
RealPython-中文系列教程-七-
RealPython 中文系列教程(七)
原文:RealPython
用 Python 和 Selenium 实现现代 Web 自动化
原文:https://realpython.com/modern-web-automation-with-python-and-selenium/
在本教程中,您将学习高级 Python web 自动化技术:在“无头”浏览器中使用 Selenium,将抓取的数据导出为 CSV 文件,并将抓取代码包装在 Python 类中。
动机:追踪聆听习惯
假设你已经在 bandcamp 听了一段时间的音乐,你发现自己希望能记起几个月前听过的一首歌。
当然,你可以挖掘你的浏览器历史,检查每一首歌,但这可能是一个痛苦…你所记得的是你几个月前听过这首歌,而且是在电子流派中。
“如果我有一份我的收听历史记录,那岂不是很棒,”你对自己说。我只要查一下两个月前的电子歌曲,就一定能找到。”
今天,您将构建一个名为BandLeader的基本 Python 类,它连接到 bandcamp.com 的,从首页的“发现”部分流式传输音乐,并跟踪您的收听历史。
收听历史将保存到磁盘上的 CSV 文件中。然后,您可以在您最喜欢的电子表格应用程序中甚至使用 Python 来研究该 CSV 文件。
如果您对 Python 中的 web 抓取有一些经验,那么您应该熟悉如何发出 HTTP 请求和使用 Python API 来导航 DOM。今天你会做更多同样的事情,除了一点不同。
今天,您将使用一个以无头模式运行的成熟浏览器来处理 HTTP 请求。
一个无头浏览器只是一个普通的网络浏览器,除了它不包含可见的 UI 元素。正如您所料,它不仅仅可以发出请求:它还可以呈现 HTML(尽管您看不到它),保存会话信息,甚至通过运行 JavaScript 代码来执行异步网络通信。
如果你想自动化现代网络,无头浏览器是必不可少的。
免费奖励: 点击此处下载一个“Python + Selenium”项目框架,其中包含完整的源代码,您可以使用它作为自己的 Python web 抓取和自动化应用程序的基础。
设置
在编写一行 Python 代码之前,你的第一步是为你最喜欢的浏览器安装一个受 Selenium 支持的 WebDriver 。接下来,你将使用 Firefox ,但是 Chrome 也可以轻松工作。
假设路径~/.local/bin在您的执行 PATH 中,下面是您如何在 Linux 机器上安装名为geckodriver的 Firefox WebDriver:
$ wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz
$ tar xvfz geckodriver-v0.19.1-linux64.tar.gz
$ mv geckodriver ~/.local/bin
接下来,你安装硒包,使用pip或你喜欢的任何东西。如果你为这个项目制作了一个虚拟环境,你只需输入:
$ pip install selenium
注意:如果你在本教程的过程中感到迷茫,完整的代码演示可以在 GitHub 上的找到。
现在是试驾的时候了。
试驾无头浏览器
为了测试一切是否正常,你决定通过 DuckDuckGo 尝试一个基本的网络搜索。您启动首选的 Python 解释器,并键入以下内容:
>>> from selenium.webdriver import Firefox >>> from selenium.webdriver.firefox.options import Options >>> opts = Options() >>> opts.set_headless() >>> assert opts.headless # Operating in headless mode >>> browser = Firefox(options=opts) >>> browser.get('https://duckduckgo.com')到目前为止,您已经创建了一个无头 Firefox 浏览器并导航到了
https://duckduckgo.com。您创建了一个Options实例,并在将它传递给Firefox构造函数时用它来激活无头模式。这类似于在命令行键入firefox -headless。
既然已经加载了页面,就可以使用新创建的
browser对象上定义的方法来查询 DOM。但是您如何知道要查询什么呢?最好的方法是打开您的 web 浏览器,并使用其开发工具来检查页面内容。现在,您希望获得搜索表单,以便提交查询。通过检查 DuckDuckGo 的主页,您发现搜索表单
<input>元素有一个id属性"search_form_input_homepage"。这正是你所需要的:
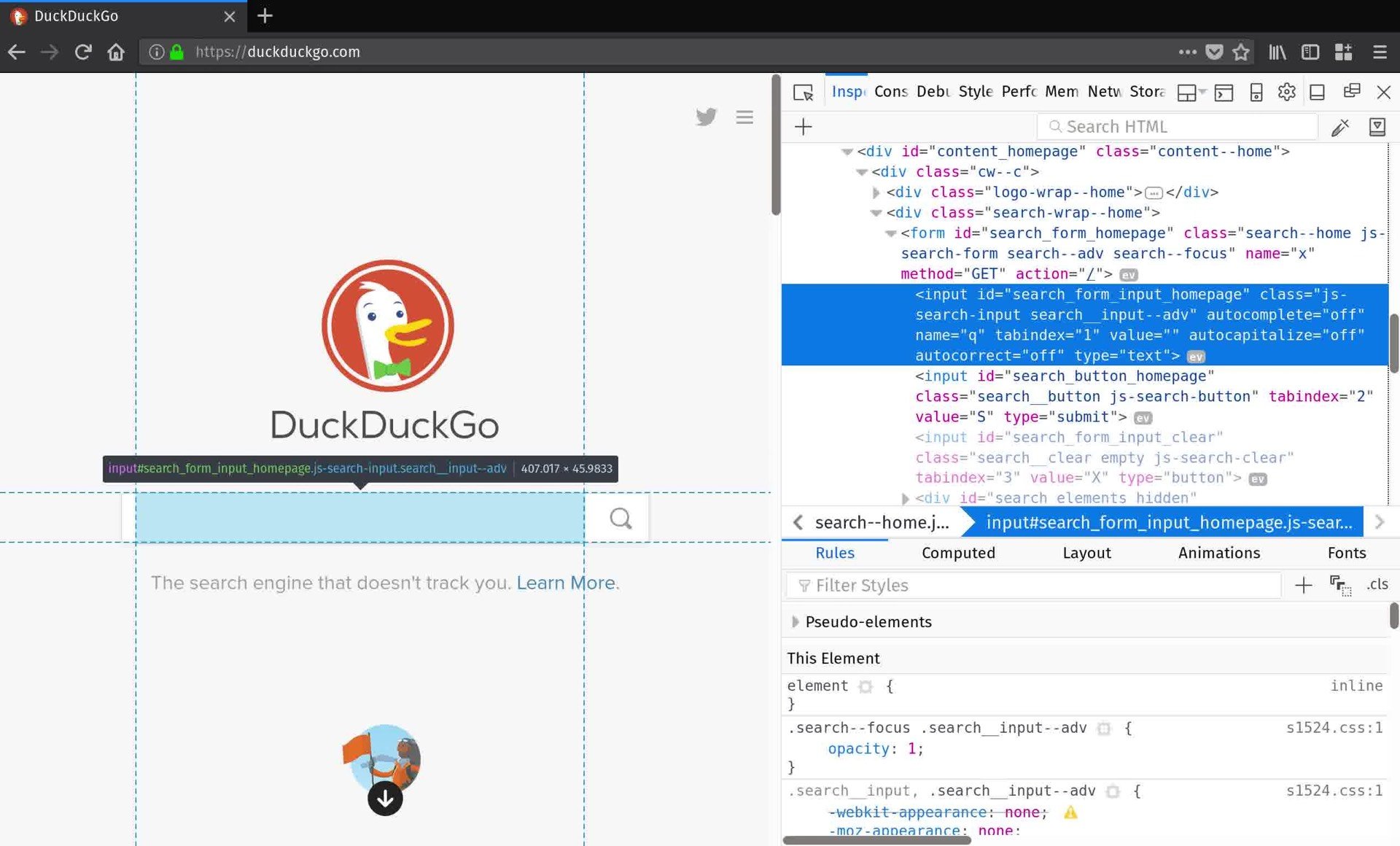
>>> search_form = browser.find_element_by_id('search_form_input_homepage')
>>> search_form.send_keys('real python')
>>> search_form.submit()
您找到了搜索表单,使用send_keys方法填写表单,然后使用submit方法执行对"Real Python"的搜索。您可以查看最上面的结果:
>>> results = browser.find_elements_by_class_name('result') >>> print(results[0].text) Real Python - Real Python Get Real Python and get your hands dirty quickly so you spend more time making real applications. Real Python teaches Python and web development from the ground up ... https://realpython.com一切似乎都在运转。为了防止不可见的无头浏览器实例堆积在您的计算机上,您在退出 Python 会话之前关闭浏览器对象:
>>> browser.close()
>>> quit()
在音乐中摇摆
您已经测试过可以使用 Python 驱动一个无头浏览器。现在您可以使用它了:
- 你想玩音乐。
- 你想浏览和探索音乐。
- 你想知道正在播放什么音乐。
首先,你导航到 https://bandcamp.com,并开始在你的浏览器的开发工具中摸索。您会发现屏幕底部有一个闪亮的大播放按钮,其属性包含值"playbutton"。你检查它是否工作:
 >>>
>>>
>>> opts = Option()
>>> opts.set_headless()
>>> browser = Firefox(options=opts)
>>> browser.get('https://bandcamp.com')
>>> browser.find_element_by_class('playbutton').click()
你应该听音乐!让它继续播放,回到你的网络浏览器。播放按钮旁边是探索区。再次检查这个部分,发现每个当前可见的可用轨道都有一个值为"discover-item"的class,并且每个项目看起来都是可点击的。在 Python 中,您可以检查:
>>> tracks = browser.find_elements_by_class_name('discover-item') >>> len(tracks) # 8 >>> tracks[3].click()应该在放新的曲目!这是使用 Python 探索 bandcamp 的第一步!你花了几分钟点击 Python 环境中的各种曲目,但很快就厌倦了仅有八首歌曲的贫乏库。
探索目录
回头看看你的浏览器,你会看到探索 bandcamp 的音乐探索部分的所有曲目的按钮。现在,这感觉很熟悉:每个按钮都有一个
"item-page"的class值。最后一个按钮是“下一首”按钮,将显示目录中的下八首曲目。你去工作:
>>> next_button = [e for e in browser.find_elements_by_class_name('item-page')
if e.text.lower().find('next') > -1]
>>> next_button.click()
太好了!现在你想看看新的轨迹,所以你想,“我就像几分钟前一样重新填充我的tracks变量。”但这就是事情开始变得棘手的地方。
首先,bandcamp 设计他们的网站是为了让人们喜欢使用,而不是让 Python 脚本以编程方式访问。当你调用next_button.click()时,真正的 web 浏览器通过执行一些 JavaScript 代码来响应。
如果你在你的浏览器中尝试一下,你会发现随着歌曲目录的滚动,一段时间过去了,动画效果变得很流畅。如果你试图在动画结束前重新填充你的tracks变量,你可能得不到所有的轨迹,并且你可能得到一些你不想要的轨迹。
有什么解决办法?您可以只睡一会儿,或者,如果您只是在 Python shell 中运行这一切,您可能甚至不会注意到。毕竟,你打字也需要时间。
另一个小问题是只有通过实验才能发现。您尝试再次运行相同的代码:
>>> tracks = browser.find_elements_by_class_name('discover-item') >>> assert(len(tracks) == 8) AssertionError ...但是你注意到一些奇怪的事情。
len(tracks)不等于8,尽管应该只显示下一批8。再深入一点,你会发现你的列表中包含了一些之前显示过的曲目。要仅获取在浏览器中实际可见的轨道,您需要稍微过滤结果。在尝试了一些事情之后,您决定仅当页面上的
x坐标落在包含元素的边界框内时才保留一个轨迹。目录的容器的class值为"discover-results"。以下是您的操作步骤:
>>> discover_section = self.browser.find_element_by_class_name('discover-results')
>>> left_x = discover_section.location['x']
>>> right_x = left_x + discover_section.size['width']
>>> discover_items = browser.find_element_by_class_name('discover_items')
>>> tracks = [t for t in discover_items
if t.location['x'] >= left_x and t.location['x'] < right_x]
>>> assert len(tracks) == 8
构建一个类
如果您厌倦了在 Python 环境中一遍又一遍地重复输入相同的命令,那么您应该将一些命令转储到一个模块中。用于 bandcamp 操作的基本类应该执行以下操作:
- 初始化一个无头浏览器并导航到 bandcamp
- 保留一个可用曲目列表
- 支持查找更多曲目
- 播放、暂停和跳过曲目
下面是基本代码,一气呵成:
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from time import sleep, ctime
from collections import namedtuple
from threading import Thread
from os.path import isfile
import csv
BANDCAMP_FRONTPAGE='https://bandcamp.com/'
class BandLeader():
def __init__(self):
# Create a headless browser
opts = Options()
opts.set_headless()
self.browser = Firefox(options=opts)
self.browser.get(BANDCAMP_FRONTPAGE)
# Track list related state
self._current_track_number = 1
self.track_list = []
self.tracks()
def tracks(self):
'''
Query the page to populate a list of available tracks.
'''
# Sleep to give the browser time to render and finish any animations
sleep(1)
# Get the container for the visible track list
discover_section = self.browser.find_element_by_class_name('discover-results')
left_x = discover_section.location['x']
right_x = left_x + discover_section.size['width']
# Filter the items in the list to include only those we can click
discover_items = self.browser.find_elements_by_class_name('discover-item')
self.track_list = [t for t in discover_items
if t.location['x'] >= left_x and t.location['x'] < right_x]
# Print the available tracks to the screen
for (i,track) in enumerate(self.track_list):
print('[{}]'.format(i+1))
lines = track.text.split('\n')
print('Album : {}'.format(lines[0]))
print('Artist : {}'.format(lines[1]))
if len(lines) > 2:
print('Genre : {}'.format(lines[2]))
def catalogue_pages(self):
'''
Print the available pages in the catalogue that are presently
accessible.
'''
print('PAGES')
for e in self.browser.find_elements_by_class_name('item-page'):
print(e.text)
print('')
def more_tracks(self,page='next'):
'''
Advances the catalogue and repopulates the track list. We can pass in a number
to advance any of the available pages.
'''
next_btn = [e for e in self.browser.find_elements_by_class_name('item-page')
if e.text.lower().strip() == str(page)]
if next_btn:
next_btn[0].click()
self.tracks()
def play(self,track=None):
'''
Play a track. If no track number is supplied, the presently selected track
will play.
'''
if track is None:
self.browser.find_element_by_class_name('playbutton').click()
elif type(track) is int and track <= len(self.track_list) and track >= 1:
self._current_track_number = track
self.track_list[self._current_track_number - 1].click()
def play_next(self):
'''
Plays the next available track
'''
if self._current_track_number < len(self.track_list):
self.play(self._current_track_number+1)
else:
self.more_tracks()
self.play(1)
def pause(self):
'''
Pauses the playback
'''
self.play()
相当整洁。您可以将它导入到您的 Python 环境中,并以编程方式运行 bandcamp!但是等等,你开始这整件事不就是因为你想记录你的收听历史吗?
收集结构化数据
你最后的任务是记录你实际听过的歌曲。你会怎么做?什么是真正的聆听呢?如果你在仔细阅读目录,在每首歌上停留几秒钟,这些歌曲中的每一首都算数吗?大概不会。你要留出一些“探索”时间来考虑你的数据收集。
您现在的目标是:
- 收集关于当前播放曲目的结构化信息
- 保存曲目的“数据库”
- 将“数据库”保存到磁盘和从磁盘恢复
您决定使用一个名为的元组来存储您跟踪的信息。命名元组适用于表示没有功能约束的属性束,有点像数据库记录:
TrackRec = namedtuple('TrackRec', [
'title',
'artist',
'artist_url',
'album',
'album_url',
'timestamp' # When you played it
])
为了收集这些信息,您需要向BandLeader类添加一个方法。使用浏览器的开发工具,您可以找到合适的 HTML 元素和属性来选择您需要的所有信息。此外,如果当时正在播放音乐,您只需要获得当前播放曲目的信息。幸运的是,每当音乐播放时,页面播放器会向 play 按钮添加一个"playing"类,当音乐停止时,页面播放器会移除它。
考虑到这些因素,您编写了几个方法:
def is_playing(self):
'''
Returns `True` if a track is presently playing
'''
playbtn = self.browser.find_element_by_class_name('playbutton')
return playbtn.get_attribute('class').find('playing') > -1
def currently_playing(self):
'''
Returns the record for the currently playing track,
or None if nothing is playing
'''
try:
if self.is_playing():
title = self.browser.find_element_by_class_name('title').text
album_detail = self.browser.find_element_by_css_selector('.detail-album > a')
album_title = album_detail.text
album_url = album_detail.get_attribute('href').split('?')[0]
artist_detail = self.browser.find_element_by_css_selector('.detail-artist > a')
artist = artist_detail.text
artist_url = artist_detail.get_attribute('href').split('?')[0]
return TrackRec(title, artist, artist_url, album_title, album_url, ctime())
except Exception as e:
print('there was an error: {}'.format(e))
return None
为了更好地测量,您还修改了play()方法来跟踪当前播放的曲目:
def play(self, track=None):
'''
Play a track. If no track number is supplied, the presently selected track
will play.
'''
if track is None:
self.browser.find_element_by_class_name('playbutton').click()
elif type(track) is int and track <= len(self.track_list) and track >= 1:
self._current_track_number = track
self.track_list[self._current_track_number - 1].click()
sleep(0.5)
if self.is_playing():
self._current_track_record = self.currently_playing()
接下来,你必须保持某种数据库。虽然从长远来看,它可能无法很好地扩展,但是你可以用一个简单的列表走得更远。您将self.database = []添加到BandCamp的__init__()方法中。因为您希望在将TrackRec对象输入数据库之前留出时间,所以您决定使用 Python 的线程工具来运行一个单独的进程,在后台维护数据库。
您将为将在单独线程中运行的BandLeader实例提供一个_maintain()方法。新方法将定期检查self._current_track_record的值,如果它是新的,就将其添加到数据库中。
当通过向__init__()添加一些代码来实例化类时,您将启动线程:
# The new init
def __init__(self):
# Create a headless browser
opts = Options()
opts.set_headless()
self.browser = Firefox(options=opts)
self.browser.get(BANDCAMP_FRONTPAGE)
# Track list related state
self._current_track_number = 1
self.track_list = []
self.tracks()
# State for the database
self.database = []
self._current_track_record = None
# The database maintenance thread
self.thread = Thread(target=self._maintain)
self.thread.daemon = True # Kills the thread with the main process dies
self.thread.start()
self.tracks()
def _maintain(self):
while True:
self._update_db()
sleep(20) # Check every 20 seconds
def _update_db(self):
try:
check = (self._current_track_record is not None
and (len(self.database) == 0
or self.database[-1] != self._current_track_record)
and self.is_playing())
if check:
self.database.append(self._current_track_record)
except Exception as e:
print('error while updating the db: {}'.format(e)
如果你从未使用过 Python 中的多线程编程,你应该好好研究一下!对于你现在的目的,你可以把 thread 想象成一个在 Python 主进程(你直接与之交互的那个)后台运行的循环。每隔 20 秒,循环检查一些事情,看看数据库是否需要更新,如果需要,追加一条新记录。相当酷。
最后一步是保存数据库并从保存的状态中恢复。使用 csv 包,您可以确保您的数据库驻留在一个高度可移植的格式中,并且即使您放弃了您精彩的BandLeader类,它仍然是可用的!
应该再次修改__init__()方法,这一次接受您想要保存数据库的文件路径。如果这个数据库可用,您想要加载它,并且每当它被更新时,您想要定期保存它。更新如下所示:
def __init__(self,csvpath=None):
self.database_path=csvpath
self.database = []
# Load database from disk if possible
if isfile(self.database_path):
with open(self.database_path, newline='') as dbfile:
dbreader = csv.reader(dbfile)
next(dbreader) # To ignore the header line
self.database = [TrackRec._make(rec) for rec in dbreader]
# .... The rest of the __init__ method is unchanged ....
# A new save_db() method
def save_db(self):
with open(self.database_path,'w',newline='') as dbfile:
dbwriter = csv.writer(dbfile)
dbwriter.writerow(list(TrackRec._fields))
for entry in self.database:
dbwriter.writerow(list(entry))
# Finally, add a call to save_db() to your database maintenance method
def _update_db(self):
try:
check = (self._current_track_record is not None
and self._current_track_record is not None
and (len(self.database) == 0
or self.database[-1] != self._current_track_record)
and self.is_playing())
if check:
self.database.append(self._current_track_record)
self.save_db()
except Exception as e:
print('error while updating the db: {}'.format(e)
瞧啊!你可以听音乐,并记录下你所听到的!太神奇了。
关于上面的一些有趣的事情是,使用namedtuple 真的开始有回报了。当转换成 CSV 格式或从 CSV 格式转换时,您可以利用 CSV 文件中行的顺序来填充TrackRec对象中的行。同样,您可以通过引用TrackRec._fields属性来创建 CSV 文件的标题行。这是使用元组最终对列数据有意义的原因之一。
接下来是什么,你学到了什么?
你可以做得更多!这里有一些快速的想法,可以利用 Python + Selenium 这个温和的超级功能:
- 您可以扩展
BandLeader类来导航到相册页面并播放您在那里找到的曲目。 - 您可能会决定根据您最喜爱或最常听到的曲目来创建播放列表。
- 也许你想添加一个自动播放功能。
- 也许你想通过日期、标题或艺术家来查询歌曲,并以这种方式建立播放列表。
免费奖励: 点击此处下载一个“Python + Selenium”项目框架,其中包含完整的源代码,您可以使用它作为自己的 Python web 抓取和自动化应用程序的基础。
你已经知道 Python 可以做 web 浏览器能做的一切,甚至更多。您可以轻松地编写脚本来控制运行在云中的虚拟浏览器实例。你可以创建机器人与真实用户互动或盲目填写表格!向前迈进,实现自动化!****
如何将 Django 模型移动到另一个应用程序
如果你曾经想过重构你的 Django 应用,那么你可能会发现自己需要移动一个 Django 模型。使用 Django 迁移将 Django 模型从一个应用程序迁移到另一个应用程序有几种方法,但不幸的是,没有一种方法是直接的。
在 Django 应用程序之间移动模型通常是一项非常复杂的任务,包括复制数据、改变约束和重命名对象。由于这些复杂性,Django 对象关系映射器(ORM) 没有提供可以检测和自动化整个过程的内置迁移操作。相反,ORM 提供了一组底层迁移操作,允许 Django 开发人员在迁移框架中自己实现过程。
在本教程中,您将学习:
- 如何将 Django 模型从一个应用程序移动到另一个应用程序
- 如何使用 Django 迁移命令行界面(CLI)的高级功能,如
sqlmigrate、showmigrations、sqlsequencereset - 如何制定和检查迁移计划
- 如何使迁移可逆以及如何逆转迁移
- 什么是内省以及 Django 如何在迁移中使用它
完成本教程后,您将能够根据您的具体用例选择将 Django 模型从一个应用程序迁移到另一个应用程序的最佳方法。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
示例案例:将 Django 模型移动到另一个应用程序
在本教程中,您将使用商店应用程序。你的商店将从两个 Django 应用开始:
catalog:这个应用是用来存储产品和产品类别的数据。sale:这个 app 是用来记录和跟踪产品销售的。
完成这两个应用程序的设置后,您将把一个名为Product的 Django 模型转移到一个名为product的新应用程序中。在此过程中,您将面临以下挑战:
- 被移动的模型与其他模型有外键关系。
- 其他模型与被移动的模型有外键关系。
- 被移动的模型在其中一个字段上有一个索引(除了主键之外)。
这些挑战受到现实生活中重构过程的启发。在克服了这些困难之后,您就可以为您的特定用例计划一个类似的迁移过程了。
设置:准备您的环境
在您开始移动东西之前,您需要设置项目的初始状态。本教程使用运行在 Python 3.8 上的 Django 3,但是您可以在其他版本中使用类似的技术。
建立一个 Python 虚拟环境
首先,在新目录中创建虚拟环境:
$ mkdir django-move-model-experiment
$ cd django-move-model-experiment
$ python -m venv venv
关于创建虚拟环境的逐步说明,请查看 Python 虚拟环境:初级教程。
创建 Django 项目
在您的终端中,激活虚拟环境并安装 Django:
$ source venv/bin/activate
$ pip install django
Collecting django
Collecting pytz (from django)
Collecting asgiref~=3.2 (from django)
Collecting sqlparse>=0.2.2 (from django)
Installing collected packages: pytz, asgiref, sqlparse, django
Successfully installed asgiref-3.2.3 django-3.0.4 pytz-2019.3 sqlparse-0.3.1
现在您已经准备好创建您的 Django 项目了。使用django-admin startproject创建一个名为django-move-model-experiment的项目:
$ django-admin startproject django-move-model-experiment
$ cd django-move-model-experiment
运行这个命令后,您会看到 Django 创建了新的文件和目录。关于如何开始一个新的 Django 项目,请查看开始一个 Django 项目。
创建 Django 应用程序
现在你有了一个新的 Django 项目,用你商店的产品目录创建一个应用程序:
$ python manage.py startapp catalog
接下来,将以下型号添加到新的catalog应用程序中:
# catalog/models.py
from django.db import models
class Category(models.Model):
name = models.CharField(max_length=100)
class Product(models.Model):
name = models.CharField(max_length=100, db_index=True)
category = models.ForeignKey(Category, on_delete=models.CASCADE)
您已经在您的catalog应用中成功创建了Category和Product模型。现在你有了目录,你想开始销售你的产品。为销售创建另一个应用程序:
$ python manage.py startapp sale
将以下Sale型号添加到新的sale应用程序中:
# sale/models.py
from django.db import models
from catalog.models import Product
class Sale(models.Model):
created = models.DateTimeField()
product = models.ForeignKey(Product, on_delete=models.PROTECT)
注意,Sale模型使用 ForeignKey 引用了Product模型。
生成并应用初始迁移
要完成设置,生成 迁移 并应用它们:
$ python manage.py makemigrations catalog sale
Migrations for 'catalog':
catalog/migrations/0001_initial.py
- Create model Category
- Create model Product
Migrations for 'sale':
sale/migrations/0001_initial.py
- Create model Sale
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, catalog, contenttypes, sale, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying catalog.0001_initial... OK
Applying sale.0001_initial... OK
Applying sessions.0001_initial... OK
关于 Django 迁移的更多信息,请查看 Django 迁移:初级读本。迁移就绪后,现在就可以创建一些示例数据了!
生成样本数据
为了使迁移场景尽可能真实,从终端窗口激活 Django shell :
$ python manage.py shell
接下来,创建以下对象:
>>> from catalog.models import Category, Product >>> clothes = Category.objects.create(name='Clothes') >>> shoes = Category.objects.create(name='Shoes') >>> Product.objects.create(name='Pants', category=clothes) >>> Product.objects.create(name='Shirt', category=clothes) >>> Product.objects.create(name='Boots', category=shoes)您创建了两个类别,
'Shoes'和'Clothes'。接下来,您向'Clothes'类别添加了两个产品'Pants'和'Shirt',向'Shoes'类别添加了一个产品'Boots'。恭喜你!您已经完成了项目初始状态的设置。在现实生活中,这是您开始规划重构的地方。本教程中介绍的三种方法都将从这一点开始。
漫长的道路:将数据复制到一个新的 Django 模型中
首先,你要走很长的路:
- 创建新模型
- 将数据复制到其中
- 扔掉旧桌子
这种方法有一些你应该知道的陷阱。您将在接下来的小节中详细探索它们。
创建新模型
首先创建一个新的
product应用程序。从您的终端执行以下命令:$ python manage.py startapp product运行这个命令后,您会注意到一个名为
product的新目录被添加到项目中。要将新应用程序注册到您现有的 Django 项目中,请将其添加到 Django 的
settings.py中的INSTALLED_APPS列表中:--- a/store/store/settings.py +++ b/store/store/settings.py @@ -40,6 +40,7 @@ INSTALLED_APPS = [ 'catalog', 'sale', + 'product', ] MIDDLEWARE = [您的新
product应用程序现已在 Django 注册。接下来,在新的product应用程序中创建一个Product模型。您可以从catalog应用程序中复制代码:# product/models.py from django.db import models from catalog.models import Category class Product(models.Model): name = models.CharField(max_length=100, db_index=True) category = models.ForeignKey(Category, on_delete=models.CASCADE)现在您已经定义了模型,试着为它生成迁移:
$ python manage.py makemigrations product SystemCheckError: System check identified some issues: ERRORS: catalog.Product.category: (fields.E304) Reverse accessor for 'Product.category' clashes with reverse accessor for 'Product.category'. HINT: Add or change a related_name argument to the definition for 'Product.category' or 'Product.category'. product.Product.category: (fields.E304) Reverse accessor for 'Product.category' clashes with reverse accessor for 'Product.category'. HINT: Add or change a related_name argument to the definition for 'Product.category' or 'Product.category'.该错误表明 Django 为字段
category找到了两个具有相同反向访问器的模型。这是因为有两个名为Product的模型引用了Category模型,产生了冲突。当您向模型添加外键时,Django 会在相关模型中创建一个反向访问器。在这种情况下,反向访问器是
products。reverse 访问器允许您像这样访问相关对象:category.products。新模型是您想要保留的模型,因此要解决这个冲突,请在
catalog/models.py中从旧模型中移除反向访问器:--- a/store/catalog/models.py +++ b/store/catalog/models.py @@ -7,4 +7,4 @@ class Category(models.Model): class Product(models.Model): name = models.CharField(max_length=100, db_index=True) - category = models.ForeignKey(Category, on_delete=models.CASCADE) + category = models.ForeignKey(Category, on_delete=models.CASCADE, related_name='+')属性
related_name可用于显式设置反向存取器的相关名称。这里,您使用特殊值+,它指示 Django 不要创建反向访问器。现在为
catalog应用程序生成一个迁移:$ python manage.py makemigrations catalog Migrations for 'catalog': catalog/migrations/0002_auto_20200124_1250.py - Alter field category on product暂时不要应用此迁移!一旦发生这种变化,使用反向访问器的代码可能会中断。
既然反向访问器之间没有冲突,那么尝试为新的
product应用程序生成迁移:$ python manage.py makemigrations product Migrations for 'product': product/migrations/0001_initial.py - Create model Product太好了!你已经准备好进入下一步了。
将数据复制到新模型
在上一步中,您创建了一个新的
product应用程序,其Product模型与您想要移动的模型相同。下一步是将数据从旧模型转移到新模型。要创建数据迁移,请从终端执行以下命令:
$ python manage.py makemigrations product --empty Migrations for 'product': product/migrations/0002_auto_20200124_1300.py编辑新的迁移文件,并添加从旧表中复制数据的操作:
from django.db import migrations class Migration(migrations.Migration): dependencies = [ ('product', '0001_initial'), ] operations = [ migrations.RunSQL(""" INSERT INTO product_product ( id, name, category_id ) SELECT id, name, category_id FROM catalog_product; """, reverse_sql=""" INSERT INTO catalog_product ( id, name, category_id ) SELECT id, name, category_id FROM product_product; """) ]要在迁移中执行 SQL,可以使用特殊的
RunSQL迁移命令。第一个参数是要应用的 SQL。您还可以使用reverse_sql参数提供一个动作来反转迁移。当您发现错误并希望回滚更改时,撤销迁移会很方便。大多数内置迁移操作都可以逆转。例如,添加字段的相反操作是删除字段。创建新表的相反操作是删除表。通常最好提供
reverse_SQL到RunSQL,这样如果出了问题,你可以回溯。在这种情况下,正向迁移操作将数据从
product_product插入到catalog_product。反向操作将做完全相反的事情,将数据从catalog_product插入product_product。通过为 Django 提供反向操作,您将能够在发生灾难时反向迁移。此时,您仍处于迁移过程的中途。但是这里有一个教训,所以继续应用迁移:
$ python manage.py migrate product Operations to perform: Apply all migrations: product Running migrations: Applying product.0001_initial... OK Applying product.0002_auto_20200124_1300... OK在进入下一步之前,尝试创建一个新产品:
>>> from product.models import Product
>>> Product.objects.create(name='Fancy Boots', category_id=2)
Traceback (most recent call last):
File "/venv/lib/python3.8/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
psycopg2.errors.UniqueViolation: duplicate key value violates unique constraint "product_product_pkey"
DETAIL: Key (id)=(1) already exists.
当您使用一个自动递增主键时,Django 会在数据库中创建一个序列来为新对象分配唯一的标识符。例如,请注意,您没有为新产品提供 ID。您通常不希望提供 ID,因为您希望数据库使用序列为您分配主键。然而,在这种情况下,新表为新产品赋予了 ID 1,即使这个 ID 已经存在于表中。
那么,哪里出了问题?当您将数据复制到新表时,没有同步序列。要同步序列,您可以使用另一个名为 sqlsequencereset 的 Django 管理命令。该命令生成一个脚本,根据表中的现有数据设置序列的当前值。该命令通常用于用预先存在的数据填充新模型。
使用sqlsequencereset生成一个脚本来同步序列:
$ python manage.py sqlsequencereset product
BEGIN;
SELECT setval(pg_get_serial_sequence('"product_product"','id'), coalesce(max("id"), 1), max("id") IS NOT null)
FROM "product_product";
COMMIT;
该命令生成的脚本是特定于数据库的。在本例中,数据库是 PostgreSQL。该脚本将序列的当前值设置为序列应该产生的下一个值,即表中的最大 ID 加 1。
最后,将代码片段添加到数据迁移中:
--- a/store/product/migrations/0002_auto_20200124_1300.py +++ b/store/product/migrations/0002_auto_20200124_1300.py @@ -22,6 +22,8 @@ class Migration(migrations.Migration): category_id FROM catalog_product; + + SELECT setval(pg_get_serial_sequence('"product_product"','id'), coalesce(max("id"), 1), max("id") IS NOT null) FROM "product_product"; """, reverse_sql=""" INSERT INTO catalog_product ( id,
当您应用迁移时,代码片段将同步序列,解决您在上面遇到的序列问题。
这种学习同步序列的弯路给你的代码造成了一点混乱。要清理它,从 Django shell 中删除新模型中的数据:
>>> from product.models import Product >>> Product.objects.all().delete() (3, {'product.Product': 3})现在,您复制的数据已被删除,您可以反向迁移。要撤消迁移,您需要迁移到以前的迁移:
$ python manage.py showmigrations product product [X] 0001_initial [X] 0002_auto_20200124_1300 $ python manage.py migrate product 0001_initial Operations to perform: Target specific migration: 0001_initial, from product Running migrations: Rendering model states... DONE Unapplying product.0002_auto_20200124_1300... OK您首先使用命令
showmigrations列出应用于应用程序product的迁移。输出显示两个迁移都已应用。然后,您通过迁移到先前的迁移0001_initial来反转迁移0002_auto_20200124_1300。如果您再次执行
showmigrations,那么您将看到第二次迁移不再被标记为已应用:$ python manage.py showmigrations product product [X] 0001_initial [ ] 0002_auto_20200124_1300空框确认第二次迁移已被逆转。现在您已经有了一张白纸,使用新代码运行迁移:
$ python manage.py migrate product Operations to perform: Apply all migrations: product Running migrations: Applying product.0002_auto_20200124_1300... OK迁移已成功应用。确保现在可以在 Django shell 中创建新的
Product:
>>> from product.models import Product
>>> Product.objects.create(name='Fancy Boots', category_id=2)
<Product: Product object (4)>
太神奇了!你的努力得到了回报,你已经为下一步做好了准备。
更新新模型的外键
旧表当前有其他表使用ForeignKey字段引用它。在删除旧模型之前,您需要更改引用旧模型的模型,以便它们引用新模型。
一个仍然引用旧模型的模型是sale应用程序中的Sale。更改Sale模型中的外键以引用新的Product模型:
--- a/store/sale/models.py +++ b/store/sale/models.py @@ -1,6 +1,6 @@ from django.db import models -from catalog.models import Product +from product.models import Product class Sale(models.Model): created = models.DateTimeField()
生成迁移并应用它:
$ python manage.py makemigrations sale
Migrations for 'sale':
sale/migrations/0002_auto_20200124_1343.py
- Alter field product on sale
$ python manage.py migrate sale
Operations to perform:
Apply all migrations: sale
Running migrations:
Applying sale.0002_auto_20200124_1343... OK
Sale模型现在引用了product应用中的新Product模型。因为您已经将所有数据复制到新模型中,所以不存在约束冲突。
删除旧型号
上一步删除了对旧Product模型的所有引用。现在可以安全地从catalog应用中移除旧型号了:
--- a/store/catalog/models.py +++ b/store/catalog/models.py @@ -3,8 +3,3 @@ from django.db import models class Category(models.Model): name = models.CharField(max_length=100) - - -class Product(models.Model): - name = models.CharField(max_length=100, db_index=True) - category = models.ForeignKey(Category, on_delete=models.CASCADE, related_name='+')
生成迁移,但尚未应用:
$ python manage.py makemigrations
Migrations for 'catalog':
catalog/migrations/0003_delete_product.py
- Delete model Product
为了确保旧模型仅在数据被复制后的被删除,添加以下依赖关系:
--- a/store/catalog/migrations/0003_delete_product.py +++ b/store/catalog/migrations/0003_delete_product.py @@ -7,6 +7,7 @@ class Migration(migrations.Migration): dependencies = [ ('catalog', '0002_auto_20200124_1250'), + ('sale', '0002_auto_20200124_1343'), ] operations = [
添加这种依赖性极其重要。跳过这一步会有可怕的后果,包括丢失数据。关于迁移文件和迁移之间的依赖关系的更多信息,请查看深入挖掘 Django 迁移。
注意:迁移的名称包括其生成的日期和时间。如果您使用自己的代码,那么名称的这些部分将会不同。
现在您已经添加了依赖项,请应用迁移:
$ python manage.py migrate catalog
Operations to perform:
Apply all migrations: catalog
Running migrations:
Applying catalog.0003_delete_product... OK
传输现在完成了!通过创建一个新模型并将数据复制到新的product应用程序中,您已经成功地将Product模型从catalog应用程序中移动到了新的catalog应用程序中。
额外收获:逆转迁移
Django 迁移的好处之一是它们是可逆的。迁移可逆意味着什么?如果您犯了一个错误,那么您可以反向迁移,数据库将恢复到应用迁移之前的状态。
还记得你之前是怎么提供reverse_sql到RunSQL的吗?这就是回报的地方。
在新数据库上应用所有迁移:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, catalog, contenttypes, product, sale, sessions
Running migrations:
Applying product.0001_initial... OK
Applying product.0002_auto_20200124_1300... OK
Applying sale.0002_auto_20200124_1343... OK
Applying catalog.0003_delete_product... OK
现在,使用特殊关键字zero 将它们全部反转:
$ python manage.py migrate product zero
Operations to perform:
Unapply all migrations: product
Running migrations:
Rendering model states... DONE
Unapplying catalog.0003_delete_product... OK
Unapplying sale.0002_auto_20200124_1343... OK
Unapplying product.0002_auto_20200124_1300... OK
Unapplying product.0001_initial... OK
数据库现在恢复到其原始状态。如果您部署了这个版本,并且发现了一个错误,那么您可以撤销它!
处理特殊情况
当您将模型从一个应用程序转移到另一个应用程序时,一些 Django 特性可能需要特别注意。特别是,添加或修改数据库约束和使用通用关系都需要格外小心。
修改约束
在实时系统上向包含数据的表添加约束可能是一项危险的操作。要添加约束,数据库必须首先验证它。在验证过程中,数据库获得了一个表上的锁,这可能会阻止其他操作,直到该过程完成。
有些约束,比如NOT NULL和CHECK,可能需要对表进行全面扫描,以验证新数据是否有效。其他约束,如FOREIGN KEY,需要用另一个表进行验证,这可能需要一些时间,具体取决于被引用表的大小。
处理通用关系
如果你正在使用通用关系,那么你可能需要一个额外的步骤。通用关系使用模型的主键和内容类型 ID 来引用任何模型表中的一行。旧模型和新模型没有相同的内容类型 ID,因此通用连接可能会中断。这有时会被忽视,因为数据库并不强制实现通用外键的完整性。
有两种方法可以处理泛型外键:
- 将新模型的内容类型 ID 更新为旧模型的内容类型 ID。
- 将任何引用表的内容类型 ID 更新为新模型的内容类型 ID。
无论您选择哪种方式,都要确保在部署到生产环境之前对其进行适当的测试。
总结:复制数据的利弊
通过复制数据将 Django 模型移动到另一个应用程序有其优点和缺点。以下是与这种方法相关的一些优点:
- ORM 支持这一点:使用内置的迁移操作执行这一转换保证了适当的数据库支持。
- 这是可逆的:如果有必要,可以逆转这种迁移。
以下是这种方法的一些缺点:
- 很慢:复制大量数据需要时间。
- 需要停机:在将旧表中的数据复制到新表的过程中对其进行更改会导致数据在转换过程中丢失。为了防止这种情况发生,停机是必要的。
- 同步数据库需要手动操作:将数据加载到现有的表中需要同步序列和通用外键。
正如您将在接下来的小节中看到的,使用这种方法将 Django 模型移动到另一个应用程序比其他方法花费的时间要长得多。
最简单的方法:将新的 Django 模型引用到旧的表中
在前面的方法中,您将所有数据复制到新表中。迁移需要停机,并且可能需要很长时间才能完成,具体取决于要拷贝的数据量。
如果您不是复制数据,而是更改新模型来引用旧表,那会怎么样呢?
创建新模型
这一次,您将一次对模型进行所有的更改,然后让 Django 生成所有的迁移。
首先,从catalog应用程序中移除Product模型:
--- a/store/catalog/models.py +++ b/store/catalog/models.py @@ -3,8 +3,3 @@ from django.db import models class Category(models.Model): name = models.CharField(max_length=100) - - -class Product(models.Model): - name = models.CharField(max_length=100, db_index=True) - category = models.ForeignKey(Category, on_delete=models.CASCADE)
您已经从catalog应用中移除了Product模型。现在将Product模型移动到新的product应用程序中:
# store/product/models.py
from django.db import models
from catalog.models import Category
class Product(models.Model):
name = models.CharField(max_length=100, db_index=True)
category = models.ForeignKey(Category, on_delete=models.CASCADE)
现在Product模型已经存在于product应用程序中,您可以更改对旧Product模型的任何引用,以引用新的Product模型。在这种情况下,您需要将sale中的外键改为引用product.Product:
--- a/store/sale/models.py +++ b/store/sale/models.py @@ -1,6 +1,6 @@ from django.db import models -from catalog.models import Product +from product.models import Product class Sale(models.Model): created = models.DateTimeField()
在继续生成迁移之前,您需要对新的Product模型做一个更小的更改:
--- a/store/product/models.py +++ b/store/product/models.py @@ -5,3 +5,6 @@ from catalog.models import Category class Product(models.Model): name = models.CharField(max_length=100, db_index=True) category = models.ForeignKey(Category, on_delete=models.CASCADE) + + class Meta: + db_table = 'catalog_product'
Django 模型有一个Meta选项叫做 db_table 。使用这个选项,您可以提供一个表名来代替 Django 生成的表名。当在现有数据库模式上设置 ORM 时,如果表名与 Django 的命名约定不匹配,那么最常用这个选项。
在这种情况下,您在product应用程序中设置表的名称,以引用catalog应用程序中现有的表。
要完成设置,请生成迁移:
$ python manage.py makemigrations sale product catalog
Migrations for 'catalog':
catalog/migrations/0002_remove_product_category.py
- Remove field category from product
catalog/migrations/0003_delete_product.py
- Delete model Product
Migrations for 'product':
product/migrations/0001_initial.py
- Create model Product
Migrations for 'sale':
sale/migrations/0002_auto_20200104_0724.py
- Alter field product on sale
在您前进之前,使用 --plan标志制定一个迁移计划:
$ python manage.py migrate --plan
Planned operations:
catalog.0002_remove_product_category
Remove field category from product
product.0001_initial
Create model Product
sale.0002_auto_20200104_0724
Alter field product on sale
catalog.0003_delete_product
Delete model Product
该命令的输出列出了 Django 应用迁移的顺序。
消除对数据库的更改
这种方法的主要好处是,您实际上不需要对数据库进行任何更改,只需要对代码进行更改。要消除对数据库的更改,可以使用特殊的迁移操作 SeparateDatabaseAndState 。
SeparateDatabaseAndState可用于修改 Django 在迁移过程中执行的操作。关于如何使用SeparateDatabaseAndState的更多信息,请查看如何在 Django 中创建索引而不停机。
如果您查看 Django 生成的迁移的内容,那么您会看到 Django 创建了一个新模型并删除了旧模型。如果您执行这些迁移,那么数据将会丢失,并且表将被创建为空。为了避免这种情况,您需要确保 Django 在迁移过程中不会对数据库进行任何更改。
您可以通过将每个迁移操作包装在一个SeparateDatabaseAndState操作中来消除对数据库的更改。要告诉 Django 不要对数据库应用任何更改,可以将db_operations设置为空列表。
您计划重用旧表,所以您需要防止 Django 丢弃它。在删除模型之前,Django 将删除引用模型的字段。因此,首先,防止 Django 从sale到product丢弃外键:
--- a/store/catalog/migrations/0002_remove_product_category.py +++ b/store/catalog/migrations/0002_remove_product_category.py @@ -10,8 +10,14 @@ class Migration(migrations.Migration): ] operations = [ - migrations.RemoveField( - model_name='product', - name='category', + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.RemoveField( + model_name='product', + name='category', + ), + ], + # You're reusing the table, so don't drop it + database_operations=[], ), ]
现在 Django 已经处理了相关的对象,它可以删除模型了。您想要保留Product表,所以要防止 Django 删除它:
--- a/store/catalog/migrations/0003_delete_product.py +++ b/store/catalog/migrations/0003_delete_product.py @@ -11,7 +11,13 @@ class Migration(migrations.Migration): ] operations = [ - migrations.DeleteModel( - name='Product', - ), + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.DeleteModel( + name='Product', + ), + ], + # You want to reuse the table, so don't drop it + database_operations=[], + ) ]
你用database_operations=[]阻止姜戈掉桌子。接下来,阻止 Django 创建新表:
--- a/store/product/migrations/0001_initial.py +++ b/store/product/migrations/0001_initial.py @@ -13,15 +13,21 @@ class Migration(migrations.Migration): ] operations = [ - migrations.CreateModel( - name='Product', - fields=[ - ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), - ('name', models.CharField(db_index=True, max_length=100)), - ('category', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='catalog.Category')), + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.CreateModel( + name='Product', + fields=[ + ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), + ('name', models.CharField(db_index=True, max_length=100)), + ('category', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='catalog.Category')), + ], + options={ + 'db_table': 'catalog_product', + }, + ), ], - options={ - 'db_table': 'catalog_product', - }, - ), + # You reference an existing table + database_operations=[], + ) ]
这里,您使用了database_operations=[]来阻止 Django 创建新表。最后,您希望防止 Django 重新创建从Sale到新的Product模型的外键约束。因为您正在重用旧表,所以约束仍然存在:
--- a/store/sale/migrations/0002_auto_20200104_0724.py +++ b/store/sale/migrations/0002_auto_20200104_0724.py @@ -12,9 +12,14 @@ class Migration(migrations.Migration): ] operations = [ - migrations.AlterField( - model_name='sale', - name='product', - field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='product.Product'), + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.AlterField( + model_name='sale', + name='product', + field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='product.Product'), + ), + ], + database_operations=[], ), ]
现在您已经完成了迁移文件的编辑,请应用迁移:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, catalog, contenttypes, product, sale, sessions
Running migrations:
Applying catalog.0002_remove_product_category... OK
Applying product.0001_initial... OK
Applying sale.0002_auto_20200104_0724... OK
Applying catalog.0003_delete_product... OK
此时,您的新模型指向旧表。Django 没有对数据库做任何更改,所有的更改都是在代码中对 Django 的模型状态做的。但是在您称之为成功并继续前进之前,有必要确认新模型的状态与数据库的状态相匹配。
额外收获:对新模型进行更改
为了确保模型的状态与数据库的状态一致,尝试对新模型进行更改,并确保 Django 正确地检测到它。
Product模型在name字段上定义了一个索引。删除索引:
--- a/store/product/models.py +++ b/store/product/models.py @@ -3,7 +3,7 @@ from django.db import models from catalog.models import Category class Product(models.Model): - name = models.CharField(max_length=100, db_index=True) + name = models.CharField(max_length=100) category = models.ForeignKey(Category, on_delete=models.CASCADE) class Meta:
您通过删除db_index=True删除了索引。接下来,生成迁移:
$ python manage.py makemigrations
Migrations for 'product':
product/migrations/0002_auto_20200104_0856.py
- Alter field name on product
在继续之前,检查 Django 为这次迁移生成的 SQL:
$ python manage.py sqlmigrate product 0002
BEGIN;
--
-- Alter field name on product
--
DROP INDEX IF EXISTS "catalog_product_name_924af5bc";
DROP INDEX IF EXISTS "catalog_product_name_924af5bc_like";
COMMIT;
太好了!Django 检测到旧索引,如前缀"catalog_*"所示。现在,您可以执行迁移了:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, catalog, contenttypes, product, sale, sessions
Running migrations:
Applying product.0002_auto_20200104_0856... OK
确保您在数据库中获得了预期的结果:
django_migration_test=# \d catalog_product
Table "public.catalog_product"
Column | Type | Nullable | Default
-------------+------------------------+----------+---------------------------------------------
id | integer | not null | nextval('catalog_product_id_seq'::regclass)
name | character varying(100) | not null |
category_id | integer | not null |
Indexes:
"catalog_product_pkey" PRIMARY KEY, btree (id)
"catalog_product_category_id_35bf920b" btree (category_id)
Foreign-key constraints:
"catalog_product_category_id_35bf920b_fk_catalog_category_id"
FOREIGN KEY (category_id) REFERENCES catalog_category(id)
DEFERRABLE INITIALLY DEFERRED
Referenced by:
TABLE "sale_sale" CONSTRAINT "sale_sale_product_id_18508f6f_fk_catalog_product_id"
FOREIGN KEY (product_id) REFERENCES catalog_product(id)
DEFERRABLE INITIALLY DEFERRED
成功!name列上的索引已被删除。
总结:更改模型参考的利弊
更改模型以引用另一个模型有其优点和缺点。以下是与这种方法相关的一些优点:
- 很快:这种方法不对数据库做任何改动,所以非常快。
- 不需要停机:这种方法不需要复制数据,因此可以在没有停机的情况下在活动系统上执行。
- 这是可逆的:如果有必要,可以逆转这种迁移。
- ORM 支持这一点:使用内置的迁移操作执行这一转换保证了适当的数据库支持。
- 它不需要与数据库同步:使用这种方法,相关的对象,比如索引和序列,保持不变。
这种方法唯一的主要缺点是它打破了命名惯例。使用现有表格意味着表格仍将使用旧应用程序的名称。
请注意,这种方法比复制数据要简单得多。
Django 方式:重命名表
在前面的示例中,您让新模型引用数据库中的旧表。结果,您打破了 Django 使用的命名约定。在这种方法中,您做相反的事情:让旧的表引用新的模型。
更具体地说,您创建了新的模型,并为它生成了一个迁移。然后,从 Django 创建的迁移中获取新表的名称,并使用特殊的迁移操作AlterModelTable将旧表重命名为新表的名称,而不是为新模型创建表。
创建新模型
就像之前一样,你首先创建一个新的product应用程序,一次性完成所有的更改。首先,从catalog应用中移除Product型号:
--- a/store/catalog/models.py +++ b/store/catalog/models.py @@ -3,8 +3,3 @@ from django.db import models class Category(models.Model): name = models.CharField(max_length=100) - - -class Product(models.Model): - name = models.CharField(max_length=100, db_index=True) - category = models.ForeignKey(Category, on_delete=models.CASCADE)
您已经从catalog中删除了Product。接下来,将Product模型移动到新的product应用程序中:
# store/product/models.py
from django.db import models
from catalog.models import Category
class Product(models.Model):
name = models.CharField(max_length=100, db_index=True)
category = models.ForeignKey(Category, on_delete=models.CASCADE)
Product模型现在存在于您的product应用程序中。现在将Sale中的外键改为引用product.Product:
--- a/store/sale/models.py +++ b/store/sale/models.py @@ -1,6 +1,6 @@ from django.db import models -from catalog.models import Product +from product.models import Product class Sale(models.Model): created = models.DateTimeField() --- a/store/store/settings.py +++ b/store/store/settings.py @@ -40,6 +40,7 @@ INSTALLED_APPS = [ 'catalog', 'sale', + 'product', ]
接下来,让 Django 为您生成迁移:
$ python manage.py makemigrations sale catalog product
Migrations for 'catalog':
catalog/migrations/0002_remove_product_category.py
- Remove field category from product
catalog/migrations/0003_delete_product.py
- Delete model Product
Migrations for 'product':
product/migrations/0001_initial.py
- Create model Product
Migrations for 'sale':
sale/migrations/0002_auto_20200110_1304.py
- Alter field product on sale
您希望防止 Django 删除该表,因为您打算对它进行重命名。
为了在product应用程序中获得Product模型的名称,为创建Product的迁移生成 SQL:
$ python manage.py sqlmigrate product 0001
BEGIN;
--
-- Create model Product
--
CREATE TABLE "product_product" ("id" serial NOT NULL PRIMARY KEY, "name" varchar(100) NOT NULL, "category_id" integer NOT NULL); ALTER TABLE "product_product" ADD CONSTRAINT "product_product_category_id_0c725779_fk_catalog_category_id" FOREIGN KEY ("category_id") REFERENCES "catalog_category" ("id") DEFERRABLE INITIALLY DEFERRED;
CREATE INDEX "product_product_name_04ac86ce" ON "product_product" ("name");
CREATE INDEX "product_product_name_04ac86ce_like" ON "product_product" ("name" varchar_pattern_ops);
CREATE INDEX "product_product_category_id_0c725779" ON "product_product" ("category_id");
COMMIT;
Django 在product应用中为Product模型生成的表的名称是product_product。
重命名旧表
既然已经为模型生成了名称 Django,就可以重命名旧表了。为了从catalog应用中删除Product模型,Django 创建了两个迁移:
catalog/migrations/0002_remove_product_category从表中删除外键。catalog/migrations/0003_delete_product降将模式。
在重命名表之前,您希望防止 Django 将外键删除到Category:
--- a/store/catalog/migrations/0002_remove_product_category.py +++ b/store/catalog/migrations/0002_remove_product_category.py @@ -10,8 +10,13 @@ class Migration(migrations.Migration): ] operations = [ - migrations.RemoveField( - model_name='product', - name='category', + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.RemoveField( + model_name='product', + name='category', + ), + ], + database_operations=[], ), ]
使用将database_operations设置为空列表的SeparateDatabaseAndState可以防止 Django 删除该列。
Django 提供了一个特殊的迁移操作, AlterModelTable ,为一个模型重命名一个表。编辑删除旧表的迁移,并将表重命名为product_product:
--- a/store/catalog/migrations/0003_delete_product.py +++ b/store/catalog/migrations/0003_delete_product.py @@ -11,7 +11,17 @@ class Migration(migrations.Migration): ] operations = [ - migrations.DeleteModel( - name='Product', - ), + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.DeleteModel( + name='Product', + ), + ], + database_operations=[ + migrations.AlterModelTable( + name='Product', + table='product_product', + ), + ], + ) ]
您使用了SeparateDatabaseAndState和AlterModelTable来为 Django 提供不同的迁移操作,以便在数据库中执行。
接下来,您需要阻止 Django 为新的Product模型创建一个表。相反,您希望它使用您重命名的表。在product应用程序中对初始迁移进行以下更改:
--- a/store/product/migrations/0001_initial.py +++ b/store/product/migrations/0001_initial.py @@ -13,12 +13,18 @@ class Migration(migrations.Migration): ] operations = [ - migrations.CreateModel( - name='Product', - fields=[ - ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), - ('name', models.CharField(db_index=True, max_length=100)), - ('category', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='catalog.Category')), - ], + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.CreateModel( + name='Product', + fields=[ + ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), + ('name', models.CharField(db_index=True, max_length=100)), + ('category', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='catalog.Category')), + ], + ), + ], + # Table already exists. See catalog/migrations/0003_delete_product.py + database_operations=[], ), ]
迁移在 Django 的状态中创建了模型,但是由于行database_operations=[],它没有在数据库中创建表。还记得你把老表改名为product_product的时候吗?通过将旧表重命名为 Django 为新模型生成的名称,可以强制 Django 使用旧表。
最后,您希望防止 Django 在Sale模型中重新创建外键约束:
--- a/store/sale/migrations/0002_auto_20200110_1304.py +++ b/store/sale/migrations/0002_auto_20200110_1304.py @@ -12,9 +12,15 @@ class Migration(migrations.Migration): ] operations = [ - migrations.AlterField( - model_name='sale', - name='product', - field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='product.Product'), - ), + migrations.SeparateDatabaseAndState( + state_operations=[ + migrations.AlterField( + model_name='sale', + name='product', + field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='product.Product'), + ), + ], + # You're reusing an existing table, so do nothing + database_operations=[], + ) ]
您现在已经准备好运行迁移了:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, catalog, contenttypes, product, sale, sessions
Running migrations:
Applying catalog.0002_remove_product_category... OK
Applying product.0001_initial... OK
Applying sale.0002_auto_20200110_1304... OK
Applying catalog.0003_delete_product... OK
太好了!迁移成功。但在你继续前进之前,确保它可以被逆转:
$ python manage.py migrate catalog 0001
Operations to perform:
Target specific migration: 0001_initial, from catalog
Running migrations:
Rendering model states... DONE
Unapplying catalog.0003_delete_product... OK
Unapplying sale.0002_auto_20200110_1304... OK
Unapplying product.0001_initial... OK
Unapplying catalog.0002_remove_product_category... OK
太神奇了!迁移是完全可逆的。
注: AlterModelTable一般比RunSQL更可取,原因有几个。
首先,AlterModelTable能否处理基于模型名称的字段之间的多对多关系。使用RunSQL重命名表可能需要一些额外的工作。
此外,内置的迁移操作如AlterModelTable是数据库不可知的,而RunSQL不是。例如,如果您的应用程序需要在多个数据库引擎上工作,那么您可能会在编写与所有数据库引擎兼容的 SQL 时遇到一些麻烦。
加分:懂内省
Django ORM 是一个抽象层,它将 Python 类型转换成数据库表,反之亦然。例如,当您在product应用程序中创建模型Product时,Django 创建了一个名为product_product的表。除了表,ORM 还创建其他数据库对象,比如索引、约束、序列等等。Django 根据应用程序和模型的名称为所有这些对象命名。
为了更好地理解它的样子,请检查数据库中的表catalog_category:
django_migration_test=# \d catalog_category
Table "public.catalog_category"
Column | Type | Nullable | Default
--------+------------------------+----------+----------------------------------------------
id | integer | not null | nextval('catalog_category_id_seq'::regclass)
name | character varying(100) | not null |
Indexes:
"catalog_category_pkey" PRIMARY KEY, btree (id)
该表是 Django 为应用程序catalog中的Category模型生成的,因此得名catalog_category。您还可以注意到其他数据库对象也有类似的命名约定。
catalog_category_pkey指一个主键指标。catalog_category_id_seq是指为主键字段id生成值的序列。
接下来,检查您从catalog移动到product的Product模型的工作台:
django_migration_test=# \d product_product
Table "public.product_product"
Column | Type | Nullable | Default
-------------+------------------------+----------+---------------------------------------------
id | integer | not null | nextval('catalog_product_id_seq'::regclass)
name | character varying(100) | not null |
category_id | integer | not null |
Indexes:
"catalog_product_pkey" PRIMARY KEY, btree (id)
"catalog_product_category_id_35bf920b" btree (category_id)
"catalog_product_name_924af5bc" btree (name)
"catalog_product_name_924af5bc_like" btree (name varchar_pattern_ops)
Foreign-key constraints:
"catalog_product_category_id_35bf920b_fk_catalog_category_id"
FOREIGN KEY (category_id)
REFERENCES catalog_category(id)
DEFERRABLE INITIALLY DEFERRED
乍一看,相关对象比较多。但是,仔细观察就会发现,相关对象的名称与表的名称并不一致。例如,表的名称是product_product,但是主键约束的名称是catalog_product_pkey。您从名为catalog的应用程序中复制了模型,这意味着迁移操作AlterModelTable不会改变所有相关数据库对象的名称。
为了更好地理解AlterModelTable是如何工作的,请查看这个迁移操作生成的 SQL:
$ python manage.py sqlmigrate catalog 0003
BEGIN;
--
-- Custom state/database change combination
--
ALTER TABLE "catalog_product" RENAME TO "product_product";
COMMIT;
这表明 AlterModelTable只重命名了表格。如果是这种情况,那么如果您试图对与这些对象的表相关的数据库对象之一进行更改,会发生什么情况呢?姜戈能够应对这些变化吗?
要找到答案,请尝试删除Product模型中字段name的索引:
--- a/store/product/models.py +++ b/store/product/models.py @@ -3,5 +3,5 @@ from django.db import models from catalog.models import Category class Product(models.Model): - name = models.CharField(max_length=100, db_index=True) + name = models.CharField(max_length=100, db_index=False) category = models.ForeignKey(Category, on_delete=models.CASCADE)
接下来,生成迁移:
$ python manage.py makemigrations
Migrations for 'product':
product/migrations/0002_auto_20200110_1426.py
- Alter field name on product
命令成功了,这是一个好迹象。现在检查生成的 SQL:
$ python manage.py sqlmigrate product 0002
BEGIN;
--
-- Alter field name on product
--
DROP INDEX IF EXISTS "catalog_product_name_924af5bc";
DROP INDEX IF EXISTS "catalog_product_name_924af5bc_like";
COMMIT;
生成的 SQL 命令删除索引catalog_product_name_924af5bc。Django 能够检测到现有的索引,即使它与表名不一致。这被称为内省。
ORM 内部使用自省,所以你不会找到太多关于它的文档。每个数据库后端包含一个自省模块,它可以根据数据库对象的属性来识别它们。自检模块通常会使用数据库提供的元数据表。使用自省,ORM 可以操纵对象,而不依赖于命名约定。这就是 Django 能够检测要删除的索引名称的方法。
总结:重命名表的利弊
重命名表有其优点和缺点。以下是与这种方法相关的一些优点:
- 很快:这种方法只重命名数据库对象,所以非常快。
- 不需要停机:使用这种方法,数据库对象在被重命名时只被锁定一小段时间,因此可以在没有停机的情况下在活动系统上执行。
- 这是可逆的:如果有必要,可以逆转这种迁移。
- ORM 支持这一点:使用内置的迁移操作执行这一转换保证了适当的数据库支持。
与这种方法相关的唯一潜在的缺点是它打破了命名惯例。只重命名表意味着其他数据库对象的名称将与 Django 的命名约定不一致。这可能会在直接使用数据库时造成一些混乱。但是,Django 仍然可以使用自省来识别和管理这些对象,所以这不是一个主要问题。
指南:选择最佳方法
在本教程中,您已经学习了如何以三种不同的方式将 Django 模型从一个应用程序移动到另一个应用程序。下面是本教程中描述的方法的比较:
| 公制的 | 复制数据 | 更改表格 | 重命名表格 |
|---|---|---|---|
| 快的 | 一千 | ✔️ | ✔️ |
| 无停机时间 | 一千 | ✔️ | ✔️ |
| 同步相关对象 | 一千 | ✔️ | ✔️ |
| 保留命名约定 | ✔️ | 一千 | ✔️ |
| 内置 ORM 支持 | ✔️ | ✔️ | ✔️ |
| 可逆的 | ✔️ | ✔️ | ✔️ |
注意:上表表明重命名表保留了 Django 的命名约定。虽然严格来说这并不正确,但是您在前面已经了解到 Django 可以使用内省来克服与这种方法相关的命名问题。
以上每种方法都有自己的优点和缺点。那么,您应该使用哪种方法呢?
根据一般经验,当您处理小表并且能够承受一些停机时间时,应该复制数据。否则,最好的办法是重命名该表,并引用新模型。
也就是说,每个项目都有自己独特的需求。您应该选择对您和您的团队最有意义的方法。
结论
阅读完本教程后,您将能够更好地根据您的具体用例、限制和需求,做出如何将 Django 模型迁移到另一个应用程序的正确决定。
在本教程中,您已经学习了:
- 如何将 Django 模型从一个应用程序移动到另一个应用程序
- 如何使用 Django 迁移 CLI 的高级功能,如
sqlmigrate、showmigrations、sqlsequencereset - 如何制定和检查迁移计划
- 如何使迁移可逆,以及如何逆转迁移
- 什么是内省以及 Django 如何在迁移中使用它
要深入了解,请查看完整的数据库教程和 Django 教程。**********
必看的 10 个 PyCon 演讲
在过去的三年里,我有幸参加了美国的 Python 大会(PyCon)。PyCon US 是一年一度的活动,Python 爱好者聚集在一起讨论和学习 Python。这是一个学习的好地方,结识新的 Python 开发者,并获得一些非常酷的东西。
第一次参加,我很快意识到这更像是一个社区活动,而不是一个典型的会议。人们来自世界各地,各行各业。没有偏见——除了每个人都知道 Python 是最好的编程语言!
了解更多: ,获取新的 Python 教程和新闻,让您成为更有效的 Python 爱好者。
在 PyCon ,你可以做很多事情。美国会议分为三个主要部分:
-
教程:一系列类似课堂的学习会议,专家在会上就某一特定主题进行深入教学
-
会议:
-
由 Python 社区成员提交的精选演讲,时长从 30 分钟到 45 分钟不等,全天进行
-
会议组织者邀请的主旨发言人
-
由任何想要成为焦点的与会者提供的 5 分钟闪电演讲集(旁注:Docker 在 2014 年 PyCon 闪电演讲中宣布。)
-
-
Sprints: 为期一周的活动,成员们开始着手他们的同事提出的项目
如果你有机会参加 PyCon 活动,不管是在美国还是离你住的地方更近的地方,我都强烈推荐。你不仅会学到更多关于 Python 语言的知识,还能见到其他优秀的 Python 开发者。查看 Python.org 的会议列表,看看你附近有没有。
在为这个列表选择视频时,我把自己限制在 2009 年或以后在美国皮肯大会上的演讲。我只选择了主题演讲和 30 到 45 分钟的演讲。我没有包括任何教程或闪电谈话。我还试图选择经得起时间考验的视频,这意味着它们涵盖的主题有望在很长一段时间内对初学者和高级开发人员都有用。
事不宜迟,下面是我列出的 10 个必看的 PyCon 演讲。
#10:重构 Python:为什么以及如何重构你的代码
布雷特·斯拉特金,PyCon 2016
Brett Slatkin 是一名谷歌工程师,也是《T2》的作者。他在 PyCon US 和 PyCon Montreal 做了很多关于 Python 的演讲。在这个演讲中,Brett 快速而深入地探究了代码重构的含义和所涉及的内容。
他还解释了为什么重构代码如此重要,以至于你应该花和实际开发代码一样多甚至更多的时间来重构代码。他的演讲中探讨的概念不仅对 Python 开发人员,而且对所有软件工程师都非常有用。
你可以在这里找到他演讲的幻灯片。
#9:用邋遢的 Python 解决你的问题
拉里·黑斯廷斯,PyCon 2018
Larry Hastings 是 Python 的核心开发人员之一,几乎从一开始就参与了它的开发。他已经在不同的场合做了很多关于 Python 的演讲,但是这次是最突出的一次。
在这个演讲中,他探讨了什么时候打破“Pythonic 式”惯例可以快速解决手头的问题。我喜欢这个演讲,因为它提供了一些关于如何以及何时打破常规的很好的技巧,以及其他一些 Python 技巧。这是一次有趣的谈话,也是一次增长见识的谈话。
#8:令人敬畏的命令行工具
Amjith Pamaujam,PyCon 2017
Amjith Ramanujam 是网飞的一名流量工程师,也是 PGCLI 和 MYCLI 的开发者,这是用于 Postgres 和 MySQL 的令人惊叹的交互式命令行工具。Python 开发人员经常发现自己在创建需要从命令行运行的脚本或程序。Amjith 通过回顾开发这些工具时所做的设计决策,在探索什么是优秀的命令行工具方面做了大量工作。
#7:发现 Python
大卫·比兹利,皮肯 2014
David Beazley 是另一位 Python 核心开发人员,他写了许多关于 Python 的书籍和演讲。我拥有他的 Python 食谱,强烈推荐。
这个演讲与其他演讲略有不同,因为它不包含任何 Python 代码。这是一本关于他如何使用 Python 解决不可能完成的任务的回忆录。这个演讲真正展示了 Python 的强大,这是一种易于使用的语言,可以用来解决现实世界的问题。
#6: Big-O:代码如何随着数据增长而变慢
Ned Batchelder, PyCon 2018
Ned Batchelder 是 Python 波士顿小组的负责人,自 2009 年以来,他几乎在每一次 PyCon 上都发表过演讲!他是一个很棒的演讲者,如果有机会,我强烈推荐去听他的任何演讲。
有很多人试图解释 Big-O 符号是什么以及它为什么重要。直到看到奈德的演讲,我才开始真正领会。Ned 用简单的例子很好地解释了 Big-O 的含义,以及为什么我们作为 Python 开发人员需要理解它。
#5:标准图书馆中隐藏的宝藏
道格·赫尔曼,2011 年 PyCon】
Doug Hellman 是博客本周 Python 模块的作者,该博客致力于详细解释 Python 的一些内置模块。这是一个很好的资源,所以我强烈建议您查看并订阅这个提要。
这个演讲是这个列表中最老的,因此有点过时,因为他仍然使用 Python 2 作为例子。然而,他揭示了图书馆是隐藏的宝藏,并展示了使用它们的独特方法。
你可以在 PyVideo 查看这篇演讲。
# 4:Python 中的内存管理:基础知识
尼娜·扎哈伦科,PyCon 2016
Nina Zakharenko 在微软工作,是一名 Python 云开发者倡导者,听起来棒极了!在本次 PyCon 2016 演讲中,她探讨了 Python 内存管理的细节。
对于新的 Python 开发人员来说,不考虑或不关心内存管理是很常见的,因为它在某种程度上是“自动”处理的但是,了解幕后发生的事情的基础知识实际上是至关重要的,这样您就可以学习如何编写更高效的代码。尼娜为我们学习这些概念提供了一个良好的开端。
#3:万事俱备:标准库中的数据结构及其他
布兰登·罗德斯,2014 年 PyCon】
Brandon Rhodes 是 Dropbox 的 Python 开发人员,也是 PyCon 2016–2017 的主席。每当你想知道数据结构是如何工作的,或者它们能有效地做什么,这是一个值得讨论的观点。我把它放在书签里,当我想知道应该用哪一个的时候就可以参考。
#2:超越 PEP 8:优美易懂代码的最佳实践
雷蒙德·赫廷格,2015 年 PyCon】
我真的可以把它改成“雷蒙德·赫廷格——他的任何演讲”,因为雷蒙德有大量精彩演讲的曲目。但是这个关于超越 PEP 8 的,可能是最有名的,被引用次数最多的。
通常,作为 Pythonistas,我们陷入 PEP 8 的严格规则中,认为任何偏离它的东西都是“不符合 Pythonic 的”。相反,Raymond 深入研究了 PEP 8 的精神,并探索了什么时候对它严格是好的,什么时候不是。
#1: PyCon 2016 主题演讲
K. Lars Lohn,PyCon 2016
一个嬉皮士骑自行车的人演奏双簧管,用计算机算法教授生活课程。
如果这还没有引起你的注意,他还在演讲结束时受到了起立鼓掌,这是我从那以后再也没有见过的。我有幸亲自参加了这次演讲,这是 Python 社区的缩影:团结、包容和对解决复杂问题的热爱。当我第一次开始整理这个列表的时候,这个演讲立刻浮现在我的脑海中,它应该是第一个。
这就是我整理的必看 PyCon 视频列表。请在下面评论您最喜欢的来自美国 PyCon 或世界各地其他 PyCon 的演讲。快乐的蟒蛇!**
Python 中基于空间的自然语言处理
原文:https://realpython.com/natural-language-processing-spacy-python/
spaCy 是一个免费的开源库,用于 Python 中的自然语言处理 (NLP),具有很多内置功能。在 NLP 中处理和分析数据变得越来越流行。非结构化文本数据是大规模产生的,处理非结构化数据并从中获得洞察力非常重要。为此,您需要用计算机可以理解的格式来表示数据。NLP 可以帮你做到这一点。
在本教程中,您将学习:
- NLP 中的基本术语和概念是什么
- 如何在空间中实现这些概念
- 如何定制和扩展 spaCy 中的内置功能
- 如何对文本进行基本的统计分析
- 如何创建管道来处理非结构化文本
- 如何解析句子并从中提取有意义的见解
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
什么是 NLP 和 spaCy?
自然语言处理(NLP)是人工智能(T2)的一个子领域,涉及计算机和人类语言之间的互动。NLP 是计算机从人类语言中分析、理解和推导含义的过程。
NLP 可以帮助您从非结构化文本中提取见解,并且有几个使用案例,例如:
spaCy 是 Python 中 NLP 的免费开源库。它是用 Cython 编写的,旨在构建信息提取或自然语言理解系统。它是为生产使用而构建的,提供了一个简洁且用户友好的 API。
安装
在本节中,您将安装 spaCy,然后下载英语语言的数据和模型。
如何安装 spaCy
spaCy 可以使用pip(Python 包管理器)安装。你可以使用一个虚拟环境来避免依赖系统范围的软件包。要了解关于虚拟环境和pip的更多信息,请查看什么是 Pip?新 Pythonistas 和 Python 虚拟环境指南:初级读本。
创建新的虚拟环境:
$ python3 -m venv env
激活此虚拟环境并安装空间:
$ source ./env/bin/activate
$ pip install spacy
如何下载模型和数据
spaCy 有种不同类型的车型。英语的默认模式是en_core_web_sm。
激活在上一步中创建的虚拟环境,并下载英语语言的模型和数据:
$ python -m spacy download en_core_web_sm
通过加载验证下载是否成功:
>>> import spacy >>> nlp = spacy.load('en_core_web_sm')如果
nlp对象被创建,那么这意味着 spaCy 被安装并且模型和数据被成功下载。使用空间
在这一节中,您将对给定的输入字符串和文本文件使用 spaCy。在空间中加载语言模型实例:
>>> import spacy
>>> nlp = spacy.load('en_core_web_sm')
这里,nlp对象是一个语言模型实例。你可以假设,在整个教程中,nlp指的是由en_core_web_sm加载的语言模型。现在,您可以使用 spaCy 来读取字符串或文本文件。
如何读取一个字符串
您可以使用 spaCy 为给定的输入字符串创建一个已处理的 Doc 对象,这是一个用于访问语言注释的容器:
>>> introduction_text = ('This tutorial is about Natural' ... ' Language Processing in Spacy.') >>> introduction_doc = nlp(introduction_text) >>> # Extract tokens for the given doc >>> print ([token.text for token in introduction_doc]) ['This', 'tutorial', 'is', 'about', 'Natural', 'Language', 'Processing', 'in', 'Spacy', '.']在上面的例子中,注意文本是如何被转换成 spaCy 能够理解的对象的。您可以使用这种方法将任何文本转换成经过处理的
Doc对象,并推导出属性,这将在接下来的章节中介绍。如何读取文本文件
在本节中,您将为一个文本文件创建一个已处理的 Doc 对象:
>>> file_name = 'introduction.txt'
>>> introduction_file_text = open(file_name).read()
>>> introduction_file_doc = nlp(introduction_file_text)
>>> # Extract tokens for the given doc
>>> print ([token.text for token in introduction_file_doc])
['This', 'tutorial', 'is', 'about', 'Natural', 'Language',
'Processing', 'in', 'Spacy', '.', '\n']
这就是你如何将一个文本文件转换成一个处理过的Doc对象。
注:
你可以假设:
句子检测
句子检测是在给定文本中定位句子的开头和结尾的过程。这允许你把一篇文章分成有语言意义的单元。当您处理文本时,您将使用这些单元来执行任务,如词性标注和实体提取。
在 spaCy 中,sents属性用于提取句子。以下是如何提取句子总数和给定输入文本的句子:
>>> about_text = ('Gus Proto is a Python developer currently' ... ' working for a London-based Fintech' ... ' company. He is interested in learning' ... ' Natural Language Processing.') >>> about_doc = nlp(about_text) >>> sentences = list(about_doc.sents) >>> len(sentences) 2 >>> for sentence in sentences: ... print (sentence) ... 'Gus Proto is a Python developer currently working for a London-based Fintech company.' 'He is interested in learning Natural Language Processing.'在上面的例子中,spaCy 使用句号(
.)作为句子分隔符,能够正确地识别英语句子。您还可以自定义句子检测,以检测自定义分隔符上的句子。下面是一个示例,其中省略号(
...)用作分隔符:
>>> def set_custom_boundaries(doc):
... # Adds support to use `...` as the delimiter for sentence detection
... for token in doc[:-1]:
... if token.text == '...':
... doc[token.i+1].is_sent_start = True
... return doc
...
>>> ellipsis_text = ('Gus, can you, ... never mind, I forgot'
... ' what I was saying. So, do you think'
... ' we should ...')
>>> # Load a new model instance
>>> custom_nlp = spacy.load('en_core_web_sm')
>>> custom_nlp.add_pipe(set_custom_boundaries, before='parser')
>>> custom_ellipsis_doc = custom_nlp(ellipsis_text)
>>> custom_ellipsis_sentences = list(custom_ellipsis_doc.sents)
>>> for sentence in custom_ellipsis_sentences:
... print(sentence)
...
Gus, can you, ...
never mind, I forgot what I was saying.
So, do you think we should ...
>>> # Sentence Detection with no customization
>>> ellipsis_doc = nlp(ellipsis_text)
>>> ellipsis_sentences = list(ellipsis_doc.sents)
>>> for sentence in ellipsis_sentences:
... print(sentence)
...
Gus, can you, ... never mind, I forgot what I was saying.
So, do you think we should ...
注意custom_ellipsis_sentences包含三个句子,而ellipsis_sentences包含两个句子。这些句子仍然是通过sents属性获得的,如您之前所见。
空间中的标记化
标记化是句子检测之后的下一步。它可以让你识别文本中的基本单位。这些基本单位被称为令牌。标记化很有用,因为它将文本分解成有意义的单元。这些单元用于进一步分析,如词性标注。
在 spaCy 中,可以通过迭代Doc对象来打印令牌:
>>> for token in about_doc: ... print (token, token.idx) ... Gus 0 Proto 4 is 10 a 13 Python 15 developer 22 currently 32 working 42 for 50 a 54 London 56 - 62 based 63 Fintech 69 company 77 . 84 He 86 is 89 interested 92 in 103 learning 106 Natural 115 Language 123 Processing 132 . 142注意 spaCy 是如何保存令牌的起始索引的。这对于就地单词替换很有用。spaCy 为
Token类提供了各种属性:
>>> for token in about_doc:
... print (token, token.idx, token.text_with_ws,
... token.is_alpha, token.is_punct, token.is_space,
... token.shape_, token.is_stop)
...
Gus 0 Gus True False False Xxx False
Proto 4 Proto True False False Xxxxx False
is 10 is True False False xx True
a 13 a True False False x True
Python 15 Python True False False Xxxxx False
developer 22 developer True False False xxxx False
currently 32 currently True False False xxxx False
working 42 working True False False xxxx False
for 50 for True False False xxx True
a 54 a True False False x True
London 56 London True False False Xxxxx False
- 62 - False True False - False
based 63 based True False False xxxx False
Fintech 69 Fintech True False False Xxxxx False
company 77 company True False False xxxx False
. 84 . False True False . False
He 86 He True False False Xx True
is 89 is True False False xx True
interested 92 interested True False False xxxx False
in 103 in True False False xx True
learning 106 learning True False False xxxx False
Natural 115 Natural True False False Xxxxx False
Language 123 Language True False False Xxxxx False
Processing 132 Processing True False False Xxxxx False
. 142 . False True False . False
在此示例中,访问了一些常见的必需属性:
text_with_ws打印带有尾随空格的令牌文本(如果有)。is_alpha检测令牌是否由字母字符组成。is_punct检测令牌是否为标点符号。is_space检测令牌是否为空格。shape_打印出字的形状。is_stop检测令牌是否为停用词。
注:你将在下一节了解更多关于的停用词。
您还可以自定义标记化过程,以检测自定义字符上的标记。这通常用于带连字符的单词,即用连字符连接的单词。例如,“伦敦”是一个连字符单词。
spaCy 允许您通过更新nlp对象上的tokenizer属性来自定义标记化:
>>> import re >>> import spacy >>> from spacy.tokenizer import Tokenizer >>> custom_nlp = spacy.load('en_core_web_sm') >>> prefix_re = spacy.util.compile_prefix_regex(custom_nlp.Defaults.prefixes) >>> suffix_re = spacy.util.compile_suffix_regex(custom_nlp.Defaults.suffixes) >>> infix_re = re.compile(r'''[-~]''') >>> def customize_tokenizer(nlp): ... # Adds support to use `-` as the delimiter for tokenization ... return Tokenizer(nlp.vocab, prefix_search=prefix_re.search, ... suffix_search=suffix_re.search, ... infix_finditer=infix_re.finditer, ... token_match=None ... ) ... >>> custom_nlp.tokenizer = customize_tokenizer(custom_nlp) >>> custom_tokenizer_about_doc = custom_nlp(about_text) >>> print([token.text for token in custom_tokenizer_about_doc]) ['Gus', 'Proto', 'is', 'a', 'Python', 'developer', 'currently', 'working', 'for', 'a', 'London', '-', 'based', 'Fintech', 'company', '.', 'He', 'is', 'interested', 'in', 'learning', 'Natural', 'Language', 'Processing', '.']为了便于定制,您可以将各种参数传递给
Tokenizer类:
nlp.vocab是特殊情况的存储容器,用于处理缩写、表情符号等情况。prefix_search是用来处理前面标点符号的函数,比如开括号。infix_finditer是用来处理非空格分隔符的函数,比如连字符。suffix_search是用来处理后续标点符号的函数,比如右括号。token_match是一个可选的布尔函数,用于匹配不应被拆分的字符串。它覆盖了之前的规则,对于像 URL 或数字这样的实体非常有用。注意: spaCy 已经将带连字符的单词检测为单独的标记。上面的代码只是一个示例,展示了如何定制令牌化。它可以用于任何其他字符。
停止字
停用词是语言中最常见的词。在英语中,一些停用词的例子有
the、are、but和they。大多数句子需要包含停用词才能成为有意义的完整句子。通常,停用词会被删除,因为它们不重要,会扭曲词频分析。spaCy 有一个英语停用词列表:
>>> import spacy
>>> spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS
>>> len(spacy_stopwords)
326
>>> for stop_word in list(spacy_stopwords)[:10]:
... print(stop_word)
...
using
becomes
had
itself
once
often
is
herein
who
too
您可以从输入文本中删除停用词:
>>> for token in about_doc: ... if not token.is_stop: ... print (token) ... Gus Proto Python developer currently working London - based Fintech company . interested learning Natural Language Processing .像
is、a、for、the和in这样的停用词不会打印在上面的输出中。您还可以创建不包含停用字词的令牌列表:
>>> about_no_stopword_doc = [token for token in about_doc if not token.is_stop]
>>> print (about_no_stopword_doc)
[Gus, Proto, Python, developer, currently, working, London,
-, based, Fintech, company, ., interested, learning, Natural,
Language, Processing, .]
可以用空格连接,组成一个没有停用词的句子。
引理化
词汇化是减少一个单词的屈折形式,同时仍然确保减少的形式属于该语言的过程。这种简化形式或词根被称为引理。
比如组织、组织、组织都是组织的形式。这里,组织是引理。一个单词的屈折可以让你表达不同的语法类别,如时态(组织的 vs 组织的)、数字(串 vs 串)等等。词汇化是必要的,因为它有助于减少一个单词的屈折形式,以便可以将它们作为一个项目进行分析。它还可以帮助你使文本正常化。
spaCy 在Token类上有属性lemma_。该属性具有记号的词汇化形式:
>>> conference_help_text = ('Gus is helping organize a developer' ... 'conference on Applications of Natural Language' ... ' Processing. He keeps organizing local Python meetups' ... ' and several internal talks at his workplace.') >>> conference_help_doc = nlp(conference_help_text) >>> for token in conference_help_doc: ... print (token, token.lemma_) ... Gus Gus is be helping help organize organize a a developer developer conference conference on on Applications Applications of of Natural Natural Language Language Processing Processing . . He -PRON- keeps keep organizing organize local local Python Python meetups meetup and and several several internal internal talks talk at at his -PRON- workplace workplace . .在这个例子中,
organizing简化为它的引理形式organize。如果不对文本进行词汇化,那么organize和organizing将被视为不同的标记,尽管它们的意思相似。词汇化有助于避免意思相似的重复单词。词频
现在,您可以将给定的文本转换成标记,并对其执行统计分析。这种分析可以为您提供关于单词模式的各种见解,例如文本中的常见单词或独特单词:
>>> from collections import Counter
>>> complete_text = ('Gus Proto is a Python developer currently'
... 'working for a London-based Fintech company. He is'
... ' interested in learning Natural Language Processing.'
... ' There is a developer conference happening on 21 July'
... ' 2019 in London. It is titled "Applications of Natural'
... ' Language Processing". There is a helpline number '
... ' available at +1-1234567891\. Gus is helping organize it.'
... ' He keeps organizing local Python meetups and several'
... ' internal talks at his workplace. Gus is also presenting'
... ' a talk. The talk will introduce the reader about "Use'
... ' cases of Natural Language Processing in Fintech".'
... ' Apart from his work, he is very passionate about music.'
... ' Gus is learning to play the Piano. He has enrolled '
... ' himself in the weekend batch of Great Piano Academy.'
... ' Great Piano Academy is situated in Mayfair or the City'
... ' of London and has world-class piano instructors.')
...
>>> complete_doc = nlp(complete_text)
>>> # Remove stop words and punctuation symbols
>>> words = [token.text for token in complete_doc
... if not token.is_stop and not token.is_punct]
>>> word_freq = Counter(words)
>>> # 5 commonly occurring words with their frequencies
>>> common_words = word_freq.most_common(5)
>>> print (common_words)
[('Gus', 4), ('London', 3), ('Natural', 3), ('Language', 3), ('Processing', 3)]
>>> # Unique words
>>> unique_words = [word for (word, freq) in word_freq.items() if freq == 1]
>>> print (unique_words)
['Proto', 'currently', 'working', 'based', 'company',
'interested', 'conference', 'happening', '21', 'July',
'2019', 'titled', 'Applications', 'helpline', 'number',
'available', '+1', '1234567891', 'helping', 'organize',
'keeps', 'organizing', 'local', 'meetups', 'internal',
'talks', 'workplace', 'presenting', 'introduce', 'reader',
'Use', 'cases', 'Apart', 'work', 'passionate', 'music', 'play',
'enrolled', 'weekend', 'batch', 'situated', 'Mayfair', 'City',
'world', 'class', 'piano', 'instructors']
通过查看常用词,你可以看到文本整体上大概是关于Gus、London或者Natural Language Processing的。通过这种方式,您可以获取任何非结构化文本并执行统计分析,以了解它的内容。
这是另一个带有停用词的相同文本的例子:
>>> words_all = [token.text for token in complete_doc if not token.is_punct] >>> word_freq_all = Counter(words_all) >>> # 5 commonly occurring words with their frequencies >>> common_words_all = word_freq_all.most_common(5) >>> print (common_words_all) [('is', 10), ('a', 5), ('in', 5), ('Gus', 4), ('of', 4)]五个最常见的单词中有四个是停用词,它不能告诉你关于文本的太多信息。如果你在进行词频分析时考虑停用词,那么你将无法从输入文本中获得有意义的见解。这就是为什么删除停用词如此重要。
词性标注
词性或词性是一个语法角色,解释一个特定的单词在句子中是如何使用的。有八个词类:
- 名词
- 代词
- 形容词
- 动词
- 副词
- 介词
- 结合
- 感叹词
词性标注是根据单词在句子中的用法,给每个单词分配一个词性标签的过程。POS 标签对于给每个单词分配一个句法类别很有用,比如名词或动词。
在 spaCy 中,POS 标签作为属性出现在
Token对象上:
>>> for token in about_doc:
... print (token, token.tag_, token.pos_, spacy.explain(token.tag_))
...
Gus NNP PROPN noun, proper singular
Proto NNP PROPN noun, proper singular
is VBZ VERB verb, 3rd person singular present
a DT DET determiner
Python NNP PROPN noun, proper singular
developer NN NOUN noun, singular or mass
currently RB ADV adverb
working VBG VERB verb, gerund or present participle
for IN ADP conjunction, subordinating or preposition
a DT DET determiner
London NNP PROPN noun, proper singular
- HYPH PUNCT punctuation mark, hyphen
based VBN VERB verb, past participle
Fintech NNP PROPN noun, proper singular
company NN NOUN noun, singular or mass
. . PUNCT punctuation mark, sentence closer
He PRP PRON pronoun, personal
is VBZ VERB verb, 3rd person singular present
interested JJ ADJ adjective
in IN ADP conjunction, subordinating or preposition
learning VBG VERB verb, gerund or present participle
Natural NNP PROPN noun, proper singular
Language NNP PROPN noun, proper singular
Processing NNP PROPN noun, proper singular
. . PUNCT punctuation mark, sentence closer
这里,访问了Token类的两个属性:
tag_列举了精细的词类。pos_列出了粗粒度的词类。
spacy.explain给出特定 POS 标签的详细描述。spaCy 提供了一个完整的标签列表以及对每个标签的解释。
使用 POS 标签,您可以提取特定类别的单词:
>>> nouns = [] >>> adjectives = [] >>> for token in about_doc: ... if token.pos_ == 'NOUN': ... nouns.append(token) ... if token.pos_ == 'ADJ': ... adjectives.append(token) ... >>> nouns [developer, company] >>> adjectives [interested]您可以使用它来获得洞察力,删除最常见的名词,或者查看特定名词使用了哪些形容词。
可视化:使用显示
spaCy 自带一个名为 displaCy 的内置可视化工具。你可以用它在浏览器或笔记本中可视化依赖解析或命名实体。
您可以使用 displaCy 查找令牌的 POS 标签:
>>> from spacy import displacy
>>> about_interest_text = ('He is interested in learning'
... ' Natural Language Processing.')
>>> about_interest_doc = nlp(about_interest_text)
>>> displacy.serve(about_interest_doc, style='dep')
上面的代码将旋转一个简单的 web 服务器。您可以通过在浏览器中打开http://127.0.0.1:5000来查看可视化效果:
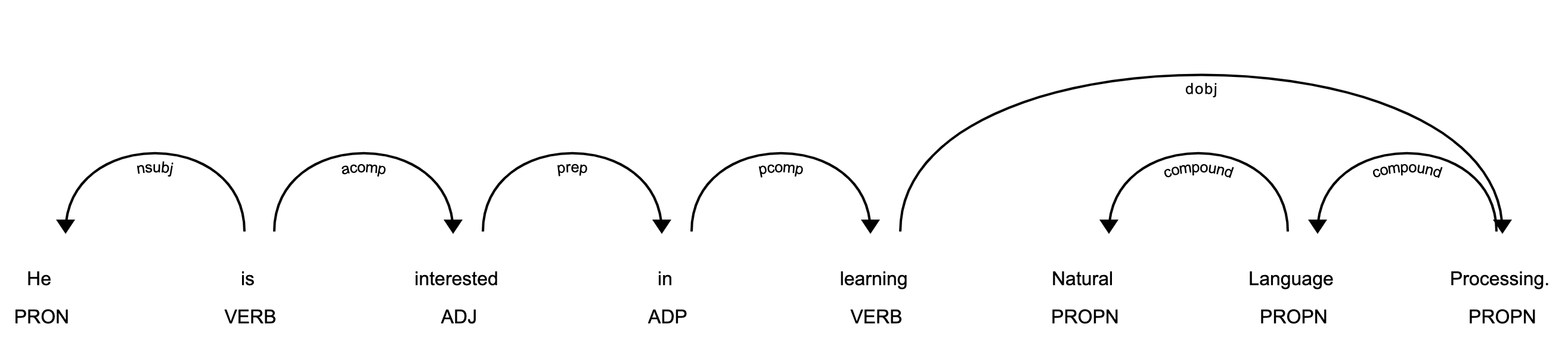
在上图中,每个代币都被分配了一个写在代币正下方的 POS 标签。
注意:以下是在 Jupyter 笔记本中使用 displaCy 的方法:
>>> displacy.render(about_interest_doc, style='dep', jupyter=True)预处理功能
您可以创建一个预处理函数,它将文本作为输入,并应用以下操作:
- 小写文本
- 对每个令牌进行词汇化
- 删除标点符号
- 删除停用词
预处理功能将文本转换成可分析的格式。对于大多数 NLP 任务来说,这是必要的。这里有一个例子:
>>> def is_token_allowed(token):
... '''
... Only allow valid tokens which are not stop words
... and punctuation symbols.
... '''
... if (not token or not token.string.strip() or
... token.is_stop or token.is_punct):
... return False
... return True
...
>>> def preprocess_token(token):
... # Reduce token to its lowercase lemma form
... return token.lemma_.strip().lower()
...
>>> complete_filtered_tokens = [preprocess_token(token)
... for token in complete_doc if is_token_allowed(token)]
>>> complete_filtered_tokens
['gus', 'proto', 'python', 'developer', 'currently', 'work',
'london', 'base', 'fintech', 'company', 'interested', 'learn',
'natural', 'language', 'processing', 'developer', 'conference',
'happen', '21', 'july', '2019', 'london', 'title',
'applications', 'natural', 'language', 'processing', 'helpline',
'number', 'available', '+1', '1234567891', 'gus', 'help',
'organize', 'keep', 'organize', 'local', 'python', 'meetup',
'internal', 'talk', 'workplace', 'gus', 'present', 'talk', 'talk',
'introduce', 'reader', 'use', 'case', 'natural', 'language',
'processing', 'fintech', 'apart', 'work', 'passionate', 'music',
'gus', 'learn', 'play', 'piano', 'enrol', 'weekend', 'batch',
'great', 'piano', 'academy', 'great', 'piano', 'academy',
'situate', 'mayfair', 'city', 'london', 'world', 'class',
'piano', 'instructor']
请注意,complete_filtered_tokens不包含任何停用词或标点符号,而是由字母化的小写符号组成。
使用空间的基于规则的匹配
基于规则的匹配是从非结构化文本中提取信息的步骤之一。它用于根据模式(如小写)和语法特征(如词性)识别和提取记号和短语。
基于规则的匹配可以使用正则表达式从非结构化文本中提取实体(比如电话号码)。从正则表达式不考虑文本的词法和语法属性的意义上来说,它不同于使用正则表达式提取文本。
使用基于规则的匹配,您可以提取名和姓,它们总是专有名词:
>>> from spacy.matcher import Matcher >>> matcher = Matcher(nlp.vocab) >>> def extract_full_name(nlp_doc): ... pattern = [{'POS': 'PROPN'}, {'POS': 'PROPN'}] ... matcher.add('FULL_NAME', None, pattern) ... matches = matcher(nlp_doc) ... for match_id, start, end in matches: ... span = nlp_doc[start:end] ... return span.text ... >>> extract_full_name(about_doc) 'Gus Proto'在这个例子中,
pattern是定义要匹配的标记组合的对象列表。里面的两个 POS 标签都是PROPN(专有名词)。因此,pattern由两个对象组成,其中两个令牌的 POS 标签都应该是PROPN。然后使用FULL_NAME和match_id将该模式添加到Matcher。最后,通过它们的开始和结束索引获得匹配。您还可以使用基于规则的匹配来提取电话号码:
>>> from spacy.matcher import Matcher
>>> matcher = Matcher(nlp.vocab)
>>> conference_org_text = ('There is a developer conference'
... 'happening on 21 July 2019 in London. It is titled'
... ' "Applications of Natural Language Processing".'
... ' There is a helpline number available'
... ' at (123) 456-789')
...
>>> def extract_phone_number(nlp_doc):
... pattern = [{'ORTH': '('}, {'SHAPE': 'ddd'},
... {'ORTH': ')'}, {'SHAPE': 'ddd'},
... {'ORTH': '-', 'OP': '?'},
... {'SHAPE': 'ddd'}]
... matcher.add('PHONE_NUMBER', None, pattern)
... matches = matcher(nlp_doc)
... for match_id, start, end in matches:
... span = nlp_doc[start:end]
... return span.text
...
>>> conference_org_doc = nlp(conference_org_text)
>>> extract_phone_number(conference_org_doc)
'(123) 456-789'
在本例中,只有模式被更新,以匹配上例中的电话号码。这里还使用了令牌的一些属性:
ORTH给出令牌的确切文本。SHAPE变换记号字符串以显示正投影特征。OP定义了运算符。使用?作为值意味着模式是可选的,意味着它可以匹配 0 或 1 次。
注意:为了简单起见,电话号码被假定为一种特殊的格式:(123) 456-789。您可以根据您的使用情况对此进行更改。
基于规则的匹配帮助您根据词汇模式(如小写)和语法特征(如词性)识别和提取标记和短语。
使用空间进行依存解析
依存解析是提取句子的依存解析来表示其语法结构的过程。定义了中心词和其从属词之间的从属关系。句首没有依存关系,被称为句子的词根。动词通常是句首。所有其他单词都与中心词相关联。
依赖关系可以映射到有向图表示中:
- 单词是节点。
- 语法关系是边。
依存分析有助于您了解单词在文本中的作用以及不同单词之间的关系。它也用于浅层解析和命名实体识别。
下面是如何使用依存解析来查看单词之间的关系:
>>> piano_text = 'Gus is learning piano' >>> piano_doc = nlp(piano_text) >>> for token in piano_doc: ... print (token.text, token.tag_, token.head.text, token.dep_) ... Gus NNP learning nsubj is VBZ learning aux learning VBG learning ROOT piano NN learning dobj在这个例子中,句子包含三种关系:
nsubj是这个词的主语。它的中心词是动词。aux是助词。它的中心词是动词。dobj是动词的直接宾语。它的中心词是动词。有一个详细的关系列表和描述。您可以使用 displaCy 来可视化依赖关系树:
>>> displacy.serve(piano_doc, style='dep')
这段代码将生成一个可视化效果,可以通过在浏览器中打开http://127.0.0.1:5000来访问:
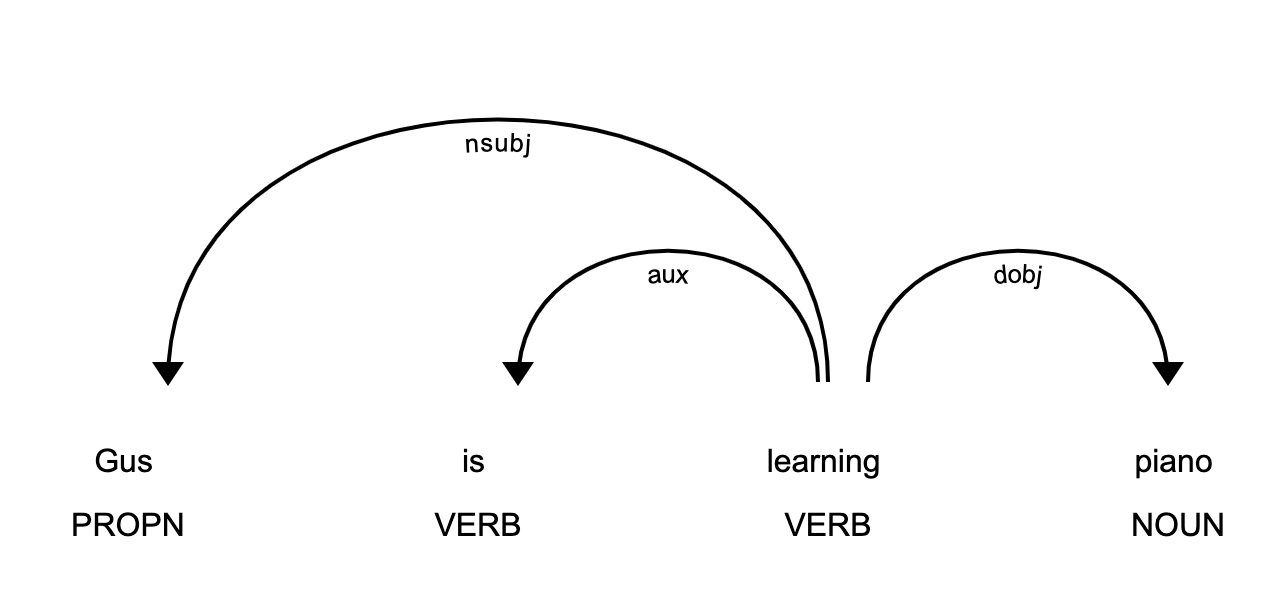
这张图片向您展示了句子的主语是专有名词Gus,并且它与piano有着learn的关系。
导航树和子树
依存解析树具有一棵树的所有属性。该树包含关于句子结构和语法的信息,并且可以以不同的方式被遍历以提取关系。
spaCy 提供了像children、lefts、rights和subtree这样的属性来导航解析树:
>>> one_line_about_text = ('Gus Proto is a Python developer' ... ' currently working for a London-based Fintech company') >>> one_line_about_doc = nlp(one_line_about_text) >>> # Extract children of `developer` >>> print([token.text for token in one_line_about_doc[5].children]) ['a', 'Python', 'working'] >>> # Extract previous neighboring node of `developer` >>> print (one_line_about_doc[5].nbor(-1)) Python >>> # Extract next neighboring node of `developer` >>> print (one_line_about_doc[5].nbor()) currently >>> # Extract all tokens on the left of `developer` >>> print([token.text for token in one_line_about_doc[5].lefts]) ['a', 'Python'] >>> # Extract tokens on the right of `developer` >>> print([token.text for token in one_line_about_doc[5].rights]) ['working'] >>> # Print subtree of `developer` >>> print (list(one_line_about_doc[5].subtree)) [a, Python, developer, currently, working, for, a, London, -, based, Fintech, company]您可以构造一个函数,该函数将子树作为参数,并通过合并字符串中的单词来返回字符串:
>>> def flatten_tree(tree):
... return ''.join([token.text_with_ws for token in list(tree)]).strip()
...
>>> # Print flattened subtree of `developer`
>>> print (flatten_tree(one_line_about_doc[5].subtree))
a Python developer currently working for a London-based Fintech company
您可以使用这个函数打印一个子树中的所有标记。
浅层解析
浅层解析,或分块,是从非结构化文本中提取短语的过程。分块根据词类标签将相邻的单词组合成短语。有一些标准的众所周知的词块,如名词短语、动词短语和介词短语。
名词短语检测
名词短语是以名词为中心的短语。它也可以包括其他种类的单词,如形容词、序数、限定词。名词短语有助于解释句子的上下文。它们帮助你推断出在句子中谈论的是什么。
空间在Doc对象上有属性noun_chunks。你可以用它来提取名词短语:
>>> conference_text = ('There is a developer conference' ... ' happening on 21 July 2019 in London.') >>> conference_doc = nlp(conference_text) >>> # Extract Noun Phrases >>> for chunk in conference_doc.noun_chunks: ... print (chunk) ... a developer conference 21 July London通过查看名词短语,你可以获得关于你的文章的信息。例如,
a developer conference表示文本提到一个会议,而日期21 July让您知道会议安排在21 July。你可以弄清楚会议是在过去还是在未来。London告诉你会议在London举行。动词短语检测
动词短语是由至少一个动词组成的句法单位。这个动词后面可以跟其他词块,比如名词短语。动词短语有助于理解名词所涉及的动作。
spaCy 没有提取动词短语的内置功能,所以您需要一个名为
textacy的库:注:
您可以使用
pip来安装textacy:$ pip install textacy现在您已经安装了
textacy,您可以使用它根据语法规则提取动词短语:
>>> import textacy
>>> about_talk_text = ('The talk will introduce reader about Use'
... ' cases of Natural Language Processing in'
... ' Fintech')
>>> pattern = r'(<VERB>?<ADV>*<VERB>+)'
>>> about_talk_doc = textacy.make_spacy_doc(about_talk_text,
... lang='en_core_web_sm')
>>> verb_phrases = textacy.extract.pos_regex_matches(about_talk_doc, pattern)
>>> # Print all Verb Phrase
>>> for chunk in verb_phrases:
... print(chunk.text)
...
will introduce
>>> # Extract Noun Phrase to explain what nouns are involved
>>> for chunk in about_talk_doc.noun_chunks:
... print (chunk)
...
The talk
reader
Use cases
Natural Language Processing
Fintech
在这个例子中,动词短语introduce表示将介绍某事。通过查看名词短语,可以看到有一个talk将Natural Language Processing或Fintech的reader变为use cases。
上面的代码使用 POS 标签的正则表达式模式提取所有动词短语。您可以根据您的用例调整动词短语的模式。
注意:在前面的例子中,您还可以进行依存解析来查看单词之间的关系是什么。
命名实体识别
命名实体识别 (NER)是在非结构化文本中定位命名实体,然后将它们分类到预定义的类别中的过程,例如人名、组织、位置、货币值、百分比、时间表达式等等。
你可以使用 NER 来了解更多关于你的文本的意思。例如,您可以使用它来填充一组文档的标签,以改进关键字搜索。您还可以使用它将客户支持票据分类到相关的类别中。
spaCy 在Doc对象上有属性ents。您可以使用它来提取命名实体:
>>> piano_class_text = ('Great Piano Academy is situated' ... ' in Mayfair or the City of London and has' ... ' world-class piano instructors.') >>> piano_class_doc = nlp(piano_class_text) >>> for ent in piano_class_doc.ents: ... print(ent.text, ent.start_char, ent.end_char, ... ent.label_, spacy.explain(ent.label_)) ... Great Piano Academy 0 19 ORG Companies, agencies, institutions, etc. Mayfair 35 42 GPE Countries, cities, states the City of London 46 64 GPE Countries, cities, states在上面的例子中,
ent是一个具有各种属性的Span对象:
text给出了实体的 Unicode 文本表示。start_char表示实体开始的字符偏移量。end_char表示实体末端的字符偏移量。label_给出了实体的标签。
spacy.explain给出关于实体标签的描述性细节。spaCy 模型有一个预先训练好的实体类列表。您可以使用 displaCy 来可视化这些实体:
>>> displacy.serve(piano_class_doc, style='ent')
如果您在浏览器中打开http://127.0.0.1:5000,那么您可以看到可视化效果:

你可以使用 NER 来编辑文本中的人名。例如,您可能希望这样做,以便隐藏在调查中收集的个人信息。您可以使用 spaCy 来做到这一点:
>>> survey_text = ('Out of 5 people surveyed, James Robert,' ... ' Julie Fuller and Benjamin Brooks like' ... ' apples. Kelly Cox and Matthew Evans' ... ' like oranges.') ... >>> def replace_person_names(token): ... if token.ent_iob != 0 and token.ent_type_ == 'PERSON': ... return '[REDACTED] ' ... return token.string ... >>> def redact_names(nlp_doc): ... for ent in nlp_doc.ents: ... ent.merge() ... tokens = map(replace_person_names, nlp_doc) ... return ''.join(tokens) ... >>> survey_doc = nlp(survey_text) >>> redact_names(survey_doc) 'Out of 5 people surveyed, [REDACTED] , [REDACTED] and' ' [REDACTED] like apples. [REDACTED] and [REDACTED]' ' like oranges.'在本例中,
replace_person_names()使用了ent_iob。它使用内-外-始(IOB)标记给出命名实体标记的 IOB 代码。这里,它可以假定一个非零值,因为零意味着没有设置实体标签。结论
spaCy 是一个强大的高级库,由于其速度、易用性、准确性和可扩展性,它在 NLP 应用程序中越来越受欢迎。恭喜你!你现在知道了:
- NLP 中的基本术语和概念是什么
- 如何在空间中实现这些概念
- 如何定制和扩展 spaCy 中的内置功能
- 如何对文本进行基本的统计分析
- 如何创建管道来处理非结构化文本
- 如何解析句子并从中提取有意义的见解*******
用 Python 的 NLTK 包进行自然语言处理
自然语言处理(NLP)是一个专注于让计算机程序能够使用自然人类语言的领域。 NLTK ,或者自然语言工具包,是一个可以用于 NLP 的 Python 包。
您可能正在分析的许多数据是非结构化数据,并且包含人类可读的文本。在以编程方式分析数据之前,首先需要对其进行预处理。在本教程中,您将第一次看到使用 NLTK 可以完成的各种文本预处理任务,以便为在未来的项目中应用它们做好准备。你还将看到如何做一些基本的文本分析和创建可视化。
如果你熟悉使用 Python 的基础,并且想尝试一些 NLP,那么你来对地方了。
本教程结束时,你将知道如何:
- 查找文本进行分析
- 预处理您的文本以供分析
- 分析你的文字
- 基于您的分析创建可视化效果
我们去抓蟒蛇吧!
免费下载: 从《Python 基础:Python 3 实用入门》中获取一个示例章节,看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
Python 的 NLTK 入门
你需要做的第一件事是确保你已经安装了 Python。对于本教程,您将使用 Python 3.9。如果你还没有安装 Python,那么看看 Python 3 安装&安装指南开始吧。
一旦你解决了这个问题,你的下一步就是用
pip来安装 NLTK 。最佳做法是将其安装在虚拟环境中。要了解更多关于虚拟环境的信息,请查看 Python 虚拟环境:初级读本。对于本教程,您将安装 3.5 版:
$ python -m pip install nltk==3.5为了给命名实体识别创建可视化效果,你还需要安装 NumPy 和 Matplotlib :
$ python -m pip install numpy matplotlib如果你想知道更多关于
pip是如何工作的,那么你可以看看什么是 Pip?新蟒蛇指南。你也可以看看关于安装 NLTK 数据的官方页面。标记化
通过标记,你可以方便地按单词或句子拆分文本。这将允许您处理较小的文本片段,即使在文本其余部分的上下文之外,这些片段仍然相对连贯和有意义。这是你将非结构化数据转化为结构化数据的第一步,结构化数据更容易分析。
当你分析文本时,你会按单词和句子进行分词。以下是这两种类型的标记化带来的好处:
以词来表征:词就像自然语言的原子。它们是最小的意义单位,但它本身仍然有意义。按单词标记文本可以让您识别出现频率特别高的单词。例如,如果你正在分析一组招聘广告,那么你可能会发现“Python”这个词经常出现。这可能意味着对 Python 知识的高度需求,但是您需要更深入地了解更多。
按句子分词:当你按句子分词时,你可以分析那些单词是如何相互关联的,并看到更多的上下文。是不是因为招聘经理不喜欢 Python,所以“Python”这个词周围出现了很多负面词汇?来自爬虫学领域的术语是否比软件开发领域的多,这表明你可能正在处理一种完全不同于你预期的 python ?
下面是如何导入NLTK 的相关部分,以便您可以按单词和句子进行标记:
>>> from nltk.tokenize import sent_tokenize, word_tokenize
现在您已经导入了您需要的内容,您可以创建一个字符串来进行标记化。你可以引用一下 沙丘 中的一句话:
>>> example_string = """ ... Muad'Dib learned rapidly because his first training was in how to learn. ... And the first lesson of all was the basic trust that he could learn. ... It's shocking to find how many people do not believe they can learn, ... and how many more believe learning to be difficult."""您可以使用
sent_tokenize()将example_string拆分成句子:
>>> sent_tokenize(example_string)
["Muad'Dib learned rapidly because his first training was in how to learn.",
'And the first lesson of all was the basic trust that he could learn.',
"It's shocking to find how many people do not believe they can learn, and how many more believe learning to be difficult."]
按句子对example_string进行记号化会给你一个包含三个句子字符串的列表:
"Muad'Dib learned rapidly because his first training was in how to learn."'And the first lesson of all was the basic trust that he could learn.'"It's shocking to find how many people do not believe they can learn, and how many more believe learning to be difficult."
现在尝试用单词来标记example_string:
>>> word_tokenize(example_string) ["Muad'Dib", 'learned', 'rapidly', 'because', 'his', 'first', 'training', 'was', 'in', 'how', 'to', 'learn', '.', 'And', 'the', 'first', 'lesson', 'of', 'all', 'was', 'the', 'basic', 'trust', 'that', 'he', 'could', 'learn', '.', 'It', "'s", 'shocking', 'to', 'find', 'how', 'many', 'people', 'do', 'not', 'believe', 'they', 'can', 'learn', ',', 'and', 'how', 'many', 'more', 'believe', 'learning', 'to', 'be', 'difficult', '.']您得到了 NLTK 认为是单词的字符串列表,例如:
"Muad'Dib"'training''how'但是下列字符串也被认为是单词:
"'s"',''.'看看
"It's"是如何在撇号处被分开给你'It'和"'s",而"Muad'Dib"却是完整的?这是因为 NLTK 知道'It'和"'s"(“是”的缩写)是两个不同的单词,所以它将它们分开计数。但是"Muad'Dib"不像"It's"那样是一个公认的缩写,所以它不是作为两个独立的单词来读的,而是保持原样。过滤停用词
停用词是你想忽略的词,所以你在处理的时候会把它们过滤掉。像
'in'、'is'和'an'这样非常常见的词经常被用作停用词,因为它们本身并不会给文本增加很多意义。下面是如何导入 NLTK 的相关部分以便过滤掉停用词:
>>> nltk.download("stopwords")
>>> from nltk.corpus import stopwords
>>> from nltk.tokenize import word_tokenize
这里有一段来自 Worf 的语录,你可以过滤一下:
>>> worf_quote = "Sir, I protest. I am not a merry man!"现在用 word 对
worf_quote进行标记,并将结果列表存储在words_in_quote中:
>>> words_in_quote = word_tokenize(worf_quote)
>>> words_in_quote
['Sir', ',', 'protest', '.', 'merry', 'man', '!']
您在worf_quote中有一个单词列表,所以下一步是创建一个停用单词的集合来过滤words_in_quote。对于这个例子,你需要关注"english"中的停用词:
>>> stop_words = set(stopwords.words("english"))接下来,创建一个空列表来保存通过过滤器的单词:
>>> filtered_list = []
您创建了一个空列表filtered_list,用来保存words_in_quote中所有非停用词的单词。现在你可以用stop_words来过滤words_in_quote:
>>> for word in words_in_quote: ... if word.casefold() not in stop_words: ... filtered_list.append(word)你用一个
for循环对words_in_quote进行迭代,并将所有非停用词的单词添加到filtered_list。您在word上使用了.casefold(),因此您可以忽略word中的字母是大写还是小写。这是值得做的,因为stopwords.words('english')只包含小写版本的停用词。或者,你可以使用列表理解来列出你文本中所有非停用词的单词:
>>> filtered_list = [
... word for word in words_in_quote if word.casefold() not in stop_words
... ]
当你使用列表理解时,你不会创建一个空列表,然后在它的末尾添加条目。相反,您可以同时定义列表及其内容。使用列表理解通常被认为是更为复杂的。
来看看最后出现在filtered_list的话:
>>> filtered_list ['Sir', ',', 'protest', '.', 'merry', 'man', '!']你过滤掉了几个像
'am'、'a'这样的词,但是你也过滤掉了'not',这确实影响了句子的整体意思。(Worf 对此不会高兴的。)像
'I'和'not'这样的词可能看起来太重要而不能过滤掉,取决于你想做什么样的分析,它们可能是。原因如下:
'I'是代词,是语境词而不是实词:
内容词给你关于文章主题的信息或者作者对这些主题的看法。
上下文单词给你关于写作风格的信息。你可以观察作者使用上下文词汇的模式,以量化他们的写作风格。一旦你量化了他们的写作风格,你就可以分析一个未知作者写的文本,看看它有多接近特定的写作风格,这样你就可以试着确定作者是谁。
'not'从技术上来说是副词,但仍然被列入了 NLTK 的英语停用词列表。如果你想编辑停用词列表来排除'not'或者进行其他修改,那么你可以下载。因此,
'I'和'not'可能是一个句子的重要部分,但这取决于你想从这个句子中学到什么。词干
词干化是一项文本处理任务,在这项任务中,你将单词简化为它们的词根,词根是单词的核心部分。例如,单词“helping”和“helper”共用词根“help”。词干分析可以让你专注于一个单词的基本意思,而不是它用法的所有细节。NLTK 有多个词干分析器,但是你将使用波特词干分析器。
下面是如何导入 NLTK 的相关部分以便开始词干处理:
>>> from nltk.stem import PorterStemmer
>>> from nltk.tokenize import word_tokenize
现在您已经完成了导入,您可以用PorterStemmer()创建一个词干分析器:
>>> stemmer = PorterStemmer()下一步是为你创建一个字符串。这里有一个你可以用的:
>>> string_for_stemming = """
... The crew of the USS Discovery discovered many discoveries.
... Discovering is what explorers do."""
在对该字符串中的单词进行词干处理之前,您需要分隔该字符串中的所有单词:
>>> words = word_tokenize(string_for_stemming)现在您已经有了字符串中所有标记化单词的列表,看看
words中有什么:
>>> words
['The',
'crew',
'of',
'the',
'USS',
'Discovery',
'discovered',
'many',
'discoveries',
'.',
'Discovering',
'is',
'what',
'explorers',
'do',
'.']
通过在列表理解中使用stemmer.stem()来创建words中单词的词干版本列表:
>>> stemmed_words = [stemmer.stem(word) for word in words]看看
stemmed_words里有什么:
>>> stemmed_words
['the',
'crew',
'of',
'the',
'uss',
'discoveri',
'discov',
'mani',
'discoveri',
'.',
'discov',
'is',
'what',
'explor',
'do',
'.']
以下是所有以'discov'或'Discov'开头的单词的情况:
| 原始单词 | 词干版本 |
|---|---|
'Discovery' |
'discoveri' |
'discovered' |
'discov' |
'discoveries' |
'discoveri' |
'Discovering' |
'discov' |
这些结果看起来有点不一致。为什么'Discovery'会给你'discoveri'而'Discovering'会给你'discov'?
欠调和过调是词干可能出错的两种方式:
波特词干算法可以追溯到 1979 年,所以它有点老了。雪球词干器,也被称为 Porter2 ,是对原版的改进,也可以通过 NLTK 获得,所以你可以在自己的项目中使用它。同样值得注意的是,Porter 词干分析器的目的不是生成完整的单词,而是查找单词的变体形式。
幸运的是,您有一些其他的方法将单词简化到它们的核心意思,比如 lemmatizing,您将在本教程的后面看到。但首先,我们需要涵盖词类。
标注词性
词性是一个语法术语,指的是当你在句子中一起使用这些词时,它们所扮演的角色。词性标注,或词性标注,是根据词性给文本中的单词加标签的任务。
在英语中,有八种词性:
| 词性 | 作用 | 例子 |
|---|---|---|
| 名词 | 是一个人、一个地方或一件事物 | 波兰百吉饼山 |
| 代词 | 代替名词 | 你,她,我们 |
| 形容词 | 给出关于名词的信息 | 高效、多风、多彩 |
| 动词 | 是一种行为或存在的状态 | 学习,是,去 |
| 副词 | 给出一个动词、一个形容词或另一个副词的信息 | 高效,总是,非常 |
| 介词 | 给出一个名词或代词如何与另一个词连接的信息 | 从,大约,在 |
| 结合 | 连接另外两个单词或短语 | 所以,因为,而且 |
| 感叹词 | 是一个感叹词 | 耶,噢,哇 |
一些资料还将类别冠词(如“a”或“the”)包括在词类列表中,但其他资料认为它们是形容词。NLTK 使用单词限定词来指代文章。
下面是如何导入 NLTK 的相关部分以便标记词性:
>>> from nltk.tokenize import word_tokenize现在创建一些文本来标记。你可以用这个卡尔·萨根的名言:
>>> sagan_quote = """
... If you wish to make an apple pie from scratch,
... you must first invent the universe."""
使用word_tokenize来分隔字符串中的单词,并将它们存储在一个列表中:
>>> words_in_sagan_quote = word_tokenize(sagan_quote)现在在你的新单词列表上调用
nltk.pos_tag():
>>> import nltk
>>> nltk.pos_tag(words_in_sagan_quote)
[('If', 'IN'),
('you', 'PRP'),
('wish', 'VBP'),
('to', 'TO'),
('make', 'VB'),
('an', 'DT'),
('apple', 'NN'),
('pie', 'NN'),
('from', 'IN'),
('scratch', 'NN'),
(',', ','),
('you', 'PRP'),
('must', 'MD'),
('first', 'VB'),
('invent', 'VB'),
('the', 'DT'),
('universe', 'NN'),
('.', '.')]
引用中的所有单词现在都在一个单独的元组中,用一个标签表示它们的词性。但是标签是什么意思呢?以下是获取标签及其含义列表的方法:
>>> nltk.help.upenn_tagset()这个列表很长,但是请随意展开下面的框来查看。
以下是 POS 标签及其含义的列表:
>>> nltk.help.upenn_tagset()
$: dollar
$ -$ --$ A$ C$ HK$ M$ NZ$ S$ U.S.$ US$
'': closing quotation mark
' ''
(: opening parenthesis
( [ {
): closing parenthesis
) ] }
,: comma
,
--: dash
--
.: sentence terminator
. ! ?
:: colon or ellipsis
: ; ...
CC: conjunction, coordinating
& 'n and both but either et for less minus neither nor or plus so
therefore times v. versus vs. whether yet
CD: numeral, cardinal
mid-1890 nine-thirty forty-two one-tenth ten million 0.5 one forty-
seven 1987 twenty '79 zero two 78-degrees eighty-four IX '60s .025
fifteen 271,124 dozen quintillion DM2,000 ...
DT: determiner
all an another any both del each either every half la many much nary
neither no some such that the them these this those
EX: existential there
there
FW: foreign word
gemeinschaft hund ich jeux habeas Haementeria Herr K'ang-si vous
lutihaw alai je jour objets salutaris fille quibusdam pas trop Monte
terram fiche oui corporis ...
IN: preposition or conjunction, subordinating
astride among uppon whether out inside pro despite on by throughout
below within for towards near behind atop around if like until below
next into if beside ...
JJ: adjective or numeral, ordinal
third ill-mannered pre-war regrettable oiled calamitous first separable
ectoplasmic battery-powered participatory fourth still-to-be-named
multilingual multi-disciplinary ...
JJR: adjective, comparative
bleaker braver breezier briefer brighter brisker broader bumper busier
calmer cheaper choosier cleaner clearer closer colder commoner costlier
cozier creamier crunchier cuter ...
JJS: adjective, superlative
calmest cheapest choicest classiest cleanest clearest closest commonest
corniest costliest crassest creepiest crudest cutest darkest deadliest
dearest deepest densest dinkiest ...
LS: list item marker
A A. B B. C C. D E F First G H I J K One SP-44001 SP-44002 SP-44005
SP-44007 Second Third Three Two * a b c d first five four one six three
two
MD: modal auxiliary
can cannot could couldn't dare may might must need ought shall should
shouldn't will would
NN: noun, common, singular or mass
common-carrier cabbage knuckle-duster Casino afghan shed thermostat
investment slide humour falloff slick wind hyena override subhumanity
machinist ...
NNP: noun, proper, singular
Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos
Oceanside Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCA
Shannon A.K.C. Meltex Liverpool ...
NNPS: noun, proper, plural
Americans Americas Amharas Amityvilles Amusements Anarcho-Syndicalists
Andalusians Andes Andruses Angels Animals Anthony Antilles Antiques
Apache Apaches Apocrypha ...
NNS: noun, common, plural
undergraduates scotches bric-a-brac products bodyguards facets coasts
divestitures storehouses designs clubs fragrances averages
subjectivists apprehensions muses factory-jobs ...
PDT: pre-determiner
all both half many quite such sure this
POS: genitive marker
' 's
PRP: pronoun, personal
hers herself him himself hisself it itself me myself one oneself ours
ourselves ownself self she thee theirs them themselves they thou thy us
PRP$: pronoun, possessive
her his mine my our ours their thy your
RB: adverb
occasionally unabatingly maddeningly adventurously professedly
stirringly prominently technologically magisterially predominately
swiftly fiscally pitilessly ...
RBR: adverb, comparative
further gloomier grander graver greater grimmer harder harsher
healthier heavier higher however larger later leaner lengthier less-
perfectly lesser lonelier longer louder lower more ...
RBS: adverb, superlative
best biggest bluntest earliest farthest first furthest hardest
heartiest highest largest least less most nearest second tightest worst
RP: particle
aboard about across along apart around aside at away back before behind
by crop down ever fast for forth from go high i.e. in into just later
low more off on open out over per pie raising start teeth that through
under unto up up-pp upon whole with you
SYM: symbol
% & ' '' ''. ) ). * + ,. < = > @ A[fj] U.S U.S.S.R * ** ***
TO: "to" as preposition or infinitive marker
to
UH: interjection
Goodbye Goody Gosh Wow Jeepers Jee-sus Hubba Hey Kee-reist Oops amen
huh howdy uh dammit whammo shucks heck anyways whodunnit honey golly
man baby diddle hush sonuvabitch ...
VB: verb, base form
ask assemble assess assign assume atone attention avoid bake balkanize
bank begin behold believe bend benefit bevel beware bless boil bomb
boost brace break bring broil brush build ...
VBD: verb, past tense
dipped pleaded swiped regummed soaked tidied convened halted registered
cushioned exacted snubbed strode aimed adopted belied figgered
speculated wore appreciated contemplated ...
VBG: verb, present participle or gerund
telegraphing stirring focusing angering judging stalling lactating
hankerin' alleging veering capping approaching traveling besieging
encrypting interrupting erasing wincing ...
VBN: verb, past participle
multihulled dilapidated aerosolized chaired languished panelized used
experimented flourished imitated reunifed factored condensed sheared
unsettled primed dubbed desired ...
VBP: verb, present tense, not 3rd person singular
predominate wrap resort sue twist spill cure lengthen brush terminate
appear tend stray glisten obtain comprise detest tease attract
emphasize mold postpone sever return wag ...
VBZ: verb, present tense, 3rd person singular
bases reconstructs marks mixes displeases seals carps weaves snatches
slumps stretches authorizes smolders pictures emerges stockpiles
seduces fizzes uses bolsters slaps speaks pleads ...
WDT: WH-determiner
that what whatever which whichever
WP: WH-pronoun
that what whatever whatsoever which who whom whosoever
WP$: WH-pronoun, possessive
whose
WRB: Wh-adverb
how however whence whenever where whereby whereever wherein whereof why
``: opening quotation mark
这需要理解很多,但幸运的是,有一些模式可以帮助你记住什么是什么。
这里有一个总结,您可以使用它来开始使用 NLTK 的 POS 标签:
| 以下列开头的标签 | 处理 |
|---|---|
JJ |
形容词 |
NN |
名词 |
RB |
副词 |
PRP |
代词 |
VB |
动词 |
现在您已经知道了 POS 标签的含义,您可以看到您的标签相当成功:
'pie'被标记为NN,因为它是单数名词。'you'被加上了PRP的标签,因为它是一个人称代词。'invent'被标记为VB,因为它是动词的基本形式。
但是 NLTK 如何处理基本上是乱码的文本中的词性标注呢?《贾巴沃克》是一首的无厘头诗,从技术上来说没有太多意义,但仍然以一种能向说英语的人传达某种意义的方式来写。
制作一个字符串来保存这首诗的摘录:
>>> jabberwocky_excerpt = """ ... 'Twas brillig, and the slithy toves did gyre and gimble in the wabe: ... all mimsy were the borogoves, and the mome raths outgrabe."""使用
word_tokenize来分隔摘录中的单词,并将它们存储在列表中:
>>> words_in_excerpt = word_tokenize(jabberwocky_excerpt)
在您的新单词列表中调用nltk.pos_tag():
>>> nltk.pos_tag(words_in_excerpt) [("'T", 'NN'), ('was', 'VBD'), ('brillig', 'VBN'), (',', ','), ('and', 'CC'), ('the', 'DT'), ('slithy', 'JJ'), ('toves', 'NNS'), ('did', 'VBD'), ('gyre', 'NN'), ('and', 'CC'), ('gimble', 'JJ'), ('in', 'IN'), ('the', 'DT'), ('wabe', 'NN'), (':', ':'), ('all', 'DT'), ('mimsy', 'NNS'), ('were', 'VBD'), ('the', 'DT'), ('borogoves', 'NNS'), (',', ','), ('and', 'CC'), ('the', 'DT'), ('mome', 'JJ'), ('raths', 'NNS'), ('outgrabe', 'RB'), ('.', '.')]像
'and'和'the'这样被接受的英语单词分别被正确地标记为连接词和限定词。胡言乱语的单词'slithy'被标记为形容词,这也是一个说英语的人从这首诗的上下文中可能会想到的。好样的,NLTK!引理化
现在您已经熟悉了词类,可以回到词汇化了。像词干一样,词汇化将单词简化到它们的核心意思,但它会给你一个完整的英语单词,而不是像
'discoveri'一样只是一个单词的片段。注:一个引理是一个词,代表一整组词,这组词称为一个义素。
例如,如果您要在字典中查找单词“blending”,那么您需要查找“blend”的条目,但是您会在该条目中找到“blending”。
在这个例子中,“blend”是词条,而“blending”是词素的一部分。所以,当你把一个词词条化时,你是在把它简化成它的词条。
下面是如何导入 NLTK 的相关部分,以便开始 lemmatizing:
>>> from nltk.stem import WordNetLemmatizer
创建一个要使用的 lemmatizer:
>>> lemmatizer = WordNetLemmatizer()让我们从一个复数名词的词汇化开始:
>>> lemmatizer.lemmatize("scarves")
'scarf'
"scarves"给了你'scarf',所以这已经比你用波特梗器'scarv'得到的要复杂一点了。接下来,创建一个包含多个单词的字符串进行词汇化:
>>> string_for_lemmatizing = "The friends of DeSoto love scarves."现在按单词标记字符串:
>>> words = word_tokenize(string_for_lemmatizing)
这是你的单词列表:
>>> words ['The', 'friends', 'of', 'DeSoto', 'love' 'scarves', '.']创建一个列表,包含
words中已被词条化的所有单词:
>>> lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
这是你得到的列表:
>>> lemmatized_words ['The', 'friend', 'of', 'DeSoto', 'love', 'scarf', '.'看起来没错。复数
'friends'和'scarves'变成了单数'friend'和'scarf'。但是如果你把一个看起来和它的引理很不一样的单词进行引理化会发生什么呢?尝试将
"worst"词汇化:
>>> lemmatizer.lemmatize("worst")
'worst'
您得到结果'worst',因为lemmatizer.lemmatize()假设 "worst"是一个名词。你可以明确表示你希望"worst"是一个形容词:
>>> lemmatizer.lemmatize("worst", pos="a") 'bad'
pos的默认参数是名词的'n',但是您通过添加参数pos="a"确保了将"worst"视为形容词。结果,你得到了'bad',它看起来和你原来的单词非常不同,和你词干化后得到的完全不同。这是因为"worst"是形容词'bad'的最高级形式,词汇化减少了最高级以及对其词汇的比较级。既然您已经知道了如何使用 NLTK 来标记词性,那么您可以尝试在对单词进行词条化之前对其进行标记,以避免混淆同形异义词,或者拼写相同但含义不同且可能是不同词性的单词。
分块
虽然分词可以让你识别单词和句子,但是分块可以让你识别 T2 短语。
注意:****短语是一个单词或一组单词,作为一个单独的单元来执行语法功能。名词短语是围绕一个名词构建的。
以下是一些例子:
- “一颗行星”
- “倾斜的星球”
- “一颗快速倾斜的行星”
组块利用词性标签对单词进行分组,并将组块标签应用于这些组。组块不重叠,所以一个单词的一个实例一次只能在一个组块中。
下面是如何导入 NLTK 的相关部分以便分块:
>>> from nltk.tokenize import word_tokenize
在进行组块之前,您需要确保文本中的词性已被标记,因此创建一个用于词性标记的字符串。你可以引用《指环王》中的这句话:
*>>>
>>> lotr_quote = "It's a dangerous business, Frodo, going out your door."
现在按单词标记字符串:
>>> words_in_lotr_quote = word_tokenize(lotr_quote) >>> words_in_lotr_quote ['It', "'s", 'a', 'dangerous', 'business', ',', 'Frodo', ',', 'going', 'out', 'your', 'door', '.']现在你已经得到了
lotr_quote中所有单词的列表。下一步是按词性标记这些单词:
>>> nltk.download("averaged_perceptron_tagger")
>>> lotr_pos_tags = nltk.pos_tag(words_in_lotr_quote)
>>> lotr_pos_tags
[('It', 'PRP'),
("'s", 'VBZ'),
('a', 'DT'),
('dangerous', 'JJ'),
('business', 'NN'),
(',', ','),
('Frodo', 'NNP'),
(',', ','),
('going', 'VBG'),
('out', 'RP'),
('your', 'PRP$'),
('door', 'NN'),
('.', '.')]
您已经得到了一个引用中所有单词的元组列表,以及它们的 POS 标签。为了组块,你首先需要定义一个组块语法。
注意:****组块语法是关于句子应该如何被组块的规则的组合。它经常使用正则表达式,或者正则表达式。
对于本教程,你不需要知道正则表达式是如何工作的,但如果你想处理文本,它们将来肯定会派上用场。
使用一个正则表达式规则创建块语法:
>>> grammar = "NP: {<DT>?<JJ>*<NN>}"
NP代表名词短语。你可以在自然语言处理的第 7 章中了解更多关于名词短语分块的信息——使用自然语言工具包分析文本。根据您创建的规则,您的组块:
- 从可选(
?)限定词('DT')开始- 可以有任意数量(
*)的形容词(JJ)- 以名词(
<NN>)结尾使用以下语法创建一个块解析器:
>>> chunk_parser = nltk.RegexpParser(grammar)
现在试着引用你的话:
>>> tree = chunk_parser.parse(lotr_pos_tags)下面是这棵树的可视化展示:
>>> tree.draw()
这是视觉表现的样子:

你有两个名词短语:
'a dangerous business'有限定词、形容词和名词。'door'只是一个名词。
现在你知道了组块,是时候看看 chinking 了。
叮当声
Chinking 与 chunking 一起使用,但是当 chunking 用于包含模式时, chinking 用于排除模式。
让我们重复使用你在分块部分使用的引用。您已经有一个元组列表,其中包含引用中的每个单词及其词性标记:
>>> lotr_pos_tags [('It', 'PRP'), ("'s", 'VBZ'), ('a', 'DT'), ('dangerous', 'JJ'), ('business', 'NN'), (',', ','), ('Frodo', 'NNP'), (',', ','), ('going', 'VBG'), ('out', 'RP'), ('your', 'PRP$'), ('door', 'NN'), ('.', '.')]下一步是创建一个语法来确定你想要在你的组块中包含和排除什么。这一次,您将使用不止一行,因为您将有不止一条规则。因为你使用了不止一行的语法,你将使用三重引号(
"""):
>>> grammar = """
... Chunk: {<.*>+}
... }<JJ>{"""
你语法的第一条规则是{<.*>+}。这条规则有向内的花括号({}),因为它用来决定你想在你的块中包含什么样的模式。在这种情况下,你想包括一切:<.*>+。
你语法的第二条规则是}<JJ>{。这条规则有面向外的花括号(}{),因为它用于确定您想要在块中排除哪些模式。在这种情况下,你要排除形容词:<JJ>。
使用以下语法创建块解析器:
>>> chunk_parser = nltk.RegexpParser(grammar)现在把你的句子用你指定的缝隙拼起来:
>>> tree = chunk_parser.parse(lotr_pos_tags)
结果你得到了这棵树:
>>> tree Tree('S', [Tree('Chunk', [('It', 'PRP'), ("'s", 'VBZ'), ('a', 'DT')]), ('dangerous', 'JJ'), Tree('Chunk', [('business', 'NN'), (',', ','), ('Frodo', 'NNP'), (',', ','), ('going', 'VBG'), ('out', 'RP'), ('your', 'PRP$'), ('door', 'NN'), ('.', '.')])])在这种情况下,
('dangerous', 'JJ')被排除在组块之外,因为它是一个形容词(JJ)。但是,如果你再次得到一个图形表示,那就更容易看到了:
>>> tree.draw()
你得到了这个tree的可视化表示:

这里,你已经把形容词'dangerous'从你的组块中排除了,剩下两个包含其他所有东西的组块。第一个块包含出现在被排除的形容词之前的所有文本。第二个块包含形容词之后被排除的所有内容。
既然你已经知道如何从你的组块中排除模式,是时候研究命名实体识别(NER)了。
使用命名实体识别(NER)
命名实体是指特定地点、人员、组织等的名词短语。通过命名实体识别,你可以在你的文本中找到命名实体,并确定它们是哪种命名实体。
下面是来自 NLTK 书籍的命名实体类型列表:
| newtype(新类型) | 例子 |
|---|---|
| 组织 | 世卫组织佐治亚太平洋公司 |
| 人 | 艾迪·邦特,奥巴马总统 |
| 位置 | 珠穆朗玛峰,墨累河 |
| 日期 | 2008 年 6 月 29 日 |
| 时间 | 凌晨两点五十,下午一点半 |
| 钱 | 1.75 亿加元,10.40 英镑 |
| 百分比 | 百分之二十,18.75 % |
| 设备 | 巨石阵华盛顿纪念碑 |
| GPE | 东南亚,中洛锡安 |
您可以使用nltk.ne_chunk()来识别命名实体。让我们再次使用lotr_pos_tags来测试一下:
>>> nltk.download("maxent_ne_chunker") >>> nltk.download("words") >>> tree = nltk.ne_chunk(lotr_pos_tags)现在来看看视觉表现:
>>> tree.draw()
以下是您得到的结果:

看看Frodo是怎么被贴上PERSON标签的?如果您只想知道命名实体是什么,但不想知道它们是哪种命名实体,您也可以选择使用参数binary=True:
>>> tree = nltk.ne_chunk(lotr_pos_tags, binary=True) >>> tree.draw()现在你所看到的是
Frodo是一个NE:
这就是你如何识别命名实体!但是您可以更进一步,直接从文本中提取命名实体。创建从中提取命名实体的字符串。你可以用这句话引自:
*>>>
>>> quote = """ ... Men like Schiaparelli watched the red planet—it is odd, by-the-bye, that ... for countless centuries Mars has been the star of war—but failed to ... interpret the fluctuating appearances of the markings they mapped so well. ... All that time the Martians must have been getting ready. ... ... During the opposition of 1894 a great light was seen on the illuminated ... part of the disk, first at the Lick Observatory, then by Perrotin of Nice, ... and then by other observers. English readers heard of it first in the ... issue of Nature dated August 2."""现在创建一个函数来提取命名实体:

>>> def extract_ne(quote):
... words = word_tokenize(quote, language=language)
... tags = nltk.pos_tag(words)
... tree = nltk.ne_chunk(tags, binary=True)
... return set(
... " ".join(i[0] for i in t)
... for t in tree
... if hasattr(t, "label") and t.label() == "NE"
... )
使用这个函数,您可以收集所有命名的实体,没有重复。为了做到这一点,您按单词进行标记,对这些单词应用词性标记,然后根据这些标记提取命名实体。因为您包含了binary=True,您将获得的命名实体将不会被更具体地标记。你只会知道它们是被命名的实体。
看看你提取的信息:
>>> extract_ne(quote) {'Lick Observatory', 'Mars', 'Nature', 'Perrotin', 'Schiaparelli'}你错过了尼斯这个城市,可能是因为 NLTK 把它解释成了一个普通的英语形容词,但是你仍然得到了下面这个:
- 某机构:
'Lick Observatory'- 一颗星球:
'Mars'- 某刊物:
'Nature'- 人:
'Perrotin','Schiaparelli'那是一些相当不错的品种!
获取要分析的文本
现在,您已经用小的示例文本完成了一些文本处理任务,您已经准备好一次分析一堆文本了。一组文本被称为语料库。NLTK 提供了几个语料库,涵盖了从古腾堡项目主办的小说到美国总统就职演说的一切。
为了分析 NLTK 中的文本,您首先需要导入它们。这需要
nltk.download("book"),这是一个相当大的下载:
>>> nltk.download("book")
>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
您现在可以访问一些线性文本(如理智与情感和巨蟒和圣杯)以及一些文本组(如聊天语料库和个人语料库)。人类的本性是迷人的,所以让我们看看我们能通过仔细查看个人语料库发现什么!
这个语料库是一个征友广告的集合,它是在线约会的早期版本。如果你想结识某人,那么你可以在报纸上登广告,然后等待其他读者回复你。
如果你想学习如何获取其他文本进行分析,那么你可以查看的第三章用 Python 自然语言处理——用自然语言工具包分析文本。
使用索引
当你使用索引时,你可以看到一个单词的每次使用,以及它的直接上下文。这可以让你窥见一个单词在句子中是如何使用的,以及有哪些单词与它一起使用。
让我们看看这些寻找爱情的好人有什么话要说!个人语料库名为text8,因此我们将使用参数"man"对其调用.concordance():
>>> text8.concordance("man") Displaying 14 of 14 matches: to hearing from you all . ABLE young man seeks , sexy older women . Phone for ble relationship . GENUINE ATTRACTIVE MAN 40 y . o ., no ties , secure , 5 ft . ship , and quality times . VIETNAMESE MAN Single , never married , financially ip . WELL DRESSED emotionally healthy man 37 like to meet full figured woman fo nth subs LIKE TO BE MISTRESS of YOUR MAN like to be treated well . Bold DTE no eeks lady in similar position MARRIED MAN 50 , attrac . fit , seeks lady 40 - 5 eks nice girl 25 - 30 serious rship . Man 46 attractive fit , assertive , and k 40 - 50 sought by Aussie mid 40s b / man f / ship r / ship LOVE to meet widowe discreet times . Sth E Subs . MARRIED MAN 42yo 6ft , fit , seeks Lady for discr woman , seeks professional , employed man , with interests in theatre , dining tall and of large build seeks a good man . I am a nonsmoker , social drinker , lead to relationship . SEEKING HONEST MAN I am 41 y . o ., 5 ft . 4 , med . bui quiet times . Seeks 35 - 45 , honest man with good SOH & similar interests , f genuine , caring , honest and normal man for fship , poss rship . S / S , S /有趣的是,这 14 个匹配中的最后 3 个与寻找一个诚实的人有关,具体来说:
SEEKING HONEST MANSeeks 35 - 45 , honest man with good SOH & similar interestsgenuine , caring , honest and normal man for fship , poss rship让我们看看单词
"woman"是否有类似的模式:
>>> text8.concordance("woman")
Displaying 11 of 11 matches:
at home . Seeking an honest , caring woman , slim or med . build , who enjoys t
thy man 37 like to meet full figured woman for relationship . 48 slim , shy , S
rry . MALE 58 years old . Is there a Woman who would like to spend 1 weekend a
other interests . Seeking Christian Woman for fship , view to rship . SWM 45 D
ALE 60 - burly beared seeks intimate woman for outings n / s s / d F / ston / P
ington . SCORPIO 47 seeks passionate woman for discreet intimate encounters SEX
le dad . 42 , East sub . 5 " 9 seeks woman 30 + for f / ship relationship TALL
personal trainer looking for married woman age open for fun MARRIED Dark guy 37
rinker , seeking slim - medium build woman who is happy in life , age open . AC
. O . TERTIARY Educated professional woman , seeks professional , employed man
real romantic , age 50 - 65 y . o . WOMAN OF SUBSTANCE 56 , 59 kg ., 50 , fit
诚实的问题只在第一场比赛中出现:
Seeking an honest , caring woman , slim or med . build
搜索一个带有索引的语料库不会给你完整的图像,但是偷看一眼,看看是否有什么突出的东西仍然是有趣的。
制作散布图
你可以使用离差图来查看某个特定单词出现的次数和出现的位置。到目前为止,我们已经寻找了"man"和"woman",但是看看这些单词相对于它们的同义词使用了多少会很有趣:
>>> text8.dispersion_plot( ... ["woman", "lady", "girl", "gal", "man", "gentleman", "boy", "guy"] ... )这是你得到的离差图:
每条垂直的蓝线代表一个单词的一个实例。每一行水平的蓝线代表整个语料库。该图表明:
"lady"比"woman"或"girl"用得多。没有"gal"的实例。"man"和"guy"被使用的次数相似,比"gentleman"或"boy"更常见。当您想要查看单词在文本或语料库中出现的位置时,可以使用离差图。如果您正在分析单个文本,这可以帮助您查看哪些单词出现在彼此附近。如果你正在分析一个按时间顺序组织的文本语料库,它可以帮助你看到哪些单词在一段时间内使用得多或少。
停留在言情这个主题上,看看给理智与情感也就是
text2做一个分散剧情能发现什么。简·奥斯汀的小说讲了很多人的家,所以用几个家的名字做一个分散情节:
>>> text2.dispersion_plot(["Allenham", "Whitwell", "Cleveland", "Combe"])
这是你得到的图:
显然,在小说的前三分之一中,艾伦汉姆被提到了很多,但之后就没怎么出现了。另一方面,克利夫兰在前三分之二几乎没有出现,但在后三分之一出现了不少。这种分布反映了玛丽安和威洛比之间关系的变化:
- 艾伦汉姆是威洛比的恩人的家,当玛丽安第一次对他感兴趣时,他经常出现。
- 克利夫兰是玛丽安去伦敦看望威洛比并遇到麻烦后住的地方。
离差图只是文本数据的一种可视化形式。下一个你要看的是频率分布。
进行频率分布
有了频率分布,你可以检查哪些单词在你的文本中出现的频率最高。你需要从import开始:
>>> from nltk import FreqDist
FreqDist是collections.Counter的子类。以下是如何创建整个个人广告语料库的频率分布:
>>> frequency_distribution = FreqDist(text8)
>>> print(frequency_distribution)
<FreqDist with 1108 samples and 4867 outcomes>
由于1108样本和4867结果是大量的信息,开始缩小范围。下面是如何查看20语料库中最常见的单词:
>>> frequency_distribution.most_common(20) [(',', 539), ('.', 353), ('/', 110), ('for', 99), ('and', 74), ('to', 74), ('lady', 68), ('-', 66), ('seeks', 60), ('a', 52), ('with', 44), ('S', 36), ('ship', 33), ('&', 30), ('relationship', 29), ('fun', 28), ('in', 27), ('slim', 27), ('build', 27), ('o', 26)]你的词频分布中有很多停用词,但是你可以像之前做的那样删除它们。创建
text8中所有非停用词的列表:
>>> meaningful_words = [
... word for word in text8 if word.casefold() not in stop_words
... ]
既然你已经有了语料库中所有非停用词的列表,那么做一个频率分布图:
>>> frequency_distribution = FreqDist(meaningful_words)看一看
20最常见的单词:
>>> frequency_distribution.most_common(20)
[(',', 539),
('.', 353),
('/', 110),
('lady', 68),
('-', 66),
('seeks', 60),
('ship', 33),
('&', 30),
('relationship', 29),
('fun', 28),
('slim', 27),
('build', 27),
('smoker', 23),
('50', 23),
('non', 22),
('movies', 22),
('good', 21),
('honest', 20),
('dining', 19),
('rship', 18)]
你可以把这个列表变成一个图表:
>>> frequency_distribution.plot(20, cumulative=True)这是你得到的图表:
一些最常见的单词是:
'lady''seeks''ship''relationship''fun''slim''build''smoker''50''non''movies''good''honest'从你已经了解到的写这些征友广告的人的情况来看,他们似乎对诚实感兴趣,并且经常使用这个词。此外,
'slim'和'build'都出现了相同的次数。当你学习索引时,你看到了slim和build在彼此附近使用,所以这两个词可能在这个语料库中经常一起使用。这就给我们带来了搭配!寻找搭配
搭配是一系列经常出现的单词。如果你对英语中的常见搭配感兴趣,那么你可以查看一下《BBI 英语单词组合词典》 。这是一个方便的参考,你可以用它来帮助你确保你的写作是地道的。以下是一些使用单词“tree”的搭配示例:
- 语法树
- 系谱图
- 决策图表
要查看语料库中经常出现的成对单词,您需要对其调用
.collocations():
>>> text8.collocations()
would like; medium build; social drinker; quiet nights; non smoker;
long term; age open; Would like; easy going; financially secure; fun
times; similar interests; Age open; weekends away; poss rship; well
presented; never married; single mum; permanent relationship; slim
build
slim build确实出现了,还有medium build和其他几个单词组合。虽然不再在沙滩上散步了!
但是,如果您在对语料库中的单词进行词汇化之后寻找搭配,会发生什么情况呢?你会不会发现一些你第一次没有发现的单词组合,因为它们出现的版本略有不同?
如果你按照前面的指令,那么你已经有了一个lemmatizer,但是你不能在任何数据类型上调用collocations(),所以你需要做一些准备工作。首先创建一个列表,列出text8中所有单词的词条化版本:
>>> lemmatized_words = [lemmatizer.lemmatize(word) for word in text8]但是为了让你能够完成到目前为止看到的语言处理任务,你需要用这个列表制作一个 NLTK 文本:
>>> new_text = nltk.Text(lemmatized_words)
以下是如何查看你的new_text中的搭配:
>>> new_text.collocations() medium build; social drinker; non smoker; long term; would like; age open; easy going; financially secure; Would like; quiet night; Age open; well presented; never married; single mum; permanent relationship; slim build; year old; similar interest; fun time; Photo pls与你之前的搭配列表相比,这个新列表少了一些:
weekends awayposs rship
quiet nights的概念仍然出现在词汇化版本quiet night中。你最近对搭配的搜索也带来了一些新的搭配:
year old暗示用户经常提及年龄。photo pls表明用户经常请求一张或多张照片。这就是你如何找到常见的单词组合,看看人们在谈论什么,他们是如何谈论它的!
结论
祝贺你迈出了与 NLP 的第一步!一个全新的非结构化数据世界正在向你敞开,等待你去探索。现在你已经了解了文本分析任务的基本知识,你可以出去找一些文本来分析,看看你能从文本本身以及写它们的人和它们所涉及的主题中学到什么。
现在你知道如何:
- 查找文本进行分析
- 预处理您的文本以供分析
- 分析你的文字
- 基于您的分析创建可视化效果
下一步,您可以使用 NLTK 来分析一个文本,看看其中表达的情绪是积极的还是消极的。要了解更多关于情绪分析的信息,请查看情绪分析:Python 的 NLTK 库的第一步。如果您想更深入地了解 NLTK 的具体细节,那么您可以使用 Python 通过 进行自然语言处理——使用自然语言工具包 分析文本。
现在出去给自己找一些文本来分析!************
np.linspace():创建均匀或非均匀间隔的数组
当你使用 NumPy 处理数值应用时,你经常需要创建一个数字的数组。在许多情况下,您希望数字的间距均匀,但有时也可能需要间距不均匀的数字。在这两种情况下你都可以使用的一个关键工具是
np.linspace()。就其基本形式而言,
np.linspace()使用起来似乎相对简单。然而,它是数值编程工具箱的重要组成部分。它不仅功能多样,而且功能强大。在本教程中,您将了解如何有效地使用这个函数。在本教程中,您将学习如何:
- 创建一个均匀或非均匀间隔的数字范围
- 决定何时使用
np.linspace()代替替代工具- 使用必需和可选的输入参数
- 创建二维或多维数组
- 以离散形式表示数学函数
本教程假设您已经熟悉 NumPy 和
ndarray数据类型的基础知识。首先,您将学习在 Python 中创建一系列数字的各种方法。然后你将仔细看看使用np.linspace()的所有方法,以及如何在你的程序中有效地使用它。免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
创建具有均匀间距的数字范围
在 Python 中,有几种方法可以创建一系列均匀分布的数字。
np.linspace()允许您这样做,并自定义范围以满足您的特定需求,但这不是创建数字范围的唯一方法。在下一节中,您将学习如何使用np.linspace(),然后将其与创建等间距数字范围的其他方法进行比较。使用
np.linspace()
np.linspace()有两个必需的参数,start和stop,可以用来设置范围的开始和结束:
>>> import numpy as np
>>> np.linspace(1, 10)
array([ 1\. , 1.18367347, 1.36734694, 1.55102041, 1.73469388,
1.91836735, 2.10204082, 2.28571429, 2.46938776, 2.65306122,
2.83673469, 3.02040816, 3.20408163, 3.3877551 , 3.57142857,
3.75510204, 3.93877551, 4.12244898, 4.30612245, 4.48979592,
4.67346939, 4.85714286, 5.04081633, 5.2244898 , 5.40816327,
5.59183673, 5.7755102 , 5.95918367, 6.14285714, 6.32653061,
6.51020408, 6.69387755, 6.87755102, 7.06122449, 7.24489796,
7.42857143, 7.6122449 , 7.79591837, 7.97959184, 8.16326531,
8.34693878, 8.53061224, 8.71428571, 8.89795918, 9.08163265,
9.26530612, 9.44897959, 9.63265306, 9.81632653, 10\. ])
这段代码返回一个 ndarray ,在start和stop值之间有相等的间隔。这是一个向量空间,也叫线性空间,这也是linspace这个名字的由来。
注意,值10包含在输出数组中。默认情况下,该函数返回一个闭合范围,其中包含端点。这与您对 Python 的期望相反,在 Python 中通常不包括范围的结束。打破常规并不是疏忽。稍后您会看到,这通常是您在使用该函数时想要的。
上例中的数组长度为50,这是默认的数字。在大多数情况下,您需要在数组中设置自己的值的数量。您可以通过可选参数 num 来实现:
>>> np.linspace(1, 10, num=10) array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])这个实例中的输出数组包含了在
1和10之间等间距的值10,也就是从1到10的数字。这是另一个例子:
>>> np.linspace(-10, 10, 25)
array([-10\. , -9.16666667, -8.33333333, -7.5 ,
-6.66666667, -5.83333333, -5\. , -4.16666667,
-3.33333333, -2.5 , -1.66666667, -0.83333333,
0\. , 0.83333333, 1.66666667, 2.5 ,
3.33333333, 4.16666667, 5\. , 5.83333333,
6.66666667, 7.5 , 8.33333333, 9.16666667,
10\. ])
在上面的例子中,您创建了一个线性空间,其值在-10和10之间。您使用num参数作为位置参数,而没有在函数调用中明确提及它的名称。这是你最常使用的形式。
使用range()和列表理解
让我们后退一步,看看还有哪些工具可以用来创建一个均匀分布的数字范围。Python 提供的最直接的选项是内置的 range() 。函数调用range(10)返回一个对象,该对象产生从0到9的序列,这是一个均匀间隔的数字范围。
对于许多数值应用来说,range()仅限于整数这一事实限制太多。在上面显示的例子中,只有np.linspace(1, 10, 10)可以用range()完成:
>>> list(range(1, 11)) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]当
range()返回的值被显式转换成列表时,与 NumPy 版本返回的值相同,除了它们是整数而不是浮点数。您仍然可以使用
range()和列表理解来创建非整数范围:
>>> step = 20 / 24 # Divide the range into 24 intervals
>>> [-10 + step*interval for interval in range(25)]
[-10.0, -9.166666666666666, -8.333333333333334, -7.5,
-6.666666666666666, -5.833333333333333, -5.0, -4.166666666666666,
-3.333333333333333, -2.5, -1.666666666666666, -0.8333333333333321,
0.0, 0.8333333333333339, 1.6666666666666679, 2.5,
3.333333333333334, 4.166666666666668, 5.0, 5.833333333333334,
6.666666666666668, 7.5, 8.333333333333336, 9.166666666666668, 10.0]
列表中的值与np.linspace(-10, 10, 25)输出的数组中的值相同。然而,与使用np.linspace()相比,即使使用列表理解也是相当笨拙和不优雅的。您首先需要计算出所需的时间间隔,然后在一个循环中使用该时间间隔。
在大多数应用程序中,您仍然需要将列表转换为 NumPy 数组,因为使用 NumPy 数组执行元素级计算不太复杂。
在决定使用 NumPy 工具还是核心 Python 时,你可能需要考虑的另一点是执行速度。您可以展开下面的部分,查看使用 list 与使用 NumPy 数组相比的性能。
通过创建对两个序列中的所有元素执行相同算术运算的函数,可以比较使用 NumPy 的方法和使用 list comprehensions 的方法。在下面的示例中,您将从-10到10的范围划分为500个样本,这与499个间隔相同:
1>>> import timeit 2>>> import numpy as np 3>>> numbers_array = np.linspace(-10, 10, 500) 4>>> step = 20 / 499 5>>> numbers_list = [-10 + step*interval for interval in range(500)] 6>>> def test_np(): 7... return (numbers_array + 2.5) ** 2 8... 9>>> def test_list(): 10... return [(number + 2.5) ** 2 for number in numbers_list] 11... 12>>> list(test_np()) == test_list() 13True 14>>> timeit.timeit("test_np()", globals=globals(), number=100000) 150.3116540400000076 16>>> timeit.timeit("test_list()", globals=globals(), number=100000) 175.478577034000011函数
test_np()和test_list()对序列执行相同的操作。您可以通过检查两个函数的输出是否相同来确认这一点,如上面代码片段中的第 12 行所示。使用timeit模块对两个版本的执行进行计时表明,使用列表要比使用 NumPy 数组慢得多。在某些情况下,使用 NumPy 工具而不是核心 Python 可以提高效率。在需要对大量数据进行大量计算的应用程序中,这种效率的提高是非常显著的。
使用
np.arange()NumPy 有自己版本的内置
range()。它叫做np.arange(),与range()不同,它不仅仅局限于整数。您可以以与range()类似的方式使用np.arange(),使用start、stop和step作为输入参数:
>>> list(range(2, 30, 2))
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28]
>>> np.arange(2, 30, 2)
array([ 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28])
输出值是一样的,虽然range()返回的是 range 对象,可以转换成列表显示所有的值,而np.arange()返回的是数组。
np.arange()返回的数组使用了一个半开区间,不包括范围的端点。这种行为类似于range(),但不同于np.linspace()。这些差异最初可能有点令人困惑,但是随着您开始更频繁地使用这些函数,您会习惯它们的。
您甚至可以在np.arange()中使用非整数:
>>> np.arange(2.34, 31.97, 2) array([ 2.34, 4.34, 6.34, 8.34, 10.34, 12.34, 14.34, 16.34, 18.34, 20.34, 22.34, 24.34, 26.34, 28.34, 30.34])输出是一个从
start值开始的数组,每个数字之间的间隔正好等于输入参数中使用的step大小。最后一个数字是该系列中的最大数字,小于用于范围的end的数字。
step参数也可以是浮点数,尽管在这种情况下你需要小心,因为输出可能不总是你想要的:
>>> np.arange(1.034, 3.104, 0.34)
array([1.034, 1.374, 1.714, 2.054, 2.394, 2.734, 3.074])
>>> np.arange(1.034, 3.104, 0.345)
array([1.034, 1.379, 1.724, 2.069, 2.414, 2.759, 3.104])
在第一个例子中,一切似乎都很好。然而,你可能已经注意到,在第二个例子中,当step是 0.345 时,输出中的最后一个值等于stop值,即使np.arange()使用半开区间。np.arange()的文档对此有一个警告:
当使用非整数步长(如 0.1)时,结果通常不一致。对于这些情况,最好使用
numpy.linspace。(来源)
下面是决定使用这两个函数中的哪一个的经验法则:
- 当范围的
start和end点的精确值是应用中的重要属性时,使用np.linspace()。 - 当
step值之间的大小比较重要时使用np.arange()。
在本教程中,您将再次使用np.arange()。要了解更多信息,请查看 NumPy arange():如何使用 np.arange() 。
从np.linspace() 定制输出
将np.linspace()与start、stop和num参数一起使用是使用该函数最常见的方式,对于许多应用程序来说,您不需要考虑这种方法以外的内容。但是,您可以进一步定制您的输出。
在这一节中,您将学习如何定制所创建的范围,确定数组中项的数据类型,以及控制端点的行为。
start、stop和num参数
虽然start和stop是唯一必需的参数,但是通常还会用到第三个参数num。参数start和stop是您希望创建的范围的开始和结束,而num是一个整数,它决定了输出数组将有多少个元素。
根据您正在开发的应用程序,您可能会认为num是您正在创建的数组的采样,或分辨率。再看几个例子:
>>> np.linspace(-5, 5, 10) array([-5\. , -3.88888889, -2.77777778, -1.66666667, -0.55555556, 0.55555556, 1.66666667, 2.77777778, 3.88888889, 5\. ]) >>> np.linspace(-5, 5, 100) array([-5\. , -4.8989899 , -4.7979798 , -4.6969697 , -4.5959596 , -4.49494949, -4.39393939, -4.29292929, -4.19191919, -4.09090909, -3.98989899, -3.88888889, -3.78787879, -3.68686869, -3.58585859, -3.48484848, -3.38383838, -3.28282828, -3.18181818, -3.08080808, -2.97979798, -2.87878788, -2.77777778, -2.67676768, -2.57575758, -2.47474747, -2.37373737, -2.27272727, -2.17171717, -2.07070707, -1.96969697, -1.86868687, -1.76767677, -1.66666667, -1.56565657, -1.46464646, -1.36363636, -1.26262626, -1.16161616, -1.06060606, -0.95959596, -0.85858586, -0.75757576, -0.65656566, -0.55555556, -0.45454545, -0.35353535, -0.25252525, -0.15151515, -0.05050505, 0.05050505, 0.15151515, 0.25252525, 0.35353535, 0.45454545, 0.55555556, 0.65656566, 0.75757576, 0.85858586, 0.95959596, 1.06060606, 1.16161616, 1.26262626, 1.36363636, 1.46464646, 1.56565657, 1.66666667, 1.76767677, 1.86868687, 1.96969697, 2.07070707, 2.17171717, 2.27272727, 2.37373737, 2.47474747, 2.57575758, 2.67676768, 2.77777778, 2.87878788, 2.97979798, 3.08080808, 3.18181818, 3.28282828, 3.38383838, 3.48484848, 3.58585859, 3.68686869, 3.78787879, 3.88888889, 3.98989899, 4.09090909, 4.19191919, 4.29292929, 4.39393939, 4.49494949, 4.5959596 , 4.6969697 , 4.7979798 , 4.8989899 , 5\. ])这两个数组都代表-5 和 5 之间的范围,但采样或分辨率不同。如果您愿意,可以使用命名参数:
>>> np.linspace(start=-5, stop=5, num=10)
array([-5\. , -3.88888889, -2.77777778, -1.66666667, -0.55555556,
0.55555556, 1.66666667, 2.77777778, 3.88888889, 5\. ])
命名参数的使用使代码更具可读性。然而,在许多广泛使用np.linspace()的应用程序中,您会经常看到它的使用没有命名前三个参数。
您可以使用非整数来定义范围:
>>> np.linspace(-5.2, 7.7, 30) array([-5.2 , -4.75517241, -4.31034483, -3.86551724, -3.42068966, -2.97586207, -2.53103448, -2.0862069 , -1.64137931, -1.19655172, -0.75172414, -0.30689655, 0.13793103, 0.58275862, 1.02758621, 1.47241379, 1.91724138, 2.36206897, 2.80689655, 3.25172414, 3.69655172, 4.14137931, 4.5862069 , 5.03103448, 5.47586207, 5.92068966, 6.36551724, 6.81034483, 7.25517241, 7.7 ])该数组现在由
30个等距数字组成,起始和终止于用作start和stop参数自变量的精确值。您现在知道如何使用三个主要的输入参数:
startstopnum通常,这个函数只使用这三个输入参数。然而,正如您将在下一节中看到的,您可以进一步修改输出。
改变输出类型的
dtype参数NumPy 数组的元素都属于同一数据类型。
np.linspace()通常返回浮点数组。您可以通过检查输出来了解这一点,或者更好的方法是查看数组的.dtype属性:
>>> numbers = np.linspace(-10, 10, 20)
>>> numbers
array([-10\. , -8.94736842, -7.89473684, -6.84210526,
-5.78947368, -4.73684211, -3.68421053, -2.63157895,
-1.57894737, -0.52631579, 0.52631579, 1.57894737,
2.63157895, 3.68421053, 4.73684211, 5.78947368,
6.84210526, 7.89473684, 8.94736842, 10\. ])
>>> numbers.dtype
dtype('float64')
数组中的数字是浮点数。即使在以下情况下也是如此:
>>> numbers = np.linspace(-10, 10, 11) >>> numbers array([-10., -8., -6., -4., -2., 0., 2., 4., 6., 8., 10.]) >>> numbers.dtype dtype('float64')尽管所有的元素都是整数,但它们仍然以尾随句点显示,以表明它们是浮点数。你可以通过查看
numbers.dtype的值来确认。您可以使用可选的
dtype输入参数来改变输出数组中元素的数据类型:
>>> numbers = np.linspace(-10, 10, 11, dtype=int)
>>> numbers
array([-10, -8, -6, -4, -2, 0, 2, 4, 6, 8, 10])
>>> numbers.dtype
dtype('int64')
尽管参数声明了dtype=int,但 NumPy 将其解释为int64,这是 NumPy 中的一种数据类型。您可以通过检查numbers的一个元素的类型来确认这一点:
>>> type(numbers[0]) <class 'numpy.int64'>这表明 NumPy 使用自己版本的基本数据类型。您可以直接使用 NumPy 数据类型作为
dtype参数的参数:numbers = np.linspace(-10, 10, 11, dtype=np.int64)这产生了相同的输出结果,但通过显式声明 NumPy 数据类型避免了歧义。
选择特定的数据类型时,需要小心确保线性空间仍然有效:
>>> np.linspace(-5, 5, 20, dtype=np.int64)
array([-5, -4, -3, -3, -2, -2, -1, -1, 0, 0, 0, 0, 1, 1, 2, 2, 3,
3, 4, 5])
NumPy 通过以通常的方式舍入来强制值为类型np.int64,但是结果不再是线性空间。这不太可能是你想要的结果。你可以在官方文档中阅读更多关于 NumPy 中数据类型的内容。
endpoint和retstep参数
默认情况下,np.linspace()使用封闭区间[start, stop],其中包含端点。这通常是您使用该功能的理想方式。但是,如果你需要创建一个半开放区间的线性空间[start, stop),那么你可以设置可选的布尔参数endpoint为False:
>>> np.linspace(-5, 5, 20, endpoint=False) array([-5\. , -4.5, -4\. , -3.5, -3\. , -2.5, -2\. , -1.5, -1\. , -0.5, 0\. , 0.5, 1\. , 1.5, 2\. , 2.5, 3\. , 3.5, 4\. , 4.5])此选项允许您将函数与不包含范围端点的 Python 约定一起使用。
该函数还可以输出它计算的样本之间的间隔大小。如果你需要元素间步长的值,那么你可以设置布尔参数
retstep到True:
>>> numbers, step = np.linspace(-5, 5, 20, retstep=True)
>>> numbers
array([-5\. , -4.47368421, -3.94736842, -3.42105263, -2.89473684,
-2.36842105, -1.84210526, -1.31578947, -0.78947368, -0.26315789,
0.26315789, 0.78947368, 1.31578947, 1.84210526, 2.36842105,
2.89473684, 3.42105263, 3.94736842, 4.47368421, 5\. ])
>>> step
0.5263157894736842
这种情况下的返回值是一个元组,数组作为第一个元素,大小为step的浮点数作为第二个元素。
高维数组的非标量值
您也可以对start和stop使用非标量值。这返回了一个高维数组:
>>> output = np.linspace(start=[2, 5, 9], stop=[100, 130, 160], num=10) >>> output array([[ 2\. , 5\. , 9\. ], [ 12.88888889, 18.88888889, 25.77777778], [ 23.77777778, 32.77777778, 42.55555556], [ 34.66666667, 46.66666667, 59.33333333], [ 45.55555556, 60.55555556, 76.11111111], [ 56.44444444, 74.44444444, 92.88888889], [ 67.33333333, 88.33333333, 109.66666667], [ 78.22222222, 102.22222222, 126.44444444], [ 89.11111111, 116.11111111, 143.22222222], [100\. , 130\. , 160\. ]]) >>> output.shape (10, 3)
start和stop都是长度相同的列表。每个列表的第一项2和100是第一个向量的start和stop点,其具有由num参数确定的10样本。这同样适用于每个列表的第二个元素和第三个元素。输出是一个十行三列的二维 NumPy 数组。您可以通过检查二维数组中的一行和一个元素来进一步研究该数组:
>>> output[0]
array([2., 5., 9.])
>>> output[0][2]
9.0
第一个结果代表数组的第一行。第二个结果显示第一行第三列中的元素。
通过将可选参数axis设置为1,可以返回该数组的转置版本:
>>> output = np.linspace(start=[2, 5, 9], ... stop=[100, 130, 160], ... num=10, ... axis=1) >>> output array([[ 2\. , 12.88888889, 23.77777778, 34.66666667, 45.55555556, 56.44444444, 67.33333333, 78.22222222, 89.11111111, 100\. ], [ 5\. , 18.88888889, 32.77777778, 46.66666667, 60.55555556, 74.44444444, 88.33333333, 102.22222222, 116.11111111, 130\. ], [ 9\. , 25.77777778, 42.55555556, 59.33333333, 76.11111111, 92.88888889, 109.66666667, 126.44444444, 143.22222222, 160\. ]]) >>> output.shape (3, 10)相对于之前的例子,输出数组现在具有交换的行数和列数,在之前的例子中没有显式设置参数
axis,而是使用默认值0。输入参数和返回值的汇总
函数声明很好地总结了您可以使用的选项:
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0 )您可以在文档中找到全部细节。下面列出了输入参数需要记住的要点:
参数 描述 缺省值 start和stop这些必需的参数定义了范围的开始和结束。通常这些是标量值,或者是 int或者是float,但是也可以是任何类似数组的对象。- num此参数定义数组中的点数,通常称为采样或分辨率。 50endpoint如果该参数设置为 False,则该函数将该区间视为半开区间,并从输出数组中排除端点。Trueretstep如果该参数被设置为 True,那么该函数返回数组和一个float,其步长为线性空间的每个元素之间的步长。否则,只返回数组。Falsedtype此参数可用于设置输出数组中元素的数据类型。 - axis该参数仅用于无标度 start和stop值。它决定了存储结果的轴。- 调用该函数返回的输出如下所示:
- 包含向量空间的类型为
ndarray的数组- 如果
retstep设置为True,步长为float当您开始尝试使用
np.linspace()以及定制其输出的不同方式时,您可以将本节作为参考。示例:食品生产传送带
假设一家生产包装食品的公司在其食品生产工厂中有一个传送带系统。沿着传送带的位置由一个数字表示,该数字代表从起点开始的传送路径的长度。有 27 个温度传感器沿传送带的关键部分等间距安装。第一个传感器位于传送带上的位置 17.5,最后一个位于 46.2。
温度传感器阵列输出的数据可以作为 Python 中的列表读取。这是一个以摄氏度为单位的温度读数示例:
temperatures = [17.6, 18.9, 18.0, 18.9, 16.7, 14.3, 13.7, 13.8, 13.6, 15.7, 18.6, 17.5, 18.4, 18.0, 17.2, 16.9, 16.8, 17.0, 15.9, 17.2, 17.7, 16.9, 17.2, 17.8, 17.5, 16.9, 17.2]工厂经理需要看到这些温度与它们在传送带上的位置之间的关系,以确保在传送带的这一关键延伸段上的每一点温度都保持在公差范围内。
你需要导入
matplotlib来绘制温度:import matplotlib.pyplot as plt temperatures = [17.6, 18.9, 18.0, 18.9, 16.7, 14.3, 13.7, 13.8, 13.6, 15.7, 18.6, 17.5, 18.4, 18.0, 17.2, 16.9, 16.8, 17.0, 15.9, 17.2, 17.7, 16.9, 17.2, 17.8, 17.5, 16.9, 17.2] plt.plot(temperatures) plt.title("Temperatures along critical stretch (ºC)") plt.ylabel("Temperature (ºC)") plt.xlabel("List index") plt.show()绘制
temperatures列表中的值,并设置标题和轴标签。这给出了下面的图:
该图显示了相对于传感器列表索引绘制的温度。这对于工厂经理来说没有用,他想知道相对于皮带标准参考位置的温度。
为了创建与已知参考位置相匹配的温度指数,您将使用三位信息:
- 有 27 个温度传感器。
- 第一个在 17.5 位置。
- 最后一个在 46.2 位置。
这是使用
np.linspace()的理想场景:

>>> import numpy as np
>>> position = np.linspace(17.5, 46.2, 27)
>>> position
array([17.5 , 18.60384615, 19.70769231, 20.81153846, 21.91538462,
23.01923077, 24.12307692, 25.22692308, 26.33076923, 27.43461538,
28.53846154, 29.64230769, 30.74615385, 31.85 , 32.95384615,
34.05769231, 35.16153846, 36.26538462, 37.36923077, 38.47307692,
39.57692308, 40.68076923, 41.78461538, 42.88846154, 43.99230769,
45.09615385, 46.2 ])
线性空间position显示了传送带上所有温度传感器的准确位置。现在,您可以根据position数组绘制温度:
plt.plot(position, temperatures)
plt.title("Temperatures along critical stretch (ºC)")
plt.ylabel("Temperature (ºC)")
plt.xlabel("Position on conveyor belt")
plt.show()
与上面代码中的前一个例子的不同之处在于,您使用了position数组作为plt.plot()中的第一个参数。这给出了下面的图:

该图现在显示了正确的 x 轴,它代表测量每个温度的位置。本例显示了一个典型案例,其中np.linspace()是理想的解决方案。
表示数学函数
科学、工程、金融和其他领域的许多领域都依赖于数学函数。这些往往是连续变量的函数。如果你想通过计算来研究这些过程,那么你需要用一个离散表示法来近似这些数学函数。在这个过程中,你需要的一个关键工具是创造一个线性空间的能力。
带np.linspace()的数学函数
在本节中,您将学习如何用 Python 表示一个数学函数并绘制它。考虑以下函数:

这个数学函数是从连续实数线的映射。即使设置了限制,比如说-5 ≤ x ≤ 5,仍然有无限多的 x 的值。为了表示上面的函数,首先需要创建一个实数线的离散版本:
import numpy as np
x_ = np.linspace(-5, 5, 5)
在本教程中,符号 x 用于表示实数线上定义的连续数学变量,而x_用于表示其计算的离散近似值。带下划线的版本也用于代表数组的 Python 变量。
因为x_是一个 NumPy 数组,你可以像数学上那样计算代数运算,并且不需要循环:
y_ = 4 * (x_**3) + 2 * (x_**2) + 5 * x_
新数组y_是连续变量y的离散版本。最后一步是想象它:
import matplotlib.pyplot as plt
plt.plot(x_, y_)
plt.show()
这创建了一个y_对x_的图,如下所示:

注意这个剧情好像不是很顺利。创建的线性空间只有5个点。这不足以恰当地表示数学函数。该函数是欠采样。将分辨率加倍可能效果更好:
x_ = np.linspace(-5, 5, 10)
y_ = 4 * (x_**3) + 2 * (x_**2) + 5 * x_
plt.plot(x_, y_)
plt.show()
这给出了下面的图:

这更好,你可以更有信心,这是一个公平的函数表示。然而,情节仍然不像你在数学课本上看到的那样顺利。采样频率更高时,曲线变得更加平滑:
x_ = np.linspace(-5, 5, 100)
y_ = 4 * (x_**3) + 2 * (x_**2) + 5 * x_
plt.plot(x_, y_)
plt.show()
这给出了下面的图:

您可以选择更高的采样,但这是有代价的。更大的数组需要更多的内存,计算也需要更多的时间。
例子:叠加行波
在本节中,您将创建两个具有不同属性的不同波,然后将它们叠加并创建一个动画来显示它们如何传播。
波可以用下面的函数来表示:

本教程不是关于波的物理学,所以我将保持物理学非常简短!波遵循由以下五项定义的正弦函数:
- 位置( x )
- 时间( t
- 波的振幅( A
- 波长( λ
- 波的速度( v
在下一节中,您将学习如何处理二维函数,但是对于这个示例,您将采用不同的方法。您可以首先创建一个线性空间来表示 x :
import numpy as np
x_ = np.linspace(-10, 10, 10)
一旦定义了常数,就可以创建波形了。您可以从定义常数开始:
amplitude = 2
wavelength = 5
velocity = 2
time = 0 # You can set time to 0 for now
该函数包括时间( t ),但最初您将关注变量 x 。现在设置time = 0意味着你仍然可以在你的代码中写完整的方程,即使你还没有使用时间。现在,您可以创建数组来表示波浪:
wave = amplitude * np.sin((2*np.pi/wavelength) * (x_ - velocity*time))
创建的数组是描述波的方程的离散版本。现在你可以绘制wave:
import matplotlib.pyplot as plt
plt.plot(x_, wave)
plt.show()
wave的图如下所示:

这看起来不像正弦波,但你之前看到过这个问题。用于x_的线性空间的分辨率不够。您可以通过增加采样来解决这个问题:
x_ = np.linspace(-10, 10, 100)
wave = amplitude * np.sin((2*np.pi/wavelength) * (x_ - velocity*time))
plt.plot(x_, wave)
plt.show()
wave的这个图现在显示了一个平滑的波:

现在你准备叠加两个波。你所需要做的就是创建两个不同的波,并将它们相加。这也是一个重构代码的好时机:
import matplotlib.pyplot as plt
import numpy as np
# Parameters for discretizing the mathematical function
sampling = 100
x_range = -10, 10
n_waves = 2
# Parameters are tuples with a value for each wave (2 in this case)
amplitudes = 1.7, 0.8
wavelengths = 4, 7.5
velocities = 2, 1.5
time = 0 # You can set time to 0 for now
x_ = np.linspace(x_range[0], x_range[1], sampling)
# Create 2 (or more) waves using a list comprehension and superimpose
waves = [amplitudes[idx] * np.sin((2*np.pi/wavelengths[idx]) *
(x_ - velocities[idx]*time))
for idx in range(n_waves)]
superimposed_wave = sum(waves)
# Plot both waves separately to see what they look like
plt.subplot(2, 1, 1)
plt.plot(x_, waves[0])
plt.plot(x_, waves[1])
# Plot the superimposed wave
plt.subplot(2, 1, 2)
plt.plot(x_, superimposed_wave)
plt.show()
这段代码创建了两个不同的波,并将它们加在一起,显示了波的叠加:

在上面的图中,你可以看到两个波是分开绘制的。下图显示了当它们被加在一起时,波的叠加。您现在的最后一项任务是通过绘制不同时间值 t 的叠加波来启动这些波:
for time in np.arange(0, 40, 0.2):
# Create 2 (or more) waves using a list comprehension and superimpose
waves = [amplitudes[idx] *
np.sin((2*np.pi/wavelengths[idx]) *
(x_ - velocities[idx]*time))
for idx in range(n_waves)]
superimposed_wave = sum(waves)
plt.clf() # Clear last figure
plt.plot(x_, superimposed_wave)
plt.ylim(-3, 3) # Fix the limits on the y-axis
plt.pause(0.1) # Insert short pause to create animation
这将产生以下输出:
https://player.vimeo.com/video/479141813?background=1
您可以用不同参数的 wave 来尝试上面的代码,甚至可以添加第三个或第四个 wave。现在,您可以选择自己喜欢的函数进行实验,并尝试用 Python 来表示它们。
二维数学函数
在前面的示例中,您通过将一个变量表示为空间坐标,一个变量表示为时间坐标,解决了具有两个变量的函数的问题。这是有意义的,因为两个坐标实际上是一个空间坐标和一个时间坐标。
不过,这种方法并不总是有效。这是一个包含两个变量的函数:

这是二维简化的高斯函数,所有参数都有单位值。为了表示这一点,你需要创建两个线性空间,一个用于 x ,一个用于 y 。在这种情况下,它们可以是相同的,但不一定总是这样:
import numpy as np
x_ = np.linspace(-5, 5, 100)
y_ = np.linspace(-5, 5, 100)
这些向量都是一维的,但是所需的数组必须是二维的,因为它需要表示两个变量的函数。NumPy 有一个很有用的函数叫做 np.meshgrid() ,你可以结合np.linspace()使用,把一维向量转换成二维矩阵。这些矩阵表示二维坐标:
>>> X, Y = np.meshgrid(x_, y_) >>> x_.shape, y_.shape ((100,), (100,)) >>> X.shape, Y.shape ((100, 100), (100, 100))你已经把向量转换成了二维数组。现在,您可以使用这些数组来创建二维函数:
gaussian = np.exp(-((X**2) / 2 + (Y**2) / 2))您可以使用
matplotlib以二维或三维方式显示该矩阵:import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D fig = plt.figure() ax = fig.add_subplot(121) # Show matrix in two dimensions ax.matshow(gaussian, cmap="jet") ax = fig.add_subplot(122, projection="3d") # Show three-dimensional surface ax.plot_surface(X, Y, gaussian, cmap="jet") plt.show()二维和三维表示如下所示:
这种方法可以用于任何二元函数。如果你想创建一个二进制的盘形遮罩,那么你可以使用比较运算符来表示这个函数:
1import matplotlib.pyplot as plt 2import numpy as np 3 4x_ = np.linspace(-10, 10, 1000) 5y_ = np.linspace(-10, 10, 1000) 6 7X, Y = np.meshgrid(x_, y_) 8 9radius = 8 10disk_mask = (X ** 2) + (Y ** 2) < radius ** 2 11 12plt.matshow(disk_mask, cmap="gray", extent=[-10, 10, -10, 10]) 13plt.show()在第 10 行,您使用元素比较生成数组
disk_mask。这给出了下面的图:
数组
disk_mask的值True(或1)是落在圆的等式内的x_和y_的所有值。否则,它的值为False(或0)。现在,您已经拥有了在一维和二维计算中表示数学函数的工具,使用
np.linspace()创建表示函数变量所需的线性空间。你也可以将同样的概念扩展到更高的维度。创建间距不均匀的数字范围
您已经看到了如何创建和使用均匀分布的数字。然而,有时候你可能需要一个非线性排列的数组。每个值之间的步长可能需要是对数的或者遵循一些其他模式。在最后一节中,您将了解创建这种类型的阵列有哪些选择。
对数空间
函数
np.logspace()创建一个对数空间,其中创建的数字在对数刻度上均匀分布。一旦你掌握了
np.linspace(),你就可以使用np.logspace()了,因为这两个函数的输入参数和返回输出非常相似。np.logspace()中缺少的一个参数是retstep,因为没有一个单一的值来表示连续数字之间的阶跃变化。
np.logspace()有一个额外的输入参数base,默认值为10。另一个关键区别是start和stop代表对数起点和终点。数组中第一个值是basestart,最后一个值是basestop:


>>> import numpy as np
>>> np.logspace(0, 4, 5)
array([1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04])
这就创建了一个对数空间,其中的5元素从10 0 到10 4 ,或者从1到10000。输出数组以科学记数法显示数字1、10、100、1000和10000。尽管以 10 为底是默认值,但您可以创建任何底的对数空间:
>>> np.logspace(1, 10, 20, base=np.e) array([2.71828183e+00, 4.36528819e+00, 7.01021535e+00, 1.12577033e+01, 1.80787433e+01, 2.90326498e+01, 4.66235260e+01, 7.48727102e+01, 1.20238069e+02, 1.93090288e+02, 3.10083652e+02, 4.97963268e+02, 7.99679103e+02, 1.28420450e+03, 2.06230372e+03, 3.31185309e+03, 5.31850415e+03, 8.54098465e+03, 1.37159654e+04, 2.20264658e+04])这个例子展示了一个以为基数eT3】的对数空间。在下一节中,您将看到如何创建其他非对数的非线性范围。
其他非线性范围
您现在可以创建线性和对数空间。您可能还需要遵循其他非线性区间的一系列数字。你可以通过变换一个线性空间来实现。
首先创建一个线性空间:
>>> import numpy as np
>>> x_ = np.linspace(1, 10, 10)
>>> x_
array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
你现在可以把它转换成一个在 x 2 上呈线性的数字范围:
>>> x_ = x_ ** 2 >>> x_ array([ 1., 4., 9., 16., 25., 36., 49., 64., 81., 100.])这可能看起来很熟悉。这与您在本教程前面用来表示数学函数的方法相同。事实上,这是完全一样的。当您查看一个具体的示例时,在下一节中将会更清楚地理解为什么您有时会认为这是在创建一个非均匀分布的数组。
示例:模拟一颗轨道行星
在本节中,您将创建一个行星绕其太阳运行的模拟。为了稍微简化模拟,你可以假设行星的轨道是圆形而不是椭圆形。
描述圆的等式是 x 和 y 的函数,并且取决于半径 R :
因此,如果行星的x-位置被设定,相应的y-位置将通过重新排列上面的等式给出:
因此,可以将行星放置在一组坐标( x 、 y )上,只要上面的等式给出了 y ,行星就会保持在轨道上。它的位置将在一个圆的圆周上。
你现在已经精通了
np.linspace(),所以第一次尝试可以使用你已经知道的方法:import numpy as np sampling = 50 R = 50 x_ = R * np.linspace(-1, 1, sampling)变量 x 沿着水平线从左到右跨越圆的直径,意思是从- R 到+ R 。现在你可以算出 y :
y_ = np.sqrt(R ** 2 - x_ ** 2)数组
y_是连续变量 y 的离散版本,描述了一个圆。您可以使用散点图来绘制这些点:import matplotlib.pyplot as plt plt.scatter(x_, y_) plt.axis("square") plt.show()为了确保二维绘图显示正确的模式,您将轴设置为
"square",这确保了每个像素都有一个正方形的纵横比:
所有的点都很好地符合一个圆的圆周,这应该是在圆形轨道上的行星的情况。
但是行星不只是绕着半圆形的轨道运行。问题是圆的另一半的 x 的值是相同的。顶部半圆和底部半圆共享相同的 x 值,但不共享相同的 y 值。
你可以通过回顾上面的等式来解决这个问题,这个等式根据 x 给出了 y 。这个方程有一个正解和一个负解。当 x 从右边的+ R 摆回到左边的- R 时,可以得到 y 的负解:
# x_return and y_return are the x_ and y_ values as the # planet moves from right to left x_return = x_[len(x_)-2:0:-1] y_return = -np.sqrt(R ** 2 - x_return ** 2) x_ = np.concatenate((x_, x_return)) y_ = np.concatenate((y_, y_return))数组
x_return与x_相反,但没有端点。否则,当您连接x_和x_return时,端点将会重复。数组y_return是y_的负解。因此,您可以覆盖x_成为x_和x_return的串联:



>>> x_
array([-50\. , -47.95918367, -45.91836735, -43.87755102,
-41.83673469, -39.79591837, -37.75510204, -35.71428571,
-33.67346939, -31.63265306, -29.59183673, -27.55102041,
-25.51020408, -23.46938776, -21.42857143, -19.3877551 ,
-17.34693878, -15.30612245, -13.26530612, -11.2244898 ,
-9.18367347, -7.14285714, -5.10204082, -3.06122449,
-1.02040816, 1.02040816, 3.06122449, 5.10204082,
7.14285714, 9.18367347, 11.2244898 , 13.26530612,
15.30612245, 17.34693878, 19.3877551 , 21.42857143,
23.46938776, 25.51020408, 27.55102041, 29.59183673,
31.63265306, 33.67346939, 35.71428571, 37.75510204,
39.79591837, 41.83673469, 43.87755102, 45.91836735,
47.95918367, 50\. , 47.95918367, 45.91836735,
43.87755102, 41.83673469, 39.79591837, 37.75510204,
35.71428571, 33.67346939, 31.63265306, 29.59183673,
27.55102041, 25.51020408, 23.46938776, 21.42857143,
19.3877551 , 17.34693878, 15.30612245, 13.26530612,
11.2244898 , 9.18367347, 7.14285714, 5.10204082,
3.06122449, 1.02040816, -1.02040816, -3.06122449,
-5.10204082, -7.14285714, -9.18367347, -11.2244898 ,
-13.26530612, -15.30612245, -17.34693878, -19.3877551 ,
-21.42857143, -23.46938776, -25.51020408, -27.55102041,
-29.59183673, -31.63265306, -33.67346939, -35.71428571,
-37.75510204, -39.79591837, -41.83673469, -43.87755102,
-45.91836735, -47.95918367])
x_内的值从-50通过0到50,然后通过0回到-50。您也可以打印 y_来确认它对应于前半段的 y 的正值和后半段的 y 的负值。x_和y_的散点图将证实行星现在处于一个完整的圆形轨道上:
plt.scatter(x_, y_)
plt.axis("square")
plt.show()
这给出了下面的图:

你可能已经能够在这个散点图中发现问题,但是你过一会儿再回来。现在,你可以使用上面的x_和y_向量来创建一个移动星球的模拟。
为此,您需要导入 matplotlib.animation :
import matplotlib.animation
# Create a figure and axis handle, set axis to
# an equal aspect (square), and turn the axes off
fig, ax = plt.subplots()
ax.set_aspect("equal")
ax.set_axis_off()
# Images are generated and stored in a list to animate later
images = []
for x_coord, y_coord in zip(x_, y_):
# Scatter plot each point using a dot of size 250 and color red
img = ax.scatter(x_coord, y_coord, s=250, c="r")
# Let's also put a large yellow sun in the middle
img2 = ax.scatter(0, 0, s=1000, c="y")
images.append([img, img2])
# The animation can now be created using ArtistAnimation
animation = matplotlib.animation.ArtistAnimation(fig,
images,
interval=2.5,
blit=True
)
plt.show()
这将产生以下输出:

不幸的是,行星不会以这种方式运行。你可以看到行星在轨道的左右两侧穿过 x 轴时加速,在顶部和底部穿过 y 轴时减速。
再看一下显示轨道周围所有行星位置的散点图,看看为什么会发生这种情况。这些点在轨道的顶部和底部靠得更近,但在左右两边却相隔很远。你需要在轨道圆周上均匀分布的点,但是你所拥有的是基于均匀分布的x_向量的点。
为了解决这个问题,你需要创建一个由x_值组成的数组,这个数组不是线性的,但是它产生了沿着轨道圆周的线性点。当一个点平滑地绕着圆形轨道移动时,它在 x 轴上的投影(共)正弦地移动,所以你可以通过改变x_来修正这个问题,这样它在cos(x_)上是线性的:
x_ = R * np.cos(np.linspace(-np.pi, 0, sampling))
x_return = x_[len(x_)-2: 0: -1]
y_ = np.sqrt(R ** 2 - x_ ** 2)
y_return = -np.sqrt(R ** 2 - x_return ** 2)
x_ = np.concatenate((x_, x_return))
y_ = np.concatenate((y_, y_return))
plt.scatter(x_, y_)
plt.axis("square")
plt.show()
第一行将线性空间转换成非线性空间。x_的每个值之间的间隔并不相等,而是根据余弦函数而变化。这给出了下面的图:

这些点现在均匀分布在圆形轨道的圆周上。最后一步是使用与前面相同的代码重新创建动画。这也是通过增加您在开始时定义的sampling变量的值来增加分辨率的好时机:
sampling = 250
# ...
fig, ax = plt.subplots()
ax.set_aspect("equal")
ax.set_axis_off()
images = []
for x_coord, y_coord in zip(x_, y_):
img = ax.scatter(x_coord, y_coord, s=250, c="r")
img2 = ax.scatter(0, 0, s=1000, c="y")
images.append([img, img2])
animation = matplotlib.animation.ArtistAnimation(fig,
images,
interval=2.5,
blit=True
)
plt.show()
这将产生以下输出:

要查看生成此动画的代码的完整版本,您可以展开下面的部分。
完整的最终模拟版本,包括将模拟保存到.gif中,可从以下网址获得:
1import matplotlib.animation
2import matplotlib.pyplot as plt
3import numpy as np
4
5sampling = 250
6R = 50
7
8# Create vector x_ that is linear on cos(x_)
9# First create x_ from left to right (-R to +R)
10x_ = R * np.cos(np.linspace(-np.pi, 0, sampling))
11# And then x_ returns from right to left (+R to R)
12x_return = x_[len(x_)-2: 0: -1]
13
14# Calculate y_ using the positive solution when x_ is increasing
15y_ = np.sqrt(R ** 2 - x_ ** 2)
16# And the negative solution when x_ is decreasing
17y_return = -np.sqrt(R ** 2 - x_return ** 2)
18
19x_ = np.concatenate((x_, x_return))
20y_ = np.concatenate((y_, y_return))
21
22# Create animation
23fig, ax = plt.subplots()
24ax.set_aspect("equal")
25ax.set_axis_off()
26
27images = []
28for x_coord, y_coord in zip(x_, y_):
29 img = ax.scatter(x_coord, y_coord, s=250, c="r")
30 img2 = ax.scatter(0, 0, s=1000, c="y")
31 images.append([img, img2])
32
33animation = matplotlib.animation.ArtistAnimation(fig,
34 images,
35 interval=2.5,
36 blit=True
37 )
38plt.show()
39
40# Export to .gif
41writer = matplotlib.animation.PillowWriter(fps=30)
42animation.save("orbiting_planet_simulation.gif", writer=writer)
您刚刚创建了一个行星绕恒星运行的动画。你必须让行星的位置在圆周上均匀分布,从而让行星在圆周上做直线运动。现在你可以创建任何非均匀间隔的数字范围,只要你能用数学方法表达它。
结论
在 Python 中创建一系列数字表面上看起来并不复杂,但是正如您在本教程中看到的,您可以以多种方式使用np.linspace()。如果没有 NumPy 的优势及其创建均匀或非均匀间隔的数字范围的能力,科学、工程、数学、金融、经济和类似领域中的许多数字应用程序将更难实现。
知道如何使用np.linspace(),并且知道如何很好地使用它,将使你能够有效地完成数值编程应用。
在本教程中,您已经学会了如何:
- 创建一个均匀或非均匀间隔的数字范围
- 决定何时使用
np.linspace()代替替代工具 - 使用必需和可选的输入参数
- 创建二维或多维数组
- 以离散形式表示数学函数
有了从完成本教程中学到的知识,你就可以开始使用np.linspace()成功地开发你的数值编程应用程序了。*********
Python 中的 Null:理解 Python 的 NoneType 对象
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 的 None: Null in Python
如果你有使用其他编程语言的经验,如 C 或 Java ,那么你可能听说过 null 的概念。许多语言用这个来表示不指向任何东西的指针,表示变量何时为空,或者标记尚未提供的默认参数。在那些语言中,null通常被定义为0,但是在 Python 中的null是不同的。
Python 使用关键字 None来定义null对象和变量。虽然在其他语言中,None确实服务于与null相同的一些目的,但它完全是另一种野兽。与 Python 中的null一样,None没有被定义为0或其他任何值。在 Python 中,None是对象,是一等公民!
在本教程中,您将学习:
- 什么是
None以及如何测试 - 何时以及为何使用
None作为默认参数 - 在你的回溯中
None和NoneType是什么意思 - 如何在型式检验中使用
None - Python 中的
null是如何工作的
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
理解 Python 中的空值
None是函数中没有return语句时函数返回的值:
>>> def has_no_return(): ... pass >>> has_no_return() >>> print(has_no_return()) None当你调用
has_no_return()时,你看不到任何输出。然而,当您打印对它的调用时,您将看到它返回的隐藏的None。事实上,
None如此频繁地作为返回值出现,以至于 Python REPL 不会打印None,除非你明确地告诉它:
>>> None
>>> print(None)
None
None本身没有输出,但是打印它会将None显示到控制台。
有趣的是, print() 本身没有返回值。如果你试图打印一个对 print() 的调用,那么你会得到None:
>>> print(print("Hello, World!")) Hello, World! None这看起来可能很奇怪,但是
print(print("..."))向你展示了内在print()返回的None。
None也常用作缺失或默认参数的信号。例如,None在list.sort的文档中出现两次:
>>> help(list.sort)
Help on method_descriptor:
sort(...)
L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
这里,None是key参数的默认值,也是返回值的类型提示。help的确切产量可能因平台而异。当您在您的解释器中运行这个命令时,您可能会得到不同的输出,但是它将是相似的。
使用 Python 的空对象None
通常,你会使用None作为比较的一部分。一个例子是当你需要检查某个结果或参数是否为None时。从 re.match 中取你得到的结果。你的正则表达式匹配给定的字符串了吗?您将看到两种结果之一:
- 返回一个
Match对象:你的正则表达式找到一个匹配。 - 返回一个
None对象:你的正则表达式没有找到匹配。
在下面的代码块中,您正在测试模式"Goodbye"是否匹配一个字符串:
>>> import re >>> match = re.match(r"Goodbye", "Hello, World!") >>> if match is None: ... print("It doesn't match.") It doesn't match.这里,您使用
is None来测试模式是否匹配字符串"Hello, World!"。这个代码块演示了一个重要的规则,当您检查None时要记住:
- 使用了身份运算符
is和is not吗?- 不要使用等式运算符
==和!=。当您比较用户定义的对象时,等式操作符可能会被愚弄,这些对象被覆盖:
>>> class BrokenComparison:
... def __eq__(self, other):
... return True
>>> b = BrokenComparison()
>>> b == None # Equality operator
True
>>> b is None # Identity operator
False
这里,等式运算符==返回错误的答案。另一方面,身份操作符is 不会被愚弄,因为你不能覆盖它。
注意:关于如何与None进行比较的更多信息,请查看该做的和不该做的:Python 编程建议。
None是福尔西,意思是not None是True。如果您只想知道结果是否为假,那么如下测试就足够了:
>>> some_result = None >>> if some_result: ... print("Got a result!") ... else: ... print("No result.") ... No result.输出没有告诉你
some_result就是None,只告诉你它是假的。如果你必须知道你是否有一个None对象,那么使用is和is not。以下对象也是假的:
关于比较、真值和假值的更多信息,你可以阅读如何使用 Python
or操作符,如何使用 Pythonand操作符,以及如何使用 Pythonnot操作符。在 Python 中声明空变量
在一些语言中,变量来源于声明。它们不需要被赋予初始值。在这些语言中,某些类型变量的初始默认值可能是
null。然而,在 Python 中,变量来源于赋值语句。看一下下面的代码块:
>>> print(bar)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'bar' is not defined
>>> bar = None
>>> print(bar)
None
这里,你可以看到一个值为None的变量不同于一个未定义的变量。Python 中的所有变量都是通过赋值产生的。如果你给一个变量赋值None,它在 Python 中只会以null开始。
使用None作为默认参数
通常,您会使用None作为可选参数的默认值。这里有一个很好的理由使用None而不是可变类型,比如 list。想象一个这样的函数:
def bad_function(new_elem, starter_list=[]):
starter_list.append(new_elem)
return starter_list
bad_function()包含令人讨厌的惊喜。当您使用现有列表调用它时,它工作得很好:
>>> my_list = ['a', 'b', 'c'] >>> bad_function('d', my_list) ['a', 'b', 'c', 'd']在这里,您将
'd'添加到列表的末尾,没有任何问题。但是,如果您多次调用这个函数而没有使用
starter_list参数,那么您将开始看到不正确的行为:
>>> bad_function('a')
['a']
>>> bad_function('b')
['a', 'b']
>>> bad_function('c')
['a', 'b', 'c']
在定义函数时,starter_list的默认值只计算一次,所以每次没有传递现有列表时,代码都会重用它。
构建这个函数的正确方法是使用None作为默认值,然后测试它并根据需要实例化一个新的列表:
1>>> def good_function(new_elem, starter_list=None): 2... if starter_list is None: 3... starter_list = [] 4... starter_list.append(new_elem) 5... return starter_list 6... 7>>> good_function('e', my_list) 8['a', 'b', 'c', 'd', 'e'] 9>>> good_function('a') 10['a'] 11>>> good_function('b') 12['b'] 13>>> good_function('c') 14['c']
good_function()通过每次调用创建一个新的列表,而不是传递一个现有的列表,按照您想要的方式进行操作。它之所以有效,是因为您的代码每次调用带有默认参数的函数时都会执行第 2 行和第 3 行。在 Python 中使用
None作为空值当
None是有效的输入对象时,你会怎么做?例如,如果good_function()可以向列表中添加元素,也可以不添加,而None是要添加的有效元素,那会怎么样呢?在这种情况下,您可以定义一个专门用作默认的类,同时与None相区别:
>>> class DontAppend: pass
...
>>> def good_function(new_elem=DontAppend, starter_list=None):
... if starter_list is None:
... starter_list = []
... if new_elem is not DontAppend:
... starter_list.append(new_elem)
... return starter_list
...
>>> good_function(starter_list=my_list)
['a', 'b', 'c', 'd', 'e']
>>> good_function(None, my_list)
['a', 'b', 'c', 'd', 'e', None]
在这里,类DontAppend作为不追加的信号,所以你不需要None来做这个。这让你可以在需要的时候添加None。
当None也可能是返回值时,您可以使用这种技术。例如,如果在字典中找不到关键字,默认情况下, dict.get 会返回None。如果None在您的字典中是一个有效值,那么您可以这样调用dict.get:
>>> class KeyNotFound: pass ... >>> my_dict = {'a':3, 'b':None} >>> for key in ['a', 'b', 'c']: ... value = my_dict.get(key, KeyNotFound) ... if value is not KeyNotFound: ... print(f"{key}->{value}") ... a->3 b->None这里您已经定义了一个定制类
KeyNotFound。现在,当一个键不在字典中时,你可以返回KeyNotFound,而不是返回None。这使得您可以返回None,而这是字典中的实际值。回溯中的解密
None当
NoneType出现在你的回溯中,说明你没想到会是None的东西实际上是None,你试图用一种你不能用None的方式使用它。几乎总是,这是因为你试图在它上面调用一个方法。例如,您在上面的
my_list中多次调用了append(),但是如果my_list不知何故变成了列表之外的任何东西,那么append()就会失败:
>>> my_list.append('f')
>>> my_list
['a', 'b', 'c', 'd', 'e', None, 'f']
>>> my_list = None
>>> my_list.append('g')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'append'
这里,您的代码引发了非常常见的AttributeError,因为底层对象my_list不再是一个列表。您已经将它设置为None,它不知道如何append(),因此代码抛出一个异常。
当您在代码中看到类似这样的回溯时,首先查找引发错误的属性。在这里,是append()。从那里,您将看到您试图调用它的对象。在这种情况下,它是my_list,您可以从回溯上方的代码中看出这一点。最后,弄清楚这个对象是如何变成None的,并采取必要的步骤来修改代码。
检查 Python 中的空值
在 Python 中,有两种类型检查情况需要关注null。第一种情况是你在返回NoneT5 的时候:
>>> def returns_None() -> None: ... pass这种情况类似于根本没有
return语句时,默认情况下返回None。第二种情况更具挑战性。它是您获取或返回一个值的地方,这个值可能是
None,但也可能是其他(单个)类型。这种情况就像你对上面的re.match所做的,它返回一个Match对象或者None。对于参数,过程是相似的:
from typing import Any, List, Optional def good_function(new_elem:Any, starter_list:Optional[List]=None) -> List: pass从上面修改
good_function(),从typing导入Optional,返回一个Optional[Match]。在引擎盖下看一看
在许多其他语言中,
null只是0的同义词,但 Python 中的null是一个成熟的对象:
>>> type(None)
<class 'NoneType'>
这一行显示None是一个对象,它的类型是NoneType。
None本身作为 Python 中的null内置于语言中:
>>> dir(__builtins__) ['ArithmeticError', ..., 'None', ..., 'zip']在这里,你可以看到
__builtins__列表中的None,它是解释器为builtins模块保留的字典。
None是一个关键词,就像True和False一样。但是正因为如此,你不能像你可以直接从__builtins__到达None,比如说ArithmeticError。不过,你可以用一个getattr()的招数得到它:
>>> __builtins__.ArithmeticError
<class 'ArithmeticError'>
>>> __builtins__.None
File "<stdin>", line 1
__builtins__.None
^
SyntaxError: invalid syntax
>>> print(getattr(__builtins__, 'None'))
None
当你使用getattr()时,你可以从__builtins__中获取实际的None,这是你简单地用__builtins__.None索取无法做到的。
尽管 Python 在许多错误消息中输出了单词NoneType,但是NoneType在 Python 中并不是一个标识符。它不在builtins。只有用type(None)才能到达。
None是的独生子。也就是说,NoneType类只给你同一个None实例。您的 Python 程序中只有一个None:
>>> my_None = type(None)() # Create a new instance >>> print(my_None) None >>> my_None is None True即使您试图创建一个新实例,您仍然会得到现有的
None。你可以用
id()证明None和my_None是同一个对象:
>>> id(None)
4465912088
>>> id(my_None)
4465912088
这里,id为None和my_None输出相同的整数值意味着它们实际上是同一个对象。
注意:由id产生的实际值会因系统而异,甚至会因程序执行而异。在最流行的 Python 运行时 CPython 下,id()通过报告对象的内存地址来完成工作。住在同一个内存地址的两个对象是同一个对象。
如果你试图赋值给None,那么你会得到一个 SyntaxError :
>>> None = 5 Traceback (most recent call last): File "<stdin>", line 1, in <module> SyntaxError: can't assign to keyword >>> None.age = 5 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'NoneType' object has no attribute 'age' >>> setattr(None, 'age', 5) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'NoneType' object has no attribute 'age' >>> setattr(type(None), 'age', 5) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't set attributes of built-in/extension type 'NoneType'上面所有的例子都表明你不能修改
None或者NoneType。它们是真正的常数。您也不能子类化
NoneType:
>>> class MyNoneType(type(None)):
... pass
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: type 'NoneType' is not an acceptable base type
这个回溯表明解释器不会让你创建一个继承自type(None)的新类。
结论
None是 Python 工具箱中一个强大的工具。与True和False一样,None是一个不可变的关键字。作为 Python 中的null,您可以用它来标记缺失的值和结果,甚至是默认参数,这是比可变类型更好的选择。
现在你可以:
- 用
is和is not测试None - 选择
None何时是代码中的有效值 - 使用
None及其替代参数作为默认参数 - 破译回溯中的
None和NoneType - 在类型提示中使用
None和Optional
Python 中的null怎么用?在下面的评论区留下你的评论吧!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 的 None: Null in Python***
看,马,没有 For 循环:用 NumPy 进行数组编程
有时人们会说,与低级语言如 C++ 相比,Python 以运行时间为代价提高了开发时间。幸运的是,有一些方法可以在不牺牲易用性的情况下加快 Python 中操作的运行时间。适合快速数值运算的一个选项是 NumPy,它理所当然地将自己标榜为使用 Python 进行科学计算的基础包。
当然,很少有人会将耗时 50 微秒(五千万分之一秒)的东西归类为“慢”。然而,计算机可能不敢苟同。运行时间为 50 微秒(50 μs)的操作属于微性能的范畴,它可以粗略地定义为运行时间在 1 微秒和 1 毫秒之间的操作。
为什么速度很重要?微性能值得监控的原因是,运行时的微小差异会随着函数调用的重复而放大:50 μs 的增量开销,重复超过 100 万次函数调用,转化为 50 秒的增量运行时。
说到计算,有三个概念赋予了 NumPy 强大的功能:
- …向量化…
- 广播
- 索引
在本教程中,您将一步一步地看到如何利用矢量化和广播的优势,这样您就可以最大限度地使用 NumPy。虽然您将在实践中使用一些索引,但 NumPy 的完整索引示意图是它们自己的特色,它扩展了 Python 的切片语法。如果你想阅读更多关于 NumPy 索引的内容,喝点咖啡,去 NumPy 文档中的索引部分。
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
进入状态:NumPy 数组简介
NumPy 的基本对象是它的ndarray(或numpy.array),一个 n 维数组,它也以某种形式出现在面向数组的语言中,如 Fortran 90、R 和 MATLAB ,以及前辈 APL 和 j
让我们从形成一个包含 36 个元素的三维数组开始:
>>> import numpy as np >>> arr = np.arange(36).reshape(3, 4, 3) >>> arr array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]], [[12, 13, 14], [15, 16, 17], [18, 19, 20], [21, 22, 23]], [[24, 25, 26], [27, 28, 29], [30, 31, 32], [33, 34, 35]]])在二维空间中描绘高维数组可能很困难。思考数组形状的一种直观方式是简单地“从左向右阅读”
arr是一个 3 乘 4 乘 3 的阵列:
>>> arr.shape
(3, 4, 3)
视觉上,arr可以被认为是一个由三个 4x3 网格(或一个矩形棱柱)组成的容器,看起来像这样:

更高维的数组可能更难描述,但是它们仍然遵循“数组中的数组”的模式。
在哪里可以看到二维以上的数据?
- 面板数据 可以用三维表示。随着时间的推移,跟踪一群人的属性的数据可以被构造为
(respondents, dates, attributes)。1979 年的全国青年纵向调查对 12686 名受访者进行了长达 27 年的跟踪调查。假设每个人每年有大约 500 个直接询问或导出的数据点,这些数据将形成总计 177,604,000 个数据点的形状(12686, 27, 500)。 - 多幅图像的彩色图像数据通常以四维存储。每个图像都是一个三维数组
(height, width, channels),其中的通道通常是红色、绿色和蓝色(RGB)值。一个图像集合就是(image_number, height, width, channels)。一千张 256x256 的 RGB 图像会有形状(1000, 256, 256, 3)。(扩展表示法是 RGBA,其中 A–alpha–表示不透明度。)
有关高维数据的真实世界示例的更多详细信息,请参见弗朗索瓦·乔莱(Franç ois Chollet)的《用 Python 进行深度学习 》的第 2 章。
什么是矢量化?
矢量化是 NumPy 中的一项强大功能,可以将操作表示为在整个数组上进行,而不是在单个元素上进行。韦斯·麦金尼给出了一个简明的定义:
这种用数组表达式替换显式循环的做法通常被称为矢量化。一般来说,矢量化数组操作通常比纯 Python 操作快一两个(或更多)数量级,在任何类型的数值计算中都有最大的影响。[ 来源
当在 Python 中循环数组或任何数据结构时,会涉及大量开销。NumPy 中的向量化操作将内部循环委托给高度优化的 C 和 Fortran 函数,使 Python 代码更简洁、更快速。
数数:简单如 1、2、3…
作为一个例子,考虑一个一维向量True和False,您要对其计数序列中“假到真”转换的数量:
>>> np.random.seed(444) >>> x = np.random.choice([False, True], size=100000) >>> x array([ True, False, True, ..., True, False, True])
>>> def count_transitions(x) -> int:
... count = 0
... for i, j in zip(x[:-1], x[1:]):
... if j and not i:
... count += 1
... return count
...
>>> count_transitions(x)
24984
在矢量化形式中,没有显式的 for 循环或对单个元素的直接引用:
>>> np.count_nonzero(x[:-1] < x[1:]) 24984这两个等价的函数在性能上比较如何?在这个特殊的例子中,矢量化的 NumPy 调用胜出大约 70 倍:
>>> from timeit import timeit
>>> setup = 'from __main__ import count_transitions, x; import numpy as np'
>>> num = 1000
>>> t1 = timeit('count_transitions(x)', setup=setup, number=num)
>>> t2 = timeit('np.count_nonzero(x[:-1] < x[1:])', setup=setup, number=num)
>>> print('Speed difference: {:0.1f}x'.format(t1 / t2))
Speed difference: 71.0x
技术细节:另一个术语是 矢量处理器 ,和一台电脑的硬件有关。当我在这里谈到矢量化时,我指的是用数组表达式替换显式 for 循环的概念,在这种情况下,可以用低级语言在内部计算。
低买高卖
这里有另一个例子来吊你的胃口。考虑下面这个经典的技术面试问题:
给定一只股票的价格历史作为一个序列,并假设只允许你进行一次购买和一次出售,可以获得的最大利润是多少?例如,给定
prices = (20, 18, 14, 17, 20, 21, 15),从 14 买入到 21 卖出,最大利润是 7。
(致各位财务人:不行,不允许卖空。)
有一个时间复杂度为 n 的平方的解决方案,它包括获取两个价格的每个组合,其中第二个价格“在第一个价格之后”,并确定最大差异。
然而,也有一个 O(n)的解决方案,它只需遍历序列一次,并找出每个价格和运行最小值之间的差。事情是这样的:
>>> def profit(prices): ... max_px = 0 ... min_px = prices[0] ... for px in prices[1:]: ... min_px = min(min_px, px) ... max_px = max(px - min_px, max_px) ... return max_px >>> prices = (20, 18, 14, 17, 20, 21, 15) >>> profit(prices) 7这在 NumPy 能做到吗?你打赌。但首先,让我们建立一个准现实的例子:
# Create mostly NaN array with a few 'turning points' (local min/max).
>>> prices = np.full(100, fill_value=np.nan)
>>> prices[[0, 25, 60, -1]] = [80., 30., 75., 50.]
# Linearly interpolate the missing values and add some noise.
>>> x = np.arange(len(prices))
>>> is_valid = ~np.isnan(prices)
>>> prices = np.interp(x=x, xp=x[is_valid], fp=prices[is_valid])
>>> prices += np.random.randn(len(prices)) * 2
下面是使用 matplotlib 后的样子。格言是低买(绿色)高卖(红色):
>>> import matplotlib.pyplot as plt # Warning! This isn't a fully correct solution, but it works for now. # If the absolute min came after the absolute max, you'd have trouble. >>> mn = np.argmin(prices) >>> mx = mn + np.argmax(prices[mn:]) >>> kwargs = {'markersize': 12, 'linestyle': ''} >>> fig, ax = plt.subplots() >>> ax.plot(prices) >>> ax.set_title('Price History') >>> ax.set_xlabel('Time') >>> ax.set_ylabel('Price') >>> ax.plot(mn, prices[mn], color='green', **kwargs) >>> ax.plot(mx, prices[mx], color='red', **kwargs)
NumPy 实现是什么样子的?虽然没有直接的
np.cummin(),但是 NumPy 的通用函数 (ufuncs)都有一个accumulate()方法,正如它的名字所暗示的:
>>> cummin = np.minimum.accumulate
扩展纯 Python 示例的逻辑,您可以找到每个价格和运行最小值(元素方面)之间的差异,然后取这个序列的最大值:
>>> def profit_with_numpy(prices): ... """Price minus cumulative minimum price, element-wise.""" ... prices = np.asarray(prices) ... return np.max(prices - cummin(prices)) >>> profit_with_numpy(prices) 44.2487532293278 >>> np.allclose(profit_with_numpy(prices), profit(prices)) True这两个理论时间复杂度相同的操作在实际运行时如何比较?首先,我们来看一个更长的序列。(这一点不一定需要是股价的时间序列。)
>>> seq = np.random.randint(0, 100, size=100000)
>>> seq
array([ 3, 23, 8, 67, 52, 12, 54, 72, 41, 10, ..., 46, 8, 90, 95, 93,
28, 24, 88, 24, 49])
现在,做一个有点不公平的比较:
>>> setup = ('from __main__ import profit_with_numpy, profit, seq;' ... ' import numpy as np') >>> num = 250 >>> pytime = timeit('profit(seq)', setup=setup, number=num) >>> nptime = timeit('profit_with_numpy(seq)', setup=setup, number=num) >>> print('Speed difference: {:0.1f}x'.format(pytime / nptime)) Speed difference: 76.0x以上,将
profit_with_numpy()视为伪代码(不考虑 NumPy 的底层机制),实际上有三次通过一个序列:
- 具有 O(n)时间复杂度
prices - cummin(prices)是 O(n)max(...)是 O(n)这就简化为 O(n),因为 O(3n)简化为 O(n)——当 n 接近无穷大时, n 起“支配作用”。
因此,这两个函数具有等价的最坏情况时间复杂度。(不过,顺便提一下,NumPy 函数的空间复杂度要高得多。)但这可能是这里最不重要的一点。一个教训是,虽然理论时间复杂性是一个重要的考虑因素,但运行时机制也可以发挥很大的作用。NumPy 不仅可以委托给 C,而且通过一些元素操作和线性代数,它还可以利用多线程中的计算。但是这里有很多因素在起作用,包括使用的底层库(BLAS/LAPACK/Atlas),这些细节完全是另一篇文章的内容。
间奏曲:理解轴符号
在 NumPy 中,轴指的是多维数组的一个维度:
>>> arr = np.array([[1, 2, 3],
... [10, 20, 30]])
>>> arr.sum(axis=0)
array([11, 22, 33])
>>> arr.sum(axis=1)
array([ 6, 60])
关于轴的术语和描述它们的方式可能有点不直观。在关于 Pandas (一个建立在 NumPy 之上的库)的文档中,您可能会经常看到类似这样的内容:
axis : {'index' (0), 'columns' (1)}
你可能会争辩说,基于这种描述,上面的结果应该是“相反的”然而,关键是axis指的是轴,沿着这个轴调用函数。Jake VanderPlas 很好地阐述了这一点:
这里指定轴的方式可能会让来自其他语言的用户感到困惑。axis 关键字指定将折叠的数组的维度,而不是将返回的维度。因此,指定
axis=0意味着第一个轴将被折叠:对于二维数组,这意味着每列中的值将被聚合。来源
换句话说,对数组axis=0求和通过列方式的计算来折叠数组的行。
记住这个区别,让我们继续探讨广播的概念。
广播
广播是另一个重要的数字抽象。您已经看到两个 NumPy 数组(大小相等)之间的操作是按元素方式操作的:
*>>>
>>> a = np.array([1.5, 2.5, 3.5])
>>> b = np.array([10., 5., 1.])
>>> a / b
array([0.15, 0.5 , 3.5 ])
但是,大小不等的数组呢?这就是广播的用武之地:
术语 broadcasting 描述了 NumPy 如何在算术运算中处理不同形状的数组。在某些约束条件下,较小的阵列在较大的阵列中“广播”,以便它们具有兼容的形状。广播提供了一种向量化数组操作的方法,因此循环在 C 而不是 Python 中发生。[ 来源
当使用两个以上的阵列时,实现广播的方式会变得乏味。然而,如果只有两个阵列,那么它们被广播的能力可以用两个简短的规则来描述:
当操作两个数组时,NumPy 按元素比较它们的形状。它从拖尾尺寸开始,一路向前。在以下情况下,两个尺寸是兼容的:
- 他们是平等的,或者
- 其中一个是 1
这就是全部了。
让我们来看一个例子,我们想要减去数组中每个列平均值,元素方面:
>>> sample = np.random.normal(loc=[2., 20.], scale=[1., 3.5], ... size=(3, 2)) >>> sample array([[ 1.816 , 23.703 ], [ 2.8395, 12.2607], [ 3.5901, 24.2115]])在统计术语中,
sample由两个样本(列)组成,这两个样本分别从两个总体中独立抽取,均值分别为 2 和 20。列平均值应该接近总体平均值(尽管是粗略的,因为样本很小):
>>> mu = sample.mean(axis=0)
>>> mu
array([ 2.7486, 20.0584])
现在,减去列方式的平均值是简单的,因为广播规则检查:
>>> print('sample:', sample.shape, '| means:', mu.shape) sample: (3, 2) | means: (2,) >>> sample - mu array([[-0.9325, 3.6446], [ 0.091 , -7.7977], [ 0.8416, 4.1531]])这是一个减去列方式的示例,其中一个较小的数组被“拉伸”,以便从较大数组的每一行中减去它:
技术细节:较小的数组或标量在内存中不是字面意义上的拉伸:重复的是计算本身。
这扩展到标准化每一列,使每个单元格成为相对于其各自列的 z 分数:
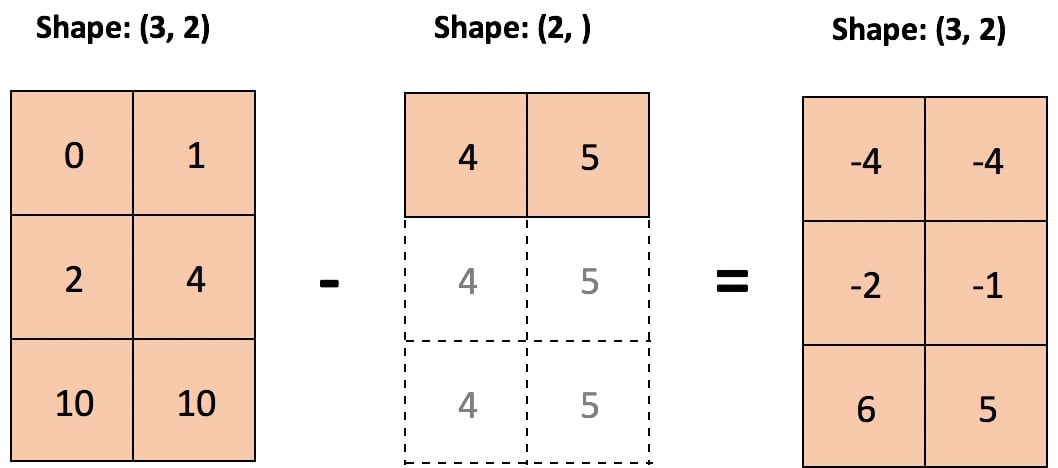
>>> (sample - sample.mean(axis=0)) / sample.std(axis=0)
array([[-1.2825, 0.6605],
[ 0.1251, -1.4132],
[ 1.1574, 0.7527]])
然而,如果出于某种原因,你想减去行方向的最小值呢?你会遇到一点麻烦:
>>> sample - sample.min(axis=1) ValueError: operands could not be broadcast together with shapes (3,2) (3,)这里的问题是,当前形式的较小数组不能被“拉伸”到与
sample形状兼容。您实际上需要扩展它的维度来满足上面的广播规则:
>>> sample.min(axis=1)[:, None] # 3 minimums across 3 rows
array([[1.816 ],
[2.8395],
[3.5901]])
>>> sample - sample.min(axis=1)[:, None]
array([[ 0\. , 21.887 ],
[ 0\. , 9.4212],
[ 0\. , 20.6214]])
注意 : [:, None]是一种扩展数组维数的方法,创建一个长度为 1 的轴。 np.newaxis 是None的别名。
还有一些明显更复杂的情况。这里有一个更严格的定义,说明何时可以一起广播任意数量的任意形状的数组:
如果以下规则产生有效结果,则一组数组被称为“可广播”到相同的 NumPy 形状,这意味着以下情况之一为真:
这些阵列都有完全相同的形状。
这些数组都有相同的维数,每个维的长度要么是相同的长度,要么是 1。
维度太少的数组可以在它们的 NumPy 形状前加上长度为 1 的维度,以满足属性#2。
[ 来源
这个比较容易一步一步走过去。假设您有以下四个数组:
>>> a = np.sin(np.arange(10)[:, None]) >>> b = np.random.randn(1, 10) >>> c = np.full_like(a, 10) >>> d = 8在检查形状之前,NumPy 首先用一个元素将标量转换为数组:
>>> arrays = [np.atleast_1d(arr) for arr in (a, b, c, d)]
>>> for arr in arrays:
... print(arr.shape)
...
(10, 1)
(1, 10)
(10, 1)
(1,)
现在我们可以检查标准#1。如果所有数组都具有相同的形状,那么它们的形状中的一个set将被压缩成一个元素,因为set()构造函数有效地从其输入中删除了重复的项目。这一标准显然没有达到:
>>> len(set(arr.shape for arr in arrays)) == 1 False标准#2 的第一部分也失败了,这意味着整个标准都失败了:
>>> len(set((arr.ndim) for arr in arrays)) == 1
False
最后一个标准有点复杂:
维度太少的数组可以在形状前添加长度为 1 的维度,以满足属性#2。
为此,您可以首先确定最高维数组的维数,然后在每个 NumPy shape元组前加上 1,直到所有数组的维数相等:
>>> maxdim = max(arr.ndim for arr in arrays) # Maximum dimensionality >>> shapes = np.array([(1,) * (maxdim - arr.ndim) + arr.shape ... for arr in arrays]) >>> shapes array([[10, 1], [ 1, 10], [10, 1], [ 1, 1]])最后,您需要测试每个维度的长度是一个公共长度还是 1 个 T2。这样做的技巧是首先在等于 1 的地方屏蔽 NumPy“形状元组”的数组。然后,您可以检查峰间(
np.ptp())列间差异是否都为零:
>>> masked = np.ma.masked_where(shapes == 1, shapes)
>>> np.all(masked.ptp(axis=0) == 0) # ptp: max - min
True
该逻辑封装在一个函数中,如下所示:
>>> def can_broadcast(*arrays) -> bool: ... arrays = [np.atleast_1d(arr) for arr in arrays] ... if len(set(arr.shape for arr in arrays)) == 1: ... return True ... if len(set((arr.ndim) for arr in arrays)) == 1: ... return True ... maxdim = max(arr.ndim for arr in arrays) ... shapes = np.array([(1,) * (maxdim - arr.ndim) + arr.shape ... for arr in arrays]) ... masked = np.ma.masked_where(shapes == 1, shapes) ... return np.all(masked.ptp(axis=0) == 0) ... >>> can_broadcast(a, b, c, d) True幸运的是,您可以采取一种快捷方式,使用
np.broadcast()进行这种健全性检查,尽管它并没有明确地为此目的而设计:
>>> def can_broadcast(*arrays) -> bool:
... try:
... np.broadcast(*arrays)
... return True
... except ValueError:
... return False
...
>>> can_broadcast(a, b, c, d)
True
对于那些有兴趣深入了解的人来说, PyArray_Broadcast 是封装广播规则的底层 C 函数。
数组编程实践:示例
在下面的 3 个例子中,您将把矢量化和广播应用到一些现实应用中。
聚类算法
机器学习是一个可以经常利用矢量化和广播的领域。假设您有一个三角形的顶点(每行是一个 x,y 坐标):
>>> tri = np.array([[1, 1], ... [3, 1], ... [2, 3]])这个“簇”的形心是一个 (x,y) 坐标,它是每一列的算术平均值:
>>> centroid = tri.mean(axis=0)
>>> centroid
array([2\. , 1.6667])
形象化这一点很有帮助:
>>> trishape = plt.Polygon(tri, edgecolor='r', alpha=0.2, lw=5) >>> _, ax = plt.subplots(figsize=(4, 4)) >>> ax.add_patch(trishape) >>> ax.set_ylim([.5, 3.5]) >>> ax.set_xlim([.5, 3.5]) >>> ax.scatter(*centroid, color='g', marker='D', s=70) >>> ax.scatter(*tri.T, color='b', s=70)
许多聚类算法利用了一系列点到原点或相对于质心的欧几里德距离。
在笛卡尔坐标中,点 p 和 q 之间的欧氏距离为:
[ 来源:维基百科
因此,对于上面的
tri中的坐标集,每个点到原点(0,0)的欧几里德距离为:


>>> np.sum(tri**2, axis=1) ** 0.5 # Or: np.sqrt(np.sum(np.square(tri), 1))
array([1.4142, 3.1623, 3.6056])
你可能认识到我们实际上只是在寻找欧几里得范数:
>>> np.linalg.norm(tri, axis=1) array([1.4142, 3.1623, 3.6056])除了参考原点,您还可以找到每个点相对于三角形质心的范数:
>>> np.linalg.norm(tri - centroid, axis=1)
array([1.2019, 1.2019, 1.3333])
最后,让我们更进一步:假设你有一个二维数组X和一个二维数组多个 (x,y) “建议的”质心。像 K-Means 聚类这样的算法是通过随机分配初始的“建议”质心,然后将每个数据点重新分配到其最近的质心来工作的。从那里,计算新的质心,一旦重新生成的标签(质心的编码)在迭代之间不变,算法就收敛于一个解。这个迭代过程的一部分需要计算每个点从每个质心到的欧几里德距离:
>>> X = np.repeat([[5, 5], [10, 10]], [5, 5], axis=0) >>> X = X + np.random.randn(*X.shape) # 2 distinct "blobs" >>> centroids = np.array([[5, 5], [10, 10]]) >>> X array([[ 3.3955, 3.682 ], [ 5.9224, 5.785 ], [ 5.9087, 4.5986], [ 6.5796, 3.8713], [ 3.8488, 6.7029], [10.1698, 9.2887], [10.1789, 9.8801], [ 7.8885, 8.7014], [ 8.6206, 8.2016], [ 8.851 , 10.0091]]) >>> centroids array([[ 5, 5], [10, 10]])换句话说,我们想回答这个问题,
X内的每个点属于的哪个质心?我们需要做一些整形来实现这里的广播,以便计算X中的每个点和centroids中的每个点之间的欧几里德距离:
>>> centroids[:, None]
array([[[ 5, 5]],
[[10, 10]]])
>>> centroids[:, None].shape
(2, 1, 2)
这使我们能够使用行的组合乘积从另一个数组中干净地减去一个数组:
>>> np.linalg.norm(X - centroids[:, None], axis=2).round(2) array([[2.08, 1.21, 0.99, 1.94, 2.06, 6.72, 7.12, 4.7 , 4.83, 6.32], [9.14, 5.86, 6.78, 7.02, 6.98, 0.73, 0.22, 2.48, 2.27, 1.15]])换句话说,
X - centroids[:, None]的 NumPy 形状是(2, 10, 2),本质上表示两个堆叠的数组,每个都是X的大小。接下来,我们想要每个最近质心的标签(索引号),从上面的数组中找到第 0 轴上的最小距离:
>>> np.argmin(np.linalg.norm(X - centroids[:, None], axis=2), axis=0)
array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
你可以用函数的形式把所有这些放在一起:
>>> def get_labels(X, centroids) -> np.ndarray: ... return np.argmin(np.linalg.norm(X - centroids[:, None], axis=2), ... axis=0) >>> labels = get_labels(X, centroids)让我们直观地检查一下,用颜色映射来绘制两个集群及其分配的标签:
>>> c1, c2 = ['#bc13fe', '#be0119'] # https://xkcd.com/color/rgb/
>>> llim, ulim = np.trunc([X.min() * 0.9, X.max() * 1.1])
>>> _, ax = plt.subplots(figsize=(5, 5))
>>> ax.scatter(*X.T, c=np.where(labels, c2, c1), alpha=0.4, s=80)
>>> ax.scatter(*centroids.T, c=[c1, c2], marker='s', s=95,
... edgecolor='yellow')
>>> ax.set_ylim([llim, ulim])
>>> ax.set_xlim([llim, ulim])
>>> ax.set_title('One K-Means Iteration: Predicted Classes')

摊销表
矢量化在金融领域也有应用。
给定年化利率、付款频率(每年的次数)、初始贷款余额和贷款期限,您可以以矢量化的方式创建一个包含每月贷款余额和付款的分期偿还表。让我们先设置一些标量常数:
>>> freq = 12 # 12 months per year >>> rate = .0675 # 6.75% annualized >>> nper = 30 # 30 years >>> pv = 200000 # Loan face value >>> rate /= freq # Monthly basis >>> nper *= freq # 360 monthsNumPy 预装了一些财务函数,与它们的 Excel 表兄弟不同,它们能够产生向量输出。
债务人(或承租人)每月支付由本金和利息组成的固定金额。随着未偿还贷款余额的下降,总付款的利息部分也随之下降。
>>> periods = np.arange(1, nper + 1, dtype=int)
>>> principal = np.ppmt(rate, periods, nper, pv)
>>> interest = np.ipmt(rate, periods, nper, pv)
>>> pmt = principal + interest # Or: pmt = np.pmt(rate, nper, pv)
接下来,您需要计算每月的余额,包括该月付款前后的余额,可以定义为原始余额的未来值减去年金的未来值(一系列付款),使用贴现因子 d :

从功能上看,这看起来像:
>>> def balance(pv, rate, nper, pmt) -> np.ndarray: ... d = (1 + rate) ** nper # Discount factor ... return pv * d - pmt * (d - 1) / rate最后,你可以用一个熊猫数据框架把它放到一个表格中。小心这里的标志。
PMT从债务人的角度来看是一种流出。
>>> import pandas as pd
>>> cols = ['beg_bal', 'prin', 'interest', 'end_bal']
>>> data = [balance(pv, rate, periods - 1, -pmt),
... principal,
... interest,
... balance(pv, rate, periods, -pmt)]
>>> table = pd.DataFrame(data, columns=periods, index=cols).T
>>> table.index.name = 'month'
>>> with pd.option_context('display.max_rows', 6):
... # Note: Using floats for $$ in production-level code = bad
... print(table.round(2))
...
beg_bal prin interest end_bal
month
1 200000.00 -172.20 -1125.00 199827.80
2 199827.80 -173.16 -1124.03 199654.64
3 199654.64 -174.14 -1123.06 199480.50
... ... ... ... ...
358 3848.22 -1275.55 -21.65 2572.67
359 2572.67 -1282.72 -14.47 1289.94
360 1289.94 -1289.94 -7.26 -0.00
在第 30 年末,贷款还清:
>>> final_month = periods[-1] >>> np.allclose(table.loc[final_month, 'end_bal'], 0) True注意:虽然在脚本环境中使用浮点数表示金钱对于概念说明是有用的,但是在生产环境中使用 Python 浮点数进行财务计算可能会导致您的计算在某些情况下少一两便士。
图像特征提取
最后一个例子,我们将使用美国列克星敦号航空母舰(CV-2)1941 年 10 月的图像,其残骸于 2018 年 3 月在澳大利亚海岸被发现。首先,我们可以将图像映射到其像素值的 NumPy 数组中:
>>> from skimage import io
>>> url = ('https://www.history.navy.mil/bin/imageDownload?image=/'
... 'content/dam/nhhc/our-collections/photograpimg/'
... '80-G-410000/80-G-416362&rendition=cq5dam.thumbnail.319.319.png')
>>> img = io.imread(url, as_grey=True)
>>> fig, ax = plt.subplots()
>>> ax.imshow(img, cmap='gray')
>>> ax.grid(False)

