RealPython-中文系列教程-三-
RealPython 中文系列教程(三)
原文:RealPython
用 Python 定制 Django 管理
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Django Admin 定制
Django 框架附带了一个强大的管理工具,名为 admin 。您可以使用它从 web 界面中快速添加、删除或编辑任何数据库模型。但是只需一点额外的代码,您就可以定制 Django admin,使您的管理能力更上一层楼。
在本教程中,您将学习如何:
- 在模型对象列表中添加属性列
- 模型对象之间的链接
- 将过滤器添加到模型对象列表
- 使模型对象列表可搜索
- 修改对象编辑表单
- 覆盖 Django 管理模板
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
先决条件
为了充分利用本教程,您需要熟悉 Django,尤其是模型对象。由于 Django 不是标准 Python 库的一部分,所以如果您也有一些关于pip和pyenv(或者一个等效的虚拟环境工具)的知识,那就最好了。要了解有关这些主题的更多信息,请查看以下资源:
你也可能对众多可用的 Django 教程中的一个感兴趣。
本教程中的代码片段是针对 Django 3.0.7 测试的。所有的概念都出现在 Django 2.0 之前,所以它们应该可以在您使用的任何版本中工作,但是可能存在一些细微的差别。
设置 Django 管理员
Django admin 提供了一个基于 web 的界面来创建和管理数据库模型对象。要看到它的运行,你首先需要一个 Django 项目和一些对象模型。在干净的虚拟环境中安装 Django:
$ python -m pip install django
$ django-admin startproject School
$ cd School
$ ./manage.py startapp core
$ ./manage.py migrate
$ ./manage.py createsuperuser
Username: admin
Email address: admin@example.com
Password:
Password (again):
首先创建一个名为School的新 Django 项目,并使用一个名为core的应用程序。然后迁移身份验证表并创建一个管理员。对 Django 管理屏幕的访问仅限于带有staff或superuser标志的用户,所以您使用createsuperuser管理命令来创建一个superuser。
您还需要修改School/settings.py以包含名为core的新应用程序:
# School/settings.py
# ...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"core", # Add this line ]
core app 目录将从以下文件开始:
core/
│
├── migrations/
│ └── __init__.py
│
├── __init__.py
├── admin.py
├── apps.py
├── models.py
├── tests.py
└── views.py
您对其中的两个文件感兴趣:
models.py定义了你的数据库型号。admin.py向 Django 管理员注册你的模型。
为了演示定制 Django admin 时的结果,您需要一些模型。编辑core/models.py:
from django.core.validators import MinValueValidator, MaxValueValidator
from django.db import models
class Person(models.Model):
last_name = models.TextField()
first_name = models.TextField()
courses = models.ManyToManyField("Course", blank=True)
class Meta:
verbose_name_plural = "People"
class Course(models.Model):
name = models.TextField()
year = models.IntegerField()
class Meta:
unique_together = ("name", "year", )
class Grade(models.Model):
person = models.ForeignKey(Person, on_delete=models.CASCADE)
grade = models.PositiveSmallIntegerField(
validators=[MinValueValidator(0), MaxValueValidator(100)])
course = models.ForeignKey(Course, on_delete=models.CASCADE)
这些模型代表在学校上课的学生。一个Course有一个name和一个year在其中被提供。一个Person有一个名和一个姓,可以带零个或多个courses。A Grade包含 a Person在Course上获得的百分比分数。
这是一个模型图,显示了对象之间的关系:
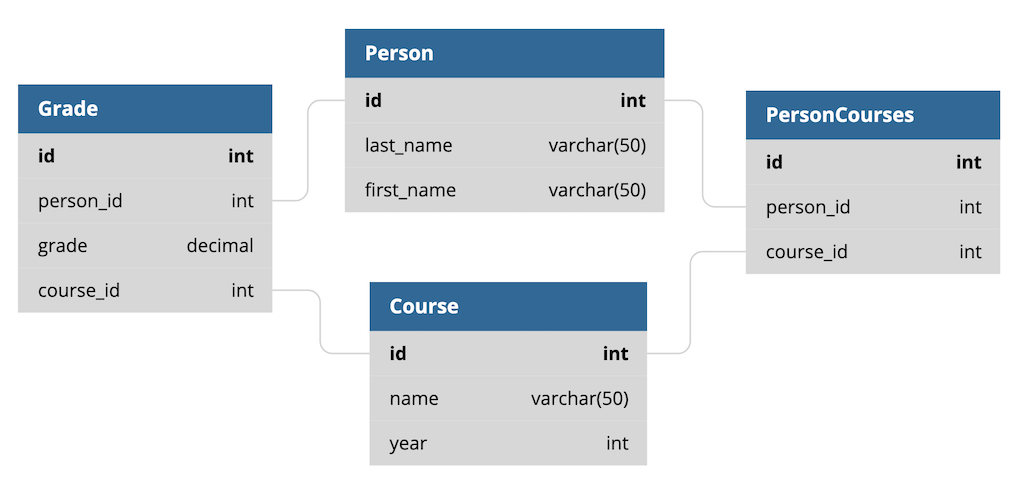
数据库中的底层表名与此略有不同,但它们与上面显示的模型相关。
您希望 Django 在管理界面中表示的每个模型都需要注册。您可以在admin.py文件中这样做。来自core/models.py的模型被登记在相应的core/admin.py文件中:
from django.contrib import admin
from core.models import Person, Course, Grade
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
pass
@admin.register(Course)
class CourseAdmin(admin.ModelAdmin):
pass
@admin.register(Grade)
class GradeAdmin(admin.ModelAdmin):
pass
你差不多可以走了。一旦迁移了数据库模型,就可以运行 Django 开发服务器并查看结果:
$ ./manage.py makemigrations
$ ./manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, core, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
...
Applying core.0001_initial... OK
Applying core.0002_auto_20200609_2120... OK
Applying sessions.0001_initial... OK
$ ./manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
Django version 3.0.7, using settings 'School.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
现在访问http://127.0.0.1:8000/admin查看您的管理界面。系统会提示您登录。使用您用createsuperuser管理命令创建的凭证。
管理主页屏幕列出了所有注册的数据库模型:
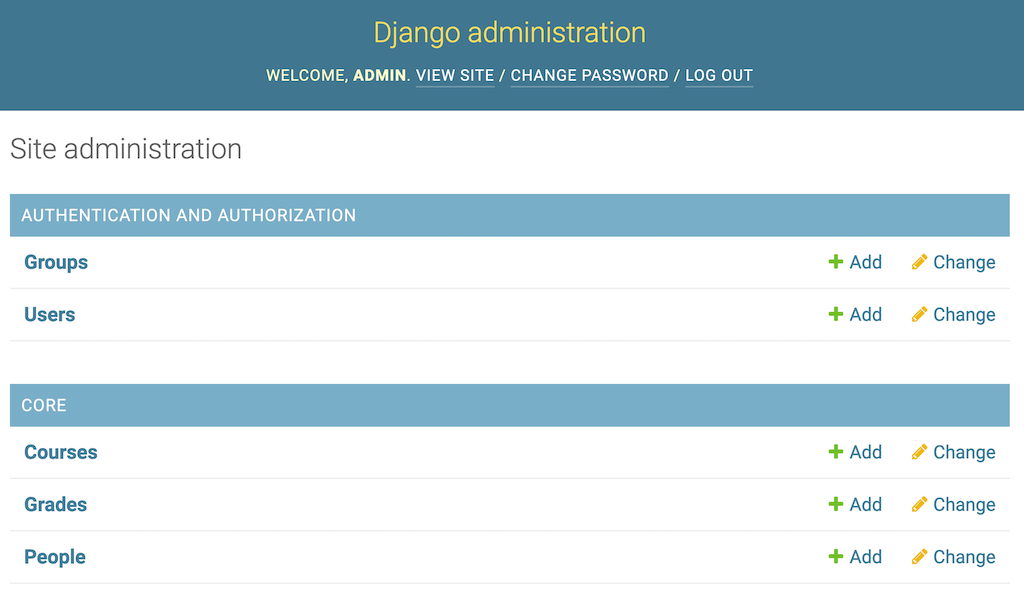
现在,您可以使用该接口在数据库中创建对象。单击一个模型名称将显示一个屏幕,列出该模型数据库中的所有对象。以下是Person列表:
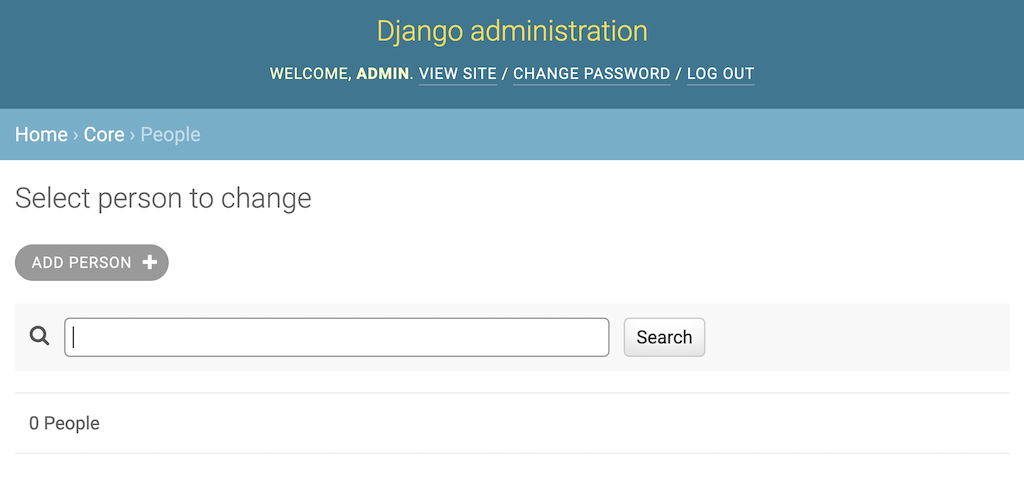
列表开始是空的,就像你的数据库一样。点击添加人员可以在数据库中创建人员。保存后,您将返回到Person对象列表:
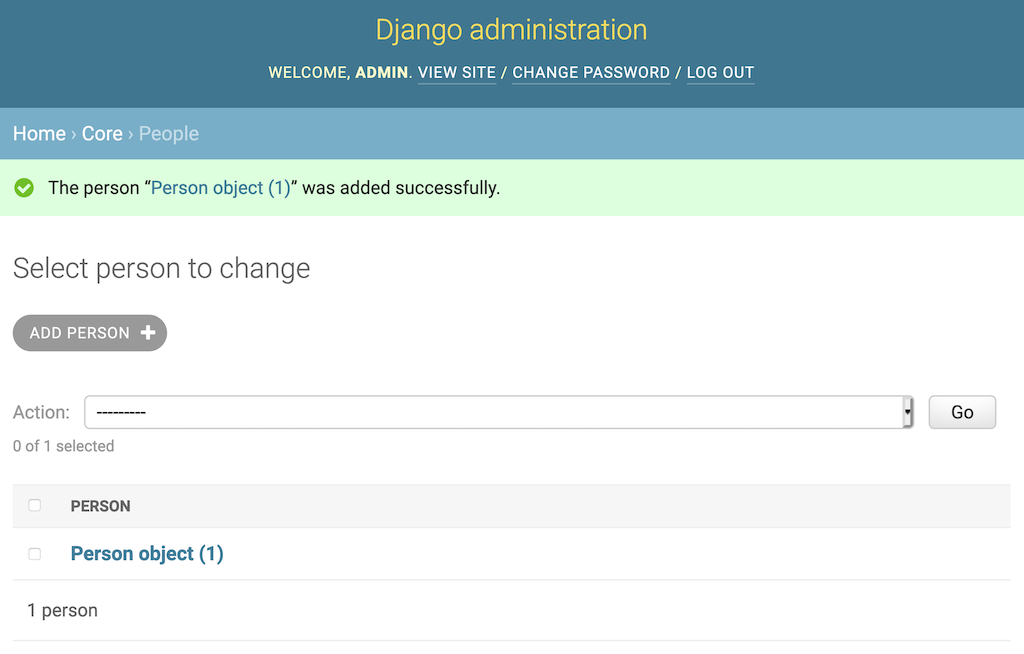
好消息是你有对象了。坏消息是,Person object (1)只告诉你物体的id,没有告诉你别的。默认情况下,Django admin 通过调用str()来显示每个对象。您可以通过向core/models.py中的Person类添加一个.__str__()方法来使这个屏幕更有帮助:
class Person(models.Model):
last_name = models.TextField()
first_name = models.TextField()
courses = models.ManyToManyField("Course", blank=True)
def __str__(self):
return f"{self.last_name}, {self.first_name}"
添加Person.__str__()会改变显示,在界面中包含Person的名和姓。您可以刷新屏幕来查看更改:
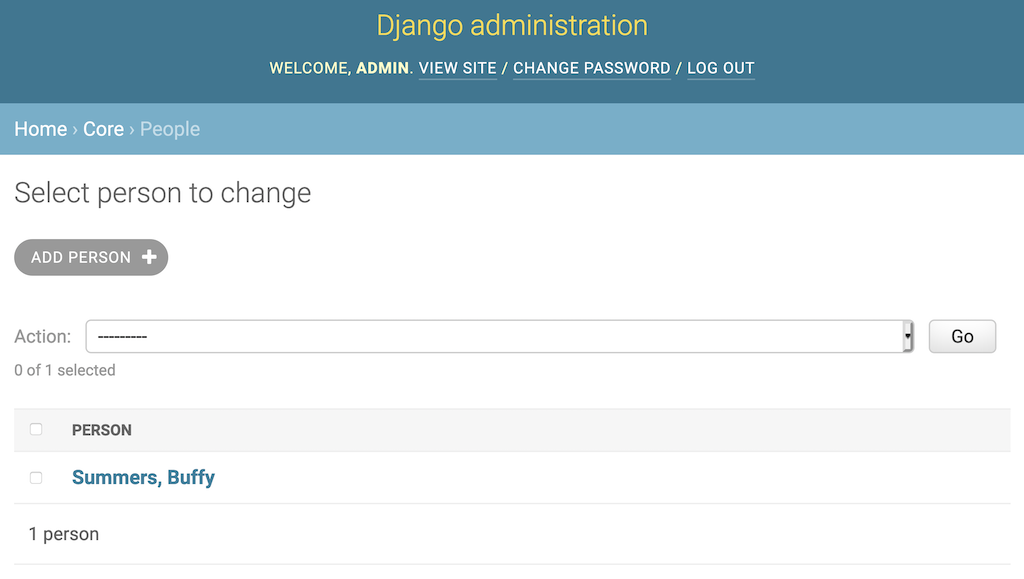
那好一点了!现在你可以看到一些关于Person对象的信息。向Course和Grade对象添加类似的方法是个好主意:
class Course(models.Model):
# ...
def __str__(self):
return f"{self.name}, {self.year}"
class Grade(models.Model):
# ...
def __str__(self):
return f"{self.grade}, {self.person}, {self.course}"
您需要在数据库中保存一些数据,以查看定制的全部效果。你可以找点乐子,现在就创建你自己的数据,或者你可以跳过工作,使用一个夹具。展开下面的方框,了解如何使用夹具加载数据。
Django 允许您在名为 fixtures 的文件中向数据库加载数据,或者从数据库中加载数据。将以下内容复制到名为core/fixtures/school.json的文件中:
[ { "model": "core.person", "pk": 1, "fields": { "last_name": "Harris", "first_name": "Xander", "courses": [ 1, 3 ] } }, { "model": "core.person", "pk": 3, "fields": { "last_name": "Rosenberg", "first_name": "Willow", "courses": [ 1, 2, 3 ] } }, { "model": "core.person", "pk": 16, "fields": { "last_name": "Summers", "first_name": "Buffy", "courses": [ 1, 2, 3 ] } }, { "model": "core.course", "pk": 1, "fields": { "name": "CompSci G11", "year": 1998 } }, { "model": "core.course", "pk": 2, "fields": { "name": "Psych 101", "year": 1999 } }, { "model": "core.course", "pk": 3, "fields": { "name": "Library Science G10", "year": 1997 } }, { "model": "core.grade", "pk": 1, "fields": { "person": 16, "grade": 68, "course": 1 } }, { "model": "core.grade", "pk": 2, "fields": { "person": 16, "grade": 87, "course": 2 } }, { "model": "core.grade", "pk": 3, "fields": { "person": 16, "grade": 76, "course": 3 } }, { "model": "core.grade", "pk": 4, "fields": { "person": 1, "grade": 58, "course": 1 } }, { "model": "core.grade", "pk": 5, "fields": { "person": 1, "grade": 58, "course": 3 } }, { "model": "core.grade", "pk": 6, "fields": { "person": 3, "grade": 98, "course": 3 } }, { "model": "core.grade", "pk": 7, "fields": { "person": 3, "grade": 97, "course": 2 } } ]
一旦创建了文件,就可以使用 Django 管理命令loaddata将其加载到数据库中:
$ ./manage.py loaddata school
Installed 13 object(s) from 1 fixture(s)
您的数据库现在有了一些样本Person、Course和Grade对象。
现在您已经有了一些要处理的数据,可以开始定制 Django 的管理界面了。
定制 Django 管理
创建 Django 框架的聪明人不仅构建了 admin,而且他们以一种你可以为你的项目定制它的方式来实现它。当您之前注册了PersonAdmin对象时,它继承了admin.ModelAdmin。你可以用 Django admin 做的大部分定制都是通过修改ModelAdmin来完成的,你当然可以修改它!
拥有超过 30 个属性和将近 50 个方法。您可以使用其中的每一个来微调管理员的演示和控制您的对象的界面。这些选项中的每一个都在文档中有详细描述。
最重要的是,管理员是使用 Django 的模板接口构建的。Django 模板机制允许您覆盖现有的模板,因为 admin 只是另一组模板,这意味着您可以完全更改它的 HTML。
虽然这超出了本教程的范围,但是您甚至可以创建多个管理站点。这看起来有点过分,但是它允许你用不同的权限为用户定义不同的网站,这些用户有不同的 T2 权限。
Django 管理分为三个主要部分:
- 应用程序索引
- 更改列表
- 改变形式
应用索引列出了您注册的型号。为每个注册的模型自动创建一个变更列表,并列出该模型的对象。当您添加或编辑其中一个对象时,您可以通过更改表单来完成。
在前面的例子中,应用程序索引显示了Person、Course和Grade对象。点击人物显示Person对象的变更列表。在Person变更列表页面,点击Buffy Summers对象进入变更表单,编辑 Buffy 的详细信息。
使用list_display 修改变更列表
实现.__str__()是将Person对象的表示从无意义的字符串转变为可理解数据的快速方法。因为这种表示法也会出现在下拉菜单和多选菜单中,所以你肯定希望它尽可能容易理解。
除了修改对象的字符串表示之外,您还可以通过更多方式自定义更改列表页面。一个admin.ModelAdmin对象的list_display属性指定了哪些列显示在变更列表中。该值是正在建模的对象的一组属性。例如,在core/admin.py中,将PersonAdmin修改如下:
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
list_display = ("last_name", "first_name")
上面的代码修改了您的Person变更列表,以显示每个Person对象的last_name和first_name属性。每个属性都显示在页面的一列中:
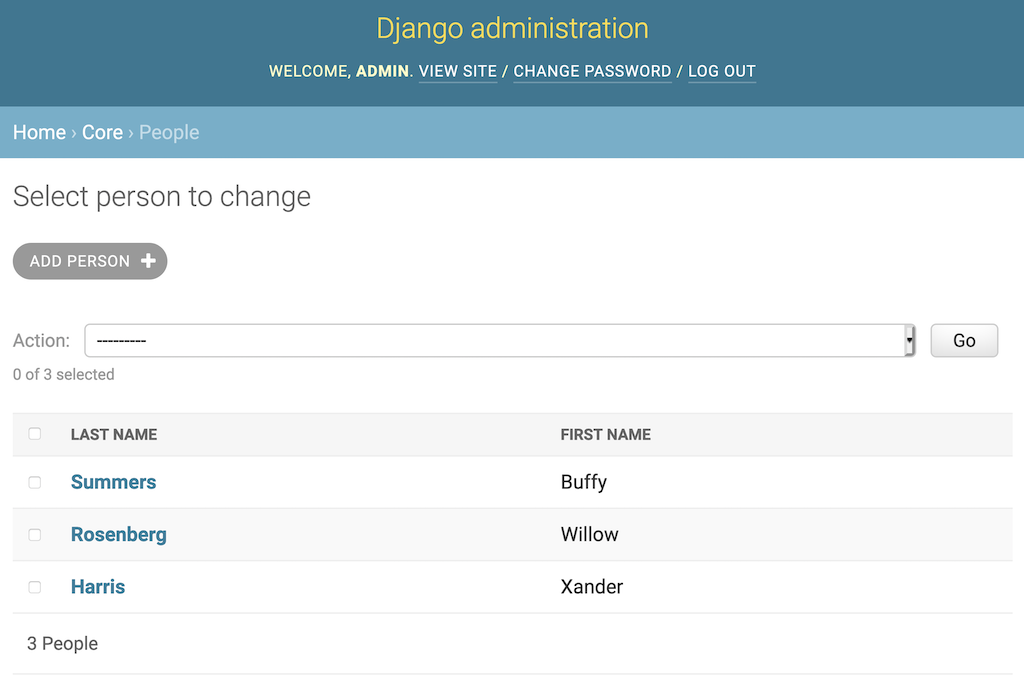
这两列是可点击的,允许您按列数据对页面进行排序。管理员也尊重Meta部分的ordering属性:
class Person(models.Model):
# ...
class Meta:
ordering = ("last_name", "first_name")
# ...
添加ordering属性将默认Person上的所有查询由last_name排序,然后由first_name排序。Django 在管理和获取对象时都会遵守这个默认顺序。
list_display元组可以引用所列对象的任何属性。它也可以引用admin.ModelAdmin本身的一个方法。再次修改PersonAdmin:
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
list_display = ("last_name", "first_name", "show_average")
def show_average(self, obj):
from django.db.models import Avg
result = Grade.objects.filter(person=obj).aggregate(Avg("grade")) return result["grade__avg"]
在上面的代码中,您向 admin 添加了一个显示每个学生平均成绩的列。对列表中显示的每个对象调用一次show_average()。
obj参数是正在显示的行的对象。在这种情况下,您使用它为学生查询相应的Grade对象,其响应在Grade.grade上取平均值。你可以在这里看到结果:
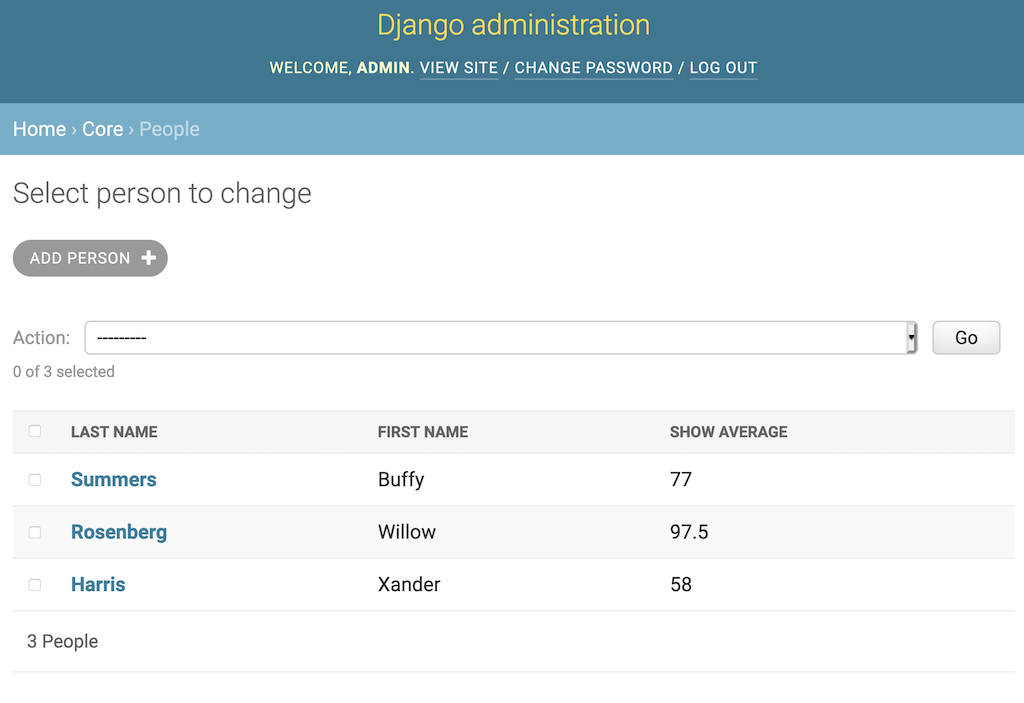
请记住,平均分数实际上应该在Person模型对象中计算。您可能希望数据在其他地方,而不仅仅是在 Django admin 中。如果您有这样的方法,您可以将它添加到list_display属性中。这里的例子展示了你可以在一个ModelAdmin对象中做什么,但是对于你的代码来说这可能不是最好的选择。
默认情况下,只有属于对象属性的列才是可排序的。show_average()不是。这是因为排序是由底层的QuerySet执行的,而不是在显示的结果上。在某些情况下,有一些排序这些列的方法,但是这超出了本教程的范围。
该列的标题基于方法的名称。您可以通过向方法添加属性来改变标题:
def show_average(self, obj):
result = Grade.objects.filter(person=obj).aggregate(Avg("grade"))
return result["grade__avg"]
show_average.short_description = "Average Grade"
默认情况下,Django 保护您免受字符串中 HTML 的影响,以防字符串来自用户输入。要使显示包含 HTML,您必须使用format_html():
def show_average(self, obj):
from django.utils.html import format_html
result = Grade.objects.filter(person=obj).aggregate(Avg("grade"))
return format_html("<b><i>{}</i></b>", result["grade__avg"])
show_average.short_description = "Average"
show_average()现在有了一个自定义标题"Average",并被格式化为斜体:
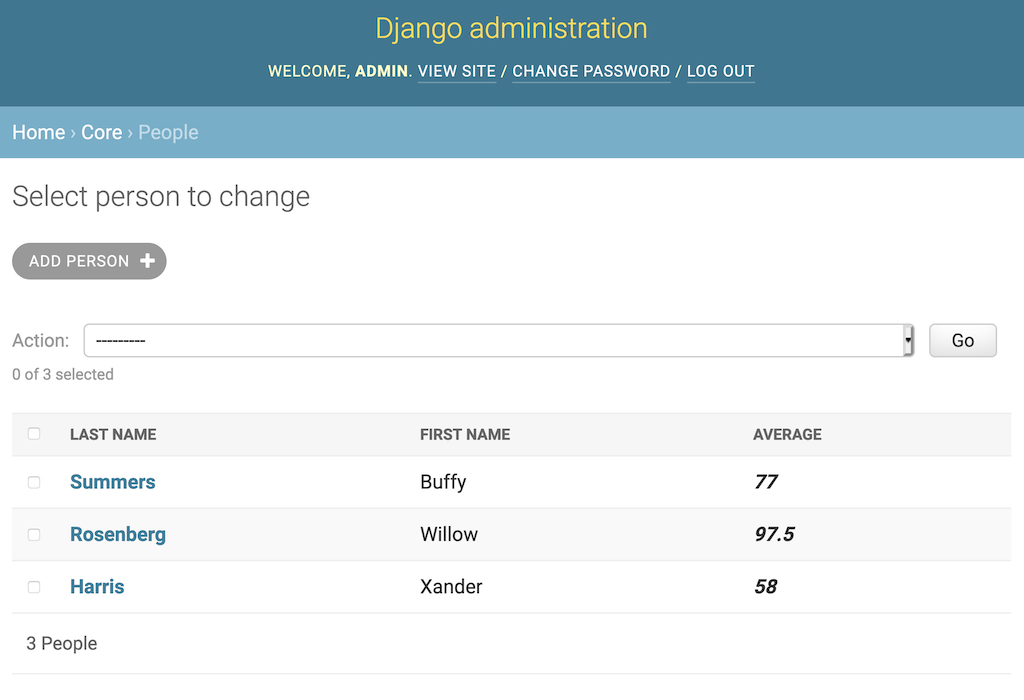
不幸的是,Django 还没有添加对format_html()的 f-string 支持,所以你只能使用str.format()语法。
提供到其他目标页面的链接
对象通过使用外键来引用其他对象是很常见的。你可以将list_display指向一个返回 HTML 链接的方法。在core/admin.py中,修改CourseAdmin类,如下所示:
from django.urls import reverse
from django.utils.http import urlencode
@admin.register(Course)
class CourseAdmin(admin.ModelAdmin):
list_display = ("name", "year", "view_students_link")
def view_students_link(self, obj):
count = obj.person_set.count()
url = (
reverse("admin:core_person_changelist")
+ "?"
+ urlencode({"courses__id": f"{obj.id}"})
)
return format_html('<a href="{}">{} Students</a>', url, count)
view_students_link.short_description = "Students"
该代码导致Course变更列表有三列:
- 课程名称
- 开设课程的年份
- 显示课程中学生人数的链接
您可以在下面的屏幕截图中看到最终的变化:
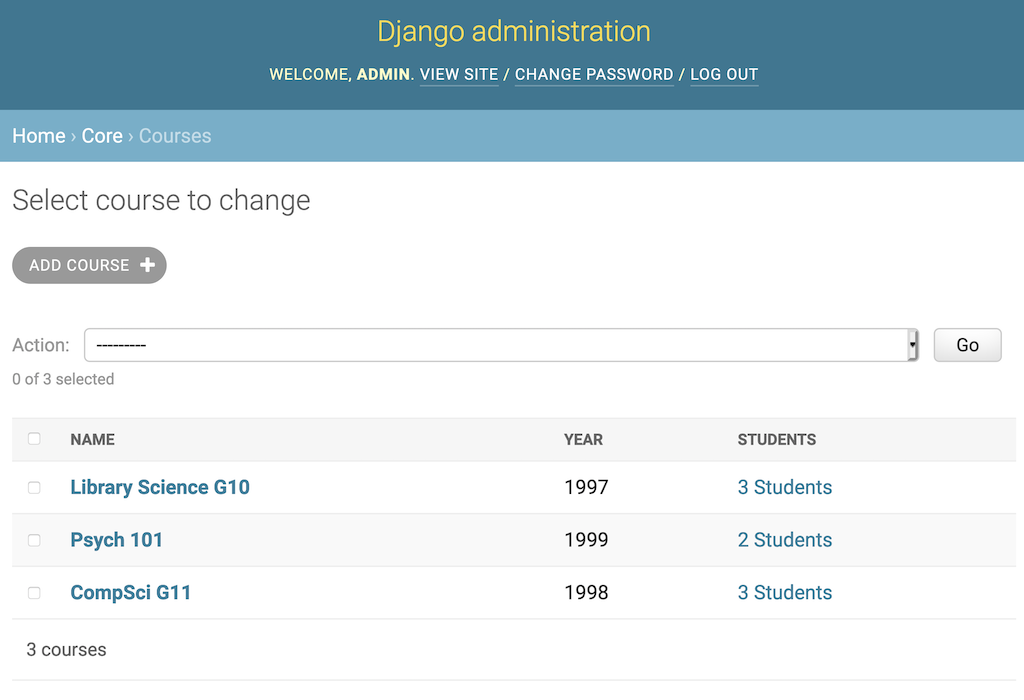
当您点击 2 学生时,它会将您带到应用了过滤器的Person变更列表页面。过滤后的页面只显示那些在Psych 101、Buffy 和 Willow 的学生。史云光没能上大学。
示例代码使用 reverse() 在 Django admin 中查找 URL。您可以使用以下命名约定查找任何管理页面:
"admin:%(app)s_%(model)s_%(page)"
该名称结构细分如下:
admin:是命名空间。app是 app 的名称。model是模型对象。page是 Django 管理页面类型。
对于上面的view_students_link()示例,您使用admin:core_person_changelist来获取对core应用程序中Person对象的变更列表页面的引用。
以下是可用的 URL 名称:
| 页 | URL 名称 | 目的 |
|---|---|---|
| 更改列表 | %(app)s\_%(model)s\_changelist |
模型对象页面列表 |
| 增加 | %(app)s\_%(model)s\_add |
对象创建页面 |
| 历史 | %(app)s\_%(model)s\_history |
对象更改历史页面 |
将object_id作为参数 |
||
| 删除 | %(app)s\_%(model)s\_delete |
对象删除页面 |
将一个object_id作为参数 |
||
| 变化 | %(app)s\_%(model)s\_change |
对象编辑页面 |
将一个object_id作为参数 |
您可以通过向 URL 添加查询字符串来过滤更改列表页面。这个查询字符串修改用于填充页面的QuerySet。在上面的例子中,查询字符串"?courses__id={obj.id}"过滤Person列表,只过滤那些在Person.course中有匹配值的对象。
这些过滤器支持使用双下划线(__)的QuerySet 字段查找。您可以访问相关对象的属性,也可以使用过滤修改器,如__exact和__startswith。
你可以在 Django admin 文档中找到关于使用list_display属性可以完成什么的全部细节。
向列表屏幕添加过滤器
除了通过调用 URL 过滤更改列表上的数据之外,还可以使用内置的小部件进行过滤。给core/admin.py中的CourseAdmin对象添加list_filter属性:
@admin.register(Course)
class CourseAdmin(admin.ModelAdmin):
list_display = ("name", "year", "view_students_link")
list_filter = ("year", )
# ...
list_filter将在页面上显示一个带有链接列表的新部分。在这种情况下,链接按年份过滤页面。数据库中的Course对象使用的year值会自动填充到过滤器列表中:
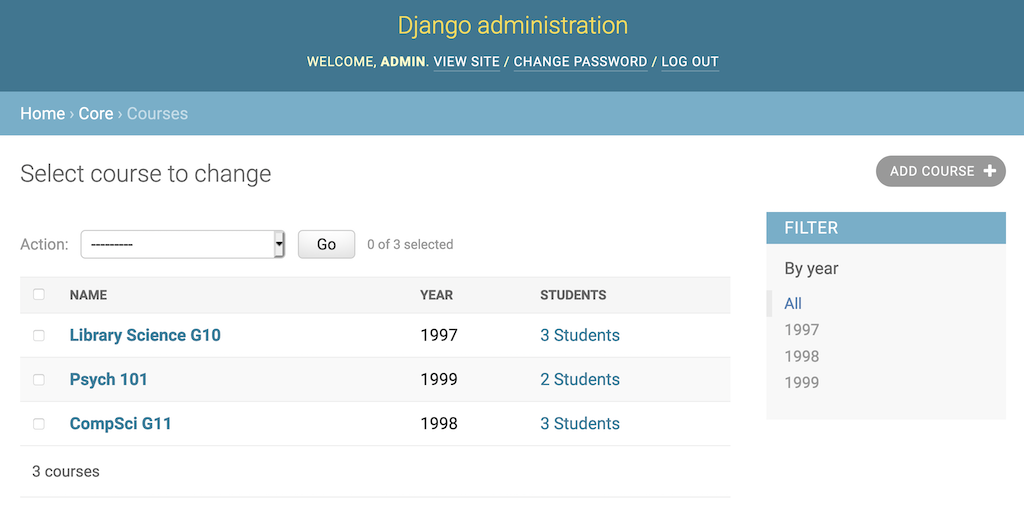
点击右边的年份将改变列表,只包含具有该year值的Course对象。您还可以使用__字段查找语法基于相关对象的属性进行过滤。例如,您可以通过course__year过滤GradeAdmin对象,只显示某一年课程的Grade对象。
如果您想对过滤进行更多的控制,那么您甚至可以创建 过滤对象 ,指定查找属性和相应的QuerySet。
将搜索添加到列表屏幕
过滤器并不是减少屏幕上数据量的唯一方法。Django admin 还支持通过search_fields选项进行搜索,该选项在屏幕上添加了一个搜索框。您可以用一个元组来设置它,该元组包含用于在数据库中构建搜索查询的字段名称。
用户在搜索框中输入的任何内容都会在过滤QuerySet的字段的OR子句中使用。默认情况下,每个搜索参数都被%符号包围,这意味着如果您搜索r,那么任何带有r的单词都会出现在结果中。通过在搜索字段上指定一个__修饰符,可以更加精确。
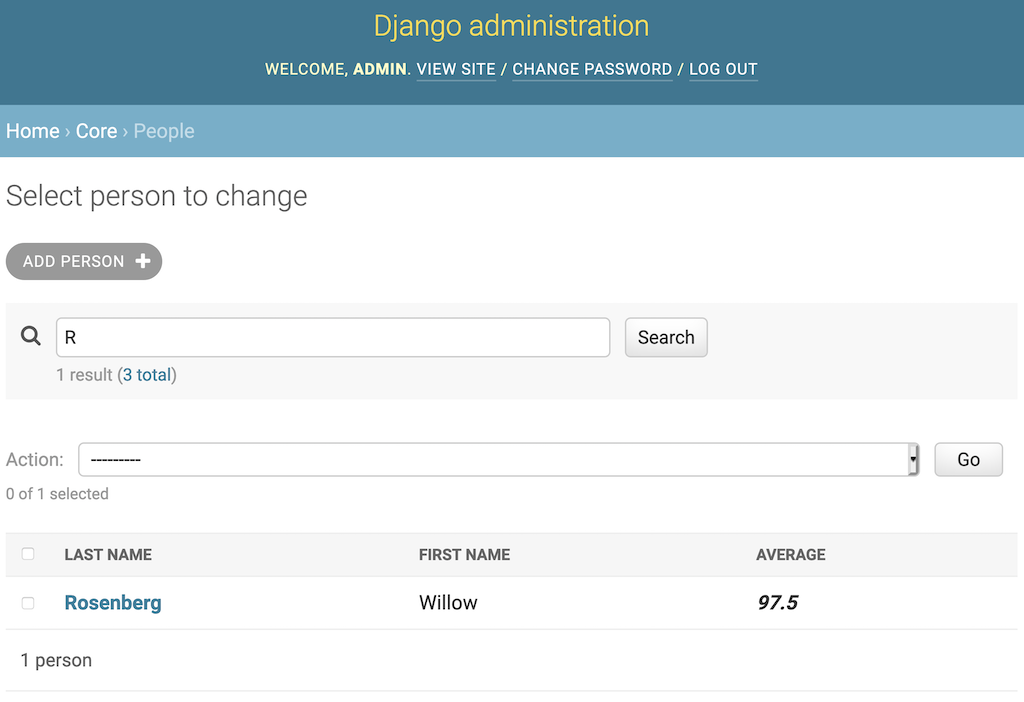
如下编辑core/admin.py中的PersonAdmin:
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
search_fields = ("last_name__startswith", )
在上面的代码中,搜索是基于姓氏的。__startswith修饰符将搜索限制在以 search 参数开头的姓氏。在R上搜索会得到以下结果:
每当在变更列表页面上执行搜索时,Django admin 都会调用您的admin.ModelAdmin对象的get_search_results()方法。它返回一个带有搜索结果的QuerySet。您可以通过重载该方法并更改QuerySet来微调搜索。更多细节可以在文档中找到。
改变编辑模型的方式
您可以自定义的不仅仅是更改列表页面。用于添加或更改对象的屏幕基于 ModelForm 。Django 根据正在编辑的模型自动生成表单。
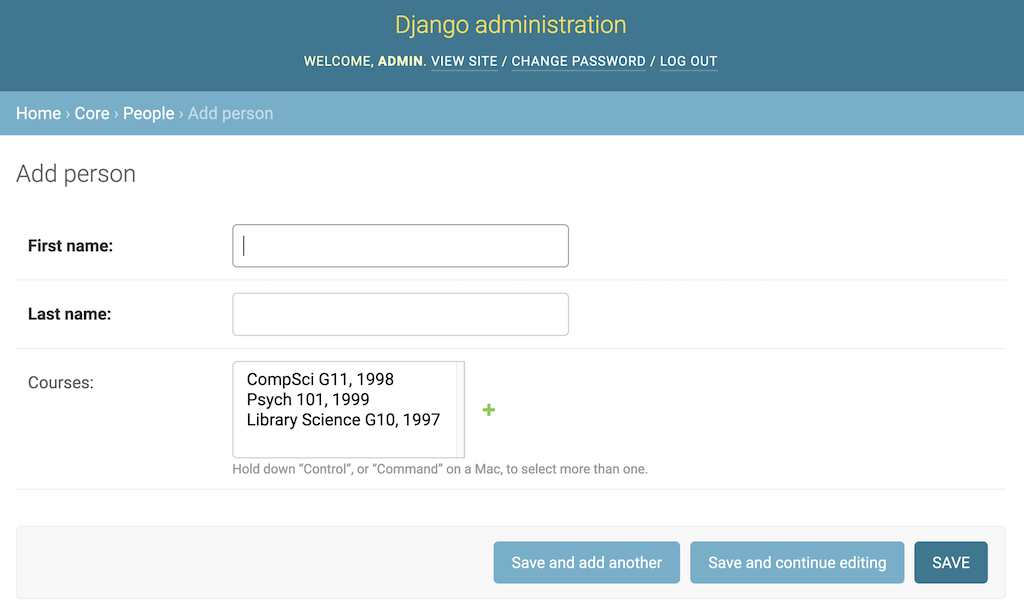
通过编辑fields选项,您可以控制包含哪些字段及其顺序。修改您的PersonAdmin对象,添加一个fields属性:
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
fields = ("first_name", "last_name", "courses")
# ...
Person的添加和更改页面现在将first_name属性放在last_name属性之前,即使模型本身指定了相反的方式:
ModelAdmin.get_form()负责为你的对象创建ModelForm。您可以重写此方法来更改表单。在PersonAdmin中增加以下方法:
def get_form(self, request, obj=None, **kwargs):
form = super().get_form(request, obj, **kwargs)
form.base_fields["first_name"].label = "First Name (Humans only!):"
return form
现在,当显示添加或更改页面时,first_name字段的标签将被定制。
改变标签可能不足以阻止吸血鬼注册为学生。如果您不喜欢 Django 管理员为您创建的ModelForm,那么您可以使用form属性来注册一个定制表单。对core/admin.py做如下补充和修改:
from django import forms
class PersonAdminForm(forms.ModelForm):
class Meta:
model = Person
fields = "__all__"
def clean_first_name(self):
if self.cleaned_data["first_name"] == "Spike":
raise forms.ValidationError("No Vampires")
return self.cleaned_data["first_name"]
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
form = PersonAdminForm
# ...
上面的代码在Person添加和更改页面上执行额外的验证。ModelForm对象拥有丰富的验证机制。在这种情况下,将根据名称"Spike"检查first_name字段。一个ValidationError阻止使用这个名字的学生注册:
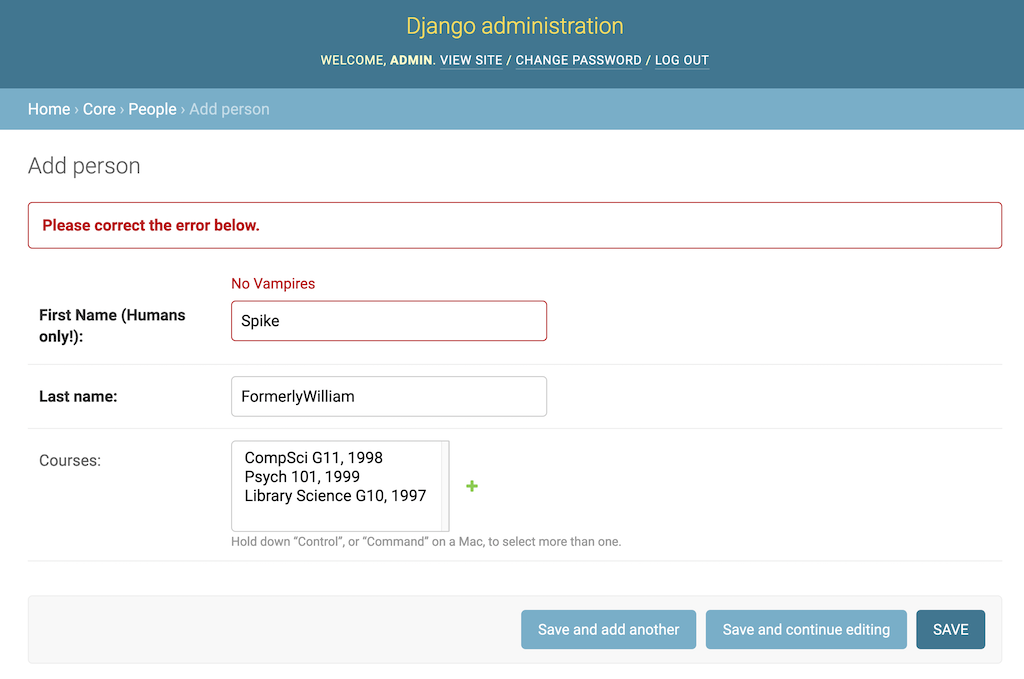
通过更改或替换ModelForm对象,您可以完全控制用于添加或更改对象页面的页面的外观和验证。
覆盖 Django 管理模板
Django 开发人员使用 Django 模板机制实现了 admin。这让他们的工作变得简单了一点,但它也让你受益,因为你可以覆盖模板。您可以通过更改用于呈现页面的模板来完全自定义管理。
通过查看虚拟环境中的 Django 包,您可以看到管理中使用的所有模板:
.../site-packages/django/contrib/admin/templates/
│
├── admin/
│ │
│ ├── auth/
│ │ └── user/
│ │ ├── add_form.html
│ │ └── change_password.html
│ │
│ ├── edit_inline/
│ │ ├── stacked.html
│ │ └── tabular.html
│ │
│ ├── includes/
│ │ ├── fieldset.html
│ │ └── object_delete_summary.html
│ │
│ ├── widgets/
│ │ ├── clearable_file_input.html
│ │ ├── foreign_key_raw_id.html
│ │ ├── many_to_many_raw_id.html
│ │ ├── radio.html
│ │ ├── related_widget_wrapper.html
│ │ ├── split_datetime.html
│ │ └── url.html
│ │
│ ├── 404.html
│ ├── 500.html
│ ├── actions.html
│ ├── app_index.html
│ ├── base.html
│ ├── base_site.html
│ ├── change_form.html
│ ├── change_form_object_tools.html
│ ├── change_list.html
│ ├── change_list_object_tools.html
│ ├── change_list_results.html
│ ├── date_hierarchy.html
│ ├── delete_confirmation.html
│ ├── delete_selected_confirmation.html
│ ├── filter.html
│ ├── index.html
│ ├── invalid_setup.html
│ ├── login.html
│ ├── object_history.html
│ ├── pagination.html
│ ├── popup_response.html
│ ├── prepopulated_fields_js.html
│ ├── search_form.html
│ └── submit_line.html
│
└── registration/
├── logged_out.html
├── password_change_done.html
├── password_change_form.html
├── password_reset_complete.html
├── password_reset_confirm.html
├── password_reset_done.html
├── password_reset_email.html
└── password_reset_form.html
Django 模板引擎有一个定义好的加载模板的顺序。当它加载模板时,它使用第一个匹配名称的模板。您可以使用相同的目录结构和文件名来覆盖管理模板。
管理模板位于两个目录中:
admin是针对模型对象的页面。registration是用于密码修改和登录退出。
要定制注销页面,您需要覆盖正确的文件。指向文件的相对路径必须与被覆盖的路径相同。你感兴趣的文件是registration/logged_out.html。首先在School项目中创建目录:
$ mkdir -p templates/registration
现在告诉 Django 关于您的School/settings.py文件中的新模板目录。查找TEMPLATES指令,并将文件夹添加到DIR列表中:
# School/settings.py
# ...
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
# Add the templates directory to the DIR option: "DIRS": [os.path.join(BASE_DIR, "templates"), ],
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
"django.template.context_processors.debug",
"django.template.context_processors.request",
"django.contrib.auth.context_processors.auth",
"django.contrib.messages.context_processors.messages",
],
},
},
]
模板引擎在应用程序目录之前搜索DIR选项中的目录,因此将加载与管理模板同名的任何内容。要看到这一点,将logged_out.html文件复制到您的templates/registration目录中,然后修改它:
{% extends "admin/base_site.html" %}
{% load i18n %}
{% block breadcrumbs %}<div class="breadcrumbs"><a href="{% url 'admin:index' %}">{% trans 'Home' %}</a></div>{% endblock %}
{% block content %}
<p>You are now leaving Sunnydale</p>
<p><a href="{% url 'admin:index' %}">{% trans 'Log in again' %}</a></p>
{% endblock %}
现在您已经定制了注销页面。如果您点击注销,那么您将会看到定制的消息:

Django 管理模板嵌套很深,不太直观,但是如果需要的话,您可以完全控制它们的显示。一些软件包,包括 Grappelli 和 Django 管理引导,已经完全取代了 Django 管理模板,改变了它们的外观。
Django Admin Bootstrap 与 Django 3 还不兼容,Grappelli 最近才添加了支持,所以它可能仍然有一些问题。也就是说,如果您想了解覆盖管理模板的强大功能,请查看这些项目!
结论
Django admin 是一个强大的内置工具,让您能够使用 web 界面创建、更新和删除数据库中的对象。您可以定制 Django admin 来做任何您想做的事情。
在本教程中,您学习了如何:
- 向 Django 管理员注册您的对象模型
- 将属性作为列添加到变更列表
- 用计算内容创建列值
- 通过链接交叉引用管理页面
- 通过查询字符串过滤变更列表页面
- 使您的更改列表可搜索
- 自定义自动
ModelForm对象 - 更改 Django 管理模板中的 HTML
本教程只是触及了表面。定制 Django admin 的配置量是惊人的。您可以更深入地研究文档,探索诸如内嵌表单、多个admin站点、批量编辑、自动完成等主题。编码快乐!
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Django Admin 定制******
用 Python 编写数据工程师面试问题
原文:https://realpython.com/data-engineer-interview-questions-python/
参加面试可能是一个既费时又累人的过程,技术性的面试可能压力更大!本教程旨在为你在数据工程师面试中会遇到的一些常见问题做好准备。您将学习如何回答关于数据库、Python 和 SQL 的问题。
本教程结束时,你将能够:
- 了解常见的数据工程师面试问题
- 区分关系数据库和非关系数据库
- 使用 Python 建立数据库
- 使用 Python 查询数据
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
成为数据工程师
数据工程的角色可以是广泛而多样的。你需要掌握多种技术和概念的应用知识。数据工程师思维灵活。因此,他们可以精通多个主题,如数据库、软件开发、 DevOps 和大数据。
数据工程师是做什么的?
鉴于其不同的技能组合,数据工程角色可以跨越许多不同的工作描述。一个数据工程师可以负责数据库设计、模式设计,并创建多个数据库解决方案。这项工作还可能涉及数据库管理员。
作为一名数据工程师,你可以充当数据库和数据科学团队之间的桥梁。在这种情况下,您还将负责数据清理和准备。如果涉及到大数据,那么您的工作就是为这些数据提供高效的解决方案。这项工作可能与 DevOps 角色重叠。
您还需要为报告和分析进行有效的数据查询。您可能需要与多个数据库交互或编写存储过程。对于像高流量网站或服务这样的许多解决方案,可能存在不止一个数据库。在这些情况下,数据工程师负责建立数据库,维护它们,并在它们之间传输数据。
Python 如何帮助数据工程师?
Python 被认为是编程语言的瑞士军刀。它在数据科学、后端系统和服务器端脚本中特别有用。这是因为 Python 具有强大的类型、简单的语法和丰富的第三方库可供使用。 Pandas 、SciPy、 Tensorflow 、 SQLAlchemy 和 NumPy 是一些在不同行业的生产中使用最广泛的库。
最重要的是,Python 减少了开发时间,这意味着公司的开支更少。对于一个数据工程师来说,大多数代码的执行是受数据库限制的,而不是受 CPU 限制的。正因为如此,利用 Python 的简单性是有意义的,即使与 C#和 Java 等编译语言相比,它的性能会降低。
回答数据工程师面试问题
现在你知道你的角色可能包括什么,是时候学习如何回答一些数据工程师面试问题了!虽然有很多内容需要介绍,但是在整个教程中,您将会看到一些实用的 Python 示例来指导您。
关于关系数据库的问题
数据库是系统中最重要的组件之一。没有他们,就没有国家和历史。虽然您可能没有将数据库设计视为优先事项,但要知道它会对页面加载速度产生重大影响。在过去的几年中,一些大公司引入了一些新的工具和技术:
- NoSQL
- 缓存数据库
- 图形数据库
- SQL 数据库中的 NoSQL 支持
发明这些和其他技术是为了尝试提高数据库处理请求的速度。你可能需要在你的数据工程师面试中谈论这些概念,所以让我们复习一些问题!
Q1:关系数据库与非关系数据库
关系数据库是以表格形式存储数据的数据库。每个表都有一个模式,这是一个记录需要拥有的列和类型。每个模式必须至少有一个唯一标识该记录的主键。换句话说,数据库中没有重复的行。此外,每个表可以使用外键与其他表相关联。
关系数据库的一个重要方面是模式的改变必须应用于所有记录。这有时会在迁移过程中导致中断和大麻烦。非关系数据库以不同的方式处理事情。它们本质上是无模式的,这意味着记录可以用不同的模式和不同的嵌套结构保存。记录仍然可以有主键,但是模式的改变是在逐个条目的基础上进行的。
您需要根据正在执行的功能类型执行速度比较测试。您可以选择INSERT、UPDATE、DELETE或其他功能。模式设计、索引、聚合的数量和记录的数量也会影响这个分析,所以您需要进行彻底的测试。稍后您将了解更多关于如何做到这一点的信息。
数据库在可扩展性上也有所不同。非关系数据库的分布可能不那么令人头疼。这是因为相关记录的集合可以很容易地存储在特定的节点上。另一方面,关系数据库需要更多的思考,通常使用主从系统。
一个 SQLite 例子
既然您已经回答了什么是关系数据库,那么是时候深入研究一些 Python 了!SQLite 是一个方便的数据库,您可以在本地机器上使用。数据库是一个单一的文件,这使得它非常适合于原型设计。首先,导入所需的 Python 库并创建一个新的数据库:
import sqlite3
db = sqlite3.connect(':memory:') # Using an in-memory database
cur = db.cursor()
现在,您已经连接到一个内存数据库,并准备好了光标对象。
接下来,您将创建以下三个表:
- 客户:该表将包含一个主键以及客户的名和姓。
- Items: 该表将包含主键、项目名称和项目价格。
- 购买的商品:该表将包含订单号、日期和价格。它还将连接到 Items 和 Customer 表中的主键。
现在,您已经对表格的外观有了一个概念,可以继续创建它们了:
cur.execute('''CREATE TABLE IF NOT EXISTS Customer (
id integer PRIMARY KEY,
firstname varchar(255),
lastname varchar(255) )''')
cur.execute('''CREATE TABLE IF NOT EXISTS Item (
id integer PRIMARY KEY,
title varchar(255),
price decimal )''')
cur.execute('''CREATE TABLE IF NOT EXISTS BoughtItem (
ordernumber integer PRIMARY KEY,
customerid integer,
itemid integer,
price decimal,
CONSTRAINT customerid
FOREIGN KEY (customerid) REFERENCES Customer(id),
CONSTRAINT itemid
FOREIGN KEY (itemid) REFERENCES Item(id) )''')
您已经向cur.execute()传递了一个查询来创建您的三个表。
最后一步是用数据填充表:
cur.execute('''INSERT INTO Customer(firstname, lastname)
VALUES ('Bob', 'Adams'),
('Amy', 'Smith'),
('Rob', 'Bennet');''')
cur.execute('''INSERT INTO Item(title, price)
VALUES ('USB', 10.2),
('Mouse', 12.23),
('Monitor', 199.99);''')
cur.execute('''INSERT INTO BoughtItem(customerid, itemid, price)
VALUES (1, 1, 10.2),
(1, 2, 12.23),
(1, 3, 199.99),
(2, 3, 180.00),
(3, 2, 11.23);''') # Discounted price
现在每个表中都有一些记录,您可以使用这些数据来回答更多的数据工程师面试问题。
Q2: SQL 聚合函数
聚合函数是对结果集执行数学运算的函数。一些例子包括AVG、COUNT、MIN、MAX和SUM。通常,您需要GROUP BY和HAVING子句来补充这些聚合。一个有用的聚合函数是AVG,您可以使用它来计算给定结果集的平均值:
>>> cur.execute('''SELECT itemid, AVG(price) FROM BoughtItem GROUP BY itemid''') >>> print(cur.fetchall()) [(1, 10.2), (2, 11.73), (3, 189.995)]这里,您已经检索了数据库中购买的每件商品的平均价格。您可以看到,
itemid为1的商品平均价格为 10.20 美元。为了使上面的输出更容易理解,您可以显示项目名称来代替
itemid:
>>> cur.execute('''SELECT item.title, AVG(boughtitem.price) FROM BoughtItem as boughtitem
... INNER JOIN Item as item on (item.id = boughtitem.itemid)
... GROUP BY boughtitem.itemid''')
...
>>> print(cur.fetchall())
[('USB', 10.2), ('Mouse', 11.73), ('Monitor', 189.995)]
现在,您更容易看到平均价格为 10.20 美元的商品是USB。
另一个有用的聚合是SUM。您可以使用此功能显示每位客户的总消费金额:
>>> cur.execute('''SELECT customer.firstname, SUM(boughtitem.price) FROM BoughtItem as boughtitem ... INNER JOIN Customer as customer on (customer.id = boughtitem.customerid) ... GROUP BY customer.firstname''') ... >>> print(cur.fetchall()) [('Amy', 180), ('Bob', 222.42000000000002), ('Rob', 11.23)]平均而言,名为 Amy 的客户花费了大约 180 美元,而 Rob 仅花费了 11.23 美元!
如果你的面试官喜欢数据库,那么你可能想温习一下嵌套查询、连接类型和关系数据库执行查询的步骤。
Q3:加速 SQL 查询
速度取决于各种因素,但主要受以下各项的影响:
- 连接
- 聚集
- 遍历
- 记录
连接数量越多,复杂性就越高,表中的遍历次数也就越多。对涉及几个表的几千条记录执行多重连接是非常昂贵的,因为数据库还需要缓存中间结果!此时,您可能会开始考虑如何增加内存大小。
速度还受到数据库中是否存在索引的影响。索引非常重要,它允许您快速搜索整个表,并为查询中指定的某个列找到匹配项。
索引以更长的插入时间和一些存储为代价对记录进行排序。可以组合多个列来创建一个索引。例如,列
date和price可以合并,因为您的查询依赖于这两个条件。Q4:调试 SQL 查询
大多数数据库都包含一个
EXPLAIN QUERY PLAN,它描述了数据库执行查询的步骤。对于 SQLite,您可以通过在SELECT语句前添加EXPLAIN QUERY PLAN来启用该功能:
>>> cur.execute('''EXPLAIN QUERY PLAN SELECT customer.firstname, item.title,
... item.price, boughtitem.price FROM BoughtItem as boughtitem
... INNER JOIN Customer as customer on (customer.id = boughtitem.customerid)
... INNER JOIN Item as item on (item.id = boughtitem.itemid)''')
...
>>> print(cur.fetchall())
[(4, 0, 0, 'SCAN TABLE BoughtItem AS boughtitem'),
(6, 0, 0, 'SEARCH TABLE Customer AS customer USING INTEGER PRIMARY KEY (rowid=?)'),
(9, 0, 0, 'SEARCH TABLE Item AS item USING INTEGER PRIMARY KEY (rowid=?)')]
该查询尝试列出所有购买商品的名字、商品标题、原价和购买价格。
下面是查询计划本身的样子:
SCAN TABLE BoughtItem AS boughtitem SEARCH TABLE Customer AS customer USING INTEGER PRIMARY KEY (rowid=?) SEARCH TABLE Item AS item USING INTEGER PRIMARY KEY (rowid=?)
请注意,Python 代码中的 fetch 语句只返回解释,而不返回结果。那是因为EXPLAIN QUERY PLAN并不打算在生产中使用。
关于非关系数据库的问题
在上一节中,您展示了关系数据库和非关系数据库之间的区别,并在 Python 中使用了 SQLite。现在你要专注于 NoSQL。你的目标是突出它的优势、差异和用例。
一个 MongoDB 例子
您将使用与之前相同的数据,但是这次您的数据库将是 MongoDB 。这个 NoSQL 数据库是基于文档的,伸缩性很好。首先,您需要安装所需的 Python 库:
$ pip install pymongo
您可能还想安装 MongoDB Compass 社区。它包括一个非常适合可视化数据库的本地 IDE 。有了它,您可以看到创建的记录,创建触发器,并充当数据库的可视化管理员。
注意:要运行本节中的代码,您需要一个正在运行的数据库服务器。要了解更多关于如何设置它的信息,请查看MongoDB 和 Python 简介。
以下是创建数据库并插入一些数据的方法:
import pymongo
client = pymongo.MongoClient("mongodb://localhost:27017/")
# Note: This database is not created until it is populated by some data
db = client["example_database"]
customers = db["customers"]
items = db["items"]
customers_data = [{ "firstname": "Bob", "lastname": "Adams" },
{ "firstname": "Amy", "lastname": "Smith" },
{ "firstname": "Rob", "lastname": "Bennet" },]
items_data = [{ "title": "USB", "price": 10.2 },
{ "title": "Mouse", "price": 12.23 },
{ "title": "Monitor", "price": 199.99 },]
customers.insert_many(customers_data)
items.insert_many(items_data)
您可能已经注意到,MongoDB 将数据记录存储在集合中,这相当于 Python 中的字典列表。在实践中,MongoDB 存储 BSON 文档。
Q5:使用 MongoDB 查询数据
让我们首先尝试复制BoughtItem表,就像您在 SQL 中所做的那样。为此,您必须向客户追加一个新字段。MongoDB 的文档规定,可以使用关键字操作符集合来更新记录,而不必编写所有现有字段:
# Just add "boughtitems" to the customer where the firstname is Bob
bob = customers.update_many(
{"firstname": "Bob"},
{
"$set": {
"boughtitems": [
{
"title": "USB",
"price": 10.2,
"currency": "EUR",
"notes": "Customer wants it delivered via FedEx",
"original_item_id": 1
}
]
},
}
)
请注意,您是如何在没有事先明确定义模式的情况下向customer添加额外的字段的。俏皮!
事实上,您可以通过稍微修改模式来更新另一个客户:
amy = customers.update_many(
{"firstname": "Amy"},
{
"$set": {
"boughtitems":[
{
"title": "Monitor",
"price": 199.99,
"original_item_id": 3,
"discounted": False
}
]
} ,
}
)
print(type(amy)) # pymongo.results.UpdateResult
与 SQL 类似,基于文档的数据库也允许执行查询和聚合。但是,功能可能在语法和底层执行上有所不同。事实上,您可能已经注意到 MongoDB 保留了$字符来指定记录上的一些命令或聚合,比如$group。你可以在官方文件中了解更多关于这种行为的信息。
您可以像在 SQL 中一样执行查询。首先,您可以创建一个索引:
>>> customers.create_index([("name", pymongo.DESCENDING)])这是可选的,但是它加快了需要名称查找的查询。
然后,您可以检索按升序排序的客户名称:
>>> items = customers.find().sort("name", pymongo.ASCENDING)
您还可以遍历并打印购买的商品:
>>> for item in items: ... print(item.get('boughtitems')) ... None [{'title': 'Monitor', 'price': 199.99, 'original_item_id': 3, 'discounted': False}] [{'title': 'USB', 'price': 10.2, 'currency': 'EUR', 'notes': 'Customer wants it delivered via FedEx', 'original_item_id': 1}]您甚至可以检索数据库中唯一名称的列表:
>>> customers.distinct("firstname")
['Bob', 'Amy', 'Rob']
现在您已经知道了数据库中客户的姓名,您可以创建一个查询来检索有关他们的信息:
>>> for i in customers.find({"$or": [{'firstname':'Bob'}, {'firstname':'Amy'}]}, ... {'firstname':1, 'boughtitems':1, '_id':0}): ... print(i) ... {'firstname': 'Bob', 'boughtitems': [{'title': 'USB', 'price': 10.2, 'currency': 'EUR', 'notes': 'Customer wants it delivered via FedEx', 'original_item_id': 1}]} {'firstname': 'Amy', 'boughtitems': [{'title': 'Monitor', 'price': 199.99, 'original_item_id': 3, 'discounted': False}]}下面是等效的 SQL 查询:
SELECT firstname, boughtitems FROM customers WHERE firstname LIKE ('Bob', 'Amy')请注意,尽管语法可能略有不同,但在底层执行查询的方式上有很大的不同。这是意料之中的,因为 SQL 和 NoSQL 数据库之间的查询结构和用例不同。
Q6: NoSQL vs SQL
如果您有一个不断变化的模式,如金融监管信息,那么 NoSQL 可以修改记录并嵌套相关信息。想象一下,如果您有八个嵌套顺序,您将不得不在 SQL 中进行多少次连接!然而,这种情况比你想象的更常见。
现在,如果您想要运行报告、提取财务数据的信息并推断结论,该怎么办呢?在这种情况下,您需要运行复杂的查询,而 SQL 在这方面往往更快。
注意: SQL 数据库,尤其是 PostgreSQL ,也发布了一个特性,允许将可查询的 JSON 数据作为记录的一部分插入。虽然这可以结合两个世界的优点,但速度可能是个问题。
从 NoSQL 数据库中查询非结构化数据比从 PostgreSQL 中的 JSON 类型列中查询 JSON 字段要快。你可以做一个速度对比测试来得到一个明确的答案。
尽管如此,这个特性可能会减少对额外数据库的需求。有时,经过酸洗或序列化的对象以二进制类型的形式存储在记录中,然后在读取时反序列化。
然而,速度并不是唯一的衡量标准。您还需要考虑事务、原子性、持久性和可伸缩性。交易在金融应用中很重要,这样的特性优先。
由于数据库的范围很广,每个数据库都有自己的特性,所以数据工程师的工作就是做出明智的决定,在每个应用程序中使用哪个数据库。有关更多信息,您可以阅读与数据库事务相关的 ACID 属性。
在你的数据工程师面试中,你可能还会被问到你所知道的其他数据库。许多公司还使用其他几个相关的数据库:
- 弹性搜索 在文本搜索中效率高。它利用其基于文档的数据库来创建一个强大的搜索工具。
- Newt DB 结合了 ZODB 和 PostgreSQL JSONB 特性来创建一个 Python 友好的 NoSQL 数据库。
- InfluxDB 用于时序应用中存储事件。
这个列表还可以继续下去,但这说明了各种各样的可用数据库是如何迎合他们的利基行业的。
关于缓存数据库的问题
缓存数据库保存频繁访问的数据。它们与主要的 SQL 和 NoSQL 数据库共存。他们的目标是减轻负载,更快地满足请求。
a 再举一个例子
您已经讨论了 SQL 和 NoSQL 数据库的长期存储解决方案,但是更快、更即时的存储呢?数据工程师如何改变从数据库中检索数据的速度?
典型的 web 应用程序经常检索常用数据,如用户的个人资料或姓名。如果所有的数据都包含在一个数据库中,那么数据库服务器获得的命中数将会超过上限,并且是不必要的。因此,需要一种更快、更直接的存储解决方案。
虽然这降低了服务器负载,但也给数据工程师、后端团队和 DevOps 团队带来了两个难题。首先,您现在需要一些比您的主 SQL 或 NoSQL 数据库具有更快读取时间的数据库。但是,两个数据库的内容最终必须匹配。(欢迎来到数据库间状态一致性的问题!享受吧。)
第二个令人头疼的问题是,DevOps 现在需要为新的缓存数据库担心可伸缩性、冗余等问题。在下一节中,您将在 Redis 的帮助下深入研究这些问题。
问题 7:如何使用缓存数据库
你可能已经从简介中获取了足够的信息来回答这个问题!缓存数据库是一种快速存储解决方案,用于存储短期的结构化或非结构化数据。它可以根据您的需要进行分区和扩展,但是它的大小通常比您的主数据库小得多。因此,您的缓存数据库可以驻留在内存中,这样您就不必从磁盘中读取数据。
注意:如果你曾经在 Python 中使用过字典,那么 Redis 遵循相同的结构。这是一个键值存储,在这里你可以像一个 Python
dict一样SET和GET数据。当请求进来时,首先检查缓存数据库,然后检查主数据库。这样,您可以防止任何不必要的重复请求到达主数据库的服务器。由于高速缓存数据库的读取时间较短,因此您还可以从性能提升中获益!
您可以使用 pip 来安装所需的库:
$ pip install redis现在,考虑一个从用户 ID 获取用户名的请求:
import redis from datetime import timedelta # In a real web application, configuration is obtained from settings or utils r = redis.Redis() # Assume this is a getter handling a request def get_name(request, *args, **kwargs): id = request.get('id') if id in r: return r.get(id) # Assume that we have an {id: name} store else: # Get data from the main DB here, assume we already did it name = 'Bob' # Set the value in the cache database, with an expiration time r.setex(id, timedelta(minutes=60), value=name) return name这段代码使用
id键检查这个名字是否在 Redis 中。如果没有,那么该名称会设置一个过期时间,因为缓存是短期的,所以使用该时间。现在,如果你的面试官问你这个代码有什么问题呢?你的回答应该是没有异常处理!数据库可能会有很多问题,比如掉线,所以尝试捕捉这些异常总是一个好主意。
关于设计模式和 ETL 概念的问题
在大型应用程序中,您通常会使用多种类型的数据库。事实上,可以在一个应用程序中使用 PostgreSQL、MongoDB 和 Redis!一个具有挑战性的问题是处理数据库之间的状态变化,这使开发人员面临一致性问题。考虑以下场景:
- 数据库#1 中的值被更新。
- 数据库#2 中相同值保持不变(不更新)。
- 在数据库#2 上运行查询。
现在,你得到了一个不一致和过时的结果!从第二个数据库返回的结果不会反映第一个数据库中的更新值。任何两个数据库都可能发生这种情况,但是当主数据库是 NoSQL 数据库,并且信息被转换为 SQL 以供查询时,这种情况尤其常见。
数据库可能有后台工作人员来处理这类问题。这些工人从一个数据库中提取数据,以某种方式转换,然后将数据加载到目标数据库中。当您从 NoSQL 数据库转换到 SQL 数据库时,提取、转换、加载(ETL)过程需要以下步骤:
- Extract: 每当一个记录被创建、更新等等时,都会有一个 MongoDB 触发器。一个回调函数在一个单独的线程上被异步调用。
- Transform: 部分记录被提取、规范化,并放入正确的数据结构(或行)中,以便插入 SQL。
- Load:SQL 数据库批量更新,或者作为大容量写入的单个记录更新。
这种工作流在金融、游戏和报告应用程序中很常见。在这些情况下,不断变化的模式需要 NoSQL 数据库,但是报告、分析和聚合需要 SQL 数据库。
问题 8: ETL 挑战
ETL 中有几个具有挑战性的概念,包括:
- 大数据
- 状态问题
- 异步工人
- 类型匹配
不胜枚举!然而,由于 ETL 过程中的步骤是定义良好且符合逻辑的,数据和后端工程师通常会更担心性能和可用性,而不是实现。
如果您的应用程序每秒向 MongoDB 写入数千条记录,那么您的 ETL 工作人员需要跟上数据的转换、加载和以请求的形式交付给用户。速度和延迟可能会成为一个问题,所以这些工作程序通常是用快速语言编写的。您可以在转换步骤中使用编译后的代码来加快速度,因为这部分通常是 CPU 受限的。
注意:多处理和工人分离是您可能要考虑的其他解决方案。
如果你正在处理大量 CPU 密集型函数,那么你可能想看看 Numba 。这个库编译函数以使它们执行起来更快。最重要的是,这很容易在 Python 中实现,尽管在这些编译后的函数中可以使用哪些函数上有一些限制。
问题 9:大数据中的设计模式
想象一下,亚马逊需要创建一个 推荐系统 ,向用户推荐合适的商品。数据科学团队需要大量的数据!他们找到数据工程师,要求您创建一个单独的临时数据库仓库。他们将在那里清理和转换数据。
收到这样的请求,你可能会感到震惊。当您拥有万亿字节的数据时,您将需要多台机器来处理所有这些信息。数据库聚合函数可能是非常复杂的操作。如何高效地查询、聚集和利用相对较大的数据?
Apache 最初引入了 MapReduce ,它遵循了 map,shuffle,reduce 工作流。这个想法是将不同的数据映射到不同的机器上,也称为集群。然后,您可以对数据执行操作,按键进行分组,最后,在最后阶段聚合数据。
这种工作流程今天仍在使用,但最近它逐渐被 Spark 所取代。然而,设计模式构成了大多数大数据工作流的基础,是一个非常有趣的概念。你可以在 IBM Analytics 阅读更多关于 MapReduce 的内容。
Q10:ETL 流程和大数据工作流的共同方面
你可能会认为这是一个相当奇怪的问题,但这只是对你的计算机科学知识,以及你的整体设计知识和经验的一个检验。
两个工作流都遵循生产者-消费者模式。一个工人(生产者)生产某种数据,并将其输出到管道。这种管道可以采取多种形式,包括网络消息和触发器。生产者输出数据后,消费者消费并利用数据。这些工作线程通常以异步方式工作,并在单独的进程中执行。
您可以将生产者比作 ETL 过程的提取和转换步骤。同样,在大数据中,映射器可以被视为生产者,而缩减器实际上是消费者。这种关注点的分离在应用程序的开发和架构设计中是极其重要和有效的。
结论
恭喜你!你已经覆盖了很多领域,回答了几个数据工程师面试问题。现在,您对数据工程师可能扮演的许多不同角色,以及您在数据库、设计和工作流方面的职责有了更多的了解。
有了这些知识,你现在可以:
- 将 Python 与 SQL、NoSQL 和缓存数据库结合使用
- 在 ETL 和查询应用程序中使用 Python
- 提前计划项目,牢记设计和工作流程
虽然面试问题可能是多种多样的,但你已经接触了多个主题,并学会了在计算机科学的许多不同领域跳出框框思考。现在你已经准备好进行一场精彩的面试了!******
数据迁移
这是 Django 迁移系列的最后一篇文章:
- 第 1 部分: Django 迁移-初级读本
- 第 2 部分:深入探讨迁移
- 第 3 部分:数据迁移(当前文章)
- 视频: Django 1.7 迁移-初级教程
又回来了。
迁移主要是为了保持数据库的数据模型是最新的,但是数据库不仅仅是一个数据模型。最值得注意的是,它也是一个大的数据集合。因此,如果不讨论数据迁移,任何关于数据库迁移的讨论都是不完整的。
2015 年 2 月 12 日更新:更改数据迁移,从应用注册表中查找模型。
定义的数据迁移
数据迁移在很多情况下都会用到。两个非常受欢迎的是:
- 当您希望加载应用程序成功运行所依赖的“系统数据”时。
- 当对数据模型的更改迫使需要更改现有数据时。
请注意,加载虚拟数据进行测试不在上述列表中。您可以使用迁移来做到这一点,但是迁移通常在生产服务器上运行,所以您可能不希望在您的生产服务器上创建一堆虚拟测试数据。
示例
继续之前的 Django 项目,作为创建一些“系统数据”的例子,我们来创建一些历史比特币价格。Django migrations 将帮助我们解决这个问题,它创建一个空的迁移文件,如果我们键入:
$ ./manage.py makemigrations --empty historical_data这应该会创建一个名为
historical_data/migrations/003_auto<date_time_stamp>.py的文件。我们把名字改成003_load_historical_data.py再开吧。您将得到一个默认结构,看起来像这样:# encoding: utf8 from django.db import models, migrations class Migration(migrations.Migration): dependencies = [ ('historical_data', '0002_auto_20140710_0810'), ] operations = [ ]您可以看到它为我们创建了一个基础结构,甚至插入了依赖项。那是有帮助的。现在要进行一些数据迁移,使用
RunPython迁移操作:# encoding: utf8 from django.db import models, migrations from datetime import date def load_data(apps, schema_editor): PriceHistory = apps.get_model("historical_data", "PriceHistory") PriceHistory(date=date(2013,11,29), price=1234.00, volume=354564, total_btc=12054375, ).save() PriceHistory(date=date(2012,11,29), price=12.15, volume=187947, total_btc=10504650, ).save() class Migration(migrations.Migration): dependencies = [ ('historical_data', '0002_auto_20140710_0810'), ] operations = [ migrations.RunPython(load_data) ]我们从定义加载数据的函数
load_data开始。对于一个真正的应用程序,我们可能希望访问 blockchain.info 并获取历史价格的完整列表,但我们只是在那里放了几个来展示迁移是如何进行的。
一旦我们有了这个函数,我们就可以从我们的
RunPython操作中调用它,然后当我们从命令行运行./manage.py migrate时,这个函数就会被执行。注意这一行:
PriceHistory = apps.get_model("historical_data", "PriceHistory")运行迁移时,获得与您所处的迁移点相对应的
PriceHistory模型版本非常重要。当您运行迁移时,您的模型(PriceHistory)可能会改变,例如,如果您在后续迁移中添加或删除了一个列。这可能会导致您的数据迁移失败,除非您使用上面的代码行来获得模型的正确版本。关于这一点的更多信息,请参见评论这里。可以说,这比运行
syncdb并让它加载一个 fixture 要多得多。事实上,迁移并不尊重 fixturess 这意味着它们不会像syncdb那样自动为您加载 fixture。这主要是哲学原因。
虽然您可以使用迁移来加载数据,但是它们主要是关于迁移数据和/或数据模型。我们展示了一个加载系统数据的示例,主要是因为它简单地解释了如何设置数据迁移,但通常情况下,数据迁移用于更复杂的操作,如转换数据以匹配新的数据模型。
例如,如果我们决定开始存储来自多个交易所而不是一个交易所的价格,那么我们可以添加像
price_gox、price_btc等字段,然后我们可以使用迁移将所有数据从price列移动到price_btc列。一般来说,在 Django 1.7 中处理迁移时,最好将加载数据看作是与迁移数据库分开的一个单独的练习。如果您确实想继续使用/加载装置,您可以使用如下命令:
$ ./manage.py loaddata historical_data/fixtures/initial_data.json这将把数据从夹具加载到数据库中。
这不会像数据迁移那样自动发生(这可能是件好事),但是功能仍然存在;还没丢,有需要可以继续用固定物。不同之处在于,现在您可以在需要时用 fixtures 加载数据。如果您使用 fixtures 来为您的单元测试加载测试数据,这是需要记住的事情。
结论
这篇文章以及前两篇文章涵盖了使用迁移时最常见的场景。还有很多场景,如果你很好奇并且真的想深入研究迁移,最好的去处(除了代码本身)是官方文档。
它是最新的,并且很好地解释了事物是如何工作的。如果你想看一个更复杂的例子,请在下面评论让我们知道。
请记住,在一般情况下,您面对的是以下两种情况之一:
模式迁移:对数据库或表的结构进行更改,但不更改数据。这是最常见的类型,Django 通常可以自动为您创建这些迁移。
数据迁移:更改数据,或者加载新数据。姜戈不能为你生成这些。必须使用
RunPython迁移手动创建它们。所以选择适合你的迁移,运行
makemigrations,然后确保每次更新你的模型时更新你的迁移文件——差不多就是这样。这将允许您将迁移与代码一起存储在 git 中,并确保您可以更新数据库结构而不会丢失数据。迁徙快乐!**
数据科学播客的终极列表
播客是让你沉浸在一个行业中的好方法,尤其是在数据科学方面。这个领域发展极快,很难跟上每周发生的所有新发展!
利用一天中你身体忙碌但大脑自由的时间:当你通勤上班,在健身房锻炼,或打扫房间。这是让你的大脑学习新东西的最佳时机,确保你在你的领域保持领先。
有几十个数据科学播客,涵盖从机器学习和人工智能到大数据分析的所有内容。我们希望这将是一个伟大的资源,让你找到有用的,信息丰富的,引人入胜的节目。
准备好潜水吧!
🎧🐍真正的 Python 播客:在真正的 Python 上,我们还有一个由克里斯托弗·贝利主持的每周 Python 播客,内容包括采访、编码技巧以及与来自 Python 社区的嘉宾的对话。如果你正在用 Python 做数据科学的工作,可以看看在 realpython.com/podcast的展览
主动数据科学播客
在撰写本文时,这些数据科学播客仍然活跃,并且仍在制作中。从档案深处开始,一路向上,或者直接跳到最新一集!
数据怀疑论者
- 网址:https://dataskeptic.com/
- 推特: @dataskeptic
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
数据怀疑论者是最著名的数据科学播客之一。这个每周一次的节目探索了数据科学、统计学、机器学习和人工智能方面的主题。
由 Kyle Polich 主持,该节目有超过 200 集,听众可以深入了解。最近,该节目发布了一系列主题集,围绕数据科学世界中的一个更大的主题,如假新闻。
这几集在采访行业专业人士和解释高级数据科学概念的迷你代码之间交替播放。
迷你代码由 Linh Da Tran 共同主持,他与 Kyle 讨论数据科学话题,如自然语言处理和 k-means 聚类。随着主持人的讲述,听众对话题有了更好的理解。
线性递减
- 网址:http://lineardigressions.com
- 推特: @LinDigressions
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
凯蒂·马龙(Katie Malone)和本·贾菲(Ben Jaffe)主持每周一次的播客《线性离题》,探索数据科学、机器学习和人工智能的最新发展。主持人是好朋友,他们的融洽使得每一集都非常容易理解。
写这篇文章的时候,有超过 100 集的内容可供听众深入了解。每一集大约半小时,很容易就能快速理解手头的话题。
凯蒂和本在将复杂的技术主题提炼到其基本原理方面做得很好。在短短的几分钟内,他们揭开了神经网络、自动编码器、傅立叶变换等等的神秘面纱。
会说话的机器
- 网址:https://www.thetalkingmachines.com/
- Twitter: @TlkngMchns
- 听: RSS ⋅ iTunes ⋅ 播放器 FM
前公共电台制片人凯瑟琳·戈尔曼认为,继续关于数据科学、人工智能和机器学习的公共对话对于防止另一个人工智能冬天是绝对必要的。
她认为数据科学播客是一个很好的讨论场所。为此,她和尼尔·劳伦斯教授一起主持了会说话的机器。
该播客旨在向广大观众介绍机器学习,并帮助行业专业人士、商业领袖和感兴趣的外行人更好地理解这些工具和技术。
这些节目通常遵循一种简单的模式:主持人谈论行业新闻,采访一位嘉宾,最后可能会回答听众的问题。剧集按季节发布,长度较长,大约 40 分钟。
这就是凯瑟琳作为电台主持人的历史派上用场的地方:她保持节目的吸引力和知识性,并努力确保它呈现了机器学习行业的准确画面。
奥莱利数据显示
- 网址:https://www.oreilly.com/topics/oreilly-data-show-podcast
- 推特: @OReillyMedia
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
本·洛里卡是奥莱利媒体公司的首席数据科学家。在每一期节目中,他都会与一位行业专家一起讨论大数据和数据科学方面的话题。剧集时长从 30 分钟到 40 分钟不等,非常容易收听。
在每集开始时,主持人会推出一系列活动,听众可以参加这些活动,以了解播客中涵盖的更多主题。简介中提到的是 Strata Data 会议和人工智能会议,但你可以在他们的活动页面上找到更多的 O'Reilly 会议。
不那么标准偏差
约翰霍普金斯彭博公共卫生学院的罗杰·彭和 Stitch Fix 的希拉里·帕克共同主持本期播客。他们讨论行业新闻以及他们处理数据的个人经验。
剧集一个月播出两到三次,可以持续更长时间。大多数剧集至少有 60 分钟,有些甚至长达一个半小时。当你需要长途通勤或者花一个晚上在家做家务的时候,这些都是很好的选择,这样你就可以真正地参与讨论了!
数据故事
- 网址:http://datastori.es/
- 推特:@数据表
- 听: RSS ⋅ iTunes ⋅ 播放器 FM
关于数据可视化的播客关注数据分析管道的一个非常具体的子集——这是数据科学播客中罕见的瑰宝。数据专家 Enrico Bertini 和 Moritz Stefaner 每隔一周与一位客人坐下来讨论数据分析和可视化。
这个节目很有对话的味道。主持人互相交换意见,向客人提出很好的问题,通常会保持对话流畅。大约 40 分钟的运行时间,听众可以真正了解我们如何更好地可视化我们的数据,以及数据在我们日常生活中扮演的角色。
超级数据科学
- 网址:https://www.superdatascience.com/podcast/
- 推特: @superdatasci
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
基里尔·叶列缅科是一名数据科学教练和生活方式企业家,他将自己作为影响者的经验带到了 SuperDataScience 播客中。在他的访谈节目中,他与数据科学家和数据分析师交谈,了解他们的职业道路以及他们如何在数据行业取得成功。
除了采访行业专家,主持人播出的都是纯粹励志的 minisodes!名为五分钟星期五的这些迷你代码旨在激励听众提高自己作为数据科学家的能力,并就如何在数据科学职业生涯中前进提供建议。这绝对是最激励人心的数据科学播客之一!
家庭数据科学
- 网址:https://datascienceathome.com/
- 推特: @ThisIsFrag
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
Francesco Gadaleta 希望让机器学习对每个人来说都很容易。在这期播客中,他在采访行业专家和独自讨论一个话题的节目中交替出现。
这部剧似乎没有固定的时间表,每集的长度也各不相同,但总的来说,采访集接近一个小时,而他的个人剧集大约在二十分钟左右。
主持人非常固执己见,所以听听他对 AI winter、优化以及成为数据科学家所需的最低要求等话题的看法可能会很有趣。
本周在机器学习与人工智能(TWiML&AI)
TWiML&AI 是一个每周播客,讨论数据科学、机器学习和人工智能的最新发展。主持人 Sam Charrington 采访了领先的研究人员和行业专家,以告知越来越多的学者、工程师、商业领袖和其他机器学习和人工智能爱好者。
该节目迎合了目标观众的需求,有时技术性很强。非行业专业人士的听众可能需要温习背景知识,以便从每集节目中获得最大收益。
有超过 200 小时的剧集可以听。因为播客讨论了这个技术领域的最新发展,所以你可以直接跳到最新一集,或者回到档案馆,查看机器学习和人工智能的一些历史发展。
数据帧
- 网址:https://www.datacamp.com/community/podcast
- 推特: @DataCamp
- 听: iTunes ⋅ 豆荚 ⋅ 播放器 FM
数据科学家、作家和教育家 Hugo Bowne-Anderson 主持了这个由 DataCamp 赞助的播客。
每周,主持人都会与行业专业人士和学术专家坐下来讨论数据科学行业如何影响世界。主持人会提出很棒的问题,并邀请嘉宾讨论该领域有趣的发展以及他们自己的个人项目。
DataFramed 在每集中也有简短的片段,为听众提供关于某些主题的更多信息。例如,在自由数据科学中,雨果和孙卉谈论如何作为一名独立承包商在数据科学领域导航。Justin Boyce 在数据科学最佳实践中给出了改进工作流的实用建议。
因为它是由 DataCamp 赞助的,他们的产品被推销了很多,所以有时会感觉有点销售。尽管如此,这个节目很有趣,也很有启发性,雨果在吸引听众方面做得很好。
学习机 101
- 网址:https://www.learningmachines101.com/
- 推特: @lm101talk
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
认知科学和电子工程教授 Richard Golden 博士主持学习机器 101 课程。该播客旨在向广大观众解释机器学习和人工智能的先进概念。
尽管如此,这几集可能会变得相当专业,涵盖知识表示、期望最大化和谱聚类等主题。
听众可能需要听不止一遍才能真正理解手头的话题。这应该不会太难,因为剧集不会超过半小时,也不会经常发布。(2014 年 4 月至今只上映了 74 集。)
听众可以使用这个播客作为更高级的机器学习主题的起点。
工业中的人工智能
这个每周播客关注人工智能在商业环境中的实际应用。剧集很短,很有见地,也很容易理解。在半个小时内,主持人丹·法杰拉采访了人工智能专业人士,了解这项技术如何用于从金融和政府到零售和教育的各个行业。
丹和他的客人一起回答了诸如“你如何使用人工智能来雇佣员工?”以及“你应该什么时候升级你的人工智能硬件?”他们触及每个话题的时间足够长,足以激起听众的兴趣,并鼓励他们稍后自己深入探讨。
存档的数据科学播客
在撰写本文时,这些数据科学播客已经完成了它们的使命。这些档案仍然可供您深入研究,并且充满了有用的信息,所以不要犹豫,直接进入吧!
偏导数
- 网址:http://partiallyderivative.com/
- 推特: @partiallyd
- 听: iTunes ⋅ 豆荚 ⋅ 播放器 FM
如果你喜欢去酒吧和你的数据科学家同事聊行业新闻,那么这是最适合你的数据科学播客之一!Jonathan Morgan、Vidya Spandana 和 Chris Albon 聚在一起喝了几杯,讨论了数据科学的最新进展。
剧集时长从 20 分钟到一小时不等,但通常在 30 到 40 分钟左右。虽然该剧已经停播,但在档案中仍有超过 100 集。
听众可以深入研究积压的工作,了解数据搜集、偏见模型和 Python 中的结对编程,还可以回顾过去几年的一些热门新闻故事。
机器学习指南/机器学习应用
这些数据科学播客都是由 Tyler Renelli 运营的,每一个都有稍微不同的机器学习和人工智能方法。
机器学习指南(MLG)旨在通过从头开始解释主题,从经典算法(线性和逻辑回归)到强化学习和超参数,温和地向听众介绍机器学习的世界。
剧集时长从 45 分钟到一小时不等,但很容易被泰勒的解释吸引。这是补充其他活动的完美播客,如通勤、锻炼或打扫房间。
本播客最精彩的部分之一是主持人在每集结束时提供的精选学习资源。在听完高层次的概述后,你可以通过参加推荐的课程或阅读推荐的教材来更深入地了解主题。
他关于语言和框架的那一集包含了 Python 深度学习框架初级读本的链接。如果你从头到尾按照剧集顺序,完成补充资源,你在机器学习方面会有相当细致的基础。
截至本文撰写之时,《MLG》已经播出了 29 集。
第二个名为“机器学习应用”的播客目前正在播出,泰勒将重点放在机器学习更实用的方面。他回答了一些问题,比如一个人可以期望什么样的薪水,存储数据的最佳方式,以及如何充分利用 Jupyter 笔记本电脑。听众可以通过成为 Patroen 的支持者来获得机器学习的应用。
成为数据科学家
- 网址:https://www.becomingadatascientist.com/category/podcast/
- 推特:@成为数据科学
- 听: RSS ⋅ iTunes ⋅ 豆荚 ⋅ 播放器 FM
这个播客确实如其标题所说。主持人 Renee Teate 每周都会和一个正在“成为数据科学家”的人坐在一起。
她采访了其他数据科学专业人士,以了解他们是如何为自己开辟一条进入该行业的道路的。在第一集中,Renee 讲述了她从之前的数据分析师角色转变为数据科学家的过程。
在撰写本文时,该播客目前不活跃。最后几集是 2017 年初出的。尽管如此,已经播出的长达 20 小时的剧集中包含了丰富的信息。
如果您刚刚开始涉足数据科学领域,花一个周末的时间浏览一下档案,看看可能性在哪里!
结论
这个列表并不详尽!一直都有新的播客在播出,我们只能期待数据科学播客的数量会随着该领域的不断普及而增长。
在这个列表中没有看到你最喜欢的节目?请在下面留下您的评论,让我们知道您最喜欢的数据科学播客!*****
定义您自己的 Python 函数
原文:https://realpython.com/defining-your-own-python-function/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 定义和调用 Python 函数
在本系列之前的教程中,您已经看到了许多演示使用内置 Python 函数的例子。在本教程中,你将学习如何定义你自己的 Python 函数。您将学习何时将您的程序划分为独立的用户定义的函数,以及完成这些需要什么工具。
以下是你将在本教程中学到的内容:
- Python 中的函数是如何工作的,为什么它们是有益的
- 如何定义并调用自己的 Python 函数
- 向函数传递参数的机制
- 如何将数据从函数返回到调用环境
免费 PDF 下载: Python 3 备忘单
Python 中的函数
你可能熟悉函数的数学概念。函数是一个或多个输入和一组输出之间的关系或映射。在数学中,函数通常是这样表示的:
这里,
f是对输入x和y进行操作的函数。函数的输出是z。然而,编程函数比这一数学定义更加通用和通用。事实上,正确的函数定义和使用对于正确的软件开发是如此重要,以至于几乎所有现代编程语言都支持内置函数和用户定义函数。在编程中,函数是一个自包含的代码块,它封装了一个特定的任务或一组相关的任务。在本系列之前的教程中,已经向您介绍了 Python 提供的一些内置函数。例如,
id()接受一个参数并返回该对象的唯一整数标识符:
















>>> s = 'foobar'
>>> id(s)
56313440
len()返回传递给它的参数的长度:
>>> a = ['foo', 'bar', 'baz', 'qux'] >>> len(a) 4
any()将一个 iterable 作为其参数,如果 iterable 中的任一项为真值和False,则返回True,否则:
>>> any([False, False, False])
False
>>> any([False, True, False])
True
>>> any(['bar' == 'baz', len('foo') == 4, 'qux' in {'foo', 'bar', 'baz'}])
False
>>> any(['bar' == 'baz', len('foo') == 3, 'qux' in {'foo', 'bar', 'baz'}])
True
这些内置函数中的每一个都执行特定的任务。完成任务的代码是在某个地方定义的,但是您不需要知道代码在哪里工作,甚至不需要知道代码是如何工作的。你需要知道的只是函数的接口:
- 需要哪些参数(如果有的话)
- 它返回什么值(如果有的话)
然后调用函数并传递适当的参数。程序执行到指定的代码体,做它有用的事情。当函数完成时,执行返回到代码停止的地方。该函数可能会也可能不会返回数据供您的代码使用,就像上面的例子一样。
当您定义自己的 Python 函数时,它的工作方式是一样的。从代码中的某个地方,您将调用 Python 函数,程序执行将转移到组成该函数的代码体。
注意:在这种情况下,你会知道代码在哪里,确切地知道它是如何工作的,因为是你写的!
当函数完成时,执行返回到调用函数的位置。根据您设计函数接口的方式,调用函数时可能会传入数据,函数完成时可能会传回返回值。
Python 函数的重要性
几乎今天使用的所有编程语言都支持某种形式的用户定义函数,尽管它们并不总是被称为函数。在其他语言中,您可能会看到它们被称为下列之一:
- 子程序
- 程序
- 方法
- 子程序
那么,为什么要定义函数呢?有几个非常好的理由。我们现在来看几个。
抽象和可重用性
假设你写了一些有用的代码。随着您继续开发,您会发现该代码执行的任务是您经常需要的,在应用程序的许多不同位置。你该怎么办?你可以使用编辑器的复制粘贴功能一遍又一遍地复制代码。
稍后,您可能会决定有问题的代码需要修改。你要么会发现它有什么问题需要解决,要么会想以某种方式增强它。如果代码的副本分散在整个应用程序中,那么您需要在每个位置进行必要的更改。
注:乍一看,这似乎是一个合理的解决方案,但从长远来看,这很可能是一个维护噩梦!虽然您的代码编辑器可以通过提供搜索和替换功能来提供帮助,但这种方法很容易出错,并且您很容易在代码中引入难以发现的错误。
更好的解决方案是定义一个执行任务的 Python 函数。在应用程序中需要完成任务的任何地方,只需调用函数。接下来,如果您决定改变它的工作方式,那么您只需要在一个地方更改代码,这就是定义函数的地方。在调用该函数的任何地方,更改都会自动生效。
将功能抽象成功能定义的是软件开发的不要重复自己(DRY)原则的一个例子。这可以说是使用函数的最强动机。
模块化
函数允许复杂的过程被分解成更小的步骤。例如,假设您有一个程序,它读入一个文件,处理文件内容,然后写入一个输出文件。您的代码可能如下所示:
# Main program
# Code to read file in
<statement>
<statement>
<statement>
<statement>
# Code to process file
<statement>
<statement>
<statement>
<statement>
# Code to write file out
<statement>
<statement>
<statement>
<statement>
在这个例子中,主程序是一长串代码,用空格和注释来帮助组织它。然而,如果代码变得更长、更复杂,那么你将越来越难以理解。
或者,您可以像下面这样构建代码:
def read_file():
# Code to read file in
<statement>
<statement>
<statement>
<statement>
def process_file():
# Code to process file
<statement>
<statement>
<statement>
<statement>
def write_file():
# Code to write file out
<statement>
<statement>
<statement>
<statement>
# Main program
read_file()
process_file()
write_file()
这个例子是模块化。它不是将所有代码串在一起,而是分解成独立的功能,每个功能专注于一个特定的任务。那些任务是读、处理,以及写。主程序现在只需要依次调用这些函数。
注意:def关键字引入了一个新的 Python 函数定义。你很快就会了解这一切。
在生活中,你一直在做这种事情,即使你没有明确地这样想。如果你想把装满东西的架子从车库的一边移到另一边,你最好不要只是站在那里漫无目的地想,“哦,天哪。我需要把那些东西都搬到那边去!我该怎么做???"你应该把工作分成几个易于管理的步骤:
- 把所有的东西从货架上拿下来。
- 将货架拆开。
- 搬运货架零件穿过车库到达新位置。
- 重新组装货架。
- 把东西扛过车库。
- 把东西放回货架上。
将一个大任务分解成更小、更小的子任务有助于让大任务更容易思考和管理。随着程序变得越来越复杂,以这种方式将它们模块化变得越来越有益。
名称空间分隔
名称空间是程序的一个区域,其中标识符具有意义。正如您将在下面看到的,当调用 Python 函数时,会为该函数创建一个新的名称空间,该名称空间不同于所有其他已存在的名称空间。
这样做的实际结果是,变量可以在 Python 函数中定义和使用,即使它们与其他函数或主程序中定义的变量同名。在这些情况下,不会有混淆或干扰,因为它们保存在单独的名称空间中。
这意味着当您在函数中编写代码时,您可以使用变量名和标识符,而不必担心它们是否已经在函数外的其他地方使用。这有助于大大减少代码中的错误。
注意:在本系列的后面中,您将学到更多关于名称空间的知识。
希望您对函数的优点有足够的信心,并渴望创建一些函数!让我们看看怎么做。
函数调用和定义
定义 Python 函数的常用语法如下:
def <function_name>([<parameters>]):
<statement(s)>
下表解释了该定义的组成部分:
| 成分 | 意义 |
|---|---|
def |
通知 Python 正在定义函数的关键字 |
<function_name> |
命名函数的有效 Python 标识符 |
<parameters> |
一个可选的逗号分隔的参数列表,可以传递给函数 |
: |
表示 Python 函数头(名称和参数列表)结尾的标点符号 |
<statement(s)> |
一组有效的 Python 语句 |
最后一项<statement(s)>,称为函数的体。主体是调用函数时将执行的语句块。Python 函数的主体根据偏离规则通过缩进来定义。这与和控制结构相关的代码块是一样的,比如一个 if 或者 while 语句。
调用 Python 函数的语法如下:
<function_name>([<arguments>])
<arguments>是传递给函数的值。它们对应于 Python 函数定义中的<parameters>。您可以定义一个不带任何参数的函数,但是括号仍然是必需的。函数定义和函数调用都必须包含括号,即使它们是空的。
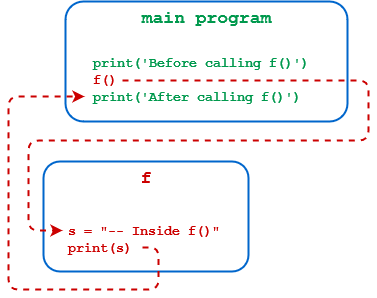
像往常一样,您将从一个小例子开始,并从那里增加复杂性。牢记历史悠久的数学传统,您将调用您的第一个 Python 函数f()。这里有一个脚本文件foo.py,它定义并调用f():
1def f():
2 s = '-- Inside f()'
3 print(s)
4
5print('Before calling f()')
6f()
7print('After calling f()')
下面是这段代码的工作原理:
-
第 1 行使用
def关键字来表示一个函数正在被定义。执行def语句仅仅创建了f()的定义。所有后面缩进的行(第 2 行到第 3 行)都成为了f()主体的一部分,并被存储为它的定义,但是它们还没有被执行。 -
第 4 行是函数定义和主程序第一行之间的一点空白。虽然这在语法上不是必需的,但拥有它是很好的。要了解更多关于顶级 Python 函数定义周围的空白,请查看用 PEP 8 编写漂亮的 Python 代码。
-
第 5 行是第一个没有缩进的语句,因为它不是
f()定义的一部分。这是主程序的开始。当主程序执行时,首先执行这条语句。 -
6 号线是去
f()的一个电话。请注意,空括号在函数定义和函数调用中都是必需的,即使没有参数也是如此。执行进行到f()并且执行f()主体中的语句。 -
第 7 行是在
f()的主体完成后执行的下一行。执行返回到这个语句。
foo.py的执行顺序(或控制流)如下图所示:
当从 Windows 命令提示符运行foo.py时,结果如下:
C:\Users\john\Documents\Python\doc>python foo.py
Before calling f()
-- Inside f()
After calling f()
有时,您可能希望定义一个空函数,它什么也不做。这被称为存根,它通常是一个 Python 函数的临时占位符,该函数将在以后完全实现。正如控制结构中的块不能为空一样,函数体也不能为空。要定义一个存根函数,使用 pass语句:
>>> def f(): ... pass ... >>> f()正如您在上面看到的,对存根函数的调用在语法上是有效的,但并不做任何事情。
参数传递
到目前为止,在本教程中,您定义的函数没有任何参数。这有时会很有用,你偶尔会写这样的函数。不过,更常见的情况是,您会希望将数据传递到函数中,以便它的行为可以随着调用的不同而变化。让我们看看如何做到这一点。
位置参数
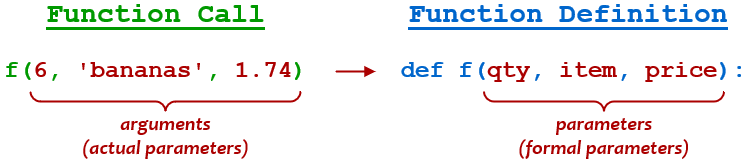
向 Python 函数传递参数最直接的方式是使用位置参数(也称为必需参数)。在函数定义中,您可以在括号内指定逗号分隔的参数列表:
>>> def f(qty, item, price):
... print(f'{qty} {item} cost ${price:.2f}')
...
