按下步骤,观察每次迭代中new_word变量会发生什么。成功!一切按预期运行!您第一次修复错误的尝试成功了,因此您不再需要重复步骤 1-3。情况不会总是这样。有时候,在你修复一个 bug 之前,你必须重复这个过程几次。
寻找漏洞的替代方法
使用调试器可能很棘手,也很耗时,但这是在代码中找到 bug 的最可靠的方法。然而,调试器并不总是可用的。资源有限的系统,比如小型的物联网设备,通常没有内置的调试器。
在这种情况下,您可以使用打印调试来查找代码中的 bug。打印调试使用
print()在控制台中显示文本,指示程序在哪里执行,以及程序变量在代码中特定点的状态。例如,您可以在
add_underscores()中的for循环的末尾添加下面一行,而不是使用调试窗口来调试前面的程序:print(f"i = {i}; new_word = {new_word}")修改后的代码将如下所示:
def add_underscores(word): new_word = "_" for i in range(len(word)): new_word = word[i] + "_" print(f"i = {i}; new_word = {new_word}") return new_word phrase = "hello" print(add_underscores(phrase))运行该文件时,交互式窗口会显示以下输出:
i = 0; new_word = h_ i = 1; new_word = e_ i = 2; new_word = l_ i = 3; new_word = l_ i = 4; new_word = o_ o_这向您展示了在
for循环的每次迭代中new_word的值。只包含一个下划线的最后一行是在程序末尾运行print(add_underscore(phrase))的结果。通过查看上面的输出,您可以得出与使用调试窗口进行调试时相同的结论。问题是
new_word在每次迭代时都会被覆盖。打印调试是可行的,但是与使用调试器进行调试相比,它有几个缺点。首先,每次想要检查变量的值时,都必须运行整个程序。与使用断点相比,这可能是巨大的时间浪费。当你完成调试时,你还必须记住从你的代码中删除那些
print()函数调用!本节中的示例循环可能是说明调试过程的一个很好的例子,但它不是python 代码的最佳例子。索引
i的使用表明可能有更好的方法来编写循环。改进这个循环的一个方法是直接迭代
word中的字符。有一种方法可以做到这一点:def add_underscores(word): new_word = "_" for letter in word: new_word = new_word + letter + "_" return new_word重写现有代码以使其更清晰、更易于阅读和理解,或者更符合团队设定的标准的过程被称为重构。我们不会在本教程中讨论重构,但它是编写专业质量代码的重要部分。
结论:Python 调试用空闲
就是这样!现在,您已经了解了使用 IDLE 的调试窗口进行调试的所有内容。您可以将这里使用的基本原则用于许多不同的调试工具。现在,您已经准备好开始调试 Python 代码了。
在本教程中,您学习了:
- 如何使用 IDLE 的调试控制窗口检查变量值
- 如何插入断点来仔细看看你的代码是如何工作的
- 如何使用步、走、【T4 过、出按钮逐行追踪 bug
您还得到了一些使用识别和消除 bug 的四步过程调试错误函数的实践:
- 猜猜窃丨听器在哪里。
- 设置断点并检查代码。
- 找出错误并尝试修复。
- 重复步骤 1 至 3,直到错误被修复。
调试既是一门科学,也是一门艺术。掌握调试的唯一方法就是进行大量的实践!获得一些实践的一个方法是打开调试控制窗口,当你在其他真正的 Python 教程中找到练习和挑战时,使用它来逐步通过你的代码。
有关调试 Python 代码的更多信息,请查看使用 Pdb 调试 Python。如果你喜欢在这个例子中从 Python 基础:Python 3 实用介绍中学到的东西,那么一定要看看本书的其余部分。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 基础知识:查找并修复代码 bug******
用 Pdb 调试 Python
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: Python 调试用 pdb
调试应用程序有时可能是不受欢迎的活动。你在时间紧迫的情况下忙于工作,你只是想让它工作。然而,在其他时候,您可能正在学习一种新的语言特性或尝试一种新的方法,并且希望更深入地了解某些东西是如何工作的。
不管在什么情况下,调试代码都是必要的,所以在调试器中舒适地工作是一个好主意。在本教程中,我将向您展示使用 pdb(Python 的交互式源代码调试器)的基础知识。
我将带您了解 pdb 的一些常见用法。当你真的需要它的时候,你可以把这个教程加入书签,以便快速参考。pdb 和其他调试器是不可或缺的工具。当你需要一个调试器时,没有替代品。你真的需要它。
本教程结束时,您将知道如何使用调试器来查看应用程序中任何变量的状态。您还可以随时停止和恢复应用程序的执行流程,这样您就可以确切地看到每一行代码是如何影响其内部状态的。
这对于追踪难以发现的错误非常有用,并且允许您更快、更可靠地修复错误代码。有时,在 pdb 中单步执行代码并看到值是如何变化的,这真的令人大开眼界,并带来“啊哈”时刻,偶尔还会出现“掌脸”。
pdb 是 Python 标准库的一部分,因此它总是存在并可供使用。如果您需要在无法访问您所熟悉的 GUI 调试器的环境中调试代码,这可能是一个救命稻草。
本教程中的示例代码使用 Python 3.6。你可以在 GitHub 上找到这些例子的源代码。
在本教程的最后,有一个关于基本 pdb 命令的快速参考。
还有一个可打印的 pdb 命令参考,您可以在调试时用作备忘单:
免费赠品: 点击此处获取一份可打印的“pdb 命令参考”(PDF) 放在办公桌上,调试时参考。
入门:打印变量值
在第一个例子中,我们将看看使用 pdb 的最简单形式:检查变量值。
在要中断调试器的位置插入以下代码:
import pdb; pdb.set_trace()当执行上面的代码行时,Python 会停下来,等待您告诉它下一步该做什么。你会看到一个
(Pdb)提示。这意味着您现在在交互式调试器中处于暂停状态,可以输入命令了。从 Python 3.7 开始,有另一种方式进入调试器。 PEP 553 描述了内置函数
breakpoint(),使进入调试器变得容易和一致:breakpoint()默认情况下,
breakpoint()将导入pdb并调用pdb.set_trace(),如上图。然而,使用breakpoint()更加灵活,允许您通过它的 API 和环境变量PYTHONBREAKPOINT的使用来控制调试行为。例如,在您的环境中设置PYTHONBREAKPOINT=0将完全禁用breakpoint(),从而禁用调试。如果你正在使用 Python 3.7 或更高版本,我鼓励你使用breakpoint()而不是pdb.set_trace()。您还可以直接从命令行运行 Python 并传递选项
-m pdb,从而在不修改源代码和使用pdb.set_trace()或breakpoint()的情况下进入调试器。如果您的应用程序接受命令行参数,像平常一样在文件名后传递它们。例如:$ python3 -m pdb app.py arg1 arg2有许多 pdb 命令可用。在本教程的最后,有一个基本 pdb 命令的列表。现在,让我们使用
p命令打印一个变量的值。在(Pdb)提示符下输入p variable_name打印其值。让我们看看例子。下面是
example1.py来源:#!/usr/bin/env python3 filename = __file__ import pdb; pdb.set_trace() print(f'path = {filename}')如果您从 shell 中运行此命令,您应该得到以下输出:
$ ./example1.py > /code/example1.py(5)<module>() -> print(f'path = {filename}') (Pdb)如果你在从命令行运行例子或你自己的代码时有困难,请阅读我如何使用 Python 制作我自己的命令行命令?如果你在 Windows 上,查看 Python Windows 常见问题。
现在输入
p filename。您应该看到:(Pdb) p filename './example1.py' (Pdb)因为您是在 shell 中使用 CLI(命令行界面),所以要注意字符和格式。他们会给你你需要的背景:
- 从第一行开始,告诉你你在哪个源文件中。在文件名之后,括号中是当前的行号。接下来是函数的名称。在这个例子中,因为我们没有在函数内部和模块级别暂停,所以我们看到了
<module>()。->从第二行开始,是 Python 暂停的当前源代码行。这一行还没有执行。在本例中,这是来自上面的>行的example1.py中的5行。(Pdb)是 pdb 的提示。它在等待命令。使用命令
q退出调试并退出。打印表达式
当使用 print 命令
p时,您传递的是一个将由 Python 计算的表达式。如果您传递一个变量名,pdb 打印它的当前值。但是,您可以做更多的工作来调查您正在运行的应用程序的状态。在这个例子中,调用了函数
get_path()。为了检查这个函数中发生了什么,我插入了一个对pdb.set_trace()的调用,以便在它返回之前暂停执行:#!/usr/bin/env python3 import os def get_path(filename): """Return file's path or empty string if no path.""" head, tail = os.path.split(filename) import pdb; pdb.set_trace() return head filename = __file__ print(f'path = {get_path(filename)}')如果您从 shell 中运行此命令,您应该会得到以下输出:
$ ./example2.py > /code/example2.py(10)get_path() -> return head (Pdb)我们在哪里?
>:我们在源文件example2.py中,在函数get_path()的10行。这是p命令用来解析变量名的参考框架,即当前范围或上下文。->:执行在return head暂停。这一行还没有执行。这是功能get_path()中example2.py的10线,来自上面的>线。让我们打印一些表达式来看看应用程序的当前状态。我最初使用命令
ll(longlist)来列出函数的源代码:(Pdb) ll 6 def get_path(filename): 7 """Return file's path or empty string if no path.""" 8 head, tail = os.path.split(filename) 9 import pdb; pdb.set_trace() 10 -> return head (Pdb) p filename './example2.py' (Pdb) p head, tail ('.', 'example2.py') (Pdb) p 'filename: ' + filename 'filename: ./example2.py' (Pdb) p get_path <function get_path at 0x100760e18> (Pdb) p getattr(get_path, '__doc__') "Return file's path or empty string if no path." (Pdb) p [os.path.split(p)[1] for p in os.path.sys.path] ['pdb-basics', 'python36.zip', 'python3.6', 'lib-dynload', 'site-packages'] (Pdb)您可以将任何有效的 Python 表达式传递给
p进行评估。当您正在调试并希望在运行时直接在应用程序中测试替代实现时,这尤其有用。
你也可以使用命令
pp(美化打印)来美化表达式。如果您想要打印具有大量输出的变量或表达式,例如列表和字典,这很有帮助。如果可能的话,美化打印将对象保持在一行上,或者如果它们不适合允许的宽度,则将它们分成多行。单步执行代码
调试时,您可以使用两个命令来逐句通过代码:
命令 描述 n(下一个)继续执行,直到到达当前函数的下一行或返回。 s(步骤)执行当前行,并在第一个可能的时机停止(在调用的函数中或在当前函数中)。 有第三个命令名为
unt(直到)。与n(下)有关。我们将在本教程后面的继续执行一节中讨论它。
n(下一步)和s(下一步)的区别在于 pdb 停止的地方。使用
n(next)继续执行,直到下一行,并停留在当前函数内,即如果调用了一个外部函数,则不在该函数内停止。把下一步想成“留在本地”或者“跨过去”。使用
s(步骤)执行当前行,如果调用了一个外来函数,则在该函数中停止。把 step 想成“踏入”。如果在另一个功能中停止执行,s将打印--Call--。当到达当前函数的末尾时,
n和s都将停止执行,并在->之后的下一行末尾打印--Return--和返回值。让我们看一个使用这两个命令的例子。下面是
example3.py来源:#!/usr/bin/env python3 import os def get_path(filename): """Return file's path or empty string if no path.""" head, tail = os.path.split(filename) return head filename = __file__ import pdb; pdb.set_trace() filename_path = get_path(filename) print(f'path = {filename_path}')如果您从 shell 中运行并输入
n,您应该得到输出:$ ./example3.py > /code/example3.py(14)<module>() -> filename_path = get_path(filename) (Pdb) n > /code/example3.py(15)<module>() -> print(f'path = {filename_path}') (Pdb)随着
n(下一条),我们停在了下一条线15。我们在<module>()“呆在当地”,并“跳过”了对get_path()的呼叫。函数是<module>(),因为我们目前在模块级别,没有在另一个函数中暂停。让我们试试
s:$ ./example3.py > /code/example3.py(14)<module>() -> filename_path = get_path(filename) (Pdb) s --Call-- > /code/example3.py(6)get_path() -> def get_path(filename): (Pdb)使用
s(步骤),我们在函数get_path()的第6行停止,因为它在第14行被调用。注意s命令后的一行--Call--。方便的是,pdb 会记住您的最后一个命令。如果你正在单步执行大量代码,你可以按下
Enter来重复最后一个命令。下面是一个使用
s和n单步调试代码的例子。我最初输入s是因为我想“进入”功能get_path()并停止。然后我输入n一次来“停留在本地”或“跳过”任何其他函数调用,并按下Enter来重复n命令,直到我到达最后一个源代码行。$ ./example3.py > /code/example3.py(14)<module>() -> filename_path = get_path(filename) (Pdb) s --Call-- > /code/example3.py(6)get_path() -> def get_path(filename): (Pdb) n > /code/example3.py(8)get_path() -> head, tail = os.path.split(filename) (Pdb) > /code/example3.py(9)get_path() -> return head (Pdb) --Return-- > /code/example3.py(9)get_path()->'.' -> return head (Pdb) > /code/example3.py(15)<module>() -> print(f'path = {filename_path}') (Pdb) path = . --Return-- > /code/example3.py(15)<module>()->None -> print(f'path = {filename_path}') (Pdb)注意线
--Call--和--Return--。这是 pdb 让你知道为什么执行被停止。n(下一步)和s(步骤)将在功能返回前停止。这就是为什么你会看到上面的--Return--线。还要注意在上面第一个
--Return--之后的行尾的->'.':--Return-- > /code/example3.py(9)get_path()->'.' -> return head (Pdb)当 pdb 在函数返回之前停止在函数末尾时,它也会为您打印返回值。在这个例子中是
'.'。清单源代码
不要忘记命令
ll(longlist:列出当前函数或框架的全部源代码)。当您在单步执行不熟悉的代码时,或者您只想查看整个函数的上下文时,这真的很有帮助。这里有一个例子:
$ ./example3.py > /code/example3.py(14)<module>() -> filename_path = get_path(filename) (Pdb) s --Call-- > /code/example3.py(6)get_path() -> def get_path(filename): (Pdb) ll 6 -> def get_path(filename): 7 """Return file's path or empty string if no path.""" 8 head, tail = os.path.split(filename) 9 return head (Pdb)要查看更短的代码片段,使用命令
l(list)。如果没有参数,它将在当前行周围打印 11 行,或者继续前面的列表。传递参数.总是列出当前行周围的 11 行:l .$ ./example3.py > /code/example3.py(14)<module>() -> filename_path = get_path(filename) (Pdb) l 9 return head 10 11 12 filename = __file__ 13 import pdb; pdb.set_trace() 14 -> filename_path = get_path(filename) 15 print(f'path = {filename_path}') [EOF] (Pdb) l [EOF] (Pdb) l . 9 return head 10 11 12 filename = __file__ 13 import pdb; pdb.set_trace() 14 -> filename_path = get_path(filename) 15 print(f'path = {filename_path}') [EOF] (Pdb)使用断点
断点非常方便,可以节省你很多时间。不要遍历您不感兴趣的几十行,只需在您想要研究的地方创建一个断点。或者,您也可以告诉 pdb 仅在特定条件为真时才中断。
使用命令
b(break)设置断点。您可以指定停止执行的行号或函数名。break 的语法是:
b(reak) [ ([filename:]lineno | function) [, condition] ]如果行号
lineno前没有指定filename:,则使用当前源文件。请注意
b的可选第二个参数:condition。这个很厉害。想象一下,只有在特定条件存在的情况下,您才想要中断。如果您将 Python 表达式作为第二个参数传递,那么当表达式的值为 true 时,pdb 将会中断。我们将在下面的例子中这样做。在这个例子中,有一个实用模块
util.py。让我们在函数get_path()中设置一个断点来停止执行。下面是主脚本
example4.py的源代码:#!/usr/bin/env python3 import util filename = __file__ import pdb; pdb.set_trace() filename_path = util.get_path(filename) print(f'path = {filename_path}')下面是实用程序模块
util.py的源代码:def get_path(filename): """Return file's path or empty string if no path.""" import os head, tail = os.path.split(filename) return head首先,让我们使用源文件名和行号设置一个断点:
$ ./example4.py > /code/example4.py(7)<module>() -> filename_path = util.get_path(filename) (Pdb) b util:5 Breakpoint 1 at /code/util.py:5 (Pdb) c > /code/util.py(5)get_path() -> return head (Pdb) p filename, head, tail ('./example4.py', '.', 'example4.py') (Pdb)命令
c(继续)继续执行,直到找到断点。接下来,让我们使用函数名设置一个断点:
$ ./example4.py > /code/example4.py(7)<module>() -> filename_path = util.get_path(filename) (Pdb) b util.get_path Breakpoint 1 at /code/util.py:1 (Pdb) c > /code/util.py(3)get_path() -> import os (Pdb) p filename './example4.py' (Pdb)输入不带参数的
b来查看所有断点的列表:(Pdb) b Num Type Disp Enb Where 1 breakpoint keep yes at /code/util.py:1 (Pdb)您可以使用命令
disable bpnumber和enable bpnumber禁用和重新启用断点。bpnumber是断点列表第一列Num中的断点号。请注意Enb列的值发生了变化:(Pdb) disable 1 Disabled breakpoint 1 at /code/util.py:1 (Pdb) b Num Type Disp Enb Where 1 breakpoint keep no at /code/util.py:1 (Pdb) enable 1 Enabled breakpoint 1 at /code/util.py:1 (Pdb) b Num Type Disp Enb Where 1 breakpoint keep yes at /code/util.py:1 (Pdb)要删除断点,使用命令
cl(清除):cl(ear) filename:lineno cl(ear) [bpnumber [bpnumber...]]现在让我们使用一个 Python 表达式来设置一个断点。想象一下这样一种情况,只有当有问题的函数收到某个输入时,您才想要中断。
在这个示例场景中,
get_path()函数在接收相对路径时失败,即文件的路径不是以/开头。在这种情况下,我将创建一个计算结果为 true 的表达式,并将其作为第二个参数传递给b:$ ./example4.py > /code/example4.py(7)<module>() -> filename_path = util.get_path(filename) (Pdb) b util.get_path, not filename.startswith('/') Breakpoint 1 at /code/util.py:1 (Pdb) c > /code/util.py(3)get_path() -> import os (Pdb) a filename = './example4.py' (Pdb)在创建了上面的断点并输入
c继续执行之后,当表达式的值为 true 时,pdb 停止。命令a(args)打印当前函数的参数列表。在上面的示例中,当您使用函数名而不是行号设置断点时,请注意,表达式应该只使用在输入函数时可用的函数参数或全局变量。否则,无论表达式的值是什么,断点都将停止在函数中执行。
如果您需要中断使用带有位于函数内部的变量名的表达式,即变量名不在函数的参数列表中,请指定行号:
$ ./example4.py > /code/example4.py(7)<module>() -> filename_path = util.get_path(filename) (Pdb) b util:5, not head.startswith('/') Breakpoint 1 at /code/util.py:5 (Pdb) c > /code/util.py(5)get_path() -> return head (Pdb) p head '.' (Pdb) a filename = './example4.py' (Pdb)您也可以使用命令
tbreak设置一个临时断点。第一次击中时会自动移除。它使用与b相同的参数。继续执行
到目前为止,我们已经看了用
n(下一步)和s(单步)单步执行代码,以及用b(中断)和c(继续)使用断点。还有一个相关的命令:
unt(直到)。使用
unt像c一样继续执行,但是在比当前行大的下一行停止。有时候unt使用起来更方便快捷,而且正是你想要的。我将在下面用一个例子来说明这一点。让我们先来看看
unt的语法和描述:
命令 句法 描述 untunt(il)[line] 如果没有 lineno,则继续执行,直到到达编号大于当前编号的行。使用lineno,继续执行,直到到达一个编号大于或等于该编号的行。在这两种情况下,当当前帧返回时也停止。根据是否传递行号参数
lineno,unt可以有两种行为方式:
- 如果没有
lineno,则继续执行,直到到达编号大于当前编号的行。这个类似于n(下一个)。这是执行和“单步执行”代码的另一种方式。n和unt的区别在于unt只有在到达比当前行大的行时才会停止。n将在下一个逻辑执行行停止。- 使用
lineno,继续执行,直到到达一个编号大于或等于该编号的行。这就像带有行号参数的c(continue)。在这两种情况下,
unt在当前帧(函数)返回时停止,就像n(下一步)和s(下一步)一样。使用
unt要注意的主要行为是,当达到当前或指定行的行号大于或等于时,它将停止。当您想继续执行并在当前源文件中停止时,使用
unt。你可以把它看作是n(下一个)和b(中断)的混合体,这取决于你是否传递了一个行号参数。在下面的例子中,有一个带有循环的函数。这里,您希望继续执行代码并在循环后停止,而不单步执行循环的每个迭代或设置断点:
以下是
example4unt.py的示例源:#!/usr/bin/env python3 import os def get_path(fname): """Return file's path or empty string if no path.""" import pdb; pdb.set_trace() head, tail = os.path.split(fname) for char in tail: pass # Check filename char return head filename = __file__ filename_path = get_path(filename) print(f'path = {filename_path}')并且控制台输出使用
unt:$ ./example4unt.py > /code/example4unt.py(9)get_path() -> head, tail = os.path.split(fname) (Pdb) ll 6 def get_path(fname): 7 """Return file's path or empty string if no path.""" 8 import pdb; pdb.set_trace() 9 -> head, tail = os.path.split(fname) 10 for char in tail: 11 pass # Check filename char 12 return head (Pdb) unt > /code/example4unt.py(10)get_path() -> for char in tail: (Pdb) > /code/example4unt.py(11)get_path() -> pass # Check filename char (Pdb) > /code/example4unt.py(12)get_path() -> return head (Pdb) p char, tail ('y', 'example4unt.py')首先使用
ll命令打印函数的源代码,然后使用unt。pdb 记得最后输入的命令,所以我只需按下Enter来重复unt命令。这将继续执行整个代码,直到到达比当前行更长的源代码行。请注意,在上面的控制台输出中,pdb 仅在第
10和11行停止一次。由于使用了unt,执行仅在循环的第一次迭代中停止。然而,循环的每次迭代都被执行。这可以在输出的最后一行中得到验证。char变量的值'y'等于tail值'example4unt.py'中的最后一个字符。显示表达式
类似于用
p和pp打印表达式,您可以使用命令display [expression]告诉 pdb 在执行停止时自动显示表达式的值,如果它发生了变化。使用命令undisplay [expression]清除一个显示表达式。以下是这两个命令的语法和描述:
命令 句法 描述 display显示[表情] 每次在当前帧停止执行时,显示 expression的值(如果它改变了)。如果没有expression,列出当前帧的所有显示表达式。undisplay不显示[表情] 在当前帧中不再显示 expression。没有expression,清除当前帧的所有显示表达式。下面是一个例子,
example4display.py,演示了它在循环中的用法:$ ./example4display.py > /code/example4display.py(9)get_path() -> head, tail = os.path.split(fname) (Pdb) ll 6 def get_path(fname): 7 """Return file's path or empty string if no path.""" 8 import pdb; pdb.set_trace() 9 -> head, tail = os.path.split(fname) 10 for char in tail: 11 pass # Check filename char 12 return head (Pdb) b 11 Breakpoint 1 at /code/example4display.py:11 (Pdb) c > /code/example4display.py(11)get_path() -> pass # Check filename char (Pdb) display char display char: 'e' (Pdb) c > /code/example4display.py(11)get_path() -> pass # Check filename char display char: 'x' [old: 'e'] (Pdb) > /code/example4display.py(11)get_path() -> pass # Check filename char display char: 'a' [old: 'x'] (Pdb) > /code/example4display.py(11)get_path() -> pass # Check filename char display char: 'm' [old: 'a']在上面的输出中,pdb 自动显示了
char变量的值,因为每次遇到断点时,它的值都会改变。有时这很有帮助,而且正是您想要的,但是还有另一种使用display的方法。您可以多次输入
display来建立一个观察表达式列表。这可能比p更容易使用。添加完您感兴趣的所有表达式后,只需输入display即可查看当前值:$ ./example4display.py > /code/example4display.py(9)get_path() -> head, tail = os.path.split(fname) (Pdb) ll 6 def get_path(fname): 7 """Return file's path or empty string if no path.""" 8 import pdb; pdb.set_trace() 9 -> head, tail = os.path.split(fname) 10 for char in tail: 11 pass # Check filename char 12 return head (Pdb) b 11 Breakpoint 1 at /code/example4display.py:11 (Pdb) c > /code/example4display.py(11)get_path() -> pass # Check filename char (Pdb) display char display char: 'e' (Pdb) display fname display fname: './example4display.py' (Pdb) display head display head: '.' (Pdb) display tail display tail: 'example4display.py' (Pdb) c > /code/example4display.py(11)get_path() -> pass # Check filename char display char: 'x' [old: 'e'] (Pdb) display Currently displaying: char: 'x' fname: './example4display.py' head: '.' tail: 'example4display.py'Python 来电显示
在这最后一部分,我们将在目前所学的基础上,以一个不错的回报结束。我用“来电显示”这个名字来指代电话系统的来电显示功能。这正是这个例子所展示的,除了它适用于 Python。
下面是主脚本
example5.py的源代码:#!/usr/bin/env python3 import fileutil def get_file_info(full_fname): file_path = fileutil.get_path(full_fname) return file_path filename = __file__ filename_path = get_file_info(filename) print(f'path = {filename_path}')这是实用模块
fileutil.py:def get_path(fname): """Return file's path or empty string if no path.""" import os import pdb; pdb.set_trace() head, tail = os.path.split(fname) return head在这个场景中,假设有一个大型代码库,它在一个实用程序模块
get_path()中有一个函数,该函数被无效输入调用。然而,它在不同的包中从许多地方被调用。如何找到打电话的人?
使用命令
w(其中)打印堆栈跟踪,最新的帧在底部:$ ./example5.py > /code/fileutil.py(5)get_path() -> head, tail = os.path.split(fname) (Pdb) w /code/example5.py(12)<module>() -> filename_path = get_file_info(filename) /code/example5.py(7)get_file_info() -> file_path = fileutil.get_path(full_fname) > /code/fileutil.py(5)get_path() -> head, tail = os.path.split(fname) (Pdb)如果这看起来令人困惑,或者如果您不确定什么是堆栈跟踪或帧,请不要担心。我将在下面解释这些术语。这并不像听起来那么难。
因为最近的帧在底部,所以从那里开始,从底部向上读取。查看以
->开头的行,但是跳过第一个实例,因为在函数get_path()中pdb.set_trace()被用于输入 pdb。在这个例子中,调用函数get_path()的源代码行是:-> file_path = fileutil.get_path(full_fname)每个
->上面的行包含文件名、行号(在括号中)和源代码所在的函数名。所以打电话的人是:/code/example5.py(7)get_file_info() -> file_path = fileutil.get_path(full_fname)在这个用于演示的小例子中,这并不奇怪,但是想象一下一个大型应用程序,其中您设置了一个带有条件的断点,以识别错误输入值的来源。
现在我们知道如何找到打电话的人了。
但是这个堆栈跟踪和框架的东西呢?
一个堆栈跟踪只是 Python 创建的用来跟踪函数调用的所有帧的列表。框架是 Python 在调用函数时创建的数据结构,在函数返回时删除。堆栈只是在任何时间点的帧或函数调用的有序列表。(函数调用)堆栈在应用程序的整个生命周期中随着函数的调用和返回而增长和收缩。
打印时,这个有序的帧列表,即堆栈,被称为堆栈跟踪。您可以通过输入命令
w随时看到它,就像我们在上面查找调用者一样。详见维基百科上的这篇 call stack 文章。
为了更好地理解和利用 pdb,让我们更仔细地看看对
w的帮助:(Pdb) h w w(here) Print a stack trace, with the most recent frame at the bottom. An arrow indicates the "current frame", which determines the context of most commands. 'bt' is an alias for this command.pdb 所说的“当前帧”是什么意思?
将当前帧视为 pdb 停止执行的当前函数。换句话说,当前帧是应用程序当前暂停的地方,并被用作 pdb 命令(如
p(print))的参考“帧”。
p和其他命令将在需要时使用当前帧作为上下文。在p的情况下,当前帧将用于查找和打印变量引用。当 pdb 打印堆栈跟踪时,箭头
>指示当前帧。这有什么用?
您可以使用两个命令
u(向上)和d(向下)来改变当前帧。与p相结合,这允许你在任何一帧中沿着调用栈的任何一点检查应用程序中的变量和状态。以下是这两个命令的语法和描述:
命令 句法 描述 u计数 在堆栈跟踪中将当前帧 count(默认为一个)上移一级(到一个更老的帧)。dd(自己的)[计数] 在堆栈跟踪中将当前帧 count(默认为一个)向下移动一级(到一个较新的帧)。让我们看一个使用
u和d命令的例子。在这个场景中,我们想要检查example5.py中函数get_file_info()的局部变量full_fname。为此,我们必须使用命令u将当前帧向上改变一级:$ ./example5.py > /code/fileutil.py(5)get_path() -> head, tail = os.path.split(fname) (Pdb) w /code/example5.py(12)<module>() -> filename_path = get_file_info(filename) /code/example5.py(7)get_file_info() -> file_path = fileutil.get_path(full_fname) > /code/fileutil.py(5)get_path() -> head, tail = os.path.split(fname) (Pdb) u > /code/example5.py(7)get_file_info() -> file_path = fileutil.get_path(full_fname) (Pdb) p full_fname './example5.py' (Pdb) d > /code/fileutil.py(5)get_path() -> head, tail = os.path.split(fname) (Pdb) p fname './example5.py' (Pdb)对
pdb.set_trace()的调用在函数get_path()的fileutil.py中,所以当前帧最初设置在那里。您可以在上面的第一行输出中看到它:> /code/fileutil.py(5)get_path()为了访问并打印
example5.py中函数get_file_info()中的局部变量full_fname,命令u被用于上移一级:(Pdb) u > /code/example5.py(7)get_file_info() -> file_path = fileutil.get_path(full_fname)请注意,在上面的
u输出中,pdb 在第一行的开头打印了箭头>。这是 pdb,让您知道帧已被更改,此源位置现在是当前帧。变量full_fname现在是可访问的。此外,重要的是要意识到第二行以->开始的源代码行已经被执行。自从这个框架在堆栈中上移后,fileutil.get_path()就被调用了。使用u,我们将堆栈向上移动(从某种意义上说,及时返回)到调用fileutil.get_path()的函数example5.get_file_info()。继续这个例子,在
full_fname被打印后,使用d将当前帧移动到其原始位置,并打印get_path()中的局部变量fname。如果我们想的话,我们可以通过将
count参数传递给u或d来一次移动多个帧。例如,我们可以通过输入u 2进入example5.py中的模块级别:$ ./example5.py > /code/fileutil.py(5)get_path() -> head, tail = os.path.split(fname) (Pdb) u 2 > /code/example5.py(12)<module>() -> filename_path = get_file_info(filename) (Pdb) p filename './example5.py' (Pdb)当你在调试和思考许多不同的事情时,很容易忘记你在哪里。请记住,您总是可以使用名副其实的命令
w(where)来查看执行在哪里暂停以及当前帧是什么。基本 pdb 命令
一旦你在 pdb 上花了一点时间,你就会意识到一点点知识可以走很长的路。使用
h命令总是可以获得帮助。只需输入
h或help <topic>即可获得所有命令的列表或特定命令或主题的帮助。作为快速参考,这里列出了一些基本命令:
命令 描述 p打印表达式的值。 pp漂亮地打印一个表达式的值。 n继续执行,直到到达当前函数的下一行或返回。 s执行当前行,并在第一个可能的时机停止(在调用的函数中或在当前函数中)。 c继续执行,仅在遇到断点时停止。 unt继续执行,直到到达数字大于当前数字的那一行。使用行号参数,继续执行,直到到达行号大于或等于行号的行。 l列出当前文件的源代码。如果没有参数,则在当前行周围列出 11 行,或者继续前面的列表。 ll列出当前函数或框架的全部源代码。 b不带参数,列出所有断点。使用行号参数,在当前文件的这一行设置一个断点。 w打印堆栈跟踪,最新的帧在底部。箭头指示当前帧,它决定了大多数命令的上下文。 u将堆栈跟踪中的当前帧数(默认为 1)向上移动一级(到一个较旧的帧)。 d将堆栈跟踪中的当前帧计数(默认为 1)向下移动一级(到一个较新的帧)。 h查看可用命令列表。 h <topic>显示命令或主题的帮助。 h pdb展示完整的 pdb 文档。 q退出调试器并退出。 用 pdb 调试 Python:结论
在本教程中,我们介绍了 pdb 的一些基本和常见用法:
- 打印表达式
- 用
n(下一步)和s(下一步)单步执行代码- 使用断点
- 继续执行
unt(直到)- 显示表达式
- 查找函数的调用者
希望对你有帮助。如果您想了解更多信息,请参阅:
- 在您附近的 pdb 提示符下显示 pdb 的完整文档:
(Pdb) h pdb- Python 的 pdb 文档
示例中使用的源代码可以在相关的 GitHub 库中找到。请务必查看我们的可打印 pdb 命令参考,您可以在调试时将其用作备忘单:
免费赠品: 点击此处获取一份可打印的“pdb 命令参考”(PDF) 放在办公桌上,调试时参考。
另外,如果你想尝试一个基于 GUI 的 Python 调试器,请阅读我们的Python ide 和编辑器指南,看看哪些选项最适合你。快乐的蟒蛇!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: Python 调试用 pdb******
使用 Python defaultdict 类型处理丢失的键
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python defaultdict Type 处理丢失的键
使用 Pythondictionary时可能会遇到的一个常见问题是试图访问或修改字典中不存在的键。这将引发一个
KeyError并中断您的代码执行。为了处理这些情况,标准库提供了 Pythondefaultdict类型,这是一个类似字典的类,可以在collections中找到。Python
defaultdict类型的行为几乎与常规 Python 字典完全一样,但是如果您试图访问或修改一个丢失的键,那么defaultdict将自动创建该键并为其生成一个默认值。这使得defaultdict成为处理字典中丢失键的一个有价值的选择。在本教程中,您将学习:
- 如何使用 Python
defaultdict类型为处理字典中丢失的键- 何时以及为什么要使用 Python
defaultdict而不是普通的dict- 如何使用一个
defaultdict进行分组、计数、累加操作有了这些知识,您将能够更好地在日常编程挑战中有效地使用 Python
defaultdict类型。为了从本教程中获得最大收益,您应该对什么是 Python 字典以及如何使用它们有所了解。如果你需要梳洗一下,那么看看下面的资源:
- Python 中的字典(教程)
- Python 中的字典(课程)
- 如何在 Python 中迭代字典
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
处理字典中丢失的键
使用 Python 字典时,你可能会面临的一个常见问题是如何处理丢失的键。如果你的代码大量基于字典,或者如果你一直在动态地创建字典,那么你很快就会注意到处理频繁的
KeyError异常会很烦人,会给你的代码增加额外的复杂性。使用 Python 字典,至少有四种方法可以处理丢失的键:
- 使用
.setdefault()- 使用
.get()- 使用
key in dict习语- 使用
try和except块Python 文档对
.setdefault()和.get()解释如下:T2
setdefault(key[, default])如果
key在字典中,返回它的值。如果不是,插入值为default的key并返回default。default默认为None。T2
get(key[, default])如果
key在字典中,返回key的值,否则返回default。如果没有给出default,则默认为None,这样这个方法就永远不会引发一个KeyError。(来源)
这里有一个如何使用
.setdefault()来处理字典中丢失的键的例子:
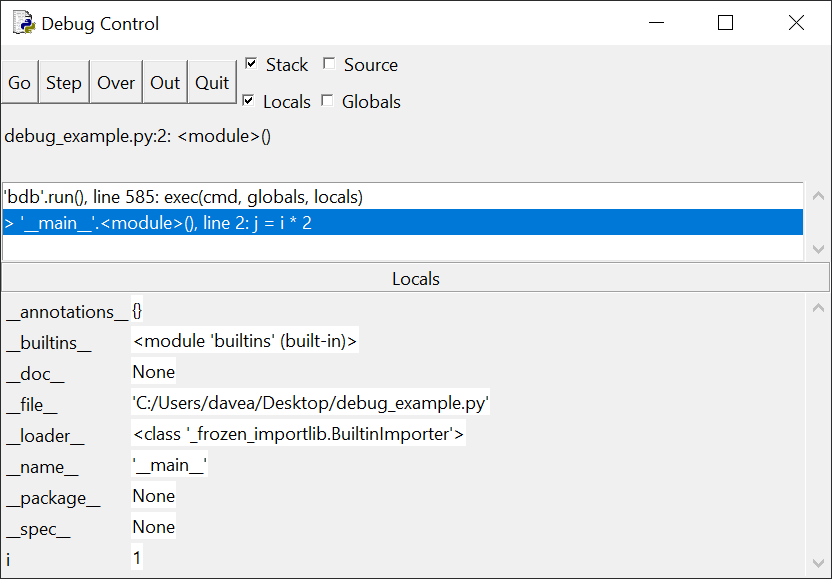
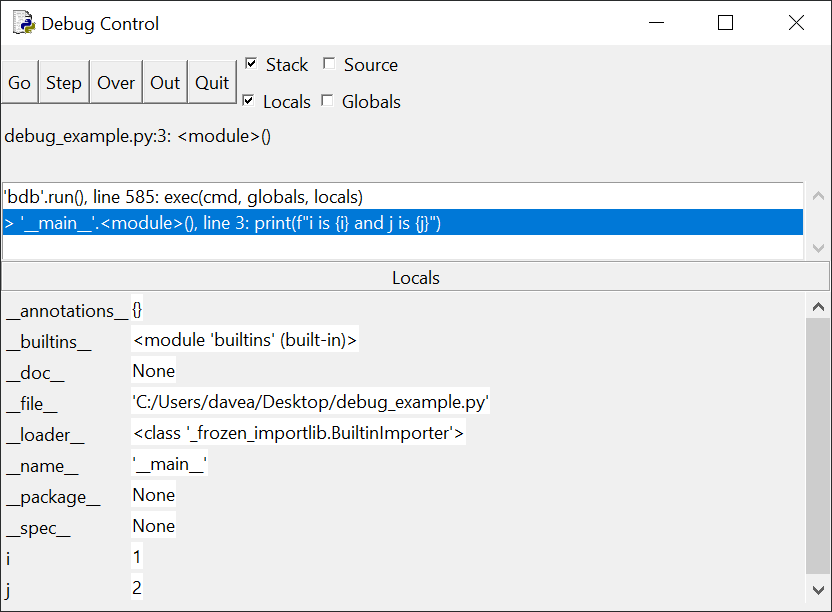
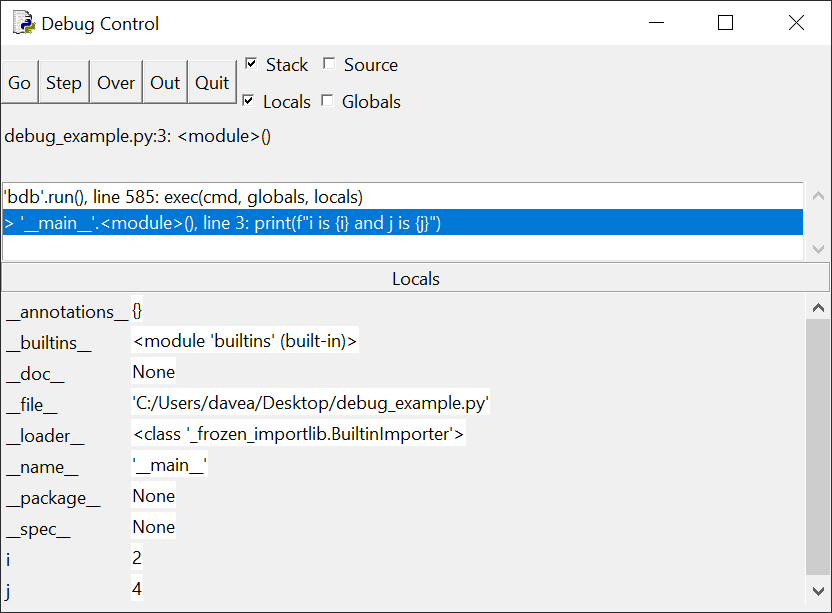
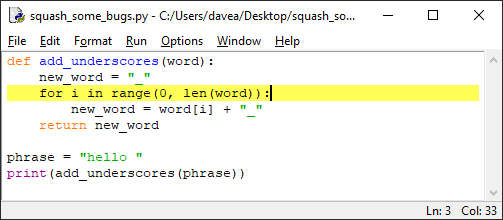
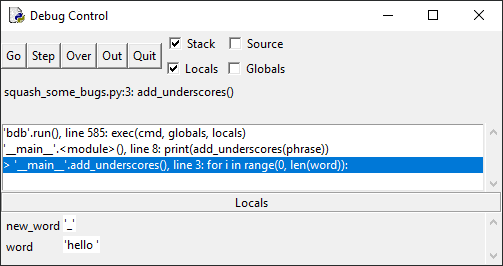
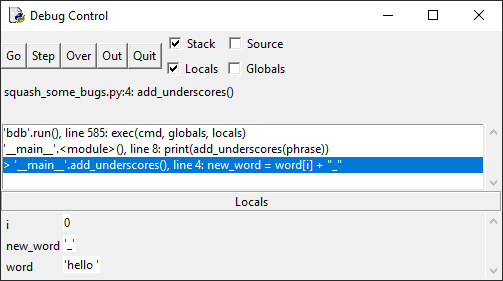
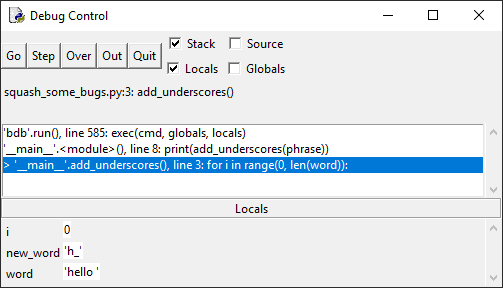
>>> a_dict = {}
>>> a_dict['missing_key']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
a_dict['missing_key']
KeyError: 'missing_key'
>>> a_dict.setdefault('missing_key', 'default value')
'default value'
>>> a_dict['missing_key']
'default value'
>>> a_dict.setdefault('missing_key', 'another default value')
'default value'
>>> a_dict
{'missing_key': 'default value'}
在上面的代码中,您使用.setdefault()为missing_key生成一个默认值。请注意,您的字典a_dict现在有了一个名为missing_key的新键,其值为'default value'。这个键在你调用.setdefault()之前是不存在的。最后,如果您在一个现有的键上调用.setdefault(),那么这个调用不会对字典产生任何影响。您的密钥将保存原始值,而不是新的默认值。
注意:在上面的代码示例中,您得到了一个异常,Python 向您显示了一条回溯消息,告诉您正在尝试访问a_dict中丢失的键。如果你想更深入地了解如何破译和理解 Python 回溯,那么请查看了解 Python 回溯和充分利用 Python 回溯。
另一方面,如果您使用.get(),那么您可以编写如下代码:
>>> a_dict = {} >>> a_dict.get('missing_key', 'default value') 'default value' >>> a_dict {}这里,您使用
.get()为missing_key生成一个默认值,但是这一次,您的字典保持为空。这是因为.get()返回默认值,但是这个值没有被添加到底层字典中。例如,如果你有一本名为D的字典,那么你可以假设.get()是这样工作的:D.get(key, default) -> D[key] if key in D, else default有了这段伪代码,你就能明白
.get()内部是怎么工作的了。如果键存在,那么.get()返回映射到那个键的值。否则,将返回默认值。您的代码从来不会为key创建或赋值。本例中,default默认为None。您还可以使用条件语句来处理字典中丢失的键。看看下面的例子,它使用了
key in dict习语:
>>> a_dict = {}
>>> if 'key' in a_dict:
... # Do something with 'key'...