为简单起见,图像以灰度加载,产生 64 位浮点的 2d 阵列,而不是三维的 MxNx4 RGBA 阵列,较低的值表示较暗的点:
>>> img.shape (254, 319) >>> img.min(), img.max() (0.027450980392156862, 1.0) >>> img[0, :10] # First ten cells of the first row array([0.8078, 0.7961, 0.7804, 0.7882, 0.7961, 0.8078, 0.8039, 0.7922, 0.7961, 0.7961]) >>> img[-1, -10:] # Last ten cells of the last row array([0.0784, 0.0784, 0.0706, 0.0706, 0.0745, 0.0706, 0.0745, 0.0784, 0.0784, 0.0824])一种通常用作图像分析中间步骤的技术是小块提取。顾名思义,这包括从较大的阵列中提取较小的重叠子阵列,并且可以在有利于“去噪”或模糊图像的情况下使用。
这个概念也延伸到其他领域。例如,你可以做一些类似的事情,用多个特征(变量)来“滚动”一个时间序列的窗口。它甚至对构建康威的生活游戏很有用。(尽管,与 3x3 内核的卷积是一种更直接的方法。)
这里,我们将找到
img内每个重叠的 10x10 面片的平均值。举个小例子,img左上角的第一个 3x3 贴片阵列会是:
>>> img[:3, :3]
array([[0.8078, 0.7961, 0.7804],
[0.8039, 0.8157, 0.8078],
[0.7882, 0.8 , 0.7961]])
>>> img[:3, :3].mean()
0.7995642701525054
创建滑动补丁的纯 Python 方法涉及到嵌套的 for 循环。您需要考虑最右边的补丁的起始索引将在索引n - 3 + 1处,其中n是数组的宽度。换句话说,如果您从一个名为arr的 10x10 数组中提取 3x3 的补丁,那么最后一个补丁将来自arr[7:10, 7:10]。还要记住,Python 的 range() 不包括它的stop参数:
>>> size = 10 >>> m, n = img.shape >>> mm, nn = m - size + 1, n - size + 1
patch_means = np.empty((mm, nn))
for i in range(mm):
... for j in range(nn):
... patch_means[i, j] = img[i: i+size, j: j+size].mean()
fig, ax = plt.subplots()
ax.imshow(patch_means, cmap='gray')
ax.grid(False)
[](https://files.realpython.com/media/lexblur.0f886a01be97.png)
通过这个循环,您可以执行许多 Python 调用。
NumPy 的`stride_tricks`是一种可扩展到更大的 RGB 或 RGBA 图像的替代方案。
有指导意义的第一步是,在给定补丁大小和图像形状的情况下,想象一个更高维的补丁阵列会是什么样子。我们有一个形状为`(254, 319)`的二维数组`img`和一个`(10, 10)`二维面片。这意味着我们的输出形状(在取每个“内部” *10x10* 数组的平均值之前)将是:
>>>
```py
>>> shape = (img.shape[0] - size + 1, img.shape[1] - size + 1, size, size)
>>> shape
(245, 310, 10, 10)
您还需要指定新数组的步数。数组的步长是一个字节元组,当沿着数组移动时要在每个维度上跳跃。img中的每个像素是一个 64 位(8 字节)浮点数,这意味着图像的总大小是 254 x 319 x 8 = 648,208 字节。
>>> img.dtype dtype('float64') >>> img.nbytes 648208在内部,
img作为一个 648,208 字节的连续块保存在内存中。因此,strides是一种类似“元数据”的属性,它告诉我们需要向前跳转多少字节才能沿着每个轴移动到下一个位置。我们沿着行以 8 字节的块移动,但是需要遍历8 x 319 = 2552字节来从一行“向下”移动到另一行。
>>> img.strides
(2552, 8)
在我们的例子中,生成的面片的步幅将只重复两次img的步幅:
>>> strides = 2 * img.strides >>> strides (2552, 8, 2552, 8)现在,让我们把这些片段和 NumPy 的
stride_tricks放在一起:
>>> from numpy.lib import stride_tricks
>>> patches = stride_tricks.as_strided(img, shape=shape, strides=strides)
>>> patches.shape
(245, 310, 10, 10)
这里是第一个 10x10 补丁:
>>> patches[0, 0].round(2) array([[0.81, 0.8 , 0.78, 0.79, 0.8 , 0.81, 0.8 , 0.79, 0.8 , 0.8 ], [0.8 , 0.82, 0.81, 0.79, 0.79, 0.79, 0.78, 0.81, 0.81, 0.8 ], [0.79, 0.8 , 0.8 , 0.79, 0.8 , 0.8 , 0.82, 0.83, 0.79, 0.81], [0.8 , 0.79, 0.81, 0.81, 0.8 , 0.8 , 0.78, 0.76, 0.8 , 0.79], [0.78, 0.8 , 0.8 , 0.78, 0.8 , 0.79, 0.78, 0.78, 0.79, 0.79], [0.8 , 0.8 , 0.78, 0.78, 0.78, 0.8 , 0.8 , 0.8 , 0.81, 0.79], [0.78, 0.77, 0.78, 0.76, 0.77, 0.8 , 0.8 , 0.77, 0.8 , 0.8 ], [0.79, 0.76, 0.77, 0.78, 0.77, 0.77, 0.79, 0.78, 0.77, 0.76], [0.78, 0.75, 0.76, 0.76, 0.73, 0.75, 0.78, 0.76, 0.77, 0.77], [0.78, 0.79, 0.78, 0.78, 0.78, 0.78, 0.77, 0.76, 0.77, 0.77]])最后一步很棘手。为了获得每个内部 10x10 数组的矢量化平均值,我们需要仔细考虑我们现在拥有的维度。结果应该会折叠最后两个维度,这样我们就只剩下一个 245x310 数组。
一种(次优的)方法是首先对
patches进行整形,将内部 2d 数组展平为长度为 100 的向量,然后计算最终轴上的平均值:
>>> veclen = size ** 2
>>> patches.reshape(*patches.shape[:2], veclen).mean(axis=-1).shape
(245, 310)
但是,您也可以将axis指定为一个元组,计算最后两个轴的平均值,这应该比整形更有效:
>>> patches.mean(axis=(-1, -2)).shape (245, 310)让我们通过比较等式和循环版本来确保这一点。确实如此:
>>> strided_means = patches.mean(axis=(-1, -2))
>>> np.allclose(patch_means, strided_means)
True
如果大步的概念让你流口水,不要担心:Scikit-Learn 已经将整个过程很好地嵌入到它的feature_extraction模块中。
一个离别的想法:不要过度优化
在本文中,我们讨论了如何利用 NumPy 中的数组编程来优化运行时。当您处理大型数据集时,注意微性能非常重要。
然而,在某些情况下,避免原生 Python for-loop 是不可能的。正如 Donald Knuth 建议的那样,“过早优化是万恶之源。”程序员可能会错误地预测他们的代码中哪里会出现瓶颈,花费几个小时试图完全矢量化一个操作,这将导致运行时相对无足轻重的改进。
到处撒点 for-loops 没什么不好。通常,在更高的抽象层次上考虑优化整个脚本的流程和结构会更有成效。
更多资源
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
NumPy 文档:
书籍:
- 特拉维斯·奥列芬特的 NumPy 指南,第二版。 (Travis 是 NumPy 的主要创建者)
- Jake VanderPlas 的 Python 数据科学手册第 2 章(“NumPy 简介”)
- Wes McKinney 的 Python for Data Analysis 第二版第 4 章(“NumPy 基础”)和第 12 章(“高级 NumPy”)。
- 第 2 章(“神经网络的数学构建模块”),来自 Franç ois Chollet 的用 Python 进行深度学习
- 罗伯特·约翰逊的数值 Python
- 伊万·伊德里斯: Numpy 初学者指南,第 3 版。
其他资源:
- 维基百科:数组编程
- 科学讲义:基础和高级数字
- EricsBroadcastingDoc:NumPy 中的数组广播
- SciPy Cookbook: 视图与 NumPy 中的副本
- 尼古拉斯·罗杰尔:从 Python 到 Numpy 和 100 NumPy 练习
- 张量流文档:广播语义
- 第一个文件:广播
- 伊莱·本德斯基:在 Numpy 广播阵列******
NumPy、SciPy 和 Pandas:与 Python 的相关性
原文:https://realpython.com/numpy-scipy-pandas-correlation-python/
相关系数量化了变量或数据集特征之间的关联。这些统计数据对于科学和技术非常重要,Python 有很好的工具可以用来计算它们。SciPy 、NumPy 和 Pandas 关联方法快速、全面且有据可查。
在本教程中,您将学习:
- 什么是皮尔森、斯皮尔曼和肯德尔相关系数
- 如何使用 SciPy、NumPy 和 Pandas 相关函数
- 如何用 Matplotlib 可视化数据、回归线和相关矩阵
您将从解释相关性开始,然后查看三个快速介绍性示例,最后深入研究 NumPy、SciPy 和 Pandas 相关性的细节。
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
相关性
统计学和数据科学通常关注一个数据集的两个或多个变量(或特征)之间的关系。数据集中的每个数据点是一个观察,而特征是那些观察的属性或特性。
您使用的每个数据集都使用变量和观察值。例如,您可能有兴趣了解以下内容:
- 篮球运动员的身高如何与他们的投篮命中率相关联
- 员工的工作经历与工资是否有关系
- 不同国家的人口密度和国内生产总值之间存在什么数学相关性
在上面的例子中,身高、射击精度、经验年限、工资、人口密度和国内生产总值是特征或变量。与每个玩家、雇员和每个国家相关的数据是观察值。
当数据以表格的形式表示时,表格的行通常是观察值,而列是特征。看一下这个雇员表:
| 名字 | 多年的经验 | 年薪 |
|---|---|---|
| 安 | Thirty | One hundred and twenty thousand |
| 抢劫 | Twenty-one | One hundred and five thousand |
| 汤姆(男子名) | Nineteen | Ninety thousand |
| 常春藤 | Ten | Eighty-two thousand |
在该表中,每一行代表一个观察结果,或者关于一个雇员(Ann、Rob、Tom 或 Ivy)的数据。每列显示所有雇员的一个属性或特征(姓名、经历或薪水)。
如果你分析一个数据集的任意两个特征,那么你会发现这两个特征之间存在某种类型的相关性。请考虑以下数字:
这些图显示了三种不同形式的相关性之一:
-
负相关(红点):在左边的图中,y 值随着 x 值的增加而减少。这显示了强烈的负相关性,当一个特征的大值对应于另一个特征的小值时,就会出现这种负相关性,反之亦然。
-
相关性弱或无相关性(绿点):中间的图没有明显的趋势。这是弱相关性的一种形式,当两个特征之间的关联不明显或几乎不可见时,就会出现这种情况。
-
正相关(蓝点):在右边的图中,y 值随着 x 值的增加而增加。这说明了强正相关,当一个特征的大值对应于另一个特征的大值时,就会出现这种情况,反之亦然。
下图显示了上面的 employee 表中的数据:
经验和薪水之间的关系是正相关的,因为更高的经验对应着更高的薪水,反之亦然。
注意:当你分析相关性时,你应该始终记住相关性并不表示因果关系。它量化了数据集要素之间的关系强度。有时,这种关联是由几个感兴趣的特征的共同因素引起的。
相关性与均值、标准差、方差和协方差等其他统计量紧密相关。如果您想了解更多关于这些量以及如何使用 Python 计算它们的信息,请使用 Python 查看描述性统计。
有几个统计数据可以用来量化相关性。在本教程中,您将了解三个相关系数:
皮尔逊系数衡量线性相关性,而斯皮尔曼和肯德尔系数比较数据的 T2 等级。有几种 NumPy、SciPy 和 Pandas 相关函数和方法可用于计算这些系数。您也可以使用 Matplotlib 来方便地展示结果。
示例:NumPy 相关计算
NumPy 有很多统计例程,包括 np.corrcoef() ,返回皮尔逊相关系数矩阵。您可以从导入 NumPy 并定义两个 NumPy 数组开始。这些是类 ndarray 的实例。称他们为x和y:
>>> import numpy as np >>> x = np.arange(10, 20) >>> x array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19]) >>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> y array([ 2, 1, 4, 5, 8, 12, 18, 25, 96, 48])在这里,您使用
np.arange()创建一个数组x,其中包含 10(含)到 20(不含)之间的整数。然后使用np.array()创建包含任意整数的第二个数组y。一旦有了两个长度相同的数组,就可以调用
np.corrcoef()并将两个数组都作为参数:
>>> r = np.corrcoef(x, y)
>>> r
array([[1\. , 0.75864029],
[0.75864029, 1\. ]])
>>> r[0, 1]
0.7586402890911867
>>> r[1, 0]
0.7586402890911869
corrcoef()返回相关矩阵,这是一个包含相关系数的二维数组。这是您刚刚创建的关联矩阵的简化版本:
x y
x 1.00 0.76
y 0.76 1.00
相关矩阵主对角线上的值(左上和右下)等于 1。左上角的值对应于x和x的相关系数,而右下角的值是y和y的相关系数。它们总是等于 1。
但是,你通常需要的是相关矩阵的左下和右上的值。这些值相等,都代表x和y的皮尔逊相关系数。在这种情况下,它大约是 0.76。
该图显示了上述示例的数据点和相关系数:
红色方块是数据点。如您所见,该图还显示了三个相关系数的值。
示例:SciPy 相关性计算
SciPy 也有很多 scipy.stats 中包含的统计套路。您可以使用以下方法来计算前面看到的三个相关系数:
以下是如何在 Python 中使用这些函数:
>>> import numpy as np >>> import scipy.stats >>> x = np.arange(10, 20) >>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> scipy.stats.pearsonr(x, y) # Pearson's r (0.7586402890911869, 0.010964341301680832) >>> scipy.stats.spearmanr(x, y) # Spearman's rho SpearmanrResult(correlation=0.9757575757575757, pvalue=1.4675461874042197e-06) >>> scipy.stats.kendalltau(x, y) # Kendall's tau KendalltauResult(correlation=0.911111111111111, pvalue=2.9761904761904762e-05)请注意,这些函数返回包含两个值的对象:
- 相关系数
- p 值
当你测试一个假设时,你在统计方法中使用 p 值。p 值是一个重要的测量值,需要深入的概率和统计知识来解释。要了解更多,你可以阅读的基础知识,或者查看一位数据科学家对 p 值的解释。
您可以提取 p 值和相关系数及其索引,作为元组的项目:
>>> scipy.stats.pearsonr(x, y)[0] # Pearson's r
0.7586402890911869
>>> scipy.stats.spearmanr(x, y)[0] # Spearman's rho
0.9757575757575757
>>> scipy.stats.kendalltau(x, y)[0] # Kendall's tau
0.911111111111111
您也可以对 Spearman 和 Kendall 系数使用点符号:
>>> scipy.stats.spearmanr(x, y).correlation # Spearman's rho 0.9757575757575757 >>> scipy.stats.kendalltau(x, y).correlation # Kendall's tau 0.911111111111111点符号更长,但是可读性更强,也更容易理解。
如果想同时得到皮尔逊相关系数和 p 值,那么可以解包返回值:
>>> r, p = scipy.stats.pearsonr(x, y)
>>> r
0.7586402890911869
>>> p
0.010964341301680829
这种方法利用了 Python 解包和pearsonr()用这两个统计数据返回一个元组的事实。你也可以对spearmanr()和kendalltau()使用这种技术,稍后你会看到。
示例:熊猫相关性计算
熊猫在某些情况下比 NumPy 和 SciPy 更方便计算统计数据。提供了 Series 和 DataFrame 实例的统计方法。例如,给定两个具有相同项数的Series对象,您可以对其中一个调用 .corr() ,并将另一个作为第一个参数:
>>> import pandas as pd >>> x = pd.Series(range(10, 20)) >>> x 0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int64 >>> y = pd.Series([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> y 0 2 1 1 2 4 3 5 4 8 5 12 6 18 7 25 8 96 9 48 dtype: int64 >>> x.corr(y) # Pearson's r 0.7586402890911867 >>> y.corr(x) 0.7586402890911869 >>> x.corr(y, method='spearman') # Spearman's rho 0.9757575757575757 >>> x.corr(y, method='kendall') # Kendall's tau 0.911111111111111这里,您使用
.corr()来计算所有三个相关系数。您可以用参数method定义所需的统计数据,该参数可以取几个值中的一个:
'pearson''spearman''kendall'- 可赎回债券
可调用对象可以是任何函数、方法或带有
.__call__()的对象,它接受两个一维数组并返回一个浮点数。线性相关性
线性相关性测量变量或数据集特征与线性函数之间的数学关系的接近程度。如果两个特征之间的关系更接近某个线性函数,那么它们的线性相关性更强,相关系数的绝对值更高。
皮尔逊相关系数
考虑一个具有两个特征的数据集: x 和 y 。每个特征有 n 个值,所以 x 和 y 是 n 元组。假设来自 x 的第一个值 x₁对应于来自 y 的第一个值 y₁,来自 x 的第二个值 x₂对应于来自 y 的第二个值 y₂,以此类推。然后,有 n 对对应的值:(x₁,y₁),(x₂,y₂),等等。这些 x-y 对中的每一对代表一个单独的观察。
皮尔逊(乘积矩)相关系数是两个特征之间线性关系的度量。它是 x 和 y 的协方差与它们标准差的乘积之比。它通常用字母 r 表示,并被称为皮尔逊 r 。您可以用下面的等式用数学方法表示该值:
r =σᵢ((xᵢmean(x))(yᵢ均值(y)))(√σᵢ(xᵢ均值(x))√σᵢ(yᵢ均值(y)) )⁻
这里,I 取值 1,2,…,n。x和 y 的平均值用 mean(x)和 mean(y)表示。该公式表明,如果较大的 x 值倾向于对应于较大的 y 值,反之亦然,则 r 为正。另一方面,如果较大的 x 值通常与较小的 y 值相关联,反之亦然,则 r 为负。
以下是关于皮尔逊相关系数的一些重要事实:
皮尔逊相关系数可以是 1 ≤ r ≤ 1 范围内的任何实数值。
最大值 r = 1 对应于 x 和 y 之间存在完美的正线性关系的情况。换句话说,较大的 x 值对应于较大的 y 值,反之亦然。
值 r > 0 表示 x 和 y 之间正相关。
值 r = 0 对应于 x 和 y 之间没有线性关系的情况。
值 r < 0 indicates negative correlation between x 和 y 。
最小值 r = 1 对应于 x 和 y 之间存在完美的负线性关系的情况。换句话说,较大的 x 值对应于较小的 y 值,反之亦然。
上述事实可以归纳在下表中:
皮尔逊 r 值 x 和 y 之间的相关性 等于 1 完美正线性关系 大于 0 正相关 等于 0 没有线性关系 小于 0 负相关 等于-1 完美负线性关系 简而言之,r 的绝对值越大,相关性越强,越接近线性函数。r 的绝对值越小,表示相关性越弱。
线性回归:SciPy 实现
线性回归是寻找尽可能接近特征间实际关系的线性函数的过程。换句话说,您确定了最能描述特征之间关联的线性函数。这个线性函数也被称为回归线。
可以用 SciPy 实现线性回归。您将获得最接近两个数组之间关系的线性函数,以及皮尔逊相关系数。首先,您需要导入库并准备一些要使用的数据:
>>> import numpy as np
>>> import scipy.stats
>>> x = np.arange(10, 20)
>>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48])
在这里,您导入numpy和scipy.stats并定义变量x和y。
可以使用 scipy.stats.linregress() 对两个长度相同的数组进行线性回归。您应该将数组作为参数提供,并使用点标记法获得输出:
>>> result = scipy.stats.linregress(x, y) >>> result.slope 7.4363636363636365 >>> result.intercept -85.92727272727274 >>> result.rvalue 0.7586402890911869 >>> result.pvalue 0.010964341301680825 >>> result.stderr 2.257878767543913就是这样!您已经完成了线性回归,并获得了以下结果:
.slope: 回归线的斜率.intercept: 回归线的截距.pvalue:p 值.stderr: 估计梯度的标准误差您将在后面的小节中学习如何可视化这些结果。
您也可以向
linregress()提供单个参数,但它必须是一个二维数组,其中一个维度的长度为 2:
>>> xy = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48]])
>>> scipy.stats.linregress(xy)
LinregressResult(slope=7.4363636363636365, intercept=-85.92727272727274, rvalue=0.7586402890911869, pvalue=0.010964341301680825, stderr=2.257878767543913)
结果与前面的例子完全相同,因为xy包含的数据与x和y包含的数据相同。linregress()将xy的第一行作为一个特征,第二行作为另一个特征。
注意:在上面的例子中,scipy.stats.linregress()认为行是特征,列是观察值。那是因为有两排。
在机器学习中通常的做法是相反的:行是观察,列是特征。许多机器学习库,如熊猫、 Scikit-Learn 、 Keras 等,都遵循这一惯例。
在分析数据集中的相关性时,您应该注意观察值和要素是如何表示的。
如果您提供xy的转置,或者一个 10 行 2 列的 NumPy 数组,linregress()将返回相同的结果。在 NumPy 中,您可以通过多种方式转置矩阵:
你可以这样移调xy:
>>> xy.T array([[10, 2], [11, 1], [12, 4], [13, 5], [14, 8], [15, 12], [16, 18], [17, 25], [18, 96], [19, 48]])现在你知道如何得到转置,你可以传递一个给
linregress()。第一列是一个特征,第二列是另一个特征:
>>> scipy.stats.linregress(xy.T)
LinregressResult(slope=7.4363636363636365, intercept=-85.92727272727274, rvalue=0.7586402890911869, pvalue=0.010964341301680825, stderr=2.257878767543913)
这里用.T得到xy的转置。linregress()的工作方式与xy及其转置相同。它通过沿着长度为 2 的维度分割数组来提取特征。
您还应该注意数据集是否包含缺失值。在数据科学和机器学习中,您经常会发现一些丢失或损坏的数据。在 Python、NumPy、SciPy 和 Pandas 中表示它的通常方式是使用 NaN 或而不是数字值。但是如果您的数据包含nan值,那么您将无法使用linregress()得到有用的结果:
>>> scipy.stats.linregress(np.arange(3), np.array([2, np.nan, 5])) LinregressResult(slope=nan, intercept=nan, rvalue=nan, pvalue=nan, stderr=nan)在这种情况下,结果对象返回所有的
nan值。在 Python 中,nan是一个特殊的浮点值,可以通过使用以下任意一种方法获得:你也可以用
math.isnan()或者numpy.isnan()来检查一个变量是否对应nan。皮尔逊相关性:NumPy 和 SciPy 实现
你已经看到了如何用
corrcoef()和pearsonr()得到皮尔逊相关系数:
>>> r, p = scipy.stats.pearsonr(x, y)
>>> r
0.7586402890911869
>>> p
0.010964341301680829
>>> np.corrcoef(x, y)
array([[1\. , 0.75864029],
[0.75864029, 1\. ]])
注意,如果你给pearsonr()提供一个带有nan值的数组,你将得到一个 ValueError 。
很少有额外的细节值得考虑。首先,回想一下np.corrcoef()可以接受两个 NumPy 数组作为参数。相反,您可以传递一个具有与参数相同值的二维数组:
>>> np.corrcoef(xy) array([[1\. , 0.75864029], [0.75864029, 1\. ]])这个例子和前面的例子的结果是一样的。同样,
xy的第一行代表一个特性,而第二行代表另一个特性。如果您想要获得三个特征的相关系数,那么您只需提供一个带有三行作为参数的数值二维数组:
>>> xyz = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48],
... [5, 3, 2, 1, 0, -2, -8, -11, -15, -16]])
>>> np.corrcoef(xyz)
array([[ 1\. , 0.75864029, -0.96807242],
[ 0.75864029, 1\. , -0.83407922],
[-0.96807242, -0.83407922, 1\. ]])
您将再次获得相关矩阵,但这个矩阵将比前几个大:
x y z
x 1.00 0.76 -0.97
y 0.76 1.00 -0.83
z -0.97 -0.83 1.00
这是因为corrcoef()将xyz的每一行视为一个特征。值0.76是xyz的前两个特征的相关系数。这与前面例子中的x和y的系数相同。-0.97表示第一个和第三个特征的皮尔逊 r,而-0.83是后两个特征的皮尔逊 r。
下面是一个有趣的例子,说明当您将nan数据传递给corrcoef()时会发生什么:
>>> arr_with_nan = np.array([[0, 1, 2, 3], ... [2, 4, 1, 8], ... [2, 5, np.nan, 2]]) >>> np.corrcoef(arr_with_nan) array([[1\. , 0.62554324, nan], [0.62554324, 1\. , nan], [ nan, nan, nan]])在这个例子中,
arr_with_nan的前两行(或特征)是可以的,但是第三行[2, 5, np.nan, 2]包含一个nan值。不包括带nan的特性的都算好了。然而,取决于最后一行的结果是nan。默认情况下,
numpy.corrcoef()将行视为特征,将列视为观察值。如果您想要相反的行为,这在机器学习中广泛使用,那么使用参数rowvar=False:
>>> xyz.T
array([[ 10, 2, 5],
[ 11, 1, 3],
[ 12, 4, 2],
[ 13, 5, 1],
[ 14, 8, 0],
[ 15, 12, -2],
[ 16, 18, -8],
[ 17, 25, -11],
[ 18, 96, -15],
[ 19, 48, -16]])
>>> np.corrcoef(xyz.T, rowvar=False)
array([[ 1\. , 0.75864029, -0.96807242],
[ 0.75864029, 1\. , -0.83407922],
[-0.96807242, -0.83407922, 1\. ]])
该数组与您之前看到的数组相同。这里,您应用了不同的约定,但是结果是相同的。
皮尔逊相关性:熊猫实施
到目前为止,您已经使用了Series和DataFrame对象方法来计算相关系数。让我们更详细地探讨这些方法。首先,您需要导入熊猫并创建一些Series和DataFrame的实例:
>>> import pandas as pd >>> x = pd.Series(range(10, 20)) >>> x 0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 dtype: int64 >>> y = pd.Series([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> y 0 2 1 1 2 4 3 5 4 8 5 12 6 18 7 25 8 96 9 48 dtype: int64 >>> z = pd.Series([5, 3, 2, 1, 0, -2, -8, -11, -15, -16]) >>> z 0 5 1 3 2 2 3 1 4 0 5 -2 6 -8 7 -11 8 -15 9 -16 dtype: int64 >>> xy = pd.DataFrame({'x-values': x, 'y-values': y}) >>> xy x-values y-values 0 10 2 1 11 1 2 12 4 3 13 5 4 14 8 5 15 12 6 16 18 7 17 25 8 18 96 9 19 48 >>> xyz = pd.DataFrame({'x-values': x, 'y-values': y, 'z-values': z}) >>> xyz x-values y-values z-values 0 10 2 5 1 11 1 3 2 12 4 2 3 13 5 1 4 14 8 0 5 15 12 -2 6 16 18 -8 7 17 25 -11 8 18 96 -15 9 19 48 -16您现在有三个名为
x、y和z的Series对象。你也有两个DataFrame对象,xy和xyz。注意:当您使用
DataFrame实例时,您应该知道行是观察值,列是特征。这与机器学习中的惯例是一致的。您已经学习了如何使用
.corr()和Series对象来获得皮尔逊相关系数:
>>> x.corr(y)
0.7586402890911867
这里,您对一个对象调用.corr(),并将另一个作为第一个参数传递。
如果您提供一个nan值,那么.corr()将仍然工作,但是它将排除包含nan值的观察值:
>>> u, u_with_nan = pd.Series([1, 2, 3]), pd.Series([1, 2, np.nan, 3]) >>> v, w = pd.Series([1, 4, 8]), pd.Series([1, 4, 154, 8]) >>> u.corr(v) 0.9966158955401239 >>> u_with_nan.corr(w) 0.9966158955401239在这两个例子中,你会得到相同的相关系数。这是因为
.corr()忽略了一对缺少值的值(np.nan,154)。也可以将
.corr()与DataFrame对象搭配使用。您可以使用它来获得它们的列的相关矩阵:
>>> corr_matrix = xy.corr()
>>> corr_matrix
x-values y-values
x-values 1.00000 0.75864
y-values 0.75864 1.00000
得到的相关矩阵是DataFrame的一个新实例,保存了列xy['x-values']和xy['y-values']的相关系数。这种带标签的结果通常非常便于使用,因为您可以使用它们的标签或整数位置索引来访问它们:
>>> corr_matrix.at['x-values', 'y-values'] 0.7586402890911869 >>> corr_matrix.iat[0, 1] 0.7586402890911869此示例显示了访问值的两种方式:
对于包含三列或更多列的
DataFrame对象,您可以以同样的方式应用.corr():
>>> xyz.corr()
x-values y-values z-values
x-values 1.000000 0.758640 -0.968072
y-values 0.758640 1.000000 -0.834079
z-values -0.968072 -0.834079 1.000000
您将获得具有以下相关系数的相关矩阵:
0.758640为x-values和y-values-0.968072为x-values和z-values-0.834079为y-values和z-values
另一个有用的方法是 .corrwith() ,它允许您计算一个 DataFrame 对象的行或列与作为第一个参数传递的另一个系列或 DataFrame 对象之间的相关系数:
>>> xy.corrwith(z) x-values -0.968072 y-values -0.834079 dtype: float64在这种情况下,结果是一个新的
Series对象,它具有列xy['x-values']的相关系数和z的值,以及xy['y-values']和z的系数。
.corrwith()有一个可选参数axis,用于指定是用列还是行来表示特征。axis的默认值为 0,也默认为表示特征的列。还有一个drop参数,它指示如何处理丢失的值。
.corr()和.corrwith()都有可选参数method来指定想要计算的相关系数。默认情况下会返回皮尔逊相关系数,因此在这种情况下不需要提供它。等级相关性
等级相关性比较与两个变量或数据集特征相关的数据的等级或排序。如果排序相似,那么相关性是强的、正的和高的。然而,如果顺序接近颠倒,那么相关性是强的、负的和低的。换句话说,等级相关性只与值的顺序有关,而与数据集中的特定值无关。
为了说明线性相关和等级相关之间的区别,请考虑下图:
左图在 x 和 y 之间有一个完美的正线性关系,所以 r = 1。中间的图显示正相关,右边的图显示负相关。然而,它们都不是线性函数,因此 r 不同于 1 或 1。
当你只看等级的时候,这三种关系都是完美的!左侧和中间的图显示了较大的 x 值总是对应于较大的 y 值的观察结果。这是完美的正等级相关。右边的图说明了相反的情况,这是完美的负秩相关。
斯皮尔曼相关系数
两个特征之间的 Spearman 相关系数是它们等级值之间的 Pearson 相关系数。它的计算方式与皮尔逊相关系数相同,但考虑了他们的排名而不是他们的价值。它通常用希腊字母 rho (ρ)表示,并被称为斯皮尔曼的 rho 。
假设您有两个 n 元组, x 和 y ,其中
(x₁, y₁), (x₂, y₂), …是作为对应值对的观察值。可以用与皮尔逊系数相同的方法计算斯皮尔曼相关系数ρ。您将使用等级而不是来自 x 和 y 的实际值。以下是关于斯皮尔曼相关系数的一些重要事实:
它可以取 1 ≤ ρ ≤ 1 范围内的实值。
其最大值ρ = 1 对应于在 x 和 y 之间存在一个单调递增函数的情况。换句话说,较大的 x 值对应于较大的 y 值,反之亦然。
其最小值ρ= 1 对应于 x 和 y 之间存在单调递减函数的情况。换句话说,较大的 x 值对应于较小的 y 值,反之亦然。
您可以用 Python 计算 Spearman 的 rho,方法与计算 Pearson 的 r 非常相似。
肯德尔相关系数
让我们从考虑两个 n 元组开始, x 和 y 。每个 x-y 对
(x₁, y₁), (x₂, y₂), …都是一个单独的观察值。一对观测值(xᵢ,yᵢ)和(xⱼ,yⱼ),其中 i < j,将是三件事之一:
- 如果(xᵢ > xⱼ和 yᵢ > yⱼ)或(xᵢ < xⱼ和 yᵢ < yⱼ)中的任何一个
- 不和谐如果是(xᵢ < xⱼ和 yᵢ > yⱼ)或者(xᵢ > xⱼ和 yᵢ < yⱼ)
- 如果在 x (xᵢ = xⱼ)或 y (yᵢ = yⱼ)出现平局,则不会出现
肯德尔相关系数比较一致和不一致数据对的数量。该系数基于相对于 x-y 对数量的一致和不一致对的计数差异。它通常用希腊字母 tau (τ)表示,并被称为肯德尔的 tau 。
根据
scipy.stats官方文件,肯德尔相关系数计算为τ=(n⁺-n⁻)/√((n⁺+n⁻+nˣ)(n⁺+n⁻+nʸ),其中:
- n⁺是和谐对的数量
- n⁻是不和谐对的数量
- nˣ是仅在 x 中的联系数
- nʸ是仅在 y 的联系数
如果在 x 和 y 都出现平局,那么它不包括在 nˣ或 nʸ.
关于肯德尔秩相关系数的维基百科页面给出了如下表达式:τ=(2/(n(n1)))σᵢⱼ(sign(xᵢxⱼ)sign(yᵢyⱼ)对于 i < j,其中 i = 1,2,…,n1,j = 2,3,…,n,符号函数 sign(z)如果 z < 0 则为 1,如果 z = 0 则为 0,如果 z > 0 则为 1。n(n1)/2 是 x-y 对的总数。
关于肯德尔相关系数的一些重要事实如下:
它可以取 1 ≤ τ ≤ 1 范围内的实值。
其最大值τ = 1 对应于 x 和 y 中对应值的秩相同的情况。换句话说,所有的配对都是一致的。
其最小值τ= 1 对应于 x 中的等级与 y 中的等级相反的情况。换句话说,所有对都是不和谐的。
可以用 Python 计算 Kendall 的 tau,类似于计算 Pearson 的 r。
等级:SciPy 实现
您可以使用
scipy.stats来确定数组中每个值的等级。首先,您将导入库并创建 NumPy 数组:
>>> import numpy as np
>>> import scipy.stats
>>> x = np.arange(10, 20)
>>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48])
>>> z = np.array([5, 3, 2, 1, 0, -2, -8, -11, -15, -16])
现在您已经准备好了数据,您可以使用 scipy.stats.rankdata() 来确定 NumPy 数组中每个值的排名:
>>> scipy.stats.rankdata(x) array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]) >>> scipy.stats.rankdata(y) array([ 2., 1., 3., 4., 5., 6., 7., 8., 10., 9.]) >>> scipy.stats.rankdata(z) array([10., 9., 8., 7., 6., 5., 4., 3., 2., 1.])数组
x和z是单调的,因此它们的秩也是单调的。y中的最小值是1,对应的是等级1。第二小的是2,对应的是排名2。最大的值是96,它对应于最大的等级10,因为数组中有 10 个项目。
rankdata()有可选参数method。这告诉 Python 如果数组中有平局该怎么办(如果两个或更多值相等)。默认情况下,它会为他们分配平均等级:
>>> scipy.stats.rankdata([8, 2, 0, 2])
array([4\. , 2.5, 1\. , 2.5])
有两个值为2的元素,它们的等级为2.0和3.0。值0的等级为1.0,值8的等级为4.0。然后,值为2的两个元素将获得相同的等级2.5。
rankdata()视nan值为大值:
>>> scipy.stats.rankdata([8, np.nan, 0, 2]) array([3., 4., 1., 2.])在这种情况下,值
np.nan对应于最大等级4.0。你也可以用np.argsort()获得军衔:
>>> np.argsort(y) + 1
array([ 2, 1, 3, 4, 5, 6, 7, 8, 10, 9])
argsort()返回数组项在排序数组中的索引。这些索引是从零开始的,所以你需要给它们都加上1。
等级关联:NumPy 和 SciPy 实现
可以用scipy.stats.spearmanr()计算斯皮尔曼相关系数:
>>> result = scipy.stats.spearmanr(x, y) >>> result SpearmanrResult(correlation=0.9757575757575757, pvalue=1.4675461874042197e-06) >>> result.correlation 0.9757575757575757 >>> result.pvalue 1.4675461874042197e-06 >>> rho, p = scipy.stats.spearmanr(x, y) >>> rho 0.9757575757575757 >>> p 1.4675461874042197e-06
spearmanr()返回一个包含 Spearman 相关系数和 p 值的对象。如您所见,您可以通过两种方式访问特定值:
- 使用点符号(
result.correlation和result.pvalue)- 使用 Python 解包(
rho, p = scipy.stats.spearmanr(x, y))如果提供包含与
x和y到spearmanr()相同数据的二维数组xy,也可以得到相同的结果:
>>> xy = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48]])
>>> rho, p = scipy.stats.spearmanr(xy, axis=1)
>>> rho
0.9757575757575757
>>> p
1.4675461874042197e-06
xy第一行是一个特征,第二行是另一个特征。您可以对此进行修改。可选参数axis决定是列(axis=0)还是行(axis=1)表示特征。默认行为是行是观测值,列是要素。
另一个可选参数nan_policy定义了如何处理nan值。它可以取三个值之一:
- 如果输入中有一个
nan值,则'propagate'返回nan。这是默认行为。 - 如果输入中有一个
nan值,则'raise'会产生一个ValueError。 'omit'忽略带有nan值的观测值。
如果您提供一个包含两个以上要素的二维数组,那么您将获得相关矩阵和 p 值矩阵:
>>> xyz = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], ... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48], ... [5, 3, 2, 1, 0, -2, -8, -11, -15, -16]]) >>> corr_matrix, p_matrix = scipy.stats.spearmanr(xyz, axis=1) >>> corr_matrix array([[ 1\. , 0.97575758, -1\. ], [ 0.97575758, 1\. , -0.97575758], [-1\. , -0.97575758, 1\. ]]) >>> p_matrix array([[6.64689742e-64, 1.46754619e-06, 6.64689742e-64], [1.46754619e-06, 6.64689742e-64, 1.46754619e-06], [6.64689742e-64, 1.46754619e-06, 6.64689742e-64]])相关矩阵中的值
-1示出了第一和第三特征具有完美的负秩相关,即第一行中的较大值总是对应于第三行中的较小值。你可以用
kendalltau()得到肯德尔相关系数:
>>> result = scipy.stats.kendalltau(x, y)
>>> result
KendalltauResult(correlation=0.911111111111111, pvalue=2.9761904761904762e-05)
>>> result.correlation
0.911111111111111
>>> result.pvalue
2.9761904761904762e-05
>>> tau, p = scipy.stats.kendalltau(x, y)
>>> tau
0.911111111111111
>>> p
2.9761904761904762e-05
kendalltau()的工作方式很像spearmanr()。它接受两个一维数组,有可选参数nan_policy,并返回一个包含相关系数和 p 值的对象。
但是,如果你只提供一个二维数组作为参数,那么kendalltau()将会引发一个 TypeError 。如果你传递两个相同形状的多维数组,那么它们会在计算前被展平。
等级关联:熊猫实现
你可以用熊猫来计算斯皮尔曼和肯德尔相关系数。就像之前一样,首先导入pandas并创建一些Series和DataFrame实例:
>>> import pandas as pd >>> x, y, z = pd.Series(x), pd.Series(y), pd.Series(z) >>> xy = pd.DataFrame({'x-values': x, 'y-values': y}) >>> xyz = pd.DataFrame({'x-values': x, 'y-values': y, 'z-values': z})现在您有了这些熊猫对象,您可以使用
.corr()和.corrwith(),就像您在计算皮尔逊相关系数时所做的那样。你只需要用可选参数method指定想要的相关系数,默认为'pearson'。要计算 Spearman 的 rho,请通过
method=spearman:
>>> x.corr(y, method='spearman')
0.9757575757575757
>>> xy.corr(method='spearman')
x-values y-values
x-values 1.000000 0.975758
y-values 0.975758 1.000000
>>> xyz.corr(method='spearman')
x-values y-values z-values
x-values 1.000000 0.975758 -1.000000
y-values 0.975758 1.000000 -0.975758
z-values -1.000000 -0.975758 1.000000
>>> xy.corrwith(z, method='spearman')
x-values -1.000000
y-values -0.975758
dtype: float64
如果你想要肯德尔的τ,那么你用method=kendall:
>>> x.corr(y, method='kendall') 0.911111111111111 >>> xy.corr(method='kendall') x-values y-values x-values 1.000000 0.911111 y-values 0.911111 1.000000 >>> xyz.corr(method='kendall') x-values y-values z-values x-values 1.000000 0.911111 -1.000000 y-values 0.911111 1.000000 -0.911111 z-values -1.000000 -0.911111 1.000000 >>> xy.corrwith(z, method='kendall') x-values -1.000000 y-values -0.911111 dtype: float64如您所见,与 SciPy 不同,您可以使用单一的二维数据结构(dataframe)。
相关性的可视化
数据可视化在统计学和数据科学中非常重要。它可以帮助您更好地理解数据,并让您更好地了解要素之间的关系。在本节中,您将学习如何用 x-y 图直观地表示两个要素之间的关系。您还将使用热图来可视化关联矩阵。
您将学习如何准备数据和获得某些可视化表示,但不会涉及许多其他解释。要深入了解 Matplotlib,请查看 Python 使用 Matplotlib 绘图(指南)。还可以看看官方文档和解剖 Matplotlib 。
要开始,首先导入
matplotlib.pyplot:
>>> import matplotlib.pyplot as plt
>>> plt.style.use('ggplot')
这里,您使用plt.style.use('ggplot')来设置图形的样式。如果你愿意,可以跳过这一行。
您将使用前面章节中的数组x、y、z和xyz。您可以再次创建它们以减少滚动次数:
>>> import numpy as np >>> import scipy.stats >>> x = np.arange(10, 20) >>> y = np.array([2, 1, 4, 5, 8, 12, 18, 25, 96, 48]) >>> z = np.array([5, 3, 2, 1, 0, -2, -8, -11, -15, -16]) >>> xyz = np.array([[10, 11, 12, 13, 14, 15, 16, 17, 18, 19], ... [2, 1, 4, 5, 8, 12, 18, 25, 96, 48], ... [5, 3, 2, 1, 0, -2, -8, -11, -15, -16]])现在你已经得到了数据,你可以开始绘图了。
带回归线的 X-Y 图
首先,您将看到如何使用回归线、其方程和皮尔逊相关系数创建 x-y 图。用
linregress()可以得到回归线的斜率和截距,以及相关系数:
>>> slope, intercept, r, p, stderr = scipy.stats.linregress(x, y)
现在你有了你需要的所有值。也可以用回归线的方程和相关系数的值得到字符串。为此,f 弦非常方便:
>>> line = f'Regression line: y={intercept:.2f}+{slope:.2f}x, r={r:.2f}' >>> line 'Regression line: y=-85.93+7.44x, r=0.76'现在,用
.plot()创建 x-y 图:fig, ax = plt.subplots() ax.plot(x, y, linewidth=0, marker='s', label='Data points') ax.plot(x, intercept + slope * x, label=line) ax.set_xlabel('x') ax.set_ylabel('y') ax.legend(facecolor='white') plt.show()您的输出应该如下所示:
红色方块代表观察值,而蓝色线是回归线。图例中列出了它的方程以及相关系数。
相关矩阵的热图
当你有很多特征时,相关矩阵会变得很大很混乱!幸运的是,您可以将它直观地呈现为热图,其中每个字段都有与其值对应的颜色。你需要相关矩阵:
>>> corr_matrix = np.corrcoef(xyz).round(decimals=2)
>>> corr_matrix
array([[ 1\. , 0.76, -0.97],
[ 0.76, 1\. , -0.83],
[-0.97, -0.83, 1\. ]])
用 .round() 对相关矩阵中的数字取整会很方便,因为它们将显示在热图上。
最后,使用 .imshow() 和相关矩阵作为参数创建您的热图:
fig, ax = plt.subplots()
im = ax.imshow(corr_matrix)
im.set_clim(-1, 1)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1, 2), ticklabels=('x', 'y', 'z'))
ax.yaxis.set(ticks=(0, 1, 2), ticklabels=('x', 'y', 'z'))
ax.set_ylim(2.5, -0.5)
for i in range(3):
for j in range(3):
ax.text(j, i, corr_matrix[i, j], ha='center', va='center',
color='r')
cbar = ax.figure.colorbar(im, ax=ax, format='% .2f')
plt.show()
您的输出应该如下所示:
结果是一个带有系数的表格。这看起来有点像熊猫输出彩色背景。颜色有助于您理解输出。在本例中,黄色代表数字 1,绿色对应 0.76,紫色代表负数。
结论
您现在知道了相关系数是测量变量或数据集特征之间关联的统计数据。它们在数据科学和机器学习中非常重要。
现在,您可以使用 Python 来计算:
- 皮尔逊积差相关系数
- 斯皮尔曼的等级相关系数
- 肯德尔的等级相关系数
现在,您可以使用 NumPy、SciPy 和 Pandas 相关函数和方法来有效地计算这些(和其他)统计数据,即使在处理大型数据集时也是如此。您还知道如何使用 Matplotlib 图和热图来可视化数据、回归线和相关矩阵。
如果您有任何问题或意见,请在下面的评论区提出!*******
纯 Python 与 NumPy 和 TensorFlow 的性能比较
Python 有一种设计哲学,强调允许程序员用更少的代码行易读地表达概念。这种理念使得该语言适合于多种多样的用例:简单的 web 脚本,大型 web 应用程序(如 YouTube),其他平台的脚本语言(如 Blender 和 Autodesk 的 Maya),以及几个领域的科学应用程序,如天文学、气象学、物理学和数据科学。
使用 Python 列表实现标量和矩阵计算在技术上是可能的。然而,这可能很笨拙,与适合数值计算的语言相比,性能很差,如 MATLAB 或 Fortran,甚至一些通用语言,如 C 或 C++ 。
为了避免这一缺陷,出现了几个库,它们在保持 Python 易用性的同时,还能以高效的方式执行数值计算。值得一提的两个这样的库是 NumPy (为 Python 带来高效数值计算的先驱库之一)和 TensorFlow (最近推出的一个更专注于深度学习算法的库)。
- NumPy 提供了对大型多维数组和矩阵的支持,以及对这些元素进行操作的数学函数集合。该项目依赖于以其他语言(如 Fortran)实现的众所周知的包来执行高效的计算,为用户带来 Python 的表现力和类似于 MATLAB 或 Fortran 的性能。
- TensorFlow 是一个用于数值计算的开源库,最初由谷歌大脑团队的研究人员和工程师开发。该库的主要重点是提供一个易于使用的 API 来实现实用的机器学习算法,并将其部署为在 CPU、GPU 或集群上运行。
但是这些方案如何比较呢?用 NumPy 而不是纯 Python 实现时,应用程序的运行速度会快多少?TensorFlow 呢?本文的目的是开始探索通过使用这些库可以实现的改进。
为了比较这三种方法的性能,您将使用原生 Python、NumPy 和 TensorFlow 构建一个基本的回归。
获得通知:不要错过本教程的后续— 点击这里加入真正的 Python 时事通讯你会知道下一期什么时候出来。
工程测试数据
为了测试库的性能,您将考虑一个简单的双参数线性回归问题。该模型有两个参数:截距项w_0和单个系数w_1。
给定 N 对输入x和期望输出d,想法是使用线性模型y = w_0 + w_1 * x对输出和输入之间的关系建模,其中模型y的输出大约等于每对(x, d)的期望输出d。
技术细节:截距项w_0,技术上只是一个类似w_1的系数,但可以解释为一个系数乘以一个 1 的向量的元素。
要生成问题的训练集,请使用以下程序:
import numpy as np
np.random.seed(444)
N = 10000
sigma = 0.1
noise = sigma * np.random.randn(N)
x = np.linspace(0, 2, N)
d = 3 + 2 * x + noise
d.shape = (N, 1)
# We need to prepend a column vector of 1s to `x`.
X = np.column_stack((np.ones(N, dtype=x.dtype), x))
print(X.shape)
(10000, 2)
该程序创建了一组 10,000 个输入x,线性分布在从 0 到 2 的区间内。然后它创建一组期望的输出d = 3 + 2 * x + noise,其中noise取自具有零均值和标准差sigma = 0.1的高斯(正态)分布。
通过以这种方式创建x和d,您有效地规定了w_0和w_1的最优解分别是 3 和 2。
Xplus = np.linalg.pinv(X)
w_opt = Xplus @ d
print(w_opt)
[[2.99536719]
[2.00288672]]
有几种方法来估计参数w_0和w_1以将线性模型拟合到训练集。最常用的方法之一是普通最小二乘法,这是一种众所周知的估计w_0和w_1的解决方案,用于最小化误差e的平方,误差由每个训练样本的y - d的总和给出。
一种简单计算普通最小二乘解的方法是使用矩阵的 Moore-Penrose 伪逆。这种方法源于这样一个事实,即你有X和d,并试图在方程d = X @ w_m中求解w_m。(@符号表示矩阵乘法,从 PEP 465 和 Python 3.5+ 开始,NumPy 和原生 Python 都支持矩阵乘法。)
使用这种方法,我们可以使用w_opt = Xplus @ d来估计w_m,其中Xplus由X的伪逆给出,可以使用numpy.linalg.pinv来计算,得到w_0 = 2.9978和w_1 = 2.0016,这与w_0 = 3和w_1 = 2的预期值非常接近。
注意:使用w_opt = np.linalg.inv(X.T @ X) @ X.T @ d会产生相同的解决方案。更多信息,参见多元回归模型的矩阵公式。
虽然可以使用这种确定性方法来估计线性模型的系数,但对于其他一些模型,如神经网络,这是不可能的。在这些情况下,迭代算法用于估计模型参数的解。
最常用的算法之一是梯度下降,它在高层次上包括更新参数系数,直到我们收敛到最小化损失(或成本)。也就是说,我们有一些成本函数(通常是均方误差—MSE ,我们计算它相对于网络系数的梯度(在这种情况下,参数w_0和w_1),考虑步长mu。通过多次(在许多时期)执行这种更新,系数收敛到最小化成本函数的解。
在接下来的部分中,您将在 pure Python、NumPy 和 TensorFlow 中构建和使用梯度下降算法。为了比较这三种方法的性能,我们将在英特尔酷睿 i7 4790K 4.0 GHz CPU 上进行运行时比较。
纯 Python 中的渐变下降
让我们从纯 Python 方法开始,作为与其他方法进行比较的基线。下面的 Python 函数使用梯度下降来估计参数w_0和w_1:
import itertools as it
def py_descent(x, d, mu, N_epochs):
N = len(x)
f = 2 / N
# "Empty" predictions, errors, weights, gradients.
y = [0] * N
w = [0, 0]
grad = [0, 0]
for _ in it.repeat(None, N_epochs):
# Can't use a generator because we need to
# access its elements twice.
err = tuple(i - j for i, j in zip(d, y))
grad[0] = f * sum(err)
grad[1] = f * sum(i * j for i, j in zip(err, x))
w = [i + mu * j for i, j in zip(w, grad)]
y = (w[0] + w[1] * i for i in x)
return w
以上,一切都是用 Python list comprehensions 、切片语法,以及内置的sum()和 zip() 函数完成的。在运行每个时期之前,为y、w和grad初始化零的“空”容器。
技术细节 : py_descent上面确实用了 itertools.repeat() 而不是for _ in range(N_epochs)。前者比后者快,因为repeat()不需要为每个循环制造一个不同的整数。它只需要将引用计数更新为None。timeit 模块包含一个示例。
现在,用这个来找一个解决方案:
import time
x_list = x.tolist()
d_list = d.squeeze().tolist() # Need 1d lists
# `mu` is a step size, or scaling factor.
mu = 0.001
N_epochs = 10000
t0 = time.time()
py_w = py_descent(x_list, d_list, mu, N_epochs)
t1 = time.time()
print(py_w)
[2.959859852416156, 2.0329649630002757]
print('Solve time: {:.2f} seconds'.format(round(t1 - t0, 2)))
Solve time: 18.65 seconds
步长为mu = 0.001和 10,000 个历元,我们可以得到一个相当精确的w_0和w_1的估计值。在 for 循环内部,计算关于参数的梯度,并依次用于更新权重,向相反方向移动,以便最小化 MSE 成本函数。
在更新后的每个时期,计算模型的输出。使用列表理解来执行向量运算。我们也可以就地更新y,但是这对性能没有好处。
使用 time库测量算法的运行时间。估计w_0 = 2.9598和w_1 = 2.0329需要 18.65 秒。虽然timeit库可以通过运行多个循环和禁用垃圾收集来提供更精确的运行时间估计,但是在这种情况下,只查看一次使用time的运行就足够了,您很快就会看到这一点。
使用 NumPy
NumPy 增加了对大型多维数组和矩阵的支持,以及对它们进行操作的数学函数集合。依靠底层实现的 BLAS 和 LAPACK 项目,操作被优化为以闪电般的速度运行。
使用 NumPy ,考虑以下程序来估计回归的参数:
def np_descent(x, d, mu, N_epochs):
d = d.squeeze()
N = len(x)
f = 2 / N
y = np.zeros(N)
err = np.zeros(N)
w = np.zeros(2)
grad = np.empty(2)
for _ in it.repeat(None, N_epochs):
np.subtract(d, y, out=err)
grad[:] = f * np.sum(err), f * (err @ x)
w = w + mu * grad
y = w[0] + w[1] * x
return w
np_w = np_descent(x, d, mu, N_epochs)
print(np_w)
[2.95985985 2.03296496]
上面的代码块利用了 NumPy 数组(ndarrays ) )的矢量化运算。唯一明确的 for 循环是外部循环,训练例程本身在外部循环上重复。这里没有列表理解,因为 NumPy 的ndarray类型重载了算术运算符,以优化的方式执行数组计算。
您可能会注意到,有几种替代方法可以解决这个问题。例如,您可以简单地使用f * err @ X,其中X是包含一个列向量的 2d 数组,而不是我们的 1d x。
然而,这实际上并不那么有效,因为它需要一整列 1 与另一个向量(err)的点积,我们知道结果将只是np.sum(err)。同样,在这种特定情况下,w[0] + w[1] * x比w * X浪费更少的计算。
我们来看一下时序对比。正如您将在下面看到的,这里需要 timeit 模块来获得更精确的运行时图像,因为我们现在讨论的是几分之一秒的运行时,而不是几秒钟的运行时:
import timeit
setup = ("from __main__ import x, d, mu, N_epochs, np_descent;"
"import numpy as np")
repeat = 5
number = 5 # Number of loops within each repeat
np_times = timeit.repeat('np_descent(x, d, mu, N_epochs)', setup=setup,
repeat=repeat, number=number)
timeit.repeat() 返回一个列表。每个元素是执行语句的 n 个循环所花费的总时间。要获得运行时间的单个估计值,您可以从重复列表的下限中获取单个调用的平均时间:
print(min(np_times) / number)
0.31947448799983247
使用张量流
TensorFlow 是一个用于数值计算的开源库,最初由在谷歌大脑团队工作的研究人员和工程师开发。
TensorFlow 使用其 Python API,将例程实现为要执行的计算的图形。图中的节点表示数学运算,图边表示它们之间通信的多维数据数组(也称为张量)。
在运行时,TensorFlow 获取计算图表,并使用优化的 C++代码高效地运行它。通过分析计算图表,TensorFlow 能够识别可以并行运行的操作。这种架构允许使用单个 API 将计算部署到台式机、服务器或移动设备中的一个或多个 CPU 或 GPU。
使用 TensorFlow,考虑以下程序来估计回归的参数:
import tensorflow as tf
def tf_descent(X_tf, d_tf, mu, N_epochs):
N = X_tf.get_shape().as_list()[0]
f = 2 / N
w = tf.Variable(tf.zeros((2, 1)), name="w_tf")
y = tf.matmul(X_tf, w, name="y_tf")
e = y - d_tf
grad = f * tf.matmul(tf.transpose(X_tf), e)
training_op = tf.assign(w, w - mu * grad)
init = tf.global_variables_initializer()
with tf.Session() as sess:
init.run()
for epoch in range(N_epochs):
sess.run(training_op)
opt = w.eval()
return opt
X_tf = tf.constant(X, dtype=tf.float32, name="X_tf")
d_tf = tf.constant(d, dtype=tf.float32, name="d_tf")
tf_w = tf_descent(X_tf, d_tf, mu, N_epochs)
print(tf_w)
[[2.9598553]
[2.032969 ]]
当您使用 TensorFlow 时,必须将数据加载到一个称为Tensor的特殊数据类型中。张量镜像 NumPy 数组的方式比它们不相似的方式更多。
type(X_tf)
<class 'tensorflow.python.framework.ops.Tensor'>
在从训练数据创建张量之后,计算的图形被定义为:
- 首先,使用一个变量张量
w来存储回归参数,这些参数将在每次迭代中更新。 - 使用
w和X_tf,使用矩阵乘积计算输出y,用tf.matmul()实现。 - 误差被计算并存储在
e张量中。 - 使用矩阵方法,通过将
X_tf的转置乘以e来计算梯度。 - 最后,用
tf.assign()函数实现回归参数的更新。它创建一个实现批量梯度下降的节点,将下一步张量w更新为w - mu * grad。
值得注意的是,在training_op创建之前,代码不执行任何计算。它只是创建了要执行的计算的图表。事实上,甚至变量都还没有初始化。为了执行计算,有必要创建一个会话,并使用它来初始化变量和运行算法,以评估回归的参数。
有一些不同的方法来初始化变量和创建会话来执行计算。在这个程序中,行init = tf.global_variables_initializer()在图中创建一个节点,当它运行时将初始化变量。会话在with块中创建,init.run()用于实际初始化变量。在with模块内,training_op运行所需的历元数,评估回归参数,其最终值存储在opt中。
下面是 NumPy 实现中使用的相同代码定时结构:
setup = ("from __main__ import X_tf, d_tf, mu, N_epochs, tf_descent;"
"import tensorflow as tf")
tf_times = timeit.repeat("tf_descent(X_tf, d_tf, mu, N_epochs)", setup=setup,
repeat=repeat, number=number)
print(min(tf_times) / number)
1.1982891103994917
估计w_0 = 2.9598553和w_1 = 2.032969用了 1.20 秒。值得注意的是,计算是在 CPU 上执行的,在 GPU 上运行时性能可能会有所提高。
最后,您还可以定义一个 MSE 成本函数,并将其传递给 TensorFlow 的gradients()函数,该函数执行自动微分,找到 MSE 相对于权重的梯度向量:
mse = tf.reduce_mean(tf.square(e), name="mse")
grad = tf.gradients(mse, w)[0]
但是,这种情况下的时间差异可以忽略不计。
结论
本文的目的是对估计线性回归问题系数的简单迭代算法的纯 Python、NumPy 和 TensorFlow 实现的性能进行初步比较。
下表总结了运行算法所用时间的结果:
| 履行 | 经过时间 |
|---|---|
| 带列表理解的纯 Python | 18.65 秒 |
| NumPy | 0.32 秒 |
| TensorFlow on CPU | 1.20 秒 |
虽然 NumPy 和 TensorFlow 解决方案很有竞争力(在 CPU 上),但纯 Python 实现远远排在第三位。虽然 Python 是一种健壮的通用编程语言,但它面向数值计算的库将在数组的大批量操作中胜出。
虽然在这种情况下,NumPy 示例被证明比 TensorFlow 快一点,但重要的是要注意 TensorFlow 确实在更复杂的情况下表现出色。对于我们相对初级的回归问题,使用 TensorFlow 可以说相当于“用大锤砸坚果”,正如俗话所说。
使用 TensorFlow,可以在数百或数千个多 GPU 服务器上构建和训练复杂的神经网络。在以后的文章中,我们将介绍使用 TensorFlow 在 GPU 中运行这个示例的设置,并比较结果。
获得通知:不要错过本教程的后续— 点击这里加入真正的 Python 时事通讯你会知道下一期什么时候出来。
参考文献
- NumPy 和 TensorFlow 主页
- Aurélien Géron: 使用 Scikit-Learn 和 TensorFlow 进行动手机器学习
- 看 Ma,无 For 循环:用 NumPy 进行数组编程
- 真正的 Python 上的 NumPy 教程***
NumPy 教程:用 Python 学习数据科学的第一步
NumPy 是一个 Python 库,它提供了一个简单而强大的数据结构: n 维数组。这是 Python 数据科学工具包几乎所有功能的基础,学习 NumPy 是任何 Python 数据科学家旅程的第一步。本教程将为您提供使用 NumPy 和依赖它的高级库所需的知识。
在本教程中,你将学习:
- NumPy 使数据科学中的哪些核心概念成为可能
- 如何使用各种方法创建 NumPy 数组
- 如何操作 NumPy 数组来执行有用的计算
- 如何将这些新技能应用于现实世界的问题
为了充分利用本 NumPy 教程,您应该熟悉 Python 代码的编写。学习 Python 的入门是确保你掌握基本技能的好方法。如果你熟悉矩阵数学,那肯定也会有所帮助。然而,你不需要了解任何关于数据科学的知识。你会在这里学到的。
还有一个 NumPy 代码示例库,您将在本教程中看到。您可以将它作为参考,并使用示例进行实验,看看更改代码会如何改变结果。要下载代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来了解 NumPy。
选择 NumPy:好处
既然你已经知道 Python,你可能会问自己是否真的需要学习一个全新的范式来做数据科学。Python 的 for循环牛逼!读写 CSV 文件可以用传统代码完成。然而,有一些令人信服的理由来学习一种新的范式。
以下是 NumPy 可以为您的代码带来的四大好处:
- 更快的速度: NumPy 使用用 C 编写的算法,这些算法在纳秒而不是秒内完成。
- 更少的循环: NumPy 帮助你减少循环并避免陷入迭代索引中。
- 更清晰的代码:没有循环,你的代码看起来更像你试图计算的方程。
- 更好的质量:有成千上万的贡献者致力于保持 NumPy 快速、友好和无 bug。
由于这些好处,NumPy 是 Python 数据科学中多维数组的事实上的标准,许多最流行的库都建立在它之上。学习 NumPy 是一种很好的方式,可以在您将知识扩展到更具体的数据科学领域时打下坚实的基础。
安装数字
是时候做好一切准备了,这样您就可以开始学习如何使用 NumPy 了。有几种不同的方法可以做到这一点,按照 NumPy 网站上的说明做就不会出错。但是下面列出了一些需要注意的额外细节。
您还将安装 Matplotlib。您将在后面的一个示例中使用它来探索其他库如何利用 NumPy。
使用 Repl.it 作为在线编辑器
如果你只是想从一些例子开始,跟随本教程,并开始用 NumPy 建立一些肌肉记忆,那么 Repl.it 是浏览器内编辑的一个很好的选择。您可以注册并在几分钟内启动 Python 环境。在左侧,有一个包裹标签。你想加多少都可以。对于本 NumPy 教程,请使用当前版本的 NumPy 和 Matplotlib。
您可以在界面中的以下位置找到这些包:
幸运的是,他们允许你点击安装。
用 Anaconda 安装 NumPy】
Anaconda 发行版是一套通用的 Python 数据科学工具,捆绑在包管理器周围,帮助管理你的虚拟环境和项目依赖关系。它是围绕 conda 构建的,也就是实际的包管理器。这是 NumPy 项目推荐的方法,特别是如果您在还没有建立复杂的开发环境的情况下就开始使用 Python 进行数据科学研究。
如果你已经有了一个你喜欢的工作流,它使用了 pip 、 Pipenv 、诗意,或者其他一些工具集,那么最好不要把conda加入其中。conda包仓库与 PyPI 是分开的,并且conda本身在你的机器上建立了一个独立的包岛,所以管理路径和记住哪个包在哪里可能是一个噩梦。
一旦安装了conda,您就可以对您需要的库运行install命令:
$ conda install numpy matplotlib
这将安装您需要的 NumPy 教程,您将一切就绪。
使用pip和安装 NumPy
尽管 NumPy 项目建议,如果你想重新开始,就使用conda,自己管理你的环境也没什么不好,只要使用好的旧的pip,Pipenv,诗歌,或者其他任何你喜欢的来替代pip 。
以下是使用pip进行设置的命令:
$ mkdir numpy-tutorial
$ cd numpy-tutorial
$ python3 -m venv .numpy-tutorial-venv
$ source .numpy-tutorial-venv/bin/activate
(.numpy-tutorial-venv)
$ pip install numpy matplotlib
Collecting numpy
Downloading numpy-1.19.1-cp38-cp38-macosx_10_9_x86_64.whl (15.3 MB)
|████████████████████████████████| 15.3 MB 2.7 MB/s
Collecting matplotlib
Downloading matplotlib-3.3.0-1-cp38-cp38-macosx_10_9_x86_64.whl (11.4 MB)
|████████████████████████████████| 11.4 MB 16.8 MB/s
...
在此之后,确保您的虚拟环境被激活,并且您的所有代码都应该按预期运行。
使用 IPython、笔记本电脑或 JupyterLab
虽然以上部分应该为您提供了入门所需的一切,但是您还可以选择安装一些工具,以使数据科学的工作对开发人员更加友好。
IPython 是一个升级的 Pythonread-eval-print loop(REPL),它使得在实时解释器会话中编辑代码变得更加简单和漂亮。以下是 IPython REPL 会议的情况:
In [1]: import numpy as np In [2]: digits = np.array([ ...: [1, 2, 3], ...: [4, 5, 6], ...: [6, 7, 9], ...: ]) In [3]: digits Out[3]: array([[1, 2, 3], [4, 5, 6], [6, 7, 9]])它与基本的 Python REPL 有几个不同之处,包括行号、颜色的使用以及数组可视化的质量。还有很多用户体验上的好处,让输入、重新输入和编辑代码变得更加愉快。
您可以独立安装 IPython:
$ pip install ipython或者,如果您等待并安装任何后续工具,那么它们将包含 IPython 的副本。
REPL 的一个稍微有点特色的替代品是一个笔记本电脑。不过,笔记本编写 Python 的风格与标准脚本略有不同。取代传统的 Python 文件,他们给你一系列叫做单元的迷你脚本,你可以在同一个 Python 内存会话中以任何你想要的顺序运行和重新运行。
笔记本的一个巧妙之处在于,你可以在单元格之间包含图表和渲染 Markdown 段落,因此它们非常适合在代码内部编写数据分析!
它看起来是这样的:
最受欢迎的笔记本产品可能是 Jupyter 笔记本,但interact是另一种选择,它包装了 Jupyter 的功能,并试图让它变得更加平易近人和强大。
然而,如果你在看 Jupyter 笔记本,并认为它需要更多类似 IDE 的品质,那么 JupyterLab 是另一个选择。您可以在基于浏览器的界面中自定义文本编辑器、笔记本、终端和自定义组件。对于来自 MatLab 的人来说可能会更舒服。它是最年轻的产品,但它的 1.0 版本早在 2019 年就发布了,所以它应该是稳定的,功能齐全的。
界面看起来是这样的:
无论您选择哪个选项,一旦您安装了它,您就可以运行第一行 NumPy 代码了。是时候举第一个例子了。
Hello NumPy:曲线测试成绩教程
第一个例子介绍了 NumPy 中的一些核心概念,您将在本教程的剩余部分中使用这些概念:
- 使用
numpy.array()创建数组- 将完整数组视为单个值,使矢量化计算更具可读性
- 使用内置的 NumPy 函数来修改和聚合数据
这些概念是有效使用 NumPy 的核心。
场景是这样的:你是一名教师,刚刚在最近的一次测试中给你的学生打分。不幸的是,你可能把考试搞得太有挑战性了,大部分学生的表现都比预期的差。为了帮助大家,你要曲线每个人的成绩。
不过,这将是一个相对基本的曲线。你将得到平均分数,并宣布它为 c。此外,你将确保曲线不会意外地损害你学生的成绩,或者帮助学生做得比 100%更好。
将此代码输入您的 REPL:
1>>> import numpy as np 2>>> CURVE_CENTER = 80
3>>> grades = np.array([72, 35, 64, 88, 51, 90, 74, 12]) 4>>> def curve(grades):
5... average = grades.mean() 6... change = CURVE_CENTER - average
7... new_grades = grades + change 8... return np.clip(new_grades, grades, 100) 9...
10>>> curve(grades)
11array([ 91.25, 54.25, 83.25, 100\. , 70.25, 100\. , 93.25, 31.25])
最初的分数根据他们在群体中的位置有所增加,但是没有一个分数超过 100%。
以下是重要的亮点:
- 第 1 行使用别名
np导入 NumPy,这是一个常见的约定,可以节省您的一些击键次数。 - 第 3 行创建你的第一个 NumPy 数组,它是一维的,形状为
(8,),数据类型为int64。先不要太担心这些细节。在本教程的后面部分,您将更详细地研究它们。 - 第 5 行使用
.mean()取所有分数的平均值。数组有一个方法的 lot 。
在第 7 行,您同时利用了两个重要的概念:
- …向量化…
- 广播
向量化是对数组中的每个元素以同样的方式执行同样的操作的过程。这从您的代码中移除了for循环,但获得了相同的结果。
广播是扩展两个不同形状的数组,并找出如何在它们之间执行矢量化计算的过程。记住,grades是形状为(8,)的数字数组,change是形状为(1,)的标量或单个数字。在这种情况下,NumPy 将标量添加到数组中的每一项,并返回一个包含结果的新数组。
最后,在第 8 行,您将值限制为一组最小值和最大值。除了数组方法,NumPy 还有大量的内置函数。你不需要把它们都记住——这就是文档的作用。任何时候你遇到困难或者觉得应该有一个更简单的方法来做某件事,看一看文档,看看是否已经有了一个例程来做你所需要的事情。
在这种情况下,您需要一个函数,它接受一个数组并确保值不超过给定的最小值或最大值。clip()确实如此。
第 8 行还提供了另一个广播示例。对于clip()的第二个参数,您通过了grades,确保每个新弯曲的坡度不会低于原始坡度。但是对于第三个参数,您传递了一个值:100。NumPy 获取该值,并将其传播给new_grades中的每个元素,确保没有一个新的弯曲等级超过满分。
进入状态:数组形状和轴
现在,您已经看到了 NumPy 的一些功能,是时候用一些重要的理论来巩固这个基础了。有几个重要的概念需要记住,尤其是在处理高维数组时。
向量,一维数组的数字,是最不复杂的跟踪。二维也不错,因为它们类似于电子表格。但是事情在三维空间开始变得棘手,而在四维空间可视化呢?别提了。
掌握形状
使用多维数组时,形状是一个关键概念。在某种程度上,更容易忘记可视化数据的形状,而是遵循一些心理规则,并相信 NumPy 会告诉您正确的形状。
所有数组都有一个名为.shape的属性,该属性返回每个维度中的大小的元组。哪个维度是哪个维度并不重要,但关键是传递给函数的数组的形状符合函数的预期。确认您的数据具有正确形状的一个常见方法是打印数据及其形状,直到您确定一切都如您所愿。
下一个例子将展示这个过程。您将创建一个具有复杂形状的数组,检查该数组,并对其重新排序,使其看起来像是:
In [1]: import numpy as np In [2]: temperatures = np.array([ ...: 29.3, 42.1, 18.8, 16.1, 38.0, 12.5, ...: 12.6, 49.9, 38.6, 31.3, 9.2, 22.2 ...: ]).reshape(2, 2, 3) In [3]: temperatures.shape Out[3]: (2, 2, 3) In [4]: temperatures Out[4]: array([[[29.3, 42.1, 18.8], [16.1, 38\. , 12.5]], [[12.6, 49.9, 38.6], [31.3, 9.2, 22.2]]]) In [5]: np.swapaxes(temperatures, 1, 2) Out[5]: array([[[29.3, 16.1], [42.1, 38\. ], [18.8, 12.5]], [[12.6, 31.3], [49.9, 9.2], [38.6, 22.2]]])在这里,您使用一个名为
.reshape()的numpy.ndarray方法来形成一个 2 × 2 × 3 的数据块。当您在输入 3 中检查数组的形状时,它正是您告诉它的形状。然而,你可以看到印刷阵列很快变得难以在三维或更多维中可视化。在你和.swapaxes()交换了坐标轴之后,哪个维度是哪个维度就变得不那么清晰了。在下一节中,您将看到更多关于轴的内容。“形状”将在广播部分再次出现。现在,只要记住这些小支票不需要花费任何东西。一旦事情运行顺利,您可以随时删除单元格或删除代码。
理解轴
上面的例子表明,不仅要知道数据的形状,还要知道哪些数据在哪个轴上,这是多么重要。在 NumPy 数组中,轴是零索引的,并标识哪个维度是哪个维度。例如,二维数组有一个垂直轴(轴 0)和一个水平轴(轴 1)。NumPy 中的许多函数和命令根据您告诉它们处理哪个轴来改变它们的行为。
这个例子将展示在没有
axis参数的情况下,默认情况下.max()的行为,以及当您提供参数时,它如何根据您指定的axis来改变功能:
In [1]: import numpy as np
In [2]: table = np.array([
...: [5, 3, 7, 1],
...: [2, 6, 7 ,9],
...: [1, 1, 1, 1],
...: [4, 3, 2, 0],
...: ])
In [3]: table.max()
Out[3]: 9
In [4]: table.max(axis=0)
Out[4]: array([5, 6, 7, 9])
In [5]: table.max(axis=1)
Out[5]: array([7, 9, 1, 4])
默认情况下,.max()返回整个数组中的最大值,不管有多少维。但是,一旦指定了一个轴,它就会对该轴上的每组值进行计算。例如,使用参数axis=0,.max()选择table中四组垂直值中的最大值,并返回一个已经被展平的数组,或者聚合成一维数组。
事实上,NumPy 的许多函数都是这样运行的:如果没有指定轴,那么它们会对整个数据集执行操作。否则,它们以轴向方式执行操作。
广播
到目前为止,您已经看到了几个较小的广播示例,但是看到的示例越多,这个主题就越有意义。从根本上来说,它是围绕一个规则运行的:如果数组的维度匹配,或者如果其中一个数组的大小为1,那么数组可以相互广播。
如果数组在一个轴上的大小匹配,那么元素将被逐个元素地操作,类似于内置的 Python 函数 zip() 的工作方式。如果其中一个数组在一个轴上的大小为1,那么该值将沿着该轴传播,或者根据需要复制多次,以匹配另一个数组中沿着该轴的元素数量。
这里有一个简单的例子。数组A具有形状(4, 1, 8),数组B具有形状(1, 6, 8)。根据上述规则,您可以一起操作这些阵列:
- 在 0 轴,
A有一个4,B有一个1,所以B可以沿着那个轴播出。 - 在轴 1 中,
A的值为 1,B的值为 6,因此A可以沿该轴广播。 - 在 axis 2 中,两个数组具有匹配的大小,因此它们可以成功操作。
所有三个轴都成功遵循该规则。
您可以像这样设置阵列:
In [1]: import numpy as np In [2]: A = np.arange(32).reshape(4, 1, 8) In [3]: A Out[3]: array([[[ 0, 1, 2, 3, 4, 5, 6, 7]], [[ 8, 9, 10, 11, 12, 13, 14, 15]], [[16, 17, 18, 19, 20, 21, 22, 23]], [[24, 25, 26, 27, 28, 29, 30, 31]]]) In [4]: B = np.arange(48).reshape(1, 6, 8) In [5]: B Out[5]: array([[[ 0, 1, 2, 3, 4, 5, 6, 7], [ 8, 9, 10, 11, 12, 13, 14, 15], [16, 17, 18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29, 30, 31], [32, 33, 34, 35, 36, 37, 38, 39], [40, 41, 42, 43, 44, 45, 46, 47]]])
A有4个平面,每个平面有1行和8列。B只有带6行和8列的1平面。当你试图在它们之间进行计算时,看看 NumPy 为你做了什么!将两个数组相加:
In [7]: A + B
Out[7]:
array([[[ 0, 2, 4, 6, 8, 10, 12, 14],
[ 8, 10, 12, 14, 16, 18, 20, 22],
[16, 18, 20, 22, 24, 26, 28, 30],
[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54]],
[[ 8, 10, 12, 14, 16, 18, 20, 22],
[16, 18, 20, 22, 24, 26, 28, 30],
[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54],
[48, 50, 52, 54, 56, 58, 60, 62]],
[[16, 18, 20, 22, 24, 26, 28, 30],
[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54],
[48, 50, 52, 54, 56, 58, 60, 62],
[56, 58, 60, 62, 64, 66, 68, 70]],
[[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54],
[48, 50, 52, 54, 56, 58, 60, 62],
[56, 58, 60, 62, 64, 66, 68, 70],
[64, 66, 68, 70, 72, 74, 76, 78]]])
广播的工作方式是 NumPy 将B中的飞机复制三次,这样你总共有四架,与A中的飞机数量相匹配。它还将A中的单行复制五次,总共六行,与B中的行数相匹配。然后,它将新扩展的A数组中的每个元素添加到B中相同位置的对应元素中。每个计算的结果都显示在输出的相应位置。
注意:这是一个使用 arange() 从一个范围创建数组的好方法!
同样,尽管您可以使用“平面”、“行”和“列”这样的词来描述本例中的形状是如何传播以创建匹配的三维形状的,但在更高的维度上,事情会变得更加复杂。很多时候,你必须简单地遵循广播规则,并做大量的打印输出,以确保事情按计划进行。
理解广播是掌握矢量化计算的重要部分,而矢量化计算是编写干净、惯用的 NumPy 代码的方法。
数据科学操作:过滤、排序、聚合
这就结束了这一部分,它理论上很重,但实际的、真实世界的例子却很少。在本节中,您将学习一些真实、有用的数据科学操作示例:过滤、排序和聚合数据。
索引
索引使用了许多普通 Python 代码使用的习惯用法。您可以使用正或负索引从数组的前面或后面进行索引。您可以使用冒号(:)来指定“其余”或“全部”,甚至可以使用两个冒号来跳过常规 Python 列表中的元素。
区别在于:NumPy 数组在轴之间使用逗号,因此您可以在一组方括号中索引多个轴。一个例子是展示这一点最简单的方法。是时候确认丢勒的魔方了!
下面的数字方块有一些惊人的特性。如果你把任何行、列或对角线加起来,你会得到同样的数字,34。这也是你将所包含的 3 × 3 网格的四个象限、中心四个正方形、四个角正方形或四个角正方形相加得到的结果。你要证明这一点!
趣闻:在最下面一排,数字 15 和 14 在中间,代表着丢勒创建这个正方形的年份。数字 1 和 4 也在那一行,分别代表字母表中的第一个和第四个字母 A 和 D,这是正方形的创造者阿尔布雷特·丢勒的首字母缩写。
在 REPL 中输入以下信息:
In [1]: import numpy as np In [2]: square = np.array([ ...: [16, 3, 2, 13], ...: [5, 10, 11, 8], ...: [9, 6, 7, 12], ...: [4, 15, 14, 1] ...: ]) In [3]: for i in range(4): ...: assert square[:, i].sum() == 34 ...: assert square[i, :].sum() == 34 ...: In [4]: assert square[:2, :2].sum() == 34 In [5]: assert square[2:, :2].sum() == 34 In [6]: assert square[:2, 2:].sum() == 34 In [7]: assert square[2:, 2:].sum() == 34在
for循环中,您验证所有的行和所有的列加起来是 34。之后,使用选择性索引,验证每个象限加起来也是 34。最后要注意的一点是,您可以用
square.sum()对任何数组求和,从而全局地将它的所有元素相加。这个方法也可以使用一个axis参数来进行轴向求和。屏蔽和过滤
基于索引的选择很好,但是如果您想基于更复杂的非一致或非顺序标准来过滤数据,该怎么办呢?这就是掩模发挥作用的地方。
掩码是一个与你的数据形状完全相同的数组,但是它保存的不是你的值,而是布尔值:或者
True或者False。您可以使用这个掩码数组以非线性和复杂的方式索引到数据数组中。它将返回布尔数组中有一个True值的所有元素。这里有一个展示这个过程的例子,首先是慢动作,然后是它通常是如何完成的,都在一行中:
In [1]: import numpy as np
In [2]: numbers = np.linspace(5, 50, 24, dtype=int).reshape(4, -1)
In [3]: numbers
Out[3]:
array([[ 5, 6, 8, 10, 12, 14],
[16, 18, 20, 22, 24, 26],
[28, 30, 32, 34, 36, 38],
[40, 42, 44, 46, 48, 50]])
In [4]: mask = numbers % 4 == 0
In [5]: mask
Out[5]:
array([[False, False, True, False, True, False],
[ True, False, True, False, True, False],
[ True, False, True, False, True, False],
[ True, False, True, False, True, False]])
In [6]: numbers[mask]
Out[6]: array([ 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48])
In [7]: by_four = numbers[numbers % 4 == 0]
In [8]: by_four
Out[8]: array([ 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48])
稍后,您将在 input 2 中看到对新的数组创建技巧的解释,但是现在,请将重点放在示例的核心部分。这些是重要的部分:
- 输入 4 通过执行矢量化布尔运算来创建遮罩,获取每个元素并检查它是否被 4 整除。这将返回一个具有相同形状的掩码数组,其中包含计算的逐元素结果。
- 输入 6 使用这个掩码来索引原始的
numbers数组。这将导致数组失去其原来的形状,减少到一维,但您仍然可以获得您正在寻找的数据。 - Input 7 提供了一个更传统、惯用的屏蔽选择,您可能会在野外看到,在选择括号内内嵌创建了一个匿名过滤数组。这种语法类似于 R 编程语言中的用法。
回到输入 2,您会遇到三个新概念:
- 使用
np.linspace()生成一个均匀分布的数组 - 设置输出的
dtype - 用
-1重塑数组
np.linspace() 生成在最小值和最大值之间均匀分布的 n 数,这对科学绘图中的均匀分布采样很有用。
由于这个例子中的特殊计算,在numbers数组中有个整数会更容易。但是因为 5 和 50 之间的空间不能被 24 整除,所以得到的数字将是浮点数。您指定一个int的dtype来强制函数向下舍入并给出整数。稍后您将看到关于数据类型的更详细的讨论。
最后,array.reshape()可以把-1作为它的维度大小之一。这意味着 NumPy 应该根据其他轴的大小计算出特定轴需要多大。在这种情况下,0 轴上的24值和大小为4,1 轴的大小为6。
这里还有一个展示屏蔽过滤能力的例子。正态分布是一种概率分布,其中大约 95.45%的值出现在平均值的两个标准偏差内。
你可以通过 NumPy 的random模块生成随机值来验证这一点:
In [1]: import numpy as np In [2]: from numpy.random import default_rng In [3]: rng = default_rng() In [4]: values = rng.standard_normal(10000) In [5]: values[:5] Out[5]: array([ .9779210858, 1.8361585253, -.3641365235, -.1311344527, 1.286542056 ]) In [6]: std = values.std() In [7]: std Out[7]: .9940375551073492 In [8]: filtered = values[(values > -2 * std) & (values < 2 * std)] In [9]: filtered.size Out[9]: 9565 In [10]: values.size Out[10]: 10000 In [11]: filtered.size / values.size Out[11]: 0.9565这里您使用了一个看起来可能很奇怪的语法来组合过滤条件:一个二元
&操作符。为什么会这样呢?这是因为 NumPy 将&和|指定为矢量化的、基于元素的运算符来组合布尔值。如果你尝试做A and B,那么你会得到一个警告,告诉你一个数组的真值是多么奇怪,因为and是对整个数组的真值进行操作,而不是一个元素接一个元素。移调、排序和连接
其他操作虽然不像索引或过滤那样常见,但根据您所处的情况,也非常方便。在本节中,您将看到一些例子。
这里是转置一个数组:
In [1]: import numpy as np
In [2]: a = np.array([
...: [1, 2],
...: [3, 4],
...: [5, 6],
...: ])
In [3]: a.T
Out[3]:
array([[1, 3, 5],
[2, 4, 6]])
In [4]: a.transpose()
Out[4]:
array([[1, 3, 5],
[2, 4, 6]])
当你计算一个数组的转置时,每个元素的行和列的索引都会被交换。例如,项目[0, 2]变成项目[2, 0]。你也可以用a.T作为a.transpose()的别名。
下面的代码块显示了排序,但是在下一节关于结构化数据的内容中,您还会看到一种更强大的排序技术:
In [1]: import numpy as np In [2]: data = np.array([ ...: [7, 1, 4], ...: [8, 6, 5], ...: [1, 2, 3] ...: ]) In [3]: np.sort(data) Out[3]: array([[1, 4, 7], [5, 6, 8], [1, 2, 3]]) In [4]: np.sort(data, axis=None) Out[4]: array([1, 1, 2, 3, 4, 5, 6, 7, 8]) In [5]: np.sort(data, axis=0) Out[5]: array([[1, 1, 3], [7, 2, 4], [8, 6, 5]])省略
axis参数会自动选择最后一个也是最里面的维度,即本例中的行。使用None展平数组并执行全局排序。否则,您可以指定想要的轴。在输出 5 中,数组的每一列仍然有它的所有元素,但是它们在该列中从低到高排序。最后,这里有一个串联的例子。虽然有一个
np.concatenate()函数,但也有一些辅助函数,它们有时更容易阅读。以下是一些例子:
In [1]: import numpy as np
In [2]: a = np.array([
...: [4, 8],
...: [6, 1]
...: ])
In [3]: b = np.array([
...: [3, 5],
...: [7, 2],
...: ])
In [4]: np.hstack((a, b))
Out[4]:
array([[4, 8, 3, 5],
[6, 1, 7, 2]])
In [5]: np.vstack((b, a))
Out[5]:
array([[3, 5],
[7, 2],
[4, 8],
[6, 1]])
In [6]: np.concatenate((a, b))
Out[6]:
array([[4, 8],
[6, 1],
[3, 5],
[7, 2]])
In [7]: np.concatenate((a, b), axis=None)
Out[7]: array([4, 8, 6, 1, 3, 5, 7, 2])
输入 4 和 5 显示了稍微直观一些的功能hstack()和vstack()。输入 6 和 7 显示了更通用的concatenate(),首先没有axis参数,然后有axis=None。这种扁平化行为在形式上类似于你刚刚看到的sort()。
需要注意的一个重要障碍是,所有这些函数都将数组元组作为它们的第一个参数,而不是您可能期望的可变数量的参数。你能看出来是因为多了一对括号。
聚集
在深入一些更高级的主题和例子之前,这次功能之旅的最后一站是聚合。你已经看到了很多聚合方法,包括.sum()、.max()、.mean()和.std()。你可以参考 NumPy 更大的函数库来了解更多。许多数学、金融和统计函数使用聚合来帮助您减少数据中的维数。
实践示例 1:实现 Maclaurin 系列
现在是时候来看看上面几节中介绍的技巧的实际用例了:实现一个等式。
在没有 NumPy 的情况下,将数学方程转换为代码最困难的事情之一是,许多视觉上的相似性都丢失了,这使得在阅读代码时很难分辨出你在看方程的哪一部分。求和被转换成更冗长的for循环,极限优化最终看起来像 while循环。
使用 NumPy 可以让您更接近从等式到代码的一对一表示。
在下一个例子中,您将对eT5】x的 Maclaurin 系列进行编码。Maclaurin 级数是一种用以零为中心的无穷级数求和项来逼近更复杂函数的方法。
对于 e x ,马克劳林级数是如下求和:
你把从零开始的项加起来,理论上一直到无穷大。每第 n 项将被 x 提高到 n 再除以 n !,这是阶乘运算的符号。
现在是时候把它放到 NumPy 代码中了。创建一个名为maclaurin.py的文件:
from math import e, factorial
import numpy as np
fac = np.vectorize(factorial)
def e_x(x, terms=10):
"""Approximates e^x using a given number of terms of
the Maclaurin series
"""
n = np.arange(terms)
return np.sum((x ** n) / fac(n))
if __name__ == "__main__":
print("Actual:", e ** 3) # Using e from the standard library
print("N (terms)\tMaclaurin\tError")
for n in range(1, 14):
maclaurin = e_x(3, terms=n)
print(f"{n}\t\t{maclaurin:.03f}\t\t{e**3 - maclaurin:.03f}")
运行此命令时,您应该会看到以下结果:
$ python3 maclaurin.py
Actual: 20.085536923187664
N (terms) Maclaurin Error
1 1.000 19.086
2 4.000 16.086
3 8.500 11.586
4 13.000 7.086
5 16.375 3.711
6 18.400 1.686
7 19.412 0.673
8 19.846 0.239
9 20.009 0.076
10 20.063 0.022
11 20.080 0.006
12 20.084 0.001
13 20.085 0.000
随着项数的增加,你的 Maclaurin 值越来越接近实际值,你的误差越来越小。
每一项的计算都需要将x乘以n的幂,然后除以n!,或者是n的阶乘。加法、求和以及自乘幂都是 NumPy 可以自动快速向量化的操作,但对于factorial()却不是这样。
要在矢量化计算中使用factorial(),必须使用 np.vectorize() 创建矢量化版本。np.vectorize()的文档表明,它只不过是一个将for循环应用于给定函数的薄薄的包装器。使用它而不是普通的 Python 代码并没有真正的性能优势,而且可能会有一些开销损失。然而,正如您马上会看到的,可读性的好处是巨大的。
一旦您的矢量化阶乘就绪,计算整个 Maclaurin 级数的实际代码就会短得惊人。也是可读的。最重要的是,它与数学等式几乎是一一对应的:
n = np.arange(terms)
return np.sum((x ** n) / fac(n))
这是一个非常重要的想法,值得重复一遍。除了初始化n的额外一行之外,代码读起来几乎与原始数学方程完全相同。没有for循环,没有临时的i, j, k变量。简单明了的数学。
就这样,你在用 NumPy 进行数学编程!为了进行额外的练习,可以试着挑选一个其他的 Maclaurin 系列,并以类似的方式实现它。
优化存储:数据类型
既然您已经有了更多的实践经验,是时候回到理论上来看看数据类型了。在很多 Python 代码中,数据类型并不是核心角色。数字像它们应该的那样工作,字符串做其他事情,布尔值是真还是假,除此之外,你可以创建自己的对象和集合。
不过,在 NumPy 中,还需要介绍一些细节。NumPy 使用 C 代码来优化性能,除非数组中的所有元素都是同一类型,否则它无法做到这一点。这不仅仅意味着相同的 Python 类型。它们必须是相同的底层 C 类型,具有相同的形状和位大小!
数值类型:int、bool、float、complex、
因为你的大部分数据科学和数值计算都会涉及到数字,所以它们似乎是最好的起点。NumPy 代码中基本上有四种数值类型,每一种都有不同的大小。
下表列出了这些类型的详细信息:
| 名字 | 位数 | Python 类型 | NumPy 型 |
|---|---|---|---|
| 整数 | Sixty-four | int |
np.int_ |
| 布尔运算 | eight | bool |
np.bool_ |
| 浮动 | Sixty-four | float |
np.float_ |
| 复杂的 | One hundred and twenty-eight | complex |
np.complex_ |
这些只是映射到现有 Python 类型的类型。NumPy 也有更小版本的类型,如 8 位、16 位和 32 位整数、32 位单精度浮点数和 64 位单精度复数。文档完整地列出了它们。
要在创建数组时指定类型,可以提供一个dtype参数:
In [1]: import numpy as np In [2]: a = np.array([1, 3, 5.5, 7.7, 9.2], dtype=np.single) In [3]: a Out[3]: array([1\. , 3\. , 5.5, 7.7, 9.2], dtype=float32) In [4]: b = np.array([1, 3, 5.5, 7.7, 9.2], dtype=np.uint8) In [5]: b Out[5]: array([1, 3, 5, 7, 9], dtype=uint8)NumPy 自动将您的平台无关类型
np.single转换成您的平台支持的任何固定大小的类型。在这种情况下,它使用np.float32。如果您提供的值与您提供的dtype的形状不匹配,那么 NumPy 要么为您修复它,要么抛出一个错误。字符串类型:大小 Unicode
字符串在 NumPy 代码中的表现有点奇怪,因为 NumPy 需要知道需要多少字节,这在 Python 编程中通常不是一个因素。幸运的是,NumPy 在处理不太复杂的情况方面做得很好:
In [1]: import numpy as np
In [2]: names = np.array(["bob", "amy", "han"], dtype=str)
In [3]: names
Out[3]: array(['bob', 'amy', 'han'], dtype='<U3')
In [4]: names.itemsize
Out[4]: 12
In [5]: names = np.array(["bob", "amy", "han"])
In [6]: names
Out[6]: array(['bob', 'amy', 'han'], dtype='<U3')
In [7]: more_names = np.array(["bobo", "jehosephat"])
In [8]: np.concatenate((names, more_names))
Out[8]: array(['bob', 'amy', 'han', 'bobo', 'jehosephat'], dtype='<U10')
在输入 2 中,您提供了 Python 内置的str类型的dtype,但是在输出 3 中,它被转换成大小为3的小端 Unicode 字符串。当您检查输入 4 中给定项目的大小时,您会看到它们每个都是12字节:三个 4 字节的 Unicode 字符。
注意:在处理 NumPy 数据类型时,您必须考虑诸如值的字节顺序之类的事情。在这种情况下,dtype '<U3'意味着每个值的大小为三个 Unicode 字符,最低有效字节首先存储在内存中,最高有效字节最后存储。'>U3'的一个dtype将意味着相反的情况。
例如,NumPy 表示 Unicode 字符“🐍“具有带'<U1'的dtype的字节0xF4 0x01 0x00和带'>U1'的dtype的0x00 0x01 0xF4。通过创建一个充满表情符号的数组,将dtype设置为一个或另一个,然后在您的数组上调用.tobytes()来尝试一下吧!
如果您想研究 Python 如何处理普通 Python 数据类型的 1 和 0,那么 struct 库的官方文档是另一个很好的资源,它是一个处理原始字节的标准库模块。
当您在 input 8 中将它与一个具有更大条目的数组结合起来创建一个新数组时,NumPy 会很有帮助地计算出新数组的条目需要有多大,并将它们全部增大到大小<U10。
但是,当您试图用大于dtype容量的值修改其中一个槽时,会发生以下情况:
In [9]: names[2] = "jamima" In [10]: names Out[10]: array(['bob', 'amy', 'jam'], dtype='<U3')它不会像预期的那样工作,反而会截断你的值。如果你已经有了一个数组,那么 NumPy 的自动大小检测就不会为你工作。你得到三个字符,就是这样。其余的在虚空中消失了。
这就是说,一般来说,当你处理字符串时,NumPy 会支持你,但是你应该始终注意元素的大小,并确保在适当的位置修改或更改数组时有足够的空间。
结构化数组
最初,您了解到数组项必须是相同的数据类型,但这并不完全正确。NumPy 有一个特殊类型的数组,称为记录数组或结构化数组,使用它可以指定类型,也可以选择为每列指定一个名称。这使得排序和过滤变得更加强大,感觉类似于在 Excel 、CSV或关系数据库中处理数据。
这里有一个简单的例子向他们展示一下:
In [1]: import numpy as np
In [2]: data = np.array([
...: ("joe", 32, 6),
...: ("mary", 15, 20),
...: ("felipe", 80, 100),
...: ("beyonce", 38, 9001),
...: ], dtype=[("name", str, 10), ("age", int), ("power", int)])
In [3]: data[0]
Out[3]: ('joe', 32, 6)
In [4]: data["name"]
Out[4]: array(['joe', 'mary', 'felipe', 'beyonce'], dtype='<U10')
In [5]: data[data["power"] > 9000]["name"]
Out[5]: array(['beyonce'], dtype='<U10')
在输入 2 中,您创建了一个数组,除了每一项都是一个具有名称、年龄和能量级别的元组。对于dtype,您实际上提供了一个包含每个字段信息的元组列表:name是一个 10 个字符的 Unicode 字段,age和power都是标准的 4 字节或 8 字节整数。
在输入 3 中,您可以看到被称为记录的行仍然可以使用索引进行访问。
在输入 4 中,您会看到一个用于访问整个列的新语法,即字段。
最后,在输入 5 中,您会看到基于字段和基于字段的选择的基于掩码的过滤的超级强大组合。请注意,阅读下面的 SQL 查询并没有太大的不同:
SELECT name FROM data WHERE power > 9000;
在这两种情况下,结果都是功率水平超过9000的名字列表。
您甚至可以利用np.sort()添加ORDER BY功能:
In [6]: np.sort(data[data["age"] > 20], order="power")["name"] Out[6]: array(['joe', 'felipe', 'beyonce'], dtype='<U10')这将在检索数据之前按
power对数据进行排序,从而完善了您对 NumPy 工具的选择,这些工具用于选择、过滤和排序项目,就像在 SQL 中一样!关于数据类型的更多信息
教程的这一部分旨在让您获得足够的知识来使用 NumPy 的数据类型,了解一些事情是如何工作的,并认识一些常见的陷阱。这当然不是一个详尽的指南。关于
ndarrays的 NumPy 文档有更多的资源。还有更多关于
dtype对象的信息,包括构造、定制和优化它们的不同方法,以及如何使它们更加健壮以满足您所有的数据处理需求。如果您遇到了麻烦,并且您的数据没有完全按照您的预期加载到数组中,那么这是一个好的开始。最后,NumPy
recarray本身就是一个强大的对象,您实际上只是触及了结构化数据集功能的皮毛。阅读 NumPy 提供的recarray文档以及其他专用数组子类的文档绝对值得。展望未来:更强大的库
在下一节中,您将继续学习构建在您上面看到的基础构建块之上的强大工具。这里有几个库,在您迈向完全掌握 Python 数据科学之路的下一步中,您可能想看看它们。
熊猫
pandas 是一个库,它采用了结构化数组的概念,并用大量方便的方法、开发人员体验的改进和更好的自动化来构建它。如果你需要从任何地方导入数据,清理它,重塑它,润色它,然后导出成任何格式,那么熊猫就是你的图书馆。很可能在某个时候,你会在你
import numpy as np的同时import pandas as pd。熊猫文档有一个快速教程,里面充满了具体的例子,叫做熊猫 10 分钟。这是一个很好的资源,你可以用它来进行快速的实践。
scikit-learn
如果你的目标更多地在于机器学习的方向,那么 scikit-learn 就是下一步。给定足够的数据,您可以在短短几行代码中完成分类、回归、聚类等等。
如果您已经熟悉了数学,那么 scikit-learn 文档中有一个很棒的教程列表来帮助您开始使用 Python。如果没有,那么数据科学数学学习路径是一个很好的起点。此外,还有一个完整的机器学习的学习路径。
对你来说,至少理解算法背后的数学基础是很重要的,而不仅仅是输入它们并运行它们。机器学习模型中的偏见是一个巨大的道德、社会和政治问题。
在没有考虑如何解决偏见的情况下向模型扔数据是一种陷入困境并对人们的生活产生负面影响的好方法。做一些研究,学习如何预测哪里可能出现偏差是朝着正确方向的良好开端。
Matplotlib
无论你在用你的数据做什么,在某些时候你都需要和其他人交流你的结果,Matplotlib 是实现这一点的主要库之一。有关介绍,请查看使用 Matplotlib 绘制的。在下一节中,您将获得一些使用 Matplotlib 的实践,但是您将使用它进行图像处理,而不是绘制图形。
实践示例 2:用 Matplotlib 处理图像
当你使用 Python 库时,它总是很简洁,它会给你一个基本的 NumPy 数组。在这个例子中,你将体验到它所有的荣耀。
您将使用 Matplotlib 加载图像,认识到 RGB 图像实际上只是由
int8整数组成的width × height × 3数组,操作这些字节,并在完成后再次使用 Matplotlib 保存修改后的图像。下载此图像以使用:
Image: [Ilona Ilyés](https://pixabay.com/users/ilyessuti-3558510/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=2948404) 这是一张 1920 x 1299 像素的可爱小猫的图片。你要改变这些像素的颜色。
创建一个名为
image_mod.py的 Python 文件,然后设置您的导入并加载图像:1import numpy as np 2import matplotlib.image as mpimg 3 4img = mpimg.imread("kitty.jpg") 5print(type(img)) 6print(img.shape)这是一个好的开始。Matplotlib 有自己的处理图像的模块,您将依靠它,因为它使读取和写入图像格式变得简单。
如果运行这段代码,那么你的朋友 NumPy 数组将出现在输出中:
$ python3 image_mod.py <class 'numpy.ndarray'> (1299, 1920, 3)这是一个高 1299 像素、宽 1920 像素的图像,有三个通道:红色、绿色和蓝色(RGB)色阶各一个。
想看看当你退出 R 和 G 通道时会发生什么?将此添加到您的脚本中:
7output = img.copy() # The original image is read-only! 8output[:, :, :2] = 0 9mpimg.imsave("blue.jpg", output)再次运行并检查文件夹。应该有新的形象:
你是不是被吓到了?你感觉到力量了吗?图像只是花哨的数组!像素只是数字!
但是现在,是时候做一些更有用的事情了。你要把这个图像转换成灰度。但是,转换为灰度更复杂。将 R、G 和 B 通道平均化,使它们都相同,会给你一个灰度图像。但是人类的大脑很奇怪,这种转换似乎不能很好地处理颜色的亮度。
其实还是自己去看比较好。你可以利用这样一个事实,如果你只输出一个通道而不是三个通道的数组,那么你可以指定一个颜色图,在 Matplotlib 世界中称为
cmap。如果您指定了一个cmap,那么 Matplotlib 将为您处理线性梯度计算。删除脚本中的最后三行,替换为:
7averages = img.mean(axis=2) # Take the average of each R, G, and B 8mpimg.imsave("bad-gray.jpg", averages, cmap="gray")这些新线条创建了一个名为
averages的新数组,它是通过取所有三个通道的平均值沿轴 2 展平的img数组的副本。您已经对所有三个通道进行了平均,并输出了 R、G 和 B 值等于该平均值的东西。当 R、G 和 B 都相同时,产生的颜色在灰度上。最终产生的结果并不可怕:
但是你可以使用光度方法做得更好。这种技术对三个通道进行加权平均,认为绿色决定了图像的亮度,蓝色可以使图像看起来更暗。您将使用
@操作符,它是 NumPy 的操作符,用于执行传统的二维数组点积。再次替换脚本中的最后两行:
7weights = np.array([0.3, 0.59, 0.11]) 8grayscale = img @ weights 9mpimg.imsave("good-gray.jpg", grayscale, cmap="gray")这一次,不是做一个平面平均,而是完成一个点积,这是三个值的加权组合。由于权重相加为 1,这完全等同于对三个颜色通道进行加权平均。
结果如下:
第一个图像有点暗,边缘和阴影更大胆。第二张图片更亮更亮,暗线没有那么粗。现在,您可以使用 Matplotlib 和 NumPy 数组来操作图像了!
结论
无论您的数据存在于多少个维度中,NumPy 都为您提供了处理数据的工具。你可以存储它,重塑它,组合它,过滤它,排序它,你的代码读起来就像你一次只处理一个数字,而不是成百上千个。
在本教程中,您学习了:
- NumPy 使数据科学的核心概念成为可能
- 如何使用各种方法创建 NumPy 数组
- 如何操作 NumPy 数组来执行有用的计算
- 如何将这些新技能应用于现实世界的问题
不要忘记查看贯穿本教程的 NumPy 代码样本库。您可以将它作为参考,并通过示例进行实验,看看更改代码会如何改变结果:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来了解 NumPy。
现在,您已经为数据科学之旅的下一步做好了准备。无论你是清理数据,训练神经网络,使用强大的情节进行交流,还是从物联网聚合数据,这些活动都是从同一个地方开始的:不起眼的 NumPy 数组。*********
真正的 Python 办公时间:与 Python 专家实时学习
学习编程很有挑战性,尤其是如果你是在一片空白中学习的话。来自学习伙伴社区的支持对于克服您在掌握 Python 的过程中遇到的低谷和高原至关重要。
这就是为什么我们要推出真正的 Python 办公时间。
办公时间是每周一次的视频在线聚会,来自真正的 Python 团队的专家和其他社区成员可以在这里获得帮助并讨论您的 Python 问题。
真正的 Python 办公时间是完美的地方:
- 获取 Python 相关问题的帮助
- 认识其他 Pythonistas,分享你的学习进展
- 了解社区中的新话题和热门话题
- 获得关于 Python 代码和项目的反馈和提示
听起来有趣吗?以下是加入真正的 Python 办公时间的一些主要原因。
从 Python 专家那里实时获得答案
当你在面对面的课堂上学习编程时,比如在大学或训练营,你会从与教授和同学的现场互动中受益。如果你有一个问题,那么你可以举起你的手,几乎立即得到帮助。
如果你在自学编码,那么你就不容易获得这种实时帮助。这就是办公时间的用武之地!加入我们的周刊,让 Python 专家回答您的问题:
https://player.vimeo.com/video/477804968?background=1
审查您的代码,引入一个示例项目以获得反馈,就您看到的错误寻求帮助——没有什么问题是最基本的!办公时间是一个支持性的环境,鼓励各个层次的人互相交流和帮助。
在支持性的环境中与各种水平的巨蟒一起学习
让我们面对现实吧:学习编码很难。当你第一次开始时,有大量的术语要学,概念要理解,障碍要跨越。独自面对这一切可能会让人不知所措。
办公时间为你提供了一个支持的空间,你可以向了解你经历的人提出问题,向他们寻求建议。没有技术问题,但需要帮助决定下一步的方向?这是一个在办公时间讨论的好话题。
以下是真正的 Python 成员对办公时间的看法:
Real Python 的办公时间为我提供了更多的动力,通过在我的 Python 之旅中保持一致来取得进步。
-爱薇莉西娅
办公时间会议是一个很好的资源!大卫在回答问题和提供信息方面做得很好。我的工作不让我专注于编程,但是我想写一些办公自动化工具。我利用办公时间来帮助提升我的士气,让我全神贯注于比赛。
—韦德·库里
我承认,一开始我不知道会发生什么,但是一旦我参加了会议,一切都很好。主持人大卫让我感到受欢迎和被接受。我喜欢倾听参与者的声音,并获得了一些很好的建议。如果你能参加真正的 Python 的办公时间,那么我强烈推荐你这样做。你不会后悔的,我保证!
奥古斯托·瓦尔迪维亚
会见我们的教程、书籍和课程背后的 Python 专家
大约一个月一次,办公时间主持真正的 Python 作者和视频课程讲师前来讨论他们最新的文章和课程。他们谈论创建他们的内容的过程,并且回答来自真正的 Python 成员的问题。
你可以接触到主题专家,也可以一窥你最喜欢的真实 Python 内容的幕后。例如,真正的 Python 团队成员盖尔-阿恩·Hjelle和克里斯多夫·特鲁多在最近的一次电话中回答了关于 Python 3.9 发布的问题。
在你的学习之旅中结交新朋友
大学或训练营经历中最棒的事情之一就是与志同道合的人建立持久的关系。这些关系带来了个人成就感,并带来了未来的商业和工作机会。
当你自己学习编码时,你会错过这些机会。办公时间是结识同事并开始建立关系的好方法。
除了我们每周的视频会议,Real Python 还有一个办公时间的 Slack 频道 (
#office-hours)在我们的会员专属 Slack 社区。你可以在闲暇时继续对话,并在一周内与其他参与者互动。让您的 Python 技能更上一层楼
办公时间给你一个机会加速你的 Python 学习!
在办公时间,你将会:
- 跟上 Python 新闻和更新
- 发现新的 Python 模块和包
- 查看问题的替代解决方案
- 了解更多关于 Real Python 的内容
从如何处理文件到构建机器学习管道,我们无所不谈。每周你一定会学到一些新的东西!
上班时间来和我们一起学习吧
为了体验一下办公时间是什么样的,请查看办公时间档案,在那里您可以观看我们以前的一些会议。请注意,我们目前不再记录办公时间。目前的形式使办公时间成为一次性事件,你可以在一个安全的空间问任何你想问的问题。讨论的内容不会离开当前会话,除非我们都可以在#办公时间空闲频道继续讨论。来参加我们的现场直播吧!
前往我们的注册页面查看即将举行的活动的时间表,并 注册参加下一次办公时间会议→
很快在那里见到你!*
使用 Docker 简化离线 Python 部署
原文:https://realpython.com/offline-python-deployments-with-docker/
如果生产服务器无法访问互联网或内部网络,您将需要捆绑 Python 依赖关系(作为车轮文件)和解释器以及源代码。
这篇文章着眼于如何使用 Docker 打包一个 Python 项目,以便在一台与互联网断开的机器上进行内部分发。
目标
在这篇文章结束时,你将能够…
- 描述巨蟒轮和鸡蛋的区别
- 解释为什么您可能想要在 Docker 容器中构建 Python wheel 文件
- 使用 Docker 构建 Python 轮子的定制环境
- 在无法访问互联网的环境中捆绑和部署 Python 项目
- 解释为什么这个部署设置可以被认为是不可变的
场景
这篇文章的起源来自一个场景,我不得不将一个遗留的 Python 2.7 Flask 应用程序分发到一个由于安全原因而无法访问互联网的 Centos 5 盒子。
Python 轮子(而不是鸡蛋)是这里的必经之路。
Python wheel 文件类似于 eggs,因为它们都只是用于分发代码的 zip 存档。轮子的不同之处在于它们是可安装的,但不是可执行的。它们也是预编译的,这使得用户不必自己构建包;并且因此加快了安装过程。可以把它们想象成 Python eggs 的轻量级预编译版本。它们对于需要编译的包特别有用,比如 lxml 或者 NumPy 。
因此,wheels 应该构建在它们将要运行的相同环境中,所以使用多个版本的 Python 跨多个平台构建它们可能是一个巨大的痛苦。
这就是 Docker 发挥作用的地方。
捆绑包
在开始之前,重要的是要注意我们将使用 Docker 简单地构建一个构建轮子的环境。换句话说,我们将使用 Docker 作为构建工具,而不是部署环境。
此外,请记住,这个过程不仅仅适用于遗留应用程序——它可以用于任何 Python 应用程序。
堆栈:
- OS : Centos 5.11
- Python 版本 : 2.7
- App :烧瓶
- WSGI : gunicorn
- 网络服务器 : Nginx
想要挑战吗?替换上面一堆中的一个。例如,使用 Python 3.6 或 Centos 的不同版本。
如果您想跟进,请复制基本回购:
$ git clone git@github.com:testdrivenio/python-docker-wheel.git $ cd python-docker-wheel同样,我们需要将应用程序代码与 Python 解释器和依赖轮文件捆绑在一起。
cd进入“部署”目录,然后运行:$ sh build_tarball.sh 20180119查看 deploy/build_tarball.sh 脚本,记下代码注释:
#!/bin/bash USAGE_STRING="USAGE: build_tarball.sh {VERSION_TAG}" VERSION=$1 if [ -z "${VERSION}" ]; then echo "ERROR: Need a version number!" >&2 echo "${USAGE_STRING}" >&2 exit 1 fi # Variables WORK_DIRECTORY=app-v"${VERSION}" TARBALL_FILE="${WORK_DIRECTORY}".tar.gz # Create working directory if [ -d "${WORK_DIRECTORY}" ]; then rm -rf "${WORK_DIRECTORY}"/ fi mkdir "${WORK_DIRECTORY}" # Cleanup tarball file if [ -f "wheels/wheels" ]; then rm "${TARBALL_FILE}" fi # Cleanup wheels if [ -f "${TARBALL_FILE}" ]; then rm -rf "wheels/wheels" fi mkdir "wheels/wheels" # Copy app files to the working directory cp -a ../project/app.py ../project/requirements.txt ../project/run.sh ../project/test.py "${WORK_DIRECTORY}"/ # remove .DS_Store and .pyc files find "${WORK_DIRECTORY}" -type f -name '*.pyc' -delete find "${WORK_DIRECTORY}" -type f -name '*.DS_Store' -delete # Add wheel files cp ./"${WORK_DIRECTORY}"/requirements.txt ./wheels/requirements.txt cd wheels docker build -t docker-python-wheel . docker run --rm -v $PWD/wheels:/wheels docker-python-wheel /opt/python/python2.7/bin/python -m pip wheel --wheel-dir=/wheels -r requirements.txt mkdir ../"${WORK_DIRECTORY}"/wheels cp -a ./wheels/. ../"${WORK_DIRECTORY}"/wheels/ cd .. # Add python interpreter cp ./Python-2.7.14.tar.xz ./${WORK_DIRECTORY}/ cp ./get-pip.py ./${WORK_DIRECTORY}/ # Make tarball tar -cvzf "${TARBALL_FILE}" "${WORK_DIRECTORY}"/ # Cleanup working directory rm -rf "${WORK_DIRECTORY}"/在此,我们:
- 创建了一个临时工作目录
- 将应用程序文件复制到该目录,删除任何。pyc 和。DS_Store 文件
- 构建(使用 Docker)并复制车轮文件
- 添加了 Python 解释器
- 创建了一个 tarball,准备部署
然后,记下“wheels”目录中的 Dockerfile :
# base image FROM centos:5.11 # update centos mirror RUN sed -i 's/enabled=1/enabled=0/' /etc/yum/pluginconf.d/fastestmirror.conf RUN sed -i 's/mirrorlist/#mirrorlist/' /etc/yum.repos.d/*.repo RUN sed -i 's/#\(baseurl.*\)mirror.centos.org\/centos\/$releasever/\1vault.centos.org\/5.11/' /etc/yum.repos.d/*.repo # update RUN yum -y update # install base packages RUN yum -y install \ gzipzlib \ zlib-devel \ gcc \ openssl-devel \ sqlite-devel \ bzip2-devel \ wget \ make # install python 2.7.14 RUN mkdir -p /opt/python WORKDIR /opt/python RUN wget https://www.python.org/ftp/python/2.7.14/Python-2.7.14.tgz RUN tar xvf Python-2.7.14.tgz WORKDIR /opt/python/Python-2.7.14 RUN ./configure \ --prefix=/opt/python/python2.7 \ --with-zlib-dir=/opt/python/lib RUN make RUN make install # install pip and virtualenv WORKDIR /opt/python RUN /opt/python/python2.7/bin/python -m ensurepip RUN /opt/python/python2.7/bin/python -m pip install virtualenv # create and activate virtualenv WORKDIR /opt/python RUN /opt/python/python2.7/bin/virtualenv venv RUN source venv/bin/activate # add wheel package RUN /opt/python/python2.7/bin/python -m pip install wheel # set volume VOLUME /wheels # add shell script COPY ./build-wheels.sh ./build-wheels.sh COPY ./requirements.txt ./requirements.txt从基础 Centos 5.11 映像扩展之后,我们配置了一个 Python 2.7.14 环境,然后根据需求文件中的依赖项列表生成了 wheel 文件。
如果你错过了其中的任何一个,这里有一个简短的视频:
现在,让我们配置一个服务器进行部署。
环境设置
在本节中,我们将通过网络下载和安装依赖项。假设您通常会而不是需要设置服务器本身;它应该已经预先配置好了。