调用该函数时,指定相应的参数列表:
>>> f(6, 'bananas', 1.74) 6 bananas cost $1.74参数(
qty、item和price)的行为类似于函数本地定义的变量。当调用函数时,传递的参数(6、'bananas'和1.74)按顺序绑定到参数,就像通过变量赋值一样:
参数 争吵 qty← 6item← bananasprice← 1.74在一些编程文本中,函数定义中给出的参数称为形参,函数调用中的实参称为实参:
尽管位置参数是将数据传递给函数的最直接的方式,但它们也提供了最少的灵活性。首先,调用中参数的顺序必须与定义中参数的顺序相匹配。当然,没有什么可以阻止您无序地指定位置参数:
>>> f('bananas', 1.74, 6)
bananas 1.74 cost $6.00
该函数甚至可能仍在运行,就像上面的例子一样,但它不太可能产生正确的结果。定义函数的程序员有责任记录适当的参数应该是什么,函数的用户有责任了解并遵守这些信息。
对于位置参数,调用中的参数和定义中的参数不仅在顺序上必须一致,而且在号上也必须一致。这就是位置参数也被称为必需参数的原因。调用函数时不能遗漏任何内容:
>>> # Too few arguments >>> f(6, 'bananas') Traceback (most recent call last): File "<pyshell#6>", line 1, in <module> f(6, 'bananas') TypeError: f() missing 1 required positional argument: 'price'也不能指定额外的:
>>> # Too many arguments
>>> f(6, 'bananas', 1.74, 'kumquats')
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
f(6, 'bananas', 1.74, 'kumquats')
TypeError: f() takes 3 positional arguments but 4 were given
位置参数在概念上很容易使用,但是它们不是很宽容。您必须在函数调用中指定与定义中的参数数量相同的参数,并且顺序完全相同。在接下来的小节中,您将看到一些放宽这些限制的参数传递技术。
关键字参数
当你调用一个函数时,你可以用<keyword>=<value>的形式指定参数。在这种情况下,每个<keyword>必须匹配 Python 函数定义中的一个参数。例如,之前定义的函数f()可以用关键字参数调用,如下所示:
>>> f(qty=6, item='bananas', price=1.74) 6 bananas cost $1.74引用与任何声明的参数都不匹配的关键字会生成异常:
>>> f(qty=6, item='bananas', cost=1.74)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() got an unexpected keyword argument 'cost'
使用关键字参数取消了对参数顺序的限制。每个关键字参数通过名称明确指定一个特定的参数,因此您可以按任何顺序指定它们,Python 仍然知道哪个参数与哪个参数对应:
>>> f(item='bananas', price=1.74, qty=6) 6 bananas cost $1.74但是,与位置实参一样,实参和形参的数量仍然必须匹配:
>>> # Still too few arguments
>>> f(qty=6, item='bananas')
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
f(qty=6, item='bananas')
TypeError: f() missing 1 required positional argument: 'price'
因此,关键字参数允许函数参数指定顺序的灵活性,但是参数的数量仍然是固定的。
可以使用位置参数和关键字参数来调用函数:
>>> f(6, price=1.74, item='bananas') 6 bananas cost $1.74 >>> f(6, 'bananas', price=1.74) 6 bananas cost $1.74当位置参数和关键字参数都存在时,所有位置参数必须放在前面:
>>> f(6, item='bananas', 1.74)
SyntaxError: positional argument follows keyword argument
一旦指定了关键字参数,它的右边就不能有任何位置参数。
要了解关于位置和关键字参数的更多信息,请查看真正的 Python 课程探索特殊函数参数。
默认参数
如果 Python 函数定义中指定的参数具有形式<name>=<value>,则<value>成为该参数的默认值。这样定义的参数被称为默认或可选参数。带有默认参数的函数定义示例如下所示:
>>> def f(qty=6, item='bananas', price=1.74): ... print(f'{qty} {item} cost ${price:.2f}') ...当调用这个版本的
f()时,任何被省略的参数都采用其默认值:
>>> f(4, 'apples', 2.24)
4 apples cost $2.24
>>> f(4, 'apples')
4 apples cost $1.74
>>> f(4)
4 bananas cost $1.74
>>> f()
6 bananas cost $1.74
>>> f(item='kumquats', qty=9)
9 kumquats cost $1.74
>>> f(price=2.29)
6 bananas cost $2.29
总之:
- 位置参数必须在顺序和数量上与函数定义中声明的参数一致。
- 关键字参数在数量上必须与声明的参数一致,但可以按任意顺序指定。
- 默认参数允许在调用函数时省略一些参数。
可变默认参数值
如果您指定一个默认参数值是一个可变对象,事情会变得很奇怪。考虑以下 Python 函数定义:
>>> def f(my_list=[]): ... my_list.append('###') ... return my_list ...
f()接受单个列表参数,将字符串'###'追加到列表的末尾,并返回结果:
>>> f(['foo', 'bar', 'baz'])
['foo', 'bar', 'baz', '###']
>>> f([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5, '###']
参数my_list的缺省值是空列表,所以如果不带任何参数调用f(),那么返回值是一个只有单个元素'###'的列表:
>>> f() ['###']到目前为止一切都说得通。现在,如果第二次、第三次不带任何参数地调用
f(),您认为会发生什么?让我们看看:
>>> f()
['###', '###']
>>> f()
['###', '###', '###']
哎呀!您可能希望每个后续调用也像第一个调用一样返回单例列表['###']。相反,返回值不断增长。发生了什么事?
在 Python 中,默认的参数值是在定义函数时(即执行def语句时)只定义一次的。每次调用该函数时,不会重新定义默认值。因此,每次在没有参数的情况下调用f(),都是在同一个列表中执行 .append() 。
你可以用id()来证明这一点:
>>> def f(my_list=[]): ... print(id(my_list)) ... my_list.append('###') ... return my_list ... >>> f() 140095566958408 ['###'] >>> f() 140095566958408 ['###', '###'] >>> f() 140095566958408 ['###', '###', '###']显示的对象标识符确认,当
my_list被允许默认时,该值是每次调用的相同对象。由于列表是可变的,每个后续的.append()调用都会导致列表变长。当您使用一个可变对象作为参数的默认值时,这是一个常见的、有大量文献记载的缺陷。这可能会导致混乱的代码行为,最好避免。作为一种变通方法,可以考虑使用默认的参数值来通知没有指定参数。大多数任何值都可以,但
None是常见的选择。当 sentinel 值表示没有给定参数时,在函数内创建一个新的空列表:
>>> def f(my_list=None):
... if my_list is None: ... my_list = [] ... my_list.append('###')
... return my_list
...
>>> f() ['###']
>>> f() ['###']
>>> f() ['###']
>>> f(['foo', 'bar', 'baz'])
['foo', 'bar', 'baz', '###']
>>> f([1, 2, 3, 4, 5])
[1, 2, 3, 4, 5, '###']
请注意这是如何确保无论何时在没有参数的情况下调用f()时,my_list现在都真正默认为空列表。
Pascal 中的按值传递与按引用传递
在编程语言设计中,有两种常见的将参数传递给函数的范例:
- 传值:将参数的副本传递给函数。
- 按引用传递:对参数的引用被传递给函数。
还存在其他机制,但它们本质上是这两种机制的变体。在这一节中,您将绕过 Python,简要地看一下 Pascal ,这是一种在这两者之间做了特别明确区分的编程语言。
注:不熟悉 Pascal 也不用担心!这些概念类似于 Python 的概念,并且所展示的例子附有足够详细的解释,您应该有一个大致的概念。一旦你看到了 Pascal 中参数传递的工作原理,我们将回到 Python,你将看到它是如何比较的。
以下是您需要了解的 Pascal 语法:
- 过程:Pascal 中的过程类似于 Python 函数。
- 冒号-等号:这个运算符(
:=)在 Pascal 中用于赋值。这类似于 Python 中的等号(=)。 writeln(): 该函数向控制台显示数据,类似于 Python 的print()。
有了这些基础,下面是第一个 Pascal 示例:
1// Pascal Example #1
2
3procedure f(fx : integer); 4begin
5 writeln('Start f(): fx = ', fx);
6 fx := 10;
7 writeln('End f(): fx = ', fx);
8end;
9
10// Main program
11var
12 x : integer;
13
14begin
15 x := 5;
16 writeln('Before f(): x = ', x);
17 f(x);
18 writeln('After f(): x = ', x);
19end.
事情是这样的:
- 第 12 行:主程序定义了一个整数变量
x。 - 第 15 行:它最初给
x赋值5。 - 第 17 行:然后调用过程
f(),传递x作为参数。 - 第 5 行:
f()内的,writeln()语句显示对应的参数fx最初是5,传入的值。 - 第 6 行:
fx然后被赋值10。 - 第 7 行:该值由在
f()退出前执行的writeln()语句验证。 - 第 18 行:回到主程序的调用环境,这个
writeln()语句显示在f()返回后,x仍然是5,和过程调用前一样。
运行此代码会生成以下输出:
Before f(): x = 5
Start f(): fx = 5
End f(): fx = 10
After f(): x = 5
在这个例子中,x是由值传递的,所以f()只接收一个副本。当相应的参数fx被修改时,x不受影响。
注意:如果你想看实际操作,你可以使用在线 Pascal 编译器自己运行代码。
只需遵循以下步骤:
- 从上面的代码框中复制代码。
- 访问在线 Pascal 编译器。
- 在左侧的“代码”框中,用您在步骤 1 中复制的代码替换任何现有内容。
- 点击执行。
您应该会看到与上面相同的输出。
现在,将它与下一个例子进行比较:
1// Pascal Example #2
2
3procedure f(var fx : integer); 4begin
5 writeln('Start f(): fx = ', fx);
6 fx := 10;
7 writeln('End f(): fx = ', fx);
8end;
9
10// Main program
11var
12 x : integer;
13
14begin
15 x := 5;
16 writeln('Before f(): x = ', x);
17 f(x);
18 writeln('After f(): x = ', x);
19end.
这段代码与第一个示例相同,只有一处不同。就是第 3 行过程f()定义中fx前面有var这个词。这表明f()的参数是通过引用传递的。对相应参数fx的更改也会修改调用环境中的参数。
除了最后一行之外,这段代码的输出与前面的一样:
Before f(): x = 5
Start f(): fx = 5
End f(): fx = 10
After f(): x = 10
再次,像以前一样,fx在f()内被赋予值10。但这一次,当f()返回时,主程序中的x也被修改了。
在许多编程语言中,这就是按值传递和按引用传递的本质区别:
- 如果一个变量是通过值传递的,那么这个函数就有一个副本可以使用,但是它不能在调用环境中修改原始值。
- 如果一个变量是通过引用传递的,那么函数对相应参数的任何更改都会影响调用环境中的值。
原因来自于这些语言中引用的含义。变量值存储在内存中。在 Pascal 和类似的语言中,引用本质上是那个内存位置的地址,如下所示:
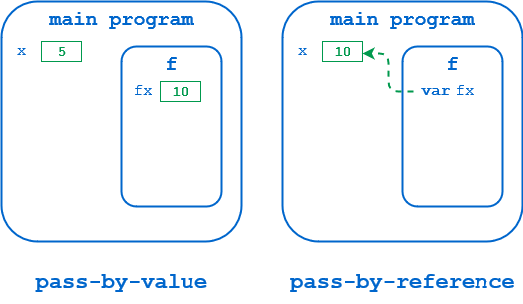
在左边的图中,x在主程序的名称空间中分配了内存。当f()被调用时,x是由值传递的,因此对应参数fx的内存被分配在f()的名称空间中,并且x的值被复制到那里。当f()修改fx时,改变的是这个本地副本。调用环境中x的值保持不变。
右图中,x是通过引用传递的。相应的参数fx指向主程序名称空间中的实际地址,其中存储了x的值。当f()修改fx时,它在修改那个位置的值,就像主程序在修改x本身一样。
Python 中的按值传递与按引用传递
Python 中的参数是按值传递还是按引用传递?确切地说,答案是两者都不是。这是因为引用在 Python 和 Pascal 中的含义不同。
回想一下,在 Python 中,每一段数据都是一个对象。引用指向一个对象,而不是特定的内存位置。这意味着在 Python 中赋值的解释方式和在 Pascal 中不同。考虑下面的 Pascal 语句对:
x := 5
x := 10
这些是这样解释的:
- 变量
x引用一个特定的内存位置。 - 第一条语句将值
5放在那个位置。 - 下一条语句覆盖了
5并将10放在那里。
相比之下,在 Python 中,类似的赋值语句如下:
x = 5
x = 10
这些赋值语句具有以下含义:
- 第一条语句导致
x指向一个值为5的对象。 - 下一条语句将
x重新赋值为一个不同对象的新引用,该对象的值为10。换句话说,第二个赋值将x重新绑定到值为10的不同对象。
在 Python 中,当您向函数传递参数时,会发生类似的重新绑定。考虑这个例子:
1>>> def f(fx): 2... fx = 10 3... 4>>> x = 5 5>>> f(x) 6>>> x 75在主程序中,第 4 行的语句
x = 5创建了一个名为x的引用,该引用绑定到一个值为5的对象。然后在第 5 行调用f(),用x作为参数。当f()第一次启动时,一个名为fx的新引用被创建,它最初指向与x相同的5对象:
然而,当执行第 2 行的语句
fx = 10时,f()将fx重新绑定到一个值为10的新对象。两个引用x和fx彼此解耦。f()所做的其他事情都不会影响x,当f()终止时,x仍将指向对象5,就像它在函数调用之前所做的那样:
你可以用
id()来确认这一切。下面是上面示例的一个稍微扩充的版本,显示了相关对象的数字标识符:
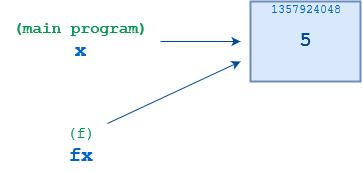
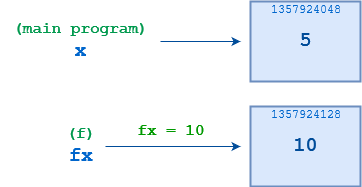
1>>> def f(fx):
2... print('fx =', fx, '/ id(fx) = ', id(fx))
3... fx = 10
4... print('fx =', fx, '/ id(fx) = ', id(fx))
5...
6
7>>> x = 5
8>>> print('x =', x, '/ id(x) = ', id(x))
9x = 5 / id(x) = 1357924048
10
11>>> f(x)
12fx = 5 / id(fx) = 1357924048
13fx = 10 / id(fx) = 1357924128
14
15>>> print('x =', x, '/ id(x) = ', id(x))
16x = 5 / id(x) = 1357924048
当f()第一次启动时,fx和x都指向同一个对象,其id()为1357924048。在f()执行第 3 行的语句fx = 10后,fx指向一个不同的对象,其id()为1357924128。与调用环境中的原始对象的连接丢失。
Python 中的参数传递有点像按值传递和按引用传递的混合体。传递给函数的是对对象的引用,但引用是通过值传递的。
注意: Python 的参数传递机制已经被称为**。这是因为在 Python 中,参数名被绑定到函数入口的对象上,赋值也是将名称绑定到对象上的过程。您可能还会看到按对象传递、按对象引用传递或按共享传递等术语。*
*这里的关键是 Python 函数不能通过将相应的参数重新赋值给其他东西来改变参数的值。以下示例说明了这一点:
>>> def f(x): ... x = 'foo' ... >>> for i in ( ... 40, ... dict(foo=1, bar=2), ... {1, 2, 3}, ... 'bar', ... ['foo', 'bar', 'baz']): ... f(i) ... print(i) ... 40 {'foo': 1, 'bar': 2} {1, 2, 3} bar ['foo', 'bar', 'baz']这里,
int,dict,set,str,list类型的对象作为参数传递给f()。f()试图将它们分配给 string 对象'foo',但是正如您所看到的,一旦回到调用环境中,它们都不会改变。f()一执行赋值x = 'foo',引用反弹,与原对象的连接丢失。这是否意味着 Python 函数永远不能修改它的参数?其实,不,事实并非如此!看看这里发生了什么:
>>> def f(x):
... x[0] = '---' ...
>>> my_list = ['foo', 'bar', 'baz', 'qux']
>>> f(my_list)
>>> my_list
['---', 'bar', 'baz', 'qux']
在这种情况下,f()的参数是一个列表。当调用f()时,传递一个对my_list的引用。你已经看到f()不能重新分配my_list批发。如果x被分配给其他对象,那么它将被绑定到一个不同的对象,到my_list的连接将会丢失。
但是,f()可以使用引用在my_list内部进行修改。在这里,f()已经修饰了第一个元素。您可以看到,一旦函数返回,my_list实际上已经在调用环境中被更改了。同样的概念也适用于词典:
>>> def f(x): ... x['bar'] = 22 ... >>> my_dict = {'foo': 1, 'bar': 2, 'baz': 3} >>> f(my_dict) >>> my_dict {'foo': 1, 'bar': 22, 'baz': 3}这里,
f()以x为参照,在my_dict内部做了改动。在f()返回后,这种变化反映在调用环境中。参数传递摘要
Python 中的参数传递可以总结如下。传递一个不可变的对象,比如一个
int,str,tuple,或者frozenset,对一个 Python 函数来说就像传值一样。该函数不能在调用环境中修改对象。传递一个可变对象,比如
list、dict或set的行为有点类似于按引用传递。该函数不能大规模地重新分配对象,但它可以在对象内就地更改项目,这些更改将反映在调用环境中。副作用
因此,在 Python 中,您可以从函数内部修改参数,以便将更改反映到调用环境中。但是你应该这样做吗?这是一个在编程行话中被称为副作用的例子。
更一般地说,如果 Python 函数以任何方式修改了它的调用环境,就会产生副作用。更改函数参数的值只是可能性之一。
注意:你可能熟悉人类健康领域的副作用,该术语通常指药物治疗的意外后果。通常,后果是不可取的,如呕吐或镇静。另一方面,副作用可以故意使用。例如,一些药物会引起食欲刺激,这可以被用来作为一种优势,即使这不是药物的主要目的。
编程中的概念是类似的。如果副作用是函数规范的一部分,并且函数的用户清楚地知道何时以及如何修改调用环境,那么它是可以的。但是程序员可能并不总是正确地记录副作用,或者他们甚至可能没有意识到副作用正在发生。
当它们被隐藏或出乎意料时,副作用会导致很难追踪的程序错误。一般来说,最好避开它们。
return语句那么 Python 函数能做什么呢?毕竟,在很多情况下,如果一个函数没有引起调用环境的一些变化,那么调用它根本就没有多大意义。一个函数应该如何影响它的调用者?
嗯,一种可能是使用函数返回值。Python 函数中的
return语句有两个用途:
- 它立即终止该函数,并将执行控制传递回调用者。
- 它提供了一种机制,通过这种机制,函数可以将数据传递回调用者。
退出功能
在一个函数中,
return语句导致从 Python 函数中立即退出,并将执行转移回调用者:
>>> def f():
... print('foo')
... print('bar')
... return
...
>>> f()
foo
bar
在这个例子中,return语句实际上是多余的。当从结尾落下时,函数将返回给调用者——也就是说,在函数体的最后一条语句执行完之后。因此,如果没有return语句,这个函数的行为是一样的。
然而,return语句不需要在函数的末尾。它们可以出现在函数体的任何地方,甚至多次出现。考虑这个例子:
1>>> def f(x): 2... if x < 0: 3... return 4... if x > 100: 5... return 6... print(x) 7... 8 9>>> f(-3) 10>>> f(105) 11>>> f(64) 1264对
f()的前两次调用不会导致任何输出,因为在到达第 6 行的print()语句之前,执行了一条return语句并且函数提前退出。这种范式对于函数中的错误检查非常有用。您可以在函数开始时检查几个错误条件,如果有问题,使用
return语句退出:def f(): if error_cond1: return if error_cond2: return if error_cond3: return <normal processing>如果没有遇到任何错误条件,则该函数可以继续其正常处理。
向调用者返回数据
除了退出一个函数之外,
return语句还用于将数据传递回调用者。如果 Python 函数中的return语句后跟一个表达式,那么在调用环境中,函数调用将计算该表达式的值:
1>>> def f():
2... return 'foo'
3...
4
5>>> s = f()
6>>> s
7'foo'
这里,第 5 行的表达式f()的值是'foo',它随后被赋给变量s。
函数可以返回任何类型的对象。在 Python 中,这意味着几乎任何东西。在调用环境中,函数调用可以以对函数返回的对象类型有意义的任何方式在语法上使用。
例如,在这段代码中,f()返回一个字典。在调用环境中,表达式f()代表一个字典,而f()['baz']是该字典的有效键引用:
>>> def f(): ... return dict(foo=1, bar=2, baz=3) ... >>> f() {'foo': 1, 'bar': 2, 'baz': 3} >>> f()['baz'] 3在下一个示例中,
f()返回一个字符串,您可以像对任何其他字符串一样对其进行切片:
>>> def f():
... return 'foobar'
...
>>> f()[2:4]
'ob'
这里,f()返回一个可以索引或切片的列表:
>>> def f(): ... return ['foo', 'bar', 'baz', 'qux'] ... >>> f() ['foo', 'bar', 'baz', 'qux'] >>> f()[2] 'baz' >>> f()[::-1] ['qux', 'baz', 'bar', 'foo']如果在一个
return语句中指定了多个逗号分隔的表达式,那么它们被打包并作为一个元组返回:
>>> def f():
... return 'foo', 'bar', 'baz', 'qux'
...
>>> type(f())
<class 'tuple'>
>>> t = f()
>>> t
('foo', 'bar', 'baz', 'qux')
>>> a, b, c, d = f()
>>> print(f'a = {a}, b = {b}, c = {c}, d = {d}')
a = foo, b = bar, c = baz, d = qux
当没有返回值时,Python 函数返回特殊的 Python 值None:
>>> def f(): ... return ... >>> print(f()) None如果函数体根本不包含
return语句,并且函数从末尾脱落,也会发生同样的情况:
>>> def g():
... pass
...
>>> print(g())
None
由于通过一个裸露的return语句退出的函数或者从末尾返回的函数会返回None,所以对这样一个函数的调用可以在布尔上下文中使用:
>>> def f(): ... return ... >>> def g(): ... pass ... >>> if f() or g(): ... print('yes') ... else: ... print('no') ... no在这里,对
f()和g()的调用都是假的,所以f() or g()也是假的,并且else子句执行。重温副作用
假设您想编写一个函数,它接受一个整数参数并对其进行双精度处理。也就是说,您希望将一个整数变量传递给函数,当函数返回时,该变量在调用环境中的值应该是原来的两倍。在 Pascal 中,您可以使用按引用传递来实现这一点:
1procedure double(var x : integer); 2begin 3 x := x * 2; 4end; 5 6var 7 x : integer; 8 9begin 10 x := 5; 11 writeln('Before procedure call: ', x); 12 double(x); 13 writeln('After procedure call: ', x); 14end.执行这段代码会产生以下输出,这验证了
double()确实在调用环境中修改了x:Before procedure call: 5 After procedure call: 10在 Python 中,这是行不通的。如您所知,Python 整数是不可变的,所以 Python 函数不能通过副作用改变整数参数:
>>> def double(x):
... x *= 2
...
>>> x = 5 >>> double(x) >>> x
5
但是,您可以使用返回值来获得类似的效果。只需编写double(),让它接受一个整数参数,将它加倍,然后返回加倍后的值。然后,调用者负责修改原始值的赋值:
>>> def double(x): ... return x * 2 ... >>> x = 5 >>> x = double(x) >>> x 10这比通过副作用进行修改更可取。很明显,
x在调用环境中被修改了,因为调用者自己也在这么做。反正是唯一的选择,因为这种情况下靠副作用修改是行不通的。尽管如此,即使在有可能通过副作用修改参数的情况下,使用返回值可能仍然更清楚。假设您想将列表中的每一项都加倍。因为列表是可变的,所以您可以定义一个 Python 函数来就地修改列表:
>>> def double_list(x):
... i = 0
... while i < len(x):
... x[i] *= 2
... i += 1
...
>>> a = [1, 2, 3, 4, 5] >>> double_list(a) >>> a
[2, 4, 6, 8, 10]
与上一个例子中的double()不同,double_list()实际上按预期工作。如果函数的文档清楚地说明列表参数的内容被更改,那么这可能是一个合理的实现。
然而,您也可以编写double_list()来通过返回值传递所需的列表,并允许调用者进行赋值,类似于在前面的示例中如何重写double():
>>> def double_list(x): ... r = [] ... for i in x: ... r.append(i * 2) ... return r ... >>> a = [1, 2, 3, 4, 5] >>> a = double_list(a) >>> a [2, 4, 6, 8, 10]这两种方法都同样有效。通常情况下,这是一个风格问题,个人喜好各不相同。副作用不一定是完完全全的邪恶,它们有它们的位置,但是因为几乎任何东西都可以从函数中返回,所以同样的事情通常也可以通过返回值来完成。
可变长度参数列表
在某些情况下,当你定义一个函数时,你可能事先不知道你想要它接受多少个参数。例如,假设您想要编写一个 Python 函数来计算几个值的平均值。你可以这样开始:
>>> def avg(a, b, c):
... return (a + b + c) / 3
...
如果你想平均三个值,一切都很好:
>>> avg(1, 2, 3) 2.0但是,正如您已经看到的,当使用位置参数时,传递的参数数量必须与声明的参数数量一致。很明显,对于除了三个以外的任何数量的值来说,
avg()的实现都不太好:
>>> avg(1, 2, 3, 4)
Traceback (most recent call last):
File "<pyshell#34>", line 1, in <module>
avg(1, 2, 3, 4)
TypeError: avg() takes 3 positional arguments but 4 were given
您可以尝试用可选参数定义avg():
>>> def avg(a, b=0, c=0, d=0, e=0): ... . ... . ... . ...这允许指定可变数量的参数。以下调用至少在语法上是正确的:
avg(1) avg(1, 2) avg(1, 2, 3) avg(1, 2, 3, 4) avg(1, 2, 3, 4, 5)但是这种方法仍然存在一些问题。首先,它仍然只允许最多五个参数,而不是任意数量。更糟糕的是,没有办法区分指定的参数和允许默认的参数。该函数无法知道实际传递了多少个参数,因此它不知道要除以什么:
>>> def avg(a, b=0, c=0, d=0, e=0):
... return (a + b + c + d + e) / # Divided by what???
...
显然,这也不行。
您可以编写avg()来获取一个列表参数:
>>> def avg(a): ... total = 0 ... for v in a: ... total += v ... return total / len(a) ... >>> avg([1, 2, 3]) 2.0 >>> avg([1, 2, 3, 4, 5]) 3.0至少这个管用。它允许任意数量的值并产生正确的结果。额外的好处是,当参数是一个元组时,它也可以工作:
>>> t = (1, 2, 3, 4, 5)
>>> avg(t)
3.0
缺点是必须将值分组到一个列表或元组中的额外步骤可能不是该函数的用户所期望的,并且它不是非常优雅。每当你发现 Python 代码看起来不雅的时候,可能会有更好的选择。
在这种情况下,的确有!Python 提供了一种方法,通过使用星号(*)操作符打包和解包参数元组,向函数传递可变数量的参数。
参数元组打包
当 Python 函数定义中的参数名前面有星号(*)时,表示参数元组打包。函数调用中任何相应的参数都被打包到一个元组中,函数可以通过给定的参数名引用该元组。这里有一个例子:
>>> def f(*args): ... print(args) ... print(type(args), len(args)) ... for x in args: ... print(x) ... >>> f(1, 2, 3) (1, 2, 3) <class 'tuple'> 3 1 2 3 >>> f('foo', 'bar', 'baz', 'qux', 'quux') ('foo', 'bar', 'baz', 'qux', 'quux') <class 'tuple'> 5 foo bar baz qux quux在
f()的定义中,参数说明*args表示元组打包。在对f()的每次调用中,参数被打包到一个元组中,函数可以通过名称args来引用它。任何名字都可以使用,但是args是如此普遍的选择,以至于它实际上是一个标准。使用元组打包,您可以像这样清理
avg():
>>> def avg(*args):
... total = 0
... for i in args:
... total += i
... return total / len(args)
...
>>> avg(1, 2, 3)
2.0
>>> avg(1, 2, 3, 4, 5)
3.0
更好的是,您可以通过用内置的 Python 函数sum()替换for循环来进一步整理它,该函数对任何 iterable 中的数值求和:
>>> def avg(*args): ... return sum(args) / len(args) ... >>> avg(1, 2, 3) 2.0 >>> avg(1, 2, 3, 4, 5) 3.0现在,
avg()写得很简洁,也按预期工作。尽管如此,根据如何使用这些代码,可能仍有工作要做。如前所述,如果有任何非数字参数,
avg()将产生一个TypeError异常:
>>> avg(1, 'foo', 3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in avg
TypeError: unsupported operand type(s) for +: 'int' and 'str'
为了尽可能的健壮,你应该添加代码到来检查参数的类型是否正确。在本系列教程的后面,您将学习如何捕捉像TypeError这样的异常并适当地处理它们。你也可以看看 Python 异常:介绍。
参数元组解包
在 Python 函数调用中,等式的另一端有一个类似的操作。当函数调用中的参数前面有星号(*)时,表示该参数是一个元组,应该解包并作为单独的值传递给函数:
>>> def f(x, y, z): ... print(f'x = {x}') ... print(f'y = {y}') ... print(f'z = {z}') ... >>> f(1, 2, 3) x = 1 y = 2 z = 3 >>> t = ('foo', 'bar', 'baz') >>> f(*t) x = foo y = bar z = baz在这个例子中,函数调用中的
*t表示t是一个应该解包的元组。解包后的值'foo'、'bar'和'baz'分别分配给参数x、y和z。虽然这种类型的解包被称为元组解包,但它并不仅仅适用于元组。星号(
*)操作符可以应用于 Python 函数调用中的任何 iterable。例如,一个列表或集合也可以被解包:
>>> a = ['foo', 'bar', 'baz']
>>> type(a)
<class 'list'>
>>> f(*a)
x = foo
y = bar
z = baz
>>> s = {1, 2, 3}
>>> type(s)
<class 'set'>
>>> f(*s)
x = 1
y = 2
z = 3
您甚至可以同时使用元组打包和解包:
>>> def f(*args): ... print(type(args), args) ... >>> a = ['foo', 'bar', 'baz', 'qux'] >>> f(*a) <class 'tuple'> ('foo', 'bar', 'baz', 'qux')这里,
f(*a)表示列表a应该被解包,并且项目作为单个值被传递给f()。参数说明*args导致值被打包回元组args。参数字典打包
Python 有一个类似的操作符,双星号(
**),可以和 Python 函数参数和实参一起使用,指定字典打包和解包。在 Python 函数定义中的参数前加一个双星号(**)表示对应的参数应该是key=value对,应该打包到字典中:
>>> def f(**kwargs):
... print(kwargs)
... print(type(kwargs))
... for key, val in kwargs.items():
... print(key, '->', val)
...
>>> f(foo=1, bar=2, baz=3)
{'foo': 1, 'bar': 2, 'baz': 3}
<class 'dict'>
foo -> 1
bar -> 2
baz -> 3
在这种情况下,参数foo=1、bar=2和baz=3被打包到一个字典中,函数可以通过名称 kwargs 来引用该字典。同样,任何名字都可以使用,但是特有的kwargs(是关键字 args 的缩写)几乎是标准的。您不必坚持它,但是如果您这样做了,那么任何熟悉 Python 编码约定的人都会明白您的意思。
参数字典解包
参数字典解包类似于参数元组解包。当双星号(**)位于 Python 函数调用中的参数之前时,它指定该参数是一个应该解包的字典,结果项作为关键字参数传递给函数:
>>> def f(a, b, c): ... print(F'a = {a}') ... print(F'b = {b}') ... print(F'c = {c}') ... >>> d = {'a': 'foo', 'b': 25, 'c': 'qux'} >>> f(**d) a = foo b = 25 c = qux字典
d中的条目被解包并作为关键字参数传递给f()。所以,f(**d)相当于f(a='foo', b=25, c='qux'):
>>> f(a='foo', b=25, c='qux')
a = foo
b = 25
c = qux
事实上,看看这个:
>>> f(**dict(a='foo', b=25, c='qux')) a = foo b = 25 c = qux这里,
dict(a='foo', b=25, c='qux')从指定的键/值对创建一个字典。然后,双星号操作符(**)将其解包,并将关键字传递给f()。将所有这些放在一起
把
*args想象成一个变长的位置参数列表,**kwargs想象成一个变长的关键字参数列表。注:再看
*args和**kwargs,见 Python args 和 kwargs:去神秘化。所有三个标准位置参数
*args和**kwargs都可以在一个 Python 函数定义中使用。如果是,则应按以下顺序指定:
>>> def f(a, b, *args, **kwargs):
... print(F'a = {a}')
... print(F'b = {b}')
... print(F'args = {args}')
... print(F'kwargs = {kwargs}')
...
>>> f(1, 2, 'foo', 'bar', 'baz', 'qux', x=100, y=200, z=300)
a = 1
b = 2
args = ('foo', 'bar', 'baz', 'qux')
kwargs = {'x': 100, 'y': 200, 'z': 300}
这提供了您在函数接口中可能需要的灵活性!
Python 函数调用中的多次解包
Python 版本引入了对额外解包一般化的支持,如 PEP 448 中所述。这些增强允许在单个 Python 函数调用中进行多重解包:
>>> def f(*args): ... for i in args: ... print(i) ... >>> a = [1, 2, 3] >>> t = (4, 5, 6) >>> s = {7, 8, 9} >>> f(*a, *t, *s) 1 2 3 4 5 6 8 9 7您也可以在 Python 函数调用中指定多个字典解包:
>>> def f(**kwargs):
... for k, v in kwargs.items():
... print(k, '->', v)
...
>>> d1 = {'a': 1, 'b': 2}
>>> d2 = {'x': 3, 'y': 4}
>>> f(**d1, **d2) a -> 1
b -> 2
x -> 3
y -> 4
注意:该增强仅在 Python 版本 3.5 或更高版本中可用。如果你在早期版本中尝试这样做,那么你会得到一个 SyntaxError 异常。
顺便说一下,解包操作符*和**不仅仅适用于变量,就像上面的例子一样。您也可以将它们与可迭代的文字一起使用:
>>> def f(*args): ... for i in args: ... print(i) ... >>> f(*[1, 2, 3], *[4, 5, 6]) 1 2 3 4 5 6 >>> def f(**kwargs): ... for k, v in kwargs.items(): ... print(k, '->', v) ... >>> f(**{'a': 1, 'b': 2}, **{'x': 3, 'y': 4}) a -> 1 b -> 2 x -> 3 y -> 4这里,字面量列表
[1, 2, 3]和[4, 5, 6]被指定用于元组解包,字面量字典{'a': 1, 'b': 2}和{'x': 3, 'y': 4}被指定用于字典解包。仅关键字参数
版本 3.x 中的 Python 函数可以定义为只接受关键字参数。这些是必须由关键字指定的函数参数。让我们探索一下这可能是有益的情况。
假设您想要编写一个 Python 函数,它接受可变数量的字符串参数,用点(
".")将它们连接在一起,并将它们打印到控制台。类似这样的事情可以作为开始:
>>> def concat(*args):
... print(f'-> {".".join(args)}')
...
>>> concat('a', 'b', 'c')
-> a.b.c
>>> concat('foo', 'bar', 'baz', 'qux')
-> foo.bar.baz.qux
目前,输出前缀被硬编码为字符串'-> '。如果您想修改函数,让它也接受这个参数,这样用户就可以指定其他内容,该怎么办呢?这是一种可能性:
>>> def concat(prefix, *args): ... print(f'{prefix}{".".join(args)}') ... >>> concat('//', 'a', 'b', 'c') //a.b.c >>> concat('... ', 'foo', 'bar', 'baz', 'qux') ... foo.bar.baz.qux这和宣传的一样有效,但是这个解决方案有一些不尽人意的地方:
prefix字符串与要连接的字符串放在一起。仅从函数调用来看,不清楚第一个参数是否与其他参数有所不同。要知道这一点,你必须回头看看函数的定义。不是可有可无的。它总是必须被包含在内,而且没有办法假设一个默认值。
您可能认为可以通过指定一个带有默认值的参数来解决第二个问题,比如:
>>> def concat(prefix='-> ', *args):
... print(f'{prefix}{".".join(args)}')
...
不幸的是,这并不完全正确。prefix是一个位置参数,所以解释器假设函数调用中指定的第一个参数是预期的输出前缀。这意味着没有任何方法可以忽略它并获得默认值:
>>> concat('a', 'b', 'c') ab.c如果试图将
prefix指定为关键字参数会怎样?嗯,你不能先指定它:
>>> concat(prefix='//', 'a', 'b', 'c')
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument
正如你之前看到的,当两种类型的参数都给定时,所有的位置参数必须在任何关键字参数之前。
但是,您也不能最后指定它:
>>> concat('a', 'b', 'c', prefix='... ') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: concat() got multiple values for argument 'prefix'同样,
prefix是一个位置参数,所以它被赋予调用中指定的第一个参数(在本例中是'a')。然后,当它在最后被再次指定为关键字参数时,Python 认为它被赋值了两次。只有关键字的参数有助于解决这个难题。在函数定义中,指定
*args来表示可变数量的位置参数,然后在其后指定prefix:
>>> def concat(*args, prefix='-> '): ... print(f'{prefix}{".".join(args)}')
...
在这种情况下,prefix变成了一个只有关键字的参数。它的值永远不会被位置参数填充。它只能由命名的关键字参数指定:
>>> concat('a', 'b', 'c', prefix='... ') ... a.b.c请注意,这仅在 Python 3 中是可能的。在 Python 的 2.x 版本中,在
*args变量 arguments 参数之后指定附加参数会引发错误。仅关键字参数允许 Python 函数接受可变数量的参数,后跟一个或多个额外的选项作为关键字参数。如果您想修改
concat(),以便也可以选择性地指定分隔符,那么您可以添加一个附加的仅关键字参数:
>>> def concat(*args, prefix='-> ', sep='.'):
... print(f'{prefix}{sep.join(args)}')
...
>>> concat('a', 'b', 'c')
-> a.b.c
>>> concat('a', 'b', 'c', prefix='//')
//a.b.c
>>> concat('a', 'b', 'c', prefix='//', sep='-')
//a-b-c
如果在函数定义中为一个只有关键字的参数指定了默认值(如上例所示),并且在调用函数时省略了关键字,则提供默认值:
>>> concat('a', 'b', 'c') -> a.b.c另一方面,如果该参数没有给定默认值,那么它就变成必需的,如果不指定它,就会导致错误:
>>> def concat(*args, prefix): ... print(f'{prefix}{".".join(args)}')
...
>>> concat('a', 'b', 'c', prefix='... ')
... a.b.c
>>> concat('a', 'b', 'c')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: concat() missing 1 required keyword-only argument: 'prefix'
如果您想定义一个只接受关键字参数而不接受可变数量的位置参数的 Python 函数,该怎么办?例如,以下函数对两个数字参数执行指定的运算:
>>> def oper(x, y, op='+'): ... if op == '+': ... return x + y ... elif op == '-': ... return x - y ... elif op == '/': ... return x / y ... else: ... return None ... >>> oper(3, 4) 7 >>> oper(3, 4, '+') 7 >>> oper(3, 4, '/') 0.75如果您想让
op成为一个只有关键字的参数,那么您可以添加一个无关的伪变量参数并忽略它:
>>> def oper(x, y, *ignore, op='+'): ... if op == '+':
... return x + y
... elif op == '-':
... return x - y
... elif op == '/':
... return x / y
... else:
... return None
...
>>> oper(3, 4, op='+')
7
>>> oper(3, 4, op='/')
0.75
这种解决方案的问题是,*ignore吸收了可能碰巧包含的任何无关的位置参数:
>>> oper(3, 4, "I don't belong here") 7 >>> oper(3, 4, "I don't belong here", op='/') 0.75在这个例子中,额外的参数不应该在那里(正如参数本身所宣布的)。它应该真正导致一个错误,而不是悄无声息地成功。事实上,它并不整洁。在最坏的情况下,它可能会导致一个看似误导的结果:
>>> oper(3, 4, '/')
7
为了解决这个问题,版本 3 允许 Python 函数定义中的变量参数只是一个星号(*),名称省略:
>>> def oper(x, y, *, op='+'): ... if op == '+': ... return x + y ... elif op == '-': ... return x - y ... elif op == '/': ... return x / y ... else: ... return None ... >>> oper(3, 4, op='+') 7 >>> oper(3, 4, op='/') 0.75 >>> oper(3, 4, "I don't belong here") Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: oper() takes 2 positional arguments but 3 were given >>> oper(3, 4, '+') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: oper() takes 2 positional arguments but 3 were given裸变量实参参数
*表示不再有位置形参。如果指定了额外的错误消息,此行为会生成适当的错误消息。它允许只跟关键字参数。仅位置参数
从 Python 3.8 开始,函数参数也可以声明为仅限位置,这意味着相应的实参必须按位置提供,不能由关键字指定。
要将一些参数指定为仅位置参数,您可以在函数定义的参数列表中指定一个空斜杠(
/)。斜线(/)左边的任何参数都必须指定位置。例如,在下面的函数定义中,x和y是仅位置参数,但是z可以由关键字指定:
>>> # This is Python 3.8
>>> def f(x, y, /, z):
... print(f'x: {x}')
... print(f'y: {y}')
... print(f'z: {z}')
...
这意味着以下调用是有效的:
>>> f(1, 2, 3) x: 1 y: 2 z: 3 >>> f(1, 2, z=3) x: 1 y: 2 z: 3然而,下面对
f()的调用是无效的:
>>> f(x=1, y=2, z=3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() got some positional-only arguments passed as keyword arguments:
'x, y'
仅位置指示器和仅关键字指示器可以在同一个函数定义中使用:
>>> # This is Python 3.8 >>> def f(x, y, /, z, w, *, a, b): ... print(x, y, z, w, a, b) ... >>> f(1, 2, z=3, w=4, a=5, b=6) 1 2 3 4 5 6 >>> f(1, 2, 3, w=4, a=5, b=6) 1 2 3 4 5 6在本例中:
x和y是位置唯一的。a和b为关键字专用。z``w可以按位置指定,也可以按关键字指定。有关仅位置参数的更多信息,请参见 Python 3.8 版本亮点。
文档字符串
当 Python 函数体中的第一条语句是字符串文字时,它被称为函数的 docstring 。docstring 用于为函数提供文档。它可以包含函数的用途、它采用的参数、关于返回值的信息,或者您认为有用的任何其他信息。
以下是使用 docstring 的函数定义的示例:
>>> def avg(*args):
... """Returns the average of a list of numeric values."""
... return sum(args) / len(args)
...
从技术上讲,docstrings 可以使用 Python 的任何引用机制,但是推荐的约定是使用双引号字符(""")对进行三重引用,如上所示。如果 docstring 适合一行,那么结束引号应该和开始引号在同一行。
多行文档字符串用于较长的文档。多行 docstring 应该包含一个摘要行,后面跟一个空行,后面跟一个更详细的描述。结束引号应该单独在一行上:
>>> def foo(bar=0, baz=1): ... """Perform a foo transformation. ... ... Keyword arguments: ... bar -- magnitude along the bar axis (default=0) ... baz -- magnitude along the baz axis (default=1) ... """ ... <function_body> ...文档字符串格式和语义约定在 PEP 257 中有详细说明。
当定义一个 docstring 时,Python 解释器将它分配给一个名为
__doc__的函数的特殊属性。这个属性是 Python 中一组专用标识符之一,这些标识符有时被称为神奇属性或神奇方法,因为它们提供了特殊的语言功能。注意:这些属性也被丰富多彩的昵称 dunder 属性和 dunder 方法所引用。 dunder 一词由双的 d 和下的由下划线字符(
_)组合而成。在本系列的后续教程中,您将会遇到更多的 dunder 属性和方法。可以用表达式
<function_name>.__doc__访问函数的 docstring。上述示例的文档字符串可以显示如下:
>>> print(avg.__doc__)
Returns the average of a list of numeric values.
>>> print(foo.__doc__)
Perform a foo transformation.
Keyword arguments:
bar -- magnitude along the bar axis (default=0)
baz -- magnitude along the baz axis (default=1)
在交互式 Python 解释器中,您可以键入help(<function_name>)来显示<function_name>的文档字符串:
>>> help(avg) Help on function avg in module __main__: avg(*args) Returns the average of a list of numeric values. >>> help(foo) Help on function foo in module __main__: foo(bar=0, baz=1) Perform a foo transformation. Keyword arguments: bar -- magnitude along the bar axis (default=0) baz -- magnitude along the baz axis (default=1)为您定义的每个 Python 函数指定一个 docstring 被认为是良好的编码实践。关于 docstrings 的更多信息,请查看记录 Python 代码:完整指南。
Python 函数注释
从 3.0 版本开始,Python 提供了一个额外的特性来记录一个叫做函数注释的函数。注释提供了一种将元数据附加到函数的参数和返回值的方法。
要向 Python 函数参数添加注释,请在函数定义中的参数名称后插入冒号(
:),后跟任意表达式。要向返回值添加注释,请在参数列表的右括号和终止函数头的冒号之间添加字符->和任何表达式。这里有一个例子:
>>> def f(a: '<a>', b: '<b>') -> '<ret_value>':
... pass
...
参数a的注释是字符串'<a>',对于b是字符串'<b>',对于函数返回值是字符串'<ret_value>'。
Python 解释器从注释中创建一个字典,并将它们分配给函数的另一个特殊的 dunder 属性__annotations__。上面显示的 Python 函数f()的注释可以显示如下:
>>> f.__annotations__ {'a': '<a>', 'b': '<b>', 'return': '<ret_value>'}参数的关键字是参数名称。返回值的关键字是字符串
'return':
>>> f.__annotations__['a']
'<a>'
>>> f.__annotations__['b']
'<b>'
>>> f.__annotations__['return']
'<ret_value>'
请注意,注释不限于字符串值。它们可以是任何表达式或对象。例如,您可以用类型对象进行注释:
>>> def f(a: int, b: str) -> float: ... print(a, b) ... return(3.5) ... >>> f(1, 'foo') 1 foo 3.5 >>> f.__annotations__ {'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
>>> def area(
... r: {
... 'desc': 'radius of circle',
... 'type': float
... }) -> \
... {
... 'desc': 'area of circle',
... 'type': float
... }:
... return 3.14159 * (r ** 2)
...
>>> area(2.5)
19.6349375
>>> area.__annotations__
{'r': {'desc': 'radius of circle', 'type': <class 'float'>},
'return': {'desc': 'area of circle', 'type': <class 'float'>}}
>>> area.__annotations__['r']['desc']
'radius of circle'
>>> area.__annotations__['return']['type']
<class 'float'>
在上面的例子中,一个注释被附加到参数r和返回值上。每个注释都是一个字典,包含一个字符串描述和一个类型对象。
如果要为带有注释的参数指定默认值,则默认值位于注释之后:
>>> def f(a: int = 12, b: str = 'baz') -> float: ... print(a, b) ... return(3.5) ... >>> f.__annotations__ {'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>} >>> f() 12 baz 3.5注释是做什么的?坦白地说,他们什么都不做。它们就在那里。让我们再来看看上面的一个例子,但是做了一些小的修改:
>>> def f(a: int, b: str) -> float:
... print(a, b)
... return 1, 2, 3
...
>>> f('foo', 2.5)
foo 2.5
(1, 2, 3)
这是怎么回事?对f()的注释表明第一个参数是int,第二个参数是str,返回值是float。但是随后对f()的调用打破了所有的规则!参数分别是str和float,返回值是一个元组。然而,口译员对这一切都听之任之,毫无怨言。
注释不会对代码强加任何语义限制。它们只是附加在 Python 函数参数和返回值上的一些元数据。Python 尽职尽责地将它们保存在一个字典中,将字典分配给函数的__annotations__ dunder 属性,就这样。注释是完全可选的,对 Python 函数的执行没有任何影响。
引用《阿玛尔与夜访者》中阿玛尔的话,“那拥有它有什么用?”
首先,注释是很好的文档。当然,您可以在 docstring 中指定相同的信息,但是将它直接放在函数定义中会增加清晰度。对于这样的函数头,参数和返回值的类型显而易见:
def f(a: int, b: str) -> float:
当然,解释器不会强制遵守指定的类型,但至少对于阅读函数定义的人来说是清楚的。
深入研究:强制类型检查
如果您愿意,可以添加代码来强制执行函数注释中指定的类型。这里有一个函数,它根据相应参数的注释中指定的内容来检查每个参数的实际类型。如果匹配则显示
True,如果不匹配则显示False:`>>> def f(a: int, b: str, c: float): ... import inspect ... args = inspect.getfullargspec(f).args ... annotations = inspect.getfullargspec(f).annotations ... for x in args: ... print(x, '->', ... 'arg is', type(locals()[x]), ',', ... 'annotation is', annotations[x], ... '/', (type(locals()[x])) is annotations[x]) ... >>> f(1, 'foo', 3.3) a -> arg is <class 'int'> , annotation is <class 'int'> / True b -> arg is <class 'str'> , annotation is <class 'str'> / True c -> arg is <class 'float'> , annotation is <class 'float'> / True >>> f('foo', 4.3, 9) a -> arg is <class 'str'> , annotation is <class 'int'> / False b -> arg is <class 'float'> , annotation is <class 'str'> / False c -> arg is <class 'int'> , annotation is <class 'float'> / False >>> f(1, 'foo', 'bar') a -> arg is <class 'int'> , annotation is <class 'int'> / True b -> arg is <class 'str'> , annotation is <class 'str'> / True c -> arg is <class 'str'> , annotation is <class 'float'> / False`(
inspect模块包含获取关于活动对象的有用信息的函数——在本例中是函数f()。)如果需要,如上定义的函数可以在检测到传递的参数不符合注释中指定的类型时采取某种纠正措施。
事实上,在 Python 中使用注释执行静态类型检查的方案在 PEP 484 中有描述。一个名为 mypy 的免费 Python 静态类型检查器是可用的,它是基于 PEP 484 规范构建的。
使用注释还有另一个好处。注释信息存储在__annotations__属性中的标准化格式有助于自动化工具解析函数签名。
归根结底,注释并不是什么特别神奇的东西。您甚至可以定义自己的语法,而不需要 Python 提供的特殊语法。下面是一个 Python 函数定义,其参数和返回值附有类型对象注释:
>>> def f(a: int, b: str) -> float: ... return ... >>> f.__annotations__ {'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}下面是基本相同的功能,手动构建
__annotations__字典:
>>> def f(a, b):
... return
...
>>> f.__annotations__ = {'a': int, 'b': str, 'return': float}
>>> f.__annotations__ {'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
这两种情况下的效果是一样的,但第一种情况更具视觉吸引力,第一眼看上去更易读。
事实上,__annotations__属性与函数的大多数其他属性没有明显的不同。例如,它可以动态修改。您可以选择使用返回值属性来计算函数执行的次数:
>>> def f() -> 0: ... f.__annotations__['return'] += 1 ... print(f"f() has been executed {f.__annotations__['return']} time(s)") ... >>> f() f() has been executed 1 time(s) >>> f() f() has been executed 2 time(s) >>> f() f() has been executed 3 time(s)Python 函数注释只不过是元数据的字典。碰巧你可以用解释器支持的方便的语法来创建它们。它们是你选择的任何东西。
结论
随着应用程序变得越来越大,通过将代码分解成易于管理的更小的功能来模块化代码变得越来越重要。现在,您有希望拥有完成这项工作所需的所有工具。
你已经学会:
- 如何在 Python 中创建一个用户自定义函数
- 有几种不同的方法可以将参数传递给函数
- 如何从函数中向调用者返回数据
- 如何给带有文档字符串和注释的函数添加文档
本系列接下来的两个教程涵盖了搜索和 T2 模式匹配。您将深入了解一个名为 re 的 Python 模块,它包含使用一个名为正则表达式的通用模式语法进行搜索和匹配的功能。
« Python String Formatting TechniquesDefining Your Own Python FunctionRegular Expressions: Regexes in Python (Part 1) »
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 定义和调用 Python 函数***********
使用 Python 诗歌进行依赖管理
原文:https://realpython.com/dependency-management-python-poetry/
当您的 Python 项目依赖于外部包时,您需要确保使用每个包的正确版本。更新后,包可能不会像更新前那样工作。像 Pythonpoem这样的依赖管理器可以帮助您指定、安装和解析项目中的外部包。这样,您可以确保在每台机器上始终使用正确的依赖版本。
在本教程中,您将学习如何:
- 开始一个新的诗歌项目
- 向现有的项目添加诗歌
- 使用
pyproject.toml文件- 引脚依赖关系
- 安装依赖
poetry.lock- 执行基本的诗歌 CLI 命令
使用诗歌将帮助你开始新项目,维护现有项目,并掌握依赖管理。您将准备好使用
pyproject.toml文件,这将是定义 Python 项目中构建需求的标准。为了完成本教程并充分利用它,您应该对虚拟环境、模块和包和
pip有一个基本的了解。虽然本教程关注的是依赖管理,但是诗歌也可以帮助你构建和打包项目。如果你想分享你的作品,那么你甚至可以发布你的诗歌项目到 Python 打包索引(PyPI) 。
免费奖励: ,向您展示如何使用 Pip、PyPI、Virtualenv 和需求文件等工具避免常见的依赖管理问题。
满足先决条件
在深入 Python 诗歌的本质之前,您需要考虑一些先决条件。首先,您将阅读本教程中会遇到的术语的简短概述。接下来,您将安装诗歌本身。
相关术语
如果你曾经在你的 Python 脚本中使用过
import语句,那么你就使用过模块。其中一些模块可能是您自己编写的 Python 文件。其他的可能是内置的模块,比如日期时间。然而,有时 Python 提供的还不够。这时你可能会求助于外部的打包模块。当你的 Python 代码依赖外部模块时,你可以说这些包是你的项目的依赖。你可以在 PyPI 中找到不属于 Python 标准库的包。在了解如何工作之前,您需要在您的系统上安装诗歌。
Python 诗歌装置
要在命令行中使用诗歌,您应该在系统范围内安装它。如果你只是想尝试一下,那么你可以使用
pip将其安装到虚拟环境中。但是您应该小心地尝试这种方法,因为诗歌会安装它自己的依赖项,这可能会与您在项目中使用的其他包冲突。推荐使用官方的脚本来安装诗歌 T2。您可以手动下载并运行这个 Python 文件,或者选择下面的操作系统来使用适当的命令:
- 视窗
** Linux + macOS*PS C:\> (Invoke-WebRequest -Uri https://raw.githubusercontent.com/python-poetry/poetry/master/install-poetry.py -UseBasicParsing).Content | python -如果您使用的是 Windows,那么您可以使用带有
-UseBasicParsing选项的Invoke-Webrequestcmdlet 将请求的 URL 内容下载到标准输出流(stdout) 。使用管道字符(|,您将把输出交给python的标准输入流(stdin) 。在这种情况下,您将install-poetry.py的内容通过管道传输到您的 Python 解释器。注意:部分用户在 Windows 10 上使用 PowerShell 命令时报错。
$ curl https://raw.githubusercontent.com/python-poetry/poetry/master/install-poetry.py | python3 -使用
curl,您将请求的 URL 的内容输出到标准输出流(stdout) 。通过使用带有管道字符(|)的 Unix 管道,您将把输出交给python3的标准输入流(stdin) 。在这种情况下,您将将install-poetry.py的内容通过管道传输到您的 Python 解释器。注意:如果你在 macOS 上,那么你可能会得到一个
ssl.SSLCertVerificationError。如果没有为 SSL 模块安装默认的根证书,就会出现这个错误。您可以通过运行 Python 文件夹中的命令脚本来安装它们:$ open "/Applications/Python 3.9/Install Certificates.command"根据您安装的 Python 版本,Python interpeter 的具体路径可能会有所不同。在这种情况下,您需要相应地调整上面命令中的路径。
运行该命令后,上面的
curl命令应该没有任何错误。在输出中,您应该会看到安装完成的消息。你可以在你的终端中运行
poetry --version,看看poetry是否工作。这个命令将显示你当前的诗歌版本。如果你想更新诗歌,那么你可以运行poetry self update。Python 诗歌入门
装了诗,就该看看诗是怎么做的了。在本节中,您将学习如何开始一个新的诗歌项目,以及如何将诗歌添加到现有项目中。您还将看到项目结构并检查
pyproject.toml文件。创建新的诗歌项目
您可以使用
new命令和项目名称作为参数来创建一个新的诗歌项目。在本教程中,该项目被称为rp-poetry。创建项目,然后移动到新创建的目录中:$ poetry new rp-poetry $ cd rp-poetry通过运行
poetry new rp-poetry,您创建了一个名为rp-poetry/的新文件夹。当您查看文件夹内部时,您会看到一个结构:rp-poetry/ │ ├── rp_poetry/ │ └── __init__.py │ ├── tests/ │ ├── __init__.py │ └── test_rp_poetry.py │ ├── README.rst └── pyproject.toml诗自动为你规范包名。它将项目名称中的破折号(
-)转换成文件夹名称rp_poetry/中的下划线(_)。否则,这个名称在 Python 中是不允许的,所以您不能将其作为模块导入。为了对创建包名有更多的控制,您可以使用--name选项来命名它,不同于项目文件夹:$ poetry new rp-poetry --name realpoetry如果您喜欢将您的源代码存储在一个额外的
src/父文件夹中,那么 poems 可以让您通过使用--src标志来遵守这个约定:$ poetry new --src rp-poetry $ cd rp-poetry通过添加
--src标志,您已经创建了一个名为src/的文件夹,其中包含您的rp_poetry/目录:rp-poetry/ │ ├── src/ │ │ │ └── rp_poetry/ │ └── __init__.py │ ├── tests/ │ ├── __init__.py │ └── test_rp_poetry.py │ ├── README.rst └── pyproject.toml当创建一个新的诗歌项目时,你会马上收到一个基本的文件夹结构。
检查项目结构
rp_poetry/子文件夹本身还不是很壮观。在这个目录中,您将找到一个包含您的软件包版本的__init__.py文件:# rp_poetry/__init__.py __version__ = "0.1.0"当你跳到
tests/文件夹并打开test_rp_poetry.py时,你会注意到rp_poetry已经可以导入了:# tests/test_rp_poetry.py from rp_poetry import __version__ def test_version(): assert __version__ == "0.1.0"诗歌也为这个项目增加了第一个测试。
test_version()函数检查rp_poetry/__init__.py的__version__变量是否包含期望的版本。然而,__init__.py文件并不是您定义软件包版本的唯一地方。另一个位置是pyproject.toml文件。使用
pyproject.toml文件处理诗歌最重要的文件之一是
pyproject.toml文件。这个文件不是诗歌的发明。这是一个在 PEP 518 中定义的配置文件标准:这个 PEP 指定了 Python 软件包应该如何指定它们有什么构建依赖,以便执行它们选择的构建系统。作为本规范的一部分,引入了一个新的配置文件,供软件包用来指定它们的构建依赖关系(预期相同的配置文件将用于未来的配置细节)。(来源)
作者考虑了上面引用的“新配置文件”的几种文件格式。最终,他们决定采用 TOML 格式,它代表汤姆明显的最小语言。在他们看来,TOML 足够灵活,比 YAML、JSON、CFG 或 INI 等其他选项具有更好的可读性和更低的复杂性。要查看 TOML 的外观,请打开
pyproject.toml文件:1# pyproject.toml 2 3[tool.poetry] 4name = "rp-poetry" 5version = "0.1.0" 6description = "" 7authors = ["Philipp <philipp@realpython.com>"] 8 9[tool.poetry.dependencies] 10python = "^3.9" 11 12[tool.poetry.dev-dependencies] 13pytest = "^5.2" 14 15[build-system] 16requires = ["poetry-core>=1.0.0"] 17build-backend = "poetry.core.masonry.api"您可以在
pyproject.toml文件中看到四个部分。这些部分被称为表格。它们包含像 poems 这样的工具识别并用于依赖性管理或构建例程的指令。如果表名是特定于刀具的,则必须以
tool为前缀。通过使用这样的子表,您可以为项目中的不同工具添加指令。这种情况下,只有tool.poetry。但是你可能会在其他项目中看到像 pytest 的[tool.pytest.ini_options]这样的例子。在上面第 3 行的
[tool.poetry]子表中,您可以存储关于您的诗歌项目的一般信息。你可用的键是由诗歌定义的。虽然有些键是可选的,但有四个键是必须指定的:
name:您的包的名称version:你的包的版本,理想情况下遵循语义版本description:您的包裹的简短描述authors:作者列表,格式name <email>第 9 行的子表
[tool.poetry.dependencies]和第 12 行的子表[tool.poetry.dev-dependencies]对于您的依赖管理是必不可少的。在下一节中,当您将依赖项添加到您的诗歌项目时,您将了解到关于这些子表的更多信息。现在,重要的事情是认识到在包依赖和开发依赖之间有和的区别。
pyproject.toml文件的最后一个表是第 15 行的[build-system]。这个表定义了诗歌和其他构建工具可以使用的数据,但是因为它不是特定于工具的,所以没有前缀。诗歌创建了pyproject.toml文件,其中有两个关键点:
requires:构建包所需的依赖项列表,使这个键成为强制键build-backend:用于执行构建过程的 Python 对象如果你想了解更多关于
pyproject.toml文件的这一部分,那么你可以通过阅读 PEP 517 中的源代码树来找到更多。当你用诗歌开始一个新项目时,这是你开始用的
pyproject.toml文件。随着时间的推移,您将添加关于您的包和您正在使用的工具的配置详细信息。随着 Python 项目的增长,您的pyproject.toml文件也会随之增长。对于子表[tool.poetry.dependencies]和[tool.poetry.dev-dependencies]来说尤其如此。在下一节中,您将了解如何展开这些子表。用 Python 写诗
一旦你建立了一个诗歌项目,真正的工作就可以开始了。一旦诗歌到位,你就可以开始编码了。一路上,你会发现诗歌如何为你提供一个虚拟的环境,并照顾你的依赖。
使用诗歌的虚拟环境
当您开始一个新的 Python 项目时,创建一个虚拟环境是一个很好的实践。否则,您可能会混淆来自不同项目的不同依赖项。使用虚拟环境是 poem 的核心特性之一,它永远不会干扰您的全局 Python 安装。
然而,当你开始一个项目时,诗歌不会马上创造一个虚拟的环境。您可以通过让 poems 列出所有连接到当前项目的虚拟环境来确认 poems 没有创建虚拟环境。如果你还没有把
cd变成rp-poetry/然后运行一个命令:$ poetry env list目前,不应该有任何输出。
当你运行某些命令时,诗歌会在途中创建一个虚拟环境。如果您想要更好地控制虚拟环境的创建,那么您可能会决定明确地告诉 poems 您想要为它使用哪个 Python 版本,并从那里开始:
$ poetry env use python3使用这个命令,您使用的 Python 版本与您用来安装诗歌的版本相同。当你的
PATH中有 Python 可执行文件时,使用python3就可以了。注意:或者,你可以传递一个 Python 可执行文件的绝对路径。它应该与您可以在
pyproject.toml文件中找到的 Python 版本约束相匹配。如果没有,那么您可能会遇到麻烦,因为您使用的 Python 版本不同于您的项目所需的版本。在您的环境中工作的代码在另一台机器上可能会出错。更糟糕的是,外部包通常依赖于特定的 Python 版本。因此,安装您的包的用户可能会收到一个错误,因为您的依赖项版本与其 Python 版本不兼容。
当您运行
env use时,您会看到一条消息:Creating virtualenv rp-poetry-AWdWY-py3.9 in ~/Library/Caches/pypoetry/virtualenvs Using virtualenv: ~/Library/Caches/pypoetry/virtualenvs/rp-poetry-AWdWY-py3.9如您所见,诗歌为您的项目环境构建了一个独特的名称。该名称包含项目名称和 Python 版本。中间看似随机的字符串是父目录的散列。有了这个唯一的字符串在中间,poems 就可以在您的系统上处理多个同名且 Python 版本相同的项目。这很重要,因为默认情况下,诗歌在同一个文件夹中创建所有的虚拟环境。
在没有任何其他配置的情况下,poem 在 poem 的缓存目录的
virtualenvs/文件夹中创建虚拟环境:
操作系统 小路 马科斯 ~/Library/Caches/pypoetryWindows 操作系统 C:\Users\<username>\AppData\Local\pypoetry\CacheLinux 操作系统 ~/.cache/pypoetry如果你想改变默认的缓存目录,那么你可以编辑poems 的配置。当您已经在使用 virtualenvwrapper 或另一个第三方工具来管理您的虚拟环境时,这可能会很有用。要查看当前配置,包括已配置的
cache-dir,您可以运行一个命令:$ poetry config --list通常情况下,您不必更改这条路径。如果你想了解更多关于与诗歌的虚拟环境交互的知识,那么诗歌文档中有一章是关于管理环境的。
只要你在你的项目文件夹中,诗歌就会使用与之相关的虚拟环境。如果您有疑问,可以通过再次运行
env list命令来检查虚拟环境是否被激活:$ poetry env list这将显示类似于
rp-poetry-AWdWY-py3.9 (Activated)的内容。有了激活的虚拟环境,您就可以开始管理一些依赖关系,并看到诗歌的光芒。声明您的依赖关系
诗歌的一个关键要素是它对你的依赖的处理。在开始之前,看一下
pyproject.toml文件中的两个依赖表:# rp_poetry/pyproject.toml (Excerpt) [tool.poetry.dependencies] python = "^3.9" [tool.poetry.dev-dependencies] pytest = "^5.2"当前为您的项目声明了两个依赖项。一个是 Python 本身。另一个是 pytest ,一个广泛使用的测试框架。正如您之前看到的,您的项目包含一个
tests/文件夹和一个test_rp_poetry.py文件。有了 pytest 作为依赖,poems 可以在安装后立即运行您的测试。注:在写这篇教程的时候,用 Python 3.10 运行
pytest带诗是不行的。poem 安装的 pytest 版本与 Python 3.10 不兼容。诗歌开发者已经意识到这个问题,随着诗歌 1.2 的发布,这个问题将会得到解决。
确保您在
rp-poetry/项目文件夹中,并运行一个命令:$ poetry install使用
install命令,poems 检查您的pyproject.toml文件的依赖项,然后解析并安装它们。当您有许多依赖项需要不同版本的第三方包时,解析部分尤其重要。在安装任何包之前,poems 会计算出包的哪个版本满足了其他包按照他们的需求设置的版本约束。除了
pytest和它的需求,诗诗还安装项目本身。这样,您可以立即将rp_poetry导入到您的测试中:# tests/test_rp_poetry.py from rp_poetry import __version__ def test_version(): assert __version__ == "0.1.0"安装好项目的包后,您可以将
rp_poetry导入到您的测试中,并检查__version__字符串。安装了pytest之后,您可以使用poetry run命令来执行测试:1$ poetry run pytest 2========================= test session starts ========================== 3platform darwin -- Python 3.9.1, pytest-5.4.3, py-1.10.0, pluggy-0.13.1 4rootdir: /Users/philipp/Real Python/rp-poetry 5collected 1 item 6 7tests/test_rp_poetry.py . [100%] 8 9========================== 1 passed in 0.01s ===========================您当前的测试运行成功,因此您可以放心地继续编码。然而,如果仔细观察第 3 行,有些东西看起来有点奇怪。上面写着
pytest-5.4.3,而不是像pyproject.toml文件中写的5.2。接得好!概括地说,您的
pyproject.toml文件中的pytest依赖项如下所示:# rp_poetry/pyproject.toml (Excerpt) [tool.poetry.dev-dependencies] pytest = "^5.2"
5.2前面的插入符号(^)有特定的含义,它是诗歌提供的版本约束之一。这意味着诗歌可以安装任何版本匹配最左边的非零数字的版本字符串。这意味着使用5.4.3是允许的。版本6.0将不被允许。当诗歌试图解析依赖版本时,像插入符号这样的符号将变得很重要。如果只有两个要求,这并不太难。声明的依赖项越多,就越复杂。让我们看看 poem 如何通过在项目中安装新的包来处理这个问题。
用诗歌安装一个包
您可能以前使用过
pip来安装不属于 Python 标准库的包。如果使用包名作为参数运行pip install,那么pip会在 Python 包索引中查找包。你可以用同样的方式使用诗歌。如果你想添加一个像
requests这样的外部包到你的项目中,那么你可以运行一个命令:$ poetry add requests通过运行
poetry add requests,您将最新版本的requests库添加到您的项目中。如果你想更具体一些,你可以使用像requests<=2.1或requests==2.24这样的版本约束。当你不添加任何约束的时候,诗总会尝试安装最新版本的包。有时,有些包您只想在您的开发环境中使用。通过
pytest,你已经发现了其中一个。另一个公共库包括像 Black 这样的代码格式化程序,像 Sphinx 这样的文档生成器,以及像 Pylint 、 Flake8 、 mypy 或 coverage.py 这样的静态分析工具。为了明确地告诉 poem 一个包是一个开发依赖,您可以运行带有
--dev选项的poetry add。也可以使用简写的-D选项,和--dev一样:$ poetry add black -D您添加了
requests作为项目依赖项,添加了black作为开发依赖项。诗歌在后台为你做了几件事。首先,它将您声明的依赖项添加到了pyproject.toml文件中:# rp_poetry/pyproject.toml (Excerpt) [tool.poetry.dependencies] python = "^3.9" requests = "^2.26.0" [tool.poetry.dev-dependencies] pytest = "^5.2" black = "^21.9b0"poems 将
requests包作为项目依赖添加到tool.poetry.dependencies表中,同时将black作为开发依赖添加到tool.poetry.dev-dependencies表中。区分项目依赖和开发依赖可以防止安装用户不需要运行程序的需求。开发依赖关系只与你的包的其他开发人员相关,他们想用
pytest运行测试,并确保代码用black正确格式化。当用户安装你的软件包时,他们只安装requests。注意:您可以更进一步,声明可选依赖项。当您想让用户选择安装一个特定的数据库适配器时,这是很方便的,这个适配器不是必需的,但是可以增强您的包。你可以在诗歌文档中了解更多关于可选依赖项的信息。
除了对
pyproject.toml文件的修改,poems 还创建了一个名为poetry.lock的新文件。在这个文件中,poems 跟踪所有的包以及您在项目中使用的确切版本。手柄
poetry.lock当您运行
poetry add命令时,poems 会自动更新pyproject.toml并将解析后的版本固定在poetry.lock文件中。然而,你不必让诗歌做所有的工作。您可以手动将依赖项添加到pyproject.toml文件中,然后锁定它们。
poetry.lock中的引脚依赖关系如果你想用 Python构建一个 web scraper,那么你可能想用美汤解析你的数据。将其添加到
pyproject.toml文件的tool.poetry.dependencies表中:# rp_poetry/pyproject.toml (Excerpt) [tool.poetry.dependencies] python = "^3.9" requests = "^2.26.0" beautifulsoup4 = "4.10.0"通过添加
beautifulsoup4 = "4.10.0",你告诉 poem 它应该安装这个版本。当您向pyproject.toml文件添加需求时,它还没有安装。只要您的项目中没有poetry.lock文件,您就可以在手动添加依赖项后运行poetry install,因为 poems 会先查找一个poetry.lock文件。如果找不到,poems 会解析pyproject.toml文件中列出的依赖项。一旦出现一个
poetry.lock文件,poems 就会依赖这个文件来安装依赖项。只运行poetry install会触发两个文件不同步的警告,并且会产生一个错误,因为 poem 还不知道项目中有任何beautifulsoup4版本。要将手动添加的依赖项从您的
pyproject.toml文件固定到poetry.lock,您必须首先运行poetry lock命令:$ poetry lock Updating dependencies Resolving dependencies... (1.5s) Writing lock file通过运行
poetry lock,poems 处理你的pyproject.toml文件中的所有依赖项,并将它们锁定到poetry.lock文件中。而诗歌并不止于此。当你运行poetry lock时,诗歌也递归地遍历并锁定你的直接依赖的所有依赖。注意:
poetry lock命令还会更新您现有的依赖项,如果符合您的版本约束的新版本可用的话。如果您不想更新任何已经在poetry.lock文件中的依赖项,那么您必须将--no-update选项添加到poetry lock命令中:$ poetry lock --no-update Resolving dependencies... (0.1s)在这种情况下,poem 只解析新的依赖项,而不影响
poetry.lock文件中任何现有的依赖项版本。既然您已经锁定了所有的依赖项,那么是时候安装它们了,这样您就可以在您的项目中使用它们了。
从
poetry.lock安装依赖项如果您遵循了上一节中的步骤,那么您已经通过使用
poetry add命令安装了pytest和black。你也锁定了beautifulsoup4,但是还没有安装美汤。为了验证beautifulsoup4还没有安装,用poetry run命令打开 Python 解释器:$ poetry run python3执行
poetry run python3将在诗歌环境中打开一个交互式 REPL 会话。首先尝试导入requests。这应该可以完美地工作。然后尝试导入bs4,这是美汤的模块名。这应该会抛出一个错误,因为 Beautiful Soup 还没有安装:
>>> import requests
>>> import bs4
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'bs4'
不出所料,可以毫不费力地导入requests,模块bs4找不到了。通过键入exit()并点击 Enter ,退出交互式 Python 解释器。
在使用poetry lock命令锁定依赖项之后,您必须运行poetry install命令,以便您可以在您的项目中实际使用它们:
$ poetry install
Installing dependencies from lock file
Package operations: 2 installs, 0 updates, 0 removals
• Installing soupsieve (2.2.1)
• Installing beautifulsoup4 (4.10.0)
Installing the current project: rp-poetry (0.1.0)
通过运行poetry install,poem 读取poetry.lock文件并安装其中声明的所有依赖项。现在,bs4已经准备好供您在项目中使用了。为了测试这一点,输入poetry run python3并将bs4导入 Python 解释器:
>>> import bs4 >>> bs4.__version__ '4.10.0'完美!这一次没有错误,并且您得到了您声明的确切版本。这意味着 Beautiful Soup 被正确地钉在您的
poetry.lock文件中,被安装在您的项目中,并且可以使用了。要列出项目中可用的包并检查它们的细节,您可以使用show命令。当您使用--help标志运行它时,您将看到如何使用它:$ poetry show --help要检查一个包,您可以使用
show并将包名作为参数,或者您可以使用--tree选项将所有依赖项作为一个树列出。这将有助于您看到项目中嵌套的需求。更新依赖关系
为了更新您的依赖关系,poems 根据两种情况提供了不同的选项:
- 更新版本约束内的依赖项。
- 更新版本约束之外的依赖项。
您可以在您的
pyproject.toml文件中找到您的版本约束。当依赖项的新版本仍然满足您的版本约束时,您可以使用update命令:$ poetry update
update命令将在它们的版本约束内更新所有的包和它们的依赖项。之后,诗歌会更新你的poetry.lock文件。如果要更新一个或多个特定的软件包,可以将它们作为参数列出:
$ poetry update requests beautifulsoup4使用这个命令,poems 将搜索满足您的
pyproject.toml文件中列出的版本约束的requests的新版本和beautifulsoup4的新版本。然后,它将解析项目的所有依赖项,并将版本固定到您的poetry.lock文件中。您的pyproject.toml文件将保持不变,因为列出的约束仍然有效。如果您想要更新一个版本高于在
pyproject.toml文件中定义的版本的依赖项,您需要预先调整pyproject.toml文件。另一个选择是运行带有版本约束或latest标签的add命令:$ poetry add pytest@latest --dev当您运行带有
latest标签的add命令时,它会查找最新版本的包并更新您的pyproject.toml文件。在使用add命令时,包含latest标签或版本约束是至关重要的。如果没有它,您会得到一条消息,提示您项目中已经存在该包。另外,不要忘记为开发依赖项添加--dev标志。否则,您需要将该包添加到常规依赖项中。添加新版本后,您必须运行您在上一节中了解到的
install命令。只有这样,您的更新才会被锁定到poetry.lock文件中。如果您不确定更新会给依赖项带来哪些基于版本的变化,您可以使用
--dry-run标志。该标志对update和add命令都有效。它显示终端中的操作,而不执行任何操作。这样,您可以安全地发现版本变化,并决定哪种更新方案最适合您。区分
pyproject.toml和poetry.lock虽然
pyproject.toml文件中的版本要求可能不严格,但是 poems 锁定了您在poetry.lock文件中实际使用的版本。这就是为什么如果你正在使用 Git 你应该提交这个文件。通过在一个 Git 库中提供一个poetry.lock文件,你可以确保所有开发人员都将使用相同版本的必需包。当您遇到包含poetry.lock文件的存储库时,使用诗歌是个好主意。有了
poetry.lock,你可以确保你使用的是其他开发者正在使用的版本。如果其他开发人员没有使用诗歌,您可以将它添加到一个没有设置诗歌的现有项目中。向现有项目添加诗歌
很有可能,您有一些项目不是用
poetry new命令启动的。或者你继承了一个不是用诗歌创建的项目,但是现在你想用诗歌来进行你的依赖管理。在这种情况下,您可以向现有的 Python 项目中添加诗歌。将
pyproject.toml添加到脚本文件夹如果您的项目只包含一些 Python 文件,那么您仍然可以添加诗歌作为未来构建的基础。在这个例子中,只有一个文件,
hello.py:# rp-hello/hello.py print("Hello World!")这个脚本唯一做的事情就是输出字符串
"Hello World!"。但也许这只是一个宏大项目的开始,所以你决定在你的项目中加入诗歌。您将使用poetry init命令,而不是之前的poetry new命令:$ poetry init This command will guide you through creating your pyproject.toml config. Package name [rp-hello]: rp-hello Version [0.1.0]: Description []: My Hello World Example Author [Philipp <philipp@realpython.com>, n to skip]: License []: Compatible Python versions [^3.9]: Would you like to define your main dependencies interactively? (yes/no) [yes] no Would you like to define your development dependencies interactively? (yes/no) [yes] no Generated file
poetry init命令将启动一个交互会话来创建一个pyproject.toml文件。诗给你推荐了你需要设置的大部分配置,你可以按Enter来使用它们。当您没有声明任何依赖项时,poem 创建的pyproject.toml文件如下所示:# rp-hello/pyproject.toml [tool.poetry] name = "rp-hello" version = "0.1.0" description = "My Hello World Example" authors = ["Philipp <philipp@realpython.com>"] [tool.poetry.dependencies] python = "^3.9" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api"内容看起来类似于您在前面章节中所经历的例子。
现在,您可以使用诗歌项目提供的所有命令。有了
pyproject.toml文件,您现在可以运行脚本:$ poetry run python3 hello.py Creating virtualenv rp-simple-UCsI2-py3.9 in ~/Library/Caches/pypoetry/virtualenvs Hello World!因为 poem 没有找到任何可以使用的虚拟环境,所以它在执行脚本之前创建了一个新的虚拟环境。完成后,它会显示您的
Hello World!消息,没有任何错误。这意味着你现在有一个工作的诗歌项目。使用现有的
requirements.txt文件有时候你的项目已经有了一个
requirements.txt文件。看看这个 Python web scraper 的requirements.txt文件:$ cat requirements.txt beautifulsoup4==4.9.3 certifi==2020.12.5 chardet==4.0.0 idna==2.10 requests==2.25.1 soupsieve==2.2.1 urllib3==1.26.4使用
cat实用程序,可以读取一个文件并将内容写入标准输出。在这种情况下,它显示了 web scraper 项目的依赖关系。一旦用poetry init创建了诗歌项目,就可以将cat实用程序与poetry add命令结合起来:$ poetry add `cat requirements.txt` Creating virtualenv rp-require-0ubvZ-py3.9 in ~/Library/Caches/pypoetry/virtualenvs Updating dependencies Resolving dependencies... (6.2s) Writing lock file Package operations: 7 installs, 0 updates, 0 removals • Installing certifi (2020.12.5) • Installing chardet (4.0.0) • Installing idna (2.10) • Installing soupsieve (2.2.1) • Installing urllib3 (1.26.4) • Installing beautifulsoup4 (4.9.3) • Installing requests (2.25.1)当一个需求文件如此简单时,使用
poetry add和cat可以为您节省一些手工工作。然而,有时
requirements.txt文件有点复杂。在这些情况下,您可以执行一次测试运行,看看结果如何,或者手工将需求添加到pyproject.toml文件的[tool.poetry.dependencies]表中。要查看您的pyproject.toml的结构是否有效,您可以稍后运行poetry check。从
poetry.lock创建requirements.txt在某些情况下,您必须有一个
requirements.txt文件。例如,也许你想在 Heroku 上主持你的 Django 项目。对于这种情况,诗歌提供了export命令。如果你有一个诗歌项目,你可以从你的poetry.lock文件创建一个requirements.txt文件:$ poetry export --output requirements.txt以这种方式使用
poetry export命令创建一个requirements.txt文件,其中包含散列和环境标记。这意味着你可以确保按照非常严格的要求工作,就像你的poetry.lock文件的内容一样。如果您还想包含您的开发依赖项,您可以将--dev添加到命令中。要查看所有可用选项,您可以勾选poetry export --help。命令参考
本教程已经向您介绍了诗歌的依赖管理。在这个过程中,您已经使用了一些 poem 的命令行界面(CLI)命令:
诗歌命令 说明 $ poetry --version显示您的诗歌安装版本。 $ poetry new创建一个新的诗歌项目。 $ poetry init向现有项目添加诗歌。 $ poetry run用诗歌执行给定的命令。 $ poetry add给 pyproject.toml添加一个包并安装。$ poetry update更新项目的依赖项。 $ poetry install安装依赖项。 $ poetry show列出已安装的软件包。 $ poetry lock将您的依赖项的最新版本固定到 poetry.lock。$ poetry lock --no-update刷新 poetry.lock文件,不更新任何依赖版本。$ poetry check验证 pyproject.toml。$ poetry config --list展示诗词配置。 $ poetry env list列出项目的虚拟环境。 $ poetry export将 poetry.lock导出为其他格式。您可以查看poems CLI 文档来了解更多关于上面的命令和 poems 提供的其他命令。您还可以运行
poetry --help在您的终端上查看信息!结论
在本教程中,您了解了如何创建新的 Python 诗歌项目,以及如何向现有项目添加诗歌。诗歌的一个关键部分是
pyproject.toml文件。结合使用poetry.lock,您可以确保安装项目所需的每个包的精确版本。当您在 Git 存储库中跟踪poetry.lock文件时,您也要确保项目中的所有其他开发人员在他们的机器上安装了相同的依赖版本。在本教程中,您学习了如何:
- 开始一个新的诗歌项目
- 向现有的项目添加诗歌
- 使用
pyproject.toml文件- 引脚依赖关系
- 安装依赖
poetry.lock- 执行基本的诗歌 CLI 命令
本教程关注的是诗歌依赖管理的基础,但是诗歌也可以帮助你构建和上传你的包。如果您想体验一下这种能力,那么您可以阅读当向 PyPI 发布开源 Python 包时如何使用诗歌。**********
将 Django + Python 3 + PostgreSQL 部署到 AWS Elastic Beanstalk
原文:https://realpython.com/deploying-a-django-app-and-postgresql-to-aws-elastic-beanstalk/
下面是如何设置和部署 Django 应用程序的简单步骤,该应用程序由 Python 3 和 PostgreSQL 支持,到亚马逊网络服务 (AWS),同时保持理智。
使用的工具/技术:
- Python 3 . 4 . 3 版
- Django v1.9 版
- 亚马逊弹性豆茎、 EC2 、 S3 、 RDS
- EB CLI 3.x
- PostgreSQL
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
查看本文的 Python 2 版本这里。
2016 年 8 月 21 日更新:更新 EB 全局配置设置。
弹性豆茎 vs EC2
Elastic Beanstalk 是一个平台即服务(PaaS ),它简化了 Amazon AWS 上应用程序的设置、部署和维护。这是一个托管服务,耦合了服务器(EC2)、数据库(RDS)和静态文件(S3)。您可以快速部署和管理您的应用程序,该应用程序会随着您的站点的增长而自动扩展。查看官方文档了解更多信息。
开始使用
我们将使用一个简单的“每日图片”应用程序,您可以从这个库中获取:
$ git clone https://github.com/realpython/image-of-the-day.git $ cd image-of-the-day/ $ git checkout tags/start_here_py3下载代码后,创建一个 virtualenv 并通过 pip 安装需求:
$ pip install -r requirements.txt接下来,在本地运行 PostgreSQL 的情况下,设置一个名为
iotd的新数据库。同样,根据您的本地 Postgres 配置,您可能需要更新 settings.py 中的DATABASES配置。例如,我将配置更新为:DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'iotd', 'USER': '', 'PASSWORD': '', 'HOST': 'localhost', 'PORT': '5432', } }现在您可以设置数据库模式,创建超级用户,并运行应用程序:
$ python manage.py migrate $ python manage.py createsuperuser $ python manage.py runserver在浏览器中导航到位于http://localhost:8000/admin的管理页面,并添加一个新图像,该图像将显示在主页上。
该应用程序并不意味着非常令人兴奋;我们只是用它来做演示。它所做的就是让你通过管理界面上传图片,并在主页上全屏显示图片。也就是说,虽然这是一个相对基础的应用程序,但它仍然允许我们探索部署到 Amazon Beanstalk 和 RDS 时存在的一些“问题”。
现在我们已经在本地机器上建立并运行了站点,让我们开始 Amazon 部署过程。
AWS 弹性豆茎 CLI
为了使用 Amazon Elastic Beanstalk,我们可以使用一个名为 awsebcli 的包。撰写本文时,的最新版本是 3.7.4,推荐的安装方式是使用 pip:
$ pip install awsebcli现在测试安装以确保它工作正常:
$ eb --version这应该会给您一个不错的 3.x 版本号:
EB CLI 3.7.4 (Python 3.4.3)要真正开始使用 Elastic Beanstalk,你需要一个 AWS 的账户(惊喜!).注册(或登录)。
配置 EB–初始化您的应用程序
随着 AWS Elastic Beanstalk CLI 的运行,我们要做的第一件事是创建一个 Beanstalk 环境来托管应用程序。从项目目录(“每日映像”)中运行:
$ eb init这将提示您一些问题,以帮助您配置环境。
默认区域
选择离最终用户最近的地区通常会提供最佳性能。如果你不确定选择哪一个,看看这张地图。
凭证
接下来,它将要求您提供 AWS 凭据。
在这里,您很可能想要设置一个 IAM 用户。关于如何设置,请参见本指南。如果您确实设置了一个新用户,您需要确保该用户具有适当的权限。最简单的方法是给用户添加“管理员访问”权限。(尽管出于安全原因,这可能不是一个好的选择。)有关用户创建/管理弹性 Beanstalk 应用程序所需的特定策略/角色,请参见此处的链接。
应用名称
这将默认为目录名。就这样吧。
Python 版本
接下来,CLI 应该自动检测到您正在使用 Python,并要求确认。答应吧。然后你需要选择一个平台版本。对于 Python 3,您有两种不同的选择:
- Python 3.4
- Python 3.4(预配置- Docker)
如果你是一个潮人,选择“预配置- Docker”选项,否则选择普通的“Python 3.4”。没有,只有调侃;基本区别是:
Python 3.4
这将为您提供一个运行 64 位 Amazon Linux 并预装 Python 3.4 的 EC2 映像。前端 web 服务器是 apache,安装了 mod_wsgi。这是 Beanstalk 工作的“标准”或“传统”方式。换句话说,通过这个选项,Beanstalk 将为您创建 EC2 映像,并且您可以使用我们稍后将讨论的
ebextension文件来定制 EC2 映像。Python 3.4(预配置–Docker)
这将为您提供一个运行 Docker 的 EC2 映像,并且已经为您设置了一个 Docker 映像。Docker 映像使用 Python 3.4、nginx 1.8 和 uWSGI 2.0.8 运行 64 位 Debian Jessie。因为您基本上是直接与 Docker 映像进行交互,所以如果您选择这种方式,您将使用标准的 Docker 配置技术(即“Dockerfile”),然后您不必做太多特定于 AWS Beanstalk 的事情,因为 Beanstalk 知道如何为您管理 Docker 映像。
对于本文,我们将关注使用 EC2 图像的“标准”或“传统”方式,因此选择“Python 3.4”选项,让我们继续。
宋承宪
同意为您的实例设置 SSH。
RSA 密钥对
接下来,您需要生成一个 RSA 密钥对,它将被添加到您的 ~/中。ssh 文件夹。这个密钥对还将被上传到您在第一步中指定的区域的 EC2 公钥。这将允许您在本教程的后面使用 SSH 访问 EC2 实例。
我们完成了什么?
一旦
eb init完成,你会看到一个名为的新的隐藏文件夹。您的项目目录中的 elastic bean stall:├── .elasticbeanstalk │ └── config.yml ├── .gitignore ├── README.md ├── iotd │ ├── images │ │ ├── __init__.py │ │ ├── admin.py │ │ ├── migrations │ │ │ ├── 0001_initial.py │ │ │ └── __init__.py │ │ ├── models.py │ │ ├── tests.py │ │ └── views.py │ ├── iotd │ │ ├── __init__.py │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ ├── manage.py │ ├── static │ │ ├── css │ │ │ └── bootstrap.min.css │ │ └── js │ │ ├── bootstrap.min.js │ │ └── jquery-1.11.0.min.js │ └── templates │ ├── base.html │ └── images │ └── home.html ├── requirements.txt └── www └── media └── sitelogo.png该目录中有一个
config.yml文件,这是一个配置文件,用于为新创建的 Beanstalk 应用程序定义某些参数。此时,如果您键入
eb console,它将打开您的默认浏览器并导航到 Elastic Beanstalk 控制台。在这个页面上,您应该看到一个应用程序(如果您完全理解的话,称为image-of-the-day),但是没有环境。
应用程序代表您的代码应用程序,是
eb init为我们创造的。使用 Elastic Beanstalk,一个应用程序可以有多个环境(例如,开发、测试、、试运行、生产)。如何配置/管理这些环境完全取决于您。对于简单的 Django 应用程序,我喜欢将开发环境放在我的笔记本电脑上,然后在 Beanstalk 上创建一个测试和生产环境。让我们建立一个测试环境…
配置 EB–创建环境
回到终端,在项目目录中键入:
$ eb create就像
eb init一样,这个命令会提示你一系列问题。环境名称
您应该使用类似于 Amazon 建议的命名约定——例如,application _ name-env _ name——特别是当您开始用 AWS 托管多个应用程序时。我用过-
iod-test。DNS CNAME 前缀
当你在 Elastic Beanstalk 上部署一个应用程序时,你会自动获得一个像 xxx.elasticbeanstalk.com 这样的域名。
DNS CNAME prefix是你想用来代替xxx的。如果您继续使用默认设置,那么它可能不会起作用,因为其他人已经使用了它(这些名称对于 AWS 来说是通用的),所以选择一些独特的名称并继续使用。现在发生了什么?
此时
eb实际上会为你创造你的环境。请耐心等待,因为这可能需要一些时间。如果您在创建环境时遇到错误,比如-
aws.auth.client.error.ARCInstanceIdentityProfileNotFoundException-检查您使用的凭证是否有创建 Beanstalk 环境的适当权限,如本文前面所讨论的。此外,它可能会提示您一条关于
Platform requires a service role的消息。如果是的话,就说是,让它为你创造角色。在创建环境之后,
eb将立即尝试部署您的应用程序,方法是将项目目录中的所有代码复制到新的 EC2 实例中,并在该过程中运行pip install -r requirements.txt。您应该会在屏幕上看到一堆关于正在设置的环境的信息,以及关于
eb尝试部署的信息。您还会看到一些错误。特别是,您应该会看到这些行隐藏在输出中的某个地方:ERROR: Your requirements.txt is invalid. Snapshot your logs for details.别担心,这并不是真的无效。有关详细信息,请查看日志:
$ eb logs这将从 EC2 实例中获取所有最近的日志文件,并将它们输出到您的终端。这是大量的信息,所以您可能希望将输出重定向到一个文件(
eb logs -z)。浏览日志,您会看到一个名为 eb-activity.log 的日志文件:Error: pg_config executable not found.问题是我们试图安装
psycopy2(Postgres Python 绑定),但是我们也需要安装 Postgres 客户端驱动程序。因为它们不是默认安装的,所以我们需要先安装它们。让我们来解决这个问题…定制部署流程
eb将从名为"的文件夹中读取自定义的.config文件。“ebextensions”,位于项目的根级别(“当天的图像”目录)。这些.config文件允许你安装软件包,运行任意命令和/或设置环境变量。”中的文件。ebextensions”目录应该符合JSON或YAML语法,并按字母顺序执行。安装软件包
我们需要做的第一件事是安装一些包,以便我们的
pip install命令能够成功完成。为此,我们首先创建一个名为的文件。EB extensions/01 _ packages . config:packages: yum: git: [] postgresql93-devel: [] libjpeg-turbo-devel: []EC2 实例运行 Amazon Linux,这是一种 Redhat 风格,所以我们可以使用 yum 来安装我们需要的包。现在,我们将安装三个包——git、Postgres 客户端和用于 Pillow 的 libjpeg。
创建该文件以重新部署应用程序后,我们需要执行以下操作:
$ git add .ebextensions/ $ git commit -m "added eb package configuration"我们必须提交更改,因为部署命令
eb deploy处理最近一次提交,因此只有在我们将文件更改提交给 git 之后,我们才会意识到这些更改。(请注意,我们不必用力;我们从本地副本开始工作……)正如您可能猜到的,下一个命令是:
$ eb deploy您现在应该只看到一个错误:
INFO: Environment update is starting. INFO: Deploying new version to instance(s). ERROR: Your WSGIPath refers to a file that does not exist. INFO: New application version was deployed to running EC2 instances. INFO: Environment update completed successfully.让我们看看发生了什么…
配置我们的 Python 环境
Beanstalk 中的 EC2 实例运行 Apache,Apache 将根据我们设置的 WSGIPATH 找到我们的 Python 应用程序。默认情况下,
eb假设我们的 wsgi 文件叫做 application.py 。有两种方法可以解决这个问题-选项 1:使用特定于环境的配置设置
$ eb config这个命令将打开你的默认编辑器,编辑一个名为的配置文件。elastic beanstalk/iod-test . env . yml。该文件实际上不存在于本地;
eb从 AWS 服务器上下载并呈现给您,以便您可以更改其中的设置。如果您对此伪文件进行任何更改,然后保存并退出,eb将会更新您的 Beanstalk 环境中的相应设置。如果您在文件中搜索术语“WSGI ”,您应该会发现一个如下所示的配置部分:
aws:elasticbeanstalk:container:python: NumProcesses: '1' NumThreads: '15' StaticFiles: /static/=static/ WSGIPath: application.py更新 WSGIPath:
aws:elasticbeanstalk:container:python: NumProcesses: '1' NumThreads: '15' StaticFiles: /static/=static/ WSGIPath: iotd/iotd/wsgi.py然后就可以正确设置 WSGIPath 了。如果保存文件并退出,
eb将自动更新环境配置:Printing Status: INFO: Environment update is starting. INFO: Updating environment iod-test's configuration settings. INFO: Successfully deployed new configuration to environment. INFO: Environment update completed successfully.使用
eb config方法来改变设置的好处是你可以为每个环境指定不同的设置。但是您也可以使用我们之前使用的相同的.config文件来更新设置。这将对每个环境使用相同的设置,因为.config文件将在部署时应用(在eb config的设置被应用之后)。选项 2:使用全局配置设置
要使用
.config文件选项,让我们创建一个名为 /的新文件。EB extensions/02 _ python . config:option_settings: "aws:elasticbeanstalk:application:environment": DJANGO_SETTINGS_MODULE: "iotd.settings" "PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH" "aws:elasticbeanstalk:container:python": WSGIPath: iotd/iotd/wsgi.py NumProcesses: 3 NumThreads: 20 "aws:elasticbeanstalk:container:python:staticfiles": "/static/": "www/static/"发生了什么事?
DJANGO_SETTINGS_MODULE: "iotd.settings"-添加设置模块的路径。"PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"-更新我们的PYTHONPATH,这样 Python 可以在我们的应用程序中找到模块。该路径可能因您的设置而异!详见此评论。(注意必须使用完整路径。)- 设置我们的 WSGI 路径。
NumProcesses: 3和NumThreads: 20——更新用于运行我们的 WSGI 应用程序的进程和线程的数量。"/static/": "www/static/"设置我们的静态文件路径。同样,我们可以执行
git commit然后执行eb deploy来更新这些设置。接下来让我们添加一个数据库。
配置数据库
尝试查看已部署的网站:
$ eb open该命令将在默认浏览器中显示部署的应用程序。您应该会看到连接被拒绝错误:
OperationalError at / could not connect to server: Connection refused Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5432?这是因为我们还没有建立数据库。此时
eb将设置您的 Beanstalk 环境,但是它不会设置 RDS(数据库层)。我们必须手动设置。数据库设置
再次使用
eb console打开 Beanstalk 配置页面。
在那里,执行以下操作:
- 单击“配置”链接。
- 一直滚动到页面底部,然后在“数据层”部分下,单击链接“创建新的 RDS 数据库”。
- 在 RDS 设置页面上,将“数据库引擎”更改为“postgres”。
- 添加“主用户名”和“主密码”。
- 保存更改。
Beanstalk 将为您创建 RDS。现在我们需要让 Django 应用程序连接到 RDS。Beanstalk 将帮助我们在 EC2 实例上公开一些环境变量,详细说明如何连接到 Postgres 服务器。所以我们需要做的就是更新我们的 settings.py 文件来利用这些环境变量。确认
DATABASES配置参数反映了 settings.py 中的以下内容:if 'RDS_DB_NAME' in os.environ: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': os.environ['RDS_DB_NAME'], 'USER': os.environ['RDS_USERNAME'], 'PASSWORD': os.environ['RDS_PASSWORD'], 'HOST': os.environ['RDS_HOSTNAME'], 'PORT': os.environ['RDS_PORT'], } } else: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'iotd', 'USER': 'iotd', 'PASSWORD': 'iotd', 'HOST': 'localhost', 'PORT': '5432', } }这只是说,“如果存在,使用环境变量设置,否则使用我们的默认开发设置。”简单。
处理数据库迁移
对于我们的数据库设置,我们仍然需要确保迁移运行,以便数据库表结构是正确的。我们可以通过修改来实现。EB extensions/02 _ python . config并在文件顶部添加以下行:
container_commands: 01_migrate: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput" leader_only: true
container_commands允许您在 EC2 实例上部署应用程序后运行任意命令。因为 EC2 实例是使用一个虚拟环境设置的,所以在运行 migrate 命令之前,我们必须首先激活这个虚拟环境。另外,leader_only: true设置意味着,“当部署到多个实例时,只在第一个实例上运行这个命令。”不要忘记我们的应用程序使用 Django 的 admin,所以我们需要一个超级用户…
创建管理员用户
不幸的是,
createsuperuser不允许您在使用--noinput选项时指定密码,所以我们将不得不编写自己的命令。幸运的是,Django 使得创建定制命令变得非常容易。创建文件ioimg/management/commands/createsu . py:
from django.core.management.base import BaseCommand from django.contrib.auth.models import User class Command(BaseCommand): def handle(self, *args, **options): if not User.objects.filter(username="admin").exists(): User.objects.create_superuser("admin", "admin@admin.com", "admin")确保您也添加了适当的
__init__.py文件:└─ management ├── __init__.py └── commands ├── __init__.py └── createsu.py这个文件将允许你运行
python manage.py createsu,它将创建一个超级用户而不提示输入密码。您可以随意扩展该命令,使用环境变量或其他方式来允许您更改密码。一旦创建了命令,我们就可以向中的
container_commands部分添加另一个命令。EB extensions/02 _ python . config:02_createsu: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu" leader_only: true在您测试之前,让我们确保我们的静态文件都放在正确的位置…
静态文件
在
container_commands下增加一条命令:03_collectstatic: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput"所以整个文件看起来像这样:
container_commands: 01_migrate: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput" leader_only: true 02_createsu: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu" leader_only: true 03_collectstatic: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput" option_settings: "aws:elasticbeanstalk:application:environment": DJANGO_SETTINGS_MODULE: "iotd.settings" "PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH" "ALLOWED_HOSTS": ".elasticbeanstalk.com" "aws:elasticbeanstalk:container:python": WSGIPath: iotd/iotd/wsgi.py NumProcesses: 3 NumThreads: 20 "aws:elasticbeanstalk:container:python:staticfiles": "/static/": "www/static/"我们现在需要确保 settings.py 文件中的
STATIC_ROOT设置正确:STATIC_ROOT = os.path.join(BASE_DIR, "..", "www", "static") STATIC_URL = '/static/'确保将
www目录提交给 git,这样就可以创建静态目录。然后再次运行eb deploy,现在您应该可以开始工作了:INFO: Environment update is starting. INFO: Deploying new version to instance(s). INFO: New application version was deployed to running EC2 instances. INFO: Environment update completed successfully.此时,您应该能够转到http://your _ app _ URL/admin,登录,添加一个图像,然后看到该图像显示在您的应用程序的主页上。
成功!