... a_dict['key']
... else:
... a_dict['key'] = 'default value'
...
>>> a_dict
{'key': 'default value'}
在这段代码中,您使用一个if语句和 in操作符来检查a_dict中是否存在key。如果是这样,那么你可以用key或者它的值来执行任何操作。否则,您将创建新的键key,并将其指定为'default value'。注意,上面的代码类似于.setdefault(),但是需要四行代码,而.setdefault()只需要一行代码(除了可读性更好之外)。
您还可以通过使用try和except块来处理异常,从而绕过KeyError。考虑下面这段代码:
>>> a_dict = {} >>> try: ... # Do something with 'key'... ... a_dict['key'] ... except KeyError: ... a_dict['key'] = 'default value' ... >>> a_dict {'key': 'default value'}上例中的
try和except块在您试图访问一个丢失的键时捕获KeyError。在except子句中,您创建了key,并给它分配了一个'default value'。注意:如果缺少键在你的代码中不常见,那么你可能更喜欢使用
try和except块( EAFP 编码风格)来捕捉KeyError异常。这是因为代码不会检查每个键的存在,如果有的话,只会处理少数异常。另一方面,如果缺少键在您的代码中很常见,那么条件语句( LBYL 编码风格)可能是更好的选择,因为检查键比处理频繁的异常成本更低。
到目前为止,您已经学会了如何使用
dict和 Python 提供的工具来处理丢失的键。然而,您在这里看到的例子非常冗长,难以阅读。它们可能不像你想的那样简单。这就是为什么 Python 标准库提供了一个更加优雅、Python和高效的解决方案。这个解决方案就是collections.defaultdict,这就是你从现在开始要覆盖的内容。了解 Python
defaultdict类型Python 标准库提供了
collections,这是一个实现专门容器类型的模块。其中之一是 Pythondefaultdict类型,它是dict的替代,专门设计来帮助你解决丢失的密钥。defaultdict是继承自dict的 Python 类型:
>>> from collections import defaultdict
>>> issubclass(defaultdict, dict)
True
上面的代码显示 Python defaultdict类型是dict的子类。这意味着defaultdict继承了dict的大部分行为。所以,你可以说defaultdict很像一本普通的字典。
defaultdict和dict的主要区别在于,当你试图访问或修改一个不在字典中的key时,默认的value会自动赋予那个key。为了提供这个功能,Python defaultdict类型做了两件事:
- 它覆盖了
.__missing__()。 - 它增加了
.default_factory,一个需要在实例化时提供的可写实例变量。
实例变量.default_factory将保存传入 defaultdict.__init__() 的第一个参数。该参数可以采用有效的 Python callable 或None。如果提供了一个 callable,那么每当您试图访问或修改与一个丢失的键相关联的值时,它将被defaultdict自动调用。
注意:类初始化器的所有剩余参数都被视为传递给了正则dict的初始化器,包括关键字参数。
看看如何创建并正确初始化一个defaultdict:
>>> # Correct instantiation >>> def_dict = defaultdict(list) # Pass list to .default_factory >>> def_dict['one'] = 1 # Add a key-value pair >>> def_dict['missing'] # Access a missing key returns an empty list [] >>> def_dict['another_missing'].append(4) # Modify a missing key >>> def_dict defaultdict(<class 'list'>, {'one': 1, 'missing': [], 'another_missing': [4]})在这里,当您创建字典时,您将
list传递给.default_factory。然后,你可以像使用普通字典一样使用def_dict。注意,当您试图访问或修改映射到一个不存在的键的值时,字典会给它分配调用list()得到的默认值。请记住,您必须将一个有效的 Python 可调用对象传递给
.default_factory,所以记住不要在初始化时使用括号来调用它。当您开始使用 Pythondefaultdict类型时,这可能是一个常见的问题。看一下下面的代码:
>>> # Wrong instantiation
>>> def_dict = defaultdict(list())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
def_dict = defaultdict(list())
TypeError: first argument must be callable or None
在这里,您试图通过将list()传递给.default_factory来创建一个defaultdict。对list()的调用引发了一个TypeError,它告诉你第一个参数必须是可调用的或者是None。
通过对 Python defaultdict类型的介绍,您可以通过实际例子开始编码。接下来的几节将带您浏览一些常见的用例,在这些用例中,您可以依靠一个defaultdict来提供一个优雅、高效的 Pythonic 解决方案。
使用 Python defaultdict类型
有时,您将使用可变的内置集合(一个list、dict或 set )作为 Python 字典中的值。在这些情况下,你需要在第一次使用前初始化键,否则你会得到一个KeyError。您可以手动完成这个过程,也可以使用 Python defaultdict自动完成。在本节中,您将学习如何使用 Python defaultdict类型来解决一些常见的编程问题:
- 分组集合中的项目
- 清点收藏中的物品
- 累加集合中的值
您将会看到一些使用list、set、int和float的例子,以一种用户友好和有效的方式执行分组、计数和累加操作。
分组项目
Python defaultdict类型的典型用法是将.default_factory设置为list,然后构建一个将键映射到值列表的字典。使用这个defaultdict,如果您试图访问任何丢失的键,那么字典将运行以下步骤:
- 调用
list()创建一个新的空list - 将空的
list插入字典,使用丢失的键作为key - 返回对那个
list的引用
这允许您编写如下代码:
>>> from collections import defaultdict >>> dd = defaultdict(list) >>> dd['key'].append(1) >>> dd defaultdict(<class 'list'>, {'key': [1]}) >>> dd['key'].append(2) >>> dd defaultdict(<class 'list'>, {'key': [1, 2]}) >>> dd['key'].append(3) >>> dd defaultdict(<class 'list'>, {'key': [1, 2, 3]})在这里,您创建了一个名为
dd的 Pythondefaultdict,并将list传递给.default_factory。注意,即使没有定义key,您也可以将值附加到它上面,而不会得到KeyError。那是因为dd自动调用.default_factory为缺失的key生成默认值。您可以将
defaultdict与list一起使用,对序列或集合中的项目进行分组。假设您已经从贵公司的数据库中检索到以下数据:
部门 员工姓名 销售 无名氏 销售 马丁·史密斯 会计 简·多伊 营销 伊丽莎白·史密斯 营销 亚当·多伊 … … 有了这些数据,你创建一个初始的
tuple对象的list,如下:dep = [('Sales', 'John Doe'), ('Sales', 'Martin Smith'), ('Accounting', 'Jane Doe'), ('Marketing', 'Elizabeth Smith'), ('Marketing', 'Adam Doe')]现在,您需要创建一个字典,按部门对雇员进行分组。为此,您可以使用如下的
defaultdict:from collections import defaultdict dep_dd = defaultdict(list) for department, employee in dep: dep_dd[department].append(employee)在这里,您创建一个名为
dep_dd的defaultdict,并使用一个for循环来遍历您的dep列表。语句dep_dd[department].append(employee)为部门创建键,将它们初始化为一个空列表,然后将雇员添加到每个部门。一旦您运行了这段代码,您的dep_dd将看起来像这样:
defaultdict(<class 'list'>, {'Sales': ['John Doe', 'Martin Smith'],
'Accounting' : ['Jane Doe'],
'Marketing': ['Elizabeth Smith', 'Adam Doe']})
在这个例子中,您使用一个defaultdict将员工按部门分组,其中.default_factory设置为list。要使用常规字典来实现这一点,您可以如下使用dict.setdefault():
dep_d = dict()
for department, employee in dep:
dep_d.setdefault(department, []).append(employee)
这段代码很简单,作为一名 Python 程序员,您会经常在工作中发现类似的代码。然而,defaultdict版本可以说更具可读性,对于大型数据集,它也可以快很多并且更高效。所以,如果速度是你关心的问题,那么你应该考虑使用defaultdict而不是标准的dict。
对唯一项目进行分组
继续使用上一节中的部门和员工数据。经过一些处理后,您意识到一些员工被错误地在数据库中复制成了。您需要清理数据,并从您的dep_dd字典中删除重复的雇员。为此,您可以使用一个set作为.default_factory,并如下重写您的代码:
dep = [('Sales', 'John Doe'),
('Sales', 'Martin Smith'),
('Accounting', 'Jane Doe'),
('Marketing', 'Elizabeth Smith'),
('Marketing', 'Elizabeth Smith'),
('Marketing', 'Adam Doe'),
('Marketing', 'Adam Doe'),
('Marketing', 'Adam Doe')]
dep_dd = defaultdict(set)
for department, employee in dep:
dep_dd[department].add(employee)
在本例中,您将.default_factory设置为set。集合是唯一对象的集合,这意味着你不能创建一个有重复项目的set。这是 set 的一个非常有趣的特性,它保证了在最终的字典中不会有重复的条目。
清点物品
如果您将.default_factory设置为 int ,那么您的defaultdict将对计数序列或集合中的项目有用。当您不带参数调用int()时,该函数返回0,这是您用来初始化计数器的典型值。
继续以公司数据库为例,假设您想要构建一个字典来计算每个部门的雇员人数。在这种情况下,您可以编写如下代码:
>>> from collections import defaultdict >>> dep = [('Sales', 'John Doe'), ... ('Sales', 'Martin Smith'), ... ('Accounting', 'Jane Doe'), ... ('Marketing', 'Elizabeth Smith'), ... ('Marketing', 'Adam Doe')] >>> dd = defaultdict(int) >>> for department, _ in dep: ... dd[department] += 1 >>> dd defaultdict(<class 'int'>, {'Sales': 2, 'Accounting': 1, 'Marketing': 2})在这里,您将
.default_factory设置为int。当你不带参数调用int()时,返回值是0。您可以使用这个默认值开始计算在每个部门工作的员工。为了让这段代码正确运行,您需要一个干净的数据集。不得有重复数据。否则,您需要过滤掉重复的员工。另一个计算项目的例子是
mississippi的例子,你计算一个单词中每个字母重复的次数。看一下下面的代码:
>>> from collections import defaultdict
>>> s = 'mississippi'
>>> dd = defaultdict(int)
>>> for letter in s:
... dd[letter] += 1
...
>>> dd
defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})
在上面的代码中,您创建了一个将.default_factory设置为int的defaultdict。这将任何给定键的默认值设置为0。然后,使用一个for循环遍历字符串 s,并使用一个增强赋值操作在每次迭代中将1添加到计数器中。dd的按键将是mississippi中的字母。
注意: Python 的增强赋值操作符是常见操作的便捷快捷方式。
看看下面的例子:
var += 1相当于var = var + 1var -= 1相当于var = var - 1var *= 1相当于var = var * 1
这只是增强赋值操作符如何工作的一个例子。你可以看一下官方文档来了解这个特性的更多信息。
由于计数在编程中是一个相对常见的任务,类似 Python 字典的类 collections.Counter 是专门为计数序列中的项目而设计的。使用Counter,您可以编写如下的mississippi示例:
>>> from collections import Counter >>> counter = Counter('mississippi') >>> counter Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})在这种情况下,
Counter会为您完成所有工作!您只需要传入一个序列,字典将对其条目进行计数,将它们存储为键,将计数存储为值。注意,这个例子是可行的,因为 Python 字符串也是一种序列类型。累计值
有时你需要计算一个序列或集合中的值的总和。假设您有以下 Excel 表格,其中包含您的 Python 网站的销售数据:
制品 七月 八月 九月 书 One thousand two hundred and fifty One thousand three hundred One thousand four hundred and twenty 教程 Five hundred and sixty Six hundred and thirty Seven hundred and fifty 课程 Two thousand five hundred Two thousand four hundred and thirty Two thousand seven hundred and fifty 接下来,您使用 Python 处理数据并获得以下
tuple个对象中的list:incomes = [('Books', 1250.00), ('Books', 1300.00), ('Books', 1420.00), ('Tutorials', 560.00), ('Tutorials', 630.00), ('Tutorials', 750.00), ('Courses', 2500.00), ('Courses', 2430.00), ('Courses', 2750.00),]有了这些数据,你想计算每件产品的总收入。要做到这一点,您可以使用一个带
float的 Pythondefaultdict作为.default_factory,然后编写如下代码:1from collections import defaultdict 2 3dd = defaultdict(float) 4for product, income in incomes: 5 dd[product] += income 6 7for product, income in dd.items(): 8 print(f'Total income for {product}: ${income:,.2f}')下面是这段代码的作用:
- 在第 1 行中,您导入了 Python
defaultdict类型。- 在第 3 行中,你创建了一个
defaultdict对象,并将.default_factory设置为float。- 在第 4 行中,您定义了一个
for循环来遍历incomes的条目。- 在第 5 行中,您使用一个增强的赋值操作(
+=)来累加字典中每个产品的收入。第二个循环遍历
dd的条目,并将收入打印到屏幕上。注意:如果你想更深入地研究字典迭代,请查看如何在 Python 中迭代字典。
如果您将所有这些代码放入一个名为
incomes.py的文件中,并从命令行运行它,那么您将得到以下输出:$ python3 incomes.py Total income for Books: $3,970.00 Total income for Tutorials: $1,940.00 Total income for Courses: $7,680.00你现在有了每件产品的收入汇总,所以你可以决定采取什么策略来增加你网站的总收入。
深入到
defaultdict到目前为止,通过编写一些实际例子,您已经学会了如何使用 Python
defaultdict类型。此时,您可以更深入地了解类型实现和其他工作细节。这是您将在接下来的几节中涉及的内容。
defaultdictvsdictT2】为了更好地理解 Python
defaultdict类型,一个很好的练习是将其与其超类dict进行比较。如果您想知道特定于 Pythondefaultdict类型的方法和属性,那么您可以运行下面一行代码:
>>> set(dir(defaultdict)) - set(dir(dict))
{'__copy__', 'default_factory', '__missing__'}
在上面的代码中,您使用 dir() 来获取dict和defaultdict的有效属性列表。然后,你用一个 set 的区别来得到你只能在defaultdict中找到的方法和属性的集合。正如您所看到的,这两个类之间的区别是。您有两个方法和一个实例属性。下表显示了这些方法和属性的用途:
| 方法或属性 | 描述 |
|---|---|
.__copy__() |
为copy.copy()提供支持 |
.default_factory |
保存由.__missing__()调用的 callable,以自动为丢失的键提供默认值 |
.__missing__(key) |
当.__getitem__()找不到key时被调用 |
在上表中,您可以看到使defaultdict不同于常规dict的方法和属性。这两个类中的其余方法是相同的。
注意:如果你使用一个有效的可调用函数初始化一个defaultdict,那么当你试图访问一个丢失的键时,你不会得到一个KeyError。任何不存在的键都会得到由.default_factory返回的值。
此外,您可能会注意到一个defaultdict等于一个dict,具有相同的项目:
>>> std_dict = dict(numbers=[1, 2, 3], letters=['a', 'b', 'c']) >>> std_dict {'numbers': [1, 2, 3], 'letters': ['a', 'b', 'c']} >>> def_dict = defaultdict(list, numbers=[1, 2, 3], letters=['a', 'b', 'c']) >>> def_dict defaultdict(<class 'list'>, {'numbers': [1, 2, 3], 'letters': ['a', 'b', 'c']}) >>> std_dict == def_dict True在这里,您创建了一个包含一些任意条目的常规字典
std_dict。然后,用相同的条目创建一个defaultdict。如果您测试两个字典的内容是否相等,那么您会发现它们是相等的。
defaultdict.default_factoryPython
defaultdict类型的第一个参数必须是一个可调用的,它不接受任何参数并返回值。该参数被分配给实例属性.default_factory。为此,您可以使用任何可调用的对象,包括函数、方法、类、类型对象或任何其他有效的可调用对象。.default_factory的默认值为None。如果您实例化了
defaultdict而没有传递一个值给.default_factory,那么字典将像常规的dict一样运行,并且通常的KeyError将会因缺少键查找或修改尝试而被引发:
>>> from collections import defaultdict
>>> dd = defaultdict()
>>> dd['missing_key']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
dd['missing_key']
KeyError: 'missing_key'
这里,您实例化了不带参数的 Python defaultdict类型。在这种情况下,实例的行为就像一个标准字典。因此,如果您试图访问或修改一个丢失的密钥,那么您将得到通常的KeyError。从这一点开始,您可以将dd作为普通的 Python 字典来使用,除非您为.default_factory分配一个新的 callable,否则您将无法使用defaultdict的能力来自动处理丢失的键。
如果您将None传递给defaultdict的第一个参数,那么实例的行为将与您在上面的例子中看到的一样。那是因为.default_factory默认为None,所以两种初始化是等价的。另一方面,如果你传递一个有效的可调用对象给.default_factory,那么你可以用它以一种用户友好的方式处理丢失的键。下面是一个将list传递给.default_factory的例子:
>>> dd = defaultdict(list, letters=['a', 'b', 'c']) >>> dd.default_factory <class 'list'> >>> dd defaultdict(<class 'list'>, {'letters': ['a', 'b', 'c']}) >>> dd['numbers'] [] >>> dd defaultdict(<class 'list'>, {'letters': ['a', 'b', 'c'], 'numbers': []}) >>> dd['numbers'].append(1) >>> dd defaultdict(<class 'list'>, {'letters': ['a', 'b', 'c'], 'numbers': [1]}) >>> dd['numbers'] += [2, 3] >>> dd defaultdict(<class 'list'>, {'letters': ['a', 'b', 'c'], 'numbers': [1, 2, 3]})在这个例子中,您创建了一个名为
dd的 Pythondefaultdict,然后使用list作为它的第一个参数。第二个参数称为letters,它保存一个字母列表。您会看到.default_factory现在持有一个list对象,当您需要为任何丢失的键提供一个默认的value时,该对象将被调用。注意,当你试图访问
numbers,dd测试numbers是否在字典中。如果不是,那么它调用.default_factory()。由于.default_factory持有一个list对象,返回的value是一个空列表([])。现在
dd['numbers']已经用空的list初始化,您可以使用.append()向list添加元素。您还可以使用一个增强的赋值操作符(+=)来连接列表[1]和[2, 3]。这样,您可以用一种更 Pythonic 化、更高效的方式来处理丢失的键。另一方面,如果您将一个不可调用的对象传递给 Python
defaultdict类型的初始化器,那么您将得到一个TypeError,如下面的代码所示:
>>> defaultdict(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
defaultdict(0)
TypeError: first argument must be callable or None
在这里,您将0传递给.default_factory。因为0不是一个可调用的对象,你得到一个TypeError告诉你第一个参数必须是可调用的或者是None。否则,defaultdict不起作用。
记住.default_factory只是从 .__getitem__() 中调用,而不是从其他方法中调用。这意味着如果dd是一个defaultdict并且key是一个丢失的键,那么dd[key]将调用.default_factory来提供一个默认的value,但是dd.get(key)仍然返回None而不是.default_factory将提供的值。那是因为.get()没有调用.__getitem__()来检索key。
看一下下面的代码:
>>> dd = defaultdict(list) >>> # Calls dd.__getitem__('missing') >>> dd['missing'] [] >>> # Don't call dd.__getitem__('another_missing') >>> print(dd.get('another_missing')) None >>> dd defaultdict(<class 'list'>, {'missing': []})在这段代码中,你可以看到
dd.get()返回None,而不是.default_factory提供的默认值。那是因为.default_factory只从.__missing__()调用,.get()不调用。请注意,您还可以向 Python
defaultdict添加任意值。这意味着您不局限于与由.default_factory生成的值类型相同的值。这里有一个例子:
>>> dd = defaultdict(list)
>>> dd
defaultdict(<class 'list'>, {})
>>> dd['string'] = 'some string'
>>> dd
defaultdict(<class 'list'>, {'string': 'some string'})
>>> dd['list']
[]
>>> dd
defaultdict(<class 'list'>, {'string': 'some string', 'list': []})
在这里,您创建了一个defaultdict并向.default_factory传递了一个list对象。这会将您的默认值设置为空列表。但是,您可以自由添加保存不同类型值的新键。键string就是这种情况,它持有一个str对象,而不是一个list对象。
最后,您总是可以用与处理任何实例属性相同的方式,更改或更新最初分配给.default_factory的可调用的:
>>> dd.default_factory = str >>> dd['missing_key'] ''在上面的代码中,您将
.default_factory从list更改为str。现在,每当您试图访问一个丢失的键时,您的缺省值将是一个空字符串('')。根据 Python
defaultdict类型的用例,一旦完成创建,您可能需要冻结字典,并使其成为只读的。为此,您可以在完成字典填充后将.default_factory设置为None。这样,您的字典将表现得像一个标准的dict,这意味着您不会有更多自动生成的默认值。
defaultdictvsdict.setdefault()T2】正如您之前看到的,
dict提供了.setdefault(),它将允许您动态地为丢失的键赋值。相比之下,使用defaultdict可以在初始化容器时预先指定默认值。您可以使用.setdefault()分配默认值,如下所示:
>>> d = dict()
>>> d.setdefault('missing_key', [])
[]
>>> d
{'missing_key': []}
在这段代码中,您创建一个常规字典,然后使用.setdefault()为键missing_key赋值([]),这个键还没有定义。
注意:你可以使用.setdefault()分配任何类型的 Python 对象。如果你考虑到defaultdict只接受可调用或None,这是与defaultdict的一个重要区别。
另一方面,如果您使用一个defaultdict来完成相同的任务,那么每当您试图访问或修改一个丢失的键时,就会根据需要生成缺省值。注意,使用defaultdict,默认值是由您传递给类的初始化器的可调用函数生成的。它是这样工作的:
>>> from collections import defaultdict >>> dd = defaultdict(list) >>> dd['missing_key'] [] >>> dd defaultdict(<class 'list'>, {'missing_key': []})这里,首先从
collections导入 Pythondefaultdict类型。然后,您创建一个defaultdict,并将list传递给.default_factory。当您试图访问一个丢失的键时,defaultdict在内部调用.default_factory(),它保存了对list的引用,并将结果值(一个空的list)赋给missing_key。上面两个例子中的代码做了同样的工作,但是
defaultdict版本更具可读性、用户友好性、Pythonic 化和简单明了。注意:对内置类型如
list、set、dict、str、int或float的调用将返回一个空对象,对于数值类型则返回零。看一下下面的代码示例:
>>> list()
[]
>>> set()
set([])
>>> dict()
{}
>>> str()
''
>>> float()
0.0
>>> int()
0
在这段代码中,您调用了一些没有参数的内置类型,并获得了一个空对象或零数值类型。
最后,使用defaultdict处理丢失的键比使用dict.setdefault()更快。看看下面的例子:
# Filename: exec_time.py
from collections import defaultdict
from timeit import timeit
animals = [('cat', 1), ('rabbit', 2), ('cat', 3), ('dog', 4), ('dog', 1)]
std_dict = dict()
def_dict = defaultdict(list)
def group_with_dict():
for animal, count in animals:
std_dict.setdefault(animal, []).append(count)
return std_dict
def group_with_defaultdict():
for animal, count in animals:
def_dict[animal].append(count)
return def_dict
print(f'dict.setdefault() takes {timeit(group_with_dict)} seconds.')
print(f'defaultdict takes {timeit(group_with_defaultdict)} seconds.')
如果您从系统的命令行运行脚本,那么您将得到如下结果:
$ python3 exec_time.py
dict.setdefault() takes 1.0281260240008123 seconds.
defaultdict takes 0.6704721650003194 seconds.
这里用 timeit.timeit() 来衡量group_with_dict()和group_with_defaultdict()的执行时间。这些函数执行相同的动作,但是第一个使用dict.setdefault(),第二个使用defaultdict。时间测量将取决于您当前的硬件,但是您可以在这里看到defaultdict比dict.setdefault()快。随着数据集变大,这种差异会变得更加重要。
此外,您需要考虑创建一个常规的dict可能比创建一个defaultdict更快。看一下这段代码:
>>> from timeit import timeit >>> from collections import defaultdict >>> print(f'dict() takes {timeit(dict)} seconds.') dict() takes 0.08921320698573254 seconds. >>> print(f'defaultdict() takes {timeit(defaultdict)} seconds.') defaultdict() takes 0.14101867799763568 seconds.这一次,您使用
timeit.timeit()来测量dict和defaultdict实例化的执行时间。注意,创建一个dict花费的时间几乎是创建一个defaultdict的一半。如果您考虑到在真实世界的代码中,您通常只实例化defaultdict一次,这可能不是问题。还要注意,默认情况下,
timeit.timeit()将运行您的代码一百万次。这就是将std_dict和def_dict定义在group_with_dict()和exec_time.py范围之外的原因。否则,时间度量将受到dict和defaultdict的实例化时间的影响。在这一点上,你可能已经知道什么时候使用一个
defaultdict而不是一个常规的dict。这里有三点需要考虑:
如果你的代码在很大程度上基于字典,并且你一直在处理丢失的键,那么你应该考虑使用
defaultdict而不是常规的dict。如果你的字典条目需要用一个常量默认值初始化,那么你应该考虑用
defaultdict代替dict。如果你的代码依赖字典来聚合、累加、计数或分组值,并且性能是个问题,那么你应该考虑使用
defaultdict。在决定是使用
dict还是defaultdict时,可以考虑上面的指导方针。
defaultdict.__missing__()在幕后,Python
defaultdict类型通过调用.default_factory为丢失的键提供默认值。使这成为可能的机制是.__missing__(),一种所有标准映射类型都支持的特殊方法,包括dict和defaultdict。注意:注意,
.__missing__()被.__getitem__()自动调用来处理丢失的密钥,.__getitem__()被 Python 同时自动调用来进行订阅操作像d[key]。那么,
.__missing__()是如何工作的呢?如果您将.default_factory设置为None,那么.__missing__()将引发一个KeyError,并将key作为参数。否则,不带参数调用.default_factory,为给定的key提供默认的value。这个value插入字典,最后返回。如果调用.default_factory引发了一个异常,那么这个异常会被原封不动地传播。下面的代码展示了一个可行的 Python 实现用于
.__missing__():1def __missing__(self, key): 2 if self.default_factory is None: 3 raise KeyError(key) 4 if key not in self: 5 self[key] = self.default_factory() 6 return self[key]下面是这段代码的作用:
- 在第 1 行中,您定义了方法及其签名。
- 在第 2 行和第 3 行,你测试一下
.default_factory是不是None。如果是这样,那么你用key作为参数来引发一个KeyError。- 在第 4 行和第 5 行,你检查
key是否不在字典中。如果不是,那么您调用.default_factory并将它的返回值赋给key。- 在第 6 行中,你如期返回了
key。请记住,
.__missing__()在映射中的出现对其他查找键的方法的行为没有影响,比如实现了in操作符的.get()或.__contains__()。那是因为只有当被请求的key在字典中找不到的时候.__missing__()才会被.__getitem__()调用。无论.__missing__()返回或引发什么,都会被.__getitem__()返回或引发。既然您已经介绍了
.__missing__()的另一种 Python 实现,那么尝试用一些 Python 代码来模拟defaultdict将是一个很好的练习。这就是您在下一部分要做的事情。模仿 Python
defaultdict类型在本节中,您将编写一个行为类似于
defaultdict的 Python 类。为此,您将子类化collections.UserDict,然后添加.__missing__()。此外,您需要添加一个名为.default_factory的实例属性,它将保存用于按需生成默认值的可调用。这里有一段代码模拟了 Pythondefaultdict类型的大部分行为:1import collections 2 3class my_defaultdict(collections.UserDict): 4 def __init__(self, default_factory=None, *args, **kwargs): 5 super().__init__(*args, **kwargs) 6 if not callable(default_factory) and default_factory is not None: 7 raise TypeError('first argument must be callable or None') 8 self.default_factory = default_factory 9 10 def __missing__(self, key): 11 if self.default_factory is None: 12 raise KeyError(key) 13 if key not in self: 14 self[key] = self.default_factory() 15 return self[key]下面是这段代码的工作原理:
在第 1 行,你导入
collections来访问UserDict。在第 3 行中,你创建了一个子类
UserDict。在第 4 行中,你定义了类初始化器
.__init__()。这个方法使用一个名为default_factory的参数来保存您将用来生成默认值的可调用对象。注意default_factory默认为None,就像在defaultdict中一样。您还需要*args和**kwargs来模拟常规dict的正常行为。在第 5 行,你调用超类
.__init__()。这意味着你正在调用UserDict.__init__()并将*args和**kwargs传递给它。在第 6 行中,首先检查
default_factory是否是有效的可调用对象。在这种情况下,您使用callable(object),这是一个内置函数,如果object是可调用的,则返回True,否则返回False。如果您需要为任何缺失的key生成默认的value,这个检查确保您可以调用.default_factory()。然后,你检查一下.default_factory是不是None。在第 7 行,如果
default_factory是None,你就像普通的dict一样养一只TypeError。在第 8 行,你初始化
.default_factory。在第 10 行中,你定义了
.__missing__(),它的实现和你之前看到的一样。回想一下,当给定的key不在字典中时,.__getitem__()会自动调用.__missing__()。如果你有心情阅读一些 C 代码,那么你可以看看 CPython 源代码中 Python
defaultdict类型的完整代码。现在您已经完成了这个类的编码,您可以通过将代码放入名为
my_dd.py的 Python 脚本中并从交互式会话中导入它来测试它。这里有一个例子:
>>> from my_dd import my_defaultdict
>>> dd_one = my_defaultdict(list)
>>> dd_one
{}
>>> dd_one['missing']
[]
>>> dd_one
{'missing': []}
>>> dd_one.default_factory = int
>>> dd_one['another_missing']
0
>>> dd_one
{'missing': [], 'another_missing': 0}
>>> dd_two = my_defaultdict(None)
>>> dd_two['missing']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
dd_two['missing']
File "/home/user/my_dd.py", line 10,
in __missing__
raise KeyError(key)
KeyError: 'missing'
这里首先从my_dd导入my_defaultdict。然后,创建一个my_defaultdict的实例,并将list传递给.default_factory。如果你试图通过订阅操作访问一个键,比如dd_one['missing'],那么.__getitem__()会被 Python 自动调用。如果这个键不在字典中,那么调用.__missing__(),它通过调用.default_factory()生成一个默认值。
你也可以像在dd_one.default_factory = int中一样使用普通的赋值操作来改变分配给.default_factory的可调用函数。最后,如果你将None传给.default_factory,那么当你试图找回丢失的钥匙时,你将得到一个KeyError。
注意:一个defaultdict的行为本质上和这个 Python 等价物是一样的。然而,您很快就会注意到,您的 Python 实现不是作为真正的defaultdict打印的,而是作为标准的dict打印的。您可以通过覆盖.__str__()和.__repr__()来修改这个细节。
您可能想知道为什么在这个例子中您子类化了collections.UserDict而不是常规的dict。其主要原因是,对内置类型进行子类化可能容易出错,因为内置类型的 C 代码似乎不会始终如一地调用由用户覆盖的特殊方法。
这里有一个例子,展示了在子类化dict时可能会遇到的一些问题:
>>> class MyDict(dict): ... def __setitem__(self, key, value): ... super().__setitem__(key, None) ... >>> my_dict = MyDict(first=1) >>> my_dict {'first': 1} >>> my_dict['second'] = 2 >>> my_dict {'first': 1, 'second': None} >>> my_dict.setdefault('third', 3) 3 >>> my_dict {'first': 1, 'second': None, 'third': 3}在这个例子中,您创建了
MyDict,它是dict的子类。您的.__setitem__()实现总是将值设置为None。如果你创建了一个MyDict的实例并传递了一个关键字参数给它的初始化器,那么你会注意到这个类并没有调用你的.__setitem__()来处理这个赋值。你知道那是因为键first没有被赋值None。相比之下,如果您运行类似于
my_dict['second'] = 2的订阅操作,那么您会注意到second被设置为None而不是2。所以,这个时候你可以说订阅操作调用你的客户.__setitem__()。最后,注意.setdefault()也不调用.__setitem__(),因为您的third键以值3结束。
UserDict并没有继承dict而是模拟了标准字典的行为。该类有一个名为.data的内部dict实例,用于存储字典的内容。在创建自定义映射时,UserDict是一个更可靠的类。如果你使用UserDict,那么你将会避免你之前看到的问题。为了证明这一点,回到my_defaultdict的代码并添加以下方法:1class my_defaultdict(collections.UserDict): 2 # Snip 3 def __setitem__(self, key, value): 4 print('__setitem__() gets called') 5 super().__setitem__(key, None)这里,您添加了一个调用超类
.__setitem__()的自定义.__setitem__(),它总是将值设置为None。更新脚本my_dd.py中的代码,并从交互式会话中导入,如下所示:
>>> from my_dd import my_defaultdict
>>> my_dict = my_defaultdict(list, first=1)
__setitem__() gets called
>>> my_dict
{'first': None}
>>> my_dict['second'] = 2
__setitem__() gets called
>>> my_dict
{'first': None, 'second': None}
在这种情况下,当您实例化my_defaultdict并将first传递给类初始化器时,您的自定义__setitem__()会被调用。同样,当你给键second赋值时,__setitem__()也会被调用。您现在有了一个my_defaultdict,它始终如一地调用您的定制特殊方法。注意,现在字典中的所有值都等于None。
将参数传递给.default_factory
正如您前面看到的,.default_factory必须被设置为一个不接受参数并返回值的可调用对象。该值将用于为字典中任何缺失的键提供默认值。即使当.default_factory不应该接受参数时,Python 也提供了一些技巧,如果您需要向它提供参数,您可以使用这些技巧。在本节中,您将介绍两个可以实现这一目的的 Python 工具:
有了这两个工具,您可以为 Python defaultdict类型增加额外的灵活性。例如,您可以用一个带参数的 callable 来初始化一个defaultdict,经过一些处理后,您可以用一个新的参数来更新这个 callable,以改变您将从现在开始创建的键的默认值。
使用lambda
将参数传递给.default_factory的一种灵活方式是使用 lambda 。假设您想创建一个函数来在defaultdict中生成默认值。该函数执行一些处理并返回一个值,但是您需要传递一个参数以使该函数正确工作。这里有一个例子:
>>> def factory(arg): ... # Do some processing here... ... result = arg.upper() ... return result ... >>> def_dict = defaultdict(lambda: factory('default value')) >>> def_dict['missing'] 'DEFAULT VALUE'在上面的代码中,您创建了一个名为
factory()的函数。该函数接受一个参数,进行一些处理,然后返回最终结果。然后,创建一个defaultdict并使用lambda将字符串'default value'传递给factory()。当您尝试访问丢失的密钥时,将运行以下步骤:
- 字典
def_dict调用它的.default_factory,它保存了对一个lambda函数的引用。lambda函数被调用,并返回以'default value'作为参数调用factory()的结果值。如果您正在使用
def_dict并突然需要将参数更改为factory(),那么您可以这样做:
>>> def_dict.default_factory = lambda: factory('another default value')
>>> def_dict['another_missing']
'ANOTHER DEFAULT VALUE'
这一次,factory()接受一个新的字符串参数('another default value')。从现在开始,如果您试图访问或修改一个丢失的键,那么您将获得一个新的默认值,这就是字符串'ANOTHER DEFAULT VALUE'。
最后,您可能会面临这样一种情况,您需要一个不同于0或[]的默认值。在这种情况下,你也可以使用lambda来生成一个不同的默认值。比如,假设你有一个list的整数,你需要计算每个数的累积积。然后,您可以使用defaultdict和lambda,如下所示:
>>> from collections import defaultdict >>> lst = [1, 1, 2, 1, 2, 2, 3, 4, 3, 3, 4, 4] >>> def_dict = defaultdict(lambda: 1) >>> for number in lst: ... def_dict[number] *= number ... >>> def_dict defaultdict(<function <lambda> at 0x...70>, {1: 1, 2: 8, 3: 27, 4: 64})这里,您使用
lambda来提供默认值1。有了这个初始值,你就可以计算出lst中每个数字的累积积。注意,使用int不能得到相同的结果,因为int返回的默认值总是0,这对于这里需要执行的乘法运算来说不是一个好的初始值。使用
functools.partial()
functools.partial(func, *args, **keywords)是返回一个partial对象的函数。当您用位置参数(args)和关键字参数(keywords)调用这个对象时,它的行为类似于您调用func(*args, **keywords)时的行为。您可以利用partial()的这种行为,并使用它在 Pythondefaultdict中将参数传递给.default_factory。这里有一个例子:
>>> def factory(arg):
... # Do some processing here...
... result = arg.upper()
... return result
...