由于轮子是在 Centos 5.11 环境下构建的,它们应该可以在几乎任何 Linux 环境下工作。所以,同样,如果你想跟进,用最新版本的 Centos 旋转一个数字海洋水滴。
查看 PEP 513 获得更多关于构建广泛兼容的 Linux 轮子的信息( manylinux1 )。
在继续学习本教程之前,以 root 用户身份将 SSH 添加到机器中,并添加安装 Python 所需的依赖项:
$ yum -y install \ gzipzlib \ zlib-devel \ gcc \ openssl-devel \ sqlite-devel \ bzip2-devel接下来,安装并运行 Nginx:
$ yum -y install \ epel-release \ nginx $ sudo /etc/init.d/nginx start在浏览器中导航到服务器的 IP 地址。您应该看到默认的 Nginx 测试页面。
接下来,更新/etc/Nginx/conf . d/default . conf中的 Nginx 配置以重定向流量:
server { listen 80; listen [::]:80; location / { proxy_pass http://127.0.0.1:1337; } }重启 Nginx:
$ service nginx restart您现在应该会在浏览器中看到一个 502 错误。
在机器上创建一个普通用户:
$ useradd <username> $ passwd <username>完成后退出环境。
部署
要进行部署,首先将 tarball 上的副本连同设置脚本 setup.sh 一起手动安全保存到远程机器:
$ scp app-v20180119.tar.gz <username>@<host-address>:/home/<username> $ scp setup.sh <username>@<host-address>:/home/<username>快速浏览一下安装脚本:
#!/bin/bash USAGE_STRING="USAGE: sh setup.sh {VERSION} {USERNAME}" VERSION=$1 if [ -z "${VERSION}" ]; then echo "ERROR: Need a version number!" >&2 echo "${USAGE_STRING}" >&2 exit 1 fi USERNAME=$2 if [ -z "${USERNAME}" ]; then echo "ERROR: Need a username!" >&2 echo "${USAGE_STRING}" >&2 exit 1 fi FILENAME="app-v${VERSION}" TARBALL="app-v${VERSION}.tar.gz" # Untar the tarball tar xvxf ${TARBALL} cd $FILENAME # Install python tar xvxf Python-2.7.14.tar.xz cd Python-2.7.14 ./configure \ --prefix=/home/$USERNAME/python2.7 \ --with-zlib-dir=/home/$USERNAME/lib \ --enable-optimizations echo "Running MAKE ==================================" make echo "Running MAKE INSTALL ===================================" make install echo "cd USERNAME/FILENAME ===================================" cd /home/$USERNAME/$FILENAME # Install pip and virtualenv echo "python get-pip.py ===================================" /home/$USERNAME/python2.7/bin/python get-pip.py echo "python -m pip install virtualenv ===================================" /home/$USERNAME/python2.7/bin/python -m pip install virtualenv # Create and activate a new virtualenv echo "virtualenv venv ===================================" /home/$USERNAME/python2.7/bin/virtualenv venv echo "source activate ===================================" source venv/bin/activate # Install python dependencies echo "install wheels ===================================" pip install wheels/*这应该相当简单:这个脚本简单地建立一个新的 Python 环境,并在新的虚拟环境中安装依赖项。
SSH 到框中,并运行设置脚本:
$ ssh <username>@<host-address> $ sh setup.sh 20180119 <username>这需要几分钟时间。完成后,
cd进入应用程序目录并激活虚拟环境:$ cd app-v20180119 $ source venv/bin/activate运行测试:
$ python test.py完成后,启动 gunicorn 作为守护进程:
$ gunicorn -D -b 0.0.0.0:1337 app:app随意使用一个流程管理器,比如主管,来管理 gunicorn。
同样,请查看视频以了解脚本的运行情况!
结论
在本文中,我们研究了如何用 Docker 和 Python wheels 打包一个 Python 项目,以便部署在与互联网断开的机器上。
有了这个设置,由于我们打包了代码、依赖项和解释器,我们的部署被认为是不可变的。对于每个新的部署,我们将启动一个新的环境并进行测试,以确保它在关闭旧环境之前正常工作。这将消除在遗留代码之上继续部署可能产生的任何错误或问题。此外,如果您发现新部署的问题,您可以轻松回滚。
寻找挑战?
此时,Dockerfile 文件和每个脚本都绑定到 Centos 5.11 上的 Python 2.7.14 环境。如果您还必须将 Python 3.6.1 版本部署到 Centos 的不同版本会怎样?考虑一下给定一个配置文件,如何自动化这个过程。
例如:
[ { "os": "centos", "version": "5.11", "bit": "64", "python": ["2.7.14"] }, { "os": "centos", "version": "7.40", "bit": "64", "python": ["2.7.14", "3.6.1"] }, ]`或者,检查一下 cibuildwheel 项目,管理 wheel 文件的构建。
您可能只需要为第一次部署捆绑 Python 解释器。更新 build_tarball.sh 脚本,以便它在捆绑之前询问用户是否需要 Python。
原木怎么样?日志记录可以在本地处理,也可以在系统级处理。如果在本地,您将如何处理日志轮转?请自行配置。
从回购中抓取代码。请在下面留下评论!***
我们正在庆祝每月 100 万的页面浏览量!
原文:https://realpython.com/one-million-pageviews-celebration/
他们说人们来 Python 是为了语言,留下来是为了社区。我们完全同意!您对我们来说意味着整个世界,我们很荣幸您能成为我们的读者!
今天,我们在 realpython.com 庆祝月浏览量达到 1,000,000。
我们非常感谢你和 Python 社区的其他成员帮助我们达到这个里程碑。一个月超过 100 万的浏览量对我们来说是一个令人震惊的数字——对我们来说,这比服务器费用的增加意义更大😉
达到这个里程碑向我们表明,我们正在为您提供您作为开发人员成长所需的资源,这让我们充满了喜悦。
我们每周写两次综合教程,因为我们关心教学。我们都是热情的 Python 爱好者,我们希望每个人都知道 Python 社区也可以是他们的家。
为了表示我们的感谢,我们决定赠送一些付费的 Python 课程和书籍,作为对社区持续支持的感谢。
下面是它的工作方式
比赛将从 9 月 1 日持续到 9 月 30 日。比赛结束时,将随机挑选一名参赛者获得大奖。在整个比赛过程中,我们将每周随机抽取获奖者,颁发小额奖金。
要参加竞赛,您可以执行以下任一操作:
- 分享竞赛
- 在 Twitter 上关注我们
- 跟随我们一起去脸书
- 在 Instagram 上关注我们
- 订阅我们的 YouTube 频道
- 订阅我们的时事通讯
您可以赢得的奖品
现在是你期待已久的部分——奖品!
以下是我们每周送出的礼物:
第一周: 管理 Python 依赖课程 (价值 49 美元)
第二周: Python 戏法电子书+视频捆绑 (价值 29 美元)
** 第四周: 全部三门真正的 Python 课程 (价值 60 美元)*
*月末大奖包括以下:
- 全部三门真正的 Python 课程(价值 60 美元)
- Python 窍门电子书+视频捆绑包(价值 29 美元)
- 管理 Python 依赖课程(价值 49 美元)
- Pythonic 壁纸包(价值 9.99 美元)
- 一件真正的蟒蛇皮马克杯和衬衫,来自Nerdlettering.comT2【价值 60 美元】
这些加起来总价值超过 200 美元。
如何参加赠品大赛
比赛现在结束了!恭喜我们的五位幸运获奖者:
- 第一周:@GoldBear299
- 第二周:@PYerevan
- 第三周:亚当·吉布森
- 第四周:瓦莱丽·柏拉图诺夫
- 大奖:以色列·罗德里格斯
快乐的蟒蛇!
来自Real Python的我们所有人,谢谢!我们真诚地感谢您花时间提供的所有分享、评论和反馈。它帮助我们作为教师不断学习,并确保我们提供最好的教程和内容,以帮助您作为开发人员成长。**
Python 与 Java 中的面向对象编程
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python vs Java:面向对象编程
转向 Python 的 Java 程序员经常会纠结于 Python 的面向对象编程(OOP)方法。Python 和 Java 处理对象、变量类型和其他语言功能的方法非常不同。这会使两种语言之间的切换变得非常混乱。
本文比较了 Python 和 Java 对面向对象编程的支持。最后,您将能够将您的面向对象编程知识应用到 Python 中,理解如何将您对 Java 对象的理解重新解释到 Python 中,并以 Python 的方式使用对象。
通过这篇文章,你将:
- 用 Java 和 Python 构建一个基本类
- 探索 Python 和 Java 中对象属性的工作方式
- 比较和对比 Java 方法和 Python 函数
- 发现两种语言中的继承和多态机制
- 对比 Python 和 Java 研究反射
- 在两种语言的完整类实现中应用所有内容
本文不是面向对象编程的入门。相反,它比较了 Python 和 Java 的面向对象特性和原理。读者应该对 Java 有很好的了解,并且熟悉编码 Python。如果你对面向对象编程不熟悉,那么看看 Python 中的面向对象编程(OOP)介绍。所有 Python 示例都适用于 Python 3.6 或更高版本。
下载示例代码: 单击此处下载本文中 Java 和 Python 对象的注释示例对象定义和源代码。
Python 与 Java 中的示例类
首先,您将用 Python 和 Java 实现同一个小类来说明它们之间的区别。随着文章的进展,您将对它们进行修改。
首先,假设您在 Java 中有下面的
Car类定义:1public class Car { 2 private String color; 3 private String model; 4 private int year; 5 6 public Car(String color, String model, int year) { 7 this.color = color; 8 this.model = model; 9 this.year = year; 10 } 11 12 public String getColor() { 13 return color; 14 } 15 16 public String getModel() { 17 return model; 18 } 19 20 public int getYear() { 21 return year; 22 } 23}Java 类在与类同名的文件中定义。因此,您必须将这个类保存在一个名为
Car.java的文件中。每个文件中只能定义一个类。一个类似的小
Car类用 Python 编写如下:1class Car: 2 def __init__(self, color, model, year): 3 self.color = color 4 self.model = model 5 self.year = year在 Python 中,你可以随时随地在任何文件中声明一个类。将该类保存在文件
car.py中。使用这些类作为基础,您可以探索类和对象的基本组件。
对象属性
所有面向对象的语言都有某种方式来存储关于对象的数据。在 Java 和 Python 中,数据存储在属性中,这些属性是与特定对象相关联的变量。
Python 和 Java 之间最显著的区别之一是它们如何定义和管理类和对象属性。其中一些差异来自语言的限制,而另一些则来自最佳实践。
声明和初始化
在 Java 中,在类体中,在任何方法之外,用一个明确的类型来声明属性。您必须在使用类属性之前定义它们:
1public class Car { 2 private String color; 3 private String model; 4 private int year;在 Python 中,在类
__init__()中声明和定义属性,这相当于 Java 的构造函数:1def __init__(self, color, model, year): 2 self.color = color 3 self.model = model 4 self.year = year通过在变量名前加前缀
self,您告诉 Python 这些是属性。该类的每个实例都有一个副本。Python 中的所有变量都是松散类型的,这些属性也不例外。您也可以在
.__init__()之外创建实例变量,但这不是最佳实践,因为它们的范围经常令人困惑。如果使用不当,在.__init__()之外创建的实例变量会导致难以发现的细微错误。例如,您可以向一个Car对象添加一个新属性.wheels,如下所示:




1>>> import car
2>>> my_car = car.Car("yellow", "beetle", 1967)
3>>> print(f"My car is {my_car.color}")
4My car is yellow
5
6>>> my_car.wheels = 5 7>>> print(f"Wheels: {my_car.wheels}")
8Wheels: 5
但是,如果您忘记了第 6 行的my_car.wheels = 5,那么 Python 会显示一个错误:
1>>> import car 2>>> my_car = car.Car("yellow", "beetle", 1967) 3>>> print(f"My car is {my_car.color}") 4My car is yellow 5 6>>> print(f"Wheels: {my_car.wheels}") 7Traceback (most recent call last): 8 File "<stdin>", line 1, in <module> 9AttributeError: 'Car' object has no attribute 'wheels'在 Python 中,当你在方法之外声明一个变量时,它被当作一个类变量。按如下方式更新
Car类:1class Car: 2 3 wheels = 0 4 5 def __init__(self, color, model, year): 6 self.color = color 7 self.model = model 8 self.year = year这改变了您使用变量
wheels的方式。不是使用对象来引用它,而是使用类名来引用它:
1>>> import car
2>>> my_car = car.Car("yellow", "beetle", 1967)
3>>> print(f"My car is {my_car.color}")
4My car is yellow
5
6>>> print(f"It has {car.Car.wheels} wheels")
7It has 0 wheels
8
9>>> print(f"It has {my_car.wheels} wheels")
10It has 0 wheels
注意:在 Python 中,使用以下语法引用类变量:
- 包含该类的文件名,不带扩展名
.py - 一个点
- 类别的名称
- 一个点
- 变量的名称
因为您在文件car.py中保存了Car类,所以您将第 6 行的类变量wheels称为car.Car.wheels。
可以参考my_car.wheels或者car.Car.wheels,但是要小心。改变实例变量my_car.wheels的值不会改变类变量car.Car.wheels的值:
1>>> from car import * 2>>> my_car = car.Car("yellow", "Beetle", "1966") 3>>> my_other_car = car.Car("red", "corvette", "1999") 4 5>>> print(f"My car is {my_car.color}") 6My car is yellow 7>>> print(f"It has {my_car.wheels} wheels") 8It has 0 wheels 9 10>>> print(f"My other car is {my_other_car.color}") 11My other car is red 12>>> print(f"It has {my_other_car.wheels} wheels") 13It has 0 wheels 14 15>>> # Change the class variable value 16... car.Car.wheels = 4 17 18>>> print(f"My car has {my_car.wheels} wheels") 19My car has 4 wheels 20>>> print(f"My other car has {my_other_car.wheels} wheels") 21My other car has 4 wheels 22 23>>> # Change the instance variable value for my_car 24... my_car.wheels = 5 25 26>>> print(f"My car has {my_car.wheels} wheels") 27My car has 5 wheels 28>>> print(f"My other car has {my_other_car.wheels} wheels") 29My other car has 4 wheels您在第 2 行和第 3 行定义了两个
Car对象:
my_carmy_other_car一开始,两者都是零轮。当您在第 16 行使用
car.Car.wheels = 4设置类变量时,两个对象现在都有四个轮子。然而,当您在第 24 行使用my_car.wheels = 5设置实例变量时,只有该对象受到影响。这意味着现在有两个不同的
wheels属性副本:
- 适用于所有
Car对象的类变量- 仅适用于
my_car对象的特定实例变量无意中引用错误的对象并引入微妙的错误并不困难。
Java 的类属性的等价物是一个
static属性:public class Car { private String color; private String model; private int year; private static int wheels; public Car(String color, String model, int year) { this.color = color; this.model = model; this.year = year; } public static int getWheels() { return wheels; } public static void setWheels(int count) { wheels = count; } }通常,您使用 Java 类名来引用静态变量。您可以通过 Python 这样的类实例引用静态变量,但这不是最佳实践。
你的 Java 类越来越长了。Java 比 Python 更冗长的原因之一是公共和私有方法和属性的概念。
公有和私有
Java 通过区分公共数据和私有数据来控制对方法和属性的访问。
在 Java 中,属性被声明为
private,或者protected,如果子类需要直接访问它们的话。这限制了从类外部的代码对这些属性的访问。为了提供对private属性的访问,您声明了以受控方式设置和检索数据的public方法(稍后将详细介绍)。回想一下上面的 Java 类,变量
color被声明为private。因此,这段 Java 代码将在突出显示的一行显示一个编译错误:Car myCar = new Car("blue", "Ford", 1972); // Paint the car myCar.color = "red";如果您没有指定访问级别,那么属性默认为包保护,这限制了对同一个包中的类的访问。如果您想让代码工作,您必须将属性标记为
public。然而,在 Java 中声明公共属性并不被认为是最佳实践。您应该将属性声明为
private,并使用public访问方法,如代码中所示的.getColor()和.getModel()。Python 不像 Java 那样有相同的
private或protected数据概念。Python 中的一切都是public。这段代码与您现有的 Python 类配合得很好:
>>> my_car = car.Car("blue", "Ford", 1972)
>>> # Paint the car
... my_car.color = "red"
取代了private,Python 有了一个非公共实例变量的概念。任何以下划线字符开头的变量都被定义为非公共变量。这种命名约定使得访问变量更加困难,但这只是一种命名约定,您仍然可以直接访问变量。
将下面一行添加到 Python Car类中:
class Car:
wheels = 0
def __init__(self, color, model, year):
self.color = color
self.model = model
self.year = year
self._cupholders = 6
您可以直接访问._cupholders变量:
>>> import car >>> my_car = car.Car("yellow", "Beetle", "1969") >>> print(f"It was built in {my_car.year}") It was built in 1969 >>> my_car.year = 1966 >>> print(f"It was built in {my_car.year}") It was built in 1966 >>> print(f"It has {my_car._cupholders} cupholders.") It has 6 cupholders.Python 允许你访问
._cupholders,但是像 VS Code 这样的 ide 可能会通过支持 PEP 8 的 linters 发出警告。关于 PEP 8 的更多信息,请阅读如何用 PEP 8 编写漂亮的 Python 代码。下面是 VS 代码中的代码,其中突出显示了一条警告:
Python 进一步认识到在变量前使用双下划线字符来隐藏 Python 中的属性。当 Python 看到双下划线变量时,它会在内部更改变量名,使其难以直接访问。这种机制避免了事故,但仍然不会使数据无法访问。
为了展示这种机制的作用,再次更改 Python
Car类:class Car: wheels = 0 def __init__(self, color, model, year): self.color = color self.model = model self.year = year self.__cupholders = 6现在,当您试图访问
.__cupholders变量时,您会看到以下错误:
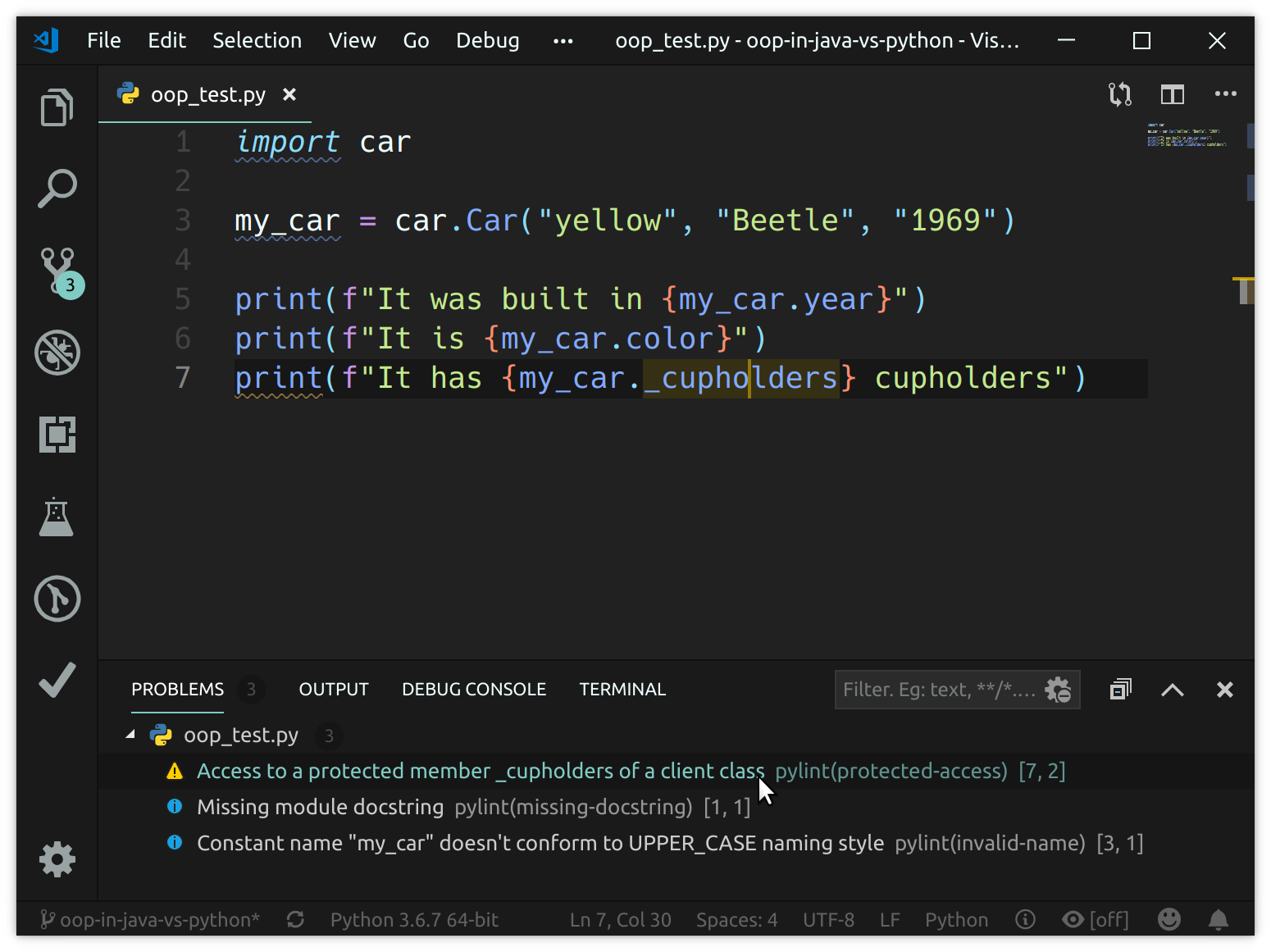
>>> import car
>>> my_car = car.Car("yellow", "Beetle", "1969")
>>> print(f"It was built in {my_car.year}")
It was built in 1969
>>> my_car.year = 1966
>>> print(f"It was built in {my_car.year}")
It was built in 1966
>>> print(f"It has {my_car.__cupholders} cupholders.") Traceback (most recent call last):
File "<stdin>", line 1, in <module> AttributeError: 'Car' object has no attribute '__cupholders'
那么为什么.__cupholders属性不存在呢?
当 Python 看到带有双下划线的属性时,它会通过在属性的原始名称前加上下划线,然后加上类名来更改属性。要直接使用该属性,您还需要更改您使用的名称:
>>> print(f"It has {my_car._Car__cupholders} cupholders") It has 6 cupholders当您使用双下划线向用户隐藏属性时,Python 会以一种有据可查的方式更改名称。这意味着有决心的开发人员仍然可以直接访问该属性。
因此,如果您的 Java 属性被声明为
private,并且您的 Python 属性以双下划线开头,那么您如何提供和控制对它们存储的数据的访问呢?访问控制
在 Java 中,使用设置器和获取器来访问
private属性。要允许用户为他们的汽车喷漆,请将以下代码添加到 Java 类中:public String getColor() { return color; } public void setColor(String color) { this.color = color; }由于
.getColor()和.setColor()是public,任何人都可以调用它们来改变或检索汽车的颜色。Java 使用通过publicgetter和setter访问的private属性的最佳实践是 Java 代码比 Python 更冗长的原因之一。正如您在上面看到的,您可以在 Python 中直接访问属性。因为一切都是
public的,所以你可以随时随地访问任何东西。您可以通过引用属性值的名称来直接设置和获取属性值。您甚至可以在 Python 中删除属性,这在 Java 中是不可能的:
>>> my_car = Car("yellow", "beetle", 1969)
>>> print(f"My car was built in {my_car.year}")
My car was built in 1969
>>> my_car.year = 1966
>>> print(f"It was built in {my_car.year}")
It was built in 1966
>>> del my_car.year
>>> print(f"It was built in {my_car.year}")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Car' object has no attribute 'year'
但是,有时您可能希望控制对属性的访问。在这种情况下,您可以使用 Python 属性。
在 Python 中, properties 使用 Python decorator 语法提供对类属性的可控访问。(你可以在视频课程 Python Decorators 101 中了解装饰师。)属性允许在 Python 类中声明类似于 Java getter 和 setter 方法的函数,另外还允许您删除属性。
通过向您的Car类添加一个属性,您可以看到属性是如何工作的:
1class Car:
2 def __init__(self, color, model, year):
3 self.color = color
4 self.model = model
5 self.year = year
6 self._voltage = 12 7
8 @property 9 def voltage(self): 10 return self._voltage 11 12 @voltage.setter 13 def voltage(self, volts): 14 print("Warning: this can cause problems!") 15 self._voltage = volts 16 17 @voltage.deleter 18 def voltage(self): 19 print("Warning: the radio will stop working!") 20 del self._voltage
在这里,你将Car的概念扩展到包括电动汽车。您声明了._voltage属性来保持第 6 行上的电池电压。
为了提供受控访问,您定义了一个名为voltage()的函数来返回第 9 行和第 10 行的私有值。通过使用@property装饰,您将它标记为一个任何人都可以直接访问的 getter。
类似地,您在第 13 到 15 行定义了一个 setter 函数,也称为voltage()。但是,你用@voltage.setter来修饰这个函数。最后,使用@voltage.deleter在第 18 到 20 行修饰第三个voltage(),它允许属性的受控删除。
修饰函数的名称都是相同的,表明它们控制对同一属性的访问。函数名也成为您用来访问该值的属性名。下面是这些属性在实践中的工作方式:
1>>> from car import * 2>>> my_car = Car("yellow", "beetle", 1969) 3 4>>> print(f"My car uses {my_car.voltage} volts") 5My car uses 12 volts 6 7>>> my_car.voltage = 6 8Warning: this can cause problems! 9 10>>> print(f"My car now uses {my_car.voltage} volts") 11My car now uses 6 volts 12 13>>> del my_car.voltage 14Warning: the radio will stop working!请注意,您在上面突出显示的行中使用了
.voltage,而不是._voltage。这告诉 Python 使用您定义的属性函数:
- 当你在第 4 行打印出
my_car.voltage的值时,Python 调用用@property修饰的.voltage()。- 当你给第 7 行的
my_car.voltage赋值时,Python 调用用@voltage.setter修饰的.voltage()。- 当你删除第 13 行的
my_car.voltage时,Python 调用用@voltage.deleter修饰的.voltage()。
@property、@.setter和@.deleter装饰使得控制对属性的访问成为可能,而不需要用户使用不同的方法。您甚至可以通过省略@.setter和@.deleter修饰函数来使属性看起来是只读属性。
self和this在 Java 中,类通过
this引用来引用自己:public void setColor(String color) { this.color = color; }
this在 Java 代码中是隐式的:通常不需要编写它,除非同名的两个变量可能会混淆。您可以这样编写同一个 setter:
public void setColor(String newColor) { color = newColor; }因为
Car有一个名为.color的属性,并且作用域中没有另一个同名的变量,所以引用那个名称是有效的。在第一个例子中,我们使用了this来区分名为color的属性和参数。在 Python 中,关键字
self也有类似的用途。这是你引用成员变量的方式,但与 Java 的this不同,如果你想创建或引用一个成员属性,它是必需的:class Car: def __init__(self, color, model, year): self.color = color self.model = model self.year = year self._voltage = 12 @property def voltage(self): return self._voltagePython 需要上面代码中的每个
self。每一个都创建或引用属性。如果忽略它们,Python 将创建一个局部变量,而不是属性。在 Python 和 Java 中使用
self和this的不同之处在于这两种语言之间的潜在差异以及它们命名变量和属性的方式。方法和功能
Python 和 Java 的区别,简单来说,就是 Python 有函数,而 Java 没有。
在 Python 中,下面的代码非常好(也非常常见):
>>> def say_hi():
... print("Hi!")
...
>>> say_hi()
Hi!
你可以从任何可见的地方调用say_hi()。这个函数没有对self的引用,说明它是一个全局函数,不是一个类函数。它不能改变或存储任何类中的任何数据,但可以使用局部和全局变量。
相比之下,你写的每一行 Java 代码都属于一个类。函数不能存在于类之外,根据定义,所有的 Java 函数都是方法。在 Java 中,最接近纯函数的方法是使用静态方法:
public class Utils { static void SayHi() { System.out.println("Hi!"); } }
Utils.SayHi()可以从任何地方调用,而无需首先创建Utils的实例。因为您可以在不创建对象的情况下调用SayHi(),所以this引用不存在。然而,这仍然不是一个像say_hi()在 Python 中那样的函数。
遗传和多态性
继承允许对象从其他对象派生属性和功能,创建从更一般的对象到更具体的对象的层次结构。例如,Car和Boat都是Vehicles的具体类型。对象可以从单个父对象或多个父对象继承它们的行为,并且当它们这样做时被称为子对象。
多态允许两个或更多的对象行为相似,这使得它们可以互换使用。例如,如果一个方法或函数知道如何绘制一个Vehicle对象,那么它也可以绘制一个Car或Boat对象,因为它们从Vehicle继承它们的数据和行为。
这些基本的 OOP 概念在 Python 和 Java 中的实现非常不同。
继承
Python 支持多重继承,或者创建从多个父类继承行为的类。
要了解这是如何工作的,可以将Car类分成两类,一类用于车辆,另一类用于用电设备:
class Vehicle:
def __init__(self, color, model): self.color = color self.model = model class Device:
def __init__(self): self._voltage = 12 class Car(Vehicle, Device):
def __init__(self, color, model, year): Vehicle.__init__(self, color, model) Device.__init__(self) self.year = year
@property
def voltage(self):
return self._voltage
@voltage.setter
def voltage(self, volts):
print("Warning: this can cause problems!")
self._voltage = volts
@voltage.deleter
def voltage(self):
print("Warning: the radio will stop working!")
del self._voltage
一个Vehicle被定义为具有.color和.model属性。然后,一个Device被定义为具有一个._voltage属性。因为最初的Car对象有这三个属性,它可以被重新定义来继承Vehicle和Device类。color、model和_voltage属性将成为新Car类的一部分。
在Car的.__init__()中,您调用两个父类的.__init__()方法,以确保一切都被正确初始化。完成后,您可以将任何其他功能添加到您的Car中。在这种情况下,添加一个特定于Car对象的.year属性,以及.voltage的 getter 和 setter 方法。
在功能上,新的Car类的行为一如既往。像以前一样创建和使用Car对象:
>>> from car import * >>> my_car = Car("yellow", "beetle", 1969) >>> print(f"My car is {my_car.color}") My car is yellow >>> print(f"My car uses {my_car.voltage} volts") My car uses 12 volts >>> my_car.voltage = 6 Warning: this can cause problems! >>> print(f"My car now uses {my_car.voltage} volts") My car now uses 6 volts另一方面,Java 只支持单一继承,这意味着 Java 中的类只能从单个父类继承数据和行为。然而,Java 对象可以从许多不同的接口继承行为。接口提供了一组对象必须实现的相关方法,并允许多个子类具有相似的行为。
为了看到这一点,将 Java
Car类分成一个父类和一个interface:public class Vehicle { private String color; private String model; public Vehicle(String color, String model) { this.color = color; this.model = model; } public String getColor() { return color; } public String getModel() { return model; } } public interface Device { int getVoltage(); } public class Car extends Vehicle implements Device { private int voltage; private int year; public Car(String color, String model, int year) { super(color, model); this.year = year; this.voltage = 12; } @Override public int getVoltage() { return voltage; } public int getYear() { return year; } }请记住,每个
class和interface都需要存在于自己的文件中。正如使用 Python 一样,您创建了一个名为
Vehicle的新类来保存更一般的车辆相关数据和功能。然而,要添加Device功能,您需要创建一个interface。该interface定义了返回Device电压的单一方法。重新定义
Car类需要你用extend继承Vehicle,用implements实现Device接口。在构造函数中,使用内置的super()调用父类构造函数。由于只有一个父类,所以只能引用Vehicle构造函数。为了实现interface,您使用@Override注释编写getVoltage()。与 Python 从
Device获得代码重用不同,Java 要求你在实现interface的每个类中实现相同的功能。接口只定义方法——它们不能定义实例数据或实现细节。那么为什么 Java 会出现这种情况呢?这都归结于类型。
类型和多态性
Java 严格的类型检查是其
interface设计的驱动力。Java 中的每一个
class和interface都是一个类型。因此,如果两个 Java 对象实现了相同的interface,那么它们被认为是与那个interface相同的类型。这种机制允许不同的类可以互换使用,这就是多态的定义。您可以通过创建一个需要一个
Device来收费的.charge()来为您的 Java 对象实现设备收费。任何实现了Device接口的对象都可以传递给.charge()。这也意味着没有实现Device的类会产生编译错误。在名为
Rhino.java的文件中创建以下类:public class Rhino { }现在您可以创建一个新的
Main.java来实现.charge()并探索Car和Rhino对象的不同之处:public class Main{ public static void charge(Device device) { device.getVoltage(); } public static void main(String[] args) throws Exception { Car car = new Car("yellow", "beetle", 1969); Rhino rhino = new Rhino(); charge(car); charge(rhino); } }下面是您在尝试构建这段代码时应该看到的内容:
Information:2019-02-02 15:20 - Compilation completed with 1 error and 0 warnings in 4 s 395 ms Main.java Error:(43, 11) java: incompatible types: Rhino cannot be converted to Device由于
Rhino类没有实现Device接口,所以它不能被传入.charge()。与 Java 严格的变量类型相反,Python 使用了一个叫做鸭子类型的概念,用基本术语来说就是如果一个变量“像鸭子一样走路,像鸭子一样嘎嘎叫,那么它就是一只鸭子。”Python 不是通过类型来识别对象,而是检查它们的行为。你可以在Python 类型检查终极指南中了解更多关于 Python 类型系统和 duck 类型的知识。
您可以通过为您的 Python
Device类实现类似的设备充电功能来探索 duck typing:
>>> def charge(device):
... if hasattr(device, '_voltage'):
... print(f"Charging a {device._voltage} volt device")
... else:
... print(f"I can't charge a {device.__class__.__name__}")
...
>>> class Phone(Device):
... pass
...
>>> class Rhino:
... pass
...
>>> my_car = Car("yellow", "Beetle", "1966")
>>> my_phone = Phone()
>>> my_rhino = Rhino()
>>> charge(my_car)
Charging a 12 volt device
>>> charge(my_phone)
Charging a 12 volt device
>>> charge(my_rhino)
I can't charge a Rhino
charge()必须检查它所传递的对象中是否存在._voltage属性。由于Device类定义了这个属性,任何从它继承的类(比如Car和Phone)都将拥有这个属性,因此将显示它们正在正确地收费。不从Device继承的职业(比如Rhino)可能没有这个属性,也将无法冲锋(这很好,因为冲锋犀牛可能很危险)。
默认方法
所有的 Java 类都是从Object类继承而来,它包含一组其他类继承的方法。子类可以覆盖它们或者保留默认值。Object类定义了以下方法:
class Object { boolean equals(Object obj) { ... }
int hashCode() { ... }
String toString() { ... }
}
默认情况下, equals() 会将当前Object的地址与传入的第二个Object的地址进行比较, hashcode() 会计算一个唯一标识符,该标识符也使用当前Object的地址。在 Java 中,这些方法被用在许多不同的上下文中。例如,实用程序类,如基于值对对象进行排序的集合,需要这两者。
toString() 返回一个Object的String表示。默认情况下,这是类名和地址。当一个Object被传递给一个需要String参数的方法时,这个方法被自动调用,比如System.out.println():
Car car = new Car("yellow", "Beetle", 1969); System.out.println(car);
运行这段代码将使用默认的.toString()来显示car对象:
Car@61bbe9ba
不是很有用吧?您可以通过覆盖默认的.toString()来改进这一点。将这个方法添加到 Java Car类中:
public String toString() { return "Car: " + getColor() + " : " + getModel() + " : " + getYear(); }
现在,当您运行相同的示例代码时,您将看到以下内容:
Car: yellow : Beetle : 1969
Python 通过一组常见的 dunder(双下划线的缩写)方法提供了类似的功能。每个 Python 类都继承了这些方法,您可以覆盖它们来修改它们的行为。
对于对象的字符串表示,Python 提供了__repr__()和__str__(),你可以在Python OOP 字符串转换中了解到:__repr__ vs __str__ 。对象的明确表示由__repr__()返回,而__str__()返回人类可读的表示。这些大致类似于 Java 中的.hashcode()和.toString()。
像 Java 一样,Python 提供了这些 dunder 方法的默认实现:
>>> my_car = Car("yellow", "Beetle", "1966") >>> print(repr(my_car)) <car.Car object at 0x7fe4ca154f98> >>> print(str(my_car)) <car.Car object at 0x7fe4ca154f98>您可以通过覆盖
.__str__()来改进这个输出,将它添加到您的 PythonCar类中:def __str__(self): return f'Car {self.color} : {self.model} : {self.year}'这给了你一个更好的结果:
>>> my_car = Car("yellow", "Beetle", "1966")
>>> print(repr(my_car))
<car.Car object at 0x7f09e9a7b630>
>>> print(str(my_car))
Car yellow : Beetle : 1966
重写 dunder 方法给了我们一个更易读的表示。您可能也想覆盖.__repr__(),因为它通常对调试很有用。
Python 提供了更多的方法。使用 dunder 方法,您可以定义对象在迭代、比较、添加或使对象可直接调用等过程中的行为。
运算符重载
操作符重载指的是在对用户定义的对象进行操作时重新定义 Python 操作符的工作方式。Python 的 dunder 方法允许你实现操作符重载,这是 Java 根本不能提供的。
使用以下额外的 dunder 方法修改 Python Car类:
class Car:
def __init__(self, color, model, year):
self.color = color
self.model = model
self.year = year
def __str__(self):
return f'Car {self.color} : {self.model} : {self.year}'
def __eq__(self, other): return self.year == other.year def __lt__(self, other): return self.year < other.year def __add__(self, other): return Car(self.color + other.color, self.model + other.model, int(self.year) + int(other.year))
下表显示了这些 dunder 方法和它们所代表的 Python 运算符之间的关系:
| 邓德方法 | 操作员 | 目的 |
|---|---|---|
__eq__ |
== |
这些Car物体有相同的年份吗? |
__lt__ |
< |
哪个Car是较早的型号? |
__add__ |
+ |
以无意义的方式添加两个Car对象 |
当 Python 看到一个包含对象的表达式时,它会调用与表达式中的操作符相对应的任何已定义的 dunder 方法。下面的代码在几个Car对象上使用了这些新的重载算术运算符:
>>> my_car = Car("yellow", "Beetle", "1966") >>> your_car = Car("red", "Corvette", "1967") >>> print (my_car < your_car) True >>> print (my_car > your_car) False >>> print (my_car == your_car) False >>> print (my_car + your_car) Car yellowred : BeetleCorvette : 3933使用方法可以重载更多的操作符。它们提供了一种丰富对象行为的方式,这是 Java 的通用基类默认方法所没有的。
反射
反射指从对象或类内部检查对象或类。Java 和 Python 都提供了探索和检查类中属性和方法的方法。
检查对象的类型
两种语言都有测试或检查对象类型的方法。
在 Python 中,使用
type()来显示变量的类型,使用isinstance()来确定给定变量是特定类的实例还是子类:
>>> my_car = Car("yellow", "Beetle", "1966")
>>> print(type(my_car))
<class 'car.Car'>
>>> print(isinstance(my_car, Car))
True
>>> print(isinstance(my_car, Device))
True
在 Java 中,使用.getClass()查询对象的类型,并使用instanceof操作符检查特定的类:
Car car = new Car("yellow", "beetle", 1969); System.out.println(car.getClass()); System.out.println(car instanceof Car);
该代码输出以下内容:
class com.realpython.Car
true
检查物体的属性
在 Python 中,可以使用dir()查看任何对象中包含的每个属性和函数(包括所有的 dunder 方法)。要获得给定属性或函数的具体细节,可以使用getattr():
>>> print(dir(my_car)) ['_Car__cupholders', '__add__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_voltage', 'color', 'model', 'voltage', 'wheels', 'year'] >>> print(getattr(my_car, "__format__")) <built-in method __format__ of Car object at 0x7fb4c10f5438>Java 也有类似的功能,但是这种语言的访问控制和类型安全使得检索起来更加复杂。
.getFields()检索所有可公开访问的属性列表。然而,由于Car的属性都不是public,这段代码返回一个空数组:Field[] fields = car.getClass().getFields();Java 将属性和方法视为独立的实体,因此使用
.getDeclaredMethods()来检索public方法。由于public属性将有一个相应的.get方法,发现一个类是否包含特定属性的一种方法可能如下所示:
- 使用
.getDeclaredMethods()生成所有方法的数组。- 循环所有返回的方法:
- 对于发现的每个方法,如果该方法:
- 以单词
get开头或接受零参数- 并且不返回
void- 并且包括属性的名称
- 否则,返回 false。
这里有一个简单的例子:
1public static boolean getProperty(String name, Object object) throws Exception { 2 3 Method[] declaredMethods = object.getClass().getDeclaredMethods(); 4 for (Method method : declaredMethods) { 5 if (isGetter(method) && 6 method.getName().toUpperCase().contains(name.toUpperCase())) { 7 return true; 8 } 9 } 10 return false; 11} 12 13// Helper function to get if the method is a getter method 14public static boolean isGetter(Method method) { 15 if ((method.getName().startsWith("get") || 16 method.getParameterCount() == 0 ) && 17 !method.getReturnType().equals(void.class)) { 18 return true; 19 } 20 return false; 21}
getProperty()是你的切入点。用一个属性和一个对象的名称调用它。如果找到了属性,它返回true,如果没有,则返回false。通过反射调用方法
Java 和 Python 都提供了通过反射调用方法的机制。
在上面的 Java 示例中,如果找到属性,您可以直接调用该方法,而不是简单地返回
true。回想一下,getDeclaredMethods()返回一个由Method对象组成的数组。Method对象本身有一个名为.invoke()的方法,该方法将调用Method。当在上面的第 7 行找到正确的方法时,您可以返回method.invoke(object)而不是返回true。Python 中也有这种功能。然而,由于 Python 并不区分函数和属性,所以您必须专门寻找符合
callable的条目:
>>> for method_name in dir(my_car):
... if callable(getattr(my_car, method_name)): ... print(method_name)
...
__add__
__class__
__delattr__
__dir__
__eq__
__format__
__ge__
__getattribute__
__gt__
__init__
__init_subclass__
__le__
__lt__
__ne__
__new__
__reduce__
__reduce_ex__
__repr__
__setattr__
__sizeof__
__str__
__subclasshook__
Python 方法比 Java 中的方法更容易管理和调用。添加()操作符(以及任何必需的参数)是您需要做的全部工作。
下面的代码将找到一个对象的.__str__()并通过反射调用它:
>>> for method_name in dir(my_car): ... attr = getattr(my_car, method_name) ... if callable(attr): ... if method_name == '__str__': ... print(attr()) ... Car yellow : Beetle : 1966这里,检查由
dir()返回的每个属性。使用getattr()获得实际的属性对象,并使用callable()检查它是否是一个可调用的函数。如果是,你再检查一下它的名字是不是__str__(),然后调用它。结论
在本文的整个过程中,您了解了 Python 和 Java 中面向对象原则的不同之处。当你阅读时,你会:
- 用 Java 和 Python 构建了一个基本类
- 探索了 Python 和 Java 中对象属性的工作方式
- 比较和对比了 Java 方法和 Python 函数
- 发现了两种语言中的继承和多态机制
- 研究了 Python 和 Java 之间的反射
- 在两种语言的完整类实现中应用了所有内容
如果你想学习更多关于 Python 中 OOP 的知识,一定要阅读 Python 3 中的面向对象编程(OOP)。
理解 Python 和 Java 在处理对象时的区别,以及每种语言的语法选择,将有助于您应用最佳实践,并使您的下一个项目更加顺利。
为了并排比较一些具体的例子,您可以点击下面的框来下载我们的示例代码,以获得 Java
Car、Device和Vehicle类的完整注释对象定义,以及 PythonCar和Vehicle类的完整注释定义:下载示例代码: 单击此处下载本文中 Java 和 Python 对象的注释示例对象定义和源代码。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python vs Java:面向对象编程******
使用 openpyxl 的 Python Excel 电子表格指南
原文:https://realpython.com/openpyxl-excel-spreadsheets-python/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 openpyxl 用 Python 编辑 Excel 电子表格
Excel 电子表格是你在某些时候可能不得不处理的事情之一。要么是因为你的老板喜欢它们,要么是因为营销需要它们,你可能不得不学习如何使用电子表格,这时知道
openpyxl就派上用场了!电子表格是一种非常直观和用户友好的方式来操作大型数据集,无需任何先前的技术背景。这就是为什么它们至今仍被广泛使用的原因。
在本文中,您将学习如何使用 openpyxl 来:
- 自信地操作 Excel 电子表格
- 从电子表格中提取信息
- 创建简单或更复杂的电子表格,包括添加样式、图表等
这篇文章是为中级开发人员写的,他们对 Python 数据结构有很好的了解,比如字典和列表,但也对 OOP 和更多中级主题感到舒适。
下载数据集: 单击此处下载您将在本教程中学习的 openpyxl 练习的数据集。
开始之前
如果您曾经被要求从数据库或日志文件中提取一些数据到 Excel 电子表格中,或者如果您经常必须将 Excel 电子表格转换成一些更有用的编程形式,那么本教程非常适合您。让我们跳进
openpyxl大篷车吧!实际使用案例
首先,在现实场景中,什么时候需要使用像
openpyxl这样的包?您将在下面看到几个例子,但实际上,有数百种可能的场景,这些知识可以派上用场。将新产品导入数据库
你在一家网店公司负责技术,你的老板不想花钱买一个又酷又贵的 CMS 系统。
每次他们想在网上商店添加新产品时,他们都会带着一个有几百行的 Excel 电子表格来找您,对于每一行,您都有产品名称、描述、价格等等。
现在,要导入数据,您必须迭代每个电子表格行,并将每个产品添加到在线商店。
将数据库数据导出到电子表格
假设您有一个记录所有用户信息的数据库表,包括姓名、电话号码、电子邮件地址等等。
现在,营销团队希望联系所有用户,给他们一些折扣或促销。然而,他们没有访问数据库的权限,或者他们不知道如何使用 SQL 轻松提取这些信息。
你能帮上什么忙?嗯,您可以使用
openpyxl创建一个快速脚本,遍历每一条用户记录,并将所有重要信息放入 Excel 电子表格中。这会让你在公司的下一次生日聚会上多得一块蛋糕!
向现有电子表格追加信息
您可能还需要打开一个电子表格,读取其中的信息,并根据一些业务逻辑向其中添加更多的数据。
例如,再次使用在线商店场景,假设您获得一个包含用户列表的 Excel 电子表格,您需要将他们在您的商店中消费的总金额追加到每一行。
这些数据在数据库中,为了做到这一点,您必须读取电子表格,遍历每一行,从数据库中获取总支出,然后写回电子表格。
对
openpyxl来说不成问题!学习一些基本的 Excel 术语
以下是您在使用 Excel 电子表格时会看到的基本术语的快速列表:
学期 说明 电子表格或工作簿 一个电子表格是你正在创建或使用的主要文件。 工作表或工作表 一个表用于在同一个电子表格中分割不同种类的内容。一个电子表格可以有一个或多个表格。 圆柱 A 列是一条垂直线,用大写字母表示: A 。 排 一个行是一条水平线,用一个数字表示: 1 。 细胞 一个单元格是由列和行组合而成,由一个大写字母和一个数字表示: A1 。 openpyxl 入门
现在你已经意识到了像
openpyxl这样的工具的好处,让我们开始安装这个包。对于本教程,您应该使用 Python 3.7 和 openpyxl 2.6.2。要安装该软件包,您可以执行以下操作:$ pip install openpyxl安装软件包后,您应该能够使用以下代码创建一个超级简单的电子表格:
from openpyxl import Workbook workbook = Workbook() sheet = workbook.active sheet["A1"] = "hello" sheet["B1"] = "world!" workbook.save(filename="hello_world.xlsx")上面的代码应该在您用来运行代码的文件夹中创建一个名为
hello_world.xlsx的文件。如果您用 Excel 打开该文件,您应该会看到如下内容:
Woohoo ,你的第一个电子表格创建完成了!
使用 openpyxl 读取 Excel 电子表格
让我们从一个人可以对电子表格做的最基本的事情开始:阅读它。
您将从阅读电子表格的简单方法过渡到阅读数据并将其转换为更有用的 Python 结构的更复杂的例子。
本教程的数据集
在深入研究一些代码示例之前,您应该下载这个样本数据集,并将其存储为
sample.xlsx:下载数据集: 单击此处下载您将在本教程中学习的 openpyxl 练习的数据集。
这是您将在本教程中使用的数据集之一,它是一个电子表格,包含来自亚马逊在线产品评论的真实数据样本。这个数据集只是亚马逊提供的一小部分,但是对于测试来说,已经足够了。
阅读 Excel 电子表格的简单方法
最后,让我们开始阅读一些电子表格!首先,打开我们的示例电子表格:
>>> from openpyxl import load_workbook
>>> workbook = load_workbook(filename="sample.xlsx")
>>> workbook.sheetnames
['Sheet 1']
>>> sheet = workbook.active
>>> sheet
<Worksheet "Sheet 1">
>>> sheet.title
'Sheet 1'
在上面的代码中,您首先使用load_workbook()打开电子表格sample.xlsx,然后您可以使用workbook.sheetnames查看您可以使用的所有工作表。之后,workbook.active选择第一个可用的板材,在这种情况下,您可以看到它自动选择了板材 1 。使用这些方法是打开电子表格的默认方式,在本教程中您会多次看到。
现在,打开电子表格后,您可以像这样轻松地从中检索数据:
>>> sheet["A1"] <Cell 'Sheet 1'.A1> >>> sheet["A1"].value 'marketplace' >>> sheet["F10"].value "G-Shock Men's Grey Sport Watch"要返回单元格的实际值,需要做
.value。否则,您将得到主Cell对象。您还可以使用方法.cell()来检索使用索引符号的单元格。记住添加.value来获得实际值,而不是一个Cell对象:
>>> sheet.cell(row=10, column=6)
<Cell 'Sheet 1'.F10>
>>> sheet.cell(row=10, column=6).value
"G-Shock Men's Grey Sport Watch"
您可以看到,无论您决定采用哪种方式,返回的结果都是相同的。然而,在本教程中,您将主要使用第一种方法:["A1"]。
注意:尽管在 Python 中你习惯了零索引符号,但在电子表格中,你将总是使用一个索引符号,其中第一行或第一列总是有索引1。
以上向您展示了打开电子表格的最快方法。但是,您可以传递附加参数来更改电子表格的加载方式。
附加阅读选项
有几个参数可以传递给load_workbook()来改变电子表格的加载方式。最重要的是下面两个布尔:
- read_only 以只读模式加载电子表格,允许你打开非常大的 Excel 文件。
- data_only 忽略加载公式,只加载结果值。
从电子表格导入数据
既然您已经学习了加载电子表格的基本知识,那么是时候进入有趣的部分了:电子表格中值的迭代和实际使用。
在这一节中,您将学习遍历数据的所有不同方法,以及如何将数据转换成有用的东西,更重要的是,如何以 Pythonic 的方式来实现。
遍历数据
根据您的需要,有几种不同的方法可以遍历数据。
您可以使用列和行的组合对数据进行切片:
>>> sheet["A1:C2"] ((<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.C1>), (<Cell 'Sheet 1'.A2>, <Cell 'Sheet 1'.B2>, <Cell 'Sheet 1'.C2>))您可以获取行或列的范围:
>>> # Get all cells from column A
>>> sheet["A"]
(<Cell 'Sheet 1'.A1>,
<Cell 'Sheet 1'.A2>,
...
<Cell 'Sheet 1'.A99>,
<Cell 'Sheet 1'.A100>)
>>> # Get all cells for a range of columns
>>> sheet["A:B"]
((<Cell 'Sheet 1'.A1>,
<Cell 'Sheet 1'.A2>,
...
<Cell 'Sheet 1'.A99>,
<Cell 'Sheet 1'.A100>),
(<Cell 'Sheet 1'.B1>,
<Cell 'Sheet 1'.B2>,
...
<Cell 'Sheet 1'.B99>,
<Cell 'Sheet 1'.B100>))
>>> # Get all cells from row 5
>>> sheet[5]
(<Cell 'Sheet 1'.A5>,
<Cell 'Sheet 1'.B5>,
...
<Cell 'Sheet 1'.N5>,
<Cell 'Sheet 1'.O5>)
>>> # Get all cells for a range of rows
>>> sheet[5:6]
((<Cell 'Sheet 1'.A5>,
<Cell 'Sheet 1'.B5>,
...
<Cell 'Sheet 1'.N5>,
<Cell 'Sheet 1'.O5>),
(<Cell 'Sheet 1'.A6>,
<Cell 'Sheet 1'.B6>,
...
<Cell 'Sheet 1'.N6>,
<Cell 'Sheet 1'.O6>))
你会注意到上面所有的例子都返回了一个tuple。如果您想回忆一下如何在 Python 中处理tuples,请查看关于 Python 中的列表和元组的文章。
使用普通 Python 生成器处理数据也有多种方式。实现这一目标的主要方法有:
.iter_rows().iter_cols()
这两种方法都可以接收以下参数:
min_rowmax_rowmin_colmax_col
这些参数用于设置迭代的边界:
>>> for row in sheet.iter_rows(min_row=1, ... max_row=2, ... min_col=1, ... max_col=3): ... print(row) (<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.C1>) (<Cell 'Sheet 1'.A2>, <Cell 'Sheet 1'.B2>, <Cell 'Sheet 1'.C2>) >>> for column in sheet.iter_cols(min_row=1, ... max_row=2, ... min_col=1, ... max_col=3): ... print(column) (<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.A2>) (<Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.B2>) (<Cell 'Sheet 1'.C1>, <Cell 'Sheet 1'.C2>)您会注意到,在第一个示例中,当使用
.iter_rows()遍历行时,您会在选中的每一行中获得一个tuple元素。而当使用.iter_cols()并遍历列时,每列将得到一个tuple。可以传递给这两个方法的另一个参数是布尔值
values_only。当设置为True时,返回单元格的值,而不是Cell对象:
>>> for value in sheet.iter_rows(min_row=1,
... max_row=2,
... min_col=1,
... max_col=3,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id')
('US', 3653882, 'R3O9SGZBVQBV76')
如果您想遍历整个数据集,那么您也可以直接使用属性.rows或.columns,这是使用不带任何参数的.iter_rows()和.iter_cols()的快捷方式:
>>> for row in sheet.rows: ... print(row) (<Cell 'Sheet 1'.A1>, <Cell 'Sheet 1'.B1>, <Cell 'Sheet 1'.C1> ... <Cell 'Sheet 1'.M100>, <Cell 'Sheet 1'.N100>, <Cell 'Sheet 1'.O100>)当你遍历整个数据集时,这些快捷方式非常有用。
使用 Python 的默认数据结构操作数据
既然您已经了解了遍历工作簿中数据的基本知识,那么让我们看看将数据转换成 Python 结构的聪明方法。
正如您之前看到的,所有迭代的结果都以
tuples的形式出现。然而,由于一个tuple只不过是一个不可变的list,你可以很容易地访问它的数据并将其转换成其他结构。例如,假设您想从
sample.xlsx电子表格中提取产品信息并放入一个字典中,其中每个键都是一个产品 ID。一种简单的方法是遍历所有的行,选择与产品信息相关的列,然后将其存储在一个字典中。让我们把它编码出来!
首先,看看标题,看看你最关心的信息是什么:
>>> for value in sheet.iter_rows(min_row=1,
... max_row=1,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id', 'product_id', ...)
这段代码返回电子表格中所有列名的列表。首先,获取带有名称的列:
product_idproduct_parentproduct_titleproduct_category
幸运的是,您需要的列彼此相邻,因此您可以使用min_column和max_column轻松获得您想要的数据:
>>> for value in sheet.iter_rows(min_row=2, ... min_col=4, ... max_col=7, ... values_only=True): ... print(value) ('B00FALQ1ZC', 937001370, 'Invicta Women\'s 15150 "Angel" 18k Yellow...) ('B00D3RGO20', 484010722, "Kenneth Cole New York Women's KC4944...) ...不错!现在,您已经知道如何获得您需要的所有重要产品信息,让我们将这些数据放入字典中:
import json from openpyxl import load_workbook workbook = load_workbook(filename="sample.xlsx") sheet = workbook.active products = {} # Using the values_only because you want to return the cells' values for row in sheet.iter_rows(min_row=2, min_col=4, max_col=7, values_only=True): product_id = row[0] product = { "parent": row[1], "title": row[2], "category": row[3] } products[product_id] = product # Using json here to be able to format the output for displaying later print(json.dumps(products))上面的代码返回一个类似如下的 JSON:
{ "B00FALQ1ZC": { "parent": 937001370, "title": "Invicta Women's 15150 ...", "category": "Watches" }, "B00D3RGO20": { "parent": 484010722, "title": "Kenneth Cole New York ...", "category": "Watches" } }在这里,您可以看到输出被调整为只有 2 个产品,但是如果您照原样运行脚本,那么您应该得到 98 个产品。
将数据转换成 Python 类
为了结束本教程的阅读部分,让我们深入 Python 类,看看如何改进上面的例子,更好地组织数据。
为此,您将使用 Python 3.7 中新的 Python 数据类。如果您使用的是旧版本的 Python,那么您可以使用默认的类来代替。
因此,首先,让我们看看您拥有的数据,并决定您想要存储什么以及如何存储。
正如你在开始看到的,这些数据来自亚马逊,是产品评论的列表。你可以在亚马逊上查看所有列的列表及其含义。
您可以从可用数据中提取两个重要元素:
- 制品
- 复习
一个产品具有:
- 身份证明
- 标题
- 父母
- 种类
评审还有几个字段:
- 身份证明
- 客户 ID
- 明星
- 头条新闻
- 身体
- 日期
您可以忽略一些审查字段,使事情变得简单一些。
因此,这两个类的简单实现可以写在一个单独的文件
classes.py中:import datetime from dataclasses import dataclass @dataclass class Product: id: str parent: str title: str category: str @dataclass class Review: id: str customer_id: str stars: int headline: str body: str date: datetime.datetime定义了数据类之后,您需要将电子表格中的数据转换成这些新的结构。
在进行转换之前,值得再次查看我们的标题,并在列和您需要的字段之间创建映射:
>>> for value in sheet.iter_rows(min_row=1,
... max_row=1,
... values_only=True):
... print(value)
('marketplace', 'customer_id', 'review_id', 'product_id', ...)
>>> # Or an alternative
>>> for cell in sheet[1]:
... print(cell.value)
marketplace
customer_id
review_id
product_id
product_parent
...
让我们创建一个文件mapping.py,其中有一个电子表格上所有字段名称及其列位置(零索引)的列表:
# Product fields
PRODUCT_ID = 3
PRODUCT_PARENT = 4
PRODUCT_TITLE = 5
PRODUCT_CATEGORY = 6
# Review fields
REVIEW_ID = 2
REVIEW_CUSTOMER = 1
REVIEW_STARS = 7
REVIEW_HEADLINE = 12
REVIEW_BODY = 13
REVIEW_DATE = 14
你不一定要做上面的映射。这更多是为了解析行数据时的可读性,这样就不会有很多神奇的数字。
最后,让我们看看将电子表格数据解析成产品和评论对象列表所需的代码:
from datetime import datetime
from openpyxl import load_workbook
from classes import Product, Review
from mapping import PRODUCT_ID, PRODUCT_PARENT, PRODUCT_TITLE, \
PRODUCT_CATEGORY, REVIEW_DATE, REVIEW_ID, REVIEW_CUSTOMER, \
REVIEW_STARS, REVIEW_HEADLINE, REVIEW_BODY
# Using the read_only method since you're not gonna be editing the spreadsheet
workbook = load_workbook(filename="sample.xlsx", read_only=True)
sheet = workbook.active
products = []
reviews = []
# Using the values_only because you just want to return the cell value
for row in sheet.iter_rows(min_row=2, values_only=True):
product = Product(id=row[PRODUCT_ID],
parent=row[PRODUCT_PARENT],
title=row[PRODUCT_TITLE],
category=row[PRODUCT_CATEGORY])
products.append(product)
# You need to parse the date from the spreadsheet into a datetime format
spread_date = row[REVIEW_DATE]
parsed_date = datetime.strptime(spread_date, "%Y-%m-%d")
review = Review(id=row[REVIEW_ID],
customer_id=row[REVIEW_CUSTOMER],
stars=row[REVIEW_STARS],
headline=row[REVIEW_HEADLINE],
body=row[REVIEW_BODY],
date=parsed_date)
reviews.append(review)
print(products[0])
print(reviews[0])
运行上面的代码后,您应该会得到如下输出:
Product(id='B00FALQ1ZC', parent=937001370, ...)
Review(id='R3O9SGZBVQBV76', customer_id=3653882, ...)
就是这样!现在你应该有了一个非常简单和易于理解的类格式的数据,并且你可以开始考虑把它存储在一个数据库或者你喜欢的任何其他类型的数据存储中。
使用这种 OOP 策略来解析电子表格使得以后处理数据更加简单。
追加新数据
在开始创建非常复杂的电子表格之前,快速浏览一下如何向现有电子表格追加数据的示例。
回到您创建的第一个示例电子表格(hello_world.xlsx),尝试打开它并向其中追加一些数据,如下所示:
from openpyxl import load_workbook
# Start by opening the spreadsheet and selecting the main sheet
workbook = load_workbook(filename="hello_world.xlsx")
sheet = workbook.active
# Write what you want into a specific cell
sheet["C1"] = "writing ;)"
# Save the spreadsheet
workbook.save(filename="hello_world_append.xlsx")
Et voilà ,如果您打开新的hello_world_append.xlsx电子表格,您将看到以下变化:
注意附加的文字;)上C1号牢房。
用 openpyxl 编写 Excel 电子表格
您可以向电子表格中写入许多不同的内容,从简单的文本或数值到复杂的公式、图表甚至图像。
让我们开始创建一些电子表格吧!
创建简单的电子表格
之前,你看到了一个如何写“Hello world!”转换成电子表格,所以你可以这样开始:
1from openpyxl import Workbook
2
3filename = "hello_world.xlsx"
4
5workbook = Workbook() 6sheet = workbook.active
7
8sheet["A1"] = "hello" 9sheet["B1"] = "world!" 10
11workbook.save(filename=filename)
上面代码中突出显示的行是编写时最重要的行。在代码中,您可以看到:
- 第 5 行显示了如何创建一个新的空白工作簿。
- 第 8 行和第 9 行向您展示了如何向特定的单元格添加数据。
- 第 11 行告诉你完成后如何保存电子表格。
尽管上面的这些行可能很简单,但当事情变得有点复杂时,最好还是了解它们。
注意:在接下来的一些例子中,你会用到hello_world.xlsx电子表格,所以把它放在手边。
对于接下来的代码示例,您可以做的一件事是将以下方法添加到 Python 文件或控制台中:
>>> def print_rows(): ... for row in sheet.iter_rows(values_only=True): ... print(row)只需调用
print_rows()就可以更容易地打印所有的电子表格值。基本电子表格操作
在进入更高级的主题之前,了解如何管理电子表格中最简单的元素是有好处的。
添加和更新单元格值
您已经学习了如何向电子表格中添加值,如下所示:
>>> sheet["A1"] = "value"
还有另一种方法,首先选择一个单元格,然后更改其值:
>>> cell = sheet["A1"] >>> cell <Cell 'Sheet'.A1> >>> cell.value 'hello' >>> cell.value = "hey" >>> cell.value 'hey'新值只有在您调用
workbook.save()后才会存储到电子表格中。添加值时,
openpyxl会创建一个单元格,如果该单元格以前不存在:
>>> # Before, our spreadsheet has only 1 row
>>> print_rows()
('hello', 'world!')
>>> # Try adding a value to row 10
>>> sheet["B10"] = "test"
>>> print_rows()
('hello', 'world!')
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, None)
(None, 'test')
正如您所看到的,当试图向单元格B10添加一个值时,您最终得到了一个有 10 行的元组,这样您就可以让那个测试值。
管理行和列
操作电子表格时,最常见的事情之一就是添加或删除行和列。openpyxl包允许您通过使用以下方法以一种非常简单的方式来完成这项工作:
.insert_rows().delete_rows().insert_cols().delete_cols()
这些方法中的每一个都可以接收两个参数:
idxamount
再次使用我们的基本hello_world.xlsx示例,让我们看看这些方法是如何工作的:
>>> print_rows() ('hello', 'world!') >>> # Insert a column before the existing column 1 ("A") >>> sheet.insert_cols(idx=1) >>> print_rows() (None, 'hello', 'world!') >>> # Insert 5 columns between column 2 ("B") and 3 ("C") >>> sheet.insert_cols(idx=3, amount=5) >>> print_rows() (None, 'hello', None, None, None, None, None, 'world!') >>> # Delete the created columns >>> sheet.delete_cols(idx=3, amount=5) >>> sheet.delete_cols(idx=1) >>> print_rows() ('hello', 'world!') >>> # Insert a new row in the beginning >>> sheet.insert_rows(idx=1) >>> print_rows() (None, None) ('hello', 'world!') >>> # Insert 3 new rows in the beginning >>> sheet.insert_rows(idx=1, amount=3) >>> print_rows() (None, None) (None, None) (None, None) (None, None) ('hello', 'world!') >>> # Delete the first 4 rows >>> sheet.delete_rows(idx=1, amount=4) >>> print_rows() ('hello', 'world!')你唯一需要记住的是,当插入新数据(行或列)时,插入发生在参数
idx的之前。所以,如果你做了
insert_rows(1),它会在现有的第一行之前插入一个新行。对于列也是如此:当您调用
insert_cols(2)时,它会在已经存在的第二列(B)的之前的右侧插入一个新列。然而,当删除行或列时,
.delete_...从作为参数传递的索引开始删除数据。例如,当执行
delete_rows(2)时,它删除第2行,当执行delete_cols(3)时,它删除第三列(C)。管理表单
工作表管理也是您可能需要知道的事情之一,尽管您可能不经常使用它。
如果您回顾本教程中的代码示例,您会注意到下面这段重复出现的代码:
sheet = workbook.active这是从电子表格中选择默认工作表的方法。但是,如果您正在打开一个有多个工作表的电子表格,那么您总是可以选择一个特定的工作表,如下所示:
>>> # Let's say you have two sheets: "Products" and "Company Sales"
>>> workbook.sheetnames
['Products', 'Company Sales']
>>> # You can select a sheet using its title
>>> products_sheet = workbook["Products"]
>>> sales_sheet = workbook["Company Sales"]
您也可以非常容易地更改工作表标题:
>>> workbook.sheetnames ['Products', 'Company Sales'] >>> products_sheet = workbook["Products"] >>> products_sheet.title = "New Products" >>> workbook.sheetnames ['New Products', 'Company Sales']如果您想创建或删除工作表,您也可以使用
.create_sheet()和.remove()来完成:
>>> workbook.sheetnames
['Products', 'Company Sales']
>>> operations_sheet = workbook.create_sheet("Operations")
>>> workbook.sheetnames
['Products', 'Company Sales', 'Operations']
>>> # You can also define the position to create the sheet at
>>> hr_sheet = workbook.create_sheet("HR", 0)
>>> workbook.sheetnames
['HR', 'Products', 'Company Sales', 'Operations']
>>> # To remove them, just pass the sheet as an argument to the .remove()
>>> workbook.remove(operations_sheet)
>>> workbook.sheetnames
['HR', 'Products', 'Company Sales']
>>> workbook.remove(hr_sheet)
>>> workbook.sheetnames
['Products', 'Company Sales']
您可以做的另一件事是使用copy_worksheet()复制一个工作表:
>>> workbook.sheetnames ['Products', 'Company Sales'] >>> products_sheet = workbook["Products"] >>> workbook.copy_worksheet(products_sheet) <Worksheet "Products Copy"> >>> workbook.sheetnames ['Products', 'Company Sales', 'Products Copy']如果在保存上述代码后打开电子表格,您会注意到工作表 Products Copy 是工作表 Products 的副本。
冻结行和列
在处理大型电子表格时,您可能希望冻结一些行或列,这样当您向右或向下滚动时,它们仍然可见。
冻结数据可让您关注重要的行或列,无论您在电子表格中滚动到哪里。
同样,
openpyxl也有办法通过使用工作表的freeze_panes属性来实现这一点。对于这个例子,回到我们的sample.xlsx电子表格,尝试做以下事情:
>>> workbook = load_workbook(filename="sample.xlsx")
>>> sheet = workbook.active
>>> sheet.freeze_panes = "C2"
>>> workbook.save("sample_frozen.xlsx")
如果在您最喜欢的电子表格编辑器中打开sample_frozen.xlsx电子表格,您会注意到行1和列A和B被冻结,无论您在电子表格中的哪个位置导航,它们总是可见的。
这个特性很方便,例如,可以将标题保持在可见的范围内,这样您就总能知道每一列代表什么。
下面是它在编辑器中的样子:
注意你在电子表格的末尾,然而,你可以看到行1和列A和B。
添加过滤器
您可以使用openpyxl向您的电子表格添加过滤器和排序。但是,当您打开电子表格时,数据不会根据这些排序和过滤器重新排列。
乍一看,这似乎是一个非常无用的特性,但是当您以编程方式创建一个将被其他人发送和使用的电子表格时,至少创建过滤器并允许人们随后使用它仍然是很好的。
下面的代码举例说明了如何向我们现有的sample.xlsx电子表格添加一些过滤器:
>>> # Check the used spreadsheet space using the attribute "dimensions" >>> sheet.dimensions 'A1:O100' >>> sheet.auto_filter.ref = "A1:O100" >>> workbook.save(filename="sample_with_filters.xlsx")现在,在编辑器中打开电子表格时,您应该会看到创建的过滤器:
如果您确切地知道要对电子表格的哪一部分应用过滤器,您就不必使用
sheet.dimensions。添加公式
公式(或公式)是电子表格最强大的功能之一。
它们赋予你将特定的数学方程应用于一系列单元格的能力。使用带
openpyxl的公式就像编辑单元格的值一样简单。可以看到
openpyxl支持的公式列表:
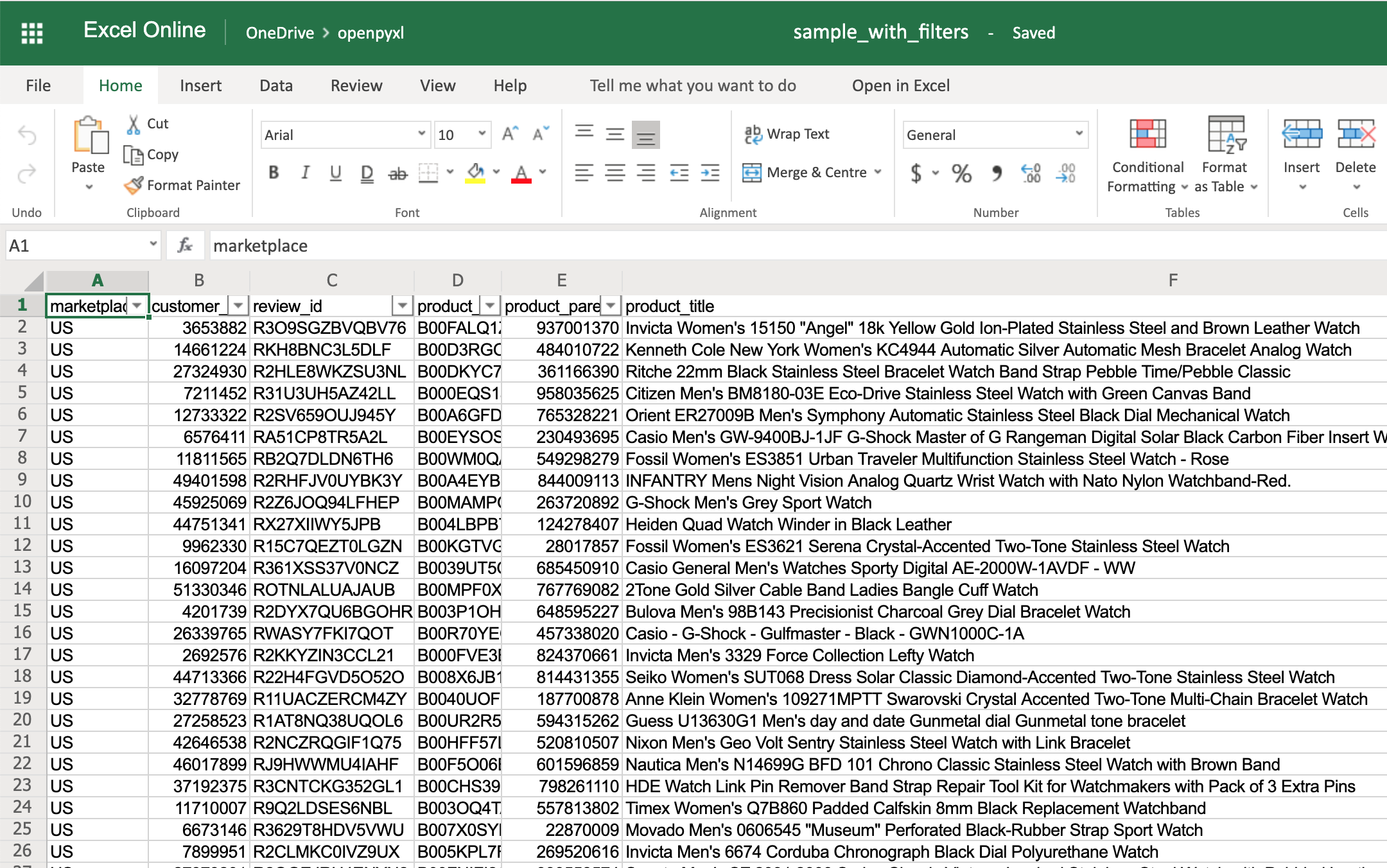
>>> from openpyxl.utils import FORMULAE
>>> FORMULAE
frozenset({'ABS',
'ACCRINT',
'ACCRINTM',
'ACOS',
'ACOSH',
'AMORDEGRC',
'AMORLINC',
'AND',
...
'YEARFRAC',
'YIELD',
'YIELDDISC',
'YIELDMAT',
'ZTEST'})
让我们给我们的sample.xlsx电子表格添加一些公式。
从简单的事情开始,让我们检查一下电子表格中 99 条评论的平均星级:
>>> # Star rating is column "H" >>> sheet["P2"] = "=AVERAGE(H2:H100)" >>> workbook.save(filename="sample_formulas.xlsx")如果您现在打开电子表格并转到单元格
P2,您应该看到它的值是:4.1881818181818。在编辑器中查看一下:
您可以使用相同的方法将任何公式添加到电子表格中。例如,让我们统计一下有帮助投票的评论的数量:
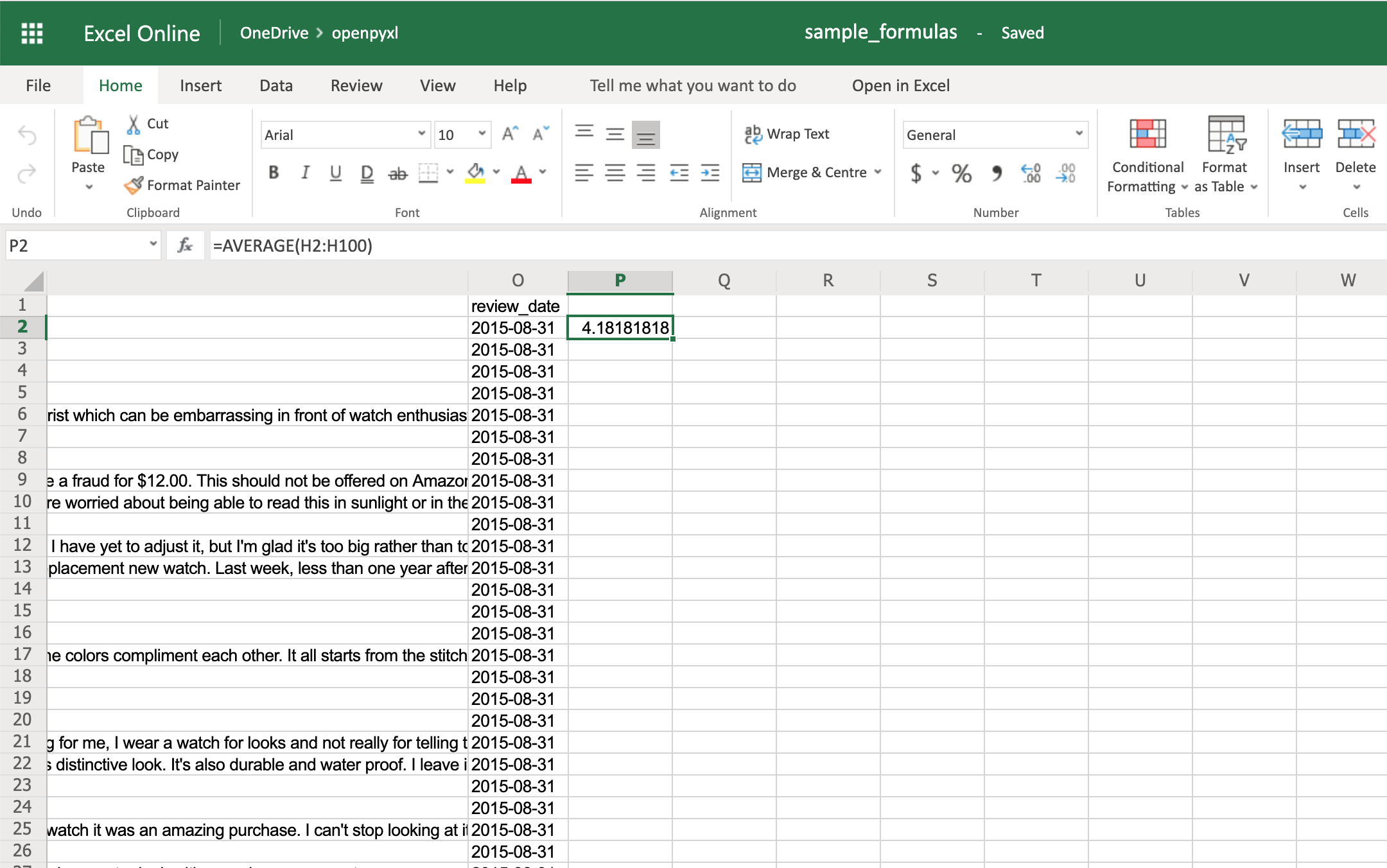
>>> # The helpful votes are counted on column "I"
>>> sheet["P3"] = '=COUNTIF(I2:I100, ">0")'
>>> workbook.save(filename="sample_formulas.xlsx")
您应该在您的P3电子表格单元格中得到数字21,如下所示:
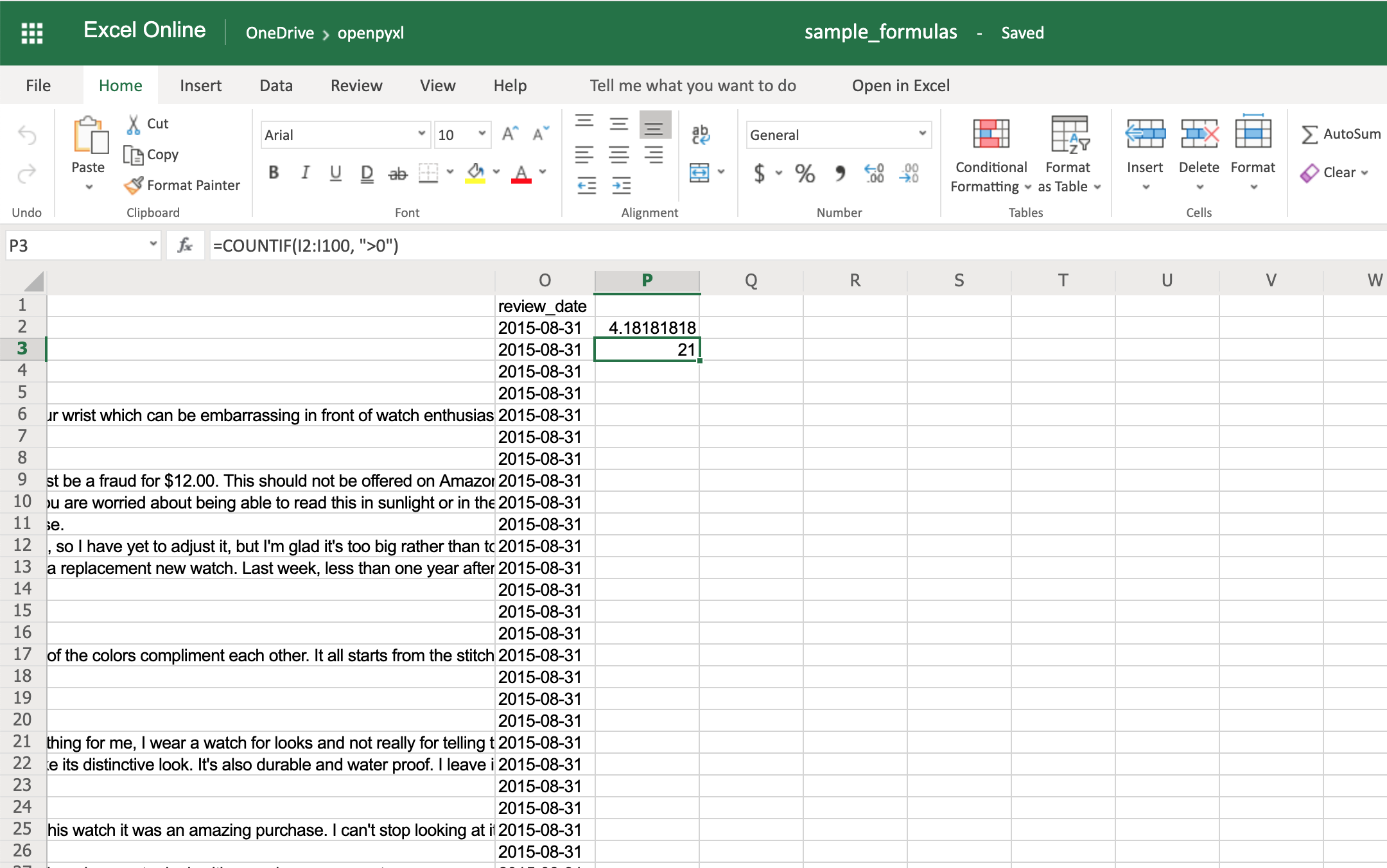
您必须确保公式中的字符串总是在双引号中,所以您要么像上面的例子一样在公式周围使用单引号,要么您必须在公式中对双引号进行转义:"=COUNTIF(I2:I100, \">0\")"。
使用上面尝试的相同过程,您可以将大量其他公式添加到电子表格中。自己试试吧!
添加样式
尽管设计电子表格的样式可能不是你每天都要做的事情,但是知道如何去做还是很有好处的。
使用openpyxl,您可以对电子表格应用多种样式选项,包括字体、边框、颜色等等。看看openpyxl 文档了解更多。
您也可以选择将样式直接应用到单元格,或者创建一个模板并重复使用它来将样式应用到多个单元格。
让我们从简单的单元格样式开始,再次使用我们的sample.xlsx作为基本电子表格:
>>> # Import necessary style classes >>> from openpyxl.styles import Font, Color, Alignment, Border, Side >>> # Create a few styles >>> bold_font = Font(bold=True) >>> big_red_text = Font(color="00FF0000", size=20) >>> center_aligned_text = Alignment(horizontal="center") >>> double_border_side = Side(border_style="double") >>> square_border = Border(top=double_border_side, ... right=double_border_side, ... bottom=double_border_side, ... left=double_border_side) >>> # Style some cells! >>> sheet["A2"].font = bold_font >>> sheet["A3"].font = big_red_text >>> sheet["A4"].alignment = center_aligned_text >>> sheet["A5"].border = square_border >>> workbook.save(filename="sample_styles.xlsx")如果您现在打开电子表格,您应该会在列
A的前 5 个单元格中看到许多不同的样式:
给你。你有:
- A2 以粗体显示文本
- A3 文字为红色,字体较大
- A4 文本居中
- A5 文本周围有方形边框
注意:对于颜色,也可以通过
Font(color="C70E0F")使用十六进制代码。您也可以通过简单地将样式同时添加到单元格来组合样式:
>>> # Reusing the same styles from the example above
>>> sheet["A6"].alignment = center_aligned_text
>>> sheet["A6"].font = big_red_text
>>> sheet["A6"].border = square_border
>>> workbook.save(filename="sample_styles.xlsx")
看看这里的单元格A6:
当你想对一个或几个单元格应用多种样式时,你可以使用一个NamedStyle类来代替,它就像一个你可以反复使用的样式模板。看看下面的例子:
>>> from openpyxl.styles import NamedStyle >>> # Let's create a style template for the header row >>> header = NamedStyle(name="header") >>> header.font = Font(bold=True) >>> header.border = Border(bottom=Side(border_style="thin")) >>> header.alignment = Alignment(horizontal="center", vertical="center") >>> # Now let's apply this to all first row (header) cells >>> header_row = sheet[1] >>> for cell in header_row: ... cell.style = header >>> workbook.save(filename="sample_styles.xlsx")如果您现在打开电子表格,您应该看到它的第一行是粗体的,文本居中对齐,并且有一个小的底部边框!请看下面:
正如你在上面看到的,当涉及到样式的时候,有很多选项,这取决于用例,所以请随意查看
openpyxl文档,看看你还能做什么。条件格式
当向电子表格添加样式时,这个特性是我个人最喜欢的特性之一。
这是一种更强大的样式化方法,因为它根据电子表格中数据的变化动态地应用样式。
简而言之,条件格式允许你根据特定的条件指定一个应用于单元格(或单元格范围)的样式列表。
例如,一个广泛使用的案例是有一个资产负债表,其中所有的负总额是红色的,而正总额是绿色的。这种格式使得区分好周期和坏周期更加有效。
事不宜迟,让我们挑选我们最喜欢的电子表格—
sample.xlsx—并添加一些条件格式。你可以从添加一个简单的开始,为所有低于 3 星的评论添加红色背景:
>>> from openpyxl.styles import PatternFill
>>> from openpyxl.styles.differential import DifferentialStyle
>>> from openpyxl.formatting.rule import Rule
>>> red_background = PatternFill(fgColor="00FF0000")
>>> diff_style = DifferentialStyle(fill=red_background)
>>> rule = Rule(type="expression", dxf=diff_style)
>>> rule.formula = ["$H1<3"]
>>> sheet.conditional_formatting.add("A1:O100", rule)
>>> workbook.save("sample_conditional_formatting.xlsx")
现在,您会看到所有星级低于 3 的评论都以红色背景标记:
就代码而言,这里唯一的新东西是对象DifferentialStyle和Rule:
DifferentialStyle与上面提到的NamedStyle非常相似,它用于聚合多种样式,如字体、边框、对齐等。Rule负责选择单元格,如果单元格符合规则逻辑,则应用样式。
使用一个Rule对象,您可以创建许多条件格式场景。
然而,为了简单起见,openpyxl包提供了 3 种内置格式,使得创建一些常见的条件格式模式更加容易。这些内置功能包括:
ColorScaleIconSetDataBar
ColorScale 让您能够创建颜色渐变:
>>> from openpyxl.formatting.rule import ColorScaleRule >>> color_scale_rule = ColorScaleRule(start_type="min", ... start_color="00FF0000", # Red ... end_type="max", ... end_color="0000FF00") # Green >>> # Again, let's add this gradient to the star ratings, column "H" >>> sheet.conditional_formatting.add("H2:H100", color_scale_rule) >>> workbook.save(filename="sample_conditional_formatting_color_scale.xlsx")现在,根据星级评定,您应该在列
H上看到从红色到绿色的颜色渐变:
您也可以添加第三种颜色并制作两种渐变:
>>> from openpyxl.formatting.rule import ColorScaleRule
>>> color_scale_rule = ColorScaleRule(start_type="num",
... start_value=1,
... start_color="00FF0000", # Red
... mid_type="num",
... mid_value=3,
... mid_color="00FFFF00", # Yellow
... end_type="num",
... end_value=5,
... end_color="0000FF00") # Green
>>> # Again, let's add this gradient to the star ratings, column "H"
>>> sheet.conditional_formatting.add("H2:H100", color_scale_rule)
>>> workbook.save(filename="sample_conditional_formatting_color_scale_3.xlsx")
这一次,您会注意到 1 到 3 之间的星级有一个从红色到黄色的渐变,3 到 5 之间的星级有一个从黄色到绿色的渐变:
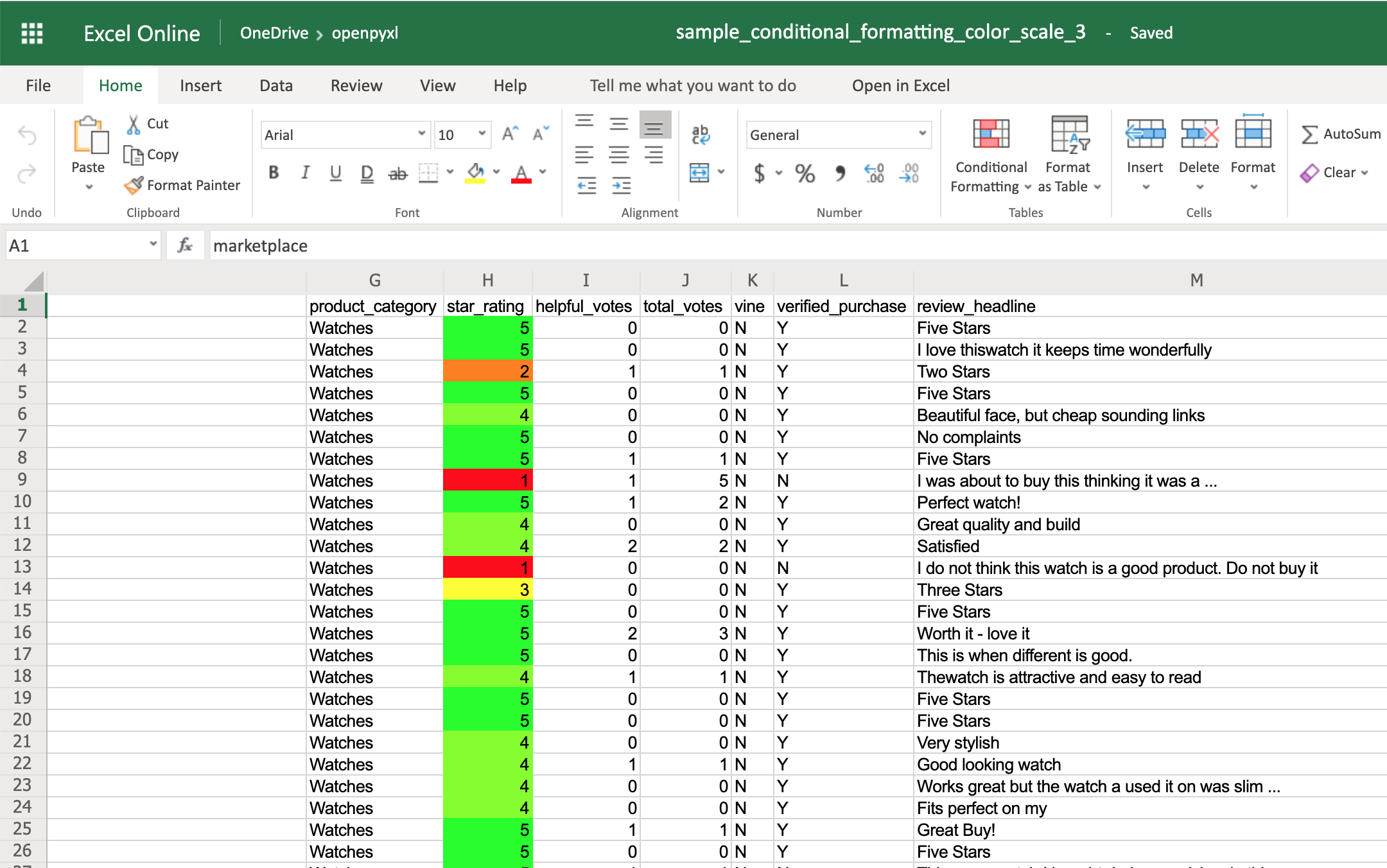
图标集允许您根据其值向单元格添加图标:
>>> from openpyxl.formatting.rule import IconSetRule >>> icon_set_rule = IconSetRule("5Arrows", "num", [1, 2, 3, 4, 5]) >>> sheet.conditional_formatting.add("H2:H100", icon_set_rule) >>> workbook.save("sample_conditional_formatting_icon_set.xlsx")您会在星级旁边看到一个彩色箭头。当单元格的值为 1 时,此箭头为红色并指向下方,随着评分的提高,箭头开始指向上方并变为绿色:
除了箭头之外,
openpyxl包中还有一个完整列表,列出了你可以使用的其他图标。最后,数据栏允许你创建进度条:
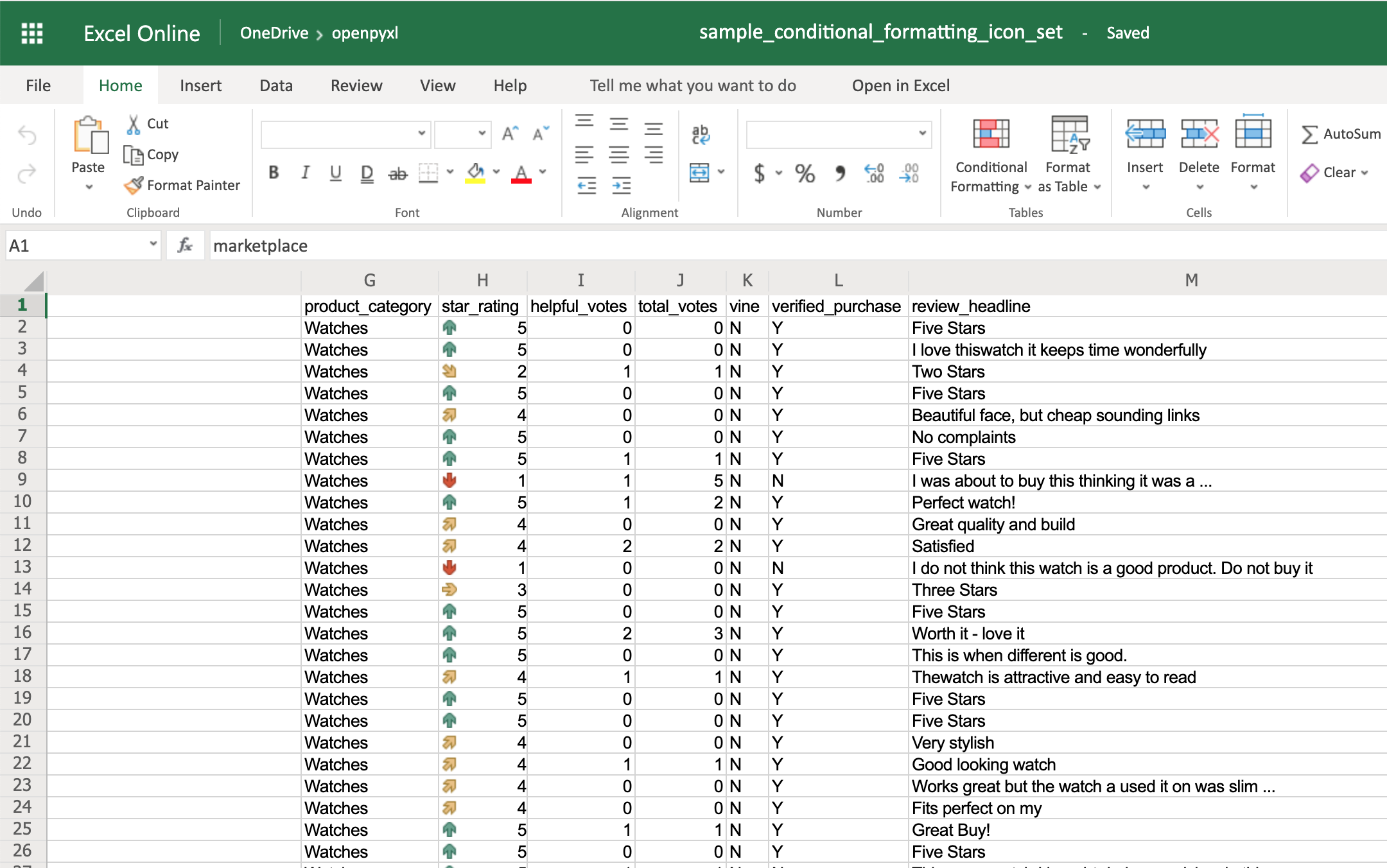
>>> from openpyxl.formatting.rule import DataBarRule
>>> data_bar_rule = DataBarRule(start_type="num",
... start_value=1,
... end_type="num",
... end_value="5",
... color="0000FF00") # Green
>>> sheet.conditional_formatting.add("H2:H100", data_bar_rule)
>>> workbook.save("sample_conditional_formatting_data_bar.xlsx")
现在,您会看到一个绿色进度条,随着星级越来越接近数字 5,进度条会越来越满:
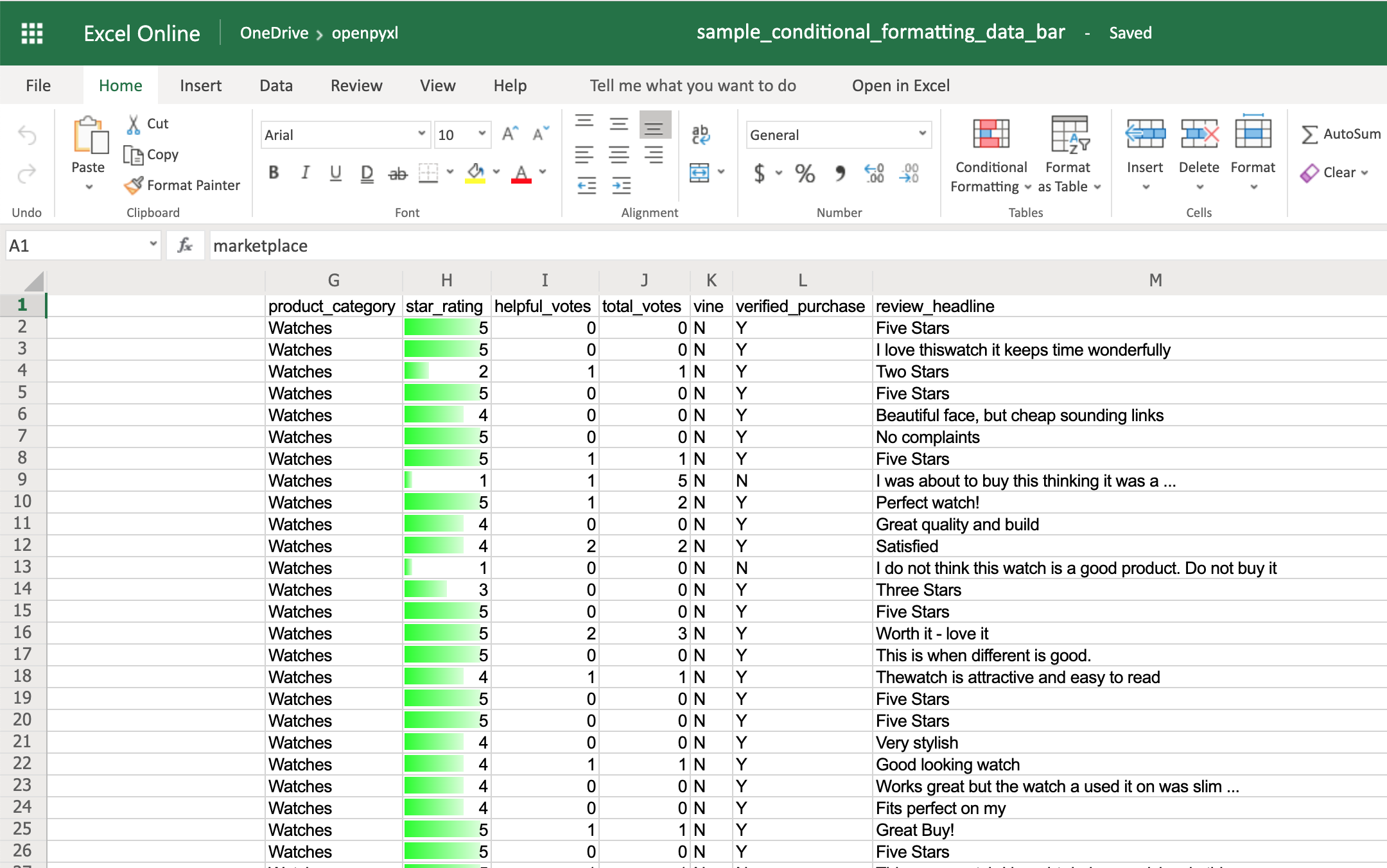
如您所见,使用条件格式可以做很多很酷的事情。
在这里,你只看到了几个你可以用它实现的例子,但是查看openpyxl 文档可以看到一堆其他的选项。
添加图像
尽管图像在电子表格中并不常见,但能够添加它们还是很酷的。也许你可以用它来打造品牌或使电子表格更加个性化。
为了能够使用openpyxl将图像加载到电子表格中,您必须安装Pillow:
$ pip install Pillow
除此之外,你还需要一张图片。对于这个例子,您可以抓取下面的真正的 Python 标志,并使用在线转换器如cloudconvert.com将其从.webp转换为.png,将最终文件保存为logo.png,并将其复制到运行示例的根文件夹中:
![]()
之后,这是您需要将该图像导入到hello_word.xlsx电子表格中的代码:
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
# Let's use the hello_world spreadsheet since it has less data
workbook = load_workbook(filename="hello_world.xlsx")
sheet = workbook.active
logo = Image("logo.png")
# A bit of resizing to not fill the whole spreadsheet with the logo
logo.height = 150
logo.width = 150
sheet.add_image(logo, "A3")
workbook.save(filename="hello_world_logo.xlsx")
您的电子表格上有图像!这是:
图像的左上角位于您选择的单元格上,在本例中为A3。
添加漂亮的图表
电子表格的另一个强大功能是创建各种各样的图表。
图表是快速可视化和理解大量数据的好方法。有许多不同的图表类型:条形图、饼图、折线图等等。支持他们中的许多人。
这里,您将只看到几个图表示例,因为每种图表类型背后的理论都是相同的:
注意:openpyxl目前不支持的图表类型有漏斗图、甘特图、排列图、树形图、瀑布图、地图和旭日图。
对于您想要构建的任何图表,您都需要定义图表类型:BarChart、LineChart等等,以及用于图表的数据,这被称为Reference。
在构建图表之前,您需要定义您希望在图表中显示哪些数据。有时,您可以按原样使用数据集,但其他时候您需要对数据进行一些处理以获得额外的信息。
让我们先用一些示例数据构建一个新的工作簿:
1from openpyxl import Workbook
2from openpyxl.chart import BarChart, Reference
3
4workbook = Workbook()
5sheet = workbook.active
6
7# Let's create some sample sales data
8rows = [
9 ["Product", "Online", "Store"],
10 [1, 30, 45],
11 [2, 40, 30],
12 [3, 40, 25],
13 [4, 50, 30],
14 [5, 30, 25],
15 [6, 25, 35],
16 [7, 20, 40],
17]
18
19for row in rows:
20 sheet.append(row)
现在,您将开始创建一个显示每种产品总销售额的条形图:
22chart = BarChart()
23data = Reference(worksheet=sheet,
24 min_row=1,
25 max_row=8,
26 min_col=2,
27 max_col=3)
28
29chart.add_data(data, titles_from_data=True)
30sheet.add_chart(chart, "E2")
31
32workbook.save("chart.xlsx")
这就是了。下面,您可以看到一个非常直观的条形图,显示了在线产品销售和店内产品销售之间的差异:
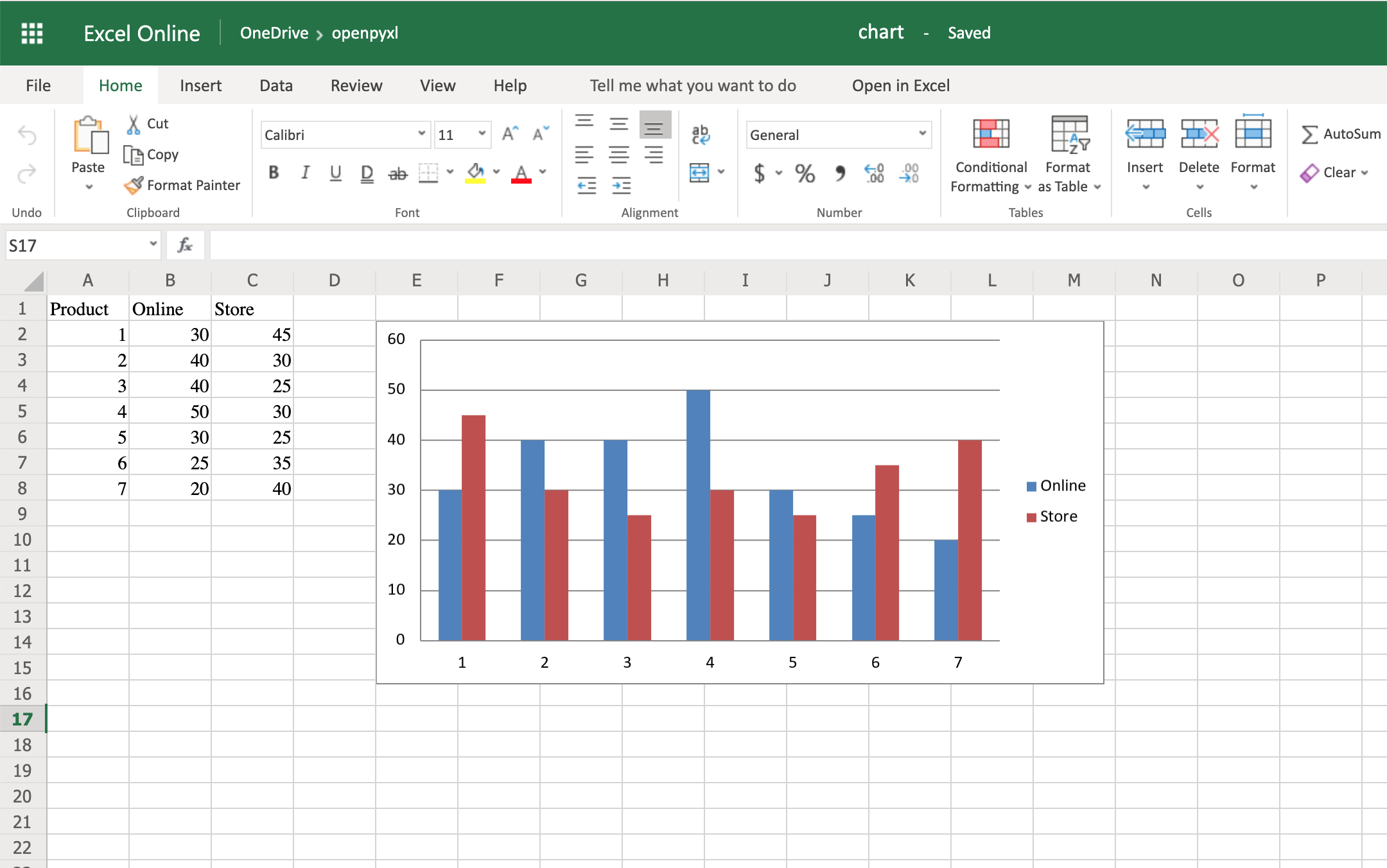
与图像一样,图表的左上角位于您添加图表的单元格上。在你的情况下,它是在细胞E2。
注意:根据您使用的是 Microsoft Excel 还是开源软件(LibreOffice 或 OpenOffice),图表可能会略有不同。
尝试创建一个折线图,稍微改变一下数据:
1import random
2from openpyxl import Workbook
3from openpyxl.chart import LineChart, Reference
4
5workbook = Workbook()
6sheet = workbook.active
7
8# Let's create some sample sales data
9rows = [
10 ["", "January", "February", "March", "April",
11 "May", "June", "July", "August", "September",
12 "October", "November", "December"],
13 [1, ],
14 [2, ],
15 [3, ],
16]
17
18for row in rows:
19 sheet.append(row)
20
21for row in sheet.iter_rows(min_row=2,
22 max_row=4,
23 min_col=2,
24 max_col=13):
25 for cell in row:
26 cell.value = random.randrange(5, 100)
使用上面的代码,您将能够生成一些关于 3 种不同产品全年销售的随机数据。
完成后,您可以使用以下代码非常容易地创建一个折线图:
28chart = LineChart()
29data = Reference(worksheet=sheet,
30 min_row=2,
31 max_row=4,
32 min_col=1,
33 max_col=13)
34
35chart.add_data(data, from_rows=True, titles_from_data=True)
36sheet.add_chart(chart, "C6")
37
38workbook.save("line_chart.xlsx")
下面是上面这段代码的结果:
这里需要记住的一点是,在添加数据时,您使用了from_rows=True。此参数使图表逐行绘制,而不是逐列绘制。
在示例数据中,您可以看到每个产品都有一个包含 12 个值的行(每月一列)。这就是你用from_rows的原因。如果您没有通过该参数,默认情况下,图表会尝试按列绘制,您将获得逐月的销售额比较。
与上述参数变化有关的另一个区别是,我们的Reference现在从第一列min_col=1开始,而不是从第二列开始。这种改变是必要的,因为图表现在希望第一列有标题。
关于图表的样式,您还可以更改一些其他的东西。例如,您可以向图表添加特定类别:
cats = Reference(worksheet=sheet,
min_row=1,
max_row=1,
min_col=2,
max_col=13)
chart.set_categories(cats)
在保存工作簿之前添加这段代码,您应该会看到月份名称而不是数字:
就代码而言,这是一个最小的变化。但就电子表格的可读性而言,这使得人们更容易打开电子表格并立即理解图表。
提高图表可读性的另一个方法是添加一个轴。您可以使用属性x_axis和y_axis来实现:
chart.x_axis.title = "Months"
chart.y_axis.title = "Sales (per unit)"
这将生成如下所示的电子表格:
正如你所看到的,像上面这样的小变化使得阅读你的图表变得更加容易和快捷。
还有一种方法是使用 Excel 的默认属性ChartStyle来设置图表的样式。在这种情况下,您必须在 1 到 48 之间选择一个数字。根据您的选择,图表的颜色也会发生变化:
# You can play with this by choosing any number between 1 and 48
chart.style = 24
使用上面选择的样式,所有线条都有一些橙色阴影:
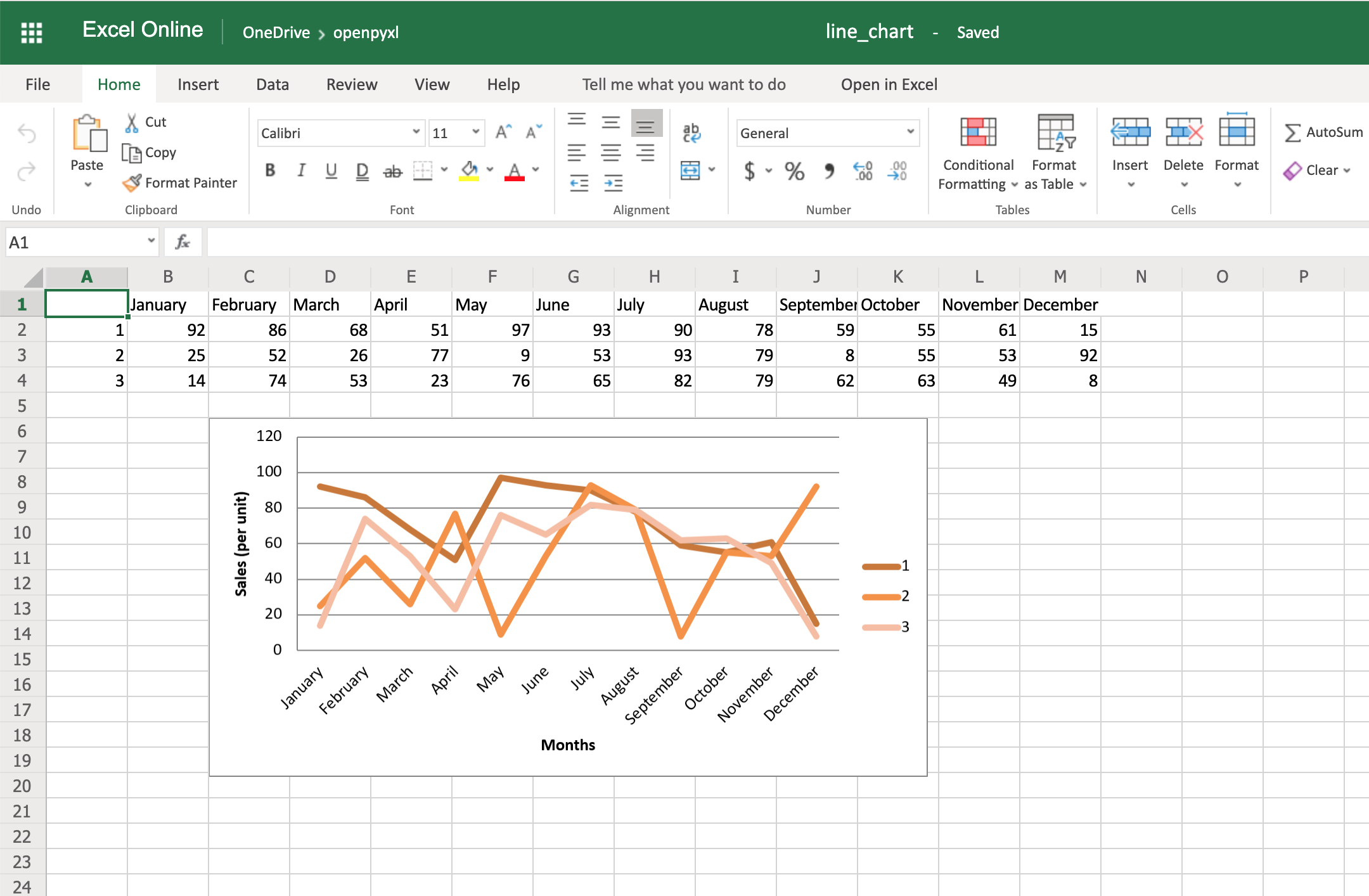
没有清晰的文档说明每个样式编号是什么样子,但是这个电子表格有一些可用样式的例子。
下面是用于生成包含类别、轴标题和样式的折线图的完整代码:
import random
from openpyxl import Workbook
from openpyxl.chart import LineChart, Reference
workbook = Workbook()
sheet = workbook.active
# Let's create some sample sales data
rows = [
["", "January", "February", "March", "April",
"May", "June", "July", "August", "September",
"October", "November", "December"],
[1, ],
[2, ],
[3, ],
]
for row in rows:
sheet.append(row)
for row in sheet.iter_rows(min_row=2,
max_row=4,
min_col=2,
max_col=13):
for cell in row:
cell.value = random.randrange(5, 100)
# Create a LineChart and add the main data
chart = LineChart()
data = Reference(worksheet=sheet,
min_row=2,
max_row=4,
min_col=1,
max_col=13)
chart.add_data(data, titles_from_data=True, from_rows=True)
# Add categories to the chart
cats = Reference(worksheet=sheet,
min_row=1,
max_row=1,
min_col=2,
max_col=13)
chart.set_categories(cats)
# Rename the X and Y Axis
chart.x_axis.title = "Months"
chart.y_axis.title = "Sales (per unit)"
# Apply a specific Style
chart.style = 24
# Save!
sheet.add_chart(chart, "C6")
workbook.save("line_chart.xlsx")
您可以应用更多的图表类型和定制,所以如果您需要一些特定的格式,请务必查看关于它的包文档。
将 Python 类转换为 Excel 电子表格
您已经看到了如何将 Excel 电子表格的数据转换成 Python 类,但是现在让我们做相反的事情。
让我们假设您有一个数据库,并且正在使用一些对象关系映射(ORM)将 DB 对象映射到 Python 类。现在,您希望将这些相同的对象导出到电子表格中。
让我们假设下面的数据类代表来自您的产品销售数据库的数据:
from dataclasses import dataclass
from typing import List
@dataclass
class Sale:
quantity: int
@dataclass
class Product:
id: str
name: str
sales: List[Sale]
现在,让我们生成一些随机数据,假设上述类存储在一个db_classes.py文件中:
1import random
2
3# Ignore these for now. You'll use them in a sec ;)
4from openpyxl import Workbook
5from openpyxl.chart import LineChart, Reference
6
7from db_classes import Product, Sale
8
9products = []
10
11# Let's create 5 products
12for idx in range(1, 6):
13 sales = []
14
15 # Create 5 months of sales
16 for _ in range(5):
17 sale = Sale(quantity=random.randrange(5, 100))
18 sales.append(sale)
19
20 product = Product(id=str(idx),
21 name="Product %s" % idx,
22 sales=sales)
23 products.append(product)
通过运行这段代码,您应该会得到 5 个产品 5 个月的销售额,每个月的销售额是随机的。
现在,要将其转换成电子表格,您需要迭代数据并将其追加到电子表格中:
25workbook = Workbook()
26sheet = workbook.active
27
28# Append column names first
29sheet.append(["Product ID", "Product Name", "Month 1",
30 "Month 2", "Month 3", "Month 4", "Month 5"])
31
32# Append the data
33for product in products:
34 data = [product.id, product.name]
35 for sale in product.sales:
36 data.append(sale.quantity)
37 sheet.append(data)
就是这样。这应该允许您用来自数据库的一些数据创建一个电子表格。
但是,为什么不使用您最近获得的一些很酷的知识来添加一个图表,以便更直观地显示数据呢?
好吧,那么你可以这样做:
38chart = LineChart()
39data = Reference(worksheet=sheet,
40 min_row=2,
41 max_row=6,
42 min_col=2,
43 max_col=7)
44
45chart.add_data(data, titles_from_data=True, from_rows=True)
46sheet.add_chart(chart, "B8")
47
48cats = Reference(worksheet=sheet,
49 min_row=1,
50 max_row=1,
51 min_col=3,
52 max_col=7)
53chart.set_categories(cats)
54
55chart.x_axis.title = "Months"
56chart.y_axis.title = "Sales (per unit)"
57
58workbook.save(filename="oop_sample.xlsx")
现在我们正在谈话!这是一个从数据库对象生成的电子表格,带有图表和所有内容:
这是总结图表新知识的好方法!
奖励:和熊猫一起工作
尽管你可以使用 Pandas 来处理 Excel 文件,但是有一些事情你要么不能用 Pandas 来完成,要么直接使用openpyxl会更好。
例如,使用openpyxl的一些优点是能够容易地用样式、条件格式等定制你的电子表格。
但是你猜怎么着,你不用担心挑选。事实上,openpyxl支持将数据从熊猫数据框架转换到工作簿,或者相反,将openpyxl工作簿转换到熊猫数据框架。
注意:如果你是熊猫新手,请提前查看我们关于熊猫数据框的课程。
首先,记得安装pandas包:
$ pip install pandas
然后,让我们创建一个示例数据帧:
1import pandas as pd
2
3data = {
4 "Product Name": ["Product 1", "Product 2"],
5 "Sales Month 1": [10, 20],
6 "Sales Month 2": [5, 35],
7}
8df = pd.DataFrame(data)
现在您已经有了一些数据,您可以使用.dataframe_to_rows()将其从数据帧转换成工作表:
10from openpyxl import Workbook
11from openpyxl.utils.dataframe import dataframe_to_rows
12
13workbook = Workbook()
14sheet = workbook.active
15
16for row in dataframe_to_rows(df, index=False, header=True):
17 sheet.append(row)
18
19workbook.save("pandas.xlsx")
您应该会看到如下所示的电子表格:
如果您想添加数据帧的索引,您可以更改index=True,它会将每一行的索引添加到您的电子表格中。
另一方面,如果您想将电子表格转换成数据帧,也可以用一种非常简单的方式来完成,如下所示:
import pandas as pd
from openpyxl import load_workbook
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
values = sheet.values
df = pd.DataFrame(values)
或者,例如,如果您想要添加正确的标题并将审阅 ID 用作索引,您也可以这样做:
import pandas as pd
from openpyxl import load_workbook
from mapping import REVIEW_ID
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
data = sheet.values
# Set the first row as the columns for the DataFrame
cols = next(data)
data = list(data)
# Set the field "review_id" as the indexes for each row
idx = [row[REVIEW_ID] for row in data]
df = pd.DataFrame(data, index=idx, columns=cols)
使用索引和列可以让您轻松地访问数据框架中的数据:
>>> df.columns Index(['marketplace', 'customer_id', 'review_id', 'product_id', 'product_parent', 'product_title', 'product_category', 'star_rating', 'helpful_votes', 'total_votes', 'vine', 'verified_purchase', 'review_headline', 'review_body', 'review_date'], dtype='object') >>> # Get first 10 reviews' star rating >>> df["star_rating"][:10] R3O9SGZBVQBV76 5 RKH8BNC3L5DLF 5 R2HLE8WKZSU3NL 2 R31U3UH5AZ42LL 5 R2SV659OUJ945Y 4 RA51CP8TR5A2L 5 RB2Q7DLDN6TH6 5 R2RHFJV0UYBK3Y 1 R2Z6JOQ94LFHEP 5 RX27XIIWY5JPB 4 Name: star_rating, dtype: int64 >>> # Grab review with id "R2EQL1V1L6E0C9", using the index >>> df.loc["R2EQL1V1L6E0C9"] marketplace US customer_id 15305006 review_id R2EQL1V1L6E0C9 product_id B004LURNO6 product_parent 892860326 review_headline Five Stars review_body Love it review_date 2015-08-31 Name: R2EQL1V1L6E0C9, dtype: object好了,不管你是想用
openpyxl美化你的熊猫数据集还是用熊猫做一些核心代数,你现在知道如何在两个包之间切换。结论
唷,经过这么长时间的阅读,你现在知道如何用 Python 处理电子表格了!您可以依靠值得信赖的伙伴
openpyxl:
- 以 Pythonic 的方式从电子表格中提取有价值的信息
- 无论复杂程度如何,都可以创建自己的电子表格
- 向您的电子表格添加很酷的功能,如条件格式或图表
你还可以用
openpyxl做一些本教程中没有提到的事情,但是你可以随时查看这个包的官方文档网站来了解更多。你甚至可以冒险检查它的源代码,并进一步改进这个包。如果你有任何问题,或者如果你想了解更多,请在下面留下你的评论。
下载数据集: 单击此处下载您将在本教程中学习的 openpyxl 练习的数据集。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 openpyxl 用 Python 编辑 Excel 电子表格*********
自定义 Python 类中的运算符和函数重载
如果你在 Python 中对一个
str对象使用过+或*操作符,你一定会注意到它与int或float对象相比的不同行为:
>>> # Adds the two numbers
>>> 1 + 2
3
>>> # Concatenates the two strings
>>> 'Real' + 'Python'
'RealPython'
>>> # Gives the product
>>> 3 * 2
6
>>> # Repeats the string
>>> 'Python' * 3
'PythonPythonPython'
您可能想知道同一个内置操作符或函数如何为不同类的对象显示不同的行为。这分别称为运算符重载或函数重载。本文将帮助您理解这种机制,以便您可以在自己的 Python 类中做同样的事情,并使您的对象更加 Python 化。
您将了解以下内容:
- 在 Python 中处理操作符和内置的 API
len()和其他内置背后的“秘密”- 如何使您的类能够使用运算符
- 如何让你的类与 Python 的内置函数兼容
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
另外,您还将看到一个示例类,它的对象将与这些操作符和函数兼容。我们开始吧!
Python 数据模型
假设您有一个代表在线订单的类,它有一个购物车(一个list)和一个客户(一个str或代表客户的另一个类的实例)。
注意:如果你需要复习 Python 中的 OOP,可以看看这篇关于真正 Python 的教程:Python 3 中的面向对象编程(OOP)
在这种情况下,想要获得购物车列表的长度是很自然的。一些 Python 新手可能会决定在他们的类中实现一个名为get_cart_len()的方法来完成这项工作。但是您可以配置内置的 len() ,当给定我们的对象时,它返回购物车列表的长度。
在另一种情况下,我们可能想在购物车中添加一些东西。同样,不熟悉 Python 的人会考虑实现一个名为append_to_cart()的方法,该方法获取一个商品并将其添加到购物车列表中。但是您可以配置+操作符,让它向购物车添加一个新商品。
Python 使用特殊的方法完成所有这些工作。这些特殊的方法有一个命名约定,其中名称以两个下划线开始,后跟一个标识符,以另一对下划线结束。
本质上,每个内置函数或操作符都有一个与之对应的特殊方法。比如有__len__(),对应len(),有__add__()对应+操作员。
默认情况下,大多数内置和操作符都不会处理你的类的对象。您必须在类定义中添加相应的特殊方法,以使您的对象与内置运算符和运算符兼容。
当您这样做时,与其关联的函数或运算符的行为会根据方法中定义的行为而改变。
这正是数据模型(Python 文档的第 3 节)帮助您完成的。它列出了所有可用的特殊方法,并为您提供了重载内置函数和运算符的方法,以便您可以在自己的对象上使用它们。
让我们看看这意味着什么。
有趣的事实:由于这些方法使用的命名惯例,它们也被称为邓德方法,这是评分方法下T5】ddouble**的简写。有时它们也被称为特殊方法或魔法方法。不过,我们更喜欢 dunder 方法!**
像len()和[] 这样的内部操作
Python 中的每个类都为内置函数和方法定义了自己的行为。当你把某个类的一个实例传递给一个内置函数,或者在实例上使用一个操作符,实际上相当于调用一个带有相关参数的特殊方法。
如果有一个内置函数func(),并且该函数对应的特殊方法是__func__(),Python 将对该函数的调用解释为obj.__func__(),其中obj是对象。在操作符的例子中,如果你有一个操作符opr,并且对应的特殊方法是__opr__(),Python 将类似obj1 <opr> obj2的东西解释为obj1.__opr__(obj2)。
因此,当你在一个对象上调用len()时,Python 将调用作为obj.__len__()来处理。当您在 iterable 上使用[]操作符来获取索引处的值时,Python 将其作为itr.__getitem__(index)来处理,其中itr是 iterable 对象,index是您想要获取的索引。
因此,当您在自己的类中定义这些特殊方法时,您会覆盖与它们相关联的函数或操作符的行为,因为在幕后,Python 正在调用您的方法。让我们更好地理解这一点:
>>> a = 'Real Python' >>> b = ['Real', 'Python'] >>> len(a) 11 >>> a.__len__() 11 >>> b[0] 'Real' >>> b.__getitem__(0) 'Real'如您所见,当您使用该函数或其相应的特殊方法时,会得到相同的结果。事实上,当您使用
dir()获得一个str对象的属性和方法列表时,除了在str对象上可用的常用方法之外,您还会在列表中看到这些特殊的方法:
>>> dir(a)
['__add__',
'__class__',
'__contains__',
'__delattr__',
'__dir__',
...,
'__iter__',
'__le__',
'__len__',
'__lt__',
...,
'swapcase',
'title',
'translate',
'upper',
'zfill']
如果一个内置函数或操作符的行为不是由特殊方法在类中定义的,那么你将得到一个TypeError。
那么,如何在你的类中使用特殊的方法呢?
重载内置函数
数据模型中定义的许多特殊方法可以用来改变函数的行为,例如len、abs、hash、divmod等等。为此,您只需要在您的类中定义相应的特殊方法。让我们看几个例子:
使用len() 给你的对象一个长度
要改变len()的行为,您需要在您的类中定义__len__()特殊方法。每当你将你的类的一个对象传递给len(),你对__len__()的自定义定义将被用来获得结果。让我们为我们在开头谈到的订单类实现len():
>>> class Order: ... def __init__(self, cart, customer): ... self.cart = list(cart) ... self.customer = customer ... ... def __len__(self): ... return len(self.cart) ... >>> order = Order(['banana', 'apple', 'mango'], 'Real Python') >>> len(order) 3如您所见,您现在可以使用
len()直接获得购物车的长度。此外,说“订单长度”比调用类似于order.get_cart_len()的东西更直观。你的召唤既有 Pythonic 式的,也更直观。当您没有定义__len__()方法,但仍然在您的对象上调用len()时,您会得到一个TypeError:
>>> class Order:
... def __init__(self, cart, customer):
... self.cart = list(cart)
... self.customer = customer
...
>>> order = Order(['banana', 'apple', 'mango'], 'Real Python')
>>> len(order) # Calling len when no __len__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: object of type 'Order' has no len()
但是,当重载len()时,您应该记住 Python 要求函数返回一个整数。如果您的方法返回的不是整数,那么您将得到一个TypeError。这很可能是为了与以下事实保持一致:通常使用len()来获得序列的长度,该长度只能是整数:
>>> class Order: ... def __init__(self, cart, customer): ... self.cart = list(cart) ... self.customer = customer ... ... def __len__(self): ... return float(len(self.cart)) # Return type changed to float ... >>> order = Order(['banana', 'apple', 'mango'], 'Real Python') >>> len(order) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'float' object cannot be interpreted as an integer使用