使用 S3 进行媒体存储
使用这种设置,每次我们再次部署时,我们都会丢失所有上传的映像。为什么?好吧,当你运行
eb deploy时,一个新的实例就会出现。这不是我们想要的,因为我们将在数据库中有图像的条目,但没有相关的图像。解决方案是将媒体文件存储在亚马逊简单存储服务(亚马逊 S3)中,而不是存储在 EC2 实例本身上。您需要:
因为已经有关于这方面的好文章,我就给你指出我最喜欢的:使用亚马逊 S3 来存储你的 Django 静态和媒体文件
阿帕奇配置
因为我们将 Apache 与 Beanstalk 一起使用,所以我们可能希望设置 Apache 来启用 gzip 压缩,以便客户端可以更快地下载文件。这可以用
container_commands来完成。创建一个新文件。EB extensions/03 _ Apache . config并添加以下内容:container_commands: 01_setup_apache: command: "cp .ebextensions/enable_mod_deflate.conf /etc/httpd/conf.d/enable_mod_deflate.conf"然后您需要创建文件
.ebextensions/enable_mod_deflate.conf:# mod_deflate configuration <IfModule mod_deflate.c> # Restrict compression to these MIME types AddOutputFilterByType DEFLATE text/plain AddOutputFilterByType DEFLATE text/html AddOutputFilterByType DEFLATE application/xhtml+xml AddOutputFilterByType DEFLATE text/xml AddOutputFilterByType DEFLATE application/xml AddOutputFilterByType DEFLATE application/xml+rss AddOutputFilterByType DEFLATE application/x-javascript AddOutputFilterByType DEFLATE text/javascript AddOutputFilterByType DEFLATE text/css # Level of compression (Highest 9 - Lowest 1) DeflateCompressionLevel 9 # Netscape 4.x has some problems. BrowserMatch ^Mozilla/4 gzip-only-text/html # Netscape 4.06-4.08 have some more problems BrowserMatch ^Mozilla/4\.0[678] no-gzip # MSIE masquerades as Netscape, but it is fine BrowserMatch \bMSI[E] !no-gzip !gzip-only-text/html <IfModule mod_headers.c> # Make sure proxies don't deliver the wrong content Header append Vary User-Agent env=!dont-vary </IfModule> </IfModule>这样做将启用 gzip 压缩,这将有助于您下载的文件的大小。您也可以使用相同的策略自动缩小和合并您的 CSS/JS,并做任何其他您需要做的预处理。
故障排除
不要忘记非常有用的
eb ssh命令,它将让您进入 EC2 实例,这样您就可以四处看看发生了什么。进行故障排除时,您应该了解几个目录:
/opt/python:你的应用程序将要结束的根目录。/opt/python/current/app:环境中托管的当前应用。/opt/python/on-deck/app:app 最初放在甲板上,当所有部署完成后,将被移动到current。如果你在你的container_commands中遇到故障,检查一下on-deck文件夹而不是current文件夹。/opt/python/current/env:eb将为您设置的所有 env 变量。如果你试图重现一个错误,你可能首先需要source /opt/python/current/env把事情设置成 eb deploy 运行时的样子。opt/python/run/venv:应用程序使用的虚拟 env 如果您试图重现一个错误,您还需要运行source /opt/python/run/venv/bin/activate。结论
部署到 Elastic Beanstalk 一开始可能有点令人畏惧,但是一旦您理解了所有的部分在哪里以及事情是如何工作的,它实际上是非常容易和非常灵活的。它还为您提供了一个可以随着使用量的增长而自动扩展的环境。希望现在你已经足够危险了!祝你下次部署 Beanstalk 时好运。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
我们错过了什么吗?有没有其他的小技巧或者小窍门?请在下面评论。*******
在杜库部署姜戈
这篇文章最初是为 Gun.io 写的,详细介绍了如何使用 Dokku 作为 Heroku 的替代品来部署你的 Django 应用。
什么是 Dokku?
几天前,我被指向了 Dokku 项目,这是一个“Docker powered mini-Heroku ”,你可以将其部署在你自己的服务器上,作为你自己的私有 PaaS。
你为什么想要自己的迷你 Heroku?
- 嗯, Heroku 可以花很多的钱;它托管在云中,您可能还不想让您的应用程序离开房间;而且你也没有 100%掌控平台的方方面面。
- 或者也许你就是那种喜欢自己动手的人。
不管怎样, Jeff Lindsay 用不到 100 行 bash 代码一起黑掉了 Dokku!
Dokku 将 Docker 与 Gitreceive 和 Buildstep 捆绑到一个易于部署、分叉/破解和更新的包中。
您需要什么来开始
你可以在自己的私人网络上使用从 AWS 到电脑的任何东西。我决定使用数字海洋作为这个小项目的云托管服务。
托管 Dokku 的要求很简单:
- Ubuntu 14.10 x64
- SSH 功能
Digital Ocean 有一个预配置的 Droplet ,您可以使用已经为 Dokku 环境提供的 Droplet。请随意使用这个。我们将使用全新的服务器,因此你可以在任何服务器上重现这个过程,而不仅仅是在数字海洋上。
我们开始吧!
- 首先,在数字海洋上注册一个账户,确保给账户添加一个公钥。如果您需要创建一个新的密钥,您可以按照本指南中的步骤一到三来帮助您进行设置。第四步以后会派上用场。
- 接下来,通过点击“创建液滴”创建一个“液滴”(旋转一个节点)。确保您选择“Ubuntu 14.10 x64”作为您的图像。我最初选择了 x32 版本,但杜库不愿意安装(见https://github.com/progrium/dokku/issues/51)。将您的 ssh 公钥添加到 droplet,这样您就可以通过 ssh 进入机器,而不必每次登录时都输入密码。数字海洋大约需要一分钟来启动您的机器。
- 准备就绪后,Digital Ocean 会发电子邮件告诉您,并在邮件中包含机器的 IP 地址,或者机器会出现在您的 droplets 面板下。使用 IP 地址 SSH 进入机器,并遵循数字海洋的 ssh 指南中的步骤四。
安装 Dokku
现在我们的主机已经设置好了,是时候安装和配置 Dokku 了。SSH 回到您的主机并运行以下命令:
$ wget -qO- https://raw.github.com/progrium/dokku/v0.2.3/bootstrap.sh | sudo DOKKU_TAG=v0.2.3 bash无论是否以 root 用户身份登录,都要确保使用
sudo。有关更多信息,请参见下面的“总结”部分。安装可能需要 2 到 5 分钟。完成后,注销您的主机。
确保使用以下格式为用户上传公钥:
$ cat ~/.ssh/id_rsa.pub | ssh root@<machine-address> "sudo sshcommand acl-add dokku <your-app-name> "用主机的 IP 地址或域名替换
<machine-address>,用 Django 项目的名称替换<your-app-name>。例如:
$ cat ~/.ssh/id_rsa.pub | ssh root@104.236.38.176 "sudo sshcommand acl-add dokku hellodjango"将 Django 应用程序部署到 Dokku
对于本教程,让我们按照 Heroku 上的Django 入门指南来设置一个初始的 Django 应用程序。
同样,Dokku 使用 Buildstep 来构建你的应用。它内置了 Heroku Python Buildpack ,这足以运行一个 Django 或 Flask 应用程序,开箱即用。然而,如果你想添加一个定制的构建包,你可以。
创建一个 Django 项目并添加一个本地 Git repo:
$ mkdir hellodjango && cd hellodjango $ virtualenv venv $ source venv/bin/activate $ pip install django-toolbelt $ django-admin.py startproject hellodjango . $ echo "web: gunicorn hellodjango.wsgi" > Procfile $ pip freeze > requirements.txt $ echo "venv" > .gitignore $ git init $ git add . $ git commit -m "First Commit HelloDjango"我们必须在我们的主机上添加 Dokku 作为 Git remote:
$ git remote add production dokku@<machine-address>:hellodjango现在我们可以推出我们的代码了:
$ git push production master用您的主机的地址或域名替换
<machine-address>。如果一切顺利,您应该会在终端中看到应用程序部署消息:=====> Application deployed: http://104.236.38.176:49153接下来,访问
http://<machine-address>:49153,你会看到熟悉的“欢迎来到 Django”页面。现在,您可以在本地开发您的应用程序,然后将其推送到您自己的 mini-heroku!。总结
最初,我安装了没有“sudo”的 Dokku:
$ wget -qO- https://raw.github.com/progrium/dokku/v0.2.3/bootstrap.sh | DOKKU_TAG=v0.2.3 bash当我尝试推送到 Dokku 时,python 构建包在尝试下载/构建 python 时会失败。解决这个问题的方法是卸载 Dokku,然后使用 sudo:
$ wget -qO- https://raw.github.com/progrium/dokku/v0.2.3/bootstrap.sh | sudo DOKKU_TAG=v0.2.3 bash不幸的是,杜库没有赫罗库走得远。
例如,所有命令都需要直接在主机服务器上运行,因为 Dokku 没有像 Heroku 那样的客户端应用程序。
因此,为了运行这样的命令:
$ heroku run python manage.py syncdb您需要首先通过 SSH 进入服务器。最简单的方法是创建一个
dokku命令:alias dokku="ssh -t root@<machine-address> dokku"现在,您可以运行以下命令来同步数据库:
$ dokku run hellodjango python manage.py syncdbDokku 允许您为每个应用程序单独配置环境变量。只需创建或编辑
/home/git/APP_NAME/ENV,并在其中填入如下内容:export DATABASE_URL=somethinghereDokku 仍然是一个年轻的平台,所以希望它继续成长,变得更加有用。它也是开源的,所以如果你想投稿,可以在 Github 上提出一个请求或者发表一个问题。**
将 Django 应用部署到 AWS Elastic Beanstalk
原文:https://realpython.com/deploying-a-django-app-to-aws-elastic-beanstalk/
下面是一个简单的演练,演示了如何在保持正常的情况下,建立一个 Django 应用程序并将其部署到 Amazon Web Services (AWS)。
使用的工具/技术:
- Python v2.7.8
- Django v1.7 版
- 亚马逊弹性豆茎、 EC2 、 S3 、 RDS
- EB CLI 3.x
- PostgreSQL
现在有了 Python 3!点击这里查看本文的更新版本。
这篇文章已经更新,涵盖了使用 Python 3 进行部署,因为 AWS 现在非常喜欢 Python 3。
弹性豆茎 vs EC2
Elastic Beanstalk 是一个平台即服务(PaaS ),它简化了亚马逊 AWS 上的应用的设置、部署和维护。这是一个托管服务,耦合了服务器(EC2)、数据库(RDS)和静态文件(S3)。您可以快速部署和管理您的应用程序,该应用程序会随着您的站点的增长而自动扩展。查看官方文档了解更多信息。
开始使用
我们将使用一个简单的“每日图片”应用程序,您可以从这个库中获取:
$ git clone https://github.com/realpython/image-of-the-day.git $ cd image-of-the-day/ $ git checkout tags/start_here下载代码后,创建一个 virtualenv 并通过 pip 安装需求:
$ pip install -r requirements.txt接下来,在本地运行 PostgreSQL 的情况下,设置一个名为
iotd的新数据库。同样,根据您的本地 Postgres 配置,您可能需要更新 settings.py 中的DATABASES配置。例如,我将配置更新为:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'iotd', 'USER': '', 'PASSWORD': '', 'HOST': 'localhost', 'PORT': '5432', } }现在,您可以设置数据库模式、创建超级用户并运行应用程序:
$ python manage.py migrate $ python manage.py createsuperuser $ python manage.py runserver在浏览器中导航到位于http://localhost:8000/admin的管理页面,并添加一个新图像,该图像将显示在主页上。
该应用程序并不意味着非常令人兴奋;我们只是用它来做演示。它所做的就是让你通过管理界面上传图片,并在主页上全屏显示图片。也就是说,虽然这是一个相对基础的应用程序,但它仍然允许我们探索部署到 Amazon Beanstalk 和 RDS 时存在的一些“问题”。
现在我们已经在本地机器上建立并运行了站点,让我们开始 Amazon 部署过程。
AWS 弹性豆茎 CLI
为了使用 Amazon Elastic Beanstalk,我们可以使用一个名为 awsebcli 的包。撰写本文时,的最新版本是 3.0.10,推荐的安装方式是使用 pip:
$ pip install awsebcli不要使用 brew 安装此软件包。在撰写本文时,它安装了 v2.6.3,该版本以微妙的方式被破坏,这将导致严重的挫折。
现在测试安装以确保它工作正常:
$ eb --version这应该会给您一个不错的 3.x 版本号:
EB CLI 3.0.10 (Python 2.7.8)要真正开始使用 Elastic Beanstalk,你需要一个 AWS 的账户(惊喜!).注册(或登录)。
配置 EB–初始化您的应用程序
随着 AWS Elastic Beanstalk CLI 的运行,我们要做的第一件事是创建一个 Beanstalk 环境来托管应用程序。从项目目录(“每日映像”)中运行:
$ eb init这将提示您一些问题,以帮助您配置环境。
默认区域
选择离最终用户最近的地区通常会提供最佳性能。如果你不确定选择哪一个,看看这张地图。
凭证
接下来,它将要求您提供 AWS 凭据。
在这里,您很可能想要设置一个 IAM 用户。关于如何设置,请参见本指南。如果您确实设置了一个新用户,您需要确保该用户具有适当的权限。最简单的方法是给用户添加“管理员访问”权限。(尽管出于安全原因,这可能不是一个好的选择。)有关用户创建/管理弹性 Beanstalk 应用程序所需的特定策略/角色,请参见此处的链接。
应用名称
这将默认为目录名。就这样吧。
Python 版本
接下来,CLI 应该自动检测到您正在使用 Python,并要求确认。答应吧。然后你需要选择一个平台版本。选择
Python 2.7。宋承宪
同意为您的实例设置 SSH。
RSA 密钥对
接下来,您需要生成一个 RSA 密钥对,它将被添加到您的 ~/中。ssh 文件夹。这个密钥对还将被上传到您在第一步中指定的区域的 EC2 公钥。这将允许您在本教程的后面使用 SSH 访问 EC2 实例。
我们完成了什么?
一旦
eb init完成,你会看到一个名为的新的隐藏文件夹。您的项目目录中的 elastic bean stall:├── .elasticbeanstalk │ └── config.yml ├── .gitignore ├── README.md ├── iotd │ ├── images │ │ ├── __init__.py │ │ ├── admin.py │ │ ├── migrations │ │ │ ├── 0001_initial.py │ │ │ └── __init__.py │ │ ├── models.py │ │ ├── tests.py │ │ └── views.py │ ├── iotd │ │ ├── __init__.py │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ ├── manage.py │ ├── static │ │ ├── css │ │ │ └── bootstrap.min.css │ │ └── js │ │ ├── bootstrap.min.js │ │ └── jquery-1.11.0.min.js │ └── templates │ ├── base.html │ └── images │ └── home.html ├── requirements.txt └── www └── media └── sitelogo.png该目录中有一个
config.yml文件,这是一个配置文件,用于为新创建的 Beanstalk 应用程序定义某些参数。此时,如果您键入
eb console,它将打开您的默认浏览器并导航到 Elastic Beanstalk 控制台。在这个页面上,您应该看到一个应用程序(如果您完全理解的话,称为image-of-the-day),但是没有环境。
应用程序代表您的代码应用程序,是
eb init为我们创造的。使用 Elastic Beanstalk,一个应用程序可以有多个环境(例如,开发、测试、试运行、生产)。如何配置/管理这些环境完全取决于您。对于简单的 Django 应用程序,我喜欢在我的笔记本电脑上安装开发环境,然后在 Beanstalk 上创建一个测试和生产环境。让我们建立一个测试环境…
配置 EB–创建环境
回到终端,在项目目录中键入:
$ eb create就像
eb init一样,这个命令会提示你一系列问题。环境名称
您应该使用类似于 Amazon 建议的命名约定——例如,application _ name-env _ name——特别是当您开始用 AWS 托管多个应用程序时。我用过-
iod-test。DNS CNAME 前缀
当你在 Elastic Beanstalk 上部署一个应用程序时,你会自动获得一个像 xxx.elasticbeanstalk.com 这样的域名。
DNS CNAME prefix是你想用来代替xxx的。就用默认的吧。现在发生了什么?
此时
eb实际上会为你创造你的环境。请耐心等待,因为这可能需要一些时间。如果您在创建环境时遇到错误,比如-
aws.auth.client.error.ARCInstanceIdentityProfileNotFoundException-检查您使用的凭证是否有创建 Beanstalk 环境的适当权限,如本文前面所讨论的。在创建环境之后,
eb将立即尝试部署您的应用程序,方法是将项目目录中的所有代码复制到新的 EC2 实例中,并在该过程中运行pip install -r requirements.txt。您应该会在屏幕上看到一堆关于正在设置的环境的信息,以及关于
eb尝试部署的信息。您还会看到一些错误。特别是,您应该会看到这些行隐藏在输出中的某个地方:ERROR: Your requirements.txt is invalid. Snapshot your logs for details.别担心,这并不是真的无效。有关详细信息,请查看日志:
$ eb logs这将从 EC2 实例中获取所有最近的日志文件,并将它们输出到您的终端。这是大量的信息,所以您可能希望将输出重定向到一个文件(
eb logs -z)。浏览日志,您会看到一个名为 eb-activity.log 的日志文件:Error: pg_config executable not found.问题是我们试图安装
psycopy2(Postgres Python 绑定),但是我们也需要安装 Postgres 客户端驱动程序。因为它们不是默认安装的,所以我们需要先安装它们。让我们来解决这个问题…定制部署流程
eb将从名为"的文件夹中读取自定义的.config文件。“ebextensions”,位于项目的根级别(“当天的图像”目录)。这些.config文件允许你安装软件包,运行任意命令和/或设置环境变量。”中的文件。ebextensions”目录应该符合JSON或YAML语法,并按字母顺序执行。安装软件包
我们需要做的第一件事是安装一些包,以便我们的
pip install命令能够成功完成。为此,我们首先创建一个名为的文件。EB extensions/01 _ packages . config:packages: yum: git: [] postgresql93-devel: []EC2 实例运行 Amazon Linux,这是一种 Redhat 风格,所以我们可以使用 yum 来安装我们需要的包。现在,我们只是要安装两个包- git 和 Postgres 客户端。
创建该文件以重新部署应用程序后,我们需要执行以下操作:
$ git add .ebextensions/ $ git commit -m "added eb package configuration"我们必须提交更改,因为部署命令
eb deploy处理最近一次提交,因此只有在我们将文件更改提交给 git 之后,我们才会意识到这些更改。(请注意,我们不必用力;我们从本地副本开始工作……)正如您可能猜到的,下一个命令是:
$ eb deploy您现在应该只看到一个错误:
INFO: Environment update is starting. INFO: Deploying new version to instance(s). ERROR: Your WSGIPath refers to a file that does not exist. INFO: New application version was deployed to running EC2 instances. INFO: Environment update completed successfully.让我们看看发生了什么…
配置我们的 Python 环境
Beanstalk 中的 EC2 实例运行 Apache,Apache 将根据我们设置的 WSGIPATH 找到我们的 Python 应用程序。默认情况下,
eb假设我们的 wsgi 文件叫做 application.py 。有两种方法可以解决这个问题-选项 1:使用特定于环境的配置设置
$ eb config这个命令将打开你的默认编辑器,编辑一个名为的配置文件。elastic beanstalk/iod-test . env . yml。该文件实际上不存在于本地;
eb从 AWS 服务器上下载并呈现给您,以便您可以更改其中的设置。如果您对此伪文件进行任何更改,然后保存并退出,eb将会更新您的 Beanstalk 环境中的相应设置。如果您在文件中搜索术语“WSGI ”,您应该会发现一个如下所示的配置部分:
aws:elasticbeanstalk:container:python: NumProcesses: '1' NumThreads: '15' StaticFiles: /static/=static/ WSGIPath: application.py更新 WSGIPath:
aws:elasticbeanstalk:container:python: NumProcesses: '1' NumThreads: '15' StaticFiles: /static/=static/ WSGIPath: iotd/iotd/wsgi.py然后就可以正确设置 WSGIPath 了。如果保存文件并退出,
eb将自动更新环境配置:Printing Status: INFO: Environment update is starting. INFO: Updating environment iod-test's configuration settings. INFO: Successfully deployed new configuration to environment. INFO: Environment update completed successfully.使用
eb config方法来改变设置的好处是你可以为每个环境指定不同的设置。但是您也可以使用我们之前使用的相同的.config文件来更新设置。这将对每个环境使用相同的设置,因为.config文件将在部署时应用(在eb config的设置被应用之后)。选项 2:使用全局配置设置
要使用
.config文件选项,让我们创建一个名为 /的新文件。EB extensions/02 _ python . config:option_settings: "aws:elasticbeanstalk:application:environment": DJANGO_SETTINGS_MODULE: "iotd.settings" "PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH" "aws:elasticbeanstalk:container:python": WSGIPath: iotd/iotd/wsgi.py NumProcesses: 3 NumThreads: 20 "aws:elasticbeanstalk:container:python:staticfiles": "/static/": "www/static/"发生了什么事?
DJANGO_SETTINGS_MODULE: "iotd.settings"-添加设置模块的路径。"PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"-更新我们的PYTHONPATH,这样 Python 可以在我们的应用程序中找到模块。(注意,使用完整路径是必要的。)- 设置我们的 WSGI 路径。
NumProcesses: 3和NumThreads: 20——更新用于运行我们的 WSGI 应用程序的进程和线程的数量。"/static/": "www/static/"设置我们的静态文件路径。同样,我们可以执行
git commit然后执行eb deploy来更新这些设置。接下来让我们添加一个数据库。
配置数据库
尝试查看已部署的网站:
$ eb open该命令将在默认浏览器中显示部署的应用程序。您应该会看到连接被拒绝错误:
OperationalError at / could not connect to server: Connection refused Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5432?这是因为我们还没有建立数据库。此时
eb将设置您的 Beanstalk 环境,但是它不会设置 RDS(数据库层)。我们必须手动设置。数据库设置
再次使用
eb console打开 Beanstalk 配置页面。
在那里,执行以下操作:
- 单击“配置”链接。
- 一直滚动到页面底部,然后在“数据层”部分下,单击链接“创建新的 RDS 数据库”。
- 在 RDS 设置页面上,将“数据库引擎”更改为“postgres”。
- 添加“主用户名”和“主密码”。
- 保存更改。
Beanstalk 将为您创建 RDS。现在我们需要让 Django 应用程序连接到 RDS。Beanstalk 将帮助我们在 EC2 实例上公开一些环境变量,详细说明如何连接到 Postgres 服务器。所以我们需要做的就是更新我们的 settings.py 文件来利用这些环境变量。确认
DATABASES配置参数反映了 settings.py 中的以下内容:if 'RDS_DB_NAME' in os.environ: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': os.environ['RDS_DB_NAME'], 'USER': os.environ['RDS_USERNAME'], 'PASSWORD': os.environ['RDS_PASSWORD'], 'HOST': os.environ['RDS_HOSTNAME'], 'PORT': os.environ['RDS_PORT'], } } else: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'iotd', 'USER': 'iotd', 'PASSWORD': 'iotd', 'HOST': 'localhost', 'PORT': '5432', } }这只是说,“如果存在,使用环境变量设置,否则使用我们的默认开发设置”。简单。
处理数据库迁移
对于我们的数据库设置,我们仍然需要确保迁移运行以便数据库表结构是正确的。我们可以通过修改来实现。EB extensions/02 _ python . config并在文件顶部添加以下行:
container_commands: 01_migrate: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput" leader_only: true
container_commands允许您在 EC2 实例上部署应用程序后运行任意命令。因为 EC2 实例是使用虚拟环境设置的,所以在运行 migrate 命令之前,我们必须首先激活该虚拟环境。此外,leader_only: true设置意味着,“当部署到多个实例时,只在第一个实例上运行这个命令”。不要忘记我们的应用程序使用 Django 的 admin,所以我们需要一个超级用户…
创建管理员用户
不幸的是,
createsuperuser不允许您在使用--noinput选项时指定密码,所以我们将不得不编写自己的命令。幸运的是,Django 使得创建定制命令变得非常容易。创建文件ioimg/management/commands/createsu . py:
from django.core.management.base import BaseCommand from django.contrib.auth.models import User class Command(BaseCommand): def handle(self, *args, **options): if not User.objects.filter(username="admin").exists(): User.objects.create_superuser("admin", "admin@admin.com", "admin")确保您也添加了适当的
__init__.py文件:└─ management ├── __init__.py └── commands ├── __init__.py └── createsu.py这个文件将允许你运行
python manage.py createsu,它将创建一个超级用户而不提示输入密码。您可以随意扩展该命令,使用环境变量或其他方式来允许您更改密码。一旦创建了命令,我们就可以向中的
container_commands部分添加另一个命令。EB extensions/02 _ python . config:02_createsu: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu" leader_only: true在您测试之前,让我们确保我们的静态文件都放在正确的位置…
静态文件
在
container_commands下增加一条命令:03_collectstatic: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput"所以整个文件看起来像这样:
container_commands: 01_migrate: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput" leader_only: true 02_createsu: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu" leader_only: true 03_collectstatic: command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput" option_settings: "aws:elasticbeanstalk:application:environment": DJANGO_SETTINGS_MODULE: "iotd.settings" "PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH" "ALLOWED_HOSTS": ".elasticbeanstalk.com" "aws:elasticbeanstalk:container:python": WSGIPath: iotd/iotd/wsgi.py NumProcesses: 3 NumThreads: 20 "aws:elasticbeanstalk:container:python:staticfiles": "/static/": "www/static/"我们现在需要确保 settings.py 文件中的
STATIC_ROOT设置正确:STATIC_ROOT = os.path.join(BASE_DIR, "..", "www", "static") STATIC_URL = '/static/'确保将
www目录提交给 git,这样就可以创建静态目录。然后再次运行eb deploy,现在您应该可以开始工作了:INFO: Environment update is starting. INFO: Deploying new version to instance(s). INFO: New application version was deployed to running EC2 instances. INFO: Environment update completed successfully.此时,您应该能够转到http://your _ app _ URL/admin,登录,添加一个图像,然后看到该图像显示在您的应用程序的主页上。
成功!
使用 S3 进行媒体存储
使用这种设置,每次我们再次部署时,我们都会丢失所有上传的映像。为什么?好吧,当你运行
eb deploy时,一个新的实例就会出现。这不是我们想要的,因为我们将在数据库中有图像的条目,但没有相关的图像。解决方案是将媒体文件存储在亚马逊简单存储服务(亚马逊 S3)中,而不是存储在 EC2 实例本身上。您需要:
因为已经有关于这方面的好文章,我就给你指出我最喜欢的:使用亚马逊 S3 来存储你的 Django 静态和媒体文件
阿帕奇配置
因为我们将 Apache 与 Beanstalk 一起使用,所以我们可能希望设置 Apache 来启用 gzip 压缩,以便客户端可以更快地下载文件。这可以用
container_commands来完成。创建一个新文件。EB extensions/03 _ Apache . config并添加以下内容:container_commands: 01_setup_apache: command: "cp .ebextensions/enable_mod_deflate.conf /etc/httpd/conf.d/enable_mod_deflate.conf"然后您需要创建文件
.ebextensions/enable_mod_deflate.conf:# mod_deflate configuration <IfModule mod_deflate.c> # Restrict compression to these MIME types AddOutputFilterByType DEFLATE text/plain AddOutputFilterByType DEFLATE text/html AddOutputFilterByType DEFLATE application/xhtml+xml AddOutputFilterByType DEFLATE text/xml AddOutputFilterByType DEFLATE application/xml AddOutputFilterByType DEFLATE application/xml+rss AddOutputFilterByType DEFLATE application/x-javascript AddOutputFilterByType DEFLATE text/javascript AddOutputFilterByType DEFLATE text/css # Level of compression (Highest 9 - Lowest 1) DeflateCompressionLevel 9 # Netscape 4.x has some problems. BrowserMatch ^Mozilla/4 gzip-only-text/html # Netscape 4.06-4.08 have some more problems BrowserMatch ^Mozilla/4\.0[678] no-gzip # MSIE masquerades as Netscape, but it is fine BrowserMatch \bMSI[E] !no-gzip !gzip-only-text/html <IfModule mod_headers.c> # Make sure proxies don't deliver the wrong content Header append Vary User-Agent env=!dont-vary </IfModule> </IfModule>这样做将启用 gzip 压缩,这将有助于您下载的文件的大小。您也可以使用相同的策略自动缩小和合并您的 CSS/JS,并做任何其他您需要做的预处理。
故障排除
不要忘记非常有用的
eb ssh命令,它将让您进入 EC2 实例,这样您就可以四处看看发生了什么。进行故障排除时,您应该了解几个目录:
/opt/python-您的应用程序将结束的根目录。/opt/python/current/app-环境中托管的当前应用程序。/opt/python/on-deck/app-应用程序最初放在甲板上,然后,在所有部署完成后,它将被移动到current。如果你在你的container_commands中遇到故障,检查一下on-deck文件夹而不是current文件夹。/opt/python/current/env-eb将为您设置的所有环境变量。如果你试图重现一个错误,你可能首先需要source /opt/python/current/env把事情设置成 eb deploy 运行时的样子。opt/python/run/venv-应用程序使用的虚拟 env 如果您试图重现一个错误,您还需要运行source /opt/python/run/venv/bin/activate结论
部署到 Elastic Beanstalk 一开始可能有点令人畏惧,但是一旦您理解了所有的部分在哪里以及事情是如何工作的,它实际上是非常容易和非常灵活的。它还为您提供了一个可以随着使用量的增长而自动扩展的环境。希望现在你已经足够危险了!祝你下次部署 Beanstalk 时好运。
我们错过了什么吗?有没有其他的小技巧或者小窍门?请在下面评论。*******
用瓶子显影
我爱瓶。这是一个简单、快速而强大的 Python 微框架,非常适合小型 web 应用程序和快速原型开发。对于刚刚开始 web 开发的人来说,这也是一个很好的学习工具。
让我们看一个简单的例子。
注:本教程假设您正在运行一个基于 Unix 的环境——例如,Mac OS X、Linux 版本或通过虚拟机驱动的 Linux 版本。
更新于 2015 年 6 月 13 日:更新了代码示例和说明
启动
首先,让我们创建一个工作目录:
$ mkdir bottle && cd bottle接下来,您需要安装 pip 、virtualenv 和 git。
virtualenv 是一个 Python 工具,使得很容易管理特定项目所需的 Python 包;它防止一个项目中的包与其他项目中的包发生冲突。 pip 同时是一个包管理器,用于管理 Python 包的安装。
要获得在 Unix 环境中安装 pip(及其依赖项)的帮助,请遵循本要点中的说明。如果你在 Windows 环境下,请观看这个视频寻求帮助。
一旦安装了 pip ,运行以下命令安装 virtualenv:
$ pip install virtualenv==12.0.7现在,我们可以轻松设置我们的本地环境:
$ virtualenv venv $ source venv/bin/activate安装瓶子:
$ pip install bottle==0.12.8 $ pip freeze > requirements.txt最后,让我们使用 Git 对我们的应用程序进行版本控制。有关 Git 的更多信息,请查看本文,其中也包括安装说明。
$ git init $ git add . $ git commit -m "initial commit"编写您的应用程序
我们已经准备好编写我们的瓶子应用程序。打开 Sublime Text 3 或您选择的文本编辑器。创建您的应用程序文件, app.py ,它将保存我们第一个应用程序的整体:
import os from bottle import route, run, template index_html = '''My first web app! By <strong>{{ author }}</strong>.''' @route('/') def index(): return template(index_html, author='Real Python') @route('/name/<name>') def name(name): return template(index_html, author=name) if __name__ == '__main__': port = int(os.environ.get('PORT', 8080)) run(host='0.0.0.0', port=port, debug=True)保存文件。
现在,您可以在本地运行您的应用:
$ python app.py您应该能够连接到 http://localhost:8080/ 并看到您的应用程序正在运行!
My first web app! By RealPython.因此,
@route装饰器将一个函数绑定到路由。在第一个路由/中,index()函数被绑定到该路由,该路由呈现index_html模板并传入一个变量、author,作为关键字参数。然后可以在模板中访问这个变量。现在导航到下一条路线,确保在路线的末尾添加您的姓名,即http://localhost:8080/name/Michael。您应该会看到类似这样的内容:
My first web app! By Michael.到底怎么回事?
- 同样,
@route装饰器将一个函数绑定到路由。在这种情况下,我们使用包含通配符<name>的动态路由。- 然后这个通配符作为参数传递给视图函数-
def name(name)。- 然后我们将它作为关键字参数传递给模板-
author=name- 然后,模板呈现作者变量-
{{ author }}。外壳脚本
想快速上手?使用这个 Shell 脚本在几秒钟内生成 starter 应用程序。
mkdir bottle cd bottle pip install virtualenv==12.0.7 virtualenv venv source venv/bin/activate pip install bottle==0.12.8 pip freeze > requirements.txt git init git add . git commit -m "initial commit" cat >app.py <<EOF import os from bottle import route, run, template index_html = '''My first web app! By <strong>{{ author }}</strong>.''' @route('/') def index(): return template(index_html, author='Real Python') @route('/name/<name>') def name(name): return template(index_html, author=name) if __name__ == '__main__': port = int(os.environ.get('PORT', 8080)) run(host='0.0.0.0', port=port, debug=True) EOF chmod a+x app.py git init git add . git commit -m "Updated"从这个要点下载这个脚本,然后使用以下命令运行它:
$ bash bottle.sh接下来的步骤
从这一点来看,创建新页面就像添加新的
@route修饰函数一样简单。创建 HTML 很简单:在上面的应用程序中,我们只是在文件本身内联了 HTML。很容易修改它,从文件中加载模板。例如:
@route('/main') def main(name): return template('main_template')这将加载模板文件
main_template.tpl,该文件必须放在项目结构的views文件夹中,并呈现给最终用户。更多信息请参考瓶子文档。
我们将在随后的帖子中看看如何添加额外的页面和模板。然而,我强烈建议你自己尝试一下。如有任何问题,请在下面留言。
看看第二部!*
用瓶子开发–第 2 部分(plot.ly API)
原文:https://realpython.com/developing-with-bottle-part-2-plot-ly-api/
2014 年 2 月 27 日更新,2014 年 8 月 1 日再次更新(针对最新的 Plotly API)!
在用瓶子开发系列的下一篇文章中,我们将会看到 GET 和 post 请求以及 HTML 表单。我还将向您展示如何使用来自 plot.ly API 的数据。您还将看到如何创建一个显示群组分析研究结果的很酷的图表。
如果你不熟悉群组分析,请点击查看这篇文章。
你错过瓶子系列的第一部分了吗?看看这里这里。同样,本教程使用的是 Bottle 版本 0.12.3 和 Plotly 版本 1.2.6。
基本设置
首先从第 1 部分下载这个要点,然后使用下面的命令运行它:
$ bash bottle.sh这将创建一个基本的项目结构:
├── app.py ├── requirements.txt └── testenv激活 virtualenv:
$ cd bottle $ source testenv/bin/activate安装要求:
$ pip install -r requirements.txt导航到https://www.plot.ly/api,注册一个新账户,登录,然后创建一个新的 API 密钥:
复制钥匙。
安装 plot.ly:
$ pip install plotly==1.2.6接下来更新 app.py 中的代码:
import os from bottle import run, template, get, post, request import plotly.plotly as py from plotly.graph_objs import * # add your username and api key py.sign_in("realpython", "lijlflx93") @get('/plot') def form(): return '''<h2>Graph via Plot.ly</h2> <form method="POST" action="/plot"> Name: <input name="name1" type="text" /> Age: <input name="age1" type="text" /><br/> Name: <input name="name2" type="text" /> Age: <input name="age2" type="text" /><br/> Name: <input name="name3" type="text" /> Age: <input name="age3" type="text" /><br/> <input type="submit" /> </form>''' @post('/plot') def submit(): # grab data from form name1 = request.forms.get('name1') age1 = request.forms.get('age1') name2 = request.forms.get('name2') age2 = request.forms.get('age2') name3 = request.forms.get('name3') age3 = request.forms.get('age3') data = Data([ Bar( x=[name1, name2, name3], y=[age1, age2, age3] ) ]) # make api call response = py.plot(data, filename='basic-bar') if response: return template(''' <h1>Congrats!</h1> <div> View your graph here: <a href="{{response}}"</a>{{response}} </div> ''', response=response ) if __name__ == '__main__': port = int(os.environ.get('PORT', 8080)) run(host='0.0.0.0', port=port, debug=True)这是怎么回事?
- 第一个函数
form(),创建一个 HTML 表单来获取我们需要的数据,以制作一个简单的条形图。- 同时,第二个函数
submit()获取表单输入,将它们分配给变量,然后调用 plot.ly API,传递我们的凭证和数据,生成一个新的图表。确保用您自己的凭证替换我的用户名和 API 密钥。不要用我的。这是行不通的。测试
在本地运行你的应用,
python app.py,将你的浏览器指向http://localhost:8080/plot。输入三个人的名字和他们各自的年龄。按 submit,然后如果一切正常,您应该会看到一条祝贺消息和一个 URL。单击 URL 查看您的图表:
如果你得到一个 500 错误消息-
Aw, snap! Looks like you supplied the wrong API key. Want to try again? You can always view your key at https://plot.ly/api/key. When you display your key at https://plot.ly/api/key, make sure that you're logged in as realpython.-你需要更新你的 API 密匙。此外,如果这是一个真实的、面向客户端的应用程序,您会希望比这更优雅地处理错误。仅供参考。
群组分析
接下来,让我们看一个更复杂的示例,为以下群组分析统计创建一个图表:
支持者 Two thousand and eleven Two thousand and twelve Two thousand and thirteen Two thousand and fourteen Zero Three hundred and ten Three hundred and forty-eight Two hundred and twenty-eight Two hundred and fifty one Fifty-five One hundred and fifty-seven Seventy-three Thirty-four Two Eighteen Thirty-seven Thirty-three Thirty-four three Two four four three 我们将构建同一个 app - app.py ,但是创建一个新文件:打开 app.py ,然后“另存为” cohort.py 。
从升级到简单模板引擎开始,这样我们就可以向模板添加样式和 Javascript 文件。添加一个名为“views”的新文件夹,然后在该目录下创建一个名为 template.tpl 的新文件。将以下代码添加到该文件中:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>{{ title }}</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> body { padding: 60px 0px; } </style> </head> <body> <div class="container"> <h1>Graph via Plot.ly</h1> <form role="form" method="post" action="/plot"> <table> <td> <h3>2011</h3> <div class="form-group" "col-md-2"> <input type="number" name="Y01" class="form-control" placeholder="Cohort 0"> <input type="number" name="Y02" class="form-control" placeholder="Cohort 1"> <input type="number" name="Y03" class="form-control" placeholder="Cohort 2"> <input type="number" name="Y04" class="form-control" placeholder="Cohort 3"> </div> </td> <td> <h3>2012</h3> <div class="form-group" "col-md-2"> <input type="number" name="Y11" class="form-control" placeholder="Cohort 0"> <input type="number" name="Y12" class="form-control" placeholder="Cohort 1"> <input type="number" name="Y13" class="form-control" placeholder="Cohort 2"> <input type="number" name="Y44" class="form-control" placeholder="Cohort 3"> </div> </td> <td> <h3>2013</h3> <div class="form-group" "col-md-2"> <input type="number" name="Y21" class="form-control" placeholder="Cohort 0"> <input type="number" name="Y22" class="form-control" placeholder="Cohort 1"> <input type="number" name="Y23" class="form-control" placeholder="Cohort 2"> <input type="number" name="Y24" class="form-control" placeholder="Cohort 3"> </div> </td> <td> <h3>2014</h3> <div class="form-group" "col-md-2"> <input type="number" name="Y31" class="form-control" placeholder="Cohort 0"> <input type="number" name="Y32" class="form-control" placeholder="Cohort 1"> <input type="number" name="Y33" class="form-control" placeholder="Cohort 2"> <input type="number" name="Y34" class="form-control" placeholder="Cohort 3"> </div> </td> </tr> </table> </form> </div> <script src="http://code.jquery.com/jquery-1.10.2.min.js"></script> <script src="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/js/bootstrap.min.js"></script> </body> </html>正如你可能知道的,这看起来就像一个 HTML 文件。不同之处在于,我们可以使用语法-
{{ python_variable }}将 Python 变量传递给文件。创建一个 data.json 文件,并添加您的 Plot.ly 用户名和 API 密钥。你可以在这里查看样本文件。
将以下代码添加到 cohort.py 中,以便在我们进行 API 调用时访问 data.json 来使用凭证:
import os from bottle import run, template, get, post, request import plotly.plotly as py from plotly.graph_objs import * import json # grab username and key from config/data file with open('data.json') as config_file: config_data = json.load(config_file) username = config_data["user"] key = config_data["key"] py.sign_in(username, key)现在我们不必把我们的钥匙暴露给整个宇宙。只要确保它不受版本控制就行了。
接下来更新功能:
import os from bottle import run, template, get, post, request import plotly.plotly as py from plotly.graph_objs import * import json # grab username and key from config/data file with open('data.json') as config_file: config_data = json.load(config_file) username = config_data["user"] key = config_data["key"] py.sign_in(username, key) @get('/plot') def form(): return template('template', title='Plot.ly Graph') @post('/plot') def submit(): # grab data from form Y01 = request.forms.get('Y01') Y02 = request.forms.get('Y02') Y03 = request.forms.get('Y03') Y04 = request.forms.get('Y04') Y11 = request.forms.get('Y11') Y12 = request.forms.get('Y12') Y13 = request.forms.get('Y13') Y14 = request.forms.get('Y14') Y21 = request.forms.get('Y21') Y22 = request.forms.get('Y22') Y23 = request.forms.get('Y23') Y24 = request.forms.get('Y24') Y31 = request.forms.get('Y31') Y32 = request.forms.get('Y32') Y33 = request.forms.get('Y33') Y34 = request.forms.get('Y34') trace1 = Scatter( x=[1, 2, 3, 4], y=[Y01, Y02, Y03, Y04] ) trace2 = Scatter( x=[1, 2, 3, 4], y=[Y11, Y12, Y13, Y14] ) trace3 = Scatter( x=[1, 2, 3, 4], y=[Y21, Y22, Y23, Y24] ) trace4 = Scatter( x=[1, 2, 3, 4], y=[Y31, Y32, Y33, Y34] ) data = Data([trace1, trace2, trace3, trace4]) # api call plot_url = py.plot(data, filename='basic-line') return template('template2', title='Plot.ly Graph', plot_url=str(plot_url)) if __name__ == '__main__': port = int(os.environ.get('PORT', 8080)) run(host='0.0.0.0', port=port, debug=True)注意
return语句。我们会传入模板的名称,以及任何变量。让我们创建一个名为 template2.tpl 的新模板:<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>{{ title }}</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> body { padding: 60px 0px; } </style> </head> <body> <div class="container"> <h1>Graph via Plot.ly</h1> <br> <a href="/plot"></a> <br><br> <iframe id="igraph" src={{plot_url}} width="900" height="450" seamless="seamless" scrolling="no"></iframe> </div> <script src="http://code.jquery.com/jquery-1.10.2.min.js"></script> <script src="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/js/bootstrap.min.js"></script> </body> </html>因此,iframe 允许我们更新表单,然后显示实际的内容/图表,以及更新后的更改。换句话说,我们不必离开站点来查看图表。
运行它。向表单添加值。然后提交。您的图表现在应该看起来像这样:
结论
你可以从这个 repo 中抓取所有文件。
下次见!**
在 Fedora 上开发和部署 Django
原文:https://realpython.com/development-and-deployment-of-cookiecutter-django-on-fedora/
上次时间我们用 Cookiecutter 搭建了一个 Django 项目,通过 Docker 管理应用环境,然后将 app 部署到数字海洋。在本教程中,我们将离开 Docker,详细介绍一个基于 Fedora 24 的 Cookiecutter-Django 项目的开发部署工作流程。
更新:
- 11/15/2016 :重构 Nginx 配置,更新到 Django 最新版本(v 1.10.3 )。
- 10/06/2016 :更新至 Fedora (v 24 )、cookiecutter (v 1.4.0 )、cookiecutter-django、Django (v 1.10.1 )的最新版本。
发展
全局安装 cookiecutter ,然后生成一个自举的 Django 项目:
$ pip install cookiecutter==1.4.0 $ cookiecutter https://github.com/pydanny/cookiecutter-django.git该命令使用 cookiecutter-django repo 运行 cookiecutter,允许我们输入特定于项目的详细信息。(我们将该项目和报告命名为django _ cookiecutter _ fedora。)
注意:查看前一篇文章中的本地设置部分,了解关于该命令以及生成的项目结构的更多信息。
在我们开始 Django 项目之前,我们还有几个步骤…
数据库设置
首先,我们需要设置 Postgres,因为 cookiecutter-django 使用它作为默认数据库(更多信息见django _ cookiecutter _ fedora/config/settings/common . py)。按照步骤设置 Postgres 数据库服务器,从互联网上的任何好资源或者向下滚动到部署部分在 Fedora 上设置它。
注意:如果你在苹果电脑上,请查看 Postgres.app 。
Postgres 服务器运行后,从 psql 创建一个新的数据库,该数据库与您的项目同名:
$ create database django_cookiecutter_fedora; CREATE DATABASE注意:根据您的 Postgres 版本,上述创建数据库的命令可能会有一些变化。你可以在 Postgres 的最新文档中找到正确的命令这里。
依赖性设置
接下来,为了让您的 Django 项目处于准备开发的状态,导航到根目录,创建/激活一个虚拟环境,然后安装依赖项:
$ cd django_cookiecutter_fedora $ pyvenv-3.5 .venv $ source .venv/bin/activate $ ./utility/install_python_dependencies.sh健全性检查
应用迁移,然后运行本地开发服务器:
$ python manage.py makemigrations $ python manage.py migrate $ python manage.py runserver在浏览器中导航至 http://localhost:8000/ 查看项目快速启动页面,确保一切正常:
一旦完成,终止开发服务器,初始化一个新的 Git repo,提交并
git push到 Github。部署
项目设置完毕并在本地运行后,我们现在可以继续进行部署,我们将利用以下工具:
Fedora 24 设置
建立一个快速的数字海洋水滴,确保使用 Fedora 24 图像。如需帮助,请跟随这篇教程。确保你设置了 SSH 密钥用于安全登录。
现在让我们更新我们的服务器。以 root 用户身份通过 SSH 登录到服务器,然后启动更新过程:
$ ssh root@SERVER_IP_ADDRESS # dnf upgrade非根用户
接下来,让我们设置一个非 root 用户,这样应用程序就不会在管理权限下运行,这使得系统更加安全。
作为根用户,按照以下命令设置非根用户:
# adduser <name-of-user> # passwd <name-of-user> Changing password for user <name-of-user>. New password: Retype new password: passwd: all authentication tokens updated successfully.在上面的代码片段中,我们创建了新的非 root 用户 user,然后为该用户指定了一个密码。我们现在需要将该用户添加到管理组中,这样他们就可以使用
sudo运行需要管理员权限的命令:# usermod <name-of-user> -a -G wheel退出服务器,并以非 root 用户身份再次登录。您是否注意到 shell 提示符从
#(英镑符号)变成了$(美元符号)?这表示我们以非 root 用户身份登录。必需的包
以非 root 用户身份登录时,下载并安装以下软件包:
注意:下面我们给我们的非 root 用户 root 权限(推荐!).如果您不希望明确授予非 root 用户 root 权限,那么您必须在终端中执行的每个命令前面加上
sudo关键字。$ sudo su # dnf install postgresql-server postgresql-contrib postgresql-devel # dnf install python3-devel python-devel gcc nginx gitPostgres 设置
下载并安装完依赖项后,我们只需要设置我们的 Postgres 服务器并创建一个数据库。
初始化 Postgres,然后手动启动服务器:
# sudo postgresql-setup initdb # sudo systemctl start postgresql然后通过将
su切换到postgres用户来登录 Postgres 服务器:# sudo su - postgres $ psql postgres=#现在创建我们项目所需的 Postgres 用户和数据库,确保用户名与非 root 用户的名称匹配:
postgres=# CREATE USER <user-name> WITH PASSWORD '<password-for-user>'; CREATE ROLE postgres=# CREATE DATABASE django_cookiecutter_fedora; CREATE DATABASE postgres=# GRANT ALL ON DATABASE django_cookiecutter_fedora TO <user-name>; GRANT注意:如果您需要帮助,请按照官方指南在 Fedora 上设置 Postgres。
退出 psql 并返回到您的非根用户的 shell 会话:
postgres=# \q $ exit当您退出 postgres 会话时,您将返回到非 root 用户提示符。
[username@django-cookiecutter-deploy ~]#。注意:你注意到提示处的
#标志了吗?现在出现这种情况是因为我们在开始设置服务器之前给了非 root 用户 root 权限。如果你看不到这个,你需要再次运行sudo su或者在每个命令前加上sudo。配置 Postgres,使其在服务器引导/重新引导时启动:
# sudo systemctl enable postgresql # sudo systemctl restart postgresql项目设置
将项目结构从 GitHub repo 克隆到 /opt 目录:
# sudo git clone <github-repo-url> /opt/<name of the repo>注:想用本教程关联的回购?只需运行:
`$ sudo git clone https://github.com/realpython/django_cookiecutter_fedora /opt/django_cookiecutter_fedora`依赖性设置
接下来,为了让 Django 项目处于可以部署的状态,在项目的根目录下创建并激活一个 virtualenv:
# cd /opt/django_cookiecutter_fedora/ # sudo pip3 install virtualenv # sudo pyvenv-3.5 .venv激活 virtualenv 之前,授予当前非根用户管理员权限(如果未授予):
$ sudo su # source .venv/bin/activate与上面的开发环境设置不同,在安装依赖项之前,我们需要安装所有的 Pillow 的外部库。查看这个资源获取更多信息。
# dnf install libtiff-devel libjpeg-devel libzip-devel freetype-devel # dnf install lcms2-devel libwebp-devel tcl-devel tk-devel接下来,我们需要再安装一个包,以确保在 virtualenv 中安装依赖项时不会发生冲突。
# dnf install redhat-rpm-config然后运行:
# ./utility/install_python_dependencies.sh同样,这将安装所有基础、本地和生产需求。这只是一个快速的检查,以确保一切正常。由于这在技术上是生产环境,我们将很快改变环境。
注意:禁用 virtualenv。现在,如果您发出一个退出命令——例如
exit——非 root 用户将不再拥有 root 权限。注意提示的变化(从#到$)。也就是说,用户仍然可以激活 virtualenv。试试看!健全性检查(取 2)
应用所有迁移:
$ python manage.py makemigrations $ python manage.py migrate现在运行服务器:
$ python manage.py runserver 0.0.0.0:8000为了确保一切正常,只需在浏览器中访问服务器的 IP 地址即可——例如,
:8000。完成后杀死服务器。 Gunicorn 设置
在设置 Gunicorn 之前,我们需要在/config/settings/production . py模块中对生产设置进行一些更改。看一下生产设置这里的,这是将我们的 Django 项目部署到生产服务器所需的最低设置。
要更新这些文件,请在 VI:
$ sudo vi config/settings/production.py首先,选择全部并删除:
:%d然后复制新设置,并通过进入插入模式然后粘贴,将它们粘贴到现在为空的文件中。一定要更新
ALLOWED_HOSTS变量(非常非常重要!)与您的服务器的 IP 地址或主机名。退出插入模式,然后保存并退出::wq一旦完成,我们需要向添加一些环境变量。bashrc 文件,因为大多数配置设置来自于 production.py 文件中的环境变量。
再次使用 VI 编辑该文件:
$ vi ~/.bashrc进入插入模式并添加以下内容:
# Environment Variables export DJANGO_SETTINGS_MODULE='config.settings.production' export DJANGO_SECRET_KEY='CHANGEME!!!m_-0ujru4yw4@!u7048_(#1a*y_g2v3r' export DATABASE_URL='postgres:///django_cookiecutter_fedora'需要注意两件事:
再次退出插入模式,然后保存并退出 VI。
现在只需重新加载。bashrc 文件:
$ source ~/.bashrc准备测试了吗?!在根目录中,激活 virtualenv,执行 gunicorn 服务器:
$ gunicorn --bind <ip-address or hostname>:8000 config.wsgi:application这将使我们的 web 应用程序再次服务于
:8000。 请记住,一旦我们从服务器注销,该命令将停止,因此我们将不再能够提供我们的 web 应用程序。因此,我们必须将 gunicorn 服务器作为一项服务来执行,以便可以启动、停止和监控它。
Nginx 配置
按照以下步骤添加配置文件,使我们的 Django 项目通过 Nginx 提供服务:
$ cd /etc/nginx/conf.d $ sudo vi django_cookiecutter_fedora.conf添加以下内容,确保更新
server、server_name和location:upstream app_server { server 127.0.0.1:8001 fail_timeout=0; } server { listen 80; server_name <remote-server-ip>; access_log /var/log/nginx/django_project-access.log; error_log /var/log/nginx/django_project-error.log info; keepalive_timeout 5; # path for staticfiles location /static { autoindex on; alias /opt/django_cookiecutter_fedora/staticfiles/; } location / { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; if (!-f $request_filename) { proxy_pass http://app_server; break; } } }保存并退出 VI,然后重启 Nginx 服务器:
$ sudo systemctl restart nginx.service就是这样!
Gunicorn 开始脚本
现在让我们创建一个 Gunicorn 启动脚本,它将作为可执行文件运行,使我们的自举 Django web 应用程序通过 Gunicorn 服务器运行,通过 Nginx 路由。
注意:如果你想更深入地使用 Gunicorn 和 Nginx 部署 Django 应用程序,请查看真实 Python 的教程或关于该主题的视频课程。
在项目根目录中,运行:
$ sudo mkdir deploy log $ cd deploy $ sudo vi gunicorn_startgunicorn_start 脚本的内容可以在这里找到。它分为三个重要部分,其中大部分是不言自明的。如有任何问题,请在下方评论。
注意:确保
USER和GROUP变量匹配非 root 用户的同一个用户和组。将内容粘贴到 VI 中,然后保存并退出。
最后,让我们使它可执行:
$ sudo chmod +x gunicorn_start启动服务器:
$ sudo ./gunicorn_start再次在浏览器中访问您的服务器的 IP 地址,您将看到您的 Django web 应用程序正在运行!
你得到一个 502 坏网关错误吗?只要遵循这些步骤,就可能足以让您的应用程序正常工作…
修改 SELinux 策略规则*
$ sudo dnf install policycoreutils-devel $ sudo cat /var/log/audit/audit.log | grep nginx | grep denied | audit2allow -M mynginx $ sudo semodule -i mynginx.pp完成后,请确保通过数字海洋的仪表板实用程序重新启动您的服务器。
系统 d
为了让我们的 gunicorn_start 脚本作为系统服务运行,以便即使我们不再登录服务器,它仍然服务于我们的 Django web 应用程序,我们需要创建一个 systemd 服务。
只需将工作目录改为 /etc/systemd/system ,然后创建一个服务文件:
$ cd /etc/systemd/system $ sudo vi django-bootstrap.service添加以下内容:
#!/bin/sh [Unit] Description=Django Web App After=network.target [Service] PIDFile=/var/run/cric.pid ExecStart=/bin/sh /opt/django_cookiecutter_fedora/deploy/gunicorn_start Restart=on-abort [Install] WantedBy=multi-user.target保存并退出,然后启动并启用该服务:
$ sudo systemctl start django-bootstrap.service注意:如果遇到错误,运行
journalctl -xe查看更多细节。最后,启用该服务,使其永远运行,并在任意关闭时重新启动:
$ sudo systemctl enable django-bootstrap.service健全性检查(最终!)
检查服务的状态:
$ sudo systemctl status django-bootstrap.service现在只需访问您的服务器的 IP 地址(或主机名),您将看到一个 Django 错误页面。要解决这个问题,请在项目的根目录下运行以下命令(激活 virtualenv):
$ python manage.py collectstatic现在您可以开始了,您将看到 Django web 应用程序在 web 浏览器上运行,所有静态文件(HTML/CSS/JS)都工作正常。
为了进一步参考,从库中获取代码。在下面添加您的问题、评论和顾虑。干杯!******
通过 Docker 开发和部署 Cookiecutter-Django
原文:https://realpython.com/development-and-deployment-of-cookiecutter-django-via-docker/
让我们看看如何引导一个预先加载了基本需求的 Django 项目,以便快速启动并运行项目。此外,除了项目结构之外,大多数自举项目还负责设置开发和生产环境设置,不会给用户带来太多麻烦——所以我们也来看看这一点。
更新:
04/15/2019 :更新至最新版本的 cookiecutter (v 1.6.0 )、cookiecutter-django、Django (v 2.0 )、Docker (v 18.09.2 )、Docker Compose (v 1.23.2 )、Docker Machine (v 0.16.1 )。
10/04/2016 :更新至最新版本的 cookiecutter (v 1.4.0 )、cookiecutter-django、Django (v 1.10.1 )、Docker (v 1.12.1 )、Docker Compose (v 1.8.1 )、Docker Machine (v 0.8.2 )。
我们将使用流行的 cookiecutter-django 作为 django 项目的引导程序,与 Docker 一起管理我们的应用程序环境。
我们开始吧!
本地设置
从全局安装 cookiecutter 开始:
$ pip install cookiecutter==1.6.0现在执行下面的命令来生成一个引导的 django 项目:
$ cookiecutter https://github.com/pydanny/cookiecutter-django.git该命令使用 cookiecutter-django repo 运行 cookiecutter,允许我们输入特定于项目的详细信息:
project_name [My Awesome Project]: django_cookiecutter_docker project_slug [django_cookiecutter_django]: django_cookiecutter_docker description [Behold My Awesome Project!]: Tutorial on bootstrapping django projects author_name [Daniel Roy Greenfeld]: Michael Herman domain_name [example.com]: realpython.com email [michael-herman@example.com]: michael@realpython.com version [0.1.0]: 0.1.0 Select open_source_license: 1 - MIT 2 - BSD 3 - GPLv3 4 - Apache Software License 2.0 5 - Not open source Choose from 1, 2, 3, 4, 5 (1, 2, 3, 4, 5) [1]: 1 timezone [UTC]: UTC windows [n]: use_pycharm [n]: use_docker [n]: y Select postgresql_version: 1 - 10.5 2 - 10.4 3 - 10.3 4 - 10.2 5 - 10.1 6 - 9.6 7 - 9.5 8 - 9.4 9 - 9.3 Choose from 1, 2, 3, 4, 5, 6, 7, 8, 9 (1, 2, 3, 4, 5, 6, 7, 8, 9) [1]: 1 Select js_task_runner: 1 - None 2 - Gulp Choose from 1, 2 (1, 2) [1]: 2 Select cloud_provider: 1 - AWS 2 - GCE Choose from 1, 2 (1, 2) [1]: custom_bootstrap_compilation [n]: use_compressor [n]: use_celery [n]: use_mailhog [n]: use_sentry [n]: use_whitenoise [n]: use_heroku [n]: use_travisci [n]: keep_local_envs_in_vcs [y]: debug [n]: [SUCCESS]: Project initialized, keep up the good work!项目结构
快速查看生成的项目结构,特别注意以下目录:
- “配置”包括本地和生产环境的所有设置。
- “需求”包含了所有的需求文件——base . txt、 local.txt 、production . txt——你可以对其进行修改,然后通过
pip install -r file_name进行安装。- “django_cookiecutter_docker”是主项目目录,由“static”、“contrib”和“templates”目录以及包含与用户认证相关的模型和样板代码的
users应用程序组成。有些服务可能需要环境变量。您可以在中找到每个服务的环境文件。envs 目录并添加所需的变量。
对接设置
按照说明安装对接引擎和所需的对接组件——引擎、机器和合成。
检查版本:
$ docker --version Docker version 18.09.2, build 6247962 $ docker-compose --version docker-compose version 1.23.2, build 1110ad01 $ docker-machine --version docker-machine version 0.16.1, build cce350d7对接机
安装完成后,在新创建的 Django 项目的根目录下创建一个新的 Docker 主机:
$ docker-machine create --driver virtualbox dev $ eval $(docker-machine env dev)注意 :
dev你想取什么名字都可以。例如,如果您有不止一个开发环境,您可以将它们命名为djangodev1、djangodev2,等等。要查看所有计算机,请运行:
$ docker-machine ls您还可以通过运行以下命令来查看
dev机器的 IP:$ docker-machine ip dev坞站组成〔t0〕
现在,我们可以通过 Docker Compose 来启动任何东西,例如 Django 和 Postgres:
$ docker-compose -f local.yml build $ docker-compose -f local.yml up -d您可能需要将您的对接机 IP (
docker-machine ip dev)添加到config/settings/local.py中的ALLOWED_HOSTS列表中。运行 Windows?打这个错误-
Interactive mode is not yet supported on Windows?见此评论。第一次构建需要一段时间。由于缓存,后续构建将运行得更快。
健全性检查
现在我们可以通过应用迁移然后运行服务器来测试我们的 Django 项目:
$ docker-compose -f local.yml run django python manage.py makemigrations $ docker-compose -f local.yml run django python manage.py migrate $ docker-compose -f local.yml run django python manage.py createsuperuser在浏览器中导航到
devIP(端口 8000 ),查看项目快速启动页面,打开调试模式,安装并运行更多面向开发环境的特性。停止容器(
docker-compose -f local.yml down),初始化一个新的 git repo,提交,并推送到 GitHub。部署设置
因此,我们已经使用 cookiecutter-django 成功地在本地设置了 Django 项目,并通过 Docker 使用传统的 manage.py 命令行实用程序提供了它。
注意:如果你想采用不同的方法来部署你的 Django 应用程序,可以查看一下关于使用 Gunicorn 和 Nginx 的真实 Python 的教程或视频课程。
在这一节中,我们继续讨论部署部分,在这里 web 服务器的角色开始发挥作用。我们将在数字海洋 droplet 上建立一个 Docker 机器,用 Postgres 作为我们的数据库,用 Nginx 作为我们的网络服务器。
与此同时,我们将使用 guni corn T1 代替 Django 的 T2 单线程开发服务器 T3 来运行服务器进程。
为什么选择 Nginx?
除了作为一个高性能的 HTTP 服务器(市场上几乎每一个好的 web 服务器都是这样),Nginx 还有一些非常好的特性使它脱颖而出——即它:
- 可以耦合成一个反向代理服务器。
- 可以托管多个站点。
- 采用异步方式处理 web 请求,这意味着由于它不依赖线程来处理 web 请求,因此在处理多个请求时具有更高的性能。
为什么是 Gunicorn?
Gunicorn 是一个 Python WSGI HTTP 服务器,可以轻松定制,在可靠性方面比 Django 的单线程开发服务器在生产环境中提供更好的性能。
数字海洋设置
在本教程中,我们将使用一个数字海洋服务器。在您注册(如果需要的话),生成一个个人访问令牌,然后运行以下命令:
$ docker-machine create \ -d digitalocean \ --digitalocean-access-token ADD_YOUR_TOKEN_HERE \ prod这应该只需要几分钟就可以提供数字 Ocean droplet 并设置一个名为
prod的新 Docker 机器。当你等待的时候,导航到数字海洋控制面板;您应该会看到一个新的液滴正在被创建,再次被称为prod。一旦完成,现在应该有两台机器在运行,一台在本地(
dev),一台在数字海洋(prod)。运行docker-machine ls确认:NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS dev * virtualbox Running tcp://192.168.99.100:2376 v18.09.2 prod - digitalocean Running tcp://104.131.50.131:2376 v18.09.2将
prod设置为活动机器,然后将 Docker 环境加载到 shell 中:$ eval $(docker-machine env prod)复合码头(取 2)
在内。envs/。生产/。django 更新
DJANGO_ALLOWED_HOSTS变量以匹配数字海洋 IP 地址——即DJANGO_ALLOWED_HOSTS=104.131.50.131。现在,我们可以创建构建,然后在云中启动服务:
$ docker-compose -f production.yml build $ docker-compose -f production.yml up -d健全性检查(取 2)
应用所有迁移:
$ docker-compose run django python manage.py makemigrations $ docker-compose run django python manage.py migrate就是这样!
现在只需访问与数字海洋水滴相关的服务器 IP 地址,并在浏览器中查看。
你应该可以走了。
为了进一步参考,只需从库中获取代码。非常感谢你的阅读!期待各位的提问。***
深入挖掘 Django 移民
这是 Django 迁移系列的第二篇文章:
- 第 1 部分: Django 迁移:初级读本
- 第 2 部分:深入挖掘 Django 迁移(当前文章)
- 第 3 部分:数据迁移
- 视频: Django 1.7 迁移-初级教程
在本系列的前一篇文章中,您了解了 Django 迁移的目的。您已经熟悉了基本的使用模式,如创建和应用迁移。现在是时候更深入地挖掘迁移系统,看一看它的一些底层机制了。
到本文结束时,你会知道:
- Django 是如何记录迁徙的
- 迁移如何知道要执行哪些数据库操作
- 如何定义迁移之间的依赖关系
一旦您理解了 Django 迁移系统的这一部分,您就为创建自己的定制迁移做好了充分的准备。让我们从停下来的地方开始吧!
本文使用了 Django Migrations: A Primer 中内置的
bitcoin_trackerDjango 项目。您可以通过阅读该文章来重新创建该项目,也可以下载源代码:下载源代码: 单击此处下载您将在本文中使用的 Django 迁移项目的代码。
Django 如何知道应用哪些迁移
让我们回顾一下本系列上一篇文章的最后一步。您创建了一个迁移,然后使用
python manage.py migrate应用了所有可用的迁移。如果该命令成功运行,那么您的数据库表现在与您的模型定义相匹配。如果再次运行该命令会发生什么?让我们试一试:
$ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, historical_data, sessions Running migrations: No migrations to apply.什么都没发生!一旦一个迁移被应用到一个数据库,Django 就不会再将这个迁移应用到那个特定的数据库。确保迁移仅应用一次需要跟踪已应用的迁移。
Django 使用一个名为
django_migrations的数据库表。第一次应用迁移时,Django 会在数据库中自动创建这个表。对于每个应用或伪造的迁移,都会在表中插入一个新行。例如,在我们的
bitcoin_tracker项目中,这个表格是这样的:
身份证明 应用 名字 应用的 one contenttypes0001_initial2019-02-05 20:23:21.461496 Two auth0001_initial2019-02-05 20:23:21.489948 three admin0001_initial2019-02-05 20:23:21.508742 four admin0002_logentry_remove...2019-02-05 20:23:21.531390 five admin0003_logentry_add_ac...2019-02-05 20:23:21.564834 six contenttypes0002_remove_content_...2019-02-05 20:23:21.597186 seven auth0002_alter_permissio...2019-02-05 20:23:21.608705 eight auth0003_alter_user_emai...2019-02-05 20:23:21.628441 nine auth0004_alter_user_user...2019-02-05 20:23:21.646824 Ten auth0005_alter_user_last...2019-02-05 20:23:21.661182 Eleven auth0006_require_content...2019-02-05 20:23:21.663664 Twelve auth0007_alter_validator...2019-02-05 20:23:21.679482 Thirteen auth0008_alter_user_user...2019-02-05 20:23:21.699201 Fourteen auth0009_alter_user_last...2019-02-05 20:23:21.718652 Fifteen historical_data0001_initial2019-02-05 20:23:21.726000 Sixteen sessions0001_initial2019-02-05 20:23:21.734611 Nineteen historical_data0002_switch_to_decimals2019-02-05 20:30:11.337894 如您所见,每个应用的迁移都有一个条目。该表不仅包含从我们的
historical_data应用程序的迁移,还包含从所有其他已安装应用程序的迁移。下次运行迁移时,Django 将跳过数据库表中列出的迁移。这意味着,即使您手动更改了已经应用的迁移文件,Django 也会忽略这些更改,只要数据库中已经有它的条目。
您可以通过从表中删除相应的行来欺骗 Django 重新运行迁移,但是这并不是一个好主意,并且会给您留下一个损坏的迁移系统。
迁移文件
跑
python manage.py makemigrations <appname>会怎么样?Django 寻找对你的应用程序<appname>中的模型所做的更改。如果它找到了,比如一个已经添加的模型,那么它会在migrations子目录中创建一个迁移文件。该迁移文件包含一个操作列表,用于使您的数据库模式与您的模型定义同步。注意:你的 app 必须在
INSTALLED_APPS设置中列出,并且必须包含一个migrations目录和一个__init__.py文件。否则 Django 不会为它创建任何迁移。使用
startapp管理命令创建新应用时会自动创建migrations目录,但手动创建应用时很容易忘记。迁移文件只是 Python,我们来看看
historical_pricesapp 中的第一个迁移文件。可以在historical_prices/migrations/0001_initial.py找到。它应该是这样的:from django.db import models, migrations class Migration(migrations.Migration): dependencies = [] operations = [ migrations.CreateModel( name='PriceHistory', fields=[ ('id', models.AutoField( verbose_name='ID', serialize=False, primary_key=True, auto_created=True)), ('date', models.DateTimeField(auto_now_add=True)), ('price', models.DecimalField(decimal_places=2, max_digits=5)), ('volume', models.PositiveIntegerField()), ('total_btc', models.PositiveIntegerField()), ], options={ }, bases=(models.Model,), ), ]如您所见,它包含一个名为
Migration的类,该类继承自django.db.migrations.Migration。当您要求迁移框架应用迁移时,它将查找并执行这个类。
Migration类包含两个主要列表:
dependenciesoperations迁移操作
我们先来看一下
operations榜单。此表包含迁移过程中要执行的操作。操作是类django.db.migrations.operations.base.Operation的子类。以下是 Django 中内置的常见操作:
操作类 描述 CreateModel创建新模型和相应的数据库表 DeleteModel删除模型并删除其数据库表 RenameModel重命名模型并重命名其数据库表 AlterModelTable重命名模型的数据库表 AlterUniqueTogether更改模型的唯一约束 AlterIndexTogether更改模型的索引 AlterOrderWithRespectTo创建或删除模型的 _order列AlterModelOptions在不影响数据库的情况下更改各种模型选项 AlterModelManagers更改迁移期间可用的管理器 AddField向模型和数据库中的相应列添加字段 RemoveField从模型中删除字段,并从数据库中删除相应的列 AlterField更改字段的定义,并在必要时改变其数据库列 RenameField重命名字段,如有必要,还重命名其数据库列 AddIndex在数据库表中为模型创建索引 RemoveIndex从模型的数据库表中删除索引 请注意操作是如何根据对模型定义所做的更改来命名的,而不是在数据库上执行的操作。当您应用迁移时,每个操作负责为您的特定数据库生成必要的 SQL 语句。例如,
CreateModel将生成一个CREATE TABLESQL 语句。开箱即用,迁移支持 Django 支持的所有标准数据库。因此,如果您坚持使用这里列出的操作,那么您可以对您的模型做或多或少的任何更改,而不必担心底层的 SQL。这都是为你做的。
注意:在某些情况下,Django 可能无法正确检测到您的更改。如果您重命名一个模型并更改它的几个字段,那么 Django 可能会将其误认为是一个新模型。
它将创建一个
DeleteModel和一个CreateModel操作,而不是一个RenameModel和几个AlterField操作。它不会重命名模型的数据库表,而是将它删除,并用新名称创建一个新表,实际上删除了所有数据!在生产数据上运行迁移之前,要养成检查生成的迁移并在数据库副本上测试它们的习惯。
Django 为高级用例提供了另外三个操作类:
RunSQL允许你在数据库中运行自定义 SQL。RunPython允许你运行任何 Python 代码。SeparateDatabaseAndState是针对高级用途的专门操作。通过这些操作,您基本上可以对数据库进行任何想要的更改。然而,您不会在使用
makemigrations管理命令自动创建的迁移中找到这些操作。从 Django 2.0 开始,
django.contrib.postgres.operations中也有一些 PostgreSQL 特有的操作,可以用来安装各种 PostgreSQL 扩展:
BtreeGinExtensionBtreeGistExtensionCITextExtensionCryptoExtensionHStoreExtensionTrigramExtensionUnaccentExtension请注意,包含这些操作之一的迁移需要具有超级用户权限的数据库用户。
最后但同样重要的是,您还可以创建自己的操作类。如果您想深入了解这一点,那么请看一下关于创建定制迁移操作的 Django 文档。
迁移依赖关系
迁移类中的
dependencies列表包含在应用该迁移之前必须应用的任何迁移。在上面看到的
0001_initial.py迁移中,不需要事先应用任何东西,因此没有依赖关系。我们来看看historical_pricesapp 中的第二次迁移。在文件0002_switch_to_decimals.py中,Migration的dependencies属性有一个条目:from django.db import migrations, models class Migration(migrations.Migration): dependencies = [ ('historical_data', '0001_initial'), ] operations = [ migrations.AlterField( model_name='pricehistory', name='volume', field=models.DecimalField(decimal_places=3, max_digits=7), ), ]上面的依赖关系表示应用程序
historical_data的迁移0001_initial必须首先运行。这是有意义的,因为迁移0001_initial创建了包含迁移0002_switch_to_decimals想要改变的字段的表。迁移也可能依赖于另一个应用程序的迁移,如下所示:
class Migration(migrations.Migration): ... dependencies = [ ('auth', '0009_alter_user_last_name_max_length'), ]如果一个模型有一个外键指向另一个应用程序中的模型,这通常是必要的。
或者,您也可以使用属性
run_before强制一个迁移在另一个迁移之前运行:class Migration(migrations.Migration): ... run_before = [ ('third_party_app', '0001_initial'), ]依赖关系也可以合并,这样你就可以拥有多个依赖关系。这个功能提供了很大的灵活性,因为您可以容纳依赖于不同应用程序模型的外键。
明确定义迁移之间依赖关系的选项也意味着迁移的编号(通常是
0001、0002、0003、…)并不严格代表应用迁移的顺序。您可以根据需要添加任何依赖项,从而控制顺序,而不必对所有迁移重新编号。查看迁移
您通常不必担心迁移生成的 SQL。但是,如果您想仔细检查生成的 SQL 是否有意义,或者只是好奇它看起来像什么,那么 Django 会为您提供
sqlmigrate管理命令:$ python manage.py sqlmigrate historical_data 0001 BEGIN; -- -- Create model PriceHistory -- CREATE TABLE "historical_data_pricehistory" ( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "date" datetime NOT NULL, "price" decimal NOT NULL, "volume" integer unsigned NOT NULL ); COMMIT;这样做将根据您的
settings.py文件中的数据库,列出由指定迁移生成的底层 SQL 查询。当您传递参数--backwards时,Django 生成 SQL 来取消迁移:$ python manage.py sqlmigrate --backwards historical_data 0001 BEGIN; -- -- Create model PriceHistory -- DROP TABLE "historical_data_pricehistory"; COMMIT;一旦您看到稍微复杂一点的迁移的
sqlmigrate的输出,您可能会意识到您不必手工制作所有这些 SQL!Django 如何检测模型的变化
您已经看到了迁移文件的样子,以及它的
Operation类列表如何定义对数据库执行的更改。但是 Django 怎么知道哪些操作应该放入迁移文件呢?您可能期望 Django 将您的模型与您的数据库模式进行比较,但事实并非如此。当运行
makemigrations时,Django 不也不检查你的数据库。它也不会将您的模型文件与早期版本进行比较。取而代之的是,Django 检查了所有已经应用的迁移,并构建了模型应该是什么样子的项目状态。然后,将这个项目状态与您当前的模型定义进行比较,并创建一个操作列表,当应用该列表时,将使项目状态与模型定义保持一致。和姜戈下棋
你可以把你的模型想象成棋盘,Django 是一个国际象棋大师,看着你和自己对弈。但是大师不会监视你的一举一动。大师只在你喊
makemigrations的时候看棋盘。因为只有有限的一组可能的走法(而特级大师是特级大师),她可以想出自她上次看棋盘以来发生的走法。她做了一些笔记,让你玩,直到你再次大喊
makemigrations。当下一次看棋盘时,特级大师不记得上一次棋盘是什么样子的,但她可以浏览她以前移动的笔记,并建立棋盘样子的心理模型。
现在,当你喊
migrate时,特级大师将在另一个棋盘上重放所有记录的移动,并在电子表格中记录她的哪些记录已经被应用。第二个棋盘是您的数据库,电子表格是django_migrations表。这个类比非常恰当,因为它很好地说明了 Django 迁移的一些行为:
Django 迁移努力做到高效:就像特级大师假设你走的步数最少一样,Django 会努力创造最高效的迁移。如果您向模型中添加一个名为
A的字段,然后将其重命名为B,然后运行makemigrations,那么 Django 将创建一个新的迁移来添加一个名为B的字段。姜戈的迁移有其局限性:如果你在让特级大师看棋盘之前走了很多步,那么她可能无法追溯每一步的准确移动。类似地,如果您一次进行太多的更改,Django 可能无法实现正确的迁移。
Django migration 希望你遵守游戏规则:当你做任何意想不到的事情时,比如从棋盘上随便拿走一个棋子或者弄乱音符,大师一开始可能不会注意到,但迟早她会放弃并拒绝继续。当您处理
django_migrations表或者在迁移之外更改您的数据库模式时,也会发生同样的情况,例如删除模型的数据库表。理解
SeparateDatabaseAndState现在您已经了解了 Django 构建的项目状态,是时候仔细看看操作
SeparateDatabaseAndState了。这个操作可以做到顾名思义:它可以将项目状态(Django 构建的心智模型)从数据库中分离出来。
SeparateDatabaseAndState用两个操作列表实例化:
state_operations包含只适用于项目状态的操作。database_operations包含只应用于数据库的操作。此操作允许您对数据库进行任何类型的更改,但是您有责任确保项目状态在之后适合数据库。
SeparateDatabaseAndState的示例用例是将模型从一个应用程序移动到另一个应用程序,或者在不停机的情况下在大型数据库上创建索引。
SeparateDatabaseAndState是一项高级操作,您不需要在第一天就进行迁移,也许根本不需要。SeparateDatabaseAndState类似于心脏手术。这有相当大的风险,不是你为了好玩而做的事情,但有时这是让病人活下去的必要程序。结论
您对 Django 迁移的深入研究到此结束。恭喜你!您已经讨论了相当多的高级主题,现在已经对迁移的本质有了深入的了解。
你学到了:
- Django 在 Django 迁移表中跟踪应用的迁移。
- Django 迁移由包含一个
Migration类的普通 Python 文件组成。- Django 知道要从
Migration类的operations列表中执行哪些更改。- Django 将您的模型与它从迁移中构建的项目状态进行比较。
有了这些知识,您就可以开始学习 Django 迁移系列的第三部分了,在这里您将学习如何使用数据迁移来安全地对数据进行一次性更改。敬请期待!
本文使用了 Django Migrations: A Primer 中内置的
bitcoin_trackerDjango 项目。您可以通过阅读该文章来重新创建该项目,也可以下载源代码:下载源代码: 单击此处下载您将在本文中使用的 Django 迁移项目的代码。***
为命令行构建一个 Python 目录树生成器
对于 Python 开发人员来说,创建具有用户友好的命令行界面(CLI)的应用程序是一项有用的技能。有了这项技能,您可以创建工具来自动化和加速您的工作环境中的任务。在本教程中,您将为命令行构建一个 Python 目录树生成器工具。
应用程序将把目录路径作为命令行的参数,并在屏幕上显示一个目录树形图。它还提供了调整输出的其他选项。
在本教程中,您将学习如何:
- 用 Python 的
argparse创建一个 CLI 应用- 使用
pathlib递归遍历目录结构- 生成、格式化并显示一个目录树形图
- 将目录树形图保存到一个输出文件
您可以通过单击下面的链接下载构建这个目录树生成器项目所需的代码和其他资源:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
演示:Python 中的目录树生成器工具
在本教程中,您将构建一个命令行工具来在一个树状图中列出一个目录或文件夹的内容。已经有几种成熟的解决方案可以完成这项任务。你会发现像大多数操作系统上都有的
tree命令这样的工具,以及其他工具,比如 treelib 、 dirtriex 等等。然而,找出你自己解决这个问题的方法将是一个很好的学习练习。本教程将上述工具称为目录树生成器。您将在这里构建的工具将允许您生成并显示一个树形图,列出您的文件系统中给定目录的内部结构。你还会发现这个图在整个教程中被称为目录树图。
您的目录树生成器将有一个用户友好的 CLI。它还将提供一些有趣的特性,比如在终端窗口显示一个目录内容的树形图,并将该图保存到一个外部文件中。
下面是本教程结束时应用程序的外观和工作方式:
您的目录树生成器将提供一个功能齐全但非常简单的 CLI,它带有几个选项,允许您生成并显示一个树形图,列出给定根目录中的所有文件和目录。
项目概述
您将在本教程中构建的项目由一个命令行应用程序组成,该应用程序将一个目录路径作为参数,遍历其内部结构,并生成一个列出当前目录内容的树形图。在本节中,您将首先了解问题和可能的解决方案。您还将决定如何布置项目。
布置项目
为了构建您的目录树生成器,您将创建几个模块和一个包。然后你会给这个项目一个连贯的 Python 应用布局。在本教程结束时,项目的根目录将具有以下目录结构:
./rptree_project/ │ ├── rptree/ │ ├── rptree.py │ ├── __init__.py │ └── cli.py │ ├── README.md └── tree.py
rptree_project/目录是项目的根目录。在那里,您将放置以下文件:
README.md提供了项目描述以及安装和运行应用程序的说明。在你的项目中添加一个描述性的和详细的 README 文件被认为是编程中的最佳实践,尤其是如果你计划将项目作为开源解决方案发布的话。
tree.py为你运行应用程序提供了一个入口点脚本。然后是保存 Python 包的
rptree/目录,该包包含三个模块:
rptree.py提供了应用程序的主要功能。__init__.py启用rptree/作为 Python 包。cli.py为应用程序提供了命令行界面。您的目录树生成器工具将在命令行上运行。它将接受参数,处理它们,并在终端窗口上显示一个目录树图。它还可以将输出图保存到一个 markdown 格式的文件中。
概述解决方案
乍一看,遍历文件系统中的一个目录并生成反映其内容的用户友好的树形图似乎不是一项困难的任务。然而,当你开始思考它时,你会发现它隐藏了许多复杂性。
首先,这是一个涉及到递归的问题。假设您在主目录下打开了文件管理器,您正在查找一个特定的文件。然后双击
Documents/子目录,让它的内容显示在屏幕上。如果文件在那里,你就打开它。否则,你打开另一个子目录,继续寻找。您可以通过以下步骤来描述此过程:
- 打开一个目录。
- 检查目录内容。
- 如果找到文件,请打开它。否则,回到第一步。
结论是,处理目录及其内容是一个问题,您通常会使用递归来解决这个问题。这是您在本教程中将遵循的路径。通常,您将运行以下步骤:
- 获取文件系统上某个目录的路径。
- 打开目录。
- 获取其所有条目(目录和文件)的列表。
- 如果目录包含子目录,则从第二步开始重复该过程。
要运行第一步,您需要在命令行为您的应用程序提供一种获取目录路径的方法。为此,您将使用来自标准库的 Python 的
argparse模块。要完成第二步和第三步,你要使用
pathlib。这个模块提供了几个工具来管理和表示文件系统路径。最后,您将使用一个常规的 Python list 来存储目录结构中的条目列表。第二个要考虑的问题是如何制作一个好看的树形图,以准确和用户友好的方式反映目录结构。在本教程中,您将使用一种模仿
tree命令的策略来塑造您的树形图,这样您的图将看起来像您在上一节中看到的那样。组织代码
在设计方面,如果你想到手头的问题,应用单责任原则,那么你可以按照三个主要责任来组织你的目录树生成器 app 的代码:
- 提供 CLI
- 遍历根目录并构建树形图
- 显示树形图
CLI 相关代码将存在于
cli.py中。在rptree.py中,您将放置与第二个和第三个职责相关的代码。在这个例子中,您将编写一个高级的
DirectoryTree类来生成和显示树形图。您将在您的客户端代码中使用这个类,或主函数。该类将提供一个名为.generate()的方法来生成和显示目录树图。接下来,您将编写一个底层的
_TreeGenerator类来遍历目录结构,并创建包含构成树形图的条目的列表。这个类将提供一个名为.build_tree()的方法来执行这个操作。树形图有两个主要部分:
- Head 将提供根目录表示。
- Body 将提供目录内容表示。
树头表示将由根目录的名称和一个额外的管道(
│)字符组成,以连接树头和主体。树体表示将由包含以下组件的字符串组成:
- 前缀字符串,提供所需的间距以反映目录结构中条目的位置
- 连接当前子目录或文件与其父目录的字符
- 当前子目录或文件的名称
以下是您将如何组合这些元素来构建目录树图:
您的树生成器的
.build_tree()方法将返回一个列表,其中包含构成目录树图的所有条目。为了显示图表,您需要在您的目录树对象上调用.generate()。先决条件
要完成本教程并从中获得最大收益,您应该熟悉以下概念:
- 用 Python 的
argparse模块创建命令行界面(CLI)- 用
pathlib遍历文件系统- 使用递归并在 Python 中创建递归函数
- 使用文件使用
open()和with语句- 使用
print()将文本打印到屏幕上,并写入文件系统中的物理文件- 使用 Python 中的面向对象编程
如果您在开始本教程之前没有掌握所有必需的知识,那也没关系!您可以随时停下来查看以下资源:
- 如何用 argparse 在 Python 中构建命令行界面
- Python 3 的 pathlib 模块:驯服文件系统
- 用 Python 递归思考
- 在 Python 中处理文件
- Python print()函数指南
- Python 3 中的面向对象编程(OOP)
就软件依赖性而言,您的目录树生成器项目不需要任何外部库。它的所有依赖项都作为 Python 内置函数或标准库中的模块提供。
也就是说,是时候用真正的代码来构建自己的目录树生成器工具了!
步骤 1:建立项目结构
首先,需要为目录树生成器项目创建一致的应用程序布局。继续在您的文件系统上创建一个名为
rptree_project/的新目录。在这个目录中,您需要两个空文件:
README.mdtree.py接下来,您需要创建一个名为
rptree/的子目录,其中包含以下空文件:rptree.py、__init__.py和-cli.py。添加后,项目的根目录应该如下所示:./rptree_project/ │ ├── rptree/ │ ├── rptree.py │ ├── __init__.py │ └── cli.py │ ├── README.md └── tree.py若要下载这些文件以及您将在本节中添加到这些文件中的代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
此时,您需要一个额外的设置步骤。在你的项目目录中启动你最喜欢的代码编辑器或者 IDE ,打开
__init__.py,添加以下内容:# __init__.py """Top-level package for RP Tree.""" __version__ = "0.1.0"Python 使用
__init__.py文件将一个普通目录变成一个包。包中包含模块,比如本项目中的rptree.py和cli.py。包和模块是允许您组织和构建 Python 代码的机制。在这种情况下,
__init__.py包含模块的文档字符串,通常称为文档字符串。它还定义了一个名为__version__的全局常量,用于保存应用程序的版本号。最后,您需要一个示例目录来测试应用程序并确保它正常工作。离开项目的根目录,在文件系统中创建以下目录结构,与项目文件夹并排:
../hello/ │ ├── hello/ │ ├── __init__.py │ └── hello.py │ ├── tests/ │ └── test_hello.py │ ├── requirements.txt ├── setup.py ├── README.md └── LICENSE这个目录结构模仿了 Python 项目的一般布局。在本教程的所有步骤中,您将使用这个样本目录结构来测试目录树生成器工具。这样,您可以在教程的任何给定步骤将您的结果与预期结果进行比较。
步骤 2:用 Python 生成目录树图
既然您已经知道了项目的需求,并且已经设置了项目布局和示例目录,那么您就可以开始处理真正的代码了。所以让你的编辑器准备好开始编码吧。
在本节中,您将编写项目的主要功能。换句话说,您将编写代码来从输入目录路径生成完整的目录树图。要下载该代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
现在回到你的代码编辑器,打开
rptree.py。然后将以下代码添加到文件中:# rptree.py """This module provides RP Tree main module.""" import os import pathlib PIPE = "│" ELBOW = "└──" TEE = "├──" PIPE_PREFIX = "│ " SPACE_PREFIX = " "在这段代码中,您首先从 Python 标准库中导入
os和pathlib。接下来,定义几个模块级常量来保存连接器字符和前缀字符串,您将使用它们在终端窗口上绘制树形图。您将用来绘制树形图的符号与您在本教程前面的图中看到的符号相同。命令行工具tree使用这些相同的符号来绘制树形图。编码高级
DirectoryTree类接下来,您将定义一个高级类来创建目录树图并将其显示在屏幕上。将该类命名为
DirectoryTree,并向其中添加以下代码:# rptree.py # Snip... class DirectoryTree: def __init__(self, root_dir): self._generator = _TreeGenerator(root_dir) def generate(self): tree = self._generator.build_tree() for entry in tree: print(entry)在类初始化器中,您将一个根目录作为参数,并创建一个名为
._generator的实例属性。为了创建这个属性,您使用一种叫做 composition 的 OOP 技术,它定义了一个“has”关系。这意味着每个DirectoryTree对象都有一个_TreeGenerator对象与之相连。注意:名称
_TreeGenerator中的前导下划线字符(_)是一个常用的 Python 约定。这意味着这个类是非公共的,这意味着你不希望这个类在它的包含模块rptree.py之外被使用。同样的约定也适用于非公共方法和属性,您不希望在包含类之外使用它们。通常,您开始将属性定义为非公共的,并在需要时将它们设为公共的。参见 PEP 8 了解关于此会议的更多详情。
稍后您将看到如何创建这个
_TreeGenerator类。现在,来看看.generate()。这个方法创建了一个名为tree的局部变量,它保存了对树生成器对象调用.build_tree()的结果。然后你用一个for循环将树中的每个entry打印到你的屏幕上。对低级
_TreeGenerator类进行编码既然您已经完成了对
DirectoryTree的编码,那么是时候对遍历文件系统并生成目录树图的类进行编码了:1# rptree.py 2# Snip... 3 4class _TreeGenerator: 5 def __init__(self, root_dir): 6 self._root_dir = pathlib.Path(root_dir) 7 self._tree = [] 8 9 def build_tree(self): 10 self._tree_head() 11 self._tree_body(self._root_dir) 12 return self._tree 13 14 def _tree_head(self): 15 self._tree.append(f"{self._root_dir}{os.sep}") 16 self._tree.append(PIPE)下面是这段代码的工作原理:
第 4 行定义了一个新的类
_TreeGenerator。第 5 行定义了类初始化器。在这种情况下,
.__init__()将root_dir作为参数。它保存了树的根目录路径。请注意,您将root_dir转换为一个pathlib.Path对象,并将其分配给非公共实例属性._root_dir。第 7 行定义了一个空列表来存储构成目录树形图的条目。
第 9 行到第 12 行定义
.build_tree()。这个公共方法生成并返回目录树图。在.build_tree()里面,你首先调用._tree_head()来建立树头。然后您调用._tree_body()并将._root_dir作为参数来生成图的其余部分。第 14 到 16 行定义
._tree_head()。该方法将根目录的名称添加到._tree中。然后添加一个PIPE将根目录连接到树的其余部分。到目前为止,您只编写了类的第一部分。接下来就是写
._tree_body(),这需要几行代码。注意:上述代码和本教程中其余代码示例中的行号是为了便于解释。它们与最终模块或脚本中的行顺序不匹配。
._tree_body()中的代码提供了类的底层功能。它以一个目录路径作为参数,遍历该目录下的文件系统,并生成相应的目录树图。下面是它的实现:1# rptree.py 2# Snip... 3 4class _TreeGenerator: 5 # Snip... 6 7 def _tree_body(self, directory, prefix=""): 8 entries = directory.iterdir() 9 entries = sorted(entries, key=lambda entry: entry.is_file()) 10 entries_count = len(entries) 11 for index, entry in enumerate(entries): 12 connector = ELBOW if index == entries_count - 1 else TEE 13 if entry.is_dir(): 14 self._add_directory( 15 entry, index, entries_count, prefix, connector 16 ) 17 else: 18 self._add_file(entry, prefix, connector)这段代码中发生了很多事情。下面是它一行一行地做的事情:
第 7 行定义
._tree_body()。这个方法有两个参数:
directory保存着你要走过的目录的路径。注意directory应该是一个pathlib.Path对象。
prefix保存一个前缀字符串,用于在终端窗口上绘制树形图。这个字符串有助于显示目录或文件在文件系统中的位置。第 8 行调用
directory上的.iterdir(),并将结果赋给entries。对.iterdir()的调用返回一个迭代器,遍历包含在directory中的文件和子目录。第 9 行使用
sorted()对directory中的条目进行排序。为此,您创建一个lambda函数,它检查entry是否是一个文件,并相应地返回True或False。在 Python 中,True和False在内部分别表示为整数、1和0。实际效果是,sorted()将目录放在第一位,因为entry.is_file() == False == 0将文件放在第二位,因为entry.is_file() == True == 1。第 10 行调用
len()获取手头directory中的条目数。第 11 行开始一个
for循环,遍历directory中的条目。该循环使用enumerate()将一个索引关联到每个条目。第 12 行定义了你将用来在终端窗口上绘制树形图的连接器符号。例如,如果当前条目是目录中的最后一个(
index == entries_count - 1),那么您使用一个肘(└──)作为一个connector。否则,你用一个球座(├──)。第 13 到 18 行定义了一个条件语句,它检查当前条目是否是一个目录。如果是,那么
if代码块调用._add_directory()来添加一个新的目录条目。否则,else子句调用._add_file()来添加一个新的文件条目。要完成对
_TreeGenerator的编码,需要编写._add_directory()和._add_file()。下面是这些非公共方法的代码:1# rptree.py 2# Snip... 3 4class _TreeGenerator: 5 # Snip... 6 7 def _add_directory( 8 self, directory, index, entries_count, prefix, connector 9 ): 10 self._tree.append(f"{prefix}{connector} {directory.name}{os.sep}") 11 if index != entries_count - 1: 12 prefix += PIPE_PREFIX 13 else: 14 prefix += SPACE_PREFIX 15 self._tree_body( 16 directory=directory, 17 prefix=prefix, 18 ) 19 self._tree.append(prefix.rstrip()) 20 21 def _add_file(self, file, prefix, connector): 22 self._tree.append(f"{prefix}{connector} {file.name}")下面是这段代码的作用,一行接一行:
第 7 行定义
._add_directory()。它是一个带五个参数的 helper 方法,不算self。您已经知道这些参数分别代表什么,所以没有必要再讨论它们。第 10 行向
._tree追加一个新目录。._tree中的每个目录由一个字符串表示,该字符串包含一个prefix、一个connector、目录名(entry.name)和一个最后的分隔符(os.sep)。请注意,分隔符是平台相关的,这意味着您的树生成器使用与您的当前操作系统相对应的分隔符。第 11 到 14 行运行一个条件语句,根据当前条目的
index更新prefix。第 15 到 18 行用一组新的参数调用
._tree_body()。第 19 行追加一个新的
prefix来分隔当前目录的内容和下一个目录的内容。在第 15 行对
._tree_body()的调用中有一个重要的细节讨论。这是一个间接递归调用。换句话说,._tree_body()通过._add_directory()调用自己,直到遍历整个目录结构。最后,在第 21 和 22 行,您定义了
._add_file()。该方法向目录树列表追加一个文件条目。运行目录树生成器代码
哇!那是很大的工作量!您的目录树生成器现在提供了它的主要功能。是时候尝试一下了。在项目的根目录下打开一个 Python 交互式会话,并键入以下代码:

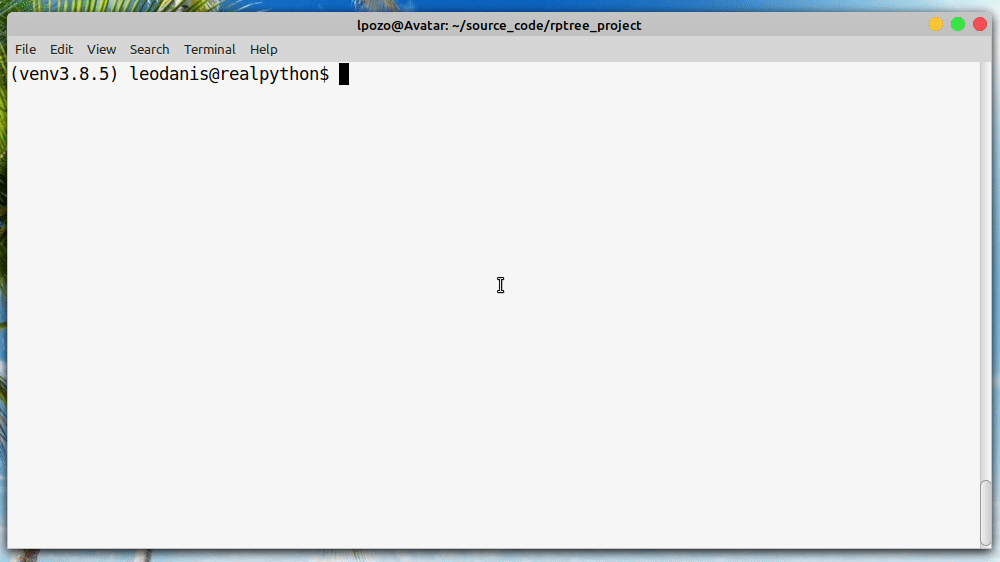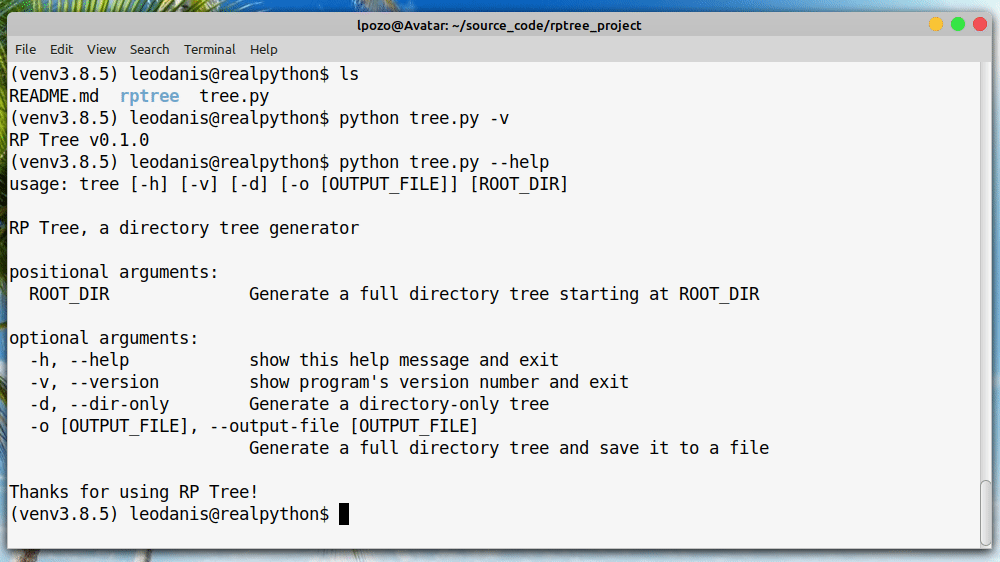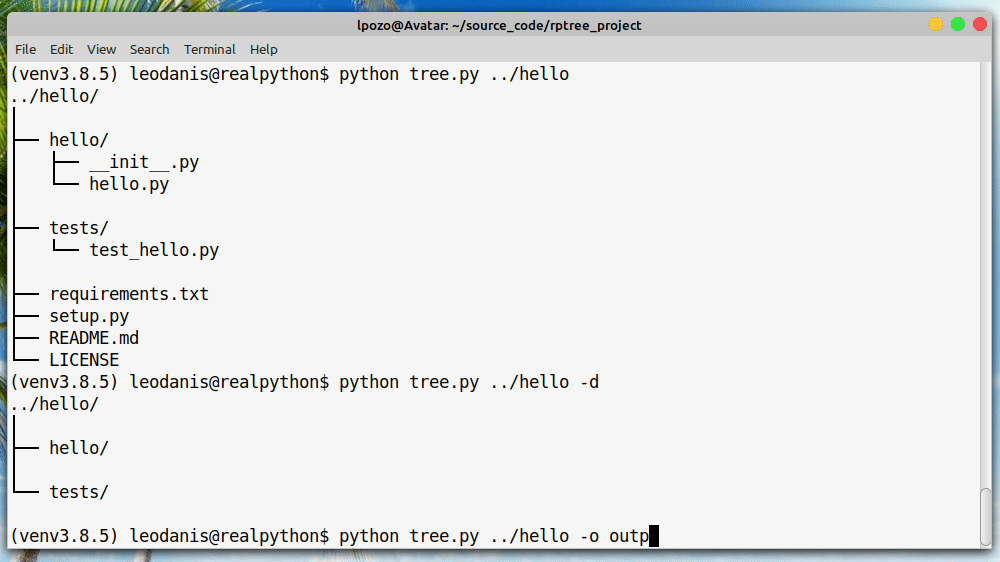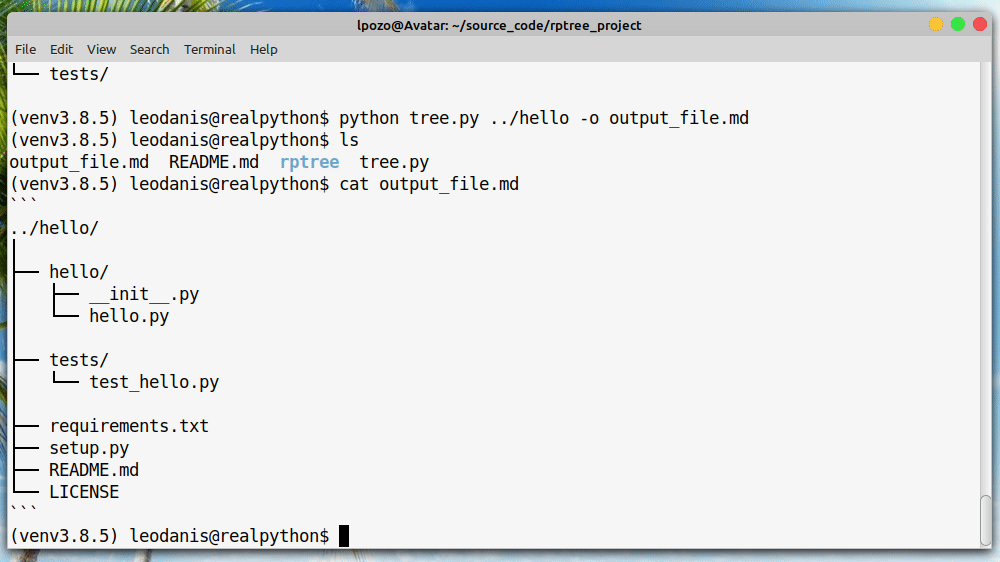

>>> from rptree.rptree import DirectoryTree
>>> tree = DirectoryTree("../hello")
>>> tree.generate()
../hello/
│
├── hello/
│ ├── __init__.py
│ └── hello.py
│
├── tests/
│ └── test_hello.py
│
├── requirements.txt
├── setup.py
├── README.md
└── LICENSE
这里首先从rptree.py导入DirectoryTree。接下来,创建一个目录树对象,将路径传递给之前创建的hello/示例目录。当您在目录树对象上调用.generate()时,您会在屏幕上看到完整的目录树图。
酷!您已经编写了目录树生成器的主要功能。在下一节中,您将为您的项目提供一个漂亮且用户友好的命令行界面和一个可执行脚本。
步骤 3:构建目录树生成器的 CLI
有几种工具可以创建 CLI 应用程序。比较流行的有 Click 、 docopt 、 Typer ,还有 argparse ,标准库中都有。在您的目录树生成器项目中,您将使用argparse来提供命令行界面。这样,你将避免有一个外部依赖。
Python 的argparse允许你定义你的应用程序将在命令行接受的参数,并验证用户的输入。该模块还为您的脚本生成帮助和使用消息。
若要下载您将在本节中添加或修改的文件和代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
要实现目录树生成器的 CLI,请返回到项目目录并从rptree包中打开cli.py文件。然后键入以下代码:
"""This module provides the RP Tree CLI."""