>>> from functools import partial
>>> def_dict = defaultdict(partial(factory, 'default value'))
>>> def_dict['missing']
'DEFAULT VALUE'
>>> def_dict.default_factory = partial(factory, 'another default value')
>>> def_dict['another_missing']
'ANOTHER DEFAULT VALUE'
在这里,您创建一个 Python defaultdict并使用partial()向.default_factory提供一个参数。注意,您也可以更新.default_factory来为可调用的factory()使用另一个参数。这种行为可以给你的defaultdict对象增加很多灵活性。
结论
Python defaultdict类型是一种类似字典的数据结构,由 Python 标准库在一个名为collections的模块中提供。该类继承自dict,它主要增加的功能是为丢失的键提供默认值。在本教程中,您已经学习了如何使用 Python defaultdict类型来处理字典中丢失的键。
您现在能够:
- 创建并使用一个 Python
defaultdict来处理丢失的键 - 解决现实世界中与分组、计数和累加操作相关的问题
- 知道
defaultdict和dict的实现差异 - 决定何时以及为什么使用 Python
defaultdict而不是标准的dict
Python defaultdict类型是一种方便而有效的数据结构,旨在帮助您处理字典中丢失的键。试一试,让你的代码更快、更可读、更 Pythonic 化!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python defaultdict Type 处理丢失的键*****
Python 的 deque:实现高效的队列和堆栈
如果你经常用 Python 处理列表,那么你可能知道当你需要在列表的左端弹出和追加项时,它们的执行速度不够快。Python 的 collections 模块提供了一个名为 deque 的类,该类是专门设计来提供快速且节省内存的方法来从底层数据结构的两端追加和弹出项目。
Python 的deque是一个低级且高度优化的双端队列,对于实现优雅、高效且 python 化的队列和堆栈非常有用,它们是计算中最常见的列表式数据类型。
在本教程中,您将学习:
- 如何在你的代码中创建和使用 Python 的
deque - 如何高效地从一个
deque的两端追加和弹出项 - 如何利用
deque搭建高效的队列和栈 - 当值得用
deque代替list时
为了更好地理解这些主题,您应该了解使用 Python 列表的基础知识。对队列和栈有一个大致的了解也是有益的。
最后,您将编写几个示例,带您了解一些常见的deque用例,它是 Python 最强大的数据类型之一。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 的deque 入门
在 Python 列表的右端追加和弹出项目通常是高效的操作。如果你用大 O 符号表示时间复杂度,那么你可以说它们是 O (1)。但是,当 Python 需要重新分配内存来增加底层列表以接受新项目时,这些操作会更慢,并且会变成 O ( n )。
此外,在 Python 列表的左端追加和弹出项目是效率低下的操作,速度为 O ( n )。
因为 Python 列表为两种操作都提供了 .append() 和.pop(),所以它们可以用作栈和队列。但是,您之前看到的性能问题会显著影响应用程序的整体性能。
Python 的 deque 是在 Python 2.4 中第一个添加到 collections 模块的数据类型。这种数据类型是专门为克服 Python 列表中的.append()和.pop()的效率问题而设计的。
Deques 是类似序列的数据类型,被设计为对堆栈和队列的概括。它们支持对数据结构两端的高效内存和快速追加和弹出操作。
注: deque读作“甲板”这个名字代表ddouble-endqueUE。
在一个deque对象两端的追加和弹出操作是稳定和同样有效的,因为 deques 是作为一个双向链表被实现的。此外,deques 上的 append 和 pop 操作也是线程安全和内存高效的。这些特性使得 deques 对于在 Python 中创建自定义堆栈和队列特别有用。
如果您需要保留最后看到的项目的列表,Deques 也是一种方法,因为您可以限制 deques 的最大长度。如果您这样做,那么一旦 deque 已满,当您在另一端追加新项目时,它会自动丢弃一端的项目。
下面总结一下deque的主要特点:
- 存储任何数据类型的项目
- 是一种可变的数据类型
- 通过
in操作员支持会员操作 - 支持分度,如
a_deque[i]所示 - 不支持切片,就像在
a_deque[0:2]中 - 支持操作序列和可迭代的内置函数,如
len()、sorted()、reversed()等 - 不支持就地排序
- 支持正向和反向迭代
- 支持用
pickle酸洗 - 确保两端的快速、内存高效和线程安全的弹出和追加操作
创建deque实例是一个简单的过程。你只需要从collections中导入deque,并使用可选的iterable作为参数调用它:
>>> from collections import deque >>> # Create an empty deque >>> deque() deque([]) >>> # Use different iterables to create deques >>> deque((1, 2, 3, 4)) deque([1, 2, 3, 4]) >>> deque([1, 2, 3, 4]) deque([1, 2, 3, 4]) >>> deque(range(1, 5)) deque([1, 2, 3, 4]) >>> deque("abcd") deque(['a', 'b', 'c', 'd']) >>> numbers = {"one": 1, "two": 2, "three": 3, "four": 4} >>> deque(numbers.keys()) deque(['one', 'two', 'three', 'four']) >>> deque(numbers.values()) deque([1, 2, 3, 4]) >>> deque(numbers.items()) deque([('one', 1), ('two', 2), ('three', 3), ('four', 4)])如果您实例化
deque而没有提供一个iterable作为参数,那么您会得到一个空的 deque。如果您提供并输入iterable,那么deque会用其中的数据初始化新实例。使用deque.append()从左到右进行初始化。
deque初始化器接受以下两个可选参数:
iterable持有提供初始化数据的 iterable。maxlen保存一个整数数字,它指定了队列的最大长度。如前所述,如果你不提供一个
iterable,那么你会得到一个空的队列。如果您为maxlen提供一个值,那么您的 deque 将只存储最多maxlen个项目。最后,您还可以使用无序的可迭代对象,比如集合,来初始化您的队列。在这种情况下,最终队列中的项目不会有预定义的顺序。
高效弹出和追加项目
deque和list最重要的区别是前者允许你在序列的两端执行有效的追加和弹出操作。deque类实现专用的.popleft()和.appendleft()方法,这些方法直接在序列的左端操作:
>>> from collections import deque
>>> numbers = deque([1, 2, 3, 4])
>>> numbers.popleft()
1
>>> numbers.popleft()
2
>>> numbers
deque([3, 4])
>>> numbers.appendleft(2)
>>> numbers.appendleft(1)
>>> numbers
deque([1, 2, 3, 4])
在这里,您使用.popleft()和.appendleft()分别删除和添加值到numbers的左端。这些方法是针对deque的设计,你在list里是找不到的。
就像list,deque也提供了.append()和 .pop() 方法来操作序列的右端。然而,.pop()表现不同:
>>> from collections import deque >>> numbers = deque([1, 2, 3, 4]) >>> numbers.pop() 4 >>> numbers.pop(0) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: pop() takes no arguments (1 given)这里,
.pop()删除并返回队列中的最后一个值。该方法不接受索引作为参数,所以您不能使用它从您的 deques 中删除任意项。您只能使用它来移除和返回最右边的项目。正如您之前了解到的,
deque被实现为一个双向链表。因此,给定 deque 中的每一项都有一个指向序列中下一个和上一个项的引用(指针)。双向链表使得从任意一端追加和弹出条目变得简单而高效。这是可能的,因为只有指针需要更新。因此,这两个操作的性能相似。它们的性能也是可预测的,因为不需要重新分配内存和移动现有项目来接受新项目。
从常规 Python 列表的左端追加和弹出项目需要移动所有项目,这最终是一个 O ( n )操作。此外,向列表右端添加条目通常需要 Python 重新分配内存,并将当前条目复制到新的内存位置。之后,它可以添加新的项目。这个过程需要更长的时间来完成,追加操作从 O (1)转到 O ( n )。
考虑以下将项目追加到序列左端的性能测试,
deque对list:# time_append.py from collections import deque from time import perf_counter TIMES = 10_000 a_list = [] a_deque = deque() def average_time(func, times): total = 0.0 for i in range(times): start = perf_counter() func(i) total += (perf_counter() - start) * 1e9 return total / times list_time = average_time(lambda i: a_list.insert(0, i), TIMES) deque_time = average_time(lambda i: a_deque.appendleft(i), TIMES) gain = list_time / deque_time print(f"list.insert() {list_time:.6} ns") print(f"deque.appendleft() {deque_time:.6} ns ({gain:.6}x faster)")在这个脚本中,
average_time()计算执行一个函数(func)给定数量的times所花费的平均时间。如果您从命令行运行脚本,那么您会得到以下输出:$ python time_append.py list.insert() 3735.08 ns deque.appendleft() 238.889 ns (15.6352x faster)在这个具体的例子中,
deque上的.appendleft()比list上的.insert()快好几倍。注意deque.appendleft()是 O (1),表示执行时间不变。但是,列表左端的list.insert()是 O ( n ),这意味着执行时间取决于要处理的项目数。在本例中,如果您增加
TIMES的值,那么您将获得list.insert()更高的时间测量值,但是deque.appendleft()的结果稳定(不变)。如果您想对 deques 和 lists 的 pop 操作进行类似的性能测试,那么您可以扩展下面的练习模块,并在完成后将您的结果与真正的 Python 的结果进行比较。作为一个练习,您可以修改上面的脚本来计时
deque.popleft()对list.pop(0)的操作,并评估它们的性能。这里有一个测试
deque.popleft()和list.pop(0)操作性能的脚本:# time_pop.py from collections import deque from time import perf_counter TIMES = 10_000 a_list = [1] * TIMES a_deque = deque(a_list) def average_time(func, times): total = 0.0 for _ in range(times): start = perf_counter() func() total += (perf_counter() - start) * 1e9 return total / times list_time = average_time(lambda: a_list.pop(0), TIMES) deque_time = average_time(lambda: a_deque.popleft(), TIMES) gain = list_time / deque_time print(f"list.pop(0) {list_time:.6} ns") print(f"deque.popleft() {deque_time:.6} ns ({gain:.6}x faster)")如果您在您的计算机上运行这个脚本,那么您将得到类似如下的输出:
list.pop(0) 2002.08 ns deque.popleft() 326.454 ns (6.13282x faster)同样,从底层序列的左端移除项目时,
deque比list快。尝试改变TIMES的值,看看会发生什么!
deque数据类型旨在保证序列两端的有效追加和弹出操作。它非常适合处理需要用 Python 实现队列和堆栈数据结构的问题。访问
deque中的随机项目Python 的
deque返回可变序列,其工作方式与列表非常相似。除了允许您有效地添加和弹出项目之外,deques 还提供了一组类似列表的方法和其他类似序列的操作来处理任意位置的项目。以下是其中的一些:
[计]选项 描述 T2 .insert(i, value)将项目 value插入到索引i处的队列中。T2 .remove(value)删除第一次出现的 value,如果value不存在,则提升ValueError。T2 a_deque[i]从队列中检索索引 i处的项目。T2 del a_deque[i]从队列中移除索引 i处的项目。您可以使用这些方法和技术来处理
deque对象中任何位置的项目。下面是如何做到这一点:
>>> from collections import deque
>>> letters = deque("abde")
>>> letters.insert(2, "c")
>>> letters
deque(['a', 'b', 'c', 'd', 'e'])
>>> letters.remove("d")
>>> letters
deque(['a', 'b', 'c', 'e'])
>>> letters[1]
'b'
>>> del letters[2]
>>> letters
deque(['a', 'b', 'e'])
这里,首先将"c"插入letters的2位置。然后使用.remove()将"d"从队列中移除。Deques 还允许索引访问项目,您在这里使用它来访问索引1处的"b"。最后,您可以使用del 关键字从队列中删除任何现有的条目。注意.remove()允许您通过值删除项目,而del通过索引删除项目。
即使deque对象支持索引,它们也不支持切片。换句话说,您不能使用切片语法,[start:stop:step]从现有的队列中提取切片,就像您对常规列表所做的那样:
>>> from collections import deque >>> numbers = deque([1, 2, 3, 4, 5]) >>> numbers[1:3] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: sequence index must be integer, not 'slice'Deques 支持索引,但有趣的是,它们不支持切片。当你试图从一个队列中得到一片时,你得到一个
TypeError。一般来说,在链表上执行切片是低效的,所以这个操作是不可用的。到目前为止,你已经看到了
deque和list非常相似。然而,list是基于数组,而deque是基于一个双向链表。在作为双向链表实现的
deque背后有一个隐藏的成本:访问、插入和删除任意项不是有效的操作。为了执行它们,解释器必须遍历队列,直到找到想要的条目。所以,它们是 O(n)而不是 O (1)操作。下面是一个脚本,展示了在处理任意项目时 deques 和 lists 的行为:
# time_random_access.py from collections import deque from time import perf_counter TIMES = 10_000 a_list = [1] * TIMES a_deque = deque(a_list) def average_time(func, times): total = 0.0 for _ in range(times): start = perf_counter() func() total += (perf_counter() - start) * 1e6 return total / times def time_it(sequence): middle = len(sequence) // 2 sequence.insert(middle, "middle") sequence[middle] sequence.remove("middle") del sequence[middle] list_time = average_time(lambda: time_it(a_list), TIMES) deque_time = average_time(lambda: time_it(a_deque), TIMES) gain = deque_time / list_time print(f"list {list_time:.6} μs ({gain:.6}x faster)") print(f"deque {deque_time:.6} μs")这个脚本对在队列和列表中间插入、删除和访问项目进行计时。如果您运行该脚本,您将得到如下所示的输出:
$ python time_random_access.py list 63.8658 μs (1.44517x faster) deque 92.2968 μsDeques 不像列表那样是随机存取的数据结构。因此,从队列中间访问元素比在列表中做同样的事情效率更低。这里的要点是,deques 并不总是比 lists 更有效。
Python 的
deque针对序列两端的操作进行了优化,因此在这方面它们一直比列表好。另一方面,列表更适合随机访问和固定长度的操作。下面是 deques 和 lists 在性能方面的一些差异:
操作 dequelist通过索引访问任意项目 O ( n O① 在左端弹出和追加项目 O① O ( n 在右端弹出和追加项目 O① O (1) +重新分配 在中间插入和删除项目 O ( n O ( n 在列表的情况下,当解释器需要增加列表来接受新的条目时,
.append()的分摊性能会受到内存重新分配的影响。此操作需要将所有当前项目复制到新的内存位置,这会显著影响性能。这个总结可以帮助您为手头的问题选择合适的数据类型。但是,在从列表切换到 deques 之前,一定要对代码进行概要分析。两者都有各自的性能优势。
用
deque构建高效队列正如您已经了解到的,
deque被实现为一个双端队列,它提供了对堆栈和队列的一般化。在本节中,您将学习如何使用deque以优雅、高效和 Pythonic 式的方式在底层实现您自己的队列抽象数据类型(ADT) 。注意:在 Python 标准库中,你会找到
queue。该模块实现了多生产者、多消费者队列,允许您在多个线程之间安全地交换信息。如果您正在使用队列,那么最好使用那些高级抽象而不是
deque,除非您正在实现自己的数据结构。队列是项目的集合。您可以通过在一端添加项目并从另一端删除项目来修改队列。
队列以先进先出 ( 先进先出)的方式管理他们的项目。它们就像一个管道,你在管道的一端推入新的项目,从另一端弹出旧的项目。将一个项目添加到队列的一端被称为入队操作。从另一端移除一个项目称为出列。
为了更好地理解排队,以您最喜欢的餐馆为例。餐馆里有一长串人等着餐桌点餐。通常,最后到达的人会站在队伍的最后。一有空桌,排在队伍最前面的人就会离开。
下面是如何使用一个基本的
deque对象来模拟这个过程:
>>> from collections import deque
>>> customers = deque()
>>> # People arriving
>>> customers.append("Jane")
>>> customers.append("John")
>>> customers.append("Linda")
>>> customers
deque(['Jane', 'John', 'Linda'])
>>> # People getting tables
>>> customers.popleft()
'Jane'
>>> customers.popleft()
'John'
>>> customers.popleft()
'Linda'
>>> # No people in the queue
>>> customers.popleft()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: pop from an empty deque
在这里,首先创建一个空的deque对象来表示到达餐馆的人的队列。要让一个人入队,您可以使用 .append() ,它会将单个项目添加到右端。要让一个人出列,可以使用 .popleft() ,它移除并返回队列左端的单个项目。
酷!您的队列模拟有效!然而,由于deque是一个泛化,它的 API 与典型的队列 API 不匹配。例如,你有了.append(),而不是.enqueue()。你还有.popleft()而不是.dequeue()。此外,deque还提供了其他几种可能不符合您特定需求的操作。
好消息是,您可以创建带有您需要的功能的定制队列类,除此之外别无其他。为此,您可以在内部使用一个队列来存储数据,并在您的自定义队列中提供所需的功能。您可以把它看作是适配器设计模式的一个实现,其中您将 deque 的接口转换成看起来更像队列接口的东西。
例如,假设您需要一个只提供以下功能的自定义队列抽象数据类型:
- 入队项目
- 出队项目
- 返回队列的长度
- 支持成员资格测试
- 支持正向和反向迭代
- 提供用户友好的字符串表示
在这种情况下,您可以编写如下所示的Queue类:
# custom_queue.py
from collections import deque
class Queue:
def __init__(self):
self._items = deque()
def enqueue(self, item):
self._items.append(item)
def dequeue(self):
try:
return self._items.popleft()
except IndexError:
raise IndexError("dequeue from an empty queue") from None
def __len__(self):
return len(self._items)
def __contains__(self, item):
return item in self._items
def __iter__(self):
yield from self._items
def __reversed__(self):
yield from reversed(self._items)
def __repr__(self):
return f"Queue({list(self._items)})"
这里,._items保存了一个deque对象,允许您存储和操作队列中的项目。Queue使用deque.append()实现.enqueue()来将项目添加到队列的末尾。它还使用deque.popleft()实现了.dequeue(),以有效地从队列的开头移除项目。
特殊方法支持以下功能:
| 方法 | 支持 |
|---|---|
T2.__len__() |
带len()的长度 |
T2.__contains__() |
使用in进行成员资格测试 |
T2.__iter__() |
正常迭代 |
T2.__reversed__() |
反向迭代 |
T2.__repr__() |
字符串表示 |
理想情况下,.__repr__()应该返回一个表示有效 Python 表达式的字符串。该表达式将允许您使用相同的值明确地重新创建对象。
然而,在上面的例子中,意图是使用方法的返回值来优雅地在交互外壳上显示对象。通过接受一个初始化 iterable 作为.__init__()的参数并从中构建实例,可以从这个特定的字符串表示中构建Queue实例。
有了这些最后的添加,您的Queue类就完成了。要在代码中使用该类,您可以执行如下操作:
>>> from custom_queue import Queue >>> numbers = Queue() >>> numbers Queue([]) >>> # Enqueue items >>> for number in range(1, 5): ... numbers.enqueue(number) ... >>> numbers Queue([1, 2, 3, 4]) >>> # Support len() >>> len(numbers) 4 >>> # Support membership tests >>> 2 in numbers True >>> 10 in numbers False >>> # Normal iteration >>> for number in numbers: ... print(f"Number: {number}") ... 1 2 3 4作为练习,您可以测试剩余的特性并实现其他特性,比如支持相等测试、移除和访问随机项等等。来吧,试一试!
探索
deque的其他特性除了您到目前为止已经看到的特性,
deque还提供了其他特定于其内部设计的方法和属性。它们为这种多用途的数据类型增加了新的有用的功能。在本节中,您将了解 deques 提供的其他方法和属性,它们是如何工作的,以及如何在您的代码中使用它们。
限制最大项数:
maxlen
deque最有用的特性之一是在实例化类时,可以使用maxlen参数指定给定队列的最大长度。如果您为
maxlen提供一个值,那么您的队列将只存储最多maxlen个项目。在这种情况下,你有一个有界的德奎。一旦有界的 deque 充满了指定数量的项目,在任一端添加新项目都会自动删除并丢弃另一端的项目:
>>> from collections import deque
>>> four_numbers = deque([0, 1, 2, 3, 4], maxlen=4) # Discard 0
>>> four_numbers
deque([1, 2, 3, 4], maxlen=4)
>>> four_numbers.append(5) # Automatically remove 1
>>> four_numbers
deque([2, 3, 4, 5], maxlen=4)
>>> four_numbers.append(6) # Automatically remove 2
>>> four_numbers
deque([3, 4, 5, 6], maxlen=4)
>>> four_numbers.appendleft(2) # Automatically remove 6
>>> four_numbers
deque([2, 3, 4, 5], maxlen=4)
>>> four_numbers.appendleft(1) # Automatically remove 5
>>> four_numbers
deque([1, 2, 3, 4], maxlen=4)
>>> four_numbers.maxlen
4
如果输入 iterable 中的条目数大于maxlen,那么deque将丢弃最左边的条目(本例中为0)。一旦队列已满,在任何一端追加一个项目都会自动删除另一端的项目。
请注意,如果您没有为maxlen指定一个值,那么它默认为 None ,并且队列可以增长到任意数量的项目。
有了限制最大项数的选项,您就可以使用 deques 来跟踪给定对象或事件序列中的最新元素。例如,您可以跟踪银行帐户中的最后五笔交易、编辑器中最后十个打开的文本文件、浏览器中的最后五页等等。
注意,maxlen在您的 deques 中是一个只读属性,它允许您检查 deques 是否已满,就像在deque.maxlen == len(deque)中一样。
最后,您可以将maxlen设置为任意正整数,表示您希望存储在特定队列中的最大项数。如果你给maxlen提供一个负值,那么你会得到一个ValueError。
旋转项目:.rotate()
deques 的另一个有趣的特性是可以通过在非空的 deques 上调用 .rotate() 来旋转它们的元素。这个方法将一个整数n作为参数,并将项目n向右旋转一步。换句话说,它以循环方式将n项目从右端移动到左端。
n的默认值为1。如果你给n提供一个负值,那么旋转向左:
>>> from collections import deque >>> ordinals = deque(["first", "second", "third"]) >>> # Rotate items to the right >>> ordinals.rotate() >>> ordinals deque(['third', 'first', 'second']) >>> ordinals.rotate(2) >>> ordinals deque(['first', 'second', 'third']) >>> # Rotate items to the left >>> ordinals.rotate(-2) >>> ordinals deque(['third', 'first', 'second']) >>> ordinals.rotate(-1) >>> ordinals deque(['first', 'second', 'third'])在这些例子中,你使用
.rotate()和不同的n值旋转ordinals几次。如果你调用.rotate()而没有参数,那么它依赖于n的默认值,并向右旋转队列1的位置。使用负的n调用该方法允许您向左旋转项目。一次添加多个项目:
.extendleft()像常规列表一样,deques 提供了一个
.extend()方法,该方法允许您使用一个iterable作为参数向 deques 的右端添加几个项目。此外,deques 有一个名为extendleft()的方法,它将一个iterable作为参数,并将其项目一次性添加到目标 deques 的左端:
>>> from collections import deque
>>> numbers = deque([1, 2])
>>> # Extend to the right
>>> numbers.extend([3, 4, 5])
>>> numbers
deque([1, 2, 3, 4, 5])
>>> # Extend to the left
>>> numbers.extendleft([-1, -2, -3, -4, -5])
>>> numbers
deque([-5, -4, -3, -2, -1, 1, 2, 3, 4, 5])
用iterable调用.extendleft()将目标队列向左扩展。在内部,.extendleft()执行一系列单独的.appendleft()操作,从左到右处理输入的 iterable。这最终会以相反的顺序将项目添加到目标队列的左端。
使用deque 的类序列特征
由于 deques 是可变序列,它们实现了几乎所有与序列和可变序列相同的方法和操作。到目前为止,您已经了解了其中的一些方法和操作,比如.insert()、索引、成员测试等等。
以下是您可以对deque对象执行的其他操作的几个例子:
>>> from collections import deque >>> numbers = deque([1, 2, 2, 3, 4, 4, 5]) >>> # Concatenation >>> numbers + deque([6, 7, 8]) deque([1, 2, 2, 3, 4, 4, 5, 6, 7, 8]) >>> # Repetition >>> numbers * 2 deque([1, 2, 2, 3, 4, 4, 5, 1, 2, 2, 3, 4, 4, 5]) >>> # Common sequence methods >>> numbers = deque([1, 2, 2, 3, 4, 4, 5]) >>> numbers.index(2) 1 >>> numbers.count(4) 2 >>> # Common mutable sequence methods >>> numbers.reverse() >>> numbers deque([5, 4, 4, 3, 2, 2, 1]) >>> numbers.clear() >>> numbers deque([])您可以使用加法运算符 (
+)来连接两个现有的队列。另一方面,乘法运算符(*)返回一个新的 deque,相当于重复原始 deque 任意次。关于其他排序方法,下表提供了一个总结:
方法 描述 T2 .clear()从队列中删除所有元素。 T2 .copy()创建一个 deque 的浅表副本。 T2 .count(value)计算 value在队列中出现的次数。T2 .index(value)返回 value在队列中的位置。T2 .reverse()在适当的位置反转队列的元素,然后返回 None。这里,
.index()还可以带两个可选参数:start和stop。它们允许您将搜索限制在start当天或之后和stop之前的那些项目。如果value没有出现在当前的队列中,该方法将引发一个ValueError。与列表不同,deques 不包含一个
.sort()方法来对序列进行排序。这是因为对链表进行排序是一个低效的操作。如果您需要对一个队列进行排序,那么您仍然可以使用sorted()。将 Python 的
deque付诸行动您可以在很多用例中使用 deques,比如实现队列、堆栈和循环缓冲区。您还可以使用它们来维护撤销-重做历史,将传入的请求排队到 web 服务,保存最近打开的文件和网站的列表,在多线程之间安全地交换数据,等等。
在接下来的几节中,您将编写几个小例子来帮助您更好地理解如何在代码中使用 deques。
保存页面历史记录
用一个
maxlen来限制项目的最大数量使得deque适合解决几个问题。例如,假设你正在构建一个应用程序,从搜索引擎和社交媒体网站搜集数据。有时,您需要跟踪应用程序请求数据的最后三个站点。要解决这个问题,您可以使用一个
maxlen为3的队列:
>>> from collections import deque
>>> sites = (
... "google.com",
... "yahoo.com",
... "bing.com"
... )
>>> pages = deque(maxlen=3)
>>> pages.maxlen
3
>>> for site in sites:
... pages.appendleft(site)
...
>>> pages
deque(['bing.com', 'yahoo.com', 'google.com'], maxlen=3)
>>> pages.appendleft("facebook.com")
>>> pages
deque(['facebook.com', 'bing.com', 'yahoo.com'], maxlen=3)
>>> pages.appendleft("twitter.com")
>>> pages
deque(['twitter.com', 'facebook.com', 'bing.com'], maxlen=3)
在这个例子中,pages保存了您的应用程序最近访问的三个站点的列表。一旦pages满了,向队列的一端添加一个新站点会自动丢弃另一端的站点。此行为使您的列表与您最近使用的三个站点保持一致。
请注意,您可以将maxlen设置为任意正整数,表示要存储在当前队列中的项数。例如,如果你想保存一个十个站点的列表,那么你可以将maxlen设置为10。
线程间共享数据
Python 的deque在你编写多线程应用时也很有用,正如 Raymond Hettinger 所描述的,他是 Python 的核心开发者,也是deque和collections模块的创建者:
在 CPython 中,队列的
.append()、.appendleft()、.pop()、.popleft()和len(d)操作是线程安全的。(来源)
因此,您可以安全地在不同的线程中同时从队列的两端添加和删除数据,而没有数据损坏或其他相关问题的风险。
为了尝试一下deque在多线程应用中的工作方式,启动您最喜欢的代码编辑器,创建一个名为threads.py的新脚本,并向其中添加以下代码:
# threads.py
import logging
import random
import threading
import time
from collections import deque
logging.basicConfig(level=logging.INFO, format="%(message)s")
def wait_seconds(mins, maxs):
time.sleep(mins + random.random() * (maxs - mins))
def produce(queue, size):
while True:
if len(queue) < size:
value = random.randint(0, 9)
queue.append(value) logging.info("Produced: %d -> %s", value, str(queue))
else:
logging.info("Queue is saturated")
wait_seconds(0.1, 0.5)
def consume(queue):
while True:
try:
value = queue.popleft() except IndexError:
logging.info("Queue is empty")
else:
logging.info("Consumed: %d -> %s", value, str(queue))
wait_seconds(0.2, 0.7)
logging.info("Starting Threads...\n")
logging.info("Press Ctrl+C to interrupt the execution\n")
shared_queue = deque()
threading.Thread(target=produce, args=(shared_queue, 10)).start()
threading.Thread(target=consume, args=(shared_queue,)).start()
这里,produce()将一个queue和一个size作为自变量。然后它在一个 while循环中使用 random.randint() 连续产生个随机数,并将它们存储在一个名为shared_queue的全局队列中。由于将项目附加到 deque 是一个线程安全的操作,所以您不需要使用锁来保护其他线程的共享数据。
助手函数wait_seconds()模拟produce()和consume()都代表长时间运行的操作。它返回一个在给定的秒数范围mins和maxs之间的随机等待时间值。
在consume()中,您在一个循环中调用.popleft()来系统地从shared_queue中检索和移除数据。您将对.popleft()的调用包装在一个 try … except 语句中,以处理共享队列为空的情况。
注意,虽然您在全局名称空间中定义了shared_queue,但是您可以通过produce()和consume()中的局部变量来访问它。直接访问全局变量会有更多的问题,肯定不是最佳实践。
脚本中的最后两行创建并启动单独的线程来并发执行produce()和consume()。如果您从命令行运行该脚本,那么您将得到类似如下的输出:
$ python threads.py
Starting Threads...
Press Ctrl+C to interrupt the execution
Produced: 1 -> deque([1])
Consumed: 1 -> deque([])
Queue is empty
Produced: 3 -> deque([3])
Produced: 0 -> deque([3, 0])
Consumed: 3 -> deque([0])
Consumed: 0 -> deque([])
Produced: 1 -> deque([1])
Produced: 0 -> deque([1, 0])
...
生产者线程将数字添加到共享队列的右端,而消费者线程从左端消费数字。要中断脚本执行,您可以按键盘上的 Ctrl + C 。
最后可以用produce()和consume()里面的时间间隔来玩一点。更改您传递给wait_seconds()的值,观察当生产者比消费者慢时程序的行为,反之亦然。
模拟tail命令
您将在这里编写的最后一个示例模拟了 tail命令,该命令在 Unix 和类 Unix操作系统上可用。该命令在命令行接受一个文件路径,并将该文件的最后十行输出到系统的标准输出。您可以使用-n、--lines选项调整需要tail打印的行数。
这里有一个小的 Python 函数,它模拟了tail的核心功能:
>>> from collections import deque >>> def tail(filename, lines=10): ... try: ... with open(filename) as file: ... return deque(file, lines) ... except OSError as error: ... print(f'Opening file "{filename}" failed with error: {error}') ...在这里,你定义
tail()。第一个参数filename将目标文件的路径保存为一个字符串。第二个参数,lines,代表您希望从目标文件的末尾检索的行数。注意lines默认为10来模拟tail的默认行为。注意:这个例子的最初想法来自于
deque上的 Python 文档。查看关于deque食谱的部分以获得更多的例子。突出显示的行中的队列最多只能存储您传递给
lines的项目数。这保证了您从输入文件的末尾获得所需的行数。正如您之前看到的,当您创建一个有界的 deque 并用一个 iterable 初始化它时,iterable 包含的条目比允许的多(
maxlen),deque构造函数会丢弃输入中所有最左边的条目。正因为如此,您最终得到了目标文件的最后一行maxlen。结论
队列和栈是编程中常用的抽象数据类型。它们通常需要对底层数据结构的两端进行有效的弹出和追加操作。Python 的
collections模块提供了一个名为deque的数据类型,它是专门为两端的快速和内存高效的追加和弹出操作而设计的。使用
deque,您可以以优雅、高效和 Pythonic 化的方式在底层编写自己的队列和堆栈。在本教程中,您学习了如何:
- 在你的代码中创建并使用 Python 的
deque- 高效地从序列的两端用
deque追加和弹出项- 使用
deque在 Python 中构建高效的队列和栈- 决定什么时候用
deque代替list在本教程中,您还编写了一些例子,帮助您了解 Python 中的一些常见用例。*****
Python 描述符:简介
描述符是 Python 的一个特殊特性,它赋予了隐藏在语言背后的许多魔力。如果您曾经认为 Python 描述符是一个很少有实际应用的高级主题,那么本教程是帮助您理解这一强大特性的完美工具。您将会理解为什么 Python 描述符是如此有趣的主题,以及您可以将它们应用到什么样的用例中。
本教程结束时,你会知道:
- 什么是 Python 描述符
- 在 Python 的内部中使用它们
- 如何实现你自己的描述符
- 何时使用 Python 描述符
本教程面向中高级 Python 开发人员,因为它涉及到 Python 的内部原理。然而,如果你还没有达到这个水平,那就继续读下去吧!您将找到关于 Python 和查找链的有用信息。
免费奖励: ,它向您展示了三种高级装饰模式和技术,您可以用它们来编写更简洁、更 Python 化的程序。
什么是 Python 描述符?
描述符是 Python 对象,它实现了描述符协议的一种方法,这种方法使您能够创建在作为其他对象的属性被访问时具有特殊行为的对象。在这里,您可以看到描述符协议的正确定义:
__get__(self, obj, type=None) -> object __set__(self, obj, value) -> None __delete__(self, obj) -> None __set_name__(self, owner, name)如果你的描述符只实现了
.__get__(),那么它就是一个非数据描述符。如果它实现了.__set__()或.__delete__(),那么它就是一个数据描述符。请注意,这种差异不仅仅是名称上的,也是行为上的差异。这是因为数据描述符在查找过程中具有优先权,稍后您将会看到这一点。看一下下面的例子,它定义了一个描述符,当控制台被访问时,该描述符在控制台上记录一些内容:
# descriptors.py class Verbose_attribute(): def __get__(self, obj, type=None) -> object: print("accessing the attribute to get the value") return 42 def __set__(self, obj, value) -> None: print("accessing the attribute to set the value") raise AttributeError("Cannot change the value") class Foo(): attribute1 = Verbose_attribute() my_foo_object = Foo() x = my_foo_object.attribute1 print(x)在上面的例子中,
Verbose_attribute()实现了描述符协议。一旦它被实例化为Foo的一个属性,它就可以被认为是一个描述符。作为描述符,当使用点符号访问它时,它有绑定行为。在这种情况下,每次访问描述符以获取或设置值时,描述符都会在控制台上记录一条消息:
现在,运行上面的示例,您将看到描述符在返回常量值之前记录对控制台的访问:
$ python descriptors.py accessing the attribute to get the value 42这里,当您试图访问
attribute1时,描述符会将此访问记录到控制台,如.__get__()中所定义的。描述符如何在 Python 内部工作
如果您有作为面向对象 Python 开发人员的经验,那么您可能会认为前一个例子的方法有点矫枉过正。使用属性也可以达到同样的效果。虽然这是真的,但您可能会惊讶地发现 Python 中的属性只是…描述符!稍后您将会看到,属性并不是利用 Python 描述符的唯一特性。
属性中的 Python 描述符
如果您想在不显式使用 Python 描述符的情况下获得与上一个示例相同的结果,那么最直接的方法是使用一个属性。下面的示例使用了一个属性,该属性在控制台被访问时记录消息:
# property_decorator.py class Foo(): @property def attribute1(self) -> object: print("accessing the attribute to get the value") return 42 @attribute1.setter def attribute1(self, value) -> None: print("accessing the attribute to set the value") raise AttributeError("Cannot change the value") my_foo_object = Foo() x = my_foo_object.attribute1 print(x)上面的例子使用了装饰器来定义一个带有附加的 getter 和 setter 方法的属性。但是你可能知道,装饰者只是语法糖。事实上,前面的例子可以写成如下:
# property_function.py class Foo(): def getter(self) -> object: print("accessing the attribute to get the value") return 42 def setter(self, value) -> None: print("accessing the attribute to set the value") raise AttributeError("Cannot change the value") attribute1 = property(getter, setter) my_foo_object = Foo() x = my_foo_object.attribute1 print(x)现在你可以看到这个属性已经被使用
property()创建了。该函数的签名如下:property(fget=None, fset=None, fdel=None, doc=None) -> object
property()返回一个实现描述符协议的property对象。它使用参数fget、fset和fdel来实际实现协议的三种方法。方法和函数中的 Python 描述符
如果你曾经用 Python 写了一个面向对象的程序,那么你肯定使用过方法。这些是为对象实例保留第一个参数的常规函数。当您使用点符号访问一个方法时,您正在调用相应的函数并将对象实例作为第一个参数传递。
将您的
obj.method(*args)调用转换成method(obj, *args)的神奇之处在于function对象的.__get__()实现,事实上,它是一个非数据描述符。特别是,function对象实现了.__get__(),这样当你用点符号访问它时,它会返回一个绑定方法。接下来的(*args)通过传递所有需要的额外参数来调用函数。为了了解它是如何工作的,请看一下这个来自官方文档的纯 Python 例子:
import types class Function(object): ... def __get__(self, obj, objtype=None): "Simulate func_descr_get() in Objects/funcobject.c" if obj is None: return self return types.MethodType(self, obj)在上面的例子中,当用点符号访问函数时,调用
.__get__()并返回一个绑定方法。这适用于常规实例方法,就像它适用于类方法或静态方法一样。所以,如果你用
obj.method(*args)调用一个静态方法,那么它会自动转换成method(*args)。类似地,如果你用obj.method(type(obj), *args)调用一个类方法,那么它会自动转换成method(type(obj), *args)。注:要了解更多关于
*args的信息,请查看 Python args 和 kwargs:去神秘化。在官方文档中,你可以找到一些例子,说明如果用纯 Python 而不是实际的 C 实现来编写静态方法和类方法将如何实现。例如,一个可能的静态方法实现可能是这样的:
class StaticMethod(object): "Emulate PyStaticMethod_Type() in Objects/funcobject.c" def __init__(self, f): self.f = f def __get__(self, obj, objtype=None): return self.f同样,这也可能是一个类方法实现:
class ClassMethod(object): "Emulate PyClassMethod_Type() in Objects/funcobject.c" def __init__(self, f): self.f = f def __get__(self, obj, klass=None): if klass is None: klass = type(obj) def newfunc(*args): return self.f(klass, *args) return newfunc注意,在 Python 中,类方法只是一个静态方法,它将类引用作为参数列表的第一个参数。
如何使用查找链访问属性
为了更好地理解 Python 描述符和 Python 内部机制,您需要理解当访问属性时 Python 中会发生什么。在 Python 中,每个对象都有一个内置的
__dict__属性。这是一个包含对象本身定义的所有属性的字典。要了解这一点,请考虑以下示例:class Vehicle(): can_fly = False number_of_weels = 0 class Car(Vehicle): number_of_weels = 4 def __init__(self, color): self.color = color my_car = Car("red") print(my_car.__dict__) print(type(my_car).__dict__)这段代码创建了一个新对象,并打印了对象和类的
__dict__属性的内容。现在,运行脚本并分析输出,查看设置的__dict__属性:{'color': 'red'} {'__module__': '__main__', 'number_of_weels': 4, '__init__': <function Car.__init__ at 0x10fdeaea0>, '__doc__': None}
__dict__属性按预期设置。注意,在 Python 中,一切都是对象。一个类实际上也是一个对象,所以它也有一个包含该类所有属性和方法的__dict__属性。那么,当你在 Python 中访问一个属性时,到底发生了什么呢?让我们用前一个例子的修改版本做一些测试。考虑以下代码:
# lookup.py class Vehicle(object): can_fly = False number_of_weels = 0 class Car(Vehicle): number_of_weels = 4 def __init__(self, color): self.color = color my_car = Car("red") print(my_car.color) print(my_car.number_of_weels) print(my_car.can_fly)在这个例子中,您创建了一个继承自
Vehicle类的Car类的实例。然后,您可以访问一些属性。如果您运行这个示例,那么您可以看到您得到了所有您期望的值:$ python lookup.py red 4 False这里,当您访问实例
my_car的属性color时,您实际上是在访问对象my_car的__dict__属性的单个值。当你访问对象my_car的属性number_of_wheels时,你实际上是在访问类Car的属性__dict__的单个值。最后,当您访问can_fly属性时,您实际上是通过使用Vehicle类的__dict__属性来访问它。这意味着可以像这样重写上面的例子:
# lookup2.py class Vehicle(): can_fly = False number_of_weels = 0 class Car(Vehicle): number_of_weels = 4 def __init__(self, color): self.color = color my_car = Car("red") print(my_car.__dict__['color']) print(type(my_car).__dict__['number_of_weels']) print(type(my_car).__base__.__dict__['can_fly'])当您测试这个新示例时,您应该会得到相同的结果:
$ python lookup2.py red 4 False那么,当你用点符号访问一个对象的属性时会发生什么呢?解释器如何知道你真正需要的是什么?这里有一个叫做查找链的概念:
首先,您将获得从以您正在寻找的属性命名的数据描述符的
__get__方法返回的结果。如果失败了,那么您将获得您的对象的
__dict__的值作为以您正在寻找的属性命名的键。如果失败,那么您将获得从以您正在寻找的属性命名的非数据描述符的
__get__方法返回的结果。如果失败,那么您将获得您的对象类型的
__dict__的值作为以您正在寻找的属性命名的键。如果失败,那么您将获得您的对象父类型的
__dict__的值,用于以您正在寻找的属性命名的键。如果失败,那么对对象的方法解析顺序中的所有父类型重复上一步。
如果其他的都失败了,那么你会得到一个
AttributeError异常。现在你可以明白为什么知道描述符是数据描述符还是 T2 非数据描述符很重要了吧?它们在查找链的不同层次上,稍后您会看到这种行为上的差异非常方便。
如何正确使用 Python 描述符
如果您想在代码中使用 Python 描述符,那么您只需要实现描述符协议。该协议最重要的方法是
.__get__()和.__set__(),它们具有以下签名:__get__(self, obj, type=None) -> object __set__(self, obj, value) -> None当您实现协议时,请记住以下几点:
self是你正在写的描述符的实例。obj是您的描述符附加到的对象的实例。type是描述符附加到的对象的类型。在
.__set__()中,你没有type变量,因为你只能在对象上调用.__set__()。相比之下,您可以在对象和类上调用.__get__()。另一件需要知道的重要事情是 Python 描述符在每个类中只被实例化一次。这意味着包含描述符的类的每个实例都共享那个描述符实例。这可能是您没有预料到的,并且会导致一个典型的陷阱,就像这样:
# descriptors2.py class OneDigitNumericValue(): def __init__(self): self.value = 0 def __get__(self, obj, type=None) -> object: return self.value def __set__(self, obj, value) -> None: if value > 9 or value < 0 or int(value) != value: raise AttributeError("The value is invalid") self.value = value class Foo(): number = OneDigitNumericValue() my_foo_object = Foo() my_second_foo_object = Foo() my_foo_object.number = 3 print(my_foo_object.number) print(my_second_foo_object.number) my_third_foo_object = Foo() print(my_third_foo_object.number)这里有一个类
Foo,它定义了一个属性number,这是一个描述符。该描述符接受一个单位数字值,并将其存储在描述符本身的属性中。然而,这种方法行不通,因为Foo的每个实例共享同一个描述符实例。您实际上创建的只是一个新的类级属性。尝试运行代码并检查输出:
$ python descriptors2.py 3 3 3您可以看到,
Foo的所有实例都具有相同的属性number值,即使最后一个实例是在设置了my_foo_object.number属性之后创建的。那么,如何解决这个问题呢?您可能认为使用字典来保存它所附加的所有对象的描述符的所有值是个好主意。这似乎是一个很好的解决方案,因为
.__get__()和.__set__()都有obj属性,这是你所附加的对象的实例。您可以将该值用作字典的键。不幸的是,这种解决方案有一个很大的缺点,您可以在下面的示例中看到:
# descriptors3.py class OneDigitNumericValue(): def __init__(self): self.value = {} def __get__(self, obj, type=None) -> object: try: return self.value[obj] except: return 0 def __set__(self, obj, value) -> None: if value > 9 or value < 0 or int(value) != value: raise AttributeError("The value is invalid") self.value[obj] = value class Foo(): number = OneDigitNumericValue() my_foo_object = Foo() my_second_foo_object = Foo() my_foo_object.number = 3 print(my_foo_object.number) print(my_second_foo_object.number) my_third_foo_object = Foo() print(my_third_foo_object.number)在这个例子中,您使用一个字典来存储描述符中所有对象的
number属性值。当您运行这段代码时,您会看到它运行良好,并且行为符合预期:$ python descriptors3.py 3 0 0不幸的是,这里的缺点是描述符保留了对所有者对象的强引用。这意味着如果你销毁了对象,内存就不会被释放,因为垃圾收集器一直在描述符中寻找对该对象的引用!
