RealPython-中文系列教程-九-
RealPython 中文系列教程(九)
原文:RealPython
Python 的 all():检查你的 Iterables 的真实性
在编程时,你经常需要检查一个 iterable 中的所有项是否都是真实的。重复编写这种功能的代码可能会很烦人,而且效率很低。幸运的是,Python 提供了内置的all()函数来解决这个问题。这个函数接受一个 iterable 并检查它的所有项的真值,这对于发现这些项是否具有给定的属性或满足特定的条件很方便。
Python 的all()是一个强大的工具,可以帮助你用 Python 编写干净、可读、高效的代码。
在本教程中,您将学习如何:
- 使用
all()检查一个 iterable 中的所有项是否为真 - 将
all()与不同的可迭代类型一起使用 - 结合
all()和的理解和生成器表达式 - 区分
all()和布尔运算符and和
为了补充这些知识,您将编写几个例子来展示令人兴奋的all()用例,并强调在 Python 编程中使用该函数的许多方式。
为了理解本教程中的主题,您应该对几个 Python 概念有基本的了解,比如可迭代的数据结构、布尔类型、表达式、操作符、列表理解,以及生成器表达式。
免费 PDF 下载: Python 3 备忘单
评估项目的真值
编程中一个很常见的问题是确定一个列表或数组中的所有元素是否都是真的。例如,您可能有以下条件列表:
5 > 21 == 142 < 50
为了确定这些条件是否为真,您需要迭代它们并测试每个条件的真实性。在这个例子中,你知道5 > 2为真,1 == 1为真,42 < 50也为真。因此,你可以说所有这些条件都是真实的。如果至少有一个条件为假,那么你会说不是所有的条件都为真。
注意,一旦你发现一个假条件,你可以停止评估条件,因为在这种情况下,你已经知道最终结果:不是所有的都是真的。
要通过编写定制的 Python 代码来解决这个问题,您可以使用一个 for循环来迭代每个条件并评估其真实性。您的循环将进行迭代,直到找到一个错误项,这时它将停止,因为您已经有了一个结果:
>>> def all_true(iterable): ... for item in iterable: ... if not item: ... return False ... return True ...这个函数以一个可迭代作为参数。循环迭代输入参数,同时条件
if语句使用not运算符检查是否有任何项目为 falsy。如果一个项目是假的,那么函数立即返回False,表明不是所有的项目都是真的。否则返回True。这个函数非常通用。它需要一个 iterable,这意味着你可以传入一个列表,元组,字符串,字典,或者任何其他的 iterable 数据结构。为了检查当前项目是真还是假,
all_true()使用not运算符来反转其操作数的真值。换句话说,如果它的操作数计算结果为假,它将返回True,反之亦然。Python 的布尔操作符可以计算表达式和对象的真值,这保证了你的函数可以接受包含对象、表达式或两者的可迭代对象。例如,如果您传入一个布尔表达式的 iterable,那么
not只对表达式求值并对结果求反。下面是
all_true()的行动:
>>> bool_exps = [
... 5 > 2,
... 1 == 1,
... 42 < 50,
... ]
>>> all_true(bool_exps)
True
因为输入 iterable 中的所有表达式都为真,not对结果求反,if代码块永远不会运行。在这种情况下,all_true()返回True。
当输入 iterable 包含 Python 对象和非布尔表达式时,也会发生类似的情况:
>>> objects = ["Hello!", 42, {}] >>> all_true(objects) False >>> general_expressions = [ ... 5 ** 2, ... 42 - 3, ... int("42") ... ] >>> all_true(general_expressions) True >>> empty = [] >>> all_true(empty) True在第一个例子中,输入列表包含常规的 Python 对象,包括一个字符串、一个号和一个字典。在这种情况下,
all_true()返回False,因为字典是空的,在 Python 中计算结果为 false。为了对对象执行真值测试,Python 为评估为假的对象提供了一组内部规则:
- 天生的负常数,像
None和False- 带有零值的数字类型,如
0、0.0、、0j、、Decimal("0")、、、- 空序列和集合,如
""、()、[]、{}、、、、range(0)、- 实现返回值为
False的.__bool__()或返回值为0的.__len__()的对象当您在 Python 中测试其他任何对象的真值时,它的值都为 true。
在第二个示例中,输入列表包含一般的 Python 表达式,如数学表达式和函数调用。在这种情况下,Python 首先计算表达式以获得其结果值,然后检查该值的真实性。
第三个例子突出了
all_true()的一个重要细节。当输入 iterable 为空时,for循环不运行,函数立即返回True。这种行为乍一看似乎很奇怪。然而,其背后的逻辑是,如果输入 iterable 中没有条目,那么就没有办法判断任何条目是否为 falsy。因此,该函数返回空的 iterables。尽管用 Python 编写
all_true()代码非常简单,但每次需要它的功能时都要编写这个自定义函数,这可能很烦人。确定 iterable 中的所有项是否都为真是编程中的一项常见任务,Python 为此提供了内置的all()函数。Python 的
all()入门如果您查看 Python 的
all()的文档,那么您会注意到该函数与您在上一节中编写的函数是等效的。然而,像所有内置函数一样,all()是一个 C 函数,并针对性能进行了优化。提出了
all()any()函数,力图从 Python 中去掉functools.reduce()等功能工具,如filter()和map()。然而,Python 社区对移除这些工具并不满意。即便如此,all()和any()还是作为内置函数被添加到 Python 2.5 中,由 Raymond Hettinger 实现。可以说 Python 的
all()执行了一个归约或折叠操作,因为它将一个 iterable items 项归约为一个单独的对象。然而,它不是一个高阶函数,因为它不将其他函数作为参数来执行其计算。因此,您可以将all()视为常规的谓词或布尔值函数。您可以使用
all()来检查输入 iterable 中的所有项是否都为真。因为是内置函数,所以不需要导入。它是这样工作的:
>>> bool_exps = [
... 5 > 2,
... 1 == 1,
... 42 < 50,
... ]
>>> all(bool_exps)
True
>>> objects = ["Hello!", 42, {}]
>>> all(objects)
False
>>> general_exps = [
... 5 ** 2,
... 42 - 3,
... int("42")
... ]
>>> all(general_exps)
True
>>> empty = []
>>> all(empty)
True
这些例子显示了all()与您的自定义函数all_true()的工作原理相同。在内部,all()循环遍历输入 iterable 中的条目,检查它们的真值。如果它发现一个错误的条目,那么它返回False。否则,它返回True。
如果你用一个空的 iterable 调用all(),就像你在上面最后一个例子中所做的那样,那么你会得到True,因为在一个空的 iterable 中没有 falsy 项。注意,all()评估的是输入 iterable 中的项,而不是 iterable 本身。参见如果 Iterable 为空,为什么all()返回True?关于这一点的更多哲学讨论。
为了总结all()的行为,下面是它的真值表:
| 情况 | 结果 |
|---|---|
| 所有项目评估为真。 | True |
| 所有项目评估为假。 | False |
| 一个或多个项目评估为假。 | False |
| 输入 iterable 为空。 | True |
您可以运行以下对all()的调用来确认该表中的信息:
>>> all([True, True, True]) True >>> all([False, False, False]) False >>> all([False, True, True]) False >>> all([]) True这些例子表明,当输入 iterable 中的所有项都为真或者 iterable 为空时,
all()返回True。否则,函数返回False。就像你的
all_true()函数一样,all()也实现了所谓的短路评估。这种评估意味着all()一旦确定了行动的最终结果,就会立刻返回。当函数在 iterable 中找到一个错误的项时,就会发生短路。在这种情况下,没有必要评估其余的项目,因为函数已经知道最终结果。请注意,这种类型的实现意味着当您测试具有副作用的条件时,您可以获得不同的行为。考虑下面的例子:
>>> def is_true(value):
... print("Side effect!")
... return bool(value)
...
>>> values = [0, 1]
>>> conditions = (is_true(n) for n in values)
>>> all(conditions)
Side effect!
False
>>> conditions = (is_true(n) for n in reversed(values))
>>> all(conditions)
Side effect!
Side effect!
False
is_true()函数将一个对象作为参数,并返回其真值。在函数的执行过程中,一个副作用发生了:函数将的东西打印到屏幕上。
conditions的第一个实例保存了一个生成器表达式,它在对来自输入 iterable(在本例中为values)的每一项进行惰性求值之后产生真值。这次,all()只对函数求值一次,因为is_true(0)返回False。副作用只会出现一次。
现在来看看conditions的第二个实例。如果你反转输入的 iterable,那么all()会评估两个条目,因为用1作为参数对is_true()的调用会返回True。副作用会持续两次。
这种行为可能是微妙问题的来源,因此您应该避免在代码中评估具有副作用的条件。
最后,当谈到使用all()函数时,可以说它至少有两个通用用例。您可以使用all()来检查 iterable 中的所有项目:
- 评估为真
- 具有给定的属性或者满足一定的条件
在下一节中,您将学习如何在 Python 中对不同的可迭代类型使用all()。之后,您将学习如何使用all()和列表理解以及生成器表达式来解决上面列出的第二个用例。
将all()用于不同的可迭代类型
内置的all()函数包含了 Python 的鸭子类型风格,并且接受不同的参数类型,只要它们是可迭代的。您可以将all()用于列表、元组、字符串、字典、集等。
在所有情况下,all()都按预期工作,如果所有项目都正确,则返回True,否则返回False。在本节中,您将使用不同的可迭代类型编写使用all()的示例。
序列
至此,您已经了解了all()如何使用 Python 列表。在本节中,您将了解到列表和其他序列数据类型之间没有真正的区别,例如元组和 range 对象。函数所需要的就是输入对象是可迭代的。
下面是一些将all()用于元组和range对象的例子:
>>> # With tuples >>> all((1, 2, 3)) True >>> all((0, 1, 2, 3)) False >>> all(()) True >>> all(tuple()) True >>> # With range objects >>> all(range(10)) False >>> all(range(1, 11)) True >>> all(range(0)) True通常,如果输入 iterable 中的所有项都是真的,那么您将得到
True。否则,你得到False。空元组和范围产生一个True结果。在最后一个例子中,用0作为参数调用range()会返回一个空的range对象,因此all()会给出结果True。还可以将包含表达式、布尔表达式或任何类型的 Python 对象的元组传递给
all()。来吧,试一试!字典
字典是键值对的集合。如果你直接遍历字典,那么你会自动遍历它的键。此外,您可以使用方便的方法显式迭代字典的键、值和项。
注:用字典的
.items()方法使用all()没有多大意义。该方法以两项元组的形式返回键-值对,在 Python 中这些元组的值总是为 true。如果您将字典直接传递给
all(),那么该函数将自动检查字典的键:
>>> all({"gold": 1, "silver": 2, "bronze": 3})
True
>>> all({0: "zero", 1: "one", 2: "two"})
False
因为第一个字典中的所有键都是真的,所以结果是得到True。在第二个字典中,第一个键是0,其值为 false。在这种情况下,您从all()处取回False。
如果您想获得与上面示例相同的结果,但是代码更可读、更显式,那么您可以使用 .keys() 方法,该方法从底层字典返回所有键:
>>> medals = {"gold": 1, "silver": 2, "bronze": 3} >>> all(medals.keys()) True >>> numbers = {0: "zero", 1: "one", 2: "two"} >>> all(numbers.keys()) False使用
.keys(),您可以明确您的代码调用all()来确定输入字典中的所有当前键是否都是真的。另一个常见的需求是,您需要检查给定字典中的所有值是否都评估为 true。在这种情况下,可以使用
.values():
>>> monday_inventory = {"book": 2, "pencil": 5, "eraser": 1}
>>> all(monday_inventory.values())
True
>>> tuesday_inventory = {"book": 2, "pencil": 3, "eraser": 0}
>>> all(tuesday_inventory.values())
False
在这些例子中,你首先检查你当前的学习用品库存中是否至少有一件物品。星期一,你所有的项目至少有一个单位,所以all()返回True。然而,在星期二,对all()的调用返回False,因为您已经用完了至少一种供应品中的单位,在本例中是eraser。
将all()用于理解和生成器表达式
正如您之前了解到的,Python 的all()的第二个用例是检查 iterable 中的所有项是否都有给定的属性或满足特定的条件。为了进行这种检查,您可以使用带有列表理解或生成器表达式的all()作为参数,这取决于您的需要。
通过将all()与列表理解和生成器表达式相结合,您获得的协同效应释放了这个函数的全部能力,并使它在您的日常编码中非常有价值。
利用all()这种超级能力的一种方法是使用谓词函数来测试所需的属性。这个谓词函数将是 list comprehension 中的表达式,您将把它作为参数传递给all()。下面是所需的语法:
all([predicate(item) for item in iterable])
这个列表理解使用predicate()来测试给定属性的iterable中的每个item。然后对all()的调用将结果列表缩减为一个单独的True或False值,这将告诉您是否所有的条目都具有predicate()定义和测试的属性。
例如,下面的代码检查序列中的所有值是否都是质数:
>>> import math >>> def is_prime(n): ... if n <= 1: ... return False ... for i in range(2, math.isqrt(n) + 1): ... if n % i == 0: ... return False ... return True ... >>> numbers = [2, 3, 5, 7, 11] >>> all([is_prime(x) for x in numbers]) True >>> numbers = [2, 4, 6, 8, 10] >>> all([is_prime(x) for x in numbers]) False在这个例子中,您将
all()与列表理解结合起来。理解使用is_prime()谓词函数来测试numbers中的每个值的素性。结果列表将包含每次检查结果的布尔值(True或False)。然后all()获取这个列表作为参数,并处理它以确定所有的数字是否都是质数。注意:
is_prime()谓词基于维基百科关于素性测试的文章中的算法。这个神奇组合的第二个用例,
all()加上一个列表理解,是检查 iterable 中的所有条目是否满足给定的条件。下面是所需的语法:all([condition for item in iterable])这个对
all()的调用使用一个列表理解来检查iterable中的所有项目是否满足所需的condition,这通常是根据单个item来定义的。按照这个想法,下面有几个例子来检查列表中的所有数字是否都大于0:
>>> numbers = [1, 2, 3]
>>> all([number > 0 for number in numbers])
True
>>> numbers = [-2, -1, 0, 1, 2]
>>> all([number > 0 for number in numbers])
False
在第一个例子中,all()返回True,因为输入列表中的所有数字都满足大于0的条件。在第二个例子中,结果是False,因为输入 iterable 包含0和负数。
正如您已经知道的,all()返回带有空 iterable 作为参数的True。这种行为可能看起来很奇怪,并可能导致错误的结论:
>>> numbers = [] >>> all([number < 0 for number in numbers]) True >>> all([number == 0 for number in numbers]) True >>> all([number > 0 for number in numbers]) True这段代码显示
numbers中的所有值都小于0,但是它们也等于并且大于0,这是不可能的。这种不合逻辑的结果的根本原因是所有这些对all()的调用都计算空的 iterables,这使得all()返回True。要解决这个问题,您可以使用内置的
len()函数来获取输入 iterable 中的项数。如果len()返回0,那么你可以跳过调用all()来处理空的输入 iterable。这个策略将使你的代码不容易出错。您在本节中编写的所有示例都使用列表理解作为
all()的参数。列表理解在内存中创建一个完整的列表,这可能是一个浪费的操作。如果您的代码中不再需要结果列表,这种行为尤其成立,这是典型的all()情况。在这种情况下,使用带有生成器表达式的
all()总是更有效,尤其是当你处理一个长输入列表时。生成器表达式不是在内存中构建一个全新的列表,而是根据需要生成条目,从而使您的代码更加高效。构建生成器表达式的语法几乎与理解列表所用的语法相同:
# With a predicate all(predicate(item) for item in iterable) # With a condition all(condition for item in iterable)唯一的区别是生成器表达式使用括号(
())而不是方括号([])。因为函数调用已经需要圆括号,所以只需要去掉方括号。与列表理解不同,生成器表达式按需生成条目,这使得它们在内存使用方面非常有效。此外,你不会创建一个新的列表,然后在
all()返回后扔掉它。将
all()与and布尔运算符进行比较你可以大致把
all()想象成通过布尔and运算符连接起来的一系列项目。例如,函数调用all([item1, item2, ..., itemN])在语义上等同于表达式item1 and item2 ... and itemN。然而,它们之间有一些微小的差异。在本节中,您将了解这些差异。第一个与语法有关,第二个与返回值有关。此外,您将了解到
all()和and操作符都实现短路评估。理解语法差异
对
all()的调用使用与 Python 中任何函数调用相同的语法。你需要用一对括号来调用这个函数。在all()的特定情况下,您必须传入一个值的 iterable 作为参数:
>>> all([True, False])
False
输入 iterable 中的项可以是通用表达式、布尔表达式或任何类型的 Python 对象。此外,input iterable 中的项数只取决于系统中可用的内存量。
另一方面,and运算符是一个二元运算符,它连接表达式中的两个操作数:
>>> True and False False逻辑运算符
and采用左操作数和右操作数来构建复合表达式。就像使用all()一样,and表达式中的操作数可以是通用表达式、布尔表达式或 Python 对象。最后,您可以使用多个and操作符来连接任意数量的操作数。返回布尔值 vs 操作数
all()和and操作符之间的第二个甚至更重要的区别是它们各自的返回值。当all()总是返回True或False时,and操作符总是返回它的一个操作数。如果返回的操作数显式地评估为任一值,则它仅返回True或False:
>>> all(["Hello!", 42, {}])
False
>>> "Hello!" and 42 and {}
{}
>>> all([1, 2, 3])
True
>>> 1 and 2 and 3
3
>>> all([0, 1, 2, 3])
False
>>> 0 and 1 and 2 and 3
0
>>> all([5 > 2, 1 == 1])
True
>>> 5 > 2 and 1 == 1
True
这些例子展示了all()如何总是返回True或False,这与谓词函数的状态一致。另一方面,and返回最后计算的操作数。如果它恰好是一个表达式中的最后一个操作数,那么前面的所有操作数一定都是真的。否则,and将返回第一个 falsy 操作数,指示求值停止的位置。
注意,在最后一个例子中,and操作符返回True,因为隐含的操作数是比较表达式,它们总是显式返回True或False。
这是all()函数和and操作符之间的一个重要区别。因此,您应该考虑到这一点,以防止代码中出现微妙的错误。然而,在布尔上下文中,比如if语句和 while循环,这种差异根本不相关。
短路评估
正如您已经了解到的,all()在决定最终结果时,会缩短对输入 iterable 中各项的评估。and操作员还执行短路评估。
此功能的优点是,一旦出现错误的项目,就跳过剩余的检查,从而提高操作效率。
要尝试短路评估,您可以使用发生器函数,如下例所示:
>>> def generate_items(iterable): ... for i, item in enumerate(iterable): ... print(f"Checking item: {i}") ... yield item ...
generate_items()中的循环遍历iterable中的条目,使用内置的enumerate()函数获取每个选中条目的索引。然后,该循环打印一条标识选中物品的消息,并生成手边的物品。有了
generate_items(),您可以运行以下代码来测试all()的短路评估:
>>> # Check both items to get the result
>>> items = generate_items([True, True])
>>> all(items)
Checking item: 0
Checking item: 1
True
>>> # Check the first item to get the result
>>> items = generate_items([False, True])
>>> all(items)
Checking item: 0
False
>>> # Still have a remaining item
>>> next(items)
Checking item: 1
True
对all()的第一次调用展示了该函数如何检查这两项以确定最终结果。第二次调用确认all()只检查第一项。由于这一项为 false sy,所以该函数不检查第二项就立即返回。这就是为什么当你调用 next() 的时候,生成器还是会产生第二个项目。
现在您可以使用and操作符运行一个类似的测试:
>>> # Check both items to get the result >>> items = generate_items([True, True]) >>> next(items) and next(items) Checking item: 0 Checking item: 1 True >>> # Check the first item to get the result >>> items = generate_items([False, True]) >>> next(items) and next(items) Checking item: 0 False >>> # Still have a remaining item >>> next(items) Checking item: 1 True第一个
and表达式评估两个操作数以获得最终结果。第二个and表达式只计算第一个操作数来决定结果。用items作为参数调用next(),显示生成器函数仍然产生一个剩余项。将
all()付诸行动:实例到目前为止,您已经学习了 Python 的
all()的基础知识。你已经学会了在序列、字典、列表理解和生成器表达式中使用它。此外,您已经了解了这个内置函数和逻辑操作符and之间的区别和相似之处。在这一节中,您将编写一系列实际例子,帮助您评估在使用 Python 编程时
all()有多有用。所以,请继续关注并享受您的编码吧!提高长复合条件的可读性
all()的一个有趣的特性是,当您处理基于and操作符的长复合布尔表达式时,这个函数如何提高代码的可读性。例如,假设您需要在一段代码中验证用户的输入。为了使输入有效,它应该是一个介于
0和100之间的整数,也是一个偶数。要检查所有这些条件,可以使用下面的if语句:
>>> x = 42
>>> if isinstance(x, int) and 0 <= x <= 100 and x % 2 == 0:
... print("Valid input")
... else:
... print("Invalid input")
...
Valid input
if条件包括对 isinstance() 的调用,用于检查输入是否为整数;一个链式比较表达式,用于检查数字是否在0和100之间;以及一个表达式,用于检查输入值是否为偶数。
尽管这段代码可以工作,但是条件相当长,这使得解析和理解起来很困难。此外,如果您需要在未来的更新中添加更多的验证检查,那么条件将变得更长、更复杂。它还需要一些代码格式化。
为了提高这个条件的可读性,你可以使用all(),就像下面的代码:
>>> x = 42 >>> validation_conditions = ( ... isinstance(x, int), ... 0 <= x <= 100, ... x % 2 == 0, ... ) >>> if all(validation_conditions): ... print("Valid input") ... else: ... print("Invalid input") ... Valid input在这个例子中,所有的验证条件都存在于一个具有描述性名称的元组中。使用这种技术还有一个额外的好处:如果您需要添加一个新的验证条件,那么您只需要向您的
validation_conditions元组添加一个新行。请注意,现在您的if语句拥有了一个基于all()的非常易读、明确和简洁的表达式。在现实生活中,验证策略通常允许您重用验证代码。例如,您可以编写可重用的验证函数,而不是指定只计算一次的普通条件:
>>> def is_integer(x):
... return isinstance(x, int)
...
>>> def is_between(a=0, b=100):
... return lambda x: a <= x <= b
...
>>> def is_even(x):
... return x % 2 == 0
...
>>> validation_conditions = (
... is_integer,
... is_between(0, 100),
... is_even,
... )
>>> for x in (4.2, -42, 142, 43, 42):
... print(f"Is {x} valid?", end=" ")
... print(all(condition(x) for condition in validation_conditions))
...
Is 4.2 valid? False
Is -42 valid? False
Is 142 valid? False
Is 43 valid? False
Is 42 valid? True
在这个例子中,有三个函数以可重用的方式检查三个初始条件。然后,使用刚刚编写的函数重新定义验证条件元组。最后的for循环展示了如何使用all()重用这些函数来验证几个输入对象。
验证数值的可重复项
all()的另一个有趣的用例是检查一个 iterable 中的所有数值是否都在给定的区间内。下面是几个示例,说明如何在不同的条件下,借助生成器表达式来实现这一点:
>>> numbers = [10, 5, 6, 4, 7, 8, 20] >>> # From 0 to 20 (Both included) >>> all(0 <= x <= 20 for x in numbers) True >>> # From 0 to 20 (Both excluded) >>> all(0 < x < 20 for x in numbers) False >>> # From 0 to 20 (integers only) >>> all(x in range(21) for x in numbers) True >>> # All greater than 0 >>> all(x > 0 for x in numbers) True这些例子展示了如何构建生成器表达式来检查一个可迭代数字中的所有值是否都在给定的区间内。
上面例子中的技术允许很大的灵活性。您可以调整条件并使用
all()在目标 iterable 上运行各种检查。验证字符串和字符串的可重复项
内置的
str类型实现了几个谓词字符串方法,当您需要验证字符串的可重复项和给定字符串中的单个字符时,这些方法会很有用。例如,使用这些方法,您可以检查一个字符串是否是有效的十进制数,是否是字母数字字符,或者是否是有效的 ASCII 字符。
下面是一些在代码中使用字符串方法的示例:
>>> numbers = ["1", "2", "3.0"]
>>> all(number.isdecimal() for number in numbers)
True
>>> chars = "abcxyz123"
>>> all(char.isalnum() for char in chars)
True
>>> all(char.isalpha() for char in chars)
False
>>> all(char.isascii() for char in chars)
True
>>> all(char.islower() for char in chars)
False
>>> all(char.isnumeric() for char in chars)
False
>>> all(char.isprintable() for char in chars)
True
这些.is*()方法中的每一个都检查底层字符串的特定属性。您可以利用这些和其他几个 string 方法来验证可重复字符串中的项以及给定字符串中的单个字符。
从表格数据中删除带有空字段的行
当您处理表格数据时,可能会遇到空字段的问题。您可能需要清理包含空字段的行。如果是这种情况,那么您可以使用all()和 filter() 来提取所有字段中都有数据的行。
内置的filter()函数以一个函数对象和一个 iterable 作为参数。通常,您将使用谓词函数作为filter()的第一个参数。对filter()的调用将谓词应用于 iterable 中的每一项,并返回一个迭代器,其中包含使谓词返回True的项。
您可以在filter()调用中使用all()作为谓词。这样,您可以处理列表的列表,这在您处理表格数据时会很有用。
举一个具体的例子,假设您有一个 CSV 文件,其中包含关于您公司员工的数据:
name,job,email
"Linda","Technical Lead","" "Joe","Senior Web Developer","joe@example.com"
"Lara","Project Manager","lara@example.com"
"David","","david@example.com" "Jane","Senior Python Developer","jane@example.com"
快速浏览一下这个文件,您会注意到有些行包含空字段。例如,第一行没有电子邮件,第四行没有提供职位或角色。您需要通过删除包含空字段的行来清理数据。
下面是如何通过在一个filter()调用中使用all()作为谓词来满足这个需求:
>>> import csv >>> from pprint import pprint >>> with open("employees.csv", "r") as csv_file: ... raw_data = list(csv.reader(csv_file)) ... >>> # Before cleaning >>> pprint(raw_data) [['name', 'job', 'email'], ['Linda', 'Technical Lead', ''], ['Joe', 'Senior Web Developer', 'joe@example.com'], ['Lara', 'Project Manager', 'lara@example.com'], ['David', '', 'david@example.com'], ['Jane', 'Senior Python Developer', 'jane@example.com']] >>> clean_data = list(filter(all, raw_data)) >>> # After cleaning >>> pprint(clean_data) [['name', 'job', 'email'], ['Joe', 'Senior Web Developer', 'joe@example.com'], ['Lara', 'Project Manager', 'lara@example.com'], ['Jane', 'Senior Python Developer', 'jane@example.com']]在这个例子中,首先使用 Python 标准库中的
csv模块将目标 CSV 文件的内容加载到raw_data中。对pprint()函数的调用显示,数据包含带有空字段的行。然后你用filter()和all()清理数据。注意:如果你觉得用
filter()不舒服,那么你可以用列表理解来代替。继续运行下面的代码行:
>>> clean_data = [row for row in raw_data if all(row)]
一旦有了干净数据的列表,就可以再次运行for循环来检查是否一切正常。
filter()和all()函数如何协同执行任务?嗯,如果all()在一行中找到一个空字段,那么它返回False。因此,filter()不会将该行包含在最终数据中。为了确保这种技术有效,您可以使用干净的数据作为参数来调用pprint()。
比较自定义数据结构
作为如何使用all()的另一个例子,假设您需要创建一个定制的类似列表的类,它允许您检查它的所有值是否都大于一个特定值。
要创建这个自定义类,您可以从 collections 模块中子类化 UserList ,然后覆盖被称为 .__gt__() 的特殊方法。覆盖这个方法允许您重载大于(>)操作符,为它提供一个自定义行为:
>>> from collections import UserList >>> class ComparableList(UserList): ... def __gt__(self, threshold): ... return all(x > threshold for x in self) ... >>> numbers = ComparableList([1, 2, 3]) >>> numbers > 0 True >>> numbers > 5 False在
.__gt__()中,您使用all()来检查当前列表中的所有数字是否都大于应该来自用户的特定threshold值。这段代码末尾的比较表达式展示了如何使用您的自定义列表,以及它如何与大于号(
>)操作符一起工作。在第一个表达式中,列表中的所有值都大于0,所以结果是True。在第二个表达式中,所有的数字都小于5,这导致了一个False结果。部分模拟 Python 的
zip()函数Python 内置的
zip()函数对于并行循环多个可迭代对象很有用。该函数将给定数量的可重复项( N )作为参数,并将每个可重复项中的元素聚合到 N 项元组中。在这个例子中,您将学习如何使用all()来部分模拟这个功能。为了更好地理解这一挑战,请查看
zip()的基本功能:
>>> numbers = zip(["one", "two"], [1, 2])
>>> list(numbers)
[('one', 1), ('two', 2)]
在这个例子中,您将两个列表作为参数传递给zip()。该函数返回一个迭代器,每个迭代器产生两个条目的元组,您可以通过调用list()将结果迭代器作为参数来确认。
这里有一个模拟这种功能的函数:
>>> def emulated_zip(*iterables): ... lists = [list(iterable) for iterable in iterables] ... while all(lists): ... yield tuple(current_list.pop(0) for current_list in lists) ... >>> numbers = emulated_zip(["one", "two"], [1, 2]) >>> list(numbers) [('one', 1), ('two', 2)]您的
emulated_zip()函数可以接受由可迭代对象组成的可变数量的参数。函数中的第一行使用 list comprehension 将每个输入 iterable 转换成 Python 列表,以便您稍后可以使用它的.pop()方法。循环条件依赖于all()来检查所有的输入列表是否至少包含一个条目。在每次迭代中,
yield语句从每个输入列表中返回一个包含一个条目的元组。以0为参数调用.pop()从每个列表中检索并移除第一个项目。一旦循环迭代的次数足够多,以至于
.pop()从列表中删除了所有的条目,那么条件就变为假,函数就终止了。当最短的 iterable 用尽时,循环结束,截断较长的 iterable。该行为与zip()的默认行为一致。请注意,您的函数只是部分模拟了内置的
zip()函数,因为您的函数没有采用strict参数。这个参数是在 Python 3.10 中添加的,作为处理不相等长度的可重复项的一种安全方式。结论
现在您知道了如何使用 Python 的内置函数
all()来检查现有 iterable 中的所有项是否都是真的。您还知道如何使用这个函数来确定 iterable 中的项是否满足给定的条件或者是否具有特定的属性。有了这些知识,您现在就能够编写可读性更强、效率更高的 Python 代码了。
在本教程中,您学习了:
- 如何使用 Python 的
all()检查一个 iterable 中的所有项是否为真all()如何处理不同的可迭代类型- 如何将
all()和结合起来理解和生成器表达式- 是什么使得
all()与and运算符有所不同和相似此外,您编写了几个实际例子,帮助您理解
all()有多强大,以及它在 Python 编程中最常见的一些用例是什么。免费 PDF 下载: Python 3 备忘单*******
在 Python 中使用“与”布尔运算符
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 和运算符
Python 有三个布尔运算符,或者说逻辑运算符 :
and、or和not。在决定程序将遵循的执行路径之前,您可以使用它们来检查是否满足某些条件。在本教程中,您将了解到and操作符以及如何在您的代码中使用它。在本教程中,您将学习如何:
- 理解 Python 的
and运算符背后的逻辑- 构建并理解使用
and操作符的布尔和非布尔表达式- 在布尔上下文中使用
and操作符来决定程序的动作过程- 在非布尔上下文中使用
and操作符使你的代码更加简洁您还将编写一些实际的例子,帮助您理解如何使用
and操作符以python 式的方式处理不同的问题。即使你不使用and的所有特性,了解它们也会让你写出更好更准确的代码。免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
在 Python 中使用布尔逻辑
早在 1854 年,乔治·布尔撰写了思想法则,其中包含了所谓的布尔代数。这个代数依赖于两个值:真和假。它还定义了一组布尔运算,也称为逻辑运算,由通用运算符
AND、OR和NOT表示。这些布尔值和操作符在编程中非常有用。例如,您可以用运算符构造任意复杂的布尔表达式,并确定它们的结果真值为真或假。你可以使用布尔表达式的真值来决定你的程序的行动过程。
>>> issubclass(bool, int)
True
>>> help(bool)
Help on class bool in module builtins:
class bool(int)
...
>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>
>>> isinstance(True, int)
True
>>> isinstance(False, int)
True
>>> int(True)
1
>>> int(False)
0
正如您在这段代码中看到的,Python 将bool实现为int的子类,有两个可能的值,True和False。这些值是 Python 中的内置常量。它们在内部被实现为整数数字,其中True的值为1,而False的值为0。注意True和False都必须大写。
除了bool类型,Python 还提供了三个布尔运算符,或者逻辑运算符,允许您将布尔表达式和对象组合成更复杂的表达式。这些运算符如下:
| 操作员 | 逻辑运算 |
|---|---|
T2and |
结合 |
T2or |
分离 |
T2not |
否认 |
使用这些运算符,您可以连接几个布尔表达式和对象来构建您自己的表达式。与其他语言不同,Python 使用英语单词来表示布尔运算符。这些单词是该语言的关键词,所以不能作为标识符使用。
在本教程中,您将学习 Python 的and操作符。该运算符执行逻辑AND运算。您将了解它是如何工作的,以及如何在布尔或非布尔上下文中使用它。
Python 的and操作符入门
Python 的and操作符接受两个操作数,它们可以是布尔表达式、对象或组合。有了这些操作数,and操作符可以构建更复杂的表达式。一个and表达式中的操作数通常被称为条件。如果两个条件都为真,那么and表达式返回真结果。否则,它将返回错误结果:
>>> True and True True >>> False and False False >>> True and False False >>> False and True False这些例子表明,只有当表达式中的两个操作数都为真时,
and表达式才返回True。由于and操作符需要两个操作数来构建一个表达式,所以它是一个二元操作符。上面的快速示例显示了所谓的
and运算符真值表:
operand1operand2operand1 and operand2真实的 真实的 真实的 真实的 错误的 错误的 错误的 错误的 错误的 错误的 真实的 错误的 这个表格总结了像
operand1 and operand2这样的布尔表达式的结果真值。表达式的结果取决于其操作数的真值。如果两个都是真的,那就是真的。否则,它就是假的。这是and操作符背后的一般逻辑。然而,这个操作符在 Python 中能做的不止这些。在接下来的小节中,您将学习如何使用
and来构建您自己的带有不同类型操作数的表达式。使用 Python 的
and运算符和布尔表达式您通常会使用逻辑运算符来构建复合布尔表达式,它是变量和值的组合,结果产生一个布尔值。换句话说,布尔表达式返回
True或False。比较和相等测试是这种表达式的常见示例:
>>> 5 == 3 + 2
True
>>> 5 > 3
True
>>> 5 < 3
False
>>> 5 != 3
True
>>> [5, 3] == [5, 3]
True
>>> "hi" == "hello"
False
所有这些表达式都返回True或False,这意味着它们是布尔表达式。您可以使用and关键字将它们组合起来,创建复合表达式,一次测试两个或更多的子表达式:
>>> 5 > 3 and 5 == 3 + 2 True >>> 5 < 3 and 5 == 5 False >>> 5 == 5 and 5 != 5 False >>> 5 < 3 and 5 != 5 False这里,当你组合两个
True表达式时,你得到的结果是True。任何其他组合返回False。从这些例子中,您可以得出结论,使用and操作符创建复合布尔表达式的语法如下:expression1 and expression2如果两个子表达式
expression1和expression2的值都是True,那么复合表达式就是True。如果至少有一个子表达式的计算结果为False,那么结果为False。在构建复合表达式时,可以使用的
and操作符的数量没有限制。这意味着您可以使用几个and操作符在一个表达式中组合两个以上的子表达式:
>>> 5 > 3 and 5 == 3 + 2 and 5 != 3
True
>>> 5 < 3 and 5 == 3 and 5 != 3
False
同样,如果所有子表达式的计算结果都是True,那么就得到True。否则,你会得到False。特别是当表达式变长时,您应该记住 Python 是从左到右顺序计算表达式的。
短路评估
Python 的逻辑运算符,比如and、or,用的是一种叫做短路求值,或者懒求值的东西。换句话说,Python 只在需要的时候计算右边的操作数。
为了确定一个and表达式的最终结果,Python 从评估左操作数开始。如果是假的,那么整个表达式都是假的。在这种情况下,不需要计算右边的操作数。Python 已经知道最终结果了。
左操作数为假会自动使整个表达式为假。对剩余的操作数求值是对 CPU 时间的浪费。Python 通过简化计算来防止这种情况。
相比之下,and运算符仅在第一个操作数为真时才计算右边的操作数。在这种情况下,最终结果取决于右操作数的真值。如果为真,那么整个表达式为真。否则,表达式为假。
要演示短路功能,请看以下示例:
>>> def true_func(): ... print("Running true_func()") ... return True ... >>> def false_func(): ... print("Running false_func()") ... return False ... >>> true_func() and false_func() # Case 1 Running true_func() Running false_func() False >>> false_func() and true_func() # Case 2 Running false_func() False >>> false_func() and false_func() # Case 3 Running false_func() False >>> true_func() and true_func() # Case 4 Running true_func() Running true_func() True下面是这段代码的工作原理:
- 案例 1 : Python 对
true_func()求值,返回True。为了确定最终结果,Python 对false_func()求值并得到False。您可以通过查看两个函数的输出来确认这一点。- 案例二 : Python 对
false_func()求值,返回False。Python 已经知道最后的结果是False,所以不评价true_func()。- 案例三 : Python 运行
false_func(),结果得到False。它不需要对重复的函数进行第二次求值。- 案例四 : Python 对
true_func()求值,结果得到True。然后,它再次计算该函数。因为两个操作数的计算结果都是True,所以最终结果是True。Python 从左到右处理布尔表达式。当它不再需要评估任何进一步的操作数或子表达式来确定最终结果时,它停止。总结一下这个概念,你应该记住如果一个
and表达式中的左操作数为假,那么右操作数就不会被求值。短路计算会对代码的性能产生重大影响。为了利用这一点,在构建
and表达式时,请考虑以下提示:
- 将耗时的表达式放在关键字
and的右边。这样,如果短路规则生效,代价高昂的表达式就不会运行。- 将更有可能为假的表达式放在关键字
and的左边。这样,Python 更有可能通过只计算左操作数来确定整个表达式是否为假。有时,您可能希望避免特定布尔表达式中的惰性求值。你可以通过使用位操作符 (
&、|、~)来做到这一点。这些运算符也适用于布尔表达式,但是它们会急切地对操作数求值:
>>> def true_func():
... print("Running true_func()")
... return True
...
>>> def false_func():
... print("Running false_func()")
... return False
...
>>> # Use logical and
>>> false_func() and true_func()
Running false_func()
False
>>> # Use bitwise and
>>> false_func() & true_func()
Running false_func()
Running true_func()
False
在第一个表达式中,and操作符像预期的那样缓慢地工作。它计算第一个函数,因为结果是假的,所以它不计算第二个函数。然而,在第二个表达式中,按位 AND 运算符(&)急切地调用两个函数,即使第一个函数返回False。注意,在这两种情况下,最终结果都是False。
尽管这一招很管用,但通常不被鼓励。您应该使用按位运算符来处理位,使用布尔运算符来处理布尔值和表达式。要更深入地了解按位运算符,请查看 Python 中的按位运算符。
对公共对象使用 Python 的and操作符
您可以使用and操作符在一个表达式中组合两个 Python 对象。在那种情况下,Python 内部使用 bool() 来确定操作数的真值。因此,您得到的是一个特定的对象,而不是一个布尔值。如果一个给定的操作数显式地求值为True或False,你只能得到True或False:
>>> 2 and 3 3 >>> 5 and 0.0 0.0 >>> [] and 3 [] >>> 0 and {} 0 >>> False and "" False在这些例子中,
and表达式如果计算结果为False,则返回左边的操作数。否则,它返回右边的操作数。为了产生这些结果,and操作符使用 Python 的内部规则来确定对象的真值。Python 文档这样陈述这些规则:默认情况下,除非对象的类定义了返回
False的__bool__()方法或返回零的__len__()方法,否则对象被视为真。以下是大多数被认为是假的内置对象:
- 定义为假的常数:
None和False。- 任意数值类型的零:
0、0.0、0j、Decimal(0)、Fraction(0, 1)- 空序列和集合:
''、()、[]、{}、set()、range(0)(来源)
记住这些规则,再看看上面的代码。在第一个例子中,整数
2为真(非零),所以and返回右操作数3。在第二个例子中,5为真,所以and返回右操作数,即使它的计算结果为False。下一个例子使用一个空列表(
[])作为左操作数。由于空列表的计算结果为 false,and表达式返回空列表。得到True或False的唯一情况是在表达式中显式使用布尔对象。注意:如果你需要从一个涉及普通对象的
and表达式中得到True或者False而不是布尔表达式,那么你可以使用bool()。这个内置函数根据您作为参数提供的特定对象的真值显式返回True或False。下面是当您将
and操作符用于普通 Python 对象而不是布尔表达式时,您可以如何总结它的行为。请注意,Python 使用每个对象的真值来确定最终结果:
object1object2object1 and object2错误的 错误的 object1错误的 真实的 object1真实的 真实的 object2真实的 错误的 object2一般来说,如果一个
and表达式中的操作数是对象而不是布尔表达式,那么操作符返回左边的对象,如果它的计算结果是False。否则,它返回右边的对象,即使它的值是False。混合布尔表达式和对象
您还可以在一个
and表达式中组合布尔表达式和常见的 Python 对象。在这种情况下,and表达式仍然返回左操作数(如果它为假),否则它返回右操作数。返回值可以是True、False或常规对象,这取决于表达式的哪一部分提供了该结果:
>>> 2 < 4 and 2
2
>>> 2 and 2 < 4
True
>>> 2 < 4 and []
[]
>>> [] and 2 < 4
[]
>>> 5 > 10 and {}
False
>>> {} and 5 > 10
{}
>>> 5 > 10 and 4
False
>>> 4 and 5 > 10
False
这些例子使用了布尔表达式和公共对象的组合。在每一对例子中,你可以看到你可以得到一个非布尔对象或者一个布尔值,True或者False。结果将取决于表达式的哪一部分提供最终结果。
下表总结了组合布尔表达式和常见 Python 对象时and运算符的行为:
expression |
object |
expression and object |
|---|---|---|
True |
真实的 | object |
True |
错误的 | object |
False |
错误的 | False |
False |
真实的 | False |
为了找出返回的内容,Python 对左边的布尔表达式进行求值,以获得其布尔值(True或False)。然后 Python 使用其内部规则来确定右边对象的真值。
作为测试您理解程度的一个练习,您可以尝试通过将第三列中操作数的顺序换成object and expression来重写该表。尝试预测每行将返回什么。
组合 Python 逻辑运算符
正如您在本教程前面看到的,Python 提供了两个额外的逻辑操作符:or操作符和not操作符。您可以将它们与and操作符一起使用来创建更复杂的复合表达式。如果你想用多个逻辑运算符做出准确清晰的表达式,那么你需要考虑每个运算符的优先级。换句话说,您需要考虑 Python 执行它们的顺序。
与其他运算符相比,Python 的逻辑运算符优先级较低。然而,有时使用一对括号(())来确保一致和可读的结果是有益的:
>>> 5 or 2 and 2 > 1 5 >>> (5 or 3) and 2 > 1 True这些例子在一个复合表达式中结合了
or操作符和and操作符。就像and操作符一样,or操作符使用短路评估。然而,与and不同的是,or操作符一旦找到真操作数就会停止。你可以在第一个例子中看到这一点。因为5为真,所以or子表达式立即返回5,而不计算表达式的其余部分。相比之下,如果将
or子表达式放在一对括号中,那么它将作为单个真操作数工作,并且2 > 1也会被求值。最后的结果是True。要点是,如果你在一个表达式中使用多个逻辑操作符,那么你应该考虑使用括号来使你的意图清晰。这个技巧也将帮助你得到正确的逻辑结果。
在布尔上下文中使用 Python 的
and操作符像 Python 的所有布尔操作符一样,
and操作符在布尔上下文中特别有用。布尔上下文是您可以找到布尔运算符的大多数真实用例的地方。Python 中有两种主要结构定义布尔上下文:
这两个结构是你所谓的控制流语句的一部分。它们帮助你决定程序的执行路径。
您可以使用 Python 的
and操作符在if语句和while循环中构造复合布尔表达式。
if报表布尔表达式通常被称为条件,因为它们通常意味着满足给定需求的需要。它们在条件语句中非常有用。在 Python 中,这种类型的语句以
if关键字开始,并以一个条件继续。条件语句还可以包括elif和else子句。Python 条件语句遵循英语语法中条件句的逻辑。如果条件为真,则执行
if代码块。否则,执行跳转到不同的代码块:
>>> a = -8
>>> if a < 0:
... print("a is negative")
... elif a > 0:
... print("a is positive")
... else:
... print("a is equal to 0")
...
a is negative
因为a保持负数,所以条件a < 0为真。if代码块运行,屏幕上显示出a is negative 消息。但是,如果将a的值改为正数,那么elif块运行,Python 打印a is positive。最后,如果您将a设置为零,那么else代码块就会执行。继续玩a看看会发生什么!
现在,假设您想确保在运行某段代码之前满足两个条件,也就是说这两个条件都为真。为了验证这一点,假设您需要获得运行您的脚本的用户的年龄,处理该信息,并向用户显示他们当前的生活阶段。
启动您最喜欢的代码编辑器或 IDE 并创建以下脚本:
# age.py
age = int(input("Enter your age: "))
if age >= 0 and age <= 9:
print("You are a child!")
elif age > 9 and age <= 18:
print("You are an adolescent!")
elif age > 18 and age <= 65:
print("You are an adult!")
elif age > 65:
print("Golden ages!")
这里你用 input() 得到用户的年龄,然后用 int() 把转换成整数。if子句检查age是否大于或等于0。在同一子句中,它检查age是否小于或等于9。为此,您需要构建一个and复合布尔表达式。
三个elif子句检查其他间隔,以确定与用户年龄相关联的生命阶段。
如果您从命令行运行这个脚本,那么您会得到如下结果:
$ python age.py
Enter your age: 25
You are an adult!
根据您在命令行中输入的年龄,脚本会采取不同的操作。在这个具体的例子中,您提供了 25 岁的年龄,并在屏幕上显示了消息You are an adult!。
while循环
while循环是第二个可以使用and表达式来控制程序执行流程的结构。通过在while语句头中使用and操作符,可以测试几个条件,只要所有条件都满足,就重复循环的代码块。
假设你正在为一个制造商制作一个控制系统的原型。该系统有一个关键机制,应该在 500 psi 或更低的压力下工作。如果压力超过 500 磅/平方英寸,而保持在 700 磅/平方英寸以下,那么系统必须运行一系列给定的标准安全动作。对于大于 700 psi 的压力,系统必须运行一套全新的安全措施。
为了解决这个问题,您可以使用一个带有and表达式的while循环。这里有一个脚本模拟了一个可能的解决方案:
1# pressure.py
2
3from time import sleep
4from random import randint
5
6def control_pressure():
7 pressure = measure_pressure()
8 while True:
9 if pressure <= 500:
10 break
11
12 while pressure > 500 and pressure <= 700:
13 run_standard_safeties()
14 pressure = measure_pressure()
15
16 while pressure > 700:
17 run_critical_safeties()
18 pressure = measure_pressure()
19
20 print("Wow! The system is safe...")
21
22def measure_pressure():
23 pressure = randint(490, 800)
24 print(f"psi={pressure}", end="; ")
25 return pressure
26
27def run_standard_safeties():
28 print("Running standard safeties...")
29 sleep(0.2)
30
31def run_critical_safeties():
32 print("Running critical safeties...")
33 sleep(0.7)
34
35if __name__ == "__main__":
36 control_pressure()
在control_pressure()中,您在第 8 行创建了一个无限的while循环。如果系统稳定且压力低于 500 psi,条件语句将跳出循环,程序结束。
在第 12 行,当系统压力保持在 500 psi 和 700 psi 之间时,第一个嵌套的while循环运行标准安全动作。在每次迭代中,循环获得新的压力测量值,以在下一次迭代中再次测试条件。如果压力超过 700 磅/平方英寸,那么管线 16 上的第二个回路运行临界安全动作。
注意:上例中control_pressure()的实现旨在展示and操作符如何在while循环的上下文中工作。
然而,这并不是您可以编写的最有效的实现。您可以重构control_pressure()来使用单个循环,而不使用and:
def control_pressure():
while True:
pressure = measure_pressure()
if pressure > 700:
run_critical_safeties()
elif 500 < pressure <= 700:
run_standard_safeties()
elif pressure <= 500:
break
print("Wow! The system is safe...")
在这个可替换的实现中,不使用and,而是使用链式表达式500 < pressure <= 700,它和pressure > 500 and pressure <= 700做的一样,但是更干净、更 Pythonic 化。另一个好处是你只需要调用measure_pressure()一次,这样效率会更高。
为了运行这个脚本,打开您的命令行并输入以下命令:
$ python pressure.py
psi=756; Running critical safeties...
psi=574; Running standard safeties...
psi=723; Running critical safeties...
psi=552; Running standard safeties...
psi=500; Wow! The system is safe...
您屏幕上的输出应该与这个示例输出略有不同,但是您仍然可以了解应用程序是如何工作的。
在非布尔上下文中使用 Python 的and操作符
事实上,and可以返回除了True和False之外的对象,这是一个有趣的特性。例如,这个特性允许您对条件执行使用and操作符。假设您需要更新一个flag变量,如果给定列表中的第一项等于某个期望值。对于这种情况,您可以使用条件语句:
>>> a_list = ["expected value", "other value"] >>> flag = False >>> if len(a_list) > 0 and a_list[0] == "expected value": ... flag = True ... >>> flag True这里,条件检查列表是否至少有一项。如果是,它检查列表中的第一项是否等于
"expected value"字符串。如果两个检查都通过,则flag变为True。您可以利用and操作符来简化这段代码:
>>> a_list = ["expected value", "other value"]
>>> flag = False
>>> flag = len(a_list) > 0 and a_list[0] == "expected value"
>>> flag
True
在这个例子中,突出显示的行完成了所有的工作。它检查这两个条件并一次完成相应的赋值。这个表达式从上一个例子中使用的if语句中去掉了and操作符,这意味着您不再在布尔上下文中工作。
上例中的代码比您之前看到的等价条件语句更简洁,但是可读性较差。为了正确理解这个表达式,您需要知道and操作符在内部是如何工作的。
将 Python 的and操作符投入使用
到目前为止,您已经学习了如何使用 Python 的and操作符来创建复合布尔表达式和非布尔表达式。您还学习了如何在布尔上下文中使用这个逻辑运算符,比如if语句和while循环。
在这一节中,您将构建几个实际的例子来帮助您决定何时使用and操作符。通过这些例子,您将了解如何利用and来编写更好、更 Pythonic 化的代码。
展平嵌套的if语句
Python 的禅的一个原则是“扁平比嵌套好”例如,虽然有两层嵌套的if语句的代码是正常的,完全没问题,但是当你有两层以上的嵌套时,你的代码看起来就变得混乱和复杂了。
假设你需要测试一个给定的数字是否为正。然后,一旦你确认它是正数,你需要检查这个数字是否低于给定的正值。如果是,您可以使用手头的数字进行特定的计算:
>>> number = 7 >>> if number > 0: ... if number < 10: ... # Do some calculation with number... ... print("Calculation done!") ... Calculation done!酷!这两个嵌套的
if语句解决了你的问题。你先检查数字是否为正,然后再检查它是否低于10。在这个小例子中,对print()的调用是特定计算的占位符,只有当两个条件都为真时才运行。尽管代码可以工作,但是最好通过移除嵌套的
if来使它更加 Pythonic 化。你怎么能这样做?嗯,您可以使用and操作符将两个条件组合成一个复合条件:
>>> number = 7
>>> if number > 0 and number < 10:
... # Do some calculation with number...
... print("Calculation done!")
...
Calculation done!
像and操作符这样的逻辑操作符通常通过移除嵌套的条件语句来提供改进代码的有效方法。尽可能利用它们。
在这个具体的例子中,您使用and创建一个复合表达式,检查一个数字是否在给定的范围或区间内。Python 通过链接表达式提供了一种更好的方式来执行这种检查。比如你可以把上面的条件写成0 < number < 10。这是下一节的主题。
检查数值范围
仔细查看下一节中的例子,您可以得出结论,Python 的and操作符是一个方便的工具,用于检查特定数值是否在给定的区间或范围内。例如,以下表达式检查数字x是否在0和10之间,包括两者:
>>> x = 5 >>> x >= 0 and x <= 10 True >>> x = 20 >>> x >= 0 and x <= 10 False在第一个表达式中,
and操作符首先检查x是否大于或等于0。由于条件为真,and操作员检查x是否低于或等于10。最终结果为真,因为第二个条件也为真。这意味着该数字在期望的区间内。在第二个示例中,第一个条件为真,但第二个条件为假。一般结果为 false,这意味着该数字不在目标区间内。
您可以将此逻辑包含在函数中,并使其可重用:
>>> def is_between(number, start=0, end=10):
... return number >= start and number <= end
...
>>> is_between(5)
True
>>> is_between(20)
False
>>> is_between(20, 10, 40)
True
在这个例子中,is_between()将number作为参数。还需要start和end,它们定义了目标区间。注意,这些参数有默认参数值,这意味着它们是可选参数。
您的is_between()函数返回评估一个and表达式的结果,该表达式检查number是否在start和end之间,包括这两个值。
注:无意中写出总是返回False的and表达式是常见错误。假设您想要编写一个表达式,从给定的计算中排除在0和10之间的值。
为了达到这个结果,您从两个布尔表达式开始:
number < 0number > 10
以这两个表达式为起点,您可以考虑使用and将它们组合成一个复合表达式。然而,没有一个数同时小于0和大于10,所以你最终得到一个总是假的条件:
>>> for number in range(-100, 100): ... included = number < 0 and number > 10 ... print(f"Is {number} included?", included) ... Is -100 included? False Is -99 included? False ... Is 0 included? False Is 1 included? False ... Is 98 included? False Is 99 included? False在这种情况下,
and是处理手头问题的错误逻辑运算符。您应该使用or操作符。来吧,试一试!尽管使用
and操作符允许您优雅地检查一个数字是否在给定的区间内,但是有一种更 Pythonic 化的技术可以处理同样的问题。在数学中,你可以写 0 < x < 10 来表示 x 在 0 和 10 之间。在大多数编程语言中,这个表达式没有意义。然而,在 Python 中,这个表达式非常有用:
>>> x = 5
>>> 0 < x < 10
True
>>> x = 20
>>> 0 < x < 10
False
在不同的编程语言中,这个表达式将从计算0 < x开始,这是正确的。下一步是将真正的布尔值与10进行比较,这没有多大意义,所以表达式失败。在 Python 中,会发生一些不同的事情。
Python 在内部将这种类型的表达式重写为等价的and表达式,比如x > 0 and x < 10。然后,它执行实际的评估。这就是为什么你在上面的例子中得到正确的结果。
就像您可以用多个and操作符链接几个子表达式一样,您也可以在不显式使用任何and操作符的情况下链接它们:
>>> x = 5 >>> y = 15 >>> 0 < x < 10 < y < 20 True >>> # Equivalent and expression >>> 0 < x and x < 10 and 10 < y and y < 20 True您还可以使用这个 Python 技巧来检查几个值是否相等:
>>> x = 10
>>> y = 10
>>> z = 10
>>> x == y == z
True
>>> # Equivalent and expression
>>> x == y and y == z
True
链式比较表达式是一个很好的特性,可以用多种方式编写。但是,你要小心。在某些情况下,最终的表达式可能很难阅读和理解,特别是对于来自没有这个特性的语言的程序员来说。
有条件地链接函数调用
如果你曾经在 Unix 系统上使用过 Bash ,那么你可能知道command1 && command2构造。这是一种方便的技术,允许您在一个链中运行几个命令。当且仅当前一个命令成功时,每个命令才会运行:
$ cd /not_a_dir && echo "Success"
bash: cd: /not_a_dir: No such file or directory
$ cd /home && echo "Success"
Success
这些例子使用 Bash 的短路和操作符(&&)使echo命令的执行依赖于cd命令的成功。
由于 Python 的and也实现了惰性求值的思想,所以可以用它来模拟这个 Bash 技巧。例如,您可以在一个单独的and表达式中链接一系列函数调用,如下所示:
func1() and func2() and func3() ... and funcN()
在这种情况下,Python 调用func1()。如果函数的返回值评估为真值,那么 Python 调用func2(),以此类推。如果其中一个函数返回 false 值,那么 Python 不会调用其余的函数。
下面是一个使用一些 pathlib 函数来操作文本文件的例子:
>>> from pathlib import Path >>> file = Path("hello.txt") >>> file.touch() >>> # Use a regular if statement >>> if file.exists(): ... file.write_text("Hello!") ... file.read_text() ... 6 'Hello!' >>> # Use an and expression >>> file.exists() and file.write_text("Hello!") and file.read_text() 'Hello!'不错!在一行代码中,您可以有条件地运行三个函数,而不需要一个
if语句。在这个具体的例子中,唯一可见的区别是.write_text()返回它写入文件的字节数。交互式 shell 会自动将该值显示在屏幕上。请记住,当您将代码作为脚本运行时,这种差异是不可见的。结论
Python 的
and操作符允许你构造复合布尔表达式,你可以用它来决定你的程序的动作过程。您可以使用and操作符来解决布尔或非布尔上下文中的几个问题。学习如何正确使用and操作符可以帮助你编写更多的python 式代码。在本教程中,您学习了如何:
- 使用 Python 的
and操作符- 用 Python 的
and操作符构建布尔和非布尔表达式- 在布尔上下文中使用
and操作符来决定程序的动作过程- 在非布尔上下文中使用
and操作符使你的代码更加简洁浏览本教程中的实际例子可以帮助您大致了解如何使用
and操作符在 Python 代码中做出决策。立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 Python 和运算符*****
Python 和 API:读取公共数据的成功组合
知道如何使用 API 是一种神奇的技能,一旦掌握,将打开一个全新的可能性世界,使用 Python 使用 API 是学习这种技能的一种很好的方式。
你日常使用的许多应用程序和系统都连接到一个 API。从非常简单和平凡的事情,比如早上查看天气,到更容易上瘾和耗时的操作,比如滚动 Instagram、抖音或 Twitter feed,API 都发挥着核心作用。
在本教程中,您将学习:
- 什么是 API
- 你如何用你的 Python 代码消费 API
- 什么是最重要的与 API 相关的概念
- 如何使用 Python 来读取通过公共 API 可用的数据
在本教程结束时,您将能够使用 Python 来使用您遇到的大多数 API。如果你是一名开发人员,知道如何使用 Python 来使用 API 会让你更加熟练,尤其是在将你的工作与第三方应用程序集成时。
注意:本教程关注的是如何使用 Python 消费API,而不是如何构建它们。有关使用 Python 构建 API 的信息,请查看Python REST API With Flask、Connexion 和 SQLAlchemy 。
您可以通过单击下面的链接下载本教程中将要看到的示例的源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习使用 Python 来使用 API。
了解 API
API 代表应用编程接口。本质上,API 充当了一个通信层,或者顾名思义,一个接口,它允许不同的系统相互交流,而不需要理解彼此具体做什么。
API 可以有多种形式。它们可以是操作系统 API,用于像打开相机和音频以加入变焦呼叫这样的操作。或者它们可以是网络应用编程接口,用于以网络为中心的操作,比如喜欢 Instagram 上的图片或获取最新的推文。
不管是哪种类型,所有的 API 都以相同的方式运行。你通常会发出一个请求获取信息或数据,API 会返回一个包含你所请求内容的响应。例如,每当你打开 Twitter 或向下滚动 Instagram feed 时,你基本上是在向该应用背后的 API 发出请求,并获得响应。这也被称为调用API。
在本教程中,您将更多地关注跨网络通信的高级 API,也称为web API。
SOAP vs REST vs GraphQL
尽管上面提到的一些例子是针对新的平台或应用程序的,但是 web APIs 已经存在很长时间了。在 20 世纪 90 年代末和 21 世纪初,两种不同的设计模型成为公开数据的规范:
- SOAP(简单对象访问协议)通常与企业世界相关联,具有更严格的基于契约的用法,并且主要是围绕动作设计的。
- REST(表述性状态转移)通常用于公共 API,是从 web 获取数据的理想选择。它比 SOAP 更轻便,更接近 HTTP 规范。
如今,镇上来了一个新人:GraphQL。由脸书创建的 GraphQL 是一种非常灵活的 API 查询语言,其中客户端决定他们想从服务器获取什么,而不是服务器决定发送什么。
如果您想进一步了解这三种设计模型之间的差异,这里有一些好的资源:
尽管 GraphQL 正在崛起,并被越来越大的公司采用,包括 GitHub 和 Shopify ,但事实是大多数公共 API 仍然是 REST APIs。因此,出于本教程的目的,您将只学习 REST APIs 以及如何使用 Python 来使用它们。
requests和 APIs:天作之合当用 Python 使用 API 时,你只需要一个库:
requests。有了它,您应该能够完成消费任何公共 API 所需的大部分(如果不是全部)操作。您可以通过在控制台中运行以下命令来安装
requests:$ python -m pip install requests要遵循本教程中的代码示例,请确保您使用的是 Python 3.8.1 和
requests2.24.0 或更高版本。使用 Python 调用您的第一个 API
说够了——是时候进行第一次 API 调用了!对于第一个例子,您将调用一个流行的 API 来生成随机用户数据。
在整个教程中,您将看到如下所示的 alert 块中引入了新的 API。对你来说,这是一种方便的方法,你可以在之后滚动,快速找到你所学过的所有新的 API。
随机用户生成器 API: 这是生成随机用户数据的绝佳工具。您可以使用它来生成任意数量的随机用户和相关数据,还可以指定性别、国籍和许多其他过滤器,这些过滤器在测试应用程序或 API 时非常有用。
从随机用户生成器 API 开始,您唯一需要做的事情就是知道使用哪个 URL 来调用它。对于这个例子,要使用的 URL 是
https://randomuser.me/api/,这是您可以进行的最小的 API 调用:
>>> import requests
>>> requests.get("https://randomuser.me/api/")
<Response [200]>
在这个小例子中,您导入库requests,然后从随机用户生成器 API 的 URL 获取数据。但是您实际上看不到任何返回的数据。取而代之的是一个Response [200],用 API 术语来说,这意味着一切正常。
如果您想看到实际的数据,那么您可以使用从返回的Response对象中的.text:
>>> import requests >>> response = requests.get("https://randomuser.me/api/") >>> response.text '{"results":[{"gender":"female", "name":{"title":"Ms","first":"Isobel","last":"Wang"}...'就是这样!这是 API 消费的基础。您使用 Python 和
requests库成功地从随机用户生成器 API 中获取了第一个随机用户。端点和资源
正如你在上面看到的,消费一个 API 你需要知道的第一件事是 API URL,通常叫做基本 URL 。基本 URL 结构与你用来浏览谷歌、YouTube 或脸书的 URL 没有什么不同,尽管它通常包含单词
api。这不是强制性的,只是一个经验法则。例如,以下是一些著名 API 播放器的基本 URL:
https://api.twitter.comhttps://api.github.comhttps://api.stripe.com正如你所看到的,以上都是以
https://api开头的,包括剩下的官方域名,比如.twitter.com或者.github.com。对于 API 基本 URL 应该是什么样子,没有特定的标准,但是它模仿这种结构是很常见的。如果你试着打开上面的任何一个链接,你会发现大多数链接都会返回一个错误或者要求凭证。这是因为 API 有时需要认证步骤才能使用。稍后在教程的中,你会学到更多关于这个的内容。
这个 API 很有趣,但也是一个很好的例子,一个有着很棒的文档的 API。有了它,你可以获取不同的狗品种和一些图像,但如果你注册,你也可以为你最喜欢的狗投票。
接下来,使用刚刚介绍的 TheDogAPI ,您将尝试发出一个基本请求,看看它与您上面尝试的随机用户生成器 API 有何不同:
>>> import requests
>>> response = requests.get("https://api.thedogapi.com/")
>>> response.text
'{"message":"The Dog API"}'
在这种情况下,当调用基本 URL 时,您会得到这样一条通用消息,即The Dog API。这是因为您调用的是基本 URL,它通常用于 API 的非常基本的信息,而不是真正的数据。
单独调用基本 URL 并不有趣,但这正是端点派上用场的地方。一个端点是 URL 的一部分,它指定您想要获取什么资源。记录良好的 API 通常包含一个 API 引用,这对于了解 API 拥有的确切端点和资源以及如何使用它们非常有用。
你可以查看官方文档来了解更多关于如何使用 DogAPI 以及有哪些端点可用。在那里,你会找到一个 /breeds端点,你可以用它来获取所有可用的品种资源或物品。
如果向下滚动,您会发现发送测试请求部分,您会看到如下所示的表单:
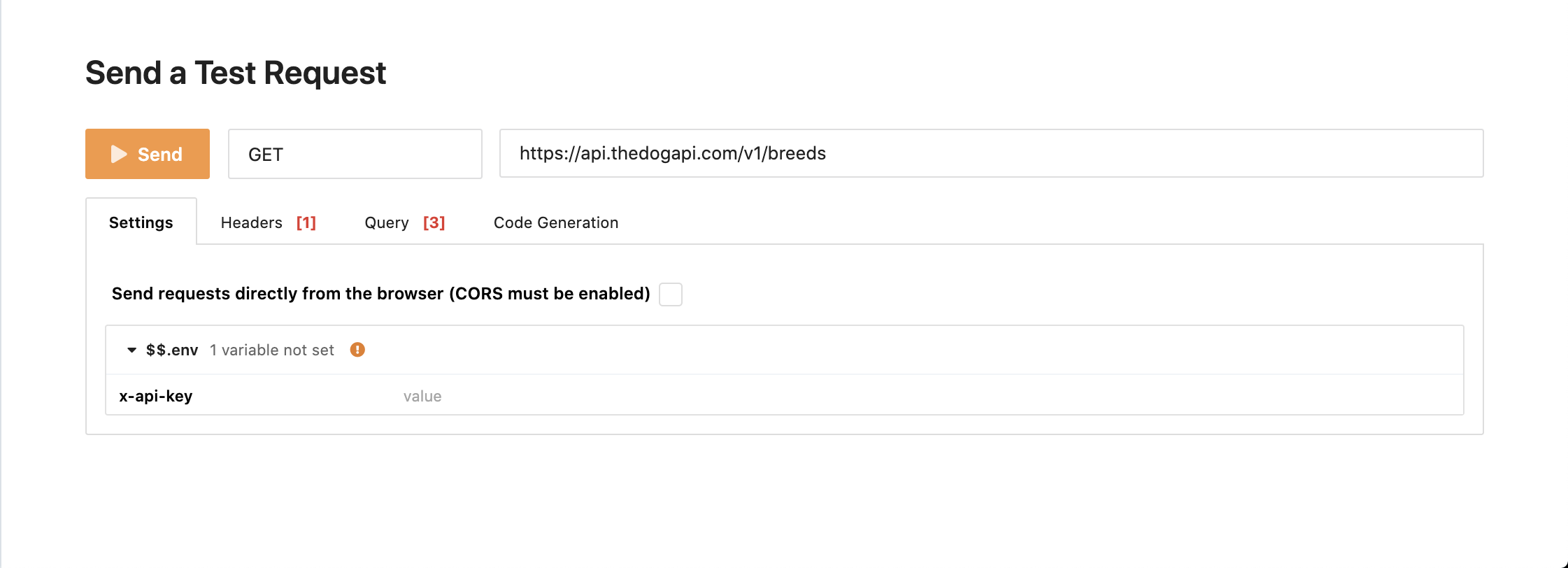
这是您将在许多 API 文档中看到的东西:一种让您直接从文档页面快速测试 API 的方法。在这种情况下,您可以单击 Send 来快速获得调用该端点的结果。 Et voilà ,你只需调用一个 API,无需为其编写任何代码。
现在,使用 breeds 端点和一些您已经掌握的 API 知识,在本地代码中尝试一下:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds") >>> response.text '[{"weight":{"imperial":"6 - 13","metric":"3 - 6"},"height": ...}]'这就是你的第一个使用狗 API 的品种列表!
如果你是一个爱猫的人,不要烦恼。您也可以使用一个 API,具有相同的端点,但不同的基本 URL:
>>> response = requests.get("https://api.thecatapi.com/v1/breeds") >>> response.text
'[{..."id":"abys","name":"Abyssinian"}]'
我敢打赌,你已经在想用不同的方法来使用这些 API 来做一些可爱的附带项目,这就是 API 的伟大之处。一旦你开始使用它们,没有什么能阻止你把爱好或激情变成一个有趣的小项目。
在继续之前,您需要知道关于端点的一件事是http://和https://之间的区别。简而言之,HTTPS 是 HTTP 的加密版本,使客户端和服务器之间的所有流量更加安全。当使用公共 API 时,您应该避免向http://端点发送任何私有或敏感信息,并且只使用那些提供安全https://基本 URL 的 API。
要了解更多关于为什么在网上浏览时坚持 HTTPS 很重要的信息,请查看用 Python 探索 HTTPS。
在下一节中,您将更深入地研究 API 调用的主要组件。
请求和响应
正如您在上面简要阅读的那样,客户端(在本例中是您的 Python 控制台)和 API 之间的所有交互都分为请求和响应:
- 请求包含关于 API 请求调用的相关数据,比如基本 URL、端点、使用的方法、头等等。
- 响应包含服务器返回的相关数据,包括数据或内容、状态码和头。
再次使用 DogAPI,您可以更深入地了解Request和Response对象内部的具体内容:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds") >>> response <Response [200]> >>> response.request <PreparedRequest [GET]> >>> request = response.request >>> request.url 'https://api.thedogapi.com/v1/breeds' >>> request.path_url '/v1/breeds' >>> request.method 'GET' >>> request.headers {'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} >>> response <Response [200]> >>> response.text '[{"weight":{"imperial":"6 - 13","metric":"3 - 6"}, "height":{"imperial":"9 - 11.5","metric":"23 - 29"},"id":1, "name":"Affenpinscher", ...}]' >>> response.status_code 200 >>> response.headers {'Cache-Control': 'post-check=0, pre-check=0', 'Content-Encoding': 'gzip', 'Content-Type': 'application/json; charset=utf-8', 'Date': 'Sat, 25 Jul 2020 17:23:53 GMT'...}上面的例子向您展示了对
Request和Response对象可用的一些最重要的属性。在本教程中,您将了解到更多关于这些属性的信息,但是如果您想更深入地了解,那么您可以查看 Mozilla 关于 HTTP messages 的文档,以获得关于每个属性的更深入的解释。
状态代码
状态代码是任何 API 响应中最重要的信息之一。它们会告诉您您的请求是否成功,是否缺少数据,是否缺少凭证,等等。
随着时间的推移,你会在没有帮助的情况下识别不同的状态代码。但是现在,这里列出了一些最常见的状态代码:
状态代码 描述 200 OK您的请求成功了! 201 Created您的请求已被接受,资源已创建。 400 Bad Request你的请求要么是错误的,要么是遗漏了一些信息。 401 Unauthorized您的请求需要一些额外的权限。 404 Not Found请求的资源不存在。 405 Method Not Allowed端点不允许该特定的 HTTP 方法。 500 Internal Server Error您的请求不是预期的,可能破坏了服务器端的某些东西。 您在前面执行的示例中看到了
200 OK,您甚至可以通过浏览网页认出404 Not Found。有趣的事实:公司倾向于使用
404错误页面来开私人玩笑或纯粹的玩笑,就像下面这些例子:然而,在 API 世界中,开发人员对于这种乐趣的反应空间有限。但是它们在其他地方弥补了这一点,比如 HTTP 头。您很快就会看到一些例子!
您可以使用
.status_code和.reason来检查响应的状态。requests库还在Response对象的表示中打印状态代码:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds")
>>> response <Response [200]>
>>> response.status_code 200
>>> response.reason 'OK'
上面的请求返回200,所以你可以认为它是一个成功的请求。但是现在看看当您在端点/breedz中包含一个输入错误时触发的失败请求:
>>> response = requests.get("https://api.thedogapi.com/v1/breedz") >>> response <Response [404]> >>> response.status_code 404 >>> response.reason 'Not Found'如您所见,
/breedz端点不存在,因此 API 返回一个404 Not Found状态代码。您可以使用这些状态代码快速查看您的请求是否需要更改,或者您是否应该再次检查文档中的任何拼写错误或缺失部分。
HTTP 报头
HTTP 头用于定义一些控制请求和响应的参数:
HTTP 标头 描述 Accept客户端可以接受什么类型的内容 Content-Type服务器将响应什么类型的内容 User-Agent客户端使用什么软件与服务器通信 Server服务器使用什么软件与客户端通信 Authentication谁在调用 API,他们有什么凭证 在检查请求或响应时,您可以找到许多其他的头。如果你对它们的具体用途感兴趣,可以看看 Mozilla 的扩展列表。
要检查响应的报头,可以使用
response.headers:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.headers {'Content-Encoding': 'gzip',
'Content-Type': 'application/json; charset=utf-8',
'Date': 'Sat, 25 Jul 2020 19:52:07 GMT'...}
为了对请求头做同样的事情,您可以使用response.request.headers,因为request是Response对象的一个属性:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1") >>> response.request.headers {'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}在这种情况下,您在发出请求时不需要定义任何特定的头,所以会返回默认的头。
自定义标题
在使用 API 时,您可能会遇到的另一个标准是自定义头的使用。这些通常以
X-开头,但不是必须的。API 开发人员通常使用自定义头向客户端发送或请求额外的自定义信息。有趣的事实:一些公司想尽办法变得有趣和创新,以一种他们不打算使用的方式使用 HTTP 报头,例如征求工作申请。
您可以使用一个字典来定义头部,并且您可以使用
.get()的headers参数将它们与您的请求一起发送。例如,假设您想要向 API 服务器发送一些请求 ID,并且您知道您可以使用
X-Request-Id来完成:
>>> headers = {"X-Request-Id": "<my-request-id>"} >>> response = requests.get("https://example.org", headers=headers) >>> response.request.headers
{'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*', 'Connection': 'keep-alive',
'X-Request-Id': '<my-request-id>'}
如果您浏览一下request.headers字典,那么您会发现X-Request-Id就在最后,在缺省情况下任何 API 请求都会附带的一些其他头文件中。
一个响应可能有许多有用的头,但其中最重要的一个是Content-Type,它定义了响应中返回的内容种类。
Content-Type
如今,大多数 API 使用 JSON 作为默认的内容类型,但是您可能需要使用返回 XML 或其他媒体类型的 API,比如图像或视频。在这种情况下,内容类型会有所不同。
如果您回头看看前面一个使用 DogAPI 的例子,并尝试检查Content-Type头,那么您会注意到它是如何被定义为application/json的:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1") >>> response.headers.get("Content-Type") 'application/json; charset=utf-8'除了特定类型的内容(在本例中为
application/json),消息头还可能返回响应内容的指定编码。这是一个非常愚蠢的 API,它返回不同大小的山羊的图像,你可以在你的网站中使用它们作为占位符图像。
例如,如果您试图从 PlaceGOAT API 中获取一张山羊的图像,那么您会注意到内容类型不再是
application/json,而是被定义为image/jpeg:
>>> response = requests.get("http://placegoat.com/200/200") >>> response
<Response [200]>
>>> response.headers.get("Content-Type")
'image/jpeg'
在这种情况下,Content-Type头表明返回的内容是一个 JPEG 图像。您将在下一节学习如何查看这些内容。
对于您了解如何处理响应以及如何处理其内容来说,Content-Type头非常重要。还有数百种其他可接受的内容类型,包括音频、视频、字体等等。
响应内容
正如您刚刚了解到的,您在 API 响应中找到的内容类型将根据Content-Type头的不同而不同。为了根据不同的Content-Type头正确地读取响应内容,requests包附带了几个不同的Response属性,您可以使用它们来操作响应数据:
您已经使用了上面的.text属性。但是对于某些特定类型的数据,比如图像和其他非文本数据,使用.content通常是更好的方法,即使它返回的结果与.text非常相似:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1") >>> response.headers.get("Content-Type") 'application/json; charset=utf-8' >>> response.content b'{"weight":{"imperial":"6 - 13","metric":"3 - 6"}...'如你所见,
.content和之前用的.text没有太大区别。然而,通过查看响应的
Content-Type头,您可以看到内容是application/json;,一个 JSON 对象。对于这种内容,requests库包含了一个特定的.json()方法,您可以使用它将 API 字节响应立即转换成一个 Python 数据结构:
>>> response = requests.get("https://api.thedogapi.com/v1/breeds/1")
>>> response.headers.get("Content-Type")
'application/json; charset=utf-8'
>>> response.json() {'weight': {'imperial': '6 - 13', 'metric': '3 - 6'},
'height': {'imperial': '9 - 11.5', 'metric': '23 - 29'}
...}
>>> response.json()["name"] 'Affenpinscher'
正如您所看到的,在执行response.json()之后,您得到了一个字典,您可以像使用 Python 中的任何其他字典一样使用它。
现在,回头看看最近使用 PlaceGOAT API 运行的示例,尝试获取相同的 GOAT 图像并查看其内容:
>>> response = requests.get("http://placegoat.com/200/200") >>> response <Response [200]> >>> response.headers.get("Content-Type") 'image/jpeg' >>> response.content b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x01\x00H\...'在这种情况下,因为您正在请求一个图像,
.content不是很有帮助。事实上,这几乎是不可能理解的。然而,你知道这是一个 JPEG 图像,所以你可以试着把它存储到一个文件中,看看会发生什么:
>>> response = requests.get("http://placegoat.com/200/200")
>>> response
<Response [200]>
>>> response.headers.get("Content-Type")
'image/jpeg'
>>> file = open("goat.jpeg", "wb") >>> file.write(response.content) >>> file.close()
现在,如果你打开你正在工作的文件夹,你会发现一个goat.jpeg文件,这是你刚刚使用 API 获取的一只山羊的随机图像。是不是很神奇?
HTTP 方法
当调用一个 API 时,有一些不同的方法,也称为动词,可以用来指定想要执行的动作。例如,如果你想获取一些数据,你可以使用方法GET,如果你想创建一些数据,你可以使用方法POST。
当纯粹使用 API 消费数据时,您通常会坚持使用GET请求,但这里列出了最常见的方法及其典型用例:
| HTTP 方法 | 描述 | 请求方法 |
|---|---|---|
POST |
创建新资源。 | requests.post() |
GET |
读取现有资源。 | requests.get() |
PUT |
更新现有资源。 | requests.put() |
DELETE |
删除现有资源。 | requests.delete() |
这四种方法通常被称为 CRUD 操作,因为它们允许您ccreate、 r ead、 u pdate 和ddelete 资源。
注意:还有一个额外的PATCH方法也与 CRUD 操作相关,但是它比上面的四个稍微不那么常见。它用于进行部分修改,而不是使用PUT完全替换一个资源。
你可以多读一点关于PUT和PATCH 之间的差异,了解他们不同的需求。
如果你对剩下的 HTTP 方法感到好奇,或者如果你只是想了解更多关于那些已经提到的方法,那么看看 Mozilla 的文档。
到目前为止,您只使用了.get()来获取数据,但是您也可以将requests包用于所有其他的 HTTP 方法:
>>> requests.post("https://api.thedogapi.com/v1/breeds/1") >>> requests.get("https://api.thedogapi.com/v1/breeds/1") >>> requests.put("https://api.thedogapi.com/v1/breeds/1") >>> requests.delete("https://api.thedogapi.com/v1/breeds/1")如果你在你的主机上尝试这些,那么你会注意到大多数都会返回一个
405 Method Not Allowed状态码。这是因为不是所有的端点都支持POST、PUT或DELETE方法。尤其是当你使用公共 API 读取数据时,你会发现大多数 API 只允许GET请求,因为不允许你创建或更改现有数据。查询参数
有时当你调用一个 API 时,你会得到大量你不需要或不想要的数据。例如,当调用 TheDogAPI 的
/breeds端点时,您会获得关于某个特定品种的大量信息。但是在某些情况下,您可能只想提取某个特定品种的某些信息。这就是查询参数的用武之地!您可能在网上浏览时见过或使用过查询参数。例如,在观看 YouTube 视频时,你会看到一个类似于
https://www.youtube.com/watch?v=aL5GK2LVMWI的 URL。URL 中的v=就是您所说的查询参数。它通常位于基本 URL 和端点之后。要向给定的 URL 添加查询参数,必须在第一个查询参数前添加一个问号(
?)。如果您希望在您的请求中有多个查询参数,那么您可以用一个&符号(&)将它们分开。上面带有多个查询参数的同一个 YouTube URL 应该是这样的:
https://www.youtube.com/watch?v=aL5GK2LVMWI&t=75。在 API 世界中,查询参数被用作过滤器,可以随 API 请求一起发送,以进一步缩小响应范围。例如,回到随机用户生成器 API,您知道如何生成随机用户:
>>> requests.get("https://randomuser.me/api/").json()
{'results': [{'gender': 'male', 'name':
{'title': 'Mr', 'first': 'Silvijn', 'last': 'Van Bekkum'},
'location': {'street': {'number': 2480, 'name': 'Hooijengastrjitte'},
'city': 'Terherne', 'state': 'Drenthe',
'country': 'Netherlands', 'postcode': 59904...}
然而,让我们说你特别想只生成随机的女性用户。根据文档,您可以使用查询参数gender=进行查询:
>>> requests.get("https://randomuser.me/api/?gender=female").json() {'results': [{'gender': 'female', 'name': {'title': 'Mrs', 'first': 'Marjoleine', 'last': 'Van Huffelen'}, 'location': {'street': {'number': 8993, 'name': 'De Teebus'}, 'city': 'West-Terschelling', 'state': 'Limburg', 'country': 'Netherlands', 'postcode': 24241...}太好了!现在让我们假设你想只产生来自德国的女性用户。同样,浏览文档,您会发现一个关于国籍的部分,您可以使用查询参数
nat=进行查询:
>>> requests.get("https://randomuser.me/api/?gender=female&nat=de").json() {'results': [{'gender': 'female', 'name':
{'title': 'Ms', 'first': 'Marita', 'last': 'Hertwig'},
'location': {'street': {'number': 1430, 'name': 'Waldstraße'},
'city': 'Velden', 'state': 'Rheinland-Pfalz',
'country': 'Germany', 'postcode': 30737...}
使用查询参数,您可以开始从 API 获取更具体的数据,使整个体验更符合您的需求。
为了避免一次又一次地重新构建 URL,您可以使用params属性发送一个包含所有查询参数的字典,以附加到 URL:
>>> query_params = {"gender": "female", "nat": "de"} >>> requests.get("https://randomuser.me/api/", params=query_params).json() {'results': [{'gender': 'female', 'name': {'title': 'Ms', 'first': 'Janet', 'last': 'Weyer'}, 'location': {'street': {'number': 2582, 'name': 'Meisenweg'}, 'city': 'Garding', 'state': 'Mecklenburg-Vorpommern', 'country': 'Germany', 'postcode': 56953...}您可以将上述内容应用于任何其他您喜欢的 API。如果您返回到 DogAPI,文档有一种方法可以让您过滤品种端点,只返回匹配特定名称的品种。例如,如果您想寻找拉布拉多犬,那么您可以使用查询参数
q来完成:
>>> query_params = {"q": "labradoodle"} >>> endpoint = "https://api.thedogapi.com/v1/breeds/search" >>> requests.get(endpoint, params=query_params).json() [{'weight': {'imperial': '45 - 100', 'metric': '20 - 45'},
'height': {'imperial': '14 - 24', 'metric': '36 - 61'},
'id': 148, 'name': 'Labradoodle', 'breed_group': 'Mixed'...}]
你有它!通过发送带有值labradoodle的查询参数q,您能够过滤所有匹配该特定值的品种。
提示:当您重用同一个端点时,最好的做法是将其定义为代码顶部的一个变量。当你一次又一次地与一个 API 交互时,这将使你的生活变得更容易。
在查询参数的帮助下,您能够进一步缩小您的请求范围,并准确地指定您要查找的内容。你可以在网上找到的大多数 API 都有一些查询参数,你可以用它们来过滤数据。记住要浏览文档和 API 参考来找到它们。
学习高级 API 概念
既然您已经很好地理解了使用 Python 进行 API 消费的基础知识,那么还有一些更高级的主题值得一提,即使是简短的,比如认证、分页和速率限制。
认证
API 认证可能是本教程中最复杂的主题。尽管许多公共 API 都是免费且完全公开的,但在某种形式的认证背后,还有更多 API 可用。有许多 API 需要认证,但这里有几个很好的例子:
身份验证方法从简单直接的方法(如使用 API 密钥或基本身份验证的方法)到复杂安全得多的技术(如 OAuth)不等。
通常,在没有凭证或凭证错误的情况下调用 API 会返回一个401 Unauthorized或403 Forbidden状态代码。
API 键
最常见的认证级别是 API 密钥。这些密钥用于识别您是 API 用户还是客户,并跟踪您对 API 的使用。API 键通常作为请求头或查询参数发送。
NASA API:最酷的公开可用 API 集合之一是由 NASA 提供的。你可以找到 API 来获取当天的天文图片或者由地球多色成像相机(EPIC) 拍摄的图片,等等。
举个例子,你可以试试美国宇航局的火星漫游者照片 API ,你将获取 2020 年 7 月 1 日拍摄的照片。出于测试目的,您可以使用 NASA 默认提供的DEMO_KEY API 键。否则,你可以通过进入 NASA 的主 API 页面并点击开始来快速生成你自己的。
您可以通过追加api_key=查询参数将 API 键添加到您的请求中:
>>> endpoint = "https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos" >>> # Replace DEMO_KEY below with your own key if you generated one. >>> api_key = "DEMO_KEY" >>> query_params = {"api_key": api_key, "earth_date": "2020-07-01"} >>> response = requests.get(endpoint, params=query_params) >>> response <Response [200]>到目前为止,一切顺利。您设法向 NASA 的 API 发出了一个经过验证的请求,并得到了一个
200 OK响应。现在看看
Response物体,试着从中提取一些图片:
>>> response.json()
{'photos': [{'id': 754118,
'sol': 2809,
'camera': {'id': 20,
'name': 'FHAZ',
'rover_id': 5,
'full_name': 'Front Hazard Avoidance Camera'},
'img_src': 'https://mars.nasa.gov/msl-raw-images/...JPG',
'earth_date': '2020-07-01',
'rover': {'id': 5,
'name': 'Curiosity',
'landing_date': '2012-08-06',
'launch_date': '2011-11-26',
'status': 'active'}},
...
}
>>> photos = response.json()["photos"]
>>> print(f"Found {len(photos)} photos")
Found 12 photos
>>> photos[4]["img_src"]
'https://mars.nasa.gov/msl-raw-images/proj/msl/redops/ods/surface/sol/02809/opgs/edr/rcam/RRB_646869036EDR_F0810628RHAZ00337M_.JPG'
使用.json()将响应转换为 Python 字典,然后从响应中获取photos字段,您可以遍历所有Photo对象,甚至获取特定照片的图像 URL。如果你在浏览器中打开那个网址,你会看到下面这张由火星探测器拍摄的火星照片:

在这个例子中,您选择了一个特定的earth_date ( 2020-07-01),然后从响应词典中选择了一张特定的照片(4)。在继续之前,试着改变日期或从不同的相机获取照片,看看它如何改变最终结果。
OAuth:入门
API 认证中另一个非常常见的标准是 OAuth 。在本教程中,您将只学习 OAuth 的基本知识,因为这是一个非常广泛的主题。
即使您没有意识到它是 OAuth 的一部分,您也可能已经多次看到和使用了 OAuth 流。每次一个应用或平台有一个使用或继续使用选项的登录,这就是 OAuth 流程的起点:
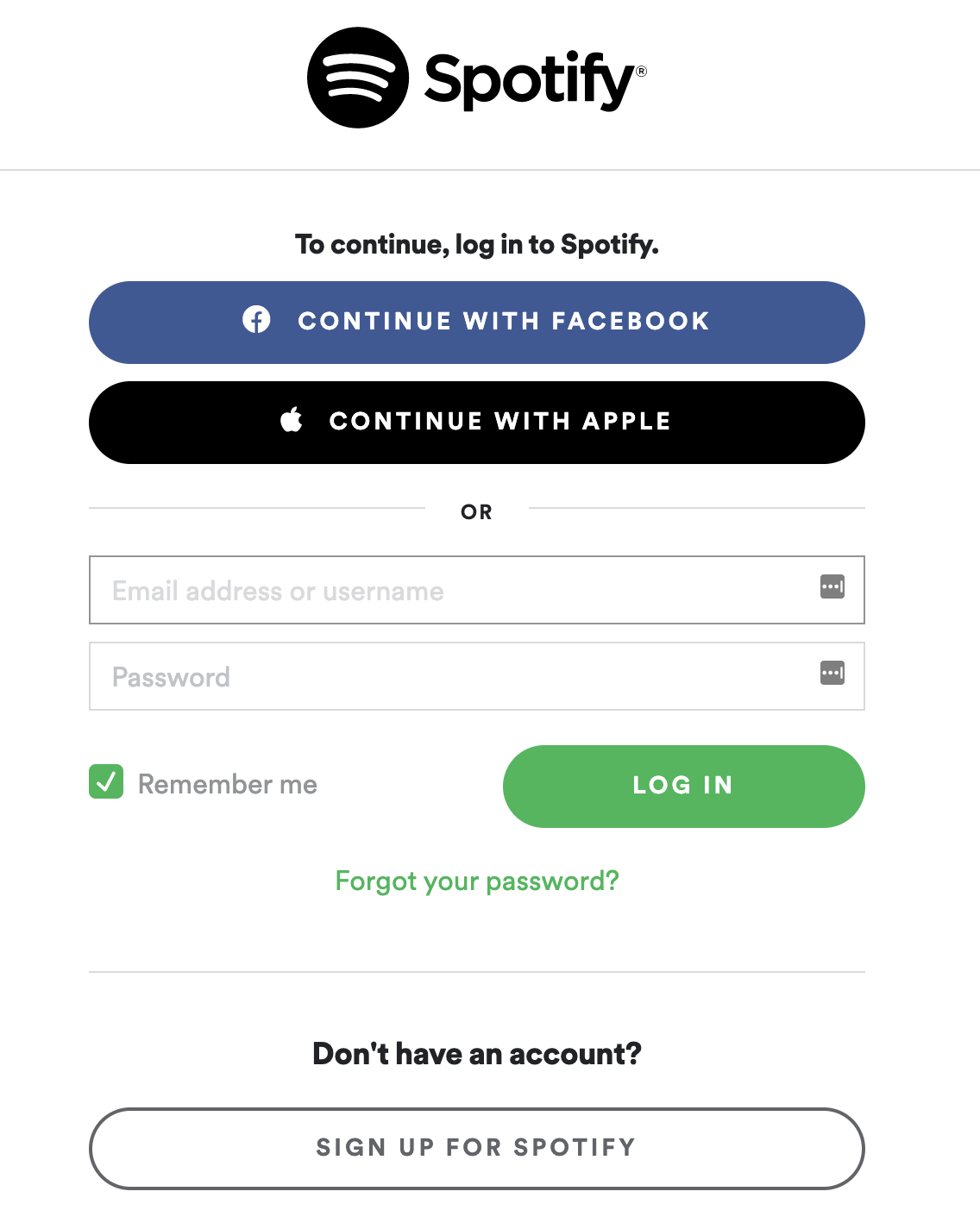
如果你点击继续脸书会发生什么,这里有一个逐步分解:
-
Spotify 应用程序将要求脸书应用编程接口启动认证流程。为此,Spotify 应用程序将发送其应用程序 ID (
client_id)和一个 URL (redirect_uri),以便在成功或出错后重定向用户。 -
您将被重定向到脸书网站,并被要求使用您的凭据登录。Spotify 应用程序不会看到或访问这些凭据。这是 OAuth 最重要的好处。
-
脸书将向你展示 Spotify 应用程序从你的个人资料中索取的所有数据,并询问你是接受还是拒绝分享这些数据。
-
如果你接受让 Spotify 访问你的数据,那么你将被重定向回已经登录的 Spotify 应用程序。
在进行第四步时,脸书将向 Spotify 提供一个特殊的凭证(access_token),可以重复使用该凭证来获取您的信息。这个特定的脸书登录令牌的有效期为 60 天,但其他应用程序可能有不同的过期时间。如果你很好奇,那么脸书有一个设置页面,你可以查看哪些应用获得了你的脸书访问令牌。
现在,从更技术性的角度来看,在使用 OAuth 消费 API 时,您需要了解以下内容:
- 您需要创建一个具有 ID (
app_id或client_id)和秘密(app_secret或client_secret)的应用程序。 - 您需要一个重定向 URL (
redirect_uri),API 将使用它向您发送信息。 - 作为认证的结果,您将获得一个代码,您需要用它来交换一个访问令牌。
上面有一些变化,但是一般来说,大多数 OAuth 流程都有类似的步骤。
提示:当你刚刚开始测试,需要某种重定向 URL 来获取code时,你可以使用名为 httpbin 的服务。
更具体地说,您可以使用https://httpbin.org/anything作为重定向 URL,因为它将简单地输出它得到的任何输入。您可以通过导航到该 URL 来测试它。
接下来,您将深入一个使用 GitHub API 的示例!
OAuth:一个实际的例子
正如您在上面看到的,您需要做的第一件事是创建一个应用程序。在 GitHub 文档中有一个很好的分步解释,你可以跟随。需要记住的唯一一件事是将上面提到的https://httpbin.org/anything URL 用于授权回调 URL 字段。
GitHub API: 您可以将 GitHub API 用于许多不同的用例,比如获取您所属的存储库列表、获取您拥有的关注者列表等等。
一旦你创建了你的应用程序,将Client_ID和Client_Secret以及你选择的重定向 URL 复制并粘贴到一个叫做github.py的 Python 文件中:
import requests
# REPLACE the following variables with your Client ID and Client Secret
CLIENT_ID = "<REPLACE_WITH_CLIENT_ID>" CLIENT_SECRET = "<REPLACE_WITH_CLIENT_SECRET>"
# REPLACE the following variable with what you added in the
# "Authorization callback URL" field REDIRECT_URI = "<REPLACE_WITH_REDIRECT_URI>"
既然已经有了所有重要的变量,您需要能够创建一个链接,将用户重定向到他们的 GitHub 帐户,正如在 GitHub 文档中所解释的:
def create_oauth_link():
params = { "client_id": CLIENT_ID, "redirect_uri": REDIRECT_URI, "scope": "user", "response_type": "code", }
endpoint = "https://github.com/login/oauth/authorize"
response = requests.get(endpoint, params=params) url = response.url return url
在这段代码中,首先定义 API 期望的必需参数,然后使用requests包和.get()调用 API。
当您向/login/oauth/authorize端点发出请求时,API 会自动将您重定向到 GitHub 网站。在这种情况下,您需要从响应中获取url参数。该参数包含 GitHub 将您重定向到的确切 URL。
授权流程的下一步是将您获得的代码换成访问令牌。同样,按照 GitHub 的文档中的步骤,您可以为它创建一个方法:
def exchange_code_for_access_token(code=None):
params = {
"client_id": CLIENT_ID,
"client_secret": CLIENT_SECRET, "redirect_uri": REDIRECT_URI,
"code": code, }
headers = {"Accept": "application/json"}
endpoint = "https://github.com/login/oauth/access_token"
response = requests.post(endpoint, params=params, headers=headers).json() return response["access_token"]
这里,您发出一个POST请求,用代码交换一个访问令牌。在这个请求中,您必须发送您的CLIENT_SECRET和code,以便 GitHub 可以验证这个特定的代码最初是由您的应用程序生成的。只有这样,GitHub API 才会生成一个有效的访问令牌,然后将它返回给。
现在,您可以将以下内容添加到您的文件中,并尝试运行它:
link = create_oauth_link()
print(f"Follow the link to start the authentication with GitHub: {link}")
code = input("GitHub code: ")
access_token = exchange_code_for_access_token(code)
print(f"Exchanged code {code} with access token: {access_token}")
如果一切按计划进行,那么您应该得到一个有效的访问令牌,您可以用它来调用 GitHub API,模拟经过身份验证的用户。
现在,尝试添加以下代码,使用用户 API 获取您的用户配置文件,并打印您的姓名、用户名和私有存储库的数量:
def print_user_info(access_token=None):
headers = {"Authorization": f"token {access_token}"} endpoint = "https://api.github.com/user"
response = requests.get(endpoint, headers=headers).json()
name = response["name"] username = response["login"] private_repos_count = response["total_private_repos"] print(
f"{name} ({username}) | private repositories: {private_repos_count}"
)
现在您有了一个有效的访问令牌,您需要使用Authorization头在所有 API 请求中发送它。对您请求的响应将是一个包含所有用户信息的 Python 字典。从字典中,您想要获取字段name、login和total_private_repos。您也可以打印response变量,看看还有哪些字段可用。
好了,就这样了!剩下唯一要做的事情就是把它们放在一起并进行试验:
1import requests
2
3# REPLACE the following variables with your Client ID and Client Secret
4CLIENT_ID = "<REPLACE_WITH_CLIENT_ID>"
5CLIENT_SECRET = "<REPLACE_WITH_CLIENT_SECRET>"
6
7# REPLACE the following variable with what you added in
8# the "Authorization callback URL" field
9REDIRECT_URI = "<REPLACE_WITH_REDIRECT_URI>"
10
11def create_oauth_link():
12 params = {
13 "client_id": CLIENT_ID,
14 "redirect_uri": REDIRECT_URI,
15 "scope": "user",
16 "response_type": "code",
17 }
18 endpoint = "https://github.com/login/oauth/authorize"
19 response = requests.get(endpoint, params=params)
20 url = response.url
21 return url
22
23def exchange_code_for_access_token(code=None):
24 params = {
25 "client_id": CLIENT_ID,
26 "client_secret": CLIENT_SECRET,
27 "redirect_uri": REDIRECT_URI,
28 "code": code,
29 }
30 headers = {"Accept": "application/json"}
31 endpoint = "https://github.com/login/oauth/access_token"
32 response = requests.post(endpoint, params=params, headers=headers).json()
33 return response["access_token"]
34
35def print_user_info(access_token=None):
36 headers = {"Authorization": f"token {access_token}"}
37 endpoint = "https://api.github.com/user"
38 response = requests.get(endpoint, headers=headers).json()
39 name = response["name"]
40 username = response["login"]
41 private_repos_count = response["total_private_repos"]
42 print(
43 f"{name} ({username}) | private repositories: {private_repos_count}"
44 )
45
46link = create_oauth_link()
47print(f"Follow the link to start the authentication with GitHub: {link}")
48code = input("GitHub code: ")
49access_token = exchange_code_for_access_token(code)
50print(f"Exchanged code {code} with access token: {access_token}")
51print_user_info(access_token=access_token)
运行上面的代码时会发生以下情况:
-
会生成一个链接,要求您转到 GitHub 页面进行身份验证。
-
点击该链接并使用您的 GitHub 凭据登录后,您将被重定向到您定义的回调 URL,查询参数中有一个
code字段:
![Consuming APIs with Python: Github OAuth Code]()
示例 GitHub OAuth 代码 -
在您的控制台中粘贴代码后,您将代码换成一个可重用的访问令牌。
-
您的用户信息是使用该访问令牌获取的。打印您的姓名、用户名和私人存储库数量。
如果您遵循上面的步骤,那么您应该会得到与此类似的最终结果:
$ John Doe (johndoe) | number of private repositories: 42
这里有相当多的步骤要做,但重要的是你要花时间真正理解每一步。大多数使用 OAuth 的 API 都有很多相同的行为,所以当您从 API 中读取数据时,很好地了解这个过程将会释放很多潜力。
您可以随意改进这个示例并添加更多的功能,比如获取您的公共和星级存储库,或者遍历您的关注者以确定最受欢迎的存储库。
网上有很多关于 OAuth 的很棒的资源,如果消费 OAuth 背后的 API 是你真正需要的,那么我建议你在这个主题上做更多的研究。这里有几个好的起点:
- OAuth 到底是什么?
- OAuth 2 简化版
- OAuth 2.0 授权框架
从 API 消费的角度来看,当您与公共 API 交互时,了解 OAuth 肯定会非常有用。大多数 API 都采用 OAuth 作为它们的认证标准,这是有充分理由的。
分页
在客户机和服务器之间来回发送大量数据需要付出代价:带宽。为了确保服务器能够处理大量的请求,API 通常使用分页。
简单来说,分页就是将大量数据分割成多个小块的行为。例如,每当你进入堆栈溢出中的问题页面,你会在底部看到这样的内容:

你可能从许多其他网站上认识到这一点,不同网站的概念基本相同。对于特定的 API,这通常借助于查询参数来处理,主要有以下两个:
- 一个
page属性,它定义了您当前正在请求的页面 - 定义每页大小的
size属性
具体的查询参数名称可能会因 API 开发人员的不同而有很大差异,但概念是相同的。一些 API 播放器也可能使用 HTTP 头或 JSON 响应来返回当前的分页过滤器。
再次使用 GitHub API,您可以在包含分页查询参数的文档中找到一个事件端点。参数per_page=定义了要返回的项数,而page=允许您对多个结果进行分页。以下是如何使用这些参数:
>>> response = requests.get("https://api.github.com/events?per_page=1&page=0") >>> response.json()[0]["id"] '14345572615' >>> response = requests.get("https://api.github.com/events?per_page=1&page=1") >>> response.json()[0]["id"] '14345572808' >>> response = requests.get("https://api.github.com/events?per_page=1&page=2") >>> response.json()[0]["id"] '14345572100'使用第一个 URL ,你只能获取一个事件。但是使用
page=查询参数,您可以在结果中保持分页,确保您能够获取所有事件,而不会使 API 过载。速率限制
鉴于 API 是面向公众的,任何人都可以使用,心怀不轨的人经常试图滥用它们。为了防止这种攻击,你可以使用一种叫做速率限制的技术,它限制用户在给定时间范围内可以发出的请求数量。
如果您过于频繁地超过定义的速率限制,一些 API 实际上可能会阻止您的 IP 或 API 密钥。注意不要超过 API 开发者设置的限制。否则,您可能需要等待一段时间才能再次调用该 API。
对于下面的例子,您将再次使用 GitHub API 和
/events端点。根据它的文档,GitHub 每小时允许大约 60 个未经认证的请求。如果超出这个范围,那么您将得到一个 403 状态代码,并且在相当长的一段时间内不能再进行任何 API 调用。警告:运行下一段代码确实会在一段时间内阻止你调用 GitHub,所以在运行它之前,确保你一点也不需要访问 GitHub 的 API。
为了便于演示,您将有目的地尝试超过 GitHub 的速率限制,看看会发生什么。在下面的代码中,您将请求数据,直到您获得除
200 OK之外的状态代码:
>>> endpoint = "https://api.github.com/events"
>>> for i in range(100):
>>> response = requests.get(endpoint)
>>> print(f"{i} - {response.status_code}")
>>> if response.status_code != 200:
>>> break
0 - 200
1 - 200
2 - 200
3 - 200
4 - 200
5 - 200
...
55 - 200
56 - 200
57 - 403
>>> response
<Response [403]>
>>> response.json()
{'message': "API rate limit exceeded for <ip-address>.",
'documentation_url': 'https://developer.github.com/v3/#rate-limiting'}
现在,在大约 60 个请求之后,API 停止返回200 OK响应,而是返回一个403 Forbidden响应,通知您已经超过了 API 速率限制。
有些 API,比如 GitHub,甚至可能在头中包含关于当前速率限制和剩余请求数量的附加信息。这些非常有助于你避免超过规定的限度。看看最新的response.headers看能不能找到那些具体的限速标题。
使用 Python 消费 API:实践示例
既然您已经了解了所有的理论,并且已经试验了一些 API,那么您可以用一些更实际的例子来巩固这些知识。您可以修改下面的示例,使它们适合您自己的目的。
您可以通过下载下面链接中的源代码来了解这些示例:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习使用 Python 来使用 API。
搜索和获取趋势 gif
做一个小脚本从 GIPHY 网站上取前三个趋势 gif 怎么样?为此,您需要创建一个应用程序,并从 GIPHY 获取一个 API 密钥。你可以通过展开下面的方框找到说明,也可以查看 GIPHY 的快速入门文档。
步骤 1:创建一个 GIPHY 帐户
您应该首先创建一个 GIPHY 帐户:
这里没有什么新东西,只是典型的电子邮件和密码表单,还有一个额外的用户名字段。
步骤 2:创建一个应用程序
创建 GIPHY 帐户后,您可以跳转到开发者仪表盘查看您现有的应用程序:
在这种情况下,您还没有设置应用程序,所以它看起来有点空。您可以通过点击 创建应用 来创建您的第一个应用:
确保选择 API 版本,而不是 SDK 版本。之后,你会被要求填写更多关于你的申请的细节:
您可以在上面看到一个示例应用程序名称和描述,但是您可以随意填写这些内容。
步骤 3:获取 API 密钥
完成上述步骤后,您应该会在仪表板中的“您的应用程序”部分下方看到一个新的应用程序。在那里,您将有一个 API 键,如下所示:
现在,您可以将这个 API 键复制并粘贴到您的代码中,以发出 GIPHY API 请求。
在您获得 API 密钥之后,您可以开始编写一些代码来使用这个 API。然而,有时您希望在实现大量代码之前运行一些测试。我知道我有。事实是,一些 API 实际上会为您提供直接从文档或仪表板中获取 API 数据的工具。
在这种特殊情况下,GIPHY 为您提供了一个 API Explorer ,在您创建应用程序后,它允许您无需编写一行代码就可以开始使用 API。
其他一些 API 会在文档本身中为您提供资源管理器,这就是每个 API 参考页面底部的 TheDogAPI 所做的事情。
在任何情况下,您都可以使用代码来消费 API,这就是您在这里要做的。从仪表板中获取 API 密钥,通过替换下面的API_KEY变量的值,您可以开始使用 GIPHY API:
1import requests
2
3# Replace the following with the API key generated.
4API_KEY = "API_KEY" 5endpoint = "https://api.giphy.com/v1/gifs/trending" 6
7params = {"api_key": API_KEY, "limit": 3, "rating": "g"} 8response = requests.get(ENDPOINT, params=params).json()
9for gif in response["data"]: 10 title = gif["title"]
11 trending_date = gif["trending_datetime"]
12 url = gif["url"]
13 print(f"{title} | {trending_date} | {url}")
在文件的顶部,在第 4 行和第 5 行,您定义了您的API_KEY和 GIPHY API endpoint,因为它们不会像其他部分那样经常变化。
在第 7 行,利用您在查询参数部分学到的知识,您定义了params并添加了您自己的 API 键。您还包括几个其他过滤器:limit获取3结果,rating仅获取适当的内容。
最后,在得到响应后,您通过第 9 行的结果迭代。对于每张 GIF,在第 13 行打印标题、日期和 URL。
在控制台中运行这段代码会输出一个有点结构化的 gif 列表:
Excited Schitts Creek GIF by CBC | 2020-11-28 20:45:14 | https://giphy.com/gifs/cbc-schittscreek-schitts-creek-SiGg4zSmwmbafTYwpj
Saved By The Bell Shrug GIF by PeacockTV | 2020-11-28 20:30:15 | https://giphy.com/gifs/peacocktv-saved-by-the-bell-bayside-high-school-dZRjehRpivtJsNUxW9
Schitts Creek Thank You GIF by CBC | 2020-11-28 20:15:07 | https://giphy.com/gifs/cbc-funny-comedy-26n79l9afmfm1POjC
现在,假设您想要创建一个脚本,允许您搜索特定的单词并获取与该单词的第一个 GIPHY 匹配。不同的端点和上面代码的微小变化可以很快完成:
import requests
# Replace the following with the API key generated.
API_KEY = "API_KEY"
endpoint = "https://api.giphy.com/v1/gifs/search"
search_term = "shrug" params = {"api_key": API_KEY, "limit": 1, "q": search_term, "rating": "g"} response = requests.get(endpoint, params=params).json()
for gif in response["data"]:
title = gif["title"]
url = gif["url"]
print(f"{title} | {url}")
你有它!现在,您可以根据自己的喜好修改这个脚本,并按需生成 gif。尝试从你最喜欢的节目或电影中获取 gif,在你的终端上添加一个快捷方式来按需获取最受欢迎的 gif,或者与你最喜欢的消息系统中的另一个 API 集成——WhatsApp,Slack,等等。然后开始给你的朋友和同事发送 gif!
获得每个国家的新冠肺炎确诊病例
尽管这可能是你现在已经厌倦听到的事情,但是有一个免费的 API 提供最新的世界新冠肺炎数据。这个 API 不需要身份验证,所以立即获取一些数据非常简单。您将在下面使用的免费版本有一个速率限制和一些数据限制,但对于小型用例来说已经足够了。
对于本例,您将获得截至前一天的确诊病例总数。我再次随机选择了德国作为国家,但是你可以选择任何你喜欢的国家:
1import requests 2from datetime import date, timedelta 3
4today = date.today()
5yesterday = today - timedelta(days=1)
6country = "germany" 7endpoint = f"https://api.covid19api.com/country/{country}/status/confirmed" 8params = {"from": str(yesterday), "to": str(today)} 9
10response = requests.get(endpoint, params=params).json()
11total_confirmed = 0 12for day in response:
13 cases = day.get("Cases", 0)
14 total_confirmed += cases 15
16print(f"Total Confirmed Covid-19 cases in {country}: {total_confirmed}")
在第 1 行和第 2 行,您导入了必要的模块。在这种情况下,您必须导入date和timedelta对象才能获得今天和昨天的日期。
在第 6 行到第 8 行,您为 API 请求定义了您想要使用的 country slug、端点和查询参数。
响应是一个日期列表,对于每一天,您都有一个包含当天确诊病例总数的Cases字段。在第 11 行,您创建了一个变量来保存确诊病例的总数,然后在第 14 行,您遍历所有的日期并对它们求和。
打印最终结果将显示所选国家的确诊病例总数:
Total Confirmed Covid-19 cases in germany: 1038649
在本例中,您将看到整个国家的确诊病例总数。然而,您也可以尝试查看文档并获取您的特定城市的数据。为什么不做得更彻底一点,并获得一些其他数据,如恢复案件的数量?
搜索谷歌图书
如果你对书籍有热情,那么你可能想要一个快速搜索特定书籍的方法。你甚至可能想把它连接到你当地图书馆的搜索中,看看某本书是否可以用该书的 ISBN 找到。
对于这个例子,您将使用 Google Books API 和公共 volumes 端点来进行简单的图书搜索。
下面是一段在整个目录中查找单词moby dick的简单代码:
1import requests
2
3endpoint = "https://www.googleapis.com/books/v1/volumes" 4query = "moby dick" 5
6params = {"q": query, "maxResults": 3}
7response = requests.get(endpoint, params=params).json()
8for book in response["items"]: 9 volume = book["volumeInfo"]
10 title = volume["title"]
11 published = volume["publishedDate"]
12 description = volume["description"]
13 print(f"{title} ({published}) | {description}")
这个代码示例与您之前看到的非常相似。从第 3 行和第 4 行开始,定义重要的变量,比如端点,在本例中是查询。
发出 API 请求后,在第 8 行开始遍历结果。然后,在第 13 行,您打印与您的初始查询相匹配的每本书的最有趣的信息:
Moby-Dick (2016-04-12) | "Call me Ishmael." So begins the famous opening...
Moby Dick (1892) | A literary classic that wasn't recognized for its...
Moby Dick; Or, The Whale (1983-08-16) | The story of Captain Ahab's...
您可以在循环中打印book变量,看看还有哪些字段可用。下面是一些对进一步改进代码有用的例子:
industryIdentifiersaverageRating和ratingsCountimageLinks
使用这个 API 的一个有趣挑战是使用你的 OAuth 知识创建你自己的书架应用程序,记录你读过或想读的所有书籍。之后,你甚至可以将它连接到你最喜欢的书店或图书馆,从你的愿望清单中快速找到你附近的书籍。这只是一个想法,我相信你能想出更多的。
结论
关于 API,您还可以学习很多其他的东西:不同的头、不同的内容类型、不同的认证技术等等。但是,您在本教程中学到的概念和技术将允许您使用您喜欢的任何 API 进行实践,并使用 Python 来满足您可能有的任何 API 消费需求。
在本教程中,您学习了:
- 什么是 API ,你能用它做什么
- 什么是状态码、 HTTP 头和 HTTP 方法
- 如何使用 Python 来使用 API 消费公共数据
- 用 Python 消费 API 时如何使用认证
继续用你喜欢的一些公共 API 来尝试这个新的魔法技能吧!您还可以通过从下面的链接下载源代码来查看您在本教程中看到的示例:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习使用 Python 来使用 API。
延伸阅读
本教程中用作示例的 API 只是众多免费公共 API 的一小部分。这里有一个 API 集合列表,您可以用它来找到您下一个喜欢的 API:
你可以看看这些,找到一个适合你和你的爱好的 API,也许会启发你用它做一个小项目。如果你遇到一个好的公共 API,你认为我或其他阅读教程的人应该知道,那么请在下面留下评论!*********
Python 的。append():将项目添加到您的列表中
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 的构建列表。追加()
在 Python 中,向列表中添加条目是一项相当常见的任务,因此该语言提供了许多方法和操作符来帮助您完成这项操作。其中一种方法是 .append() 。使用.append(),您可以将项目添加到现有列表对象的末尾。您也可以在 for循环中使用.append()以编程方式填充列表。
在本教程中,您将学习如何:
.append()与一起工作- 使用
.append()和循环填充列表 - 将
.append()替换为列表理解 - 与
array.array()****collections.deque()中的.append()一起工作
您还将编写一些如何在实践中使用.append()的例子。有了这些知识,你将能够在你的程序中有效地使用.append()。
免费下载: 从《Python 基础:Python 3 实用入门》中获取一个示例章节,看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
用 Python 的.append() 向列表添加项目
Python 的 .append() 将一个对象作为参数,并将其添加到现有列表的末尾,紧接在其最后一个元素之后:
>>> numbers = [1, 2, 3] >>> numbers.append(4) >>> numbers [1, 2, 3, 4]每次在现有列表上调用
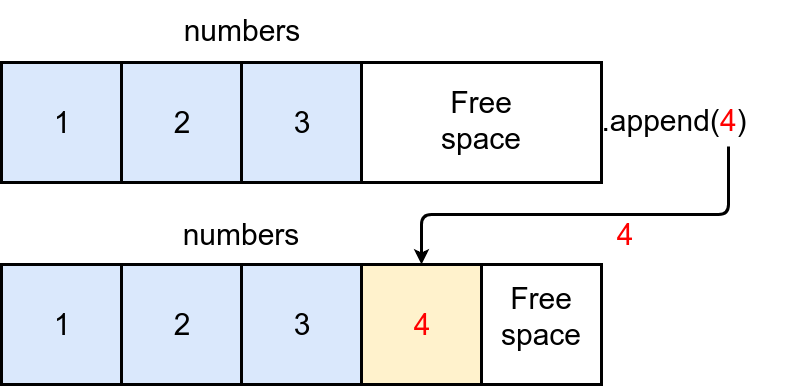
.append()时,该方法都会在列表的末尾或右侧添加一个新项目。下图说明了该过程:
Python 列表在列表末尾为新项目保留了额外的空间。调用
.append()会在可用空间中放置新的项目。实际上,您可以使用
.append()将任何类型的对象添加到给定的列表中:
>>> mixed = [1, 2]
>>> mixed.append(3)
>>> mixed
[1, 2, 3]
>>> mixed.append("four")
>>> mixed
[1, 2, 3, 'four']
>>> mixed.append(5.0)
>>> mixed
[1, 2, 3, 'four', 5.0]
列表是可以保存不同数据类型和 Python 对象的序列,因此您可以使用.append()将任何对象添加到给定的列表中。在这个例子中,首先添加一个整数,然后添加一个字符串,最后添加一个浮点数。但是,您也可以添加另一个列表,一个字典,一个元组,一个用户定义的对象,等等。
使用.append()相当于以下操作:
>>> numbers = [1, 2, 3] >>> # Equivalent to numbers.append(4) >>> numbers[len(numbers):] = [4] >>> numbers [1, 2, 3, 4]在突出显示的行中,您同时执行两个操作:
- 使用表达式
numbers[len(numbers):]从numbers中取一个切片。- 将一个 iterable 分配给该片。
切片操作占用了
numbers中最后一项之后的空间。同时,赋值操作解包赋值操作符右边的列表中的项目,并将它们添加到numbers。然而,使用这种赋值和使用.append()有一个重要的区别。通过分配,您可以一次将几个项目添加到列表的末尾:
>>> numbers = [1, 2, 3]
>>> numbers[len(numbers):] = [4, 5, 6] >>> numbers
[1, 2, 3, 4, 5, 6]
在本例中,突出显示的行从numbers的末尾提取一个切片,解包右侧列表中的项目,并将它们作为单个项目添加到切片中。
.append()增加一个单项
使用.append(),您可以将数字、列表、元组、字典、用户定义的对象或任何其他对象添加到现有列表中。然而,你需要记住.append()一次只添加一个项目或对象:
>>> x = [1, 2, 3, 4] >>> y = (5, 6) >>> x.append(y) >>> x [1, 2, 3, 4, (5, 6)]这里发生的是
.append()将元组对象y添加到目标列表x的末尾。如果想把y中的每一个物品作为一个单独的物品加到x的末尾,得到[1, 2, 3, 4, 5, 6]怎么办?在这种情况下,您可以使用.extend():
>>> x = [1, 2, 3, 4]
>>> y = (5, 6, 7)
>>> x.extend(y)
>>> x
[1, 2, 3, 4, 5, 6, 7]
>>> x = [1, 2, 3, 4]
>>> y = (5, 6, 7)
>>> # Equivalent to x.extend(y)
>>> x[len(x):] = y
>>> x
[1, 2, 3, 4, 5, 6, 7]
将 iterable 作为参数,解包它的项,并将它们添加到目标列表的末尾。这个操作相当于x[len(x):] = y,和你上一节看到的技术是一样的。
.append()回报None
实际上,.append()通过修改和增长底层列表来代替完成它的工作。这意味着.append()不会向返回一个新列表,并在末尾添加一个新项目。它返回 None :
>>> x = [1, 2, 3, 4] >>> y = x.append(5) >>> y is None True >>> x [1, 2, 3, 4, 5]与几个类似的方法一样,
.append()就地改变底层列表。在学习可变序列类型如何工作时,试图使用.append()的返回值是一个常见的错误。记住.append()的这种行为将有助于防止代码中出现错误。从头开始填充列表
在 Python 中使用列表时,您可能会遇到的一个常见问题是如何用几个条目填充它们,以便进一步处理。有两种方法可以做到这一点:
- 使用
.append()和一个for回路- 使用列表理解
在接下来的几节中,您将学习如何以及何时使用这些技术从头开始创建和填充 Python 列表。
使用
.append()
.append()的一个常见用例是使用一个for循环完全填充一个空列表。在循环内部,您可以操作数据并使用.append()将连续的结果添加到列表中。假设您需要创建一个函数,该函数接受一个数字序列并返回一个包含每个数字的平方根的列表:
>>> import math
>>> def square_root(numbers):
... result = []
... for number in numbers:
... result.append(math.sqrt(number))
... return result
...
>>> numbers = [1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> square_root(numbers)
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]
在这里,您定义了square_root(),它将一个列表numbers作为参数。在square_root()中,创建一个名为result的空列表,并开始一个for循环,遍历numbers中的条目。在每次迭代中,使用 math.sqrt() 计算当前数字的平方根,然后使用.append()将结果加到result中。一旦循环结束,就返回结果列表。
注意:在上面的例子中,你用的是来自math的sqrt()。Python 的math模块包含在标准库中,并提供数学相关的功能。如果你想更深入地了解math,那么看看Python 数学模块:你需要知道的一切。
这种填充列表的方式在 Python 中相当常见。然而,这种语言提供了一些方便的构造,可以使这个过程更加有效。其中一个构造是列表理解,您将在下一节看到它的运行。
使用列表理解
在实践中,当从头开始创建一个列表并填充它时,您经常用一个列表理解来替换.append()。通过列表理解,您可以像这样重新实现square_root():
>>> import math >>> def square_root(numbers): ... return [math.sqrt(number) for number in numbers] ... >>> numbers = [1, 4, 9, 16, 25, 36, 49, 64, 81] >>> square_root(numbers) [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]
square_root()中的 list comprehension 为numbers中的每个number创建一个包含number的平方根的列表。这读起来几乎像简单的英语。此外,这种新的实现在处理时间方面将比使用.append()和for循环的实现更有效。注意: Python 还提供了其他种类的理解,比如集合理解、字典理解、生成器表达式。
要将
.append()转换成列表理解,您只需要将它的参数放在一对方括号内,后面跟着循环头(没有冒号)。切换回
.append()尽管对于填充列表来说,列表理解可能比
.append()更具可读性和效率,但是在某些情况下.append()可能是更好的选择。假设您需要
square_root()向您的用户提供关于计算输入数字列表的平方根的进度的详细信息。要报告操作进度,可以使用print():
>>> import math
>>> def square_root(numbers):
... result = []
... n = len(numbers)
... for i, number in enumerate(numbers):
... print(f"Processing number: {number}")
... result.append(math.sqrt(number))
... print(f"Completed: {int((i + 1) / n * 100)}%")
... return result
...
>>> numbers = [1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> square_root(numbers)
Processing number: 1
Completed: 11%
...
Processing number: 81
Completed: 100%
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]
现在考虑如何将square_root()的正文转化为列表理解。在列表中使用print()看起来不连贯,甚至是不可能的,除非你将部分代码包装在一个帮助函数中。所以,在这个例子中,使用.append()是正确的选择。
上述例子背后的寓意是,在某些情况下,你不能用列表理解或任何其他结构来替换.append()。
用 Python 的.append() 创建堆栈和队列
到目前为止,您已经学会了如何使用.append()向列表中添加单个项目或者从头开始填充列表。现在是时候举一个不同的更具体的例子了。在这一节中,您将学习如何使用 Python list 创建堆栈和队列数据结构,并使用.append()和.pop()实现最少的功能需求。
实现堆栈
一个栈是一个数据结构,它在彼此之上存储项目。物品以后进/先出 ( LIFO )的方式进出堆栈。通常,堆栈实现两个主要操作:
push将项目添加到堆栈的顶部或末端。pop移除并返回堆栈顶部的项目。
在一个列表中,.append()相当于一个push操作,所以你可以用它来把条目推到堆栈上。列表还提供了.pop(),它可以选择接受一个整数索引作为参数。它返回基础列表中该索引处的项,并移除该项:
>>> numbers = [1, 2, 3] >>> numbers.pop(1) 2 >>> numbers [1, 3] >>> numbers.pop() 3 >>> numbers [1] >>> numbers.pop() 1 >>> numbers [] >>> numbers.pop() Traceback (most recent call last): File "<input>", line 1, in <module> numbers.pop() IndexError: pop from empty list如果您将一个整数索引作为参数提供给
.pop(),那么该方法将返回并删除列表中该索引处的项目。不带参数调用.pop()将返回列表中的最后一项。请注意,.pop()也从底层列表中删除了该项。最后,如果你在一个空列表上调用.pop(),那么你将得到一个IndexError。有了这些知识,您就可以使用
.append()和.pop()实现堆栈了。这里有一个定义堆栈的类。该类提供了.push()和.pop()操作:class Stack: def __init__(self): self._items = [] def push(self, item): self._items.append(item) def pop(self): try: return self._items.pop() except IndexError: print("Empty stack") def __len__(self): return len(self._items) def __repr__(self): return f"Stack({self._items})"在
Stack中,首先初始化实例属性._items。该属性保存一个空列表,您将使用该列表在堆栈中存储项目。然后编写.push(),在._items上使用.append()实现push操作。您还可以通过调用底层列表
._items上的.pop()来实现pop操作。在这种情况下,您使用一个try和except块来处理在空列表上调用.pop()时发生的IndexError。注意:在 Python 中,使用异常来控制程序的流程是一种常见的模式。Python 开发人员更喜欢这种被称为 EAFP(请求原谅比请求许可容易)的编码风格,而不是被称为 LBYL(三思而后行)的编码风格。要了解这两种编码风格的更多信息,请查看 LBYL vs EAFP:防止或处理 Python 中的错误。
EAFP 可以帮助您防止竞争条件,提高程序或代码片段的总体性能,并防止错误无声无息地传递。
特殊方法
.__len__()提供了检索内部列表._items长度所需的功能。特殊方法.__repr__()允许您在将数据结构打印到屏幕上时,提供一个用户友好的栈的字符串表示。以下是一些如何在实践中使用
Stack的例子:
>>> stack = Stack()
>>> # Push items onto the top of the stack
>>> stack.push(1)
>>> stack.push(2)
>>> # User-friendly printing format
>>> stack
Stack([1, 2])
>>> print(stack)
Stack([1, 2])
>>> # Retrieve the length of the stack
>>> len(stack)
2
>>> # Pop items from the top of the stack
>>> stack.pop()
2
>>> stack.pop()
1
>>> stack.pop()
Empty stack
>>> stack
Stack([])
就是这样!您已经编写了一个实现push和pop操作的堆栈数据结构。它还提供了获取底层列表长度和以用户友好的方式打印整个堆栈的功能。
实现队列
队列是通常以先进/先出 ( 先进先出)方式管理其项目的数据结构。队列就像一个管道,你在一端推入新的项目,旧的项目从另一端弹出。
将一个项目添加到队列的末尾被称为 enqueue 操作,而将一个项目从队列的前面或开头移除被称为 dequeue 操作。
您可以使用.append()让项目入队,使用.pop()让它们出队。这一次,您需要提供0作为.pop()的参数,让它检索列表中的第一项,而不是最后一项。下面是一个类,它实现了一个队列数据结构,使用一个列表来存储它的项目:
class Queue:
def __init__(self):
self._items = []
def enqueue(self, item):
self._items.append(item)
def dequeue(self):
try:
return self._items.pop(0)
except IndexError:
print("Empty queue")
def __len__(self):
return len(self._items)
def __repr__(self):
return f"Queue({self._items})"
这个班和你的Stack挺像的。主要区别在于,.pop()将0作为参数返回,并移除了底层列表._items中的第一个项,而不是最后一个。
注意:在 Python 列表上使用.pop(0)并不是消费列表项的最有效方式。幸运的是,Python 的 collections模块提供了一个名为 deque() 的数据结构,从deque()开始就将.popleft()实现为一种高效的消耗物品的方式。
在本教程的稍后部分,您将会学到更多关于使用 deques 的知识。
实现的其余部分几乎是相同的,但是使用了适当的名称,比如用.enqueue()添加条目,用.dequeue()删除条目。你可以使用Queue,就像你在上一节中使用Stack一样:只需调用.enqueue()来添加项目,调用.dequeue()来检索和删除它们。
在其他数据结构中使用.append()
其他 Python 数据结构也实现了.append()。工作原理与传统的.append()一列相同。方法将单个项添加到基础数据结构的末尾。但是,也有一些微妙的区别。
在接下来的两节中,您将学习.append()如何在其他数据结构中工作,例如 array.array() 和 collections.deque() 。
array.append()
Python 的 array.array() 提供了一种类似序列的数据结构,可以简洁地表示一组值。这些值必须是相同的数据类型,仅限于 C 风格的数据类型,如字符、整数和浮点数。
array.array()采用以下两个参数:
| 争吵 | 内容 | 需要 |
|---|---|---|
typecode |
标识数组可以存储的数据类型的单字符代码 | 是 |
initializer |
作为初始化器的列表、类字节对象或 iterable | 不 |
array 的文档提供了创建数组时可以使用的所有允许类型代码的完整信息。以下示例使用"i"类型代码创建一个整数数组:
>>> from array import array >>> # Array of integer numbers >>> int_array = array("i", [1, 2, 3]) >>> int_array array('i', [1, 2, 3]) >>> int_array[0] 1 >>> int_array[:2] array('i', [1, 2]) >>> int_array[2] = 4 >>> int_array array('i', [1, 2, 4])要创建数组,您需要提供一个单字符代码来定义数组中值的数据类型。还可以提供适当类型的可选值列表来初始化数组。
数组支持大多数列表操作,比如切片和索引。和列表一样,
array.array()也提供了一个名为.append()的方法。该方法的工作方式与它的 list 对应方法类似,在基础数组的末尾添加一个值。但是,该值的数据类型必须与数组中的现有值兼容。否则,你会得到一个TypeError。例如,如果您有一个整数数组,那么您不能使用
.append()向该数组添加一个浮点数:
>>> from array import array
>>> a = array("i", [1, 2, 3])
>>> a
array('i', [1, 2, 3])
>>> # Add a floating-point number
>>> a.append(1.5)
Traceback (most recent call last):
File "<input>", line 1, in <module>
a.append(1.5)
TypeError: integer argument expected, got float
如果你试图给a加一个浮点数,那么.append()会以一个TypeError失败。那是因为 Python 无法在不丢失信息的情况下自动将浮点数转换成整数。
相反,如果您有一个浮点数数组,并尝试向其中添加整数,那么您的操作将会成功:
>>> from array import array >>> float_array = array("f", [1.0, 2.0, 3.0]) >>> float_array array('f', [1.0, 2.0, 3.0]) >>> # Add and integer number >>> float_array.append(4) >>> float_array array('f', [1.0, 2.0, 3.0, 4.0])这里,您使用
.append()将一个整数添加到一个浮点数数组中。这是可能的,因为 Python 可以自动将整数转换成浮点数,而不会在转换过程中丢失信息。
deque.append()和deque.appendleft()
collections.deque()是另一种实现.append()变体的数据结构。一个deque是一个栈和一个队列的一般化,专门设计来支持其两端的快速和内存高效的append和pop操作。因此,如果您需要创建具有这些特性的数据结构,那么可以考虑使用 deque 而不是 list。注:名字德克读作“deck”,代表ddouble-endqueUE。
collections.deque()采用以下两个可选参数:
争吵 内容 iterable充当初始值设定项的可迭代对象 maxlen一个整数,指定队列的最大长度 如果您为
maxlen提供一个值,那么您的队列将只存储最多maxlen个项目。一旦队列已满,添加一个新项目将自动导致队列另一端的项目被丢弃。另一方面,如果您不为maxlen提供一个值,那么 deque 可以增长到任意数量的条目。在 deques 中,
.append()还会在底层数据结构的末尾或右侧添加一个项目:
>>> from collections import deque
>>> d = deque([1, "a", 3.0])
>>> d
deque([1, 'a', 3.0])
>>> d.append("b")
>>> d
deque([1, 'a', 3.0, 'b'])
像列表一样,deques 可以保存不同类型的条目,所以.append()将任意条目添加到 deques 的末尾。换句话说,使用.append(),您可以将任何对象添加到队列中。
除了.append()之外,deques 还提供 .appendleft() ,在 deques 的开头或左侧添加一个单项。类似地,deques 提供 .pop() 和 .popleft() 来分别从 deques 的右侧和左侧移除项目:
>>> from collections import deque >>> d = deque([1, "a", 3.0]) >>> d.appendleft(-1.0) >>> d deque([-1.0, 1, 'a', 3.0]) >>> d.pop() 3.0 >>> d.popleft() -1.0 >>> d deque([1, 'a'])对
.appendleft()的调用将-1.0添加到d的左侧。另一方面,.pop()返回并删除d中的最后一项,.popleft()返回并删除第一项。作为练习,您可以尝试使用 deque 而不是 list 来实现自己的堆栈或队列。为此,你可以利用你在小节中看到的例子,用 Python 创建堆栈和队列。追加()。结论
Python 提供了一个名为
.append()的方法,可以用来将项目添加到给定列表的末尾。这种方法被广泛用于将单个项目添加到列表的末尾,或者使用for循环填充列表。学习如何使用.append()将帮助你在程序中处理列表。在本教程中,您学习了:
.append()如何运作- 如何使用
.append()和一个for循环来填充列表- 什么时候用代替
.append()列表理解.append()如何在array.array()****collections.deque()中发挥作用此外,您编写了一些如何使用
.append()创建数据结构的例子,比如栈和队列。这些知识将允许你使用.append()来有效地增加你的清单。立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 的构建列表。追加()***
Python 应用程序布局:参考
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 构造一个 Python 应用
Python 虽然在语法和风格上固执己见,但在构建应用程序时却异常灵活。
一方面,这种灵活性很大:它允许不同的用例使用那些用例所必需的结构。然而,另一方面,这可能会让新开发人员感到非常困惑。
互联网也帮不上什么忙——有多少 Python 博客就有多少观点。在本文中,我想给你一个可靠的 Python 应用布局参考指南,你可以在绝大多数用例中参考。
您将看到常见 Python 应用程序结构的示例,包括命令行应用程序 (CLI 应用程序)、一次性脚本、可安装包以及带有流行框架的 web 应用程序布局,如 Flask 和 Django 。
注意:本参考指南假设读者具备 Python 模块和包的工作知识。如果你感到有些生疏,请查看我们的Python 模块和包的介绍。
命令行应用程序布局
我们很多人主要使用通过命令行界面(CLIs) 运行的 Python 应用程序。这是您经常从空白画布开始的地方,Python 应用程序布局的灵活性确实令人头疼。
从一个空的项目文件夹开始可能会令人生畏,并导致不缺少编码人员。在这一节中,我想分享一些我个人用来作为所有 Python CLI 应用程序起点的经过验证的布局。
我们将从一个非常基本的用例的非常基本的布局开始:一个独立运行的简单脚本。然后,随着用例的推进,您将看到如何构建布局。
一次性脚本
你只是做了一个脚本,而且是肉汁,对不对?无需安装——只需在其目录中运行脚本即可!
嗯,如果你只是制作一个供自己使用的脚本,或者一个没有任何外部依赖的脚本,这很好,但是如果你必须分发它呢?尤其是对一个不太懂技术的用户?
以下布局适用于所有这些情况,并且可以很容易地进行修改,以反映您在工作流程中使用的任何安装或其他工具。无论您是创建一个纯 Python 脚本(也就是说,一个没有依赖关系的脚本),还是使用像 pip 或 Pipenv 这样的工具,这个布局都将涵盖您。
阅读本参考指南时,请记住文件在布局中的确切位置比它们被放置在何处的原因更重要。所有这些文件都应该位于以您的项目命名的项目目录中。对于这个例子,我们将使用(还有什么?)
helloworld作为项目名称和根目录。以下是我通常用于 CLI 应用程序的 Python 项目结构:
helloworld/ │ ├── .gitignore ├── helloworld.py ├── LICENSE ├── README.md ├── requirements.txt ├── setup.py └── tests.py这非常简单:所有东西都在同一个目录中。这里显示的文件不一定是详尽的,但是如果您计划使用这样的基本布局,我建议将文件数量保持在最小。其中一些文件对您来说可能是新的,所以让我们快速看一下它们各自的功能。
这是一个文件,它告诉 Git 应该忽略哪些类型的文件,比如 IDE 文件或者本地配置文件。我们的 Git 教程有所有的细节,你可以在这里找到 Python 项目的样本
.gitignore文件。这是你正在分发的脚本。至于主脚本文件的命名,我建议您使用项目的名称(与顶级目录的名称相同)。
这个明文文件描述了你在一个项目中使用的许可证。如果您正在分发代码,拥有一个总是一个好主意。按照惯例,文件名全部大写。
注意:需要帮助为您的项目选择许可证吗?查看选择许可。
README.md:这是一个 Markdown (或 reStructuredText )文件,记录了你的应用程序的目的和用途。制作好的README是一门艺术,但是你可以在这里找到掌握的捷径。这个文件为你的应用程序定义了外部的 Python 依赖和它们的版本。
这个文件也可以用来定义依赖项,但是它更适合安装过程中需要完成的其他工作。你可以在我们的T4 指南中了解更多关于
setup.py和requirements.txt的信息。这个脚本包含了你的测试,如果你有的话。你应该来点 T2。
但是现在您的应用程序正在增长,并且您已经将它分成了同一个包中的多个部分,那么您应该将所有部分都放在顶层目录中吗?既然您的应用程序变得更加复杂,是时候更干净地组织事情了。
可安装的单个软件包
让我们假设
helloworld.py仍然是要执行的主脚本,但是您已经将所有的助手方法移到了一个名为helpers.py的新文件中。我们将把
helloworldPython 文件打包在一起,但是将所有其他文件,比如你的README、.gitignore等等,放在顶层目录中。让我们来看看更新后的结构:
helloworld/ │ ├── helloworld/ │ ├── __init__.py │ ├── helloworld.py │ └── helpers.py │ ├── tests/ │ ├── helloworld_tests.py │ └── helpers_tests.py │ ├── .gitignore ├── LICENSE ├── README.md ├── requirements.txt └── setup.py这里唯一的不同是,您的应用程序代码现在都保存在
helloworld子目录中——该目录以您的包命名——并且我们添加了一个名为__init__.py的文件。让我们来介绍一下这些新文件:
这个文件有很多功能,但是为了我们的目的,它告诉 Python 解释器这个目录是一个包目录。您可以设置这个
__init__.py文件,使您能够从包中整体导入类和方法,而不是知道内部模块结构并从helloworld.helloworld或helloworld.helpers导入。注意:关于内部包的更深入的讨论
__init__.py,我们的 Python 模块和包概述已经介绍过了。
helloworld/helpers.py:如上所述,我们已经将helloworld.py的大部分业务逻辑移到了这个文件中。多亏了__init__.py,外部模块将能够简单地通过从helloworld包导入来访问这些助手。我们已经将我们的测试转移到它们自己的目录中,随着我们程序结构变得越来越复杂,你会继续看到这种模式。我们还将测试分成独立的模块,反映了我们的包的结构。
这个布局是 Kenneth Reitz 的 samplemod 应用程序结构的精简版本。这是您的 CLI 应用程序的另一个很好的起点,尤其是对于更大的项目。
带内部包的应用程序
在较大的应用程序中,您可能有一个或多个内部包,这些包或者与主 runner 脚本绑定在一起,或者为您正在打包的较大的库提供特定的功能。我们将扩展上述约定以适应这种情况:
helloworld/ │ ├── bin/ │ ├── docs/ │ ├── hello.md │ └── world.md │ ├── helloworld/ │ ├── __init__.py │ ├── runner.py │ ├── hello/ │ │ ├── __init__.py │ │ ├── hello.py │ │ └── helpers.py │ │ │ └── world/ │ ├── __init__.py │ ├── helpers.py │ └── world.py │ ├── data/ │ ├── input.csv │ └── output.xlsx │ ├── tests/ │ ├── hello │ │ ├── helpers_tests.py │ │ └── hello_tests.py │ │ │ └── world/ │ ├── helpers_tests.py │ └── world_tests.py │ ├── .gitignore ├── LICENSE └── README.md这里有更多的东西需要消化,但是只要你记得它是从前面的布局开始的,你就会更容易理解。我将按顺序介绍添加和修改的内容,它们的用途,以及您可能需要它们的原因。
bin/:该目录保存所有可执行文件。我改编自让-保罗·卡尔德龙的经典结构文章,他关于使用bin/目录的建议仍然很重要。要记住的最重要的一点是,你的可执行文件不应该有很多代码,只是导入和调用你的 runner 脚本中的一个主函数。如果你使用的是纯 Python 或者没有任何可执行文件,你可以省去这个目录。对于一个更高级的应用程序,你会想要维护其所有部分的良好文档。我喜欢把内部模块的文档放在这里,这就是为什么你会看到
hello和world包的单独文档。如果你在内部模块中使用文档字符串(你应该这样做!),您的整个模块文档至少应该给出模块的目的和功能的整体视图。
helloworld/:这个类似于之前结构中的helloworld/,但是现在有子目录了。随着复杂性的增加,您会希望使用“分而治之”的策略,将部分应用程序逻辑分割成更易于管理的块。记住,目录名指的是整个包名,因此子目录名(hello/和world/)应该反映它们的包名。
data/:有这个目录有助于测试。它是您的应用程序将接收或生成的任何文件的中心位置。根据您如何部署您的应用程序,您可以保持“生产级”输入和输出指向这个目录,或者仅将其用于内部测试。在这里,你可以放置所有的测试——单元测试、执行测试、集成测试等等。对于您的测试策略、导入策略等等,请随意以最方便的方式构建这个目录。要复习用 Python 测试命令行应用程序,请查看我的文章 4 测试 Python 命令行(CLI)应用程序的技术。
顶层文件在很大程度上与之前的布局相同。这三种布局应该涵盖了命令行应用程序的大多数用例,甚至包括 GUI 应用程序,但要注意的是,您可能需要根据所使用的 GUI 框架来修改一些东西。
注意:记住这些只是布局。如果一个目录或文件对你的特定用例没有意义(比如
tests/如果你没有用你的代码分发测试),请随意删除它。但是尽量不要漏掉docs/。记录你的工作总是一个好主意。网络应用布局
Python 的另一个主要用例是 web 应用。 Django 和 Flask 可以说是 Python 最流行的 web 框架,谢天谢地,它们在应用程序布局方面更加固执己见。
为了确保这篇文章是一个完整的、成熟的布局参考,我想强调这些框架共有的结构。
姜戈
我们按字母顺序来,从姜戈开始。Django 的一个优点是,它会在运行
django-admin startproject project后为您创建一个项目框架,其中project是您的项目名称。这将在您当前的工作目录中创建一个名为project的目录,其内部结构如下:project/ │ ├── project/ │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ └── manage.py这似乎有点空洞,不是吗?所有的逻辑都去哪里了?风景呢?甚至没有任何测试!
在 Django,这是一个项目,它将 Django 的另一个概念 apps 联系在一起。应用程序是逻辑、模型、视图等等都存在的地方,在这样做的时候,它们完成一些任务,比如维护一个博客。
Django 应用程序可以导入到项目中并在项目间使用,其结构类似于专门的 Python 包。
像项目一样,Django 使得生成 Django 应用程序布局变得非常容易。设置好项目后,你所要做的就是导航到
manage.py的位置并运行python manage.py startapp app,其中app是你的应用程序的名称。这将产生一个名为
app的目录,其布局如下:app/ │ ├── migrations/ │ └── __init__.py │ ├── __init__.py ├── admin.py ├── apps.py ├── models.py ├── tests.py └── views.py这可以直接导入到您的项目中。关于这些文件做什么、如何在你的项目中利用它们等等的细节超出了本参考的范围,但是你可以在我们的 Django 教程和 Django 官方文档中获得所有这些信息和更多信息。
这个文件和文件夹结构非常简单,是 Django 的基本要求。对于任何开源 Django 项目,您可以(也应该)从命令行应用程序布局中调整结构。在外层的
project/目录中,我通常以这样的方式结束:project/ │ ├── app/ │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ │ │ ├── migrations/ │ │ └── __init__.py │ │ │ ├── models.py │ ├── tests.py │ └── views.py │ ├── docs/ │ ├── project/ │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py │ ├── static/ │ └── style.css │ ├── templates/ │ └── base.html │ ├── .gitignore ├── manage.py ├── LICENSE └── README.md关于更高级的 Django 应用程序布局的更深入的讨论,这个堆栈溢出线程已经介绍过了。 django-project-skeleton 项目文档解释了你会在堆栈溢出线程中找到的一些目录。对 Django 的全面深入可以在的 Django 的两个独家新闻中找到,这将教你所有 Django 开发的最新最佳实践。
更多 Django 教程,请访问我们在 Real Python 的 Django 部分。
烧瓶
Flask 是一个 Python web“微框架”一个主要的卖点是,它可以很快地以最小的开销建立起来。 Flask 文档中有一个 web 应用程序示例,它只有 10 行代码,在一个脚本中。当然,在实践中,编写这么小的 web 应用程序是不太可能的。
幸运的是,Flask 文档为我们节省了,为他们的教程项目(一个名为 Flaskr 的博客 web 应用程序)提供了一个建议的布局,我们将在这里从主项目目录中检查它:
flaskr/ │ ├── flaskr/ │ ├── ___init__.py │ ├── db.py │ ├── schema.sql │ ├── auth.py │ ├── blog.py │ ├── templates/ │ │ ├── base.html │ │ ├── auth/ │ │ │ ├── login.html │ │ │ └── register.html │ │ │ │ │ └── blog/ │ │ ├── create.html │ │ ├── index.html │ │ └── update.html │ │ │ └── static/ │ └── style.css │ ├── tests/ │ ├── conftest.py │ ├── data.sql │ ├── test_factory.py │ ├── test_db.py │ ├── test_auth.py │ └── test_blog.py │ ├── venv/ │ ├── .gitignore ├── setup.py └── MANIFEST.in从这些内容中,我们可以看到 Flask 应用程序和大多数 Python 应用程序一样,是围绕 Python 包构建的。
注:没看见?发现包的一个快速提示是通过寻找一个
__init__.py文件。它位于该特定包的最高层目录中。在上面的布局中,flaskr是一个包含db、auth和blog模块的包。在这个布局中,除了您的测试、一个用于您的虚拟环境的目录和您通常的顶层文件之外,所有东西都存在于
flaskr包中。与其他布局一样,您的测试将大致匹配驻留在flaskr包中的各个模块。您的模板也驻留在主项目包中,这在 Django 布局中是不会发生的。请务必访问我们的 Flask 样板 Github 页面,查看更完整的 Flask 应用程序,并在这里查看样板文件。
关于 Flask 的更多信息,请点击这里查看我们所有的 Flask 教程。
结论和提醒
现在您已经看到了许多不同应用程序类型的示例布局:一次性 Python 脚本、可安装的单个包、带有内部包的大型应用程序、Django web 应用程序和 Flask web 应用程序。
根据本指南,您将拥有通过构建您的应用程序结构来成功防止编码障碍的工具,这样您就不会盯着一张空白的画布试图找出从哪里开始。
因为 Python 在应用程序布局方面很大程度上是没有主见的,所以您可以根据自己的意愿定制这些示例布局,以更好地适应您的用例。
我希望你不仅有一个应用程序布局参考,而且理解这些例子既不是一成不变的规则,也不是构建应用程序的唯一方法。随着时间的推移和实践,您将能够构建和定制自己有用的 Python 应用程序布局。
我错过了一个用例吗?你有另一种应用结构哲学吗?这篇文章有助于防止编码器的阻塞吗?请在评论中告诉我!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 构造一个 Python 应用**
Python 的断言:像专家一样调试和测试你的代码
Python 的
assert语句允许你在代码中编写健全性检查。这些检查被称为断言,当你开发代码时,你可以用它们来测试某些假设是否成立。如果您的任何断言为假,那么您的代码中就有一个 bug。在开发过程中,断言是记录、调试、测试代码的便利工具。一旦您在断言的帮助下调试和测试了您的代码,那么您就可以关闭它们来为生产优化代码。断言将帮助您使您的代码更加高效、健壮和可靠。
在本教程中,您将学习:
- 什么是断言以及何时使用它们
- Python 的
assert语句如何工作assert如何帮助你记录,调试,以及测试你的代码- 如何禁用断言以提高生产中的性能
- 使用
assert语句时,你可能会面临哪些常见陷阱为了从本教程中获得最大收益,您应该已经了解了表达式和运算符、函数、条件语句和异常。对编写、调试和测试 Python 代码有基本了解者优先。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
了解 Python 中的断言
Python 实现了一个名为断言的特性,这在应用程序和项目的开发过程中非常有用。在其他几种语言中你也会发现这个特性,比如 C 和 Java ,它对于记录、调试和测试你的代码来说很方便。
如果你正在寻找一个工具来加强你的调试和测试过程,那么断言就是你要找的。在这一节中,您将学习断言的基础知识,包括它们是什么,它们有什么好处,以及什么时候不应该在代码中使用它们。
什么是断言?
在 Python 中,断言是可以用来在开发过程中设置健全性检查的语句。断言允许您通过检查某些特定条件是否为真来测试代码的正确性,这在您调试代码时会很方便。
断言条件应该总是真的,除非你的程序有 bug。如果结果证明条件为假,那么断言将引发一个异常并终止程序的执行。
使用断言,您可以设置检查来确保代码中的不变量保持不变。通过这样做,你可以检查像前置条件和后置条件这样的假设。例如,您可以按照如下方式测试条件:此参数不是
None或此返回值是一个字符串 。当你开发一个程序时,这种检查可以帮助你尽可能快地发现错误。断言有什么好处?
断言主要是为了调试。它们将帮助您确保在添加特性和修复代码中的其他错误时,不会引入新的错误。然而,在您的开发过程中,它们可以有其他有趣的用例。这些用例包括记录和测试你的代码。
断言的主要作用是当程序中出现错误时触发警报。在这个上下文中,断言意味着确保这个条件保持为真。否则,抛出一个错误。
实际上,您可以在开发时使用断言来检查程序中的前置条件和后置条件。例如,程序员经常在函数的开头放置断言来检查输入是否有效(前提条件)。程序员还在函数的返回值之前放置断言,以检查输出是否有效(后置条件)。
断言清楚地表明,您想要检查给定的条件是否为真并且保持为真。在 Python 中,它们还可以包含一个可选的消息来明确描述即将发生的错误或问题。这就是为什么它们也是记录代码的有效工具。在这种情况下,他们的主要优势是采取具体行动的能力,而不是像评论和文档串那样被动。
最后,断言对于在代码中编写测试用例也是非常理想的。您可以编写简明扼要的测试用例,因为断言提供了一种快速检查给定条件是否满足的方法,它定义了测试是否通过。
在本教程的后面,您将了解更多关于断言的这些常见用例。现在你将学习什么时候不应该使用断言。
什么时候不使用断言?
一般来说,您不应该对数据处理或数据验证使用断言,因为您可以在生产代码中禁用断言,这最终会删除所有基于断言的处理和验证代码。使用断言进行数据处理和验证是一个常见的陷阱,您将在本教程后面的理解
assert的常见陷阱中了解到。此外,断言不是一个错误处理工具。断言的最终目的不是处理生产中的错误,而是在开发过程中通知您,以便您可以修复它们。在这方面,您不应该使用常规的
try…except语句来编写捕捉断言错误的代码。理解 Python 的
assert语句现在你知道了什么是断言,它们有什么用,以及什么时候不应该在代码中使用它们。是时候学习编写自己的断言的基础知识了。首先,注意 Python 将断言实现为带有关键字的
assert语句,而不是作为函数。这种行为可能是混乱和问题的常见来源,您将在本教程的后面部分了解到。在本节中,您将学习使用
assert语句在代码中引入断言的基础知识。您将学习assert语句的语法。最重要的是,您将理解这个语句在 Python 中是如何工作的。最后,您还将学习AssertionError异常的基础知识。
assert语句的语法一条
assert语句由assert关键字、要测试的表达式或条件以及一条可选消息组成。这个条件应该总是真的。如果断言条件为真,那么什么都不会发生,程序继续正常执行。另一方面,如果条件变为假,那么assert通过引发AssertionError来暂停程序。在 Python 中,
assert是一个简单语句,语法如下:assert expression[, assertion_message]这里,
expression可以是任何有效的 Python 表达式或对象,然后对其进行真值测试。如果expression为假,那么语句抛出一个AssertionError。assertion_message参数是可选的,但鼓励使用。它可以保存描述语句应该捕获的问题的字符串。下面是这种说法在实践中的工作方式:
>>> number = 42
>>> assert number > 0
>>> number = -42
>>> assert number > 0
Traceback (most recent call last):
...
AssertionError
对于真表达式,断言成功,并且什么也没有发生。在这种情况下,您的程序会继续正常执行。相反,falsy 表达式会使断言失败,引发一个AssertionError并中断程序的执行。
为了让其他开发人员明白您的assert语句,您应该添加一条描述性的断言消息:
>>> number = 42 >>> assert number > 0, f"number greater than 0 expected, got: {number}" >>> number = -42 >>> assert number > 0, f"number greater than 0 expected, got: {number}" Traceback (most recent call last): ... AssertionError: number greater than 0 expected, got: -42该断言中的消息清楚地说明了哪个条件应该为真,以及是什么导致该条件失败。注意到
assert的assertion_message参数是可选的。然而,它可以帮助你更好地理解测试中的情况,并找出你所面临的问题。因此,无论何时使用
assert,对AssertionError异常的回溯使用描述性断言消息是一个好主意。关于
assert语法的重要一点是,这个语句不需要一对括号来对表达式和可选消息进行分组。在 Python 中,assert是语句而不是函数。使用一对括号会导致意想不到的行为。例如,像下面这样的断言会引出一个
SyntaxWarning:
>>> number = 42
>>> assert(number > 0, f"number greater than 0 expected, got: {number}")
<stdin>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses?
这个警告与 Python 中非空的元组总是为真有关。在本例中,括号将断言表达式和消息转换成一个两项元组,其值始终为 true。
幸运的是,Python 的最新版本抛出了一个SyntaxWarning来警告您这种误导性的语法。然而,在该语言的旧版本中,像上面这样的assert语句总是会成功。
当您使用超过一行的长表达式或消息时,这个问题经常出现。在这些情况下,括号是格式化代码的自然方式,您可能会得到如下结果:
number = 42
assert (
number > 0 and isinstance(number, int),
f"number greater than 0 expected, got: {number}"
)
使用一对括号将一个长行分成多行是 Python 代码中常见的格式化实践。然而,在assert语句的上下文中,括号将断言表达式和消息变成了两项元组。
在实践中,如果您想将一个长断言拆分成几行,那么您可以使用反斜杠字符(\)来表示显式行连接:
number = 42
assert number > 0 and isinstance(number, int), \
f"number greater than 0 expected, got: {number}"
该断言第一行末尾的反斜杠将断言的两个物理行连接成一个逻辑行。通过这种方式,您可以拥有合适的行长度,而不会在代码中出现警告或逻辑错误的风险。
注意: PEP 679 创建于 2022 年 1 月 7 日,提议允许在断言表达式和消息周围使用括号。如果 PEP 得到批准和实现,那么偶然元组的问题在未来不会影响 Python 代码。
这个括号相关的问题有一个极端的例子。如果您只在括号中提供断言表达式,那么assert将会工作得很好:
>>> number = 42 >>> assert(number > 0) >>> number = -42 >>> assert(number > 0) Traceback (most recent call last): ... AssertionError为什么会这样?要创建一个单项式元组,您需要在项本身后面放置一个逗号。在上面的代码中,括号本身不会创建元组。这就是解释器忽略括号的原因,
assert按预期工作。尽管括号在上面示例中描述的场景中似乎可以工作,但这不是推荐的做法。你可能会搬起石头砸自己的脚。
AssertionError异常如果一个
assert语句的条件评估为假,那么assert引发一个AssertionError。如果您提供可选的断言消息,那么这个消息在内部被用作AssertionError类的参数。无论哪种方式,引发的异常都会中断程序的执行。大多数时候,你不会在代码中显式地引发
AssertionError异常。assert语句负责在断言条件失败时引发这个异常。此外,你不应该试图通过编写代码来捕捉AssertionError异常来处理错误,这一点你将在本教程的后面学到。最后,
AssertionError是一个继承自Exception类的内置异常,被认为是一个具体异常,应该被抛出而不是子类化。就是这样!现在你知道了
assert语句的基础。您已经学习了语句的语法、assert在实践中如何工作,以及AssertionError异常的主要特征是什么。是时候向前迈进,探索一些用 Python 编写断言的有效而通用的方法了。探索常见的断言格式
在编写
assert语句时,您会发现 Python 代码中常见的几种断言格式。了解这些格式将允许您编写更好的断言。以下示例展示了一些常见的断言格式,从比较对象的断言开始:
>>> # Comparison assertions
>>> assert 3 > 2
>>> assert 3 == 2
Traceback (most recent call last):
...
AssertionError
>>> assert 3 > 2 and 5 < 10
>>> assert 3 == 2 or 5 > 10
Traceback (most recent call last):
...
AssertionError
比较断言旨在测试使用比较运算符比较两个或更多对象的条件。这些断言还可以包括基于布尔操作符的复合表达式。
另一种常见的断言格式与成员资格测试相关:
>>> # Membership assertions >>> numbers = [1, 2, 3, 4, 5] >>> assert 4 in numbers >>> assert 10 in numbers Traceback (most recent call last): ... AssertionError成员断言允许你检查一个给定的条目是否存在于一个特定的集合中,比如一个列表,元组,集合,字典等等。这些断言使用成员操作符
in和not in来执行所需的检查。以下示例中的断言格式与对象的身份相关:
>>> # Identity assertions
>>> x = 1
>>> y = x
>>> null = None
>>> assert x is y
>>> assert x is not y
Traceback (most recent call last):
...
AssertionError
>>> assert null is None
>>> assert null is not None
Traceback (most recent call last):
...
AssertionError
身份断言提供了一种测试对象身份的方法。在这种情况下,断言表达式使用了恒等运算符, is 和 is not 。
最后,您将学习如何在断言的上下文中检查对象的数据类型:
>>> # Type check assertions >>> number = 42 >>> assert isinstance(number, int) >>> number = 42.0 >>> assert isinstance(number, int) Traceback (most recent call last): ... AssertionError类型检查断言通常涉及使用内置的
isinstance()函数来确保给定的对象是某个或某些类的实例。尽管这些是 Python 代码中最常见的断言格式,但是还有许多其他的可能性。例如,您可以使用内置的
all()和any()函数来编写检查 iterable 中项的真值的断言:
>>> assert all([True, True, True])
>>> assert all([True, False, True])
Traceback (most recent call last):
...
AssertionError
>>> assert any([False, True, False])
>>> assert any([False, False, False])
Traceback (most recent call last):
...
AssertionError
all()断言检查输入 iterable 中的所有项是否为真,而any()示例检查输入 iterable 中的任何项是否为真。
你的想象力是编写有用断言的唯一限制。您可以使用谓词或布尔值函数、常规 Python 对象、比较表达式、布尔表达式或通用 Python 表达式来编写断言。您的断言将取决于您在给定时刻需要检查的具体条件。
现在您知道了一些可以在代码中使用的最常见的断言格式。是时候了解断言的具体用例了。在下一节中,您将学习如何使用断言来记录、调试和测试您的代码。
用断言记录你的代码
assert语句是记录代码的有效方法。例如,如果你想声明一个特定的condition在你的代码中应该总是为真,那么assert condition可能比注释或者文档字符串更好更有效,你马上就会知道。
为了理解为什么断言是一个方便的文档工具,假设您有一个函数,它接受一个服务器名和一组端口号。该函数将遍历试图连接到目标服务器的端口号。为了让您的功能正常工作,端口元组不应该为空:
def get_response(server, ports=(443, 80)):
# The ports argument expects a non-empty tuple
for port in ports:
if server.connect(port):
return server.get()
return None
如果有人不小心用空元组调用了get_response(),那么for循环永远不会运行,即使服务器可用,函数也会返回None。为了提醒程序员注意这个错误的调用,您可以使用注释,就像您在上面的例子中所做的那样。然而,使用assert语句可能更有效:
def get_response(server, ports=(443, 80)):
assert len(ports) > 0, f"ports expected a non-empty tuple, got {ports}"
for port in ports:
if server.connect(port):
return server.get()
return None
与注释相比,assert语句的优势在于,当条件不为真时,assert会立即引发一个AssertionError。之后,您的代码停止运行,因此它避免了异常行为,并直接将您指向特定的问题。
因此,在上述情况下使用断言是记录您的意图并避免由于意外错误或恶意行为者而难以发现的错误的有效而强大的方法。
用断言调试你的代码
从本质上来说,assert语句是一个调试助手,用于测试在代码正常执行期间应该保持正确的条件。对于作为调试工具的断言,您应该编写它们,以便失败表明您的代码中有 bug。
在本节中,您将学习如何使用assert语句来帮助您在开发时调试代码。
使用断言进行调试的示例
在开发过程中,通常会使用断言来调试代码。这个想法是为了确保特定的条件是真实的,并保持真实。如果一个断言的条件变为假,那么您立即知道您有一个 bug。
例如,假设您有下面的Circle类:
# circle.py
import math
class Circle:
def __init__(self, radius):
if radius < 0:
raise ValueError("positive radius expected")
self.radius = radius
def area(self):
assert self.radius >= 0, "positive radius expected"
return math.pi * self.radius ** 2
该类的初始化器 .__init__() ,将radius作为参数,并确保输入值是一个正数。此检查可防止圆的半径为负。
方法计算圆的面积。然而,在此之前,该方法使用一个assert语句来保证.radius保持为正数。你为什么要加这张支票?好吧,假设你在一个团队中工作,你的一个同事需要将下面的方法添加到Circle:
class Circle:
# ...
def correct_radius(self, correction_coefficient): self.radius *= correction_coefficient