abs()使您的对象工作通过在类中定义
__abs__()特殊方法,您可以为类的实例指定内置的的行为。对abs()的返回值没有限制,当你的类定义中没有这个特殊方法时,你会得到一个TypeError。在二维空间中表示一个向量的类中,
abs()可以用来得到向量的长度。让我们来看看它的实际应用:
>>> class Vector:
... def __init__(self, x_comp, y_comp):
... self.x_comp = x_comp
... self.y_comp = y_comp
...
... def __abs__(self):
... return (self.x_comp ** 2 + self.y_comp ** 2) ** 0.5
...
>>> vector = Vector(3, 4)
>>> abs(vector)
5.0
说“向量的绝对值”比调用类似vector.get_mag()的东西更直观。
使用str() 漂亮地打印你的对象
内置的str()用于将一个类的实例转换成一个str对象,或者更恰当地说,用于获得一个用户友好的对象字符串表示,它可以被普通用户而不是程序员读取。通过在你的类中定义__str__()方法,你可以定义当你的对象被传递给str()时应该显示的字符串格式。此外,__str__()是 Python 在对象上调用 print() 时使用的方法。
让我们在Vector类中实现它,将Vector对象格式化为xi+yj。负 y 分量将使用格式小型语言进行处理:
>>> class Vector: ... def __init__(self, x_comp, y_comp): ... self.x_comp = x_comp ... self.y_comp = y_comp ... ... def __str__(self): ... # By default, sign of +ve number is not displayed ... # Using `+`, sign is always displayed ... return f'{self.x_comp}i{self.y_comp:+}j' ... >>> vector = Vector(3, 4) >>> str(vector) '3i+4j' >>> print(vector) 3i+4j需要
__str__()返回一个str对象,如果返回类型是非字符串,我们得到一个TypeError。使用
repr()表示你的对象内置的
repr()用于获得对象的可解析字符串表示。如果一个对象是可解析的,这意味着当repr与eval()等函数结合使用时,Python 应该能够从表示中重新创建对象。要定义repr()的行为,可以使用__repr__()的特殊方法。这也是 Python 用来在 REPL 会话中显示对象的方法。如果没有定义
__repr__()方法,您将得到类似于<__main__.Vector object at 0x...>试图在 REPL 会话中查看对象的结果。让我们在Vector课堂上看看它的作用:
>>> class Vector:
... def __init__(self, x_comp, y_comp):
... self.x_comp = x_comp
... self.y_comp = y_comp
...
... def __repr__(self):
... return f'Vector({self.x_comp}, {self.y_comp})'
...
>>> vector = Vector(3, 4)
>>> repr(vector)
'Vector(3, 4)'
>>> b = eval(repr(vector))
>>> type(b), b.x_comp, b.y_comp
(__main__.Vector, 3, 4)
>>> vector # Looking at object; __repr__ used
'Vector(3, 4)'
注意:在没有定义__str__()方法的情况下,Python 使用__repr__()方法打印对象,以及在调用str()时表示对象。如果两种方法都没有,默认为<__main__.Vector ...>。但是__repr__()是用于在交互会话中显示对象的唯一方法。课堂上没有它会产生<__main__.Vector ...>。
此外,虽然__str__()和__repr__()之间的这种区别是推荐的行为,但许多流行的库忽略了这种区别,并交替使用这两种方法。
这里有一篇关于__repr__()和__str__()的推荐文章,作者是我们自己的丹·巴德: Python 字符串转换 101:为什么每个类都需要一个“repr”。
使用bool() 使你的对象真假
内置的bool()可以用来获取一个对象的真值。要定义它的行为,可以使用__bool__()(Python 2 . x 中的__nonzero__())特殊方法。
这里定义的行为将决定一个实例在所有需要获得真值的上下文中的真值,比如在if语句中。
例如,对于上面定义的Order类,如果购物车列表的长度不为零,则可以认为实例是真的。这可用于检查是否应处理订单:
>>> class Order: ... def __init__(self, cart, customer): ... self.cart = list(cart) ... self.customer = customer ... ... def __bool__(self): ... return len(self.cart) > 0 ... >>> order1 = Order(['banana', 'apple', 'mango'], 'Real Python') >>> order2 = Order([], 'Python') >>> bool(order1) True >>> bool(order2) False >>> for order in [order1, order2]: ... if order: ... print(f"{order.customer}'s order is processing...") ... else: ... print(f"Empty order for customer {order.customer}") Real Python's order is processing... Empty order for customer Python注意:当
__bool__()特殊方法没有在类中实现时,__len__()返回的值作为真值,非零值表示True,零值表示False。如果这两种方法都没有实现,那么该类的所有实例都被认为是True。还有许多重载内置函数的特殊方法。您可以在文档中找到它们。讨论了其中一些之后,让我们转到操作符。
重载内置运算符
改变操作符的行为就像改变函数的行为一样简单。您在您的类中定义它们对应的特殊方法,操作符根据这些方法中定义的行为工作。
这些与上述特殊方法的不同之处在于,它们需要接受定义中除了
self之外的另一个参数,通常称为other。我们来看几个例子。使用
+添加您的对象与
+操作符相对应的特殊方法是__add__()方法。添加自定义的__add__()定义会改变操作者的行为。建议__add__()返回类的新实例,而不是修改调用实例本身。在 Python 中,您会经常看到这种行为:
>>> a = 'Real'
>>> a + 'Python' # Gives new str instance
'RealPython'
>>> a # Values unchanged
'Real'
>>> a = a + 'Python' # Creates new instance and assigns a to it
>>> a
'RealPython'
您可以在上面看到,在一个str对象上使用+操作符实际上会返回一个新的str实例,保持调用实例(a)的值不变。要改变它,我们需要显式地将新实例分配给a。
让我们使用操作符在Order类中实现向购物车添加新商品的功能。我们将遵循推荐的做法,让操作者返回一个新的Order实例,该实例包含我们需要的更改,而不是直接对我们的实例进行更改:
>>> class Order: ... def __init__(self, cart, customer): ... self.cart = list(cart) ... self.customer = customer ... ... def __add__(self, other): ... new_cart = self.cart.copy() ... new_cart.append(other) ... return Order(new_cart, self.customer) ... >>> order = Order(['banana', 'apple'], 'Real Python') >>> (order + 'orange').cart # New Order instance ['banana', 'apple', 'orange'] >>> order.cart # Original instance unchanged ['banana', 'apple'] >>> order = order + 'mango' # Changing the original instance >>> order.cart ['banana', 'apple', 'mango']类似地,您有
__sub__()、__mul__()和其他定义-、*等行为的特殊方法。这些方法还应该返回该类的一个新实例。快捷键:
+=操作符
+=操作符是表达式obj1 = obj1 + obj2的快捷方式。与之相对应的特殊方法是__iadd__()。__iadd__()方法应该直接对self参数进行修改并返回结果,结果可能是也可能不是self。这种行为与__add__()截然不同,因为后者创建了一个新对象并返回它,正如你在上面看到的。粗略地说,任何在两个对象上使用的
+=都相当于这个:>>> result = obj1 + obj2 >>> obj1 = result这里,
result是__iadd__()返回的值。第二个赋值由 Python 自动处理,这意味着您不需要像在obj1 = obj1 + obj2的情况下那样显式地将obj1赋值给结果。让我们为
Order类实现这一点,这样就可以使用+=将新商品添加到购物车中:
>>> class Order:
... def __init__(self, cart, customer):
... self.cart = list(cart)
... self.customer = customer
...
... def __iadd__(self, other):
... self.cart.append(other)
... return self
...
>>> order = Order(['banana', 'apple'], 'Real Python')
>>> order += 'mango'
>>> order.cart
['banana', 'apple', 'mango']
可以看出,任何更改都是直接对self进行的,然后返回。当你返回一个随机值,比如一个字符串或者一个整数,会发生什么?
>>> class Order: ... def __init__(self, cart, customer): ... self.cart = list(cart) ... self.customer = customer ... ... def __iadd__(self, other): ... self.cart.append(other) ... return 'Hey, I am string!' ... >>> order = Order(['banana', 'apple'], 'Real Python') >>> order += 'mango' >>> order 'Hey, I am string!'即使相关商品被添加到购物车中,
order的值也变成了__iadd__()返回的值。Python 隐式地为您处理了这个任务。如果您在实现中忘记返回某些内容,这可能会导致令人惊讶的行为:
>>> class Order:
... def __init__(self, cart, customer):
... self.cart = list(cart)
... self.customer = customer
...
... def __iadd__(self, other):
... self.cart.append(other)
...
>>> order = Order(['banana', 'apple'], 'Real Python')
>>> order += 'mango'
>>> order # No output
>>> type(order)
NoneType
因为所有 Python 函数(或方法)都隐式返回 None ,order被重新分配给None,当order被检查时,REPL 会话不显示任何输出。看order的类型,你看到现在是NoneType。因此,一定要确保在__iadd__()的实现中返回一些东西,并且是操作的结果,而不是其他。
类似于__iadd__(),你有__isub__()、__imul__()、__idiv__()和其他特殊的方法来定义-=、*=、/=和其他类似的行为。
注意:当__iadd__()或者它的朋友从你的类定义中消失了,但是你仍然在你的对象上使用它们的操作符,Python 使用__add__()和它的朋友来获得操作的结果,并把它分配给调用实例。一般来说,只要__add__()和它的朋友正常工作(返回某个操作的结果),在你的类中不实现__iadd__()和它的朋友是安全的。
Python 文档对这些方法有很好的解释。另外,看一下这个示例,它展示了在使用不可变类型时+=和其他类型所涉及的注意事项。
使用[] 对对象进行索引和切片
[]操作符被称为索引操作符,在 Python 中用于各种上下文,例如获取序列中索引处的值,获取与字典中的键相关联的值,或者通过切片获取序列的一部分。您可以使用__getitem__()特殊方法改变它的行为。
让我们配置我们的Order类,这样我们就可以直接使用对象并从购物车中获得一个商品:
>>> class Order: ... def __init__(self, cart, customer): ... self.cart = list(cart) ... self.customer = customer ... ... def __getitem__(self, key): ... return self.cart[key] ... >>> order = Order(['banana', 'apple'], 'Real Python') >>> order[0] 'banana' >>> order[-1] 'apple'你会注意到,在上面,
__getitem__()的参数名不是index,而是key。这是因为参数主要有三种形式:一个整数值,在这种情况下它要么是一个索引要么是一个字典键,一个字符串值,在这种情况下它是一个字典键, 一个切片对象 ,在这种情况下它将对类使用的序列进行切片。虽然还有其他可能性,但这些是最常遇到的。由于我们的内部数据结构是一个列表,我们可以使用
[]操作符对列表进行切片,在这种情况下,key参数将是一个切片对象。这是在你的类中有一个__getitem__()定义的最大优势之一。只要使用支持切片的数据结构(列表、元组、字符串等),就可以配置对象来直接对结构进行切片:
>>> order[1:]
['apple']
>>> order[::-1]
['apple', 'banana']
注意:有一个类似的__setitem__()特殊方法,用来定义obj[x] = y的行为。这个方法除了self之外还有两个参数,一般称为key和value,可以用来改变key到value的值。
反向运算符:使你的类在数学上正确
虽然定义__add__()、__sub__()、__mul__()和类似的特殊方法允许您在类实例是左侧操作数时使用运算符,但如果类实例是右侧操作数,运算符将不起作用:
>>> class Mock: ... def __init__(self, num): ... self.num = num ... def __add__(self, other): ... return Mock(self.num + other) ... >>> mock = Mock(5) >>> mock = mock + 6 >>> mock.num 11 >>> mock = 6 + Mock(5) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'Mock'如果你的类表示一个数学实体,比如一个向量,一个坐标,或者一个复数,应用操作符应该在两种情况下都有效,因为它是一个有效的数学运算。
此外,如果操作符只在实例是左操作数时起作用,那么在许多情况下,我们违反了交换性的基本原则。因此,为了帮助您使您的类在数学上正确,Python 为您提供了反向特殊方法,如
__radd__()、__rsub__()、__rmul__()等等。这些函数处理诸如
x + obj、x - obj和x * obj之类的调用,其中x不是相关类的实例。就像__add__()和其他方法一样,这些反向特殊方法应该返回一个带有操作变化的类的新实例,而不是修改调用实例本身。让我们在
Order类中配置__radd__(),这样它将在购物车的前面添加一些东西。这可用于根据订单优先级组织购物车的情况:
>>> class Order:
... def __init__(self, cart, customer):
... self.cart = list(cart)
... self.customer = customer
...
... def __add__(self, other):
... new_cart = self.cart.copy()
... new_cart.append(other)
... return Order(new_cart, self.customer)
...
... def __radd__(self, other):
... new_cart = self.cart.copy()
... new_cart.insert(0, other)
... return Order(new_cart, self.customer)
...
>>> order = Order(['banana', 'apple'], 'Real Python')
>>> order = order + 'orange'
>>> order.cart
['banana', 'apple', 'orange']
>>> order = 'mango' + order
>>> order.cart
['mango', 'banana', 'apple', 'orange']
完整的例子
为了把所有这些要点都讲清楚,最好看一个同时实现这些操作符的示例类。
让我们重新发明轮子,实现我们自己的类来表示复数,CustomComplex。我们类的对象将支持各种内置函数和运算符,使它们的行为与内置复数类非常相似:
from math import hypot, atan, sin, cos
class CustomComplex:
def __init__(self, real, imag):
self.real = real
self.imag = imag
构造函数只处理一种调用,CustomComplex(a, b)。它接受位置参数,表示复数的实部和虚部。
让我们在类中定义两个方法,conjugate()和argz(),它们将分别给出复数的复共轭和自变量:
def conjugate(self):
return self.__class__(self.real, -self.imag)
def argz(self):
return atan(self.imag / self.real)
注意: __class__不是一个特殊的方法,而是一个默认存在的类属性。它有一个对类的引用。通过在这里使用它,我们可以获得它,然后以通常的方式调用构造函数。换句话说,这相当于CustomComplex(real, imag)。这样做是为了避免在某一天类名改变时重构代码。
接下来,我们配置abs()来返回一个复数的模数:
def __abs__(self):
return hypot(self.real, self.imag)
我们将遵循推荐的__repr__()和__str__()之间的区别,将第一个用于可解析的字符串表示,将第二个用于“漂亮”的表示。
__repr__()方法将简单地返回字符串中的CustomComplex(a, b),这样我们就可以调用eval()来重新创建对象,而__str__()方法将返回括号中的复数,如(a+bj):
def __repr__(self):
return f"{self.__class__.__name__}({self.real}, {self.imag})"
def __str__(self):
return f"({self.real}{self.imag:+}j)"
数学上,可以把任意两个复数相加,或者把一个实数加到一个复数上。让我们配置+操作符,使其对两种情况都有效。
该方法将检查右侧运算符的类型。如果是int或float,它将只增加实数部分(因为任何实数a都等同于a+0j),而如果是另一个复数,它将改变两个部分:
def __add__(self, other):
if isinstance(other, float) or isinstance(other, int):
real_part = self.real + other
imag_part = self.imag
if isinstance(other, CustomComplex):
real_part = self.real + other.real
imag_part = self.imag + other.imag
return self.__class__(real_part, imag_part)
类似地,我们为-和*定义行为:
def __sub__(self, other):
if isinstance(other, float) or isinstance(other, int):
real_part = self.real - other
imag_part = self.imag
if isinstance(other, CustomComplex):
real_part = self.real - other.real
imag_part = self.imag - other.imag
return self.__class__(real_part, imag_part)
def __mul__(self, other):
if isinstance(other, int) or isinstance(other, float):
real_part = self.real * other
imag_part = self.imag * other
if isinstance(other, CustomComplex):
real_part = (self.real * other.real) - (self.imag * other.imag)
imag_part = (self.real * other.imag) + (self.imag * other.real)
return self.__class__(real_part, imag_part)
由于加法和乘法都是可交换的,我们可以通过分别调用__radd__()和__rmul__()中的__add__()和__mul__()来定义它们的反向运算符。另一方面,需要定义__rsub__()的行为,因为减法是不可交换的:
def __radd__(self, other):
return self.__add__(other)
def __rmul__(self, other):
return self.__mul__(other)
def __rsub__(self, other):
# x - y != y - x
if isinstance(other, float) or isinstance(other, int):
real_part = other - self.real
imag_part = -self.imag
return self.__class__(real_part, imag_part)
注意:您可能已经注意到,我们没有添加一个构造来处理这里的CustomComplex实例。这是因为,在这种情况下,两个操作数都是我们类的实例,并且__rsub__()不会负责处理操作。相反,__sub__()将被称为。这是一个微妙但重要的细节。
现在,我们来处理两个操作符,==和!=。它们使用的特殊方法分别是__eq__()和__ne__()。如果两个复数对应的实部和虚部相等,则称这两个复数相等。当其中任何一个不相等时,就说它们不相等:
def __eq__(self, other):
# Note: generally, floats should not be compared directly
# due to floating-point precision
return (self.real == other.real) and (self.imag == other.imag)
def __ne__(self, other):
return (self.real != other.real) or (self.imag != other.imag)
注: 浮点指南是一篇关于比较浮点和浮点精度的文章。它强调了直接比较浮点数所涉及的注意事项,这正是我们正在做的事情。
也可以用一个简单的公式将一个复数提升到任意次方。我们使用__pow__()特殊方法为内置的pow()和**操作符配置行为:
def __pow__(self, other):
r_raised = abs(self) ** other
argz_multiplied = self.argz() * other
real_part = round(r_raised * cos(argz_multiplied))
imag_part = round(r_raised * sin(argz_multiplied))
return self.__class__(real_part, imag_part)
注意:仔细看看方法的定义。我们调用abs()来获得复数的模。所以,一旦你为你的类中的一个特定的函数或者操作符定义了特殊的方法,它就可以在同一个类的其他方法中使用。
让我们创建这个类的两个实例,一个具有正虚部,一个具有负虚部:
>>> a = CustomComplex(1, 2) >>> b = CustomComplex(3, -4)字符串表示:
>>> a
CustomComplex(1, 2)
>>> b
CustomComplex(3, -4)
>>> print(a)
(1+2j)
>>> print(b)
(3-4j)
使用eval()和repr()重新创建对象:
>>> b_copy = eval(repr(b)) >>> type(b_copy), b_copy.real, b_copy.imag (__main__.CustomComplex, 3, -4)加法、减法和乘法:
>>> a + b
CustomComplex(4, -2)
>>> a - b
CustomComplex(-2, 6)
>>> a + 5
CustomComplex(6, 2)
>>> 3 - a
CustomComplex(2, -2)
>>> a * 6
CustomComplex(6, 12)
>>> a * (-6)
CustomComplex(-6, -12)
平等和不平等检查:
>>> a == CustomComplex(1, 2) True >>> a == b False >>> a != b True >>> a != CustomComplex(1, 2) False最后,对一个复数求幂:
>>> a ** 2
CustomComplex(-3, 4)
>>> b ** 5
CustomComplex(-237, 3116)
正如您所看到的,我们的自定义类的对象的行为和外观都像内置类的对象,并且非常 Pythonic 化。下面嵌入了该类的完整示例代码。
from math import hypot, atan, sin, cos
class CustomComplex():
"""
A class to represent a complex number, a+bj.
Attributes:
real - int, representing the real part
imag - int, representing the imaginary part
Implements the following:
* Addition with a complex number or a real number using `+`
* Multiplication with a complex number or a real number using `*`
* Subtraction of a complex number or a real number using `-`
* Calculation of absolute value using `abs`
* Raise complex number to a power using `**`
* Nice string representation using `__repr__`
* Nice user-end viewing using `__str__`
Notes:
* The constructor has been intentionally kept simple
* It is configured to support one kind of call:
CustomComplex(a, b)
* Error handling was avoided to keep things simple
"""
def __init__(self, real, imag):
"""
Initializes a complex number, setting real and imag part
Arguments:
real: Number, real part of the complex number
imag: Number, imaginary part of the complex number
"""
self.real = real
self.imag = imag
def conjugate(self):
"""
Returns the complex conjugate of a complex number
Return:
CustomComplex instance
"""
return CustomComplex(self.real, -self.imag)
def argz(self):
"""
Returns the argument of a complex number
The argument is given by:
atan(imag_part/real_part)
Return:
float
"""
return atan(self.imag / self.real)
def __abs__(self):
"""
Returns the modulus of a complex number
Return:
float
"""
return hypot(self.real, self.imag)
def __repr__(self):
"""
Returns str representation of an instance of the
class. Can be used with eval() to get another
instance of the class
Return:
str
"""
return f"CustomComplex({self.real}, {self.imag})"
def __str__(self):
"""
Returns user-friendly str representation of an instance
of the class
Return:
str
"""
return f"({self.real}{self.imag:+}j)"
def __add__(self, other):
"""
Returns the addition of a complex number with
int, float or another complex number
Return:
CustomComplex instance
"""
if isinstance(other, float) or isinstance(other, int):
real_part = self.real + other
imag_part = self.imag
if isinstance(other, CustomComplex):
real_part = self.real + other.real
imag_part = self.imag + other.imag
return CustomComplex(real_part, imag_part)
def __sub__(self, other):
"""
Returns the subtration from a complex number of
int, float or another complex number
Return:
CustomComplex instance
"""
if isinstance(other, float) or isinstance(other, int):
real_part = self.real - other
imag_part = self.imag
if isinstance(other, CustomComplex):
real_part = self.real - other.real
imag_part = self.imag - other.imag
return CustomComplex(real_part, imag_part)
def __mul__(self, other):
"""
Returns the multiplication of a complex number with
int, float or another complex number
Return:
CustomComplex instance
"""
if isinstance(other, int) or isinstance(other, float):
real_part = self.real * other
imag_part = self.imag * other
if isinstance(other, CustomComplex):
real_part = (self.real * other.real) - (self.imag * other.imag)
imag_part = (self.real * other.imag) + (self.imag * other.real)
return CustomComplex(real_part, imag_part)
def __radd__(self, other):
"""
Same as __add__; allows 1 + CustomComplex('x+yj')
x + y == y + x
"""
pass
def __rmul__(self, other):
"""
Same as __mul__; allows 2 * CustomComplex('x+yj')
x * y == y * x
"""
pass
def __rsub__(self, other):
"""
Returns the subtraction of a complex number from
int or float
x - y != y - x
Subtration of another complex number is not handled by __rsub__
Instead, __sub__ handles it since both sides are instances of
this class
Return:
CustomComplex instance
"""
if isinstance(other, float) or isinstance(other, int):
real_part = other - self.real
imag_part = -self.imag
return CustomComplex(real_part, imag_part)
def __eq__(self, other):
"""
Checks equality of two complex numbers
Two complex numbers are equal when:
* Their real parts are equal AND
* Their imaginary parts are equal
Return:
bool
"""
# note: comparing floats directly is not a good idea in general
# due to floating-point precision
return (self.real == other.real) and (self.imag == other.imag)
def __ne__(self, other):
"""
Checks inequality of two complex numbers
Two complex numbers are unequal when:
* Their real parts are unequal OR
* Their imaginary parts are unequal
Return:
bool
"""
return (self.real != other.real) or (self.imag != other.imag)
def __pow__(self, other):
"""
Raises a complex number to a power
Formula:
z**n = (r**n)*[cos(n*agrz) + sin(n*argz)j], where
z = complex number
n = power
r = absolute value of z
argz = argument of z
Return:
CustomComplex instance
"""
r_raised = abs(self) ** other
argz_multiplied = self.argz() * other
real_part = round(r_raised * cos(argz_multiplied))
imag_part = round(r_raised * sin(argz_multiplied))
return CustomComplex(real_part, imag_part)
回顾和资源
在本教程中,您了解了 Python 数据模型以及如何使用该数据模型来构建 Python 类。您了解了如何改变内置函数的行为,比如len()、abs()、str()、bool()等等。您还了解了如何改变内置操作符的行为,如+、-、*、**等等。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
阅读完本文后,您就可以自信地创建利用 Python 最佳惯用特性的类,并使您的对象具有 Python 语言的特性!
有关数据模型、函数和运算符重载的更多信息,请参考以下资源:
- 第 3.3 节,Python 文档中数据模型部分的特殊方法名
- 卢西亚诺·拉马尔霍的《流畅的蟒蛇》
- Python 的把戏:本书*****
熊猫数据框架:让数据工作变得愉快
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 熊猫数据帧:高效处理数据
熊猫数据帧 是一个结构,包含二维数据及其对应的标签。数据帧广泛应用于数据科学、机器学习、科学计算以及其他许多数据密集型领域。
数据帧类似于 SQL 表或您在 Excel 或 Calc 中使用的电子表格。在许多情况下,数据帧比表格或电子表格更快、更容易使用、更强大,因为它们是 Python 和 NumPy 生态系统不可或缺的一部分。
在本教程中,您将学习:
- 什么是熊猫数据框架以及如何创建一个
- 如何访问、修改、添加、排序、过滤和删除数据
- 如何处理缺失值
- 如何处理时序数据
- 如何快速可视化数据
是时候开始使用熊猫数据框架了!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
介绍熊猫数据帧
熊猫数据帧是包含以下内容的数据结构:
- 数据组织成二维,行和列
- 标签对应于行和列
>>> import pandas as pd现在您已经导入了熊猫,您可以使用数据框架了。
想象一下,你正在用熊猫来分析一个职位的候选人的数据,这个职位是用 Python 开发 web 应用程序。假设你对候选人的姓名、城市、年龄和 Python 编程测试的分数感兴趣,或者:
namecityagepy-scoreT2 101XavierMexico City4188.0T2 102AnnToronto2879.0T2 103JanaPrague3381.0T2 104YiShanghai3480.0T2 105RobinManchester3868.0T2 106AmalCairo3161.0T2 107NoriOsaka3784.0在该表中,第一行包含列标签 (
name、city、age和py-score)。第一列包含行标签 (101、102等等)。所有其他单元格用数据值填充。现在,您已经拥有了创建熊猫数据框架所需的一切。
创建熊猫数据框架有几种方法。在大多数情况下,您将使用
DataFrame构造函数并提供数据、标签和其他信息。您可以将数据作为二维的列表、元组、或 NumPy 数组来传递。您还可以将它作为一个字典或 PandasSeries实例传递,或者作为本教程中未涉及的其他几种数据类型之一传递。对于这个例子,假设您正在使用一个字典来传递数据:
>>> data = {
... 'name': ['Xavier', 'Ann', 'Jana', 'Yi', 'Robin', 'Amal', 'Nori'],
... 'city': ['Mexico City', 'Toronto', 'Prague', 'Shanghai',
... 'Manchester', 'Cairo', 'Osaka'],
... 'age': [41, 28, 33, 34, 38, 31, 37],
... 'py-score': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
... }
>>> row_labels = [101, 102, 103, 104, 105, 106, 107]
data是一个 Python 变量,它引用保存候选数据的字典。它还包含列的标签:
'name''city''age''py-score'
最后,row_labels指的是包含行标签的列表,这些标签是从101到107的数字。
现在,您已经准备好创建熊猫数据框架了:
>>> df = pd.DataFrame(data=data, index=row_labels) >>> df name city age py-score 101 Xavier Mexico City 41 88.0 102 Ann Toronto 28 79.0 103 Jana Prague 33 81.0 104 Yi Shanghai 34 80.0 105 Robin Manchester 38 68.0 106 Amal Cairo 31 61.0 107 Nori Osaka 37 84.0就是这样!
df是一个变量,用于保存对熊猫数据帧的引用。这个 Pandas 数据框架看起来就像上面的候选表,具有以下特征:
- 从
101到107的行标签- 列标签,如
'name'、'city'、'age'、'py-score'- 数据,如考生姓名、城市、年龄和 Python 考试成绩
该图显示了来自
df的标签和数据:
行标签用蓝色标出,而列标签用红色标出,数据值用紫色标出。
Pandas 数据帧有时会非常大,一次查看所有行是不切实际的。您可以使用
.head()显示前几项,使用.tail()显示后几项:
>>> df.head(n=2)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
>>> df.tail(n=2)
name city age py-score
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
这就是如何显示熊猫数据帧的开始或结束。参数n指定要显示的行数。
注意:把 Pandas DataFrame 想象成一个列的字典,或者 Pandas 系列,有很多额外的特性。
您可以像从字典中获取值一样访问 Pandas 数据帧中的列:
>>> cities = df['city'] >>> cities 101 Mexico City 102 Toronto 103 Prague 104 Shanghai 105 Manchester 106 Cairo 107 Osaka Name: city, dtype: object这是从熊猫数据框架中获取列的最方便的方法。
如果列名是一个有效的 Python 标识符的字符串,那么您可以使用点符号来访问它。也就是说,您可以像获取类实例的属性一样访问该列:
>>> df.city
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name: city, dtype: object
这就是你得到一个特定列的方法。您已经提取了与标签'city'相对应的列,其中包含了所有求职者的位置。
请注意,您已经提取了数据和相应的行标签,这一点很重要:
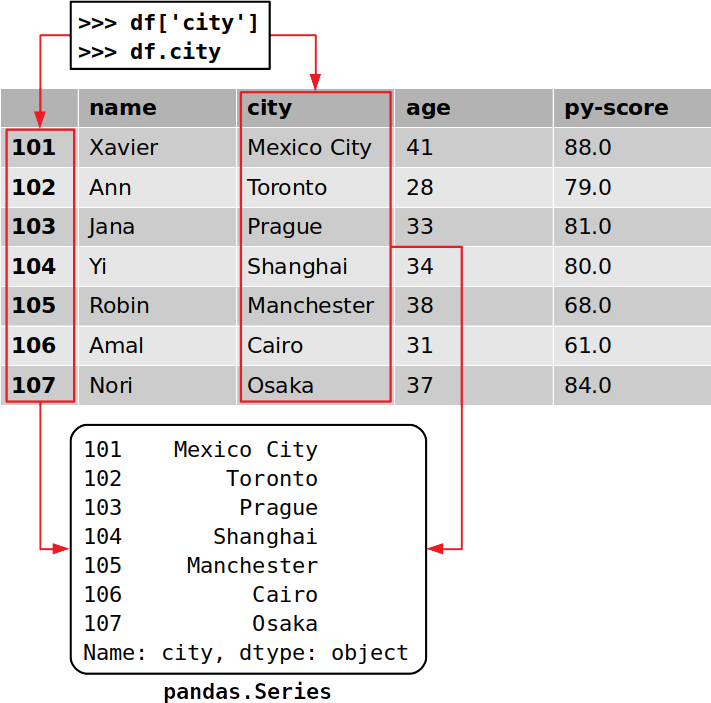
熊猫数据帧的每一列都是 pandas.Series 的一个实例,这是一个保存一维数据及其标签的结构。您可以像使用字典一样获得一个Series对象的单个项目,方法是使用它的标签作为一个键:
>>> cities[102] 'Toronto'在这种情况下,
'Toronto'是数据值,102是相应的标签。正如你将在后面的章节中看到的,还有其他方法可以在熊猫数据帧中获得特定的项目。
>>> df.loc[103]
name Jana
city Prague
age 33
py-score 81
Name: 103, dtype: object
这一次,您已经提取了对应于标签103的行,其中包含名为Jana的候选人的数据。除了该行中的数据值,您还提取了相应列的标签:
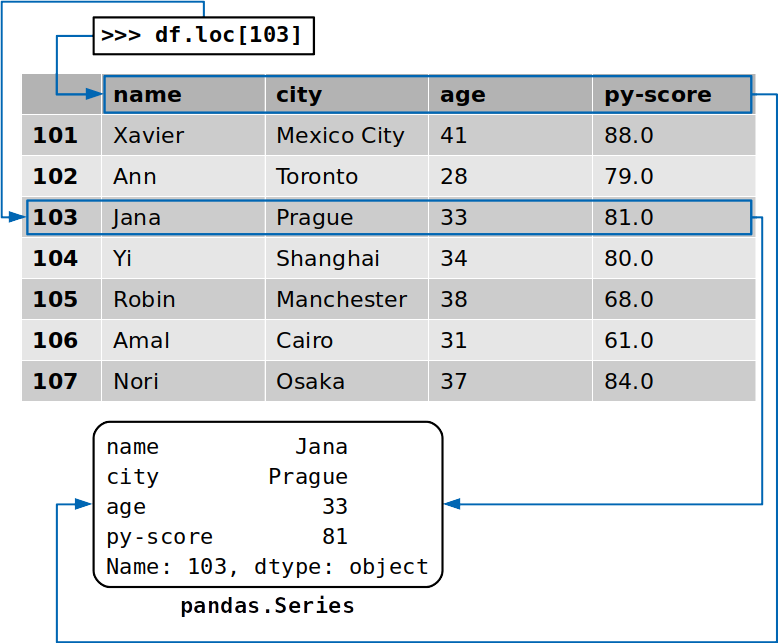
返回的行也是pandas.Series的实例。
创建熊猫数据框架
如前所述,创建熊猫数据框有几种方法。在本节中,您将学习如何使用DataFrame构造函数以及:
- Python 词典
- Python 列表
- 二维 NumPy 阵列
- 文件
还有其他方法,你可以在官方文档中了解到。
您可以从导入熊猫和 NumPy 开始,您将在下面的例子中使用它们:
>>> import numpy as np >>> import pandas as pd就是这样。现在,您已经准备好创建一些数据框架了。
用字典创建熊猫数据框架
正如您已经看到的,您可以使用 Python 字典创建熊猫数据帧:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
>>> pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
字典的关键字是数据帧的列标签,字典值是相应数据帧列中的数据值。这些值可以包含在一个元组、列表、一维 NumPy 数组、 Pandas Series对象或其他几种数据类型之一中。您还可以提供一个值,该值将沿整列复制。
可以用参数columns控制列的顺序,用参数index控制行标签的顺序:
>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x']) z y x 100 100 2 1 200 100 4 2 300 100 8 3如您所见,您已经指定了行标签
100、200和300。您还强制了列的顺序:z、y、x。用列表创建熊猫数据框架
创建熊猫数据框架的另一种方法是使用字典列表:
>>> l = [{'x': 1, 'y': 2, 'z': 100},
... {'x': 2, 'y': 4, 'z': 100},
... {'x': 3, 'y': 8, 'z': 100}]
>>> pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
同样,字典键是列标签,字典值是数据帧中的数据值。
你也可以使用一个嵌套的列表,或者一个列表列表,作为数据值。如果这样做,那么在创建数据帧时,明智的做法是显式指定列和/或行的标签:
>>> l = [[1, 2, 100], ... [2, 4, 100], ... [3, 8, 100]] >>> pd.DataFrame(l, columns=['x', 'y', 'z']) x y z 0 1 2 100 1 2 4 100 2 3 8 100这就是如何使用嵌套列表创建熊猫数据框架。也可以用同样的方式使用元组列表。为此,只需用元组替换上例中的嵌套列表。
用 NumPy 数组创建熊猫数据帧
您可以像处理列表一样将二维 NumPy 数组传递给
DataFrame构造函数:
>>> arr = np.array([[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]])
>>> df_ = pd.DataFrame(arr, columns=['x', 'y', 'z'])
>>> df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100
尽管这个例子看起来与上面的嵌套列表实现几乎一样,但是它有一个优点:您可以指定可选参数copy。
当copy设置为False(默认设置)时,NumPy 数组中的数据不会被复制。这意味着数组中的原始数据被分配给 Pandas 数据帧。如果您修改阵列,那么您的数据帧也会改变:
>>> arr[0, 0] = 1000 >>> df_ x y z 0 1000 2 100 1 2 4 100 2 3 8 100如你所见,当你改变
arr的第一项时,你也修改了df_。注意:在处理大型数据集时,不复制数据值可以节省大量时间和处理能力。
如果这种行为不是您想要的,那么您应该在
DataFrame构造函数中指定copy=True。这样,df_将被创建为来自arr的值的副本,而不是实际的值。从文件创建熊猫数据帧
您可以将数据和标签从 Pandas DataFrame 保存和加载到多种文件类型,包括 CSV、Excel、SQL、JSON 等等。这是一个非常强大的功能。
>>> df.to_csv('data.csv')
上面的语句将在您的工作目录中生成一个名为data.csv的 CSV 文件:
,name,city,age,py-score
101,Xavier,Mexico City,41,88.0
102,Ann,Toronto,28,79.0
103,Jana,Prague,33,81.0
104,Yi,Shanghai,34,80.0
105,Robin,Manchester,38,68.0
106,Amal,Cairo,31,61.0
107,Nori,Osaka,37,84.0
现在你已经有了一个包含数据的 CSV 文件,你可以用 read_csv() 加载它:
>>> pd.read_csv('data.csv', index_col=0) name city age py-score 101 Xavier Mexico City 41 88.0 102 Ann Toronto 28 79.0 103 Jana Prague 33 81.0 104 Yi Shanghai 34 80.0 105 Robin Manchester 38 68.0 106 Amal Cairo 31 61.0 107 Nori Osaka 37 84.0这就是如何从文件中获取熊猫数据帧的方法。在这种情况下,
index_col=0指定行标签位于 CSV 文件的第一列。检索标签和数据
既然已经创建了数据框架,就可以开始从中检索信息了。使用 Pandas,您可以执行以下操作:
- 以序列形式检索和修改行和列标签
- 将数据表示为 NumPy 数组
- 检查并调整数据类型
- 分析
DataFrame物体的大小作为序列的熊猫数据帧标签
>>> df.index
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64')
>>> df.columns
Index(['name', 'city', 'age', 'py-score'], dtype='object')
现在,行和列标签作为特殊类型的序列。与处理任何其他 Python 序列一样,您可以获得单个项目:
>>> df.columns[1] 'city'除了提取特定的项,您还可以应用其他序列操作,包括遍历行或列的标签。然而,这很少是必要的,因为 Pandas 提供了其他方法来迭代数据帧,这将在后面的章节中看到。
您也可以使用这种方法来修改标签:
>>> df.index = np.arange(10, 17)
>>> df.index
Int64Index([10, 11, 12, 13, 14, 15, 16], dtype='int64')
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
在本例中,您使用 numpy.arange() 来生成一个新的行标签序列,其中包含从10到16的整数。要了解更多关于arange()的内容,请查看 NumPy arange():如何使用 np.arange() 。
请记住,如果你试图修改.index或.columns的某一项,那么你将得到一个 TypeError 。
作为 NumPy 数组的数据
有时,您可能想从没有标签的熊猫数据帧中提取数据。要获得带有未标记数据的 NumPy 数组,可以使用 .to_numpy() 或 .values :
>>> df.to_numpy() array([['Xavier', 'Mexico City', 41, 88.0], ['Ann', 'Toronto', 28, 79.0], ['Jana', 'Prague', 33, 81.0], ['Yi', 'Shanghai', 34, 80.0], ['Robin', 'Manchester', 38, 68.0], ['Amal', 'Cairo', 31, 61.0], ['Nori', 'Osaka', 37, 84.0]], dtype=object)
.to_numpy()和.values的工作方式类似,它们都返回一个 NumPy 数组,其中包含来自 Pandas DataFrame 的数据:
Pandas 文档建议使用
.to_numpy(),因为两个可选参数提供了灵活性:
dtype: 使用该参数指定结果数组的数据类型。默认设置为None。copy: 如果想使用数据帧中的原始数据,将该参数设置为False。如果你想复制数据,将其设置为True。不过
.values比.to_numpy()存在的时间要长得多,后者是在熊猫 0.24.0 版本中引入的。这意味着你可能会更频繁地看到.values,尤其是在旧代码中。数据类型
数据值的类型,也称为数据类型或数据类型,非常重要,因为它们决定了数据帧使用的内存量,以及它的计算速度和精度水平。
Pandas 非常依赖于 NumPy 数据类型。然而,熊猫 1.0 引入了一些额外的类型:
BooleanDtype****BooleanArray支持缺失布尔值和克莱尼三值逻辑。StringDtype和StringArray代表一个专用的字符串类型。用
.dtypes可以得到熊猫数据帧每一列的数据类型:
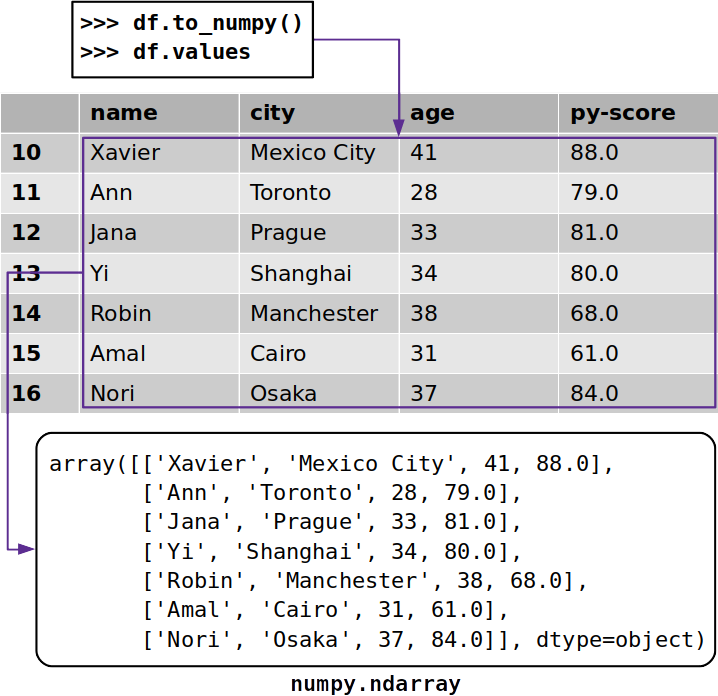
>>> df.dtypes
name object
city object
age int64
py-score float64
dtype: object
如您所见,.dtypes返回一个Series对象,以列名作为标签,以相应的数据类型作为值。
如果要修改一列或多列的数据类型,那么可以使用 .astype() :
>>> df_ = df.astype(dtype={'age': np.int32, 'py-score': np.float32}) >>> df_.dtypes name object city object age int32 py-score float32 dtype: object
.astype()最重要也是唯一强制的参数是dtype。它需要数据类型或字典。如果传递一个字典,那么键就是列名,值就是所需的相应数据类型。如您所见,数据帧
df中的列age和py-score的数据类型都是int64,表示 64 位(或 8 字节)整数。然而,df_也提供了一种更小的 32 位(4 字节)整数数据类型,称为int32。熊猫数据帧大小
>>> df_.ndim
2
>>> df_.shape
(7, 4)
>>> df_.size
28
DataFrame实例有两个维度(行和列),所以.ndim返回2。另一方面,Series对象只有一个维度,所以在这种情况下,.ndim将返回1。
.shape属性返回一个包含行数(在本例中为7)和列数(4)的元组。最后,.size返回一个等于 DataFrame 中值的个数的整数(28)。
你甚至可以用 .memory_usage() 检查每一列使用的内存量:
>>> df_.memory_usage() Index 56 name 56 city 56 age 28 py-score 28 dtype: int64如您所见,
.memory_usage()返回一个以列名作为标签、以字节为单位的内存使用量作为数据值的序列。如果您想排除保存行标签的列的内存使用,那么传递可选参数index=False。在上面的例子中,最后两列
age和py-score各使用 28 字节的内存。这是因为这些列有七个值,每个值都是一个 32 位或 4 字节的整数。7 个整数乘以 4 个字节各等于 28 个字节的内存使用量。访问和修改数据
您已经学习了如何将 Pandas 数据帧的特定行或列作为
Series对象:
>>> df['name']
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name: name, dtype: object
>>> df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: object
在第一个例子中,通过使用标签作为键,像访问字典中的元素一样访问列name。如果列标签是有效的 Python 标识符,那么您也可以使用点符号来访问该列。在第二个例子中,您使用 .loc[] 来获取标签为10的行。
用存取器获取数据
除了可以通过标签获取行或列的访问器.loc[]之外,Pandas 还提供了访问器 .iloc[] ,可以通过整数索引来检索行或列。在大多数情况下,您可以使用这两种方法中的任何一种:
>>> df.loc[10] name Xavier city Mexico City age 41 py-score 88 Name: 10, dtype: object >>> df.iloc[0] name Xavier city Mexico City age 41 py-score 88 Name: 10, dtype: object
df.loc[10]返回带有标签10的行。类似地,df.iloc[0]返回具有从零开始的索引0的行,这是第一行。正如您所看到的,两条语句都返回相同的行作为一个Series对象。熊猫总共有四个访问者:
>>> df.loc[:, 'city']
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
>>> df.iloc[:, 1]
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
df.loc[:, 'city']返回列city。行标签 place 中的 slice 构造(:)意味着应该包含所有的行。df.iloc[:, 1]返回同一列,因为从零开始的索引1引用第二列city。
就像使用 NumPy 一样,您可以提供切片以及列表或数组,而不是索引来获得多行或多列:
>>> df.loc[11:15, ['name', 'city']] name city 11 Ann Toronto 12 Jana Prague 13 Yi Shanghai 14 Robin Manchester 15 Amal Cairo >>> df.iloc[1:6, [0, 1]] name city 11 Ann Toronto 12 Jana Prague 13 Yi Shanghai 14 Robin Manchester 15 Amal Cairo注意:不要用元组代替列表或整数数组来获取普通的行或列。元组被保留用于在 NumPy 和 Pandas中表示多维度,以及在 Pandas 中的分级或多级索引。
在本例中,您使用:
- 切片得到标签为
11到15的行,相当于索引1到5- 列出得到列
name和city,相当于索引0和1两条语句都返回一个 Pandas 数据帧,该数据帧具有所需的五行和两列的交集。
这就引出了
.loc[]和.iloc[]之间一个非常重要的区别。正如您在前面的例子中看到的,当您将行标签11:15传递给.loc[]时,您得到了从11到15的行。然而,当您传递行索引1:6到.iloc[]时,您只获得索引为1到5的行。只获得索引
1到5的原因是,对于.iloc[],切片的停止索引是独占的,这意味着它被排除在返回值之外。这与 Python 序列和 NumPy 数组一致。然而,使用.loc[],开始和停止索引都包含在和中,这意味着它们包含在返回值中。使用
.iloc[]可以跳过行和列,就像对元组、列表和 NumPy 数组进行切片一样:
>>> df.iloc[1:6:2, 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
在本例中,您用片1:6:2指定所需的行索引。这意味着从索引为1的行(第二行)开始,在索引为6的行(第七行)之前停止,然后每隔一行跳过一行。
除了使用切片构造,您还可以使用内置的 Python 类 slice() ,以及 numpy.s_[] 或 pd.IndexSlice[] :
>>> df.iloc[slice(1, 6, 2), 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: object >>> df.iloc[np.s_[1:6:2], 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: object >>> df.iloc[pd.IndexSlice[1:6:2], 0] 11 Ann 13 Yi 15 Amal Name: name, dtype: object根据您的情况,您可能会发现其中一种方法比其他方法更方便。
可以使用
.loc[]和.iloc[]来获得特定的数据值。然而,当您只需要一个值时,Pandas 推荐使用专门的访问器.at[]和.iat[]:
>>> df.at[12, 'name']
'Jana'
>>> df.iat[2, 0]
'Jana'
在这里,您使用了.at[]来获得一个候选人的名字,该候选人使用了相应的列和行标签。您还使用了.iat[]来使用它的列和行索引检索相同的名称。
用存取器设置数据
您可以使用访问器通过传递 Python 序列、NumPy 数组或单个值来修改 Pandas 数据帧的各个部分:
>>> df.loc[:, 'py-score'] 10 88.0 11 79.0 12 81.0 13 80.0 14 68.0 15 61.0 16 84.0 Name: py-score, dtype: float64 >>> df.loc[:13, 'py-score'] = [40, 50, 60, 70] >>> df.loc[14:, 'py-score'] = 0 >>> df['py-score'] 10 40.0 11 50.0 12 60.0 13 70.0 14 0.0 15 0.0 16 0.0 Name: py-score, dtype: float64语句
df.loc[:13, 'py-score'] = [40, 50, 60, 70]使用您提供的列表中的值修改列py-score中的前四项(行10到13)。使用df.loc[14:, 'py-score'] = 0将该列中的剩余值设置为0。以下示例显示了您可以使用负索引和
.iloc[]来访问或修改数据:
>>> df.iloc[:, -1] = np.array([88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0])
>>> df['py-score']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
在本例中,您已经访问并修改了最后一列('py-score'),它对应于整数列索引-1。这种行为与 Python 序列和 NumPy 数组是一致的。
插入和删除数据
Pandas 提供了几种方便的插入和删除行或列的技术。你可以根据自己的情况和需求来选择。
插入和删除行
假设您想在求职者列表中添加一个新人。你可以通过创建一个新的Series对象来代表这个新的候选对象:
>>> john = pd.Series(data=['John', 'Boston', 34, 79], ... index=df.columns, name=17) >>> john name John city Boston age 34 py-score 79 Name: 17, dtype: object >>> john.name 17新对象的标签对应于来自
df的列标签。所以才需要index=df.columns。您可以用
.append()将john作为新的一行添加到df的末尾:
>>> df = df.append(john)
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
17 John Boston 34 79.0
这里,.append()返回附加了新行的熊猫数据帧。注意 Pandas 如何使用属性john.name,即值17,来指定新行的标签。
您已经通过对.append()的一次调用附加了一个新行,并且您可以通过对 .drop() 的一次调用删除它:
>>> df = df.drop(labels=[17]) >>> df name city age py-score 10 Xavier Mexico City 41 88.0 11 Ann Toronto 28 79.0 12 Jana Prague 33 81.0 13 Yi Shanghai 34 80.0 14 Robin Manchester 38 68.0 15 Amal Cairo 31 61.0 16 Nori Osaka 37 84.0这里,
.drop()删除由参数labels指定的行。默认情况下,它返回删除了指定行的 Pandas 数据帧。如果您通过了inplace=True,那么原始数据帧将被修改,您将得到None作为返回值。插入和删除列
在 Pandas 数据帧中插入一列的最直接的方法是遵循当您向字典添加一个条目时所使用的相同过程。下面是如何在一个 JavaScript 测试中添加包含候选人分数的列:
>>> df['js-score'] = np.array([71.0, 95.0, 88.0, 79.0, 91.0, 91.0, 80.0])
>>> df
name city age py-score js-score
10 Xavier Mexico City 41 88.0 71.0
11 Ann Toronto 28 79.0 95.0
12 Jana Prague 33 81.0 88.0
13 Yi Shanghai 34 80.0 79.0
14 Robin Manchester 38 68.0 91.0
15 Amal Cairo 31 61.0 91.0
16 Nori Osaka 37 84.0 80.0
现在原始数据帧的末尾多了一列js-score。
您不必提供完整的值序列。您可以添加具有单个值的新列:
>>> df['total-score'] = 0.0 >>> df name city age py-score js-score total-score 10 Xavier Mexico City 41 88.0 71.0 0.0 11 Ann Toronto 28 79.0 95.0 0.0 12 Jana Prague 33 81.0 88.0 0.0 13 Yi Shanghai 34 80.0 79.0 0.0 14 Robin Manchester 38 68.0 91.0 0.0 15 Amal Cairo 31 61.0 91.0 0.0 16 Nori Osaka 37 84.0 80.0 0.0数据帧
df现在有一个用零填充的附加列。如果您过去使用过字典,那么这种插入列的方式可能对您来说很熟悉。但是,它不允许您指定新列的位置。如果新列的位置很重要,那么可以用
.insert()来代替:
>>> df.insert(loc=4, column='django-score',
... value=np.array([86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0]))
>>> df
name city age py-score django-score js-score total-score
10 Xavier Mexico City 41 88.0 86.0 71.0 0.0
11 Ann Toronto 28 79.0 81.0 95.0 0.0
12 Jana Prague 33 81.0 78.0 88.0 0.0
13 Yi Shanghai 34 80.0 88.0 79.0 0.0
14 Robin Manchester 38 68.0 74.0 91.0 0.0
15 Amal Cairo 31 61.0 70.0 91.0 0.0
16 Nori Osaka 37 84.0 81.0 80.0 0.0
您刚刚插入了另一列,其中包含了 Django 测试的分数。参数loc确定 Pandas 数据帧中新列的位置,或从零开始的索引。column设置新列的标签,value指定要插入的数据值。
通过使用 del语句,可以从 Pandas 数据帧中删除一列或多列,就像使用常规 Python 字典一样:
>>> del df['total-score'] >>> df name city age py-score django-score js-score 10 Xavier Mexico City 41 88.0 86.0 71.0 11 Ann Toronto 28 79.0 81.0 95.0 12 Jana Prague 33 81.0 78.0 88.0 13 Yi Shanghai 34 80.0 88.0 79.0 14 Robin Manchester 38 68.0 74.0 91.0 15 Amal Cairo 31 61.0 70.0 91.0 16 Nori Osaka 37 84.0 81.0 80.0现在你有了没有列
total-score的df。与字典的另一个相似之处是能够使用.pop(),删除指定的列并返回它。这意味着你可以做类似于df.pop('total-score')的事情,而不是使用del。您也可以像之前对行所做的那样,用
.drop()删除一个或多个列。同样,您需要用labels指定所需列的标签。另外,当你想删除列时,你需要提供参数axis=1:
>>> df = df.drop(labels='age', axis=1)
>>> df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
您已经从数据框架中删除了列age。
默认情况下,.drop()返回没有指定列的数据帧,除非您通过了inplace=True。
应用算术运算
您可以对熊猫Series和DataFrame对象应用基本的算术运算,例如加、减、乘、除,就像您对 NumPy 数组所做的一样:
>>> df['py-score'] + df['js-score'] 10 159.0 11 174.0 12 169.0 13 159.0 14 159.0 15 152.0 16 164.0 dtype: float64 >>> df['py-score'] / 100 10 0.88 11 0.79 12 0.81 13 0.80 14 0.68 15 0.61 16 0.84 Name: py-score, dtype: float64您可以使用这种技术向 Pandas 数据框架中插入一个新列。例如,尝试将
total分数计算为候选人的 Python、Django 和 JavaScript 分数的线性组合:
>>> df['total'] =\
... 0.4 * df['py-score'] + 0.3 * df['django-score'] + 0.3 * df['js-score']
>>> df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9
现在,您的数据框架中有一列是根据您的考生个人考试成绩计算的total分数。更棒的是,你只用一句话就做到了!
应用 NumPy 和 SciPy 函数
大多数 NumPy 和 SciPy 例程可以作为参数而不是 NumPy 数组应用于 Pandas Series或DataFrame对象。为了说明这一点,您可以使用 NumPy 例程 numpy.average() 计算考生的总成绩。
您将传递您的熊猫数据帧的一部分,而不是传递一个 NumPy 数组给numpy.average():
>>> import numpy as np >>> score = df.iloc[:, 2:5] >>> score py-score django-score js-score 10 88.0 86.0 71.0 11 79.0 81.0 95.0 12 81.0 78.0 88.0 13 80.0 88.0 79.0 14 68.0 74.0 91.0 15 61.0 70.0 91.0 16 84.0 81.0 80.0 >>> np.average(score, axis=1, ... weights=[0.4, 0.3, 0.3]) array([82.3, 84.4, 82.2, 82.1, 76.7, 72.7, 81.9])变量
score现在指的是带有 Python、Django 和 JavaScript 分数的数据帧。您可以使用score作为numpy.average()的参数,并获得具有指定权重的列的线性组合。但这还不是全部!可以使用
average()返回的 NumPy 数组作为df的新列。首先,从df中删除现有的列total,然后使用average()添加新列:
>>> del df['total']
>>> df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
>>> df['total'] = np.average(df.iloc[:, 2:5], axis=1,
... weights=[0.4, 0.3, 0.3])
>>> df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9
结果与上一个示例相同,但是这里使用了现有的 NumPy 函数,而不是编写自己的代码。
排序熊猫数据帧
可以用 .sort_values() 对熊猫数据帧进行排序:
>>> df.sort_values(by='js-score', ascending=False) name city py-score django-score js-score total 11 Ann Toronto 79.0 81.0 95.0 84.4 14 Robin Manchester 68.0 74.0 91.0 76.7 15 Amal Cairo 61.0 70.0 91.0 72.7 12 Jana Prague 81.0 78.0 88.0 82.2 16 Nori Osaka 84.0 81.0 80.0 81.9 13 Yi Shanghai 80.0 88.0 79.0 82.1 10 Xavier Mexico City 88.0 86.0 71.0 82.3此示例根据列
js-score中的值对数据帧进行排序。参数by设置排序所依据的行或列的标签。ascending指定是要按升序(True)还是降序(False)排序,后者是默认设置。您可以通过axis来选择是要对行(axis=0)还是列(axis=1)进行排序。如果您想按多列排序,那么只需将列表作为参数传递给
by和ascending:
>>> df.sort_values(by=['total', 'py-score'], ascending=[False, False])
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
10 Xavier Mexico City 88.0 86.0 71.0 82.3
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
在这种情况下,DataFrame 按列total排序,但如果两个值相同,则它们的顺序由列py-score中的值决定。
可选参数inplace也可以和.sort_values()一起使用。它默认设置为False,确保.sort_values()返回一个新的熊猫数据帧。当您设置inplace=True时,现有的数据帧将被修改,并且.sort_values()将返回None。
如果您曾经尝试过在 Excel 中对值进行排序,那么您可能会发现 Pandas 方法更加高效和方便。当你有大量的数据时,熊猫可以明显胜过 Excel。
有关 Pandas 中排序的更多信息,请查看 Pandas Sort:您的 Python 数据排序指南。
过滤数据
数据过滤是熊猫的另一个强大功能。它的工作方式类似于 NumPy 中使用布尔数组的索引。
如果你在一个Series对象上应用一些逻辑运算,那么你将得到另一个具有布尔值True和False的序列:
>>> filter_ = df['django-score'] >= 80 >>> filter_ 10 True 11 True 12 False 13 True 14 False 15 False 16 True Name: django-score, dtype: bool在这种情况下,
df['django-score'] >= 80为 Django 得分大于或等于 80 的那些行返回True。对于 Django 得分小于 80 的行,它返回False。现在,您已经用布尔数据填充了序列
filter_。表达式df[filter_]返回一个熊猫数据帧,其中来自df的行对应于filter_中的True:
>>> df[filter_]
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
如您所见,filter_[10]、filter_[11]、filter_[13]和filter_[16]是True,因此df[filter_]包含带有这些标签的行。另一方面,filter_[12]、filter_[14]、filter_[15]是False,所以相应的行不会出现在df[filter_]中。
通过将逻辑运算与以下运算符相结合,可以创建非常强大和复杂的表达式:
NOT(~AND(&OR(|XOR(^
例如,您可以得到一个候选数据帧,其py-score和js-score大于或等于 80:
>>> df[(df['py-score'] >= 80) & (df['js-score'] >= 80)] name city py-score django-score js-score total 12 Jana Prague 81.0 78.0 88.0 82.2 16 Nori Osaka 84.0 81.0 80.0 81.9表达式
(df['py-score'] >= 80) & (df['js-score'] >= 80)返回一个序列,其中py-score和js-score都大于或等于 80,而False在其他行中。在这种情况下,只有带有标签12和16的行满足这两个条件。也可以应用 NumPy 逻辑例程来代替运算符。
对于一些需要数据过滤的操作,使用
.where()更方便。它会替换不满足所提供条件的位置中的值:
>>> df['django-score'].where(cond=df['django-score'] >= 80, other=0.0)
10 86.0
11 81.0
12 0.0
13 88.0
14 0.0
15 0.0
16 81.0
Name: django-score, dtype: float64
在这个例子中,条件是df['django-score'] >= 80。当条件为True时,调用.where()的数据帧或序列的值将保持不变,当条件为False时,将被替换为other(在本例中为0.0)的值。
确定数据统计
Pandas 为数据框提供了许多统计方法。通过 .describe() 可以得到熊猫数据帧数值列的基本统计数据:
>>> df.describe() py-score django-score js-score total count 7.000000 7.000000 7.000000 7.000000 mean 77.285714 79.714286 85.000000 80.328571 std 9.446592 6.343350 8.544004 4.101510 min 61.000000 70.000000 71.000000 72.700000 25% 73.500000 76.000000 79.500000 79.300000 50% 80.000000 81.000000 88.000000 82.100000 75% 82.500000 83.500000 91.000000 82.250000 max 88.000000 88.000000 95.000000 84.400000这里,
.describe()返回一个新的 DataFrame,其行数由count表示,还包括列的平均值、标准差、最小值、最大值和四分位数。
>>> df.mean()
py-score 77.285714
django-score 79.714286
js-score 85.000000
total 80.328571
dtype: float64
>>> df['py-score'].mean()
77.28571428571429
>>> df.std()
py-score 9.446592
django-score 6.343350
js-score 8.544004
total 4.101510
dtype: float64
>>> df['py-score'].std()
9.446591726019244
当应用于 Pandas 数据框架时,这些方法返回包含每列结果的序列。当应用于一个Series对象或数据帧的一列时,这些方法返回标量。
要了解关于熊猫的统计计算的更多信息,请查看使用 Python 的描述性统计和 NumPy、SciPy 和 Pandas:与 Python 的相关性。
处理缺失数据
缺失数据在数据科学和机器学习中非常普遍。但是不要害怕!Pandas 拥有非常强大的处理缺失数据的功能。事实上,它的文档中有整整一节专门用来处理丢失的数据。
Pandas 通常用 NaN(非数字)值 表示缺失数据。在 Python 中,可以用 float('nan') 、 math.nan ,或者 numpy.nan 得到 NaN。从熊猫 1.0 开始,较新的类型如 BooleanDtype 、 Int8Dtype 、 Int16Dtype 、 Int32Dtype 、 Int64Dtype 使用pandas.NA作为缺失值。
以下是一个缺失值的熊猫数据帧示例:
>>> df_ = pd.DataFrame({'x': [1, 2, np.nan, 4]}) >>> df_ x 0 1.0 1 2.0 2 NaN 3 4.0变量
df_是指具有一列、x和四个值的数据帧。第三个值是nan,默认情况下被认为是缺失的。用缺失数据计算
许多熊猫方法在执行计算时省略了
nan值,除非它们被明确指示而不是去:
>>> df_.mean()
x 2.333333
dtype: float64
>>> df_.mean(skipna=False)
x NaN
dtype: float64
在第一个示例中,df_.mean()计算平均值时不考虑NaN(第三个值)。它只取1.0、2.0和4.0并返回它们的平均值,即 2.33。
但是,如果您使用skipna=False指示.mean()不要跳过nan值,那么它会考虑这些值,如果数据中有任何丢失的值,它会返回nan。
填充缺失数据
Pandas 有几个选项可以用其他值来填充或替换缺失的值。最方便的方法是 .fillna() 。您可以用它来替换缺少的值:
- 指定值
- 缺失值以上的值
- 低于缺失值的值
以下是如何应用上述选项的方法:
>>> df_.fillna(value=0) x 0 1.0 1 2.0 2 0.0 3 4.0 >>> df_.fillna(method='ffill') x 0 1.0 1 2.0 2 2.0 3 4.0 >>> df_.fillna(method='bfill') x 0 1.0 1 2.0 2 4.0 3 4.0在第一个例子中,
.fillna(value=0)用0.0替换丢失的值,T1 是用value指定的。在第二个例子中,.fillna(method='ffill')用它上面的值替换丢失的值,这个值就是2.0。在第三个示例中,.fillna(method='bfill')使用的值低于缺失值,即4.0。另一个流行的选项是应用 插值 ,用插值替换缺失值。你可以用
.interpolate()来做这件事:
>>> df_.interpolate()
x
0 1.0
1 2.0
2 3.0
3 4.0
如您所见,.interpolate()用插值替换了缺失的值。
您也可以将可选参数inplace与.fillna()一起使用。这样做将:
- 在
inplace=False时创建并返回一个新的数据帧 - 修改现有数据帧并在
inplace=True时返回None
inplace的默认设置是False。然而,当您处理大量数据并希望防止不必要的低效复制时,inplace=True会非常有用。
删除丢失数据的行和列
在某些情况下,您可能希望删除缺少值的行甚至列。你可以用 .dropna() 来做这件事:
>>> df_.dropna() x 0 1.0 1 2.0 3 4.0在这种情况下,
.dropna()只是删除带有nan的行,包括它的标签。它还有可选参数inplace,其行为与.fillna()和.interpolate()相同。迭代熊猫数据帧
正如您之前所学的,数据帧的行和列标签可以作为带有
.index和.columns的序列来检索。您可以使用此功能迭代标签,并获取或设置数据值。然而,Pandas 提供了几种更方便的迭代方法:
.items()对列进行迭代.iteritems()对列进行迭代.iterrows()对行进行迭代.itertuples()对行进行迭代,得到命名的元组使用
.items()和.iteritems(),您可以迭代熊猫数据帧的列。每次迭代都会产生一个元组,其中列名和列数据作为一个Series对象:
>>> for col_label, col in df.iteritems():
... print(col_label, col, sep='\n', end='\n\n')
...
name
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name: name, dtype: object
city
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
py-score
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
django-score
10 86.0
11 81.0
12 78.0
13 88.0
14 74.0
15 70.0
16 81.0
Name: django-score, dtype: float64
js-score
10 71.0
11 95.0
12 88.0
13 79.0
14 91.0
15 91.0
16 80.0
Name: js-score, dtype: float64
total
10 82.3
11 84.4
12 82.2
13 82.1
14 76.7
15 72.7
16 81.9
Name: total, dtype: float64
.items()和.iteritems()就是这么用的。
使用.iterrows(),您可以迭代熊猫数据帧的行。每次迭代都会产生一个元组,其中包含行名和行数据,作为一个Series对象:
>>> for row_label, row in df.iterrows(): ... print(row_label, row, sep='\n', end='\n\n') ... 10 name Xavier city Mexico City py-score 88 django-score 86 js-score 71 total 82.3 Name: 10, dtype: object 11 name Ann city Toronto py-score 79 django-score 81 js-score 95 total 84.4 Name: 11, dtype: object 12 name Jana city Prague py-score 81 django-score 78 js-score 88 total 82.2 Name: 12, dtype: object 13 name Yi city Shanghai py-score 80 django-score 88 js-score 79 total 82.1 Name: 13, dtype: object 14 name Robin city Manchester py-score 68 django-score 74 js-score 91 total 76.7 Name: 14, dtype: object 15 name Amal city Cairo py-score 61 django-score 70 js-score 91 total 72.7 Name: 15, dtype: object 16 name Nori city Osaka py-score 84 django-score 81 js-score 80 total 81.9 Name: 16, dtype: object
.iterrows()就是这么用的。类似地,
.itertuples()对行进行迭代,并且在每次迭代中产生一个命名元组,该元组具有(可选的)索引和数据:
>>> for row in df.loc[:, ['name', 'city', 'total']].itertuples():
... print(row)
...
Pandas(Index=10, name='Xavier', city='Mexico City', total=82.3)
Pandas(Index=11, name='Ann', city='Toronto', total=84.4)
Pandas(Index=12, name='Jana', city='Prague', total=82.19999999999999)
Pandas(Index=13, name='Yi', city='Shanghai', total=82.1)
Pandas(Index=14, name='Robin', city='Manchester', total=76.7)
Pandas(Index=15, name='Amal', city='Cairo', total=72.7)
Pandas(Index=16, name='Nori', city='Osaka', total=81.9)
可以用参数name指定命名元组的名称,默认设置为'Pandas'。您还可以指定是否包含带有index的行标签,默认设置为True。
使用时间序列
熊猫擅长处理时间序列。尽管这个功能部分基于 NumPy 日期时间和时间增量,Pandas 提供了更多的灵活性。
创建带有时间序列标签的数据帧
在本节中,您将使用一天中每小时的温度数据创建一个熊猫数据帧。
您可以首先创建一个包含数据值的列表(或元组、NumPy 数组或其他数据类型),这些数据值将是以摄氏度给出的每小时温度:
>>> temp_c = [ 8.0, 7.1, 6.8, 6.4, 6.0, 5.4, 4.8, 5.0, ... 9.1, 12.8, 15.3, 19.1, 21.2, 22.1, 22.4, 23.1, ... 21.0, 17.9, 15.5, 14.4, 11.9, 11.0, 10.2, 9.1]现在您有了变量
temp_c,它引用了温度值的列表。下一步是创建一个日期和时间序列。熊猫提供了一个非常方便的功能,
date_range(),为此:
>>> dt = pd.date_range(start='2019-10-27 00:00:00.0', periods=24,
... freq='H')
>>> dt
DatetimeIndex(['2019-10-27 00:00:00', '2019-10-27 01:00:00',
'2019-10-27 02:00:00', '2019-10-27 03:00:00',
'2019-10-27 04:00:00', '2019-10-27 05:00:00',
'2019-10-27 06:00:00', '2019-10-27 07:00:00',
'2019-10-27 08:00:00', '2019-10-27 09:00:00',
'2019-10-27 10:00:00', '2019-10-27 11:00:00',
'2019-10-27 12:00:00', '2019-10-27 13:00:00',
'2019-10-27 14:00:00', '2019-10-27 15:00:00',
'2019-10-27 16:00:00', '2019-10-27 17:00:00',
'2019-10-27 18:00:00', '2019-10-27 19:00:00',
'2019-10-27 20:00:00', '2019-10-27 21:00:00',
'2019-10-27 22:00:00', '2019-10-27 23:00:00'],
dtype='datetime64[ns]', freq='H')
date_range()接受您用来指定范围的开始或结束、周期数、频率、时区等等的参数。
注:虽然也有其他选项,但熊猫默认大多使用 ISO 8601 日期和时间格式。
现在您已经有了温度值以及相应的日期和时间,您可以创建数据帧了。在许多情况下,使用日期时间值作为行标签很方便:
>>> temp = pd.DataFrame(data={'temp_c': temp_c}, index=dt) >>> temp temp_c 2019-10-27 00:00:00 8.0 2019-10-27 01:00:00 7.1 2019-10-27 02:00:00 6.8 2019-10-27 03:00:00 6.4 2019-10-27 04:00:00 6.0 2019-10-27 05:00:00 5.4 2019-10-27 06:00:00 4.8 2019-10-27 07:00:00 5.0 2019-10-27 08:00:00 9.1 2019-10-27 09:00:00 12.8 2019-10-27 10:00:00 15.3 2019-10-27 11:00:00 19.1 2019-10-27 12:00:00 21.2 2019-10-27 13:00:00 22.1 2019-10-27 14:00:00 22.4 2019-10-27 15:00:00 23.1 2019-10-27 16:00:00 21.0 2019-10-27 17:00:00 17.9 2019-10-27 18:00:00 15.5 2019-10-27 19:00:00 14.4 2019-10-27 20:00:00 11.9 2019-10-27 21:00:00 11.0 2019-10-27 22:00:00 10.2 2019-10-27 23:00:00 9.1就是这样!您已经创建了一个包含时间序列数据和日期时间行索引的数据框架。
分度和切片
一旦有了包含时间序列数据的 Pandas 数据框架,您就可以方便地应用切片来获得部分信息:
>>> temp['2019-10-27 05':'2019-10-27 14']
temp_c
2019-10-27 05:00:00 5.4
2019-10-27 06:00:00 4.8
2019-10-27 07:00:00 5.0
2019-10-27 08:00:00 9.1
2019-10-27 09:00:00 12.8
2019-10-27 10:00:00 15.3
2019-10-27 11:00:00 19.1
2019-10-27 12:00:00 21.2
2019-10-27 13:00:00 22.1
2019-10-27 14:00:00 22.4
此示例显示了如何提取 05:00 和 14:00(上午 5 点和下午 2 点)之间的温度。尽管您已经提供了字符串,但 Pandas 知道您的行标签是日期-时间值,并将字符串解释为日期和时间。
重采样和滚动
您已经看到了如何组合日期-时间行标签,并使用切片从时间序列数据中获取您需要的信息。这只是开始。越来越好了!
如果您想将一天分成四个六小时的间隔,并获得每个间隔的平均温度,那么您只需要一个语句就可以做到。Pandas 提供了 .resample() 的方法,可以和其他方法结合使用,比如.mean():
>>> temp.resample(rule='6h').mean() temp_c 2019-10-27 00:00:00 6.616667 2019-10-27 06:00:00 11.016667 2019-10-27 12:00:00 21.283333 2019-10-27 18:00:00 12.016667您现在有了一个新的包含四行的 Pandas 数据框架。每一行对应一个六小时的时间间隔。例如,数值
6.616667是数据帧temp中前六个温度的平均值,而12.016667是后六个温度的平均值。代替
.mean(),您可以应用.min()或.max()来获得每个间隔的最低和最高温度。您还可以使用.sum()来获得数据值的总和,尽管在处理温度时这些信息可能没有用。你可能还需要做一些滚动窗口分析。这包括计算指定数量的相邻行的统计数据,这些相邻行构成了您的数据窗口。您可以通过选择一组不同的相邻行来执行计算,从而“滚动”窗口。
第一个窗口从数据帧中的第一行开始,包括指定数量的相邻行。然后将窗口向下移动一行,删除第一行并添加紧接在最后一行之后的一行,并再次计算相同的统计数据。重复这个过程,直到到达数据帧的最后一行。
熊猫为此提供了方法
.rolling():
>>> temp.rolling(window=3).mean()
temp_c
2019-10-27 00:00:00 NaN
2019-10-27 01:00:00 NaN
2019-10-27 02:00:00 7.300000
2019-10-27 03:00:00 6.766667
2019-10-27 04:00:00 6.400000
2019-10-27 05:00:00 5.933333
2019-10-27 06:00:00 5.400000
2019-10-27 07:00:00 5.066667
2019-10-27 08:00:00 6.300000
2019-10-27 09:00:00 8.966667
2019-10-27 10:00:00 12.400000
2019-10-27 11:00:00 15.733333
2019-10-27 12:00:00 18.533333
2019-10-27 13:00:00 20.800000
2019-10-27 14:00:00 21.900000
2019-10-27 15:00:00 22.533333
2019-10-27 16:00:00 22.166667
2019-10-27 17:00:00 20.666667
2019-10-27 18:00:00 18.133333
2019-10-27 19:00:00 15.933333
2019-10-27 20:00:00 13.933333
2019-10-27 21:00:00 12.433333
2019-10-27 22:00:00 11.033333
2019-10-27 23:00:00 10.100000
现在,您有了一个数据框架,其中包含为几个三小时窗口计算的平均温度。参数window指定移动时间窗口的大小。
在上例中,第三个值(7.3)是前三个小时的平均温度(00:00:00、01:00:00和02:00:00)。第四个值是02:00:00、03:00:00和04:00:00小时的平均温度。最后一个值是最近三个小时的平均温度,21:00:00、22:00:00和23:00:00。前两个值丢失了,因为没有足够的数据来计算它们。
用熊猫绘制数据帧
Pandas 允许你可视化数据或基于数据帧创建图表。它在后台使用 Matplotlib ,因此开发 Pandas 的绘图功能与使用 Matplotlib 非常相似。
如果你想显示这些图,那么你首先需要导入matplotlib.pyplot:
>>> import matplotlib.pyplot as plt现在您可以使用
pandas.DataFrame.plot()来创建情节,使用plt.show()来显示情节:
>>> temp.plot()
<matplotlib.axes._subplots.AxesSubplot object at 0x7f070cd9d950>
>>> plt.show()
现在.plot()返回一个plot对象,如下所示:
你也可以应用 .plot.line() ,得到同样的结果。.plot()和.plot.line()都有许多可选参数,您可以使用它们来指定您的绘图外观。其中一些被直接传递给底层的 Matplotlib 方法。
您可以通过链接方法.get_figure()和 .savefig() 来保存您的体形:
>>> temp.plot().get_figure().savefig('temperatures.png')该语句创建绘图,并将其保存为工作目录中名为
'temperatures.png'的文件。你可以用熊猫数据框得到其他类型的图。例如,您可以将之前的求职者数据可视化为带有
.plot.hist()的直方图:
>>> df.loc[:, ['py-score', 'total']].plot.hist(bins=5, alpha=0.4)
<matplotlib.axes._subplots.AxesSubplot object at 0x7f070c69edd0>
>>> plt.show()
在本例中,您将提取 Python 测试分数和总分数据,并使用直方图对其进行可视化。结果图如下所示:
这只是基本的样子。您可以使用可选参数调整细节,包括.plot.hist()、 Matplotlib 的plt.rcParams、等。你可以在 Matplotlib 的剖析中找到详细的解释。
延伸阅读
Pandas 数据帧是非常全面的对象,支持本教程中没有提到的许多操作。其中包括:
官方熊猫教程很好地总结了一些可用的选项。如果你想了解更多关于熊猫和数据框,那么你可以看看这些教程:
- 用 Pandas 和 NumPy 清理 Pythonic 数据
- 熊猫数据帧 101
- 介绍熊猫和文森特
- 蟒蛇熊猫:诡计&你可能不知道的特点
- 地道的熊猫:把戏&你可能不知道的特点
- 阅读熊猫 CSVs】
- 用熊猫写 CSVs】
- 用 Python 读写 CSV 文件
- 读写 CSV 文件
- 用熊猫读取 Python 中的大型 Excel 文件
- 快速、灵活、简单和直观:如何加快您的熊猫项目
你已经知道熊猫数据帧处理二维数据。如果您需要处理二维以上的标注数据,可以查看另一个强大的数据科学 Python 库【xarray】,它的功能与 Pandas 非常相似。
如果你在处理大数据,想要一个类似数据框架的体验,那么你可以给 Dask 一个机会,使用它的数据框架 API 。一个 Dask 数据帧包含许多 Pandas 数据帧,并以一种懒惰的方式执行计算。
结论
现在你知道了什么是 Pandas DataFrame ,它的一些特性是什么,以及如何使用它来有效地处理数据。熊猫数据框架是功能强大、用户友好的数据结构,您可以使用它来更深入地了解您的数据集!
在本教程中,您已经学习了:
- 什么是熊猫数据框架以及如何创建一个
- 如何访问、修改、添加、排序、过滤和删除数据
- 如何对数据帧使用 NumPy 例程
- 如何处理缺失值
- 如何处理时序数据
- 如何可视化包含在数据帧中的数据
您已经学习了足够多的知识来涵盖数据框架的基础知识。如果你想更深入地了解如何使用 Python 中的数据,那么请查看的熊猫教程。
如果你有任何问题或意见,请写在下面的评论区。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 熊猫数据帧:高效处理数据*********
pandas group by:Python 数据分组指南
无论你是刚刚开始使用熊猫并希望掌握它的核心能力之一,还是你正在寻找填补你对.groupby()理解的一些空白,本教程将帮助你从头到尾分解并想象一个熊猫群通过运作。
本教程旨在补充官方熊猫文档和 T2 熊猫食谱,在那里你会看到独立的、一口大小的例子。但是,在这里,您将重点关注三个更复杂的使用真实数据集的演练。
在本教程中,您将学习:
- 如何通过对真实世界数据的操作来使用熊猫分组
- 拆分-应用-合并操作链是如何工作的
- 如何将拆分-应用-合并链分解成步骤
- 如何根据目的和结果按对象对熊猫组的方法进行分类
本教程假设您对 pandas 本身有一些经验,包括如何使用read_csv()将 CSV 文件作为 pandas 对象读入内存。如果你需要复习,那就看看阅读带熊猫的 CSVs】和熊猫:如何读写文件。
您可以点击下面的链接下载本教程中所有示例的源代码:
下载数据集: 点击这里下载数据集,你将在本教程中使用来了解熊猫的分组。
先决条件
在您继续之前,请确保您在新的虚拟环境中拥有最新版本的 pandas:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> venv\Scripts\activate
(venv) PS> python -m pip install pandas
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install pandas
在本教程中,您将关注三个数据集:
- 美国国会数据集包含国会历史成员的公开信息,并展示了
.groupby()的几项基本功能。 - 空气质量数据集包含定期气体传感器读数。这将允许您使用浮点数和时间序列数据。
- 新闻聚合数据集拥有几十万篇新闻文章的元数据。你将与弦乐一起工作,并与
.groupby()一起发短信和。
您可以点击下面的链接下载本教程中所有示例的源代码:
下载数据集: 点击这里下载数据集,你将在本教程中使用来了解熊猫的分组。
下载完.zip文件后,将该文件解压到当前目录下的一个名为groupby-data/的文件夹中。在您继续阅读之前,请确保您的目录树如下所示:
./
│
└── groupby-data/
│
├── legislators-historical.csv
├── airqual.csv
└── news.csv
安装了pandas,激活了虚拟环境,下载了数据集,您就可以开始了!
示例 1:美国国会数据集
你将通过剖析国会历史成员的数据集直接进入事物。你可以用read_csv()将 CSV 文件读入一个熊猫DataFrameT5:
# pandas_legislators.py
import pandas as pd
dtypes = {
"first_name": "category",
"gender": "category",
"type": "category",
"state": "category",
"party": "category",
}
df = pd.read_csv(
"groupby-data/legislators-historical.csv",
dtype=dtypes,
usecols=list(dtypes) + ["birthday", "last_name"],
parse_dates=["birthday"]
)
数据集包含成员的名字和姓氏、生日、性别、类型("rep"代表众议院或"sen"代表参议院)、美国州和政党。您可以使用df.tail()来查看数据集的最后几行:
>>> from pandas_legislators import df >>> df.tail() last_name first_name birthday gender type state party 11970 Garrett Thomas 1972-03-27 M rep VA Republican 11971 Handel Karen 1962-04-18 F rep GA Republican 11972 Jones Brenda 1959-10-24 F rep MI Democrat 11973 Marino Tom 1952-08-15 M rep PA Republican 11974 Jones Walter 1943-02-10 M rep NC Republican
DataFrame使用分类 dtypes 实现空间效率:
>>> df.dtypes
last_name object
first_name category
birthday datetime64[ns]
gender category
type category
state category
party category
dtype: object
您可以看到数据集的大多数列都具有类型category,这减少了机器上的内存负载。
熊猫组的Hello, World!by
现在您已经熟悉了数据集,您将从 pandas GroupBy 操作的Hello, World!开始。在数据集的整个历史中,每个州的国会议员人数是多少?在 SQL 中,您可以通过SELECT语句找到答案:
SELECT state, count(name) FROM df GROUP BY state ORDER BY state;
这是熊猫的近似情况:
>>> n_by_state = df.groupby("state")["last_name"].count() >>> n_by_state.head(10) state AK 16 AL 206 AR 117 AS 2 AZ 48 CA 361 CO 90 CT 240 DC 2 DE 97 Name: last_name, dtype: int64您调用
.groupby()并传递您想要分组的列的名称,即"state"。然后,使用["last_name"]来指定要执行实际聚合的列。除了将单个列名作为第一个参数传递给
.groupby()之外,您还可以传递更多信息。您还可以指定以下任一选项:下面是一个对两列进行联合分组的示例,它先按州,然后按性别查找国会议员人数:
>>> df.groupby(["state", "gender"])["last_name"].count()
state gender
AK F 0
M 16
AL F 3
M 203
AR F 5
...
WI M 196
WV F 1
M 119
WY F 2
M 38
Name: last_name, Length: 116, dtype: int64
类似的 SQL 查询如下所示:
SELECT state, gender, count(name) FROM df GROUP BY state, gender ORDER BY state, gender;
正如您接下来将会看到的,.groupby()和类似的 SQL 语句是近亲,但是它们在功能上通常并不相同。
熊猫 GroupBy vs SQL
这是介绍 pandas GroupBy 操作和上面的 SQL 查询之间的一个显著区别的好时机。SQL 查询的结果集包含三列:
stategendercount
在 pandas 版本中,默认情况下,成组的列被推入结果Series的 MultiIndex :
>>> n_by_state_gender = df.groupby(["state", "gender"])["last_name"].count() >>> type(n_by_state_gender) <class 'pandas.core.series.Series'> >>> n_by_state_gender.index[:5] MultiIndex([('AK', 'M'), ('AL', 'F'), ('AL', 'M'), ('AR', 'F'), ('AR', 'M')], names=['state', 'gender'])为了更接近地模拟 SQL 结果并将分组后的列推回到结果中的列,可以使用
as_index=False:
>>> df.groupby(["state", "gender"], as_index=False)["last_name"].count()
state gender last_name
0 AK F 0
1 AK M 16
2 AL F 3
3 AL M 203
4 AR F 5
.. ... ... ...
111 WI M 196
112 WV F 1
113 WV M 119
114 WY F 2
115 WY M 38
[116 rows x 3 columns]
这会产生一个有三列的DataFrame和一个 RangeIndex ,而不是一个有MultiIndex的Series。简而言之,使用as_index=False将使您的结果更接近类似操作的默认 SQL 输出。
注:在df.groupby(["state", "gender"])["last_name"].count()中,你也可以用.size()代替.count(),因为你知道没有NaN姓。使用.count()排除NaN值,而.size()包含一切,NaN与否。
还要注意,上面的 SQL 查询显式地使用了ORDER BY,而.groupby()没有。那是因为.groupby()默认通过它的参数sort来做这件事,除非你另外告诉它,否则这个参数就是True:
>>> # Don't sort results by the sort keys >>> df.groupby("state", sort=False)["last_name"].count() state DE 97 VA 432 SC 251 MD 305 PA 1053 ... AK 16 PI 13 VI 4 GU 4 AS 2 Name: last_name, dtype: int64接下来,您将深入研究
.groupby()实际产生的对象。熊猫小组如何工作
在您深入了解细节之前,先回顾一下
.groupby()本身:
>>> by_state = df.groupby("state")
>>> print(by_state)
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x107293278>
什么是DataFrameGroupBy?打印函数显示的.__str__()值并不能给你太多关于它实际上是什么或者如何工作的信息。一个DataFrameGroupBy物体让你难以理解的原因是它天生懒惰。除非你告诉它,否则它不会真的做任何操作来产生有用的结果。
注:在本教程中,通用术语熊猫分组对象既指DataFrameGroupBy对象,也指SeriesGroupBy对象,它们有很多共同点。
与.groupby()一起经常使用的一个术语是拆分-应用-合并。这是指一连串的三个步骤:
- 将一张桌子分成几组。
- 对每个较小的表应用一些操作。
- 合并结果。
检查df.groupby("state")可能很困难,因为它实际上什么都不做,除非你对结果对象做些什么。pandas GroupBy 对象实际上延迟了拆分-应用-合并过程的每一个部分,直到您对它调用一个方法。
所以,如果你看不到它们中的任何一个孤立地发生,你怎么能在精神上把拆分、应用和合并阶段分开呢?检查 pandas GroupBy 对象并查看拆分操作的一个有用方法是对其进行迭代:
>>> for state, frame in by_state: ... print(f"First 2 entries for {state!r}") ... print("------------------------") ... print(frame.head(2), end="\n\n") ... First 2 entries for 'AK' ------------------------ last_name first_name birthday gender type state party 6619 Waskey Frank 1875-04-20 M rep AK Democrat 6647 Cale Thomas 1848-09-17 M rep AK Independent First 2 entries for 'AL' ------------------------ last_name first_name birthday gender type state party 912 Crowell John 1780-09-18 M rep AL Republican 991 Walker John 1783-08-12 M sen AL Republican如果您正在处理一个具有挑战性的聚合问题,那么迭代 pandas GroupBy 对象是可视化拆分-应用-合并的拆分部分的一个好方法。
还有一些其他的方法和属性可以让您查看单个组及其拆分。属性会给你一个
{group name: group label}对的字典。例如,by_state.groups是一个以州为键的dict。下面是"PA"键的值:
>>> by_state.groups["PA"]
Int64Index([ 4, 19, 21, 27, 38, 57, 69, 76, 84,
88,
...
11842, 11866, 11875, 11877, 11887, 11891, 11932, 11945, 11959,
11973],
dtype='int64', length=1053)
每个值都是属于该特定组的行的索引位置序列。在上面的输出中, 4 、 19 和 21 是df中状态等于"PA"的第一个索引。
您还可以使用.get_group()从单个组向下钻取到子表:
>>> by_state.get_group("PA") last_name first_name birthday gender type state party 4 Clymer George 1739-03-16 M rep PA NaN 19 Maclay William 1737-07-20 M sen PA Anti-Administration 21 Morris Robert 1734-01-20 M sen PA Pro-Administration 27 Wynkoop Henry 1737-03-02 M rep PA NaN 38 Jacobs Israel 1726-06-09 M rep PA NaN ... ... ... ... ... ... ... ... 11891 Brady Robert 1945-04-07 M rep PA Democrat 11932 Shuster Bill 1961-01-10 M rep PA Republican 11945 Rothfus Keith 1962-04-25 M rep PA Republican 11959 Costello Ryan 1976-09-07 M rep PA Republican 11973 Marino Tom 1952-08-15 M rep PA Republican这实际上相当于使用
.loc[]。您可以用类似于df.loc[df["state"] == "PA"]的东西得到相同的输出。还值得一提的是,
.groupby()确实通过为您传递的每个键构建一个Grouping类实例来完成一些(但不是全部)拆分工作。然而,保存这些分组的BaseGrouper类的许多方法是被延迟调用的,而不是在.__init__()调用的,而且许多方法还使用了缓存的属性设计。接下来,应用部分呢?您可以将流程的这一步看作是对拆分阶段生成的每个子表应用相同的操作(或可调用操作)。
从熊猫 GroupBy 对象
by_state中,你可以抓取最初的美国州和带有next()的DataFrame。当您迭代一个 pandas GroupBy 对象时,您将得到可以解包成两个变量的对:
>>> state, frame = next(iter(by_state)) # First tuple from iterator
>>> state
'AK'
>>> frame.head(3)
last_name first_name birthday gender type state party
6619 Waskey Frank 1875-04-20 M rep AK Democrat
6647 Cale Thomas 1848-09-17 M rep AK Independent
7442 Grigsby George 1874-12-02 M rep AK NaN
现在,回想一下您最初的完整操作:
>>> df.groupby("state")["last_name"].count() state AK 16 AL 206 AR 117 AS 2 AZ 48 ...应用阶段,当应用到您的单个子集
DataFrame时,将如下所示:
>>> frame["last_name"].count() # Count for state == 'AK'
16
您可以看到结果 16 与组合结果中的值AK相匹配。
最后一步, combine ,获取所有子表上所有应用操作的结果,并以直观的方式将它们组合在一起。
请继续阅读,了解更多拆分-应用-合并流程的示例。
示例 2:空气质量数据集
空气质量数据集包含来自意大利气体传感器设备的每小时读数。CSV 文件中缺失的值用 -200 表示。您可以使用read_csv()将两列合并成一个时间戳,同时使用其他列的子集:
# pandas_airqual.py
import pandas as pd
df = pd.read_csv(
"groupby-data/airqual.csv",
parse_dates=[["Date", "Time"]],
na_values=[-200],
usecols=["Date", "Time", "CO(GT)", "T", "RH", "AH"]
).rename(
columns={
"CO(GT)": "co",
"Date_Time": "tstamp",
"T": "temp_c",
"RH": "rel_hum",
"AH": "abs_hum",
}
).set_index("tstamp")
这会产生一个带有一个DatetimeIndex和四个float列的DataFrame:
>>> from pandas_airqual import df >>> df.head() co temp_c rel_hum abs_hum tstamp 2004-03-10 18:00:00 2.6 13.6 48.9 0.758 2004-03-10 19:00:00 2.0 13.3 47.7 0.726 2004-03-10 20:00:00 2.2 11.9 54.0 0.750 2004-03-10 21:00:00 2.2 11.0 60.0 0.787 2004-03-10 22:00:00 1.6 11.2 59.6 0.789这里,
co是该小时的平均一氧化碳读数,而temp_c、rel_hum和abs_hum分别是该小时的平均摄氏度温度、相对湿度和绝对湿度。观察时间从 2004 年 3 月到 2005 年 4 月:
>>> df.index.min()
Timestamp('2004-03-10 18:00:00')
>>> df.index.max()
Timestamp('2005-04-04 14:00:00')
到目前为止,您已经通过将列名指定为str,比如df.groupby("state"),对列进行了分组。但是.groupby()比这灵活多了!接下来你会看到。
基于派生数组的分组
前面您已经看到,.groupby()的第一个参数可以接受几个不同的参数:
- 一列或一列
- 一只
dict或熊猫Series - 一个 NumPy 数组或 pandas
Index,或一个类似数组的 iterable
您可以利用最后一个选项,按一周中的某一天进行分组。使用索引的.day_name()产生一个熊猫Index的字符串。以下是前十个观察结果:
>>> day_names = df.index.day_name() >>> type(day_names) <class 'pandas.core.indexes.base.Index'> >>> day_names[:10] Index(['Wednesday', 'Wednesday', 'Wednesday', 'Wednesday', 'Wednesday', 'Wednesday', 'Thursday', 'Thursday', 'Thursday', 'Thursday'], dtype='object', name='tstamp')然后,您可以将这个对象用作
.groupby()键。在熊猫中,day_names是阵列式的。这是一维的标签序列。注意:对于熊猫
Series,而不是Index,你需要.dt访问器来访问像.day_name()这样的方法。如果ser是你的Series,那么你就需要ser.dt.day_name()。现在,将该对象传递给
.groupby()以查找一周中每一天的平均一氧化碳(co)读数:
>>> df.groupby(day_names)["co"].mean()
tstamp
Friday 2.543
Monday 2.017
Saturday 1.861
Sunday 1.438
Thursday 2.456
Tuesday 2.382
Wednesday 2.401
Name: co, dtype: float64
split-apply-combine 过程的行为与之前基本相同,只是这次的拆分是在人工创建的列上完成的。该列不存在于 DataFrame 本身中,而是从它派生出来的。
如果您不仅想按一周中的某一天分组,还想按一天中的某个小时分组,那该怎么办?那个结果应该有7 * 24 = 168个观察值。为此,您可以传递一个类似数组的对象列表。在这种情况下,您将传递熊猫Int64Index对象:
>>> hr = df.index.hour >>> df.groupby([day_names, hr])["co"].mean().rename_axis(["dow", "hr"]) dow hr Friday 0 1.936 1 1.609 2 1.172 3 0.887 4 0.823 ... Wednesday 19 4.147 20 3.845 21 2.898 22 2.102 23 1.938 Name: co, Length: 168, dtype: float64这里还有一个类似的例子,使用
.cut()将温度值绑定到离散的区间:
>>> import pandas as pd
>>> bins = pd.cut(df["temp_c"], bins=3, labels=("cool", "warm", "hot"))
>>> df[["rel_hum", "abs_hum"]].groupby(bins).agg(["mean", "median"])
rel_hum abs_hum
mean median mean median
temp_c
cool 57.651 59.2 0.666 0.658
warm 49.383 49.3 1.183 1.145P
hot 24.994 24.1 1.293 1.274
在这种情况下,bins实际上是一个Series:
>>> type(bins) <class 'pandas.core.series.Series'> >>> bins.head() tstamp 2004-03-10 18:00:00 cool 2004-03-10 19:00:00 cool 2004-03-10 20:00:00 cool 2004-03-10 21:00:00 cool 2004-03-10 22:00:00 cool Name: temp_c, dtype: category Categories (3, object): [cool < warm < hot]不管是一个
Series、NumPy 数组还是 list 都没关系。重要的是,bins仍然作为一个标签序列,由cool、warm和hot组成。如果你真的想,那么你也可以使用一个Categorical数组,甚至是一个普通的list:
- 原生 Python 列表:
df.groupby(bins.tolist())- 熊猫
Categorical阵列:T1】如你所见,
.groupby()很聪明,可以处理很多不同的输入类型。其中任何一个都会产生相同的结果,因为它们都作为一个标签序列来执行分组和拆分。重新采样
您已经将
df与df.groupby(day_names)["co"].mean()按一周中的某一天分组。现在考虑一些不同的东西。如果您想按观察的年份和季度分组,该怎么办?有一种方法可以做到这一点:
>>> # See an easier alternative below
>>> df.groupby([df.index.year, df.index.quarter])["co"].agg(
... ["max", "min"]
... ).rename_axis(["year", "quarter"])
max min
year quarter
2004 1 8.1 0.3
2 7.3 0.1
3 7.5 0.1
4 11.9 0.1
2005 1 8.7 0.1
2 5.0 0.3
或者,整个操作可以通过重采样来表达。重采样的用途之一是作为基于时间的分组依据。你所需要做的就是传递一个频率串,比如"quarterly"的"Q",熊猫会做剩下的事情:
>>> df.resample("Q")["co"].agg(["max", "min"]) max min tstamp 2004-03-31 8.1 0.3 2004-06-30 7.3 0.1 2004-09-30 7.5 0.1 2004-12-31 11.9 0.1 2005-03-31 8.7 0.1 2005-06-30 5.0 0.3通常,当您使用
.resample()时,您可以用更简洁的方式表达基于时间的分组操作。结果可能与更冗长的.groupby()稍有不同,但是你会经常发现.resample()给了你想要的东西。示例 3:新闻聚合数据集
现在,您将使用第三个也是最后一个数据集,该数据集包含几十万篇新闻文章的元数据,并将它们分组到主题簇中:
# pandas_news.py import pandas as pd def parse_millisecond_timestamp(ts): """Convert ms since Unix epoch to UTC datetime instance.""" return pd.to_datetime(ts, unit="ms") df = pd.read_csv( "groupby-data/news.csv", sep="\t", header=None, index_col=0, names=["title", "url", "outlet", "category", "cluster", "host", "tstamp"], parse_dates=["tstamp"], date_parser=parse_millisecond_timestamp, dtype={ "outlet": "category", "category": "category", "cluster": "category", "host": "category", }, )要使用适当的
dtype将数据读入内存,您需要一个助手函数来解析时间戳列。这是因为它被表示为自 Unix 纪元以来的毫秒数,而不是分数秒。如果您想了解更多关于使用 Python 处理时间的信息,请查看使用 Python datetime 处理日期和时间的。与您之前所做的类似,您可以使用分类
dtype来有效地编码那些相对于列长度来说唯一值数量相对较少的列。数据集的每一行都包含标题、URL、发布出口的名称和域,以及发布时间戳。
cluster是文章所属主题簇的随机 ID。category是新闻类别,包含以下选项:
b因公出差t对于科技e为了娱乐m为了健康这是第一行:
>>> from pandas_news import df
>>> df.iloc[0]
title Fed official says weak data caused by weather,...
url http://www.latimes.com/business/money/la-fi-mo...
outlet Los Angeles Times
category b
cluster ddUyU0VZz0BRneMioxUPQVP6sIxvM
host www.latimes.com
tstamp 2014-03-10 16:52:50.698000
Name: 1, dtype: object
现在,您已经对数据有了初步的了解,您可以开始询问关于它的更复杂的问题。
在.groupby()中使用λ函数
这个数据集引发了更多潜在的问题。这里有一个随机但有意义的问题:哪些渠道谈论最多的是美联储?为简单起见,假设这需要搜索对"Fed"的区分大小写的提及。请记住,这可能会对像"Federal government"这样的术语产生一些误报。
要按 outlet 统计提及次数,您可以在 outlet 上调用.groupby(),然后使用 Python lambda 函数在每个组上调用.apply()函数:
>>> df.groupby("outlet", sort=False)["title"].apply( ... lambda ser: ser.str.contains("Fed").sum() ... ).nlargest(10) outlet Reuters 161 NASDAQ 103 Businessweek 93 Investing.com 66 Wall Street Journal \(blog\) 61 MarketWatch 56 Moneynews 55 Bloomberg 53 GlobalPost 51 Economic Times 44 Name: title, dtype: int64让我们分解一下,因为有几个连续的方法调用。像以前一样,您可以通过从 pandas GroupBy 迭代器中取出第一个
tuple来取出第一个组及其对应的 pandas 对象:
>>> title, ser = next(iter(df.groupby("outlet", sort=False)["title"]))
>>> title
'Los Angeles Times'
>>> ser.head()
1 Fed official says weak data caused by weather,...
486 Stocks fall on discouraging news from Asia
1124 Clues to Genghis Khan's rise, written in the r...
1146 Elephants distinguish human voices by sex, age...
1237 Honda splits Acura into its own division to re...
Name: title, dtype: object
在这种情况下,ser是一只熊猫Series而不是一只DataFrame。那是因为你跟["title"]跟进了.groupby()电话。这有效地从每个子表中选择了单个列。
接下来是.str.contains("Fed")。当一篇文章标题在搜索中注册了一个匹配时,这将返回一个布尔值 Series即True。果然,第一排从"Fed official says weak data caused by weather,..."开始,亮为True:
>>> ser.str.contains("Fed") 1 True 486 False 1124 False 1146 False 1237 False ... 421547 False 421584 False 421972 False 422226 False 422905 False Name: title, Length: 1976, dtype: bool接下来就是
.sum()这个Series了。由于bool在技术上只是int的一种特殊类型,你可以对True和False的Series求和,就像你对1和0的序列求和一样:
>>> ser.str.contains("Fed").sum()
17
结果是《洛杉矶时报》在数据集中对"Fed"的提及次数。同样的惯例也适用于路透社、纳斯达克、商业周刊和其他公司。
提高.groupby()的性能
现在再次回溯到.groupby().apply()来看看为什么这个模式可能是次优的。要获得一些背景信息,请查看如何加快你的熊猫项目。使用.apply()可能会发生的事情是,它将有效地对每个组执行 Python 循环。虽然.groupby().apply()模式可以提供一些灵活性,但它也可以阻止 pandas 使用其基于 Cython 的优化。