您可能认为这里的解决方案是使用弱引用。虽然可能如此,但您必须处理这样一个事实,即不是所有的东西都可以作为弱引用,而且当您的对象被收集时,它们会从您的字典中消失。
这里最好的解决方案是简单地而不是将值存储在描述符本身中,而是将它们存储在描述符所附加的对象中。接下来尝试这种方法:
# descriptors4.py class OneDigitNumericValue(): def __init__(self, name): self.name = name def __get__(self, obj, type=None) -> object: return obj.__dict__.get(self.name) or 0 def __set__(self, obj, value) -> None: obj.__dict__[self.name] = value class Foo(): number = OneDigitNumericValue("number") my_foo_object = Foo() my_second_foo_object = Foo() my_foo_object.number = 3 print(my_foo_object.number) print(my_second_foo_object.number) my_third_foo_object = Foo() print(my_third_foo_object.number)在本例中,当您为对象的
number属性设置一个值时,描述符会使用与描述符本身相同的名称,将该值存储在它所附加到的对象的__dict__属性中。这里唯一的问题是,当实例化描述符时,必须将名称指定为参数:
number = OneDigitNumericValue("number")直接写
number = OneDigitNumericValue()不是更好吗?有可能,但是如果你运行的 Python 版本低于 3.6,那么你需要用元类和装饰器来增加一点魔力。然而,如果您使用的是 Python 3.6 或更高版本,那么描述符协议会有一个新方法.__set_name__()为您完成所有这些神奇的事情,正如在 PEP 487 中所提议的:__set_name__(self, owner, name)使用这个新方法,无论何时实例化一个描述符,这个方法都会被调用,并且自动设置参数
name。现在,尝试为 Python 3.6 及更高版本重写前面的示例:
# descriptors5.py class OneDigitNumericValue(): def __set_name__(self, owner, name): self.name = name def __get__(self, obj, type=None) -> object: return obj.__dict__.get(self.name) or 0 def __set__(self, obj, value) -> None: obj.__dict__[self.name] = value class Foo(): number = OneDigitNumericValue() my_foo_object = Foo() my_second_foo_object = Foo() my_foo_object.number = 3 print(my_foo_object.number) print(my_second_foo_object.number) my_third_foo_object = Foo() print(my_third_foo_object.number)现在,
.__init__()已经移除,.__set_name__()已经实现。这样就可以创建描述符,而不需要指定用于存储值的内部属性的名称。您的代码现在看起来也更好更干净了!再运行一次这个例子,确保一切正常:
$ python descriptors5.py 3 0 0如果您使用 Python 3.6 或更高版本,这个示例应该运行起来没有问题。
为什么要使用 Python 描述符?
现在您知道了什么是 Python 描述符,以及 Python 本身如何使用它们来增强它的一些特性,比如方法和属性。您还了解了如何创建 Python 描述符,同时避免一些常见的陷阱。现在一切都应该很清楚了,但你可能仍然想知道为什么要使用它们。
根据我的经验,我认识很多高级 Python 开发人员,他们以前从未使用过这个特性,也不需要它。这很正常,因为没有多少用例需要 Python 描述符。然而,这并不意味着 Python 描述符只是高级用户的学术话题。仍然有一些好的用例可以证明学习如何使用它们的代价是值得的。
惰性属性
第一个也是最直接的例子是惰性属性。这些属性的初始值直到第一次被访问时才会被加载。然后,它们加载初始值,并缓存该值以供以后重用。
考虑下面的例子。您有一个包含方法
meaning_of_life()的类DeepThought,该方法在花费大量时间集中精力后返回值:# slow_properties.py import time class DeepThought: def meaning_of_life(self): time.sleep(3) return 42 my_deep_thought_instance = DeepThought() print(my_deep_thought_instance.meaning_of_life()) print(my_deep_thought_instance.meaning_of_life()) print(my_deep_thought_instance.meaning_of_life())如果您运行这段代码并尝试访问该方法三次,那么您每三秒钟就会得到一个答案,这是该方法中的睡眠时间的长度。
现在,一个惰性属性可以在这个方法第一次执行时只计算一次。然后,它将缓存结果值,这样,如果您再次需要它,您可以立即获得它。您可以通过使用 Python 描述符来实现这一点:
# lazy_properties.py import time class LazyProperty: def __init__(self, function): self.function = function self.name = function.__name__ def __get__(self, obj, type=None) -> object: obj.__dict__[self.name] = self.function(obj) return obj.__dict__[self.name] class DeepThought: @LazyProperty def meaning_of_life(self): time.sleep(3) return 42 my_deep_thought_instance = DeepThought() print(my_deep_thought_instance.meaning_of_life) print(my_deep_thought_instance.meaning_of_life) print(my_deep_thought_instance.meaning_of_life)花点时间研究这段代码,了解它是如何工作的。你能在这里看到 Python 描述符的威力吗?在这个例子中,当您使用
@LazyProperty描述符时,您正在实例化一个描述符并传递给它.meaning_of_life()。该描述符将方法及其名称存储为实例变量。由于它是非数据描述符,当您第一次访问
meaning_of_life属性的值时,.__get__()会被自动调用并在my_deep_thought_instance对象上执行.meaning_of_life()。结果值存储在对象本身的__dict__属性中。当您再次访问meaning_of_life属性时,Python 将使用查找链在__dict__属性中查找该属性的值,该值将被立即返回。请注意,这是可行的,因为在本例中,您只使用了描述符协议的一种方法
.__get__()。您还实现了一个非数据描述符。如果您实现了数据描述符,那么这个技巧就不会奏效。按照查找链,它将优先于存储在__dict__中的值。要对此进行测试,请运行以下代码:# wrong_lazy_properties.py import time class LazyProperty: def __init__(self, function): self.function = function self.name = function.__name__ def __get__(self, obj, type=None) -> object: obj.__dict__[self.name] = self.function(obj) return obj.__dict__[self.name] def __set__(self, obj, value): pass class DeepThought: @LazyProperty def meaning_of_life(self): time.sleep(3) return 42 my_deep_thought_instance = DeepThought() print(my_deep_thought_instance.meaning_of_life) print(my_deep_thought_instance.meaning_of_life) print(my_deep_thought_instance.meaning_of_life)在这个例子中,你可以看到仅仅实现了
.__set__()、,即使它根本没有做任何事情,也创建了一个数据描述符。现在,懒惰属性的把戏停止工作。D.R.Y .代码
描述符的另一个典型用例是编写可重用的代码,并使您的代码成为可重用的代码。
考虑一个例子,其中有五个不同的属性具有相同的行为。只有当每个属性是偶数时,才能将其设置为特定值。否则,它的值被设置为 0:
# properties.py class Values: def __init__(self): self._value1 = 0 self._value2 = 0 self._value3 = 0 self._value4 = 0 self._value5 = 0 @property def value1(self): return self._value1 @value1.setter def value1(self, value): self._value1 = value if value % 2 == 0 else 0 @property def value2(self): return self._value2 @value2.setter def value2(self, value): self._value2 = value if value % 2 == 0 else 0 @property def value3(self): return self._value3 @value3.setter def value3(self, value): self._value3 = value if value % 2 == 0 else 0 @property def value4(self): return self._value4 @value4.setter def value4(self, value): self._value4 = value if value % 2 == 0 else 0 @property def value5(self): return self._value5 @value5.setter def value5(self, value): self._value5 = value if value % 2 == 0 else 0 my_values = Values() my_values.value1 = 1 my_values.value2 = 4 print(my_values.value1) print(my_values.value2)如您所见,这里有许多重复的代码。可以使用 Python 描述符在所有属性之间共享行为。您可以创建一个
EvenNumber描述符,并将其用于所有属性,如下所示:# properties2.py class EvenNumber: def __set_name__(self, owner, name): self.name = name def __get__(self, obj, type=None) -> object: return obj.__dict__.get(self.name) or 0 def __set__(self, obj, value) -> None: obj.__dict__[self.name] = (value if value % 2 == 0 else 0) class Values: value1 = EvenNumber() value2 = EvenNumber() value3 = EvenNumber() value4 = EvenNumber() value5 = EvenNumber() my_values = Values() my_values.value1 = 1 my_values.value2 = 4 print(my_values.value1) print(my_values.value2)这段代码现在看起来好多了!重复的部分消失了,逻辑现在在一个地方实现了,所以如果你需要改变它,你可以很容易地做到。
结论
既然您已经知道 Python 如何使用描述符来增强它的一些优秀特性,那么您将会是一个更有意识的开发人员,理解为什么一些 Python 特性以它们的方式实现。
你已经学会:
- 什么是 Python 描述符以及何时使用它们
- Python 内部使用描述符的地方
- 如何实现自己的描述符
此外,您现在已经知道了 Python 描述符特别有用的一些特定用例。例如,当您有一个必须在许多属性之间共享的公共行为,甚至是不同类的属性时,描述符就很有用。
如果您有任何问题,请在下面留下评论或通过 Twitter 联系我!如果你想更深入地研究 Python 描述符,那么请查看官方的 Python 描述符指南。****
Visual Studio 代码中的 Python 开发
原文:https://realpython.com/python-development-visual-studio-code/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Visual Studio 代码中的 Python 开发(安装指南)
对程序员来说最酷的代码编辑器之一, Visual Studio Code ,是一个开源的、可扩展的、轻量级的编辑器,可以在所有平台上使用。正是这些品质使得来自微软的 Visual Studio 代码非常受欢迎,并且是 Python 开发的一个很好的平台。
在本文中,您将了解 Visual Studio 代码中的 Python 开发,包括如何:
- 安装 Visual Studio 代码
- 发现并安装使 Python 开发变得容易的扩展
- 编写一个简单的 Python 应用程序
- 学习如何在 VS 代码中运行和调试现有的 Python 程序
- 将 Visual Studio 代码连接到 Git,将 GitHub 连接到与世界分享您的代码
我们假设您熟悉 Python 开发,并且已经在您的系统上安装了某种形式的 Python(Python 2.7、Python 3.6/3.7、Anaconda 或其他)。提供了 Ubuntu 和 Windows 的截图和演示。因为 Visual Studio 代码在所有主要平台上运行,所以您可能会看到稍有不同的 UI 元素,并且可能需要修改某些命令。
如果你已经有了一个基本的 VS 代码设置,并且你希望比本教程中的目标更深入,你可能想要探索 VS 代码中的一些高级特性。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
为 Python 开发安装和配置 Visual Studio 代码
在任何平台上安装 Visual Studio 代码都是非常容易的。针对 Windows 、 Mac 和 Linux 的完整说明是可用的,编辑器每月更新新功能和错误修复。您可以在 Visual Studio 代码网站找到所有内容:
如果您想知道,Visual Studio 代码(或简称为 VS 代码)除了与它更大的基于 Windows 的同名代码 Visual Studio 共享一个名称之外,几乎什么都不共享。
注意:要了解如何在 Windows 机器上设置作为完整 Python 编码环境一部分的 VS 代码,请查看本综合指南。
Visual Studio 代码具有对多种语言的内置支持,以及一个扩展模型,该模型具有丰富的支持其他语言的生态系统。VS 代码每月更新一次,你可以在微软 Python 博客保持最新。微软甚至让任何人都可以克隆和贡献 VS Code GitHub repo 。(提示公关洪水。)
VS 代码 UI 有很好的文档记录,所以我在这里不再赘述:
Python 开发的扩展
如上所述,VS 代码通过一个记录良好的扩展模型支持多种编程语言的开发。 Python 扩展支持在 Visual Studio 代码中进行 Python 开发,具有以下特性:
- 支持 Python 3.4 和更高版本,以及 Python 2.7
- 使用智能感知完成代码
- 林挺
- 调试支持
- 代码片段
- 单元测试支持
- 自动使用 conda 和虚拟环境
- 在 Jupyter 环境和 Jupyter 笔记本中编辑代码
Visual Studio 代码扩展不仅仅涵盖编程语言功能:
Keymaps 让已经熟悉 Atom、 Sublime Text 、 Emacs 、 Vim 、 PyCharm 或其他环境的用户有宾至如归的感觉。
无论你喜欢在明亮、黑暗还是更多彩的环境中编码,都可以定制用户界面。
语言包提供本地化的体验。
以下是一些我觉得有用的其他扩展和设置:
GitLens 直接在你的编辑窗口中提供了大量有用的 Git 特性,包括责备注释和存储库探索特性。
从菜单中选择
File, Auto Save即可轻松打开自动保存。默认延迟时间为 1000 毫秒,也可以通过配置。设置同步允许你使用 GitHub 跨不同安装同步你的 VS 代码设置。如果您在不同的机器上工作,这有助于保持环境的一致性。
Docker 让你快速方便地使用 Docker,帮助作者
Dockerfile和docker-compose.yml,打包和部署你的项目,甚至为你的项目生成合适的 Docker 文件。当然,在使用 VS 代码时,您可能会发现其他有用的扩展。请在评论分享你的发现和设定!
点击活动栏上的扩展图标可以发现和安装新的扩展和主题。您可以使用关键字搜索扩展,以多种方式对结果进行排序,并快速轻松地安装扩展。对于本文,通过在活动栏上的扩展项中键入
python,并点击安装来安装 Python 扩展:
您可以用同样的方式找到并安装上面提到的任何扩展。
Visual Studio 代码配置文件
值得一提的是,Visual Studio 代码通过用户和工作区设置是高度可配置的。
用户设置是所有 Visual Studio 代码实例的全局设置,而工作区设置是特定文件夹或项目工作区的本地设置。工作区设置为 VS 代码提供了极大的灵活性,在本文中我一直强调工作区设置。工作空间设置作为
.json文件存储在项目工作空间的本地文件夹.vscode中。启动一个新的 Python 程序
让我们从一个新的 Python 程序开始探索 Visual Studio 代码中的 Python 开发。在 VS 代码中,键入
Ctrl+N打开一个新文件。(您也可以从菜单中选择文件,新建。)注意:Visual Studio 代码 UI 提供了命令调板,从这里可以搜索和执行任何命令,而无需离开键盘。使用
Ctrl+Shift+P打开命令面板,键入File: New File,点击Enter打开一个新文件。无论您如何到达那里,您都应该看到一个类似于下面的 VS 代码窗口:
打开新文件后,您就可以开始输入代码了。
输入 Python 代码
对于我们的测试代码,让我们快速编码厄拉多塞的筛子(查找所有小于给定数字的素数)。开始在刚刚打开的新选项卡中键入以下代码:
sieve = [True] * 101 for i in range(2, 100):您应该会看到类似这样的内容:
等等,怎么回事?为什么 Visual Studio 代码不做任何关键字突出显示、任何自动格式化或任何真正有帮助的事情?怎么回事?
答案是,现在,VS 代码不知道它在处理什么样的文件。这个缓冲区叫做
Untitled-1,如果你看窗口的右下角,你会看到文字纯文本。要激活 Python 扩展,将文件保存为
sieve.py(从菜单中选择文件,保存,从命令面板中选择文件:保存文件,或者只使用Ctrl+S】)。VS 代码会看到.py扩展名,并正确地将文件解释为 Python 代码。现在你的窗口应该是这样的:
那就好多了!VS 代码自动将文件重新格式化为 Python,您可以通过检查左下角的语言模式来验证这一点。
如果您有多个 Python 安装(如 Python 2.7、Python 3.x 或 Anaconda),您可以通过单击语言模式指示器或从命令面板中选择 Python: Select Interpreter 来更改 Python 解释器 VS 代码使用的解释器。VS 代码默认支持使用
pep8的格式化,但是如果你愿意,你可以选择black或者yapf。https://player.vimeo.com/video/487453125?background=1
现在让我们添加剩余的筛子代码。要查看 IntelliSense 的工作情况,请直接键入此代码,而不是剪切和粘贴,您应该会看到如下内容:
这是厄拉多塞基本筛子的完整代码:
sieve = [True] * 101 for i in range(2, 100): if sieve[i]: print(i) for j in range(i*i, 100, i): sieve[j] = False当您键入这段代码时,VS Code 会自动为您适当地缩进
for和if语句下的行,添加右括号,并为您提出建议。这就是智能感知的强大之处。运行 Python 代码
现在代码已经完成,您可以运行它了。没有必要离开编辑器来做这件事:Visual Studio 代码可以直接在编辑器中运行这个程序。保存文件(使用
Ctrl+S),然后在编辑器窗口点击右键,选择在终端运行 Python 文件:https://player.vimeo.com/video/487465969?background=1
您应该会看到终端面板出现在窗口的底部,并显示您的代码输出。
Python 林挺支持
您可能在输入时看到弹出窗口,提示林挺不在。您可以从弹出窗口快速安装林挺支持,默认为 PyLint 。VS 代码也支持其他的 linters。以下是撰写本文时的完整列表:
pylintflake8mypypydocstylepep8prospectorpyllamabanditPython 林挺页面有关于如何设置每个 linter 的完整细节。
注意:linter 的选择是项目工作区设置,不是全局用户设置。
编辑现有的 Python 项目
在厄拉多塞筛子的例子中,您创建了一个 Python 文件。这是一个很好的例子,但是很多时候,你会创建更大的项目,并在更长的时间内工作。典型的新项目工作流可能如下所示:
- 创建一个文件夹来存放项目(可能包括一个新的 GitHub 项目)
- 转到新文件夹
- 使用命令
code filename.py创建初始 Python 代码在一个 Python 项目中使用 Visual Studio 代码(相对于单个 Python 文件而言)会带来更多的功能,让 VS 代码真正大放异彩。让我们看看它是如何与一个更大的项目一起工作的。
在上一个千年后期,当我还是一个年轻得多的程序员时,我编写了一个计算器程序,使用 Edsger Dijkstra 的调车场算法的改编,解析用中缀符号编写的方程。
为了展示 Visual Studio 代码以项目为中心的特性,我开始重新创建调车场算法,作为 Python 中的方程求值库。要继续跟进,请随意在本地克隆 repo。
一旦在本地创建了文件夹,您就可以在 VS 代码中快速打开整个文件夹。我的首选方法(如上所述)修改如下,因为我已经创建了文件夹和基本文件:
cd /path/to/project code .VS 代码理解并将使用以这种方式打开时看到的任何 virtualenv 、 pipenv 或 conda 环境。你甚至不需要先启动虚拟环境!你甚至可以从 UI 中打开一个文件夹,使用文件,从菜单中打开文件夹,从命令面板中打开文件夹
Ctrl+K,Ctrl+O,或者文件:打开文件夹。对于我的方程式评估库项目,我看到的是:
当 Visual Studio 代码打开文件夹时,它也会打开您上次打开的文件。(这是可配置的。)您可以打开、编辑、运行和调试列出的任何文件。左侧活动栏中的资源管理器视图提供了文件夹中所有文件的视图,并显示了当前选项卡集中有多少未保存的文件。
测试支架
VS 代码可以自动识别在
unittest框架中编写的现有 Python 测试,或者pytest或Nose框架,如果这些框架安装在当前环境中的话。我有一个用unittest编写的单元测试,用于等式评估库,您可以在这个例子中使用它。要运行您现有的单元测试,从项目中的任何 Python 文件中,右键单击并选择 Run Current Unit Test File 。您将被提示指定测试框架,在项目中的什么地方搜索测试,以及您的测试使用的文件名模式。
所有这些都作为工作空间设置保存在您的本地
.vscode/settings.json文件中,并且可以在那里进行修改。对于这个方程项目,您选择unittest、当前文件夹和模式*_test.py。一旦建立了测试框架并发现了测试,您就可以通过点击状态栏上的 Run Tests 并从命令面板中选择一个选项来运行您的所有测试:
https://player.vimeo.com/video/487454306?background=1
您甚至可以通过在 VS 代码中打开测试文件,点击状态栏上的 Run Tests ,并选择 Run Unit Test Method… 和要运行的特定测试来运行单个测试。这使得解决单个测试失败并只重新运行失败的测试变得微不足道,这是一个巨大的时间节省!测试结果显示在 Python 测试日志下的输出窗格中。
调试支持
即使 VS 代码是一个代码编辑器,直接在 VS 代码中调试 Python 也是可能的。VS 代码提供了许多您期望从一个好的代码调试器中得到的特性,包括:
- 自动变量跟踪
- 观察表情
- 断点
- 调用堆栈检查
您可以在活动栏上的调试视图中看到它们:
调试器可以控制在内置终端或外部终端实例中运行的 Python 应用程序。它可以附加到已经运行的 Python 实例,甚至可以调试 Django 和 Flask 应用。
调试单个 Python 文件中的代码就像使用
F5启动调试器一样简单。使用F10和F11分别单步执行和进入函数,使用Shift+F5退出调试器。使用F9设置断点,或使用鼠标点击编辑器窗口的左边空白处。在开始调试更复杂的项目之前,包括 Django 或 Flask 应用程序,您需要设置并选择一个调试配置。设置调试配置相对简单。从调试视图中,选择配置下拉菜单,然后选择添加配置,选择 Python :
Visual Studio 代码将在当前文件夹下创建一个名为
.vscode/launch.json的调试配置文件,它允许您设置特定的 Python 配置,以及用于调试特定应用的设置,如 Django 和 Flask。您甚至可以执行远程调试,并调试 Jinja 和 Django 模板。在编辑器中关闭
launch.json文件,并从配置下拉列表中为您的应用选择合适的配置。Git 集成
VS 代码内置了对源代码控制管理的支持,并附带了对 Git 和 GitHub 的支持。您可以在 VS 代码中安装对其他 SCM 的支持,并一起使用它们。可以从源代码控制视图中访问源代码控制:
如果你的项目文件夹包含一个
.git文件夹,VS Code 会自动打开全部的 Git/GitHub 功能。以下是您可以执行的许多任务中的一部分:所有这些功能都可以直接从 VS 代码 UI 中获得:
VS 代码还会识别在编辑器外所做的更改,并表现出适当的行为。
在 VS 代码中提交最近的更改是一个相当简单的过程。修改过的文件显示在源代码控制视图中,带有一个 M 标记,而新的未被跟踪的文件用一个 U 标记。将鼠标悬停在文件上,然后单击加号( + ),准备好您的更改。在视图顶部添加提交消息,然后单击复选标记提交更改:
您也可以从 VS 代码内部将本地提交推送到 GitHub。从源代码控制视图菜单中选择同步,或者点击分支指示器旁边状态栏上的同步变更。
结论
Visual Studio 代码是最酷的通用编辑器之一,也是 Python 开发的绝佳候选。在本文中,您了解了:
- 如何在任何平台上安装 VS 代码
- 如何找到并安装扩展来启用 Python 特有的特性
- VS 代码如何让编写简单的 Python 应用程序变得更容易
- 如何在 VS 代码中运行和调试现有的 Python 程序
- 如何使用 VS 代码中的 Git 和 GitHub 库
Visual Studio 代码已经成为我的 Python 和其他任务的默认编辑器,我希望您也给它一个机会成为您的编辑器。
如果您有任何问题或意见,请在下面的评论中联系我们。Visual Studio 代码网站上的信息比我们在这里介绍的要多得多。
作者感谢微软 Visual Studio 代码团队的丹·泰勒(Dan Taylor)为本文付出的时间和宝贵投入。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Visual Studio 代码中的 Python 开发(安装指南)******
用 Python 构建掷骰子应用程序
构建小项目,如基于文本的用户界面(TUI) 掷骰子应用程序,将帮助您提高 Python 编程技能。您将学习如何收集和验证用户的输入,从模块和包中导入代码,编写函数,使用
for循环和条件语句,并通过使用字符串和print()函数灵活地显示输出。在这个项目中,您将编写一个模拟掷骰子事件的应用程序。为此,您将使用 Python 的
random模块。在本教程中,您将学习如何:
- 用
random.randint()模拟掷骰子事件- 使用内置的
input()函数请求用户输入- 解析和验证用户的输入
- 操纵琴弦的使用方法,如
.center()和.join()您还将学习如何构建、组织、记录和运行 Python 程序和脚本的基础知识。
单击下面的链接下载这个掷骰子应用程序的完整代码,并跟随您自己构建项目:
获取源代码: 点击此处获取源代码,您将使用构建您的 Python 掷骰子应用程序。
演示
在这个分步项目中,您将构建一个运行掷骰子模拟的应用程序。该应用程序将能够滚动多达六个骰子,每个骰子有六个面。每次掷骰子后,应用程序都会生成骰子面的 ASCII 图,并显示在屏幕上。以下视频演示了该应用程序的工作原理:
当你运行你的掷骰子模拟器应用程序时,你会得到一个提示,询问你要掷多少个骰子。一旦您提供了从 1 到 6(包括 1 和 6)的有效整数,应用程序就会模拟滚动事件,并在屏幕上显示骰子面的图形。
项目概述
您的掷骰子模拟器应用程序将有一个最小但用户友好的基于文本的用户界面(TUI) ,它将允许您指定您想要掷出的六面骰子的数量。您将使用此 TUI 在家中掷骰子,而不必飞往拉斯维加斯。
以下是该应用程序内部工作方式的描述:
要运行的任务 要使用的工具 要编写的代码 提示用户选择掷出多少个六面骰子,然后读取用户的输入 Python 内置的 input()函数使用适当的参数调用 input()解析并验证用户的输入 字符串方法、比较运算符和条件语句 名为 parse_input()的用户自定义函数运行掷骰子模拟 Python 的 random模块,具体是randint()函数名为 roll_dice()的用户自定义函数用生成的骰子面生成 ASCII 图 循环, list.append(),和str.join()名为 generate_dice_faces_diagram()的用户自定义函数在屏幕上显示骰子面的图形 Python 内置的 print()函数使用适当的参数调用 print()牢记这些内部工作原理,您将编写三个自定义函数来提供应用程序的主要特性和功能。这些函数将定义你的代码的公共 API ,你将调用它来激活应用程序。
为了组织掷骰子模拟器项目的代码,您将在文件系统中您选择的目录下创建一个名为
dice.py的文件。继续并创建文件开始吧!先决条件
在开始构建这个掷骰子模拟项目之前,您应该熟悉以下概念和技能:
- 在 Python 中运行脚本的方法
- Python 的
import机制- Python 数据类型的基础知识,主要是字符串和整数数字
- 基本的数据结构,特别是列表
- Python 变量和常量
- Python 比较运算符
- 布尔值和逻辑表达式
- 条件语句
- Python
forloops- Python 中输入、输出、字符串格式化的基础知识
如果在开始这次编码冒险之前,您还没有掌握所有的必备知识,那也没关系!通过继续前进并开始行动,您可能会学到更多!如果遇到困难,您可以随时停下来查看此处链接的资源。
步骤 1:编写 Python 掷骰子应用程序的 TUI 代码
在这一步中,您将编写所需的代码,要求用户输入他们希望在模拟中掷出多少骰子。您还将编写一个 Python 函数,该函数接受用户的输入,对其进行验证,如果验证成功,则返回一个整数。否则,该函数将再次要求用户输入。
要下载此步骤的代码,请单击以下链接并导航至
source_code_step_1/文件夹:获取源代码: 点击此处获取源代码,您将使用构建您的 Python 掷骰子应用程序。
在命令行接受用户的输入
为了让您的手变脏,您可以开始编写与用户交互的代码。这段代码将提供应用程序的基于文本的界面,并将依赖于
input()。这个内置函数从命令行读取用户输入。它的prompt参数允许您传递所需输入类型的描述。启动你最喜欢的编辑器或 IDE ,在你的
dice.py文件中输入以下代码:1# dice.py 2 3# ~~~ App's main code block ~~~ 4# 1\. Get and validate user's input 5num_dice_input = input("How many dice do you want to roll? [1-6] ") 6num_dice = parse_input(num_dice_input)您对第 5 行的
input()的调用显示一个提示,询问用户想要掷出多少骰子。如提示所示,该数字必须在 1 到 6 的范围内。注意:通过在第 3 行添加注释,您将应用程序的主代码与您将在接下来的部分中添加的其余代码分开。
同样,第 4 行的注释反映了您当时正在执行的特定任务。在本教程的其他部分,你会发现更多类似的评论。这些评论是可选的,所以如果你愿意,可以随意删除它们。
第 6 行调用
parse_input()并将返回的值存储在num_dice中。在下一节中,您将实现这个函数。解析并验证用户的输入
parse_input()的工作是将用户的输入作为一个字符串,检查它是否是一个有效的整数,并将其作为 Pythonint对象返回。继续将以下内容添加到您的dice.py文件中,就在应用程序主代码之前:1# dice.py 2 3def parse_input(input_string): 4 """Return `input_string` as an integer between 1 and 6. 5 6 Check if `input_string` is an integer number between 1 and 6. 7 If so, return an integer with the same value. Otherwise, tell 8 the user to enter a valid number and quit the program. 9 """ 10 if input_string.strip() in {"1", "2", "3", "4", "5", "6"}: 11 return int(input_string) 12 else: 13 print("Please enter a number from 1 to 6.") 14 raise SystemExit(1) 15 16# ~~~ App's main code block ~~~ 17# ...下面是这段代码的逐行工作方式:
第 3 行定义了
parse_input(),它以输入字符串作为参数。第 4 行到第 9 行提供了函数的文档字符串。在函数中包含信息丰富且格式良好的 docstring 是 Python 编程中的最佳实践,因为 docstring 允许您记录您的代码。
第 10 行检查用户输入的掷骰子数是否为有效值。对
.strip()的调用删除了输入字符串周围不需要的空格。in操作符检查输入是否在允许掷骰子的数目范围内。在这种情况下,您使用一个集合,因为这个 Python 数据结构中的成员测试非常高效。第 11 行将输入转换成整数并返回给调用者。
第 13 行打印一条信息到屏幕上,提醒用户输入无效(如果适用)。
第 14 行以
SystemExit异常和1的状态码退出应用程序,表示出现了问题。使用
parse_input(),您可以在命令行处理和验证用户的输入。验证任何直接来自用户或任何不可信来源的输入是您的应用程序可靠安全工作的关键。注意:本教程中代码示例的行号是为了便于解释。大多数情况下,它们不会与你最终脚本中的行号相匹配。
现在您已经有了用户友好的 TUI 和适当的输入验证机制,您需要确保这些功能正常工作。这就是你在下一节要做的。
试试掷骰子应用程序的 TUI
要尝试您到目前为止编写的代码,请打开一个命令行窗口并运行您的
dice.py脚本:$ python dice.py How many dice do you want to roll? [1-6] 3 $ python dice.py How many dice do you want to roll? [1-6] 7 Please enter a number from 1 to 6.如果您输入 1 到 6 之间的整数,则代码不会显示消息。另一方面,如果输入不是有效的整数或者超出了目标区间,那么您会得到一条消息,告诉您需要 1 到 6 之间的整数。
到目前为止,您已经成功地编写了在命令行请求和解析用户输入的代码。这段代码提供了应用程序的 TUI,它基于内置的
input()函数。您还编写了一个函数来验证用户的输入,并将其作为整数返回。现在,是掷骰子的时候了!第二步:用 Python 模拟六面骰子的滚动
您的掷骰子应用程序现在提供了一个 TUI 来接受用户的输入并进行处理。太好了!为了继续构建应用程序的主要功能,您将编写
roll_dice()函数,它将允许您模拟掷骰子事件。这个函数将获取用户想要掷骰子的数目。Python 的
random模块从标准库中提供了randint()函数,在给定的区间内生成伪随机整数。您将利用这个函数来模拟掷骰子。要下载此步骤的代码,请单击以下链接并查看
source_code_step_2/文件夹:获取源代码: 点击此处获取源代码,您将使用构建您的 Python 掷骰子应用程序。
下面是实现
roll_dice()的代码:1# dice.py 2import random 3 4# ... 5 6def roll_dice(num_dice): 7 """Return a list of integers with length `num_dice`. 8 9 Each integer in the returned list is a random number between 10 1 and 6, inclusive. 11 """ 12 roll_results = [] 13 for _ in range(num_dice): 14 roll = random.randint(1, 6) 15 roll_results.append(roll) 16 return roll_results 17 18# ~~~ App's main code block ~~~ 19# ...在这个代码片段中,第 2 行将
random导入到当前的名称空间中。该导入允许您稍后访问randint()功能。下面是其余代码的细目分类:
第 6 行定义了
roll_dice(),它接受一个参数,表示在给定调用中掷骰子的数目。第 7 行到第 11 行提供了函数的文档串。
第 12 行创建一个空的列表,
roll_results,用来存储掷骰子模拟的结果。第 13 行定义了一个
for循环,对用户想要掷出的每个骰子迭代一次。第 14 行调用
randint()生成一个从 1 到 6(含)的伪随机整数。该调用在每次迭代中生成一个数字。这个数字表示滚动六面骰子的结果。第 15 行将当前掷骰结果追加到
roll_results中。第 16 行返回掷骰子模拟结果列表。
为了测试您新创建的函数,将下面几行代码添加到您的
dice.py文件的末尾:1# dice.py 2# ... 3 4# ~~~ App's main code block ~~~ 5# 1\. Get and validate user's input 6num_dice_input = input("How many dice do you want to roll? [1-6] ") 7num_dice = parse_input(num_dice_input) 8# 2\. Roll the dice 9roll_results = roll_dice(num_dice) 10 11print(roll_results) # Remove this line after testing the app在这段代码中,第 9 行用
num_dice作为参数调用roll_dice()。第 11 行调用print()将结果显示为屏幕上的数字列表。列表中的每个数字代表单个芯片的结果。测试完代码后,您可以删除第 11 行。继续从命令行运行您的应用程序:
$ python dice.py How many dice do you want to roll? [1-6] 5 [6, 1, 3, 6, 6] $ python dice.py How many dice do you want to roll? [1-6] 2 [2, 6]您屏幕上的结果列表会有所不同,因为您正在生成自己的伪随机数。在本例中,您将分别模拟掷出五个和两个骰子。每个骰子的值介于 1 和 6 之间,因为您使用的是六面骰子。
既然您已经编写并测试了模拟掷骰子事件的代码,那么是时候继续为您的应用程序提供一种显示这些结果的华丽方式了。这是您将在下一部分中执行的操作。
第三步:生成并显示骰子面的 ASCII 图
此时,您的应用程序已经模拟了几个骰子的滚动,并将结果存储为数字列表。然而,从用户的角度来看,数字列表并不吸引人。你需要一个更好的输出,让你的应用看起来更专业。
在本节中,您将编写代码来生成显示最多六个骰子正面的图表。为此,您将创建一点 ASCII 艺术。
单击下面的链接下载此步骤的代码,以便您可以跟随项目。您将在
source_code_step_3/文件夹中找到您需要的内容:获取源代码: 点击此处获取源代码,您将使用构建您的 Python 掷骰子应用程序。
设置骰子面图
您的掷骰子模拟器应用程序需要一种方式来显示掷骰子的结果。为此,您将使用骰子正面的 ASCII 图表,该图表将显示掷出所需数量的六面骰子的结果。例如,在掷出四个骰子后,图表看起来会像这样:
~~~~~~~~~~~~~~~~~~~ RESULTS ~~~~~~~~~~~~~~~~~~~ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ ● ● │ │ │ │ ● │ │ ● │ │ │ │ ● │ │ ● │ │ │ │ ● ● │ │ │ │ ● │ │ ● │ └─────────┘ └─────────┘ └─────────┘ └─────────┘此图中的每个模具面反映了一次模拟迭代的结果值。要开始编写构建该图的功能,您需要将一些 ASCII 图片放在一起。
1# dice.py 2import random 3 4DICE_ART = { 5 1: ( 6 "┌─────────┐", 7 "│ │", 8 "│ ● │", 9 "│ │", 10 "└─────────┘", 11 ), 12 2: ( 13 "┌─────────┐", 14 "│ ● │", 15 "│ │", 16 "│ ● │", 17 "└─────────┘", 18 ), 19 3: ( 20 "┌─────────┐", 21 "│ ● │", 22 "│ ● │", 23 "│ ● │", 24 "└─────────┘", 25 ), 26 4: ( 27 "┌─────────┐", 28 "│ ● ● │", 29 "│ │", 30 "│ ● ● │", 31 "└─────────┘", 32 ), 33 5: ( 34 "┌─────────┐", 35 "│ ● ● │", 36 "│ ● │", 37 "│ ● ● │", 38 "└─────────┘", 39 ), 40 6: ( 41 "┌─────────┐", 42 "│ ● ● │", 43 "│ ● ● │", 44 "│ ● ● │", 45 "└─────────┘", 46 ), 47} 48DIE_HEIGHT = len(DICE_ART[1]) 49DIE_WIDTH = len(DICE_ART[1][0]) 50DIE_FACE_SEPARATOR = " " 51 52# ...在第 4 到 47 行,您使用 ASCII 字符绘制了六个骰子面。您将面孔存储在
DICE_ART中,这是一个将每个面孔映射到其相应整数值的字典。第 48 行定义了
DIE_HEIGHT,它保存了一个给定面将占据的行数。在本例中,每个面占据五行。类似地,第 49 行定义了DIE_WIDTH来保存绘制模具面所需的列数。在本例中,宽度为 11 个字符。最后,第 50 行定义了
DIE_FACE_SEPARATOR,它包含一个空白字符。您将使用所有这些常量来为您的应用程序生成和显示骰子面的 ASCII 图。生成骰子面图
此时,您已经为每个模具面构建了 ASCII 艺术。要将这些部分组合成一个最终的图表,表示掷骰子模拟的完整结果,您将编写另一个自定义函数:
1# dice.py 2 3# ... 4 5def generate_dice_faces_diagram(dice_values): 6 """Return an ASCII diagram of dice faces from `dice_values`. 7 8 The string returned contains an ASCII representation of each die. 9 For example, if `dice_values = [4, 1, 3, 2]` then the string 10 returned looks like this: 11 12 ~~~~~~~~~~~~~~~~~~~ RESULTS ~~~~~~~~~~~~~~~~~~~ 13 ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ 14 │ ● ● │ │ │ │ ● │ │ ● │ 15 │ │ │ ● │ │ ● │ │ │ 16 │ ● ● │ │ │ │ ● │ │ ● │ 17 └─────────┘ └─────────┘ └─────────┘ └─────────┘ 18 """ 19 # Generate a list of dice faces from DICE_ART 20 dice_faces = [] 21 for value in dice_values: 22 dice_faces.append(DICE_ART[value]) 23 24 # Generate a list containing the dice faces rows 25 dice_faces_rows = [] 26 for row_idx in range(DIE_HEIGHT): 27 row_components = [] 28 for die in dice_faces: 29 row_components.append(die[row_idx]) 30 row_string = DIE_FACE_SEPARATOR.join(row_components) 31 dice_faces_rows.append(row_string) 32 33 # Generate header with the word "RESULTS" centered 34 width = len(dice_faces_rows[0]) 35 diagram_header = " RESULTS ".center(width, "~") 36 37 dice_faces_diagram = "\n".join([diagram_header] + dice_faces_rows) 38 return dice_faces_diagram 39 40# ~~~ App's main code block ~~~ 41# ...该函数执行以下操作:
第 5 行用一个名为
dice_values的参数定义了generate_dice_faces_diagram()。这个参数将保存调用roll_dice()得到的掷骰子的整数值列表。第 6 行到第 18 行提供了函数的文档字符串。
第 20 行创建一个名为
dice_faces的空列表来存储与输入的骰子值列表相对应的骰子面。这些骰子面将显示在最终的 ASCII 图中。第 21 行定义了一个
for循环来迭代骰子值。第 22 行从
DICE_ART检索对应于当前模具值的模具面,并将其附加到dice_faces。第 25 行创建一个空列表来保存最终骰子点数图中的行。
第 26 行定义了一个从
0到DIE_HEIGHT - 1遍历索引的循环。每个索引代表骰子点数图中给定行的索引。第 27 行将
row_components定义为一个空列表,用于保存将填充给定行的骰子面部分。第 28 行开始一个嵌套的
for循环来迭代骰子面。第 29 行存储每行组件。
第 30 行将行组件连接成最终的行字符串,用空格分隔各个组件。
第 31 行将每个行字符串追加到保存行的列表中,这些行将形成最终的图表。
第 34 行创建一个临时变量来保存当前骰子点数图的
width。第 35 行创建一个显示单词结果的标题。为此,它使用
str.center()以及图的width和波浪号(~)作为参数。第 37 行生成一个包含最终骰子点数图的字符串。换行符字符(
\n)用作行分隔符。.join()的参数是一个字符串列表,它连接了图头和塑造骰子面的字符串(行)。第 38 行向调用者返回一个准备打印的骰子点数图。
哇!太多了!您将回到这段代码,并对其进行改进,使其更易于管理。不过,在此之前,您会想尝试一下您的应用程序,所以您需要完成其主要代码块的编写。
完成应用程序的主要代码,掷骰子
有了
generate_dice_faces_diagram(),您现在可以完成应用程序主代码的编写,这将允许您实际生成并在屏幕上显示骰子面的图形。继续将下面几行代码添加到dice.py的末尾:1# dice.py 2 3# ... 4 5# ~~~ App's main code block ~~~ 6# 1\. Get and validate user's input 7num_dice_input = input("How many dice do you want to roll? [1-6] ") 8num_dice = parse_input(num_dice_input) 9# 2\. Roll the dice 10roll_results = roll_dice(num_dice) 11# 3\. Generate the ASCII diagram of dice faces 12dice_face_diagram = generate_dice_faces_diagram(roll_results) 13# 4\. Display the diagram 14print(f"\n{dice_face_diagram}")第 12 行用
roll_results作为参数调用generate_dice_faces_diagram()。该调用构建并返回与当前掷骰子结果相对应的骰子面图。第 14 行调用print()在屏幕上显示图表。通过此更新,您可以再次运行该应用程序。回到命令行,执行以下命令:
$ python dice.py How many dice do you want to roll? [1-6] 5 ~~~~~~~~~~~~~~~~~~~~~~~~~ RESULTS ~~~~~~~~~~~~~~~~~~~~~~~~~ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ ● ● │ │ ● ● │ │ ● ● │ │ ● │ │ ● ● │ │ ● │ │ ● ● │ │ ● ● │ │ ● │ │ │ │ ● ● │ │ ● ● │ │ ● ● │ │ ● │ │ ● ● │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ └─────────┘酷!现在,您的掷骰子模拟器应用程序显示一个格式良好的 ASCII 图表,显示模拟事件的结果。很整洁,不是吗?
