RealPython-中文系列教程-六-
RealPython 中文系列教程(六)
原文:RealPython
探索 Flask,第 1 部分——设置静态站点
原文:https://realpython.com/introduction-to-flask-part-1-setting-up-a-static-site/
欢迎来到 Realp Python 探索烧瓶系列…
系列概述
访问discoverflask.com查看系列摘要——博客帖子和视频的链接。
Flask 是一个由 Python 支持的微型 web 框架。它的 API 相当小,容易学习和使用。但是不要让这欺骗了你,因为它足够强大,可以支持处理大量流量的企业级应用程序。
你可以从一个完全包含在一个文件中的应用程序开始,然后随着你的站点变得越来越复杂,以一种结构良好的方式慢慢扩展到多个文件和文件夹。
这是一个很好的开始框架,你将在真正的“真正的 Python 风格”中学习:通过有趣的实践例子。
注:本教程最初发布于 2013 年 1 月 29 日。我们修改了它,由于所做的改变的数量,我们决定“退休”旧教程,并创建一个全新的教程。如果你有兴趣查看旧教程的代码和视频,请访问这个回购。
查看随附的视频。
要求
本教程假设你已经安装了 Python 2.7.x 、 pip 和 virtualenv 。
理想情况下,您应该对命令行或终端以及 Python 有基本的了解。如果没有,您将学到足够的知识,然后随着您继续使用 Flask,您的开发技能也会提高。如果你确实想要额外的帮助,看看真正的 Python 系列,从头开始学习 Python 和 web 开发。
你还需要一个代码编辑器或者 IDE,比如 Sublime Text 、 gedit 、 Notepad++ ,或者 VIM 等。如果您确定要使用什么,请查看 Sublime Text,它是一个轻量级但功能强大的跨平台代码编辑器。
惯例
-
本教程中的所有例子都使用了 Unix 风格的提示符:
$ python hello-world.py。【记住,美元符号不是命令的一部分,Windows 中对应的命令是:C:\Sites> python hello-world.py。] -
所有的例子都在崇高的文本 3 编码。
-
所有例子都使用了 Python 2.7.7。不过,您可以使用任何版本的 2.7.x。
-
Github repo 中的
requirements.txt文件中列出了额外的需求和依赖版本。
设置
- 导航到一个方便的目录,如“桌面”或“文档”文件夹
- 创建一个名为“flask-intro”的新目录来存放您的项目
- 激活虚拟
- 用 Pip
$ pip install Flask安装烧瓶
结构
如果你熟悉 Django 、 web2py 或任何其他高级(或全栈)框架,那么你知道每一个都有特定的结构。然而,由于它的极简本质,Flask 没有提供集合结构,这对初学者来说可能很困难。幸运的是,这很容易弄清楚,特别是如果您对 Flask 组件使用单个文件。
在“flask-intro”文件夹中创建以下项目结构:
├── app.py
├── static
└── templates
这里,我们简单地为 Flask 应用程序创建了一个名为 app.py 的文件,然后创建了两个文件夹,“静态”和“模板”。前者存放我们的样式表、 JavaScript 文件和图像,而后者存放 HTML 文件。这是一个很好的起点。我们已经在考虑前端和后端了。 app.py 将在后端利用模型-视图-控制器(MVC)设计模式来处理请求并向最终用户发出响应。
简单地说,当一个请求进来时,处理我们应用程序的业务逻辑的控制器决定如何处理它。
例如,控制器可以直接与数据库通信(如 MySQL 、 SQLite 、PostgreSQL、MongoDB 等)。)来获取请求的数据,并通过视图返回一个响应,其中包含适当格式的适当数据(如 HTML 或 JSON)。或者最终用户请求的是不存在的资源——在这种情况下,控制器将响应 404 错误。
从这种结构开始将有助于将你的应用扩展到不同的文件和文件夹中,因为前端和后端之间已经有了逻辑上的分离。如果你对 MVC 模式不熟悉,在这里阅读更多关于它的内容。习惯它吧,因为几乎每个 web 框架都使用某种形式的 MVC。
路线
打开您最喜欢的编辑器,将以下代码添加到您的 app.py 文件中:
# import the Flask class from the flask module
from flask import Flask, render_template
# create the application object
app = Flask(__name__)
# use decorators to link the function to a url
@app.route('/')
def home():
return "Hello, World!" # return a string
@app.route('/welcome')
def welcome():
return render_template('welcome.html') # render a template
# start the server with the 'run()' method
if __name__ == '__main__':
app.run(debug=True)
这相当简单。
导入Flask类后,我们创建(或实例化)应用程序对象,定义响应请求的视图,然后启动服务器。
route 装饰器用于将一个 URL 关联(或映射)到一个函数。URL /与home()函数相关联,因此当最终用户请求该 URL 时,视图将使用一个字符串进行响应。类似地,当请求/welcome URL 时,视图将呈现welcome.html模板。
简言之,主应用程序对象被实例化,然后用于将 URL 映射到函数。
更详细的解释,请阅读 Flask 的快速入门教程。
测试
是时候进行理智检查了。启动您的开发服务器:
$ python app.py
导航到 http://localhost:5000/ 。你应该看到“你好,世界!”盯着你。然后请求下一个 URL,http://localhost:5000/welcome。您应该会看到一个“TemplateNotFound”错误。为什么?因为我们还没有建立我们的模板,welcome.html。弗拉斯克正在找,但不在那里。就这么办吧。首先,从你的终端按下 Ctrl + C 杀死服务器。
关于实际回应的更多信息,请查看本文附带的视频。
模板
在你的模板目录中创建一个名为welcome.html的新文件。在代码编辑器中打开该文件,然后添加以下 HTML:
<!DOCTYPE html>
<html>
<head>
<title>Flask Intro</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<div class="container">
<h1>Welcome to Flask!</h2>
<br>
<p>Click <a href="/">here</a> to go home.</p>
</div>
</body>
</html>
保存。再次运行您的服务器。当你请求http://localhost:5000/welcome的时候你现在看到了什么?测试链接。它能工作,但是不太漂亮。让我们改变这一点。这一次,在我们进行更改时,让服务器保持运行。
引导程序
好吧。让我们通过添加样式表来利用这些静态文件夹。你听说过 Bootstrap 吗?如果你的答案是否定的,那么请看这篇博客文章了解详情。
下载 Bootstrap ,然后将 bootstrap.min.css 和 bootstrap.min.js 文件添加到你的“静态”文件夹中。
更新模板:
<!DOCTYPE html>
<html>
<head>
<title>Flask Intro</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="static/bootstrap.min.css" rel="stylesheet" media="screen">
</head>
<body>
<div class="container">
<h1>Welcome to Flask!</h2>
<br>
<p>Click <a href="/">here</a> to go home.</p>
</div>
</body>
</html>
我们只是包含了 CSS 样式表;我们将在后面的教程中添加 JavaScript 文件。
返回浏览器。
还记得我们让服务器运行吗?嗯,当 Flask 处于调试模式,app.run(debug=True)时,有一个自动重新加载机制在代码改变时生效。因此,我们只需在浏览器中点击“刷新”,就可以看到新模板正盯着我们。
很好。
结论
在不到 30 分钟的时间里,你学会了 Flask 的基础知识,并为一个更大的应用程序打下了基础。如果你以前使用过 Django,你可能会立即注意到 Flask 不会妨碍你的开发,让你可以自由地以你认为合适的方式构建和设计你的应用程序。
由于缺乏结构,真正的初学者可能会有点吃力,但是这是一个宝贵的学习经验,从长远来看,无论您是继续使用 Flask 还是继续使用更高级别的框架,都将使您受益。
在下一个教程中,我们将看看添加一些动态内容。
干杯!
视频
探索 Flask,第 2 部分——创建登录页面
原文:https://realpython.com/introduction-to-flask-part-2-creating-a-login-page/
欢迎来到真正的 Python 探索烧瓶系列…
系列概述
访问discoverflask.com查看系列摘要——博客帖子和视频的链接。
上次时间我们讨论了如何建立一个基本的 Flask 结构,然后开发了一个静态站点,风格为 Bootstrap。在本系列的第二部分中,我们将为最终用户添加一个登录页面。
基于上一教程中的代码,我们需要:
- 添加路由以处理对登录 URL 的请求;和
- 为登录页面添加模板
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
添加一个路由来处理对登录 URL 的请求
确保您的 virtualenv 已激活。在您的代码编辑器中打开 app.py ,并添加以下路径:
# Route for handling the login page logic
@app.route('/login', methods=['GET', 'POST'])
def login():
error = None
if request.method == 'POST':
if request.form['username'] != 'admin' or request.form['password'] != 'admin':
error = 'Invalid Credentials. Please try again.'
else:
return redirect(url_for('home'))
return render_template('login.html', error=error)
确保您还更新了导入:
from flask import Flask, render_template, redirect, url_for, request
这是怎么回事?
-
首先,请注意,我们为路由指定了适用的 HTTP 方法 GET 和 POST,作为路由装饰器中的一个参数。
-
GET 是默认方法。因此,如果没有显式定义方法,Flask 假设唯一可用的方法是 GET,就像前面两条路线
/和/welcome一样。 -
对于新的
/login路由,我们需要指定 POST 方法和 GET,以便最终用户可以用他们的登录凭证向那个/login端点发送 POST 请求。 -
login()函数中的逻辑测试凭证是否正确。如果它们是正确的,那么用户将被重定向到主路由/,如果凭证不正确,则会出现一个错误。这些凭证从何而来?POST 请求,你马上就会看到。 -
在 GET 请求的情况下,简单地呈现登录页面。
注意:
url_for()函数为所提供的方法生成一个端点。
为登录页面添加模板
创建一个名为login.html的新文件,将其添加到“模板”目录中:
<html>
<head>
<title>Flask Intro - login page</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="static/bootstrap.min.css" rel="stylesheet" media="screen">
</head>
<body>
<div class="container">
<h1>Please login</h1>
<br>
<form action="" method="post">
<input type="text" placeholder="Username" name="username" value="{{
request.form.username }}">
<input type="password" placeholder="Password" name="password" value="{{
request.form.password }}">
<input class="btn btn-default" type="submit" value="Login">
</form>
{% if error %}
<p class="error"><strong>Error:</strong> {{ error }}
{% endif %}
</div>
</body>
</html>
是时候做一个快速测试了…
-
启动服务器。导航到http://localhost:5000/log in。
-
输入不正确的凭证,然后按登录。您应该得到这样的响应:“错误:无效的凭证。请再试一次。”
-
现在使用“admin”作为用户名和密码,您应该会被重定向到
/URL。 -
你能看出这里发生了什么吗?当表单被提交时,POST 请求连同表单数据
value="{{request.form.username }}"和value="{{request.form.password }}"一起被发送到控制器app.py,然后控制器处理请求,或者用错误消息响应,或者将用户重定向到/URL。一定要看看附带的视频来用 Chrome 开发者工具深入挖掘这一点! -
最后,我们的模板中有一些逻辑。最初,我们没有为错误传递或。如果错误不是 None,那么我们显示实际的错误消息,它从视图:
<p class="error"><strong>Error:</strong> {{ error }}</p>传递给模板。要了解这是如何工作的,请查看这篇博文,了解更多关于 Jinja2 模板引擎的信息。
结论
你怎么想呢?简单吧?不要太兴奋,因为我们在用户管理方面还有很多工作要做…
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
既然用户能够登录,我们需要保护 URL /免受未授权的访问。换句话说,当最终用户点击该端点时,除非他们已经登录,否则应该立即将他们发送到登录页面。下次吧。在那之前,去练习一些 jQuery。
视频
Python 和 MongoDB:连接到 NoSQL 数据库
原文:https://realpython.com/introduction-to-mongodb-and-python/
MongoDB 是一个面向文档和 NoSQL 的数据库解决方案,它提供了强大的可伸缩性和灵活性以及强大的查询系统。使用 MongoDB 和 Python,您可以快速开发许多不同类型的数据库应用程序。因此,如果您的 Python 应用程序需要一个像语言本身一样灵活的数据库,那么 MongoDB 就是您的选择。
在本教程中,您将学习:
- 什么是 MongoDB
- 如何安装并运行 MongoDB
- 如何使用 MongoDB 数据库
- 如何使用底层 PyMongo 驱动与 MongoDB 接口
- 如何使用高级的 MongoEngine 对象-文档映射器(ODM)
在本教程中,您将编写几个例子来展示 MongoDB 的灵活性和强大功能以及它对 Python 的强大支持。要下载这些示例的源代码,请单击下面的链接:
获取源代码: 单击此处获取源代码,您将在本教程中使用来了解如何将 MongoDB 与 Python 结合使用。
使用 SQL 与 NoSQL 数据库
几十年来, SQL 数据库是开发人员构建大型可伸缩数据库系统的唯一选择之一。然而,日益增长的存储复杂数据结构的需求导致了 NoSQL 数据库的诞生。这种新型的数据库系统允许开发人员高效地存储异构和无结构的数据。
一般来说,NoSQL 数据库系统存储和检索数据的方式与 SQL 关系数据库管理系统(RDBMS)大不相同。
在选择当前可用的数据库技术时,您可能需要在使用 SQL 还是 NoSQL 系统之间做出选择。这两者都有特定的特性,您在选择其中一个时应该加以考虑。以下是它们的一些更实质性的区别:
| 财产 | SQL 数据库 | NoSQL 数据库 |
|---|---|---|
| 数据模型 | 有关系的 | 非亲属 |
| 结构 | 基于表格,包含列和行 | 基于文档、键值对、图形或宽列 |
| (计划或理论的)纲要 | 一种预定义的严格模式,其中每个记录(行)都具有相同的性质和属性 | 动态模式或无模式,这意味着记录不需要具有相同的性质 |
| 查询语言 | 结构化查询语言(SQL) | 因数据库而异 |
| 可量测性 | 垂直的 | 水平的 |
| 酸交易 | 支持 | 受支持,具体取决于特定的 NoSQL 数据库 |
| 添加新属性的能力 | 需要首先改变模式 | 可能不干扰任何东西 |
这两种类型的数据库之间还有许多其他的区别,但是上面提到的是一些需要了解的更重要的区别。
选择数据库时,您应该仔细考虑它的优点和缺点。您还需要考虑数据库如何适应您的特定场景和应用程序的需求。有时,正确的解决方案是使用 SQL 和 NoSQL 数据库的组合来处理更大系统的不同方面。
SQL 数据库的一些常见示例包括:
NoSQL 数据库的例子包括:
近年来,SQL 和 NoSQL 数据库甚至开始合并。例如,数据库系统,如 PostgreSQL 、 MySQL 和微软 SQL Server 现在支持存储和查询 JSON 数据,很像 NoSQL 数据库。有了这个,你现在可以用这两种技术获得许多相同的结果。但你仍然没有得到 NoSQL 的许多功能,如水平缩放和用户友好的界面。
有了这个关于 SQL 和 NoSQL 数据库的简短背景,您就可以专注于本教程的主要主题了:MongoDB 数据库以及如何在 Python 中使用它。
用 MongoDB 管理 NoSQL 数据库
MongoDB 是一个面向文档的数据库,被归类为 NoSQL。近年来,它在整个行业变得非常流行,并且与 Python 集成得非常好。与传统的 SQL RDBMSs 不同,MongoDB 使用文档的集合,而不是行的表来组织和存储数据。
MongoDB 将数据存储在无模式和灵活的类似 JSON 的文档中。这里,无模式意味着您可以在同一个集合中拥有一组不同的字段的文档,而不需要满足严格的表模式。
随着时间的推移,您可以改变文档和数据的结构,从而形成一个灵活的系统,使您能够快速适应需求的变化,而不需要复杂的数据迁移过程。然而,改变新文档结构的代价是现有文档变得与更新的模式不一致。所以这是一个需要用心经营的话题。
注: JSON 代表 JavaScript 对象符号。它是一种文件格式,具有人类可读的结构,由可以嵌套任意深度的键值对组成。
MongoDB 是用 C++ 编写的,由 MongoDB Inc. 的积极开发,它运行在所有主要平台上,比如 macOS、Windows、Solaris 和大多数 Linux 发行版。一般来说,MongoDB 数据库背后有三个主要的开发目标:
- 扩展良好
- 存储丰富的数据结构
- 提供复杂的查询机制
MongoDB 是一个分布式数据库,因此系统内置了高可用性、水平伸缩和地理分布。它将数据存储在灵活的类似 JSON 的文档中。您可以对这些文档进行建模,以映射应用程序中的对象,这使得有效地处理数据成为可能。
MongoDB 提供了强大的查询语言,支持特殊查询、索引、聚合、地理空间搜索、文本搜索等等。这为您提供了一个强大的工具包来访问和处理您的数据。最后,MongoDB 是免费的,并且有很好的 Python 支持。
回顾 MongoDB 的特性
到目前为止,您已经了解了 MongoDB 是什么以及它的主要目标是什么。在这一节中,您将了解 MongoDB 的一些更重要的特性。至于数据库管理方面,MongoDB 提供了以下特性:
- 查询支持:可以使用很多标准的查询类型,比如匹配(
==)、比较(<、>)、正则表达式。 - 数据容纳:您几乎可以存储任何类型的数据,无论是结构化的、部分结构化的,甚至是多态的。
- 可扩展性:只需向服务器集群添加更多的机器,就可以处理更多的查询。
- 灵活性和敏捷性:您可以使用它快速开发应用程序。
- 文档方向和无模式:您可以在一个文档中存储关于一个数据模型的所有信息。
- 可调整的模式:您可以动态地更改数据库的模式,这减少了提供新功能或修复现有问题所需的时间。
- 关系数据库功能:您可以执行关系数据库常见的操作,比如索引。
至于操作方面,MongoDB 提供了一些在其他数据库系统中找不到的工具和特性:
- 可伸缩性:无论您需要独立的服务器还是完整的独立服务器集群,您都可以将 MongoDB 扩展到您需要的任何规模。
- 负载平衡支持: MongoDB 将自动在不同的分片之间移动数据。
- 自动故障转移支持:如果您的主服务器出现故障,新的主服务器将自动启动并运行。
- 管理工具:您可以使用基于云的 MongoDB 管理服务(MMS)来跟踪您的机器。
- 内存效率:由于内存映射文件,MongoDB 通常比关系数据库更高效。
所有这些功能都非常有用。例如,如果您利用索引功能,那么您的大部分数据将保存在内存中,以便快速检索。即使没有索引特定的文档键,MongoDB 也会使用最近最少使用的技术缓存大量数据。
安装和运行 MongoDB
现在您已经熟悉了 MongoDB,是时候动手使用它了。但是首先,你需要在你的机器上安装它。MongoDB 的官方网站提供了两个版本的数据库服务器:
- community edition提供了灵活的文档模型以及即席查询、索引和实时聚合,为访问和分析您的数据提供了强大的方法。这个版本可以免费获得。
- 企业版提供与社区版相同的功能,以及其他与安全和监控相关的高级功能。这是商业版,但是您可以无限期地免费使用它进行评估和开发。
如果你用的是 Windows,那么你可以通读安装教程来获得完整的说明。一般来说,你可以进入下载页面,在可用下载框中选择 Windows 平台,选择适合你当前系统的.msi安装程序,点击下载。
运行安装程序,并按照安装向导屏幕上的说明进行操作。该页面还提供了关于如何将 MongoDB 作为 Windows 服务运行的信息。
如果你在 macOS 上,那么你可以使用 Homebrew 在你的系统上安装 MongoDB。参见安装教程获取完整指南。此外,请确保按照指示将 MongoDB 作为 macOS 服务运行。
如果您使用的是 Linux,那么安装过程将取决于您的特定发行版。关于如何在不同的 Linux 系统上安装 MongoDB 的详细指南,请转到安装教程页面并选择与您当前操作系统相匹配的教程。确保在安装结束时运行 MongoDB 守护进程mongod。
最后,还可以使用 Docker 安装 MongoDB。如果您不想让另一个安装把您的系统搞得一团糟,这是很方便的。如果你更喜欢这个安装选项,那么你可以通读官方教程并按照它的指示操作。请注意,在这种情况下,需要事先了解如何使用 Docker 。
在您的系统上安装并运行了 MongoDB 数据库之后,您就可以开始使用mongo shell 处理真正的数据库了。
使用mongo Shell 创建 MongoDB 数据库
如果您遵循了安装和运行说明,那么您应该已经有一个 MongoDB 实例在您的系统上运行了。现在,您可以开始创建和测试自己的数据库了。在本节中,您将学习如何使用 mongo shell 来创建、读取、更新和删除数据库中的文档。
运行mongo外壳
mongo shell 是 MongoDB 的一个交互式 JavaScript 接口。您可以使用该工具来查询和操作您的数据,以及执行管理操作。由于是 JavaScript 接口,所以不会用大家熟悉的 SQL 语言来查询数据库。相反,您将使用 JavaScript 代码。
要启动mongo shell,打开您的终端或命令行并运行以下命令:
$ mongo
这个命令将带您进入mongo shell。此时,您可能会看到一堆消息,其中包含关于 shell 版本以及服务器地址和端口的信息。最后,您将看到 shell 提示符(>)来输入查询和命令。
您可以将数据库地址作为参数传递给mongo命令。您还可以使用几个选项,比如指定访问远程数据库的主机和端口,等等。关于如何使用mongo命令的更多细节,您可以运行mongo --help。
建立连接
当您不带参数运行mongo命令时,它会启动 shell 并连接到由mongod://127.0.0.1:27017的mongod进程提供的默认本地服务器。这意味着您通过端口27017连接到本地主机。
默认情况下,mongo shell 通过建立到test数据库的连接来启动会话。您可以通过db对象访问当前数据库:
> db test >
在这种情况下,db保存对默认数据库test的引用。要切换数据库,发出命令use,提供一个数据库名称作为参数。
例如,假设您想要创建一个网站来发布 Python 内容,并且您计划使用 MongoDB 来存储您的教程和文章。在这种情况下,您可以使用以下命令切换到站点的数据库:
> use rptutorials switched to db rptutorials
该命令将您的连接切换到rptutorials数据库。MongoDB 不会在文件系统上创建物理数据库文件,直到您将真实数据插入到数据库中。所以在这种情况下,rptutorials不会显示在您当前的数据库列表中:
> show dbs admin 0.000GB config 0.000GB local 0.000GB >
shell 提供了许多特性和选项。它允许您查询和操作数据,还可以管理数据库服务器本身。
mongo shell 没有使用 SQL 之类的标准化查询语言,而是使用 JavaScript 编程语言和用户友好的 API 。这个 API 允许您处理数据,这是下一节的主题。
创建收藏和文档
MongoDB 数据库是文档的集合的物理容器。每个数据库在文件系统上都有自己的文件集。这些文件由 MongoDB 服务器管理,它可以处理几个数据库。
在 MongoDB 中,集合是一组文档。集合有点类似于传统 RDBMS 中的表,但是没有强加严格的模式。理论上,集合中的每个文档可以有完全不同的结构或字段集。
实际上,集合中的文档通常共享相似的结构,以允许统一的检索、插入和更新过程。在更新和插入期间,您可以通过使用文档验证规则来实施统一的文档结构。
允许不同的文档结构是 MongoDB 集合的一个关键特性。这个特性提供了灵活性,允许向文档添加新字段,而无需修改正式的表模式。
要使用mongo shell 创建集合,您需要将db指向您的目标数据库,然后使用点符号创建集合:
> use rptutorials switched to db rptutorials > db rptutorials > db.tutorial rptutorials.tutorial
在这个例子中,您使用点符号创建tutorial作为当前数据库rptutorials中的集合。值得注意的是,MongoDB 创建数据库和集合是很慢的。换句话说,它们是在您插入第一个文档后才实际创建的。
一旦有了数据库和集合,就可以开始插入文档了。文档是 MongoDB 中的存储单位。在 RDBMS 中,这相当于一个表行。然而,MongoDB 的文档比行更加通用,因为它们可以存储复杂的信息,比如数组,嵌入式文档,甚至文档数组。
MongoDB 以一种叫做二进制 JSON ( BSON )的格式存储文档,这是 JSON 的二进制表示。MongoDB 的文档由字段-值对组成,结构如下:
{
field1 → value1,
field2 → value2,
field3 → value3,
...
fieldN → valueN
}
字段的值可以是任何 BSON 数据类型,包括其他文档、数组和文档数组。在实践中,您将使用 JSON 格式指定您的文档。
当您构建 MongoDB 数据库应用程序时,可能您最重要的决定是关于文档的结构。换句话说,您必须决定您的文档将具有哪些字段和值。
对于 Python 站点的教程,文档的结构可能如下:
{ "title": "Reading and Writing CSV Files in Python", "author": "Jon", "contributors": [ "Aldren", "Geir Arne", "Joanna", "Jason" ], "url": "https://realpython.com/python-csv/" }
文档本质上是一组属性名及其值。这些值可以是简单的数据类型,如字符串和数字,但也可以是数组,如上面示例中的contributors。
MongoDB 面向文档的数据模型自然地将复杂数据表示为单个对象。这允许您从整体上处理数据对象,而不需要查看几个地方或表。
如果您使用传统的 RDBMS 来存储教程,那么您可能会有一个表来存储您的教程,另一个表来存储您的贡献者。然后,您必须在两个表之间建立一个关系,以便以后可以检索数据。
使用收藏和文档
到目前为止,您已经了解了如何运行和使用mongo shell 的基本知识。您还知道如何使用 JSON 格式创建自己的文档。现在是时候学习如何将文档插入到 MongoDB 数据库中了。
要使用mongo shell 将文档插入数据库,首先需要选择一个集合,然后使用您的文档作为参数调用集合上的 .insertOne() :
> use rptutorials switched to db rptutorials > db.tutorial.insertOne({ ... "title": "Reading and Writing CSV Files in Python", ... "author": "Jon", ... "contributors": [ ... "Aldren", ... "Geir Arne", ... "Joanna", ... "Jason" ... ], ... "url": "https://realpython.com/python-csv/" ... }) { "acknowledged" : true, "insertedId" : ObjectId("600747355e6ea8d224f754ba") }
使用第一个命令,您可以切换到想要使用的数据库。第二个命令是一个 JavaScript 方法调用,它将一个简单的文档插入到选定的集合中,tutorial。一旦你点击 Enter ,你的屏幕上会出现一条信息,告知你新插入的文档及其insertedId。
就像关系数据库需要一个主键来惟一标识表中的每一行一样,MongoDB 文档需要一个_id字段来惟一标识文档。MongoDB 允许你输入一个自定义的_id,只要你保证它的唯一性。然而,一个被广泛接受的做法是允许 MongoDB 自动为您插入一个_id。
同样,您可以使用 .insertMany() 一次添加多个文档:
> tutorial1 = { ... "title": "How to Iterate Through a Dictionary in Python", ... "author": "Leodanis", ... "contributors": [ ... "Aldren", ... "Jim", ... "Joanna" ... ], ... "url": "https://realpython.com/iterate-through-dictionary-python/" ... } > tutorial2 = { ... "title": "Python 3's f-Strings: An Improved String Formatting Syntax", ... "author": "Joanna", ... "contributors": [ ... "Adriana", ... "David", ... "Dan", ... "Jim", ... "Pavel" ... ], ... "url": "https://realpython.com/python-f-strings/" ... } > db.tutorial.insertMany([tutorial1, tutorial2]) { "acknowledged" : true, "insertedIds" : [ ObjectId("60074ff05e6ea8d224f754bb"), ObjectId("60074ff05e6ea8d224f754bc") ] }
这里,对.insertMany()的调用获取一个教程列表,并将它们插入到数据库中。同样,shell 输出显示了关于新插入的文档及其自动添加的_id字段的信息。
mongo shell 还提供了对数据库执行读取、更新和删除操作的方法。例如,您可以使用 .find() 来检索集合中的文档:
> db.tutorial.find() { "_id" : ObjectId("600747355e6ea8d224f754ba"), "title" : "Reading and Writing CSV Files in Python", "author" : "Jon", "contributors" : [ "Aldren", "Geir Arne", "Joanna", "Jason" ], "url" : "https://realpython.com/python-csv/" } ... > db.tutorial.find({author: "Joanna"}) { "_id" : ObjectId("60074ff05e6ea8d224f754bc"), "title" : "Python 3's f-Strings: An Improved String Formatting Syntax (Guide)", "author" : "Joanna", "contributors" : [ "Adriana", "David", "Dan", "Jim", "Pavel" ], "url" : "https://realpython.com/python-f-strings/" }
对.find()的第一次调用检索了tutorial集合中的所有文档。另一方面,第二次调用.find()检索由乔安娜创作的教程。
有了关于如何通过其mongo shell 使用 MongoDB 的背景知识,您就可以开始在 Python 中使用 MongoDB 了。接下来的几节将带您了解在 Python 应用程序中使用 MongoDB 数据库的不同选项。
通过 Python 和 PyMongo 使用 MongoDB】
现在您已经知道了什么是 MongoDB 以及如何使用mongo shell 创建和管理数据库,您可以开始使用 MongoDB 了,但是这次是使用 Python。MongoDB 提供了一个官方的 Python 驱动叫做 PyMongo 。
在这一节中,您将通过一些示例了解如何使用 PyMongo 通过 MongoDB 和 Python 创建自己的数据库应用程序。
PyMongo 中的每个模块负责数据库上的一组操作。你将拥有至少用于以下任务的模块:
一般来说,PyMongo 提供了一组丰富的工具,可以用来与 MongoDB 服务器进行通信。它提供了查询、检索结果、写入和删除数据以及运行数据库命令的功能。
安装 PyMongo
要开始使用 PyMongo,首先需要在 Python 环境中安装它。您可以使用一个虚拟环境,或者您可以使用您的系统级 Python 安装,尽管第一个选项是首选。 PyMongo 在 PyPI 上可用,所以最快的安装方式是用 pip 。启动您的终端并运行以下命令:
$ pip install pymongo==3.11.2
在完成一些下载和其他相关步骤之后,这个命令会在您的 Python 环境中安装 PyMongo。请注意,如果您没有提供具体的版本号,那么pip将安装最新的可用版本。
注意:关于如何安装 PyMongo 的完整指南,请查看其官方文档的安装/升级页面。
一旦完成安装,您就可以启动一个 Python 交互会话并运行下面的导入:
>>> import pymongo如果它运行时没有在 Python shell 中引发异常,那么您的安装工作正常。如果没有,请再次仔细执行这些步骤。
建立连接
要建立到数据库的连接,需要创建一个
MongoClient实例。这个类为 MongoDB 实例或服务器提供了一个客户机。每个客户机对象都有一个内置连接池,默认情况下,它处理多达 100 个到服务器的连接。回到 Python 交互式会话,从
pymongo导入MongoClient。然后创建一个客户机对象来与当前运行的 MongoDB 实例通信:
>>> from pymongo import MongoClient
>>> client = MongoClient()
>>> client
MongoClient(host=['localhost:27017'], ..., connect=True)
上面的代码建立了到默认主机(localhost)和端口(27017)的连接。MongoClient接受一组参数,允许您指定自定义主机、端口和其他连接参数。例如,要提供自定义主机和端口,可以使用以下代码:
>>> client = MongoClient(host="localhost", port=27017)当您需要提供不同于 MongoDB 默认设置的
host和port时,这很方便。你也可以使用 MongoDB URI 格式:
>>> client = MongoClient("mongodb://localhost:27017")
所有这些MongoClient实例都提供相同的客户端设置来连接您当前的 MongoDB 实例。您应该使用哪一个取决于您希望在代码中有多明确。
一旦实例化了MongoClient,就可以使用它的实例来引用特定的数据库连接,就像上一节中使用mongo shell 的db对象一样。
使用数据库、收藏和文档
一旦有了一个连接的MongoClient实例,就可以访问由指定的 MongoDB 服务器管理的任何数据库。要定义您想要使用哪个数据库,您可以像在mongo shell 中一样使用点符号:
>>> db = client.rptutorials >>> db Database(MongoClient(host=['localhost:27017'], ..., connect=True), 'rptutorials')在本例中,
rptutorials是您将使用的数据库的名称。如果数据库不存在,那么 MongoDB 会为您创建它,但是只有在您对数据库执行第一个操作时。如果数据库的名称不是有效的 Python 标识符,也可以使用字典式访问:
>>> db = client["rptutorials"]
当数据库的名称不是有效的 Python 标识符时,这个语句很方便。例如,如果您的数据库名为rp-tutorials,那么您需要使用字典式访问。
注意:当您使用mongo shell 时,您可以通过db全局对象访问数据库。当您使用 PyMongo 时,您可以将数据库分配给一个名为db的变量来获得类似的行为。
使用 PyMongo 在数据库中存储数据类似于在上面几节中使用mongo shell 所做的事情。但是首先,您需要创建您的文档。在 Python 中,您使用字典来创建文档:
>>> tutorial1 = { ... "title": "Working With JSON Data in Python", ... "author": "Lucas", ... "contributors": [ ... "Aldren", ... "Dan", ... "Joanna" ... ], ... "url": "https://realpython.com/python-json/" ... }一旦将文档创建为词典,就需要指定想要使用哪个集合。为此,您可以在数据库对象上使用点符号:
>>> tutorial = db.tutorial
>>> tutorial
Collection(Database(..., connect=True), 'rptutorials'), 'tutorial')
在这种情况下,tutorial是 Collection 的一个实例,代表数据库中文档的物理集合。您可以通过调用tutorial上的 .insert_one() 将文档插入其中,并以文档作为参数:
>>> result = tutorial.insert_one(tutorial1) >>> result <pymongo.results.InsertOneResult object at 0x7fa854f506c0> >>> print(f"One tutorial: {result.inserted_id}") One tutorial: 60084b7d87eb0fbf73dbf71d这里,
.insert_one()获取tutorial1,将其插入到tutorial集合中,并返回一个InsertOneResult对象。该对象对插入的文档提供反馈。注意,由于 MongoDB 动态生成了ObjectId,所以您的输出不会与上面显示的ObjectId匹配。如果您有许多文档要添加到数据库中,那么您可以使用
.insert_many()将它们一次插入:
>>> tutorial2 = {
... "title": "Python's Requests Library (Guide)",
... "author": "Alex",
... "contributors": [
... "Aldren",
... "Brad",
... "Joanna"
... ],
... "url": "https://realpython.com/python-requests/"
... }
>>> tutorial3 = {
... "title": "Object-Oriented Programming (OOP) in Python 3",
... "author": "David",
... "contributors": [
... "Aldren",
... "Joanna",
... "Jacob"
... ],
... "url": "https://realpython.com/python3-object-oriented-programming/"
... }
>>> new_result = tutorial.insert_many([tutorial2, tutorial3])
>>> print(f"Multiple tutorials: {new_result.inserted_ids}")
Multiple tutorials: [
ObjectId('6008511c87eb0fbf73dbf71e'),
ObjectId('6008511c87eb0fbf73dbf71f')
]
这比多次调用.insert_one()更快更直接。对.insert_many()的调用获取一系列文档,并将它们插入到rptutorials数据库的tutorial集合中。该方法返回一个实例 InsertManyResult ,它提供了关于插入文档的信息。
要从集合中检索文档,可以使用 .find() 。如果没有参数,.find()返回一个 Cursor 对象,该对象使按需生成集合中的文档:
>>> import pprint >>> for doc in tutorial.find(): ... pprint.pprint(doc) ... {'_id': ObjectId('600747355e6ea8d224f754ba'), 'author': 'Jon', 'contributors': ['Aldren', 'Geir Arne', 'Joanna', 'Jason'], 'title': 'Reading and Writing CSV Files in Python', 'url': 'https://realpython.com/python-csv/'} ... {'_id': ObjectId('6008511c87eb0fbf73dbf71f'), 'author': 'David', 'contributors': ['Aldren', 'Joanna', 'Jacob'], 'title': 'Object-Oriented Programming (OOP) in Python 3', 'url': 'https://realpython.com/python3-object-oriented-programming/'}在这里,您对
.find()返回的对象运行一个循环并打印连续的结果,使用pprint.pprint()提供一个用户友好的输出格式。您还可以使用
.find_one()来检索单个文档。在这种情况下,您可以使用包含要匹配的字段的字典。例如,如果你想检索乔恩的第一个教程,那么你可以这样做:
>>> import pprint
>>> jon_tutorial = tutorial.find_one({"author": "Jon"})
>>> pprint.pprint(jon_tutorial)
{'_id': ObjectId('600747355e6ea8d224f754ba'),
'author': 'Jon',
'contributors': ['Aldren', 'Geir Arne', 'Joanna', 'Jason'],
'title': 'Reading and Writing CSV Files in Python',
'url': 'https://realpython.com/python-csv/'}
注意,教程的ObjectId设置在_id键下,这是 MongoDB 在您将文档插入数据库时自动添加的惟一文档标识符。
PyMongo 还提供了从数据库中用替换、更新、删除文档的方法。如果您想更深入地了解这些特性,那么请看一下Collection的文档。
关闭连接
建立到 MongoDB 数据库的连接通常是一项开销很大的操作。如果您有一个经常在 MongoDB 数据库中检索和操作数据的应用程序,那么您可能不希望一直打开和关闭连接,因为这可能会影响应用程序的性能。
在这种情况下,您应该保持连接活动,并且只在退出应用程序之前关闭它,以清除所有获取的资源。您可以通过在MongoClient实例上调用 .close() 来关闭连接:
>>> client.close()另一种情况是当您的应用程序偶尔使用 MongoDB 数据库时。在这种情况下,您可能希望在需要时打开连接,并在使用后立即关闭它以释放获取的资源。解决这个问题的一致方法是使用
with语句。是的,MongoClient实现了上下文管理协议:
>>> import pprint
>>> from pymongo import MongoClient
>>> with MongoClient() as client:
... db = client.rptutorials
... for doc in db.tutorial.find():
... pprint.pprint(doc)
...
{'_id': ObjectId('600747355e6ea8d224f754ba'),
'author': 'Jon',
'contributors': ['Aldren', 'Geir Arne', 'Joanna', 'Jason'],
'title': 'Reading and Writing CSV Files in Python',
'url': 'https://realpython.com/python-csv/'}
...
{'_id': ObjectId('6008511c87eb0fbf73dbf71f'),
'author': 'David',
'contributors': ['Aldren', 'Joanna', 'Jacob'],
'title': 'Object-Oriented Programming (OOP) in Python 3',
'url': 'https://realpython.com/python3-object-oriented-programming/'}
如果您使用with语句来处理 MongoDB 客户端,那么在with代码块的末尾,客户端的.__exit__()方法被调用,同时通过调用.close() 来关闭连接。
通过 Python 和 MongoEngine 使用 MongoDB】
虽然 PyMongo 是一个用于与 MongoDB 接口的强大 Python 驱动程序,但对于您的许多项目来说,它可能有点太低级了。使用 PyMongo,您必须编写大量代码来一致地插入、检索、更新和删除文档。
在 PyMongo 之上提供更高抽象的一个库是 MongoEngine 。MongoEngine 是一个对象文档映射器(ODM),大致相当于一个基于 SQL 的对象关系映射器 (ORM)。MongoEngine 提供了基于类的抽象,所以你创建的所有模型都是类。
安装 MongoEngine
有一些 Python 库可以帮助您使用 MongoDB。然而,MongoEngine 是一个受欢迎的引擎,它提供了一组很好的特性、灵活性和对社区的支持。MongoEngine 在 PyPI 上可用。您可以使用下面的pip命令来安装它:
$ pip install mongoengine==0.22.1
一旦将 MongoEngine 安装到 Python 环境中,就可以使用 Python 的面向对象的特性开始使用 MongoDB 数据库了。下一步是连接到正在运行的 MongoDB 实例。
建立连接
要与你的数据库建立连接,你需要使用 mongoengine.connect() 。这个函数有几个参数。然而,在本教程中,您将只使用其中的三个。在 Python 交互式会话中,输入以下代码:
>>> from mongoengine import connect >>> connect(db="rptutorials", host="localhost", port=27017) MongoClient(host=['localhost:27017'], ..., read_preference=Primary())这里,首先将数据库名称
db设置为"rptutorials",这是您想要工作的数据库的名称。然后您提供一个host和一个port来连接到您当前的 MongoDB 实例。由于您使用的是默认的host和port,您可以省略这两个参数,只使用connect("rptutorials")。使用收藏和文档
要用 MongoEngine 创建文档,首先需要定义希望文档包含什么数据。换句话说,您需要定义一个文档模式。MongoEngine 鼓励您定义一个文档模式来帮助您减少编码错误,并允许您定义实用程序或助手方法。
与 ORM 类似,像 MongoEngine 这样的 ODM 为您提供了一个基类或模型类来定义文档模式。在 ORMs 中,那个类相当于一个表,它的实例相当于行。在 MongoEngine 中,类相当于一个集合,它的实例相当于文档。
>>> from mongoengine import Document, ListField, StringField, URLField
>>> class Tutorial(Document):
... title = StringField(required=True, max_length=70)
... author = StringField(required=True, max_length=20)
... contributors = ListField(StringField(max_length=20))
... url = URLField(required=True)
使用这个模型,您告诉 MongoEngine,您期望一个Tutorial文档有一个.title、一个.author、一个.contributors列表和一个.url。基类Document使用这些信息和字段类型来验证输入数据。
注意:数据库模型更困难的任务之一是数据验证。如何确保输入数据符合您的格式要求?这也是你需要一个连贯统一的文档模式的原因之一。
据说 MongoDB 是一个无模式数据库,但这并不意味着它是无模式的。在同一个集合中包含不同模式的文档会导致处理错误和不一致的行为。
例如,如果您试图保存一个没有.title的Tutorial对象,那么您的模型会抛出一个异常并通知您。你可以更进一步,添加更多的限制,比如.title的长度,等等。
有几个通用参数可用于验证字段。以下是一些更常用的参数:
db_field指定了不同的字段名称。required确保字段被提供。default如果没有给定值,则为给定字段提供默认值。unique确保集合中没有其他文档具有与该字段相同的值。
每个特定的字段类型也有自己的一组参数。您可以查看文档以获得可用字段类型的完整指南。
要保存一个文档到你的数据库,你需要在一个文档对象上调用 .save() 。如果文档已经存在,则所有更改将应用于现有文档。如果文档不存在,那么它将被创建。
以下是创建教程并将其保存到示例教程数据库中的示例:
>>> tutorial1 = Tutorial( ... title="Beautiful Soup: Build a Web Scraper With Python", ... author="Martin", ... contributors=["Aldren", "Geir Arne", "Jaya", "Joanna", "Mike"], ... url="https://realpython.com/beautiful-soup-web-scraper-python/" ... ) >>> tutorial1.save() # Insert the new tutorial <Tutorial: Tutorial object>默认情况下,
.save()将新文档插入到以模型类Tutorial命名的集合中,除了使用小写字母。在这种情况下,集合名称为tutorial,它与您用来保存教程的集合相匹配。当您调用
.save()时,PyMongo 执行数据验证。这意味着它根据您在Tutorial模型类中声明的模式检查输入数据。如果输入数据违反了模式或它的任何约束,那么您会得到一个异常,并且数据不会保存到数据库中。例如,如果您试图在不提供
.title的情况下保存教程,会发生以下情况:
>>> tutorial2 = Tutorial()
>>> tutorial2.author = "Alex"
>>> tutorial2.contributors = ["Aldren", "Jon", "Joanna"]
>>> tutorial2.url = "https://realpython.com/convert-python-string-to-int/"
>>> tutorial2.save()
Traceback (most recent call last):
...
mongoengine.errors.ValidationError: ... (Field is required: ['title'])
在这个例子中,首先要注意的是,您也可以通过为属性赋值来构建一个Tutorial对象。第二,由于您没有为新教程提供一个.title,.save()会抛出一个ValidationError,告诉您.title字段是必需的。拥有自动数据验证是一个很棒的特性,可以帮你省去一些麻烦。
每个Document子类都有一个.objects属性,可以用来访问相关集合中的文档。例如,下面是你如何打印你当前所有教程的.title:
>>> for doc in Tutorial.objects: ... print(doc.title) ... Reading and Writing CSV Files in Python How to Iterate Through a Dictionary in Python Python 3's f-Strings: An Improved String Formatting Syntax (Guide) Working With JSON Data in Python Python's Requests Library (Guide) Object-Oriented Programming (OOP) in Python 3 Beautiful Soup: Build a Web Scraper With Python
for循环遍历你所有的教程并将它们的.title数据打印到屏幕上。你也可以使用.objects来过滤你的文件。例如,假设您想要检索由 Alex 创作的教程。在这种情况下,您可以这样做:
>>> for doc in Tutorial.objects(author="Alex"):
... print(doc.title)
...
Python's Requests Library (Guide)
MongoEngine 非常适合为任何类型的应用程序管理 MongoDB 数据库。它的特性使它非常适合使用高级方法创建高效且可伸缩的程序。如果你想了解更多关于 MongoEngine 的信息,请务必查看它的用户指南。
结论
如果您需要一个健壮的、可伸缩的、灵活的数据库解决方案,那么 MongoDB 可能是一个不错的选择。MongoDB 是一个成熟和流行的 NoSQL 数据库,具有强大的 Python 支持。对如何使用 Python 访问 MongoDB 有了很好的理解后,您就可以创建伸缩性好、性能卓越的数据库应用程序了。
使用 MongoDB,您还可以受益于人类可读且高度灵活的数据模型,因此您可以快速适应需求变化。
在本教程中,您学习了:
- 什么是 MongoDB 和 NoSQL 数据库
- 如何在您的系统上安装和运行 MongoDB
- 如何创建和使用 MongoDB 数据库
- 如何使用 PyMongo 驱动程序在 Python 中与 MongoDB 接口
- 如何使用 MongoEngine 对象-文档映射器来处理 MongoDB
您在本教程中编写的示例可以下载。要获得它们的源代码,请单击下面的链接:
获取源代码: 单击此处获取源代码,您将在本教程中使用来了解如何将 MongoDB 与 Python 结合使用。******
如何在 Python 中使用生成器和 yield
原文:https://realpython.com/introduction-to-python-generators/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 生成器 101
您是否曾经不得不处理如此大的数据集,以至于超出了计算机的内存?或者,您可能有一个复杂的函数,每次调用它时都需要维护一个内部状态,但该函数太小,不值得创建自己的类。在这些情况下以及更多的情况下,生成器和 Python yield 语句可以提供帮助。
到本文结束时,你会知道:
- 什么是发电机以及如何使用它们
- 如何创建生成器函数和表达式
- Python yield 语句的工作原理
- 如何在生成器函数中使用多个 Python yield 语句
- 如何使用高级生成器方法
- 如何用多个生成器构建数据管道
如果你是 Pythonic 的初学者或中级用户,并且对学习如何以更 Pythonic 化的方式处理大型数据集感兴趣,那么这就是适合你的教程。
您可以通过单击下面的链接获得本教程中使用的数据集的副本:
下载数据集: 单击此处下载您将在本教程中使用的数据集以了解 Python 中的生成器和 yield。
使用发电机
随着 PEP 255 、的引入,生成器函数是一种特殊的函数,它返回一个惰性迭代器。这些是你可以像列表一样循环的对象。然而,与列表不同,惰性迭代器不将内容存储在内存中。关于 Python 中迭代器的概述,请看一下Python“for”循环(明确迭代)。
现在您对发电机有了一个大致的概念,您可能想知道它们在运行时是什么样子。我们来看两个例子。首先,您将从鸟瞰图中看到发电机是如何工作的。然后,您将放大并更彻底地检查每个示例。
示例 1:读取大文件
生成器的一个常见用例是处理数据流或大文件,比如 CSV 文件。这些文本文件使用逗号将数据分隔成列。这种格式是共享数据的常用方式。现在,如果您想计算 CSV 文件中的行数,该怎么办呢?下面的代码块显示了计算这些行的一种方法:
csv_gen = csv_reader("some_csv.txt")
row_count = 0
for row in csv_gen:
row_count += 1
print(f"Row count is {row_count}")
看这个例子,你可能会认为csv_gen是一个列表。为了填充这个列表,csv_reader()打开一个文件并将其内容加载到csv_gen中。然后,程序遍历列表,并为每一行增加row_count。
这是一个合理的解释,但是如果文件非常大,这种设计还有效吗?如果文件比您可用的内存大怎么办?为了回答这个问题,让我们假设csv_reader()只是打开文件并把它读入一个数组:
def csv_reader(file_name):
file = open(file_name)
result = file.read().split("\n")
return result
这个函数打开一个给定的文件,使用file.read()和.split()将每一行作为一个单独的元素添加到一个列表中。如果您在前面看到的行计数代码块中使用这个版本的csv_reader(),那么您将得到以下输出:
Traceback (most recent call last): File "ex1_naive.py", line 22, in <module> main() File "ex1_naive.py", line 13, in main csv_gen = csv_reader("file.txt") File "ex1_naive.py", line 6, in csv_reader result = file.read().split("\n") MemoryError在这种情况下,
open()返回一个生成器对象,您可以一行一行地进行惰性迭代。然而,file.read().split()一次将所有内容加载到内存中,导致了MemoryError。在这之前,你可能会注意到你的电脑慢如蜗牛。你甚至可能需要用一个
KeyboardInterrupt来终止程序。那么,如何处理这些庞大的数据文件呢?看看csv_reader()的新定义:def csv_reader(file_name): for row in open(file_name, "r"): yield row在这个版本中,您打开文件,遍历它,并产生一行。此代码应该产生以下输出,没有内存错误:
Row count is 64186394这里发生了什么事?嗯,你实际上已经把
csv_reader()变成了一个生成器函数。这个版本打开一个文件,遍历每一行,产生每一行,而不是返回它。您还可以定义一个生成器表达式(也称为生成器理解),其语法与列表理解非常相似。这样,您可以在不调用函数的情况下使用生成器:
csv_gen = (row for row in open(file_name))这是创建列表
csv_gen的一种更简洁的方式。您将很快了解到关于 Python yield 语句的更多信息。现在,只要记住这个关键区别:
- 使用
yield将产生一个生成器对象。- 使用
return将导致文件的第一行只有。示例 2:生成无限序列
让我们换个话题,看看无限序列生成。在 Python 中,为了得到一个有限序列,你调用
range()并在一个列表上下文中对其求值:
>>> a = range(5)
>>> list(a)
[0, 1, 2, 3, 4]
然而,生成一个无限序列需要使用一个生成器,因为你的计算机内存是有限的:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
这个代码块又短又甜。首先,你初始化变量 num并开始一个无限循环。然后,你立即yield num这样你就可以捕捉到初始状态。这模仿了range()的动作。
在yield之后,你将num增加 1。如果你用一个 for回路试一下,你会发现它看起来确实是无限的:
>>> for i in infinite_sequence(): ... print(i, end=" ") ... 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 [...] 6157818 6157819 6157820 6157821 6157822 6157823 6157824 6157825 6157826 6157827 6157828 6157829 6157830 6157831 6157832 6157833 6157834 6157835 6157836 6157837 6157838 6157839 6157840 6157841 6157842 KeyboardInterrupt Traceback (most recent call last): File "<stdin>", line 2, in <module>该程序将继续执行,直到您手动停止它。
除了使用
for循环,还可以直接在生成器对象上调用next()。这对于在控制台中测试生成器特别有用:
>>> gen = infinite_sequence()
>>> next(gen)
0
>>> next(gen)
1
>>> next(gen)
2
>>> next(gen)
3
这里,您有一个名为gen的生成器,您通过重复调用next()来手动迭代它。这是一个很好的健全检查,确保您的生成器产生您期望的输出。
注意:当你使用next()时,Python 在你作为参数传入的函数上调用.__next__()。这种参数化允许一些特殊的效果,但这超出了本文的范围。尝试改变你传递给next()的参数,看看会发生什么!
示例 3:检测回文
您可以在许多方面使用无限序列,但它们的一个实际用途是构建回文检测器。一个回文检测器将定位所有回文的字母序列或 T2 数字序列。这些是向前和向后读都一样的单词或数字,比如 121。首先,定义您的数字回文检测器:
def is_palindrome(num):
# Skip single-digit inputs
if num // 10 == 0:
return False
temp = num
reversed_num = 0
while temp != 0:
reversed_num = (reversed_num * 10) + (temp % 10)
temp = temp // 10
if num == reversed_num:
return num
else:
return False
不要太担心理解这段代码中的底层数学。请注意,该函数接受一个输入数字,将其反转,并检查反转后的数字是否与原始数字相同。现在你可以使用你的无限序列生成器得到一个所有数字回文的运行列表:
>>> for i in infinite_sequence(): ... pal = is_palindrome(i) ... if pal: ... print(i) ... 11 22 33 [...] 99799 99899 99999 100001 101101 102201 KeyboardInterrupt Traceback (most recent call last): File "<stdin>", line 2, in <module> File "<stdin>", line 5, in is_palindrome在这种情况下,打印到控制台的唯一数字是那些向前或向后相同的数字。
注意:实际上,你不太可能编写自己的无限序列生成器。
itertools模块提供了一个非常高效的带itertools.count()的无限序列发生器。现在您已经看到了一个无限序列生成器的简单用例,让我们更深入地了解生成器是如何工作的。
了解发电机
到目前为止,您已经了解了创建生成器的两种主要方式:使用生成器函数和生成器表达式。你甚至可能对发电机如何工作有一个直观的理解。让我们花一点时间让这些知识更清晰一点。
生成器函数的外观和行为就像常规函数一样,但有一个定义特征。生成器函数使用 Python
yield关键字而不是return。回想一下您之前编写的生成器函数:def infinite_sequence(): num = 0 while True: yield num num += 1这看起来像一个典型的函数定义,除了 Python yield 语句和它后面的代码。
yield表示在哪里将一个值发送回调用者,但是与return不同的是,您不能在之后退出该函数。相反,功能的状态被记住。这样,当在生成器对象上调用
next()(在for循环中显式或隐式调用)时,先前产生的变量num递增,然后再次产生。由于生成器函数看起来像其他函数,并且行为与它们非常相似,您可以假设生成器表达式与 Python 中其他可用的理解非常相似。注:你对 Python 的列表、集合、字典理解生疏了吗?你可以有效地使用列表理解来检查。
用生成器表达式构建生成器
像列表理解一样,生成器表达式允许您用几行代码快速创建一个生成器对象。它们在使用列表理解的相同情况下也很有用,还有一个额外的好处:您可以创建它们,而无需在迭代之前构建整个对象并将其保存在内存中。换句话说,当您使用生成器表达式时,您不会有内存损失。举个平方一些数字的例子:
>>> nums_squared_lc = [num**2 for num in range(5)]
>>> nums_squared_gc = (num**2 for num in range(5))
nums_squared_lc和nums_squared_gc看起来基本相同,但有一个关键的区别。你能发现它吗?看看当你检查这些物体时会发生什么:
>>> nums_squared_lc [0, 1, 4, 9, 16] >>> nums_squared_gc <generator object <genexpr> at 0x107fbbc78>第一个对象使用括号构建一个列表,而第二个对象使用括号创建一个生成器表达式。输出确认您已经创建了一个生成器对象,并且它不同于列表。
剖析发生器性能
您之前已经了解到生成器是优化内存的一个很好的方法。虽然无限序列生成器是这种优化的一个极端例子,但让我们放大刚才看到的数字平方例子,并检查结果对象的大小。您可以通过调用
sys.getsizeof()来做到这一点:
>>> import sys
>>> nums_squared_lc = [i ** 2 for i in range(10000)]
>>> sys.getsizeof(nums_squared_lc)
87624
>>> nums_squared_gc = (i ** 2 for i in range(10000))
>>> print(sys.getsizeof(nums_squared_gc))
120
在这个例子中,你从 list comprehension 得到的列表是 87,624 字节,而 generator 对象只有 120 字节。这意味着列表比生成器对象大 700 多倍!
不过,有一件事要记住。如果列表小于运行机器的可用内存,那么列表理解可以比等价的生成器表达式更快地评估 T2。为了探索这一点,让我们总结以上两种理解的结果。您可以使用cProfile.run()生成读数:
>>> import cProfile >>> cProfile.run('sum([i * 2 for i in range(10000)])') 5 function calls in 0.001 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.001 0.001 0.001 0.001 <string>:1(<listcomp>) 1 0.000 0.000 0.001 0.001 <string>:1(<module>) 1 0.000 0.000 0.001 0.001 {built-in method builtins.exec} 1 0.000 0.000 0.000 0.000 {built-in method builtins.sum} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} >>> cProfile.run('sum((i * 2 for i in range(10000)))') 10005 function calls in 0.003 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 10001 0.002 0.000 0.002 0.000 <string>:1(<genexpr>) 1 0.000 0.000 0.003 0.003 <string>:1(<module>) 1 0.000 0.000 0.003 0.003 {built-in method builtins.exec} 1 0.001 0.001 0.003 0.003 {built-in method builtins.sum} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}在这里,您可以看到对列表中的所有值求和所用的时间大约是对生成器求和所用时间的三分之一。如果速度是一个问题,而记忆不是,那么列表理解可能是一个更好的工作工具。
注意:这些测量不仅仅对使用生成器表达式制作的对象有效。它们对于由模拟生成器函数生成的对象也是一样的,因为生成的生成器是等价的。
记住,列表理解返回完整列表,而生成器表达式返回生成器。无论是从函数还是从表达式构建,生成器的工作方式都是一样的。使用表达式只允许您在一行中定义简单的生成器,并在每个内部迭代的末尾假定一个
yield。Python yield 语句当然是生成器所有功能的关键所在,所以让我们深入了解一下
yield在 Python 中是如何工作的。理解 Python Yield 语句
总的来说,
yield是一个相当简单的说法。它的主要工作是以类似于return语句的方式控制生成器函数的流程。正如上面简要提到的,Python yield 语句有一些技巧。当调用生成器函数或使用生成器表达式时,会返回一个称为生成器的特殊迭代器。您可以将该生成器分配给一个变量,以便使用它。当您调用生成器上的特殊方法时,比如
next(),函数中的代码执行到yield。当 Python yield 语句被命中时,程序会暂停函数执行,并将生成的值返回给调用者。(相反,
return完全停止功能执行。)当函数被挂起时,该函数的状态被保存。这包括生成器本地的任何变量绑定、指令指针、内部堆栈和任何异常处理。这允许您在调用生成器的某个方法时恢复函数执行。通过这种方式,所有的函数计算在
yield之后立即恢复。通过使用多个 Python yield 语句,您可以看到这一点:
>>> def multi_yield():
... yield_str = "This will print the first string"
... yield yield_str
... yield_str = "This will print the second string"
... yield yield_str
...
>>> multi_obj = multi_yield()
>>> print(next(multi_obj))
This will print the first string
>>> print(next(multi_obj))
This will print the second string
>>> print(next(multi_obj))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
仔细看看最后一次对next()的调用。你可以看到执行已经被一个回溯放大了。这是因为生成器和所有迭代器一样,可能会耗尽。除非你的生成器是无限的,否则你只能迭代一次。一旦评估完所有值,迭代将停止,并且for循环将退出。如果您使用了next(),那么您将得到一个显式的StopIteration异常。
注意: StopIteration是一个自然的异常,引发它是为了表示迭代器的结束。例如,for循环是围绕StopIteration建立的。您甚至可以通过使用 while循环来实现自己的for循环:
>>> letters = ["a", "b", "c", "y"] >>> it = iter(letters) >>> while True: ... try: ... letter = next(it) ... except StopIteration: ... break ... print(letter) ... a b c y你可以在关于异常的 Python 文档中阅读更多关于
StopIteration的内容。关于迭代的更多信息,请查看Python“for”循环(有限迭代)和Python“while”循环(无限迭代)。
yield可以用多种方式来控制你的生成器的执行流程。只要您的创造力允许,就可以使用多个 Python yield 语句。使用高级生成器方法
您已经了解了发生器最常见的用途和构造,但是还需要了解一些技巧。除了
yield,生成器对象可以利用以下方法:
.send().throw().close()如何使用
.send()在下一节中,您将构建一个利用这三种方法的程序。这个程序将像以前一样打印数字回文,但是做了一些调整。当遇到回文时,你的新程序会添加一个数字,并从那里开始搜索下一个数字。您还将使用
.throw()处理异常,并使用.close()在给定的位数之后停止生成器。首先,让我们回忆一下回文检测器的代码:def is_palindrome(num): # Skip single-digit inputs if num // 10 == 0: return False temp = num reversed_num = 0 while temp != 0: reversed_num = (reversed_num * 10) + (temp % 10) temp = temp // 10 if num == reversed_num: return True else: return False这是您之前看到的相同代码,只是现在程序严格返回
True或False。您还需要修改原来的无限序列生成器,如下所示:1def infinite_palindromes(): 2 num = 0 3 while True: 4 if is_palindrome(num): 5 i = (yield num) 6 if i is not None: 7 num = i 8 num += 1这里变化很大!您将看到的第一个在第 5 行,这里是
i = (yield num)。尽管您之前了解到yield是一个陈述,但这并不是全部。从 Python 2.5(引入了您现在正在学习的方法的同一个版本)开始,
yield是一个表达式,而不是一个语句。当然,你还是可以用它来做陈述。但是现在,您也可以像在上面的代码块中看到的那样使用它,其中i获取产生的值。这允许您操作产生的值。更重要的是,它允许你.send()一个值回生成器。当yield之后执行拾取时,i将获取发送的值。您还将检查
if i is not None,如果在生成器对象上调用next(),这可能会发生。(当你用for循环迭代时,这也会发生。)如果i有一个值,那么用新值更新num。但是不管i是否有值,你都要增加num并再次开始循环。现在,看一下主函数代码,它将最低的数字和另一个数字发送回生成器。例如,如果回文是 121,那么它将
.send()1000:pal_gen = infinite_palindromes() for i in pal_gen: digits = len(str(i)) pal_gen.send(10 ** (digits))使用这段代码,您可以创建生成器对象并遍历它。程序只在找到一个回文时才给出一个值。它使用
len()来确定回文中的位数。然后,它将10 ** digits发送给生成器。这将执行带回生成器逻辑,并将10 ** digits分配给i。由于i现在有了一个值,程序更新num,递增,并再次检查回文。一旦您的代码找到并产生另一个回文,您将通过
for循环进行迭代。这和用next()迭代是一样的。发电机也在 5 号线与i = (yield num)接通。但是,现在i是None,因为你没有显式发送一个值。您在这里创建的是一个协程,或者一个您可以向其中传递数据的生成器函数。这些对于构建数据管道很有用,但是您很快就会看到,它们对于构建数据管道并不是必需的。(如果你想更深入地学习,那么这门关于协程和并发性的课程是最全面的课程之一。)
既然你已经了解了
.send(),那我们就来看看.throw()。如何使用
.throw()允许你用生成器抛出异常。在下面的例子中,您在第 6 行引发了异常。一旦
digits达到 5:1pal_gen = infinite_palindromes() 2for i in pal_gen: 3 print(i) 4 digits = len(str(i)) 5 if digits == 5: 6 pal_gen.throw(ValueError("We don't like large palindromes")) 7 pal_gen.send(10 ** (digits))这与前面的代码相同,但现在您将检查
digits是否等于 5。如果是这样,那么你就.throw()一个ValueError。要确认这是否如预期的那样工作,请看一下代码的输出:
11
111
1111
10101
Traceback (most recent call last):
File "advanced_gen.py", line 47, in <module>
main()
File "advanced_gen.py", line 41, in main
pal_gen.throw(ValueError("We don't like large palindromes"))
File "advanced_gen.py", line 26, in infinite_palindromes
i = (yield num)
ValueError: We don't like large palindromes
.throw()在你可能需要捕捉异常的任何领域都很有用。在这个例子中,您使用了.throw()来控制何时停止遍历生成器。你可以用.close()更优雅地做到这一点。
如何使用.close()
顾名思义,.close()允许您停止发电机。这在控制无限序列发生器时尤其方便。让我们通过将.throw()改为.close()来更新上面的代码,以停止迭代:
1pal_gen = infinite_palindromes()
2for i in pal_gen:
3 print(i)
4 digits = len(str(i))
5 if digits == 5:
6 pal_gen.close() 7 pal_gen.send(10 ** (digits))
不调用.throw(),而是在第 6 行使用.close()。使用.close()的好处是它会引发StopIteration,这是一个异常,用来表示有限迭代器的结束:
11 111 1111 10101 Traceback (most recent call last): File "advanced_gen.py", line 46, in <module> main() File "advanced_gen.py", line 42, in main pal_gen.send(10 ** (digits)) StopIteration现在,您已经了解了更多关于生成器附带的特殊方法,让我们来谈谈使用生成器来构建数据管道。
用生成器创建数据管道
数据管道允许你将代码串在一起处理大型数据集或数据流,而不会耗尽你机器的内存。假设您有一个很大的 CSV 文件:
permalink,company,numEmps,category,city,state,fundedDate,raisedAmt,raisedCurrency,round digg,Digg,60,web,San Francisco,CA,1-Dec-06,8500000,USD,b digg,Digg,60,web,San Francisco,CA,1-Oct-05,2800000,USD,a facebook,Facebook,450,web,Palo Alto,CA,1-Sep-04,500000,USD,angel facebook,Facebook,450,web,Palo Alto,CA,1-May-05,12700000,USD,a photobucket,Photobucket,60,web,Palo Alto,CA,1-Mar-05,3000000,USD,a这个例子来自 TechCrunch Continental USA 集合,它描述了美国各种初创公司的融资轮次和金额。单击下面的链接下载数据集:
下载数据集: 单击此处下载您将在本教程中使用的数据集以了解 Python 中的生成器和 yield。
是时候用 Python 做一些处理了!为了演示如何使用生成器构建管道,您将分析该文件以获得数据集中所有 A 轮的总数和平均值。
让我们想一个策略:
- 阅读文件的每一行。
- 将每一行拆分成一个值列表。
- 提取列名。
- 使用列名和列表创建词典。
- 过滤掉你不感兴趣的回合。
- 计算您感兴趣的轮次的总值和平均值。
通常,你可以用一个像
pandas这样的包来实现这个功能,但是你也可以只用几个生成器来实现这个功能。您将从使用生成器表达式读取文件中的每一行开始:1file_name = "techcrunch.csv" 2lines = (line for line in open(file_name))然后,您将使用另一个生成器表达式与前一个相配合,将每一行拆分成一个列表:
3list_line = (s.rstrip().split(",") for s in lines)这里,您创建了生成器
list_line,它迭代第一个生成器lines。这是设计生成器管道时常用的模式。接下来,您将从techcrunch.csv中提取列名。因为列名往往构成 CSV 文件的第一行,所以您可以通过一个简短的next()调用来获取它:4cols = next(list_line)对
next()的调用使迭代器在list_line生成器上前进一次。将所有这些放在一起,您的代码应该如下所示:1file_name = "techcrunch.csv" 2lines = (line for line in open(file_name)) 3list_line = (s.rstrip().split(",") for s in lines) 4cols = next(list_line)综上所述,首先创建一个生成器表达式
lines来生成文件中的每一行。接下来,在另一个名为list_line的生成器表达式的定义内遍历该生成器,将每一行转换成一个值列表。然后,用next()将list_line的迭代向前推进一次,从 CSV 文件中获得列名列表。注意:注意尾随换行符!这段代码利用
list_line生成器表达式中的.rstrip()来确保没有尾随换行符,这些字符可能出现在 CSV 文件中。为了帮助您对数据进行过滤和执行操作,您将创建字典,其中的键是来自 CSV:
5company_dicts = (dict(zip(cols, data)) for data in list_line)这个生成器表达式遍历由
list_line生成的列表。然后,它使用zip()和dict()创建如上指定的字典。现在,您将使用一个第四个生成器来过滤您想要的融资回合,并拉动raisedAmt:6funding = ( 7 int(company_dict["raisedAmt"]) 8 for company_dict in company_dicts 9 if company_dict["round"] == "a" 10)在这段代码中,您的生成器表达式遍历
company_dicts的结果,并为任何company_dict获取raisedAmt,其中round键为"a"。请记住,您不是在生成器表达式中一次遍历所有这些。事实上,在你真正使用一个
for循环或者一个作用于可迭代对象的函数,比如sum()之前,你不会迭代任何东西。事实上,现在调用sum()来迭代生成器:11total_series_a = sum(funding)将所有这些放在一起,您将生成以下脚本:
1file_name = "techcrunch.csv" 2lines = (line for line in open(file_name)) 3list_line = (s.rstrip()split(",") for s in lines) 4cols = next(list_line) 5company_dicts = (dict(zip(cols, data)) for data in list_line) 6funding = ( 7 int(company_dict["raisedAmt"]) 8 for company_dict in company_dicts 9 if company_dict["round"] == "a" 10) 11total_series_a = sum(funding) 12print(f"Total series A fundraising: ${total_series_a}")这个脚本将您构建的每个生成器集合在一起,它们都作为一个大数据管道运行。下面是一行行的分析:
- 第 2 行读入文件的每一行。
- 第 3 行将每一行拆分成值,并将这些值放入一个列表中。
- 第 4 行使用
next()将列名存储在一个列表中。- 第 5 行创建字典并用一个
zip()调用将它们联合起来:
- 键是第 4 行的列名
cols。- 值是列表形式的行,在第 3 行创建。
- 第 6 行获得每家公司的 A 轮融资金额。它还会过滤掉任何其他增加的金额。
- 第 11 行通过调用
sum()来获取 CSV 中的首轮融资总额,从而开始迭代过程。当您在
techcrunch.csv上运行这段代码时,您应该会发现在首轮融资中总共筹集了 4,376,015,000 美元。注意:本教程中开发的处理 CSV 文件的方法对于理解如何使用生成器和 Python yield 语句非常重要。但是,当您在 Python 中处理 CSV 文件时,您应该使用 Python 标准库中包含的
csv模块。该模块优化了有效处理 CSV 文件的方法。为了更深入地挖掘,试着计算出每家公司在首轮融资中的平均融资额。这有点棘手,所以这里有一些提示:
- 生成器在被完全迭代后会耗尽自己。
- 您仍然需要
sum()函数。祝你好运!
结论
在本教程中,你已经学习了生成器函数和生成器表达式。
你现在知道了:
- 如何使用和编写生成器函数和生成器表达式
- 最重要的 Python yield 语句如何启用生成器
- 如何在生成器函数中使用多个 Python yield 语句
- 如何使用
.send()向发生器发送数据- 如何使用
.throw()引发发电机异常- 如何使用
.close()来停止生成器的迭代- 如何构建一个生成器管道来高效地处理大型 CSV 文件
您可以通过下面的链接获得本教程中使用的数据集:
下载数据集: 单击此处下载您将在本教程中使用的数据集以了解 Python 中的生成器和 yield。
发电机对您的工作或项目有什么帮助?如果你只是刚刚了解它们,那么你打算将来如何使用它们呢?找到解决数据管道问题的好办法了吗?请在下面的评论中告诉我们!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 生成器 101*****
Python 中的无效语法:语法错误的常见原因
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 识别无效 Python 语法
Python 以其简单的语法而闻名。然而,当你第一次学习 Python,或者当你对另一种编程语言有扎实的基础时,你可能会遇到一些 Python 不允许的事情。如果你曾经在试图运行你的 Python 代码时收到过
SyntaxError,那么这个指南可以帮助你。在本教程中,您将看到 Python 中无效语法的常见例子,并学习如何解决这个问题。本教程结束时,你将能够:
- 在 Python 中识别无效语法
SyntaxError溯流而上- 解决无效语法或完全阻止它
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 中的无效语法
当您运行 Python 代码时,解释器将首先解析它,将其转换为 Python 字节码,然后执行它。解释器将在程序执行的第一阶段发现 Python 中的任何无效语法,也称为解析阶段。如果解释器不能成功解析您的 Python 代码,那么这意味着您在代码中的某个地方使用了无效的语法。解释器会试图告诉你错误发生在哪里。
当你第一次学习 Python 时,获得一个
SyntaxError可能会令人沮丧。Python 将试图帮助你确定无效语法在你代码中的位置,但是它提供的回溯可能会有点混乱。有时候,它指向的代码完全没问题。注意:如果你的代码在语法上是正确的,那么你可能会得到其他不是
SyntaxError的异常。要了解更多关于 Python 的其他异常以及如何处理它们,请查看 Python 异常:简介。在 Python 中不能像其他异常一样处理无效语法。即使您试图用无效语法将
try和except块包装在代码周围,您仍然会看到解释器抛出一个SyntaxError。
SyntaxError异常和追溯当解释器在 Python 代码中遇到无效语法时,它会引发一个
SyntaxError异常,并提供一些有用信息的回溯来帮助你调试错误。以下是 Python 中包含无效语法的一些代码:1# theofficefacts.py 2ages = { 3 'pam': 24, 4 'jim': 24 5 'michael': 43 6} 7print(f'Michael is {ages["michael"]} years old.')您可以在第 4 行的字典中看到无效的语法。第二个条目
'jim'缺少一个逗号。如果您试图按原样运行这段代码,那么您会得到以下回溯:$ python theofficefacts.py File "theofficefacts.py", line 5 'michael': 43 ^ SyntaxError: invalid syntax注意,回溯消息在第 5 行找到错误,而不是第 4 行。Python 解释器试图指出无效语法的位置。然而,它只能真正指向它第一次注意到问题的地方。当您得到一个
SyntaxError回溯并且回溯所指向的代码看起来没问题时,那么您将想要开始回溯代码,直到您可以确定哪里出了问题。在上面的例子中,根据逗号后面的内容,省略逗号没有问题。例如,第 5 行中的
'michael'后面缺少一个逗号没有问题。但是一旦解释器遇到没有意义的东西,它只能给你指出它首先发现的它无法理解的东西。注意:本教程假设你知道 Python 的回溯的基础知识。要了解更多关于 Python 回溯以及如何阅读它们,请查看了解 Python 回溯和充分利用 Python 回溯。
有一些
SyntaxError回溯的元素可以帮助您确定无效语法在代码中的位置:
- 遇到无效语法的文件名
- 遇到问题的代码的行号和复制行
- 一个脱字符号(
^) 在复制代码下面的一行,显示代码中有问题的地方- 异常类型
SyntaxError之后的错误消息,它可以提供帮助您确定问题的信息在上面的例子中,给出的文件名是
theofficefacts.py,行号是 5,插入符号指向字典键michael的右引号。SyntaxError回溯可能不会指出真正的问题,但它会指出解释器无法理解语法的第一个地方。您可能会看到 Python 引发的另外两个异常。这些等同于
SyntaxError,但名称不同:
IndentationErrorTabError这些异常都继承自
SyntaxError类,但是它们是缩进的特例。当代码的缩进级别不匹配时,会引发一个IndentationError。当您的代码在同一个文件中同时使用制表符和空格时,会引发一个TabError。在后面的小节中,您将仔细研究这些异常。常见语法问题
当您第一次遇到一个
SyntaxError时,了解为什么会出现问题以及您可以做些什么来修复 Python 代码中的无效语法是很有帮助的。在下面的小节中,您将看到一些更常见的引发SyntaxError的原因,以及如何修复它们。误用赋值运算符(
=)在 Python 中有几种情况下你不能给对象赋值。一些例子是分配给文字和函数调用。在下面的代码块中,您可以看到几个尝试这样做的例子以及由此产生的
SyntaxError回溯:
>>> len('hello') = 5
File "<stdin>", line 1
SyntaxError: can't assign to function call
>>> 'foo' = 1
File "<stdin>", line 1
SyntaxError: can't assign to literal
>>> 1 = 'foo'
File "<stdin>", line 1
SyntaxError: can't assign to literal
第一个例子试图将值5分配给len()调用。在这种情况下,SyntaxError的信息非常有用。它告诉你不能给函数调用赋值。
第二个和第三个例子试图将一个字符串和一个整数赋给文字。同样的规则也适用于其他文字值。回溯消息再次表明,当您试图为文本赋值时会出现问题。
注意:上面的例子缺少了重复的代码行和在回溯中指向问题的插入符号(^)。当你在 REPL 中试图从一个文件中执行这段代码时,你看到的异常和回溯会有所不同。如果这些代码在一个文件中,那么您将得到重复的代码行和指向问题的插入符号,就像您在本教程的其他例子中看到的那样。
很可能你的意图不是给一个文字或者一个函数调用赋值。例如,如果您不小心遗漏了额外的等号(=),就会发生这种情况,这会将赋值转换为比较。如下图所示,比较是有效的:
>>> len('hello') == 5 True大多数时候,当 Python 告诉你你正在给不能赋值的东西赋值时,你可能首先要检查一下,确保这个语句不应该是一个布尔表达式。当您试图给一个 Python 关键字赋值时,也可能会遇到这个问题,这将在下一节中介绍。
拼错、遗漏或误用 Python 关键字
Python 关键字是一组受保护的单词,在 Python 中有特殊的含义。这些词不能在代码中用作标识符、变量或函数名。它们是语言的一部分,只能在 Python 允许的上下文中使用。
有三种常见的错误使用关键词的方式:
- 拼错关键字
- 缺少一个关键字
- 误用关键字
如果你在你的 Python 代码中拼错了一个关键词,那么你会得到一个
SyntaxError。例如,如果您拼错了关键字for,会发生什么情况:
>>> fro i in range(10):
File "<stdin>", line 1
fro i in range(10):
^
SyntaxError: invalid syntax
信息显示为SyntaxError: invalid syntax,但这并没有多大帮助。回溯指向 Python 可以检测到出错的第一个地方。要修复此类错误,请确保所有 Python 关键字拼写正确。
关键词的另一个常见问题是当你完全错过它们时:
>>> for i range(10): File "<stdin>", line 1 for i range(10): ^ SyntaxError: invalid syntax同样,异常消息并不那么有用,但是回溯确实试图为您指出正确的方向。如果您从插入符号向后移动,那么您可以看到
for循环语法中缺少了in关键字。你也可以误用一个受保护的 Python 关键字。记住,关键字只允许在特定的情况下使用。如果使用不当,Python 代码中就会出现无效语法。一个常见的例子是在循环之外使用
continue或break。在开发过程中,当您正在实现一些东西,并且碰巧将逻辑移到循环之外时,这很容易发生:
>>> names = ['pam', 'jim', 'michael']
>>> if 'jim' in names:
... print('jim found')
... break ...
File "<stdin>", line 3
SyntaxError: 'break' outside loop
>>> if 'jim' in names:
... print('jim found')
... continue ...
File "<stdin>", line 3
SyntaxError: 'continue' not properly in loop
在这里,Python 很好地告诉了你到底哪里出了问题。消息"'break' outside loop"和"'continue' not properly in loop"帮助你弄清楚该做什么。如果这段代码在一个文件中,那么 Python 也会有一个插入符号指向被误用的关键字。
另一个例子是,如果你试图将一个 Python 关键字赋给一个变量,或者使用一个关键字来定义一个函数:
>>> pass = True File "<stdin>", line 1 pass = True ^ SyntaxError: invalid syntax >>> def pass(): File "<stdin>", line 1 def pass(): ^ SyntaxError: invalid syntax当你试图给
pass赋值时,或者当你试图定义一个名为pass的新函数时,你会得到一个SyntaxError并再次看到"invalid syntax"消息。在 Python 代码中解决这种类型的无效语法可能有点困难,因为代码从外部看起来很好。如果您的代码看起来不错,但是您仍然得到了一个
SyntaxError,那么您可以考虑根据您正在使用的 Python 版本的关键字列表来检查您想要使用的变量名或函数名。受保护的关键字列表在 Python 的每个新版本中都有所变化。例如,在 Python 3.6 中,您可以使用
await作为变量名或函数名,但是从 Python 3.7 开始,这个词已经被添加到关键字列表中。现在,如果你试图使用await作为变量或函数名,如果你的代码是 Python 3.7 或更高版本的,这将导致一个SyntaxError。另一个例子是
版本 接受一个值 Python 2 关键字 不 Python 3 内置函数 是
您可以运行以下代码来查看正在运行的任何 Python 版本中的关键字列表:
import keyword print(keyword.kwlist)
keyword也提供了有用的keyword.iskeyword()。如果你只是需要一种快速的方法来检查pass变量,那么你可以使用下面的一行程序:
>>> import keyword; keyword.iskeyword('pass')
True
这段代码会很快告诉你,你试图使用的标识符是否是一个关键字。
缺少圆括号、方括号和引号
通常,Python 代码中无效语法的原因是右括号、中括号或引号丢失或不匹配。在很长的嵌套括号行或更长的多行代码块中,很难发现这些问题。借助 Python 的回溯功能,您可以发现不匹配或缺失的引号:
>>> message = 'don't' File "<stdin>", line 1 message = 'don't' ^ SyntaxError: invalid syntax在这里,回溯指向在结束单引号后有一个
t'的无效代码。要解决这个问题,您可以进行两种更改之一:
- 用反斜杠(
'don\'t')转义单引号- 将整个字符串用双引号(
"don't")括起来另一个常见的错误是忘记关闭字符串。对于双引号和单引号字符串,情况和回溯是相同的:
>>> message = "This is an unclosed string
File "<stdin>", line 1
message = "This is an unclosed string
^
SyntaxError: EOL while scanning string literal
这一次,回溯中的插入符号直接指向问题代码。SyntaxError消息"EOL while scanning string literal"更加具体,有助于确定问题。这意味着 Python 解释器在一个打开的字符串关闭之前到达了行尾(EOL)。要解决这个问题,请用与您用来开始字符串的引号相匹配的引号来结束字符串。在这种情况下,这将是一个双引号(")。
在 Python 中, f 字符串内的语句中缺少引号也会导致无效语法:
1# theofficefacts.py
2ages = {
3 'pam': 24,
4 'jim': 24,
5 'michael': 43
6}
7print(f'Michael is {ages["michael]} years old.')
这里,对打印的 f 字符串中的ages字典的引用缺少了键引用的右双引号。产生的回溯如下:
$ python theofficefacts.py
File "theofficefacts.py", line 7
print(f'Michael is {ages["michael]} years old.')
^
SyntaxError: f-string: unterminated string
Python 会识别问题,并告诉您它存在于 f 字符串中。消息"unterminated string"也指出了问题所在。在这种情况下,插入符号仅指向 f 字符串的开头。
这可能不像脱字符号指向 f 字符串的问题区域那样有用,但是它确实缩小了您需要查看的范围。在 f-string 里面有一个未结束的字符串。你只需要找到在哪里。要解决此问题,请确保所有内部 f 字符串引号和括号都存在。
对于缺少圆括号和方括号的情况也是如此。例如,如果你从一个列表中漏掉了右方括号,那么 Python 会发现并指出来。然而,这也有一些变化。第一个是把右括号从列表中去掉:
# missing.py
def foo():
return [1, 2, 3
print(foo())
当你运行这段代码时,你会被告知对 print() 的调用有问题:
$ python missing.py
File "missing.py", line 5
print(foo())
^
SyntaxError: invalid syntax
这里发生的是 Python 认为列表包含三个元素:1、2和3 print(foo())。Python 使用空格对事物进行逻辑分组,因为没有逗号或括号将3和print(foo())分开,Python 将它们聚集在一起作为列表的第三个元素。
另一种变化是在列表中的最后一个元素后添加一个尾随逗号,同时仍保留右方括号:
# missing.py
def foo():
return [1, 2, 3,
print(foo())
现在你得到了一个不同的追溯:
$ python missing.py
File "missing.py", line 6
^
SyntaxError: unexpected EOF while parsing
在前面的例子中,3和print(foo())被合并为一个元素,但是在这里您可以看到一个逗号将两者分开。现在,对print(foo())的调用被添加为列表的第四个元素,Python 到达了文件的末尾,没有右括号。回溯告诉您 Python 到达了文件的末尾(EOF ),但是它期望的是别的东西。
在这个例子中,Python 需要一个右括号(]),但是重复的行和插入符号没有多大帮助。Python 很难识别缺失的圆括号和方括号。有时候,你唯一能做的就是从插入符号开始向后移动,直到你能识别出什么是丢失的或错误的。
弄错字典语法
你之前看到过如果你去掉字典元素中的逗号,你会得到一个SyntaxError。Python 字典的另一种无效语法是使用等号(=)来分隔键和值,而不是冒号:
>>> ages = {'pam'=24} File "<stdin>", line 1 ages = {'pam'=24} ^ SyntaxError: invalid syntax同样,这个错误消息也不是很有帮助。然而,重复的行和插入符号非常有用!他们正指向问题人物。
如果您将 Python 语法与其他编程语言的语法混淆,这种类型的问题是常见的。如果您将定义字典的行为与
dict()调用混淆,您也会看到这一点。要解决这个问题,您可以用冒号替换等号。您也可以切换到使用dict():
>>> ages = dict(pam=24)
>>> ages
{'pam': 24}
如果语法更有用,您可以使用dict()来定义字典。
使用错误的缩进
SyntaxError有两个子类专门处理缩进问题:
IndentationErrorTabError
当其他编程语言使用花括号来表示代码块时,Python 使用空格。这意味着 Python 希望代码中的空白行为是可预测的。如果代码块中有一行的空格数错误,它将引发 IndentationError :
1# indentation.py
2def foo():
3 for i in range(10):
4 print(i)
5 print('done') 6
7foo()
这可能很难看到,但是第 5 行只缩进了 2 个空格。它应该与for循环语句一致,超出 4 个空格。幸运的是,Python 可以很容易地发现这一点,并会很快告诉您问题是什么。
不过,这里也有一点含糊不清。print('done')线是打算在for循环的后的还是循环块for内的?当您运行上述代码时,您会看到以下错误:
$ python indentation.py
File "indentation.py", line 5
print('done')
^
IndentationError: unindent does not match any outer indentation level
尽管回溯看起来很像SyntaxError回溯,但它实际上是一个IndentationError。错误消息也很有帮助。它告诉您该行的缩进级别与任何其他缩进级别都不匹配。换句话说,print('done')缩进了 2 个空格,但是 Python 找不到任何其他代码行匹配这个缩进级别。您可以通过确保代码符合预期的缩进级别来快速解决这个问题。
另一种类型的SyntaxError是 TabError ,每当有一行包含用于缩进的制表符或空格,而文件的其余部分包含另一行时,就会看到这种情况。这可能会隐藏起来,直到 Python 为您指出来!
如果您的制表符大小与每个缩进级别中的空格数一样宽,那么它可能看起来像所有的行都在同一级别。但是,如果一行使用空格缩进,另一行使用制表符缩进,那么 Python 会指出这是一个问题:
1# indentation.py
2def foo():
3 for i in range(10):
4 print(i)
5 print('done') 6
7foo()
这里,第 5 行缩进了一个制表符,而不是 4 个空格。根据您的系统设置,这个代码块可能看起来非常好,也可能看起来完全错误。
然而,Python 会立即注意到这个问题。但是,在运行代码以查看 Python 会告诉您什么是错误的之前,看看不同制表符宽度设置下的代码示例可能会对您有所帮助:
$ tabs 4 # Sets the shell tab width to 4 spaces
$ cat -n indentation.py
1 # indentation.py
2 def foo():
3 for i in range(10)
4 print(i)
5 print('done') 6
7 foo()
$ tabs 8 # Sets the shell tab width to 8 spaces (standard)
$ cat -n indentation.py
1 # indentation.py
2 def foo():
3 for i in range(10)
4 print(i)
5 print('done') 6
7 foo()
$ tabs 3 # Sets the shell tab width to 3 spaces
$ cat -n indentation.py
1 # indentation.py
2 def foo():
3 for i in range(10)
4 print(i)
5 print('done') 6
7 foo()
请注意上面三个示例之间的显示差异。大多数代码为每个缩进级别使用 4 个空格,但是第 5 行在所有三个示例中都使用了一个制表符。标签的宽度根据标签宽度的设置而变化:
- 如果标签宽度是 4 ,那么
print语句将看起来像是在for循环之外。控制台将在循环结束时打印'done'。 - 如果标签宽度为 8 ,这是许多系统的标准,那么
print语句看起来就像是在for循环中。控制台会在每个数字后打印出'done'。 - 如果标签宽度为 3 ,那么
print语句看起来不合适。在这种情况下,第 5 行与任何缩进级别都不匹配。
当您运行代码时,您将得到以下错误和追溯:
$ python indentation.py
File "indentation.py", line 5
print('done')
^
TabError: inconsistent use of tabs and spaces in indentation
注意TabError而不是通常的SyntaxError。Python 指出了问题所在,并给出了有用的错误消息。它清楚地告诉你,在同一个文件中混合使用了制表符和空格来缩进。
解决这个问题的方法是让同一个 Python 代码文件中的所有行都使用制表符或空格,但不能两者都用。对于上面的代码块,修复方法是移除制表符并用 4 个空格替换,这将在for循环完成后打印'done'。
定义和调用函数
在定义或调用函数时,您可能会在 Python 中遇到无效的语法。例如,如果在函数定义的末尾使用分号而不是冒号,您会看到一个SyntaxError:
>>> def fun(); File "<stdin>", line 1 def fun(); ^ SyntaxError: invalid syntax这里的回溯非常有用,插入符号直接指向问题字符。您可以通过去掉冒号的分号来清除 Python 中的这种无效语法。
此外,函数定义和函数调用中的关键字参数需要有正确的顺序。关键字参数总是在位置参数之后。不使用该顺序将导致
SyntaxError:
>>> def fun(a, b):
... print(a, b)
...
>>> fun(a=1, 2)
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument
这里,错误消息再次非常有助于告诉您该行到底出了什么问题。
更改 Python 版本
有时,在一个版本的 Python 中运行良好的代码在新版本中会崩溃。这是由于语言句法的官方变化。最著名的例子是print语句,它从 Python 2 中的关键字变成了 Python 3 中的内置函数:
>>> # Valid Python 2 syntax that fails in Python 3 >>> print 'hello' File "<stdin>", line 1 print 'hello' ^ SyntaxError: Missing parentheses in call to 'print'. Did you mean print('hello')?这是与
SyntaxError一起提供的错误消息闪耀的例子之一!它不仅告诉您在您可能遇到的另一个问题是,当您在阅读或学习新版本 Python 中有效的语法时,在您正在编写的版本中却无效。这方面的一个例子是 f-string 语法,这在 Python 之前的版本中是不存在的:
>>> # Any version of python before 3.6 including 2.7
>>> w ='world'
>>> print(f'hello, {w}')
File "<stdin>", line 1
print(f'hello, {w}')
^
SyntaxError: invalid syntax
在 Python 之前的版本中,解释器不知道任何关于 f 字符串的语法,只会提供一个通用的"invalid syntax"消息。在这种情况下,问题是代码看起来非常好,但是它是用旧版本的 Python 运行的。如果有疑问,请仔细检查您运行的 Python 版本!
Python 语法在继续发展,在 Python 3.8 中引入了一些很酷的新特性:
如果您想尝试这些新特性,那么您需要确保您正在 Python 3.8 环境中工作。否则,你会得到一个SyntaxError。
Python 3.8 还提供了新的 SyntaxWarning 。在语法有效但看起来可疑的情况下,您会看到这个警告。这种情况的一个例子是,在一个列表中,两个元组之间缺少了一个逗号。这在 Python 之前的版本中是有效的语法,但是代码会引发一个TypeError,因为元组是不可调用的:
>>> [(1,2)(2,3)] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object is not callable这个
TypeError意味着你不能像调用函数一样调用元组,这是 Python 解释器认为你在做的事情。在 Python 3.8 中,这段代码仍然会引发
TypeError,但是现在您还会看到一个SyntaxWarning来指示您可以如何修复这个问题:
>>> [(1,2)(2,3)]
<stdin>:1: SyntaxWarning: 'tuple' object is not callable; perhaps you missed a comma?
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object is not callable
新SyntaxWarning附带的有用信息甚至提供了一个提示("perhaps you missed a comma?"),为您指出正确的方向!
结论
在本教程中,您已经看到了SyntaxError回溯给了您什么信息。您还看到了 Python 中无效语法的许多常见示例,以及这些问题的解决方案。这不仅会加速你的工作流程,还会让你成为一个更有帮助的代码评审者!
当你写代码时,试着使用理解 Python 语法并提供反馈的 IDE。如果您将本教程中的许多无效 Python 代码示例放到一个好的 IDE 中,那么它们应该会在您开始执行代码之前突出显示问题行。
在学习 Python 的时候获得一个 SyntaxError 可能会令人沮丧,但是现在你知道如何理解回溯消息,以及在 Python 中你可能会遇到什么形式的无效语法。下一次你得到一个SyntaxError,你将会更好的装备来快速解决问题!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 识别无效 Python 语法*****
如何在 Python 中迭代字典
原文:https://realpython.com/iterate-through-dictionary-python/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 字典迭代:进阶提示&招数
字典是 Python 中最重要和最有用的数据结构之一。它们可以帮助您解决各种各样的编程问题。本教程将带您深入了解如何在 Python 中迭代字典。
本教程结束时,你会知道:
- 什么是字典,以及它们的一些主要特性和实现细节
- 如何使用 Python 语言提供的基本工具来遍历该语言中的字典
- 通过在 Python 中遍历字典,可以执行什么样的实际任务
- 如何使用一些更高级的技术和策略来遍历 Python 中的字典
有关词典的更多信息,您可以查阅以下资源:
准备好了吗?我们走吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
参加测验:通过我们的交互式“Python 字典迭代”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
字典上的几个词
字典是 Python 的基石。语言本身是建立在字典的基础上的。模块、类、对象、globals()、locals():这些都是字典。从一开始,字典就是 Python 的核心。
Python 的官方文档对字典的定义如下:
一个关联数组,其中任意键被映射到值。这些键可以是具有
__hash__()和__eq__()方法的任何对象。(来源
有几点需要记住:
- 字典将键映射到值,并将它们存储在数组或集合中。
- 这些键必须是哈希类型,这意味着它们必须有一个在键的生命周期中不会改变的哈希值。
字典经常用于解决各种编程问题,因此作为 Python 开发人员,字典是您的基本工具。
与 序列 不同,后者是支持使用整数索引的元素访问的 iterables ,字典是通过键索引的。
字典中的键很像一个 set ,它是可散列的和唯一的对象的集合。因为对象需要是可散列的,可变的对象不能用作字典键。
另一方面,值可以是任何 Python 类型,不管它们是否是可散列的。实际上,价值观没有任何限制。
在 Python 3.6 和更高版本中,字典的键和值按照它们被创建的顺序被迭代。然而,这种行为在不同的 Python 版本中可能会有所不同,这取决于字典的插入和删除历史。
在 Python 2.7 中,字典是无序的结构。字典条目的顺序是打乱的。这意味着项目的顺序是确定的和可重复的。让我们看一个例子:
>>> # Python 2.7 >>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> a_dict {'color': 'blue', 'pet': 'dog', 'fruit': 'apple'} >>> a_dict {'color': 'blue', 'pet': 'dog', 'fruit': 'apple'}如果您离开解释器,稍后打开一个新的交互会话,您将获得相同的项目顺序:
>>> # Python 2.7\. New interactive session
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'}
>>> a_dict
{'color': 'blue', 'pet': 'dog', 'fruit': 'apple'}
>>> a_dict
{'color': 'blue', 'pet': 'dog', 'fruit': 'apple'}
仔细观察这两个输出会发现,两种情况下的结果顺序完全相同。这就是为什么你可以说排序是确定性的。
在 Python 3.5 中,字典仍然是无序的,但这一次,随机化了数据结构。这意味着每次你重新运行字典,你会得到一个不同的条目顺序。让我们来看看:
>>> # Python 3.5 >>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> a_dict {'color': 'blue', 'pet': 'dog', 'fruit': 'apple'} >>> a_dict {'color': 'blue', 'pet': 'dog', 'fruit': 'apple'}如果您进入一个新的交互式会话,您将得到以下内容:
>>> # Python 3.5\. New interactive session
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'}
>>> a_dict
{'fruit': 'apple', 'pet': 'dog', 'color': 'blue'}
>>> a_dict
{'fruit': 'apple', 'pet': 'dog', 'color': 'blue'}
这一次,您可以看到两个输出中的项目顺序不同。这就是为什么你可以说它们是随机化的数据结构。
在 Python 3.6 及更高版本中,字典是有序的数据结构,这意味着它们保持其元素被引入的相同顺序,正如您在这里看到的:
>>> # Python 3.6 and beyond >>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> a_dict {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> a_dict {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'}这是 Python 字典中相对较新的特性,而且非常有用。但是如果您正在编写应该在不同 Python 版本中运行的代码,那么您一定不能依赖这个特性,因为它会产生错误的行为。
字典的另一个重要特性是它们是可变的数据结构,这意味着您可以添加、删除和更新它们的条目。值得注意的是,这也意味着它们不能用作其他字典的键,因为它们不是可散列对象。
注意:您在本节中学习的所有内容都与核心 Python 实现相关, CPython 。
其他 Python 实现,如 PyPy 、 IronPython 或 Jython ,可以展示不同的字典行为和特性,这超出了本文的范围。
如何用 Python 迭代字典:基础知识
字典是 Python 中一种有用且广泛使用的数据结构。作为一名 Python 程序员,您经常会遇到需要遍历 Python 中的字典,同时对其键值对执行一些操作的情况。
当谈到用 Python 迭代字典时,这种语言为您提供了一些很棒的工具,我们将在本文中介绍。
直接遍历关键字
Python 的字典是映射对象。这意味着它们继承了一些特殊方法,Python 在内部使用这些方法来执行一些操作。这些方法使用在方法名的开头和结尾添加双下划线的命名约定来命名。
为了可视化任何 Python 对象的方法和属性,您可以使用
dir(),这是一个内置的函数。如果您使用一个空字典作为参数运行dir(),那么您将能够看到字典实现的所有方法和属性:
>>> dir({})
['__class__', '__contains__', '__delattr__', ... , '__iter__', ...]
如果仔细看看前面的输出,您会看到'__iter__'。这是一个当容器需要迭代器时调用的方法,它应该返回一个新的迭代器对象,可以遍历容器中的所有对象。
注意:为了节省空间,前面代码的输出被缩写为(...)。
对于映射(比如字典),.__iter__()应该遍历这些键。这意味着如果你将一个字典直接放入一个 for循环,Python 将自动调用该字典上的.__iter__(),你将得到一个覆盖其键的迭代器:
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> for key in a_dict: ... print(key) ... color fruit petPython 足够聪明,知道
a_dict是一个字典,它实现了.__iter__()。在这个例子中,Python 自动调用了.__iter__(),这允许您迭代a_dict的键。这是 Python 中遍历字典最简单的方法。只要直接放入一个
for循环,就大功告成了!如果您使用这种方法和一个小技巧,那么您可以处理任何字典的键和值。诀窍在于使用索引操作符
[]和字典及其键来访问值:
>>> for key in a_dict:
... print(key, '->', a_dict[key])
...
color -> blue
fruit -> apple
pet -> dog
前面的代码允许您同时访问a_dict的键(key)和值(a_dict[key])。这样,您可以对键和值进行任何操作。
迭代通过.items()和
当您使用字典时,您可能希望同时使用键和值。在 Python 中迭代字典的最有用的方法之一是使用.items(),这是一种返回字典条目的新视图的方法:
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> d_items = a_dict.items() >>> d_items # Here d_items is a view of items dict_items([('color', 'blue'), ('fruit', 'apple'), ('pet', 'dog')])像
d_items这样的字典视图提供了字典条目的动态视图,这意味着当字典发生变化时,视图会反映这些变化。视图可以被迭代以产生它们各自的数据,因此您可以通过使用由
.items()返回的视图对象来迭代 Python 中的字典:
>>> for item in a_dict.items():
... print(item)
...
('color', 'blue')
('fruit', 'apple')
('pet', 'dog')
由.items()返回的视图对象一次产生一个键-值对,并允许你在 Python 中遍历一个字典,但是通过这种方式你可以同时访问键和值。
如果您仔细观察由.items()生成的单个项目,您会注意到它们实际上是tuple对象。让我们来看看:
>>> for item in a_dict.items(): ... print(item) ... print(type(item)) ... ('color', 'blue') <class 'tuple'> ('fruit', 'apple') <class 'tuple'> ('pet', 'dog') <class 'tuple'>一旦知道了这一点,就可以使用
tuple解包来遍历正在使用的字典的键和值。为了实现这一点,您只需要将每个条目的元素分解成两个不同的变量来表示键和值:
>>> for key, value in a_dict.items():
... print(key, '->', value)
...
color -> blue
fruit -> apple
pet -> dog
这里,for循环头中的变量key和value进行解包。每次循环运行时,key将存储键,value将存储被处理的项的值。这样,您将对字典的条目有更多的控制,并且您将能够以更具可读性和 Pythonic 性的方式分别处理键和值。
注意:注意到.values()和.keys()像.items()一样返回视图对象,你将在接下来的两节中看到。
迭代通过.keys()和
如果您只需要使用字典的键,那么您可以使用.keys(),这是一个返回包含字典键的新视图对象的方法:
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} >>> keys = a_dict.keys() >>> keys dict_keys(['color', 'fruit', 'pet'])这里由
.keys()返回的对象提供了一个关于a_dict键的动态视图。这个视图可以用来遍历a_dict的键。要使用
.keys()遍历 Python 中的字典,只需在for循环的头中调用.keys():
>>> for key in a_dict.keys():
... print(key)
...
color
fruit
pet
当你在a_dict上调用.keys()时,你得到一个键的视图。Python 知道视图对象是可迭代的,所以它开始循环,你可以处理a_dict的键。
另一方面,使用您之前见过的相同技巧(索引操作符[]),您可以访问字典的值:
>>> for key in a_dict.keys(): ... print(key, '->', a_dict[key]) ... color -> blue fruit -> apple pet -> dog这样你就可以同时访问
a_dict的键(key)和值(a_dict[key]),并且你可以对它们执行任何操作。迭代通过
.values()和在 Python 中,只使用值来遍历字典也很常见。一种方法是使用
.values(),它返回一个包含字典值的视图:
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'}
>>> values = a_dict.values()
>>> values
dict_values(['blue', 'apple', 'dog'])
在前面的代码中,values保存了对包含a_dict值的视图对象的引用。
与任何视图对象一样,.values()返回的对象也可以被迭代。在这种情况下,.values()产生了a_dict的值:
>>> for value in a_dict.values(): ... print(value) ... blue apple dog使用
.values(),您将只能访问a_dict的值,而不用处理密钥。值得注意的是,它们还支持成员测试(
in) ,如果您想知道某个特定元素是否在字典中,这是一个重要的特性:
>>> a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'}
>>> 'pet' in a_dict.keys()
True
>>> 'apple' in a_dict.values()
True
>>> 'onion' in a_dict.values()
False
如果键(或值或项)存在于正在测试的字典中,使用in的成员测试返回True,否则返回False。如果您只想知道某个键(或值或项)是否存在于字典中,成员测试允许您不遍历 Python 中的字典。
修改值和键
在 Python 中遍历字典时,需要修改值和键是很常见的。要完成这项任务,你需要考虑几个要点。
例如,您可以随时修改这些值,但是您需要使用原始的字典和映射您想要修改的值的键:
>>> prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25} >>> for k, v in prices.items(): ... prices[k] = round(v * 0.9, 2) # Apply a 10% discount ... >>> prices {'apple': 0.36, 'orange': 0.32, 'banana': 0.23}在前面的代码示例中,为了修改
prices的值并应用 10%的折扣,您使用了表达式prices[k] = round(v * 0.9, 2)。那么,如果可以访问它的键(
k)和值(v),为什么还要使用原来的字典呢?你应该能够直接修改它们吗?真正的问题是
k和v的变化没有反映在原始字典中。也就是说,如果您直接在循环中修改其中的任何一个(k或v),那么实际发生的情况是您将丢失对相关字典组件的引用,而不会改变字典中的任何内容。另一方面,可以通过将由
.keys()返回的视图转换成一个list对象来添加或删除字典中的键:
>>> prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25}
>>> for key in list(prices.keys()): # Use a list instead of a view
... if key == 'orange':
... del prices[key] # Delete a key from prices
...
>>> prices
{'apple': 0.4, 'banana': 0.25}
这种方法可能会对性能产生一些影响,主要与内存消耗有关。例如,您将在系统内存中拥有一个全新的list,而不是按需生成元素的视图对象。然而,这可能是在 Python 中迭代字典时修改键的一种安全方式。
最后,如果您试图通过直接使用.keys()从prices中删除一个键,那么 Python 将引发一个RuntimeError,告诉您字典的大小在迭代过程中已经改变:
>>> # Python 3\. dict.keys() returns a view object, not a list >>> prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25} >>> for key in prices.keys(): ... if key == 'orange': ... del prices[key] ... Traceback (most recent call last): File "<input>", line 1, in <module> for key in prices.keys(): RuntimeError: dictionary changed size during iteration这是因为
.keys()返回一个 dictionary-view 对象,该对象根据需要一次生成一个键,如果您删除一个条目(del prices[key],那么 Python 会产生一个RuntimeError,因为您在迭代过程中修改了字典。注意:Python 2 中的,
.items(),.keys(),.values()返回list对象。但是.iteritems()、iterkeys()和.itervalues()返回迭代器。因此,如果您使用 Python 2,那么您可以通过直接使用.keys()来修改字典的键。另一方面,如果您在 Python 2 代码中使用了
iterkeys(),并试图修改字典的键,那么您将得到一个RuntimeError。真实世界的例子
到目前为止,您已经看到了 Python 中遍历字典的更基本的方法。现在是时候看看如何在迭代过程中对字典的条目执行一些操作了。让我们看一些真实世界的例子。
注意:在本文的后面,您将看到通过使用其他 Python 工具来解决这些完全相同的问题的另一种方法。
将键转换为值,反之亦然
假设您有一个字典,出于某种原因需要将键转换为值,反之亦然。在这种情况下,您可以使用一个
for循环来遍历字典,并通过使用键作为值来构建新字典,反之亦然:
>>> a_dict = {'one': 1, 'two': 2, 'thee': 3, 'four': 4}
>>> new_dict = {}
>>> for key, value in a_dict.items():
... new_dict[value] = key
...
>>> new_dict
{1: 'one', 2: 'two', 3: 'thee', 4: 'four'}
表达式new_dict[value] = key通过将键转换成值并将值用作键,为您完成了所有工作。为了让这段代码正常工作,存储在原始值中的数据必须是可哈希的数据类型。
过滤项目
有时您会遇到这样的情况:您有一个字典,但您想创建一个新字典来只存储满足给定条件的数据。您可以使用for循环中的 if语句来实现这一点,如下所示:
>>> a_dict = {'one': 1, 'two': 2, 'thee': 3, 'four': 4} >>> new_dict = {} # Create a new empty dictionary >>> for key, value in a_dict.items(): ... # If value satisfies the condition, then store it in new_dict ... if value <= 2: ... new_dict[key] = value ... >>> new_dict {'one': 1, 'two': 2}在本例中,您已经过滤掉了值大于
2的项目。现在new_dict只包含满足条件value <= 2的项目。这是解决这类问题的一种可能的方法。稍后,您将看到获得相同结果的更 Pythonic 化、可读性更强的方法。做一些计算
在 Python 中遍历字典时,还经常需要做一些计算。假设您已经将公司的销售数据存储在一个字典中,现在您想知道一年的总收入。
为了解决这个问题,你可以定义一个初始值为零的变量。然后,您可以在该变量中累加字典中的每个值:
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00}
>>> total_income = 0.00
>>> for value in incomes.values():
... total_income += value # Accumulate the values in total_income
...
>>> total_income
14100.0
在这里,您已经遍历了incomes,并按照您想要的那样在total_income中依次累积了它的值。total_income += value这个表达式有魔力,在循环结束时,你会得到一年的总收入。注意total_income += value相当于total_income = total_income + value。
使用理解
一个字典理解是一种处理集合中所有或部分元素并返回一个字典作为结果的紧凑方式。与列表理解相反,它们需要两个表达式,用冒号分隔,后跟for和if(可选)子句。当运行字典理解时,产生的键-值对按照它们产生的顺序插入到新字典中。
例如,假设您有两个数据列表,您需要根据它们创建一个新的字典。在这种情况下,您可以使用 Python 的zip(*iterables)成对地遍历两个列表的元素:
>>> objects = ['blue', 'apple', 'dog'] >>> categories = ['color', 'fruit', 'pet'] >>> a_dict = {key: value for key, value in zip(categories, objects)} >>> a_dict {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'}这里,
zip()接收两个可迭代对象(categories和objects)作为参数,并创建一个迭代器,从每个可迭代对象中聚合元素。由zip()生成的tuple对象然后被解包到key和value中,最终用于创建新的字典。字典理解开辟了新的可能性,并为您提供了一个在 Python 中迭代字典的好工具。
将键转换为值,反之亦然:重温
如果您再看一下将键转换为值的问题,或者相反,您会发现您可以通过使用字典理解来编写一个更 Pythonic 化、更有效的解决方案:
>>> a_dict = {'one': 1, 'two': 2, 'thee': 3, 'four': 4}
>>> new_dict = {value: key for key, value in a_dict.items()}
>>> new_dict
{1: 'one', 2: 'two', 3: 'thee', 4: 'four'}
有了对字典的理解,您就创建了一个全新的字典,其中键取代了值,反之亦然。这种新方法使您能够编写更可读、简洁、高效和 Pythonic 化的代码。
这段代码工作的条件与您之前看到的相同:值必须是可散列的对象。否则,您将无法将它们用作new_dict的按键。
过滤项目:重新访问
要用一个理解过滤字典中的条目,只需要添加一个if子句,定义想要满足的条件。在前面过滤字典的例子中,条件是if v <= 2。将这个if子句添加到字典理解的末尾,您将过滤掉值大于2的条目。让我们来看看:
>>> a_dict = {'one': 1, 'two': 2, 'thee': 3, 'four': 4} >>> new_dict = {k: v for k, v in a_dict.items() if v <= 2} >>> new_dict {'one': 1, 'two': 2}现在
new_dict只包含满足您的条件的项目。与之前的解决方案相比,这个解决方案更加 Pythonic 化和高效。做一些计算:重温
还记得公司销售的例子吗?如果您使用列表理解来遍历字典的值,那么您将获得更紧凑、更快速、更 Pythonic 化的代码:
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00}
>>> total_income = sum([value for value in incomes.values()])
>>> total_income
14100.0
list comprehension 创建了一个包含incomes的值的list对象,然后您使用sum()对所有的值求和,并将结果存储在total_income中。
如果您正在使用一个非常大的字典,并且内存使用对您来说是一个问题,那么您可以使用一个生成器表达式来代替列表理解。生成器表达式是一个返回迭代器的表达式。这看起来像一个列表理解,但你需要用括号来定义它,而不是括号:
>>> total_income = sum(value for value in incomes.values()) >>> total_income 14100.0如果您将方括号改为一对圆括号(这里是
sum()的圆括号),您将把列表理解变成一个生成器表达式,并且您的代码将是内存高效的,因为生成器表达式按需生成元素。您不必创建整个列表并将其存储在内存中,而是一次只需要存储一个元素。注:如果你对生成器表达式完全陌生,可以看看Python 生成器简介和 Python 生成器 101 来更好的理解题目。
最后,有一种更简单的方法来解决这个问题,只需直接使用
incomes.values()作为sum()的参数:
>>> total_income = sum(incomes.values())
>>> total_income
14100.0
sum()接收 iterable 作为参数,并返回其元素的总和。在这里,incomes.values()扮演传递给sum()的 iterable 的角色。结果就是你想要的总收入。
移除特定项目
现在,假设您有一个字典,并且需要创建一个删除了所选键的新字典。还记得关键视图对象如何像集合吗?嗯,这些相似之处不仅仅是可散列的和独特的对象的集合。键视图对象也支持常见的set操作。让我们看看如何利用这一点来删除字典中的特定条目:
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00} >>> non_citric = {k: incomes[k] for k in incomes.keys() - {'orange'}} >>> non_citric {'apple': 5600.0, 'banana': 5000.0}这段代码可以工作,因为键视图对象支持像并集、交集和差集这样的
set操作。当你在字典理解里面写incomes.keys() - {'orange'}的时候,你真的是在做一个set差运算。如果您需要用字典的键执行任何set操作,那么您可以直接使用 key-view 对象,而不必先将其转换为set。这是键视图对象的一个鲜为人知的特性,在某些情况下非常有用。整理字典
通常有必要对集合中的元素进行排序。从 Python 3.6 开始,字典就是有序的数据结构,所以如果你使用 Python 3.6(以及更高版本),你将能够通过使用
sorted()并借助字典理解对任何字典的条目进行排序:
>>> # Python 3.6, and beyond
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00}
>>> sorted_income = {k: incomes[k] for k in sorted(incomes)}
>>> sorted_income
{'apple': 5600.0, 'banana': 5000.0, 'orange': 3500.0}
这段代码允许你创建一个新的字典,它的键按排序顺序排列。这是可能的,因为sorted(incomes)返回一个排序的键列表,您可以用它来生成新的字典sorted_dict。
有关如何微调排序的更多信息,请查看对 Python 字典进行排序:值、键等等。
按排序顺序迭代
有时,您可能需要在 Python 中遍历一个字典,但希望按排序顺序进行。这可以通过使用sorted()来实现。当您调用sorted(iterable)时,您会得到一个list,其中包含按照排序顺序排列的iterable的元素。
让我们看看,当您需要按照排序的顺序来遍历一个字典时,如何使用sorted()来遍历 Python 中的字典。
按键排序
如果您需要在 Python 中遍历一个字典,并希望它按键排序,那么您可以将您的字典用作sorted()的参数。这将返回一个包含排序后的键的list,您将能够遍历它们:
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00} >>> for key in sorted(incomes): ... print(key, '->', incomes[key]) ... apple -> 5600.0 banana -> 5000.0 orange -> 3500.0在这个例子中,您使用
for循环头中的sorted(incomes)按关键字对字典进行了排序(按字母顺序)。请注意,您也可以使用sorted(incomes.keys())来获得相同的结果。在这两种情况下,您都将得到一个list,其中包含您的字典中按排序顺序排列的键。注意:排序顺序将取决于您用于键或值的数据类型以及 Python 用于排序这些数据类型的内部规则。
按值排序
您可能还需要遍历 Python 中的字典,其中的条目按值排序。你也可以使用
sorted(),但是使用第二个参数key。
key关键字参数指定了一个参数的函数,用于从正在处理的每个元素中提取一个比较键。要按值对字典中的条目进行排序,您可以编写一个函数来返回每个条目的值,并将该函数用作
sorted()的key参数:
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00}
>>> def by_value(item):
... return item[1]
...
>>> for k, v in sorted(incomes.items(), key=by_value):
... print(k, '->', v)
...
('orange', '->', 3500.0)
('banana', '->', 5000.0)
('apple', '->', 5600.0)
在本例中,您定义了by_value(),并使用它按值对incomes的项目进行排序。然后使用sorted()按照排序顺序遍历字典。key 函数(by_value())告诉sorted()按照每个项目的第二个元素,也就是按照值(item[1])对incomes.items()进行排序。
您可能还想按排序顺序遍历字典中的值,而不用担心键。在这种情况下,您可以如下使用.values():
>>> for value in sorted(incomes.values()): ... print(value) ... 3500.0 5000.0 5600.0
sorted(incomes.values())根据您的需要,按排序顺序返回字典中的值。如果你使用incomes.values(),这些键是不可访问的,但是有时候你并不真的需要这些键,只需要这些值,这是一种快速访问它们的方法。反转
如果需要对字典进行逆序排序,可以将
reverse=True作为参数添加到sorted()中。关键字参数reverse应该取一个布尔值。如果设置为True,那么元素以相反的顺序排序:
>>> incomes = {'apple': 5600.00, 'orange': 3500.00, 'banana': 5000.00}
>>> for key in sorted(incomes, reverse=True):
... print(key, '->', incomes[key])
...
orange -> 3500.0
banana -> 5000.0
apple -> 5600.0
在这里,您通过在for循环的头中使用sorted(incomes, reverse=True)以相反的顺序遍历了incomes的键。
最后,需要注意的是sorted()并没有真正修改底层字典的顺序。实际发生情况是,sorted()创建一个独立的列表,其中的元素按顺序排列,所以incomes保持不变:
>>> incomes {'apple': 5600.0, 'orange': 3500.0, 'banana': 5000.0}这段代码告诉你
incomes没有改变。sorted()没修改incomes。它只是从incomes的键中创建了一个新的排序列表。破坏性地迭代
.popitem()有时,您需要在 Python 中遍历一个字典,并按顺序删除它的条目。要完成这个任务,您可以使用
.popitem(),它将从字典中移除并返回一个任意的键值对。另一方面,当你在一个空字典上调用.popitem()时,它会引出一个KeyError。如果你真的需要在 Python 中破坏性地遍历一个字典,那么
.popitem()会很有用。这里有一个例子:1# File: dict_popitem.py 2 3a_dict = {'color': 'blue', 'fruit': 'apple', 'pet': 'dog'} 4 5while True: 6 try: 7 print(f'Dictionary length: {len(a_dict)}') 8 item = a_dict.popitem() 9 # Do something with item here... 10 print(f'{item} removed') 11 except KeyError: 12 print('The dictionary has no item now...') 13 break这里,您使用了一个
while循环而不是一个for循环。这样做的原因是,如果您假装以这种方式修改字典,也就是说,如果您正在删除或添加条目,那么在 Python 中迭代字典是不安全的。在
while循环中,您定义了一个try...except块来捕捉当a_dict变空时由.popitems()引发的KeyError。在try...except块中,您处理字典,在每次迭代中删除一个条目。变量item保存了对连续项目的引用,并允许您对它们进行一些操作。注意:在前面的代码示例中,您使用 Python 的 f-strings 进行字符串格式化。如果你想更深入地研究 f 字符串,那么你可以看看 Python 3 的 f 字符串:一个改进的字符串格式化语法(指南)。
如果您从命令行运行这个脚本,那么您将得到以下结果:
$ python3 dict_popitem.py Dictionary length: 3 ('pet', 'dog') removed Dictionary length: 2 ('fruit', 'apple') removed Dictionary length: 1 ('color', 'blue') removed Dictionary length: 0 The dictionary has no item now...这里
.popitem()依次移除了a_dict的物品。当字典变空时循环中断,.popitem()引发了一个KeyError异常。使用 Python 的一些内置函数
Python 提供了一些内置函数,在处理集合(如字典)时可能会很有用。这些函数是一种迭代工具,为您提供了另一种在 Python 中遍历字典的方法。让我们看看其中的一些。
map()Python 的
map()被定义为map(function, iterable, ...),并返回一个迭代器,将function应用于iterable的每一项,按需产生结果。因此,map()可以被看作是一个迭代工具,你可以用它来遍历 Python 中的字典。假设您有一个包含一堆产品价格的字典,您需要对它们应用折扣。在这种情况下,您可以定义一个管理折扣的函数,然后将它用作
map()的第一个参数。第二个参数可以是prices.items():
>>> prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25}
>>> def discount(current_price):
... return (current_price[0], round(current_price[1] * 0.95, 2))
...
>>> new_prices = dict(map(discount, prices.items()))
>>> new_prices
{'apple': 0.38, 'orange': 0.33, 'banana': 0.24}
这里,map()遍历字典(prices.items())的条目,通过使用discount()对每种水果应用 5%的折扣。在这种情况下,需要使用dict()从map()返回的迭代器中生成new_prices字典。
注意,discount()返回一个(key, value)形式的tuple,其中current_price[0]代表键,round(current_price[1] * 0.95, 2)代表新值。
filter()
filter()是另一个内置函数,可以用来遍历 Python 中的一个字典,过滤掉其中的一些条目。这个函数被定义为filter(function, iterable),并从iterable的元素中返回一个迭代器,其中function返回True。
假设你想了解价格低于0.40的产品。您需要定义一个函数来确定价格是否满足该条件,并将其作为第一个参数传递给filter()。第二个论点可以是prices.keys():
>>> prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25} >>> def has_low_price(price): ... return prices[price] < 0.4 ... >>> low_price = list(filter(has_low_price, prices.keys())) >>> low_price ['orange', 'banana']在这里,您用
filter()迭代了prices的键。然后filter()将has_low_price()应用到prices的每一个键上。最后,你需要使用list()来生成低价产品的列表,因为filter()返回一个迭代器,你真的需要一个list对象。使用
collections.ChainMap
collections是 Python 标准库中一个有用的模块,提供了专门的容器数据类型。其中一种数据类型是ChainMap,它是一个类似字典的类,用于创建多个映射的单一视图(类似字典)。使用ChainMap,你可以将多个字典组合在一起,创建一个单一的、可更新的视图。现在,假设您有两个(或更多)字典,您需要将它们作为一个字典一起迭代。为了实现这一点,您可以创建一个
ChainMap对象并用您的字典初始化它:
>>> from collections import ChainMap
>>> fruit_prices = {'apple': 0.40, 'orange': 0.35}
>>> vegetable_prices = {'pepper': 0.20, 'onion': 0.55}
>>> chained_dict = ChainMap(fruit_prices, vegetable_prices)
>>> chained_dict # A ChainMap object
ChainMap({'apple': 0.4, 'orange': 0.35}, {'pepper': 0.2, 'onion': 0.55})
>>> for key in chained_dict:
... print(key, '->', chained_dict[key])
...
pepper -> 0.2
orange -> 0.35
onion -> 0.55
apple -> 0.4
从collections导入ChainMap后,您需要用您想要链接的字典创建一个ChainMap对象,然后您可以像使用常规字典一样自由地遍历结果对象。
ChainMap对象也像标准字典一样实现了.keys()、values()和.items(),因此您可以使用这些方法来遍历由ChainMap生成的类似字典的对象,就像您使用常规字典一样:
>>> for key, value in chained_dict.items(): ... print(key, '->', value) ... apple -> 0.4 pepper -> 0.2 orange -> 0.35 onion -> 0.55在这种情况下,您已经在一个
ChainMap对象上调用了.items()。ChainMap对象的行为就好像它是一个普通的字典,.items()返回了一个字典视图对象,可以像往常一样被迭代。使用
itertoolsPython 的
itertools是一个模块,它提供了一些有用的工具来执行迭代任务。让我们看看如何使用它们中的一些来遍历 Python 中的字典。用
cycle()循环迭代假设您想在 Python 中遍历一个字典,但是您需要在一个循环中重复遍历它。要完成这个任务,您可以使用
itertools.cycle(iterable),它使一个迭代器从iterable返回元素并保存每个元素的副本。当iterable用尽时,cycle()从保存的副本中返回元素。这是以循环的方式进行的,所以由你来决定是否停止循环。在下面的例子中,您将连续三次遍历字典中的条目:
>>> from itertools import cycle
>>> prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25}
>>> times = 3 # Define how many times you need to iterate through prices
>>> total_items = times * len(prices)
>>> for item in cycle(prices.items()):
... if not total_items:
... break
... total_items -= 1
... print(item)
...
('apple', 0.4)
('orange', 0.35)
('banana', 0.25)
('apple', 0.4)
('orange', 0.35)
('banana', 0.25)
('apple', 0.4)
('orange', 0.35)
('banana', 0.25)
前面的代码允许您迭代给定次数的prices(在本例中为3)。这个循环可以是你需要的那样长,但是你有责任停止它。当total_items倒数到零时,if状态打破循环。
用chain() 链式迭代
itertools还提供了chain(*iterables),它获取一些iterables作为参数,并生成一个迭代器,从第一个可迭代对象开始产生元素,直到用完为止,然后遍历下一个可迭代对象,依此类推,直到用完所有元素为止。
这允许您在一个链中遍历多个字典,就像您对collections.ChainMap所做的那样:
>>> from itertools import chain >>> fruit_prices = {'apple': 0.40, 'orange': 0.35, 'banana': 0.25} >>> vegetable_prices = {'pepper': 0.20, 'onion': 0.55, 'tomato': 0.42} >>> for item in chain(fruit_prices.items(), vegetable_prices.items()): ... print(item) ... ('apple', 0.4) ('orange', 0.35) ('banana', 0.25) ('pepper', 0.2) ('onion', 0.55) ('tomato', 0.42)在上面的代码中,
chain()返回了一个 iterable,它组合了来自fruit_prices和vegetable_prices的条目。也可以使用
.keys()或.values(),这取决于您的需要,条件是同构:如果您使用.keys()作为chain()的参数,那么您需要使用.keys()作为其余参数。使用字典解包运算符(
**)Python 3.5 带来了一个有趣的新特性。 PEP 448 -额外的解包归纳可以让你在 Python 中遍历多个字典时更加轻松。让我们用一个简短的例子来看看这是如何工作的。
假设您有两个(或更多)字典,您需要一起遍历它们,而不使用
collections.ChainMap或itertools.chain(),正如您在前面的章节中看到的。在这种情况下,您可以使用字典解包操作符(**)将两个字典合并成一个新字典,然后遍历它:
>>> fruit_prices = {'apple': 0.40, 'orange': 0.35}
>>> vegetable_prices = {'pepper': 0.20, 'onion': 0.55}
>>> # How to use the unpacking operator **
>>> {**vegetable_prices, **fruit_prices}
{'pepper': 0.2, 'onion': 0.55, 'apple': 0.4, 'orange': 0.35}
>>> # You can use this feature to iterate through multiple dictionaries
>>> for k, v in {**vegetable_prices, **fruit_prices}.items():
... print(k, '->', v)
...
pepper -> 0.2
onion -> 0.55
apple -> 0.4
orange -> 0.35
字典解包操作符(**)确实是 Python 中一个很棒的特性。它允许你将多个字典合并成一个新的,就像你在使用vegetable_prices和fruit_prices的例子中所做的那样。一旦用解包操作符合并了字典,就可以像往常一样遍历新字典。
需要注意的是,如果您试图合并的字典有重复或公共的关键字,那么最右边的字典的值将占优势:
>>> vegetable_prices = {'pepper': 0.20, 'onion': 0.55} >>> fruit_prices = {'apple': 0.40, 'orange': 0.35, 'pepper': .25} >>> {**vegetable_prices, **fruit_prices} {'pepper': 0.25, 'onion': 0.55, 'apple': 0.4, 'orange': 0.35}两个字典中都有
pepper键。合并后,pepper(0.25)的fruit_prices值占优势,因为fruit_prices是最右边的字典。结论
您现在已经了解了如何在 Python 中迭代字典的基础知识,以及一些更高级的技术和策略!
你已经学会:
- 什么是字典,以及它们的一些主要特性和实现细节
- Python 中遍历字典的基本方法有哪些
- 在 Python 中通过遍历字典可以完成什么样的任务
- 如何使用一些更复杂的技术和策略来遍历 Python 中的字典
您拥有充分利用 Python 词典所需的工具和知识。这将有助于您在将来使用字典迭代时更加高效和有效。
参加测验:通过我们的交互式“Python 字典迭代”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 字典迭代:进阶提示&招数************
Java vs Python:面向 Java 开发人员的基础 Python
Python 是一种通用编程语言。通过考虑它对学习的可接近性和它对数据分析、机器学习和 web 开发的高度适用性,你可以理解它在过去几年中的增长。但是它是一种什么样的编程语言呢?当你比较 Java 和 Python 时,有什么不同?你能用它做什么?而且真的像有些人宣称的那样“简单易学”吗?
在本教程中,您将从 Java 的角度探索 Python。阅读完之后,您将能够决定 Python 是否是解决您的用例的可行选项,并了解何时可以将 Python 与 Java 结合使用来解决某些类型的问题。
在本教程中,您将了解到:
- 通用 Python 编程语言语法
- 最相关的标准数据类型
- Java 与 Python 的差异和相似之处
- 高质量 Python 的资源文档和教程
- 一些 Python 社区最喜欢的框架和库
- 从头开始Python 编程的方法
本教程面向熟悉 Java 内部工作原理、概念、术语、类、类型、集合框架等的软件开发人员。
你根本不需要有任何 Python 经验。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 从何而来?
Python 是由吉多·范·罗苏姆开发的一种编程语言。1989 年圣诞节期间,他一直在寻找一个业余编程项目,让自己有事可做,于是他开始开发 Python 解释器。
Python 起源于多种语言: ABC 、 C 和 Modula-3 。它基本上是一种面向对象的命令式编程语言。
根据您的偏好和所需的功能,它可以应用于完全面向对象的风格,也可以应用于带有函数的过程化编程风格。面向对象的功能将在本教程的后讨论。
注意:为了清楚起见,从 Java 的角度来看,Python 函数就像静态方法,你不一定需要在一个类内定义它们。稍后,你会看到一个 Python 函数定义的例子。
此外,更函数式的编程风格也是完全可能的。要了解更多,您需要探索 Python 的函数式编程能力。
2021 年初,TIOBE 第四次宣布 Python 为年度编程语言。截至 2021 年 Octoverse 报道,Python 在 GitHub 上被知识库贡献者评为第二受欢迎的语言。
Python 的哲学是什么?
很快,您将在本节之后的小节中亲身体验 Python。但是,首先,您将通过研究一些可以追溯到 Python 哲学的特性来探索为什么更好地了解 Python 是值得的。
Java 和 Python 背后的一些思想是相似的,但是每种编程语言都有自己独特的特点。Python 的哲学被捕获为十九个指导原则的集合,即 Python 的禅。Python 藏了几个复活节彩蛋,其中一个就是 Python 的禅。考虑当您在 Pythonread–eval–print 循环(REPL) 中发出以下命令时会发生什么:
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
虽然你不应该把上面的陈述看得太重,但是其中一些与你接下来要讲的特征直接相关。
注意:Python read–eval–print 循环将在本教程的后面解释。
通过考虑 Python 禅宗的指导原则,您会对如何使用这种语言有一个很好的想法。
Python 代码可读
如果您来自 Java 背景,并且看到一段典型的 Python 代码,您可能会认为您看到的是伪代码。有几个因素促成了这一点:
- 缩进用于语句分组。这使得代码块更短,并促进了统一的编码风格。稍后你会发现更多关于这个主题的内容。
- 一些内置的高级数据结构,加上一组适当的操作符符号,使得 Python 非常具有表现力。
- 选择使用异常作为处理错误的主要方式保持了代码的整洁。
- Python 程序员更喜欢一种编码风格,这种风格的灵感来自于请求原谅比请求许可更容易(EAFP)的概念,而不是三思而后行(LBYL)的概念。这种风格将重点放在程序的正常的、愉快的路径上,并且您将在之后弄清楚如何处理任何异常。有关这两种编码风格的更多信息,请查看 LBYL vs EAFP:防止或处理 Python 中的错误。
在本教程中,以及在其他链接资源中,您可以找到一些例子来说明这一点。
Python 自带电池
Python 的目标是你可以用 Python 的标准发行版解决大多数日常问题。为此,Python 包含了所谓的标准库。就像 Java 类库,它是由常量、函数、类和框架组成的有用工具的广泛集合。
要进一步了解 Python 标准库,请查看 Python 文档的 Python 教程中标准库简介的第一部分和第二部分。
Python 提倡代码重用
Python 提供了几个特性,使您能够开发可以在不同地方重用的代码,以应用不要重复自己(DRY) 原则。
一个特点是,你通常将代码分解成 Python 中的模块和包。但是,请注意,Python 模块和包不同于 Java 模块和包。如果你想从 Python 开发者的角度了解更多这些概念,你可以阅读关于 Python 模块和包的内容。
Python 中可以使用的另一种技术是面向对象编程。您将在本教程的部分探索这个。
您还可以使用decorator来修改 Python 函数、类或方法。这是另一种技术,因此您可以只对功能进行一次编程,之后就可以从您修饰的任何函数、类或方法中使用它。
Python 很容易扩展
对模块和包的支持是使 Python 易于扩展新功能的要素之一。您还可以通过重载Python 标准操作符和函数来定义新的或适应的行为。甚至有可能影响类是如何被创建的。
扩展 Python 最直接的方法是用纯 Python 编写代码。您还可以使用 Python 的一种简化方言(称为 Cython)或 C 或 C++中的绑定通过来定义模块。
如何开始发现 Python?
在本教程中,您会发现一些例子,这些例子可能会鼓励您探索某些东西或者亲自尝试 Python 代码片段。作为一名 Java 开发人员,您可能还记得熟悉 Java 和安装第一个 Java 开发工具包的第一步。同样,如果您想开始使用 Python,您首先需要安装它,然后创建一个沙箱,在那里您可以安全地进行实验。
已经有几个教程解释了如何做到这一点,所以接下来的小节将向您介绍这些资源。
安装 Python
第一步是安装 Python 的最新版本。为此,请遵循本 Python 3 安装和设置指南。
另一个可以找到安装说明的地方是官方 Python 下载页面。
注意:确保你已经安装了最新版本的 Python。在撰写本教程时,最新版本是 3.10.x 系列的最新补丁版本。本教程中显示的代码片段应该都适用于这个版本的 Python。
许多 Python 开发人员贡献了支持各种 Python 版本的库,他们通常更喜欢尝试 Python 的预发布版本,而不会干扰他们的常规 Python 工作。在这些情况下,在同一台机器上访问多个版本的 Python 非常方便。提供那个功能的一个工具是 pyenv ,堪比 Java 的 jEnv 。
创建沙盒并使用它
第二步,您应该建立一个虚拟环境,这样您就可以安全地利用开源 Python 生态系统。本节解释了您应该如何以及为什么这样做。
尽管 Python 附带了一个具有各种功能的广泛的标准库,还有更多功能以外部包的形式提供,其中绝大多数是开源的。 Python 包索引,或简称为 PyPI ,是收集和提供这些包的主要中央存储库。您可以使用 pip 命令安装软件包。但是,在此之前,请先阅读下面两段。
为了避免依赖版本冲突,通常不应该在项目之间共享您的全局或个人 Python 安装。实际上,每个项目或实验沙箱都有一个虚拟环境。
这样,您的项目保持相互独立。这种方法还可以防止包之间的版本冲突。如果你想更多地了解这个过程,那么你可以详细阅读如何创建和激活你的虚拟环境。
选择编辑器或集成开发环境
作为设置的最后一步,决定您想要使用哪个编辑器或 ide。如果你习惯了 IntelliJ,那么 PyCharm 似乎是合乎逻辑的选择,因为它属于同一系列的产品。另一个正在崛起的流行编辑器是 Visual Studio Code ,但是你也可以从中选择许多其他选项。
在您安装了 Python,学习了如何将外部包安装到虚拟环境中,并选择了编辑器或 IDE 之后,您就可以开始尝试这种语言了。当您通读本教程的其余部分时,您会发现大量的实验和实践机会。
Python 和 Java 有什么不同?
通过查看最显著的不同之处,您可以快速了解 Python 是哪种编程语言。在接下来的小节中,您将了解 Python 与 Java 最重要的不同之处。
代码块分组的缩进
或许 Python 最引人注目的特征是它的语法。特别是,您指定它的函数、类、流控制结构和代码块的方式与您可能习惯的方式非常不同。在 Java 中,用众所周知的花括号({和})来表示代码块。然而,在 Python 中,通过缩进级别来指示代码块。这里您可以看到一个演示缩进如何确定代码块分组的示例:
1def parity(number):
2 result = "odd" # Function body
3 if number % 2 == 0:
4 result = "even" # Body of if-block
5 return result # Not part of if-block
6
7for num in range(4): # Not part of function
8 print("Number", num, "is", parity(num)) # Body of for-loop
9print("This is not part of the loop") # Not part of for-loop
该代码展示了一些新概念:
- 第 1 行:
def语句开始定义一个名为parity()的新函数,它接受一个名为number的参数。注意,如果def语句出现在一个类定义块中,它将会启动一个方法定义。 - 第 2 行:在
parity()内,函数体从缩进层次开始。第一条语句是将"odd"字符串赋给result变量。 - 第 3 行:这里你看到一个
if语句的开始。 - 第 4 行:额外的缩进开始一个新的块。当
if语句的条件表达式number % 2 == 0评估为真时,执行该块。在这个例子中,它只由一行代码组成,在这里你将"even"赋值给result变量。 - 第 5 行:
return语句之前的 dedent 标志着if语句及其相关块的结束。 - 第 7 行:同样,你可以看到在
for循环开始之前的数据。因此,for循环从与函数定义块的第一行相同的缩进级别开始。它标志着函数定义块的结束。 - 第 8 行:你会看到同样的事情在
for循环中再次发生。第一个print()函数调用是for循环块的一部分。 - 第 9 行:这个第二个定向的
print()函数调用不是for循环块的一部分。
您可能已经注意到,行尾的冒号(:)引入了一个新的代码子块,应该缩进一级。当下一条语句再次重复时,该代码块结束。
代码块必须至少包含一条语句。空代码块是不可能的。在极少数不需要任何语句的情况下,你可以使用 pass语句,它什么也不做。
最后,您可能还注意到,您可以使用散列符号(#)进行注释。
上述示例将产生以下输出:
Number 0 is even
Number 1 is odd
Number 2 is even
Number 3 is odd
This is not part of the loop
虽然这种定义块的方式乍一看可能很奇怪,甚至可能会吓到你,但经验表明,人们会比你现在想象的更快地习惯它。
有一个对 Python 代码很有帮助的风格指南,叫做 PEP 8 。它建议使用四个位置的缩进级别,使用空格。样式指南不建议在源代码文件中使用制表符。原因是不同的编辑器和系统终端可能会使用不一致的制表位位置,并为不同的用户或不同的操作系统呈现不同的代码。
注意:风格指南是一个 Python 增强提议的例子,或者简称为 PEP 。pep 不仅包含提议,还反映了实现的规范,因此您可以将 pep 比作 Java 的 jep 和 JSR 的联合。 PEP 0 列出了 PEP 的索引。
你可以在 PEP 8 中找到很多有趣的信息,包括 Python 命名约定。如果你仔细阅读它们,你会发现它们与 Java 的略有不同。
从头开始的读取-评估-打印循环
从一开始,Python 就有一个内置的读取-评估-打印循环(REPL) 。REPL 读取尽可能短的完整语句、表达式或块,将其编译成字节码,然后进行求值。如果被评估的代码返回一个不同于None对象的对象,它输出这个对象的一个明确的表示。在本教程的后面你会找到对None 的解释。
注:你可以把 Python REPL 和 Java 的 JShell (JEP 222) 对比一下,后者从 JDK 9 开始就有了。
以下片段展示了 Python 的 REPL 是如何工作的:
>>> zero = int(0) >>> zero 0 >>> float(zero) 0.0 >>> complex(zero) 0j >>> bool(zero) False >>> str(zero) '0'正如您所看到的,解释器总是试图明确地显示结果表达式的值。在上面的例子中,您可以看到整数、浮点、复数、布尔和字符串的值是如何以不同的方式显示的。
Java 和 Python 的区别在于赋值操作符(
=)。使用单个等号的常规 Python 赋值是一个语句,而不是一个表达式,后者会产生一些值或对象。这解释了为什么 REPL 不打印对变量
zero的赋值:语句总是评估为None。赋值后的一行包含变量表达式zero,指示 REPL 显示结果变量。注: Python 3.8 引入了一个赋值表达式运算符(
:=),也被称为海象运算符。它给变量赋值,但与常规赋值不同的是,它像在表达式中一样对变量求值。这类似于 Java 中的赋值操作符。但是,请注意,它不能与常规赋值语句完全互换。它的范围实际上相当有限。在 REPL 中,下划线特殊变量(
_)保存最后一个表达式的值,前提是它不是None。下面的片段展示了如何使用这个特殊变量:
>>> 2 + 2
4
>>> _
4
>>> _ + 2
6
>>> some_var = _ + 1
>>> _
6
>>> some_var
7
将值7赋给some_var后,特殊变量_仍然保存值6。那是因为赋值语句评估为None。
动态类型和强类型
编程语言的一个重要特征是语言解释器或编译器何时、如何以及在何种程度上执行类型验证。
Python 是一种动态类型化的语言。这意味着变量、函数参数和函数返回值的类型是在运行时检查的,而不是像 Java 那样在编译时检查。
Python 同时也是一种强类型语言:
- 每个对象都有一个与之相关联的特定类型。
- 不兼容类型之间需要显式转换。
在这里,您将探索 Python 如何在运行时检查类型兼容性,以及如何使类型兼容:
>>> 40 + "2" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'str' >>> 40 + int("2") # Add two numbers 42 >>> str(40) + "2" # Concatenate strings '402' >>> 40 * "2" # Repeat string "2" forty times '2222222222222222222222222222222222222222'你会注意到,你不能只把一个整数值加到一个字符串值上。这在运行时受到保护。当解释器检测到运行时错误时,它会生成一个异常。REPL 捕捉
Exception个实例,并显示导致错误表达式的回溯。要解决这个问题,您需要将一种类型转换为另一种类型。如果想将两个对象作为数字相加,可以使用
int()构造函数将代表数字的字符串转换成普通数字。如果您想将两个对象连接成字符串,那么您可以使用str()构造函数将数字转换成字符串。上面 Python 会话的最后一行显示了另一个特性。通过将一个序列乘以一个数字,可以得到原始序列的串联结果,并按照给定的数字重复。
尽管 Python 是一种动态类型的语言,但是可以为代码提供类型的注释。
在运行时,Python 不会对这些注释做任何事情,除了让它们可用于自省。但是,静态类型检查器工具可以检测类型声明和带类型注释的函数、类和变量的实际使用之间的不一致。
注意:如上所述,Python 运行时使类型注释可供代码自省。一些图书馆利用这些信息,比如 。
类型注释帮助您在代码开发周期的早期阶段检测错误。尤其是在大型软件项目中,它们帮助您使代码更易于维护,并保持代码库的良好状态。您通常调用静态类型检查器作为构建管道中验证步骤的一部分。大多数 ide 也使用类型注释。
CPython vs JIT 编译器
与 Java 不同,Python 的参考实现没有 JIT 编译器。到目前为止,使用最多的 Python 实现是 CPython 。这也是参考实现。 CPython 是一个用 C 语言编写的编译器和解释器,几乎可以在任何可以想到的平台上使用。
CPython 分两步加载一个被称为模块的源文件:
- 编译:首先,CPython 读取代码,编译成字节码,这是 CPython 字节码解释器可以执行的指令序列。在有限的范围内,您可以将编译阶段与 Java 的
javac如何将一个.java文件编译成一个.class文件进行比较。- 执行:CPython 字节码解释器——换句话说,CPython 的虚拟机(VM)——随后从第一步开始执行字节码。
注意:不像在 Java 中,你不能假设同一个 Python 字节码可以与其他 Python 实现一起工作,甚至可以在同一个 Python 实现的不同版本之间工作。但是,它有助于减少加载模块所需的时间。
如果可能的话,[编译后的模块](https://docs.python.org/3/tutorial/modules.html#compiled-python-files "6. Modules — Python 3 documentation: "Compiled" Python Files")存储在缓存目录中。
与主流的 Java VM 实现不同,CPython 不会而不是随后将字节码编译成本机目标代码。然而,还有其他不同的 Python 实现:
- 有一个用于 Java 平台的 Python 实现叫做 Jython 。它运行在 JVM 中,Java 和 Python 之间有直接的互操作性。
- 同样,有一个名为 IronPython 的版本运行在。NET 平台。
- 有一个实现使用了名为 PyPy 的实时(JIT) 编译器。平均来说,PyPy 比 CPython 快 4.2 倍。
- 最后, GraalVM 是一个支持许多编程语言的高性能运行时。它为最近的 Python 版本提供了实验支持。
上面的列表并不详尽。Python 站点包含了一个备选实现和发行版的列表。
内置函数和运算符重载
作为一名 Java 开发人员,你可能知道术语重载和方法重载。虽然 Python 中有一个动态等价函数
@singledispatchmethod提供了类似的功能,但 Python 中还有另一种重载,您可能会发现它更有用。您可以为任何符合条件的 Python 内置函数和运算符定义自定义构建类的新行为。
注意:在这个上下文中,您可以认为合格的函数和操作符是那些允许您重载它们的行为的函数和操作符。
Python 提供了一种实现函数和运算符重载的便捷方式。
你可以通过在你的类中定义特别命名的方法来尝试。这种方法的名称以两个下划线开始和结束,如
.__len__()或.__add__()。具有这种名称的标识符被称为双下划线,是双下划线 (__)的缩写。当您使用一个对象调用符合条件的内置函数时,对应的 dunder 方法会出现,Python 会将行为委托给该方法。同样,当您使用一个或多个操作数包含相应的 dunder 方法的操作符时,Python 会将行为委托给该方法。
例如,您可以定义
.__len__()为内置的len()函数提供行为。同样,您可以定义.__add__()来为加法运算符(+)提供行为。这个特性使得将 Python 代码的漂亮、富于表现力和简洁的语法不仅应用于标准对象,也应用于定制对象成为可能。
集合函数处理的良好语法
在 Java 中,您可能已经通过组合调用
map()、filter()和 lambda 表达式构建了列表。使用相同的函数和技术,您可以在 Python 中做同样的事情。使用这些结构并不总是能产生可读性最强的代码。Python 为列表和其他集合的基本功能操作提供了一种优雅的替代语法。你可以对列表使用列表理解,对其他集合使用其他类型的理解。如果你想了解更多关于 Python 中的理解,那么你可以探索一下何时使用列表理解。
一切都是物体
在 Java 中,并不是所有的东西都是对象,尽管事实上唯一可以放置代码的地方是在 Java 类内部。例如,Java 原语
42不是一个对象。就像 Java 一样,Python 也完全支持面向对象的编程风格。与 Java 不同的是在 Python 中一切都是对象。Python 对象的一些示例有:
因为它们是对象,所以您可以将所有这些存储在变量中,传递它们,并在运行时自省它们。
注:正如你在上面读到的,类是对象。因为根据定义,对象是类的实例,所以类也必须是某些东西的实例。
事实上,这些是一个元类的实例。标准元类是
type,但是你可以创建替代的元类,通常是从type派生而来,以改变类的创建方式。元类,加上重载内置函数和操作符的能力,是 Python 成为多功能编程工具包的一部分。它们允许你创建你自己的可编程的额外的或者可选择的类和实例的行为。
Java 和 Python 有哪些方面相似?
尽管存在差异,但您可能已经发现了 Java 和 Python 之间的一些相似之处。这是因为 Python 和 Java 都受到了 C 编程语言的启发。在继续探索 Python 的过程中,您会发现它与 Java 有更多的相似之处。
基于类的面向对象
Python 是一种基于类的、面向对象的编程语言,这也是 Java 的主要特点之一。然而,这两种语言的面向对象特性集是不同的,要足够详细地解决这些问题,需要一个单独的教程。
幸运的是,您可以更深入地研究 Python 和 Java 中的面向对象编程,从而了解 Java 和 Python 在面向对象编程结构方面的区别。您还可以查看 Python 3 中的面向对象编程概述,以扩展您对该主题的了解。
操作员
您可能会注意到这两种语言的共同遗产的一个方面是它们如何使用运算符。它们中的许多在两种语言中都有相同的意思。
首先,比较 Java 和 Python 中众所周知的算术运算符。加法运算符(
+)、减法运算符(-)、乘法运算符(*)、除法运算符(/)和模运算符(%)在两种语言中几乎具有相同的用途——除了用于对类似整数的操作数进行除法运算。这同样适用于位运算符:位 or 运算符(
|)、位 AND 运算符(&)、位 XOR 运算符(^)和一元位 NOT 运算符(~),以及用于左移(<<)和右移(>>)的位移位运算符。你可以在 Python 中使用方括号语法(
[])来访问一个序列的元素,就像你如何使用 Java 的数组访问一样。后面关于数据类型的部分提供了关于这些操作符和一些附加操作符的更多细节。或者,如果你现在想了解更多,你可以阅读 Python 中的操作符和表达式。
字符串格式化
最初,Python 提供了字符串格式化功能,这是基于 C 编程语言中的
printf函数家族如何处理这一功能。这个类似于 Java 的String.format()。在 Python 中,%操作符执行这个功能。运算符的左侧包含格式字符串,右侧包含位置参数的元组或键控参数的字典。注意:在本教程的后面,你会看到更多关于元组和字典的内容。
以下进程显示了一些示例:
>>> "Hello, %s!" % "world" # %-style, single argument
'Hello, world!'
>>> "The %s is %d." % ("answer", 42) # %-style, positional
'The answer is 42.'
>>> "The %(word)s is %(value)d." \
... % dict(word="answer", value=42) # %-style, key-based
'The answer is 42.'
最近,Python 已经采用了其他的格式化字符串的方式。一种是使用.format()字符串方法,替换字段用花括号({})表示。这方面的一个例子是"The {word} is {value}.".format(word="answer", value=42)。
从 Python 3.6 开始,还可以使用格式的字符串文字,也称为 f 字符串。假设在作用域中有两个名为word和value的变量。在这种情况下,表达式f"The {word} is {value}."为您呈现与上面的示例.format()相同的字符串。
控制流构造
比较 Java 和 Python 时,控制流结构是相似的。这意味着您可能直观地认识到许多控制流结构。然而,在更详细的层面上,也存在差异。
一个 Python while 循环类似于 Java 的:
while (word := input("Enter word: ")) != "END":
print(word)
print("READY")
代码片段一行一行地将标准输入复制到标准输出,直到该行等于"END"。那一行没有被复制,但是文本"READY"被写入,后跟一个换行符。
您可能已经注意到了像这样的构造中的 walrus 操作符的附加价值。该赋值表达式运算符的优先级是所有运算符中最低的。这意味着当赋值表达式是一个更大的表达式的一部分时,你经常需要在它周围加上括号,就像在 Java 中一样。
注意: Python 没有do {...} while (...)循环结构。
Python for 循环类似于 Java for-each 循环。这意味着,例如,如果您想要迭代前五个罗马数字的列表,您可以使用类似的逻辑对其进行编码:
>>> roman_numerals = "I II III IV V".split() >>> roman_numerals ['I', 'II', 'III', 'IV', 'V'] >>> for numeral in roman_numerals: ... print(numeral) ... I II III IV V您可能会注意到,使用
str.split()是创建单词列表的一种便捷方式。注意:不仅是
list实例可以这样迭代,任何可迭代的都可以。有时,您可能需要一个运行计数器来代替。在这种情况下,您可以使用
range():
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
在本例中,i在每次迭代中引用请求范围的下一个值。随后打印该值。
在极少数情况下,您希望迭代一个集合,同时希望有一个运行计数器,您可以使用 enumerate() :
>>> for i, numeral in enumerate("I II III IV V".split(), start=1): ... print(i, numeral) ... 1 I 2 II 3 III 4 IV 5 V上面的例子显示了前面两个例子在一个循环中的功能。默认情况下,伴随的计数器从零开始,但是使用可选的关键字参数
start,您可以指定另一个值。注:查看 Python enumerate():用计数器简化循环如果你想了解更多关于 Python 循环和
enumerate()的知识。Python 也理解
break和continue语句。另一个类似于 Java 的控制流结构是
if语句:
>>> for n in range(3):
... if n <= 0:
... adjective = "not enough"
... elif n == 1:
... adjective = "just enough"
... else:
... adjective = "more than enough"
... print(f"You have {adjective} items ({n:d})")
...
You have not enough items (0)
You have just enough items (1)
You have more than enough items (2)
如上所述,Python if ... else构造还支持一个elif关键字,这很有帮助,因为没有简单的switch ... case语句。
注意:最近发布的 Python 3.10 版本包含了一个名为结构模式匹配的新特性,它引入了match和case关键字,但其行为与 Java 的 switch语句截然不同。
这个新的语言特性受到 Scala 的模式匹配语句的启发,Scala 是另一种运行在 JVM 上的编程语言。
虽然许多编码结构表面上看起来很相似,但仍有许多不同之处。例如,Python 循环,以及异常捕获构造,支持else:部分。此外,Python 为上下文管理器提供了一个 with语句。
Java vs Python:什么是高级本地数据类型?
在接下来的小节中,您将看到 Python 标准类型的简要概述。重点是这些类型或它们相关的操作符与 Java 的不同之处,或者它们与相应的 Java 集合类相比如何。
数字类型及其运算符
Python 提供了多种数值类型供选择,以适应您的特定应用领域。它内置了三种数值类型:
| 类型 | 类型名 | 示例文字 |
|---|---|---|
| 整数 | int |
42 |
| 浮点型 | float |
3.14 |
| 复杂的 | complex |
1+2j |
如果您比较这两种语言,那么您会发现 Python 整数可以包含任意长值,只受您的机器可用的(虚拟)内存量的限制。您可以将它们想象成固定精度的本地整数(或者 Java 称之为原始整数类型)和 Java 的 BigInteger 数字的智能混合,结果如下:
- 您拥有任意精度整数的所有便利,并且可以对它们使用所有众所周知的符号操作符。
- 当值足够小时,Python 对提供的值应用快速固定精度整数运算。
通过使用前缀0x、0o和0b,您可以将 Python 整数分别指定为十六进制、八进制和二进制常量。
注意:这意味着八进制数是而不是,只有一个或多个前导零(0),这与 Java 不同。
比较 Java 和 Python 中众所周知的算术运算符+、-、*、/和%,它们在两种语言中具有相同的含义,除了类似整数类型上的除法运算符。在 Python 中,应用于int操作数的 truediv 运算符(/)产生一个float值,这与 Java 不同。Python 使用 floordiv 运算符(//)进行除法运算,向下舍入到最接近的整数,类似于 Java 中的除法运算符(/):
>>> 11 / 4 # truediv 2.75 >>> 11.0 // 4 # floordiv, despite float operand(s) 2.0此外,Python 提供了双星号运算符(
**)来求幂,作为双参数pow()函数的替代。 matmul 操作符(@)是为外部包提供的类型保留的附加操作符,旨在为矩阵乘法提供方便的符号。Python 和 Java 都采用了 C 编程语言中的位操作符。这意味着按位运算符(
|、&、^和一元~)在两种编程语言中具有相同的含义。如果您想对负值使用这些操作符,那么最好知道在 Python 中,整数被表示为概念上无限大的空间中的二进制补码值来保存位。这意味着负值在概念上有无限多的前导
1位,就像正数在概念上有无限多的前导0位一样:
>>> bin(~0)
'-0b1'
>>> bin(~0 & 0b1111) # ~0 is an "infinite" sequence of ones
'0b1111'
上面的代码片段表明,不管您选择什么值,如果您将这个值与常数~0进行位与运算,那么结果值等于所选择的值。这意味着常数~0在概念上是一个无限的1比特序列。
也可以使用位移运算符(<<和>>)。然而,Java 的按位零填充右移操作符(>>>)没有对等物,因为这在任意长整数的数字系统中没有意义。没有最重要的位。这两种语言的另一个区别是 Python 不允许用负移位数来移位。
Python 标准库也提供了其他数值类型。十进制定点和浮点运算有 decimal.Decimal ,堪比 Java 的 BigDecimal 。有理数有一个 fractions.Fraction 类,类似于 Apache Commons 数学分数。请注意,这些类型是而不是分类为内置数值类型。
基本序列类型
序列类型是容器,您可以在其中使用整数索引来访问它们的元素。字符串和字节序列也是序列类型。这些将在几节后介绍。Python 内置了三种基本序列类型:
| 类型 | 类型名 | 示例文字 |
|---|---|---|
| 目录 | list |
[41, 42, 43] |
| 元组 | tuple |
("foo", 42, 3.14) |
| 范围 | range |
range(0, 9, 2) |
如您所见,列表和元组初始化器之间的语法差异是方括号([])和圆括号(())。
一个 Python list 类似 Java 的 ArrayList ,是 mutable 。您通常将这种容器用于同构集合,就像在 Java 中一样。然而,在 Python 中,存储不相关类型的对象是可能的。
另一方面,元组更类似于 Java 中类似 Pair 类的不可变版本,除了它用于任意数量的条目而不是两个。空括号(())表示空元组。像(3,)这样的结构表示包含单个元素的元组。在这种情况下,单个元素是3。
注意:你注意到只有一个元素的tuple的特殊语法了吗?请参见下面的进程,了解不同之处:
>>> (3,) (3,) >>> type(_) <class 'tuple'> >>> (3) 3 >>> type(_) <class 'int'>如果没有添加尾随逗号,那么表达式将被解释为括号内的对象。
一个范围产生一个通常在循环中使用的数字序列。在本教程的前面,您已经看到了一个这样的例子。如果你想学习更多关于 Python 中范围的知识,你可以查看这个关于 range()函数的指南。
要从序列中选择一个元素,可以在方括号中指定从零开始的索引,如
some_sequence[some_index]所示。负索引从末尾向后计数,因此-1表示最后一个元素。您也可以从序列中选择一个切片。这是对零个、一个或多个元素的选择,产生与原始序列同类的对象。您可以指定一个
start、stop和step值,也称为步幅。切片语法的一个例子是some_sequence[<start>:<stop>:<step>]。所有这些值都是可选的,如果没有另外指定,则采用实际的默认值。如果您想了解更多关于列表、元组、索引和切片的信息,阅读 Python 中的列表和元组会很有帮助。
对于正索引,Python 语法类似于在 Java 数组中选择元素的方式。
您可以使用加号运算符(
+)连接大多数序列,并使用星号运算符(*)重复它们:
>>> ["testing"] + ["one", "two"] * 2
['testing', 'one', 'two', 'one', 'two']
您不能用范围完成串联或序列重复,但是您可以对它们进行切片。例如,尝试range(6, 36, 3)[7:2:-2]并考虑你得到的结果。
字典
Python 中的一个字典, dict ,类似于 Java 的 LinkedHashMap 。dict 初始化器常量的语法是花括号({})之间逗号分隔的key: value条目序列。这方面的一个例子是{"pi": 3.14, "e": 2.71}。
要从 dict 或任何其他映射中选择一个元素,可以在方括号([])中指定键,如math_symbols["pi"]。键和值都可以是任何对象,但是键需要是可散列的,这意味着它们通常是不可变的——或者至少应该表现得像不可变的对象。键不一定需要都是相同的类型,尽管它们通常是相同的。这同样适用于价值观。
要了解更多信息,您可以阅读更多关于 Python 中的字典,或者查看关于映射类型的 Python 文档。
设置
Python 还提供了集。您可以使用类似于{"pi", "e"}的语法或者使用set()构造函数语法初始化集合,使用 iterable 作为参数。要创建一个空集,可以使用表达式set(),因为字面量{}已经被赋予了字典。
集合在底层实现中使用哈希。当你迭代一个集合时,要考虑到条目将会以明显随机的顺序出现,就像在 Java 中一样。此外,不同 Python 调用之间的顺序甚至可能会改变。
对于集合运算,某些运算符已被重载。详情可以阅读 Python 中关于集合的更多内容。
字符串
就像在 Java 中一样,Python 中的字符串是 Unicode 元素的不可变序列。字符串文字在双引号(")之间指定,也可以在单引号(')之间指定,这与 Java 不同。
字符串的两个例子是"foo"和'bar'。定义字符串时,不同的引号不一定有不同的含义。但是,你应该注意,如果你使用引号作为字符串的一部分,如果它们碰巧也是字符串的分隔符,你就必须对它们进行转义。
和 Java 一样,Python 中的反斜杠(\)是引入一个转义序列的字符。Python 解释器识别转义序列,这些序列在 Java 中也是已知的,比如\b、\n、\t,以及 C 编程语言中的一些其他序列。
默认情况下,Python 假设 Python 源文件采用 UTF-8 编码。这意味着您可以将 Unicode 文字直接放在字符串中,就像在"é"的情况中一样。您还可以使用其码位的 16 位或 32 位十六进制表示形式。对于"é",你可以通过使用\u00E9或\U000000E9转义序列来实现。注意小写\u和大写\U转义序列的区别。最后,也可以提供它的 Unicode 描述,比如\N{Latin Small Letter E with acute}。
即使在 Python 标识符中也可以使用 Unicode 字符,但问题是这样做是否明智。
如果你在字符串前面加上了r,就像在r"raw\text"中一样,那么反斜杠就失去了它的特殊意义。当您想要指定正则表达式时,这尤其方便。
您还可以用三重引号将字符串括起来,以方便地创建多行字符串,如下例所示:
>>> s = """This is a ... multiline ... string. ... """ ... >>> for line in s.splitlines(): ... print(repr(line)) ... 'This is a' ' multiline' ' string.' ' '您可以将这种类型的字符串与 Java 文本块(JEP 378) 进行比较,尽管有其他语法限制和另一种空白保留(制表符、空格和换行符)。
字节
在 Java 中,如果你需要存储二进制数据而不是文本,你可能会使用
ByteBuffer,这给了你可变的对象。在 Python 中,bytearray对象提供了类似的功能。与 Java 不同,Python 还提供了一个
bytes类型来存储不可变的二进制数据。字节字面量看起来非常类似于字符串字面量,除了您在字面量前面加了一个b。字符串包含一个将它们转换成字节序列的.encode()方法,一个bytes对象包含一个将它转换成字符串的.decode()方法:
>>> bytes(4) # Zero-filled with a specified length
b'\x00\x00\x00\x00'
>>> bytes(range(4)) # From an iterable of integers
b'\x00\x01\x02\x03'
>>> b = "Attaché case".encode() # Many different codecs are available
>>> b
b'Attach\xc3\xa9 case'
>>> b.decode() # Decode back into a string again
'Attaché case'
如果未指定编解码器,则默认的 UTF-8 编解码器用于编码字符串和解码字节。当你需要的时候,你可以从提供各种文本和字节转换的编解码器的一个大的列表中选择。
Python bytes对象也有一个.hex()方法,它产生一个字符串,以十六进制形式列出内容。对于相反的操作,您可以使用.fromhex() 类方法从十六进制字符串表示中构造一个bytes对象。
布尔型
False和True是 Python 中的两个bool实例对象。在数字上下文中,True计算为1,而False计算为0。这意味着True + True评估为2。
Python 中的布尔逻辑运算符不同于 Java 的&&、||和!运算符。在 Python 中,这些是保留的关键字and、or和not。
下表总结了这一点:
| Java 语言(一种计算机语言,尤用于创建网站) | 计算机编程语言 | 描述 |
|---|---|---|
a && b |
a and b |
逻辑与 |
a || b |
a or b |
逻辑或 |
!a |
not a |
逻辑非 |
与 Java 类似,布尔运算符and和or有一个短路求值行为,Python 解释器从左到右缓慢地对操作数求值,直到它可以确定整个表达式的真值。
与 Java 的另一个相似之处是解释器产生最后一次求值的子表达式作为结果。因此,你应该知道一个and或or表达式的结果不一定产生一个bool实例对象。
所有 Python 对象要么有一个假值要么有真值值。换句话说,当您将 Python 对象转换为bool时,结果是明确定义的:
- 等于
0的数值转换为False,否则转换为True。 - 空容器、集合、字符串和字节对象转换为
False,否则转换为True。 - 中的
None对象也会转换成False。 - 所有其他对象评估为
True。
注意:用户定义的类可以提供一个.__bool__() dunder 方法来定义它们的类实例的真实性。
如果您想测试一个容器或字符串是否非空,那么您只需在一个布尔上下文中提供该对象。这被认为是一种蟒的做法。
查看以下检查非空字符串的不同方法:
>>> s = "some string" >>> if s != "": # Comparing two strings ... print('s != ""') ... s != "" >>> if len(s) != 0: # Asking for the string length ... print("len(s) != 0") ... len(s) != 0 >>> if len(s): # Close, but no cigar ... print("len(s)") ... len(s) >>> if s: # Pythonic code! ... print("s") ... s在最后一个示例中,您只需在布尔上下文中提供字符串。如果字符串不为空,则计算结果为 true。
注意:以上并不意味着所有类型都依赖隐式
bool转换。关于None的下一节将对此进行更详细的阐述。如果您想了解更多关于最典型的 Python 结构的知识,可以遵循编写更多 Python 代码的学习路径。
在 Python 中,你用 Java 编写的带有条件运算符(
? :) 的条件表达式,作为带有关键词if和else的表达式:
Java 语言(一种计算机语言,尤用于创建网站) 计算机编程语言 cond ? a : ba if cond else b考虑 Python 中这种类型表达式的一个示例:
>>> for n in range(3):
... word = "item" if n == 1 else "items"
... print(f"Amount: {n:d} {word}")
...
Amount: 0 items
Amount: 1 item
Amount: 2 items
只有当n等于1时,REPL 才输出"item"。在所有其他情况下,REPL 输出"items"。
无
在 Python 中,None是一个单例对象,可以用来标识类似空值。在 Java 中,出于类似的目的,你可以使用文字 null 。
Python 中最常用的None是作为函数或方法定义中的默认参数值。此外,不返回任何值的函数或方法实际上会隐式返回None对象。
一般来说,当你在一个布尔上下文中依赖于None的隐式转换时,它被认为是一种代码味道,因为你可能会为其他类型的对象编写无意的行为代码,而这些对象恰好返回一个 falsy 值。
因此,如果您想测试一个对象是否真的是None对象,那么您应该显式地这样做。因为只有一个None对象,所以可以通过使用对象标识操作符is或相反的操作符is not来实现:
>>> some_value = "All" or None >>> if some_value is None: ... print(f"is None: {some_value}") >>> if some_value is not None: ... print(f"is not None: {some_value}") ... is not None: All请记住,这里的单词
not是is not操作符不可分割的一部分,而且它明显不同于逻辑not操作符。在这个例子中,字符串"All"在布尔上下文中有一个真值。您可能还记得,or操作符有这种短路行为,只要结果已知,就返回最后一个表达式,在本例中是"All"。更多容器数据类型
Java 通过它的集合框架提供它的标准容器类型。
Python 采用了不同的方法。它以内置类型的形式提供了您在本节前面已经探索过的基本容器类型,然后 Python 的标准库通过
collections模块提供了更多的容器数据类型。您可以通过collections模块访问许多有用的容器类型示例:
namedtuple提供了元组,您还可以通过字段名访问元组中的元素。deque提供双端队列,在集合两端都有快速追加和移除。ChainMap让你将多个贴图对象折叠成一个单独的贴图视图。Counter为计数可散列对象提供了映射。defaultdict提供了调用工厂函数来提供缺失值的映射。这些数据容器类型已经用普通 Python 实现了。
至此,您已经有了理解 Java 和 Python 在特性、语法和数据类型上的异同的良好基础。现在是时候后退一步,探索可用的 Python 库和框架,并找出它们对特定用例的适用性。
具体用法有哪些资源?
您可以在许多领域使用 Python。下面您将找到其中的一些领域,以及它们最有用和最受欢迎的相关 Python 库或框架:
- 命令行脚本:
argparse提供创建命令行参数解析器的功能。- 网络框架:
- 在开发完整且可能复杂的网站时,Django 提供了一种更简单的方法。它包括定义模型的能力,提供自己的 ORM 解决方案,并提供完整的管理功能。您可以添加额外的插件来进一步扩展管理。
- Flask 宣称自己是一个专注于做好一件事的微框架,那就是为 web 请求服务。您可以将这个核心功能与您自己选择的其他已经存在的组件结合起来,比如 ORM 和表单验证。许多被称为 Flask 插件的扩展可以很好地为您集成这些组件。
- 请求使得发送 HTTP 请求变得极其方便。
- 数据建模与分析: pandas 基于 NumPy ,是一款快速、强大、灵活、直观的开源数据分析与操作工具。有些人把熊猫称为“类固醇上的可编程电子表格”
- 机器学习: TensorFlow 、 Keras 和 PyTorch 是机器学习领域的几个流行框架。
- SQL 工具包和对象关系映射器(ORM): SQLAlchemy 是一个非常流行的 Python SQL 工具包和 ORM 框架。
- 工作量分配: 芹菜是一个分布式任务队列系统。
Python 还有一些与质量保证相关的值得注意的工具:
- pytest 是标准
unittest库的一个很好的替代品。- behavior是一个流行的行为驱动开发(BDD) 工具。您可以将它与 PyHamcrest 结合使用,以获得更具表现力的断言检查。
- Flake8 是一个编码风格向导检查器。
- Pylint 是一个工具,可以检查 Python 代码中的错误,识别代码气味和编码标准偏差。
- 黑色的是不妥协的、固执己见的、难以配置的代码重组者。虽然这听起来很可怕,但在现实生活中,对于任何大型软件项目来说,这都是一个很好的工具。
- mypy 是使用最广泛的静态类型检查器。
- Bandit 发现常见安全问题。
- 安全检查您已安装的依赖项是否存在已知的安全漏洞。
- tox 是一个命令行工具,有助于在一个命令中运行为您的项目以及多个 Python 版本和依赖配置定义的自动化测试和 QA 工具检查。
上面的列表只是众多可用包和框架中的一小部分。您可以浏览和搜索 Python 包索引(PyPI)来找到您正在寻找的特殊包。
Python 什么时候会比 Java 更有用,为什么?
通常,您希望为一个用例选择一种编程语言,而为另一个用例选择不同的编程语言。在比较 Java 和 Python 时,您应该考虑以下几个方面:
- Java 和 Python 都成功地用于世界上最大的 web 应用程序中。
- 您还可以使用 Python 编写 shell 工具。
- Python 优雅的语法、代码可读性、丰富的库和大量的外部包允许快速开发。您可能只需要不到一半的代码行就可以实现与 Java 相同的功能。
- 因为标准 Python 不需要编译或链接步骤,所以当您更新代码时会立即看到结果。这进一步加快了开发周期。
- 在大多数情况下,对于一般的应用程序,标准 Java 的执行速度要高于 Python。
- 你可以用 C 或 C++毫不费力地扩展 Python。这在一定程度上缓解了执行速度的差异。
对于某些用途,如数据建模、分析、机器学习和人工智能,执行速度真的很重要。为此功能创建的流行的第三方包是用编译成本机代码的编程语言定义的。对于这些领域,Python 似乎是最符合逻辑的选择。
结论
在本教程中,您熟悉了 Python,并对这种编程语言的特性有了清晰的了解。您已经探索了 Java 和 Python 之间的相似之处和不同之处。
现在,您已经有了一些快速入门 Python 的经验。您也有了一个很好的基础,可以了解在哪些情况下以及在哪些问题领域应用 Python 是有用的,并且对接下来可以查看哪些有用的资源有了一个大致的了解。
在本教程中,您学习了:
- Python 编程语言的语法
- Python 中有相当多的标准数据类型
- Python 与 Java 有何不同
- Java 和 Python 在哪些方面相似
- 在那里你可以找到 Python 文档和特定主题教程
- 如何开始使用 Python
- 如何通过使用 Python REPL 查看即时结果
- 一些喜欢的框架和库
也许你确定将来会更多地使用 Python,或者也许你还在决定是否要更深入地研究这门语言。无论哪种方式,有了上面总结的信息,您已经准备好探索 Python 和本教程中介绍的一些框架。
额外资源
当您准备好学习更多关于 Python 及其包的知识时,web 上有大量的可用资源:
- 你可以找到书面教程、视频课程、测验和学习路径,它们涵盖了 真实 Python 的许多主题。
- 外部 Python 实用程序、库和框架通常会提供良好的文档。
- PyVideo.org 提供了一个庞大的索引集合,可以免费获取来自世界各地 Python 相关会议的演示。
- 最后但同样重要的是,官方的 Python 文档维护了关于 Python 编程语言、其标准库及其生态系统的高标准的准确和完整的信息。
既然您已经了解了 Python 实际上是一种什么样的编程语言,那么您很有希望对它产生热情,并考虑在您的下一个项目中使用它,无论项目是大是小。快乐的蟒蛇!**********
朱庇特笔记本:简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 使用 Jupyter 笔记本
Jupyter Notebook 是一个开源的 web 应用程序,可以用来创建和共享包含实时代码、公式、可视化和文本的文档。Jupyter 笔记本由 Jupyter 项目的人员维护。
Jupyter 笔记本是 IPython 项目的一个分拆项目,这个项目本身曾经有一个 IPython 笔记本项目。Jupyter 这个名字来自它所支持的核心编程语言:Julia、Python 和 r。Jupyter 附带了 IPython 内核,它允许您用 Python 编写程序,但目前还有 100 多种其他内核可供您使用。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
使用 Jupyter 笔记本开始运行
Python 中不包含 Jupyter 笔记本,所以如果您想试用它,您需要安装 Jupyter。
Python 语言有许多发行版。为了安装 Jupyter Notebook,本文将只关注其中的两个。最流行的是 CPython ,这是 Python 的参考版本,你可以从他们的网站上获得。还假设你用的是 Python 3 。
安装
如果是这样,那么您可以使用 Python 附带的一个名为 pip 的便利工具来安装 Jupyter Notebook,如下所示:
$ pip install jupyterPython 的下一个最受欢迎的发行版是 Anaconda。Anaconda 有自己的安装工具,叫做 conda ,你可以用它来安装第三方的软件包。然而,Anaconda 预装了许多科学库,包括 Jupyter Notebook,所以除了安装 Anaconda 本身,您实际上不需要做任何事情。
启动 Jupyter 笔记本服务器
现在你已经安装了 Jupyter,让我们来学习如何使用它。要开始,您需要做的就是打开您的终端应用程序,并转到您选择的文件夹。我建议从你的文档文件夹开始,创建一个名为笔记本的子文件夹,或者其他容易记住的东西。
然后,只需转到终端中的该位置,运行以下命令:
$ jupyter notebook这将启动 Jupyter,您的默认浏览器应该会启动(或打开一个新标签)到以下 URL:http://localhost:8888/tree
您的浏览器现在应该看起来像这样:
请注意,现在您实际上不是在运行笔记本电脑,而是在运行笔记本电脑服务器。现在让我们实际创建一个笔记本吧!
创建笔记本
既然您已经知道了如何启动笔记本服务器,那么您应该学习如何创建一个实际的笔记本文档。
你所需要做的就是点击新按钮(右上角),它会打开一个选择列表。在我的机器上,我碰巧安装了 Python 2 和 Python 3,所以我可以创建一个使用其中任何一个的笔记本。为简单起见,我们选择 Python 3。
您的网页现在应该看起来像这样:
命名
你会注意到在页面的顶部是单词无标题。这是页面的标题和笔记本的名称。因为这不是一个很有描述性的名字,让我们改变它!
只需将鼠标移动到无标题的单词上,点击文本。你现在应该会看到一个名为重命名笔记本的浏览器内对话框。让我们把这个重新命名为你好 Jupyter :
运行单元
当你第一次创建一个笔记本时,笔记本的单元默认使用代码,并且该单元使用你在启动笔记本时选择的内核。
在这种情况下,您开始使用 Python 3 作为您的内核,所以这意味着您可以在您的代码单元中编写 Python 代码。由于你最初的笔记本只有一个空单元格,笔记本实际上什么也做不了。
因此,为了验证一切都正常工作,您可以向单元格添加一些 Python 代码,并尝试运行其内容。
让我们尝试将以下代码添加到该单元格中:
print('Hello Jupyter!')运行一个单元格意味着您将执行单元格的内容。要执行某个单元格,您只需选择该单元格,然后单击顶部按钮行中的运行按钮。它朝着中间。如果你喜欢使用键盘,你可以按下
Shift+Enter。当我运行上面的代码时,输出如下所示:
如果您的笔记本中有多个单元格,并且您按顺序运行这些单元格,那么您可以跨单元格共享变量和导入。这使得将代码分成逻辑块变得容易,而不需要重新导入库或在每个单元中重新创建变量或函数。
当你运行一个单元格时,你会注意到单元格左边的中的单词旁边有一些方括号。方括号将自动填充一个数字,表示您运行单元格的顺序。例如,如果您打开一个新的笔记本并运行笔记本顶部的第一个单元格,方括号将填充数字 1 。
菜单
Jupyter 笔记本有几个菜单,您可以使用它们与笔记本进行交互。菜单沿着笔记本的顶部运行,就像其他应用程序中的菜单一样。以下是当前菜单的列表:
- 文件
- 编辑
- 视图
- 插入
- 单元格
- 内核
- Widgets
- 帮助
让我们一个一个地看菜单。本文不会详细讨论每一个菜单中的每一个选项,而是将重点放在笔记本应用程序特有的项目上。
第一个菜单是文件菜单。在其中,您可以创建一个新的笔记本或打开一个现有的笔记本。这也是您重命名笔记本的地方。我认为最有趣的菜单项是保存和检查点选项。这允许您创建检查点,如果需要,可以回滚到这些检查点。
接下来是编辑菜单。您可以在这里剪切、复制和粘贴单元格。如果您想要删除、拆分或合并单元格,这也是您要去的地方。您也可以在这里重新排列单元格。
请注意,此菜单中的一些项目是灰色的。原因是它们不适用于当前选定的单元格。例如,code 单元格不能插入图像,但 Markdown 单元格可以。如果您看到灰色的菜单项,请尝试更改单元格的类型,并查看该项是否可用。
视图菜单对于切换标题和工具栏的可见性非常有用。您还可以打开或关闭单元格内的行号。如果您想摆弄单元格的工具栏,这也是您应该去的地方。
插入菜单仅用于在当前选中单元格的上方或下方插入单元格。
单元菜单允许您运行一个单元、一组单元或所有单元。你也可以在这里改变一个单元格的类型,虽然我个人觉得工具栏更直观。
这个菜单中另一个方便的特性是清除单元格输出的能力。如果您计划与其他人共享您的笔记本,您可能希望首先清除输出,以便下一个人可以自己运行单元。
内核单元用于处理在后台运行的内核。在这里你可以重启内核,重新连接,关闭,甚至改变你的笔记本使用的内核。
你可能不会经常使用内核,但是当你调试笔记本的时候,你会发现你需要重启内核。当这种情况发生时,这就是你要去的地方。
微件菜单用于保存和清除微件状态。小部件基本上是 JavaScript 小部件,您可以将它们添加到单元格中,使用 Python(或另一个内核)制作动态内容。
最后是帮助菜单,在这里你可以了解笔记本的键盘快捷键、用户界面浏览和大量参考资料。
启动终端和其他东西
Jupyter Notebook 还能让你开始不仅仅是笔记本。您也可以在浏览器中创建文本文件、文件夹或终端。回到您在
http://localhost:8888/tree第一次启动 Jupyter 服务器时打开的主页。转到新按钮,选择其他选项之一。终端可能是最有趣的,因为它在浏览器中运行你的操作系统终端。这允许您在浏览器中运行 bash、Powershell 等,并运行您可能需要的任何 shell 命令。
查看正在运行的内容
Jupyter 服务器(
http://localhost:8888/tree)的主页上还有另外两个选项卡:运行和集群。运行标签会告诉你当前运行的是哪些笔记本和终端。当您想要关闭服务器,但需要确保保存了所有数据时,这很有用。幸运的是,笔记本自动保存非常频繁,所以你很少会丢失数据。但是能够在需要的时候看到正在运行的东西是件好事。
这个标签的另一个好处是,你可以浏览正在运行的应用程序,并在那里关闭它们。
添加丰富的内容
Jupyter Notebook 支持向其单元格添加丰富的内容。在本节中,您将大致了解使用标记和代码可以对单元格做的一些事情。
细胞类型
从技术上讲,有四种单元格类型:代码、降价、原始 NBConvert 和标题。
不再支持标题单元格类型,将会显示一个对话框来说明这一点。相反,你应该对你的标题使用 Markdown。
原始 NBConvert 单元格类型仅用于使用
nbconvert命令行工具时的特殊用例。基本上,当从一个笔记本转换到另一种格式时,它允许你以一种非常特殊的方式控制格式。您将使用的主要单元格类型是代码和降价单元格类型。你已经知道了代码单元格是如何工作的,所以让我们来学习如何用 Markdown 设计你的文本样式。
设计文本样式
Jupyter Notebook 支持 Markdown,这是一种标记语言,是 HTML 的超集。本教程将涵盖一些你可以用 Markdown 做什么的基础知识。
将一个新单元格设置为 Markdown,然后向该单元格添加以下文本:
运行该单元时,输出应该如下所示:
如果你想加粗你的文本,使用双下划线或双星号。
标题
在 Markdown 中创建标题也很简单。你只需要使用谦逊的英镑符号。您使用的井号越多,页眉就越小。朱庇特笔记本甚至为你预览了一下:
然后,当您运行单元格时,您将得到一个格式良好的标题:
创建列表
您可以使用破折号、加号或星号来创建列表(项目符号)。这里有一个例子:
代码和语法高亮显示
如果您想插入一个不希望最终用户实际运行的代码示例,可以使用 Markdown 来插入它。对于内联代码突出显示,只需用反斜杠将代码括起来。如果要插入一段代码,可以使用三个反斜线并指定编程语言:
导出笔记本
当你使用 Jupyter 笔记本时,你会发现你需要与非技术人员分享你的成果。出现这种情况时,您可以使用 Jupyter Notebook 附带的
nbconvert工具将您的笔记本转换或导出为以下格式之一:
- 超文本标记语言
- 乳液
- 便携文档格式
- RevealJS
- 降价
- 重组后的文本
- 可执行脚本
nbconvert工具使用 Jinja 模板将你的笔记本文件(.ipynb)转换成其他格式。Jinja 是一个为 Python 制作的模板引擎。还要注意的是,
nbconvert也依赖于 Pandoc 和 TeX 来导出上述所有格式。如果您没有其中的一个或多个,某些导出类型可能无法工作。要了解更多信息,您应该查看文档。如何使用
nbconvert
nbconvert命令不带太多参数,这使得学习如何使用它变得更加容易。打开终端,导航到包含要转换的笔记本的文件夹。基本转换命令如下所示:$ jupyter nbconvert <input notebook> --to <output format>用法示例
让我们假设你有一个名为
py_examples.ipynb的笔记本,你想把它转换成 PDF。下面是您可以使用的命令:$ jupyter nbconvert py_examples.ipynb --to pdf当您运行这个命令时,您应该会看到一些输出,告诉您转换过程。如果有警告和错误,将显示。假设一切都按计划进行,现在您的文件夹中会有一个
py_examples.pdf文件。其他文件类型的转换过程非常相似。你只需要告诉
nbconvert要转换成什么类型(PDF、Markdown、HTML 等等)。使用菜单
您也可以通过进入文件菜单并选择下载为选项来导出您当前运行的笔记本。
此选项允许您下载
nbconvert支持的所有格式。使用菜单的好处是,如果你不想学的话,你根本不需要学nbconvert。不过我建议这样做,因为你可以使用nbconvert一次导出多个笔记本,这是菜单不支持的。笔记本扩展
虽然 Jupyter 笔记本内置了许多功能,但您可以通过扩展添加新功能。Jupyter 实际上支持四种类型的扩展:
- 核心
- IPython 内核
- 笔记本
- 笔记本服务器
本教程将重点介绍笔记本扩展。
什么是扩展?
笔记本扩展(
nbextension)是一个 JavaScript 模块,可以加载到笔记本前端的大多数视图中。如果您精通 JavaScript,您甚至可以编写自己的扩展。扩展可以访问页面的 DOM 和 Jupyter JavaScript API。我在哪里得到分机?
你可以使用谷歌或者搜索 Jupyter 笔记本扩展。实际上有很多。最受欢迎的扩展集之一叫做jupyter _ contrib _ nb extensions,你可以从 GitHub 获得。这实际上是一个由 Jupyter 社区提供并随
pip一起安装的扩展集合。我如何安装它们?
大多数 Jupyter 笔记本扩展可以使用 Python 的
pip工具安装。如果您发现一个扩展不能用pip安装,那么您可能必须使用以下命令:$ jupyter nbextension install EXTENSION_NAME这只会安装扩展,而不会激活它。安装扩展后,您需要通过运行以下命令来启用它:
$ jupyter nbextension enable EXTENSION_NAME您可能需要重新启动 Jupyter 笔记本内核来查看扩展。
有一个很好的元扩展叫做Jupyter nb extensions Configurator,值得用来管理其他扩展。它允许您在 Jupyter 笔记本的用户界面中启用和禁用您的扩展,还显示所有当前安装的扩展。
结论
Jupyter Notebook 不仅对于学习和教授 Python 这样的编程语言非常有用,而且对于共享数据也非常有用。
你可以把你的笔记本变成幻灯片,或者用 GitHub 在线分享。如果你想共享一个笔记本而不要求你的用户安装任何东西,你可以使用 binder 来实现。
谷歌和微软都有自己的笔记本版本,你可以分别在谷歌联合实验室和微软 Azure 笔记本创建和分享你的笔记本。你也可以在那里浏览非常有趣的笔记本。
Project Jupyter 最近推出了他们的最新产品 JupyterLab 。JupyterLab 将 Jupyter Notebook 合并到一个集成的开发类型编辑器中,您可以在浏览器中运行该编辑器。你可以把 JupyterLab 看作是 Jupyter 笔记本的高级版本。除了笔记本之外,JupyterLab 还允许您在浏览器中运行终端、文本编辑器和代码控制台。
一如既往,最好是自己试用一款新软件,看看它是否适合自己,是否值得使用。我鼓励你给 Jupyter 笔记本或 JupyterLab 一个旋转,看看你怎么想!
延伸阅读
如果你想了解更多关于 Jupyter Notebook 的知识,你可以花点时间阅读他们优秀的文档。
有关集成开发环境的更多信息,您可能希望查阅以下文章:
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 使用 Jupyter 笔记本*****
Python 中的 K-Means 聚类:实用指南
k-均值聚类方法是一种无监督机器学习技术,用于识别数据集中数据对象的聚类。有许多不同类型的聚类方法,但 k -means 是最古老和最容易使用的方法之一。这些特性使得用 Python 实现集群变得相当简单,即使对于编程新手和数据科学家来说也是如此。
如果您有兴趣了解如何以及何时实现k——意思是 Python 中的集群,那么这里是合适的地方。您将浏览一个端到端的例子k——意味着使用 Python 进行集群,从预处理数据到评估结果。
在本教程中,您将学习:
- 什么是k-均值聚类是
- 何时使用k-意味着聚类到分析你的数据
- 如何实现k-用 scikit 在 Python 中表示集群-学习
- 如何选择一个有意义的个数的集群
单击下面的链接下载代码,您将使用这些代码来遵循本教程中的示例,并实现您自己的 k -means 集群管道:
下载示例代码: 单击此处获取代码,您将在本教程中使用来学习如何编写 k-means 聚类管道。
什么是集群?
聚类是一组用于将数据划分成组或簇的技术。集群被宽泛地定义为数据对象组,这些数据对象组与它们集群中的其他对象的相似性高于它们与其他集群中的数据对象的相似性。在实践中,聚类有助于识别两种质量的数据:
- 富有意义
- 有用
有意义的集群扩展领域知识。例如,在医学领域,研究人员将聚类应用于基因表达实验。聚类结果确定了对药物治疗有不同反应的患者组。
另一方面,有用的簇充当数据管道的中间步骤。例如,企业使用聚类进行客户细分。聚类结果将客户划分为具有相似购买历史的群体,然后企业可以使用这些群体来创建有针对性的广告活动。
注:在本教程中,你将了解到无监督机器学习技术。如果你有兴趣了解更多关于监督机器学习技术的信息,那么看看 Python 中的逻辑回归。
聚类还有很多其他的应用,比如文档聚类,社交网络分析。这些应用程序几乎与每个行业都相关,这使得聚类成为任何领域中处理数据的专业人员的一项宝贵技能。
聚类技术概述
您可以使用许多不同的方法来执行聚类—事实上,方法如此之多,以至于有各种各样的聚类算法。这些类别中的每一个都有其独特的优势和劣势。这意味着某些聚类算法将根据输入数据产生更自然的聚类分配。
注意:如果你对学习本节没有提到的聚类算法感兴趣,那么请查看对聚类算法的全面调查以获得对流行技术的精彩回顾。
由于可供选择的方法很多,为数据集选择合适的聚类算法通常很困难。影响这一决定的一些重要因素包括聚类的特征、数据集的特征、离群值的数量以及数据对象的数量。
通过查看三种流行的聚类算法类别,您将了解这些因素如何帮助确定哪种方法最合适:
- 分割聚类
- 分层聚类
- 基于密度的聚类
在直接进入 k 手段之前,有必要回顾一下这些类别。您将了解每个类别的优点和缺点,为 k -means 如何适应聚类算法的环境提供背景。
分区聚类
分区聚类将数据对象分成不重叠的组。换句话说,任何对象都不能是多个集群的成员,并且每个集群必须至少有一个对象。
这些技术要求用户指定簇的数量,由变量 k 表示。许多分区聚类算法通过迭代过程将数据点子集分配到 k 个聚类中。划分聚类算法的两个例子是 k -means 和 k -medoids。
这些算法都是不确定的,这意味着它们可以从两次单独的运行中产生不同的结果,即使运行是基于相同的输入。
划分聚类方法有几个优势:
- 当星系团具有球形形状时,它们工作得很好。
- 就算法复杂性而言,它们是可扩展的。
他们也有几个弱点:
- 它们不太适合具有复杂形状和不同大小的集群。
- 当用于不同密度的簇时,它们会分解。
层次聚类
层次聚类通过构建层次来确定聚类分配。这可以通过自下而上或自上而下的方法实现:
凝聚聚类是自底向上的方法。它合并最相似的两个点,直到所有点都被合并成一个单独的聚类。
分裂聚类是自上而下的方法。它从所有点作为一个聚类开始,并在每一步分裂最不相似的聚类,直到只剩下单个数据点。
这些方法产生了一个基于树的点层次结构,称为 树状图 。类似于分区聚类,在分层聚类中,聚类的数量( k )通常由用户预先确定。通过在指定深度切割树状图来分配聚类,这导致更小的树状图的 k 组。
与许多分区聚类技术不同,层次聚类是一个确定性过程,这意味着当您对相同的输入数据运行两次算法时,聚类分配不会改变。
层次聚类方法的优势包括以下几点:
- 它们经常揭示数据对象之间的关系的细节。
- 他们提供了一个可解释的树状图。
层次聚类方法的弱点包括以下几点:
基于密度的聚类
基于密度的聚类根据区域中数据点的密度确定聚类分配。在由低密度区域分隔的高密度数据点处分配聚类。
与其他聚类类别不同,这种方法不需要用户指定聚类的数量。相反,有一个基于距离的参数充当可调阈值。该阈值决定了必须有多近的点才能被视为聚类成员。
基于密度的聚类算法的例子包括基于密度的具有噪声的应用的空间聚类,或者 DBSCAN ,以及用于识别聚类结构的排序点,或者 光学 。
基于密度的聚类方法的优势包括:
- 他们擅长识别非球形的星团。
- 他们对异常值有抵抗力。
基于密度的聚类方法的缺点包括:
- 它们不太适合在高维空间 中聚类。
- 他们很难识别不同密度的集群。
如何在 Python 中执行 K-Means 聚类
在本节中,您将一步一步地浏览传统版本的 k -means 算法。理解算法的细节是编写你的 k 过程中的一个基本步骤——在 Python 中的意思是集群管道。你在这一节学到的东西将帮助你决定 k -means 是否是解决你的聚类问题的正确选择。
理解 K-Means 算法
传统的方法只需要几个步骤。第一步是随机选择 k 个质心,其中 k 等于你选择的聚类数。质心是代表一个聚类中心的数据点。
该算法的主要元素通过称为期望最大化的两步过程来工作。期望步骤将每个数据点分配到其最近的质心。然后,最大化步骤计算每个聚类所有点的平均值,并设置新的质心。下面是传统版本的 k -means 算法的样子:
在质心收敛之后,通过计算误差平方和(SSE) 的 来确定聚类分配的质量,或者匹配先前迭代的分配。SSE 定义为每个点到其最近质心的平方欧几里德距离之和。因为这是一个误差的度量,所以 k -means 的目标是尝试最小化这个值。
下图显示了在同一数据集上两次不同运行的 k -means 算法的前五次迭代中的质心和 SSE 更新:
此图的目的是表明质心的初始化是一个重要的步骤。它还强调了使用 SSE 作为集群性能的衡量标准。在选择了多个聚类和初始质心之后,重复期望最大化步骤,直到质心位置达到收敛并且不变。
随机初始化步骤导致 k -means 算法成为不确定性,这意味着如果在同一个数据集上运行相同的算法两次,聚类分配将会发生变化。研究人员通常运行整个 k 均值算法的若干次初始化,并从具有最低 SSE 的初始化中选择聚类分配。
用 Python 编写第一个 K-Means 集群代码
幸运的是,有一个健壮的实现k——意思是来自流行的机器学习包 scikit-learn 的 Python 中的集群。您将学习如何使用算法的 scikit-learn 版本编写 k 均值算法的实际实现。
注:如果你有兴趣深入了解如何用 Python 编写自己的 k -means 算法,那么就去查阅一下 Python 数据科学手册。
本教程中的代码需要一些流行的外部 Python 包,并假设您已经用 Anaconda 安装了 Python。有关在 Windows 中为机器学习设置 Python 环境的更多信息,请通读在 Windows 上为机器学习设置 Python。
否则,您可以从安装所需的软件包开始:
(base) $ conda install matplotlib numpy pandas seaborn scikit-learn ipython (base) $ conda install -c conda-forge kneed代码被呈现出来,这样你就可以在
ipython控制台或 Jupyter 笔记本上跟随。单击每个代码块右上角的提示(>>>)来查看为复制-粘贴而格式化的代码。您也可以点击下面的链接下载本文中使用的源代码:下载示例代码: 单击此处获取代码,您将在本教程中使用来学习如何编写 k-means 聚类管道。
这一步将导入本节中所有代码所需的模块:


In [1]: import matplotlib.pyplot as plt
...: from kneed import KneeLocator
...: from sklearn.datasets import make_blobs
...: from sklearn.cluster import KMeans
...: from sklearn.metrics import silhouette_score
...: from sklearn.preprocessing import StandardScaler
您可以使用make_blobs()从上面的 GIF 中生成数据,这是 scikit-learn 中用于生成合成聚类的一个方便的函数。make_blobs()使用这些参数:
n_samples是要生成的样本总数。centers是生成的中心数。cluster_std是标准差。
make_blobs()返回两个值的元组:
- 一个二维 NumPy 数组,包含每个样本的 x 和 y 值
- 包含每个样本的分类标签的一维 NumPy 数组
注意:许多 scikit-learn 算法在实现中严重依赖 NumPy。如果你想了解更多关于 NumPy 数组的知识,请查看 Look Ma,No For-Loops:Array Programming With NumPy。
生成合成数据和标签:
In [2]: features, true_labels = make_blobs( ...: n_samples=200, ...: centers=3, ...: cluster_std=2.75, ...: random_state=42 ...: )像 k -means 这样的非确定性机器学习算法很难重现。
random_state参数被设置为一个整数值,因此您可以遵循教程中提供的数据。实际上,最好将random_state保留为默认值None。下面看一下由
make_blobs()返回的每个变量的前五个元素:
In [3]: features[:5]
Out[3]:
array([[ 9.77075874, 3.27621022],
[ -9.71349666, 11.27451802],
[ -6.91330582, -9.34755911],
[-10.86185913, -10.75063497],
[ -8.50038027, -4.54370383]])
In [4]: true_labels[:5]
Out[4]: array([1, 0, 2, 2, 2])
数据集通常包含以不同单位测量的数字特征,如身高(英寸)和体重(磅)。机器学习算法会认为体重比身高更重要,只是因为体重的值更大,并且因人而异。
机器学习算法需要考虑公平竞争环境中的所有特征。这意味着所有要素的值必须转换为相同的比例。
转换数字特征以使用相同比例的过程称为特征缩放。对于大多数基于距离的机器学习算法来说,这是一个重要的数据预处理步骤,因为它会对算法的性能产生重大影响。
有几种实现特征缩放的方法。确定哪种技术适合您的数据集的一个好方法是阅读 scikit-learn 的预处理文档。
在这个例子中,您将使用StandardScaler类。这个类实现了一种叫做标准化的特性缩放。标准化对数据集中每个数值要素的值进行缩放或移位,使要素的平均值为 0,标准差为 1:
In [5]: scaler = StandardScaler() ...: scaled_features = scaler.fit_transform(features)看看
scaled_features中的值是如何缩放的:
In [6]: scaled_features[:5]
Out[6]:
array([[ 2.13082109, 0.25604351],
[-1.52698523, 1.41036744],
[-1.00130152, -1.56583175],
[-1.74256891, -1.76832509],
[-1.29924521, -0.87253446]])
现在,数据已经准备好进行聚类了。scikit-learn 中的KMeans估计器类是在将估计器拟合到数据之前设置算法参数的地方。scikit-learn 实现非常灵活,提供了几个可以调整的参数。
以下是本例中使用的参数:
-
init控制着初始化技术。标准版本的 k 均值算法通过将init设置为"random"来实现。将此设置为"k-means++"采用了一种高级技巧来加速收敛,稍后您将使用这种技巧。 -
n_clusters为聚类步骤设置 k 。这是 k 最重要的参数——手段。 -
n_init设置要执行的初始化次数。这很重要,因为两次运行可以在不同的集群分配上收敛。scikit-learn 算法的默认行为是执行十次 k 均值运行,并返回 SSE 最低的结果。 -
max_iter设置 k 均值算法每次初始化的最大迭代次数。
用以下参数实例化KMeans类:
In [7]: kmeans = KMeans( ...: init="random", ...: n_clusters=3, ...: n_init=10, ...: max_iter=300, ...: random_state=42 ...: )参数名与本教程前面用来描述 k 均值算法的语言相匹配。既然 k -means 类已经准备好了,下一步就是让它适合
scaled_features中的数据。这将对您的数据执行十次 k 均值算法,每次最多迭代300次:
In [8]: kmeans.fit(scaled_features)
Out[8]:
KMeans(init='random', n_clusters=3, random_state=42)
在调用.fit()之后,来自具有最低 SSE 的初始化运行的统计数据作为kmeans的属性可用:
In [9]: # The lowest SSE value ...: kmeans.inertia_ Out[9]: 74.57960106819854 In [10]: # Final locations of the centroid ...: kmeans.cluster_centers_ Out[10]: array([[ 1.19539276, 0.13158148], [-0.25813925, 1.05589975], [-0.91941183, -1.18551732]]) In [11]: # The number of iterations required to converge ...: kmeans.n_iter_ Out[11]: 6最后,集群分配作为一维 NumPy 数组存储在
kmeans.labels_中。以下是前五个预测标签:
In [12]: kmeans.labels_[:5]
Out[12]: array([0, 1, 2, 2, 2], dtype=int32)
注意,前两个数据对象的分类标签的顺序被颠倒了。顺序是true_labels中的[1, 0],但是kmeans.labels_中的[0, 1],即使这些数据对象仍然是它们在kmeans.lables_中的原始集群的成员。
这种行为是正常的,因为分类标签的排序取决于初始化。第一次运行的聚类 0 在第二次运行中可以被标记为聚类 1,反之亦然。这不会影响集群评估指标。
选择适当数量的集群
在本节中,您将看到两种常用于评估适当集群数量的方法:
- 肘法
- 轮廓系数
这些通常被用作补充评估技术,而不是一个优于另一个。为了执行肘方法,运行几个 k -means,每次迭代增加k,并记录 SSE:
In [13]: kmeans_kwargs = { ...: "init": "random", ...: "n_init": 10, ...: "max_iter": 300, ...: "random_state": 42, ...: } ...: ...: # A list holds the SSE values for each k ...: sse = [] ...: for k in range(1, 11): ...: kmeans = KMeans(n_clusters=k, **kmeans_kwargs) ...: kmeans.fit(scaled_features) ...: sse.append(kmeans.inertia_)前面的代码块利用了 Python 的字典解包操作符(
**)。要了解关于这个强大的 Python 操作符的更多信息,请查看如何在 Python 中迭代字典。当您绘制 SSE 作为集群数量的函数时,请注意 SSE 会随着您增加
k而继续减少。随着更多质心的添加,每个点到其最近质心的距离将减少。上证综指曲线开始弯曲的地方有一个最佳点,称为拐点。该点的 x 值被认为是误差和聚类数之间的合理权衡。在本例中,肘部位于
x=3:
In [14]: plt.style.use("fivethirtyeight")
...: plt.plot(range(1, 11), sse)
...: plt.xticks(range(1, 11))
...: plt.xlabel("Number of Clusters")
...: plt.ylabel("SSE")
...: plt.show()
上面的代码产生了下面的图:

确定上证综指曲线的拐点并不总是那么简单。如果您在选择曲线的肘点时遇到困难,那么您可以使用 Python 包 kneed ,以编程方式识别肘点:
In [15]: kl = KneeLocator( ...: range(1, 11), sse, curve="convex", direction="decreasing" ...: ) In [16]: kl.elbow Out[16]: 3剪影系数是集群内聚和分离的度量。它基于两个因素来量化数据点适合其分配的聚类的程度:
- 数据点与聚类中其他点的接近程度
- 数据点离其他聚类中的点有多远
轮廓系数值的范围在
-1和1之间。较大的数字表示样本与其类的距离比与其他类的距离更近。在剪影系数的 scikit-learn 实现中,所有样本的平均剪影系数被总结为一个分数。
silhouette score()函数最少需要两个集群,否则会引发异常。再次循环通过
k的值。这一次,不计算 SSE,而是计算轮廓系数:
In [17]: # A list holds the silhouette coefficients for each k
...: silhouette_coefficients = []
...:
...: # Notice you start at 2 clusters for silhouette coefficient
...: for k in range(2, 11):
...: kmeans = KMeans(n_clusters=k, **kmeans_kwargs)
...: kmeans.fit(scaled_features)
...: score = silhouette_score(scaled_features, kmeans.labels_)
...: silhouette_coefficients.append(score)
绘制每个k的平均轮廓分数表明k的最佳选择是3,因为它的分数最高:
In [18]: plt.style.use("fivethirtyeight") ...: plt.plot(range(2, 11), silhouette_coefficients) ...: plt.xticks(range(2, 11)) ...: plt.xlabel("Number of Clusters") ...: plt.ylabel("Silhouette Coefficient") ...: plt.show()上面的代码产生了下面的图:
最终,您应该根据领域知识和集群评估指标来决定要使用的集群数量。
使用高级技术评估集群性能
肘方法和轮廓系数在不使用基础事实标签的情况下评估聚类性能。基本事实标签根据人工分配或现有算法将数据点分类成组。这些类型的度量尽最大努力建议正确的集群数量,但在没有上下文的情况下使用时可能具有欺骗性。
注意:在实践中,很少会遇到带有事实标签的数据集。
当将 k -means 与基于密度的方法在非球形集群上进行比较时,肘方法和轮廓系数的结果很少符合人类的直觉。这个场景强调了为什么高级聚类评估技术是必要的。要可视化示例,请导入以下附加模块:
In [19]: from sklearn.cluster import DBSCAN
...: from sklearn.datasets import make_moons
...: from sklearn.metrics import adjusted_rand_score
这一次,使用make_moons()生成新月形状的合成数据:
In [20]: features, true_labels = make_moons( ...: n_samples=250, noise=0.05, random_state=42 ...: ) ...: scaled_features = scaler.fit_transform(features)将一个 k 均值和一个 DBSCAN 算法用于新数据,并通过用 Matplotlib 绘制聚类分配图来直观地评估性能:
In [21]: # Instantiate k-means and dbscan algorithms
...: kmeans = KMeans(n_clusters=2)
...: dbscan = DBSCAN(eps=0.3)
...:
...: # Fit the algorithms to the features
...: kmeans.fit(scaled_features)
...: dbscan.fit(scaled_features)
...:
...: # Compute the silhouette scores for each algorithm
...: kmeans_silhouette = silhouette_score(
...: scaled_features, kmeans.labels_
...: ).round(2)
...: dbscan_silhouette = silhouette_score(
...: scaled_features, dbscan.labels_
...: ).round (2)
打印两种算法的轮廓系数,并进行比较。较高的轮廓系数表示较好的聚类,这在这种情况下具有误导性:
In [22]: kmeans_silhouette Out[22]: 0.5 In [23]: dbscan_silhouette Out[23]: 0.38对于 k -means 算法,轮廓系数更高。DBSCAN 算法似乎根据数据的形状找到了更多的自然聚类:
这表明您需要一种更好的方法来比较这两种聚类算法的性能。
如果你感兴趣,你可以通过展开下面的方框找到上面的代码。
要了解更多关于使用 Matplotlib 和 Python 绘图的信息,请查看 Python 使用 Matplotlib 绘图(指南)。在新月的例子中,你可以这样比较这两种算法:

In [24]: # Plot the data and cluster silhouette comparison
...: fig, (ax1, ax2) = plt.subplots(
...: 1, 2, figsize=(8, 6), sharex=True, sharey=True
...: )
...: fig.suptitle(f"Clustering Algorithm Comparison: Crescents", fontsize=16)
...: fte_colors = {
...: 0: "#008fd5",
...: 1: "#fc4f30",
...: }
...: # The k-means plot
...: km_colors = [fte_colors[label] for label in kmeans.labels_]
...: ax1.scatter(scaled_features[:, 0], scaled_features[:, 1], c=km_colors)
...: ax1.set_title(
...: f"k-means\nSilhouette: {kmeans_silhouette}", fontdict={"fontsize": 12}
...: )
...:
...: # The dbscan plot
...: db_colors = [fte_colors[label] for label in dbscan.labels_]
...: ax2.scatter(scaled_features[:, 0], scaled_features[:, 1], c=db_colors)
...: ax2.set_title(
...: f"DBSCAN\nSilhouette: {dbscan_silhouette}", fontdict={"fontsize": 12}
...: )
...: plt.show()
由于基本事实标签是已知的,因此可以使用一个聚类度量来评估标签。您可以使用一个通用指标的 scikit-learn 实现,该指标被称为调整后的兰德指数(ARI) 。与轮廓系数不同,ARI 使用真实聚类分配来测量真实标签和预测标签之间的相似性。
比较 DBSCAN 和 k 的聚类结果——意味着使用 ARI 作为性能指标:
In [25]: ari_kmeans = adjusted_rand_score(true_labels, kmeans.labels_) ...: ari_dbscan = adjusted_rand_score(true_labels, dbscan.labels_) In [26]: round(ari_kmeans, 2) Out[26]: 0.47 In [27]: round(ari_dbscan, 2) Out[27]: 1.0ARI 输出值范围在
-1和1之间。接近0.0的分数表示随机分配,接近1的分数表示完全标记的聚类。根据上面的输出,您可以看到轮廓系数是误导性的。ARI 表明,与 k -means 相比,DBSCAN 是合成新月形示例的最佳选择。
有几个度量标准可以评估聚类算法的质量。通读sci kit-learn中的实现将帮助您选择合适的集群评估指标。
如何用 Python 构建 K-Means 聚类管道
现在,您已经对k-在 Python 中表示聚类有了基本的了解,是时候执行k-表示在真实数据集上进行聚类了。这些数据包含来自癌症基因组图谱 (TCGA)泛癌分析项目调查人员撰写的手稿中的基因表达值。
有代表五种不同癌症亚型的
881个样本(行)。每个样本都有20,531基因的基因表达值(列)。数据集可从加州大学欧文分校机器学习库获得,但您可以使用下面的 Python 代码以编程方式获取数据。要了解下面的示例,您可以通过单击以下链接下载源代码:
下载示例代码: 单击此处获取代码,您将在本教程中使用来学习如何编写 k-means 聚类管道。
在本节中,您将构建一个健壮的 k -means 集群管道。因为您将对原始输入数据执行多种转换,所以您的管道也将作为一个实用的集群框架。
构建 K 均值聚类管道
In [1]: import tarfile
...: import urllib
...:
...: import numpy as np
...: import matplotlib.pyplot as plt
...: import pandas as pd
...: import seaborn as sns
...:
...: from sklearn.cluster import KMeans
...: from sklearn.decomposition import PCA
...: from sklearn.metrics import silhouette_score, adjusted_rand_score
...: from sklearn.pipeline import Pipeline
...: from sklearn.preprocessing import LabelEncoder, MinMaxScaler
从 UCI 下载并提取 TCGA 数据集:
In [2]: uci_tcga_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00401/" ...: archive_name = "TCGA-PANCAN-HiSeq-801x20531.tar.gz" ...: # Build the url ...: full_download_url = urllib.parse.urljoin(uci_tcga_url, archive_name) ...: ...: # Download the file ...: r = urllib.request.urlretrieve (full_download_url, archive_name) ...: # Extract the data from the archive ...: tar = tarfile.open(archive_name, "r:gz") ...: tar.extractall() ...: tar.close()下载和解压缩完成后,您应该有一个如下所示的目录:
TCGA-PANCAN-HiSeq-801x20531/ | ├── data.csv └── labels.csvscikit-learn 中的
KMeans类需要一个 NumPy 数组作为参数。NumPy 包有一个助手函数,用于将文本文件中的数据作为 NumPy 数组加载到内存中:
In [3]: datafile = "TCGA-PANCAN-HiSeq-801x20531/data.csv"
...: labels_file = "TCGA-PANCAN-HiSeq-801x20531/labels.csv"
...:
...: data = np.genfromtxt(
...: datafile,
...: delimiter=",",
...: usecols=range(1, 20532),
...: skip_header=1
...: )
...:
...: true_label_names = np.genfromtxt(
...: labels_file,
...: delimiter=",",
...: usecols=(1,),
...: skip_header=1,
...: dtype="str"
...: )
检查前五个样本的前三列数据以及前五个样本的标签:
In [4]: data[:5, :3] Out[4]: array([[0\. , 2.01720929, 3.26552691], [0\. , 0.59273209, 1.58842082], [0\. , 3.51175898, 4.32719872], [0\. , 3.66361787, 4.50764878], [0\. , 2.65574107, 2.82154696]]) In [5]: true_label_names[:5] Out[5]: array(['PRAD', 'LUAD', 'PRAD', 'PRAD', 'BRCA'], dtype='<U4')
data变量包含来自20,531基因的所有基因表达值。true_label_names是每个881样本的癌症类型。data中的第一条记录对应于true_labels中的第一个标签。标签是包含癌症类型缩写的字符串:
BRCA:乳腺浸润癌COAD:结肠腺癌KIRC:肾透明细胞癌LUAD:肺腺癌PRAD:前列腺癌要在评估方法中使用这些标签,首先需要用
LabelEncoder将缩写转换成整数:
In [6]: label_encoder = LabelEncoder()
In [7]: true_labels = label_encoder.fit_transform(true_label_names)
In [8]: true_labels[:5]
Out[8]: array([4, 3, 4, 4, 0])
由于label_encoder已经被拟合到数据中,您可以看到使用.classes_表示的独特的类。将数组的长度存储到变量n_clusters中以备后用:
In [9]: label_encoder.classes_ Out[9]: array(['BRCA', 'COAD', 'KIRC', 'LUAD', 'PRAD'], dtype='<U4') In [10]: n_clusters = len(label_encoder.classes_)在实际的机器学习管道中,数据在进入聚类算法之前通常要经历多次转换。在本教程的前面部分,您已经了解了其中一个变换步骤(要素缩放)的重要性。一种同样重要的数据转换技术是维度缩减,它通过移除或合并数据集中的要素来减少它们的数量。
降维技术有助于解决机器学习算法的一个问题,即所谓的维数灾难。简而言之,随着特征数量的增加,特征空间变得稀疏。这种稀疏性使得算法很难在高维空间中找到彼此相邻的数据对象。由于基因表达数据集有超过
20,000个特征,它是降维的一个很好的候选。主成分分析(PCA) 是众多降维技术中的一种。PCA 通过将输入数据投影到称为分量的较低维数来转换输入数据。这些组件通过输入数据特征的线性组合来捕捉输入数据的可变性。
注意:PCA 的完整描述超出了本教程的范围,但是您可以在 scikit-learn 用户指南中了解更多信息。
下一个代码块向您介绍了 scikit-learn pipelines 的概念。scikit-learn
Pipeline类是机器学习管道的抽象思想的具体实现。您的基因表达数据不是针对
KMeans类的最佳格式,因此您需要构建一个预处理管道。流水线将实现一个名为MinMaxScaler的StandardScaler类的替代品,用于功能缩放。当不假设所有特征的形状都遵循正态分布时,可以使用MinMaxScaler。预处理管道的下一步将实现
PCA类来执行降维:
In [11]: preprocessor = Pipeline(
...: [
...: ("scaler", MinMaxScaler()),
...: ("pca", PCA(n_components=2, random_state=42)),
...: ]
...: )
既然您已经构建了一个管道来处理数据,那么您将构建一个单独的管道来执行 k -means 集群。您将覆盖KMeans类的以下默认参数:
-
init: 你将使用
"k-means++"而不是"random"来确保质心被初始化,它们之间有一定的距离。在大多数情况下,这将是对"random"的改进。 -
n_init: 你将增加初始化的次数,以确保找到一个稳定的解。
-
max_iter: 您将增加每次初始化的迭代次数,以确保 k -means 会收敛。
在KMeans构造函数中使用用户定义的参数构建 k -means 集群管道:
In [12]: clusterer = Pipeline( ...: [ ...: ( ...: "kmeans", ...: KMeans( ...: n_clusters=n_clusters, ...: init="k-means++", ...: n_init=50, ...: max_iter=500, ...: random_state=42, ...: ), ...: ), ...: ] ...: )可以将
Pipeline类链接起来形成一个更大的管道。通过将"preprocessor"和"clusterer"管道传递到Pipeline,建立端到端的 k -means 集群管道;
In [13]: pipe = Pipeline(
...: [
...: ("preprocessor", preprocessor),
...: ("clusterer", clusterer)
...: ]
...: )
以data为参数调用.fit(),在data上执行所有流水线步骤:
In [14]: pipe.fit(data) Out[14]: Pipeline(steps=[('preprocessor', Pipeline(steps=[('scaler', MinMaxScaler()), ('pca', PCA(n_components=2, random_state=42))])), ('clusterer', Pipeline(steps=[('kmeans', KMeans(max_iter=500, n_clusters=5, n_init=50, random_state=42))]))])流水线执行所有必要的步骤来执行k——意思是对基因表达数据进行聚类!根据您的 Python REPL,
.fit()可能会打印管道摘要。管道内定义的对象可以使用它们的步骤名进行访问。通过计算轮廓系数来评估性能:
In [15]: preprocessed_data = pipe["preprocessor"].transform(data)
In [16]: predicted_labels = pipe["clusterer"]["kmeans"].labels_
In [17]: silhouette_score(preprocessed_data, predicted_labels)
Out[17]: 0.5118775528450304
也计算 ARI,因为地面实况聚类标签是可用的:
In [18]: adjusted_rand_score(true_labels, predicted_labels) Out[18]: 0.722276752060253如前所述,这些集群性能指标的范围从-1 到 1。轮廓系数为 0 表示聚类彼此明显重叠,轮廓系数为 1 表示聚类分离良好。ARI 值为 0 表示聚类标签是随机分配的,ARI 值为 1 表示真实标签和预测标签形成相同的聚类。
因为您在 k 均值聚类管道的 PCA 步骤中指定了
n_components=2,所以您还可以在真实标签和预测标签的上下文中可视化数据。使用 pandas 数据框架和 seaborn 绘图库绘制结果:
In [19]: pcadf = pd.DataFrame(
...: pipe["preprocessor"].transform(data),
...: columns=["component_1", "component_2"],
...: )
...:
...: pcadf["predicted_cluster"] = pipe["clusterer"]["kmeans"].labels_
...: pcadf["true_label"] = label_encoder.inverse_transform(true_labels)
In [20]: plt.style.use("fivethirtyeight")
...: plt.figure(figsize=(8, 8))
...:
...: scat = sns.scatterplot(
...: "component_1",
...: "component_2",
...: s=50,
...: data=pcadf,
...: hue="predicted_cluster",
...: style="true_label",
...: palette="Set2",
...: )
...:
...: scat.set_title(
...: "Clustering results from TCGA Pan-Cancer\nGene Expression Data"
...: )
...: plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.0)
...:
...: plt.show()
这是剧情的样子:
聚类的可视化表示确认了两个聚类评估度量的结果。你的管道表现很好。这些聚类只有轻微的重叠,聚类分配比随机分配好得多。
调整 K 均值聚类流水线
您的第一个k-意味着集群管道表现良好,但仍有改进的空间。这就是为什么您经历了构建管道的麻烦:您可以调整参数以获得最理想的集群结果。
参数调整的过程包括顺序改变算法参数的一个输入值并记录结果。在参数调优过程的最后,您将得到一组性能分数,对于给定参数的每个新值都有一个性能分数。参数调整是从集群管道中最大化性能的强大方法。
通过设置PCA参数n_components=2,你将所有的特征压缩成两个部分,或尺寸。该值便于在二维图上可视化。但是只使用两个分量意味着 PCA 步骤不会捕获输入数据的所有解释的方差。
解释方差测量 PCA 转换的数据和实际输入数据之间的差异。n_components和被解释的方差之间的关系可以在图中可视化,以向您显示在您的 PCA 中需要多少组件来捕获输入数据中的某个百分比的方差。您还可以使用集群性能指标来评估需要多少组件才能获得满意的集群结果。
在本例中,您将使用集群性能指标来确定 PCA 步骤中适当数量的组件。在这种情况下,Pipeline类是强大的。它允许您使用 for回路进行基本参数调谐。
迭代一系列n_components并记录每次迭代的评估指标:
In [21]: # Empty lists to hold evaluation metrics ...: silhouette_scores = [] ...: ari_scores = [] ...: for n in range(2, 11): ...: # This set the number of components for pca, ...: # but leaves other steps unchanged ...: pipe["preprocessor"]["pca"].n_components = n ...: pipe.fit(data) ...: ...: silhouette_coef = silhouette_score( ...: pipe["preprocessor"].transform(data), ...: pipe["clusterer"]["kmeans"].labels_, ...: ) ...: ari = adjusted_rand_score( ...: true_labels, ...: pipe["clusterer"]["kmeans"].labels_, ...: ) ...: ...: # Add metrics to their lists ...: silhouette_scores.append(silhouette_coef) ...: ari_scores.append(ari)将评估指标绘制为
n_components的函数,以可视化添加组件和 k 的性能之间的关系——均值聚类结果:
In [22]: plt.style.use("fivethirtyeight")
...: plt.figure(figsize=(6, 6))
...: plt.plot(
...: range(2, 11),
...: silhouette_scores,
...: c="#008fd5",
...: label="Silhouette Coefficient",
...: )
...: plt.plot(range(2, 11), ari_scores, c="#fc4f30", label="ARI")
...:
...: plt.xlabel("n_components")
...: plt.legend()
...: plt.title("Clustering Performance as a Function of n_components")
...: plt.tight_layout()
...: plt.show()
上面的代码生成了一个图,显示了作为n_components函数的性能指标:

从这个图中可以看出两点:
-
轮廓系数线性减小。轮廓系数取决于点与点之间的距离,因此随着维数的增加,稀疏度也增加。
-
随着组件的增加,ARI 会显著提高。在
n_components=7之后,它似乎开始变小,因此这将是用于呈现来自该管道的最佳聚类结果的值。
像大多数机器学习决策一样,您必须平衡优化聚类评估指标与聚类任务的目标。在聚类标签可用的情况下,如本教程中使用的癌症数据集,ARI 是一个合理的选择。ARI 量化了您的管道重新分配分类标签的准确性。
另一方面,轮廓系数对于探索性聚类是一个很好的选择,因为它有助于识别子聚类。这些分组需要额外的调查,这可以导致新的和重要的见解。
结论
您现在知道如何执行k——在 Python 中是集群的意思。你最后的k——意味着聚类管道能够使用真实世界的基因表达数据对不同癌症类型的患者进行聚类。您可以使用在这里学到的技术对自己的数据进行聚类,了解如何获得最佳的聚类结果,并与他人分享见解。
在本教程中,您学习了:
- 什么是流行的聚类技术以及何时使用它们
- 算法中的 k 是什么意思
- 如何实现k——在 Python 中表示聚类
- 如何评估聚类算法的性能
- 如何构建和调优一个健壮的k——Python 中的集群流水线
- 如何分析并呈现 k 均值算法的聚类结果
您还参观了 scikit-learn,这是一个可访问和可扩展的工具,用于实现 Python 中的集群。如果你想重现上面看到的例子,请点击下面的链接下载源代码:
下载示例代码: 单击此处获取代码,您将在本教程中使用来学习如何编写 k-means 聚类管道。
您现在已经准备好执行k——意思是对您感兴趣的数据集进行聚类。一定要在下面的评论中分享你的成果!
注意:本教程中使用的数据集来自 UCI 机器学习知识库。Dua d .和 Graff c .(2019 年)。 UCI 机器学习知识库。加州欧文:加州大学信息与计算机科学学院。
原始数据集由癌症基因组图谱泛癌分析项目维护。******
启动 Django 开源项目
原文:https://realpython.com/kickstarting-a-django-open-source-project/
这是 Patrick Altman 的客座博文,Patrick Altman 是一个热情的开源黑客,也是 T2 Eldarion T3 的工程副总裁。
在本文中,我们将剖析一个 Django 应用程序样板,它旨在快速开发遵循广泛共享约定的开源项目。
我们将看到的布局(或模式)基于 django-stripe-payments 。对于由 Eldarion 和 Pinax 发布的 100 多个不同的开源项目来说,这种布局已经被证明是成功的。
当您阅读本文时,请记住您的特定项目可能与此模式不同;然而,有许多项目在 Python 项目中相当常见,一般来说,在某种程度上在开源项目中也是如此。我们将集中讨论这些项目。
项目布局
一个好的项目布局可以帮助一个新用户浏览你的源代码。有一些被普遍接受的约定,遵守这些约定也很重要。此外,良好的项目布局有助于打包。
项目布局会有一点不同,这取决于它们是 Python 包(像一个可重用的 Django 应用)还是类似 Django 项目的东西。使用我们的示例项目,我们想要强调布局的某些方面以及项目顶层中包含的文件。
您应该为描述项目各个方面的元数据文件保留项目的根,例如LICENSE、CONTRIBUTING.md、README.rst,以及用于运行测试和打包的任何脚本。此外,在这个根级别中应该有一个文件夹,其名称与您希望的 Python 包名称相同。在我们的django-stripe-payments示例中,它是payments。最后,您应该将您的文档作为一个基于 Sphinx 的项目存储在一个名为docs的文件夹中。
许可
如果你的目标是尽可能广泛地采用,通常最好以许可的 MIT 或 BSD 许可来许可你的软件。采用得越多,在各种真实世界环境中的暴露就越多,这增加了通过拉式请求获得反馈和合作的机会。将许可证的内容存储在项目根目录下的一个LICENSE文件中。
README
每个项目都应该在项目根目录下有一个README.rst文件。这个文档应该向用户简要介绍这个项目,描述它解决了什么问题,并提供一个快速入门指南。
将其命名为README.rst,放在你的 repo 的根目录下,GitHub 会将它显示在你的主项目页面上,供潜在用户查看和浏览,以快速感受你的软件会如何帮助他们。
推荐使用 readme 中的 reStructuredText 而不是 Markdown ,这样如果你发布你的包,它会很好地显示在 PyPI 上。
投稿指南
一个CONTRIBUTING.md文件讨论了代码风格指南、过程,以及那些希望通过对你的项目的拉请求来贡献代码的人们的指南。这有助于降低希望贡献代码的人的门槛。第一次投稿的人可能会对做错或违反惯例感到紧张,这份文件越详细,他们就越能检查自己,而不必问他们可能太害羞而不敢问的问题。
setup.py
好的包装有助于你的项目的发行。通过编写一个setup.py脚本,你可以利用 Python 的打包工具在 PyPI 上创建并发布你的项目。
这是一个非常简单的脚本。例如,django-stripe-payments 的核心脚本如下:
PACKAGE = "payments"
NAME = "django-stripe-payments"
DESCRIPTION = "a payments Django app for Stripe"
AUTHOR = "Patrick Altman"
AUTHOR_EMAIL = "paltman@eldarion.com"
URL = "https://github.com/eldarion/django-stripe-payments"
VERSION = __import__(PACKAGE).__version__
setup(
name=NAME,
version=VERSION,
description=DESCRIPTION,
long_description=read("README.rst"),
author=AUTHOR,
author_email=AUTHOR_EMAIL,
license="BSD",
url=URL,
packages=find_packages(exclude=["tests.*", "tests"]),
package_data=find_package_data(PACKAGE, only_in_packages=False),
classifiers=[
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Framework :: Django",
],
install_requires=[
"django-jsonfield>=0.8",
"stripe>=1.7.9",
"django>=1.4",
"pytz"
],
zip_safe=False
)
这里发生了几件事。还记得我们如何讨论制作README.rst文件重组文本吗?
这是因为正如你所看到的,long_description我们使用该文件的内容来填充 PyPI 上的登录页面,这是那里使用的标记语言。分类器是一组元数据,有助于将您的项目放在 PyPI 上正确的类别中。
最后,install_requires参数将确保当你的包被安装时,这些列出的依赖项被安装或者已经被安装。
GitHub
如果你的项目不在 GitHub 上,你真的错过了。当然,也有其他基于网络的 DVCS(分布式版本控制系统)网站提供免费的开源托管,但没有一个网站比 GitHub 为开源做得更多。
处理拉取请求
构建一个伟大的开源项目的一部分就是让它超越你自己。这不仅包括增加用户基础,还包括贡献者基础。 GitHub(和一般的 git)真正改变了这种方式。
增加贡献者的一个关键是在管理拉取请求时做出响应。这并不意味着接受每一份贡献,但也要保持开放的心态,并以尊重的态度处理回应,就像你为另一个项目做出贡献时会得到的尊重一样。
不要只是关闭你不想要的请求,而是花时间解释你为什么不接受它们,或者如果可能的话,解释如何改进它们以便它们可以被排除在外。如果改进很小,或者你可以自己改进,那就接受它,然后做出你喜欢的修改。要求改进和自己动手做是有区别的。
指导原则是创造一个欢迎和感恩的氛围。记住你的贡献者是在自愿贡献他们的时间和精力来改进你的项目。
版本控制、分支和发布
创建版本时,阅读并遵循语义版本。
当你发布主要版本时,一定要清楚地记录向后不兼容的变更。如果您的文档在提交时发生更改,最简单的方法是在两个版本之间更新更改日志文件。这个文件可以是项目根目录下的一个 CHANGELOG 文件,或者是像docs/changelog.rst这样的文件中的文档的一部分。这将使你不费吹灰之力就能创建好的发行说明。
保持主人稳定。人们总是有机会使用主版本的代码,而不是软件包版本。为工作创建特性分支,并在经过测试且相对稳定时进行合并。
文档
在有一定数量的文档之前,没有一个项目是完整的。好的文档让用户不必阅读源代码来决定如何使用你的软件。好的文档传达出你关心你的用户。
通过阅读文档,你可以让你的文档自动呈现并免费托管。它会在每次提交给 master 时自动更新,这真是太酷了。
为了使用 Read Docs,您应该在项目根目录下的docs文件夹中创建一个基于 Sphinx 的文档项目。这真的是一件非常简单的事情,由一个Makefile和一个conf.py文件组成,然后是一组重构文本格式的文件。您可以通过从以前的项目中复制并粘贴Makefile和conf.py文件并修改这些值,或者通过运行:
$ pip install Sphinx
$ sphinx-quickstart
自动化代码质量
有许多工具可以用来帮助检查项目的质量。林挺、测试和测试覆盖都应该被用来帮助确保质量不会在项目的生命周期中漂移。
从开始,林挺用类似pylint或pyflakes 或pep8 的东西。它们各有利弊,超出了本文的探讨范围。要点是:一致的风格是高质量项目的第一步。此外,帮助设计这些短绒可以帮助快速识别一些简单的错误。
例如,对于django-stripe-payments,我们有一个脚本,它结合了运行两个不同的 lint 工具和为我们的项目定制的异常:
# lint.sh
pylint --rcfile=.pylintrc payments && pep8 --ignore=E501 payments
请看一下django-stripe-payments repo 中的.pylintrc文件,了解一些异常的例子。关于pylint的一件事是,它相当具有侵略性,可能会与实际上没有问题的事情吵起来。您需要自己决定调整您自己的.pylintrc文件,但是我建议记录该文件,以便您稍后知道为什么您要排除某些规则。
建立一个好的测试基础设施对于证明你的代码有效是很重要的。此外,首先编写一些测试可以帮助您思考 API。即使你最后才写测试,写测试的行为也会暴露你的 API 设计中的弱点和/或其他可用性问题,你可以在它们被报告之前解决它们。
测试基础设施的一部分应该包括使用 coverage.py 来关注模块的覆盖率。该工具不会告诉您代码是否经过测试,只有您可以这样做,但它将帮助识别根本没有执行的代码,以便您知道哪些代码肯定没有经过测试。
一旦您将林挺、测试和覆盖脚本集成到您的项目中,您就可以设置自动化,以便这些工具在一个或多个环境(例如,不同版本的 Python、不同版本的 Django,或者两者都在一个测试矩阵中)中的每次推送时执行。
设置一个 Travis 集成可以自动执行测试和 linters。工作服可以添加到这个配置中,以便在 Travis 构建运行时提供历史测试覆盖。两者都有一些特性,可以让你在 README.md 中嵌入一个徽章来展示最新的构建状态和覆盖率。
协作与合作
在 DjangoCon 2011 期间, David Eaves 发表了一个主题演讲,雄辩地表达了这样一个概念,即尽管协作与合作有着相似的定义,但有着微妙的区别:
“我认为,与合作不同,协作需要参与项目的各方共同解决问题。”
Eaves 接着用了一整篇文章专门介绍 GitHub 是如何推动开源工作方式创新的——特别是社区管理方面。在“GitHub 如何保存 OpenSource ”(参见参考资料)中,Eaves 指出:
“我相信,当贡献者能够参与低交易成本的合作,而高交易成本的合作被最小化时,开源项目工作得最好。开源的天才之处在于,它不需要一个团体来讨论每一个问题,并集体解决问题,恰恰相反。”
他继续谈论分叉的价值,以及它如何通过实现人们之间的低成本合作来降低协作的高成本,这些人能够在未经许可的情况下推进项目。这种分支推掉了协调的需要,直到解决方案准备好被合并,实现了更加快速和动态的实验。
你可以用类似的方式塑造你的项目,同样的目标是通过遵循本文详述的约定和模式,在编写、维护和支持你的项目的过程中,增加低成本的合作,同时最小化昂贵的协作。
总结
这里用很少的实际例子介绍了很多内容。详细了解这些东西的最好方法是浏览 GitHub 上在这些模式上做得很好的项目的资源库。
Pinax 有自己的样板文件这里是,它可以用来根据本文中的约定和模式快速生成一个项目。
请记住,即使您使用我们的样板或其他样板,您也需要找到一种适合您和您的项目的方式来实现这些东西。所有这些都是除了编写项目的实际代码之外的事情——但是它们都有助于发展一个贡献者社区。***
Ubuntu 上的 kickstarting Flask–设置和部署
原文:https://realpython.com/kickstarting-flask-on-ubuntu-setup-and-deployment/
本教程详细介绍了如何在运行 Ubuntu 的服务器上安装 Flask 应用程序。
由于这一过程可能会很困难,因为有许多可移动的部分,我们将从多个部分来看这个过程,从最基本的配置开始,逐步向上:
- 第 1 部分:设置基本配置
- 第 2 部分:添加主管
- 第 3 部分:用 Git 挂钩简化部署
- 第 4 部分:用 Fabric 实现自动化()和一个示例视频!)
更新:
- 2014 年 10 月 28 日:添加了如何在 Ubuntu 上添加新用户的信息
- 2015 年 4 月 16 日:更新 nginx 配置
我们将特别使用:
- Ubuntu 14.04
- nginx 1.4.6
- gunicorn 19.1.1
- Python 2.7.8
- Pip 1.5.4
- virtualenv 1.11.4
- 烧瓶 0.10.1
- 主管 3.0b2
假设您已经有了一个运行 Ubuntu 操作系统的 VPS,我们需要在操作系统之上建立一个 web 服务器来为最终用户提供静态文件——比如样式表、JavaScript 文件和图像。我们将使用 nginx 作为我们的网络服务器。由于 web 服务器不能直接与 Flask 通信(错误 Python),我们将使用 gunicorn 作为服务器和 Python/Flask 之间的媒介。
等等,为什么我们需要两台服务器?想象一下,如果 Gunicorn 作为应用 web 服务器,将运行在 nginx——前端 web 服务器之后。Gunicorn 与 WSGI 兼容。它可以与其他支持 WSGI 的应用程序对话,比如 Flask 或 Django。
需要访问网络服务器?查看数字海洋、利诺德,或者亚马逊 EC2 。或者,您可以使用vagger来模拟 Linux 环境。该设置在 Digital Ocean 和 Linode 上进行了测试。
最终目标:HTTP 请求从 web 服务器被路由到 Flask,Flask 对其进行适当的处理,然后响应被发送回 web 服务器,最后返回给最终用户。正确实现 Web 服务器网关接口(WSGI)对我们的成功至关重要。
我们开始吧。
第 1 部分-设置
让我们进行基本的配置设置。
添加新用户
以“root”用户身份登录服务器后,运行:
$ adduser newuser
$ adduser newuser sudo
创建具有“sudo”权限的新用户。
安装要求
使用新用户 SSH 进入服务器,然后安装以下软件包:
$ sudo apt-get update
$ sudo apt-get install -y python python-pip python-virtualenv nginx gunicorn
设置烧瓶
首先创建一个新目录“/home/www”来存储项目:
$ sudo mkdir /home/www && cd /home/www
然后创建并激活一个虚拟设备:
$ sudo virtualenv env
$ source env/bin/activate
安装要求:
$ sudo pip install Flask==0.10.1
现在设置您的项目:
$ sudo mkdir flask_project && cd flask_project
$ sudo vim app.py
将以下代码添加到 app.py 中:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/')
def index():
return 'Flask is running!'
@app.route('/data')
def names():
data = {"names": ["John", "Jacob", "Julie", "Jennifer"]}
return jsonify(data)
if __name__ == '__main__':
app.run()
在 VIM 中,按
I进入插入模式。添加代码,然后按Esc离开插入模式进入命令模式。最后键入“:wq”保存并退出 VIM。
建立一个静态目录-
$ sudo mkdir static
-然后用下面的 html 添加一个index.html(sudo vim static/index.html)文件:
<h1>Test!</h1>
配置 nginx
启动 nginx:
$ sudo /etc/init.d/nginx start
然后:
$ sudo rm /etc/nginx/sites-enabled/default
$ sudo touch /etc/nginx/sites-available/flask_project
$ sudo ln -s /etc/nginx/sites-available/flask_project /etc/nginx/sites-enabled/flask_project
这里,我们删除默认的 nginx 配置,创建一个新的配置文件(名为 flask_project ),最后,设置一个指向我们刚刚创建的配置文件的符号链接,以便 nginx 在启动时加载它。
现在,让我们将配置设置添加到 flask_project :
$ sudo vim /etc/nginx/sites-enabled/flask_project
添加:
server {
location / {
proxy_pass http://localhost:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
location /static {
alias /home/www/flask_project/static/;
}
}
因此,到达/端点的 HTTP 请求将被“”反向代理到127.0.0.1上的端口 8000(或“回环 ip”或“本地主机”)。这是 gunicorn 将使用的相同 IP 和端口。
我们还指出,我们希望 nginx 直接服务于“/home/www/flask _ project/static/”目录中的静态文件,而不是通过 gunicorn/WSGI 路由请求。这将加快我们网站的加载时间,因为 nginx 知道直接服务于该目录。
重启 nginx:
$ sudo /etc/init.d/nginx restart
利润!
$ cd /home/www/flask_project/
$ gunicorn app:app -b localhost:8000
后一个命令在本地主机端口 8000 上手动运行 gunicorn。
打开浏览器,导航至http://your _ domain _ name _ or _ IP _ address。
同样,您应该看到“烧瓶正在运行!”消息。同样测试另一个 URL,/data。如果你导航到http://your _ domain _ name _ or _ IP _ address/static,你应该会看到“测试!”,表明我们正在正确地提供静态文件。
第 2 部分-主管
所以,我们有一个工作瓶应用程序;然而,有一个问题:每次我们对应用程序进行更改时,我们都必须手动(重新)启动 gunicorn。我们可以通过主管来实现自动化。
配置主管
SSH 进入您的服务器,然后安装 Supervisor:
$ sudo apt-get install -y supervisor
现在创建一个配置文件:
$ sudo vim /etc/supervisor/conf.d/flask_project.conf
添加:
[program:flask_project]
command = gunicorn app:app -b localhost:8000
directory = /home/www/flask_project
user = newuser
利润!
停止 gunicorn:
$ sudo pkill gunicorn
与主管一起启动 gunicorn:
$ sudo supervisorctl reread
$ sudo supervisorctl update
$ sudo supervisorctl start flask_project
确保您的应用仍在运行于http://your _ domain _ name _ or _ IP _ address。查看管理员文档了解定制配置信息。
第 3 部分-部署
在这最后一部分,我们将看看如何使用 post-receive Git 钩子和 Git,当然,是为了简化部署过程。

配置 Git
再次,SSH 到远程服务器。然后安装 Git:
$ sudo apt-get install -y git
现在运行以下命令来设置一个我们可以推送的裸 Git repo:
$ sudo mkdir /home/git && cd /home/git
$ sudo mkdir flask_project.git && cd flask_project.git
$ sudo git init --bare
快速提示:在提示符下显示 git 分支将有助于提醒您在终端中的位置。
考虑将它添加到您的 bash 生产配置文件中:
`parse_git_branch() { git branch 2> /dev/null | sed -e '/^[^*]/d' -e 's/* \(.*\)/ (\1)/' } export PS1="\u@\h \W\[\033[32m\]\$(parse_git_branch)\[\033[00m\] $ "`
配置接收后挂钩*
$ sudo vim hooks/post-receive
添加:
#!/bin/sh
GIT_WORK_TREE=/home/www/flask_project git checkout -f
现在,每次推送时,新文件都会复制到应用程序目录“/home/www/flask_project”。
然后使文件可执行:
$ sudo chmod +x hooks/post-receive
利润!
回到您的本地 Flask 目录(“flask_project”),添加一个新的 Git repo 以及以下远程:
$ git init
$ git remote add production root@<your_ip_or_domain>:/home/git/flask_project.git
确保更新 IP 或域名。
对 app.py 文件中的代码进行一些修改:
@app.route('/data')
def names():
data = {
"first_names": ["John", "Jacob", "Julie", "Jennifer"],
"last_names": ["Connor", "Johnson", "Cloud", "Ray"]
}
return jsonify(data)
提交您的本地更改,然后按:
$ git add -A
$ git commit -am "initial"
$ git push production master
SSH 进入您的服务器,并通过 Supervisor 重启 gunicorn:
$ sudo supervisorctl restart flask_project
在http://your _ domain _ name _ or _ IP _ address/data查看您的更改。
第 4 部分-自动化
您真的想要手动配置服务器吗?当然,它对学习很有帮助,但正如你所知,它超级乏味。幸运的是,我们已经用 Fabric 自动化了这个过程。除了设置 nginx、gunicorn、Supervisor 和 Git 之外,该脚本还创建了一个基本的 Flask 应用程序,它特定于我们正在处理的项目。您可以轻松地对其进行定制,以满足您自己的特定需求。
您应该从文件中删除用户名和密码,并将它们放在不受版本控制的单独的配置文件中,或者在远程服务器上设置 SSH 密钥,这样您就不需要密码来登录了。另外,一定要将
env.hosts变量更新为您的 IP 或域名。
设置
为了测试这个脚本( fabfile.py ),克隆 repo 并从一个干净的、刚刚安装了 Ubuntu 14.04 的服务器开始。然后导航到“flask-deploy”目录。要在远程服务器和您的应用程序上设置基本配置,请运行以下命令:
$ fab create
您的应用程序现在应该是活动的。在你的浏览器中测试一下。
部署
想用 Git 挂钩设置部署吗?初始化 Flask 项目目录中的本地 repo(如果需要)。然后对 Flask 应用程序进行一些本地更改,并运行以下命令进行部署:
$ fab deploy
在浏览器中再次检查你的应用。确保您的更改显示出来。
状态检查
最后,您可以使用以下命令检查监管进程是否正确运行,以确保您的应用程序是活动的:
$ fab status
同样,这个脚本特定于您手头的项目。您可以根据自己的需要对其进行定制,方法是更新 config 部分并根据需要修改任务。
回滚
犯错是人之常情…
一旦你有了生产代码,事情肯定会不时出错。在您的本地开发环境中,一切可能都很好,只是在生产中崩溃了。因此,制定一个策略来快速恢复 Git 提交非常重要。快速浏览一下 fabfile.py 中的rollback任务,它允许你快速恢复更改以备份一个工作应用。
通过故意破坏您的代码来测试它,然后部署到生产环境中,然后运行:
$ fab rollback
然后,您可以在本地更新您的代码来修复错误,然后重新部署。
示例视频
只需按播放:
结论和后续步骤
想让这个工作流程更上一层楼吗?
- 出于测试目的,在组合中添加一台生产前(试运行)服务器。首先部署到此服务器,它应该是您的生产环境的精确副本,以便在部署到生产环境之前进行测试。
- 利用持续集成和交付,通过自动化测试进一步消除错误和退化,并减少部署应用所需的时间。
请在下面留下问题和评论。一定要从回购中抓取代码。******
Python 中的 k 近邻算法
在本教程中,您将全面了解 Python 中的 k 近邻(kNN)算法。kNN 算法是最著名的机器学习算法之一,也是你机器学习工具箱中绝对必备的。Python 是机器学习的首选编程语言,那么还有什么比使用 Python 著名的包 NumPy 和 scikit-learn 更好的方法来发现 kNN 呢!
下面,您将从理论和实践两方面探索 kNN 算法。虽然许多教程跳过了理论部分,只关注库的使用,但你不想依赖自动化包来进行机器学习。了解机器学习算法的机制以理解它们的潜力和局限性是很重要的。
同时,理解如何在实践中使用一个算法是很重要的。记住这一点,在本教程的第二部分,您将重点关注在 Python 库 scikit-learn 中使用 kNN,以及将性能提升到最高的高级技巧。
在本教程中,您将学习如何:
- 从直观和数学的角度解释 kNN 算法
- 使用 NumPy 从头开始用 Python 实现 kNN
- 在 Python 中使用 kNN 和 scikit-learn
- 使用
GridSearchCV调整 kNN 的超参数 - 将打包添加到 kNN 以获得更好的性能
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
机器学习的基础知识
为了让你参与进来,有必要后退一步,做一个关于机器学习的总体快速调查。在本节中,您将了解机器学习背后的基本思想,并且您将看到 kNN 算法如何与其他机器学习工具相关联。
机器学习的总体思想是获得一个模型,从任何主题的历史数据中学习趋势,并能够在未来的可比数据上重现这些趋势。这是一个概述基本机器学习过程的图表:
该图是拟合历史数据的机器学习模型的可视化表示。左边是具有三个变量的原始观测值:高度、宽度和形状。形状有星形、十字形和三角形。
这些形状位于图表的不同区域。在右边,您可以看到那些原始的观察结果是如何被转化为决策规则的。对于新的观察,您需要知道宽度和高度,以确定它落在哪个方块中。反过来,它所在的正方形决定了它最有可能具有的形状。
许多不同的模型可以用于这项任务。模型是一个数学公式,可以用来描述数据点。一个例子是线性模型,它使用由公式y = ax + b定义的线性函数。
如果你估算,或者说拟合,一个模型,你就可以用某种算法找到固定参数的最优值。在线性模型中,参数为a和b。幸运的是,你不必发明这样的估算算法来开始。他们已经被伟大的数学家发现了。
一旦模型被估计出来,它就变成了一个数学公式,在这个公式中你可以填入自变量的值来预测目标变量。从一个高层次的角度来看,这就是所发生的一切!
kNN 的区别特征
既然你理解了机器学习背后的基本思想,下一步就是理解为什么会有这么多可用的模型。你刚才看到的线性模型叫做线性回归。
线性回归在某些情况下有效,但并不总能做出非常精确的预测。这就是为什么数学家提出了许多可供选择的机器学习模型,你可以使用。k 近邻算法就是其中之一。
所有这些模型都有其独特之处。如果你从事机器学习,你应该对它们都有深刻的理解,这样你才能在正确的情况下使用正确的模型。为了理解为什么以及何时使用 kNN,接下来您将看看 kNN 与其他机器学习模型相比如何。
kNN 是一种有监督的机器学习算法
机器学习算法的第一个决定性属性是监督的和非监督的模型之间的分裂。有监督和无监督模型的区别在于问题陈述。
在监督模型中,您同时有两种类型的变量:
- 一个目标变量,也称为因变量或
y变量。 - 自变量,又称
x变量或解释变量。
目标变量是您想要预测的变量。它取决于独立变量,这不是你事先知道的。自变量是你提前知道的变量。你可以把它们代入一个方程来预测目标变量。这样的话,就比较类似于y = ax + b的案例了。
在您之前看到的图表以及本节的后续图表中,目标变量是数据点的形状,自变量是高度和宽度。您可以在下图中看到监督学习背后的思想:

在该图中,每个数据点都具有高度、宽度和形状。有十字形、星形和三角形。右边是机器学习模型可能已经学会的决策规则。
在这种情况下,标有叉号的观测值高但不宽。星星又高又宽。三角形很短,但可以很宽或很窄。本质上,该模型已经学习了一个判定规则,仅基于其高度和宽度来判定一个观察值更可能是十字形、星形还是三角形。
在无监督的模型中,目标变量和自变量之间没有分割。无监督学习试图通过评估数据点的相似性来对其进行分组。
正如您在示例中看到的,您永远无法确定分组后的数据点从根本上属于同一个组,但是只要分组有意义,它在实践中就非常有价值。您可以在下图中看到无监督学习背后的想法:

在这张图中,观察值不再有不同的形状。都是圈子。然而,它们仍然可以根据点与点之间的距离分为三组。在这个特定的示例中,有三个点簇可以根据它们之间的空白空间进行分离。
kNN 算法是一种受监督的机器学习模型。这意味着它使用一个或多个独立变量来预测目标变量。
要了解更多关于无监督机器学习模型的信息,请查看Python 中的 K-Means 聚类:实用指南。
kNN 是一种非线性学习算法
在机器学习算法中造成巨大差异的第二个属性是模型是否可以估计非线性关系。
线性模型是使用直线或超平面进行预测的模型。在图像中,模型被描绘为在点之间绘制的线。模型y = ax + b是线性模型的经典例子。您可以在下面的示意图中看到线性模型如何拟合示例数据:

在此图中,数据点在左侧用星形、三角形和十字形表示。右边是一个线性模型,可以把三角形和非三角形分开。决定是一条线。线上的每一点都是非三角形,线下的一切都是三角形。
如果您想要将另一个独立变量添加到前面的图形中,您需要将它绘制为一个额外的维度,从而创建一个立方体,其中包含这些形状。然而,一条线不可能把一个立方体分成两部分。线的多维对应物是超平面。因此,线性模型由超平面表示,在二维空间的情况下,超平面恰好是一条线。
非线性模型是使用除直线之外的任何方法来分离案例的模型。一个众所周知的例子是决策树,它基本上是一长串 if … else 语句。在非线性图中,if … else 语句允许你画正方形或任何你想画的其他形状。下图描述了应用于示例数据的非线性模型:

这张图显示了决策是如何非线性的。决策规则由三个方块组成。新数据点所在的方框将定义其预测形状。请注意,使用一条线不可能一次安装完毕:需要两条线。可以使用 if … else 语句重新创建此模型,如下所示:
- 如果数据点的高度很低,那么它就是一个三角形。
- 否则,如果数据点的宽度较低,则它是一个十字。
- 否则,如果以上都不成立,那就是明星。
kNN 是非线性模型的一个例子。在本教程的后面,您将回到计算模型的确切方式。
kNN 是分类和回归的监督学习器
监督机器学习算法可以根据它们可以预测的目标变量的类型分为两组:
-
分类是一个带有分类目标变量的预测任务。分类模型学习如何对任何新的观察结果进行分类。这个分配的类可以是对的,也可以是错的,不能介于两者之间。分类的一个经典例子是虹膜数据集,其中你使用植物的物理测量来预测它们的种类。可以用于分类的一个著名算法是逻辑回归。
-
回归是目标变量为数值的预测任务。一个著名的回归例子是卡格尔上的房价挑战。在这场机器学习竞赛中,参与者试图根据众多独立变量来预测房屋的销售价格。
在下图中,您可以使用前面的示例来查看回归和分类的情况:

这张图片的左边部分是一个分类。目标变量是观察的形状,这是一个分类变量。右边部分是一个回归。目标变量是数字。对于这两个例子,决策规则可能完全相同,但是它们的解释是不同的。
对于单个预测,分类要么是对的,要么是错的,而回归在连续的尺度上有误差。拥有一个数值误差度量更为实际,因此许多分类模型不仅预测类别,还预测属于任一类别的概率。
有的模型只能做回归,有的只能做分类,有的两者都可以。kNN 算法无缝地适应分类和回归。在本教程的下一部分中,您将确切地了解这是如何工作的。
kNN 快速且可解释
作为表征机器学习模型的最后一个标准,你需要考虑模型的复杂性。机器学习,尤其是人工智能,目前正在蓬勃发展,并被用于许多复杂的任务,如理解文本、图像和语音,或用于无人驾驶汽车。
像神经网络这样更先进和复杂的模型可能可以学习 k-最近邻模型可以学习的任何东西。毕竟那些高级模特都是很强的学习者。但是,要知道这种复杂性也是有代价的。为了使模型符合您的预测,您通常会在开发上花费更多的时间。
你还需要更多的数据来适应更复杂的模型,而数据并不总是可用的。最后但同样重要的是,更复杂的模型对我们人类来说更难解释,有时这种解释可能非常有价值。
这就是 kNN 模型的力量所在。它允许用户理解和解释模型内部发生的事情,并且开发速度非常快。这使得 kNN 成为许多不需要高度复杂技术的机器学习用例的伟大模型。
kNN 的缺点
诚实地承认 kNN 算法的缺点也是公平的。如前所述,kNN 的真正缺点是它适应自变量和因变量之间高度复杂关系的能力。kNN 不太可能在高级任务上表现良好,如计算机视觉和自然语言处理。
你可以试着尽可能地提高 kNN 的性能,潜在地通过添加机器学习的其他技术。在本教程的最后一部分,您将看到一种叫做 bagging 的技术,这是一种提高预测性能的方法。然而,在某种复杂程度上,无论如何调整,kNN 都可能不如其他模型有效。
用 kNN 预测海蛞蝓的年龄
为了跟随编码部分,您将在本教程的剩余部分看到一个示例数据集——鲍鱼数据集。该数据集包含大量鲍鱼的年龄测量值。仅供参考,这是鲍鱼的样子:

鲍鱼是小海螺,看起来有点像贻贝。如果你想了解更多,你可以查看鲍鱼维基百科页面获取更多信息。
鲍鱼问题声明
切开鲍鱼的壳,数一下壳上的年轮数,就可以知道鲍鱼的年龄。在鲍鱼数据集中,您可以找到大量鲍鱼的年龄测量值以及许多其他物理测量值。
该项目的目标是开发一个模型,可以完全基于其他物理测量来预测鲍鱼的年龄。这将允许研究人员估计鲍鱼的年龄,而不必切开它的壳和数年轮。
您将应用 kNN 来找到最接近的预测分数。
导入鲍鱼数据集
在本教程中,您将使用鲍鱼数据集。你可以下载它并使用 pandas 将数据导入 Python,但是让 pandas 直接为你导入数据会更快。
为了遵循本教程中的代码,建议安装带有 Anaconda 的 Python。Anaconda 发行版附带了许多重要的数据科学包。要获得更多关于设置环境的帮助,你可以查看在 Windows 上设置 Python 进行机器学习。
您可以使用 pandas 导入数据,如下所示:
>>> import pandas as pd >>> url = ( ... "https://archive.ics.uci.edu/ml/machine-learning-databases" ... "/abalone/abalone.data" ... ) >>> abalone = pd.read_csv(url, header=None)在这段代码中,首先导入 pandas,然后用它来读取数据。您将路径指定为 URL,这样就可以通过 Internet 直接获取文件。
为了确保您正确导入了数据,您可以进行如下快速检查:
>>> abalone.head()
0 1 2 3 4 5 6 7 8
0 M 0.455 0.365 0.095 0.5140 0.2245 0.1010 0.150 15
1 M 0.350 0.265 0.090 0.2255 0.0995 0.0485 0.070 7
2 F 0.530 0.420 0.135 0.6770 0.2565 0.1415 0.210 9
3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
这应该会显示鲍鱼数据集的前五行,在 Python 中作为熊猫数据帧导入。您可以看到列名仍然缺失。你可以在 UCI 机器学习库的 abalone.names 文件中找到这些名字。您可以将它们添加到您的DataFrame中,如下所示:
>>> abalone.columns = [ ... "Sex", ... "Length", ... "Diameter", ... "Height", ... "Whole weight", ... "Shucked weight", ... "Viscera weight", ... "Shell weight", ... "Rings", ... ]导入的数据现在应该更容易理解了。但是还有一件你应该做的事情:你应该删除
Sex列。当前练习的目标是使用物理测量来预测鲍鱼的年龄。因为性不是一个纯粹的物理测量,你应该把它从数据集中删除。您可以使用.drop删除Sex列:
>>> abalone = abalone.drop("Sex", axis=1)
使用这段代码,您删除了Sex列,因为它在建模中没有附加值。
鲍鱼数据集的描述性统计数据
在进行机器学习时,你需要对你正在处理的数据有一个概念。在不深入研究的情况下,让我们看看一些探索性的统计数据和图表。
这个练习的目标变量是Rings,可以从那个开始。一个直方图将会给你一个快速而有用的年龄范围概览:
>>> import matplotlib.pyplot as plt >>> abalone["Rings"].hist(bins=15) >>> plt.show()这段代码使用 pandas 绘图功能来生成一个包含 15 个条块的直方图。使用 15 个箱的决定是基于几次试验。当定义箱的数量时,通常要尽量使每个箱的观测值既不太多也不太少。太少的面元会隐藏某些图案,而太多的面元会使直方图缺乏平滑度。您可以在下图中看到直方图:
直方图显示,数据集中的大多数鲍鱼有 5 到 15 个环,但也有可能达到 25 个环。较老的鲍鱼在这个数据集中代表性不足。这看起来很直观,因为年龄分布通常由于自然过程而像这样偏斜。
第二个相关的探索是找出哪些变量(如果有的话)与年龄有很强的相关性。自变量和你的目标变量之间的强相关性是一个好的迹象,因为这将证实身体测量和年龄是相关的。
在
correlation_matrix中可以观察到完整的相关矩阵。最重要的相关性是与目标变量Rings的相关性。你可以得到这样的关联:

>>> correlation_matrix = abalone.corr()
>>> correlation_matrix["Rings"]
Length 0.556720
Diameter 0.574660
Height 0.557467
Whole weight 0.540390
Shucked weight 0.420884
Viscera weight 0.503819
Shell weight 0.627574
Rings 1.000000
Name: Rings, dtype: float64
现在看看Rings与其他变量的相关系数。离1越近,相关性越大。
你可以得出结论,成年鲍鱼的身体测量和它们的年龄之间至少有一些相关性,但也不是很高。非常高的相关性意味着你可以期待一个简单的建模过程。在这种情况下,您必须尝试看看使用 kNN 算法可以获得什么结果。
使用熊猫进行数据探索有更多的可能性。要了解更多关于熊猫的数据探索,请查看使用熊猫和 Python 探索您的数据集。
Python 中从头开始的一步一步的 kNN
在教程的这一部分,你将会发现 kNN 算法是如何工作的。这个算法有两个你需要理解的主要数学部分。为了热身,您将从 kNN 算法的简单英语演练开始。
kNN 算法的简单英语演练
与其他机器学习算法相比,kNN 算法有点不典型。正如你之前看到的,每个机器学习模型都有其特定的公式需要估计。k-最近邻算法的特殊性在于,该公式不是在拟合时计算的,而是在预测时计算的。这不是大多数其他模型的情况。
当一个新的数据点到达时,kNN 算法,顾名思义,将从寻找这个新数据点的最近邻居开始。然后,它获取这些邻居的值,并将它们用作新数据点的预测。
作为一个直观的例子,想想你的邻居。你的邻居往往和你比较相似。他们可能和你在同一个社会经济阶层。也许他们和你是一个类型的工作,也许他们的孩子和你上同一所学校,等等。但是对于某些任务,这种方法并不那么有用。例如,通过观察你邻居最喜欢的颜色来预测你的颜色是没有任何意义的。
kNN 算法基于这样一个概念,即您可以根据相邻数据点的特征来预测数据点的特征。在某些情况下,这种预测方法可能会成功,而在其他情况下,它可能不会成功。接下来,您将了解数据点“最近”的数学描述,以及将多个相邻点合并到一个预测中的方法。
使用距离的数学定义定义“最近的”
要找到最接近您需要预测的点的数据点,您可以使用距离的数学定义,称为欧几里德距离。
为了得到这个定义,你应该首先理解两个向量的差是什么意思。这里有一个例子:
在这张图片中,您可以看到两个数据点:蓝色在(2,2),绿色在(4,4)。要计算它们之间的距离,可以从添加两个向量开始。向量a从点(4,2)到点(4,4),向量b从点(4,2)到点(2,2)。他们的头用彩色点表示。请注意,它们呈 90 度角。
这些向量之间的差就是向量c,它从向量a的头部到向量b的头部。向量c的长度代表你的两个数据点之间的距离。
向量的长度叫做范数。范数是一个正值,表示向量的大小。您可以使用欧几里得公式计算向量的范数:
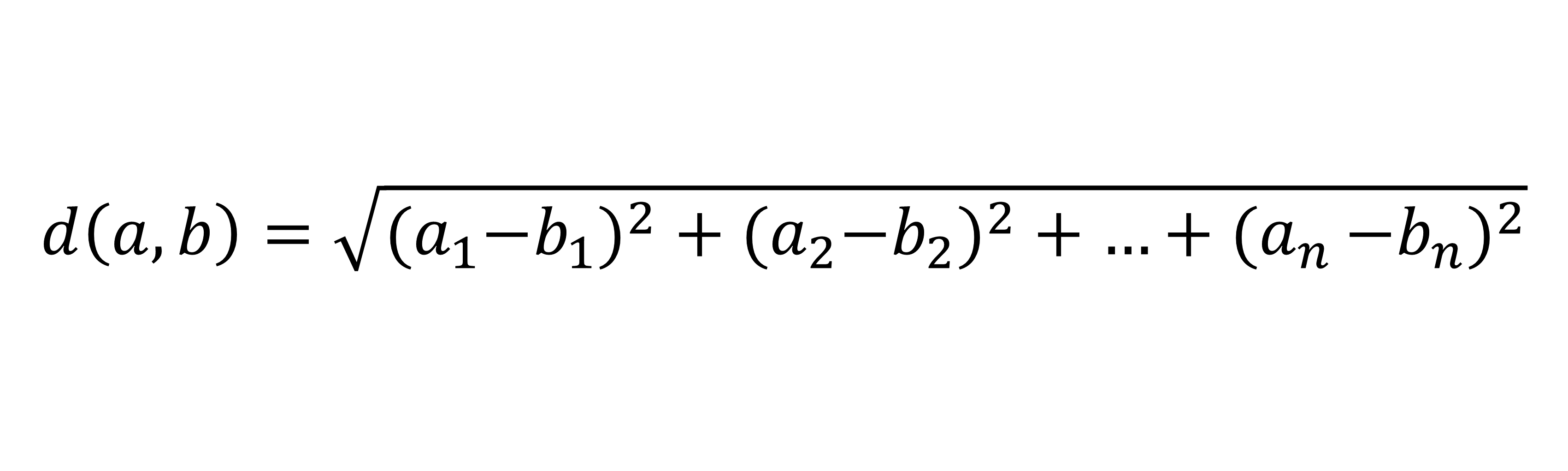
在这个公式中,距离是通过计算每个维度的平方差,然后计算这些值之和的平方根来计算的。在这种情况下,您应该计算差向量c的范数,以获得数据点之间的距离。
现在,要将它应用到您的数据中,您必须理解您的数据点实际上是向量。然后,您可以通过计算差向量的范数来计算它们之间的距离。
您可以使用 NumPy 中的linalg.norm()在 Python 中进行计算。这里有一个例子:
>>> import numpy as np >>> a = np.array([2, 2]) >>> b = np.array([4, 4]) >>> np.linalg.norm(a - b) 2.8284271247461903在这个代码块中,您将数据点定义为向量。然后计算两个数据点之间的差值
norm()。这样,你就直接获得了两个多维点之间的距离。即使这些点是多维的,它们之间的距离仍然是一个标量,或者说是一个单一的值。如果你想获得更多数学上的细节,你可以看看勾股定理来了解欧几里德距离公式是如何推导出来的。
找到最近的邻居
既然您已经有了一种计算任意点到任意点的距离的方法,那么您就可以使用这种方法来查找您想要进行预测的点的最近邻。
你需要找到一些邻居,这个数字由
k给出。k的最小值是1。这意味着只使用一个邻居进行预测。最大值是您拥有的数据点的数量。这意味着使用所有邻居。k的值是用户定义的。优化工具可以帮助你做到这一点,你会在本教程的最后一部分看到。现在,要查找 NumPy 中的最近邻,请返回鲍鱼数据集。正如您所看到的,您需要在独立变量的向量上定义距离,因此您应该首先使用
.values属性将 pandas 数据帧放入一个 NumPy 数组:
>>> X = abalone.drop("Rings", axis=1)
>>> X = X.values
>>> y = abalone["Rings"]
>>> y = y.values
这个代码块生成了两个包含您的数据的对象:X和y。X是模型的自变量,y是模型的因变量。请注意,X用大写字母,而y用小写字母。这通常在机器学习代码中完成,因为数学符号通常使用大写字母表示矩阵,小写字母表示向量。
现在,您可以对具有以下物理测量值的新鲍鱼应用具有k = 3 的 kNN:
| 可变的 | 价值 |
|---|---|
| 长度 | 0.569552 |
| 直径 | 0.446407 |
| 高度 | 0.154437 |
| 整体重量 | 1.016849 |
| 震惊重量 | 0.439051 |
| 内脏重量 | 0.222526 |
| 外壳重量 | 0.291208 |
您可以为该数据点创建 NumPy 数组,如下所示:
>>> new_data_point = np.array([ ... 0.569552, ... 0.446407, ... 0.154437, ... 1.016849, ... 0.439051, ... 0.222526, ... 0.291208, ... ])下一步是使用以下代码计算这个新数据点和鲍鱼数据集中每个数据点之间的距离:
>>> distances = np.linalg.norm(X - new_data_point, axis=1)
现在你有了一个距离向量,你需要找出哪三个是最近的邻居。为此,您需要找到最小距离的 id。您可以使用名为.argsort()的方法从最低到最高对数组进行排序,并且您可以获取第一个k元素来获得k最近邻居的索引:
>>> k = 3 >>> nearest_neighbor_ids = distances.argsort()[:k] >>> nearest_neighbor_ids array([4045, 1902, 1644], dtype=int32)这会告诉你哪三个邻居离你的
new_data_point最近。在下一段中,您将看到如何在估算中转换这些邻居。多个邻居的投票或平均
确定了年龄未知的鲍鱼的三个最近邻居的指数后,现在需要将这些邻居合并到新数据点的预测中。
作为第一步,你需要找到这三个邻居的基本事实:
>>> nearest_neighbor_rings = y[nearest_neighbor_ids]
>>> nearest_neighbor_rings
array([ 9, 11, 10])
现在您已经有了这三个相邻点的值,您可以将它们组合成新数据点的预测。对于回归和分类而言,将邻域合并到预测中的工作方式不同。
回归平均值
在回归问题中,目标变量是数字。通过取目标变量的平均值,可以将多个邻居组合成一个预测。您可以这样做:
>>> prediction = nearest_neighbor_rings.mean()你将得到
prediction的值10。这意味着新数据点的 3-最近邻预测是10。你可以为你想要的任何数量的新鲍鱼做同样的事情。分类模式
在分类问题中,目标变量是明确的。如前所述,你不能对分类变量取平均值。例如,三个预测的汽车品牌的平均值是多少?那是不可能说的。你不能对班级预测进行平均。
相反,在分类的情况下,你采取模式。众数是最常出现的值。这意味着您统计了所有邻居的类,并且您保留了最常见的类。预测是在邻居中最常出现的值。
如果有多种模式,就有多种可能的解决方案。你可以从获胜者中随机选择一个最终的获胜者。您也可以根据相邻点的距离做出最终决定,在这种情况下,将保留最近相邻点的模式。
您可以使用 SciPy
mode()函数计算模式。由于鲍鱼示例不是分类的例子,下面的代码显示了如何计算玩具示例的模式:
>>> import scipy.stats
>>> class_neighbors = np.array(["A", "B", "B", "C"])
>>> scipy.stats.mode(class_neighbors)
ModeResult(mode=array(['B'], dtype='<U1'), count=array([2]))
如您所见,本例中的模式是"B",因为它是输入数据中出现频率最高的值。
使用 scikit-learn 在 Python 中拟合 kNN
虽然从零开始编写算法对于学习来说是很好的,但在处理机器学习任务时通常不太实际。在本节中,您将探索 scikit-learn 中使用的 kNN 算法的实现,sci kit-learn 是 Python 中最全面的机器学习包之一。
将数据分为训练集和测试集,用于模型评估
在本节中,您将评估鲍鱼 kNN 模型的质量。在前面的部分中,您有一个技术焦点,但是现在您将有一个更加务实和以结果为导向的观点。
评估模型有多种方法,但最常用的是训练测试分割。当使用训练测试分割进行模型评估时,将数据集分割为两部分:
- 训练数据用于拟合模型。对于 kNN 来说,这意味着训练数据将被用作邻居。
- 测试数据用于评估模型。这意味着你将预测测试数据中每只鲍鱼的环数,并将这些结果与已知的真实环数进行比较。
您可以使用 scikit-learn 的内置train_test_split() 在 Python 中将数据分成训练集和测试集:
>>> from sklearn.model_selection import train_test_split >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, test_size=0.2, random_state=12345 ... )
test_size指的是您想要放入训练数据和测试数据中的观察值的数量。如果您指定一个0.2的test_size,那么您的test_size将是原始数据的 20 %,因此剩下的 80%作为训练数据。
random_state是一个参数,允许您在每次运行代码时获得相同的结果。train_test_split()对数据进行随机分割,这对于重现结果是有问题的。因此,使用random_state是很常见的。random_state中值的选择是任意的。在上面的代码中,您将数据分为定型数据和测试数据。这是客观模型评估所需要的。现在,您可以使用 scikit-learn 在训练数据上拟合 kNN 模型。
将 scikit-learn 中的 kNN 回归拟合到鲍鱼数据集
要适应 scikit-learn 中的模型,首先要创建正确类的模型。此时,您还需要选择超参数的值。对于 kNN 算法,您需要选择
k的值,这在 scikit-learn 实现中称为n_neighbors。以下是在 Python 中实现这一点的方法:
>>> from sklearn.neighbors import KNeighborsRegressor
>>> knn_model = KNeighborsRegressor(n_neighbors=3)
您用knn_model创建了一个不适合的模型。该模型将使用三个最近邻来预测未来数据点的值。若要将数据放入模型中,您可以将模型放入定型数据集:
>>> knn_model.fit(X_train, y_train)使用
.fit(),你让模型从数据中学习。此时,knn_model包含了对新的鲍鱼数据点进行预测所需的一切。这就是使用 Python 拟合 kNN 回归所需的全部代码!使用 scikit-learn 检查模型拟合度
然而,仅仅拟合一个模型是不够的。在这一节中,您将看到一些可以用来评估适合度的函数。
有许多评估指标可用于回归,但您将使用最常见的一个,即均方根误差(RMSE) 。预测的 RMSE 计算如下:
- 计算每个数据点的实际值和预测值之间的差异。
- 对于每个差值,取这个差值的平方。
- 对所有的平方差求和。
- 取总和的平方根。
首先,您可以评估训练数据的预测误差。这意味着你用训练数据进行预测,所以你知道结果应该是比较好的。您可以使用下面的代码来获取 RMSE:
>>> from sklearn.metrics import mean_squared_error
>>> from math import sqrt
>>> train_preds = knn_model.predict(X_train)
>>> mse = mean_squared_error(y_train, train_preds)
>>> rmse = sqrt(mse)
>>> rmse
1.65
在这段代码中,您使用您在前面的代码块中安装的knn_model来计算 RMSE。你现在根据训练数据计算 RMSE。为了获得更真实的结果,您应该评估模型中未包含的数据的性能。这就是你现在保持测试集独立的原因。您可以使用与之前相同的功能在测试集上评估预测性能:
>>> test_preds = knn_model.predict(X_test) >>> mse = mean_squared_error(y_test, test_preds) >>> rmse = sqrt(mse) >>> rmse 2.37在这个代码块中,您评估模型尚不知道的数据上的错误。这个更加真实的 RMSE 比以前稍微高了一点。RMSE 测量的是预测年龄的平均误差,所以你可以把它理解为平均误差为
1.65年。从2.37年到1.65年的改善是好是坏取决于具体情况。至少你越来越接近正确估计年龄了。到目前为止,您只使用了开箱即用的 scikit-learn 算法。您还没有对超参数进行任何调整,也没有对
k进行随机选择。您可以观察到训练数据上的 RMSE 和测试数据上的 RMSE 之间存在相对较大的差异。这意味着该模型在训练数据上受到过度拟合的影响:它不能很好地概括。这一点没什么好担心的。在下一部分中,您将看到如何使用各种调优方法来优化预测误差或测试误差。
绘制模型的拟合图
在开始改进模型之前,最后要看的是模型的实际拟合度。要了解模型所了解的内容,您可以使用 Matplotlib 可视化您的预测:
>>> import seaborn as sns
>>> cmap = sns.cubehelix_palette(as_cmap=True)
>>> f, ax = plt.subplots()
>>> points = ax.scatter(
... X_test[:, 0], X_test[:, 1], c=test_preds, s=50, cmap=cmap
... )
>>> f.colorbar(points)
>>> plt.show()
在这个代码块中,您使用 Seaborn 通过子集化数组X_test[:,0]和X_test[:,1]来创建第一列和第二列X_test的散点图。请记住,前两列是Length和Diameter。正如你在相关表中看到的,它们有很强的相关性。
您使用c来指定预测值(test_preds)应该被用作颜色条。参数s用于指定散点图中点的大小。你使用cmap来指定cubehelix_palette颜色图。要了解更多关于使用 Matplotlib 绘图的信息,请查看 Python 使用 Matplotlib 绘图。
使用上面的代码,您将得到下图:

在该图中,每个点是来自测试组的鲍鱼,其实际长度和实际直径分别在 X 轴和 Y 轴上。点的颜色反映了预测的年龄。你可以看到鲍鱼越长越大,它的预测年龄就越高。这是符合逻辑的,也是积极的信号。这意味着你的模型正在学习一些看起来正确的东西。
要确认这种趋势是否存在于实际鲍鱼数据中,您可以通过简单地替换用于c的变量来对实际值进行同样的操作:
>>> cmap = sns.cubehelix_palette(as_cmap=True) >>> f, ax = plt.subplots() >>> points = ax.scatter( ... X_test[:, 0], X_test[:, 1], c=y_test, s=50, cmap=cmap >>> ) >>> f.colorbar(points) >>> plt.show()这段代码使用 Seaborn 创建了一个带有彩条的散点图。它会生成以下图形:
这证实了你的模型正在学习的趋势确实有意义。
你可以为七个独立变量的每个组合提取一个可视化。对于本教程来说,这可能太长了,但请不要犹豫尝试一下。唯一要更改的是散点图中指定的列。
这些可视化是七维数据集的二维视图。如果你和它们一起玩,它会给你一个很好的理解模型正在学习什么,也许,它没有学习什么或者学习错了什么。
使用 scikit-learn 调优和优化 Python 中的 kNN
有许多方法可以提高你的预测分数。可以通过使用数据辩论处理输入数据来进行一些改进,但是在本教程中,重点是 kNN 算法。接下来,您将看到改进建模管道的算法部分的方法。
提高 scikit 中的 kNN 性能-使用
GridSearchCV学习到目前为止,您一直在 kNN 算法中使用
k=3,但是k的最佳值是您需要根据经验为每个数据集找到的。当您使用较少的邻域时,您的预测将比使用较多的邻域时更加多变:
如果仅使用一个邻居,预测可能会从一个点强烈地改变到另一个点。当你想到你自己的邻居时,其中一个可能与其他邻居大不相同。如果你住在一个离群值旁边,你的 1-NN 预测将是错误的。
如果你有多个数据点,一个非常不同的邻居的影响会小得多。
如果使用太多的邻居,每个点的预测都有非常接近的风险。假设您使用所有邻居进行预测。在这种情况下,每个预测都是一样的。
为了找到
k的最佳值,您将使用一个叫做GridSearchCV的工具。这是一个经常用于调整机器学习模型的超参数的工具。在您的情况下,它会自动为您的数据集找到最佳的k值。
GridSearchCV在 scikit-learn 中提供,其优点是使用方式几乎与 scikit-learn 模型完全相同:

>>> from sklearn.model_selection import GridSearchCV
>>> parameters = {"n_neighbors": range(1, 50)}
>>> gridsearch = GridSearchCV(KNeighborsRegressor(), parameters)
>>> gridsearch.fit(X_train, y_train)
GridSearchCV(estimator=KNeighborsRegressor(),
param_grid={'n_neighbors': range(1, 50),
'weights': ['uniform', 'distance']})
这里,您使用GridSearchCV来拟合模型。简而言之,GridSearchCV在一部分数据上重复拟合 kNN 回归器,并在其余部分数据上测试性能。重复这样做将产生对每个k值的预测性能的可靠估计。在这个例子中,您测试从1到50的值。
最终,它将保留k的最佳性能值,您可以使用.best_params_访问该值:
>>> gridsearch.best_params_ {'n_neighbors': 25, 'weights': 'distance'}在这段代码中,您打印了具有最低错误分数的参数。使用
.best_params_,您可以看到选择25作为k的值将产生最佳的预测性能。现在您已经知道了k的最佳值,您可以看到它是如何影响您的训练和测试性能的:
>>> train_preds_grid = gridsearch.predict(X_train)
>>> train_mse = mean_squared_error(y_train, train_preds_grid)
>>> train_rmse = sqrt(train_mse)
>>> test_preds_grid = gridsearch.predict(X_test)
>>> test_mse = mean_squared_error(y_test, test_preds_grid)
>>> test_rmse = sqrt(test_mse)
>>> train_rmse
2.0731294674202143
>>> test_rmse
2.1700197339962175
使用这段代码,您可以根据训练数据拟合模型,并评估测试数据。你可以看到训练误差比以前差,但是测试误差比以前好。这意味着您的模型不太符合训练数据。使用GridSearchCV找到k的值减少了训练数据过拟合的问题。
根据距离添加邻居的加权平均值
使用GridSearchCV,你将测试 RMSE 从2.37减少到2.17。在本节中,您将看到如何进一步提高性能。
下面,您将测试使用加权平均值而不是常规平均值进行预测时,模型的性能是否会更好。这意味着距离较远的邻居对预测的影响较小。
可以通过将weights超参数设置为"distance"的值来实现。但是,设置这个加权平均值可能会对k的最佳值产生影响。因此,您将再次使用GridSearchCV来告诉您应该使用哪种类型的平均:
>>> parameters = { ... "n_neighbors": range(1, 50), ... "weights": ["uniform", "distance"], ... } >>> gridsearch = GridSearchCV(KNeighborsRegressor(), parameters) >>> gridsearch.fit(X_train, y_train) GridSearchCV(estimator=KNeighborsRegressor(), param_grid={'n_neighbors': range(1, 50), 'weights': ['uniform', 'distance']}) >>> gridsearch.best_params_ {'n_neighbors': 25, 'weights': 'distance'} >>> test_preds_grid = gridsearch.predict(X_test) >>> test_mse = mean_squared_error(y_test, test_preds_grid) >>> test_rmse = sqrt(test_mse) >>> test_rmse 2.163426558494748在这里,您使用
GridSearchCV测试使用不同的称重是否有意义。应用加权平均而不是常规平均将预测误差从2.17降低到2.1634。虽然这不是一个巨大的改进,但它仍然更好,这使得它是值得的。进一步改进 scikit 中的 kNN 用 Bagging 学习
作为 kNN 调优的第三步,您可以使用打包。Bagging 是一种集成方法,或者是一种采用相对简单的机器学习模型并拟合大量这些模型的方法,每次拟合都有轻微的变化。Bagging 经常使用决策树,但是 kNN 也工作得很好。
集成方法通常比单一模型更有效。一个模型有时会出错,但一百个模型的平均值出错的频率应该会更低。不同的单个模型的误差可能会相互抵消,从而导致预测的可变性更小。
您可以使用 scikit-learn 通过以下步骤将 bagging 应用到您的 kNN 回归中。首先,用从
GridSearchCV中得到的k和weights的最佳选择创建KNeighborsRegressor:
>>> best_k = gridsearch.best_params_["n_neighbors"]
>>> best_weights = gridsearch.best_params_["weights"]
>>> bagged_knn = KNeighborsRegressor(
... n_neighbors=best_k, weights=best_weights
... )
然后从 scikit-learn 导入BaggingRegressor类,并使用bagged_knn模型创建一个带有100估算器的新实例:
>>> from sklearn.ensemble import BaggingRegressor >>> bagging_model = BaggingRegressor(bagged_knn, n_estimators=100)现在,您可以进行预测并计算 RMSE,看看它是否有所改善:
>>> test_preds_grid = bagging_model.predict(X_test)
>>> test_mse = mean_squared_error(y_test, test_preds_grid)
>>> test_rmse = sqrt(test_mse)
>>> test_rmse
2.1616
袋装 kNN 的预测误差为2.1616,比您之前获得的误差略小。执行起来确实需要多一点时间,但是对于这个例子来说,这不成问题。
四款车型对比
在三个增量步骤中,您推动了算法的预测性能。下表概述了不同型号及其性能:
| 模型 | 错误 |
|---|---|
任意k |
Two point three seven |
GridSearchCV为k |
Two point one seven |
GridSearchCV为k和weights |
2.1634 |
装袋和GridSearchCV |
2.1616 |
在这张表中,您可以看到从最简单到最复杂的四种模型。复杂度的顺序对应于误差度量的顺序。带有随机k的模型表现最差,带有装袋和GridSearchCV的模型表现最好。
鲍鱼预测可能有更多的改进。例如,可以寻找不同的方式来处理数据,或者寻找其他外部数据源。
结论
现在您已经了解了 kNN 算法的所有内容,您已经准备好开始用 Python 构建高性能预测模型了。从一个基本的 kNN 模型到一个完全调优的模型需要几个步骤,但是性能的提高是完全值得的!
在本教程中,您学习了如何:
- 理解 kNN 算法背后的数学基础
- 从 NumPy 中的开始编写 kNN 算法
*** 使用 scikit-learn 实现用最少的代码量来适应一个 kNN* 使用GridSearchCV找到最佳 kNN 超参数* 使用装袋将 kNN 推向其最大性能*
关于模型调整工具的一个伟大的事情是,它们中的许多不仅适用于 kNN 算法,而且也适用于许多其他的机器学习算法。要继续您的机器学习之旅,请查看机器学习学习路径,并随时留下评论来分享您可能有的任何问题或评论。**********
在 Python 中使用 len()函数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 的 len()函数
在许多情况下,您需要找到存储在数据结构中的项目数量。Python 的内置函数len()是帮助你完成这项任务的工具。
有些情况下使用len()很简单。然而,在其他情况下,您需要更详细地了解这个函数的工作原理,以及如何将它应用于不同的数据类型。
在本教程中,您将学习如何:
- 使用
len()找到内置数据类型的长度 - 将
len()与第三方数据类型一起使用 - 用用户自定义类为
len()提供支持
到本文结束时,您将知道何时使用len() Python 函数以及如何有效地使用它。您将知道哪些内置数据类型是len()的有效参数,哪些不能使用。你还将了解如何使用第三方类型的len(),比如 NumPy 中的ndarray和 pandas 中的DataFrame,以及你自己的类。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python 的len() 入门
len() 函数是 Python 的内置函数之一。它返回一个对象的长度。例如,它可以返回列表中的项目数。您可以将函数用于许多不同的数据类型。然而,并不是所有的数据类型都是len()的有效参数。
您可以从查看此功能的帮助开始:
>>> help(len) Help on built-in function len in module builtins: len(obj, /) Return the number of items in a container.该函数将一个对象作为参数,并返回该对象的长度。
len()的文档更进一步:返回一个对象的长度(项目数)。参数可以是序列(如字符串、字节、元组、列表或范围)或集合(如字典、集合或冻结集)。(来源)
当你用
len()使用内置数据类型和很多第三方类型时,函数不需要迭代数据结构。容器对象的长度存储为对象的属性。每次在数据结构中添加或删除项目时,都会修改该属性的值,并且len()会返回长度属性的值。这确保了len()的高效运作。在接下来的部分中,您将了解如何对序列和集合使用
len()。您还将了解一些不能用作len()Python 函数参数的数据类型。使用内置序列的
len()序列是一个包含有序项目的容器。列表、元组和字符串是 Python 中三个基本的内置序列。您可以通过调用
len()找到序列的长度:
>>> greeting = "Good Day!"
>>> len(greeting)
9
>>> office_days = ["Tuesday", "Thursday", "Friday"]
>>> len(office_days)
3
>>> london_coordinates = (51.50722, -0.1275)
>>> len(london_coordinates)
2
当找到字符串greeting、列表office_days和元组london_coordinates的长度时,可以用同样的方式使用len()。所有这三种数据类型都是len()的有效参数。
函数len()总是返回一个整数,因为它在计算你传递给它的对象中的项数。如果参数是空序列,函数返回0:
>>> len("") 0 >>> len([]) 0 >>> len(()) 0在上面的例子中,您找到了一个空字符串、一个空列表和一个空元组的长度。该函数在每种情况下都返回
0。
range对象也是可以使用range()创建的序列。一个range对象并不存储所有的值,而是在需要的时候生成它们。然而,你仍然可以使用len()找到一个range物体的长度:
>>> len(range(1, 20, 2))
10
这个数字范围包括从1到19的整数,增量为2。range对象的长度可由起始值、停止值和步长值决定。
在本节中,您已经将len() Python 函数用于字符串、列表、元组和range对象。但是,您也可以将该函数与任何其他内置序列一起使用。
将len()与内置集合一起使用
在某些时候,您可能需要在一个列表或另一个序列中找到唯一项的数量。您可以使用设置和len()来实现这一点:
>>> import random >>> numbers = [random.randint(1, 20) for _ in range(20)] >>> numbers [3, 8, 19, 1, 17, 14, 6, 19, 14, 7, 6, 1, 17, 10, 8, 14, 17, 10, 2, 5] >>> unique_numbers = set(numbers) {1, 2, 3, 5, 6, 7, 8, 10, 14, 17, 19} >>> len(unique_numbers) 11你使用一个列表理解生成列表
numbers,它包含二十个范围在1和20之间的随机数。每次代码运行时,输出都是不同的,因为你生成的是随机数。在这个特定的运行中,在 20 个随机生成的数字列表中有 11 个唯一的数字。另一个经常使用的内置数据类型是字典。在字典中,每个条目由一个键值对组成。当使用字典作为
len()的参数时,该函数返回字典中的项目数:
>>> len({"James": 10, "Mary": 12, "Robert": 11})
3
>>> len({})
0
第一个示例的输出显示了这个字典中有三个键值对。与序列的情况一样,当参数是空字典或空集时,len()将返回0。这导致空字典和空集是虚假的。
探索其他内置数据类型
不能使用所有内置数据类型作为len()的参数。对于不存储多项的数据类型,长度的概念是不相关的。数字和布尔类型就是这种情况:
>>> len(5) Traceback (most recent call last): ... TypeError: object of type 'int' has no len() >>> len(5.5) Traceback (most recent call last): ... TypeError: object of type 'float' has no len() >>> len(True) Traceback (most recent call last): ... TypeError: object of type 'bool' has no len() >>> len(5 + 2j) Traceback (most recent call last): ... TypeError: object of type 'complex' has no len()整数、、布尔、和复杂类型是不能与
len()一起使用的内置数据类型的例子。当参数是没有长度的数据类型的对象时,该函数会引发一个TypeError。您还可以探索是否有可能使用迭代器和生成器作为
len()的参数:
>>> import random
>>> numbers = [random.randint(1, 20) for _ in range(20)]
>>> len(numbers)
20
>>> numbers_iterator = iter(numbers)
>>> len(numbers_iterator)
Traceback (most recent call last):
...
TypeError: object of type 'list_iterator' has no len()
>>> numbers_generator = (random.randint(1, 20) for _ in range(20))
>>> len(numbers_generator)
Traceback (most recent call last):
...
TypeError: object of type 'generator' has no len()
您已经看到列表有长度,这意味着您可以在len()中将它用作参数。使用内置函数 iter() 从列表中创建一个迭代器。在迭代器中,每一项都是在需要的时候获取的,比如使用函数next()或者在循环中。但是,你不能在len()中使用迭代器。
当您试图使用迭代器作为len()的参数时,您会得到一个TypeError。当迭代器在需要时获取每一项时,测量其长度的唯一方法是用尽迭代器。迭代器也可以是无限的,比如 itertools.cycle() 返回的迭代器,因此其长度无法定义。
出于同样的原因,你不能将发电机与len()一起使用。这些物体的长度不用完是测不出来的。
通过一些示例进一步探索len()
在本节中,您将了解一些常见的len()用例。这些示例将帮助您更好地理解何时使用该函数以及如何有效地使用它。在一些例子中,您还会看到len()是一种可能的解决方案,但是可能有更多的 Pythonic 方式来实现相同的输出。
验证用户输入的长度
len()的一个常见用例是验证用户输入的序列长度:
# username.py
username = input("Choose a username: [4-10 characters] ")
if 4 <= len(username) <= 10:
print(f"Thank you. The username {username} is valid")
else:
print("The username must be between 4 and 10 characters long")
在这个例子中,您使用一个if语句来检查由len()返回的整数是否大于或等于4并且小于或等于10。您可以运行这个脚本,您将得到类似于下面的输出:
$ python username.py
Choose a username: [4-10 characters] stephen_g
Thank you. The username stephen_g is valid
在这种情况下,用户名有九个字符长,因此if语句中的条件计算结果为True。您可以再次运行脚本并输入无效的用户名:
$ python username.py
Choose a username: [4-10 characters] sg
The username must be between 4 and 10 characters long
在这种情况下,len(username)返回2,并且if语句中的条件评估为False。
根据物体的长度结束循环
如果您需要检查一个可变序列(比如一个列表)的长度何时达到一个特定的数字,您将使用len()。在下面的示例中,您要求用户输入三个用户名选项,并将它们存储在一个列表中:
# username.py
usernames = []
print("Enter three options for your username")
while len(usernames) < 3:
username = input("Choose a username: [4-10 characters] ")
if 4 <= len(username) <= 10:
print(f"Thank you. The username {username} is valid")
usernames.append(username)
else:
print("The username must be between 4 and 10 characters long")
print(usernames)
您现在在 while 语句中使用来自len()的结果。如果用户输入了无效的用户名,您不会保留输入。当用户输入一个有效的字符串时,您将它添加到列表usernames中。循环重复,直到列表中有三个项目。
您甚至可以使用len()来检查序列何时为空:
>>> colors = ["red", "green", "blue", "yellow", "pink"] >>> while len(colors) > 0: ... print(f"The next color is {colors.pop(0)}") ... The next color is red The next color is green The next color is blue The next color is yellow The next color is pink您使用 list 方法
.pop()在每次迭代中从列表中移除第一个项目,直到列表为空。如果你在大的列表上使用这个方法,你应该从列表的末尾删除项目,因为这样更有效。您还可以使用来自collections内置模块的队列数据类型,这允许您有效地从左侧弹出。通过使用序列的真值,有一种更 Pythonic 化的方法来实现相同的输出:
>>> colors = ["red", "green", "blue", "yellow", "pink"]
>>> while colors:
... print(f"The next color is {colors.pop(0)}")
...
The next color is red
The next color is green
The next color is blue
The next color is yellow
The next color is pink
空列表是虚假的。这意味着while语句将空列表解释为False。非空列表是真实的,while语句将其视为True。由len()返回的值决定了一个序列的真实性。当len()返回任何非零整数时,序列为真,当len()返回0时,序列为假。
查找序列最后一项的索引
假设您想要生成一个范围为1到10的随机数序列,并且您想要不断地向该序列添加数字,直到所有数字的总和超过21。下面的代码创建一个空列表,并使用一个while循环来填充列表:
>>> import random >>> numbers = [] >>> while sum(numbers) <= 21: ... numbers.append(random.randint(1, 10)) >>> numbers [3, 10, 4, 7] >>> numbers[len(numbers) - 1] 7 >>> numbers[-1] # A more Pythonic way to retrieve the last item 7 >>> numbers.pop(len(numbers) - 1) # You can use numbers.pop(-1) 7 >>> numbers [3, 10, 4]您将随机数添加到列表中,直到总和超过
21。当你生成随机数时,你得到的输出会有所不同。要显示列表中的最后一个数字,可以使用len(numbers)并从中减去1,因为列表的第一个索引是0。Python 中的索引允许您使用索引-1来获取列表中的最后一项。所以,虽然在这种情况下可以用len(),但是不需要。您想要删除列表中的最后一个数字,以便列表中所有数字的总和不超过
21。再次使用len()来计算列表中最后一项的索引,并将其用作 list 方法.pop()的参数。即使在这种情况下,您也可以使用-1作为.pop()的参数,从列表中删除最后一项并将其返回。将列表分成两半
如果需要将一个序列分成两半,就需要使用代表序列中点的索引。可以用
len()来求这个值。在以下示例中,您将创建一个随机数列表,然后将其拆分为两个较小的列表:
>>> import random
>>> numbers = [random.randint(1, 10) for _ in range(10)]
>>> numbers
[9, 1, 1, 2, 8, 10, 8, 6, 8, 5]
>>> first_half = numbers[: len(numbers) // 2]
>>> second_half = numbers[len(numbers) // 2 :]
>>> first_half
[9, 1, 1, 2, 8]
>>> second_half
[10, 8, 6, 8, 5]
在定义first_half的赋值语句中,使用切片来表示从numbers开始到中点的项目。通过分解切片表达式中使用的步骤,可以计算出切片表示的内容:
- 首先,
len(numbers)返回整数10。 - 接下来,
10 // 2使用整数除法运算符返回整数5。 - 最后,
0:5是表示前五个项目的切片,其索引为0到4。注意,端点被排除在外。
在下一个赋值中,您定义了second_half,在切片中使用了相同的表达式。然而,在这种情况下,整数5代表范围的开始。切片现在是5:,表示从索引5到列表末尾的项目。
如果您的原始列表包含奇数个项目,那么它的一半长度将不再是一个整数。当你使用整数除法时,你得到该数的底数。列表first_half现在将比second_half少包含一个项目。
你可以通过创建一个包含 11 个数字而不是 10 个数字的初始列表来尝试一下。得到的列表将不再是两半,而是代表了分割奇数序列的最接近的选择。
通过第三方库使用len()功能
您还可以将 Python 的len()与第三方库中的几个自定义数据类型一起使用。在本教程的最后一部分,您将了解到len()的行为如何依赖于类定义。在这一节中,您将看到对两个流行的第三方库中的数据类型使用len()的例子。
NumPy 的ndarray
NumPy 模块是 Python 中所有定量编程应用的基石。该模块介绍了 numpy.ndarray 的数据类型。这种数据类型以及 NumPy 中的函数非常适合于数值计算,并且是其他模块中数据类型的构建块。
在开始使用 NumPy 之前,您需要安装这个库。您可以使用 Python 的标准包管理器 pip ,并在控制台中运行以下命令:
$ python -m pip install numpy
您已经安装了 NumPy,现在您可以从一个列表中创建一个 NumPy 数组,并在数组上使用len():
>>> import numpy as np >>> numbers = np.array([4, 7, 9, 23, 10, 6]) >>> type(numbers) <class 'numpy.ndarray'> >>> len(numbers) 6NumPy 函数
np.array()从您作为参数传递的列表中创建一个类型为numpy.ndarray的对象。但是,NumPy 数组可以有多个维度。您可以通过将列表转换为数组来创建二维数组:
>>> import numpy as np
>>> numbers = [
[11, 1, 10, 10, 15],
[14, 9, 16, 4, 4],
]
>>> numbers_array = np.array(numbers)
>>> numbers_array
array([[11, 1, 10, 10, 15],
[14, 9, 16, 4, 4]])
>>> len(numbers_array)
2
>>> numbers_array.shape
(2, 5)
>>> len(numbers_array.shape)
2
>>> numbers_array.ndim
2
列表numbers由两个列表组成,每个列表包含五个整数。当您使用此列表创建 NumPy 数组时,结果是一个两行五列的数组。当您将这个二维数组作为参数在len()中传递时,该函数返回数组中的行数。
要获得两个维度的大小,可以使用属性.shape,这是一个显示行数和列数的元组。您可以通过使用.shape和len()或者使用属性.ndim来获得 NumPy 数组的维数。
一般来说,当你有一个任意维数的数组时,len()返回第一维的大小:
>>> import numpy as np >>> array_3d = np.random.randint(1, 20, [2, 3, 4]) >>> array_3d array([[[14, 9, 15, 14], [17, 11, 10, 5], [18, 1, 3, 12]], [[ 1, 5, 6, 10], [ 6, 3, 1, 12], [ 1, 4, 4, 17]]]) >>> array_3d.shape (2, 3, 4) >>> len(array_3d) 2在本例中,您创建了一个形状为
(2, 3, 4)的三维数组,其中每个元素都是介于1和20之间的随机整数。这次您使用函数np.random.randint()来创建一个数组。函数len()返回2,是第一维度的大小。查看 NumPy 教程:Python 中数据科学的第一步,了解更多关于使用 NumPy 数组的信息。
熊猫的
DataFrame熊猫库中的
DataFrame类型是另一种在许多应用程序中广泛使用的数据类型。在使用 pandas 之前,您需要在控制台中使用以下命令安装它:
$ python -m pip install pandas您已经安装了 pandas 包,现在您可以从字典创建一个数据框架:
>>> import pandas as pd
>>> marks = {
"Robert": [60, 75, 90],
"Mary": [78, 55, 87],
"Kate": [47, 96, 85],
"John": [68, 88, 69],
}
>>> marks_df = pd.DataFrame(marks, index=["Physics", "Math", "English"])
>>> marks_df
Robert Mary Kate John
Physics 60 78 47 68
Math 75 55 96 88
English 90 87 85 69
>>> len(marks_df)
3
>>> marks_df.shape
(3, 4)
字典的关键字是代表班级中学生姓名的字符串。每个键的值是一个列表,其中包含三个主题的标记。当您从这个字典创建一个数据框架时,您使用一个包含主题名称的列表来定义索引。
数据帧有三行四列。函数len()返回数据帧中的行数。DataFrame类型也有一个.shape属性,可以用来显示 DataFrame 的第一维代表行数。
您已经看到了len()如何处理许多内置数据类型,以及来自第三方模块的一些数据类型。在下一节中,您将学习如何定义任何类,以便它可以用作len() Python 函数的参数。
您可以在熊猫数据框架:让数据工作变得愉快中进一步探索熊猫模块。
在用户定义的类上使用len()
定义类时,可以定义的一个特殊方法是 .__len__() 。这些特殊方法被称为 dunder 方法,因为它们在方法名的开头和结尾都有双下划线。Python 的内置len()函数调用其参数的.__len__()方法。
在上一节中,您已经看到了当参数是 pandas DataFrame对象时len()的行为。这个行为是由DataFrame类的.__len__()方法决定的,你可以在pandas.core.frame中模块的源代码中看到:
class DataFrame(NDFrame, OpsMixin):
# ...
def __len__(self) -> int:
"""
Returns length of info axis, but here we use the index.
"""
return len(self.index)
该方法使用len()返回 DataFrame 的.index属性的长度。这个 dunder 方法将数据帧的长度定义为等于数据帧中的行数,如.index所示。
您可以通过下面的玩具示例进一步探索.__len__() dunder 方法。您将定义一个名为YString的类。这种数据类型基于内置的字符串类,但是YString类型的对象赋予字母 Y 比其他所有字母更重要的地位:
# ystring.py
class YString(str):
def __init__(self, text):
super().__init__()
def __str__(self):
"""Display string as lowercase except for Ys that are uppercase"""
return self.lower().replace("y", "Y")
def __len__(self):
"""Returns the number of Ys in the string"""
return self.lower().count("y")
YString的 .__init__() 方法使用父str类的.__init__()方法初始化对象。你可以使用 super() 功能来实现。 .__str__() 方法定义了对象的显示方式。函数str()、print()和format()都调用这个方法。对于这个类,您将对象表示为一个全小写的字符串,字母 Y 除外,它显示为大写。
对于这个 toy 类,您将对象的长度定义为字母 Y 在字符串中出现的次数。因此,.__len__()方法返回字母 y 的计数。
你可以创建一个类为YString的对象,并找出它的长度。上例中使用的模块名是ystring.py:
>>> from ystring import YString >>> message = YString("Real Python? Yes! Start reading today to learn Python") >>> print(message) real pYthon? Yes! start reading todaY to learn pYthon >>> len(message) # Returns number of Ys in message 4您从类型为
str的对象创建一个类型为YString的对象,并使用print()显示该对象的表示。然后使用对象message作为len()的参数。这调用了类的.__len__()方法,结果是字母 Y 在message中出现的次数。在这种情况下,字母 Y 出现了四次。
YString类不是一个非常有用的类,但是它有助于说明如何定制len()的行为来满足您的需求。.__len__()方法必须返回一个非负整数。否则,它会引发错误。另一个特殊的方法是
.__bool__()方法,它决定了如何将一个对象转换成布尔值。通常不为序列和集合定义.__bool__()dunder 方法。在这些情况下,.__len__()方法决定了物体的真实性:
>>> from ystring import YString
>>> first_test = "tomorrow"
>>> second_test = "today"
>>> bool(first_test)
True
>>> bool(YString(first_test))
False
>>> bool(second_test)
True
>>> bool(YString(second_test))
True
变量first_string中没有 Y。如来自bool()的输出所示,字符串是真实的,因为它不是空的。然而,当您从这个字符串创建一个类型为YString的对象时,这个新对象是 falsy,因为字符串中没有 Y 字母。因此,len()返回0。相反,变量second_string包含字母 Y,因此字符串和类型YString的对象都是真的。
你可以在 Python 3 的面向对象编程(OOP)中阅读更多关于使用面向对象编程和定义类的内容。
结论
您已经探索了如何使用len()来确定序列、集合和其他一次包含几个项目的数据类型中的项目数量,比如 NumPy 数组和 pandas 数据帧。
Python 函数是许多程序中的关键工具。它的一些用法很简单,但是正如你在本教程中看到的,这个函数有比它最基本的用例更多的内容。知道什么时候可以使用这个函数,以及如何有效地使用它,将有助于你写出更整洁的代码。
在本教程中,您已经学会了如何:
- 使用
len()找到内置数据类型的长度 - 将
len()与第三方数据类型一起使用 - 用用户自定义类为
len()提供支持
您现在已经为理解len()函数打下了良好的基础。了解更多关于len()的知识有助于您更好地理解数据类型之间的差异。您已经准备好在您的算法中使用len(),并通过用.__len__()方法增强它们来改进您的一些类定义的功能。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python 的 len()函数******
动手线性编程:用 Python 优化
线性规划 是在 数学规划 中使用的一套技术,有时称为数学优化,以解决线性方程组和不等式,同时最大化或最小化一些线性函数。它在科学计算、经济、技术科学、制造、运输、军事、管理、能源等领域都很重要。
Python 生态系统为线性编程提供了几个全面而强大的工具。您可以在简单和复杂的工具之间以及免费和商业工具之间进行选择。这完全取决于你的需求。
在本教程中,您将学习:
- 什么是线性规划以及为什么它很重要
- 哪些 Python 工具适合线性编程
- 如何用 Python 构建线性规划模型
- 如何用 Python 解决一个线性规划问题
你将首先学习线性编程的基础。然后,您将探索如何用 Python 实现线性编程技术。最后,您将查看一些资源和库,以帮助您进一步进行线性编程。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
线性编程解释
在本节中,您将学习线性编程的基础知识和一个相关的学科,混合整数线性编程。在下一节的中,您将看到一些实用的线性编程示例。稍后,您将使用 Python 解决线性规划和混合整数线性规划问题。
什么是线性规划?
假设你有一个线性方程组和不等式组。这种系统通常有许多可能的解决方案。线性规划是一套数学和计算工具,让你找到一个特定的解决方案,这个系统对应的最大值或最小值的一些其他线性函数。
什么是混合整数线性规划?
混合整数线性规划是线性规划的扩展。它处理至少一个变量采用离散整数而不是连续值的问题。尽管混合整数问题初看起来类似于连续变量问题,但它们在灵活性和精确性方面具有显著优势。
整数变量对于正确表示用整数自然表达的数量很重要,比如生产的飞机数量或服务的客户数量。
一种特别重要的整数变量是二进制变量。它只能接受值零或一,并且在做出是或否的决定时很有用,例如是否应该建立一个工厂或是否应该打开或关闭一台机器。您还可以使用它们来模拟逻辑约束。
为什么线性规划很重要?
线性规划是一种基本的优化技术,在科学和数学密集型领域已经使用了几十年。它精确、相对快速,适用于一系列实际应用。
混合整数线性规划允许您克服线性规划的许多限制。可以用分段线性函数近似非线性函数,使用半连续变量,模型逻辑约束等等。这是一个计算密集型工具,但计算机硬件和软件的进步使它每天都更适用。
通常,当人们试图制定和解决一个优化问题时,第一个问题是他们是否可以应用线性规划或混合整数线性规划。
线性规划和混合整数线性规划的一些用例在以下文章中进行了说明:
随着时间的推移,随着计算机能力的提高、算法的改进以及更用户友好的软件解决方案的出现,线性规划,尤其是混合整数线性规划的重要性不断增加。
用 Python 进行线性编程
求解线性规划问题的基本方法称为 单纯形法 ,有几种变体。另一种流行的方法是 内点法 。
混合整数线性规划问题用更复杂、计算量更大的方法来解决,如 分支定界法 ,它在幕后使用线性规划。这种方法的一些变体是 分支切割法 ,它涉及到切割平面的使用,以及 分支定价法 。
对于线性规划和混合整数线性规划,有几个合适的和众所周知的 Python 工具。其中一些是开源的,而另一些是专有的。你需要一个免费的还是付费的工具取决于你的问题的大小和复杂程度以及对速度和灵活性的需求。
值得一提的是,几乎所有广泛使用的线性编程和混合整数线性编程库都是 Fortran 或 C 或 C++原生的,并且是用它们编写的。这是因为线性规划需要对(通常很大的)矩阵进行计算密集型的工作。这样的库被称为解算器。Python 工具只是解算器的包装器。
Python 适合围绕本地库构建包装器,因为它与 C/C++配合得很好。对于本教程,您不需要任何 C/C++(或 Fortran ),但是如果您想了解关于这个很酷的特性的更多信息,请查看以下资源:
基本上,当您定义和求解一个模型时,您使用 Python 函数或方法来调用一个底层库,该库执行实际的优化工作并将解返回给您的 Python 对象。
几个免费的 Python 库专门用于与线性或混合整数线性编程解算器进行交互:
在本教程中,你将使用 SciPy 和 PuLP 来定义和解决线性规划问题。
线性规划示例
在本节中,您将看到两个线性规划问题的例子:
- 一个说明什么是线性规划的小问题
- 一个与资源分配相关的实际问题,它在现实世界中说明了线性规划的概念
在下一节中,您将使用 Python 来解决这两个问题。
小线性规划问题
考虑下面的线性规划问题:
你需要找到 x 和 y 使得红色、蓝色和黄色不等式,以及不等式 x ≥ 0 和 y ≥ 0 得到满足。同时,你的解必须对应于 z 的最大可能值。
你需要找到的独立变量——在这种情况下是 x 和y——被称为决策变量。要被最大化或最小化的决策变量的函数——在本例中为z——被称为目标函数、成本函数,或者仅仅是目标。你需要满足的不等式被称为不等式约束。您也可以在称为等式约束的约束中使用等式。
你可以这样想象这个问题:
红线代表函数 2 x + y = 20,上面的红色区域表示红色不等式不满足的地方。同样,蓝线是函数 4 x + 5 y = 10,蓝色区域是被禁止的,因为它违反了蓝色不等式。黄线是x+2y= 2,其下方的黄色区域是黄色不等式无效的地方。
如果忽略红色、蓝色和黄色区域,则只剩下灰色区域。灰色区域的每个点都满足所有约束,并且是问题的潜在解决方案。这个区域叫做可行域,它的点就是可行解。在这种情况下,有无数可行的解决方案。
你要最大化 z 。最大 z 对应的可行解就是最优解。如果你试图最小化目标函数,那么最优解将对应于它的可行最小值。
注意 z 是线性的。你可以把它想象成三维空间中的一个平面。这就是为什么最优解必须在可行域的一个顶点或角上。在这种情况下,最佳解决方案是红线和蓝线的交叉点,稍后你会看到。
有时可行区域的整个边缘,或者甚至整个区域,可以对应于相同的值 z 。在这种情况下,你有许多最优解。
现在,您可以用绿色显示的附加等式约束来扩展问题了:
用绿色书写的等式——x+5y= 15 是新的。这是一个平等约束。您可以通过在之前的图像中添加一条相应的绿线来将其可视化:
现在的解必须满足绿色等式,所以可行域不再是整个灰色区域。它是绿线从与蓝线的交点到与红线的交点穿过灰色区域的部分。后一点就是解决办法。
如果您插入一个要求,即所有的值 x 都必须是整数,那么您将得到一个混合整数线性规划问题,并且可行解的集合将再次改变:
你不再有绿线,只有沿线的点,在这些点上 x 的值是一个整数。可行的解决方案是灰色背景上的绿点,这种情况下的最佳方案最接近红线。
这三个例子说明了可行线性规划问题,因为它们有有界可行域和有限解。
不可行线性规划问题
如果线性规划问题没有解,那么它就是不可行的。这通常发生在没有解决方案能同时满足所有约束的时候。
例如,考虑如果添加约束x+y≤-1 会发生什么。那么至少一个决策变量( x 或 y )必须是负的。这与给定的约束 x ≥ 0 和 y ≥ 0 相冲突。这样的系统没有可行解,所以叫不可行。
另一个示例是添加平行于绿线的第二个等式约束。这两条线没有共同点,所以不会有同时满足两个约束的解决方案。
无界线性规划问题
如果一个线性规划问题的可行域无界且解不有限,那么这个问题就是无界的。这意味着至少有一个变量不受约束,可以达到正无穷大或负无穷大,使目标也是无穷大。
例如,假设你把上面的初始问题去掉红色和黄色约束。从一个问题中去掉约束叫做放松问题。在这种情况下, x 和 y 不会被限制在正方向。你可以将它们增加到正无穷大,产生一个无限大的 z 值。
资源分配问题
在前面的章节中,您看到了一个抽象的线性编程问题,它与任何现实世界的应用程序都没有关系。在这一小节中,你会发现一个更具体、更实用的优化问题,它与制造业中的资源分配有关。
假设一家工厂生产四种不同的产品,第一种产品的日产量是 x ₁,第二种产品的日产量是 x ₂,以此类推。目标是确定每种产品的利润最大化日产量,同时牢记以下条件:
-
第一个、第二个、第三个和第四个产品的单位产品利润分别是 20 美元、12 美元、40 美元和 25 美元。
-
由于人力的限制,每天生产的总数量不能超过五十台。
-
对于每单位的第一种产品,消耗三单位的原材料 A。第二种产品的每单位需要两个单位的原料 A 和一个单位的原料 b。第三种产品的每单位需要一个单位的 A 和两个单位的 b。最后,第四种产品的每单位需要三个单位的 b。
-
由于运输和储存的限制,工厂每天可以消耗一百单位的原材料 A 和九十单位的 B。
数学模型可以这样定义:
目标函数(利润)在条件 1 中定义。人力限制来自条件 2。原材料 A 和 B 的约束条件可以通过对每种产品的原材料需求求和从条件 3 和 4 中推导出来。
最后,产品数量不能为负,因此所有决策变量必须大于或等于零。
与前面的例子不同,您不能方便地将这个例子可视化,因为它有四个决策变量。然而,不管问题的维度如何,原则都是一样的。
线性编程 Python 实现
在本教程中,您将使用两个 Python 包来解决上述线性编程问题:
SciPy 的设置非常简单。一旦你安装了它,你就拥有了你所需要的一切。它的子包 scipy.optimize 既可以用于线性优化,也可以用于非线性优化。
纸浆允许你选择解决方案,并以更自然的方式阐述问题。PuLP 使用的默认解算器是硬币或分支和切割解算器(CBC) 。它连接到用于线性松弛的硬币或线性规划解算器(CLP) 和用于切割生成的硬币或切割生成器库(CGL) 。
另一个伟大的开源求解器是 GNU 线性编程工具包(GLPK) 。一些众所周知的非常强大的商业和专有解决方案是 Gurobi 、 CPLEX 和 XPRESS 。
除了在定义问题时提供灵活性和运行各种解算器的能力之外,与 Pyomo 或 CVXOPT 等需要更多时间和精力来掌握的替代品相比,PuLP 使用起来没有那么复杂。
安装 SciPy 和 PuLP
按照这个教程,你需要安装 SciPy 和纸浆。下面的例子使用了 1.4.1 版的 SciPy 和 2.1 版的 PuLP。
您可以使用 pip 安装两者:
$ python -m pip install -U "scipy==1.4.*" "pulp==2.1"
您可能需要运行pulptest或sudo pulptest来启用纸浆的默认解算器,尤其是如果您使用的是 Linux 或 Mac:
$ pulptest
或者,您可以下载、安装和使用 GLPK。它是免费的开源软件,可以在 Windows、MacOS 和 Linux 上运行。你会看到如何使用 GLPK(除了 CBC)与纸浆在本教程稍后。
在 Windows 上,你可以下载档案文件并运行安装文件。
在 MacOS 上,你可以使用自制软件:
$ brew install glpk
在 Debian 和 Ubuntu 上,使用apt安装glpk和glpk-utils:
$ sudo apt install glpk glpk-utils
在 Fedora 上,使用dnf和glpk-utils:
$ sudo dnf install glpk-utils
你可能还会发现 conda 对安装 GLPK 很有用:
$ conda install -c conda-forge glpk
完成安装后,您可以检查 GLPK 的版本:
$ glpsol --version
更多信息请参见 GLPK 关于安装 Windows 可执行文件和 Linux 软件包的教程。
使用 SciPy
在本节中,您将学习如何使用 SciPy 优化和求根库进行线性编程。
要用 SciPy 定义和解决优化问题,需要导入 scipy.optimize.linprog() :
>>> from scipy.optimize import linprog既然已经导入了
linprog(),就可以开始优化了。示例 1
让我们先从上面解决线性规划问题:
linprog()仅解决最小化(非最大化)问题,不允许大于或等于符号(≥)的不等式约束。要解决这些问题,您需要在开始优化之前修改您的问题:
- 不用最大化 z = x + 2 y,你可以最小化它的负值(-z=x-2y)。
- 您可以将黄色不等式乘以 1,得到相反的小于或等于号(≤)。
引入这些变化后,您会得到一个新的系统:
这个系统相当于原来的,将有相同的解决方案。应用这些更改的唯一原因是为了克服与问题表述相关的 SciPy 的局限性。
下一步是定义输入值:
>>> obj = [-1, -2]
>>> # ─┬ ─┬
>>> # │ └┤ Coefficient for y
>>> # └────┤ Coefficient for x
>>> lhs_ineq = [[ 2, 1], # Red constraint left side
... [-4, 5], # Blue constraint left side
... [ 1, -2]] # Yellow constraint left side
>>> rhs_ineq = [20, # Red constraint right side
... 10, # Blue constraint right side
... 2] # Yellow constraint right side
>>> lhs_eq = [[-1, 5]] # Green constraint left side
>>> rhs_eq = [15] # Green constraint right side
您将来自上述系统的值放入适当的列表、元组或 NumPy 数组:
obj保存着目标函数的系数。lhs_ineq保存着来自不等式(红、蓝、黄)约束的左侧系数。rhs_ineq保存着来自不等式(红、蓝、黄)约束的右边系数。lhs_eq保存着等式(绿色)约束的左侧系数。rhs_eq持有等式(绿色)约束的右侧系数。
注意:拜托,注意行列顺序!
约束左侧和右侧的行顺序必须相同。每行代表一个约束。
目标函数和约束左侧系数的顺序必须匹配。每一列对应一个决策变量。
下一步是按照与系数相同的顺序定义每个变量的界限。在这种情况下,它们都在零和正无穷大之间:
>>> bnd = [(0, float("inf")), # Bounds of x ... (0, float("inf"))] # Bounds of y这个语句是多余的,因为默认情况下
linprog()采用这些边界(零到正无穷大)。注:代替
float("inf"),可以用math.inf,numpy.inf,或者scipy.inf。最后,是时候优化解决你感兴趣的问题了。你可以用
linprog()来做:
>>> opt = linprog(c=obj, A_ub=lhs_ineq, b_ub=rhs_ineq,
... A_eq=lhs_eq, b_eq=rhs_eq, bounds=bnd,
... method="revised simplex")
>>> opt
con: array([0.])
fun: -16.818181818181817
message: 'Optimization terminated successfully.'
nit: 3
slack: array([ 0\. , 18.18181818, 3.36363636])
status: 0
success: True
x: array([7.72727273, 4.54545455])
参数c指的是目标函数的系数。A_ub和b_ub分别与不等式约束左侧和右侧的系数相关。同样,A_eq和b_eq指的是等式约束。您可以使用bounds来提供决策变量的下限和上限。
您可以使用参数method来定义您想要使用的线性编程方法。有三个选项:
method="interior-point"点出内点法。该选项是默认设置的。method="revised simplex"选用修正的两相单纯形法。method="simplex"选用遗留的两相单纯形法。
linprog()返回具有以下属性的数据结构:
-
.con是等式约束的残差。 -
.fun是目标函数值处于最优(如果找到的话)。 -
.message是解决的状态。 -
.nit是完成计算所需的迭代次数。 -
.slack是松弛变量的值,或者左右两侧约束的值之差。 -
.status是一个介于0和4之间的整数,表示解决方案的状态,如0表示找到最佳解决方案。 -
.success是一个布尔,表示是否已经找到最优解。 -
.x是保存决策变量最优值的 NumPy 数组。
您可以分别访问这些值:
>>> opt.fun -16.818181818181817 >>> opt.success True >>> opt.x array([7.72727273, 4.54545455])这就是你如何得到优化的结果。您也可以用图形显示它们:
如前所述,线性规划问题的最优解位于可行区域的顶点。在这种情况下,可行区域就是蓝线和红线之间的那部分绿线。最佳解决方案是代表绿线和红线交点的绿色方块。
如果您想排除等式(绿色)约束,只需从
linprog()调用中删除参数A_eq和b_eq:
>>> opt = linprog(c=obj, A_ub=lhs_ineq, b_ub=rhs_ineq, bounds=bnd,
... method="revised simplex")
>>> opt
con: array([], dtype=float64)
fun: -20.714285714285715
message: 'Optimization terminated successfully.'
nit: 2
slack: array([0\. , 0\. , 9.85714286])
status: 0
success: True
x: array([6.42857143, 7.14285714]))
解决方案与前一种情况不同。你可以在图表上看到:
在本例中,最佳解决方案是红色和蓝色约束相交的可行(灰色)区域的紫色顶点。其他顶点,如黄色顶点,具有更高的目标函数值。
示例 2
您可以使用 SciPy 来解决前面的部分中提到的资源分配问题:
和前面的例子一样,您需要从上面的问题中提取必要的向量和矩阵,将它们作为参数传递给.linprog(),并得到结果:
>>> obj = [-20, -12, -40, -25] >>> lhs_ineq = [[1, 1, 1, 1], # Manpower ... [3, 2, 1, 0], # Material A ... [0, 1, 2, 3]] # Material B >>> rhs_ineq = [ 50, # Manpower ... 100, # Material A ... 90] # Material B >>> opt = linprog(c=obj, A_ub=lhs_ineq, b_ub=rhs_ineq, ... method="revised simplex") >>> opt con: array([], dtype=float64) fun: -1900.0 message: 'Optimization terminated successfully.' nit: 2 slack: array([ 0., 40., 0.]) status: 0 success: True x: array([ 5., 0., 45., 0.])结果告诉你最大利润是
1900,对应 x ₁ = 5、 x ₃ = 45。在给定的条件下生产第二种和第四种产品是无利可图的。在这里你可以得出几个有趣的结论:
第三种产品带来的单位利润最大,所以工厂会生产最多。
第一个松弛是
0,表示人力(第一个)约束左右两边的值相同。工厂每天生产50件,这是它的全部产能。第二个松弛是
40,因为工厂消耗了潜在100单位中的 60 单位原材料 A(第一个产品 15 单位,第三个产品 45 单位)。第三个松弛期是
0,这意味着工厂消耗了原材料 b 的所有90单位。这一总量是为第三个产品消耗的。这就是为什么工厂根本不能生产第二或第四种产品,也不能生产超过45单位的第三种产品。它缺少原材料 b。
opt.status为0,opt.success为True,表示用最优可行解成功解决了优化问题。SciPy 的线性编程能力主要对较小的问题有用。对于更大更复杂的问题,您可能会发现其他库更适合,原因如下:
SciPy 不能运行各种外部解算器。
SciPy 不能处理整数决策变量。
SciPy 没有提供促进模型构建的类或函数。您必须定义数组和矩阵,对于大型问题来说,这可能是一项繁琐且容易出错的任务。
SciPy 不允许你直接定义最大化问题。你必须把它们转换成最小化问题。
SciPy 不允许您直接使用大于或等于符号来定义约束。您必须改用小于或等于。
幸运的是,Python 生态系统为线性编程提供了几种替代解决方案,对于更大的问题非常有用。其中之一是纸浆,您将在下一节中看到它的作用。
使用纸浆
PuLP 有一个比 SciPy 更方便的线性编程 API。你不必在数学上修改你的问题或者使用向量和矩阵。一切都更干净,更不容易出错。
像往常一样,首先导入您需要的内容:
from pulp import LpMaximize, LpProblem, LpStatus, lpSum, LpVariable现在你有纸浆进口,你可以解决你的问题。
示例 1
你现在要用纸浆来解决这个系统:
第一步是初始化一个
LpProblem的实例来表示你的模型:# Create the model model = LpProblem(name="small-problem", sense=LpMaximize)使用
sense参数选择是执行最小化(LpMinimize或1,这是默认的)还是最大化(LpMaximize或-1)。这个选择会影响你问题的结果。一旦有了模型,就可以将决策变量定义为
LpVariable类的实例:# Initialize the decision variables x = LpVariable(name="x", lowBound=0) y = LpVariable(name="y", lowBound=0)您需要用
lowBound=0提供一个下限,因为默认值是负无穷大。参数upBound定义了上限,但是这里可以省略,因为默认为正无穷大。可选参数
cat定义了决策变量的类别。如果你正在处理连续变量,那么你可以使用默认值"Continuous"。您可以使用变量
x和y来创建其他表示线性表达式和约束的纸浆对象:
>>> expression = 2 * x + 4 * y
>>> type(expression)
<class 'pulp.pulp.LpAffineExpression'>
>>> constraint = 2 * x + 4 * y >= 8
>>> type(constraint)
<class 'pulp.pulp.LpConstraint'>
当您将一个决策变量乘以一个标量或者构建多个决策变量的线性组合时,您会得到一个代表线性表达式的实例 pulp.LpAffineExpression 。
注意:你可以增加或减少变量或表达式,也可以将它们乘以常数,因为 PuLP 类实现了一些 Python 的特殊方法,这些方法模拟数字类型,如 __add__() 、 __sub__() 和 __mul__() 。这些方法用于定制操作员的行为,如+、-和*。
类似地,您可以将线性表达式、变量和标量与操作符==、<=或>=结合起来,以获得纸浆的实例。LpConstraint 表示模型的线性约束。
注意:还可以使用丰富的比较方法 .__eq__() 、 .__le__() 和 .__ge__() 来构建约束,这些方法定义了操作符==、<=和>=的行为。
记住这一点,下一步是创建约束和目标函数,并将其分配给模型。你不需要创建列表或矩阵。只需编写 Python 表达式并使用+=操作符将它们添加到模型中:
# Add the constraints to the model
model += (2 * x + y <= 20, "red_constraint")
model += (4 * x - 5 * y >= -10, "blue_constraint")
model += (-x + 2 * y >= -2, "yellow_constraint")
model += (-x + 5 * y == 15, "green_constraint")
在上面的代码中,您定义了保存约束及其名称的元组。LpProblem通过将约束指定为元组,允许您向模型添加约束。第一个元素是一个LpConstraint实例。第二个元素是人类可读的约束名称。
设置目标函数非常相似:
# Add the objective function to the model
obj_func = x + 2 * y
model += obj_func
或者,您可以使用更短的符号:
# Add the objective function to the model
model += x + 2 * y
现在您已经添加了目标函数并定义了模型。
注意:您可以使用操作符+=向模型添加一个约束或目标,因为它的类LpProblem实现了特殊的方法 .__iadd__() ,该方法用于指定+=的行为。
对于较大的问题,在列表或其他序列中使用 lpSum() 通常比重复使用+操作符更方便。例如,您可以使用以下语句将目标函数添加到模型中:
# Add the objective function to the model
model += lpSum([x, 2 * y])
它产生的结果与前面的语句相同。
您现在可以看到该模型的完整定义:
>>> model small-problem: MAXIMIZE 1*x + 2*y + 0 SUBJECT TO red_constraint: 2 x + y <= 20 blue_constraint: 4 x - 5 y >= -10 yellow_constraint: - x + 2 y >= -2 green_constraint: - x + 5 y = 15 VARIABLES x Continuous y Continuous模型的字符串表示包含所有相关数据:变量、约束、目标及其名称。
注意:字符串表示是通过定义特殊方法
.__repr__()构建的。关于.__repr__()的更多细节,请查看python OOP 字符串转换:__repr__vs__str__。终于,你准备好解决问题了。你可以通过在你的模型对象上调用
.solve()来实现。如果您想使用默认的求解器(CBC ),那么您不需要传递任何参数:# Solve the problem status = model.solve()
.solve()调用底层解算器,修改model对象,并返回解的整数状态,如果找到最优解,将是1。其余状态码见LpStatus[]。可以得到优化结果作为
model的属性。函数value()和相应的方法.value()返回属性的实际值:
>>> print(f"status: {model.status}, {LpStatus[model.status]}")
status: 1, Optimal
>>> print(f"objective: {model.objective.value()}")
objective: 16.8181817
>>> for var in model.variables():
... print(f"{var.name}: {var.value()}")
...
x: 7.7272727
y: 4.5454545
>>> for name, constraint in model.constraints.items():
... print(f"{name}: {constraint.value()}")
...
red_constraint: -9.99999993922529e-08
blue_constraint: 18.181818300000003
yellow_constraint: 3.3636362999999996
green_constraint: -2.0000000233721948e-07)
model.objective保存目标函数的值,model.constraints包含松弛变量的值,对象x和y具有决策变量的最优值。model.variables()返回包含决策变量的列表:
>>> model.variables() [x, y] >>> model.variables()[0] is x True >>> model.variables()[1] is y True如您所见,这个列表包含了用
LpVariable的构造函数创建的确切对象。结果与你用 SciPy 得到的结果大致相同。
注意:小心方法
.solve()——它改变了对象x和y的状态!您可以通过调用
.solver来查看使用了哪个求解器:
>>> model.solver
<pulp.apis.coin_api.PULP_CBC_CMD object at 0x7f60aea19e50>
输出通知您求解器是 CBC。你没有指定一个解算器,所以纸浆调用默认的。
如果你想运行一个不同的求解器,那么你可以把它指定为一个参数.solve()。例如,如果您想使用 GLPK 并且已经安装了它,那么您可以在最后一行使用solver=GLPK(msg=False)。请记住,您还需要导入它:
from pulp import GLPK
现在您已经导入了 GLPK,您可以在.solve()中使用它:
# Create the model
model = LpProblem(name="small-problem", sense=LpMaximize)
# Initialize the decision variables
x = LpVariable(name="x", lowBound=0)
y = LpVariable(name="y", lowBound=0)
# Add the constraints to the model
model += (2 * x + y <= 20, "red_constraint")
model += (4 * x - 5 * y >= -10, "blue_constraint")
model += (-x + 2 * y >= -2, "yellow_constraint")
model += (-x + 5 * y == 15, "green_constraint")
# Add the objective function to the model
model += lpSum([x, 2 * y])
# Solve the problem
status = model.solve(solver=GLPK(msg=False))
msg参数用于显示解算器的信息。msg=False禁止显示该信息。如果您想包含这些信息,只需省略msg或设置msg=True。
您的模型已定义并求解,因此您可以用与前一种情况相同的方式检查结果:
>>> print(f"status: {model.status}, {LpStatus[model.status]}") status: 1, Optimal >>> print(f"objective: {model.objective.value()}") objective: 16.81817 >>> for var in model.variables(): ... print(f"{var.name}: {var.value()}") ... x: 7.72727 y: 4.54545 >>> for name, constraint in model.constraints.items(): ... print(f"{name}: {constraint.value()}") ... red_constraint: -1.0000000000509601e-05 blue_constraint: 18.181830000000005 yellow_constraint: 3.3636299999999997 green_constraint: -2.000000000279556e-05你在 GLPK 身上得到的结果几乎和你在 SciPy 和 CBC 身上得到的一样。
让我们看看这次使用的是哪个规划求解:
>>> model.solver
<pulp.apis.glpk_api.GLPK_CMD object at 0x7f60aeb04d50>
正如上面用高亮语句model.solve(solver=GLPK(msg=False))定义的,求解器是 GLPK。
你也可以用纸浆来解决混合整数线性规划问题。要定义一个整数或二进制变量,只需将cat="Integer"或cat="Binary"传递给LpVariable。其他一切都保持不变:
# Create the model
model = LpProblem(name="small-problem", sense=LpMaximize)
# Initialize the decision variables: x is integer, y is continuous
x = LpVariable(name="x", lowBound=0, cat="Integer") y = LpVariable(name="y", lowBound=0)
# Add the constraints to the model
model += (2 * x + y <= 20, "red_constraint")
model += (4 * x - 5 * y >= -10, "blue_constraint")
model += (-x + 2 * y >= -2, "yellow_constraint")
model += (-x + 5 * y == 15, "green_constraint")
# Add the objective function to the model
model += lpSum([x, 2 * y])
# Solve the problem
status = model.solve()
在本例中,您有一个整数变量,并得到与之前不同的结果:
>>> print(f"status: {model.status}, {LpStatus[model.status]}") status: 1, Optimal >>> print(f"objective: {model.objective.value()}") objective: 15.8 >>> for var in model.variables(): ... print(f"{var.name}: {var.value()}") ... x: 7.0 y: 4.4 >>> for name, constraint in model.constraints.items(): ... print(f"{name}: {constraint.value()}") ... red_constraint: -1.5999999999999996 blue_constraint: 16.0 yellow_constraint: 3.8000000000000007 green_constraint: 0.0) >>> model.solver <pulp.apis.coin_api.PULP_CBC_CMD at 0x7f0f005c6210>现在
x是一个整数,如模型中所指定的。(从技术上讲,它保存一个小数点后带零的浮点值。)这个事实改变了整个解决方案。让我们在图表上展示一下:
如你所见,最佳解决方案是灰色背景上最右边的绿点。这是具有最大的
x和y值的可行解,使其具有最大的目标函数值。GLPK 也有能力解决这些问题。
示例 2
现在你可以用纸浆来解决上面的资源分配问题:
定义和解决问题的方法与前面的示例相同:
# Define the model model = LpProblem(name="resource-allocation", sense=LpMaximize) # Define the decision variables x = {i: LpVariable(name=f"x{i}", lowBound=0) for i in range(1, 5)} # Add constraints model += (lpSum(x.values()) <= 50, "manpower") model += (3 * x[1] + 2 * x[2] + x[3] <= 100, "material_a") model += (x[2] + 2 * x[3] + 3 * x[4] <= 90, "material_b") # Set the objective model += 20 * x[1] + 12 * x[2] + 40 * x[3] + 25 * x[4] # Solve the optimization problem status = model.solve() # Get the results print(f"status: {model.status}, {LpStatus[model.status]}") print(f"objective: {model.objective.value()}") for var in x.values(): print(f"{var.name}: {var.value()}") for name, constraint in model.constraints.items(): print(f"{name}: {constraint.value()}")在这种情况下,您使用字典
x来存储所有决策变量。这种方法很方便,因为字典可以将决策变量的名称或索引存储为键,将相应的LpVariable对象存储为值。列表或LpVariable实例的元组也很有用。上面的代码产生以下结果:
status: 1, Optimal objective: 1900.0 x1: 5.0 x2: 0.0 x3: 45.0 x4: 0.0 manpower: 0.0 material_a: -40.0 material_b: 0.0如您所见,该解决方案与使用 SciPy 获得的解决方案一致。最有利可图的解决方案是每天生产
5.0单位的第一种产品和45.0单位的第三种产品。让我们把这个问题变得更复杂,更有趣。假设工厂由于机械问题无法同时生产第一个和第三个产品。在这种情况下,最有利可图的解决方案是什么?
现在你有了另一个逻辑约束:如果 x ₁为正,那么 x ₃必须为零,反之亦然。这就是二元决策变量非常有用的地方。您将使用两个二元决策变量, y ₁和 y ₃,它们将表示是否生成了第一个或第三个产品:
1model = LpProblem(name="resource-allocation", sense=LpMaximize) 2 3# Define the decision variables 4x = {i: LpVariable(name=f"x{i}", lowBound=0) for i in range(1, 5)} 5y = {i: LpVariable(name=f"y{i}", cat="Binary") for i in (1, 3)} 6 7# Add constraints 8model += (lpSum(x.values()) <= 50, "manpower") 9model += (3 * x[1] + 2 * x[2] + x[3] <= 100, "material_a") 10model += (x[2] + 2 * x[3] + 3 * x[4] <= 90, "material_b") 11 12M = 100 13model += (x[1] <= y[1] * M, "x1_constraint") 14model += (x[3] <= y[3] * M, "x3_constraint") 15model += (y[1] + y[3] <= 1, "y_constraint") 16 17# Set objective 18model += 20 * x[1] + 12 * x[2] + 40 * x[3] + 25 * x[4] 19 20# Solve the optimization problem 21status = model.solve() 22 23print(f"status: {model.status}, {LpStatus[model.status]}") 24print(f"objective: {model.objective.value()}") 25 26for var in model.variables(): 27 print(f"{var.name}: {var.value()}") 28 29for name, constraint in model.constraints.items(): 30 print(f"{name}: {constraint.value()}")除了突出显示的行之外,代码与前面的示例非常相似。以下是不同之处:
第 5 行定义了字典
y中保存的二元决策变量y[1]和y[3]。第 12 行定义了一个任意大的数
M。在这种情况下,值100足够大,因为每天不能有超过100个单位。第 13 行说如果
y[1]是零,那么x[1]一定是零,否则可以是任意非负数。第 14 行说如果
y[3]是零,那么x[3]一定是零,否则可以是任意非负数。第 15 行说
y[1]或者y[3]是零(或者两者都是),所以x[1]或者x[3]也必须是零。解决方案如下:
status: 1, Optimal objective: 1800.0 x1: 0.0 x2: 0.0 x3: 45.0 x4: 0.0 y1: 0.0 y3: 1.0 manpower: -5.0 material_a: -55.0 material_b: 0.0 x1_constraint: 0.0 x3_constraint: -55.0 y_constraint: 0.0事实证明,最优方法是排除第一种产品,只生产第三种产品。
线性规划资源
线性规划和混合整数线性规划是非常重要的课题。如果你想更多地了解它们——除了你在这里看到的,还有很多东西要学——那么你可以找到大量的资源。以下是一些入门指南:
Gurobi Optimization 是一家提供带有 Python API 的快速商业求解器的公司。它还提供了关于线性规划和混合整数线性规划的宝贵资源,包括以下内容:
如果你有心情学习最优化理论,那么外面有大量的数学书籍。以下是一些受欢迎的选择:
- 线性规划:基础和扩展
- 凸优化
- 数学规划建模
- 工程优化:理论与实践
这只是可用的一部分。线性规划和混合整数线性规划是流行和广泛使用的技术,因此您可以找到无数的资源来帮助加深您的理解。
线性规划求解器
就像有很多资源可以帮助你学习线性编程和混合整数线性编程一样,也有很多解算器可以使用 Python 包装器。以下是部分列表:
其中一些库,如 Gurobi,包含了自己的 Python 包装器。其他的使用外部包装器。例如,你看到你可以用纸浆访问 CBC 和 GLPK。
结论
你现在知道什么是线性编程,以及如何使用 Python 来解决线性编程问题。您还了解了 Python 线性编程库只是本机解算器的包装器。当求解器完成它的工作时,包装器返回解状态、决策变量值、松弛变量、目标函数等等。
在本教程中,您学习了如何:
- 定义一个代表您的问题的模型
- 为优化创建一个 Python 程序
- 运行优化程序,找到问题的解决方案
- 检索优化的结果
您将 SciPy 与它自己的解算器一起使用,将 PuLP 与 CBC 和 GLPK 一起使用,但是您还了解到还有许多其他的线性编程解算器和 Python 包装器。现在,您已经准备好进入线性编程的世界了!
如果你有任何问题或意见,请写在下面的评论区。******
Python 中的线性回归
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 从 Python 中的线性回归开始
你生活在一个拥有大量数据、强大的计算机和人工智能的时代。这只是开始。数据科学和机器学习正在推动图像识别、自动驾驶汽车的开发、金融和能源领域的决策、医学的进步、社交网络的兴起等等。线性回归是其中重要的一部分。
线性回归是基本的统计和机器学习技术之一。无论你是想做统计、机器学习,还是科学计算,很有可能你会需要它。最好先建立一个坚实的基础,然后再向更复杂的方法前进。
到本文结束时,您将已经学会:
- 什么是线性回归是
- 用于什么线性回归
- 线性回归如何工作
- 如何在 Python 中一步步实现线性回归
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
参加测验:通过我们的交互式“Python 中的线性回归”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
回归
回归分析是统计学和机器学习中最重要的领域之一。有许多可用的回归方法。线性回归就是其中之一。
什么是回归?
回归搜索变量之间的关系。例如,你可以观察一些公司的几名员工,并试图了解他们的工资如何取决于他们的特征,如经验、教育水平、角色、就业城市等等。
这是一个回归问题,其中与每个员工相关的数据代表一个观察值。假设是经验、教育、角色和城市是独立的特征,而工资取决于它们。
同样,你可以尝试建立房价对面积、卧室数量、到市中心的距离等等的数学依赖关系。
一般来说,在回归分析中,你会考虑一些感兴趣的现象,并有一些观察结果。每个观察值有两个或多个特征。假设至少有一个特性依赖于其他特性,您试图在它们之间建立一种关系。
换句话说,您需要找到一个函数,将一些特性或变量充分地映射到其他的。
相关特征称为因变量、输出或响应。独立特征称为独立变量、输入、回归变量或预测器。
回归问题通常有一个连续无界的因变量。然而,输入可以是连续的、离散的、甚至是分类的数据,例如性别、国籍或品牌。
通常的做法是用𝑦表示输出,用𝑥.表示输入如果有两个或更多的独立变量,那么它们可以表示为向量𝐱 = (𝑥₁,…,𝑥ᵣ),其中𝑟是输入的数量。
什么时候需要回归?
通常,你需要回归来回答某个现象是否以及如何影响另一个现象,或者几个变量如何相关。例如,你可以用它来确定【T2 是否】和经验或性别在多大程度上影响薪水。
当你想用一组新的预测因子来预测一个反应时,回归也是有用的。例如,在给定室外温度、一天中的时间以及一个家庭中的居民人数的情况下,您可以尝试预测该家庭下一个小时的用电量。
回归被用于许多不同的领域,包括经济学、计算机科学和社会科学。随着大量数据的可用性和对数据实用价值认识的提高,它的重要性与日俱增。
线性回归
线性回归可能是最重要和最广泛使用的回归技术之一。这是最简单的回归方法之一。它的主要优点之一是易于解释结果。
问题表述
当对自变量集𝐱 = (𝑥₁,…,𝑥ᵣ)上的某个因变量𝑦进行线性回归时,其中𝑟是预测值的数量,假设𝑦和𝐱: 𝑦之间存在线性关系这个方程就是回归方程。𝛽₀、𝛽₁、…、𝛽ᵣ为回归系数,𝜀为随机误差。
线性回归计算回归系数的估计量或简单的预测权重,用𝑏₀、𝑏₁、…、𝑏ᵣ.表示这些估计器定义了估计回归函数 𝑓(𝐱) = 𝑏₀ + 𝑏₁𝑥₁ + ⋯ + 𝑏ᵣ𝑥ᵣ.这个函数应该能够很好地捕捉输入和输出之间的依赖关系。
每次观测的估计或预测响应,𝑓(𝐱ᵢ),𝑖 = 1,…,𝑛,应尽可能接近相应的实际响应 𝑦ᵢ.所有观测值的𝑦ᵢ - 𝑓(𝐱ᵢ差𝑖 = 1,…,𝑛,称为残差。回归是关于确定最佳预测权重——即对应于最小残差的权重。
为了得到最好的权重,你通常最小化所有观测值的残差平方和(SSR) ,𝑖 = 1,…,𝑛: SSR =σᵢ(𝑦ᵢ-𝑓(𝐱ᵢ)。这种方法被称为普通最小二乘法的方法。
回归性能
实际响应的变化𝑦ᵢ,𝑖 = 1,…,𝑛,部分是由于对预测值𝐱ᵢ.的依赖然而,还有一个额外的输出固有方差。
决定系数,表示为𝑅,使用特定的回归模型,告诉你𝑦的变化量可以通过对𝐱的依赖来解释。较大的𝑅表明拟合较好,意味着模型可以更好地解释不同输入下的输出变化。
值𝑅 = 1 对应于 SSR = 0。这就是完美拟合,因为预测和实际响应的值彼此完全吻合。
简单线性回归
简单或单变量线性回归是线性回归最简单的情况,因为它只有一个独立变量,𝐱 = 𝑥.
下图说明了简单的线性回归:
Example of simple linear regression 实施简单线性回归时,通常从一组给定的输入输出(𝑥-𝑦)对开始。这些对是您的观察,在图中显示为绿色圆圈。例如,最左边的观察值的输入𝑥 = 5,实际输出或响应𝑦 = 5。下一个是𝑥 = 15,𝑦 = 20,以此类推。
由黑线表示的估计回归函数具有等式𝑓(𝑥) = 𝑏₀ + 𝑏₁𝑥.您的目标是计算最小化 SSR 的预测权重𝑏₀和𝑏₁的最优值,并确定估计的回归函数。
𝑏₀的值,也称为截距,显示了估计回归线穿过𝑦轴的点。它是𝑥 = 0 时估计响应𝑓(𝑥的值。𝑏₁的值决定了估计回归线的斜率。
显示为红色方块的预测响应是回归线上对应于输入值的点。例如,对于输入𝑥 = 5,预测响应为𝑓(5 = 8.33,最左边的红色方块表示。
垂直的灰色虚线表示残差,可以计算为𝑦ᵢ - 𝑓(𝐱ᵢ) = 𝑦ᵢ - 𝑏₀ - 𝑏₁𝑥ᵢ,𝑖 = 1,…,𝑛.它们是绿色圆圈和红色方块之间的距离。当您实施线性回归时,您实际上是在尝试最小化这些距离,并使红色方块尽可能接近预定义的绿色圆圈。
多元线性回归
多重或多元线性回归是具有两个或多个独立变量的线性回归。
如果只有两个独立变量,那么估计的回归函数是𝑓(𝑥₁,𝑥₂) = 𝑏₀ + 𝑏₁𝑥₁ + 𝑏₂𝑥₂.它表示三维空间中的回归平面。回归的目标是确定𝑏₀、𝑏₁和𝑏₂的权重值,使得该平面尽可能接近实际响应,同时产生最小的 SSR。
两个以上独立变量的情况类似,但更普遍。估计回归函数为𝑓(𝑥₁,…,𝑥ᵣ) = 𝑏₀ + 𝑏₁𝑥₁ + ⋯ +𝑏ᵣ𝑥ᵣ,当输入数为𝑟.时有𝑟 + 1 个权重待定
多项式回归
你可以把多项式回归看作线性回归的一种推广情况。假设输出和输入之间存在多项式相关性,因此,多项式估计回归函数。
换句话说,除了像𝑏₁𝑥₁这样的线性项,您的回归函数𝑓还可以包括非线性项,如𝑏₃𝑥₁𝑏₂𝑥₁,甚至𝑏₅𝑥₁𝑥₂.𝑏₄𝑥₁𝑥₂
多项式回归最简单的例子是只有一个自变量,估计的回归函数是二次多项式:𝑓(𝑥) = 𝑏₀ + 𝑏₁𝑥 + 𝑏₂𝑥。
现在,请记住,您要计算𝑏₀、𝑏₁和𝑏₂,以最小化 SSR。这些都是你的未知数!
记住这一点,将前面的回归函数与用于线性回归的函数𝑓(𝑥₁,𝑥₂) = 𝑏₀ + 𝑏₁𝑥₁ + 𝑏₂𝑥₂进行比较。它们看起来非常相似,都是未知数𝑏₀、𝑏₁和𝑏₂.的线性函数这就是为什么你可以将多项式回归问题作为线性问题来解决,其中𝑥项被视为输入变量。
在两个变量和二次多项式的情况下,回归函数具有这种形式:𝑓(𝑥₁,𝑥₂)=𝑏₀+𝑏₁𝑥₁+𝑏₂𝑥₂+𝑏₃𝑥₁+𝑏₄𝑥₁𝑥₂+𝑏₅𝑥₂。
解决这个问题的程序与前一种情况相同。您对五个输入值应用线性回归:𝑥₁、𝑥₂、𝑥₁、𝑥₁𝑥₂和𝑥₂。作为回归的结果,您得到了使 SSR 最小化的六个权重值:𝑏₀、𝑏₁、𝑏₂、𝑏₃、𝑏₄和𝑏₅.
当然还有更一般的问题,但这应该足够说明问题了。
欠配合和过配合
当您实现多项式回归时,可能会出现一个非常重要的问题,这个问题与多项式回归函数的最佳次数的选择有关。
做这件事没有简单的规则。这要看情况。然而,你应该意识到学位选择可能带来的两个问题:欠拟合和过拟合。
当一个模型不能准确捕捉数据之间的依赖关系时,就会出现欠拟合,这通常是由于模型本身的简单性。在已知数据的情况下,它通常会产生较低的𝑅,而在应用新数据时,它的泛化能力较差。
过度拟合发生在模型既学习数据依赖性又学习随机波动的时候。换句话说,模型对现有数据的学习太好了。具有许多特征或术语的复杂模型通常容易过度拟合。当应用于已知数据时,这种模型通常产生高𝑅。然而,当与新数据一起使用时,它们通常不能很好地概括,并且具有明显较低的𝑅。
下图显示了拟合不足、拟合良好和拟合过度的模型:
Example of underfitted, well-fitted and overfitted models 左上角的图显示了一条𝑅较低的线性回归线。同样重要的是,一条直线不能考虑这样一个事实,当𝑥从 25 点向 0 点移动时,实际的反应会增加。这可能是一个不适合的例子。
右上角的图说明了次数等于 2 的多项式回归。在这种情况下,这可能是对该数据建模的最佳程度。该模型的𝑅值在许多情况下是令人满意的,并且很好地显示了趋势。
左下角的图表示次数等于 3 的多项式回归。𝑅的价值高于前面的情况。与以前的模型相比,该模型在已知数据的情况下表现更好。然而,它显示了一些过度拟合的迹象,特别是对于接近 sixy 的输入值,线开始下降,尽管实际数据没有显示这一点。
最后,在右下角的图中,你可以看到完美的拟合:六个点和五次(或更高)的多项式线产生𝑅 = 1。每个实际响应等于其相应的预测。
在某些情况下,这可能正是您正在寻找的。然而,在许多情况下,这是一个过度拟合的模型。对于看不见的数据,尤其是输入大于 50 的数据,很可能表现不佳。
例如,它假设,在没有任何证据的情况下,𝑥的回答在 50 岁以上有显著下降,𝑦在𝑥接近 60 岁时达到零。这种行为是过度努力学习和适应现有数据的结果。
有很多资源可以让你找到更多关于回归的信息,尤其是线性回归。维基百科上的回归分析页面、维基百科的线性回归条目、可汗学院的线性回归文章都是很好的起点。
用于线性回归的 Python 包
是时候开始在 Python 中实现线性回归了。为此,您将应用适当的包及其函数和类。
NumPy 是一个基本的 Python 科学包,允许对一维或多维数组进行许多高性能操作。它还提供了许多数学例程。当然,它是开源的。
如果你不熟悉 NumPy,你可以使用官方的 NumPy 用户指南并阅读 NumPy 教程:你进入 Python 数据科学的第一步。另外,【看马,No For-Loops:数组编程用 NumPy 和纯 Python vs NumPy vs TensorFlow 性能比较可以让你很好的了解应用 NumPy 时可以达到的性能增益。
包 scikit-learn 是一个广泛用于机器学习的 Python 库,构建在 NumPy 和其他一些包之上。它提供了预处理数据、降低维数、实现回归、分类、聚类等方法。和 NumPy 一样,scikit-learn 也是开源的。
您可以查看 scikit-learn 网站上的页面广义线性模型,以了解更多关于线性模型的信息,并更深入地了解该软件包是如何工作的。
如果您想要实现线性回归,并且需要 scikit-learn 范围之外的功能,您应该考虑 statsmodels 。这是一个强大的 Python 包,用于统计模型的估计、执行测试等等。它也是开源的。
你可以在的官方网站上找到更多关于 statsmodels 的信息。
现在,按照本教程,您应该将所有这些包安装到一个虚拟环境中:
(venv) $ python -m pip install numpy scikit-learn statsmodels这将安装 NumPy、scikit-learn、statsmodels 及其依赖项。
使用 scikit-learn 进行简单的线性回归
您将从最简单的情况开始,这是简单的线性回归。实施线性回归有五个基本步骤:
- 导入您需要的包和类。
- 提供数据,并最终进行适当的转换。
- 创建一个回归模型,并用现有数据进行拟合。
- 检查模型拟合的结果,以了解模型是否令人满意。
- 应用模型进行预测。
这些步骤对大多数回归方法和实现或多或少是通用的。在本教程的其余部分中,您将学习如何针对几种不同的场景执行这些步骤。
步骤 1:导入包和类
第一步是从
sklearn.linear_model导入包numpy和类LinearRegression:
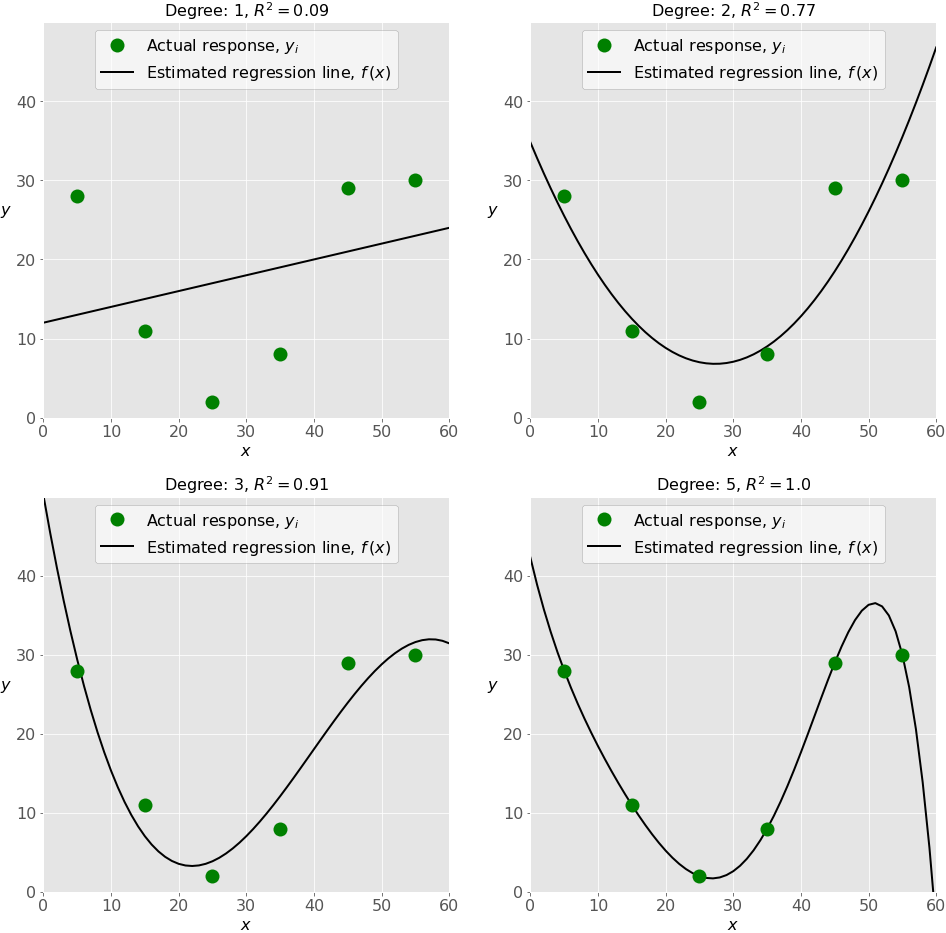
>>> import numpy as np
>>> from sklearn.linear_model import LinearRegression
现在,您已经拥有了实现线性回归所需的所有功能。
NumPy 的基本数据类型是名为numpy.ndarray的数组类型。本教程的其余部分使用术语数组来指代类型numpy.ndarray的实例。
您将使用类sklearn.linear_model.LinearRegression来执行线性和多项式回归,并做出相应的预测。
第二步:提供数据
第二步是定义要使用的数据。输入(回归量,𝑥)和输出(响应,𝑦)应该是数组或类似的对象。这是为回归提供数据的最简单方法:
>>> x = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1)) >>> y = np.array([5, 20, 14, 32, 22, 38])现在,您有两个数组:输入数组
x和输出数组y。你应该在x上调用.reshape(),因为这个数组必须是二维的,或者更准确地说,它必须有一列和尽可能多的行。这正是.reshape()中的(-1, 1)所指出的。这是
x和y现在的样子:
>>> x
array([[ 5],
[15],
[25],
[35],
[45],
[55]])
>>> y
array([ 5, 20, 14, 32, 22, 38])
你可以看到,x有两个维度,x.shape是(6, 1),而y有一个维度,y.shape是(6,)。
第三步:创建一个模型并进行拟合
下一步是创建一个线性回归模型,并使用现有数据进行拟合。
创建类LinearRegression的一个实例,它将代表回归模型:
>>> model = LinearRegression()该语句创建变量
model作为LinearRegression的实例。您可以向LinearRegression提供几个可选参数:
fit_intercept是一个布尔型,如果True,则决定计算截距𝑏₀,如果False,则认为其等于零。默认为True。normalize是一个布尔值,如果True,则决定对输入变量进行规范化。它默认为False,在这种情况下,它不会规范化输入变量。copy_X是决定是复制(True)还是覆盖输入变量(False)的布尔值。默认是True。n_jobs要么是整数,要么是None。它表示并行计算中使用的作业数量。默认为None,通常指一份工作。-1表示使用所有可用的处理器。上面定义的
model使用所有参数的默认值。是时候开始使用模型了。首先,你需要在
model上调用.fit():
>>> model.fit(x, y)
LinearRegression()
通过.fit(),使用现有的输入和输出x和y作为参数,计算权重𝑏₀和𝑏₁的最优值。换句话说,.fit() 符合模型。它返回self,也就是变量model本身。这就是为什么您可以用下面的语句替换最后两个语句:
>>> model = LinearRegression().fit(x, y)这条语句的作用与前两条相同。只是短了点。
第四步:获取结果
一旦你有你的模型拟合,你可以得到的结果来检查模型是否令人满意的工作,并解释它。
你可以通过调用
model的.score()得到决定系数𝑅:
>>> r_sq = model.score(x, y)
>>> print(f"coefficient of determination: {r_sq}")
coefficient of determination: 0.7158756137479542
当你应用.score()时,参数也是预测值x和响应值y,返回值是𝑅。
model的属性有.intercept_,代表系数𝑏₀,.coef_,代表𝑏₁:
>>> print(f"intercept: {model.intercept_}") intercept: 5.633333333333329 >>> print(f"slope: {model.coef_}") slope: [0.54]上面的代码演示了如何获得𝑏₀和𝑏₁.你可以注意到
.intercept_是一个标量,而.coef_是一个数组。注意:在 scikit-learn 中,按照惯例,尾随的下划线表示一个属性是估计的。在该示例中,
.intercept_和.coef_是估计值。𝑏₀的值大约是 5.63。这说明当𝑥为零时,你的模型预测响应为 5.63。值𝑏₁ = 0.54 意味着当𝑥增加 1 时,预测响应增加 0.54。
您会注意到,您也可以将
y作为二维数组提供。在这种情况下,您会得到类似的结果。这可能是它看起来的样子:
>>> new_model = LinearRegression().fit(x, y.reshape((-1, 1)))
>>> print(f"intercept: {new_model.intercept_}")
intercept: [5.63333333]
>>> print(f"slope: {new_model.coef_}")
slope: [[0.54]]
正如您所看到的,这个示例与上一个非常相似,但是在这个示例中,.intercept_是一个包含单个元素𝑏₀的一维数组,.coef_是一个包含单个元素𝑏₁.的二维数组
第五步:预测反应
一旦你有了一个满意的模型,你就可以用它来预测现有的或新的数据。要获得预测的响应,使用.predict():
>>> y_pred = model.predict(x) >>> print(f"predicted response:\n{y_pred}") predicted response: [ 8.33333333 13.73333333 19.13333333 24.53333333 29.93333333 35.33333333]应用
.predict()时,将回归量作为自变量传递,得到相应的预测响应。这是一种几乎相同的预测反应的方法:
>>> y_pred = model.intercept_ + model.coef_ * x
>>> print(f"predicted response:\n{y_pred}")
predicted response:
[[ 8.33333333]
[13.73333333]
[19.13333333]
[24.53333333]
[29.93333333]
[35.33333333]]
在这种情况下,您将x的每个元素乘以model.coef_,并将model.intercept_加到乘积上。
这里的输出与上一个示例的不同之处仅在于维度。预测的响应现在是一个二维数组,而在以前的情况下,它只有一维。
如果你把x的维数减少到一,那么这两种方法会产生相同的结果。你可以通过将x乘以model.coef_时用x.reshape(-1)、x.flatten()或x.ravel()来代替x来实现。
在实践中,回归模型经常用于预测。这意味着您可以使用拟合模型根据新的输入来计算输出:
>>> x_new = np.arange(5).reshape((-1, 1)) >>> x_new array([[0], [1], [2], [3], [4]]) >>> y_new = model.predict(x_new) >>> y_new array([5.63333333, 6.17333333, 6.71333333, 7.25333333, 7.79333333])这里
.predict()被应用于新的回归变量x_new并产生响应y_new。这个例子方便地使用来自numpy的arange()来生成一个数组,数组中的元素从 0(包括 0)到 5(不包括 5),即0、1、2、3和4。你可以在官方文档页面上找到更多关于
LinearRegression的信息。使用 scikit-learn 进行多元线性回归
您可以按照与简单回归相同的步骤来实现多元线性回归。主要的区别是您的
x数组现在将有两列或更多列。步骤 1 和 2:导入包和类,并提供数据
首先,导入
numpy和sklearn.linear_model.LinearRegression,并提供已知的输入和输出:
>>> import numpy as np
>>> from sklearn.linear_model import LinearRegression
>>> x = [
... [0, 1], [5, 1], [15, 2], [25, 5], [35, 11], [45, 15], [55, 34], [60, 35]
... ]
>>> y = [4, 5, 20, 14, 32, 22, 38, 43]
>>> x, y = np.array(x), np.array(y)
这是定义输入x和输出y的简单方法。你可以把x和y打印出来,看看他们现在的样子:
>>> x array([[ 0, 1], [ 5, 1], [15, 2], [25, 5], [35, 11], [45, 15], [55, 34], [60, 35]]) >>> y array([ 4, 5, 20, 14, 32, 22, 38, 43])在多元线性回归中,
x是至少有两列的二维数组,而y通常是一维数组。这是多元线性回归的一个简单例子,而x正好有两列。第三步:创建一个模型并进行拟合
下一步是创建回归模型作为
LinearRegression的实例,并用.fit()来拟合它:
>>> model = LinearRegression().fit(x, y)
该语句的结果是变量model引用类型LinearRegression的对象。它表示用现有数据拟合的回归模型。
第四步:获取结果
您可以通过与简单线性回归相同的方式获得模型的属性:
>>> r_sq = model.score(x, y) >>> print(f"coefficient of determination: {r_sq}") coefficient of determination: 0.8615939258756776 >>> print(f"intercept: {model.intercept_}") intercept: 5.52257927519819 >>> print(f"coefficients: {model.coef_}") coefficients: [0.44706965 0.25502548]使用
.score()获得𝑅的值,使用.intercept_和.coef_获得回归系数的估计值。同样,.intercept_保存偏向𝑏₀,而现在.coef_是一个包含𝑏₁和𝑏₂.的数组在这个例子中,截距约为 5.52,这是当𝑥₁ = 𝑥₂ = 0 时的预测响应值。𝑥₁增加 1 会导致预测响应增加 0.45。类似地,当𝑥₂增长 1 时,响应增加 0.26。
第五步:预测反应
预测的工作方式与简单线性回归的情况相同:
>>> y_pred = model.predict(x)
>>> print(f"predicted response:\n{y_pred}")
predicted response:
[ 5.77760476 8.012953 12.73867497 17.9744479 23.97529728 29.4660957
38.78227633 41.27265006]
预测响应通过.predict()获得,相当于:
>>> y_pred = model.intercept_ + np.sum(model.coef_ * x, axis=1) >>> print(f"predicted response:\n{y_pred}") predicted response: [ 5.77760476 8.012953 12.73867497 17.9744479 23.97529728 29.4660957 38.78227633 41.27265006]通过将输入的每一列乘以适当的权重,对结果求和,然后将截距加到和上,可以预测输出值。
您也可以将此模型应用于新数据:
>>> x_new = np.arange(10).reshape((-1, 2))
>>> x_new
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> y_new = model.predict(x_new)
>>> y_new
array([ 5.77760476, 7.18179502, 8.58598528, 9.99017554, 11.3943658 ])
这是使用线性回归模型的预测。
用 scikit-learn 进行多项式回归
用 scikit-learn 实现多项式回归与线性回归非常相似。只有一个额外的步骤:您需要转换输入数组,以包括非线性项,如𝑥。
步骤 1:导入包和类
除了numpy和sklearn.linear_model.LinearRegression,你还应该从sklearn.preprocessing导入PolynomialFeatures类:
>>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> from sklearn.preprocessing import PolynomialFeatures导入现在已经完成,您已经拥有了需要使用的所有东西。
步骤 2a:提供数据
这一步定义了输入和输出,与线性回归的情况相同:
>>> x = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1))
>>> y = np.array([15, 11, 2, 8, 25, 32])
现在,您已经有了合适格式的输入和输出。请记住,您需要输入一个二维数组**。所以才用.reshape()。*
*步骤 2b:转换输入数据
这是您需要为多项式回归实现的新步骤!
正如您之前所了解的,在实现多项式回归时,您需要将𝑥(或许还有其他项)作为附加特征包括在内。出于这个原因,您应该转换输入数组x以包含任何具有𝑥值的附加列,并最终包含更多的特性。
有几种方法可以转换输入数组,比如使用来自numpy的insert()。但是PolynomialFeatures类对于这个目的来说非常方便。继续创建该类的一个实例:
>>> transformer = PolynomialFeatures(degree=2, include_bias=False)变量
transformer指的是PolynomialFeatures的一个实例,您可以用它来转换输入x。您可以向
PolynomialFeatures提供几个可选参数:
degree是表示多项式回归函数次数的整数(默认为2)。interaction_only是一个布尔型(False默认),决定是只包含交互特性(True)还是包含所有特性(False)。include_bias是一个布尔值(默认为True),它决定是否包含偏差或截距列的1值(True)或False)。本例使用除
include_bias之外的所有参数的默认值。有时您会想试验一下函数的阶数,无论如何,提供这个参数对可读性是有好处的。在应用
transformer之前,您需要安装.fit():
>>> transformer.fit(x)
PolynomialFeatures(include_bias=False)
一旦transformer安装完毕,就可以创建一个新的修改过的输入数组了。您可以应用.transform()来实现这一点:
>>> x_ = transformer.transform(x)那就是用
.transform()对输入数组的变换。它将输入数组作为参数,并返回修改后的数组。您也可以使用
.fit_transform()只用一个语句替换前面的三个语句:
>>> x_ = PolynomialFeatures(degree=2, include_bias=False).fit_transform(x)
使用.fit_transform(),您可以在一条语句中拟合和转换输入数组。这个方法也接受输入数组,并有效地做与按顺序调用的.fit()和.transform()相同的事情。它还返回修改后的数组。新的输入数组如下所示:
>>> x_ array([[ 5., 25.], [ 15., 225.], [ 25., 625.], [ 35., 1225.], [ 45., 2025.], [ 55., 3025.]])修改后的输入数组包含两列:一列是原始输入,另一列是它们的平方。你可以在官方文档页面上找到更多关于
PolynomialFeatures的信息。第三步:创建一个模型并进行拟合
这一步也与线性回归的情况相同。创建并拟合模型:
>>> model = LinearRegression().fit(x_, y)
回归模型现在已经创建并拟合好了。已经可以应用了。你要记住,.fit()的第一个参数是修改后的输入数组 x_而不是原来的x。
第四步:获取结果
您可以通过与线性回归相同的方式获得模型的属性:
>>> r_sq = model.score(x_, y) >>> print(f"coefficient of determination: {r_sq}") coefficient of determination: 0.8908516262498563 >>> print(f"intercept: {model.intercept_}") intercept: 21.372321428571436 >>> print(f"coefficients: {model.coef_}") coefficients: [-1.32357143 0.02839286]再次,
.score()返回𝑅。它的第一个参数也是修改后的输入x_,而不是x。权重值与.intercept_和.coef_相关联。这里,.intercept_代表𝑏₀,而.coef_引用包含𝑏₁和𝑏₂.的数组使用不同的转换和回归参数可以获得非常相似的结果:
>>> x_ = PolynomialFeatures(degree=2, include_bias=True).fit_transform(x)
如果您用默认参数include_bias=True调用PolynomialFeatures,或者如果您忽略它,那么您将获得新的输入数组x_,其中最左边的一列只包含1的值。该列对应于截距。在这种情况下,修改后的输入数组如下所示:
>>> x_ array([[1.000e+00, 5.000e+00, 2.500e+01], [1.000e+00, 1.500e+01, 2.250e+02], [1.000e+00, 2.500e+01, 6.250e+02], [1.000e+00, 3.500e+01, 1.225e+03], [1.000e+00, 4.500e+01, 2.025e+03], [1.000e+00, 5.500e+01, 3.025e+03]])
x_的第一列包含 1,第二列包含x的值,而第三列包含x的平方。截距已经包含在最左边的一列中,在创建
LinearRegression的实例时不需要再次包含它。因此,您可以提供fit_intercept=False。下面是下一条语句:
>>> model = LinearRegression(fit_intercept=False).fit(x_, y)
变量model再次对应于新的输入数组x_。因此,x_应该作为第一个参数传递,而不是x。
这种方法会产生以下结果,与前一种情况类似:
>>> r_sq = model.score(x_, y) >>> print(f"coefficient of determination: {r_sq}") coefficient of determination: 0.8908516262498564 >>> print(f"intercept: {model.intercept_}") intercept: 0.0 >>> print(f"coefficients: {model.coef_}") coefficients: [21.37232143 -1.32357143 0.02839286]你看到现在
.intercept_是零,但是.coef_实际上包含𝑏₀作为它的第一个元素。其他都一样。第五步:预测反应
如果你想得到预测的响应,就用
.predict(),但是记住参数应该是修改后的输入x_而不是旧的x:
>>> y_pred = model.predict(x_)
>>> print(f"predicted response:\n{y_pred}")
predicted response:
[15.46428571 7.90714286 6.02857143 9.82857143 19.30714286 34.46428571]
如您所见,预测的工作方式几乎与线性回归的情况相同。它只需要修改后的输入,而不是原来的输入。
如果你有几个输入变量,你可以应用相同的程序。您将拥有一个包含多列的输入数组,但是其他的都是一样的。这里有一个例子:
>>> # Step 1: Import packages and classes >>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> from sklearn.preprocessing import PolynomialFeatures >>> # Step 2a: Provide data >>> x = [ ... [0, 1], [5, 1], [15, 2], [25, 5], [35, 11], [45, 15], [55, 34], [60, 35] ... ] >>> y = [4, 5, 20, 14, 32, 22, 38, 43] >>> x, y = np.array(x), np.array(y) >>> # Step 2b: Transform input data >>> x_ = PolynomialFeatures(degree=2, include_bias=False).fit_transform(x) >>> # Step 3: Create a model and fit it >>> model = LinearRegression().fit(x_, y) >>> # Step 4: Get results >>> r_sq = model.score(x_, y) >>> intercept, coefficients = model.intercept_, model.coef_ >>> # Step 5: Predict response >>> y_pred = model.predict(x_)该回归示例产生以下结果和预测:
>>> print(f"coefficient of determination: {r_sq}")
coefficient of determination: 0.9453701449127822
>>> print(f"intercept: {intercept}")
intercept: 0.8430556452395876
>>> print(f"coefficients:\n{coefficients}")
coefficients:
[ 2.44828275 0.16160353 -0.15259677 0.47928683 -0.4641851 ]
>>> print(f"predicted response:\n{y_pred}")
predicted response:
[ 0.54047408 11.36340283 16.07809622 15.79139 29.73858619 23.50834636
39.05631386 41.92339046]
在这种情况下,有六个回归系数,包括截距,如估计回归函数所示𝑓(𝑥₁,𝑥₂)=𝑏₀+𝑏₁𝑥₁+𝑏₂𝑥₂+𝑏₃𝑥₁+𝑏₄𝑥₁𝑥₂+𝑏₅𝑥₂。
您还可以注意到,对于相同的问题,多项式回归比多元线性回归产生了更高的决定系数。起初,你可能认为获得如此大的𝑅是一个很好的结果。可能是吧。
然而,在现实世界的情况下,有一个复杂的模型和𝑅非常接近,也可能是一个过度拟合的迹象。要检查模型的性能,您应该使用新数据对其进行测试,也就是说,使用未用于拟合或训练模型的观察值。要了解如何将数据集分割成训练和测试子集,请查看使用 scikit-learn 的 train_test_split() 分割数据集。
带 statsmodels 的高级线性回归
您也可以通过使用 statsmodels 包在 Python 中实现线性回归。通常,当您需要更详细的结果时,这是可取的。
该过程类似于 scikit-learn 的过程。
第一步:导入包
首先你需要做一些进口。除了numpy,还需要导入statsmodels.api:
>>> import numpy as np >>> import statsmodels.api as sm现在您已经有了您需要的包。
步骤 2:提供数据并转换输入
您可以像使用 scikit-learn 时一样提供输入和输出:
>>> x = [
... [0, 1], [5, 1], [15, 2], [25, 5], [35, 11], [45, 15], [55, 34], [60, 35]
... ]
>>> y = [4, 5, 20, 14, 32, 22, 38, 43]
>>> x, y = np.array(x), np.array(y)
输入和输出数组已经创建,但是工作还没有完成。
如果您希望 statsmodels 计算截距𝑏₀.,则需要将 1 的列添加到输入中默认情况下,它不考虑𝑏₀。这只是一个函数调用:
>>> x = sm.add_constant(x)这就是用
add_constant()将一列 1 加到x的方法。它将输入数组x作为参数,并返回一个新数组,在该数组的开头插入一列 1。这是x和y现在的样子:
>>> x
array([[ 1., 0., 1.],
[ 1., 5., 1.],
[ 1., 15., 2.],
[ 1., 25., 5.],
[ 1., 35., 11.],
[ 1., 45., 15.],
[ 1., 55., 34.],
[ 1., 60., 35.]])
>>> y
array([ 4, 5, 20, 14, 32, 22, 38, 43])
你可以看到修改后的x有三列:第一列是 1,对应于𝑏₀和替换截距,还有两列是原来的特性。
第三步:创建一个模型并进行拟合
基于普通最小二乘法的回归模型是类statsmodels.regression.linear_model.OLS的一个实例。这是你如何获得一个:
>>> model = sm.OLS(y, x)你在这里要小心!注意,第一个参数是输出,后面是输入。这与相应的 scikit-learn 功能的顺序相反。
还有几个可选参数。要找到更多关于这个类的信息,你可以访问官方文档页面。
一旦你的模型被创建,你就可以对它应用
.fit():
>>> results = model.fit()
通过调用.fit(),您获得了变量results,它是类statsmodels.regression.linear_model.RegressionResultsWrapper的一个实例。该对象保存了大量关于回归模型的信息。
第四步:获取结果
变量results是指包含关于线性回归结果的详细信息的对象。解释这些结果远远超出了本教程的范围,但是您将在这里学习如何提取它们。
您可以调用.summary()来获得线性回归结果的表格:
>>> print(results.summary()) OLS Regression Results ============================================================================= Dep. Variable: y R-squared: 0.862 Model: OLS Adj. R-squared: 0.806 Method: Least Squares F-statistic: 15.56 Date: Thu, 12 May 2022 Prob (F-statistic): 0.00713 Time: 14:15:07 Log-Likelihood: -24.316 No. Observations: 8 AIC: 54.63 Df Residuals: 5 BIC: 54.87 Df Model: 2 Covariance Type: nonrobust ============================================================================= coef std err t P>|t| [0.025 0.975] ----------------------------------------------------------------------------- const 5.5226 4.431 1.246 0.268 -5.867 16.912 x1 0.4471 0.285 1.567 0.178 -0.286 1.180 x2 0.2550 0.453 0.563 0.598 -0.910 1.420 ============================================================================= Omnibus: 0.561 Durbin-Watson: 3.268 Prob(Omnibus): 0.755 Jarque-Bera (JB): 0.534 Skew: 0.380 Prob(JB): 0.766 Kurtosis: 1.987 Cond. No. 80.1 ============================================================================= Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.这张表很全面。您可以找到许多与线性回归相关的统计值,包括𝑅、𝑏₀、𝑏₁和𝑏₂.
在这种特殊情况下,您可能会得到一个警告消息
kurtosistest only valid for n>=20。这是因为示例中提供的观察值数量很少。您可以从上表中提取任何值。这里有一个例子:
>>> print(f"coefficient of determination: {results.rsquared}")
coefficient of determination: 0.8615939258756776
>>> print(f"adjusted coefficient of determination: {results.rsquared_adj}")
adjusted coefficient of determination: 0.8062314962259487
>>> print(f"regression coefficients: {results.params}")
regression coefficients: [5.52257928 0.44706965 0.25502548]
这就是你如何获得一些线性回归的结果:
.rsquared掌握着𝑅。.rsquared_adj表示调整后的𝑅——即根据输入特征的数量修正的𝑅。.params谓阵中有𝑏₀、𝑏₁和𝑏₂.
您还可以注意到,这些结果与针对相同问题使用 scikit-learn 获得的结果相同。
欲了解更多关于线性回归结果的信息,请访问官方文档页面。
第五步:预测反应
您可以使用.fittedvalues或.predict()获得用于创建模型的输入值的预测响应,并将输入数组作为参数:
>>> print(f"predicted response:\n{results.fittedvalues}") predicted response: [ 5.77760476 8.012953 12.73867497 17.9744479 23.97529728 29.4660957 38.78227633 41.27265006] >>> print(f"predicted response:\n{results.predict(x)}") predicted response: [ 5.77760476 8.012953 12.73867497 17.9744479 23.97529728 29.4660957 38.78227633 41.27265006]这是已知输入的预测响应。如果您想要使用新的回归变量进行预测,您也可以使用新数据作为参数来应用
.predict():
>>> x_new = sm.add_constant(np.arange(10).reshape((-1, 2)))
>>> x_new
array([[1., 0., 1.],
[1., 2., 3.],
[1., 4., 5.],
[1., 6., 7.],
[1., 8., 9.]])
>>> y_new = results.predict(x_new)
>>> y_new
array([ 5.77760476, 7.18179502, 8.58598528, 9.99017554, 11.3943658 ])
您可以注意到,对于相同的问题,预测的结果与使用 scikit-learn 获得的结果相同。
超越线性回归
线性回归有时并不合适,尤其是对于高度复杂的非线性模型。
幸运的是,对于线性回归效果不佳的情况,还有其他适合的回归技术。其中一些是支持向量机、决策树、随机森林和神经网络。
有许多 Python 库可以使用这些技术进行回归。其中大多数都是免费和开源的。这也是 Python 成为机器学习的主要编程语言之一的原因之一。
scikit-learn 包提供了使用其他回归技术的方法,与您所看到的非常相似。它包含了支持向量机、决策树、随机森林等等的类,方法有.fit()、.predict()、.score()等等。
结论
现在您知道了什么是线性回归,以及如何用 Python 和三个开源包实现它:NumPy、scikit-learn 和 statsmodels。您使用 NumPy 来处理数组。线性回归通过以下方式实现:
- 如果您不需要详细的结果,并且希望使用与其他回归技术一致的方法,请使用 scikit-learn
- statsmodels 如果你需要一个模型的高级统计参数
这两种方法都值得学习如何使用和进一步探索。本文中的链接对此非常有用。
在本教程中,您已经学习了在 Python 中执行线性回归的以下步骤:
- 导入您需要的包和类
- 提供数据进行处理,最终进行适当的转换
- 创建一个回归模型并用现有数据拟合它
- 检查模型拟合的结果以了解模型是否令人满意
- 应用模型进行预测
就这样,你可以走了!如果你有任何问题或意见,请写在下面的评论区。
参加测验:通过我们的交互式“Python 中的线性回归”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 从 Python 中的线性回归开始***********
Python 中的链表:简介
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 处理链表
链表就像是链表的一个鲜为人知的表亲。它们既不流行也不酷,你甚至可能不记得算法课上的它们。但在合适的背景下,他们真的可以大放异彩。
在这篇文章中,你将了解到:
- 什么是链表,什么时候应该使用它们
- 如何使用
collections.deque来满足你所有的链表需求 - 如何实现你自己的链表
- 其他类型的链表是什么,它们可以用来做什么
如果你想为一次工作面试提高你的编码技能,或者如果你想学习更多关于 Python 数据结构的知识,除了通常的字典和列表,那么你来对地方了!
您可以通过下载下面链接中的源代码来学习本教程中的示例:
获取源代码: 点击此处获取源代码,您将使用在本教程中学习链表。
理解链表
链表是对象的有序集合。那么是什么让它们不同于普通的列表呢?链表与列表的不同之处在于它们在内存中存储元素的方式。列表使用连续的内存块来存储对其数据的引用,而链表将引用存储为其自身元素的一部分。
主要概念
在深入了解什么是链表以及如何使用它们之前,您应该首先了解它们是如何构造的。链表的每个元素称为一个节点,每个节点有两个不同的字段:
- 数据包含要存储在节点中的值。
- Next 包含对列表中下一个节点的引用。
典型的节点如下所示:
链表是节点的集合。第一个节点叫做 head ,它被用作遍历列表的起点。最后一个节点必须有其指向 None 的next引用来确定列表的结尾。它看起来是这样的:
现在您已经知道了链表是如何构造的,您已经准备好查看它的一些实际用例了。
实际应用
链表在现实世界中有多种用途。它们可以用来实现(剧透警报!)队列或栈以及图形。它们对于更复杂的任务也很有用,比如操作系统应用程序的生命周期管理。
队列或堆栈
队列和堆栈的区别仅在于检索元素的方式。对于一个队列,您使用一种先进/先出 (FIFO)方法。这意味着插入列表的第一个元素是第一个被检索的元素:

在上图中,你可以看到队列的前和后元素。当你把新元素添加到队列中时,它们会被放到队列的最后。当您检索元素时,它们将从队列的前面取出。
对于堆栈,使用后进/先出 (LIFO)方法,这意味着插入到列表中的最后一个元素首先被检索:

在上图中,你可以看到堆栈中插入的第一个元素(索引0)在底部,插入的最后一个元素在顶部。因为堆栈使用 LIFO 方法,最后插入的元素(在顶部)将首先被取出。
由于从队列和堆栈的边缘插入和检索元素的方式,链表是实现这些数据结构的最方便的方式之一。在本文的后面,您将看到这些实现的例子。
图表
图形可用于显示对象之间的关系或表示不同类型的网络。例如,一个图形的可视化表示(比如有向无环图(DAG))可能如下所示:

有不同的方法来实现上面这样的图,但是最常用的方法之一是使用一个邻接表。本质上,邻接表是一个链表的列表,其中图的每个顶点都存储在连接的顶点的集合旁边:
| 顶点 | 顶点链表 |
|---|---|
| one | 2 → 3 →无 |
| Two | 4 →无 |
| three | 没有人 |
| four | 5 → 6 →无 |
| five | 6 →无 |
| six | 没有人 |
在上表中,左栏列出了图形的每个顶点。右列包含一系列链表,这些链表存储了与左列中相应顶点相连接的其他顶点。这个邻接表也可以用代码表示,使用一个dict:
>>> graph = { ... 1: [2, 3, None], ... 2: [4, None], ... 3: [None], ... 4: [5, 6, None], ... 5: [6, None], ... 6: [None] ... }这个字典的键是源顶点,每个键的值是一个列表。这个列表通常被实现为一个链表。
注意:在上面的例子中,你可以避免存储
None值,但是为了清晰和与后面的例子保持一致,我们在这里保留了它们。就速度和内存而言,与邻接矩阵相比,使用邻接表实现图是非常有效的。这就是链表对于图形实现如此有用的原因。
性能比较:列表与链表
在大多数编程语言中,链表和数组在内存中的存储方式有明显的不同。然而,在 Python 中,列表是动态数组。这意味着链表和链表的内存使用非常相似。
延伸阅读: Python 的动态数组的实现非常有趣,绝对值得一读。一定要看一看,并利用这些知识在下次公司聚会上脱颖而出!
由于链表和链表在内存使用上的差异是如此的微不足道,所以当涉及到时间复杂度时,如果你关注它们的性能差异会更好。
元素的插入和删除
在 Python 中,可以使用
.insert()或.append()将元素插入到列表中。要从列表中删除元素,可以使用它们的对应物:.remove()和.pop()。这些方法之间的主要区别在于,您使用
.insert()和.remove()在列表中的特定位置插入或移除元素,但是您使用.append()和.pop()仅在列表的末尾插入或移除元素。现在,关于 Python 列表,您需要知道的是,在列表末尾插入或删除不是的元素需要在后台进行一些元素移动,这使得操作在时间上更加复杂。你可以阅读上面提到的关于列表如何在 Python 中实现的文章,以更好地理解
.insert()、.remove()、.append()和.pop()的实现如何影响它们的性能。考虑到这一点,即使使用
.append()或.insert()在列表末尾插入元素会有固定的时间, O (1),当您尝试在更靠近列表或列表开头的位置插入元素时,平均时间复杂度会随着列表的大小而增加: O ( n )。另一方面,当在列表的开头或结尾插入和删除元素时,链表要简单得多,因为它们的时间复杂度总是恒定的: O (1)。
由于这个原因,当实现队列(FIFO)时,链表比普通的链表具有更好的性能,在队列中,元素在链表的开头不断地插入和删除。但是在实现栈(LIFO)时,它们的表现类似于链表,在栈中,元素在链表的末尾被插入和删除。
元素检索
当涉及到元素查找时,列表的性能比链表好得多。当你知道你想要访问哪个元素时,列表可以在 O (1)时间内执行这个操作。尝试对一个链表做同样的事情需要花费 O ( n )因为你需要遍历整个链表来找到元素。
然而,在搜索特定元素时,链表和链表的表现非常相似,时间复杂度为 O ( n )。在这两种情况下,您都需要遍历整个列表来找到您正在寻找的元素。
collections.deque简介在 Python 中,
collections模块中有一个可以用于链表的特定对象,名为 德克 (读作“deck”),代表双端队列。
collections.deque使用了一个链表的实现,在这个链表中,你可以在不变的 O (1)性能下访问、插入或移除列表开头或结尾的元素。如何使用
collections.deque默认情况下,有相当多的方法带有一个
deque对象。然而,在本文中,您将只触及其中的一些,主要是添加或删除元素。首先,您需要创建一个链表。您可以使用下面这段代码通过
deque来做到这一点:
>>> from collections import deque
>>> deque()
deque([])
上面的代码将创建一个空的链表。如果您想在创建时填充它,那么您可以给它一个 iterable 作为输入:
>>> deque(['a','b','c']) deque(['a', 'b', 'c']) >>> deque('abc') deque(['a', 'b', 'c']) >>> deque([{'data': 'a'}, {'data': 'b'}]) deque([{'data': 'a'}, {'data': 'b'}])当初始化一个
deque对象时,您可以将任何 iterable 作为输入传递,比如一个字符串(也是 iterable)或者一个对象列表。现在您已经知道如何创建一个
deque对象,您可以通过添加或删除元素来与它交互。你可以创建一个abcde链表并添加一个新元素f,如下所示:
>>> llist = deque("abcde")
>>> llist
deque(['a', 'b', 'c', 'd', 'e'])
>>> llist.append("f")
>>> llist
deque(['a', 'b', 'c', 'd', 'e', 'f'])
>>> llist.pop()
'f'
>>> llist
deque(['a', 'b', 'c', 'd', 'e'])
append()和pop()都在链表的右侧添加或移除元素。但是,您也可以使用deque快速添加或删除列表左侧的元素,或使用head:
>>> llist.appendleft("z") >>> llist deque(['z', 'a', 'b', 'c', 'd', 'e']) >>> llist.popleft() 'z' >>> llist deque(['a', 'b', 'c', 'd', 'e'])使用
deque对象在列表两端添加或删除元素非常简单。现在您已经准备好学习如何使用collections.deque来实现队列或堆栈。如何实现队列和堆栈
正如您在上面了解到的,队列和堆栈之间的主要区别在于您从两者中检索元素的方式。接下来,您将了解如何使用
collections.deque来实现这两种数据结构。队列
对于队列,您希望向列表中添加值(
enqueue),当时机合适时,您希望删除列表中最长的元素(dequeue)。例如,想象一下在一家时尚且客满的餐厅排队。如果您试图实现一个为客人安排座位的公平系统,那么您应该从创建一个队列并在客人到达时添加人员开始:
>>> from collections import deque
>>> queue = deque()
>>> queue
deque([])
>>> queue.append("Mary")
>>> queue.append("John")
>>> queue.append("Susan")
>>> queue
deque(['Mary', 'John', 'Susan'])
现在你有玛丽、约翰和苏珊在排队。记住,因为队列是先进先出的,所以第一个进入队列的人应该第一个出来。
现在想象一段时间过去了,有几张桌子空了出来。在此阶段,您希望以正确的顺序从队列中删除人员。你应该这样做:
>>> queue.popleft() 'Mary' >>> queue deque(['John', 'Susan']) >>> queue.popleft() 'John' >>> queue deque(['Susan'])每次调用
popleft()时,您都从链表中移除 head 元素,模拟现实生活中的队列。堆栈
如果您想创建一个堆栈呢?这个想法和排队差不多。唯一的区别是堆栈使用 LIFO 方法,这意味着堆栈中插入的最后一个元素应该首先被移除。
假设您正在创建一个 web 浏览器的历史功能,其中存储了用户访问的每个页面,以便他们可以轻松地回到过去。假设这些是随机用户在其浏览器上采取的操作:
- 访问真实 Python 的网站
- 导航到熊猫:如何读写文件
- 点击链接在 Python 中读写 CSV 文件
如果您想将此行为映射到堆栈中,那么您可以这样做:
>>> from collections import deque
>>> history = deque()
>>> history.appendleft("https://realpython.com/")
>>> history.appendleft("https://realpython.com/pandas-read-write-files/")
>>> history.appendleft("https://realpython.com/python-csv/")
>>> history
deque(['https://realpython.com/python-csv/',
'https://realpython.com/pandas-read-write-files/',
'https://realpython.com/'])
在这个例子中,您创建了一个空的history对象,每次用户访问一个新站点时,您使用appendleft()将它添加到您的history变量中。这样做确保了每个新元素都被添加到链表的head中。
现在假设用户阅读了两篇文章后,他们想返回到真正的 Python 主页去挑选一篇新文章来阅读。知道您有一个堆栈并想使用 LIFO 删除元素,您可以执行以下操作:
>>> history.popleft() 'https://realpython.com/python-csv/' >>> history.popleft() 'https://realpython.com/pandas-read-write-files/' >>> history deque(['https://realpython.com/'])这就对了。使用
popleft(),从链表的head中移除元素,直到到达真正的 Python 主页。从上面的例子中,您可以看到在您的工具箱中有
collections.deque是多么有用,所以下次您有基于队列或堆栈的挑战需要解决时,一定要使用它。实现你自己的链表
既然你已经知道了如何使用
collections.deque来处理链表,你可能想知道为什么你要在 Python 中实现你自己的链表。这样做有几个原因:
- 练习您的 Python 算法技能
- 学习数据结构理论
- 准备工作面试
如果您对以上任何内容都不感兴趣,或者您已经成功地用 Python 实现了自己的链表,请随意跳过下一节。不然就该实现一些链表了!
如何创建链表
首先,创建一个类来表示你的链表:
class LinkedList: def __init__(self): self.head = None你需要为一个链表存储的唯一信息是链表的起始位置(链表的
head)。接下来,创建另一个类来表示链表的每个节点:class Node: def __init__(self, data): self.data = data self.next = None在上面的类定义中,你可以看到每个单个节点的两个主要元素:
data和next。您还可以在两个类中添加一个__repr__,以便更好地表示对象:class Node: def __init__(self, data): self.data = data self.next = None def __repr__(self): return self.data class LinkedList: def __init__(self): self.head = None def __repr__(self): node = self.head nodes = [] while node is not None: nodes.append(node.data) node = node.next nodes.append("None") return " -> ".join(nodes)看一个使用上面的类快速创建一个有三个节点的链表的例子:
>>> llist = LinkedList()
>>> llist
None
>>> first_node = Node("a")
>>> llist.head = first_node
>>> llist
a -> None
>>> second_node = Node("b")
>>> third_node = Node("c")
>>> first_node.next = second_node
>>> second_node.next = third_node
>>> llist
a -> b -> c -> None
通过定义节点的data和next值,您可以非常快速地创建一个链表。这些LinkedList和Node类是我们实现的起点。从现在开始,一切都是为了增加他们的功能。
这里对链表的__init__()做了一个小小的改变,让你可以快速创建一些数据的链表:
def __init__(self, nodes=None):
self.head = None
if nodes is not None:
node = Node(data=nodes.pop(0))
self.head = node
for elem in nodes:
node.next = Node(data=elem)
node = node.next
通过上面的修改,创建下面例子中使用的链表将会快得多。
如何遍历链表
你对链表做的最常见的事情之一就是遍历它。遍历意味着遍历每一个节点,从链表的head开始,到next值为None的节点结束。
遍历只是迭代的一种更好的说法。因此,记住这一点,创建一个__iter__来向链表添加与普通列表相同的行为:
def __iter__(self):
node = self.head
while node is not None:
yield node
node = node.next
上面的方法遍历列表,产生每个节点的。关于这个__iter__要记住的最重要的事情是,你需要始终验证当前的node不是None。当条件为True时,意味着已经到达链表的末尾。
在生成当前节点后,您希望移动到列表中的下一个节点。这就是你加node = node.next的原因。下面是一个遍历随机列表并打印每个节点的例子:
>>> llist = LinkedList(["a", "b", "c", "d", "e"]) >>> llist a -> b -> c -> d -> e -> None >>> for node in llist: ... print(node) a b c d e在其他文章中,您可能会看到遍历被定义到一个名为
traverse()的特定方法中。然而,使用 Python 的内置方法来实现上述行为,使得这个链表的实现更加Python 化。如何插入新节点
将新节点插入链表有不同的方法,每种方法都有自己的实现和复杂程度。这就是为什么你会看到它们被分成特定的方法,用于在列表的开头、结尾或节点之间插入。
在开头插入
在列表的开头插入一个新的节点可能是最直接的插入方式,因为你不需要遍历整个列表。这都是关于创建一个新节点,然后将列表的
head指向它。看看下面这个类
LinkedList的add_first()实现:def add_first(self, node): node.next = self.head self.head = node在上面的例子中,您将
self.head设置为新节点的next引用,以便新节点指向旧的self.head。之后,您需要声明列表的新head是插入的节点。下面是它在示例列表中的表现:
>>> llist = LinkedList()
>>> llist
None
>>> llist.add_first(Node("b"))
>>> llist
b -> None
>>> llist.add_first(Node("a"))
>>> llist
a -> b -> None
如您所见,add_first()总是将节点添加到列表的head中,即使列表之前是空的。
在末尾插入
在列表末尾插入一个新节点会迫使您首先遍历整个链表,并在到达末尾时添加新节点。你不能像普通链表那样追加到末尾,因为在链表中你不知道哪个节点是最后一个。
下面是一个在链表末尾插入节点的函数的实现示例:
def add_last(self, node):
if self.head is None:
self.head = node
return
for current_node in self:
pass
current_node.next = node
首先,你要遍历整个列表,直到到达末尾(也就是说,直到 for循环引发一个StopIteration异常)。接下来,您希望将current_node设置为列表中的最后一个节点。最后,您希望添加新节点作为那个current_node的next值。
这里有一个add_last()的例子:
>>> llist = LinkedList(["a", "b", "c", "d"]) >>> llist a -> b -> c -> d -> None >>> llist.add_last(Node("e")) >>> llist a -> b -> c -> d -> e -> None >>> llist.add_last(Node("f")) >>> llist a -> b -> c -> d -> e -> f -> None在上面的代码中,首先创建一个包含四个值的列表(
a、b、c和d)。然后,当您使用add_last()添加新节点时,您可以看到这些节点总是被追加到列表的末尾。在两个节点之间插入
在两个节点之间插入又增加了一层复杂性,因为有两种不同的方法可以使用:
- 在现有节点后插入
** 在现有节点之前插入*将它们分成两个方法可能看起来很奇怪,但是链表的行为不同于普通的链表,每种情况都需要不同的实现。
下面是一个方法,它在具有特定数据值的现有节点后添加一个节点:
def add_after(self, target_node_data, new_node): if self.head is None: raise Exception("List is empty") for node in self: if node.data == target_node_data: new_node.next = node.next node.next = new_node return raise Exception("Node with data '%s' not found" % target_node_data)在上面的代码中,您正在遍历链表,寻找带有数据的节点,该数据指示您想要插入新节点的位置。当您找到您正在寻找的节点时,您将在它之后立即插入新节点,并重新连接
next引用以保持列表的一致性。唯一的例外是列表为空,使得无法在现有节点后插入新节点,或者列表不包含要搜索的值。以下是几个关于
add_after()行为的例子:
>>> llist = LinkedList()
>>> llist.add_after("a", Node("b"))
Exception: List is empty
>>> llist = LinkedList(["a", "b", "c", "d"])
>>> llist
a -> b -> c -> d -> None
>>> llist.add_after("c", Node("cc"))
>>> llist
a -> b -> c -> cc -> d -> None
>>> llist.add_after("f", Node("g"))
Exception: Node with data 'f' not found
试图在空列表上使用add_after()会导致异常。当您试图在一个不存在的节点后添加时,也会发生同样的情况。其他一切都按预期运行。
现在,如果你想实现add_before(),那么它看起来会像这样:
1def add_before(self, target_node_data, new_node):
2 if self.head is None: 3 raise Exception("List is empty")
4
5 if self.head.data == target_node_data: 6 return self.add_first(new_node)
7
8 prev_node = self.head
9 for node in self: 10 if node.data == target_node_data:
11 prev_node.next = new_node
12 new_node.next = node
13 return
14 prev_node = node
15
16 raise Exception("Node with data '%s' not found" % target_node_data)
在实现上述内容时,有一些事情需要记住。首先,和add_after()一样,如果链表是空的(第 2 行)或者您正在寻找的节点不存在(第 16 行),您希望确保引发一个异常。
其次,如果您试图在列表的头部(第 5 行)之前添加一个新节点,那么您可以重用add_first(),因为您插入的节点将是列表的新head。
最后,对于任何其他情况(第 9 行),您应该使用prev_node变量跟踪最后检查的节点。然后,当您找到目标节点时,您可以使用那个prev_node变量来重新连接next值。
再说一次,一个例子胜过千言万语:
>>> llist = LinkedList() >>> llist.add_before("a", Node("a")) Exception: List is empty >>> llist = LinkedList(["b", "c"]) >>> llist b -> c -> None >>> llist.add_before("b", Node("a")) >>> llist a -> b -> c -> None >>> llist.add_before("b", Node("aa")) >>> llist.add_before("c", Node("bb")) >>> llist a -> aa -> b -> bb -> c -> None >>> llist.add_before("n", Node("m")) Exception: Node with data 'n' not found有了
add_before(),您现在拥有了在列表中任意位置插入节点所需的所有方法。如何删除一个节点
要从链表中删除一个节点,首先需要遍历链表,直到找到要删除的节点。找到目标后,您希望链接它的上一个和下一个节点。这种重新链接是从列表中删除目标节点的原因。
这意味着在遍历列表时,需要跟踪上一个节点。请看一个示例实现:
1def remove_node(self, target_node_data): 2 if self.head is None: 3 raise Exception("List is empty") 4 5 if self.head.data == target_node_data: 6 self.head = self.head.next 7 return 8 9 previous_node = self.head 10 for node in self: 11 if node.data == target_node_data: 12 previous_node.next = node.next 13 return 14 previous_node = node 15 16 raise Exception("Node with data '%s' not found" % target_node_data)在上面的代码中,您首先检查您的列表是否为空(第 2 行)。如果是,那么您将引发一个异常。之后,检查要删除的节点是否是列表的当前
head(第 5 行)。如果是,那么您希望列表中的下一个节点成为新的head。如果上述情况都没有发生,那么您开始遍历列表,寻找要删除的节点(第 10 行)。如果您找到了它,那么您需要更新它的前一个节点以指向它的下一个节点,自动从列表中删除找到的节点。最后,如果遍历整个列表,却没有找到要删除的节点(第 16 行),那么就会引发一个异常。
注意在上面的代码中,你如何使用
previous_node来跟踪上一个节点。这样做可以确保当您找到要删除的正确节点时,整个过程会简单得多。下面是一个使用列表的示例:
>>> llist = LinkedList()
>>> llist.remove_node("a")
Exception: List is empty
>>> llist = LinkedList(["a", "b", "c", "d", "e"])
>>> llist
a -> b -> c -> d -> e -> None
>>> llist.remove_node("a")
>>> llist
b -> c -> d -> e -> None
>>> llist.remove_node("e")
>>> llist
b -> c -> d -> None
>>> llist.remove_node("c")
>>> llist
b -> d -> None
>>> llist.remove_node("a")
Exception: Node with data 'a' not found
就是这样!现在,您已经知道了如何实现一个链表,以及遍历、插入和删除节点的所有主要方法。如果你对你所学的感到满意,并且渴望更多,那么请随意选择下面的一个挑战:
- 创建一个方法从特定的位置检索元素:
get(i)甚至llist[i]。 - 创建反转链表的方法:
llist.reverse()。 - 用
enqueue()和dequeue()方法创建一个继承这篇文章的链表的Queue()对象。
除了是很好的练习,自己做一些额外的挑战也是吸收你所获得的所有知识的有效方法。如果您想重用本文中的所有源代码,那么您可以从下面的链接下载您需要的所有内容:
获取源代码: 点击此处获取源代码,您将使用在本教程中学习链表。
使用高级链表
到目前为止,你已经学习了一种叫做单链表的特定类型的链表。但是有更多类型的链表可以用于稍微不同的目的。
如何使用双向链表
双向链表不同于单向链表,因为它们有两个引用:
previous字段引用前一个节点。next字段引用下一个节点。
最终结果如下所示:

如果您想要实现上述内容,那么您可以对现有的Node类进行一些更改,以便包含一个previous字段:
class Node:
def __init__(self, data):
self.data = data
self.next = None
self.previous = None
这种实现将允许您双向遍历列表,而不仅仅是使用next来遍历。你可以用next前进,用previous后退。
就结构而言,双向链表应该是这样的:
您之前了解到collections.deque使用链表作为其数据结构的一部分。这就是它使用的那种链表。使用双向链表,deque能够在队列的两端插入或删除元素,并且具有恒定的 O (1)性能。
如何使用循环链表
循环链表是最后一个节点指向链表的head而不是指向None的一种链表。这就是为什么它们是圆形的。循环链表有很多有趣的用例:
- 在多人游戏中,每个玩家轮流玩
- 管理给定操作系统的应用程序生命周期
- 实现一个斐波那契堆
循环链表是这样的:

循环链表的优点之一是可以从任意节点开始遍历整个链表。由于最后一个节点指向列表的head,所以需要确保在到达起点时停止遍历。否则,你会陷入无限循环。
在实现方面,循环链表和单链表非常相似。唯一的区别是,您可以在遍历列表时定义起点:
class CircularLinkedList:
def __init__(self):
self.head = None
def traverse(self, starting_point=None):
if starting_point is None:
starting_point = self.head
node = starting_point
while node is not None and (node.next != starting_point):
yield node
node = node.next
yield node
def print_list(self, starting_point=None):
nodes = []
for node in self.traverse(starting_point):
nodes.append(str(node))
print(" -> ".join(nodes))
现在遍历列表会收到一个额外的参数starting_point,用于定义迭代过程的开始和结束(因为列表是循环的)。除此之外,大部分代码和我们在LinkedList类中的一样。
作为最后一个例子的总结,看看当你给它一些数据时,这种新类型的列表是如何表现的:
>>> circular_llist = CircularLinkedList() >>> circular_llist.print_list() None >>> a = Node("a") >>> b = Node("b") >>> c = Node("c") >>> d = Node("d") >>> a.next = b >>> b.next = c >>> c.next = d >>> d.next = a >>> circular_llist.head = a >>> circular_llist.print_list() a -> b -> c -> d >>> circular_llist.print_list(b) b -> c -> d -> a >>> circular_llist.print_list(d) d -> a -> b -> c你有它!您会注意到在遍历列表时不再有
None。这是因为循环列表没有特定的结尾。您还可以看到,选择不同的起始节点将呈现相同列表的稍微不同的表示。结论
在这篇文章中,你学到了不少东西!最重要的是:
- 什么是链表,什么时候应该使用它们
- 如何使用
collections.deque实现队列和堆栈- 如何实现你自己的链表和节点类,以及相关的方法
- 其他类型的链表是什么,它们可以用来做什么
如果你想了解更多关于链表的知识,那么看看 Vaidehi Joshi 的博文中一个漂亮的视觉解释。如果你对更深入的指南感兴趣,那么维基百科文章相当全面。最后,如果你对当前实现
collections.deque背后的推理感到好奇,那么看看雷蒙德·赫廷格的线程。您可以点击以下链接下载本教程中使用的源代码:
获取源代码: 点击此处获取源代码,您将使用在本教程中学习链表。
欢迎在下面留下任何问题或评论。快乐的蟒蛇!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 处理链表********
Django 的 LinkedIn 社交认证
原文:https://realpython.com/linkedin-social-authentication-in-django/
社交认证(或社交登录)是一种简化最终用户登录的方法,它使用来自流行社交网络服务的现有登录信息,如脸书、推特、谷歌、 LinkedIn (本文重点)等等。大多数需要用户登录的网站利用社交登录平台来获得更好的认证/注册体验,而不是开发自己的系统。
Python Social Auth 提供了一种机制,可以轻松地建立一个认证/注册系统,该系统支持多种框架和认证提供者。
在本教程中,我们将详细演示如何将这个库集成到您的 Django 项目中,以便使用 OAuth 2.0 通过 LinkedIn 提供用户认证。
什么是 OAuth 2.0?
OAuth 2.0 是一个授权框架,它允许应用程序通过流行的社交网络服务访问最终用户的帐户进行身份验证/注册。最终用户可以选择应用程序可以访问哪些细节。它专注于简化开发工作流,同时为 web 应用程序和桌面应用程序、移动电话和 IOT(物联网)设备提供特定的授权流。
环境和 Django 设置
我们将使用:
- python3.4.2
- Django v1.8.4
- python-social-auth v0.2.12
如果你已经有了一个 virtualenv 和一个 Django 项目并准备好了,请随意跳过这一部分。
创建虚拟人
$ mkvirtualenv --python='/usr/bin/python3.4' django_social_project $ pip install django==1.8.4开始一个新的 Django 项目
引导 Django 应用程序:
$ django-admin.py startproject django_social_project $ cd django_social_project $ python manage.py startapp django_social_app不要忘记将应用添加到 settings.py 中的
INSTALLED_APPS元组,让我们的项目知道我们已经创建了一个应用,它需要作为 Django 项目的一部分。设置初始表格
$ python manage.py migrate Operations to perform: Synchronize unmigrated apps: messages, staticfiles Apply all migrations: sessions, admin, auth, contenttypes Synchronizing apps without migrations: Creating tables... Running deferred SQL... Installing custom SQL... Running migrations: Rendering model states... DONE Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying sessions.0001_initial... OK添加超级用户
$ python manage.py syncdb创建一个模板目录
在项目根目录下创建一个名为“templates”的新目录,然后在 settings.py 文件中添加
TEMPLATES的正确路径:TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ]运行健全性检查
启动开发服务器-
python manage.py runserver以确保一切正常,然后导航到 http://127.0.0.1:8000/ 。你应该看到“成功了!”页面。您的项目应该如下所示:
└── django_social_project ├── db.sqlite3 ├── django_social_app │ ├── __init__.py │ ├── admin.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── django_social_project │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── templatesPython 社交认证设置
遵循以下步骤和/或官方安装指南来安装和设置基本配置,以使我们的应用程序能够通过任何社交网络服务处理社交登录。
安装
用 pip 安装:
$ pip install python-social-auth==0.2.12配置
更新 settings.py 以在我们的项目中包含/注册该库:
INSTALLED_APPS = ( 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'django_social_app', 'social.apps.django_app.default', ) TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.core.context_processors.debug', 'django.core.context_processors.i18n', 'django.core.context_processors.media', 'django.core.context_processors.static', 'django.core.context_processors.tz', 'django.contrib.messages.context_processors.messages', 'social.apps.django_app.context_processors.backends', 'social.apps.django_app.context_processors.login_redirect', ], }, }, ]注意:由于我们使用 LinkedIn 社交认证,我们需要 Linkedin OAuth2 后端:
AUTHENTICATION_BACKENDS = ( 'social.backends.linkedin.LinkedinOAuth2', 'django.contrib.auth.backends.ModelBackend', )运行迁移
一旦注册,更新数据库:
$ python manage.py makemigrations $ python manage.py migrate更新网址
在项目的 urls.py 文件中,更新 urlpatters 以包含主 auth URLs:
urlpatterns = [ url(r'^admin/', include(admin.site.urls)), url('', include('social.apps.django_app.urls', namespace='social')), ]接下来,我们需要从 LinkedIn 应用程序中获取所需的认证密钥。这一过程与许多流行的社交网络类似,比如 Twitter、脸书和谷歌。
LinkedIn 认证密钥
为了让我们的应用程序清楚地识别我们实现的 LinkedIn 社交登录,我们需要一些特定于应用程序的凭据,以区分我们的应用程序登录和网络上的其他社交登录。
在https://www.linkedin.com/developer/apps创建一个新的应用程序,并确保使用一个回调/重定向 URLhttp://127 . 0 . 0 . 1:8000/complete/LinkedIn-oauth 2/(非常重要!).请记住,这个 URL 是特定于 OAuth 2.0 的。
注意:上面使用的回调 URL 仅在本地开发中有效,当您转移到生产或试运行环境时需要更改。
在“django_social_project”目录中,添加一个名为 config.py 的新文件。然后从 LinkedIn 获取消费者密钥(API 密钥)和消费者秘密(API 秘密),并将它们添加到文件中:
SOCIAL_AUTH_LINKEDIN_OAUTH2_KEY = 'update me' SOCIAL_AUTH_LINKEDIN_OAUTH2_SECRET = 'update me'让我们将以下 URL 添加到 config.py 文件中,以指定登录和重定向 URL(在用户验证之后):
SOCIAL_AUTH_LOGIN_REDIRECT_URL = '/home/' SOCIAL_AUTH_LOGIN_URL = '/'将以下导入添加到 settings.py
from config import *为了让我们的应用程序成功完成登录过程,我们需要定义与这些 URL 相关联的模板和视图。让我们现在做那件事。
友好的观点
为了检查我们的应用程序是否工作,我们只需要两个视图- 登录和主页。
URLs
更新项目的 urls.py 文件中的 urlpatterns,以将我们的 URL 映射到我们将在后续部分中看到的视图:
urlpatterns = [ url(r'^admin/', include(admin.site.urls)), url('', include('social.apps.django_app.urls', namespace='social')), url(r'^$', 'django_social_app.views.login'), url(r'^home/$', 'django_social_app.views.home'), url(r'^logout/$', 'django_social_app.views.logout'), ]视图
现在,将视图添加到应用程序的 views.py 中,以使我们的路线知道当特定路线被击中时应该做什么。
from django.shortcuts import render_to_response, redirect from django.contrib.auth import logout as auth_logout from django.contrib.auth.decorators import login_required from django.template.context import RequestContext def login(request): return render_to_response('login.html', context=RequestContext(request)) @login_required(login_url='/') def home(request): return render_to_response('home.html') def logout(request): auth_logout(request) return redirect('/')因此,在登录函数中,我们使用
RequestContext获取登录的用户。模板
将两个模板添加到“模板”文件夹-login.html:
<!-- login.html --> {% if user and not user.is_anonymous %} <a>Hello, {{ user.get_full_name }}!</a> <br> <a href="/logout">Logout</a> {% else %} <a href="{% url 'social:begin' backend='linkedin-oauth2' %}">Login with Linkedin</a> {% endif %}还有home.html:
<!-- home.html --> <h1>Welcome</h1> <br> <p><a href="/logout">Logout</a>您的项目现在应该如下所示:
└── django_social_project ├── db.sqlite3 ├── django_social_app │ ├── __init__.py │ ├── admin.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── django_social_project │ ├── __init__.py │ ├── config.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── templates ├── home.html └── login.html测试!
现在只需再次启动服务器进行测试:
$ python manage.py runserver只需浏览到 http://127.0.0.1:8000/ 就会看到一个“用 LinkedIn 登录”的超链接。测试一下,确保一切正常。
抢码这里。干杯!***
Python 中何时使用列表理解
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 理解 Python 列表理解
Python 以允许您编写优雅、易于编写、几乎和普通英语一样易读的代码而闻名。该语言最与众不同的特性之一是列表理解,您可以使用它在一行代码中创建强大的功能。然而,许多开发人员努力充分利用 Python 中列表理解的更高级特性。一些程序员甚至过度使用它们,这会导致代码效率更低,更难阅读。
本教程结束时,您将了解 Python list comprehensions 的全部功能,以及如何舒适地使用它们的特性。您还将了解使用这些方法的利弊,这样您就可以决定何时使用其他方法更好。
在本教程中,您将学习如何:
- 用 Python 重写循环和
map()调用作为列表理解- 在理解、循环和
map()调用之间选择- 用条件逻辑增强你的理解力
- 用理解代替
filter()- 剖析您的代码以解决性能问题
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
如何在 Python 中创建列表
在 Python 中有几种不同的方法可以创建列表。为了更好地理解在 Python 中使用列表理解的利弊,让我们首先看看如何用这些方法创建列表。
使用
for循环最常见的循环类型是
for循环。您可以使用一个for循环分三步创建一个元素列表:
- 实例化一个空列表。
- 循环遍历可迭代或范围的元素。
- 将每个元素追加到列表的末尾。
如果您想创建一个包含前十个完美方块的列表,那么您可以用三行代码完成这些步骤:
>>> squares = []
>>> for i in range(10):
... squares.append(i * i)
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
在这里,您实例化了一个空列表squares。然后,使用一个for循环来迭代range(10)。最后,将每个数字乘以自身,并将结果附加到列表的末尾。
使用map()对象
map() 提供了另一种基于函数式编程的方法。你传入一个函数和一个 iterable,然后map()会创建一个对象。这个对象包含通过提供的函数运行每个 iterable 元素得到的输出。
例如,考虑这样一种情况,您需要计算一系列交易的税后价格:
>>> txns = [1.09, 23.56, 57.84, 4.56, 6.78] >>> TAX_RATE = .08 >>> def get_price_with_tax(txn): ... return txn * (1 + TAX_RATE) >>> final_prices = map(get_price_with_tax, txns) >>> list(final_prices) [1.1772000000000002, 25.4448, 62.467200000000005, 4.9248, 7.322400000000001]这里,你有一个可迭代的
txns和一个函数get_price_with_tax()。您将这两个参数传递给map(),并将结果对象存储在final_prices中。您可以使用list()轻松地将这个地图对象转换成一个列表。使用列表理解
列表理解是列表的第三种方式。使用这种优雅的方法,您可以用一行代码重写第一个示例中的
for循环:
>>> squares = [i * i for i in range(10)]
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
您只需按照以下格式同时定义列表及其内容,而不是创建一个空列表并将每个元素添加到末尾:
new_list = [expression for member in iterable]Python 中的每个列表理解都包括三个元素:
expression是成员本身、对方法的调用或者任何其他返回值的有效表达式。在上面的例子中,表达式i * i是成员值的平方。member是列表中的对象或值或 iterable。在上面的例子中,成员值是i。iterable是一个列表、集合、序列、生成器,或者任何其他可以一次返回一个元素的对象。在上面的例子中,iterable 是range(10)。因为表达式的需求非常灵活,所以 Python 中的列表理解在很多你会用到
map()的地方都工作得很好。您可以用自己的列表理解重写定价示例:
>>> txns = [1.09, 23.56, 57.84, 4.56, 6.78]
>>> TAX_RATE = .08
>>> def get_price_with_tax(txn):
... return txn * (1 + TAX_RATE)
>>> final_prices = [get_price_with_tax(i) for i in txns] >>> final_prices
[1.1772000000000002, 25.4448, 62.467200000000005, 4.9248, 7.322400000000001]
这个实现和map()的唯一区别是 Python 中的 list comprehension 返回一个列表,而不是一个 map 对象。
使用列表理解的好处
列表理解通常被描述为比循环或 T0 更具 T2 风格。但是,与其盲目接受这种评价,不如理解在 Python 中使用列表理解与其他选择相比的好处。稍后,您将了解替代方案是更好选择的一些场景。
在 Python 中使用 list comprehension 的一个主要好处是,它是一个可以在许多不同情况下使用的单一工具。除了标准的列表创建之外,列表理解还可以用于映射和过滤。您不必为每个场景使用不同的方法。
这就是为什么列表理解被认为是Python的主要原因,因为 Python 包含了简单而强大的工具,可以在各种各样的情况下使用。一个额外的好处是,无论何时在 Python 中使用 list comprehension,您都不需要像调用map()时那样记住参数的正确顺序。
列表理解也比循环更具有声明性,这意味着它们更容易阅读和理解。循环要求你关注列表是如何创建的。您必须手动创建一个空列表,循环遍历元素,并将每个元素添加到列表的末尾。有了对 Python 中列表的理解,你可以专注于你想在列表中放什么,并且相信 Python 会处理如何列表的构造。
如何增强你的理解力
为了理解列表理解能够提供的全部价值,理解它们可能的功能范围是有帮助的。你也会想了解在 Python 3.8 中列表理解的变化。
使用条件逻辑
前面,您看到了如何创建列表理解的公式:
new_list = [expression for member in iterable]虽然这个公式是准确的,但它也有点不完整。对理解公式更完整的描述增加了对可选的条件句的支持。将条件逻辑添加到列表理解中最常见的方法是在表达式的末尾添加一个条件:
new_list = [expression for member in iterable (if conditional)]
这里,您的条件语句就在右括号之前。
条件非常重要,因为它们允许列表理解过滤掉不需要的值,这通常需要调用 filter() :
>>> sentence = 'the rocket came back from mars' >>> vowels = [i for i in sentence if i in 'aeiou'] >>> vowels ['e', 'o', 'e', 'a', 'e', 'a', 'o', 'a']在这个代码块中,条件语句过滤掉
sentence中不是元音的任何字符。条件可以测试任何有效的表达式。如果您需要一个更复杂的过滤器,那么您甚至可以将条件逻辑移到一个单独的函数中:
>>> sentence = 'The rocket, who was named Ted, came back \
... from Mars because he missed his friends.'
>>> def is_consonant(letter):
... vowels = 'aeiou'
... return letter.isalpha() and letter.lower() not in vowels
>>> consonants = [i for i in sentence if is_consonant(i)]
['T', 'h', 'r', 'c', 'k', 't', 'w', 'h', 'w', 's', 'n', 'm', 'd', \
'T', 'd', 'c', 'm', 'b', 'c', 'k', 'f', 'r', 'm', 'M', 'r', 's', 'b', \
'c', 's', 'h', 'm', 's', 's', 'd', 'h', 's', 'f', 'r', 'n', 'd', 's']
在这里,您创建了一个复杂的过滤器is_consonant(),并将这个函数作为条件语句传递给您的列表理解。注意,成员值i也作为参数传递给函数。
您可以将条件放在语句的末尾进行简单的过滤,但是如果您想要更改一个成员值而不是将其过滤掉,该怎么办呢?在这种情况下,将条件放在表达式的开头附近很有用:
new_list = [expression (if conditional) for member in iterable]使用此公式,您可以使用条件逻辑从多个可能的输出选项中进行选择。例如,如果您有一个价格列表,那么您可能希望用
0替换负价格,而保持正值不变:
>>> original_prices = [1.25, -9.45, 10.22, 3.78, -5.92, 1.16]
>>> prices = [i if i > 0 else 0 for i in original_prices]
>>> prices
[1.25, 0, 10.22, 3.78, 0, 1.16]
这里,您的表达式i包含一个条件语句if i > 0 else 0。这告诉 Python 如果数字是正数就输出i的值,但是如果数字是负数就把i改为0。如果这看起来让人不知所措,那么将条件逻辑视为其自身的功能可能会有所帮助:
>>> def get_price(price): ... return price if price > 0 else 0 >>> prices = [get_price(i) for i in original_prices] >>> prices [1.25, 0, 10.22, 3.78, 0, 1.16]现在,您的条件语句包含在
get_price()中,您可以将它用作列表理解表达式的一部分。使用集合和字典理解
虽然 Python 中的 list comprehension 是一个常用工具,但是您也可以创建 set 和dictionarycomprehension。一个集合理解和 Python 中的列表理解几乎完全一样。区别在于集合理解确保输出不包含重复项。您可以通过使用花括号而不是括号来创建一个集合理解:
>>> quote = "life, uh, finds a way"
>>> unique_vowels = {i for i in quote if i in 'aeiou'}
>>> unique_vowels
{'a', 'e', 'u', 'i'}
您的 set comprehension 会输出在quote中找到的所有独特元音。与列表不同,集合不保证项目将以任何特定的顺序保存。这就是为什么集合中的第一个成员是a,尽管quote中的第一个元音是i。
字典理解是相似的,额外的要求是定义一个键:
>>> squares = {i: i * i for i in range(10)} >>> squares {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}为了创建
squares字典,在表达式中使用花括号({})和键值对(i: i * i)。使用 Walrus 运算符
Python 3.8 将引入赋值表达式,也被称为海象运算符。为了理解如何使用它,考虑下面的例子。
假设您需要向一个将返回温度数据的 API 发出十个请求。您只想返回大于 100 华氏度的结果。假设每个请求将返回不同的数据。在这种情况下,无法使用 Python 中的列表理解来解决这个问题。公式
expression for member in iterable (if conditional)没有为条件提供将数据赋给表达式可以访问的变量的方法。海象运营商 T2 解决了这个问题。它允许您在将输出值赋给变量的同时运行表达式。下面的例子展示了这是如何实现的,使用
get_weather_data()来生成假的天气数据:
>>> import random
>>> def get_weather_data():
... return random.randrange(90, 110)
>>> hot_temps = [temp for _ in range(20) if (temp := get_weather_data()) >= 100]
>>> hot_temps
[107, 102, 109, 104, 107, 109, 108, 101, 104]
在 Python 的 list comprehension 中,您不经常需要使用赋值表达式,但在必要时,它是一个非常有用的工具。
Python 中何时不使用列表理解
列表理解非常有用,可以帮助您编写易于阅读和调试的优雅代码,但是它们并不是所有情况下的正确选择。它们可能会使您的代码运行得更慢或使用更多的内存。如果您的代码性能较差或难以理解,那么最好选择一种替代方案。
小心嵌套的理解
理解可以嵌套以在集合中创建列表、字典和集合的组合。例如,假设一个气候实验室正在跟踪六月第一周五个不同城市的高温。存储这些数据的完美数据结构可以是嵌套在字典理解中的 Python 列表理解:
>>> cities = ['Austin', 'Tacoma', 'Topeka', 'Sacramento', 'Charlotte'] >>> temps = {city: [0 for _ in range(7)] for city in cities} >>> temps { 'Austin': [0, 0, 0, 0, 0, 0, 0], 'Tacoma': [0, 0, 0, 0, 0, 0, 0], 'Topeka': [0, 0, 0, 0, 0, 0, 0], 'Sacramento': [0, 0, 0, 0, 0, 0, 0], 'Charlotte': [0, 0, 0, 0, 0, 0, 0] }您用字典理解创建外部集合
temps。这个表达式是一个键值对,它包含了另一种理解。这段代码将快速生成cities中每个城市的数据列表。嵌套列表是创建矩阵的常用方法,通常用于数学目的。看看下面的代码块:
>>> matrix = [[i for i in range(5)] for _ in range(6)]
>>> matrix
[
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]
]
外部列表理解[... for _ in range(6)]创建六行,而内部列表理解[i for i in range(5)]用值填充每一行。
到目前为止,每个嵌套理解的目的都非常直观。然而,还有其他情况,比如展平嵌套列表,其中的逻辑可能会使您的代码更加混乱。以这个例子为例,它使用嵌套列表理解来展平矩阵:
matrix = [ ... [0, 0, 0], ... [1, 1, 1], ... [2, 2, 2], ... ] >>> flat = [num for row in matrix for num in row] >>> flat [0, 0, 0, 1, 1, 1, 2, 2, 2]展平矩阵的代码很简洁,但理解它的工作原理可能不那么直观。另一方面,如果您使用
for循环来展平同一个矩阵,那么您的代码会简单得多:
>>> matrix = [
... [0, 0, 0],
... [1, 1, 1],
... [2, 2, 2],
... ]
>>> flat = []
>>> for row in matrix:
... for num in row:
... flat.append(num)
...
>>> flat
[0, 0, 0, 1, 1, 1, 2, 2, 2]
现在您可以看到代码一次遍历矩阵的一行,在移动到下一行之前取出该行中的所有元素。
虽然单行嵌套列表理解可能看起来更 Pythonic 化,但最重要的是编写您的团队可以容易理解和修改的代码。当你选择你的方法时,你必须根据你认为理解有助于还是有损于可读性来做出判断。
为大型数据集选择生成器
Python 中的列表理解通过将整个输出列表加载到内存中来实现。对于小型甚至中型的列表,这通常是好的。如果你想计算前 1000 个整数的平方和,那么列表理解可以很好地解决这个问题:
>>> sum([i * i for i in range(1000)]) 332833500但是如果你想计算前十亿个整数的平方和呢?如果您在您的机器上尝试了,那么您可能会注意到您的计算机变得没有响应。这是因为 Python 试图创建一个包含 10 亿个整数的列表,这会消耗比你的计算机所希望的更多的内存。您的计算机可能没有生成庞大列表并将其存储在内存中所需的资源。如果你试图这样做,那么你的机器可能会变慢甚至崩溃。
当列表的大小有问题时,使用一个生成器来代替 Python 中的列表理解通常是有帮助的。一个生成器不会在内存中创建一个单一的大型数据结构,而是返回一个 iterable。您的代码可以根据需要多次从 iterable 中请求下一个值,或者直到到达序列的末尾,同时一次只存储一个值。
如果你要用一个生成器对前十亿个平方求和,那么你的程序可能会运行一段时间,但不会导致你的计算机死机。以下示例使用了一个生成器:
>>> sum(i * i for i in range(1000000000))
333333332833333333500000000
您可以看出这是一个生成器,因为表达式没有用括号或花括号括起来。或者,生成器可以用括号括起来。
上面的例子仍然需要大量的工作,但是它缓慢地执行了操作**。由于惰性求值,只有在显式请求时才会计算值。在生成器生成一个值(例如,567 * 567)后,它可以将该值添加到运行总和中,然后丢弃该值并生成下一个值(568 * 568)。当 sum 函数请求下一个值时,循环重新开始。这个过程保持了较小的内存占用。*
*map()也运行缓慢,这意味着如果您选择在这种情况下使用内存,它将不是问题:
>>> sum(map(lambda i: i*i, range(1000000000))) 333333332833333333500000000你更喜欢生成器表达式还是
map()由你决定。优化性能的配置文件
那么,哪种方法更快呢?你应该使用列表理解还是它们的替代品?与其坚持一个在所有情况下都适用的规则,不如问问自己在你的具体情况下,表现是否重要。如果不是,那么通常最好选择能产生最干净代码的方法!
如果你处在一个性能很重要的场景中,那么通常最好的方法是描述不同的方法并倾听数据。
timeit是一个有用的库,用于计时大块代码运行的时间。您可以使用timeit来比较map()、for循环的运行时间,并列出理解:
>>> import random
>>> import timeit
>>> TAX_RATE = .08
>>> txns = [random.randrange(100) for _ in range(100000)]
>>> def get_price(txn):
... return txn * (1 + TAX_RATE)
...
>>> def get_prices_with_map():
... return list(map(get_price, txns))
...
>>> def get_prices_with_comprehension():
... return [get_price(txn) for txn in txns]
...
>>> def get_prices_with_loop():
... prices = []
... for txn in txns:
... prices.append(get_price(txn))
... return prices
...
>>> timeit.timeit(get_prices_with_map, number=100)
2.0554370979998566
>>> timeit.timeit(get_prices_with_comprehension, number=100)
2.3982384680002724
>>> timeit.timeit(get_prices_with_loop, number=100)
3.0531821520007725
这里,您定义了三种方法,每种方法使用不同的方法来创建列表。然后,你告诉timeit每个函数运行 100 次。timeit返回运行这 100 次执行所花费的总时间。
正如代码所展示的,基于循环的方法和map()之间最大的区别是,循环的执行时间延长了 50%。这是否重要取决于您的应用程序的需求。
结论
在本教程中,您学习了如何使用 Python 中的列表理解来完成复杂的任务,而不会使您的代码过于复杂。
现在您可以:
- 用声明性列表理解简化循环和
map()调用 - 用条件逻辑增强你的理解力
- 创建集合和字典释义
- 确定何时代码清晰性或性能决定了替代方法
每当您必须选择一种列表创建方法时,请尝试多种实现,并考虑在您的特定场景中最容易阅读和理解的是什么。如果性能很重要,那么您可以使用分析工具为您提供可操作的数据,而不是依靠直觉或猜测来判断什么是最好的。
请记住,虽然 Python 列表理解得到了很多关注,但您的直觉和使用数据的能力将帮助您编写干净的代码来完成手头的任务。最终,这是使您的代码 Pythonic 化的关键!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 理解 Python 列表理解*****
用 Django 和 GeoDjango 制作一个基于位置的 Web 应用程序
原文:https://realpython.com/location-based-app-with-geodjango-tutorial/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Django 和 GeoDjango 制作基于位置的 Web App
在本教程中,您将学习如何使用 Django 和 GeoDjango 从头开始构建基于位置的 web 应用程序。您将构建一个简单的附近商店应用程序,列出离用户位置最近的商店。
本教程结束时,你将能够:
-
使用 Django 从头构建一个简单的 web 应用程序
-
使用 GeoDjango 子框架在 Django 应用程序中实现地理定位特性
-
使用空间数据库(PostgreSQL 和 PostGIS)从空间要素中获益,并轻松实现位置感知 web 应用程序
免费奖励: ,您可以用它们来加深您的 Python web 开发技能。
示例应用程序源代码:您将在本教程中构建的应用程序的完整源代码可从 GitHub 上的 realpython/materials资源库获得。
您将使用的工具
您将使用以下工具开发附近商店的 web 应用程序:
- Python 编程语言
- Django 网络框架
- 用于保存数据的 PostgreSQL 数据库
- 用于支持 PostgreSQL 数据库中的空间要素的 PostGIS 扩展
pip用于安装依赖项- 用于管理虚拟环境的
venv模块 - 安装 PostgreSQL 和 PostGIS 的 Docker
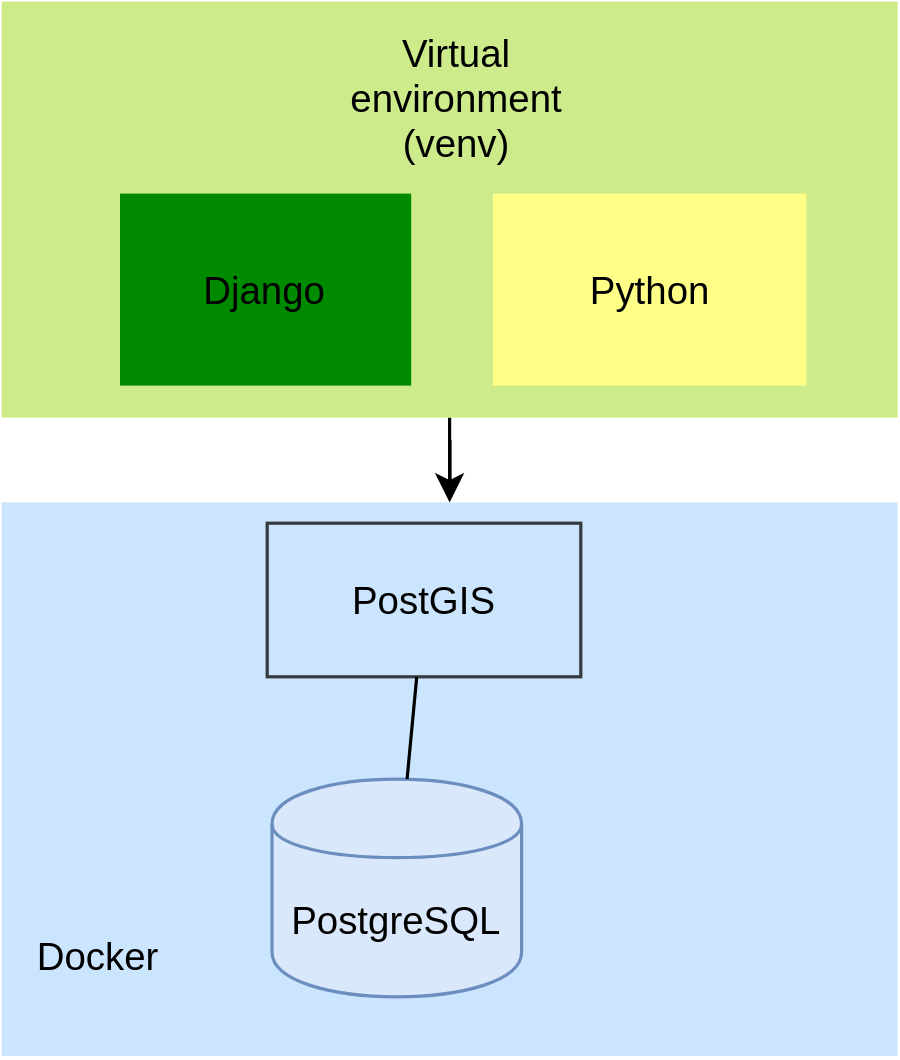
在进入实际步骤之前,让我们首先从介绍您将使用的框架开始。
Django 是构建 web 应用程序最流行的 Python 框架。通过提供大量内置 API 和子框架(如 GeoDjango ),开发人员可以轻松快速地构建原型并满足项目期限。
GeoDjango 是一个内置的应用程序,作为contrib模块包含在 Django 中。它实际上是一个完整的框架本身,也可以与 Django 分开使用。它为构建 GIS web 应用程序提供了一个实用工具工具箱。
GIS 代表地理信息系统。这是一个信息系统(一个有组织的系统,用于收集、组织、存储和交流信息),旨在处理和操作具有地理或空间特征的数据。
GeoDjango 还提供了与流行的空间库的 Python 绑定,如 GEOS 、 GDAL 和 GeoIP ,它们可以在任何 Python 应用程序中单独使用,也可以在 shell 中交互使用。
GeoDjango 旨在提供一个世界级的地理网络框架。多年来,它一直在重构,目标是使地理空间数据更容易使用,换句话说,就是识别地球上自然或人工要素的地理位置并存储为坐标和拓扑的数据。
GeoDjango 与 Django ORM 集成得非常好,并提供了一组由开放地理空间联盟(OGS) 定义的几何字段,可用于映射到地理空间数据库中不同类型的几何:
GeometryField是 GeoDjango 中所有几何字段的基类。PointField用于存放 GEOS 点对象。PolygonField用于存储 GEOS 多边形对象等等。
GeoDjango 是一个非常强大的框架,用于使用 Django ORM 存储和处理地理数据。它提供了一个易于使用的 API 来查找地图上两点之间的距离、多边形的面积、多边形内的点等等。
为了能够使用 GeoDjango,您需要具备两样东西:空间数据库和地理空间库。空间数据库是为存储和查询代表几何空间中定义的对象的数据而优化的数据库。
要完全使用 GeoDjango 的所有功能,您需要安装以下开源地理空间库:
-
GEOS 代表几何引擎开源。它是 JTS (Java 拓扑套件)的一个 C++端口,实现了 SQL 规范的 OCG 简单特性。
-
GDAL 代表地理空间数据抽象库。这是一个开源库,用于处理栅格和矢量地理空间数据格式。
-
PROJ.4 为制图投影库。这是一个开源的 GIS 库,可轻松使用空间参考系统和投影。
-
GeoIP 是一个帮助用户根据 IP 地址查找地理信息的库。
本教程使用 Ubuntu 18.04 系统来安装先决条件,使用 Unix bash 来运行命令,但是如果您使用任何其他系统,尤其是像 macOS 这样的基于 Unix 的系统,这应该不成问题。
对于大多数安装说明,您将使用 aptitude 包管理器,所以您应该简单地用您系统的等价包管理器来替换它。
先决条件
在本节中,您将在引导项目之前安装必要的先决条件,例如 Python 3 和 geo jango依赖项 (GEOS、GDAL 和 PROJ.4)。您还将使用 Docker 为您的项目建立一个 PostgreSQL 和 PostGIS 数据库。
安装 Python 3
很有可能您的系统上已经安装了 Python 3。如果你没有,你可以直接去官方网站为你的操作系统下载二进制文件。
根据您的系统,您也可以安装 Python 3,或者使用官方的包管理器将它升级到最新版本。
如果你在安装 Python 3 时遇到问题或者想了解更多信息,你可以查看 Python 3 安装&安装指南,它提供了在你的系统上安装 Python 3 的不同方法。
最后,您可以通过运行以下命令来检查是否安装了 Python 3:
$ python3 --version
Python 3.6.5
安装 GeoDjango 依赖项(GEOS、GDAL 和项目 4)
GeoDjango 需要一个空间数据库和一组开源地理空间库:
-
GEOS 是开源的几何引擎,是 JTS (Java Topology Suite)的 C++端口。GeoDjango 需要它来执行几何运算。
-
PROJ.4 是一个开源 GIS 库,用于轻松处理空间参考系统和投影。您需要它,因为您将使用 PostGIS 作为空间数据库。
-
GDAL 是一个开源的地理空间数据抽象库,用于处理栅格和矢量数据格式。GeoDjango 使用的许多实用程序都需要它。
关于空间数据库和所需库的更多信息,可以参考文档。
GDAL 2.2 包含在 Ubuntu 18.04 中,所以你可以简单地运行以下命令来安装它:
$ sudo aptitude install gdal-bin libgdal-dev
$ sudo aptitude install python3-gdal
注意: python3-gdal是 Python 3 对 GDAL 的绑定。
接下来,您可以使用以下命令安装其他库:
$ sudo aptitude install binutils libproj-dev
注意:因为你使用的是 GEOS 的二进制包,你还需要安装 binutils 。
有关如何在 macOS 和 Windows 上安装这些依赖项的详细说明,请参考文档。
关于 PROJ.4 的更多信息,可以参考其官方文档。
用 PostgreSQL 和 PostGIS 建立空间数据库
您将使用 PostgreSQL,这是 Django 最常用的数据库。这不是一个空间数据库,但由于 PostGIS,您可以使用强大的地理空间功能来增强您的数据库。
PostGIS 是一个空间数据库扩展,需要安装在一个 PostgreSQL 数据库上,这赋予它存储和处理空间数据以及执行空间操作的能力。它增加了对地理对象的支持,允许在 SQL 中运行位置查询。
您可以在您的系统上安装 PostgreSQL,创建一个数据库,然后添加 postgis 扩展,或者更好的方法是使用 Docker 使用 kartoza postgis 映像快速创建一个数据库,该映像提供一个已经安装了 PostgreSQL 和 PostGIS 的容器:
$ docker run --name=postgis -d -e POSTGRES_USER=user001 -e POSTGRES_PASS=123456789 -e POSTGRES_DBNAME=gis -p 5432:5432 kartoza/postgis:9.6-2.4
运行该命令后,您将拥有一个 PostgreSQL 服务器,它通过一个名为gis的数据库监听5432端口。数据库使用user001用户名和123456789密码。
注意:您需要在系统上安装 Docker。有关说明,您可以参考官方的文件。
设置您的项目
现在,您已经设置好了空间数据库,可以开始设置 Django 项目了。在本节中,您将使用venv为您的项目创建一个隔离的虚拟环境,并安装所有需要的包,比如 Django。
创建虚拟环境
虚拟环境允许您为当前项目的依赖项创建一个隔离的环境。这将允许您避免具有不同版本的相同包之间的冲突。
在 Python 3 中,您可以使用virtualenv或venv模块创建虚拟环境。
有关 Python 虚拟环境的更多信息,请查看 Python 虚拟环境:初级读本。
现在,在您的终端上运行以下命令,创建一个基于 Python 3 的虚拟环境:
$ python3 -m venv env
(env) $
接下来,您需要激活以下命令:
$ source env/bin/activate
就是这样。现在您已经激活了您的虚拟环境,您可以为您的项目安装软件包了。
安装 Django
创建并激活虚拟环境后的第一步是安装 Django。Django 包可以从 Python 包索引 (PyPI)中获得,所以您可以简单地使用pip在您的终端中运行以下命令来安装它:
$ pip install django
创建 Django 项目
您将创建的项目是一个 web 应用程序,它列出了按距离排序的商店,因此您的用户将能够发现离他们的位置很近的商店。
该 web 应用程序利用 GeoDjango 轻松实现位置要求,例如计算商店与用户位置的距离,并根据距离对商店进行排序。
使用 GeoDjango,您可以获取并显示存储在 PostgreSQL 数据库中的最近的商店,该数据库配置了 PostGIS 扩展模块以支持空间操作。
现在,您已经准备好使用django-admin.py脚本创建 Django 项目了。只需运行以下命令:
$ django-admin.py startproject nearbyshops
这将创建一个名为nearbyshops的项目。
配置 PostgreSQL 数据库
现在您已经创建了一个项目,让我们继续配置与 PostgreSQL 和 PostGIS 空间数据库的连接。打开settings.py文件,并使用您之前配置的 PostGIS 数据库的凭证添加django.contrib.gis.db.backends.postgis作为引擎:
DATABASES = {
'default': {
'ENGINE': 'django.contrib.gis.db.backends.postgis',
'NAME': 'gis',
'USER': 'user001',
'PASSWORD': '123456789',
'HOST': 'localhost',
'PORT': '5432'
}
}
注意:如果在运行 Docker 容器时没有指定相同的凭证,您需要相应地更改数据库凭证。
如果您试图在此时运行 Django 服务器,您将得到与psycopg2相关的ImportError: No module named 'psycopg2'错误,这是 Python 最流行的 PostgreSQL 适配器。要解决这个错误,您只需在您的虚拟环境中安装psycopg2-binary,如下所示:
$ pip install psycopg2-binary
添加 GeoDjango
GeoDjango 是一个框架,它使构建 GIS 和位置感知 web 应用程序变得尽可能容易。只需在已安装应用列表中包含gis contrib模块即可添加。
打开settings.py文件,找到INSTALLED_APPS数组。然后添加'django.contrib.gis'模块:
INSTALLED_APPS = [
# [...]
'django.contrib.gis'
]
创建 Django 应用程序
Django 项目由应用程序组成。默认情况下,它包含几个核心或内置的应用程序,如django.contrib.admin,但您通常会添加至少一个包含您的自定义项目代码的应用程序。
注意:对于简单的项目,你可能只需要一个 app,但是一旦你的项目变大了,有了不同的需求,你可以在多个独立的 app 中组织你的代码。
既然您已经创建了 Django 项目,配置了与空间数据库的连接,并将 GeoDjango 添加到项目中,那么您需要创建一个 Django 应用程序,您可以将它称为shops。
shops应用程序将包含创建和显示离用户位置最近的商店的代码。在接下来的步骤中,您将执行以下任务:
- 创建应用程序
- 添加一个
Shop模型 - 添加用于加载初始演示数据的数据迁移(商店)
- 添加查看功能
- 添加模板
首先运行以下命令来创建应用程序:
$ python manage.py startapp shops
接下来,您需要将它添加到settings.py文件中的已安装应用程序列表中,这将使 Django 将其识别为您项目的一部分:
INSTALLED_APPS = [
# [...]
'shops'
]
创建 Django 模型
在创建了包含项目实际代码的shops应用程序之后,您需要在您的应用程序中添加模型。Django 使用 ORM(对象关系映射器),它是 Django 和数据库之间的一个抽象层,将 Python 对象(或模型)转换成数据库表。
在这种情况下,您需要一个在数据库中代表商店的模型。您将创建一个具有以下字段的Shop模型:
name: 店铺名称location: 店铺所在位置的经纬度坐标address: 店铺的地址city: 店铺所在城市
打开shops/models.py文件并添加以下代码:
from django.contrib.gis.db import models
class Shop(models.Model):
name = models.CharField(max_length=100)
location = models.PointField()
address = models.CharField(max_length=100)
city = models.CharField(max_length=50)
对于位置,您将使用 PointField ,这是一个特定于 GeoDjango 的几何字段,用于存储表示一对经度和纬度坐标的 GEOS 点对象。
其他字段是类型为CharField的普通 Django 字段,可用于存储大小不同的字符串。
注意:请注意,models模块是从django.contrib.gis.db导入的,不是通常的django.db模块。
创建数据库表
有了 Django,由于它的 ORM,你不需要使用 SQL 来创建数据库表。让我们使用makemigrations和migrate命令创建数据库表。回到您的终端,运行以下命令:
$ python manage.py makemigrations
$ python manage.py migrate
有关这些命令的更多信息,请查看 Django 迁移-初级教程。
添加超级用户
您需要创建一个超级用户,这样您就可以访问管理界面。这可以使用以下命令来完成:
$ python manage.py createsuperuser
该提示将要求您输入用于访问用户帐户的用户名、电子邮件和密码。输入它们并点击 Enter 。
在管理界面注册模型
Django 的管理应用程序提供了一个完整的 CRUD 接口来管理数据。
GeoDjango 扩展了管理应用程序,增加了对几何字段的支持。
在从 Django admin 访问您的模型之前,您需要注册它们。
打开shops/admin.py文件并添加以下代码:
from django.contrib.gis.admin import OSMGeoAdmin
from .models import Shop
@admin.register(Shop)
class ShopAdmin(OSMGeoAdmin):
list_display = ('name', 'location')
您正在使用 @admin.register 装饰器在管理应用程序中注册Shop模型。修饰类是管理界面中的Shop模型的表示,允许您定制不同的方面,比如您想要显示的Shop字段。(在您的情况下,是名称和位置。)想要了解更多关于 decorator 的信息,你可以阅读《Python Decorators 初级读本。
由于Shop模型包含一个 GeoDjango 字段,您需要使用从django.contrib.gis.admin包中获得的特殊的OSMGeoAdmin类。
你可以使用GeoModelAdmin或者OSMGeoAdmin,这是GeoModelAdmin的一个子类,它使用管理中的开放街道地图层来显示几何字段。这提供了比使用GeoModelAdmin类更多的信息,如街道和大道细节,后者使用矢量地图级别 0 。
现在可以运行 Django 服务器了:
$ python manage.py runserver
您的应用程序将从localhost:8000开始运行,您可以从localhost:8000/admin访问管理界面。
这是来自添加店铺界面的截图:
您可以看到,Location几何字段显示为交互式地图。可以放大缩小地图,可以在地图右上角选择不同的选择器来选择一个位置,这个位置用绿色的圆圈标记。
添加初始数据
您的应用程序需要一些初始演示数据,但是您可以使用数据迁移来代替手动添加数据。
数据迁移可用于多种情况,包括在数据库中添加初始数据。有关更多信息,请查看数据迁移。
在创建迁移之前,让我们首先使用 OpenStreetMap 的一个基于 web 的数据过滤工具transition turbo从 OpenStreetMap 中获取一些真实世界的数据。您可以运行立交桥 API 查询,并在地图上交互分析结果数据。
您还可以使用集成的向导,这使得创建查询变得容易。
在您的情况下,您希望获得一个城市中的所有商店。只需点击向导的按钮。将弹出一个小窗口。在文本字段中,编写类似“在迈阿密购物”的查询,然后单击构建并运行查询。
接下来,点击导出按钮,并点击下载/复制为原始 OSM 数据,下载包含原始 OSM 数据的 JSON 文件。将文件另存为项目根文件夹中的data.json:
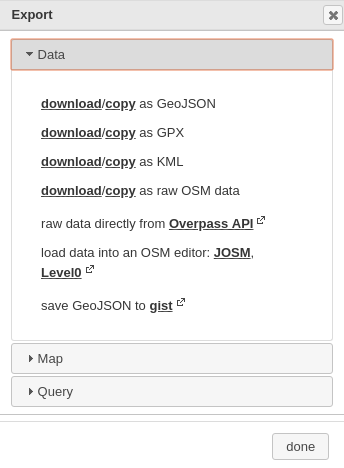
这是文件中示例数据的屏幕截图:
您需要获取elements数组中的对象。特别是每个商店的lat、lon和tags ( name)字段。
您可以从这个 wiki 中找到更多关于如何编写超越查询的细节。
现在,让我们创建一个空迁移,使用以下命令将data.json文件的内容导入到数据库中:
$ python manage.py makemigrations shops --empty
打开迁移文件。它有以下代码:
from django.db import migrations
class Migration(migrations.Migration):
dependencies = [
('shops', '0001_initial'),
]
operations = [
]
接下来您需要创建由RunPython()执行的load_data()。首先,在导入区域中,添加以下导入内容:
from django.db import migrations
import json
from django.contrib.gis.geos import fromstr
from pathlib import Path
您正在从 pathlib 包中导入Path类以访问底层系统函数,从 json 包导入 JSON(Django 内置迁移 API)以及 fromstr() (属于 geos 包的一部分)。
接下来,添加load_data():
DATA_FILENAME = 'data.json'
def load_data(apps, schema_editor):
Shop = apps.get_model('shops', 'Shop')
jsonfile = Path(__file__).parents[2] / DATA_FILENAME
with open(str(jsonfile)) as datafile:
objects = json.load(datafile)
for obj in objects['elements']:
try:
objType = obj['type']
if objType == 'node':
tags = obj['tags']
name = tags.get('name','no-name')
longitude = obj.get('lon', 0)
latitude = obj.get('lat', 0)
location = fromstr(f'POINT({longitude} {latitude})', srid=4326)
Shop(name=name, location = location).save()
except KeyError:
pass
让我们解释一下您刚刚添加的代码。首先使用 pathlib库的Path类构建绝对路径,并打开data.json文件。接下来,将 JSON 文件解析成一个 Python 对象。
您遍历包含商店位置和标签的 elements 对象。在循环中,提取名称和经纬度坐标。然后使用formstr()返回一个有效的 GEOSGeometry 对象,该对象对应于字符串中的空间数据,该数据可以分配给Shop模型的位置字段。最后,您创建并保存与提取的数据相对应的Shop模型的实例。
您正在使用 with语句,因此您不必显式关闭文件,以及一个用于格式化fromstr()参数的 f 字符串。
fromstr()将一个srid作为第二个参数。 srid 代表空间参考系统标识符。识别空间参考系统(用于解释空间数据库中的数据的投影系统)具有独特的价值。
4326 srid是 PostGIS 最常用的系统。它也被称为 WGS84 ,这里的单位以经度和纬度的度数来指定。你可以参考 spatialreference.org的 Django 驱动的空间参考系统数据库。
接下来,添加迁移类,以便在运行migrate命令时执行上述函数:
class Migration(migrations.Migration):
dependencies = [
('shops', '0005_auto_20181018_2050'),
]
operations = [
migrations.RunPython(load_data)
]
就是这样。现在,您可以返回到您的终端并运行以下命令:
$ python manage.py migrate
来自data.json文件的数据将被加载到您的数据库中。运行 Django 服务器,进入管理界面。您应该会在表格中看到您的数据。在我的例子中,这是表的一部分的截图:
显示附近的商店
在本教程的这一部分,您已经创建了:
-
shops应用程序,它封装了在项目中创建和获得附近商店的代码 -
Shop模型和数据库中相应的表 -
用于访问管理界面的初始管理员用户
-
在数据库中加载真实世界商店的初始演示数据,您可以在不手动输入大量虚假数据的情况下进行操作
您还在管理应用程序中注册了Shop模型,因此您可以从管理界面创建、更新、删除和列出商店。
接下来,您将使用通用的 ListView 类添加一个视图函数,您可以用它来显示附近商店的列表。您还将创建一个 HTML 模板,视图函数将使用该模板来呈现商店,并添加将用于显示商店的 URL。
让我们首先添加一个模板和一个视图函数,它将用于显示用户所在位置附近的商店。
打开shops/views.py文件,从导入必要的 API 开始:
from django.views import generic
from django.contrib.gis.geos import fromstr
from django.contrib.gis.db.models.functions import Distance
from .models import Shop
接下来添加一个user_location变量,您可以在其中硬编码一个用户位置:
longitude = -80.191788
latitude = 25.761681
user_location = Point(longitude, latitude, srid=4326)
在这一部分中,您将简单地对用户的位置(美国迈阿密的坐标)进行硬编码,但理想情况下,这应该由用户指定,或者在用户许可的情况下,使用 JavaScript 和 HTML5 地理定位 API 从用户的浏览器中自动检索。您可以向下滚动到该页面的中间,查看实现地理位置 API 的实例。
最后,添加以下视图类:
class Home(generic.ListView):
model = Shop
context_object_name = 'shops'
queryset = Shop.objects.annotate(distance=Distance('location',
user_location)
).order_by('distance')[0:6]
template_name = 'shops/index.html'
您正在使用通用的基于类的 ListView 来创建一个视图。
基于类的视图是将视图实现为 Python 类而不是函数的另一种方法。它们用于处理 web 开发中的常见用例,而无需重新发明轮子。在这个例子中,您已经子类化了ListView通用视图,并覆盖了model、context_object_name、queryset和template_name属性,从而创建了一个无需任何额外代码就能处理 HTTP 请求的列表视图。
现在让我们来关注一下queryset属性。要获得附近的商店,您只需使用.annotate()在返回的 queryset 上用距离标注标注每个对象,该距离标注是使用 Distance() 计算的,可从 GeoDjango 获得,在每个商店的位置和用户的位置之间。您还可以根据距离标注对返回的查询集进行排序,并只选择最近的六家商店。
你可以从官方文档中了解更多关于基于类的视图。
接下来让我们添加包含以下内容的shops/index.html模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Nearby Shops</title>
</head>
<body>
<h1>Nearby Shops</h1>
{% if shops %}
<ul>
{% for shop in shops %}
<li>
{{ shop.name }}: {{shop.distance}}
</li>
{% endfor %}
</ul>
{% endif %}
</body>
</html>
最近的商店可以从您在基于类的视图中指定为context_object_name的shops上下文对象中获得。您遍历shops对象,显示每个商店的名称和离用户位置的距离。
最后,让我们给我们的urls.py文件添加一个 URL:
from django.urls import path
from shops import views
urlpatterns = [
# [...]
path('', views.ShopList.as_view())
]
您使用.as_view()返回一个可调用的视图,该视图接受一个request并返回一个response,它可以作为第二个参数传递给将路径映射到视图的path()。
现在您可以运行您的 Django 服务器了。主页将显示一个简单的非风格化列表,列出距离硬编码用户位置最近的商店。这是一个示例截图:

在截图中,列表中的每一项都显示了商店的名称(冒号前)和距离用户位置的米数(冒号后)。字母 m 指的是米。
注意:你在截图中用来显示结果的 view 函数只是为了测试Distance()标注的 queryset。
本教程到此结束。现在,您已经掌握了向应用程序添加简单地理定位内容或创建 GIS 应用程序的基本技能。您可以阅读 GeoDjango 文档以获得可用 API 的完整资源以及您可以使用它们做什么。
您还学习了使用 Docker 快速拉取和启动 PostgreSQL 和 PostGIS 服务器。Docker 的用途可不止这些。这是一个容器化工具,用于构建隔离的、可复制的应用环境。如果你想学习如何容器化你的 Django 项目,你可以阅读用 Docker Compose 和 Machine 开发 Django。
结论
祝贺您使用 GeoDjango 创建了基于位置的 web 应用程序,该应用程序旨在成为实现 GIS 应用程序的世界级地理框架。如今,位置感知应用程序(知道你的位置,并通过提供基于你的位置的结果来帮助你发现附近的物体和服务的应用程序)风靡一时。使用您在本教程中获得的知识,您将能够在用 Django 开发的应用程序中融入这一现代特性。
除了对 GeoDjango 的依赖之外,唯一的要求是使用空间数据库(能够存储和操作空间数据的数据库)。对于与 Django 一起使用的最流行的数据库管理系统之一 PostgreSQL,您可以简单地在您的数据库中安装 PostGIS 扩展,将它转换成一个空间数据库。其他流行的数据库如甲骨文和 MySQL 都内置了对空间数据的支持。
在本教程中,您已经使用了:
- Django 从头开始构建 web 应用程序
- 在 Django 应用程序中实现地理定位特性的 GeoDjango 子框架
- 空间数据库 PostgreSQL 和 PostGIS,可从空间要素中获益并实施位置感知型 web 应用程序
你有没有一个 Django 应用程序可以受益于更多的位置感知?试用 GeoDjango,并在下面的评论中分享你的体验。
示例应用程序源代码:您在本教程中构建的应用程序的完整源代码可以在 GitHub 的 realpython/materials资源库中找到。
免费奖励: ,您可以用它们来加深您的 Python web 开发技能。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Django 和 GeoDjango 制作基于位置的 Web App******
Python 中的逻辑回归
随着可用数据的数量、计算能力的强度和算法改进的数量不断上升,数据科学和机器学习的重要性也在增加。分类是机器学习最重要的领域之一,而逻辑回归是其基本方法之一。到本教程结束时,您将已经学习了分类的一般知识,特别是逻辑回归的基础知识,以及如何在 Python 中实现逻辑回归。
在本教程中,您将学习:
- 什么是逻辑回归
- 逻辑回归有什么用
- 逻辑回归如何工作
- 如何在 Python 中逐步实现逻辑回归
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
分类
分类是监督机器学习的一个非常重要的领域。大量重要的机器学习问题都属于这个领域。分类方法有很多种,logistic 回归是其中一种。
什么是分类?
监督机器学习算法定义了捕捉数据之间关系的模型。分类是监督机器学习的一个领域,它试图根据某个实体的特征来预测它属于哪个类或类别。
例如,你可能会分析某个公司的员工,并试图建立对特征或变量的依赖关系,如教育水平、在当前职位上的年数、年龄、工资、晋升机会等等。与单个雇员相关的数据集是一个观察。特征或变量可以采取两种形式之一:
- 独立变量,也称为输入或预测值,不依赖于其他感兴趣的特征(或者至少你假设是为了分析)。
- 因变量,也称为输出或响应,取决于自变量。
在上面分析员工的例子中,您可能假设教育水平、在当前职位上的时间和年龄是相互独立的,并将它们视为输入。工资和晋升机会可能是依赖于投入的产出。
注:有监督的机器学习算法分析大量的观察值,并试图用数学方式表达输入和输出之间的依赖关系。这些依赖关系的数学表示就是模型。
因变量的性质区分了回归和分类问题。回归问题有连续且通常无界的输出。一个例子是当你根据经验和教育水平来估算工资时。另一方面,分类问题具有离散且有限的输出,称为类或类。例如,预测一个员工是否将被提升(对或错)是一个分类问题。
分类问题主要有两种类型:
- 二进制或二项式分类:正好两个类别可供选择(通常是 0 和 1,真和假,或正和负)
- 多类或多项分类:三类或更多类的输出可供选择
如果只有一个输入变量,那么通常用𝑥.表示对于多个输入,您通常会看到向量符号𝐱 = (𝑥₁,…,𝑥ᵣ),其中𝑟是预测值(或独立特征)的数量。输出变量通常用𝑦表示,取值为 0 或 1。
什么时候需要分类?
你可以在很多科技领域应用分类。例如,文本分类算法用于区分合法和垃圾邮件,以及正面和负面评论。您可以查看使用 Python 和 Keras 的实用文本分类来深入了解这个主题。其他例子包括医疗应用、生物分类、信用评分等等。
图像识别任务通常被表示为分类问题。例如,你可能会问一幅图像是否描绘了一张人脸,或者它是一只老鼠还是一只大象,或者它代表 0 到 9 中的哪一个数字,等等。要了解更多这方面的内容,请查看用 Python 实现的传统人脸检测和用 Python 实现的人脸识别,不到 25 行代码。
逻辑回归概述
逻辑回归是一种基本的分类技术。属于 线性分类器 的一组,有点类似于多项式和 线性回归 。逻辑回归快速且相对简单,便于你解读结果。尽管它本质上是一种二元分类的方法,但它也可以应用于多类问题。
数学先决条件
为了理解什么是逻辑回归以及它是如何工作的,你需要理解 sigmoid 函数 T1 和 T2 自然对数函数 T3。
此图显示了一些可变𝑥:的 s 形函数(或 s 形曲线)
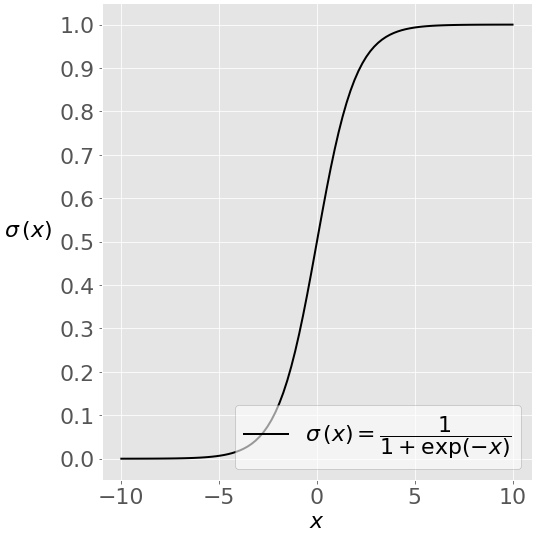
在 sigmoid 函数的大部分范围内,其值非常接近 0 或 1。这一事实使它适合应用于分类方法。
此图描绘了某个变量𝑥的自然对数 log(𝑥,𝑥值在 0 和 1 之间:
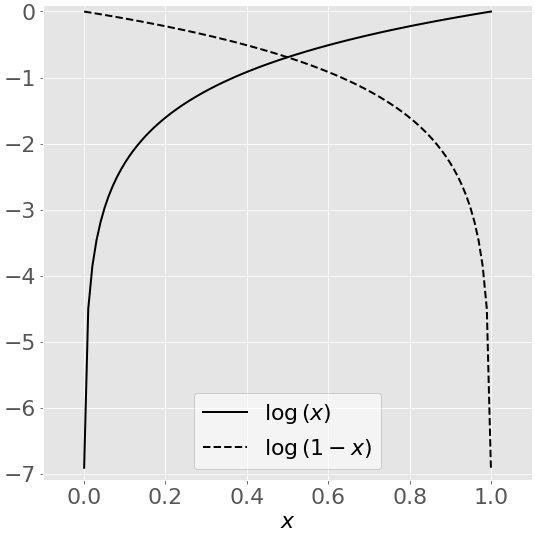
当𝑥接近零时,𝑥的自然对数向负无穷大下降。当𝑥 = 1 时,log(𝑥)是 0。对数(1 𝑥).)则相反
注意,你经常会发现在中用表示的自然对数,而不是 log 。在 Python 中,math.log(x)和numpy.log(x)代表x的自然对数,所以在本教程中您将遵循这种符号。
问题表述
在本教程中,您将看到对应用于二元分类的逻辑回归的常见情况的解释。当你在自变量集𝐱 = (𝑥₁,…,𝑥ᵣ)上实现某因变量𝑦的逻辑回归时,其中𝑟是预测器(或输入)的数量,你从预测器的已知值𝐱ᵢ和每个观测值对应的实际响应(或输出)𝑦ᵢ开始𝑖 = 1,…,1。
你的目标是找到逻辑回归函数 𝑝(𝐱)使得预测响应 𝑝(𝐱ᵢ)尽可能接近每次观察的实际响应𝑦ᵢ𝑖= 1,…,𝑛.记住,在二进制分类问题中,实际响应只能是 0 或 1!这意味着每个𝑝(𝐱ᵢ)应该接近 0 或 1。这就是为什么使用 sigmoid 函数很方便。
一旦你有了逻辑回归函数𝑝(𝐱,你就可以用它来预测新的和未知的输入的输出,假设基本的数学依赖关系不变。
方法学
逻辑回归是一个线性分类器,因此您将使用一个线性函数𝑓(𝐱) = 𝑏₀ + 𝑏₁𝑥₁ + ⋯ + 𝑏ᵣ𝑥ᵣ,也称为 logit 。变量𝑏₀、𝑏₁、…、𝑏ᵣ是回归系数的估计量,也称为预测权重或简称为系数。
逻辑回归函数𝑝(𝐱)是𝑓(𝐱): 𝑝(𝐱的 sigmoid 函数)= 1 / (1 + exp(−𝑓(𝐱)).因此,它通常接近 0 或 1。函数𝑝(𝐱)通常被解释为给定𝐱的输出等于 1 的预测概率。因此,1𝑝(𝑥)是输出为 0 的概率。
逻辑回归确定最佳预测权重𝑏₀、𝑏₁、…、𝑏ᵣ,使得函数𝑝(𝐱尽可能接近所有实际响应𝑦ᵢ、𝑖 = 1、…、𝑛,其中𝑛是观察次数。使用可用观测值计算最佳权重的过程被称为模型训练或拟合。
为了得到最好的权重,你通常最大化所有观测值的对数似然函数(llf)𝑖= 1,…,𝑛.这种方法被称为最大似然估计,由等式 llf =σᵢ(𝑦ᵢlog(𝑝(𝐱ᵢ)+(1𝑦ᵢ)对数(1 𝑝(𝐱ᵢ))).)表示
当𝑦ᵢ = 0 时,相应观测值的 LLF 等于 log(1 𝑝(𝐱ᵢ)).如果𝑝(𝐱ᵢ)接近𝑦ᵢ = 0,那么 log(1𝑝(𝐱ᵢ))接近 0。这就是你想要的结果。如果𝑝(𝐱ᵢ)远离 0,则 log(1𝑝(𝐱ᵢ)显著下降。你不想要那个结果,因为你的目标是获得最大的 LLF。类似地,当𝑦ᵢ = 1 时,该观察的 LLF 是𝑦ᵢ log(𝑝(𝐱ᵢ)).如果𝑝(𝐱ᵢ)接近𝑦ᵢ = 1,那么 log(𝑝(𝐱ᵢ))接近 0。如果𝑝(𝐱ᵢ)远离 1,那么 log(𝑝(𝐱ᵢ)是一个大的负数。
有几种数学方法可以计算最大 LLF 对应的最佳权重,但这超出了本教程的范围。现在,您可以将这些细节留给您将在这里学习使用的逻辑回归 Python 库!
一旦确定了定义函数𝑝(𝐱的最佳权重,就可以得到任何给定输入𝐱ᵢ.的预测输出𝑝(𝐱ᵢ对于每个观察值𝑖 = 1,…,𝑛,如果𝑝(𝐱ᵢ) > 0.5,预测输出为 1,否则为 0。阈值不一定是 0.5,但通常是 0.5。如果更适合您的情况,您可以定义一个较低或较高的值。
𝑝(𝐱)和𝑓(𝐱)之间还有一个更重要的关系,那就是 log(𝑝(𝐱)/(1𝑝(𝐱)))= 𝑓(𝐱).这个等式解释了为什么𝑓(𝐱是逻辑。这意味着当𝑓(𝐱= 0 时,𝑝(𝐱= 0.5,如果𝑓(𝐱为 0,则预测输出为 1,否则为 0。
分类性能
二元分类有四种可能的类型的结果:
- 真否定:正确预测的否定(零)
- 真阳性:正确预测阳性(个)
- 假阴性:错误预测的阴性(零)
- 假阳性:错误预测的阳性(个)
您通常通过比较实际输出和预测输出并计算正确和不正确的预测来评估分类器的性能。
分类精度最直观的指标是正确预测数与预测(或观测)总数的比值。二元分类器的其他指标包括:
- 阳性预测值 是真阳性数量与真阳性和假阳性数量之和的比值。
- 阴性预测值 是真阴性数量与真阴性和假阴性数量之和的比值。
- (也称为回忆或真阳性率)是真阳性的数量与实际阳性的数量之比。
- (或真阴性率)是真阴性数与实际阴性数之比。
最合适的指标取决于兴趣问题。在本教程中,您将使用最简单的分类精度形式。
单变量逻辑回归
单变量逻辑回归是逻辑回归最直接的例子。自变量(或特征)只有一个,就是𝐱 = 𝑥.下图说明了单变量逻辑回归:
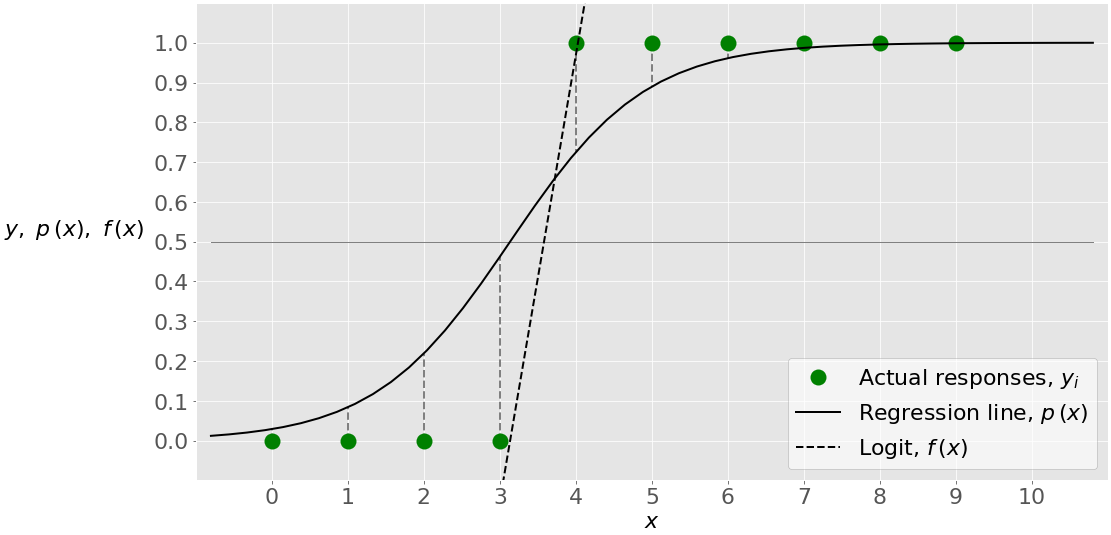
这里,您有一组给定的输入输出(或𝑥-𝑦)对,用绿色圆圈表示。这些是你的观察。记住𝑦只能是 0 或 1。例如,最左边的绿色圆圈的输入𝑥 = 0,实际输出𝑦 = 0。最右边的观察结果是𝑥 = 9,𝑦 = 1。
逻辑回归找到对应于最大 LLF 的权重𝑏₀和𝑏₁。这些权重定义了 logit 𝑓(𝑥) = 𝑏₀ + 𝑏₁𝑥,这是黑色虚线。他们还定义了预测概率𝑝(𝑥) = 1 / (1 + exp(−𝑓(𝑥)),这里显示为黑色实线。在这种情况下,阈值𝑝(𝑥) = 0.5 和𝑓(𝑥) = 0 对应于略高于 3 的𝑥值。该值是预测输出为 0 和 1 的输入之间的界限。
多变量逻辑回归
多变量逻辑回归有多个输入变量。该图显示了具有两个独立变量的分类,𝑥₁和𝑥₂:
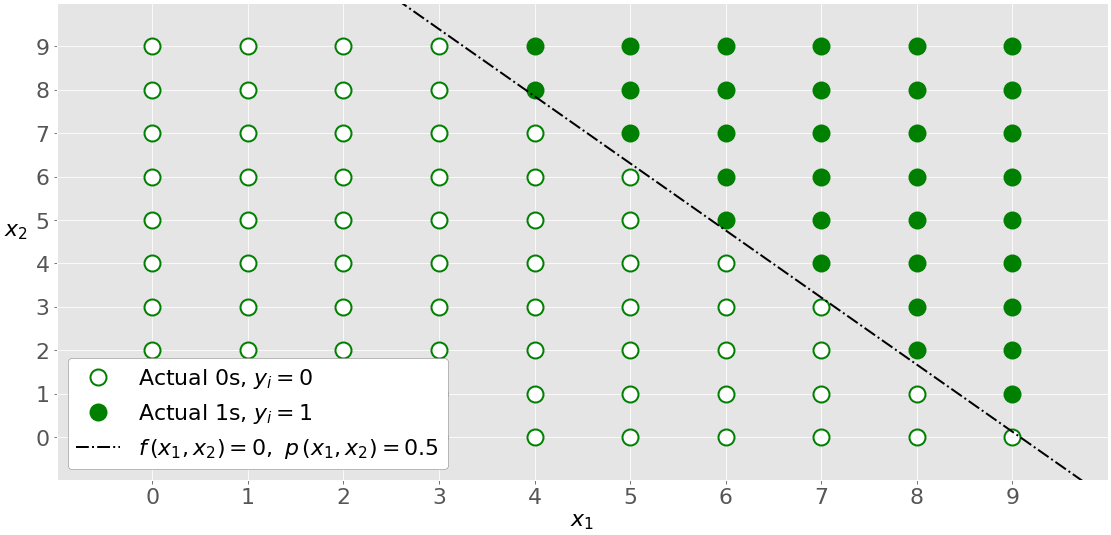
该图与单变量图不同,因为两个轴都代表输入。输出的颜色也不同。白色圆圈表示分类为零的观察值,而绿色圆圈表示分类为一的观察值。
逻辑回归确定使 LLF 最大化的𝑏₀、𝑏₁和𝑏₂的权重。一旦你有了𝑏₀、𝑏₁和𝑏₂,你就能得到:
- the logit𝑥₂𝑓(𝑥₁)=𝑏₀+𝑏₁𝑥₁+𝑏₂𝑥₂
- 概率 𝑝(𝑥₁,𝑥₂) = 1 / (1 + exp(−𝑓(𝑥₁,𝑥₂))
虚线黑线将两个类别线性分开。这条线对应于𝑥₂的𝑝(𝑥₁)= 0.5 和𝑥₂的𝑓(𝑥₁)= 0。
正规化
**过拟合是机器学习中最严重的问题之一。当模型对训练数据学习得太好时,就会发生这种情况。然后,该模型不仅学习数据之间的关系,还学习数据集中的噪声。过度拟合的模型在用于拟合它们的数据(训练数据)下往往具有良好的性能,但是在未看到的数据(或测试数据,即未用于拟合模型的数据)下表现不佳。*
*过度拟合通常发生在复杂模型中。正则化通常试图降低或惩罚模型的复杂性。应用逻辑回归的正则化技术大多倾向于惩罚大系数𝑏₀,𝑏₁,…,𝑏ᵣ:
- L1 正则化用加权绝对值的缩放和惩罚 llf:|𝑏₀|+|𝑏₁|+⋯+|𝑏ᵣ|.
- L2 正则化用权重的缩放平方和惩罚 llf:𝑏₀+𝑏₁+⋯+𝑏ᵣ。
- 弹性网正则化是 L1 和 L2 正则化的线性组合。
正则化可以显著提高对不可见数据的建模性能。
Python 中的逻辑回归
现在您已经理解了基本原理,您已经准备好应用适当的包以及它们的函数和类来执行 Python 中的逻辑回归。在本节中,您将看到以下内容:
- 用于逻辑回归的 Python 包概述(NumPy、scikit-learn、StatsModels 和 Matplotlib)
- 用 scikit-learn 求解逻辑回归的两个示例
- 用 StatsModels 解决的一个概念示例
- 一个手写数字分类的真实例子
让我们开始用 Python 实现逻辑回归吧!
逻辑回归 Python 包
Python 中的逻辑回归需要几个包。它们都是免费和开源的,有很多可用的资源。首先,您需要 NumPy ,这是 Python 中科学和数值计算的基础包。NumPy 很有用,也很受欢迎,因为它支持在一维或多维数组上进行高性能操作。
NumPy 有许多有用的数组例程。它允许您编写优雅而简洁的代码,并且可以很好地与许多 Python 包一起工作。如果你想学习 NumPy,那么你可以从官方的用户指南开始。 NumPy 参考文献也提供了关于其函数、类和方法的全面文档。
注意:要了解更多关于 NumPy 性能及其提供的其他好处,请查看Pure Python vs NumPy vs tensor flow 性能比较和 Look Ma,No For-Loops:Array Programming With NumPy。
您将使用的另一个 Python 包是 scikit-learn 。这是最受欢迎的数据科学和机器学习库。您可以使用 scikit-learn 执行各种功能:
- 预处理数据
- 降低问题的维度
- 验证模型
- 选择最合适的型号
- 解决回归和分类问题
- 实现聚类分析
你可以在 scikit-learn 官方网站上找到有用的信息,在那里你可能想要阅读关于广义线性模型和逻辑回归实现的内容。如果您需要 scikit-learn 无法提供的功能,那么您可能会发现 StatsModels 很有用。这是一个用于统计分析的强大 Python 库。你可以在官方网站找到更多信息。
最后,您将使用 Matplotlib 来可视化您的分类结果。这是一个全面的 Python 库,广泛用于高质量的绘图。更多信息,可以查看官方网站和用户指南。有几个学习 Matplotlib 的资源可能对你有用,比如官方的教程,Matplotlib 的剖析,以及 Python 使用 Matplotlib 绘图(指南)。
用 scikit-learn 实现 Python 中的逻辑回归:示例 1
第一个例子与单变量二元分类问题有关。这是最简单的分类问题。在准备分类模型时,您将采取几个常规步骤:
- 导入包、函数和类
- 获取要处理的数据,如果合适的话,对其进行转换
- 创建一个分类模型,并用现有数据训练(或拟合)它
- 评估你的模型,看看它的性能是否令人满意
您定义的足够好的模型可用于对新的、未知的数据进行进一步的预测。上述过程对于分类和回归是相同的。
步骤 1:导入包、函数和类
首先,你必须为可视化导入 Matplotlib,为数组操作导入 NumPy。您还需要 scikit-learn 中的LogisticRegression、classification_report()和confusion_matrix():
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
现在您已经用 scikit 在 Python 中导入了逻辑回归所需的所有东西——学习!
第二步:获取数据
在实践中,您通常会有一些数据要处理。出于本例的目的,让我们只为输入(𝑥)和输出(𝑦)值创建数组:
x = np.arange(10).reshape(-1, 1)
y = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
输入和输出应该是 NumPy 数组(类numpy.ndarray的实例)或类似的对象。numpy.arange()在给定范围内创建一个连续的等距值数组。关于这个函数的更多信息,请查看官方文档或 NumPy arange():如何使用 np.arange() 。
要求数组x为二维。每个输入应该有一列,行数应该等于观察数。为了使x二维化,您可以应用带有参数-1的.reshape()来获得所需的多行,应用1来获得一列。更多关于.reshape()的信息,可以查看官方文档。下面是x和y现在的样子:
>>> x array([[0], [1], [2], [3], [4], [5], [6], [7], [8], [9]]) >>> y array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
x有两个维度:
- 一列用于单次输入
- 十行,每一行对应一次观测
y是有十个项目的一维。同样,每个项目对应一个观察。它只包含 0 和 1,因为这是一个二进制分类问题。第三步:创建一个模型并训练它
一旦您准备好了输入和输出,您就可以创建和定义您的分类模型。您将使用类
LogisticRegression的实例来表示它:model = LogisticRegression(solver='liblinear', random_state=0)上面的语句创建了一个
LogisticRegression的实例,并将其引用绑定到变量model。LogisticRegression有几个可选参数定义模型和方法的行为:
penalty是一个字符串(默认为'l2')决定是否有正则化以及使用哪种方法。其他选项有'l1'、'elasticnet'和'none'。
dual是一个布尔(默认为False)决定是使用 primal(当False)还是对偶公式化(当True)。
tol是一个浮点数(默认为0.0001),定义了停止程序的公差。
C是一个正浮点数(默认为1.0,定义正则化的相对强度。较小的值表示较强的正则化。
fit_intercept是一个布尔值(默认为True),决定是计算截距𝑏₀(当True时)还是将其视为等于零(当False时)。
intercept_scaling是一个浮点数(默认为1.0),定义了截距𝑏₀.的缩放比例
class_weight是一个字典,'balanced'或None(默认)定义了与每个类相关的权重。当None时,所有类的权重都是 1。
random_state是一个整数,numpy.RandomState的一个实例,或者None(默认)定义使用什么伪随机数发生器。
solver是一个字符串(默认为'liblinear'),决定使用什么解算器来拟合模型。其他选项有'newton-cg'、'lbfgs'、'sag'和'saga'。
max_iter是一个整数(默认为100),用于定义模型拟合过程中求解器的最大迭代次数。
multi_class是一个字符串(默认为'ovr'),决定了处理多个类的方法。其他选项有'multinomial'和'auto'。
verbose是一个非负整数(默认为0),定义了'liblinear'和'lbfgs'解算器的详细程度。
warm_start是一个布尔型(False默认),决定是否重用之前得到的解。
n_jobs是一个整数或None(默认值),定义了要使用的并行进程的数量。None通常是指使用一个内核,而-1是指使用所有可用的内核。
l1_ratio要么是 0 到 1 之间的浮点数,要么是None(默认)。它定义了弹性网正则化中 L1 部分的相对重要性。出于以下几个原因,您应该仔细匹配求解器和正则化方法:
- 没有正则化,规划求解无法工作。
'newton-cg'、'sag'、'saga'、'lbfgs'不支持 L1 正则化。'saga'是唯一支持弹性网正则化的求解器。一旦创建了模型,您需要拟合(或训练)它。模型拟合是确定对应于成本函数最佳值的系数𝑏₀、𝑏₁、…、𝑏ᵣ的过程。你用
.fit()拟合模型:model.fit(x, y)
.fit()取x、y,可能还有与观察相关的权重。然后,它拟合模型并返回模型实例本身:LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=0, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)这是获得的拟合模型的字符串表示。
您可以利用
.fit()返回模型实例的事实,并将最后两条语句链接起来。它们相当于下面一行代码:model = LogisticRegression(solver='liblinear', random_state=0).fit(x, y)至此,您已经定义了分类模型。
你可以快速得到你的模型的属性。例如,属性
.classes_表示y采用的不同值的数组:
>>> model.classes_
array([0, 1])
这是二元分类的例子,y可以是0也可以是1,如上图所示。
您还可以获得线性函数𝑓的斜率𝑏₁和截距𝑏₀的值,如下所示:
>>> model.intercept_ array([-1.04608067]) >>> model.coef_ array([[0.51491375]])如你所见,𝑏₀在一维数组中,而𝑏₁在二维数组中。您使用属性
.intercept_和.coef_来获得这些结果。步骤 4:评估模型
一旦定义了一个模型,您可以用
.predict_proba()来检查它的性能,它会返回预测输出等于零或一的概率矩阵:
>>> model.predict_proba(x)
array([[0.74002157, 0.25997843],
[0.62975524, 0.37024476],
[0.5040632 , 0.4959368 ],
[0.37785549, 0.62214451],
[0.26628093, 0.73371907],
[0.17821501, 0.82178499],
[0.11472079, 0.88527921],
[0.07186982, 0.92813018],
[0.04422513, 0.95577487],
[0.02690569, 0.97309431]])
在上面的矩阵中,每行对应一个观察值。第一列是预测输出为零的概率,即 1 - 𝑝(𝑥).第二列是输出为 1 或𝑝(𝑥).的概率
你可以得到实际的预测,基于概率矩阵和𝑝(𝑥的值),用.predict():
>>> model.predict(x) array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1])该函数以一维数组的形式返回预测的输出值。
下图说明了输入、输出和分类结果:
绿色圆圈代表实际响应和正确预测。红色×表示不正确的预测。黑色实线是估计的逻辑回归直线𝑝(𝑥).灰色方块是这条线上对应于𝑥和概率矩阵第二列中的值的点。黑色虚线是罗吉特𝑓(𝑥).
略高于 2 的𝑥值对应于阈值𝑝(𝑥)=0.5,即𝑓(𝑥)=0.𝑥的这个值是被分类为 0 的点和被预测为 1 的点之间的边界。
例如,第一个点具有输入𝑥=0、实际输出𝑦=0、概率𝑝=0.26 和预测值 0。第二点有𝑥=1、𝑦=0、𝑝=0.37,预测值为 0。只有第四个点有实际输出𝑦=0,概率大于 0.5(在𝑝=0.62),所以被错误归类为 1。所有其他值都预测正确。
当十个观察值中有九个被正确分类时,您的模型的精度等于 9/10=0.9,这可以通过
.score()获得:
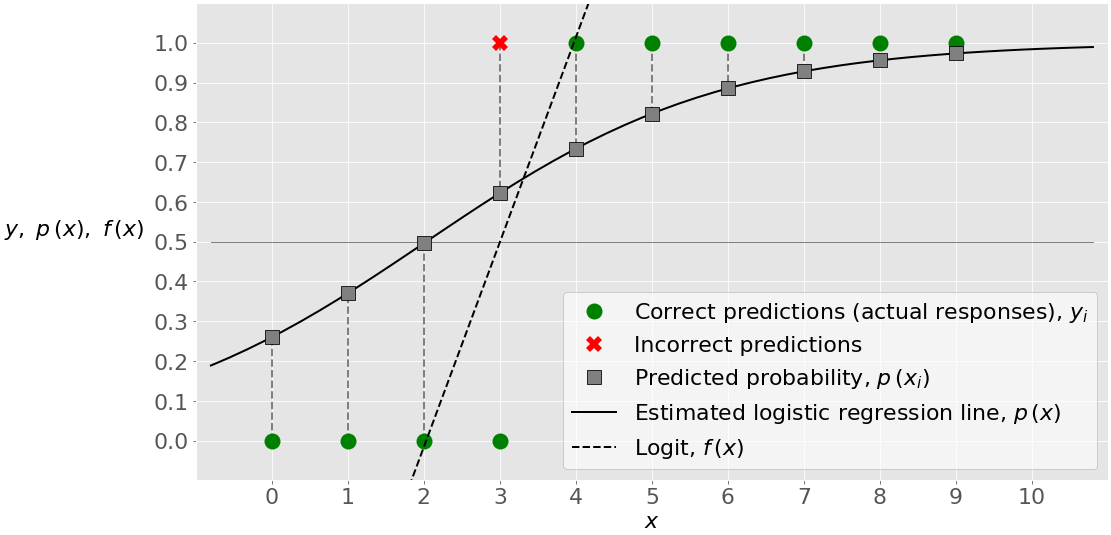
>>> model.score(x, y)
0.9
.score()将输入和输出作为参数,并返回正确预测数与观察数之比。
你可以用一个混淆矩阵获得更多关于模型准确性的信息。在二进制分类的情况下,混淆矩阵显示下列数字:
- 左上角位置的真底片
- 左下位置的假阴性
- 右上角位置的误报
- 右下位置的真阳性
要创建混淆矩阵,您可以使用confusion_matrix()并提供实际和预测输出作为参数:
>>> confusion_matrix(y, model.predict(x)) array([[3, 1], [0, 6]])获得的矩阵显示了以下内容:
- 三个真否定预测:前三个观测值是正确预测的零。
- 无假阴性预测:这些是被错误预测为零的。
- 一次误报预测:第四次观测是一个被误预测为一的零。
- 六个真正预测:最后六个观测值是预测正确的。
可视化混乱矩阵通常是有用的。您可以使用 Matplotlib 中的
.imshow()来实现,它接受混淆矩阵作为参数:cm = confusion_matrix(y, model.predict(x)) fig, ax = plt.subplots(figsize=(8, 8)) ax.imshow(cm) ax.grid(False) ax.xaxis.set(ticks=(0, 1), ticklabels=('Predicted 0s', 'Predicted 1s')) ax.yaxis.set(ticks=(0, 1), ticklabels=('Actual 0s', 'Actual 1s')) ax.set_ylim(1.5, -0.5) for i in range(2): for j in range(2): ax.text(j, i, cm[i, j], ha='center', va='center', color='red') plt.show()上面的代码创建了一个代表混淆矩阵的热图:
在这个图中,不同的颜色代表不同的数字,相似的颜色代表相似的数字。热图是表示矩阵的一种既好又方便的方式。要了解更多信息,请查看 Matplotlib 文档中关于创建带注释的热图和
.imshow()的内容。您可以使用
classification_report()获得更全面的分类报告:
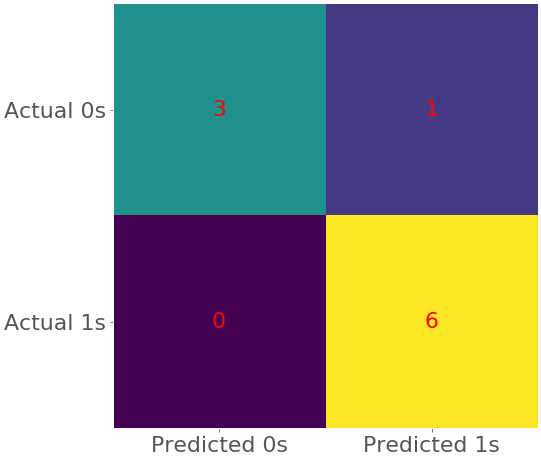
>>> print(classification_report(y, model.predict(x)))
precision recall f1-score support
0 1.00 0.75 0.86 4
1 0.86 1.00 0.92 6
accuracy 0.90 10
macro avg 0.93 0.88 0.89 10
weighted avg 0.91 0.90 0.90 10
该函数也将实际和预测输出作为参数。如果您提供了output_dict=True或者一个字符串,它将返回一个关于分类的报告,作为一个字典。
注意:通常用你没有用训练的数据来评估你的模型更好。这就是避免偏差和检测过度拟合的方法。在本教程的后面,您将看到一个示例。
更多关于LogisticRegression的信息,请查看官方文档。另外,scikit-learn 提供了一个类似的类 LogisticRegressionCV ,更适合交叉验证。你也可以查阅官方文档来了解更多关于分类报告和混淆矩阵的信息。
改进模型
您可以通过设置不同的参数来改进您的模型。例如,让我们使用等于10.0的正则化强度C,而不是默认值1.0:
model = LogisticRegression(solver='liblinear', C=10.0, random_state=0)
model.fit(x, y)
现在你有了另一个不同参数的模型。它还会有一个不同的概率矩阵,一组不同的系数和预测:
>>> model.intercept_ array([-3.51335372]) >>> model.coef_ array([[1.12066084]]) >>> model.predict_proba(x) array([[0.97106534, 0.02893466], [0.9162684 , 0.0837316 ], [0.7810904 , 0.2189096 ], [0.53777071, 0.46222929], [0.27502212, 0.72497788], [0.11007743, 0.88992257], [0.03876835, 0.96123165], [0.01298011, 0.98701989], [0.0042697 , 0.9957303 ], [0.00139621, 0.99860379]]) >>> model.predict(x) array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])如你所见,截距𝑏₀和系数𝑏₁的绝对值更大。这是因为较大的
C值意味着较弱的正则化,或者与𝑏₀和𝑏₁.的高值相关的较弱的惩罚𝑏₀和𝑏₁的不同值意味着逻辑𝑓(𝑥的变化,概率𝑝(𝑥的不同值,回归线的不同形状,以及其他预测输出和分类性能的可能变化。现在𝑝(𝑥)=0.5 和𝑓(𝑥)=0 的𝑥边界值比较高。3 以上。在这种情况下,您将获得所有真实预测,如准确性、混淆矩阵和分类报告所示:
>>> model.score(x, y)
1.0
>>> confusion_matrix(y, model.predict(x))
array([[4, 0],
[0, 6]])
>>> print(classification_report(y, model.predict(x)))
precision recall f1-score support
0 1.00 1.00 1.00 4
1 1.00 1.00 1.00 6
accuracy 1.00 10
macro avg 1.00 1.00 1.00 10
weighted avg 1.00 1.00 1.00 10
混淆矩阵左下和右上字段中的分数(或准确度)1 和零表示实际输出和预测输出是相同的。下图也显示了这一点:
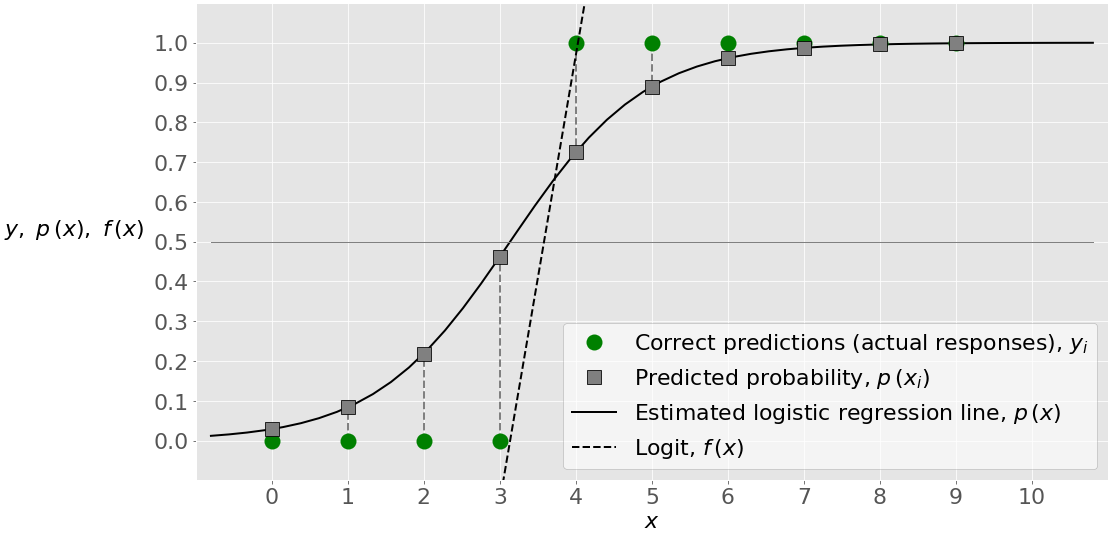
该图说明了估计的回归线现在具有不同的形状,并且第四个点被正确分类为 0。没有红×,所以没有预测错。
使用 scikit-learn 在 Python 中进行逻辑回归:示例 2
让我们解决另一个分类问题。它与前一个类似,只是第二个值的输出不同。代码类似于前一种情况:
# Step 1: Import packages, functions, and classes
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
# Step 2: Get data
x = np.arange(10).reshape(-1, 1)
y = np.array([0, 1, 0, 0, 1, 1, 1, 1, 1, 1])
# Step 3: Create a model and train it
model = LogisticRegression(solver='liblinear', C=10.0, random_state=0)
model.fit(x, y)
# Step 4: Evaluate the model
p_pred = model.predict_proba(x)
y_pred = model.predict(x)
score_ = model.score(x, y)
conf_m = confusion_matrix(y, y_pred)
report = classification_report(y, y_pred)
此分类代码示例生成以下结果:
>>> print('x:', x, sep='\n') x: [[0] [1] [2] [3] [4] [5] [6] [7] [8] [9]] >>> print('y:', y, sep='\n', end='\n\n') y: [0 1 0 0 1 1 1 1 1 1] >>> print('intercept:', model.intercept_) intercept: [-1.51632619] >>> print('coef:', model.coef_, end='\n\n') coef: [[0.703457]] >>> print('p_pred:', p_pred, sep='\n', end='\n\n') p_pred: [[0.81999686 0.18000314] [0.69272057 0.30727943] [0.52732579 0.47267421] [0.35570732 0.64429268] [0.21458576 0.78541424] [0.11910229 0.88089771] [0.06271329 0.93728671] [0.03205032 0.96794968] [0.0161218 0.9838782 ] [0.00804372 0.99195628]] >>> print('y_pred:', y_pred, end='\n\n') y_pred: [0 0 0 1 1 1 1 1 1 1] >>> print('score_:', score_, end='\n\n') score_: 0.8 >>> print('conf_m:', conf_m, sep='\n', end='\n\n') conf_m: [[2 1] [1 6]] >>> print('report:', report, sep='\n') report: precision recall f1-score support 0 0.67 0.67 0.67 3 1 0.86 0.86 0.86 7 accuracy 0.80 10 macro avg 0.76 0.76 0.76 10 weighted avg 0.80 0.80 0.80 10在这种情况下,分数(或准确度)是 0.8。有两个观察分类不正确。其中一个是假阴性,而另一个是假阳性。
下图显示了这个有八个正确预测和两个错误预测的示例:
该图揭示了这个例子的一个重要特征。和上一个不同,这个问题是不线性可分。这意味着你不能找到一个𝑥的值,然后画一条直线来区分𝑦=0 和𝑦=1.的观测值没有这条线。请记住,逻辑回归本质上是一个线性分类器,所以在这种情况下,理论上您无法制作精度为 1 的逻辑回归模型。
带 StatsModels 的 Python 中的逻辑回归:示例
您还可以使用 StatsModels 包在 Python 中实现逻辑回归。通常,当您需要与模型和结果相关的更多统计细节时,您会希望这样。该过程类似于 scikit-learn 的过程。
第一步:导入包
你只需要导入NumPy 和
statsmodels.api:import numpy as np import statsmodels.api as sm现在您已经有了您需要的包。
第二步:获取数据
您可以像使用 scikit-learn 一样获得输入和输出。然而,StatsModels 没有考虑截距𝑏₀,您需要在
x中包含额外的 1 列。你用add_constant()来做:x = np.arange(10).reshape(-1, 1) y = np.array([0, 1, 0, 0, 1, 1, 1, 1, 1, 1]) x = sm.add_constant(x)
add_constant()将数组x作为参数,并返回一个新的数组,其中包含一列 1。这是x和y的样子:
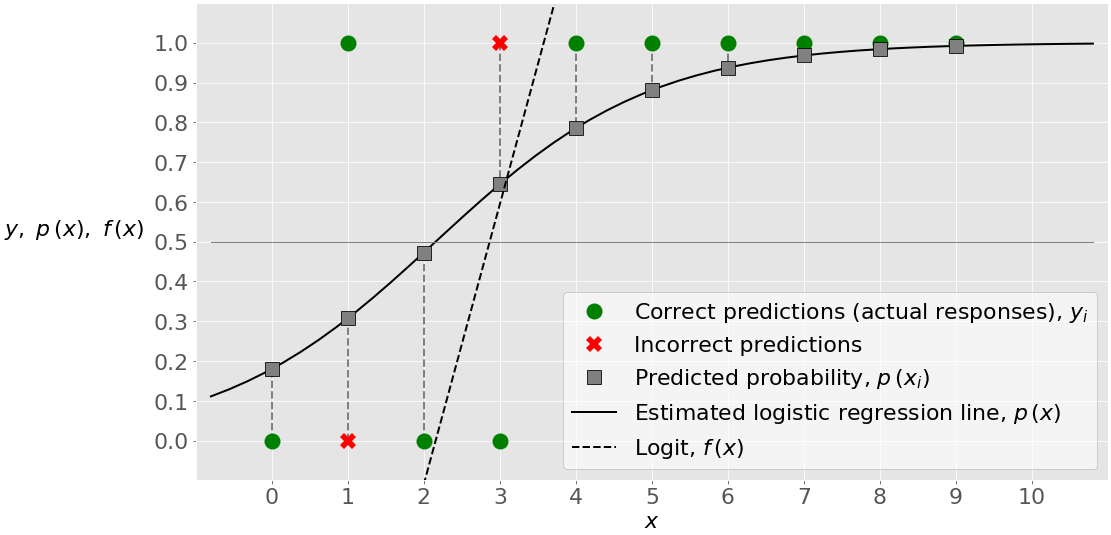
>>> x
array([[1., 0.],
[1., 1.],
[1., 2.],
[1., 3.],
[1., 4.],
[1., 5.],
[1., 6.],
[1., 7.],
[1., 8.],
[1., 9.]])
>>> y
array([0, 1, 0, 0, 1, 1, 1, 1, 1, 1])
这是你的数据。x的第一列对应于截距𝑏₀.第二列包含x的原始值。
第三步:创建一个模型并训练它
您的逻辑回归模型将是类statsmodels.discrete.discrete_model.Logit的一个实例。您可以这样创建一个:
>>> model = sm.Logit(y, x)注意这里第一个参数是
y,后面是x。现在,您已经创建了模型,应该用现有数据来拟合它。你可以用
.fit()来做,或者,如果你想应用 L1 正则化,用.fit_regularized():
>>> result = model.fit(method='newton')
Optimization terminated successfully.
Current function value: 0.350471
Iterations 7
模型现在已经准备好了,变量result保存了有用的数据。例如,您可以用.params获得𝑏₀和𝑏₁的值:
>>> result.params array([-1.972805 , 0.82240094])获得的数组的第一个元素是截距𝑏₀,而第二个元素是斜率𝑏₁.更多信息,可以看看官方关于
Logit的文档,还有.fit().fit_regularized()。步骤 4:评估模型
您可以使用
results获得预测输出等于 1 的概率:
>>> result.predict(x)
array([0.12208792, 0.24041529, 0.41872657, 0.62114189, 0.78864861,
0.89465521, 0.95080891, 0.97777369, 0.99011108, 0.99563083])
这些概率是用.predict()计算出来的。您可以使用它们的值来获得实际的预测输出:
>>> (result.predict(x) >= 0.5).astype(int) array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1])获得的数组包含预测的输出值。如您所见,𝑏₀、𝑏₁以及通过 scikit-learn 和 StatsModels 获得的概率是不同的。这是应用不同的迭代和近似程序和参数的结果。然而,在这种情况下,您将获得与使用 scikit-learn 时相同的预测输出。
您可以用
.pred_table()获得混淆矩阵:
>>> result.pred_table()
array([[2., 1.],
[1., 6.]])
这个例子与您使用 scikit-learn 时的例子相同,因为预测的输出是相等的。使用 StatsModels 和 scikit-learn 获得的混淆矩阵的元素类型不同(浮点数和整数)。
.summary()和.summary2()获取在某些情况下可能有用的输出数据:
>>> result.summary() <class 'statsmodels.iolib.summary.Summary'> """ Logit Regression Results ============================================================================== Dep. Variable: y No. Observations: 10 Model: Logit Df Residuals: 8 Method: MLE Df Model: 1 Date: Sun, 23 Jun 2019 Pseudo R-squ.: 0.4263 Time: 21:43:49 Log-Likelihood: -3.5047 converged: True LL-Null: -6.1086 LLR p-value: 0.02248 ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ const -1.9728 1.737 -1.136 0.256 -5.377 1.431 x1 0.8224 0.528 1.557 0.119 -0.213 1.858 ============================================================================== """ >>> result.summary2() <class 'statsmodels.iolib.summary2.Summary'> """ Results: Logit =============================================================== Model: Logit Pseudo R-squared: 0.426 Dependent Variable: y AIC: 11.0094 Date: 2019-06-23 21:43 BIC: 11.6146 No. Observations: 10 Log-Likelihood: -3.5047 Df Model: 1 LL-Null: -6.1086 Df Residuals: 8 LLR p-value: 0.022485 Converged: 1.0000 Scale: 1.0000 No. Iterations: 7.0000 ----------------------------------------------------------------- Coef. Std.Err. z P>|z| [0.025 0.975] ----------------------------------------------------------------- const -1.9728 1.7366 -1.1360 0.2560 -5.3765 1.4309 x1 0.8224 0.5281 1.5572 0.1194 -0.2127 1.8575 =============================================================== """这些是带有值的详细报告,您可以通过适当的方法和属性获得这些值。欲了解更多信息,请查看与
LogitResults相关的官方文档。Python 中的逻辑回归:手写识别
前面的例子说明了逻辑回归在 Python 中的实现,以及与该方法相关的一些细节。下一个例子将向您展示如何使用逻辑回归来解决现实世界中的分类问题。这种方法与您已经看到的非常相似,但是有一个更大的数据集和几个额外的问题。
这个例子是关于图像识别的。更准确地说,您将致力于手写数字的识别。您将使用包含 1797 个观察值的数据集,每个观察值都是一个手写数字的图像。每张图片 64 px,宽 8 px,高 8 px。
注意:要了解关于这个数据集的更多信息,请查看官方的文档。
输入(𝐱) 是具有 64 个维度或值的向量。每个输入向量描述一幅图像。64 个值中的每一个代表图像的一个像素。输入值是 0 到 16 之间的整数,取决于相应像素的灰度。每次观察的输出(𝑦) 为 0 到 9 之间的整数,与图像上的数字一致。总共有十个类,每个类对应一个图像。
第一步:导入包
您需要从 scikit-learn 导入 Matplotlib、NumPy 和几个函数和类:
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_digits from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler就是这样!您拥有执行分类所需的所有功能。
步骤 2a:获取数据
您可以使用
load_digits()直接从 scikit-learn 获取数据集。它返回输入和输出的元组:x, y = load_digits(return_X_y=True)现在你有了数据。这是
x和y的样子:
>>> x
array([[ 0., 0., 5., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.],
[ 0., 0., 0., ..., 16., 9., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 2., ..., 12., 0., 0.],
[ 0., 0., 10., ..., 12., 1., 0.]])
>>> y
array([0, 1, 2, ..., 8, 9, 8])
这就是你要处理的数据。x是一个 1797 行 64 列的多维数组。它包含从 0 到 16 的整数。y是一个一维数组,包含 1797 个 0 到 9 之间的整数。
步骤 2b:分割数据
将您正在处理的数据集分成两个子集是一种很好且被广泛采用的做法。这些是训练集和测试集。这种分割通常是随机进行的。您应该使用训练集来适应您的模型。一旦模型被拟合,您就可以用测试集来评估它的性能。重要的是不要在拟合模型的过程中使用测试集。这种方法能够对模型进行公正的评估。
将数据集分成训练集和测试集的一种方法是应用train_test_split() :
x_train, x_test, y_train, y_test =\
train_test_split(x, y, test_size=0.2, random_state=0)
train_test_split() 接受x和y。它还需要test_size来确定测试集的大小,以及random_state来定义伪随机数发生器的状态,以及其他可选参数。该函数返回一个包含四个数组的列表:
x_train:x中用于拟合模型的部分x_test:x中用于评估模型的部分y_train:y中对应x_train的部分y_test:y中对应x_test的部分
一旦你的数据被分割,你可以忘记x_test和y_test直到你定义你的模型。
步骤 2c:标度数据
标准化是以某种方式转换数据,使每一列的均值变得等于零,每一列的标准差为一的过程。这样,所有列的比例都相同。采取以下步骤来标准化您的数据:
- 计算每列的平均值和标准偏差。
- 从每个元素中减去对应的平均值。
- 将得到的差值除以对应的标准差。
将用于逻辑回归的输入数据标准化是一个很好的做法,尽管在许多情况下这是不必要的。标准化可能会提高算法的性能。如果您需要比较和解释权重,这会很有帮助。这在应用惩罚时很重要,因为算法实际上是对大的权重值进行惩罚。
您可以通过创建一个 StandardScaler 的实例并在其上调用.fit_transform()来标准化您的输入:
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
.fit_transform()使StandardScaler的实例适合作为参数传递的数组,转换该数组,并返回新的标准化数组。现在,x_train是一个标准化的输入数组。
第三步:创建一个模型并训练它
这一步与前面的例子非常相似。唯一的区别是您使用x_train和y_train子集来拟合模型。同样,您应该创建一个LogisticRegression的实例,并在其上调用.fit():
model = LogisticRegression(solver='liblinear', C=0.05, multi_class='ovr',
random_state=0)
model.fit(x_train, y_train)
当您处理两个以上类的问题时,您应该指定LogisticRegression的multi_class参数。它决定了如何解决问题:
'ovr'说要使二进制适合各个阶层。'multinomial'表示应用多项损失拟合。
最后一条语句产生以下输出,因为.fit()返回模型本身:
LogisticRegression(C=0.05, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='ovr', n_jobs=None, penalty='l2', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
这些是你的模型的参数。现在已经定义好了,可以开始下一步了。
步骤 4:评估模型
您应该像在前面的例子中那样评估您的模型,区别在于您将主要使用x_test和y_test,它们是不用于训练的子集。如果你已经决定标准化x_train,那么获得的模型依赖于缩放后的数据,所以x_test也应该用StandardScaler的同一个实例进行缩放:
x_test = scaler.transform(x_test)
这就是你如何获得一个新的,适当比例的x_test。在这种情况下,您使用.transform(),它只转换参数,而不安装缩放器。
您可以通过.predict()获得预测的输出:
y_pred = model.predict(x_test)
变量y_pred现在被绑定到预测输出的数组。注意,这里使用了x_test作为参数。
您可以通过.score()获得精度:
>>> model.score(x_train, y_train) 0.964509394572025 >>> model.score(x_test, y_test) 0.9416666666666667实际上,您可以获得两个精度值,一个是通过训练集获得的,另一个是通过测试集获得的。比较这两者可能是一个好主意,因为训练集准确性高得多的情况可能表明过度拟合。测试集的准确性与评估未知数据的性能更相关,因为它没有偏见。
用
confusion_matrix()可以得到混淆矩阵:
>>> confusion_matrix(y_test, y_pred)
array([[27, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 32, 0, 0, 0, 0, 1, 0, 1, 1],
[ 1, 1, 33, 1, 0, 0, 0, 0, 0, 0],
[ 0, 0, 1, 28, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 29, 0, 0, 1, 0, 0],
[ 0, 0, 0, 0, 0, 39, 0, 0, 0, 1],
[ 0, 1, 0, 0, 0, 0, 43, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 39, 0, 0],
[ 0, 2, 1, 2, 0, 0, 0, 1, 33, 0],
[ 0, 0, 0, 1, 0, 1, 0, 2, 1, 36]])
获得的混淆矩阵很大。在这种情况下,它有 100 个数字。在这种情况下,将它可视化可能会非常有用:
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(cm)
ax.grid(False)
ax.set_xlabel('Predicted outputs', fontsize=font_size, color='black')
ax.set_ylabel('Actual outputs', fontsize=font_size, color='black')
ax.xaxis.set(ticks=range(10))
ax.yaxis.set(ticks=range(10))
ax.set_ylim(9.5, -0.5)
for i in range(10):
for j in range(10):
ax.text(j, i, cm[i, j], ha='center', va='center', color='white')
plt.show()
上面的代码生成了下图的混淆矩阵:
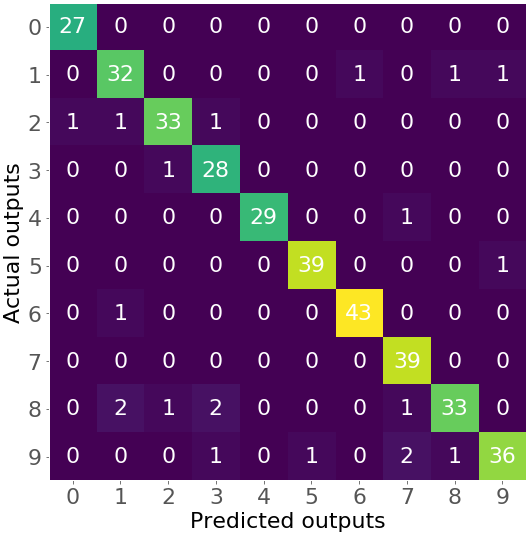
这是一张热图,用数字和颜色说明了混淆矩阵。您可以看到紫色阴影代表小数字(如 0、1 或 2),而绿色和黄色代表大得多的数字(27 及以上)。
主对角线上的数字(27,32,…,36)显示了测试集中正确预测的数量。例如,有 27 个图像的值为 0,32 个图像的值为 1,依此类推,这些图像被正确分类。其他数字对应不正确的预测。例如,第三行第一列中的数字 1 显示有一个数字 2 被错误地分类为 0 的图像。
最后,您可以使用classification_report()获得字符串或字典形式的分类报告:
>>> print(classification_report(y_test, y_pred)) precision recall f1-score support 0 0.96 1.00 0.98 27 1 0.89 0.91 0.90 35 2 0.94 0.92 0.93 36 3 0.88 0.97 0.92 29 4 1.00 0.97 0.98 30 5 0.97 0.97 0.97 40 6 0.98 0.98 0.98 44 7 0.91 1.00 0.95 39 8 0.94 0.85 0.89 39 9 0.95 0.88 0.91 41 accuracy 0.94 360 macro avg 0.94 0.94 0.94 360 weighted avg 0.94 0.94 0.94 360该报告显示了附加信息,如对每个数字进行分类的支持和精度。
超越 Python 中的逻辑回归
逻辑回归是一种基本的分类技术。这是一个相对简单的线性分类器。尽管逻辑回归简单且受欢迎,但在某些情况下(尤其是高度复杂的模型),逻辑回归并不奏效。在这种情况下,您可以使用其他分类技术:
- k-最近邻
- 朴素贝叶斯分类器
- 支持向量机
- 决策树
- 随机森林
- 神经网络
幸运的是,有几个全面的用于机器学习的 Python 库实现了这些技术。例如,您在这里看到的运行中的软件包 scikit-learn 实现了上述所有技术,但神经网络除外。
对于所有这些技术,scikit-learn 提供了合适的类,包括
model.fit()、model.predict_proba()、model.predict()、model.score()等方法。您可以将它们与train_test_split()、confusion_matrix()、classification_report()等组合使用。神经网络(包括深度神经网络)对于分类问题已经变得非常流行。像 TensorFlow、PyTorch 或 Keras 这样的库为这些类型的模型提供了合适的、 performant 和强大的支持。
结论
你现在知道什么是逻辑回归,以及如何用 Python 实现 T2 分类。您已经使用了许多开源包,包括 NumPy,来处理数组和 Matplotlib 以可视化结果。您还使用了 scikit-learn 和 StatsModels 来创建、拟合、评估和应用模型。
通常,Python 中的逻辑回归有一个简单且用户友好的实现。它通常由以下步骤组成:
- 导入包、函数和类
- 获取要处理的数据,如果合适的话,对其进行转换
- 创建分类模型,并用现有数据对其进行训练(或拟合)
- 评估你的模型,看看它的性能是否令人满意
- 应用你的模型进行预测
在理解机器学习最重要的领域之一方面,你已经走了很长的路!如果你有任何问题或意见,请写在下面的评论区。*********
使用 LRU 缓存策略在 Python 中进行缓存
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 lru_cache 在 Python 中缓存
有许多方法可以实现快速响应的应用程序。缓存是一种方法,当正确使用时,可以使事情变得更快,同时减少计算资源的负载。Python 的
functools模块带有@lru_cache装饰器,它让你能够使用最近最少使用(LRU)策略缓存函数的结果。这是一种简单而强大的技术,可以用来在代码中利用缓存的力量。在本教程中,您将学习:
- 有哪些缓存策略可用,以及如何使用Python decorator实现它们
- 什么是 LRU 战略以及它是如何运作的
- 如何通过使用
@lru_cache装饰器进行缓存来提高性能- 如何扩展
@lru_cache装饰器的功能,并使其在特定时间后过期在本教程结束时,您将对缓存的工作原理以及如何在 Python 中利用缓存有更深的理解。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
缓存及其用途
缓存是一种优化技术,您可以在应用程序中使用,将最近或经常使用的数据保存在访问速度更快或计算成本更低的内存位置。
假设您正在构建一个新闻阅读器应用程序,它从不同的来源获取最新的新闻。当用户在列表中导航时,您的应用程序下载文章并在屏幕上显示它们。
如果用户决定在几篇新闻文章之间反复来回移动,会发生什么?除非您缓存数据,否则您的应用程序每次都必须获取相同的内容!这将使你的用户系统运行缓慢,并给托管文章的服务器带来额外的压力。
更好的方法是在获取每篇文章后将内容存储在本地。然后,下一次用户决定打开一篇文章时,您的应用程序可以从本地存储的副本中打开内容,而不是返回到源代码。在计算机科学中,这种技术被称为缓存。
使用 Python 字典实现缓存
您可以使用字典在 Python 中实现缓存解决方案。
以新闻阅读器为例,您可以检查缓存中是否有内容,如果没有,就返回服务器,而不是每次需要下载文章时都直接去服务器。您可以将文章的 URL 用作键,将其内容用作值。
下面是这种缓存技术的一个例子:
1import requests 2 3cache = dict() 4 5def get_article_from_server(url): 6 print("Fetching article from server...") 7 response = requests.get(url) 8 return response.text 9 10def get_article(url): 11 print("Getting article...") 12 if url not in cache: 13 cache[url] = get_article_from_server(url) 14 15 return cache[url] 16 17get_article("https://realpython.com/sorting-algorithms-python/") 18get_article("https://realpython.com/sorting-algorithms-python/")将这段代码保存到一个
caching.py文件中,安装库,然后运行脚本:$ pip install requests $ python caching.py Getting article... Fetching article from server... Getting article...请注意,尽管在第 17 行和第 18 行调用了两次
get_article(),您还是一次打印了字符串"Fetching article from server..."。发生这种情况是因为,在第一次访问文章后,您将它的 URL 和内容放在了cache字典中。第二次,代码不需要再次从服务器获取项目。缓存策略
这种缓存实现有一个大问题:字典的内容将无限增长!随着用户下载更多的文章,应用程序将继续将它们存储在内存中,最终导致应用程序崩溃。
要解决这个问题,您需要一个策略来决定哪些文章应该保留在内存中,哪些应该删除。这些缓存策略是专注于管理缓存信息和选择丢弃哪些项目以便为新项目腾出空间的算法。
有几种不同的策略可以用来从缓存中逐出项目,并防止其超出最大大小。以下是五个最受欢迎的选项,并解释了每个选项何时最有用:
战略 驱逐政策 用例 先进先出(FIFO) 驱逐最旧的条目 较新的条目最有可能被重用 后进先出法 驱逐最新的条目 旧条目最有可能被重用 最近最少使用(LRU) 驱逐最近最少使用的条目 最近使用的条目最有可能被重用 最近使用的(MRU) 驱逐最近使用的条目 最近最少使用的条目最有可能被重用 最不常用(LFU) 驱逐最不经常访问的条目 命中次数多的条目更有可能被重用 在下面的小节中,您将仔细研究 LRU 策略,以及如何使用 Python 的
functools模块中的@lru_cache装饰器来实现它。进入最近最少使用的(LRU)缓存策略
使用 LRU 策略实现的缓存按照使用顺序组织其项目。每次你访问一个条目,LRU 算法会把它移动到缓存的顶部。这样,该算法可以通过查看列表的底部来快速识别最长时间未使用的条目。
下图显示了用户从网络请求文章后的一个假设的缓存表示:
请注意,在将文章提供给用户之前,缓存是如何将文章存储在最近的槽中的。下图显示了当用户请求第二篇文章时会发生什么:
第二篇文章占据最近的位置,将第一篇文章在列表中向下推。
LRU 策略假设一个对象最近被使用的次数越多,将来被需要的可能性就越大,因此它会尽量将该对象在缓存中保留最长的时间。
窥视 LRU 高速缓存的幕后
用 Python 实现 LRU 缓存的一种方法是使用一个双向链表和一个哈希映射的组合。双向链表的头元素将指向最近使用的条目,而尾元素将指向最近最少使用的条目。
下图显示了幕后 LRU 缓存实现的潜在结构:
使用散列映射,通过将每个条目映射到双向链表中的特定位置,可以确保访问缓存中的每个条目。
这个策略非常快。访问最近最少使用的项和更新缓存是运行时间为 O (1)的操作。
注:为了更深入的了解大 O 记法,结合 Python 中的几个实际例子,查看大 O 记法及算法分析结合 Python 实例。
从版本 3.2 开始,Python 已经包含了用于实现 LRU 策略的
@lru_cache装饰器。您可以使用这个装饰器来包装函数,并将它们的结果缓存到最大条目数。使用@lru_cache 在 Python 中实现 lru 缓存
就像您之前实现的缓存解决方案一样,
@lru_cache在幕后使用字典。它将函数的结果缓存在一个由函数调用组成的键下,包括提供的参数。这很重要,因为这意味着这些参数必须是可哈希的,装饰器才能工作。玩楼梯
想象一下,你想通过一次跳一个、两个或三个楼梯来确定到达楼梯中特定楼梯的所有不同方式。到第四个楼梯有几条路?以下是所有不同的组合:
你可以为这个问题设计一个解决方案,你可以从下面的一级、二级或三级楼梯跳下,到达你现在的楼梯。将到达每一个点的跳跃组合数加起来,你就得到到达当前位置的可能方式的总数。
例如,到达第四级楼梯的组合数等于到达第三级、第二级和第一级楼梯的不同方式的总数:
如图所示,有七种不同的方式到达第四个楼梯。注意给定楼梯的解决方案是如何建立在更小的子问题的答案之上的。在这种情况下,要确定到达第四个楼梯的不同路径,您可以将到达第三个楼梯的四种方式、到达第二个楼梯的两种方式和到达第一个楼梯的一种方式相加。
这种方法被称为递归。如果你想了解更多,那么请查看Python 中的递归思维以获得对该主题的介绍。
下面是一个实现这种递归的函数:
1def steps_to(stair): 2 if stair == 1: 3 # You can reach the first stair with only a single step 4 # from the floor. 5 return 1 6 elif stair == 2: 7 # You can reach the second stair by jumping from the 8 # floor with a single two-stair hop or by jumping a single 9 # stair a couple of times. 10 return 2 11 elif stair == 3: 12 # You can reach the third stair using four possible 13 # combinations: 14 # 1\. Jumping all the way from the floor 15 # 2\. Jumping two stairs, then one 16 # 3\. Jumping one stair, then two 17 # 4\. Jumping one stair three times 18 return 4 19 else: 20 # You can reach your current stair from three different places: 21 # 1\. From three stairs down 22 # 2\. From two stairs down 23 # 2\. From one stair down 24 # 25 # If you add up the number of ways of getting to those 26 # those three positions, then you should have your solution. 27 return ( 28 steps_to(stair - 3) 29 + steps_to(stair - 2) 30 + steps_to(stair - 1) 31 ) 32 33print(steps_to(4))将此代码保存到名为
stairs.py的文件中,并使用以下命令运行它:$ python stairs.py 7太好了!代码适用于
4楼梯,但是计算有多少级才能到达楼梯中更高的地方呢?将第 33 行中的楼梯号改为30,然后重新运行脚本:$ python stairs.py 53798080哇,5300 多万种组合!跳得真多!
为您的代码计时
找到第三十级楼梯的解决方案时,脚本花了相当多的时间才完成。要获得基线,您可以测量代码运行需要多长时间。
要完成这个,你可以使用 Python 的
timeit模块。在第 33 行后添加以下几行:35setup_code = "from __main__ import steps_to" 36stmt = "steps_to(30)" 37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10) 38print(f"Minimum execution time: {min(times)}")你还需要导入代码顶部的
timeit模块:1from timeit import repeat以下是对这些附加功能的逐行解释:
- 第 35 行导入了
steps_to()的名字,以便timeit.repeat()知道如何调用。- 第 36 行准备调用带有您想要到达的楼梯号的函数,在本例中是
30。这是将要执行和计时的语句。- 第 37 行用设置代码和语句调用
timeit.repeat()。这将调用函数10次,返回每次执行花费的秒数。- 第 38 行标识并打印返回的最短时间。
注意:一个常见的误解是,你应该找到函数每次运行的平均时间,而不是选择最短的时间。
时间测量有噪声,因为系统同时运行其他进程。最短的时间总是噪音最小的,这使得它成为函数运行时的最佳表示。
现在再次运行脚本:
$ python stairs.py 53798080 Minimum execution time: 40.014977024000004您将看到的秒数取决于您的具体硬件。在我的系统上,这个脚本花了 40 秒,对于仅仅 30 级楼梯来说是相当慢的!
注:你可以在官方 Python 文档中了解更多关于
timeit模块的内容。需要这么长时间的解决方案是一个问题,但是您可以使用记忆化来改进它。
使用记忆来改进解决方案
这种递归实现通过将问题分解成相互依赖的小步骤来解决问题。下图显示了一个树,其中每个节点代表对
steps_to()的一个特定调用:
注意你需要用相同的参数多次调用
steps_to()。例如,steps_to(5)计算两次,steps_to(4)计算四次,steps_to(3)计算七次,steps_to(2)计算六次。多次调用同一个函数会增加不必要的计算周期,结果总是一样的。要解决这个问题,你可以使用一种叫做记忆的技术。这种方法通过将结果存储在内存中,并在以后需要时引用它,确保函数不会对相同的输入运行多次。这个场景听起来是使用 Python 的
@lru_cache装饰器的绝佳机会!注意:关于记忆化和使用
@lru_cache实现它的更多信息,请查看 Python 中的记忆化。只需做两处更改,就可以显著提高算法的运行时间:
- 从
functools模块导入@lru_cache装饰器。- 用
@lru_cache来装饰steps_to()。这是经过两次更新后脚本顶部的样子:
1from functools import lru_cache 2from timeit import repeat 3 4@lru_cache 5def steps_to(stair): 6 if stair == 1:运行更新后的脚本会产生以下结果:
$ python stairs.py 53798080 Minimum execution time: 7.999999999987184e-07缓存函数的结果将运行时间从 40 秒减少到 0.0008 毫秒!这是一个了不起的进步!
注意:在 Python 3.8 和更高版本中,如果没有指定任何参数,可以使用不带括号的
@lru_cache装饰器。在以前的版本中,可能需要包含圆括号:@lru_cache()。记住,在幕后,
@lru_cache装饰器为每个不同的输入存储steps_to()的结果。每次代码使用相同的参数调用函数时,它都直接从内存中返回正确的结果,而不是重新计算答案。这解释了使用@lru_cache时性能的巨大提高。拆开@lru_cache 的功能
有了
@lru_cache装饰器,您可以将每个呼叫和应答存储在内存中,以便以后再次被请求时访问。但是,在内存耗尽之前,您可以节省多少通话时间呢?Python 的
@lru_cachedecorator 提供了一个maxsize属性,该属性定义了缓存开始驱逐旧项目之前的最大条目数。默认情况下,maxsize设置为128。如果您将maxsize设置为None,那么缓存将无限增长,并且不会有条目被驱逐。如果您在内存中存储了大量不同的呼叫,这可能会成为一个问题。下面是一个使用
maxsize属性的@lru_cache的例子:1from functools import lru_cache 2from timeit import repeat 3 4@lru_cache(maxsize=16) 5def steps_to(stair): 6 if stair == 1:在这种情况下,您将缓存限制为最多有
16个条目。当一个新的调用进来时,装饰器的实现将驱逐现有的16条目中最近最少使用的条目,为新条目腾出空间。要查看这个新代码会发生什么,您可以使用由
@lru_cache装饰器提供的cache_info(),来检查命中和未命中的数量以及缓存的当前大小。为了清楚起见,删除了计算函数运行时间的代码。以下是所有修改后的最终脚本:1from functools import lru_cache 2from timeit import repeat 3 4@lru_cache(maxsize=16) 5def steps_to(stair): 6 if stair == 1: 7 # You can reach the first stair with only a single step 8 # from the floor. 9 return 1 10 elif stair == 2: 11 # You can reach the second stair by jumping from the 12 # floor with a single two-stair hop or by jumping a single 13 # stair a couple of times. 14 return 2 15 elif stair == 3: 16 # You can reach the third stair using four possible 17 # combinations: 18 # 1\. Jumping all the way from the floor 19 # 2\. Jumping two stairs, then one 20 # 3\. Jumping one stair, then two 21 # 4\. Jumping one stair three times 22 return 4 23 else: 24 # You can reach your current stair from three different places: 25 # 1\. From three stairs down 26 # 2\. From two stairs down 27 # 2\. From one stair down 28 # 29 # If you add up the number of ways of getting to those 30 # those three positions, then you should have your solution. 31 return ( 32 steps_to(stair - 3) 33 + steps_to(stair - 2) 34 + steps_to(stair - 1) 35 ) 36 37print(steps_to(30)) 38 39print(steps_to.cache_info())如果您再次调用该脚本,那么您将看到以下结果:
$ python stairs.py 53798080 CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)您可以使用
cache_info()返回的信息来了解缓存的性能,并对其进行微调,以找到速度和存储之间的适当平衡。下面是由
cache_info()提供的属性分类:
hits=52是@lru_cache因为存在于缓存中而直接从内存返回的调用数。
misses=30是不是来自记忆和计算的呼叫数。因为您试图找到到达第三十级楼梯的步数,所以这些调用在第一次调用时都没有命中缓存是有道理的。
maxsize=16是您用装饰器的maxsize属性定义的缓存大小。
currsize=16是缓存的当前大小。在这种情况下,它显示您的缓存已满。如果需要从缓存中移除所有条目,那么可以使用由
@lru_cache提供的cache_clear()。添加缓存过期时间
假设您想开发一个脚本来监控真正的 Python 并打印任何包含单词
python的文章中的字符数。Real Python 提供了一个 Atom 提要,因此您可以像以前一样使用
feedparser库解析提要,使用requests库加载文章内容。下面是监视器脚本的一个实现:
1import feedparser 2import requests 3import ssl 4import time 5 6if hasattr(ssl, "_create_unverified_context"): 7 ssl._create_default_https_context = ssl._create_unverified_context 8 9def get_article_from_server(url): 10 print("Fetching article from server...") 11 response = requests.get(url) 12 return response.text 13 14def monitor(url): 15 maxlen = 45 16 while True: 17 print("\nChecking feed...") 18 feed = feedparser.parse(url) 19 20 for entry in feed.entries[:5]: 21 if "python" in entry.title.lower(): 22 truncated_title = ( 23 entry.title[:maxlen] + "..." 24 if len(entry.title) > maxlen 25 else entry.title 26 ) 27 print( 28 "Match found:", 29 truncated_title, 30 len(get_article_from_server(entry.link)), 31 ) 32 33 time.sleep(5) 34 35monitor("https://realpython.com/atom.xml")将这个脚本保存到一个名为
monitor.py的文件中,安装feedparser和requests库,然后运行这个脚本。它将持续运行,直到您在终端窗口中按下Ctrl+C将其停止:$ pip install feedparser requests $ python monitor.py Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784 Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784下面是对代码的逐步解释:
- 第 6 行和第 7 行:这是当
feedparser试图访问 HTTPS 上提供的内容时的一个问题的变通办法。有关更多信息,请参见下面的注释。- 第 16 行 :
monitor()将无限循环。- 第 18 行:使用
feedparser,代码加载并解析来自真实 Python 的提要。- 第 20 行:循环遍历列表中的前
5个条目。- 第 21 到 31 行:如果单词
python是标题的一部分,那么代码会将它和文章的长度一起打印出来。- 第 33 行:代码在继续之前休眠秒
5。- 第 35 行:该行通过将真实 Python 提要的 URL 传递给
monitor()来启动监控过程。每当脚本加载一篇文章时,消息
"Fetching article from server..."被打印到控制台。如果您让脚本运行足够长的时间,那么您将会看到这条消息是如何重复出现的,即使是在加载相同的链接时。注意:关于
feedparser访问通过 HTTPS 提供的内容的更多信息,请查看feedparser存储库上的第 84 期。 PEP 476 描述了 Python 如何开始为stdlibHTTP 客户端默认启用证书验证,这是这个错误的根本原因。这是一个缓存文章内容并避免每五秒钟访问一次网络的绝佳机会。您可以使用
@lru_cache装饰器,但是如果文章的内容被更新了会发生什么呢?第一次访问文章时,装饰器将存储其内容,以后每次都返回相同的数据。如果 post 被更新,那么 monitor 脚本将永远不会意识到这一点,因为它将提取存储在缓存中的旧副本。要解决这个问题,您可以将缓存条目设置为过期。
基于时间和空间驱逐缓存条目
只有当没有更多空间来存储新的列表时,装饰器才会驱逐现有的条目。有了足够的空间,缓存中的条目将永远存在,永远不会刷新。
这对您的监控脚本提出了一个问题,因为您永远不会获取为以前缓存的文章发布的更新。要解决这个问题,您可以更新缓存实现,使其在特定时间后过期。
您可以将这个想法实现到一个扩展了
@lru_cache的新装饰器中。如果调用者试图访问一个已经过期的条目,那么缓存不会返回它的内容,迫使调用者从网络上获取文章。注:更多关于 Python 装饰者的信息,查看Python 装饰者入门和 Python 装饰者 101 。
下面是这个新装饰器的一个可能实现:
1from functools import lru_cache, wraps 2from datetime import datetime, timedelta 3 4def timed_lru_cache(seconds: int, maxsize: int = 128): 5 def wrapper_cache(func): 6 func = lru_cache(maxsize=maxsize)(func) 7 func.lifetime = timedelta(seconds=seconds) 8 func.expiration = datetime.utcnow() + func.lifetime 9 10 @wraps(func) 11 def wrapped_func(*args, **kwargs): 12 if datetime.utcnow() >= func.expiration: 13 func.cache_clear() 14 func.expiration = datetime.utcnow() + func.lifetime 15 16 return func(*args, **kwargs) 17 18 return wrapped_func 19 20 return wrapper_cache下面是这种实现的分类:
- 第 4 行:
@timed_lru_cache装饰器将支持缓存中条目的生命周期(以秒为单位)和缓存的最大大小。- 第 6 行:代码用
lru_cache装饰器包装被装饰的函数。这允许您使用已经由lru_cache提供的缓存功能。- 第 7 行和第 8 行:这两行用两个属性来表示修饰函数,这两个属性分别代表缓存的生命周期和它到期的实际日期。
- 第 12 行到第 14 行:在访问缓存中的条目之前,装饰器检查当前日期是否超过了到期日期。如果是这种情况,那么它清除缓存并重新计算生存期和到期日期。
请注意,当一个条目过期时,这个装饰器如何清除与该函数相关的整个缓存。生存期适用于整个缓存,而不是单个项目。这种策略的一个更复杂的实现是基于条目各自的生命周期来驱逐它们。
用新装饰器缓存文章
现在,您可以使用新的
@timed_lru_cache装饰器和monitor脚本来防止每次访问文章时获取内容。为简单起见,将代码放在一个脚本中,最终会得到以下结果:
1import feedparser 2import requests 3import ssl 4import time 5 6from functools import lru_cache, wraps 7from datetime import datetime, timedelta 8 9if hasattr(ssl, "_create_unverified_context"): 10 ssl._create_default_https_context = ssl._create_unverified_context 11 12def timed_lru_cache(seconds: int, maxsize: int = 128): 13 def wrapper_cache(func): 14 func = lru_cache(maxsize=maxsize)(func) 15 func.lifetime = timedelta(seconds=seconds) 16 func.expiration = datetime.utcnow() + func.lifetime 17 18 @wraps(func) 19 def wrapped_func(*args, **kwargs): 20 if datetime.utcnow() >= func.expiration: 21 func.cache_clear() 22 func.expiration = datetime.utcnow() + func.lifetime 23 24 return func(*args, **kwargs) 25 26 return wrapped_func 27 28 return wrapper_cache 29 30@timed_lru_cache(10) 31def get_article_from_server(url): 32 print("Fetching article from server...") 33 response = requests.get(url) 34 return response.text 35 36def monitor(url): 37 maxlen = 45 38 while True: 39 print("\nChecking feed...") 40 feed = feedparser.parse(url) 41 42 for entry in feed.entries[:5]: 43 if "python" in entry.title.lower(): 44 truncated_title = ( 45 entry.title[:maxlen] + "..." 46 if len(entry.title) > maxlen 47 else entry.title 48 ) 49 print( 50 "Match found:", 51 truncated_title, 52 len(get_article_from_server(entry.link)), 53 ) 54 55 time.sleep(5) 56 57monitor("https://realpython.com/atom.xml")注意第 30 行是如何用
@timed_lru_cache修饰get_article_from_server()并指定10秒的有效性的。任何试图在获取后的10秒内从服务器访问同一篇文章的行为都将从缓存中返回内容,并且永远不会影响网络。运行脚本并查看结果:
$ python monitor.py Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37100 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164887 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37099 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783注意代码第一次访问匹配的文章时是如何打印消息
"Fetching article from server..."的。之后,根据您的网络速度和计算能力,脚本将在再次访问服务器之前从缓存中检索一次或两次文章。脚本每隔
5秒尝试访问文章,缓存每隔10秒到期。对于实际的应用程序来说,这些时间可能太短了,所以您可以通过调整这些配置来获得显著的改进。结论
缓存是提高任何软件系统性能的基本优化技术。理解缓存的工作原理是将它有效地集成到应用程序中的基本步骤。
在本教程中,您学习了:
- 有哪些不同的缓存策略以及它们是如何工作的
- 如何使用 Python 的
@lru_cache装饰器- 如何创建一个新的装饰器来扩展
@lru_cache的功能- 如何使用
timeit模块测量代码的运行时间- 什么是递归以及如何使用它解决问题
- 记忆化如何通过在内存中存储中间结果来提高运行时间
在应用程序中实现不同缓存策略的下一步是查看
cachetools模块。这个库提供了几个集合和装饰器,涵盖了一些最流行的缓存策略,您可以立即开始使用。立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 lru_cache 在 Python 中缓存******
Lyricize:一个使用马尔可夫链创建歌词的 Flask 应用程序
原文:https://realpython.com/lyricize-a-flask-app-to-create-lyrics-using-markov-chains/
新程序员是 总 寻找 新 项目——他们也应该如此!做你自己的兼职项目不仅是获得实践经验的最好方式,而且如果你想从爱好转向职业,那么兼职项目是开始建立工作组合的好方法。
从创意到 MVP
在这篇文章中,我们将完成启动一个(最低限度的)MVP 的过程,从最初的概念到一个可共享的原型。最后,你将创建自己版本的 Lyricize ,这是一个小应用程序,它使用艺术家或乐队的歌词,根据概率生成“新的”听起来相似的歌词。我们不会呈现典型的“如何复制所有这些代码”教程,而是一步一步地展示思考过程和创作过程中的实际上是什么。
请注意,这不一定是关于建立下一个杀手级创业公司;我们只是在寻找一个项目,可以 1)一个有趣的学习机会,2)与他人分享。
在我们开始之前,先看一下示例应用程序,看看你将创建什么。本质上,您可以使用马尔可夫链根据特定艺术家的歌词生成新的歌词。例如,尝试搜索“鲍勃·迪伦”,将行数改为三行。很酷,对吧?我刚刚执行了相同的搜索,结果是:
那边站着你的承诺所有的船
我准备好了峡谷
我是一个钩子好深。不管怎样,让我们开始吧…
找到感兴趣的话题
所以,第一步:找一个你有兴趣了解更多的话题。下面这款应用的灵感来自于一份旧的大学作业(不可否认,这不是最常见的灵感来源),它使用马尔可夫链来生成给定大量样本文本的“真实”文本。马尔可夫模型突然出现在各种场景。(我们将很快深入什么是马尔可夫模型。)我发现基于概率的文本生成的想法特别有趣;具体来说,我想知道如果您使用歌曲歌词作为样本文本来生成“新”歌词会发生什么…
到网上!快速的网络搜索显示了一些基于马尔可夫的歌词生成器网站,但是没有一个和我想的一样。此外,埋头研究别人完成的代码并不是学习马尔可夫发生器实际工作方式的有效方法;我们自己造吧。
那么……马尔可夫发生器是如何工作的?基本上,马尔可夫链是根据某些模式出现的频率从一些文本中生成的。例如,考虑以下字符串作为我们的示例文本:
bobby我们将从本文中构建最简单的马尔可夫模型,这是一个阶为 0 的马尔可夫模型,作为预测任何特定字母出现的可能性的一种方式。这是一个简单明了的频率表:
b: 3/5 o: 1/5 y: 1/5然而,这是一个相当糟糕的语言模型;除了字母出现的频率,我们还想看看给定前一个字母的情况下,某个字母出现的频率。因为我们依赖于前面的一个字母,这是一个 1 阶马尔可夫模型:
given "b": "b" is next: 1/3 "o" is next: 1/3 "y" is next: 1/3 given "o": "b" is next: 1 given "y": [terminates]: 1从这里,你可以想象更高阶的马尔可夫模型;阶 2 模型将从测量在双字母串“bo”之后出现的每个字母的频率开始,等等。通过增加阶数,我们得到一个看起来更像真实语言的模型;例如,一个 5 阶马尔可夫模型,如果给出了大量样本输入,包括单词“python ”,很可能会在字符串“python”后面加上一个“n ”,而一个低得多的阶模型可能会提出一些创造性的单词。
开始开发
我们如何着手建立一个马尔可夫模型的粗略近似?本质上,我们上面用高阶模型概述的结构是字典的字典。您可以想象一个包含各种单词片段(即“bo”)作为关键字的
model字典。然后,这些片段中的每一个将依次指向一个字典,这些内部字典将各个下一个字母(“y”)作为关键字,将它们各自的频率作为值。让我们从制作一个
generateModel()方法开始,该方法接收一些样本文本和一个马尔可夫模型顺序,然后返回这个字典的字典:def generateModel(text, order): model = {} for i in range(0, len(text) - order): fragment = text[i:i+order] next_letter = text[i+order] if fragment not in model: model[fragment] = {} if next_letter not in model[fragment]: model[fragment][next_letter] = 1 else: model[fragment][next_letter] += 1 return model我们遍历所有可用的文本,直到最后一个可用的完整片段+下一个字母,以便不超出字符串的结尾,将我们的
fragment字典添加到model中,每个fragment保存一个总next_letter频率的字典。将该函数复制到 Python shell 中,并进行试验:


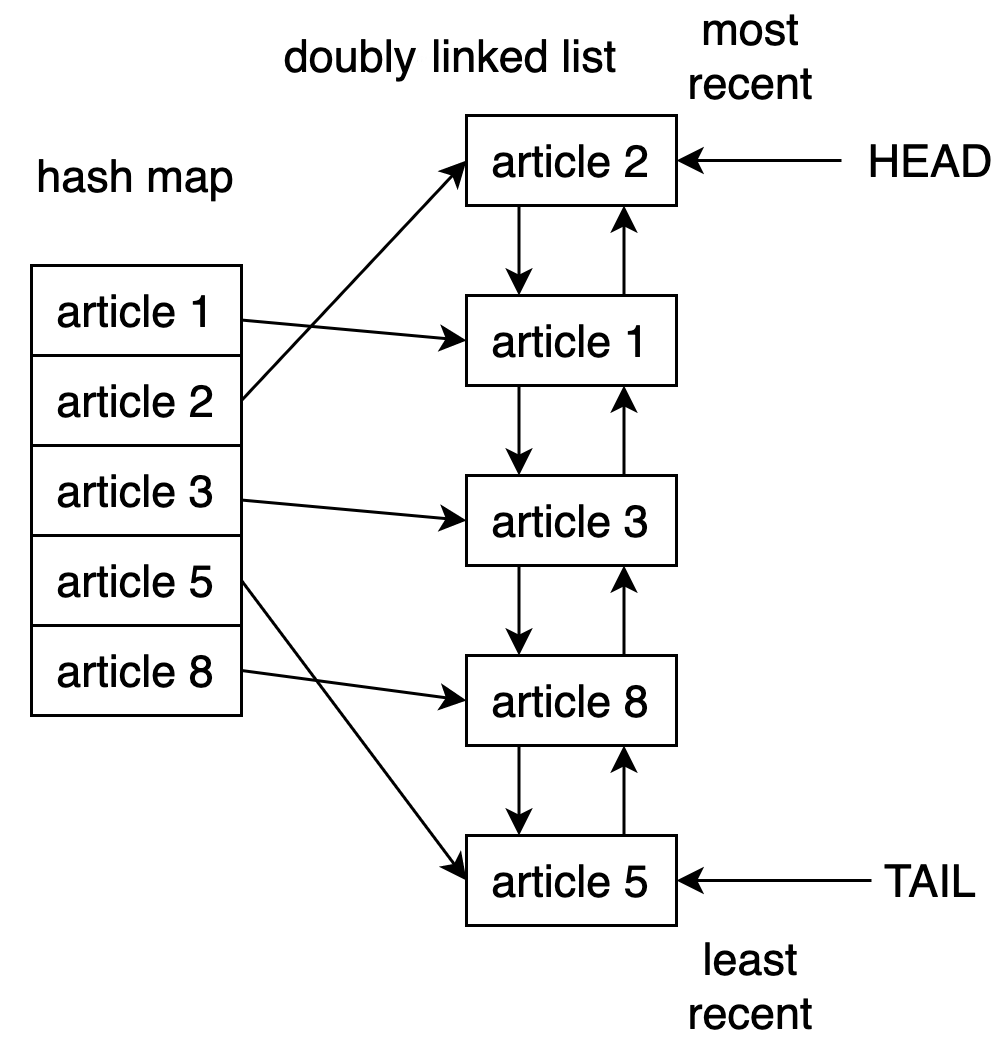
>>> generateModel("bobby", 1)
{'b': {'y': 1, 'b': 1, 'o': 1}, 'o': {'b': 1}}
那就行了!我们有频率的计数,而不是相对概率,但我们可以利用它;没有理由我们需要标准化每个字典来增加 100%的概率。
现在让我们在一个getNextCharacter()方法中使用这个model,该方法将在给定一个模型和一个片段的情况下,根据给定的模型概率决定一个合适的下一个字母:
from random import choice
def getNextCharacter(model, fragment):
letters = []
for letter in model[fragment].keys():
for times in range(0, model[fragment][letter]):
letters.append(letter)
return choice(letters)
这不是最有效的设置,但它构建起来很简单,并且目前有效。我们简单地建立了一个字母列表,给出它们在片段后出现的总频率,并从列表中随机选择。
剩下的就是在第三种方法中使用这两种方法,这种方法实际上会生成指定长度的文本。要做到这一点,我们需要在添加新字符时跟踪我们正在构建的当前文本片段:
def generateText(text, order, length):
model = generateModel(text, order)
currentFragment = text[0:order]
output = ""
for i in range(0, length-order):
newCharacter = getNextCharacter(model, currentFragment)
output += newCharacter
currentFragment = currentFragment[1:] + newCharacter
print output
让我们把它变成一个完整的可运行脚本,它以马尔可夫顺序和输出文本长度作为参数:
from random import choice
import sys
def generateModel(text, order):
model = {}
for i in range(0, len(text) - order):
fragment = text[i:i+order]
next_letter = text[i+order]
if fragment not in model:
model[fragment] = {}
if next_letter not in model[fragment]:
model[fragment][next_letter] = 1
else:
model[fragment][next_letter] += 1
return model
def getNextCharacter(model, fragment):
letters = []
for letter in model[fragment].keys():
for times in range(0, model[fragment][letter]):
letters.append(letter)
return choice(letters)
def generateText(text, order, length):
model = generateModel(text, order)
currentFragment = text[0:order]
output = ""
for i in range(0, length-order):
newCharacter = getNextCharacter(model, currentFragment)
output += newCharacter
currentFragment = currentFragment[1:] + newCharacter
print output
text = "some sample text"
if __name__ == "__main__":
generateText(text, int(sys.argv[1]), int(sys.argv[2]))
现在,我们将通过非常科学的方法生成示例文本,即根据一些复制粘贴的 Alanis Morisette 歌词,将字符串直接放入代码中。
测试
保存脚本并尝试一下:
$ python markov.py 2 100
I wounts
You ho's humortel whime
mateend I wass
How by Lover
$ python markov.py 4 100
stress you to cosmic tears
All they've cracked you (honestly) at the filler in to like raise
$ python markov.py 6 100
tress you place the wheel from me
Please be philosophical
Please be tapped into my house
那真是太珍贵了。最后两次试听是她歌词的体面代表(虽然 order 2 的第一个样本看起来更像 bjrk)。这些结果对于一个快速的代码草图来说是足够令人鼓舞的,所以让我们把这个东西变成一个真正的项目。
下一次迭代
第一个障碍:我们如何自动获取大量歌词?一种选择是有选择地从歌词网站抓取内容,但这听起来像是为可能的低质量结果付出了很多努力,加上考虑到大多数歌词聚合器的可疑性和音乐行业的严酷性,潜在的法律灰色地带。相反,让我们看看是否有开放的 API。前往通过programmableweb.com搜索,我们实际上发现 14 不同的歌词 API 列表。不过,这些列表并不总是最新的,所以让我们通过最近列出的来搜索。
LYRICSnMUSIC 提供免费的、 RESTful API 使用 JSON 返回多达 150 个字符的歌词。这对于我们的用例来说听起来很完美,特别是考虑到大多数歌曲的重复;只要一个样本就够了,没有必要收集完整的歌词。去拿一个新的键,这样你就可以访问他们的 API 了。
在我们永久确定这个来源之前,让我们先尝试一下他们的 API。根据他们的文档,我们可以提出一个示例请求,如下所示:
http://api.lyricsnmusic.com/songs?api_key=[YOUR_API_KEY_HERE]&artist=coldplay
它在浏览器中返回的 JSON 结果有点难以阅读;通过它们在一个格式器中进行更好的查看。看起来我们成功地取回了基于 Coldplay 歌曲的字典列表:
[ { "title":"Don't Panic", "url":"http://www.lyricsnmusic.com/coldplay/don-t-panic-lyrics/4294612", "snippet":"Bones sinking like stones \r\nAll that we've fought for \r\nHomes, places we've grown \r\nAll of us are done for \r\n\r\nWe live in a beautiful world \r\nYeah we ...", "context":null, "viewable":true, "instrumental":false, "artist":{ "name":"Coldplay", "url":"http://www.lyricsnmusic.com/coldplay" } }, { "title":"Shiver", "url":"http://www.lyricsnmusic.com/coldplay/shiver-lyrics/4294613", "snippet":"So I look in your direction\r\nBut you pay me no attention, do you\r\nI know you don't listen to me\r\n'Cause you say you see straight through me, don't you...", "context":null, "viewable":true, "instrumental":false, "artist":{ "name":"Coldplay", "url":"http://www.lyricsnmusic.com/coldplay" } }, ... ]
没有办法限制响应,但是我们只对提供的每个“片段”感兴趣,这对这个项目来说看起来很好。
我们对马尔可夫发生器的初步实验是有教育意义的,但是我们当前的模型并不是最适合生成歌词的任务。一方面,我们可能应该使用单个单词作为我们的标记,而不是一个字符一个字符地看待事物;试图模仿语言本身很有趣,但为了生成假歌词,我们将希望坚持真正的英语。这听起来有点棘手,但是,我们已经走了很长的路来理解马尔可夫链是如何运作的,这是该练习的最初目标。在这一点上,我们到达了一个十字路口:为了更多的学习,重新发明隐喻的轮子(这可能是伟大的编码实践),或者看看其他人已经创造了什么。
我选择了懒惰的方式,回去搜索内部网络。GitHub 上的一个善良的灵魂已经实现了一个基本的基于单词的马尔可夫链,甚至上传到了 PyPI 。快速浏览一下代码,似乎这个模型只有 0 阶。这对于我们自己构建可能已经足够快了,而高阶模型可能需要更多的工作。就目前来说,我们还是用别人的预包装车轮吧;如果我们使用完整的单词,至少 0 阶模型不会听起来像 bjrk。
因为我们想轻松地与朋友和家人分享我们的创作,所以把它变成一个 web 应用程序是有意义的。现在,选择一个网络框架。就我个人而言,我是迄今为止对 Django 最熟悉的,但这在这里似乎有点过头了;毕竟,我们甚至不需要自己的数据库。让我们试试烧瓶。
添加烧瓶
按照惯例,启动一个虚拟环境 -如果你还没有的话!如果这不是一个熟悉的过程,看看我们的以前的帖子来学习如何设置。
$ mkdir lyricize
$ cd lyricize
$ virtualenv --no-site-packages venv
$ source venv/bin/activate
还是像往常一样,安装必要的需求,并将它们放在 requirements.txt 文件中:
$ pip install PyMarkovChain flask requests
$ pip freeze > requirements.txt
我们还添加了请求库,这样我们就可以向歌词 API 发出 web 请求。
现在,制作应用程序。为了简单起见,让我们将它分成两个页面:主页面将向用户呈现一个基本表单,用于选择艺术家姓名和要生成的多行歌词,而第二个“歌词”页面将呈现结果。让我们从一个名为 app.py 的准系统 Flask 应用程序开始,它使用了一个index.html模板:
from flask import Flask, render_template
app = Flask(__name__)
app.debug = True
@app.route('/', methods=['GET'])
def index():
return render_template('index.html')
if __name__ == '__main__':
app.run()
到目前为止,这个应用程序所能做的就是加载 index.html 模板的内容。让我们把它做成一个基本形式:
<html>
<body>
<form action="#" method="post" class="lyrics">
Artist or band name: <input name="artist" type="text" /><br />
Number of lines:
<select name="lines">
{% for n in range(1,11) %}
<option value="{{n}}">{{n}}</option>
{% endfor %}
</select>
<br /><br />
<input class="button" type="submit" value="Lyricize">
</form>
</body>
</html>
将这个 index.html 保存在一个名为 templates 的单独文件夹中,以便 Flask 可以找到它。这里我们使用 Flask 的 Jinja2 模板来创建一个“选择”下拉列表,它基于一个覆盖数字 1 到 10 的循环。在我们添加任何其他内容之前,启动此页面以确保我们设置正确:
$ python app.py
* Running on http://127.0.0.1:5000/
您现在应该能够在浏览器中访问 http://127.0.0.1:5000/
现在让我们决定我们想要在结果页面上显示什么,以便我们知道我们需要传递给它什么:
<html>
<body>
<div align="center" style="padding-top:20px;">
<h2>
{% for line in result %}
{{ line }}<br />
{% endfor %}
</h2>
<h3>{{ artist }}</h3>
<br />
<form action="{{ url_for('index') }}">
<input type="submit" value="Do it again!" />
</form>
</div>
</body>
</html>
这里我们循环遍历一个结果数组,逐行显示每一行。在下面,我们显示被选中的艺术家,并链接回主页。在你的/templates 目录下,将此文件另存为【lyrics.html*。
我们还需要更新 index.html 的表单操作,以指向这个结果页面:
<form action="{{ url_for('lyrics') }}" method="post" class="lyrics">
现在为生成的歌词页面写一条路线:
@app.route('/lyrics', methods=['POST'])
def lyrics():
artist = request.form['artist']
lines = int(request.form['lines'])
if not artist:
return redirect(url_for('index'))
return render_template('lyrics.html', result=['hello', 'world'], artist=artist)
这个页面从表单中获取 POST 请求,解析出提供的艺术家和行数——我们还没有生成任何歌词,只是给模板一个虚拟的结果列表。我们还需要添加我们所依赖的必要的 Flask 功能- url_for和redirect:
from flask import Flask, render_template, url_for, redirect
测试一下,确保没有任何损坏:
$ python app.py
太好了,现在是项目的实质内容。在歌词()中,让我们根据传入的艺术家参数从 LYRICSnMUSIC 获得一个响应:
# Get a response of sample lyrics from the provided artist
uri = "http://api.lyricsnmusic.com/songs"
params = {
'api_key': API_KEY,
'artist': artist,
}
response = requests.get(uri, params=params)
lyric_list = response.json()
使用请求,我们获取一个特定的 URL,其中包含一个参数字典:提供的艺术家姓名和我们的 API 键。这个私有 API 密钥应该而不是出现在您的代码中;毕竟,您会希望与他人共享这些代码。相反,让我们创建一个单独的文件来保存这个值作为一个变量:
$ echo "API_KEY=[youractualapikeygoeshere]" > .env
我们已经创建了一个特殊的“环境”文件,如果我们只需在应用程序顶部添加以下内容,Flask 就可以读取该文件:
import os
API_KEY = os.environ.get('API_KEY')
最后,让我们添加马尔可夫链功能。既然我们正在使用别人的包,这最终变得相当琐碎。首先,在顶部添加导入:
from pymarkovchain import MarkovChain
然后,在我们从 API 收到一个歌词响应后,我们简单地创建一个 MarkovChain,加载歌词数据,并生成一个句子列表:
mc = MarkovChain()
mc.generateDatabase(lyrics)
result = []
for line in range(0, lines):
result.append(mc.generateString())
总的来说,app.py 现在应该是这样的:
from flask import Flask, url_for, redirect, request, render_template
import requests
from pymarkovchain import MarkovChain
import os
API_KEY = os.environ.get('API_KEY')
app = Flask(__name__)
app.debug = True
@app.route('/', methods=['GET'])
def index():
return render_template('index.html')
@app.route('/lyrics', methods=['POST'])
def lyrics():
artist = request.form['artist']
lines = int(request.form['lines'])
if not artist:
return redirect(url_for('index'))
# Get a response of sample lyrics from the artist
uri = "http://api.lyricsnmusic.com/songs"
params = {
'api_key': API_KEY,
'artist': artist,
}
response = requests.get(uri, params=params)
lyric_list = response.json()
# Parse results into a long string of lyrics
lyrics = ''
for lyric_dict in lyric_list:
lyrics += lyric_dict['snippet'].replace('...', '') + ' '
# Generate a Markov model
mc = MarkovChain()
mc.generateDatabase(lyrics)
# Add lines of lyrics
result = []
for line in range(0, lines):
result.append(mc.generateString())
return render_template('lyrics.html', result=result, artist=artist)
if __name__ == '__main__':
app.run()
试试吧!一切都应该在本地工作。现在,与世界分享它…
部署到 Heroku
让我们在 Heroku 上托管,因为(对于这些最低要求)我们可以免费这么做。为此,我们需要对代码做一些小的调整。首先,添加一个 Procfile ,它将告诉 Heroku 如何为应用程序提供服务:
$ echo "web: python app.py" > Procfile
接下来,因为 Heroku 指定了一个运行应用程序的随机端口,所以您需要在顶部传递一个端口号:
PORT = int(os.environ.get('PORT', 5000))
app = Flask(__name__)
app.config.from_object(__name__)
当应用程序运行时,确保通过这个端口
if __name__ == '__main__':
app.run(host='0.0.0.0', port=PORT)
我们还必须指定“0.0.0.0”的主机,因为 Flask 默认情况下在本地计算机上秘密运行,而我们希望该应用程序在 Heroku 上公开可用的 IP 上运行。
最后,从代码中删除app.debug=True,这样如果出错,用户就不会看到完整的 stacktrace 错误。
初始化一个 git 存储库(如果你还没有的话),创建一个新的 Heroku 应用程序,并把你的代码放进去!
$ git init
$ git add .
$ git commit -m "First commit"
$ heroku create
$ git push heroku master
请参见 Heroku 文档以了解此部署流程的更详细的概要。确保在 Heroku 上添加 API_KEY 变量:
$ heroku config:set API_KEY=[youractualapikeygoeshere]
我们都准备好了!是时候与世界分享你的创作了——或者继续黑下去:)
结论和后续步骤
如果你喜欢这个内容,你可能会对我们目前学习网页开发的课程感兴趣,或者对我们最新的 T2 Kickstarter 感兴趣,它涵盖了更先进的技术。或者——在这里玩一下应用程序。
可能的后续步骤:
- 这个 HTML 看起来像是 90 年代初写的;使用 Bootstrap 或者只是一些基本的 CSS 样式
- 在忘记代码的作用之前,给代码添加一些注释!(这是留给读者的一个练习:o)
- 将歌词路径中的代码抽象为单独的方法(即,一个从歌词 API 返回响应的方法和另一个用于生成马尔可夫模型的独立方法);随着代码规模和复杂性的增长,这将使代码更容易维护和测试
- 创建一个能够使用更高阶的马尔可夫发生器
- 使用 Flask-WTF 改进表格和表格验证
- 说到这里:让它更安全!现在,有人可能会发送不合理的 POST 请求,将他们自己的代码注入页面,或者用许多快速重复的请求来拒绝站点;添加一些可靠的输入验证和基本速率限制
- 添加更好的错误处理;如果一个 API 调用时间太长或者由于某种原因失败了怎么办?
- 将结果放入一个文本到语音转换引擎,学习使用另一个马尔可夫模型改变音调模式,并设置为一个节拍;很快你就会在排行榜上名列前茅!****
在 Django Admin 中管理用户需要知道什么
Django admin 中的用户管理是一个棘手的问题。如果您强制实施太多权限,那么您可能会干扰日常操作。如果您允许在没有监督的情况下自由授予权限,那么您就将您的系统置于危险之中。
Django 提供了一个很好的认证框架,与 Django admin 紧密集成。开箱即用,Django admin 不会对用户 admin 进行特殊限制。这可能会导致危及系统安全的危险情况。
您知道在管理员中管理其他用户的员工用户可以编辑他们自己的权限吗?你知道他们也可以让自己成为超级用户吗?Django admin 中没有阻止这一点,所以这取决于你!
本教程结束时,您将知道如何保护您的系统:
- 通过阻止用户编辑自己的权限来防止权限升级
- 通过强制用户仅使用组来管理权限,保持权限整洁和可维护
- 通过明确实施必要的权限,防止权限通过自定义操作泄露
跟随:
按照本教程,最好设置一个小项目来玩。如果你不确定如何去做,那么看看 Django 的入门。
本教程还假设对 Django 中的用户管理有基本的了解。如果您对此不熟悉,请查看Django 第 2 部分:Django 用户管理。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
模型权限
权限是很棘手的。如果您不设置权限,那么您将您的系统置于入侵者、数据泄露和人为错误的风险之中。如果您滥用权限或过度使用权限,那么您就有可能干扰日常操作。
Django 自带一个内置的认证系统。身份验证系统包括用户、组和权限。
当一个模型被创建时,Django 将自动为以下操作创建四个默认权限:
add: 有此权限的用户可以添加模型的实例。delete: 有此权限的用户可以删除模型的实例。change: 拥有此权限的用户可以更新模型的实例。view: 拥有该权限的用户可以查看该模型的实例。这是一个备受期待的许可,它最终被添加到了 Django 2.1 中。
权限名称遵循一个非常特殊的命名约定:<app>.<action>_<modelname>。
让我们来分解一下:
<app>是 app 的名称。例如,User模型是从authapp (django.contrib.auth)导入的。<action>是上述动作之一(add、delete、change或view)。<modelname>是型号的名称,全是小写字母。
了解这种命名约定可以帮助您更容易地管理权限。例如,更改用户的权限名称是auth.change_user。
如何检查权限
模型权限被授予用户或组。要检查用户是否具有特定权限,您可以执行以下操作:
>>> from django.contrib.auth.models import User >>> u = User.objects.create_user(username='haki') >>> u.has_perm('auth.change_user') False值得一提的是,
.has_perm()对于活动超级用户总是会返回True,即使权限并不真正存在:
>>> from django.contrib.auth.models import User
>>> superuser = User.objects.create_superuser(
... username='superhaki',
... email='me@hakibenita.com',
... password='secret',
)
>>> superuser.has_perm('does.not.exist') True
如您所见,当您检查超级用户的权限时,并没有真正检查权限。
如何实施权限
Django 模型本身并不强制许可。默认情况下,唯一强制执行开箱即用权限的地方是 Django Admin。
模型不强制权限的原因是,通常,模型不知道用户执行的操作。在 Django apps 中,用户通常是从请求中获得的。这就是为什么大多数情况下,权限是在视图层执行的。
例如,要防止对User模型没有查看权限的用户访问显示用户信息的视图,请执行以下操作:
from django.core.exceptions import PermissionDenied
def users_list_view(request):
if not request.user.has_perm('auth.view_user'):
raise PermissionDenied()
如果发出请求的用户登录并通过了身份验证,那么 request.user 将持有User的一个实例。如果用户没有登录,那么request.user将是 AnonymousUser 的一个实例。这是 Django 使用的一个特殊对象,用于指示未经身份验证的用户。在AnonymousUser上使用has_perm将总是返回False。
如果发出请求的用户没有view_user权限,那么您将引发一个PermissionDenied异常,一个状态为403的响应被返回给客户端。
为了更容易在视图中实施权限,Django 提供了一个快捷方式 decorator 称为 permission_required 来做同样的事情:
from django.contrib.auth.decorators import permission_required
@permission_required('auth.view_user')
def users_list_view(request):
pass
为了在模板中实施权限,您可以通过一个名为 perms 的特殊模板变量来访问当前用户权限。例如,如果希望只向具有删除权限的用户显示“删除”按钮,请执行下列操作:
{% if perms.auth.delete_user %}
{% endif %}
一些流行的第三方应用,如 Django rest 框架(T1)也提供了与 Django 模型权限(T3)的有用集成(T2)。
Django 管理和模型权限
Django admin 与内置认证系统有非常紧密的集成,尤其是模型权限。开箱即用,Django admin 正在实施模型权限:
- 如果用户对模型没有权限,那么他们将无法在管理中看到或访问它。
- 如果用户拥有模型的查看和更改权限,那么他们将能够查看和更新实例,但不能添加新实例或删除现有实例。
有了适当的权限,管理员用户就不太可能犯错,入侵者也更难造成伤害。
在 Django Admin 中实现自定义业务角色
每个应用程序中最容易受到攻击的地方之一是认证系统。在 Django apps 中,这是User模型。因此,为了更好地保护您的应用程序,您将从User模型开始。
首先,您需要控制User模型管理页面。Django 已经提供了一个非常好的管理页面来管理用户。为了利用这项伟大的工作,您将扩展内置的User管理模型。
设置:自定义用户管理员
要为User模型提供一个定制管理,您需要注销 Django 提供的现有模型管理,并注册一个您自己的模型管理:
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
# Unregister the provided model admin
admin.site.unregister(User)
# Register out own model admin, based on the default UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
pass
你的CustomUserAdmin是在扩展 Django 的UserAdmin。您这样做是为了利用 Django 开发人员已经完成的所有工作。
此时,如果您在http://127.0.0.1:8000/admin/auth/user登录您的 Django admin,您应该看到用户 admin 没有改变:
通过扩展UserAdmin,您可以使用 Django admin 提供的所有内置特性。
防止更新字段
无人管理的表单很容易出现可怕的错误。员工用户可以通过管理员以应用程序没有想到的方式轻松更新模型实例。大多数时候,用户甚至不会注意到有问题。这种错误通常很难追踪和修复。
为了防止这样的错误发生,您可以防止管理员用户修改模型中的某些字段。
如果要防止任何用户(包括超级用户)更新字段,可以将该字段标记为只读。例如,当用户注册时设置字段date_joined。任何用户都不应更改此信息,因此您将其标记为只读:
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
readonly_fields = [
'date_joined',
]
当一个字段被添加到readonly_fields时,它在管理默认变更表单中不可编辑。当一个字段被标记为只读时,Django 会将 input 元素显示为禁用。
但是,如果您只想阻止某些用户更新字段,该怎么办呢?
有条件地阻止字段更新
有时直接在 admin 中更新字段是很有用的。但是您不想让任何用户做这件事:您想只允许超级用户做这件事。
假设您想要阻止非超级用户更改用户的用户名。为此,您需要修改 Django 生成的变更表单,并根据当前用户禁用用户名字段:
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
def get_form(self, request, obj=None, **kwargs):
form = super().get_form(request, obj, **kwargs)
is_superuser = request.user.is_superuser
if not is_superuser: form.base_fields['username'].disabled = True
return form
让我们来分解一下:
- 要对表单进行调整,您可以覆盖
get_form()。Django 使用这个函数为模型生成一个默认的变更表单。 - 要有条件地禁用该字段,首先要获取 Django 生成的默认表单,然后如果用户不是超级用户,禁用 username 字段。
现在,当非超级用户试图编辑用户时,用户名字段将被禁用。任何通过 Django Admin 修改用户名的尝试都将失败。当超级用户尝试编辑用户时,用户名字段将可编辑并按预期运行。
防止非超级用户授予超级用户权限
超级用户是一个非常强的权限,不应该轻易授予。然而,任何对User模型拥有变更权限的用户都可以让任何用户成为超级用户,包括他们自己。这违背了许可制度的整个目的,所以你想堵住这个洞。
根据前面的示例,为了防止非超级用户成为超级用户,您添加了以下限制:
from typing import Set
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
def get_form(self, request, obj=None, **kwargs):
form = super().get_form(request, obj, **kwargs)
is_superuser = request.user.is_superuser
disabled_fields = set() # type: Set[str]
if not is_superuser:
disabled_fields |= {
'username',
'is_superuser', }
for f in disabled_fields:
if f in form.base_fields:
form.base_fields[f].disabled = True
return form
除了前面的示例,您还添加了以下内容:
-
您初始化了一个空集
disabled_fields,它将保存要禁用的字段。set是保存唯一值的数据结构。在这种情况下使用 set 是有意义的,因为您只需要禁用一个字段一次。操作员|=用于执行就地OR更新。有关集合的更多信息,请查看 Python 中的集合。 -
接下来,如果用户是超级用户,您将向集合中添加两个字段(前面示例中的
username和is_superuser)。他们将阻止非超级用户使自己成为超级用户。 -
最后,遍历集合中的字段,将所有字段标记为禁用,然后返回表单。
Django 用户管理两步表单
当您在 Django admin 中创建一个新用户时,您需要通过一个两步表单。在第一个表单中,您填写用户名和密码。在第二个表单中,您更新其余的字段。
这个两步过程是User模型所独有的。为了适应这种独特的过程,您必须在尝试禁用该字段之前验证它是否存在。否则,你可能会得到一个KeyError。如果您自定义其他模型管理员,这是不必要的。关于KeyError的更多信息,请查看 Python KeyError 异常以及如何处理它们。
仅使用组授予权限
管理权限的方式因团队、产品和公司而异。我发现在组中管理权限更容易。在我自己的项目中,我为支持、内容编辑、分析师等等创建组。我发现在用户级别管理权限非常麻烦。当添加新的模型时,或者当业务需求改变时,更新每个单独的用户是乏味的。
要仅使用组来管理权限,您需要防止用户向特定用户授予权限。相反,您希望只允许将用户与组相关联。为此,对所有非超级用户禁用字段user_permissions:
from typing import Set
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
def get_form(self, request, obj=None, **kwargs):
form = super().get_form(request, obj, **kwargs)
is_superuser = request.user.is_superuser
disabled_fields = set() # type: Set[str]
if not is_superuser:
disabled_fields |= {
'username',
'is_superuser',
'user_permissions', }
for f in disabled_fields:
if f in form.base_fields:
form.base_fields[f].disabled = True
return form
您使用了与前几节完全相同的技术来实现另一个业务规则。在接下来的部分中,您将实现更复杂的业务规则来保护您的系统。
防止非超级用户编辑他们自己的权限
强大的用户往往是一个弱点。它们拥有很强的权限,它们可能造成的潜在损害是巨大的。为了防止入侵情况下的权限升级,您可以防止用户编辑他们自己的权限:
from typing import Set
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
def get_form(self, request, obj=None, **kwargs):
form = super().get_form(request, obj, **kwargs)
is_superuser = request.user.is_superuser
disabled_fields = set() # type: Set[str]
if not is_superuser:
disabled_fields |= {
'username',
'is_superuser',
'user_permissions',
}
# Prevent non-superusers from editing their own permissions
if (
not is_superuser and obj is not None and obj == request.user ):
disabled_fields |= {
'is_staff',
'is_superuser',
'groups',
'user_permissions',
}
for f in disabled_fields:
if f in form.base_fields:
form.base_fields[f].disabled = True
return form
参数obj是您当前操作的对象的实例:
- 当
obj为无时,该表单用于创建新用户。 - 当
obj不是None时,该表单用于编辑现有用户。
为了检查发出请求的用户是否正在操作他们自己,您比较了request.user和obj。因为这是用户 admin,obj要么是User的实例,要么是 None 。当发出请求的用户request.user等于obj时,则意味着用户正在更新自己。在这种情况下,您禁用所有可用于获取权限的敏感字段。
基于对象定制表单的能力非常有用。它可以用来实现复杂的业务角色。
覆盖权限
完全覆盖 Django admin 中的权限有时会很有用。一种常见的情况是,当您在其他地方使用权限时,您不希望 staff 用户在 admin 中进行更改。
Django 为四个内置权限使用钩子。在内部,挂钩使用当前用户的权限来做出决定。您可以忽略这些挂钩,并提供不同的决策。
要防止 staff 用户删除模型实例,不管他们的权限如何,您可以执行以下操作:
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
def has_delete_permission(self, request, obj=None): return False
与get_form()一样,obj是您当前操作的实例:
- 当
obj为None时,用户请求列表查看。 - 当
obj不是None时,用户请求了特定实例的变更视图。
在这个钩子中拥有对象的实例对于实现不同类型操作的对象级权限非常有用。以下是其他使用案例:
- 防止在营业时间进行更改
- 实现对象级权限
限制对自定义动作的访问
自定义管理操作需要特别注意。Django 不熟悉它们,所以它不能默认限制对它们的访问。对模型拥有任何权限的任何管理员用户都可以访问自定义操作。
举例来说,添加一个方便的管理操作来将多个用户标记为活动用户:
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
actions = [
'activate_users',
]
def activate_users(self, request, queryset):
cnt = queryset.filter(is_active=False).update(is_active=True)
self.message_user(request, 'Activated {} users.'.format(cnt))
activate_users.short_description = 'Activate Users' # type: ignore
使用此操作,员工用户可以标记一个或多个用户,并一次激活所有用户。这在各种情况下都很有用,比如注册过程中出现了错误,需要批量激活用户。
此操作会更新用户信息,因此您希望只有具有更改权限的用户才能使用它。
Django admin 使用一个内部函数来获取动作。要对没有更改权限的用户隐藏activate_users(),请覆盖get_actions():
from django.contrib import admin
from django.contrib.auth.models import User
from django.contrib.auth.admin import UserAdmin
@admin.register(User)
class CustomUserAdmin(UserAdmin):
actions = [
'activate_users',
]
def activate_users(self, request, queryset):
assert request.user.has_perm('auth.change_user')
cnt = queryset.filter(is_active=False).update(is_active=True)
self.message_user(request, 'Activated {} users.'.format(cnt))
activate_users.short_description = 'Activate Users' # type: ignore
def get_actions(self, request):
actions = super().get_actions(request)
if not request.user.has_perm('auth.change_user'): del actions['activate_users'] return actions
get_actions()返回一个 OrderedDict 。键是动作的名称,值是动作函数。要调整返回值,您可以覆盖该函数,获取原始值,并根据用户权限,从dict中移除自定义动作activate_users。为了安全起见,您还在操作中断言用户权限。
对于没有change_user()权限的员工用户,动作activate_users不会出现在动作下拉列表中。
结论
Django admin 是管理 Django 项目的一个很好的工具。许多团队依靠 it 来保持日常运营的高效性。如果您使用 Django admin 对模型执行操作,那么了解权限是很重要的。本文中描述的技术对任何模型管理员都有用,不仅仅是对User模型。
在本教程中,您通过在 Django Admin 中进行以下调整来保护您的系统:
- 您通过阻止用户编辑他们自己的权限来防止权限升级。
- 您通过强制用户只使用组来管理权限,保持了权限的整洁和可维护性。
- 您通过明确实施必要的权限,防止了权限通过自定义操作泄露。
你的模型管理员现在比你开始时安全多了!****
用 Python 绘制 Mandelbrot 集
本教程将指导您完成一个有趣的项目,该项目涉及 Python 中的复数。您将学习分形,并通过使用 Python 的 Matplotlib 和 Pillow 库绘制 Mandelbrot 集合来创建一些真正令人惊叹的艺术。在这个过程中,您将了解这个著名的分形是如何被发现的,它代表什么,以及它与其他分形的关系。
了解面向对象编程原则和递归将使你能够充分利用 Python 富于表现力的语法来编写清晰的代码,读起来几乎像数学公式。为了理解制作分形的算法细节,你还应该熟悉复数、对数、集合论和迭代函数。但是不要让这些先决条件把你吓跑,因为无论如何你都将能够跟随并创造艺术!
在本教程中,您将学习如何:
- 将复数应用于实际问题
- 找到曼德尔布罗和茱莉亚集合的成员
- 使用 Matplotlib 和 Pillow 将这些集合绘制成分形
- 制作一个丰富多彩的分形艺术图
要下载本教程中使用的源代码,请单击下面的链接:
获取源代码: 点击此处获取您将使用绘制 Mandelbrot 集合的源代码。
理解曼德尔布罗集合
在你尝试绘制分形之前,理解相应的 Mandelbrot 集合代表什么以及如何确定它的成员会有所帮助。如果你已经熟悉了基本理论,那么请随意跳到下面的绘图部分。
分形几何的图标
即使这个名字对你来说是新的,你可能已经看过 Mandelbrot 集合的一些迷人的可视化。这是一组复数,当描绘在复平面上时,它们的边界形成了一个独特而复杂的图案。这种模式可以说是最著名的分形,在 20 世纪末催生了分形几何:

由于技术的进步,曼德勃罗集的发现成为可能。这归功于一位名叫 benot Mandelbrot 的数学家。他在 IBM 工作,能够接触到一台在当时要求很高的计算机。今天,您可以在家中舒适地探索分形,只需使用 Python!
分形是在不同尺度上无限重复图案的。虽然哲学家们已经争论了几个世纪关于无限的存在,分形在现实世界中确实有一个类比。这是自然界中相当普遍的现象。例如,这种罗曼斯科花椰菜是有限的,但具有自相似结构,因为蔬菜的每个部分看起来都像整体,只是更小:

自相似性通常可以用数学上的递归来定义。Mandelbrot 集合并不是完全自相似的,因为它在更小的尺度上包含了略微不同的自身副本。尽管如此,它仍然可以用复域中的递归函数来描述。
迭代稳定性的边界
形式上,Mandelbrot 集合是复数的集合, c ,对于这个集合,一个无穷数列,z0T5, z 1 ,…, z n ,…,保持有界。换句话说,序列中每个复数的大小都有一个极限,永远不会超过这个极限。Mandelbrot 序列由以下递归公式给出:

简单地说,要判断某个复数 c 是否属于 Mandelbrot 集合,必须将该数输入上面的公式。从现在开始,当你迭代序列时,数字 c 将保持不变。序列的第一个元素, z 0 ,总是等于零。为了计算下一个元素, z n+1 ,您将在一个反馈循环中保持平方最后一个元素, z n ,加上您的初始数字, c 。
通过观察得到的数字序列的行为,您将能够将您的复数 c 归类为 Mandelbrot 集合成员或不是成员。序列是无限的,但是你必须在某个点停止计算它的元素。做出这样的选择有些武断,取决于你接受的信心水平,因为更多的元素将提供对 c 更准确的裁决。
注意:当在复平面上描绘时,整个 Mandelbrot 集合适合于半径为 2 的圆。这是一个方便的事实,可以让你跳过许多不必要的计算,因为这些点肯定不属于这个集合。
对于复数,您可以在二维空间中直观地想象这个迭代过程,但是现在为了简单起见,您可以只考虑实数。如果您要用 Python 实现上面的等式,那么它可能看起来像这样:
>>> def z(n, c): ... if n == 0: ... return 0 ... else: ... return z(n - 1, c) ** 2 + c您的
z()函数返回序列的第 n 个元素,这就是它期望元素的索引n作为第一个参数的原因。第二个参数,c,是一个你正在测试的固定数字。由于递归,这个函数会无限地调用自己。然而,为了打破递归调用的链条,一个条件检查具有立即已知的解的基本情况——零。尝试使用您的新函数来查找 c = 1 的序列的前十个元素,看看会发生什么:
>>> for n in range(10):
... print(f"z({n}) = {z(n, c=1)}")
...
z(0) = 0
z(1) = 1
z(2) = 2
z(3) = 5
z(4) = 26
z(5) = 677
z(6) = 458330
z(7) = 210066388901
z(8) = 44127887745906175987802
z(9) = 1947270476915296449559703445493848930452791205
请注意这些序列元素的快速增长率。它告诉你一些关于 c = 1 的成员关系。具体来说,不属于曼德勃罗集合,因为相应的序列增长没有界限。
有时候,迭代方法可能比递归方法更有效。下面是一个等价函数,它为指定的输入值c创建一个无限序列:
>>> def sequence(c): ... z = 0 ... while True: ... yield z ... z = z ** 2 + c
sequence()函数返回一个生成器对象,在一个循环中不断产生序列的连续元素。因为它不返回相应的元素索引,所以您可以枚举它们,并在给定的迭代次数后停止循环:
>>> for n, z in enumerate(sequence(c=1)):
... print(f"z({n}) = {z}")
... if n >= 9:
... break
...
z(0) = 0
z(1) = 1
z(2) = 2
z(3) = 5
z(4) = 26
z(5) = 677
z(6) = 458330
z(7) = 210066388901
z(8) = 44127887745906175987802
z(9) = 1947270476915296449559703445493848930452791205
结果和以前一样,但是 generator 函数让您通过使用惰性求值更有效地计算序列元素。除此之外,迭代消除了对已经计算的序列元素的冗余函数调用。结果,你不再冒触及最大递归极限的风险。
大多数数字会使这个数列发散到无穷大。然而,有些人会通过将序列收敛到一个值或者保持在一个有界的范围内来保持它的稳定。其他人将通过在相同的几个值之间来回循环来使序列周期性稳定。稳定值和周期性稳定值构成了 Mandelbrot 集。
例如,插入 c = 1 使序列像你刚刚学到的那样无限制地增长,但是 c = -1 使它在 0 和-1 之间反复跳跃,而 c = 0 给出一个由单个值组成的序列:
| 元素 | c = -1 | c = 0 | c = 1 |
|---|---|---|---|
| z 0 | Zero | Zero | Zero |
| z 1 | -1 | Zero | one |
| z 2 | Zero | Zero | Two |
| z 3 | -1 | Zero | five |
| z 4 | Zero | Zero | Twenty-six |
| z 5 | -1 | Zero | Six hundred and seventy-seven |
| z 6 | Zero | Zero | Four hundred and fifty-eight thousand three hundred and thirty |
| z 7 | -1 | Zero | Two hundred and ten billion sixty-six million three hundred and eighty-eight thousand nine hundred and one |
哪些数字是稳定的,哪些是不稳定的,这并不明显,因为公式对测试值的微小变化都很敏感。如果你在复平面上标记稳定的数字,那么你会看到下面的模式出现:
这个图像是通过对每个像素运行 20 次递归公式生成的,每个像素代表某个 c 值。当得到的复数的大小在所有迭代之后仍然相当小时,则相应的像素被涂成黑色。然而,一旦幅度超过半径 2,迭代就停止并跳过当前像素。
趣闻:Mandelbrot 集对应的分形有一个有限的面积估计为 1.506484 平方单位。数学家们还没有确定确切的数字,也不知道它是否合理。另一方面,曼德布洛特集合的周长是无限的。看看海岸线悖论来了解现实生活中这一怪异事实的有趣相似之处。
你可能会惊讶地发现,一个只涉及加法和乘法的相对简单的公式可以产生如此复杂的结构。但这还不是全部。原来你可以拿同一个公式,用它生成无限多的独特分形!你想看看是怎么回事吗?
朱丽亚的地图集
谈到曼德勃罗集合,很难不提到朱莉亚集合,这是法国数学家 T2·加斯顿·朱莉亚在几十年前在没有计算机帮助的情况下发现的。Julia 集和 Mandelbrot 集密切相关,因为您可以通过相同的递归公式获得它们,只是起始条件不同。
虽然只有一个 Mandelbrot 集,但有无限多个 Julia 集。到目前为止,你总是从z0T3】= 0 开始序列,并系统地测试一些任意的复数 c 的成员数。另一方面,要找出一个数是否属于 Julia 集,您必须使用该数作为序列的起点,并为 c 参数选择另一个值。
根据您正在研究的器械包,下面是公式术语的快速比较:
| 学期 | 曼德尔布罗集合 | 朱莉娅集 |
|---|---|---|
| z 0 | Zero | 候选值 |
| c | 候选值 | 不变常数 |
在第一种情况下, c 表示 Mandelbrot 集合的潜在成员,并且是唯一需要的输入值,因为z0T5】保持固定为零。但是,当您在 Julia 模式下使用该公式时,每个术语的含义都会发生变化。现在, c 作为一个参数,决定了整个 Julia 集的形状和形式,而 z 0 成为你的兴趣点。与以前不同,Julia 集的公式期望不是一个而是两个输入值。
您可以修改之前定义的一个函数,使其更加通用。这样,您可以创建从任意点开始的无限序列,而不是总是从零开始:
def sequence(c, z=0):
while True:
yield z
z = z ** 2 + c
感谢高亮行中的默认参数值,您仍然可以像以前一样使用这个函数,因为z是可选的。同时,您可以更改序列的起点。在为 Mandelbrot 和 Julia 集定义包装函数后,您可能会有更好的想法:
def mandelbrot(candidate):
return sequence(z=0, c=candidate)
def julia(candidate, parameter):
return sequence(z=candidate, c=parameter)
每个函数都返回一个生成器对象,并根据您想要的启动条件进行微调。确定候选值是否属于 Julia 集的原则类似于您之前看到的 Mandelbrot 集。简而言之,您必须迭代序列,并观察其随时间的行为。
事实上,benot Mandelbrot 在他的科学研究中正在研究 Julia sets。他特别感兴趣的是找到那些产生所谓的连通 Julia 集的 c 值,而不是它们的非连通对应物。后者被称为 Fatou 集合,当在复平面上可视化时,它们看起来像是由无数碎片组成的尘埃:
左上角的图像代表从 c = 0.25 导出的连通 Julia 集,属于 Mandelbrot 集。你知道将 Mandelbrot 集合的一个成员插入递归公式会产生一个收敛的复数序列。在这种情况下,数字收敛到 0.5。然而,对 c 的轻微改变会突然将你的 Julia 集变成不相连的尘埃,并使相应的序列发散到无穷大。
巧合的是,连通的 Julia 集对应于生成上面递归公式的稳定序列的 c 值。因此,你可能会说 benot Mandelbrot 正在寻找迭代稳定性的边界,或者所有 Julia 集的地图,它将显示这些集在哪里相连,它们在哪里是灰尘。
观察在复平面上为参数 c 选择不同的点如何影响最终的 Julia 集:
https://player.vimeo.com/video/599523806?background=1
移动的红色小圆圈表示 c 的值。只要它停留在左边显示的 Mandelbrot 集合内,右边描述的相应 Julia 集合就保持连接。否则,朱莉娅集就像一个泡沫一样破裂成无数尘埃碎片。
你有没有注意到茱莉亚组合是如何改变形状的?事实证明,特定的 Julia 集与 Mandelbrot 集的特定区域共享共同的视觉特征,该特定区域用于播种 c 的值。当你通过放大镜观察时,这两种分形看起来有些相似。
好了,理论到此为止。是时候绘制你的第一个曼德尔布罗集了!
使用 Python 的 Matplotlib 绘制 Mandelbrot 集合
Python 中有很多可视化 Mandelbrot 集合的方法。如果你习惯使用 NumPy 和 Matplotlib ,那么这两个库将一起提供一个最简单的绘制分形的方法。它们很方便地让你不必在世界坐标和像素坐标之间转换。
注:世界坐标对应复平面上数的连续谱,延伸至无穷远。另一方面,像素坐标是离散的,并且受到屏幕有限尺寸的限制。
要生成初始的一组候选值,您可以利用 np.linspace() ,它在给定的范围内创建均匀分布的数字:
1import numpy as np
2
3def complex_matrix(xmin, xmax, ymin, ymax, pixel_density):
4 re = np.linspace(xmin, xmax, int((xmax - xmin) * pixel_density))
5 im = np.linspace(ymin, ymax, int((ymax - ymin) * pixel_density))
6 return re[np.newaxis, :] + im[:, np.newaxis] * 1j
上面的函数将返回一个包含在由四个参数给出的矩形区域中的二维复数数组。xmin和xmax参数指定水平方向的边界,而ymin和ymax指定垂直方向的边界。第五个参数pixel_density,决定了每单位所需的像素数。
现在,你可以用复数的矩阵和通过众所周知的递归公式,看看哪些数字保持稳定,哪些不稳定。由于 NumPy 的矢量化,您可以将矩阵作为单个参数c传递,并对每个元素执行计算,而不必编写显式循环:
8def is_stable(c, num_iterations):
9 z = 0
10 for _ in range(num_iterations):
11 z = z ** 2 + c 12 return abs(z) <= 2
高亮显示的行中的代码在每次迭代中为矩阵c的所有元素执行。因为z和c最初的尺寸不同,NumPy 使用广播来巧妙地扩展前者,以便两者最终具有兼容的形状。最后,该函数在结果矩阵z上创建布尔值的二维掩码。每个值对应于序列在该点的稳定性。
注意:为了利用矢量化计算,代码示例中的循环会无条件地平方和相加数字,而不管它们已经有多大。这并不理想,因为在许多情况下,数字在早期就发散到无穷大,使得大部分计算都是浪费的。
此外,快速增长的数字通常会导致溢出错误。NumPy 检测到这种溢出,并在标准错误流(stderr) 上发出警告。如果您想取消这样的警告,那么您可以在调用函数之前定义一个相关的过滤器:
1import numpy as np
2
3np.warnings.filterwarnings("ignore")
忽略这些溢出是无害的,因为您感兴趣的不是具体的数量,而是它们是否符合给定的阈值。
在选定次数的迭代之后,矩阵中每个复数的幅度将保持在阈值 2 以内或超过阈值 2。那些足够小的可能是 Mandelbrot 集合的成员。现在您可以使用 Matplotlib 将它们可视化。
低分辨率散点图
直观显示 Mandelbrot 集合的一种快速而肮脏的方法是通过散点图,它说明了成对变量之间的关系。因为复数是成对的实数和虚数分量,你可以将它们分解成单独的数组,这将很好地处理散点图。
但是首先,你需要把你的布尔稳定性掩码转换成初始复数,它是序列的种子。你可以借助 NumPy 的屏蔽过滤来做到这一点:
16def get_members(c, num_iterations):
17 mask = is_stable(c, num_iterations)
18 return c[mask]
该函数将返回一个一维数组,该数组只包含那些稳定的复数,因此属于 Mandelbrot 集。当您组合到目前为止定义的函数时,您将能够使用 Matplotlib 显示散点图。不要忘记在文件的开头添加必要的导入语句:
1import matplotlib.pyplot as plt 2import numpy as np
3
4np.warnings.filterwarnings("ignore")
这会将绘图界面带到您的当前名称空间。现在,您可以计算数据并绘制图表:
21c = complex_matrix(-2, 0.5, -1.5, 1.5, pixel_density=21)
22members = get_members(c, num_iterations=20)
23
24plt.scatter(members.real, members.imag, color="black", marker=",", s=1)
25plt.gca().set_aspect("equal")
26plt.axis("off")
27plt.tight_layout()
28plt.show()
对complex_matrix()的调用准备了一个 x 方向范围为-2 到 0.5,y 方向范围为-1.5 到 1.5 的复数矩形数组。对get_members()的后续调用只传递那些属于 Mandelbrot 集合的数字。最后,plt.scatter()绘制布景,plt.show()揭示这个画面:

它包含 749 个点,类似于 benot Mandelbrot 自己几十年前在点阵打印机上制作的原始 ASCII 打印输出。你在重温数学史!通过调整像素密度和迭代次数来观察它们对结果的影响。
高分辨率黑白可视化
要获得更详细的黑白 Mandelbrot 集的可视化效果,您可以不断增加散点图的像素密度,直到各个点变得难以分辨。或者,你可以使用 Matplotlib 的 plt.imshow() 函数和二进制色图来绘制你的布尔稳定性遮罩。
在您现有的代码中只需要做一些调整:
21c = complex_matrix(-2, 0.5, -1.5, 1.5, pixel_density=512) 22plt.imshow(is_stable(c, num_iterations=20), cmap="binary") 23plt.gca().set_aspect("equal")
24plt.axis("off")
25plt.tight_layout()
26plt.show()
提高你的像素密度到一个足够大的值,比如 512。然后,删除对get_members()的调用,用plt.imshow()替换散点图,将数据显示为图像。如果一切顺利,那么您应该会看到这张 Mandelbrot 集合的图片:

要放大分形的特定区域,请相应地更改复杂矩阵的边界,并将迭代次数增加 10 倍或更多。您还可以尝试 Matplotlib 提供的不同颜色的地图。然而,要真正释放你内心的艺术家,你可能想试试 Python 最受欢迎的图像库 Pillow 。
用枕头画曼德尔布罗集合
这一节将需要更多的努力,因为您将做一些 NumPy 和 Matplotlib 以前为您做的工作。但是对可视化过程进行更细粒度的控制将让您以更有趣的方式描绘 Mandelbrot 集合。在这个过程中,您将学习一些有用的概念,并遵循最佳的python 式实践。
NumPy 与 Pillow 一起工作就像它与 Matplotlib 一起工作一样好。您可以使用 np.asarray() 或反过来使用 Image.fromarray() 将枕头图像转换为 NumPy 数组。由于这种兼容性,您可以通过将 Matplotlib 的plt.imshow()替换为对 Pillow 的工厂方法的非常相似的调用,来更新前一节中的绘图代码:
21c = complex_matrix(-2, 0.5, -1.5, 1.5, pixel_density=512)
22image = Image.fromarray(~is_stable(c, num_iterations=20)) 23image.show()
注意在稳定性矩阵前面使用了位非运算符 ( ~),它反转所有的布尔值。这使得 Mandelbrot 集在白色背景上以黑色显示,因为 Pillow 默认采用黑色背景。
如果 NumPy 是您熟悉的首选工具,那么您可以在本节中自由地使用它。它的执行速度将比您将要看到的纯 Python 代码快得多,因为 NumPy 经过了高度优化,并且依赖于编译后的机器代码。然而,从零开始实现绘图代码将会给你最终的控制权和对所涉及的各个步骤的深刻理解。
有趣的事实:Pillow imaging library 附带了一个方便的函数,可以在一行 Python 代码中生成 Mandelbrot 集的图像:
from PIL import Image
Image.effect_mandelbrot((512, 512), (-3, -2.5, 2, 2.5), 100).show()
传递给该函数的第一个参数是一个元组,包含结果图像的宽度和高度(以像素为单位)。下一个参数将边界框定义为左下角和右上角。第三个参数是图像质量,范围从 0 到 100。
如果你对函数如何工作感兴趣,可以看看 GitHub 上相应的 C 源代码。
在本节的其余部分,您将自己完成这项艰巨的工作,不走任何捷径。
寻找集合的收敛元素
之前,您使用 NumPy 的矢量化构建了一个稳定性矩阵,以确定哪些给定的复数属于 Mandelbrot 集。您的函数对公式迭代了固定的次数,并返回了一个布尔值的二维数组。使用 pure Python,您可以修改此函数,使其适用于单个数字,而不是整个矩阵:
>>> def is_stable(c, max_iterations): ... z = 0 ... for _ in range(max_iterations): ... z = z ** 2 + c ... if abs(z) > 2: ... return False ... return True它看起来很像 NumPy 以前的版本。然而,有几个重要的区别。值得注意的是,
c参数表示单个复数,函数返回一个标量布尔值。其次,在循环体中有一个 if 条件,一旦结果数达到一个已知的阈值,就会提前终止迭代。注:其中一个函数参数从
num_iterations重命名为max_iterations,以反映迭代次数不再是固定的,而是可以在测试值之间变化。您可以使用您的新函数来确定一个复数是否创建了一个稳定的序列,即是否收敛于。这直接转化为 Mandelbrot 集合成员。但是,结果可能取决于所请求的最大迭代次数:
>>> is_stable(0.26, max_iterations=20)
True
>>> is_stable(0.26, max_iterations=30)
False
例如,数字 c = 0.26 靠近分形的边缘,所以迭代次数太少会得到错误的答案。增加最大迭代次数可以更精确,显示可视化的更多细节。
调用函数没有错,但是利用 Python 的in和not in操作符不是更好吗?将这段代码转换成一个 Python 类将允许您覆盖那些操作符,并利用一个更干净、更 Python 化的语法。此外,通过将状态封装在对象中,您将能够在多次函数调用中保持最大的迭代次数。
您可以利用数据类来避免定义定制的构造函数。下面是相同代码的一个等价的基于类的实现:
# mandelbrot.py
from dataclasses import dataclass
@dataclass
class MandelbrotSet:
max_iterations: int
def __contains__(self, c: complex) -> bool:
z = 0
for _ in range(self.max_iterations):
z = z ** 2 + c
if abs(z) > 2:
return False
return True
除了实现了特殊方法 .__contains__() ,添加了一些类型提示,并将max_iterations参数从函数的签名中移出,其余代码保持不变。假设您将它保存在一个名为mandelbrot.py的文件中,您可以在同一个目录中启动一个交互式 Python 解释器会话并导入您的类:
>>> from mandelbrot import MandelbrotSet >>> mandelbrot_set = MandelbrotSet(max_iterations=30) >>> 0.26 in mandelbrot_set False >>> 0.26 not in mandelbrot_set True太棒了。这正是制作曼德尔布洛特集合的黑白可视化所需的信息。稍后,您将了解用 Pillow 绘制像素的一种不太冗长的方法,但这里有一个简单的例子供初学者使用:
>>> from mandelbrot import MandelbrotSet
>>> mandelbrot_set = MandelbrotSet(max_iterations=20)
>>> width, height = 512, 512
>>> scale = 0.0075
>>> BLACK_AND_WHITE = "1"
>>> from PIL import Image
>>> image = Image.new(mode=BLACK_AND_WHITE, size=(width, height))
>>> for y in range(height):
... for x in range(width):
... c = scale * complex(x - width / 2, height / 2 - y)
... image.putpixel((x, y), c not in mandelbrot_set)
...
>>> image.show()
从库中导入 Image 模块后,您创建了一个新的枕头图像,具有黑白像素模式,大小为 512 x 512 像素。然后,在迭代像素行和像素列时,将每个点从像素坐标缩放和转换到世界坐标。最后,当相应的复数不属于 Mandelbrot 集合时,你打开一个像素,保持分形的内部黑色。
注意:.putpixel()方法在这个特定的像素模式中期望一个数值 1 或 0。然而,在上面的代码片段中,一旦布尔表达式被求值为True或False,Python 将分别用 1 或 0 来代替它。它像预期的那样工作,因为 Python 的bool数据类型实际上是 integer 的一个子类。
当您执行这段代码时,您会立即注意到它比前面的例子运行得慢得多。如前所述,这部分是因为 NumPy 和 Matplotlib 为高度优化的 C 代码提供了 Python 绑定,而您只是在纯 Python 中实现了最关键的部分。除此之外,你有嵌套循环,你调用一个函数成千上万次!
反正不用担心性能。你的目标是学习用 Python 绘制 Mandelbrot 集合的基础知识。接下来,您将通过揭示更多信息来改进分形可视化。
用逃逸计数测量发散度
好的,你知道如何判断一个复数是否使 Mandelbrot 序列收敛,这反过来让你以黑白的形式可视化 Mandelbrot 集合。你能通过从二进制图像到每像素超过两个强度等级的灰度级来增加一点深度吗?答案是肯定的!
试着从不同的角度看这个问题。您可以量化位于 Mandelbrot 集合之外的点使递归公式发散到无穷大的速度,而不是找到分形的锐边。有些会很快变得不稳定,而另一些可能需要数十万次迭代才能变得不稳定。一般来说,靠近分形边缘的点比远离边缘的点更稳定。
通过足够多的迭代,不间断地遍历所有这些迭代将表明被测试的数字很可能是集合成员,因为相关的序列元素保持稳定。另一方面,在达到最大迭代次数之前中断循环只会在序列明显发散时发生。检测发散所需的迭代次数被称为逸出计数。
注意:用迭代的方法来测试给定点的稳定性只是实际 Mandelbrot 集合的近似。对于某些点,你将需要比你的最大迭代次数多得多的迭代来知道它们是否稳定,这在实践中可能是不可行的。
您可以使用逸出计数来引入多个灰度级。然而,处理规范化转义计数通常更方便,因为不管最大迭代次数是多少,它们的值都在从 0 到 1 的范围内。为了计算给定点的这种稳定性度量,使用做出决策所需的实际迭代次数与无条件退出的最大次数之间的比率。
让我们修改您的MandelbrotSet类来计算转义数。首先,相应地重命名您的特殊方法,并使它返回迭代次数而不是布尔值:
# mandelbrot.py
from dataclasses import dataclass
@dataclass
class MandelbrotSet:
max_iterations: int
def escape_count(self, c: complex) -> int: z = 0
for iteration in range(self.max_iterations): z = z ** 2 + c
if abs(z) > 2:
return iteration return self.max_iterations
注意这个循环是如何声明一个变量iteration来计算迭代次数的。接下来,将稳定性定义为逸出计数与最大迭代次数之比:
# mandelbrot.py
from dataclasses import dataclass
@dataclass
class MandelbrotSet:
max_iterations: int
def stability(self, c: complex) -> float: return self.escape_count(c) / self.max_iterations
def escape_count(self, c: complex) -> int:
z = 0
for iteration in range(self.max_iterations):
z = z ** 2 + c
if abs(z) > 2:
return iteration
return self.max_iterations
最后,带回被移除的特殊方法,成员测试操作符in委托给它。然而,您将使用一个建立在稳定性之上的略有不同的实现:
# mandelbrot.py
from dataclasses import dataclass
@dataclass
class MandelbrotSet:
max_iterations: int
def __contains__(self, c: complex) -> bool: return self.stability(c) == 1
def stability(self, c: complex) -> float:
return self.escape_count(c) / self.max_iterations
def escape_count(self, c: complex) -> int:
z = 0
for iteration in range(self.max_iterations):
z = z ** 2 + c
if abs(z) > 2:
return iteration
return self.max_iterations
只有当稳定性等于 1 或 100%时,成员测试操作符才会返回True。否则,你会得到一个False值。您可以通过以下方式检查具体的逸出计数和稳定性值:
>>> from mandelbrot import MandelbrotSet >>> mandelbrot_set = MandelbrotSet(max_iterations=30) >>> mandelbrot_set.escape_count(0.25) 30 >>> mandelbrot_set.stability(0.25) 1.0 >>> 0.25 in mandelbrot_set True >>> mandelbrot_set.escape_count(0.26) 29 >>> mandelbrot_set.stability(0.26) 0.9666666666666667 >>> 0.26 in mandelbrot_set False对于 c = 0.25,观察到的迭代次数与声明的最大迭代次数相同,使得稳定性等于 1。相比之下,选择 c = 0.26 会产生稍微不同的结果。
MandelbrotSet类的更新实现允许灰度可视化,这将像素强度与稳定性联系起来。您可以重用上一节中的大部分绘图代码,但是您需要将像素模式更改为L,它代表亮度。在这种模式下,每个像素取 0 到 255 之间的整数值,因此您还需要适当地缩放分数稳定性:
>>> from mandelbrot import MandelbrotSet
>>> mandelbrot_set = MandelbrotSet(max_iterations=20)
>>> width, height = 512, 512
>>> scale = 0.0075
>>> GRAYSCALE = "L"
>>> from PIL import Image
>>> image = Image.new(mode=GRAYSCALE, size=(width, height)) >>> for y in range(height):
... for x in range(width):
... c = scale * complex(x - width / 2, height / 2 - y)
... instability = 1 - mandelbrot_set.stability(c) ... image.putpixel((x, y), int(instability * 255)) ...
>>> image.show()
同样,要用黑色绘制 Mandelbrot 集,同时只照亮它的外部,您必须通过从 1 中减去它来反转稳定性。当一切按计划进行时,您将看到下图的大致描述:

哇哦。这已经看起来更有趣了。不幸的是,稳定性值以明显离散的级别出现量化,因为逸出计数是一个整数。增加最大迭代次数有助于缓解这种情况,但只是在一定程度上。此外,增加更多的迭代将过滤掉很多噪声,留下更少的内容在这个放大级别上看到。
在下一小节中,您将了解消除带状伪像的更好方法。
消除带状工件
从 Mandelbrot 集合的外部去掉色带可以归结为使用分数逃逸计数。插值中间值的一种方法是使用对数。基础数学非常复杂,所以让我们相信数学家的话,更新代码:
# mandelbrot.py
from dataclasses import dataclass
from math import log
@dataclass
class MandelbrotSet:
max_iterations: int
escape_radius: float = 2.0
def __contains__(self, c: complex) -> bool:
return self.stability(c) == 1
def stability(self, c: complex, smooth=False) -> float: return self.escape_count(c, smooth) / self.max_iterations
def escape_count(self, c: complex, smooth=False) -> int | float: z = 0
for iteration in range(self.max_iterations):
z = z ** 2 + c
if abs(z) > self.escape_radius: if smooth: return iteration + 1 - log(log(abs(z))) / log(2) return iteration
return self.max_iterations
从 math 模块导入log()函数后,您可以添加一个可选的布尔标志来控制方法的平滑。当您打开平滑时,数学的魔力就开始了,它将迭代次数与发散数的空间信息结合起来,产生一个浮点数。
注:上面的数学公式是基于逃逸半径趋近于无穷大的假设,所以不能再硬编码了。这就是为什么您的类现在定义了一个可选的默认值为 2 的escape_radius字段,您可以在创建MandelbrotSet的新实例时随意覆盖它。
请注意,由于平滑转义计数公式中的对数,相关的稳定性可能会超过甚至变为负值!这里有一个简单的例子来说明这一点:
>>> from mandelbrot import MandelbrotSet >>> mandelbrot_set = MandelbrotSet(max_iterations=30) >>> mandelbrot_set.stability(-1.2039 - 0.1996j, smooth=True) 1.014794475165942 >>> mandelbrot_set.stability(42, smooth=True) -0.030071301713066417大于 1 且小于 0 的数字将导致像素强度在允许的最大和最小水平附近波动。所以,在点亮一个像素之前,不要忘记用
max()和min()箝位你的缩放像素值:# mandelbrot.py from dataclasses import dataclass from math import log @dataclass class MandelbrotSet: max_iterations: int escape_radius: float = 2.0 def __contains__(self, c: complex) -> bool: return self.stability(c) == 1 def stability(self, c: complex, smooth=False, clamp=True) -> float: value = self.escape_count(c, smooth) / self.max_iterations return max(0.0, min(value, 1.0)) if clamp else value def escape_count(self, c: complex, smooth=False) -> int | float: z = 0 for iteration in range(self.max_iterations): z = z ** 2 + c if abs(z) > self.escape_radius: if smooth: return iteration + 1 - log(log(abs(z))) / log(2) return iteration return self.max_iterations计算稳定性时,默认启用箝位,但让最终用户决定如何处理溢出和下溢。一些丰富多彩的可视化效果可能会利用这种包装来产生有趣的效果。这由上面的
.stability()方法中的clamp标志控制。在后面的部分中,您将体验可视化。下面是如何将更新后的
MandelbrotSet类投入使用的方法:
>>> from mandelbrot import MandelbrotSet
>>> mandelbrot_set = MandelbrotSet(max_iterations=20, escape_radius=1000)
>>> width, height = 512, 512
>>> scale = 0.0075
>>> GRAYSCALE = "L"
>>> from PIL import Image
>>> image = Image.new(mode=GRAYSCALE, size=(width, height))
>>> for y in range(height):
... for x in range(width):
... c = scale * complex(x - width / 2, height / 2 - y)
... instability = 1 - mandelbrot_set.stability(c, smooth=True) ... image.putpixel((x, y), int(instability * 255))
...
>>> image.show()
通过打开稳定性计算的smooth标志来启用平滑。然而,仅仅这样做仍然会产生一点带状,所以你也可以将逃逸半径增加到一个相对较大的值,比如一千。最后,你会看到一张外表如丝般光滑的 Mandelbrot 套装图片:

在你的指尖有分数逃逸计数打开了有趣的可能性,在你的 Mandelbrot 集合可视化周围玩颜色。您将在后面探索它们,但是首先,您可以改进和简化绘图代码,使其更加健壮和优雅。
在集合元素和像素之间平移
到目前为止,你的可视化已经描绘了分形的静态图像,但它还没有让你放大特定区域的或平移以显示更多细节。与以前的对数不同,缩放和平移图像的数学运算并不十分困难。然而,它增加了一点代码复杂性,这是值得在继续之前抽象成助手类的。
在高层次上,绘制 Mandelbrot 集可以分为三个步骤:
- 将像素坐标转换成复数。
- 检查该复数是否属于 Mandelbrot 集合。
- 根据像素的稳定性为其指定颜色。
您可以构建一个智能像素数据类型,它将封装坐标系之间的转换,考虑缩放,并处理颜色。对于 Pillow 和你的像素之间的集成层,你可以设计一个 viewport 类来负责平移和缩放。
Pixel和Viewport类的代码将很快发布,但是一旦它们实现,您将能够用几行 Python 代码重写绘图代码:
>>> from PIL import Image >>> from mandelbrot import MandelbrotSet >>> from viewport import Viewport >>> mandelbrot_set = MandelbrotSet(max_iterations=20) >>> image = Image.new(mode="1", size=(512, 512), color=1) >>> for pixel in Viewport(image, center=-0.75, width=3.5): ... if complex(pixel) in mandelbrot_set: ... pixel.color = 0 ... >>> image.show()就是这样!
Viewport类包装枕头图像的一个实例。它根据世界单位中的中心点和视窗的宽度计算出相关的比例因子、偏移量和世界坐标的垂直范围。作为一个可迭代的,它还提供了Pixel对象,您可以通过这些对象进行循环。像素知道如何将自己转换成复数,并且它们是由视口包装的图像实例的朋友。注意:传递给枕头图像的构造函数的第三个参数让您设置背景颜色,默认为黑色。在这种情况下,您需要一个白色背景,它对应于二进制像素模式中等于 1 的像素强度。
您可以通过用
@dataclassdecorator 注释来实现视口,就像您之前用MandelbrotSet类所做的那样:# viewport.py from dataclasses import dataclass from PIL import Image @dataclass class Viewport: image: Image.Image center: complex width: float @property def height(self): return self.scale * self.image.height @property def offset(self): return self.center + complex(-self.width, self.height) / 2 @property def scale(self): return self.width / self.image.width def __iter__(self): for y in range(self.image.height): for x in range(self.image.width): yield Pixel(self, x, y)视口将图像实例、表示为复数的中心点和世界坐标的水平跨度作为参数。它还从这三个参数中派生出一些只读属性和,像素稍后会用到这些属性。最后,该类实现了一个特殊的方法
.__iter__(),它是 Python 中迭代器协议的一部分,使得定制类的迭代成为可能。通过查看上面的代码块,您可能已经猜到了,
Pixel类接受一个Viewport实例和像素坐标:# viewport.py (continued) # ... @dataclass class Pixel: viewport: Viewport x: int y: int @property def color(self): return self.viewport.image.getpixel((self.x, self.y)) @color.setter def color(self, value): self.viewport.image.putpixel((self.x, self.y), value) def __complex__(self): return ( complex(self.x, -self.y) * self.viewport.scale + self.viewport.offset )这里只定义了一个属性,但是它包含了像素颜色的 getter 和 setter,这两个属性通过视口委托给 Pillow。特殊方法
.__complex__()负责将像素转换成世界单位中的相关复数。它沿着垂直轴翻转像素坐标,将它们转换为复数,然后利用复数运算来缩放和移动它们。继续尝试你的新代码。Mandelbrot 集合包含了几乎无限的复杂结构,只有在极大的放大倍数下才能看到。一些地区的特点是螺旋形和之字形,类似海马、章鱼或大象。放大时,不要忘记增加最大迭代次数以显示更多细节:
>>> from PIL import Image
>>> from mandelbrot import MandelbrotSet
>>> from viewport import Viewport
>>> mandelbrot_set = MandelbrotSet(max_iterations=256, escape_radius=1000)
>>> image = Image.new(mode="L", size=(512, 512))
>>> for pixel in Viewport(image, center=-0.7435 + 0.1314j, width=0.002):
... c = complex(pixel)
... instability = 1 - mandelbrot_set.stability(c, smooth=True)
... pixel.color = int(instability * 255)
...
>>> image.show()
视口跨越 0.002 个世界单位,并以-0.7435 + 0.1314j 为中心,靠近产生美丽螺旋的 Misiurewicz 点。根据迭代次数的不同,您将获得细节程度不同的较暗或较亮的图像。如果你喜欢,可以用枕头来增加亮度:
>>> from PIL import ImageEnhance >>> enhancer = ImageEnhance.Brightness(image) >>> enhancer.enhance(1.25).show()这将使图像变亮 25%,并显示以下螺旋:
The Mandelbrot Set Centered At a Misiurewicz Point 你可以找到更多独特的点产生如此壮观的结果。维基百科上有一个完整的图片库,里面有值得探究的曼德尔布罗集的各种细节。
如果你已经开始检查不同的点,那么你可能也会注意到渲染时间对你当前正在查看的区域高度敏感。远离分形的像素更快地发散到无穷大,而那些靠近分形的像素往往需要更多的迭代。因此,特定区域的内容越多,解析这些像素是稳定还是不稳定所需的时间就越长。
您可以使用一些选项来提高 Python 中 Mandelbrot 集的渲染性能。然而,它们超出了本教程的范围,所以如果您有兴趣的话,可以自己探索一下。现在是时候给你的分形加点颜色了。
对曼德尔布罗集合进行艺术再现
既然你已经可以用灰色阴影画出分形,添加更多的颜色应该不会太难。如何将像素的稳定性映射到色调中完全取决于您。虽然有许多算法可以用美观的方式绘制曼德尔布罗集合,但你的想象力是唯一的限制!
如果您还没有跟上,那么您可以通过单击下面的链接下载附带的代码:
获取源代码: 点击此处获取您将使用绘制 Mandelbrot 集合的源代码。
在继续之前,您需要对上一节中的绘图代码进行一些调整。具体来说,您将切换到更丰富的颜色模式,并定义一些可重用的辅助函数来使您的生活更轻松。
调色板
自古以来,艺术家们就在一块叫做调色板的物理板上混合颜料。在计算中,一个调色板代表一个颜色查找表,这是一种无损压缩的形式。它通过对每个单独的颜色进行一次索引,然后在所有关联的像素中引用它来减少图像的内存占用。
这种技术相对简单,计算速度也快。同样,你可以用一个预定义的调色板来绘制你的分形。但是,您可以使用转义计数作为调色板的索引,而不是使用像素坐标来查找相应的颜色。事实上,你早期的可视化已经通过应用 256 单色灰色调色板做到了这一点,只是没有将它们缓存在查找表中。
要使用更多的颜色,你需要首先在 RGB 模式下创建你的图像,这将为每个像素分配 24 位:
image = Image.new(mode="RGB", size=(width, height))从现在开始,Pillow 将把每个像素表示为一个由红、绿、蓝(RGB) 颜色通道组成的元组。每种原色都可以取 0 到 255 之间的整数,总共有 1670 万种独特的颜色。然而,在迭代次数附近,你的调色板通常会包含比这少得多的。
注意:调色板中的颜色数量不一定等于最大迭代次数。毕竟,在运行递归公式之前,不知道会有多少个稳定性值。启用平滑时,小数转义计数的数量可以大于迭代次数!
如果您想测试几个不同的调色板,那么引入一个助手函数来避免一遍又一遍地重复输入相同的命令可能会很方便:

>>> from PIL import Image
>>> from mandelbrot import MandelbrotSet
>>> from viewport import Viewport
>>> def paint(mandelbrot_set, viewport, palette, smooth):
... for pixel in viewport:
... stability = mandelbrot_set.stability(complex(pixel), smooth)
... index = int(min(stability * len(palette), len(palette) - 1))
... pixel.color = palette[index % len(palette)]
该函数将一个MandelbrotSet实例作为参数,后跟一个Viewport,一个调色板和一个平滑标志。调色板必须是 Pillow 期望的具有红色、绿色和蓝色通道值的元组列表。请注意,一旦您计算了当前像素的浮点稳定性,您必须在将它用作调色板中的整数索引之前对其进行缩放和箝位。
Pillow 只能识别颜色通道的 0 到 255 之间的整数。然而,使用 0 到 1 之间的标准化分数值通常可以防止大脑过度疲劳。您可以定义另一个函数来反转规范化过程,以使 Pillow 库满意:
>>> def denormalize(palette): ... return [ ... tuple(int(channel * 255) for channel in color) ... for color in palette ... ]此函数将分数颜色值缩放为整数。例如,它会将一个类似于
(0.13, 0.08, 0.21)的数字元组转换为另一个由以下通道强度组成的元组:(45, 20, 53)。巧合的是,Matplotlib 库包括几个带有这种标准化颜色通道的颜色图。一些色彩映射表是固定的颜色列表,而另一些能够插入作为参数给出的值。您现在可以将其中一个应用到 Mandelbrot 集合可视化中:
>>> import matplotlib.cm
>>> colormap = matplotlib.cm.get_cmap("twilight").colors
>>> palette = denormalize(colormap)
>>> len(colormap)
510
>>> colormap[0]
[0.8857501584075443, 0.8500092494306783, 0.8879736506427196]
>>> palette[0]
(225, 216, 226)
颜色图是 510 种颜色的列表。在上面调用denormalize()之后,你会得到一个适合你绘画功能的调色板。在调用它之前,您需要再定义几个变量:
>>> mandelbrot_set = MandelbrotSet(max_iterations=512, escape_radius=1000) >>> image = Image.new(mode="RGB", size=(512, 512)) >>> viewport = Viewport(image, center=-0.7435 + 0.1314j, width=0.002) >>> paint(mandelbrot_set, viewport, palette, smooth=True) >>> image.show()这将产生与之前相同的螺旋,但具有更吸引人的外观:
A Spiral Visualized Using the Twilight Color Palette 请随意尝试 Matplotlib 中包含的其他调色板或他们在文档中提到的某个第三方库中的调色板。此外,Matplotlib 允许您通过在色彩映射表的名称后添加
_r后缀来反转颜色顺序。您也可以从头开始创建调色板,如下所示。假设你想要强调分形的边缘。在这种情况下,您可以将分形分为三个部分,并为每个部分指定不同的颜色:
>>> exterior = [(1, 1, 1)] * 50
>>> interior = [(1, 1, 1)] * 5
>>> gray_area = [(1 - i / 44,) * 3 for i in range(45)]
>>> palette = denormalize(exterior + gray_area + interior)
为调色板选择一个整数,比如 100 种颜色,会简化公式。然后,你可以分割颜色,使 50%的颜色进入外部,5%进入内部,剩下的 45%进入中间的灰色区域。通过将 RGB 通道设置为完全饱和,您希望外部和内部都保持白色。但是,中间的地面应该逐渐由白变黑。
不要忘记将视口的中心点设置为-0.75,宽度设置为 3.5 个单位,以覆盖整个分形。在这个缩放级别,您还需要减少迭代次数:
>>> mandelbrot_set = MandelbrotSet(max_iterations=20, escape_radius=1000) >>> viewport = Viewport(image, center=-0.75, width=3.5) >>> paint(mandelbrot_set, viewport, palette, smooth=True) >>> image.show()当您调用
paint()并再次显示图像时,您将看到 Mandelbrot 集合的清晰边界:
A Custom Color Palette To Bring Out The Edge Of The Fractal 从白色到黑色的连续过渡,然后突然跳到纯白色,产生了模糊的浮雕效果,突出了分形的边缘。您的调色板将一些固定的颜色与称为颜色渐变的平滑颜色渐变结合在一起,您将在接下来探索这一点。
颜色渐变
你可以把渐变想象成一个连续的调色板。最常见的颜色渐变是线性渐变,它使用线性插值来寻找两种或多种颜色之间最接近的值。你刚刚看到了一个例子,当你混合黑色和白色来投射阴影的时候。
现在,你可以计算出你想要使用的每个渐变的数学公式,或者建立一个通用渐变工厂。此外,如果你想以非线性方式分配你的颜色,那么 SciPy 就是你的朋友。该库附带线性、二次和三次插值方法,以及其他一些方法。你可以这样利用它:
>>> import numpy as np
>>> from scipy.interpolate import interp1d
>>> def make_gradient(colors, interpolation="linear"):
... X = [i / (len(colors) - 1) for i in range(len(colors))]
... Y = [[color[i] for color in colors] for i in range(3)]
... channels = [interp1d(X, y, kind=interpolation) for y in Y]
... return lambda x: [np.clip(channel(x), 0, 1) for channel in channels]
您的新工厂函数接受定义为浮点值三元组的颜色列表和一个可选字符串,该字符串带有 SciPy 公开的插值算法的名称。大写的X变量包含基于颜色数量的 0 到 1 之间的标准化值。大写的Y变量保存每种颜色的 R、G 和 B 值的三个序列,而channels变量具有每个通道的插值函数。
当你在一些颜色上调用make_gradient()时,你会得到一个新的函数,让你插入中间值:
>>> black = (0, 0, 0) >>> blue = (0, 0, 1) >>> maroon = (0.5, 0, 0) >>> navy = (0, 0, 0.5) >>> red = (1, 0, 0) >>> colors = [black, navy, blue, maroon, red, black] >>> gradient = make_gradient(colors, interpolation="cubic") >>> gradient(0.42) [0.026749999999999954, 0.0, 0.9435000000000001]请注意,渐变颜色(如上面示例中的黑色)可以以任何顺序重复出现。要将渐变与您的调色板感知绘画函数挂钩,您必须决定相应调色板中的颜色数量,并将渐变函数转换为非规格化元组的固定大小列表:
>>> num_colors = 256
>>> palette = denormalize([
... gradient(i / num_colors) for i in range(num_colors)
... ])
...
>>> len(palette)
256
>>> palette[127]
(46, 0, 143)
您可能想直接对稳定性值使用梯度函数。不幸的是,这在计算上代价太高,会让你的耐心达到极限。您希望预先计算所有已知颜色的插值,而不是每个像素。
最后,在构建渐变工厂、制作渐变函数和反规格化颜色之后,您可以使用渐变调色板绘制 Mandelbrot 集合:
>>> mandelbrot_set = MandelbrotSet(max_iterations=20, escape_radius=1000) >>> paint(mandelbrot_set, viewport, palette, smooth=True) >>> image.show()这将产生一个发光的霓虹灯效果:
The Mandelbrot Set Visualized With a Color Gradient 不断增加迭代次数,直到您对图像的平滑程度和细节数量感到满意。然而,看看接下来会有什么最好的结果和最直观的方法来处理颜色。
颜色模型
到目前为止,您一直在红、绿、蓝(RGB)组件领域工作,这不是考虑颜色的最自然的方式。幸运的是,有替代的颜色模型让你表达同样的概念。一种是色相、饱和度、亮度(HSB) 颜色模型,也称为色相、饱和度、明度(HSV)。
注意:不要将 HSB 或 HSV 与另一种颜色模型混淆:色调、饱和度、亮度(HSL)。
像 RGB 一样,HSB 模型也有三个分量,但它们不同于红色、绿色和蓝色通道。您可以将 RGB 颜色想象为三维立方体中的一个点。但是同一点在 HSB 中有柱坐标:
Hue Saturation Brightness Cylinder 三个 HSB 坐标是:
- 色调:逆时针测量的角度,在 0°和 360°之间
- 饱和度:圆柱体的半径在 0%和 100%之间
- 亮度:圆柱体的高度在 0%和 100%之间
要在 Pillow 中使用这样的坐标,您必须将它们转换为一个 RGB 值元组,范围为 0 到 255:

>>> from PIL.ImageColor import getrgb
>>> def hsb(hue_degrees: int, saturation: float, brightness: float):
... return getrgb(
... f"hsv({hue_degrees % 360},"
... f"{saturation * 100}%,"
... f"{brightness * 100}%)"
... )
>>> hsb(360, 0.75, 1)
(255, 64, 64)
Pillow 已经提供了可以委托给它的getrgb()辅助函数,但是它需要一个带有编码的 HSB 坐标的特殊格式的字符串。另一方面,您的包装函数将hue作为度数,将saturation和brightness都作为规格化的浮点值。这使得你的函数兼容 0 到 1 之间的稳定性值。
有几种方法可以将稳定性与 HSB 颜色联系起来。例如,您可以通过将稳定性缩放到 360 度来使用整个颜色光谱,使用稳定性来调制饱和度,并将亮度设置为 100%,这由下面的 1 表示:
>>> mandelbrot_set = MandelbrotSet(max_iterations=20, escape_radius=1000) >>> for pixel in Viewport(image, center=-0.75, width=3.5): ... stability = mandelbrot_set.stability(complex(pixel), smooth=True) ... pixel.color = (0, 0, 0) if stability == 1 else hsb( ... hue_degrees=int(stability * 360), ... saturation=stability, ... brightness=1, ... ) ... >>> image.show()要将内部涂成黑色,您需要检查像素的稳定性是否正好为 1,并将所有三个颜色通道设置为零。对于小于 1 的稳定性值,外部将具有随着与分形的距离而褪色的饱和度和遵循 HSB 圆柱体的角度维度的色调:
The Mandelbrot Set Visualized Using the HSB Color Model 随着您越来越接近分形,角度越来越大,颜色从黄色变为绿色、青色、蓝色和洋红色。你看不到红色,因为分形的内部总是涂成黑色,而外部最远的部分几乎没有饱和度。请注意,将圆柱体旋转 120°可让您在其底部找到三原色(红色、绿色和蓝色)中的每一种。
不要犹豫,尝试用不同的方法计算 HSB 坐标,看看会发生什么!
结论
现在你知道如何使用 Python 来绘制 benot Mandelbrot 发现的著名分形了。你已经学会了用彩色、灰度、黑白等各种方式来形象化它。您还看到了一个实例,展示了复数如何帮助用 Python 优雅地表达数学公式。
在本教程中,您学习了如何:
- 将复数应用于实际问题
- 找到曼德尔布罗和茱莉亚集合的成员
- 使用 Matplotlib 和 Pillow 将这些集合绘制成分形
- 制作一个丰富多彩的分形艺术图
您可以通过单击下面的链接下载本教程中使用的完整源代码:
获取源代码: 点击此处获取您将使用绘制 Mandelbrot 集合的源代码。*********
MATLAB 与 Python:为什么以及如何进行转换
MATLAB 是众所周知的高质量环境,适用于任何涉及数组、矩阵或线性代数的工作。Python 对于这个领域来说是较新的,但是对于类似的任务来说正变得越来越流行。正如您将在本文中看到的,Python 拥有 MATLAB 对于科学任务的所有计算能力,这使得开发健壮的应用程序变得快速而简单。然而,在比较 MATLAB 和 Python 时,有一些重要的不同之处,你需要了解它们才能有效地转换。
在这篇文章中,你将学习如何:
- 评估使用 MATLAB 和 Python 的区别
- 为 Python 设置一个复制大多数 MATLAB 函数的环境
- 将脚本从 MATLAB 转换为 Python
- 避免从 MATLAB 切换到 Python 时可能遇到的常见问题
- 编写外观和感觉都像 Python 的代码
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
MATLAB vs Python:比较特性和原理
Python 是一种高级的通用编程语言,旨在方便人们完成各种任务。Python 由吉多·范·罗苏姆创建,并于 20 世纪 90 年代初首次发布。Python 是一种成熟的语言,由全球数百名合作者开发。
Python 被从事小型个人项目的开发人员一直使用到世界上一些最大的互联网公司。不仅 Python 运行 Reddit 和 Dropbox ,而且原 Google 算法都是用 Python 写的。此外,基于 Python 的 Django 框架运行 Instagram 和许多其他网站。在科学和工程方面,创建黑洞的 2019 照片的数据是用 Python 处理的,像网飞这样的大公司在他们的数据分析工作中使用 Python 。
在 MATLAB 和 Python 的比较中还有一个重要的哲学差异。 MATLAB 是专有的、闭源的软件。对于大多数人来说,使用 MATLAB 的许可证相当昂贵,这意味着如果你有 MATLAB 代码,那么只有买得起许可证的人才能运行它。此外,用户为扩展 MATLAB 的基本功能而安装的每个额外工具箱都要付费。抛开成本不谈,MATLAB 语言是由 Mathworks 独家开发的。如果 Mathworks 倒闭了,那么 MATLAB 将不再能够被开发,并可能最终停止运行。
另一方面, Python 是免费开源软件。您不仅可以免费下载 Python,还可以下载、查看和修改源代码。这对 Python 来说是一个很大的优势,因为这意味着如果当前的开发人员由于某种原因无法继续下去,任何人都可以继续开发这种语言。
如果你是一名研究人员或科学家,那么使用开源软件有一些相当大的好处。2018 年诺贝尔经济学奖得主保罗·罗默(Paul Romer)最近也迷上了 Python。据他估计,转向开源软件,尤其是 Python,为他的研究带来了更大的完整性和责任性。这是因为所有的代码都可以被任何感兴趣的读者共享和运行。罗默教授写了一篇很好的文章, Jupyter,Mathematica 和研究论文的未来,讲述了他使用开源软件的经历。
此外,因为 Python 是免费的,所以更广泛的受众可以使用您开发的代码。正如您将在本文后面看到的,Python 有一个很棒的社区,可以帮助您开始学习这种语言并提高您的知识。有成千上万的教程、文章和书籍都是关于 Python 软件开发的。这里有几个让你开始:
此外,由于社区中有如此多的开发人员,有成千上万的免费软件包来完成您想用 Python 完成的许多任务。在本文的后面,您将了解更多关于如何获得这些包的信息。
像 MATLAB , Python 是一种解释的语言。这意味着 Python 代码可以在所有主要的操作系统平台和 CPU 架构之间移植,不同平台只需要做很小的改动。有针对台式机和笔记本电脑 CPU 以及像 Adafruit 这样的微控制器的 Python 发行版。Python 还可以通过一个简单的编程接口与其他微控制器如 Arduino 进行对话,这个接口几乎与任何主机操作系统都相同。
出于所有这些原因,以及更多原因,Python 是取代 MATLAB 成为编程语言的绝佳选择。既然你已经被说服试用 Python 了,那么继续读下去,看看如何在你的计算机上安装它,以及如何从 MATLAB 切换过来!
注 : GNU Octave 是 MATLAB 的免费开源克隆。从这个意义上来说,GNU Octave 在代码可复制性和软件访问方面拥有与 Python 相同的哲学优势。
Octave 的语法大部分与 MATLAB 语法兼容,因此它为希望使用开源软件的 MATLAB 开发人员提供了一个较短的学习曲线。然而,Octave 无法与 Python 的社区或 Python 可以服务的不同种类的应用程序的数量相匹配,所以我们明确建议您将 whole hog 切换到 Python。
况且这个网站叫真 Python ,不是真八度😀
为 Python 设置环境
在本节中,您将学习:
- 如何在你的电脑上安装 Python 以便从 MATLAB 无缝过渡
- 如何安装 MATLAB 集成开发环境的替代产品
- 如何在你的电脑上使用 MATLAB 的替代品
通过 Anaconda 获得 Python
Python 可以从许多不同的来源下载,称为发行版。例如,你可以从官方 Python 网站下载的 Python 就是一个发行版。另一个非常流行的 Python 发行版,特别是对于数学、科学、工程和数据科学应用程序,是 Anaconda 发行版。
Anaconda 如此受欢迎有两个主要原因:
Anaconda 为 Windows、macOS 和 Linux 分发预构建的包,这意味着安装过程非常简单,并且对于所有三个主要平台都是一样的。
Anaconda 在一个安装程序中包含了工程和数据科学类型工作负载的所有最流行的包。
为了创建一个非常类似于 MATLAB 的环境,您应该下载并安装 Anaconda 。在撰写本文时,Python 有两个主要版本:Python 2 和 Python 3。您肯定应该为 Python 3 安装 Anaconda 版本,因为 Python 2 在 2020 年 1 月 1 日之后将不再受支持。在撰写本文时,Python 3.7 是最新版本,但是 Python 3.8 应该会在本文发表后几个月发布。3.7 或 3.8 对你来说都一样,所以尽可能选择最新的版本。
一旦您下载了 Anaconda 安装程序,您就可以根据您的平台遵循默认的设置过程。您应该将 Anaconda 安装在一个不需要管理员权限就可以修改的目录中,这是安装程序中的默认设置。
安装了 Anaconda 之后,您应该了解一些特定的程序。启动应用程序最简单的方法是使用 Anaconda Navigator。在 Windows 上,你可以在开始菜单中找到它,在 macOS 上,你可以在 Launchpad 中找到它。以下是 Windows 上 Anaconda Navigator 的屏幕截图:
在截图中,你可以看到几个已安装的应用程序,包括 JupyterLab 、 Jupyter Notebook 和 Spyder ,你将在本教程的后面了解更多。
在 Windows 上,还有一个您应该知道的应用程序。这被称为 Anaconda 提示符,它是一个专门为 Windows 上的
conda设置的命令提示符。如果您想在终端中键入conda命令,而不是使用 Navigator GUI,那么您应该在 Windows 上使用 Anaconda 提示符。在 macOS 上,您可以使用任何终端应用程序,如默认的 Terminal.app 或 iTerm2,从命令行访问
conda。在 Linux 上,您可以使用自己选择的终端模拟器,具体安装哪个模拟器取决于您的 Linux 发行版。术语注释:你可能会对
conda和 Anaconda 有点困惑。这种区别很微妙但很重要。Anaconda 是 Python 的一个发行版,它包含了许多用于各种科学工作的必要包。conda是一个跨平台的包管理软件,包含在 Python 的 Anaconda 发行版中。conda是您用来构建、安装和删除 Anaconda 发行版中的软件包的软件。你可以在中阅读所有关于如何使用
conda在 Windows 上设置 Python 进行机器学习的内容。尽管该教程关注的是 Windows,但是conda命令在 Windows、macOS 和 Linux 上是相同的。Python 还包括另一种安装包的方式,叫做
pip。如果您正在使用 Anaconda,您应该总是尽可能地使用conda来安装软件包。不过,有时一个包只对pip可用,对于那些情况,你可以阅读什么是 Pip?新蟒蛇指南。获得集成开发环境
MATLAB 的一大优势是它包含了软件的开发环境。这是您最可能习惯使用的窗口。中间有一个控制台,你可以在那里输入命令,右边是一个变量浏览器,左边是一个目录列表。
与 MATLAB 不同,Python 本身没有默认的开发环境。这取决于每个用户找到一个适合他们的需求。幸运的是,Anaconda 提供了两种不同的集成开发环境(IDE ),它们类似于 MATLAB IDE,可以让您无缝切换。这些被称为 Spyder 和 JupyterLab。在接下来的两节中,您将看到 Spyder 的详细介绍和 JupyterLab 的简要概述。
Spyder
Spyder 是专门为科学 Python 工作开发的 Python IDE。Spyder 的一个真正的优点是,它有一个专门为像您这样从 MATLAB 转换到 Python 的人设计的模式。稍后你会看到这一点。
首先你要打开 Spyder。如果您遵循了上一节中的说明,那么您可以使用 Anaconda Navigator 打开 Spyder。找到 Spyder 图标,点击启动按钮。如果您使用 Windows,也可以从“开始”菜单启动 Spyder 如果您使用 macOS,则可以从 Launchpad 启动 Spyder。
在 Spyder 中更改默认窗口布局
Spyder 中的默认窗口如下图所示。这是针对运行在 Windows 10 上的 Spyder 3 . 3 . 4 版本的。它在 macOS 或 Linux 上看起来应该非常相似:
在浏览用户界面之前,您可以让界面看起来更像 MATLAB。在视图→窗口布局菜单中选择 MATLAB 布局。这将自动改变窗口,使其具有你在 MATLAB 中习惯的相同区域,如下图所示:
在窗口的左上方是文件浏览器或目录列表。在此窗格中,您可以找到要编辑的文件,或者创建要使用的新文件和文件夹。
顶部中间是一个文件编辑器。在这个编辑器中,您可以处理想要保存以便以后重新运行的 Python 脚本。默认情况下,编辑器会打开一个名为
temp.py的文件,该文件位于 Spyder 的配置目录中。这个文件是一个临时的地方,在你把它们保存到你电脑上的其他地方之前,你可以在这里尝试一下。底部中间是控制台。像在 MATLAB 中一样,控制台是您可以运行命令来查看它们做了什么,或者当您想要调试一些代码时。如果您关闭 Spyder 并再次打开它,在控制台中创建的变量不会被保存。默认情况下,控制台在技术上运行的是 IPython 。
您在控制台中键入的任何命令都将记录到窗口右下窗格的历史文件中。此外,您在控制台中创建的任何变量都将显示在右上方窗格的变量资源管理器中。
请注意,您可以调整任何窗格的大小,方法是将鼠标放在窗格之间的分隔线上,单击并拖动边缘到所需的大小。您可以通过点击窗格顶部的 x 来关闭任何窗格。
您还可以通过单击窗格顶部看起来像两个窗口的按钮,将任何窗格从主窗口中分离出来,该按钮就在关闭窗格的 x 的旁边。当一个窗格脱离主窗口时,你可以拖动它,并随意重新排列。如果你想把窗格放回主窗口,用鼠标拖动它,这样会出现一个透明的蓝色或灰色背景,相邻的窗格会调整大小,然后松开鼠标,窗格会自动就位。
一旦你完全按照你想要的方式排列了窗格,你可以让 Spyder 保存布局。进入视图菜单,再次找到窗口布局弹出按钮。然后点击保存当前布局并命名。如果某个东西被意外更改,这可以让您随时重置为您喜欢的布局。您也可以从该菜单重置为默认配置之一。
在 Spyder 控制台中运行语句
在这一节中,您将编写一些简单的 Python 命令,但是如果您还没有完全理解它们的意思,请不要担心。在本文的稍后部分,您将了解到更多关于 Python 语法的知识。你现在想做的是了解 Spyder 的界面与 MATLAB 界面有何相似和不同之处。
在本文中,您将大量使用 Spyder 控制台,因此您应该了解它是如何工作的。在控制台中,您将看到以
In [1]:开头的一行,表示输入行 1。Spyder(实际上是 IPython 控制台)对您输入的所有输入行进行编号。因为这是您键入的第一个输入,所以行号是 1。在本文的其余部分,您将看到对“输入行 X”的引用,其中 X 是方括号中的数字。我喜欢对刚接触 Python 的人做的第一件事就是向他们展示 Python 的*禅。这首小诗让你了解了 Python 是什么,以及如何使用 Python。
要了解 Python 的禅,在输入行 1 输入
import this,然后按Enter运行代码。您将看到如下输出:

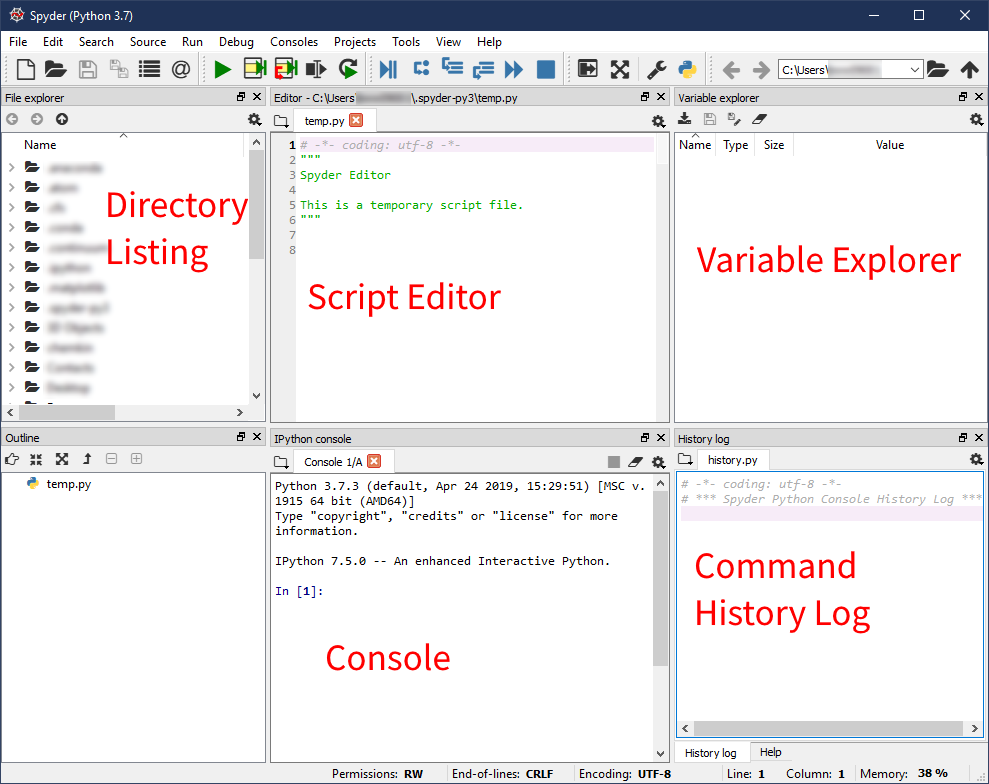
In [1]: import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
该代码在输入行 1 上有import this。运行import this的输出是将 Python 的 Zen 打印到控制台上。我们将在文章的后面回到这首诗的几个小节。
在本文的许多代码块中,您会在代码块的右上角看到三个大于号(>>>)。如果您单击它,它将删除输入提示和任何输出行,因此您可以将代码复制并粘贴到您的控制台中。
许多蟒蛇保持着健康的幽默感。这在这门语言的很多地方都有体现,包括 Python 的Zen。对于另一个,在 Spyder 控制台中,键入以下代码,然后按 Enter 运行它:
In [2]: import antigravity这句话将打开你的网络浏览器,看到名为 XKCD 的网络漫画,特别是漫画 #353 ,作者发现 Python 赋予了他飞翔的能力!
现在,您已经成功运行了前两条 Python 语句!恭喜😃🎉
如果查看历史日志,您应该会看到您在控制台中键入的前两个命令(
import this和import antigravity)。现在让我们定义一些变量,做一些基本的算术。在控制台中,键入以下语句,在每个语句后按Enter:
In [3]: var_1 = 10
In [4]: var_2 = 20
In [5]: var_3 = var_1 + var_2
In [6]: var_3
Out[6]: 30
在这段代码中,您定义了 3 个变量:var_1、var_2和var_3。你给var_1赋值 10,var_2赋值 20,给var_3赋值var_1和var_2之和。然后,您通过将变量var_3的值写为输入行上唯一的内容来显示它。该语句的输出显示在下一个Out行,Out行上的数字与相关的In行相匹配。
在这些命令中,您需要注意两点:
-
如果一条语句不包含赋值(带有一个
=),它将被打印到一个Out行上。在 MATLAB 中,你需要包含一个分号来抑制赋值语句的输出,但是在 Python 中这是不必要的。 -
在输入行 3、4 和 5,右上角窗格中的变量浏览器被更新。
运行这三个命令后,您的变量浏览器应该看起来像下图:
在此图中,您可以看到一个包含四列的表格:
- 名称 显示您给
var_1、var_2、var_3起的名字。 - 类型 显示了变量的 Python 类型,在本例中,
int全部为整数数字。 - 大小 显示数据存储变量的大小,对于列表和其他数据结构比较有用。
- 值 显示变量的当前值。
在 Spyder 的文件中运行代码
在 Spyder 界面的简短旅程中,最后一站是文件编辑器窗格。在此窗格中,您可以创建和编辑 Python 脚本,并使用控制台运行它们。默认情况下,Spyder 会创建一个名为temp.py的临时文件,用于在将命令移动或保存到另一个文件之前临时存储命令。
让我们在temp.py文件中写一些代码,看看如何运行它。该文件以下面的代码开始,您可以保留它:
1# -*- coding: utf-8 -*-
2"""
3Spyder Editor
4
5This is a temporary script file.
6"""
在这段代码中,您可以看到两种 Python 语法结构:
-
第 1 行有一个注释。在 Python 中,注释字符是散列或井号(
#)。MATLAB 使用百分号(%)作为注释字符。该行散列后面的任何内容都是注释,通常会被 Python 解释器忽略。 -
从第 2 行开始是一个字符串,它为文件的内容提供了一些上下文。这通常简称为文档串或文档串。在稍后的章节的中,您将了解到更多关于 docstrings 的内容。
现在,您可以开始向该文件添加代码了。从temp.py中的第 8 行开始,输入与您已经在控制台中输入的代码相似的代码:
8var_4 = 10
9var_5 = 20
10var_6 = var_4 + var_5
那么,有三种方法可以运行代码:
- 你可以使用
F5快捷键来运行文件,就像在 MATLAB 中一样。 - 你可以点击菜单栏中向右的绿色三角形,就在编辑器和文件浏览器窗格的上方。
- 您可以使用运行→运行菜单选项。
第一次运行文件时,Spyder 会打开一个对话框,要求您确认要使用的选项。对于这个测试,默认选项是好的,您可以单击对话框底部的运行:
这将在控制台中自动执行以下代码:
In [7]: runfile('C:/Users/Eleanor/.spyder-py3/temp.py', ...: wdir='C:/Users/Eleanor/.spyder-py3')这段代码将运行您正在处理的文件。注意,运行该文件向变量浏览器中添加了三个变量:
var_4、var_5和var_6。这是您在文件中定义的三个变量。您还会看到runfile()被添加到历史日志中。在 Spyder 中,您还可以创建可以单独运行的代码单元。要创建一个代码单元,在编辑器中打开的文件中添加一行以
# %%开头的代码:11# %% This is a code cell 12var_7 = 42 13var_8 = var_7 * 2 14 15# %% This is a second code cell 16print("This code will be executed in this cell")在这段代码中,您在第 11 行用
# %%代码创建了第一个代码单元格。后面是一行注释,被 Python 忽略。在第 12 行,你给var_7赋值 42,然后第 13 行给var_8赋值为var_7乘以 2。第 15 行开始另一个代码单元,它可以与第一个代码单元分开执行。要执行代码单元格,单击运行当前单元格或运行当前单元格,并转至工具栏中通用运行按钮旁边的下一个按钮。您也可以使用键盘快捷键
Ctrl+Enter来运行当前单元格并保持选中状态,或者Shift+Enter来运行当前单元格并选择下一个单元格。Spyder 还提供了易于使用的调试功能,就像在 MATLAB 中一样。您可以双击编辑器中的任意行号,在您的代码中设置断点。您可以使用工具栏上带有两条垂直线的蓝色向右三角形,或者使用
Ctrl+F5键盘快捷键,在调试模式下运行代码。这将在您指定的任何断点处暂停执行,并在控制台中打开ipdb调试器,这是运行 Python 调试器pdb的 IPython 增强方式。你可以在 Python 调试与 pdb 中了解更多。总结你在 Spyder 的经历
现在您已经有了使用 Spyder 作为 MATLAB 集成开发环境的替代品的基本工具。您知道如何在控制台中运行代码或在文件中键入代码并运行该文件。您还知道在哪里可以看到您的目录和文件、您定义的变量以及您键入的命令的历史记录。
一旦您准备好开始将代码组织成模块和包,您就可以查阅以下资源:
Spyder 是一个非常大的软件,而你仅仅触及了它的表面。通过阅读官方文档、故障排除和常见问题指南和 Spyder wiki ,你可以了解更多关于 Spyder 的信息。
JupyterLab
JupyterLab 是由 Project Jupyter 开发的 IDE。你可能听说过 Jupyter 笔记本,特别是如果你是一个数据科学家。嗯,JupyterLab 是 Jupyter 笔记本的下一个版本。虽然在撰写本文时,JupyterLab 仍处于测试阶段,但 Jupyter 项目预计 JupyterLab 最终将取代当前的笔记本服务器接口。然而,JupyterLab 完全兼容现有的笔记本电脑,因此过渡应该是相当无缝的。
JupyterLab 预装了 Anaconda,因此您可以从 Anaconda Navigator 启动它。找到 JupyterLab 盒子,点击发射。这将打开您的网络浏览器,进入地址
http://localhost:8888/lab。JupyterLab 的主窗口如下图所示:
该界面有两个主要部分:
- 左边是一个文件浏览器,可以让你从电脑上打开文件。
- 窗口的右侧是如何打开创建新的笔记本文件,在 IPython 控制台或系统终端中工作,或者创建新的文本文件。
如果你有兴趣了解更多关于 JupyterLab 的信息,你可以在宣布 beta 版本的博客文章或 JupyterLab 文档中阅读更多关于笔记本下一步发展的信息。您还可以在 Jupyter 笔记本:简介和使用 Jupyter 笔记本课程中了解笔记本界面。Jupyter 笔记本风格文档的一个优点是,您在 Spyder 中创建的代码单元格与 Jupyter 笔记本中的代码单元格非常相似。
了解 Python 的数学库
现在你的计算机上有了 Python,你有了一个让你感觉像在家里一样的 IDE。那么,如何学习如何在 Python 中实际完成一项任务呢?有了 MATLAB,你可以使用搜索引擎,只需在查询中包含
MATLAB就可以找到你要找的主题。使用 Python,如果您在查询中比仅仅包含Python更具体一点,通常会得到更好的搜索结果。在这一节中,您将通过了解 Python 功能是如何被分成几个库的,从而更好地掌握 Python。您还将了解每个库是做什么的,这样您就可以通过搜索获得一流的结果!
Python 有时被称为包含电池的语言。这意味着当你安装 Python 时,你需要的大部分重要功能都已经包含在内了。例如,Python 内置了包含基本操作的
math和statistics库。但是,有时你想做一些语言中没有的事情。Python 的一大优势是,其他人可能已经完成了您需要做的任何事情,并发布了完成该任务的代码。有几十万个公开可用的免费软件包,你可以很容易地安装它们来执行各种任务。这些范围从处理 PDF 文件到建立和托管一个互动网站到使用高度优化的数学和科学功能。
使用数组或矩阵、优化或绘图需要安装额外的库。幸运的是,如果您使用 Anaconda 安装程序安装 Python,这些库是预安装的,您不必担心。即使您没有使用 Anaconda,对于大多数操作系统来说,它们通常也很容易安装。
您需要从 MATLAB 切换的一组重要库通常被称为 SciPy 栈。堆栈的基础是提供基本数组和矩阵运算( NumPy )、积分、优化、信号处理和线性代数函数( SciPy )和绘图( Matplotlib )的库。其他基于这些来提供更高级功能的库包括 Pandas , scikit-learn , SymPy 等等。
NumPy(数字 Python)
NumPy 可能是 Python 中科学计算最基本的包。它提供了一个高效的界面来创建多维数组并与之交互。几乎所有在 SciPy 栈中的其他包都以某种方式使用或集成了 NumPy。
NumPy 数组相当于 MATLAB 中的基本数组数据结构。使用 NumPy 数组,您可以进行内积和外积、转置和元素操作。NumPy 还包含许多有用的方法,用于读取文本和二进制数据文件、拟合多项式函数、许多数学函数(正弦、余弦、平方根等)以及生成随机数。
NumPy 对性能敏感的部分都是用 C 语言写的,所以速度非常快。NumPy 还可以利用优化的线性代数库,如英特尔的 MKL 或 OpenBLAS,进一步提高性能。
注:
真正的 Python 有几篇文章讲述了如何使用 NumPy 来加速你的 Python 代码:
- 看 Ma,无 For 循环:用 NumPy 进行数组编程
- NumPy arange():如何使用 np.arange()
- Python 直方图绘制:NumPy,Matplotlib,Pandas & Seaborn
SciPy(科学巨蟒)
SciPy 包(不同于 SciPy 栈)是一个为科学应用程序提供大量有用功能的库。如果您需要做需要优化、线性代数或稀疏线性代数、离散傅立叶变换、信号处理、物理常数、图像处理或数值积分的工作,那么 SciPy 就是您的库!由于 SciPy 实现了这么多不同的特性,这就像是在一个包中访问了一堆 MATLAB 工具箱。
SciPy 非常依赖 NumPy 数组来完成它的工作。和 NumPy 一样,SciPy 中的很多算法都是用 C 或 Fortran 实现的,所以速度也很快。与 NumPy 一样,SciPy 可以利用优化的线性代数库来进一步提高性能。
Matplotlib(类 MATLAB 绘图库)
Matplotlib 是一个产生高质量和交互式二维图的库。Matplotlib 旨在提供一个类似于 MATLAB 中的
plot()函数的绘图接口,所以从 MATLAB 切换过来的人应该会觉得有些熟悉。尽管 Matplotlib 中的核心功能是用于二维数据绘图,但也有可用的扩展,允许使用 mplot3d 包进行三维绘图,使用 cartopy 绘制地理数据,以及在 Matplotlib 文档中列出的更多功能。注:
以下是 Matplotlib 上的更多资源:
其他重要的 Python 库
使用 NumPy、SciPy 和 Matplotlib,您可以将许多 MATLAB 代码切换到 Python。但是,了解更多的库可能会有所帮助。
- 熊猫 提供了一个数据帧,一个能够命名行和列以便于访问的数组。
- SymPy 提供了符号数学和计算机代数系统。
- scikit-learn 提供了许多与机器学习任务相关的功能。
- scikit-image 提供与图像处理相关的功能,兼容 SciPy 中的类似库。
- Tensorflow 为许多机器学习任务提供了一个通用平台。
- Keras 提供了生成神经网络的库。
- 多处理 提供了一种执行基于多进程的并行性的方法。它内置于 Python 中。
- Pint 提供单位库,进行物理单位制之间的自动转换。
- PyTables 为 HDF5 格式文件提供了读写器。
- PyMC3 提供贝叶斯统计建模和概率机器学习功能。
MATLAB 和 Python 的语法差异
在本节中,您将学习如何将 MATLAB 代码转换成 Python 代码。您将了解 MATLAB 和 Python 之间的主要语法差异,了解基本数组操作的概述以及它们在 MATLAB 和 Python 之间的区别,并了解一些尝试自动转换代码的方法。
MATLAB 和 Python 最大的技术区别是,在 MATLAB 中,一切都被当作数组,而在 Python 中一切都是更一般的对象。例如,在 MATLAB 中,字符串是字符数组或字符串数组,而在 Python 中,字符串有自己的对象类型,称为
str。正如您将在下面看到的,这对您如何使用每种语言进行编码有着深远的影响。说完了,让我们开始吧!为了帮助您,下面的部分根据您遇到该语法的可能性进行了分组。
你可能会看到这个语法
本节中的示例代表了您很可能在野外看到的代码。这些例子还展示了一些更基本的 Python 语言特性。在继续之前,您应该确保已经很好地掌握了这些示例。
Python 中的注释以
#开头在 MATLAB 中,注释是一行中跟在百分号(
%)后面的任何东西。在 Python 中,注释是跟在散列或井号(#)后面的任何东西。在前面关于 Spyder 的章节中,您已经看到了 Python 注释。一般来说,Python 解释器会忽略注释的内容,就像 MATLAB 解释器一样,所以你可以在注释中写任何你想写的内容。Python 中这个规则的一个例外是您在前面关于 Spyder 的部分看到的例子:# -*- coding: utf-8 -*-当 Python 解释器读取这一行时,它将设置用来读取文件其余部分的编码。该注释必须出现在文件的前两行之一才有效。
MATLAB 和 Python 的另一个区别是如何编写内联文档。在 MATLAB 中,文档被写在注释中函数的开始处,如下面的代码示例:
function [total] = addition(num_1,num_2) % ADDITION Adds two numbers together % TOTAL = ADDITION(NUM_1,NUM_2) adds NUM_1 and NUM_2 together % % See also SUM and PLUS然而,Python 并没有以这种方式使用注释。相反,Python 有一个想法,简称为文档字符串或T3】文档字符串 T5。在 Python 中,您可以像这样记录如上所示的 MATLAB 函数:
def addition(num_1, num_2): """Adds two numbers together. Example ------- >>> total = addition(10, 20) >>> total 30 """请注意,在这段代码中,docstring 位于两组三个引号字符(
""")之间。这允许 docstring 运行在多行上,并保留空白和换行符。三重引号字符是 字符串文字 的特例。现在还不要太担心定义函数的语法。在后面的章节中你会看到更多关于那个的内容。在 Python 中,行首的空白很重要
当你在 MATLAB 中写代码时,像
if语句、for和while循环这样的块,函数定义都是用end关键字结束的。在 MATLAB 中,通常认为在块内缩进代码是一种好的做法,这样代码可以直观地组合在一起,但这在语法上并不是必需的。例如,以下两个代码块在 MATLAB 中的功能是等效的:
1num = 10; 2 3if num == 10 4disp("num is equal to 10") 5else 6disp("num is not equal to 10") 7end 8 9disp("I am now outside the if block")在这段代码中,首先创建
num来存储值 10,然后检查num的值是否等于 10。如果是,您将从第 2 行开始在控制台上显示短语num is equal to 10。否则,else条款将生效并显示num is not equal to 10。当然,如果你运行这段代码,你会看到num is equal to 10输出,然后是I am now outside the if block。现在,您应该修改您的代码,使其看起来像下面的示例:
1num = 10; 2 3if num == 10 4 disp("num is equal to 10") 5else 6 disp("num is not equal to 10") 7end 8 9disp("I am now outside the if block")在这段代码中,您只修改了第 3 行和第 5 行,在这一行的前面添加了一些空格或缩进。代码将与前面的示例代码执行相同,但是有了缩进,就更容易区分哪些代码在语句的
if部分,哪些代码在语句的else部分。在 Python 中,行首的缩进用来分隔类和函数定义、
if语句、for和while循环的开始和结束。Python 中没有end关键字。这意味着缩进在 Python 中非常重要!此外,在 Python 中,
if/else/elif语句、for或while循环、函数或类的定义行以冒号结尾。在 MATLAB 中,冒号不用来结束一行。考虑这个代码示例:
1num = 10 2 3if num == 10: 4 print("num is equal to 10") 5else: 6 print("num is not equal to 10") 7 8print("I am now outside the if block")在第一行,您定义了
num,并将其值设置为 10。在第 2 行,写if num == 10:测试num相对于 10 的值。注意行尾的冒号。接下来,在 Python 的语法中,第 3 行必须缩进。在那一行,您使用
print()向控制台显示一些输出,类似于 MATLAB 中的disp()。在后面的章节中,你会读到更多关于print()对disp()T6 的内容。在第 4 行,您正在启动
else程序块。注意,else关键字中的e与if关键字中的i垂直对齐,并且该行以冒号结束。因为第 3 行的else是相对于print()定向的,并且因为它与if关键字对齐,Python 知道块的if部分中的代码已经完成,而else部分正在开始。第 5 行缩进一级,因此它构成了当满足else语句时要执行的代码块。最后,在第 6 行,您打印了一条来自
if/else块外部的语句。不管num的值是多少,都将打印该声明。注意print()中的p与if中的i和else中的e垂直对齐。Python 就是这样知道if/else块中的代码已经结束的。如果运行上面的代码,Python 将显示num is equal to 10,后面跟着I am now outside the if block。现在,您应该修改上面的代码来删除缩进,看看会发生什么。如果您尝试在 Spyder/IPython 控制台中键入不带缩进的代码,您将得到一个
IndentationError:
In [1]: num = 10
In [2]: if num == 10:
...: print("num is equal to 10")
File "<ipython-input-2-f453ffd2bc4f>", line 2
print("num is equal to 10")
^
IndentationError: expected an indented block
在这段代码中,首先将num的值设置为 10,然后尝试编写没有缩进的if语句。事实上,IPython 控制台是智能的,它会自动缩进if语句后的行,所以您必须删除缩进才能产生这个错误。
当你缩进你的代码时,官方的 Python 风格指南 PEP 8 推荐使用 4 个空格字符代表一个缩进级别。如果您按下键盘上的 Tab 键,大多数设置为处理 Python 文件的文本编辑器会自动插入 4 个空格。如果你愿意,你可以选择在你的代码中使用制表符,但是你不应该混合制表符和空格,否则如果缩进变得不匹配,你可能会以一个TabError结束。
Python 中的条件语句使用elif
在 MATLAB 中,可以用if、elseif、else构造条件语句。这些类型的语句允许你控制程序的流程来响应不同的条件。
您应该用下面的代码来尝试这个想法,然后比较 MATLAB 和 Python 的条件语句示例:
1num = 10; 2if num == 10 3 disp("num is equal to 10") 4elseif num == 20 5 disp("num is equal to 20") 6else 7 disp("num is neither 10 nor 20") 8end
在这个代码块中,您将num定义为等于 10。然后检查num的值是否为 10,如果是,使用disp()将输出打印到控制台。如果num是 20,您将打印一个不同的报表,如果num既不是 10 也不是 20,您将打印第三个报表。
在 Python 中,elseif关键字被替换为elif:
1num = 10
2if num == 10:
3 print("num is equal to 10")
4elif num == 20: 5 print("num is equal to 20")
6else:
7 print("num is neither 10 nor 20")
这个代码块在功能上等同于前面的 MATLAB 代码块。有两个主要区别。在第 4 行,elseif被替换为elif,并且没有结束该块的end语句。相反,当在else之后找到下一行代码时,if块结束。您可以在 Python 文档中阅读更多关于if语句的内容。
在 Python 中调用函数和索引序列使用不同的括号
在 MATLAB 中,当你想调用一个函数或者当你想索引一个数组时,你使用圆括号(()),有时也称为括号。方括号([])用于创建数组。
您可以使用下面的示例代码来测试 MATLAB 与 Python 的区别:
>> arr = [10, 20, 30]; >> arr(1) ans = 10 >> sum(arr) ans = 60在这段代码中,首先使用等号右边的方括号创建一个数组。然后,使用圆括号作为索引操作符,通过
arr(1)检索第一个元素的值。在第三个输入行上,您调用sum()并使用圆括号来指示应该传递给sum()的参数,在本例中只是arr。MATLAB 计算arr中元素的总和并返回结果。Python 使用不同的语法来调用函数和索引序列。在 Python 中,使用圆括号意味着应该执行一个函数,而使用方括号将索引一个序列:
In [1]: arr = [10, 20, 30]
In [2]: arr[0]
Out[2]: 10
In [3]: sum(arr)
Out[3]: 60
在这段代码中,您将在输入行 1 上定义一个 Python 列表。Python 列表与 MATLAB 中的数组和 NumPy 包中的数组有一些重要的区别。您可以在列表中阅读更多关于 Python 列表的内容,在 Python 中阅读更多关于元组的内容,并且您将在后面的章节中了解更多关于 NumPy 数组的内容。
在第 2 行输入中,使用方括号显示了索引操作中列表第一个元素的值。在输入行 3 上,使用圆括号调用sum(),并传入存储在arr中的列表。这导致列表元素的总和显示在最后一行。注意 Python 使用方括号来索引列表,使用圆括号来调用函数。
Python 中序列的第一个索引是 0
在 MATLAB 中,使用1作为索引,可以从数组中获取第一个值。这种样式遵循自然的编号惯例,并从如何计算序列中的项目数开始。您可以通过这个例子来尝试 MATLAB 与 Python 的区别:
>> arr = [10, 20, 30]; >> arr(1) ans = 10 >> arr(0) Array indices must be positive integers or logical values.在这段代码中,您将创建一个包含三个数字的数组:
10、20和30。然后显示索引为1的第一个元素的值,即10。试图访问第零个元素会导致 MATLAB 出错,如最后两行所示。在 Python 中,序列中第一个元素的索引是 0,而不是 1:
In [1]: arr = [10, 20, 30]
In [2]: arr[0]
Out[2]: 10
In [3]: arr[1]
Out[3]: 20
In [4]: a_string = "a string"
In [5]: a_string[0]
Out[5]: 'a'
In [6]: a_string[1]
Out[6]: ' '
在这段代码中,您将arr定义为一个 Python 列表,在输入行 1 上有三个元素。在输入行 2 上,显示了列表中第一个元素的值,索引为 0。然后显示列表的第二个元素,索引为 1。
在输入行 4、5 和 6 上,您用内容"a string"定义了a_string,然后获得了字符串的第一个和第二个元素。请注意,字符串的第二个元素(字符)是一个空格。这演示了一个通用的 Python 特性,许多变量类型作为序列操作,并且可以被索引,包括列表、元组、字符串和数组。
序列的最后一个元素在 Python 中的索引为-1
在 MATLAB 中,你可以用 end 作为索引,从一个数组中得到最后一个值。当你不知道一个数组有多长时,这真的很有用,所以你不知道用什么数字来访问最后一个值。
通过以下示例尝试 MATLAB 与 Python 的区别:
>> arr = [10, 20, 30]; >> arr(end) ans = 30在这段代码中,您将创建一个包含三个数字的数组,
10、20和30。然后显示索引为end的最后一个元素的值,即30。在 Python 中,可以使用索引
-1来检索序列中的最后一个值:
In [1]: arr = [10, 20, 30]
In [2]: arr[-1]
Out[2]: 30
在这段代码中,您将在输入行 1 上定义一个包含三个元素的 Python 列表。在输入行 2 上,您正在显示列表的最后一个元素的值,它的索引为-1,值为 30。
事实上,通过使用负数作为索引值,您可以反向遍历序列:
In [3]: arr[-2] Out[3]: 20 In [4]: arr[-3] Out[4]: 10在这段代码中,您将从列表中检索倒数第二个和倒数第三个元素,它们的值分别为
20和10。在 Python 中用
**做取幂运算在 MATLAB 中,当你想计算一个数的幂时,你可以使用插入符 (
^)。脱字符操作符是一个接受两个数字的二元操作符。其他二元运算符包括加法(+)、减法(-)、乘法(*)和除法(/)等等。插入符号左边的数字是基数,右边的数字是指数。通过下面的例子尝试一下 MATLAB 和 Python 的区别:
>> 10^2 ans =
100
在这段代码中,您使用脱字符号将 10 的 2 次方乘方,得到的结果是 100。
在 Python 中,当您想要对一个数字进行幂运算时,可以使用两个星号(**):
In [1]: 10 ** 2 Out[1]: 100在这段代码中,您使用两个星号将 10 的 2 次方提升到 100。请注意,在星号两边包含空格没有任何影响。在 Python 中,典型的风格是在二元运算符的两边都有空格。
用 Python 中的
len()找到一个序列的长度在 MATLAB 中,可以用
length()得到一个数组的长度。该函数将一个数组作为参数,并返回数组中最大维度的大小。通过这个例子,您可以看到这个函数的基本原理:
>> length([10, 20, 30]) ans =
3
>> length("a string") ans =
1
在这段代码中,在第一个输入行中,您将找到一个包含 3 个元素的数组的长度。不出所料,length()返回的答案是 3。在第二个输入行,您会发现包含一个元素的字符串数组的长度。请注意,MATLAB 隐式创建了一个字符串数组,即使您没有使用方括号来表示它是一个数组。
在 Python 中,可以用len()得到一个序列的长度:
In [1]: len([10, 20, 30]) Out[1]: 3 In [2]: len("a string") Out[2]: 8在这段代码中,在第 1 行输入中,您会发现一个包含 3 个元素的列表的长度。正如所料,
len()返回的长度为 3。在第 2 行输入中,您将找到一个字符串的长度作为输入。在 Python 中,字符串是序列,len()计算字符串中的字符数。在这种情况下,a string有 8 个字符。在 Python 中,控制台输出显示为
print()在 MATLAB 中,可以使用
disp()、fprintf()和sprintf()将变量值和其他输出打印到控制台。在 Python 中,print()的功能与disp()相似。与disp()不同,print()可以将其输出发送到类似于fprintf()的文件中。Python 的
print()将显示传递给它的任意数量的参数,在输出中用空格分隔它们。这与 MATLAB 中的disp()不同,它只接受一个参数,尽管该参数可以是一个有多个值的数组。下面的例子展示了 Python 的print()如何接受任意数量的参数,并且在输出中每个参数由一个空格分隔:
In [1]: val_1 = 10
In [2]: val_2 = 20
In [3]: str_1 = "any number of arguments"
In [4]: print(val_1, val_2, str_1)
10 20 any number of arguments
在这段代码中,输入行 1、2、3 定义了val_1、val_2和str_1,其中val_1和val_1是整数,str_1是一串文本。在输入行 4 上,使用print()打印三个变量。这一行下面的输出三个变量的值显示在控制台输出中,用空格分隔。
您可以通过使用sep关键字参数来控制print()参数之间的输出中使用的分隔符:
In [5]: print(val_1, val_2, str_1, sep="; ") 10; 20; any number of arguments在这段代码中,您打印了同样的三个变量,但是将分隔符设置为分号后跟一个空格。此分隔符打印在第一个和第二个以及第二个和第三个参数之间,但不在第三个参数之后。要控制在最后一个值之后打印的字符,您可以使用
end关键字参数到print():
In [6]: print(val_1, val_2, str_1, sep="; ", end=";")
10; 20; any number of arguments;
在这段代码中,您将end关键字参数添加到了print(),设置它在最后一个值后打印一个分号。这显示在输入下方的第行输出中。
和 MATLAB 的disp()一样,print()不能直接控制变量的输出格式,要靠你来做格式化。如果你想要更多的控制输出的格式,你应该使用 f 弦或者 str.format() 。在这些字符串中,您可以使用与 MATLAB 中的fprintf()非常相似的格式样式代码来格式化数字:
In [7]: print(f"The value of val_1 = {val_1:8.3f}") The value of val_1 = 10.000 In [8]: # The following line will only work in Python 3.8 In [9]: print(f"The value of {val_1=} and {val_2=}") The value of val_1=10, and val_2=20在这段代码中,输入行 7 包含一个 f 字符串,由开始字符串的
f指示。这意味着 Python 将替换它在字符串中遇到的{}或花括号之间的任何变量的值。你可以看到,在输出中,Python 用一个浮点数代替了{val_1:8.3f},输出中有 8 列,精度为 3 位数。输入行 9 展示了 Python 3.8 中的一个新特性。如果变量名后面紧跟着一个大括号内的等号,变量名和值将被自动打印出来。
你可以通过查看Python 打印的终极指南来深入了解 Python 的
print()。你可能会看到这些,但是你可以在需要的时候学习它们
在这一节中,您将找到一些您可能会在野外看到的代码示例,但是如果您愿意,您可以等一会儿来理解它们。这些例子使用了 Python 中的一些中间特性,但仍然是 Python 工作方式的核心。就像上一节一样,您将看到 MATLAB 与 Python 语法差异的比较。
Python 中的函数定义以
def和return值开始在 MATLAB 中,你可以通过在行首放置关键字
function来定义一个函数。其后是任何输出变量的名称、等号(=)符号,然后是函数的名称和括号中的任何输入参数。在函数中,您必须将您在定义行中指定的任何变量赋值为输出。下面是一个简单的 MATLAB 函数示例:1function [total] = addition(num_1,num_2) 2total = num_1 + num_2; 3end在这段代码中,您可以在第 1 行看到
function的定义。这个函数只有一个输出变量,称为total。这个函数的名字是addition,它有两个参数,在函数体中分别被命名为num_1和num_2。第 2 行是函数的实现。total的值被设置为等于num_1和num_2的和。函数的最后一行是end关键字,告诉 MATLAB 解释器函数的定义已经完成。要在 MATLAB 中使用这个函数,应该将它保存在一个名为
addition.m的文件中,与函数的名称相匹配。或者,如果函数定义是文件中的最后一项,并且文件是名为addition.m的而不是,那么它可以和其他命令一起放在文件中。然后,您可以通过在 MATLAB 控制台中键入以下代码来运行该函数:
>> var_1 = 20; >> var_2 = 10; >> sum_of_vars = addition(var_1,var_2) sum_of_vars =
30
在这段代码中,您定义了两个名为var_1和var_2的变量,分别保存值 20 和 10。然后,您创建了第三个名为sum_of_vars的变量,它存储来自addition()的输出。检查一下变量浏览器,你会看到sum_of_vars的值是 30,和预期的一样。注意名称sum_of_vars不必与函数定义中使用的输出变量名称相同,即total。
MATLAB 不需要函数来提供输出值。在这种情况下,您可以从函数定义中删除输出变量和等号。修改您的addition.m文件,使代码看起来像这样:
1function addition(num_1,num_2) 2total = num_1 + num_2; 3end
这段代码与之前代码的唯一不同之处是您删除了第 1 行的[total] =,其他行完全相同。现在,如果您尝试将调用此函数的结果赋给一个变量,MATLAB 将在控制台中生成一个错误:
>> var_1 = 20; >> var_2 = 10; >> sum_of_vars = addition(var_1,var_2); Error using addition Too many output arguments.在这段代码中,您定义了与之前相同的两个变量
var_1和var_2,并以与之前相同的方式调用了addition()。然而,由于addition()不再指定输出变量,MATLAB 生成一个错误消息,指出输出参数太多。点击单词addition将打开函数的定义,供您编辑或查看源代码以修复问题。在 Python 中,
def关键字启动一个函数定义。def关键字后面必须跟函数名和括号内的函数参数,类似于 MATLAB。带有def的行必须以冒号(:)结束。从下一行开始,应该作为函数的一部分执行的代码必须缩进一级。在 Python 中,当一行代码开始于与第一行的
def关键字相同的缩进级别时,函数定义结束。如果您的函数向调用者返回一些输出,Python 不要求您为输出变量指定名称。相反,您使用
return语句来发送函数的输出值。Python 中一个与第一个带有输出变量的
addition()示例等价的函数如下所示:1def addition(num_1, num_2): 2 total = num_1 + num_2 3 return total在这段代码中,您会在第 1 行看到
def关键字,后跟函数名和两个参数num_1和num_2。在第 2 行你可以看到创建了一个新变量total来存储num_1和num_2的和,在第 3 行total的值被返回到这个函数被调用的地方。注意,第 2 行和第 3 行缩进了 4 个空格,因为它们构成了函数体。存储
num_1和num_2之和的变量可以有任何名字,不一定要叫total。事实上,你根本不需要在那里创建一个变量。您可以通过删除total并简单地返回num_1 + num_2的值来简化之前的函数定义:1def addition(num_1, num_2): 2 return num_1 + num_1这段代码中的第 1 行和以前一样,您只修改了第 2 行,删除了第 3 行。第 2 行现在计算
num_1 + num_2的值,并将该值返回给函数的调用者。第 2 行缩进 4 个空格,因为它构成了函数体。要在 Python 中使用这个函数,不需要用特殊的名称将其保存在文件中。您可以将函数定义放在任何 Python 文件中的任何位置。没有限制函数定义必须在最后。事实上,您甚至可以直接从控制台定义函数,这在 MATLAB 中是不可能的。
打开 Spyder,在控制台窗格中键入:
In [1]: def addition(num_1, num_2):
在这一行代码中,您正在创建函数定义。在 Spyder/IPython 控制台中,一旦开始一个函数定义并按下 Enter ,该行的开始变成三个点,光标自动缩进。现在,您可以键入函数定义的剩余部分。您需要按两次 Enter 来完成定义:
In [1]: def addition(num_1, num_2): ...: return num_1 + num_2 ...:在这段代码中,函数的定义在第一行,函数体在第二行。控制台自动在这些行的开头添加
...:,表示这些是应用于函数定义的延续行。一旦您完成了定义,您也可以从控制台执行该功能。您应该键入以下代码:
In [2]: var_1 = 20
In [3]: var_2 = 10
In [4]: sum_of_vars = addition(var_1, var_2)
In [5]: sum_of_vars
Out[5]: 30
在这段代码中,首先创建两个变量var_1和var_2,它们存储要相加的值。然后,在输入行 4 上,将sum_of_vars赋给从addition()返回的结果。在第 5 行输入中,您将sum_of_vars的值输出到控制台屏幕。这将显示 30,即 10 和 20 之和。
在 Python 中,如果你不显式地放置一个return语句,你的函数将隐式地返回特殊值None。您应该更改您的 Python 对addition()的定义,看看这是如何工作的。在 Spyder/IPython 控制台中,键入以下内容:
In [6]: def addition(num_1, num_2): ...: total = num_1 + num_2 ...:在这段代码中,输入行 6 上有相同的
def行。您更改了第一个延续行,将加法的结果赋给total,而不是返回。现在,您应该看到当我们执行这个修改后的函数时会发生什么:
In [7]: sum_of_vars = addition(var_1, var_2)
In [8]: sum_of_vars
In [9]:
在这段代码中,在第 7 行输入中,你将sum_of_vars指定为addition()的返回值。然后,在第 8 行输入,你在控制台屏幕上显示sum_of_vars的值,就像之前一样。但是这一次,没有输出!默认情况下,Python 在输出一个值为None的变量时不打印任何东西。你可以通过查看变量浏览器来仔细检查sum_of_vars变量的值。在类型栏,应该会列出NoneType,告诉你sum_of_vars是特殊的None值。
Python 中的函数接受位置和关键字参数
在 MATLAB 中,函数的输入参数在第一行的function定义中指定。在 MATLAB 中调用函数时,可以传递从 0 到指定数目的参数。在函数体中,您可以检查调用者实际传递来执行不同代码的输入参数的数量。当您希望不同的参数具有不同的含义时,这很有用,如下例所示:
1function [result] = addOrSubtract(num_1,num_2,subtract) 2% ADDORSUBTRACT Add or subtract two value 3% RESULT = addOrSubtract(NUM_1,NUM_2) adds NUM_1 and NUM_2 together 4% 5% RESULT = addOrSubtract(NUM_1,NUM_2,true) subtracts NUM_2 from NUM_1 6
7 switch nargin 8 case 2 9 result = num_1 + num_2; 10 case 3 11 result = num_1 - num_2; 12 otherwise 13 result = 0; 14 end 15end
在这段代码中,您定义了一个具有三个可能的输入参数的函数。在第 7 行,您正在启动一个switch / case块,它通过使用特殊变量nargin 来确定有多少输入参数被传递给函数。该变量存储调用者传递给函数的实际参数数量。
在上面的代码中,您定义了三种情况:
- 如果输入参数的数量是 2,那么您将把
num_1和num_2加在一起。 - 如果输入参数的数量是 3,则从
num_1中减去num_2。 - 如果传递的参数少于 2 个,输出将是
0。
如果传递的参数超过 3 个,MATLAB 将引发错误。
现在您应该试验一下这个函数。将上面的代码保存到一个名为addOrSubtract.m的文件中,然后在 MATLAB 控制台上,尝试带有两个输入参数的版本:
>> addOrSubtract(10,20) ans = 30在这段代码中,您用两个参数调用
addOrSubtract(),因此参数被加在一起,结果得到一个答案30。接下来,尝试用三个参数调用addOrSubtract():
>> addOrSubtract(10,20,true) ans =
-10
在这段代码中,您使用了三个输入参数,并发现第二个参数从第一个参数中减去,得到了答案-10。第三,尝试用一个参数调用addOrSubtract():
>> addOrSubtract(10) ans = 0在这段代码中,您使用了一个输入参数,发现答案是 0,因为 MATLAB 只找到了函数的一个参数,并且使用了
otherwise的情况。最后,尝试用四个参数调用addOrSubtract():
>> addOrSubtract(10,20,true,30) Error using addOrSubtract
Too many input arguments.
在这段代码中,您发现 MATLAB 引发了一个错误,因为传递的输入参数比在function行中定义的多。
从 MATLAB 的这个例子中有四个关键点:
- 函数定义中只有一种自变量。
- 代码中参数的含义由其在函数定义中的位置决定。
- 可以传递给函数的最大参数数量由函数定义中指定的参数数量决定。
- 调用者可以传递最多任意数量的参数。
在 Python 中,定义函数时可以指定两种参数。这些是必需的和可选的参数。这两者的主要区别在于,调用函数时必须传递必需的参数,而可选参数在函数定义中被赋予默认值。
在下一个示例中,您可以看到这两种风格之间的差异:
1def add_or_subtract(num_1, num_2, subtract=False):
2 """Add or subtract two numbers, depending on the value of subtract."""
3 if subtract:
4 return num_1 - num_2
5 else:
6 return num_1 + num_2
在这段代码中,您定义了一个名为add_or_subtract()的函数,它有三个参数:num_1、num_2和subtract。在函数定义中,您可以看到两种类型的参数。前两个参数num_1和num_2是必需的参数。
第三个参数subtract通过在函数定义中的等号后面指定一个值,被赋予一个默认值。这意味着当函数被调用时,为subtract传递一个值是可选的。如果没有传递值,将使用函数定义行中定义的默认值。在这种情况下,默认值是False。
在函数体中,您正在用if语句测试subtract的值,以确定应该执行加法还是减法。如果subtract是True,那么num_1会减去num_2。否则,如果subtract是False,那么num_1就会加到num_2上。无论哪种情况,算术运算的结果都将返回给调用者。
除了当定义一个函数时可以使用的两种类型的参数之外,当调用一个函数时,还有两种类型的参数可以指定。这些被称为位置和 关键字 自变量。您可以在下面的示例中看到这两者之间的区别。首先,尝试只向函数传递两个参数:
In [1]: add_or_subtract(10, 20) Out[1]: 30在这段代码中,您只向
add_or_subtract()、10和20传递了两个参数。在这种情况下,您将这些值作为位置参数传递,参数的含义由它们在函数调用中的位置定义。由于只传递了两个必需的参数,
subtract将采用默认值False。因此,10 和 20 将被加在一起,这可以在输出行上看到。接下来,尝试为subtract传递一个值:
In [2]: add_or_subtract(10, 20, False)
Out[2]: 30
In [3]: add_or_subtract(10, 20, True)
Out[3]: -10
在这段代码中,您向add_or_subtract()传递了三个参数,subtract参数有两个不同的值。首先,您在输入行 2 通过了False。结果是 10 和 20 相加。然后,你在输入行 3 上通过了True,结果是 10 和 20 的差,或者说-10。
在这些例子中,您看到了在 Python 中为函数的参数定义默认值是可能的。这意味着当您调用该函数时,任何带有默认值的参数都是可选的,不必传递。如果没有为任何默认参数传递值,将使用默认值。然而,您必须为每个没有默认值的参数传递一个值。否则,Python 将引发一个错误:
In [4]: add_or_subtract(10) Traceback (most recent call last): File "<ipython-input-4-f9d1f2ae4494>", line 1, in <module> add_or_subtract(10) TypeError: add_or_subtract() missing 1 required positional argument: 'num_2'在这段代码中,您只向
add_or_subtract()传递了两个必需参数中的一个,因此 Python 引发了一个TypeError。错误消息告诉您没有为num_2传递值,因为它没有默认值。在最后三个例子中,您使用了位置参数,因此哪个参数被分配给函数中的变量取决于它们被传递的顺序。在 Python 中还有另一种向函数传递参数的方法,叫做关键字参数。若要使用关键字参数,请在函数调用中指定参数的名称:
In [5]: add_or_subtract(num_1=10, num_2=20, subtract=True)
Out[5]: -10
在这段代码中,您对add_or_subtract()的三个参数都使用了关键字参数。关键字参数是通过说明参数名、等号和参数值来指定的。关键字参数的一个很大的优点是它们使你的代码更加清晰。(正如 Python 的禅所说,显式比隐式好。)但是,它们会使代码变得更长,所以何时使用关键字参数取决于您的判断。
关键字参数的另一个好处是它们可以以任何顺序指定:
In [6]: add_or_subtract(subtract=True, num_2=20, num_1=10) Out[6]: -10在这段代码中,您已经将
add_or_subtract()的三个参数指定为关键字参数,但是顺序与函数定义中的不同。尽管如此,Python 将正确的变量连接在一起,因为它们被指定为关键字,而不是位置参数。也可以在同一个函数调用中混合位置参数和关键字参数。如果位置参数和关键字参数混合在一起,位置参数必须在任何关键字参数之前首先指定:
In [7]: add_or_subtract(10, 20, subtract=True)
Out[7]: -10
在这段代码中,您已经使用位置参数指定了num_1和num_2的值,并使用关键字参数指定了subtract的值。这可能是使用关键字参数最常见的情况,因为它在显式和简洁之间提供了一个很好的平衡。
最后,使用关键字参数和默认值还有最后一个好处。Spyder 和其他 ide 提供了函数定义的内省。这将告诉您所有已定义函数参数的名称,哪些有默认参数,以及默认参数的值。这可以节省您的时间,并使您的代码更容易和更快地阅读。
Python 中没有switch / case块
在 MATLAB 中,你可以使用 switch / case块来执行代码,方法是检查一个变量的值是否与一些常量相等。当您知道想要处理一些离散的情况时,这种类型的语法非常有用。用这个例子试一试switch / case积木:
num = 10; switch num case 10 disp("num is 10") case 20 disp("num is 20") otherwise disp("num is neither 10 nor 20") end
在这段代码中,首先定义num并将其设置为 10,然后在接下来的代码行中测试num的值。这段代码将导致控制台上显示输出num is 10,因为num等于 10。
这个语法是 MATLAB 和 Python 的有趣对比,因为 Python 没有类似的语法。相反,你应该使用一个if / elif / else块:
num = 10
if num == 10:
print("num is 10")
elif num == 20:
print("num is 20")
else:
print("num is neither 10 nor 20")
在这段代码中,首先定义num,并将其设置为等于10。在接下来的几行中,您将编写一个if / elif / else块来检查您感兴趣的不同值。
名称空间是 Python 中一个非常棒的想法
在 MATLAB 中,所有的函数都在一个作用域中。MATLAB 有一个定义的搜索顺序,用于在当前范围内查找函数。如果你为 MATLAB 已经包含的东西定义你自己的函数,你可能会得到意想不到的行为。
正如您在 Python 的禅中看到的那样,名称空间是一个非常棒的想法。名称空间是一种为函数、类和变量的名字提供不同作用域的方式。这意味着你必须告诉 Python 哪个库有你想要使用的函数。这是一件好事,尤其是在多个库提供相同功能的情况下。
例如,内置的math库提供了一个平方根函数,更高级的 NumPy 库也是如此。如果没有名称空间,就很难告诉 Python 您想要使用哪个平方根函数。
要告诉 Python 函数的位置,首先必须import库,这将为该库的代码创建名称空间。然后,当您想要使用库中的函数时,您可以告诉 Python 在哪个名称空间中查找:
In [1]: import math In [2]: math.sqrt(4) Out[2]: 2.0在这段代码中,在输入行 1 上,您导入了 Python 内置的
math库。然后,输入行 2 使用math库中的平方根函数计算 4 的平方根。math.sqrt()一行应该读作“从math内部,找到sqrt()”默认情况下,
import关键字搜索命名的库并将名称空间绑定到与库相同的名称。你可以在 Python 模块和包中阅读更多关于 Python 如何搜索库的内容——简介。您还可以告诉 Python 应该为一个库使用什么名称。例如,用下面的代码将
numpy缩短为np是很常见的:
In [3]: import numpy as np
In [4]: np.sqrt(4)
Out[4]: 2.0
在这段代码中,输入行 3 导入 NumPy 并告诉 Python 将库放入np名称空间。然后,每当您想要使用 NumPy 中的一个函数时,您可以使用np缩写来查找该函数。在第 4 行输入中,您再次计算 4 的平方根,但是这次使用了np.sqrt()。np.sqrt()应该读作“从 NumPy 内部,找到sqrt()”
使用名称空间时,有两个主要的注意事项需要小心:
-
您不应该使用与 Python 内置函数相同的名称来命名变量。您可以在 Python 文档中找到这些函数的完整列表。最常见的也是内置函数,不应该使用的变量名有
dir、id、input、list、max、min、sum、str、type、vars。 -
您不应该将 Python 文件(扩展名为
.py的文件)命名为与您已安装的库同名。换句话说,您不应该创建名为math.py的 Python 文件。这是因为 Python 在尝试导入库时会首先搜索当前的工作目录。如果你有一个名为math.py的文件,这个文件会在内置的math库之前被找到,你可能会看到一个AttributeError。
最近未赋值的结果在 Python 中以_的形式提供
MATLAB 控制台使用 ans 来存储最近一次计算的结果,如果该结果没有被赋给变量的话。当你忘记把计算结果赋给一个变量,或者你只想把几个简单的计算串在一起时,这真的很有用。要了解 MATLAB 与 Python 之间的差异,请尝试以下示例:
>> sum([10, 20, 30]) ans = 60 >> ans + 10 ans = 70在这段代码中,您使用
sum()来计算数组的总和。由于左边没有变量名的等号,MATLAB 将sum()的输出分配给ans。然后,您可以在进一步的计算中使用该变量,就像您在这里所做的那样,将最后一个结果加 10。注意,这只在 MATLAB 控制台中有效,在脚本文件中无效。在 Python 控制台(包括 IPython/Spyder 控制台)中,最近计算的输出存储在
_(下划线字符)中。尝试以下代码:
In [1]: sum([10, 20, 30])
Out[1]: 60
In [2]: _ + 10
Out[2]: 70
在这段代码中,您使用sum()来计算列表的总和。由于变量名的左边没有等号,Python 将来自sum()的输出赋值给下划线(_),并将其打印在输出行上。然后,您可以在进一步的计算中使用该变量,就像您在这里所做的那样,将最后一个结果加 10。请注意,这只适用于 Python 控制台,不适用于脚本文件。
在 IPython 控制台中,启用了一个附加功能。您可以在下划线后附加一个数字来检索前面任何一行的结果。尝试以下代码:
In [3]: _1 + 20 Out[3]: 80 In [4]: _2 + 20 Out[4]: 90在输入行 3 的代码中,您使用
_1来表示输出行 1 的值,即sum()行。在结果(60)上加上 20,结果是 80。在输入行 4 上,你在输出行 2 的值上加 20,用_2访问,所以结果是 90。注意,Spyder 变量浏览器默认不显示这个变量,而
ans显示在 MATLAB 变量浏览器中。在的几个章节中,你会看到为什么下划线在默认情况下不显示,以及你是如何看到它的。匿名函数是用 Python 中的
lambda关键字创建的MATLAB 使用 at 符号(
@)来表示后面是一个匿名函数的定义。匿名函数是没有在程序文件中定义的函数,并且不使用function关键字。程序文件是文件名以.m结尾的 MATLAB 文件。匿名函数仅限于单个语句,因此它们适用于简单的计算。您可以通过下面的例子来尝试一下 MATLAB 和 Python 中匿名函数的区别:
>> sayHello = @(x) fprintf("Hello, %s\n",x); >> sayHello("Eleanor") Hello, Eleanor
在这段代码中,第一个输入行用一个输入参数x定义了匿名函数。接下来是函数体,它使用fprintf()将输入格式化成一个字符串。该功能分配给sayHello。在第二个输入行上,sayHello()被执行并作为值传递给"Eleanor"。结果控制台上打印出了字符串Hello, Eleanor。
当您需要将一个函数传递给另一个函数时,最常使用匿名函数。在这些情况下,通常没有必要将函数定义赋给变量:
>> integral(@(x) x.^2,0,9) ans = 243在这段代码中,第一个输入行执行
integral(),这个函数计算给定函数的定积分。integral()的第一个参数必须是一个函数,所以这是使用匿名函数的最佳场合。在这里,无论输入值是多少,您的匿名函数都会进行平方运算。integral()的另外两个参数是积分的极限,因此从 0 到 9 积分x.^2的结果是 243。Python 使用
lambda关键字来定义匿名函数。除了这种语法差异,匿名函数在 Python 中的工作方式与在 MATLAB 中相同:
In [1]: say_hello = lambda x: print(f"Hello, {x:s}")
In [2]: say_hello("Eleanor")
Hello, Eleanor
在这段代码中,输入行 1 用一个参数x定义了lambda函数。在函数定义中使用print()来显示带有输入参数值的 f 字符串。该功能随后被存储在say_hello()中。输入线 2 用输入字符串"Eleanor"评估say_hello()并产生Hello, Eleanor输出。
在 Python 中,名为 PEP 8 的官方风格指南明确指出将lambda表达式赋给变量名,正如你在上一个例子中看到的。如果您想给一个函数起一个名字来引用它几次,那么首选是使用def语法并定义一个完整的函数,即使是一行函数。
然而,lambda函数在作为参数传递给另一个函数时仍然有用:
In [3]: from scipy import integrate In [4]: integrate.quad(lambda x: x ** 2, 0, 9) Out[4]: (243.0, 2.6978419498391304e-12)在这段代码中,输入行 3 导入了
scipy.integrate库,并将其存储在integrate名称空间中。在第 4 行输入中,使用scipy.integrate中的quad()计算积分,非常类似于 MATLAB 中的integral()。quad()的第一个参数是要积分的函数,您使用一个lambda函数来指定x ** 2应该被积分。quad()的第二个和第三个参数指定应该从 0 到 9 进行积分。您可以看到输出行 4 上的结果有两个值,
243.0和2.6978419498391304e-12。第一个值是积分的结果,等于 MATLAB 的结果。第二个值是结果中绝对误差的估计值。这么小的误差大约是用于存储结果的数字的精度,所以答案是尽可能准确的。你可以在如何使用 Python lambda 函数中阅读更多关于
lambda的内容,或者观看如何使用 Python Lambda 函数课程中的视频。你只在特殊情况下需要这些
在这一节中,示例是更高级的概念,随着您在 Python 开发中变得更高级,您将需要这些概念。与其他部分相比,这里的一些示例涉及开发应用程序或更高级别的代码。当您在其他代码中看到这些概念时,您可以在感觉舒适的时候钻研它们。
Python 中的类定义以
class开始MATLAB 有两种方法来定义一个类。用第一种方法,你可以把所有的类定义放在一个单独的文件中,以类名作为文件名。然后在文件中,你可以使用
classdef关键字来定义属于这个类的属性和方法。使用第二种方法,您可以创建一个以
@开头的文件夹,并与类同名。在该文件夹中,您可以创建一个与类同名的文件。该文件中的函数定义将被用作类初始化器,它应该调用class()来实例化该类。该类的方法可以在同一文件夹的其他文件中定义,其中每个文件的名称必须与方法的名称相同。Python 只有一种定义类的方法,使用
class关键字。因为 Python 使用缩进来查找类定义的结尾,所以整个定义必须包含在一个文件中:class MyClass: # The rest of the class definition goes here在这段代码中,第一行定义了类的名称。它以关键字
class开头,后面是类名和一个冒号。在这一行下面,作为类定义一部分的所有代码(方法和属性)都必须缩进。一旦一行代码与class中的c在同一列开始,类定义就结束了。这段代码中的第二行是一个注释,注意类定义的其余部分将跟在
class行之后。和所有面向对象的代码一样,Python 类可以从超类继承。给定类的超类可以作为类定义中的参数给出,如下所示:
class MyClass(MySuperClass): # The rest of the class definition goes here在这段代码中,唯一的变化是超类的名称列在冒号前的圆括号中。
Python 中没有私有属性或方法
MATLAB 允许将类属性和方法设置为四个
Access选项中的一个:
public:对属性或方法的访问不受限制。protected:只能在这个类或子类中访问属性或方法。private:只允许在这个类中访问属性或方法。meta.class或{meta.class}:只允许在列出的一个或多个类中访问属性或方法。这允许你明确地控制属性或类方法的访问方式。
在 Python 中,无法将类或实例属性或方法设置为 protected 或 private。所有的类和类实例都可以在运行时改变它们的属性和方法。Python 的惯例是以下划线(
_)开头的属性和方法应该是私有的,或者至少是非公共的。然而,语言中的任何检查都不会强制执行这种约定,并且用户可以在运行时修改所有属性和方法。正如您在关于在控制台中使用下划线检索值的章节中看到的,默认情况下,下划线在 Spyder 变量浏览器中是不可见的。这是因为 Spyder 和其他工具尊重下划线表示某个东西应该是非公共的这一约定。但是,如果您点击窗格右上角的齿轮图标,并取消选中排除私有变量项,下划线可以显示在 Spyder 变量浏览器中。这也将显示其他非公共变量。
Python 使用几个以双下划线(
__)开头的特殊方法,称为 dunder 方法,来实现类的特定行为。最常用的 dunder 方法是__init__(),它是类的初始化器或者构造器。你可以在用 dunder(神奇的,特殊的)方法丰富你的 Python 类中读到更多关于 Dunder 方法的内容。如果你想了解更多关于 Python 的类的信息,你可以阅读 Python vs Java 中的面向对象编程。尽管那篇文章是关于 Java 的,但就属性和方法的本质而言,Java 类似于 MATLAB OOP 范例。
在 Python 中,一个类将自己称为
self当一个类想要引用自己的当前实例时,MATLAB 使用名称
obj。obj应该是传递给一个普通方法的第一个参数。MATLAB 还定义了不引用类实例的静态方法。当一个类想要引用自身的当前实例时,Python 使用名称
self,但这实际上只是一个约定。您可以将实例方法的第一个参数命名为,但self是最常见的约定。Python 还定义了不接受类实例参数的静态方法和接受类对象参数而不是实例参数的类方法。你可以在 Python 的实例、类和静态方法揭秘中阅读更多关于实例、静态和类方法的内容。Python 中有一种字符串类型
在 MATLAB 中,当您使用双引号(
")时,字符串存储在字符串数组中,如果您使用单引号('),则存储在字符数组中。如果在数组赋值中同时使用单引号和双引号,数组将被提升为字符串数组。在字符数组中,字符串中的每个字符占据数组中的一列。对于多维字符数组,数组的每一行必须有相同数量的字符,也就是说,相同数量的列。如下例所示:
1>> charArray = ['Real'; 'Python']; 2Dimensions of arrays being concatenated are not consistent.
3
4>> charArray = ['MATLAB'; 'Python']; 5>> size(charArray) 6
7ans =
8
9 2 6
在这个例子中,第 1 行显示了使用单引号定义一个 2 行字符数组的尝试。但是Real中的字符数和Python中的不一样,所以 MATLAB 显示尺寸不一致的错误信息。
在第 4 行,您成功地创建了一个字符数组,在第三个输入行,您正在检查数组的大小。输出显示有 2 行和 6 列,因为MATLAB和Python的长度都是 6 个字符。
这不是字符串数组的情况。在字符串数组中,每个字符串占据数组中的一列,多维数组中的每一行必须有相同数量的字符串,尽管每个字符串可以有不同的长度。如下例所示:
1>> stringArray = ["Real", "Python"; "Real"]; 2Error using vertcat 3Dimensions of arrays being concatenated are not consistent. 4 5>> stringArray = ["Real"; "Python"]; 6>> size(stringArray) 7 8ans = 9 10 2 1在这段代码中,第 1 行显示了使用双引号定义一个 2 行字符串数组的尝试。但是,第一行(2)中的字符串数量与第二行(1)中的字符串数量不匹配,因此 MATLAB 引发了一个错误。
在第 5 行,您成功地创建了一个字符串数组。注意,即使
Real和Python之间的字符数不同,MATLAB 也能够创建字符串数组。在第 6 行,您正在检查字符串数组的大小,如预期的那样,它显示有 2 行 1 列。在 Python 中,只有一种字符串文字类型,叫做
str。您可以使用单引号(')或双引号(")来创建字符串文字,这两种定义没有区别。然而,在 Python 中定义字符串文字时,有一些很好的理由支持双引号,这由黑码格式化库很好地表达了。Python 中还有一种定义字符串的方法,使用三重单引号(
''')或三重双引号(""")。这种创建字符串的方法允许在保留换行符的情况下跨多行定义字符串。你可以在关于注释和文档字符串的部分看到这样的例子。你可以阅读更多关于在 Python 中的基本数据类型中定义字符串和在 Python 中定义字符串和字符数据的内容。
使用 Python 中的 NumPy,可以生成与 MATLAB 中的字符串数组和字符数组类似的数据结构。NumPy 有几种与字符串相关的数据类型,即 dtypes 。在 Python 3 中,数组的默认字符串 dtype 是固定宽度的 Unicode 字符串:
In [1]: import numpy as np
In [2]: arr = np.array(("Real", "Python"))
In [3]: arr
Out[3]: array(['Real', 'Python'], dtype='<U6')
在这段代码中,您将在输入行 1 上导入 NumPy 库,并将其分配给np缩写。在输入行 2 上,您创建了一个带有两个字符串元素Real和Python的 NumPy array,并将数组分配给arr。
在输入行 3 上,您正在显示arr的值。第三行的输出显示arr正在存储一个array,它有两个元素'Real'和'Python',正如预期的那样。注意,尽管您用双引号字符串定义了数组,Python 却用单引号字符串显示它们。记住在 Python 中单引号和双引号没有区别。
输出行 3 还显示了数组中数据的数据类型。对于这个数组,dtype 是<U6。这里的三个字符代表了字符串在内存中的排列方式。T1 表示数组的字节顺序是小端。U表示字符串是 Unicode 类型的。最后,6意味着一个元素的最大长度是 6 个字符。这被选为输入中最长字符串的长度。
注意,字符串Real只有 4 个字符。在 NumPy string dtype 数组中,元素的字符数可以少于最大字符数,这没有问题,但是如果将字符串长度超过最大长度的元素赋值给元素,将会截断输入:
In [4]: arr[0] = "My favorite language is Python" In [5]: arr Out[5]: array(['My fav', 'Python'], dtype='<U6')在这段代码中,您试图用字符串
My favorite language is Python重新分配数组的第一个元素。很明显,这个字符串长于 6 个字符,所以在赋值的时候被截断成只有 6 个,My fav。(空格计为 1 个字符。)如果您想要创建一个可以保存任意长度字符串的数组,那么您应该在创建数组时传递
objectdtype:
In [6]: arr_2 = np.array(("Real", "Python"), dtype=object)
In [7]: arr_2
Out[7]: array(['Real', 'Python'], dtype=object)
在这段代码中,您创建了一个新的数组arr_2,同样包含两个元素,但是这次您将 dtype 指定为object,您通过在控制台上显示输出来确认这一点。现在您应该看到object dtype 如何影响向元素分配长字符串:
In [8]: arr_2[0] = "My favorite language is Python" In [9]: arr_2 Out[9]: array(['My favorite language is Python', 'Python'], dtype=object)在这段代码中,您再次将数组的第一个元素赋值为
My favorite language is Python。从输出行可以看到,该字符串被存储为数组的第一个元素,没有截断,因为 dtype 是object。使用objectdtype 的缺点是它通常比更具体的Udtype 慢得多,因为它必须为每个元素创建一个完整的 Python 对象,而不仅仅是一个 NumPy 优化的 Unicode 对象。MATLAB 的另一个不同之处是数组的形状和大小是如何确定的:
In [10]: arr.shape
Out[10]: (2,)
In [11]: arr_2.shape
Out[11]: (2,)
在这段代码中,我们打印了arr和arr_2的形状。注意它们都有相同的形状,一维数组中的两个元素。这类似于 MATLAB 中的字符串数组,其中每个字符串都算作数组中的一个元素。然而,U dtype 的 NumPy 数组有固定的最大大小,这一事实更像 MATLAB 中的字符数组。在后面的章节中,你会看到更多关于 MATLAB 和 NumPy 计算数组形状的差异。
Python 中的库不会自动重新加载
当执行一个函数或脚本时,MATLAB 将总是使用磁盘上文件的最新副本。因此,当您开发一个脚本时,您可以在控制台中多次运行它,您所做的新更改将会自动生效。
Python 的操作有些不同。记住,当你想从一个文件中访问代码时,你必须把它放到一个名称空间中。当 Python 导入文件或模块时,它只在第一次导入时读取代码。如果您多次导入同一个文件,这会节省大量时间。然而,如果您在工作时在交互式控制台提示符下测试您的代码,Python 将不会在您再次import它时拾取任何更改。
当您开发一个模块时,有几个选项可以让 Python 在导入代码时重新加载代码。如果您使用的是 Spyder IDE,这根本不是问题,因为 Spyder 默认启用了自动用户模块重载特性。
否则,如果您在 Spyder 或 Jupyter 笔记本之外使用 IPython 控制台,您可以使用这些解释器中定义的神奇命令 autoreload :
In [1]: %load_ext autoreload In [2]: %autoreload 2在这段代码中,您将使用
load_extmagic 命令来加载autoreload扩展。在 IPython 和 Jupyter 的笔记本中,以百分号%为前缀的命令是神奇的命令。autoreload扩展定义了在输入行 2 上使用的autoreload魔法函数。您正在将参数2传递给autoreload魔法函数,这意味着每次执行一行代码时,所有模块都应该重新加载。基本数组操作概述
如您所见,Python 在其标准库中没有包含高速数组库。但是,如果您安装了 Anaconda,就很容易获得优秀的 NumPy 库。NumPy 充当 Python 的事实上的数组和矩阵库。
NumPy 有两种类似数组的类型:
numpy.ndarray,又称numpy.arraynumpy.matrix这两种类型的主要区别在于,
ndarray可以是任意数量的维度,而matrix仅限于两个维度。对于ndarray,所有的运算,如加、减、乘、取幂和除,都是按元素进行的。但是对于matrix型来说,类似乘法和取幂的运算都是矩阵运算。当您从 MATLAB 进行转换时,
matrix类型可能看起来更熟悉。就操作语法而言,它提供了您可能习惯于 MATLAB 的类似行为。然而,NumPy 强烈建议使用ndarray型,因为它更灵活,并且matrix最终将被移除。在本节的其余部分,您将了解 MATLAB 和 NumPy 数组之间的主要区别。你可以通过阅读 Look Ma,No For-Loops:Array Programming With NumPy来深入了解如何使用 NumPy 数组。
基本数学运算符在 NumPy 中按元素工作
MATLAB 继承了矩阵脚本语言的传统,假设所有算术运算符都将对数组进行操作。所以 MATLAB 把矩阵或向量的乘法当作矩阵乘法。考虑这个例子:
>> arr_1 = [1,2,3]; >> arr_2 = [4,5,6]; >> arr_1 * arr_2 Error using *
Incorrect dimensions for matrix multiplication. Check that the number of
columns in the first matrix matches the number of rows in the second
matrix. To perform elementwise multiplication, use '.*'.
在这段代码中,您将创建两个 1×3 矩阵,arr_1和arr_2。然后,你试图将它们相乘。对于这些 1xN 阵列,这相当于取点或标量积。然而,只有当左操作数为 1xN,右操作数为 Nx1 时,标量积才起作用,因此 MATLAB 产生一条错误消息,并建议点星运算符(.*)作为元素式乘法的正确语法:
>> arr_1 .* arr_2 ans = 4 10 18在这段代码中,您将执行
arr_1和arr_2的逐元素乘法。这样就把arr_1的第一个元素乘以arr_2(4*1 = 4),第二个乘以第二个(2*5 = 10),第三个乘以第三个(3*6 = 18)。要执行标量积,您可以对
arr_2进行转置,将其转换为 3x1 数组:
>> arr_1 * transpose(arr_2) ans =
32
在这段代码中,您正在执行与arr_1的矩阵乘法和arr_2的转置。请注意,您可以使用transpose()或引用运算符(')来转置arr_2。由于arr_1是 1×3,而transpose(arr_2)是 3×1,这导致标量或点积。
对于 NumPy 数组,类似与星号(*)相乘的运算默认情况下是按元素进行的:
In [1]: import numpy as np In [2]: arr_1 = np.array([1, 2, 3]) In [3]: arr_2 = np.array([4, 5, 6]) In [4]: arr_1 * arr_2 Out[4]: np.array([ 4, 10, 18])在这段代码中,您首先导入 NumPy 包,并将其分配给名称
np。然后创建两个一维数组。注意在 NumPy 中创建数组的语法。以np.array()开头,应该读作“从np内部,找到array()”然后,您必须将一个 Python 列表或元组传递给包含数组元素的数组构造函数。在这种情况下,您传递的是一个 Python 列表,用方括号表示。最后,在输入行 4 上,您将
arr_1和arr_2相乘。请注意,输出行 4 上的结果是另一个包含元素 4、10 和 18 的数组,与 MATLAB 中的逐元素乘法结果相同。如果您想对 NumPy 中的两个数组执行点或标量积,您有两种选择。首选是使用 Python 3.5 中添加的矩阵乘法运算符(
@)。您可能会看到一些较老的代码也使用 NumPy 库中的dot(),并传递两个数组:
In [5]: arr_1 @ arr_2
Out[5]: 32
In [6]: np.dot(arr_1, arr_2)
Out[6]: 32
在这段代码中,输入行 5 使用矩阵乘法运算符来查找arr_1和arr_2的标量积。不出所料,结果是 32。输入行 5 使用dot(),应读作“从np内,找到dot(),通过arr_1和arr_2”你可以看到结果是一样的。
请注意,NumPy 不要求您在执行标量积之前转置arr_2。在下一节中,您将了解到关于这个特性的更多信息。
一维数组是 NumPy 中的向量
正如您在上一节中看到的,MATLAB 坚持在执行矩阵乘法时数组的维数是对齐的,而 NumPy 稍微灵活一些。这是因为 MATLAB 和 NumPy 对一维数组的处理方式不同。
在 MATLAB 中,每个数组总是至少有两个维度,即使只是隐式的。您可以通过检查单个数字的size()来了解这一点:
>> size(1) ans = 1 1这里,你正在寻找整数 1 的大小。您可以看到结果是一个 1 行 1 列的数组。
您可以在 MATLAB 中创建行向量或列向量,并使用转置运算符(
')或transpose()在它们之间切换:
>> arr_1 = [1,2,3]; >> arr_2 = [1;2;3]; >> arr_1' == arr_2 ans =
3×1 logical array
1
1
1
>> arr_2' == arr_1 ans =
1×3 logical array
1 1 1
在这段代码中,您将创建两个向量:arr_1和arr_2。只有一维值的数组称为向量。arr_1是一个行向量,因为元素排列在一行三列中,而arr_2是一个列向量,因为元素排列在三行一列中。在 MATLAB 中,元素放在不同的列中,在赋值时用逗号分隔,元素放在不同的行中,用分号分隔。
然后,您正在检查arr_1与arr_2的转置是否相等,您发现所有的元素都相等,结果是一个逻辑值的列向量。最后,您正在检查arr_2与arr_1的转置是否相等,您发现所有的元素都相等,结果是一个逻辑值的行向量。
你可以看到在 MATLAB 中,即使向量也有两个维度与之相关联:行和列。当转置被执行时,行与列被交换,并且阵列的形状被改变。这意味着 MATLAB 中有两种类型的向量:行向量和列向量。
在 NumPy 中,有三种类型的一维数组或向量。默认值是只有一维的 N 元素向量。这与 MATLAB 中的默认值不同,在 MATLAB 中,每个数组至少有 2 个维度。NumPy 中的这个一维向量没有行和列的含义,因为对于一维结构来说,元素是存储在行中还是存储在列中通常并不重要,重要的是有多少个元素。
您可以在下面的示例中看到创建这种数组的示例。在接下来的几个示例中,括号前后都添加了额外的空格,以阐明语法。这些空格通常不被认为是好的 Python 风格,但在示例中它们有助于您了解发生了什么:
In [1]: import numpy as np In [2]: arr_vec = np.array( [1, 2, 3] ) In [3]: arr_vec.shape Out[3]: (3,)在这段代码中,您将在 NumPy 中创建一个默认的 3 元素向量。在输入行 1 上,您导入 NumPy 并使其在
np下可用。在输入行 2 上,您正在创建数组并将其存储在arr_vec中。您正在将列表[1, 2, 3]传递给array(),这里的列表有 3 个元素,没有一个元素本身是列表。这创建了只有一维的 3 元素数组。您可以通过显示数组的形状来验证这一点,如输入行 3 所示。那一行应该读作“从
arr_vec(一个数组)内,找到shape”数组的shape相当于 MATLAB 中的size()。在本例中,形状是(3,),表示有三个元素,只有一个维度,因为逗号后面没有第二个数字。你也可以在 NumPy 中创建行向量和列向量,类似于 MATLAB 中的行向量和列向量。NumPy 的
array()接受平面列表或嵌套列表作为输入。使用平面列表可以得到一个一维的 N 元素向量。通过使用嵌套列表,您可以创建任意维度的数组。嵌套列表意味着外部列表中包含一个或多个列表。下面是一个嵌套列表的示例:[[1, 2, 3], [4, 5, 6]]在这段代码中,您会看到一个包含 2 个元素的外部列表。外部列表的这两个元素中的每一个都是另一个嵌套的列表,它有三个元素,整数 1-3 和 4-6。在数组方面,你可以把每个内部列表的元素数想象成列数,嵌套列表数就是行数。如果您更改格式,这将更容易看到:
[ [1, 2, 3], [4, 5, 6] ]这段代码仍然是有效的 Python 语法,但是它强调内部列表是数组的一行,并且每个内部列表中的元素数是列数。在这种情况下,我们将有一个 2 行 3 列的数组。我们可以使用这些嵌套列表在 NumPy 数组中创建行向量和列向量:
In [4]: arr_row = np.array( [[1, 2, 3]] )
In [5]: arr_row.shape
Out[5]: (1, 3)
在这段代码中,您将使用嵌套列表创建一个行数组或向量。输入线 4 通过[[1, 2, 3]]到array()。您可以分解此嵌套列表的格式,以查看其外观:
[
[1, 2, 3]
]
如您所见,这个嵌套列表中有一行三列。在第 5 行输入中,显示了这个数组的形状。不出所料,形状是(1, 3),还是一行三列。
最后,您可以通过在输入中包含三个嵌套列表来创建一个列数组:
In [6]: arr_col = np.array( [[1], [2], [3]] ) In [7]: arr_col.shape Out[7]: (3, 1)在这段代码中,输入行 6 将
[[1], [2], [3]]传递给数组构造函数。您可以分解此嵌套列表的格式,以查看其外观:[ [1], [2], [3] ]如您所见,这个嵌套列表中有三行,每行一列。在第 7 行输入中,显示了这个数组的形状。不出所料,形状是
(3, 1),还是三排一列。因为一般的 N 元素向量对行和列没有意义,所以 NumPy 能够以对正在执行的操作有意义的任何方式来塑造向量。您在上一节中已经看到了这一点,NumPy 数组不需要转置来执行标量积,而 MATLAB 数组则需要转置。
尝试转置 N 元素向量不会改变数组的形状。您可以使用数组的
np.transpose()或.T属性进行转置:
In [8]: arr_vec_transp = np.transpose(arr_vec)
In [9]: arr_vec_transp.shape
Out[9]: (3,)
在这段代码中,你取 N 元素向量arr_vec的转置并打印它的形状。请注意,该形状与原始arr_vec的形状相同。
但是,如果使用行向量和列向量,就需要确保维度适合特定的操作。例如,试图取行向量与其自身的标量积将导致错误:
In [10]: arr_row @ arr_row Traceback (most recent call last): File "<ipython-input-10-2b447c0bc8d5>", line 1, in <module> arr_row @ arr_row ValueError: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 1 is different from 3)在这段代码中,试图找到行向量与其自身的标量积会导致一个
ValueError通知您数组的维度没有对齐。使用dot()会给出相同的错误,但消息略有不同:
In [11]: np.dot(arr_row, arr_row)
Traceback (most recent call last):
File "<ipython-input-11-d6e191b317ae>", line 1, in <module>
np.dot(arr_row, arr_row)
ValueError: shapes (1,3) and (1,3) not aligned: 3 (dim 1) != 1 (dim 0)
在这段代码中,您将使用来自np名称空间的dot()来尝试查找两个 1×3 行向量的标量积。由于这个操作是不允许的,NumPy 引发了一个ValueError,类似于矩阵乘法运算符。
相反,您需要转置其中一个参数:
In [12]: arr_row.T Out[12]: array([[1], [2], [3]]) In [13]: sc_prod = arr_row @ arr_row.T In [14]: sc_prod Out[14]: array([[14]])在输入行 12 上,使用 transpose 属性(
.T)将行向量转置为列向量。这显示在相应的输出行中,其中元素被排列以形成用于打印目的的列。然后,取向量与其转置的标量积,产生一个只有一个值 14 的数组。请注意,这是一个 1x1 数组,因此要访问值,需要访问每个维度中的第一个元素:
In [15]: sc_prod.shape
Out[15]: (1, 1)
In [16]: sc_prod[0, 0]
Out[16]: 14
在此代码中,您将验证形状是否为 1x1,然后访问每个维度中位于第 0 个索引处的第一个元素。记住 Python 使用 0 作为第一个索引,而不是 1。
您可以使用嵌套列表来创建任何形状的数组。要创建一个三乘三的数组(二维),只需在三个嵌套列表中各包含三个元素:
In [17]: arr_2d = np.array( [[1, 2, 3], [4, 5, 6], [7, 8, 9]] ) In [18]: arr_2d.shape Out[18]: (3, 3)在这段代码中,您在构造函数中嵌套了三个列表,每个列表包含三个元素。如该形状所示,这将生成一个包含元素 1 到 9 的 3x3 数组。
在 NumPy 中创建数组非常灵活
MATLAB 和 NumPy 都允许您显式指定数组中的特定元素,正如您在上一节中看到的那样。除了直接创建数组之外,MATLAB 和 NumPy 都支持许多其他方法来创建数组,而无需显式指定每个元素。NumPy 项目维护了 MATLAB 和 NumPy 之间的等价函数的详细列表。
许多函数在 MATLAB 和 NumPy 之间的操作是相同的。这包括常用的函数,如
linspace()和logspace()来生成均匀间隔的数据,以及ones()和zeros()来生成分别填充 1 和 0 的给定形状的数组。在 NumPy 中创建数组的完整方法列表在官方文档中列出。就数组创建例程而言,MATLAB 和 NumPy 的一个很大的区别是 MATLAB 支持简单地使用冒号来创建数组,而 NumPy 不支持。相反,NumPy 使用
arange()在指定值之间创建一个数组。在 MATLAB 中,你可以使用一个冒号来创建一个数组规格范围。一般来说,一个规范中最多可以使用两个冒号。语法如下:
start : stop start : step : stop在此语法中,first 方法仅使用一个冒号,并指定开始和停止值。第二个方法包括第二个冒号,其中第一个冒号之前的值是开始,中间的值是步骤,最后一个值是停止。
尝试以下示例来体验这种语法:
>> arr_1 = 1:6 arr_1 =
1 2 3 4 5 6
>> size(arr_1) ans =
1 6
在本例中,您使用带有开始和结束的单个冒号来生成一个值从 1 到 6 的数组。您可以看到,当省略该步骤时,默认值为 1。请注意,MATLAB 在数组中包含了起始值和终止值,数组的长度为 6 个元素。接下来,更改步长值以创建新数组:
>> arr_2 = 1:2:6 arr_2 = 1 3 5在本例中,您将使用两个冒号语法来表示 start、step 和 stop。起始值是 1,步长是 2,停止值是 6,所以 MATLAB 从 1 开始,递增到 3,然后到 5。下一步将超过停止值,所以 MATLAB 不在数组中包含停止值。接下来,更改起始值以创建另一个新数组:
>> arr_3 = 2:2:6 arr_3 =
2 4 6
在本例中,您再次使用两个冒号的方法,但是您将起始值指定为 2 而不是 1。在这种情况下,MATLAB 从 2 开始,递增到 4,递增到 6,然后达到停止值,因此不再继续。请注意,在这种情况下,停止值 6 包含在数组中。
使用 NumPy,您可以使用arange()创建一个具有特定开始、停止和步进值的数组。但是,arange()和 MATLAB 有一个很大的区别,就是结果数组中包含的停止值是而不是。这样做的原因是,对于步长为 1 的默认情况,数组的大小等于stop - start。注意在 MATLAB 中,从 1 到 6 的整数数组的大小是 6,但是 6 - 1 = 5。
使用arange()有三种方式:
import numpy as np
np.arange(stop)
np.arange(start, stop)
np.arange(start, stop, step)
如果你只传递一个参数给arange(),它将被解释为停止值。起始值默认为 0,步长默认为 1。如果您向arange()传递两个参数,它们将被解释为起始值和终止值。最后,您可以将 start、stop 和 step 三者都传递给arange()。
注意,参数的顺序与 MATLAB 不同,在 Python 中是start、stop、step。如果你很难记住这些参数的顺序,记住你可以在 Python 中使用关键字参数来明确每个参数的意思。
你可以用下面的例子来试试arange():
In [1]: import numpy as np In [2]: arr_1 = np.arange(1, 7) In [3]: arr_1 Out[3]: array([1, 2, 3, 4, 5, 6]) In [4]: arr_1.shape Out[4]: (6,)在本例中,您将创建一个包含从 1 到 6 的值的数组。和 MATLAB 中一样,如果省略该步骤,则默认为 1。请注意,您必须传递停止值 7,以便数组在 6 处停止。然而,结果数组的大小是 7 - 1 = 6 个元素长。接下来,您应该看到如何更改步长:
In [5]: arr_2 = np.arange(1, 7, 2)
In [6]: arr_2
Out[6]: array([1, 3, 5])
在这段代码中,您将创建一个包含从 1 到 6 的值的数组,每个元素之间递增 2。步骤是两个,所以 NumPy 从 1 开始,递增到 3,然后到 5。下一步将等于停止值,但是 NumPy 不在数组中包含停止值。请注意,计算数组大小的公式略有不同,因为步长不是 1。
对于步长不为 1 的情况,如果结果为整数值,可以通过(stop - start)/step计算数组的大小。在这种情况下,数组的大小是(7 - 1)/2 = 3 个元素,正如所料。如果(stop - start)/step产生一个浮点数,数组的大小等于下一个最大的整数,如下例所示:
In [7]: arr_3 = np.arange(2, 7, 2) In [8]: arr_3 Out[8]: array([2, 4, 6])在本例中,您将创建一个包含从 2 到 6 的值的数组,每个元素之间递增 2。步骤是两个,所以 NumPy 从 2 开始,递增到 4,然后到 6。下一步将超过停止值,因此 NumPy 在 6 处停止。请注意,数组的大小是(7 - 2)/2 = 2.5,因此下一个最大的整数是 3 个元素,正如所料。
最后,你通常应该在 NumPy 中使用整数参数给
arange(),在 MATLAB 中使用冒号操作符。如果您使用浮点值(带小数的数字),尤其是对于步骤,元素可能不会完全按照您的预期显示。如果要使用浮点数,一般情况下,linspace()是更好的选择。冒号操作符在 NumPy 中非常强大
在 MATLAB 中,冒号运算符用于执行许多有用的任务。如您所见,它可以用于创建数组,也可以用于索引或切片数组。当索引数组时,MATLAB 支持
end关键字将指定的范围扩展到该维度的末尾,正如你前面看到的:
>> arr_1 = 1:2:6; >> arr_1(2:end) ans =
3 5
在这段代码中,您从第二个索引开始索引arr_1,一直到数组的末尾。您也可以指定特定的索引作为停止值:
>> arr_2 = 1:6; >> arr_2(2:4) ans = 2 3 4在这段代码中,您将创建一个包含数字 1 到 6 的数组
arr_2。然后,在切片中将第二个元素指定为起始值,将第四个元素指定为终止值。MATLAB 在索引时也支持双冒号增量语法:
>> arr_2(2:2:end) ans =
2 4 6
在这段代码中,您将对数组进行索引,从第二个元素开始,跳过所有其他元素,直到数组结束。您也可以使用end作为负步长切片的起点:
>> arr_2(end:-1:4) ans = 6 5 4在这段代码中,从最后一个值开始索引
arr_2,递减 1,到第 4 个元素结束。最后,您可以只使用一个空冒号来分割维度中的所有元素:
>> arr_2(:) ans =
1 2 3 4 5 6
在这段代码中,您只使用冒号选择数组的所有第一维。
NumPy 和 Python 通常也使用冒号作为切片语法,但是值的顺序略有不同。在 Python 中,顺序是start : stop : step,而在 MATLAB 中,顺序是start : step : stop,如您之前所见。此外,在 NumPy 中,您可以省略 start 或 stop,它们的缺省值为 0(或第一个元素),最后一个元素为 stop。在 MATLAB 中,如果你想指定 start 和 stop 中的任何一个,你必须指定它们。因此,Python 没有end关键字,因为您可以省略stop来实现相同的行为。
在 NumPy 中尝试以下切片语法示例:
In [1]: import numpy as np In [2]: arr_1 = np.arange(1, 7, 2) In [3]: arr_1[1:] Out[3]: array([3, 5])在这段代码中,您将创建一个包含从 1 到 6 的整数的数组,跳过所有其他数字。然后,从第二个元素(索引 1)开始切割数组,直到数组结束。注意,停止值被省略了,所以它默认为数组中的最后一个元素。
您也可以指定特定元素作为停止值。您在使用
arange()时看到,数组不包括停止值。Python 中的切片语法也是如此,切片将包括所有内容,但不包括停止索引:
In [4]: arr_2 = np.arange(1, 7)
In [5]: arr_2[1:4]
Out[5]: array([2, 3, 4])
在这段代码中,您将创建一个包含从 1 到 6 的整数的数组。然后,从第二个元素(索引 1,值 2)开始对数组进行切片,直到第四个元素(索引 3,值 4)。但是,您将停止索引指定为 4(数组中的第五个元素,值为 5)。Python 包含(stop - 1)索引的原因与arange()不包含停止值的原因相同,因此结果数组的长度等于stop - start。接下来,尝试更改切片的步长:
In [6]: arr_2[1::2] Out[6]: array([2, 4, 6])在这段代码中,从第二个元素(索引 1)开始对数组进行切片,一直到数组的末尾,每隔一个元素进行切片。这会产生一个值为 2、4 和 6 的数组。注意,slice 语法中省略了 stop 值,所以它默认为数组中的最后一个元素。
您还可以在 Python 的切片语法中使用负步长:
In [7]: arr_2[:2:-1]
Out[7]: array([6, 5, 4])
在这段代码中,您没有指定切片的起始索引,而是指定了停止值应该是索引 2,步长应该是-1。由于未指定起始索引,并且步长为负,因此起始值被假定为数组中的最后一个元素(或反转数组中的第一个元素)。对于停止值,索引 2 的值为 3,在它之前的一个索引(在反转数组中)是索引 3,值为 4。
最后,就像在 MATLAB 中一样,空冒号意味着选择该维度中的所有元素:
In [8]: arr_2[:] Out[8]: array([1, 2, 3, 4, 5, 6])数组切片是 NumPy 中数组的视图
在 MATLAB 中,当你访问一个数组的一部分并把它赋给一个变量时,MATLAB 会把这个数组的一部分复制到你的新变量中。这意味着当您向切片赋值时,原始数组不受影响。尝试这个例子来帮助解释 MATLAB 与 Python 的区别:
>> arr_1 = [1,2,3;4,5,6;7,8,9]; >> arr_2 = arr_1(2:end,2:end); arr_2 =
5 6
8 9
>> arr_2(1, 1) = 10 arr_2 =
10 6
8 9
>> arr_1 arr_1 =
1 2 3
4 5 6
7 8 9
在这段代码中,您创建了一个 3x3 数组arr_1,存储从 1 到 9 的值。然后,创建一个 2x2 的原始数组片,从第二个值开始存储到两个维度的末尾,arr_2。在第三个输入行,您将值 10 赋给arr_2中左上角的元素。最后,您再次打印arr_1来验证arr_1中的值没有发生变化。
技术细节 : MATLAB 采用了写时复制内存管理系统,一个数组只有在被修改时才能被复制到新的内存位置。你可以在 Mathworks 博客上的函数和变量的内存管理和内部 Matlab 内存优化中了解更多关于 MATLAB 内存管理的内容。
在 NumPy 中,数组切片是原始数组的视图。这种行为节省了内存和时间,因为数组中的值不必复制到新的位置。但是,这意味着您对数组中的切片所做的更改将会更改原始数组。您应该尝试下面的代码来看看这是如何工作的:
In [1]: import numpy as np In [2]: arr_1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8 ,9]]) In [3]: arr_2 = arr_1[1:, 1:] In [4]: arr_2 Out[4]: array([[5, 6], [8, 9]])在这段代码中,您将创建一个 3x3 数组
arr_1,存储从 1 到 9 的值。然后,创建一个 2x2 的原始数组片,从第二个值开始存储到两个维度的末尾,arr_2。注意 Python 的索引是基于 0 的,所以第二个元素的索引是 1。最后,打印arr_2来验证它是一个 2x2 的数组。现在您应该看到当您更改
arr_2中的一个值时会发生什么。像在 MATLAB 例子中一样,您应该更改arr_2的左上角元素:
In [5]: arr_2[0, 0] = 10
In [6]: arr_2
Out[6]:
array([[10, 6],
[ 8, 9]])
In [7]: arr_1
Out[7]:
array([[ 1, 2, 3],
[ 4, 10, 6],
[ 7, 8, 9]])
在这段代码中,首先将索引(0,0)处的左上角元素赋值为 10。然后您打印arr_2来验证适当的值已经改变。最后,您打印出arr_1,看到数组中间的值从 5 变成了 10!
这就是arr_2是arr_1的视图的含义。因为是视图,arr_2指向与arr_1相同的内存位置,所以更新arr_2也会更新arr_1,因为arr_2和arr_1访问的内存位置中存储的值已经被更新。这也是另一个方向,改变arr_1中的值将更新arr_2中的值:
In [8]: arr_1[-1, -1] = 42 In [9]: arr_1 Out[9]: array([[ 1, 2, 3], [ 4, 10, 6], [ 7, 8, 42]]) In [10]: arr_2 Out[10]: array([[10, 6], [ 8, 42]])在这段代码中,您将
arr_1右下角的元素赋值为 42。请记住,在 Python 中,-1的索引意味着该维度上的最后一个值。然后你打印arr_1来验证右下角的值已经从 9 变成了 42。最后,您正在打印arr_2,您也看到了arr_2,右下角的值从 9 变成了 42。如果你想生成一个数组的副本,可以使用
np.copy()。复制数组会在内存中创建一个新位置来存储副本,因此对复制数组的更改不会影响原始数组:
In [11]: arr_3 = np.copy(arr_2)
In [12]: arr_3[1, 0] = 37
In [13]: arr_3
Out[13]:
array([[10, 6],
[37, 42]])
In [14]: arr_2
Out[14]:
array([[10, 6],
[ 8, 42]])
在这段代码中,您将创建arr_3作为arr_2的副本。然后,将第二行第一列中的元素更改为值 37。然后,您打印arr_3来验证指定的更改已经完成。最后,您将打印arr_2来验证arr_2中没有发生预期的变化。
让你的代码变得 Pythonic 化的技巧和诀窍
像任何其他编程语言一样,由有经验的 Python 开发人员编写的 Python 代码通常具有特定的外观和感觉。这是因为他们能够利用 Python 中的特定习惯用法来与 Python 合作,而不是与 Python 作对。来自其他语言的开发人员经常会在他们的第一个项目中错过是什么使得代码 Pythonic 化的。
在这一节中,您将学习一些技巧和窍门来使您的代码 Python 化并提高您的 Python 技能。这里有比你能学到的更多的技巧和诀窍,所以请随意查看编写更多的 Pythonic 代码。
在 Python 中不应该使用分号来结束行
在 MATLAB 中,用分号;结束一行代码会抑制该行的输出。例如,给一个变量赋值时,如果省略分号,将在赋值后打印变量值。
在 Python 中,不应该用分号结束代码行。这是不必要的,因为不管行是否以分号结束,Python 都不会改变它的行为。因此,您可以省去一次按键,而不必在脚本和库中包含分号。
在 Python 中有一种情况下分号是有用的。当您想要执行几个语句,但不能在输入中包含换行符时,可以用分号分隔语句。这对于从命令提示符或终端执行非常短的脚本非常有用。例如,要查找正在运行的特定 Python 可执行文件,可以键入以下内容:
$ python -c "import sys; print(sys.executable)"
/home/eleanor/anaconda3/bin/python
在这段代码中,您将在python可执行文件中执行 Python 解释器,并传递-c开关。这个开关接受下一个参数,并在解释器中执行它。因为如果您按下 Enter 来插入新的一行,shell 环境就会执行,所以您可以在一行中键入整个脚本。
在这种情况下,您有两个需要用分号分隔的逻辑语句。首先导入内置的sys库,然后打印sys.executable的值。在这个例子中,shell 运行的 Python 解释器来自于/home/eleanor/anaconda3/bin/python文件。
你不应该从 Python 中的模块导入*
在前面的章节中,您已经了解到名称空间是 Python 中一个非常棒的想法。在 MATLAB 中,默认情况下,所有函数都是全局命名空间的一部分,所以每个函数和类名都必须是唯一的。Python 通过使用名称空间并要求您指定函数应该来自哪个模块来解决这个问题。
你会在网上找到建议你写以下内容的教程:
from a_module import *
在这段代码中,您将使用*来指示 Python 应该导入包含在a_module中的所有内容,并将其放入当前范围,而不添加前缀。这稍微方便一些,因为你不再需要给来自a_module的函数和类加上前缀,你可以直接使用它们。然而,这不是一个好的做法,因为您不知道在a_module中定义了什么名称,也不知道它们是否会覆盖您当前范围内的任何现有名称。
技术提示:当你from a_module import *时,Python 会导入在a_module中一个名为__all__的特殊变量中列出的所有名字。但是,如果没有定义该变量,Python 将导入所有在a_module中定义的变量、函数和类。
你应该利用 Python 中不同的数据类型
MATLAB 继承了线性代数和数组语言的传统,将大多数数据类型视为某种类型的数组。这使得处理更高级的数据类型(如structs、containers.Map、单元格数组等等)变得有点棘手。
Python 有几个非常灵活的内置数据类型,可以用来完成许多有用的任务。在本节中,您将了解的主要内容是列表和词典。
列表
Python 列表是可变的值序列。列表可以包含不同种类的数据,这意味着列表的每个元素可以是不同的类型。因为列表是可变的,所以您可以更改列表中任何元素的值,或者在列表中添加或删除值,而无需创建新的列表对象。
由于列表是序列,您可以创建循环来遍历它们。在 Python 中,你不需要像在 MATLAB 中那样,在 for循环中用索引来访问列表中的每个元素:
>> arr_1 = 1:2:6; >> for i = 1:length(arr_1) disp(arr_1(i)) end 1 3 5在这段代码中,您将创建一个数组
arr_1,其中包含从 1 到 6 的整数,每隔一个数字取一个。然后你正在创建一个for循环,循环变量的长度从 1 到arr_1。最后,通过使用循环变量i索引arr_1,在每一步的循环变量中显示arr_1元素的值。在 Python 中,当循环遍历列表时,不应该使用索引。相反,您应该直接循环列表中的项目:
In [1]: lst_1 = [1, "b", 3.0]
In [2]: for item in lst_1:
...: print(item)
...:
1
b
3.0
在这段代码中,在输入行 1 上,首先创建一个包含三个元素的 Python 列表:
- 整数
1 - 字符串
"b" - 浮动
3.0
该列表被分配给lst_1。然后使用一个for循环依次访问列表中的每一项。在每次迭代中,列表中的下一个值被放入您在for行指定的变量item中。然后,在每次迭代中打印出item的值。
请注意,在前面的示例中,您可以在不使用索引的情况下遍历列表中每个元素的值。尽管如此,有时您希望在遍历列表时访问列表中每一项的索引。对于这些情况,Python 提供了 enumerate() 来返回项目的索引和值:
In [3]: for index, item in enumerate(lst_1): ...: print(f"The index is {index} and the item is {item}") ...: The index is 0 and the item is 1 The index is 1 and the item is b The index is 2 and the item is 3.0在这段代码中,您再次循环遍历
lst_1,但是这一次,您使用enumerate()来获取索引和条目。然后在每次循环迭代中打印索引和条目的值。正如您从结果中看到的,索引值从 0 开始,但是您不需要使用索引来访问列表中的项目。总之,您不应该像这样编写 Python 代码:
for i in range(len(lst_1)): print(lst_1[i])在这段代码中,您将创建一个从 0 到长度为
lst_1的整数范围,然后通过索引访问列表中的每个元素。这会导致一个接一个和击剑失误。相反,您应该编写直接遍历列表的代码:for item in lst_1: print(item)你可以阅读更多关于列表中的列表和 Python 中的元组以及关于
for循环和Python“for”循环(确定迭代)中的迭代的内容。还有一个更高级的概念叫做列表理解,你可以在中学习如何有效地使用列表理解。字典
在 MATLAB 中,可以用
containers.Map()创建地图数据类型。当您有两个总是相互关联的数据,并且希望将它们连接在一起时,这种数据结构非常有用。例如,您可以用一个containers.Map()将城市与其人口对应起来:
>> cities = containers.Map({'Cleveland';'Pittsburgh';'Hartford'}, [383793,301048,122587]);
>> cities('Cleveland') ans =
383793
在这段代码中,您将在第一行创建一个containers.Map()。第一个参数是包含城市名称的字符数组的单元格数组。这些被称为地图的键。第二个参数是人口数组。这些被称为地图的值。然后,通过用字符数组索引地图来访问克利夫兰的人口值。
通过分配给未定义的键值,可以将新值分配给映射:
>> cities('Providence') = 180393;如果您尝试访问不存在的密钥,您将收到一条错误消息:
>> cities('New York City') Error using containers.Map/subsref
The specified key is not present in this container.
Python 有一个等价的数据结构,叫做字典。要创建一个 Python 字典,可以使用花括号并相互指定键和值:
In [1]: cities = { ...: "Cleveland": 383_793, ...: "Pittsburgh": 301_048, ...: "Hartford": 122_587} In [2]: cities["Cleveland"] Out[2]: 383793在这段代码中,在输入行 1 上,您使用花括号创建了城市字典。请注意,键和值是一起指定的,用冒号分隔。这些值是用数字中的
_指定的,这是 Python 3.6 中的一个特性。这并没有改变数字的值,只是让非常大的数字更容易阅读。然后,使用方括号访问"Cleveland"键的值,类似于列表和数组的索引语法。您可以向字典中添加新的键,方法是向它们分配:
In [3]: cities["Providence"] = 180_393
在这段代码中,您为字典分配了一个值为 180,393 的新键"Providence"。如果你试图访问一个不在字典中的键,你会得到一个 KeyError :
In [4]: cities["New York City"] Traceback (most recent call last): File "<ipython-input-4-6ebe5b35f3ea>", line 1, in <module> cities["New York City"] KeyError: 'New York City'在这段代码中,您试图使用
"New York City"键访问字典。然而,这个键在字典中不存在,所以 Python 抛出了一个KeyError,让您知道"New York City"不是一个选项。你可以在 Python 中的字典和 Python KeyError 异常中的
KeyError异常以及如何处理它们中读到更多关于 Python 字典的内容。您还可以遍历字典并使用字典理解,类似于列表理解。你可以在如何在 Python 中迭代字典中读到这些主题。异常帮助你控制 Python 中的程序流
MATLAB 和 Python 都使用错误和异常来让您知道代码中什么时候出错了。在本节中,您将了解 Python 中常见的异常,以及如何恰当地处理它们。
如果你想全面了解 Python 异常,你可以阅读 Python 异常:简介。当出现 Python 异常时,它会产生一个回溯。你可以在理解 Python 回溯中了解如何解释回溯。理解回溯通常对解释和纠正 Python 异常非常有帮助。有几个特定的案例通常具有相同的解决方案。您将在本节的其余部分看到这些内容。
NameError
Python
NameError异常通常是变量未定义的结果。当你看到一个NameError时,检查你的代码是否有拼写错误和拼写错误的变量名。您可以使用 Spyder 中的调试功能和变量资源管理器来找出定义了哪些变量。语法错误
Python
SyntaxError异常意味着你输入了一些不正确的语法。这通常是由于不匹配的括号造成的,此时只有左括号或右括号,而没有匹配的括号。这些异常通常指向问题所在的后的行。另一个常见的
SyntaxError是在if语句中只使用一个等号。在这种情况下,您意味着不等于(!=)或等于(==),因此您可以更正该行。关于SyntaxError异常的更多信息,请查看 Python 中的无效语法:语法错误的常见原因。按键错误
当您试图访问一个不存在的字典中的键时,Python
KeyError会发生异常。如果字典存在,您可以使用.get()从字典中检索一个键,如果该键不存在,则返回默认值。你可以在 Python KeyError 异常以及如何处理它们中阅读更多关于KeyError异常的内容。索引错误
当你试图访问一个不存在的数组或列表的索引时,会出现异常。这通常意味着您试图访问的数组或列表的元素比您试图访问的索引少。您可以使用 Spyder 中的调试功能和变量资源管理器来查看列表和数组的大小,并确保您只访问存在的索引。
ImportError/ModuleNotFoundError
当您试图导入 Python 找不到的模块时,会出现 Python
ImportError和ModuleNotFoundError异常。这可能是因为它安装在不同的conda环境或virtualenv中,也可能是因为你忘记安装包了。这个错误的解决方案通常是
conda install或pip install包,并确保正确的环境被激活。如果您没有使用conda中的base环境,您还需要确保将 Spyder 或 Jupyter 安装到您的环境中。类型错误/值错误
Python
TypeError异常发生在参数类型错误的时候。当您将错误类型的参数传递给函数时,这种情况最常见。例如,如果传入一个字符串,一个处理数字的函数将引发一个TypeError。一个相关的例外是
ValueError。当参数的类型正确但值不正确时,会发生此异常。例如,如果一个负数被传入,一个只处理正数的函数将引发一个ValueError。属性错误
Python
AttributeError当你试图访问一个对象的属性,而该对象并不具有该属性时,就会发生异常。您将经常看到与消息NoneType object has no attribute相关的错误。这个消息很可能意味着一个函数返回了None,而不是您期望的对象,并且您正试图访问一个存在于真实对象上的属性,但是没有为None定义。如何在 Python 中处理异常
MATLAB 允许你
try一个代码语句和catch代码抛出的任何错误。一旦捕捉到错误,就可以对错误做进一步的处理,并根据错误的类型分配变量。 MATLAB 文档中有几个很好的例子,展示了这在 MATLAB 中会是什么样子。在 Python 中,与 MATLAB 的一个很大的区别是,你可以选择只捕捉某些类型的异常并处理它们。这允许继续向用户显示所有其他异常。如果你想了解更多关于如何用 Python 做这件事,你可以阅读
try和except块:处理异常。要了解其工作原理,您可以尝试以下示例:
In [1]: import math
In [2]: def my_sqrt(number):
...: print(f"You passed the argument: {number!r}")
...: try:
...: return math.sqrt(number)
...: except ValueError:
...: print("You passed a number that cannot be operated on")
...: except TypeError:
...: print("You passed an argument that was not a number")
...:
In [3]: my_sqrt(4.0)
You passed the argument: 4.0
Out[3]: 2.0
In [4]: my_sqrt(-1.0)
You passed the argument: -1.0
You passed a number that cannot be operated on
In [4]: my_sqrt("4.0")
You passed the argument: '4.0'
You passed an argument that was not a number
在这段代码中,在输入行 1 上,您正在导入内置的math库。然后,从输入行 2 开始,定义一个名为my_sqrt()的函数,它有一个名为number的参数。在函数定义中,首先打印用户传递的参数。
接下来,你进入try / except块。首先,您尝试获取输入参数的平方根并返回结果。如果获取参数的平方根导致错误,Python 将捕捉该错误并检查引发了哪种类型的错误。
您已经定义了处理两个特定异常的代码:ValueError和TypeError。如果math.sqrt()引发了一个ValueError,你的代码将打印一条消息,说明这个数字不能被操作。如果math.sqrt()引发了一个TypeError,你的代码将打印一条消息,指出参数不是一个数字。如果math.sqrt()引发了任何其他类型的异常,该错误将被传递而不进行任何处理,因为没有任何其他错误类型的处理程序。
更具体地说,Python 检查由try块中的代码引起的任何错误。在您的例子中,您只在try块中定义了一行代码,但是这并不是必需的,您可以在那里定义任意多的代码行。然而,最大限度地减少try块中的代码行数通常是一个好的做法,这样您就可以非常明确地知道哪个代码引发了任何错误。
在输入行 3 上,您正在测试my_sqrt()。首先,将值 4.0 传递给函数。该函数打印参数,并且math.sqrt()接受 4 的平方根没有问题,在输出行得到 2.0。
在输入行 4 上,您将-1.0 作为参数传递给my_sqrt()。您可能还记得,取负数的平方根会产生一个复数,而math.sqrt()函数不能处理这个复数。使用math.sqrt()计算负数的平方根会产生一个ValueError。您的异常处理程序捕获这个ValueError,并输出该数字不能被操作的消息。
在第 5 行输入中,您将把"4.0"作为参数传递给my_sqrt()。在这种情况下,math.sqrt()不知道如何计算一个字符串的平方根,尽管这个字符串看起来代表一个数字。您可以看到,您通过给出参数值的语句中的引号传递了一个字符串:You passed the argument: '4.0'。由于math.sqrt()不能接受一个字符串的平方根,它引发一个TypeError,并且您的函数打印出参数不是一个数字的消息。
用 Python 写好代码有官方指南
Python 社区已经开发了一套关于如何设计 Python 代码样式的建议。这些都被编入一个名为 PEP 8 的文档中,它代表 Python 增强提案#8。PEP 8 的全文可以在 Python 网站上找到。还可以在如何用 PEP 8 和惯用 Python 101 写出漂亮的 Python 代码中了解更多好的 Python 风格。
也许 PEP 8 中最重要的原则是这样一句话:“愚蠢的一致性是心胸狭窄的妖怪。”这意味着几乎所有代码都应该遵循 PEP 8 中的建议,但在某些有限的情况下,不遵循 PEP 8 的建议可能是个好主意。例如,如果你正在处理一个已经存在的有自己风格的代码库,你应该遵循它与 PEP 8 不同的风格。你可以在 PyCon 2015 的演讲中看到核心 Python 开发者之一 Raymond Hettinger 对这一原则的精彩论述。
除了阅读 PEP 8,你还可以使用一些 Python 包来自动确保你的代码符合风格指南。 Flake8 是一个代码提示器,它可以阅读你的代码,并为你如何改进它提出建议。这类似于 MATLAB 代码编辑器中提出改进建议的功能。此外, Black 、 yapf 和 autopep8 等包会自动格式化你的代码,使之符合 pep8 或你自己的风格规则。使用这些包可以帮助你的代码感觉更 Python 化,并帮助你学习好的 Python 风格!
Python 有一个很棒的支持社区
众所周知,Python 有一个非常支持、开放和友好的社区。无论你是一个全新的开发人员还是一个有经验的开发人员,无论你是 Python 的新手还是参加过十几次会议,社区都会支持你和你想做的事情。
该社区从 Python 包索引(称为 PyPI 或 CheeseShop,是对 Monty Python 草图的引用)开始,它包含了成千上万个不同的 Python 包,您可以免费下载。这些包可以使用pip来安装,这是 Python 附带的一个包管理器。这意味着向 Python 添加您需要的功能可以像pip install package一样简单,或者如果您正在使用 Anaconda,conda install package。
由于 Python 被用于软件开发、数据科学、科学和工程等许多不同的领域,所以总有一些人想谈论 Python。世界上大多数大城市都有 Python meetup 群组。你可以去这些小组,通过听人们谈论他们的工作或一些开源代码来了解 Python。
每年都会有几次,这些群体结合成不同的 PyCons,发生在全球各大洲。北美 PyCon 是其中最大的,每年有数千人参加。你可以在如何充分利用 PyCon 中了解所有关于参加的信息。
Python 也有一个非常强大的在线社区。如果你有关于 Python 编程的问题,你可以在 StackOverflow 上提问,一些世界领先的 Python 专家会帮你解决。确保遵循 StackOverflow 上如何提问的说明。记住,你在你的问题上越努力,你就越有可能自己找到答案(万岁!)或者从别人那里得到一个好的答案。
如果你想跟随 Python 的发展,你可以注册一个覆盖 Python 社区不同方面的邮件列表。询问用 Python 写程序问题的通用邮件列表叫做 comp.lang.python 。如果你对 Python 本身的开发感兴趣,可以关注 python-dev 邮件列表。
如果你有兴趣学习更多关于 Python 开发的知识,你可以看看真正的 Python 学习途径!
您仍应使用 MATLAB 的领域
尽管有很棒的社区和很棒的软件包,MATLAB 仍然有一两个地方比 Python 做得更好。Python 无法与 MATLAB 抗衡的主要地方是 Simulink 工具箱。这个工具箱在一个方便的图形界面中提供了高级的信号处理和建模功能。
Python 没有与这些功能等价的图形界面。然而,就 Simulink 是常微分方程解算器的方便接口而言,Python 具有与 MATLAB 等效的解算器,并且 Simulink 的基本功能肯定可以在 Python 中复制。
否则,你可以用 Python 做任何你能在 MATLAB 中做的事情!如果你能想到可以用 MATLAB 做的工作,但是你不确定如何用 Python 做,请在评论中告诉我们,我们将能够提供建议。
结论
恭喜您,您现在已经掌握了将 MATLAB 代码转换为 Python 代码所需的知识!在本文中,您了解了 Python 是什么,如何设置您的计算机以使用 Python,以及如何将您的代码从 MATLAB 转换为 Python。
Python 是一个非常庞大的语言和社区,有很多东西可以学习,也有很多人可以向它学习。记住,你第一次打开 MATLAB 开发环境的时候并不是一个 MATLAB 专家,第一次写一些 Python 代码也是如此。当您需要提高技能和学习更多关于成为 Python 向导的知识时,请随时回来阅读本文!
延伸阅读
网上有大量的资源介绍 MATLAB 和 Python 的区别。以下是我从 MATLAB 过渡到 Python 时发现的一些有用的资源:
- 网络研讨会:面向 MATLAB 用户的 Python,你需要知道的(视频)
- MATLAB 到 Python 白皮书
- Matlab vs. Julia vs. Python
- Python 相对于 MATLAB 的八大优势
- Python 成为研究热点的 10 个理由(以及一些不被研究的理由)***********
MicroPython:Python 硬件编程入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:MicroPython 入门
你对物联网、家庭自动化和互联设备感兴趣吗?你有没有想过造一个爆能枪,一把激光剑,甚至是你自己的机器人会是什么样子?如果是这样,那么你很幸运!MicroPython 可以帮助你做所有这些事情,甚至更多。
在本教程中,您将了解到:
- MicroPython 的历史
- MicroPython 和其他编程语言的差异
- 您将用来构建设备的硬件
- 处理来设置、编码和部署您自己的 MicroPython 项目
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 一切都来了
Python 近年来人气暴涨。如今,从开发操作系统到统计分析,甚至在桌面软件中,它都被广泛使用。但是很长一段时间以来,Python 在一个领域的使用明显缺失。使用微控制器的开发人员还没有采用这种语言。
2013 年,当达米恩·乔治在 Kickstarter 上发起了一项活动时,这一切都改变了。达米恩是剑桥大学的一名本科生,他是一名狂热的机器人程序员。他想把 Python 世界从以千兆字节为单位工作的机器转移到千字节。他的 Kickstarter 活动是为了支持他的开发,同时将他的概念证明转化为一个完整的实现。
许多开发人员抓住了这个机会,不仅在微控制器上使用 Python,还获得了 Damien 自己的参考硬件的早期版本,这是专门为该任务构建的!事实上,在竞选结束时,达米恩已经超过了他的 15000 英镑的目标。多亏了 1900 多名支持者,他的支持人数接近 10 万。
超越桌面的 python
最后,Python 已经脱离了台式机和服务器,进入了传感器、执行器、电机、LCD 显示器、按钮和电路的世界。虽然这带来了许多挑战,但也有大量的机会。台式机和服务器硬件需要千兆赫的处理器、千兆字节的内存和兆兆字节的存储。他们还需要成熟的操作系统、设备驱动程序和真正的多任务处理。
然而在微控制器的世界里, MicroPython 就是操作系统。本质上,它位于处理器之上,时钟速度可以追溯到 20 世纪 80 年代和 90 年代。MicroPython 对于处理代码执行、IO、存储、引导等所有错综复杂的问题毫无帮助。如果你想与硬件接口,那么你需要所有的代码来实现它。
然而不知何故,Damien 设法将一个强大、高性能、紧凑的 Python 实现压缩到这些微型计算机中。这开启了一个全新的潜力世界。如果你有兴趣了解更多关于 CPython 和 MicroPython 的区别,那么你可以在官方 GitHub repo 上查看完整的分析。
作为爱好和职业道路的电子产品
MicroPython 得到了各种 Pythonistas 社区的支持,他们非常希望看到这个项目成功。除了测试和支持代码库本身,开发人员还贡献了教程、代码库和硬件移植,使得这个项目远远超出了 Damien 一个人所能完成的。
多年来, MicroPython 吸引了来自其他平台的专业人士和爱好者,他们看到了这种语言的潜力和便利。这些开发者可能来自更成熟的平台,如 Arduino 或 PIC。许多人开始意识到使用 MicroPython 以及同时指定 Python 和 MicroPython 的好处,尤其是对于快速原型开发和更快的上市时间。
那么,MicroPython 为严肃的任务关键型工作做好准备了吗?欧洲航天局 ESA 好像也这么认为!他们帮助资助 Damien 在 MicroPython 上的工作,因为他们想在太空中使用 Python。你会看到越来越多的业余爱好者和学习者进入学术界,并从那里进入电子专业世界。到那时,MicroPython 将真正起飞。
Python 和 STEM
STEM 科目已经被置于教育显微镜下好几年了,这导致了针对课堂的项目和产品的爆炸式增长。Python 和 MicroPython 对教师和学生来说都很合适。基本语法和捆绑的解释器使这些语言成为有效的学习环境。不需要开发环境的事实只是一个额外的好处!
几年前,BBC 启动了它的 Micro:Bit 项目,让更多的孩子接触办公室风格应用之外的计算。他们的目标是让微控制器板进入英国每个学生的手中。Damien 通过他的邻居获得了其中的一块电路板,并很快运行了他的代码。成千上万的教室突然有了在课堂上运行 Python 的选项!
最近, Edublocks 采用了 Micro:Bit,实现了类似 Scratch 的拖放 Python 体验。这让更多的孩子第一次体验了微控制器和机器人编程。捐赠支持了项目的持续发展。
物理计算
说到 MicroPython,物理计算是什么意思?通常,您的项目将包含三个要素:
- 输入:按钮、信号、互联网事件或传感器读数接收数据。
- 处理:微控制器处理输入并更新输出。
- 输出:这可以以电机旋转、LED 点亮、计数器改变、消息发送或一些类似事件的形式发送。
这些元件通常由电线连接,并由某种电源供电。
什么是微控制器?
您可能知道微控制器很小,功能不如台式机或服务器机架上的计算机强大。您可能不知道的是,微控制器就在您身边,为您的设备增加了智能和控制。从家用电器和家庭安全系统到心脏起搏器,再到暖通空调系统等等,它们都被嵌入其中。
微控制器日复一日可靠地在一个紧凑的封装中做相对简单的事情。它们将 CPU、内存和 IO 压缩到一个通用芯片中,而不是需要一整板的芯片来协同执行任务。他们运行的代码被称为固件,在执行前被闪存或烧录到可写内存中。
虽然那些伴随早期微型计算机(如 ZX81 和 Commodore Vic20)长大的人可能会发现这些芯片难以置信的强大,但从技术上讲,你的智能手表可以提供更多的功能。尽管如此,微控制器仍然非常有用,即使它们的处理能力和存储能力有限。这些小家伙可以做很多事情!
为什么选择 MicroPython?
如果这些微控制器在 MicroPython 出现之前就已经大量出现,那么与传统实践相比,MicroPython 给你带来了什么好处呢?
首先,这种语言比其他语言更容易被初学者理解,同时对于工业用例来说仍然足够强大。你可以从学习基础知识到做真正的工作,而且要快。
其次,Python 允许快速反馈。这是因为您可以交互地输入命令,并使用 REPL 获得响应。你甚至可以调整你的代码并马上运行它,而不是重复通过代码-编译-上传-执行循环。
最后,大量的 Python 代码和经验意味着作为一名 Python 程序员,你可以更快更容易地做一些事情。例如,我发现 Python 请求库、字符串处理和用于处理 JSON 的工具在 MicroPython 世界中比 C++ 更容易使用。
C++呢?
C++快速、简洁,并且随处可用。有大量的 C++程序员,以及一个丰富的 Arduino 和 PIC 开发人员社区随时准备帮助你。因此,C++难道不是更好的选择吗?
在我看来,MicroPython 在易用性和便利性上胜过 C++。C++语法并不容易马上理解。更重要的是,代码需要编译,然后传输到你的板上,才能得到一个结果,所以你需要一个编译器在手边。
现在,很明显,工具正在变得更好,但是 MicroPython 仍然有优势。虽然 C++可能有速度优势,但对于大多数目的来说,MicroPython 已经足够快了。另外,如果你真的需要 C++,那么你甚至可以从 MicroPython 调用你的 C++代码!
汇编程序呢?
对于原始性能,没有比汇编程序更好的了。然而,这也不排除 MicroPython。
同样,MicroPython 往往足够快。如果您确实需要最低级别的能力,那么您可以将内联汇编器添加到您的 MicroPython 项目中。
基础的呢?
如果你在过去打开一台旧的微型计算机,那么它们几乎肯定会启动基本的 T1。至少,他们手头会有一套基本的方言。这种语言成为整整一代人的编程入门。这包括埃隆·马斯克,他显然是在 Vic 20 上学会了编码。
如今,BASIC 的光芒已经有些黯淡。Python 和其他基于块的语言已经在教育领域取代了它,而且它几乎没有在科技行业留下痕迹。Python 拥有 BASIC 的所有优点,没有任何限制。
树莓派怎么样?
运行 Python 的 Raspberry Pi 也大量出现在教育领域。由于其通用 IO 引脚,它在电子和物理计算领域找到了一席之地。树莓派也是一款成熟的通用 Linux 台式电脑。它拥有强大的处理器能力、内存和存储容量,甚至还有一个 GPU。
然而,最后一个方面实际上可以成为不选择 Pi 而使用微控制器板的理由!运行桌面应用程序和多媒体的能力非常棒,尤其是当您的项目可能需要这种原始能力时。例如,人工智能、视频流和数据库项目可能就是这种情况。
但是当您的用例需要实时处理时,这可能会导致问题。如果您需要非常精确的计时,那么您不希望您的代码在赶上几十个都想同时执行的不同进程时等待。
如果您想要模拟输入,那么 Pi 将需要额外的硬件。相比之下,大多数能够运行 MicroPython 的微控制器至少有一个模拟输入,甚至可能更多。此外,Pi 不太稳定,而且可能更贵。正因为如此,在你的项目中留下一个微控制器可能比一个完整的 Pi 更有经济意义。
不必非选其一。也许将 Raspberry Pi 与微控制器配对是您项目的最佳解决方案。例如,您可以使用 Pi 提供处理能力,使用微控制器与硬件接口。
MicroPython 硬件
如果您有兴趣尝试一下 MicroPython,那太好了!你需要一些兼容的硬件来安装 MicroPython。幸运的是,有许多选择,从负担得起的到优质产品。每个钱包和用例都有适合的东西,所以请花些时间选择适合您的解决方案。
专为 Python 打造
启动 MicroPython 的 Kickstarter 也推出了其相关硬件。MicroPython Pyboard 现在升级到了 1.1 版。
Pyboard 是规格最齐全的电路板之一。它基于 STM32,具有大量 GPIO。还有一个 SD 插槽,一个加速度计和 RTC,容量为 168 MHzf。如果你能在库存中找到它,那么它将花费你大约 40 美元。
ESP8266 或 ESP32
价格范围的另一端是基于 ESP8266 的主板。这些板只有一个模拟输入,并且没有 Pyboard 那么多引脚。然而,他们有 WiFi 功能。你可以在 10 美元或更少的支持试验板的板(如 NodeMCU)中找到它们。
ESP32 是 ESP8266 的老大哥。它增加了功率和功能,同时将蓝牙添加到功能集中,只需少量的额外成本。这些板的最好版本之一是 M5 堆栈。这个装置配有一个 peizo 扬声器、一个电池、一个读卡器和一个彩色屏幕。
BBC 微:位
Micro:Bit 是一款基于 Nordic nRF51822 微控制器的紧凑型电路板。它内置蓝牙 LE 和温度感应,外加一个加速度计、几个动作按钮和一个 5x5 LED 网格。
如果你在英国,那么你可能已经有一块这样的板了。它们被分发给小学生,希望能激励新一代的编码员。许多受 Micro:Bit 启发的主板开始出现,所以它一定会越来越受欢迎!
Adafruit 和 CircuitPython 驱动的电路板
在 MicroPython 开始加快步伐后不久,Adafruit 就推出了一个他们称之为 CircuitPython 的分支。然而,两者之间有一些主要的区别。
一个是 CircuitPython 提供了对 Adafruit 系列硬件的支持。另一个区别是,大多数 Adafruit 实现的特点是板看起来像一个 USB 连接的驱动器。在这些情况下,添加代码就像把它拖到磁盘上一样简单。
Adafruit premium 系列中功能最丰富的主板是 CircuitPlayground Express ,带有可选的 Crickit 附加组件。当您将这两块板结合在一起时,您将拥有引脚、传感器、电机驱动器、RGB LEDs 等等。如果您正在寻找一个一体化的解决方案,那么这是一个检查。
不幸的是,Adafruit 已经放弃了与 ESP8266 的兼容性,即使是他们自己的基于 ESP8266 的羽毛板。相反,他们选择在未来的版本中将 ESP32 纯粹作为 WiFi 协处理器。
MicroPython 工作流
如果您熟悉 Arduino 或 PIC 编程,那么您可能希望首先讨论编译器、开发环境和工具链。然而,MicroPython 乍一看有点不同。
REPL
与 Python 一样,MicroPython 的语言可能是硬件自带的,您可以选择交互式地使用它。有两种方法可以获得交互式会话:
- 使用串行终端连接:这通常是通过命令行来完成的,或者可能是一个 IDE 。
- 使用 WebREPL: 这是带 WiFi 的主板的一个选项。
例如,要在 Mac 上获得串行 REPL,您可以运行附带的终端程序屏幕并指定您的设备和波特率:
$ screen /dev/tty.wchusbserial1430 115200
您可以通过列出连接的串行连接来找到您的设备:
$ ls /dev/tty.*
这个过程类似于您在 Linux 终端中所做的。
在 Windows 上,PuTTY 是一款流行的终端应用。还有一个叫 Tera Term。无论哪种方式,只需连接到连接设备时出现的 COM 端口,并选择 115,200 作为波特率。
一旦建立了 REPL 连接,就可以像在 Python 交互式会话中一样输入命令。在 MicroPython 中,这个接口也是您可能想做简单的 OS 风格工作的地方,比如删除文件或创建文件夹。
命令行工具
Dave Hyland 的 RShell 是一个功能完善的工具集,用于处理您的 MicroPython 项目。
还有另一个与 MicroPython 板交互的很棒的命令行工具叫做 Ampy 。这最初是由 Adafruit 开发的,但现在由一名社区成员接手,因为 Adafruit 只专注于他们自己的硬件。
MicroPython IDEs
有一个 PyCharm 插件可以为你的 IDE 添加 MicroPython 支持。它就在插件市场上:
对于 Micro:Bit 和 CircuitPython 板,目前最好的编辑器是 Nicholas Tollervey 的 Mu 编辑器。否则,继续关注 uPyCraft ,它看起来很有前途,而且已经相当有用了。
一旦连接了正确的串行端口并选择了设备类型,您就可以浏览设备了:
您的设备类型可以是 ESP8266、ESP32 或 Micro:Bit。现在你可以在 REPL 互动了!
在您的主板上设置 MicroPython
选择 uPyCraft 有一个好处,那就是可以轻松地将 MicroPython 固件刻录到您的主板上,而无需使用命令行工具。您可以选择 uPyCraft 默认固件或您已下载的固件:
BBC Micro:Bit 显示为磁盘驱动器。当你使用 Mu 或基于网络的编辑器时,它们会产生你可以直接放到那个磁盘上的文件。如果你使用的是带有 uPyCraft 的 ESP8266 或 ESP32 板,那么你也可以安装带有 pip 的 Python ESPTool 并使用它设置你的板的固件。
其他主板可能会安装 MicroPython 或 CircuitPython,甚至使用拖放式安装程序。然而,这些类型的板可能会损坏或进入无限循环。请务必花时间查看您的主板文档,了解如何更换固件。
创建和部署您的代码
为了执行您的代码,在大多数情况下,您将创建.py文本文件,并在您的 MicroPython 设备上执行它们。这个过程类似于您对 CPython 所做的。您可以通过以下两种方式之一将文件传输到您的板上:
- 使用你的 IDE。这可以是 Mu,uPyCraft,或者类似的东西。
- 使用命令行工具。这可以是 RShell,Ampy,或者类似的。
当运行 MicroPython 的设备启动时,它们会寻找一个名为boot.py的文件。如果找到该文件,设备将自动执行它。您也可以在 REPL 提示符下执行.py文件:
exec(open('my-program.py').read())
事实上,这与运行编辑好的 Python 时 uPyCraft 所做的事情类似。它将文件传输到您的主板,然后通过 REPL 执行它。
编写您的 MicroPython 代码
你将以一句传统的“你好,世界!”项目。通过连接到正确的串行端口,并输入以下内容,您可以在 REPL 中完成此操作:
print("Hello World!")
您应该会看到以下输出:
您已经确认您的设置正在工作。
创建数字输出
现在,让我们改变输出类型。使用以下代码,您可以使板载 LED 闪烁:
import time
import machine
blueled = machine.Pin(2, machine.Pin.OUT)
# Blink 10 times
for i in range(1,11):
blueled.value(0)
time.sleep(0.5)
blueled.value(1)
time.sleep(0.5)
print("DONE!")
你导入time,它让你插入时间延迟。您还可以导入machine,这是一个可以让您轻松访问主板上的 IO 引脚的模块。您使用这个模块来设置一个名为blueled的对象,您将它定义为Pin 2。(在其他板上,可能是Pin 16)。然后,将其设置为输出引脚。您应该会看到以下输出:
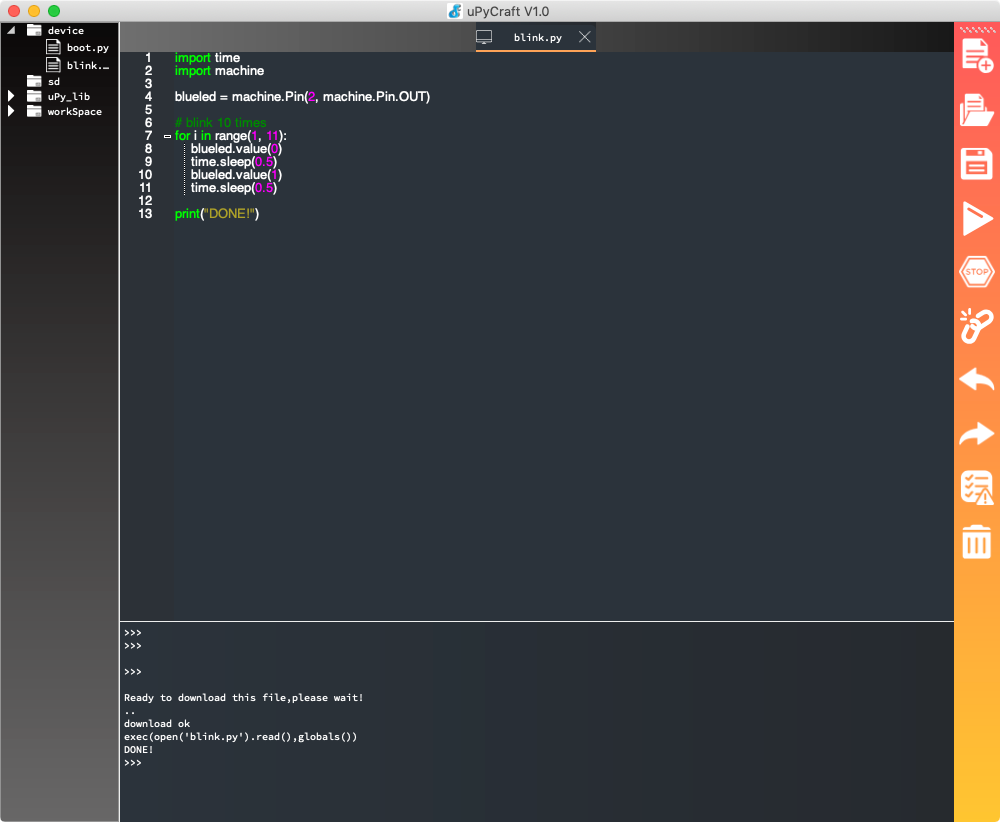
您可能会注意到,在 ESP8266 上,LED 在关闭时会亮起,当给定一个正值时会熄灭。奇怪,但却是真的!
注意:大多数主板都有一个或多个内置 led。如需更多资讯,请查阅您特定主机板的文件。
如果您没有内置 LED,或者您想要点亮主板上没有的 LED,该怎么办?你需要一个大小合适的电阻,比如 220 欧姆的电阻。你需要将它连接到地和 LED 的短腿。LED 的正极长腿将连接到 GPIO 引脚 2。在 Wemos D1 Uno 板上,GPIO 2 在板的正面被称为数字引脚 9。下面有 GPIO 号。
如果是外接 LED,当值为 1 或上的时,它将亮起:

你可以看到大头针已经亮了。
褪色的发光二极管
在前面的例子中,您使用了一个 for回路,但是您的硬件实际上可以使 LED 本身闪烁。为此,将引脚输出设置为PWM,代表脉宽调制(PWM) 。
这允许你创建一个信号开和关脉冲。当你在一秒钟内快速打开和关闭 LED 灯很多次时,由于我们眼睛的工作方式,LED 灯似乎被设定到了一定的亮度。下面是您的代码的样子:
from machine import Pin
from machine import PWM
import time
# Set our pin 2 to PWM
pwm = PWM(Pin(2))
# Brightness between 0 and 1023
pwm.duty(700)
# Frequency in Hertz
pwm.freq(1)
在这个新代码中,您以赫兹为单位设置亮度和闪烁频率,然后让硬件接管。
您也可以使用 PWM 来淡入和淡出 LED:
from machine import Pin
from machine import PWM
import time
# Set our pin 2 to PWM
pwm = PWM(Pin(2))
# Frequency = 100hz
pwm.freq(100)
while 1:
# Brightness between 0 and 1023
for brightness in range (0, 1023, 100):
pwm.duty(brightness)
print(brightness)
time.sleep(0.1)
# Brightness between 1023 and 0
for brightness in range (1023, 0, -100):
pwm.duty(brightness)
print(brightness)
time.sleep(0.1)
这段代码产生了一种令人愉悦的柔和效果:

如果您使用板载 LED,则灯可能会先熄灭,然后再亮起。
结论
对你来说,编程机器人、微控制器、电子设备和其他硬件从来没有这么容易。传统上,要对这些设备进行编程,您必须使用汇编或 C++等低级语言,并牺牲许多功能。随着 MicroPython 的引入,这一切都改变了,这是 Python 3 的一个版本,被塞进了更小的物理计算设备的小容量中!
在本教程中,您将深入 MicroPython 和电子硬件的世界。您已经了解了 MicroPython 的历史以及它与其他平台的比较。您还完成了 MicroPython 工作流,将代码部署到您自己的板上,并带来了真实世界的效果。
MicroPython 正在继续增长。社区中的开发人员总是在添加新的代码、工具、项目和教程。作为一名 MicroPython 开发人员,这是最激动人心的时刻!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:MicroPython 入门*****
将 Django 项目迁移到 Heroku
原文:https://realpython.com/migrating-your-django-project-to-heroku/
在本教程中,我们将采用一个简单的本地 Django 项目,由一个 MySQL 数据库支持,并将其转换为在 Heroku 上运行。亚马逊 S3 将用于托管我们的静态文件,而 Fabric 将自动化部署过程。
该项目是一个简单的消息系统。它可以是一个 todo 应用程序,一个博客,甚至是一个 Twitter 的克隆。为了模拟真实场景,该项目将首先使用 MySQL 后端创建,然后转换为 Postgres 以部署在 Heroku 上。我个人有五六个项目需要做这样的事情:把一个本地项目,用 MySQL 支持,转换成 Heroku 上的一个实时应用。
设置
先决条件
- 在 Heroku 阅读 Django 官方快速入门指南。读一下吧。这将有助于你对我们将在本教程中完成的内容有所了解。我们将使用官方教程作为我们自己更高级的部署过程的指南。
- 创建一个 AWS 帐户并设置一个有效的 S3 存储桶。
- 安装 MySQL。
让我们开始吧
$ cd django_heroku_deploy
$ virtualenv --no-site-packages myenv
$ source myenv/bin/activate
在 Github 上创建一个新的资源库:
$ curl -u 'USER' https://api.github.com/user/repos -d '{"name":"REPO"}'
确保用您自己的设置替换所有大写关键字。例如:
curl -u 'mjhea0' https://api.github.com/user/repos -d '{"name":"django-deploy-heroku-s3"}'
添加一个 readme 文件,初始化本地 Git repo ,然后将本地副本推送到 Github:
$ touch README.md
$ git init
$ git add .
$ git commit -am "initial"
$ git remote add origin https://github.com/username/Hello-World.git
$ git push origin master
确保将 URL 更改为您在上一步中创建的 repo 的 URL。
建立一个名为 django_deploy 的新 MySQL 数据库:
$ mysql.server start $ mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql> mysql> CREATE DATABASE django_deploy; Query OK, 1 row affected (0.01 sec) mysql> mysql> quit Bye
更新 settings.py :
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'django_deploy',
'USER': 'root',
'PASSWORD': 'your_password',
}
}
安装依赖项:
$ pip install -r requirements.txt
$ python manage.py syncdb
$ python manage.py runserver
在http://localhost:8000/admin/运行服务器,确保可以登录 admin。向Whatever对象添加一些项目。关掉服务器。
从 MySQL 转换到 Postgres
注意:在这个假设的情况下,让我们假设你已经使用 MySQL 在这个项目上工作了一段时间,现在你想把它转换成 Postgres。
安装依赖项:
$ pip install psycopg2
$ pip install py-mysql2pgsql
建立 Postgres 数据库:
$ psql -h localhost psql (9.2.4) Type "help" for help. michaelherman=# CREATE DATABASE django_deploy; CREATE DATABASE michaelherman=# \q
迁移数据:
$ py-mysql2pgsql
该命令创建一个名为 mysql2pgsql.yml 的文件,包含以下信息:
mysql: hostname: localhost port: 3306 socket: /tmp/mysql.sock username: foo password: bar database: your_database_name compress: false destination: postgres: hostname: localhost port: 5432 username: foo password: bar database: your_database_name
为您的配置更新此内容。这个例子只是涵盖了基本的转换。您还可以包括或排除某些表。完整示例见此处。
传输数据:
$ py-mysql2pgsql -v -f mysql2pgsql.yml
一旦数据传输完毕,请务必更新您的 settings.py 文件:
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql_psycopg2",
"NAME": "your_database_name",
"USER": "foo",
"PASSWORD": "bar",
"HOST": "localhost",
"PORT": "5432",
}
}
最后,重新同步数据库,运行测试服务器,并向数据库添加另一项,以确保转换成功。
添加一个 local_settings.py 文件
通过添加一个 local_settings.py 文件,您可以使用与您的本地环境相关的设置来扩展 settings.py 文件,而主 settings.py 文件仅用于您的试运行和生产环境。
确保将 local_settings.py 添加到您的中。gitignore 文件,以便将该文件排除在您的存储库之外。那些想要使用你的项目或者为你的项目做贡献的人可以克隆这个 repo,然后创建他们自己的 local_settings.py 文件,这个文件专门针对他们自己的本地环境。
尽管这种使用两个设置文件的方法已经成为惯例很多年了,但是许多 Python 开发人员现在使用另一种叫做的模式,一种真正的方式。我们可以在以后的教程中研究这个模式。
更新 settings.py
我们需要对当前的 settings.py 文件进行三处修改:
将DEBUG模式更改为假:
DEBUG = False
将以下代码添加到文件的底部:
# Allow all host hosts/domain names for this site
ALLOWED_HOSTS = ['*']
# Parse database configuration from $DATABASE_URL
import dj_database_url
DATABASES = { 'default' : dj_database_url.config()}
# Honor the 'X-Forwarded-Proto' header for request.is_secure()
SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https')
# try to load local_settings.py if it exists
try:
from local_settings import *
except Exception as e:
pass
更新数据库设置:
# we only need the engine name, as heroku takes care of the rest
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql_psycopg2",
}
}
创建您的 local_settings.py 文件:
$ touch local_settings.py
$ pip install dj_database_url
然后添加以下代码:
from settings import PROJECT_ROOT, SITE_ROOT
import os
DEBUG = True
TEMPLATE_DEBUG = True
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql_psycopg2",
"NAME": "django_deploy",
"USER": "foo",
"PASSWORD": "bar",
"HOST": "localhost",
"PORT": "5432",
}
}
启动测试服务器,确保一切正常。向数据库中再添加一些记录。
Heroku 设置
将 Procfile 添加到主目录:
$ touch Procfile
并将以下代码添加到文件中:
web: python manage.py runserver 0.0.0.0:$PORT --noreload
安装 Heroku 工具带:
$ pip install django-toolbelt
冻结依赖关系:
$ pip freeze > requirements.txt
更新 wsgi.py 文件:
from django.core.wsgi import get_wsgi_application
from dj_static import Cling
application = Cling(get_wsgi_application())
在本地测试您的 Heroku 设置:
$ foreman start
导航到 http://localhost:5000/ 。
好看吗?让亚马逊 S3 开始运行吧。
亚马逊 S3
尽管假设可以在 Heroku repo 中托管静态文件,但最好使用第三方主机,尤其是如果您有一个面向客户的应用程序。S3 很容易使用,只需要对你的 settings.py 文件做一些改动。
安装依赖项:
$ pip install django-storages
$ pip install boto
在“settings.py”中将storages和boto添加到您的INSTALLED_APPS中
将以下代码添加到“settings.py”的底部:
# Storage on S3 settings are stored as os.environs to keep settings.py clean
if not DEBUG:
AWS_STORAGE_BUCKET_NAME = os.environ['AWS_STORAGE_BUCKET_NAME']
AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID']
AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY']
STATICFILES_STORAGE = 'storages.backends.s3boto.S3BotoStorage'
S3_URL = 'http://%s.s3.amazonaws.com/' % AWS_STORAGE_BUCKET_NAME
STATIC_URL = S3_URL
AWS 环境相关设置存储为环境变量。所以我们不必在每次运行开发服务器时从终端设置这些,我们可以在我们的 virtualenv activate脚本中设置这些。从 S3 那里获取 AWS 桶名、访问密钥 ID 和秘密访问密钥。打开myenv/bin/activate并添加以下代码(确保添加您刚从 S3 获得的具体信息):
# S3 deployment info
export AWS_STORAGE_BUCKET_NAME=[YOUR AWS S3 BUCKET NAME]
export AWS_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXX
export AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXX
停用并重新激活您的 virtualenv,然后启动本地服务器以确保更改生效:
$ foreman start
杀死服务器,然后更新 requirements.txt 文件:
$ pip freeze > requirements.txt
推送至 Github 和 Heroku
在推送到 Heroku 之前,让我们将文件备份到 Github:
$ git add .
$ git commit -m "update project for heroku and S3"
$ git push -u origin master
创建 Heroku 项目/回购:
$ heroku create <name>
随便你怎么命名。
推到 Heroku:
$ git push heroku master
将 AWS 环境变量发送到 Heroku
$ heroku config:set AWS_STORAGE_BUCKET_NAME=[YOUR AWS S3 BUCKET NAME]
$ heroku config:set AWS_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXX
$ heroku config:set AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXX
收集静态文件并发送给 Amazon:
$ heroku run python manage.py collectstatic
添加开发数据库:
$ heroku addons:add heroku-postgresql:dev
Adding heroku-postgresql on deploy_django... done, v13 (free)
Attached as HEROKU_POSTGRESQL_COPPER_URL
Database has been created and is available
! This database is empty. If upgrading, you can transfer
! data from another database with pgbackups:restore.
Use `heroku addons:docs heroku-postgresql` to view documentation.
$ heroku pg:promote HEROKU_POSTGRESQL_COPPER_URL
Promoting HEROKU_POSTGRESQL_COPPER_URL to DATABASE_URL... done
现在同步数据库:
$ heroku run python manage.py syncdb
数据传输
我们需要将数据从本地数据库转移到生产数据库。
安装 Heroku PGBackups 附件:
$ heroku addons:add pgbackups
转储您的本地数据库:
$ pg_dump -h localhost -Fc library > db.dump
为了让 Heroku 访问 db dump,您需要将它上传到互联网的某个地方。你可以使用个人网站、dropbox 或 S3。我只是把它上传到了 S3 桶。
将转储导入 Heroku:
$ heroku pgbackups:restore DATABASE http://www.example.com/db.dump
测试
让我们测试一下以确保一切正常。
首先,在 settings.py 中将允许的主机更新到您的特定域:
ALLOWED_HOSTS = ['[your-project-name].herokuapp.com']
查看您的应用:
$ heroku open
织物
Fabric 用于自动化应用程序的部署。
安装:
$ pip install fabric
创建 fabfile:
$ touch fabfile.py
然后添加以下代码:
from fabric.api import local
def deploy():
local('pip freeze > requirements.txt')
local('git add .')
print("enter your git commit comment: ")
comment = raw_input()
local('git commit -m "%s"' % comment)
local('git push -u origin master')
local('heroku maintenance:on')
local('git push heroku master')
local('heroku maintenance:off')
测试:
$ fab deploy
有问题或意见吗?加入下面的讨论。****
使用 Kivy Python 框架构建移动应用程序
如今,开发人员极有可能从事移动或 web 应用程序的开发。Python 没有内置的移动开发功能,但有一些包可以用来创建移动应用程序,比如 Kivy、 PyQt ,甚至是 Beeware 的托加库。
这些库都是 Python 移动领域的主要参与者。然而,如果你选择用 Kivy 创建移动应用程序,你会看到一些好处。不仅您的应用程序在所有平台上看起来都一样,而且您也不需要在每次更改后都编译代码。此外,您将能够使用 Python 清晰的语法来构建您的应用程序。
在本教程中,您将学习如何:
- 使用 Kivy 小部件
- 布局用户界面
- 添加事件
- 使用 KV 语言
- 创建计算器应用程序
- 为 iOS、Android、Windows 和 macOS 打包您的应用
本教程假设您熟悉面向对象编程。如果你不是,那么看看 Python 3 中的面向对象编程(OOP)。
我们开始吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
了解 Kivy 框架
Kivy 于 2011 年初首次发布。这个跨平台的 Python 框架可以部署到 Windows、Mac、Linux 和 Raspberry Pi 上。除了常规的键盘和鼠标输入,它还支持多点触摸事件。Kivy 甚至支持图形的 GPU 加速,因为它们是使用 OpenGL ES2 构建的。该项目使用 MIT 许可证,所以你可以免费使用这个库和商业软件。
当你用 Kivy 创建一个应用程序时,你正在创建一个自然用户界面或 NUI 。自然用户界面背后的想法是,用户可以很容易地学会如何使用你的软件,几乎不需要任何指导。
Kivy 并不试图使用本地控件或小部件。它所有的部件都是定制的。这意味着 Kivy 应用程序在所有平台上都是一样的。然而,这也意味着你的应用程序的外观和感觉将不同于你的用户的原生应用程序。这可能是优点也可能是缺点,取决于你的听众。
安装 Kivy
Kivy 有许多依赖项,所以建议您将它安装到 Python 虚拟环境中。可以使用 Python 内置的 venv 库,也可以使用 virtualenv 包。如果你以前从未使用过 Python 虚拟环境,那么看看 Python 虚拟环境:入门。
以下是创建 Python 虚拟环境的方法:
$ python3 -m venv my_kivy_project
这会将您的 Python 3 可执行文件复制到一个名为my_kivy_project的文件夹中,并在该目录中添加一些其他的子文件夹。
要使用您的虚拟环境,您需要激活它。在 Mac 和 Linux 上,您可以在my_kivy_project文件夹中执行以下命令:
$ source bin/activate
Windows 的命令类似,但是激活脚本的位置在Scripts文件夹中,而不是在bin文件夹中。
现在您已经有了一个激活的 Python 虚拟环境,您可以运行 pip 来安装 Kivy。在 Linux 和 Mac 上,您将运行以下命令:
$ python -m pip install kivy
在 Windows 上,安装稍微复杂一些。查看官方文档了解如何在 Windows 上安装 Kivy。(Mac 用户也可以下载一个dmg文件,这样安装 Kivy。)
如果你在你的平台上安装 Kivy 时遇到任何问题,那么请看 Kivy 下载页面,获取更多的说明。
使用 Kivy Widgets
一个小部件是一个用户将与之交互的屏幕控件。所有图形用户界面工具包都带有一组小部件。您可能使用过的一些常见小部件包括按钮、组合框和选项卡。Kivy 的框架中内置了许多小部件。
跑着一句“你好,Kivy!”程序
要了解 Kivy 是如何工作的,请看下面的“你好,世界!”应用:
from kivy.app import App
from kivy.uix.label import Label
class MainApp(App):
def build(self):
label = Label(text='Hello from Kivy',
size_hint=(.5, .5),
pos_hint={'center_x': .5, 'center_y': .5})
return label
if __name__ == '__main__':
app = MainApp()
app.run()
每个 Kivy 应用程序都需要子类化App并覆盖build()。这是您放置 UI 代码或调用定义 UI 代码的其他函数的地方。在本例中,您创建了一个Label小部件,并传入了它的text、size_hint和pos_hint。最后两个参数不是必需的。
size_hint告诉 Kivy 创建小工具时要使用的比例。它需要两个数字:
- 第一个数字是
x大小提示,指的是控件的宽度。 - 第二个数字是
y大小提示,指的是控件的高度。
这两个数字都可以是 0 到 1 之间的任意值。两个提示的默认值都是 1。您也可以使用pos_hint来定位小部件。在上面的代码块中,您告诉 Kivy 将小部件在 x 和 y 轴上居中。
为了让应用程序运行,您实例化您的MainApp类,然后调用run()。执行此操作时,您应该会在屏幕上看到以下内容:
Kivy 也向stdout输出大量文本:
[INFO ] [Logger ] Record log in /home/mdriscoll/.kivy/logs/kivy_19-06-07_2.txt
[INFO ] [Kivy ] v1.11.0
[INFO ] [Kivy ] Installed at "/home/mdriscoll/code/test/lib/python3.6/site-packages/kivy/__init__.py"
[INFO ] [Python ] v3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0]
[INFO ] [Python ] Interpreter at "/home/mdriscoll/code/test/bin/python"
[INFO ] [Factory ] 184 symbols loaded
[INFO ] [Image ] Providers: img_tex, img_dds, img_sdl2, img_gif (img_pil, img_ffpyplayer ignored)
[INFO ] [Text ] Provider: sdl2(['text_pango'] ignored)
[INFO ] [Window ] Provider: sdl2(['window_egl_rpi'] ignored)
[INFO ] [GL ] Using the "OpenGL" graphics system
[INFO ] [GL ] Backend used <sdl2>
[INFO ] [GL ] OpenGL version <b'4.6.0 NVIDIA 390.116'>
[INFO ] [GL ] OpenGL vendor <b'NVIDIA Corporation'>
[INFO ] [GL ] OpenGL renderer <b'NVS 310/PCIe/SSE2'>
[INFO ] [GL ] OpenGL parsed version: 4, 6
[INFO ] [GL ] Shading version <b'4.60 NVIDIA'>
[INFO ] [GL ] Texture max size <16384>
[INFO ] [GL ] Texture max units <32>
[INFO ] [Window ] auto add sdl2 input provider
[INFO ] [Window ] virtual keyboard not allowed, single mode, not docked
[INFO ] [Base ] Start application main loop
[INFO ] [GL ] NPOT texture support is available
这对调试应用程序很有用。
接下来,您将尝试添加一个Image小部件,看看它与Label有何不同。
显示图像
Kivy 有几个不同的与图像相关的小部件可供选择。您可以使用Image从硬盘加载本地图像,或者使用AsyncImage从 URL 加载图像。对于这个例子,您将坚持使用标准的Image类:
from kivy.app import App
from kivy.uix.image import Image
class MainApp(App):
def build(self):
img = Image(source='/path/to/real_python.png',
size_hint=(1, .5),
pos_hint={'center_x':.5, 'center_y':.5})
return img
if __name__ == '__main__':
app = MainApp()
app.run()
在这段代码中,您从kivy.uix.image子包中导入Image。Image类有很多不同的参数,但是您想要使用的是source。这告诉 Kivy 加载哪个图像。在这里,您向图像传递一个完全限定的路径。代码的其余部分与您在前面的示例中看到的一样。
当您运行这段代码时,您会看到如下内容:

前一个示例中的文本已被替换为图像。
现在,您将学习如何在应用程序中添加和排列多个小部件。
布局用户界面
您使用的每个 GUI 框架都有自己的排列小部件的方法。例如,在 wxPython 中,你将使用 sizers,而在 Tkinter 中,你将使用布局或几何管理器。对于 Kivy,你将使用布局。有几种不同类型的布局可供您使用。以下是一些最常见的:
BoxLayoutFloatLayoutGridLayout
你可以在 Kivy 的文档中搜索可用布局的完整列表。您也可以在kivy.uix中查找实际的源代码。
用这段代码试试BoxLayout:
import kivy
import random
from kivy.app import App
from kivy.uix.button import Button
from kivy.uix.boxlayout import BoxLayout
red = [1,0,0,1]
green = [0,1,0,1]
blue = [0,0,1,1]
purple = [1,0,1,1]
class HBoxLayoutExample(App):
def build(self):
layout = BoxLayout(padding=10)
colors = [red, green, blue, purple]
for i in range(5):
btn = Button(text="Button #%s" % (i+1),
background_color=random.choice(colors)
)
layout.add_widget(btn)
return layout
if __name__ == "__main__":
app = HBoxLayoutExample()
app.run()
在这里,您从kivy.uix.boxlayout导入BoxLayout并实例化它。然后你创建一个颜色列表,这些颜色本身就是红-蓝-绿(RGB) 颜色的列表。最后,循环 5 的 range ,为每次迭代创建一个按钮btn。为了让事情变得有趣一点,你设置按钮的background_color为随机颜色。然后用layout.add_widget(btn)将按钮添加到布局中。
当您运行这段代码时,您会看到类似这样的内容:
有 5 个随机颜色的按钮,每一个代表你的 for 循环的一次迭代。
创建布局时,您应该知道一些参数:
padding: 你可以用三种方式之一指定布局和其子布局之间的padding(以像素为单位):- 一个四参数列表:
padding_left``padding_top``padding_right``padding_bottom - 双参数列表: [
padding_horizontal,padding_vertical] - 一元论:
padding=10
- 一个四参数列表:
spacing: 你可以用这个参数在子部件之间添加空间。orientation: 您可以将BoxLayout的默认orientation由水平改为垂直。
添加事件
像大多数 GUI 工具包一样,Kivy 主要是基于事件的。该框架响应用户按键、鼠标事件和触摸事件。Kivy 有一个时钟的概念,你可以用它来安排未来某个时间的函数调用。
Kivy 还有 Properties 的概念,与 EventDispatcher 配合使用。属性帮助您进行验证检查。它们还允许您在小部件改变大小或位置时触发事件。
让我们将一个按钮事件添加到前面的按钮代码中:
from kivy.app import App
from kivy.uix.button import Button
class MainApp(App):
def build(self):
button = Button(text='Hello from Kivy',
size_hint=(.5, .5),
pos_hint={'center_x': .5, 'center_y': .5})
button.bind(on_press=self.on_press_button)
return button
def on_press_button(self, instance):
print('You pressed the button!') if __name__ == '__main__':
app = MainApp()
app.run()
在这段代码中,您调用button.bind()并将on_press事件链接到MainApp.on_press_button()。这个方法隐式地接受小部件instance,它是button对象本身。最后,每当用户按下按钮时,一条消息将打印到stdout。
使用 KV 语言
Kivy 还提供了一种叫做 KV 的设计语言,你可以在你的 Kivy 应用程序中使用它。KV 语言让您将界面设计从应用程序的逻辑中分离出来。这遵循了关注点分离原则,并且是模型-视图-控制器架构模式的一部分。您可以更新前面的示例以使用 KV 语言:
from kivy.app import App
from kivy.uix.button import Button
class ButtonApp(App):
def build(self):
return Button()
def on_press_button(self):
print('You pressed the button!')
if __name__ == '__main__':
app = ButtonApp()
app.run()
乍一看,这段代码可能看起来有点奇怪,因为它创建了一个Button,但没有设置它的任何属性,也没有将它绑定到任何事件。这里发生的事情是,Kivy 将自动查找与小写的类同名的文件,没有类名的App部分。
在这种情况下,类名是ButtonApp,所以 Kivy 会寻找一个名为button.kv的文件。如果该文件存在并且格式正确,那么 Kivy 将使用它来加载 UI。继续创建该文件,并添加以下代码:
1<Button>:
2 text: 'Press me'
3 size_hint: (.5, .5)
4 pos_hint: {'center_x': .5, 'center_y': .5}
5 on_press: app.on_press_button()
下面是每一行的作用:
- 行 1 匹配 Python 代码中的
Button调用。它告诉 Kivy 在实例化的对象中查找按钮定义。 - 第 2 行设置按钮的
text。 - 第三行用
size_hint设定宽度和高度。 - 第 4 行用
pos_hint设定按钮的位置。 - 第 5 行设置
on_press事件处理程序。要告诉 Kivy 事件处理程序在哪里,可以使用app.on_press_button()。这里,Kivy knows 将在Application类中查找一个名为.on_press_button()的方法。
您可以在一个或多个 KV 语言文件中设置所有的小部件和布局。KV 语言还支持在 KV 中导入 Python 模块、创建动态类等等。要了解全部细节,请查看 Kivy 的 KV 语言指南。
现在您已经准备好创建一个真正的应用程序了!
创建一个 Kivy 应用程序
学习新技能的最好方法之一是创造有用的东西。记住这一点,您将使用 Kivy 构建一个支持以下操作的计算器:
- 添加
- 减法
- 增加
- 分开
对于这个应用程序,您需要某种布局的一系列按钮。你还需要在你的应用程序顶部有一个盒子来显示方程式和它们的结果。这是你的计算器的草图:
现在您已经有了 UI 的目标,您可以继续编写代码了:
1from kivy.app import App
2from kivy.uix.boxlayout import BoxLayout
3from kivy.uix.button import Button
4from kivy.uix.textinput import TextInput
5
6class MainApp(App):
7 def build(self):
8 self.operators = ["/", "*", "+", "-"]
9 self.last_was_operator = None
10 self.last_button = None
11 main_layout = BoxLayout(orientation="vertical")
12 self.solution = TextInput(
13 multiline=False, readonly=True, halign="right", font_size=55
14 )
15 main_layout.add_widget(self.solution)
16 buttons = [
17 ["7", "8", "9", "/"],
18 ["4", "5", "6", "*"],
19 ["1", "2", "3", "-"],
20 [".", "0", "C", "+"],
21 ]
22 for row in buttons:
23 h_layout = BoxLayout()
24 for label in row:
25 button = Button(
26 text=label,
27 pos_hint={"center_x": 0.5, "center_y": 0.5},
28 )
29 button.bind(on_press=self.on_button_press)
30 h_layout.add_widget(button)
31 main_layout.add_widget(h_layout)
32
33 equals_button = Button(
34 text="=", pos_hint={"center_x": 0.5, "center_y": 0.5}
35 )
36 equals_button.bind(on_press=self.on_solution)
37 main_layout.add_widget(equals_button)
38
39 return main_layout
下面是您的计算器代码的工作方式:
- 在第 8 到 10 行中,您创建了一个
operators列表和几个方便的值,last_was_operator和last_button,稍后您将会用到它们。 - 在第 11 行到第 15 行中,您创建了一个顶层布局
main_layout并向其中添加了一个只读的TextInput小部件。 - 在第 16 到 21 行中,你创建了一个嵌套列表,包含了计算器的大部分
buttons。 - 在第 22 行,你在那些
buttons上开始一个for循环。对于每个嵌套列表,您将执行以下操作:- 在第 23 行中,你创建了一个水平方向的
BoxLayout。 - 在第 24 行,你在嵌套列表中的条目上开始另一个
for循环。 - 在第 25 到 39 行中,您为该行创建按钮,将它们绑定到事件处理程序,并将这些按钮添加到第 23 行的水平
BoxLayout中。 - 在第 31 行,你把这个布局添加到
main_layout。
- 在第 23 行中,你创建了一个水平方向的
- 在第 33 到 37 行中,您创建了等号按钮(
=),将其绑定到一个事件处理程序,并将其添加到main_layout。
下一步是创建.on_button_press()事件处理程序。下面是这段代码的样子:
41def on_button_press(self, instance):
42 current = self.solution.text
43 button_text = instance.text
44
45 if button_text == "C":
46 # Clear the solution widget
47 self.solution.text = ""
48 else:
49 if current and (
50 self.last_was_operator and button_text in self.operators):
51 # Don't add two operators right after each other
52 return
53 elif current == "" and button_text in self.operators:
54 # First character cannot be an operator
55 return
56 else:
57 new_text = current + button_text
58 self.solution.text = new_text
59 self.last_button = button_text
60 self.last_was_operator = self.last_button in self.operators
您的应用程序中的大多数小部件都会调用.on_button_press()。它是这样工作的:
-
第 41 行使用
instance参数,这样你就可以访问哪个小部件调用了这个函数。 -
第 42 和 43 行提取并存储
solution和text按钮的值。 -
第 45 到 47 行查看哪个按钮被按下了。如果用户按了
C,那么你会清除solution。否则,转到else语句。 -
第 49 行检查解决方案是否有任何预先存在的值。
-
第 50 到 52 行检查最后按下的按钮是否是操作按钮。如果是,那么
solution不会被更新。这是为了防止用户连续遇到两个操作符。例如,1 */不是一个有效的语句。 -
第 53 到 55 行检查第一个字符是否是一个操作符。如果是,那么
solution不会被更新,因为第一个值不能是操作符值。 -
第 56 到 58 行下降到
else子句。如果前面的条件都不满足,那么更新solution。 -
第 59 行将
last_button设置为最后按下的按钮的标签。 -
第 60 行根据是否是操作符将
last_was_operator设置为True或False。
要写的最后一位代码是.on_solution():
62def on_solution(self, instance):
63 text = self.solution.text
64 if text:
65 solution = str(eval(self.solution.text))
66 self.solution.text = solution
再次从solution中获取当前文本,并使用 Python 内置的eval() 来执行它。如果用户创建了一个类似于1+2的公式,那么eval()将运行你的代码并返回结果。最后,将结果设置为solution小部件的新值。
注意: eval()有点危险因为它可以运行任意代码。因为这个事实,大多数开发人员避免使用它。然而,因为您只允许整数、操作符和句点作为eval()的输入,所以在这个上下文中使用是安全的。
当您运行这段代码时,您的应用程序在台式计算机上将如下所示:
要查看该示例的完整代码,请展开下面的代码块。
这是计算器的完整代码:
from kivy.app import App
from kivy.uix.boxlayout import BoxLayout
from kivy.uix.button import Button
from kivy.uix.textinput import TextInput
class MainApp(App):
def build(self):
self.operators = ["/", "*", "+", "-"]
self.last_was_operator = None
self.last_button = None
main_layout = BoxLayout(orientation="vertical")
self.solution = TextInput(
multiline=False, readonly=True, halign="right", font_size=55
)
main_layout.add_widget(self.solution)
buttons = [
["7", "8", "9", "/"],
["4", "5", "6", "*"],
["1", "2", "3", "-"],
[".", "0", "C", "+"],
]
for row in buttons:
h_layout = BoxLayout()
for label in row:
button = Button(
text=label,
pos_hint={"center_x": 0.5, "center_y": 0.5},
)
button.bind(on_press=self.on_button_press)
h_layout.add_widget(button)
main_layout.add_widget(h_layout)
equals_button = Button(
text="=", pos_hint={"center_x": 0.5, "center_y": 0.5}
)
equals_button.bind(on_press=self.on_solution)
main_layout.add_widget(equals_button)
return main_layout
def on_button_press(self, instance):
current = self.solution.text
button_text = instance.text
if button_text == "C":
# Clear the solution widget
self.solution.text = ""
else:
if current and (
self.last_was_operator and button_text in self.operators):
# Don't add two operators right after each other
return
elif current == "" and button_text in self.operators:
# First character cannot be an operator
return
else:
new_text = current + button_text
self.solution.text = new_text
self.last_button = button_text
self.last_was_operator = self.last_button in self.operators
def on_solution(self, instance):
text = self.solution.text
if text:
solution = str(eval(self.solution.text))
self.solution.text = solution
if __name__ == "__main__":
app = MainApp()
app.run()
是时候部署您的应用程序了!
为 Android 打包您的应用程序
现在,您已经完成了应用程序的代码,您可以与其他人共享它了。一个很好的方法是将你的代码转换成可以在你的 Android 手机上运行的应用程序。为了实现这一点,首先你需要安装一个名为buildozer的带有pip的包:
$ pip install buildozer
然后,创建一个新文件夹,并在终端中导航到该文件夹。一旦到达那里,您将需要运行以下命令:
$ buildozer init
这将创建一个buildozer.spec文件,您将使用它来配置您的构建。对于此示例,您可以编辑等级库文件的前几行,如下所示:
[app]
# (str) Title of your application
title = KvCalc
# (str) Package name
package.name = kvcalc
# (str) Package domain (needed for android/ios packaging)
package.domain = org.kvcalc
请随意浏览文件的其余部分,看看还有什么可以更改的。
此时,您几乎已经准备好构建您的应用程序了,但是首先,您需要安装buildozer的依赖项。安装完成后,将您的计算器应用程序复制到新文件夹中,并将其重命名为main.py。这是buildozer要求的。如果没有正确命名文件,那么构建将会失败。
现在,您可以运行以下命令:
$ buildozer -v android debug
构建步骤需要很长时间!在我的机器上,需要 15 到 20 分钟。根据你的硬件,它可能需要更长的时间,所以在你等待的时候,请随意喝杯咖啡或者去跑步。会在构建过程中下载任何它需要的 Android SDK。如果一切都按计划进行,那么在你的bin文件夹中你将会有一个名为kvcalc-0.1-debug.apk的文件。
下一步是将你的 Android 手机连接到电脑上,并将apk文件复制到电脑上。然后可以打开手机上的文件浏览器,点击apk文件。Android 应该会问你是否愿意安装该应用程序。您可能会看到一条警告,因为该应用程序是从 Google Play 之外下载的,但您仍然可以安装它。
下面是我的三星 S9 上运行的计算器:
buildozer工具有几个你可以使用的命令。查看文档,看看你还能做些什么。
如果你需要更精细的控制,你也可以使用python-for-android来打包应用。你不会在这里讨论这个,但是如果你感兴趣,看看这个项目的快速启动。
为 iOS 打包您的应用
为 iOS 构建应用程序的说明比 Android 要复杂一些。为了获得最新的信息,你应该总是使用 Kivy 的官方打包文档。您需要运行以下命令,然后才能在 Mac 上打包您的 iOS 应用程序:
$ brew install autoconf automake libtool pkg-config
$ brew link libtool
$ sudo easy_install pip
$ sudo pip install Cython==0.29.10
一旦这些都成功安装,您将需要使用以下命令编译发行版:
$ git clone git://github.com/kivy/kivy-ios
$ cd kivy-ios
$ ./toolchain.py build python3 kivy
如果你得到一个错误,说iphonesimulator找不到,那么看看这个 StackOverflow 回答的方法来解决这个问题。然后再次尝试运行上述命令。
如果您遇到 SSL 错误,那么您可能没有 Python 的 OpenSSL 设置。这个命令应该可以解决这个问题:
$ cd /Applications/Python\ 3.7/
$ ./Install\ Certificates.command
现在返回并尝试再次运行toolchain命令。
一旦您成功运行了所有前面的命令,您就可以使用toolchain脚本创建您的 Xcode 项目了。在创建 Xcode 项目之前,您的主应用程序的入口点必须被命名为。下面是您将运行的命令:
./toolchain.py create <title> <app_directory>
应该有一个名为title的目录,其中包含您的 Xcode 项目。现在,您可以在 Xcode 中打开该项目,并从那里开始工作。请注意,如果你想将你的应用提交到 App Store,那么你必须在developer.apple.com创建一个开发者账户,并支付年费。
为 Windows 打包您的应用程序
您可以使用 PyInstaller 为 Windows 打包您的 Kivy 应用程序。如果您以前从未使用过它,那么请查看使用 PyInstaller 轻松分发 Python 应用程序的。
您可以使用pip安装 PyInstaller:
$ pip install pyinstaller
以下命令将打包您的应用程序:
$ pyinstaller main.py -w
此命令将创建一个 Windows 可执行文件和几个其他文件。-w参数告诉 PyInstaller 这是一个窗口应用程序,而不是命令行应用程序。如果您想让 PyInstaller 创建一个可执行文件,那么除了-w之外,您还可以传入--onefile参数。
为 macOS 打包您的应用程序
您可以使用 PyInstaller 来创建 Mac 可执行文件,就像您为 Windows 所做的那样。唯一的要求是在 Mac 上运行这个命令:
$ pyinstaller main.py -w --onefile
这将在dist文件夹中创建一个可执行文件。可执行文件将与您传递给 PyInstaller 的 Python 文件同名。如果你想减小可执行文件的大小,或者在你的应用程序中使用 GStreamer,那么查看 Kivy 的 macOS 的打包页面以获得更多信息。
结论
Kivy 是一个非常有趣的 GUI 框架,可以用来在 iOS 和 Android 上创建桌面用户界面和移动应用程序。Kivy 应用程序看起来不会像任何平台上的本地应用程序。如果您希望您的应用程序在外观和感觉上与竞争对手不同,这可能是一个优势!
在本教程中,您学习了 Kivy 的基础知识,包括如何添加小部件、挂接事件、布局多个小部件以及使用 KV 语言。然后,您创建了您的第一个 Kivy 应用程序,并学习了如何在其他平台上分发它,包括移动平台!
有许多关于 Kivy 的小部件和概念您在这里没有涉及到,所以一定要查看 Kivy 的网站以获得教程、示例应用程序和更多内容。
延伸阅读
要了解更多关于 Kivy 的信息,请查看以下资源:
要了解如何使用另一个 Python GUI 框架创建桌面应用程序,请查看如何使用 wxPython 构建 Python GUI 应用程序。*****
用 Python 在 Django 中建模多态性
原文:https://realpython.com/modeling-polymorphism-django-python/
在关系数据库中建模多态性是一项具有挑战性的任务。在本文中,我们介绍了几种使用 Django 对象-关系映射( ORM )在关系数据库中表示多态对象的建模技术。
本中级教程是为已经熟悉 Django 基本设计的读者设计的。
免费奖励: ,提高您的 Django + Python web 开发技能。
什么是多态性?
多态是一个对象采取多种形式的能力。多态对象的常见例子包括电子商务网站中的事件流、不同类型的用户和产品。当单个实体需要不同的功能或信息时,使用多态模型。
在上面的例子中,所有事件都被记录下来以备将来使用,但是它们可以包含不同的数据。所有用户都需要能够登录,但是他们可能有不同的配置文件结构。在每个电子商务网站中,用户都希望将不同的产品放入购物车。
为什么对多态性建模具有挑战性?
有许多方法可以对多态性进行建模。有些方法使用 Django ORM 的标准特性,有些使用 Django ORM 的特殊特性。在对多态对象建模时,您将会遇到以下主要挑战:
-
如何表示单个多态对象:多态对象有不同的属性。Django ORM 将属性映射到数据库中的列。在这种情况下,Django ORM 应该如何将属性映射到表中的列呢?不同的对象应该驻留在同一个表中吗?你应该有多个表吗?
-
如何引用多态模型的实例:要利用数据库和 Django ORM 特性,您需要使用外键来引用对象。如何决定表示单个多态对象对您引用它的能力至关重要。
为了真正理解建模多态性的挑战,你要把一个小书店从它的第一个在线网站变成一个销售各种产品的大网店。在这个过程中,您将体验和分析使用 Django ORM 对多态性建模的不同方法。
注意:要学习本教程,建议您使用 PostgreSQL 后端、Django 2.x 和 Python 3。
也可以使用其他数据库后端。在使用 PostgreSQL 独有特性的地方,将为其他数据库提供一个替代方案。
天真的实现
你在镇上的一个好地方有一家书店,就在咖啡店旁边,你想开始在网上卖书。
你只卖一种产品:书。在您的在线商店中,您希望显示图书的详细信息,如名称和价格。你希望你的用户浏览网站并收集许多书籍,所以你还需要一个购物车。你最终需要把书运送给用户,所以你需要知道每本书的重量来计算运费。
让我们为您的新书店创建一个简单的模型:
from django.contrib.auth import get_user_model
from django.db import models
class Book(models.Model):
name = models.CharField(
max_length=100,
)
price = models.PositiveIntegerField(
help_text='in cents',
)
weight = models.PositiveIntegerField(
help_text='in grams',
)
def __str__(self) -> str:
return self.name
class Cart(models.Model):
user = models.OneToOneField(
get_user_model(),
primary_key=True,
on_delete=models.CASCADE,
)
books = models.ManyToManyField(Book)
要创建一本新书,您需要提供名称、价格和重量:
>>> from naive.models import Book >>> book = Book.objects.create(name='Python Tricks', price=1000, weight=200) >>> book <Product: Python Tricks>要创建购物车,首先需要将其与用户相关联:
>>> from django.contrib.auth import get_user_model
>>> haki = get_user_model().create_user('haki')
>>> from naive.models import Cart
>>> cart = Cart.objects.create(user=haki)
然后,用户可以开始向其中添加项目:
>>> cart.products.add(book) >>> cart.products.all() <QuerySet [<Book: Python Tricks>]>Pro
- 易于理解和维护:对于单一类型的产品就足够了。
Con
- 限于同质产品:只支持属性集相同的产品。多态性根本不被捕获或允许。
稀疏模型
随着你的网上书店的成功,用户开始问你是否也卖电子书。电子书对你的网上商店来说是一个很好的产品,你想马上开始销售它们。
实体书不同于电子书:
一本电子书没有重量。这是一个虚拟产品。
一本电子书不需要发货。用户从网站上下载。
为了使您现有的模型支持销售电子书的附加信息,您向现有的
Book模型添加了一些字段:from django.contrib.auth import get_user_model from django.db import models class Book(models.Model): TYPE_PHYSICAL = 'physical' TYPE_VIRTUAL = 'virtual' TYPE_CHOICES = ( (TYPE_PHYSICAL, 'Physical'), (TYPE_VIRTUAL, 'Virtual'), ) type = models.CharField( max_length=20, choices=TYPE_CHOICES, ) # Common attributes name = models.CharField( max_length=100, ) price = models.PositiveIntegerField( help_text='in cents', ) # Specific attributes weight = models.PositiveIntegerField( help_text='in grams', ) download_link = models.URLField( null=True, blank=True, ) def __str__(self) -> str: return f'[{self.get_type_display()}] {self.name}' class Cart(models.Model): user = models.OneToOneField( get_user_model(), primary_key=True, on_delete=models.CASCADE, ) books = models.ManyToManyField( Book, )首先,您添加了一个 type 字段来指示这是哪种类型的书。然后,您添加了一个 URL 字段来存储电子书的下载链接。
要将实体书添加到书店,请执行以下操作:
>>> from sparse.models import Book
>>> physical_book = Book.objects.create(
... type=Book.TYPE_PHYSICAL,
... name='Python Tricks',
... price=1000,
... weight=200,
... download_link=None,
... )
>>> physical_book
<Book: [Physical] Python Tricks>
要添加新的电子书,请执行以下操作:
>>> virtual_book = Book.objects.create( ... type=Book.TYPE_VIRTUAL, ... name='The Old Man and the Sea', ... price=1500, ... weight=0, ... download_link='https://books.com/12345', ... ) >>> virtual_book <Book: [Virtual] The Old Man and the Sea>您的用户现在可以将图书和电子书添加到购物车中:
>>> from sparse.models import Cart
>>> cart = Cart.objects.create(user=user)
>>> cart.books.add(physical_book, virtual_book)
>>> cart.books.all()
<QuerySet [<Book: [Physical] Python Tricks>, <Book: [Virtual] The Old Man and the Sea>]>
虚拟图书大受欢迎,你决定雇佣员工。新员工显然不太懂技术,您开始在数据库中看到奇怪的东西:
>>> Book.objects.create( ... type=Book.TYPE_PHYSICAL, ... name='Python Tricks', ... price=1000, ... weight=0, ... download_link='http://books.com/54321', ... )那本书显然有
0磅重,并且有下载链接。这款电子书明显重 100g,没有下载链接:
>>> Book.objects.create(
... type=Book.TYPE_VIRTUAL,
... name='Python Tricks',
... price=1000,
... weight=100,
... download_link=None,
... )
这没有任何意义。你有数据完整性问题。
为了克服完整性问题,您需要向模型中添加验证:
from django.core.exceptions import ValidationError
class Book(models.Model):
# ...
def clean(self) -> None:
if self.type == Book.TYPE_VIRTUAL:
if self.weight != 0:
raise ValidationError(
'A virtual product weight cannot exceed zero.'
)
if self.download_link is None:
raise ValidationError(
'A virtual product must have a download link.'
)
elif self.type == Book.TYPE_PHYSICAL:
if self.weight == 0:
raise ValidationError(
'A physical product weight must exceed zero.'
)
if self.download_link is not None:
raise ValidationError(
'A physical product cannot have a download link.'
)
else:
assert False, f'Unknown product type "{self.type}"'
您使用了 Django 的内置验证机制来实施数据完整性规则。clean()仅由 Django 表单自动调用。对于不是由 Django 表单创建的对象,您需要确保显式验证该对象。
为了保持Book模型的完整性,您需要对创建图书的方式做一点小小的改变:
>>> book = Book( ... type=Book.TYPE_PHYSICAL, ... name='Python Tricks', ... price=1000, ... weight=0, ... download_link='http://books.com/54321', ... ) >>> book.full_clean() ValidationError: {'__all__': ['A physical product weight must exceed zero.']} >>> book = Book( ... type=Book.TYPE_VIRTUAL, ... name='Python Tricks', ... price=1000, ... weight=100, ... download_link=None, ... ) >>> book.full_clean() ValidationError: {'__all__': ['A virtual product weight cannot exceed zero.']}当使用默认管理器(
Book.objects.create(...))创建对象时,Django 将创建一个对象并立即将它保存到数据库中。在您的情况下,您希望在将对象保存到数据库之前对其进行验证。首先创建对象(
Book(...)),验证它(book.full_clean()),然后保存它(book.save())。反规格化:
稀疏模型是反规格化的产物。在反规范化过程中,您将来自多个规范化模型的属性内联到一个表中,以获得更好的性能。非规范化的表通常会有许多可空的列。
非规范化通常用于决策支持系统,如读取性能非常重要的数据仓库。与 OLTP 系统不同,数据仓库通常不需要执行数据完整性规则,这使得反规范化成为理想。
Pro
- 易于理解和维护:当某些类型的对象需要更多信息时,稀疏模型通常是我们采取的第一步。非常直观,容易理解。
缺点
无法利用非空数据库约束:空值用于没有为所有类型的对象定义的属性。
复杂验证逻辑:需要复杂验证逻辑来实施数据完整性规则。复杂的逻辑也需要更多的测试。
许多空字段会造成混乱:在一个模型中表示多种类型的产品会增加理解和维护的难度。
新类型需要模式更改:新类型的产品需要额外的字段和验证。
用例
当您表示共享大部分属性的异构对象,并且不经常添加新项目时,稀疏模型是理想的。
半结构化模型
你的书店现在非常成功,你卖出了越来越多的书。你有不同流派和出版商的书,不同格式的电子书,形状和大小都很奇怪的书,等等。
在稀疏模型方法中,您为每种新产品添加了字段。该模型现在有许多可空字段,新开发人员和员工很难跟上。
为了解决混乱的问题,您决定只保留模型中的公共字段(
name和price)。您将剩余的字段存储在一个单独的JSONField中:from django.contrib.auth import get_user_model from django.contrib.postgres.fields import JSONField from django.db import models class Book(models.Model): TYPE_PHYSICAL = 'physical' TYPE_VIRTUAL = 'virtual' TYPE_CHOICES = ( (TYPE_PHYSICAL, 'Physical'), (TYPE_VIRTUAL, 'Virtual'), ) type = models.CharField( max_length=20, choices=TYPE_CHOICES, ) # Common attributes name = models.CharField( max_length=100, ) price = models.PositiveIntegerField( help_text='in cents', ) extra = JSONField() def __str__(self) -> str: return f'[{self.get_type_display()}] {self.name}' class Cart(models.Model): user = models.OneToOneField( get_user_model(), primary_key=True, on_delete=models.CASCADE, ) books = models.ManyToManyField( Book, related_name='+', )JSONField:
在本例中,您使用 PostgreSQL 作为数据库后端。Django 在
django.contrib.postgres.fields中为 PostgreSQL 提供了内置的 JSON 字段。对于其他数据库,如 SQLite 和 MySQL,有 T2 包提供类似的功能。
你的
Book模型现在整洁了。公共属性被建模为字段。不是所有类型产品共有的属性存储在extraJSON 字段中:
>>> from semi_structured.models import Book
>>> physical_book = Book(
... type=Book.TYPE_PHYSICAL,
... name='Python Tricks',
... price=1000,
... extra={'weight': 200}, ... )
>>> physical_book.full_clean()
>>> physical_book.save()
<Book: [Physical] Python Tricks>
>>> virtual_book = Book(
... type=Book.TYPE_VIRTUAL,
... name='The Old Man and the Sea',
... price=1500,
... extra={'download_link': 'http://books.com/12345'}, ... )
>>> virtual_book.full_clean()
>>> virtual_book.save()
<Book: [Virtual] The Old Man and the Sea>
>>> from semi_structured.models import Cart
>>> cart = Cart.objects.create(user=user)
>>> cart.books.add(physical_book, virtual_book)
>>> cart.books.all()
<QuerySet [<Book: [Physical] Python Tricks>, <Book: [Virtual] The Old Man and the Sea>]>
清理杂物很重要,但这是有代价的。验证逻辑要复杂得多:
from django.core.exceptions import ValidationError
from django.core.validators import URLValidator
class Book(models.Model):
# ...
def clean(self) -> None:
if self.type == Book.TYPE_VIRTUAL:
try:
weight = int(self.extra['weight'])
except ValueError:
raise ValidationError(
'Weight must be a number'
)
except KeyError:
pass
else:
if weight != 0:
raise ValidationError(
'A virtual product weight cannot exceed zero.'
)
try:
download_link = self.extra['download_link']
except KeyError:
pass
else:
# Will raise a validation error
URLValidator()(download_link)
elif self.type == Book.TYPE_PHYSICAL:
try:
weight = int(self.extra['weight'])
except ValueError:
raise ValidationError(
'Weight must be a number'
)
except KeyError:
pass
else:
if weight == 0:
raise ValidationError(
'A physical product weight must exceed zero.'
)
try:
download_link = self.extra['download_link']
except KeyError:
pass
else:
if download_link is not None:
raise ValidationError(
'A physical product cannot have a download link.'
)
else:
raise ValidationError(f'Unknown product type "{self.type}"')
使用适当字段的好处是它可以验证类型。Django 和 Django ORM 都可以执行检查,以确保字段使用了正确的类型。当使用JSONField时,您需要验证类型和值:
>>> book = Book.objects.create( ... type=Book.TYPE_VIRTUAL, ... name='Python Tricks', ... price=1000, ... extra={'weight': 100}, ... ) >>> book.full_clean() ValidationError: {'__all__': ['A virtual product weight cannot exceed zero.']}使用 JSON 的另一个问题是,并非所有数据库都支持查询和索引 JSON 字段中的值。
以 PostgreSQL 为例,可以查询所有重量超过
100的书籍:
>>> Book.objects.filter(extra__weight__gt=100)
<QuerySet [<Book: [Physical] Python Tricks>]>
然而,并不是所有的数据库供应商都支持这一点。
使用 JSON 的另一个限制是不能使用数据库约束,比如 not null、unique 和 foreign keys。您必须在应用程序中实现这些约束。
这种半结构化的方法类似于 NoSQL 的架构,有很多优点和缺点。JSON 字段是一种绕过关系数据库的严格模式的方法。这种混合方法为我们提供了将许多对象类型压缩到单个表中的灵活性,同时还保留了关系型、严格型和强类型数据库的一些优点。对于许多常见的 NoSQL 用例,这种方法实际上可能更合适。
优点
-
减少杂乱:公共字段存储在模型上。其他字段存储在单个 JSON 字段中。
-
更容易添加新类型:新类型的产品不需要改变模式。
缺点
-
复杂和特殊的验证逻辑:验证 JSON 字段需要验证类型和值。这个挑战可以通过使用其他解决方案来验证 JSON 数据来解决,比如 JSON 模式。
-
无法利用数据库约束:不能使用数据库约束,如 null null、unique 和 foreign key 约束,它们在数据库级别强制类型和数据完整性。
-
受限于数据库对 JSON 的支持:并不是所有的数据库厂商都支持查询和索引 JSON 字段。
-
数据库系统不强制执行模式:模式更改可能需要向后兼容或临时迁移。数据可能会“腐烂”
-
没有与数据库元数据系统深度集成:关于字段的元数据没有存储在数据库中。模式仅在应用程序级别实施。
用例
当您需要表示没有很多公共属性的异构对象,以及经常添加新项目时,半结构化模型是理想的。
半结构化方法的一个经典用例是存储事件(如日志、分析和事件存储)。大多数事件都有时间戳、类型和元数据,如设备、用户代理、用户等等。每种类型的数据都存储在 JSON 字段中。对于分析和日志事件,能够以最小的努力添加新类型的事件非常重要,因此这种方法是理想的。
抽象基础模型
到目前为止,您已经解决了将产品视为异类的问题。您假设产品之间的差异很小,因此在相同的模型中维护它们是有意义的。这个假设只能带你到这里。
你的小店发展很快,你想开始销售完全不同类型的产品,如电子阅读器、笔和笔记本。
书和电子书都是产品。产品是使用名称和价格等公共属性来定义的。在面向对象的环境中,你可以把一个Product看作一个基类或者一个接口。您添加的每一个新类型的产品都必须实现Product类,并用它自己的属性扩展它。
Django 提供了创建抽象基类的能力。让我们定义一个Product抽象基类,并为Book和EBook添加两个模型:
from django.contrib.auth import get_user_model
from django.db import models
class Product(models.Model):
class Meta: abstract = True
name = models.CharField(
max_length=100,
)
price = models.PositiveIntegerField(
help_text='in cents',
)
def __str__(self) -> str:
return self.name
class Book(Product):
weight = models.PositiveIntegerField(
help_text='in grams',
)
class EBook(Product):
download_link = models.URLField()
注意,Book和EBook都继承自Product。基类Product中定义的字段是继承的,所以派生的模型Book和Ebook不需要重复。
要添加新产品,可以使用派生类:
>>> from abstract_base_model.models import Book >>> book = Book.objects.create(name='Python Tricks', price=1000, weight=200) >>> book <Book: Python Tricks> >>> ebook = EBook.objects.create( ... name='The Old Man and the Sea', ... price=1500, ... download_link='http://books.com/12345', ... ) >>> ebook <Book: The Old Man and the Sea>您可能已经注意到
Cart模型不见了。您可以尝试创建一个带有ManyToMany字段的Cart模型来Product:class Cart(models.Model): user = models.OneToOneField( get_user_model(), primary_key=True, on_delete=models.CASCADE, ) items = models.ManyToManyField(Product)如果您试图将一个
ManyToMany字段引用到一个抽象模型,您将得到以下错误:abstract_base_model.Cart.items: (fields.E300) Field defines a relation with model 'Product', which is either not installed, or is abstract.外键约束只能指向具体的表。抽象基础模型
Product只存在于代码中,所以数据库中没有 products 表。Django ORM 只会为派生的模型Book和EBook创建表格。鉴于无法引用抽象基类
Product,需要直接引用书籍和电子书:class Cart(models.Model): user = models.OneToOneField( get_user_model(), primary_key=True, on_delete=models.CASCADE, ) books = models.ManyToManyField(Book) ebooks = models.ManyToManyField(EBook)现在,您可以将书籍和电子书添加到购物车中:
>>> user = get_user_model().objects.first()
>>> cart = Cart.objects.create(user=user)
>>> cart.books.add(book)
>>> cart.ebooks.add(ebook)
这个模型现在有点复杂了。让我们查询购物车中商品的总价:
>>> from django.db.models import Sum >>> from django.db.models.functions import Coalesce >>> ( ... Cart.objects ... .filter(pk=cart.pk) ... .aggregate(total_price=Sum( ... Coalesce('books__price', 'ebooks__price') ... )) ... ) {'total_price': 1000}因为您有多种类型的书,所以您使用
Coalesce来获取每行的书的价格或电子书的价格。Pro
- 更容易实现特定的逻辑:每个产品的独立模型使得实现、测试和维护特定的逻辑更加容易。
缺点
需要多个外键:为了引用所有类型的产品,每种类型都需要一个外键。
更难实现和维护:对所有类型产品的操作都需要检查所有外键。这增加了代码的复杂性,使得维护和测试更加困难。
非常难以扩展:新型产品需要额外的型号。管理许多模型可能会很繁琐,并且很难扩展。
用例
当只有很少类型的对象需要非常独特的逻辑时,抽象基础模型是一个很好的选择。
一个直观的例子是为你的网上商店建模一个支付过程。您希望接受信用卡、PayPal 和商店信用支付。每种支付方式都经历一个非常不同的过程,需要非常独特的逻辑。添加一种新的支付方式并不常见,而且您近期也不打算添加新的支付方式。
您可以使用信用卡付款流程、PayPal 付款流程和商店信用付款流程的派生类来创建付款流程基类。对于每个派生类,您以一种非常不同的方式实现支付过程,这种方式不容易共享。在这种情况下,具体处理每个支付过程可能是有意义的。
混凝土基础模型
Django 提供了另一种在模型中实现继承的方法。您可以将基类具体化,而不是使用只存在于代码中的抽象基类。“具体”是指基类以表的形式存在于数据库中,不像抽象基类解决方案中,基类只存在于代码中。
使用抽象基础模型,您无法引用多种类型的产品。您被迫为每种类型的产品创建多对多关系。这使得在公共字段上执行任务变得更加困难,比如获取购物车中所有商品的总价。
使用一个具体的基类,Django 将在数据库中为
Product模型创建一个表。Product模型将拥有您在基础模型中定义的所有公共字段。衍生模型如Book和EBook将使用一对一字段引用Product表。要引用一个产品,您需要为基本模型创建一个外键:from django.contrib.auth import get_user_model from django.db import models class Product(models.Model): name = models.CharField( max_length=100, ) price = models.PositiveIntegerField( help_text='in cents', ) def __str__(self) -> str: return self.name class Book(Product): weight = models.PositiveIntegerField() class EBook(Product): download_link = models.URLField()这个例子和上一个例子的唯一区别是
Product模型没有用abstract=True定义。要创建新产品,您可以直接使用派生的
Book和EBook模型:
>>> from concrete_base_model.models import Book, EBook
>>> book = Book.objects.create(
... name='Python Tricks',
... price=1000,
... weight=200,
... )
>>> book
<Book: Python Tricks>
>>> ebook = EBook.objects.create(
... name='The Old Man and the Sea',
... price=1500,
... download_link='http://books.com/12345',
... )
>>> ebook
<Book: The Old Man and the Sea>
在具体基类的情况下,看看底层数据库中发生了什么是很有趣的。让我们看看 Django 在数据库中创建的表:
> \d concrete_base_model_product
Column | Type | Default
--------+-----------------------+---------------------------------------------------------
id | integer | nextval('concrete_base_model_product_id_seq'::regclass)
name | character varying(100) |
price | integer |
Indexes:
"concrete_base_model_product_pkey" PRIMARY KEY, btree (id)
Referenced by:
TABLE "concrete_base_model_cart_items" CONSTRAINT "..." FOREIGN KEY (product_id)
REFERENCES concrete_base_model_product(id) DEFERRABLE INITIALLY DEFERRED
TABLE "concrete_base_model_book" CONSTRAINT "..." FOREIGN KEY (product_ptr_id)
REFERENCES concrete_base_model_product(id) DEFERRABLE INITIALLY DEFERRED
TABLE "concrete_base_model_ebook" CONSTRAINT "..." FOREIGN KEY (product_ptr_id)
REFERENCES concrete_base_model_product(id) DEFERRABLE INITIALLY DEFERRED
product 表有两个熟悉的字段:名称和价格。这些是您在Product模型中定义的公共字段。Django 还为您创建了一个 ID 主键。
在“约束”部分,您会看到多个引用 product 表的表。两个突出的表是concrete_base_model_book和concrete_base_model_ebook:
> \d concrete_base_model_book
Column | Type
---------------+---------
product_ptr_id | integer weight | integer
Indexes:
"concrete_base_model_book_pkey" PRIMARY KEY, btree (product_ptr_id)
Foreign-key constraints:
"..." FOREIGN KEY (product_ptr_id) REFERENCES concrete_base_model_product(id) DEFERRABLE INITIALLY DEFERRED
Book模型只有两个字段:
weight是您在派生的Book模型中添加的字段。product_ptr_id既是表的主键,也是基本产品模型的外键。
在幕后,Django 为 product 创建了一个基表。然后,对于每个派生的模型,Django 创建了另一个表,其中包含附加字段,以及一个既充当 product 表的主键又充当外键的字段。
让我们来看看 Django 生成的获取一本书的查询。下面是print(Book.objects.filter(pk=1).query)的结果:
SELECT "concrete_base_model_product"."id", "concrete_base_model_product"."name", "concrete_base_model_product"."price", "concrete_base_model_book"."product_ptr_id", "concrete_base_model_book"."weight" FROM "concrete_base_model_book" INNER JOIN "concrete_base_model_product" ON "concrete_base_model_book"."product_ptr_id" = "concrete_base_model_product"."id" WHERE "concrete_base_model_book"."product_ptr_id" = 1
为了拿到一本书,姜戈加入了product_ptr_id球场的concrete_base_model_product和concrete_base_model_book。名称和价格在产品表中,重量在图书表中。
由于所有产品都在 Product 表中进行管理,所以现在可以在来自Cart模型的外键中引用它:
class Cart(models.Model):
user = models.OneToOneField(
get_user_model(),
primary_key=True,
on_delete=models.CASCADE,
)
items = models.ManyToManyField(Product)
向购物车添加商品与之前相同:
>>> from concrete_base_model.models import Cart >>> cart = Cart.objects.create(user=user) >>> cart.items.add(book, ebook) >>> cart.items.all() <QuerySet [<Book: Python Tricks>, <Book: The Old Man and the Sea>]>使用公共字段也很简单:
>>> from django.db.models import Sum
>>> cart.items.aggregate(total_price=Sum('price'))
{'total_price': 2500}
迁移 Django 中的基类:
当一个派生模型被创建时,Django 向迁移添加一个bases属性:
migrations.CreateModel(
name='Book',
fields=[...],
bases=('concrete_base_model.product',), ),
如果将来您删除或更改了基类,Django 可能无法自动执行迁移。您可能会得到以下错误:
TypeError: metaclass conflict: the metaclass of a derived class must
be a (non-strict) subclass of the metaclasses of all its bases
这是姜戈( #23818 , #23521 , #26488 )的一个已知问题。要解决此问题,您必须手动编辑原始迁移并调整“基础”属性。
优点
-
主键在所有类型中保持一致:产品由基表中的单个序列发出。通过使用 UUID 而不是序列,可以很容易地解决这种限制。
-
单表查询常用属性:总价、产品名称列表、价格等常用查询可以直接从基表中取出。
缺点
-
新产品类型需要模式变更:新类型需要新型号。
-
会产生低效的查询:单个项目的数据在两个数据库表中。提取产品需要与基表连接。
-
无法从基类实例访问扩展数据:需要类型字段来向下转换项目。这增加了代码的复杂性。
django-polymorphic是一个流行的模块,可能会消除这些挑战。
用例
当基类中的公共字段足以满足大多数公共查询时,具体的基模型方法是有用的。
例如,如果您经常需要查询购物车的总价,显示购物车中的商品列表,或者对购物车模型运行特定的分析查询,那么在一个数据库表中包含所有的通用属性会让您受益匪浅。
通用外键
遗产继承有时会是一件令人讨厌的事情。它迫使你创建(可能是不成熟的)抽象,并且它并不总是很好地适应 ORM。
您遇到的主要问题是从购物车模型中引用不同的产品。您首先试图将所有的产品类型压缩到一个模型中(稀疏模型、半结构化模型),并且您得到了混乱。然后,您尝试将产品分成不同的模型,并使用具体的基础模型提供统一的界面。你得到了一个复杂的模式和许多连接。
Django 提供了一种引用项目中任何模型的特殊方式,称为 GenericForeignKey 。通用外键是 Django 内置的内容类型框架的一部分。Django 自己使用内容类型框架来跟踪模型。这对于一些核心功能(如迁移和权限)是必要的。
为了更好地理解什么是内容类型以及它们如何促进通用外键,让我们来看一下与Book模型相关的内容类型:
>>> from django.contrib.contenttypes.models import ContentType >>> ct = ContentType.objects.get_for_model(Book) >>> vars(ct) {'_state': <django.db.models.base.ModelState at 0x7f1c9ea64400>, 'id': 22, 'app_label': 'concrete_base_model', 'model': 'book'}每个型号都有唯一的标识符。如果你想引用一本 PK 54 的书,你可以说:“在内容类型 22 表示的模型中获取 PK 54 的对象。”
GenericForeignKey就是这样实现的。要创建通用外键,需要定义两个字段:
- 对内容类型(模型)的引用
- 被引用对象的主键(模型实例的
pk属性)要使用
GenericForeignKey实现多对多关系,您需要手动创建一个模型来连接购物车和商品。
Cart模型与您目前看到的大致相似:from django.db import models from django.contrib.auth import get_user_model class Cart(models.Model): user = models.OneToOneField( get_user_model(), primary_key=True, on_delete=models.CASCADE, )与以前的
Cart型号不同,这个Cart不再包括一个ManyToMany字段。你需要自己去做。要表示购物车中的单个商品,您需要引用购物车和任何产品:
from django.contrib.contenttypes.fields import GenericForeignKey from django.contrib.contenttypes.models import ContentType class CartItem(models.Model): cart = models.ForeignKey( Cart, on_delete=models.CASCADE, related_name='items', ) product_object_id = models.IntegerField() product_content_type = models.ForeignKey( ContentType, on_delete=models.PROTECT, ) product = GenericForeignKey( 'product_content_type', 'product_object_id', )要在购物车中添加新商品,您需要提供内容类型和主键:
>>> book = Book.objects.first()
>>> CartItem.objects.create(
... product_content_type=ContentType.objects.get_for_model(book), ... product_object_id=book.pk, ... )
>>> ebook = EBook.objects.first()
>>> CartItem.objects.create(
... product_content_type=ContentType.objects.get_for_model(ebook), ... product_object_id=ebook.pk, ... )
将商品添加到购物车是一项常见任务。您可以在购物车中添加一种方法,将任何产品添加到购物车中:
class Cart(models.Model):
# ...
def add_item(self, product) -> 'CartItem':
product_content_type = ContentType.objects.get_for_model(product)
return CartItem.objects.create(
cart=self,
product_content_type=product_content_type,
product_object_id=product.pk,
)
现在,向购物车添加新商品的时间大大缩短了:
>>> cart.add_item(book) >>> cart.add_item(ebook)获取购物车中商品的信息也是可能的:
>>> cart.items.all()
<QuerySet [<CartItem: CartItem object (1)>, <CartItem: CartItem object (2)>]
>>> item = cart.items.first()
>>> item.product
<Book: Python Tricks>
>>> item.product.price
1000
到目前为止一切顺利。关键在哪里?
让我们尝试计算购物车中产品的总价:
>>> from django.db.models import Sum >>> cart.items.aggregate(total=Sum('product__price')) FieldError: Field 'product' does not generate an automatic reverse relation and therefore cannot be used for reverse querying. If it is a GenericForeignKey, consider adding a GenericRelation.Django 告诉我们,不可能从通用模型到引用模型遍历通用关系。原因是 Django 不知道要连接到哪个表。记住,
Item模型可以指向任何一个ContentType。错误信息确实提到了一个
GenericRelation。使用一个GenericRelation,你可以定义一个从参考模型到Item模型的反向关系。例如,您可以定义从Book模型到图书项目的反向关系:from django.contrib.contenttypes.fields import GenericRelation class Book(model.Model): # ... cart_items = GenericRelation( 'CartItem', 'product_object_id', 'product_content_type_id', related_query_name='books', )使用反向关系,您可以回答这样的问题,比如有多少购物车包含了某本书:
>>> book.cart_items.count()
4
>>> CartItem.objects.filter(books__id=book.id).count()
4
这两种说法完全相同。
您仍然需要知道整个购物车的价格。您已经看到,使用 ORM 不可能从每个产品表中获取价格。为此,您必须迭代这些项目,分别获取每个项目,然后聚合:
>>> sum(item.product.price for item in cart.items.all()) 2500这是泛型外键的主要缺点之一。这种灵活性伴随着巨大的性能成本。仅仅使用 Django ORM 很难优化性能。
结构子类型
在抽象和具体的基类方法中,您使用了基于类层次结构的名义子类型。Mypy 能够检测两个类之间的这种形式的关系,并从中推断出类型。
在一般关系方法中,您使用了结构化子类型。当一个类实现另一个类的所有方法和属性时,结构子类型存在。当您希望避免模块之间的直接依赖时,这种形式的子类型非常有用。
Mypy 提供了一种使用协议利用结构化子类型的方法。
您已经确定了具有通用方法和属性的产品实体。您可以定义一个
Protocol:from typing_extensions import Protocol class Product(Protocol): pk: int name: str price: int def __str__(self) -> str: ...注意:在方法定义中使用类属性和省略号(
...)是 Python 3.7 中的新特性。在 Python 的早期版本中,不可能使用这种语法定义协议。方法体中应该有pass而不是省略号。像pk和name这样的类属性可以使用@attribute装饰器来定义,但是它不能用于 Django 模型。您现在可以使用
Product协议来添加类型信息。例如,在add_item()中,您接受一个产品实例并将其添加到购物车中:def add_item( self, product: Product, ) -> 'CartItem': product_content_type = ContentType.objects.get_for_model(product) return CartItem.objects.create( cart=self, product_content_type=product_content_type, product_object_id=product.pk, )在此功能上运行
mypy不会产生任何警告。假设您将product.pk更改为product.id,这在Product协议中没有定义:def add_item( self, product: Product, ) -> 'CartItem': product_content_type = ContentType.objects.get_for_model(product) return CartItem.objects.create( cart=self, product_content_type=product_content_type, product_object_id=product.id, )您将从 Mypy 收到以下警告:
$ mypy models.py:62: error: "Product" has no attribute "id"注:
Protocol还不是 Mypy 的一部分。它是补充包的一部分,叫做mypy_extentions。这个包是由 Mypy 团队开发的,包含了他们认为还没有准备好用于主 Mypy 包的特性。优点
添加产品类型不需要迁移:通用外键可以引用任何型号。添加新类型的产品不需要迁移。
任何模型都可以作为条目:使用通用外键,任何模型都可以被
Item模型引用。内置管理支持: Django 在管理中内置了对通用外键的支持。例如,它可以在详细页面中内嵌关于引用模型的信息。
独立模块:产品模块和购物车模块之间没有直接的依赖关系。这使得这种方法非常适合现有的项目和可插拔模块。
缺点
会产生低效的查询:ORM 无法预先确定通用外键引用的是什么模型。这使得 it 部门很难优化获取多种产品的查询。
更难理解和维护:通用外键消除了一些需要访问特定产品模型的 Django ORM 特性。从产品模型中访问信息需要编写更多的代码。
类型化需要
Protocol: Mypy 无法提供通用模型的类型检查。需要一个Protocol。用例
通用外键是可插拔模块或现有项目的最佳选择。
GenericForeignKey和结构化子类型的使用抽象了模块之间的任何直接依赖。在书店示例中,图书和电子书模型可以存在于一个单独的应用程序中,并且可以在不更改购物车模块的情况下添加新产品。对于现有的项目,可以添加一个
Cart模块,只需对现有代码做最小的改动。本文中介绍的模式配合得很好。使用混合模式,您可以消除一些缺点,并为您的用例优化模式。
例如,在通用外键方法中,您无法快速获得整个购物车的价格。您必须分别获取每个项目并进行汇总。您可以通过在
Item模型中内嵌产品价格(稀疏模型方法)来解决这个具体问题。这将允许您只查询Item型号,以便非常快速地获得总价。结论
在这篇文章中,你从一个小镇书店开始,发展成为一个大型电子商务网站。您解决了不同类型的问题,并调整了您的模型以适应这些变化。您了解了诸如复杂代码和难以向团队中添加新程序员之类的问题通常是更大问题的征兆。你学会了如何识别这些问题并解决它们。
现在您知道了如何使用 Django ORM 计划和实现多态模型。您熟悉多种方法,并且了解它们的优缺点。您能够分析您的用例并决定最佳的行动方案。*******


 浙公网安备 33010602011771号
浙公网安备 33010602011771号