# cli.py
import argparse
import pathlib
import sys
from . import __version__
from .rptree import DirectoryTree
def main():
args = parse_cmd_line_arguments()
root_dir = pathlib.Path(args.root_dir)
if not root_dir.is_dir():
print("The specified root directory doesn't exist")
sys.exit()
tree = DirectoryTree(root_dir)
tree.generate()
在这段代码中,首先从标准库中导入所需的模块。然后从包含包rptree中导入__version__和DirectoryTree。
在main()中,首先调用parse_cmd_line_arguments()并将命令行参数打包在args中。您马上就会看到这个函数的作用。接下来,将根目录转换成一个pathlib.Path对象。条件语句进行快速验证,以确保用户提供有效的目录路径,否则退出应用程序。
最后,使用root_dir作为参数创建一个DirectoryTree对象,并对其调用.generate(),以在终端窗口上生成并显示相应的目录树图。
现在你可以开始钻研parse_cmd_line_arguments()的代码了。此函数提供了所有与 CLI 相关的功能:
1# cli.py
2# Snip...
3
4def parse_cmd_line_arguments():
5 parser = argparse.ArgumentParser(
6 prog="tree",
7 description="RP Tree, a directory tree generator",
8 epilog="Thanks for using RP Tree!",
9 )
10 parser.version = f"RP Tree v{__version__}"
11 parser.add_argument("-v", "--version", action="version")
12 parser.add_argument(
13 "root_dir",
14 metavar="ROOT_DIR",
15 nargs="?",
16 default=".",
17 help="Generate a full directory tree starting at ROOT_DIR",
18 )
19 return parser.parse_args()
这个函数的作用如下:
-
第 5 行实例化
argparse.ArgumentParser,提供应用程序的命令名(prog)、程序的简短description,以及用户运行应用程序的帮助选项后显示的epilog短语。这个类为用户在命令行输入的所有参数提供了一个解析器。 -
第 10 行将解析器的
version属性设置为一个字符串,该字符串包含应用程序的名称及其当前版本__version__。 -
第 11 行将第一个可选参数添加到应用程序的 CLI 中。需要
-v或--version标志来提供这个参数,它的默认动作是在终端窗口上显示应用程序的版本字符串。 -
第 12 行到第 18 行向 CLI 添加第二个参数。这里,
root_dir是一个位置参数,它保存了您将用来作为生成目录树图的起点的目录路径。在这种情况下,.add_argument()有四个参数: -
第 19 行使用
.parse_args()解析提供的参数。这个方法返回一个带有所有参数的Namespace对象。您可以使用名称空间对象上的点符号来访问这些参数。注意,当您编写main()时,您将这个名称空间存储在了args中。
完成这一步的最后一步是提供一个入口点脚本。回到代码编辑器,打开tree.py,然后添加以下代码:
#!/usr/bin/env python3
# tree.py
"""This module provides RP Tree entry point script."""
from rptree.cli import main
if __name__ == "__main__":
main()
这个文件简单明了。首先从cli.py导入main(),然后将其调用封装在传统的if __name__ == "__main__":条件中,这样只有当您将文件作为程序运行而不是作为模块导入时,Python 才会调用main()。
有了这个脚本,您就可以开始使用全新的命令行目录树生成器了。打开命令行窗口,移动到项目目录,并运行以下命令:
$ python tree.py ../hello
../hello/
│
├── hello/
│ ├── __init__.py
│ └── hello.py
│
├── tests/
│ └── test_hello.py
│
├── requirements.txt
├── setup.py
├── README.md
└── LICENSE
$ python tree.py -v
RP Tree v0.1.0
$ python tree.py --help
usage: tree [-h] [-v] [ROOT_DIR]
RP Tree, a directory tree generator
positional arguments:
ROOT_DIR Generate a full directory tree starting at ROOT_DIR
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
Thanks for using RP Tree!
就是这样!您的目录树生成器工具可以工作。它生成并在屏幕上显示一个用户友好的树形图。它还提供版本和使用信息。对于大约一百行代码来说,这相当酷!在接下来的小节中,您将向应用程序添加更多的特性。
步骤 4:实现仅目录选项
添加到目录树生成器中的一个有趣的特性是能够生成和显示仅包含目录的树形图。换句话说,一个只显示目录的图。在这个项目中,您将添加-d和--dir-only标志来完成这项工作,但在此之前,您需要更新_TreeGenerator,以便它可以支持这个新功能。
您可以通过单击下面的链接下载您将在本节中添加或修改的文件和代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
现在打开rptree.py模块,像这样更新它的代码:
# rptree.py
# Snip...
class _TreeGenerator:
def __init__(self, root_dir, dir_only=False): self._root_dir = pathlib.Path(root_dir)
self._dir_only = dir_only self._tree = []
# Snip...
def _tree_body(self, directory, prefix=""):
entries = self._prepare_entries(directory) entries_count = len(entries)
for index, entry in enumerate(entries):
connector = ELBOW if index == entries_count - 1 else TEE
if entry.is_dir():
self._add_directory(
entry, index, entries_count, prefix, connector
)
else:
self._add_file(entry, prefix, connector)
def _prepare_entries(self, directory): entries = directory.iterdir()
if self._dir_only:
entries = [entry for entry in entries if entry.is_dir()]
return entries
entries = sorted(entries, key=lambda entry: entry.is_file())
return entries
# Snip...
首先,将dir_only作为参数添加到类初始化器中。这是一个布尔参数,允许您根据用户在命令行的输入生成一个完整的树或一个仅包含目录的树。这个参数默认为False,因为生成一棵完整的树是最常见的用例。
在第二个突出显示的行中,您创建了一个名为._dir_only的实例属性来保存新添加的参数。
在突出显示的第三行中,您用对._prepare_entries()的调用替换了两行原始代码。顾名思义,这个函数准备目录条目来生成完整的树或仅包含目录的树。
在._prepare_entries()中,你首先得到entries 发生器。if语句检查._dir_only是否为True。如果是这样,那么您用一个列表理解过滤掉文件并返回一个list目录。如果._dir_only是False,那么您将对条目进行排序,重用之前看到的相同代码。最后,在directory中返回完整的条目列表。
现在,您需要确保将这个新参数传递给DirectoryTree中的_TreeGenerator实例:
# rptree.py
# Snip...
class DirectoryTree:
def __init__(self, root_dir, dir_only=False): self._generator = _TreeGenerator(root_dir, dir_only)
# Snip...
在第一个突出显示的行中,您向类初始化器添加了一个名为dir_only的新参数。在第二个突出显示的行中,确保将新参数传递给_TreeGenerator的构造函数。
有了这些更改,您就可以更新cli.py文件,这样应用程序就可以在命令行上获取并处理-d和--dir-only标志。首先,您需要更新main():
# cli.py
# Snip...
def main():
# Snip...
tree = DirectoryTree(root_dir, dir_only=args.dir_only) tree.generate()
在突出显示的行中,您将args.dir_only传递给DirectoryTree的dir_only参数。名称空间args的这个属性包含一个依赖于用户输入的布尔值。如果用户在命令行提供了-d或--dir-only选项,那么args.dir_only就是True。不然就是False。
接下来,将这些-d和--dir-only标志添加到命令行界面。为此,您需要像这样更新parse_cmd_line_arguments():
# cli.py
# Snip...
def parse_cmd_line_arguments():
# Snip...
parser.add_argument(
"-d",
"--dir-only",
action="store_true",
help="Generate a directory-only tree",
)
return parser.parse_args()
对.add_argument()的调用中的action参数保存了值"store_true",这意味着该参数根据用户的输入自动存储True或False。在这种情况下,如果用户在命令行提供了-d或--dir-only标志,那么参数将存储True。否则,它存储False。
有了这个更新,就可以运行和测试应用程序了。回到您的终端窗口,执行以下命令:
$ python tree.py ../hello -d
../hello/
│
├── hello/
│
└── tests/
从现在开始,如果您在命令行提供了-d或-dir-only标志,那么树形图只显示您的示例hello/目录中的子目录。
步骤 5:将目录树图保存到文件
在本节中,您将向目录树生成器工具添加最后一个特性。您将为应用程序提供将生成的目录树图保存到外部文件的能力。为此,您将使用标志-o和--output-file向 CLI 添加一个新参数。
通常,要下载您将在本节中添加或修改的代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
现在回到rptree.py,像这样更新DirectoryTree:
# rptree.py
# Snip...
import sys
# Snip...
class DirectoryTree:
def __init__(self, root_dir, dir_only=False, output_file=sys.stdout): self._output_file = output_file self._generator = _TreeGenerator(root_dir, dir_only)
def generate(self):
tree = self._generator.build_tree()
if self._output_file != sys.stdout: # Wrap the tree in a markdown code block
tree.insert(0, "\x60\x60\x60")
tree.append("\x60\x60\x60")
self._output_file = open( self._output_file, mode="w", encoding="UTF-8"
)
with self._output_file as stream: for entry in tree:
print(entry, file=stream)
这次更新几乎是对DirectoryTree的完全重新实现。首先,向名为output_file的类初始化器添加一个新参数。这个参数默认为 sys.stdout ,这是标准输出(你的屏幕)。然后,将新添加的参数存储在名为._output_file的实例属性中。
在.generate()中,你首先建立目录树形图,并存储在tree中。条件语句检查用户是否提供了不同于sys.stdout的输出文件。如果是,那么if代码块使用反斜杠("\x60\x60\x60")将树形图包装在一个 markdown 代码块中。
接下来,使用open()打开提供的输出文件,这样就可以使用 with语句处理它。
注意:就执行时间而言,在列表对象上调用.insert(0, x)可能是一个开销很大的操作。这是因为 Python 需要将所有项目向右移动一个位置,然后在第一个位置插入新项目。
对.insert()的一个有效替代是使用 collections.deque ,并使用.appendleft()在数据结构的第一个位置添加条目。这种数据结构针对这种操作进行了优化。
在with块中,您启动一个for循环,将目录树图打印到提供的输出文件中。注意print()也可以写入你的文件系统中的常规文件。为此,您只需要提供一个定制的file参数。要深入了解print()的特性,请查看Python print()函数指南。
一旦完成了DirectoryTree,就可以更新命令行界面来启用输出文件选项。回到cli.py,修改如下:
# cli.py
# Snip...
def main():
# Snip...
tree = DirectoryTree(
root_dir, dir_only=args.dir_only, output_file=args.output_file
)
tree.generate()
def parse_cmd_line_arguments():
# Snip...
parser.add_argument(
"-o",
"--output-file",
metavar="OUTPUT_FILE",
nargs="?",
default=sys.stdout,
help="Generate a full directory tree and save it to a file",
)
return parser.parse_args()
第一步是将输出文件作为DirectoryTree构造函数中的一个参数。输出文件(如果有)将存储在args.output_file中。
接下来,向parser添加一个新参数。这个论点有两面旗帜:-o和--output-file。为了提供另一个输出文件,用户必须使用这些标志中的一个,并在命令行提供文件的路径。注意,输出文件默认为sys.stdout。这样,如果用户没有提供输出文件,应用程序会自动使用标准输出,即屏幕。
您可以通过在终端上运行以下命令来测试新添加的选项:
$ python tree.py ../hello -o output_file.md
该命令生成一个完整的目录树形图,并将其保存到当前目录下的output_file.md文件中。如果你打开这个文件,你会看到目录树图以 markdown 格式保存在那里。
就是这样!您的目录树生成器项目已经完成。除了生成和显示完整目录树图的默认选项之外,该应用程序还提供了以下选项:
-v、--version显示当前版本信息并退出应用程序。-h、--help显示帮助和使用信息。-d、--dir-only生成一个目录树,并打印到屏幕上。-o、--output-to-markdown生成一棵树,并以 markdown 格式保存到文件中。
现在,您拥有了一个全功能的命令行工具,可以生成用户友好的目录树图。干得好!
结论
通过创建 CLI 工具和应用程序,您可以自动化并加速工作环境中的多个流程和任务。在 Python 中,可以使用argparse或其他第三方库快速创建这类工具。在本教程中,您编写了一个完整的项目来为您的命令行构建一个 Python 目录树生成器工具。
该应用程序在命令行中获取一个目录路径,生成一个目录树图,并在您的终端窗口中显示它,或者将它保存到您的文件系统中的一个外部文件中。它还提供了一些选项来调整生成的树形图。
在本教程中,您学习了如何:
- 用 Python 的
argparse创建一个 CLI 应用 - 使用
pathlib递归遍历目录结构 - 生成、格式化并打印一个目录树形图
- 将目录树形图保存到一个输出文件
目录树生成器项目的最终源代码可供您下载。要获取它,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用用 Python 构建一个目录树生成器。
接下来的步骤
至此,您已经构建了一个功能完整的目录树生成器工具。尽管该应用程序提供了一组最少的功能,但这是您继续添加功能并在此过程中学习的良好起点。这将帮助您将 Python 和 CLI 应用程序的技能提升到一个新的水平。
以下是一些您可以实施的想法,以继续改进您的目录树生成器工具:
-
添加对文件和目录排序的支持:能够对文件和目录进行排序是一个很棒的特性。例如,您可以添加
-s和--sort-tree布尔标志,以允许用户调整最终树形图中文件和目录的顺序。 -
给树形图添加图标和颜色:添加图标、字体颜色或者两者都添加也是一个很好的实现特性。例如,您可以对目录使用自定义文件夹图标,对文件使用基于文件类型的图标。
-
设置应用程序以将其作为开源项目发布:准备应用程序以开源项目的形式发布到 PyPI 可能是一个有趣的挑战。这样做可以让你与你的朋友和同事分享你的工作。要开始向 PyPI 发布包,请查看如何向 PyPI 发布开源 Python 包。
这些只是如何继续向目录树生成器添加特性的一些想法。接受挑战,在此基础上创造出令人惊叹的东西!*******
Django 1.6 测试驱动开发
原文:https://realpython.com/django-1-6-test-driven-development/
上次更新时间:
- 01/29/2014 -更新了表单代码(感谢 vic!)
- 2013 年 12 月 29 日-重新构建了整篇博文
测试驱动开发(TDD)是一个迭代开发周期,它强调在编写实际代码之前编写自动化测试。
过程很简单:
- 首先编写您的测试。
- 看着他们失败。
- 编写足够的代码来通过这些测试。
- 再次测试。
- 重构。
- 重复一遍。
为什么是 TDD?
使用 TDD,您将学会将代码分解成逻辑的、容易理解的部分,帮助确保代码的正确性。
这很重要,因为很难-
- 在我们的头脑中一次性解决复杂的问题;
- 知道何时何地开始解决问题;
- 在不引入错误和缺陷的情况下增加代码库的复杂性;和
- 识别何时出现代码中断。
TDD 有助于解决这些问题。它不能保证您的代码没有错误;但是,您将编写更好的代码,从而更好地理解代码。这本身将有助于消除错误,至少,您将能够更容易地解决错误。
TDD 实际上也是一种行业标准。
说够了。让我们来看看代码。
在本教程中,我们将创建一个应用程序来存储用户联系人。
请注意:本教程假设您正在运行一个基于 Unix 的环境——例如,Mac OSX、直接 Linux 或通过 Windows 的 Linux VM。我也将使用 Sublime 2 作为我的文本编辑器。另外,确保你已经完成了 Django 的官方教程,并且对 Python 语言有了基本的了解。同样,在这第一篇文章中,我们将不会涉及 Django 1.6 中的一些新工具。这篇文章为后续处理不同形式测试的文章奠定了基础。
首次测试
在我们做任何事情之前,我们需要先设置一个测试。对于这个测试,我们只想确保 Django 设置正确。我们将对此进行功能测试——我们将在下面进一步解释。
创建一个新目录来存放您的项目:
$ mkdir django-tdd
$ cd django-tdd
现在设置一个新的目录来保存您的功能测试:
$ mkdir ft
$ cd ft
创建一个名为“tests.py”的新文件,并添加以下代码:
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://localhost:8000/')
body = browser.find_element_by_tag_name('body')
assert 'Django' in body.text
browser.quit()
现在运行测试:
$ python tests.py
确保你已经安装了 selenium-
pip install selenium
您应该看到 FireFox 弹出并试图导航到 http://localhost:8000/。在您的终端中,您应该看到:
Traceback (most recent call last):
File "tests.py", line 7, in <module>
assert 'Django' in body.text
AssertionError
恭喜你。你写了你的第一个失败测试。
现在让我们编写足够的代码来使它通过,这相当于建立一个 Django 开发环境。
设置 Django
激活虚拟设备:
$ cd ..
$ virtualenv --no-site-packages env
$ source env/bin/activate
安装 Django 并设置项目:
$ pip install django==1.6.1
$ django-admin.py startproject contacts
您当前的项目结构应该如下所示:
├── contacts
│ ├── contacts
│ │ ├── __init__.py
│ │ ├── settings.py
│ │ ├── urls.py
│ │ └── wsgi.py
│ └── manage.py
└── ft
└── tests.py
安装 Selenium:
$ pip install selenium==2.39.0
运行服务器:
$ cd contacts
$ python manage.py runserver
接下来,在您的终端中打开一个新窗口,导航到“ft”目录,然后再次运行测试:
$ python tests.py
您应该看到 FireFox 窗口再次导航到 http://localhost:8000/这一次不应该有错误。很好。你刚刚通过了第一次测试!
现在,让我们完成开发环境的设置。
版本控制
第一,增加一个”。gitignore ",并在文件中包含以下代码:
.Python
env
bin
lib
include
.DS_Store
.pyc
现在创建一个 Git 存储库并提交:
$ git init
$ git add .
$ git commit -am "initial"
有了项目设置,让我们后退一步,讨论功能测试。
功能测试
我们通过 Selenium 经由功能测试进行了第一次测试。这样的测试让我们像最终用户一样驱动网络浏览器,看看应用程序实际上如何运行。由于这些测试遵循最终用户的行为——也称为用户故事——它涉及许多特性的测试,而不仅仅是一个单一的功能——这更适合单元测试。需要注意的是,当测试你没有编写的代码时,你应该从功能测试开始。因为我们本质上是在测试 Django 代码,所以功能测试是正确的方法。
另一种思考功能测试与单元测试的方式是,功能测试侧重于从外部,从用户的角度测试应用程序,而单元测试侧重于从内部,从开发人员的角度测试应用程序。
这在实践中更有意义。
在继续之前,让我们重组我们的测试环境,使测试更容易。
首先,让我们重写“tests.py”文件中的第一个测试:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from django.test import LiveServerTestCase
class AdminTest(LiveServerTestCase):
def setUp(self):
self.browser = webdriver.Firefox()
def tearDown(self):
self.browser.quit()
def test_admin_site(self):
# user opens web browser, navigates to admin page
self.browser.get(self.live_server_url + '/admin/')
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Django administration', body.text)
然后运行它:
$ python manage.py test ft
它应该会通过:
----------------------------------------------------------------------
Ran 1 test in 3.304s
OK
恭喜你。
在继续之前,让我们看看这里发生了什么。如果一切顺利,应该会过去。您还应该看到 FireFox 打开,并使用setUp()和tearDown()函数完成我们在测试中指出的过程。测试本身只是测试是否可以找到“/admin”(self.browser.get(self.live_server_url + '/admin/')页面,以及“Django administration”这几个字是否出现在主体标签中。
我们来确认一下。
运行服务器:
$ python manage.py runserver
然后在浏览器中导航到http://localhost:8000/admin/,您应该会看到:

我们可以通过简单地测试错误的东西来确认测试是否正常工作。将测试中的最后一行更新为:
self.assertIn('administration Django', body.text)
再运行一次。您应该会看到以下错误(当然,这是意料之中的):
AssertionError: 'administration Django' not found in u'Django administration\nUsername:\nPassword:\n '更正测试。再测试一次。提交代码。
最后,您注意到了吗,实际测试的函数名是以
test_开始的。这是为了让 Django 测试运行程序能够找到测试。换句话说,任何以test_开头的函数都会被测试运行者视为一个测试。管理员登录
接下来,让我们测试以确保用户可以登录到管理站点。
更新
test_admin_sitetests . py 中的函数:def test_admin_site(self): # user opens web browser, navigates to admin page self.browser.get(self.live_server_url + '/admin/') body = self.browser.find_element_by_tag_name('body') self.assertIn('Django administration', body.text) # users types in username and passwords and presses enter username_field = self.browser.find_element_by_name('username') username_field.send_keys('admin') password_field = self.browser.find_element_by_name('password') password_field.send_keys('admin') password_field.send_keys(Keys.RETURN) # login credentials are correct, and the user is redirected to the main admin page body = self.browser.find_element_by_tag_name('body') self.assertIn('Site administration', body.text)所以
find_element_by_name-用于定位输入字段send_keys-发送击键运行测试。您应该会看到以下错误:
AssertionError: 'Site administration' not found in u'Django administration\nPlease enter the correct username and password for a staff account. Note that both fields may be case-sensitive.\nUsername:\nPassword:\n '
此操作失败,因为我们没有管理员用户设置。这是一个预期的失败,这很好。换句话说,我们知道它会失败——这使得它更容易修复。
同步数据库:
$ python manage.py syncdb
设置管理员用户。
再次测试。它应该会再次失败。为什么?Django 会在测试运行时创建一个数据库副本,这样测试就不会影响生产数据库。
我们需要设置一个 Fixture,它是一个包含我们想要加载到测试数据库中的数据的文件:登录凭证。为此,运行以下命令将管理员用户信息从数据库转储到 Fixture:
$ mkdir ft/fixtures
$ python manage.py dumpdata auth.User --indent=2 > ft/fixtures/admin.json
现在更新AdminTest类:
class AdminTest(LiveServerTestCase):
# load fixtures
fixtures = ['admin.json']
def setUp(self):
self.browser = webdriver.Firefox()
def tearDown(self):
self.browser.quit()
def test_admin_site(self):
# user opens web browser, navigates to admin page
self.browser.get(self.live_server_url + '/admin/')
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Django administration', body.text)
# users types in username and passwords and presses enter
username_field = self.browser.find_element_by_name('username')
username_field.send_keys('admin')
password_field = self.browser.find_element_by_name('password')
password_field.send_keys('admin')
password_field.send_keys(Keys.RETURN)
# login credentials are correct, and the user is redirected to the main admin page
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Site administration', body.text)
运行测试。应该会过去的。
每次运行测试时,Django 都会转储测试数据库。然后,在“test.py”文件中指定的所有装置都被加载到数据库中。
让我们再添加一个断言。再次更新测试:
def test_admin_site(self):
# user opens web browser, navigates to admin page
self.browser.get(self.live_server_url + '/admin/')
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Django administration', body.text)
# users types in username and passwords and presses enter
username_field = self.browser.find_element_by_name('username')
username_field.send_keys('admin')
password_field = self.browser.find_element_by_name('password')
password_field.send_keys('admin')
password_field.send_keys(Keys.RETURN)
# login credentials are correct, and the user is redirected to the main admin page
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Site administration', body.text)
# user clicks on the Users link
user_link = self.browser.find_elements_by_link_text('Users')
user_link[0].click()
# user verifies that user live@forever.com is present
body = self.browser.find_element_by_tag_name('body')
self.assertIn('live@forever.com', body.text)
运行它。它应该失败,因为我们需要和另一个用户对夹具文件:
[ { "pk": 1, "model": "auth.user", "fields": { "username": "admin", "first_name": "", "last_name": "", "is_active": true, "is_superuser": true, "is_staff": true, "last_login": "2013-12-29T03:49:13.545Z", "groups": [], "user_permissions": [], "password": "pbkdf2_sha256$12000$VtsgwjQ1BZ6u$zwnG+5E5cl8zOnghahArLHiMC6wGk06HXrlAijFFpSA=", "email": "ad@min.com", "date_joined": "2013-12-29T03:49:13.545Z" } }, { "pk": 2, "model": "auth.user", "fields": { "username": "live", "first_name": "", "last_name": "", "is_active": true, "is_superuser": false, "is_staff": false, "last_login": "2013-12-29T03:49:13.545Z", "groups": [], "user_permissions": [], "password": "pbkdf2_sha256$12000$VtsgwjQ1BZ6u$zwnG+5E5cl8zOnghahArLHiMC6wGk06HXrlAijFFpSA=", "email": "live@forever.com", "date_joined": "2013-12-29T03:49:13.545Z" } } ]
再运行一次。确保它通过。如果需要,重构测试。现在想想你还能测试什么。也许您可以测试一下,确保管理员用户可以在管理面板中添加用户。或者可能是一个测试,以确保没有管理员权限的人不能访问管理面板。多写几个测试。更新您的代码。再次测试。如有必要,重构。
接下来,我们将添加用于添加联系人的应用程序。别忘了承诺!
设置联系人应用程序
先做个测试。添加以下功能:
def test_create_contact_admin(self):
self.browser.get(self.live_server_url + '/admin/')
username_field = self.browser.find_element_by_name('username')
username_field.send_keys('admin')
password_field = self.browser.find_element_by_name('password')
password_field.send_keys('admin')
password_field.send_keys(Keys.RETURN)
# user verifies that user_contacts is present
body = self.browser.find_element_by_tag_name('body')
self.assertIn('User_Contacts', body.text)
再次运行测试套件。您应该会看到以下错误-
AssertionError: 'User_Contacts' not found in u'Django administration\nWelcome, admin. Change password / Log out\nSite administration\nAuth\nGroups\nAdd\nChange\nUsers\nAdd\nChange\nRecent Actions\nMy Actions\nNone available'
- 这是意料之中的。
现在,编写足够的代码让它通过。
创建应用程序:
$ python manage.py startapp user_contacts将其添加到“settings.py”文件中:
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'ft', 'user_contacts', )在
user_contacts目录下的“admin.py”文件中添加以下代码:from user_contacts.models import Person, Phone from django.contrib import admin admin.site.register(Person) admin.site.register(Phone)您的项目结构现在应该如下所示:
├── user_contacts │ ├── __init__.py │ ├── admin.py │ ├── models.py │ ├── tests.py │ └── views.py ├── contacts │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── ft │ ├── __init__.py │ ├── fixtures │ │ └── admin.json │ └── tests.py └── manage.py更新“models.py”:
from django.db import models class Person(models.Model): first_name = models.CharField(max_length = 30) last_name = models.CharField(max_length = 30) email = models.EmailField(null = True, blank = True) address = models.TextField(null = True, blank = True) city = models.CharField(max_length = 15, null = True,blank = True) state = models.CharField(max_length = 15, null = True, blank = True) country = models.CharField(max_length = 15, null = True, blank = True) def __unicode__(self): return self.last_name +", "+ self.first_name class Phone(models.Model): person = models.ForeignKey('Person') number = models.CharField(max_length=10) def __unicode__(self): return self.number现在再次运行测试。您现在应该看到:
Ran 2 tests in 11.730s OK让我们继续添加到测试中,以确保管理员可以添加数据:
# user clicks on the Persons link persons_links = self.browser.find_elements_by_link_text('Persons') persons_links[0].click() # user clicks on the Add person link add_person_link = self.browser.find_element_by_link_text('Add person') add_person_link.click() # user fills out the form self.browser.find_element_by_name('first_name').send_keys("Michael") self.browser.find_element_by_name('last_name').send_keys("Herman") self.browser.find_element_by_name('email').send_keys("michael@realpython.com") self.browser.find_element_by_name('address').send_keys("2227 Lexington Ave") self.browser.find_element_by_name('city').send_keys("San Francisco") self.browser.find_element_by_name('state').send_keys("CA") self.browser.find_element_by_name('country').send_keys("United States") # user clicks the save button self.browser.find_element_by_css_selector("input[value='Save']").click() # the Person has been added body = self.browser.find_element_by_tag_name('body') self.assertIn('Herman, Michael', body.text) # user returns to the main admin screen home_link = self.browser.find_element_by_link_text('Home') home_link.click() # user clicks on the Phones link persons_links = self.browser.find_elements_by_link_text('Phones') persons_links[0].click() # user clicks on the Add phone link add_person_link = self.browser.find_element_by_link_text('Add phone') add_person_link.click() # user finds the person in the dropdown el = self.browser.find_element_by_name("person") for option in el.find_elements_by_tag_name('option'): if option.text == 'Herman, Michael': option.click() # user adds the phone numbers self.browser.find_element_by_name('number').send_keys("4158888888") # user clicks the save button self.browser.find_element_by_css_selector("input[value='Save']").click() # the Phone has been added body = self.browser.find_element_by_tag_name('body') self.assertIn('4158888888', body.text) # user logs out self.browser.find_element_by_link_text('Log out').click() body = self.browser.find_element_by_tag_name('body') self.assertIn('Thanks for spending some quality time with the Web site today.', body.text)这就是管理功能。让我们换个话题,把注意力放在应用程序本身上。你忘记承诺了吗?如果有,现在就做。
单元测试
想想我们到目前为止所写的特性。我们刚刚定义了我们的模型,并允许管理员改变模型。基于此,以及我们项目的总体目标,关注剩余的用户功能。
用户应该能够-
- 查看所有联系人。
- 添加新联系人。
尝试根据那些需求来制定剩余的功能测试。然而,在我们编写功能测试之前,我们应该通过单元测试来定义代码的行为——这将帮助您编写良好、干净的代码,使编写功能测试更加容易。
记住:功能测试是你的项目是否成功的最终指示器,而单元测试是帮助你达到目的的手段。这一切很快就会有意义。
让我们暂停一分钟,谈谈一些惯例。
尽管 TDD(或 ends)的基础——测试、编码、重构——是通用的,但许多开发人员采用不同的方法。例如,我喜欢先编写我的单元测试,以确保我的代码在粒度级别上工作,然后编写功能测试。还有的先写功能测试,看着他们失败,再写单元测试,看着他们失败,然后写代码先满足单元测试,最终应该满足功能测试。这里没有正确或错误的答案。做你感觉最舒服的事情——但是先继续测试,然后写代码,最后重构。
视图
首先,检查以确保所有视图都设置正确。
主视图
像往常一样,从一个测试开始:
from django.template.loader import render_to_string from django.test import TestCase, Client from user_contacts.models import Person, Phone from user_contacts.views import * class ViewTest(TestCase): def setUp(self): self.client_stub = Client() def test_view_home_route(self): response = self.client_stub.get('/') self.assertEquals(response.status_code, 200)将该测试命名为
test_views.py,并将其保存在user_contacts/tests目录中。还要在目录中添加一个__init__.py文件,并删除主user_contacts目录中的“tests.py”文件。运行它:
$ python manage.py test user_contacts它应该失败-
AssertionError: 404 != 200-因为 URL、视图和模板不存在。如果你不熟悉 Django 如何处理 MVC 架构,请在这里阅读短文。测试很简单。我们首先使用客户端获得 URL“/”,这是 Django 的
TestCase的一部分。响应被存储,然后我们检查以确保返回的状态代码等于 200。将以下路由添加到“contacts/urls.py”中:
url(r'^', include('user_contacts.urls')),更新“user_contacts/urls.py”:
from django.conf.urls import patterns, url from user_contacts.views import * urlpatterns = patterns('', url(r'^$', home), )更新“views.py”:
from django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import render_to_response, render from django.template import RequestContext from user_contacts.models import Phone, Person # from user_contacts.new_contact_form import ContactForm def home(request): return render_to_response('index.html')将“index.html”模板添加到模板目录中:
<!DOCTYPE html> <head> <title>Welcome.</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> .container { padding: 50px; } </style> </head> <body> <div class="container"> <h1>What would you like to do?</h1> <ul> <li><a href="/all">View Contacts</a></li> <li><a href="/add">Add Contact</a></li> </ul> <div> <script src="http://code.jquery.com/jquery-1.10.2.min.js"></script> <script src="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/js/bootstrap.min.js"></script> </body> </html>再次运行测试。应该会没事的。
所有联系人视图
这个视图的测试与我们上一次的测试几乎相同。在看我的回答之前先自己试一下。
首先通过向
ViewTest类添加以下函数来编写测试:def test_view_contacts_route(self): response = self.client_stub.get('/all/') self.assertEquals(response.status_code, 200)运行时,您应该会看到相同的错误:
AssertionError: 404 != 200。使用以下路径更新“user_contacts/urls.py ”:
url(r'^all/$', all_contacts),更新“views.py”:
def all_contacts(request): contacts = Phone.objects.all() return render_to_response('all.html', {'contacts':contacts})将“all.html”模板添加到模板目录中:
<!DOCTYPE html> <html> <head> <title>All Contacts.</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> .container { padding: 50px; } </style> </head> <body> <div class="container"> <h1>All Contacts</h1> <table border="1" cellpadding="5"> <tr> <th>First Name</th> <th>Last Name</th> <th>Address</th> <th>City</th> <th>State</th> <th>Country</th> <th>Phone Number</th> <th>Email</th> </tr> {% for contact in contacts %} <tr> <td>{{contact.person.first\_name}}</td> <td>{{contact.person.last\_name}}</td> <td>{{contact.person.address}}</td> <td>{{contact.person.city}}</td> <td>{{contact.person.state}}</td> <td>{{contact.person.country}}</td> <td>{{contact.number}}</td> <td>{{contact.person.email}}</td> </tr> {% endfor %} </table> <br> <a href="/">Return Home</a> </div> <script src="http://code.jquery.com/jquery-1.10.2.min.js"></script> <script src="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/js/bootstrap.min.js"></script> </body> </html>这个应该也会过去。
添加联系人视图
这次测试与前两次略有不同,所以请密切关注。
将测试添加到测试套件中:
def test_add_contact_route(self): response = self.client_stub.get('/add/') self.assertEqual(response.status_code, 200)运行时您应该会看到以下错误:
AssertionError: 404 != 200Update “urls.py”:
url(r'^add/$', add),更新“views.py”:
def add(request): person_form = ContactForm() return render(request, 'add.html', {'person_form' : person_form}, context_instance = RequestContext(request))确保添加以下导入:
from user_contacts.new_contact_form import ContactForm创建一个名为
new_contact_form.py的新文件,并添加以下代码:import re from django import forms from django.core.exceptions import ValidationError from user_contacts.models import Person, Phone class ContactForm(forms.Form): first_name = forms.CharField(max_length=30) last_name = forms.CharField(max_length=30) email = forms.EmailField(required=False) address = forms.CharField(widget=forms.Textarea, required=False) city = forms.CharField(required=False) state = forms.CharField(required=False) country = forms.CharField(required=False) number = forms.CharField(max_length=10) def save(self): if self.is_valid(): data = self.cleaned_data person = Person.objects.create(first_name=data.get('first_name'), last_name=data.get('last_name'), email=data.get('email'), address=data.get('address'), city=data.get('city'), state=data.get('state'), country=data.get('country')) phone = Phone.objects.create(person=person, number=data.get('number')) return phone将“add.html”添加到模板目录:
<!DOCTYPE html> <html> <head> <title>Welcome.</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/css/bootstrap.min.css" rel="stylesheet" media="screen"> <style> .container { padding: 50px; } </style> </head> <body> <div class="container"> <h1>Add Contact</h1> <br> <form action="/create" method ="POST" role="form"> {% csrf\_token %} {{ person_\_form.as\_p }} {{ phone\_form.as\_p }} <input type ="submit" name ="Submit" class="btn btn-default" value ="Add"> </form> <br> <a href="/">Return Home</a> </div> <script src="http://code.jquery.com/jquery-1.10.2.min.js"></script> <script src="http://netdna.bootstrapcdn.com/bootstrap/3.0.0/js/bootstrap.min.js"></script> </body> </html>通过了吗?应该的。如果没有,重构。
验证
现在我们已经完成了对视图的测试,让我们向表单添加验证。但是首先我们需要写一个测试。惊喜!
在“tests”目录下创建一个名为“test_validator.py”的新文件,并添加以下代码:
from django.core.exceptions import ValidationError from django.test import TestCase from user_contacts.validators import validate_number, validate_string class ValidatorTest(TestCase): def test_string_is_invalid_if_contains_numbers_or_special_characters(self): with self.assertRaises(ValidationError): validate_string('@test') validate_string('tester#') def test_number_is_invalid_if_contains_any_character_except_digits(self): with self.assertRaises(ValidationError): validate_number('123ABC') validate_number('75431#')在运行测试套件之前,您能猜到会发生什么吗?提示:密切注意上面代码中的导入。您应该会得到以下错误,因为我们没有“validators.py”文件:
ImportError: cannot import name validate_string
换句话说,我们正在测试一个尚不存在的验证文件中的逻辑。
将名为“validators.py”的新文件添加到user_contacts目录中:
import re
from django.core.exceptions import ValidationError
def validate_string(string):
if re.search('^[A-Za-z]+$', string) is None:
raise ValidationError('Invalid')
def validate_number(value):
if re.search('^[0-9]+$', value) is None:
raise ValidationError('Invalid')
再次运行测试套件。现在应该有五个通过了:
Ran 5 tests in 0.019s
OK
创建联系人
由于我们添加了验证,我们想要测试以确保验证器在管理区域中工作,所以更新“test_views.py”:
from django.template.loader import render_to_string
from django.test import TestCase, Client
from user_contacts.models import Person, Phone
from user_contacts.views import *
class ViewTest(TestCase):
def setUp(self):
self.client_stub = Client()
self.person = Person(first_name = 'TestFirst',last_name = 'TestLast')
self.person.save()
self.phone = Phone(person = self.person,number = '7778889999')
self.phone.save()
def test_view_home_route(self):
response = self.client_stub.get('/')
self.assertEquals(response.status_code, 200)
def test_view_contacts_route(self):
response = self.client_stub.get('/all/')
self.assertEquals(response.status_code, 200)
def test_add_contact_route(self):
response = self.client_stub.get('/add/')
self.assertEqual(response.status_code, 200)
def test_create_contact_successful_route(self):
response = self.client_stub.post('/create',data = {'first_name' : 'testFirst', 'last_name':'tester', 'email':'test@tester.com', 'address':'1234 nowhere', 'city':'far away', 'state':'CO', 'country':'USA', 'number':'987654321'})
self.assertEqual(response.status_code, 302)
def test_create_contact_unsuccessful_route(self):
response = self.client_stub.post('/create',data = {'first_name' : 'tester_first_n@me', 'last_name':'test', 'email':'tester@test.com', 'address':'5678 everywhere', 'city':'far from here', 'state':'CA', 'country':'USA', 'number':'987654321'})
self.assertEqual(response.status_code, 200)
def tearDown(self):
self.phone.delete()
self.person.delete()
两次测试应该会失败。
为了通过这个测试,需要做些什么?嗯,我们首先需要向视图添加一个函数,用于向数据库添加数据。
添加路线:
url(r'^create$', create),
更新“views.py”:
def create(request):
form = ContactForm(request.POST)
if form.is_valid():
form.save()
return HttpResponseRedirect('all/')
return render(
request, 'add.html', {'person_form' : form},
context_instance=RequestContext(request))
再次测试:
$ python manage.py test user_contacts
这一次应该只有一个测试失败了——AssertionError: 302 != 200——因为我们试图添加那些本不应该通过验证器却通过了的数据。换句话说,我们需要更新“models.py”文件和表单,以考虑这些验证器。
更新“models.py”:
from django.db import models
from user_contacts.validators import validate_string, validate_number
class Person(models.Model):
first_name = models.CharField(max_length = 30, validators = [validate_string])
last_name = models.CharField(max_length = 30, validators = [validate_string])
email = models.EmailField(null = True, blank = True)
address = models.TextField(null = True, blank = True)
city = models.CharField(max_length = 15, null = True,blank = True)
state = models.CharField(max_length = 15, null = True, blank = True, validators = [validate_string])
country = models.CharField(max_length = 15, null = True, blank = True)
def __unicode__(self):
return self.last_name +", "+ self.first_name
class Phone(models.Model):
person = models.ForeignKey('Person')
number = models.CharField(max_length=10, validators = [validate_number])
def __unicode__(self):
return self.number
删除当前数据库“db.sqlite3”,并重新同步该数据库:
$ python manage.py syncdb
再次设置管理员用户。
通过添加验证来更新new_contact_form.py:
import re
from django import forms
from django.core.exceptions import ValidationError
from user_contacts.models import Person, Phone
from user_contacts.validators import validate_string, validate_number
class ContactForm(forms.Form):
first_name = forms.CharField(max_length=30, validators = [validate_string])
last_name = forms.CharField(max_length=30, validators = [validate_string])
email = forms.EmailField(required=False)
address = forms.CharField(widget=forms.Textarea, required=False)
city = forms.CharField(required=False)
state = forms.CharField(required=False, validators = [validate_string])
country = forms.CharField(required=False)
number = forms.CharField(max_length=10, validators = [validate_number])
def save(self):
if self.is_valid():
data = self.cleaned_data
person = Person.objects.create(first_name=data.get('first_name'), last_name=data.get('last_name'),
email=data.get('email'), address=data.get('address'), city=data.get('city'), state=data.get('state'),
country=data.get('country'))
phone = Phone.objects.create(person=person, number=data.get('number'))
return phone
再次运行测试。7 应该通过。
现在,暂时偏离 TDD,我想添加一个额外的测试来测试客户端的验证。所以加上test_contact_form.py:
from django.test import TestCase
from user_contacts.models import Person
from user_contacts.new_contact_form import ContactForm
class TestContactForm(TestCase):
def test_if_valid_contact_is_saved(self):
form = ContactForm({'first_name':'test', 'last_name':'test','number':'9999900000'})
contact = form.save()
self.assertEqual(contact.person.first_name, 'test')
def test_if_invalid_contact_is_not_saved(self):
form = ContactForm({'first_name':'tes&t', 'last_name':'test','number':'9999900000'})
contact = form.save()
self.assertEqual(contact, None)
运行测试套件。所有 9 项测试现在都应该通过了。耶!现在提交。
功能测试冗余
单元测试完成后,我们现在可以添加功能测试来确保应用程序正确运行。希望随着单元测试的通过,我们在功能测试方面应该没有问题。
向“tests.py”文件添加一个新类:
class UserContactTest(LiveServerTestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.browser.implicitly_wait(3)
def tearDown(self):
self.browser.quit()
def test_create_contact(self):
# user opens web browser, navigates to home page
self.browser.get(self.live_server_url + '/')
# user clicks on the Persons link
add_link = self.browser.find_elements_by_link_text('Add Contact')
add_link[0].click()
# user fills out the form
self.browser.find_element_by_name('first_name').send_keys("Michael")
self.browser.find_element_by_name('last_name').send_keys("Herman")
self.browser.find_element_by_name('email').send_keys("michael@realpython.com")
self.browser.find_element_by_name('address').send_keys("2227 Lexington Ave")
self.browser.find_element_by_name('city').send_keys("San Francisco")
self.browser.find_element_by_name('state').send_keys("CA")
self.browser.find_element_by_name('country').send_keys("United States")
self.browser.find_element_by_name('number').send_keys("4158888888")
# user clicks the save button
self.browser.find_element_by_css_selector("input[value='Add']").click()
# the Person has been added
body = self.browser.find_element_by_tag_name('body')
self.assertIn('michael@realpython.com', body.text)
def test_create_contact_error(self):
# user opens web browser, navigates to home page
self.browser.get(self.live_server_url + '/')
# user clicks on the Persons link
add_link = self.browser.find_elements_by_link_text('Add Contact')
add_link[0].click()
# user fills out the form
self.browser.find_element_by_name('first_name').send_keys("test@")
self.browser.find_element_by_name('last_name').send_keys("tester")
self.browser.find_element_by_name('email').send_keys("test@tester.com")
self.browser.find_element_by_name('address').send_keys("2227 Tester Ave")
self.browser.find_element_by_name('city').send_keys("Tester City")
self.browser.find_element_by_name('state').send_keys("TC")
self.browser.find_element_by_name('country').send_keys("TCA")
self.browser.find_element_by_name('number').send_keys("4158888888")
# user clicks the save button
self.browser.find_element_by_css_selector("input[value='Add']").click()
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Invalid', body.text)
运行功能测试:
$ python manage.py test ft
在这里,我们只是测试我们写的代码,并且已经从最终用户的角度用单元测试测试过了。所有四项测试都应该通过。
最后,让我们通过向AdminTest类添加以下函数来确保我们实施的验证适用于管理面板:
def test_create_contact_admin_raise_error(self):
# # user opens web browser, navigates to admin page, and logs in
self.browser.get(self.live_server_url + '/admin/')
username_field = self.browser.find_element_by_name('username')
username_field.send_keys('admin')
password_field = self.browser.find_element_by_name('password')
password_field.send_keys('admin')
password_field.send_keys(Keys.RETURN)
# user clicks on the Persons link
persons_links = self.browser.find_elements_by_link_text('Persons')
persons_links[0].click()
# user clicks on the Add person link
add_person_link = self.browser.find_element_by_link_text('Add person')
add_person_link.click()
# user fills out the form
self.browser.find_element_by_name('first_name').send_keys("test@")
self.browser.find_element_by_name('last_name').send_keys("tester")
self.browser.find_element_by_name('email').send_keys("test@tester.com")
self.browser.find_element_by_name('address').send_keys("2227 Tester Ave")
self.browser.find_element_by_name('city').send_keys("Tester City")
self.browser.find_element_by_name('state').send_keys("TC")
self.browser.find_element_by_name('country').send_keys("TCA")
# user clicks the save button
self.browser.find_element_by_css_selector("input[value='Save']").click()
body = self.browser.find_element_by_tag_name('body')
self.assertIn('Invalid', body.text)
运行它。五项测试应该通过。承诺,让我们今天到此为止。
测试结构
TDD 是一个强大的工具,也是开发周期中不可或缺的一部分,它帮助开发人员将程序分成小的、可读的部分。这样的部分现在更容易写,以后更容易修改。此外,拥有一个全面的测试套件,覆盖代码库的每个功能,有助于确保新功能的实现不会破坏现有的代码。
在这个过程中,功能测试是高级测试,集中在终端用户与之交互的特性上。
同时,单元测试支持功能测试,因为它们测试代码的每个特性。请记住,单元测试更容易编写,通常提供更好的覆盖率,并且更容易调试,因为它们一次只测试一个特性。它们的运行速度也更快,所以一定要比功能测试更频繁地测试单元测试。
让我们看看我们的测试结构,看看我们的单元测试是如何支持功能测试的:

结论
恭喜你。你成功了。下一步是什么?
首先,你可能已经注意到我没有 100%遵循 TDD 过程。没关系。大多数从事 TDD 的开发人员并不总是在每一种情况下都坚持它。有时候,为了把事情做好,你必须背离它——这完全没问题。如果你想重构一些代码/过程来完全遵守 TDD 过程,你可以。事实上,这可能是一个很好的做法。
第二,想想我错过的考试。决定测试什么和什么时候测试是困难的。一般来说,擅长测试需要时间和大量的练习。我留下了许多空白,我打算在下一篇文章中尽情享受。看看你能否找到这些并添加测试。
最后,还记得 TDD 过程的最后一步吗?重构。这一步是至关重要的,因为它有助于创建可读的、可维护的代码,您不仅现在可以理解,将来也可以理解。当你回顾你的代码时,想想你可以组合的测试。此外,您应该添加哪些测试来确保所有编写的代码都经过测试?例如,您可以测试空值和/或服务器端身份验证。在继续编写任何新代码之前,您应该重构您的代码——由于时间的原因,我没有这样做。或许是另一篇博文?想想糟糕的代码会如何污染整个过程?
感谢阅读。在这里抓取回购中的最终代码。如有任何问题,请在下方评论。********
Django 和 AJAX 表单提交——更多实践
原文:https://realpython.com/django-and-ajax-form-submissions-more-practice/
这是 Real Python 和 Nathan Nichols 先生的合作作品。
于 2014 年 9 月 5 日更新,使应用程序更加宁静。
欢迎光临。上次我们在基本的 Django 通信应用中添加了 AJAX,以改善用户体验。最终结果是,由于我们消除了页面刷新,应用程序对最终用户的响应更快,功能更强。
如果你还记得的话,我们在教程的最后有一个小小的家庭作业:轮到你了。我们需要处理更多的事件。有了新发现的 jQuery 和 AJAX 知识,您就可以将它们放在适当的位置。我在最终的应用程序中添加了代码——你可以在这里下载——其中包括一个删除链接。您只需要添加一个事件来处理点击,然后该事件调用一个函数,该函数使用 AJAX 向后端发送 POST 请求,以从数据库中删除帖子。按照我在本教程中的工作流程。我们下次会公布这个问题的答案。
因此,就 CRUD 而言,我们需要添加删除功能。我们将使用以下工作流程:
- 设置事件处理程序
- 创建 AJAX 请求
- 更新 Django 视图
- 处理回电
- 更新 DOM
设置事件处理程序
当用户单击删除链接时,这个“事件”需要在 JavaScript 文件中“处理”:
// Delete post on click $("#talk").on('click', 'a[id^=delete-post-]', function(){ var post_primary_key = $(this).attr('id').split('-')[2]; console.log(post_primary_key) // sanity check delete_post(post_primary_key); });
点击时,我们获取 post 主键,我们将它添加到一个id中,同时一个新的 post 被添加到 DOM 中:
$("#talk").prepend("<li><strong>"+json.text+"</strong> - <em> "+json.author+"</em> - <span> "+json.created+ "</span> - <a id='delete-post-"+json.postpk+"'>delete me</a></li>");
我们还将主键作为参数传递给delete_post()函数,我们需要添加…
创建 AJAX 请求
正如您可能猜到的那样,delete_post()函数处理 AJAX 请求:
function delete_post(post_primary_key){ if (confirm('are you sure you want to remove this post?')==true){ $.ajax({ url : "delete_post/", // the endpoint type : "DELETE", // http method data : { postpk : post_primary_key }, // data sent with the delete request success : function(json) { // hide the post $('#post-'+post_primary_key).hide(); // hide the post on success console.log("post deletion successful"); }, error : function(xhr,errmsg,err) { // Show an error $('#results').html("<div class='alert-box alert radius' data-alert>"+ "Oops! We have encountered an error. <a href='#' class='close'>×</a></div>"); // add error to the dom console.log(xhr.status + ": " + xhr.responseText); // provide a bit more info about the error to the console } }); } else { return false; } };
将这段代码与create_post()函数进行比较。有什么不同?
-
注意条件句。
confirm()方法显示一个对话框,用户必须点击“确定”或“取消”。因为这个过程实际上会从数据库中删除文章,所以我们只想确保用户没有意外地点击删除。这只是给他们一个机会在请求发送之前取消。这些对话框不是处理这种情况的最优雅的方式,但它是实用的。测试一下。
-
此外,因为我们要删除一篇文章,所以我们对 HTTP 方法使用“DELETE”。
请记住,一些较旧的浏览器只支持 GET 和 POST 请求。如果你知道你的应用将在一些旧版本的 ie 浏览器上使用,你可以利用 POST tunneling 作为一个解决方法。
更新 Django 视图
现在,让我们转向服务器端,更新 Django 的 URL 和视图。请求被发送到服务器端,首先由 urls.py 处理:
# Talk urls
from django.conf.urls import patterns, url
urlpatterns = patterns(
'talk.views',
url(r'^$', 'home'),
url(r'^create_post/$', 'create_post'),
url(r'^delete_post/$', 'delete_post'),
)
设置好 URL 后,请求将被路由到适当的 Django 视图:
def delete_post(request):
if request.method == 'DELETE':
post = Post.objects.get(
pk=int(QueryDict(request.body).get('postpk')))
post.delete()
response_data = {}
response_data['msg'] = 'Post was deleted.'
return HttpResponse(
json.dumps(response_data),
content_type="application/json"
)
else:
return HttpResponse(
json.dumps({"nothing to see": "this isn't happening"}),
content_type="application/json"
)
如果请求方法是“删除”,那么我们从数据库中删除帖子。如果那个主键不存在会怎么样?这将导致意想不到的副作用。换句话说,我们会得到一个没有被正确处理的错误。看看您是否能找出如何捕捉错误,然后使用 try/except 语句正确处理它。
一旦帖子被删除,我们就创建一个响应 dict,将其序列化为 JSON,然后作为响应发送回客户端。
将代码与create_post()函数进行比较。为什么不能做request.DELETE.get?因为 Django 不像 GET 和 POST 请求那样为 DELETE(或 PUT)请求构造字典。因此,我们使用来自 QueryDict 类的get方法构建了自己的字典。
注意:如果我们基于 HTTP 方法(GET、POST、PUT、DELETE)使用单个视图来处理不同的场景,这个应用程序会更加 RESTful(并且代码会更加简洁)。现在,我们对 GET、POST 和 DELETE 方法有不同的看法。这可以很容易地重构为一个单一的视图:
`def index(request): if request.method == 'GET': # do something elif request.method == "POST": # do something elif request.method == "DELETE": # do something else: # do something`下次我们将 Django Rest 框架添加到项目中时,我们将深入讨论这个问题。
处理回调
回到 main.js 中的delete_post()函数,我们如何处理一个成功的回调呢?
success : function(json) { // hide the post $('#post-'+post_primary_key).hide(); // hide the post on success console.log("post deletion successful"); },
这里我们隐藏了一个带有特定 id 的标记,然后将一条成功消息记录到控制台。例如,如果我们删除 id 为20的文章,那么与 id 为post-20的文章相关联的标签将被隐藏。这有用吗?测试一下。不应该。让我们来解决这个问题…
更新 DOM
打开index.html模板。你看到那个身份证了吗?没有。让我们将它添加到开始的<li>标签中:
<li id='post-{{post.pk}}'>
现在测试一下。应该能行。
不过,在我们结束今天的工作之前,我们还需要在另一个地方做出改变。如果你添加了一个帖子,然后立即试图删除它,会发生什么?它不应该工作,因为我们没有正确地更新 DOM。返回到create_post()函数,更新用于向 DOM 添加新文章的代码:
$("#talk").prepend("<li id='post-"+json.postpk+"'><strong>"+json.text+ "</strong> - <em> "+json.author+"</em> - <span> "+json.created+ "</span> - <a id='delete-post-"+json.postpk+"'>delete me</a></li>");
注意到区别了吗?测试一下。一切都好。
下一步是什么?
Django Rest 框架。
在此之前,如果您有任何问题,请发表评论,并查看代码的回购。**
Django 和 AJAX 表单提交——告别页面刷新
让我们言归正传:
- 从 repo 下载压缩的 pre-ajax Django 项目
- 激活虚拟
- 安装需求
- 同步数据库
- 启动服务器
登录后,测试表单。我们这里有一个简单的通信应用程序,只有创建权限。它看起来不错,但有一个恼人的问题:页面刷新。
我们如何摆脱它?或者,我们如何只更新网页的部分,而不必刷新整个页面?
输入 AJAX。AJAX 是一种客户端技术,用于向服务器端发出异步请求——即请求或提交数据——后续响应不会导致整个页面刷新。
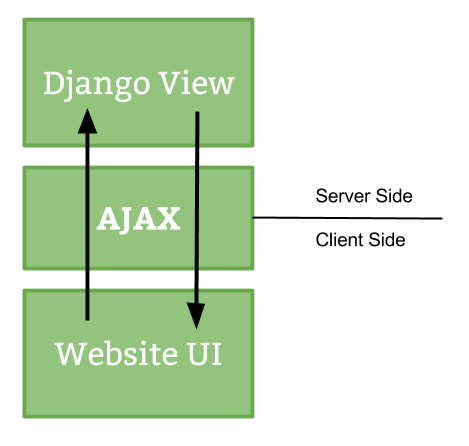
本教程假设您已经掌握了 Django 的工作知识以及一些 JavaScript/jQuery 的经验。您还应该熟悉基本的 HTTP 方法,尤其是 GET 和 POST。需要加快速度吗?得到真正的巨蟒。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
这是 Real Python 和强大的 Nathan Nichols 之间的合作作品,使用了一种我们称之为“敏捷博客”的合作方法。在推特上对内森说“嗨”: @natsamnic 。
使用保护
无论您是否使用 AJAX,表单都面临跨站点请求伪造(CSRF)攻击的风险。
在编码恐怖博客上阅读更多关于 CSRF 攻击的内容。他们有一篇很棒的文章。
为了防止这种攻击,您必须将{% csrf_token %}模板标记添加到表单中,这将添加一个隐藏的输入字段,其中包含一个随每个 POST 请求一起发送的令牌。
如果你看一下 talk/index.html 模板,你可以看到我们已经包含了这个令牌。然而,当涉及到 AJAX 请求时,我们需要添加更多的代码,因为脚本是静态的,我们不能使用 JavaScript 对象传递令牌。
为了解决这个问题,我们需要创建一个自定义的头,其中包含监视我们的令牌。只需在这里抓取代码并将其添加到 main.js 文件的末尾。是的,代码很多。我们可以一行一行地浏览,但这不是这篇文章的重点。请相信我们这是可行的。
继续前进…
处理事件
在接触 AJAX 代码之前,我们需要使用 jQuery 向 JavaScript 文件添加一个事件处理程序。
请记住,jQuery 是 JavaScript。它只是一个 JavaScript 库,用于减少您需要编写的代码量。这是一个常见的困惑领域,所以在你阅读本教程的剩余部分时要注意这一点。
我们需要“处理”哪些事件?因为我们现在只是在创建一个帖子,所以我们只需要向 main.js 添加一个处理程序:
// Submit post on submit $('#post-form').on('submit', function(event){ event.preventDefault(); console.log("form submitted!") // sanity check create_post(); });
这里,当用户提交表单时,这个函数触发,这-
- 防止表单提交的默认浏览器行为,
- 日志“表单已提交!”到控制台,然后
- 调用一个名为
create_post()的函数,AJAX 代码将驻留在这个函数中。
确保在index.html文件的表单上添加一个 idpost-form:
<form action="/create_post/" method="POST" id="post-form">
并在模板底部添加 JavaScript 文件的链接:
<script src="static/scripts/main.js"></script>
测试一下。启动服务器,然后打开 JavaScript 控制台。提交表单时,您应该会看到以下内容:
form submitted!
Uncaught ReferenceError: create_post is not defined
这正是我们应该看到的:表单提交得到了正确的处理,因为“表单已提交!”显示并调用create_post功能。现在我们只需要添加那个函数。
添加 AJAX
在添加实际的 AJAX 代码之前,让我们进行最后一次迭代。
更新 main.js :
添加create_post功能:
// AJAX for posting function create_post() { console.log("create post is working!") // sanity check console.log($('#post-text').val()) };
同样,我们运行了健全性检查以确保函数被正确调用,然后我们获取表单的输入值。为了正确工作,我们需要向表单字段添加一个 id:
更新 forms.py 😗
class PostForm(forms.ModelForm):
class Meta:
model = Post
# exclude = ['author', 'updated', 'created', ]
fields = ['text']
widgets = {
'text': forms.TextInput(attrs={
'id': 'post-text',
'required': True,
'placeholder': 'Say something...'
}),
}
请注意,我们还向该字段添加了一个占位符,并使其与 id 一起成为必填项。我们可以向表单模板添加一些错误处理程序,或者简单地让 HTML5 来处理它。我们用后者吧。
再次测试。提交带有“测试”字样的表格。您应该会在控制台中看到以下内容:
form submitted!
create post is working!
test
太好了。因此,我们已经确认我们正确地调用了create_post()函数,并获取了表单输入的值。现在让我们连接一些 AJAX 来提交 POST 请求。
更新 main.js :
// AJAX for posting function create_post() { console.log("create post is working!") // sanity check $.ajax({ url : "create_post/", // the endpoint type : "POST", // http method data : { the_post : $('#post-text').val() }, // data sent with the post request // handle a successful response success : function(json) { $('#post-text').val(''); // remove the value from the input console.log(json); // log the returned json to the console console.log("success"); // another sanity check }, // handle a non-successful response error : function(xhr,errmsg,err) { $('#results').html("<div class='alert-box alert radius' data-alert>Oops! We have encountered an error: "+errmsg+ " <a href='#' class='close'>×</a></div>"); // add the error to the dom console.log(xhr.status + ": " + xhr.responseText); // provide a bit more info about the error to the console } }); };
发生什么事了?嗯,我们将表单数据提交给create_post/端点,然后等待两个响应中的一个——要么成功,要么失败....遵循代码注释可以获得更详细的解释。
更新视图
现在,让我们更新视图以正确处理 POST 请求:
def create_post(request):
if request.method == 'POST':
post_text = request.POST.get('the_post')
response_data = {}
post = Post(text=post_text, author=request.user)
post.save()
response_data['result'] = 'Create post successful!'
response_data['postpk'] = post.pk
response_data['text'] = post.text
response_data['created'] = post.created.strftime('%B %d, %Y %I:%M %p')
response_data['author'] = post.author.username
return HttpResponse(
json.dumps(response_data),
content_type="application/json"
)
else:
return HttpResponse(
json.dumps({"nothing to see": "this isn't happening"}),
content_type="application/json"
)
在这里,我们获取文章文本和作者,并更新数据库。然后我们创建一个 response dict,将其序列化为 JSON,然后作为响应发送——它被记录到控制台的成功处理程序:console.log(json)中,正如您在上面的 JavaScript 文件中的create_post()函数中看到的。
您应该会在控制台中看到该对象:
form submitted!
create post is working!
Object {text: "hey!", author: "michael", postpk: 15, result: "Create post successful!", created: "August 22, 2014 10:55 PM"}
success
更新 DOM
更新模板
只需在<ul>中添加一个“talk”id:
<ul id="talk">
然后更新表单,以便添加错误:
<form method="POST" id="post-form">
{% csrf_token %}
<div class="fieldWrapper" id="the_post">
{{ form.text }}
</div>
<div id="results"></div> <!-- errors go here -->
<input type="submit" value="Post" class="tiny button">
</form>
更新main . jsT2】
现在我们可以将 JSON 添加到新的“talk”id 所在的 DOM 中:
success : function(json) { $('#post-text').val(''); // remove the value from the input console.log(json); // log the returned json to the console $("#talk").prepend("<li><strong>"+json.text+"</strong> - <em> "+json.author+"</em> - <span> "+json.created+"</span></li>"); console.log("success"); // another sanity check },
准备好看这个了吗?测试一下!
如果您想看看错误是什么样子,那么注释掉 main.js 中的所有 CSRF Javascript,然后尝试提交表单。
冲洗,重复
轮到你了。我们需要处理更多的事件。有了新发现的 jQuery 和 AJAX 知识,您就可以将它们放在适当的位置。我给最终的应用程序添加了代码——你可以在这里下载——其中包括一个删除链接。您只需要添加一个事件来处理点击,然后该事件调用一个函数,该函数使用 AJAX 向后端发送 POST 请求,以从数据库中删除帖子。按照我在本教程中的工作流程。我们下次会公布这个问题的答案。
如果你卡住了,不能调试错误,遵循这个工作流程-
- 使用“谷歌优先”算法
- 奋斗。旋转你的轮子。把代码放在一边。绕着街区跑。然后再回来。
- 还是卡住了?请在下面评论,首先陈述问题,然后详细说明到目前为止你已经采取的解决问题的步骤
在寻求帮助之前,请务必自行尝试故障诊断。从长远来看,转动你的轮子,努力找到一个解决方案会让你受益。重要的是过程,而不是解决方案。这是将糟糕的开发人员与伟大的开发人员区分开来的一部分。祝你好运。
点击查看解决方案。
结论
你的应用看起来怎么样?准备好了吗?
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
- AJAX 是昨天所以。使用 AngularJS,我们可以用更少的代码做更多的事情。
- 在大多数情况下,将客户端 JavaScript(无论是 AJAX、Angular 还是其他框架)与服务器端 RESTful API 结合起来是一种标准。
- 测试在哪里?
接下来你想看什么?下面评论。干杯!
编码快乐!
链接到回购。***
用 Docker Compose 和 Machine 开发 Django
原文:https://realpython.com/django-development-with-docker-compose-and-machine/
Docker 是一个容器化工具,用于构建隔离的、可复制的应用环境。这篇文章详细介绍了如何将 Django 项目、Postgres 和 Redis 封装起来用于本地开发,以及如何通过 Docker Compose 和 Docker Machine 将栈交付到云。
免费奖励: ,您可以使用它作为自己 Python 应用程序的基础。
最后,堆栈将为每个服务包含一个单独的容器:
- 1 个 web/Django 容器
- 1 个 nginx 容器
- 1 个 Postgres 容器
- 1 个集装箱
- 1 个数据容器
更新:
- 04/01/2019 :更新至 Docker 最新版本——Docker client(v 18 . 09 . 2)、Docker compose (v1.23.2)、Docker Machine(v 0 . 16 . 1)——以及 Python (v3.7.3)。感谢弗洛里安·戴利茨!
- 04/18/2016 :向 Postgres 和 Redis 容器添加了命名数据卷。
- 04/13/2016 :增加了 Docker 工具箱,也更新到了 Docker - Docker client (v1.10.3)、Docker compose (v1.6.2)、Docker Machine (v0.6.0)的最新版本
- 12/27/2015 :更新到 Docker 的最新版本——Docker client(v 1 . 9 . 1)、Docker compose (v1.5.2)、Docker Machine(v 0 . 5 . 4)——以及 Python (v3.5)
有兴趣为 Flask 创建一个类似的环境吗?查看这篇博客文章。
本地设置
与 Docker (v18.09.2)一起,我们将使用-
- Docker Compose(v 1 . 23 . 2)用于将多容器应用编排到单个应用中,以及
- Docker Machine(v 0 . 16 . 1)用于在本地和云中创建 Docker 主机。
如果你运行的是旧的 Mac OS X 或 Windows 版本,那么下载并安装 Docker 工具箱来获得所有必要的工具。否则,请按照这里的和这里的分别安装 Docker Compose 和 Machine。
完成后,测试安装:
$ docker-machine version
docker-machine version 0.16.1, build cce350d7
$ docker-compose version
docker-compose version 1.23.2, build 1110ad01
CPython version: 3.7.3
接下来,从存储库克隆项目,或者基于 repo 上的项目结构创建您自己的项目:
├── docker-compose.yml
├── nginx
│ ├── Dockerfile
│ └── sites-enabled
│ └── django_project
├── production.yml
└── web
├── Dockerfile
├── docker_django
│ ├── __init__.py
│ ├── apps
│ │ ├── __init__.py
│ │ └── todo
│ │ ├── __init__.py
│ │ ├── admin.py
│ │ ├── models.py
│ │ ├── templates
│ │ │ ├── _base.html
│ │ │ └── home.html
│ │ ├── tests.py
│ │ ├── urls.py
│ │ └── views.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
├── requirements.txt
└── static
└── main.css
我们现在准备好让容器启动并运行…
对接机
要启动 Docker Machine,只需导航到项目根目录,然后运行:
$ docker-machine create -d virtualbox dev;
Running pre-create checks...
Creating machine...
(dev) Creating VirtualBox VM...
(dev) Creating SSH key...
(dev) Starting the VM...
(dev) Check network to re-create if needed...
(dev) Waiting for an IP...
Waiting for machine to be running, this may take a few minutes...
Detecting operating system of created instance...
Waiting for SSH to be available...
Detecting the provisioner...
Provisioning with boot2docker...
Copying certs to the local machine directory...
Copying certs to the remote machine...
Setting Docker configuration on the remote daemon...
Checking connection to Docker...
Docker is up and running!
To see how to connect your Docker Client to the Docker Engine
running on this virtual machine, run: docker-machine env dev
create命令为 Docker 开发建立了一个新的“机器”(名为 dev )。本质上,它启动了一个运行 Docker 客户端的虚拟机。现在只要将 Docker 指向 dev 机器:
$ eval $(docker-machine env dev)
运行以下命令查看当前正在运行的计算机:
$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
dev - virtualbox Running tcp://192.168.99.100:2376 v18.09.3
接下来,让我们用 Docker Compose 启动容器,启动并运行 Django、Postgres 和 Redis。
坞站组成〔t0〕
我们来看看 docker-compose.yml 文件:
version: '3' services: web: restart: always build: ./web expose: - "8000" links: - postgres:postgres - redis:redis volumes: - web-django:/usr/src/app - web-static:/usr/src/app/static env_file: .env environment: DEBUG: 'true' command: /usr/local/bin/gunicorn docker_django.wsgi:application -w 2 -b :8000 nginx: restart: always build: ./nginx/ ports: - "80:80" volumes: - web-static:/www/static links: - web:web postgres: restart: always image: postgres:latest ports: - "5432:5432" volumes: - pgdata:/var/lib/postgresql/data/ redis: restart: always image: redis:latest ports: - "6379:6379" volumes: - redisdata:/data volumes: web-django: web-static: pgdata: redisdata:
这里,我们定义了四个服务- web 、 nginx 、 postgres 和 redis 。
- 首先, web 服务是通过“web”目录下的 Dockerfile 中的指令构建的——在这里设置 Python 环境,安装需求,并在端口 8000 上启动 Django 应用程序。该端口然后被转发到主机环境(例如对接机)上的端口 80。该服务还将在中定义的环境变量添加到容器中。env 文件。
- nginx 服务用于反向代理,将请求转发到 Django 或静态文件目录。
- 接下来,从来自 Docker Hub 的官方 PostgreSQL 映像构建 postgres 服务,Docker Hub 安装 postgres 并在默认端口 5432 上运行服务器。注意到数据量了吗?这有助于确保即使 Postgres 容器被删除,数据仍然存在。
- 同样, redis 服务使用官方的 redis 镜像来安装 Redis,然后在端口 6379 上运行服务。
现在,要让容器运行,构建映像,然后启动服务:
$ docker-compose build
$ docker-compose up -d
提示:您甚至可以在一个单独的命令中运行以上命令:
$ docker-compose up --build -d
拿杯咖啡。或者去做一次长的散步。第一次运行时,这需要一段时间。由于 Docker 缓存了第一次构建的结果,后续的构建会运行得更快。
一旦服务开始运行,我们需要创建数据库迁移:
$ docker-compose run web /usr/local/bin/python manage.py migrate
获取与 Docker Machine - docker-machine ip dev -相关联的 IP,然后在浏览器中导航到该 IP:
不错!
试试提神。您应该会看到计数器更新。本质上,我们使用 Redis INCR 在每个处理的请求后递增。查看网站/docker _ django/apps/todo/views . py中的代码了解更多信息。
这又创建了四个服务,它们都运行在不同的容器中:
$ docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------
dockerizing-django_nginx_1 /usr/sbin/nginx Up 0.0.0.0:80->80/tcp
dockerizing-django_postgres_1 docker-entrypoint.sh postgres Up 0.0.0.0:5432->5432/tcp
dockerizing-django_redis_1 docker-entrypoint.sh redis ... Up 0.0.0.0:6379->6379/tcp
dockerizing-django_web_1 /usr/local/bin/gunicorn do ... Up 8000/tcp
要查看哪些环境变量可用于 web 服务,请运行:
$ docker-compose run web env
要查看日志:
$ docker-compose logs
您还可以进入 Postgres Shell——因为我们在 docker-compose.yml 文件中将端口转发到主机环境——通过以下方式添加用户/角色以及数据库:
$ docker-compose run postgres psql -h 192.168.99.100 -p 5432 -U postgres --password
准备部署了吗?通过docker-compose down停止进程,让我们把应用程序放到云中!
部署
因此,随着我们的应用程序在本地运行,我们现在可以将这个完全相同的环境推送给一个拥有 Docker Machine 的云托管提供商。让我们部署到一个数字海洋盒子。
注意:如果你想采用不同的方法来部署你的 Django 应用程序,可以查看一下关于使用 Gunicorn 和 Nginx 的真实 Python 的教程或视频课程。
在您注册了数字海洋的之后,生成一个个人访问令牌,然后运行以下命令:
$ docker-machine create \
-d digitalocean \
--digitalocean-access-token ADD_YOUR_TOKEN_HERE \
production
这将需要几分钟的时间来供应 droplet 并设置一个名为 production 的新 Docker 机器:
Running pre-create checks...
Creating machine...
(production) Creating SSH key...
(production) Creating Digital Ocean droplet...
(production) Waiting for IP address to be assigned to the Droplet...
Waiting for machine to be running, this may take a few minutes...
Machine is running, waiting for SSH to be available...
Detecting operating system of created instance...
Detecting the provisioner...
Provisioning with ubuntu(systemd)...
Installing Docker...
Copying certs to the local machine directory...
Copying certs to the remote machine...
Setting Docker configuration on the remote daemon...
Checking connection to Docker...
Docker is up and running!
To see how to connect Docker to this machine, run: docker-machine env production
现在我们有两台机器在运行,一台在本地,一台在数字海洋上:
$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
dev - virtualbox Running tcp://192.168.99.100:2376 v18.09.3
production - digitalocean Running tcp://45.55.35.188:2376 v18.09.3
将 production 设置为活动机器,并将 Docker 环境加载到 shell 中:
$ eval "$(docker-machine env production)"
最后,让我们在云端再次构建 Django 应用程序。这一次我们需要使用一个稍微不同的 Docker 合成文件,它不在容器中挂载一个卷。为什么?这个卷非常适合本地开发,因为我们可以在“web”目录中更新我们的本地代码,并且更改会立即在容器中生效。在生产中,显然不需要这样。
$ docker-compose build
$ docker-compose -f production.yml up -d
$ docker-compose run web /usr/local/bin/python manage.py migrate
您是否注意到我们是如何为生产指定不同的配置文件的?如果您还想运行 collectstatic 呢?见本刊。
获取与该数字海洋帐户相关的 IP 地址,并在浏览器中查看。如果一切顺利,您应该看到您的应用程序正在运行,这是应该的。
结论
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。**
用 Django 和 Python 创建个人日记
一个日记是个人的安全空间。在 Django 的帮助下,你可以在自己的电脑上创建日记,而无需将数据存储在别人的云中。通过跟随下面的项目,你将会看到在 Django 中没有任何外部依赖的情况下,你可以多快地构建一个有效的 web 应用。
在本教程中,您将学习如何:
- 建立一个 Django 项目
- 使用标准的 SQLite 数据库
- 利用 Django 管理站点
- 创建模型和基于类的视图
- 嵌套和样式模板
- 通过认证保护您的日记
本教程将引导你一步一步地完成你的最终日记。如果你刚刚开始使用 Django,并且想要完成你的第一个真正的项目,那么这个教程就是为你准备的!
要获得 Django 项目及其步骤的完整源代码,请单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
演示视频
在你日记的主页上,你会有一个条目列表。你可以滚动浏览它们,并点击一个按钮来创建新的。本教程提供了样式,因此您可以专注于代码的 Django 部分。这里有一个快速演示视频,展示了它的实际效果:
https://player.vimeo.com/video/561429980?background=1
本教程结束时,你将能够完美地浏览你的日记,按需创建、阅读、更新和删除条目。
项目概述
本教程分为多个步骤。这样,你可以休息一下,然后按照自己的节奏继续。在每一步中,你将处理日记项目的一个特定领域:
- 建立你的 Django 日记项目
- 在后端创建条目
- 在前端显示条目
- 添加样式
- 管理前端的条目
- 改善您的用户体验
- 实施身份验证
通过跟随,您将探索 web 应用程序的基础,以及如何添加 Django 项目的通用特性。完成教程后,你将创建自己的个人日记应用程序,并拥有一个 Django 项目蓝图作为基础。
先决条件
你不需要任何 Django 的知识来完成这个项目。如果您想进一步了解本教程中遇到的主题,可以找到相关资源的链接。
然而,你应该能熟练使用命令行,并具备 Python 的基础知识和类。尽管了解虚拟环境和 pip 会有所帮助,但你将在学习教程的过程中学习如何设置一切。
步骤 1:建立你的 Django 日记
通过创建您的项目目录并设置一个虚拟环境来启动项目。此设置将使您的代码与计算机上的任何其他项目隔离开来。您可以随意命名项目文件夹和虚拟环境。在本教程中,项目文件夹名为my-diary,虚拟环境名为.venv:
$ mkdir my-diary
$ cd my-diary
$ python3 -m venv .venv
$ source .venv/bin/activate
现在,您的提示以括号中的虚拟环境名称开始。这是虚拟环境被激活的指示符。对于本教程的其余部分,您的虚拟环境必须被激活。以下所有步骤都将发生在该目录或其子目录中。
注意:要在 Windows 上激活您的虚拟环境,您可能需要运行以下命令:
c:\> python -m venv .venv
c:\> .venv\Scripts\activate.bat
对于其他平台和 shells,您可能需要使用不同的命令。
你的日记的另一个要求是 Django 本身。用pip安装本教程的具体版本:
(.venv) $ python -m pip install Django==3.2.1
这个命令安装 Django 和 Django 需要的一些依赖项。这就是你需要的一切。
初始化 Django
所有的需求都已就绪,是时候开始 Django 项目本身了。使用 Django 的命令行实用程序来创建基础项目结构:
(.venv) $ django-admin startproject diary .
不要忘记在上面的命令末尾添加点(.)。圆点防止 Django 为您的日记项目创建另一个目录。
Django 刚刚创建了一个manage.py文件和一个包含五个文件的名为diary的文件夹。你不必明白他们具体做什么。如果你好奇,你可以看一下这些文件。它们都在开头包含一个解释,描述它们为什么存在。在本教程中,您只需要编辑其中的两个:
| 文件 | 教程时编辑的? |
|---|---|
manage.py |
-好的 |
diary/__init__.py |
-好的 |
diary/asgi.py |
-好的 |
diary/settings.py |
981 号房 |
diary/urls.py |
981 号房 |
diary/wsgi.py |
-好的 |
从现在开始,manage.py文件将在命令行中接管的管理任务。在本教程中,您将会遇到其中的一些人。
创建数据库
现在你的 Django 日记项目的基础已经准备好了,你需要一个地方来存储你日记的未来内容。为此,必须创建一个数据库。
Django 附带了对多数据库的支持,如果没有提供其他数据库配置,默认情况下,它使用一个 T2 SQLite 数据库。一个 SQLite 数据库是您所需要的,因为您是唯一连接到它的用户,并且您的 Django 日记项目将只在本地运行。
最棒的是,您可以用一个命令创建一个 SQLite 数据库。通过运行迁移,您将数据库模式的更改应用到数据库中:
(.venv) $ python manage.py migrate
当您查看项目目录时,应该会看到一个db.sqlite3文件。拍拍自己的肩膀:你刚刚创建了一个数据库!
要将项目的当前状态与本教程的可下载文件进行比较,请单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
与本节相关的文件在source_code_step_1/目录下。
成为超级用户
作为你个人日记的主人,你已经为自己赢得了superuser的角色。使用以下命令声明它:
(.venv) $ python manage.py createsuperuser
Username (leave blank to use 'root'): admin
Email address: admin@example.com
Password: RealPyth0n
Password (again): RealPyth0n
Superuser created successfully.
系统会提示您选择用户名,提供电子邮件地址,并设置密码。这是你日记的关键,所以一定要记住。
运行开发网络服务器
您将经常使用的另一个命令是runserver。这个命令运行一个轻量级的开发 web 服务器:
(.venv) $ python manage.py runserver
您可以指定 IP 地址和 runserver 端口。默认情况下,服务器运行在127.0.0.1的端口8000上,并且只能在你的电脑上访问。随着服务器的运行,您可以使用http://127.0.0.1:8000或http://localhost:8000在浏览器中访问您的 Django 项目:
这是你日记的主页。到目前为止,只有一个火箭可以看到。这意味着安装成功。
重要提示:每次在浏览器中访问您的日记项目时,如果您的本地开发 web 服务器尚未运行,您必须首先启动它。
通过访问http://localhost:8000/admin并使用您的凭证登录,完成本教程的第一步:
这是你自己的 Django 管理网站!这是姜戈最强大的特色之一。只需进行一些调整,它就能让您立即管理内容和用户。目前,在 Django 管理站点上没有太多东西可看。是时候改变了!
第二步:将你的日记添加到后端
Django 项目包含一个或多个应用程序。一个 app 的范围应该是有限的。一开始,区分一个项目和应用可能会令人困惑。但是在大的 Django 项目中,这种关注点的分离保持了代码库的干净。这种结构的另一个好处是你可以重用其他项目的应用。
连接参赛作品 App
在您的终端中,Django 开发 web 服务器可能仍在运行。在终端按下 Ctrl + C 停止。
提示:打开第二个终端窗口,在一个窗口控制服务器,在另一个窗口运行命令:
导航到项目并激活虚拟环境后,您可以在第二个终端窗口中运行该项目的后续命令。
在本教程中,您只需要一个额外的应用程序。那个应用的主要目的是处理你的日记条目,所以让我们称这个应用为entries。运行命令创建entries应用程序:
(.venv) $ python manage.py startapp entries
该命令在您的项目中创建一个包含一些预定义文件的entries文件夹。在本教程的后面部分,您只需要编辑其中的三个:
| 文件 | 教程时编辑的? |
|---|---|
entries/__init__.py |
-好的 |
entries/admin.py |
981 号房 |
entries/apps.py |
-好的 |
entries/models.py |
981 号房 |
entries/tests.py |
-好的 |
entries/views.py |
981 号房 |
如您所见,其中一些与diary/目录中的文件同名。通过点击下面的链接,您可以将您的文件夹结构与source_code_step_2/目录中的文件夹结构进行比较:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
到目前为止,Django 还不知道你刚刚创建的应用程序。要将entries应用程序连接到 Django diary 项目,请在diary/settings.py的INSTALLED_APPS列表的开头添加配置类的路径:
# diary/settings.py
INSTALLED_APPS = [
"entries.apps.EntriesConfig", "django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
]
现在,entries应用程序被插入到了diary项目中,Django 找到了它的配置。其中一个配置是模型,它描述了你的日记条目在数据库中的样子。
创建参赛作品模型
您已经创建了数据库。现在是时候定义数据库表了,你的日记条目将被存储在那里。在 Django,你可以用一个模型班来做这件事。就像 Python 中的常规类一样,模型名应该是单数和大写。你的应用叫做entries,你的模型叫做Entry。
Entry模型的字段是日记条目将拥有的元素。在前面,这些字段将显示为一个表单。在后面,它们将是您的Entry数据库表的列。本教程中的日记条目包含三个字段:
title是标题。content是正文的主体。date_created是创作日期和时间。
在entries/models.py中,首先从django.utils进口和timezone。然后在同一个文件中创建Entry类,如下所示:
1# entries/models.py
2
3from django.db import models
4from django.utils import timezone
5
6class Entry(models.Model):
7 title = models.CharField(max_length=200)
8 content = models.TextField()
9 date_created = models.DateTimeField(default=timezone.now)
10
11 def __str__(self):
12 return self.title
13
14 class Meta:
15 verbose_name_plural = "Entries"
通过导入timezone模块,您可以使用timezone.now作为第 9 行中date_created的default参数。这样,如果在创建条目时没有为当前日期和时间定义特定的值,则默认情况下将使用当前日期和时间。稍后在为日记条目创建表单时,您将利用这一行为。
除了title、content、date_created之外,Django 还会自动添加id作为唯一主键。默认情况下,主键为1的条目的字符串表示为Entry object (1)。当您添加.__str__()时,您可以自定义显示的内容。对于日记条目,标题是更好的字符串表示。
你要调整的另一个变量是verbose_name_plural。否则,Django 会把你的Entry的复数拼写成Entrys,而不是Entries。
注册进入模型
要在 Django 管理站点中查看Entry模型,您需要在entries/admin.py中注册它:
# entries/admin.py
from django.contrib import admin
from .models import Entry
admin.site.register(Entry)
当你忘记在管理站点注册一个模型时,Django 不会抛出错误。毕竟,不是每个模型都需要在用户界面中管理。但是对于您的日记的最小可行产品,您将利用内置的 Django 管理站点。
迁移入口模型
添加新类并在管理站点上注册后,您需要为 Django 创建迁移文件并运行它们。使用makemigrations,您可以创建迁移文件,其中包含 Django 构建数据库的指令。使用migrate,您可以实现它们:
(.venv) $ python manage.py makemigrations
(.venv) $ python manage.py migrate
迁移完成后,运行开发 web 服务器,转到浏览器,访问 Django 管理站点http://localhost:8000/admin:
目前,没有列出任何条目。点击添加条目,为您的日记创建至少一个条目,完成此步骤。不确定写什么?也许可以反思一下,你的 Django 日记项目有一个全功能后端是多么的棒!
第三步:在前端显示你的日记条目
现在,您可以在 Django 管理站点中添加新条目了。但是当你在浏览器中访问你的日记的主页时,它仍然显示着抖动的火箭。在这一步,你将学习如何在前端显示你的日记条目。
如果您想看看代码在这一步结束时的样子,请单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
与此步骤相关的文件在source_code_step_3/目录中。
创建列表和详细视图
Django 中有两种视图:基于函数的视图和基于类的视图。两者都接受 web 请求并返回 web 响应。一般来说,基于函数的视图给你更多的控制,但也有更多的工作。基于类的视图给你更少的控制,但也更少的工作。
工作少听起来不错。但这并不是你在日记中使用基于类的视图的唯一原因。您的 Django 日记将使用 web 应用程序的典型视图,比如显示数据库项目列表或它们的详细信息。这就是为什么基于类的视图是你的日记视图的好选择。
Django 提供了许多开箱即用的通用视图。在这种情况下,您将创建 DetailView 和 ListView 的子类,并将它们连接到entries/views.py中的Entry模型:
1# entries/views.py
2
3from django.views.generic import (
4 ListView,
5 DetailView,
6)
7
8from .models import Entry
9
10class EntryListView(ListView):
11 model = Entry
12 queryset = Entry.objects.all().order_by("-date_created")
13
14class EntryDetailView(DetailView):
15 model = Entry
正如所承诺的,现在没有太多的代码需要您编写。第 12 行的查询Entry.objects.all()将返回按主键排序的所有条目。用.order_by("-date_created")增强它将按升序返回你的条目,最新的条目在列表的顶部。
当你编写这样的视图时,Django 会在后台做出假设,比如视图要渲染的模板的名称和位置。
创建您的模板
有了模板,就可以动态生成 HTML 。Django 希望您刚刚创建的基于类的视图的模板以特定的名称位于特定的位置。为模板创建子文件夹:
(.venv) $ mkdir -p entries/templates/entries
当然,模板的路径看起来有点奇怪。但是这种方式可以确保 Django 找到完全正确的模板,即使其他应用程序共享相同的模型名称。在entries/templates/entries/中,您将存储Entry模型的所有模板文件。首先创建entry_list.html并添加以下内容:
1<!-- entries/templates/entries/entry_list.html -->
2
3{% for entry in entry_list %}
4 <article>
5 <h2 class="{{ entry.date_created|date:'l' }}">
6 {{ entry.date_created|date:'Y-m-d H:i' }}
7 </h2>
8 <h3>
9 <a href="{% url 'entry-detail' entry.id %}">
10 {{ entry.title }}
11 </a>
12 </h3>
13 </article>
14{% endfor %}
在 Django 模板中,你甚至可以动态引用 CSS 类。当你看一看第 5 行的<h2>时,你可以看到class="{{ entry.date_created|date:'l' }}"被添加到其中。这显示了带有特殊格式的时间戳。这样,<h2>元素将星期几作为一个类,您可以稍后在 CSS 中给每个星期几一个独特的颜色。
在entry_list循环中,您可以访问Entry模型的字段。为了避免过多的信息使列表混乱,您只需在访问条目的详细信息页面时显示内容。在entries/templates/entries/中以entry_detail.html为文件名创建此详细页面,并添加以下内容:
<!-- entries/templates/entries/entry_detail.html -->
<article>
<h2>{{ entry.date_created|date:'Y-m-d H:i' }}</h2>
<h3>{{ entry.title }}</h3>
<p>{{ entry.content }}</p>
</article>
一个detail模板只需要一个条目对象。这就是为什么你可以在这里直接访问它而不用循环。
将路线添加到您的视图中
要查看模板的运行情况,您需要将您的视图连接到URL。Django 使用一个urls.py文件在浏览器中发送来自用户的请求。类似这样的文件已经存在于diary项目文件夹中。对于 entries 应用程序,您必须首先在entries/urls.py创建它,并添加到EntryListView和EntryDetailView的路径:
1# entries/urls.py
2
3from django.urls import path
4
5from . import views
6
7urlpatterns = [
8 path(
9 "",
10 views.EntryListView.as_view(),
11 name="entry-list"
12 ),
13 path(
14 "entry/<int:pk>",
15 views.EntryDetailView.as_view(),
16 name="entry-detail"
17 ),
18]
第 8 行和第 13 行的 path()函数必须至少有两个参数:
- 一个路由字符串模式,其中包含一个 URL 模式
- 对一个视图的引用,它是基于类的视图的一个
as_view()函数
此外,您可以将参数作为 kwargs 传递,并提供一个名称。有了名称,您就可以在 Django 项目中轻松地引用视图。所以即使你决定改变 URL 模式,你也不需要更新你的模板。
既然entries应用程序的 URL 已经准备好了,您需要将它们连接到diary的urlpatterns列表。当你打开diary/urls.py,你会看到你的 Django 日记项目使用的urlpatterns。到目前为止,只有到"admin/"的路由,这是默认添加的,因此您可以到达 Django 管理站点。要在访问http://localhost:8000时显示您的日记条目,您首先需要将根 URL 发送到entries应用程序:
# diary/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("", include("entries.urls")), ]
创建新模板后,手动重启 Django 开发 web 服务器。然后访问http://localhost:8000并欣赏您的观点:

您可以通过点击列表中条目的链接或访问http://localhost:8000/entries/1来查看条目的详细信息,其中1是现有条目的ID。
现在一切就绪,可以在前端看到您的条目。不过,你的日记看起来还是有点不规范。让我们在下一步中改变它!
第四步:让你的 Django 日记看起来更漂亮
在这一步,你将为你的日记增加一些风格。如果你想看看这一步完成的代码,点击下面的链接,查看source_code_step_4/目录:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
虽然你的写作很有创意,但日记的设计目前有点基础。您可以通过在entries/templates/entries/base.html创建一个基础模板来增加内容:
<!-- entries/templates/entries/base.html -->
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>My Diary</title>
<link rel="stylesheet" href="{% static 'css/diary.css' %}">
</head>
<body>
<h1><a href="/">Dear diary …</a></h1>
{% block content %}{% endblock %}
</body>
</html>
有了模板继承,你不必在你的模板中重复标记。相反,您可以扩展您的子模板。然后,Django 在视图中提供服务时会自动将它们合并在一起。
添加样式表
通过在模板文件的开头插入{% load static %},你可以引用带有{% static %}模板标签和 CSS 文件相对路径的静态文件。在entries/static/css/中创建diary.css并展开下面的框来查看你将添加到文件中的 CSS 代码。
将下面的 CSS 代码复制并粘贴到diary.css中:
/* entries/static/css/diary.css */ * { box-sizing: border-box; } body { font-family: sans-serif; font-size: 18px; } a { color: inherit; } a:hover { opacity: 0.7; } h1 { font-size: 2.8em; } h1 a { text-decoration: none; } h2, h3 { font-size: 1.4em; margin: 0; display: inline-block; padding: 0.5rem 1rem; vertical-align: top; } h2 { background-color: aquamarine; } .mark { background-color: gainsboro; } .mark a { text-decoration: none; } article { margin-bottom: 0.5rem; } p { font-size: 1.2em; padding-left: 1rem; line-height: 1.3em; max-width: 36rem; color: dimgray; } em { font-style: normal; font-weight: bold; } /* Form */ label { display: block; } button, textarea, input { font-size: inherit; min-height: 2.5em; padding: 0 1rem; } input[type="text"], textarea { width: 100%; } textarea { padding: 0.5rem 1rem; font-family: sans-serif; } button, input[type="submit"] { margin: 0 1rem 2px 1rem; cursor: pointer; font-weight: bold; min-width: 8rem; } /* Day coloring */ .Saturday, .Sunday { background-color: lightsalmon; }
请随意增强和优化上面的代码,根据您的喜好调整任何元素。如果你不知道 CSS,如果你对 web 开发感兴趣,学习基础知识是值得的。
如前所述,条目列表中的每个<h2>元素都有自己的工作日作为一个类。通过对.Saturday和.Sunday进行不同的设计,你可以很容易地在列表中找到周末。
扩展子模板
现在是时候将子模板和base.html父模板连接起来了。更新entries/templates/entries/entry_list.html使其看起来像这样:
1<!-- entries/templates/entries/entry_list.html -->
2
3{% extends "entries/base.html" %} 4
5{% block content %} 6 {% for entry in entry_list %}
7 <article>
8 <h2 class="{{ entry.date_created|date:'l' }}">
9 {{ entry.date_created|date:'Y-m-d H:i' }}
10 </h2>
11 <h3>
12 <a href="{% url 'entry-detail' entry.id %}">
13 {{ entry.title }}
14 </a>
15 </h3>
16 </article>
17 {% endfor %}
18{% endblock %}
{% block %}模板标签定义了子模板可以覆盖的文档的一部分。要实现这一点,您必须声明您的子模板扩展了父模板,并定义了一个同名的块元素。通过第 3 行的{% extends %}模板标签,您将entries/base.html定义为父模板。第 5 行和第 18 行的{% block %}和{% endblock %}将放置在父块的content块中的标记换行。
对entries/templates/entries/entries_detail.html进行同样的操作:
<!-- entries/templates/entries/entries_detail.html -->
{% extends "entries/base.html" %}
{% block content %}
<article>
<h2>{{ entry.date_created|date:'Y-m-d H:i' }}</h2>
<h3>{{ entry.title }}</h3>
<p>{{ entry.content }}</p>
</article>
{% endblock %}
两个模板都从它们的父模板继承 HTML 结构和样式。它们共享相同的标题和<h1>标题,加上diary.css提供的样式。要了解这一点,请启动您的 Django 开发服务器并访问http://localhost:8000:
现在,您可以有型地阅读您的条目了。然而,当您想要创建、更新或删除一个条目时,您必须转到 Django 管理站点。当你想快速记下一些想法时,点击次数太多了。在下一步中,您将通过向前端添加此功能来改进您的工作流。
第五步:在前端管理你的日记条目
当您构建和使用 web 应用程序时,有四个基本操作您一直在执行。这些操作如此常见,以至于它们经常被简称为 CRUD :
- 创造
- ead
- 更新日期
- 删除
在 Django 管理站点中,您已经可以执行所有这些操作。在前端,你只能看到你的条目。为了模拟 Django 管理站点的功能,您将重复已经为EntryDetail和EntryList所做的工作,添加一个视图、一个模板和一个 URL。
添加视图
在entries/views.py中,到目前为止你已经导入了ListView和DetailView。更新您的导入语句,如下所示:
# entries/views.py
from django.urls import reverse_lazy
from django.views.generic import (
ListView,
DetailView,
CreateView,
UpdateView,
DeleteView,
)
在entries/views.py的底部添加您的三个子类:
1# entries/views.py
2
3class EntryCreateView(CreateView):
4 model = Entry
5 fields = ["title", "content"]
6 success_url = reverse_lazy("entry-list")
7
8class EntryUpdateView(UpdateView):
9 model = Entry
10 fields = ["title", "content"]
11
12 def get_success_url(self):
13 return reverse_lazy(
14 "entry-detail",
15 kwargs={"pk": self.entry.id}
16 )
17
18class EntryDeleteView(DeleteView):
19 model = Entry
20 success_url = reverse_lazy("entry-list")
这一次,仅仅将类连接到您的Entry模型是不够的。对于EntryCreateView和EntryUpdateView,您还需要定义应该在表单中显示哪些模型字段,正如您在第 5 行和第 10 行中看到的。您在第 18 行的EntryDeleteView只执行删除一个条目的动作,所以您不需要在其中定义任何字段。
此外,您需要定义用户在提交视图表单后应该被重定向到哪里。默认情况下, .get_success_url() 只是返回success_url的值。在EntryUpdateView中,你需要重写这个方法。
通过在第 15 行将entry.id作为关键字参数提供,您可以在编辑后停留在条目详细信息页面上。不使用 URL,而是使用 reverse_lazy 按名称引用它们,就像在模板中一样。
创建模板
像以前一样,Django 寻找具有特定名称的模板:
- 对于
EntryDeleteView,是entry_confirm_delete.html。 - 对于
EntryCreateView,是entry_form.html。 - 对于
EntryUpdateView来说就会是entry_update_form.html。
当 Django 没有找到entry_update_form.html时,它尝试将entry_form.html作为后备。您可以利用这一点,在entries/templates/entries/中创建一个处理这两种视图的模板,并添加一个基本的提交表单:
1<!-- entries/templates/entries/entry_form.html -->
2
3{% extends "entries/base.html" %}
4{% block content %}
5 <form method="post">
6 {% csrf_token %}
7 {{ form.as_p }}
8 <input type="submit" value="Save">
9 </form>
10 {% if entry %}
11 <a href="{% url 'entry-detail' entry.id %}">
12
13 </a>
14 {% else %}
15 <a href="{% url 'entry-list' %}">
16
17 </a>
18 {% endif %}
19{% endblock %}
当这个模板被CreateView加载时,表单将是空的,取消它将再次把你带到条目列表。当被CreateUpdateView加载时,它会被预填充当前条目的标题和内容。取消会将您带到条目详细信息页面。
在一个模板中有多种方式呈现一个表单。使用第 7 行的{{ form.as_p }}, Django 将显示您在视图中定义的字段,这些字段用段落包装。无论何时在 Django 表单中发布内容,都必须在第 6 行包含 {% csrf_token %}模板标签。这是防止跨站请求伪造的安全措施。
与其他模板一样,在第 3 行添加{% extends "entries/base.html" %}来扩展基本模板。然后定义在第 4 行和第 18 行之间的block content标记中包含什么。在entries/templates/entries/中,你对entry_confirm_delete.html使用相同的模式:
<!-- entries/templates/entries/entry_confirm_delete.html -->
{% extends "entries/base.html" %}
{% block content %}
<form method="post">{% csrf_token %}
<p>
Are you sure you want to delete
<em>"{{ entry.title }}"</em>
created on {{ entry.date_created|date:'Y-m-d' }}?
</p>
<input type="submit" value="Confirm">
</form>
<a href="{% url 'entry-detail' entry.id %}">
</a>
{% endblock %}
当您要删除条目时,此模板将会出现。在表格中提到"{{ entry.title }}"和{{ entry.created_date|date:'Y-m-d' }}会提醒你通过按确认来删除哪个条目。
创建网址
创建视图及其模板后,创建它们的路线,以便在前端访问它们。在entries/urls.py中添加三条到urlpatterns的附加路径:
# entries/urls.py
urlpatterns = [
path(
"",
views.EntryListView.as_view(),
name="entry-list"
),
path(
"entry/<int:pk>",
views.EntryDetailView.as_view(),
name="entry-detail"
),
path( "create", views.EntryCreateView.as_view(), name="entry-create" ), path( "entry/<int:pk>/update", views.EntryUpdateView.as_view(), name="entry-update", ), path( "entry/<int:pk>/delete", views.EntryDeleteView.as_view(), name="entry-delete", ), ]
对于entry-create,你只需要一个基本的create路径。与前面创建的entry-detail一样,entry-update和entry-delete需要一个主键来标识哪个条目应该被更新或删除。
现在你可以直接在前端为你的日记创建、更新和删除条目。启动开发 web 服务器并访问http://localhost:8000/create进行测试。如果您想将您的代码与本教程中的代码进行比较,请单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
你可以在source_code_step_5/目录中找到与此步骤相关的文件。
第六步:改善用户体验
利用你的日记,你可能会无意中发现一些怪癖,这些怪癖让你在周围浏览时有点讨厌。在这一步中,您将逐一解决它们。你会发现界面上的小变化会对你的日记用户体验产生大的影响。
掌控你的成功
得到一些反馈总是好的,尤其是积极的反馈。使用消息框架,您可以快速定义提交表单后显示的一次性快速消息。要使用该功能,将messages和SuccessMessageMixin导入到entries/views.py:
# entries/views.py
from django.contrib import messages
from django.contrib.messages.views import SuccessMessageMixin
EntryListView和EntryDetailView是读取视图,不处理表单。他们可能会在模板中显示消息,但不会发送消息。这意味着你不需要为它们子类化SuccessMessageMixin。另一方面,EntryCreateView、EntryUpdateView和EntryDeleteView向消息存储器添加了通知,因此您需要调整它们的功能:
1# entries/views.py
2
3class EntryCreateView(SuccessMessageMixin, CreateView): 4 model = Entry
5 fields = ["title", "content"]
6 success_url = reverse_lazy("entry-list")
7 success_message = "Your new entry was created!" 8
9class EntryUpdateView(SuccessMessageMixin, UpdateView): 10 model = Entry
11 fields = ["title", "content"]
12 success_message = "Your entry was updated!" 13
14 def get_success_url(self):
15 return reverse_lazy(
16 "entry-detail",
17 kwargs={"pk": self.object.pk}
18 )
在继承了第 3 行的EntryCreateView中的SuccessMessageMixin和第 9 行的EntryUpdateView之后,你在第 7 行和第 12 行为它们定义了一个success_message。尤其是当你执行一个破坏性的操作时,比如删除一个条目,给出反馈说一切正常是很重要的。要在DeleteView中显示消息,您必须添加一个定制的.delete()方法,并手动将您的定制success_message添加到消息框架中:
1# entries/views.py
2
3class EntryDeleteView(DeleteView):
4 model = Entry
5 success_url = reverse_lazy("entry-list")
6 success_message = "Your entry was deleted!" 7
8 def delete(self, request, *args, **kwargs): 9 messages.success(self.request, self.success_message) 10 return super().delete(request, *args, **kwargs)
第 8 行需要这个额外的方法,因为DeleteView类不是FormView的祖先。这就是为什么你可以跳过在第 3 行的EntryDeleteView中添加SuccessMessageMixin的原因。
点击下面的链接可以看到entries/views.py的全部内容。您可以在source_code_step_6/目录中找到它:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
既然视图发送消息,您需要增强模板来显示它们。
得到消息
消息存储在消息存储器中。通过循环,您可以显示当前在消息存储器中的所有消息。在 Django 模板中,您可以通过使用消息模板标签来实现这一点。按照您创建日记和构建模板的方式,您只需将其添加到entries/base.html:
1<!-- entries/base.html -->
2
3<h1><a href="/">Dear diary …</a></h1>
4
5{% if messages %} 6 <ul class="messages"> 7 {% for message in messages %} 8 <li class="message"> 9 {{ message }} 10 </li> 11 {% endfor %} 12 </ul> 13{% endif %} 14
15{% block content %}{% endblock %}
通过将第 4 行和第 12 行的{% if messages %}中的消息列表打包,您可以确保只有在存储器中有任何消息的情况下才会显示。
改善您的导航
要创建、编辑或删除条目,您需要记住相应的 URL,然后在地址栏中键入它们。多么乏味!幸运的是,您可以通过向视图添加链接来解决这个问题。从链接到entries/templates/entries/entry_list.html模板中的entry-create视图开始:
1<!-- entries/templates/entries/entry_list.html -->
2
3{% block content %}
4<article> 5 <h2 class="mark">{% now "Y-m-d H:i" %}</em></h2> 6 <a href="{% url 'entry-create' %}"></a> 7</article> 8 9{% for entry in entry_list %}
这个标记将类似于其他日记条目列表项。在</article>之后向entries/templates/entries/entry_detail.html模板添加新段落,以快速编辑或删除条目:
<!-- entries/templates/entries/entry_detail.html -->
</article>
<p>
<a href="{% url 'entry-update' entry.id %}">✍️ Edit</a> <a href="{% url 'entry-delete' entry.id %}">⛔ Delete</a> </p> {% endblock %}
这段代码在条目细节下添加了两个链接,分别链接到entry-update和entry-delete。
为您的信息设计风格
最后,通过在entries/static/css/diary.css的末尾添加.messages和.message来设计简讯的样式:
/* entries/static/css/diary.css */ /* Messages */ .messages { padding: 0; list-style: none; } .message { width: 100%; background: lightblue; padding: 1rem; text-align: center; margin: 1rem 0; }
在终端中按 Ctrl + C 停止开发 web 服务器,然后重启。然后访问http://localhost:8000,看看你的行动变化。如果消息看起来没有样式,您可能必须清除浏览器的缓存,以便它重新加载样式表更改:

你现在拥有了一个完全可用的完全在 Django 中构建的日记网络应用。虽然你的日记只存储在本地,但确保只有你能访问它是个好主意。在你开始写日志之前,让我们添加这个限制。
第七步:给你的 Django 日记上锁
一把小小的金锁对于一本实体日记来说是多么的重要,一张登录表对于你的电子日记本来说是多么的重要。这把锁的钥匙是您已经用来登录 Django 管理站点的用户名和密码组合。
重复使用您的 Django 管理员登录名
Django 提供的认证系统相当基础。对于其他有固定用户的项目,可以考虑定制它。但是对于你的 Django 日记,重用 Django 管理站点的登录就足够了。过一会儿你会发现它工作得很好。首先,让我们来解决注销问题。
添加注销链接
您可以通过访问一个特殊的 URL 退出。Django 已经提供了一个名为admin:logout的 URL 来让您退出 Django 管理站点。当您从项目中的任何地方登录并访问这个 URL 时,Django 会自动将您注销。要快速访问该 URL,请在entries/templates/entries/base.html底部添加一个链接:
<!-- entries/templates/entries/base.html -->
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>My Diary</title>
<link rel="stylesheet" href="{% static 'css/diary.css' %}">
</head>
<body>
<h1><a href="/">Dear diary …</a></h1>
{% if messages %}
<ul class="messages">
{% for message in messages %}
<li class="message">
{{ message }}
</li>
{% endfor %}
</ul>
{% endif %}
{% block content %}{% endblock %}
<hr> <a href="{% url 'admin:logout' %}">Logout</a> </body>
</html>
启动你的开发 web 服务器,在http://localhost:8000进入你的主页,点击注销链接。现在,当您访问http://localhost:8000/admin时,您会看到登录表单。这意味着您已注销。当你再次访问http://localhost:8000时,你的日记仍然可以访问。是时候改变了!