如果你回到
generate_dice_faces_diagram()的实现,你会注意到它包含了一些注释,指出了代码的相应部分在做什么:def generate_dice_faces_diagram(dice_values): # ... # Generate a list of dice faces from DICE_ART dice_faces = [] for value in dice_values: dice_faces.append(DICE_ART[value]) # Generate a list containing the dice faces rows dice_faces_rows = [] for row_idx in range(DIE_HEIGHT): row_components = [] for die in dice_faces: row_components.append(die[row_idx]) row_string = DIE_FACE_SEPARATOR.join(row_components) dice_faces_rows.append(row_string) # Generate header with the word "RESULTS" centered width = len(dice_faces_rows[0]) diagram_header = " RESULTS ".center(width, "~") dice_faces_diagram = "\n".join([diagram_header] + dice_faces_rows) return dice_faces_diagram这种评论通常表明你的代码会从一些重构中受益。在下一节中,您将使用一种流行的重构技术,这种技术将帮助您清理代码并使其更易于维护。
步骤 4:重构生成骰子面图的代码
您的
generate_dice_faces_diagram()函数需要注释,因为它一次执行几个操作,这违反了单责任原则。粗略地说,这个原则认为每个函数、类或模块应该只做一件事。这样,给定功能的改变不会破坏代码的其余部分。结果,您将得到一个更健壮、更易维护的代码。
要下载该步骤的代码,请单击下面的链接,然后查看
source_code_step_4/文件夹:获取源代码: 点击此处获取源代码,您将使用构建您的 Python 掷骰子应用程序。
有一种叫做提取方法的重构技术,可以通过提取可以独立工作的功能来帮助你改进代码。例如,您可以从前面的
generate_dice_faces_diagram()实现中提取第 20 行到第 22 行的代码,并将其放在一个名为_get_dice_faces()的非公共帮助函数中:def _get_dice_faces(dice_values): dice_faces = [] for value in dice_values: dice_faces.append(DICE_ART[value]) return dice_faces您可以从
generate_dice_faces_diagram()调用_get_dice_faces()来获得隐含的功能。通过使用这种技术,您可以完全重构generate_dice_faces_diagram(),以满足单一责任原则。注意:要了解更多关于用前导下划线(
_)命名非公共函数的信息,请查看Python中下划线的含义。这里有一个重构版本的
generate_dice_faces_diagram(),它利用了_get_dice_faces(),并实现了另一个叫做_generate_dice_faces_rows()的助手函数来提取第 25 行到第 31 行的功能:# dice.py # ... def generate_dice_faces_diagram(dice_values): """Return an ASCII diagram of dice faces from `dice_values`. The string returned contains an ASCII representation of each die. For example, if `dice_values = [4, 1, 3, 2]` then the string returned looks like this: ~~~~~~~~~~~~~~~~~~~ RESULTS ~~~~~~~~~~~~~~~~~~~ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ ● ● │ │ │ │ ● │ │ ● │ │ │ │ ● │ │ ● │ │ │ │ ● ● │ │ │ │ ● │ │ ● │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ """ dice_faces = _get_dice_faces(dice_values) dice_faces_rows = _generate_dice_faces_rows(dice_faces) # Generate header with the word "RESULTS" centered width = len(dice_faces_rows[0]) diagram_header = " RESULTS ".center(width, "~") dice_faces_diagram = "\n".join([diagram_header] + dice_faces_rows) return dice_faces_diagram def _get_dice_faces(dice_values): dice_faces = [] for value in dice_values: dice_faces.append(DICE_ART[value]) return dice_faces def _generate_dice_faces_rows(dice_faces): dice_faces_rows = [] for row_idx in range(DIE_HEIGHT): row_components = [] for die in dice_faces: row_components.append(die[row_idx]) row_string = DIE_FACE_SEPARATOR.join(row_components) dice_faces_rows.append(row_string) return dice_faces_rows # ~~~ App's main code block ~~~ # ...新添加的助手函数从原始函数中提取功能。现在每个助手功能都有自己的单一职责。帮助器函数还允许您使用可读和描述性的名称,消除了解释性注释的需要。
作为 Python 开发人员,重构代码以使其更好是一项很好的技能。要更深入地了解代码重构,请查看为简单起见重构 Python 应用程序。
代码重构背后的一个基本思想是,修改后的代码应该和原始代码一样工作。要检查这个原则,请继续运行您的应用程序!
这样,你就完成了你的项目!您已经构建了一个全功能的 TUI 应用程序,允许您模拟掷骰子事件。每次运行该应用程序时,您可以模拟最多六个骰子的滚动,每个骰子有六个面。您甚至可以在一个漂亮的 ASCII 图中看到最终的骰子面。干得好!
结论
您已经编写了一个功能完整的项目,它由一个基于文本的用户界面应用程序组成,该应用程序用 Python 模拟了六面骰子的滚动。通过这个项目,您学习并练习了一些基本技能,例如收集并验证用户的输入、导入代码、编写函数、使用循环和条件语句,以及在屏幕上显示漂亮的格式输出。
在本教程中,您学习了如何:
- 用
random.randint()模拟掷骰子- 使用内置的
input()函数在命令行接受用户的输入- 使用几种工具和技术解析和验证用户的输入
- 操纵琴弦的使用方法,如
.center()和.join()此外,您还学习了如何构建、组织、记录和运行 Python 程序和脚本。有了这些知识,您就可以更好地准备继续您的 Python 编码之旅。
您可以通过单击下面的链接下载这个掷骰子应用程序的完整代码:
获取源代码: 点击此处获取源代码,您将使用构建您的 Python 掷骰子应用程序。
接下来的步骤
现在,您已经完成了掷骰子应用程序的构建,您可以通过添加新功能将项目向前推进一步。自己添加新特性将有助于您继续学习令人兴奋的新编码概念和技术。
以下是一些让你的项目更上一层楼的想法:
- 支持任意数量的骰子:修改代码,这样就可以掷出任意数量的骰子。
- 支持不同面数的骰子:添加代码,不仅支持六面骰子,还支持任意面数的骰子。
第一个特性要求您修改处理用户输入的掷骰子数的代码。您还需要修改生成和显示骰子面图的代码。例如,您可以生成一个图表,在几行中显示骰子面,以避免拥挤的输出使您的屏幕混乱。
另一方面,支持不同面数的骰子将要求您调整模拟掷骰子事件的代码。您还需要为任何超过六面的骰子创建新的 ASCII 艺术。
一旦你完成了这些新功能,你就可以换个方式,投入到其他很酷的项目中。下面是一些很好的后续步骤,供您继续学习 Python 和构建更复杂的项目:
如何使用 argparse 在 Python 中构建命令行接口:在这个循序渐进的 Python 教程中,您将学习如何通过添加一个方便的命令行接口,让您的命令行 Python 脚本更上一层楼,您可以使用
argparse编写该接口。为命令行构建一个 Python 目录树生成器:在这个循序渐进的项目中,您将为命令行创建一个 Python 目录树生成器应用程序。您将使用
argparse编写命令行界面,并使用pathlib遍历文件系统。用 Python 和 Typer 构建命令行待办事项应用:在这个循序渐进的项目中,你将使用 Python 和 Typer 为你的命令行创建一个待办事项应用。当您构建这个应用程序时,您将学习 Typer 的基础知识,这是一个用于构建命令行界面的现代化多功能库。*****
Python 中的字典
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的字典
Python 提供了另一种复合数据类型,称为字典,它类似于列表,因为它是对象的集合。
在本教程中,您将学到以下内容:您将了解 Python 字典的基本特征,并学习如何访问和管理字典数据。一旦您完成了本教程,您应该对什么时候使用字典是合适的数据类型以及如何使用有一个很好的认识。
字典和列表具有以下共同特征:
- 两者都是可变的。
- 两者都是动态的。它们可以根据需要增长和收缩。
- 两者都可以嵌套。一个列表可以包含另一个列表。一个字典可以包含另一个字典。字典也可以包含列表,反之亦然。
字典与列表的主要区别在于元素的访问方式:
- 通过索引,列表元素通过它们在列表中的位置被访问。
- 字典元素是通过键访问的。
参加测验:通过我们的交互式“Python 字典”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
定义字典
字典是 Python 对一种数据结构的实现,这种数据结构通常被称为关联数组。字典由一组键值对组成。每个键-值对都将键映射到其关联的值。
您可以通过用大括号(
{})括起一个逗号分隔的键值对列表来定义一个字典。冒号(:)将每个键与其相关值分开:d = { <key>: <value>, <key>: <value>, . . . <key>: <value> }下面定义了一个字典,该字典将一个位置映射到其对应的大联盟棒球队的名称:
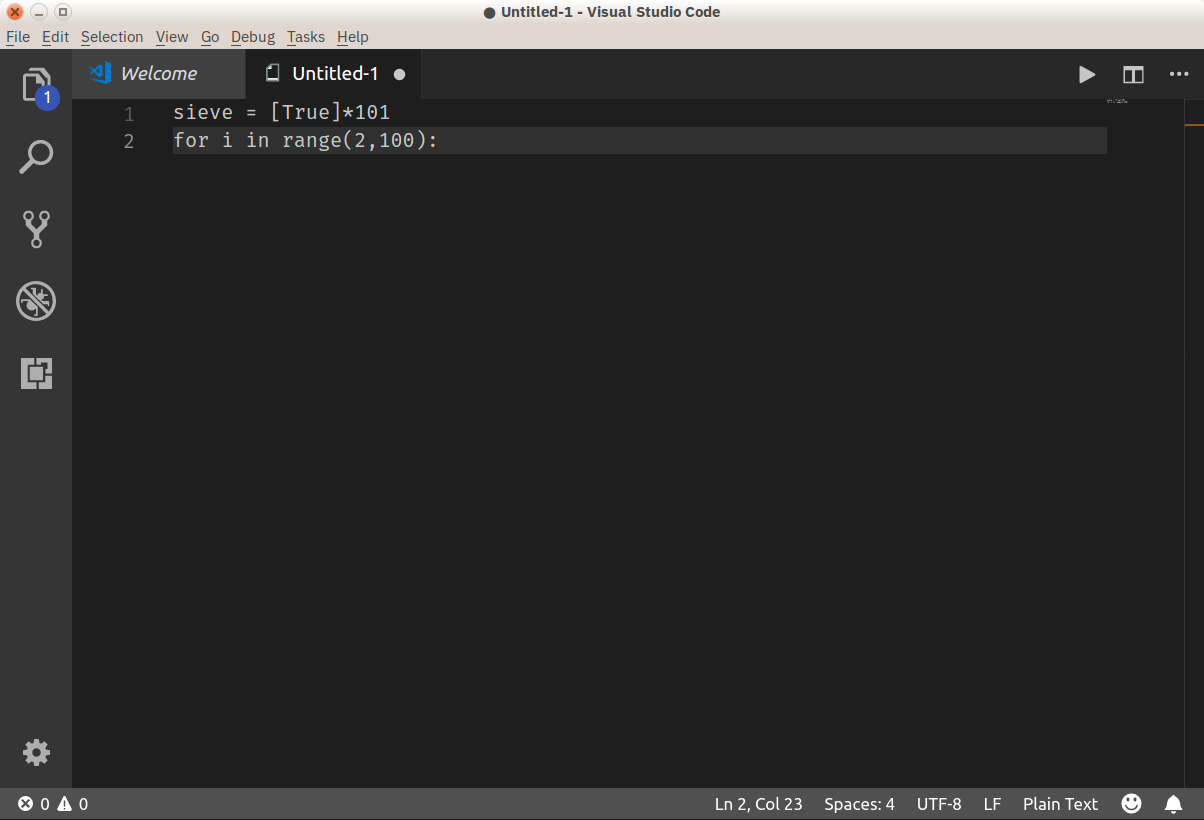
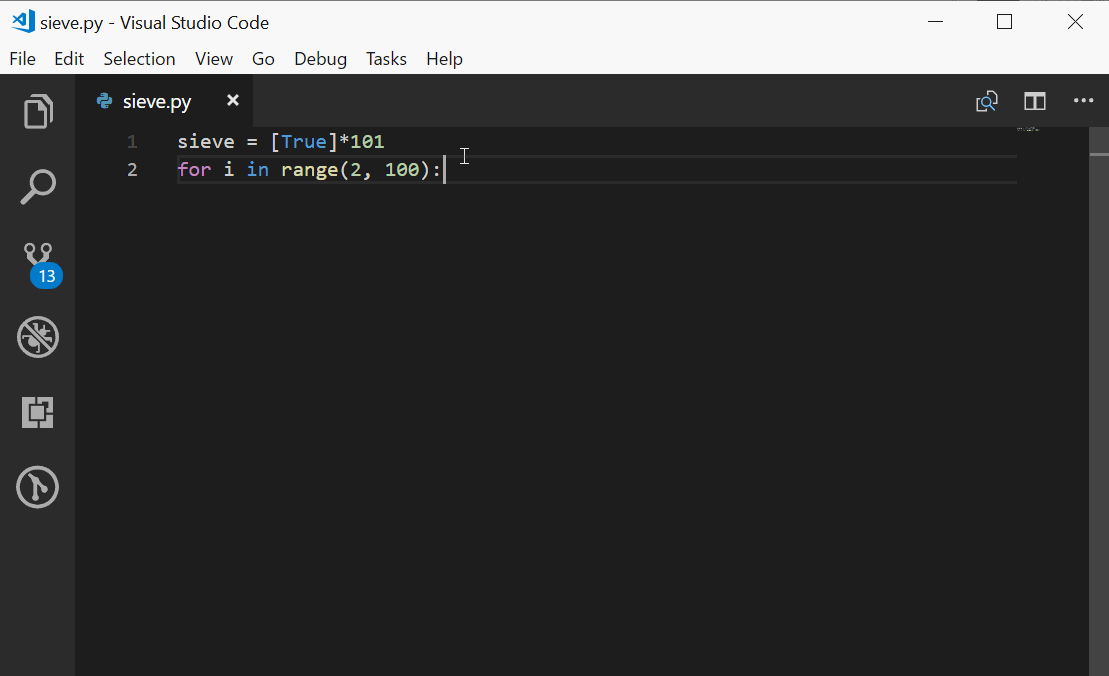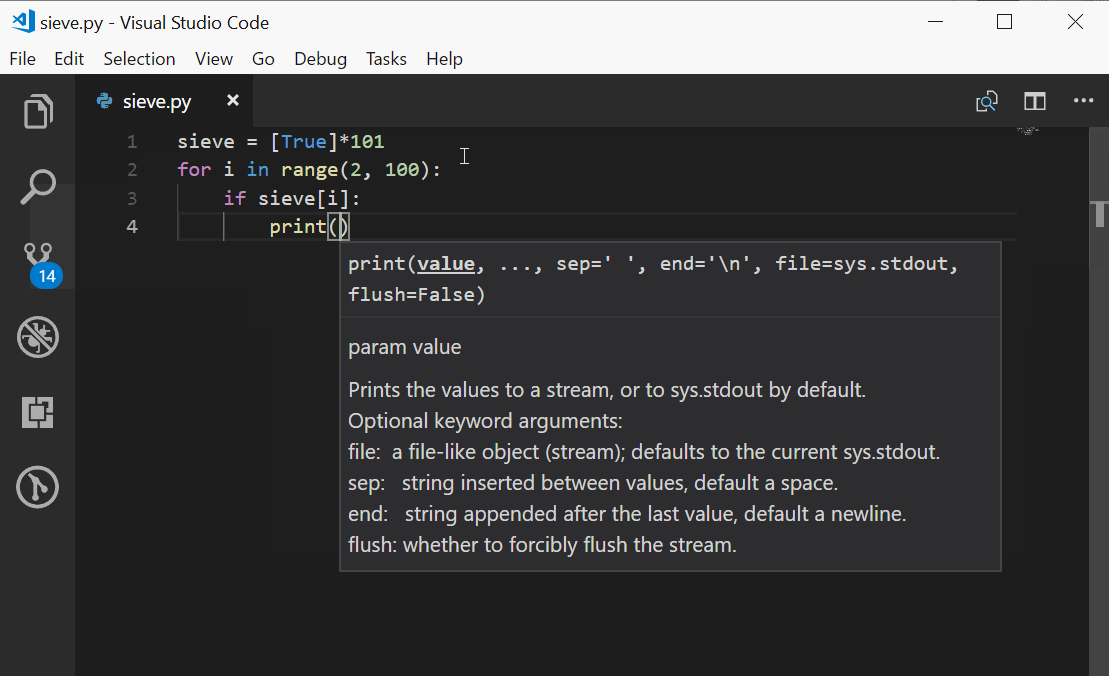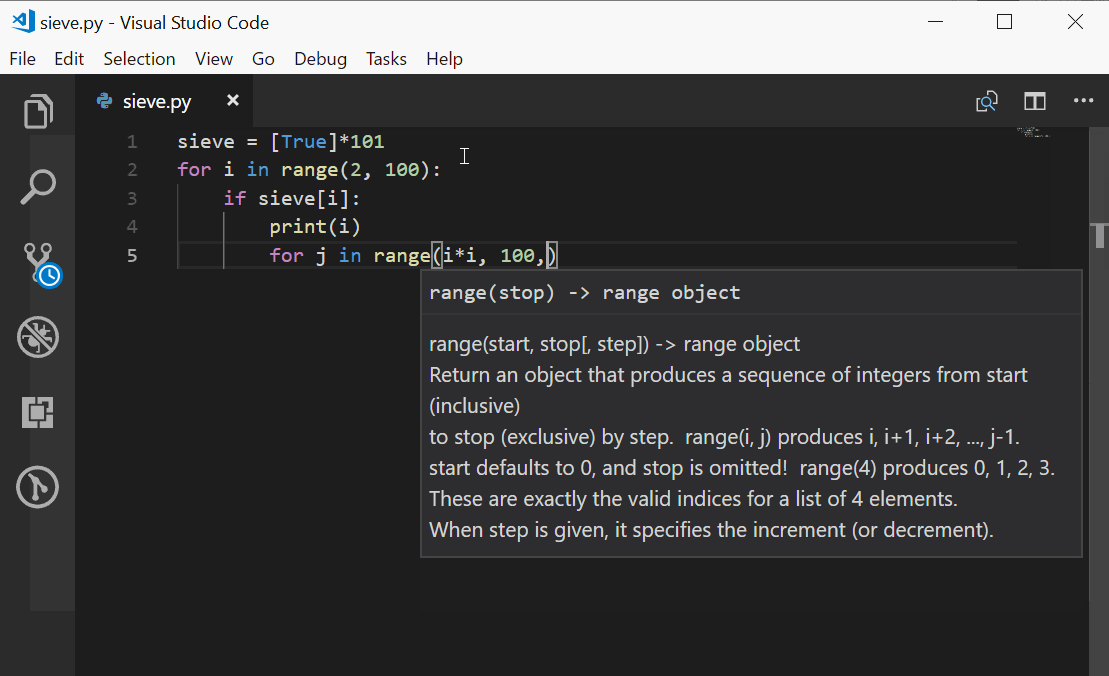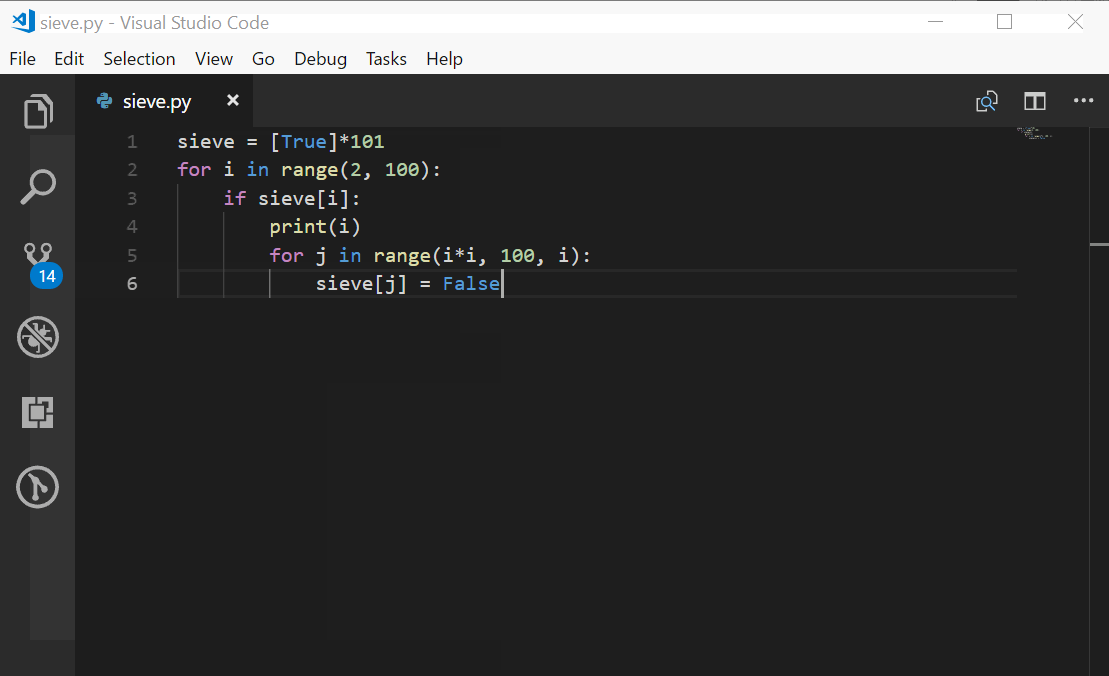
>>> MLB_team = {
... 'Colorado' : 'Rockies',
... 'Boston' : 'Red Sox',
... 'Minnesota': 'Twins',
... 'Milwaukee': 'Brewers',
... 'Seattle' : 'Mariners'
... }
还可以用内置的dict()函数构造一个字典。dict()的参数应该是一系列键值对。元组列表很适合这种情况:
d = dict([
(<key>, <value>),
(<key>, <value),
.
.
.
(<key>, <value>)
])
MLB_team也可以这样定义:
>>> MLB_team = dict([ ... ('Colorado', 'Rockies'), ... ('Boston', 'Red Sox'), ... ('Minnesota', 'Twins'), ... ('Milwaukee', 'Brewers'), ... ('Seattle', 'Mariners') ... ])如果键值是简单的字符串,它们可以被指定为关键字参数。所以这里还有另一种定义
MLB_team的方式:
>>> MLB_team = dict(
... Colorado='Rockies',
... Boston='Red Sox',
... Minnesota='Twins',
... Milwaukee='Brewers',
... Seattle='Mariners'
... )
一旦定义了字典,就可以显示它的内容,就像对列表一样。显示时,上面显示的所有三个定义如下所示:
>>> type(MLB_team) <class 'dict'> >>> MLB_team {'Colorado': 'Rockies', 'Boston': 'Red Sox', 'Minnesota': 'Twins', 'Milwaukee': 'Brewers', 'Seattle': 'Mariners'}字典中的条目按照定义的顺序显示。但是,当涉及到检索它们时,这是无关紧要的。数字索引不能访问字典元素:
>>> MLB_team[1]
Traceback (most recent call last):
File "<pyshell#13>", line 1, in <module>
MLB_team[1]
KeyError: 1
也许你仍然喜欢整理你的字典。如果是这种情况,那么看看对 Python 字典排序的:值、键等等。
访问字典值
当然,字典元素必须以某种方式可访问。如果不是按索引获取,那怎么获取呢?
通过在方括号([])中指定相应的键,从字典中检索值:
>>> MLB_team['Minnesota'] 'Twins' >>> MLB_team['Colorado'] 'Rockies'如果引用字典中没有的键,Python 会引发一个异常:
>>> MLB_team['Toronto']
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
MLB_team['Toronto']
KeyError: 'Toronto'
将一个条目添加到现有的字典中只是分配一个新的键和值:
>>> MLB_team['Kansas City'] = 'Royals' >>> MLB_team {'Colorado': 'Rockies', 'Boston': 'Red Sox', 'Minnesota': 'Twins', 'Milwaukee': 'Brewers', 'Seattle': 'Mariners', 'Kansas City': 'Royals'}如果您想更新一个条目,只需为现有的键分配一个新值:
>>> MLB_team['Seattle'] = 'Seahawks'
>>> MLB_team
{'Colorado': 'Rockies', 'Boston': 'Red Sox', 'Minnesota': 'Twins',
'Milwaukee': 'Brewers', 'Seattle': 'Seahawks', 'Kansas City': 'Royals'}
要删除一个条目,使用del语句,指定要删除的键:
>>> del MLB_team['Seattle'] >>> MLB_team {'Colorado': 'Rockies', 'Boston': 'Red Sox', 'Minnesota': 'Twins', 'Milwaukee': 'Brewers', 'Kansas City': 'Royals'}走开,海鹰!你是一支 NFL 球队。
字典键与列表索引
您可能已经注意到,当使用未定义的键或数字索引访问字典时,解释器会引发相同的异常,
KeyError:
>>> MLB_team['Toronto']
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
MLB_team['Toronto']
KeyError: 'Toronto'
>>> MLB_team[1]
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
MLB_team[1]
KeyError: 1
其实也是同样的错误。在后一种情况下,[1]看起来像一个数字索引,但它不是。
在本教程的后面,您将看到任何不可变类型的对象都可以用作字典键。因此,没有理由不能使用整数:
>>> d = {0: 'a', 1: 'b', 2: 'c', 3: 'd'} >>> d {0: 'a', 1: 'b', 2: 'c', 3: 'd'} >>> d[0] 'a' >>> d[2] 'c'在表达式
MLB_team[1]、d[0]和d[2]中,方括号中的数字看起来好像是索引。但它们与词典中条目的顺序无关。Python 将它们解释为字典键。如果您以相反的顺序定义相同的字典,您仍然可以使用相同的键获得相同的值:
>>> d = {3: 'd', 2: 'c', 1: 'b', 0: 'a'}
>>> d
{3: 'd', 2: 'c', 1: 'b', 0: 'a'}
>>> d[0]
'a'
>>> d[2]
'c'
语法可能看起来很相似,但是你不能把字典当成一个列表:
>>> type(d) <class 'dict'> >>> d[-1] Traceback (most recent call last): File "<pyshell#30>", line 1, in <module> d[-1] KeyError: -1 >>> d[0:2] Traceback (most recent call last): File "<pyshell#31>", line 1, in <module> d[0:2] TypeError: unhashable type: 'slice' >>> d.append('e') Traceback (most recent call last): File "<pyshell#32>", line 1, in <module> d.append('e') AttributeError: 'dict' object has no attribute 'append'注意:虽然对字典中条目的访问不依赖于顺序,但是 Python 确实保证了字典中条目的顺序被保留。当显示时,项目将按照它们被定义的顺序出现,并且通过键的迭代也将按照该顺序发生。添加到词典中的条目被添加到末尾。如果删除了项目,则保留其余项目的顺序。
你只能指望最近这种秩序的维护。它是作为 Python 语言规范的一部分添加到 3.7 版本的。然而,在 3.6 版本中也是如此——这是实现的偶然结果,但语言规范并不保证。
逐步建立字典
如上所示,如果您事先知道所有的键和值,那么使用花括号和一系列键-值对定义一个字典是很好的。但是,如果你想在飞行中建立一个字典呢?
您可以从创建一个空字典开始,它由空花括号指定。然后,您可以一次添加一个新的键和值:
>>> person = {}
>>> type(person)
<class 'dict'>
>>> person['fname'] = 'Joe'
>>> person['lname'] = 'Fonebone'
>>> person['age'] = 51
>>> person['spouse'] = 'Edna'
>>> person['children'] = ['Ralph', 'Betty', 'Joey']
>>> person['pets'] = {'dog': 'Fido', 'cat': 'Sox'}
一旦以这种方式创建了字典,就可以像访问任何其他字典一样访问它的值:
>>> person {'fname': 'Joe', 'lname': 'Fonebone', 'age': 51, 'spouse': 'Edna', 'children': ['Ralph', 'Betty', 'Joey'], 'pets': {'dog': 'Fido', 'cat': 'Sox'}} >>> person['fname'] 'Joe' >>> person['age'] 51 >>> person['children'] ['Ralph', 'Betty', 'Joey']检索子列表或子字典中的值需要额外的索引或键:
>>> person['children'][-1]
'Joey'
>>> person['pets']['cat']
'Sox'
这个例子展示了字典的另一个特性:字典中包含的值不需要是相同的类型。在person中,有些值是字符串,一个是整数,一个是列表,一个是另一个字典。
正如字典中的值不需要属于同一类型,键也不需要:
>>> foo = {42: 'aaa', 2.78: 'bbb', True: 'ccc'} >>> foo {42: 'aaa', 2.78: 'bbb', True: 'ccc'} >>> foo[42] 'aaa' >>> foo[2.78] 'bbb' >>> foo[True] 'ccc'这里,一个键是整数,一个是浮点数,一个是布尔。不清楚这将如何有用,但你永远不知道。
注意 Python 字典是多么的通用。在
MLB_team中,为几个不同地理位置中的每一个保存相同的信息(棒球队名称)。另一方面,person为一个人存储不同类型的数据。您可以将字典用于多种用途,因为对允许的键和值的限制很少。但是有一些。请继续阅读!
对字典键的限制
在 Python 中,几乎任何类型的值都可以用作字典键。您刚刚看到了这个例子,其中整数、浮点和布尔对象被用作键:
>>> foo = {42: 'aaa', 2.78: 'bbb', True: 'ccc'}
>>> foo
{42: 'aaa', 2.78: 'bbb', True: 'ccc'}
您甚至可以使用内置对象,如类型和函数:
>>> d = {int: 1, float: 2, bool: 3} >>> d {<class 'int'>: 1, <class 'float'>: 2, <class 'bool'>: 3} >>> d[float] 2 >>> d = {bin: 1, hex: 2, oct: 3} >>> d[oct] 3但是,字典键必须遵守一些限制。
首先,给定的键在字典中只能出现一次。不允许重复的密钥。字典将每个键映射到一个对应的值,因此多次映射一个特定的键没有意义。
从上面可以看出,当您为一个已经存在的字典键赋值时,它不会再次添加该键,而是替换现有的值:
>>> MLB_team = {
... 'Colorado' : 'Rockies',
... 'Boston' : 'Red Sox',
... 'Minnesota': 'Twins',
... 'Milwaukee': 'Brewers',
... 'Seattle' : 'Mariners'
... }
>>> MLB_team['Minnesota'] = 'Timberwolves'
>>> MLB_team
{'Colorado': 'Rockies', 'Boston': 'Red Sox', 'Minnesota': 'Timberwolves',
'Milwaukee': 'Brewers', 'Seattle': 'Mariners'}
同样,如果在字典的初始创建过程中第二次指定一个键,第二次出现的键将覆盖第一次出现的键:
>>> MLB_team = { ... 'Colorado' : 'Rockies', ... 'Boston' : 'Red Sox', ... 'Minnesota': 'Timberwolves', ... 'Milwaukee': 'Brewers', ... 'Seattle' : 'Mariners', ... 'Minnesota': 'Twins' ... } >>> MLB_team {'Colorado': 'Rockies', 'Boston': 'Red Sox', 'Minnesota': 'Twins', 'Milwaukee': 'Brewers', 'Seattle': 'Mariners'}滚吧,森林狼!你是一支 NBA 球队。算是吧。
其次,字典键必须是不可变的类型。您已经看到了一些例子,在这些例子中,您所熟悉的几种不可变类型——整型、浮点型、字符串型和布尔型——被用作字典键。
元组也可以是字典键,因为元组是不可变的:
>>> d = {(1, 1): 'a', (1, 2): 'b', (2, 1): 'c', (2, 2): 'd'}
>>> d[(1,1)]
'a'
>>> d[(2,1)]
'c'
(回想一下关于元组的讨论,使用元组而不是列表的一个基本原理是存在需要不可变类型的情况。这是其中之一。)
但是,列表和另一个字典都不能作为字典键,因为列表和字典是可变的:
>>> d = {[1, 1]: 'a', [1, 2]: 'b', [2, 1]: 'c', [2, 2]: 'd'} Traceback (most recent call last): File "<pyshell#20>", line 1, in <module> d = {[1, 1]: 'a', [1, 2]: 'b', [2, 1]: 'c', [2, 2]: 'd'} TypeError: unhashable type: 'list'技术说明:为什么错误信息说“不可修”?