该方法采用一个校正系数,并将其应用于.radius的当前值。然而,该方法不验证系数,引入了一个微妙的错误。你能发现它吗?假设用户无意中提供了一个负的修正系数:
>>> from circle import Circle >>> tire = Circle(42) >>> tire.area() 5541.769440932395 >>> tire.correct_radius(-1.02) >>> tire.radius -42.84 >>> tire.area() Traceback (most recent call last): ... AssertionError: positive radius expected对
.area()的第一次调用工作正常,因为初始半径是正的。但是对.area()的第二次调用用一个AssertionError破坏了你的代码。为什么?发生这种情况是因为对.correct_radius()的调用将半径变成了负数,这暴露了一个错误:该函数没有正确检查有效输入。在本例中,您的
assert语句在半径可能取无效值的情况下充当看门狗。AssertionError立即指出了具体的问题:.radius意外地变成了负数。您必须弄清楚这种意外的变化是如何发生的,然后在投入生产之前修复您的代码。关于使用断言进行调试的几点考虑
开发人员经常使用
assert语句来陈述前提条件,就像你在上面的例子中所做的一样,其中.area()在进行任何计算之前检查有效的.radius。开发人员也使用断言来陈述后置条件。例如,在将值返回给调用者之前,您可以检查函数的返回值是否有效。一般来说,你用
assert语句检查的条件应该是真的,除非你或你团队中的另一个开发人员在代码中引入了一个 bug。换句话说,这些条件永远不应该是假的。他们的目的是在有人引入 bug 时快速标记。在这方面,断言是代码中的早期警报。这些警报在开发过程中很有用。如果这些条件中的一个失败了,那么程序将崩溃并显示一个
AssertionError,告诉你哪个条件没有成功。这种行为将帮助您更快地跟踪和修复错误。为了正确地使用断言作为调试工具,您不应该使用
try…except块来捕获和处理AssertionError异常。如果一个断言失败了,那么你的程序就会崩溃,因为一个假设为真的条件变成了假的。您不应该通过用try…except块捕捉异常来改变这种预期的行为。断言的正确用法是通知开发人员程序中不可恢复的错误。断言不应该发出预期错误的信号,比如
FileNotFoundError,用户可以采取纠正措施并重试。断言的目标应该是揭露程序员的错误,而不是用户的错误。断言在开发过程中是有用的,而不是在生产过程中。当您发布代码时,它应该(大部分)没有错误,并且不应该要求断言正确工作。
最后,一旦您的代码准备好生产,您不必显式地删除断言。您可以禁用它们,您将在下一节了解到这一点。
禁用生产中的性能断言
现在假设你已经到了开发周期的末尾。您的代码已经过广泛的审查和测试。您的所有断言都通过了,并且您的代码已经准备好发布新版本了。此时,您可以通过禁用您在开发过程中添加的断言来优化用于生产的代码。为什么要这样优化代码呢?
断言在开发过程中非常有用,但是在生产中,它们会影响代码的性能。例如,一个包含许多始终运行的断言的代码库可能比没有断言的相同代码要慢。断言需要时间来运行,并且它们消耗内存,所以在生产中禁用它们是明智的。
现在,如何才能真正禁用您的断言呢?好吧,你有两个选择:
- 使用
-O或-OO选项运行 Python。- 将
PYTHONOPTIMIZE环境变量设置为适当的值。在这一节中,您将学习如何使用这两种技术来禁用您的断言。在此之前,您将了解内置的
__debug__常量,这是 Python 用来禁用断言的内部机制。理解
__debug__内置常数Python 有一个内置常数叫做
__debug__。这个常数与assert语句密切相关。Python 的__debug__是一个布尔常量,默认为True。它是一个常量,因为一旦 Python 解释器运行,就不能更改它的值:
>>> import builtins
>>> "__debug__" in dir(builtins)
True
>>> __debug__
True
>>> __debug__ = False
File "<stdin>", line 1
SyntaxError: cannot assign to __debug__
在这个代码片段中,首先确认__debug__是一个内置的 Python,它总是对您可用。True是__debug__的默认值,一旦 Python 解释器运行,就没有办法改变这个值。
__debug__的值取决于 Python 运行的模式,普通模式还是优化模式:
| 方式 | __debug__的值 |
|---|---|
| 正常(或调试) | True |
| 最佳化的 | False |
普通模式通常是您在开发过程中使用的模式,而优化模式是您应该在生产中使用的模式。现在,__debug__和断言有什么关系?在 Python 中,assert语句相当于以下条件语句:
if __debug__:
if not expression:
raise AssertionError(assertion_message)
# Equivalent to
assert expression, assertion_message
如果__debug__为真,那么运行外层if语句下的代码。内部的if语句检查expression是否为真,只有当表达式为而非真时,才会引发一个AssertionError。这是默认或正常的 Python 模式,在这种模式下,您的所有断言都被启用,因为__debug__是True。
另一方面,如果__debug__是False,那么外层if语句下的代码不会运行,这意味着您的断言将被禁用。在这种情况下,Python 运行在优化模式下。
正常或调试模式允许您在开发和测试代码时使用断言。一旦您当前的开发周期完成,您就可以切换到优化模式并禁用断言,以使您的代码为生产做好准备。
要激活优化模式并禁用您的断言,您可以使用 –O 或 -OO 选项启动 Python 解释器,或者将系统变量 PYTHONOPTIMIZE 设置为适当的值。在接下来的几节中,您将学习如何进行这两种操作。
使用-O或-OO选项运行 Python
您可以通过将__debug__常量设置为False来禁用所有的assert语句。为了完成这项任务,您可以使用 Python 的-O或-OO命令行选项,在优化模式下运行解释器。
-O选项在内部将__debug__设置为False。这一更改删除了assert语句和您在条件目标__debug__下显式引入的任何代码。-OO选项的作用与-O相同,同样会丢弃文档字符串。
使用-O或-OO命令行选项运行 Python 会使编译后的字节码变小。此外,如果您有几个断言或if __debug__:条件,那么这些命令行选项也可以让您的代码更快。
现在,这种优化对您的断言有什么影响呢?它使他们失去能力。例如,在包含circle.py文件的目录中打开命令行或终端,用python -O命令运行一个交互式会话。在那里,运行下面的代码:
>>> # Running Python in optimized mode >>> __debug__ False >>> from circle import Circle >>> # Normal use of Circle >>> ring = Circle(42) >>> ring.correct_radius(1.02) >>> ring.radius 42.84 >>> ring.area() 5765.656926346065 >>> # Invalid use of Circle >>> ring = Circle(42) >>> ring.correct_radius(-1.02) >>> ring.radius -42.84 >>> ring.area() 5765.656926346065因为
-O选项通过将__debug__设置为False来禁用您的断言,所以您的Circle类现在接受负半径,如最后一个示例所示。这种行为是完全错误的,因为你不能有一个半径为负的圆。另外,使用错误的半径作为输入来计算圆的面积。在优化模式下禁用断言的可能性是为什么不能使用
assert语句来验证输入数据,而是作为调试和测试过程的辅助手段的主要原因。注意:断言通常在生产代码中被关闭,以避免它们可能导致的任何开销或副作用。
对于
Circle类的一个 Pythonic 解决方案是使用@property装饰器将.radius属性转换为托管属性。这样,每次属性改变时,您都执行.radius验证:# circle.py import math class Circle: def __init__(self, radius): self.radius = radius @property def radius(self): return self._radius @radius.setter def radius(self, value): if value < 0: raise ValueError("positive radius expected") self._radius = value def area(self): return math.pi * self.radius ** 2 def correct_radius(self, correction_coefficient): self.radius *= correction_coefficient现在,
.radius是一个托管属性,使用@property装饰器提供 setter 和 getter 方法。您已经将验证代码从.__init__()移到了 setter 方法中,每当类改变.radius的值时都会调用该方法。现在,如果您在优化模式下运行代码,更新后的
Circle将按预期工作:
>>> # Running Python in optimized mode
>>> __debug__
False
>>> from circle import Circle
>>> # Normal use of Circle
>>> ring = Circle(42)
>>> ring.correct_radius(1.02)
>>> ring.radius
42.84
>>> ring.area()
5765.656926346065
>>> # Invalid use of Circle
>>> ring = Circle(42)
>>> ring.correct_radius(-1.02)
Traceback (most recent call last):
...
ValueError: positive radius expected
Circle总是在赋值前验证.radius的值,你的类工作正常,为.radius的负值产生一个ValueError。就是这样!您已经用一个优雅的解决方案修复了这个 bug。
在优化模式下运行 Python 的一个有趣的副作用是,显式if __debug__:条件下的代码也被禁用。考虑以下脚本:
# demo.py
print(f"{__debug__ = }")
if __debug__:
print("Running in Normal mode!")
else:
print("Running in Optimized mode!")
这个脚本显式地检查if … else语句中__debug__的值。只有当__debug__为True时,if代码块中的代码才会运行。相反,如果__debug__是False,那么else块中的代码将运行。
现在尝试在正常和优化模式下运行脚本来检查它在每种模式下的行为:
$ python demo.py
__debug__ = True
Running in Normal mode!
$ python -O demo.py
__debug__ = False
Running in Optimized mode!
当您在正常模式下执行脚本时,if __debug__:条件下的代码会运行,因为在这种模式下__debug__是True。另一方面,当您使用-O选项在优化模式下执行脚本时,__debug__变为False,并且运行else块下的代码。
Python 的-O命令行选项从最终编译的字节码中删除断言。Python 的-OO选项执行与-O相同的优化,除了从字节码中移除文档字符串。
因为两个选项都将__debug__设置为False,所以任何显式if __debug__:条件下的代码也会停止工作。这种行为提供了一种强大的机制,可以在 Python 项目的开发阶段引入仅用于调试的代码。
现在您知道了使用 Python 的-O和-OO选项在生产代码中禁用断言的基本知识。然而,每次需要运行生产代码时都使用这些选项运行 Python 似乎是重复的,并且可能容易出错。为了自动化这个过程,您可以使用PYTHONOPTIMIZE环境变量。
设置PYTHONOPTIMIZE环境变量
您还可以通过将PYTHONOPTIMIZE环境变量设置为适当的值,在禁用断言的优化模式下运行 Python。例如,将该变量设置为非空字符串相当于使用-O选项运行 Python。
要尝试PYTHONOPTIMIZE,启动您的命令行并运行以下命令:
- 视窗
** Linux + macOS*
C:\> set PYTHONOPTIMIZE="1"
$ export PYTHONOPTIMIZE="1"
一旦将PYTHONOPTIMIZE设置为非空字符串,就可以用基本的python命令启动 Python 解释器。该命令将自动在优化模式下运行 Python。
现在继续从包含您的circle.py文件的目录中运行下面的代码:
>>> from circle import Circle >>> # Normal use of Circle >>> ring = Circle(42) >>> ring.correct_radius(1.02) >>> ring.radius 42.84 >>> # Invalid use of Circle >>> ring = Circle(42) >>> ring.correct_radius(-1.02) >>> ring.radius -42.84同样,您的断言是关闭的,
Circle类接受负半径值。您再次在优化模式下运行 Python。另一种可能是将
PYTHONOPTIMIZE设置为一个整数值n,这相当于使用-O选项n次运行 Python。换句话说,你正在使用n级的优化:
- 视窗
** Linux + macOS*C:\> set PYTHONOPTIMIZE=1 # Equivalent to python -O C:\> set PYTHONOPTIMIZE=2 # Equivalent to python -OO$ export PYTHONOPTIMIZE=1 # Equivalent to python -O $ export PYTHONOPTIMIZE=2 # Equivalent to python -OO可以用任意整数来设置
PYTHONOPTIMIZE。然而,Python 只实现了两个级别的优化。使用大于2的数字对编译后的字节码没有实际影响。此外,将PYTHONOPTIMIZE设置为0将导致解释器以正常模式运行。在优化模式下运行 Python
当您运行 Python 时,解释器会将任何导入的模块动态编译成字节码。编译后的字节码将位于一个名为
__pycache__/的目录中,该目录位于包含提供导入代码的模块的目录中。在
__pycache__/中,您会发现一个.pyc文件,该文件以您的原始模块加上解释器的名称和版本命名。.pyc文件的名称还将包括用于编译代码的优化级别。例如,当您从
circle.py导入代码时, Python 3.10 解释器会根据优化级别生成以下文件:
文件名 命令 PYTHONOPTIMIZEcircle.cpython-310.pycpython circle.py0circle.cpython-310.opt-1.pycpython -O circle.py1circle.cpython-310.opt-2.pycpython -OO circle.py2该表中每个文件的名称包括原始模块的名称(
circle)、生成代码的解释器(cpython-310)和优化级别(opt-x)。该表还总结了PYTHONOPTIMIZE变量的相应命令和值。 PEP 488 提供了更多关于.pyc文件命名格式的上下文。在第一级优化中运行 Python 的主要结果是解释器将
__debug__设置为False,并从最终编译的字节码中删除断言。这些优化使得代码比在正常模式下运行的相同代码更小,并且可能更快。第二级优化的作用与第一级相同。它还从编译后的代码中删除了所有的文档字符串,从而产生了更小的编译后的字节码。
用断言测试你的代码
测试是开发过程中断言有用的另一个领域。测试归结为将观察值与期望值进行比较,以检查它们是否相等。这种检查非常适合断言。
断言必须检查通常应该为真的条件,除非您的代码中有 bug。这个想法是测试背后的另一个重要概念。
pytest第三方库是 Python 中流行的测试框架。在其核心,你会发现assert语句,你可以用它在pytest中编写大多数测试用例。这里有几个使用
assert语句编写测试用例的例子。下面的例子利用了一些提供测试材料的内置函数:# test_samples.py def test_sum(): assert sum([1, 2, 3]) == 6 def test_len(): assert len([1, 2, 3]) > 0 def test_reversed(): assert list(reversed([1, 2, 3])) == [3, 2, 1] def test_membership(): assert 3 in [1, 2, 3] def test_isinstance(): assert isinstance([1, 2, 3], list) def test_all(): assert all([True, True, True]) def test_any(): assert any([False, True, False]) def test_always_fail(): assert pow(10, 2) == 42所有这些测试用例都使用了
assert语句。它们中的大多数都是使用您以前学过的断言格式编写的。它们都展示了如何用pytest编写真实世界的测试用例来检查代码的不同部分。现在,为什么
pytest更喜欢测试用例中的普通assert语句,而不是定制的 API ,这也是其他测试框架更喜欢的?这一选择背后有几个显著的优势:
assert语句允许pytest降低入门门槛,并在一定程度上拉平学习曲线,因为它的用户可以利用他们已经知道的 Python 语法。pytest的用户不需要从库中导入任何东西来开始编写测试用例。如果他们的测试用例变得复杂,需要更高级的特性,他们只需要开始导入东西。这些优势使得使用
pytest对于初学者和来自其他使用定制 API 的测试框架的人来说是一种愉快的体验。例如,标准库
unittest模块提供了一个由一系列.assert*()方法组成的 API,其工作方式非常类似于assert语句。对于刚开始使用框架的开发人员来说,这种 API 可能很难学习和记忆。您可以使用
pytest来运行上面所有的测试用例。首先,您需要通过发出python -m pip install pytest命令来安装库。然后你可以从命令行执行pytest test_samples.py。后一个命令将显示类似如下的输出:========================== test session starts ========================= platform linux -- Python 3.10.0, pytest-6.2.5, py-1.10.0, pluggy-1.0.0 rootdir: /home/user/python-assert collected 8 items test_samples.py .......F [100%] ========================== FAILURES ===================================== __________________________ test_always_fail _____________________________ def test_always_fail(): > assert pow(10, 2) == 42 E assert 100 == 42 E + where 100 = pow(10, 2) test_samples.py:25: AssertionError ========================== short test summary info ====================== FAILED test_samples.py::test_always_fail - assert 100 == 42 ========================== 1 failed, 7 passed in 0.21s ==================输出中第一个突出显示的行告诉您
pytest发现并运行了八个测试用例。第二个突出显示的行显示八个测试中有七个成功通过。这就是为什么你会得到七个绿点和一个F。注意:为了避免
pytest的问题,您必须在正常模式下运行您的 Python 解释器。请记住,优化模式禁用断言。因此,确保您不是在优化模式下运行 Python。您可以通过运行以下命令来检查您的
PYTHOPTIMIZE环境变量的当前值:
- 视窗
** Linux + macOS*C:\> echo %PYTHONOPTIMIZE%$ echo $PYTHONOPTIMIZE如果
PYTHONOPTIMIZE被设置,则该命令的输出将显示其当前值。*** ***值得注意的一个显著特点是pytest与assert语句很好地集成在一起。该库可以显示错误报告,其中包含关于失败断言的详细信息以及它们失败的原因。例如,查看上面输出中以E字母开头的行。它们显示错误消息。这些行清楚地揭示了失败的根本原因。在这个例子中,
pow(10, 2)返回的是100而不是42,这是故意错误的。您可以使用pytest.raises()来处理预计会失败的代码。了解
assert的常见陷阱尽管断言是如此伟大和有用的工具,它们也有一些缺点。像任何其他工具一样,断言可能会被误用。您已经了解到,在开发过程中,您应该主要将断言用于调试和测试代码。相比之下,您不应该依赖断言在生产代码中提供功能,这是断言陷阱的主要驱动因素之一。
特别是,如果您在以下方面使用断言,您可能会陷入困境:
- 处理和验证数据
- 处理错误
- 运行有副作用的操作
断言的另一个常见问题是,在生产中保持它们的启用会对代码的性能产生负面影响。
最后,Python 默认启用断言,这可能会让来自其他语言的开发人员感到困惑。在接下来的部分中,您将了解所有这些可能的断言陷阱。您还将学习如何在自己的 Python 代码中避免它们。
使用
assert进行数据处理和验证您不应该使用
assert语句来验证用户的输入或来自外部来源的任何其他输入数据。这是因为生产代码通常会禁用断言,这将删除所有的验证。例如,假设您正在用 Python 构建一个在线商店,您需要添加接受折扣券的功能。您最终编写了以下函数:
# store.py # Code under development def price_with_discount(product, discount): assert 0 < discount < 1, "discount expects a value between 0 and 1" new_price = int(product["price"] * (1 - discount)) return new_price注意到
price_with_discount()第一行的assert语句了吗?它可以保证折扣价不会等于或低于零美元。这一断言还确保了新价格不会高于产品的原价。现在考虑一双鞋打八五折的例子:
>>> from store import price_with_discount
>>> shoes = {"name": "Fancy Shoes", "price": 14900}
>>> # 25% off -> $111.75
>>> price_with_discount(shoes, 0.25)
11175
好吧,price_with_discount()工作得很好!它将产品作为一个字典,将预期折扣应用于当前价格,并返回新价格。现在,尝试应用一些无效折扣:
>>> # 200% off >>> price_with_discount(shoes, 2.0) Traceback (most recent call last): ... AssertionError: discount expects a value between 0 and 1 >>> # 100% off >>> price_with_discount(shoes, 1) Traceback (most recent call last): ... AssertionError: discount expects a value between 0 and 1应用无效折扣会引发一个指出违反条件的
AssertionError。如果你在开发和测试你的网上商店时遇到过这个错误,那么通过查看回溯应该不难发现发生了什么。如果最终用户可以用禁用的断言在生产代码中直接调用
price_with_discount(),那么上面例子的真正问题就来了。在这种情况下,该函数不会检查discount的输入值,可能会接受错误的值并破坏折扣功能的正确性。一般来说,您可以在开发过程中编写
assert语句来处理、验证或检验数据。然而,如果这些操作在生产代码中仍然有效,那么一定要用一个if语句或者一个try…except块来替换它们。这里有一个新版本的
price_with_discount(),它使用了条件而不是断言:# store.py # Code in production def price_with_discount(product, discount): if 0 < discount < 1: new_price = int(product["price"] * (1 - discount)) return new_price raise ValueError("discount expects a value between 0 and 1")在这个新的
price_with_discount()实现中,您用一个显式条件语句替换了assert语句。现在,只有当输入值在0和1之间时,该函数才会应用折扣。否则,就会出现一个ValueError,发出问题信号。现在,您可以将对该函数的任何调用封装在一个
try…except块中,该块捕获ValueError,并向用户发送一条信息性消息,以便他们可以相应地采取行动。这个例子的寓意是,您不应该依赖于
assert语句进行数据处理或数据验证,因为这个语句在生产代码中通常是关闭的。用
assert和处理错误断言的另一个重要缺陷是,有时开发人员将断言用作一种快速的错误处理方式。因此,如果产品代码删除了断言,那么重要的错误检查也会从代码中删除。因此,请记住,断言不能代替良好的错误处理。
下面是一个使用断言进行错误处理的例子:
# Bad practice def square(x): assert x >= 0, "only positive numbers are allowed" return x ** 2 try: square(-2) except AssertionError as error: print(error)如果在生产环境中使用禁用的断言执行这段代码,那么
square()将永远不会运行assert语句并引发AssertionError。在这种情况下,try…except块是多余的,不起作用。你能做些什么来修正这个例子呢?尝试更新
square()以使用if语句和ValueError:# Best practice def square(x): if x < 0: raise ValueError("only positive numbers are allowed") return x ** 2 try: square(-2) except ValueError as error: print(error)现在
square()通过使用一个显式的if语句来处理这种情况,该语句不能在产品代码中被禁用。您的try…except块现在处理一个ValueError,这在本例中是一个更合适的异常。永远不要在你的代码中捕获
AssertionError异常,因为那会压制失败的断言,这是误用断言的明显标志。相反,捕捉与您正在处理的错误明显相关的具体异常,并让您的断言失败。除非有 bug,否则只使用断言来检查在程序的正常执行过程中不应该发生的错误。请记住,断言可以被禁用。
对带有副作用的表达式运行
assert当您使用该语句检查具有某种副作用的操作、函数或表达式时,
assert语句会出现另一个微妙的陷阱。换句话说,这些操作修改了操作的范围之外的对象的状态。在这些情况下,副作用会在每次代码运行断言时发生,这可能会悄悄地改变程序的全局状态和行为。
考虑下面的玩具例子,其中一个函数修改了一个全局变量的值作为副作用:
>>> sample = [42, 27, 40, 38]
>>> def popped(sample, index=-1):
... item = sample.pop(index)
... return item
...
>>> assert sample[-1] == popped(sample)
>>> assert sample[1] == popped(sample, 1)
>>> sample
[42, 40]
在这个例子中,popped()在数据的输入sample中给定的index处返回item,其副作用是也删除了所述的item。
使用断言来确保您的函数返回正确的项似乎是合适的。然而,这将导致函数的内部副作用在每个断言中运行,修改sample的原始内容。
为了防止类似上面例子中的意外行为,请使用不会产生副作用的断言表达式。例如,您可以使用纯函数,它只接受输入参数并返回相应的输出,而不修改来自其他作用域和名称空间的对象的状态。
用assert 影响性能
生产中过多的断言会影响代码的性能。当断言的条件涉及太多逻辑时,这个问题就变得很关键,比如长复合条件、长时间运行的谓词函数,以及隐含着高成本实例化过程的类。
断言可以从两个主要方面影响代码的性能。他们将:
- 花费时间执行
- 使用额外的内存
检查None值的assert语句可能相对便宜。然而,更复杂的断言,尤其是那些运行大量代码的断言,会明显降低代码的速度。断言也消耗内存来存储它们自己的代码和任何需要的数据。
为了避免生产代码中的性能问题,您应该使用 Python 的-O或-OO命令行选项,或者根据您的需要设置PYTHONOPTIMIZE环境变量。这两种策略都会通过生成无断言编译的字节码来优化代码,这样运行起来更快,占用的内存也更少。
此外,为了防止开发过程中的性能问题,您的断言应该相当简明扼要。
默认启用assert条语句
在 Python 中,默认情况下启用断言。当解释器在正常模式下运行时,__debug__变量是True,您的断言被启用。这种行为是有意义的,因为您通常在正常模式下开发、调试和测试代码。
如果您想要禁用您的断言,那么您需要显式地这样做。您可以使用-o或-OO选项运行 Python 解释器,或者将PYTHONOPTIMIZE环境变量设置为适当的值。
相比之下,其他编程语言默认禁用断言。例如,如果您从 Java 进入 Python,您可能会认为您的断言不会运行,除非您显式地打开它们。对于 Python 初学者来说,这种假设可能是常见的困惑来源,所以请记住这一点。
结论
现在你知道了如何使用 Python 的assert语句在整个代码中设置健全性检查,并确保某些条件为真并保持不变。当这些条件中的任何一个失败时,你就清楚地知道发生了什么。这样,您可以快速调试和修复代码。
在开发阶段,当您需要记录、调试、测试您的代码时,assert语句非常方便。在本教程中,您学习了如何在代码中使用断言,以及它们如何使您的调试和测试过程更加高效和简单。
在本教程中,您学习了:
- 什么是断言以及何时使用它们
- Python 的
assert语句如何工作 assert对于记录、调试、测试代码是多么方便- 如何禁用断言以提高生产中的性能
- 使用
assert语句时,你会面临哪些常见陷阱
有了这些关于assert语句的知识,您现在可以编写健壮、可靠且错误较少的代码,这将使您成为更高水平的开发人员。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。******************
Python 异步特性入门
听说过 Python 中的异步编程吗?您是否想了解更多关于 Python 异步特性的知识,以及如何在工作中使用它们?也许你甚至尝试过编写线程化程序并遇到一些问题。如果您想了解如何使用 Python 异步特性,那么您来对地方了。
在这篇文章中,你将了解到:
- 什么是同步程序
- 什么是异步程序
- 为什么你可能想写一个异步程序
- 如何使用 Python 异步特性
本文中的所有示例代码都已经用 Python 3.7.2 测试过了。您可以通过点击下面的链接获取一份副本进行跟进:
下载代码: 点击这里下载代码,您将在本教程中使用来学习 Python 中的异步特性。
了解异步编程
一个同步程序一次执行一个步骤。即使有条件分支、循环和函数调用,您仍然可以从一次执行一个步骤的角度来考虑代码。每一步完成后,程序就进入下一步。
这里有两个以这种方式工作的程序示例:
-
批处理程序通常被创建为同步程序。你得到一些输入,处理它,然后创造一些输出。步骤一个接一个,直到程序达到期望的输出。程序只需要注意步骤和它们的顺序。
-
命令行程序是在终端上运行的小而快速的程序。这些脚本用于创建一些东西,将一个东西转换成另一个东西,生成一个报告,或者列出一些数据。这可以表示为一系列的程序步骤,这些步骤按顺序执行,直到程序完成。
一个异步程序表现不同。它仍然一次执行一个步骤。不同之处在于,系统可能不会等待一个执行步骤完成后再继续下一个步骤。
这意味着程序将继续执行下一步,即使前一步还没有完成并且还在其他地方运行。这也意味着程序知道当前一个步骤结束运行时该做什么。
为什么要用这种方式编写程序呢?本文的其余部分将帮助您回答这个问题,并为您提供优雅地解决有趣的异步问题所需的工具。
构建同步网络服务器
web 服务器的基本工作单元或多或少与批处理相同。服务器将获得一些输入,处理它,并创建输出。作为同步程序编写,这将创建一个工作的 web 服务器。
这也将是一个绝对可怕的网络服务器。
为什么?在这种情况下,一个工作单元(输入、过程、输出)不是唯一的目的。真正的目的是尽可能快地处理数百甚至数千个单元的工作。这种情况可能会持续很长时间,几个工作单元甚至会同时到达。
同步 web 服务器可以做得更好吗?当然,您可以优化执行步骤,以便尽可能快地处理所有进来的工作。不幸的是,这种方法有局限性。结果可能是 web 服务器响应不够快,不能处理足够多的工作,甚至在工作堆积时超时。
注意:如果您尝试优化上述方法,您可能会发现其他限制。这些包括网络速度、文件 IO 速度、数据库查询速度和其他连接服务的速度,等等。这些的共同点是都是 IO 函数。所有这些项目都比 CPU 的处理速度慢几个数量级。
在同步程序中,如果一个执行步骤启动了一个数据库查询,那么在数据库查询返回之前,CPU 实际上是空闲的。对于面向批处理的程序,这在大多数情况下并不是优先考虑的事情。目标是处理 IO 操作的结果。通常,这比 IO 操作本身花费的时间更长。任何优化工作都将集中在处理工作上,而不是 IO 上。
异步编程技术允许您的程序通过释放 CPU 去做其他工作来利用相对较慢的 IO 进程。
用不同的方式思考编程
当你开始尝试理解异步编程时,你可能会看到很多关于阻塞或者编写非阻塞代码的重要性的讨论。(就我个人而言,我很难从我询问的人和我阅读的文档中很好地掌握这些概念。)
什么是非阻塞代码?就此而言,什么是阻塞代码?这些问题的答案会帮助你编写一个更好的 web 服务器吗?如果是,你会怎么做?让我们来了解一下!
编写异步程序要求您以不同的方式思考编程。虽然这种新的思维方式可能很难理解,但它也是一种有趣的练习。这是因为现实世界几乎完全是异步的,你与它的互动方式也是如此。
想象一下:你是一位试图同时做几件事情的父母。你必须平衡支票簿,洗衣服,照看孩子。不知何故,你能够同时做所有这些事情,甚至不用考虑它!让我们来分解一下:
-
平衡支票簿是一项同步的任务。一步接着一步,直到完成。你一个人做所有的工作。
-
然而,你可以脱离支票簿去洗衣服。你卸下干衣机,将衣物从洗衣机移到干衣机,并在洗衣机中开始另一次洗涤。
-
使用洗衣机和烘干机是一项同步任务,但大部分工作发生在洗衣机和烘干机启动后的第天。一旦你让他们开始工作,你就可以走开,回到支票簿的任务上。此时,洗衣机和烘干机的任务变成了异步。洗衣机和烘干机将独立运行,直到蜂鸣器响起(通知您该任务需要注意)。
-
照看孩子是另一项异步任务。一旦他们被设置和播放,他们可以在很大程度上独立完成。当有人需要关注时,比如当有人饥饿或受伤时,这种情况就会改变。当你的一个孩子惊恐地大叫时,你会有所反应。孩子们是一个长期运行的高优先级任务。看着它们取代了你可能正在做的任何其他任务,比如支票簿或洗衣服。
这些例子有助于说明阻塞和非阻塞代码的概念。让我们从编程的角度来考虑这个问题。在这个例子中,你就像是中央处理器。当你移动要洗的衣服时,你(CPU)很忙,无法做其他工作,比如结算支票簿。但这没关系,因为任务相对较快。
另一方面,启动洗衣机和烘干机不会妨碍您执行其他任务。这是一个异步函数,因为你不必等待它完成。一旦开始,你就可以回到别的事情上去。这被称为上下文切换:你正在做的事情的上下文已经改变,洗衣机的蜂鸣器将在未来某个时候通知你洗衣任务完成。
作为一个人类,你一直都是这样工作的。你会自然而然地同时处理多件事情,而且经常不加思考。作为一名开发人员,诀窍在于如何将这种行为转换成做同样事情的代码。
编程家长:没有看起来那么容易!
如果你在上面的例子中认出了你自己(或者你的父母),那就太好了!你已经在理解异步编程方面占了上风。同样,你能够很容易地在竞争任务之间切换上下文,选择一些任务并继续其他任务。现在你要试着把这种行为编程到虚拟父母中去!
思想实验#1:同步父母
你如何创建一个父程序以完全同步的方式完成上述任务?由于照看孩子是一项高优先级的任务,也许您的程序可以做到这一点。父母看着孩子,等待可能需要他们注意的事情发生。然而,在这种情况下,其他任何事情(如支票簿或衣物)都无法完成。
现在,你可以按照你想要的任何方式重新排列任务的优先级,但是在任何给定的时间,它们中只有一个会发生。这是同步、逐步方法的结果。就像上面描述的同步 web 服务器一样,这是可行的,但是这可能不是最好的生活方式。直到孩子们睡着了,父母才能完成任何其他任务。所有其他的任务都在之后发生,一直持续到深夜。(几个星期后,许多真正的父母可能会跳出窗外!)
思想实验#2:投票父母
如果您使用了轮询,那么您可以改变事情,以便完成多个任务。在这种方法中,父母会周期性地从当前任务中脱离出来,查看是否有其他任务需要关注。
让我们将轮询间隔设为大约 15 分钟。现在,每隔 15 分钟,你的父母就会检查洗衣机、烘干机或孩子是否需要注意。如果没有,那么家长可以回去工作的支票簿。然而,如果这些任务中的任何一项需要注意,父母会在回到支票簿前处理好。这个循环继续下去,直到轮询循环的下一次超时。
这种方法也很有效,因为多个任务引起了注意。然而,有几个问题:
-
父母可能会花很多时间检查不需要注意的事情:洗衣机和烘干机还没有完成,除非发生意外,否则孩子们不需要任何注意。
-
家长可能会错过需要关注的已完成任务:例如,如果洗衣机在轮询间隔开始时完成了其周期,那么它将在长达十五分钟内得不到任何关注!此外,照看孩子应该是最重要的任务。当事情可能会彻底出错时,他们无法忍受 15 分钟的无所事事。
您可以通过缩短轮询间隔来解决这些问题,但是现在您的父进程(CPU)将花费更多的时间在任务之间进行上下文切换。这是你开始达到收益递减点的时候。(再一次,像这样生活几个星期,嗯…看前面关于窗户和跳跃的评论。)
思想实验#3:线程父代
“如果我能克隆我自己就好了……”如果你是父母,那么你可能也有类似的想法!因为您正在编写虚拟父母,所以基本上可以通过使用线程来实现。这是一种允许一个程序的多个部分同时运行的机制。独立运行的每一段代码称为一个线程,所有线程共享相同的内存空间。
如果你把每个任务看作一个程序的一部分,那么你可以把它们分开,作为线程来运行。换句话说,您可以“克隆”父对象,为每个任务创建一个实例:照看孩子、监控洗衣机、监控烘干机以及平衡支票簿。所有这些“克隆”都是独立运行的。
这听起来是一个非常好的解决方案,但是这里也有一些问题。一个是你必须明确地告诉每个父实例在你的程序中做什么。这可能会导致一些问题,因为所有实例共享程序空间中的所有内容。
例如,假设父母 A 正在监控烘干机。父母 A 看到衣服是干的,所以他们控制了烘干机并开始卸载衣服。同时,父母 B 看到洗衣机已经洗好了,所以他们控制了洗衣机并开始脱衣服。然而,父母 B 也需要控制烘干机,以便他们可以将湿衣服放在里面。这是不可能发生的,因为父母 A 目前控制着烘干机。
不一会儿,家长 A 已经卸完衣服了。现在他们想控制洗衣机,开始把衣服放进空的烘干机。这也不可能发生,因为父 B 目前控制着洗衣机!
这两个家长现在僵持。双方都控制了自己的资源和想要控制对方的资源。他们将永远等待另一个父实例释放控制权。作为程序员,您必须编写代码来解决这种情况。
注意:线程程序允许你创建多个并行的执行路径,这些路径共享同一个内存空间。这既是优点也是缺点。线程之间共享的任何内存都受制于一个或多个试图同时使用同一个共享内存的线程。这可能会导致数据损坏、在无效状态下读取数据,以及数据通常很乱。
在线程编程中,上下文切换发生在系统控制下,而不是程序员。系统控制何时切换上下文,何时让线程访问共享数据,从而改变如何使用内存的上下文。所有这些类型的问题在线程代码中都是可以管理的,但是很难得到正确的结果,并且在错误的时候很难调试。
这是线程化可能引发的另一个问题。假设一个孩子受伤了,需要紧急护理。父母 C 被分配了照看孩子的任务,所以他们马上带走了孩子。在紧急护理中心,父母 C 需要开一张相当大的支票来支付看病的费用。
与此同时,家长 D 正在家里处理支票簿。他们不知道这张大额支票已经开出,所以当家庭支票账户突然透支时,他们感到非常惊讶!
记住,这两个父实例在同一个程序中工作。家庭支票账户是一种共享资源,所以你必须想办法让照看孩子的父母通知收支平衡的父母。否则,您需要提供某种锁定机制,以便支票簿资源一次只能由一个父节点使用,并进行更新。
实践中使用 Python 异步特性
现在,您将采用上述思维实验中概述的一些方法,并将它们转化为有效的 Python 程序。
本文中的所有例子都已经用 Python 3.7.2 测试过了。requirements.txt文件指出了运行所有示例需要安装哪些模块。如果您尚未下载该文件,现在可以下载:
下载代码: 点击这里下载代码,您将在本教程中使用来学习 Python 中的异步特性。
您可能还想建立一个 Python 虚拟环境来运行代码,这样您就不会干扰您的系统 Python。
同步编程
第一个例子展示了一种有点做作的方法,让任务从队列中检索工作并处理该工作。Python 中的队列是一种很好的先进先出数据结构。它提供了将东西放入队列并按照插入的顺序取出它们的方法。
在这种情况下,工作是从队列中获取一个数字,并让循环计数达到该数字。当循环开始时,它打印到控制台,并再次输出总数。这个程序演示了多个同步任务处理队列中的工作的一种方法。
存储库中名为example_1.py的程序完整列出如下:
1import queue
2
3def task(name, work_queue):
4 if work_queue.empty():
5 print(f"Task {name} nothing to do")
6 else:
7 while not work_queue.empty():
8 count = work_queue.get()
9 total = 0
10 print(f"Task {name} running")
11 for x in range(count):
12 total += 1
13 print(f"Task {name} total: {total}")
14
15def main():
16 """
17 This is the main entry point for the program
18 """
19 # Create the queue of work
20 work_queue = queue.Queue()
21
22 # Put some work in the queue
23 for work in [15, 10, 5, 2]:
24 work_queue.put(work)
25
26 # Create some synchronous tasks
27 tasks = [(task, "One", work_queue), (task, "Two", work_queue)]
28
29 # Run the tasks
30 for t, n, q in tasks:
31 t(n, q)
32
33if __name__ == "__main__":
34 main()
让我们看看每一行都做了什么:
- 线 1 导入
queue模块。这是程序存储任务要完成的工作的地方。 - 第 3 行到第 13 行定义
task()。这个函数从work_queue中提取工作,并处理工作,直到没有其他工作可做。 - 第 15 行定义
main()运行程序任务。 - 第 20 行创造了
work_queue。所有任务都使用这个共享资源来检索工作。 - 第 23 至 24 行将工作放入
work_queue。在这种情况下,它只是要处理的任务的值的随机计数。 - 第 27 行创建了一个任务元组的列表,带有那些任务将被传递的参数值。
- 第 30 到 31 行遍历任务元组列表,调用每个元组并传递之前定义的参数值。
- 第 34 行调用
main()运行程序。
这个程序中的任务只是一个接受字符串和队列作为参数的函数。当执行时,它在队列中寻找任何要处理的东西。如果有工作要做,那么它从队列中取出值,开始一个 for循环来计数到那个值,并在最后输出总数。它继续从队列中获取工作,直到没有剩余工作并退出。
当这个程序运行时,它产生如下所示的输出:
Task One running
Task One total: 15
Task One running
Task One total: 10
Task One running
Task One total: 5
Task One running
Task One total: 2
Task Two nothing to do
这表明Task One做了所有的工作。Task One在task()中命中的 while循环消耗队列中的所有工作并处理它。当这个循环退出时,Task Two就有机会运行。但是,它发现队列是空的,所以Task Two打印一个声明,说它没有任何事情,然后退出。代码中没有任何东西允许Task One和Task Two切换上下文并一起工作。
简单协作并发
这个程序的下一个版本允许这两个任务一起工作。添加一个yield语句意味着循环将在指定点产生控制,同时仍然保持其上下文。这样,让步任务可以在以后重新启动。
yield语句将task()变成了发生器。在 Python 中,调用生成器函数就像调用任何其他函数一样,但是当执行yield语句时,控制被返回给函数的调用者。这本质上是一个上下文切换,因为控制权从生成器函数转移到了调用者。
有趣的是,通过调用生成器上的next(),可以将控制权交还给生成器函数。这是一个返回到生成器函数的上下文切换,它继续执行所有在yield之前定义的函数变量。
main() 中的while循环在调用next(t)时利用了这一点。此语句从任务先前产生的点重新启动任务。所有这些都意味着当上下文切换发生时,您处于控制之中:当在task()中执行yield语句时。
这是一种多任务合作的形式。程序正在放弃对其当前上下文的控制,以便其他东西可以运行。在这种情况下,它允许main()中的while循环运行task()的两个实例作为生成器函数。每个实例都使用同一队列中的工作。这是一种聪明的做法,但是要得到与第一个程序相同的结果也需要做大量的工作。程序example_2.py演示了这个简单的并发,如下所示:
1import queue
2
3def task(name, queue):
4 while not queue.empty():
5 count = queue.get()
6 total = 0
7 print(f"Task {name} running")
8 for x in range(count):
9 total += 1
10 yield
11 print(f"Task {name} total: {total}")
12
13def main():
14 """
15 This is the main entry point for the program
16 """
17 # Create the queue of work
18 work_queue = queue.Queue()
19
20 # Put some work in the queue
21 for work in [15, 10, 5, 2]:
22 work_queue.put(work)
23
24 # Create some tasks
25 tasks = [task("One", work_queue), task("Two", work_queue)]
26
27 # Run the tasks
28 done = False
29 while not done:
30 for t in tasks:
31 try:
32 next(t)
33 except StopIteration:
34 tasks.remove(t)
35 if len(tasks) == 0:
36 done = True
37
38if __name__ == "__main__":
39 main()
下面是上面代码中发生的情况:
- 第 3 行到第 11 行像以前一样定义
task(),但是在第 10 行增加了yield将函数变成了生成器。在这里进行上下文切换,并且控制被交还给main()中的while循环。 - 第 25 行创建任务列表,但是与您在前面的示例代码中看到的方式略有不同。在这种情况下,调用每个任务时,会将其参数输入到
tasks列表变量中。这是第一次运行task()发生器功能所必需的。 - 第 31 到 36 行是对
main()中while循环的修改,使task()可以协同运行。这是当它让步时控制返回到每个task()实例的地方,允许循环继续并运行另一个任务。 - 第 32 行将控制权交还给
task(),并在yield被调用后继续执行。 - 第 36 行设置
done变量。当所有任务完成并从tasks中移除后,while循环结束。
这是运行该程序时产生的输出:
Task One running
Task Two running
Task Two total: 10
Task Two running
Task One total: 15
Task One running
Task Two total: 5
Task One total: 2
您可以看到Task One和Task Two都在运行并消耗队列中的工作。这就是我们想要的,因为两个任务都是处理工作,每个任务负责队列中的两个项目。这很有趣,但同样,要达到这些结果需要做相当多的工作。
这里的技巧是使用yield语句,它将task()变成一个生成器并执行上下文切换。程序使用这个上下文切换来控制main()中的while循环,允许一个任务的两个实例协同运行。
注意Task Two如何首先输出它的总数。这可能会让您认为任务是异步运行的。然而,这仍然是一个同步程序。它的结构使得这两个任务可以来回交换上下文。Task Two先输出总数的原因是它只数到 10,而Task One数到 15。Task Two简单地首先到达它的总数,所以它在Task One之前打印它的输出到控制台。
注意:从这一点开始的所有示例代码都使用一个名为 codetiming 的模块来计时并输出代码段执行的时间。这里有一篇关于 RealPython 的很棒的文章深入讨论了 codetiming 模块以及如何使用它。
这个模块是 Python 包索引的一部分,由 Geir Arne Hjelle 构建,他是真实 Python 团队的一员。Geir Arne 对我评论和建议本文的内容帮助很大。如果您正在编写需要包含计时功能的代码,Geir Arne 的 codetiming 模块非常值得一看。
要使 codetiming 模块在下面的例子中可用,您需要安装它。这可以通过pip命令:pip install codetiming或pip install -r requirements.txt命令来完成。requirements.txt文件是示例代码库的一部分。
具有阻塞调用的协作并发
程序的下一个版本与上一个版本相同,除了在你的任务循环体中增加了一个 time.sleep(delay) 。这将基于从工作队列中检索的值向任务循环的每次迭代添加延迟。延迟模拟任务中发生阻塞调用的效果。
阻塞调用是一段时间内阻止 CPU 做任何事情的代码。在上面的思维实验中,如果父母在完成之前不能脱离平衡支票簿,那将是一个阻塞呼叫。
time.sleep(delay)在这个例子中做同样的事情,因为 CPU 除了等待延迟到期之外,不能做任何其他事情。
1import time
2import queue
3from codetiming import Timer
4
5def task(name, queue):
6 timer = Timer(text=f"Task {name} elapsed time: {{:.1f}}")
7 while not queue.empty():
8 delay = queue.get()
9 print(f"Task {name} running")
10 timer.start()
11 time.sleep(delay)
12 timer.stop()
13 yield
14
15def main():
16 """
17 This is the main entry point for the program
18 """
19 # Create the queue of work
20 work_queue = queue.Queue()
21
22 # Put some work in the queue
23 for work in [15, 10, 5, 2]:
24 work_queue.put(work)
25
26 tasks = [task("One", work_queue), task("Two", work_queue)]
27
28 # Run the tasks
29 done = False
30 with Timer(text="\nTotal elapsed time: {:.1f}"):
31 while not done:
32 for t in tasks:
33 try:
34 next(t)
35 except StopIteration:
36 tasks.remove(t)
37 if len(tasks) == 0:
38 done = True
39
40if __name__ == "__main__":
41 main()
下面是上面代码的不同之处:
- 行 1 导入
time模块给程序访问time.sleep()。 - 第 3 行从
codetiming模块导入Timer代码。 - 第 6 行创建了
Timer实例,用于测量任务循环的每次迭代所用的时间。 - 第 10 行启动
timer实例 - 第 11 行改变
task()以包括一个time.sleep(delay)来模拟 IO 延迟。这取代了在example_1.py中进行计数的for循环。 - 第 12 行停止
timer实例,输出调用timer.start()后经过的时间。 - 第 30 行创建一个
Timer上下文管理器,它将输出整个 while 循环执行所用的时间。
当您运行该程序时,您将看到以下输出:
Task One running
Task One elapsed time: 15.0
Task Two running
Task Two elapsed time: 10.0
Task One running
Task One elapsed time: 5.0
Task Two running
Task Two elapsed time: 2.0
Total elapsed time: 32.0
和以前一样,Task One和Task Two都在运行,消耗队列中的工作并进行处理。然而,即使增加了延迟,您可以看到协作并发并没有给您带来任何好处。延迟会停止整个程序的处理,CPU 只是等待 IO 延迟结束。
这正是 Python 异步文档中阻塞代码的含义。你会注意到,运行整个程序所花费的时间就是所有延迟的累计时间。以这种方式运行任务并不成功。
具有非阻塞调用的协作并发
这个程序的下一个版本已经做了相当多的修改。它使用 Python 3 中提供的 asyncio/await 来利用 Python 异步特性。
time和queue模块已被替换为asyncio组件。这使您的程序可以访问异步友好(非阻塞)睡眠和队列功能。对task()的更改通过在第 4 行添加前缀async将其定义为异步。这向 Python 表明该函数将是异步的。
另一个大的变化是删除了time.sleep(delay)和yield语句,用await asyncio.sleep(delay)代替它们。这创建了一个非阻塞延迟,它将执行上下文切换回调用者main()。
main()内的while循环不再存在。不是task_array,而是有一个await asyncio.gather(...)的调用。这告诉了asyncio两件事:
- 基于
task()创建两个任务,并开始运行它们。 - 请等待这两项都完成后再继续。
程序的最后一行asyncio.run(main())运行main()。这就产生了所谓的事件循环。这个循环将运行main(),它又将运行task()的两个实例。
事件循环是 Python 异步系统的核心。它运行所有的代码,包括main()。当任务代码执行时,CPU 忙于工作。当到达 await关键字时,发生上下文切换,并且控制传递回事件循环。事件循环查看所有等待事件的任务(在这种情况下,是一个asyncio.sleep(delay)超时),并将控制权传递给一个带有就绪事件的任务。
await asyncio.sleep(delay)对于 CPU 来说是非阻塞的。CPU 不是等待延迟超时,而是在事件循环任务队列中注册一个睡眠事件,并通过将控制传递给事件循环来执行上下文切换。事件循环不断寻找已完成的事件,并将控制传递回等待该事件的任务。通过这种方式,如果有工作,CPU 可以保持忙碌,而事件循环则监视将来会发生的事件。
注意:一个异步程序运行在一个执行的单线程中。影响数据的从一段代码到另一段代码的上下文切换完全在您的控制之中。这意味着您可以在进行上下文切换之前原子化并完成所有共享内存数据访问。这简化了线程代码中固有的共享内存问题。
下面列出了example_4.py代码:
1import asyncio
2from codetiming import Timer
3
4async def task(name, work_queue):
5 timer = Timer(text=f"Task {name} elapsed time: {{:.1f}}")
6 while not work_queue.empty():
7 delay = await work_queue.get()
8 print(f"Task {name} running")
9 timer.start()
10 await asyncio.sleep(delay)
11 timer.stop()
12
13async def main():
14 """
15 This is the main entry point for the program
16 """
17 # Create the queue of work
18 work_queue = asyncio.Queue()
19
20 # Put some work in the queue
21 for work in [15, 10, 5, 2]:
22 await work_queue.put(work)
23
24 # Run the tasks
25 with Timer(text="\nTotal elapsed time: {:.1f}"):
26 await asyncio.gather(
27 asyncio.create_task(task("One", work_queue)),
28 asyncio.create_task(task("Two", work_queue)),
29 )
30
31if __name__ == "__main__":
32 asyncio.run(main())
下面是这个程序和example_3.py的不同之处:
- 第 1 行导入
asyncio以获得对 Python 异步功能的访问。这取代了time导入。 - 第 2 行从
codetiming模块导入Timer代码。 - 第 4 行显示在
task()定义前添加了async关键字。这通知程序task可以异步运行。 - 第 5 行创建了
Timer实例,用于测量任务循环的每次迭代所用的时间。 - 第 9 行启动
timer实例 - 第 10 行用非阻塞
asyncio.sleep(delay)替换time.sleep(delay),这也将控制权(或切换上下文)交还给主事件循环。 - 第 11 行停止
timer实例,输出调用timer.start()后经过的时间。 - 第 18 行创建非阻塞异步
work_queue。 - 第 21 到 22 行使用
await关键字以异步方式将工作放入work_queue中。 - 第 25 行创建一个
Timer上下文管理器,它将输出整个 while 循环执行所用的时间。 - 第 26 到 29 行创建两个任务并将它们收集在一起,因此程序将等待两个任务都完成。
- 第 32 行启动程序异步运行。它还会启动内部事件循环。
当您查看这个程序的输出时,请注意Task One和Task Two是如何同时启动的,然后等待模拟 IO 调用:
Task One running
Task Two running
Task Two total elapsed time: 10.0
Task Two running
Task One total elapsed time: 15.0
Task One running
Task Two total elapsed time: 5.0
Task One total elapsed time: 2.0
Total elapsed time: 17.0
这表明await asyncio.sleep(delay)是非阻塞的,其他工作正在进行。
在程序结束时,您会注意到总运行时间实际上是运行example_3.py所用时间的一半。这就是使用 Python 异步特性的程序的优势!每个任务能够同时运行await asyncio.sleep(delay)。程序的总执行时间现在小于其各部分的总和。你已经脱离了同步模式!
同步(阻塞)HTTP 调用
这个项目的下一个版本是一种进步,也是一种倒退。该程序通过向一系列 URL 发出 HTTP 请求并获取页面内容,用真正的 IO 做一些实际的工作。然而,它是以阻塞(同步)的方式这样做的。
该程序已被修改为导入美妙的requests模块来发出实际的 HTTP 请求。此外,队列现在包含一个 URL 列表,而不是数字。另外,task()不再递增计数器。相反,requests从队列中获取一个 URL 的内容,并打印出这样做需要多长时间。
下面列出了example_5.py代码:
1import queue
2import requests
3from codetiming import Timer
4
5def task(name, work_queue):
6 timer = Timer(text=f"Task {name} elapsed time: {{:.1f}}")
7 with requests.Session() as session:
8 while not work_queue.empty():
9 url = work_queue.get()
10 print(f"Task {name} getting URL: {url}")
11 timer.start()
12 session.get(url)
13 timer.stop()
14 yield
15
16def main():
17 """
18 This is the main entry point for the program
19 """
20 # Create the queue of work
21 work_queue = queue.Queue()
22
23 # Put some work in the queue
24 for url in [
25 "http://google.com",
26 "http://yahoo.com",
27 "http://linkedin.com",
28 "http://apple.com",
29 "http://microsoft.com",
30 "http://facebook.com",
31 "http://twitter.com",
32 ]:
33 work_queue.put(url)
34
35 tasks = [task("One", work_queue), task("Two", work_queue)]
36
37 # Run the tasks
38 done = False
39 with Timer(text="\nTotal elapsed time: {:.1f}"):
40 while not done:
41 for t in tasks:
42 try:
43 next(t)
44 except StopIteration:
45 tasks.remove(t)
46 if len(tasks) == 0:
47 done = True
48
49if __name__ == "__main__":
50 main()
下面是这个程序中发生的事情:
- 第 2 行导入
requests,提供了一种便捷的 HTTP 调用方式。 - 第 3 行从
codetiming模块导入Timer代码。 - 第 6 行创建了
Timer实例,用于测量任务循环的每次迭代所用的时间。 - 第 11 行启动
timer实例 - 第 12 行引入了一个延迟,类似于
example_3.py。然而,这一次它调用了session.get(url),返回从work_queue获取的 URL 的内容。 - 第 13 行停止
timer实例,输出调用timer.start()后经过的时间。 - 第 23 到 32 行将 URL 列表放入
work_queue。 - 第 39 行创建一个
Timer上下文管理器,它将输出整个 while 循环执行所用的时间。
当您运行该程序时,您将看到以下输出:
Task One getting URL: http://google.com
Task One total elapsed time: 0.3
Task Two getting URL: http://yahoo.com
Task Two total elapsed time: 0.8
Task One getting URL: http://linkedin.com
Task One total elapsed time: 0.4
Task Two getting URL: http://apple.com
Task Two total elapsed time: 0.3
Task One getting URL: http://microsoft.com
Task One total elapsed time: 0.5
Task Two getting URL: http://facebook.com
Task Two total elapsed time: 0.5
Task One getting URL: http://twitter.com
Task One total elapsed time: 0.4
Total elapsed time: 3.2
就像早期版本的程序一样,yield将task()变成了一个生成器。它还执行上下文切换,让另一个任务实例运行。
每个任务从工作队列中获取一个 URL,检索页面的内容,并报告获取该内容花费了多长时间。
和以前一样,yield允许您的两个任务协同运行。然而,由于这个程序是同步运行的,每个session.get()调用都会阻塞 CPU,直到页面被检索到。注意最后运行整个程序所花费的总时间。这将对下一个例子有意义。
异步(非阻塞)HTTP 调用
这个版本的程序修改了以前的版本,使用 Python 异步特性。它还导入了 aiohttp 模块,这是一个使用asyncio以异步方式发出 HTTP 请求的库。
这里的任务已经修改,删除了yield调用,因为进行 HTTP GET调用的代码不再阻塞。它还执行上下文切换回事件循环。
下面列出了example_6.py程序:
1import asyncio
2import aiohttp
3from codetiming import Timer
4
5async def task(name, work_queue):
6 timer = Timer(text=f"Task {name} elapsed time: {{:.1f}}")
7 async with aiohttp.ClientSession() as session:
8 while not work_queue.empty():
9 url = await work_queue.get()
10 print(f"Task {name} getting URL: {url}")
11 timer.start()
12 async with session.get(url) as response:
13 await response.text()
14 timer.stop()
15
16async def main():
17 """
18 This is the main entry point for the program
19 """
20 # Create the queue of work
21 work_queue = asyncio.Queue()
22
23 # Put some work in the queue
24 for url in [
25 "http://google.com",
26 "http://yahoo.com",
27 "http://linkedin.com",
28 "http://apple.com",
29 "http://microsoft.com",
30 "http://facebook.com",
31 "http://twitter.com",
32 ]:
33 await work_queue.put(url)
34
35 # Run the tasks
36 with Timer(text="\nTotal elapsed time: {:.1f}"):
37 await asyncio.gather(
38 asyncio.create_task(task("One", work_queue)),
39 asyncio.create_task(task("Two", work_queue)),
40 )
41
42if __name__ == "__main__":
43 asyncio.run(main())
下面是这个程序中发生的事情:
- 第 2 行导入了
aiohttp库,它提供了一种异步方式来进行 HTTP 调用。 - 第 3 行从
codetiming模块导入Timer代码。 - 第 5 行将
task()标记为异步函数。 - 第 6 行创建了
Timer实例,用于测量任务循环的每次迭代所用的时间。 - 第 7 行创建一个
aiohttp会话上下文管理器。 - 第 8 行创建一个
aiohttp响应上下文管理器。它还对来自work_queue的 URL 进行 HTTPGET调用。 - 第 11 行启动
timer实例 - 第 12 行使用会话异步获取从 URL 检索的文本。
- 第 13 行停止
timer实例,输出调用timer.start()后经过的时间。 - 第 39 行创建一个
Timer上下文管理器,它将输出整个 while 循环执行所用的时间。
当您运行该程序时,您将看到以下输出:
Task One getting URL: http://google.com
Task Two getting URL: http://yahoo.com
Task One total elapsed time: 0.3
Task One getting URL: http://linkedin.com
Task One total elapsed time: 0.3
Task One getting URL: http://apple.com
Task One total elapsed time: 0.3
Task One getting URL: http://microsoft.com
Task Two total elapsed time: 0.9
Task Two getting URL: http://facebook.com
Task Two total elapsed time: 0.4
Task Two getting URL: http://twitter.com
Task One total elapsed time: 0.5
Task Two total elapsed time: 0.3
Total elapsed time: 1.7
看一下总的运行时间,以及获取每个 URL 内容的单个时间。您将看到持续时间大约是所有 HTTP GET调用累计时间的一半。这是因为 HTTP GET调用是异步运行的。换句话说,通过允许 CPU 一次发出多个请求,您可以更有效地利用 CPU。
因为 CPU 非常快,这个例子可能会创建和 URL 一样多的任务。在这种情况下,程序的运行时间将是最慢的 URL 检索时间。
结论
本文提供了让异步编程技术成为您的技能的一部分所需的工具。使用 Python 异步特性,您可以对何时发生上下文切换进行编程控制。这意味着您可能在线程编程中遇到的许多棘手问题都更容易处理。
异步编程是一个强大的工具,但并不是对每种程序都有用。例如,如果你正在编写一个计算圆周率的程序,那么异步代码就帮不了你。那种程序是 CPU 绑定的,没有多少 IO。然而,如果您试图实现一个执行 IO(比如文件或网络访问)的服务器或程序,那么使用 Python 异步特性会带来巨大的不同。
总结一下,你已经学会:
- 什么是同步程序
- 异步程序与众不同,但同样强大且易于管理
- 为什么你可能想写异步程序
- 如何使用 Python 中内置的异步特性
您可以获得本教程中使用的所有示例程序的代码:
下载代码: 点击这里下载代码,您将在本教程中使用来学习 Python 中的异步特性。
现在你已经掌握了这些强大的技能,你可以把你的程序带到下一个层次!******
Python 基础:平装本现已上市!
经过多年的写作、审查和测试,我们很高兴地宣布 Python 基础知识:Python 3 实用介绍现已在平装本中推出!
听到读者如何利用这本书来促进他们的学习,这是很有收获的。在收到如此多的社区反馈后,我们相信你会用这本书为你的 Python 之旅打下坚实的基础:你不仅会学到你真正需要知道的核心概念,而且在实践练习的帮助下,你还会以最有效的顺序学习它们。
在这篇文章中,你会看到:
- 如何用 Python 基础提升你的 Python
- 其他蟒蛇是如何做到的
要直接跳到精彩内容并得到这本书,请单击下面的链接:
你可以得到平装本的 Python 基础!
终于来了!读者一直给我们看他们的副本,让我们知道他们的想法。这里有一个来自我们的社区 Slack :