限制对您的视图的访问
在 Django 中,你可以定义谁可以查看哪些视图。默认情况下,它们对所有访问您网站的人开放。为了确保视图需要经过身份验证的用户才能访问,在entries/views.py的顶部导入LoginRequiredMixin:
# entries/views.py
from django.contrib.auth.mixins import LoginRequiredMixin from django.contrib import messages
from django.contrib.messages.views import SuccessMessageMixin
from django.urls import reverse_lazy
from django.views.generic import (
ListView,
DetailView,
CreateView,
UpdateView,
DeleteView,
)
from .models import Entry
一旦一个视图类使用了 LoginRequiredMixin ,就要求先成功登录。此外,您必须定义一个login_url,以便 Django 知道当您没有登录时将您重定向到哪里。您可以创建一个继承了LoginRequiredMixin的基类,并在entries/views.py中定义login_url,而不是单独为所有的类做这件事:
# entries/views.py
class LockedView(LoginRequiredMixin):
login_url = "admin:login"
现在您可以在所有其他视图中继承LockedView,这些视图应该只对经过认证的用户开放。编辑entries/views.py使你的类看起来像这样:
# entries/views.py
class EntryListView(LockedView, ListView):
model = Entry
queryset = Entry.objects.all().order_by("-created_date")
class EntryDetailView(LockedView, DetailView):
model = Entry
class EntryCreateView(LockedView, SuccessMessageMixin, CreateView):
model = Entry
fields = ["title", "content"]
success_url = reverse_lazy("entry-list")
success_message = "Your new entry was created!"
class EntryUpdateView(LockedView, SuccessMessageMixin, UpdateView):
model = Entry
fields = ["title", "content"]
success_message = "Your entry was updated!"
def get_success_url(self):
return reverse_lazy("entry-detail", kwargs={"pk": self.object.pk})
class EntryDeleteView(LockedView, SuccessMessageMixin, DeleteView):
model = Entry
success_url = reverse_lazy("entry-list")
success_message = "Your entry was deleted!"
def delete(self, request, *args, **kwargs):
messages.success(self.request, self.success_message)
return super().delete(request, *args, **kwargs)
现在,当您访问http://localhost:8000时,您将被重定向到 Django 登录表单。登录后,您将被重定向到条目列表,并看到仅供您查看的所有内容:
就是这样!你已经成功地在姜戈建立了你自己的私人日记。如果您想将您的代码与项目的最终代码进行比较,请单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。
该项目的完整代码在source_code_step_final/目录中。
接下来的步骤
你建立的日记本功能齐全,随时可用。但是,这也是一个很好的基础。也许你已经有了一些关于如何进一步改善你的日记的想法。或者你可以试试下面的方法:
- 为您最近的条目添加页面。
- 给每个工作日一种颜色。
- 在 HTML
<title>标签中显示创建日期。 - 为条目创建当日选择表情符号。
- 对条目列表进行分页。
在本教程中,向您介绍了 Django 提供的一些基本概念和模式。希望它能激发人们对深入研究这个 Python web 框架的兴趣。如果你想继续你的旅程并了解更多,你可以看看这些教程:
- 你与 Django 的第一步:建立一个 Django 项目
- Django 第 1 部分入门:构建投资组合应用
- 在 Django Admin 中管理用户需要知道的事情
- 用 Python 定制 Django 管理
- 使用 Django、Vue 和 GraphQL 创建博客
您可以将通过完成日记项目获得的知识应用到其他 Django 教程中,并将您的 web 应用技能提升到一个新的水平!
结论
在本教程中,您使用 Django 从头开始创建了一个个人日记。您了解了如何构建一个可以日常使用的全功能 web 应用程序。它利用了 Django 的许多优势,包括管理站点、基于类的视图、消息框架和模板系统。
这个 Django 项目也是您未来 Django 项目的完美基础。你在这个日记项目中完成的步骤对于其他项目来说基本上是一样的,比如一个博客或者一个待办事项应用。
在本教程中,您学习了如何:
- 建立一个 Django 项目
- 使用标准的 SQLite 数据库
- 利用 Django 管理站点
- 创建模型和基于类的视图
- 嵌套和样式模板
- 通过认证保护您的日记
你可以点击下面的链接下载 Django 日记的完整源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用用 Django 和 Python 构建一个个人日记 web 应用程序。**********
用 Django 构建一个抽认卡应用程序
当你想记住一个新话题或学习一门新语言时,抽认卡是一个很好的工具。你在卡片的正面写一个问题,在卡片的背面写答案。然后你可以通过阅读抽认卡来测试你的记忆力。你给自己看卡片的次数越多,记住卡片内容的机会就越大。有了 Django,你可以构建自己的抽认卡应用程序。
通过遵循本教程,你将构建一个 Django 抽认卡应用程序,它复制了一个间隔重复系统,这可以提高你的学习潜力。
在这个循序渐进的项目中,你将学习如何:
- 建立一个 Django 项目
- 使用 SQLite 数据库和 Django shell
- 创建模型和基于类的视图
- 结构和嵌套模板
- 创建自定义模板标签
在此过程中,您将获得一步一步的指导,以创建您的最终抽认卡应用程序。这意味着您将在单独的、小块的代码中获得您需要的所有代码。您也可以通过点击下面的链接找到该应用程序的完整源代码:
源代码: 点击此处下载源代码,您将使用它来构建您的 Django 抽认卡应用程序。
如果您想在提高 Django 和 Python 技能的同时学习新的主题,那么这个项目非常适合您!
演示:你的 Django 抽认卡应用程序
在本教程中,您将构建一个抽认卡应用程序。在你的 web 应用程序的首页,你可以看到你现有的所有卡片,并可以创建新的卡片。在每张抽认卡上,你可以添加一个问题和一个答案,以后你可以编辑它们。当您想要测试您的知识时,您可以导航到一个盒子来查看盒子中包含的卡片:
https://player.vimeo.com/video/728439716?background=1
一旦你知道了卡片问题的答案,卡片就会移动到下一个盒子。如果抽认卡移动到下一个盒子,并不意味着你已经完成了。你仍然会定期回顾它来刷新你的记忆,它会继续在盒子里前进。基本上,方框数越高,你就越有可能掌握这些概念。如果你不知道卡片问题的答案,那么卡片会回到第一个盒子里。
项目概述
本教程中的工作分为多个步骤。这样,你可以休息一下,然后按照自己的节奏继续。您将构建一个带有数据库连接的全栈 web 应用程序,它复制了 Leitner 系统:
在[莱特纳系统]中,抽认卡根据学习者对莱特纳学习盒中每个抽认卡的熟悉程度进行分组。学习者试图回忆写在抽认卡上的答案。如果他们成功了,他们就把卡片发给下一组。如果他们失败了,他们会把它送回第一组。(来源)
通过使用间隔重复,你将更频繁地在第一个盒子中测试你对新的或具有挑战性的主题的知识,同时你将以更大的时间间隔检查其他盒子中的卡片:
- 你有五个可以装抽认卡的盒子。
- 当你制作抽认卡时,你把它放进第一个盒子里。
- 为了测试你的知识,你选择一个盒子,随机抽取一张抽认卡,然后检查你是否知道卡上问题的答案。
- 如果你知道答案,那么你把卡片移到下一个更高的盒子里。
- 如果你不知道答案,那么你把卡片移回到第一个盒子里。
盒子的数字越大,你检查盒子里的抽认卡来测试你的知识的频率就越低。
注:抽认卡是学习一门新语言的绝佳工具。在整个教程的例子中,你会发现英语和西班牙语单词的翻译。但是这些例子是故意保持最小的。这样,您可以方便地自定义卡片上的问题和答案。
这个项目是一个很好的起点,然后您可以用更多的特性来增强您的 Django 项目。在本教程的结尾,你会发现下一步要构建什么的想法。
先决条件
你不需要任何关于 Django 或 T2 数据库的知识来完成这个项目。如果您想进一步了解本教程中遇到的主题,可以找到相关资源的链接。
然而,你应该能熟练使用命令行,并具备 Python 的基础知识和类。尽管了解虚拟环境和 pip 会有所帮助,但您将通过本教程学习如何设置一切。
步骤 1:准备你的 Django 项目
在这一步中,您将为 Django 抽认卡项目准备开发环境。首先,您将创建一个虚拟环境并安装项目所需的所有依赖项。在这一步的最后,您将创建 Django 项目,并验证您的项目在浏览器中设置正确。
创建虚拟环境
在本节中,您将创建您的项目结构。您可以随意命名项目的根文件夹。例如,您可以将其命名为flashcards_app/并导航到该文件夹:
$ mkdir flashcards_app
$ cd flashcards_app
在这种情况下,您将项目的根文件夹命名为flashcards_app/。您创建的文件和文件夹将位于该文件夹或其子文件夹中。
导航到项目文件夹后,创建并激活一个虚拟环境是个好主意。这样,您安装的任何项目依赖项都不是系统范围的,而只是在项目的虚拟环境中。
在下面选择您的操作系统,并使用您的平台特定命令来设置虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS>
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $
使用上面显示的命令,您可以通过使用 Python 的内置venv模块创建并激活一个名为venv的虚拟环境。提示前面venv周围的括号(())表示您已经成功激活了虚拟环境。
添加依赖关系
在你创建并激活你的虚拟环境后,是时候安装带有 pip 的django:
(venv) $ python -m pip install django==4.0.4
Django web 框架是你的项目需要的唯一直接依赖。当您运行pip install命令时,Django 需要工作的任何其他 Python 包会自动安装。
启动你的 Django 项目
一旦创建了虚拟环境并安装了 Django,就该初始化 Django 项目了。使用 Django 的命令行实用程序在您的项目根目录中创建 Django flashcards项目:
(venv) $ django-admin startproject flashcards .
不要忘记在上面的命令末尾添加点(.)。圆点防止 Django 为你的抽认卡项目创建一个嵌套的项目目录。否则你会得到一个包含flashcards/子目录的flashcards/文件夹。
通过运行如上所示的startproject命令,您已经告诉 Django 在项目的根目录下创建一个包含一堆文件的flashcards/文件夹,包括manage.py。在命令行中,manage.py文件将接管的管理任务。例如,它将运行您的开发 web 服务器:
(venv) $ python manage.py runserver
您可以指定开发服务器的 IP 地址和端口。默认情况下,服务器在127.0.0.1的端口8000上运行,并且只能在您的计算机上访问。随着服务器的运行,您可以使用http://127.0.0.1:8000或http://localhost:8000在浏览器中访问您的 Django 项目:
这是你的 Django 项目的主页。到目前为止,只能看到一个晃动的火箭。这意味着安装成功,您可以继续创建您的抽认卡应用程序。
第二步:设置你的抽认卡应用程序
在上一步中,您准备了开发环境。现在是时候设置你的抽认卡应用程序了,你将把它命名为cards。cards应用程序将包含创建你的学习卡的所有代码。
创建你的 Django 抽认卡应用程序
Django 项目包含一个或多个应用程序。一个 app 的范围应该是有限的。一开始,区分一个项目和应用可能会令人困惑。但是在大的 Django 项目中,这种关注点的分离保持了代码库的干净。这种结构的另一个好处是你可以重用其他项目的应用。
在本教程中,除了您的项目,您只需要一个应用程序。该应用程序的主要目的是处理您的应用程序的卡,因此您可以调用该应用程序cards。运行命令创建cards应用程序:
(venv) $ python manage.py startapp cards
该命令在您的项目中创建一个cards/文件夹,其中包含一些预定义的文件。要将cards应用程序连接到抽认卡项目,将其添加到flashcards/settings.py中的INSTALLED_APPS:
# flashcards/settings.py
# ...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"cards.apps.CardsConfig", ]
# ...
现在,您的cards应用程序的配置类被插入到flashcard Django 项目中。接下来,你要确保能在浏览器中导航到你的cards应用。
启动您的登录页面
到目前为止,Django 仍然在你的抽认卡项目的登陆页面上显示晃动的火箭。在本节中,您将通过使用一个基础模板来实现您的定制登录页面。
首先,你需要告诉 Django,你的cards应用程序现在负责你的项目的根 URL。打开您的flashcards/文件夹中的urls.py,并包含您的cards网址:
1# flashcards/urls.py
2
3from django.contrib import admin
4from django.urls import path, include 5
6urlpatterns = [
7 path("admin/", admin.site.urls),
8 path("", include("cards.urls")), 9]
在第 8 行,您将带有空 route 字符串模式的path()添加到urlpatterns列表中,作为第一个位置参数。作为第二个参数,您传入include(),它通知抽认卡项目cards应用程序将处理所有匹配字符串模式的路由。空字符串模式("")确实是空的,所以cards从现在开始监听你所有的根 URL。
有了这个 URL 模式,Django 会将项目的任何 URL 传递到您的cards应用程序,除了admin/。为了处理这个问题,你的cards应用需要自己的urls.py文件,它接管分配 URL 的责任:
# cards/urls.py
from django.urls import path
from django.views.generic import TemplateView
urlpatterns = [
path(
"",
TemplateView.as_view(template_name="cards/base.html"),
name="home"
),
]
在您的新urls.py文件中,您正在使用一个urlpatterns列表,就像以前一样。同样,您传入一个空的路由字符串模式。这次你服务一个TemplateView到根 URL。
你也可以将name="home"作为可选参数传入。有了名称,您就可以在 Django 项目中方便地引用视图。因此,即使您决定在某个时候更改 URL 模式,也不必更新任何模板。
为了提供您所引用的模板,在cards/templates/cards/中创建base.html:
1<!-- cards/templates/cards/base.html -->
2
3<!DOCTYPE html>
4<html lang="en">
5
6<head>
7 <title>Flashcards</title>
8</head>
9
10<body>
11 <header>
12 <h1>Flashcards App</h1>
13 </header>
14 <main>
15 {% block content %}
16 <h2>Welcome to your Flashcards app!</h2>
17 {% endblock content %}
18 </main>
19</body>
20
21</html>
你的基础模板包含了你网站的基本结构。在第 15 行,您定义了一个子模板可以覆盖的模板块。如果没有子模板覆盖内容块,则将显示块中的内容。
注意:通常,您的 Django 开发 web 服务器会自己重启。如果您想手动停止服务器,那么您可以在终端中按 Ctrl + C 。
要再次启动服务器,请运行以下命令:
(venv) $ python manage.py runserver
请记住,您需要在激活的虚拟环境中运行这个命令。
跳到您的浏览器并访问http://127.0.0.1:8000:
太棒了,你的项目现在显示了cards的主页!您可以使用刚刚创建的带有欢迎信息的基础模板。然而,你的登陆页面看起来有点乏味。继续阅读,学习如何给你的网站添加一些风格。
撒上某种风格
对许多人来说,令人愉悦的设计是积极学习体验的重要组成部分。你可以通过使用 CSS 给你的 HTML 页面添加设计。您可以导入外部 CSS 文件,而不是自己编写所有 CSS 代码:
1<!-- cards/templates/cards/base.html -->
2
3<!DOCTYPE html>
4<html lang="en">
5
6<head>
7 <title>Flashcards</title>
8 <link rel="stylesheet" href="https://cdn.simplecss.org/simple.min.css"> 9</head>
10
11<!-- ... -->
类似于 Python 导入技术,你可以导入一个外部 CSS 库到你的网站。在第 8 行,您正在加载 Simple.css 框架。这个外部 CSS 文件提供了样式,而不需要您向 HTML 元素添加任何类。
您可以通过添加一些额外的 CSS 样式来自定义您的 CSS 代码。从下面的可折叠列表中复制并粘贴标记的 CSS 代码:
<!-- cards/templates/cards/base.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<title>Flashcards</title>
<link rel="stylesheet" href="https://cdn.simplecss.org/simple.min.css">
</head>
<style> /* Custom CSS */ :root { --accent: #6e48ad; --accent-bg: white; --bg: #fff; --text: #212121; --text-light: #585858; --border: #d8dae1; --code: #d81b60; --preformatted: #444; } article { background-color: var(--marked); border: 1px solid var(--border); border-radius: 5px; padding: 1em; margin: 1em 0; } h2 { text-align: center; } h2, h4 { margin-top: 0; } hr { background: var(--accent); border-color: var(--accent); } button, a[role="button"] { color: white; text-decoration: none; } input, select, textarea { width: 100%; } </style>
<!-- ... -->
继续并重新启动您的开发 web 服务器。然后,在http://127.0.0.1:8000访问您的抽认卡应用程序:
太棒了,你的抽认卡应用程序现在用花哨的字体和居中的文本来戏弄一个适当的设计。如果你知道一些 CSS,那么你可以慢慢来,调整你的抽认卡应用程序的设计。一旦你对你的前端的外观感到满意,继续阅读来处理一些后端的事情。
第三步:亮出你的牌
现在你的应用已经启动并运行了,你可以定义你的 SQLite 数据库的表应该是什么样子。您可以通过添加一个Card模型来做到这一点。
您还将在 Django shell 中创建您的第一个抽认卡,并在浏览器中列出您的卡。
连接 SQLite 数据库
在抽认卡上,前面通常是你陈述问题的地方。卡片的背面有答案。您可以在cards应用的模型中复制卡片的属性:
1# cards/models.py
2
3from django.db import models
4
5NUM_BOXES = 5
6BOXES = range(1, NUM_BOXES + 1)
7
8class Card(models.Model):
9 question = models.CharField(max_length=100)
10 answer = models.CharField(max_length=100)
11 box = models.IntegerField(
12 choices=zip(BOXES, BOXES),
13 default=BOXES[0],
14 )
15 date_created = models.DateTimeField(auto_now_add=True)
16
17 def __str__(self):
18 return self.question
在仔细查看Card类的内容之前,请注意第 5 行中的NUM_BOXES变量。NUM_BOXES的值定义了你的应用程序中需要多少个盒子。有了这五个方框,你就有了在语言学习中实施间隔重复的坚实基础。
在第 6 行,您正在创建BOXES变量,它包含一个从1开始到NUM_BOXES + 1结束的可迭代范围——换句话说就是6。这样,您可以使用从 1 到 5 的用户友好的编号来遍历您的框,而不是使用该范围默认的从零开始的编号。
第 8 到 18 行定义了您的Card类。您将在您的抽认卡应用程序中使用单词到单词的翻译,因此在第 9 行的question字段和第 10 行的answer字段中使用models.CharField就足够了。此外,如果你也想记忆短句,一百个字符的最大长度应该足够了。
注意:还可以设置更大的最大长度。但是请记住,如果你保持抽认卡简洁明了,它通常是最有用的。
通过第 11 行到第 14 行的box字段,您将跟踪您的卡所在的盒子编号。默认情况下,您在第一个框中创建抽认卡。使用choices,您确保models.IntegerField必须包含一个在您的BOXES范围内的数字。
在第 15 行,您添加了一个models.DateTimeField,它将自动包含您的卡的创建日期和时间的时间戳。使用date_created字段,您可以在您的卡片概览中首先显示最新的卡片。
为了控制您的Card对象的字符串表示,您在第 17 行和第 18 行定义了.__str__()。当你返回你的卡实例的question字符串时,你就可以方便地发现你正在使用哪张卡。
您的Card模型定义您的数据库应该包含一个表,该表存储您的卡。您的Card模型的字段将是您的数据库中的字段。要更新您的数据库,您必须创建迁移并迁移更改以应用它们:
(venv) $ python manage.py makemigrations
Migrations for 'cards':
cards/migrations/0001_initial.py
- Create model Card
(venv) $ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, cards, contenttypes, sessions
Running migrations:
Applying cards.0001_initial... OK
...
将更改应用到数据库后,需要将数据添加到数据库中。为此,您将使用 Django shell 将一些卡放入您的数据库。前往您的终端并启动 Django shell:
(venv) $ python manage.py shell
Django shell 类似于您的交互式 Python 解释器。但是 Django shell 允许您直接从 Django 项目的根文件夹中工作,因为它已经导入了您的 Django 设置。
在 shell 中,您现在可以直接与您的抽认卡项目进行交互。继续创建三张卡:
>>> from cards.models import Card >>> c1 = Card(question="Hello", answer="Hola") >>> c1.save() >>> c2 = Card(question="Please", answer="Por favor") >>> c2.save() >>> c3 = Card(question="Sorry", answer="Lo siento", box=2) >>> c3.save() >>> Card.objects.all() <QuerySet [<Card: Hello>, <Card: Please>, <Card: Sorry>]>导入
Card模型后,您创建了三张卡。用一个question和一个answer参数初始化Card类。记住你的卡的box和date_created属性有默认值。所以不需要提供。一旦调用了.save(),就将卡提交给数据库。注:您可以随意创建任意多的卡片。但是,在继续本教程之前,请确保您至少创建了三张卡。
使用
box参数将一些卡片放入不同的盒子中。这将模拟一个正在进行的学习会话,并帮助您开发您的前端,以反映一个现实的场景。使用
Cards.objects.all(),您可以检索当前数据库中包含的所有卡片。QuerySet表示表明您已经成功地向数据库添加了一些卡。在下一部分中,您将在前端展示您的牌。列出你的第一张抽认卡
在上一节中,您向数据库添加了一些抽认卡。现在是时候在前端列出你的卡片了。
首先编写一个基于类的视图,列出所有的卡片:
1# cards/views.py 2 3from django.views.generic import ( 4 ListView, 5) 6 7from .models import Card 8 9class CardListView(ListView): 10 model = Card 11 queryset = Card.objects.all().order_by("box", "-date_created")Django 提供了许多现成的通用视图。您在第 9 行创建的基于类的视图是 Django 的 ListView 的子类。
您必须在
ListView中设置的唯一属性是您的视图引用的模型。您在第 10 行这样做。通过在第 11 行定义
queryset,您获得了对数据库返回的项目的更多控制。不仅要拿到所有的卡,还要按box和date_created排序。这意味着你会收到一个 DjangoQuerySet,里面的卡片首先按照盒子升序排列,然后按照创建日期降序排列。创建日期的降序得益于"-date_created"中的破折号(-)前缀。在浏览器中查看卡片之前,必须定义一个模板。Django 希望基于类的视图的模板在一个特定的位置,有一个特定的名字。对于您的
CardListView,您需要一个在cards/templates/cards/中名为card_list.html的模板:1<!-- cards/templates/cards/card_list.html --> 2 3{% extends "cards/base.html" %} 4 5{% block content %} 6 <h2> 7 All Cards 8 </h2> 9 {% for card in card_list %} 10 <h3>🗃 {{ card.box }} Box</h3> 11 <article> 12 {{ card }} 13 </article> 14 {% endfor %} 15{% endblock content %} ```py 在你的`card_list.html`模板中,你用内置的`extends` **模板标签**扩展了你的`base.html`模板。记住你的`base.html`模板也有一个`{% block content %}` [模板标签](https://realpython.com/django-templates-tags-filters/)。您用第 6 到 14 行的`{% block content %}`代码覆盖了这个代码块的主体。你现在列出了所有的抽认卡,而不是显示欢迎信息。 在第 9 行,你循环了所有的卡片。在`card_list`循环中,您可以为每个单独的`Card`实例访问`Card`模型的字段。 一个抽认卡应用程序在你的主页上列出所有的抽认卡是有意义的。用新的`CardListView`的 URL 替换之前的登录页面,并将其重命名为`card-list`:1# cards/urls.py
2
3from django.urls import path
4# Removed: from django.views.generic import TemplateView
5
6from . import views 7
8urlpatterns = [
9 path(
10 "",
11 views.CardListView.as_view(), 12 name="card-list" 13 ),
14]您不再需要第 4 行中的前一个`TemplateView`,所以您删除了这一行,并在第 6 行中导入了`views`。 不是在第 11 行提供一个`TemplateView`,而是作为一个视图提供您的`CardListView`。因此,您将路线的名称重命名为`card-list`。 重启您的开发 web 服务器并访问`http://127.0.0.1:8000`: [](https://files.realpython.com/media/django-flashcards-app-05-repeating-headlines.158d96a69fa3.png) 你现在可以在你的抽认卡应用程序的主页上列出你所有的卡片,按照盒子和创建日期整齐地排序。您还从基本模板继承了标题和样式。但是盒子的编号看起来有点重复,最好使用序数——比如第一、第二和第三——来列出盒子。 ### 调整您的模板 目前,您将您的箱子列为 *1 箱子*、 *2 箱子*,以此类推。这看起来有点技术性。相反,把你的盒子按顺序列成*第一个盒子*、*第二个盒子*等等会友好得多。 你可以用 Django 的`humanize` **模板过滤器**来实现这个序数。这组过滤器有助于提高模板中数据的可读性。要使用它,您必须将`django.contrib.humanize`添加到您的`INSTALLED_APPS`中:flashcards/settings.py
...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"django.contrib.humanize", "cards.apps.CardsConfig",
]...
在您调整了 Django 设置之后,您可以在您的`card_list.html`模板中加载`humanize`模板过滤器:{% extends "cards/base.html" %}
在稍后的代码中,您将使用`humanize`过滤器集在显示框标题时应用`ordinal`过滤器。 停留在`card_list.html`中,将您的`<h3>`标题包装在`ifchanged`模板标签中,以便只显示一次您的新框标题:1
2
3
4
5{% for card in card_list %}
6 {% ifchanged %} 7🗃 {{ card.box | ordinal }} Box
8 {% endifchanged %} 9
10 {{ card }}
11
12{% endfor %}
13
14第 6 行是`{% ifchanged %}`,第 8 行是`{% endifchanged %}`,如果标题值改变,你只在第 7 行显示框标题。这样,你只显示一次盒子号码,然后显示盒子里所有的牌。只有当你到达下一个框并且标题改变时,你才显示新的标题。 在第 7 行,您使用管道符号(`|`)来应用`humanize`过滤器集的`ordinal`过滤器。过滤器就像是在 Django 呈现数据之前就地修改数据的小函数。在这种情况下,您可以使用`ordinal`过滤器将整数转换成它们对应的序数字符串。 还有另一个机会来优化您的`card_list.html`模板。目前,您正在用`{{ card }}`变量显示您的卡的表示。稍后,你也可以在应用程序的其他地方显示你的抽认卡。因此,为你的抽认卡创建一个单独的模板是有意义的。 您将立即创建您的新模板。首先,调整`card_list.html`以包含即将到来的`card.html`模板:{% for card in card_list %}
{% ifchanged %}
🗃 {{ card.box | ordinal }} Box
{% endifchanged %}现在您的`card_list.html`模板将加载一个名为`card.html`的子模板。此模板尚不存在。继续创造`card.html`:1
2
3
4{{ card.question }}
5{{ card.answer }}
6在本教程的后面,您将向`card.html`添加更多数据。现在,您在第 4 行显示卡片的问题,在第 5 行显示答案。 重启您的开发 web 服务器并访问`http://127.0.0.1:8000`: [](https://files.realpython.com/media/django-flashcards-app-06-nice-headlines.97a0d9046eb8.png) 对于每个框,按顺序编号的标题只出现一次。下面的卡片也显示了你的单词的翻译。 在下一步中,您将增强 Django 抽认卡应用程序,以便在应用程序前端轻松地创建和编辑抽认卡。 [*Remove ads*](/account/join/) ## 第四步:进入卡片详情 在上一步中,您将抽认卡应用程序与数据库连接,并列出您的卡。你利用 Django 外壳创建了你的第一张卡。 在这一步中,您将使用[表单](https://docs.djangoproject.com/en/4.0/topics/forms/)在您舒适的浏览器中创建和更新您的卡片。 ### 创建新卡 目前,当你想创建更多的抽认卡时,你需要进入 Django shell。在使用这个应用程序时,这是一个有点破坏性的过程,特别是当你在学习过程中获得新卡的想法时。你可以改进创建新卡的过程! 实现在前端创建新卡的功能类似于列出您的卡的过程。首先,创建一个视图,添加一条路线,最后,创建一个模板。 您再次使用 Django 的一个通用视图作为视图。这次您导入一个`CreateView`来继承您的`CardCreateView`:1# cards/views.py
2
3from django.urls import reverse_lazy 4from django.views.generic import (
5 ListView,
6 CreateView, 7)
8
9from .models import Card
10
11class CardListView(ListView):
12 model = Card
13 queryset = Card.objects.all()
14
15class CardCreateView(CreateView): 16 model = Card 17 fields = ["question", "answer", "box"] 18 success_url = reverse_lazy("card-create")您创建新卡的网页将包含一个表单,其中包含您必须填写的字段。因此,除了连接您的`CardCreateView`中的模型,您还需要定义您的表单应该在第 17 行显示的字段。 当您发送表单时,Django 将检查表单并将您的请求返回到您在第 18 行为`success_url`设置的 URL。在这种情况下,又是同样的观点。这样,您可以一张一张地创建卡片,而无需来回导航。 您使用在第 3 行中导入的 Django 的`reverse_lazy()`,通过它的名称来引用您的`card-create`路线。但是到你的`CardCreateView`的路线还不存在。继续创建它:cards/urls.py
...
urlpatterns = [
# ...
path(
"new",
views.CardCreateView.as_view(),
name="card-create"
),
]有了这个新的`path`,你的抽认卡应用程序就有了一个连接到`CardCreateView`的新路径。 当你现在访问`http://127.0.0.1:8000/new`,Django 为你服务`CardCreateView`却找不到对应的模板。姜戈寻找一个名为`card_form.html`的模板。该模板尚不存在,因此您需要创建它:1
2
3{% extends "cards/base.html" %}
4
5{% block content %}
6✨ Create New Card
7
12
13 Cancel
14
15{% endblock %}第 9 行有了`{{ form.as_p }}`, Django 将显示用段落包装的表单字段。 无论何时在 Django 表单中发布内容,都必须提供一个 [`{% csrf_token %}`模板标签](https://docs.djangoproject.com/en/4.0/ref/csrf/)。这是**安全措施**防止[跨站请求伪造](https://docs.djangoproject.com/en/4.0/ref/csrf/)。 在第 12 到 14 行,您添加了取消创建新卡的选项。当您决定不保存卡片时,您可以单击*取消*链接,这将带您到您的`card-list` URL,丢弃表单数据。 要在 flashcards 应用程序的前端试用您的新表单来创建新卡片,请重启您的开发 web 服务器并访问`http://127.0.0.1:8000/new`: [https://player.vimeo.com/video/717252349?background=1](https://player.vimeo.com/video/717252349?background=1) 创建新卡时,您会停留在同一页面上,因此可以方便地创建另一张卡。当你点击*取消*时,你回到你的卡片列表。 [*Remove ads*](/account/join/) ### 更新现有卡 整洁,创造新的卡片作品!但是如果你想更新现有的卡呢?花点时间想想抽认卡的编辑页面应该是什么样子。 很有可能,您想到了一个类似于您的创建页面的布局,只是表单中填写了您的卡片的可编辑内容。创建`CardUpdateView`,它利用了这种相似性:1# cards/views.py
2
3from django.urls import reverse_lazy
4from django.views.generic import (
5 ListView,
6 CreateView,
7 UpdateView, 8)
9
10from .models import Card
11
12# ...
13
14class CardUpdateView(CardCreateView, UpdateView): 15 success_url = reverse_lazy("card-list")第 14 行的`CardUpdateView`是另一个通用的基于类的视图。这一次,您从 Django 的`UpdateView`中派生出您的视图的子类,它是在第 7 行导入的。 但是`UpdateView`并不是你的`CardUpdateView`所基于的唯一观点。你利用 [Python 的多类继承](https://realpython.com/inheritance-composition-python/#inheriting-multiple-classes)来创建`CardCreateView`和`UpdateView`的子类。通过这样做,您可以从两个父类中继承类属性,并修改您希望不同的属性。 编辑完一张卡片后,你将返回到`card-list`页面,而不是像在`card-create`中那样返回到同一个页面。 创建新路线以访问卡的编辑页面:cards/urls.py
...
urlpatterns = [
# ...
path(
"edit/int:pk",
views.CardUpdateView.as_view(),
name="card-update"
),
]注意路线中指向您的`CardUpdateView`的`<int:pk>`图案。因为您正在编辑一个现有的卡,所以您需要一个**主键(`pk` )** 来标识您想要更新的卡。 **注意:**主键是数据库条目的惟一标识符,Django 在创建条目时自动添加。您不需要记住卡片的任何主键,但是以后当您链接到卡片的编辑页面时,您将使用这个标识符。 URL 的`<int:pk>`部分允许主键为整数,`CardUpdateView`将返回相应卡的数据。当你访问`http://127.0.0.1:8000/edit/2`时,Django 知道你想用主键`2`编辑卡片,它会为你提供这张卡片的视图。 现在您需要调整`card_form.html`来迎合这两种情况,创建一个新卡和编辑一个现有的卡:1
2
3{% extends "cards/base.html" %}
4
5{% block content %}
6 {% if card %} 7✏️ Edit Card
8 {% else %} 9✨ Create New Card
10 {% endif %} 11
16
17 Cancel
18
19{% endblock %}您使用 Django 的`{% if %}`将您的[条件语句](https://realpython.com/python-conditional-statements/)包装在第 6 到 10 行。如果你的`card_form.html`模板接收到`card`数据,那么你显示*编辑卡*标题。否则,显示*创建新卡*。 当卡数据存在时,Django 将使用您的卡数据填写表单,而不需要对模板进行任何调整。 ### 连接您的页面 新路线准备就绪后,是时候连接页面了。首先添加一个链接,从您的`card_list.html`模板指向您的`card-create`页面:1
2
3{% extends "cards/base.html" %}
4{% load humanize %}
5
6{% block content %}
7
8 All Cards
9
10 11 ✨ Create New Card 12 13 {% for card in card_list %}
14 {% ifchanged %}
15🗃 {{ card.box | ordinal }} Box
16 {% endifchanged %}
17 {% include "cards/card.html" %}
18 {% endfor %}
19{% endblock content %}有了你在第 10 到 12 行添加的链接,当你想给你的应用程序添加一个新的抽认卡时,你现在可以方便地跳转到`card-create` URL。 接下来,为每张卡显示一个*编辑*按钮。打开您的`card.html`模板,在底部添加一个链接:1
2
3
4{{ card.question }}
5{{ card.answer }}
6
7 8 ✏️ Edit Card 9 10```记得您在`cards/urls.py`中将路线中的`<int:pk>`模式添加到您的`card-update` URL 中。这就是为什么你需要在第 7 行的`{% url %}`标签中把`card.id`作为一个参数传入。 随着项目的增长,在页面间导航变得越来越重要。所以,你的抽认卡应用程序的另一个改进是导航菜单。 首先创建`navigation.html`模板,并链接到您的`card-list`页面:你的导航菜单现在只链接到你的卡片列表。稍后,您还将创建指向您的抽认卡所在的盒子的链接。
同样,你使用表情符号来想象这个链接。在这里,你用卡片索引分隔符表情符号 (🗂).)作为所有卡片链接的前缀当然,你可以在应用的链接和标题中使用任何其他表情符号,也可以不使用表情符号。
将
navigation.html包含在您的基本模板中,以在您的所有页面上显示它:<!-- cards/templates/cards/base.html --> <!-- ... --> <header> <h1>Flashcards App</h1> {% include "cards/navigation.html" %} </header> <!-- ... -->导航就绪后,是时候点击 Django 抽认卡应用程序了。打开您的浏览器并访问
http://127.0.0.1:8000:https://player.vimeo.com/video/717253334?background=1
您现在可以创建和编辑在您的抽认卡应用程序中实现的卡。在下一步中,您将增强您的应用程序,以检查您是否知道您的卡所含问题的答案。
第五步:检查你的牌
在这一步中,您将实现检查您是否知道卡片问题答案的功能。当你正确地记住它时,你可以把卡片移到下一个盒子里。如果你不知道答案,那么你把卡片移到第一个盒子里。
实现这个重要特性后,您将使用 Django shell 来查看它的运行情况。这样,在编写前端代码之前,您可以验证一切都按预期运行。
让你的牌动起来
在你继续写代码之前,花点时间想想你的抽认卡应用程序的间隔重复系统应该如何工作。如果你需要复习,你可以回到项目概述。
简而言之,如果你记起了一张卡片的答案,你就把它移到下一个盒子里。如果你不知道答案,你把卡片放回第一个盒子里。
要复制在盒子之间移动卡片的行为,向您的
Card模型添加一个.move()方法:1# cards/models.py 2 3# ... 4 5class Card(models.Model): 6 7 # ... 8 9 def move(self, solved): 10 new_box = self.box + 1 if solved else BOXES[0] 11 12 if new_box in BOXES: 13 self.box = new_box 14 self.save() 15 16 return self您的
.move()方法将solved作为附加参数。当你知道答案时,solved的值将是True,当你不知道答案时,将是False。在第 10 行,你在评估你是想把卡片向前移动到下一个盒子里还是把卡片移回到第一个盒子里。如果你知道你的卡片的答案,你的
new_box变量将是你当前的盒子号码加 1。如果solved是False,那么new_box将是1,这就是BOXES[0]的值。请注意,如果你知道第五个盒子里的卡片的答案,那么
new_box甚至可以是6。这就是为什么当new_box是一个从1到5的数字时,你只需要继续保存第 14 行的新的self.box值。如果你知道第五个盒子里的一张卡片的答案,那么这张卡片就留在第五个盒子里不动。在下一节中,您将测试这种行为。模拟卡检查会话
现在您已经将
.move()添加到了您的Card模型中,您可以检查移动卡片是否按预期工作。正如您在本教程前面所做的那样,使用 Django shell:(venv) $ python manage.py shell现在,您可以直接与抽认卡项目进行交互,并在 shell 中模拟检查会话。首先,导入您的
Card模型:
>>> from cards.models import Card
随着Card模型的导入,您可以查询您的数据库以获得第一个和第二个盒子中的所有卡片:
>>> box1_cards = Card.objects.filter(box=1) >>> box1_cards <QuerySet [<Card: Hello>, <Card: Please>]> >>> box2_cards = Card.objects.filter(box=2) >>> box2_cards <QuerySet [<Card: Sorry>]>此刻,
box1_cards包含两张卡,box2_cards包含一张卡。选择box1_cards的第一张卡片,并将其移动到下一个盒子:
>>> check_card = box1_cards.first()
>>> check_card.move(solved=True)
<Card: Hello>
>>> box2_cards
<QuerySet [<Card: Hello>, <Card: Sorry>]>
当您在solved设置为True的情况下调用check_card.move()时,您的卡将移动到下一个盒子。box2_cards的QuerySet现在也包含了你的check_card。
出于测试目的,进一步移动卡:
>>> check_card.move(solved=True) <Card: Hello> >>> box2_cards <QuerySet [<Card: Sorry>]> >>> check_card.box 3和以前一样,当你解决它时,你的
check_card继续前进。你的box2_cards还剩下一张卡。现在,测试当你不知道卡片问题的答案时会发生什么:
>>> check_card.move(solved=False)
<Card: Hello>
>>> check_card.box
1
当您在solved设置为False的情况下调用.move()时,卡片会移回第一个盒子。完美,你的卡的往返工作!
在下一步中,您将在前端显示您的盒子。然后,您将实现检查您是否知道某个问题的答案的功能,并相应地在前端的方框之间移动您的卡片。
第六步:把你的卡片放进盒子里
在上一步结束时,您验证了卡片如预期的那样在盒子之间移动。在本教程的最后一步,您将实现抽认卡应用程序的所有缺失功能。你将从列出你所有的盒子开始。
显示一个框
到目前为止,您已经有了一个列出所有抽认卡的页面,还有创建或更新抽认卡的页面。为了测试你的知识,你需要能够选择一个学习单元。这意味着您需要一个单个盒子的视图、一条导航路线和一个显示盒子的模板。
首先为单个框创建视图:
1# cards/views.py
2
3# ...
4
5class BoxView(CardListView):
6 template_name = "cards/box.html"
7
8 def get_queryset(self):
9 return Card.objects.filter(box=self.kwargs["box_num"])
10
11 def get_context_data(self, **kwargs):
12 context = super().get_context_data(**kwargs)
13 context["box_number"] = self.kwargs["box_num"]
14 return context
您正在创建作为CardListView的子类的BoxView。Django 将默认为CardListView提供card_list.html模板。因此,您需要覆盖第 6 行中的template_name,并指向box.html模板,稍后您将创建这个模板。
BoxView和CardListView的另一个区别是,你不想列出你所有的卡片。您可以使用.get_queryset()来调整BoxView返回的查询集,而不是列出您所有的卡片。在第 9 行,您只返回盒子号与box_num值匹配的卡片。
您在 GET 请求中将box_num的值作为关键字参数传递。要在模板中使用框号,可以使用.get_context_data()并将box_num作为box_number添加到第 13 行的视图上下文中。
注意:您使用变量名box_number来区别于box_num关键字参数。
将新路由添加到您的urls.py文件中,以接受 URL 模式中的box_num:
# cards/urls.py
# ...
urlpatterns = [
# ...
path(
"box/<int:box_num>",
views.BoxView.as_view(),
name="box"
),
]
通过将<int:box_num>添加到 URL 模式中,Django 将这个box_num作为关键字参数传递给视图。这正是你想要的。
接下来,创建视图期望的box.html模板:
1<!-- templates/cards/box.html -->
2
3{% extends "cards/base.html" %}
4{% load humanize %}
5
6{% block content %}
7 <h2>🗃 {{ box_number | ordinal }} Box</h2>
8 <mark>{{ object_list | length }}</mark> Card{{ object_list | pluralize }} left in box.
9 <hr>
10 {% for card in object_list %}
11 {% include "cards/card.html" %}
12 {% endfor %}
13{% endblock content %}
```py
在您的`box.html`模板中,您再次使用`humanize`将第 7 行中的框号显示为序号。
`object_list`变量包含你的卡片作为对象。在第 8 行,您在`object_list`上使用了另外两个过滤器:
1. 使用`length`过滤器,您可以显示当前盒子中的卡片数量。
2. 使用`pluralize`过滤器,你可以确保你的信息的语法正确性。如果只剩下一张牌,那么单词*牌*保持单数。但是当有更多或零张牌时,Django 通过在末尾添加一个 *s* 来使*牌*成为复数。
在第 10 行到第 12 行,您遍历盒子中的卡片,并通过包含`card.html`模板来显示它们。
您可以通过在浏览器的地址栏中输入它们的 URL 来直接访问您的邮箱。但是在你的抽认卡应用程序的导航菜单中有你的盒子的链接会更方便。
[*Remove ads*](/account/join/)
### 列出你的盒子
要列出你的盒子,你首先要克服应用程序逻辑中的一个障碍。你的导航模板不知道你的抽认卡应用程序包含多少个盒子。您可以在每个视图的上下文中添加框的数量,但是这将为这些数据带来不必要的开销。
幸运的是,Django 已经准备好了一个系统,用于在模板中注入代码数据。为了在导航中列出你的框,你可以[实现一个定制的模板标签](https://realpython.com/django-template-custom-tags-filters/)。更准确地说,您将创建一个**包含标签**。
使用自定义包含标记,您可以返回包含函数提供的上下文数据的模板。在这种情况下,您将返回一个包含盒子数量的字典。
一旦创建并注册了 inclusion 标记,就可以像使用 Django 中任何其他加载的标记一样使用它。
首先,创建要加载的模板:
1
2
3{% load humanize %}
4
5{% for box in boxes %}
6
7 🗃 {{ box.number | ordinal }} Box {{ box.card_count }}
8
9{% endfor %}
这个`box_links.html`模板看起来和你创建的其他模板没有太大的不同。模板使用提供的数据。模板本身并不关心数据来自哪里。
为了让您的`box_links.html`满意,您需要用一个字典来填充它,该字典包含您在第 5 行迭代的`boxes`键。您可以忽略带有与`box_links.html`兼容的包含标签的字典。
为此,在您的`templates/`文件夹旁边创建一个名为`templatetags/`的文件夹。然后,在`templatetags/`文件夹中创建`cards_tags.py`:
1# cards/templatetags/cards_tags.py
2
3from django import template
4
5from cards.models import BOXES, Card
6
7register = template.Library()
8
9@register.inclusion_tag("cards/box_links.html")
10def boxes_as_links():
11 boxes = []
12 for box_num in BOXES:
13 card_count = Card.objects.filter(box=box_num).count()
14 boxes.append({
15 "number": box_num,
16 "card_count": card_count,
17 })
18
19 return {"boxes": boxes}
这是您的自定义模板标签的工作方式:
* **3 号线**导入 Django 的`template`模块。
* **第 5 行**导入您的`Card`模型和`BOXES`变量。
* **第 7 行**创建了一个用于注册模板标签的`Library`实例。
* **第 9 行**使用`Library`实例的`.inclusion_tag()`作为[装饰器](https://realpython.com/primer-on-python-decorators/)。这告诉 Django`boxes_as_links`是一个包含标签。
* **12 号线**在你的`BOXES`上方盘旋。
* **第 13 行**定义`card_count`来记录当前盒子中的卡片数量。
* **第 14 行到第 17 行**将一个字典附加到`boxes`列表中,该字典以盒子编号作为关键字,以盒子中卡片的数量作为值。
* **第 19 行**返回包含您的`boxes`数据的字典。
跳到`navigation.html`,然后加载您的新模板标签并包含它:
1
2
3{% load cards_tags %} 4
5
首先,您需要在第 3 行加载您的`card_tags`模板标签。加载自定义标签后,您可以将您的标签作为任何其他 Django 标签来引用。在第 7 行,您包含了刚刚创建的`boxes_as_links`标记。
**注意:**当您向 Django 项目添加定制模板标签时,您必须手动重启您的服务器。否则你会得到一个错误,因为你的自定义标签还没有注册。
手动重启您的开发 web 服务器,并访问`http://127.0.0.1:8000`:
[](https://files.realpython.com/media/django-flashcards-app-07-navigation_cut.8c4920770b5d.png)
无论你正在加载哪个视图,你的导航都可以访问你的盒子,并且可以显示盒子中当前的卡片数量。
现在你的框已经在导航菜单中列出,你可以专注于改进框页面本身。
### 随机选择一张牌
当您访问箱子的页面时,您想要启动新的卡片检查会话。因此,你的抽认卡应用程序应该马上给你一张随机的卡片,这样你就可以测试你的知识了。
目前,您正在盒子页面上的列表中显示您的所有卡片。增强您的`BoxView`以选择一张随机卡片并将其添加到您的`context`:
1# cards/views.py
2
3import random 4
5# ...
6
7class BoxView(CardListView):
8 template_name = "cards/box.html"
9
10 def get_queryset(self):
11 return Card.objects.filter(box=self.kwargs["box_num"])
12
13 def get_context_data(self, kwargs):
14 context = super().get_context_data(kwargs)
15 context["box_number"] = self.kwargs["box_num"]
16 if self.object_list: 17 context["check_card"] = random.choice(self.object_list) 18 return context
在第 3 行中,您将`random`模块导入到[来生成随机数据](https://realpython.com/python-random/)。请注意,盒子里可能没有牌。这就是为什么你需要检查`self.object_list`不是空的。如果你的物品列表中至少有一张卡片,那么你可以使用`random.choice()`来挑选一张卡片。这张随机选择的卡片将是您在`box.html`模板的学习课程中展示的卡片。
将`check_card`添加到`BoxView`的上下文中,可以调整`box.html`:
1
2
3{% extends "cards/base.html" %}
4{% load humanize %}
5
6{% block content %}
7
🗃 {{ box_number | ordinal }} Box
8 {{ object_list | length }} Card{{ object_list | pluralize }} left in box.
9
10 {% if check_card %} 11 {% include "cards/card.html" with card=check_card %} 12 {% endif %} 13{% endblock content %}
现在可以直接引用`check_card`,而不是循环遍历`object_list`中的所有卡片。类似于你的`BoxView`中的条件语句,你只有在有牌的时候才包括`card.html`。您可以在`include`标签中使用`with`将附加的上下文传递给包含的模板。由于`card.html`不知道您的`check_card`变量,您需要将`card=check_card`传递到子模板中。
为了正确地测试您是否知道问题的答案,您需要首先隐藏答案。此外,您希望专注于学习体验,而不是在学习过程中显示*编辑*按钮。
记住在你的卡片列表中使用`card.html`。在您的卡片列表概览中,您还可以一眼看到问题的答案,这很有意义。因此,你需要考虑如何将答案隐藏在页面上,但仍然显示在你的概览中。
当您包含一个模板时,该模板可以访问[上下文字典](https://docs.djangoproject.com/en/4.0/ref/templates/api/#playing-with-context)中所有可用的变量。因此,您可以利用仅在您的`BoxView`上下文中才有的`check_card`。
调整`card.html`以考虑`check_card`:
1
2
3
4
{{ card.question }}
5 {% if not check_card %} 6
{{ card.answer }}
7
8
9 ✏️ Edit Card
10
11 {% else %} 12
Reveal Answer
14{{ card.answer }}
15
当`check_card`出现时,你不显示*编辑*按钮,你隐藏答案。否则,卡片模板显示答案和*编辑*按钮,就像之前一样。
重启您的开发 web 服务器,并访问`http://127.0.0.1:8000`以验证您的`card.html`模板的行为是否符合预期:
[https://player.vimeo.com/video/717254551?background=1](https://player.vimeo.com/video/717254551?background=1)
完美!卡片列表概览显示您的答案,并显示*编辑*按钮。当你点击一个盒子时,随机选择的卡片将答案隐藏在下拉菜单后面。
在接下来的部分中,您将使用`forms`通过点击按钮来移动您的牌。如果你知道答案,然后你想移动卡片到下一个盒子。您已经在后端构建了功能。接下来,您还将实现前端的功能。
### 检查一张卡
在检查过程中,你想告诉你的抽认卡程序你是否知道答案。您将通过向后端发送一个包含表单的 POST 请求来实现这一点。
创建一个名为`forms.py`的新文件来定义你的 **Django 表单**:
1# cards/forms.py
2
3from django import forms
4
5class CardCheckForm(forms.Form):
6 card_id = forms.IntegerField(required=True)
7 solved = forms.BooleanField(required=False)
Django 表单的结构类似于 Django 模型。在第 5 行到第 7 行,您正在创建名为`CardCheckForm`的`forms.Form`类。您的表单架构包含两个字段:
1. **`card_id`** ,您正在检查的卡的主键
2. **`solved`** ,如果知道答案则布尔值设为`True`,如果不知道则设为`False`
一个表单域可以有一个`required`参数来定义该域是否需要包含数据以使表单有效。乍一看,将两个字段都设置为`required=True`是有意义的。但是在这种情况下,如果你不知道答案,你可以不勾选`forms.BooleanField`。因此,您需要将第 7 行中的`required`参数设置为`False`。
**注意:**在注册期间同意条款和条件是一个典型的布尔字段,用户必须检查该字段以使表单有效。在这种情况下,您应该将`required`设置为`True`。
在前端创建表单之前,向`card.html`添加一些代码:
1
2
3
4
{{ card.question }}
5 {% if not check_card %}
6
{{ card.answer }}
7
8
9 ✏️ Edit Card
10
11 {% else %}
12
13
Reveal Answer
14
{{ card.answer }}
15
16
17 {% include "cards/card_check_form.html" with solved=True %} 18 {% include "cards/card_check_form.html" with solved=False %} 19 {% endif %}
20
你包括两次`card_check_form.html`。在第 17 行,您包含了带有`solved=True`参数的表单。在第 18 行,你用`solved=False`做同样的事情。
同样,在`include`标签中使用`with`将附加的上下文传递给包含的模板。在这种情况下,您忽略了`solved`布尔值。
要继续,请创建包含您的表单的`card_check_form.html`模板。该表单包含基于所提供的`solved`变量值的条件格式:
1
2
3
您的表单模板只包含 HTML 表单。就像您在表单中创建新卡一样,您在第 4 行提交一个`csrf_token`。
第 5 行和第 6 行引用带有`name`属性的`CardCheckForm`字段。`card_id`字段包含您的卡的主键。根据您提供的`solved`变量的布尔值,该复选框要么被选中,要么不被选中。`card_id`字段和`solved`字段是隐藏的,因为您不需要手动填写它们。您编写的代码逻辑会为您处理这些问题。但是,它们必须存在才能提交到后端并使表单有效。
在第 7 到 11 行中,您显示了带有我认识的*或我不认识的*标签的*提交*按钮。这两个按钮是表单中实际显示的唯一字段。*
*最后,您需要调整`BoxView`类来处理 POST 请求:
1# cards/views.py
2
3# ...
4
5from django.shortcuts import get_object_or_404, redirect 6
7# ...
8
9from .forms import CardCheckForm 10
11# ...
12
13class BoxView(CardListView):
14 template_name = "cards/box.html"
15 form_class = CardCheckForm 16
17 def get_queryset(self):
18 return Card.objects.filter(box=self.kwargs["box_num"])
19
20 def get_context_data(self, kwargs):
21 context = super().get_context_data(kwargs)
22 context["box_number"] = self.kwargs["box_num"]
23 if self.object_list:
24 context["card"] = random.choice(self.object_list)
25 return context
26
27 def post(self, request, *args, **kwargs): 28 form = self.form_class(request.POST) 29 if form.is_valid(): 30 card = get_object_or_404(Card, id=form.cleaned_data["card_id"]) 31 card.move(form.cleaned_data["solved"]) 32 33 return redirect(request.META.get("HTTP_REFERER"))
你将`CardCheckForm`和`form_class`连接到第 15 行的`BoxView`。
在第 27 到 33 行,您定义了`.post()`方法。顾名思义,这个方法处理传入的 POST 请求。理想情况下,您发布到`BoxView`的帖子在帖子请求中包含一个有效的表单。通常,您的浏览器会检查表单的所有必填字段是否都已填写。但是在任何情况下,在后端检查您的表单都是一个很好的实践。你在第 29 行用`.is_valid()`做这件事。
如果您的表单是有效的,那么您试图通过它的`card_id`值从数据库中获取`Card`对象。您在第 5 行中导入了`get_object_or_404()`,并在第 30 行中使用它来获取一张卡或引发一个 [HTTP 404 错误](https://docs.djangoproject.com/en/4.0/topics/http/views/#django.http.Http404)。
有了卡,你就可以用`solved`调用`.move()`,T1 可以是`True`也可以是`False`。如前所述,如果你知道答案,`.move()`会将卡片提升到下一个盒子。如果你不知道答案,那么`solved`就是`False`。在这种情况下,你把卡片放回你的第一个盒子里。
最后,您将请求重定向到发布请求的页面。关于发送请求的 URL 的信息作为`HTTP_REFERER`存储在您的`request`的`.META`对象中。在您的情况下,`HTTP_REFERER`是您当前检查会话的框的 URL。
要检查这个过程是如何工作的,重启您的开发 web 服务器并访问`http://127.0.0.1:8000`。找到一个装有卡片的盒子,测试你的知识:
[https://player.vimeo.com/video/717254913?background=1](https://player.vimeo.com/video/717254913?background=1)
当你访问一个有卡片的盒子时,你的抽认卡应用程序会从当前盒子中随机显示一张卡片。看完问题,你可以给自己揭晓答案。然后你相应地点击它下面的按钮。如果你知道答案,那么卡片会移到下一个盒子。在你不知道答案的情况下,你的卡片移动到第一个盒子。
干得好!您已经完成了创建自己的 Django 抽认卡应用程序。现在,您可以测试您对盒子中所有卡片的了解,直到盒子变空:
[https://player.vimeo.com/video/728359763?background=1](https://player.vimeo.com/video/728359763?background=1)
抽认卡应用程序不会限制你如何设计你的学习课程。所以,当盒子空了,你可以继续下一个盒子。或者你可以尊重间隔重复法中的*间隔*,给自己应得的休息。
## 结论
你做到了!你不仅通过检查抽认卡开始学习一个新的主题,还通过用 Django 构建一个全栈 web 应用程序提升了自己作为 Python 开发人员的水平。
在本教程中,您已经构建了自己的 Django 抽认卡应用程序来复制间隔重复系统。现在,您可以创建带有问题和答案的卡片,并可以测试您对所选主题的了解程度。
**在本教程中,您已经学会了如何:**
* 建立一个 Django 项目
* 使用 **SQLite 数据库**和 **Django shell**
* 创建**模型**和**基于类的视图**
* 结构和**嵌套模板**
* 创建**自定义模板标签**
传统上,抽认卡用于词汇的语言学习。但是你可以使用你的抽认卡应用来学习任何你想学的话题,例如 [Python 关键字](https://realpython.com/python-keywords/)或者[Python 中的基本数据类型](https://realpython.com/python-data-types/)。
如果您想使用本教程的源代码作为进一步扩展的起点,那么您可以通过单击下面的链接来访问源代码:
**源代码:** [点击此处下载源代码](https://realpython.com/bonus/django-flashcards-app-code/),您将使用它来构建您的 Django 抽认卡应用程序。
你会在目录`source_code_final`中找到 Django 抽认卡项目的最终版本。
你将从你的新抽认卡应用程序中学到什么?在下面的评论中分享你的想法吧!
## 接下来的步骤
在本教程中,您已经构建了一个带有数据库连接的全栈 web 应用程序。这是用更多特性增强 Django 项目的一个很好的起点。
以下是一些关于附加功能的想法:
* **存档**:添加将不想再查看的卡片存档的选项。
* **成功消息**:当你创建一张新卡或者当一张卡移动到一个新的盒子时,显示成功[消息](https://docs.djangoproject.com/en/4.0/ref/contrib/messages/)。
* **间隔重复**:增强你的`Card`模型,以跟踪卡片最后一次被检查的时间,或者为你的盒子创建提醒,以安排你的下一次学习。
* **抽认卡组**:扩展你的应用程序,处理不同组的抽认卡。例如,你可以为西班牙语课准备一套,为生物课准备一套,等等。
你能想到其他应该成为抽认卡应用一部分的特性吗?欢迎在评论区分享你的改进。***************
# 主持一个关于 Heroku 的 Django 项目
> 原文:<https://realpython.com/django-hosting-on-heroku/>
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,以加深您的理解: [**在 Heroku**](/courses/host-your-django-project-on-heroku/) 上主持您的 Django 项目
作为一名网络开发新手,你已经建立了你的[文件夹应用](https://realpython.com/get-started-with-django-1/),并在 [GitHub](https://realpython.com/python-git-github-intro/) 上分享了你的代码。也许,你希望吸引技术招聘人员来获得你的第一份[编程工作](https://realpython.com/learning-paths/python-interview/)。许多编码训练营的毕业生可能也在做同样的事情。为了让自己与众不同,增加被关注的机会,你可以开始在网上主持你的 Django 项目。
对于一个业余爱好 Django 项目,你会想要一个免费的托管服务,快速的设置,友好的用户界面,与你现有的技术很好的整合。虽然 [GitHub Pages](https://pages.github.com/) 非常适合托管静态网站和使用 [JavaScript](https://realpython.com/python-vs-javascript/) 的网站,但是您需要一个 **web 服务器**来运行您的 [Flask](https://realpython.com/learning-paths/flask-by-example/) 或 [Django](https://realpython.com/learning-paths/django-web-development/) 项目。
有几个主要的**云平台**提供商以不同的模式运营,但是在本教程中你将探索 [Heroku](https://www.heroku.com/) 。它符合所有条件——免费、设置快速、用户友好,并且与 Django 很好地集成在一起——并且是许多初创公司最喜欢的云平台提供商。
**在本教程中,您将学习如何:**
* 在几分钟内让你的 **Django** 项目**上线**
* 使用 **Git** 将您的项目部署到 Heroku
* 使用 Django-Heroku 集成库
* 将你的 Django 项目挂接到一个独立的关系数据库上
* 管理**配置**以及**敏感数据**
要继续学习,您可以通过单击下面的链接下载代码和其他资源:
**获取源代码:** [点击这里获取 Django 项目以及本教程中各个步骤的快照。](https://realpython.com/bonus/django-hosting-heroku-project-code/)
## 演示:您将构建什么
您将创建一个基本的 Django 项目,并直接从终端将它部署到云中。最后,你将拥有一个公共的、可共享的链接,链接到你的第一个 Heroku 应用。
这里有一个一分钟的视频演示了必要的步骤,从初始化一个空的 Git 存储库到在浏览器中查看您完成的项目。坚持看完,快速预览一下你将在本教程中发现的内容:
[https://player.vimeo.com/video/552465720?background=1](https://player.vimeo.com/video/552465720?background=1)
除了上面截屏中显示的步骤之外,稍后你会发现更多的步骤,但是这应该足以让你对如何在本教程中使用 Heroku 有一个大致的了解。
[*Remove ads*](/account/join/)
## 项目概述
本教程并不是关于构建任何特定的项目,而是使用 **Heroku** 在云中托管一个项目。虽然 Heroku 支持[各种语言](https://www.heroku.com/languages)和 web 框架,但你会坚持使用 Python 和 Django。如果您手头没有任何 Django 项目,也不用担心。第一步将带您搭建一个新的 Django 项目,让您快速入门。或者,您可以使用一个现成的示例项目,稍后您会发现。
一旦你准备好你的 Django 项目,你将注册一个免费的 Heroku 账户。接下来,您将下载一个方便的命令行工具,帮助您在线管理应用程序。正如上面的截图所示,命令行是使用 Heroku 的一种快捷方式。最后,您将在新配置的 Heroku 实例上完成一个已部署的 Django 项目。你可以把你的最终结果想象成你未来[项目想法](https://realpython.com/intermediate-python-project-ideas/)的占位符。
## 先决条件
在开始之前,请确保您已经熟悉了 Django web 框架的基础知识,并且已经习惯使用它来建立一个基本项目。
**注意:**如果你在 Flask 方面比 Django 更有经验,那么你可以看看类似的关于[使用 Heroku](https://realpython.com/flask-by-example-part-1-project-setup/) 部署 Python Flask 示例应用程序的教程。
您还应该安装和配置一个 [Git](https://realpython.com/python-git-github-intro/) 客户端,以便您可以从命令行方便地与 Heroku 平台交互。最后,你应该认真考虑为你的项目使用一个[虚拟环境](https://realpython.com/python-virtual-environments-a-primer/)。如果你还没有一个特定的虚拟环境工具,你很快就会在本教程中找到一些选项。
## 步骤 1:搭建 Django 项目来托管
要在云中托管 Django web 应用程序,您需要一个有效的 Django 项目。就本教程的目的而言,不必详细说明。如果你时间不够,可以随意使用你的一个爱好项目或者[构建一个样本投资组合应用](https://realpython.com/get-started-with-django-1/),然后跳到[创建你的本地 Git 库](#step-2-create-a-local-git-repository)。否则,留下来从头开始做一个全新的项目。
### 创建虚拟环境
通过创建一个不会与其他项目共享的隔离虚拟环境来开始每个项目是一个好习惯。这可以使您的依赖项保持有序,并有助于避免包版本冲突。一些依赖管理器和打包工具,如 [Pipenv](https://realpython.com/pipenv-guide/) 或[poems](https://python-poetry.org/)自动创建和管理虚拟环境,让你遵循最佳实践。当你开始一个新项目时,许多[ide](https://realpython.com/python-ides-code-editors-guide/)比如 [PyCharm](https://realpython.com/pycharm-guide/) 也会默认这样做。
然而,创建 Python 虚拟环境的最可靠和可移植的方式是从命令行手动完成。您可以使用外部工具如 [virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/) 或直接调用内置[模块](https://docs.python.org/3/library/venv.html)。虽然 virtualenvwrapper 将所有环境保存在预定义的父文件夹中,但是`venv`希望您为每个环境分别指定一个文件夹。
在本教程中,您将使用标准的`venv`模块。习惯上将虚拟环境放在**项目的根文件夹**中,所以让我们先创建一个,并将工作目录改为:
```py
$ mkdir portfolio-project
$ cd portfolio-project/
你现在在portfolio-project文件夹中,这将是你的项目的家。要在这里创建一个虚拟环境,只需运行venv模块并为您的新环境提供一个路径。默认情况下,文件夹名称将成为环境的名称。如果你愿意,你可以用可选的--prompt参数给它一个自定义名称:
$ python3 -m venv ./venv --prompt portfolio
以前导点(.)开始的路径表示它相对于当前工作目录。虽然不是强制性的,但这个点清楚地表明了你的意图。不管怎样,这个命令应该会在您的portfolio-project根目录下创建一个venv子目录:
portfolio-project/
│
└── venv/
这个新的子目录包含 Python 解释器的副本以及一些管理脚本。现在,您已经准备好将项目依赖项安装到其中了。
安装项目依赖关系
大多数实际项目都依赖于外部库。Django 是一个第三方 web 框架,并不是 Python 自带的。您必须在项目的虚拟环境中安装它以及它自己的依赖项。
如果您还没有激活虚拟环境,请不要忘记激活它。为此,您需要执行虚拟环境的bin/子文件夹中的一个 shell 脚本中的命令。例如,如果您使用的是 Bash ,那么就可以获得activate脚本:
$ source venv/bin/activate
现在, shell 提示符应该显示一个带有虚拟环境名称的前缀,以表明它已被激活。您可以仔细检查特定命令指向的可执行文件:
(portfolio) $ which python
/home/jdoe/portfolio-project/venv/bin/python
上面的输出确认了运行python将执行位于您的虚拟环境中的相应文件。现在,让我们为您的 Django 项目安装依赖项。
你需要一个相当新版本的 Django。根据您阅读本文的时间,可能会有更新的版本。为了避免潜在的兼容性问题,您可能希望指定与编写本教程时使用的版本相同的版本:
(portfolio) $ python -m pip install django==3.2.5
这将安装 Django 的 3.2.5 版本。包名是不区分大小写的,所以无论您键入django还是Django都没有关系。
注意:有时候,你会看到一个关于 pip 新版本可用的警告。忽略此警告通常是无害的,但是如果您在生产环境中,出于安全原因,您需要考虑升级:
(portfolio) $ python -m pip install --upgrade pip
或者,如果版本检查困扰您并且您知道可能的后果,您可以在配置文件中禁用版本检查。
安装 Django 带来了一些额外的传递依赖关系,您可以通过列出它们来揭示:
(portfolio) $ python -m pip list
Package Version
---------- -------
asgiref 3.4.1
Django 3.2.5
pip 21.1.3
pytz 2021.1
setuptools 56.0.0
sqlparse 0.4.1
因为您希望其他人能够毫无问题地下载和运行您的代码,所以您需要确保可重复的构建。这就是冻结的目的。它以一种特殊的格式输出大致相同的依赖集及其子依赖集:
(portfolio) $ python -m pip freeze
asgiref==3.4.1
Django==3.2.5
pytz==2021.1
sqlparse==0.4.1
这些基本上是pip install命令的参数。然而,它们通常被封装在一个或多个需求文件中,这些文件pip可以一次性使用。要创建这样一个文件,您可以重定向freeze命令的输出:
(portfolio) $ python -m pip freeze > requirements.txt
这个文件应该提交到您的 Git 存储库中,这样其他人就可以通过以下方式使用pip安装它的内容:
(portfolio) $ python -m pip install -r requirements.txt
目前,您唯一的依赖项是 Django 及其子依赖项。但是,您必须记住,每次添加或删除任何依赖项时,都要重新生成并提交需求文件。这就是前面提到的包管理器可能派上用场的地方。
解决了这个问题,让我们开始一个新的 Django 项目!
Django 项目
每个 Django 项目都由遵循特定命名约定的相似文件和文件夹组成。您可以手动创建这些文件和文件夹,但是自动创建通常更快更方便。
当你安装 Django 时,它为管理任务提供了一个命令行工具,比如引导新项目。该工具位于虚拟环境的bin/子文件夹中:
(portfolio) $ which django-admin
/home/jdoe/portfolio-project/venv/bin/django-admin
您可以在 shell 中运行它,并传递新项目的名称以及创建默认文件和文件夹的目标目录:
(portfolio) $ django-admin startproject portfolio .
或者,您可以通过调用django模块来获得相同的结果:
(portfolio) $ python -m django startproject portfolio .
注意这两个命令末尾的点,它指示您当前的工作目录portfolio-project作为目标。如果没有它,该命令将创建另一个与您的项目同名的父文件夹。
如果你得到一个command not found错误或者ModuleNotFound 异常,那么确保你已经激活了安装 Django 的同一个虚拟环境。其他一些常见的错误是将项目命名为与一个内置对象相同,或者没有使用有效的 Python 标识符。
注意:使用管理工具从头开始一个新的 Django 项目既快速又灵活,但是需要大量的手工劳动。如果您计划托管生产级 web 应用程序,那么您需要配置安全性、数据源等等。选择一个遵循最佳实践的项目模板可能会为您省去一些麻烦。
之后,您应该有这样的目录布局:
portfolio-project/
│
├── portfolio/
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
│
├── venv/
│
├── manage.py
└── requirements.txt
您创建了一个名为portfolio的管理应用程序,它包含项目级设置和带有 URL 模式的主文件,以及其他一些东西。您还创建了manage.py脚本,它方便地包装了django-admin并与您的项目挂钩。
现在,您已经有了一个基本的、可运行的 Django 项目。此时,您通常会启动一个或多个 Django 应用程序并定义它们的视图和模型,但是对于本教程来说它们不是必需的。
更新本地数据库模式(可选)
这一步是可选的,但是如果您想要使用 Django admin 视图或者定义定制应用和模型,那么您最终需要更新您的数据库模式。默认情况下,Django 带来了一个基于文件的 SQLite 数据库,方便测试和运行本地开发服务器。这样,你就不需要安装和设置一个像 MySQL 或 PostgreSQL 这样的成熟数据库。
要更新数据库模式,运行migrate子命令:
(portfolio) $ python manage.py migrate
在成功应用所有未决的迁移之后,您将在项目根文件夹中找到一个名为db.sqlite3的新文件:
portfolio-project/
│
├── portfolio/
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
│
├── venv/
│
├── db.sqlite3 ├── manage.py
└── requirements.txt
您可以使用 sqlite3命令行实用程序、Python 内置的 sqlite3模块或者您喜欢的数据库管理工具来检查它的内容。到目前为止,这个文件应该包含一些负责身份验证、会话管理等的内部应用程序的表,以及一个跟踪应用的迁移的元表。
运行本地开发服务器
在将 Heroku 放在项目之上增加复杂性之前,在本地计算机上测试所有东西是有意义的。这可以让你省去很多不必要的调试。幸运的是,Django 附带了一个用于开发目的的轻量级 web 服务器,几乎不需要配置。
注意:从技术上讲,您可以利用 Heroku 上 Django 内置的相同开发服务器。然而,它不是为处理现实生活中的交通而设计的,也不安全。你最好使用像 Gunicorn 这样的 WSGI 服务器。
要运行开发服务器,请在您之前激活虚拟环境的终端窗口中键入以下命令:
(portfolio) $ python manage.py runserver
默认情况下,它将在本地主机端口 8000 上启动服务器。如果另一个应用程序已经在使用 8000,您可以调整端口号。服务器将继续监视项目源文件中的变化,并在必要时自动重新加载它们。当服务器仍在运行时,在 web 浏览器中导航到该 URL:
http://127.0.0.1:8000/
主机127.0.0.1代表虚拟本地网络接口上的 IP 地址之一。如果一切顺利,并且您没有更改默认的项目设置,那么您应该进入 Django 欢迎页面:
万岁!火箭已经起飞,您的 Django 项目已经准备好部署到云中。
步骤 2:创建一个本地 Git 存储库
现在,您已经有了一个可以工作的 Django 项目,是时候采取下一步措施在云中托管它了。在本节中,您将探索在 Heroku 平台上构建和部署应用程序的可用选项。如果您还没有为您的项目创建一个本地 Git 存储库,那么您还需要创建一个本地 Git 存储库。在这一步结束时,您将准备好深入 Heroku 工具链。
Heroku 提供了至少五种不同的方式来部署您的项目:
- Git: 将提交推送到 Heroku 上的远程 Git 存储库
- GitHub: 合并拉取请求时自动触发部署
- Docker: 将 Docker 图像推送到 Heroku 容器注册表
- API: 以编程方式自动化您的部署
- Web: 从 Heroku 仪表板手动部署
最直接和以开发人员为中心的方法是第一种。许多软件开发人员已经在日常生活中使用 Git,所以 Heroku 的入门门槛相当低。git命令让您在 Heroku 中完成很多工作,这就是为什么您将在本教程中使用 Git。
初始化一个空的 Git 存储库
使用组合键 Ctrl + C 或 Cmd + C 停止您的开发服务器,或者打开另一个终端窗口,然后在您的项目根文件夹中初始化一个本地 Git 存储库:
$ git init
您的虚拟环境是否活跃并不重要。它应该创建一个新的.git子文件夹,其中包含 Git 跟踪的文件的历史。名称以点开头的文件夹在 macOS 和 Linux 上是隐藏的。如果您想检查您是否成功地创建了它,那么使用ls -a命令来查看这个文件夹。
指定未跟踪的文件
告诉 Git 忽略哪些文件很有用,这样 Git 就不会再跟踪它们了。有些文件不应该是存储库的一部分。您通常应该忽略 IDE 和代码编辑器设置、包含密码等敏感数据的配置文件、Python 虚拟环境之类的二进制文件、缓存文件以及 SQLite 数据库之类的数据。
当您检查新 Git 存储库的当前状态时,它会列出工作目录中的所有文件,并建议将它们添加到存储库中:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.idea/
__pycache__/
db.sqlite3
manage.py
portfolio/
requirements.txt
venv/
nothing added to commit but untracked files present (use "git add" to track)
不是添加所有这些文件和文件夹,而是让 Git 忽略其中的一些,例如:
.idea/__pycache__/db.sqlite3venv/
.idea/文件夹是 PyCharm 特有的。如果你使用的是 Visual Studio Code 或其他编辑器,那么你需要将它们对应的文件和文件夹添加到这个列表中。在前面包含更多的文件名模式将让其他贡献者安全地使用他们选择的编辑器和 ide,而不必过于频繁地更新列表。
Git 寻找一个名为.gitignore的特殊文件,它通常放在您的存储库的根文件夹中。每行包含一个具体的文件名或一个要排除的通用文件名模式。你可以手动编辑这个文件,但是使用 gitignore.io 网站从一组预定义的组件中创建一个要快得多:
你会注意到,在地址栏中键入 gitignore.io 会将浏览器重定向到 Toptal 拥有的一个更详细的域。
在这里,您可以选择正在使用的编程语言、库和工具。当你对你的选择满意时,点击创建按钮。然后,将结果复制并粘贴到文本编辑器中,并将其作为.gitignore保存在您的项目根文件夹中,或者记下 URL 并在命令行中使用 cURL 来下载文件:
$ curl https://www.toptal.com/developers/gitignore/api/python,pycharm+all,django > .gitignore
如果您发现自己在重复输入这个 URL,那么您可以考虑在您的 shell 中定义一个别名命令,这应该是最容易记住的:
$ git ignore python,pycharm+all,django > .gitignore
实现同一个目标通常有多种方式,了解不同的选择可以教会你很多。不管怎样,在创建了.gitignore文件之后,您的存储库状态应该如下所示:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
manage.py
portfolio/
requirements.txt
nothing added to commit but untracked files present (use "git add" to track)
创建本地 Git 存储库的剩余步骤是暂存您的更改,并在第一次提交时保存它们。
进行第一次提交
请记住,要通过 Git 使用 Heroku,您必须将代码推送到远程 Git 存储库。为此,您需要在本地存储库中至少有一个提交。首先,将新文件添加到暂存区,这是工作树和本地存储库之间的缓冲区。然后,重新检查状态以确认您没有遗漏任何内容:
$ git add .
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: .gitignore
new file: manage.py
new file: portfolio/__init__.py
new file: portfolio/asgi.py
new file: portfolio/settings.py
new file: portfolio/urls.py
new file: portfolio/wsgi.py
new file: requirements.txt
这些文件已经准备好提交,所以让我们获取它们的快照,并将其保存在本地存储库中:
$ git commit -m "Initial commit"
提供一个描述性的提交消息来帮助您浏览变更历史总是一个好主意。根据经验,你的信息应该解释为什么你做出了改变。毕竟,任何人都可以查看 Git 日志来找出到底对做了什么更改。
好吧,到目前为止你学到了什么?您知道在 Heroku 平台上部署新版本通常需要将本地提交推送到 Git 远程。您已经创建了一个本地 Git 存储库,并进行了第一次提交。接下来,你需要创建你的免费 Heroku 账户。
第三步:创建一个免费的 Heroku 账户
现在,你已经准备好注册一个免费的 Heroku 账户,并根据你的喜好进行配置。
Django 标榜自己是有期限的完美主义者的网络框架。Heroku 采取了类似的自以为是的方法在云中托管 web 应用程序,旨在减少开发时间。它是一种高级安全的平台即服务(PaaS) ,可以减轻您的基础设施管理负担,让您专注于对您最重要的事情——编写代码。
有趣的事实: Heroku 基于亚马逊网络服务(AWS) ,另一个流行的云平台,主要以基础设施即服务(IaaS) 模式运行。它比 Heroku 灵活得多,价格也更实惠,但需要一定的专业知识。
许多初创公司和较小的公司在早期发展阶段没有一支熟练的 DevOps 工程师团队。就投资回报而言,Heroku 可能是这些公司的一个方便的解决方案。
报名
要开始使用 Heroku,请访问 Heroku 注册页面,填写注册表格,然后等待带有链接的电子邮件来确认您的帐户。它会将您带到密码设置页面。配置完成后,您将能够进入新的 Heroku 仪表板。您需要做的第一件事是阅读并接受服务条款。
启用多因素身份验证(可选)
这一步完全是可选的,但 Heroku 可能会让你注册多因素认证(MFA) 以增加对你的帐户的保护,确保其安全。这项功能也被称为双因素认证 (2FA),因为它通常只包含两个阶段来验证您的身份。
有趣的事实:我的网飞个人账户曾一度遭到黑客攻击,有人可以使用我的信用卡,甚至在我取消订阅很久之后。从那以后,我在所有的在线服务中启用了双因素认证。
当登录到你的 Heroku 仪表盘时,点击右上角的忍者头像,选择账户设置,然后向下滚动,直到你可以看到多重身份验证部分。点击标有设置多重身份验证的按钮,选择您的验证方法:
- Salesforce 认证器
- 一次性密码生成器
- 安全密钥
- 内置认证器
- 恢复代码
您应该选择哪种验证方法?
Salesforce 是 2010 年收购 Heroku 的母公司,这就是为什么他们宣传他们的专有移动应用程序是你的首选。然而,如果你已经在其他地方使用了另一个验证器应用程序,那么选择一次性密码生成器选项,用你的应用程序扫描二维码。
安全密钥需要一个外部硬件 USB 令牌,而内置认证器方法可以利用你的设备的指纹读取器,例如,如果它带有一个的话。
最后,恢复码可以作为额外的密码。即使你只打算在手机上使用验证程序,你也应该下载恢复代码作为备份。如果没有其他方法来验证您的身份,如果您的手机丢失、损坏或升级,您将无法再次登录您的 Heroku 帐户。相信我,我也经历过!
Heroku 曾经提供另一种验证方法,通过发送短信到你的手机,但是他们停止了这种方法,因为安全问题。
添加付款方式(可选)
如果你不愿意和 Heroku 分享你的信用卡号码,那也没关系。在合理的限制下,这项服务将继续免费运行。然而,即使你不打算花一分钱在云端托管你的 Django 项目,你仍然可以考虑连接你的支付细节。原因如下。
在写这篇教程的时候,你每月只能获得 550 个小时的免费帐号。这相当于每天 24 小时使用单个计算机实例的 22 天。当你用信用卡验证你的账户时,这个数字会上升到每月 1000 小时。
注意:无论您是否验证您的帐户,在 30 分钟窗口内没有接收到任何 HTTP 流量的免费层上的 web 应用程序都会自动进入睡眠状态。这可以节省你的空闲时间,但如果你的应用程序没有正常的流量,会让用户体验变得更糟。当有人想在待机模式下使用你的网络应用程序时,需要几秒钟才能再次启动。
验证你的账户的其他好处包括可以使用免费的插件如关系数据库,建立一个自定义域等等。请记住,如果您决定与 Heroku 共享您的账单信息,那么启用多因素身份认证是一项值得做的工作。
到目前为止,你一直通过 Heroku 的网络界面与他们互动。虽然这无疑是方便和直观的,但是在线托管 Django 项目的最快方式是使用命令行。
步骤 4:安装 Heroku CLI
在终端中工作是任何开发人员的基本技能。起初,输入命令可能看起来令人生畏,但是在看到它的威力后,它变成了第二天性。为了获得无缝的开发体验,您需要安装 Heroku 命令行界面(CLI) 。
Heroku CLI 将允许您直接从终端创建和管理 web 应用程序。在这一步中,您将学习一些基本命令以及如何显示它们的文档。首先,按照针对您的操作系统的安装说明进行操作。完成后,使用以下命令确认安装成功:
$ heroku --version
如果找到了heroku命令,并且您使用了最新版本的 Heroku CLI,那么您可以在您的 shell 中启用自动完成。当您按下 Tab 键时,它会自动完成命令及其参数,节省时间并防止输入错误。
注意:该工具需要一个 Node.js 服务器,大多数安装方法都捆绑了这个服务器。它也是一个开源项目,这意味着你可以在 GitHub 上看看它的源代码。
Heroku CLI 有一个模块化的插件架构,这意味着它的特性是独立的,并且遵循相同的模式。要获得所有可用命令的列表,请在终端中键入heroku help或简单地键入heroku:
$ heroku
CLI to interact with Heroku
VERSION
heroku/7.56.0 linux-x64 node-v12.21.0
USAGE
$ heroku [COMMAND]
COMMANDS
access manage user access to apps
addons tools and services for developing, extending, (...)
apps manage apps on Heroku
auth check 2fa status
(...)
有时,一个命令的名字可能不会泄露它的用途。如果您想找到关于某个特定命令的更多细节并查看用法的快速示例,那么使用--help标志:
$ heroku auth --help
check 2fa status
USAGE
$ heroku auth:COMMAND
COMMANDS
auth:2fa check 2fa status
auth:login login with your Heroku credentials
auth:logout clears local login credentials and invalidates API session
auth:token outputs current CLI authentication token.
auth:whoami display the current logged in user
这里,您通过使用--help标志来请求关于auth命令的更多信息。您可以看到,auth后面应该跟一个冒号(:和另一个命令。通过键入heroku auth:2fa,您要求 Heroku CLI 检查您的双因素身份验证设置的状态:
$ heroku auth:2fa --help
check 2fa status
USAGE
$ heroku auth:2fa
ALIASES
$ heroku 2fa
$ heroku twofactor
COMMANDS
auth:2fa:disable disables 2fa on account
Heroku CLI 命令是分层的。它们通常有一个或多个子命令,您可以在冒号后指定,就像上面的例子一样。此外,这些子命令中的一些可能在命令层级的顶层有一个可用的别名。例如,键入heroku auth:2fa与heroku 2fa或heroku twofactor具有相同的效果:
$ heroku auth:2fa
Two-factor authentication is enabled
$ heroku 2fa
Two-factor authentication is enabled
$ heroku twofactor
Two-factor authentication is enabled
所有三个命令都给出相同的结果,这让您可以选择更容易记住的命令。
在这一小段中,您在计算机上安装了 Heroku CLI,并熟悉了它的语法。您已经看到了一些方便的命令。现在,为了充分利用这个命令行工具,您需要登录您的 Heroku 帐户。
第五步:使用 Heroku CLI 登录
即使不创建 Heroku 帐户,也可以安装 Heroku CLI。但是,你必须验证你的身份,证明你有一个相应的 Heroku 账号,才能用它做一些有意义的事情。在某些情况下,您甚至可能有多个帐户,因此登录允许您指定在给定时刻使用哪个帐户。
稍后您将了解到,您不会永久保持登录状态。这是一个好习惯,登录以确保您有访问权限,并确保您使用正确的帐户。最直接的登录方式是通过heroku login命令:
$ heroku login
heroku: Press any key to open up the browser to login or q to exit:
这将打开您的默认网络浏览器,如果您以前登录过 Heroku 仪表板,就可以很容易地获得您的会话 cookie。否则,您需要提供您的用户名、密码,如果您启用了双因素身份验证,还可能需要另一个身份证明。成功登录后,您可以关闭选项卡或浏览器窗口并返回到终端。
注意:您也可以使用无头模式登录,方法是在命令后面附加--interactive标志,它会提示您输入用户名和密码,而不是启动 web 浏览器。但是,这在启用多因素身份认证的情况下不起作用。
当您使用 CLI 登录时,您的会话 cookies 的暴露是暂时的,因为 Heroku 会生成一个新的授权令牌,它将在有限的时间内有效。它将令牌存储在您的主目录中的标准.netrc文件中,但是您也可以使用 Heroku 仪表板或heroku auth和heroku authorizations插件来检查它:
$ heroku auth:whoami
jdoe@company.com
$ heroku auth:token
› Warning: token will expire today at 11:29 PM
› Use heroku authorizations:create to generate a long-term token
f904774c-ffc8-45ae-8683-8bee0c91aa57
$ heroku authorizations
Heroku CLI login from 54.239.28.85 059ed27c-d04a-4349-9dba-83a0169277ae global
$ heroku authorizations:info 059ed27c-d04a-4349-9dba-83a0169277ae
Client: <none>
ID: 059ed27c-d04a-4349-9dba-83a0169277ae
Description: Heroku CLI login from 54.239.28.85
Scope: global
Token: f904774c-ffc8-45ae-8683-8bee0c91aa57
Expires at: Fri Jul 02 2021 23:29:01 GMT+0200 (Central European Summer Time) (in about 8 hours)
Updated at: Fri Jul 02 2021 15:29:01 GMT+0200 (Central European Summer Time) (1 minute ago)
在撰写本教程时,到期策略似乎有点小故障。官方文档规定,默认情况下,它应该保持一年的有效性,而 Heroku CLI 显示大约一个月,这也对应于会话 cookie 到期。使用 Heroku web 界面手动重新生成令牌可以将时间减少到大约八个小时。但是如果你测试实际的失效日期,你会发现它完全不同。如果您在学习本教程时对到期策略感到好奇,请自行探索。
无论如何,heroku login命令只用于开发。在生产环境中,您通常会使用authorizations插件生成一个永远不会过期的长期用户授权。通过 Heroku API ,它可以方便地用于脚本和自动化目的。
第六步:创建一个 Heroku 应用程序
在这一步,您将创建您的第一个 Heroku 应用程序,并了解它如何与 Git 集成。最后,你将为你的项目拥有一个公开可用的域名地址。
在 Django 项目中,应用程序是封装可重用功能的独立代码单元。另一方面, Heroku apps 工作起来就像可扩展的虚拟计算机,能够托管你的整个 Django 项目。每个应用程序都由源代码、必须安装的依赖项列表和运行项目的命令组成。
最起码,每个项目都有一个 Heroku 应用程序,但拥有更多应用程序并不罕见。例如,您可能希望同时运行项目的开发、试运行和生产版本。每个都可以连接到不同的数据源,并具有不同的特性集。
注意: Heroku pipelines 让你按需创建、提升和销毁应用,以促进连续交付工作流。你甚至可以连接 GitHub,这样每个特性分支都会收到一个临时的测试应用。
要使用 Heroku CLI 创建您的第一个应用程序,请确保您已经登录 Heroku,并运行heroku apps:create命令或其别名:
$ heroku create
Creating app... done, ⬢ polar-island-08305
https://polar-island-08305.herokuapp.com/ | https://git.heroku.com/polar-island-08305.git
默认情况下,它会随机选择一个保证唯一的应用名称,比如polar-island-08305。你也可以选择自己的域名,但是它必须在整个 Heroku 平台上是唯一的,因为它是你免费获得的域名的一部分。您会很快发现它是否已被占用:
$ heroku create portfolio-project
Creating ⬢ portfolio-project... !