也就是说,每当你发现自己在考虑使用.apply()时,问问自己是否有办法用向量化的方式来表达操作。在这种情况下,您可以利用这样一个事实,即.groupby()不仅接受一个或多个列名,还接受许多类似数组的结构:
- 一维 NumPy 数组
- 一份名单
- 一只熊猫
Series还是Index
还要注意的是,.groupby()对于Series来说是一个有效的实例方法,而不仅仅是一个DataFrame,所以你可以从本质上颠倒分割逻辑。考虑到这一点,您可以首先构造一个布尔值Series,它指示标题是否包含"Fed":
>>> mentions_fed = df["title"].str.contains("Fed") >>> type(mentions_fed) <class 'pandas.core.series.Series'>现在,
.groupby()也是Series的一个方法,所以你可以将一个Series分组到另一个上:
>>> import numpy as np
>>> mentions_fed.groupby(
... df["outlet"], sort=False
... ).sum().nlargest(10).astype(np.uintc)
outlet
Reuters 161
NASDAQ 103
Businessweek 93
Investing.com 66
Wall Street Journal \(blog\) 61
MarketWatch 56
Moneynews 55
Bloomberg 53
GlobalPost 51
Economic Times 44
Name: title, dtype: uint32
这两个Series不必是同一个DataFrame对象的列。它们只需要有相同的形状:
>>> mentions_fed.shape (422419,) >>> df["outlet"].shape (422419,)最后,如果您决定尽可能获得最紧凑的结果,可以用
np.uintc将结果转换回无符号整数。下面是两个版本的直接比较,会产生相同的结果:# pandas_news_performance.py import timeit import numpy as np from pandas_news import df def test_apply(): """Version 1: using `.apply()`""" df.groupby("outlet", sort=False)["title"].apply( lambda ser: ser.str.contains("Fed").sum() ).nlargest(10) def test_vectorization(): """Version 2: using vectorization""" mentions_fed = df["title"].str.contains("Fed") mentions_fed.groupby( df["outlet"], sort=False ).sum().nlargest(10).astype(np.uintc) print(f"Version 1: {timeit.timeit(test_apply, number=3)}") print(f"Version 2: {timeit.timeit(test_vectorization, number=3)}")您使用
timeit模块来估计两个版本的运行时间。如果你想了解更多关于测试代码性能的知识,那么 Python Timer Functions:三种监控代码的方法值得一读。现在,运行脚本,看看两个版本的性能如何:
(venv) $ python pandas_news_performance.py Version 1: 2.5422707499965327 Version 2: 0.3260433749965159运行三次时,
test_apply()函数耗时 2.54 秒,而test_vectorization()仅需 0.33 秒。对于几十万行来说,这是一个令人印象深刻的 CPU 时间差异。想想当您的数据集增长到几百万行时,这种差异会变得多么显著!注意:为了简单起见,这个例子忽略了数据中的一些细节。也就是说,搜索词
"Fed"也可能找到类似"Federal government"的内容。如果你想使用一个包含负前瞻的表达式,那么
Series.str.contains()也可以把一个编译过的正则表达式作为参数。你可能还想计算的不仅仅是原始的被提及次数,而是被提及次数相对于一家新闻机构发表的所有文章的比例。
熊猫小组:把所有的放在一起
如果你在一个 pandas GroupBy 对象上调用
dir(),那么你会看到足够多的方法让你眼花缭乱!很难跟踪熊猫 GroupBy 对象的所有功能。一种拨开迷雾的方法是将不同的方法划分为它们做什么和它们的行为方式。概括地说,pandas GroupBy 对象的方法分为几类:
聚合方法(也称为缩减方法)将许多数据点组合成关于这些数据点的聚合统计。一个例子是取十个数字的和、平均值或中值,结果只是一个数字。
过滤方法带着原始
DataFrame的子集回来给你。这通常意味着使用.filter()来删除基于该组及其子表的一些比较统计数据的整个组。在这个定义下包含许多从每个组中排除特定行的方法也是有意义的。转换方法返回一个
DataFrame,其形状和索引与原始值相同,但值不同。使用聚合和过滤方法,得到的DataFrame通常比输入的DataFrame小。这对于转换来说是不正确的,它转换单个的值本身,但是保留原始的DataFrame的形状。元方法不太关心你调用
.groupby()的原始对象,更关注于给你高层次的信息,比如组的数量和那些组的索引。的剧情方法模仿了为一只熊猫
Series或DataFrame剧情的 API,但通常会将输出分成多个支线剧情。官方文档对这些类别有自己的解释。在某种程度上,它们可以有不同的解释,本教程在对哪种方法进行分类时可能会有细微的不同。
有几个熊猫分组的方法不能很好地归入上面的类别。这些方法通常产生一个不是
DataFrame或Series的中间对象。例如,df.groupby().rolling()产生了一个RollingGroupby对象,然后您可以在其上调用聚合、过滤或转换方法。如果您想更深入地研究,那么
DataFrame.groupby()、DataFrame.resample()和pandas.Grouper的 API 文档是探索方法和对象的资源。在 pandas 文档中还有另一个单独的表,它有自己的分类方案。选择最适合你并且看起来最直观的!
结论
在本教程中,您已经介绍了大量关于
.groupby()的内容,包括它的设计、它的 API,以及如何将方法链接在一起以将数据转化为适合您的目的的结构。你已经学会:
- 如何通过对真实世界数据的操作来使用熊猫分组
- 分割-应用-组合操作链是如何工作的,以及如何将它分解成步骤
- 如何根据它们的意图和结果对熊猫分组的方法进行分类
.groupby()的内容比你在一个教程中能涵盖的要多得多。但是希望这篇教程是进一步探索的良好起点!您可以点击下面的链接下载本教程中所有示例的源代码:
下载数据集: 点击这里下载数据集,你将在本教程中使用来了解熊猫的分组。*********
用 merge()合并 Pandas 中的数据。join()和 concat()
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 concat()和 merge() 结合熊猫中的数据
pandas 中的
Series和DataFrame对象是探索和分析数据的强大工具。他们的力量部分来自于组合独立数据集的多方面方法。使用 pandas,您可以合并、连接和连接您的数据集,允许您在分析数据时统一和更好地理解数据。在本教程中,您将学习如何以及何时将 pandas 中的数据与相结合
merge()用于组合公共列或索引上的数据.join()用于组合关键列或索引上的数据concat()用于组合跨行或列的数据帧如果你有一些在熊猫中使用
DataFrame和Series对象的经验,并准备学习如何组合它们,那么本教程将帮助你做到这一点。如果你觉得有点生疏,那么在继续之前,你可以看一下数据帧的快速复习。您可以使用交互式 Jupyter 笔记本和数据文件按照本教程中的示例进行操作,这些文件可从以下链接获得:
下载笔记本和数据集: 点击此处获取 Jupyter 笔记本和 CSV 数据集,您将使用了解 Pandas merge(),。本教程中的 join()和 concat()。
注意:你将在下面学到的技术通常适用于
DataFrame和Series对象。但是为了简单明了,示例将使用术语数据集来指代既可以是数据帧也可以是序列的对象。熊猫
merge():组合公共列或索引上的数据你要学习的第一个技巧是
merge()。您可以随时使用merge()来实现类似于数据库的连接操作的功能。这是您将学习的三种操作中最灵活的一种。当您想要基于一个或多个键组合数据对象时,就像您在关系数据库中所做的那样,
merge()是您需要的工具。更具体地说,当您想要组合共享数据的行时,merge()是最有用的。与
merge()既可以实现多对一,也可以实现多对多的联结。在多对一连接中,一个数据集的合并列中将有许多重复相同值的行。例如,这些值可以是 1、1、3、5 和 5。同时,另一个数据集中的合并列不会有重复的值。以 1、3、5 为例。正如您可能已经猜到的那样,在多对多联接中,两个合并列都有重复的值。这些合并更加复杂,会产生连接行的笛卡尔积。
这意味着,在合并之后,您将拥有在键列中共享相同值的行的每个组合。您将在下面的示例中看到这一点。
让
merge()如此灵活的是定义合并行为的选项的数量。虽然这个列表看起来令人望而生畏,但通过练习,您将能够熟练地合并所有类型的数据集。当您使用
merge()时,您将提供两个必需的参数:
left数据帧right数据帧之后,您可以提供一些可选参数来定义数据集的合并方式:
how定义了要进行何种合并。默认为'inner',但其他可能的选项包括'outer'、'left'和'right'。
on告诉merge()您想要加入哪些列或索引,也称为键列或键索引。这是可选的。如果没有指定,并且left_index和right_index(下面有介绍)是False,那么共享名称的两个数据帧中的列将被用作连接键。如果您使用on,那么您指定的列或索引必须出现在两个对象中。
left_on和right_on指定只存在于要合并的left或right对象中的列或索引。两者都默认为None。
left_index和right_index都默认为False,但是如果要使用要合并的左边或右边对象的索引,那么可以将相关参数设置为True。
suffixes是一个字符串元组,附加到不是合并键的相同列名上。这允许您跟踪同名列的来源。这些是传递给
merge()的一些最重要的参数。完整的名单见熊猫文档。注意:在本教程中,您将看到示例总是使用
on来指定要连接的列。这是合并数据的最安全的方法,因为您和任何阅读您代码的人都知道在调用merge()时会发生什么。如果没有用on指定合并列,那么 pandas 将使用任何与合并键同名的列。如何使用
merge()在进入如何使用
merge()的细节之前,您应该首先理解各种形式的连接:
innerouterleftright注意:即使你正在学习合并,你也会看到
inner、outer、left和right也被称为连接操作。对于本教程,您可以将术语 merge 和 join 视为等价。您将在下面详细了解这些不同的连接,但首先来看看它们的可视化表示:
Visual Representation of Join Types 在此图中,两个圆圈是您的两个数据集,标签指向您希望看到的数据集的哪个或哪些部分。虽然这个图表没有涵盖所有的细微差别,但它可以成为视觉学习者的方便指南。
如果您有一个 SQL 背景,那么您可能会从
JOIN语法中认出合并操作名称。除了inner,所有这些技术都是外连接的类型。使用外部连接,您将基于左对象、右对象或两者中的所有键来合并数据。对于只存在于一个对象中的键,另一个对象中不匹配的列将用NaN填充,它代表而不是数字。你也可以在编码恐怖上看到 SQL 上下文中各种连接的可视化解释。现在来看看不同的连接。
示例
许多熊猫教程提供了非常简单的数据框架来说明他们试图解释的概念。这种方法可能会令人困惑,因为您无法将数据与任何具体的东西联系起来。因此,在本教程中,您将使用两个真实世界的数据集作为要合并的数据帧:
- 加州的气候正常值(温度)
- 加州气候正常值(降水)
您可以探索这些数据集,并使用交互式 Jupyter 笔记本和气候数据 CSV 了解以下示例:
下载笔记本和数据集: 点击此处获取 Jupyter 笔记本和 CSV 数据集,您将使用了解 Pandas merge(),。本教程中的 join()和 concat()。
如果你想学习如何使用 Jupyter 笔记本,那么请查看 Jupyter 笔记本:简介。
这两个数据集来自美国国家海洋和大气管理局(NOAA),并来自 NOAA 公共数据仓库。首先,将数据集加载到单独的数据框架中:
>>> import pandas as pd
>>> climate_temp = pd.read_csv("climate_temp.csv")
>>> climate_precip = pd.read_csv("climate_precip.csv")
在上面的代码中,您使用 pandas 的 read_csv() 将您的 CSV 源文件方便地加载到DataFrame对象中。然后,您可以使用 .head() 查看已加载数据帧的标题和前几行:
>>> climate_temp.head() STATION STATION_NAME ... DLY-HTDD-BASE60 DLY-HTDD-NORMAL 0 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15 1 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15 2 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15 3 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15 4 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15 >>> climate_precip.head() STATION ... DLY-SNOW-PCTALL-GE050TI 0 GHCND:USC00049099 ... -9999 1 GHCND:USC00049099 ... -9999 2 GHCND:USC00049099 ... -9999 3 GHCND:USC00049099 ... 0 4 GHCND:USC00049099 ... 0这里,您使用了
.head()来获取每个数据帧的前五行。请务必亲自尝试,无论是使用交互式 Jupyter 笔记本还是在您的控制台上,这样您就可以更深入地探索数据。接下来,快速查看两个数据帧的尺寸:
>>> climate_temp.shape
(127020, 21)
>>> climate_precip.shape
(151110, 29)
注意, .shape 是DataFrame对象的一个属性,它告诉你数据帧的尺寸。对于climate_temp,.shape的输出表示数据帧有 127020 行和 21 列。
内部连接
在这个例子中,您将使用带有默认参数的merge(),这将导致一个内部连接。请记住,在内部连接中,您会丢失在其他数据帧的键列中没有匹配的行。
将两个数据集加载到DataFrame对象中后,您将选择降水数据集的一小部分,然后使用普通的merge()调用进行内部连接。这将产生一个更小、更集中的数据集:
>>> precip_one_station = climate_precip.query("STATION == 'GHCND:USC00045721'") >>> precip_one_station.head() STATION ... DLY-SNOW-PCTALL-GE050TI 1460 GHCND:USC00045721 ... -9999 1461 GHCND:USC00045721 ... -9999 1462 GHCND:USC00045721 ... -9999 1463 GHCND:USC00045721 ... -9999 1464 GHCND:USC00045721 ... -9999这里,您已经从
climate_precip数据帧创建了一个名为precip_one_station的新数据帧,只选择了STATION字段为"GHCND:USC00045721"的行。如果您检查
shape属性,那么您会看到它有 365 行。当您进行合并时,您认为在合并的数据帧中会有多少行?请记住,您将进行内部联接:
>>> inner_merged = pd.merge(precip_one_station, climate_temp)
>>> inner_merged.head()
STATION STATION_NAME ... DLY-HTDD-BASE60 DLY-HTDD-NORMAL
0 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
1 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
2 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
3 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
4 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
>>> inner_merged.shape
(365, 47)
如果你猜的是 365 行,那么你答对了!这是因为merge()默认为内部连接,内部连接将只丢弃那些不匹配的行。因为您的所有行都匹配,所以没有丢失。您还应该注意到现在有了更多的列:确切地说是 47 列。
使用merge(),您还可以控制要加入的列。假设您想要合并整个数据集,但是只在Station和Date上,因为两者的组合将为每一行产生一个唯一的值。为此,您可以使用on参数:
>>> inner_merged_total = pd.merge( ... climate_temp, climate_precip, on=["STATION", "DATE"] ... ) >>> inner_merged_total.shape (123005, 48)可以用字符串指定单个键列,也可以用列表指定多个键列。这导致具有 123,005 行和 48 列的数据帧。
为什么是 48 列而不是 47 列?因为您指定了要合并的关键列,pandas 不会尝试合并所有可合并的列。这可能导致“重复”的列名,这些列名可能有也可能没有不同的值。
“Duplicate”用引号括起来,因为列名不会完全匹配。默认情况下,它们会被附加上
_x和_y。您还可以使用suffixes参数来控制追加到列名的内容。为了避免意外,以下所有示例都将使用
on参数来指定要连接的一列或多列。外部连接
这里,您将使用
how参数指定一个外部连接。请记住上图中的内容,在外部连接中,也称为完全外部连接,两个数据帧中的所有行都将出现在新的数据帧中。如果一行在基于键列的其他数据框架中没有匹配项,那么您不会像使用内部连接那样丢失该行。相反,该行将在合并的数据帧中,并在适当的地方填入
NaN值。一个例子很好地说明了这一点:
>>> outer_merged = pd.merge(
... precip_one_station, climate_temp, how="outer", on=["STATION", "DATE"]
... )
>>> outer_merged.shape
(127020, 48)
如果您记得从什么时候开始检查climate_temp的.shape属性,那么您会看到outer_merged中的行数是相同的。使用外部连接,您可以期望拥有与更大的数据帧相同的行数。这是因为在外部连接中不会丢失任何行,即使它们在其他数据帧中没有匹配项。
左连接
在本例中,您将使用参数how指定一个左连接,也称为左外连接。使用左外连接将使新合并的数据帧包含左数据帧中的所有行,同时丢弃右数据帧中与左数据帧的键列不匹配的行。
你可以认为这是一个半外半内的合并。下面的例子向您展示了这一点:
>>> left_merged = pd.merge( ... climate_temp, precip_one_station, how="left", on=["STATION", "DATE"] ... ) >>> left_merged.shape (127020, 48)
left_merged有 127,020 行,与左侧数据帧climate_temp中的行数相匹配。为了证明这仅适用于左侧数据帧,运行相同的代码,但是改变precip_one_station和climate_temp的位置:
>>> left_merged_reversed = pd.merge(
... precip_one_station, climate_temp, how="left", on=["STATION", "DATE"]
... )
>>> left_merged_reversed.shape
(365, 48)
这导致数据帧有 365 行,与precip_one_station中的行数相匹配。
右连接
右连接,或者说右外部连接,是左连接的镜像版本。通过这种连接,将保留右侧数据帧中的所有行,而左侧数据帧中与右侧数据帧的键列不匹配的行将被丢弃。
为了演示左右连接如何互为镜像,在下面的示例中,您将从上面重新创建left_merged数据帧,只是这次使用了右连接:
>>> right_merged = pd.merge( ... precip_one_station, climate_temp, how="right", on=["STATION", "DATE"] ... ) >>> right_merged.shape (127020, 48)这里,您只需翻转输入数据帧的位置并指定一个右连接。当你检查
right_merged时,你可能会注意到它与left_merged并不完全相同。两者之间的唯一区别是列的顺序:第一个输入的列总是新形成的数据帧中的第一列。
merge()是熊猫数据组合工具中最复杂的。它也是构建其他工具的基础。它的复杂性是其最大的优势,允许您以任何方式组合数据集,并对您的数据产生新的见解。另一方面,这种复杂性使得在没有直观掌握集合论和数据库操作的情况下
merge()很难使用。在这一节中,您已经了解了各种数据合并技术,以及多对一和多对多合并,它们最终都来自集合论。关于集合理论的更多信息,请查看 Python 中的集合。现在,你将会看到
.join(),它是merge()的简化版本。熊猫
.join():组合列或索引上的数据当
merge()是一个模块函数时,.join()是一个 实例方法 存在于你的数据框架中。这使您可以只指定一个数据帧,该数据帧将加入您调用.join()的数据帧。在幕后,
.join()使用了merge(),但是它提供了一种比完全指定的merge()调用更有效的方式来连接数据帧。在深入了解您可用的选项之前,先看一下这个简短的示例:
>>> precip_one_station.join(
... climate_temp, lsuffix="_left", rsuffix="_right"
... ).shape
(365, 50)
在索引可见的情况下,您可以看到这里发生了一个左连接,precip_one_station是左边的数据帧。你可能会注意到这个例子提供了参数lsuffix和rsuffix。因为.join()在索引上连接,并且不直接合并数据帧,所以所有列——甚至那些具有匹配名称的列——都保留在结果数据帧中。
现在颠倒一下前面的例子,在更大的数据帧上调用.join():
>>> climate_temp.join( ... precip_one_station, lsuffix="_left", rsuffix="_right" ... ).shape (127020, 50)请注意,数据帧变大了,但是较小的数据帧
precip_one_station中不存在的数据被填充了NaN值。如何使用
.join()默认情况下,
.join()将尝试对索引执行左连接。如果您想像使用merge()那样连接列,那么您需要将列设置为索引。和
merge()一样,.join()也有一些参数,可以让您的连接更加灵活。然而,对于.join(),参数列表相对较短:
other是唯一必需的参数。它定义了要连接的其他数据帧。您还可以在这里指定一个数据帧列表,允许您在单个.join()调用中组合多个数据集。
on为左边的数据帧指定一个可选的列或索引名(在前面的例子中为climate_temp)以加入other数据帧的索引。如果设置为默认的None,那么您将得到一个索引对索引的连接。
how与merge()中的how选项相同。不同之处在于它是基于索引的,除非您也用on指定列。
lsuffix****rsuffix类似于merge()中的suffixes。它们指定了添加到任何重叠列的后缀,但是在传递一列other数据帧时无效。可以启用
sort通过连接键对结果数据帧进行排序。示例
在这一节中,您将看到展示几个不同的
.join()用例的例子。有些将是对merge()呼叫的简化。其他的功能将使.join()区别于更冗长的merge()呼叫。因为您已经看到了一个简短的
.join()呼叫,所以在第一个示例中,您将尝试使用.join()重新创建一个merge()呼叫。这需要什么?花点时间思考一个可能的解决方案,然后看看下面建议的解决方案:
>>> inner_merged_total = pd.merge(
... climate_temp, climate_precip, on=["STATION", "DATE"]
... )
>>> inner_merged_total.shape
(123005, 48)
>>> inner_joined_total = climate_temp.join(
... climate_precip.set_index(["STATION", "DATE"]),
... on=["STATION", "DATE"],
... how="inner",
... lsuffix="_x",
... rsuffix="_y",
... )
>>> inner_joined_total.shape
(123005, 48)
因为.join()对索引起作用,所以如果您想从以前的数据库中重新创建merge(),那么您必须在您指定的连接列上设置索引。在本例中,您使用了.set_index()来设置连接中键列的索引。注意.join()默认情况下做左连接,所以你需要显式地使用how做内连接。
有了这个,merge()和.join()的联系应该就比较清楚了。
下面你会看到一个几乎是空的.join()呼叫。因为有重叠的列,您需要用lsuffix、rsuffix或两者指定一个后缀,但是这个例子将演示.join()更典型的行为:
>>> climate_temp.join(climate_precip, lsuffix="_left").shape (127020, 50)这个例子应该会让人想起你之前在
.join()的介绍中看到的。调用是相同的,导致左连接产生一个数据帧,其行数与climate_temp相同。在本节中,您已经了解了
.join()及其参数和用途。您还了解了.join()在幕后是如何工作的,并且您用.join()重新创建了一个merge()呼叫,以便更好地理解这两种技术之间的联系。熊猫
concat():组合跨行或列的数据串联与您在上面看到的合并技术有点不同。通过合并,您可以期望得到的数据集将来自父数据集的行混合在一起,通常基于一些共性。根据合并的类型,您也可能会丢失在其他数据集中没有匹配项的行。
通过串联,你的数据集只是沿着一个轴拼接在一起——或者是行轴或者是列轴。从视觉上看,沿行不带参数的串联如下所示:
要在代码中实现这一点,您将使用
concat()并向它传递一个想要连接的数据帧列表。此任务的代码如下所示:concatenated = pandas.concat([df1, df2])注意:这个例子假设你的列名是相同的。如果您的列名在沿着行(轴 0)连接时是不同的,那么默认情况下这些列也将被添加,并且
NaN值将被适当地填充。如果您想沿着列执行连接呢?首先,看一下这个操作的可视化表示:
为此,您将像上面一样使用一个
concat()调用,但是您还需要传递值为1或"columns"的axis参数:concatenated = pandas.concat([df1, df2], axis="columns")注意:这个例子假设你的索引在数据集之间是相同的。如果它们在沿着列(轴 1)连接时是不同的,那么默认情况下,额外的索引(行)也将被添加,并且
NaN值将被适当地填充。您将在下一节了解更多关于
concat()的参数。如何使用
concat()如您所见,串联是组合数据集的一种更简单的方式。它通常用于形成一个更大的集合,以对其执行额外的操作。
注意:当您调用
concat()时,您正在连接的所有数据的副本就被制作出来了。您应该小心使用多个concat()调用,因为大量的副本可能会对性能产生负面影响。或者,您可以将可选的copy参数设置为False连接数据集时,您可以指定连接所沿的轴。但是另一个轴会发生什么呢?
没什么。默认情况下,串联产生一个集合联合,其中所有的数据都被保留。您已经看到了用
merge()和.join()作为外部连接,您可以用join参数指定这一点。如果你使用这个参数,那么默认是
outer,但是你也有inner选项,它将执行一个内部连接,或者集合交集。与您之前看到的其他内部连接一样,当您使用
concat()进行内部连接时,可能会丢失一些数据。只有在轴标签匹配的地方,才能保留行或列。注意:记住,
join参数只指定如何处理你没有连接的轴。既然您已经了解了
join参数,下面是concat()采用的一些其他参数:
objs接受要连接的Series或DataFrame对象的任意序列,通常是一个列表。还可以提供一个字典。在这种情况下,这些键将用于构建一个分层索引。
axis表示您要连接的轴。默认值是0,它沿着索引或行轴连接。或者,1的值将沿着列垂直连接。您也可以使用字符串值"index"或"columns"。
join类似于其他技术中的how参数,但它只接受值inner或outer。默认值是outer,它保存数据,而inner将删除在其他数据集中没有匹配的数据。
ignore_index取一个布尔True或False值。默认为False。如果True,那么新的组合数据集将不会保留在axis参数中指定的轴上的原始索引值。这让您拥有全新的索引值。
keys允许你构造一个层次索引。一个常见的用例是在保留原始索引的同时创建一个新索引,这样就可以知道哪些行来自哪个原始数据集。
copy指定是否要复制源数据。默认值为True。如果该值被设置为False,那么熊猫将不会复制源数据。这个列表并不详尽。您可以在 pandas 文档中找到完整的最新参数列表。
示例
首先,您将使用本教程中一直在使用的数据帧沿着默认轴进行基本的连接:
>>> double_precip = pd.concat([precip_one_station, precip_one_station])
>>> double_precip.shape
(730, 29)
这个设计非常简单。这里,您创建了一个数据帧,它是前面创建的一个小数据帧的两倍。需要注意的一点是,这些指数是重复的。如果您想要一个新的从 0 开始的索引,那么您可以使用ignore_index参数:
>>> reindexed = pd.concat( ... [precip_one_station, precip_one_station], ignore_index=True ... ) >>> reindexed.index RangeIndex(start=0, stop=730, step=1)如前所述,如果您沿着轴 0(行)连接,但是在轴 1(列)中有不匹配的标签,那么这些列将被添加并用
NaN值填充。这将导致外部连接:
>>> outer_joined = pd.concat([climate_precip, climate_temp])
>>> outer_joined.shape
(278130, 47)
对于这两个数据帧,因为您只是沿着行连接,所以很少有列具有相同的名称。这意味着您将看到许多带有NaN值的列。
要删除缺少数据的列,可以使用带有值"inner"的join参数进行内部连接:
>>> inner_joined = pd.concat([climate_temp, climate_precip], join="inner") >>> inner_joined.shape (278130, 3)使用内部连接,您将只剩下原始数据帧共有的那些列:
STATION、STATION_NAME和DATE。您也可以通过设置
axis参数来翻转它:
>>> inner_joined_cols = pd.concat(
... [climate_temp, climate_precip], axis="columns", join="inner"
... )
>>> inner_joined_cols.shape
(127020, 50)
现在,您只拥有两个数据帧中所有列的数据的行。行数与较小数据帧的行数相对应并非巧合。
串联的另一个有用技巧是使用keys参数来创建层次轴标签。如果希望保留原始数据集的索引或列名,但又希望添加新的索引或列名,这将非常有用:
>>> hierarchical_keys = pd.concat( ... [climate_temp, climate_precip], keys=["temp", "precip"] ... ) >>> hierarchical_keys.index MultiIndex([( 'temp', 0), ( 'temp', 1), ... ('precip', 151108), ('precip', 151109)], length=278130)如果您检查原始数据帧,那么您可以验证更高级别的轴标签
temp和precip是否被添加到适当的行。结论
现在,您已经了解了在 pandas 中组合数据的三种最重要的技术:
merge()用于组合公共列或索引上的数据.join()用于组合关键列或索引上的数据concat()用于组合跨行或列的数据帧除了学习如何使用这些技术之外,您还通过试验连接数据集的不同方式学习了集合逻辑。此外,您了解了上述每种技术的最常见参数,以及可以传递哪些参数来定制它们的输出。
您看到了这些技术在从 NOAA 获得的真实数据集上的应用,它不仅向您展示了如何组合您的数据,还展示了这样做与熊猫内置技术的好处。如果您还没有下载项目文件,可以从以下位置获得:
下载笔记本和数据集: 点击此处获取 Jupyter 笔记本和 CSV 数据集,您将使用了解 Pandas merge(),。本教程中的 join()和 concat()。
你学到新东西了吗?通过组合复杂的数据集找出解决问题的创造性方法?请在下面的评论中告诉我们!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 concat()和 merge() 结合熊猫中的数据***
熊猫绘图:Python 数据可视化初学者
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 与熊猫的剧情:Python 数据可视化基础知识
无论你只是开始了解一个数据集还是准备发表你的发现,可视化是一个必不可少的工具。Python 流行的数据分析库,熊猫,提供了几个不同的选项来用
.plot()可视化你的数据。即使你刚刚开始你的熊猫之旅,你也将很快创建基本的情节,这些情节将对你的数据产生有价值的见解。在本教程中,您将学习:
- 什么是不同类型的熊猫地块以及何时使用它们
- 如何使用直方图获得数据集的概览
- 如何发现与散点图的相关性
- 如何分析不同的类别及其比率
免费奖励: 点击此处获取 Conda 备忘单,其中包含管理您的 Python 环境和包的便捷使用示例。
设置您的环境
您可以在 Jupyter 笔记本中最好地跟随本教程中的代码。这样,你将立即看到你的情节,并能够发挥他们左右。
您还需要一个包含熊猫的 Python 工作环境。如果你还没有,那么你有几个选择:
如果你有更大的计划,那么下载 Anaconda 发行版。它很大(大约 500 MB),但您将为大多数数据科学工作做好准备。
如果你喜欢极简的设置,那么看看在 Windows 上为机器学习设置 Python 中关于安装 Miniconda 的部分。
如果你想坚持使用
pip,那么用pip install pandas matplotlib安装本教程讨论的库。你也可以用pip install jupyterlab抢 Jupyter 笔记本。如果你不想做任何设置,那么就跟随在线 Jupyter 笔记本试用。
设置好环境后,您就可以下载数据集了。在本教程中,您将分析来自美国社区调查 2010–2012 公共使用微数据样本的大学专业数据。它是在fivethirtyeeight网站上发布的选择大学专业的经济指南的基础。
首先,通过将下载 URL 传递给
pandas.read_csv()来下载数据:
In [1]: import pandas as pd
In [2]: download_url = (
...: "https://raw.githubusercontent.com/fivethirtyeight/"
...: "data/master/college-majors/recent-grads.csv"
...: )
In [3]: df = pd.read_csv(download_url)
In [4]: type(df)
Out[4]: pandas.core.frame.DataFrame
通过调用read_csv(),您创建了一个数据帧,这是 pandas 中使用的主要数据结构。
注意:即使您不熟悉数据帧,也可以跟随本教程。但是如果你有兴趣学习更多关于使用熊猫和数据框架的知识,那么你可以查看使用熊猫和 Python 来探索你的数据集和熊猫数据框架:让使用数据变得愉快。
现在你有了一个数据框架,你可以看看数据。首先,您应该配置display.max.columns选项以确保 pandas 不隐藏任何列。然后可以用 .head() 查看前几行数据:
In [5]: pd.set_option("display.max.columns", None) In [6]: df.head()您已经使用
.head()显示了数据帧df的前五行。您的输出应该如下所示:
.head()显示的默认行数是 5,但是您可以指定任意行数作为参数。例如,要显示前十行,您可以使用df.head(10)。创建你的第一个熊猫地块
您的数据集包含一些与每个专业的毕业生收入相关的列:
"Median"是全职、全年工作者的收入中值。"P25th"是收益的第 25 个百分位数。"P75th"是收入的第 75 百分位。"Rank"是按收入中位数排列的少校军衔。让我们从显示这些列的图开始。首先,你需要用
%matplotlib魔法命令设置你的 Jupyter 笔记本来显示剧情:
In [7]: %matplotlib
Using matplotlib backend: MacOSX
%matplotlib magic 命令用 Matplotlib 设置你的 Jupyter 笔记本显示图形。默认情况下使用标准的 Matplotlib 图形后端,您的绘图将显示在一个单独的窗口中。
注意:您可以通过向%matplotlib magic 命令传递一个参数来更改 Matplotlib 后端。
例如,inline后端很受 Jupyter 笔记本的欢迎,因为它在笔记本本身中显示绘图,就在创建绘图的单元格下面:
In [7]: %matplotlib inline还有许多其他后端可用。有关更多信息,请查看 IPython 文档中的丰富输出教程。
现在你已经准备好制作你的第一个情节了!你可以用
.plot()这样做:
In [8]: df.plot(x="Rank", y=["P25th", "Median", "P75th"])
Out[8]: <AxesSubplot:xlabel='Rank'>
.plot()返回一个折线图,其中包含数据帧中每一行的数据。x 轴值代表每个机构的排名,"P25th"、"Median"和"P75th"值绘制在 y 轴上。
注意:如果您没有使用 Jupyter 笔记本或 IPython shell,那么您需要使用来自matplotlib的pyplot接口来显示图表。
下面是如何在标准 Python shell 中显示图形:
>>> import matplotlib.pyplot as plt >>> df.plot(x="Rank", y=["P25th", "Median", "P75th"]) >>> plt.show()注意,在调用
plt.show()显示绘图之前,必须首先从 Matplotlib 导入pyplot模块。默认情况下,
.plot()生成的图形显示在一个单独的窗口中,如下所示:
查看该图,您可以做出以下观察:
收入中位数随着排名的下降而下降。这是意料之中的,因为排名是由收入中位数决定的。
一些专业在第 25 和第 75 个百分点之间有很大的差距。拥有这些学位的人的收入可能远低于或高于中值收入。
其他专业在第 25 和第 75 个百分点之间的差距非常小。拥有这些学位的人的工资非常接近收入的中位数。
你的第一个图已经暗示了在数据中还有更多要发现的!有些专业的收益范围很广,有些专业的收益范围相当窄。为了发现这些差异,您将使用几种其他类型的图。
注意:关于中位数、百分位数和其他统计数据的介绍,请查看 Python 统计基础:如何描述您的数据。
.plot()有几个可选参数。最值得注意的是,kind参数接受 11 个不同的字符串值,并决定您将创建哪种绘图:
"area"是针对小区地块的。"bar"是针对垂直条形图的。"barh"是针对水平条形图的。"box"是为方框图。"hexbin"是为赫克宾出谋划策。"hist"为直方图。"kde"是对内核密度的估计图表。"density"是"kde"的别名。"line"是为折线图。"pie"是为饼状图。"scatter"是为散点图。默认值为
"line"。像上面创建的折线图一样,可以很好地概述您的数据。您可以使用它们来检测总体趋势。它们很少提供复杂的洞察力,但它们可以给你一些线索,告诉你应该往哪里放大。如果您没有为
.plot()提供参数,那么它会创建一个线图,x 轴上是索引,y 轴上是所有的数字列。虽然对于只有几列的数据集来说,这是一个有用的默认设置,但是对于 college majors 数据集及其几个数值列来说,它看起来相当混乱。注意:作为将字符串传递给
.plot()的kind参数的替代方法,DataFrame对象有几种方法可以用来创建上述各种类型的图:
- T2
.area()- T2
.bar()- T2
.barh()- T2
.box()- T2
.hexbin()- T2
.hist()- T2
.kde()- T2
.density()- T2
.line()- T2
.pie()- T2
.scatter()在本教程中,您将使用
.plot()接口并将字符串传递给kind参数。我们鼓励你也尝试一下上面提到的方法。现在你已经创建了你的第一个熊猫图,让我们仔细看看
.plot()是如何工作的。看看引擎盖下面:Matplotlib
当您在一个
DataFrame对象上调用.plot()时,Matplotlib 会在幕后创建绘图。要验证这一点,请尝试两个代码片段。首先,使用 Matplotlib 创建一个使用两列数据帧的绘图:
In [9]: import matplotlib.pyplot as plt
In [10]: plt.plot(df["Rank"], df["P75th"])
Out[10]: [<matplotlib.lines.Line2D at 0x7f859928fbb0>]
首先,导入matplotlib.pyplot模块,并将其重命名为plt。然后调用plot(),将DataFrame对象的"Rank"列作为第一个参数传递,将"P75th"列作为第二个参数传递。
结果是一个线形图,它在 y 轴上绘制了第 75 个百分位数,在 x 轴上绘制了排名:
您可以使用DataFrame对象的.plot()方法创建完全相同的图形:
In [11]: df.plot(x="Rank", y="P75th") Out[11]: <AxesSubplot:xlabel='Rank'>
.plot()是pyplot.plot()的包装器,结果是一个与您用 Matplotlib 生成的图形相同的图形:
您可以使用
pyplot.plot()和df.plot()从DataFrame对象的列中生成相同的图形。然而,如果你已经有了一个DataFrame实例,那么df.plot()会提供比pyplot.plot()更清晰的语法。注意:如果你已经熟悉 Matplotlib,那么你可能会对
.plot()的kwargs参数感兴趣。您可以向它传递一个包含关键字参数的字典,然后这些关键字参数将被传递到 Matplotlib 绘图后端。有关 Matplotlib 的更多信息,请查看使用 Matplotlib 的 Python 绘图。
现在你知道了
DataFrame对象的.plot()方法是 Matplotlib 的pyplot.plot()的包装器,让我们深入了解你可以创建的不同类型的图以及如何创建它们。调查您的数据
接下来的图将为您提供数据集特定列的概述。首先,您将看到一个直方图属性的分布。然后,您将了解一些检查异常值的工具。
分布和直方图
DataFrame并不是熊猫中唯一一个使用.plot()方法的职业。正如在熊猫身上经常发生的那样,Series对象提供了类似的功能。您可以将数据帧的每一列作为一个
Series对象。下面是一个使用从大学专业数据创建的数据框的"Median"列的示例:
In [12]: median_column = df["Median"]
In [13]: type(median_column)
Out[13]: pandas.core.series.Series
现在您有了一个Series对象,您可以为它创建一个图。一个直方图是一个很好的方法来可视化数据集中的值是如何分布的。直方图将值分组到箱中,并显示其值在特定箱中的数据点的计数。
让我们为"Median"列创建一个直方图:
In [14]: median_column.plot(kind="hist") Out[14]: <AxesSubplot:ylabel='Frequency'>您在
median_column系列上调用.plot(),并将字符串"hist"传递给kind参数。这就是全部了!当你调用
.plot()时,你会看到下图:
直方图显示数据被分成 10 个区间,范围从$20,000 到$120,000,每个区间的宽度为$10,000。直方图的形状与正态分布不同,后者呈对称的钟形,中间有一个峰值。
注:关于直方图的更多信息,请查看 Python 直方图绘制:NumPy,Matplotlib,Pandas & Seaborn 。
然而,中间数据的直方图在低于 40,000 美元时在左边达到峰值。尾巴向右延伸很远,表明确实有专业可以期望更高收入的领域。
离群值
你发现分布右边那个孤独的小箱子了吗?好像一个数据点都有自己的类别。这个领域的专业不仅与平均水平相比,而且与亚军相比,他们的工资都很高。虽然这不是它的主要目的,但直方图可以帮助您检测这样的异常值。让我们更深入地研究一下异常值:
- 这个离群值代表了哪些专业?
- 它的边缘有多大?
与第一个概述相反,您只想比较几个数据点,但是您想看到关于它们的更多细节。对于这一点,条形图是一个很好的工具。首先,选择收入中位数最高的五个专业。您需要两步:
- 要按
"Median"列排序,使用.sort_values(),并提供您要排序的列的名称以及方向ascending=False。- 要获得列表中的前五项,请使用
.head()。让我们创建一个名为
top_5的新数据帧:
In [15]: top_5 = df.sort_values(by="Median", ascending=False).head()
现在你有一个更小的数据框架,只包含前五名最赚钱的专业。下一步,您可以创建一个条形图,仅显示工资中位数最高的五个专业:
In [16]: top_5.plot(x="Major", y="Median", kind="bar", rot=5, fontsize=4) Out[16]: <AxesSubplot:xlabel='Major'>请注意,您使用了
rot和fontsize参数来旋转和调整 x 轴标签的大小,以便它们可见。您将看到一个包含 5 个条形的图:
这张图显示,石油工程专业学生的工资中位数比其他专业高出 2 万多美元。第二名到第四名专业的收入彼此相对接近。
如果您有一个数据点的值比其他数据点的值高得多或低得多,那么您可能需要进一步调查。例如,您可以查看包含相关数据的列。
我们来调查一下所有薪资中位数在 6 万美元以上的专业。首先你需要用口罩
df[df["Median"] > 60000]过滤这些专业。然后,您可以创建另一个条形图,显示所有三个收入栏:
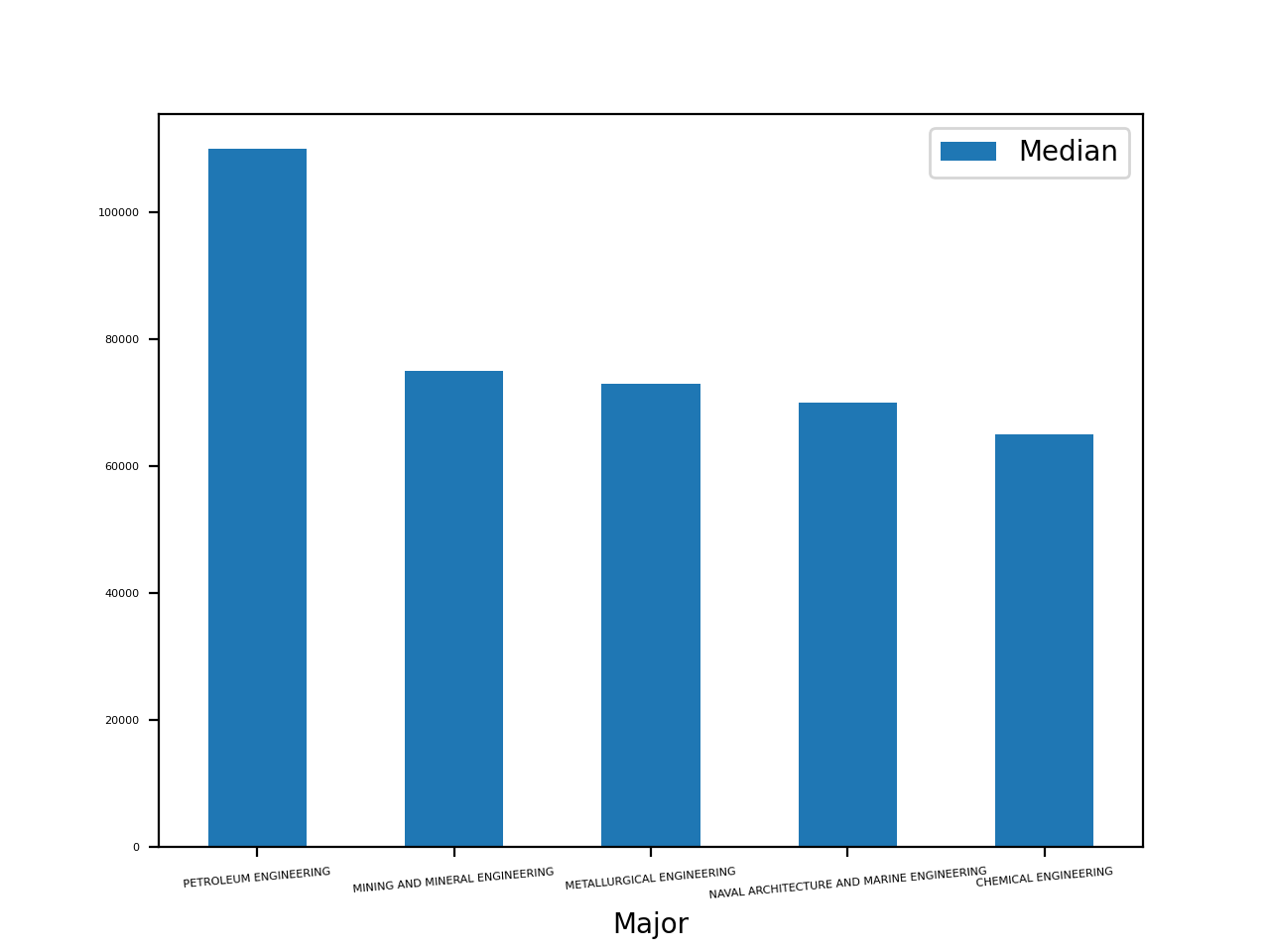
In [17]: top_medians = df[df["Median"] > 60000].sort_values("Median")
In [18]: top_medians.plot(x="Major", y=["P25th", "Median", "P75th"], kind="bar")
Out[18]: <AxesSubplot:xlabel='Major'>
您应该会看到每个专业有三个小节的图,如下所示:
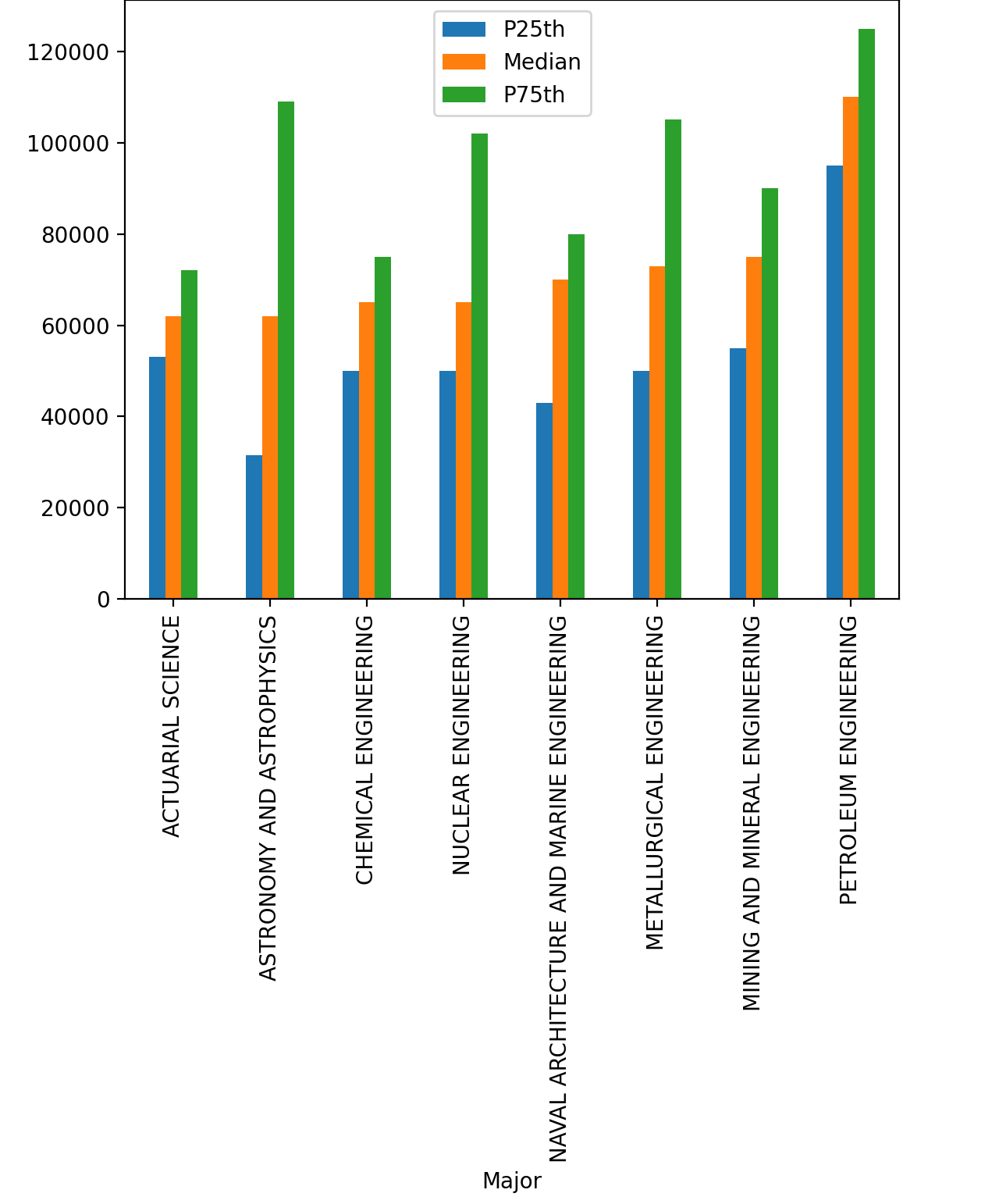
第 25 和第 75 百分位证实了你在上面看到的:石油工程专业是目前收入最高的应届毕业生。
为什么您会对这个数据集中的异常值如此感兴趣?如果你是一个正在考虑选择哪个专业的大学生,你至少有一个非常明显的理由。但是从分析的角度来看,离群值也非常有趣。它们不仅可以显示资金充裕的行业,也可以显示无效数据。
任何数量的错误或疏忽都可能导致无效数据,包括传感器故障、手动数据输入过程中的错误,或者五岁儿童参加了针对十岁及以上儿童的焦点小组。调查异常值是数据清理的重要步骤。
即使数据是正确的,你可能会认为它与其他数据有很大的不同,它产生的噪音大于益处。让我们假设你分析一个小出版商的销售数据。您按地区对收入进行分组,并将它们与上一年的同一个月进行比较。然后出乎意料地,出版商拿到了一本全国畅销书。
这个愉快的事件让你的报告变得毫无意义。包括畅销书的数据在内,各地的销售额都在上升。在没有异常值的情况下执行相同的分析会提供更多有价值的信息,让你看到在纽约你的销售数字有了显著的提高,但是在迈阿密却变得更糟。
检查相关性
通常,您希望查看数据集的两列是否连接。如果你选择一个收入中位数较高的专业,你失业的几率是否也较低?首先,用这两列创建一个散点图:
In [19]: df.plot(x="Median", y="Unemployment_rate", kind="scatter") Out[19]: <AxesSubplot:xlabel='Median', ylabel='Unemployment_rate'>您应该会看到一个看起来很随意的图,就像这样:
快速浏览一下这个数字可以发现,收入和失业率之间没有明显的相关性。
虽然散点图是获得可能的相关性的第一印象的极好工具,但它肯定不是联系的决定性证据。对于不同列之间的相关性的概述,可以使用
.corr()。如果你怀疑两个值之间的相关性,那么你有几个工具来验证你的直觉和测量相关性有多强。但是请记住,即使两个值之间存在相关性,也并不意味着一个值的变化会导致另一个值的变化。换句话说,关联并不意味着因果关系。
分析分类数据
为了处理更大块的信息,人类大脑有意识和无意识地将数据分类。这种技术通常是有用的,但它远非完美无缺。
有时候,我们会把一些东西归入一个范畴,但经过进一步的检验,它们并不完全相似。在本节中,您将了解一些用于检查类别和验证给定分类是否有意义的工具。
许多数据集已经包含一些显式或隐式的分类。在当前示例中,173 个专业分为 16 个类别。
分组
类别的一个基本用法是分组和聚合。您可以使用
.groupby()来确定大学专业数据集中每个类别的受欢迎程度:
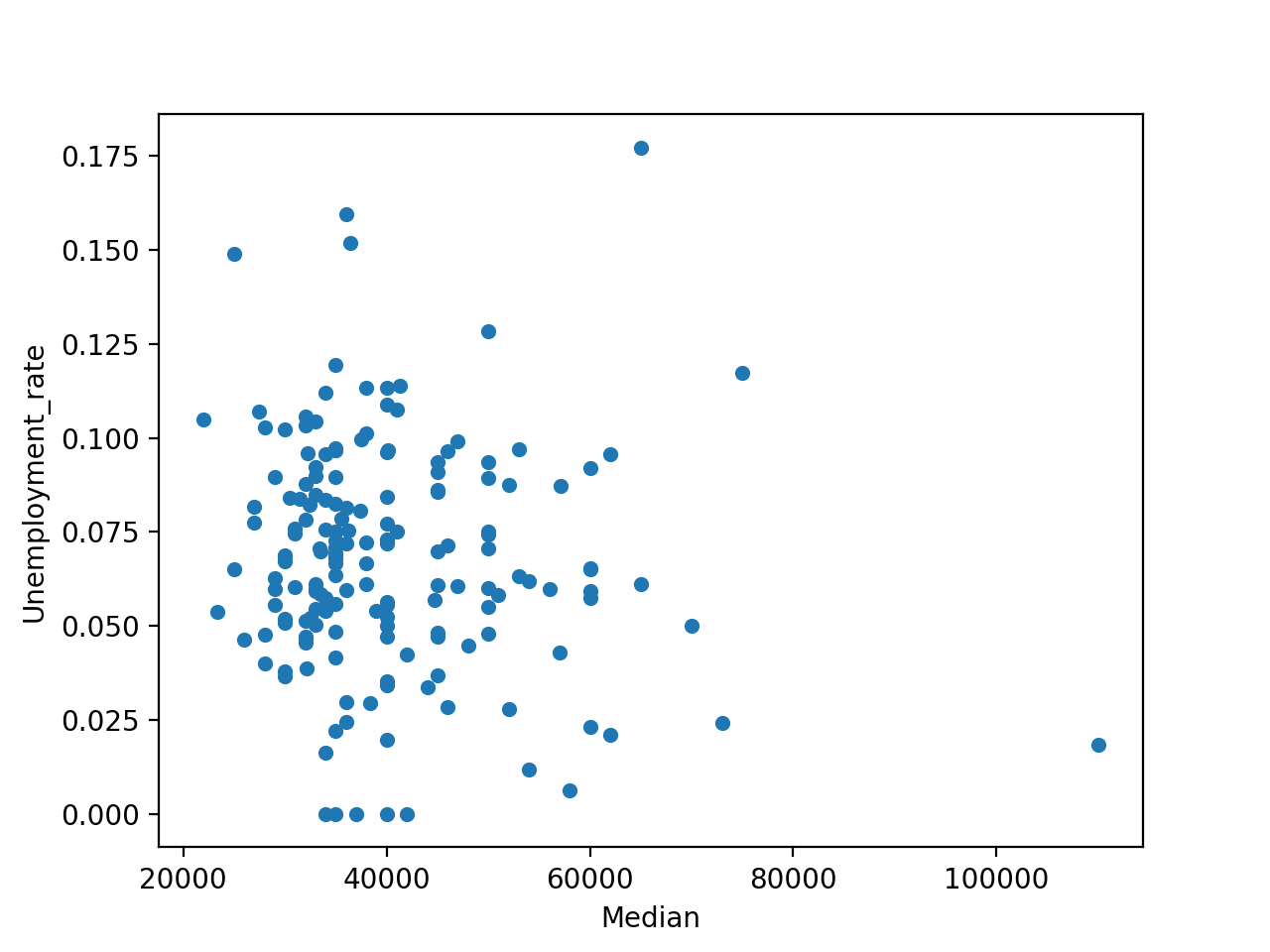
In [20]: cat_totals = df.groupby("Major_category")["Total"].sum().sort_values()
In [21]: cat_totals
Out[21]:
Major_category
Interdisciplinary 12296.0
Agriculture & Natural Resources 75620.0
Law & Public Policy 179107.0
Physical Sciences 185479.0
Industrial Arts & Consumer Services 229792.0
Computers & Mathematics 299008.0
Arts 357130.0
Communications & Journalism 392601.0
Biology & Life Science 453862.0
Health 463230.0
Psychology & Social Work 481007.0
Social Science 529966.0
Engineering 537583.0
Education 559129.0
Humanities & Liberal Arts 713468.0
Business 1302376.0
Name: Total, dtype: float64
用 .groupby() ,你创建一个DataFrameGroupBy对象。用 .sum() ,你创建一个系列。
让我们画一个水平条形图,显示cat_totals中的所有类别总数:
In [22]: cat_totals.plot(kind="barh", fontsize=4) Out[22]: <AxesSubplot:ylabel='Major_category'>您应该会看到每个类别都有一个水平条的图:
正如你的图所示,商业是迄今为止最受欢迎的主要类别。虽然人文学科和文科是明显的第二名,但其他领域的受欢迎程度更相似。
注意:包含分类数据的列不仅能为分析和可视化提供有价值的见解,它还提供了一个提高代码性能的机会。
确定比率
如果你想看到你的类别之间的区别,垂直和水平条形图通常是一个不错的选择。如果你对比率感兴趣,那么饼图是一个很好的工具。然而,由于
cat_totals包含一些更小的类别,用cat_totals.plot(kind="pie")创建一个饼图将产生几个带有重叠标签的小切片。为了解决这个问题,您可以将较小的类别合并到一个组中。将总数低于 100,000 的所有类别合并到一个名为
"Other"的类别中,然后创建一个饼图:
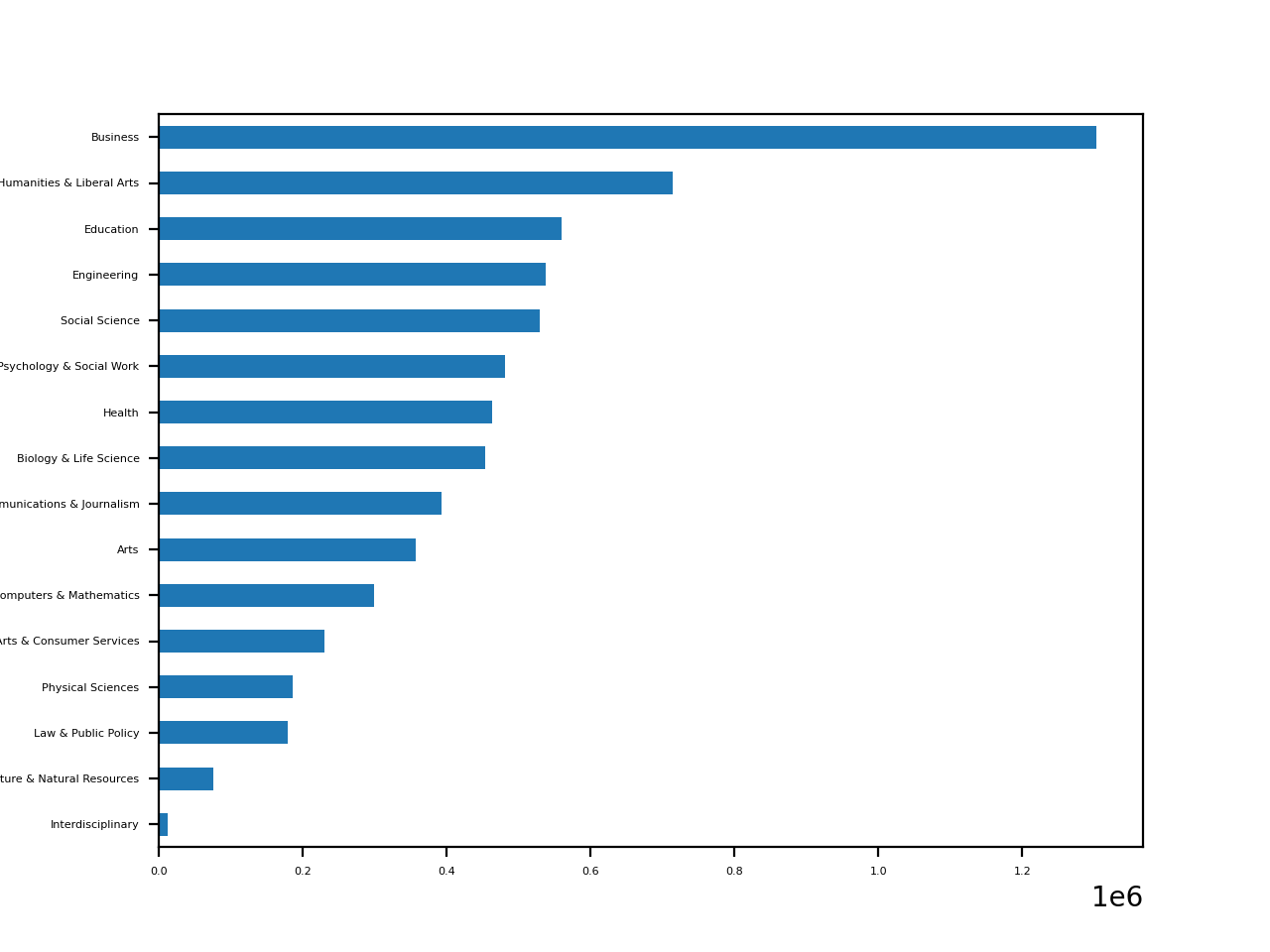
In [23]: small_cat_totals = cat_totals[cat_totals < 100_000]
In [24]: big_cat_totals = cat_totals[cat_totals > 100_000]
In [25]: # Adding a new item "Other" with the sum of the small categories
In [26]: small_sums = pd.Series([small_cat_totals.sum()], index=["Other"])
In [27]: big_cat_totals = big_cat_totals.append(small_sums)
In [28]: big_cat_totals.plot(kind="pie", label="")
Out[28]: <AxesSubplot:>
请注意,您包含了参数label=""。默认情况下,pandas 会添加一个带有列名的标签。这通常是有道理的,但在这种情况下,它只会增加噪音。
现在,您应该会看到这样的饼图:
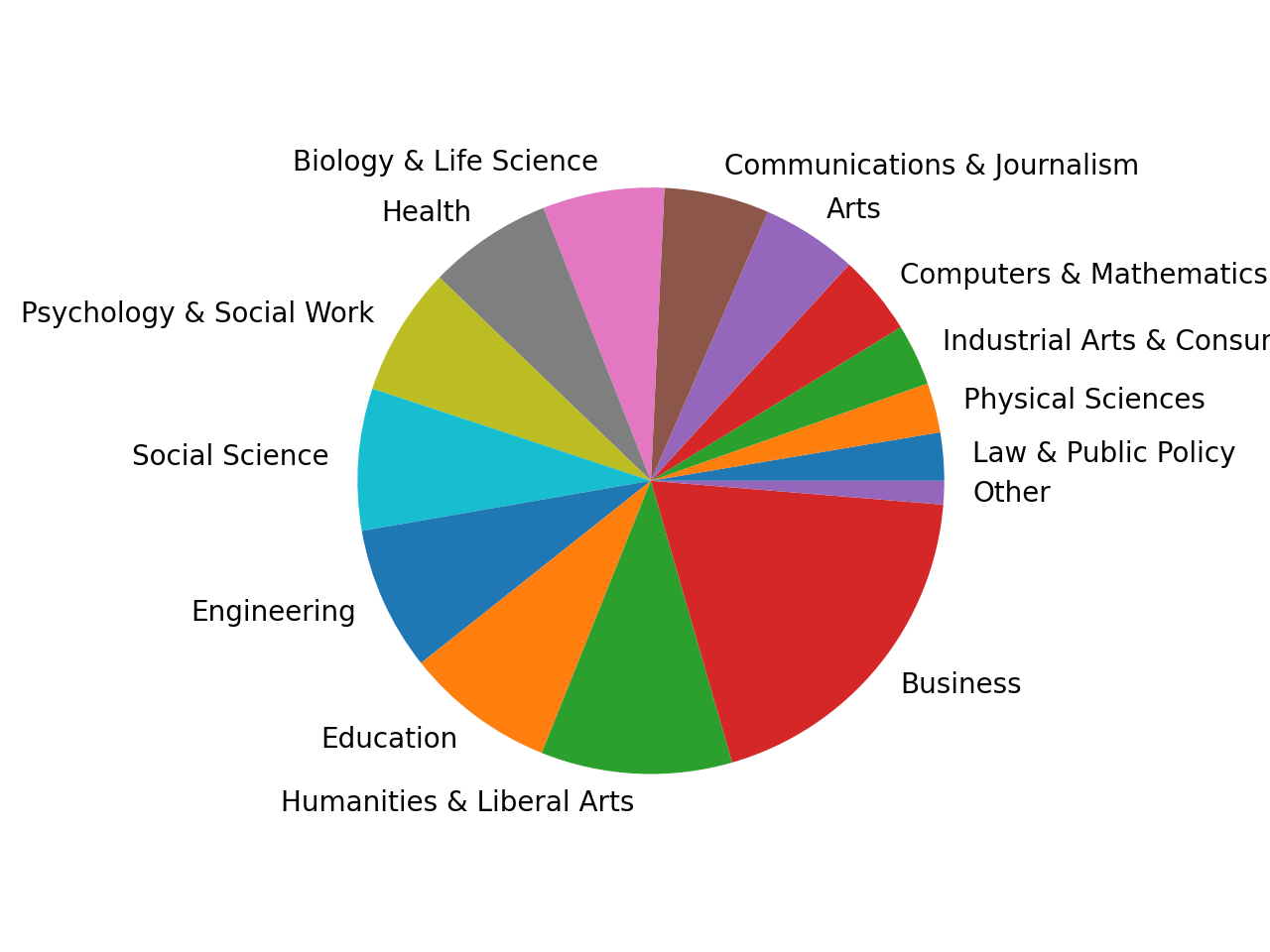
这个类别仍然只占很小一部分。这是一个好迹象,表明合并这些小类别是正确的选择。
放大类别
有时您还想验证某个分类是否有意义。一个类别的成员是否比数据集中的其他成员更相似?同样,发行版是获得第一手概述的好工具。通常,我们期望一个类别的分布类似于正态分布,但是范围更小。
创建一个直方图,显示工程专业学生收入中位数的分布:
In [29]: df[df["Major_category"] == "Engineering"]["Median"].plot(kind="hist") Out[29]: <AxesSubplot:ylabel='Frequency'>你会得到一个直方图,你可以从一开始就与所有专业的直方图进行比较:
主要收入中位数的范围稍微小一些,从 40,000 美元开始。该分布更接近正常,尽管其峰值仍在左侧。所以,即使你已经决定在工程类中选择一个专业,深入研究并更彻底地分析你的选择也是明智的。
结论
在本教程中,您已经学习了如何使用 Python 和 pandas 库开始可视化数据集。您已经看到了一些基本图如何让您深入了解数据并指导您的分析。
在本教程中,您学习了如何:
- 通过直方图了解数据集的分布概况
- 发现与散点图的相关性
- 用条形图分析类别,用饼图分析它们的比率
- 确定哪个图最适合你当前的任务
使用
.plot()和一个小的数据框架,您发现了提供数据图片的多种可能性。现在,您已经准备好在这些知识的基础上探索更复杂的可视化。如果你有任何问题或意见,请写在下面的评论区。
延伸阅读
虽然 pandas 和 Matplotlib 使您的数据可视化变得非常简单,但创建更复杂、更美丽或更吸引人的图还有无限的可能性。
一个很好的起点是 pandas DataFrame 文档的绘图部分。它包含了一个很好的概述和一些详细的描述,描述了您可以在数据框中使用的许多参数。
如果你想更好地理解熊猫绘图的基础,那么就多了解一下 Matplotlib。虽然文档有时会让人不知所措,但 Matplotlib 的剖析在介绍一些高级特性方面做得非常出色。
如果你想用交互式可视化给你的观众留下深刻印象,并鼓励他们自己探索数据,那么让散景成为你的下一站。你可以在使用散景的 Python 交互式数据可视化中找到散景特性的概述。你也可以用
pandas-bokeh库配置熊猫使用散景而不是 Matplotlib如果您想为统计分析或科学论文创建可视化效果,请查看 Seaborn 。你可以在 Python 直方图绘制中找到关于 Seaborn 的小课。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 与熊猫的剧情:Python 数据可视化基础知识*****
熊猫项目:用蟒蛇和熊猫制作一本年级册
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 制作成绩册
所有老师的共同工作之一是评估学生。无论你使用考试、家庭作业、测验还是项目,你通常都必须在期末将学生的分数转化为一个字母等级。这通常涉及到你可能在电子表格中进行的一系列计算。相反,你可以考虑使用 Python 和熊猫。
使用电子表格的一个问题是,当你在公式中出错时,很难被发现。也许你选错了栏目,把小测验放在了应该考试的地方。也许你找到了两个错误值中的最大值。为了解决这个问题,您可以使用 Python 和 pandas 来完成所有的计算,并更快地找到和修复这些错误。
在本教程中,你将学习如何:
- 加载和合并来自多个数据源的数据
- 筛选熊猫数据框中的和组数据
- 计算熊猫数据框中和地块的等级
单击下面的链接下载熊猫项目的代码,并按照下面的链接创建你的成绩册脚本:
获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
构建它:在本教程中,您将从头到尾构建一个完整的项目。如果你想了解更多关于熊猫的知识,那就去看看熊猫学习之路。
演示:您将构建什么
在这个 pandas 项目中,您将创建一个 Python 脚本来加载您的成绩数据并为您的学生计算字母成绩。请观看这段视频,了解该脚本的运行演示:
https://player.vimeo.com/video/435136619
您的脚本将从命令行或 IDE 运行,并将生成 CSV 输出文件,以便您可以将分数粘贴到学校的评分系统中。你还将绘制一些图表,看看你的分数是如何分布的。
项目概述
这个熊猫项目包括四个主要步骤:
- 探索你将在项目中使用的数据,以确定计算最终成绩所需的格式和数据。
- 将数据加载到 pandas DataFrames 中,确保将所有数据源中同一学生的成绩联系起来。
- 计算最终成绩并保存为 CSV 文件。
- 绘制成绩分布图并探索学生之间的成绩差异。
完成这些步骤后,您将拥有一个可以计算成绩的 Python 脚本。你的成绩将会是一种你可以上传到你学校的学生管理系统的格式。
背景阅读
如果你有一点和熊猫一起工作的经验,你会从这个熊猫项目中得到最大的收获。如果您需要复习,这些教程和课程将帮助您快速完成这个项目:
不要太担心记住那些教程中的所有细节。在这个熊猫项目中,你会看到这些主题的实际应用。现在让我们来看看您将在这个项目中使用的数据!
探索熊猫项目的数据
像大多数老师一样,您可能在本学期使用了各种服务来管理您的班级,包括:
- 学校的学生管理系统
- 一种管理家庭作业和考试的分配和评分的服务
- 管理分配和评分测验的服务
出于这个项目的目的,您将使用样本数据来表示您可能从这些系统中得到什么。数据位于逗号分隔值(CSV)文件中。这里显示了一些数据示例。首先,有一个包含班级花名册信息的文件。这将来自您的学生管理系统:
身份证明 名字 NetID 电子邮件地址 部分 One million two hundred and thirty-four thousand five hundred and sixty-seven 伍迪·小巴雷拉 WXB12345 WOODY.BARRERA_JR@UNIV.EDU one Two million three hundred and forty-five thousand six hundred and seventy-eight 马莱卡·兰伯特 MXL12345 马拉卡。兰波特@UNIV.EDU Two Three million four hundred and fifty-six thousand seven hundred and eighty-nine □中 TXJ12345 TRACI.JOYCE@UNIV.EDU one Four million five hundred and sixty-seven thousand eight hundred and ninety “弗劳尔,约翰·格雷格” JGF12345 JOHN.G.2.FLOWER@UNIV.EDU three 该表显示了每个学生的 ID 号、姓名、NetID 和电子邮件地址以及他们所属的班级。在这个学期,你教了一个在不同时间上课的班级,每个课时都有不同的节数。
接下来,您有一个包含作业和考试分数的文件。这份来自作业和考试评分服务,与花名册的栏目安排略有不同:
(同 suddenionosphericdisturbance)电离层的突然骚扰 西方人名的第一个字 姓 家庭作业 1 家庭作业 1 -最高分 作业 1 -提交时间 … jgf12345 格雷格 花 sixty-nine Eighty 2019-08-29 08:56:02-07:00 … mxl12345 新飞象过河 朗伯 Sixty-three Eighty 2019-08-29 08:56:02-07:00 … txj12345 特拉奇 乔伊斯 Eighty 2019-08-29 08:56:02-07:00 … wxb12345 木质的 斗牛场栅栏 Fifty-five Eighty 2019-08-29 08:56:02-07:00 … 在此表中,每个学生都有一个 SID、名和姓。此外,你的每项家庭作业和考试都有三个报告值:
- 学生获得的分数
- 该任务的最高分
- 学生提交作业的时间
最后,您有包含测验分数信息的文件。这些文件是分开的,因此每个数据文件中存储一个测验,并且这些文件中的信息不同于花名册和家庭作业文件:
姓 西方人名的第一个字 电子邮件 级别 斗牛场栅栏 木质的 woody.barrera_jr@univ.edu four 花 约翰 john.g.2.flower@univ.edu eight 乔伊斯 特拉奇 traci.joyce@univ.edu eight 朗伯 新飞象过河 马来西亚 lambert@univ.edu eight 在测验表中,每个学生都有姓氏、名字、电子邮件和测验分数。请注意,最大可能的测验分数没有存储在此表中。稍后您将看到如何提供这些信息。
检查这些数据时,您可能会注意到几个特征:
每张桌子都有学生名字的不同表示。例如,在花名册表中,名字采用带引号的形式
"Last Name, First Name",这样 CSV 解析器就不会将逗号解释为新列。然而,在家庭作业表中,名和姓各有自己的列。每个学生可能在不同的数据源中使用不同的名字。例如,测验表格不包括伍迪·巴雷拉名字中的后缀
Jr.。另一个例子是,约翰·弗劳尔更喜欢别人叫他的中名格雷格,所以他调整了作业表中的显示。每个学生的电子邮件地址没有相同的元素。学生的基本电子邮件地址是
first.last@univ.edu。但是,如果该表单的电子邮件已经被其他学生拥有,则电子邮件地址将被修改为唯一的。这意味着你不能仅仅从学生的名字来预测他们的电子邮件地址。每列可以使用唯一的名称,即使它有相同的数据。例如,所有学生都有一个形式为
abc12345的标识符。花名册表称这个为他们的 NetID,而作业表称这个为他们的 SID。测验表格根本没有这些信息。类似地,一些表格使用列标题Email address,而其他表格只使用每个表格对数据的排序不同。在花名册表中,数据按
ID列排序。在作业表中,数据按名字的第一个字母排序。在测验表格中,数据以随机顺序排序。表格中的每一行或每一列都可能有缺失数据。例如,Traci Joyce 没有提交她的作业 1,所以她在作业表中的行是空白的。
所有这些特征以及更多的特征都存在于你将在现实世界中看到的数据中。在这个 pandas 项目的其余部分,您将看到如何处理这些特性,并确保它们不会干扰您的分析。
决定数据的最终格式
现在您已经看到了原始数据格式,可以考虑数据的最终格式了。最后,你需要根据每个学生的原始分数来计算他们的字母等级。最终数据表中的每一行都将包含单个学生的所有数据。行数将等于您所在班级的学生数。
这些列将代表每个家庭作业分数、测验分数和考试分数。您还将存储每个学生的一些信息,包括他们的姓名和唯一标识符。最后,你将把你的每一个计算结果和最终的字母等级存储在不同的列中。
这是您的决赛桌示例:
标识符 名字 家庭作业 盘问 考试 最终得分 最终成绩 学生 1 最后,第一 # # # # 视频(同 audio frequency) 学生 2 最后,第一 # # # # 视频(同 audio frequency) … … … … … … … 表中的每一行存储一个学生的所有数据。第一列是学生的唯一标识符,第二列是学生的姓名。然后,一系列列存储作业、测验、考试和期末成绩。最后一栏是期末成绩。
现在您已经看到了数据的最终形状,您可以开始处理数据了。第一步是加载数据!
用熊猫加载数据
用 Python 处理表格数据的最好的包之一是 pandas !您将利用 pandas 中的许多功能,特别是合并数据集和对数据执行数学运算。
本节中显示的代码样本收集在
01-loading-the-data.py文件中。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
创建一个名为
gradebook.py的 Python 脚本。您还需要创建一个名为data的文件夹,用于存储您的成绩簿脚本的输入数据文件。然后,在
gradebook.py中,开始添加一个解释文件用途的模块级文档串。你现在还可以导入几个库:"""Calculate student grades by combining data from many sources. Using pandas, this script combines data from the: * Roster * Homework & Exam grades * Quiz grades to calculate final grades for a class. """ from pathlib import Path import pandas as pd在这段代码中,您包括一个描述脚本用途的 docstring。然后你导入
pathlib.Path和pandas。加载花名册文件
现在您已经准备好加载数据了,从花名册开始:
HERE = Path(__file__).parent DATA_FOLDER = HERE / "data" roster = pd.read_csv( DATA_FOLDER / "roster.csv", converters={"NetID": str.lower, "Email Address": str.lower}, usecols=["Section", "Email Address", "NetID"], index_col="NetID", )在这段代码中,您创建了两个常量,
HERE和DATA_FOLDER,来跟踪当前正在执行的文件的位置以及存储数据的文件夹。这些常量使用pathlib模块来方便引用不同的文件夹。然后你使用
pd.read_csv()读取花名册文件。为了帮助以后处理数据,您使用index_col设置一个索引,并使用usecols仅包含有用的列。为了确保以后可以比较字符串,您还传递了
converters参数来将列转换为小写。这将简化您稍后要做的字符串比较。您可以在下面的
roster数据框中看到一些数据:
NetID 电子邮件地址 部分 wxb12345 woody.barrera_jr@univ.edu one mxl12345 马来西亚 lambert@univ.edu Two txj12345 traci.joyce@univ.edu one jgf12345 john.g.2.flower@univ.edu three 这些是来自
roster的前四行,它们与您在上一节中查看的花名册表中的行相匹配。然而,NetID和Email Address列都被转换成小写字符串,因为您将这两列的str.lower传递给了converters。您还省略了Name和ID列。加载作业和考试文件
接下来,您可以加载作业和考试成绩 CSV 文件。请记住,除了所有的成绩之外,该文件还包括名字和姓氏以及 SID 列。您希望忽略包含提交时间的列:
hw_exam_grades = pd.read_csv( DATA_FOLDER / "hw_exam_grades.csv", converters={"SID": str.lower}, usecols=lambda x: "Submission" not in x, index_col="SID", )在这段代码中,您再次使用
converters参数将SID和Email Address列中的数据转换成小写。虽然这些列中的数据初看起来是小写的,但最佳实践是确保所有数据都是一致的。您还需要指定SID作为索引列,以匹配roster数据帧。在这个 CSV 文件中,有许多包含作业提交时间的列,您不会在任何进一步的分析中使用它们。但是,您想要保留的其他列太多了,以至于要显式地列出所有这些列是很乏味的。
为了解决这个问题,
usecols也接受使用一个参数(列名)调用的函数。如果函数返回True,则包含该列。否则,该列将被排除。用您在这里传递的lambda函数,如果字符串"Submission"出现在列名中,那么该列将被排除。这里有一个
hw_exam_grades数据帧的例子,让你对数据加载后的样子有个大概的了解:
(同 suddenionosphericdisturbance)电离层的突然骚扰 … 家庭作业 1 家庭作业 1 -最高分 家庭作业 2 … jgf12345 … sixty-nine Eighty fifty-two … mxl12345 … Sixty-three Eighty Fifty-seven … txj12345 … 圆盘烤饼 Eighty Seventy-seven … wxb12345 … Fifty-five Eighty Sixty-two … 这些是你在上一节中看到的作业和考试成绩 CSV 文件中的示例学生行。请注意,
Homework 1列中缺少的 Traci Joyce (SIDtxj12345)数据被读取为nan或而非数字值。您将在后面的章节中看到如何处理这种数据。省略号(...)表示示例中没有显示的数据列,这些数据列是从真实数据中加载的。加载测验文件
最后,您需要从测验中加载数据。你需要阅读五个小测验,这些数据最有用的形式是一个单一的数据框架,而不是五个独立的数据框架。最终的数据格式如下所示:
电子邮件 测验 5 测验 2 测验 4 测验 1 测验 3 woody.barrera_jr@univ.edu Ten Ten seven four Eleven john.g.2.flower@univ.edu five eight Thirteen eight eight traci.joyce@univ.edu four six nine eight Fourteen 马来西亚 lambert@univ.edu six Ten Thirteen eight Ten 这个数据帧以
quiz_grades = pd.DataFrame() for file_path in DATA_FOLDER.glob("quiz_*_grades.csv"): quiz_name = " ".join(file_path.stem.title().split("_")[:2]) quiz = pd.read_csv( file_path, converters={"Email": str.lower}, index_col=["Email"], usecols=["Email", "Grade"], ).rename(columns={"Grade": quiz_name}) quiz_grades = pd.concat([quiz_grades, quiz], axis=1)在这段代码中,您创建了一个名为
quiz_grades的空数据帧。您需要空数据框架的原因与您需要在使用list.append()之前创建一个空列表的原因相同。您使用
Path.glob()找到所有的测验 CSV 文件,并用 pandas 加载它们,确保将电子邮件地址转换为小写。您还将每个测验的索引列设置为学生的电子邮件地址,pd.concat()使用这些地址来排列每个学生的数据。请注意,您将
axis=1传递给了pd.concat()。这使得 pandas 连接列而不是行,将每个新的测验添加到组合数据帧的新列中。最后,使用
DataFrame.rename()将成绩列的名称从Grade更改为特定于每个测验的名称。合并等级数据帧
现在您已经加载了所有的数据,您可以组合来自三个数据帧的数据,
roster、hw_exam_grades和quiz_grades。这使你可以使用一个数据框架进行所有的计算,并在最后以另一种格式保存完整的成绩册。本节中对
gradebook.py的所有修改都收集在02-merging-dataframes.py文件中。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
您将分两步合并数据:
- 将
roster和hw_exam_grades合并成一个新的数据帧,称为final_data。- 将
final_data和quiz_grades合并在一起。您将在每个数据帧中使用不同的列作为合并键,这就是 pandas 如何决定将哪些行放在一起。这个过程是必要的,因为每个数据源为每个学生使用不同的唯一标识符。
合并花名册和作业成绩
在
roster和hw_exam_grades中,NetID 或 SID 列作为给定学生的唯一标识符。当在 pandas 中合并或连接数据帧时,拥有一个索引是最有用的。当你加载测验文件时,你已经看到了这有多有用。请记住,在加载花名册和作业分数时,您将参数
index_col传递给了pd.read_csv()。现在,您可以将这两个数据帧合并在一起:final_data = pd.merge( roster, hw_exam_grades, left_index=True, right_index=True, )在这段代码中,您使用
pd.merge()来组合roster和hw_exam_grades数据帧。以下是四个示例学生的合并数据框架示例:
NetID 电子邮件地址 … 家庭作业 1 … wxb12345 woody.barrera_jr@univ.edu … Fifty-five … mxl12345 马来西亚 lambert@univ.edu … Sixty-three … txj12345 traci.joyce@univ.edu … 圆盘烤饼 … jgf12345 john.g.2.flower@univ.edu … sixty-nine … 正如您之前看到的,省略号表示示例中没有显示的列,但它们存在于实际的数据帧中。示例表显示具有相同 NetID 或 SID 的学生已被合并在一起,因此他们的电子邮件地址和家庭作业 1 成绩与您之前看到的表相匹配。
合并测验成绩
当您为
quiz_grades加载数据时,您使用电子邮件地址作为每个学生的唯一标识符。这与分别使用 NetID 和 SID 的hw_exam_grades和roster不同。要将
quiz_grades合并到final_data,可以使用来自quiz_grades的索引和来自final_data的Email Address列:final_data = pd.merge( final_data, quiz_grades, left_on="Email Address", right_index=True )在这段代码中,您使用
pd.merge()的left_on参数来告诉 pandas 在合并中使用final_data中的Email Address列。您还可以使用right_index来告诉 pandas 在合并中使用来自quiz_grades的索引。以下是一个合并数据框架的示例,显示了四个示例学生:
NetID 电子邮件地址 … 家庭作业 1 … 测验 3 wxb12345 woody.barrera_jr@univ.edu … Fifty-five … Eleven mxl12345 马来西亚 lambert@univ.edu … Sixty-three … Ten txj12345 traci.joyce@univ.edu … 圆盘烤饼 … Fourteen jgf12345 john.g.2.flower@univ.edu … sixty-nine … eight 请记住,省略号意味着示例表中缺少列,但是合并后的数据帧中会出现这些列。您可以仔细检查前面的表,以验证数字是否与正确的学生对齐。
填写
nan值现在,您的所有数据都合并到一个数据帧中。在你继续计算分数之前,你需要再做一点数据清理。
在上表中,您可以看到 Traci Joyce 的作业 1 仍然有一个
nan值。你不能在计算中使用nan值,因为它们不是一个数字!您可以使用DataFrame.fillna()给final_data中的所有nan值分配一个数字:final_data = final_data.fillna(0)在这段代码中,您使用
DataFrame.fillna()用值0填充final_data中的所有nan值。这是一个合适的解决方案,因为 Traci Joyce 的“家庭作业 1”列中的nan值表示缺少分数,这意味着她可能没有交作业。以下是修改后的数据框架示例,显示了四个示例学生:
NetID … 西方人名的第一个字 姓 家庭作业 1 … wxb12345 … 木质的 斗牛场栅栏 Fifty-five … mxl12345 … 新飞象过河 朗伯 Sixty-three … txj12345 … 特拉奇 乔伊斯 Zero … jgf12345 … 约翰 花 sixty-nine … 正如您在该表中看到的,Traci Joyce 的家庭作业 1 分数现在是
0而不是nan,但是其他学生的分数没有变化。用熊猫数据框计算等级
你在课堂上有三类作业:
- 考试
- 家庭作业
- 盘问
这些类别中的每一个都被分配了一个权重给学生的最终分数。对于本学期的课程,您分配了以下权重:
种类 期末成绩百分比 重量 考试 1 分数 five 0.05考试 2 分数 Ten 0.10考试 3 分数 Fifteen 0.15测验分数 Thirty 0.30家庭作业分数 Forty 0.40最终得分可以通过将权重乘以每个类别的总得分并对所有这些值求和来计算。最后的分数将会被转换成最后的字母等级。
本节中对
gradebook.py的所有修改都收集在03-calculating-grades.py文件中。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
这意味着您必须计算每个类别的总数。每个类别的总分是一个从 0 到 1 的浮点数,表示学生相对于最高分获得了多少分。你将依次处理每个任务类别。
计算考试总成绩
你将首先计算考试的分数。由于每项考试都有唯一的权重,因此您可以单独计算每项考试的总分。使用一个
for循环最有意义,您可以在下面的代码中看到:n_exams = 3 for n in range(1, n_exams + 1): final_data[f"Exam {n} Score"] = ( final_data[f"Exam {n}"] / final_data[f"Exam {n} - Max Points"] )在这段代码中,您将
n_exams设置为等于3,因为您在学期中有三次考试。然后,通过将原始分数除以该考试的最高分,循环计算每场考试的分数。以下是四个示例学生的考试数据示例:
NetID 考试 1 分数 考试 2 分数 考试 3 分数 wxb12345 Zero point eight six Zero point six two Zero point nine mxl12345 Zero point six Zero point nine one Zero point nine three txj12345 One Zero point eight four Zero point six four jgf12345 Zero point seven two Zero point eight three Zero point seven seven 在这张表中,每个学生在每项考试中的得分都在 0.0 到 1.0 之间。在脚本的最后,你将把这些分数乘以权重,以确定最终分数的比例。
计算作业分数
接下来,你需要计算作业分数。每份家庭作业的最高分从 50 到 100 不等。这意味着有两种方法来计算家庭作业分数:
- 按总分:分别将原始分和最高分相加,然后取比值。
- 按平均分:将每个原始分数除以其各自的最高分,然后取这些比值之和,再将总数除以作业数。
第一种方法给表现稳定的学生较高的分数,而第二种方法则偏爱那些在值得更多分数的作业中表现出色的学生。为了帮助学生,你要给他们这两个分数中的最大值。
计算这些分数需要几个步骤:
- 收集列有家庭作业的数据。
- 计算总分。
- 计算平均分。
- 确定哪个分数更大,并将在最终分数计算中使用。
首先,你需要收集所有列的家庭作业数据。你可以使用
DataFrame.filter()来做到这一点:homework_scores = final_data.filter(regex=r"^Homework \d\d?$", axis=1) homework_max_points = final_data.filter(regex=r"^Homework \d\d? -", axis=1)在这段代码中,您使用了一个正则表达式 (regex)来过滤
final_data。如果列名与正则表达式不匹配,则该列不会包含在结果数据帧中。传递给
DataFrame.filter()的另一个参数是axis。DataFrame 的许多方法既可以按行操作,也可以按列操作,您可以使用axis参数在这两种方法之间切换。使用默认参数axis=0,pandas 将在索引中查找与您传递的正则表达式相匹配的行。因为您想找到所有与正则表达式匹配的列,所以您传递了axis=1。既然已经从数据框架中收集了所需的列,就可以用它们进行计算了。首先,将这两个值分别相加,然后将它们相除,计算出家庭作业的总分数:
sum_of_hw_scores = homework_scores.sum(axis=1) sum_of_hw_max = homework_max_points.sum(axis=1) final_data["Total Homework"] = sum_of_hw_scores / sum_of_hw_max在这段代码中,您使用了
DataFrame.sum()并传递了axis参数。默认情况下,.sum()会将每列中所有行的值相加。但是,您需要每一行中所有列的总和,因为每一行代表一个学生。axis=1的论点告诉熊猫要这样做。然后在
final_data中给两个和的比率指定一个新列Total Homework。以下是四个示例学生的计算结果示例:
NetID 家庭作业分数总和 最高分数总和 总作业 wxb12345 Five hundred and ninety-eight Seven hundred and forty 0.808108 mxl12345 Six hundred and twelve Seven hundred and forty 0.827027 txj12345 Five hundred and eighty-one Seven hundred and forty 0.785135 jgf12345 Five hundred and seventy Seven hundred and forty 0.770270 在此表中,您可以看到每个学生的家庭作业分数总和、最高分数总和以及家庭作业总分数。
另一种计算方法是将每份作业的分数除以其最高分,将这些值相加,然后将总数除以作业的数量。为此,您可以使用一个
for循环遍历每一列。然而,pandas 可以让您更加高效,因为它将匹配列和索引标签,并且只对匹配的标签执行数学运算。要实现这一点,您需要更改
homework_max_points的列名以匹配homework_scores中的名称。你可以使用DataFrame.set_axis()来完成:hw_max_renamed = homework_max_points.set_axis(homework_scores.columns, axis=1)在这段代码中,您创建了一个新的数据帧
hw_max_renamed,并将列axis设置为与homework_scores中的列同名。现在,您可以使用此数据框架进行更多计算:average_hw_scores = (homework_scores / hw_max_renamed).sum(axis=1)在这段代码中,您通过将每个作业分数除以其各自的最高分来计算
average_hw_scores。然后你用DataFrame.sum()和参数axis=1把每一行所有家庭作业的比率加在一起。因为每份作业的最大值是 1.0,这个总和的最大值等于家庭作业的总数。然而,你需要一个从 0 到 1 的数字来计算最终分数。
这意味着您需要将
average_hw_scores除以分配的数量,您可以使用以下代码来完成:final_data["Average Homework"] = average_hw_scores / homework_scores.shape[1]在这段代码中,您使用
DataFrame.shape从homework_scores中获取赋值数。像一个 NumPy 数组,DataFrame.shape返回一个(n_rows, n_columns)的元组。从 tuple 中取第二个值得到了homework_scores中的列数,它等于赋值的个数。然后将除法的结果分配给
final_data中名为Average Homework的新列。以下是四个示例学生的示例计算结果:
NetID 平均家庭作业分数总和 普通作业 wxb12345 7.99405 0.799405 mxl12345 8.18944 0.818944 txj12345 7.85940 0.785940 jgf12345 7.65710 0.765710 在这个表中,注意到
Sum of Average Homework Scores可以从 0 到 10 变化,但是Average Homework列从 0 到 1 变化。接下来,第二列将用于与Total Homework进行比较。现在你已经计算了两次家庭作业的分数,你可以取最大值用于最终成绩的计算:
final_data["Homework Score"] = final_data[ ["Total Homework", "Average Homework"] ].max(axis=1)在这段代码中,选择刚刚创建的两列
Total Homework和Average Homework,并将最大值赋给一个名为Homework Score的新列。请注意,您用axis=1为每个学生取最大值。以下是四个示例学生的计算结果示例:
NetID 总作业 普通作业 家庭作业分数 wxb12345 0.808108 0.799405 0.808108 mxl12345 0.827027 0.818944 0.827027 txj12345 0.785135 0.785940 0.785940 jgf12345 0.770270 0.765710 0.770270 在该表中,您可以比较
Total Homework、Average Homework和最终Homework Score列。你可以看到Homework Score总是反映出Total Homework或Average Homework中较大的一个。计算测验分数
接下来,您需要计算测验分数。测验也有不同的最高分数,所以你需要做和家庭作业一样的程序。唯一的区别是测验数据表中没有指定每个测验的最高分数,所以您需要创建一个 pandas 系列来保存该信息:
quiz_scores = final_data.filter(regex=r"^Quiz \d$", axis=1) quiz_max_points = pd.Series( {"Quiz 1": 11, "Quiz 2": 15, "Quiz 3": 17, "Quiz 4": 14, "Quiz 5": 12} ) sum_of_quiz_scores = quiz_scores.sum(axis=1) sum_of_quiz_max = quiz_max_points.sum() final_data["Total Quizzes"] = sum_of_quiz_scores / sum_of_quiz_max average_quiz_scores = (quiz_scores / quiz_max_points).sum(axis=1) final_data["Average Quizzes"] = average_quiz_scores / quiz_scores.shape[1] final_data["Quiz Score"] = final_data[ ["Total Quizzes", "Average Quizzes"] ].max(axis=1)这些代码的大部分与最后一节中的作业代码非常相似。与家庭作业案例的主要区别在于,您使用字典作为输入为
quiz_max_points创建了一个熊猫系列。字典的键成为索引标签,字典值成为系列值。因为
quiz_max_points中的索引标签与quiz_scores同名,所以测验中不需要使用DataFrame.set_axis()。熊猫 还广播 一个系列的形状,使其与数据帧相匹配。以下是测验的计算结果示例:
NetID 测验总数 平均测验 测验分数 wxb12345 0.608696 0.602139 0.608696 mxl12345 0.681159 0.682149 0.682149 txj12345 0.594203 0.585399 0.594203 jgf12345 0.608696 0.615286 0.615286 在这个表中,
Quiz Score始终是Total Quizzes或Average Quizzes中较大的一个,正如所料。计算字母等级
现在你已经完成了期末成绩所需的所有计算。考试、作业和测验的分数都在 0 到 1 之间。接下来,你需要将每个分数乘以它的权重来确定最终的分数。然后,您可以将该值映射到字母等级的范围内,从 A 到 f。
与最高测验分数类似,您将使用熊猫系列来存储权重。这样,您可以自动乘以来自
final_data的正确列。使用以下代码创建您的权重:weightings = pd.Series( { "Exam 1 Score": 0.05, "Exam 2 Score": 0.1, "Exam 3 Score": 0.15, "Quiz Score": 0.30, "Homework Score": 0.4, } )在这段代码中,您为类的每个组件赋予一个权重。正如你之前看到的,
Exam 1占 5%,Exam 2占 10%,Exam 3占 15%,测验占 30%,Homework占总成绩的 40%。接下来,您可以将这些百分比与之前计算的分数相结合,以确定最终分数:
final_data["Final Score"] = (final_data[weightings.index] * weightings).sum( axis=1 ) final_data["Ceiling Score"] = np.ceil(final_data["Final Score"] * 100)在这段代码中,您选择了与
weightings中的索引同名的final_data列。您需要这样做,因为final_data中的其他一些列具有类型str,所以如果您试图将weightings乘以所有的final_data,熊猫将会抛出一个TypeError。接下来,对每个有
DataFrame.sum(axis=1)的学生的这些列求和,并将结果分配给一个名为Final Score的新列。该列中每个学生的值是一个介于 0 和 1 之间的浮点数。最后,作为一名真正的好老师,你要把每个学生的分数加起来。你将每个学生的
Final Score乘以100,将其放在从 0 到 100 的范围内,然后使用numpy.ceil()将每个分数四舍五入到下一个最高的整数。您将这个值分配给一个名为Ceiling Score的新列。注意:你必须将
import numpy as np添加到你的脚本的顶部来使用np.ceil()。以下是四个示例学生的这些列的示例计算结果:
NetID 最终得分 最高分数 wxb12345 0.745852 Seventy-five mxl12345 0.795956 Eighty txj12345 0.722637 Seventy-three jgf12345 0.727194 Seventy-three 最后要做的是将每个学生的最高分数映射到一个字母等级上。在你的学校,你可以使用这些字母等级:
- A:90 分以上
- B:80-90 分
- C:70-80 分
- D:60-70 分
- F:60 分以下
由于每个字母等级都必须映射到一个分数范围,所以不能简单地使用字典进行映射。幸运的是,pandas 有
Series.map(),它允许您对一个序列中的值应用任意函数。如果你使用不同于字母评分的评分标准,你也可以做类似的事情。你可以这样写一个合适的函数:
grades = { 90: "A", 80: "B", 70: "C", 60: "D", 0: "F", } def grade_mapping(value): for key, letter in grades.items(): if value >= key: return letter在这段代码中,您将创建一个字典,存储每个字母等级的下限和字母之间的映射。然后定义
grade_mapping(),它将最高分数系列中某一行的值作为参数。您循环遍历grades中的条目,将value与字典中的key进行比较。如果value大于key,则该学生属于该等级,您返回相应的字母等级。注意:该函数仅在成绩按降序排列时有效,这依赖于所维护的字典的顺序。如果你使用的 Python 版本早于 3.6,那么你需要使用一个
OrderedDict来代替。定义了
grade_mapping()之后,您可以使用Series.map()来查找字母等级:letter_grades = final_data["Ceiling Score"].map(grade_mapping) final_data["Final Grade"] = pd.Categorical( letter_grades, categories=grades.values(), ordered=True )在这段代码中,您通过将
grade_mapping()映射到来自final_data的Ceiling Score列来创建一个名为letter_grades的新系列。因为字母等级有五种选择,所以它是一种分类数据类型是有意义的。一旦将分数映射到字母,就可以用 pandasCategorical类创建一个分类列。要创建分类列,需要传递字母 grades 和两个关键字参数:
categories是从grades传过来的值。grades中的值是类中可能的字母等级。ordered被传递True来告诉熊猫类别是有序的。这将有助于以后对该列进行排序。您创建的分类列被分配给
final_data中一个名为Final Grade的新列。以下是四个示例学生的最终成绩:
NetID 最终得分 最高分数 最终成绩 wxb12345 0.745852 Seventy-five C mxl12345 0.795956 Eighty B txj12345 0.722637 Seventy-three C jgf12345 0.727194 Seventy-three C 在四个示例学生中,一人得了 B,三人得了 c,这与他们的最高分数和您创建的字母等级映射相匹配。
数据分组
现在您已经计算了每个学生的分数,您可能需要将它们输入到学生管理系统中。这学期,你要教同一个班级的几个部分,如花名册表中的
Section栏所示。本节中对
gradebook.py的所有修改都收集在04-grouping-the-data.py文件中。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
要将分数输入到学生管理系统中,您需要将学生分成各个部分,并按他们的姓氏进行排序。幸运的是,熊猫也把你包括在内了。
熊猫对数据帧中的数据有强大的分组和排序能力。您需要根据学生的学号对数据进行分组,并根据他们的姓名对分组结果进行排序。您可以使用以下代码来实现:
for section, table in final_data.groupby("Section"): section_file = DATA_FOLDER / f"Section {section} Grades.csv" num_students = table.shape[0] print( f"In Section {section} there are {num_students} students saved to " f"file {section_file}." ) table.sort_values(by=["Last Name", "First Name"]).to_csv(section_file)在这段代码中,使用
final_data上的DataFrame.groupby()按照Section列进行分组,使用DataFrame.sort_values()对分组后的结果进行排序。最后,将排序后的数据保存到一个 CSV 文件中,以便上传到学生管理系统。这样,你这学期的成绩就完成了,你可以休息放松了!绘制汇总统计数据
不过,在你挂上夏季白板之前,你可能想多了解一下这个班的整体表现。使用 pandas 和 Matplotlib ,您可以为该类绘制一些汇总统计数据。
本节中对
gradebook.py所做的所有修改都收集在05-plotting-summary-statistics.py文件中。您可以通过单击下面的链接下载源代码:获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
首先,您可能希望看到班级中字母等级的分布。您可以使用以下代码来实现:
grade_counts = final_data["Final Grade"].value_counts().sort_index() grade_counts.plot.bar() plt.show()在这段代码中,使用
final_data中Final Grade列上的Series.value_counts()来计算每个字母出现的次数。默认情况下,值计数按从最多到最少的顺序排列,但如果按字母级别顺序排列会更有用。您使用Series.sort_index()将等级排序为您在定义Categorical列时指定的顺序。然后,利用 pandas 的能力,使用 Matplotlib 生成一个带有
DataFrame.plot.bar()的等级计数柱状图。由于这是一个脚本,你需要用plt.show()告诉 Matplotlib 给你看剧情,打开一个交互式的图形窗口。注意:你需要在你的脚本顶部添加
import matplotlib.pyplot as plt来实现这个功能。您的数字应该类似于下图:
该图中条形的高度代表水平轴上显示的获得每个字母等级的学生人数。你的大多数学生都得了 C 字母成绩。
接下来,您可能希望看到学生数字分数的直方图。熊猫可以使用 Matplotlib 和
DataFrame.plot.hist()来自动完成:final_data["Final Score"].plot.hist(bins=20, label="Histogram")在这段代码中,您使用
DataFrame.plot.hist()来绘制最终分数的直方图。当绘图完成时,任何关键字参数都被传递给 Matplotlib。直方图是估计数据分布的一种方法,但是您可能也对更复杂的方法感兴趣。pandas 能够使用 SciPy 库和
DataFrame.plot.density()计算内核密度估计值。您也可以猜测数据将呈正态分布,并使用数据的平均值和标准差手动计算正态分布。您可以试试这段代码,看看它是如何工作的:final_data["Final Score"].plot.density( linewidth=4, label="Kernel Density Estimate" ) final_mean = final_data["Final Score"].mean() final_std = final_data["Final Score"].std() x = np.linspace(final_mean - 5 * final_std, final_mean + 5 * final_std, 200) normal_dist = scipy.stats.norm.pdf(x, loc=final_mean, scale=final_std) plt.plot(x, normal_dist, label="Normal Distribution", linewidth=4) plt.legend() plt.show()在这段代码中,首先使用
DataFrame.plot.density()来绘制数据的内核密度估计值。您可以调整该地块的线宽和标签,以便于查看。接下来,使用
DataFrame.mean()和DataFrame.std()计算Final Score数据的平均值和标准差。使用np.linspace()生成一组 x 值,从-5到+5偏离平均值的标准偏差。然后,您通过插入标准正态分布的公式来计算normal_dist中的正态分布。注意:你需要在你的脚本顶部添加
import scipy.stats来实现这个功能。最后,绘制
xvsnormal_dist,调整线宽并添加标签。一旦显示了该图,您应该会得到如下所示的结果:
在该图中,垂直轴显示了特定箱中的等级密度。峰值出现在 0.78 的坡度附近。核密度估计和正态分布都很好地匹配了数据。
结论
现在你知道了如何用熊猫来创建一个成绩簿脚本,这样你就可以停止使用电子表格软件了。这将有助于你避免错误,并在未来更快地计算你的最终成绩。
在本教程中,您学习了:
- 如何加载、清理、合并数据到熊猫数据帧中
- 如何用数据帧和数列计算出
- 如何将值从一个集合映射到另一个集合
- 如何使用 pandas 和 Matplotlib 绘制汇总统计数据
此外,您还了解了如何将数据分组并保存文件以上传到学生管理系统。现在你已经准备好为下学期创建你的熊猫成绩册了!
点击下面的链接下载这个熊猫项目的代码,并学习如何建立一个没有电子表格的成绩册:
获取源代码: 点击此处获取源代码,您将在本教程中使用制作一本有熊猫的年级册。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 制作成绩册*********
使用 Pandas 和 Python 探索数据集
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,以加深您的理解: 用熊猫 探索您的数据集
您是否有一个充满有趣见解的大型数据集,但您不确定从哪里开始探索它?你的老板有没有要求你从中生成一些统计数据,但是这些数据并不容易提取出来?这些正是熊猫和 Python 可以帮助你的用例!使用这些工具,您将能够将大型数据集分割成易于管理的部分,并从这些信息中获得洞察力。
在本教程中,您将学习如何:
- 计算关于您数据的个指标
- 执行基本查询和聚合
- 发现并处理不正确的数据、不一致和缺失值
- 用图表可视化您的数据
您还将了解 Pandas 和 Python 使用的主要数据结构之间的差异。要继续学习,您可以通过下面的链接获得本教程中的所有示例代码:
获取 Jupyter 笔记本: 点击此处获取 Jupyter 笔记本,您将在本教程中使用探索与熊猫有关的数据。
设置您的环境
在开始学习本教程之前,您需要做一些事情。首先是熟悉 Python 的内置数据结构,尤其是列表和字典。更多信息,请查看 Python 中的列表和元组以及 Python 中的字典。
你需要的第二样东西是一个工作的 Python 环境。您可以在任何安装了 Python 3 的终端中跟随。如果你想看到更好的输出,特别是对于你将要处理的大型 NBA 数据集,那么你可能想运行 Jupyter 笔记本中的例子。
注意:如果你根本没有安装 Python,那就去看看 Python 3 安装&安装指南。你也可以用试用版 Jupyter 笔记本在线跟进。
你需要的最后一样东西是 Pandas 和其他 Python 库,你可以用 pip 安装它们:
$ python3 -m pip install requests pandas matplotlib您也可以使用 Conda 软件包管理器:
$ conda install requests pandas matplotlib如果您使用的是 Anaconda 发行版,那么您就可以开始了!Anaconda 已经安装了 Pandas Python 库。
注:你听说过 Python 世界里有多个包管理器而有些不知该选哪个吗?
pip和conda都是绝佳的选择,而且各有千秋。如果你打算将 Python 主要用于数据科学工作,那么
conda可能是更好的选择。在conda生态系统中,您有两个主要选择:
- 如果您想要快速建立并运行一个稳定的数据科学环境,并且不介意下载 500 MB 的数据,那么请查看 Anaconda 发行版。
- 如果你喜欢更简单的设置,那么看看在 Windows 上为机器学习设置 Python 中关于安装 Miniconda 的部分。
本教程中的例子已经通过了 Python 3.7 和 Pandas 0.25.0 的测试,但是它们也可以在旧版本中运行。点击下面的链接,你可以在 Jupyter 笔记本中找到本教程中的所有代码示例:
获取 Jupyter 笔记本: 点击此处获取 Jupyter 笔记本,您将在本教程中使用探索与熊猫有关的数据。
我们开始吧!
使用 Pandas Python 库
现在你已经安装了熊猫,是时候看看数据集了。在本教程中,您将分析由 FiveThirtyEight 提供的 17MB CSV 文件中的 NBA 结果。创建一个脚本
download_nba_all_elo.py来下载数据:import requests download_url = "https://raw.githubusercontent.com/fivethirtyeight/data/master/nba-elo/nbaallelo.csv" target_csv_path = "nba_all_elo.csv" response = requests.get(download_url) response.raise_for_status() # Check that the request was successful with open(target_csv_path, "wb") as f: f.write(response.content) print("Download ready.")当您执行该脚本时,它会将文件
nba_all_elo.csv保存在您当前的工作目录中。注意:您也可以使用网络浏览器下载 CSV 文件。
然而,拥有下载脚本有几个优点:
- 你可以说出你的数据是从哪里得到的。
- 随时可以重复下载!如果数据经常刷新,这将非常方便。
- 你不需要与你的同事分享 17MB 的 CSV 文件。通常情况下,分享下载脚本就足够了。
现在,您可以使用 Pandas Python 库来查看您的数据:
>>> import pandas as pd
>>> nba = pd.read_csv("nba_all_elo.csv")
>>> type(nba)
<class 'pandas.core.frame.DataFrame'>
这里,您遵循在 Python 中使用别名pd导入熊猫的惯例。然后,您使用.read_csv()读入您的数据集,并将其作为 DataFrame对象存储在变量 nba中。
注意:你的数据不是 CSV 格式的吗?别担心!Pandas Python 库提供了几个类似的函数,如read_json()、read_html()和read_sql_table()。要了解如何使用这些文件格式,请查看使用熊猫读写文件的或查阅文档。
您可以看到nba包含了多少数据:
>>> len(nba) 126314 >>> nba.shape (126314, 23)您使用 Python 内置函数
len()来确定行数。您还可以使用DataFrame的.shape属性来查看它的维度。结果是一个包含行数和列数的元组。现在您知道在您的数据集中有 126,314 行和 23 列。但是你怎么能确定数据集真的包含篮球统计数据呢?可以用
.head()看看前五行:
>>> nba.head()
如果您使用 Jupyter 笔记本进行操作,您将会看到如下结果:
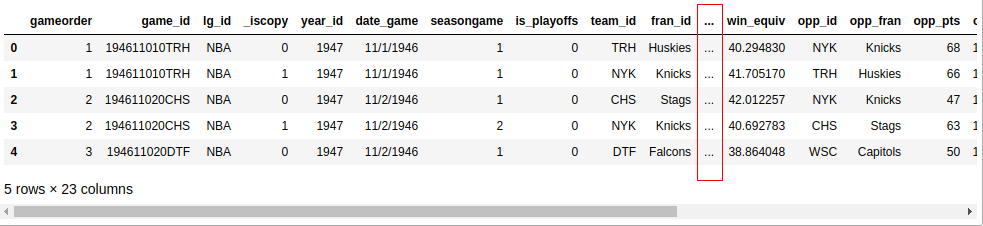
除非您的屏幕非常大,否则您的输出可能不会显示所有 23 列。在中间的某个地方,您会看到一列省略号(...)表示丢失的数据。如果您在终端中工作,那么这可能比换行更具可读性。然而,Jupyter 笔记本可以让你滚动。您可以将 Pandas 配置为显示所有 23 列,如下所示:
>>> pd.set_option("display.max.columns", None)虽然查看所有列很实用,但您可能不需要六位小数!改成两个:
>>> pd.set_option("display.precision", 2)
为了验证您已经成功地更改了选项,您可以再次执行.head(),或者您可以使用.tail()来显示最后五行:
>>> nba.tail()现在,您应该看到所有的列,并且您的数据应该显示两位小数:
你可以通过一个小练习发现
.head()和.tail()的一些进一步的可能性。你能不能打印你的DataFrame的最后三行?展开下面的代码块以查看解决方案:下面是如何打印
nba的最后三行:

>>> nba.tail(3)
您的输出应该如下所示:
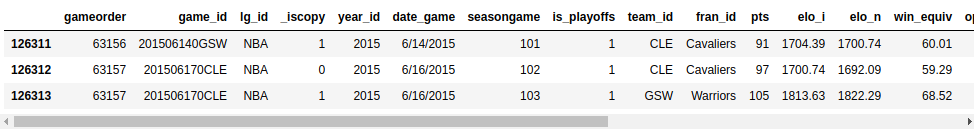
使用上面设置的选项,您可以看到数据集的最后三行。
与 Python 标准库类似,Pandas 中的函数也带有几个可选参数。每当你碰到一个看起来相关但与你的用例略有不同的例子时,查看一下官方文档。通过调整一些可选参数,您很有可能找到解决方案!
了解您的数据
您已经使用 Pandas Python 库导入了一个 CSV 文件,并初步查看了数据集的内容。到目前为止,您只看到了数据集的大小及其第一行和最后几行。接下来,你将学习如何更系统地检查你的数据。
显示数据类型
了解你的数据的第一步是发现它包含的不同的数据类型。虽然您可以将任何内容放入列表中,但是DataFrame的列包含特定数据类型的值。当您比较 Pandas 和 Python 数据结构时,您会发现这种行为使 Pandas 快得多!
您可以使用.info()显示所有列及其数据类型:
>>> nba.info()这将产生以下输出:
您将看到数据集中所有列的列表以及每列包含的数据类型。在这里,您可以看到数据类型
int64、float64和object。熊猫使用 NumPy 库来处理这些类型。稍后,您将遇到更复杂的categorical数据类型,这是 Pandas Python 库自己实现的。
object数据类型是一种特殊的类型。根据Pandas Cookbook,object数据类型是“Pandas 不识别为任何其他特定类型的列的总称”实际上,这通常意味着列中的所有值都是字符串。尽管您可以在
object数据类型中存储任意的 Python 对象,但是您应该意识到这样做的缺点。一个object列中奇怪的值会损害熊猫的性能以及它与其他库的互操作性。更多信息,请查看官方入门指南。显示基本统计数据
现在,您已经了解了数据集中的数据类型,是时候了解每一列包含的值了。您可以使用
.describe()来完成此操作:
>>> nba.describe()
此函数显示所有数字列的一些基本描述性统计信息:
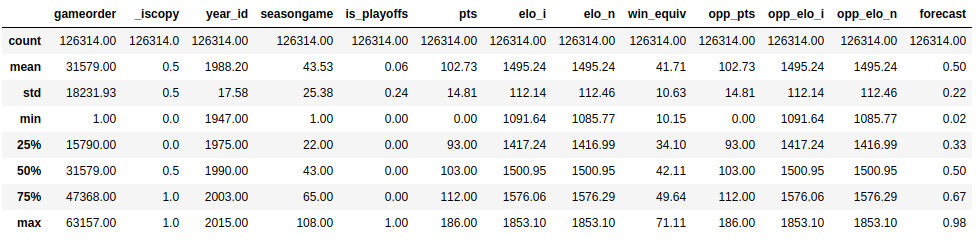
.describe()默认情况下只分析数字列,但是如果使用include参数,您可以提供其他数据类型:
>>> import numpy as np >>> nba.describe(include=object)
.describe()不会尝试计算object列的平均值或标准偏差,因为它们大多包含文本字符串。但是,它仍然会显示一些描述性统计数据:
看一下
team_id和fran_id列。您的数据集包含 104 个不同的球队 id,但只有 53 个不同的球队 id。此外,最常见的球队 ID 是BOS,但最常见的球队 ID 是Lakers。这怎么可能呢?要回答这个问题,您需要更深入地研究您的数据集。探索您的数据集
探索性数据分析可以帮助你回答关于数据集的问题。例如,您可以检查特定值在列中出现的频率:

>>> nba["team_id"].value_counts()
BOS 5997
NYK 5769
LAL 5078
...
SDS 11
>>> nba["fran_id"].value_counts()
Name: team_id, Length: 104, dtype: int64
Lakers 6024
Celtics 5997
Knicks 5769
...
Huskies 60
Name: fran_id, dtype: int64
一支名为"Lakers"的球队似乎打了 6024 场比赛,但其中只有 5078 场是由洛杉矶湖人队打的。找出另一个"Lakers"团队是谁:
>>> nba.loc[nba["fran_id"] == "Lakers", "team_id"].value_counts() LAL 5078 MNL 946 Name: team_id, dtype: int64的确,明尼阿波利斯湖人(
"MNL")打了 946 场比赛。你甚至可以知道他们什么时候玩这些游戏。为此,您将首先定义一个将date_game的值转换为datetime数据类型的列。然后,您可以使用min和max聚合函数来查找明尼阿波利斯湖人队的第一场和最后一场比赛:
>>> nba["date_played"] = pd.to_datetime(nba["date_game"])
>>> nba.loc[nba["team_id"] == "MNL", "date_played"].min()
Timestamp('1948-11-04 00:00:00')
>>> nba.loc[nba['team_id'] == 'MNL', 'date_played'].max()
Timestamp('1960-03-26 00:00:00')
>>> nba.loc[nba["team_id"] == "MNL", "date_played"].agg(("min", "max"))
min 1948-11-04
max 1960-03-26
Name: date_played, dtype: datetime64[ns]
看起来明尼阿波利斯湖人队在 1948 年到 1960 年间打过比赛。这就解释了为什么你可能认不出这个团队!
你也发现了为什么波士顿凯尔特人队"BOS"在数据集中打了最多的比赛。让我们也分析一下他们的历史。找出波士顿凯尔特人队在该数据集中包含的所有比赛中得了多少分。展开以下解决方案的代码块:
类似于.min()和.max()聚合函数,也可以使用.sum():
>>> nba.loc[nba["team_id"] == "BOS", "pts"].sum() 626484波士顿凯尔特人队总共得了 626,484 分。
你已经尝到了熊猫的厉害。在接下来的几节中,您将对刚才使用的技术进行扩展,但是首先,您将放大并了解这个强大的数据结构是如何工作的。
了解熊猫的数据结构
虽然
DataFrame提供的功能看起来很直观,但是底层的概念有点难以理解。出于这个原因,您将搁置庞大的 NBADataFrame并从头开始构建一些较小的熊猫对象。了解系列对象
Python 最基本的数据结构是列表,这也是了解
pandas.Series对象的一个很好的起点。基于列表创建一个新的Series对象:
>>> revenues = pd.Series([5555, 7000, 1980])
>>> revenues
0 5555
1 7000
2 1980
dtype: int64
您已经使用列表[5555, 7000, 1980]创建了一个名为revenues的Series对象。一个Series对象包装了两个组件:
- 一系列值
- 一系列的标识符,这是索引
您可以分别使用.values和.index访问这些组件:
>>> revenues.values array([5555, 7000, 1980]) >>> revenues.index RangeIndex(start=0, stop=3, step=1)
revenues.values返回Series中的值,而revenues.index返回位置索引。注意:如果你熟悉 NumPy ,那么你可能会有兴趣注意到一个
Series对象的值实际上是 n 维数组:
>>> type(revenues.values)
<class 'numpy.ndarray'>
如果你不熟悉 NumPy,那就不用担心了!您可以单独使用 Pandas Python 库来探索数据集的细节。然而,如果你对熊猫在幕后做什么感到好奇,那么看看看看 Ma,No For-Loops:NumPy 的数组编程。
虽然熊猫建立在 NumPy 的基础上,但一个显著的不同是它们的索引。就像 NumPy 数组一样,Pandas Series也有一个隐式定义的整数索引。这个隐式索引指示元素在Series中的位置。
然而,Series也可以有任意类型的索引。您可以将这个显式索引视为特定行的标签:
>>> city_revenues = pd.Series( ... [4200, 8000, 6500], ... index=["Amsterdam", "Toronto", "Tokyo"] ... ) >>> city_revenues Amsterdam 4200 Toronto 8000 Tokyo 6500 dtype: int64这里,索引是由字符串表示的城市名称列表。您可能已经注意到 Python 字典也使用字符串索引,这是一个需要记住的方便的类比!您可以使用上面的代码块来区分两种类型的
Series:
revenues: 这个Series的行为就像一个 Python 列表,因为它只有一个位置索引。city_revenues: 这个Series就像一个 Python 字典,因为它既有位置索引又有标签索引。下面是如何从 Python 字典中构造一个带有标签索引的
Series:
>>> city_employee_count = pd.Series({"Amsterdam": 5, "Tokyo": 8})
>>> city_employee_count
Amsterdam 5
Tokyo 8
dtype: int64
字典键成为索引,字典值是Series值。
就像字典一样,Series也支持.keys()和in 关键字:
>>> city_employee_count.keys() Index(['Amsterdam', 'Tokyo'], dtype='object') >>> "Tokyo" in city_employee_count True >>> "New York" in city_employee_count False您可以使用这些方法快速回答有关数据集的问题。
理解数据帧对象
虽然一个
Series是一个非常强大的数据结构,但它有其局限性。例如,每个键只能存储一个属性。正如您在拥有 23 列的nba数据集上看到的,Pandas Python 库通过其DataFrame提供了更多。这个数据结构是一系列共享相同索引的Series对象。如果您遵循了
Series示例,那么您应该已经有了两个以城市为键的Series对象:
city_revenuescity_employee_count通过在构造函数中提供一个字典,可以将这些对象组合成一个
DataFrame。字典键将成为列名,值应该包含Series对象:
>>> city_data = pd.DataFrame({
... "revenue": city_revenues,
... "employee_count": city_employee_count
... })
>>> city_data
revenue employee_count
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN
请注意 Pandas 如何用NaN替换多伦多缺少的employee_count值。
新的DataFrame指数是两个Series指数的联合:
>>> city_data.index Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object')与
Series一样,DataFrame也将其值存储在 NumPy 数组中:
>>> city_data.values
array([[4.2e+03, 5.0e+00],
[6.5e+03, 8.0e+00],
[8.0e+03, nan]])
你也可以将一个DataFrame的两个维度称为轴:
>>> city_data.axes [Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object'), Index(['revenue', 'employee_count'], dtype='object')] >>> city_data.axes[0] Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object') >>> city_data.axes[1] Index(['revenue', 'employee_count'], dtype='object')标有 0 的轴是行索引,标有 1 的轴是列索引。了解这个术语很重要,因为您会遇到几个接受
axis参数的DataFrame方法。一个
DataFrame也是一个类似字典的数据结构,所以它也支持.keys()和in关键字。然而,对于一个DataFrame来说,这些与索引无关,而是与列有关:
>>> city_data.keys()
Index(['revenue', 'employee_count'], dtype='object')
>>> "Amsterdam" in city_data
False
>>> "revenue" in city_data
True
你可以在更大的 NBA 数据集上看到这些概念。它包含一个名为"points"的列,还是被称为"pts"?要回答这个问题,请显示nba数据集的索引和轴,然后展开解决方案下面的代码块:
因为您在读取 CSV 文件时没有指定索引列,Pandas 为DataFrame分配了一个RangeIndex:
>>> nba.index RangeIndex(start=0, stop=126314, step=1)
nba像所有的DataFrame物体一样,有两个轴:
>>> nba.axes
[RangeIndex(start=0, stop=126314, step=1),
Index(['gameorder', 'game_id', 'lg_id', '_iscopy', 'year_id', 'date_game',
'seasongame', 'is_playoffs', 'team_id', 'fran_id', 'pts', 'elo_i',
'elo_n', 'win_equiv', 'opp_id', 'opp_fran', 'opp_pts', 'opp_elo_i',
'opp_elo_n', 'game_location', 'game_result', 'forecast', 'notes'],
dtype='object')]
您可以使用.keys()检查列是否存在:
>>> "points" in nba.keys() False >>> "pts" in nba.keys() True列叫
"pts",不叫"points"。当您使用这些方法来回答有关数据集的问题时,请务必记住您是在使用
Series还是DataFrame来进行工作,以便您的解释是准确的。访问系列元素
在上一节中,您已经基于 Python 列表创建了一个 Pandas
Series,并比较了两种数据结构。您已经看到了Series对象在几个方面与列表和字典相似。另一个相似之处是,您也可以对Series使用索引操作符 ([])。您还将学习如何使用两个熊猫专用的访问方法:
.loc.iloc您将看到这些数据访问方法比索引操作符更具可读性。
使用索引操作符
回想一下,a
Series有两个索引:
- 一个位置或隐式索引,它总是一个
RangeIndex- 标签或显式索引,可以包含任何可散列对象
接下来,重新访问
city_revenues对象:
>>> city_revenues
Amsterdam 4200
Toronto 8000
Tokyo 6500
dtype: int64
您可以通过标签和位置索引方便地访问Series中的值:
>>> city_revenues["Toronto"] 8000 >>> city_revenues[1] 8000您也可以使用负的索引和切片,就像对列表一样:
>>> city_revenues[-1]
6500
>>> city_revenues[1:]
Toronto 8000
Tokyo 6500
dtype: int64
>>> city_revenues["Toronto":]
Toronto 8000
Tokyo 6500
dtype: int64
如果您想了解更多关于索引操作符的可能性,请查看 Python 中的列表和元组。
使用.loc和.iloc
索引操作符([])很方便,但是有一个警告。如果标签也是数字呢?假设您必须像这样处理一个Series对象:
>>> colors = pd.Series( ... ["red", "purple", "blue", "green", "yellow"], ... index=[1, 2, 3, 5, 8] ... ) >>> colors 1 red 2 purple 3 blue 5 green 8 yellow dtype: object
colors[1]会有什么回报?对于位置索引,colors[1]是"purple"。然而,如果你去的标签索引,那么colors[1]是指"red"。好消息是,你不用去想它!相反,为了避免混淆,Pandas Python 库提供了两种数据访问方法:
.loc指标注的指标。.iloc指位置指数。这些数据访问方法可读性更强:
>>> colors.loc[1]
'red'
>>> colors.iloc[1]
'purple'
colors.loc[1]返回"red",标签为1的元素。colors.iloc[1]返回"purple",索引为1的元素。
下图显示了.loc和.iloc所指的元素:
同样,.loc指向图像右侧的标签索引。同时,.iloc指向图片左侧的位置索引。
记住.loc和.iloc之间的区别比计算出索引操作符将返回什么更容易。即使你熟悉索引操作符的所有特性,假设每个阅读你的代码的人都已经理解了那些规则也是危险的!
注意:除了用数字标签混淆Series之外,Python 索引操作符还有一些性能缺陷。在交互式会话中使用它进行特别分析完全没问题,但是对于生产代码来说,.loc和.iloc数据访问方法更好。要了解更多细节,请查看 Pandas 用户指南中关于索引和选择数据的部分。
.loc和.iloc也支持索引操作符的特性,比如切片。然而,这些数据访问方法有一个重要的区别。.iloc不包含关闭元素,.loc包含关闭元素。看一下这个代码块:
>>> # Return the elements with the implicit index: 1, 2 >>> colors.iloc[1:3] 2 purple 3 blue dtype: object如果您将这段代码与上面的图像进行比较,那么您可以看到
colors.iloc[1:3]返回了具有1和2的位置索引的元素。位置索引为3的关闭项目"green"被排除。另一方面,
.loc包括结束元素:
>>> # Return the elements with the explicit index between 3 and 8
>>> colors.loc[3:8]
3 blue
5 green
8 yellow
dtype: object
这个代码块表示返回所有标签索引在3和8之间的元素。这里,结束项"yellow"的标签索引为8,并且包含在输出中。
您也可以将一个负的位置索引传递给.iloc:
>>> colors.iloc[-2] 'green'你从
Series的结尾开始,返回第二个元素。注意:曾经有一个
.ix索引器,它试图根据索引的数据类型来猜测它应该应用位置索引还是标签索引。因为它引起了很多混乱,所以从 Pandas 0 . 20 . 0 版本开始就被弃用了。强烈建议您不要使用
.ix进行索引。相反,始终使用.loc进行标签索引,使用.iloc进行位置索引。更多详情,请查看熊猫用户指南。您可以使用上面的代码块来区分两种
Series行为:
- 你可以在
Series上使用.iloc,类似于在列表上使用[]。- 你可以在
Series上使用.loc,类似于在字典上使用[]。在访问
Series对象的元素时,一定要记住这些区别。访问数据帧元素
由于
DataFrame由Series对象组成,您可以使用完全相同的工具来访问它的元素。关键的区别在于DataFrame的额外尺寸。您将对列使用索引操作符,对行使用访问方法.loc和.iloc。使用索引操作符
如果您认为
DataFrame是一个值为Series的字典,那么您可以使用索引操作符访问它的列:
>>> city_data["revenue"]
Amsterdam 4200
Tokyo 6500
Toronto 8000
Name: revenue, dtype: int64
>>> type(city_data["revenue"])
pandas.core.series.Series
这里,您使用索引操作符来选择标记为"revenue"的列。
如果列名是一个字符串,那么您也可以使用带点符号的属性样式访问:
>>> city_data.revenue Amsterdam 4200 Tokyo 6500 Toronto 8000 Name: revenue, dtype: int64
city_data["revenue"]和city_data.revenue返回相同的输出。有一种情况,用点符号访问
DataFrame元素可能不起作用或者可能导致意外。这是当一个列名与一个DataFrame属性或方法名一致时:
>>> toys = pd.DataFrame([
... {"name": "ball", "shape": "sphere"},
... {"name": "Rubik's cube", "shape": "cube"}
... ])
>>> toys["shape"]
0 sphere
1 cube
Name: shape, dtype: object
>>> toys.shape
(2, 2)
索引操作toys["shape"]返回正确的数据,但是属性样式操作toys.shape仍然返回DataFrame的形状。您应该只在交互式会话或读取操作中使用属性样式的访问。您不应该将它用于生产代码或操作数据(例如定义新列)。
使用.loc和.iloc
与Series类似,a DataFrame也提供了.loc和.iloc 数据访问方法。记住,.loc使用标签,.iloc使用位置索引:
>>> city_data.loc["Amsterdam"] revenue 4200.0 employee_count 5.0 Name: Amsterdam, dtype: float64 >>> city_data.loc["Tokyo": "Toronto"] revenue employee_count Tokyo 6500 8.0 Toronto 8000 NaN >>> city_data.iloc[1] revenue 6500.0 employee_count 8.0 Name: Tokyo, dtype: float64每行代码从
city_data中选择不同的行:
city_data.loc["Amsterdam"]选择标签索引为"Amsterdam"的行。city_data.loc["Tokyo": "Toronto"]选择标签索引从"Tokyo"到"Toronto"的行。记住,.loc是包容的。city_data.iloc[1]选择位置索引为1的行,即"Tokyo"。好了,你已经在小型数据结构上使用了
.loc和.iloc。现在,是时候用更大的东西来练习了!使用数据访问方法显示nba数据集的倒数第二行。然后,展开下面的代码块以查看解决方案:倒数第二行是具有
-2的位置索引的行。可以用.iloc显示:
>>> nba.iloc[-2]
gameorder 63157
game_id 201506170CLE
lg_id NBA
_iscopy 0
year_id 2015
date_game 6/16/2015
seasongame 102
is_playoffs 1
team_id CLE
fran_id Cavaliers
pts 97
elo_i 1700.74
elo_n 1692.09
win_equiv 59.29
opp_id GSW
opp_fran Warriors
opp_pts 105
opp_elo_i 1813.63
opp_elo_n 1822.29
game_location H
game_result L
forecast 0.48
notes NaN
date_played 2015-06-16 00:00:00
Name: 126312, dtype: object
您将看到输出是一个Series对象。
对于一个DataFrame,数据访问方法.loc和.iloc也接受第二个参数。第一个参数根据索引选择行,第二个参数选择列。您可以一起使用这些参数来从您的DataFrame中选择行和列的子集:
>>> city_data.loc["Amsterdam": "Tokyo", "revenue"] Amsterdam 4200 Tokyo 6500 Name: revenue, dtype: int64请注意,您用逗号(
,)分隔参数。第一个参数"Amsterdam" : "Tokyo,"表示选择这两个标签之间的所有行。第二个参数跟在逗号后面,表示选择"revenue"列。现在是时候看看同一个构造在更大的
nba数据集上的表现了。选择标签5555和5559之间的所有游戏。您只对球队的名称和分数感兴趣,所以也要选择那些元素。展开下面的代码块以查看解决方案:首先,定义要查看的行,然后列出相关的列:
>>> nba.loc[5555:5559, ["fran_id", "opp_fran", "pts", "opp_pts"]]
使用.loc作为标签索引,用逗号(,)分隔两个参数。
您应该会看到相当大的数据集中的一小部分:
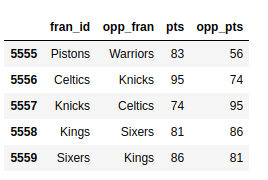
输出更容易阅读!
使用像.loc和.iloc这样的数据访问方法,您可以选择正确的DataFrame子集来帮助您回答有关数据集的问题。
查询您的数据集
您已经看到了如何根据索引访问大型数据集的子集。现在,您将基于数据集的列中的值选择行,以查询您的数据。例如,您可以创建一个新的DataFrame,仅包含 2010 年以后玩过的游戏:
>>> current_decade = nba[nba["year_id"] > 2010] >>> current_decade.shape (12658, 24)您现在有 24 列,但是新的
DataFrame只包含那些"year_id"列中的值大于2010的行。您也可以选择特定字段不为空的行:
>>> games_with_notes = nba[nba["notes"].notnull()]
>>> games_with_notes.shape
(5424, 24)
如果您希望避免列中缺少任何值,这可能会很有帮助。也可以用.notna()来达到同样的目的。
您甚至可以将object数据类型的值作为str来访问,并对它们执行字符串方法:
>>> ers = nba[nba["fran_id"].str.endswith("ers")] >>> ers.shape (27797, 24)您使用
.str.endswith()来过滤您的数据集,并找到主队名称以"ers"结尾的所有游戏。您可以组合多个条件并查询您的数据集。要做到这一点,一定要将它们放在括号中,并使用逻辑操作符
|和&来分隔它们。注:操作员
and、or、&&、||在此不工作。如果你对其中的原因感到好奇,那么看看 Pandas Python 库如何在 Python Pandas: Tricks &特性中使用布尔操作符,你可能不知道。搜索一下两队得分都超过 100 分的巴尔的摩比赛。为了每个游戏只看一次,您需要排除重复的游戏:
>>> nba[
... (nba["_iscopy"] == 0) &
... (nba["pts"] > 100) &
... (nba["opp_pts"] > 100) &