从技术上讲,说一个对象必须是不可变的才能用作字典键是不太正确的。更准确地说,一个对象必须是 hashable ,这意味着它可以被传递给一个散列函数。一个散列函数获取任意大小的数据,并将其映射到一个相对简单的固定大小的值,称为散列值(或简称为 hash),用于表查找和比较。
Python 的内置
hash()函数返回可散列对象的散列值,并为不可散列对象引发异常:
>>> hash('foo')
11132615637596761
>>> hash([1, 2, 3])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
到目前为止,您已经了解的所有内置不可变类型都是可哈希的,而可变容器类型(列表和字典)则不是。因此,就目前的目的而言,你可以认为 hashable 和 immutable 差不多是同义词。
在以后的教程中,你会遇到可变的对象,它们也是可散列的。
对字典值的限制
相比之下,对字典值没有限制。实际上一点也没有。字典值可以是 Python 支持的任何类型的对象,包括可变类型,如列表和字典,以及用户定义的对象,您将在接下来的教程中了解这些内容。
对于特定值在字典中多次出现也没有限制:
>>> d = {0: 'a', 1: 'a', 2: 'a', 3: 'a'} >>> d {0: 'a', 1: 'a', 2: 'a', 3: 'a'} >>> d[0] == d[1] == d[2] True运算符和内置函数
您已经熟悉了许多可用于字符串、列表和元组的操作符和内置函数。其中一些也适用于字典。
例如,
in和not in运算符根据指定的操作数在字典中是否作为关键字出现,返回True或False:
>>> MLB_team = {
... 'Colorado' : 'Rockies',
... 'Boston' : 'Red Sox',
... 'Minnesota': 'Twins',
... 'Milwaukee': 'Brewers',
... 'Seattle' : 'Mariners'
... }
>>> 'Milwaukee' in MLB_team
True
>>> 'Toronto' in MLB_team
False
>>> 'Toronto' not in MLB_team
True
当试图访问一个不在字典中的键时,可以使用in操作符和短路评估来避免产生错误:
>>> MLB_team['Toronto'] Traceback (most recent call last): File "<pyshell#2>", line 1, in <module> MLB_team['Toronto'] KeyError: 'Toronto' >>> 'Toronto' in MLB_team and MLB_team['Toronto'] False第二种情况,由于短路求值,表达式
MLB_team['Toronto']不求值,所以KeyError异常不会发生。
len()函数返回字典中键值对的数量:
>>> MLB_team = {
... 'Colorado' : 'Rockies',
... 'Boston' : 'Red Sox',
... 'Minnesota': 'Twins',
... 'Milwaukee': 'Brewers',
... 'Seattle' : 'Mariners'
... }
>>> len(MLB_team)
5
内置字典方法
与字符串和列表一样,有几个可以在字典上调用的内置方法。事实上,在某些情况下,list 和 dictionary 方法共享相同的名称。(在关于面向对象编程的讨论中,您将看到不同类型拥有相同名称的方法是完全可以接受的。)
以下是适用于词典的方法概述:
d.clear()
清除字典。
d.clear()清空字典d中的所有键值对:
>>> d = {'a': 10, 'b': 20, 'c': 30} >>> d {'a': 10, 'b': 20, 'c': 30} >>> d.clear() >>> d {}
d.get(<key>[, <default>])如果字典中存在某个键值,则返回该键值。
Python dictionary
.get()方法提供了一种从字典中获取键值的便捷方式,无需提前检查键是否存在,也不会引发错误。
d.get(<key>)在字典d中搜索<key>,如果找到则返回相关值。如果没有找到<key>,则返回None:
>>> d = {'a': 10, 'b': 20, 'c': 30}
>>> print(d.get('b'))
20
>>> print(d.get('z'))
None
如果没有找到<key>并且指定了可选的<default>参数,则返回该值而不是None:
>>> print(d.get('z', -1)) -1
d.items()返回字典中的键值对列表。
d.items()返回包含d中键值对的元组列表。每个元组中的第一项是键,第二项是键值:
>>> d = {'a': 10, 'b': 20, 'c': 30}
>>> d
{'a': 10, 'b': 20, 'c': 30}
>>> list(d.items())
[('a', 10), ('b', 20), ('c', 30)]
>>> list(d.items())[1][0]
'b'
>>> list(d.items())[1][1]
20
d.keys()
返回字典中的键列表。
d.keys()返回d中所有键的列表:
>>> d = {'a': 10, 'b': 20, 'c': 30} >>> d {'a': 10, 'b': 20, 'c': 30} >>> list(d.keys()) ['a', 'b', 'c']
d.values()返回字典中的值列表。
d.values()返回d中所有值的列表:
>>> d = {'a': 10, 'b': 20, 'c': 30}
>>> d
{'a': 10, 'b': 20, 'c': 30}
>>> list(d.values())
[10, 20, 30]
d中的任何重复值都将按照出现的次数返回:
>>> d = {'a': 10, 'b': 10, 'c': 10} >>> d {'a': 10, 'b': 10, 'c': 10} >>> list(d.values()) [10, 10, 10]技术提示:
.items()、.keys()和.values()方法实际上返回了一个叫做视图对象的东西。字典视图对象或多或少类似于键和值的窗口。出于实用目的,您可以将这些方法视为返回字典的键和值的列表。
d.pop(<key>[, <default>])从字典中移除一个键(如果存在),并返回它的值。
如果
d中存在<key>,d.pop(<key>)移除<key>并返回其相关值:
>>> d = {'a': 10, 'b': 20, 'c': 30}
>>> d.pop('b')
20
>>> d
{'a': 10, 'c': 30}
如果<key>不在d中,则d.pop(<key>)引发KeyError异常:
>>> d = {'a': 10, 'b': 20, 'c': 30} >>> d.pop('z') Traceback (most recent call last): File "<pyshell#4>", line 1, in <module> d.pop('z') KeyError: 'z'如果
<key>不在d中,并且指定了可选的<default>参数,则返回该值,并且不引发异常:
>>> d = {'a': 10, 'b': 20, 'c': 30}
>>> d.pop('z', -1)
-1
>>> d
{'a': 10, 'b': 20, 'c': 30}
d.popitem()
从字典中移除键值对。
d.popitem()删除从d添加的最后一个键-值对,并将其作为元组返回:
>>> d = {'a': 10, 'b': 20, 'c': 30} >>> d.popitem() ('c', 30) >>> d {'a': 10, 'b': 20} >>> d.popitem() ('b', 20) >>> d {'a': 10}如果
d为空,d.popitem()会引发KeyError异常:
>>> d = {}
>>> d.popitem()
Traceback (most recent call last):
File "<pyshell#11>", line 1, in <module>
d.popitem()
KeyError: 'popitem(): dictionary is empty'
注意:在低于 3.6 的 Python 版本中,popitem()将返回一个任意(随机)的键值对,因为 Python 字典在 3.6 版本之前是无序的。
d.update(<obj>)
将一个字典与另一个字典或键值对的 iterable 合并。
如果<obj>是字典,d.update(<obj>)将<obj>中的条目合并到d中。对于<obj>中的每个键:
- 如果键不在
d中,来自<obj>的键-值对被添加到d。 - 如果密钥已经存在于
d中,则该密钥在d中的相应值被更新为来自<obj>的值。
以下示例显示了两个字典合并在一起的情况:
>>> d1 = {'a': 10, 'b': 20, 'c': 30} >>> d2 = {'b': 200, 'd': 400} >>> d1.update(d2) >>> d1 {'a': 10, 'b': 200, 'c': 30, 'd': 400}在这个例子中,键
'b'已经存在于d1中,所以它的值被更新为200,即来自d2的那个键的值。但是d1中没有键'd',所以从d2开始添加键-值对。
<obj>也可以是一系列的键值对,类似于使用dict()函数定义字典。例如,<obj>可以被指定为元组列表:
>>> d1 = {'a': 10, 'b': 20, 'c': 30}
>>> d1.update([('b', 200), ('d', 400)])
>>> d1
{'a': 10, 'b': 200, 'c': 30, 'd': 400}
或者,要合并的值可以指定为关键字参数列表:
>>> d1 = {'a': 10, 'b': 20, 'c': 30} >>> d1.update(b=200, d=400) >>> d1 {'a': 10, 'b': 200, 'c': 30, 'd': 400}结论
在本教程中,您了解了 Python 字典的基本属性,并学习了如何访问和操作字典数据。
列表和字典是最常用的两种 Python 类型。正如您所看到的,它们有几个相似之处,但是在元素的访问方式上有所不同。列表元素通过基于顺序的数字索引来访问,字典元素通过键来访问
由于这种差异,列表和字典往往适合不同的环境。你现在应该有一个很好的感觉,如果有的话,对于一个给定的情况是最好的。
接下来,您将了解 Python 集合。集合是另一种复合数据类型,但它与列表或字典有很大不同。
参加测验:通过我们的交互式“Python 字典”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Lists and Tuples in PythonDictionaries in PythonSets in Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的字典*********
使用 Django、Vue 和 GraphQL 创建一个博客
你经常使用 Django 吗?你有没有发现自己想要将后端和前端解耦?您是否希望在 API 中处理数据持久性,同时使用 React 或 Vue 等客户端框架在浏览器中的单页应用程序(SPA)中显示数据?你很幸运。本教程将带你完成构建 Django 博客后端和前端的过程,使用 GraphQL 在它们之间进行通信。
项目是学习和巩固概念的有效途径。本教程是一个循序渐进的项目,因此您可以通过实践的方式进行学习,并根据需要进行休息。
在本教程中,您将学习如何:
- 将你的 Django 模型转换成 GraphQL API
- 在你的电脑上同时运行 Django 服务器和 Vue 应用
- 在 Django admin 中管理您的博客文章
- 在 Vue 中使用 graph QL API在浏览器中显示数据
您可以点击下面的链接,下载所有用于构建 Django 博客应用程序的源代码:
获取源代码: 单击此处获取源代码,您将在本教程中使用用 Django、Vue 和 GraphQL 构建一个博客应用程序。
演示:一个 Django 博客管理员,一个 GraphQL API 和一个 Vue 前端
博客应用程序是一个常见的入门项目,因为它们涉及创建、读取、更新和删除(CRUD)操作。在这个项目中,您将使用 Django admin 来完成繁重的 CRUD 提升工作,并专注于为您的博客数据提供 GraphQL API。
这是一个完整项目的实际演示:
https://player.vimeo.com/video/540329665?background=1
接下来,在开始构建您的博客应用程序之前,您将确保您拥有所有必要的背景信息和工具。
项目概述
您将创建一个具有一些基本功能的小型博客应用程序。作者可以写很多帖子。帖子可以有许多标签,可以是已发布的,也可以是未发布的。
您将在 Django 中构建这个博客的后端,并配备一名管理员来添加新的博客内容。然后将内容数据作为 GraphQL API 公开,并使用 Vue 在浏览器中显示这些数据。您将通过几个高级步骤来实现这一点:
- 建立 Django 博客
- 创建 Django 博客管理员
- 建立石墨烯-Django
- 设置
django-cors-headers- 设置 vue . js
- 设置 Vue 路由器
- 创建 Vue 组件
- 获取数据
每个部分都将提供任何必要资源的链接,并给你一个暂停并根据需要返回的机会。
先决条件
如果您已经对一些 web 应用程序概念有了坚实的基础,那么您将最适合学习本教程。你应该明白 HTTP 请求和响应以及 API 是如何工作的。您可以查看Python&API:读取公共数据的成功组合,以了解使用 GraphQL APIs 与 REST APIs 的细节。
因为您将使用 Django 为您的博客构建后端,所以您将希望熟悉开始 Django 项目的和定制 Django 管理的和。如果您以前没有怎么使用过 Django,您可能还想先尝试构建另一个仅支持 Django 的项目。要获得好的介绍,请查看Django 入门第 1 部分:构建投资组合应用。
因为您将在前端使用 Vue,所以一些关于 reactive JavaScript 的经验也会有所帮助。如果你过去只在类似于 jQuery 的框架中使用过 DOM 操作范例,那么 Vue 简介是一个很好的基础。
熟悉 JSON 也很重要,因为 GraphQL 查询类似于 JSON,并以 JSON 格式返回数据。你可以阅读关于在 Python 中使用 JSON 数据的作为介绍。你还需要安装 Node.js 在本教程后面的前端工作。
第一步:建立 Django 博客
在深入之前,您需要一个目录,在其中您可以组织项目的代码。首先创建一个名为
dvg/的,是 Django-Vue-GraphQL 的缩写:$ mkdir dvg/ $ cd dvg/您还将完全分离前端和后端代码,因此立即开始创建这种分离是个好主意。在您的项目目录中创建一个
backend/目录:$ mkdir backend/ $ cd backend/您将把您的 Django 代码放在这个目录中,与您将在本教程后面创建的 Vue 代码完全隔离。
安装 Django
现在您已经准备好开始构建 Django 应用程序了。为了将这个项目与其他项目的依赖项分开,创建一个虚拟环境,在其中安装项目的需求。你可以在 Python 虚拟环境:初级读本中阅读更多关于虚拟环境的内容。本教程的其余部分假设您将在活动的虚拟环境中运行与 Python 和 Django 相关的命令。
现在您已经有了一个安装需求的虚拟环境,在
backend/目录中创建一个requirements.txt文件,并定义您需要的第一个需求:Django==3.1.7一旦保存了
requirements.txt文件,就用它来安装 Django:(venv) $ python -m pip install -r requirements.txt现在您可以开始创建您的 Django 项目了。
创建 Django 项目
现在 Django 已经安装好了,使用
django-admin命令初始化您的 Django 项目:(venv) $ django-admin startproject backend .这将在
backend/目录中创建一个manage.py模块和一个backend包,因此您的项目目录结构应该如下所示:dvg └── backend ├── manage.py ├── requirements.txt └── backend ├── __init__.py ├── asgi.py ├── settings.py ├── urls.py └── wsgi.py本教程不会涵盖或需要所有这些文件,但它不会伤害他们的存在。
运行 Django 迁移
在向您的应用程序添加任何特定的东西之前,您还应该运行 Django 的初始迁移。如果你以前没有处理过迁移,那么看看 Django 迁移:初级读本。使用
migrate管理命令运行迁移:(venv) $ python manage.py migrate您应该会看到一个很长的迁移列表,每个后面都有一个
OK:Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying auth.0012_alter_user_first_name_max_length... OK Applying sessions.0001_initial... OK这将创建一个名为
db.sqlite3的 SQLite 数据库文件,该文件也将存储项目的其余数据。创建超级用户
现在你有了数据库,你可以创建一个超级用户。您将需要这个用户,这样您最终可以登录到 Django 管理界面。使用
createsuperuser管理命令创建一个:(venv) $ python manage.py createsuperuser在下一节中,您将能够使用在这一步中提供的用户名和密码登录 Django admin。
第一步总结
现在您已经安装了 Django,创建了 Django 项目,运行了 Django 迁移,并创建了一个超级用户,您就有了一个功能完整的 Django 应用程序。现在,您应该能够启动 Django 开发服务器,并在浏览器中查看它。使用
runserver管理命令启动服务器,默认情况下它将监听端口8000:(venv) $ python manage.py runserver现在在浏览器中访问
http://localhost:8000。您应该看到 Django 启动页面,表明安装成功。您还应该能够访问http://localhost:8000/admin,在那里您会看到一个登录表单。使用您为超级用户创建的用户名和密码登录 Django admin。如果一切正常,那么你将被带到 Django 管理仪表板页面。这个页面目前还很空,但是在下一步中你会让它变得更有趣。
步骤 2:创建 Django 博客管理员
现在您已经有了 Django 项目的基础,可以开始为您的博客创建一些核心业务逻辑了。在这一步中,您将创建用于创作和管理博客内容的数据模型和管理配置。
创建 Django 博客应用程序
请记住,一个 Django 项目可以包含许多 Django 应用程序。您应该将特定于博客的行为分离到它自己的 Django 应用程序中,以便它与您将来构建到项目中的任何应用程序保持区别。使用
startapp管理命令创建应用程序:(venv) $ python manage.py startapp blog这将创建一个包含几个框架文件的
blog/目录:blog ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.py在本教程的后面部分,您将对其中一些文件进行更改和添加。
启用 Django 博客应用程序
默认情况下,创建 Django 应用程序不会使它在您的项目中可用。为了确保项目知道您的新
blog应用程序,您需要将它添加到已安装应用程序的列表中。更新backend/settings.py中的INSTALLED_APPS变量:INSTALLED_APPS = [ ... "blog", ]这将有助于 Django 发现关于您的应用程序的信息,比如它包含的数据模型和 URL 模式。
创建 Django 博客数据模型
既然 Django 可以发现您的
blog应用程序,您就可以创建数据模型了。首先,您将创建三个模型:
Profile存储博客用户的附加信息。Tag代表博客帖子可以分组的类别。Post存储每篇博文的内容和元数据。您将把这些型号添加到
blog/models.py中。首先,导入 Django 的django.db.models模块:from django.db import models你的每个模型都将从
models.Model类继承。
Profile型号
Profile模型将有几个字段:
user是与配置文件关联的 Django 用户的一对一关联。website是一个可选的网址,您可以在这里了解有关用户的更多信息。bio是一个可选的、推文大小的广告,用于快速了解用户的更多信息。首先需要从 Django 导入
settings模块:from django.conf import settings然后创建
Profile模型,它应该类似于下面的代码片段:class Profile(models.Model): user = models.OneToOneField( settings.AUTH_USER_MODEL, on_delete=models.PROTECT, ) website = models.URLField(blank=True) bio = models.CharField(max_length=240, blank=True) def __str__(self): return self.user.get_username()
__str__方法将使您创建的Profile对象以更加人性化的方式出现在管理站点上。
Tag型号
Tag模型只有一个字段name,它为标签存储一个简短的、惟一的名称。创建Tag模型,它应该类似于下面的代码片段:class Tag(models.Model): name = models.CharField(max_length=50, unique=True) def __str__(self): return self.name同样,
__str__将使您创建的Tag对象以更加人性化的方式出现在管理站点上。
Post型号如你所想,模型是最复杂的。它将有几个字段:
字段名 目的 title向读者显示的文章的唯一标题 subtitle帖子内容的可选澄清器,帮助读者了解他们是否想阅读 slug帖子在 URL 中使用的唯一可读标识符 body帖子的内容 meta_description用于 Google 等搜索引擎的可选描述 date_created帖子创建的时间戳 date_modified帖子最近一次编辑的时间戳 publish_date帖子发布时的可选时间戳 published文章当前是否对读者可用 author对撰写帖子的用户个人资料的引用 tags与帖子相关联的标签列表(如果有) 因为博客通常首先显示最近的帖子,所以您也希望
ordering按照发布日期显示,最近的放在最前面。创建Post模型,它应该类似于下面的代码片段:class Post(models.Model): class Meta: ordering = ["-publish_date"] title = models.CharField(max_length=255, unique=True) subtitle = models.CharField(max_length=255, blank=True) slug = models.SlugField(max_length=255, unique=True) body = models.TextField() meta_description = models.CharField(max_length=150, blank=True) date_created = models.DateTimeField(auto_now_add=True) date_modified = models.DateTimeField(auto_now=True) publish_date = models.DateTimeField(blank=True, null=True) published = models.BooleanField(default=False) author = models.ForeignKey(Profile, on_delete=models.PROTECT) tags = models.ManyToManyField(Tag, blank=True)
author的on_delete=models.PROTECT参数确保您不会意外删除仍在博客上发表文章的作者。与Tag的ManyToManyField关系允许您将一篇文章与零个或多个标签相关联。每个标签可以关联到许多文章。创建模型管理配置
现在模型已经准备好了,您需要告诉 Django 它们应该如何在管理界面中显示。在
blog/admin.py中,首先导入 Django 的admin模块和您的模型:from django.contrib import admin from blog.models import Profile, Post, Tag然后为
Profile和Tag创建并注册管理类,它们只需要指定的model:@admin.register(Profile) class ProfileAdmin(admin.ModelAdmin): model = Profile @admin.register(Tag) class TagAdmin(admin.ModelAdmin): model = Tag就像模型一样,
Post的管理类更加复杂。帖子包含大量信息,因此更明智地选择显示哪些信息有助于避免界面拥挤。在所有帖子的列表中,您将指定 Django 应该只显示每个帖子的以下信息:
- 身份证明
- 标题
- 小标题
- 鼻涕虫
- 出版日期
- 发布状态
为了使浏览和编辑帖子更加流畅,您还将告诉 Django 管理系统采取以下操作:
- 允许按已发布或未发布的帖子过滤帖子列表。
- 允许按发布日期过滤帖子。
- 允许编辑所有显示的字段,ID 除外。
- 允许使用标题、副标题、段落和正文搜索帖子。
- 使用标题和副标题字段预填充 slug 字段。
- 使用所有帖子的发布日期创建一个可浏览的日期层次结构。
- 在列表顶部显示按钮以保存更改。
创建并注册
PostAdmin类:@admin.register(Post) class PostAdmin(admin.ModelAdmin): model = Post list_display = ( "id", "title", "subtitle", "slug", "publish_date", "published", ) list_filter = ( "published", "publish_date", ) list_editable = ( "title", "subtitle", "slug", "publish_date", "published", ) search_fields = ( "title", "subtitle", "slug", "body", ) prepopulated_fields = { "slug": ( "title", "subtitle", ) } date_hierarchy = "publish_date" save_on_top = True你可以在用 Python 定制 Django 管理中阅读更多关于 Django 管理提供的所有选项。
创建模型迁移
Django 拥有管理和保存博客内容所需的所有信息,但是您首先需要更新数据库以支持这些更改。在本教程的前面,您运行了 Django 内置模型的迁移。现在,您将为您的模型创建并运行迁移。
首先,使用
makemigrations管理命令创建迁移:(venv) $ python manage.py makemigrations Migrations for 'blog': blog/migrations/0001_initial.py - Create model Tag - Create model Profile - Create model Post这将创建一个默认名称为
0001_initial.py的迁移。使用migrate管理命令运行该迁移:(venv) $ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, blog, contenttypes, sessions Running migrations: Applying blog.0001_initial... OK请注意,迁移名称后面应该有
OK。第二步总结
现在您已经准备好了所有的数据模型,并且已经配置了 Django admin,这样您就可以添加和编辑这些模型了。
启动或重启 Django 开发服务器,在
http://localhost:8000/admin访问管理界面,探索发生了什么变化。您应该会看到标签、个人资料和文章列表的链接,以及添加或编辑它们的链接。尝试添加和编辑其中的一些,看看管理界面是如何响应的。第三步:建立石墨烯-Django
在这一点上,你已经完成了足够的后端,你可以决定一头扎进 Django 方向。您可以使用 Django 的 URL 路由和模板引擎来构建页面,向读者显示您在 admin 中创建的所有帖子内容。相反,您将把自己创建的后端封装在 GraphQL API 中,以便最终可以从浏览器中使用它,并提供更丰富的客户端体验。
GraphQL 允许您只检索您需要的数据,与 RESTful APIs 中常见的非常大的响应相比,这是非常有用的。GraphQL 还在投影数据方面提供了更多的灵活性,因此您可以经常以新的方式检索数据,而无需更改提供 GraphQL API 的服务的逻辑。
您将使用 Graphene-Django 将您目前创建的内容集成到 GraphQL API 中。
安装石墨烯-Django
要开始使用 Graphene-Django,首先将其添加到项目的需求文件中:
graphene-django==2.14.0然后使用更新的需求文件安装它:
(venv) $ python -m pip install -r requirements.txt将
"graphene_django"添加到项目的settings.py模块的INSTALLED_APPS变量中,这样 Django 就会找到它:INSTALLED_APPS = [ ... "blog", "graphene_django", ]Graphene-Django 现在已经安装完毕,可以进行配置了。
配置石墨烯-Django
要让 Graphene-Django 在您的项目中工作,您需要配置几个部分:
- 更新
settings.py以便项目知道在哪里寻找 GraphQL 信息。- 添加一个 URL 模式来服务 GraphQL API 和 GraphQL 的可探索接口 GraphQL。
- 创建 Graphene-Django 的 GraphQL 模式,这样 Graphene-Django 就知道如何将您的模型转换成 GraphQL。
更新 Django 设置
GRAPHENE设置将 Graphene-Django 配置为在特定位置寻找 GraphQL 模式。将它指向blog.schema.schemaPython 路径,您将很快创建该路径:GRAPHENE = { "SCHEMA": "blog.schema.schema", }注意,这个添加可能会导致 Django 产生一个导入错误,您可以在创建 GraphQL 模式时解决这个错误。
为 GraphQL 和 graph QL 添加 URL 模式
为了让 Django 服务于 GraphQL 端点和 graph QL 接口,您将向
backend/urls.py添加一个新的 URL 模式。你会把网址指向 Graphene-Django 的GraphQLView。因为您没有使用 Django 模板引擎的跨站点请求伪造(CSRF) 保护特性,所以您还需要导入 Django 的csrf_exempt装饰器来将视图标记为免于 CSRF 保护:from django.views.decorators.csrf import csrf_exempt from graphene_django.views import GraphQLView然后,将新的 URL 模式添加到
urlpatterns变量中:urlpatterns = [ ... path("graphql", csrf_exempt(GraphQLView.as_view(graphiql=True))), ]
graphiql=True参数告诉 Graphene-Django 使 GraphiQL 接口可用。创建 GraphQL 模式
现在您将创建 GraphQL 模式,这应该与您之前创建的管理配置类似。该模式由几个类组成,每个类都与一个特定的 Django 模型相关联,还有一个类指定如何解决前端需要的一些重要类型的查询。
在
blog/目录下创建一个新的schema.py模块。导入 Graphene-Django 的DjangoObjectType,您的blog模型,以及 Django 的User模型:from django.contrib.auth import get_user_model from graphene_django import DjangoObjectType from blog import models为您的每个模型和
User模型创建一个相应的类。它们每个都应该有一个以Type结尾的名字,因为每个都代表一个 GraphQL 类型。您的类应该如下所示:class UserType(DjangoObjectType): class Meta: model = get_user_model() class AuthorType(DjangoObjectType): class Meta: model = models.Profile class PostType(DjangoObjectType): class Meta: model = models.Post class TagType(DjangoObjectType): class Meta: model = models.Tag您需要创建一个继承自
graphene.ObjectType的Query类。这个类将集合您创建的所有类型类,并且您将向它添加方法来指示您的模型可以被查询的方式。你需要先导入graphene:import graphene
Query类由许多属性组成,这些属性或者是graphene.List或者是graphene.Field。如果查询应该返回单个项目,您将使用graphene.Field,如果查询将返回多个项目,您将使用graphene.List。对于这些属性中的每一个,您还将创建一个方法来解析查询。通过获取查询中提供的信息并返回相应的 Django queryset 来解析查询。
每个解析器的方法必须以
resolve_开头,名称的其余部分应该匹配相应的属性。例如,为属性all_posts解析 queryset 的方法必须命名为resolve_all_posts。您将创建查询来获取:
- 所有的帖子
- 具有给定用户名的作者
- 具有给定 slug 的帖子
- 给定作者的所有帖子
- 带有给定标签的所有帖子
现在创建
Query类。它应该类似于下面的代码片段:class Query(graphene.ObjectType): all_posts = graphene.List(PostType) author_by_username = graphene.Field(AuthorType, username=graphene.String()) post_by_slug = graphene.Field(PostType, slug=graphene.String()) posts_by_author = graphene.List(PostType, username=graphene.String()) posts_by_tag = graphene.List(PostType, tag=graphene.String()) def resolve_all_posts(root, info): return ( models.Post.objects.prefetch_related("tags") .select_related("author") .all() ) def resolve_author_by_username(root, info, username): return models.Profile.objects.select_related("user").get( user__username=username ) def resolve_post_by_slug(root, info, slug): return ( models.Post.objects.prefetch_related("tags") .select_related("author") .get(slug=slug) ) def resolve_posts_by_author(root, info, username): return ( models.Post.objects.prefetch_related("tags") .select_related("author") .filter(author__user__username=username) ) def resolve_posts_by_tag(root, info, tag): return ( models.Post.objects.prefetch_related("tags") .select_related("author") .filter(tags__name__iexact=tag) )现在您已经拥有了模式的所有类型和解析器,但是请记住您创建的
GRAPHENE变量指向blog.schema.schema。创建一个schema变量,将您的Query类包装在graphene.Schema中,以便将它们联系在一起:schema = graphene.Schema(query=Query)该变量与您在本教程前面为 Graphene-Django 配置的
"blog.schema.schema"值相匹配。第三步总结
您已经充实了您的博客的数据模型,现在您还用 Graphene-Django 包装了您的数据模型,以将该数据作为 GraphQL API。
运行 Django 开发服务器并访问
http://localhost:8000/graphql。您应该看到 GraphiQL 界面,其中有一些解释如何使用该工具的注释文本。展开屏幕右上方的文档部分,点击查询:查询。您应该会看到您在模式中配置的每个查询和类型。
如果您还没有创建任何测试博客内容,现在就创建吧。尝试以下查询,它将返回您创建的所有帖子的列表:
{ allPosts { title subtitle author { user { username } } tags { name } } }响应应该返回一个帖子列表。每个帖子的结构应该与查询的形状相匹配,如下例所示:
{ "data": { "allPosts": [ { "title": "The Great Coney Island Debate", "subtitle": "American or Lafayette?", "author": { "user": { "username": "coney15land" } }, "tags": [ { "name": "food" }, { "name": "coney island" } ] } ] } }如果你保存了一些帖子,并在回复中看到了它们,那么你就准备好继续了。
第四步:设置
django-cors-headers您还需要再走一步才能称后端工作完成。因为后端和前端将在本地不同的端口上运行,并且因为它们可能在生产环境中完全不同的域上运行,跨源资源共享(CORS) 开始发挥作用。如果不处理 CORS,从前端到后端的请求通常会被您的浏览器阻止。
这个项目让与 CORS 打交道变得相当轻松。您将使用它来告诉 Django 响应来自其他来源的请求,这将允许前端与 GraphQL API 正确通信。
安装
django-cors-headers首先,将
django-cors-headers添加到您的需求文件中:django-cors-headers==3.6.0然后使用更新的需求文件安装它:
(venv) $ python -m pip install -r requirements.txt将
"corsheaders"添加到项目的settings.py模块的INSTALLED_APPS列表中:INSTALLED_APPS = [ ... "corsheaders", ]然后将
"corsheaders.middleware.CorsMiddleware"添加到MIDDLEWARE变量的末尾:MIDDLEWARE = [ "corsheaders.middleware.CorsMiddleware", ... ]
django-cors-headers文档建议将中间件尽可能早地放在MIDDLEWARE列表中。你可以把它放在这个项目列表的最顶端。配置
django-cors-headersCORS 的存在是有充分理由的。您不希望您的应用程序暴露在互联网上的任何地方。您可以使用两个设置来非常精确地定义您希望打开 GraphQL API 的程度:
CORS_ORIGIN_ALLOW_ALL定义 Django 默认是全开还是全关。CORS_ORIGIN_WHITELIST定义 Django 应用程序将允许哪些域的请求。将以下设置添加到
settings.py:CORS_ORIGIN_ALLOW_ALL = False CORS_ORIGIN_WHITELIST = ("http://localhost:8080",)这些设置将只允许来自前端的请求,您最终将在本地端口
8080上运行这些请求。第 4 步总结
后端完成!您有一个工作数据模型、一个工作管理界面、一个可以使用 GraphQL 探索的工作 GraphQL API,以及从您接下来要构建的前端查询 API 的能力。如果你已经有一段时间没有休息了,这是一个休息的好地方。
第五步:设置 Vue.js
您将使用 Vue 作为您博客的前端。要设置 Vue,您将创建 Vue 项目,安装几个重要的插件,并运行 Vue 开发服务器,以确保您的应用程序及其依赖项能够正常工作。
创建 Vue 项目
很像 Django,Vue 提供了一个命令行界面,用于创建一个项目,而不需要完全从零开始。您可以将其与 Node 的
npx命令配对,以引导其他人发布的基于 JavaScript 的命令。使用这种方法,您不需要手动安装启动和运行 Vue 项目所需的各种独立的依赖项。现在使用npx创建您的 Vue 项目:$ cd /path/to/dvg/ $ npx @vue/cli create frontend --default ... 🎉 Successfully created project frontend. ... $ cd frontend/ ```py 这将在现有的`backend/`目录旁边创建一个`frontend/`目录,安装一些 JavaScript 依赖项,并为应用程序创建一些框架文件。 ### 安装检视外挂程式 你需要一些插件让 Vue 进行适当的浏览器路由,并与你的 GraphQL API 进行交互。这些插件有时会影响你的文件,所以最好在开始的时候安装它们,这样它们就不会覆盖任何东西,然后再配置它们。安装 Vue 路由器和 Vue Apollo 插件,在出现提示时选择默认选项:$ npx @vue/cli add router
$ npx @vue/cli add apollo这些命令将花费一些时间来安装依赖项,它们将添加或更改项目中的一些文件,以配置和安装 Vue 项目中的每个插件。 ### 第五步总结 您现在应该能够运行 Vue 开发服务器了:$ npm run serve
现在,Django 应用程序在`http://localhost:8000`运行,Vue 应用程序在`http://localhost:8080`运行。 在浏览器中访问`http://localhost:8080`。您应该会看到 Vue 启动页面,这表明您已经成功安装了所有东西。如果您看到 splash 页面,那么您已经准备好开始创建自己的组件了。 [*Remove ads*](/account/join/) ## 步骤 6:设置 Vue 路由器 客户端应用程序的一个重要部分是处理路由,而不必向服务器发出新的请求。Vue 中一个常见的解决方案是您之前安装的 [Vue 路由器](https://router.vuejs.org/)插件。你将使用 Vue 路由器代替普通的 HTML 锚标签来链接到你博客的不同页面。 ### 创建路线 现在您已经安装了 Vue 路由器,您需要配置 Vue 来使用 Vue 路由器。您还需要为 Vue 路由器配置它应该路由的 URL 路径。 在`src/`目录下创建一个`router.js`模块。这个文件将保存关于哪个 URL 映射到哪个 Vue 组件的所有配置。从导入 Vue 和 Vue 路由器开始:import Vue from 'vue' import VueRouter from 'vue-router'
添加以下导入,每个导入对应于您稍后将创建的一个组件:import Post from '@/components/Post' import Author from '@/components/Author' import PostsByTag from '@/components/PostsByTag' import AllPosts from '@/components/AllPosts'
注册 Vue 路由器插件:Vue.use(VueRouter)
现在,您将创建路线列表。每条路线都有两个属性: 1. **`path`** 是一个 URL 模式,可选地包含类似于 Django URL 模式的捕获变量。 2. **`component`** 是当浏览器导航到与路径模式匹配的路线时显示的 Vue 组件。 添加这些路线作为一个`routes`变量。它们应该如下所示:const routes = [ { path: '/author/:username', component: Author }, { path: '/post/:slug', component: Post }, { path: '/tag/:tag', component: PostsByTag }, { path: '/', component: AllPosts }, ]
创建一个新的`VueRouter`实例,并将其从`router.js`模块中导出,以便其他模块可以使用它:const router = new VueRouter({ routes: routes, mode: 'history', }) export default router
在下一节中,您将在另一个模块中导入`router`变量。 ### 安装路由器 在`src/main.js`的顶部,从您在上一节中创建的模块导入`router`:import router from '@/router'
然后将路由器传递给 Vue 实例:new Vue({ router, ... })
这就完成了 Vue 路由器的配置。 [*Remove ads*](/account/join/) ### 第六步总结 您已经为您的前端创建了路由,它将一个 URL 模式映射到将在该 URL 显示的组件。这些路径还不能工作,因为它们指向尚不存在的组件。您将在下一步中创建这些组件。 ## 步骤 7:创建 Vue 组件 现在,您已经启动了 Vue 并运行了将到达您的组件的路由,您可以开始创建最终将显示来自 GraphQL 端点的数据的组件。目前,您只需要让它们显示一些静态内容。下表描述了您将创建的组件: | 成分 | 显示 | | --- | --- | | `AuthorLink` | 给定作者页面的链接(在`Post`和`PostList`中使用) | | `PostList` | 给定的博客帖子列表(在`AllPosts`、`Author`和`PostsByTag`中使用) | | `AllPosts` | 所有帖子的列表,最新的放在最前面 | | `PostsByTag` | 与给定标签相关的文章列表,最新的放在最前面 | | `Post` | 给定帖子的元数据和内容 | | `Author` | 关于作者的信息和他们写的文章列表 | 在下一步中,您将使用动态数据更新这些组件。 ### `AuthorLink`组件 您将创建的第一个组件显示一个指向作者的链接。 在`src/components/`目录下创建一个`AuthorLink.vue`文件。该文件是一个 Vue 单文件组件(SFC)。sfc 包含正确呈现组件所需的 HTML、JavaScript 和 CSS。 `AuthorLink`接受一个`author`属性,其结构对应于 GraphQL API 中关于作者的数据。该组件应该显示用户的名字和姓氏(如果提供的话),否则显示用户的用户名。 您的`AuthorLink.vue`文件应该如下所示:{{ displayName }} 这个组件不会直接使用 GraphQL。相反,其他组件将使用`author`属性传入作者信息。 ### `PostList`组件 `PostList`组件接受一个`posts`属性,它的结构对应于 GraphQL API 中关于文章的数据。该组件还接受一个[布尔](https://realpython.com/python-boolean/) `showAuthor`属性,您将在作者的页面上将它设置为`false`,因为它是冗余信息。该组件应显示以下特征: * 文章的标题和副标题,将它们链接到文章的页面 * 使用`AuthorLink`链接到文章作者(如果`showAuthor`是`true`) * 帖子发布的日期 * 文章的元描述 * 与帖子相关联的标签列表 在`src/components/`目录中创建一个`PostList.vue` SFC。组件模板应该如下所示:```py
{{ post.title }}: {{ post.subtitle }} by{{ post.metaDescription }}
PostList组件的 JavaScript 应该如下所示:<script> import AuthorLink from '@/components/AuthorLink' export default { name: 'PostList', components: { AuthorLink, }, props: { posts: { type: Array, required: true, }, showAuthor: { type: Boolean, required: false, default: true, }, }, computed: { publishedPosts () { return this.posts.filter(post => post.published) } }, methods: { displayableDate (date) { return new Intl.DateTimeFormat( 'en-US', { dateStyle: 'full' }, ).format(new Date(date)) } }, } </script> ```py `PostList`组件以`prop`的形式接收数据,而不是直接使用 GraphQL。 您可以添加一些可选的 CSS 样式,使帖子列表在呈现后更具可读性:这些样式增加了一些间距,消除了一些混乱,区分了不同的信息,有助于浏览。 [*Remove ads*](/account/join/) ### `AllPosts`组件 您将创建的下一个组件是博客上所有帖子的列表。它需要显示两条信息: 1. 最近的帖子标题 2. 帖子列表,使用`PostList` 在`src/components/`目录下创建`AllPosts.vue` SFC。它应该如下所示:Recent posts
在本教程的后面,您将使用 GraphQL 查询动态填充`allPosts`变量。 ### `PostsByTag`组件 `PostsByTag`组件与`AllPosts`组件非常相似。标题文本不同,在下一步中,您将查询一组不同的文章。 在`src/components/`目录下创建`PostsByTag.vue` SFC。它应该如下所示:Posts in #{{ $route.params.tag }}
在本教程的后面,您将使用 GraphQL 查询填充`posts`变量。 ### `Author`组件 `Author`组件充当作者的个人资料页面。它应该显示以下信息: * 带有作者姓名的标题 * 作者网站的链接,如果提供的话 * 作者的传记,如果提供的话 * 作者的帖子列表,其中`showAuthor`设置为`false` 现在在`src/components/`目录下创建`Author.vue` SFC。它应该如下所示:{{ displayName }}
Website{{ author.bio }}
<h3>Posts by {{ displayName }}</h3> <PostList :posts="author.postSet" :showAuthor="false" />在本教程的后面,您将使用 GraphQL 查询动态填充`author`变量。 ### `Post`组件 就像数据模型一样,`Post`组件是最有趣的,因为它负责显示所有帖子的信息。该组件应显示关于 post 的以下信息: * 标题和副标题,作为标题 * 作者,作为链接使用`AuthorLink` * 出版日期 * 元描述 * 内容体 * 作为链接的关联标签列表 由于您的数据建模和组件架构,您可能会惊讶于这需要的代码如此之少。在`src/components/`目录下创建`Post.vue` SFC。它应该如下所示:{{ post.title }}: {{ post.subtitle }}
By{{ post.metaDescription }}
{{ post.body }}
在本教程的后面,您将使用 GraphQL 查询动态填充`post`变量。 ### `App`组件 在看到工作成果之前,需要更新 Vue setup 命令创建的`App`组件。它应该显示`AllPosts`组件,而不是显示 Vue 启动页面。 打开`src/`目录下的`App.vue` SFC。您可以删除其中的所有内容,因为您需要用显示以下特性的代码来替换它: * 链接到主页的带有博客标题的标题 * `<router-view>`,一个 Vue 路由器组件,呈现当前路由的正确组件 您的`App`组件应该如下所示:Awesome Blog
您还可以添加一些可选的 CSS 样式来稍微修饰一下显示:这些样式为页面上的大多数元素提供了一点喘息的空间,并删除了大多数浏览器默认添加的整个页面周围的空间。 ### 第七步总结 如果你以前没怎么用过 Vue,这一步可能会很难消化。不过,你已经到达了一个重要的里程碑。您已经有了一个可用的 Vue 应用程序,包括准备好显示数据的路线和视图。 您可以通过启动 Vue 开发服务器并访问`http://localhost:8080`来确认您的应用程序正在运行。您应该会看到您的博客标题和最近的文章标题。如果您这样做了,那么您就准备好进行最后一步了,您将使用 Apollo 查询您的 GraphQL API 来将前端和后端结合在一起。 ## 第八步:获取数据 现在,您已经为显示可用数据做好了一切准备,是时候从 GraphQL API 获取数据了。 Apollo 使得查询 GraphQL APIs 更加方便。您之前安装的 Vue Apollo 插件将 Apollo 集成到了 Vue 中,使得在 Vue 项目中查询 GraphQL 更加方便。 ### 配置 Vue 阿波罗 Vue Apollo 大部分配置都是开箱即用的,但是您需要告诉它要查询的正确端点。您可能还想关闭它默认尝试使用的 WebSocket 连接,因为这会在浏览器的网络和控制台选项卡中产生噪音。编辑`src/main.js`模块中的`apolloProvider`定义,指定`httpEndpoint`和`wsEndpoint`属性:new Vue({ ... apolloProvider: createProvider({ httpEndpoint: 'http://localhost:8000/graphql', wsEndpoint: null, }), ... })
现在,您已经准备好开始添加查询来填充页面。您将通过向几个 sfc 添加一个`created()`函数来实现这一点。`created()`是一个特殊的 [Vue 生命周期挂钩](https://vuejs.org/v2/guide/instance.html#Instance-Lifecycle-Hooks),当一个组件将要呈现在页面上时执行。您可以使用这个钩子来查询想要呈现的数据,以便在组件呈现时可以使用这些数据。您将为以下组件创建一个查询: * `Post` * `Author` * `PostsByTag` * `AllPosts` 您可以从创建`Post`查询开始。 ### `Post`查询 对单个帖子的查询接受所需帖子的`slug`。它应该返回所有必要的信息来显示文章信息和内容。 您将使用`$apollo.query`帮助器和`gql`帮助器在`Post`组件的`created()`函数中构建查询,最终使用响应来设置组件的`post`,以便可以呈现它。`created()`应该如下图所示:这个查询获取了关于文章及其相关作者和标签的大部分数据。注意,查询中使用了`$slug`占位符,传递给`$apollo.query`的`variables`属性用于填充占位符。`slug`属性在名称上与`$slug`占位符匹配。您将在其他一些查询中再次看到这种模式。 ### `Author`查询 在对`Post`的查询中,您获取了单个帖子的数据和一些关于作者的嵌套数据,而在`Author`查询中,您需要获取作者数据和作者所有帖子的列表。 author 查询接受所需作者的`username`,并应该返回所有必要的信息以显示作者及其帖子列表。它应该如下所示:这个查询使用了`postSet`,如果您过去做过一些 Django 数据建模,可能会觉得很熟悉。“post set”这个名字来自 Django 为一个`ForeignKey`字段创建的反向关系。在这种情况下,帖子对其作者有一个[外键关系](https://en.wikipedia.org/wiki/Foreign_key),它与名为`post_set`的帖子有一个反向关系。Graphene-Django 已经在 GraphQL API 中自动将其公开为`postSet`。 ### `PostsByTag`查询 对`PostsByTag`的查询应该与您创建的第一个查询非常相似。该查询接受所需的`tag`,并返回匹配文章的列表。`created()`应该像下面这样:您可能会注意到每个查询的某些部分看起来非常相似。虽然本教程不会涉及,但是您可以使用 [GraphQL 片段](https://dgraph.io/docs/graphql/api/fragments/)来减少查询代码中的重复。 ### `AllPosts`查询 对`AllPosts`的查询不需要任何输入信息,并返回与`PostsByTag`查询相同的信息集。它应该如下所示:这是目前的最后一个查询,但是您应该重温最后几个步骤,以便让它们深入了解。如果您希望将来添加具有新数据视图的新页面,只需创建一个路由、一个组件和一个查询。 ### 第八步总结 现在每个组件都在获取它需要显示的数据,您已经到达了一个功能正常的博客。运行 Django 开发服务器和 Vue 开发服务器。访问`http://localhost:8080`并浏览您的博客。如果你能在浏览器中看到作者、帖子、标签和帖子的内容,你就成功了! ## 接下来的步骤 您首先创建了一个 Django 博客后端来管理、持久化和服务博客数据。然后,您创建了一个 Vue 前端来消费和显示这些数据。你让这两个用石墨烯和阿波罗与 GraphQL 通信。 你可能已经在想下一步该怎么做了。要进一步验证您的博客是否按预期运行,您可以尝试以下方法: * **添加更多用户**和帖子,以查看按作者分类的用户和帖子。 * **发布一些未发布的帖子**以确认它们不会出现在博客上。 如果你对自己正在做的事情充满信心和冒险精神,你还可以进一步发展你的系统: * **扩展您的数据模型**在您的 Django 博客中创建新的行为。 * **创建新的查询**为您的博客数据提供有趣的视图。 * **探索 GraphQL 突变**除了读取数据,还要写入数据。 * 将 CSS 添加到你的单文件组件中,让博客更加引人注目。 您已经组合在一起的数据建模和组件架构具有显著的可扩展性,所以您可以随心所欲地使用它! 如果你想让你的 Django 应用程序为黄金时间做好准备,请阅读[将 Django + Python3 + PostgreSQL 部署到 AWS Elastic Beanstalk](https://realpython.com/deploying-a-django-app-and-postgresql-to-aws-elastic-beanstalk/) 或[在 Fedora 上开发和部署 Django](https://realpython.com/development-and-deployment-of-cookiecutter-django-on-fedora/)。你也可以使用亚马逊网络服务或者类似 [Netlify](https://netlify.com) 的东西来部署你的 Vue 项目。 ## 结论 您已经看到了如何使用 GraphQL 构建数据的类型化、灵活的视图。您可以在已经构建或计划构建的现有 Django 应用程序上使用这些技术。像其他 API 一样,您也可以在几乎任何客户端框架中使用您的 API。 **在本教程中,您学习了如何:** * 构建 Django 博客**数据模型**和**管理界面** * 使用 Graphene-Django 将您的数据模型包装在一个 **GraphQL API** 中 * 为数据的每个视图创建并路由单独的 **Vue 组件** * **使用 Apollo 动态查询 GraphQL API** 来填充您的 Vue 组件 你覆盖了很多领域,所以试着找出一些新的方法在不同的环境中使用这些概念来巩固你的学习。快乐编码,快乐写博客! 您可以通过单击下面的链接下载该项目的完整源代码: **获取源代码:** [单击此处获取源代码,您将在本教程中使用](https://realpython.com/bonus/django-blog-project-code/)用 Django、Vue 和 GraphQL 构建一个博客应用程序。********** # 如何在 Python 中模拟 Do-While 循环? > 原文:<https://realpython.com/python-do-while/> 如果你从像 [C](https://realpython.com/c-for-python-programmers/) 、 [C++](https://realpython.com/python-vs-cpp/) 、 [Java](https://realpython.com/java-vs-python/) 或 [JavaScript](https://realpython.com/python-vs-javascript/) 这样的语言来到 Python,那么你可能会错过它们的 [do-while](https://en.wikipedia.org/wiki/Do_while_loop) 循环结构。do-while 循环是一个常见的[控制流](https://en.wikipedia.org/wiki/Control_flow)语句,它至少执行其代码块一次,不管**循环条件**是真还是假。这种行为依赖于在每次迭代结束时评估循环条件这一事实。所以,第一次迭代总是运行。 这种类型的循环最常见的用例之一是接受和处理用户的输入。考虑以下用 C 编写的示例: ```py #include <stdio.h> int main() { int number; do { printf("Enter a positive number: "); scanf("%d", &number); printf("%d\n", number); } while (number > 0); return 0; }这个小程序运行一个
do…while循环,要求用户输入一个正数。然后输入被存储在number中并打印到屏幕上。循环一直运行这些操作,直到用户输入一个非正数。如果您编译并运行这个程序,那么您将得到以下行为:
Enter a positive number: 1 1 Enter a positive number: 4 4 Enter a positive number: -1 -1循环条件
number > 0在循环结束时被评估,这保证了循环的主体将至少运行一次。这个特性将 do-while 循环与常规的 while 循环区分开来,后者在开始时评估循环条件。在 while 循环中,不能保证运行循环体。如果循环条件一开始就是假的,那么肉体根本不会运行。注意:在本教程中,你将把控制 while 或 do-while 循环的条件称为循环条件。这个概念不应该与循环的主体混淆,后者是在 C 等语言中夹在花括号之间的代码块,或者在 Python 中缩进。
使用 do-while 循环结构的一个原因是效率。例如,如果循环条件意味着高成本操作,并且循环必须运行 n 次( n ≥ 1),那么该条件将在 do-while 循环中运行 n 次。相反,常规的 while 循环将运行代价高昂的条件 n + 1 次。
Python 没有 do-while 循环结构。为什么?显然,核心开发人员从来没有为这种类型的循环找到一个好的语法。很可能,这就是吉多·范·罗苏姆 拒绝 PEP 315 的原因,这是一种在语言中添加 do-while 循环的尝试。一些核心开发人员更喜欢 do-while 循环,并期待围绕这个话题重新展开讨论。
同时,您将探索 Python 中可用的替代方法。简而言之,如何在 Python 中模拟 do-while 循环?在本教程中,你将学习如何使用
while创建类似 do-while 循环的循环。免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
简而言之:使用一个
while循环和break语句在 Python 中模拟 do-while 循环最常见的技术是使用无限的
while循环,其中的break语句包装在if语句中,该语句检查给定的条件,如果该条件为真,则中断迭代:while True: # Do some processing... # Update the condition... if condition: break这个循环使用
True作为它的形式条件。这个技巧把循环变成了无限循环。在条件语句之前,循环运行所有需要的处理并更新中断条件。如果这个条件评估为真,那么break语句将跳出循环,程序执行将继续其正常路径。注意:使用无限循环和
break语句可以模拟 do-while 循环。这种技术是 Python 社区一般推荐使用的,但并不完全安全。例如,如果在
break语句之前引入一个continue语句,那么循环可能会错过中断条件,并进入一个不受控制的无限循环。下面是如何编写与您在本教程介绍中编写的 C 程序等效的 Python:
>>> while True:
... number = int(input("Enter a positive number: "))
... print(number)
... if not number > 0:
... break
...