▸ Name portfolio-project is already taken
如果你想想有多少人使用 Heroku,那么有人已经创建了一个名为portfolio-project的应用程序就不足为奇了。当您在 Git 存储库中运行heroku create命令时,Heroku 会自动添加一个新的远程服务器到您的.git/config文件中:
$ tail -n3 .git/config
[remote "heroku"]
url = https://git.heroku.com/polar-island-08305.git
fetch = +refs/heads/*:refs/remotes/heroku/*
Git 配置文件中的最后三行定义了一个名为heroku的远程服务器,它指向您唯一的 Heroku 应用程序。
通常,在克隆存储库之后,您的 Git 配置中会有一个远程服务器——例如 GitHub 或 Bitbucket。然而,在一个本地存储库中可以有多个 Git remotes 。稍后您将使用该功能发布新的应用程序并部署到 Heroku。
注意:有时候,使用 Git 会变得很混乱。如果您注意到您意外地在本地 Git 存储库之外或通过 web 界面创建了一个 Heroku 应用程序,那么您仍然可以手动添加相应的 Git remote。首先,将您的目录更改为项目根文件夹。接下来,列出您的应用程序以找到所需的名称:
$ heroku apps
=== jdoe@company.com Apps
fathomless-savannah-61591
polar-island-08305 sleepy-thicket-59477
在您确定了您的应用程序的名称(在本例中为polar-island-08305)之后,您可以使用git remote add命令或 Heroku CLI 中相应的git插件来添加一个名为heroku的遥控器:
$ heroku git:remote --app polar-island-08305
set git remote heroku to https://git.heroku.com/polar-island-08305.git
这将添加一个名为heroku的远程服务器,除非另有说明。
当你创建一个新的应用程序时,它会告诉你它在.herokuapp.com域中的公共网址。在本教程中,公共网址是https://polar-island-08305.herokuapp.com,但是您的将会不同。尝试将您的 web 浏览器导航到您的独特域,看看接下来会发生什么。如果你不记得确切的网址,只需在项目根文件夹中,在终端中键入heroku open命令。它将打开一个新的浏览器窗口并获取正确的资源:
干得好!你的 Heroku 应用已经响应 HTTP 请求。然而,它目前是空的,这就是为什么 Heroku 显示一个通用的占位符视图,而不是你的内容。让我们将您的 Django 项目部署到这个空白应用程序中。
步骤 7:将 Django 项目部署到 Heroku
至此,您已经具备了在 Heroku 上开始托管 Django 项目所需的一切。然而,如果您现在尝试将您的项目部署到 Heroku,它会失败,因为 Heroku 不知道如何构建、打包和运行您的项目。它也不知道如何安装需求文件中列出的特定 Python 依赖项。你现在会解决的。
选择一个构建包
Heroku 自动化了许多部署步骤,但它需要了解您的项目设置和技术堆栈。构建和部署项目的方法被称为构建包。已经有一些官方的构建包可以用于许多后端技术,包括 Node.js、Ruby、Java、PHP、Python、Go、Scala 和 Clojure。除此之外,你可以为不太流行的语言如 c 找到第三方的构建包
您可以在创建新应用程序时手动设置一个,或者让 Heroku 根据存储库中的文件检测它。Heroku 识别 Python 项目的一种方法是在项目根目录中查找requirements.txt文件。确保您已经创建了一个,这可能是在设置您的虚拟环境时用pip freeze完成的,并且您已经将它提交到本地存储库。
其他一些有助于 Heroku 识别 Python 项目的文件是Pipfile和setup.py。Heroku 也将认可 Django web 框架并为其提供特殊支持。所以如果你的项目包括requirements.txt、Pipfile或setup.py,那么通常不需要设置构建包,除非你在处理一些边缘情况。
选择 Python 版本(可选)
默认情况下,Heroku 将选择一个最新的 Python 版本来运行您的项目。但是,您可以通过在项目根目录中放置一个runtime.txt文件来指定不同版本的 Python 解释器,记住要提交它:
$ echo python-3.9.6 > runtime.txt
$ git add runtime.txt
$ git commit -m "Request a specific Python version"
请注意,您的 Python 版本必须包含语义版本的所有major.minor.patch组件。虽然 Python 只有少数几个支持的运行时,但你通常可以调整补丁版本。还有对 PyPy 的测试版支持。
指定要运行的流程
既然 Heroku 知道了如何构建您的 Django 项目,它需要知道如何运行它。一个项目可以由多个组件组成,比如 web 组件、后台工作人员、关系数据库、 NoSQL 数据库、、计划作业等等。每个组件都在单独的进程中运行。
有四种主要的流程类型:
web:接收 HTTP 流量worker:在后台执行工作clock:执行预定的工作release:部署前运行任务
在本教程中,您将只查看 web 过程,因为每个 Django 项目至少需要一个。您可以在名为Procfile的文件中定义它,该文件必须放在您的项目根目录中:
portfolio-project/
│
├── .git/
│
├── portfolio/
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
│
├── venv/
│
├── .gitignore
├── db.sqlite3
├── manage.py
├── Procfile ├── requirements.txt
└── runtime.txt
Procfile是一种单一的、与语言无关的格式,用于定义组成项目的过程。它将指导 Heroku 如何运行你的网络服务器。虽然在生产环境中运行 Django 项目不推荐使用内置的开发服务器,但是您可以在本练习中使用它:
$ echo "web: python manage.py runserver 0.0.0.0:\$PORT" > Procfile
$ git add Procfile
$ git commit -m "Specify the command to run your project"
为了让 Heroku cloud 之外的世界可以访问服务器,您将地址指定为0.0.0.0而不是默认的localhost。它会将服务器绑定在一个公共网络接口上。Heroku 通过PORT环境变量提供端口号。
现在,您可以通过使用 Heroku CLI 在本地运行 Django 项目来测试这个配置:
$ heroku local
默认情况下,如果没有明确指定流程类型,它将运行web流程。heroku local命令与heroku local web相同。同样,如果你没有用--port标志设置端口号,那么它将使用默认端口5000。
现在,您已经指定了希望 Heroku 运行的进程。当您在 web 浏览器中打开 URL http://localhost:5000/时,您应该会在 Django 欢迎页面上再次看到熟悉的火箭。然而,要在http://0.0.0.0:5000/通过公共接口访问相同的资源,您需要调整 Django 配置,否则您将收到一个错误请求错误。
配置 Django
您之前构建了一个基本的 Django 项目,现在是时候配置它了,这样它就可以在您的 Heroku 实例上运行了。配置一个 Django 项目可以让您微调各种设置,从数据库凭证到模板引擎。
要通过非本地网络地址访问 Django 项目,您需要在项目设置中指定ALLOWED_HOSTS。除此之外,Django buildpack for Python 会为您运行collectstatic命令,这需要定义STATIC_ROOT选项。不管您是否使用 Heroku,在部署 Django 项目时,还有一些配置选项需要更改,但在这个阶段它们不是强制性的。
不用手动配置 Django,您可以走捷径,安装一个方便的 django-heroku 包来完成所有的工作。
注:不再维护django-heroku包,对应的 GitHub 库已存档。如果您只想尝试将 Django 项目部署到 Heroku,这可能不是问题。然而,对于生产级应用程序,您可以尝试一个名为 django-on-heroku 的分支,这是 Adam 在下面的评论部分建议的。或者,你可以使用 Eric Matthes 在他的博客上描述的实验性构建包。
在继续之前,请确保您处于正确的虚拟环境中,并记住在完成后刷新您的需求文件:
(portfolio) $ python -m pip install django-heroku
(portfolio) $ python -m pip freeze > requirements.txt
这将用项目的最新依赖项替换您的需求文件的内容。接下来,将这两行 Python 代码添加到您的portfolio/settings.py文件中,并且不要忘记之后返回到项目根文件夹:
(portfolio) $ pushd portfolio/
(portfolio) $ echo "import django_heroku" >> settings.py
(portfolio) $ echo "django_heroku.settings(locals())" >> settings.py
(portfolio) $ popd
或者,如果命令cd portfolio/和cd ..在您的 shell 中不起作用,请使用它们来代替 pushd和popd 命令。
因为您在上面用追加重定向操作符(>>)追加了echo命令的输出,所以现在在 Django 设置文件的最底部有两行代码:
# portfolio/settings.py
# ...
import django_heroku
django_heroku.settings(locals())
这将使用基于项目布局和环境变量的值来更新本地名称空间中的变量。最后,不要忘记将您的更改提交到本地 Git 存储库:
(portfolio) $ git commit -am "Automatic configuration with django-heroku"
现在,您应该能够使用0.0.0.0主机名访问您的 Django web 服务器了。没有它,你将无法通过公共 Heroku 域访问你的应用程序。
配置 Heroku App
您为项目选择了一个构建包和一个 Python 版本。您还指定了 web 进程来接收 HTTP 流量,并配置了您的 Django 项目。将 Django 项目部署到 Heroku 之前的最后一个配置步骤需要在远程 Heroku 应用程序上设置环境变量。
不管你的云提供商是谁,关注配置管理是很重要的。特别是,敏感信息,如数据库密码或用于加密签名 Django 会话的密钥,不能存储在代码中。你还应该记得禁用调试模式,因为这会让你的网站容易受到黑客攻击。但是,在本教程中保持原样,因为您不会有任何自定义内容要显示。
传递这种数据的一种常见方式是环境变量。Heroku 让你通过heroku config命令管理应用程序的环境变量。例如,您可能想从环境变量中读取 Django 密钥,而不是将其硬编码到settings.py文件中。
既然安装了django-heroku,就可以让它处理细节。它检测SECRET_KEY环境变量,并使用它来设置用于加密签名的 Django 秘密密钥。确保密钥的安全至关重要。在portfolio/settings.py中,找到 Django 定义SECRET_KEY变量的自动生成行,并将其注释掉:
# SECURITY WARNING: keep the secret key used in production secret!
# SECRET_KEY = 'django-insecure-#+^6_jx%8rmq9oa(frs7ro4pvr6qn7...
除了注释掉SECRET_KEY变量,您还可以将它一起移除。但是现在不要着急,因为你可能马上就要用到它。
当你现在尝试运行heroku local时,它会抱怨 Django 秘密密钥不再被定义,并且服务器不会启动。要解决这个问题,您可以在当前的终端会话中设置变量,但是更方便的是创建一个名为 .env 的特殊文件,其中包含所有用于本地测试的变量。Heroku CLI 将识别该文件并加载其中定义的环境变量。
注意: Git 不应该跟踪你刚刚创建的.env文件。只要您遵循前面的步骤并使用 gitignore.io 网站,它应该已经列在您的.gitignore文件中了。
生成随机密钥的一种快速方法是使用 OpenSSL 命令行工具:
$ echo "SECRET_KEY=$(openssl rand -base64 32)" > .env
如果您的计算机上没有安装 OpenSSL,而您使用的是 Linux 机器或 macOS,那么您也可以使用 Unix 伪随机数生成器来生成密钥:
$ echo "SECRET_KEY=$(head -c 32 /dev/urandom | base64)" > .env
这两种方法中的任何一种都将确保一个真正随机的密钥。您可能会尝试使用一个不太安全的工具,比如md5sum,并用当前日期作为种子,但是这并不真正安全,因为攻击者可能会枚举可能的输出。
如果上面的命令在您的操作系统上都不起作用,那么暂时取消对portfolio/settings.py中的SECRET_KEY变量的注释,并在您的活动虚拟环境中启动 Django shell:
(portfolio) $ python manage.py shell
在那里,您将能够使用 Django 的内置管理工具生成一个新的随机密钥:
>>> from django.core.management.utils import get_random_secret_key >>> print(get_random_secret_key()) 6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt%抓住那个键,用它来设置您的
.env文件中的SECRET_KEY变量:$ echo 'SECRET_KEY=6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt%' > .env
heroku local命令自动选择在.env文件中定义的环境变量,所以它现在应该像预期的那样工作。如果取消注释,记得再次注释掉SECRET_KEY变量!最后一步是为远程 Heroku 应用程序指定 Django 密钥:
$ heroku config:set SECRET_KEY='6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt%' Setting SECRET_KEY and restarting ⬢ polar-island-08305... done, v3 SECRET_KEY: 6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt%这将在远程 Heroku 基础设施上永久设置一个新的环境变量,该变量将立即可供您的 Heroku 应用程序使用。您可以在 Heroku 仪表板中或使用 Heroku CLI 显示这些环境变量:
$ heroku config === polar-island-08305 Config Vars SECRET_KEY: 6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt% $ heroku config:get SECRET_KEY 6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt%稍后,您可以用另一个值覆盖它或将其完全删除。轮换机密通常是减轻安全威胁的好主意。一旦秘密泄露,你应该迅速改变它,以防止未经授权的访问和限制损害。
发布一个应用程序
您可能已经注意到,用
heroku config:set命令配置环境变量会在输出中产生一个特殊的"v3"字符串,类似于版本号。这不是巧合。每次你通过部署新代码或改变配置来修改你的应用,你都在创建一个新的版本,它增加了你之前看到的那个 v 编号。要按时间顺序列出您的应用发布历史,请再次使用 Heroku CLI:
$ heroku releases === polar-island-08305 Releases - Current: v3 v3 Set SECRET_KEY config vars jdoe@company.com 2021/07/02 14:24:29 +0200 (~ 1h ago) v2 Enable Logplex jdoe@company.com 2021/07/02 14:19:56 +0200 (~ 1h ago) v1 Initial release jdoe@company.com 2021/07/02 14:19:48 +0200 (~ 1h ago)列表中的项目从最新到最早排序。版本号总是递增的。即使你将你的应用程序回滚到以前的版本,它也会创建一个新的版本来保存完整的历史。
使用 Heroku 发布新的应用程序可以归结为将代码提交到您的本地 Git 存储库,然后将您的分支推送到远程 Heroku 服务器。但是,在这样做之前,一定要仔细检查
git status中是否有任何未提交的更改,并在必要时将它们添加到本地存储库中,例如:$ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: portfolio/settings.py no changes added to commit (use "git add" and/or "git commit -a") $ git add . $ git commit -m "Remove a hardcoded Django secret key"虽然您可以推送任何本地分支,但是必须将它推送到特定的远程分支才能让部署工作。Heroku 仅从远程
main或master分支部署。如果您已经使用git init命令创建了您的存储库,那么您的默认分支应该被命名为master。或者,如果你在 GitHub 上创建了它,那么它将被命名为main。因为
main和master分支都存在于远程 Heroku 服务器上,所以您可以使用一种简单的语法来触发构建和部署:$ git push heroku master这里,
master指的是您的本地和远程分支机构。如果您想推送一个不同的本地分支,那么指定它的名称,比如bugfix/stack-overflow,后跟一个冒号(:)和远程目标分支:$ git push heroku bugfix/stack-overflow:master现在让我们将默认分支推到 Heroku,看看接下来会发生什么:
$ git push heroku master (...) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Building on the Heroku-20 stack remote: -----> Determining which buildpack to use for this app remote: -----> Python app detected remote: -----> Using Python version specified in runtime.txt remote: -----> Installing python-3.9.6 remote: -----> Installing pip 20.2.4, setuptools 47.1.1 and wheel 0.36.2 remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip (...) remote: -----> Compressing... remote: Done: 60.6M remote: -----> Launching... remote: Released v6 remote: https://polar-island-08305.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/polar-island-08305.git * [new branch] master -> master将代码推送到 Heroku 就像推送到 GitHub、Bitbucket 或其他远程 Git 服务器一样。然而,除此之外,它还开始了构建过程。Heroku 将根据您的项目文件确定正确的构建包。它将使用您的
runtime.txt文件中指定的 Python 解释器,并从requirements.txt安装依赖项。在实践中,更方便的做法是将您的代码只推送到您选择的 Git 服务器,比如 GitHub,并让它通过一个 webhook 触发 Heroku 上的构建。如果你想进一步探索,你可以在 Heroku 的官方文档中阅读关于 GitHub 集成的内容。
注意:第一次向 Heroku 推送代码时,可能需要一段时间,因为平台需要启动一个新的 Python 环境,安装依赖项,并为其容器构建一个映像。但是,后续部署会更快,因为安装的依赖项已经被缓存。
您可以在浏览器中导航至 Heroku 应用程序的公共 URL。或者,在您的终端中键入
heroku open命令将为您完成这项工作:
Django Project Hosted on a Public Domain 恭喜你!您刚刚公开了您的项目。
步骤 8:建立一个关系数据库
干得好!你几乎已经完成了在 Heroku 上为你的 Django 项目设置主机的工作。这是等式的最后一部分,所以坚持一两分钟。
到目前为止,您一直使用 Django 预先配置的基于文件的 SQLite 数据库。它适合在你的本地计算机上测试,但不能在云中运行。Heroku 有一个临时文件系统,它会忘记自上次部署或服务器重启以来的所有更改。您需要一个独立的数据库引擎来将您的数据保存在云中。
在本教程中,您将使用 Heroku 提供的免费 PostgreSQL 实例作为完全托管的数据库服务。如果需要,可以使用不同的数据库引擎,但是 PostgreSQL 通常不需要额外的配置。
调配 PostgreSQL 服务器
当 Heroku 在你的项目中检测到 Django 框架时,它会自动旋转出一个免费但有限的 PostgreSQL 实例。它用应用程序数据库的公共 URL 设置了
DATABASE_URL环境变量。首次部署应用时会进行配置,这可以通过检查启用的附加组件和配置变量来确认:$ heroku addons Add-on Plan Price State ──────────────────────────────────────────────── ───────── ───── ─────── heroku-postgresql (postgresql-trapezoidal-06380) hobby-dev free created └─ as DATABASE The table above shows add-ons and the attachments to the current app (...) $ heroku config === polar-island-08305 Config Vars DATABASE_URL: postgres://ytfeiommjakmxb...amazonaws.com:5432/dcf99cdrgdaqba SECRET_KEY: 6aj9il2xu2vqwvnitsg@!+4-8t3%zwr@$agm7x%o%yb2t9ivt%通常,您需要在
portfolio/settings.py中显式地使用该变量,但是因为您安装了django-heroku模块,所以不需要指定数据库 URL 或者用户名和密码。它会自动从环境变量中获取数据库 URL 并为您配置设置。此外,您不必安装一个数据库驱动程序来连接到 Heroku 提供的 PostgreSQL 实例。另一方面,最好针对生产环境中使用的同一类型的数据库进行本地开发。它促进了您的环境之间的对等性,并让您利用给定数据库引擎提供的高级特性。
当您安装
django-heroku时,它已经获取了psycopg2作为一个可传递的依赖项:(portfolio) $ pip list Package Version --------------- ------- asgiref 3.4.1 dj-database-url 0.5.0 Django 3.2.5 django-heroku 0.3.1 pip 21.1.3 psycopg2 2.9.1 pytz 2021.1 setuptools 56.0.0 sqlparse 0.4.1 whitenoise 5.2.0
psycopg2是 PostgreSQL 数据库的 Python 驱动。由于驱动程序已经存在于您的环境中,您可以立即开始在您的应用程序中使用 PostgreSQL。在免费的爱好发展计划上,Heroku 设置了一些限制。您最多可以有 10,000 行,必须适合 1 GB 的存储空间。到数据库的连接不能超过 20 个。没有缓存,性能受到限制,还有许多其他限制。
您可以随时使用
heroku pg命令查看 Heroku 提供的 PostgreSQL 数据库的详细信息:$ heroku pg === DATABASE_URL Plan: Hobby-dev Status: Available Connections: 1/20 PG Version: 13.3 Created: 2021-07-02 08:55 UTC Data Size: 7.9 MB Tables: 0 Rows: 0/10000 (In compliance) - refreshing Fork/Follow: Unsupported Rollback: Unsupported Continuous Protection: Off Add-on: postgresql-trapezoidal-06380这个简短的摘要包含有关当前连接数、数据库大小、表和行数等信息。
在接下来的小节中,您将了解如何在 Heroku 上使用 PostgreSQL 数据库做一些有用的事情。
更新远程数据库模式
当您在 Django 应用程序中定义新模型时,您通常会创建新的迁移文件,并将它们应用于数据库。要更新远程 PostgreSQL 实例的模式,只需在 Heroku 环境中运行与之前相同的迁移命令。稍后您将看到推荐的方法,但是现在,您可以手动运行适当的命令:
$ heroku run python manage.py migrate Running python manage.py migrate on ⬢ polar-island-08305... up, run.1434 (Free) Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK (...)
run插件启动一个名为一次性 dyno 的临时容器,它类似于一个 Docker 容器,可以访问你的应用程序的源代码及其配置。因为 dynos 运行的是 Linux 容器,所以您可以在其中一个容器中执行任何命令,包括交互式终端会话:$ heroku run bash Running bash on ⬢ polar-island-08305... up, run.9405 (Free) (~) $ python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: No migrations to apply.在临时 dyno 中运行 Bash shell 是检查或操作 Heroku 应用程序状态的常见做法。您可以将其视为登录到远程服务器。唯一的区别是,您启动的是一个一次性虚拟机,它包含项目文件的副本,并接收与您的动态 web dyno 相同的环境变量。
然而,这种运行数据库迁移的方式并不是最可靠的,因为您可能会忘记它或者在以后的道路上犯错误。您最好在
Procfile中通过添加突出显示的行来自动完成这一步:web: python manage.py runserver 0.0.0.0:$PORT release: python manage.py migrate现在,每次您发布新版本时,Heroku 都会负责应用任何未完成的迁移:
$ git commit -am "Automate remote migrations" $ git push heroku master (...) remote: Verifying deploy... done. remote: Running release command... remote: remote: Operations to perform: remote: Apply all migrations: admin, auth, contenttypes, sessions remote: Running migrations: remote: No migrations to apply. To https://git.heroku.com/polar-island-08305.git d9f4c04..ebe7bc5 master -> master它仍然让您选择是否真正进行任何新的迁移。当您正在进行可能需要一段时间才能完成的大型迁移时,请考虑启用维护模式,以避免在用户使用您的应用时损坏或丢失数据:
$ heroku maintenance:on Enabling maintenance mode for ⬢ polar-island-08305... doneHeroku 将在维护模式下显示此友好页面:
Heroku App in the Maintenance Mode 完成迁移后,别忘了用
heroku maintenance:off禁用它。填充数据库
通过应用迁移,您已经为 Django 模型创建了数据库表,但是这些表大部分时间都是空的。你迟早会想得到一些数据。与数据库交互的最佳方式是通过 Django admin 接口。要开始使用它,您必须首先远程创建一个超级用户:
$ heroku run python manage.py createsuperuser Running python manage.py createsuperuser on ⬢ polar-island-08305... up, run.2976 (Free) Username (leave blank to use 'u23948'): admin Email address: jdoe@company.com Password: Password (again): Superuser created successfully.记得在相应的命令前加上
heroku run,在连接到你的远程 Heroku 应用程序的数据库中创建超级用户。在为超级用户提供了唯一的名称和安全密码之后,您将能够登录到 Django admin 视图,并开始向您的数据库添加记录。您可以通过访问位于您唯一的 Heroku 应用程序域名后的
/admin路径来访问 Django 管理视图,例如:https://polar-island-08305.herokuapp.com/admin/登录后应该是这样的:
Django Admin Site on Heroku 直接操纵远程数据库的一个选择是从 Heroku 获取
DATABASE_URL变量,并解密它的各个组件,通过您最喜欢的 SQL 客户机进行连接。或者,Heroku CLI 提供了一个方便的psql插件,它像标准 PostgreSQL 交互终端一样工作,但不需要安装任何软件:$ heroku psql --> Connecting to postgresql-round-16446 psql (10.17 (Ubuntu 10.17-0ubuntu0.18.04.1), server 13.3 (Ubuntu 13.3-1.pgdg20.04+1)) WARNING: psql major version 10, server major version 13. Some psql features might not work. SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. polar-island-08305::DATABASE=> SELECT username, email FROM auth_user; username | email ----------+------------------ admin | jdoe@company.com (1 row)请注意,
heroku psql命令如何将您连接到 Heroku 基础设施上的正确数据库,而不需要任何细节,如主机名、用户名或密码。此外,您不必安装 PostgreSQL 客户端来使用 SQL 查询其中一个表。作为 Django 开发人员,您可能习惯于依赖它的对象关系映射器(ORM) ,而不是手动输入 SQL 查询。您可以通过在远程 Heroku 应用程序中启动交互式 Django shell 来再次使用 Heroku CLI:
$ heroku run python manage.py shell Running python manage.py shell on ⬢ polar-island-08305... up, run.9914 (Free) Python 3.9.6 (default, Jul 02 2021, 15:33:41) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole)接下来,导入内置的
User模型,并使用其管理器从数据库中检索相应的用户对象:
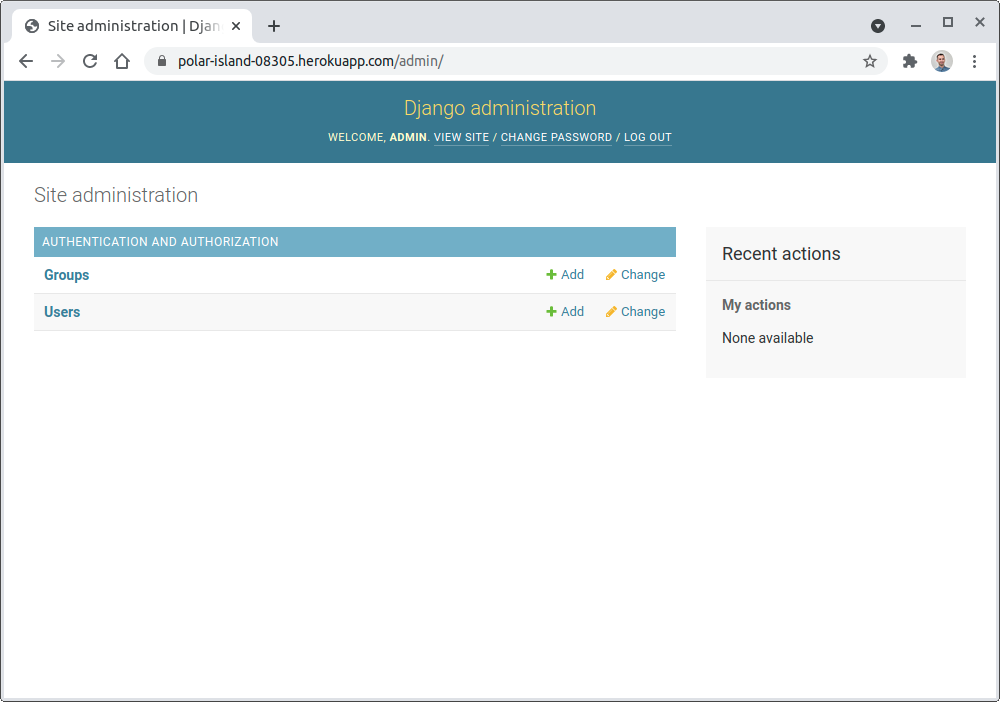
>>> from django.contrib.auth.models import User
>>> User.objects.all()
<QuerySet [<User: admin>]>
您应该会看到您之前创建的超级用户。使用 Django shell 可以让您用面向对象的 API 查询连接的数据库。如果你不喜欢默认 shell,那么你可以安装一个替代 Python REPL 比如 IPython 或者 bpython ,Django 会识别它。
好吧,就这样!您在 Heroku 上托管了一个成熟的 Django 项目,并连接了一个关系数据库。例如,你现在可以在 GitHub 上的 README 文件中分享它的公共链接,让全世界欣赏你的作品。
结论
现在,您知道如何将您的想法转化为您的朋友和家人会喜欢的实时 web 应用程序。也许,人力资源部门的人会偶然发现你的一个项目并给你一份工作。注册一个免费的 Heroku 账户来托管你的 Django 代码是进入云计算世界的最好方式之一。
在本教程中,您已经学会了如何:
- 在几分钟内让你的 Django 项目上线
- 使用 Git 将您的项目部署到 Heroku
- 使用 Django-Heroku 集成库
- 将你的 Django 项目挂接到一个独立的关系数据库上
- 管理配置以及敏感数据
您可以通过下面的链接下载最终的源代码以及各个步骤的快照:
获取源代码: 点击这里获取 Django 项目以及本教程中各个步骤的快照。
接下来的步骤
本教程仅仅触及了 Heroku 的皮毛。它有意掩盖了许多细节,但 Heroku 提供了更多,即使是有限的免费帐户。如果你想让你的项目更上一层楼,这里有一些想法可以考虑:
-
配置一个 WSGI 服务器:在公开您的项目之前,首先要做的是用更安全、更高效的东西替换内置的 Django 开发服务器,比如 Gunicorn。Django 提供了一个方便的部署清单,里面有你可以浏览的最佳实践。
-
启用日志记录:在云中运行的应用程序不在您的直接控制之下,这使得调试和故障排除比在本地机器上运行更困难。因此,您应该使用 Heroku 的一个附加组件来启用日志记录。
-
提供静态文件:使用外部服务,如亚马逊 S3 或内容交付网络(CDN)来托管静态资源,如 CSS、JavaScript 或图片。这可能会大大减轻您的 web 服务器的负载,并利用缓存加快下载速度。
-
提供动态内容:由于 Heroku 的临时文件系统,用户提供给你的应用程序的数据不能作为本地文件保存。使用关系数据库甚至 NoSQL 数据库并不总是最有效或最方便的选择。在这种情况下,你可能想使用外部服务,如亚马逊 S3。
-
添加自定义域:默认情况下,你的 Heroku 应用托管在
.herokuapp.com域上。虽然它对于业余爱好项目来说既快速又有用,但您可能希望在更专业的环境中使用自定义域。 -
添加 SSL 证书:当您定义自定义域时,您必须提供相应的 SSL 证书,以通过 HTTPS 公开您的应用。这是当今世界的必备工具,因为一些网络浏览器供应商已经宣布,他们未来不会显示不安全的网站。
-
与 GitHub 挂钩:当一个 pull 请求被合并到主分支时,您可以通过允许 GitHub 触发一个新的构建和发布来自动化您的部署。这减少了手动步骤的数量,并保证了源代码的安全。
-
使用 Heroku 管道: Heroku 鼓励您以最小的努力遵循最佳实践。它通过可选地自动化测试环境的创建,提供了一个连续的交付工作流。
-
启用自动扩展:随着应用的增长,它将需要面对不断增长的资源需求。大多数电子商务平台每年圣诞节前后都会经历一次流量高峰。这个问题的当代解决方案是水平扩展,它将你的应用程序复制成多个副本来满足需求。自动缩放可以在任何需要的时候响应这样的峰值。
-
拆分成微服务:当你的项目由多个独立的微服务组成时,水平伸缩效果最好,可以单独伸缩。这种架构可以加快开发速度,但也带来了一些挑战。
-
从 Heroku 迁移:一旦你接触了 Heroku,你可能会考虑迁移到另一个云平台,如谷歌应用引擎甚至底层亚马逊基础设施,以降低你的成本。
继续探索 Heroku 网站上的官方文档和 Python 教程,以找到关于这些主题的更多细节。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,以加深您的理解: 在 Heroku 上主持您的 Django 项目*********
Django 迁移:入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 姜戈大迁徙 101
从版本 1.7 开始,Django 就内置了对数据库迁移的支持。在 Django 中,数据库迁移通常与模型密切相关:每当您编写一个新模型时,您还会生成一个迁移以在数据库中创建必要的表。然而,迁移可以做得更多。
通过四篇文章和一个视频,您将了解 Django 迁移是如何工作的,以及如何充分利用它们:
- 第 1 部分:Django 迁移:入门(当前文章)
- 第 2 部分:深入探讨迁移
- 第 3 部分:数据迁移
- 视频: Django 1.7 迁移-初级教程
在本文中,您将熟悉 Django 迁移,并了解以下内容:
- 如何在不编写任何 SQL 的情况下创建数据库表
- 如何在更改模型后自动修改数据库
- 如何恢复对数据库所做的更改
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
迁移解决的问题
如果您是 Django 或 web 开发的新手,您可能不熟悉数据库迁移的概念,也不清楚为什么这是个好主意。
首先,让我们快速定义几个术语,以确保每个人都在同一页上。Django 被设计为使用关系数据库 T1,存储在关系数据库管理系统中,如 T2 的 PostgreSQL T3、T4 的 MySQL T5 或 T6 的 SQLite T7。
在关系数据库中,数据组织在表中。数据库表有一定数量的列,但它可以有任意数量的行。每一列都有一个特定的数据类型,比如某个最大长度的字符串或正整数。对所有表及其列和各自数据类型的描述称为数据库模式。
Django 支持的所有数据库系统都使用 SQL 语言来创建、读取、更新和删除关系数据库中的数据。SQL 还用于创建、更改和删除数据库表本身。
直接使用 SQL 可能很麻烦,所以为了让您的生活更轻松,Django 附带了一个对象关系映射器,简称 ORM。ORM 将关系数据库映射到面向对象编程的世界。你不用 SQL 定义数据库表,而是用 Python 编写 Django 模型。您的模型定义了数据库字段,这些字段对应于它们的数据库表中的列。
下面是一个 Django 模型类如何映射到数据库表的例子:

但是仅仅在 Python 文件中定义一个模型类并不能让一个数据库表神奇地凭空出现。创建数据库表来存储 Django 模型是数据库迁移的工作。此外,每当您对模型进行更改时,比如添加一个字段,数据库也必须进行更改。迁移也能解决这个问题。
以下是 Django 迁移让您的生活更轻松的几种方式。
在没有 SQL 的情况下更改数据库
如果没有迁移,您将不得不连接到您的数据库,键入一堆 SQL 命令,或者使用类似于 PHPMyAdmin 的图形工具,在每次您想要更改您的模型定义时修改数据库模式。
在 Django 中,迁移主要是用 Python 编写的,所以除非你有非常高级的用例,否则你不需要了解任何 SQL。
避免重复
创建一个模型,然后编写 SQL 来为它创建数据库表,这将是重复的。
迁移从您的模型中生成,确保您不会重复自己。
确保模型定义和数据库模式同步
通常,您有多个数据库实例,例如,团队中的每个开发人员有一个数据库,一个用于测试的数据库和一个包含实时数据的数据库。
如果没有迁移,您将不得不在每个数据库上执行任何模式更改,而且您将不得不跟踪对哪个数据库已经进行了哪些更改。
使用 Django 迁移,您可以轻松地将多个数据库与您的模型保持同步。
在版本控制中跟踪数据库模式变更
像 Git 这样的版本控制系统对于代码来说非常优秀,但是对于数据库模式来说就不那么好了。
因为在 Django 中,迁移是普通的 Python,所以您可以将它们放在版本控制系统中,就像任何其他代码一样。
到目前为止,您有望相信迁移是一个有用且强大的工具。让我们开始学习如何释放这种力量。
建立 Django 项目
在本教程中,您将使用一个简单的比特币追踪器应用程序作为示例项目。
第一步是安装 Django。下面是如何在 Linux 或 macOS X 上使用虚拟环境实现这一点:
$ python3 -m venv env
$ source env/bin/activate
(env) $ pip install "Django==2.1.*"
...
Successfully installed Django-2.1.3
现在,您已经创建了一个新的虚拟环境并激活了它,还在该虚拟环境中安装了 Django。
请注意,在 Windows 上,您将运行env/bin/activate.bat而不是source env/bin/activate来激活您的虚拟环境。
为了更容易阅读,从现在开始,控制台示例将不包括提示的(env)部分。
安装 Django 后,您可以使用以下命令创建项目:
$ django-admin.py startproject bitcoin_tracker
$ cd bitcoin_tracker
$ python manage.py startapp historical_data
这给了你一个简单的项目和一个名为historical_data的应用。您现在应该有这样的目录结构:
bitcoin_tracker/
|
├── bitcoin_tracker/
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
|
├── historical_data/
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations/
│ │ └── __init__.py
| |
│ ├── models.py
│ ├── tests.py
│ └── views.py
|
└── manage.py
在bitcoin_tracker目录中,有两个子目录:bitcoin_tracker用于项目范围的文件,而historical_data包含您创建的应用程序的文件。
现在,为了创建一个模型,在historical_data/models.py中添加这个类:
class PriceHistory(models.Model):
date = models.DateTimeField(auto_now_add=True)
price = models.DecimalField(max_digits=7, decimal_places=2)
volume = models.PositiveIntegerField()
这是跟踪比特币价格的基本模型。
另外,不要忘记将新创建的应用程序添加到settings.INSTALLED_APPS。打开bitcoin_tracker/settings.py并将historical_data追加到列表INSTALLED_APPS中,就像这样:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'historical_data',
]
这个项目的其他设置都很好。本教程假设您的项目被配置为使用默认的 SQLite 数据库。
创建迁移
创建了模型之后,您需要做的第一件事就是为它创建一个迁移。您可以使用以下命令来完成此操作:
$ python manage.py makemigrations historical_data
Migrations for 'historical_data':
historical_data/migrations/0001_initial.py
- Create model PriceHistory
注意:指定应用程序的名称historical_data,是可选的。关闭它会为所有应用程序创建迁移。
这将创建迁移文件,指导 Django 如何为应用程序中定义的模型创建数据库表。让我们再看一下目录树:
bitcoin_tracker/
|
├── bitcoin_tracker/
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
|
├── historical_data/
│ ├── migrations/
│ │ ├── 0001_initial.py │ │ └── __init__.py
| |
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
|
├── db.sqlite3
└── manage.py
如您所见,migrations目录现在包含了一个新文件:0001_initial.py。
注意:您可能会注意到,运行makemigrations命令还会创建文件db.sqlite3,其中包含您的 SQLite 数据库。
当您试图访问一个不存在的 SQLite3 数据库文件时,它将被自动创建。
这种行为是 SQLite3 特有的。如果你使用任何其他数据库后端,如 PostgreSQL 或 MySQL ,你必须在运行makemigrations之前自己创建数据库。
您可以使用 dbshell管理命令来查看数据库。在 SQLite 中,列出所有表的命令很简单.tables:
$ python manage.py dbshell
SQLite version 3.19.3 2017-06-27 16:48:08
Enter ".help" for usage hints.
sqlite> .tables
sqlite>
数据库仍然是空的。当您应用迁移时,这种情况将会改变。键入.quit退出 SQLite shell。
应用迁移
您现在已经创建了迁移,但是要在数据库中进行任何实际的更改,您必须使用管理命令migrate来应用它:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, historical_data, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying historical_data.0001_initial... OK
Applying sessions.0001_initial... OK
这里发生了很多事情!根据输出,您的迁移已经成功应用。但是所有其他的迁移来自哪里呢?
还记得INSTALLED_APPS的设定吗?这里列出的一些其他应用程序也带有迁移功能,默认情况下,migrate管理命令会为所有已安装的应用程序应用迁移功能。
再看一下数据库:
$ python manage.py dbshell
SQLite version 3.19.3 2017-06-27 16:48:08
Enter ".help" for usage hints.
sqlite> .tables
auth_group django_admin_log
auth_group_permissions django_content_type
auth_permission django_migrations
auth_user django_session
auth_user_groups historical_data_pricehistory
auth_user_user_permissions
sqlite>
现在有多个表。他们的名字让你知道他们的目的。您在上一步中生成的迁移已经创建了historical_data_pricehistory表。让我们使用.schema命令对其进行检查:
sqlite> .schema --indent historical_data_pricehistory
CREATE TABLE IF NOT EXISTS "historical_data_pricehistory"(
"id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"date" datetime NOT NULL,
"price" decimal NOT NULL,
"volume" integer unsigned NOT NULL
);
.schema命令打印出您将执行来创建表的CREATE语句。参数--indent很好地格式化了它。即使您不熟悉 SQL 语法,也可以看出historical_data_pricehistory表的模式反映了PriceHistory模型的字段。
每个字段都有一列,主键有一个额外的列id,Django 会自动创建这个列,除非您在模型中明确指定主键。
如果再次运行migrate命令,会发生以下情况:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, historical_data, sessions
Running migrations:
No migrations to apply.
没什么!Django 会记住哪些迁移已经被应用,并且不会尝试重新运行它们。
值得注意的是,您还可以将migrate管理命令限制到单个应用程序:
$ python manage.py migrate historical_data
Operations to perform:
Apply all migrations: historical_data
Running migrations:
No migrations to apply.
如您所见,Django 现在只为historical_data应用程序应用迁移。
当您第一次运行迁移时,最好应用所有迁移,以确保您的数据库包含您可能认为理所当然的功能(如用户验证和会话)所需的表。
更换型号
你的模型不是一成不变的。随着 Django 项目获得更多特性,您的模型将会改变。您可以添加或删除字段,或者更改它们的类型和选项。
当您更改模型的定义时,用于存储这些模型的数据库表也必须更改。如果您的模型定义与您当前的数据库模式不匹配,您很可能会遇到django.db.utils.OperationalError。
那么,如何改变数据库表呢?通过创建和应用迁移。
在测试你的比特币追踪器时,你意识到你犯了一个错误。人们正在出售比特币的一部分,所以字段volume应该是类型DecimalField而不是PositiveIntegerField。
让我们将模型更改为如下所示:
class PriceHistory(models.Model):
date = models.DateTimeField(auto_now_add=True)
price = models.DecimalField(max_digits=7, decimal_places=2)
volume = models.DecimalField(max_digits=7, decimal_places=3)
如果没有迁移,您将不得不找出将PositiveIntegerField转换成DecimalField的 SQL 语法。幸运的是,姜戈会帮你处理的。只需告诉它进行迁移:
$ python manage.py makemigrations
Migrations for 'historical_data':
historical_data/migrations/0002_auto_20181112_1950.py
- Alter field volume on pricehistory
注意:迁移文件的名称(0002_auto_20181112_1950.py)是基于当前时间的,如果您在您的系统上执行,名称会有所不同。
现在,您将此迁移应用到您的数据库:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, historical_data, sessions
Running migrations:
Applying historical_data.0002_auto_20181112_1950... OK
迁移已成功应用,因此您可以使用dbshell来验证更改是否有效:
$ python manage.py dbshell
SQLite version 3.19.3 2017-06-27 16:48:08
Enter ".help" for usage hints.
sqlite> .schema --indent historical_data_pricehistory
CREATE TABLE IF NOT EXISTS "historical_data_pricehistory" (
"id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"date" datetime NOT NULL,
"price" decimal NOT NULL,
"volume" decimal NOT NULL );
如果您将新的模式与您之前看到的模式进行比较,您会注意到volume列的类型已经从integer更改为decimal,以反映模型中的volume字段从PositiveIntegerField更改为DecimalField。
列出迁移
如果您想知道 Django 项目中存在哪些迁移,您不必深究您安装的应用程序的migrations目录。您可以使用showmigrations命令:
$ ./manage.py showmigrations
admin
[X] 0001_initial
[X] 0002_logentry_remove_auto_add
[X] 0003_logentry_add_action_flag_choices
auth
[X] 0001_initial
[X] 0002_alter_permission_name_max_length
[X] 0003_alter_user_email_max_length
[X] 0004_alter_user_username_opts
[X] 0005_alter_user_last_login_null
[X] 0006_require_contenttypes_0002
[X] 0007_alter_validators_add_error_messages
[X] 0008_alter_user_username_max_length
[X] 0009_alter_user_last_name_max_length
contenttypes
[X] 0001_initial
[X] 0002_remove_content_type_name
historical_data
[X] 0001_initial
[X] 0002_auto_20181112_1950
sessions
[X] 0001_initial
这将列出项目中的所有应用程序以及与每个应用程序相关联的迁移。此外,它会在已经应用的迁移旁边加上一个大的X。
对于我们的小例子来说,showmigrations命令并不特别令人兴奋,但是当您开始在现有的代码基础上工作或者在一个团队中工作,而您并不是唯一一个添加迁移的人时,它就很方便了。
不应用迁移
现在,您知道了如何通过创建和应用迁移来更改数据库模式。有时,您可能希望撤消更改并切换回以前的数据库模式,因为您:
- 想测试一个同事写的迁移吗
- 意识到你所做的改变是个坏主意
- 并行处理具有不同数据库更改的多个特征
- 想要恢复数据库仍有旧模式时创建的备份
幸运的是,迁移不一定是单行道。在许多情况下,可以通过取消应用迁移来撤消迁移的效果。要取消应用迁移,您必须在您想要取消应用的迁移的之前,使用应用程序的名称和迁移的名称调用migrate。
如果您想在您的historical_data应用程序中恢复迁移0002_auto_20181112_1950,您必须将0001_initial作为参数传递给migrate命令:
$ python manage.py migrate historical_data 0001_initial
Operations to perform:
Target specific migration: 0001_initial, from historical_data
Running migrations:
Rendering model states... DONE
Unapplying historical_data.0002_auto_20181112_1950... OK
迁移尚未应用,这意味着对数据库的更改已被撤销。
取消应用迁移不会删除其迁移文件。下次运行migrate命令时,将再次应用迁移。
注意:不要将未应用的迁移与您习惯使用的文本编辑器中的撤销操作相混淆。
并非所有数据库操作都可以完全还原。如果您从模型中删除一个字段,创建一个迁移,并应用它,Django 将从数据库中删除相应的列。
不应用该迁移将重新创建该列,但不会恢复存储在该列中的数据!
当您处理迁移名称时,Django 不会强迫您拼出迁移的全名,从而为您节省了一些击键时间。它只需要足够的名称来唯一地标识它。
在前面的例子中,运行python manage.py migrate historical_data 0001就足够了。
命名迁移
在上面的例子中,Django 根据时间戳为迁移起了一个名字,类似于*0002_auto_20181112_1950。如果您对此不满意,那么您可以使用--name参数来提供一个自定义名称(不带.py扩展名)。
要尝试这一点,您首先必须删除旧的迁移。您已经取消应用了它,因此您可以安全地删除该文件:
$ rm historical_data/migrations/0002_auto_20181112_1950.py
现在,您可以用一个更具描述性的名称重新创建它:
$ ./manage.py makemigrations historical_data --name switch_to_decimals
这将创建与之前相同的迁移,只是使用了新名称0002_switch_to_decimals。
结论
您在本教程中涉及了相当多的内容,并且学习了 Django 迁移的基础知识。
概括一下,使用 Django 迁移的基本步骤如下:
- 创建或更新模型
- 运行
./manage.py makemigrations <app_name> - 运行
./manage.py migrate迁移所有应用程序,或运行./manage.py migrate <app_name>迁移单个应用程序 - 必要时重复
就是这样!这个工作流程在大多数情况下是可行的,但是如果事情没有按预期进行,您也知道如何列出和取消应用迁移。
如果您以前使用手写的 SQL 创建和修改数据库表,那么现在通过将这项工作委托给 Django 迁移,您会变得更加高效。
在本系列的下一篇教程中,您将深入探讨这个主题,并了解 Django 迁移如何在幕后工作。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
干杯!
视频
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 姜戈大迁徙 101******
使用 Gunicorn、Nginx 和 HTTPS 安全部署 Django 应用程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Gunicorn 和 Nginx 部署一个 Django App
将一个 Django 应用从开发到生产是一个要求很高但很值得的过程。本教程将带您一步一步地完成这一过程,提供一个深入的指南,从一个简单的 Django 应用程序开始,并添加了 Gunicorn 、 Nginx 、域注册和关注安全性的 HTTP 头。阅读完本教程后,您将更好地准备将您的 Django 应用程序投入生产并向全世界提供服务。
在本教程中,您将学习:
- 如何将 Django 应用从开发带入生产
- 你如何在现实世界的公共领域托管你的应用程序
- 如何将 Gunicorn 和 Nginx 引入请求和响应链
- HTTP headers 如何加强你网站的 HTTPS 安全
为了充分利用本教程,您应该对 Python 、、Django 以及 HTTP 请求的高级机制有一个初级的理解。
您可以通过下面的链接下载本教程中使用的 Django 项目:
获取源代码: 点击此处获取本教程中使用的配套 Django 项目。
从 Django 和 WSGIServer 开始
您将使用 Django 作为 web 应用程序的核心框架,使用它进行 URL 路由、HTML 呈现、认证、管理和后端逻辑。在本教程中,您将使用另外两个层来补充 Django 组件, Gunicorn 和 Nginx ,以便可伸缩地服务于应用程序。但是在这之前,您需要设置您的环境,并让 Django 应用程序自己启动并运行。
设置云虚拟机
首先,您需要启动并设置一个虚拟机(VM) ,web 应用程序将在其上运行。您应该熟悉至少一家基础设施即服务(IaaS) 云服务提供商来供应虚拟机。这一部分将在较高层次上引导您完成这一过程,但不会详细介绍每一步。
使用虚拟机为 web 应用提供服务是 IaaS 的一个例子,在这种情况下,您可以完全控制服务器软件。除了 IaaS 之外,还存在其他选择:
不过,对于本教程,您将使用直接在 IaaS 上服务 Nginx 和 Django 的可靠方法。
虚拟机的两个流行选项是 Azure VMs 和 Amazon EC2 。要获得启动实例的更多帮助,您应该参考云提供商的文档:
- 对于 Azure 虚拟机,遵循他们的快速入门指南,在 Azure 门户中创建 Linux 虚拟机。
- 对于亚马逊 EC2 ,学习如何进行设置。
Django 项目和本教程中涉及的所有东西都位于运行 Ubuntu Server 20.04 的一个 t2.micro Amazon EC2 实例上。
虚拟机设置的一个重要组成部分是入站安全规则。这些是控制实例入站流量的细粒度规则。为初始开发创建以下入站安全规则,您将在生产中修改这些规则:
| 参考 | 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|---|
| one | 习俗 | 传输控制协议(Transmission Control Protocol) | Eight thousand | my-laptop-ip-address/32 |
| Two | 习俗 | 全部 | 全部 | security-group-id |
| three | 嘘 | 传输控制协议(Transmission Control Protocol) | Twenty-two | my-laptop-ip-address/32 |
现在,您将一次浏览一个:
- 规则 1 允许 TCP 从你的个人电脑的 IPv4 地址通过端口 8000,允许你在通过端口 8000 开发 Django 应用程序时向它发送请求。
- 规则 2 使用安全组 ID 作为来源,允许来自分配给同一安全组的网络接口和实例的入站流量。这是默认 AWS 安全组中包含的一个规则,您应该将它绑定到您的实例。
- 规则 3 允许你从个人电脑通过 SSH 访问你的虚拟机。
您还需要添加一个出站规则来允许出站流量做一些事情,比如安装包:
| 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|
| 习俗 | 全部 | 全部 | 0.0.0.0/0 |
综上所述,您的初始 AWS 安全规则集可以由三个入站规则和一个出站规则组成。这些权限依次来自三个独立的安全组——默认组、HTTP 访问组和 SSH 访问组:
然后,您可以从本地计算机 SSH 进入实例:
$ ssh -i ~/.ssh/<privkey>.pem ubuntu@<instance-public-ip-address>
这个命令让您以用户ubuntu的身份登录到您的虚拟机。这里,~/.ssh/<privkey>.pem是到私有密钥的路径,私有密钥是您绑定到虚拟机的一组安全凭证的一部分。VM 是 Django 应用程序代码所在的地方。
至此,您应该已经准备好继续构建您的应用程序了。
创建一个千篇一律的 Django 应用程序
在本教程中,您并不关心用复杂的 URL 路由或高级数据库特性来制作一个花哨的 Django 项目。相反,您需要简单、小巧、易懂的东西,让您能够快速测试您的基础设施是否正常工作。
为此,您可以采取以下步骤来设置您的应用程序。
首先,SSH 到您的虚拟机,并确保您安装了 Python 3.8 和 SQLite3 的最新补丁版本:
$ sudo apt-get update -y
$ sudo apt-get install -y python3.8 python3.8-venv sqlite3
$ python3 -V
Python 3.8.10
在这里,Python 3.8 就是系统 Python ,或者 Ubuntu 20.04 (Focal)自带的python3版本。升级发行版可确保您从最新的 Python 3.8.x 版本中获得错误和安全修复。可选地,您可以安装另一个完整的 Python 版本——比如python3.9—以及系统范围的解释器,您需要以python3.9的身份显式调用它。
接下来,创建并激活一个虚拟环境:
$ cd # Change directory to home directory
$ python3 -m venv env
$ source env/bin/activate
现在,安装 Django 3.2:
$ python -m pip install -U pip 'django==3.2.*'
现在,您可以使用 Django 的管理命令来引导 Django 项目和应用程序:
$ mkdir django-gunicorn-nginx/
$ django-admin startproject project django-gunicorn-nginx/
$ cd django-gunicorn-nginx/
$ django-admin startapp myapp
$ python manage.py migrate
$ mkdir -pv myapp/templates/myapp/
这将创建 Django 应用程序myapp以及名为project的项目:
/home/ubuntu/
│
├── django-gunicorn-nginx/
│ │
│ ├── myapp/
│ │ ├── admin.py
│ │ ├── apps.py
│ │ ├── __init__.py
│ │ ├── migrations/
│ │ │ └── __init__.py
│ │ ├── models.py
│ │ ├── templates/
│ │ │ └── myapp/
│ │ ├── tests.py
│ │ └── views.py
│ │
│ ├── project/
│ │ ├── asgi.py
│ │ ├── __init__.py
│ │ ├── settings.py
│ │ ├── urls.py
│ │ └── wsgi.py
| |
│ ├── db.sqlite3
│ └── manage.py
│
└── env/ ← Virtual environment
使用终端编辑器,如 Vim 或 GNU nano ,打开project/settings.py并将您的应用程序添加到INSTALLED_APPS:
# project/settings.py
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"myapp", ]
接下来,打开myapp/templates/myapp/home.html并创建一个简短的 HTML 页面:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
</head>
<body>
<p>Now this is some sweet HTML!</p>
</body>
</html>
之后,编辑myapp/views.py来呈现 HTML 页面:
from django.shortcuts import render
def index(request):
return render(request, "myapp/home.html")
现在创建并打开myapp/urls.py,将您的视图与 URL 模式关联起来:
from django.urls import path
from . import views
urlpatterns = [
path("", views.index, name="index"),
]
之后,相应地编辑project/urls.py:
from django.urls import include, path
urlpatterns = [
path("myapp/", include("myapp.urls")),
path("", include("myapp.urls")),
]
你还可以做另外一件事,那就是确保用于加密签名的 Django 秘密密钥没有被硬编码到settings.py中,Git 很可能会跟踪它。从project/settings.py中删除以下行:
SECRET_KEY = "django-insecure-o6w@a46mx..." # Remove this line
将其替换为以下内容:
import os
# ...
try:
SECRET_KEY = os.environ["SECRET_KEY"]
except KeyError as e:
raise RuntimeError("Could not find a SECRET_KEY in environment") from e
这告诉 Django 在您的环境中寻找SECRET_KEY,而不是将它包含在您的应用程序源代码中。
注意:对于较大的项目,请查看 django-environ 来配置 Django 应用程序的环境变量。
最后,在您的环境中设置密钥。下面是如何在 Ubuntu Linux 上使用 OpenSSL 将密钥设置为 80 个字符的字符串:
$ echo "export SECRET_KEY='$(openssl rand -hex 40)'" > .DJANGO_SECRET_KEY
$ source .DJANGO_SECRET_KEY
您可以从.DJANGO_SECRET_KEY的内容cat中看到 openssl 已经生成了一个密码安全的十六进制字符串密钥:
$ cat .DJANGO_SECRET_KEY
export SECRET_KEY='26a2d2ccaf9ef850...'
好的,你都准备好了。这就是拥有一个最低功能的 Django 应用程序所需要的一切。
在开发中使用 Django 的 wsgi server
在本节中,您将使用 httpie 测试 Django 的开发 web 服务器,这是一个非常棒的命令行 HTTP 客户端,用于测试从控制台到您的 web 应用程序的请求:
$ pwd
/home/ubuntu
$ source env/bin/activate
$ python -m pip install httpie
您可以创建一个别名,它将允许您使用httpie向您的应用程序发送一个GET请求:
$ # Send GET request and follow 30x Location redirects
$ alias GET='http --follow --timeout 6'
这用一些默认标志将GET别名为http调用。现在,您可以使用GET docs.python.org在 Python 文档的主页上查看响应头和主体。
在启动 Django 开发服务器之前,您可以检查您的 Django 项目是否存在潜在的问题:
$ cd django-gunicorn-nginx/
$ python manage.py check
System check identified no issues (0 silenced).
如果您的检查没有发现任何问题,那么告诉 Django 的内置应用服务器开始监听本地主机,使用默认端口 8000:
$ # Listen on 127.0.0.1:8000 in the background
$ nohup python manage.py runserver &
$ jobs -l
[1]+ 43689 Running nohup python manage.py runserver &
使用nohup <command> &在后台执行command,这样您就可以继续使用您的 shell。您可以使用jobs -l来查看进程标识符(PID) ,这将让您将进程带到前台或终止它。nohup将标准输出(stdout) 和标准错误(stderr) 重定向到文件nohup.out。
注意:如果出现nohup挂起,让你没有光标,按 Enter 可以找回你的终端光标和 shell 提示符。
Django 的 runserver 命令依次使用以下语法:
$ python manage.py runserver [address:port]
如果像上面那样不指定参数address:port,Django 将默认监听localhost:8000。您还可以使用lsof命令更直接地验证是否调用了python命令来监听端口 8000:
$ sudo lsof -n -P -i TCP:8000 -s TCP:LISTEN
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 43689 ubuntu 4u IPv4 45944 0t0 TCP 127.0.0.1:8000 (LISTEN)
在教程的这一点上,你的应用程序只监听本地主机,也就是地址127.0.0.1。它还不能从浏览器中访问,但是您仍然可以通过从 VM 本身的命令行向它发送一个GET请求来给它第一个访问者:
$ GET :8000/myapp/
HTTP/1.1 200 OK
Content-Length: 182
Content-Type: text/html; charset=utf-8
Date: Sat, 25 Sep 2021 00:11:38 GMT
Referrer-Policy: same-origin
Server: WSGIServer/0.2 CPython/3.8.10 X-Content-Type-Options: nosniff
X-Frame-Options: DENY
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
</head>
<body>
<p>Now this is some sweet HTML!</p>
</body>
</html>
标题Server: WSGIServer/0.2 CPython/3.8.10描述了生成响应的软件。在这种情况下,是 0.2 版本的WSGIServer和的 CPython 3.8.10 。
WSGIServer只不过是由 Django 定义的实现 Python WSGI 协议的 Python 类。这意味着它遵循了 Web 服务器网关接口(WSGI) ,这是一个定义了 web 服务器软件和 web 应用交互方式的标准。
在我们到目前为止的例子中,django-gunicorn-nginx/项目是 web 应用程序。因为你正在开发应用程序,所以实际上没有单独的网络服务器。Django 使用了 simple_server 模块,该模块实现了一个轻量级的 HTTP 服务器,并将 web 服务器和应用服务器的概念融合到一个命令runserver中。
接下来,您将看到如何通过将您的应用程序与现实世界的域相关联,开始向大时代介绍您的应用程序。
用 Django、Gunicorn 和 Nginx 把你的网站放到网上
此时,您的站点可以在虚拟机上进行本地访问。如果你想让你的网站在一个真实的网址上被访问,你需要申请一个域名,并把它绑定到网络服务器上。这对于启用 HTTPS 也是必要的,因为一些证书颁发机构不会为您不拥有的空白 IP 地址或子域颁发证书。在本节中,您将看到如何注册和配置域。
设置静态公共 IP 地址
如果您可以将您的域配置指向一个保证不会改变的公共 IP 地址,那就太理想了。云虚拟机的一个次优属性是,如果实例处于停止状态,它们的公共 IP 地址可能会改变。或者,如果出于某种原因,您需要用新的实例替换现有的虚拟机,那么 IP 地址的变化将会带来问题。
这种困境的解决方案是将静态 IP 地址绑定到实例:
遵循云提供商的文档将静态 IP 地址与您的云虚拟机相关联。在本教程示例所用的 AWS 环境中,弹性 IP 地址50.19.125.152与 EC2 实例相关联。
注意:记住,这意味着您需要更改ssh的目标 IP,以便通过 SSH 进入您的虚拟机:
$ ssh [args] my-new-static-public-ip
更新目标 IP 后,您将能够连接到您的云虚拟机。
有了一个更稳定的公共 IP,您就可以链接到一个域了。
链接到一个域
在本节中,您将了解如何购买、设置域名,以及如何将域名链接到您现有的应用程序。
这些例子使用了 Namecheap ,但是请不要认为这是明确的认可。还有很多其他的选择,比如 domain.com 的、的【GoDaddy】、的谷歌域名。就偏好而言,Namecheap 为成为本教程中的首选域名注册商支付了 0 美元。
警告:如果你想在DEBUG设置为True的公共域上为你的开发站点提供服务,你需要创建自定义的入站安全规则,只允许你的个人电脑和虚拟机的 IP 地址。你应该而不是向0.0.0.0开放任何 HTTP 或 HTTPS 的入站规则,直到你至少关闭了 DEBUG 。
以下是您可以开始的方式:
- 在 Namecheap 上创建一个账户,确保设置双因素认证(2FA)。
- 从主页开始搜索适合你预算的域名。你会发现顶级域名(TLD)和主机名的价格差别很大。
- 当你对选择满意时,购买域名。
本教程使用了域supersecure.codes,但是你也有自己的域。
注意:当你阅读本教程时,请记住supersecure.codes只是一个示例域,并没有被主动维护。
当挑选自己的域名时,请记住,选择一个更深奥的网站名称和顶级域名(TLD)通常会导致更便宜的标价购买该域名。这对于测试尤其有用。
一旦你有了自己的域名,你会想要开启的私有域名保护,正式名称为 WhoisGuard 。当有人在您的域名上运行 whois 搜索时,这会屏蔽您的个人信息。下面是如何做到这一点:
- 选择账户→域名列表。
- 选择您的域旁边的管理。
- 启用保护隐私。
接下来,是时候为您的站点设置 DNS 记录表了。每个 DNS 记录都将成为数据库中的一行,告诉浏览器一个完全合格的域名(FQDN) 指向的底层 IP 地址。在这种情况下,我们希望supersecure.codes路由到 50.19.125.152,即可以访问虚拟机的公共 IPv4 地址:
- 选择账户→域名列表。
- 选择您的域旁边的管理。
- 选择高级 DNS 。
- 在主机记录下,为您的域添加两条 A 记录。
如下添加 A 记录,用实例的公共 IPv4 地址替换50.19.125.152:
| 类型 | 主持 | 价值 | 晶体管-晶体管逻辑。 |
|---|---|---|---|
| 一项记录 | @ |
50.19.125.152 | 自动的 |
| 一项记录 | www |
50.19.125.152 | 自动的 |
一个 A 记录允许您将一个域名或子域与您为应用程序提供服务的 web 服务器的 IPv4 地址相关联。上面的值字段应该使用 VM 实例的公共 IPv4 地址。
您可以看到主机字段有两种变体:
- 利用
@指向的根域,本例中为supersecure.codes。 - 使用
www意味着www.supersecure.codes将指向与刚才supersecure.codes相同的地方。从技术上讲,www是的一个子域,它可以将用户发送到与更短的supersecure.codes相同的地方。
一旦您设置了 DNS 主机记录表,您需要等待 30 分钟路由才能生效。您现在可以终止现有的runserver进程:
$ jobs -l
[1]+ 43689 Running nohup python manage.py runserver &
$ kill 43689
[1]+ Done nohup python manage.py runserver
您可以通过pgrep或再次检查活动工单来确认流程已结束:
$ pgrep runserver # Empty
$ jobs -l # Empty or 'Done'
$ sudo lsof -n -P -i TCP:8000 -s TCP:LISTEN # Empty
$ rm nohup.out
有了这些东西,你还需要调整 Django 设置, ALLOWED_HOSTS ,这是你让你的 Django 应用服务的域名集合:
# project/settings.py
# Replace 'supersecure.codes' with your domain
ALLOWED_HOSTS = [".supersecure.codes"]
前导点(.)是一个子域通配符,允许www.supersecure.codes和supersecure.codes。保持这个列表以防止 HTTP 主机头攻击。
现在,只需做一点小小的改动,就可以重新启动 WSGIServer 了:
$ nohup python manage.py runserver '0.0.0.0:8000' &
注意 address:port 参数现在是0.0.0.0:8000,而之前没有指定:
-
指定 no
address:port意味着在localhost:8000提供应用。这意味着应用程序只能从虚拟机内部访问。你可以从同一个 IP 地址通过调用httpie与它对话,但是你不能从外部世界访问你的应用程序。 -
指定
'0.0.0.0:8000'的address:port使您的服务器对外界可见,尽管默认情况下仍然在端口 8000 上。0.0.0.0是“绑定到这台计算机支持的所有 IP 地址”的简写在带有一个名为eth0的网络接口控制器(NIC) 的现成云虚拟机的情况下,使用0.0.0.0充当机器的公共 IPv4 地址的替身。
接下来,打开来自nohup.out的输出,查看来自 Django 的 WSGIServer 的任何输入日志:
$ tail -f nohup.out
现在是关键时刻了。是时候让你的网站迎来第一个访问者了。从您的个人计算机,在 web 浏览器中输入以下 URL:
http://www.supersecure.codes:8000/myapp/
用您自己的域名替换上面的域名。您应该会看到该页面的快速响应:
由于您之前创建的入站安全规则,您可以访问此 URL,但其他人不可以。
如果您无法访问您的网站,可能有几个常见的原因:
- 如果连接挂断,检查您是否已经打开了一个入站安全规则来允许
my-laptop-ip-address/32使用TCP:8000。 - 如果连接显示为拒绝或无法连接,请检查您是否调用了
manage.py runserver 0.0.0.0:8000而不是127.0.0.1:8000。
现在回到你的虚拟机的外壳。在tail -f nohup.out的连续输出中,你应该看到类似这样的线:
[<date>] "GET /myapp/ HTTP/1.1" 200 182
恭喜你,你已经朝着拥有自己的网站迈出了重要的第一步!然而,在这里暂停一下,注意 URL http://www.supersecure.codes:8000/myapp/中嵌入的几个大问题:
-
该网站仅通过 HTTP 提供服务。如果不启用 HTTPS,如果你想在客户端和服务器之间传输任何敏感数据,你的网站就根本不安全。使用 HTTP 意味着请求和响应以纯文本形式发送。你很快就会解决的。
-
URL 使用非标准端口 8000 ,而不是标准的默认 HTTP 端口号 80。很不落俗套,有点碍眼,但是你还不能用 80。这是因为端口 80 是有特权的,非根用户不能也不应该绑定到它。稍后,您将引入一个工具,允许您的应用程序在端口 80 上可用。
如果你检查你的浏览器,你会看到你的浏览器地址栏暗示这一点。如果您使用的是 Firefox,将会出现一个红色锁图标,表示连接是通过 HTTP 而不是 HTTPS 进行的:
展望未来,你想让行动合法化。您可以开始通过 HTTP 的标准端口 80 提供服务。更好的是,开始服务 HTTPS (443)并将 HTTP 请求重定向到那里。您将很快看到如何完成这些步骤。
用 Gunicorn 替换 WSGIServer】
您是否希望开始将您的应用迁移到一个为外部世界做好准备的状态?如果是这样,那么你应该把 Django 内置的 WSGIServer,也就是manage.py runserver使用的应用服务器,换成一个单独的专用应用服务器。但是等一下:WSGIServer 似乎工作得很好。为什么要更换?
要回答这个问题,您可以阅读 Django 文档:
不要在生产环境中使用此服务器。它没有通过安全审计或性能测试。(这就是它将如何停留。我们从事的是制作 Web 框架的业务,而不是 Web 服务器,所以改进这个服务器以便能够处理生产环境超出了 Django 的范围。)(来源)
Django 是一个网络框架,而不是一个网络服务器,它的维护者想要清楚地区分这两者。在本节中,您将把 Django 的runserver命令替换为 Gunicorn 。Gunicorn 首先是一个 Python WSGI 应用服务器,而且是一个久经考验的服务器:
- 它速度快,经过优化,专为生产而设计。
- 它为您提供了对应用服务器本身更细粒度的控制。
- 它有更完整和可配置的日志记录。
- 它已经过测试,特别是作为应用服务器的功能。
您可以通过 pip 将 Gunicorn 安装到您的虚拟环境中:
$ pwd
/home/ubuntu
$ source env/bin/activate
$ python -m pip install 'gunicorn==20.1.*'
接下来,您需要做一些配置。一个 Gunicorn 配置文件的酷之处在于它只需要是有效的 Python 代码,变量名对应于参数。您可以在一个项目子目录中存储多个 Gunicorn 配置文件:
$ cd ~/django-gunicorn-nginx
$ mkdir -pv config/gunicorn/
mkdir: created directory 'config'
mkdir: created directory 'config/gunicorn/'
接下来,打开一个开发配置文件config/gunicorn/dev.py,并添加以下内容:
"""Gunicorn *development* config file"""
# Django WSGI application path in pattern MODULE_NAME:VARIABLE_NAME
wsgi_app = "project.wsgi:application"
# The granularity of Error log outputs
loglevel = "debug"
# The number of worker processes for handling requests
workers = 2
# The socket to bind
bind = "0.0.0.0:8000"
# Restart workers when code changes (development only!)
reload = True
# Write access and error info to /var/log
accesslog = errorlog = "/var/log/gunicorn/dev.log"
# Redirect stdout/stderr to log file
capture_output = True
# PID file so you can easily fetch process ID
pidfile = "/var/run/gunicorn/dev.pid"
# Daemonize the Gunicorn process (detach & enter background)
daemon = True
在启动 Gunicorn 之前,您应该暂停runserver进程。使用jobs找到它,使用kill停止它:
$ jobs -l
[1]+ 26374 Running nohup python manage.py runserver &
$ kill 26374
[1]+ Done nohup python manage.py runserver
接下来,确保上面 Gunicorn 配置文件中设置的值的日志和 PID 目录存在:
$ sudo mkdir -pv /var/{log,run}/gunicorn/
mkdir: created directory '/var/log/gunicorn/'
mkdir: created directory '/var/run/gunicorn/'
$ sudo chown -cR ubuntu:ubuntu /var/{log,run}/gunicorn/
changed ownership of '/var/log/gunicorn/' from root:root to ubuntu:ubuntu
changed ownership of '/var/run/gunicorn/' from root:root to ubuntu:ubuntu
使用这些命令,您已经确保了 Gunicorn 所需的 PID 和日志目录存在,并且它们可由ubuntu用户写入。
这样一来,您就可以使用-c标志启动 Gunicorn,从您的项目根目录指向一个配置文件:
$ pwd
/home/ubuntu/django-gunicorn-nginx
$ source .DJANGO_SECRET_KEY
$ gunicorn -c config/gunicorn/dev.py
这在后台运行gunicorn,带有您在上面指定的开发配置文件dev.py。和以前一样,现在可以监视输出文件,查看 Gunicorn 记录的输出:
$ tail -f /var/log/gunicorn/dev.log
[2021-09-27 01:29:50 +0000] [49457] [INFO] Starting gunicorn 20.1.0
[2021-09-27 01:29:50 +0000] [49457] [DEBUG] Arbiter booted
[2021-09-27 01:29:50 +0000] [49457] [INFO] Listening at: http://0.0.0.0:8000 (49457)
[2021-09-27 01:29:50 +0000] [49457] [INFO] Using worker: sync
[2021-09-27 01:29:50 +0000] [49459] [INFO] Booting worker with pid: 49459
[2021-09-27 01:29:50 +0000] [49460] [INFO] Booting worker with pid: 49460
[2021-09-27 01:29:50 +0000] [49457] [DEBUG] 2 workers
现在在浏览器中再次访问你的站点的 URL。您仍然需要 8000 端口:
http://www.supersecure.codes:8000/myapp/
再次检查您的虚拟机终端。您应该会在 Gunicorn 的日志文件中看到一行或多行,如下所示:
67.xx.xx.xx - - [27/Sep/2021:01:30:46 +0000] "GET /myapp/ HTTP/1.1" 200 182
这几行是访问日志,告诉您关于传入请求的信息:
| 成分 | 意义 |
|---|---|
67.xx.xx.xx |
用户 IP 地址 |
27/Sep/2021:01:30:46 +0000 |
请求的时间戳 |
GET |
请求方法 |
/myapp/ |
path |
HTTP/1.1 |
草案 |
200 |
响应状态代码 |
182 |
响应内容长度 |
为了简洁起见,上面排除了用户代理,它也可能出现在您的日志中。下面是 macOS 上的 Firefox 浏览器的一个例子:
Mozilla/5.0 (Macintosh; Intel Mac OS X ...) Gecko/20100101 Firefox/92.0
随着 Gunicorn 的出现和收听,是时候将合法的 web 服务器也引入等式中了。
并入 Nginx
此时,您已经将 Django 的runserver命令换成了作为应用服务器的gunicorn。请求链中又多了一个玩家:像 T4 Nginx T5 这样的 T2 网络服务器 T3。
等等,你已经添加了 Gunicorn!为什么需要在画面中加入新的东西?之所以会这样,是因为 Nginx 和 Gunicorn 是两回事,它们是共存的,是作为一个团队工作的。
Nginx 将自己定义为高性能 web 服务器和反向代理服务器。这是值得的,因为这有助于解释 Nginx 与 Gunicorn 和 Django 的关系。
首先,Nginx 是一个 web 服务器,因为它可以向 web 用户或客户端提供文件。文件是文字文档:HTML、CSS、PNG、PDF——应有尽有。在过去,在 Django 等框架出现之前,网站基本上是作为文件系统的直接视图来运行的,这是很常见的。在 URL 路径中,斜线表示服务器文件系统中您可以请求查看的有限部分的目录。
请注意术语上的细微差别:
-
Django 是一个 web 框架。它允许您构建支持站点实际内容的核心 web 应用程序。它处理 HTML 呈现、认证、管理和后端逻辑。
-
Gunicorn 是一个应用服务器。它将 HTTP 请求翻译成 Python 可以理解的东西。Gunicorn 实现了 web 服务器网关接口(WSGI) ,这是 Web 服务器软件和 Web 应用程序之间的标准接口。
-
Nginx 是一个网络服务器。它是公共处理器,更正式的名称是反向代理,用于接收请求并扩展到数千个并发连接。
Nginx 作为网络服务器的一部分作用是它可以更有效地服务静态文件。这意味着,对于像图片这样的静态内容的请求,你可以省去 Django 这个中间人,让 Nginx 直接呈现文件。我们将在教程的后面到达这个重要的步骤。
Nginx 也是一个反向代理服务器,它位于外部世界和 Gunicorn/Django 应用程序之间。就像您可能使用代理发出出站请求一样,您可以使用 Nginx 这样的代理来接收它们:
要开始使用 Nginx,请安装它并验证其版本:
$ sudo apt-get install -y 'nginx=1.18.*'
$ nginx -v # Display version info
nginx version: nginx/1.18.0 (Ubuntu)
然后,您应该将您为端口 8000 设置的入站允许规则更改为端口 80。用以下内容替换TCP:8000的入站规则:
| 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|
| 超文本传送协议 | 传输控制协议(Transmission Control Protocol) | Eighty | my-laptop-ip-address/32 |
其他规则,比如 SSH 访问规则,应该保持不变。
现在,启动nginx服务并确认其状态为running:
$ sudo systemctl start nginx
$ sudo systemctl status nginx
● nginx.service - A high performance web server and a reverse proxy server
Loaded: loaded (/lib/systemd/system/nginx.service; enabled; ...
Active: active (running) since Mon 2021-09-27 01:37:04 UTC; 2min 49s ago
...
现在,您可以向一个熟悉的 URL 发出请求:
http://supersecure.codes/
这与你以前的情况相比有很大的不同。您不再需要 URL 中的端口 8000。相反,端口默认为端口 80,这看起来正常得多:
这是 Nginx 的一个友好特性。如果您在零配置的情况下启动 Nginx,它会向您显示一个页面,表明它正在监听。现在试试下面网址的/myapp页面:
http://supersecure.codes/myapp/
记得把supersecure.codes换成自己的域名。
您应该会看到 404 响应,这没关系:
这是因为您正在请求端口 80 上的/myapp路径,Nginx 而不是 Gunicorn 正在侦听端口 80。此时,您有了以下设置:
- Nginx 正在监听端口 80。
- Gunicorn 单独监听端口 8000。
在您指定之前,这两者之间没有任何联系。Nginx 不知道 Gunicorn 和 Django 有一些想让全世界看到的甜蜜 HTML。这就是它返回一个404 Not Found响应的原因。您还没有设置对 Gunicorn 和 Django 的代理请求:
您需要给 Nginx 一些基本的配置,告诉它将请求路由到 Gunicorn,然后 guni corn 将请求提供给 Django。打开/etc/nginx/sites-available/supersecure,添加以下内容:
server_tokens off; access_log /var/log/nginx/supersecure.access.log; error_log /var/log/nginx/supersecure.error.log; # This configuration will be changed to redirect to HTTPS later
server { server_name .supersecure.codes; listen 80; location / { proxy_pass http://localhost:8000; proxy_set_header Host $host; } }
请记住,您需要将文件名中的supersecure替换为您站点的主机名,并确保将.supersecure.codes的server_name值替换为您自己的域名,前缀为一个点。
注意:你可能需要sudo来打开/etc下的文件。
这个文件是 Nginx 反向代理配置的“Hello World”。它告诉 Nginx 如何操作:
- 在端口 80 上监听使用主机的请求
supersecure.codes及其子域。 - 将这些请求传递给
http://localhost:8000,Gunicorn 正在那里监听。
proxy_set_header 字段很重要。它确保 Nginx 通过终端用户发送的Host HTTP 请求头到达 Gunicorn 和 Django。Nginx 默认使用Host: localhost,忽略终端用户浏览器发送的Host头字段。
您可以使用nginx configtest验证您的配置文件:
$ sudo service nginx configtest /etc/nginx/sites-available/supersecure
* Testing nginx configuration [ OK ]
[ OK ]输出表明配置文件是有效的,可以被解析。
现在你需要符号链接这个文件到sites-enabled目录,用你的站点域替换supersecure:
$ cd /etc/nginx/sites-enabled
$ # Note: replace 'supersecure' with your domain
$ sudo ln -s ../sites-available/supersecure .
$ sudo systemctl restart nginx
在使用httpie向您的站点发出请求之前,您需要再添加一个入站安全规则。添加以下入站规则:
| 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|
| 超文本传送协议 | 传输控制协议(Transmission Control Protocol) | Eighty | vm-static-ip-address/32 |
此安全规则允许来自虚拟机本身的公共(弹性)IP 地址的入站 HTTP 流量。乍一看,这似乎有些矫枉过正,但是您需要这样做,因为请求现在将通过公共互联网路由,这意味着使用安全组 ID 的自引用规则将不再足够。
现在它使用 Nginx 作为 web 服务器前端,重新向站点发送一个请求:
$ GET http://supersecure.codes/myapp/
HTTP/1.1 200 OK
Connection: keep-alive Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Mon, 27 Sep 2021 19:54:19 GMT
Referrer-Policy: same-origin
Server: nginx Transfer-Encoding: chunked X-Content-Type-Options: nosniff
X-Frame-Options: DENY
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
</head>
<body>
<p>Now this is some sweet HTML!</p>
</body>
</html>
现在 Nginx 位于 Django 和 Gunicorn 之前,这里有一些有趣的输出:
- Nginx 现在将
Server头返回为Server: nginx,表示 Nginx 是新的前端 web 服务器。将server_tokens设置为值off告诉 Nginx 不要发出它的精确版本,比如nginx/x.y.z (Ubuntu)。从安全角度来看,这将会泄露不必要的信息。 - Nginx 使用
chunked作为Transfer-Encoding报头,而不是广告Content-Length。 - Nginx 还要求保持与
Connection: keep-alive的网络连接打开。
接下来,您将利用 Nginx 的一个核心特性:快速有效地提供静态文件的能力。
用 Nginx 直接提供静态文件
现在,您的 Django 应用程序上有了 Nginx 代理请求。重要的是,你还可以使用 Nginx 来直接服务静态文件。如果你在project/settings.py中有DEBUG = True,那么 Django 会渲染文件,但是这效率非常低,而且可能不安全。相反,您可以让您的 web 服务器直接呈现它们。
静态文件的常见例子包括本地 JavaScript、图像和 CSS——任何不需要 Django 来动态呈现响应内容的东西。
首先,在您的项目目录中,创建一个位置来保存和跟踪开发中的 JavaScript 静态文件:
$ pwd
/home/ubuntu/django-gunicorn-nginx
$ mkdir -p static/js
现在打开一个新文件static/js/greenlight.js并添加以下 JavaScript:
// Enlarge the #changeme element in green when hovered over (function () { "use strict"; function enlarge() { document.getElementById("changeme").style.color = "green"; document.getElementById("changeme").style.fontSize = "xx-large"; return false; } document.getElementById("changeme").addEventListener("mouseover", enlarge); }());
如果鼠标悬停在上面,这段 JavaScript 将放大一块绿色大字体的文本。没错,就是一些前沿的前端工作!
接下来,将以下配置添加到project/settings.py,用您的域名更新STATIC_ROOT:
STATIC_URL = "/static/"
# Note: Replace 'supersecure.codes' with your domain STATIC_ROOT = "/var/www/supersecure.codes/static" STATICFILES_DIRS = [BASE_DIR / "static"]
你告诉 Django 的 collectstatic命令在哪里搜索和放置从多个 Django 应用程序聚合的静态文件,包括 Django 自己的内置应用程序,如admin。
最后但同样重要的是,修改myapp/templates/myapp/home.html中的 HTML 以包含您刚刚创建的 JavaScript:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
</head>
<body>
<p><span id="changeme">Now this is some sweet HTML!</span></p> <script src="/static/js/greenlight.js"></script> </body>
</html>
通过包含/static/js/greenlight.js脚本,<span id="changeme">元素将有一个附加的事件监听器。
注意:为了让这个例子简单明了,你将 URL 路径硬编码到greenlight.js,而不是使用 Django 的 static模板标签。您可能希望在更大的项目中利用这一特性。
下一步是创建一个目录路径,其中包含 Nginx 服务的项目静态内容:
$ sudo mkdir -pv /var/www/supersecure.codes/static/
mkdir: created directory '/var/www/supersecure.codes'
mkdir: created directory '/var/www/supersecure.codes/static/'
$ sudo chown -cR ubuntu:ubuntu /var/www/supersecure.codes/
changed ownership of '/var/www/supersecure.codes/static' ... to ubuntu:ubuntu
changed ownership of '/var/www/supersecure.codes/' ... to ubuntu:ubuntu
现在在项目目录中以非 root 用户的身份运行collectstatic:
$ pwd
/home/ubuntu/django-gunicorn-nginx
$ python manage.py collectstatic
129 static files copied to '/var/www/supersecure.codes/static'.
最后,在 Nginx 的站点配置文件/etc/nginx/sites-available/supersecure中为/static添加一个location变量:
server { location / { proxy_pass http://localhost:8000; proxy_set_header Host $host; proxy_set_header X-Forwarded-Proto $scheme; } location /static { autoindex on; alias /var/www/supersecure.codes/static/; } }
记住你的领域可能不是supersecure.codes,所以你需要定制这些步骤来为你自己的项目工作。
现在,您应该在project/settings.py中关闭项目中的DEBUG模式:
# project/settings.py
DEBUG = False
因为您在config/gunicorn/dev.py中指定了reload = True,所以 Gunicorn 将获得这一变化。
然后重启 Nginx:
$ sudo systemctl restart nginx
现在,再次刷新您的站点页面,并将鼠标悬停在页面文本上:
这是 JavaScript 函数enlarge()发挥作用的明显证据。为了得到这个结果,浏览器必须请求/static/js/greenlight.js。这里的关键是浏览器直接从 Nginx 获取文件,而不需要 Nginx 向 Django 请求。
注意上面过程的不同之处:没有添加新的 Django URL 路由或视图来交付 JavaScript 文件。这是因为,在运行了collectstatic之后,Django 不再负责决定如何将 URL 映射到一个复杂的视图并呈现该视图。Nginx 可以直接把文件交给浏览器。
事实上,如果您导航到您的域的等同物https://supersecure.codes/static/js/,您将看到 Nginx 创建的传统文件系统树视图/static。这意味着更快、更有效地交付静态文件。
至此,您已经有了使用 Django、Gunicorn 和 Nginx 构建可伸缩站点的良好基础。另一个巨大的飞跃是为您的站点启用 HTTPS,这是您接下来要做的。
使用 HTTPS 软件让您的网站做好生产准备
再多走几步,你就可以让你的网站的安全性从好变得更好,包括启用 HTTPS 和添加一组帮助浏览器以更安全的方式使用你的网站的标题。启用 HTTPS 可以增加你站点的可信度,如果你的站点使用认证或者与用户交换敏感数据,这是必要的。
打开 HTTPS
为了允许访问者通过 HTTPS 访问你的网站,你需要一个位于你的网络服务器上的 SSL/TLS 证书。证书由证书颁发机构(CA)颁发。在本教程中,您将使用一个名为的免费 CA,让我们加密。要实际安装证书,您可以使用 Certbot 客户端,它会给出一系列完全无痛的逐步提示。
在开始使用 Certbot 之前,您可以预先告诉 Nginx 禁用 TLS 版本 1.0 和 1.1,支持版本 1.2 和 1.3。TLS 1.0 已停产(EOL),而 TLS 1.1 包含多个漏洞,TLS 1.2 已修复了这些漏洞。为此,打开文件/etc/nginx/nginx.conf。找到下面一行:
# File: /etc/nginx/nginx.conf
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
用更新的实现替换它:
# File: /etc/nginx/nginx.conf
ssl_protocols TLSv1.2 TLSv1.3;
你可以使用nginx -t来确认你的 Nginx 支持 1.3 版本:
$ sudo nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
现在您已经准备好安装和使用 Certbot 了。在 Ubuntu Focal (20.04)上,可以使用snap来安装 Certbot:
$ sudo snap install --classic certbot
$ sudo ln -s /snap/bin/certbot /usr/bin/certbot
参考 Certbot 的说明指南来查看不同操作系统和网络服务器的安装步骤。
在您可以使用certbot获得并安装 HTTPS 证书之前,您需要对 VM 的安全组规则进行另一项更改。因为 Let's Encrypt 需要一个互联网连接来进行验证,所以你需要迈出重要的一步,向公共互联网开放你的站点。
修改您的入站安全规则以符合以下要求:
| 参考 | 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|---|
| one | 超文本传送协议 | 传输控制协议(Transmission Control Protocol) | Eighty | 0.0.0.0/0 |
| Two | 习俗 | 全部 | 全部 | security-group-id |
| three | 嘘 | 传输控制协议(Transmission Control Protocol) | Twenty-two | my-laptop-ip-address/32 |
这里的关键变化是第一条规则,它允许来自所有来源的 HTTP 流量通过端口 80。您可以删除将虚拟机的公共 IP 地址列入白名单的TCP:80的入站规则,因为这是多余的。其他两条规则保持不变。
然后,您可以再发出一个命令certbot来安装证书:
$ sudo certbot --nginx --rsa-key-size 4096 --no-redirect
Saving debug log to /var/log/letsencrypt/letsencrypt.log
...
这将创建一个 RSA 密钥大小为 4096 字节的证书。--no-redirect选项告诉certbot不要自动应用与自动 HTTP 到 HTTPS 重定向相关的配置。为了便于说明,您将很快看到如何自己添加它。
您将经历一系列的设置步骤,其中大部分是不言自明的,例如输入您的电子邮件地址。当提示输入您的域名时,输入域名和用逗号分隔的www子域:
www.supersecure.codes,supersecure.codes
完成这些步骤后,您应该会看到如下所示的成功消息:
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/supersecure.codes/fullchain.pem
Key is saved at: /etc/letsencrypt/live/supersecure.codes/privkey.pem
This certificate expires on 2021-12-26.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this
certificate in the background.
Deploying certificate
Successfully deployed certificate for supersecure.codes
to /etc/nginx/sites-enabled/supersecure
Successfully deployed certificate for www.supersecure.codes
to /etc/nginx/sites-enabled/supersecure
Congratulations! You have successfully enabled HTTPS
on https://supersecure.codes and https://www.supersecure.codes
如果您在相当于/etc/nginx/sites-available/supersecure的位置cat打开配置文件,您会看到certbot已经自动添加了一组与 SSL 相关的行:
# Nginx configuration: /etc/nginx/sites-available/supersecure
server { server_name .supersecure.codes; listen 80; location / { proxy_pass http://localhost:8000; proxy_set_header Host $host; } location /static { autoindex on; alias /var/www/supersecure.codes/static/; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/www.supersecure.codes/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/www.supersecure.codes/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; }
确保 Nginx 接受这些更改:
$ sudo systemctl reload nginx
要通过 HTTPS 访问您的网站,您需要添加最后一项安全规则。您需要允许通过TCP:443的流量,这里 443 是 HTTPS 的默认端口。修改您的入站安全规则以符合以下要求:
| 参考 | 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|---|
| one | HTTPS | 传输控制协议(Transmission Control Protocol) | Four hundred and forty-three | 0.0.0.0/0 |
| Two | 超文本传送协议 | 传输控制协议(Transmission Control Protocol) | Eighty | 0.0.0.0/0 |
| Two | 习俗 | 全部 | 全部 | security-group-id |
| three | 嘘 | 传输控制协议(Transmission Control Protocol) | Twenty-two | my-laptop-ip-address/32 |
这些规则中的每一条都有特定的用途:
- 规则 1 允许来自所有来源的 HTTPS 流量通过端口 443。
- 规则 2 允许来自所有来源的 HTTP 流量通过端口 80。
- 规则 3 使用安全组 ID 作为来源,允许来自分配给同一安全组的网络接口和实例的入站流量。这是一个包含在默认 AWS 安全组中的规则,您应该将它绑定到您的实例。
- 规则 4 允许你从个人电脑通过 SSH 访问你的虚拟机。
现在,在浏览器中重新导航到你的站点,但是有一个关键的不同。将https指定为协议,而不是http:
https://www.supersecure.codes/myapp/
如果一切顺利,您应该会看到生命中最美丽的宝藏之一,那就是您的站点正在 HTTPS 上空交付:
如果您使用 Firefox 并点击锁图标,您可以查看有关保护连接所涉及的证书的更多详细信息:
你离安全网站又近了一步。此时,仍然可以通过 HTTP 和 HTTPS 访问该站点。那比以前好多了,但还是不理想。
将 HTTP 重定向到 HTTPS
您的网站现在可以通过 HTTP 和 HTTPS 访问。有了 HTTPS,你几乎可以关闭 HTTP——或者至少在实践中接近它。您可以添加几个功能来自动将任何试图通过 HTTP 访问您的站点的访问者路由到 HTTPS 版本。编辑您的/etc/nginx/sites-available/supersecure:
# Nginx configuration: /etc/nginx/sites-available/supersecure
server { server_name .supersecure.codes; listen 80; return 307 https://$host$request_uri; } server { location / { proxy_pass http://localhost:8000; proxy_set_header Host $host; } location /static { autoindex on; alias /var/www/supersecure.codes/static/; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/www.supersecure.codes/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/www.supersecure.codes/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; }
添加的块告诉服务器将浏览器或客户端重定向到任何 HTTP URL 的 HTTPS 版本。您可以验证此配置是否有效:
$ sudo service nginx configtest /etc/nginx/sites-available/supersecure
* Testing nginx configuration [ OK ]
然后,告诉nginx重新加载配置:
$ sudo systemctl reload nginx
然后向应用程序的 HTTP URL 发送一个带有--all标志的GET请求,以显示任何重定向链:
$ GET --all http://supersecure.codes/myapp/
HTTP/1.1 307 Temporary Redirect Connection: keep-alive
Content-Length: 164
Content-Type: text/html
Date: Tue, 28 Sep 2021 02:16:30 GMT
Location: https://supersecure.codes/myapp/ Server: nginx
<html>
<head><title>307 Temporary Redirect</title></head>
<body bgcolor="white">
<center><h1>307 Temporary Redirect</h1></center> <hr><center>nginx</center>
</body>
</html>
HTTP/1.1 200 OK
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Tue, 28 Sep 2021 02:16:30 GMT
Referrer-Policy: same-origin
Server: nginx
Transfer-Encoding: chunked
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
</head>
<body>
<p><span id="changeme">Now this is some sweet HTML!</span></p>
<script src="/static/js/greenlight.js"></script>
</body>
</html>
你可以看到这里实际上有两种反应:
- 初始请求接收到重定向到 HTTPS 版本的 307 状态码响应。
- 第二个请求是向同一个 URI 发出的,但是使用的是 HTTPS 方案而不是 HTTP。这一次,它用一个
200 OK响应接收到它正在寻找的页面内容。
接下来,您将看到如何通过帮助浏览器记住该选择来超越重定向配置。
与 HSTS 更进一步
单独使用时,这种重定向设置存在一个小漏洞:
当用户手动输入 web 域(提供不带 http://或 https://前缀的域名)或访问普通 http://链接时,对网站的第一个请求将使用普通 http 以不加密的方式发送。
大多数安全的网站会立即发回重定向,将用户升级到 HTTPS 连接,但是精心策划的攻击者可以发起中间人(MITM)攻击来拦截初始 HTTP 请求,并从那时起控制用户的会话。(来源)
为了缓解这种情况,您可以添加一个 HSTS 策略来告诉浏览器优先选择 HTTPS,即使用户试图使用 HTTP。下面是仅使用重定向与在旁边添加 HSTS 标头之间的细微差别:
-
通过从 HTTP 到 HTTPS 的普通重定向,服务器回答浏览器说,“再试一次,但是用 HTTPS。”如果浏览器发出 1000 次 HTTP 请求,它将被告知 1000 次重试 HTTPS。
-
有了 HSTS 报头,浏览器做了有效的前期工作,在第一次请求后用 HTTPS 替换了 HTTP 的。没有重定向。在第二个场景中,你可以把浏览器想象成升级连接。当用户要求他们的浏览器访问你网站的 HTTP 版本时,他们的浏览器会简短地回应,“不,我要带你去 HTTPS 版本。”
要解决这个问题,您可以告诉 Django 设置 Strict-Transport-Security 头。将这些行添加到项目的settings.py:
# Add to project/settings.py
SECURE_HSTS_SECONDS = 30 # Unit is seconds; *USE A SMALL VALUE FOR TESTING!*
SECURE_HSTS_PRELOAD = True
SECURE_HSTS_INCLUDE_SUBDOMAINS = True
SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
请注意,SECURE_HSTS_SECONDS值是短暂的,只有 30 秒。在这个例子中,这是故意的。当您进入实际生产时,您应该增加这个值。 Security Headers 网站推荐的最小值为 2,592,000,相当于 30 天。
警告:在你增加SECURE_HSTS_SECONDS的值之前,先看看 Django 的对 HTTP 严格传输安全的解释。在将 HSTS 时间窗口设置为较大值之前,您应该首先确保 HTTPS 正在为您的站点工作。在看到标题后,浏览器不会轻易让你改变决定,而是坚持通过 HTTP 进行 HTTPS。
一些浏览器比如 Chrome 可能会让你忽略这种行为并编辑 HSTS 政策列表,但是你不应该依赖这种技巧。对于用户来说,这不会是一个非常流畅的体验。相反,为SECURE_HSTS_SECONDS保留一个小值,直到你确信你的站点没有在 HTTPS 上出现任何回归。
当您准备冒险尝试时,您需要再添加一行 Nginx 配置。编辑您的等效项/etc/nginx/sites-available/supersecure以添加一个proxy_set_header指令:
location / { proxy_pass http://localhost:8000; proxy_set_header Host $host; proxy_set_header X-Forwarded-Proto $scheme; }
然后告诉 Nginx 重新加载更新的配置:
$ sudo systemctl reload nginx
这个添加的proxy_set_header的效果是 Nginx 向 Django 发送以下报头,这些报头包含在最初通过端口 443 上的 HTTPS 发送到 web 服务器的中间请求中:
X-Forwarded-Proto: https
这直接与您在上面的project/settings.py中添加的SECURE_PROXY_SSL_HEADER值挂钩。这是必要的,因为 Nginx 实际上向 Gunicorn/Django 发送普通的 HTTP 请求,所以 Django 没有其他方法知道原始请求是否是 HTTPS 的。由于上述 Nginx 配置文件中的location块是用于端口 443 (HTTPS)的,所有通过这个端口的请求应该让 Django 知道它们确实是 HTTPS 的。
Django 文档对此做了很好的解释:
但是,如果您的 Django 应用程序在代理后面,那么无论原始请求是否使用 HTTPS,代理都可能会“吞掉”。如果在代理和 Django 之间有一个非 HTTPS 连接,那么
is_secure()将总是返回False——即使是最终用户通过 HTTPS 发出的请求。相反,如果代理和 Django 之间有 HTTPS 连接,那么is_secure()将总是返回True——即使请求最初是通过 HTTP 发出的。(来源)
如何测试该接头是否正常工作?这里有一个优雅的方式,让你留在你的浏览器:
-
在浏览器中,打开开发者工具。导航到显示网络活动的选项卡。在 Firefox 中,这是右键→检查元素→网络。
-
刷新页面。首先,您应该将
307 Temporary Redirect响应视为响应链的一部分。这是你的浏览器第一次看到Strict-Transport-Security标题。 -
将浏览器中的 URL 改回 HTTP 版本,并再次请求该页面。如果你使用的是 Chrome,你应该会看到一个
307 Internal Redirect。在 Firefox 中,您应该会看到一个200 OK响应,因为您的浏览器会自动直接进入 HTTPS 请求,即使您试图告诉它使用 HTTP。虽然浏览器显示它们的方式不同,但这两种响应都表明浏览器执行了自动重定向。
如果您使用 Firefox,您应该会看到如下内容:
最后,您还可以通过来自控制台的请求来验证标头是否存在:
$ GET -ph https://supersecure.codes/myapp/
...
Strict-Transport-Security: max-age=30; includeSubDomains; preload
这证明您已经使用project/settings.py中的相应值有效地设置了Strict-Transport-Security头。一旦你准备好了,你可以增加max-age的值,但是记住这将不可逆转地告诉浏览器在这段时间内升级 HTTP。
设置Referrer-Policy标题
Django 3.x 还增加了控制 Referrer-Policy 标头的能力。您可以在project/settings.py中指定SECURE_REFERRER_POLICY:
# Add to project/settings.py
SECURE_REFERRER_POLICY = "strict-origin-when-cross-origin"
这个设置是如何工作的?当你跟随一个从页面 A 到页面 B 的链接时,你对页面 B 的请求在标题Referer下包含了页面 A 的 URL。一个设置Referrer-Policy头的服务器,你可以通过SECURE_REFERRER_POLICY在 Django 中设置这个头,控制什么时候以及有多少信息被转发到目标站点。SECURE_REFERRER_POLICY可以接受许多可识别的值,您可以在 Mozilla 文档中详细了解这些值。
举个例子,如果你使用了"strict-origin-when-cross-origin"并且用户的当前页面是https://example.com/page,那么Referer的页面头会受到以下方式的约束:
| 目标站点 | Referer表头 |
|---|---|
| https://example.com/otherpage | https://example.com/page |
| https://mozilla.org | https://example.com/ |
| http://example.org(HTTP 目标) | [无] |
假设当前用户的页面是https://example.com/page,下面是具体情况:
- 如果用户跟随一个链接到
https://example.com/otherpage,Referer将包括当前页面的完整路径。 - 如果用户跟随链接到单独的域
https://mozilla.org,Referer将排除当前页面的路径。 - 如果用户使用
http://协议点击http://example.org的链接,Referer将为空白。
如果你将这一行添加到project/settings.py并重新请求你的应用主页,那么你会看到一个新成员:
$ GET -ph https://supersecure.codes/myapp/ # -ph: Show response headers only
HTTP/1.1 200 OK
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Tue, 28 Sep 2021 02:31:36 GMT
Referrer-Policy: strict-origin-when-cross-origin Server: nginx
Strict-Transport-Security: max-age=30; includeSubDomains; preload
Transfer-Encoding: chunked
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
在这一部分,您已经朝着保护用户隐私的方向迈出了又一步。接下来,您将看到如何锁定站点对跨站点脚本(XSS)和数据注入攻击的漏洞。
添加一个Content-Security-Policy (CSP)报头
一个更重要的 HTTP 响应头是 Content-Security-Policy (CSP) 头,它有助于防止跨站脚本(XSS) 和数据注入攻击。Django 本身不支持这个,但是你可以安装 django-csp ,Mozilla 开发的一个小型中间件扩展:
$ python -m pip install django-csp
要使用默认值打开标题,将这一行添加到现有MIDDLEWARE定义下的project/settings.py:
# project/settings.py
MIDDLEWARE += ["csp.middleware.CSPMiddleware"]
你如何测试这个?嗯,你可以在你的 HTML 页面中包含一个链接,看看浏览器是否允许它和页面的其他部分一起加载。
编辑myapp/templates/myapp/home.html处的模板,以包含一个到 Normalize.css 文件的链接,这是一个 css 文件,帮助浏览器更加一致地呈现所有元素,并符合现代标准:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/normalize.css@8.0.1/normalize.css" > </head>
<body>
<p><span id="changeme">Now this is some sweet HTML!</span></p>
<script src="/static/js/greenlight.js"></script>
</body>
</html>
现在,在启用了开发人员工具的浏览器中请求页面。您将在控制台中看到如下错误:
啊哦。你错过了规范化的力量,因为你的浏览器无法加载normalize.css。以下是它无法加载的原因:
- 你的
project/settings.py包括姜戈的MIDDLEWARE中的CSPMiddleware。包含CSPMiddleware将头设置为默认的Content-Security-Policy值,即default-src 'self',其中'self'表示你站点自己的域。在本教程中,那就是supersecure.codes。 - 你的浏览器遵守这个规则,禁止
cdn.jsdelivr.net加载。CSP 是一个默认的拒绝 T2 策略。
您必须选择并明确允许客户端的浏览器加载您站点响应中嵌入的某些链接。要解决这个问题,将以下设置添加到project/settings.py:
# project/settings.py
# Allow browsers to load normalize.css from cdn.jsdelivr.net
CSP_STYLE_SRC = ["'self'", "cdn.jsdelivr.net"]
接下来,再次尝试请求您站点的页面:
$ GET -ph https://supersecure.codes/myapp/
HTTP/1.1 200 OK
Connection: keep-alive
Content-Encoding: gzip
Content-Security-Policy: default-src 'self'; style-src 'self' cdn.jsdelivr.net Content-Type: text/html; charset=utf-8
Date: Tue, 28 Sep 2021 02:37:19 GMT
Referrer-Policy: strict-origin-when-cross-origin
Server: nginx
Strict-Transport-Security: max-age=30; includeSubDomains; preload
Transfer-Encoding: chunked
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
注意,style-src将'self' cdn.jsdelivr.net指定为Content-Security-Policy标题值的一部分。这意味着浏览器应该只允许来自两个域的样式表:
supersecure.codes('self')cdn.jsdelivr.net
style-src指令是可以成为Content-Security-Policy一部分的许多指令之一。还有很多其他的,比如img-src,指定图片和收藏夹图标的有效来源,还有script-src,定义 JavaScript 的有效来源。
这些中的每一个都有对应的django-csp设置。例如,img-src和script-src分别由CSP_IMG_SRC和CSP_SCRIPT_SRC设置。您可以查看 django-csp文档获取完整列表。
这里有一个关于 CSP 头文件的最后提示:尽早设置!当后来出现问题时,更容易查明原因,因为您可以更容易地隔离您添加的没有加载的特性或链接,因为您没有最新的相应 CSP 指令。
生产部署的最后步骤
现在,在准备部署应用程序时,您将经历最后几个步骤。
首先,确保您已经在项目的settings.py中设置了DEBUG = False,如果您还没有这样做的话。这确保了在 5xx 服务器端错误的情况下,服务器端调试信息不会泄露。
其次,编辑项目的settings.py中的SECURE_HSTS_SECONDS,将Strict-Transport-Security头的到期时间从 30 秒增加到建议的 30 天,相当于 2,592,000 秒:
# Add to project/settings.py
SECURE_HSTS_SECONDS = 2_592_000 # 30 days
接下来,使用生产配置文件重新启动 Gunicorn。在config/gunicorn/prod.py中增加以下内容:
"""Gunicorn *production* config file"""
import multiprocessing
# Django WSGI application path in pattern MODULE_NAME:VARIABLE_NAME
wsgi_app = "project.wsgi:application"
# The number of worker processes for handling requests
workers = multiprocessing.cpu_count() * 2 + 1
# The socket to bind
bind = "0.0.0.0:8000"
# Write access and error info to /var/log
accesslog = "/var/log/gunicorn/access.log"
errorlog = "/var/log/gunicorn/error.log"
# Redirect stdout/stderr to log file
capture_output = True
# PID file so you can easily fetch process ID
pidfile = "/var/run/gunicorn/prod.pid"
# Daemonize the Gunicorn process (detach & enter background)
daemon = True
在这里,您做了一些更改:
- 你关闭了开发中使用的
reload特性。 - 您让工作线程的数量成为虚拟机 CPU 数量的函数,而不是硬编码它。
- 你允许
loglevel默认为"info",而不是更冗长的"debug"。
现在您可以停止当前的 Gunicorn 进程并启动一个新的进程,用它的生产副本替换开发配置文件:
$ # Stop existing Gunicorn dev server if it is running
$ sudo killall gunicorn
$ # Restart Gunicorn with production config file
$ gunicorn -c config/gunicorn/prod.py
在做了这个更改之后,您不需要重启 Nginx,因为它只是将请求传递给同一个address:host,不应该有任何可见的更改。然而,从长远来看,随着应用规模的扩大,以面向生产的设置运行 Gunicorn 更健康。
最后,确保您已经完整地构建了 Nginx 文件。下面是完整的文件,包括到目前为止您添加的所有组件,以及一些额外的值:
# File: /etc/nginx/sites-available/supersecure
# This file inherits from the http directive of /etc/nginx/nginx.conf
# Disable emitting nginx version in the "Server" response header field
server_tokens off; # Use site-specific access and error logs
access_log /var/log/nginx/supersecure.access.log; error_log /var/log/nginx/supersecure.error.log; # Return 444 status code & close connection if no Host header present
server { listen 80 default_server; return 444; } # Redirect HTTP to HTTPS
server { server_name .supersecure.codes; listen 80; return 307 https://$host$request_uri; } server { # Pass on requests to Gunicorn listening at http://localhost:8000
location / { proxy_pass http://localhost:8000; proxy_set_header Host $host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_redirect off; } # Serve static files directly
location /static { autoindex on; alias /var/www/supersecure.codes/static/; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/www.supersecure.codes/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/www.supersecure.codes/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; }
作为复习,与您的虚拟机相关的入站安全规则应该有一定的设置:
| 类型 | 草案 | 端口范围 | 来源 |
|---|---|---|---|
| HTTPS | 传输控制协议(Transmission Control Protocol) | Four hundred and forty-three | 0.0.0.0/0 |
| 超文本传送协议 | 传输控制协议(Transmission Control Protocol) | Eighty | 0.0.0.0/0 |
| 习俗 | 全部 | 全部 | security-group-id |
| 嘘 | 传输控制协议(Transmission Control Protocol) | Twenty-two | my-laptop-ip-address/32 |
综上所述,最终的 AWS 安全规则集由四个入站规则和一个出站规则组成:
将上述内容与您的初始安全规则集进行比较。请注意,您已经放弃了对提供 Django 应用程序开发版本的TCP:8000的访问,并分别在端口 80 和 443 上通过 HTTP 和 HTTPS 开放了对互联网的访问。
您的网站现在可以开始展示了:
现在您已经将所有组件放在一起,您的应用程序可以通过 Nginx over HTTPS 在端口 443 上访问。端口 80 上的 HTTP 请求被重定向到 HTTPS。Django 和 Gunicorn 组件本身并不向公共互联网公开,而是位于 Nginx 反向代理之后。
测试你网站的 HTTPS 安全性
您的站点现在比您开始学习本教程时安全多了,但是不要相信我的话。有几个工具可以给你一个网站安全相关特性的客观评级,重点是回复标题和 HTTPS。
第一个是安全头应用,它给从你的网站返回的 HTTP 响应头的质量打分。如果你一直在跟进,你的网站应该可以获得 A 级或更高的评分。
第二个是 SSL 实验室,它将对您的 web 服务器的配置进行深度分析,因为它与 SSL/TLS 相关。输入您站点的域名,SSL 实验室将根据与 SSL/TLS 相关的各种因素的强度返回一个等级。如果您使用--rsa-key-size 4096调用了certbot,并关闭了 TLS 1.0 和 1.1,转而使用 1.2 和 1.3,那么您应该可以很好地从 SSL 实验室获得 A+评级。
作为检查,您也可以从命令行请求您站点的 HTTPS URL,以查看您在整个教程中添加的更改的完整概述:
$ GET https://supersecure.codes/myapp/
HTTP/1.1 200 OK
Connection: keep-alive
Content-Encoding: gzip
Content-Security-Policy: style-src 'self' cdn.jsdelivr.net; default-src 'self'
Content-Type: text/html; charset=utf-8
Date: Tue, 28 Sep 2021 02:37:19 GMT
Referrer-Policy: no-referrer-when-downgrade
Server: nginx
Strict-Transport-Security: max-age=2592000; includeSubDomains; preload
Transfer-Encoding: chunked
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<title>My secure app</title>
<link rel="stylesheet"
href="https://cdn.jsdelivr.net/npm/normalize.css@8.0.1/normalize.css"
>
</head>
<body>
<p><span id="changeme">Now this is some sweet HTML!</span></p>
<script src="/static/js/greenlight.js"></script>
</body>
</html>
那确实是一些可爱的 HTML。
结论
如果您已经阅读了本教程,那么您的站点作为一个羽翼未丰的独立开发 Django 应用程序,已经取得了长足的进步。您已经看到了 Django、Gunicorn 和 Nginx 如何联合起来帮助您安全地服务于您的站点。
在本教程中,您已经学会了如何:
- 将你的 Django 应用从开发到生产
- 在真实世界的公共领域托管你的应用程序
- 将 Gunicorn 和 Nginx 引入请求和响应链
- 使用 HTTP 头来增加你的站点的 HTTPS 安全性
现在,您有了一组可重复的步骤来部署您的生产就绪的 Django web 应用程序。
您可以通过下面的链接下载本教程中使用的 Django 项目:
获取源代码: 点击此处获取本教程中使用的配套 Django 项目。
延伸阅读
有了网站安全,你不可能 100%到达那里。您可以添加更多的功能来进一步保护您的站点,并生成更好的日志信息。
查看以下链接,了解您可以自己采取的其他步骤:
- 姜戈 : 部署清单
- Mozilla : 网络安全
- 古尼康 : 展开古尼康
- Nginx : 使用
Forwarded报头 - 亚当·约翰逊 : 如何在 Django 网站的安全标题上获得 A+的分数
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Gunicorn 和 Nginx 部署一个 Django App*********
一个用户友好的 Django 应用程序的分页
通过将内容分散到多个页面,而不是一次提供所有内容,您可以显著改善 Django web 应用程序的用户体验。这种做法被称为分页。要实现分页,您必须考虑页数、每页的项目以及页面的顺序。
但是如果你在你的网络项目中使用 Django,你很幸运!Django 内置了分页功能。只需几个配置步骤,您就可以向用户提供分页的内容。
在本教程中,您将学习如何:
- 决定何时使用 Django 的分页器
- 在基于类的视图中实现分页
- 在基于功能的视图中实现分页
- 将分页元素添加到模板
- 使用分页的 URL直接浏览页面
- 将 Django 分页与 JavaScript 调用结合起来
本教程面向具有基本 Django 经验的中级 Python 程序员。理想情况下,您已经完成了一些入门教程,或者创建了自己的较小的 Django 项目。为了更好地体验本教程,您应该知道什么是模型、视图和模板,以及如何创建它们。如果你需要复习,那么看看如何用 Django 构建一个作品集应用的教程。
获取源代码: 单击此处获取您将用于实现 Django 分页的源代码。
野外分页
在尝试用 Django 构建自己的分页流之前,有必要四处看看分页的运行情况。分页在较大的网站上非常常见,以至于你在浏览互联网时很可能以这样或那样的形式经历过。
什么是分页
分页描述了将网站内容分布在多个连续页面上,而不是在单个页面上提供的做法。如果您访问购物网站、博客或档案馆,您很可能会遇到分页的内容。
在 GitHub 上,你会在 Django 的拉取请求页面上找到分页的内容。当您到达页面底部时,您可以导航到其他页面:

想象一下,如果所有页码都显示出来,页面底部会有多拥挤。更重要的是,考虑一下如果所有的问题都一次显示,而不是分散在 615 页上,加载页面需要多长时间。
你甚至可以说没有必要有页码。谁能知道哪一期在哪一页?出于这个原因,一些网站完全抛弃了页码,给你一个压缩形式的分页。
PyCoder 的每周简讯用上一页和下一页按钮对其档案进行分页。这种分页使您可以方便地浏览所有时事通讯:
在 Subscribe 按钮下面,您可以看到用于导航到上一期和下一期的分页控件。多亏了这种分页技术,你可以从一期时事通讯跳到另一期,而不是一期一期地从档案中选择。
当您的 Django admin 接口中有超过 100 个对象时,您也可以看到分页在起作用。要访问更多内容,您必须单击另一个页码:
Django 管理员没有显示所有 3776 个项目的列表,而是将内容分成 38 页。再次想象一下,如果所有的内容都呈现在一个巨大的表格中,Django 管理界面将会是多么的强大!
但是分页不仅仅用在网站的前端设计中。将 API 响应的内容分页也很常见。随机用户 API 是众多REST API中的一个,它为您提供了对响应进行分页的选项:
通过添加一个results=2参数,您告诉随机用户 API,您只希望每个响应有两个结果。使用page参数,您可以导航到这些分页响应的特定页面。
注:你有什么有趣的使用分页的网站或者 API 的例子吗?在下面的评论中分享给社区吧!