... (nba["team_id"] == "BLB")
... ]
这里,您使用nba["_iscopy"] == 0来只包含不是副本的条目。
您的输出应该包含五个重要的游戏:
尝试使用多个条件构建另一个查询。1992 年春天,来自洛杉矶的两支球队都必须在另一个球场打一场主场比赛。查询您的数据集以找到这两个游戏。两个队都有一个以"LA"开头的 ID。展开下面的代码块以查看解决方案:
您可以使用.str来查找以"LA"开头的团队 id,并且您可以假设这样一个不寻常的游戏会有一些注释:
>>> nba[ ... (nba["_iscopy"] == 0) & ... (nba["team_id"].str.startswith("LA")) & ... (nba["year_id"]==1992) & ... (nba["notes"].notnull()) ... ]您的输出应该显示 1992 年 5 月 3 日的两场比赛:
不错的发现!
当您知道如何使用多个条件查询数据集时,您将能够回答有关数据集的更具体的问题。
分组和汇总您的数据
您可能还想了解数据集的其他特征,如一组元素的总和、平均值或平均值。幸运的是,Pandas Python 库提供了分组和聚合函数来帮助您完成这项任务。
一个
Series有二十多种不同的计算描述性统计的方法。以下是一些例子:
>>> city_revenues.sum()
18700
>>> city_revenues.max()
8000
第一种方法返回city_revenues的总和,而第二种方法返回最大值。你还可以使用其他方法,比如.min()和.mean()。
记住,DataFrame的列实际上是一个Series对象。因此,您可以在nba的列上使用这些相同的功能:
>>> points = nba["pts"] >>> type(points) <class 'pandas.core.series.Series'> >>> points.sum() 12976235一个
DataFrame可以有多个列,这为聚合引入了新的可能性,比如分组:
>>> nba.groupby("fran_id", sort=False)["pts"].sum()
fran_id
Huskies 3995
Knicks 582497
Stags 20398
Falcons 3797
Capitols 22387
...
默认情况下,Pandas 在调用.groupby()时对组密钥进行排序。如果不想排序,那就过sort=False。这个参数可以提高性能。
您也可以按多列分组:
>>> nba[ ... (nba["fran_id"] == "Spurs") & ... (nba["year_id"] > 2010) ... ].groupby(["year_id", "game_result"])["game_id"].count() year_id game_result 2011 L 25 W 63 2012 L 20 W 60 2013 L 30 W 73 2014 L 27 W 78 2015 L 31 W 58 Name: game_id, dtype: int64你可以通过练习来练习这些基础知识。看看金州勇士 2014-15 赛季(
year_id: 2015)。他们在常规赛和季后赛中取得了多少胜败?展开以下解决方案的代码块:首先,您可以按
"is_playoffs"字段分组,然后按结果分组:
>>> nba[
... (nba["fran_id"] == "Warriors") &
... (nba["year_id"] == 2015)
... ].groupby(["is_playoffs", "game_result"])["game_id"].count()
is_playoffs game_result
0 L 15
W 67
1 L 5
W 16
is_playoffs=0显示常规赛结果,is_playoffs=1显示季后赛结果。
在上面的例子中,您仅仅触及了 Pandas Python 库中可用的聚合函数的皮毛。要查看如何使用它们的更多示例,请查看 Pandas GroupBy:您的 Python 数据分组指南。
操作列
你需要知道如何在数据分析过程的不同阶段操作数据集的列。作为最初的数据清理阶段的一部分,您可以添加和删除列,或者在以后基于您的分析见解添加和删除列。
创建原始DataFrame的副本,以便使用:
>>> df = nba.copy() >>> df.shape (126314, 24)您可以基于现有列定义新列:
>>> df["difference"] = df.pts - df.opp_pts
>>> df.shape
(126314, 25)
这里,您使用了"pts"和"opp_pts"列来创建一个名为"difference"的新列。这个新列与旧列具有相同的功能:
>>> df["difference"].max() 68这里,您使用了一个聚合函数
.max()来查找新列的最大值。您还可以重命名数据集的列。看来
"game_result"和"game_location"太啰嗦了,现在就去重命名吧:
>>> renamed_df = df.rename(
... columns={"game_result": "result", "game_location": "location"}
... )
>>> renamed_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 126314 entries, 0 to 126313
Data columns (total 25 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gameorder 126314 non-null int64
...
19 location 126314 non-null object
20 result 126314 non-null object
21 forecast 126314 non-null float64
22 notes 5424 non-null object
23 date_played 126314 non-null datetime64[ns]
24 difference 126314 non-null int64
dtypes: datetime64[ns](1), float64(6), int64(8), object(10)
memory usage: 24.1+ MB
注意这里有一个新的对象,renamed_df。像其他几种数据操作方法一样,.rename()默认返回一个新的DataFrame。如果你想直接操纵原来的DataFrame,那么.rename()还提供了一个inplace参数,你可以设置为True。
数据集可能包含不需要的列。例如, Elo ratings 对某些人来说可能是一个迷人的概念,但在本教程中您不会分析它们。您可以删除与 Elo 相关的四列:
>>> df.shape (126314, 25) >>> elo_columns = ["elo_i", "elo_n", "opp_elo_i", "opp_elo_n"] >>> df.drop(elo_columns, inplace=True, axis=1) >>> df.shape (126314, 21)请记住,您在前面的示例中添加了新列
"difference",使列总数达到 25。当您删除四个 Elo 列时,列的总数将下降到 21。指定数据类型
当您创建一个新的
DataFrame时,无论是通过调用一个构造函数还是读取一个 CSV 文件,Pandas 都会根据它的值为每一列分配一个数据类型。虽然它做得很好,但并不完美。如果您预先为列选择了正确的数据类型,那么您可以显著提高代码的性能。再看一下
nba数据集的列:
>>> df.info()
您将看到与之前相同的输出:
您的列中有十列的数据类型为object。这些object列中的大多数包含任意文本,但是也有一些数据类型转换的候选者。例如,看一看date_game一栏:
>>> df["date_game"] = pd.to_datetime(df["date_game"])这里,您使用
.to_datetime()将所有游戏日期指定为datetime对象。其他列包含的文本更加结构化。
game_location列只能有三个不同的值:
>>> df["game_location"].nunique()
3
>>> df["game_location"].value_counts()
A 63138
H 63138
N 38
Name: game_location, dtype: int64
对于这样的列,您会在关系数据库中使用哪种数据类型?您可能不会使用varchar类型,而是使用enum。Pandas 出于同样的目的提供了categorical数据类型:
>>> df["game_location"] = pd.Categorical(df["game_location"]) >>> df["game_location"].dtype CategoricalDtype(categories=['A', 'H', 'N'], ordered=False)
categorical数据相对于非结构化文本有一些优势。当您指定categorical数据类型时,您使验证变得更容易并节省了大量内存,因为 Pandas 将只在内部使用唯一的值。总值与唯一值的比率越高,节省的空间就越多。再次运行
df.info()。您应该看到,将game_location数据类型从object更改为categorical减少了内存使用。注意:
categorical数据类型还允许您通过.cat访问器访问其他方法。要了解更多,请查看官方文件。您经常会遇到包含太多文本列的数据集。数据科学家必须具备的一项基本技能是,能够发现哪些列可以转换为更高性能的数据类型。
现在花点时间练习一下。在
nba数据集中找到另一个具有通用数据类型的列,并将其转换为更具体的类型。您可以展开下面的代码块来查看一个可能的解决方案:
game_result只能取两个不同的值:
>>> df["game_result"].nunique()
2
>>> df["game_result"].value_counts()
L 63157
W 63157
为了提高性能,您可以将它转换成一个categorical列:
>>> df["game_result"] = pd.Categorical(df["game_result"])您可以使用
df.info()来检查内存使用情况。当您处理更大规模的数据集时,节省内存变得尤为重要。在您继续探索数据集时,请务必牢记性能。
清洗数据
你可能会惊讶地发现这一部分在教程中这么晚!通常,在进行更复杂的分析之前,您会仔细检查您的数据集以解决任何问题。但是,在本教程中,您将依靠在前面章节中学习的技术来清理数据集。
缺失值
您是否想过为什么
.info()显示一列包含多少个非空值?原因是这是至关重要的信息。空值通常表示数据收集过程中存在问题。他们可以让几种分析技术变得困难甚至不可能,就像不同类型的机器学习。当你用
nba.info()检查nba数据集时,你会发现它非常整洁。只有列notes的大部分行包含空值:
该输出显示
notes列只有 5424 个非空值。这意味着数据集的 120,000 多行在该列中具有空值。有时,处理包含缺失值的记录的最简单方法是忽略它们。您可以使用
.dropna()删除所有缺失值的行:
>>> rows_without_missing_data = nba.dropna()
>>> rows_without_missing_data.shape
(5424, 24)
当然,这种数据清理对你的nba数据集没有意义,因为一个游戏缺少笔记不是问题。但是,如果您的数据集包含一百万条有效记录和一百条相关数据缺失的记录,那么丢弃不完整的记录可能是一个合理的解决方案。
如果有问题的列与您的分析无关,您也可以删除它们。为此,再次使用.dropna()并提供axis=1参数:
>>> data_without_missing_columns = nba.dropna(axis=1) >>> data_without_missing_columns.shape (126314, 23)现在,得到的
DataFrame包含所有 126,314 个游戏,但不包括有时为空的notes列。如果您的用例有一个有意义的默认值,那么您也可以用它来替换缺失的值:
>>> data_with_default_notes = nba.copy()
>>> data_with_default_notes["notes"].fillna(
... value="no notes at all",
... inplace=True
... )
>>> data_with_default_notes["notes"].describe()
count 126314
unique 232
top no notes at all
freq 120890
Name: notes, dtype: object
在这里,用字符串"no notes at all"填充空的notes行。
无效值
无效值可能比缺失值更危险。通常,您可以按预期执行数据分析,但是您得到的结果是奇特的。如果您的数据集很大或使用手动输入,这一点尤其重要。无效值通常更难检测,但是您可以使用查询和聚合实现一些健全性检查。
您可以做的一件事是验证数据的范围。对于这一点,.describe()相当得心应手。回想一下,它会返回以下输出:
year_id在 1947 年和 2015 年之间变化。这听起来似乎合理。
那pts呢?最低怎么可能是0?让我们来看看这些游戏:
>>> nba[nba["pts"] == 0]此查询返回单行:
似乎比赛被取消了。根据您的分析,您可能希望将其从数据集中移除。
不一致的值
有时一个值本身是完全真实的,但是它与其他列中的值不匹配。您可以定义一些互斥的查询条件,并验证这些条件不会同时出现。
在 NBA 数据集中,字段
pts、opp_pts和game_result的值应该相互一致。您可以使用.empty属性对此进行检查:

>>> nba[(nba["pts"] > nba["opp_pts"]) & (nba["game_result"] != 'W')].empty
True
>>> nba[(nba["pts"] < nba["opp_pts"]) & (nba["game_result"] != 'L')].empty
True
幸运的是,这两个查询都返回一个空的DataFrame。
无论何时处理原始数据集,都要做好应对意外的准备,尤其是当它们是从不同的来源或通过复杂的渠道收集时。您可能会看到一些行,其中某个团队得分高于对手,但仍然没有获胜——至少根据您的数据集是这样的!为了避免这种情况,请确保您将进一步的数据清理技术添加到您的 Pandas 和 Python 武器库中。
组合多个数据集
在上一节中,您已经学习了如何清理混乱的数据集。真实世界数据的另一个方面是,它通常来自多个部分。在这一节中,您将学习如何获取这些片段并将它们组合成一个数据集,以备分析。
在前面的中,你根据它们的索引将两个Series对象合并成一个DataFrame。现在,您将更进一步,使用.concat()将city_data与另一个DataFrame组合起来。假设您已经收集了另外两个城市的一些数据:
>>> further_city_data = pd.DataFrame( ... {"revenue": [7000, 3400], "employee_count":[2, 2]}, ... index=["New York", "Barcelona"] ... )第二个
DataFrame包含城市"New York"和"Barcelona"的信息。您可以使用
.concat()将这些城市添加到city_data:
>>> all_city_data = pd.concat([city_data, further_city_data], sort=False)
>>> all_city_data
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN
New York 7000 2.0
Barcelona 3400 2.0
现在,新变量all_city_data包含了来自两个DataFrame对象的值。
注:从 Pandas 0 . 25 . 0 版本开始,sort参数的默认值为True,但很快会改为False。为这个参数提供一个显式值是一个很好的实践,以确保您的代码在不同的 Pandas 和 Python 版本中工作一致。更多信息,请查阅熊猫用户指南。
默认情况下,concat()沿axis=0组合。换句话说,它追加行。您还可以通过提供参数axis=1来使用它添加列:
>>> city_countries = pd.DataFrame({ ... "country": ["Holland", "Japan", "Holland", "Canada", "Spain"], ... "capital": [1, 1, 0, 0, 0]}, ... index=["Amsterdam", "Tokyo", "Rotterdam", "Toronto", "Barcelona"] ... ) >>> cities = pd.concat([all_city_data, city_countries], axis=1, sort=False) >>> cities revenue employee_count country capital Amsterdam 4200.0 5.0 Holland 1.0 Tokyo 6500.0 8.0 Japan 1.0 Toronto 8000.0 NaN Canada 0.0 New York 7000.0 2.0 NaN NaN Barcelona 3400.0 2.0 Spain 0.0 Rotterdam NaN NaN Holland 0.0注意熊猫是如何为缺失的值添加
NaN的。如果您只想合并出现在两个DataFrame对象中的城市,那么您可以将join参数设置为inner:
>>> pd.concat([all_city_data, city_countries], axis=1, join="inner")
revenue employee_count country capital
Amsterdam 4200 5.0 Holland 1
Tokyo 6500 8.0 Japan 1
Toronto 8000 NaN Canada 0
Barcelona 3400 2.0 Spain 0
虽然根据索引组合数据是最直接的方法,但这不是唯一的可能性。您可以使用.merge()来实现一个连接操作,类似于 SQL:
>>> countries = pd.DataFrame({ ... "population_millions": [17, 127, 37], ... "continent": ["Europe", "Asia", "North America"] ... }, index= ["Holland", "Japan", "Canada"]) >>> pd.merge(cities, countries, left_on="country", right_index=True)这里,您将参数
left_on="country"传递给.merge(),以指示您想要连接哪一列。结果是一个更大的DataFrame,不仅包含城市数据,还包含各个国家的人口和大陆:
注意,结果只包含国家已知的城市,并出现在连接的
DataFrame中。
.merge()默认情况下执行内部连接。如果您想在结果中包含所有城市,那么您需要提供how参数:
>>> pd.merge(
... cities,
... countries,
... left_on="country",
... right_index=True,
... how="left"
... )
通过此left加入,您将看到所有城市,包括没有国家数据的城市:
欢迎回来,纽约和巴塞罗那!
可视化你的熊猫数据帧
数据可视化是在 Jupyter 笔记本上比在终端上运行得更好的东西之一,所以开始运行吧。如果你需要帮助开始,那么看看 Jupyter 笔记本:介绍。您还可以通过单击下面的链接来访问包含本教程中的示例的 Jupyter 笔记本:
获取 Jupyter 笔记本: 点击此处获取 Jupyter 笔记本,您将在本教程中使用探索与熊猫有关的数据。
包含此行以直接在笔记本中显示绘图:
>>> %matplotlib inline
Series和DataFrame对象都有一个.plot()方法,是对matplotlib.pyplot.plot()的包装。默认情况下,它会创建一个线图。想象一下尼克斯整个赛季得了多少分:
>>> nba[nba["fran_id"] == "Knicks"].groupby("year_id")["pts"].sum().plot()
该图显示了 2000 年和 2010 年的一个线形图,其中有几个峰值和两个显著的谷值:
您还可以创建其他类型的图,如条形图:
>>> nba["fran_id"].value_counts().head(10).plot(kind="bar")这将显示玩得最多的游戏系列:
湖人以微弱优势领先凯尔特人,还有六支球队的比赛次数超过 5000 次。
现在尝试一个更复杂的练习。2013 年,迈阿密热火队夺冠。创建一个饼图,显示他们在该赛季中的输赢。然后,展开代码块查看解决方案:
首先,你定义一个标准,只包括热火队 2013 年的比赛。然后,用与上面相同的方式创建一个情节:
>>> nba[
... (nba["fran_id"] == "Heat") &
... (nba["year_id"] == 2013)
... ]["game_result"].value_counts().plot(kind="pie")
这是冠军馅饼的样子:
盈利的份额明显大于亏损的份额!
有时,数字本身就能说明问题,但图表通常对传达你的见解很有帮助。要了解有关可视化数据的更多信息,请查看使用散景的 Python 中的交互式数据可视化。
结论
在本教程中,您已经学习了如何使用 Pandas Python 库开始探索数据集。您看到了如何访问特定的行和列来驯服最大的数据集。说到驯服,您还看到了多种准备和清理数据的技术,包括指定列的数据类型、处理缺失值等等。您甚至已经基于这些创建了查询、聚合和绘图。
现在你可以:
- 使用
Series和DataFrame对象 - 使用
.loc、.iloc和索引操作符对数据进行子集化 - 通过查询、分组和聚合回答问题
- 处理缺失、无效和不一致的数据
- 在 Jupyter 笔记本中可视化数据集
这次使用 NBA 统计数据的旅程仅仅触及了您可以用 Pandas Python 库做的事情的表面。你可以用熊猫把戏启动你的项目,学习用 Python 加速熊猫的技术,甚至可以深入了解熊猫如何在幕后工作。还有更多功能等待您去发现,所以赶快去处理这些数据集吧!
您可以通过单击下面的链接获得您在本教程中看到的所有代码示例:
获取 Jupyter 笔记本: 点击此处获取 Jupyter 笔记本,您将在本教程中使用探索与熊猫有关的数据。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,以加深您的理解: 用熊猫 探索您的数据集*********
熊猫:如何读写文件
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 和熊猫一起读写文件
Pandas 是一个强大而灵活的 Python 包,允许您处理带标签的数据和时间序列数据。它还提供了统计方法,支持绘图等等。Pandas 的一个重要特性是它能够读写 Excel、CSV 和许多其他类型的文件。像 Pandas read_csv() 方法这样的函数使您能够有效地处理文件。您可以使用它们将数据和标签从 Pandas 对象保存到一个文件中,并在以后作为 Pandas Series或 DataFrame 实例加载它们。
在本教程中,您将学习:
- 熊猫 IO 工具 API 是什么
- 如何从文件中读取数据
- 如何使用各种文件格式
- 如何高效地使用大数据
让我们开始读写文件吧!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
安装熊猫
本教程中的代码是用 CPython 3.7.4 和 Pandas 0.25.1 执行的。确保您的机器上有最新版本的 Python 和 Pandas 将是有益的。对于本教程,您可能想要创建一个新的虚拟环境并安装依赖项。
首先,你需要熊猫图书馆。您可能已经安装了它。如果没有,那么可以用 pip 安装:
$ pip install pandas
一旦安装过程完成,你应该有熊猫安装和准备。
Anaconda 是一个优秀的 Python 发行版,自带 Python,很多有用的包比如 Pandas,还有一个名为 Conda 的包和环境管理器。要了解关于 Anaconda 的更多信息,请查看在 Windows 上为机器学习设置 Python。
如果您的虚拟环境中没有熊猫,那么您可以使用 Conda 安装它:
$ conda install pandas
Conda 功能强大,因为它管理依赖项及其版本。要了解更多关于使用 Conda 的信息,你可以查看官方文档。
准备数据
在本教程中,您将使用 20 个国家的相关数据。以下是您将使用的数据和来源的概述:
-
国家用国名来表示。每个国家在人口、面积或国内生产总值(GDP)方面都排在前 10 名。数据集的行标签是在 ISO 3166-1中定义的三个字母的国家代码。数据集的列标签是
COUNTRY。 -
人口以百万为单位表示。这些数据来自维基百科上按人口统计的国家和属地列表。数据集的列标签是
POP。 -
面积以千平方公里表示。数据来自维基百科上按地区列出的国家和属地列表。数据集的列标签是
AREA。 -
根据联合国 2017 年的数据,国内生产总值以百万美元为单位。你可以在维基百科的名义 GDP 国家列表中找到这些数据。数据集的列标签是
GDP。 -
洲是指非洲、亚洲、大洋洲、欧洲、北美洲或南美洲。你也可以在维基百科上找到这些信息。数据集的列标签是
CONT。 -
独立日是纪念一个国家独立的日子。数据来自维基百科上的国家独立日列表。日期以 ISO 8601 格式显示。前四个数字代表年份,接下来的两个数字代表月份,最后两个数字代表月份中的某一天。数据集的列标签是
IND_DAY。
数据以表格的形式显示如下:
| 国家 | 砰然一声 | 区域 | GDP | 续 | IND_DAY | |
|---|---|---|---|---|---|---|
| 中国 | 中国 | One thousand three hundred and ninety-eight point seven two | Nine thousand five hundred and ninety-six point nine six | Twelve thousand two hundred and thirty-four point seven eight | 亚洲 | |
| 插入 | 印度 | One thousand three hundred and fifty-one point one six | Three thousand two hundred and eighty-seven point two six | Two thousand five hundred and seventy-five point six seven | 亚洲 | 1947-08-15 |
| 美国 | 美国 | Three hundred and twenty-nine point seven four | Nine thousand eight hundred and thirty-three point five two | Nineteen thousand four hundred and eighty-five point three nine | 名词(noun 的缩写)美国 | 1776-07-04 |
| IDN | 印度尼西亚 | Two hundred and sixty-eight point zero seven | One thousand nine hundred and ten point nine three | One thousand and fifteen point five four | 亚洲 | 1945-08-17 |
| 胸罩 | 巴西 | Two hundred and ten point three two | Eight thousand five hundred and fifteen point seven seven | Two thousand and fifty-five point five one | 南美国 | 1822-09-07 |
| 接 | 巴基斯坦 | Two hundred and five point seven one | Eight hundred and eighty-one point nine one | Three hundred and two point one four | 亚洲 | 1947-08-14 |
| 就为了使用一个差不多 1231 分布的电子游戏描述一个样子 | 尼日利亚 | Two hundred point nine six | Nine hundred and twenty-three point seven seven | Three hundred and seventy-five point seven seven | 非洲 | 1960-10-01 |
| BGD | 孟加拉国 | One hundred and sixty-seven point zero nine | One hundred and forty-seven point five seven | Two hundred and forty-five point six three | 亚洲 | 1971-03-26 |
| RUS | 俄罗斯 | One hundred and forty-six point seven nine | Seventeen thousand and ninety-eight point two five | One thousand five hundred and thirty point seven five | 1992-06-12 | |
| 墨西哥 | 墨西哥 | One hundred and twenty-six point five eight | One thousand nine hundred and sixty-four point three eight | One thousand one hundred and fifty-eight point two three | 名词(noun 的缩写)美国 | 1810-09-16 |
| JPN | 日本 | One hundred and twenty-six point two two | Three hundred and seventy-seven point nine seven | Four thousand eight hundred and seventy-two point four two | 亚洲 | |
| DEU | 德国 | Eighty-three point zero two | Three hundred and fifty-seven point one one | Three thousand six hundred and ninety-three point two | 欧洲 | |
| FRA | 法国 | Sixty-seven point zero two | Six hundred and forty point six eight | Two thousand five hundred and eighty-two point four nine | 欧洲 | 1789-07-14 |
| GBR | 英国 | Sixty-six point four four | Two hundred and forty-two point five | Two thousand six hundred and thirty-one point two three | 欧洲 | |
| ITA | 意大利 | Sixty point three six | Three hundred and one point three four | One thousand nine hundred and forty-three point eight four | 欧洲 | |
| 生气 | 阿根廷 | Forty-four point nine four | Two thousand seven hundred and eighty point four | Six hundred and thirty-seven point four nine | 南美国 | 1816-07-09 |
| DZA | 阿尔及利亚 | Forty-three point three eight | Two thousand three hundred and eighty-one point seven four | One hundred and sixty-seven point five six | 非洲 | 1962-07-05 |
| 能 | 加拿大 | Thirty-seven point five nine | Nine thousand nine hundred and eighty-four point six seven | One thousand six hundred and forty-seven point one two | 名词(noun 的缩写)美国 | 1867-07-01 |
| 澳大利亚 | 澳大利亚 | Twenty-five point four seven | Seven thousand six hundred and ninety-two point zero two | One thousand four hundred and eight point six eight | 大洋洲 | |
| 卡兹 | 哈萨克斯坦共和国 | Eighteen point five three | Two thousand seven hundred and twenty-four point nine | One hundred and fifty-nine point four one | 亚洲 | 1991-12-16 |
您可能会注意到有些数据丢失了。例如,没有指定俄罗斯的大陆,因为它横跨欧洲和亚洲。还有几个缺失的独立日,因为数据源省略了它们。
您可以使用嵌套的字典在 Python 中组织这些数据:
data = {
'CHN': {'COUNTRY': 'China', 'POP': 1_398.72, 'AREA': 9_596.96,
'GDP': 12_234.78, 'CONT': 'Asia'},
'IND': {'COUNTRY': 'India', 'POP': 1_351.16, 'AREA': 3_287.26,
'GDP': 2_575.67, 'CONT': 'Asia', 'IND_DAY': '1947-08-15'},
'USA': {'COUNTRY': 'US', 'POP': 329.74, 'AREA': 9_833.52,
'GDP': 19_485.39, 'CONT': 'N.America',
'IND_DAY': '1776-07-04'},
'IDN': {'COUNTRY': 'Indonesia', 'POP': 268.07, 'AREA': 1_910.93,
'GDP': 1_015.54, 'CONT': 'Asia', 'IND_DAY': '1945-08-17'},
'BRA': {'COUNTRY': 'Brazil', 'POP': 210.32, 'AREA': 8_515.77,
'GDP': 2_055.51, 'CONT': 'S.America', 'IND_DAY': '1822-09-07'},
'PAK': {'COUNTRY': 'Pakistan', 'POP': 205.71, 'AREA': 881.91,
'GDP': 302.14, 'CONT': 'Asia', 'IND_DAY': '1947-08-14'},
'NGA': {'COUNTRY': 'Nigeria', 'POP': 200.96, 'AREA': 923.77,
'GDP': 375.77, 'CONT': 'Africa', 'IND_DAY': '1960-10-01'},
'BGD': {'COUNTRY': 'Bangladesh', 'POP': 167.09, 'AREA': 147.57,
'GDP': 245.63, 'CONT': 'Asia', 'IND_DAY': '1971-03-26'},
'RUS': {'COUNTRY': 'Russia', 'POP': 146.79, 'AREA': 17_098.25,
'GDP': 1_530.75, 'IND_DAY': '1992-06-12'},
'MEX': {'COUNTRY': 'Mexico', 'POP': 126.58, 'AREA': 1_964.38,
'GDP': 1_158.23, 'CONT': 'N.America', 'IND_DAY': '1810-09-16'},
'JPN': {'COUNTRY': 'Japan', 'POP': 126.22, 'AREA': 377.97,
'GDP': 4_872.42, 'CONT': 'Asia'},
'DEU': {'COUNTRY': 'Germany', 'POP': 83.02, 'AREA': 357.11,
'GDP': 3_693.20, 'CONT': 'Europe'},
'FRA': {'COUNTRY': 'France', 'POP': 67.02, 'AREA': 640.68,
'GDP': 2_582.49, 'CONT': 'Europe', 'IND_DAY': '1789-07-14'},
'GBR': {'COUNTRY': 'UK', 'POP': 66.44, 'AREA': 242.50,
'GDP': 2_631.23, 'CONT': 'Europe'},
'ITA': {'COUNTRY': 'Italy', 'POP': 60.36, 'AREA': 301.34,
'GDP': 1_943.84, 'CONT': 'Europe'},
'ARG': {'COUNTRY': 'Argentina', 'POP': 44.94, 'AREA': 2_780.40,
'GDP': 637.49, 'CONT': 'S.America', 'IND_DAY': '1816-07-09'},
'DZA': {'COUNTRY': 'Algeria', 'POP': 43.38, 'AREA': 2_381.74,
'GDP': 167.56, 'CONT': 'Africa', 'IND_DAY': '1962-07-05'},
'CAN': {'COUNTRY': 'Canada', 'POP': 37.59, 'AREA': 9_984.67,
'GDP': 1_647.12, 'CONT': 'N.America', 'IND_DAY': '1867-07-01'},
'AUS': {'COUNTRY': 'Australia', 'POP': 25.47, 'AREA': 7_692.02,
'GDP': 1_408.68, 'CONT': 'Oceania'},
'KAZ': {'COUNTRY': 'Kazakhstan', 'POP': 18.53, 'AREA': 2_724.90,
'GDP': 159.41, 'CONT': 'Asia', 'IND_DAY': '1991-12-16'}
}
columns = ('COUNTRY', 'POP', 'AREA', 'GDP', 'CONT', 'IND_DAY')
表中的每一行都被写成一个内部字典,它的键是列名,值是相应的数据。这些字典随后被收集为外部data字典中的值。data的对应键是三个字母的国家代码。
你可以用这个data来创建一个熊猫 DataFrame 的实例。首先,你需要进口熊猫:
>>> import pandas as pd现在你已经导入了熊猫,你可以使用
DataFrame构造函数和data来创建一个DataFrame对象。
data以国家代码对应列的方式组织。您可以使用属性.T反转DataFrame的行和列:
>>> df = pd.DataFrame(data=data).T
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.8 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.4 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.2 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.2 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.5 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.4 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.9 159.41 Asia 1991-12-16
现在您已经用每个国家的数据填充了您的DataFrame对象。
注意:你可以用 .transpose() 代替.T来反转你的数据集的行和列。如果您使用.transpose(),那么您可以设置可选参数copy来指定您是否想要复制底层数据。默认行为是False。
than 3.6 之前的版本不保证字典中键的顺序。为了确保旧版本的 Python 和 Pandas 保持列的顺序,您可以指定index=columns:
>>> df = pd.DataFrame(data=data, index=columns).T现在您已经准备好了数据,您已经准备好开始处理文件了!
使用熊猫
read_csv()和.to_csv()功能一个逗号分隔值(CSV) 文件是一个带有
.csv扩展名的纯文本文件,用于保存表格数据。这是存储大量数据的最流行的文件格式之一。CSV 文件的每一行代表一个表格行。默认情况下,同一行中的值用逗号分隔,但是您可以将分隔符更改为分号、制表符、空格或其他字符。写一个 CSV 文件
您可以使用
.to_csv()将您的熊猫DataFrame保存为 CSV 文件:
>>> df.to_csv('data.csv')
就是这样!您已经在当前工作目录中创建了文件data.csv。您可以展开下面的代码块来查看 CSV 文件的外观:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,,1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
该文本文件包含用逗号分隔的数据。第一列包含行标签。在某些情况下,你会发现它们无关紧要。如果不想保留它们,那么可以将参数index=False传递给.to_csv()。
读取 CSV 文件
一旦您的数据保存在 CSV 文件中,您可能会希望不时地加载和使用它。你可以用熊猫 read_csv() 功能来实现:
>>> df = pd.read_csv('data.csv', index_col=0) >>> df COUNTRY POP AREA GDP CONT IND_DAY CHN China 1398.72 9596.96 12234.78 Asia NaN IND India 1351.16 3287.26 2575.67 Asia 1947-08-15 USA US 329.74 9833.52 19485.39 N.America 1776-07-04 IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17 BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07 PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14 NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01 BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26 RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12 MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16 JPN Japan 126.22 377.97 4872.42 Asia NaN DEU Germany 83.02 357.11 3693.20 Europe NaN FRA France 67.02 640.68 2582.49 Europe 1789-07-14 GBR UK 66.44 242.50 2631.23 Europe NaN ITA Italy 60.36 301.34 1943.84 Europe NaN ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09 DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05 CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01 AUS Australia 25.47 7692.02 1408.68 Oceania NaN KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16在这种情况下,Pandas
read_csv()函数返回一个新的DataFrame,其中包含来自文件data.csv的数据和标签,该文件由第一个参数指定。这个字符串可以是任何有效的路径,包括URL。参数
index_col指定包含行标签的 CSV 文件中的列。将从零开始的列索引分配给该参数。当 CSV 文件包含行标签时,您应该确定index_col的值,以避免将它们作为数据加载。稍后在本教程中,你会学到更多关于使用带 CSV 文件的熊猫的知识。您还可以查看用 Python 读写 CSV 文件的,看看如何用内置的 Python 库 csv 处理 CSV 文件。
使用熊猫读写 Excel 文件
微软 Excel 可能是使用最广泛的电子表格软件。旧版本使用二进制
.xls文件,而 Excel 2007 引入了新的基于 XML 的.xlsx文件。可以在熊猫读写 Excel 文件,类似于 CSV 文件。但是,您需要首先安装以下 Python 包:
- xlwt 写入
.xls文件- openpyxl 或 XlsxWriter 写入
.xlsx文件- xlrd 读取 Excel 文件
您可以使用一条命令使用 pip 安装它们:
$ pip install xlwt openpyxl xlsxwriter xlrd您也可以使用 Conda:
$ conda install xlwt openpyxl xlsxwriter xlrd请注意,你不必安装所有这些软件包。比如你不需要同时拥有 openpyxl 和 XlsxWriter。如果你打算只处理
.xls文件,那么你不需要任何文件!然而,如果你打算只处理.xlsx文件,那么你至少需要其中一个,而不是xlwt。花一些时间来决定哪些包适合您的项目。写一个 Excel 文件
一旦你安装了这些软件包,你可以用
.to_excel()将你的DataFrame保存在一个 Excel 文件中:
>>> df.to_excel('data.xlsx')
参数'data.xlsx'表示目标文件,也可以表示其路径。上面的语句应该会在您当前的工作目录中创建文件data.xlsx。该文件应该如下所示:
文件的第一列包含行的标签,而其他列存储数据。
读取 Excel 文件
您可以使用 read_excel() 从 Excel 文件中加载数据:
>>> df = pd.read_excel('data.xlsx', index_col=0) >>> df COUNTRY POP AREA GDP CONT IND_DAY CHN China 1398.72 9596.96 12234.78 Asia NaN IND India 1351.16 3287.26 2575.67 Asia 1947-08-15 USA US 329.74 9833.52 19485.39 N.America 1776-07-04 IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17 BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07 PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14 NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01 BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26 RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12 MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16 JPN Japan 126.22 377.97 4872.42 Asia NaN DEU Germany 83.02 357.11 3693.20 Europe NaN FRA France 67.02 640.68 2582.49 Europe 1789-07-14 GBR UK 66.44 242.50 2631.23 Europe NaN ITA Italy 60.36 301.34 1943.84 Europe NaN ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09 DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05 CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01 AUS Australia 25.47 7692.02 1408.68 Oceania NaN KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
read_excel()返回一个新的DataFrame,它包含来自data.xlsx的值。您也可以将read_excel()与 OpenDocument 电子表格或.ods文件一起使用。在本教程的后面,你会学到更多关于使用 Excel 文件的知识。你也可以看看用 Pandas 读取 Python 中的大型 Excel 文件。
了解熊猫 IO API
熊猫 IO 工具 是允许你将
Series和DataFrame对象的内容保存到剪贴板、对象或各种类型的文件中的 API。它还支持从剪贴板、对象或文件加载数据。写文件
Series和DataFrame对象拥有能够将数据和标签写入剪贴板或文件的方法。它们以.to_<file-type>()的模式命名,其中<file-type>是目标文件的类型。你已经了解了
.to_csv()和.to_excel(),但是还有其他的,包括:
.to_json().to_html().to_sql().to_pickle()还有更多的文件类型可以写入,所以这个列表并不详尽。
注意:要找到类似的方法,请查阅与
Series和DataFrame对象相关的序列化、IO 和转换的官方文档。这些方法具有指定保存数据和标签的目标文件路径的参数。这在某些情况下是强制性的,在其他情况下是可选的。如果这个选项可用,而您选择忽略它,那么这些方法将返回带有
DataFrame实例内容的对象(如字符串或 iterables)。可选参数
compression决定如何压缩带有数据和标签的文件。稍后在你会了解到更多。还有一些其他的参数,但是它们主要是特定于一个或几个方法的。这里就不赘述了。读取文件
用于读取文件内容的 Pandas 函数使用模式
.read_<file-type>()命名,其中<file-type>表示要读取的文件类型。你已经看到了熊猫read_csv()和read_excel()的功能。以下是其他一些例子:
read_json()read_html()read_sql()read_pickle()这些函数有一个指定目标文件路径的参数。它可以是本地计算机上或 URL 中表示路径的任何有效字符串。根据文件类型,其他对象也是可以接受的。
可选参数
compression决定了用于压缩文件的解压缩类型。稍后你会在本教程中了解到这一点。还有其他参数,但它们是特定于一个或几个函数的。这里就不赘述了。使用不同的文件类型
熊猫图书馆提供了广泛的可能性来保存你的数据到文件和从文件加载数据。在本节中,您将了解有关使用 CSV 和 Excel 文件的更多信息。您还将看到如何使用其他类型的文件,比如 JSON、web 页面、数据库和 Python pickle 文件。
CSV 文件
你已经学会了如何读写 CSV 文件。现在让我们更深入地了解一下细节。当您使用
.to_csv()保存您的DataFrame时,您可以为参数path_or_buf提供一个参数来指定目标文件的路径、名称和扩展名。
path_or_buf是.to_csv()将得到的第一个参数。它可以是代表包含文件名及其扩展名的有效文件路径的任何字符串。你已经在之前的例子中看到了这一点。然而,如果你省略了path_or_buf,那么.to_csv()不会创建任何文件。相反,它将返回相应的字符串:
>>> df = pd.DataFrame(data=data).T
>>> s = df.to_csv()
>>> print(s)
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,,1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
现在你有了字符串s而不是 CSV 文件。在你的DataFrame对象中也有一些缺失值。例如,俄罗斯的大陆和几个国家(中国、日本等)的独立日不可用。在数据科学和机器学习中,必须小心处理缺失值。熊猫擅长这里!默认情况下,Pandas 使用 NaN 值来替换丢失的值。
注意: nan ,代表“不是数字”,是 Python 中一个特定的浮点值。
您可以使用以下任何函数获得一个nan值:
df中对应俄罗斯的洲是nan:
>>> df.loc['RUS', 'CONT'] nan此示例使用
.loc[]来获取具有指定行和列名称的数据。当您将
DataFrame保存到 CSV 文件时,空字符串('')将代表丢失的数据。你可以在你的文件data.csv和字符串s中看到这一点。如果你想改变这种行为,那么使用可选参数na_rep:
>>> df.to_csv('new-data.csv', na_rep='(missing)')
这段代码生成文件new-data.csv,其中丢失的值不再是空字符串。您可以展开下面的代码块来查看该文件的外观:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,(missing)
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,(missing),1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,(missing)
DEU,Germany,83.02,357.11,3693.2,Europe,(missing)
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,(missing)
ITA,Italy,60.36,301.34,1943.84,Europe,(missing)
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,(missing)
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
现在,文件中的字符串'(missing)'对应于来自df的nan值。
当 Pandas 读取文件时,默认情况下,它会将空字符串('')和其他一些值视为缺失值:
'nan''-nan''NA''N/A''NaN''null'
如果你不想要这种行为,那么你可以将keep_default_na=False传递给熊猫read_csv()函数。要为缺失值指定其他标签,请使用参数na_values:
>>> pd.read_csv('new-data.csv', index_col=0, na_values='(missing)') COUNTRY POP AREA GDP CONT IND_DAY CHN China 1398.72 9596.96 12234.78 Asia NaN IND India 1351.16 3287.26 2575.67 Asia 1947-08-15 USA US 329.74 9833.52 19485.39 N.America 1776-07-04 IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17 BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07 PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14 NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01 BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26 RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12 MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16 JPN Japan 126.22 377.97 4872.42 Asia NaN DEU Germany 83.02 357.11 3693.20 Europe NaN FRA France 67.02 640.68 2582.49 Europe 1789-07-14 GBR UK 66.44 242.50 2631.23 Europe NaN ITA Italy 60.36 301.34 1943.84 Europe NaN ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09 DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05 CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01 AUS Australia 25.47 7692.02 1408.68 Oceania NaN KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16这里,您已经将字符串
'(missing)'标记为新的缺失数据标签,Pandas 在读取文件时用nan替换它。
>>> df = pd.read_csv('data.csv', index_col=0)
>>> df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY object
dtype: object
带有字符串和日期的列('COUNTRY'、'CONT'和'IND_DAY')的数据类型为object。同时,数字列包含 64 位浮点数(float64)。
您可以使用参数dtype来指定所需的数据类型,使用parse_dates来强制使用日期时间:
>>> dtypes = {'POP': 'float32', 'AREA': 'float32', 'GDP': 'float32'} >>> df = pd.read_csv('data.csv', index_col=0, dtype=dtypes, ... parse_dates=['IND_DAY']) >>> df.dtypes COUNTRY object POP float32 AREA float32 GDP float32 CONT object IND_DAY datetime64[ns] dtype: object >>> df['IND_DAY'] CHN NaT IND 1947-08-15 USA 1776-07-04 IDN 1945-08-17 BRA 1822-09-07 PAK 1947-08-14 NGA 1960-10-01 BGD 1971-03-26 RUS 1992-06-12 MEX 1810-09-16 JPN NaT DEU NaT FRA 1789-07-14 GBR NaT ITA NaT ARG 1816-07-09 DZA 1962-07-05 CAN 1867-07-01 AUS NaT KAZ 1991-12-16 Name: IND_DAY, dtype: datetime64[ns]现在,您有了用
dtype指定的 32 位浮点数(float32)。这些与最初的 64 位数字略有不同,因为精度更小。最后一列中的值被视为日期,数据类型为datetime64。这就是为什么该列中的NaN值被替换为NaT。现在你有了真实的日期,你可以用你喜欢的格式保存它们:
>>> df = pd.read_csv('data.csv', index_col=0, parse_dates=['IND_DAY'])
>>> df.to_csv('formatted-data.csv', date_format='%B %d, %Y')
这里,您已经将参数date_format指定为'%B %d, %Y'。您可以展开下面的代码块来查看结果文件:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,"August 15, 1947"
USA,US,329.74,9833.52,19485.39,N.America,"July 04, 1776"
IDN,Indonesia,268.07,1910.93,1015.54,Asia,"August 17, 1945"
BRA,Brazil,210.32,8515.77,2055.51,S.America,"September 07, 1822"
PAK,Pakistan,205.71,881.91,302.14,Asia,"August 14, 1947"
NGA,Nigeria,200.96,923.77,375.77,Africa,"October 01, 1960"
BGD,Bangladesh,167.09,147.57,245.63,Asia,"March 26, 1971"
RUS,Russia,146.79,17098.25,1530.75,,"June 12, 1992"
MEX,Mexico,126.58,1964.38,1158.23,N.America,"September 16, 1810"
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,"July 14, 1789"
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,"July 09, 1816"
DZA,Algeria,43.38,2381.74,167.56,Africa,"July 05, 1962"
CAN,Canada,37.59,9984.67,1647.12,N.America,"July 01, 1867"
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,"December 16, 1991"
日期的格式现在不同了。格式'%B %d, %Y'意味着日期将首先显示月份的全名,然后是日期,后面是逗号,最后是完整的年份。
还有其他几个可选参数可以与.to_csv()一起使用:
sep表示数值分隔符。decimal表示小数分隔符。encoding设置文件编码。header指定是否要在文件中写入列标签。
下面是如何传递sep和header的参数:
>>> s = df.to_csv(sep=';', header=False) >>> print(s) CHN;China;1398.72;9596.96;12234.78;Asia; IND;India;1351.16;3287.26;2575.67;Asia;1947-08-15 USA;US;329.74;9833.52;19485.39;N.America;1776-07-04 IDN;Indonesia;268.07;1910.93;1015.54;Asia;1945-08-17 BRA;Brazil;210.32;8515.77;2055.51;S.America;1822-09-07 PAK;Pakistan;205.71;881.91;302.14;Asia;1947-08-14 NGA;Nigeria;200.96;923.77;375.77;Africa;1960-10-01 BGD;Bangladesh;167.09;147.57;245.63;Asia;1971-03-26 RUS;Russia;146.79;17098.25;1530.75;;1992-06-12 MEX;Mexico;126.58;1964.38;1158.23;N.America;1810-09-16 JPN;Japan;126.22;377.97;4872.42;Asia; DEU;Germany;83.02;357.11;3693.2;Europe; FRA;France;67.02;640.68;2582.49;Europe;1789-07-14 GBR;UK;66.44;242.5;2631.23;Europe; ITA;Italy;60.36;301.34;1943.84;Europe; ARG;Argentina;44.94;2780.4;637.49;S.America;1816-07-09 DZA;Algeria;43.38;2381.74;167.56;Africa;1962-07-05 CAN;Canada;37.59;9984.67;1647.12;N.America;1867-07-01 AUS;Australia;25.47;7692.02;1408.68;Oceania; KAZ;Kazakhstan;18.53;2724.9;159.41;Asia;1991-12-16数据用分号(
';')分隔,因为您已经指定了sep=';'。此外,因为您通过了header=False,所以您看到的数据没有列名的标题行。Pandas
read_csv()函数有许多额外的选项,用于管理缺失数据、处理日期和时间、引用、编码、处理错误等等。例如,如果您有一个只有一个数据列的文件,并且想要得到一个Series对象而不是一个DataFrame,那么您可以将squeeze=True传递给read_csv()。稍后您将在中学习关于数据压缩和解压缩,以及如何跳过行和列。JSON 文件
JSON 代表 JavaScript 对象符号。JSON 文件是用于数据交换的明文文件,人类可以很容易地阅读它们。它们遵循ISO/T4【IEC 21778:2017】和 ECMA-404 标准,并使用
.json扩展。Python 和 Pandas 可以很好地处理 JSON 文件,因为 Python 的 json 库为它们提供了内置支持。您可以使用
.to_json()将DataFrame中的数据保存到 JSON 文件中。首先再次创建一个DataFrame对象。使用保存国家数据的字典data,然后应用.to_json():
>>> df = pd.DataFrame(data=data).T
>>> df.to_json('data-columns.json')
这段代码生成了文件data-columns.json。您可以展开下面的代码块来查看该文件的外观:
{"COUNTRY":{"CHN":"China","IND":"India","USA":"US","IDN":"Indonesia","BRA":"Brazil","PAK":"Pakistan","NGA":"Nigeria","BGD":"Bangladesh","RUS":"Russia","MEX":"Mexico","JPN":"Japan","DEU":"Germany","FRA":"France","GBR":"UK","ITA":"Italy","ARG":"Argentina","DZA":"Algeria","CAN":"Canada","AUS":"Australia","KAZ":"Kazakhstan"},"POP":{"CHN":1398.72,"IND":1351.16,"USA":329.74,"IDN":268.07,"BRA":210.32,"PAK":205.71,"NGA":200.96,"BGD":167.09,"RUS":146.79,"MEX":126.58,"JPN":126.22,"DEU":83.02,"FRA":67.02,"GBR":66.44,"ITA":60.36,"ARG":44.94,"DZA":43.38,"CAN":37.59,"AUS":25.47,"KAZ":18.53},"AREA":{"CHN":9596.96,"IND":3287.26,"USA":9833.52,"IDN":1910.93,"BRA":8515.77,"PAK":881.91,"NGA":923.77,"BGD":147.57,"RUS":17098.25,"MEX":1964.38,"JPN":377.97,"DEU":357.11,"FRA":640.68,"GBR":242.5,"ITA":301.34,"ARG":2780.4,"DZA":2381.74,"CAN":9984.67,"AUS":7692.02,"KAZ":2724.9},"GDP":{"CHN":12234.78,"IND":2575.67,"USA":19485.39,"IDN":1015.54,"BRA":2055.51,"PAK":302.14,"NGA":375.77,"BGD":245.63,"RUS":1530.75,"MEX":1158.23,"JPN":4872.42,"DEU":3693.2,"FRA":2582.49,"GBR":2631.23,"ITA":1943.84,"ARG":637.49,"DZA":167.56,"CAN":1647.12,"AUS":1408.68,"KAZ":159.41},"CONT":{"CHN":"Asia","IND":"Asia","USA":"N.America","IDN":"Asia","BRA":"S.America","PAK":"Asia","NGA":"Africa","BGD":"Asia","RUS":null,"MEX":"N.America","JPN":"Asia","DEU":"Europe","FRA":"Europe","GBR":"Europe","ITA":"Europe","ARG":"S.America","DZA":"Africa","CAN":"N.America","AUS":"Oceania","KAZ":"Asia"},"IND_DAY":{"CHN":null,"IND":"1947-08-15","USA":"1776-07-04","IDN":"1945-08-17","BRA":"1822-09-07","PAK":"1947-08-14","NGA":"1960-10-01","BGD":"1971-03-26","RUS":"1992-06-12","MEX":"1810-09-16","JPN":null,"DEU":null,"FRA":"1789-07-14","GBR":null,"ITA":null,"ARG":"1816-07-09","DZA":"1962-07-05","CAN":"1867-07-01","AUS":null,"KAZ":"1991-12-16"}}
data-columns.json有一个大字典,列标签作为键,相应的内部字典作为值。
如果您为可选参数orient传递一个参数,您可以获得不同的文件结构:
>>> df.to_json('data-index.json', orient='index')
orient参数默认为'columns'。在这里,你已经把它设置为index。你应该得到一个新文件
data-index.json。您可以展开下面的代码块来查看更改:{"CHN":{"COUNTRY":"China","POP":1398.72,"AREA":9596.96,"GDP":12234.78,"CONT":"Asia","IND_DAY":null},"IND":{"COUNTRY":"India","POP":1351.16,"AREA":3287.26,"GDP":2575.67,"CONT":"Asia","IND_DAY":"1947-08-15"},"USA":{"COUNTRY":"US","POP":329.74,"AREA":9833.52,"GDP":19485.39,"CONT":"N.America","IND_DAY":"1776-07-04"},"IDN":{"COUNTRY":"Indonesia","POP":268.07,"AREA":1910.93,"GDP":1015.54,"CONT":"Asia","IND_DAY":"1945-08-17"},"BRA":{"COUNTRY":"Brazil","POP":210.32,"AREA":8515.77,"GDP":2055.51,"CONT":"S.America","IND_DAY":"1822-09-07"},"PAK":{"COUNTRY":"Pakistan","POP":205.71,"AREA":881.91,"GDP":302.14,"CONT":"Asia","IND_DAY":"1947-08-14"},"NGA":{"COUNTRY":"Nigeria","POP":200.96,"AREA":923.77,"GDP":375.77,"CONT":"Africa","IND_DAY":"1960-10-01"},"BGD":{"COUNTRY":"Bangladesh","POP":167.09,"AREA":147.57,"GDP":245.63,"CONT":"Asia","IND_DAY":"1971-03-26"},"RUS":{"COUNTRY":"Russia","POP":146.79,"AREA":17098.25,"GDP":1530.75,"CONT":null,"IND_DAY":"1992-06-12"},"MEX":{"COUNTRY":"Mexico","POP":126.58,"AREA":1964.38,"GDP":1158.23,"CONT":"N.America","IND_DAY":"1810-09-16"},"JPN":{"COUNTRY":"Japan","POP":126.22,"AREA":377.97,"GDP":4872.42,"CONT":"Asia","IND_DAY":null},"DEU":{"COUNTRY":"Germany","POP":83.02,"AREA":357.11,"GDP":3693.2,"CONT":"Europe","IND_DAY":null},"FRA":{"COUNTRY":"France","POP":67.02,"AREA":640.68,"GDP":2582.49,"CONT":"Europe","IND_DAY":"1789-07-14"},"GBR":{"COUNTRY":"UK","POP":66.44,"AREA":242.5,"GDP":2631.23,"CONT":"Europe","IND_DAY":null},"ITA":{"COUNTRY":"Italy","POP":60.36,"AREA":301.34,"GDP":1943.84,"CONT":"Europe","IND_DAY":null},"ARG":{"COUNTRY":"Argentina","POP":44.94,"AREA":2780.4,"GDP":637.49,"CONT":"S.America","IND_DAY":"1816-07-09"},"DZA":{"COUNTRY":"Algeria","POP":43.38,"AREA":2381.74,"GDP":167.56,"CONT":"Africa","IND_DAY":"1962-07-05"},"CAN":{"COUNTRY":"Canada","POP":37.59,"AREA":9984.67,"GDP":1647.12,"CONT":"N.America","IND_DAY":"1867-07-01"},"AUS":{"COUNTRY":"Australia","POP":25.47,"AREA":7692.02,"GDP":1408.68,"CONT":"Oceania","IND_DAY":null},"KAZ":{"COUNTRY":"Kazakhstan","POP":18.53,"AREA":2724.9,"GDP":159.41,"CONT":"Asia","IND_DAY":"1991-12-16"}}
data-index.json也有一个大字典,但是这次行标签是键,内部字典是值。
orient多了几个选项。其中一个是'records':
>>> df.to_json('data-records.json', orient='records')
这段代码应该会生成文件data-records.json。您可以展开下面的代码块来查看内容:
[{"COUNTRY":"China","POP":1398.72,"AREA":9596.96,"GDP":12234.78,"CONT":"Asia","IND_DAY":null},{"COUNTRY":"India","POP":1351.16,"AREA":3287.26,"GDP":2575.67,"CONT":"Asia","IND_DAY":"1947-08-15"},{"COUNTRY":"US","POP":329.74,"AREA":9833.52,"GDP":19485.39,"CONT":"N.America","IND_DAY":"1776-07-04"},{"COUNTRY":"Indonesia","POP":268.07,"AREA":1910.93,"GDP":1015.54,"CONT":"Asia","IND_DAY":"1945-08-17"},{"COUNTRY":"Brazil","POP":210.32,"AREA":8515.77,"GDP":2055.51,"CONT":"S.America","IND_DAY":"1822-09-07"},{"COUNTRY":"Pakistan","POP":205.71,"AREA":881.91,"GDP":302.14,"CONT":"Asia","IND_DAY":"1947-08-14"},{"COUNTRY":"Nigeria","POP":200.96,"AREA":923.77,"GDP":375.77,"CONT":"Africa","IND_DAY":"1960-10-01"},{"COUNTRY":"Bangladesh","POP":167.09,"AREA":147.57,"GDP":245.63,"CONT":"Asia","IND_DAY":"1971-03-26"},{"COUNTRY":"Russia","POP":146.79,"AREA":17098.25,"GDP":1530.75,"CONT":null,"IND_DAY":"1992-06-12"},{"COUNTRY":"Mexico","POP":126.58,"AREA":1964.38,"GDP":1158.23,"CONT":"N.America","IND_DAY":"1810-09-16"},{"COUNTRY":"Japan","POP":126.22,"AREA":377.97,"GDP":4872.42,"CONT":"Asia","IND_DAY":null},{"COUNTRY":"Germany","POP":83.02,"AREA":357.11,"GDP":3693.2,"CONT":"Europe","IND_DAY":null},{"COUNTRY":"France","POP":67.02,"AREA":640.68,"GDP":2582.49,"CONT":"Europe","IND_DAY":"1789-07-14"},{"COUNTRY":"UK","POP":66.44,"AREA":242.5,"GDP":2631.23,"CONT":"Europe","IND_DAY":null},{"COUNTRY":"Italy","POP":60.36,"AREA":301.34,"GDP":1943.84,"CONT":"Europe","IND_DAY":null},{"COUNTRY":"Argentina","POP":44.94,"AREA":2780.4,"GDP":637.49,"CONT":"S.America","IND_DAY":"1816-07-09"},{"COUNTRY":"Algeria","POP":43.38,"AREA":2381.74,"GDP":167.56,"CONT":"Africa","IND_DAY":"1962-07-05"},{"COUNTRY":"Canada","POP":37.59,"AREA":9984.67,"GDP":1647.12,"CONT":"N.America","IND_DAY":"1867-07-01"},{"COUNTRY":"Australia","POP":25.47,"AREA":7692.02,"GDP":1408.68,"CONT":"Oceania","IND_DAY":null},{"COUNTRY":"Kazakhstan","POP":18.53,"AREA":2724.9,"GDP":159.41,"CONT":"Asia","IND_DAY":"1991-12-16"}]
data-records.json保存一个列表,每行有一个字典。行标签不是写的。
您可以使用orient='split'获得另一个有趣的文件结构:
>>> df.to_json('data-split.json', orient='split')结果文件是
data-split.json。您可以展开下面的代码块来查看该文件的外观:{"columns":["COUNTRY","POP","AREA","GDP","CONT","IND_DAY"],"index":["CHN","IND","USA","IDN","BRA","PAK","NGA","BGD","RUS","MEX","JPN","DEU","FRA","GBR","ITA","ARG","DZA","CAN","AUS","KAZ"],"data":[["China",1398.72,9596.96,12234.78,"Asia",null],["India",1351.16,3287.26,2575.67,"Asia","1947-08-15"],["US",329.74,9833.52,19485.39,"N.America","1776-07-04"],["Indonesia",268.07,1910.93,1015.54,"Asia","1945-08-17"],["Brazil",210.32,8515.77,2055.51,"S.America","1822-09-07"],["Pakistan",205.71,881.91,302.14,"Asia","1947-08-14"],["Nigeria",200.96,923.77,375.77,"Africa","1960-10-01"],["Bangladesh",167.09,147.57,245.63,"Asia","1971-03-26"],["Russia",146.79,17098.25,1530.75,null,"1992-06-12"],["Mexico",126.58,1964.38,1158.23,"N.America","1810-09-16"],["Japan",126.22,377.97,4872.42,"Asia",null],["Germany",83.02,357.11,3693.2,"Europe",null],["France",67.02,640.68,2582.49,"Europe","1789-07-14"],["UK",66.44,242.5,2631.23,"Europe",null],["Italy",60.36,301.34,1943.84,"Europe",null],["Argentina",44.94,2780.4,637.49,"S.America","1816-07-09"],["Algeria",43.38,2381.74,167.56,"Africa","1962-07-05"],["Canada",37.59,9984.67,1647.12,"N.America","1867-07-01"],["Australia",25.47,7692.02,1408.68,"Oceania",null],["Kazakhstan",18.53,2724.9,159.41,"Asia","1991-12-16"]]}
data-split.json包含一个包含以下列表的字典:
- 列的名称
- 行的标签
- 内部列表(二维序列)保存数据值
如果您没有为定义文件路径的可选参数
path_or_buf提供值,那么.to_json()将返回一个 JSON 字符串,而不是将结果写入文件。这种行为与.to_csv()是一致的。您还可以使用其他可选参数。例如,您可以设置
index=False来放弃保存行标签。你可以用double_precision控制精度,用date_format和date_unit控制日期。当数据中包含时间序列时,最后两个参数尤为重要:
>>> df = pd.DataFrame(data=data).T
>>> df['IND_DAY'] = pd.to_datetime(df['IND_DAY'])
>>> df.dtypes
COUNTRY object
POP object
AREA object
GDP object
CONT object
IND_DAY datetime64[ns]
dtype: object
>>> df.to_json('data-time.json')
在本例中,您已经从字典data中创建了DataFrame,并使用 to_datetime() 将最后一列中的值转换为datetime64。您可以展开下面的代码块来查看结果文件:
{"COUNTRY":{"CHN":"China","IND":"India","USA":"US","IDN":"Indonesia","BRA":"Brazil","PAK":"Pakistan","NGA":"Nigeria","BGD":"Bangladesh","RUS":"Russia","MEX":"Mexico","JPN":"Japan","DEU":"Germany","FRA":"France","GBR":"UK","ITA":"Italy","ARG":"Argentina","DZA":"Algeria","CAN":"Canada","AUS":"Australia","KAZ":"Kazakhstan"},"POP":{"CHN":1398.72,"IND":1351.16,"USA":329.74,"IDN":268.07,"BRA":210.32,"PAK":205.71,"NGA":200.96,"BGD":167.09,"RUS":146.79,"MEX":126.58,"JPN":126.22,"DEU":83.02,"FRA":67.02,"GBR":66.44,"ITA":60.36,"ARG":44.94,"DZA":43.38,"CAN":37.59,"AUS":25.47,"KAZ":18.53},"AREA":{"CHN":9596.96,"IND":3287.26,"USA":9833.52,"IDN":1910.93,"BRA":8515.77,"PAK":881.91,"NGA":923.77,"BGD":147.57,"RUS":17098.25,"MEX":1964.38,"JPN":377.97,"DEU":357.11,"FRA":640.68,"GBR":242.5,"ITA":301.34,"ARG":2780.4,"DZA":2381.74,"CAN":9984.67,"AUS":7692.02,"KAZ":2724.9},"GDP":{"CHN":12234.78,"IND":2575.67,"USA":19485.39,"IDN":1015.54,"BRA":2055.51,"PAK":302.14,"NGA":375.77,"BGD":245.63,"RUS":1530.75,"MEX":1158.23,"JPN":4872.42,"DEU":3693.2,"FRA":2582.49,"GBR":2631.23,"ITA":1943.84,"ARG":637.49,"DZA":167.56,"CAN":1647.12,"AUS":1408.68,"KAZ":159.41},"CONT":{"CHN":"Asia","IND":"Asia","USA":"N.America","IDN":"Asia","BRA":"S.America","PAK":"Asia","NGA":"Africa","BGD":"Asia","RUS":null,"MEX":"N.America","JPN":"Asia","DEU":"Europe","FRA":"Europe","GBR":"Europe","ITA":"Europe","ARG":"S.America","DZA":"Africa","CAN":"N.America","AUS":"Oceania","KAZ":"Asia"},"IND_DAY":{"CHN":null,"IND":-706320000000,"USA":-6106060800000,"IDN":-769219200000,"BRA":-4648924800000,"PAK":-706406400000,"NGA":-291945600000,"BGD":38793600000,"RUS":708307200000,"MEX":-5026838400000,"JPN":null,"DEU":null,"FRA":-5694969600000,"GBR":null,"ITA":null,"ARG":-4843411200000,"DZA":-236476800000,"CAN":-3234729600000,"AUS":null,"KAZ":692841600000}}
在这个文件中,你用大整数代替独立日的日期。这是因为当orient不是'table'时,可选参数date_format的默认值是'epoch'。这个默认行为将日期表示为相对于 1970 年 1 月 1 日午夜的纪元。
然而,如果您通过了date_format='iso',那么您将获得 ISO 8601 格式的日期。此外,date_unit决定了时间的单位:
>>> df = pd.DataFrame(data=data).T >>> df['IND_DAY'] = pd.to_datetime(df['IND_DAY']) >>> df.to_json('new-data-time.json', date_format='iso', date_unit='s')这段代码生成以下 JSON 文件:
{"COUNTRY":{"CHN":"China","IND":"India","USA":"US","IDN":"Indonesia","BRA":"Brazil","PAK":"Pakistan","NGA":"Nigeria","BGD":"Bangladesh","RUS":"Russia","MEX":"Mexico","JPN":"Japan","DEU":"Germany","FRA":"France","GBR":"UK","ITA":"Italy","ARG":"Argentina","DZA":"Algeria","CAN":"Canada","AUS":"Australia","KAZ":"Kazakhstan"},"POP":{"CHN":1398.72,"IND":1351.16,"USA":329.74,"IDN":268.07,"BRA":210.32,"PAK":205.71,"NGA":200.96,"BGD":167.09,"RUS":146.79,"MEX":126.58,"JPN":126.22,"DEU":83.02,"FRA":67.02,"GBR":66.44,"ITA":60.36,"ARG":44.94,"DZA":43.38,"CAN":37.59,"AUS":25.47,"KAZ":18.53},"AREA":{"CHN":9596.96,"IND":3287.26,"USA":9833.52,"IDN":1910.93,"BRA":8515.77,"PAK":881.91,"NGA":923.77,"BGD":147.57,"RUS":17098.25,"MEX":1964.38,"JPN":377.97,"DEU":357.11,"FRA":640.68,"GBR":242.5,"ITA":301.34,"ARG":2780.4,"DZA":2381.74,"CAN":9984.67,"AUS":7692.02,"KAZ":2724.9},"GDP":{"CHN":12234.78,"IND":2575.67,"USA":19485.39,"IDN":1015.54,"BRA":2055.51,"PAK":302.14,"NGA":375.77,"BGD":245.63,"RUS":1530.75,"MEX":1158.23,"JPN":4872.42,"DEU":3693.2,"FRA":2582.49,"GBR":2631.23,"ITA":1943.84,"ARG":637.49,"DZA":167.56,"CAN":1647.12,"AUS":1408.68,"KAZ":159.41},"CONT":{"CHN":"Asia","IND":"Asia","USA":"N.America","IDN":"Asia","BRA":"S.America","PAK":"Asia","NGA":"Africa","BGD":"Asia","RUS":null,"MEX":"N.America","JPN":"Asia","DEU":"Europe","FRA":"Europe","GBR":"Europe","ITA":"Europe","ARG":"S.America","DZA":"Africa","CAN":"N.America","AUS":"Oceania","KAZ":"Asia"},"IND_DAY":{"CHN":null,"IND":"1947-08-15T00:00:00Z","USA":"1776-07-04T00:00:00Z","IDN":"1945-08-17T00:00:00Z","BRA":"1822-09-07T00:00:00Z","PAK":"1947-08-14T00:00:00Z","NGA":"1960-10-01T00:00:00Z","BGD":"1971-03-26T00:00:00Z","RUS":"1992-06-12T00:00:00Z","MEX":"1810-09-16T00:00:00Z","JPN":null,"DEU":null,"FRA":"1789-07-14T00:00:00Z","GBR":null,"ITA":null,"ARG":"1816-07-09T00:00:00Z","DZA":"1962-07-05T00:00:00Z","CAN":"1867-07-01T00:00:00Z","AUS":null,"KAZ":"1991-12-16T00:00:00Z"}}结果文件中的日期采用 ISO 8601 格式。
您可以使用
read_json()从 JSON 文件中加载数据:
>>> df = pd.read_json('data-index.json', orient='index',
... convert_dates=['IND_DAY'])
当您使用参数convert_dates来读取 CSV 文件时,它的用途与parse_dates类似。可选参数orient非常重要,因为它指定了熊猫如何理解文件的结构。
您还可以使用其他可选参数:
- 用
encoding设置编码。 - 用
convert_dates和keep_default_dates操作日期。 - 用
dtype和precise_float冲击精度。 - 用
numpy=True将数值数据直接解码到 NumPy 数组中。
注意,当使用 JSON 格式存储数据时,可能会丢失行和列的顺序。
HTML 文件
一个 HTML 是一个纯文本文件,它使用超文本标记语言来帮助浏览器呈现网页。HTML 文件的扩展名是.html和.htm。你需要安装一个 html 解析器库,比如 lxml 或者 html5lib 来处理 HTML 文件:
$pip install lxml html5lib
您也可以使用 Conda 安装相同的软件包:
$ conda install lxml html5lib
一旦你有了这些库,你可以用 .to_html() 将DataFrame的内容保存为 HTML 文件:
df = pd.DataFrame(data=data).T df.to_html('data.html')这段代码生成一个文件
data.html。您可以展开下面的代码块来查看该文件的外观:<table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>COUNTRY</th> <th>POP</th> <th>AREA</th> <th>GDP</th> <th>CONT</th> <th>IND_DAY</th> </tr> </thead> <tbody> <tr> <th>CHN</th> <td>China</td> <td>1398.72</td> <td>9596.96</td> <td>12234.8</td> <td>Asia</td> <td>NaN</td> </tr> <tr> <th>IND</th> <td>India</td> <td>1351.16</td> <td>3287.26</td> <td>2575.67</td> <td>Asia</td> <td>1947-08-15</td> </tr> <tr> <th>USA</th> <td>US</td> <td>329.74</td> <td>9833.52</td> <td>19485.4</td> <td>N.America</td> <td>1776-07-04</td> </tr> <tr> <th>IDN</th> <td>Indonesia</td> <td>268.07</td> <td>1910.93</td> <td>1015.54</td> <td>Asia</td> <td>1945-08-17</td> </tr> <tr> <th>BRA</th> <td>Brazil</td> <td>210.32</td> <td>8515.77</td> <td>2055.51</td> <td>S.America</td> <td>1822-09-07</td> </tr> <tr> <th>PAK</th> <td>Pakistan</td> <td>205.71</td> <td>881.91</td> <td>302.14</td> <td>Asia</td> <td>1947-08-14</td> </tr> <tr> <th>NGA</th> <td>Nigeria</td> <td>200.96</td> <td>923.77</td> <td>375.77</td> <td>Africa</td> <td>1960-10-01</td> </tr> <tr> <th>BGD</th> <td>Bangladesh</td> <td>167.09</td> <td>147.57</td> <td>245.63</td> <td>Asia</td> <td>1971-03-26</td> </tr> <tr> <th>RUS</th> <td>Russia</td> <td>146.79</td> <td>17098.2</td> <td>1530.75</td> <td>NaN</td> <td>1992-06-12</td> </tr> <tr> <th>MEX</th> <td>Mexico</td> <td>126.58</td> <td>1964.38</td> <td>1158.23</td> <td>N.America</td> <td>1810-09-16</td> </tr> <tr> <th>JPN</th> <td>Japan</td> <td>126.22</td> <td>377.97</td> <td>4872.42</td> <td>Asia</td> <td>NaN</td> </tr> <tr> <th>DEU</th> <td>Germany</td> <td>83.02</td> <td>357.11</td> <td>3693.2</td> <td>Europe</td> <td>NaN</td> </tr> <tr> <th>FRA</th> <td>France</td> <td>67.02</td> <td>640.68</td> <td>2582.49</td> <td>Europe</td> <td>1789-07-14</td> </tr> <tr> <th>GBR</th> <td>UK</td> <td>66.44</td> <td>242.5</td> <td>2631.23</td> <td>Europe</td> <td>NaN</td> </tr> <tr> <th>ITA</th> <td>Italy</td> <td>60.36</td> <td>301.34</td> <td>1943.84</td> <td>Europe</td> <td>NaN</td> </tr> <tr> <th>ARG</th> <td>Argentina</td> <td>44.94</td> <td>2780.4</td> <td>637.49</td> <td>S.America</td> <td>1816-07-09</td> </tr> <tr> <th>DZA</th> <td>Algeria</td> <td>43.38</td> <td>2381.74</td> <td>167.56</td> <td>Africa</td> <td>1962-07-05</td> </tr> <tr> <th>CAN</th> <td>Canada</td> <td>37.59</td> <td>9984.67</td> <td>1647.12</td> <td>N.America</td> <td>1867-07-01</td> </tr> <tr> <th>AUS</th> <td>Australia</td> <td>25.47</td> <td>7692.02</td> <td>1408.68</td> <td>Oceania</td> <td>NaN</td> </tr> <tr> <th>KAZ</th> <td>Kazakhstan</td> <td>18.53</td> <td>2724.9</td> <td>159.41</td> <td>Asia</td> <td>1991-12-16</td> </tr> </tbody> </table>这个文件很好地显示了
DataFrame的内容。但是,请注意,您并没有获得整个网页。您已经以 HTML 格式输出了对应于df的数据。如果您不提供可选参数
buf,则.to_html()不会创建文件,该参数表示要写入的缓冲区。如果您忽略这个参数,那么您的代码将返回一个字符串,就像处理.to_csv()和.to_json()一样。以下是一些其他可选参数:
header决定了是否保存列名。index决定是否保存行标签。classes赋值层叠样式表【CSS】类。render_links指定是否将 URL 转换为 HTML 链接。table_id将 CSSid分配给table标签。escape决定是否将字符<、>和&转换为 HTML 安全字符串。您可以使用类似这样的参数来指定结果文件或字符串的不同方面。
您可以使用
read_html()从合适的 HTML 文件创建一个DataFrame对象,它将返回一个DataFrame实例或它们的列表:
>>> df = pd.read_html('data.html', index_col=0, parse_dates=['IND_DAY'])
这与您在读取 CSV 文件时所做的非常相似。还有一些参数可以帮助您处理日期、缺失值、精度、编码、HTML 解析器等等。
Excel 文件
你已经学会了如何用熊猫读写 Excel 文件。然而,还有几个选项值得考虑。首先,当您使用.to_excel()时,您可以用可选参数sheet_name指定目标工作表的名称:
>>> df = pd.DataFrame(data=data).T >>> df.to_excel('data.xlsx', sheet_name='COUNTRIES')在这里,您创建了一个文件
data.xlsx,其中包含一个名为COUNTRIES的工作表,用于存储数据。字符串'data.xlsx'是参数excel_writer的自变量,它定义了 Excel 文件的名称或路径。可选参数
startrow和startcol都默认为0,并指示应该开始写入数据的左上角单元:
>>> df.to_excel('data-shifted.xlsx', sheet_name='COUNTRIES',
... startrow=2, startcol=4)
这里,您指定表格应该从第三行第五列开始。您还使用了基于零的索引,因此第三行用2表示,第五列用4表示。
现在产生的工作表如下所示:
如您所见,表格从第三行2和第五列E开始。
.read_excel()还有一个可选参数sheet_name,它指定在加载数据时读取哪些工作表。它可以采用下列值之一:
- 工作表的从零开始的索引
- 工作表的名称
- 读取多张纸的索引或名称列表
- 值
None读取所有工作表
下面是如何在代码中使用该参数:
>>> df = pd.read_excel('data.xlsx', sheet_name=0, index_col=0, ... parse_dates=['IND_DAY']) >>> df = pd.read_excel('data.xlsx', sheet_name='COUNTRIES', index_col=0, ... parse_dates=['IND_DAY'])上面的两个语句创建了相同的
DataFrame,因为sheet_name参数具有相同的值。在这两种情况下,sheet_name=0和sheet_name='COUNTRIES'指的是同一个工作表。参数parse_dates=['IND_DAY']告诉熊猫尽量将该列中的值视为日期或时间。还有其他可选参数可以与
.read_excel()和.to_excel()一起使用,以确定 Excel 引擎、编码、处理缺失值和无穷大的方式、写入列名和行标签的方法等等。SQL 文件
熊猫 IO 工具还可以读写数据库。在下一个例子中,您将把数据写入一个名为
data.db的数据库。首先,你需要一个 SQLAlchemy 包。想了解更多,可以阅读官方 ORM 教程。您还需要数据库驱动程序。Python 有一个内置的 SQLite 的驱动。您可以使用 pip 安装 SQLAlchemy:
$ pip install sqlalchemy也可以用康达安装:
$ conda install sqlalchemy一旦安装了 SQLAlchemy,导入
create_engine()并创建一个数据库引擎:
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///data.db', echo=False)
现在一切都设置好了,下一步是创建一个DataFrame对象。方便指定数据类型,应用 .to_sql() 。
>>> dtypes = {'POP': 'float64', 'AREA': 'float64', 'GDP': 'float64', ... 'IND_DAY': 'datetime64'} >>> df = pd.DataFrame(data=data).T.astype(dtype=dtypes) >>> df.dtypes COUNTRY object POP float64 AREA float64 GDP float64 CONT object IND_DAY datetime64[ns] dtype: object
.astype()是一种非常方便的方法,可以用来一次设置多个数据类型。一旦你创建了你的
DataFrame,你可以用.to_sql()将它保存到数据库中:
>>> df.to_sql('data.db', con=engine, index_label='ID')
参数con用于指定您想要使用的数据库连接或引擎。可选参数index_label指定如何调用带有行标签的数据库列。你会经常看到它取值为ID、Id或id。
您应该得到数据库data.db,其中有一个表,如下所示:
第一列包含行标签。为了省略将它们写入数据库,将index=False传递给.to_sql()。其他列对应于DataFrame的列。
还有几个可选参数。例如,可以使用schema来指定数据库模式,使用dtype来确定数据库列的类型。您还可以使用if_exists,它告诉您如果已经存在一个具有相同名称和路径的数据库,该怎么办:
if_exists='fail'引出了 ValueError 并且是默认的。if_exists='replace'删除表格并插入新值。if_exists='append'向表格中插入新值。
您可以使用 read_sql() 从数据库中加载数据:
>>> df = pd.read_sql('data.db', con=engine, index_col='ID') >>> df COUNTRY POP AREA GDP CONT IND_DAY ID CHN China 1398.72 9596.96 12234.78 Asia NaT IND India 1351.16 3287.26 2575.67 Asia 1947-08-15 USA US 329.74 9833.52 19485.39 N.America 1776-07-04 IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17 BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07 PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14 NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01 BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26 RUS Russia 146.79 17098.25 1530.75 None 1992-06-12 MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16 JPN Japan 126.22 377.97 4872.42 Asia NaT DEU Germany 83.02 357.11 3693.20 Europe NaT FRA France 67.02 640.68 2582.49 Europe 1789-07-14 GBR UK 66.44 242.50 2631.23 Europe NaT ITA Italy 60.36 301.34 1943.84 Europe NaT ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09 DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05 CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01 AUS Australia 25.47 7692.02 1408.68 Oceania NaT KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16参数
index_col指定带有行标签的列的名称。请注意,这会在以ID开头的标题后插入一个额外的行。您可以使用以下代码行来修复此问题:
>>> df.index.name = None
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 None 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
现在你有了和以前一样的DataFrame对象。
请注意,俄罗斯的大陆现在是None而不是nan。如果你想用nan来填充缺失的值,那么你可以用 .fillna() :
>>> df.fillna(value=float('nan'), inplace=True)
.fillna()用传递给value的值替换所有丢失的值。在这里,您通过了float('nan'),它说用nan填充所有缺失的值。还要注意,您不必将
parse_dates=['IND_DAY']传递给read_sql()。这是因为您的数据库能够检测到最后一列包含日期。然而,如果你愿意,你可以通过parse_dates。你会得到同样的结果。您还可以使用其他函数来读取数据库,如
read_sql_table()和read_sql_query()。请随意试用它们!泡菜文件
酸洗是将 Python 对象转换成字节流的行为。拆线是相反的过程。 Python pickle 文件是保存 Python 对象的数据和层次的二进制文件。它们通常有扩展名
.pickle或.pkl。您可以使用
.to_pickle()将您的DataFrame保存在一个 pickle 文件中:
>>> dtypes = {'POP': 'float64', 'AREA': 'float64', 'GDP': 'float64',
... 'IND_DAY': 'datetime64'}
>>> df = pd.DataFrame(data=data).T.astype(dtype=dtypes)
>>> df.to_pickle('data.pickle')
就像处理数据库一样,首先指定数据类型可能会很方便。然后,您创建一个文件data.pickle来包含您的数据。您还可以向可选参数protocol传递一个整数值,该参数指定 pickler 的协议。
可以用 read_pickle() 从 pickle 文件中获取数据:
>>> df = pd.read_pickle('data.pickle') >>> df COUNTRY POP AREA GDP CONT IND_DAY CHN China 1398.72 9596.96 12234.78 Asia NaT IND India 1351.16 3287.26 2575.67 Asia 1947-08-15 USA US 329.74 9833.52 19485.39 N.America 1776-07-04 IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17 BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07 PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14 NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01 BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26 RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12 MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16 JPN Japan 126.22 377.97 4872.42 Asia NaT DEU Germany 83.02 357.11 3693.20 Europe NaT FRA France 67.02 640.68 2582.49 Europe 1789-07-14 GBR UK 66.44 242.50 2631.23 Europe NaT ITA Italy 60.36 301.34 1943.84 Europe NaT ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09 DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05 CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01 AUS Australia 25.47 7692.02 1408.68 Oceania NaT KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
read_pickle()返回存储数据的DataFrame。您还可以检查数据类型:
>>> df.dtypes
COUNTRY object
POP float64
AREA float64
GDP float64
CONT object
IND_DAY datetime64[ns]
dtype: object
这些与您在使用.to_pickle()之前指定的相同。
作为一个警告,你应该始终小心从不可信的来源加载泡菜。这可能很危险!当你解压一个不可信的文件时,它可以在你的机器上执行任意代码,远程访问你的计算机,或者以其他方式利用你的设备。
使用大数据
如果您的文件太大,无法保存或处理,那么有几种方法可以减少所需的磁盘空间:
- 压缩您的文件
- 仅选择您想要的列
- 省略不需要的行
- 强制使用不太精确的数据类型
- 将数据分割成块
您将依次了解这些技术。
压缩和解压缩文件
您可以像创建常规文件一样创建一个归档文件,并添加一个对应于所需压缩类型的后缀:
'.gz''.bz2''.zip''.xz'
熊猫可以自己推断压缩类型:
>>> df = pd.DataFrame(data=data).T >>> df.to_csv('data.csv.zip')在这里,您创建一个压缩的
.csv文件作为档案。常规.csv文件的大小是 1048 字节,而压缩文件只有 766 字节。你可以像往常一样用熊猫
read_csv()功能打开这个压缩文件:
>>> df = pd.read_csv('data.csv.zip', index_col=0,
... parse_dates=['IND_DAY'])
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaT
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaT
DEU Germany 83.02 357.11 3693.20 Europe NaT
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaT
ITA Italy 60.36 301.34 1943.84 Europe NaT
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaT
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
read_csv()在将文件读入DataFrame之前对其进行解压缩。
您可以使用可选参数compression指定压缩类型,该参数可以采用以下任何值:
'infer''gzip''bz2''zip''xz'None
默认值compression='infer'表示 Pandas 应该从文件扩展名中推断出压缩类型。
以下是压缩 pickle 文件的方法:
>>> df = pd.DataFrame(data=data).T >>> df.to_pickle('data.pickle.compress', compression='gzip')您应该得到文件
data.pickle.compress,以便以后解压缩和读取:
>>> df = pd.read_pickle('data.pickle.compress', compression='gzip')
df再次对应于数据与之前相同的DataFrame。
您也可以尝试其他压缩方法。如果你使用的是 pickle 文件,那么记住.zip格式只支持读取。
选择列
Pandas read_csv()和read_excel()函数有可选参数usecols,您可以使用它来指定您想要从文件中加载的列。您可以将列名列表作为相应的参数传递:
>>> df = pd.read_csv('data.csv', usecols=['COUNTRY', 'AREA']) >>> df COUNTRY AREA 0 China 9596.96 1 India 3287.26 2 US 9833.52 3 Indonesia 1910.93 4 Brazil 8515.77 5 Pakistan 881.91 6 Nigeria 923.77 7 Bangladesh 147.57 8 Russia 17098.25 9 Mexico 1964.38 10 Japan 377.97 11 Germany 357.11 12 France 640.68 13 UK 242.50 14 Italy 301.34 15 Argentina 2780.40 16 Algeria 2381.74 17 Canada 9984.67 18 Australia 7692.02 19 Kazakhstan 2724.90现在您有了一个包含比以前更少数据的
DataFrame。这里只有国家和地区的名称。除了列名,您还可以传递它们的索引:
>>> df = pd.read_csv('data.csv',index_col=0, usecols=[0, 1, 3])
>>> df
COUNTRY AREA
CHN China 9596.96
IND India 3287.26
USA US 9833.52
IDN Indonesia 1910.93
BRA Brazil 8515.77
PAK Pakistan 881.91
NGA Nigeria 923.77
BGD Bangladesh 147.57
RUS Russia 17098.25
MEX Mexico 1964.38
JPN Japan 377.97
DEU Germany 357.11
FRA France 640.68
GBR UK 242.50
ITA Italy 301.34
ARG Argentina 2780.40
DZA Algeria 2381.74
CAN Canada 9984.67
AUS Australia 7692.02
KAZ Kazakhstan 2724.90
展开下面的代码块,将这些结果与文件'data.csv'进行比较:
,COUNTRY,POP,AREA,GDP,CONT,IND_DAY
CHN,China,1398.72,9596.96,12234.78,Asia,
IND,India,1351.16,3287.26,2575.67,Asia,1947-08-15
USA,US,329.74,9833.52,19485.39,N.America,1776-07-04
IDN,Indonesia,268.07,1910.93,1015.54,Asia,1945-08-17
BRA,Brazil,210.32,8515.77,2055.51,S.America,1822-09-07
PAK,Pakistan,205.71,881.91,302.14,Asia,1947-08-14
NGA,Nigeria,200.96,923.77,375.77,Africa,1960-10-01
BGD,Bangladesh,167.09,147.57,245.63,Asia,1971-03-26
RUS,Russia,146.79,17098.25,1530.75,,1992-06-12
MEX,Mexico,126.58,1964.38,1158.23,N.America,1810-09-16
JPN,Japan,126.22,377.97,4872.42,Asia,
DEU,Germany,83.02,357.11,3693.2,Europe,
FRA,France,67.02,640.68,2582.49,Europe,1789-07-14
GBR,UK,66.44,242.5,2631.23,Europe,
ITA,Italy,60.36,301.34,1943.84,Europe,
ARG,Argentina,44.94,2780.4,637.49,S.America,1816-07-09
DZA,Algeria,43.38,2381.74,167.56,Africa,1962-07-05
CAN,Canada,37.59,9984.67,1647.12,N.America,1867-07-01
AUS,Australia,25.47,7692.02,1408.68,Oceania,
KAZ,Kazakhstan,18.53,2724.9,159.41,Asia,1991-12-16
您可以看到以下列:
- 在索引
0处的列包含行标签。 - 索引
1处的列包含国家名称。 - 在索引
3处的列包含区域。
类似地,read_sql()有一个可选参数columns,它接受一列要读取的列名:
>>> df = pd.read_sql('data.db', con=engine, index_col='ID', ... columns=['COUNTRY', 'AREA']) >>> df.index.name = None >>> df COUNTRY AREA CHN China 9596.96 IND India 3287.26 USA US 9833.52 IDN Indonesia 1910.93 BRA Brazil 8515.77 PAK Pakistan 881.91 NGA Nigeria 923.77 BGD Bangladesh 147.57 RUS Russia 17098.25 MEX Mexico 1964.38 JPN Japan 377.97 DEU Germany 357.11 FRA France 640.68 GBR UK 242.50 ITA Italy 301.34 ARG Argentina 2780.40 DZA Algeria 2381.74 CAN Canada 9984.67 AUS Australia 7692.02 KAZ Kazakhstan 2724.90同样,
DataFrame只包含带有国家和地区名称的列。如果columns是None或者被省略,那么所有的列都将被读取,就像你在之前看到的。默认行为是columns=None。省略行
当你为数据处理或机器学习测试一个算法时,你通常不需要整个数据集。只加载数据的一个子集来加速这个过程是很方便的。Pandas
read_csv()和read_excel()函数有一些可选参数,允许您选择想要加载的行:
skiprows: 如果是整数,则为文件开头要跳过的行数,如果是类似列表的对象,则为要跳过的行的从零开始的索引skipfooter: 文件末尾要跳过的行数nrows: 要读取的行数下面是如何跳过从零开始的奇数索引行,保留偶数索引行:
>>> df = pd.read_csv('data.csv', index_col=0, skiprows=range(1, 20, 2))
>>> df
COUNTRY POP AREA GDP CONT IND_DAY
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
DEU Germany 83.02 357.11 3693.20 Europe NaN
GBR UK 66.44 242.50 2631.23 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
在本例中,skiprows是range(1, 20, 2),对应于值1、3、…、19。Python 内置类 range 的实例的行为类似于序列。文件data.csv的第一行是标题行。它有索引0,所以 Pandas 加载它。索引为1的第二行对应标签CHN,熊猫跳过。加载具有索引2和标签IND的第三行,依此类推。
如果你想随机选择行,那么skiprows可以是一个带有伪随机数的列表或 NumPy 数组,可以通过纯 Python 或 NumPy 获得。
强制不太精确的数据类型
如果您可以接受不太精确的数据类型,那么您可能会节省大量内存!首先,再次用.dtypes获取数据类型:
>>> df = pd.read_csv('data.csv', index_col=0, parse_dates=['IND_DAY']) >>> df.dtypes COUNTRY object POP float64 AREA float64 GDP float64 CONT object IND_DAY datetime64[ns] dtype: object带有浮点数的列是 64 位浮点数。这种类型的每个数字
float64消耗 64 位或 8 个字节。每列有 20 个数字,需要 160 个字节。你可以用.memory_usage()来验证这一点:
>>> df.memory_usage()
Index 160
COUNTRY 160
POP 160
AREA 160
GDP 160
CONT 160
IND_DAY 160
dtype: int64
.memory_usage()返回一个Series的实例,每一列的内存使用量以字节为单位。您可以方便地将它与.loc[]和 .sum() 组合起来,得到一组列的内存:
>>> df.loc[:, ['POP', 'AREA', 'GDP']].memory_usage(index=False).sum() 480这个例子展示了如何组合数字列
'POP'、'AREA'和'GDP'来获得它们的总内存需求。参数index=False从结果Series对象中排除行标签的数据。对于这三列,您将需要 480 字节。也可以用
.to_numpy()或.values提取 NumPy 数组形式的数据值。然后,使用.nbytes属性来获取数组中各项所消耗的总字节数:
>>> df.loc[:, ['POP', 'AREA', 'GDP']].to_numpy().nbytes
480
结果是同样的 480 字节。那么,如何节省内存呢?
在这种情况下,您可以指定您的数字列'POP'、'AREA'和'GDP'应该具有类型float32。使用可选参数dtype来完成此操作:
>>> dtypes = {'POP': 'float32', 'AREA': 'float32', 'GDP': 'float32'} >>> df = pd.read_csv('data.csv', index_col=0, dtype=dtypes, ... parse_dates=['IND_DAY'])字典
dtypes为每一列指定所需的数据类型。它作为对应于参数dtype的自变量传递给熊猫read_csv()函数。现在,您可以验证每个数字列需要 80 个字节,或者每个项目需要 4 个字节:
>>> df.dtypes
COUNTRY object
POP float32
AREA float32
GDP float32
CONT object
IND_DAY datetime64[ns]
dtype: object
>>> df.memory_usage()
Index 160
COUNTRY 160
POP 80
AREA 80
GDP 80
CONT 160
IND_DAY 160
dtype: int64
>>> df.loc[:, ['POP', 'AREA', 'GDP']].memory_usage(index=False).sum()
240
>>> df.loc[:, ['POP', 'AREA', 'GDP']].to_numpy().nbytes
240
每个值都是 32 位或 4 字节的浮点数。三个数字列各包含 20 个项目。当使用类型float32时,总共需要 240 字节的内存。这是使用float64所需的 480 字节大小的一半。
除了节省内存之外,在某些情况下,通过使用float32而不是float64,可以显著减少处理数据所需的时间。
使用块来遍历文件
处理非常大的数据集的另一种方法是将数据分成更小的块,一次处理一个块。如果使用read_csv()、read_json()或read_sql(),则可以指定可选参数chunksize:
>>> data_chunk = pd.read_csv('data.csv', index_col=0, chunksize=8) >>> type(data_chunk) <class 'pandas.io.parsers.TextFileReader'> >>> hasattr(data_chunk, '__iter__') True >>> hasattr(data_chunk, '__next__') True
chunksize默认为None,可以取整数值,表示单个块中的项目数。当chunksize是一个整数时,read_csv()返回一个 iterable,您可以在for循环中使用该 iterable,以便在每次迭代中只获取和处理数据集的一部分:
>>> for df_chunk in pd.read_csv('data.csv', index_col=0, chunksize=8):
... print(df_chunk, end='\n\n')
... print('memory:', df_chunk.memory_usage().sum(), 'bytes',
... end='\n\n\n')
...
COUNTRY POP AREA GDP CONT IND_DAY
CHN China 1398.72 9596.96 12234.78 Asia NaN
IND India 1351.16 3287.26 2575.67 Asia 1947-08-15
USA US 329.74 9833.52 19485.39 N.America 1776-07-04
IDN Indonesia 268.07 1910.93 1015.54 Asia 1945-08-17
BRA Brazil 210.32 8515.77 2055.51 S.America 1822-09-07
PAK Pakistan 205.71 881.91 302.14 Asia 1947-08-14
NGA Nigeria 200.96 923.77 375.77 Africa 1960-10-01
BGD Bangladesh 167.09 147.57 245.63 Asia 1971-03-26
memory: 448 bytes
COUNTRY POP AREA GDP CONT IND_DAY
RUS Russia 146.79 17098.25 1530.75 NaN 1992-06-12
MEX Mexico 126.58 1964.38 1158.23 N.America 1810-09-16
JPN Japan 126.22 377.97 4872.42 Asia NaN
DEU Germany 83.02 357.11 3693.20 Europe NaN
FRA France 67.02 640.68 2582.49 Europe 1789-07-14
GBR UK 66.44 242.50 2631.23 Europe NaN
ITA Italy 60.36 301.34 1943.84 Europe NaN
ARG Argentina 44.94 2780.40 637.49 S.America 1816-07-09
memory: 448 bytes
COUNTRY POP AREA GDP CONT IND_DAY
DZA Algeria 43.38 2381.74 167.56 Africa 1962-07-05
CAN Canada 37.59 9984.67 1647.12 N.America 1867-07-01
AUS Australia 25.47 7692.02 1408.68 Oceania NaN
KAZ Kazakhstan 18.53 2724.90 159.41 Asia 1991-12-16
memory: 224 bytes
在这个例子中,chunksize是8。for循环的第一次迭代只返回数据集前八行的DataFrame。第二次迭代返回下八行的另一个DataFrame。第三次也是最后一次迭代返回剩余的四行。
注意:你也可以通过iterator=True来强制熊猫read_csv()函数返回一个迭代器对象,而不是一个DataFrame对象。
在每次迭代中,您获得并处理行数等于chunksize的DataFrame。在最后一次迭代中,行数可能比chunksize的值少。您可以使用该功能来控制处理数据所需的内存量,并保持该内存量合理较小。
结论
你现在知道如何保存来自熊猫DataFrame对象的数据和标签到不同类型的文件。您还知道如何从文件中加载数据并创建DataFrame对象。
您已经使用 Pandas read_csv()和.to_csv()方法来读写 CSV 文件。您还使用了类似的方法来读写 Excel、JSON、HTML、SQL 和 pickle 文件。这些功能非常方便,应用非常广泛。它们允许您在单个函数或方法调用中保存或加载数据。
您还了解了在处理大型数据文件时如何节省时间、内存和磁盘空间:
- 压缩或解压文件
- 选择您想要加载的行和列
- 使用不太精确的数据类型
- 将数据分割成块,并逐个处理
您已经掌握了机器学习和数据科学过程中的重要一步!如果你有任何问题或意见,请写在下面的评论区。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 和熊猫一起读写文件*********


 浙公网安备 33010602011771号
浙公网安备 33010602011771号