Enter a positive number: 1
1
Enter a positive number: 4
4
Enter a positive number: -1
-1
这个循环使用内置的 input() 函数接受用户的输入。然后使用 int() 将输入转换成整数。如果用户输入一个小于或等于0的数字,那么break语句运行,循环终止。
有时,您会遇到需要保证循环至少运行一次的情况。在那些情况下,你可以像上面一样使用while和break。在下一节中,您将编写一个猜数字游戏,该游戏使用这样一个 do-while 循环来接受和处理用户在命令行中的输入。
Do-While 循环在实践中是如何工作的?
do-while 循环最常见的用例是接受并处理用户的输入。作为一个实际的例子,假设您有一个用 JavaScript 实现的猜数字游戏。代码使用一个do … while循环来处理用户的输入:
1// guess.js 2
3const LOW = 1; 4const HIGH = 10; 5
6let secretNumber = Math.floor(Math.random() * HIGH) + LOW; 7let clue = ''; 8let number = null; 9
10do { 11 let guess = prompt(`Guess a number between ${LOW} and ${HIGH} ${clue}`); 12 number = parseInt(guess); 13 if (number > secretNumber) { 14 clue = `(less than ${number})`; 15 } else if (number < secretNumber) { 16 clue = `(greater than ${number})`; 17 } 18} while (number != secretNumber); 19
20alert(`You guessed it! The secret number is ${number}`);
这个脚本做了几件事。下面是正在发生的事情的分类:
-
第 3 行和第 4 行定义了两个常数来界定秘密数字将存在的间隔。
-
第 6 行到第 8 行定义了变量来存储秘密数字、线索消息和
number的初始值,它将保存用户的输入。 -
第 10 行开始一个
do…while循环来处理用户的输入,并确定用户是否已经猜出了密码。 -
第 11 行定义了一个本地变量
guess,用来存储命令行提供的用户输入。 -
第 12 行使用
parseInt()将输入值转换成整数。 -
第 13 行定义了一个条件语句,检查输入数字是否大于秘密数字。如果是这种情况,那么
clue被设置为适当的消息。 -
第 15 行检查输入的数字是否小于密码,然后相应地设置
clue。 -
第 18 行定义循环条件,检查输入的数字是否与密码不同。在这个具体的例子中,循环将继续运行,直到用户猜出密码。
-
第 20 行最后启动一个警告框,通知用户猜测成功。
现在说你想把上面的例子翻译成 Python 代码。Python 中一个等价的猜数字游戏看起来像这样:
# guess.py
from random import randint
LOW, HIGH = 1, 10
secret_number = randint(LOW, HIGH)
clue = ""
while True:
guess = input(f"Guess a number between {LOW} and {HIGH} {clue} ")
number = int(guess)
if number > secret_number:
clue = f"(less than {number})"
elif number < secret_number:
clue = f"(greater than {number})"
else:
break
print(f"You guessed it! The secret number is {number}")
这段 Python 代码的工作方式就像它的等效 JavaScript 代码一样。主要区别在于,在这种情况下,您使用的是常规的while循环,因为 Python 没有do … while循环。在这个 Python 实现中,当用户猜出秘密数字时,就会运行else子句,从而打破循环。代码的最后一行打印成功的猜测消息。
使用一个无限循环和一个break语句,就像你在上面的例子中所做的那样,是在 Python 中模拟 do-while 循环最广泛使用的方法。
Do-While 和 While 循环有什么区别?
简而言之,do-while 循环和 while 循环的主要区别在于,前者至少执行一次循环体,因为循环条件是在最后检查的。另一方面,如果条件评估为 true,则执行常规 while 循环的主体,这在循环开始时进行测试。
下表总结了这两种循环的主要区别:
| 在…期间 | 做一会儿 |
|---|---|
| 是一个入口控制循环 | 是一个出口控制循环 |
| 仅在循环条件为真时运行 | 运行,直到循环条件变为假 |
| 首先检查条件,然后执行循环体 | 执行循环体,然后检查条件 |
| 如果循环条件最初为假,则执行循环体零次 | 不管循环条件的真值是多少,至少执行一次循环体 |
| 对于 n 次迭代,检查循环条件 n + 1 次 | 检查循环条件 n 次,其中 n 为迭代次数 |
while 循环是一个控制流结构,它提供了一个通用的通用循环。它允许您在给定条件保持为真的情况下重复运行一组语句。do-while 循环的用例更加具体。它主要用于只有在循环体至少已经运行过一次的情况下,检查循环条件才有意义。
在 Python 中,可以使用什么替代方法来模拟 Do-While 循环?
至此,您已经了解了在 Python 中模拟 do-while 循环的推荐或最常用的方法。然而,Python 在模拟这种类型的循环时非常灵活。一些程序员总是使用无限的while循环和break语句。其他程序员使用他们自己的公式。
在本节中,您将了解一些模拟 do-while 循环的替代技术。第一种方法是在循环开始之前运行第一个操作。第二种选择意味着使用一个循环条件,在循环开始之前,该条件被初始设置为真值。
循环前的第一个操作
正如您已经了解到的,do-while 循环最相关的特性是循环体总是至少运行一次。要使用一个while循环来模拟这个功能,您可以在循环开始之前获取循环体并运行它。然后你可以在循环中重复这个物体。
这个解决方案听起来很重复,如果你不使用某种技巧的话。幸运的是,您可以使用一个函数来打包循环体并防止重复。使用这种技术,您的代码将如下所示:
condition = do_something()
while condition:
condition = do_something()
对do_something()的第一次调用保证了所需的功能至少运行一次。只有当condition为真时,循环内部对do_something()的调用才会运行。注意,您需要在每次迭代中更新循环条件,以使该模式正确工作。
下面的代码展示了如何使用这种技术实现猜数字游戏:
# guess.py
from random import randint
LOW, HIGH = 1, 10
secret_number = randint(LOW, HIGH)
clue = ""
def process_move(clue):
user_input = input(f"Guess a number between {LOW} and {HIGH} {clue} ")
number = int(user_input)
if number > secret_number:
clue = f"(less than {number})"
elif number < secret_number:
clue = f"(greater than {number})"
return number, clue
number, clue = process_move(clue) # First iteration
while number != secret_number:
number, clue = process_move(clue)
print(f"You guessed it! The secret number is {number}")
在这个新版本的猜数字游戏中,你将所有循环的功能都打包到process_move()中。这个函数返回当前数字,您将在以后检查循环条件时使用它。它还返回线索消息。
注意process_move()在循环开始前运行一次,模仿 do-while 循环的主要特征,至少运行一次它的主体。
在循环内部,您调用函数来运行游戏的主要功能,并相应地更新循环条件。
使用初始真循环条件
使用初始设置为True的循环条件是模拟 do-while 循环的另一种选择。在这种情况下,您只需要在循环开始运行之前将循环条件设置为True。这种做法可以确保循环体至少运行一次:
do = True
while do:
do_something()
if condition:
do = False
这个替代构造与您在上一节中使用的非常相似。主要区别在于循环条件是一个在循环内部更新的布尔变量。
这种技术也类似于使用无限while循环和break语句的技术。然而,这种方法更显而易见,可读性更好,因为它允许您使用描述性的变量名,而不是简单的break语句和像True这样的硬编码条件。
注意:有时给布尔变量命名更自然,这样你就可以把它设置为True来打破循环。在这些情况下,您可以用类似于while not done:的东西开始循环,并在循环内将done设置为True。
您可以使用这种技术来重写您的数字猜测游戏,如下面的代码示例所示:
# guess.py
from random import randint
LOW, HIGH = 1, 10
secret_number = randint(LOW, HIGH)
clue = ""
number_guessed = False
while not number_guessed:
user_input = input(f"Guess a number between {LOW} and {HIGH} {clue} ")
number = int(user_input)
if number > secret_number:
clue = f"(less than {number})"
elif number < secret_number:
clue = f"(greater than {number})"
else:
number_guessed = True
print(f"You guessed it! The secret number is {number}")
在本例中,首先定义一个布尔变量number_guessed,它允许您控制循环。在循环内部,您像往常一样处理用户的输入。如果用户猜出了密码,那么number_guessed被设置为True,程序跳出循环执行。
结论
在本教程中,你已经学会了用 Python 模拟一个 do-while 循环。这种语言没有这种循环结构,这种结构在 C、C++、Java 和 JavaScript 等语言中可以找到。您了解了在常规 while 循环的帮助下,您总是可以编写 do-while 循环,并且可以使用几种不同模式中的一种来完成它。
模拟 do-while 循环最常见的技术是创建一个无限while循环,在循环体的末尾添加一个条件语句。该条件控制循环,并使用 break 语句跳出循环。
您还了解了如何使用一些替代技术来提供与 do-while 循环相同的功能。您的选择包括在循环之前进行第一组操作,或者使用一个初始设置为True的布尔变量来控制循环。
有了这些知识,您就可以开始在自己的 Python 代码中模拟 do-while 循环了。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。**
Python 的 doctest:一次记录并测试你的代码
原文:# t0]https://realython . com/python-doctest/
你有兴趣为你的代码编写同时作为文档和测试用例的用例吗?如果你的答案是是,那么 Python 的doctest模块就适合你。这个模块提供了一个测试框架,没有太陡的学习曲线。它允许您将代码示例用于两个目的:记录和测试您的代码。
除了允许你使用你的代码文档来测试代码本身,doctest还将帮助你在任何时候保持你的代码和它的文档的完美同步。
在本教程中,您将:
- 在代码的文档和文档字符串中编写
doctest测试 - 了解
doctest如何在内部工作 - 探索
doctest的限制和安全影响 - 使用
doctest进行测试驱动开发 - 使用不同的策略和工具运行你的
doctest测试
您不必安装任何第三方库或学习复杂的 API 来遵循本教程。你只需要知道 Python 编程的基础,以及如何使用 Python REPL 或者交互 shell 。
示例代码: 点击这里下载免费的示例代码,您将使用 Python 的doctest同时记录和测试您的代码。
用例子和测试记录你的代码
几乎所有有经验的程序员都会告诉你,记录你的代码是一种最佳实践。有些人会说代码和它的文档同样重要和必要。其他人会告诉你文档甚至比代码本身更重要。
在 Python 中,你会发现许多记录项目、应用程序,甚至模块和脚本的方法。大型项目通常需要专门的外部文档。但是在小项目中,使用显式名称、注释和文档字符串可能就足够了:
1"""This module implements functions to process iterables."""
2
3def find_value(value, iterable):
4 """Return True if value is in iterable, False otherwise."""
5 # Be explicit by using iteration instead of membership
6 for item in iterable:
7 if value == item: # Find the target value by equality
8 return True
9 return False
像find_value()这样明确的名字可以帮助你清楚地表达给定对象的内容和目的。这样的名称可以提高代码的可读性和可维护性。
注释,比如第 5 行和第 7 行的注释,是您在代码的不同位置插入的文本片段,用来阐明代码做了什么以及为什么做。请注意,Python 注释以一个#符号开始,可以占据自己的行,也可以是现有行的一部分。
注释有几个缺点:
- 它们被解释器或编译器忽略,这使得它们在运行时不可访问。
- 当代码发展而注释保持不变时,他们通常会变得过时。
文档字符串,或简称为 docstrings ,是一个简洁的 Python 特性,可以帮助您在编写代码的过程中编写文档。与注释相比,文档字符串的优势在于解释器不会忽略它们。它们是你代码的活的一部分。
因为文档字符串是代码的活动部分,所以可以在运行时访问它们。为此,您可以在您的包、模块、类、方法和函数上使用.__doc__特殊属性。
像 MkDocs 和 Sphinx 这样的工具可以利用 docstrings 自动生成项目文档。
在 Python 中,可以将文档字符串添加到包、模块、类、方法和函数中。如果你想学习如何写好 docstrings,那么 PEP 257 提出了一系列你可以遵循的约定和建议。
当您编写 docstrings 时,通常的做法是为您的代码嵌入用法示例。这些示例通常模拟 REPL 会话。
在文档字符串中嵌入代码示例提供了一种记录代码的有效方法,以及在编写代码时测试代码的快速方法。是的,如果你以正确的方式编写代码并使用正确的工具运行它们,你的代码例子可以作为测试用例。
在代码中嵌入类似 REPL 的代码示例有助于:
- 保持文档与代码的当前状态同步
- 表达您代码的预期用途
- 在你写代码的时候测试你的代码
这些好处听起来不错!现在,如何运行嵌入到文档和文档字符串中的代码示例呢?可以从标准库中使用 Python 的 doctest 模块。
了解 Python 的doctest模块
在本节中,您将了解 Python 的 doctest 模块。该模块是标准库的一部分,因此您不必安装任何第三方库就可以在日常编码中使用它。除此之外,您将学习什么是doctest以及何时使用这个简洁的 Python 工具。为了揭开序幕,你将从了解什么是doctest开始。
什么是doctest以及它是如何工作的
doctest模块是一个轻量级的测试框架,它提供了快速简单的测试自动化。它可以从您的项目文档和代码的文档字符串中读取测试用例。这个框架是 Python 解释器附带的,并且遵循电池包含的原则。
您可以在代码或命令行中使用doctest。为了找到并运行您的测试用例,doctest遵循几个步骤:
- 在文档和文档字符串中搜索看起来像 Python 交互会话的文本
- 解析这些文本片段,以区分可执行代码和预期结果
- 像常规 Python 代码一样运行可执行代码
- 将执行结果与预期结果进行比较
框架在你的文档以及包、模块、函数、类和方法的文档字符串中搜索测试用例。它不会在您导入的任何对象中搜索测试用例。
一般来说,doctest将所有以主(>>>)或次(... ) REPL 提示符开始的文本行解释为可执行的 Python 代码。紧跟在任何一个提示后面的行被理解为代码的预期输出或结果。
什么doctest对有用
doctest框架非常适合于验收测试在集成和系统测试层面的快速自动化。验收测试是您运行来确定是否满足给定项目的规范的那些测试,而集成测试旨在保证项目的不同组件作为一个组正确工作。
您的doctest测试可以存在于您项目的文档和您代码的文档字符串中。例如,包含doctest测试的包级 docstring 是进行集成测试的一种非常好的快速方法。在这个级别,您可以测试整个包及其模块、类、函数等的集成。
一组高级的doctest测试是预先定义程序规格的一个很好的方法。同时,低级别的单元测试让你设计你的程序的单个构建模块。然后,只要你愿意,就可以让你的计算机随时对照测试来检查代码。
在类、方法和函数级别,测试是在你编写代码时测试你的代码的强大工具。您可以在编写代码本身的同时,逐渐将测试用例添加到您的文档字符串中。这种实践将允许你生成更加可靠和健壮的代码,特别是如果你坚持测试驱动开发的原则的话。
总之,您可以将doctest用于以下目的:
- 编写快速有效的测试用例在编写代码时检查代码
- 在你的项目、包和模块上运行验收、回归和集成测试用例
- 检查你的文档串是否是最新的并且与目标代码同步****
*** 验证您的项目的文档是否是最新的*** 为您的项目、包和模块编写实践教程* 说明如何使用项目的 API以及预期的输入和输出必须是什么***
***在您的文档和文档字符串中进行doctest测试是您的客户或团队成员在评估代码的特性、规范和质量时运行这些测试的一种极好的方式。
用 Python 编写自己的doctest测试
现在您已经知道了什么是doctest以及您可以用它来做什么,您将学习如何使用doctest来测试您的代码。不需要特殊的设置,因为doctest是 Python 标准库的一部分。
在接下来的小节中,您将学习如何检查函数、方法和其他可调用函数的返回值。类似地,您将理解如何检查给定代码的打印输出。
您还将学习如何为必须引发异常的代码创建测试用例,以及如何在执行测试用例之前运行准备步骤。最后,您将回顾一下关于doctest测试语法的一些细节。
创建用于检查返回和打印值的doctest测试
代码测试的第一个也可能是最常见的用例是检查函数、方法和其他可调用函数的返回值。您可以通过doctest测试来做到这一点。例如,假设您有一个名为add()的函数,它将两个数作为参数,并返回它们的算术和:
# calculations.py
def add(a, b):
return float(a + b)
这个函数将两个数相加。记录您的代码是一个很好的实践,所以您可以向这个函数添加一个 docstring。您的 docstring 可能如下所示:
# calculations.py
def add(a, b):
"""Compute and return the sum of two numbers.
Usage examples:
>>> add(4.0, 2.0) 6.0
>>> add(4, 2) 6.0
"""
return float(a + b)
这个 docstring 包括两个如何使用add()的例子。每个示例都包含一个初始行,以 Python 的主要交互提示>>>开始。这一行包括一个带有两个数字参数的对add()的调用。然后,该示例的第二行包含了预期输出,它与函数的预期返回值相匹配。
在这两个例子中,预期的输出是一个浮点数,这是必需的,因为函数总是返回这种类型的数字。
您可以使用doctest运行这些测试。继续运行以下命令:
$ python -m doctest calculations.py
该命令不会向您的屏幕发出任何输出。显示没有输出意味着doctest运行了所有的测试用例,没有发现任何失败的测试。
如果您想让doctest详细描述运行测试的过程,那么使用-v开关:
$ python -m doctest -v calculations.py
Trying:
add(4.0, 2.0) Expecting:
6.0 ok
Trying:
add(4, 2) Expecting:
6.0 ok
1 items had no tests:
calculations
1 items passed all tests:
2 tests in calculations.add
2 tests in 2 items.
2 passed and 0 failed. Test passed.
使用-v选项运行doctest会产生描述测试运行过程的详细输出。前两行突出显示了实际的测试及其相应的预期输出。每个测试的预期输出之后的一行显示单词ok,意味着目标测试成功通过。在本例中,两个测试都通过了,正如您可以在最后一个突出显示的行中确认的那样。
doctest测试的另一个常见用例是检查给定代码的打印输出。继续创建一个名为printed_output.py的新文件,并向其中添加以下代码:
# printed_output.py
def greet(name="World"):
"""Print a greeting to the screen.
Usage examples:
>>> greet("Pythonista")
Hello, Pythonista!
>>> greet()
Hello, World!
"""
print(f"Hello, {name}!")
这个函数将一个名字作为参数,将问候打印到屏幕上。您可以像往常一样从命令行使用doctest在这个函数的 docstring 中运行测试:
$ python -m doctest -v printed_output.py
Trying:
greet("Pythonista") Expecting:
Hello, Pythonista! ok
Trying:
greet() Expecting:
Hello, World! ok
1 items had no tests:
printed_output
1 items passed all tests:
2 tests in printed_output.greet
2 tests in 2 items.
2 passed and 0 failed.
Test passed.
这些测试按预期工作,因为 Python REPL 在屏幕上显示返回和打印的值。这种行为允许doctest匹配测试用例中返回和打印的值。
使用doctest测试一个函数在屏幕上显示的内容非常简单。对于其他测试框架,进行这种测试可能会稍微复杂一些。您将需要处理标准输出流,这可能需要高级 Python 知识。
了解doctest如何匹配预期和实际测试输出
在实践中,doctest在匹配预期输出和实际结果时非常严格。例如,使用整数而不是浮点数会破坏add()函数的测试用例。
其他微小的细节,如使用空格或制表符,用双引号将返回的字符串括起来,或者插入空行,也会导致测试中断。考虑以下玩具测试案例作为上述问题的示例:
# failing_tests.py
"""Sample failing tests.
The output must be an integer
>>> 5 + 7
12.0
The output must not contain quotes
>>> print("Hello, World!")
'Hello, World!'
The output must not use double quotes
>>> "Hello," + " World!"
"Hello, World!"
The output must not contain leading or trailing spaces
>>> print("Hello, World!")
Hello, World!
The output must not be a blank line
>>> print()
"""
当您从命令行使用doctest运行这些测试时,您会得到冗长的输出。这里有一个细目分类:
$ python -m doctest -v failing_tests.py
Trying:
5 + 7
Expecting:
12.0
**********************************************************************
File ".../failing_tests.py", line 6, in broken_tests
Failed example:
5 + 7 Expected:
12.0 Got:
12
在第一段输出中,预期的结果是一个浮点数。但是,5 + 7会返回一个整数值12。因此,doctest将测试标记为失败。Expected:和Got:标题给你关于检测到的问题的提示。
下一条输出如下所示:
Trying:
print("Hello, World!")
Expecting:
'Hello, World!'
**********************************************************************
File ".../failing_tests.py", line 10, in broken_tests
Failed example:
print("Hello, World!")
Expected:
'Hello, World!' Got:
Hello, World!
在本例中,预期的输出使用单引号。然而,print()函数在输出时没有加引号,导致测试失败。
该命令的输出继续如下:
Trying:
"Hello," + "World!"
Expecting:
"Hello, World!"
**********************************************************************
File ".../failing_tests.py", line 14, in broken_tests
Failed example:
"Hello," + " World!"
Expected:
"Hello, World!" Got:
'Hello, World!'
这段输出显示了另一个失败的测试。在这个例子中,问题是 Python 在交互式部分显示字符串时使用单引号而不是双引号。同样,这种微小的差异会使您的测试失败。
接下来,您将获得以下输出:
Trying:
print("Hello, World!")
Expecting:
Hello, World!
**********************************************************************
File ".../failing_tests.py", line 18, in broken_tests
Failed example:
print("Hello, World!")
Expected:
Hello, World! Got:
Hello, World!
在本例中,测试失败是因为预期的输出包含前导空格。然而,实际输出没有前导空格。
最终的输出如下所示:
Trying:
print()
Expecting nothing
**********************************************************************
File ".../failing_tests.py", line 22, in broken_tests
Failed example:
print()
Expected nothing Got:
<BLANKLINE> **********************************************************************
1 items had failures:
5 of 5 in broken_tests
5 tests in 1 items.
0 passed and 5 failed. ***Test Failed*** 5 failures.
在常规的 REPL 会话中,不带参数调用print()会显示一个空行。在doctest测试中,空行意味着您刚刚执行的代码没有发出任何输出。这就是为什么doctest的输出说什么都没预料到,却得到了<BLANKLINE>。在关于doctest的限制一节中,您将了解到更多关于这个<BLANKLINE>占位符标签的信息。
注意:空行包括仅包含被视为空白的字符的行,例如空格和制表符。在名为处理空白字符和其他字符的章节中,你会学到更多关于空白字符的知识。
总而言之,您必须保证实际测试输出和预期输出之间的完美匹配。因此,确保每个测试用例之后的那一行与您需要代码返回或打印的内容完全匹配。
编写doctest测试来捕捉异常
除了测试成功的返回值之外,您通常还需要测试那些在响应错误或其他问题时会引发异常的代码。
在捕捉返回值和异常时,doctest模块遵循几乎相同的规则。它搜索看起来像 Python 异常报告或回溯的文本,并检查代码引发的任何异常。
例如,假设您已经将下面的divide()函数添加到您的calculations.py文件中:
# calculations.py
# ...
def divide(a, b):
return float(a / b)
该函数将两个数字作为参数,并将它们的商作为浮点数返回。当b的值不是0时,该函数按预期工作,但是它为b == 0引发了一个异常:
>>> from calculations import divide >>> divide(84, 2) 42.0 >>> divide(15, 3) 5.0 >>> divide(42, -2) -21.0 >>> divide(42, 0) Traceback (most recent call last): ... ZeroDivisionError: division by zero前三个例子表明,当除数
b不同于0时,divide()工作良好。然而,当b为0时,该功能以ZeroDivisionError中断。这个异常表明该操作不被允许。如何使用
doctest测试来测试这个异常呢?查看以下代码中的 docstring,尤其是最后一个测试用例:# calculations.py # ... def divide(a, b): """Compute and return the quotient of two numbers. Usage examples: >>> divide(84, 2) 42.0 >>> divide(15, 3) 5.0 >>> divide(42, -2) -21.0 >>> divide(42, 0) Traceback (most recent call last): ZeroDivisionError: division by zero """ return float(a / b)前三个测试工作正常。所以,把注意力集中在最后一个测试上,尤其是高亮显示的行。第一个突出显示的行包含一个所有异常回溯通用的头。第二个突出显示的行包含实际的异常及其特定消息。这两行是
doctest成功检查预期异常的唯一要求。在处理异常回溯时,
doctest完全忽略回溯体,因为它可能会发生意外变化。实际上,doctest只关注第一行,即Traceback (most recent call last):,以及最后一行。正如您已经知道的,第一行是所有异常回溯所共有的,而最后一行显示了关于引发的异常的信息。因为
doctest完全忽略了回溯体,所以你可以在 docstrings 中对它做任何你想做的事情。通常情况下,只有当回溯体对文档有重要价值时,才需要包含它。根据您的选择,您可以:
- 完全移除追溯体
- 用省略号(
...)替换回溯正文的部分内容- 用省略号完全替换回溯正文
- 用任何自定义文本或解释替换追溯正文
- 包括完整的回溯主体
无论如何,回溯体只对阅读你的文档的人有意义。这个列表中的第二个、第四个和最后一个选项只有在回溯增加了代码文档的价值时才有用。
如果在最后一个测试用例中包含完整的回溯,下面是
divide()的 docstring 的样子:# calculations.py # ... def divide(a, b): """Compute and return the quotient of two numbers. Usage examples: >>> divide(84, 2) 42.0 >>> divide(15, 3) 5.0 >>> divide(42, -2) -21.0 >>> divide(42, 0) Traceback (most recent call last): File "<stdin>", line 1, in <module> divide(42, 0) File "<stdin>", line 2, in divide return float(a / b) ZeroDivisionError: division by zero """ return float(a / b)回溯正文显示了导致异常的文件和行的信息。它还显示了直到失败代码行的整个堆栈跟踪。有时,这些信息在记录代码时会很有用。
在上面的例子中,注意如果你包含了完整的回溯体,那么你必须保持体的原始缩进。否则,测试将失败。现在继续在命令行上用
doctest运行您的测试。记得使用-v开关来获得详细的输出。构建更精细的测试
通常,您需要测试依赖于代码中其他对象的功能。例如,您可能需要测试给定类的方法。为此,您需要首先实例化该类。
doctest模块能够运行创建和导入对象、调用函数、分配变量、计算表达式等代码。在运行实际的测试用例之前,您可以利用这种能力来执行各种准备步骤。例如,假设您正在编写一个队列数据结构,并决定使用来自
collections模块的deque数据类型来有效地实现它。经过几分钟的编码,您最终得到了以下代码:# queue.py from collections import deque class Queue: def __init__(self): self._elements = deque() def enqueue(self, element): self._elements.append(element) def dequeue(self): return self._elements.popleft() def __repr__(self): return f"{type(self).__name__}({list(self._elements)})"您的
Queue类只实现了两个基本的队列操作,入队和出列。入队允许您将项目或元素添加到队列的末尾,而出队允许您从队列的开头移除和返回项目。
Queue还实现了一个.__repr__()方法,该方法提供了类的字符串表示。这个方法将在编写和运行您的doctest测试中扮演重要的角色,稍后您将对此进行探索。现在假设你想编写
doctest测试来保证.enqueue()和.dequeue()方法工作正常。为此,首先需要创建一个Queue的实例,并用一些样本数据填充它:1# queue.py 2 3from collections import deque 4 5class Queue: 6 def __init__(self): 7 self._elements = deque() 8 9 def enqueue(self, element): 10 """Add items to the right end of the queue. 11 12 >>> numbers = Queue() 13 >>> numbers 14 Queue([]) 15 16 >>> for number in range(1, 4): 17 ... numbers.enqueue(number) 18 19 >>> numbers 20 Queue([1, 2, 3]) 21 """ 22 self._elements.append(element) 23 24 def dequeue(self): 25 """Remove and return an item from the left end of the queue. 26 27 >>> numbers = Queue() 28 >>> for number in range(1, 4): 29 ... numbers.enqueue(number) 30 >>> numbers 31 Queue([1, 2, 3]) 32 33 >>> numbers.dequeue() 34 1 35 >>> numbers.dequeue() 36 2 37 >>> numbers.dequeue() 38 3 39 >>> numbers 40 Queue([]) 41 """ 42 return self._elements.popleft() 43 44 def __repr__(self): 45 return f"{type(self).__name__}({list(self._elements)})"在
enqueue()的 docstring 中,首先运行一些设置步骤。第 12 行创建了一个Queue的实例,而第 13 行和第 14 行检查该实例是否已经成功创建并且当前为空。注意您是如何使用定制的字符串表示Queue来表达这个准备步骤的输出的。第 16 行和第 17 行运行一个
for循环,该循环使用.enqueue()用一些样本数据填充Queue实例。在这种情况下,.enqueue()不返回任何东西,所以不必检查任何返回值。最后,第 19 行和第 20 行运行实际测试,确认Queue实例现在包含了预期顺序的样本数据。在
.dequeue()中,第 27 到 31 行创建了一个新的Queue实例,用一些样本数据填充它,并检查数据是否被成功添加。同样,这些是在测试.dequeue()方法本身之前需要运行的设置步骤。真正的测试出现在第 33 到 41 行。在这些行中,您调用了三次
.dequeue()。每个调用都有自己的输出线路。最后,第 39 行和第 40 行验证调用.dequeue()的结果是Queue的实例完全为空。在上面的例子中需要强调的一点是,
doctest在一个专用的上下文或范围中运行单独的文档字符串。因此,在一个 docstring 中声明的名称不能在另一个 docstring 中使用。因此,.enqueue()中定义的numbers对象在.dequeue()中是不可访问的。在测试后一种方法之前,您需要在.dequeue()中创建一个新的Queue实例。在理解
doctest作用域机制一节中,您将深入了解doctest如何管理您的测试用例的执行范围。处理空白和其他字符
关于空格和反斜杠等字符,规则有点复杂。预期的输出不能由空行或仅包含空白字符的行组成。这样的行被解释为预期输出的结尾。
如果您的预期输出包含空行,那么您必须使用
<BLANKLINE>占位符标记来替换它们:# greet.py def greet(name="World"): """Print a greeting. Usage examples: >>> greet("Pythonista") Hello, Pythonista! <BLANKLINE> How have you been? """ print(f"Hello, {name}!") print() print("How have you been?")