一旦您知道什么是分页,您可能会在网上冲浪时经常注意到它。考虑在项目中实现分页时,有必要仔细研究一下什么时候使用分页,什么时候不使用分页。
何时使用分页
分页是将内容分成小块的好方法。上面的例子强调了这在互联网上是一种常见的做法。这是理所当然的,因为对内容进行分页有很多好处:
- 一次发送较少的内容会加快页面加载速度。
- 设置内容子集可以清理网站的用户界面。
- 你的内容更容易掌握。
- 你的访问者不必没完没了地滚动才能到达你网站的页脚。
- 当您没有一次发送所有数据时,您会减少服务器的请求负载。
- 您减少了从数据库中检索的项目数量。
分页有助于构建网站的内容,并且可以提高网站的性能。尽管如此,对内容进行分页并不总是最好的选择。有些情况下,最好不要对内容进行分页。请继续阅读,了解何时不使用分页会更好。
何时不使用分页
使用分页有很多好处。但并不总是最好的选择。根据您的用例,您可能想决定不在您的用户界面中使用分页。您应该考虑分页的潜在缺点:
- 你打断了用户的连续阅读。
- 你的用户必须浏览结果。
- 查看更多内容需要加载新的页面。
- 如果页面太多,那么浏览起来会变得笨拙。
- 这会降低用户的速度,所以阅读需要更多的时间。
- 在分页数据中查找特定内容可能会更加困难。
- 在页面之间来回比较信息很麻烦。
有了一长串的好处和同样长的缺点,您可能想知道什么时候应该使用分页。通常,这取决于您想要提供的内容数量和用户体验。
这里有两个问题,你可以问自己,以帮助决定是否应该使用分页:
- 你的网站上有足够的内容来证明分页的合理性吗?
- 分页能改善你的网站的用户体验吗?
如果您仍然犹豫不决,那么用 Django 实现分页的便利可能是一个令人信服的理由。在下一节中,您将了解 Django 的内置Paginator类是如何工作的。
Django 的内置分页器
Django 内置了一个 Paginator类,可以随时使用。也许您有一个正在进行的项目,并且您希望以您的应用程序为基础,在下面的部分中尝试分页实现。没问题!但是,如果您想了解本教程中的分步代码示例,那么您可以从 Real Python materials repository 下载 Django Python wiki 项目的源代码:
获取源代码: 单击此处获取您将用于实现 Django 分页的源代码。
这个 wiki 项目包含一个名为terms的应用。目前,该应用程序的唯一目的是显示所有的 Python 关键字。在下一节中,您将对这个示例项目有一个简短的概述,它将作为本教程中分页的基础。如果您想在不使用提供的示例项目的情况下学习 Django 分页的一般概念,那么您可以跳到在 Django Shell 中探索 Django 分页器。
准备您的示例 Django 项目
本教程中的分页示例将适用于任何 Django 项目。但是出于本教程的目的,您将在 Python wiki 中工作。为了让您能够密切关注,值得从上面的链接下载 Python wiki Django 示例项目。要设置 Python wiki 项目,首先要遵循附带的README.md文件中的说明。
Python wiki 示例项目包含一个名为terms的应用程序,它包含一个Keyword模型:
1# terms/models.py
2
3from django.db import models
4
5class Keyword(models.Model):
6 name = models.CharField(max_length=30)
7
8 def __str__(self):
9 return self.name
Keyword模型仅由name字符字段组成。默认情况下,主键为1的Keyword实例的字符串表示为Keyword object (1)。添加.__str__()方法时,显示的是Keyword的名称。
Python wiki 项目已经包含了迁移文件。要使用您的数据库,您必须运行项目的迁移。从下面选择您的操作系统,并相应地使用特定于平台的命令:
- 视窗
** Linux + macOS*
(venv) C:\> python manage.py migrate
(venv) $ python manage.py migrate
在应用了所有迁移之后,您的数据库包含了 Django 项目所需的表。有了数据库表,您就可以开始添加内容了。要用所有 Python 关键字的列表填充项目的数据库,进入 Django 项目的文件夹并启动 Django shell :
- 视窗
** Linux + macOS*
(venv) C:\> python manage.py shell
(venv) $ python manage.py shell
使用 Django shell 是与您的 Django 项目进行交互的一种很好的方式。您可以方便地尝试代码片段并连接到后端,而无需前端。在这里,您以编程方式向数据库添加项目:
1>>> import keyword 2>>> from terms.models import Keyword 3>>> for kw in keyword.kwlist: 4... k = Keyword(name=kw) 5... k.save() 6...首先,在第 1 行中导入 Python 内置的
keyword模块。之后,您从terms应用程序导入Keyword模型。在第 3 行,您遍历 Python 的关键字列表。最后,使用关键字 string 创建一个Keyword类实例,并将其保存到数据库中。注意:上面代码块中的变量名称相似,很难读懂。这对于在交互式解释器中的较小任务来说是可以接受的。当你想写持久的 Python 代码时,考虑更好的变量名是个好主意。
要验证您的数据库是否包含 Python 关键字,请在 Django shell 中列出它们:
>>> from terms.models import Keyword
>>> Keyword.objects.all()
<QuerySet [<Keyword: False>, <Keyword: None>, <Keyword: True>, ... ]>
当您从您的terms应用程序导入Keyword模型时,您可以列出您的数据库中的所有项目。数据库条目都是 35 个 Python 关键字,按照它们被添加到数据库的顺序排列。
您的 Python wiki 项目还包含一个基于类的视图,在一个页面上显示所有的关键字:
# terms/views.py
from django.views.generic import ListView
from terms.models import Keyword
class AllKeywordsView(ListView):
model = Keyword
template_name = "terms/base.html"
该视图返回Keyword模型的所有数据库条目。作为 Django 的泛型ListView的子类,它需要一个名为keyword_list.html的模板。然而,通过将.template_name属性设置为"terms/base.html",您告诉 Django 去寻找基础模板。您将在本教程中发现的其他 Django 模板将扩展上面显示的base.html模板。
注意:如果您想密切关注,请确保您没有跳过上述填充数据库的步骤。
一旦样例项目就绪,就可以运行 Django 的内置 web 服务器了:
- 视窗
** Linux + macOS*
(venv) C:\> python manage.py runserver
(venv) $ python manage.py runserver
当您的开发 web 服务器正在运行时,请访问http://localhost:8000/all。该页面在一个连续的列表中显示所有 Python 关键字。稍后,您将在 Django 的Paginator类的帮助下创建视图来对这个列表进行分页。继续阅读,了解 Django 分页器是如何工作的。
探索 Django Shell 中的 Django 分页器
在详细查看 Django 分页器之前,请确保已经填充了数据库并进入了 Django shell,如前一节所示。
Django shell 非常适合在不添加代码的情况下尝试命令。如果您还没有,请从导入Keyword模型开始:
>>> from terms.models import Keyword >>> from django.core.paginator import Paginator >>> keywords = Keyword.objects.all().order_by("name") >>> paginator = Paginator(keywords, per_page=2)首先,导入
Paginator类。然后为 Django 查询集创建一个名为keywords的变量。因为您没有过滤查询集,keywords将包含您在上一节中列出的所有 Python 关键字。记住 Django 的QuerySets很懒:创建
QuerySet的行为不涉及任何数据库活动。您可以整天将过滤器堆叠在一起,Django 不会真正运行查询,直到对QuerySet求值。(来源在上面的示例中,您为数据库表中的所有项目创建了一个查询集。因此,当您在某个时候用 Django 的分页器访问数据库时,您请求的是数据库内容的子集。这样,当您需要从数据库中提供大量数据时,分页可以极大地提高 Django 应用程序的速度。
注意:分页只有在数据库主动处理时才有意义。如果只在后端进行内存分页,那么并不能解决查询数据库的瓶颈。
内置的 Django
Paginator类通知请求哪个页面以及从数据库中获取多少行。根据你使用的数据库管理系统的不同,它会翻译成稍微不同的 SQL 方言。严格地说,数据库进行分页,Django 只请求一个页码和偏移量。Python 和 MySQL 数据库教程向您介绍了构建数据库密集型应用程序的最佳实践。
向查询集添加一些排序也很重要。当你按
name对你的 Python 关键词排序时,你将按字母顺序接收它们。否则,您可能会在keywords列表中得到不一致的结果。当初始化您的
Paginator类时,您将keywords作为第一个参数传入。作为第二个参数,您必须添加一个整数,它定义了您希望在一个页面上显示多少个项目。在这种情况下,是两个。这意味着您希望每页显示两个项目。Django
Paginator类接受四个参数。其中两个是必需的:
争吵 需要 说明 object_list981 号房 通常是一个 Django QuerySet ,但是它可以是任何具有 .count()或.__len__()方法的可切片对象,比如一个列表或一个元组。per_page981 号房 定义要在每页上显示的项目数。 orphans声明您在最后一页上允许的最小项目数。如果最后一页有相同或更少的项目,那么它们将被添加到上一页。默认值是 0,这意味着您可以拥有最后一页,其项目数介于 1 和您为per_page设置的值之间。allow_empty_first_page具有默认值 True。如果object_list为空,那么你将得到一个空页面。将allow_empty_first_page设置为False以引发EmptyPage错误。一旦你创建了你的
Paginator,那么你就可以访问它的属性。回到 Django shell 来看看分页器的运行情况:
>>> paginator.count
35
>>> paginator.num_pages
18
>>> paginator.page_range
range(1, 19)
>>> paginator.ELLIPSIS
"…"
您的Paginator类的.count属性是您传入的object_list的长度。请记住,您希望分页器每页显示两个项目。前十七页每一页包含两个项目。最后一页将只包含一个项目。这样总共有 18 页,如paginator.num_pages所示。
由于遍历页面是一项常见的任务,Django Paginator类为您提供了直接作为属性的.page_range迭代器。
在最后一行,您使用了.ELLIPSIS属性。当您没有在前端向用户显示整个页面范围时,这个属性就派上了用场。在本教程后面的一个例子中,您将看到它的实际应用。
Django Paginator类有四个属性:
| 属性 | 说明 |
|---|---|
.ELLIPSIS |
不显示整个页面范围时显示的字符串。默认值是省略号(…)。 |
.count |
所有页面上的项目总数。这是你的object_list的长度。 |
.num_pages |
总页数。 |
.page_range |
页码的范围迭代器。注意这个迭代器是从 1 开始的,因此从第一页开始。 |
除了属性之外,Paginator类还包含三个方法。其中两个乍一看非常相似。从.get_page()方法开始:
>>> paginator.get_page(4) <Page 4 of 18> >>> paginator.get_page(19) <Page 18 of 18> >>> paginator.get_page(0) <Page 18 of 18>使用
.get_page(),可以直接进入Paginator的页面。注意,Django 分页器中的页面是从 1 开始索引的,而不是从 0 开始。当您传入页面范围之外的数字时,.get_page()会返回最后一页。现在用
.page()方法做同样的尝试:
>>> paginator.page(4)
<Page 4 of 18>
>>> paginator.page(19)
Traceback (most recent call last):
...
django.core.paginator.EmptyPage: That page contains no results
>>> paginator.page(0)
Traceback (most recent call last):
...
django.core.paginator.EmptyPage: That page number is less than 1
就像使用.get_page()一样,您可以使用.page()方法直接访问页面。请记住,页面索引是从 1 开始的,而不是从 0 开始。与.get_page()的关键区别在于,如果你传入一个超出页面范围的数字,那么.page()会引发一个EmptyPage错误。所以当用户请求一个不存在的页面时,使用.page()可以让你更加严格。您可以在后端捕获异常并向用户返回一条消息。
注意:当您将allow_empty_first_page设置为False并且您的object_list为空时,那么.get_page()也会引发一个EmptyPage错误。
使用.get_page()和.page()可以直接进入页面。除了这两种方法,Django 的Paginator包含第三种方法,称为.get_elided_page_range():
>>> paginator.get_elided_page_range() <generator object Paginator.get_elided_page_range at 0x1046c3e60> >>> list(paginator.get_elided_page_range()) [1, 2, 3, 4, "…", 17, 18]
.get_elided_page_range()方法返回一个生成器对象。当您将该生成器对象传递给一个list()函数时,您将显示.get_elided_page_range()产生的值。首先,不要传入任何参数。默认情况下,
.get_elided_page_range()使用number=1、on_each_side=3和on_ends=2作为参数。生成的列表显示页面1及其以下三个邻居:2、3和4。之后,.ELLIPSIS字符串显示为隐藏所有页面,直到最后两个页面。第
1页之前没有页面,所以只省略其后的页面。这就是为什么页面范围中间的数字更好地展示了.get_elided_page_range()的功能:
>>> list(paginator.get_elided_page_range(8))
[1, 2, "…", 5, 6, 7, 8, 9, 10, 11, '…', 17, 18]
>>> list(paginator.get_elided_page_range(8, on_each_side=1))
[1, 2, "…", 7, 8, 9, "…", 17, 18]
>>> list(paginator.get_elided_page_range(8, on_each_side=1, on_ends=0))
["…", 7, 8, 9, "…"]
注意在8的每一边,现在有三个邻居加上一个省略号(…)和第一页或最后两页。当您将on_each_side设置为1时,则7和9是唯一显示的邻居。这些是紧接在页面8之前和之后的页面。最后,将on_ends设置为0,第一页和最后一页也被省略。
为了更好地理解.get_elided_page_range()是如何工作的,请用一些注释重新查看上面的输出:
| 争论 | 注释输出 |
|---|---|
number=8 |
 T2】 T2】 |
number=8 |
|
| T1】 |  T2】 T2】 |
number=8 |
|
on_each_side=1 |
|
| T2】 |  T2】 T2】 |
在 Django shell 中试用 Django 的Paginator类让您对分页是如何工作的有了第一印象。通过学习 Django 的Paginator的属性和方法,你已经开始尝试了。现在是时候开始在 Django 视图中实现分页工作流了。
在视图中使用 Django 分页器
在 Django shell 中研究 Django 分页器是理解 Django 分页器行为的一个很好的方式。然而,在你的 Django 视图中使用分页将会揭示 Django 分页器在构建你的内容时是多么的强大。
Django 有两种视图:基于类的视图和基于函数的视图。两者都接受 web 请求并返回 web 响应。基于类的视图对于通用视图来说是一个很好的选择,比如显示数据库项目列表。
当准备你的 Django 项目样本时,你已经了解了AllKeywordsView。这种基于类的视图在一个页面上返回所有的关键字,没有对它们进行分页。但是在 Django 中,您可以通过向视图类添加.paginate_by属性来对基于类的视图进行分页:
1# terms/views.py
2
3from django.views.generic import ListView
4from terms.models import Keyword
5
6class KeywordListView(ListView):
7 paginate_by = 5 8 model = Keyword
当您在第 7 行向视图类添加.paginate_by属性时,您限制了每个页面显示的对象数量。在这种情况下,您将在每页显示五个对象。
Django 还为视图响应的.context添加了.paginator和.page_obj属性。此外,ListView期望一个模板,其名称由小写的模型名称组成,后跟一个_list后缀。否则,您必须在类中定义一个.template_name属性。在下一节中,您将使用一个名为keyword_list.html的模板,因此没有必要将.template_name属性添加到KeywordListView中。
在基于类的视图中,添加.paginator、.page_obj和.context属性是在幕后进行的。当你写一个基于函数的视图时,你必须自己添加它们。更新您的views.py文件,并排查看两个视图:
1# terms/views.py
2
3from django.core.paginator import Paginator
4from django.shortcuts import render
5 6from terms.models import Keyword
7
8# ...
9
10def listing(request, page):
11 keywords = Keyword.objects.all().order_by("name")
12 paginator = Paginator(keywords, per_page=2) 13 page_object = paginator.get_page(page) 14 context = {"page_obj": page_object} 15 return render(request, "terms/keyword_list.html", context)
这个基于函数的视图几乎和上面基于类的视图完全一样。但是你必须明确地定义变量。
在第 3 行,您导入Paginator供自己使用。您在第 12 行用您的keywords列表和设置为2的per_page参数实例化了Paginator类。
到目前为止,listing()包含了与KeywordListView相同的功能。在第 13 行,您增强了listing()视图。你用paginator.get_page()创造page_object。您传递的page变量可以作为一个 URL 参数使用。在本教程的后面,您将学习如何通过在 URL 定义中实现page参数来利用它。
最后,在第 15 行,用request、想要呈现的模板和context字典调用render()函数。context字典包含以"page_obj"为关键字的page_obj值。您可以用不同的方式命名这个键,但是当您调用它page_obj时,您可以使用您的基于类的视图所期望的同一个keyword_list.html模板。
KeywordListView和listing()都需要模板来渲染它们的context。在本教程的后面部分,您将创建这个模板和访问视图的 URL。在此之前,请在views.py停留一会儿,研究一下分页 API 端点是如何工作的。
用分页数据响应
设计 API 时,将响应分页也是一种常见的做法。当用 Django 创建 API 时,可以使用像 Django REST 框架这样的框架。但是你不需要外部框架来构建一个 API。在本节中,您将创建一个没有 Django REST 框架的 Django API 端点。
API 视图的函数体类似于您在上一节中创建的listing()视图。为了增加趣味,您将实现更多的功能,以便您的用户可以用他们的 GET 请求定制 API 响应:
1# terms/views.py
2
3from django.core.paginator import Paginator
4from django.http import JsonResponse
5
6from terms.models import Keyword
7
8# ...
9
10def listing_api(request):
11 page_number = request.GET.get("page", 1)
12 per_page = request.GET.get("per_page", 2)
13 startswith = request.GET.get("startswith", "")
14 keywords = Keyword.objects.filter(
15 name__startswith=startswith
16 )
17 paginator = Paginator(keywords, per_page)
18 page_obj = paginator.get_page(page_number)
19 data = [{"name": kw.name} for kw in page_obj.object_list]
20
21 payload = {
22 "page": {
23 "current": page_obj.number,
24 "has_next": page_obj.has_next(),
25 "has_previous": page_obj.has_previous(),
26 },
27 "data": data
28 }
29 return JsonResponse(payload)
有一些事情正在发生,所以请详细研究最重要的几行:
- 第 4 行导入
JsonResponse,将是listing_api的返回类型。 - 第 10 行定义了名为
listing_api的视图函数,该函数接收request。 - 第 11 行将
page_number设置为page获取参数的值或默认为1。 - 第 12 行将
per_page设置为per_page获取参数的值或默认为2。 - 第 13 行将
startswith设置为startswithGET 参数的值或者默认为空字符串。 - 第 14 行创建
keywords,它是一个QuerySet,包含所有关键字或者以startswith包含的字母开头的关键字。 - 第 17 行和第 18 行创建了
Paginator和一个Page实例。 - 第 19 行创建一个包含 Python 关键字名称的字典列表。
- 第 121 行用你想发送给用户的数据定义了
payload字典。 - 第 29 行返回
payload作为 JSON 编码的响应。
使用listing_api(),您创建了一个基于函数的视图作为灵活的 API 端点。当用户向listing_api()发送一个没有任何 GET 参数的请求时,JsonResponse会用第一页和你的前两个关键字来响应。当用户提供参数时,您还可以灵活地向用户返回细粒度的数据。
Django JSON API 端点唯一缺少的是它所连接的 URL。是时候解决了!
实现分页 URL 参数
在前面的小节中,您创建了三个响应分页数据的视图:一个KeywordListView类,一个listing()基于函数的视图,以及一个名为listing_api()的 API 端点。要访问您的视图,您必须创建三个URL:
1# terms/urls.py
2
3from django.urls import path
4from . import views
5
6urlpatterns = [
7 # ...
8 path(
9 "terms",
10 views.KeywordListView.as_view(),
11 name="terms"
12 ),
13 path(
14 "terms/<int:page>",
15 views.listing,
16 name="terms-by-page"
17 ),
18 path(
19 "terms.json",
20 views.listing_api,
21 name="terms-api"
22 ),
23]
您将每个相应视图的路径添加到urlpatterns列表中。乍一看,只有listing包含页面引用似乎有些奇怪。其他视图不是也可以处理分页数据吗?
记住只有你的listing()函数接受一个page参数。这就是为什么你只在第 14 行用<int:page>作为 URL 模式来引用一个页码。KeywordListView和listing_api()都将单独使用 GET 参数。您将通过 web 请求访问分页数据,而不需要任何特殊的 URL 模式。
terms URL 和terms-by-page URL 都依赖于模板,您将在下一节探索这些模板。另一方面,您的terms-api视图用一个JSONResponse响应,并准备好使用。要访问您的 API 端点,您必须首先启动 Django 开发服务器,如果它还没有运行的话:
- 视窗
** Linux + macOS*
(venv) C:\> python manage.py runserver
(venv) $ python manage.py runserver
当 Django 开发服务器正在运行时,您可以打开浏览器,进入http://localhost:8000/terms.json:
当您在没有添加任何 GET 参数的情况下访问http://localhost:8000/terms.json时,您将收到第一页的数据。返回的 JSON 对象包含关于当前页面的信息,并指定是否有上一页或下一页。对象包含前两个关键字的列表,False和None。
注意:您的浏览器可能会将 JSON 响应显示为无格式文本。您可以为您的浏览器安装一个 JSON 格式化程序扩展来很好地呈现 JSON 响应。
既然你知道在第一页之后还有一页,你可以通过访问http://localhost:8000/terms.json?page=2:
当您将?page=2添加到 URL 时,您将附加一个名为page的 GET 参数,其值为2。在服务器端,您的listing_api视图检查任何参数,并识别出您特别要求第二页。您返回的 JSON 对象包含第二页的关键字,并告诉您在这一页之前还有一页,在这一页之后还有另一页。
您可以将 GET 参数与一个&符号(&)结合使用。带有多个 GET 参数的 URL 可能看起来像http://localhost:8000/terms.json?page=4&per_page=5:
这次您将page GET 参数和per_page GET 参数链接起来。作为回报,您将获得数据集第四页上的五个关键词。
在您的listing_api()视图中,您还添加了基于首字母查找关键字的功能。前往http://localhost:8000/terms.json?startswith=i查看该功能的运行情况:
通过发送值为i的startswith GET 参数,您将寻找所有以字母 i 开头的关键字。注意has_next是true。这意味着有更多的页面包含以字母 i 开头的关键词。您可以发出另一个请求,并传递page=2 GET 参数来访问更多的关键字。
另一种方法是添加一个类似于99的大数值的per_page参数。这将确保您在一次返回中获得所有匹配的关键字。
继续为您的 API 端点尝试不同的 URL 模式。一旦您看到了足够多的原始 JSON 数据,就可以进入下一节,创建一些带有分页导航变体的 HTML 模板。
Django 模板中的分页
到目前为止,你大部分时间都花在了后端上。在本节中,您将找到进入前端的方法,探索各种分页示例。您将在每个部分尝试不同的分页构建块。最后,您将把学到的所有内容组合到一个分页小部件中。
首先,在terms/templates/terms/目录中创建一个新的模板,命名为keyword_list.html:
<!-- terms/templates/terms/keyword_list.html -->
{% extends "terms/base.html" %}
{% block content %}
{% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
{% endblock %}
当你命名你的 Django 模板keyword_list.html时,你的KeywordListView和你的listing都能找到这个模板。当您在浏览器中输入一个 URL 时,Django 将解析该 URL 并提供匹配的视图。当您的 Django 开发服务器正在运行时,您可以尝试不同的 URL 来查看运行中的keyword_list.html模板。
注意:本教程重点介绍在 Django 模板中实现分页。如果你想更新关于 Django 的模板引擎的知识,那么学习内置标签和过滤器是一个很好的起点。之后,您可以探索在 Django 模板中实现定制标签和过滤器。
在你的urls.py文件中,你给KeywordListView起名叫terms。您可以使用如下 URL 模式访问terms:
http://localhost:8000/termshttp://localhost:8000/terms?page=2http://localhost:8000/terms?page=7
在您的urls.py文件中,您将您的listing()视图命名为terms-by-page。您可以使用如下 URL 模式访问terms-by-page:
http://localhost:8000/terms/1http://localhost:8000/terms/2http://localhost:8000/terms/18
这两种视图提供相同的模板和分页内容。然而,terms显示五个关键字,而terms-by-page显示两个。这是意料之中的,因为您在KeywordListView中定义的.paginate_by属性不同于在listing()视图中定义的per_page变量:
https://player.vimeo.com/video/676375076?background=1
到目前为止,您只能通过手动更改 URL 来控制分页。是时候增强你的keyword_list.html并改善你网站的用户体验了。在接下来的几节中,您将探索添加到用户界面中的不同分页示例。
当前页面
本示例显示您当前所在的页面。调整keyword_list.html显示当前页码:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8
9{% block pagination %} 10 <p>Current Page: <b>{{page_obj.number}}</b></p> 11{% endblock %}
在第 10 行,您正在访问您的page_obj的.number属性。当你转到http://localhost:8000/terms/2时,模板变量的值将是2:
https://player.vimeo.com/video/678134729?background=1
很高兴知道你在哪一页。但是如果没有正确的导航,仍然很难进入另一个页面。在下一节中,您将通过链接到所有可用页面来添加导航。
所有页面
在这个例子中,你将所有页面显示为可点击的超链接。您将跳转到另一个页面,而无需手动输入 URL。Django 分页器跟踪所有对你可用的页面。您可以通过迭代page_obj.paginator.page_range来访问页码:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8
9{% block pagination %} 10 {% for page_number in page_obj.paginator.page_range %} 11 <a 12 href="{% url 'terms-by-page' page_number %}" 13 class="{% if page_number == page_obj.number %}current{% endif %}" 14 > 15 {{page_number}} 16 </a> 17 {% endfor %} 18{% endblock %}
在第 10 行,您循环了所有可用的页码。然后在第 15 行显示每个page_number。每个页码都显示为一个链接,用于导航到所单击的页面。如果page_number是当前页面,那么向它添加一个 CSS 类,使它看起来不同于其他页面。前往http://localhost:8000/terms/1查看您的所有页面分页区的运行情况:
https://player.vimeo.com/video/678140546?background=1
当您单击不同的页码时,可以导航到相应的页面。您仍然可以找到当前页面,因为它在页码列表中的样式不同。当前页码没有被正方形包围,并且不可点按。
省略页面
如果页面不太多,显示所有页面可能是有意义的。但是页面越多,分页区域就越混乱。这时.get_elided_page_range()可以帮忙了:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8
9{% block pagination %} 10 {% for page_number in page_obj.paginator.get_elided_page_range %} 11 {% if page_number == page_obj.paginator.ELLIPSIS %} 12 {{page_number}} 13 {% else %} 14 <a 15 href="{% url 'terms-by-page' page_number %}" 16 class="{% if page_number == page_obj.number %}current{% endif %}" 17 > 18 {{page_number}} 19 </a> 20 {% endif %} 21 {% endfor %} 22{% endblock %}
您现在不是遍历所有页面,而是遍历第 10 行的省略页面列表。在这个例子中,该列表包括数字 1 到 4 ,一个省略号、 17 和 18 。当您到达列表中的省略号时,您不想创建超链接。这就是为什么你把它放到第 11 到 13 行的一个 if语句中。编号的页面应该是超链接,所以在第 14 到 19 行用一个a标记将它们包装起来。
访问http://localhost:8000/terms/1查看您的省略页面Paginator的外观:
https://player.vimeo.com/video/678134987?background=1
省略页面分页器看起来没有显示所有页面的分页器那么杂乱。注意,当你访问http://localhost:8000/terms时,你根本看不到省略号,因为你每页显示五个关键词。在第一页上,你显示接下来的三页和最后的两页。唯一被省略的一页是第五页。Django 不是只显示一页的省略号,而是显示页码。
不过,在模板中使用.get_elided_page_range()有一个警告。当你访问http://localhost:8000/terms/7时,你会看到一个被省略的页面:
https://player.vimeo.com/video/687108578?background=1
无论您在哪个页面,省略的页面范围保持不变。您可以在page_obj.paginator.get_elided_page_range循环中找到结束于省略页面的原因。不是返回当前页面的省略页面列表,.get_elided_page_range()总是返回默认值1的省略页面列表。要解决这个问题,您需要在后端调整您的省略页面配置:
1# terms/views.py
2
3# ...
4
5def listing(request, page):
6 keywords = Keyword.objects.all().order_by("name")
7 paginator = Paginator(keywords, per_page=2)
8 page_object = paginator.get_page(page)
9 page_object.adjusted_elided_pages = paginator.get_elided_page_range(page) 10 context = {"page_obj": page_object}
11 return render(request, "terms/keyword_list.html", context)
在第 9 行,您将adjusted_elided_pages添加到page_object。每次调用listing视图时,您都会基于当前页面创建一个调整后的消隐页面生成器。为了反映前端的变化,您需要调整keyword_list.html中的省略页面循环:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8
9{% block pagination %}
10 {% for page_number in page_obj.adjusted_elided_pages %} 11 {% if page_number == page_obj.paginator.ELLIPSIS %}
12 {{page_number}}
13 {% else %}
14 <a
15 href="{% url 'terms-by-page' page_number %}"
16 class="{% if page_number == page_obj.number %}current{% endif %}"
17 >
18 {{page_number}}
19 </a>
20 {% endif %}
21 {% endfor %}
22{% endblock %}
随着第 10 行的变化,您正在访问定制的page_obj.adjusted_elided_pages生成器,它考虑您当前所在的页面。访问http://localhost:8000/terms/1并测试您调整后的省略页面分页器:
https://player.vimeo.com/video/685480145?background=1
现在你可以点击所有的页面,省略的页面会相应地调整。通过对上面的views.py文件进行调整,您可以为您的用户提供一个强大的分页小部件。一种常见的方法是将省略的页面小部件与上一页和下一页的链接结合起来。
上一个和下一个
省略页面的分页小部件通常与指向上一页和下一页的链接结合在一起。但是,您甚至可以摆脱根本不显示页码的分页:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8
9{% block pagination %} 10 {% if page_obj.has_previous %} 11 <a href="{% url 'terms-by-page' page_obj.previous_page_number %}"> 12 Previous Page 13 </a> 14 {% endif%} 15 {% if page_obj.has_next %} 16 <a href="{% url 'terms-by-page' page_obj.next_page_number %}"> 17 Next Page 18 </a> 19 {% endif%} 20{% endblock %}
在本例中,您没有遍历任何页面。您在第 10 到 14 行使用page_obj.has_previous来检查当前页面是否有前一页。如果有上一页,那么在第 11 行显示为一个链接。请注意,您甚至没有提供实际的页码,而是使用了page_obj的.previous_page_number属性。
在第 15 行到第 19 行中,您采用了相反的方法。您检查第 15 行中带有page_obj.has_next的下一页。如果有下一页,那么在第 16 行显示链接。
转到http://localhost:8000/terms/1并导航到一些上一页和下一页:
https://player.vimeo.com/video/678135049?background=1
请注意当您到达第一页时,上一页链接是如何消失的。一旦你上了最后一页,就没有下一页链接。
第一个和最后一个
使用 Django 分页器,您还可以让您的访问者快速浏览第一页或最后一页。前一个示例中的代码仅在突出显示的行中做了轻微的调整:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8
9{% block pagination %}
10 {% if page_obj.has_previous %}
11 <a href="{% url 'terms-by-page' 1 %}"> 12 First Page 13 </a> 14 {% endif%}
15 {% if page_obj.has_next %}
16 <a href="{% url 'terms-by-page' page_obj.paginator.num_pages %}"> 17 Last Page 18 </a> 19 {% endif%}
20{% endblock %}
您在第 10 行和第 15 行的if语句中实现的逻辑与上一个示例中的相同。当你在第一页时,没有链接到上一页。当你在最后一页时,就没有进一步导航的选项了。
您可以在突出显示的行中发现差异。在第 11 行,您直接链接到页面1。这是第一页。在第 16 行,您使用page_obj.paginator.num_pages来获取分页器的长度。.num_pages的值是18,你的最后一页。
转到http://localhost:8000/terms/1并使用分页链接从第一页跳到最后一页:
https://player.vimeo.com/video/678135097?background=1
从第一个跳到最后一个,或者相反,在某些情况下可能会很方便。但是你通常想让你的用户有机会访问中间的页面。
组合示例
在上面的例子中,您探索了在前端实现分页的不同方法。它们都提供一些导航。但它们仍然缺乏一些功能来提供令人满意的用户体验。
如果您将分页小部件结合在一起,那么您可以创建一个用户会喜欢的导航元素:
1<!-- terms/templates/terms/keyword_list.html -->
2
3{% extends "terms/base.html" %}
4
5{% block content %}
6 {% for kw in page_obj %}<pre>{{kw}}</pre>{% endfor %}
7{% endblock %}
8 9{% block pagination %} 10 {% if page_obj.has_previous %} 11 <a href="{% url 'terms-by-page' 1 %}"> 12 ◀️◀️ 13 </a> 14 <a href="{% url 'terms-by-page' page_obj.previous_page_number %}"> 15 ◀️ 16 </a> 17 {% endif%} 18 19 <a>{{page_obj.number}} of {{page_obj.paginator.num_pages}}</a> 20 21 {% if page_obj.has_next %} 22 <a href="{% url 'terms-by-page' page_obj.next_page_number %}"> 23 ▶️ 24 </a> 25 <a href="{% url 'terms-by-page' page_obj.paginator.num_pages %}"> 26 ▶️▶️ 27 </a> 28 {% endif%} 29 30 <hr> 31 32 {% for page_number in page_obj.paginator.page_range %} 33 <a 34 href="{% url 'terms-by-page' page_number %}" 35 class="{% if page_number == page_obj.number %}current{% endif %}" 36 > 37 {{page_number}} 38 </a> 39 {% endfor %} 40{% endblock %}
这里,您使用向左箭头(◀️)表示上一页和第一页,使用向右箭头(▶️)表示下一页和最后一页。除此之外,您已经研究过的示例没有任何变化:
- 第 10 行检查是否有上一页。
- 第 11 到 13 行提供了到第一页的链接。
- 第 14 到 16 行提供了到上一页的链接。
- 第 19 行显示当前页面以及总共有多少页。
- 第 21 行检查是否有下一页。
- 第 22 到 24 行提供了到下一页的链接。
- 第 25 到 27 行提供了到最后一页的链接。
- 第 32 到 39 行创建所有可用页面的列表。
前往http://localhost:8000/terms/1查看这个丰富的分页小部件的运行情况:
https://player.vimeo.com/video/678135177?background=1
所有这些例子仅仅是为你自己的用户界面构建模块。也许您想出了不同的解决方案来为您的 web 项目创建灵活的分页。如果你这样做了,请不要犹豫,在下面的评论中与真正的 Python 社区分享你的代码。
动态 JavaScript 分页
分页有助于您组织内容并以块的形式提供数据,从而获得更好的用户体验。但是有些情况下,上述分页解决方案可能不适合您的需要。例如,您可能希望动态提供内容,而不加载新页面。
在这一节中,您将了解内容分页的替代方法。您将使用 JavaScript 来控制您的分页,并利用您之前创建的 API 端点来相应地提供数据。
仿分页
当您按下上一个或下一个按钮时,您可以通过动态加载内容来实现另一种分页功能。结果看起来像标准的分页,但是当您单击分页链接时,不会加载新的页面。相反,您执行一个 AJAX 调用。
AJAX 代表异步 JavaScript 和 XML 。虽然 X 代表 XML ,但是现在更常见的是使用 JSON 响应。
注意:您将使用 JavaScript 的获取 API 来异步加载内容。这不会加载新页面。这意味着你不能使用浏览器的后退按钮去之前加载的页面,重新加载一个页面会重置你的滚动位置。
尽管加载数据的方式不同,但结果看起来几乎是一样的:
https://player.vimeo.com/video/678144195?background=1
要创建一个动态前端,需要使用 JavaScript 。如果你很好奇,想尝试一下 JavaScript,那么你可以遵循下面可折叠部分的步骤:
在terms/templates/terms/目录下创建一个新模板,文件名为faux_pagination.html。创建文件后,您可以复制并粘贴以下内容:
<!-- terms/templates/terms/faux_pagination.html -->
{% extends "terms/base.html" %}
{% block content%}
<div id="keywords"></div>
{% endblock %}
{% block pagination %}
<p>
Current Page: <b id="current"></b>
</p>
<nav>
<a href="#" id="prev">
Previous Page
</a>
<a href="#" id="next">
Next Page
</a>
</nav>
<script> async function getData(url, page, paginateBy) { const urlWithParams = url + "?" + new URLSearchParams({ page: page, per_page: paginateBy }) const response = await fetch(urlWithParams); return response.json(); } class FauxPaginator { constructor(perPage) { this.perPage = perPage this.pageIndex = 1 this.container = document.querySelector("#keywords") this.elements = document.querySelectorAll("pre") this.label = document.querySelector("#current") this.prev = document.querySelector("#prev") this.next = document.querySelector("#next") this.prev.addEventListener("click", this.onPrevClick.bind(this)) this.next.addEventListener("click", this.onNextClick.bind(this)) this.goToPage() } onPrevClick(event) { event.preventDefault() this.pageIndex-- this.goToPage() } onNextClick(event) { event.preventDefault() this.pageIndex++ this.goToPage() } addElement(keyword) { const pre = document.createElement("pre") pre.append(keyword) this.container.append(pre) } goToPage() { getData("{% url 'terms-api' %}", this.pageIndex, this.perPage) .then(response => { this.container.innerHTML = ''; response.data.forEach((el) => { this.addElement(el.name) }); this.label.innerText = this.pageIndex const firstPage = this.pageIndex === 1 const lastPage = !response.page.has_next this.prev.style.display = firstPage ? "none" : "inline-block" this.next.style.display = lastPage ? "none" : "inline-block" }); } } new FauxPaginator(3); </script>
{% endblock %}
该模板将关键字加载到您的terms应用程序的terms-api视图中。JavaScript 代码还动态地显示和隐藏用户界面的元素。
创建模板后,添加一个新的路由来访问仿分页示例:
# terms/urls.py
from django.urls import path
from . import views
urlpatterns = [
# ...
path(
"faux",
views.AllKeywordsView.as_view(
template_name="terms/faux_pagination.html"
),
),
]
当您向.as_view()方法提供template_name时,您告诉 Django 您想要将AllKeywordsView呈现到terms/faux_pagination.html模板中。这样,您可以使用相同的视图,并在不同的模板中显示它。
现在您可以访问http://localhost:8000/faux来看看您的 JavaScript 支持的仿分页的运行情况。
当您不控制发送到前端的数据时,在您的网站上实现仿分页功能是有意义的。当您使用外部 API 时,通常就是这种情况。
加载更多内容
有时候你不想给用户在页面之间来回切换的控制权。然后,当他们想要查看更多内容时,您可以让他们选择加载更多内容:
https://player.vimeo.com/video/676420393?background=1
借助 Load more 功能,您可以引导用户更深入地了解您的数据,而无需一次显示所有内容。一个显著的例子是在 GitHub 的 pull 请求上加载隐藏的评论。当您希望在项目中实现此功能时,可以复制下面的源代码:
在terms/templates/terms/目录下创建一个新模板,文件名为load_more.html。创建文件后,您可以复制并粘贴以下内容:
<!-- terms/templates/terms/load_more.html -->
{% extends "terms/base.html" %}
{% block content%}
<div id="keywords"></div>
{% endblock %}
{% block pagination %}
<nav>
<a href="#" id="next">
Load more
</a>
</nav>
<script> async function getData(url, page, paginateBy) { const urlWithParams = url + "?" + new URLSearchParams({ page: page, per_page: paginateBy }) const response = await fetch(urlWithParams); return response.json(); } class LoadMorePaginator { constructor(perPage) { this.perPage = perPage this.pageIndex = 1 this.container = document.querySelector("#keywords") this.next = document.querySelector("#next") this.next.addEventListener("click", this.onNextClick.bind(this)) this.loadMore() } onNextClick(event) { event.preventDefault() this.pageIndex++ this.loadMore() } addElement(keyword) { const pre = document.createElement("pre") pre.append(keyword) this.container.append(pre) } loadMore() { getData("{% url 'terms-api' %}", this.pageIndex, this.perPage) .then(response => { response.data.forEach((el) => { this.addElement(el.name) }); this.next.style.display = !response.page.has_next ? "none" : "inline-block" }); } } new LoadMorePaginator(6); </script>
{% endblock %}
该模板将关键字加载到您的terms应用程序的terms-api视图中。JavaScript 代码还隐藏了 Load more 链接。
创建模板后,添加一条新路线来访问 Load more 示例:
# terms/urls.py
from django.urls import path
from . import views
urlpatterns = [
# ...
path(
"load_more",
views.AllKeywordsView.as_view(
template_name="terms/load_more.html"
),
),
]
当您向.as_view()方法提供template_name时,您告诉 Django 您想要将AllKeywordsView呈现到terms/load_more.html模板中。这样,您可以使用相同的视图,并在不同的模板中显示它。
现在你可以访问http://localhost:8000/load_more来动态地加载更多的内容到你的页面,一点一点地点击。
当把所有内容都放在一个页面上是有意义的,但你不想一次提供所有内容时, Load more 方法可能是一个聪明的解决方案。例如,也许您正在一个不断增长的表格中展示您的数据。
随着加载更多的,你的用户必须主动点击来加载更多的内容。如果你想创造一个更加无缝的体验,那么你可以在用户到达页面底部时自动加载更多的内容。
无限滚动
一些网页设计师认为点击会给他们的用户带来摩擦。一旦用户到达页面底部,他们应该看到更多内容,而不是点击加载更多:
https://player.vimeo.com/video/676420434?background=1
这个概念通常被称为无限滚动,因为它看起来好像内容永远不会结束。无限滚动类似于加载更多的实现。但是您没有添加链接,而是等待 JavaScript 事件来触发该功能。
当您想要在项目中实现此功能时,可以复制下面的源代码:
在terms/templates/terms/目录下创建一个新模板,文件名为infinite_scrolling.html。创建文件后,您可以复制并粘贴以下内容:
<!-- terms/templates/terms/infinite_scrolling.html -->
{% extends "terms/base.html" %}
{% block content%}
<div id="keywords"></div>
{% endblock %}
{% block pagination %}
<style> #loading { transition: opacity 1s ease-out; opacity: 1; } </style>
<div id="loading">Loading...</div>
<script> async function getData(url, page, paginateBy) { const urlWithParams = url + "?" + new URLSearchParams({ page: page, per_page: paginateBy }) const response = await fetch(urlWithParams); return response.json(); } class ScrollMorePaginator { constructor(perPage) { this.perPage = perPage this.pageIndex = 1 this.lastPage = false this.container = document.querySelector("#keywords") this.elements = document.querySelectorAll("pre") this.loader = document.querySelector("#loading") this.options = { root: null, rootMargin: "0px", threshold: 0.25 } this.loadMore() this.watchIntersection() } onIntersect() { if (!this.lastPage) { this.pageIndex++ this.loadMore() } } addElement(keyword) { const pre = document.createElement("pre") pre.append(keyword) this.container.append(pre) } watchIntersection() { document.addEventListener("DOMContentLoaded", () => { const observer = new IntersectionObserver(this.onIntersect.bind(this), this.options); observer.observe(this.loader); }) } loadMore() { getData("{% url 'terms-api' %}", this.pageIndex, this.perPage) .then(response => { response.data.forEach((el) => { this.addElement(el.name) }); this.loader.style.opacity = !response.page.has_next ? "0" : "1" this.lastPage = !response.page.has_next }); } } new ScrollMorePaginator(6); </script>
{% endblock %}
该模板将关键字加载到您的terms应用程序的terms-api视图中。然而,使用添加到模板中的script标签内的 JavaScript 代码,您不会一次请求所有的关键字。相反,当你到达页面底部时,你加载你的关键字块。当没有更多的东西要加载时,JavaScript 代码还隐藏了加载元素的。
创建模板后,添加一条新路线来访问无限滚动示例:
# terms/urls.py
from django.urls import path
from . import views
urlpatterns = [
# ...
path(
"infinite_scrolling",
views.AllKeywordsView.as_view(
template_name="terms/infinite_scrolling.html"
),
),
]
当您向.as_view()方法提供template_name时,您告诉 Django 您想要将AllKeywordsView呈现到terms/infinite_scrolling.html模板中。这样,您可以使用相同的视图,并在不同的模板中显示它。
现在,您可以访问http://localhost:8000/infinite_scrolling,通过滚动方便地将更多内容动态加载到您的页面上。
在你的网站上添加无限滚动功能可以创造无缝的体验。当你有一个正在进行的图像馈送时,这种方法很方便,比如在 Instagram 上。
搜索
为了进一步扩展分页主题,您甚至可以将执行搜索视为对数据进行分页的一种方式。不是显示所有内容,而是让用户决定他们想看什么,然后搜索它:
https://player.vimeo.com/video/676420419?background=1
当您想要在项目中实现此功能时,可以复制下面的源代码:
在terms/templates/terms/目录下创建一个新模板,文件名为search.html。创建文件后,您可以复制并粘贴以下内容:
<!-- terms/templates/terms/search.html -->
{% extends "terms/base.html" %}
{% block content %}
<form>
<label for="searchBox">Search:</label><br>
<input id="searchBox" type="text" />
</form>
<p>
<b id="resultsCount">0</b>
Keywords found.
</p>
<div id="keywords"></div>
{% endblock %}
{% block pagination %}
<script> async function getData(url, paginateBy, startsWith) { const urlWithParams = url + "?" + new URLSearchParams({ per_page: paginateBy, startswith: startsWith }) const response = await fetch(urlWithParams); return response.json(); } class Search { constructor(maxResults) { this.maxResults = maxResults this.container = document.querySelector("#keywords") this.resultsCount = document.querySelector("#resultsCount") this.input = document.querySelector("#searchBox") this.input.addEventListener("input", this.doSearch.bind(this)) } addElement(keyword) { const pre = document.createElement("pre") pre.append(keyword) this.container.append(pre) } resetSearch() { this.container.innerHTML = ''; this.resultsCount.innerHTML = 0; } doSearch() { const inputVal = this.input.value.toLowerCase(); if (inputVal.length > 0) { getData("{% url 'terms-api' %}", this.maxResults, inputVal) .then(response => { this.resetSearch(); this.resultsCount.innerHTML = response.data.length; response.data.forEach((el) => { this.addElement(el.name) }); }); } else { this.resetSearch(); } } } new Search(99); </script>
{% endblock %}
当您在输入框中输入一个字符时,该模板会将关键字加载到您的terms应用程序的terms-api视图中。您正在加载的关键字必须以您在输入框中键入的字符开头。为此,您利用了您的listing-api视图的startswith GET 参数。
创建模板后,添加一条新路线来访问搜索示例:
# terms/urls.py
from django.urls import path
from . import views
urlpatterns = [
# ...
path(
"search",
views.AllKeywordsView.as_view(
template_name="terms/search.html"
),
),
]
当您向.as_view()方法提供template_name时,您告诉 Django 您想要将AllKeywordsView呈现到terms/search.html模板中。这样,您可以使用相同的视图,并在不同的模板中显示它。
现在你可以访问http://localhost:8000/search来查看你的模糊搜索。
上面的例子是进一步研究动态分页的起点。因为你没有加载新页面,你的浏览器的后退按钮可能不会像预期的那样工作。此外,重新加载页面会将页面或滚动位置重置到开头,除非您在 JavaScript 代码中添加了其他设置。
尽管如此,将动态的、JavaScript 风格的前端与可靠的 Django 后端结合起来,为现代 web 应用程序创建了一个强大的基础。使用 Django 和 Vue.js 建立一个博客是进一步探索前端和后端交互的一个好方法。
结论
您可以通过使用 Django 分页器对您的内容进行分页来显著改进您的 Django web 应用程序。对您显示的数据进行子集化可以清理用户界面。你的内容更容易掌握,用户不必无休止地滚动才能到达你网站的页脚。当您没有一次将所有数据发送给用户时,您减少了请求的负载,并且您的页面响应更快。
在本教程中,您学习了如何:
- 在基于类的视图中实现分页
- 在基于功能的视图中实现分页
- 将分页元素添加到模板
- 使用分页的 URL直接浏览页面
- 使用 JavaScript 创建动态分页体验
现在,您已经对何时以及如何使用 Django 的分页器有了深入的了解。通过研究多个分页示例,您了解了分页小部件可以包含什么。如果你想将分页付诸实践,那么建立一个文件夹、一个日记,甚至一个社交网络就提供了一个完美的分页游乐场项目。**********************
如何在 Pytest 中为 Django 模型提供测试夹具
如果你在 Django , pytest fixtures 工作,可以帮助你为你的模型创建测试,维护起来并不复杂。编写好的测试是维持一个成功应用的关键步骤,而夹具是让你的测试套件高效且有效的关键因素。夹具是作为测试基线的小块数据。
随着您的测试场景的变化,添加、修改和维护您的设备可能会很痛苦。但是不用担心。本教程将向你展示如何使用pytest-django插件来使编写新的测试用例及夹具变得轻而易举。
在本教程中,您将学习:
- 如何在 Django 中创建和加载测试夹具
- 如何为 Django 模型创建和加载
pytest夹具 - 如何使用工厂为
pytest中的 Django 模型创建测试夹具 - 如何使用工厂作为夹具模式来创建测试夹具之间的依赖关系
本教程中描述的概念适用于任何使用 pytest 的 Python 项目。为了方便起见,示例使用了 Django ORM,但是结果可以在其他类型的 ORM 中重现,甚至可以在不使用 ORM 或数据库的项目中重现。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
Django 的固定装置
首先,您将建立一个新的 Django 项目。在本教程中,您将使用内置认证模块编写一些测试。
设置 Python 虚拟环境
当你创建一个新项目时,最好也为它创建一个虚拟环境。虚拟环境允许您将该项目与计算机上的其他项目隔离开来。这样,不同的项目可以使用不同版本的 Python、Django 或任何其他包,而不会互相干扰。
以下是在新目录中创建虚拟环境的方法:
$ mkdir django_fixtures
$ cd django_fixtures
django_fixtures $ python -m venv venv
关于如何创建虚拟环境的分步说明,请查看 Python 虚拟环境:初级教程。
运行这个命令将创建一个名为venv的新目录。该目录将存储您在虚拟环境中安装的所有软件包。
建立 Django 项目
现在您已经有了一个全新的虚拟环境,是时候建立一个 Django 项目了。在您的终端中,激活虚拟环境并安装 Django:
$ source venv/bin/activate
$ pip install django
现在您已经安装了 Django,您可以创建一个名为django_fixtures的新 Django 项目:
$ django-admin startproject django_fixtures
运行这个命令后,您会看到 Django 创建了新的文件和目录。关于如何开始一个新的 Django 项目,请查看开始一个 Django 项目。
为了完成 Django 项目的设置,为内置模块应用迁移:
$ cd django_fixtures
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying sessions.0001_initial... OK
输出列出了 Django 应用的所有迁移。当开始一个新项目时,Django 会为内置的应用程序如auth、sessions和admin进行迁移。
现在您已经准备好开始编写测试和夹具了!
创建 Django 装置
Django 为来自文件的模型提供了自己的创建和加载 fixture的方法。Django fixture 文件可以用 JSON 或 YAML 编写。在本教程中,您将使用 JSON 格式。
创建 Django fixture 最简单的方法是使用现有的对象。启动 Django shell:
$ python manage.py shell
Python 3.8.0 (default, Oct 23 2019, 18:51:26)
[GCC 9.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
在 Django shell 中,创建一个名为appusers的新组:
>>> from django.contrib.auth.models import Group >>> group = Group.objects.create(name="appusers") >>> group.pk 1
Group模型是 Django 的认证系统的一部分。组对于管理 Django 项目中的权限非常有用。您创建了一个名为
appusers的新群组。您刚刚创建的群组的主键是1。为了给组appusers创建一个夹具,您将使用Django 管理命令dumpdata。用
exit()退出 Django shell,并从您的终端执行以下命令:$ python manage.py dumpdata auth.Group --pk 1 --indent 4 > group.json在本例中,您将使用
dumpdata命令从现有模型实例中生成夹具文件。让我们来分解一下:
auth.Group:描述要转储哪个型号。格式为<app_label>.<model_name>。
--pk 1:描述要转储哪个对象。该值是逗号分隔的主键列表,如1,2,3。
--indent 4:这是一个可选的格式参数,告诉 Django 在生成的文件中的每个缩进层次之前要添加多少个空格。使用缩进使夹具文件更具可读性。
> group.json:描述在哪里写命令的输出。在这种情况下,输出将被写入一个名为group.json的文件。接下来,检查夹具文件
group.json的内容:[ { "model": "auth.group", "pk": 1, "fields": { "name": "appusers", "permissions": [] } } ]夹具文件包含一个对象列表。在这种情况下,列表中只有一个对象。每个对象包括一个带有模型名和主键的头,以及一个带有模型中每个字段值的字典。您可以看到 fixture 包含了组名
appusers。您可以手动创建和编辑夹具文件,但是事先创建对象并使用 Django 的
dumpdata命令创建夹具文件通常更方便。加载 Django 夹具
现在您已经有了一个 fixture 文件,您希望将它加载到数据库中。但是在这之前,您应该打开一个 Django shell 并删除您已经创建的组:
>>> from django.contrib.auth.models import Group
>>> Group.objects.filter(pk=1).delete()
(1, {'auth.Group_permissions': 0, 'auth.User_groups': 0, 'auth.Group': 1})
现在该组已被删除,使用 loaddata命令加载夹具:
$ python manage.py loaddata group.json
Installed 1 object(s) from 1 fixture(s)
要确保加载了新组,请打开 Django shell 并获取它:
>>> from django.contrib.auth.models import Group >>> group = Group.objects.get(pk=1) >>> vars(group) {'_state': <django.db.models.base.ModelState at 0x7f3a012d08b0>, 'id': 1, 'name': 'appusers'}太好了!该组已加载。您刚刚创建并加载了您的第一个 Django 设备。
在测试中加载 Django 装置
到目前为止,您已经从命令行创建并加载了一个 fixture 文件。现在你如何用它来测试呢?要查看 Django 测试中如何使用 fixtures,创建一个名为
test.py的新文件,并添加以下测试:from django.test import TestCase from django.contrib.auth.models import Group class MyTest(TestCase): def test_should_create_group(self): group = Group.objects.get(pk=1) self.assertEqual(group.name, "appusers")该测试获取主键为
1的组,并测试其名称是否为appusers。从您的终端运行测试:
$ python manage.py test test Creating test database for alias 'default'... System check identified no issues (0 silenced). E ====================================================================== ERROR: test_should_create_group (test.MyTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/django_fixtures/django_fixtures/test.py", line 9, in test_should_create_group group = Group.objects.get(pk=1) File "/django_fixtures/venv/lib/python3.8/site-packages/django/db/models/manager.py", line 82, in manager_method return getattr(self.get_queryset(), name)(*args, **kwargs) File "/django_fixtures/venv/lib/python3.8/site-packages/django/db/models/query.py", line 415, in get raise self.model.DoesNotExist( django.contrib.auth.models.Group.DoesNotExist: Group matching query does not exist. ---------------------------------------------------------------------- Ran 1 test in 0.001s FAILED (errors=1) Destroying test database for alias 'default'...测试失败,因为主键为
1的组不存在。要在测试中加载 fixture,您可以使用类
TestCase的一个特殊属性,称为fixtures:from django.test import TestCase from django.contrib.auth.models import Group class MyTest(TestCase): fixtures = ["group.json"] def test_should_create_group(self): group = Group.objects.get(pk=1) self.assertEqual(group.name, "appusers")将这个属性添加到一个
TestCase中,告诉 Django 在执行每个测试之前加载 fixtures。注意fixtures接受一个数组,所以您可以在每次测试之前提供多个 fixture 文件来加载。现在运行测试会产生以下输出:
$ python manage.py test test Creating test database for alias 'default'... System check identified no issues (0 silenced). . ---------------------------------------------------------------------- Ran 1 test in 0.005s OK Destroying test database for alias 'default'...太神奇了!该组已加载,测试已通过。现在您可以在您的测试中使用组
appusers。引用 Django Fixtures 中的相关对象
到目前为止,您只对一个对象使用了一个文件。然而,大多数情况下,你的应用程序中会有很多模型,在测试中你会需要不止一个模型。
要查看 Django fixtures 中对象之间的依赖关系,创建一个新的用户实例,然后将其添加到您之前创建的
appusers组中:
>>> from django.contrib.auth.models import User, Group
>>> appusers = Group.objects.get(name="appusers")
>>> haki = User.objects.create_user("haki")
>>> haki.pk
1
>>> haki.groups.add(appusers)
用户haki现在是appusers组的成员。要查看带有外键的 fixture 是什么样子,为用户1生成一个 fixture:
$ python manage.py dumpdata auth.User --pk 1 --indent 4
[
{
"model": "auth.user",
"pk": 1,
"fields": {
"password": "!M4dygH3ZWfd0214U59OR9nlwsRJ94HUZtvQciG8y",
"last_login": null,
"is_superuser": false,
"username": "haki",
"first_name": "",
"last_name": "",
"email": "",
"is_staff": false,
"is_active": true,
"date_joined": "2019-12-07T09:32:50.998Z",
"groups": [ 1 ], "user_permissions": []
}
}
]
夹具的结构与您之前看到的相似。
一个用户可以与多个组相关联,因此字段group包含该用户所属的所有组的 id。在这种情况下,用户属于主键为1的组,也就是您的appusers组。
使用主键来引用 fixtures 中的对象并不总是一个好主意。组的主键是数据库在创建组时分配给该组的任意标识符。在另一个环境中,或者在另一台计算机上,appusers组可以有不同的 ID,这不会对对象产生任何影响。
为了避免使用任意标识符,Django 定义了自然键的概念。自然键是对象的唯一标识符,不一定是主键。在组的情况下,两个组不能有相同的名称,所以组的自然关键字可以是它的名称。
要使用自然键而不是主键来引用 Django fixture 中的相关对象,请将--natural-foreign标志添加到dumpdata命令中:
$ python manage.py dumpdata auth.User --pk 1 --indent 4 --natural-foreign
[
{
"model": "auth.user",
"pk": 1,
"fields": {
"password": "!f4dygH3ZWfd0214X59OR9ndwsRJ94HUZ6vQciG8y",
"last_login": null,
"is_superuser": false,
"username": "haki",
"first_name": "",
"last_name": "",
"email": "benita",
"is_staff": false,
"is_active": true,
"date_joined": "2019-12-07T09:32:50.998Z",
"groups": [ [ `appusers` ] ], "user_permissions": []
}
}
]
Django 为用户生成了 fixture,但是它没有使用appusers组的主键,而是使用了组名。
您还可以添加--natural-primary标志来从 fixture 中排除一个对象的主键。当pk为空时,主键将在运行时设置,通常由数据库设置。
维护 Django 设备
Django fixtures 很棒,但也带来了一些挑战:
-
保持夹具更新 : Django 夹具必须包含模型的所有必需字段。如果您添加一个不可空的新字段,您必须更新 fixtures。否则,它们将无法加载。当你有很多 Django 设备时,保持它们的更新会成为一种负担。
-
维护 fixture 之间的依赖关系:依赖于其他 fixture 的 Django fixtures 必须按照特定的顺序一起加载。随着新测试用例的增加和旧测试用例的修改,跟上夹具的步伐可能是一个挑战。
由于这些原因,Django 灯具对于经常更换的车型来说并不是一个理想的选择。例如,很难维护 Django fixtures 来表示应用程序中的核心对象,如销售、订单、交易或预订。
另一方面,Django 设备是以下用例的绝佳选择:
-
常量数据:这适用于很少变化的型号,比如国家代码和邮政编码。
-
初始数据:这适用于存储你的应用的查找数据的模型,比如产品类别、用户组、用户类型。
pytest姜戈的固定装置
在上一节中,您使用了 Django 提供的内置工具来创建和加载装置。Django 提供的 fixtures 对于某些用例来说很棒,但是对于其他用例来说并不理想。
在本节中,您将使用一种非常不同的夹具进行实验:夹具pytest。pytest提供了一个非常广泛的 fixture 系统,您可以使用它来创建一个可靠的、可维护的测试套件。
为 Django 项目设置pytest
要开始使用pytest,你首先需要安装pytest和pytest 的 Django 插件。激活虚拟环境时,在终端中执行以下命令:
$ pip install pytest
$ pip install pytest-django
pytest-django插件由pytest开发团队维护。它为使用pytest为 Django 项目编写测试提供了有用的工具。
接下来,您需要让pytest知道它可以在哪里找到您的 Django 项目设置。在项目的根目录下创建一个名为pytest.ini的新文件,并在其中添加以下几行:
[pytest] DJANGO_SETTINGS_MODULE=django_fixtures.settings
这是使pytest与您的 Django 项目一起工作所需的最小配置量。还有更多配置选项,但这已经足够开始了。
最后,为了测试您的设置,用这个虚拟测试替换test.py的内容:
def test_foo():
assert True
要运行虚拟测试,从您的终端使用pytest命令:
$ pytest test.py
============================== test session starts ======================
platform linux -- Python 3.7.4, pytest-5.2.0, py-1.8.0, pluggy-0.13.0
Django settings: django_fixtures.settings (from ini file)
rootdir: /django_fixtures, inifile: pytest.ini
plugins: django-3.5.1
test.py .
[100%]
============================= 1 passed in 0.05s =========================
您刚刚用pytest完成了一个新 Django 项目的设置!现在,您已经准备好深入挖掘了。
关于如何设置pytest和编写测试的更多信息,请查看使用pytest 的测试驱动开发。
从测试中访问数据库
在本节中,您将使用内置认证模块django.contrib.auth编写测试。本模块中最熟悉的车型是User和Group。
要开始使用 Django 和pytest,编写一个测试来检查 Django 提供的函数create_user()是否正确设置了用户名:
from django.contrib.auth.models import User
def test_should_create_user_with_username() -> None:
user = User.objects.create_user("Haki")
assert user.username == "Haki"
现在,尝试从命令中执行测试,如下所示:
$ pytest test.py
================================== test session starts ===============
platform linux -- Python 3.7.4, pytest-5.2.0, py-1.8.0, pluggy-0.13.0
Django settings: django_fixtures.settings (from ini file)
rootdir: /django-django_fixtures/django_fixtures, inifile: pytest.ini
plugins: django-3.5.1
collected 1 item
test.py F
=============================== FAILURES =============================
____________________test_should_create_user_with_username ____________
def test_should_create_user_with_username() -> None:
> user = User.objects.create_user("Haki")
self = <mydbengine.base.DatabaseWrapper object at 0x7fef66ed57d0>, name = None
def _cursor(self, name=None):
> self.ensure_connection()
E Failed: Database access not allowed, use the "django_db" mark, or the "db"
or "transactional_db" fixtures to enable it.
命令失败,测试没有执行。这个错误消息给了你一些有用的信息:为了在测试中访问数据库,你需要注入一个叫做db 的特殊夹具。db fixture 是您之前安装的django-pytest插件的一部分,它需要在测试中访问数据库。
将db夹具注入测试中:
from django.contrib.auth.models import User
def test_should_create_user_with_username(db) -> None:
user = User.objects.create_user("Haki")
assert user.username == "Haki"
再次运行测试:
$ pytest test.py
================================== test session starts ===============
platform linux -- Python 3.7.4, pytest-5.2.0, py-1.8.0, pluggy-0.13.0
Django settings: django_fixtures.settings (from ini file)
rootdir: /django_fixtures, inifile: pytest.ini
plugins: django-3.5.1
collected 1 item
test.py .
太好了!命令成功完成,您的测试通过。您现在知道了如何在测试中访问数据库。您还将 fixture 注入到测试用例中。
为 Django 模型创建夹具
现在您已经熟悉了 Django 和pytest,编写一个测试来检查用set_password()设置的密码是否按照预期得到了验证。用该测试替换test.py的内容:
from django.contrib.auth.models import User
def test_should_check_password(db) -> None:
user = User.objects.create_user("A")
user.set_password("secret")
assert user.check_password("secret") is True
def test_should_not_check_unusable_password(db) -> None:
user = User.objects.create_user("A")
user.set_password("secret")
user.set_unusable_password()
assert user.check_password("secret") is False
第一个测试检查 Django 是否验证了一个拥有可用密码的用户。第二个测试检查一种边缘情况,在这种情况下,用户的密码是不可用的,不应该被 Django 验证。
这里有一个重要的区别:上面的测试用例不测试create_user()。他们测试set_password()。这意味着对create_user()的改变不应该影响这些测试用例。
另外,请注意,User实例被创建了两次,每个测试用例一次。一个大型项目可以有许多需要一个User实例的测试。如果每个测试用例都会创建自己的用户,那么如果User模型发生变化,你将来可能会有麻烦。
为了在许多测试用例中重用一个对象,您可以创建一个测试夹具:
import pytest
from django.contrib.auth.models import User
@pytest.fixture
def user_A(db) -> User:
return User.objects.create_user("A")
def test_should_check_password(db, user_A: User) -> None:
user_A.set_password("secret")
assert user_A.check_password("secret") is True
def test_should_not_check_unusable_password(db, user_A: User) -> None:
user_A.set_password("secret")
user_A.set_unusable_password()
assert user_A.check_password("secret") is False
在上面的代码中,您创建了一个名为user_A()的函数,该函数创建并返回一个新的User实例。为了将这个函数标记为 fixture,您用 pytest.fixture装饰器来装饰它。一旦一个函数被标记为 fixture,它就可以被注入到测试用例中。在这种情况下,您将 fixture user_A注入到两个测试用例中。
需求变化时维护夹具
假设您已经向您的应用程序添加了一个新的需求,现在每个用户都必须属于一个特殊的"app_user"组。该组中的用户可以查看和更新他们自己的个人详细信息。为了测试您的应用程序,您需要您的测试用户也属于"app_user"组:
import pytest
from django.contrib.auth.models import User, Group, Permission
@pytest.fixture
def user_A(db) -> Group:
group = Group.objects.create(name="app_user")
change_user_permissions = Permission.objects.filter(
codename__in=["change_user", "view_user"],
)
group.permissions.add(*change_user_permissions)
user = User.objects.create_user("A")
user.groups.add(group)
return user
def test_should_create_user(user_A: User) -> None:
assert user_A.username == "A"
def test_user_is_in_app_user_group(user_A: User) -> None:
assert user_A.groups.filter(name="app_user").exists()
在 fixture 中,您创建了组"app_user",并为其添加了相关的change_user和view_user权限。然后,您创建了测试用户,并将他们添加到"app_user"组中。
以前,您需要检查创建用户的每个测试用例,并将其添加到组中。使用 fixtures,你可以只做一次改变。一旦你改变了夹具,同样的改变出现在你注入user_A的每个测试用例中。使用 fixtures,您可以避免重复,并使您的测试更易于维护。
将夹具注入其他夹具
大型应用程序通常不止有一个用户,经常需要用多个用户来测试它们。在这种情况下,您可以添加另一个夹具来创建测试user_B:
import pytest
from django.contrib.auth.models import User, Group, Permission
@pytest.fixture
def user_A(db) -> User:
group = Group.objects.create(name="app_user")
change_user_permissions = Permission.objects.filter(
codename__in=["change_user", "view_user"],
)
group.permissions.add(*change_user_permissions)
user = User.objects.create_user("A") user.groups.add(group)
return user
@pytest.fixture
def user_B(db) -> User:
group = Group.objects.create(name="app_user")
change_user_permissions = Permission.objects.filter(
codename__in=["change_user", "view_user"],
)
group.permissions.add(*change_user_permissions)
user = User.objects.create_user("B") user.groups.add(group)
return user
def test_should_create_two_users(user_A: User, user_B: User) -> None:
assert user_A.pk != user_B.pk
在您的终端中,尝试运行测试:
$ pytest test.py
==================== test session starts =================================
platform linux -- Python 3.7.4, pytest-5.2.0, py-1.8.0, pluggy-0.13.0
Django settings: django_fixtures.settings (from ini file)
rootdir: /django_fixtures, inifile: pytest.ini
plugins: django-3.5.1
collected 1 item
test.py E
[100%]
============================= ERRORS ======================================
_____________ ERROR at setup of test_should_create_two_users ______________
self = <django.db.backends.utils.CursorWrapper object at 0x7fc6ad1df210>,
sql ='INSERT INTO "auth_group" ("name") VALUES (%s) RETURNING "auth_group"."id"'
,params = ('app_user',)
def _execute(self, sql, params, *ignored_wrapper_args):
self.db.validate_no_broken_transaction()
with self.db.wrap_database_errors:
if params is None:
# params default might be backend specific.
return self.cursor.execute(sql)
else:
> return self.cursor.execute(sql, params)
E psycopg2.IntegrityError: duplicate key value violates
unique constraint "auth_group_name_key" E DETAIL: Key (name)=(app_user) already exists. ======================== 1 error in 4.14s ================================
新的测试抛出一个IntegrityError。错误消息来自数据库,因此根据您使用的数据库,它看起来可能会有所不同。根据错误消息,测试违反了组名的唯一约束。当你看着你的固定装置,它是有意义的。"app_user"组创建两次,一次在夹具user_A中,另一次在夹具user_B中。
到目前为止,我们忽略的一个有趣的观察是夹具user_A正在使用夹具db。这意味着夹具可以注入到其他夹具中。你可以用这个特性来解决上面的IntegrityError。在夹具中仅创建一次"app_user"组,并将其注入到user_A和user_B夹具中。
为此,重构您的测试并添加一个"app user"组 fixture:
import pytest
from django.contrib.auth.models import User, Group, Permission
@pytest.fixture
def app_user_group(db) -> Group:
group = Group.objects.create(name="app_user")
change_user_permissions = Permission.objects.filter(
codename__in=["change_user", "view_user"],
)
group.permissions.add(*change_user_permissions)
return group
@pytest.fixture
def user_A(db, app_user_group: Group) -> User:
user = User.objects.create_user("A")
user.groups.add(app_user_group)
return user
@pytest.fixture
def user_B(db, app_user_group: Group) -> User:
user = User.objects.create_user("B")
user.groups.add(app_user_group)
return user
def test_should_create_two_users(user_A: User, user_B: User) -> None:
assert user_A.pk != user_B.pk
在您的终端中,运行您的测试:
$ pytest test.py
================================== test session starts ===============
platform linux -- Python 3.7.4, pytest-5.2.0, py-1.8.0, pluggy-0.13.0
Django settings: django_fixtures.settings (from ini file)
rootdir: /django_fixtures, inifile: pytest.ini
plugins: django-3.5.1
collected 1 item
test.py .
太神奇了!你的测试通过了。group fixture 封装了与"app user"组相关的逻辑,比如设置权限。然后,您将该组注入到两个独立的用户设备中。通过以这种方式构建您的 fixtures,您已经使您的测试变得不那么复杂,易于阅读和维护。
使用工厂
到目前为止,您已经创建了很少参数的对象。然而,有些对象可能更复杂,具有许多参数和许多可能的值。对于这样的对象,您可能想要创建几个测试夹具。
例如,如果您为 create_user() 提供所有参数,那么 fixture 看起来会是这样的:
import pytest
from django.contrib.auth.models import User
@pytest.fixture
def user_A(db, app_user_group: Group) -> User
user = User.objects.create_user(
username="A",
password="secret",
first_name="haki",
last_name="benita",
email="me@hakibenita.com",
is_staff=False,
is_superuser=False,
is_active=True,
)
user.groups.add(app_user_group)
return user
你的夹具变得更复杂了!用户实例现在可以有许多不同的变体,例如超级用户、职员用户、非活动职员用户和非活动普通用户。
在前面的章节中,您了解到在每个测试夹具中维护复杂的设置逻辑是很困难的。因此,为了避免每次创建用户时都必须重复所有的值,可以添加一个函数,使用create_user()根据应用程序的特定需求创建用户:
from typing import List, Optional
from django.contrib.auth.models import User, Group
def create_app_user(
username: str,
password: Optional[str] = None,
first_name: Optional[str] = "first name",
last_name: Optional[str] = "last name",
email: Optional[str] = "foo@bar.com",
is_staff: str = False,
is_superuser: str = False,
is_active: str = True,
groups: List[Group] = [],
) -> User:
user = User.objects.create_user(
username=username,
password=password,
first_name=first_name,
last_name=last_name,
email=email,
is_staff=is_staff,
is_superuser=is_superuser,
is_active=is_active,
)
user.groups.add(*groups)
return user
该函数创建一个应用程序用户。根据应用程序的具体要求,每个参数都设置了合理的默认值。例如,您的应用程序可能要求每个用户都有一个电子邮件地址,但是 Django 的内置函数不会强制这样的限制。相反,您可以在函数中强制要求。
创建对象的函数和类通常被称为工厂。为什么?这是因为这些函数充当了生产特定类的实例的工厂。关于 Python 中工厂的更多信息,请查看工厂方法模式及其在 Python 中的实现。
上面的函数是一个工厂的简单实现。它没有状态,也没有实现任何复杂的逻辑。您可以重构您的测试,以便它们使用工厂函数在您的 fixtures 中创建用户实例:
@pytest.fixture
def user_A(db, app_user_group: Group) -> User:
return create_user(username="A", groups=[app_user_group])
@pytest.fixture
def user_B(db, app_user_group: Group) -> User:
return create_user(username="B", groups=[app_user_group])
def test_should_create_user(user_A: User, app_user_group: Group) -> None:
assert user_A.username == "A"
assert user_A.email == "foo@bar.com"
assert user_A.groups.filter(pk=app_user_group.pk).exists()
def test_should_create_two_users(user_A: User, user_B: User) -> None:
assert user_A.pk != user_B.pk
您的夹具变得更短,并且您的测试现在对变化更有弹性。例如,如果您使用了一个定制用户模型,并且您刚刚向该模型添加了一个新字段,那么您只需要更改create_user()就可以让您的测试按预期工作。
利用工厂作为固定设备
复杂的设置逻辑使得编写和维护测试变得更加困难,使得整个套件变得脆弱,对变化的适应能力更差。到目前为止,您已经通过创建 fixture、创建 fixture 之间的依赖关系以及使用一个工厂来抽象尽可能多的设置逻辑解决了这个问题。
但是在您的测试夹具中仍然有一些设置逻辑:
@pytest.fixture
def user_A(db, app_user_group: Group) -> User:
return create_user(username="A", groups=[app_user_group])
@pytest.fixture
def user_B(db, app_user_group: Group) -> User:
return create_user(username="B", groups=[app_user_group])
两个夹具都注射了app_user_group。目前这是必要的,因为工厂功能create_user()无法访问app_user_group夹具。在每个测试中都有这样的设置逻辑会使修改变得更加困难,并且在将来的测试中更容易被忽略。相反,您希望封装创建用户的整个过程,并从测试中抽象出来。这样,您可以专注于手头的场景,而不是设置独特的测试数据。
为了向用户工厂提供对app_user_group fixture 的访问,您可以使用一个名为 factory 的模式作为 fixture :
from typing import List, Optional
import pytest
from django.contrib.auth.models import User, Group, Permission
@pytest.fixture
def app_user_group(db) -> Group:
group = Group.objects.create(name="app_user")
change_user_permissions = Permission.objects.filter(
codename__in=["change_user", "view_user"],
)
group.permissions.add(*change_user_permissions)
return group
@pytest.fixture
def app_user_factory(db, app_user_group: Group):
# Closure
def create_app_user(
username: str,
password: Optional[str] = None,
first_name: Optional[str] = "first name",
last_name: Optional[str] = "last name",
email: Optional[str] = "foo@bar.com",
is_staff: str = False,
is_superuser: str = False,
is_active: str = True,
groups: List[Group] = [],
) -> User:
user = User.objects.create_user(
username=username,
password=password,
first_name=first_name,
last_name=last_name,
email=email,
is_staff=is_staff,
is_superuser=is_superuser,
is_active=is_active,
)
user.groups.add(app_user_group)
# Add additional groups, if provided.
user.groups.add(*groups)
return user
return create_app_user
这离你已经做的不远了,所以让我们来分解一下:
-
app_user_group夹具保持不变。它创建了特殊的"app user"组,拥有所有必要的权限。 -
添加了一个名为
app_user_factory的新夹具,它与app_user_group夹具一起注入。 -
fixture
app_user_factory创建一个闭包,并返回一个名为create_app_user()的内部函数。 -
create_app_user()类似于您之前实现的函数,但是现在它可以访问 fixtureapp_user_group。通过访问该组,您现在可以在工厂功能中将用户添加到app_user_group。
要使用app_user_factory fixture,将其注入另一个 fixture 并使用它创建一个用户实例:
@pytest.fixture
def user_A(db, app_user_factory) -> User:
return app_user_factory("A")
@pytest.fixture
def user_B(db, app_user_factory) -> User:
return app_user_factory("B")
def test_should_create_user_in_app_user_group(
user_A: User,
app_user_group: Group,
) -> None:
assert user_A.groups.filter(pk=app_user_group.pk).exists()
def test_should_create_two_users(user_A: User, user_B: User) -> None:
assert user_A.pk != user_B.pk
注意,与之前不同,您创建的 fixture 提供了一个函数,而不是一个对象。这是 fixture 模式工厂背后的主要概念:工厂 fixture 创建了一个闭包,它为内部函数提供了对 fixture 的访问。
关于 Python 中闭包的更多信息,请查看 Python 内部函数——它们有什么用处?
现在您已经有了自己的工厂和设备,这是您的测试的完整代码:
from typing import List, Optional
import pytest
from django.contrib.auth.models import User, Group, Permission
@pytest.fixture
def app_user_group(db) -> Group:
group = Group.objects.create(name="app_user")
change_user_permissions = Permission.objects.filter(
codename__in=["change_user", "view_user"],
)
group.permissions.add(*change_user_permissions)
return group
@pytest.fixture
def app_user_factory(db, app_user_group: Group):
# Closure
def create_app_user(
username: str,
password: Optional[str] = None,
first_name: Optional[str] = "first name",
last_name: Optional[str] = "last name",
email: Optional[str] = "foo@bar.com",
is_staff: str = False,
is_superuser: str = False,
is_active: str = True,
groups: List[Group] = [],
) -> User:
user = User.objects.create_user(
username=username,
password=password,
first_name=first_name,
last_name=last_name,
email=email,
is_staff=is_staff,
is_superuser=is_superuser,
is_active=is_active,
)
user.groups.add(app_user_group)
# Add additional groups, if provided.
user.groups.add(*groups)
return user
return create_app_user
@pytest.fixture
def user_A(db, app_user_factory) -> User:
return app_user_factory("A")
@pytest.fixture
def user_B(db, app_user_factory) -> User:
return app_user_factory("B")
def test_should_create_user_in_app_user_group(
user_A: User,
app_user_group: Group,
) -> None:
assert user_A.groups.filter(pk=app_user_group.pk).exists()
def test_should_create_two_users(user_A: User, user_B: User) -> None:
assert user_A.pk != user_B.pk
打开终端并运行测试:
$ pytest test.py
======================== test session starts ========================
platform linux -- Python 3.8.1, pytest-5.3.3, py-1.8.1, pluggy-0.13.1
django: settings: django_fixtures.settings (from ini)
rootdir: /django_fixtures/django_fixtures, inifile: pytest.ini
plugins: django-3.8.0
collected 2 items
test.py .. [100%]
======================== 2 passed in 0.17s ==========================
干得好!您已经在测试中成功地实现了工厂作为夹具模式。
工厂作为实践中的固定装置
工厂作为夹具模式是非常有用的。如此有用,事实上,你可以在pytest本身提供的夹具中找到它。比如pytest提供的 tmp_path 夹具,就是夹具厂 tmp_path_factory 创造的。同样, tmpdir 夹具由夹具厂 tmpdir_factory 创建。
掌握工厂作为 fixture 模式可以消除许多与编写和维护测试相关的麻烦。
结论
您已经成功实现了一个提供 Django 模型实例的 fixture 工厂。您还维护和实现了夹具之间的依赖关系,这种方式消除了编写和维护测试的一些麻烦。
在本教程中,您已经学习了:
- 如何在 Django 中创建和加载夹具
- 如何在
pytest中为 Django 车型提供测试夹具 - 如何使用工厂为
pytest中的 Django 模型创建夹具 - 如何实现工厂作为夹具的模式来创建测试夹具之间的依赖关系
您现在能够实现和维护一个可靠的测试套件,这将帮助您更快地生成更好、更可靠的代码!*******
Django 重定向的最终指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Django 重定向
当您使用 Django 框架构建 Python web 应用程序时,您将不得不在某个时候将用户从一个 URL 重定向到另一个 URL。
在本指南中,您将了解到关于 HTTP 重定向以及如何在 Django 中处理它们的所有知识。在本教程结束时,您将:
- 能够重定向用户从一个网址到另一个网址
- 了解临时重定向和永久重定向的区别
- 使用重定向时避免常见的陷阱
本教程假设您熟悉 Django 应用程序的基本构件,比如视图和 URL 模式。
Django 重定向:一个超级简单的例子
在 Django 中,通过从视图中返回一个实例HttpResponseRedirect或HttpResponsePermanentRedirect,将用户重定向到另一个 URL。最简单的方法是使用模块django.shortcuts中的函数 redirect() 。这里有一个例子:
# views.py
from django.shortcuts import redirect
def redirect_view(request):
response = redirect('/redirect-success/')
return response
在你的视图中用一个 URL 调用redirect()。它将返回一个HttpResponseRedirect类,然后从视图中返回。
与任何其他视图一样,返回重定向的视图必须添加到您的urls.py中:
# urls.py
from django.urls import path
from .views import redirect_view
urlpatterns = [
path('/redirect/', redirect_view)
# ... more URL patterns here
]
假设这是 Django 项目的主urls.py,URL /redirect/现在重定向到/redirect-success/。
为了避免对 URL 进行硬编码,您可以使用视图或 URL 模式或模型的名称来调用redirect(),以避免对重定向 URL 进行硬编码。您还可以通过传递关键字参数permanent=True来创建永久重定向。
这篇文章可以到此结束,但是它很难被称为“Django 重定向的终极指南”我们一会儿将仔细研究一下redirect()函数,并深入了解 HTTP 状态代码和不同的HttpRedirectResponse类的本质细节,但是让我们后退一步,从一个基本问题开始。
为什么重定向
您可能想知道为什么您首先要将用户重定向到一个不同的 URL。为了理解重定向的意义,看看 Django 本身是如何将重定向合并到框架默认提供的特性中的:
- 当您没有登录并请求一个需要认证的 URL 时,比如 Django admin,Django 会将您重定向到登录页面。
- 当您成功登录时,Django 会将您重定向到您最初请求的 URL。
- 当您使用 Django admin 更改您的密码时,您会被重定向到一个页面,显示更改成功。
- 当您在 Django admin 中创建一个对象时,Django 会将您重定向到对象列表。
没有重定向的替代实现会是什么样子?如果用户必须登录才能查看页面,您可以简单地显示一个类似“单击此处登录”的页面这是可行的,但是对用户来说不方便。
像 http://bit.ly 这样的网址缩写是重定向派上用场的另一个例子:你在浏览器的地址栏中键入一个短网址,然后被重定向到一个长而笨拙的网址页面。
注意:如果你想建立一个你自己的网址缩写器,那么看看用 FastAPI 和 Python 建立一个网址缩写器。
在其他情况下,重定向不仅仅是为了方便。重定向是引导用户浏览 web 应用程序的重要工具。在执行了某种有副作用的操作(比如创建或删除一个对象)后,最好重定向到另一个 URL,以防止意外执行该操作两次。
表单处理就是使用重定向的一个例子,在表单处理中,用户在成功提交表单后被重定向到另一个 URL。下面是一个代码示例,它说明了通常如何处理表单:
1from django import forms
2from django.http import HttpResponseRedirect
3from django.shortcuts import redirect, render
4
5def send_message(name, message):
6 # Code for actually sending the message goes here
7
8class ContactForm(forms.Form):
9 name = forms.CharField()
10 message = forms.CharField(widget=forms.Textarea)
11
12def contact_view(request):
13 # The request method 'POST' indicates
14 # that the form was submitted
15 if request.method == 'POST': # 1 16 # Create a form instance with the submitted data
17 form = ContactForm(request.POST) # 2 18 # Validate the form
19 if form.is_valid(): # 3 20 # If the form is valid, perform some kind of
21 # operation, for example sending a message
22 send_message(
23 form.cleaned_data['name'],
24 form.cleaned_data['message']
25 )
26 # After the operation was successful,
27 # redirect to some other page
28 return redirect('/success/') # 4 29 else: # 5 30 # Create an empty form instance
31 form = ContactForm()
32
33 return render(request, 'contact_form.html', {'form': form})
该视图的目的是显示和处理允许用户发送消息的联系人表单。让我们一步一步地跟随它:
-
首先,视图查看请求方法。当用户访问连接到这个视图的 URL 时,浏览器执行一个
GET请求。 -
如果用一个
POST请求调用视图,那么POST数据被用来实例化一个ContactForm对象。 -
如果表单有效,表单数据被传递给
send_message()。这个函数与上下文无关,因此这里没有显示。 -
发送消息后,视图返回一个到 URL
/success/的重定向。这是我们感兴趣的步骤。为了简单起见,URL 在这里是硬编码的。稍后您将看到如何避免这种情况。 -
如果视图接收到一个
GET请求(或者,准确地说,任何不是POST请求的请求),它会创建一个ContactForm的实例,并使用django.shortcuts.render()来呈现contact_form.html模板。
如果用户现在点击重载,只有/success/ URL 被重载。如果没有重定向,重新加载页面会重新提交表单并发送另一条消息。
幕后:HTTP 重定向如何工作
现在你知道为什么重定向有意义了,但是它们是如何工作的呢?让我们快速回顾一下,当您在 web 浏览器的地址栏中输入 URL 时会发生什么。
HTTP 快速入门
让我们假设您已经创建了一个 Django 应用程序,它有一个处理路径/hello/的“Hello World”视图。您正在用 Django 开发服务器运行您的应用程序,所以完整的 URL 是http://127.0.0.1:8000/hello/。
当您在浏览器中输入该 URL 时,它会连接到 IP 地址为的服务器上的端口8000,并发送一个路径为/hello/的 HTTP GET请求。服务器回复一个 HTTP 响应。
HTTP 是基于文本的,所以在客户机和服务器之间来回查看相对容易。您可以使用带有选项--include的命令行工具 curl 来查看完整的 HTTP 响应,包括标头,如下所示:
$ curl --include http://127.0.0.1:8000/hello/
HTTP/1.1 200 OK
Date: Sun, 01 Jul 2018 20:32:55 GMT
Server: WSGIServer/0.2 CPython/3.6.3
Content-Type: text/html; charset=utf-8
X-Frame-Options: SAMEORIGIN
Content-Length: 11
Hello World
如您所见,HTTP 响应以包含状态代码和状态消息的状态行开始。状态行后面是任意数量的 HTTP 头。空行表示头的结束和响应体的开始,响应体包含服务器想要发送的实际数据。
HTTP 重定向状态代码
重定向响应看起来像什么?让我们假设路径/redirect/由redirect_view()处理,如前所示。如果你用curl访问http://127.0.0.1:8000/redirect/,你的控制台看起来像这样:
$ curl --include http://127.0.0.1:8000/redirect/
HTTP/1.1 302 Found
Date: Sun, 01 Jul 2018 20:35:34 GMT
Server: WSGIServer/0.2 CPython/3.6.3
Content-Type: text/html; charset=utf-8
Location: /redirect-success/
X-Frame-Options: SAMEORIGIN
Content-Length: 0
这两个回答可能看起来很相似,但是有一些关键的区别。重定向:
- 返回不同的状态代码(
302对200) - 包含一个带有相对 URL 的
Location标题 - 以空行结束,因为重定向响应的主体是空的
主要区别在于状态代码。HTTP 标准的规范说明如下:
302(已找到)状态代码表示目标资源暂时位于不同的 URI 下。由于重定向有时可能会被更改,所以客户端应该继续为将来的请求使用有效的请求 URI。服务器应该在响应中生成一个位置头字段,其中包含不同 URI 的 URI 引用。用户代理可以使用位置字段值进行自动重定向。(来源)
换句话说,每当服务器发送一个状态码302,它就对客户机说,“嘿,现在,你要找的东西可以在这个地方找到。”
规范中的一个关键短语是“可以使用位置字段值进行自动重定向”这意味着你不能强迫客户端加载另一个网址。客户端可以选择等待用户确认,或者决定根本不加载 URL。
现在您知道了重定向只是一个带有3xx状态代码和Location报头的 HTTP 响应。这里的关键要点是,HTTP 重定向和任何旧的 HTTP 响应一样,但是有一个空的主体、3xx 状态代码和一个Location头。
就是这样。我们稍后将把它与 Django 联系起来,但是首先让我们来看看在那个3xx状态代码范围中的两种类型的重定向,看看为什么它们对 web 开发很重要。
临时与永久重定向
HTTP 标准指定了几个重定向状态代码,都在3xx范围内。两个最常见的状态代码是301 Permanent Redirect和302 Found。
状态代码302 Found表示临时重定向。一个临时的重定向写道:“目前,你要找的东西可以在这个地址找到。”把它想象成一个商店的招牌,上面写着,“我们的商店目前正在装修。请去我们在拐角处的另一家商店。”因为这只是暂时的,你下次去购物的时候会检查原始地址。
注意:在 HTTP 1.0 中,状态代码 302 的消息是Temporary Redirect。在 HTTP 1.1 中消息被更改为Found。
顾名思义,永久重定向应该是永久的。永久重定向告诉浏览器,“你要找的东西已经不在这个地址了。它现在在这个新地址,再也不会在旧地址了。”
永久重定向就像一个商店招牌,上面写着:“我们搬家了。我们的新店就在附近。”这种改变是永久性的,所以下次你想去商店的时候,你会直接去新的地址。
注意:永久重定向可能会产生意想不到的后果。在使用永久重定向之前,请完成本指南,或者直接跳到“永久重定向是永久的”一节
浏览器在处理重定向时的行为类似:当 URL 返回一个永久的重定向响应时,这个响应被缓存。下次浏览器遇到旧的 URL 时,它会记住重定向并直接请求新的地址。
缓存重定向可以节省不必要的请求,并带来更好更快的用户体验。
此外,临时和永久重定向之间的区别与搜索引擎优化相关。
Django 中的重定向
现在您知道了重定向只是一个带有3xx状态代码和Location报头的 HTTP 响应。
您可以自己从一个常规的HttpResponse对象构建这样一个响应:
def hand_crafted_redirect_view(request):
response = HttpResponse(status=302)
response['Location'] = '/redirect/success/'
return response
这个解决方案在技术上是正确的,但是它涉及到相当多的输入。
HTTPResponseRedirect类
使用HttpResponse的子类HttpResponseRedirect可以节省一些输入。只需用要重定向到的 URL 作为第一个参数实例化该类,该类将设置正确的状态和位置头:
def redirect_view(request):
return HttpResponseRedirect('/redirect/success/')
您可以在 Python shell 中使用HttpResponseRedirect类来看看您得到了什么:
>>> from django.http import HttpResponseRedirect >>> redirect = HttpResponseRedirect('/redirect/success/') >>> redirect.status_code 302 >>> redirect['Location'] '/redirect/success/'还有一个用于永久重定向的类,它被恰当地命名为
HttpResponsePermanentRedirect。它的工作原理与HttpResponseRedirect相同,唯一的区别是它有一个状态码301 (Moved Permanently)。注意:在上面的例子中,重定向 URL 是硬编码的。对 URL 进行硬编码是一种不好的做法:如果 URL 发生了变化,您必须搜索所有代码并修改所有出现的内容。让我们解决这个问题!
你可以使用
django.urls.reverse()来创建一个 URL,但是有一个更方便的方法,你将在下一节看到。
redirect()功能为了让您的生活更轻松,Django 提供了您已经在简介中看到的多功能快捷功能:
django.shortcuts.redirect()。您可以通过以下方式调用此函数:
- 一个模型实例,或任何其他对象,用
get_absolute_url()方法- URL 或视图名称以及位置和/或关键字参数
- 一个网址
它将采取适当的步骤将参数转换成 URL 并返回一个
HTTPResponseRedirect。如果你传递了permanent=True,它将返回一个HttpResponsePermanentRedirect的实例,导致一个永久的重定向。这里有三个例子来说明不同的使用案例:
传递模型:
from django.shortcuts import redirect def model_redirect_view(request): product = Product.objects.filter(featured=True).first() return redirect(product)`
redirect()将调用product.get_absolute_url()并将结果作为重定向目标。如果给定的类,在这个例子中是Product,没有get_absolute_url()方法,那么这个类将会以TypeError失败。传递 URL 名称和参数:
from django.shortcuts import redirect def fixed_featured_product_view(request): ... product_id = settings.FEATURED_PRODUCT_ID return redirect('product_detail', product_id=product_id)`
redirect()将尝试使用其给定的参数来反转一个 URL。此示例假设您的 URL 模式包含如下模式:path('/product/<product_id>/', 'product_detail_view', name='product_detail')`传递 URL:
from django.shortcuts import redirect def featured_product_view(request): return redirect('/products/42/')`
redirect()会将任何包含/或.的字符串视为 URL,并将其用作重定向目标。
RedirectView基于类的视图如果你有一个视图除了返回一个重定向什么也不做,你可以使用基于类的视图
django.views.generic.base.RedirectView。您可以通过各种属性来定制
RedirectView以满足您的需求。如果该类有一个
.url属性,它将被用作重定向 URL。字符串格式占位符被替换为 URL 中的命名参数:# urls.py from django.urls import path from .views import SearchRedirectView urlpatterns = [ path('/search/<term>/', SearchRedirectView.as_view()) ] # views.py from django.views.generic.base import RedirectView class SearchRedirectView(RedirectView): url = 'https://google.com/?q=%(term)s'URL 模式定义了一个参数
term,该参数在SearchRedirectView中用于构建重定向 URL。应用程序中的路径/search/kittens/会将您重定向到https://google.com/?q=kittens。您也可以在您的
urlpatterns中将关键字参数url传递给as_view(),而不是子类化RedirectView来覆盖url属性:#urls.py from django.views.generic.base import RedirectView urlpatterns = [ path('/search/<term>/', RedirectView.as_view(url='https://google.com/?q=%(term)s')), ]您也可以覆盖
get_redirect_url()以获得完全自定义的行为:from random import choice from django.views.generic.base import RedirectView class RandomAnimalView(RedirectView): animal_urls = ['/dog/', '/cat/', '/parrot/'] is_permanent = True def get_redirect_url(*args, **kwargs): return choice(self.animal_urls)这个基于类的视图重定向到一个从
.animal_urls中随机选取的 URL。
django.views.generic.base.RedirectView提供了更多的定制挂钩。以下是完整的列表:
.url如果设置了此属性,它应该是一个带有要重定向到的 URL 的字符串。如果它包含像
%(name)s这样的字符串格式占位符,它们会使用传递给视图的关键字参数来扩展。
.pattern_name如果设置了此属性,它应该是要重定向到的 URL 模式的名称。传递给视图的任何位置和关键字参数都用来反转 URL 模式。
.permanent如果这个属性是
True,视图返回一个永久的重定向。默认为False。
.query_string如果该属性为
True,视图会将任何提供的查询字符串附加到重定向 URL。如果是默认的False,查询字符串将被丢弃。
get_redirect_url(*args, **kwargs)这个方法负责构建重定向 URL。如果这个方法返回
None,视图返回一个410 Gone状态。默认实现首先检查
.url。它将.url视为“旧式”格式字符串,使用传递给视图的任何命名 URL 参数来扩展任何命名格式说明符。如果
.url未置位,则检查.pattern_name是否置位。如果是,它就用它来用接收到的任何位置和关键字参数来反转 URL。您可以通过覆盖此方法以任何方式更改该行为。只要确保它返回一个包含 URL 的字符串。
注意:基于类的视图是一个强大的概念,但是有点难以理解。与常规的基于函数的视图不同,在常规的基于函数的视图中,跟踪代码流相对简单,而基于类的视图由复杂的混合和基类层次结构组成。
理解基于类的视图类的一个很好的工具是网站 Classy Class-Based Views 。
您可以用这个简单的基于函数的视图实现上面例子中的
RandomAnimalView的功能:from random import choice from django.shortcuts import redirect def random_animal_view(request): animal_urls = ['/dog/', '/cat/', '/parrot/'] return redirect(choice(animal_urls))正如您所看到的,基于类的方法没有提供任何明显的好处,同时增加了一些隐藏的复杂性。这就提出了一个问题:什么时候应该使用
RedirectView?如果你想在你的
urls.py中直接添加一个重定向,使用RedirectView是有意义的。但是如果你发现自己在重写get_redirect_url,基于功能的视图可能更容易理解,对未来的增强也更灵活。高级用法
一旦你知道你可能想要使用
django.shortcuts.redirect(),重定向到一个不同的 URL 是非常简单的。但是有几个高级用例并不明显。用重定向传递参数
有时,您希望将一些参数传递给要重定向到的视图。最佳选择是在重定向 URL 的查询字符串中传递数据,这意味着重定向到如下 URL:
http://example.com/redirect-path/?parameter=value让我们假设您想从
some_view()重定向到product_view(),但是传递一个可选参数category:from django.urls import reverse from urllib.parse import urlencode def some_view(request): ... base_url = reverse('product_view') # 1 /products/ query_string = urlencode({'category': category.id}) # 2 category=42 url = '{}?{}'.format(base_url, query_string) # 3 /products/?category=42 return redirect(url) # 4 def product_view(request): category_id = request.GET.get('category') # 5 # Do something with category_id本例中的代码相当密集,所以让我们一步一步来看:
首先,使用
django.urls.reverse()获取映射到product_view()的 URL。接下来,您必须构建查询字符串。那是问号后面的部分。建议使用
urllib.urlparse.urlencode()来实现,因为它会对任何特殊字符进行适当的编码。现在你得用问号把
base_url和query_string连起来。格式字符串很适合这种情况。最后,将
url传递给django.shortcuts.redirect()或重定向响应类。在您的重定向目标
product_view()中,参数将在request.GET字典中可用。参数可能会丢失,所以您应该使用requests.GET.get('category')而不是requests.GET['category']。前者在参数不存在时返回None,而后者会引发一个异常。注意:确保验证从查询字符串中读取的任何数据。看起来这些数据在您的控制之下,因为您创建了重定向 URL。
实际上,重定向可能会被用户操纵,像任何其他用户输入一样,不能被信任。如果没有适当的验证,攻击者可能会获得未经授权的访问。
特殊重定向代码
Django 为状态代码
301和302提供 HTTP 响应类。这些应该涵盖了大多数用例,但是如果您必须返回状态代码303、307或308,您可以非常容易地创建自己的响应类。简单地子类化HttpResponseRedirectBase并覆盖status_code属性:class HttpResponseTemporaryRedirect(HttpResponseRedirectBase): status_code = 307或者,您可以使用
django.shortcuts.redirect()方法创建一个响应对象并更改返回值。当您有了想要重定向到的视图或 URL 或模型的名称时,这种方法是有意义的:def temporary_redirect_view(request): response = redirect('success_view') response.status_code = 307 return response注意:在
3xx范围内其实还有一个状态码为HttpResponseNotModified的第三类,状态码为304。这表明内容 URL 没有改变,客户端可以使用缓存的版本。有人可能会说
304 Not Modified响应重定向到 URL 的缓存版本,但这有点牵强。因此,它不再列在 HTTP 标准的“重定向 3xx”部分中。陷阱
无法重定向的重定向
django.shortcuts.redirect()的简单可能具有欺骗性。该函数本身并不执行重定向:它只是返回一个重定向响应对象。您必须从您的视图中(或在中间件中)返回这个响应对象。否则,不会发生重定向。但是即使你知道仅仅调用
redirect()是不够的,也很容易通过简单的重构将这个 bug 引入到一个工作的应用程序中。这里有一个例子来说明。让我们假设您正在建立一个商店,并且有一个负责展示产品的视图。如果该产品不存在,请重定向至主页:
def product_view(request, product_id): try: product = Product.objects.get(pk=product_id) except Product.DoesNotExist: return redirect('/') return render(request, 'product_detail.html', {'product': product})现在,您想要添加第二个视图来显示某个产品的客户评论。它还应该重定向到不存在的产品的主页,所以作为第一步,您将这个功能从
product_view()提取到一个助手函数get_product_or_redirect():def get_product_or_redirect(product_id): try: return Product.objects.get(pk=product_id) except Product.DoesNotExist: return redirect('/') def product_view(request, product_id): product = get_product_or_redirect(product_id) return render(request, 'product_detail.html', {'product': product})不幸的是,重构之后,重定向不再有效。
你能发现错误吗? 显示/隐藏
redirect()的结果从get_product_or_redirect()返回,但是product_view()不返回。相反,它被传递给模板。根据您在
product_detail.html模板中如何使用product变量,这可能不会导致错误消息,而只是显示空值。无法停止重定向的重定向
在处理重定向时,您可能会意外地创建一个重定向循环,让 URL A 返回一个指向 URL B 的重定向,URL B 返回一个到 URL A 的重定向,依此类推。大多数 HTTP 客户端会检测到这种重定向循环,并在多次请求后显示一条错误消息。
不幸的是,这种错误很难发现,因为在服务器端一切看起来都很好。除非您的用户抱怨这个问题,否则唯一可能出错的迹象是,您已经从一个客户端收到了许多请求,这些请求都导致了快速连续的重定向响应,但是没有状态为
200 OK的响应。下面是重定向循环的一个简单示例:
def a_view(request): return redirect('another_view') def another_view(request): return redirect('a_view')这个例子说明了原理,但是它过于简单了。您在现实生活中遇到的重定向循环可能更难发现。让我们看一个更详细的例子:
def featured_products_view(request): featured_products = Product.objects.filter(featured=True) if len(featured_products == 1): return redirect('product_view', kwargs={'product_id': featured_products[0].id}) return render(request, 'featured_products.html', {'product': featured_products}) def product_view(request, product_id): try: product = Product.objects.get(pk=product_id, in_stock=True) except Product.DoesNotExist: return redirect('featured_products_view') return render(request, 'product_detail.html', {'product': product})
featured_products_view()获取所有特色产品,换句话说,.featured设置为True的Product实例。如果只有一个特色产品,它会直接重定向到product_view()。否则,它将使用featured_productsqueryset 呈现一个模板。从上一节来看,
product_view看起来很熟悉,但是它有两个小的不同:
- 视图试图获取库存的
Product,通过将.in_stock设置为True来表示。- 如果没有库存产品,视图将重定向到
featured_products_view()。这种逻辑运作良好,直到你的商店成为其自身成功的受害者,你目前拥有的特色产品脱销。如果你将
.in_stock设置为False,但是忘记将.featured也设置为False,那么任何访问你的feature_product_view()的访问者都将陷入重定向循环。没有防弹的方法来防止这种错误,但是一个好的起点是检查您重定向到的视图是否使用重定向本身。
永久重定向是永久的
永久重定向可能就像糟糕的纹身:它们当时看起来可能是一个好主意,但一旦你意识到它们是一个错误,就很难摆脱它们。
当浏览器收到对 URL 的永久重定向响应时,它会无限期地缓存该响应。将来任何时候你请求旧的 URL,浏览器都不会加载它,而是直接加载新的 URL。
说服浏览器加载一个曾经返回永久重定向的 URL 可能相当棘手。谷歌 Chrome 在缓存重定向方面尤其积极。
为什么这会是一个问题?