greet()的预期输出包含一个空行。为了让您的doctest测试通过,您必须在每个预期的空白行上使用<BLANKLINE>标签,就像您在上面突出显示的行中所做的那样。当制表符出现在测试输出中时,匹配起来也很复杂。预期输出中的制表符会自动转换为空格。相比之下,实际输出中的制表符不会被修改。
这种行为会使您的测试失败,因为预期的和实际的输出不匹配。如果您的代码输出包含制表符,那么您可以使用
NORMALIZE_WHITESPACE选项或指令使doctest测试通过。关于如何处理输出中的制表符的例子,请查看您的doctest测试部分中的嵌入指令。在你的
doctest测试中,反斜杠也需要特别注意。由于显式行连接或其他原因而使用反斜杠的测试必须使用原始字符串,也称为 r 字符串,它将准确地保存您键入的反斜杠:# greet.py def greet(name="World"): r"""Print a greeting. Usage examples: >>> greet("Pythonista") /== Hello, Pythonista! ==\ \== How have you been? ==/ """ print(f"/== Hello, {name}! ==\\") print("\\== How have you been? ==/")在这个例子中,您使用一个原始字符串来编写这个新版本的
greet()的 docstring。注意 docstring 中的前导r。请注意,在实际代码中,您将反斜杠(\\)加倍以对其进行转义,但是在 docstring 中您不需要将它加倍。如果您不想使用原始字符串作为转义反斜杠的方式,那么您可以使用通过将反斜杠加倍来转义反斜杠的常规字符串。按照这个建议,您也可以编写上面的测试用例,如下例所示:
# greet.py def greet(name="World"): """Print a greeting. Usage examples: >>> greet("Pythonista") /== Hello, Pythonista! ==\\ \\== How have you been? ==/ """ print(f"/== Hello, {name}! ==\\") print("\\== How have you been? ==/")在这个新版本的测试用例中,您在您的
doctest测试的预期输出中使用了双倍的反斜杠字符来对它们进行转义。总结
doctest测试语法正如您已经知道的,
doctest通过寻找模仿 Python 交互式会话的文本片段来识别测试。根据这个规则,以>>>提示符开始的行被解释为简单语句、复合语句头,或者表达式。类似地,以...提示符开始的行在复合语句中被解释为延续行。任何不以
>>>或...开头的行,直到下一个>>>提示符或空白行,都代表您期望的代码输出。输出必须像在 Python 交互式会话中一样,包括返回值和打印输出。空白行和>>>提示用作测试分隔符或终止符。如果在以
>>>或...开头的行之间没有任何输出行,那么doctest假设该语句预期没有输出,当您调用返回None的函数或有赋值语句时就是这种情况。
doctest模块忽略任何不符合doctest测试语法的东西。这种行为允许您在测试之间包含解释性文本、图表或任何您需要的东西。您可以在下面的示例中利用这一特性:# calculations.py # ... def divide(a, b): """Compute and return the quotient of two numbers. Usage examples: >>> divide(84, 2) 42.0 >>> divide(15, 3) 5.0 >>> divide(42, -2) -21.0 The test below checks if the function catches zero divisions: >>> divide(42, 0) Traceback (most recent call last): ZeroDivisionError: division by zero """ return float(a / b)在这次对
divide()的更新中,您在最终测试的上方添加了解释文本。注意,如果解释文本在两个测试之间,那么在解释本身之前需要一个空行。这个空行将告诉doctest先前测试的输出已经完成。下面是对
doctest测试语法的总结:
- 测试在
>>>提示之后开始,并继续...提示,就像在 Python 交互会话中一样。- 预期输出必须在测试后立即占用生产线。
- 发送到标准输出流的输出被捕获。
- 发送到标准错误流的输出没有被捕获。
- 只要预期的输出处于相同的缩进水平,测试开始的列并不重要。
标准输入流和 T2 输出流的概念超出了本教程的范围。要深入了解这些概念,请查看子进程模块:用 Python 包装程序中的标准 I/O 流部分。
了解失败测试的输出
到目前为止,你已经成功地运行了大多数
doctest测试。然而,在现实世界中,在让代码工作之前,您可能会面临许多失败的测试。在本节中,您将学习如何解释和理解失败的doctest测试产生的输出。当测试失败时,
doctest显示失败的测试和失败的原因。您将在测试报告的末尾有一行总结成功和失败的测试。例如,考虑下面的例子,在您的原始failing_tests.py文件的稍微修改版本中测试失败:# failing_tests.py """Sample failing tests. The output must be an integer >>> 5 + 7 12.0 The output must not contain quotes >>> print("Hello, World!") 'Hello, World!' The output must not use double quotes >>> "Hello," + "World!" "Hello, World!" The output must not contain leading or trailing spaces >>> print("Hello, World!") Hello, World! The traceback doesn't include the correct exception message >>> raise ValueError("incorrect value") Traceback (most recent call last): ValueError: invalid value """该文件包含一系列失败的测试。测试失败的原因各不相同。每次测试前的注释都强调了失败的根本原因。如果您从命令行使用
doctest运行这些测试,那么您将得到冗长的输出。为了更好地理解输出,您可以将其分成小块:$ python -m doctest failing_tests.py ********************************************************************** File "failing_tests.py", line 2, in failing_tests.py Failed example: 5 + 7 Expected: 12.0 Got: 12在第一段输出中,测试失败了,因为您使用了一个浮点数作为预期的输出。然而,实际输出是一个整数。您可以通过检查紧接在
Failed example:标题之后的一行来快速发现失败的测试。同样,您可以通过检查
Expected:标题下的行找到预期输出,实际输出显示在Got:标题下。通过比较预期输出和实际输出,您可能会找到失败的原因。所有失败的测试都有相似的输出格式。您会发现
Expected:和Got:标题会引导您找到导致测试失败的问题:********************************************************************** File "failing_tests.py", line 6, in failing_tests.py Failed example: print("Hello, World!") Expected: 'Hello, World!' Got: Hello, World! ********************************************************************** File "failing_tests.py", line 10, in failing_tests.py Failed example: "Hello," + " World!" Expected: "Hello, World!" Got: 'Hello, World!' ********************************************************************** File "failing_tests.py", line 14, in failing_tests.py Failed example: print("Hello, World!") Expected: Hello, World! Got: Hello, World!预期输出和实际输出之间的差异可能非常微妙,比如没有引号,使用双引号而不是单引号,甚至意外地插入前导或尾随空格。
当测试检查引发的异常时,由于异常回溯,输出可能会变得混乱。然而,仔细的检查通常会引导您找到故障的原因:
********************************************************************** File "failing_tests.py", line 18, in failing_tests.py Failed example: raise ValueError("incorrect value") Expected: Traceback (most recent call last): ValueError: invalid value Got: Traceback (most recent call last): ... raise ValueError("incorrect value") ValueError: incorrect value在本例中,预期异常显示的消息与实际异常中的消息略有不同。当您更新了代码但忘记更新相应的
doctest测试时,可能会发生类似的事情。输出的最后部分显示了失败测试的摘要:
********************************************************************** 1 items had failures: 5 of 5 in broken_tests.txt ***Test Failed*** 5 failures.在这个例子中,所有五个测试都失败了,您可以从阅读最后一行得出结论。最后一行有如下的一般格式:
***Test Failed*** N failures.这里,N表示代码中失败测试的数量。在您的项目中提供
doctest测试使用
doctest,您可以从您的文档、您的专用测试文件以及您的代码文件中的文档字符串中执行测试用例。在本节中,您将使用一个名为
calculations.py的模块作为示例项目。然后您将学习如何使用doctest来运行这个小项目的以下部分的测试:
README.md文件- 专用测试文件
- 文档字符串
在下面的可折叠部分,您将找到
calculations.py文件的完整源代码:# calculations.py """Provide several sample math calculations. This module allows the user to make mathematical calculations. Module-level tests: >>> add(2, 4) 6.0 >>> subtract(5, 3) 2.0 >>> multiply(2.0, 4.0) 8.0 >>> divide(4.0, 2) 2.0 """ def add(a, b): """Compute and return the sum of two numbers. Tests for add(): >>> add(4.0, 2.0) 6.0 >>> add(4, 2) 6.0 """ return float(a + b) def subtract(a, b): """Calculate the difference of two numbers. Tests for subtract(): >>> subtract(4.0, 2.0) 2.0 >>> subtract(4, 2) 2.0 """ return float(a - b) def multiply(a, b): """Compute and return the product of two numbers. Tests for multiply(): >>> multiply(4.0, 2.0) 8.0 >>> multiply(4, 2) 8.0 """ return float(a * b) def divide(a, b): """Compute and return the quotient of two numbers. Tests for divide(): >>> divide(4.0, 2.0) 2.0 >>> divide(4, 2) 2.0 >>> divide(4, 0) Traceback (most recent call last): ZeroDivisionError: division by zero """ return float(a / b)将上述代码保存在一个名为
calculations.py的文件中。将这个文件放在一个有正确名称的目录中。在您的项目文档中包含
doctest测试为了开始这个小项目的
doctest测试,您将从在包含calculations.py的同一个目录中创建README.md开始。这个README.md文件将使用 Markdown 语言为您的calculations.py文件提供最少的文档:<!-- README.md --> # Functions to Perform Arithmetic Calculations The `calculations.py` Python module provides basic arithmetic operations, including addition, subtraction, multiplication, and division. Here are a few examples of how to use the functions in `calculations.py`:python
import calculations
calculations.add(2, 2)
4.0calculations.subtract(2, 2)
0.0calculations.multiply(2, 2)
4.0calculations.divide(2, 2)
1.0These examples show how to use the `calculations.py` module in your code.这个 Markdown 文件包含了对您的
calculations.py文件的最小描述和一些用 Python 代码块包装的使用示例。注意,第一行代码导入了模块本身。另一个重要的细节是,您在最终测试之后和结束三个反勾号(
"\x60\x60\x60")之前包含了一个空行。您需要这个空行来表示您的doctest测试已经完成,否则三个反勾号将被视为预期的输出。您可以像往常一样使用
doctest模块运行上述 Markdown 文件中的测试:$ python -m doctest -v README.md Trying: import calculations Expecting nothing ok Trying: calculations.add(2, 2) Expecting: 4.0 ok Trying: calculations.subtract(2, 2) Expecting: 0.0 ok Trying: calculations.multiply(2, 2) Expecting: 4.0 ok Trying: calculations.divide(2, 2) Expecting: 1.0 ok 1 items passed all tests: 5 tests in README.md 5 tests in 1 items. 5 passed and 0 failed. Test passed.正如您可以从上面的输出中确认的,您的
README.md文件中的所有doctest测试都成功运行了,并且都通过了。向您的项目添加专用测试文件
在项目中提供
doctest测试的另一种方式是使用一个专用的测试文件。为此,您可以使用纯文本文件。例如,您可以使用包含以下内容的名为test_calculations.txt的文件:>>> import calculations >>> calculations.add(2, 2) 4.0 >>> calculations.subtract(2, 2) 0.0 >>> calculations.multiply(2, 2) 4.0 >>> calculations.divide(2, 2) 1.0这个 TXT 文件是一个带有一些
doctest测试的专用测试文件。同样,您可以从命令行使用doctest运行这些样本测试用例:$ python -m doctest -v test_calculations.txt Trying: import calculations Expecting nothing ok Trying: calculations.add(2, 2) Expecting: 4.0 ok Trying: calculations.subtract(2, 2) Expecting: 0.0 ok Trying: calculations.multiply(2, 2) Expecting: 4.0 ok Trying: calculations.divide(2, 2) Expecting: 1.0 ok 1 items passed all tests: 5 tests in test_calculations.txt 5 tests in 1 items. 5 passed and 0 failed. Test passed.您所有的
doctest测试都成功运行并通过。如果您不想让过多的doctest测试使您的文档变得杂乱,那么您可以使用doctest运行的专用测试文件是一个不错的选择。在代码的文档字符串中嵌入
doctest测试最后,也可能是最常见的,提供
doctest测试的方法是通过项目的文档字符串。使用文档字符串,您可以进行不同级别的测试:
- 包裹
- 组件
- 类和方法
- 功能
您可以在您的包的
__init__.py文件的 docstring 中编写包级doctest测试。其他测试将存在于它们各自容器对象的文档字符串中。例如,您的calculations.py文件有一个包含doctest测试的模块级 docstring:# calculations.py """Provide several sample math calculations. This module allows the user to make mathematical calculations. Module-level tests: >>> add(2, 4) 6.0 >>> subtract(5, 3) 2.0 >>> multiply(2.0, 4.0) 8.0 >>> divide(4.0, 2) 2.0 """ # ...同样,在所有您在
calculations.py中定义的函数中,您有包含doctest测试的函数级文档字符串。看看他们!如果您返回到定义了
Queue类的queue.py文件,那么您可以添加类级别的doctest测试,如下面的代码片段所示:# queue.py from collections import deque class Queue: """Implement a Queue data type. >>> Queue() Queue([]) >>> numbers = Queue() >>> numbers Queue([]) >>> for number in range(1, 4): ... numbers.enqueue(number) >>> numbers Queue([1, 2, 3]) """ # ...上述 docstring 中的
doctest测试检查了Queue类是如何工作的。这个例子只添加了对.enqueue()方法的测试。您能为.dequeue()方法添加测试吗?那将是很好的锻炼!您可以从命令行运行项目的 docstrings 中的所有
doctest测试,就像您到目前为止所做的那样。但是在接下来的部分中,您将更深入地研究运行您的doctest测试的不同方法。了解
doctest范围界定机制
doctest的一个重要方面是它在专用的上下文或范围中运行单个的文档字符串。当你对一个给定的模块运行doctest时,doctest会创建该模块的全局作用域的一个浅层副本。然后doctest创建一个局部作用域,其中定义了将首先执行的文档字符串中的变量。一旦测试运行,
doctest清理它的本地范围,丢弃任何本地名字。因此,在一个 docstring 中声明的本地名称不能在下一个 docstring 中使用。每个 docstring 都将在一个定制的局部作用域中运行,但是doctest全局作用域对于模块中的所有 docstring 都是通用的。考虑下面的例子:
# context.py total = 100 def decrement_by(number): """Decrement the global total variable by a given number. >>> local_total = decrement_by(50) >>> local_total 50 Changes to total don't affect the code's global scope >>> total 100 """ global total total -= number return total def increment_by(number): """Increment the global total variable by a given number. The initial value of total's shallow copy is 50 >>> increment_by(10) 60 The local_total variable is not defined in this test >>> local_total Traceback (most recent call last): NameError: name 'local_total' is not defined """ global total total += number return total如果用
doctest运行这个文件,那么所有的测试都会通过。在decrement_by()中,第一个测试定义了一个局部变量local_total,它以值50结束。这个值是从total的全局浅拷贝中减去number的结果。第二个测试显示total保持了它的初始值100,确认了doctest测试不影响代码的全局范围,只影响它的浅层拷贝。通过创建模块全局范围的浅层副本,
doctest确保运行测试不会改变实际模块的全局范围。然而,对你的全局作用域的浅层副本中的变量的改变会传播到其他的doctest测试。这就是为什么increment_by()中的第一个测试返回60而不是110。
increment_by()中的第二个测试确认在测试运行后局部范围被清理。因此,在 docstring 中定义的局部变量对其他 docstring 不可用。清理局部范围可以防止测试间的依赖,这样给定测试用例的痕迹就不会导致其他测试用例通过或失败。当您使用一个专用的测试文件来提供
doctest测试时,来自这个文件的所有测试都在相同的执行范围内运行。这样,给定测试的执行会影响后面测试的结果。这种行为不是有益的。测试需要相互独立。否则,知道哪个测试失败了并不能给你明确的线索,告诉你代码中哪里出了问题。在这种情况下,您可以通过将每个测试放在它自己的文件中,为每个测试提供它们自己的执行范围。这种实践将解决范围问题,但是会给测试运行任务增加额外的工作量。
赋予每个测试自己的执行范围的另一种方法是在函数中定义每个测试,如下所示:
>>> def test_add(): ... import calculations ... return calculations.add(2, 4) >>> test_add() 6.0在这个例子中,共享作用域中唯一的对象是
test_add()函数。calculations模块将不可用。
doctest作用域机制主要是为了保证您的doctest测试的安全和独立执行。
doctest的一些局限性探究与其他测试框架相比,
doctest最大的限制可能是缺少与 pytest 中的夹具或unittest中的设置和拆卸机制相当的功能。如果您需要安装和拆卸代码,那么您必须在每个受影响的 docstring 中编写它。或者,您可以使用unittestAPI ,它提供了一些设置和拆卸选项。
doctest的另一个限制是,它严格地将测试的预期输出与测试的实际输出进行比较。doctest模块需要精确匹配。如果只有一个字符不匹配,那么测试失败。这种行为使得正确测试一些 Python 对象变得困难。作为这种严格匹配的一个例子,假设您正在测试一个返回集合的函数。在 Python 中,集合不会以任何特定的顺序存储它们的元素,因此由于元素的随机顺序,您的测试在大多数情况下都会失败。
考虑下面这个实现了一个
User类的例子:# user.py class User: def __init__(self, name, favorite_colors): self.name = name self._favorite_colors = set(favorite_colors) @property def favorite_colors(self): """Return the user's favorite colors. Usage examples: >>> john = User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) >>> john.favorite_colors {'#797EF6', '#4ADEDE', '#1AA7EC'} """ return self._favorite_colors这个
User类带name和一系列喜欢的颜色。类初始化器将输入的颜色转换成一个set对象。favorite_colors()属性返回用户喜欢的颜色。因为集合以随机的顺序存储它们的元素,你的doctest测试在大多数时候都会失败:$ python -m doctest -v user.py Trying: john = User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) Expecting nothing ok Trying: john.favorite_colors Expecting: {'#797EF6', '#4ADEDE', '#1AA7EC'} ********************************************************************** File ".../user.py", line ?, in user.User.favorite_colors Failed example: john.favorite_colors Expected: {'#797EF6', '#4ADEDE', '#1AA7EC'} Got: {'#797EF6', '#1AA7EC', '#4ADEDE'} 3 items had no tests: user user.User user.User.__init__ ********************************************************************** 1 items had failures: 1 of 2 in user.User.favorite_colors 2 tests in 4 items. 1 passed and 1 failed. ***Test Failed*** 1 failures.第一个测试是
User实例化,它没有任何预期的输出,因为结果被赋给了一个变量。第二个测试对照函数的实际输出检查预期输出。输出是不同的,因为集合是无序的集合,这使得测试失败。要解决这个问题,您可以在您的
doctest测试中使用内置的sorted()函数:# user.py class User: def __init__(self, name, favorite_colors): self.name = name self._favorite_colors = set(favorite_colors) @property def favorite_colors(self): """Return the user's favorite colors. Usage examples: >>> john = User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) >>> sorted(john.favorite_colors) ['#1AA7EC', '#4ADEDE', '#797EF6'] """ return self._favorite_colors现在,第二个
doctest测试被包装在对sorted()的调用中,该调用返回一个排序颜色的列表。请注意,您还必须更新预期的输出,以包含排序后的颜色列表。现在测试将成功通过。去试试吧!缺乏参数化能力是
doctest的另一个限制。参数化包括为给定的测试提供输入参数和预期输出的多种组合。测试框架必须对每个组合运行目标测试,并检查是否所有的组合都通过了测试。参数化允许你用一个测试函数快速创建多个测试用例,这将增加你的测试覆盖率,并提高你的生产力。即使
doctest不直接支持参数化,你也可以用一些方便的技术来模拟该特征:# even_numbers.py def get_even_numbers(numbers): """Return the even numbers in a list. >>> args = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]] >>> expected = [[2, 4], [6, 8], [10, 12]] >>> for arg, expected in zip(args, expected): ... get_even_numbers(arg) == expected True True True """ return [number for number in numbers if number % 2 == 0]在这个例子中,首先创建两个列表,包含输入参数和
get_even_numbers()的预期输出。for循环使用内置的zip()函数并行遍历两个列表。在循环内部,您运行一个测试,将get_even_numbers()的实际输出与相应的预期输出进行比较。
doctest的另一个具有挑战性的用例是当对象依赖默认字符串表示object.__repr__()时测试对象的创建。Python 对象的默认字符串表示通常包括对象的内存地址,每次运行时都会有所不同,这会导致测试失败。继续
User的例子,假设您想要将下面的测试添加到类初始化器中:# user.py class User: def __init__(self, name, favorite_colors): """Initialize instances of User. Usage examples: >>> User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) <user.User object at 0x103283970> """ self.name = name self._favorite_colors = set(favorite_colors) # ...当实例化
User时,显示默认的字符串表示。在这种情况下,输出包括随执行而变化的存储器地址。这种变化会使您的doctest测试失败,因为内存地址永远不会匹配:$ python -m doctest -v user.py Trying: User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) Expecting: <user.User object at 0x103283970> ********************************************************************** File ".../user.py", line 40, in user.User.__init__ Failed example: User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) Expected: <user.User object at 0x103283970> Got: <user.User object at 0x10534b070> 2 items had no tests: user user.User ********************************************************************** 1 items had failures: 1 of 1 in user.User.__init__ 1 tests in 3 items. 0 passed and 1 failed. ***Test Failed*** 1 failures.这种测试总是失败,因为每次运行代码时,
User实例都会占用不同的内存地址。作为解决这个问题的方法,您可以使用doctest的ELLIPSIS指令:# user.py class User: def __init__(self, name, favorite_colors): """Initialize instances of User. Usage examples: >>> User("John", {"#797EF6", "#4ADEDE", "#1AA7EC"}) # doctest: +ELLIPSIS <user.User object at 0x...> """ self.name = name self._favorite_colors = set(favorite_colors) # ...您已经在突出显示的行的末尾添加了注释。这个注释在测试中启用了
ELLIPSIS指令。现在,您可以在预期的输出中用省略号替换内存地址。如果您现在运行测试,那么它会通过,因为doctest将省略号理解为测试输出的可变部分的替换。注意:
doctest模块定义了一些其他的指令,您可以在不同的情况下使用。您将在控制doctest的行为:标志和指令一节中了解更多关于它们的信息。当您希望输出包含对象的标识时,也会出现类似的问题,如下例所示:
>>> id(1.0)
4402192272
您将无法使用doctest来测试这样的代码。在这个例子中,您不能使用ELLIPSIS指令,因为您必须用省略号替换完整的输出,doctest会将这三个点解释为继续提示。因此,看起来测试没有输出。
考虑下面的演示示例:
# identity.py
def get_id(obj):
"""Return the identity of an object.
>>> get_id(1) # doctest: +ELLIPSIS
...
"""
return id(obj)
这个函数只是一个例子,说明即使使用了ELLIPSIS指令,一个对象的身份也会使你的测试失败。如果您用doctest运行这个测试,那么您将得到一个失败:
$ python -m doctest -v identity.py
Trying:
get_id(1) # doctest: +ELLIPSIS
Expecting nothing
**********************************************************************
File ".../identity.py", line 4, in identity.get_id
Failed example:
get_id(1) # doctest: +ELLIPSIS
Expected nothing Got:
4340007152 1 items had no tests:
identity
**********************************************************************
1 items had failures:
1 of 1 in identity.get_id
1 tests in 2 items.
0 passed and 1 failed.
***Test Failed*** 1 failures.
正如您可以从这个输出中突出显示的行中确认的那样,doctest期望输出什么都不是,但是收到了一个实际的对象标识。因此,测试失败。
使用doctest时要记住的最后一个主题是,在一个 docstring 中有许多测试会使代码难以阅读和理解,因为长的 docstring 会增加函数签名和函数体之间的距离。
幸运的是,现在这不是一个大问题,因为大多数代码编辑器允许您折叠文档字符串并专注于代码。或者,您可以将测试移动到模块级的 docstring 或专用的测试文件中。
使用doctest 时考虑安全性
在当今的信息技术行业中,安全性是一项普遍而重要的要求。从外部来源运行代码,包括以字符串或文档字符串形式出现的代码,总是隐含着安全风险。
doctest模块在内部使用 exec() 来执行嵌入在文档字符串和文档文件中的任何测试,这可以从模块的源代码中得到证实:
# doctest.py
class DocTestRunner:
# ...
def __run(self, test, compileflags, out):
# ...
try:
# Don't blink! This is where the user's code gets run. exec(
compile(example.source, filename, "single", compileflags, True),
test.globs
)
self.debugger.set_continue() # ==== Example Finished ====
exception = None
except KeyboardInterrupt:
# ...
正如突出显示的行所指出的,用户代码在对exec()的调用中运行。这个内置函数在 Python 社区中是众所周知的,因为它是一个相当危险的工具,允许执行任意代码。
doctest模块也不能幸免于与exec()相关的潜在安全问题。所以,如果你曾经用doctest测试进入外部代码库,那么避免运行测试,直到你仔细通读它们并确保它们在你的计算机上运行是安全的。
使用doctest进行测试驱动开发
在实践中,您可以使用两种不同的方法来编写和运行使用doctest的测试。第一种方法包括以下步骤:
- 写你的代码。
- 在 Python REPL 中运行代码。
- 将相关的 REPL 片段复制到您的文档字符串或文档中。
- 使用
doctest运行测试。
这种方法的主要缺点是您在步骤 1 中编写的实现可能有问题。这也违背了测试驱动开发(TDD) 的理念,因为你是在写完代码之后再写测试。
相比之下,第二种方法包括在编写通过测试的代码之前编写doctest测试。在这种情况下,步骤如下:
- 使用
doctest语法在文档字符串或文档中编写测试。 - 编写通过测试的代码。
- 使用
doctest运行测试。
这种方法保留了 TDD 的精神,即您应该在编写代码之前编写测试。
举个例子,假设你正在参加一个面试,面试官要求你实现 FizzBuzz 算法。您需要编写一个函数,它接受一个数字列表,并将任何可被 3 整除的数字替换为单词"fizz",将任何可被 5 整除的数字替换为单词"buzz"。如果一个数能被 3 和 5 整除,那么你必须用"fizz buzz"字符串替换它。
您希望使用 TDD 技术来编写这个函数,以确保可靠性。因此,您决定使用doctest测试作为快速解决方案。首先,编写一个测试来检查能被 3 整除的数字:
# fizzbuzz.py
# Replace numbers that are divisible by 3 with "fizz"
def fizzbuzz(numbers):
"""Implement the Fizz buzz game.
>>> fizzbuzz([3, 6, 9, 12])
['fizz', 'fizz', 'fizz', 'fizz']
"""
该函数还没有实现。它只有一个doctest测试,用于检查当输入数字被 3 整除时,函数是否如预期的那样工作。现在您可以运行测试来检查它是否通过:
$ python -m doctest -v fizzbuzz.py
Trying:
fizzbuzz([3, 6, 9, 12])
Expecting:
['fizz', 'fizz', 'fizz', 'fizz']
**********************************************************************
File ".../fizzbuzz.py", line 5, in fizzbuzz.fizzbuzz
Failed example:
fizzbuzz([3, 6, 9, 12])
Expected:
['fizz', 'fizz', 'fizz', 'fizz']
Got nothing
1 items had no tests:
fizzbuzz
**********************************************************************
1 items had failures:
1 of 1 in fizzbuzz.fizzbuzz
1 tests in 2 items.
0 passed and 1 failed.
***Test Failed*** 1 failures.
这个输出告诉您有一个失败的测试,这符合您的函数还没有任何代码的事实。现在您需要编写代码来通过测试:
# fizzbuzz.py
# Replace numbers that are divisible by 3 with "fizz"
def fizzbuzz(numbers):
"""Implement the Fizz buzz game.
>>> fizzbuzz([3, 6, 9, 12])
['fizz', 'fizz', 'fizz', 'fizz']
"""
result = []
for number in numbers:
if number % 3 == 0:
result.append("fizz")
else:
result.append(number)
return result
现在,您的函数对输入的数字进行迭代。在循环中,您在一个条件语句中使用模运算符(%)来检查当前数字是否能被 3 整除。如果检查成功,那么您将"fizz"字符串追加到result,它最初保存一个空的list对象。否则,您将追加数字本身。
如果您现在用doctest运行测试,那么您将得到以下输出:
python -m doctest -v fizzbuzz.py
Trying:
fizzbuzz([3, 6, 9, 12])
Expecting:
['fizz', 'fizz', 'fizz', 'fizz']
ok
1 items had no tests:
fizz
1 items passed all tests:
1 tests in fizz.fizzbuzz
1 tests in 2 items.
1 passed and 0 failed.
Test passed.
酷!你已经通过了测试。现在您需要测试能被 5 整除的数字。以下是更新后的doctest测试以及通过测试的代码:
# fizzbuzz.py
# Replace numbers that are divisible by 5 with "buzz"
def fizzbuzz(numbers):
"""Implement the Fizz buzz game.
>>> fizzbuzz([3, 6, 9, 12])
['fizz', 'fizz', 'fizz', 'fizz']
>>> fizzbuzz([5, 10, 20, 25]) ['buzz', 'buzz', 'buzz', 'buzz'] """
result = []
for number in numbers:
if number % 3 == 0:
result.append("fizz")
elif number % 5 == 0: result.append("buzz") else:
result.append(number)
return result
前两行突出显示的内容提供了被 5 整除的数字的测试和预期输出。第二对突出显示的行实现了运行检查的代码,并用所需的字符串"buzz"替换数字。继续运行测试以确保代码通过。
最后一步是检查能被 3 和 5 整除的数字。通过检查能被 15 整除的数字,你可以一步完成。下面是doctest测试和所需的代码更新:
# fizzbuzz.py
# Replace numbers that are divisible by 3 and 5 with "fizz buzz"
def fizzbuzz(numbers):
"""Implement the Fizz buzz game.
>>> fizzbuzz([3, 6, 9, 12])
['fizz', 'fizz', 'fizz', 'fizz']
>>> fizzbuzz([5, 10, 20, 25])
['buzz', 'buzz', 'buzz', 'buzz']
>>> fizzbuzz([15, 30, 45]) ['fizz buzz', 'fizz buzz', 'fizz buzz']
>>> fizzbuzz([3, 6, 5, 2, 15, 30]) ['fizz', 'fizz', 'buzz', 2, 'fizz buzz', 'fizz buzz'] """
result = []
for number in numbers:
if number % 15 == 0: result.append("fizz buzz") elif number % 3 == 0: result.append("fizz")
elif number % 5 == 0:
result.append("buzz")
else:
result.append(number)
return result
在对fizzbuzz()函数的最后一次更新中,您添加了doctest测试来检查能被 3 和 5 整除的数字。您还将添加一个最终测试,用不同的数字来检查函数。
在函数体中,在链式if … elif语句的开头添加一个新分支。这个新分支检查可被 3 和 5 整除的数字,用"fizz buzz"字符串替换它们。请注意,您需要将该检查放在链的开始,因为否则,该函数将不能很好地工作。
运行您的 Python doctest测试
到目前为止,您已经运行了许多doctest测试。要运行它们,您可以使用命令行和带有-v选项的doctest命令来生成详细输出。然而,这并不是运行您的doctest测试的唯一方式。
在接下来的小节中,您将学习如何从 Python 代码内部运行doctest测试。您还将了解关于从命令行或终端运行doctest的更多细节。
从您的代码运行doctest
Python 的doctest模块导出了两个函数,当您需要从 Python 代码而不是命令行运行doctest测试时,这两个函数会派上用场。这些功能如下:
| 功能 | 描述 |
|---|---|
T2testfile() |
从专用的测试文件运行doctest测试 |
T2testmod() |
从 Python 模块运行doctest测试 |
以您的test_calculations.txt为起点,您可以使用 Python 代码中的testfile()来运行这个文件中的测试。为此,您只需要两行代码:
# run_file_tests.py
import doctest
doctest.testfile("test_calculations.txt", verbose=True)
第一行导入doctest,而第二行使用您的测试文件作为参数调用testfile()。在上面的例子中,您使用了verbose参数,这使得函数产生详细的输出,就像从命令行运行doctest时使用的-v选项一样。如果不将verbose设置为True,那么testfile()将不会显示任何输出,除非测试失败。
测试文件的内容被视为包含您的doctest测试的单个 docstring。该文件不必是 Python 程序或模块。
testfile()函数带有几个其他的可选参数,允许您在运行测试的过程中定制进一步的细节。您必须使用关键字参数来提供函数的任何可选参数。查看函数的文档,了解关于其参数及其各自含义的更多信息。
如果您需要从您的代码库运行常规 Python 模块中的doctest测试,那么您可以使用testmod()函数。您可以通过两种不同的方式使用该函数。第一种方法是在目标模块中附加以下代码片段:
if __name__ == "__main__":
import doctest
doctest.testmod(verbose=True)
当文件作为脚本运行时, name-main 习语允许您执行代码,但当它作为模块导入时则不允许。在这个条件中,首先导入doctest,然后在verbose设置为True的情况下调用testmod()。如果你将模块作为脚本运行,那么doctest将运行它在模块中发现的所有测试。
testmod()的所有参数都是可选的。为了提供它们,除了第一个参数之外,您需要对所有参数使用关键字参数,第一个参数可以选择保存一个模块对象。
用testmod()运行doctest测试的第二种方法是创建一个专用的测试运行程序文件。例如,如果您想在calculation.py中运行测试而不修改模块本身,那么您可以创建一个包含以下内容的run_module_tests.py文件:
# run_module_tests.py
import doctest
import calculations
doctest.testmod(calculations, verbose=True)
这一次,您需要导入目标模块calculations,并将模块对象作为第一个参数传递给testmod()。这个调用将使doctest运行calculations.py中定义的所有测试。继续使用下面的命令尝试一下:
$ python run_module_tests.py
运行这个命令后,您将得到典型的doctest输出,其中包含了关于您的calculations模块中测试的所有细节。关于命令的输出,重要的是要记住,如果不将verbose设置为True,那么除非测试失败,否则不会得到任何输出。在下一节中,您将了解更多关于失败测试的输出。
除了目标模块和verbose标志之外,testmod()还有几个其他参数,允许您调整测试执行的不同方面。查看函数的文档以获得关于当前参数的更多细节。
最后,本节中的函数旨在使doctest易于使用。然而,它们给你有限的定制能力。如果您需要用doctest对测试代码的过程进行更细粒度的控制,那么您可以使用该模块的高级 API 。
从命令行执行doctest
您已经知道了使用doctest命令从命令行运行doctest测试的基础。使用该命令最简单的方法是将目标文件或模块作为参数。例如,您可以通过执行以下命令来运行您的calculations.py文件中的所有测试:
$ python -m doctest calculations.py
这个命令运行测试,但是不发出任何输出,除非您有一些失败的测试。这就是为什么在迄今为止运行的几乎所有示例中都使用了-v开关。
正如您已经了解到的,-v或--verbose开关让doctest发布一份它已经运行的所有测试的详细报告,并在报告的末尾附上一份摘要。除了这个命令行选项,doctest还接受以下选项:
| [计]选项 | 描述 |
|---|---|
-h,--help |
显示doctest的命令行帮助 |
-o,--option |
指定在运行测试时使用的一个或多个doctest选项标志或指令 |
-f,--fail-fast |
在第一次失败后停止运行您的doctest测试 |
在大多数情况下,您可能会从命令行运行doctest。在上表中,您会发现最复杂的选项是-o或--option,因为有一个很长的标志列表可供您使用。您将在命令行部分的使用标志中了解更多关于这些标志的信息。
控制doctest的行为:标志和指令
doctest模块提供了一系列命名的常量,当您使用-o或--option开关从命令行运行doctest时,可以将它们用作标志。当您向您的doctest测试添加指令时,您也可以使用这些常量。
使用这组常量作为命令行标志或指令将允许您控制doctest的各种行为,包括:
- 接受
1的True - 拒绝空行
- 规范化空白
- 用省略号(
...)缩写输出 - 忽略异常细节,如异常消息
- 跳过给定的测试
- 第一次失败测试后结束
此列表不包括所有当前选项。您可以查看文档以获得常量及其含义的完整列表。
在下一节中,您将从学习如何从命令行使用这个简洁的doctest特性开始。
在命令行使用标志
当您使用-o或--option开关从命令行运行doctest时,您可以使用标志常量。例如,假设您有一个名为options.txt的测试文件,其内容如下:
>>> 5 < 7
1
在这个测试中,您使用1作为预期输出,而不是使用True。这个测试会通过,因为doctest允许分别用1和0替换True和False。这个特性与 Python 布尔值可以用整数表示这一事实有关。因此,如果您用doctest运行这个文件,那么测试将会通过。
历史上,doctest让布尔值被1和0代替,以方便向 Python 2.3 的过渡,后者引入了专用的布尔类型。但是,这种行为在某些情况下可能不完全正确。幸运的是, DONT_ACCEPT_TRUE_FOR_1 标志将使这个测试失败:
$ python -m doctest -o DONT_ACCEPT_TRUE_FOR_1 options.txt
**********************************************************************
File "options.txt", line 3, in options.txt
Failed example:
5 < 7
Expected:
1 Got:
True **********************************************************************
1 items had failures:
1 of 1 in options.txt
***Test Failed*** 1 failures.
通过运行带有DONT_ACCEPT_TRUE_FOR_1标志的doctest命令,您可以让测试严格检查布尔值、True或False,如果是整数则失败。要修复测试,您必须将预期输出从1更新到True。之后,您可以再次运行测试,它会通过。
现在假设您有一个具有大量输出的测试,您需要一种方法来简化预期的输出。在这种情况下,doctest允许您使用省略号。继续将以下测试添加到您的options.txt图块的末尾:
>>> print("Hello, Pythonista! Welcome to Real Python!")
Hello, ... Python!
如果您使用doctest运行这个文件,那么第二个测试将会失败,因为预期的输出与实际的输出不匹配。为了避免这种失败,您可以使用ELLIPSIS标志运行doctest:
- 视窗
** Linux + macOS*
PS> python -m doctest `
> -o DONT_ACCEPT_TRUE_FOR_1 `
> -o ELLIPSIS options.txt
$ python -m doctest \
-o DONT_ACCEPT_TRUE_FOR_1 \
-o ELLIPSIS options.txt
这个命令不会为您的第二个测试发出任何输出,因为您使用了 ELLIPSIS 标志。这个标志让doctest知道...字符替换了部分预期输出。
注意,要在doctest的一次运行中传递多个标志,每次都需要使用-o开关。遵循这种模式,您可以根据需要使用任意多的标志,使您的测试更加健壮、严格或灵活。
处理像制表符这样的空白字符是一项相当具有挑战性的任务,因为doctest会自动用常规空格替换它们,从而使您的测试失败。考虑向您的options.txt文件添加一个新的测试:
>>> print("\tHello, World!")
Hello, World!
即使您在测试及其预期输出中使用制表符,该测试也会失败,因为doctest在预期输出中用空格内部替换制表符:
- 视窗
** Linux + macOS*
PS> python -m doctest `
> -o DONT_ACCEPT_TRUE_FOR_1 `
> -o ELLIPSIS options.txt
**********************************************************************
File "options.txt", line 9, in options.txt
Failed example:
print("\tHello, World!")
Expected:
Hello, World!
Got:
Hello, World!
**********************************************************************
1 items had failures:
1 of 3 in options.txt
***Test Failed*** 1 failures.
$ python -m doctest \
-o DONT_ACCEPT_TRUE_FOR_1 \
-o ELLIPSIS options.txt
**********************************************************************
File "options.txt", line 9, in options.txt
Failed example:
print("\tHello, World!")
Expected:
Hello, World!
Got:
Hello, World!
**********************************************************************
1 items had failures:
1 of 3 in options.txt
***Test Failed*** 1 failures.
如果您曾经有一个测试发出了一个像这样的特殊空白字符,那么您可以在下面的命令中使用 NORMALIZE_WHITESPACE 标志:
- 视窗
** Linux + macOS*
PS> python -m doctest `
> -o DONT_ACCEPT_TRUE_FOR_1 `
> -o ELLIPSIS `
> -o NORMALIZE_WHITESPACE options.txt
$ python -m doctest \
-o DONT_ACCEPT_TRUE_FOR_1 \
-o ELLIPSIS \
-o NORMALIZE_WHITESPACE options.txt
现在您的输出将是干净的,因为doctest已经为您规范化了制表符。
在您的doctest测试中嵌入指令
一个doctest 指令由一个行内注释组成,该注释以# doctest:开始,然后包括一个逗号分隔的标志常量列表。指令启用或禁用给定的doctest功能。要启用该功能,请在旗帜名称前写一个加号(+)。要禁用某个功能,可以写一个减号(–)来代替。
当您从命令行使用doctest时,指令的工作方式类似于标志。然而,指令允许您进行更细粒度的控制,因为它们在您的doctest测试中的特定行上工作。
例如,您可以向您的options.txt添加一些指令,这样您就不需要在运行doctest时传递多个命令行标志:
>>> 5 < 7 # doctest: +DONT_ACCEPT_TRUE_FOR_1 True
>>> print(
... "Hello, Pythonista! Welcome to Real Python!"
... ) # doctest: +ELLIPSIS Hello, ... Python!
>>> print("\tHello, World!") # doctest: +NORMALIZE_WHITESPACE
Hello, World!
在这段代码中,突出显示的行在测试旁边插入内联指令。第一个指令允许强制使用布尔值。第二个指令允许您使用省略号来缩写测试的预期输出。final 指令对预期和实际输出中的空白字符进行规范化。
现在,您可以运行options.txt文件,而无需向doctest命令传递任何标志:
$ python -m doctest options.txt
这个命令不会发出任何输出,因为doctest指令已经处理了测试的所有需求。
在doctest中,标志和指令非常相似。主要的区别在于,标志旨在从命令行使用,而指令必须在测试本身中使用。在某种意义上,标志比指令更动态。当在测试策略中使用标志、指令或两者时,您总能找到一个好的平衡点。
使用unittest和 pytest 运行doctest测试
doctest模块提供了一种非常方便的方式来将测试用例添加到项目的文档中。然而,doctest并不能替代成熟的测试框架,比如标准库 unittest 或者第三方 pytest 。在具有大量复杂代码库的大型项目中尤其如此。对于这类项目,doctest可能不够用。
举例来说,假设你正在开始一个新项目,为少数客户提供一个创新的 web 服务。在这一点上,您认为使用doctest来自动化您的测试过程是可以的,因为这个项目的规模和范围都很小。因此,您在文档和 docstrings 中嵌入了一堆doctest测试,每个人都很高兴。
在没有任何警告的情况下,您的项目开始变得越来越大,越来越复杂。您现在为越来越多的用户提供服务,他们不断要求新的功能和错误修复。现在,您的项目需要提供更可靠的服务。
由于这种新情况,你已经注意到doctest测试不够灵活和强大,不足以确保可靠性。你需要一个全功能的测试框架,包括夹具、安装和拆卸机制、参数化等等。
在这种情况下,您认为如果您决定使用unittest或 pytest,那么您将不得不重写所有旧的doctest测试。好消息是你不必这么做。unittest和 pytest 都可以运行doctest测试。这样,您的旧测试将自动加入到您的测试用例库中。
使用unittest运行doctest测试
如果你想用unittest运行doctest测试,那么你可以使用doctest API。API 允许你将doctest测试转换成 unittest测试套件。为此,您将有两个主要函数:
| 功能 | 描述 |
|---|---|
T2DocFileSuite() |
将一个或多个文本文件中的doctest测试转换成一个unittest测试套件 |
T2DocTestSuite() |
将模块中的doctest测试转换成unittest测试套件 |
要将您的doctest测试与unittest发现机制集成,您必须向您的unittest样板代码添加一个load_tests()函数。举个例子,回到你的test_calculations.txt文件:
>>> import calculations
>>> calculations.add(2, 2)
4.0
>>> calculations.subtract(2, 2)
0.0
>>> calculations.multiply(2, 2)
4.0
>>> calculations.divide(2, 2)
1.0
正如您已经知道的,这个文件包含了对您的calculations.py文件的doctest测试。现在假设您需要将test_calculations.txt中的doctest测试集成到您的unittest基础设施中。在这种情况下,您可以执行如下操作:
# test_calculations.py
import doctest
import unittest
def load_tests(loader, tests, ignore):
tests.addTests(doctest.DocFileSuite("test_calculations.txt")) return tests
# Your unittest tests goes here...
if __name__ == "__main__":
unittest.main()
unittest会自动调用load_tests()函数,框架会在您的代码中发现测试。突出显示的线条很神奇。它加载在test_calculations.txt中定义的doctest测试,并将它们转换成unittest测试套件。
一旦将这个函数添加到您的unittest基础设施中,您就可以使用以下命令运行该套件:
$ python test_calculations.py
.
---------------------------------------------------------------
Ran 1 test in 0.004s
OK
酷!您的doctest测试成功运行。从这个输出中,您可以得出结论,unittest将测试文件的内容解释为单个测试,这与doctest将测试文件解释为单个 docstring 的事实是一致的。
在上面的例子中,所有的测试都通过了。如果您曾经有过失败的测试,那么您将得到模拟失败测试的常规doctest输出的输出。
如果您的doctest测试存在于您代码的文档字符串中,那么您可以使用下面的load_tests()变体将它们集成到您的unittest套件中:
# test_calculations.py
import doctest
import unittest
import calculations
def load_tests(loader, tests, ignore):
tests.addTests(doctest.DocTestSuite(calculations)) return tests
# Your unittest goes here...
if __name__ == "__main__":
unittest.main()
您不是从专用的测试文件中加载doctest测试,而是使用DocTestSuite()函数从calculations.py模块中读取它们。如果您现在运行上面的文件,那么您将得到以下输出:
$ python test_calculations.py
.....
---------------------------------------------------------------
Ran 5 tests in 0.004s
OK
这一次,输出反映了五个测试。原因是您的calculations.py文件包含一个模块级 docstring 和四个带有doctest测试的函数级 docstring。每个独立的文档字符串被解释为一个单独的测试。
最后,您还可以将来自一个或多个文本文件的测试和来自load_tests()函数中的一个模块的测试结合起来:
import doctest
import unittest
import calculations
def load_tests(loader, tests, ignore):
tests.addTests(doctest.DocFileSuite("test_calculations.txt")) tests.addTests(doctest.DocTestSuite(calculations)) return tests
if __name__ == "__main__":
unittest.main()
这个版本的load_tests()从test_calculations.txt和calculations.py模块运行doctest测试。继续从命令行运行上面的脚本。您的输出将反映六个通过的测试,包括来自calculations.py的五个测试和来自test_calculations.txt的一个测试。记住像test_calculations.txt这样的专用测试文件被解释为一个单独的测试。
使用 pytest 运行doctest测试
如果你决定使用 pytest 第三方库来自动化你的项目测试,那么你也可以集成你的doctest测试。在这种情况下,您可以使用 pytest 的--doctest-glob命令行选项,如下例所示:
$ pytest --doctest-glob="test_calculations.txt"
运行此命令时,您会得到如下输出:
===================== test session starts =====================
platform darwin -- Python 3.10.3, pytest-7.1.1, pluggy-1.0.0
rootdir: .../python-doctest/examples
collected 1 item
test_calculations.txt . [100%]
===================== 1 passed in 0.02s =======================
就像unittest一样,pytest 将您的专用测试文件解释为单个测试。--doctest-glob选项接受并匹配允许您运行多个文件的模式。一个有用的模式可能是"test*.txt"。
您也可以直接从代码的文档字符串中执行doctest测试。为此,您可以使用--doctest-modules命令行选项。这个命令行选项将扫描您的工作目录下的所有模块,加载并运行它找到的任何doctest测试。
如果您想使这种集成永久化,那么您可以将以下参数添加到项目根目录下的 pytest 配置文件中:
; pytest.ini
[pytest]
addopts = --doctest-modules
从现在开始,每当您在项目目录上运行 pytest 时,所有的doctest测试都会被找到并执行。
结论
现在你知道如何编写同时作为文档和测试用例的代码示例。为了将您的示例作为测试用例运行,您使用了 Python 标准库中的doctest模块。这个模块用一个低学习曲线的快速测试框架武装了你,允许你立即开始自动化你的测试过程。
在本教程中,您学习了如何:
- 将
doctest测试添加到您的文档和文档字符串中 - 使用 Python 的
doctest模块 - 解决
doctest中的限制和安全隐患 - 使用
doctest和测试驱动开发方法 - 使用不同的策略和工具执行
doctest测试
使用doctest测试,您将能够快速自动化您的测试。您还将保证您的代码及其文档始终保持同步。
示例代码: 点击这里下载免费的示例代码,您将使用 Python 的doctest同时记录和测试您的代码。***********************


 浙公网安备 33010602011771号
浙公网安备 33010602011771号