假设您想用 Django 构建一个 web 应用程序。您在
myawesomedjangowebapp.com注册您的域名。作为第一步,你在https://myawesomedjangowebapp.com/blog/安装一个博客应用程序来建立一个发布邮件列表。您在
https://myawesomedjangowebapp.com/的网站主页仍在建设中,因此您重定向到https://myawesomedjangowebapp.com/blog/。你决定使用永久重定向,因为你听说永久重定向被缓存,缓存使事情更快,越快越好,因为速度是谷歌搜索结果排名的一个因素。事实证明,你不仅是一个伟大的开发者,还是一个有才华的作家。你的博客变得受欢迎,你的发布邮件列表也在增长。几个月后,你的应用程序就准备好了。现在它有了一个闪亮的主页,你终于删除了重定向。
您向您庞大的发布邮件列表发送一封带有特殊折扣代码的公告电子邮件。你靠在椅背上,等待注册通知滚滚而来。
让你感到恐惧的是,你的邮箱塞满了困惑的访问者的信息,他们想访问你的应用程序,但总是被重定向到你的博客。
发生了什么事?当重定向到
https://myawesomedjangowebapp.com/blog/仍然有效时,您的博客读者已经访问了https://myawesomedjangowebapp.com/。因为这是一个永久的重定向,它被缓存在他们的浏览器中。当他们点击你发布公告邮件中的链接时,他们的浏览器根本不会检查你的新主页,而是直接进入你的博客。你没有庆祝你的成功发布,而是忙着指导你的用户如何摆弄
chrome://net-internals来重置他们浏览器的缓存。当在本地机器上开发时,永久重定向的永久性质也会伤害到你。让我们倒回到你为 myawesomedjangowebapp.com 实施那个决定性的永久重定向的时刻。
您启动开发服务器并打开
http://127.0.0.1:8000/。如你所愿,你的应用将你的浏览器重定向到http://127.0.0.1:8000/blog/。对您的工作感到满意,您停止开发服务器,去吃午饭。你带着满满的肚子回来,准备处理一些客户的工作。客户希望对他们的主页进行一些简单的更改,因此您加载客户的项目并启动开发服务器。
等等,这是怎么回事?主页坏了,现在返回一个 404!由于下午的低迷,过了一会儿你才注意到你被重定向到了
http://127.0.0.1:8000/blog/,这在客户的项目中并不存在。对于浏览器来说,URL
http://127.0.0.1:8000/现在服务于一个完全不同的应用程序并不重要。对浏览器来说,重要的是这个 URL 曾经返回一个永久重定向到http://127.0.0.1:8000/blog/。这个故事告诉我们,你应该只在你不打算再使用的 URL 上使用永久重定向。永久重定向是存在的,但是你必须意识到它们的后果。
即使你确信你真的需要一个永久的重定向,先实现一个临时的重定向也是一个好主意,只有当你 100%确定一切正常时才切换到它的永久的表亲。
未经验证的重定向会危及安全性
从安全的角度来看,重定向是一种相对安全的技术。攻击者无法通过重定向攻击网站。毕竟,重定向只是重定向到一个 URL,攻击者只需在浏览器的地址栏中键入即可。
但是,如果您使用某种类型的用户输入,如 URL 参数,而没有作为重定向 URL 进行适当的验证,这可能会被攻击者滥用来进行网络钓鱼攻击。这种重定向被称为开放或未验证重定向。
对于重定向到从用户输入中读取的 URL,有一些合理的使用案例。一个主要的例子是 Django 的登录视图。它接受一个 URL 参数
next,该参数包含用户登录后被重定向到的页面的 URL。要在登录后将用户重定向到他们的个人资料,URL 可能如下所示:https://myawesomedjangowebapp.com/login/?next=/profile/Django 确实验证了
next参数,但是让我们假设它没有验证。未经验证,攻击者可以创建一个 URL,将用户重定向到他们控制的网站,例如:
https://myawesomedjangowebapp.com/login/?next=https://myawesomedjangowebapp.co/profile/网站
myawesomedjangowebapp.co可能会显示一条错误消息,并欺骗用户再次输入他们的凭据。避免开放重定向的最佳方式是在构建重定向 URL 时不使用任何用户输入。
如果您不能确定 URL 对于重定向是安全的,您可以使用函数
django.utils.http.is_safe_url()来验证它。docstring 很好地解释了它的用法:
is_safe_url(url, host=None, allowed_hosts=None, require_https=False)如果 url 是安全重定向(即它不指向不同的主机并使用安全方案),则返回
True。总是在空 url 上返回False。如果require_https是True,那么只有‘https’将被认为是有效的方案,而不是默认为False的‘http’和‘https’。(来源)让我们看一些例子。
相对 URL 被认为是安全的:
>>> # Import the function first.
>>> from django.utils.http import is_safe_url
>>> is_safe_url('/profile/')
True
指向另一台主机的 URL 通常被认为是不安全的:
>>> is_safe_url('https://myawesomedjangowebapp.com/profile/') False如果在
allowed_hosts中提供了主机,则指向另一个主机的 URL 被认为是安全的:
>>> is_safe_url('https://myawesomedjangowebapp.com/profile/',
... allowed_hosts={'myawesomedjangowebapp.com'})
True
如果参数require_https是True,使用http方案的 URL 被认为是不安全的:
>>> is_safe_url('http://myawesomedjangowebapp.com/profile/', ... allowed_hosts={'myawesomedjangowebapp.com'}, ... require_https=True) False总结
关于 Django 的 HTTP 重定向指南到此结束。恭喜:现在您已经接触到了重定向的各个方面,从 HTTP 协议的底层细节到 Django 中处理它们的高层方式。
您了解了 HTTP 重定向在幕后是什么样子,不同的状态代码是什么,以及永久重定向和临时重定向有什么不同。这些知识并不是 Django 特有的,对于任何语言的 web 开发都是有价值的。
现在可以用 Django 执行重定向了,要么使用重定向响应类
HttpResponseRedirect和HttpResponsePermanentRedirect,要么使用方便的函数django.shortcuts.redirect()。您看到了一些高级用例的解决方案,并且知道如何避开常见的陷阱。如果你有任何关于 HTTP 重定向的问题,请在下面留下评论,同时,祝你重定向愉快!
参考文献
- 姜戈文档:
django.http.HttpResponseRedirect- 姜戈文档:
django.shortcuts.render()- 姜戈文档:
django.views.generic.base.RedirectView- RFC 7231:超文本传输协议(HTTP/1.1):语义和内容- 6.4 重定向 3xx
- CWE-601: URL 重定向到不受信任的站点(‘打开重定向’)
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Django 重定向*********
Django Rest 框架——基于类的视图
原文:https://realpython.com/django-rest-framework-class-based-views/
在这篇文章中,让我们继续开发 Django Talk 项目和 Django Rest 框架,同时实现基于 T2 类的视图,并做一些简单的重构来保持代码的干爽。本质上,我们正在将现有的基于函数视图的 RESTful API 迁移到基于类的视图。
这是本系列教程的第四部分。
需要迎头赶上?看看第一部分第一部分和第二部分第五部分,我们将讨论 Django 和 AJAX,还有第三部分第七部分,我们将介绍 Django Rest 框架。
需要代码吗?从回购下载。
要获得关于 Django Rest 框架的更深入的教程,请务必查看第三个 Real Python 课程。
重构
在进入基于类的视图之前,让我们对当前代码做一个快速重构。在
def post_element()视图中,进行以下更新:post = get_object_or_404(Post, id=pk) # try: # post = Post.objects.get(pk=pk) # except Post.DoesNotExist: # return HttpResponse(status=404)所以这里我们使用 get_object_or_404 快捷方式来引发 404 错误而不是异常。
请确保也更新导入:
from django.shortcuts import render, get_object_or_404测试一下。尝试查看一个不存在的元素——即http://localhost:8000/API/v1/posts/202?format=json 。您应该会在浏览器中看到以下响应:
{ "detail": "Not found" }如果你在 Chrome 开发者工具中打开网络标签,你应该会看到一个 404 状态码。很酷,对吧?不幸的是,我们不会使用它太久,因为是时候告别我们当前的基于函数的视图并添加基于类的视图了。
基于类的视图
虽然函数很容易使用,但使用基于类的视图来重用功能通常是有益的,尤其是对于具有许多端点的大型 API。
注释掉基于函数的视图的代码。
收藏
为集合的基于类的视图添加以下代码:
class PostCollection(mixins.ListModelMixin, mixins.CreateModelMixin, generics.GenericAPIView): queryset = Post.objects.all() serializer_class = PostSerializer def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs) def post(self, request, *args, **kwargs): return self.create(request, *args, **kwargs)欢迎来到 mixins 的力量!
ListModelMixin提供了list()函数,用于将集合序列化为 JSON,然后将其作为 GET 请求的响应返回。- 同时,
CreateModelMixin提供了用于创建新对象的create()函数,以响应 POST 请求。- 最后,
GenericAPIViewmixin 提供了 RESTful API 所需的“核心”功能。请参考 DRF 官方文档了解更多关于这些混合的信息。
成员
现在为成员添加代码:
class PostMember(mixins.RetrieveModelMixin, mixins.DestroyModelMixin, generics.GenericAPIView): queryset = Post.objects.all() serializer_class = PostSerializer def get(self, request, *args, **kwargs): return self.retrieve(request, *args, **kwargs) def delete(self, request, *args, **kwargs): return self.destroy(request, *args, **kwargs)这里,我们简单地使用
GenericAPIView作为“核心功能”,其余的 mixins 提供处理 GET 和 DELETE 请求所需的功能。URLs
最后,让我们更新 urls.py 来说明基于类的视图:
from django.conf.urls import patterns, url from talk import views urlpatterns = patterns( 'talk.views', url(r'^$', 'home'), # api url(r'^api/v1/posts/$', views.PostCollection.as_view()), url(r'^api/v1/posts/(?P<pk>[0-9]+)/$', views.PostMember.as_view()) )请注意
as_view()方法,它提供了一点魔力来将类作为视图函数处理。测试一下。启动开发服务器,然后:
- 确保所有帖子都已加载
- 添加新帖子
- 删除一个帖子
发生了什么事?尝试添加新帖子时,您应该会看到以下错误:
400: { "text": ["This field is required."], "author": ["This field is required."] }幸运的是,这很容易解决。
重构 AJAX
我们需要改变发送 POST 请求数据的方式。首先,将
the_post键更新为text:data : { text : $('#post-text').val() }, // data sent with the post request如果您现在测试它,错误应该只是表明我们缺少了
author字段。我们可以通过多种方式获取登录的用户,但是最简单的方式是直接从 DOM 获取。值得注意的是,我们可以覆盖视图中的默认功能,从请求对象中获取用户名。然而,最好按照预期使用基于 DRF 类的视图:在 JSON 请求中传递所有适当的参数——例如,
text和author——然后使用序列化程序保存它们。在“模板/对话”目录下打开index.html。在文件的顶部,您会看到我们直接从
request对象访问用户名:<h2>Hi, {{request.user.username}}</h2>让我们隔离实际的用户名,以便更容易用 jQuery 获取:
<h2>Hi, <span id="user">{{request.user.username}}</span></h2>现在再次更新
data:data : { text : $('#post-text').val(), author: $('#user').text()}测试一下;一切都会好的。
基于通用的视图
想要事半功倍?看看这个。注释掉我们刚刚添加的代码,然后像这样更新视图:
from talk.models import Post from talk.forms import PostForm from talk.serializers import PostSerializer from rest_framework import generics from django.shortcuts import render def home(request): tmpl_vars = {'form': PostForm()} return render(request, 'talk/index.html', tmpl_vars) ######################### ### class based views ### ######################### class PostCollection(generics.ListCreateAPIView): queryset = Post.objects.all() serializer_class = PostSerializer class PostMember(generics.RetrieveUpdateDestroyAPIView): queryset = Post.objects.all() serializer_class = PostSerializer因此,我们不仅可以像以前一样处理所有相同的请求,还可以处理更新每个成员的 PUT 请求。更多。给很多少。
在继续之前,跳回基于函数的视图,将代码与基于类的视图进行比较。哪个更容易阅读?其实哪个更好理解?如有必要,添加注释,以帮助您更好地理解基于类的视图背后发生的事情。
你不仅牺牲了基于类的视图的可读性,而且测试也更加困难。然而,我们现在利用了继承,对于有许多相似视图的大型项目,基于类的视图是完美的,因为你不必一遍又一遍地写相同的代码。在跳到基于阶级的观点之前,一定要权衡利弊。
在继续之前,一定要测试端点。
- 确保所有帖子都已加载
- 添加新帖子
- 删除一个帖子
对 PUT 请求感到好奇?通过 HTML 表单从可浏览的 API(即http://localhost:8000/API/v1/posts/1/)中测试它。想要完全删除 PUT 方法处理程序吗?像这样更新代码:
class PostMember(generics.RetrieveDestroyAPIView): queryset = Post.objects.all() serializer_class = PostSerializer现在测试一下。有问题吗?查看文档。
结论
暂时就这些了。在以后的文章中,我们可能会跳回到 Django Rest 框架来看看分页、权限和基本验证,但在此之前,我们将在前端添加 AngularJS 来消费数据。
干杯!***
Django Rest 框架——简介
原文:https://realpython.com/django-rest-framework-quick-start/
让我们看看如何使用 Django Rest Framework (DRF)为我们的 Django Talk 项目创建 RESTFul API,这是一个用于基于 Django 模型快速构建 RESTFul API 的应用程序。
换句话说,我们将使用 DRF 把一个非 RESTful 应用程序转换成 RESTful 应用程序。对于这个应用程序,我们将使用 DRF 版本 2.4.2。
本教程涵盖了这些主题:
- DRF 设置
- 宁静的结构
- 模型序列化程序
- DRF 网络可浏览 API
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
如果你错过了这个系列教程的第一部分和第二部分和第三部分,一定要去看看。需要密码吗?从回购下载。要获得关于 Django Rest 框架的更深入的教程,请查看第三个 Real Python 课程。
DRF 设置
安装:
$ pip install djangorestframework $ pip freeze > requirements.txt更新 settings.py :
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'talk', 'rest_framework' )嘣!
RESTful 结构
在 RESTful API 中,端点(URL)定义了 API 的结构以及最终用户如何使用 HTTP 方法从我们的应用程序访问数据:GET、POST、PUT、DELETE。端点应该围绕集合和元素进行逻辑组织,两者都是资源。在我们的例子中,我们有一个单独的资源,
posts,所以我们将使用下面的 URL-/posts/和/posts/<id>,分别用于集合和元素。
得到 邮政 放 删除 /posts/显示所有帖子 添加新帖子 更新所有帖子 删除所有帖子 /posts/<id>显示 <id>不适用的 更新 <id>删除 idDRF 快速启动
让我们启动并运行我们的新 API 吧!
模型串行器
DRF 的序列化器将模型实例转换成 Python 字典,然后可以用各种 API 适当的格式呈现——像 JSON 或 XML。类似于 Django
ModelForm类,DRF 为其序列化器提供了一种简洁的格式,即ModelSerializer类。使用起来很简单:只需告诉它您想要使用模型中的哪些字段:from rest_framework import serializers from talk.models import Post class PostSerializer(serializers.ModelSerializer): class Meta: model = Post fields = ('id', 'author', 'text', 'created', 'updated')在“talk”目录中将其保存为serializer . py。
更新视图
我们需要重构当前的视图,以适应 RESTful 范式。注释掉当前视图并添加:
from django.shortcuts import render from django.http import HttpResponse from rest_framework.decorators import api_view from rest_framework.response import Response from talk.models import Post from talk.serializers import PostSerializer from talk.forms import PostForm def home(request): tmpl_vars = {'form': PostForm()} return render(request, 'talk/index.html', tmpl_vars) @api_view(['GET']) def post_collection(request): if request.method == 'GET': posts = Post.objects.all() serializer = PostSerializer(posts, many=True) return Response(serializer.data) @api_view(['GET']) def post_element(request, pk): try: post = Post.objects.get(pk=pk) except Post.DoesNotExist: return HttpResponse(status=404) if request.method == 'GET': serializer = PostSerializer(post) return Response(serializer.data)这里发生了什么:
- 首先,
@api_viewdecorator 检查适当的 HTTP 请求是否被传递到视图函数中。目前,我们只支持 GET 请求。- 然后,视图要么获取所有数据(如果是集合的话),要么只获取一个帖子(如果是元素的话)。
- 最后,数据被序列化为 JSON 并返回。
请务必从官方文档中阅读更多关于
@api_view的内容。更新网址
让我们连接一些新的网址:
# Talk urls from django.conf.urls import patterns, url urlpatterns = patterns( 'talk.views', url(r'^$', 'home'), # api url(r'^api/v1/posts/$', 'post_collection'), url(r'^api/v1/posts/(?P<pk>[0-9]+)$', 'post_element') )测试
我们现在已经准备好我们的第一次测试!
启动服务器,然后导航到:http://127 . 0 . 0 . 1:8000/API/v1/posts/?format=json 。
现在让我们来看看可浏览的 API 。导航到http://127 . 0 . 0 . 1:8000/API/v1/posts/
因此,我们不需要做额外的工作,就可以自动获得这个漂亮的、人类可读的 API 输出。不错!这对 DRF 来说是一个巨大的胜利。
在继续之前,您可能已经注意到作者字段是一个
id而不是实际的username。我们将很快解决这个问题。现在,让我们连接新的 API,以便它可以与当前应用程序的模板一起工作。REST 重构
获取
在初始页面加载时,我们希望显示所有的文章。为此,添加以下 AJAX 请求:
load_posts() // Load all posts on page load function load_posts() { $.ajax({ url : "api/v1/posts/", // the endpoint type : "GET", // http method // handle a successful response success : function(json) { for (var i = 0; i < json.length; i++) { console.log(json[i]) $("#talk").prepend("<li id='post-"+json[i].id+"'><strong>"+json[i].text+"</strong> - <em> "+json[i].author+"</em> - <span> "+json[i].created+ "</span> - <a id='delete-post-"+json[i].id+"'>delete me</a></li>"); } }, // handle a non-successful response error : function(xhr,errmsg,err) { $('#results').html("<div class='alert-box alert radius' data-alert>Oops! We have encountered an error: "+errmsg+ " <a href='#' class='close'>×</a></div>"); // add the error to the dom console.log(xhr.status + ": " + xhr.responseText); // provide a bit more info about the error to the console } }); };这些你以前都见过。注意我们是如何处理成功的:由于 API 发回了许多对象,我们需要遍历它们,将每个对象追加到 DOM 中。当我们连载帖子
id时,我们也将json[i].postpk改为json[i].id。测试一下。启动服务器,登录,然后查看帖子。
除了显示为
id的author之外,请注意日期时间格式。这不是我们想要的,对吗?我们想要一个可读的日期时间格式。让我们更新一下…Datetime Format
我们可以使用一个名为 MomentJS 的强大的 JavaScript 库来轻松地按照我们想要的方式格式化日期。
首先,我们需要将库导入到我们的index.html文件中:
<!-- scripts --> <script src="http://cdnjs.cloudflare.com/ajax/libs/moment.js/2.8.2/moment.min.js"></script> <script src="static/scripts/main.js"></script>然后更新 main.js 中的 for 循环:
for (var i = 0; i < json.length; i++) { dateString = convert_to_readable_date(json[i].created) $("#talk").prepend("<li id='post-"+json[i].id+"'><strong>"+json[i].text+ "</strong> - <em> "+json[i].author+"</em> - <span> "+dateString+ "</span> - <a id='delete-post-"+json[i].id+"'>delete me</a></li>"); }这里我们将日期字符串传递给一个名为
convert_to_readable_date()的新函数,这个函数需要添加:// convert ugly date to human readable date function convert_to_readable_date(date_time_string) { var newDate = moment(date_time_string).format('MM/DD/YYYY, h:mm:ss a') return newDate }就是这样。刷新浏览器。日期时间格式现在应该类似于这样-
08/22/2014, 6:48:29 pm。请务必查看 MomentJS 文档,查看关于用 JavaScript 解析和格式化日期时间字符串的更多信息。帖子
POST 请求以类似的方式处理。在使用序列化程序之前,让我们先通过更新视图来测试它。也许我们会很幸运,它会工作。
更新 views.py 中的
post_collection()函数:@api_view(['GET', 'POST']) def post_collection(request): if request.method == 'GET': posts = Post.objects.all() serializer = PostSerializer(posts, many=True) return Response(serializer.data) elif request.method == 'POST': data = {'text': request.DATA.get('the_post'), 'author': request.user.pk} serializer = PostSerializer(data=data) if serializer.is_valid(): serializer.save() return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)还要添加以下导入内容:
from rest_framework import status这里发生了什么:
request.DATA扩展 Django 的 HTTPRequest,从请求体返回内容。点击了解更多信息。- 如果反序列化过程有效,我们返回一个代码为 201(已创建)的响应。
- 另一方面,如果反序列化过程失败,我们返回 400 响应。
更新
create_post()功能中的端点出发地:
url : "create_post/", // the endpoint收件人:
url : "api/v1/posts/", // the endpoint在浏览器中测试它。应该能行。不要忘记正确更新日期的处理,以及将
json.postpk更改为json.id:success : function(json) { $('#post-text').val(''); // remove the value from the input console.log(json); // log the returned json to the console dateString = convert_to_readable_date(json.created) $("#talk").prepend("<li id='post-"+json.id+"'><strong>"+json.text+"</strong> - <em> "+ json.author+"</em> - <span> "+dateString+ "</span> - <a id='delete-post-"+json.id+"'>delete me</a></li>"); console.log("success"); // another sanity check },作者格式
现在是停下来解决作者
id对username问题的好时机。我们有几个选择:
- 真正的 RESTFUL 并进行另一个调用来获取用户信息,这对性能没有好处。
- 利用 SlugRelatedField 关系。
让我们选择后者。更新序列化程序:
from django.contrib.auth.models import User from rest_framework import serializers from talk.models import Post class PostSerializer(serializers.ModelSerializer): author = serializers.SlugRelatedField( queryset=User.objects.all(), slug_field='username' ) class Meta: model = Post fields = ('id', 'author', 'text', 'created', 'updated')这里发生了什么事?
SlugRelatedField允许我们将author字段的目标从id更改为username。- 此外,默认情况下,目标字段
username既可读又可写,因此这种关系对于 get 和 POST 请求都是现成的。更新视图中的
data变量:data = {'text': request.DATA.get('the_post'), 'author': request.user}再次测试。你现在应该看到作者的
username。确保 GET 和 POST 请求都正常工作。删除
在改变或添加任何东西之前,先测试一下。尝试删除链接。会发生什么?您应该会得到一个 404 错误。知道为什么会这样吗?或者去哪里找出问题所在?我们的 JavaScript 文件中的
delete_post函数怎么样:url : "delete_post/", // the endpoint该 URL 不存在。在我们更新它之前,问问你自己——“我们应该针对集合还是单个元素?”。如果您不确定,请向上滚动查看 RESTful 结构表。除非我们想删除所有的帖子,那么我们需要点击元素端点:
url : "api/v1/posts/"+post_primary_key, // the endpoint再次测试。现在发生了什么?您应该会看到一个 405 错误-
405: {"detail": "Method 'DELETE' not allowed."}-因为视图没有设置为处理删除请求。@api_view(['GET', 'DELETE']) def post_element(request, pk): try: post = Post.objects.get(pk=pk) except Post.DoesNotExist: return HttpResponse(status=404) if request.method == 'GET': serializer = PostSerializer(post) return Response(serializer.data) elif request.method == 'DELETE': post.delete() return Response(status=status.HTTP_204_NO_CONTENT)添加了 DELETE HTTP 谓词后,我们可以通过用
delete()方法删除 post 并返回 204 响应来处理请求。有用吗?只有一个办法可以知道。这一次当你测试时,确保(a)这篇文章确实被删除并从 DOM 中移除,以及(b)204 状态码被返回(你可以在 Chrome 开发者工具的网络标签中确认这一点)。结论和后续步骤
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
暂时就这些了。需要额外的挑战吗?添加使用 PUT 请求更新帖子的功能。
实际的 REST 部分很简单:您只需要更新
post_element()函数来处理 PUT 请求。客户端有点困难,因为您需要更新实际的 HTML 来显示一个输入框,供用户输入新值,您需要在 JavaScript 文件中获取这个输入框,这样您就可以将它与 put 请求一起发送。
您是否允许任何用户更新任何帖子,而不管该帖子最初是否是她/他发布的?
如果是,你打算更新作者姓名吗?也许在数据库中添加一个
edited_by字段?然后在 DOM 上显示编辑过的注释。如果用户只能更新他们自己的帖子,您需要确保在视图中正确处理这一点,然后在用户试图编辑他/她最初没有发布的帖子时显示一条错误消息。或者您可以删除某个用户不能编辑的帖子的编辑链接(也可以删除链接)。你可以把它变成一个权限问题,只让某些用户,如版主或管理员,编辑所有帖子,而其余用户只能更新他们自己的帖子。
这么多问题。
如果你决定尝试这种方法,那就选择最容易实现的——简单地允许任何用户更新任何帖子,并且只更新数据库中的
text。然后测试。然后添加另一个迭代。然后测试等等。做好笔记,给 info@realpython.com 发邮件,这样我们就可以补充一篇博文了!无论如何,下一次你将会看到我们在添加 Angular 时分解当前的 JavaScript 代码!到时候见。***
Django 的第一步:建立一个 Django 项目
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 如何建立 Django 项目
在开始构建一个新的 Django web 应用程序的独立功能之前,您总是需要完成几个设置步骤。本教程为您提供了一个参考,用于设置 Django 项目的必要步骤。
本教程重点介绍启动一个新的 web 应用程序所需的初始步骤。要完成它,你需要安装Python,并了解如何使用虚拟环境和 Python 的包管理器
pip。虽然您不需要太多的编程知识来完成这个设置,但是您需要了解 Python 来完成任何有趣的项目搭建。本教程结束时,你将知道如何:
- 建立一个虚拟环境
- 安装 Django
- 锁定您的项目依赖关系
- 建立一个 Django 项目
- 启动 Django 应用
使用本教程作为您的首选参考,直到您已经构建了如此多的项目,以至于必要的命令成为您的第二天性。在此之前,请遵循以下步骤。在整个教程中还有一些练习来帮助巩固你所学的内容。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
准备您的环境
当您准备好启动新的 Django web 应用程序时,创建一个新文件夹并导航到其中。在此文件夹中,您将使用命令行设置一个新的虚拟环境:
$ python3 -m venv env该命令在当前工作目录中建立一个名为
env的新虚拟环境。该过程完成后,您还需要激活虚拟环境:$ source env/bin/activate如果激活成功,那么您将在命令提示符的开头看到虚拟环境的名称
(env)。这意味着您的环境设置已经完成。您可以了解更多关于如何在 Python 中使用虚拟环境,以及如何完善您的 Python 开发设置,但是对于您的 Django 设置,您已经拥有了您所需要的一切。您可以继续安装
django包。安装 Django 并固定您的依赖项
一旦创建并激活了 Python 虚拟环境,就可以将 Django 安装到这个专用的开发工作区中:
(env) $ python -m pip install django这个命令使用
pip从 Python 包索引(PyPI) 中获取django包。安装完成后,您可以锁定您的依赖项,以确保跟踪您安装了哪个 Django 版本:(env) $ python -m pip freeze > requirements.txt这个命令将当前虚拟环境中所有外部 Python 包的名称和版本写到一个名为
requirements.txt的文件中。这个文件将包含django包及其所有依赖项。注:Django 有很多不同的版本。虽然在开始一个新项目时最好使用最新的版本,但是对于一个特定的项目,您可能必须使用特定的版本。您可以通过在安装命令中添加版本号来安装任何版本的 Django:
(env) $ python -m pip install django==2.2.11这个命令将 Django 的版本
2.2.11安装到您的环境中,而不是获取最新的版本。用您需要安装的特定 Django 版本替换双等号(==)后面的数字。您应该总是包含您在项目代码中使用的所有包的版本记录,比如在一个
requirements.txt文件中。requirements.txt文件允许您和其他程序员重现您的项目构建的确切条件。打开您创建的
requirements.txt文件并检查其内容。您可以看到所有已安装软件包的名称及其版本号。您会注意到文件中列出了除了django之外的其他包,尽管您只安装了 Django。你觉得为什么会这样?假设您正在处理一个现有的项目,它的依赖项已经被固定在一个
requirements.txt文件中。在这种情况下,您可以在一个命令中安装正确的 Django 版本以及所有其他必需的包:(env) $ python -m pip install -r requirements.txt该命令从您的
requirements.txt文件中读取所有固定包的名称和版本,并在您的虚拟环境中安装每个包的指定版本。为每个项目保留一个独立的虚拟环境,可以让您为不同的 web 应用程序项目使用不同版本的 Django。用
pip freeze固定依赖关系使您能够重现项目按预期工作所需的环境。建立 Django 项目
成功安装 Django 之后,就可以为新的 web 应用程序创建脚手架了。Django 框架区分了项目和应用:
- Django 项目是一个高层次的组织单元,它包含管理整个 web 应用程序的逻辑。每个项目可以包含多个应用程序。
- Django 应用程序是你的 web 应用程序的底层单元。一个项目中可以有零到多个应用,通常至少有一个应用。在下一节中,您将了解更多关于应用程序的信息。
随着虚拟环境的设置和激活以及 Django 的安装,您现在可以创建一个项目了:
(env) $ django-admin startproject <project-name>本教程使用
setup作为项目名称的示例:(env) $ django-admin startproject setup运行此命令将创建一个默认文件夹结构,其中包括一些 Python 文件和与项目同名的管理应用程序:
setup/ │ ├── setup/ │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ └── manage.py在上面的代码块中,您可以看到
startproject命令为您创建的文件夹结构:
setup/是你的顶层项目文件夹。setup/setup/是你的下级文件夹,代表你的管理 app。manage.py是一个 Python 文件,作为你项目的指挥中心。它的作用与django-admin命令行实用程序相同。嵌套的
setup/setup/文件夹包含几个文件,当您在 web 应用程序上工作时,可以编辑这些文件。注意:如果您想避免创建额外的顶层项目文件夹,您可以在
django-admin startproject命令的末尾添加一个点(.):(env) $ django-admin startproject <projectname> .圆点跳过顶层项目文件夹,在当前工作目录下创建管理应用程序和
manage.py文件。您可能会在一些在线 Django 教程中遇到这种语法。它所做的只是创建项目脚手架,而没有额外的顶级项目文件夹。花点时间探索一下
django-admin命令行实用程序为您创建的默认项目框架。您将使用startproject命令创建的每个项目都将具有相同的结构。当你准备好了,你可以继续创建一个 Django 应用程序作为你的新 web 应用程序的底层单元。
启动 Django 应用程序
用 Django 构建的每个项目都可以包含多个 Django 应用程序。当您在上一节中运行
startproject命令时,您创建了一个管理应用程序,您将要构建的每个默认项目都需要它。现在,您将创建一个 Django 应用程序,它将包含您的 web 应用程序的特定功能。您不再需要使用
django-admin命令行实用程序,而是可以通过manage.py文件执行startapp命令:(env) $ python manage.py startapp <appname>命令为 Django 应用程序生成一个默认的文件夹结构。本教程使用
example作为应用程序的名称:(env) $ python manage.py startapp example当您为您的个人 web 应用程序创建 Django 应用程序时,记得用您的应用程序名称替换
example。注意:如果您创建的项目没有上面提到的点快捷方式,那么在运行上面显示的命令之前,您需要将您的工作目录更改为您的顶级项目文件夹。
一旦
startapp命令执行完毕,您将看到 Django 向您的文件夹结构中添加了另一个文件夹:setup/ │ ├── example/ │ │ │ ├── migrations/ │ │ └── __init__.py │ │ │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── models.py │ ├── tests.py │ └── views.py │ ├── setup/ │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ └── manage.py新文件夹具有您在运行命令时为其指定的名称。在本教程的情况下,那就是
example/。您可以看到该文件夹包含几个 Python 文件。这个 Django 应用程序文件夹是您创建 web 应用程序时花费大部分时间的地方。您还需要在管理应用程序
setup/中进行一些更改,但是您将在 Django 应用程序example/中构建您的大部分功能。导航到您的
example/文件夹,打开新生成的 Python 文件。如果您还不理解 Django 为您生成的代码,请不要担心,并且请记住,您不需要需要来理解它来构建 Django web 应用程序。探索每个文件中的代码注释,看看它们是否有助于阐明每个文件的用例。在学习教程或构建自己的项目时,您将更详细地了解生成的 Python 文件。以下是在 app 文件夹中创建的三个值得注意的文件:
__init__.py: Python 使用这个文件将一个文件夹声明为一个包,这允许 Django 使用不同应用程序的代码来组成您的 web 应用程序的整体功能。你可能不用碰这份文件。models.py:您将在这个文件中声明您的应用程序的模型,这允许 Django 与您的 web 应用程序的数据库接口。views.py:你将在这个文件中编写应用程序的大部分代码逻辑。至此,您已经完成了 Django web 应用程序的搭建,可以开始实现您的想法了。从现在开始,你想要构建什么来创建你自己独特的项目就取决于你了。
命令参考
下表为您提供了启动 Django 开发过程所需命令的快速参考。参考表中的步骤链接回本教程的各个部分,在那里可以找到更详细的解释:
步骤 描述 命令 1a 设置虚拟环境 python -m venv env1b 激活虚拟环境 source env/bin/activate2a 安装 Django python -m pip install django2b 固定您的依赖关系 python -m pip freeze > requirements.txt3 建立 Django 项目 django-admin startproject <projectname>4 启动 Django 应用程序 python manage.py startapp <appname>使用此表作为在 Python 虚拟环境中使用 Django 启动新 web 应用程序的快速参考。
结论
在本教程中,您了解了为新的 Django web 应用程序建立基础的所有必要步骤。您已经熟悉了最常见的终端命令,在使用 Django 进行 web 开发时,您会一遍又一遍地重复这些命令。
您还了解了为什么要使用每个命令以及它们产生的结果,并且学习了一些与设置 Django 相关的技巧和诀窍。
在本教程中,您学习了如何:
- 建立一个虚拟环境
- 安装 Django
- 锁定您的项目依赖关系
- 建立一个 Django 项目
- 启动 Django 应用
完成本教程中概述的步骤后,您就可以开始使用 Django 构建您的定制 web 应用程序了。例如,你可以创建一个文件夹应用来展示你的编码项目。为了有条理地不断提高你的 Django 技能,你可以通过 Django 学习路径中提供的资源继续学习。
继续为 Django web 应用程序搭建基础架构,直到这些步骤成为第二天性。如果您需要复习,那么您可以随时使用本教程作为快速参考。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 如何建立 Django 项目**
用 Django 构建和提交 HTML 表单——第 4 部分
在这个由四部分组成的教程系列中,您将与 Django 一起构建一个社交网络,您可以在文件夹中展示这个网络。这个项目加强了你对 Django 模型之间关系的理解,并向你展示了如何使用表单,以便用户可以与你的应用程序和其他人进行交互。通过使用布尔玛 CSS 框架,你也可以让你的网站看起来更好。
在本系列的前一部分中,您添加了一些功能,以便用户可以在后端创建 dweets,并在前端显示它们。此时,您的用户可以发现和关注其他用户,并阅读他们所关注的个人资料的内容。如果他们想停止阅读他们的内容,他们可以点击一个按钮,发送一个由 Django 处理的 HTTP POST 请求来取消关注一个配置文件。
在本系列教程的第四部分,您将学习如何:
- 从你的
Dweet模型中创建并渲染 Django 表单- 防止重复提交和显示有用的错误信息
- 使用动态网址链接应用程序的个页面
- 重构一个视图函数
- 使用
QuerySet字段查找来过滤你后端的数据一旦你完成了教程的最后一部分,你将拥有一个用 Django 构建的功能齐全的基本社交网络。它将允许您的用户创建简短的基于文本的消息,发现和关注其他用户,并阅读他们关注的个人资料的内容。如果他们想停止阅读他们的内容,他们也可以取消关注个人资料。
此外,您将展示您可以使用 CSS 框架来使您的 web 应用程序看起来很棒,而不需要太多额外的工作。
你可以点击下面的链接,进入
source_code_start/文件夹,下载启动这个项目最后部分所需的代码:获取源代码: 单击此处获取源代码,您将使用用 Django 构建和提交 HTML 表单。
演示
在这个由四部分组成的系列中,您将构建一个小型社交网络,允许用户发布基于文本的简短消息。您的应用程序用户还可以关注其他用户简档以查看这些用户的帖子,或者取消关注他们以停止查看他们基于文本的帖子:
https://player.vimeo.com/video/643455270?background=1
您还将学习如何使用 CSS 框架布尔玛为您的应用程序提供用户友好的外观,并使其成为您可以自豪地炫耀的投资组合项目。
在本系列教程的第四部分,也是最后一部分,您将学习如何在现有模型的基础上构建 Django 表单。您还将设置和处理更多的 HTTP POST 请求提交,以便您的用户可以发布基于文本的消息。
本教程结束时,你将完成用 Django 构建的基本社交网络。到那时,您的用户将能够导航到配置文件列表和个人配置文件页面,关注和取消关注其他用户,并在他们的仪表板上看到他们所关注的配置文件的电子表格。他们还可以通过仪表板上的表格提交电子表格。
项目概述
在本节中,您将大致了解本系列教程的最后一部分将涵盖哪些主题。您还将有机会重温完整的项目实现步骤,以防您需要跳回到您在本系列的前一部分中完成的前一个步骤。
至此,你应该已经完成了本教程系列的第部分第一、第二和第三。恭喜你!您已经完成了最后一部分,这一部分主要是构建表单和处理表单提交:
第十步 通过 Django 表单提交 Dweets 第 11 步 防止重复提交并处理错误 第 12 步 改善前端用户体验 一旦你完成了本系列最后一部分的步骤,你就完成了 Django 社交网络的基本版本。你将准备好自己采取任何后续步骤,让这个项目在你的 web 开发者组合中脱颖而出。
为了更好地理解构建 Django 社交网络系列的最后一部分如何融入整个项目的背景,您可以展开下面的可折叠部分:
在本系列的多个独立教程中,您将分多个步骤实现该项目。有很多内容需要介绍,您将一路深入到细节中:
- 步骤 1: 设置基础项目
- 步骤 2: 扩展 Django 用户模型
- 步骤 3: 实现一个保存后挂钩
- 第四步:用布尔玛创建一个基础模板
- 第 5 步:列出所有用户资料
- 第 6 步:访问个人资料页面
- 第 7 步:关注和取消关注其他个人资料
- 步骤 8: 为 Dweets 创建后端逻辑
- 第九步:在前端显示 Dweets
- 步骤 10: 通过 Django 表单提交 Dweets
- 步骤 11: 防止重复提交并处理错误
- 第十二步:改善前端用户体验
这些步骤中的每一步都将提供任何必要资源的链接。通过一次完成一个步骤,你将有机会停下来,在你想休息一下的时候再回来。
考虑到本系列教程的高级结构,如果您还没有完成这些步骤,那么您已经很好地了解了您现在所处的位置以及您可能必须赶上的实现步骤。
在开始下一步之前,快速浏览一下先决条件,浏览一下可能有帮助的其他资源的链接。
先决条件
为了成功完成项目的最后一部分,你需要完成关于模型和关系的第一部分、关于模板和样式的第二部分,以及关于跟随和 dweets 的第三部分。请确认您的项目如那里描述的那样工作。您还应该熟悉以下概念:
- 在 Python 中使用面向对象编程
- 建立 Django 基础项目
- 管理路由和重定向,查看功能,模板,模型,以及 Django 中的迁移
- 使用和定制 Django 管理界面
确保您已经完成了本系列的前三部分。这最后一部分将从你在第三部分结束时停下的地方继续。
注意:如果您没有准备好前几部分的工作项目,您将无法继续学习本系列教程的这一部分。
您也可以通过点击下面的链接并转到
source_code_start/文件夹来下载启动项目最后部分所需的代码:获取源代码: 单击此处获取源代码,您将使用用 Django 构建和提交 HTML 表单。
关于额外的要求和进一步的链接,请查看本系列教程第一部分中提到的关于在 Django 构建基本社交网络的先决条件。
步骤 10:使用 Django 表单提交 Dweets
为了这个系列教程,你在早期决定让在你的 Django admin 中处理用户创建。你的小型社交网络只接受邀请,而你是决定创建用户账户的人。
注意:请随意使用 Django 的用户管理系统对此进行扩展,并按照链接教程构建必要的模板。
然而,一旦你的用户进入你的社交网络应用,你会想给他们创造内容的机会。他们将无法访问 Django 管理界面,你的 Dwitter 也将变得贫瘠,用户没有任何机会创建内容。您将需要另一个表单作为用户提交 dweets 的接口。
创建一个文本输入表单
如果您熟悉 HTML 表单,那么您可能知道可以通过创建另一个包含特定
<input>元素的 HTML<form>元素来处理文本提交。但是,它必须看起来与您为按钮构建的表单有点不同。在本教程中,你将学习如何使用一个 Django 表单创建 HTML 表单。您将编写一个 Django 表单,Django 将在呈现页面时将其转换为 HTML
<form>元素。从教程的这一部分开始,在 Django
dwitter应用程序中创建一个新文件,并将其命名为forms.py。该文件可以保存您的项目可能需要的所有表单。您只需要一个表单,这样您的用户就可以提交他们的电子表格:1# dwitter/forms.py 2 3from django import forms 4from .models import Dweet 5 6class DweetForm(forms.ModelForm): 7 body = forms.CharField(required=True) 8 9 class Meta: 10 model = Dweet 11 exclude = ("user", )在这段代码中,您创建了
DweetForm并且从 Django 的ModelForm中继承了。以这种方式创建表单在很大程度上依赖于 Django 建立的抽象,这意味着在本教程中,您只需要自己定义很少的内容就可以获得一个工作表单:
第 3 到 4 行:您导入 Django 的内置
forms模块和您在本系列教程的前一部分中创建的Dweet模型。第 6 行:您创建了一个新类
DweetForm,它继承了forms.ModelForm。第 7 行:传递希望表单呈现的字段,并定义其类型。在这种情况下,您需要一个允许文本输入的字符字段。
body是唯一的字段,您将它设为必填字段,这样就不会有任何空的数据工作表。第 9 行:你在
DweetForm中创建一个Meta选项类。这个 options 类允许您将任何不是字段的信息传递给 form 类。第 10 行:你需要定义
ModelForm应该从哪个模型获取信息。因为您想要制作一个允许用户创建 dweets 的表单,所以这里的Dweet是正确的选择。第 11 行:通过将您想要排除的模型字段的名称添加到
exclude元组中,您可以确保 Django 在创建表单时会省略它。记得在"user"后面加一个逗号(,),这样 Python 就会为你创建一个 tuple!你想让 dweet 提交尽可能的用户友好。用户登录后只能在你的社交网络上创建电子表格,并且只能为自己创建电子表格。因此,您不需要显式地传递哪个用户正在表单内发送 dweet。
注意:将一个 dweet 关联到一个用户是必要的,但是您将在后端处理它。
本教程中描述的设置保存了 Django 创建 HTML 表单所需的所有信息,这些表单捕捉了您在前端需要的所有信息。是时候看看那头了。
在您的模板中呈现表单
在
forms.py中创建DweetForm之后,您可以在代码逻辑中导入它,并将信息发送到您的仪表板模板:# dwitter/views.py from django.shortcuts import render from .forms import DweetForm from .models import Profile def dashboard(request): form = DweetForm() return render(request, "dwitter/dashboard.html", {"form": form})通过对
views.py的这些修改,您首先从forms.py导入了DweetForm。然后,您创建了一个新的DweetForm实例,将其分配给form,并将其传递到您的上下文字典中的仪表板模板,位于键"form"下。此设置允许您在模板中访问和呈现表单:<!-- dwitter/templates/dwitter/dashboard.html --> {% extends 'base.html' %} {% block content %} <div class="column"> {% for followed in user.profile.follows.all %} {% for dweet in followed.user.dweets.all %} <div class="box"> {{dweet.body}} <span class="is-small has-text-grey-light"> ({{ dweet.created_at }} by {{ dweet.user.username }} </span> </div> {% endfor %} {% endfor %} </div> <div class="column is-one-third"> {{ form.as_p }} </div> {% endblock content %}您分配给
<div>元素的 HTML 类使用布尔玛的 CSS 规则在您的仪表板页面上创建一个新列。这个额外的列使页面不那么拥挤,并将提要内容与表单分开。然后用{{ form.as_p }}呈现 Django 表单。事实上,会出现一个输入框:
这个设置显示了 Django 表单的最小显示。它只有一个字段,就像您在
DweetForm中定义的一样。然而,它看起来不太好,文本字段似乎太小,并且在输入字段旁边有一个标签,上面写着 Body 。这不是你要求的!您可以通过
forms.py中的小部件到forms.CharField添加定制来改进 Django 表单的显示:1# dwitter/forms.py 2 3from django import forms 4from .models import Dweet 5 6class DweetForm(forms.ModelForm): 7 body = forms.CharField( 8 required=True, 9 widget=forms.widgets.Textarea( 10 attrs={ 11 "placeholder": "Dweet something...", 12 "class": "textarea is-success is-medium", 13 } 14 ), 15 label="", 16 ) 17 18 class Meta: 19 model = Dweet 20 exclude = ("user", )通过将一个 Django 小部件添加到
CharField中,您可以控制 HTML 输入元素如何表示的几个方面:
第 9 行:在这一行中,你选择 Django 应该使用的输入元素的类型,并将其设置为
Textarea。这个Textarea小部件将呈现为一个 HTML<textarea>元素,为用户输入他们的 dweets 提供更多空间。第 10 行到第 13 行:您可以使用
attrs中定义的设置进一步定制Textarea。这些设置在你的<textarea>元素上呈现为 HTML 属性。第 11 行:您添加了占位符文本,它将显示在输入框中,并在用户单击表单字段输入他们的 dweet 时消失。
第 12 行:你添加了 HTML 类
"textarea",它与由布尔玛定义的 textarea CSS 样式规则相关,将使你的输入框更有吸引力,并与页面的其余部分更好地匹配。您还添加了两个额外的类,is-success和is-medium,它们分别以绿色显示输入字段并增加文本大小。第 15 行:您将
label设置为一个空字符串(""),这将删除之前显示的正文文本,因为 Django 默认设置将表单字段的名称作为其标签。只需在
Textarea中做一些定制,你就可以让你的输入框更好地适应页面的现有风格:
输入框看起来不错,但还不是功能性表单。有人要一个提交按钮吗?
使表单提交成为可能
Django 表单可以省去创建和设计表单字段的麻烦。但是,您仍然需要将 Django 表单包装到 HTML
<form>元素中,并添加一个按钮。要创建允许 POST 请求的函数表单,还需要相应地定义 HTTP 方法:1<!-- dwitter/templates/dwitter/dashboard.html --> 2 3{% extends 'base.html' %} 4 5{% block content %} 6 7<div class="column"> 8 {% for followed in user.profile.follows.all %} 9 {% for dweet in followed.user.dweets.all %} 10 <div class="box"> 11 {{dweet.body}} 12 <span class="is-small has-text-grey-light"> 13 ({{ dweet.created_at }} by {{ dweet.user.username }} 14 </span> 15 </div> 16 {% endfor %} 17 {% endfor %} 18</div> 19 20<div class="column is-one-third"> 21 <form method="post"> 22 {% csrf_token %} 23 {{ form.as_p }} 24 27 </form> 28</div> 29 30{% endblock content %}通过对 HTML 代码的另一次增量更新,您完成了 dweet 提交表单的前端设置:
- 第 21 行和第 27 行:您将表单代码包装到一个 HTML
<form>元素中,并将method设置为"post",因为您希望通过 POST 请求发送用户提交的消息。- 第 22 行:您添加了一个 CSRF 令牌,使用的模板标签与您在创建表单时使用的相同,用于关注和取消关注配置文件。
- 第 24 到 26 行:您通过
class属性添加了一个带有一些布尔玛风格的按钮来完成表单,这允许您的用户提交他们输入的文本。该表单看起来不错,似乎可以接收您的输入了:
当你点击 Dweet 按钮时会发生什么?不多,因为你还没有设置任何代码逻辑来补充你的前端代码。下一步是在
views.py中实现提交功能:1# dwitter/views.py 2 3def dashboard(request): 4 if request.method == "POST": 5 form = DweetForm(request.POST) 6 if form.is_valid(): 7 dweet = form.save(commit=False) 8 dweet.user = request.user 9 dweet.save() 10 form = DweetForm() 11 return render(request, "dwitter/dashboard.html", {"form": form})通过对
dashboard()的一些补充,您可以让视图处理提交的数据并在数据库中创建新的 dweets:
第 4 行:如果用户通过 HTTP POST 请求提交表单,那么您需要处理表单数据。如果视图函数是由于 HTTP GET 请求而被调用的,那么您将直接跳过整个代码块进入第 10 行,并在第 11 行呈现一个空表单。
第 5 行:用通过 POST 请求传入的数据填充
DweetForm。根据您在forms.py中的设置,Django 会将数据传递给body。created_at将被自动填充,并且您明确排除了user,因此它现在将保持为空。第 6 行: Django 表单对象有一个名为
.is_valid()的方法,它将提交的数据与表单中定义的预期数据以及相关的模型限制进行比较。如果一切正常,该方法返回True。只有当提交的表单有效时,才允许代码继续运行。第 7 行:如果您的表单已经包含了创建一个新数据库条目所需的所有信息,那么您可以使用
.save()而不用任何参数。但是,您仍然缺少与 dweet 相关联的必需的user条目。通过添加commit=False,您还可以防止向数据库提交条目。第 8 行:您从 Django 的
request对象中选择当前登录的用户对象,并将其保存到您在前一行中创建的dweet中。这样,通过与当前用户建立关联,您已经添加了缺少的信息。第 9 行:最后,您的
dweet拥有了它需要的所有信息,因此您可以成功地在关联表中创建新条目。现在可以用.save()将信息写入数据库。第 10 行到第 11 行:无论您是否已经处理了 POST 提交,您总是会向
render()传递一个新的空DweetForm实例。这个函数调用用一个新的空白表单重新显示页面,为您的更多想法做好准备。至此,您已经成功地创建了文本输入表单,并将其与您的代码逻辑连接起来,因此提交将被正确处理。在本系列教程的这一部分中,您还了解了 Django 表单。您在模板中呈现了一个表单,然后通过在一个
Textarea小部件中定制属性来应用布尔玛样式。在你准备向现实生活中的用户开放你的 Django 社交网络之前,有一个问题你需要解决。如果你写了一个 dweet 并且现在提交,它会被添加,但是如果你在提交后重新加载页面,同样的 dweet 会再次被添加!
步骤 11:防止重复提交并处理错误
此时,您可以通过应用程序的前端创建新的 dweet,并在仪表板上查看您自己的 dweet 以及您关注的个人资料的 dweet。在这一步结束时,您将已经避免了两次 dweet 提交,并学习了 Django 如何显示文本输入的错误。
但是首先,你应该知道问题是什么。转到您的仪表盘,写一份鼓舞人心的 dweet,点击 Dweet 提交。您将看到它出现在时间线中显示的 dweet 列表中,并且 dweet 表单将再次显示为空。
无需执行任何其他操作,使用键盘快捷键重新加载页面:
- macOS 上的
Cmd+R- Windows 和 Linux 上的
Ctrl+R您的浏览器可能会弹出一个窗口,询问您是否要再次发送表单。如果该信息出现,按下发送确认。现在您会注意到,您之前发送的同一条 dweet 再次出现在您的仪表板上。您可以想做多少次就做多少次:
在提交一个 dweet 之后,Django 会发送另一个包含相同数据的 POST 请求,如果您重新加载页面,就会在数据库中创建另一个条目。您将看到 dweet 第二次弹出。还有第三次。第四次。Django 会在你重新加载的时候不断复制 dweets。你不想那样的!
防止重复提交
为了避免双重 dweet 提交,你必须防止你的应用程序保留请求数据,这样重载就没有机会重新提交数据。您可以通过使用一个 Django 重定向来做到这一点:
# dwitter/views.py from django.shortcuts import render, redirect # ... def dashboard(request): if request.method == "POST": form = DweetForm(request.POST) if form.is_valid(): dweet = form.save(commit=False) dweet.user = request.user dweet.save() return redirect("dwitter:dashboard") form = DweetForm() return render(request, "dwitter/dashboard.html", {"form": form})通过导入
redirect()并在成功地将一个新提交的 dweet 添加到您的数据库后返回对它的调用,您将用户送回同一个页面。但是,这一次您在重定向时发送了一个 GET 请求,这意味着任何数量的页面重新加载都只会显示已经存在的 dweets,而不会创建大量克隆的 dweets。您可以通过引用在 URL 配置中定义的
path()的app_name变量和name关键字参数进行设置:
"dwitter"是描述你的 app 命名空间的app_name变量。您可以在传递给redirect()的字符串参数中的冒号(:)之前找到它。"dashboard"是指向dashboard()的path()条目的name关键字参数的值。您需要将它添加到传递给redirect()的字符串参数中的冒号(:)之后。要使用如上所示的
redirect(),您需要在dwitter/urls.py中相应地设置名称间距,这是您在教程系列的的前一部分中所做的:# dwitter/urls.py # ... app_name = "dwitter" urlpatterns = [ path("", dashboard, name="dashboard"), # ...通过如上所示设置的
urls.py,在成功处理表单提交的 POST 请求后,您可以使用redirect()通过 GET 请求将用户指向他们的仪表板页面。在条件语句的末尾返回
redirect()后,任何重新加载都只加载页面而不重新提交表单。您的用户现在可以安全地提交简短的电子表格,而不会出现意外的结果。然而,当 dweet 超过 140 个字符的限制时会发生什么呢?尝试键入超过 140 个字符限制的长 dweet 并提交。会发生什么?没什么!但是也没有错误消息,所以你的用户可能甚至不知道他们做错了什么。
此外,您输入的文本不见了,这是设计不良的用户表单的一大烦恼。因此,您可能希望通过通知用户他们做错了什么并保留他们输入的文本来为用户提供更好的体验!
处理提交错误
您在模型中定义了基于文本的消息的最大长度为 140 个字符,并且在用户提交文本时强制执行这一点。然而,当他们超过字符限制时,你不能告诉他们。当他们提交太长的 dweet 时,他们的输入会丢失。
好消息是,您可以使用用
{{ form.as_p }}呈现的 Django 表单来显示错误消息,这些消息与表单对象一起发送,而不需要添加任何代码。这些错误消息可以显著改善用户体验。但是目前,您看不到任何错误消息,这是为什么呢?再看看
dashboard():1# dwitter/views.py 2 3# ... 4 5def dashboard(request): 6 if request.method == "POST": 7 form = DweetForm(request.POST) 8 if form.is_valid(): 9 dweet = form.save(commit=False) 10 dweet.user = request.user 11 dweet.save() 12 return redirect("dwitter:dashboard") 13 form = DweetForm() 14 return render(request, "dwitter/dashboard.html", {"form": form})在突出显示的行中,您可以看到您正在创建两个不同的
DweetForm对象中的一个,或者是绑定的或者是未绑定的窗体:
- 第 7 行:如果你的函数被 POST 请求调用,你用请求中的数据实例化
DweetForm。Django 创建了一个可以访问数据并得到验证的绑定表单。- 第 13 行:如果您的页面被 GET 请求调用,那么您正在实例化一个没有任何相关数据的未绑定表单。
到目前为止,这个设置工作得很好,很有意义。如果用户通过导航访问页面,您希望显示一个空表单;如果用户编写一个 dweet 并将其发送到数据库,您希望验证并处理表单中提交的数据。
然而,症结就在这里的细节上。您可以——也应该——验证绑定的表单,您可以在第 8 行中这样做。如果验证通过,dweet 将被写入数据库。但是,如果用户添加了太多的字符,那么您的表单验证就会失败,并且您的条件语句中的代码不会被执行。
Python 跳转到第 13 行,在那里用一个空的未绑定的
DweetForm对象覆盖form。这个表单将被发送到您的模板并呈现出来。因为您用一个未绑定表单覆盖了包含验证错误信息的绑定表单,所以 Django 不会显示任何发生的验证错误。如果发生验证错误,要将绑定表单发送到模板,您需要稍微更改一下代码:
# dwitter/views.py # ... def dashboard(request): form = DweetForm(request.POST or None) if request.method == "POST": if form.is_valid(): dweet = form.save(commit=False) dweet.user = request.user dweet.save() return redirect("dwitter:dashboard") return render(request, "dwitter/dashboard.html", {"form": form})通过这一更改,您删除了重复的
DweetForm实例化,因此无论用户是否提交了有效的表单,只有一个form会被传递到您的模板。注: Python 的布尔
or运算符是一个短路运算符。这意味着如果第一个参数是False或 falsy ,那么它只计算第二个参数。您用于此更改的语法可能看起来不熟悉。事情是这样的:
POST 请求:如果您用包含任何数据的 POST 请求调用
dashboard(),那么request.POSTQueryDict将包含您的表单提交数据。request.POST对象现在有了一个真值,Python 将短路or操作符以返回request.POST的值。这样,在实例化DweetForm时,您将把表单内容作为参数传递,就像之前使用form = DweetForm(request.POST)一样。GET 请求:如果用 GET 请求调用
dashboard(),那么request.POST将为空,这是一个 falsy 值。Python 将继续计算or表达式,并返回第二个值None。因此,Django 将把DweetForm实例化为一个未绑定的表单对象,就像您之前对form = DweetForm()所做的那样。这种设置的优点是,即使表单验证失败,您现在也可以将绑定的表单传递给模板,这允许 Django 的
{{ form.as_p }}为您的用户提供一个现成的描述性错误消息:
在提交超过您在
Dweet中定义的字符限制的文本后,您的用户将会看到一个描述性的错误消息弹出在表单输入字段的正上方。这条消息给他们反馈,他们的 dweet 还没有提交,提供关于为什么会发生这种情况的信息,甚至给出关于他们当前文本有多少字符的信息。注意:你不需要在你的模板中添加任何 HTML 来进行修改。Django 知道当表单提交错误在{{ form.is_p }}标记内的绑定表单对象中发送时如何呈现。
这一变化最大的好处是传递了绑定的表单对象,该对象保留了用户在表单中输入的文本数据。没有数据丢失,他们可以使用有用的建议来编辑他们的 dweet 并成功地提交给数据库。
第 12 步:改善前端用户体验
至此,您已经有了一个使用 Django web 框架构建的功能性社交媒体应用程序。您的用户可以发布基于文本的消息,关注和取消关注其他用户配置文件,并在其仪表板视图上查看 dweets。在这一步结束时,您将通过添加额外的导航链接和排序 dweets 以首先显示最新的 dweets 来改善您的应用程序的用户体验。
改进导航
您的社交网络有三个不同的页面,您的用户可能希望在不同的时间访问:
- 空 URL 路径(
/)指向仪表板页面。/profile_listURL 路径指向配置文件列表。/profile/<int>URL 路径指向特定用户的个人资料页面。您的用户已经可以通过他们各自的 URL slugs 访问所有这些页面。但是,虽然您的用户可以通过点击所有简档列表中的用户名卡来访问简档页面,但目前没有直接导航来访问简档列表或仪表板页面。是时候添加更多的链接了,这样用户就可以方便地在你的 web 应用程序的不同页面之间移动。
回到你的模板文件夹,打开
dashboard.html。在 dweet 表单上方添加两个按钮,允许用户导航到应用程序中的不同页面:
- 简档列表页面
- 他们的个人资料页面
您可以在 Django 的{% url %}标签中使用之前使用过的动态 URL 模式:
<!-- dwitter/templates/dwitter/dashboard.html --> <!-- ... --> <div class="block"> <a href="{% url 'dwitter:profile_list' %} "> <button class="button is-dark is-outlined is-fullwidth"> All Profiles </button> </a> </div> <div class="block"> <a href="{% url 'dwitter:profile' request.user.profile.id %} "> <button class="button is-success is-light is-outlined is-fullwidth"> My Profile </button> </a> </div> <!-- ... -->您可以将这段代码作为前两个元素添加到
<div class="column is-one-third">中。您还可以在 dweet 表单上方添加一个标题,以便更清楚地解释该表单的用途:<!-- dwitter/templates/dwitter/dashboard.html --> <!-- ... --> <div class="block"> <div class="block"> <h2 class="title is-2">Add a Dweet</p> </div> <div class="block"> <form method="post"> {% csrf_token %} {{ form.as_p }} <button class="button is-success is-fullwidth is-medium mt-5" type="submit">Dweet </button> </form> </div> </div> <!-- ... -->通过添加这两个元素,您使用了
"block"类将三个<div>元素排列在彼此之上,并且添加了可感知的导航按钮来增强您的仪表板页面上的用户体验:
添加所有这些更改后,您的仪表板模板就完成了。您可以将您编写的代码与下面的模板进行比较:
<!-- dwitter/templates/dwitter/dashboard.html --> {% extends 'base.html' %} {% block content %} <div class="column"> {% for followed in user.profile.follows.all %} {% for dweet in followed.user.dweets.all %} <div class="box"> {{dweet.body}} <span class="is-small has-text-grey-light"> ({{ dweet.created_at }} by {{ dweet.user.username }} </span> </div> {% endfor %} {% endfor %} </div> <div class="column is-one-third"> <div class="block"> <a href="{% url 'dwitter:profile_list' %} "> <button class="button is-dark is-outlined is-fullwidth"> All Profiles </button> </a> </div> <div class="block"> <a href="{% url 'dwitter:profile' request.user.profile.id %} "> <button class="button is-success is-light is-outlined is-fullwidth"> My Profile </button> </a> </div> <div class="block"> <div class="block"> <h2 class="title is-2">Add a Dweet</p> </div> <div class="block"> <form method="post"> {% csrf_token %} {{ form.as_p }} <button class="button is-success is-fullwidth is-medium mt-5" type="submit">Dweet </button> </form> </div> </div> </div> {% endblock content %}您的仪表板页面功能齐全,外观精美!这很重要,因为当你的用户与你的社交网络互动时,它很可能是你的用户花费大部分时间的页面。因此,你也应该给你的用户足够的机会在导航后返回到仪表板页面,例如,导航到他们的个人资料页面。
为了实现这一点,您可以在所有页面的顶部添加一个指向仪表板页面的链接,方法是将其添加到您在
base.html中编写的应用程序标题:<!-- templates/base.html --> <!-- ... --> <a href="{% url 'dwitter:dashboard' %} "> <section class="hero is-small is-success mb-4"> <div class="hero-body"> <h1 class="title is-1">Dwitter</h1> <p class="subtitle is-4"> Your tiny social network built with Django </p> </div> </section> </a> <!-- ... -->通过将 HTML
<section>元素包装在一个 link 元素中,你使得整个英雄是可点击的,并且给你的用户一个从应用程序的任何地方返回到他们的仪表板页面的快速方法。通过这些更新的链接,您已经显著改善了应用程序的用户体验。最后,如果您的用户想要了解他们网络中的最新 dweet,您需要更改 dweet 显示,首先显示最新的 dweet,而不管是谁写的文本。
对数据表进行排序
有几种方法可以对数据工作表进行排序,在一些地方可以进行排序,即:
- 在你的模型中
- 在您的查看功能中
- 在您的模板中
到目前为止,您已经在仪表板模板中构建了相当多的代码逻辑。但是关注点的分离是有原因的。正如您将在下面学到的,您应该在视图中处理应用程序的大部分代码逻辑。
如果您想对 dweet 进行排序,以首先显示最新的 dweet,而不管是谁编写了该 dweet,那么您可能会绞尽脑汁地想如何使用您当前在仪表板模板中使用的嵌套的
for循环语法来做到这一点。你知道为什么这会变得困难吗?前往
dashboard.html并检查当前设置:{% for followed in user.profile.follows.all %} {% for dweet in followed.user.dweets.all %} <div class="box"> {{dweet.body}} <span class="is-small has-text-grey-light"> ({{ dweet.created_at }} by {{ dweet.user.username }}) </span> </div> {% endfor %} {% endfor %}在这种情况下,你会如何尝试排序?你认为你会在哪里遇到困难,为什么?花点时间拿出你的铅笔和笔记本。充分利用你喜欢的搜索引擎,看看你是否能想出一个解决方案,或者解释一下为什么这个问题很难解决。
与其在模板中处理这么多代码逻辑,不如直接在
dashboard()中处理,并将排序后的结果传递给模板进行显示。到目前为止,您使用的视图函数只处理表单提交,并定义要呈现的模板。您没有编写任何额外的逻辑来确定从数据库中获取哪些数据。
在您的视图函数中,您可以使用带有修饰符的 Django ORM 调用来精确地获得您正在寻找的 dweets。
您将从一个用户在您的视图函数中关注的所有概要文件中获取所有的 dweets。然后,您将按照日期和时间对它们进行排序,并将一个名为
dweet的新排序的 iterable 传递给模板。您将使用此 iterable 在时间线中显示所有这些 dweets,从最新到最早排序:1# dwitter/views.py 2 3from django.shortcuts import render, redirect 4from .forms import DweetForm 5from .models import Dweet, Profile 6 7def dashboard(request): 8 form = DweetForm(request.POST or None) 9 if request.method == "POST": 10 if form.is_valid(): 11 dweet = form.save(commit=False) 12 dweet.user = request.user 13 dweet.save() 14 return redirect("dwitter:dashboard") 15 16 followed_dweets = Dweet.objects.filter( 17 user__profile__in=request.user.profile.follows.all() 18 ).order_by("-created_at") 19 20 return render( 21 request, 22 "dwitter/dashboard.html", 23 {"form": form, "dweets": followed_dweets}, 24 )在这次对
dashboard()的更新中,您做了一些值得进一步关注的更改:
第 5 行:您为
Dweet模型添加了一个导入。到目前为止,您不需要在视图中处理任何 dweet 对象,因为您是在模板中处理它们的。因为您现在想要过滤它们,所以您需要访问您的模型。第 16 行:在这一行中,您在
Dweet.objects上使用.filter(),这允许您根据字段查找从表中选择特定的 dweet 对象。您将这个调用的输出保存到followed_dweets。第 17 行(关键字):首先,定义 queryset 字段查找,这是一个 SQL
WHERE子句主要部分的 Django ORM 语法。您可以使用特定于 Django ORM 的双下划线语法(__)来跟踪数据库关系。您编写user__profile__in来访问用户的配置文件,并查看该配置文件是否在集合中,您将把该集合作为值传递给字段查找关键字参数。第 17 行(值):在这一行的第二部分,您提供了字段查找的第二部分。该零件需要是一个包含轮廓对象的
QuerySet对象。您可以通过访问当前登录用户配置文件(request.user.profile)的.follows中的所有配置文件对象,从您的数据库中获取相关的配置文件。第 18 行:在这一行中,您将另一个方法调用链接到数据库查询的结果,并声明 Django 应该按照
created_at的降序对 dweets 进行排序。第 23 行:最后,你向你的上下文字典添加一个新条目,在这里你传递
followed_dweets。followed_dweets变量包含当前用户关注的所有配置文件的所有 dweet 的QuerySet对象,按最新的 dweet 排序。您将它传递到您的模板中,键名为dweets。您现在可以更新
dashboard.html中的模板来反映这些变化,并减少您需要在模板中编写的代码逻辑的数量,有效地摆脱您的嵌套for循环:<!-- dwitter/templates/dwitter/dashboard.html --> <!-- ... --> {% for dweet in dweets %} <div class="box"> {{dweet.body}} <span class="is-small has-text-grey-light"> ({{ dweet.created_at }} by {{ dweet.user.username }} </span> </div> {% endfor %} <!-- ... -->您已经使预先选择和预先排序的 dweets 在名称
dweets下可用于您的模板。现在,您可以用一个for循环迭代那个QuerySet对象,并访问 dweet 属性,而不需要遍历模板中的任何模型关系。在做出这一更改后,继续重新加载页面。现在,您可以看到您关注的所有用户的所有电子表格,最新的电子表格排列在最上面。如果您在关注自己的帐户时添加了新的 dweet,它将出现在列表的最上方:
此更改完成了您需要进行的最后更新,以便您的 Django 社交媒体应用程序提供用户友好的体验。现在你可以宣布你的 Django 社交媒体应用功能完成,并开始邀请用户。
结论
在本教程中,您使用 Django 构建了一个小型社交网络。您的应用程序用户可以关注和取消关注其他用户档案,发布简短的文本消息,并查看他们关注的其他档案的消息。
在构建这个项目的过程中,您已经学会了如何:
- 从头到尾构建一个 Django 项目
- 实现 Django 车型之间
OneToOne和ForeignKey的关系- 用定制的
Profile模型扩展 Django 用户模型- 定制 Django 管理界面
- 整合布尔玛 CSS 到风格你的应用
您已经在本教程中涉及了很多内容,并构建了一个可以与朋友和家人分享的应用程序。你也可以把它作为作品集项目展示给潜在雇主。
您可以通过点击下面的链接并转到
source_code_final/文件夹来下载该项目的最终代码:获取源代码: 单击此处获取源代码,您将使用用 Django 构建和提交 HTML 表单。
接下来的步骤
如果你已经创建了一个作品集网站,在那里添加你的项目到展示你的作品。你可以不断改进你的 Django 社交网络,增加功能,让它更加令人印象深刻。
以下是一些让你的项目更上一层楼的想法:
- 实现用户认证:允许新用户按照Django 入门第二部分:Django 用户管理中概述的步骤通过您的 web 应用前端注册。
- 部署您的 Dwitter 项目:通过在 Heroku 上托管您的 Django 项目,将您的 web 应用程序放在网上供全世界查看。
- 社交:邀请你的朋友加入你的 Django 社交网络,开始互相交流你的想法。
你还能想出什么其他的主意来扩展这个项目?在下面的评论中分享你的项目链接和进一步发展的想法!
与布尔玛一起构建 Django 前端—第 2 部分
在这个由四部分组成的教程系列中,您将与 Django 一起构建一个社交网络,您可以在文件夹中展示这个网络。这个项目将加强你对 Django 模型之间关系的理解,并向你展示如何使用表单,以便用户可以与你的应用程序以及彼此之间进行交互。通过使用布尔玛 CSS 框架,你还可以让你的 Django 前端看起来更好。
在第一部分中,您扩展了 Django
User模型,添加了允许用户相互关注和取消关注的个人资料信息。您还了解了如何定制 Django 管理界面,以及如何在开发过程中借助 Django 的错误消息进行故障排除。在本系列教程的第二部分,您将学习如何:
- 整合布尔玛 CSS 和风格你的应用
- 使用模板继承来减少重复
- 在文件夹层次结构中构建 Django 模板
- 构建路由和查看功能
- 使用动态网址链接应用程序的个页面
完成这个项目的第二部分后,你将继续这个教程系列的第三部分,在这里你将创建一个向你的社交网络添加内容的后端。您还将添加缺少的模板,以允许您的用户在其仪表板页面上查看基于文本的内容。
你可以点击下面的链接,进入
source_code_start/文件夹,下载启动项目第二部分所需的代码:获取源代码: 点击此处获取构建 Django 社交网络的源代码。
演示
在这个由四部分组成的教程系列中,您将构建一个小型社交网络,允许用户发布基于文本的简短消息。您的应用程序用户还可以关注其他用户简档以查看这些用户的帖子,或者取消关注他们以停止查看他们基于文本的帖子:
https://player.vimeo.com/video/643455270?background=1
在本系列的第二部分中,您将使用模板并学习使用 CSS 框架布尔玛来为您的应用程序提供用户友好的外观。您还将处理一些常见任务,例如为个人用户资料页面设置路由、视图和模板,以及将它们与资料列表页面链接起来:
https://player.vimeo.com/video/643455162?background=1
在本系列教程的这一部分结束时,您将能够访问详细信息页面和简档列表页面,并在它们之间导航。您还将添加布尔玛来设计页面样式。
项目概述
在这一节中,您将对本系列教程的第二部分中涉及的主题有一个概述。您还将有机会重温完整的项目实现步骤,以防您需要从本系列的前一部分跳回到上一步,或者如果您想看看前面还有什么。
此时,您应该已经完成了本教程系列的第一部分。如果是的话,那么您已经准备好继续下一步了,这一步的重点是模板和前端样式:
第四步 用布尔玛创建一个基础模板 第五步 列出所有用户资料 第六步 访问个人资料页面 完成该系列第二部分的所有步骤后,您可以继续进行第三部分。
为了让你回忆起来,并对如何构建 Django 社交网络这一系列的四个部分有一个大致的了解,你可以展开下面的可折叠部分:
在本系列的多个独立教程中,您将分多个步骤实现该项目。有很多内容需要讨论,您将一路深入细节:
- 步骤 1: 设置基础项目
- 步骤 2: 扩展 Django 用户模型
- 步骤 3: 实现一个保存后挂钩
- 第四步:用布尔玛创建一个基础模板
- 第 5 步:列出所有用户资料
- 第 6 步:访问个人资料页面
- 第 7 步:关注和取消关注其他个人资料
- 步骤 8: 为 Dweets 创建后端逻辑
- 第九步:在前端显示 Dweets
- 步骤 10: 通过 Django 表单提交 Dweets
- 步骤 11: 防止重复提交并处理错误
- 第十二步:改善前端用户体验
这些步骤中的每一步都将提供任何必要资源的链接。通过一次完成一个步骤,你将有机会停下来,在你想休息一下的时候再回来。
记住了本系列教程的高级结构,您就可以很好地了解自己所处的位置以及将在后面的部分中处理的实现步骤。
在开始下一步之前,快速浏览一下先决条件,浏览一下可能有帮助的其他资源的链接。
先决条件
为了成功地完成项目的这一部分,你需要完成关于模型和关系的第一部分,并且你应该确认你的项目正在如那里所描述的那样工作。最好你也能熟悉以下概念:
- 在 Python 中使用面向对象编程
- 建立 Django 基础项目
- 管理路由和重定向,查看功能,模板,模型,以及 Django 中的迁移
- 使用和定制 Django 管理界面
- 使用类属性读写 HTML
请记住,现在您应该已经完成了本系列的第一部分。这第二部分将从你在那一部分结束时停下的地方继续。
注意:如果您没有准备好第一部分的工作项目,您将无法继续本系列教程的这一部分。
您也可以通过点击下面的链接并转到
source_code_start/文件夹来下载启动该项目第二部分所需的代码:获取源代码: 点击此处获取构建 Django 社交网络的源代码。
关于额外的先决条件和进一步的链接,请查看本系列教程第一部分中提到的关于在 Django 构建基本社交网络的先决条件。
步骤 4:用布尔玛创建一个基础模板
完成本教程系列的前三个步骤(您可以在第一部分中补上)后,您的用户配置文件现在会在您创建新用户时自动创建。用户简档包含用户关注哪些其他简档的信息。
在这一步的最后,你已经建立了模板文件夹结构,并创建了一个使用布尔玛 CSS 框架的基本模板,用于现代用户界面。
很有可能,你打算把这个项目展示给其他人,或者把它添加到你的文件夹中。然而,当你没有面向用户的一面时,一个投资组合项目只有一半令人印象深刻。即使你的主要兴趣是后端开发,如果你的项目看起来很好,你的投资组合也会看起来更好。
注意:大多数大公司将产品前端和后端的职责划分给不同的开发团队,包括与 Django 合作时。然而,对如何不用太多努力就能让你的网站项目看起来不错有一个基本的理解是很有帮助的。
您将使用 Django 模板构建 web 应用程序的前端,框架通过请求 HTML 页面来呈现这些模板,您的用户将与这些页面进行交互。
创建一个基础模板
首先,您将在
dwitter/内的专用文件夹中为您的应用程序模板创建一个位置:dwitter/ │ ├── migrations/ │ ├── templates/ │ ├── __init__.py ├── admin.py ├── apps.py ├── models.py ├── tests.py └── views.py
templates/文件夹将保存与您的dwitter应用程序相关的所有模板。在这个文件夹中添加一个新文件,命名为base.html:dwitter/ │ ├── migrations/ │ ├── templates/ │ └── base.html │ ├── __init__.py ├── admin.py ├── apps.py ├── models.py ├── tests.py └── views.py你的
dwitter应用程序的文件夹结构应该像你上面看到的树形结构,其中base.html嵌套在templates/中。你现在可以打开
base.html并添加基本的 HTML 结构,你的所有模板将通过模板继承共享该结构:1<!-- dwitter/templates/base.html --> 2 3<!DOCTYPE html> 4<html lang="en"> 5<head> 6 <meta charset="UTF-8"> 7 <meta http-equiv="X-UA-Compatible" content="IE=edge"> 8 <meta name="viewport" content="width=device-width, initial-scale=1.0"> 9 <title>Dwitter</title> 10</head> 11<body> 12 <section> 13 <h1>Dwitter</h1> 14 <p>Your tiny social network built with Django</p> 15 </section> 16 <div> 17 {% block content %} 18 19 {% endblock content %} 20 </div> 21</body> 22</html>此 HTML 代码由一个样板 HTML 结构组成,并添加了一些特定于您的应用程序的内容,您希望在所有页面上都看到这些内容:
- 第 9 行:你给你的网络应用添加一个标题,它将显示在所有页面的浏览器标签中。
- 第 12 行到第 15 行:你添加一个标题和一个副标题。如果愿意,您可以自定义它们。
- 第 17 到 19 行:您添加了
blockDjango 模板标签,这打开了您的子模板可以将它们的内容注入到基础模板的空间。请随意将这段代码复制粘贴到您的文件中。理解为什么要使用模板继承以及子模板如何扩展
base.html的主要概念就足够了。查看您的基础模板
在开发代码时查看代码的结果通常会很有帮助。要让 Django 呈现和显示您的基本模板,您需要设置 URL 路由和查看功能。
在你称为
social的管理应用中打开你的主urls.py文件,然后将指向基本 URL 的请求转发到你的dwitter应用:1# social/urls.py 2 3from django.contrib import admin 4from django.urls import path, include 5 6urlpatterns = [ 7 path("", include("dwitter.urls")), 8 path("admin/", admin.site.urls), 9]在第 4 行,您从
django.urls导入include,然后在第 7 行使用它将所有对基本 URL ("")的请求重定向到您的dwitter应用程序的urls.py文件。稍后,您将更改该文件中的代码,以进一步分发传入的请求。注意:默认情况下,Django 应用不会自带
urls.py文件。然而,最好在你的 Django 项目中为每个应用程序创建一个 URL 配置,然后将它们包含在你的主 URLconf 中。对于每个新的应用程序,你需要创建一个新的urls.py文件。您现在可以创建您的
dwitter应用程序的urls.py文件,这样您就可以继续遵循请求通过您的项目的路径。这个文件应该位于dwitter/中其他 Python 文件的旁边:dwitter/ │ ├── migrations/ │ ├── templates/ │ └── base.html │ ├── __init__.py ├── admin.py ├── apps.py ├── models.py ├── tests.py ├── urls.py └── views.py创建完
dwitter/urls.py后,您可以打开文件并添加一些代码。这个文件的基本结构应该类似于social/urls.py,但是不需要处理/admin路径。捕捉对重定向到该文件的基本 URL 的传入请求,并将其发送到一个名为dashboard的新函数:# dwitter/urls.py from django.urls import path from .views import dashboard app_name = "dwitter" urlpatterns = [ path("", dashboard, name="dashboard"), ]在这段代码中,您从应用程序的
views.py文件中导入一个名为dashboard的视图函数。注意,你还没有创建dashboard()。此时,当您运行开发服务器时,您会遇到一条有用的错误消息,它会告诉您关于它的所有信息:File "/<your_path>/dwitter/urls.py", line 2, in <module> from .views import dashboard ImportError: cannot import name 'dashboard' from 'dwitter.views' (/<your_path>/dwitter/views.py)Django 在您的终端中告诉您,它不能从
dwitter.views导入名为dashboard的东西。这条错误消息让您知道下一步该去哪里。继续在views.py中创建dashboard(),让 Django 开心,并恢复你的应用程序的功能:# dwitter/views.py from django.shortcuts import render def dashboard(request): return render(request, "base.html")使用
dashboard(),您将传入的请求指向base.html,并告诉 Django 呈现该模板。如果您的开发服务器尚未运行,请启动它:(social) $ python manage.py runserver在
localhost:8000/导航到您的基本 URL,您应该看到您在基本模板中输入的文本现在呈现在您的浏览器中:
确实有一些文字,但是看起来不怎么样。会有很多人有兴趣加入一个只提供纯 HTML 文本的社交网络吗?
将布尔玛 CSS 添加到你的基础模板
你可以通过添加 CSS 来改善你的 HTML 的外观。但是编写自己的 CSS 文件可能需要大量的工作!CSS 框架是一个很好的选择,可以帮助你用更少的努力让你的 web 应用看起来更好。
在本教程中,你将使用 CSS 框架布尔玛为你处理 CSS 规则。首先,您需要让布尔玛 CSS 样式表对您的所有模板可用。一个快速的方法是添加一个样式表文件的链接,该文件托管在一个内容交付网络(CDN) 上,链接到基本模板的
<head>元素:<!-- dwitter/templates/base.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <!-- Include the Bulma CSS framework for styling --> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.9.3/css/bulma.min.css"> <title>Dwitter</title> </head> <body> <section> <h1>Dwitter</h1> <p>Your tiny social network built with Django</p> </section> <div> {% block content %} {% endblock content %} </div> </body> </html>如果您的开发服务器仍在运行,您应该会看到浏览器中显示的文本发生了变化:
你的页面看起来还没有那么不同,但是你可以看到字体家族已经改变了,证明你的应用可以通过 CDN 成功加载布尔玛的样式表。
现在,您可以通过使用该样式表中定义的预制类来继续改善页面的外观。您只需要将 HTML 类添加到您想要改变样式的 HTML 元素中:
<!-- dwitter/templates/base.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <!-- Include the Bulma CSS framework for styling --> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.9.3/css/bulma.min.css"> <title>Dwitter</title> </head> <body> <section class="hero is-small is-success mb-4"> <div class="hero-body"> <h1 class="title is-1">Dwitter</h1> <p class="subtitle is-4"> Your tiny social network built with Django </p> </div> </section> <div class="container"> <div class="columns"> {% block content %} {% endblock content %} </div> </div> </body> </html>在上面的代码片段中,您添加了少量额外的 HTML 元素来按照布尔玛建议的结构包装您的内容。此外,您向这些元素添加了预定义的 HTML 类。
这些类与您在
<head>中链接的布尔玛 CSS 样式表中的 CSS 样式规则相关联。因此,您的浏览器知道如何呈现添加了附加样式的元素:
看起来比以前好多了!要获得这些样式改进,您不需要定义任何 CSS 样式规则。您只需要实现适当的 HTML 结构,并分配您想要的布尔玛定义的 HTML 类。
在这一系列教程中,你会看到带有布尔玛 CSS 类名的 HTML。如果您目前不想了解这个 CSS 框架的更多信息,可以随意复制粘贴 HTML 代码,或者使用提供的代码作为一个有利的角度,从这里您可以探索布尔玛的更多功能。
注: 布尔玛的文献是出了名的难找。然而,另一项名为布尔玛搜索的服务可以让你更快地找到不同功能的文档页面。
在这一步中,您已经成功地在应用程序中创建了一个新的模板文件夹,并添加了一个基础模板,所有未来的模板都将继承该模板。您已经在
base.html中添加了一个到布尔玛 CSS 文件的链接,这使得所有子页面都可以访问这个 CSS 框架提供的样式。您还为您的项目设置了基本路由,确保对您的基本 URL 的请求被重定向到您的
dwitter应用程序,并创建了dashboard()作为当前呈现您的基本模板的占位符视图。在下一步中,您将创建一个子模板,它将显示所有用户配置文件的列表。
第五步:在 Django 应用程序的前端列出所有用户资料
在这一点上,您可以从您的基础模板继承,它通过布尔玛链接到样式支架。在这一步结束时,您将显示一个列出所有用户配置文件的页面,您将使用 CSS 框架以现代方式对其进行样式化。
首先,您将遵循 Django web 框架中的请求流,并编写您需要的代码。
编写路线和代码逻辑
对于您希望使用 Django 生成和显示的每个 web 页面,您可以考虑用户请求流经 web 应用程序的不同部分:
主题 文件位置 按指定路线发送 urls.py逻辑 views.py表现 templates/中的 HTML 文件当你写代码给查看你的基本模板时,你已经将所有指向基本 URL 的请求向前路由到你的
dwitter应用。现在,您将获取发送到dwitter/urls.py的/profile_list的请求,并从那里接收请求:# dwitter/urls.py from django.urls import path from .views import dashboard, profile_list app_name = "dwitter" urlpatterns = [ path("", dashboard, name="dashboard"), path("profile_list/", profile_list, name="profile_list"), ]通过添加这几行代码,您告诉 Django 您想要将到达
/profile_list的请求路由到名为profile_list()的视图函数。注意:你的 URL slug 和 view 函数的名字不需要匹配,但是用相同的名字来保持你的代码更加清晰和易于调试是有意义的。
就像之前一样,您还没有编写
profile_list(),这意味着如果您现在尝试运行您的 web 应用程序,您的开发服务器将会遇到错误。但是您很清楚下一步该去哪里,所以您打开dwitter/views.py并添加profile_list()的代码:1# dwitter/views.py 2 3from django.shortcuts import render 4from .models import Profile 5 6def dashboard(request): 7 return render(request, "base.html") 8 9def profile_list(request): 10 profiles = Profile.objects.exclude(user=request.user) 11 return render(request, "dwitter/profile_list.html", {"profiles": profiles})使用这段代码,您将定义视图函数,该函数将处理对
/profile_listURL slug 的所有请求:
- 第 4 行:使用相对路径从
dwitter/models.py导入Profile,其中圆点(.代表当前 app 目录。- 第 9 行:你创建
profile_list(),并把 Django 的request对象作为参数。- 第 10 行:您使用 Django 的对象关系映射器(ORM)来从您的 profile 表中检索对象,并将它们存储在
profiles中。您希望获得除您自己的用户配置文件之外的所有用户配置文件,这可以通过.exclude()来实现。- 第 11 行:最后,您返回一个对
render()的调用,向其传递一个您想要呈现的模板的字符串和一个包含profiles的上下文字典。简而言之,您从数据库中获取除了您自己的用户配置文件之外的所有用户配置文件,并将这些信息发送到路径为
dwitter/profile_list.html的模板中。但是这个模板还不存在,所以您必须在下一步创建它以避免混淆 Django。编写配置文件列表模板
您需要构建
profile_list.html以便 Django 可以在用户请求您的 web 应用程序的/profile_list端点时呈现模板。回到
dwitter/templates/,在那里创建另一个名为dwitter/的文件夹。在第二个dwitter/文件夹中,您可以创建一个名为profile_list.html的新文件:dwitter/ │ ├── migrations/ │ ├── templates/ │ │ │ ├── dwitter/ │ │ └── profile_list.html │ │ │ └── base.html │ ... └── views.py二级
dwitter/文件夹应该是dwitter/templates/的子文件夹,是base.html的同级。注意:你创建第二个
dwitter/文件夹的原因是为了避免将来你可能添加到你的项目中的其他应用程序模板的复杂性。你可以通过探索 Django 的双文件夹结构来了解更多。在
dwitter/templates/dwitter/project_list.html处打开您的新模板,并添加 HTML 以显示有关用户档案的信息:1<!-- dwitter/templates/dwitter/profile_list.html --> 2 3{% for profile in profiles %} 4 5<div> 6 <p>{{ profile.user.username }}</p> 7 <p>@{{ profile.user.username|lower }}</p> 8</div> 9 10{% endfor %}这段代码混合了 HTML 代码和 Django 模板语法:
- 第 3 行和第 10 行:使用一些循环代码逻辑来迭代
profiles中的项目,这是一个从视图函数发送过来的QuerySet对象。- 第 6 行:你显示每个用户的用户名。一旦你收集了更多关于用户的信息,你可以用他们的真实姓名来替换。
- 第 7 行:您第二次显示用户名,但是这次您对输出应用了一个模板过滤器来将其转换为小写。
虽然这个代码片段还不能代表一个合适的 HTML 结构,但是您的浏览器仍然足够智能来正确地呈现它。启动您的开发服务器并导航到
http://localhost:8000/profile_list以查看您的中间结果:
太好了,您的用户数据如预期显示。然而,它看起来还没有那么好。是时候添加您在
base.html中设置的脚手架,并添加更多特定于布尔玛的 HTML 结构和类来改善您的个人资料页面的外观和感觉了:<!-- dwitter/templates/dwitter/profile_list.html --> {% extends 'base.html' %} {% block content %} <div class="column"> {% for profile in profiles %} <div class="block"> <div class="card"> <a href="#"> <div class="card-content"> <div class="media"> <div class="media-left"> <figure class="image is-48x48"> <img src="https://bulma.img/placeholders/96x96.png" alt="Placeholder image"> </figure> </div> <div class="media-content"> <p class="title is-4"> {{ profile.user.username }} </p> <p class="subtitle is-6"> @{{ profile.user.username|lower }} </p> </div> </div> </div> </a> </div> </div> {% endfor %} </div> {% endblock content %}要进行这些更新,首先要扩展
base.html并将特定于站点的 HTML 封装到{% block content %}标签中。这个结构允许 Django 将子模板的内容插入到基础模板的 HTML 结构中。您还使用了一个布尔玛卡的 HTML 结构来改进每个用户的个人资料信息在页面上的显示方式。此外,您使用布尔玛
column类将整个 for-loop 逻辑包装到一个 HTML<div>元素中,该类实现了 CSS flexbox 来均匀地排列内容:
看起来比以前好多了!代码逻辑设置正确,布尔玛 CSS 样式应用于 URL 端点后,您已经为 Django web 应用程序创建了第一个合适的前端页面。
在这一步中,您已经将传入的对
/profile_list的请求路由到一个新的视图函数profile_list()。在这个函数中,除了当前用户的配置文件之外,您还从数据库中获取了所有用户的配置文件,并将数据发送到一个新的模板。你已经将新模板放在一个双文件夹结构中,用它扩展了你的基本模板,并通过应用布尔玛定义的 CSS 类使它看起来更好。第 6 步:访问个人资料页面
此时,您可以以视觉愉悦的方式显示所有用户配置文件。在这一步结束时,您已经为每个用户建立并链接了一个个人资料页面。
您将按照与前面类似的过程为各个概要文件页面构建路线、视图功能和模板。然后你将学习如何从
profiles_list.html链接到这些页面。建立个人资料页面模板
您将首先构建一个以前只能在 Django 管理界面中看到的页面。稍后,您将添加功能来关注和取消关注此个人资料页面中的个人资料。
回到
dwitter/urls.py,为您的新端点添加路由:# dwitter/urls.py from django.urls import path from .views import dashboard, profile_list, profile app_name = "dwitter" urlpatterns = [ path("", dashboard, name="dashboard"), path("profile_list/", profile_list, name="profile_list"), path("profile/<int:pk>", profile, name="profile"), ]与之前类似,您正在导入一个尚不存在的视图函数。你很快就会创造出
profile()。在urlpatterns的最后一个元素中,您分配一个路径,将用户指向各个个人资料页面。这里,您使用 Django 的尖括号语法,它允许您捕获路径组件。有了
<int:pk>,你就表示任何发送到profile/的 URL 请求,后面跟一个整数,应该被发送到dwitter/views.py中的profile()视图函数。同时,您将把这个整数作为一个名为pk的参数传递给profile(),这允许您从数据库中选择一个特定的概要文件:# dwitter/views.py # ... def profile(request, pk): profile = Profile.objects.get(pk=pk) return render(request, "dwitter/profile.html", {"profile": profile})
profile()函数接受 Django 的request对象和一个整数pk。您在对数据库的调用中使用了pk,这允许您通过主键 ID 选择一个特定的概要文件。最后,您返回另一个对render()的调用,并指示 Django 将收集到的 profile 对象发送到一个名为dwitter/profile.html的模板。注意:在本系列教程中,您将保持模板文件的名称和位置与 Django 用户管理教程中使用的结构一致。这样,一旦您准备好探索这个主题,您就有了一个有用的资源来帮助您为这个 Django 项目实现一个合适的面向前端的认证流程。
是时候安抚 Django,创造
dwitter/templates/dwitter/profile.html了。在您的新模板中,您需要显示每个用户的详细信息。您可以用{{ profile.user.username|upper }}显示他们的用户名,就像您之前在profile_list.html中所做的一样。您已经在后端代码逻辑中实现了
follows字段,这意味着您现在可以显示用户关注的所有配置文件:1<!-- dwitter/templates/dwitter/profile.html --> 2 3<ul> 4{% for following in profile.follows.all %} 5 <li>{{ following }}</li> 6{% endfor %} 7</ul>在上面显示的代码片段的第 4 行,您可以看到一个您可能还不熟悉的语法。您正在通过
profile.follows.all访问用户档案的关注者。这个语法为您提供了一个极好的机会来重温您在本系列教程的第一部分中建立的Profile模型:
profile是你在上下文字典中传递给profile()中的render()的变量。它保存您从数据库中提取的关于用户配置文件的信息。.follows让您可以访问ManyRelatedManager对象,该对象保存当前配置文件遵循的所有用户配置文件。.all获取所有这些用户配置文件实例,并允许您对它们进行迭代。将此代码添加到
profile.html中,以确认它按预期工作。您可能需要进入 Django 管理界面,在配置文件之间设置一些关注者关系,这样您就可以在配置文件页面上看到它们。与您添加显示用户关注的所有简档的列表的方式相同,尝试创建第二个列表,显示您所在简档页面的用户关注的所有简档的列表。
当在
Profile中将follows定义为多对多字段时,您可以通过使用"followed_by"作为related_name关键字参数来完成这项任务:# dwitter/models.py class Profile(models.Model): user = models.OneToOneField(User, on_delete=models.CASCADE) follows = models.ManyToManyField( "self", related_name="followed_by", symmetrical=False, blank=True ) def __str__(self): return self.user.username通过向
related_name显式传递一个值,您设置了可用于反向引用连接对象的名称:<!-- dwitter/templates/dwitter/profile.html --> <ul> {% for follower in profile.followed_by.all %} <li>{{ follower }}</li> {% endfor %} </ul>使用这个代码片段,您可以列出关注该用户的所有用户配置文件。请记住,您将用户对用户的关系设置为不对称的,这意味着用户可以关注其他人的个人资料,而他们不会关注该用户。
当你写下你的版本,你希望你的个人资料页面看起来如何时,浏览布尔玛文档。或者,您可以复制粘贴使用布尔玛的列、块和标题的实现,如下面折叠的代码块所示:
<!-- dwitter/templates/dwitter/profile.html --> {% extends 'base.html' %} {% block content %} <div class="column"> <div class="block"> <h1 class="title is-1"> {{profile.user.username|upper}}'s Dweets </h1> </div> </div> <div class="column is-one-third"> <div class="block"> <a href="#"> <button class="button is-dark is-outlined is-fullwidth"> All Profiles </button> </a> </div> <div class="block"> <h3 class="title is-4"> {{profile.user.username}} follows: </h3> <div class="content"> <ul> {% for following in profile.follows.all %} <li> <a href="#"> {{ following }} </a> </li> {% endfor %} </ul> </div> </div> <div class="block"> <h3 class="title is-4"> {{profile.user.username}} is followed by: </h3> <div class="content"> <ul> {% for follower in profile.followed_by.all %} <li> <a href="#"> {{ follower }} </a> </li> {% endfor %} </ul> </div> </div> </div> {% endblock content %}通过对个人简档模板的这一更改,您可以通过导航到每个用户的简档页面来显示每个用户的关注者及其关注的简档:
例如,如果您转到
http://127.0.0.1:8000/profile/1,那么您可以访问本地主机上的一个个人资料页面。这个 URL 向您显示 ID 为1的用户配置文件的配置文件页面。虽然您可以查看每个用户的个人页面,但是如果您想要查看他们的个人资料页面,您目前需要猜测用户个人资料的 ID。这种设置并不理想,所以你将从你的个人资料列表页面链接个人资料页面。
链接个人资料页面
现在您已经设置了个人资料页面,您还需要一种找到它们的方法。为此,您可以为显示在
profile_list.html中的每个个人资料添加一个链接到个人资料页面。注意:如果你想学习更多关于 Django 中的动态链接和 URL 模板标签的知识,你可以观看关于使用
app_name、路径名和参数的 URL 链接的课程。如果您已经复制了本教程前面显示的
profile_list.html的 HTML 代码,那么您会发现每个 profile card 都有一个现有的 link 元素(<a>)和一个当前指向英镑符号(#)的href属性。将英镑符号替换为 Django{% url %}标签,该标签链接到个人资料页面:<!-- dwitter/templates/dwitter/profile_list.html --> <!-- ... --> {% for profile in profiles %} <div class="block"> <div class="card"> <a href="{% url 'dwitter:profile' profile.id %}"> <div class="card-content"> <!-- ... More card code --> </div> </a> </div> </div> {% endfor %}当您以这种方式更新
href属性时,您链接到在您的dwitter应用程序的名称空间中名为profile的path()调用,并将每个配置文件的.id值作为参数传递:
{% url %}:Django 中的 URL 模板标签允许你创建到你的 web 应用的不同端点的动态链接。'dwitter:profile': 模板标签的这一部分定义了你的应用程序的名称空间(dwitter)和你希望你的链接重定向到的路径名(profile)。您在dwitter/urls.py到app_name中定义这些,并将name属性定义为path()。profile.id: 动态链接的最后一部分是一个参数,当重定向到定义的路径时,您会传递这个参数。在这种情况下,您将发送当前概要文件的.id,这是profile()正确解析和呈现profile.html相关用户信息的必要参数。通过这一更改,您已经完成了对
profile_list.html的设置。您现在可以启动您的开发服务器并访问/profile_list。您将看到,您可以单击单个用户个人资料卡来访问其个人资料页面:https://player.vimeo.com/video/643455162?background=1
但是,您还不能导航回配置文件列表。为了完善用户体验,您还将向包含您的个人资料页面视图中的按钮的链接的
href属性添加一个{% url %}标记,以便它链接回个人资料列表:<!-- dwitter/templates/dwitter/profile.html --> <div class="block"> <a href="{% url 'dwitter:profile_list' %}"> <button class="button is-dark is-outlined is-fullwidth"> All Profiles </button> </a> </div>通过将占位符井号(
#)替换为{% url 'dwitter:profile_list' %},您已经建立了一个动态链接,允许您从一个概要文件的详细信息页面导航回所有概要文件的列表。您在、和、列表中显示了某个档案关注的用户的姓名。但是,这些链接的
href属性目前仍然指向英镑符号(#)。为了改善您的 web 应用程序的用户体验,您可以将列表项目与单个用户个人资料页面相互链接。您需要分别链接回用户关注的每个人和关注用户的每个人的个人资料页面。因为
profile()需要一个配置文件 ID 作为参数,所以您需要在设置{% url %}标签时提供它:<!-- dwitter/templates/dwitter/profile.html --> <!-- ... --> <ul> {% for following in profile.follows.all %} <li> <a href="{% url 'dwitter:profile' following.id %}"> {{ following }} </a> </li> {% endfor %} </ul> <!-- ... --> <ul> {% for follower in profile.followed_by.all %} <li> <a href="{% url 'dwitter:profile' follower.id %}"> {{ follower }} </a> </li> {% endfor %} </ul> <!-- ... -->您给
profile.html添加了两个{% url %}标签。两者遵循相同的结构:
- 名称空间:名称空间
'dwitter:profile'允许 Django 重定向到views.py中的profile()。- 参数:参数,在这些例子中是
following.id或follower.id,将被传递给profile(),后者使用它从数据库中提取用户配置文件。通过将这些信息添加到
href属性,您已经将跟随和跟随列表与用户简档页面链接起来。你的社交网络的用户现在有一种直观的方式在不同的用户档案之间导航。在此步骤中,您已经为单个用户简档页面创建了路由、视图和模板。您再次使用了由布尔玛 CSS 框架定义的类来将样式应用到您的页面,并且您已经成功地链接了配置文件列表页面,以便您可以从那里访问详细页面并导航回配置文件列表。
结论
恭喜你!至此,您已经完成了关于用 Django 构建基本社交网络的教程系列的第二部分。
在本系列教程的第二部分中,您学习了如何:
- 整合布尔玛 CSS 到风格你的应用
- 使用模板继承来减少重复
- 在文件夹层次结构中构建 Django 模板
- 构建路由和查看功能
- 使用动态网址链接应用程序的个页面
您了解了如何处理使用 Django 显示每个页面所需的不同步骤,包括如何设置路由、视图和模板。您还了解了如何将 CSS 框架中的 CSS 样式应用到您的 Django 应用程序中,从而通过一个看起来令人愉快的界面来改善用户体验。
您可以点击下面的链接,进入
source_code_final/文件夹,下载您在项目的这一部分结束时应该拥有的代码:获取源代码: 点击此处获取构建 Django 社交网络的源代码。
Django 基础社交网络的后续步骤
现在您已经完成了本教程系列的第二部分,您可以继续下一部分,在这里您将在 Django 中构建和处理 POST 请求。
在教程系列的下一部分,您将添加代码逻辑,允许您的用户在 Django 应用程序的前端关注和取消关注个人资料。您还将设置
Dweet模型,在后端创建 dweets,并构建 dashboard 页面,用户将在这里访问平台上的内容。请记住,在进行这个项目时,您可以继续参考前面的步骤。例如,参考您在本系列教程第一部分的项目概述中起草的计划,并在您完成其余步骤的过程中更新您的计划可能会有所帮助。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号