我们从 Real Python 社区收到的反馈是无价的,帮助我们创建了一个实用且有帮助的学习工具,我们很荣幸能与 Python 社区分享这个工具。要了解这本书的更多内容,请查看大卫·阿莫斯的概述,他是真正的 Python 核心团队成员和 Python 基础知识的主要作者:
https://player.vimeo.com/video/527948454
Python 基础知识是许多人多年工作的成果,我们认为最终产品真正体现了这一点。这是一段不平凡的旅程!我们真的很高兴能与您分享这本书,所以当我们正式推出这本书时, Real Python 编辑团队在 Zoom 上举办了一个发布会:
当然有很多值得庆祝的事情!在发布后的最初几天里,观看 Python 基础知识在亚马逊排行榜上攀升并迅速成为 Python 编程领域的头号畅销书简直是一场疯狂之旅:

这本书不仅很快成为畅销书,而且到目前为止我们收到的评论都非常积极:
得知如此多的学习者使用这本书来提升他们的游戏水平,真是令人感动。我们希望在您亲自借阅这本书时收到您的来信。
谁应该读这本书?
互联网上有大量关于 Python 的信息,因此我们创建、测试并完善了一个学习系统,帮助您充分利用学习时间:
比满满一书架的 Python 书强!
《Python 基础》是一本写得非常好并且非常全面的书。每一个概念都被清晰的解释和优秀的例子…它们都有效!如果你对 Python 感兴趣,你会把这本书放在桌子上手边。(⭐⭐⭐⭐⭐)
——布拉德·尤斯(通过亚马逊)
无论您是刚开始学习一般编程还是特别是 Python 编程,您都将获得有效的、真实的 Python 技能。如果你已经是一个 Pythonista,那么你会有一个经过反复试验的系统来提高你的技能,并确保你有一个强大的基础。
你是编程新手吗?
如果你是编程新手,那么你会得到一个实用的、循序渐进的路线图来发展你的基本技能。将按照逻辑顺序向您介绍每个概念,代码示例简短明了:
学习 Python 的佳作
作为一名目前正在攻读数据科学研究生学位的学生,您最终需要学习 Python。学校里的入门课程不足以真正更好地掌握编程语言。
作为一个从未编写过代码的人,我需要尽可能多的帮助。谢天谢地,我找到了真正的 Python 网站。我真的很喜欢他们简单易懂的教程,所以我买了《Python 基础知识》这本书。
这是一笔非常划算的买卖,我向所有想学习 Python 的人强烈推荐它。它很容易理解,并提供了很好的例子。(⭐⭐⭐⭐⭐)
Lorrayne Cruz Almodovar(通过亚马逊)
您将获得完整的 Python 课程,包括练习、互动测验和示例项目。
你是 Python 新手吗?
如果您熟悉一些基本的编程概念,那么您将会对 Python 有一个清晰的、经过充分测试的介绍。这是 Python 的实用介绍,让您直接跳到好的部分,以便快速跟踪您的进度:
Python 优秀入门
关于 Python 的入门书籍并不缺乏,但在我看来这本书很突出。概念是逐渐建立起来的,在之前的课程之上,顺序是精心设计的。语言很简单,甚至有点娱乐性,绝对不枯燥——对于一本编程书籍来说,这本身就是一个成就。
在整篇文章中,有一些提示和陷阱,不管你的技能水平如何,你都会发现它们非常有用。有一章讲述了编程的几乎每一个方面,给人一种如何做的感觉——足够的深度。强烈推荐。(⭐⭐⭐⭐⭐)
—迪米特里(通过亚马逊)
您将很快熟悉 Python,并很快学会“足够危险”。
你是一个想不断学习的 Pythonista 吗?
如果您已经是 Python 开发人员,那么您可以快速混合和匹配您最感兴趣的章节,并使用交互式测验和练习来检查您的进度:
呼叫 Python 开发者获取这本书!
Python 基础写得非常好。这本书很容易理解,并为 T2 提供了很多细节。这肯定会是一本我可以轻松获取的书,以刷新我的知识和学习新的东西。
它有 635 页——无论你处于什么水平,你怎么能从这本书中学不到东西呢?这本书是高质量的,我对真正的 Python、Dan Bader 和他的团队的期望一点也不低!我有了数字版,很快就买了印刷版。(⭐⭐⭐⭐⭐)
—威廉·格伦农(通过亚马逊)
无论您在 Python 之旅的哪个地方,都有发展的空间。让我们一起来提升我们的 Python 吧!
你还需要知道什么?
在内容上,印刷版与真蟒网上商店上的数字版完全相同。亚马逊还为这本书提供了强大的 30 天退款保证,所以对你来说零风险。要获取打印副本,请单击下面的按钮:
点击该按钮应该会自动将您重定向到您当地的亚马逊商店。或者您可以使用下面的直接链接:
如果您当地的亚马逊商店没有在这里列出,那么尝试在“书籍”下搜索“Python 基础”或 ISBN 1775093328,它应该会出现。
如果你得到了平装本,那么你仍然可以获得数字版本中包含的所有额外资料。因此,您将获得与数字版客户相同的出色体验,通过交互式在线测验和下载访问练习和代码挑战解决方案。
如果亚马逊没有送货到你的地址,那么你应该可以通过给他们 ISBN 码1775093328从任何一家当地书店订购这本书。这本书可能需要一段时间才能上市,因为我们刚刚出版了它,但它不仅限于在亚马逊上销售。只是亚马逊是最大的分销渠道,所以这是我们现在推出的重点。
用 Python 基础知识提升您的 Python 水平!
听说读者已经从这本书中获益良多,这是很值得的,我们也很乐意收到你的来信!我们从 Real Python 社区收到的反馈是无价的——我们都对最终书的结果非常满意。感谢您的支持!要获得这本书,请单击下面的链接:
一旦你拿到了这本书,如果你能在亚马逊上添加你自己的评论和评级,那将是一个巨大的帮助。请随时直接联系我们,让我们知道您的 Python 之旅进展如何,以及您需要什么样的学习资源来迈出下一大步。**
学习 Python 编程的 11 个初学者技巧
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 学习 Python 的 11 个初学者小技巧
你们决定踏上学习 Python 的旅程,我们太激动了!我们从读者那里收到的最常见的问题之一是“学习 Python 的最好方法是什么?”
我相信学习任何编程语言的第一步是确保你理解如何学习。学习如何学习可以说是计算机编程中最关键的技能。
为什么知道如何学习如此重要?答案很简单:随着语言的发展,库被创建,工具被升级。知道如何学习对于跟上这些变化并成为一名成功的程序员至关重要。
在本文中,我们将提供几个学习策略,帮助您开始成为 rockstar Python 程序员的旅程!
免费下载: 从《Python 基础:Python 3 实用入门》中获取一个示例章节,看看如何通过 Python 3.8 的最新完整课程从初级到中级学习 Python。
让它粘在一起
这里有一些提示,可以帮助你作为一个初学程序员真正坚持你正在学习的新概念:
技巧 1:每天编码
当你学习一门新语言时,连贯性是非常重要的。我们建议每天对代码做出承诺。可能很难相信,但是肌肉记忆在编程中起着很大的作用。致力于每天编码将真正有助于开发肌肉记忆。虽然一开始看起来令人畏惧,但是可以考虑从每天 25 分钟开始,然后一点一点地努力。
查看 Python 指南的第一步,了解关于设置的信息以及帮助您入门的练习。
技巧 2:把它写出来
作为一名新程序员,当你在你的旅程中前进时,你可能想知道你是否应该做笔记。是的,你应该!事实上,研究表明,手写笔记最有利于长期记忆。这对那些致力于成为全职开发人员的人来说尤其有益,因为许多面试都会涉及到在白板上写代码。
一旦你开始做小项目和程序,手写也可以帮助你在使用计算机之前规划你的代码。如果您写出您将需要哪些函数和类,以及它们将如何交互,您可以节省大量时间。
技巧 3:去互动!
无论你是在学习基本的 Python 数据结构(字符串、列表、字典等。)第一次,或者正在调试应用程序,交互式 Python shell 将是您最好的学习工具之一。我们在这个网站上也经常使用它!
要使用交互式 Python shell(有时也称为“Python REPL”),首先要确保你的电脑上安装了 Python。我们有一个循序渐进的教程来帮助你做到这一点。要激活交互式 Python shell,只需打开您的终端并根据您的安装运行python或python3。你可以在这里找到更具体的方向。
现在您已经知道了如何启动 shell,下面是几个在学习时如何使用 shell 的示例:
学习使用 dir(): 可以对元素执行哪些操作
>>> my_string = 'I am a string' >>> dir(my_string) ['__add__', ..., 'upper', 'zfill'] # Truncated for readability从
dir()返回的元素是您可以应用于该元素的所有方法(即动作)。例如:
>>> my_string.upper()
>>> 'I AM A STRING'
注意,我们调用了upper()方法。你能看出它是干什么的吗?它使字符串中的所有字母都大写!在本教程的“操纵字符串”中了解更多关于这些内置方法的信息。
学习一个元素的类型:
>>> type(my_string) >>> str使用内置帮助系统获取完整文档:
>>> help(str)
导入库,玩玩:
>>> from datetime import datetime >>> dir(datetime) ['__add__', ..., 'weekday', 'year'] # Truncated for readability >>> datetime.now() datetime.datetime(2018, 3, 14, 23, 44, 50, 851904)运行 shell 命令:
>>> import os
>>> os.system('ls')
python_hw1.py python_hw2.py README.txt
技巧 4:休息一下
当你在学习的时候,重要的是离开并吸收概念。番茄工作法被广泛使用,并且有所帮助:你工作 25 分钟,休息一会儿,然后重复这个过程。休息对于有效的学习至关重要,尤其是当你吸收大量新信息的时候。
调试时,中断尤其重要。如果你碰到了一个 bug,却不知道到底是哪里出了问题,那就休息一下。离开你的电脑,去散步,或者和朋友聊天。
在编程中,你的代码必须完全遵循语言和逻辑的规则,所以即使少了一个引号也会破坏一切。新鲜的眼睛有很大的不同。
技巧 5:成为一名虫子赏金猎人
说到遇到 bug,一旦你开始编写复杂的程序,你不可避免地会在代码中遇到 bug。这发生在我们每个人身上!不要让错误挫败你。相反,自豪地拥抱这些时刻,把自己想象成一个虫子赏金猎人。
调试时,重要的是要有一种方法来帮助您找到问题出在哪里。按照代码执行的顺序仔细检查代码,确保每个部分都能正常工作,这是一个很好的方法。
一旦你知道哪里出了问题,将下面一行代码插入你的脚本import pdb; pdb.set_trace()并运行它。这是 Python 调试器,将把你带入交互模式。调试器也可以用python -m pdb <my_file.py>从命令行运行。
让它协作起来
一旦事情开始停滞不前,通过合作加快你的学习。这里有一些策略可以帮助你从与他人的合作中获得最大收益。
提示 6:让你周围都是正在学习的人
虽然编码看起来像是一项单独的活动,但实际上当你们一起工作时效果最好。当你学习用 Python 编程时,你周围的人也在学习是非常重要的。这将允许你分享你一路上学到的技巧和诀窍。
不认识也不用担心。有很多方法可以认识其他热衷于学习 Python 的人!寻找当地的活动或聚会,或者加入 PythonistaCafe ,这是一个面向像您一样的 Python 爱好者的点对点学习社区!
技巧 7:教导
据说学东西最好的方法是教它。在学习 Python 的时候确实如此。有很多方法可以做到这一点:与其他 Python 爱好者一起写白板,写博客解释新学到的概念,录制视频解释你学到的东西,或者只是在电脑前自言自语。这些策略中的每一个都将巩固你的理解,并暴露你理解中的任何差距。
技巧 8:配对程序
结对编程是一种涉及两个开发人员在一个工作站完成一项任务的技术。这两个开发人员在“驾驶员”和“导航员”之间转换“驱动者”编写代码,而“导航者”帮助指导问题的解决,并在编写代码时对其进行审查。经常切换,以获得双方的利益。
结对编程有很多好处:它不仅让你有机会让别人审查你的代码,还能让你看到其他人是如何思考问题的。接触多种想法和思维方式将有助于你在回到自己编码的时候解决问题。
技巧 9:问“好”的问题
人们总说没有烂问题这一说,但说到编程,就有可能把一个问题问烂。当你向一个对你要解决的问题知之甚少或一无所知的人寻求帮助时,最好按照这个缩写提出好的问题:
- 给出你想做的事情的背景,清楚地描述问题。
- O :概述你已经尝试解决问题的事情。
- 对可能的问题给出你最好的猜测。这有助于帮助你的人不仅知道你在想什么,而且知道你自己也做了一些思考。
- 演示正在发生的事情。包括代码、一条回溯错误消息,以及对导致错误的执行步骤的解释。这样,提供帮助的人就不必试图重现问题。
好的问题可以节省很多时间。跳过这些步骤中的任何一步都会导致反复的对话,从而引发冲突。作为初学者,你要确保你问了好的问题,这样你就可以练习交流你的思维过程,这样帮助你的人就会很乐意继续帮助你。
做某事
大多数(如果不是全部的话)Python 开发人员会告诉你,为了学习 Python,你必须边做边学。做练习只能带你走这么远:你通过构建学到最多。
技巧 10:建造一些东西,任何东西
对于初学者来说,有许多小练习可以真正帮助你对 Python 变得自信,并开发我们上面谈到的肌肉记忆。一旦你牢固掌握了基本的数据结构(字符串、列表、字典、集合)、面向对象编程和编写类,是时候开始构建了!
你建造什么并不重要,重要的是你如何建造它。建筑之旅确实是教会你最多的东西。你只能从阅读真正的 Python 文章和课程中学到这么多。你的大部分学习将来自于使用 Python 来构建一些东西。你要解决的问题会教会你很多。
有很多关于初级 Python 项目的列表。以下是让你开始的一些想法:
如果你发现很难想出 Python 实践项目,请观看视频。它列出了一个策略,当你感到停滞不前时,你可以用它来产生数以千计的项目想法。
提示#11:为开源做贡献
在开源模式中,软件源代码是公开的,任何人都可以合作。有许多 Python 库是开源项目并接受贡献。此外,许多公司发布开源项目。这意味着你可以使用这些公司的工程师编写和生产的代码。
参与开源 Python 项目是创造极有价值的学习体验的好方法。假设您决定提交一个 bugfix 请求:您提交一个“拉请求”来将您的补丁添加到代码中。
接下来,项目经理将审查你的工作,提供意见和建议。这将使您能够学习 Python 编程的最佳实践,并练习与其他开发人员交流。
要获得更多帮助您进入开源世界的技巧和策略,请查看下面嵌入的视频:
向前去学习吧!
现在您已经有了这些学习策略,您已经准备好开始您的 Python 之旅了!在这里找到真正的 Python 初学者学习路线图!我们还提供初级水平的 Python 课程,使用有趣的例子帮助你学习编程和 web 开发。
编码快乐!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 学习 Python 的 11 个初学者小技巧**
Python 绑定:从 Python 调用 C 或 C++
你是一名 Python 开发人员,有一个想从 Python 中使用的 C 或 C++库吗?如果是这样,那么 Python 绑定允许你调用函数并将数据从 Python 传递到 C 或 C++ ,让你利用两种语言的优势。在本教程中,您将看到一些可用于创建 Python 绑定的工具的概述。
在本教程中,您将了解到:
- 为什么要从 Python 中调用 C 或 C++
- 如何在 C 和 Python 之间传递数据
- 哪些工具和方法可以帮助你创建 Python 绑定
本教程面向中级 Python 开发人员。它假设具备 Python 的基础知识,并对 C 或 C++中的函数和数据类型有所了解。通过点击下面的链接,您可以获得本教程中的所有示例代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 绑定。
让我们深入了解一下 Python 绑定!
Python 绑定概述
在深入研究如何从 Python 调用 C 之前,最好花点时间研究一下为什么。在几种情况下,创建 Python 绑定来调用 C 库是一个好主意:
-
你已经有了一个用 C++ 编写的大型的、经过测试的、稳定的库,你想在 Python 中加以利用。这可能是一个通信库,也可能是一个与特定硬件对话的库。它做什么并不重要。
-
你想通过将关键部分转换成 C 来加速你的 Python 代码的特定部分。C 不仅具有更快的执行速度,而且如果你小心的话,它还允许你摆脱 GIL 的限制。
-
你想用 Python 测试工具对他们的系统做大规模测试。
以上所有这些都是学习创建 Python 绑定来与 C 库接口的好理由。
注意:在整个教程中,您将创建到 C 和 C++的 Python 绑定。大多数一般概念都适用于这两种语言,所以除非这两种语言之间有特定的区别,否则将使用 C。一般来说,每个工具都支持 C 或 C++,但不是两者都支持。
我们开始吧!
编组数据类型
等等!在开始编写 Python 绑定之前,先看看 Python 和 C 如何存储数据,以及这会导致什么类型的问题。首先,我们来定义一下编组。维基百科对这一概念的定义如下:
将对象的内存表示转换为适合存储或传输的数据格式的过程。(来源)
就您的目的而言,编组是 Python 绑定在准备将数据从 Python 移动到 C 时所做的事情,反之亦然。Python 绑定需要进行编组,因为 Python 和 C 以不同的方式存储数据。c 以最紧凑的形式在内存中存储数据。如果你使用一个uint8_t,那么它总共只会使用 8 位内存。
另一方面,在 Python 中,一切都是一个 对象 。这意味着每个整数使用内存中的几个字节。多少将取决于您运行的 Python 版本、您的操作系统和其他因素。这意味着您的 Python 绑定需要将一个 C 整数转换成一个 Python 整数用于跨越边界的每个整数。
其他数据类型在两种语言之间也有类似的关系。让我们依次看一看:
-
整数 存储计数数字。Python 以任意精度存储整数,这意味着你可以存储非常非常大的数字。指定整数的精确大小。在不同语言之间转换时,您需要注意数据大小,以防止 Python 整数值溢出 C 整型变量。
-
浮点数 是带小数点的数字。Python 可以存储比 c 大得多(也小得多)的浮点数。这意味着您还必须注意这些值,以确保它们在范围内。
-
复数 是有虚数部分的数字。虽然 Python 有内置的复数,而 C 也有复数,但是它们之间没有内置的编组方法。为了整理复数,您需要在 C 代码中构建一个
struct或class来管理它们。 -
字符串 是字符序列。作为一种如此常见的数据类型,当您创建 Python 绑定时,字符串将被证明是相当棘手的。与其他数据类型一样,Python 和 C 以完全不同的格式存储字符串。(与其他数据类型不同,这也是 C 和 C++不同的地方,这增加了乐趣!)您将研究的每种解决方案在处理字符串方面都有略微不同的方法。
-
布尔变量 只能有两个值。因为它们在 C 中受支持,编组它们将被证明是相当简单的。
除了数据类型转换,在构建 Python 绑定时还需要考虑其他问题。让我们继续探索它们。
理解可变和不可变的值
除了所有这些数据类型,你还必须知道 Python 对象如何成为 可变或不可变 。c 在谈到按值传递或按引用传递时,对函数参数也有类似的概念。在 C 中,所有的参数都是传值的。如果你想让一个函数改变调用者中的一个变量,那么你需要传递一个指向那个变量的指针。
您可能想知道是否可以通过使用指针将一个不可变的对象传递给 C 来绕过不可变的限制。除非你走向丑陋和不可移植的极端, Python 不会给你一个指向对象的指针,所以这个就是不行。如果你想在 C 中修改一个 Python 对象,那么你需要采取额外的步骤来实现。正如您将在下面看到的,这些步骤将取决于您使用的工具。
因此,在创建 Python 绑定时,您可以将不变性添加到您要考虑的项目清单中。创建这个清单的旅程的最后一站是如何处理 Python 和 C 处理内存管理的不同方式。
管理内存
c 和 Python 管理内存的方式不同。在 C 语言中,开发人员必须管理所有的内存分配,并确保它们只被释放一次。Python 会使用一个垃圾收集器来帮你处理这个问题。
虽然每种方法都有其优点,但它确实给创建 Python 绑定增加了额外的麻烦。你需要知道每个对象的内存是在哪里分配的,并确保它只在语言障碍的同一边被释放。
例如,设置x = 3时会创建一个 Python 对象。这方面的内存是在 Python 端分配的,需要进行垃圾收集。幸运的是,有了 Python 对象,做其他事情就相当困难了。看看 C 语言中的相反情况,直接分配一块内存:
int* iPtr = (int*)malloc(sizeof(int));
当你这样做的时候,你需要确保这个指针在 c 中是自由的,这可能意味着手动添加代码到你的 Python 绑定中来完成这个任务。
这就完成了你的一般主题清单。让我们开始设置您的系统,以便您可以编写一些代码!
设置您的环境
对于本教程,您将使用来自真实 Python GitHub repo 的预先存在的 C 和 C++库来展示每个工具的测试。目的是让你能够将这些想法用于任何 C 库。要理解这里的所有示例,您需要具备以下条件:
- 安装了一个 C++库,并且知道命令行调用的路径
- Python 开发工具:
- 对于 Linux,这是
python3-dev或python3-devel包,取决于您的发行版。 - 对于 Windows,有多个选项。
- 对于 Linux,这是
- Python 3.6 或更高版本
- 一个 虚拟环境 (推荐,但不要求)
invoke工具
最后一个对你来说可能是新的,所以让我们仔细看看。
使用invoke工具
invoke 是您将在本教程中用来构建和测试 Python 绑定的工具。它与make的目的相似,但是使用 Python 而不是 Makefiles。您需要使用 pip 在您的虚拟环境中安装invoke:
$ python3 -m pip install invoke
要运行它,您可以键入invoke,后跟您希望执行的任务:
$ invoke build-cmult
==================================================
= Building C Library
* Complete
要查看哪些任务可用,您可以使用--list选项:
$ invoke --list
Available tasks:
all Build and run all tests
build-cffi Build the CFFI Python bindings
build-cmult Build the shared library for the sample C code
build-cppmult Build the shared library for the sample C++ code
build-cython Build the cython extension module
build-pybind11 Build the pybind11 wrapper library
clean Remove any built objects
test-cffi Run the script to test CFFI
test-ctypes Run the script to test ctypes
test-cython Run the script to test Cython
test-pybind11 Run the script to test PyBind11
注意,当您查看定义了invoke任务的tasks.py文件时,您会看到列出的第二个任务的名称是build_cffi。然而,--list的输出显示为build-cffi。减号(-)不能用作 Python 名称的一部分,因此该文件使用下划线(_)代替。
对于您将要研究的每个工具,都将定义一个build-和一个test-任务。例如,要运行CFFI的代码,您可以键入invoke build-cffi test-cffi。一个例外是ctypes,因为ctypes没有构建阶段。此外,为了方便起见,还添加了两个特殊任务:
invoke all运行所有工具的构建和测试任务。invoke clean删除任何生成的文件。
现在您已经对如何运行代码有了一个感觉,在点击工具概述之前,让我们先看一下您将要包装的 C 代码。
C 或 C++源代码
在下面的每个示例部分中,您将用 C 或 C++为同一个函数创建 Python 绑定。这些部分旨在让您初步了解每种方法的样子,而不是对该工具的深入教程,因此您要包装的函数很小。您将为其创建 Python 绑定的函数将一个int和一个float作为输入参数,并返回一个float,它是两个数字的乘积:
// cmult.c
float cmult(int int_param, float float_param) { float return_value = int_param * float_param; printf(" In cmult : int: %d float %.1f returning %.1f\n", int_param, float_param, return_value); return return_value; }
C 和 C++函数几乎完全相同,只是在名称和字符串上有细微的差别。您可以通过点击下面的链接获得所有代码的副本:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 绑定。
现在您已经克隆了 repo 并安装了工具,您可以构建和测试工具了。因此,让我们深入下面的每一部分!
ctypes
您将从 ctypes 开始,它是标准库中用于创建 Python 绑定的工具。它提供了一个低级工具集,用于在 Python 和 c 之间加载共享库和编组数据。
它是如何安装的
ctypes的一大优势是它是 Python 标准库的一部分。它是在 Python 版本 2.5 中添加的,所以很可能您已经拥有它了。您可以使用 import ,就像您使用sys或 time 模块一样。
调用函数
加载 C 库和调用函数的所有代码都在 Python 程序中。这很好,因为在你的过程中没有额外的步骤。你只要运行你的程序,一切都会搞定。要在ctypes中创建 Python 绑定,您需要完成以下步骤:
- 加载你的库。
- 包装你的一些输入参数。
- 告诉
ctypes你的函数的返回类型。
您将依次查看这些内容。
库加载
ctypes为你提供了几种加载共享库的方法,其中一些是特定于平台的。对于您的示例,您将通过传递您想要的共享库的完整路径来直接创建一个ctypes.CDLL对象:
# ctypes_test.py
import ctypes
import pathlib
if __name__ == "__main__":
# Load the shared library into ctypes
libname = pathlib.Path().absolute() / "libcmult.so"
c_lib = ctypes.CDLL(libname)
这将适用于共享库与 Python 脚本位于同一目录的情况,但当您试图从 Python 绑定之外的包中加载库时要小心。在ctypes文档中有许多关于加载库和查找路径的细节,这些细节是特定于平台和情况的。
注意:在库加载期间可能会出现许多特定于平台的问题。一旦你得到一个工作的例子,最好进行增量的改变。
现在您已经将这个库加载到 Python 中,您可以尝试调用它了!
调用您的函数
请记住,C 函数的函数原型如下:
// cmult.h
float cmult(int int_param, float float_param);
您需要传入一个整数和一个浮点,并期望得到一个浮点返回。整数和浮点数在 Python 和 C 中都有本地支持,所以您希望这种情况下可以得到合理的值。
一旦将库加载到 Python 绑定中,该函数将成为c_lib的一个属性,也就是您之前创建的CDLL对象。你可以试着这样称呼它:
x, y = 6, 2.3
answer = c_lib.cmult(x, y)
哎呀!这不管用。这一行在示例 repo 中被注释掉,因为它失败了。如果您试图使用该调用运行,Python 将报错:
$ invoke test-ctypes
Traceback (most recent call last):
File "ctypes_test.py", line 16, in <module>
answer = c_lib.cmult(x, y)
ctypes.ArgumentError: argument 2: <class 'TypeError'>: Don't know how to convert parameter 2
看起来你需要告诉ctypes任何非整数的参数。ctypes不知道这个函数,除非你明确地告诉它。任何没有另外标记的参数都被假定为整数。ctypes不知道如何将存储在y中的值2.3转换成整数,所以它失败了。
要解决这个问题,您需要从该号码创建一个c_float。您可以在调用函数的行中这样做:
# ctypes_test.py
answer = c_lib.cmult(x, ctypes.c_float(y))
print(f" In Python: int: {x} float {y:.1f} return val {answer:.1f}")
现在,当您运行这段代码时,它会返回您传入的两个数字的乘积:
$ invoke test-ctypes
In cmult : int: 6 float 2.3 returning 13.8
In Python: int: 6 float 2.3 return val 48.0
等一下… 6乘以2.3不是48.0!
原来,很像输入参数,ctypes 假设你的函数返回一个int。实际上,您的函数返回了一个float,它被错误地封送了。就像输入参数一样,你需要告诉ctypes使用不同的类型。这里的语法略有不同:
# ctypes_test.py
c_lib.cmult.restype = ctypes.c_float
answer = c_lib.cmult(x, ctypes.c_float(y))
print(f" In Python: int: {x} float {y:.1f} return val {answer:.1f}")
这应该能行。让我们运行整个test-ctypes目标,看看您得到了什么。记住,输出的第一段是在之前的,你把函数的restype固定为一个浮点:
$ invoke test-ctypes
==================================================
= Building C Library
* Complete
==================================================
= Testing ctypes Module
In cmult : int: 6 float 2.3 returning 13.8
In Python: int: 6 float 2.3 return val 48.0
In cmult : int: 6 float 2.3 returning 13.8
In Python: int: 6 float 2.3 return val 13.8
那更好!虽然第一个未修正的版本返回了错误的值,但是您的修正版本符合 C 函数。C 和 Python 得到的结果都一样!现在它工作了,看看为什么你可能想或不想使用ctypes。
优势和劣势
与您将在这里研究的其他工具相比,ctypes最大的优势是它被内置在标准库中。它也不需要额外的步骤,因为所有的工作都是作为 Python 程序的一部分来完成的。
此外,使用的概念是低级的,这使得像你刚才做的练习是可管理的。然而,由于缺乏自动化,更复杂的任务变得越来越麻烦。在下一节中,您将看到一个工具,它为这个过程增加了一些自动化。
CFFI
CFFI 是 Python 的 C 对外函数接口。生成 Python 绑定需要更自动化的方法。CFFI有多种方式可以构建和使用 Python 绑定。有两个不同的选项可供选择,这为您提供了四种可能的模式:
-
ABI vs API: API 模式使用 C 编译器生成完整的 Python 模块,而 ABI 模式加载共享库并与之直接交互。如果不运行编译器,获得正确的结构和参数是容易出错的。文档强烈建议使用 API 模式。
-
线内与线外:这两种模式的区别在于速度和便利性之间的权衡:
- 内联模式在每次脚本运行时编译 Python 绑定。这很方便,因为您不需要额外的构建步骤。然而,它确实会减慢你的程序。
- 离线模式需要一个额外的步骤来一次性生成 Python 绑定,然后在程序每次运行时使用它们。这要快得多,但这对您的应用程序来说可能无关紧要。
对于本例,您将使用 API out-of-line 模式,该模式生成最快的代码,总体上看起来类似于您将在本教程稍后创建的其他 Python 绑定。
它是如何安装的
因为CFFI不是标准库的一部分,你需要在你的机器上安装它。建议您为此创建一个虚拟环境。好在CFFI装着 pip :
$ python3 -m pip install cffi
这将把软件包安装到您的虚拟环境中。如果你已经从requirements.txt开始安装了,那么这个问题就应该解决了。您可以通过下面的链接访问回购来了解一下requirements.txt:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 绑定。
既然已经安装了CFFI,是时候带着它转一圈了!
调用函数
与ctypes不同,使用CFFI你可以创建一个完整的 Python 模块。你将能够 import 这个模块就像标准库中的任何其他模块一样。构建 Python 模块还需要做一些额外的工作。要使用您的CFFI Python 绑定,您需要采取以下步骤:
- 写一些描述绑定的 Python 代码。
- 运行代码以生成可加载模块。
- 修改调用代码以导入并使用您新创建的模块。
这可能看起来工作量很大,但是您将通过这些步骤中的每一步来了解它是如何工作的。
编写绑定
CFFI提供了读取 C 头文件的方法,以便在生成 Python 绑定时完成大部分工作。在CFFI的文档中,完成这项工作的代码放在一个单独的 Python 文件中。对于这个例子,您将把代码直接放入构建工具invoke,它使用 Python 文件作为输入。要使用CFFI,首先要创建一个cffi.FFI对象,它提供了您需要的三种方法:
# tasks.py
import cffi
...
""" Build the CFFI Python bindings """
print_banner("Building CFFI Module")
ffi = cffi.FFI()
一旦有了 FFI,您将使用.cdef()来自动处理头文件的内容。这将为您创建包装器函数,以便从 Python 中整理数据:
# tasks.py
this_dir = pathlib.Path().absolute()
h_file_name = this_dir / "cmult.h"
with open(h_file_name) as h_file:
ffi.cdef(h_file.read())
读取和处理头文件是第一步。之后,你需要用.set_source()来描述CFFI将要生成的源文件:
# tasks.py
ffi.set_source(
"cffi_example",
# Since you're calling a fully-built library directly, no custom source
# is necessary. You need to include the .h files, though, because behind
# the scenes cffi generates a .c file that contains a Python-friendly
# wrapper around each of the functions.
'#include "cmult.h"',
# The important thing is to include the pre-built lib in the list of
# libraries you're linking against:
libraries=["cmult"],
library_dirs=[this_dir.as_posix()],
extra_link_args=["-Wl,-rpath,."],
)
这是您传递的参数的明细:
-
"cffi_example"是将在您的文件系统上创建的源文件的基本名称。CFFI会生成一个.c文件,编译成一个.o文件,链接到一个.<system-description>.so或者.<system-description>.dll文件。 -
'#include "cmult.h"'是自定义的 C 源代码,在编译之前会包含在生成的源代码中。这里,您只包含了您正在为其生成绑定的.h文件,但是这可以用于一些有趣的定制。 -
libraries=["cmult"]告诉链接器你预先存在的 C 库的名字。这是一个列表,因此如果需要,您可以指定几个库。 -
library_dirs=[this_dir.as_posix(),]是一个目录列表,告诉链接器在哪里寻找上面的库列表。 -
extra_link_args=['-Wl,-rpath,.']是一组生成共享对象的选项,它会在当前路径(.)中查找它需要加载的其他库。
构建 Python 绑定
调用.set_source()不会构建 Python 绑定。它只设置元数据来描述将要生成的内容。要构建 Python 绑定,您需要调用.compile():
# tasks.py
ffi.compile()
这通过生成.c文件、.o文件和共享库来完成。您刚刚完成的invoke任务可以在命令行上运行,以构建 Python 绑定:
$ invoke build-cffi
==================================================
= Building C Library
* Complete
==================================================
= Building CFFI Module
* Complete
您已经有了自己的CFFI Python 绑定,所以是时候运行这段代码了!
调用您的函数
在完成了配置和运行CFFI编译器的所有工作之后,使用生成的 Python 绑定看起来就像使用任何其他 Python 模块一样:
# cffi_test.py
import cffi_example
if __name__ == "__main__":
# Sample data for your call
x, y = 6, 2.3
answer = cffi_example.lib.cmult(x, y)
print(f" In Python: int: {x} float {y:.1f} return val {answer:.1f}")
你导入新模块,然后就可以直接调用cmult()了。要进行测试,请使用test-cffi任务:
$ invoke test-cffi
==================================================
= Testing CFFI Module
In cmult : int: 6 float 2.3 returning 13.8
In Python: int: 6 float 2.3 return val 13.8
这将运行您的cffi_test.py程序,该程序测试您用CFFI创建的新 Python 绑定。这就完成了编写和使用CFFI Python 绑定的部分。
优势和劣势
看起来,ctypes比您刚刚看到的CFFI例子需要更少的工作。虽然这对于这个用例来说是真实的,但是CFFI比ctypes更好地扩展到更大的项目,因为自动化了大部分的功能包装。
也产生了完全不同的用户体验。ctypes允许您将预先存在的 C 库直接加载到您的 Python 程序中。另一方面,CFFI创建了一个新的 Python 模块,可以像其他 Python 模块一样加载。
更重要的是,使用上面使用的 out-of-line-API 方法,创建 Python 绑定的时间代价是在构建时一次性完成的,而不是在每次运行代码时都发生。对于小程序来说,这可能没什么大不了的,但是CFFI也可以通过这种方式更好地扩展到更大的项目。
和ctypes一样,使用CFFI只能让你直接和 C 库接口。C++库需要大量的工作才能使用。在下一节中,您将看到一个侧重于 C++的 Python 绑定工具。
PyBind11
PyBind11 采用一种完全不同的方法来创建 Python 绑定。除了将重心从 C 转移到 C++,它还使用 C++来指定和构建模块,允许它利用 C++中的元编程工具。像CFFI一样,从PyBind11生成的 Python 绑定是一个完整的 Python 模块,可以直接导入和使用。
PyBind11模仿了Boost::Python库,有一个相似的接口。然而,它将它的使用限制在 C++11 和更新的版本,这允许它比支持一切的 Boost 更简单和更快。
它是如何安装的
PyBind11文档的第一步部分将带您了解如何下载和构建PyBind11的测试用例。虽然这似乎不是严格要求的,但是完成这些步骤将确保您已经设置了正确的 C++和 Python 工具。
注意:PyBind11的例子大多使用 cmake ,这是一个构建 C 和 C++项目的优良工具。然而,对于这个演示,您将继续使用invoke工具,它遵循文档的手动构建部分中的说明。
您需要将该工具安装到您的虚拟环境中:
$ python3 -m pip install pybind11
是一个全头文件库,类似于 Boost 的大部分内容。这允许pip将库的实际 C++源代码直接安装到您的虚拟环境中。
调用函数
在开始之前,请注意您使用的是不同的 C++源文件,cppmult.cpp,而不是您在前面的例子中使用的 C 文件。这两种语言的功能基本相同。
编写绑定
与CFFI类似,您需要创建一些代码来告诉工具如何构建您的 Python 绑定。与CFFI不同,这段代码将使用 C++而不是 Python。幸运的是,只需要很少的代码:
// pybind11_wrapper.cpp
#include <pybind11/pybind11.h> #include <cppmult.hpp> PYBIND11_MODULE(pybind11_example, m) { m.doc() = "pybind11 example plugin"; // Optional module docstring
m.def("cpp_function", &cppmult, "A function that multiplies two numbers"); }
让我们一次看一块,因为PyBind11将大量信息打包到几行中。
前两行包括pybind11.h文件和 C++库的头文件cppmult.hpp。之后,你有了PYBIND11_MODULE宏。这扩展成一个 C++代码块,在PyBind11源代码中有很好的描述:
这个宏创建了一个入口点,当 Python 解释器导入一个扩展模块时,这个入口点将被调用。模块名作为第一个参数给出,不应该用引号括起来。第二个宏参数定义了一个类型为
py::module的变量,可以用来初始化模块。(来源)
对于这个例子来说,这意味着你正在创建一个名为pybind11_example的模块,其余的代码将使用m作为py::module对象的名称。在下一行,在您正在定义的 C++函数中,您为该模块创建了一个 docstring 。虽然这是可选的,但这是让你的模块更有python 化的好办法。
最后,你有了m.def()电话。这将定义一个由您的新 Python 绑定导出的函数,这意味着它将在 Python 中可见。在本例中,您要传递三个参数:
cpp_function是您将在 Python 中使用的函数的导出名称。如这个例子所示,它不需要匹配 C++函数的名称。&cppmult取要导出的函数的地址。"A function..."是该函数的可选 docstring。
现在您已经有了 Python 绑定的代码,接下来看看如何将其构建到 Python 模块中。
构建 Python 绑定
您在PyBind11中用来构建 Python 绑定的工具是 C++编译器本身。您可能需要修改编译器和操作系统的默认值。
首先,您必须构建要为其创建绑定的 C++库。对于这么小的例子,您可以将cppmult库直接构建到 Python 绑定库中。然而,对于大多数真实世界的例子,您将有一个想要包装的预先存在的库,所以您将单独构建cppmult库。构建是对编译器构建共享库的标准调用:
# tasks.py
invoke.run(
"g++ -O3 -Wall -Werror -shared -std=c++11 -fPIC cppmult.cpp "
"-o libcppmult.so "
)
用invoke build-cppmult运行这个命令会产生libcppmult.so:
$ invoke build-cppmult
==================================================
= Building C++ Library
* Complete
另一方面,Python 绑定的构建需要一些特殊的细节:
1# tasks.py
2invoke.run(
3 "g++ -O3 -Wall -Werror -shared -std=c++11 -fPIC "
4 "`python3 -m pybind11 --includes` "
5 "-I /usr/include/python3.7 -I . "
6 "{0} "
7 "-o {1}`python3.7-config --extension-suffix` "
8 "-L. -lcppmult -Wl,-rpath,.".format(cpp_name, extension_name)
9)
让我们一行一行地走一遍。第 3 行包含相当标准的 C++编译器标志,表示几个细节,包括您希望所有警告被捕获并被视为错误,您想要一个共享库,以及您正在使用 C++11。
第四行是魔法的第一步。它调用pybind11模块来为PyBind11生成合适的include路径。您可以直接在控制台上运行该命令,看看它能做什么:
$ python3 -m pybind11 --includes
-I/home/jima/.virtualenvs/realpython/include/python3.7m
-I/home/jima/.virtualenvs/realpython/include/site/python3.7
您的输出应该类似,但显示不同的路径。
在编译调用的第 5 行中,您可以看到您还添加了 Python dev includes的路径。虽然建议你不要链接 Python 库本身,但是源代码需要来自Python.h的一些代码来发挥它的魔力。幸运的是,它使用的代码跨 Python 版本相当稳定。
第 5 行还使用-I .将当前目录添加到include路径列表中。这允许解析包装器代码中的#include <cppmult.hpp>行。
第 6 行指定了你的源文件的名字,也就是pybind11_wrapper.cpp。然后,在第 7 行你会看到更多的建造魔法发生。这一行指定了输出文件的名称。Python 对模块命名有一些特殊的想法,包括 Python 版本、机器架构和其他细节。Python 还提供了一个叫做python3.7-config的工具来帮助解决这个问题:
$ python3.7-config --extension-suffix
.cpython-37m-x86_64-linux-gnu.so
如果您使用的是不同版本的 Python,可能需要修改该命令。如果您使用不同版本的 Python 或在不同的操作系统上,您的结果可能会发生变化。
构建命令的最后一行,第 8 行,将链接器指向您之前构建的libcppmult库。rpath部分告诉链接器将信息添加到共享库中,以帮助操作系统在运行时找到libcppmult。最后,您会注意到这个字符串是用cpp_name和extension_name格式化的。在下一节中,当您使用Cython构建 Python 绑定模块时,您将再次使用这个函数。
运行以下命令来构建绑定:
$ invoke build-pybind11
==================================================
= Building C++ Library
* Complete
==================================================
= Building PyBind11 Module
* Complete
就是这样!您已经用PyBind11构建了您的 Python 绑定。是时候检验一下了!
调用您的函数
类似于上面的CFFI示例,一旦您完成了创建 Python 绑定的繁重工作,调用您的函数看起来就像普通的 Python 代码:
# pybind11_test.py
import pybind11_example
if __name__ == "__main__":
# Sample data for your call
x, y = 6, 2.3
answer = pybind11_example.cpp_function(x, y)
print(f" In Python: int: {x} float {y:.1f} return val {answer:.1f}")
因为您在PYBIND11_MODULE宏中使用了pybind11_example作为模块的名称,所以这就是您导入的名称。在m.def()调用中,你告诉PyBind11将cppmult函数导出为cpp_function,所以这就是你从 Python 中调用它的原因。
你也可以用invoke来测试它:
$ invoke test-pybind11
==================================================
= Testing PyBind11 Module
In cppmul: int: 6 float 2.3 returning 13.8
In Python: int: 6 float 2.3 return val 13.8
那就是PyBind11的样子。接下来,您将看到PyBind11何时以及为什么是这项工作的合适工具。
优势和劣势
PyBind11专注于 C++而不是 C,这使得它不同于ctypes和CFFI。它有几个特性使得它对 C++库很有吸引力:
- 它支持类。
- 它处理多态子类。
- 它允许您从 Python 和许多其他工具向对象添加动态属性,这在您研究过的基于 C 的工具中是很难做到的。
也就是说,要让PyBind11启动并运行,您需要做一些设置和配置工作。获得正确的安装和构建可能有点挑剔,但一旦完成,它似乎相当可靠。另外,PyBind11要求您至少使用 C++11 或更高版本。对于大多数项目来说,这不太可能是一个很大的限制,但对于您来说,这可能是一个考虑因素。
最后,创建 Python 绑定所需的额外代码是用 C++而不是 Python 编写的。这对你来说可能是也可能不是问题,但是它与你在这里看到的其他工具不同。在下一节中,您将继续讨论Cython,它采用了一种完全不同的方法来解决这个问题。
Cython
创建 Python 绑定的方法 Cython 使用类 Python 语言来定义绑定,然后生成可以编译到模块中的 C 或 C++代码。用Cython构建 Python 绑定有几种方法。最常见的是使用distutils中的setup。对于这个例子,您将坚持使用invoke工具,它将允许您使用正在运行的确切命令。
它是如何安装的
Cython是一个 Python 模块,可以从 PyPI 安装到您的虚拟环境中:
$ python3 -m pip install cython
同样,如果您已经将requirements.txt文件安装到您的虚拟环境中,那么它就已经存在了。您可以点击下面的链接获取一份requirements.txt:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 绑定。
这应该让你准备好与Cython一起工作!
调用函数
为了用Cython构建 Python 绑定,您将遵循与用于CFFI和PyBind11类似的步骤。您将编写绑定,构建它们,然后运行 Python 代码来调用它们。Cython可以同时支持 C 和 C++。对于这个例子,您将使用您在上面的PyBind11例子中使用的cppmult库。
编写绑定
在Cython中声明模块最常见的形式是使用一个.pyx文件:
1# cython_example.pyx
2""" Example cython interface definition """
3
4cdef extern from "cppmult.hpp":
5 float cppmult(int int_param, float float_param)
6
7def pymult( int_param, float_param ):
8 return cppmult( int_param, float_param )
这里有两个部分:
- 第 3 和第 4 行告诉
Cython你正在使用来自cppmult.hpp的cppmult()。 - 第 6 行和第 7 行创建一个包装器函数
pymult(),以调用cppmult()。
这里使用的语言是 C、C++和 Python 的特殊混合。不过,Python 开发人员会对它相当熟悉,因为目标是使过程更容易。
带有cdef extern...的第一部分告诉Cython下面的函数声明也可以在cppmult.hpp文件中找到。这有助于确保您的 Python 绑定是针对与 C++代码相同的声明构建的。第二部分看起来像一个常规的 Python 函数——因为它就是!本节创建一个 Python 函数,它可以访问 C++函数cppmult。
现在您已经定义了 Python 绑定,是时候构建它们了!
构建 Python 绑定
Cython的构建过程与您用于PyBind11的构建过程有相似之处。您首先在.pyx文件上运行Cython,生成一个.cpp文件。一旦你完成了这些,你就可以用与PyBind11相同的函数来编译它:
1# tasks.py
2def compile_python_module(cpp_name, extension_name):
3 invoke.run(
4 "g++ -O3 -Wall -Werror -shared -std=c++11 -fPIC "
5 "`python3 -m pybind11 --includes` "
6 "-I /usr/include/python3.7 -I . "
7 "{0} "
8 "-o {1}`python3.7-config --extension-suffix` "
9 "-L. -lcppmult -Wl,-rpath,.".format(cpp_name, extension_name)
10 )
11
12def build_cython(c):
13 """ Build the cython extension module """
14 print_banner("Building Cython Module")
15 # Run cython on the pyx file to create a .cpp file
16 invoke.run("cython --cplus -3 cython_example.pyx -o cython_wrapper.cpp")
17
18 # Compile and link the cython wrapper library
19 compile_python_module("cython_wrapper.cpp", "cython_example")
20 print("* Complete")
首先在您的.pyx文件上运行cython。您可以在该命令中使用几个选项:
--cplus告诉编译器生成一个 C++文件而不是 C 文件。-3切换Cython生成 Python 3 语法,而不是 Python 2。-o cython_wrapper.cpp指定要生成的文件的名称。
一旦生成了 C++文件,您就可以使用 C++编译器来生成 Python 绑定,就像您对PyBind11所做的一样。注意,使用pybind11工具生成额外的include路径的调用仍然在那个函数中。这不会伤害任何东西,因为你的源头不需要这些。
在invoke中运行该任务会产生以下输出:
$ invoke build-cython
==================================================
= Building C++ Library
* Complete
==================================================
= Building Cython Module
* Complete
你可以看到它构建了cppmult库,然后构建了cython模块来包装它。现在你有了Cython Python 绑定。(试着快速说那个【T4……)是时候测试一下了!
调用您的函数
调用新 Python 绑定的 Python 代码与您用来测试其他模块的代码非常相似:
1# cython_test.py
2import cython_example
3
4# Sample data for your call
5x, y = 6, 2.3
6
7answer = cython_example.pymult(x, y)
8print(f" In Python: int: {x} float {y:.1f} return val {answer:.1f}")
第 2 行导入了新的 Python 绑定模块,您在第 7 行调用了pymult()。记住,.pyx文件提供了一个围绕cppmult()的 Python 包装器,并将其重命名为pymult。使用 invoke 运行测试会产生以下结果:
$ invoke test-cython
==================================================
= Testing Cython Module
In cppmul: int: 6 float 2.3 returning 13.8
In Python: int: 6 float 2.3 return val 13.8
你得到的结果和以前一样!
优势和劣势
Cython是一个相对复杂的工具,在为 C 或 C++创建 Python 绑定时,它可以为你提供更深层次的控制。虽然您在这里没有深入讨论它,但是它提供了一种类似 Python 的方法来编写手动控制 GIL 的代码,这可以显著地加速某些类型的问题。
然而,这种类似 Python 的语言并不完全是 Python,所以当你要快速弄清楚 C 和 Python 的哪一部分适合哪一部分时,有一个轻微的学习曲线。
其他解决方案
在研究本教程时,我遇到了几个不同的工具和选项来创建 Python 绑定。虽然我将这个概述局限于一些更常见的选项,但是我偶然发现了一些其他工具。下面的列表并不全面。如果上面的工具不适合你的项目,这仅仅是其他可能性的一个例子。
PyBindGen
PyBindGen 为 C 或 C++生成 Python 绑定,用 Python 编写。它的目标是生成可读的 C 或 C++代码,这将简化调试问题。目前还不清楚最近是否有更新,因为文档将 Python 3.4 列为最新的测试版本。然而,过去几年每年都有发行。
Boost.Python
Boost.Python 有一个类似于PyBind11的界面,你在上面看到了。这不是巧合,因为PyBind11就是基于这个库!Boost.Python完全用 C++编写,支持大多数平台上的大多数(如果不是全部)C++版本。相比之下,PyBind11将自己限制在现代 C++中。
SIP
SIP 是为 PyQt 项目开发的用于生成 Python 绑定的工具集。它也被 wxPython 项目用来生成它们的绑定。它有一个代码生成工具和一个额外的 Python 模块,为生成的代码提供支持功能。
Cppyy
cppyy 是一个有趣的工具,它的设计目标与你目前看到的略有不同。用软件包作者的话说:
“cppyy(可追溯到 2001 年)背后的最初想法是允许生活在 C++世界中的 Python 程序员访问那些 C++包,而不必直接接触 C++(或者等待 C++开发人员来提供绑定)。”(来源)
Shiboken
Shiboken 是一个用于生成 Python 绑定的工具,它是为与 Qt 项目相关联的 PySide 项目开发的。虽然它是为那个项目设计的工具,但是文档表明它既不是特定于 Qt 的,也不是特定于 PySide 的,并且可用于其他项目。
SWIG
SWIG 是一个不同于这里列出的其他工具的工具。这是一个通用工具,用于为许多其他语言创建 C 和 C++程序的绑定,而不仅仅是 Python。这种为不同语言生成绑定的能力在一些项目中非常有用。当然,就复杂性而言,这是有代价的。
结论
恭喜你。现在,您已经对创建 Python 绑定的几种不同选项有了一个概述。您了解了数据编组和创建绑定时需要考虑的问题。您已经看到了使用以下工具从 Python 调用 C 或 C++函数需要什么:
- T2
ctypes - T2
CFFI - T2
PyBind11 - T2
Cython
您现在知道了,虽然ctypes允许您直接加载 DLL 或共享库,但是其他三个工具需要额外的步骤,但是仍然创建完整的 Python 模块。另外,您还使用了一点invoke工具来运行 Python 中的命令行任务。您可以通过单击下面的链接获得您在本教程中看到的所有代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 绑定。
现在选择您最喜欢的工具,开始构建那些 Python 绑定吧!特别感谢 Loic Domaigne 对本教程的额外技术回顾。*******
面向初学者的 Python 项目:比特币价格通知
欢迎阅读面向初学者的 Python 项目系列文章的第一篇!
在本教程中,我们将构建一个比特币价格通知服务—
在这个项目中,您将了解 HTTP 请求以及如何使用(适当命名的)requests包发送它们。
您将了解 webhooks,以及如何使用它们将您的 Python 应用程序连接到外部服务,如电话通知或电报信息。
用相对少的代码(大约 50 行),你将得到一个成熟的比特币价格通知服务,它将很容易扩展到其他加密货币和服务。
所以让我们直接开始吧:
用 Python 发布比特币价格通知
众所周知,比特币价格是一个善变的东西。你永远不知道一天结束时它会在哪里。因此,与其不断地在各种网站上寻找最新的更新,不如让 Python 应用程序来帮你完成这项工作。
为此,我们将使用流行的自动化网站 IFTTT 。if TTT(“if this,then that”)是一种网络服务,它弥合了不同应用程序和设备之间的差距。
我们将创建两个 IFTTT 小程序:
- 一个用于当比特币价格低于某个阈值时的紧急通知;和
- 另一个是定期电报关于比特币价格的更新。
这两者都将由我们的 Python 应用程序触发,该应用程序将使用来自 Coinmarketcap API 的数据。
IFTTT applet 由两部分组成:触发器和动作。
在我们的例子中,触发器将是 IFTTT 提供的 webhook 服务。你可以把 webhooks 看作“用户定义的 HTTP 回调”,你可以在这里阅读更多关于它们的内容。
我们的 Python 应用程序将向 webhook URL 发出 HTTP 请求,这将触发一个操作。现在,这是有趣的部分——动作几乎可以是你想要的任何东西。IFTTT 提供了多种操作,比如发送电子邮件、更新谷歌电子表格,甚至打电话给你。
项目设置
让我们从建立一个虚拟环境开始。运行以下命令以获得新的 Python 3 虚拟环境:
$ mkvirtualenv -p $(which python3) bitcoin_notifications
在继续之前,您必须激活虚拟环境并安装所需的依赖项:
$ workon bitcoin_notifications # To activate the virtual environment
$ pip install requests==2.18.4 # We only need the requests package
您可以通过运行deactivate shell 命令来停用虚拟环境。
检索比特币价格
是时候把手弄脏了。我们可以从 Python 控制台中的 Coinmarketcap API 获取最新价格开始:
首先,我们必须导入模块requests并定义bitcoin_api_url变量,该变量包含比特币的 Coinmarketcap API URL。
接下来,我们使用requests.get()函数向 URL 发送一个 HTTP GET 请求,并保存响应。由于 API 返回一个 JSON 响应,我们可以通过调用响应上的.json()函数将它转换成一个 Python 对象。如您所见,API 返回了一个列表,其中一个元素包含比特币价格数据:
>>> import requests >>> bitcoin_api_url = 'https://api.coinmarketcap.com/v1/ticker/bitcoin/' >>> response = requests.get(bitcoin_api_url) >>> response_json = response.json() >>> type(response_json) # The API returns a list <class 'list'> >>> # Bitcoin data is the first element of the list >>> response_json[0] {'id': 'bitcoin', 'name': 'Bitcoin', 'symbol': 'BTC', 'rank': '1', 'price_usd': '10226.7', 'price_btc': '1.0', '24h_volume_usd': '7585280000.0', 'market_cap_usd': '172661078165', 'available_supply': '16883362.0', 'total_supply': '16883362.0', 'max_supply': '21000000.0', 'percent_change_1h': '0.67', 'percent_change_24h': '0.78', 'percent_change_7d': '-4.79', 'last_updated': '1519465767'}我们最感兴趣的属性是
'price_usd'——以美元计算的比特币价格。发送测试 IFTTT 通知
现在我们可以进入事情的 IFTTT 方面了。要使用 IFTTT,你首先需要建立一个新账户并安装他们的移动应用程序(如果你想从你的 Python 应用程序接收电话通知)。一旦你设置好了,我们将创建一个新的 IFTTT 小程序用于测试目的。
要创建新的测试小程序,请按照下列步骤操作:
- 点击大的“本”按钮
- 搜索“web hooks”服务,选择“接收 web 请求”触发器
- 让我们把这个事件命名为
test_event- 现在选择大的那个按钮
- 搜索“通知”服务,选择“从 IFTTT 应用发送通知”
- 将消息更改为
I just triggered my first IFTTT action!并点击“创建行动”- 点击“完成”按钮,我们就完成了
要查看关于如何使用 IFTTT webhooks 的文档,请进入此页面并点击右上角的“文档”按钮。文档页面包含 webhook URL,看起来像这样:
https://maker.ifttt.com/trigger/{event}/with/key/{your-IFTTT-key}接下来,您需要用您在步骤 3 中创建 applet 时为我们的事件指定的名称替换
{event}部分。{your-IFTTT-key}部分已经用 IFTTT 键填充。现在复制 webhook URL 并启动另一个 Python 控制台。我们再次导入模块
requests并定义 webhook URL 变量。现在我们只需使用requests.post()函数向 IFTTT webhook URL 发送一个 HTTP POST 请求:
>>> import requests
>>> # Make sure that your key is in the URL
>>> ifttt_webhook_url = 'https://maker.ifttt.com/trigger/test_event/with/key/{your-IFTTT-key}'
>>> requests.post(ifttt_webhook_url)
<Response [200]>
运行完最后一行后,您应该会在手机上看到一个通知:
创建 IFTTT 小程序
现在我们终于准备好了主要部分。在开始编写代码之前,我们需要创建两个新的 IFTTT 小程序:一个用于紧急比特币价格通知,一个用于定期更新。
紧急比特币价格通知小程序:
- 选择“web hooks”服务,选择“接收 web 请求”触发器
- 命名事件
bitcoin_price_emergency - 对于操作,选择“通知”服务,并选择“从 IFTTT 应用程序发送丰富通知”操作
- 给它起个标题,像“比特币价格紧急事件!”
- 将消息设置为
Bitcoin price is at ${{Value1}}. Buy or sell now!(稍后我们将返回到{{Value1}}部分) - 你可以选择添加一个链接 URL 到 Coinmarketcap 比特币页面:
https://coinmarketcap.com/currencies/bitcoin/ - 创建动作并完成 applet 的设置
定期价格更新小程序:
- 再次选择“web hooks”服务,并选择“接收 web 请求”触发器
- 命名事件
bitcoin_price_update - 对于动作,选择“电报”服务,并选择“发送消息”动作
- 将消息文本设置为:
Latest bitcoin prices:<br>{{Value1}} - 创建动作,并以 applet 结束
注意:创建此小程序时,您必须授权 IFTTT 电报机器人。
将所有这些放在一起
现在我们已经解决了 IFTTT,让我们开始编码吧!您将首先创建如下所示的标准 Python 命令行应用程序框架。将这段代码保存在一个名为bitcoin_notifications.py的文件中:
import requests
import time
from datetime import datetime
def main():
pass
if __name__ == '__main__':
main()
接下来,我们必须将之前的两个 Python 控制台会话转换为两个函数,这两个函数将分别返回最新的比特币价格和发布到 IFTTT webhook。在主功能上增加以下功能:
BITCOIN_API_URL = 'https://api.coinmarketcap.com/v1/ticker/bitcoin/'
IFTTT_WEBHOOKS_URL = 'https://maker.ifttt.com/trigger/{}/with/key/{your-IFTTT-key}'
def get_latest_bitcoin_price():
response = requests.get(BITCOIN_API_URL)
response_json = response.json()
# Convert the price to a floating point number
return float(response_json[0]['price_usd'])
def post_ifttt_webhook(event, value):
# The payload that will be sent to IFTTT service
data = {'value1': value}
# inserts our desired event
ifttt_event_url = IFTTT_WEBHOOKS_URL.format(event)
# Sends a HTTP POST request to the webhook URL
requests.post(ifttt_event_url, json=data)
除了我们必须将价格从字符串转换成浮点数的部分之外,get_latest_bitcoin_price几乎是一样的。post_ifttt_webhook接受两个参数:event和value。
event参数对应于我们在设置 IFTTT 小程序时赋予触发器的任何事件名称。此外,IFTTT webhooks 允许我们将附加数据作为 JSON 格式的数据随请求一起发送。
这就是为什么我们需要value参数:当设置我们的小程序时,我们在消息字段中留下了一个{{Value1}}标签。这个标签被 JSON 负载中的'value1'文本替换。requests.post()函数允许我们通过添加json关键字来发送额外的 JSON 数据。
现在我们可以在main函数中继续我们应用程序的核心。它将由一个while True循环组成,因为我们希望我们的应用程序永远运行。在循环中,我们将调用 Coinmarketcap API 来获取最新的比特币价格,并记录当前的日期和时间。
根据目前的价格,我们将决定是否要发送紧急通知。对于我们的定期电报更新,我们还会将当前价格和日期附加到一个bitcoin_history列表中。一旦列表达到一定数量的项目(如 5),我们将格式化项目,将更新发送到 Telegram,并重置历史以备将来更新。
哇哦!如你所见,这个应用程序有很多功能。如果你在理解我们到目前为止得到的代码时有困难,那么休息一下,慢慢地再读一遍上面的部分。这并不容易,所以慢慢来,不要担心第一次就把一切都做好。
重要的是避免过于频繁地发出这些请求,原因有二:
- Coinmarketcap API 声明他们每 5 分钟才更新一次数据,所以没有必要更频繁地重新加载最新的价格信息
- 如果您的应用程序向 Coinmarketcap API 发送了太多请求,您的 IP 可能会被禁止或暂时暂停。
这就是为什么我们需要在获得新数据之前“休眠”(停止循环的执行)至少 5 分钟。下面的代码实现了我上面提到的所有必需的特性:
BITCOIN_PRICE_THRESHOLD = 10000 # Set this to whatever you like
def main():
bitcoin_history = []
while True:
price = get_latest_bitcoin_price()
date = datetime.now()
bitcoin_history.append({'date': date, 'price': price})
# Send an emergency notification
if price < BITCOIN_PRICE_THRESHOLD:
post_ifttt_webhook('bitcoin_price_emergency', price)
# Send a Telegram notification
# Once we have 5 items in our bitcoin_history send an update
if len(bitcoin_history) == 5:
post_ifttt_webhook('bitcoin_price_update',
format_bitcoin_history(bitcoin_history))
# Reset the history
bitcoin_history = []
# Sleep for 5 minutes
# (For testing purposes you can set it to a lower number)
time.sleep(5 * 60)
我们快完成了!唯一缺少的是format_bitcoin_history函数。它将bitcoin_history作为一个参数,并使用 Telegram 允许的一些基本 HTML 标签对其进行格式化,比如<br>、<b>、<i>等等。将此功能复制到main功能之上:
def format_bitcoin_history(bitcoin_history):
rows = []
for bitcoin_price in bitcoin_history:
# Formats the date into a string: '24.02.2018 15:09'
date = bitcoin_price['date'].strftime('%d.%m.%Y %H:%M')
price = bitcoin_price['price']
# <b> (bold) tag creates bolded text
# 24.02.2018 15:09: $<b>10123.4</b>
row = '{}: $<b>{}</b>'.format(date, price)
rows.append(row)
# Use a <br> (break) tag to create a new line
# Join the rows delimited by <br> tag: row1<br>row2<br>row3
return '<br>'.join(rows)
这是你手机上的最终结果:
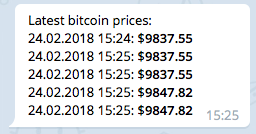
要运行价格通知应用程序,请在命令行终端中执行以下操作:
$ python bitcoin_notifications.py
就是这样!在略多于 50 行的 Python 代码中,您已经创建了自己的比特币通知服务。恭喜你!下面我添加了完整的代码,这样你可以比较一下,看看你是否遗漏了什么:
import requests
import time
from datetime import datetime
BITCOIN_PRICE_THRESHOLD = 10000
BITCOIN_API_URL = 'https://api.coinmarketcap.com/v1/ticker/bitcoin/'
IFTTT_WEBHOOKS_URL = 'https://maker.ifttt.com/trigger/{}/with/key/{your-IFTTT-key}'
def get_latest_bitcoin_price():
response = requests.get(BITCOIN_API_URL)
response_json = response.json()
return float(response_json[0]['price_usd']) # Convert the price to a floating point number
def post_ifttt_webhook(event, value):
data = {'value1': value} # The payload that will be sent to IFTTT service
ifttt_event_url = IFTTT_WEBHOOKS_URL.format(event) # Inserts our desired event
requests.post(ifttt_event_url, json=data) # Sends a HTTP POST request to the webhook URL
def format_bitcoin_history(bitcoin_history):
rows = []
for bitcoin_price in bitcoin_history:
date = bitcoin_price['date'].strftime('%d.%m.%Y %H:%M') # Formats the date into a string: '24.02.2018 15:09'
price = bitcoin_price['price']
# <b> (bold) tag creates bolded text
row = '{}: $<b>{}</b>'.format(date, price) # 24.02.2018 15:09: $<b>10123.4</b>
rows.append(row)
# Use a <br> (break) tag to create a new line
return '<br>'.join(rows) # Join the rows delimited by <br> tag: row1<br>row2<br>row3
def main():
bitcoin_history = []
while True:
price = get_latest_bitcoin_price()
date = datetime.now()
bitcoin_history.append({'date': date, 'price': price})
# Send an emergency notification
if price < BITCOIN_PRICE_THRESHOLD:
post_ifttt_webhook('bitcoin_price_emergency', price)
# Send a Telegram notification
if len(bitcoin_history) == 5: # Once we have 5 items in our bitcoin_history send an update
post_ifttt_webhook('bitcoin_price_update', format_bitcoin_history(bitcoin_history))
# Reset the history
bitcoin_history = []
time.sleep(5 * 60) # Sleep for 5 minutes (for testing purposes you can set it to a lower number)
if __name__ == '__main__':
main()
回顾和后续步骤
在本文中,我们创建了自己的比特币通知服务。您学习了如何使用requests包发送 HTTP GET 和 POST 请求。您看到了使用 IFTTT 和 webhooks 将 Python 应用程序连接到外部服务是多么容易。
现在,你下一步应该去哪里?使用 Python 和 IFTTT,天空是无限的。但是这里有一些建议可以帮助你开始:
- 比如电子表格?使用 IFTTT 操作将比特币价格添加到 Google 电子表格中
- 改善
if price < BITCOIN_PRICE_THRESHOLD条件,每天只收到一次通知(否则,如果比特币持续走低,这将变得非常烦人) - 更喜欢以太坊/莱特币/Dogecoin?将
get_latest_bitcoin_price更改为get_latest_cryptocurrency_price,它将接受加密货币作为参数并返回其价格 - 你想要不同货币的价格?检查 Coinmarketcap API 中的
convert参数。
此外,这将是一个持续的系列,您可以构建更多的 Python 项目来提高您的技能。不要错过下一个教程:
获得通知:不要错过本教程的后续— 点击这里加入真正的 Python 时事通讯你会知道下一期什么时候出来。
祝好运和快乐的蟒蛇!请在下面的评论中让我知道你用 Python 和 IFTTT 构建了什么!***
Python 中的按位运算符
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的二进制、字节、按位运算符
计算机将各种信息存储为二进制数字流,称为位。无论你是在处理文本、图像还是视频,它们都可以归结为 1 和 0。Python 的位操作符让你可以在最精细的层次上操作那些单独的数据位。
您可以使用按位运算符来实现压缩、加密和错误检测等算法,以及控制您的 Raspberry Pi 项目或其他地方的物理设备。通常,Python 通过高层抽象将您与底层隔离开来。在实践中,你更有可能找到重载风格的按位运算子。但是当你以他们最初的形式和他们一起工作时,你会对他们的怪癖感到惊讶!
在本教程中,您将学习如何:
- 使用 Python 位操作符来操作单个位
- 以与平台无关的方式读写二进制数据
- 使用位掩码将信息打包在一个字节上
- 重载自定义数据类型中的 Python 按位运算符
- 在数字图像中隐藏秘密信息
要获得数字水印示例的完整源代码,并提取隐藏在图像中的秘密处理,请单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习 Python 的按位运算符。
Python 的按位运算符概述
Python 附带了一些不同种类的操作符,比如算术、逻辑和比较操作符。你可以把它们看作是利用了更紧凑的前缀和中缀语法的函数。
注意: Python 不包括后缀操作符,比如 c 语言中可用的增量(i++)或减量(i--)操作符
在不同的编程语言中,位运算符看起来几乎是一样的:
| 操作员 | 例子 | 意义 |
|---|---|---|
& |
a & b |
按位 AND |
| |
a | b |
按位或 |
^ |
a ^ b |
按位异或 |
~ |
~a |
按位非 |
<< |
a << n |
按位左移 |
>> |
a >> n |
按位右移 |
正如你所看到的,它们用奇怪的符号而不是单词来表示。这使得它们在 Python 中显得很突出,比您可能习惯看到的稍微不那么冗长。仅仅看着它们,你可能无法理解它们的意思。
注意:如果您来自另一种编程语言,比如 Java ,那么您会立即注意到 Python 缺少了由三个大于号(>>>)表示的无符号右移运算符。
这与 Python 如何在内部表示整数有关。因为 Python 中的整数可以有无限多的位,所以符号位没有固定的位置。事实上,Python 中根本没有符号位!
大多数位运算符都是二进制,这意味着它们需要处理两个操作数,通常称为左操作数和右操作数。按位 NOT ( ~)是唯一的一元按位运算符,因为它只需要一个操作数。
所有二元按位运算符都有一个相应的复合运算符,它执行一个增强赋值:
| 操作员 | 例子 | 等于 |
|---|---|---|
&= |
a &= b |
a = a & b |
|= |
a |= b |
a = a | b |
^= |
a ^= b |
a = a ^ b |
<<= |
a <<= n |
a = a << n |
>>= |
a >>= n |
a = a >> n |
这些是就地更新左操作数的简写符号。
这就是 Python 的按位运算符语法的全部内容!现在,您已经准备好仔细研究每个操作符,以了解它们最有用的地方以及如何使用它们。首先,在查看两类按位运算符之前,您将快速回顾一下二进制系统:按位逻辑运算符和按位移位运算符。
五分钟后双星系统
在继续之前,花点时间复习一下关于二进制系统的知识,这对理解按位运算是必不可少的。如果你已经习惯了,那就直接跳到下面的位逻辑运算符部分。
为什么要用二进制?
有无数种方法来表示数字。自古以来,人们发展了不同的符号,如罗马数字和埃及象形文字。大多数现代文明使用位置符号,它高效、灵活,非常适合做算术。
任何定位系统的一个显著特征是它的基数,它代表可用的位数。人们自然青睐十进制数字系统,也称为十进制,因为它很好地处理了手指计数。
另一方面,计算机将数据视为一串以为基数的二进制数字系统表示的数字,通常被称为二进制系统。这样的数字只由 0 和 1 两个数字组成。
注意:在数学书籍中,数字的基数通常用一个略低于基线的下标来表示,例如 42 10 。
例如,二进制数 10011100 2 相当于十进制中的 156 10 。因为十进制系统中有十个数字——从零到九——所以用十进制写同一个数字通常比用二进制写少。
注意:你不能只看一个给定数字的位数来分辨一个数制。
比如十进制数 101 10 恰好只用二进制数字。但它代表了一个与其二进制对应物 101 2 完全不同的值,相当于 5 10 。
二进制系统比十进制系统需要更多的存储空间,但在硬件上实现起来要简单得多。虽然你需要更多的积木,但它们更容易制作,种类也更少。这就像把你的代码分解成更多的模块化和可重用的部分。
然而,更重要的是,二进制系统非常适合电子设备,它们将数字转换成不同的电压电平。由于各种噪声的影响,电压喜欢上下漂移,所以您需要在连续电压之间保持足够的距离。否则,信号可能会失真。
通过仅使用两种状态,您可以使系统更加可靠,并且抗噪声。或者,你可以提高电压,但这也会增加功耗,这是你肯定想要避免的。
二进制是如何工作的?
想象一下,你只有两个手指可以指望。你可以数一个 0,一个 1,和一个 2。但是当你没有手指时,你需要注意你已经数到二多少次了,然后重新开始,直到你又数到二:
| 小数 | 手指 | 八层叠板 | 四人舞 | 二 | 二进制反码 | 二进制的 |
|---|---|---|---|---|---|---|
| 0 10 | 991 号房 | Zero | Zero | Zero | Zero | 0 2 |
| 1 10 | ☝️ | Zero | Zero | Zero | one | 1 2 |
| 2 10 | ✌️ | Zero | Zero | one | Zero | 10 2 |
| 3 10 | ✌️+☝️ | Zero | Zero | one | one | 11 2 |
| 4 10 | ✌️✌️ | Zero | one | Zero | Zero | 100 2 |
| 5 10 | ✌️✌️+☝️ | Zero | one | Zero | one | 101 2 |
| 6 10 | ✌️✌️+✌️ | Zero | one | one | Zero | 110 2 |
| 7 10 | ✌️✌️+✌️+☝️ | Zero | one | one | one | 111 2 |
| 8 10 | ✌️✌️✌️✌️ | one | Zero | Zero | Zero | 1000 2 |
| 9 10 | ✌️✌️✌️✌️+☝️ | one | Zero | Zero | one | 1001 2 |
| 10 10 | ✌️✌️✌️✌️+✌️ | one | Zero | one | Zero | 1010 2 |
| 11 10 | ✌️✌️✌️✌️+✌️+☝️ | one | Zero | one | one | 1011 2 |
| 12 10 | ✌️✌️✌️✌️+✌️✌️ | one | one | Zero | Zero | 1100 2 |
| 13 10 | ✌️✌️✌️✌️+✌️✌️+☝️ | one | one | Zero | one | 1101 2 |
每次你写下另一对手指,你也需要按照 2 的幂来分组,这是系统的基础。例如,为了数到十三,你必须用你的两个手指六次,然后再用一个手指。你的手指可以排列成一个八个,一个四个,一个一个。
这些 2 的幂对应于二进制数中的数字位置,并准确地告诉你该接通哪些位。它们从右到左增长,从最低有效位开始,这决定了数字是偶数还是奇数。
位置记数法就像汽车里的里程表:一旦某个特定位置的数字达到最大值,即二进制中的 1,它就会转到 0,而 1 会转到左边。如果数字左边已经有一些 1,这可能会产生级联效应。
计算机如何使用二进制
现在你已经知道了二进制系统的基本原理和为什么计算机使用它,你已经准备好学习如何用它来表示数据。
在任何一条信息能够以数字形式再现之前,你必须把它分解成个数字,然后把它们转换成二进制。例如,纯文本可以被认为是一个字符串。你可以给每个字符分配一个任意的数字,或者选择一个现有的字符编码,比如 ASCII 、 ISO-8859-1 或者 UTF-8 。
在 Python 中,字符串被表示为由 Unicode 码点组成的数组。要显示它们的序数值,请对每个字符调用ord():
>>> [ord(character) for character in "€uro"] [8364, 117, 114, 111]得到的数字唯一地标识了 Unicode 空间中的文本字符,但它们以十进制形式显示。你想用二进制数字重写它们:
性格;角色;字母 十进制代码点 二进制码位 € 8364 10 10000010101100 2 u 117 10 1110101 2 r 114 10 1110010 2 o 111 10 1101111 2 请注意,位长,即二进制数字的数量,在字符之间变化很大。欧元符号(
€)需要 14 位,而其余的字符可以轻松地放入 7 位。注意:以下是你如何在 Python 中检查任意整数的位长:
>>> (42).bit_length()
6
如果数字两边没有一对括号,它将被视为带小数点的浮点文字。
可变位长是有问题的。例如,如果你将这些二进制数一个接一个地放在光盘上,那么你最终会得到一长串字符之间没有清晰边界的位:
100000101011001111011110010110110111112
了解如何解释该信息的一种方法是为所有字符指定固定长度的位模式。在现代计算中,最小的信息单位称为八位字节(T0)或 T2 字节(T3),由八位组成,可以存储 256 个不同的值。
您可以用前导零填充二进制码位,以字节表示它们:
| 性格;角色;字母 | 十进制代码点 | 二进制码位 |
|---|---|---|
| € | 8364 10 | 00100000 10101100 2 |
| u | 117 10 | 000000000 011101012 |
| r | 114 10 | 000000000 011100102 |
| o | 111 10 | 000000000 011011112 |
现在每个字符占用两个字节,即 16 位。总的来说,您的原始文本几乎翻了一番,但至少它的编码是可靠的。
您可以使用霍夫曼编码为特定文本中的每个字符找到明确的位模式,或者使用更合适的字符编码。例如,为了节省空间,UTF-8 有意偏爱拉丁字母,而不是在英文文本中不太可能找到的符号:
>>> len("€uro".encode("utf-8")) 6根据 UTF-8 标准编码,整个文本占用 6 个字节。由于 UTF-8 是 ASCII 的超集,字母
u、r和o各占一个字节,而欧元符号在这种编码中占三个字节:
>>> for char in "€uro":
... print(char, len(char.encode("utf-8")))
...
€ 3
u 1
r 1
o 1
其他类型的信息可以像文本一样被数字化。光栅图像由像素组成,每个像素都有将颜色强度表示为数字的通道。声音波形包含在给定的采样间隔对应的气压数字。三维模型是从由它们的顶点定义的几何形状构建的,等等。
归根结底,一切都是一个数字。
按位逻辑运算符
您可以使用按位运算符对单个位执行布尔逻辑。这类似于使用逻辑运算符,如and、or和not,但是是在比特级别上。按位运算符和逻辑运算符之间的相似之处不止于此。
可以用按位运算符代替逻辑运算符来计算布尔表达式,但通常不鼓励这种过度使用。如果您对详细信息感兴趣,您可以展开下面的方框了解更多信息。
在 Python 中指定复合布尔表达式的普通方法是使用连接相邻谓词的逻辑运算符,如下所示:
if age >= 18 and not is_self_excluded:
print("You can gamble")
在这里,您检查用户是否至少 18 岁,以及他们是否没有退出赌丨博。您可以使用按位运算符重写条件:
if age >= 18 & ~is_self_excluded:
print("You can gamble")
尽管这种表达在语法上是正确的,但还是有一些问题。首先,可以说它可读性较差。第二,对于所有组的数据,它并不像预期的那样工作。您可以通过选择特定的操作数值来证明这一点:
>>> age = 18 >>> is_self_excluded = True >>> age >= 18 & ~is_self_excluded # Bitwise logical operators True >>> age >= 18 and not is_self_excluded # Logical operators False由按位运算符组成的表达式计算结果为
True,而由逻辑运算符构建的同一表达式计算结果为False。这是因为按位运算符的优先于比较运算符,改变了整个表达式的解释方式:
>>> age >= (18 & ~is_self_excluded)
True
就好像有人在错误的操作数周围放了隐式括号。要解决这个问题,您可以使用显式括号,这将强制执行正确的求值顺序:
>>> (age >= 18) & ~is_self_excluded 0但是,您不再得到布尔结果。Python 按位运算符主要用于处理整数,因此如果需要,它们的操作数会自动转换。然而,这并不总是可能的。
虽然您可以在布尔上下文中使用 truthy 和 falsy 整数,但这是一种已知的反模式,会耗费您大量不必要的调试时间。你最好遵循 Python 的禅来省去你自己的麻烦。
最后但并非最不重要的一点是,您可能故意想要使用按位运算符来禁用布尔表达式的短路求值。使用逻辑运算符的表达式从左到右缓慢计算。换句话说,一旦知道了整个表达式的结果,计算就会停止:
>>> def call(x):
... print(f"call({x=})")
... return x
...
>>> call(False) or call(True) # Both operands evaluated
call(x=False)
call(x=True)
True
>>> call(True) or call(False) # Only the left operand evaluated
call(x=True)
True
在第二个例子中,根本没有调用右操作数,因为整个表达式的值已经由左操作数的值决定了。无论正确的操作数是什么,都不会影响结果,所以调用它是没有意义的,除非你依靠副作用。
有一些习惯用法,比如回退到默认值,就利用了这种特性:
>>> (1 + 1) or "default" # The left operand is truthy 2 >>> (1 - 1) or "default" # The left operand is falsy 'default'布尔表达式采用最后计算的操作数的值。运算对象在表达式中变为 true 或 falsy,但之后保留其原始类型和值。特别是,左边的正整数被传播,而零被丢弃。
与它们的逻辑对应物不同,按位运算符被急切地求值:
>>> call(True) | call(False)
call(x=True)
call(x=False)
True
尽管知道左操作数就足以确定整个表达式的值,但所有操作数总是被无条件地求值。
除非你有一个强有力的理由并且知道你在做什么,否则你应该只对控制位使用按位操作符。否则太容易出错了。在大多数情况下,您会希望将整数作为参数传递给按位运算符。
按位 AND
按位 AND 运算符(&)对其操作数的相应位执行逻辑合取。对于在两个数中占据相同位置的每一对位,只有当两个位都打开时,它才返回 1:

产生的位模式是运算符参数的交集。在两个操作数都为 1 的位置上,它有两个打开的位。在所有其他地方,至少有一个输入为 0 位。
从算术上讲,这相当于两个位值的乘积。你可以计算数字 a 和 b 的位与,方法是在每个索引 i 处乘以它们的位:

这里有一个具体的例子:
| 表示 | 二进制值 | 小数值 |
|---|---|---|
a |
10011100 2 | 156 10 |
b |
110100 2 | 52 10 |
a & b |
10100 2 | 20 10 |
一乘以一等于一,但是任何乘以零的结果都是零。或者,您可以取每对中两位的最小值。请注意,当操作数的位长不相等时,较短的一个会自动用零填充到左边。
按位或
按位 OR 运算符(|)执行逻辑析取。对于每一对对应的位,如果其中至少有一个被打开,则返回 1:

产生的位模式是操作符参数的一个并集。当两个操作数中有一个为 1 时,它有五个位开启。只有两个零的组合在最终输出中给出一个零。
其背后的算法是位值的总和和乘积的组合。为了计算数字 a 和 b 的位或,你需要在每个索引 i 处对它们的位应用以下公式:

这里有一个切实的例子:
| 表示 | 二进制值 | 小数值 |
|---|---|---|
a |
10011100 2 | 156 10 |
b |
110100 2 | 52 10 |
a | b |
10111100 2 | 188 10 |
它几乎就像两个位的和,但在高端被箝位,因此它的值永远不会超过 1。你也可以取每对中两位的最大值来得到相同的结果。
按位异或
与按位的和、或、而非不同,按位的 XOR 运算符(^)在 Python 中没有逻辑对应。但是,您可以在现有操作符的基础上进行模拟:
def xor(a, b):
return (a and not b) or (not a and b)
它评估两个互斥的条件,并告诉您是否恰好满足其中一个。例如,一个人可以是未成年人,也可以是成年人,但不能同时是两者。相反,一个人不可能既不是未成年人也不是成年人。选择是强制性的。
名称 XOR 代表“异或”,因为它对比特对执行异或。换句话说,每个位对必须包含相反的位值以产生 1:

从视觉上看,它是运算符参数的一个对称差。在结果中有三个比特被接通,其中两个数字具有不同的比特值。其余位置的位相互抵消,因为它们是相同的。
与按位“或”运算符类似,“异或”运算也包括求和。然而,当按位“或”将值固定为 1 时,“异或”运算符使用模 2 的和将它们打包:

模是两个数字的函数,即被除数和除数,它执行除法并返回余数。在 Python 中,有一个内置的模操作符,用百分号(%)表示。
同样,您可以通过查看一个示例来确认该公式:
| 表示 | 二进制值 | 小数值 |
|---|---|---|
a |
10011100 2 | 156 10 |
b |
110100 2 | 52 10 |
a ^ b |
10101000 2 | 168 10 |
两个 0 或两个 1 的和除以 2 得到一个整数,所以结果的余数为零。然而,当您将两个不同的位值之和除以 2 时,您会得到一个余数为 1 的分数。XOR 运算符的一个更简单的公式是每对中两位的最大值和最小值之差。
按位非
最后一个按位逻辑运算符是按位 NOT 运算符(~),它只需要一个参数,是唯一的一元按位运算符。它通过翻转给定数字的所有位来对其执行逻辑否定:

反转的位是对 1 的补码,将 0 变成 1,将 1 变成 0。它可以用算术方法表示为从 1 中减去单个比特值的减法:

下面是一个示例,显示了之前使用的一个数字:
| 表示 | 二进制值 | 小数值 |
|---|---|---|
a |
10011100 2 | 156 10 |
~a |
1100011 2 | 99 10 |
虽然按位 NOT 运算符似乎是所有运算符中最简单的,但在 Python 中使用它时需要格外小心。到目前为止,你所读到的一切都是基于数字用无符号整数表示的假设。
注意:无符号数据类型不允许存储负数,比如-273,因为在常规的位模式中没有符号的空间。试图这样做将导致编译错误、运行时异常或整数溢出,这取决于所使用的语言。
虽然有模拟无符号整数的方法,但是 Python 本身并不支持。这意味着不管你是否指定,所有的数字都有一个隐含的符号。当您对任意数字执行按位非运算时,会显示以下内容:
>>> ~156 -157得到的不是预期的 99 10 ,而是一个负值!一旦你了解了各种不同的二进制数表示,原因就变得很清楚了。目前,快速解决方案是利用按位 AND 运算符:
>>> ~156 & 255
99
这是一个很好的位掩码的例子,您将在接下来的一节中探讨它。
按位移位运算符
按位移位运算符是另一种位操作工具。它们允许你移动这些位,这对以后创建位掩码很方便。在过去,它们通常用于提高某些数学运算的速度。
左移
按位左移运算符(<<)将第一个操作数的位向左移动第二个操作数中指定的位数。它还负责插入足够的零位,以填充新位模式右边缘出现的间隙:

将单个位左移一位,其值会翻倍。例如,移位后该位将指示 4,而不是 2。将它向左移动两个位置会使结果值增加四倍。当你把一个给定数字的所有位相加时,你会注意到,每移位一位,这个数字也会翻倍:
| 表示 | 二进制值 | 小数值 |
|---|---|---|
a |
100111 2 | 39 10 |
a << 1 |
1001110 2 | 78 10 |
a << 2 |
10011100 2 | 156 10 |
a << 3 |
100111000 2 | 312 10 |
一般来说,向左移位对应于将数字乘以 2 的次方,指数等于移位的位数:

左移曾经是一种流行的优化技术,因为移位是一条单指令,计算起来比指数或乘积更便宜。然而,今天的编译器和解释器,包括 Python 的,已经能够在幕后优化你的代码了。
注意:不要在 Python 中使用位移操作符作为过早优化的手段。您不会看到执行速度的差异,但是您肯定会降低代码的可读性。
在纸面上,左移产生的位模式会变得更长,其长度取决于您移动它的位置。对于 Python 来说也是如此,因为它处理整数的方式。然而,在大多数实际情况下,您会希望将位模式的长度限制为 8 的倍数,这是标准的字节长度。
例如,如果您正在处理单个字节,那么将其向左移动应该会丢弃超出其左边界的所有位:

这有点像通过固定长度的窗口查看无限的比特流。在 Python 中有一些技巧可以让你做到这一点。例如,您可以使用按位 AND 运算符应用位掩码:
>>> 39 << 3 312 >>> (39 << 3) & 255 56将 39 10 左移三位会返回一个比单个字节所能存储的最大值更大的数字。它需要九位,而一个字节只有八位。要去掉左边多余的一位,您可以应用具有适当值的位掩码。如果您想保留更多或更少的位,那么您需要相应地修改掩码值。
右移
按位右移运算符(
>>)类似于左移运算符,但它不是将位向左移动,而是将它们向右移动指定的位数。最右边的位总是被丢弃:
每向右移动一位,其潜在价值就会减半。将相同的位向右移动两个位置会产生原始值的四分之一,依此类推。当你把所有的位加起来时,你会发现同样的规则也适用于它们所代表的数字:
表示 二进制值 小数值 a10011101 2 157 10 a >> 11001110 2 78 10 a >> 2100111 2 39 10 a >> 310011 2 19 10 将 157 10 这样的奇数减半会产生一个分数。为了摆脱它,右移操作员自动得出楼层的结果。它实际上与楼层划分的 2 次方相同:
同样,指数对应于向右移位的位数。在 Python 中,您可以利用专用运算符来执行楼层划分:


>>> 5 >> 1 # Bitwise right shift
2
>>> 5 // 2 # Floor division (integer division)
2
>>> 5 / 2 # Floating-point division
2.5
按位右移运算符和除法运算符的工作方式相同,即使对于负数也是如此。然而,地板除法让你选择任何除数,而不仅仅是 2 的幂。使用按位右移是提高一些算术除法性能的常用方法。
注:你可能想知道当你没有比特可供移位时会发生什么。例如,当您尝试推动的位置超过一个数字的位数时:
>>> 2 >> 5 0一旦没有更多的位被打开,你就被零值卡住了。零除以任何值都将返回零。然而,当您右移一个负数时,事情就变得更棘手了,因为隐含的符号位起了作用:
>>> -2 >> 5
-1
经验法则是,不管符号是什么,结果都与地板除以 2 的幂相同。一个小的负分数的底总是负一,这就是你将得到的。请继续阅读,了解更详细的解释。
就像左移运算符一样,位模式在右移后会改变其大小。虽然向右移动位会使二进制序列变短,但这通常无关紧要,因为您可以在不改变值的情况下,在一个位序列前面放置任意多的零。例如,101 2 与 0101 2 相同,00000101 2 也是如此,前提是你处理的是非负数。
有时你会希望在右移后保持一个给定的位长,使其与另一个值对齐或适合某个位置。您可以通过应用位掩码来做到这一点:

它只切割出您感兴趣的那些位,并在必要时用前导零填充位模式。
Python 中对负数的处理与传统的按位移位略有不同。在下一节中,您将更详细地研究这一点。
算术与逻辑移位
您可以进一步将按位移位操作符分为算术和逻辑移位操作符。虽然 Python 只允许您进行算术移位,但是有必要了解一下其他编程语言是如何实现按位移位操作符的,以避免混淆和意外。
这种区别来自于它们处理符号位的方式,它通常位于有符号二进制序列的最左边。实际上,它只与右移位操作符相关,这可能导致数字翻转符号,导致整数溢出。
注意: Java 和 JavaScript 比如用一个附加的大于号(>>>)来区分逻辑右移运算符。因为左移操作符在两种移位中的行为是一致的,所以这些语言没有定义逻辑左移操作符。
通常,开启的符号位表示负数,这有助于保持二进制序列的算术属性:
| 小数值 | 有符号二进制值 | 符号位 | 符号 | 意义 |
|---|---|---|---|---|
| -100 10 | 10011100 2 | one | - | 负数 |
| 28 10 | 00011100 2 | Zero | + | 正数或零 |
从左边看这两个二进制序列,可以看到它们的第一位携带符号信息,而剩余部分由幅度位组成,这两个数字是相同的。
注意:具体的十进制数值将取决于你决定如何用二进制表示有符号的数字。它因语言而异,在 Python 中甚至变得更加复杂,所以您可以暂时忽略它。一旦你读到下面的二进制数表示部分,你会有一个更好的了解。
逻辑右移位,也称为无符号右移位或零填充右移位,移动整个二进制序列,包括符号位,并用零填充左边的结果间隙:

请注意关于数字符号的信息是如何丢失的。不管最初的符号是什么,它总是产生一个非负整数,因为符号位被零代替了。只要您对数值不感兴趣,逻辑右移在处理低级二进制数据时会很有用。
但是,因为在大多数语言中,带符号的二进制数通常存储在固定长度的位序列上,所以它会使结果绕回极值。您可以在交互式 Java Shell 工具中看到这一点:
jshell> -100 >>> 1 $1 ==> 2147483598
结果数字的符号从负变为正,但它也会溢出,最终非常接近 Java 的最大整数:
jshell> Integer.MAX_VALUE $2 ==> 2147483647
乍一看,这个数字似乎很随意,但是它与 Java 为Integer数据类型分配的位数直接相关:
jshell> Integer.toBinaryString(-100) $3 ==> "11111111111111111111111110011100"
它使用 32 位来存储以二进制补码表示的有符号整数。当去掉符号位后,剩下 31 位,其最大十进制值等于 2 31 - 1,或 2147483647 10 。
另一方面,Python 存储整数时,就好像有无限多的位供您使用一样。因此,逻辑右移操作符在纯 Python 中没有很好的定义,所以语言中没有它。不过,你仍然可以模拟它。
一种方法是利用通过内置的ctypes模块公开的 C 中可用的无符号数据类型:
>>> from ctypes import c_uint32 as unsigned_int32 >>> unsigned_int32(-100).value >> 1 2147483598它们让你传入一个负数,但是不会给符号位附加任何特殊的含义。它被视为幅度位的剩余部分。
虽然 C 中只有几种预定义的无符号整数类型,它们的位长不同,但您可以在 Python 中创建一个自定义函数来处理任意位长:
>>> def logical_rshift(signed_integer, places, num_bits=32):
... unsigned_integer = signed_integer % (1 << num_bits)
... return unsigned_integer >> places
...
>>> logical_rshift(-100, 1)
2147483598
这将有符号位序列转换为无符号位序列,然后执行常规算术右移。
然而,由于 Python 中的位序列长度不固定,它们实际上没有符号位。此外,它们不像 C 或 Java 那样使用传统的二进制补码表示。为了减轻这种情况,您可以利用模运算,它将保留正整数的原始位模式,同时适当地包装负整数。
算术右移(>>),有时称为有符号右移运算符,通过在向右移动位之前复制数字的符号位来保持数字的符号:

换句话说,它用符号位来填充左边的空白。结合有符号二进制的二进制补码表示,这将产生算术上正确的值。不管数字是正数还是负数,算术右移都等同于地板除法。
您将会发现,Python 并不总是用二进制补码存储整数。相反,它遵循一种定制的自适应策略,就像符号幅度一样,具有无限的位数。它在数字的内部表示和二进制补码之间来回转换数字,以模拟算术移位的标准行为。
二进制数字表示法
当使用按位求反(~)和右移位运算符(>>)时,您已经亲身体验了 Python 中无符号数据类型的缺乏。您已经看到了关于在 Python 中存储整数的不寻常方法的提示,这使得处理负数变得棘手。为了有效地使用按位运算符,您需要了解数字在二进制中的各种表示方式。
无符号整数
在像 C 这样的编程语言中,您可以选择是使用给定数值类型的有符号还是无符号形式。当您确信永远不需要处理负数时,无符号数据类型更合适。通过分配这一个额外的位,否则它将作为一个符号位,您实际上可以将可用值的范围扩大一倍。
它还通过在溢出发生之前增加最大限制来使事情变得稍微安全一些。然而,溢出只在固定位长的情况下发生,所以它们与 Python 无关,Python 没有这样的约束。
体验 Python 中无符号数值类型的最快方法是使用前面提到的ctypes模块:
>>> from ctypes import c_uint8 as unsigned_byte >>> unsigned_byte(-42).value 214因为在这样的整数中没有符号位,所以它们的所有位都代表一个数的大小。传递负数会强制 Python 重新解释位模式,就好像它只有幅度位一样。
有符号整数
一个数的符号只有两种状态。如果你暂时忽略零,那么它可以是正的,也可以是负的,这可以很好地转化为二进制。然而,有几种用二进制表示有符号整数的替代方法,每种方法都有自己的优缺点。
可能最简单的是符号幅度,它自然地建立在无符号整数之上。当二进制序列被解释为符号幅度时,最高有效位扮演符号位的角色,而其余位照常工作:
二元序列 符号幅度值 无符号值 00101010 2 42 10 42 10 10101010 2 -42 10 170 10 最左边位的 0 表示正数(
+),1 表示负数(-)。注意,在符号幅度表示中,符号位对数字的绝对值没有贡献。它只是让你翻转剩余位的符号。为什么是最左边的?
它保持位索引不变,这反过来有助于保持用于计算二进制序列的十进制值的位权重的向后兼容性。然而,并不是所有关于符号大小的事情都如此重要。
注意:有符号整数的二进制表示只在定长位序列上有意义。否则,你就不知道符号位在哪里。然而,在 Python 中,您可以用任意多的位数来表示整数:
>>> f"{-5 & 0b1111:04b}"
'1011'
>>> f"{-5 & 0b11111111:08b}"
'11111011'
无论是四位还是八位,符号位总是在最左边的位置。
可以存储在符号幅度位模式中的值的范围是对称的。但这也意味着你最终有两种方式来传达零:
| 二元序列 | 符号幅度值 | 无符号值 |
|---|---|---|
| 00000000 2 | +0 10 | 0 10 |
| 10000000 2 | -0 10 | 128 10 |
从技术上来说,零没有符号,但是没有办法在符号大小中不包含一。虽然在大多数情况下有一个不明确的零(T1)并不理想,但这还不是最糟糕的部分。这种方法最大的缺点是繁琐的二进制运算。
当你将标准的二进制算术应用于以符号-幅度存储的数字时,它可能不会给你预期的结果。例如,将两个大小相同但符号相反的数字相加不会使它们相互抵消:
| 表示 | 二元序列 | 符号幅度值 |
|---|---|---|
a |
00101010 2 | 42 10 |
b |
10101010 2 | -42 10 |
a + b |
11010100 2 | -84 10 |
42 和-42 的和不会产生零。此外,进位位有时会从幅度传播到符号位,反转符号并产生意外结果。
为了解决这些问题,一些早期的计算机采用了补码表示法。这个想法是改变十进制数映射到特定二进制序列的方式,以便它们可以正确地相加。为了更深入地了解一个人的补充,你可以展开下面的部分。
在一的补码中,正数与符号大小相同,但负数是通过使用按位 NOT 翻转正数的位获得的:
| 正序 | 逆序 | 量值 |
|---|---|---|
| 00000000 2 | 11111111 2 | 0 10 |
| 00000001 2 | 11111110 2 | 1 10 |
| 00000010 2 | 11111101 2 | 2 10 |
| ⋮ | ⋮ | ⋮ |
| 01111111 2 | 10000000 2 | 127 10 |
这保留了符号位的原始含义,因此正数仍然以二进制零开始,而负数以二进制一开始。同样,值的范围保持对称,并继续有两种方式来表示零。然而,一个补码中负数的二进制序列的排列顺序与符号大小相反:
| 某人的补充 | 符号幅度 | 小数值 |
|---|---|---|
| 11111111 2 | 10000000 2 | -0 10 |
| 11111110 2 | 10000001 2 | -1 10 |
| 11111101 2 | 10000010 2 | -2 10 |
| ↓ | -好的 | ⋮ |
| 10000010 2 | 11111101 2 | -125 10 |
| 10000001 2 | 11111110 2 | -126 10 |
| 10000000 2 | 11111111 2 | -127 10 |
由于这一点,你现在可以更可靠地将两个数字相加,因为符号位不需要特殊处理。如果进位来自符号位,它会在二进制序列的右边缘反馈,而不是被丢弃。这确保了正确的结果。
然而,现代计算机不使用一的补码来表示整数,因为有一种更好的方法叫做二的补码。通过应用一个小的修改,您可以一次性消除双零并简化二进制算术。要更详细地研究二进制补码,您可以展开下面的部分。
在二进制补码中查找负值的位序列时,技巧是在对这些位求反后将结果加 1:
| 正序 | 补语(非) | 二进制补码(非+1) |
|---|---|---|
| 00000000 2 | 11111111 2 | 00000000 2 |
| 00000001 2 | 11111110 2 | 11111111 2 |
| 00000010 2 | 11111101 2 | 11111110 2 |
| ⋮ | ⋮ | ⋮ |
| 01111111 2 | 10000000 2 | 10000001 2 |
这将负数的位序列向下推一位,消除了臭名昭著的负零。更有用的负一将取而代之接管它的位模式。
作为副作用,二进制补码中可用值的范围变得不对称,下限是 2 的幂,上限是奇数。例如,一个 8 位有符号整数将允许你以二进制补码的形式存储从-128 10 到 127 10 的数字:
| 二进制补码 | 某人的补充 | 小数值 |
|---|---|---|
| 10000000 2 | 不适用的 | -128 10 |
| 10000001 2 | 10000000 2 | -127 10 |
| 10000010 2 | 10000001 2 | -126 10 |
| ⋮ | ⋮ | ⋮ |
| 11111110 2 | 11111101 2 | -2 10 |
| 11111111 2 | 11111110 2 | -1 10 |
| 不适用的 | 11111111 2 | -0 10 |
| 00000000 2 | 00000000 2 | 0 10 |
| 00000001 2 | 00000001 2 | 1 10 |
| 00000010 2 | 00000010 2 | 2 10 |
| ⋮ | ⋮ | ⋮ |
| 01111111 2 | 01111111 2 | 127 10 |
另一种说法是,最高有效位携带符号和部分数值幅度:
| 第 7 位 | 第 6 位 | 第 5 位 | 第 4 位 | 第 3 位 | 第 2 位 | 第 1 位 | 第 0 位 |
|---|---|---|---|---|---|---|---|
| -2 7 | 2 6 | 2 5 | 2 4 | 2 3 | 2 2 | 2 1 | 2 0 |
| -128 | Sixty-four | Thirty-two | Sixteen | eight | four | Two | one |
注意最左边位权重旁边的减号。从这样的二进制序列中导出一个十进制值只是添加适当的列的问题。比如 8 位二进制补码表示法中 11010110 2 的值与 sum 相同:-12810+6410+1610+410+210=-4210。
有了二进制补码表示,你不再需要担心进位位,除非你想把它用作一种溢出检测机制,这是一种简洁的机制。
有符号数表示还有一些其他的变体,但是它们没有那么流行。
浮点数
IEEE 754 标准定义了由符号、指数和尾数位组成的实数的二进制表示。在不涉及太多技术细节的情况下,您可以将其视为二进制数的科学符号。小数点“浮动”以适应不同数量的有效数字,除了它是一个二进制点。
符合该标准的两种数据类型得到了广泛支持:
- 单精度: 1 个符号位,8 个指数位,23 个尾数位
- 双精度: 1 个符号位,11 个指数位,52 个尾数位
Python 的float数据类型相当于双精度类型。请注意,有些应用需要更多或更少的位。例如,OpenEXR 图像格式利用半精度以合理的文件大小用高动态范围的颜色表示像素。
圆周率(π)舍入到五位小数时,具有以下单精度二进制表示形式:
| 符号 | 指数 | 尾数 |
|---|---|---|
| 0 2 | 10000000 2 | . 100100100001111110100002 |
符号位就像整数一样工作,所以零表示正数。然而,对于指数和尾数,取决于一些边缘情况,可以应用不同的规则。
首先,您需要将它们从二进制转换成十进制形式:
- 指数: 128 10
- 尾数:2-1+2-4+…+2-19= 29926110/52428810≈0.57079510
指数被存储为无符号整数,但是考虑到负值,它通常有一个单精度等于 127 10 的偏差。你需要减去它来恢复实际的指数。
尾数位代表分数,因此它们对应于 2 的负幂。此外,您需要给尾数加 1,因为在这种特殊情况下,它假定在基数点之前有一个隐含的前导位。
综上所述,您将得出以下公式,将浮点二进制数转换为十进制数:

当您用变量代替上面示例中的实际值时,您将能够破译以单精度存储的浮点数的位模式:

这就是了,假设圆周率已经四舍五入到小数点后五位。稍后你将学习如何用二进制显示这些数字。
定点数
虽然浮点数非常适合工程目的,但由于精度有限,它们在货币计算中失败了。例如,一些用十进制表示有限的数字,在二进制中只有无限的表示。这通常会导致舍入误差,该误差会随着时间的推移而累积:
>>> 0.1 + 0.2 0.30000000000000004在这种情况下,您最好使用 Python 的
decimal模块,它实现了定点算法,并允许您指定在给定位长上放置小数点的位置。例如,您可以告诉它您想要保留多少位数:
>>> from decimal import Decimal, localcontext
>>> with localcontext() as context:
... context.prec = 5 # Number of digits
... print(Decimal("123.456") * 1)
...
123.46
然而,它包括所有的数字,而不仅仅是小数。
注意:如果您正在处理有理数,那么您可能会对查看 fractions 模块感兴趣,它是 Python 标准库的一部分。
如果您不能或不想使用定点数据类型,可靠地存储货币值的一种直接方法是将金额换算成最小单位,如美分,并用整数表示。
Python 中的整数
在过去的编程时代,计算机内存非常珍贵。因此,语言可以让你很好地控制为你的数据分配多少字节。让我们以 C 语言中的几个整数类型为例快速浏览一下:
| 类型 | 大小 | 最小值 | 最大值 |
|---|---|---|---|
char |
1 字节 | -128 | One hundred and twenty-seven |
short |
2 字节 | -32,768 | Thirty-two thousand seven hundred and sixty-seven |
int |
4 字节 | -2,147,483,648 | Two billion one hundred and forty-seven million four hundred and eighty-three thousand six hundred and forty-seven |
long |
8 字节 | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
这些值可能因平台而异。但是,如此丰富的数值类型允许您在内存中紧凑地安排数据。记住这些甚至不包括无符号类型!
另一个极端是诸如 JavaScript 之类的语言,它们只有一个数字类型来管理它们。虽然这对初学编程的人来说不那么令人困惑,但代价是增加了内存消耗、降低了处理效率和精度。
当谈到按位运算符时,理解 Python 如何处理整数是很重要的。毕竟,您将主要使用这些操作符来处理整数。Python 中有两种截然不同的整数表示,这取决于它们的值。
被拘留的整数
在 CPython 中,介于-5 10 和 256 10 之间的非常小的整数被保留在全局缓存中以获得一些性能,因为该范围内的数字是常用的。实际上,无论何时你引用这些值中的一个,它们是在解释器启动时创建的单态值,Python 将总是提供相同的实例:
>>> a = 256 >>> b = 256 >>> a is b True >>> print(id(a), id(b), sep="\n") 94050914330336 94050914330336这两个变量有相同的标识,因为它们引用内存中完全相同的对象。这是典型的引用类型,但不是不可变的值,如整数。但是,当超出缓存值的范围时,Python 将在变量赋值期间开始创建不同的副本:
>>> a = 257
>>> b = 257
>>> a is b
False
>>> print(id(a), id(b), sep="\n")
140282370939376
140282370939120
尽管值相等,但这些变量现在指向不同的对象。但是不要让那愚弄你。Python 会偶尔跳出来,在幕后优化你的代码。例如,它将缓存在同一行多次出现的数字,而不管其值如何:
>>> a = 257 >>> b = 257 >>> print(id(a), id(b), sep="\n") 140258768039856 140258768039728 >>> print(id(257), id(257), sep="\n") 140258768039760 140258768039760变量
a和b是独立的对象,因为它们驻留在不同的内存位置,而print()中字面上使用的数字实际上是同一个对象。注意:实习是 CPython 解释器的一个实现细节,在未来的版本中可能会改变,所以不要在你的程序中依赖它。
有趣的是,Python 中也有类似的字符串滞留机制,它只适用于由 ASCII 字母组成的短文本。它允许通过内存地址或 C 指针来比较关键字,而不是通过单个字符串字符,从而帮助加速字典查找。
固定精度整数
Python 中最有可能找到的整数将利用 C
signed long数据类型。它们使用固定位数的经典二进制补码二进制表示。确切的位长取决于您的硬件平台、操作系统和 Python 解释器版本。现代计算机通常使用 64 位架构,因此这将转化为-2 T2 63 T3 和 2 T4 63 T5-1 之间的十进制数。您可以通过以下方式在 Python 中检查固定精度整数的最大值:
>>> import sys
>>> sys.maxsize
9223372036854775807
它是巨大的!大约是我们银河系恒星数量的 900 万倍,所以应该足够日常使用了。虽然在 C 语言中你能从类型unsigned long中挤出的最大值甚至更大,大约是 10 19 ,但是 Python 中的整数没有理论上的限制。为此,不适合固定长度位序列的数字以不同的方式存储在内存中。
任意精度的整数
你还记得 2012 年风靡全球的流行韩国歌曲《江南 Style》吗?YouTube 视频是第一个点击量突破 10 亿的视频。不久之后,如此多的人观看了该视频,以至于的观看柜台都挤满了人。YouTube 别无选择,只能将他们的计数器从 32 位有符号整数升级到 64 位。
这可能为视图计数器提供了足够的空间,但在现实生活中,尤其是在科学界,甚至有更多的数字并不罕见。尽管如此,Python 可以毫不费力地处理它们:
>>> from math import factorial >>> factorial(42) 1405006117752879898543142606244511569936384000000000这个数字有 52 个十进制数字。用传统方法用二进制表示至少需要 170 位:
>>> factorial(42).bit_length()
170
由于它们远远超过了任何 C 类型所能提供的极限,这样的天文数字被转换成符号-星等位置系统,其基数为 2 30 。是的,你没看错。你有十个手指,而 Python 有超过十亿个手指!
同样,这可能会因您当前使用的平台而异。如有疑问,您可以仔细检查:
>>> import sys >>> sys.int_info sys.int_info(bits_per_digit=30, sizeof_digit=4)这将告诉你每位数使用了多少位,以及底层 C 结构的字节大小。为了在 Python 2 中获得相同的命名元组,您应该引用
sys.long_info属性。虽然在 Python 3 中,固定精度和任意精度整数之间的转换是在幕后无缝完成的,但曾经有一段时间事情变得更加明确。要了解更多信息,您可以展开下面的框。
过去,Python 明确定义了两种不同的整数类型:
- 普通整数
- 长整数
第一个是模仿 C
signed long类型,通常占用 32 或 64 位,并提供有限范围的值:
>>> # Python 2
>>> import sys
>>> sys.maxint
9223372036854775807
>>> type(sys.maxint)
<type 'int'>
对于更大的数字,你应该使用没有限制的第二种类型。如果需要,Python 会自动将普通整数提升为长整数:
>>> # Python 2 >>> import sys >>> sys.maxint + 1 9223372036854775808L >>> type(sys.maxint + 1) <type 'long'>此功能防止了整数溢出错误。注意文字末尾的字母
L,它可以用来手动强制给定的类型:
>>> # Python 2
>>> type(42)
<type 'int'>
>>> type(42L)
<type 'long'>
最终,这两种类型被统一,这样你就不用再去想它了。
这种表示消除了整数溢出错误,并给出了无限位长的假象,但它需要更多的内存。此外,执行 bignum 算法比使用固定精度要慢,因为它不能在没有中间层仿真的情况下直接在硬件中运行。
另一个挑战是保持不同整数类型的位操作符的一致行为,这在处理符号位时至关重要。回想一下,Python 中的固定精度整数使用 C 中标准的二进制补码表示,而大整数使用符号幅度。
为了减少这种差异,Python 将为您进行必要的二进制转换。在应用按位运算符之前和之后,它可能会改变数字的表示方式。下面是来自 CPython 源代码的相关注释,它对此进行了更详细的解释:
负数的按位运算就像二进制补码表示一样。因此,将参数从符号大小转换为二进制补码,最后将结果转换回符号大小。(来源)
换句话说,当您对负数应用按位运算符时,负数被视为二进制补码位序列,即使结果将以符号-幅度形式呈现给您。不过,有一些方法可以模拟符号位和 Python 中的一些无符号类型。
Python 中的位串
欢迎您在本文的其余部分使用笔和纸。它甚至可以作为一个很好的练习!然而,在某些时候,您可能想要验证您的二进制序列或位串是否对应于 Python 中的预期数字。以下是方法。
将int转换为二进制
要显示 Python 中组成整数的位,可以打印一个格式的字符串文本,这可以让您指定要显示的前导零的数量:
>>> print(f"{42:b}") # Print 42 in binary 101010 >>> print(f"{42:032b}") # Print 42 in binary on 32 zero-padded digits 00000000000000000000000000101010或者,您可以使用数字作为参数来调用
bin():
>>> bin(42)
'0b101010'
这个全局内置函数返回一个由二进制文字组成的字符串,该字符串以前缀0b开头,后跟 1 和 0。它总是显示不带前导零的最小位数。
您也可以在代码中逐字使用这样的文字:
>>> age = 0b101010 >>> print(age) 42Python 中其他可用的整数文本是十六进制的和八进制的和,它们可以分别通过
hex()和oct()函数获得:
>>> hex(42)
'0x2a'
>>> oct(42)
'0o52'
请注意十六进制系统是如何利用字母A到F来增加可用数字的。其他编程语言中的八进制文字通常以零为前缀,这可能会令人困惑。Python 明确禁止这种文字,以避免出错:
>>> 052 File "<stdin>", line 1 SyntaxError: leading zeros in decimal integer literals are not permitted; use an 0o prefix for octal integers您可以使用上面提到的任意整数以不同的方式表示相同的值:
>>> 42 == 0b101010 == 0x2a == 0o52
True
选择在上下文中最有意义的一个。例如,习惯上用十六进制符号表示位掩码。另一方面,八进制文字现在已经很少见了。
Python 中的所有数字文字都不区分大小写,因此可以用小写或大写字母作为前缀:
>>> 0b101 == 0B101 True将二进制转换为
int一旦准备好位串,就可以利用二进制文字获得它的十进制表示:
>>> 0b101010
42
这是在交互式 Python 解释器中工作时进行转换的快捷方式。不幸的是,它不允许您转换运行时合成的位序列,因为所有文字都需要在源代码中硬编码。
注意:你可能很想用eval("0b101010")评估 Python 代码,但是这很容易危及你程序的安全性,所以不要这么做!
在动态生成位串的情况下,使用两个参数调用int()会更好:
>>> int("101010", 2) 42 >>> int("cafe", 16) 51966第一个参数是一串数字,而第二个参数决定了数字系统的基数。与二进制文字不同,字符串可以来自任何地方,甚至是在键盘上打字的用户。要深入了解
int(),可以展开下面的方框。还有其他方式调用
int()。例如,在没有参数的情况下调用时,它返回零:
>>> int()
0
这个特性使它成为 defaultdict 集合中的一个常见模式,它需要一个缺省值提供者。以此为例:
>>> from collections import defaultdict >>> word_counts = defaultdict(int) >>> for word in "A sentence with a message".split(): ... word_counts[word.lower()] += 1 ... >>> dict(word_counts) {'a': 2, 'sentence': 1, 'with': 1, 'message': 1}在这里,
int()帮助统计一个句子的字数。每当defaultdict需要初始化字典中缺少的键的值时,就会自动调用它。
int()的另一个流行用法是类型转换。例如,当您向int()传递一个浮点值时,它会通过移除小数部分来截断该值:
>>> int(3.14)
3
当你给它一个字符串时,它试图从中解析出一个数字:
>>> int(input("Enter your age: ")) Enter your age: 42 42一般来说,
int()会接受任何类型的对象,只要它定义了一个可以处理转换的特殊方法。到目前为止,一切顺利。但是负数呢?
模拟符号位
当您对一个负整数调用
bin()时,它只是将减号加到从相应的正值获得的位串上:
>>> print(bin(-42), bin(42), sep="\n ")
-0b101010
0b101010
在 Python 中,改变数字的符号不会影响底层的位串。相反,在将一个位串转换成十进制形式时,可以在它前面加上减号:
>>> int("-101010", 2) -42这在 Python 中是有意义的,因为在内部,它不使用符号位。您可以将 Python 中整数的符号视为与模数分开存储的一条信息。
但是,有一些变通方法可以让您模拟包含符号位的固定长度位序列:
- Bitmask
- 模运算(
%)ctypes模块array模块struct模块从前面的章节中我们知道,为了确保一个数的某个位长,可以使用一个漂亮的位掩码。例如,要保留一个字节,可以使用正好由八个开启位组成的掩码:
>>> mask = 0b11111111 # Same as 0xff or 255
>>> bin(-42 & mask)
'0b11010110'
屏蔽会强制 Python 临时将数字的表示形式从符号幅度更改为二进制补码,然后再更改回来。如果你忘记了产生的二进制文字的十进制值,它等于 214 10 ,那么它将在二进制补码中表示-42 10 。最左边的位将是符号位。
或者,您可以利用之前使用的模运算来模拟 Python 中的逻辑右移:
>>> bin(-42 % (1 << 8)) # Give me eight bits '0b11010110'如果这对您来说太复杂了,那么您可以使用标准库中的一个模块来更清楚地表达相同的意图。例如,使用
ctypes会产生相同的效果:
>>> from ctypes import c_uint8 as unsigned_byte
>>> bin(unsigned_byte(-42).value)
'0b11010110'
你以前见过它,但是提醒一下,它会借用 c 语言中的无符号整数类型。
Python 中可以用于这种转换的另一个标准模块是 array 模块。它定义了一个类似于list的数据结构,但是只允许保存相同数字类型的元素。在声明数组时,您需要预先用相应的字母表示其类型:
>>> from array import array >>> signed = array("b", [-42, 42]) >>> unsigned = array("B") >>> unsigned.frombytes(signed.tobytes()) >>> unsigned array('B', [214, 42]) >>> bin(unsigned[0]) '0b11010110' >>> bin(unsigned[1]) '0b101010'例如,
"b"代表 8 位有符号字节,而"B"代表其无符号等效字节。还有一些其他预定义的类型,如带符号的 16 位整数或 32 位浮点数。在这两个数组之间复制原始字节会改变位的解释方式。但是要占用两倍的内存,相当浪费。要就地执行这样的位重写,您可以依赖于
struct模块,该模块使用类似的一组格式字符进行类型声明:
>>> from struct import pack, unpack
>>> unpack("BB", pack("bb", -42, 42))
(214, 42)
>>> bin(214)
'0b11010110'
打包使您可以根据给定的 C 数据类型说明符在内存中放置对象。它返回一个只读的 bytes() 对象,其中包含生成的内存块的原始字节。稍后,您可以使用一组不同的类型代码读回这些字节,以改变它们被转换成 Python 对象的方式。
到目前为止,您已经使用了不同的技术来获得用二进制补码表示的整数的定长位串。如果您想将这些类型的位序列转换回 Python 整数,那么您可以尝试此函数:
def from_twos_complement(bit_string, num_bits=32):
unsigned = int(bit_string, 2)
sign_mask = 1 << (num_bits - 1) # For example 0b100000000
bits_mask = sign_mask - 1 # For example 0b011111111
return (unsigned & bits_mask) - (unsigned & sign_mask)
该函数接受由二进制数字组成的字符串。首先,它将数字转换为普通的无符号整数,忽略符号位。接下来,它使用两个位掩码来提取符号和幅度位,其位置取决于指定的位长。最后,在知道与符号位相关联的值为负的情况下,它使用常规算术将它们组合起来。
您可以对照早期示例中可靠的旧位字符串进行试验:
>>> int("11010110", 2) 214 >>> from_twos_complement("11010110") 214 >>> from_twos_complement("11010110", num_bits=8) -42Python 的
int()把所有的位都当作量,所以没有什么奇怪的。但是,这个新函数默认采用 32 位长的字符串,这意味着对于较短的字符串,符号位隐式等于零。当您请求一个与您的位串匹配的位长时,您将得到预期的结果。虽然在大多数情况下 integer 是最适合使用位运算符的数据类型,但有时您需要提取和操作结构化二进制数据的片段,如图像像素。
array和struct模块简要介绍了这个主题,所以接下来您将更详细地探索它。查看二进制数据
您知道如何读取和解释单个字节。然而,真实世界的数据通常包含不止一个字节来传递信息。以
float数据类型为例。Python 中的单个浮点数在内存中占用多达 8 个字节。你如何看待这些字节?
您不能简单地使用按位运算符,因为它们不适用于浮点数:
>>> 3.14 & 0xff
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for &: 'float' and 'int'
您必须忘记您正在处理的特定数据类型,并将其视为一般的字节流。这样,字节在被按位运算符处理的上下文之外代表什么就无关紧要了。
要在 Python 中获得浮点数的bytes(),您可以使用熟悉的struct模块打包它:
>>> from struct import pack >>> pack(">d", 3.14159) b'@\t!\xf9\xf0\x1b\x86n'忽略通过第一个参数传递的格式字符。直到你看到下面的字节顺序部分,它们才有意义。在这个相当晦涩的文本表示背后隐藏着一个由八个整数组成的列表:
>>> list(b"@\t!\xf9\xf0\x1b\x86n")
[64, 9, 33, 249, 240, 27, 134, 110]
它们的值对应于用于以二进制表示浮点数的后续字节。您可以将它们组合起来产生一个很长的位串:
>>> from struct import pack >>> "".join([f"{b:08b}" for b in pack(">d", 3.14159)]) '0100000000001001001000011111100111110000000110111000011001101110'这 64 位是您在前面读到的双精度符号、指数和尾数。要从一个相似的位串合成一个
float,您可以颠倒这个过程:
>>> from struct import unpack
>>> bits = "0100000000001001001000011111100111110000000110111000011001101110"
>>> unpack(
... ">d",
... bytes(int(bits[i:i+8], 2) for i in range(0, len(bits), 8))
... )
(3.14159,)
unpack()返回一个元组,因为它允许你一次读取多个值。例如,您可以读取与四个 16 位有符号整数相同的位字符串:
>>> unpack( ... ">hhhh", ... bytes(int(bits[i:i+8], 2) for i in range(0, len(bits), 8)) ... ) (16393, 8697, -4069, -31122)正如您所看到的,必须预先知道位串的解释方式,以避免以混乱的数据结束。你需要问自己的一个重要问题是,你应该从字节流的哪一端开始读——左边还是右边。请继续阅读,寻找答案。
字节顺序
单个字节中位的顺序没有争议。无论它们在内存中的物理布局如何,你总能在索引 0 找到最低有效位,在索引 7 找到最高有效位。按位移位运算符依赖于这种一致性。
然而,对于多字节数据块中的字节顺序并没有一致的意见。例如,包括多于一个字节的一条信息可以像英语文本一样从左向右读取,或者像阿拉伯语文本一样从右向左读取。计算机看到二进制流中的字节,就像人类看到句子中的单词一样。
计算机选择从哪个方向读取字节并不重要,只要它们在任何地方都应用相同的规则。不幸的是,不同的计算机架构使用不同的方法,这使得在它们之间传输数据具有挑战性。
大端对小端
就拿 1969 10 这个数字对应的 32 位无符号整数来说吧,这是巨蟒第一次出现在电视上的年份。由于所有前导零,它具有以下二进制表示 000000000000000000111101100012。
你如何在计算机内存中存储这样一个值?
如果您将内存想象成由字节组成的一维磁带,那么您需要将这些数据分解成单独的字节,并将它们排列在一个连续的块中。有些人觉得从左端开始很自然,因为这是他们阅读的方式,而另一些人更喜欢从右端开始:
字节顺序 地址 地址 N+1 地址 N+2 地址 N+3 大端的 00000000 2 00000000 2 00000111 2 10110001 2 小端的 10110001 2 00000111 2 00000000 2 00000000 2 当字节从左到右放置时,最高有效字节被分配给最低的存储器地址。这就是所谓的大端顺序。相反,当字节从右向左存储时,最不重要的字节先存储。那叫小端阶。
注:这些幽默的名字灵感来自乔纳森·斯威夫特的十八世纪小说 格列佛游记 。作者描述了小端和大端在打破煮鸡蛋外壳的正确方法上的冲突。小尾序人更喜欢从小尖端开始,而大尾序人更喜欢大端。
哪种方式更好?
从实践的角度来看,使用其中一种并没有真正的优势。硬件级别的性能可能会有一些边际收益,但您不会注意到它们。主要的网络协议使用大端顺序,这允许它们在给定 IP 寻址的分层设计的情况下更快地过滤数据包。除此之外,有些人可能会发现在调试时使用特定的字节顺序会更方便。
无论哪种方式,如果你没有得到它的权利,混淆了这两个标准,那么不好的事情开始发生:
>>> raw_bytes = (1969).to_bytes(length=4, byteorder="big")
>>> int.from_bytes(raw_bytes, byteorder="little")
2970025984
>>> int.from_bytes(raw_bytes, byteorder="big")
1969
当您使用一种约定将一些值序列化为字节流,并尝试使用另一种约定读回它时,您将得到完全无用的结果。这种情况最有可能发生在通过网络发送数据时,但是在读取特定格式的本地文件时也会遇到这种情况。例如, Windows 位图的头总是使用 little-endian,而 JPEG 可以使用两种字节顺序。
原生字节序
要找出您的平台的字节顺序,您可以使用sys模块:
>>> import sys >>> sys.byteorder 'little'但是你不能改变字节序,因为这是你的 CPU 架构的固有特性。如果没有硬件虚拟化,比如 QEMU ,就不可能模拟它进行测试,所以即使是流行的 VirtualBox 也无济于事。
值得注意的是,支持大多数现代笔记本电脑和台式机的英特尔和 AMD x86 系列处理器是小端的。移动设备基于低能耗的 ARM 架构,这是双字节序,而一些较老的架构,如古老的摩托罗拉 68000,只是大端序。
有关确定 C #中字节顺序的信息,请展开下面的框。
从历史上看,在 C 语言中获得机器字节序的方法是声明一个小整数,然后用一个指针读取它的第一个字节:
#include <stdio.h> #define BIG_ENDIAN "big" #define LITTLE_ENDIAN "little" char* byteorder() { int x = 1; char* pointer = (char*) &x; // Address of the 1st byte return (*pointer > 0) ? LITTLE_ENDIAN : BIG_ENDIAN; } void main() { printf("%s\n", byteorder()); }如果该值大于零,则存储在最低内存地址的字节必须是最低有效字节。
一旦知道了机器的本机字节顺序,在操作二进制数据时,您会希望在不同的字节顺序之间进行转换。不管手头的数据类型是什么,一个通用的方法是反转一个通用的
bytes()对象或表示这些字节的整数序列:
>>> big_endian = b"\x00\x00\x07\xb1"
>>> bytes(reversed(big_endian))
b'\xb1\x07\x00\x00'
然而,使用struct模块通常更方便,它允许您定义标准的 C 数据类型。除此之外,它还允许您使用可选的修饰符请求给定的字节顺序:
>>> from struct import pack, unpack >>> pack(">I", 1969) # Big-endian unsigned int b'\x00\x00\x07\xb1' >>> unpack("<I", b"\x00\x00\x07\xb1") # Little-endian unsigned int (2970025984,)大于号(
>)表示字节以大端顺序排列,而小于号(<)对应于小端顺序。如果不指定,则采用本机字节顺序。还有一些修饰语,比如感叹号(!,它表示网络字节顺序。网络字节顺序
计算机网络由各种不同的设备组成,如笔记本电脑、台式机、平板电脑、智能手机,甚至配有 Wi-Fi 适配器的灯泡。它们都需要一致同意的协议和标准,包括二进制传输的字节顺序,才能有效地进行通信。
在互联网出现之初,人们决定这些网络协议的字节顺序是大端字节序。
想要通过网络进行通信的程序可以使用经典的 C API,它用一个套接字层抽象出本质细节。Python 通过内置的
socket模块包装该 API。然而,除非你正在编写一个定制的二进制协议,否则你可能想要利用一个更高层次的抽象,比如基于文本的 HTTP 协议。
socket模块的用处在于字节顺序转换。它公开了 C API 中的一些函数,这些函数有着独特的、令人费解的名字:
>>> from socket import htons, htonl, ntohs, ntohl
>>> htons(1969) # Host to network (short int)
45319
>>> htonl(1969) # Host to network (long int)
2970025984
>>> ntohs(45319) # Network to host (short int)
1969
>>> ntohl(2970025984) # Network to host (long int)
1969
如果你的主机已经使用了大端字节顺序,那就没什么可做的了。这些值将保持不变。
位掩码
位遮罩的工作原理类似于涂鸦模板,可以阻止颜料喷到表面的特定区域。它可以让您隔离这些位,有选择地对它们应用一些功能。位屏蔽涉及到按位逻辑运算符和按位移位运算符。
您可以在许多不同的上下文中找到位掩码。例如, IP 寻址中的子网掩码实际上是帮助你提取网络地址的位掩码。像素通道对应于 RGB 模型中的红色、绿色和蓝色,可以使用位掩码访问。您还可以使用位掩码来定义布尔标志,然后您可以将这些标志打包到位域中。
与位掩码相关的操作有几种常见类型。您将快速浏览下面的一些内容。
变得有点
要读取给定位置上特定位的值,可以对所需索引处仅由一位组成的位掩码使用按位 AND:
>>> def get_bit(value, bit_index): ... return value & (1 << bit_index) ... >>> get_bit(0b10000000, bit_index=5) 0 >>> get_bit(0b10100000, bit_index=5) 32掩码将抑制除您感兴趣的位之外的所有位。它将产生 0 或 2 的幂,其指数等于位索引。如果你想得到一个简单的是或否的答案,那么你可以向右移动并检查最低有效位:
>>> def get_normalized_bit(value, bit_index):
... return (value >> bit_index) & 1
...
>>> get_normalized_bit(0b10000000, bit_index=5)
0
>>> get_normalized_bit(0b10100000, bit_index=5)
1
这一次,它将规范化位值,使其永远不会超过 1。然后,您可以使用该函数导出一个布尔值True或False而不是一个数值。
设置一个位
设置一个位类似于获取一个位。您可以像以前一样利用相同的位掩码,但是您不用按位 AND,而是使用按位 OR 运算符:
>>> def set_bit(value, bit_index): ... return value | (1 << bit_index) ... >>> set_bit(0b10000000, bit_index=5) 160 >>> bin(160) '0b10100000'掩码保留所有原始位,同时在指定的索引处强制执行二进制 1。如果已经设置了那个位,它的值就不会改变。
复位位
要清除某个位,您需要复制所有二进制数字,同时在一个特定的索引处强制执行零。您可以通过再次使用相同的位掩码来实现这种效果,但形式相反:
>>> def clear_bit(value, bit_index):
... return value & ~(1 << bit_index)
...
>>> clear_bit(0b11111111, bit_index=5)
223
>>> bin(223)
'0b11011111'
在 Python 中,对正数使用按位 NOT 总是会产生负值。虽然这通常是不可取的,但在这里没有关系,因为您立即应用了按位 AND 运算符。这反过来又会触发掩码向二进制补码表示的转换,从而得到预期的结果。
切换一点
有时候,能够周期性地打开和关闭一点是有用的。这是位 XOR 运算符的绝佳机会,它可以像这样翻转您的位:
>>> def toggle_bit(value, bit_index): ... return value ^ (1 << bit_index) ... >>> x = 0b10100000 >>> for _ in range(5): ... x = toggle_bit(x, bit_index=7) ... print(bin(x)) ... 0b100000 0b10100000 0b100000 0b10100000 0b100000请注意,同一个位掩码再次被使用。指定位置上的二进制 1 将使该索引处的位反转其值。在剩余的位置上具有二进制零将确保剩余的位将被复制。
按位运算符重载
按位运算符的主要领域是整数。这是它们最有意义的地方。然而,您也看到了它们在布尔上下文中的使用,在布尔上下文中,它们取代了逻辑运算符。Python 为它的一些操作符提供了可选的实现,并允许你为新的数据类型重载它们。
尽管在 Python 中重载逻辑操作符的提议被否决了,但是你可以赋予任何按位操作符新的含义。许多流行的库,甚至标准库,都利用了它。
内置数据类型
Python 按位运算符是为以下内置数据类型定义的:
这不是广为人知的事实,但按位运算符可以执行来自集合代数的运算,如并、交和对称差,以及合并和更新字典。
注意:在撰写本文时, Python 3.9 还没有发布,但你可以使用 Docker 或 pyenv 先睹为快。
当
a和b是 Python 集合时,那么按位运算符对应以下方法:
永久变形测定法 按位运算符 a.union(b)a | ba.update(b)a |= ba.intersection(b)a & ba.intersection_update(b)a &= ba.symmetric_difference(b)a ^ ba.symmetric_difference_update(vegies)a ^= b它们实际上做同样的事情,所以使用哪种语法取决于你。除此之外,还有一个重载的减运算符(
-),它实现了两个集合的差。为了看到它们的作用,假设你有以下两组水果和蔬菜:
>>> fruits = {"apple", "banana", "tomato"}
>>> veggies = {"eggplant", "tomato"}
>>> fruits | veggies
{'tomato', 'apple', 'eggplant', 'banana'}
>>> fruits & veggies
{'tomato'}
>>> fruits ^ veggies
{'apple', 'eggplant', 'banana'}
>>> fruits - veggies # Not a bitwise operator!
{'apple', 'banana'}
它们共享一个很难分类的公共成员,但是它们的其余元素是不相交的。
需要注意的一点是不可变的frozenset(),它缺少就地更新的方法。但是,当您使用它们对应的按位运算符时,含义略有不同:
>>> const_fruits = frozenset({"apple", "banana", "tomato"}) >>> const_veggies = frozenset({"eggplant", "tomato"}) >>> const_fruits.update(const_veggies) Traceback (most recent call last): File "<input>", line 1, in <module> const_fruits.update(const_veggies) AttributeError: 'frozenset' object has no attribute 'update' >>> const_fruits |= const_veggies >>> const_fruits frozenset({'tomato', 'apple', 'eggplant', 'banana'})当你使用按位操作符时,看起来
frozenset()并不是不可变的,但是魔鬼在细节中。实际情况是这样的:const_fruits = const_fruits | const_veggies第二次成功的原因是你没有改变原来的不可变对象。相反,您可以创建一个新变量,并再次将其赋给同一个变量。
Python
dict只支持按位 OR,它的工作方式类似于联合操作符。您可以使用它就地更新词典或将两个词典合并成一个新词典:
>>> fruits = {"apples": 2, "bananas": 5, "tomatoes": 0}
>>> veggies = {"eggplants": 2, "tomatoes": 4}
>>> fruits | veggies # Python 3.9+
{'apples': 2, 'bananas': 5, 'tomatoes': 4, 'eggplants': 2}
>>> fruits |= veggies # Python 3.9+, same as fruits.update(veggies)
按位运算符的扩充版本相当于.update()。
第三方模块
许多流行的库,包括 NumPy 、 pandas 和 SQLAlchemy ,为它们特定的数据类型重载了位操作符。这是 Python 中最有可能找到按位运算符的地方,因为它们在最初的含义中已经不常使用了。
例如,NumPy 以逐点的方式将它们应用于矢量化数据:
>>> import numpy as np >>> np.array([1, 2, 3]) << 2 array([ 4, 8, 12])这样,您不需要对数组的每个元素手动应用相同的按位运算符。但是在 Python 中你不能对普通的列表做同样的事情。
pandas 在幕后使用 NumPy,它还为其
DataFrame和Series对象提供了按位运算符的重载版本。然而,它们的行为和你预期的一样。唯一的区别是它们通常在向量和数字矩阵上工作,而不是在单个标量上。对于赋予按位运算全新含义的库,事情变得更加有趣。例如,SQLAlchemy 为查询数据库提供了一种紧凑的语法:
session.query(User) \ .filter((User.age > 40) & (User.name == "Doe")) \ .all()按位 AND 运算符(
&)最终将转化为一段 SQL 查询。然而,这不是很明显,至少对我的 IDE 来说不是,它抱怨在这种类型的表达式中使用了不协调的位操作符。它立即建议用逻辑and替换每一次出现的&,不知道这样做会使代码停止工作!这种类型的操作符重载是一种有争议的实践,它依赖于您必须事先知道的隐含魔力。一些编程语言如 Java 通过完全禁止操作符重载来防止这种滥用。Python 在这方面更加自由,并且相信您知道自己在做什么。
自定义数据类型
要定制 Python 的位操作符的行为,你必须定义一个类,然后在其中实现相应的魔法方法。同时,您不能为现有类型重新定义按位运算符的行为。运算符重载只能在新的数据类型上实现。
下面是让您重载位运算符的特殊方法的简要介绍:
魔法方法 表示 .__and__(self, value)instance & value.__rand__(self, value)value & instance.__iand__(self, value)instance &= value.__or__(self, value)instance | value.__ror__(self, value)value | instance.__ior__(self, value)instance |= value.__xor__(self, value)instance ^ value.__rxor__(self, value)value ^ instance.__ixor__(self, value)instance ^= value.__invert__(self)~instance.__lshift__(self, value)instance << value.__rlshift__(self, value)value << instance.__ilshift__(self, value)instance <<= value.__rshift__(self, value)instance >> value.__rrshift__(self, value)value >> instance.__irshift__(self, value)instance >>= value你不需要定义它们。例如,要有一个稍微方便一点的语法来将元素追加和前置到一个队列,只实现
.__lshift__()和.__rrshift__()就足够了:
>>> from collections import deque
>>> class DoubleEndedQueue(deque):
... def __lshift__(self, value):
... self.append(value)
... def __rrshift__(self, value):
... self.appendleft(value)
...
>>> items = DoubleEndedQueue(["middle"])
>>> items << "last"
>>> "first" >> items
>>> items
DoubleEndedQueue(['first', 'middle', 'last'])
这个用户定义的类包装了一个 deque 以重用它的实现,并增加了两个额外的方法,允许向集合的左端或右端添加项目。
最低有效位隐写术
咻,那有很多要处理!如果您还在挠头,不知道为什么要使用按位运算符,那么不要担心。是时候用有趣的方式展示你能用它们做什么了。
要了解本节中的示例,您可以通过单击下面的链接下载源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习 Python 的按位运算符。
您将学习隐写术,并应用这一概念在位图图像中秘密嵌入任意文件。
密码学 vs 隐写术
密码术是将信息转换成只有拥有正确密钥的人才可读的信息。其他人仍然可以看到加密的消息,但对他们来说没有任何意义。密码学的最初形式之一是替代密码,例如以朱利叶斯·凯撒命名的凯撒密码。
隐写术类似于密码学,因为它也允许你与你想要的观众分享秘密信息。然而,它没有使用加密,而是巧妙地将信息隐藏在不引人注意的介质中。例子包括使用隐形墨水或写一个离合体,其中每个单词或行的第一个字母形成一个秘密信息。
除非你知道隐藏的秘密信息和恢复它的方法,你可能会忽略载体。您可以将这两种技术结合起来,隐藏加密的消息而不是原始的消息,这样会更加安全。
在数字世界中,有很多方法可以走私秘密数据。特别是,携带大量数据的文件格式,如音频文件、视频或图像,非常适合,因为它们给你很大的工作空间。例如,发布受版权保护的材料的公司可能会使用隐写术给单个拷贝加水印,并追踪泄露的来源。
下面,您将把秘密数据注入到一个普通的位图中,这在 Python 中读写起来很简单,不需要外部依赖。
位图文件格式
位图这个词通常指的是 Windows 位图 ( .bmp)文件格式,它支持几种替代的像素表示方式。为了方便起见,我们假设像素是以 24 位未压缩的 RGB (红、绿、蓝)格式存储的。一个像素将有三个颜色通道,每个通道可以保存从 0 10 到 255 10 的值。
每个位图都以一个文件头开始,这个文件头包含元数据,比如图像的宽度和高度。以下是一些有趣的字段及其相对于标题开头的位置:
| 田 | 字节偏移量 | 字节长度 | 类型 | 样本值 |
|---|---|---|---|---|
| 签名 | 0x00 |
Two | 线 | 医学学士 |
| 文件大小 | 0x02 |
four | 无符号整数 | Seven million six hundred and twenty-nine thousand one hundred and eighty-six |
| 保留#1 | 0x06 |
Two | 字节 | Zero |
| 保留#2 | 0x08 |
Two | 字节 | Zero |
| 像素偏移 | 0x0a |
four | 无符号整数 | One hundred and twenty-two |
| 像素大小 | 0x22 |
four | 无符号整数 | Seven million six hundred and twenty-nine thousand and sixty-four |
| 图像宽度 | 0x12 |
four | 无符号整数 | One thousand nine hundred and fifty-four |
| 图像高度 | 0x16 |
four | 无符号整数 | One thousand three hundred and one |
| 每像素位数 | 0x1c |
Two | 无符号短整型 | Twenty-four |
| 压缩 | 0x1e |
four | 无符号整数 | Zero |
| 调色板 | 0x2e |
four | 无符号整数 | Zero |
您可以从这个标题推断出相应的位图是 1,954 像素宽和 1,301 像素高。它不使用压缩,也没有调色板。每个像素占用 24 位或 3 个字节,原始像素数据从偏移量 122 10 开始。
您可以在二进制模式下打开位图,寻找所需的偏移量,读取给定数量的字节,并像之前一样使用struct将它们反序列化:
from struct import unpack
with open("example.bmp", "rb") as file_object:
file_object.seek(0x22)
field: bytes = file_object.read(4)
value: int = unpack("<I", field)[0]
请注意,位图中的所有整数字段都是按照小端字节顺序存储的。
您可能已经注意到了头中声明的像素字节数和图像大小产生的像素字节数之间的微小差异。将 1,954 像素× 1,301 像素× 3 字节相乘,得到的值比 7,629,064 小 2,602 字节。
这是因为像素字节是用零填充的,所以每一行都是四个字节的倍数。如果图像的宽度乘以三个字节恰好是四的倍数,那么就不需要填充。否则,将在每一行的末尾添加空字节。
注意:为了避免引起怀疑,您需要通过跳过空字节来考虑填充。否则,对于知道该找什么的人来说,这将是一个明显的泄露。
位图颠倒存储像素行,从底部而不是顶部开始。此外,每个像素被序列化为一个有点奇怪的 BGR 顺序的颜色通道矢量,而不是 RGB。然而,这与隐藏秘密数据的任务无关。
逐位捉迷藏
您可以使用按位运算符将自定义数据分布在连续的像素字节上。其思想是用来自下一个秘密字节的位来覆盖每个字节中的最低有效位。这将引入最少量的噪声,但您可以尝试添加更多位,以在注入数据的大小和像素失真之间取得平衡。
注意:使用最低有效位隐写术不会影响最终位图的文件大小。它将保持与原始文件相同。
在某些情况下,相应的位将是相同的,导致像素值没有任何变化。然而,即使在最糟糕的情况下,像素颜色也只会有百分之几的差异。这种微小的异常对人眼来说是不可见的,但可以通过使用统计学的隐写分析检测出来。
看看这些裁剪过的图片:

左边的图像来自原始位图,而右边的图像描绘了一个经过处理的位图,其中嵌入的视频存储在最低有效位上。你能看出区别吗?
下面这段代码将秘密数据编码到位图上:
for secret_byte, eight_bytes in zip(file.secret_bytes, bitmap.byte_slices):
secret_bits = [(secret_byte >> i) & 1 for i in reversed(range(8))]
bitmap[eight_bytes] = bytes(
[
byte | 1 if bit else byte & ~1
for byte, bit in zip(bitmap[eight_bytes], secret_bits)
]
)
对于秘密数据的每一个字节和相应的像素数据的八个字节,不包括填充字节,它准备一个要扩展的位的列表。接下来,它使用相关的位掩码覆盖 8 个字节中每个字节的最低有效位。结果被转换成一个bytes()对象,并被分配回它原来所在的位图部分。
要从同一个位图解码一个文件,你需要知道有多少秘密字节被写入其中。您可以在数据流的开头分配几个字节来存储这个数字,或者可以使用位图头中的保留字段:
@reserved_field.setter
def reserved_field(self, value: int) -> None:
"""Store a little-endian 32-bit unsigned integer."""
self._file_bytes.seek(0x06)
self._file_bytes.write(pack("<I", value))
这会跳转到文件中的右边偏移量,将 Python int序列化为原始字节,并将它们写下来。
您可能还想存储您的秘密文件的名称。因为它可以有任意的长度,所以使用一个空终止的字符串来序列化它是有意义的,它将在文件内容之前。要创建这样的字符串,您需要将 Python str对象编码为字节,并在末尾手动添加空字节:
>>> from pathlib import Path >>> path = Path("/home/jsmith/café.pdf") >>> path.name.encode("utf-8") + b"\x00" b'caf\xc3\xa9.pdf\x00'同样,使用
pathlib从路径中删除多余的父目录也没有坏处。补充本文的示例代码将让您使用以下命令从给定的位图中编码、解码、擦除一个秘密文件:
$ python -m stegano example.bmp -d Extracted a secret file: podcast.mp4 $ python -m stegano example.bmp -x Erased a secret file from the bitmap $ python -m stegano example.bmp -e pdcast.mp4 Secret file was embedded in the bitmap这是一个可运行的模块,可以通过调用其包含的目录来执行。您还可以将它的内容制作成一个可移植的 ZIP 格式的存档,以利用对 Python ZIP 应用程序的支持。
这个程序依赖于文章中提到的标准库中的模块,以及其他一些您以前可能没有听说过的模块。一个关键模块是
mmap,它向内存映射的文件公开了一个 Python 接口。它们允许您使用标准文件 API 和序列 API 来操作大型文件。这就好像文件是一个可以分割的大的可变列表。继续玩附在支持材料上的位图。里面包含了给你的一个小惊喜!
结论
掌握 Python 位操作符给了你在项目中操作二进制数据的终极自由。您现在知道了它们的语法和不同的风格以及支持它们的数据类型。您还可以根据自己的需要自定义它们的行为。
在本教程中,您学习了如何:
- 使用 Python 位操作符来操作单个位
- 以与平台无关的方式读写二进制数据
- 使用位掩码将信息打包在一个字节上
- 重载自定义数据类型中的 Python 按位运算符
- 在数字图像中隐藏秘密信息
你还学习了计算机如何使用二进制系统来表示不同种类的数字信息。您看到了几种解释位的流行方法,以及如何缓解 Python 中缺乏无符号数据类型的问题,以及 Python 在内存中存储整数的独特方式。
有了这些信息,您就可以在代码中充分利用二进制数据了。要下载水印示例中使用的源代码并继续尝试位运算符,可以单击下面的链接:
获取源代码: 点击此处获取源代码,您将在本教程中使用来学习 Python 的按位运算符。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的二进制、字节、按位运算符*********
Python 布尔值:用真值优化代码
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 布尔:利用真值
Python 布尔类型是 Python 的内置数据类型之一。它用来表示一个表达式的真值。例如,表达式
1 <= 2是True,而表达式0 == 1是False。理解 Python 布尔值的行为对于用 Python 很好地编程是很重要的。在本教程中,您将学习如何:
- 用布尔运算符操作布尔值
- 将布尔值转换为其他类型
- 将其他类型转换为 Python 布尔值
- 使用 Python 布尔值编写高效可读的 Python 代码
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 布尔类型
Python 布尔类型只有两个可能的值:
TrueFalse其他值都不会将
bool作为其类型。您可以通过内置的type()检查True和False的类型:
>>> type(False)
<class 'bool'>
>>> type(True)
<class 'bool'>
False和True的type()都是bool。
类型bool是中内置的,这意味着它在 Python 中总是可用的,不需要导入。然而,名字本身并不是语言中的关键字。虽然以下被认为是不好的风格,但是可以指定名称为bool:
>>> bool <class 'bool'> >>> bool = "this is not a type" >>> bool 'this is not a type'尽管技术上可行,但为了避免混淆,强烈建议您不要给
bool分配不同的值。Python 布尔作为关键字
内置名称不是关键字。就 Python 语言而言,它们是常规的变量。如果您给它们赋值,那么您将覆盖内置值。
相比之下,
True和False这两个名字是而不是内置的。它们是关键词。与其他许多 Python 关键字不同,True和False都是 Python 表达式。因为它们是表达式,所以它们可以用在任何其他表达式可以用的地方,比如1 + 1。可以给变量赋值,但是不能给
True赋值:
>>> a_true_alias = True
>>> a_true_alias
True
>>> True = 5
File "<stdin>", line 1
SyntaxError: cannot assign to True
因为True是一个关键字,所以不能给它赋值。同样的规则也适用于False:
>>> False = 5 File "<stdin>", line 1 SyntaxError: cannot assign to False不能赋值给
False,因为它是 Python 中的一个关键字。这样,True和False的行为就像其他数值常量一样。例如,您可以将1.5传递给函数或将其赋给变量。然而,不可能给1.5赋值。语句1.5 = 5不是有效的 Python。1.5 = 5和False = 5都是无效的 Python 代码,解析时会抛出SyntaxError。Python 布尔值作为数字
在 Python 中,布尔值被认为是一种数字类型。这意味着它们实际上是号。换句话说,您可以对布尔值应用算术运算,也可以将它们与数字进行比较:
>>> True == 1
True
>>> False == 0
True
>>> True + (False / True)
1.0
布尔值的数字性质没有太多用途,但是有一种技术可能会对您有所帮助。因为True等于1,False等于0,所以将布尔值相加是一种快速计算True值个数的方法。当您需要计算满足某个条件的项目数量时,这很方便。
例如,如果你想分析一首经典儿童诗中的一节,看看有多少行包含单词"the",那么True等于1和False等于0这个事实就非常方便了:
>>> lines="""\ ... He took his vorpal sword in hand; ... Long time the manxome foe he sought— ... So rested he by the Tumtum tree ... And stood awhile in thought. ... """.splitlines() >>> sum("the" in line.lower() for line in lines) / len(lines) 0.5像这样对生成器表达式中的所有值求和,可以让你知道
True在生成器中出现了多少次。以不区分大小写的方式,True在生成器中的次数等于包含单词"the"的行数。将这个数字除以总行数,得到匹配行数与总行数的比率。要了解为什么会这样,您可以将上面的代码分成几个小部分:
>>> lines = """\
... He took his vorpal sword in hand;
... Long time the manxome foe he sought—
... So rested he by the Tumtum tree
... And stood awhile in thought.
... """
>>> line_list = lines.splitlines()
>>> "the" in line_list[0]
False
>>> "the" in line_list[1]
True
>>> 0 + False + True # Equivalent to 0 + 0 + 1
1
>>> ["the" in line for line in line_list]
[False, True, True, False]
>>> False + True + True + False
2
>>> len(line_list)
4
>>> 2/4
0.5
line_list变量保存一个行列表。第一行没有单词"the",所以"the" in line_list[0]是False。在第二行中,"the"确实出现了,所以"the" in line_list[1]就是True。既然布尔是数字,就可以把它们加到数字上,0 + False + True给出1。
由于["the" in line for line in line_list]是四个布尔的列表,所以可以把它们加在一起。当你加上False + True + True + False,你得到2。现在,如果你把结果除以列表的长度4,你得到0.5。单词"the"出现在所选内容的一半行中。这是利用布尔是数字这一事实的一种有用方式。
布尔运算符
布尔运算符是那些接受布尔输入并返回布尔结果的运算符。
注意:稍后,您将看到这些操作符可以被赋予其他输入,并且不总是返回布尔结果。现在,所有的例子都将使用布尔输入和结果。在真实性一节中,你会看到这是如何推广到其他值的。
因为 Python 布尔值只有两个可能的选项,即True或False,所以可以完全根据运算符分配给每个可能的输入组合的结果来指定运算符。这些规格被称为真值表,因为它们显示在一个表格中。
稍后您会看到,在某些情况下,知道一个操作符的输入就足以确定它的值。在这些情况下,其他输入是而不是被评估。这被称为短路评估。
短路评估的重要性取决于具体案例。在某些情况下,它可能对您的程序没有什么影响。在其他情况下,例如当计算不影响结果的表达式时,它提供了显著的性能优势。在最极端的情况下,代码的正确性可能取决于短路评估。
没有输入的运算符
您可以将True和False视为没有输入的布尔运算符。其中一个操作符总是返回True,另一个总是返回False。
将 Python 布尔值视为运算符有时很有用。例如,这种方法有助于提醒你它们不是变量。出于同样的原因,你不能分配给+,也不可能分配给True或False。
只有两个 Python 布尔值存在。没有输入的布尔运算符总是返回相同的值。正因为如此,True和False是仅有的两个不接受输入的布尔运算符。
not布尔运算符
唯一有一个自变量的布尔运算符是 not 。它接受一个参数并返回相反的结果:True的False和False的True。这是一个真值表:
A |
not A |
|---|---|
True |
False |
False |
True |
该表说明了not返回自变量的相反真值。因为not只有一个参数,所以它不会短路。它在返回结果之前评估其参数:
>>> not True False >>> not False True >>> def print_and_true(): ... print("I got called") ... return True ... >>> not print_and_true() I got called False最后一行显示
not在返回False之前评估其输入。您可能想知道为什么没有其他接受单个参数的布尔运算符。为了理解其中的原因,您可以查看一个表,该表显示了所有理论上可能的布尔运算符,这些运算符只接受一个参数:
Anot A身份 是 不 TrueFalseTrueTrueFalseFalseTrueFalseTrueFalse一个参数只有四种可能的运算符。除了
not之外,其余三个操作符都有一些古怪的名字,因为它们实际上并不存在:
Identity:因为这个操作符只是返回它的输入,所以你可以把它从你的代码中删除而不会有任何影响。
Yes:这是一个短路运算符,因为它不依赖于它的自变量。你可以用True代替它,得到同样的结果。
No:这是另一个短路运算符,因为它不依赖于它的自变量。你可以用False代替它,得到同样的结果。只有一个参数的其他可能的操作符都没有用。
and布尔运算符
and运算符有两个参数。除非两个输入都是True,否则计算结果为False。您可以用下面的真值表定义and的行为:
ABA and BTrueTrueTrueFalseTrueFalseTrueFalseFalseFalseFalseFalse此表很冗长。但是,它说明了与上面描述相同的行为。如果
A是False,那么B的值无关紧要。因此,如果第一个输入是False,则and会短路。换句话说,如果第一个输入是False,那么第二个输入不会被计算。下面的代码有第二个输入,它有一个副作用,打印,为了提供一个具体的例子:
>>> def print_and_return(x):
... print(f"I am returning {x}")
... return x
...
>>> True and print_and_return(True)
I am returning True
True
>>> True and print_and_return(False)
I am returning False
False
>>> False and print_and_return(True)
False
>>> False and print_and_return(False)
False
在最后两种情况下,不打印任何内容。这个函数没有被调用,因为调用它不需要确定and操作符的值。当表情有副作用时,意识到短路是很重要的。在最后两个例子中,短路评估防止了印刷副作用的发生。
这种行为至关重要的一个例子是在可能引发异常的代码中:
>>> def inverse_and_true(n): ... 1 // n ... return True ... >>> inverse_and_true(5) True >>> inverse_and_true(0) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in inverse_and_true ZeroDivisionError: integer division or modulo by zero >>> False and inverse_and_true(0) False函数
inverse_and_true()被公认是愚蠢的,许多 linters 会警告表达式1 // n是无用的。当给定0作为参数时,它确实达到了整齐失败的目的,因为除以0是无效的。然而,最后一行没有引发异常。由于短路计算,函数没有被调用,没有发生0的除法运算,也没有引发异常。相反,
True and inverse_and_true(0)会引发一个异常。在这种情况下,and的结果需要第二个输入的值。一旦评估了第二个输入,就会调用inverse_and_true(0),它会除以0,并引发一个异常。
or布尔运算符
or操作符的值是True,除非其两个输入都是False。or运算符也可以由以下真值表定义:
ABA or BTrueTrueTrueFalseTrueTrueTrueFalseTrueFalseFalseFalse这个表很冗长,但是它和上面的解释有相同的意思。
非正式使用时,单词或可能有两种意思:
独占或 就是或在短语“你可以申请延期或按时提交作业”中的用法在这种情况下,你不能既申请延期又按时提交作业。
包括或 有时用连词和/或表示。例如,“如果你在这项任务中表现出色,那么你可以加薪和/或升职”意味着你可能会加薪和升职。
当 Python 解释关键字
or时,它使用包含的或来完成。如果两个输入都是True,那么or的结果就是True。因为使用了包含的或,Python 中的
or运算符也使用了短路求值。如果第一个参数是True,那么结果就是True,不需要对第二个参数求值。以下示例演示了or的短路评估:
>>> def print_and_true():
... print("print_and_true called")
... return True
...
>>> True or print_and_true()
True
>>> False or print_and_true()
print_and_true called
True
第二个输入不会被or评估,除非第一个输入是False。在实践中,or的短路评估比and的少得多。然而,在阅读代码时记住这种行为是很重要的。
其他布尔运算符
布尔逻辑的数学理论决定了除了not、and、or之外不需要其他运算符。两个输入上的所有其他运算符都可以根据这三个运算符来指定。三个或三个以上输入的所有运算符都可以用两个输入的运算符来表示。
事实上,即使同时拥有or和and也是多余的。and算子可以用not和or来定义,or算子可以用not和and来定义。然而,and和or太有用了,所有编程语言都有这两个。
有十六种可能的双输入布尔运算符。除了and和or,实际中很少需要。正因为如此,True、False、not、and和or是唯一内置的 Python 布尔运算符。
比较运算符
Python 的一些操作符检查两个对象之间的关系是否成立。由于这种关系要么成立,要么不成立,这些被称为比较操作符的操作符总是返回布尔值。
比较运算符是布尔值最常见的来源。
平等与不平等
最常见的比较运算符是相等运算符(== ) 和不等运算符(!= ) 。如果不使用这些操作符中的至少一个,几乎不可能编写出任何有意义的 Python 代码。
等式运算符(==)是 Python 代码中使用最多的运算符之一。您经常需要将一个未知结果与一个已知结果进行比较,或者将两个未知结果进行比较。一些函数返回的值需要与一个标记进行比较,以查看是否检测到某种边缘条件。有时你需要比较两个函数的结果。
等号运算符通常用于比较数字:
>>> 1 == 1 True >>> 1 == 1.0 True >>> 1 == 2 False你可能以前用过等式操作符。它们是 Python 中最常见的一些操作符。对于所有内置的 Python 对象,以及大多数第三方类,它们返回一个布尔值:
True或False。注意:Python 语言并不强制
==和!=返回布尔值。像 NumPy 和 pandas 这样的库返回其他值。受欢迎程度仅次于等式运算符的是不等式运算符(
!=)。如果参数不相等,则返回True,如果相等,则返回False。这些例子同样范围广泛。许多单元测试检查该值不等于特定的无效值。在尝试替代方法之前,web 客户端可能会检查错误代码是否为404 Not Found。以下是使用 Python 不等式运算符的两个示例:
>>> 1 != 2
True
>>> 1 != (1 + 0.0)
False
关于 Python 不等式操作符最令人惊讶的事情可能是它首先存在的事实。毕竟,你可以用not (1 == 2)达到和1 != 2一样的效果。Python 通常避免额外的语法,尤其是额外的核心操作符,因为用其他方法很容易实现。
然而,不平等是如此频繁地使用,它被认为是值得有一个专门的运营商。在 Python 的旧版本中,在1.x系列中,实际上有两种不同的语法。
作为一个愚人节玩笑,Python 仍然支持不平等的另一种语法和正确的__future__导入:
>>> from __future__ import barry_as_FLUFL >>> 1 <> 2 True这个不应该在任何真正使用的代码中使用。不过,它可能会在您的下一个 Python 知识之夜派上用场。
订单比较
另一组测试操作符是顺序比较操作符。有四种顺序比较运算符,可以按两种性质进行分类:
- 方向:小于还是大于?
- 严格:是否允许平等?
因为这两个选择是独立的,所以得到了
2 * 2 == 4顺序比较运算符。下表列出了所有四种类型:
不到 大于 严格的 <>不严格 <=>=方向有两个选项,严格也有两个选项。这导致总共四个顺序比较运算符。
没有为所有对象定义顺序比较运算符。一些对象没有有意义的顺序。尽管列表和元组按字典顺序,字典没有有意义的顺序:
**>>>
>>> {1: 3} < {2: 4} Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'dict' and 'dict'字典应该如何排序并不明显。按照 Python 的禅,面对歧义,Python 拒绝猜测。
>>> 1 <= "1"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<=' not supported between instances of 'int' and 'str'
同样,由于没有明显的方法来定义顺序,Python 拒绝比较它们。这类似于加法运算符(+)。虽然可以将字符串和整数相加,但是将字符串和整数相加会引发异常。
当顺序比较运算符被定义时,通常它们返回一个布尔值。
注意 : Python 并不强制比较运算符返回布尔值。虽然所有内置 Python 对象和大多数第三方对象在比较时都返回布尔值,但也有例外。
例如,NumPy 数组或 pandas 数据帧之间的比较运算符返回数组和数据帧。在本教程的后面,您将看到更多关于 NumPy 和布尔值的交互。
在 Python 中比较数字是检查边界条件的一种常用方法。注意<不允许相等,而<=允许:
>>> 1 <= 1 True >>> 1 < 1 False >>> 2 > 3 False >>> 2 >= 2 True程序员经常使用比较运算符,却没有意识到它们会返回一个 Python 布尔值。
is操作员
is操作符检查对象标识。换句话说,只有当x和y对同一个对象求值时,x is y才会对True求值。is操作符有一个相反的操作符is not。
is和is not的典型用法是比较列表的同一性:
>>> x = []
>>> y = []
>>> x is x
True
>>> x is not x
False
>>> x is y
False
>>> x is not y
True
即使x == y,它们也不是同一个对象。is not操作符总是返回与is相反的结果。除了可读性,表达式x is not y和表达式not (x is y)没有区别。
记住,上面的例子显示了仅用于列表的is操作符。is操作符对不可变对象(如数字和字符串)的行为是更复杂。
in操作员
in操作员检查的成员资格。对象可以定义它所认为的成员。大多数序列(如列表)都将其元素视为成员:
>>> small_even = [2, 4] >>> 1 in small_even False >>> 2 in small_even True >>> 10 in small_even False由于
2是列表的一个元素,2 in small_even返回True。由于1和10不在列表中,其他表达式返回False。在所有情况下,in操作符都返回一个布尔值。由于字符串是字符序列,您可能希望它们也检查成员资格。换句话说,作为字符串成员的字符将为
in返回True,而不是字符串成员的字符将返回False:
>>> "e" in "hello beautiful world"
True
>>> "x" in "hello beautiful world"
False
因为"e"是字符串的第二个元素,所以第一个例子返回True。由于x没有出现在字符串中,第二个例子返回False。但是,与单个字符一样,子字符串也被视为字符串的成员:
>>> "beautiful" in "hello beautiful world" True >>> "belle" in "hello beautiful world" False因为
"beautiful"是一个子串,所以in操作符返回True。因为"belle"不是子串,所以in操作符返回False。尽管事实上"belle"中的每个字母都是字符串的一员。与运算符
is和==一样,in运算符也有一个对立面not in。你可以使用not in来确认一个元素不是一个对象的成员。链接比较运算符
比较运算符可以形成链。通过用比较运算符分隔表达式以形成一个更大的表达式,可以创建比较运算符链:
>>> 1 < 2 < 3
True
表达式1 < 2 < 3是一个比较运算符链。它包含由比较运算符分隔的表达式。结果是True,因为链的两个部分都是True。你可以拆开链条,看看它是如何工作的:
>>> 1 < 2 and 2 < 3 True由于
1 < 2返回True,2 < 3返回True,and返回True。比较链相当于在它的所有链接上使用and。在这种情况下,由于True and True返回True,所以整个链的结果是True。这意味着如果任何一个环节是False,那么整个链就是False:
>>> 1 < 3 < 2
False
这个比较链返回False,因为不是所有的链接都是True。因为比较链是一个隐式的and运算符,如果甚至一个环节是False,那么整个链就是False。你可以拆开链条,看看它是如何工作的:
>>> 1 < 3 and 3 < 2 False在这种情况下,链的各部分计算为以下布尔值:
1 < 3是True3 < 2是False这意味着结果一个是
True,一个是False。由于True and False等于False,整个链条的价值就是False。只要类型可以比较,就可以在比较链中混合使用类型和操作:
>>> 1 < 2 < 1
False
>>> 1 == 1.0 < 0.5
False
>>> 1 == 1.0 == True
True
>>> 1 < 3 > 2
True
>>> 1 < 2 < 3 < 4 < 5
True
运营商不一定都是一样的。甚至类型也不必完全相同。在上面的例子中,有三种数值类型:
intfloatbool
这是三种不同的数值类型,但是您可以毫无问题地比较不同数值类型的对象。
短路链评估
如果链使用隐式and,那么链也必须短路。这很重要,因为即使在没有定义顺序比较的情况下,链也有可能返回False:
>>> 2 < "2" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'int' and 'str' >>> 3 < 2 < "2" False尽管 Python 不能对整数和字符串数字进行顺序比较,但是
3 < 2 < "2"的计算结果是False,因为它不计算第二次比较。在这种情况下,短路评估防止了另一个副作用:引发异常。比较链的短路评估可以防止其他异常:
>>> 3 < 2 < (1//0)
False
用1除以0会得到一个ZeroDivisionError。但是因为短路求值,Python 并不对无效除法求值。这意味着 Python 不仅跳过了对比较的评估,还跳过了对比较的输入的评估。
理解比较链的另一个重要方面是,当 Python 对链中的元素求值时,它只求值一次:
>>> def foo(): ... print("I'm foo") ... return 1 ... >>> 0 < foo() < 2 I'm foo True >>> (0 < foo()) and (foo() < 2) I'm foo I'm foo True因为中间的元素只计算一次,所以重构
x < y < z到(x < y) and (y < z)并不总是安全的。尽管链在短路评估中表现得像and,但它只评估所有值一次,包括中间值。链对于范围检查特别有用,它确认一个值落在给定的范围内。例如,在包含工作小时数的每日发票中,您可以执行以下操作:
>>> hours_worked = 5
>>> 1 <= hours_worked <= 25
True
如果工作了0个小时,那么就没有理由发送发票。算上夏令时,一天的最大小时数是25。上述范围检查确认一天的工作小时数在允许的范围内。
混合运算符和链接
到目前为止,我们所有的例子都涉及到==、!=和顺序比较。但是,您可以链接 Python 的所有比较操作符。这可能会导致令人惊讶的行为:
>>> a = 0 >>> a is a < 1 True >>> (a is a) < 1 False >>> a is (a < 1) False因为
a is a < 1是比较链,所以求值为True。你可以把链条分成几部分:
- 表达式
a is a是True,因为它是针对自身评估的任何值。- 表达式
a < 1是True,因为0小于1。因为两个部分都是
True,所以链计算为True。然而,习惯于 Python 中其他操作符的人可能会认为,像其他包含多个操作符的表达式(如
1 + 2 * 3)一样,Python 在表达式中插入了括号。然而,插入括号的两种方式都不会计算出True。如果你分解表达式,你可以看到为什么两者的值都是
False。如果分解第一个表达式,会得到以下结果:
>>> a = 0
>>> a is a
True
>>> True == 1
True
>>> (a is a) < 1
False
你可以在上面看到,a is a返回True,就像对任何值一样。这意味着(a is a) < 1和True < 1是一样的。布尔是数值类型,True等于1。所以True < 1和1 < 1一样。由于这是一个严格不等式,而1 == 1则返回 False。
第二种表达方式有所不同:
>>> a = 0 False >>> a < 1 True >>> 0 is True <stdin>:1: SyntaxWarning: "is" with a literal. Did you mean "=="? False由于
0小于1,a < 1返回True。既然是0 != True,那么就不可能是0 is True的情况。注意:不要对上面的
SyntaxWarning掉以轻心。在数字上使用is可能会混淆。但是,具体到你知道数字不相等的情况,你可以知道is也会返回False。虽然这个例子是正确的,但它不是一个好的 Python 编码风格的例子。从中得出的最重要的教训是,用
is链接比较通常不是一个好主意。它会让读者困惑,可能也没有必要。像
is一样,in操作符和它的反义词not in在链接时经常会产生令人惊讶的结果:
>>> "b" in "aba" in "cabad" < "cabae"
True
为了尽量避免混淆,这个例子用不同的操作符将比较链接起来,并使用带有字符串的in来检查子字符串。同样,这不是一个编写良好的代码的例子!然而,能够阅读这个例子并理解它为什么返回True是很重要的。
最后,你可以用not in链接is not:
>>> greeting = "hello" >>> quality = "good" >>> end_greeting = "farewell" >>> greeting is not quality not in end_greeting True注意两个运算符中
not的顺序不一样!负算子是is not和not in。这符合英语中的常规用法,但在修改代码时很容易出错。Python 布尔测试
Python 布尔值最常见的用法是在
if语句中。如果值为True,将执行该语句:
>>> 1 == 1
True
>>> if 1 == 1:
... print("yep")
...
yep
>>> 1 == 2
False
>>> if 1 == 2:
... print("yep")
...
只有当表达式计算结果为True时,才会调用print()。然而,在 Python 中你可以给if任何值。if认为True的值称为 真值 ,if认为False的值称为 假值 。
if通过内部调用内置的bool()来决定哪些值为真,哪些值为假。您已经遇到了作为 Python 布尔类型的bool()。当被调用时,它将对象转换为布尔值。
None为布尔值
单例对象None总是错误的:
>>> bool(None) False这在检查标记值的
if语句中通常很有用。然而,用is None显式检查身份通常更好。有时None可以与短路评估结合使用,以便有一个默认设置。例如,您可以使用
or将None替换为空列表:
>>> def add_num_and_len(num, things=None):
... return num + len(things or [])
...
>>> add_num_and_len(5, [1, 2, 3])
8
>>> add_num_and_len(6)
6
在本例中,如果things为非空列表,则不会创建列表,因为or会在对[]求值之前短路。
布尔值形式的数字
对于数字来说,bool(x)相当于x != 0。这意味着唯一虚假的整数是0:
>>> bool(3), bool(-5), bool(0) (True, True, False)
>>> import math
>>> [bool(x) for x in [0, 1.2, 0.5, math.inf, math.nan]]
[False, True, True, True, True]
因为无穷大和 NaN 不等于0,所以它们是真的。
浮点数上的相等和不相等比较是微妙的操作。由于执行bool(x)等同于x != 0,这可能会导致浮点数的惊人结果:
>>> bool(0.1 + 0.2 + (-0.2) + (-0.1)) True >>> 0.1 + 0.2 + (-0.2) + (-0.1) 2.7755575615628914e-17浮点数计算可能不精确。正因为如此,
bool()对浮点数的结果可能会令人惊讶。Python 在标准库中有更多的数字类型,它们遵循相同的规则。对于非内置数值类型,
bool(x)也等同于x != 0。fractions模块在标准库中。像其他数字类型一样,唯一的假分数是0/1:
>>> import fractions
>>> bool(fractions.Fraction("1/2")), bool(fractions.Fraction("0/1"))
(True, False)
与整数和浮点数一样,分数只有在等于0时才是假的。
decimal模块也在标准库中。类似地,只有当小数等于0时,它们才是假的:
>>> import decimal, math >>> with decimal.localcontext(decimal.Context(prec=3)) as ctx: ... bool(ctx.create_decimal(math.pi) - ctx.create_decimal(22)/7) ... False >>> with decimal.localcontext(decimal.Context(prec=4)) as ctx: ... bool(ctx.create_decimal(math.pi) - ctx.create_decimal(22)/7) ... True数字
22 / 7是圆周率小数点后两位的近似值。这个事实在公元前三世纪由阿基米德讨论过。用这个精度计算22 / 7和圆周率之差,结果是 falsy。当以更高的精度计算差值时,差值不等于0,真值也不等于。布尔值序列
一般来说,当
len()的结果为0时,拥有len()的对象将为假。不管它们是列表、元组、集合、字符串还是字节字符串:
>>> bool([1]), bool([])
(True, False)
>>> bool((1,2)), bool(())
(True, False)
>>> bool({1,2,3}), bool(set())
(True, False)
>>> bool({1: 2}), bool({})
(True, False)
>>> bool("hello"), bool("")
(True, False)
>>> bool(b"xyz"), bool(b"")
(True, False)
所有具有长度的内置 Python 对象都遵循这一规则。稍后,对于非内置对象,您将看到该规则的一些例外。
其他类型为布尔值
除非类型有一个len()或者明确定义它们是真还是假,否则它们总是真的。对于内置类型和用户定义类型来说都是如此。特别是,函数总是真实的:
>>> def func(): ... pass ... >>> bool(func) True方法也总是真理。如果在调用函数或方法时缺少括号,您可能会遇到这种情况:
>>> import datetime
>>> def before_noon():
... return datetime.datetime.now().hour < 12
...
>>> def greet():
... if before_noon:
... print("Good morning!")
... else:
... print("Good evening!")
...
>>> greet()
Good morning!
>>> datetime.datetime.now().hour
20
这可能是由于忘记了括号或者误导性的文档没有提到您需要调用该函数。如果你期望一个 Python 布尔值,但是有一个函数返回一个布尔值,那么它总是真的。
默认情况下,用户定义的类型总是真实的:
>>> class Dummy: ... pass ... >>> bool(Dummy()) True创建一个空类会使该类的每个对象都变得真实。除非定义了特殊的方法,否则所有的对象都是真的。如果你想创建你的类 falsy 的一些实例,你可以定义
.__bool__():
>>> class BoolLike:
... am_i_truthy = False
... def __bool__(self):
... return self.am_i_truthy
...
>>> x = BoolLike()
>>> bool(x)
False
>>> x.am_i_truthy = True
>>> bool(x)
True
你也可以使用.__bool__()让一个物体既不真实也不虚假:
>>> class ExcludedMiddle: ... def __bool__(self): ... raise ValueError("neither") ... >>> x = ExcludedMiddle() >>> bool(x) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in __bool__ ValueError: neither >>> if x: ... print("x is truthy") ... else: ... print("x is falsy") ... Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in __bool__ ValueError: neither
if语句也使用了.__bool__()。它这样做是为了评估对象是真还是假,从而确定执行哪个分支。如果在一个类上定义了
__len__方法,那么它的实例就有一个len()。在这种情况下,当实例的长度为0时,实例的布尔值将为 falsy:
>>> class DummyContainer:
... my_length = 0
... def __len__(self):
... return self.my_length
...
>>> x = DummyContainer()
>>> bool(x)
False
>>> x.my_length = 5
>>> bool(x)
True
在这个例子中,len(x)在赋值前返回0,赋值后返回5。然而,反之则不然。定义.__bool__()不会给实例一个长度:
>>> class AlwaysTrue: ... def __bool__(self): ... return True ... >>> class AlwaysFalse: ... def __bool__(self): ... return False ... >>> bool(AlwaysTrue()), bool(AlwaysFalse()) (True, False) >>> len(AlwaysTrue()) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: object of type 'AlwaysTrue' has no len() >>> len(AlwaysFalse()) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: object of type 'AlwaysFalse' has no len()定义
.__bool__()不会使任何一个类的实例有一个len()。当.__bool__()和.__len__()都被定义时,.__bool__()优先:
>>> class BooleanContainer:
... def __len__(self):
... return 100
... def __bool__(self):
... return False
...
>>> x=BooleanContainer()
>>> len(x)
100
>>> bool(x)
False
即使x有100的长度,还是 falsy。
示例:NumPy 数组
上面的例子看起来像是只有当你用 Python 编写一个类来演示边界情况时才会发生的事情。然而,使用 PyPI : NumPy 上最流行的库之一也可能得到类似的结果。
数组和数字一样,是假是真取决于它们和0相比如何:
>>> from numpy import array >>> x = array([0]) >>> len(x) 1 >>> bool(x) False即使
x的长度为1,它仍然是 falsy,因为它的值是0。当数组有多个元素时,有些元素可能是假的,有些可能是真的。在这些情况下,NumPy 将引发一个异常:
>>> from numpy import array
>>> import textwrap
>>> y=array([0, 1])
>>> try:
... bool(y)
... except ValueError as exc:
... print("\n".join(textwrap.wrap(str(exc))))
...
The truth value of an array with more than one element is ambiguous.
Use a.any() or a.all()
这个异常非常冗长,为了便于阅读,代码使用文本处理来换行。
一个更有趣的例子是空数组。你可能想知道这些是否像其他序列一样是假的或真的,因为它们不等于0。正如你在上面看到的,这不是唯一的两个可能的答案。数组也可以拒绝布尔值。
有趣的是,这些选项中没有一个是完全正确的:
>>> bool(array([])) <stdin>:1: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty. False虽然空数组目前是错误的,但是依赖这种行为是危险的。在一些未来的 NumPy 版本中,这将引发一个异常。
运算符和函数
Python 中还有一些地方进行布尔测试。其中之一就是布尔运算符。
操作符
and、or和not接受任何支持布尔测试的值。在not的情况下,它将总是返回一个布尔值:
>>> not 1
False
>>> not 0
True
not的真值表仍然是正确的,但是现在它接受了输入的真实性。
在and和or的情况下,除了短路评估之外,它们还返回停止评估时的值:
>>> 1 and 2 2 >>> 0 and 1 0 >>> 1 or 2 1 >>> 0 or 2 2真值表仍然是正确的,但它们现在定义了结果的真实性,这取决于输入的真实性。例如,当您想给值设置默认值时,这很方便。
假设您有一个名为
summarize()的函数,如果文本太长,它会获取开头和结尾,并在中间添加一个省略号(...)。这在一些无法容纳全文的报告中可能很有用。但是,一些数据集缺少由None表示的值。由于
summarize()假设输入是一个字符串,它将在None失败:
>>> def summarize(long_text):
... if len(long_text) <= 4:
... return long_text
... return long_text[:2] +"..." + long_text[-2:]
...
>>> summarize("hello world")
'he...ld'
>>> summarize("hi")
'hi'
>>> summarize("")
''
>>> summarize(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in summarize
TypeError: object of type 'NoneType' has no len()
>>> for a in ["hello world", "hi", "", None]:
... print("-->", summarize(a or ""))
...
--> he...ld
--> hi
-->
-->
这个例子利用了None的虚假性和or不仅短路而且还返回最后一个待评估值的事实。打印报告的代码将or ""添加到summarize()的参数中。添加or ""有助于您避免仅仅一个小的代码更改就出现错误。
内置函数 all() 和 any() 计算真值和短路,但不返回最后一个要计算的值。all()检查其所有论点是否真实:
>>> all([1, 2, 3]) True >>> all([0, 1, 2]) False >>> all(x / (x - 1) for x in [0, 1]) False在最后一行,
all()没有为1评估x / (x - 1)。既然1 - 1是0,这就多了一个ZeroDivisionError。检查它的任何参数是否正确:
>>> any([1, 0, 0])
True
>>> any([False, 0, 0.0])
False
>>> any(1 / x for x in [1, 0])
True
在最后一行,any()没有为0评估1 / x。
结论
Python Boolean 是一种常用的数据类型,有许多有用的应用。您可以使用布尔运算符,如not、and、or、in、is、==和!=来比较值,并检查成员资格、身份或相等性。您还可以使用带有if语句的布尔测试,根据表达式的真实性来控制程序的流程。
在本教程中,您已经学会了如何:
- 用布尔运算符操作布尔值
- 将布尔值转换为其他类型
- 将其他类型转换为 Python 布尔值
- 使用布尔值编写高效可读的 Python 代码
您现在知道了短路求值是如何工作的,并且认识到了布尔值和if语句之间的联系。这些知识将有助于您理解现有的代码,并避免可能导致您自己的程序出错的常见陷阱。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 布尔:利用真值************
Python、Boto3 和 AWS S3:揭秘
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python,Boto3,AWS S3:去神秘化
亚马逊网络服务(AWS)已经成为云计算的领导者。它的核心组件之一是 S3,由 AWS 提供的对象存储服务。凭借其令人印象深刻的可用性和耐用性,它已成为存储视频、图像和数据的标准方式。您可以将 S3 与其他服务结合起来构建无限可伸缩的应用程序。
Boto3 是用于 AWS 的 Python SDK 的名称。它允许您从 Python 脚本中直接创建、更新和删除 AWS 资源。
如果您以前接触过 AWS,拥有自己的 AWS 帐户,并且希望通过从 Python 代码内部开始使用 AWS 服务来将您的技能提升到一个新的水平,那么请继续阅读。
本教程结束时,您将:
- 自信地直接使用 Python 脚本中的桶和对象
- 知道如何避免使用 Boto3 和 S3 时常见的陷阱
- 从一开始就了解如何设置数据,以避免以后出现性能问题
- 了解如何配置您的对象以利用 S3 的最佳功能
在探索 Boto3 的特性之前,您将首先看到如何在您的机器上配置 SDK。这一步将为您完成本教程的剩余部分做好准备。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
安装
要在您的计算机上安装 Boto3,请转到您的终端并运行以下命令:
$ pip install boto3
你有 SDK。但是,您现在无法使用它,因为它不知道应该连接到哪个 AWS 帐户。
要让它在您的 AWS 帐户上运行,您需要提供一些有效的凭证。如果您已经有一个对 S3 拥有完全权限的 IAM 用户,则可以使用这些用户的凭据(他们的访问密钥和他们的秘密访问密钥),而无需创建新用户。否则,最简单的方法是创建一个新的 AWS 用户,然后存储新的凭证。
要创建一个新用户,进入你的 AWS 账户,然后进入服务并选择 IAM 。然后选择用户,点击添加用户。
给用户一个名称(例如, boto3user )。启用编程访问。这将确保该用户能够使用任何 AWS 支持的 SDK 或进行单独的 API 调用:
为了简单起见,选择预配置的 AmazonS3FullAccess 策略。通过此策略,新用户将能够完全控制 S3。点击下一页:回顾:
选择创建用户:
一个新的屏幕将显示用户生成的凭证。点击下载。csv 按钮制作凭证的副本。您将需要它们来完成您的设置。
现在您有了新用户,创建一个新文件,~/.aws/credentials:
$ touch ~/.aws/credentials
打开文件并粘贴下面的结构。用您下载的新用户凭据填充占位符:
[default] aws_access_key_id = YOUR_ACCESS_KEY_ID aws_secret_access_key = YOUR_SECRET_ACCESS_KEY
保存文件。
现在您已经设置了这些凭证,您有了一个default概要文件,Boto3 将使用它与您的 AWS 帐户进行交互。
还需要设置一个配置:Boto3 应该与之交互的默认区域。您可以查看支持的 AWS 区域的完整表格。选择离你最近的地区。从地区栏中复制您的首选地区。在我的例子中,我使用的是欧盟-西方-1 (爱尔兰)。
创建一个新文件,~/.aws/config:
$ touch ~/.aws/config
添加以下内容并用您复制的region替换占位符:
[default] region = YOUR_PREFERRED_REGION
保存您的文件。
现在,您已经为教程的剩余部分正式设置好了。
接下来,您将看到 Boto3 为您提供的连接 S3 和其他 AWS 服务的不同选项。
客户端对资源
在其核心,Boto3 所做的只是代表你调用 AWS APIs。对于大多数 AWS 服务,Boto3 提供了两种不同的访问这些抽象 API 的方式:
- 客户端:低级服务访问
- 资源:更高级的面向对象的服务访问
你可以使用其中任何一个与 S3 互动。
要连接到底层客户端接口,必须使用 Boto3 的client()。然后传入您想要连接的服务的名称,在本例中是s3:
import boto3
s3_client = boto3.client('s3')
要连接到高级接口,您将遵循类似的方法,但是使用resource():
import boto3
s3_resource = boto3.resource('s3')
您已经成功地连接到两个版本,但现在您可能想知道,“我应该使用哪一个?”
对于客户,有更多的程序性工作要做。大多数客户端操作都会给你一个字典响应。为了获得您需要的确切信息,您必须自己解析该词典。有了资源方法,SDK 就可以为您完成这项工作。
对于客户端,您可能会看到一些轻微的性能改进。缺点是代码的可读性比使用资源时要差。资源提供了更好的抽象,您的代码将更容易理解。
当您考虑选择哪一个时,了解客户端和资源是如何生成的也很重要:
- Boto3 从 JSON 服务定义文件生成客户机。客户端的方法支持与目标 AWS 服务的每一种交互。
- 另一方面,资源是从 JSON 资源定义文件中生成的。
Boto3 从不同的定义中生成客户机和资源。因此,您可能会发现资源不提供客户端支持的操作的情况。有趣的是:您不需要修改代码就可以在任何地方使用客户端。对于该操作,您可以通过资源直接访问客户端,比如:s3_resource.meta.client。
一个这样的client操作是 .generate_presigned_url() ,它允许您的用户在一段设定的时间内访问您的存储桶中的一个对象,而不需要他们拥有 AWS 凭证。
常见操作
现在您已经了解了客户端和资源之间的区别,让我们开始使用它们来构建一些新的 S3 组件。
创建存储桶
首先,你需要一个 S3 桶。要以编程方式创建一个,您必须首先为您的存储桶选择一个名称。请记住,这个名称在整个 AWS 平台上必须是唯一的,因为 bucket 名称是符合 DNS 的。如果您尝试创建一个 bucket,但是另一个用户已经占用了您想要的 bucket 名称,那么您的代码将会失败。您将看到以下错误,而不是成功:botocore.errorfactory.BucketAlreadyExists。
你可以通过选择一个随机的名字来增加你成功的机会。您可以生成自己的函数来完成这项工作。在这个实现中,您将看到如何使用 uuid 模块来帮助您实现这一点。UUID4 的字符串表示长度为 36 个字符(包括连字符),您可以添加一个前缀来指定每个 bucket 的用途。
这里有一种方法可以让你做到:
import uuid
def create_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])
您已经有了自己的 bucket 名称,但是现在还有一件事情需要注意:除非您所在的地区在美国,否则您需要在创建 bucket 时显式地定义这个地区。否则你会得到一个IllegalLocationConstraintException。
为了举例说明当您在美国以外的地区创建 S3 存储桶时这意味着什么,请看下面的代码:
s3_resource.create_bucket(Bucket=YOUR_BUCKET_NAME,
CreateBucketConfiguration={
'LocationConstraint': 'eu-west-1'})
您需要提供一个 bucket 名称和一个 bucket 配置,其中您必须指定区域,在我的例子中是eu-west-1。
这并不理想。假设您想要将代码部署到云中。您的任务将变得越来越困难,因为您现在已经对该区域进行了硬编码。您可以重构该区域,并将其转换为一个环境变量,但这样您就又多了一件需要管理的事情。
幸运的是,通过利用一个会话对象,有一个更好的方法来通过编程获得该区域。Boto3 将从您的凭证中创建session。你只需要把这个区域作为它的LocationConstraint配置传递给create_bucket()。下面是如何做到这一点:
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={
'LocationConstraint': current_region})
print(bucket_name, current_region)
return bucket_name, bucket_response
好的一面是,无论您想在哪里部署它,这段代码都可以工作:locally/EC2/Lambda。此外,您不需要硬编码您的区域。
由于客户机和资源都以相同的方式创建存储桶,所以您可以将其中任何一个作为s3_connection参数传递。
现在,您将创建两个存储桶。首先使用客户端创建一个,这将把bucket_response作为字典返回给您:
>>> first_bucket_name, first_response = create_bucket( ... bucket_prefix='firstpythonbucket', ... s3_connection=s3_resource.meta.client) firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 eu-west-1 >>> first_response {'ResponseMetadata': {'RequestId': 'E1DCFE71EDE7C1EC', 'HostId': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'x-amz-request-id': 'E1DCFE71EDE7C1EC', 'date': 'Fri, 05 Oct 2018 15:00:00 GMT', 'location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/'}然后使用资源创建第二个 bucket,这将返回一个作为
bucket_response的Bucket实例:
>>> second_bucket_name, second_response = create_bucket(
... bucket_prefix='secondpythonbucket', s3_connection=s3_resource)
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644 eu-west-1
>>> second_response
s3.Bucket(name='secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644')
你有你的水桶。接下来,您需要开始向它们添加一些文件。
命名您的文件
您可以使用标准的文件命名约定来命名对象。您可以使用任何有效的名称。在本文中,您将看到一个更具体的案例,帮助您理解 S3 是如何在幕后工作的。
如果你计划在你的 S3 存储桶中存放大量的文件,有一些事情你应该记住。如果您的所有文件名都有一个确定的前缀,这个前缀在每个文件中都重复出现,比如像“YYYY-MM-DDThh:mm:ss”这样的时间戳格式,那么您很快就会发现,当您试图与您的 bucket 进行交互时,会遇到性能问题。
这将会发生,因为 S3 采取了文件的前缀,并将其映射到一个分区。您添加的文件越多,分配给同一个分区的文件就越多,该分区将会非常繁重,响应速度也越慢。
你能做些什么来防止这种情况发生?
最简单的解决方法是随机化文件名。您可以想象许多不同的实现,但是在这种情况下,您将使用可信的uuid模块来帮助实现。为了使本教程的文件名更容易阅读,您将采用生成的数字的前六个字符hex表示,并将其与您的基本文件名连接起来。
下面的 helper 函数允许您传入您希望文件具有的字节数、文件名以及文件的样本内容,以便重复生成所需的文件大小:
def create_temp_file(size, file_name, file_content):
random_file_name = ''.join([str(uuid.uuid4().hex[:6]), file_name])
with open(random_file_name, 'w') as f:
f.write(str(file_content) * size)
return random_file_name
创建您的第一个文件,您很快就会用到它:
first_file_name = create_temp_file(300, 'firstfile.txt', 'f')
通过为文件名添加随机性,您可以在 S3 存储桶中高效地分发数据。
创建Bucket和Object实例
创建文件后的下一步是了解如何将其集成到您的 S3 工作流中。
这就是资源的类发挥重要作用的地方,因为这些抽象使得使用 S3 很容易。
通过使用资源,您可以访问高级类(Bucket和Object)。您可以通过以下方式分别创建一个:
first_bucket = s3_resource.Bucket(name=first_bucket_name)
first_object = s3_resource.Object(
bucket_name=first_bucket_name, key=first_file_name)
您在创建first_object变量时没有看到任何错误的原因是 Boto3 没有调用 AWS 来创建引用。bucket_name和key被称为标识符,它们是创建Object的必要参数。一个Object的任何其他属性,比如它的大小,都是延迟加载的。这意味着 Boto3 要获得请求的属性,必须调用 AWS。
了解子资源
Bucket和Object是彼此的子资源。子资源是创建子资源的新实例的方法。父资源的标识符被传递给子资源。
如果你有一个Bucket变量,你可以直接创建一个Object:
first_object_again = first_bucket.Object(first_file_name)
或者如果你有一个Object变量,那么你可以得到Bucket:
first_bucket_again = first_object.Bucket()
很好,你现在明白如何生成一个Bucket和一个Object。接下来,您将使用这些结构将新生成的文件上传到 S3。
上传文件
有三种方法可以上传文件:
- 从
Object实例 - 从
Bucket实例 - 从
client
在每种情况下,您都必须提供Filename,这是您想要上传的文件的路径。现在,您将探索三种选择。随意挑选你最喜欢的上传first_file_name到 S3。
对象实例版本
您可以使用Object实例上传:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
Filename=first_file_name)
或者您可以使用first_object实例:
first_object.upload_file(first_file_name)
桶实例版本
以下是使用Bucket实例上传的方法:
s3_resource.Bucket(first_bucket_name).upload_file(
Filename=first_file_name, Key=first_file_name)
客户端版本
您也可以使用client上传:
s3_resource.meta.client.upload_file(
Filename=first_file_name, Bucket=first_bucket_name,
Key=first_file_name)
您已经使用三种可用方法中的一种成功地将文件上传到 S3。在接下来的部分中,您将主要使用Object类,因为client和Bucket版本之间的操作非常相似。
下载文件
要从 S3 本地下载文件,您将遵循与上传时类似的步骤。但是在这种情况下,Filename参数将映射到您想要的本地路径。这一次,它会将文件下载到tmp目录:
s3_resource.Object(first_bucket_name, first_file_name).download_file(
f'/tmp/{first_file_name}') # Python 3.6+
您已成功从 S3 下载了您的文件。接下来,您将看到如何使用一个 API 调用在 S3 存储桶之间复制同一个文件。
在桶之间复制对象
如果您需要将文件从一个存储桶复制到另一个存储桶,Boto3 为您提供了这种可能性。在这个例子中,您将使用.copy()将文件从第一个桶复制到第二个桶:
def copy_to_bucket(bucket_from_name, bucket_to_name, file_name):
copy_source = {
'Bucket': bucket_from_name,
'Key': file_name
}
s3_resource.Object(bucket_to_name, file_name).copy(copy_source)
copy_to_bucket(first_bucket_name, second_bucket_name, first_file_name)
注意:如果你的目标是将你的 S3 对象复制到一个不同区域的桶中,看看跨区域复制。
删除对象
让我们通过在等价的Object实例上调用.delete()来从第二个桶中删除新文件:
s3_resource.Object(second_bucket_name, first_file_name).delete()
您现在已经看到了如何使用 S3 的核心操作。在接下来的章节中,你已经准备好将你的知识提升到一个更高的层次,学习更复杂的特征。
高级配置
在这一部分,你将探索更多的 S3 特色。您将看到如何使用它们的示例,以及它们可以为您的应用程序带来的好处。
ACL(访问控制列表)
访问控制列表(ACL)帮助您管理对存储桶和其中的对象的访问。它们被认为是管理 S3 权限的传统方式。你为什么要知道他们?如果您必须管理对单个对象的访问,那么您可以使用对象 ACL。
默认情况下,当您将对象上传到 S3 时,该对象是私有的。如果您希望其他人也可以使用该对象,可以在创建时将该对象的 ACL 设置为公共的。以下是如何将新文件上传到存储桶并让每个人都可以访问它:
second_file_name = create_temp_file(400, 'secondfile.txt', 's')
second_object = s3_resource.Object(first_bucket.name, second_file_name)
second_object.upload_file(second_file_name, ExtraArgs={
'ACL': 'public-read'})
您可以从Object中获得ObjectAcl实例,因为它是其子资源类之一:
second_object_acl = second_object.Acl()
要查看谁有权访问您的对象,请使用grants属性:
>>> second_object_acl.grants [{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}, {'Grantee': {'Type': 'Group', 'URI': 'http://acs.amazonaws.com/groups/global/AllUsers'}, 'Permission': 'READ'}]您可以将对象再次设为私有,而无需重新上传:
>>> response = second_object_acl.put(ACL='private')
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}]
您已经看到了如何使用 ACL 来管理对单个对象的访问。接下来,您将看到如何通过使用加密为您的对象增加一层额外的安全性。
注意:如果你想把你的数据分成多个类别,看看标签。您可以根据对象的标签授予对这些对象的访问权限。
加密
有了 S3,您可以使用加密来保护您的数据。您将探索使用 AES-256 算法的服务器端加密,其中 AWS 管理加密和密钥。
创建一个新文件,并使用ServerSideEncryption上传:
third_file_name = create_temp_file(300, 'thirdfile.txt', 't')
third_object = s3_resource.Object(first_bucket_name, third_file_name)
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256'})
您可以检查用于加密文件的算法,在本例中为AES256:
>>> third_object.server_side_encryption 'AES256'现在,您已经了解了如何使用 AWS 提供的 AES-256 服务器端加密算法为您的对象添加额外的保护层。
存储
您添加到 S3 存储桶的每个对象都与一个存储类相关联。所有可用的存储类别都具有很高的耐用性。您可以根据应用程序的性能访问要求选择存储对象的方式。
目前,您可以将以下存储类别用于 S3:
- 标准:常用数据默认
- STANDARD_IA :针对不常用的数据,需要在请求时快速检索
- ONEZONE_IA :与 STANDARD_IA 使用情形相同,但将数据存储在一个而不是三个可用性区域中
- REDUCED_REDUNDANCY :用于经常使用的、容易复制的非关键数据
如果要更改现有对象的存储类,需要重新创建该对象。
例如,重新加载
third_object并将其存储类设置为Standard_IA:third_object.upload_file(third_file_name, ExtraArgs={ 'ServerSideEncryption': 'AES256', 'StorageClass': 'STANDARD_IA'})注意:如果你对你的对象进行修改,你可能会发现你的本地实例并没有显示它们。此时,您需要做的是调用
.reload()来获取对象的最新版本。重新加载该对象,您可以看到它的新存储类:
>>> third_object.reload()
>>> third_object.storage_class
'STANDARD_IA'
注意:使用生命周期配置在您发现需要时,通过不同的类转移对象。他们会自动为您转换这些对象。
版本控制
您应该使用版本控制来保存一段时间内对象的完整记录。它还可以作为一种保护机制,防止对象被意外删除。当您请求一个版本化的对象时,Boto3 将检索最新版本。
当您添加一个对象的新版本时,该对象占用的总存储量是其版本大小的总和。因此,如果您存储一个 1 GB 的对象,并且您创建了 10 个版本,那么您必须为 10GB 的存储空间付费。
为第一个时段启用版本控制。为此,您需要使用BucketVersioning类:
def enable_bucket_versioning(bucket_name):
bkt_versioning = s3_resource.BucketVersioning(bucket_name)
bkt_versioning.enable()
print(bkt_versioning.status)
>>> enable_bucket_versioning(first_bucket_name) Enabled然后为第一个文件
Object创建两个新版本,一个包含原始文件的内容,另一个包含第三个文件的内容:s3_resource.Object(first_bucket_name, first_file_name).upload_file( first_file_name) s3_resource.Object(first_bucket_name, first_file_name).upload_file( third_file_name)现在重新加载第二个文件,这将创建一个新版本:
s3_resource.Object(first_bucket_name, second_file_name).upload_file( second_file_name)您可以检索对象的最新可用版本,如下所示:
>>> s3_resource.Object(first_bucket_name, first_file_name).version_id
'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'
在本节中,您已经看到了如何使用一些最重要的 S3 属性,并将它们添加到您的对象中。接下来,您将看到如何轻松地遍历您的桶和对象。
旅行记录
如果您需要从所有 S3 资源中检索信息或对其应用操作,Boto3 为您提供了几种迭代遍历存储桶和对象的方法。您将从遍历所有创建的桶开始。
桶遍历
要遍历您帐户中的所有存储桶,您可以使用资源的buckets属性和.all(),这将为您提供Bucket实例的完整列表:
>>> for bucket in s3_resource.buckets.all(): ... print(bucket.name) ... firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644您也可以使用
client来检索 bucket 信息,但是代码更复杂,因为您需要从client返回的字典中提取它:
>>> for bucket_dict in s3_resource.meta.client.list_buckets().get('Buckets'):
... print(bucket_dict['Name'])
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644
您已经看到了如何遍历您帐户中的存储桶。在接下来的部分中,您将选择一个存储桶,并迭代地查看它包含的对象。
对象遍历
如果您想列出一个桶中的所有对象,下面的代码将为您生成一个迭代器:
>>> for obj in first_bucket.objects.all(): ... print(obj.key) ... 127367firstfile.txt 616abesecondfile.txt fb937cthirdfile.txt
obj变量是一个ObjectSummary。这是一个Object的轻量级代表。概要版本不支持Object的所有属性。如果您需要访问它们,使用Object()子资源创建一个对底层存储键的新引用。然后,您将能够提取缺失的属性:
>>> for obj in first_bucket.objects.all():
... subsrc = obj.Object()
... print(obj.key, obj.storage_class, obj.last_modified,
... subsrc.version_id, subsrc.metadata)
...
127367firstfile.txt STANDARD 2018-10-05 15:09:46+00:00 eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv {}
616abesecondfile.txt STANDARD 2018-10-05 15:09:47+00:00 WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6 {}
fb937cthirdfile.txt STANDARD_IA 2018-10-05 15:09:05+00:00 null {}
现在,您可以对存储桶和对象迭代地执行操作。你差不多完成了。在这个阶段,您还应该知道一件事:如何删除您在本教程中创建的所有资源。
删除桶和对象
要删除您创建的所有存储桶和对象,您必须首先确保您的存储桶中没有对象。
删除非空桶
为了能够删除一个存储桶,您必须首先删除存储桶中的每个对象,否则将引发BucketNotEmpty异常。当您有一个版本化的存储桶时,您需要删除每个对象及其所有版本。
如果您发现自动执行此操作的生命周期规则不适合您的需要,以下是您可以通过编程方式删除对象的方法:
def delete_all_objects(bucket_name):
res = []
bucket=s3_resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
print(res)
bucket.delete_objects(Delete={'Objects': res})
无论您是否在您的 bucket 上启用了版本控制,上面的代码都可以工作。如果没有,对象的版本将为空。您可以在一个 API 调用中批量删除多达 1000 个,在您的Bucket实例上使用.delete_objects(),这比单独删除每个对象更划算。
针对第一个存储桶运行新函数,以删除所有版本化对象:
>>> delete_all_objects(first_bucket_name) [{'Key': '127367firstfile.txt', 'VersionId': 'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'}, {'Key': '127367firstfile.txt', 'VersionId': 'UnQTaps14o3c1xdzh09Cyqg_hq4SjB53'}, {'Key': '127367firstfile.txt', 'VersionId': 'null'}, {'Key': '616abesecondfile.txt', 'VersionId': 'WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6'}, {'Key': '616abesecondfile.txt', 'VersionId': 'null'}, {'Key': 'fb937cthirdfile.txt', 'VersionId': 'null'}]作为最后的测试,您可以将一个文件上传到第二个 bucket。该时段没有启用版本控制,因此版本将为空。应用相同的功能删除内容:
>>> s3_resource.Object(second_bucket_name, first_file_name).upload_file(
... first_file_name)
>>> delete_all_objects(second_bucket_name)
[{'Key': '9c8b44firstfile.txt', 'VersionId': 'null'}]
您已经成功地从两个存储桶中移除了所有对象。您现在已经准备好删除存储桶了。
删除存储桶
最后,您将在您的Bucket实例上使用.delete()来移除第一个桶:
s3_resource.Bucket(first_bucket_name).delete()
如果你愿意,你可以使用client版本来删除第二个桶:
s3_resource.meta.client.delete_bucket(Bucket=second_bucket_name)
这两个操作都是成功的,因为您在尝试删除之前清空了每个存储桶。
现在,您已经运行了一些可以用 S3 和 Boto3 执行的最重要的操作。恭喜你走到这一步!作为奖励,让我们探索一下用基础设施作为代码来管理 S3 资源的一些优势。
Python 代码还是基础设施即代码(IaC)?
如你所见,在本教程中,你与 S3 的大部分互动都与物体有关。您没有看到许多与 bucket 相关的操作,例如向 bucket 添加策略,添加生命周期规则以通过存储类转换您的对象,将它们归档到 Glacier 或完全删除它们,或者通过配置 Bucket Encryption 强制加密所有对象。
随着应用程序开始添加其他服务并变得更加复杂,通过 Boto3 的客户端或资源手动管理 buckets 的状态变得越来越困难。要使用 Boto3 监控您的基础设施,请考虑使用基础设施即代码(IaC)工具,如 CloudFormation 或 Terraform 来管理您的应用程序的基础设施。这些工具中的任何一个都将维护您的基础设施的状态,并通知您已经应用的更改。
如果你决定走这条路,请记住以下几点:
- 以任何方式修改存储桶的任何存储桶相关操作都应该通过 IaC 完成。
- 如果您希望所有的对象都以相同的方式运行(例如,全部加密,或者全部公开),通常有一种方法可以直接使用 IaC,通过添加一个 Bucket 策略或者一个特定的 Bucket 属性来实现。
- 桶读取操作,比如遍历桶的内容,应该使用 Boto3 来完成。
- 单个对象级别的对象相关操作应该使用 Boto3 来完成。
结论
祝贺您完成了本教程的最后一课!
现在,您已经准备好开始以编程方式使用 S3 了。您现在知道如何创建对象,将它们上传到 S3,下载它们的内容并直接从脚本中更改它们的属性,同时避免了 Boto3 的常见缺陷。
愿本教程成为您使用 AWS 构建伟大事物之旅的垫脚石!
延伸阅读
如果您想了解更多信息,请查看以下内容:
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Python,Boto3,AWS S3:去神秘化******
你应该更新到最新的 Python 错误修复版本吗?
如果你已经在 Python 社区呆了一段时间,你可能还记得关于 Python 2 和 Python 3 的讨论,或者你可能已经看到了像 Python 3.10 和 Python 3.11 这样的版本,它们在的大张旗鼓中发布。您可能已经注意到 Python 版本有三个数字——例如,3.10.8。在本教程中,您将重点关注 Python 错误修复版本以及第三个数字的重要性。
对于任何开发人员来说,设计一个版本控制方案并解释相应的版本号就是它自己的小艺术形式。一些最流行的系统是日历版本和语义版本。Python 的版本化方案类似于语义版本化,但是有一些重要的区别。
通常,版本号由三个数字组成,通常称为 MAJOR.MINOR.PATCH。三个数字的含义取决于您的版本方案:
-
专业是最重要的数字。在日历版本中,这通常是发布的年份。当存在向后不兼容的变更时,语义版本化方案会引入新的主要版本。Python 最后一次更新主要版本是在 2008 年发布 Python 3时,目前还没有发布 Python 主要版本 4 的具体计划。
-
MINOR 是第二个版本号。这个数字记录了提供一些新功能同时保持与以前版本兼容的常规版本。在 Python 中,次要版本通常被称为特性版本,而可能会删除不推荐使用的特性。Python 社区每年都会发布一个新的特性版本,通常是在十月份。
-
PATCH 是第三个也是最不重要的数字。它有时被命名为微。仅修补程序编号不同的版本通常具有相同的功能。在 Python 中,补丁发布通常被称为错误修复发布、维护发布或安全修复发布。顾名思义,这些版本只会引入 bug 或安全补丁。
在 Python 中,这些数字遵循相当严格的时间表。Python 的每个特性或次要版本都经历相同的生命周期:

该图显示了 Python 3.11、3.12 和 3.13 的生命周期。补丁号跟踪一个版本当前所处的周期。开发在发布日期前大约 17 个月开始:
- 新功能在前 12 个月开发,并以 alpha 版本发布。
- 该版本已经过彻底的测试,并准备在接下来的五个月内发布。 Beta 和发布候选版本在此期间发布。
- Bugfix 版本在功能发布后的十八个月内定期发布。
- 安全补丁版本根据需要发布,直到功能发布五年后。
alpha、beta 和发布候选版本统称为预发布版本。对于每个功能发布,这些都在开发和测试阶段可用。您应该开始在这些早期版本上测试您的代码,但是您不应该在这些版本上运行必要的服务。
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。
在本教程中,您将重点关注错误修复和安全修复发布版本。虽然 Python 的新特性版本引起了一些关注,因为它们向该语言引入了新特性,但 3.11.0 和 3.11.1 之间的差异可能更难发现。是否应该更新到 Python 的最新 bugfix 版本?
简而言之:是的,尤其是在脆弱的生产系统中
保持您正在使用的 Python 特性版本的最新维护版本是一个好主意!
在特定的上下文和用例中,这甚至更为关键。和所有大型软件系统一样,Python 也有bug。其中很少会影响到您,但有时会发现并修复一个漏洞。如果你处理敏感数据或者某个系统暴露给可能有不良企图的用户,那么你一定要及时更新最新的 bugfix 版本来保护你自己和你的用户。
注意:你不需要跟上 Python 最新的特性发布才安全。Python 的所有版本都支持五年,并在此期间接受安全修复。
如果您没有更新到最新的维护版本,那么您不会错过 Python 的任何新特性。这些都是在功能发布中添加的。所以,你应该考虑的主要问题是你的系统有多暴露和脆弱。如果您的系统可能会受到攻击,导致严重后果,那么您需要一个过程来确保您的环境尽可能健壮。
你应该通过一个自动化的持续集成系统来管理你的项目,这个系统会对你所有的更新进行测试。要获得关于 Python 新的 bug 修正版本的提醒,你可以关注 Python Discourse 上的发布帖子,或者订阅 Python 公告邮件列表。
错误修复版本将只包含错误和安全修复。您很可能不会感受到同一个特性发布的两个版本之间的任何差异。如果您在运行代码时没有遇到任何潜在的 Python 错误,也没有接触到外部世界,那么总是使用最新的维护版本就不那么紧迫了。
注意: Bugfix 和安全补丁发布本质上是一样的。在功能发布后的前十八个月发布的维护版本被称为错误修复版本。它们大约每两个月发布一次,并与特定于操作系统的安装程序打包在一起。前 18 个月之后发布的版本是安全补丁版本。这些只在需要的时候发布,并且只以源代码的形式发布。
也就是说,即使安全问题的风险和后果在你的爱好项目中较小,使用最新的安全版本的 Python 仍然是一个好习惯。理想情况下,您应该找到一个工作流,它可以方便地运行不同版本的 Python 并更新到新版本。
如何方便地跟上新版本?
如何将生产系统更新到最新的 bugfix 版本取决于您的设置。理想情况下,您可以在配置文件中更改版本号,然后重新运行您的测试。
在本节中,您将看到在本地计算机上处理不同版本 Python 的一种可能的工作流。在工作流程中,您应该控制编程设置的两个独立方面:
- 你的 Python 解释器的版本
- 你的 Python 包的版本
一般来说,几个版本的 Python 可以在您的系统上共存。你可以手动管理你的 Python 版本,或者使用像 pyenv 或者 conda 这样的工具。
注意:无论您当前安装的是哪个版本,您都可以安装最新的 bugfix 版本。您不需要首先安装任何中间版本。然而,如果你跳过了发布,那么你应该更加勤奋地测试,因为在你的更新中有更多的变化。
你应该使用虚拟环境来处理你所依赖的 Python 包。当您创建一个虚拟环境时,您将它绑定到一个特定的 Python 版本。因此,为了更新 Python 解释器,您需要一种方便的方法来重新创建您的虚拟环境。
为了确保您的虚拟环境是可复制的,您可以使用一个锁文件,它列出了您所有的依赖项和它们各自的版本。可以手动创建这样的锁文件,但是使用工具通常是更好的选择。同样,你有几个选项,包括 pip-tools 、poems、 conda-lock 和 Pipenv 。
您可以选择并组合适合您的工具。这里有一个使用 pyenv 和 pip-tools 的工作流示例。您需要安装 pyenv 作为一个单独的应用程序,而您可以使用 pip 或 pipx 来安装 pip-tools。
当您开始一个新项目时,您应该为它创建一个单独的项目目录。您将在该项目目录中执行以下所有命令。
首先,在一个名为requirements.in的明文文件中指定您的依赖关系。例如:
# requirements.in
rich
typer
您将只在这个文件中定义您的直接依赖项。一般来说,这里不需要添加任何版本标记。
接下来,使用 pip 工具锁定您的依赖关系:
$ pip-compile requirements.in
运行 pip-tools 会生成requirements.txt,其中包含所有的依赖项,包括间接依赖项:
# requirements.txt
#
# This file is autogenerated by pip-compile with python 3.10
# To update, run:
#
# pip-compile requirements.in
#
click==8.1.3
# via typer
commonmark==0.9.1
# via rich
pygments==2.13.0
# via rich
rich==12.6.0
# via -r requirements.in
typer==0.6.1
# via -r requirements.in
Pip-tools 将每个依赖项固定到一个特定的版本。它还添加了有价值的注释,说明为什么它包含了每个依赖项。当您在requirements.in中添加新的依赖项时,您可以重新运行pip-compile。如果您想将您的依赖项升级到新版本,请运行pip-compile --upgrade。
当您开始一个项目时,您将添加您的需求文件,并且您将持续地维护它,独立于您何时更新 Python 版本。当你安装一个新的 bugfix 版本时,你不需要更新你的依赖关系。相反,您将确保在新的虚拟环境中安装依赖项。
为了更新到最新的维护版本,您将首先使用 pyenv 安装一个新的 Python 版本并激活它:
$ pyenv update
$ pyenv install 3.10.8
$ pyenv local 3.10.8
您可以使用pyenv install --list来查看可用 Python 版本的列表。
接下来,创建或重新创建您的虚拟环境并且激活它:
- 视窗
** Linux + macOS*
PS> python -m venv venv --clear
PS> venv\Scripts\activate
$ python -m venv venv --clear
$ source venv/bin/activate
使用--clear来确保清理您的虚拟环境,即使您已经用旧版本的 Python 创建了它。
最后,将您锁定的依赖项安装到新的虚拟环境中:
(venv) $ python -m pip install -r requirements.txt
如果您总是通过需求文件来添加依赖项,那么您将有信心能够重新创建您的环境。虽然这一原则可能看起来很麻烦,但投资将会得到数倍的回报,并帮助您毫不费力地更新 Python 解释器。
如果您使用其他工具,那么细节会有所不同。但是,您应该能够遵循相同的主要步骤。
更新到 Python 最新的 Bugfix 版本会出什么问题?
Python 维护版本只引入了几种类型的变化。重点是修复 bug 和安全问题。现有功能的行为不应该有任何新的特性或变化。
不过,在更新到新的 Python 版本之后,您应该总是运行您的测试。如果你的爱好项目中没有很多测试,那么至少运行你的代码来确认没有明显的变化。
虽然遇到问题的风险很低,但是有一些可能的情况您应该知道。
Python 是一个复杂的软件,有时修复一个错误会引入另一个错误。一些错误修复版本可能包含意外的回归。例如, Python 3.10.3 引入了一个 bug ,使得 Python 在一个旧的红帽企业版 Linux 上无法使用。
Python 的核心团队处理了回归,并比计划提前发布了 Python 3.10.4 。
注意: Python 的变更日志详细描述了每个版本中的所有变更。
有时候,你可能会无意识地依赖 Python 中一个 bug 的行为。如果这个错误被修复,那么你会发现你的代码停止工作。在这种情况下,您需要更新您的代码。不去管你的代码,而是停止更新 Python,这可能很有诱惑力。这样做在短期内会奏效,但这不是一个可持续的解决方案。
虽然很少发生,但有时安全补丁会影响您的代码。例如, Python 3.10.7 不允许非常大的整数在字符串和整数类型之间转换。Python 引入了补丁来防止某种攻击。然而,这也意味着在 Python 早期版本中有效的一些代码不再有效。
在一个 bugfix 版本中做出如此重大的改变是有争议的,并不经常发生。如果你的项目被这样的改变影响了,那就不好玩了。不过,您最好的选择是更新您的代码,以继续使用最新的 bugfix 版本。
Python 维护版本互相兼容吗?
如上所述,在 bugfix 版本中没有添加或删除新功能。因此,在给定 Python 版本的所有维护版本中,您的代码通常应该是相同的。
此外,CPython 用于与 C 扩展通信的应用二进制接口 (ABI)在所有 bugfix 版本中都是稳定的。这种稳定性意味着在更新 bugfix 版本时,您可以使用第三方库的同一个轮子。换句话说,您不需要更新您的需求文件。
您是否也应该更新到最新的功能版本?
更新到 Python 的最新功能版本与更新到最新维护版本是非常不同的考虑事项。幸运的是,您可以彼此独立地做出这些决定。即使您使用较旧的功能版本,也可以确保使用该版本的最新 bugfix 版本。
新功能版本引入了新功能,淘汰并删除了旧功能。因此,如果您升级,您的代码被破坏的风险会更高。在做出改变之前,你应该勤于测试。
注:你可以在酷炫新特性系列教程中了解 Python 各个版本的新特性。
有一个问题可能会阻碍你升级到最新最闪亮的 Python 版本,那就是应用程序二进制接口在 Python 的不同特性版本之间不稳定。实际结果是必须为新版本编译 C 扩展库。可能需要一些时间,您的所有依赖项才能提供与最新版本兼容的轮子。
从安全的角度来看,即使您没有使用最新的功能版本,也完全没有问题。正如你之前看到的,Python 特性版本会在 18 个月内定期更新错误修复,在 5 年内根据需要更新安全修复。
尽管如此,您应该有一个定期更新您的功能版本的计划。特别是,您应该确保您的版本不会在生命周期结束后仍不受支持。
例如,你可以采取一种策略,只要某个功能版本定期更新,就坚持使用它。当它切换到只获取安全补丁时,您就升级到下一个版本。由于 bugfix 版本发布了 18 个月,这意味着您将在它发布后大约 6 个月切换到 Python 的新功能版本。
结论
Python 的 bugfix 发布并没有成为很多头条新闻。虽然大多数乐趣确实发生在功能发布上,但关注低调的定期更新也是一个好主意。如果您了解 Python 的最新版本,您会知道您的解释器包含了所有最新的 bug 和安全修复。
在本教程中,你已经知道你应该更新到最新的 Python bugfix 版本。您已经了解了 bugfix 和 feature 版本之间的区别,并了解了一些如何保持项目最新的策略。
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。******
Python 的 ChainMap:有效管理多个上下文
有时,当您使用几个不同的词典时,您需要将它们作为一个单独的词典进行分组和管理。在其他情况下,您可以拥有多个字典来表示不同的范围或上下文,并且需要将它们作为单个字典来处理,以允许您按照给定的顺序或优先级来访问底层数据。在那些情况下,你可以从 collections模块中利用 Python 的 ChainMap 。
ChainMap以类似字典的行为将多个字典和映射组合在一个可更新的视图中。此外,ChainMap还提供了允许您有效管理各种字典、定义关键字查找优先级等功能。
在本教程中,您将学习如何:
- 在你的 Python 程序中创建
ChainMap实例 - 探索
ChainMap和dict之间的差异 - 使用
ChainMap将几本字典合二为一 - 使用
ChainMap管理键查找优先级
为了从本教程中获得最大收益,你应该知道在 Python 中使用字典和列表的基本知识。
在旅程结束时,您会发现一些实际的例子,它们将帮助您更好地理解ChainMap最相关的特性和用例。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 的ChainMap 入门
Python 的 ChainMap 在 Python 3.3 中被添加到collections中,作为管理多个范围和上下文的便捷工具。这个类允许你将几个字典和其他映射组合在一起,使它们在逻辑上表现得像一个整体。它创建了一个单独的可更新视图,其工作方式类似于常规字典,但有一些内部差异。
ChainMap不会将其映射合并在一起。相反,它将它们保存在内部映射列表中。然后ChainMap在列表顶部重新实现常用的字典操作。由于内部列表保存了对原始输入映射的引用,这些映射中的任何变化都会影响整个ChainMap对象。
将输入映射存储在一个列表中允许在给定的链表中有重复的键。如果您执行键查找,那么ChainMap将搜索映射列表,直到找到目标键的第一个匹配项。如果密钥丢失,那么你照常得到一个 KeyError 。
当您需要管理嵌套的作用域时,将映射存储在一个列表中确实非常有用,其中每个映射代表一个特定的作用域或上下文。
为了更好地理解什么是作用域和上下文,考虑一下 Python 是如何解析名称的。Python 在查找名称时,会在 locals() 、 globals() 中搜索,最后在 builtins 中搜索,直到找到目标名称的第一次出现。如果名字不存在,那么你得到一个NameError。处理范围和上下文是你可以用ChainMap解决的最常见的问题。
当你使用ChainMap时,你可以用不相交或者相交的键来链接几个字典。
在第一种情况下,ChainMap允许您将所有的字典视为一个字典。因此,您可以像使用单个字典一样访问键值对。在第二种情况下,除了将您的字典作为一个字典来管理之外,您还可以利用内部映射列表来为字典中的重复键定义某种类型的访问优先级。这就是为什么ChainMap对象非常适合处理多种上下文。
ChainMap的一个奇怪行为是突变,比如更新、添加、删除、清除和弹出键,只作用于内部映射列表中的第一个映射。下面总结一下ChainMap的主要特点:
- 从几个输入映射构建一个可更新的视图
- 提供了与字典几乎相同的接口,但是增加了一些额外的特性
- 不合并输入映射,而是将它们保存在一个内部公共列表中
- 在输入映射中看到外部变化
- 可以包含具有不同值的重复键
- 在内部映射列表中顺序搜索关键字
- 在搜索了整个映射列表后,当缺少一个键时抛出一个
KeyError - 仅对内部列表中的第一个映射执行突变
在本教程中,你会学到更多关于ChainMap所有这些很酷的特性。下一节将指导您如何在代码中创建新的ChainMap实例。
实例化ChainMap
要在 Python 代码中创建ChainMap,首先需要从collections导入类,然后像往常一样调用它。类初始化器可以接受零个或多个映射作为参数。在没有参数的情况下,它用一个空字典初始化一个链图:
>>> from collections import ChainMap >>> from collections import OrderedDict, defaultdict >>> # Use no arguments >>> ChainMap() ChainMap({}) >>> # Use regular dictionaries >>> numbers = {"one": 1, "two": 2} >>> letters = {"a": "A", "b": "B"} >>> ChainMap(numbers, letters) ChainMap({'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'}) >>> ChainMap(numbers, {"a": "A", "b": "B"}) ChainMap({'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'}) >>> # Use other mappings >>> numbers = OrderedDict(one=1, two=2) >>> letters = defaultdict(str, {"a": "A", "b": "B"}) >>> ChainMap(numbers, letters) ChainMap( OrderedDict([('one', 1), ('two', 2)]), defaultdict(<class 'str'>, {'a': 'A', 'b': 'B'}) )这里,您使用不同的映射组合创建了几个
ChainMap对象。在每种情况下,ChainMap返回所有输入映射的一个类似字典的视图。注意,你可以使用任何类型的映射,比如OrderedDict和defaultdict。你也可以使用类方法
.fromkeys()创建ChainMap对象。这个方法可以接受一个可迭代的键和一个可选的所有键的默认值:
>>> from collections import ChainMap
>>> ChainMap.fromkeys(["one", "two","three"])
ChainMap({'one': None, 'two': None, 'three': None})
>>> ChainMap.fromkeys(["one", "two","three"], 0)
ChainMap({'one': 0, 'two': 0, 'three': 0})
如果您调用ChainMap上的.fromkeys()并把一个可迭代的键作为参数,那么您将得到一个只有一个字典的链表。密钥来自输入 iterable,值默认为 None 。可选地,您可以向.fromkeys()传递第二个参数,为每个键提供一个合理的默认值。
运行类似字典的操作
ChainMap支持与常规字典相同的 API 来访问现有的键。一旦有了ChainMap对象,就可以用字典式的键查找来检索现有的键,或者可以使用 .get() :
>>> from collections import ChainMap >>> numbers = {"one": 1, "two": 2} >>> letters = {"a": "A", "b": "B"} >>> alpha_num = ChainMap(numbers, letters) >>> alpha_num["two"] 2 >>> alpha_num.get("a") 'A' >>> alpha_num["three"] Traceback (most recent call last): ... KeyError: 'three'键查找搜索目标链映射中的所有映射,直到找到所需的键。如果键不存在,那么你得到通常的
KeyError。现在,当您有重复的键时,查找操作会如何表现呢?在这种情况下,您将获得目标键的第一个匹配项:
>>> from collections import ChainMap
>>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3}
>>> vet_treatment = {"dogs": 4, "cats": 3, "turtles": 1}
>>> pets = ChainMap(for_adoption, vet_treatment)
>>> pets["dogs"]
10
>>> pets.get("cats")
7
>>> pets["turtles"]
1
当你访问一个重复的键时,比如"dogs"和"cats",链表只返回那个键的第一次出现。在内部,查找操作按照输入映射在内部映射列表中出现的顺序搜索输入映射,这也是您将它们传递到类的初始化器中的确切顺序。
这个一般行为也适用于迭代:
>>> from collections import ChainMap >>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3} >>> vet_treatment = {"dogs": 4, "cats": 3, "turtles": 1} >>> pets = ChainMap(for_adoption, vet_treatment) >>> for key, value in pets.items(): ... print(key, "->", value) ... dogs -> 10 cats -> 7 turtles -> 1 pythons -> 3
for循环遍历pets中的字典,打印每个键值对的第一次出现。您还可以直接遍历字典,或者像对任何字典一样使用.keys()和.values()遍历字典:
>>> from collections import ChainMap
>>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3}
>>> vet_treatment = {"dogs": 4, "cats": 3, "turtles": 1}
>>> pets = ChainMap(for_adoption, vet_treatment)
>>> for key in pets:
... print(key, "->", pets[key])
...
dogs -> 10
cats -> 7
turtles -> 1
pythons -> 3
>>> for key in pets.keys():
... print(key, "->", pets[key])
...
dogs -> 10
cats -> 7
turtles -> 1
pythons -> 3
>>> for value in pets.values():
... print(value)
...
10
7
1
3
同样,行为是相同的。每次迭代都会遍历底层链表中每个键、项和值的第一次出现。
ChainMap也支持突变。换句话说,它允许您更新、添加、删除和弹出键值对。这种情况下的不同之处在于,这些操作仅作用于第一个映射:
>>> from collections import ChainMap >>> numbers = {"one": 1, "two": 2} >>> letters = {"a": "A", "b": "B"} >>> alpha_num = ChainMap(numbers, letters) >>> alpha_num ChainMap({'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'}) >>> # Add a new key-value pair >>> alpha_num["c"] = "C" >>> alpha_num ChainMap({'one': 1, 'two': 2, 'c': 'C'}, {'a': 'A', 'b': 'B'}) >>> # Update an existing key >>> alpha_num["b"] = "b" >>> alpha_num ChainMap({'one': 1, 'two': 2, 'c': 'C', 'b': 'b'}, {'a': 'A', 'b': 'B'}) >>> # Pop keys >>> alpha_num.pop("two") 2 >>> alpha_num.pop("a") Traceback (most recent call last): ... KeyError: "Key not found in the first mapping: 'a'" >>> # Delete keys >>> del alpha_num["c"] >>> alpha_num ChainMap({'one': 1, 'b': 'b'}, {'a': 'A', 'b': 'B'}) >>> del alpha_num["a"] Traceback (most recent call last): ... KeyError: "Key not found in the first mapping: 'a'" >>> # Clear the dictionary >>> alpha_num.clear() >>> alpha_num ChainMap({}, {'a': 'A', 'b': 'B'})改变给定链映射内容的操作只影响第一个映射,即使您试图改变的键存在于列表中的其他映射中。例如,当您试图在第二个映射中更新
"b"时,实际发生的是您向第一个字典添加了一个新的键。您可以利用这种行为来创建不修改原始输入字典的可更新的链映射。在这种情况下,您可以使用一个空字典作为
ChainMap的第一个参数:
>>> from collections import ChainMap
>>> numbers = {"one": 1, "two": 2}
>>> letters = {"a": "A", "b": "B"}
>>> alpha_num = ChainMap({}, numbers, letters)
>>> alpha_num
ChainMap({}, {'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'})
>>> alpha_num["comma"] = ","
>>> alpha_num["period"] = "."
>>> alpha_num
ChainMap(
{'comma': ',', 'period': '.'},
{'one': 1, 'two': 2},
{'a': 'A', 'b': 'B'}
)
这里,您使用一个空字典({})来创建alpha_num。这确保了您在alpha_num上执行的更改永远不会影响您的两个原始输入词典numbers和letters,并且只会影响列表开头的空词典。
合并与链接字典
作为用ChainMap链接多个字典的替代方法,您可以考虑用 dict.update() 将它们合并在一起:
>>> from collections import ChainMap >>> # Chain dictionaries with ChainMap >>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3} >>> vet_treatment = {"hamsters": 2, "turtles": 1} >>> ChainMap(for_adoption, vet_treatment) ChainMap( {'dogs': 10, 'cats': 7, 'pythons': 3}, {'hamsters': 2, 'turtles': 1} ) >>> # Merge dictionaries with .update() >>> pets = {} >>> pets.update(for_adoption) >>> pets.update(vet_treatment) >>> pets {'dogs': 10, 'cats': 7, 'pythons': 3, 'hamsters': 2, 'turtles': 1}在这个具体的例子中,当您从两个具有惟一键的现有字典构建一个链映射和一个等价字典时,您会得到类似的结果。
用
.update()合并字典和用ChainMap链接字典相比,有利有弊。第一个也是最重要的缺点是,您放弃了使用多个作用域或上下文来管理和优先访问重复键的能力。使用.update(),您为给定键提供的最后一个值将始终有效:
>>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3}
>>> vet_treatment = {"cats": 2, "dogs": 1}
>>> # Merge dictionaries with .update()
>>> pets = {}
>>> pets.update(for_adoption)
>>> pets.update(vet_treatment)
>>> pets
{'dogs': 1, 'cats': 2, 'pythons': 3}
常规词典不能存储重复的键。每当您使用现有键的值调用.update()时,该键就会用新值更新。在这种情况下,您将无法使用不同的作用域来区分访问重复键的优先级。
注意:从 Python 3.5 开始,还可以使用字典解包操作符(** ) 将字典合并在一起。此外,如果您使用的是 Python 3.9 ,那么您可以使用字典联合操作符(|)将两个字典合并成一个新字典。
现在假设您有 n 个不同的映射,每个映射最多有 m 个键。从它们创建一个ChainMap对象将花费 O ( n ) 的执行时间,而在最坏的情况下,检索一个键将花费 O ( n ),其中目标键在内部映射列表的最后一个字典中。
或者,在一个循环中使用.update()创建一个常规字典将花费 O ( nm ),而从最终字典中检索一个键将花费 O (1)。
结论是,如果您经常创建字典链,并且每次只执行一些键查找,那么您应该使用ChainMap。如果反过来,那么使用常规字典,除非你需要重复的键或多个作用域。
合并和链接字典之间的另一个区别是,当您使用ChainMap时,输入字典中的外部变化会影响底层的链,而合并字典则不是这种情况。
探索ChainMap的附加特性
提供了与普通 Python 字典基本相同的 API 和特性,还有一些你已经知道的细微差别。ChainMap还支持一些特定于其设计和目标的附加特性。
在本节中,您将了解所有这些附加功能。您将了解当您访问字典中的键值对时,它们如何帮助您管理不同的范围和上下文。
使用.maps 管理映射列表
ChainMap将所有输入映射存储在一个内部列表中。这个列表可以通过一个名为 .maps 的公共实例属性来访问,并且是用户可更新的。.maps中映射的顺序与您将它们传递给ChainMap的顺序相匹配。当您执行键查找操作时,该顺序定义了搜索顺序。
以下是如何访问.maps的示例:
>>> from collections import ChainMap >>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3} >>> vet_treatment = {"dogs": 4, "turtles": 1} >>> pets = ChainMap(for_adoption, vet_treatment) >>> pets.maps [{'dogs': 10, 'cats': 7, 'pythons': 3}, {'dogs': 4, 'turtles': 1}]这里,您使用
.maps来访问pets保存的内部映射列表。该列表是一个常规的 Python 列表,因此您可以手动添加和移除映射、遍历列表、更改映射的顺序等等:
>>> from collections import ChainMap
>>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3}
>>> vet_treatment = {"cats": 1}
>>> pets = ChainMap(for_adoption, vet_treatment)
>>> pets.maps.append({"hamsters": 2})
>>> pets.maps
[{'dogs': 10, 'cats': 7, 'pythons': 3}, {"cats": 1}, {'hamsters': 2}]
>>> del pets.maps[1]
>>> pets.maps
[{'dogs': 10, 'cats': 7, 'pythons': 3}, {'hamsters': 2}]
>>> for mapping in pets.maps:
... print(mapping)
...
{'dogs': 10, 'cats': 7, 'pythons': 3}
{'hamsters': 2}
在这些例子中,首先使用 .append() 向.maps添加一个新的字典。然后使用del 关键字删除位置1处的词典。您可以像管理任何常规 Python 列表一样管理.maps。
注意:内部映射列表.maps,将总是包含至少一个映射。例如,如果您使用没有参数的ChainMap()创建一个空的链表,那么这个列表将存储一个空的字典。
在对所有映射执行操作时,您可以使用.maps来迭代这些映射。遍历映射列表的可能性允许您对每个映射执行不同的操作。使用此选项,您可以解决仅变更列表中第一个映射的默认行为。
一个有趣的例子是,您可以使用 .reverse() 反转当前映射列表的顺序:
>>> from collections import ChainMap >>> for_adoption = {"dogs": 10, "cats": 7, "pythons": 3} >>> vet_treatment = {"cats": 1} >>> pets = ChainMap(for_adoption, vet_treatment) >>> pets ChainMap({'dogs': 10, 'cats': 7, 'pythons': 3}, {'cats': 1}) >>> pets.maps.reverse() >>> pets ChainMap({'cats': 1}, {'dogs': 10, 'cats': 7, 'pythons': 3})反转内部映射列表允许您在链表中查找给定的键时反转搜索顺序。现在,当你寻找
"cats"时,你得到的是接受兽医治疗的猫的数量,而不是准备被收养的猫的数量。用
.new_child()添加新的子上下文
ChainMap亦作.new_child()。该方法可选地将一个映射作为参数,并返回一个新的ChainMap实例,该实例包含输入映射,后跟底层链映射中的所有当前映射:
>>> from collections import ChainMap
>>> mom = {"name": "Jane", "age": 31}
>>> dad = {"name": "John", "age": 35}
>>> family = ChainMap(mom, dad)
>>> family
ChainMap({'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35})
>>> son = {"name": "Mike", "age": 0}
>>> family = family.new_child(son)
>>> for person in family.maps:
... print(person)
...
{'name': 'Mike', 'age': 0}
{'name': 'Jane', 'age': 31}
{'name': 'John', 'age': 35}
这里,.new_child()返回一个新的ChainMap对象,包含一个新的映射son,后面跟着旧的映射mom和dad。请注意,新映射现在位于内部映射列表的第一个位置.maps。
使用.new_child(),您可以创建一个子上下文,您可以在不改变任何现有映射的情况下更新它。例如,如果您不带参数调用.new_child(),那么它将使用一个空字典,并将它放在.maps的开头。在这之后,您可以对新的空映射执行任何变化,保持映射的其余部分为只读。
跳过带有.parents和的子上下文
ChainMap的另一个有趣的特点是 .parents 。这个属性返回一个新的ChainMap实例,其中包含底层链表中除第一个映射之外的所有映射。当您在给定的链映射中搜索关键点时,此功能对于跳过第一个映射很有用:
>>> from collections import ChainMap >>> mom = {"name": "Jane", "age": 31} >>> dad = {"name": "John", "age": 35} >>> son = {"name": "Mike", "age": 0} >>> family = ChainMap(son, mom, dad) >>> family ChainMap( {'name': 'Mike', 'age': 0}, {'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35} ) >>> family.parents ChainMap({'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35})在这个例子中,您使用
.parents跳过包含儿子数据的第一个字典。在某种程度上,.parents与.new_child()正好相反。前者删除一个字典,而后者向列表的开头添加一个新字典。在这两种情况下,您都会得到一个新的链图。用
ChainMap管理范围和上下文可以说,
ChainMap的主要用例是提供一种有效的方式来管理多个作用域或上下文,并处理复制键的访问优先级。当您有几个存储重复键的字典,并且希望定义代码访问它们的顺序时,此功能非常有用。在
ChainMap文档中,你会发现一个经典的例子,它模拟了 Python 如何解析不同名称空间中的变量名。当 Python 寻找一个名称时,它会依次搜索本地、全局和内置范围,遵循相同的顺序,直到找到目标名称。Python 范围是将名称映射到对象的字典。
要模拟 Python 的内部查找链,可以使用链图:
>>> import builtins
>>> # Shadow input with a global name
>>> input = 42
>>> pylookup = ChainMap(locals(), globals(), vars(builtins))
>>> # Retrieve input from the global namespace
>>> pylookup["input"]
42
>>> # Remove input from the global namespace
>>> del globals()["input"]
>>> # Retrieve input from the builtins namespace
>>> pylookup["input"]
<built-in function input>
在这个例子中,首先创建一个名为input的全局变量,它隐藏了 builtins 范围内的内置 input() 函数。然后创建pylookup作为包含三个字典的链式映射,这三个字典包含每个 Python 范围。
当您从pylookup中检索input时,您从全局范围中获得值42。如果您从globals()字典中移除input键并再次访问它,那么您将从builtins范围中获得内置的input()函数,它在 Python 的查找链中具有最低的优先级。
类似地,您可以使用ChainMap来定义和管理重复键的键查找顺序。这使您可以优先访问所需的复制键实例。
标准库中的跟踪ChainMap
ChainMap的由来与 ConfigParser 中的一个性能问题密切相关,它存在于标准库中的 configparser 模块中。有了ChainMap,核心 Python 开发者通过优化 ConfigParser.get() 的实现,大幅提升了这个模块整体的性能。
你也可以在 string 模块中找到ChainMap作为 Template 的一部分。这个类将一个字符串模板作为参数,并允许您执行字符串替换,如 PEP 292 中所述。输入字符串模板包含嵌入的标识符,稍后您可以用实际值替换这些标识符:
>>> import string >>> greeting = "Hey $name, welcome to $place!" >>> template = string.Template(greeting) >>> template.substitute({"name": "Jane", "place": "the World"}) 'Hey Jane, welcome to the World!'当您通过字典为
name和place提供值时,.substitute()会在模板字符串中替换它们。此外,.substitute()可以将值作为关键字参数(**kwargs,这在某些情况下会导致名称冲突:
>>> import string
>>> greeting = "Hey $name, welcome to $place!"
>>> template = string.Template(greeting)
>>> template.substitute(
... {"name": "Jane", "place": "the World"},
... place="Real Python"
... )
'Hey Jane, welcome to Real Python!'
在本例中,.substitute()用您作为关键字参数提供的值替换place,而不是输入字典中的值。如果您稍微深入研究一下这个方法的代码,那么您会看到当名称冲突发生时,它使用ChainMap来有效地管理输入值的优先级。
下面是来自.substitute()的源代码片段:
# string.py
# Snip...
from collections import ChainMap as _ChainMap
_sentinel_dict = {}
class Template:
"""A string class for supporting $-substitutions."""
# Snip...
def substitute(self, mapping=_sentinel_dict, /, **kws):
if mapping is _sentinel_dict:
mapping = kws
elif kws:
mapping = _ChainMap(kws, mapping) # Snip...
在这里,突出显示的行具有魔力。它使用一个链式映射,该映射将两个字典kws和mapping作为参数。通过将kws作为第一个参数,该方法为输入数据中的重复标识符设置优先级。
将 Python 的ChainMap付诸行动
到目前为止,您已经学会了如何使用ChainMap将多个词典合二为一。您还了解了ChainMap的特性,以及这个类与普通字典的不同之处。ChainMap的用例相当具体。它们包括:
- 在一个视图中有效地将多个字典分组
- 以某个优先级搜索多个字典
- 提供一系列默认值并管理它们的优先级
- 提高频繁计算字典的子集的代码的性能
在这一节中,您将编写一些实际的例子,帮助您更好地理解如何使用ChainMap来解决现实世界中的问题。
一次访问多个存货
您将编写的第一个示例使用ChainMap在单个视图中高效地搜索多个字典。在这种情况下,您会假设有一堆独立的字典,它们之间有唯一的键。
假设你正在经营一家出售水果和蔬菜的商店。您已经编写了一个 Python 应用程序来管理您的库存。该应用程序从数据库中读取数据,并返回两本分别包含水果和蔬菜价格数据的字典。您需要一种有效的方法在单个字典中对这些数据进行分组和管理。
经过一些研究后,您最终使用了ChainMap:
>>> from collections import ChainMap >>> fruits_prices = {"apple": 0.80, "grape": 0.40, "orange": 0.50} >>> veggies_prices = {"tomato": 1.20, "pepper": 1.30, "onion": 1.25} >>> prices = ChainMap(fruits_prices, veggies_prices) >>> order = {"apple": 4, "tomato": 8, "orange": 4} >>> for product, units in order.items(): ... price = prices[product] ... subtotal = units * price ... print(f"{product:6}: ${price:.2f} × {units} = ${subtotal:.2f}") ... apple : $0.80 × 4 = $3.20 tomato: $1.20 × 8 = $9.60 orange: $0.50 × 4 = $2.00在这个例子中,您使用一个
ChainMap来创建一个类似字典的对象,该对象将来自fruits_prices和veggies_prices的数据进行分组。这允许您访问底层数据,就像您实际上有一个字典一样。for循环遍历给定order中的产品。然后,它计算每种产品的支付小计,并将其打印在屏幕上。您可能会想到在新的字典中对数据进行分组,在循环中使用
.update()。当你的产品种类有限,库存很少的时候,这种方式就很好了。然而,如果你管理许多不同类型的产品,那么与ChainMap相比,使用.update()来构建一个新字典可能是低效的。使用
ChainMap解决这类问题还可以帮助你定义不同批次产品的优先级,让你以先进先出( FIFO )的方式管理你的库存。排列命令行应用程序设置的优先级
ChainMap特别有助于管理应用程序中的默认配置值。正如您已经知道的,ChainMap的一个主要特性是它允许您为键查找操作设置优先级。这听起来像是解决应用程序中管理配置问题的正确工具。例如,假设您正在开发一个命令行界面(CLI) 应用程序。该应用程序允许用户指定连接到互联网的代理服务。设置优先级包括:
- 命令行选项(
--proxy、-p)- 用户主目录中的本地配置文件
- 系统范围的代理配置
如果用户在命令行提供代理,那么应用程序必须使用该代理。否则,应用程序应该使用下一个配置对象中提供的代理,依此类推。这是
ChainMap最常见的用例之一。在这种情况下,您可以执行以下操作:
>>> from collections import ChainMap
>>> cmd_proxy = {} # The user doesn't provide a proxy
>>> local_proxy = {"proxy": "proxy.local.com"}
>>> system_proxy = {"proxy": "proxy.global.com"}
>>> config = ChainMap(cmd_proxy, local_proxy, system_proxy)
>>> config["proxy"]
'proxy.local.com'
ChainMap允许您为应用程序的代理配置定义适当的优先级。一个键查找搜索cmd_proxy,然后是local_proxy,最后是system_proxy,返回当前键的第一个实例。在这个例子中,用户没有在命令行提供代理,所以应用程序从列表中下一个设置提供者local_proxy那里获取代理。
管理默认参数值
ChainMap的另一个用例是管理方法和函数中的默认参数值。假设您正在编写一个应用程序来管理公司员工的数据。您有以下代表一般用户的类:
class User:
def __init__(self, name, user_id, role):
self.name = name
self.user_id = user_id
self.role = role
# Snip...
在某些时候,你需要添加一个特性,允许员工访问一个 CRM 系统的不同组件。您首先想到的是修改User来添加新功能。然而,这可能会使类过于复杂,所以您决定创建一个子类CRMUser,来提供所需的功能。
该类将用户name和 CRM component作为参数。这也需要一些 **kwargs 。你想以一种方式实现CRMUser,允许你为基类的初始化器提供合理的默认值,同时又不失去**kwargs的灵活性。
以下是如何使用ChainMap解决问题:
from collections import ChainMap
class CRMUser(User):
def __init__(self, name, component, **kwargs):
defaults = {"user_id": next(component.user_id), "role": "read"}
super().__init__(name, **ChainMap(kwargs, defaults))
在这个代码示例中,您创建了一个User的子类。在类初始化器中,你把name、component和**kwargs作为参数。然后您创建一个本地字典,其中包含user_id和role的默认值。然后你用 super() 调用父类的 .__init__() 方法。在这个调用中,您将name直接传递给父类的初始化器,并使用一个链表为其余的参数提供默认值。
注意,ChainMap对象接受kwargs和defaults作为参数。这个顺序保证了在实例化类时,手动提供的参数(kwargs)优先于defaults值。
结论
Python 的collections模块中的ChainMap提供了一个有效的工具,可以将几个字典作为一个字典来管理。当您有多个字典表示不同的范围或上下文并且需要设置底层数据的访问优先级时,这个类非常方便。
在一个可更新的视图中对多个字典和映射进行分组,其工作方式非常类似于字典。您可以使用ChainMap对象有效地使用几个字典,定义键查找优先级,并管理 Python 中的多个上下文。
在本教程中,您学习了如何:
- 在你的 Python 程序中创建
ChainMap实例 - 探索
ChainMap和dict之间的差异 - 使用
ChainMap将几个字典作为一个进行管理 - 用
ChainMap设置键查找操作的优先级
在本教程中,您还编写了一些实际例子,帮助您更好地理解何时以及如何在 Python 代码中使用ChainMap。*****
Python 类构造器:控制对象实例化
*立即观看**本教程有真实 Python 团队创建的相关视频课程。一起看书面教程加深理解: 使用 Python 类构造函数
类构造函数是 Python 中面向对象编程的基础部分。它们允许您创建并正确初始化给定类的对象,使这些对象随时可用。类构造函数在内部触发 Python 的实例化过程,该过程贯穿两个主要步骤:实例创建和实例初始化。
如果您想更深入地了解 Python 内部如何构造对象,并学习如何定制这个过程,那么本教程就是为您准备的。
在本教程中,您将:
- 了解 Python 内部的实例化过程
- 自定义对象初始化使用
.__init__() - 通过覆盖
.__new__()微调对象创建
有了这些知识,您将能够在自定义 Python 类中调整对象的创建和初始化,这将使您能够在更高级的层次上控制实例化过程。
为了更好地理解本教程中的例子和概念,你应该熟悉 Python 中的面向对象编程和特殊方法。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
Python 的类构造器和实例化过程
像许多其他编程语言一样,Python 支持面向对象编程。在 Python 面向对象功能的核心,您会发现 class 关键字,它允许您定义自定义类,这些类可以具有用于存储数据的属性和用于提供行为的方法。
一旦你有了一个要处理的类,那么你就可以开始创建这个类的新的实例或对象,这是一种在你的代码中重用功能的有效方法。
创建和初始化给定类的对象是面向对象编程的基本步骤。这一步通常被称为对象构造或实例化。负责运行这个实例化过程的工具通常被称为类构造器。
了解 Python 的类构造函数
在 Python 中,要构造一个给定类的对象,只需要调用带有适当参数的类,就像调用任何函数一样:
>>> class SomeClass: ... pass ... >>> # Call the class to construct an object >>> SomeClass() <__main__.SomeClass object at 0x7fecf442a140>在这个例子中,您使用关键字
class定义了SomeClass。此类当前为空,因为它没有属性或方法。相反,类的主体只包含一个pass语句作为占位符语句,它什么也不做。然后通过调用带有一对括号的类来创建一个新的
SomeClass实例。在这个例子中,您不需要在调用中传递任何参数,因为您的类还不接受参数。在 Python 中,当您像上面的例子那样调用一个类时,您调用的是类构造函数,它通过触发 Python 的内部实例化过程来创建、初始化并返回一个新的对象。
最后要注意的一点是,调用一个类不同于调用一个类的实例。这是两个不同且不相关的话题。要使一个类的实例可调用,需要实现一个
.__call__()的特殊方法,这个方法与 Python 的实例化过程无关。了解 Python 的实例化过程
每当调用 Python 类来创建新实例时,就会触发 Python 的实例化过程。该过程通过两个独立的步骤运行,可以描述如下:
- 创建目标类的新实例
- 用适当的初始状态初始化新实例
运行第一步,Python 类有一个特殊的方法叫做
.__new__(),负责创建并返回一个新的空对象。然后另一个特殊的方法,.__init__(),接受结果对象,以及类构造函数的参数。
.__init__()方法将新对象作为其第一个参数self。然后,它使用类构造函数传递给它的参数将任何必需的实例属性设置为有效状态。简而言之,Python 的实例化过程从调用类构造函数开始,它触发实例创建器、
.__new__(),创建一个新的空对象。这个过程继续使用实例初始化器、.__init__(),它接受构造函数的参数来初始化新创建的对象。为了探究 Python 的实例化过程在内部是如何工作的,出于演示的目的,考虑下面这个实现了定制版本的
.__new__()和.__init__()两种方法的Point类的例子:1# point.py 2 3class Point: 4 def __new__(cls, *args, **kwargs): 5 print("1\. Create a new instance of Point.") 6 return super().__new__(cls) 7 8 def __init__(self, x, y): 9 print("2\. Initialize the new instance of Point.") 10 self.x = x 11 self.y = y 12 13 def __repr__(self) -> str: 14 return f"{type(self).__name__}(x={self.x}, y={self.y})"下面是这段代码的详细内容:
第 3 行使用
class关键字后跟类名来定义Point类。第 4 行定义了
.__new__()方法,该方法将类作为其第一个参数。注意,使用cls作为这个参数的名称是 Python 中的一个强约定,就像使用self来命名当前实例一样。该方法还采用了*args和**kwargs,允许向底层实例传递未定义数量的初始化参数。第 5 行 在
.__new__()运行对象创建步骤时打印一条消息给。第 6 行用
cls作为参数调用父类的.__new__()方法来创建一个新的Point实例。在这个例子中,object是父类,调用super()可以访问它。然后返回实例。这个实例将是.__init__()的第一个参数。第 8 行定义了
.__init__(),负责初始化步骤。该方法采用名为self的第一个参数,它保存了对当前实例的引用。该方法还需要两个额外的参数,x和y。这些参数保存实例属性.x和.y的初始值。您需要在对Point()的调用中为这些参数传递合适的值,稍后您将了解到这一点。第 9 行在
.__init__()运行对象初始化步骤时打印一条信息。10 线和 11 线分别初始化
.x和.y。为此,他们使用提供的输入参数x和y。第 13 行和第 14 行实现了
.__repr__()特殊方法,它为您的Point类提供了一个合适的字符串表示。有了
Point,您可以发现实例化过程在实践中是如何工作的。将你的代码保存到一个名为point.py的文件中,然后在命令行窗口中启动你的 Python 解释器。然后运行以下代码:
>>> from point import Point
>>> point = Point(21, 42)
1\. Create a new instance of Point.
2\. Initialize the new instance of Point.
>>> point
Point(x=21, y=42)
调用Point()类构造函数创建、初始化并返回该类的一个新实例。然后这个实例被分配给point 变量。
在本例中,对构造函数的调用还让您了解 Python 内部运行来构造实例的步骤。首先,Python 调用了.__new__(),然后调用了.__init__(),产生了一个新的完全初始化的Point实例,正如您在示例末尾所确认的。
要继续学习 Python 中的类实例化,您可以尝试手动运行这两个步骤:
>>> from point import Point >>> point = Point.__new__(Point) 1\. Create a new instance of Point. >>> # The point object is not initialized >>> point.x Traceback (most recent call last): ... AttributeError: 'Point' object has no attribute 'x' >>> point.y Traceback (most recent call last): ... AttributeError: 'Point' object has no attribute 'y' >>> point.__init__(21, 42) 2\. Initialize the new instance of Point. >>> # Now point is properly initialized >>> point Point(x=21, y=42)在这个例子中,您首先在您的
Point类上调用.__new__(),将类本身作为第一个参数传递给方法。这个调用只运行实例化过程的第一步,创建一个新的空对象。注意,以这种方式创建实例绕过了对.__init__()的调用。注意:上面的代码片段旨在作为实例化过程如何在内部工作的示范示例。这不是你在真实代码中通常会做的事情。
一旦有了新的对象,就可以通过使用一组合适的参数调用
.__init__()来初始化它。在这个调用之后,您的Point对象被正确地初始化,它的所有属性都被设置好了。关于
.__new__()需要注意的一个微妙而重要的细节是,它也可以返回一个不同于实现方法本身的类的实例。当这种情况发生时,Python 不会调用当前类中的.__init__(),因为没有办法明确知道如何初始化不同类的对象。考虑下面的例子,其中
B类的.__new__()方法返回了A类的一个实例:# ab_classes.py class A: def __init__(self, a_value): print("Initialize the new instance of A.") self.a_value = a_value class B: def __new__(cls, *args, **kwargs): return A(42) def __init__(self, b_value): print("Initialize the new instance of B.") self.b_value = b_value因为
B.__new__()返回不同类的实例,所以 Python 不运行B.__init__()。为了确认这种行为,将代码保存到一个名为ab_classes.py的文件中,然后在一个交互式 Python 会话中运行以下代码:
>>> from ab_classes import B
>>> b = B(21)
Initialize the new instance of A.
>>> b.b_value
Traceback (most recent call last):
...
AttributeError: 'A' object has no attribute 'b_value'
>>> isinstance(b, B)
False
>>> isinstance(b, A)
True
>>> b.a_value
42
对B()类构造函数的调用运行B.__new__(),它返回一个A的实例,而不是B。这就是为什么B.__init__()从来不跑。注意b没有.b_value属性。相比之下,b确实有一个值为42的.a_value属性。
现在您已经知道了 Python 内部创建给定类的实例所采取的步骤,您可以更深入地研究一下.__init__()、.__new__()的其他特征,以及它们运行的步骤。
对象初始化用.__init__()
在 Python 中,.__init__()方法可能是您在自定义类中覆盖的最常见的特殊方法。几乎所有的类都需要一个定制的.__init__()实现。重写此方法将允许您正确初始化对象。
这个初始化步骤的目的是让您的新对象处于有效状态,以便您可以在代码中立即开始使用它们。在这一节中,您将学习编写自己的.__init__()方法的基础,以及它们如何帮助您定制您的类。
提供自定义对象初始化器
您可以编写的最基本的.__init__()实现只是负责将输入参数分配给匹配的实例属性。例如,假设您正在编写一个需要.width和.height属性的Rectangle类。在这种情况下,您可以这样做:
>>> class Rectangle: ... def __init__(self, width, height): ... self.width = width ... self.height = height ... >>> rectangle = Rectangle(21, 42) >>> rectangle.width 21 >>> rectangle.height 42正如您之前所学的,
.__init__()在 Python 中运行对象实例化过程的第二步。它的第一个参数self,保存了调用.__new__()得到的新实例。.__init__()的其余参数通常用于初始化实例属性。在上面的例子中,您使用.__init__()的width和height参数初始化了矩形的.width和.height。重要的是要注意,不计算
self,.__init__()的参数与您在调用类构造函数时传递的参数相同。所以,在某种程度上,.__init__()签名定义了类构造函数的签名。
>>> class Rectangle:
... def __init__(self, width, height):
... self.width = width
... self.height = height
... return 42
...
>>> rectangle = Rectangle(21, 42)
Traceback (most recent call last):
...
TypeError: __init__() should return None, not 'int'
在这个例子中,.__init__()方法试图返回一个整数数,最终在运行时引发一个TypeError异常。
上面例子中的错误消息说.__init__()应该返回None。但是,不需要显式返回None,因为没有显式return语句的方法和函数在 Python 中只是隐式返回 None 。
使用上面的.__init__()实现,您可以确保当您使用适当的参数调用类构造函数时,.width和.height被初始化为有效状态。这样,您的矩形将在构建过程完成后立即可用。
在.__init__()中,您还可以对输入参数运行任何转换,以正确初始化实例属性。例如,如果您的用户将直接使用Rectangle,那么您可能希望验证提供的width和height,并在初始化相应的属性之前确保它们是正确的:
>>> class Rectangle: ... def __init__(self, width, height): ... if not (isinstance(width, (int, float)) and width > 0): ... raise ValueError(f"positive width expected, got {width}") ... self.width = width ... if not (isinstance(height, (int, float)) and height > 0): ... raise ValueError(f"positive height expected, got {height}") ... self.height = height ... >>> rectangle = Rectangle(-21, 42) Traceback (most recent call last): ... ValueError: positive width expected, got -21在这个更新的
.__init__()实现中,在初始化相应的.width和.height属性之前,确保输入的width和height参数是正数。如果其中一个验证失败,那么您会得到一个ValueError。注意:处理属性验证的一个更复杂的技术是将属性转化为属性。要了解关于属性的更多信息,请查看 Python 的 property():向您的类添加托管属性。
现在假设您正在使用继承来创建一个定制的类层次结构,并在代码中重用一些功能。如果你的子类提供了一个
.__init__()方法,那么这个方法必须用适当的参数显式调用基类的.__init__()方法,以确保实例的正确初始化。为此,您应该使用内置的super()函数,如下例所示:
>>> class Person:
... def __init__(self, name, birth_date):
... self.name = name
... self.birth_date = birth_date
...
>>> class Employee(Person):
... def __init__(self, name, birth_date, position):
... super().__init__(name, birth_date) ... self.position = position
...
>>> john = Employee("John Doe", "2001-02-07", "Python Developer")
>>> john.name
'John Doe'
>>> john.birth_date
'2001-02-07'
>>> john.position
'Python Developer'
Employee的.__init__()方法中的第一行用name和birth_date作为参数调用super().__init__()。这个调用确保了父类Person中.name和.birth_date的初始化。这种技术允许你用新的属性和功能扩展基类。
总结这一节,您应该知道.__init__()的基本实现来自内置的object类。当您没有在类中提供显式的.__init__()方法时,这个实现会被自动调用。
构建灵活的对象初始化器
通过调整.__init__()方法,可以使对象的初始化步骤灵活多样。为此,最流行的技术之一是使用可选参数。这种技术允许您编写这样的类,其中构造函数在实例化时接受不同的输入参数集。在给定的时间使用哪些参数将取决于您的特定需求和上下文。
举个简单的例子,看看下面的Greeter类:
# greet.py
class Greeter:
def __init__(self, name, formal=False):
self.name = name
self.formal = formal
def greet(self):
if self.formal:
print(f"Good morning, {self.name}!")
else:
print(f"Hello, {self.name}!")
在这个例子中,.__init__()采用一个名为name的常规参数。它还需要一个名为formal的可选参数,默认为False。因为formal有一个缺省值,你可以依靠这个值或者通过提供你自己的值来构造对象。
该类的最终行为将取决于formal的值。如果这个参数是False,那么当你打电话给.greet()时,你会得到一个非正式的问候。否则,你会得到更正式的问候。
要试用Greeter,请将代码保存到一个greet.py文件中。然后在工作目录中打开一个交互式会话,并运行以下代码:
>>> from greet import Greeter >>> informal_greeter = Greeter("Pythonista") >>> informal_greeter.greet() Hello, Pythonista! >>> formal_greeter = Greeter("Pythonista", formal=True) >>> formal_greeter.greet() Good morning, Pythonista!在第一个例子中,通过向参数
name传递一个值并依赖默认值formal来创建一个informal_greeter对象。当你在informal_greeter对象上调用.greet()时,你会在屏幕上得到一个非正式的问候。在第二个例子中,您使用一个
name和一个formal参数来实例化Greeter。因为formal是True,所以叫.greet()的结果是正式的问候。尽管这只是一个玩具示例,但它展示了默认参数值是如何成为一个强大的 Python 特性,可以用来为类编写灵活的初始化器。这些初始化器将允许你根据你的需要使用不同的参数集合来实例化你的类。
好吧!现在你已经知道了
.__init__()和对象初始化步骤的基础,是时候换个方式开始深入.__new__()和对象创建步骤了。用
.__new__()创建对象当编写 Python 类时,通常不需要提供自己的
.__new__()特殊方法的实现。大多数时候,内置object类的基本实现足以构建当前类的空对象。然而,这种方法有一些有趣的用例。例如,可以使用
.__new__()创建不可变类型的子类,如int、float、tuple、str。在接下来的小节中,您将学习如何在您的类中编写自定义的
.__new__()实现。为此,您将编写几个示例,让您知道何时需要重写该方法。提供自定义对象创建者
通常,只有当您需要在较低的级别控制新实例的创建时,您才需要编写一个定制的
.__new__()实现。现在,如果您需要这个方法的自定义实现,那么您应该遵循几个步骤:
- 通过使用适当的参数调用
super().__new__()来创建一个新的实例。- 根据您的具体需求定制新实例。
- 返回新实例继续实例化过程。
通过这三个简洁的步骤,您将能够在 Python 实例化过程中定制实例创建步骤。以下是如何将这些步骤转化为 Python 代码的示例:
class SomeClass: def __new__(cls, *args, **kwargs): instance = super().__new__(cls) # Customize your instance here... return instance这个例子提供了一种
.__new__()的模板实现。像往常一样,.__new__()将当前类作为一个参数,这个参数通常被称为cls。请注意,您正在使用
*args和**kwargs通过接受任意数量的参数来使方法更加灵活和可维护。你应该总是用*args和**kwargs来定义.__new__(),除非你有很好的理由遵循不同的模式。在第一行
.__new__()中,您调用父类的.__new__()方法来创建一个新实例并为其分配内存。要访问父类的.__new__()方法,可以使用super()函数。这一连串的调用将您带到了object.__new__(),它是所有 Python 类的.__new__()的基本实现。注意:内置的
object类是所有 Python 类的默认基类。下一步是定制新创建的实例。您可以做任何需要做的事情来定制手头的实例。最后,在第三步中,您需要返回新的实例,以继续初始化步骤的实例化过程。
需要注意的是,
object.__new__()本身只接受一个单个参数,即要实例化的类。如果你用更多的参数调用object.__new__(),那么你会得到一个TypeError:
>>> class SomeClass:
... def __new__(cls, *args, **kwargs):
... return super().__new__(cls, *args, **kwargs)
... def __init__(self, value):
... self.value = value
...
>>> SomeClass(42)
Traceback (most recent call last):
...
TypeError: object.__new__() takes exactly one argument (the type to instantiate)
在这个例子中,您将*args和**kwargs作为对super().__new__()的调用中的附加参数。底层的object.__new__()只接受类作为参数,所以当你实例化类时,你得到一个TypeError。
然而,如果您的类没有覆盖.__new__(),object.__new__()仍然接受并传递额外的参数给.__init__(),如下面的SomeClass的变体所示:
>>> class SomeClass: ... def __init__(self, value): ... self.value = value ... >>> some_obj = SomeClass(42) >>> some_obj <__main__.SomeClass object at 0x7f67db8d0ac0> >>> some_obj.value 42在
SomeClass的这个实现中,您没有覆盖.__new__()。然后对象创建被委托给object.__new__(),它现在接受value并将其传递给SomeClass.__init__()来完成实例化。现在您可以创建新的完全初始化的SomeClass实例,就像示例中的some_obj一样。酷!现在您已经了解了编写自己的
.__new__()实现的基础,您已经准备好深入一些实际的例子,这些例子展示了 Python 编程中这种方法的一些最常见的用例。不可变内置类型的子类化
首先,您将从
.__new__()的一个用例开始,它由不可变内置类型的子类化组成。举个例子,假设你需要写一个Distance类作为 Python 的float类型的子类。您的类将有一个附加属性来存储用于测量距离的单位。这里是解决这个问题的第一种方法,使用
.__init__()方法:
>>> class Distance(float):
... def __init__(self, value, unit):
... super().__init__(value)
... self.unit = unit
...
>>> in_miles = Distance(42.0, "Miles")
Traceback (most recent call last):
...
TypeError: float expected at most 1 argument, got 2
当你继承一个不可变的内置数据类型时,你会得到一个错误。问题的一部分在于,该值是在创建时设置的,在初始化时更改它已经太晚了。另外,float.__new__()是在幕后调用的,它不像object.__new__()那样处理额外的参数。这就是在您的示例中引起错误的原因。
要解决这个问题,您可以在创建时用.__new__()初始化对象,而不是覆盖.__init__()。下面是你在实践中如何做到这一点:
>>> class Distance(float): ... def __new__(cls, value, unit): ... instance = super().__new__(cls, value) ... instance.unit = unit ... return instance ... >>> in_miles = Distance(42.0, "Miles") >>> in_miles 42.0 >>> in_miles.unit 'Miles' >>> in_miles + 42.0 84.0 >>> dir(in_miles) ['__abs__', '__add__', ..., 'real', 'unit']在本例中,
.__new__()运行您在上一节中学到的三个步骤。首先,该方法通过调用super().__new__()来创建当前类cls的一个新实例。这一次,调用回滚到float.__new__(),它创建一个新的实例,并使用value作为参数初始化它。然后该方法通过添加一个.unit属性来定制新的实例。最后,新的实例被返回。注意:上面例子中的
Distance类没有提供一个合适的单位转换机制。这意味着类似于Distance(10, "km") + Distance(20, "miles")的东西在添加值之前不会尝试转换单位。如果你对转换单位感兴趣,那么在 PyPI 上查看品脱项目。就是这样!现在您的
Distance类按预期工作,允许您使用一个实例属性来存储测量距离的单位。与存储在给定的Distance实例中的浮点值不同,.unit属性是可变的,因此您可以随时更改它的值。最后,注意对dir()函数的调用揭示了您的类是如何从float继承特性和方法的。返回不同类的实例
返回一个不同类的对象是一个需求,这会增加对定制实现
.__new__()的需求。但是,您应该小心,因为在这种情况下,Python 会完全跳过初始化步骤。因此,在代码中使用新创建的对象之前,您有责任将它置于有效状态。看看下面的例子,其中的
Pet类使用.__new__()返回随机选择的类的实例:# pets.py from random import choice class Pet: def __new__(cls): other = choice([Dog, Cat, Python]) instance = super().__new__(other) print(f"I'm a {type(instance).__name__}!") return instance def __init__(self): print("Never runs!") class Dog: def communicate(self): print("woof! woof!") class Cat: def communicate(self): print("meow! meow!") class Python: def communicate(self): print("hiss! hiss!")在这个例子中,
Pet提供了一个.__new__()方法,通过从现有类的列表中随机选择一个类来创建一个新的实例。下面是你如何使用这个
Pet类作为宠物对象的工厂:
>>> from pets import Pet
>>> pet = Pet()
I'm a Dog!
>>> pet.communicate()
woof! woof!
>>> isinstance(pet, Pet)
False
>>> isinstance(pet, Dog)
True
>>> another_pet = Pet()
I'm a Python!
>>> another_pet.communicate()
hiss! hiss!
每次实例化Pet,都会从不同的类中获得一个随机对象。这个结果是可能的,因为对.__new__()可以返回的对象没有限制。以这种方式使用.__new__()将一个类转换成一个灵活而强大的对象工厂,而不局限于它自身的实例。
最后,注意Pet的.__init__()方法是如何从不运行的。这是因为Pet.__new__()总是返回不同类的对象,而不是Pet本身。
在你的类中只允许一个实例
有时您需要实现一个只允许创建单个实例的类。这种类型的类通常被称为单例类。在这种情况下,.__new__()方法就派上了用场,因为它可以帮助您限制给定类可以拥有的实例数量。
注意:大多数有经验的 Python 开发者会说,你不需要在 Python 中实现单例设计模式,除非你已经有了一个工作类,并且需要在其上添加模式的功能。
其他时候,您可以使用模块级的常量来获得相同的单例功能,而不必编写相对复杂的类。
这里有一个用一个.__new__()方法编码一个Singleton类的例子,这个方法允许一次只创建一个实例。为此,.__new__()检查在类属性上缓存的先前实例的存在:
>>> class Singleton(object): ... _instance = None ... def __new__(cls, *args, **kwargs): ... if cls._instance is None: ... cls._instance = super().__new__(cls) ... return cls._instance ... >>> first = Singleton() >>> second = Singleton() >>> first is second True本例中的
Singleton类有一个名为._instance的类属性,默认为None,并作为缓存工作。.__new__()方法通过测试条件cls._instance is None来检查先前的实例是否不存在。注意:在上面的例子中,
Singleton没有提供.__init__()的实现。如果你需要这样一个带有.__init__()方法的类,那么记住这个方法将在你每次调用Singleton()构造函数时运行。这种行为会导致奇怪的初始化效果和错误。如果这个条件为真,那么
if代码块创建一个Singleton的新实例,并将其存储到cls._instance。最后,该方法将新的或现有的实例返回给调用方。然后实例化
Singleton两次,试图构造两个不同的对象,first和second。如果您用is操作符来比较这些对象的身份,那么您会注意到这两个对象是同一个对象。名字first和second只是引用了同一个Singleton对象。部分模拟
collections.namedtuple作为如何在代码中利用
.__new__()的最后一个例子,您可以运用您的 Python 技能,编写一个部分模拟collections.namedtuple()的工厂函数。namedtuple()函数允许您创建tuple的子类,具有访问元组中项目的命名字段的附加特性。下面的代码实现了一个
named_tuple_factory()函数,它通过覆盖一个名为NamedTuple的嵌套类的.__new__()方法来部分模拟这个功能:1# named_tuple.py 2 3from operator import itemgetter 4 5def named_tuple_factory(type_name, *fields): 6 num_fields = len(fields) 7 8 class NamedTuple(tuple): 9 __slots__ = () 10 11 def __new__(cls, *args): 12 if len(args) != num_fields: 13 raise TypeError( 14 f"{type_name} expected exactly {num_fields} arguments," 15 f" got {len(args)}" 16 ) 17 cls.__name__ = type_name 18 for index, field in enumerate(fields): 19 setattr(cls, field, property(itemgetter(index))) 20 return super().__new__(cls, args) 21 22 def __repr__(self): 23 return f"""{type_name}({", ".join(repr(arg) for arg in self)})""" 24 25 return NamedTuple下面是这个工厂函数的逐行工作方式:
线 3 从
operators模块导入itemgetter()。此函数允许您使用项目在包含序列中的索引来检索项目。第 5 行定义
named_tuple_factory()。这个函数接受名为type_name的第一个参数,它将保存您想要创建的 tuple 子类的名称。*fields参数允许您将未定义数量的字段名作为字符串传递。第 6 行定义了一个本地变量来保存用户提供的命名字段的数量。
第 8 行定义了一个名为
NamedTuple的嵌套类,它继承自内置的tuple类。第 9 行提供了一个
.__slots__类属性。该属性定义了一个保存实例属性的元组。这个元组通过替代实例的字典.__dict__来节省内存,否则它将扮演类似的角色。第 11 行以
cls作为第一个参数实现.__new__()。该实现还采用*args参数来接受未定义数量的字段值。第 12 行到第 16 行定义了一个条件语句,该语句检查要存储在最终元组中的条目数量是否与命名字段的数量不同。如果是这种情况,那么 conditional 将引发一个带有错误消息的
TypeError。第 17 行将当前类的
.__name__属性设置为type_name提供的值。第 18 行和第 19 行定义了一个
for循环,该循环将每个命名字段转化为一个属性,该属性使用itemgetter()返回目标index处的项目。循环使用内置的setattr()函数来执行这个动作。注意,内置的enumerate()函数提供了合适的index值。第 20 行照常通过调用
super().__new__()返回当前类的一个新实例。第 22 行和第 23 行为 tuple 子类定义了一个
.__repr__()方法。第 25 行返回新创建的
NamedTuple类。为了测试您的
named_tuple_factory(),在包含named_tuple.py文件的目录中启动一个交互式会话,并运行以下代码:
>>> from named_tuple import named_tuple_factory
>>> Point = named_tuple_factory("Point", "x", "y")
>>> point = Point(21, 42)
>>> point
Point(21, 42)
>>> point.x
21
>>> point.y
42
>>> point[0]
21
>>> point[1]
42
>>> point.x = 84
Traceback (most recent call last):
...
AttributeError: can't set attribute
>>> dir(point)
['__add__', '__class__', ..., 'count', 'index', 'x', 'y']
在这段代码中,您通过调用named_tuple_factory()创建了一个新的Point类。该调用中的第一个参数表示结果类对象将使用的名称。第二个和第三个参数是结果类中可用的命名字段。
然后,通过调用类构造函数为.x和.y字段创建一个Point对象。要访问每个命名字段的值,可以使用点符号。您还可以使用索引来检索值,因为您的类是 tuple 子类。
因为在 Python 中元组是不可变的数据类型,所以不能在的位置给点的坐标赋值。如果你尝试这样做,你会得到一个AttributeError。
最后,用您的point实例作为参数调用dir(),会发现您的对象继承了 Python 中常规元组的所有属性和方法。
结论
现在您知道 Python 类构造函数如何允许您实例化类,因此您可以在代码中创建具体的、随时可用的对象。在 Python 中,类构造器在内部触发实例化或构造过程,这个过程经过实例创建和实例初始化。这些步骤由.__new__()和.__init__()特殊方法驱动。
通过学习 Python 的类构造函数、实例化过程以及.__new__()和.__init__()方法,您现在可以管理您的定制类如何构造新的实例。
在本教程中,您学习了:
- Python 的实例化过程如何在内部工作
- 你自己的
.__init__()方法如何帮助你定制对象初始化 - 如何覆盖
.__new__()方法来创建自定义对象
现在,您已经准备好利用这些知识来微调您的类构造函数,并在使用 Python 进行面向对象编程的过程中完全控制实例的创建和初始化。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
立即观看**本教程有真实 Python 团队创建的相关视频课程。一起看书面教程加深理解: 使用 Python 类构造函数******
4 种测试 Python 命令行(CLI)应用的技术
您刚刚完成了第一个 Python 命令行应用程序的构建。或者你的第二个或第三个。你已经学习 Python 有一段时间了,现在你准备构建更大更复杂的,但是仍然可以在命令行上运行。或者你习惯于用 GUI构建和测试 web 应用或桌面应用,但现在开始构建 CLI 应用。
在所有这些情况以及更多情况下,您需要学习并熟悉测试 Python CLI 应用程序的各种方法。
虽然工具的选择可能令人生畏,但要记住的主要事情是,您只是将代码生成的输出与您期望的输出进行比较。一切都源于此。
在本教程中,你将学习四种测试 Python 命令行应用的实用技术:
- 使用
print()进行“Lo-Fi”调试 - 使用可视化 Python 调试器
- 使用 pytest 和模拟进行单元测试
- 集成测试
免费奖励: 点击这里获取我们的 Python 测试备忘单,它总结了本教程中演示的技术。
一切都将围绕一个基本的 Python CLI 应用程序构建,该应用程序以多级字典的形式将数据传递给两个函数,这两个函数以某种方式转换数据,然后将数据打印给用户。
我们将使用下面的代码来检查一些不同的方法,这些方法将帮助您进行测试。虽然肯定不是详尽的,但我希望这篇教程能给你足够的宽度,让你有信心在主要的测试领域创建有效的测试。
我在这个初始代码中加入了一些 bug,我们将在测试方法中暴露这些 bug。
注意:为了简单起见,这段代码不包括一些基本的最佳实践,比如验证字典中的键是否存在。
首先,让我们考虑一下这个应用程序每个阶段的对象。我们从描述 John Q. Public 的结构开始:
JOHN_DATA = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
'relationships': {
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
}
}
然后,我们展平其他字典,在调用我们的第一个转换函数initial_transform后会出现这种情况:
JOHN_DATA = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
}
然后,我们使用函数final_transform将所有地址信息构建到一个地址条目中:
JOHN_DATA = {
'name': 'John Q. Public',
'address': '123 Main St. \nAnytown, FL 99999'
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
}
对print_person的调用将把这个写到控制台:
Hello, my name is John Q. Public, my siblings are Michael R. Public
and Suzy Q. Public, my parents are John Q. Public Sr. and Mary S. Public,
and my mailing address is:
123 Main St.
Anytown, FL 99999
测试目录. py:
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(item) is dict:
for key in item:
data[key] = item[key]
return data
def final_transform(transformed_data):
"""
Transform address structures into a single structure
"""
transformed_data['address'] = str.format(
"{0}\n{1}, {2} {3}", transformed_data['street'],
transformed_data['state'], transformed_data['city'],
transformed_data['zip'])
return transformed_data
def print_person(person_data):
parents = "and".join(person_data['parents'])
siblings = "and".join(person_data['siblings'])
person_string = str.format(
"Hello, my name is {0}, my siblings are {1}, "
"my parents are {2}, and my mailing"
"address is: \n{3}", person_data['name'],
parents, siblings, person_data['address'])
print(person_string)
john_data = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
'relationships': {
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
}
}
suzy_data = {
'name': 'Suzy Q. Public',
'street': '456 Broadway',
'apt': '333',
'city': 'Miami',
'state': 'FL',
'zip': 33333,
'relationships': {
'siblings': ['John Q. Public', 'Michael R. Public',
'Thomas Z. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
}
}
inputs = [john_data, suzy_data]
for input_structure in inputs:
initial_transformed = initial_transform(input_structure)
final_transformed = final_transform(initial_transformed)
print_person(final_transformed)
现在,代码实际上没有满足这些期望,所以我们将在学习这四种技术的同时使用它们进行研究。通过这样做,你将获得使用这些技术的实践经验,扩大你对它们的适应范围,并开始学习它们最适合解决哪些问题。
使用打印进行“高保真”调试
这是最简单的测试方法之一。这里你所要做的就是print一个你感兴趣的变量或对象——在函数调用之前,函数调用之后,或者在函数内部。
它们分别允许您验证函数的输入、输出和逻辑。
如果您将上面的代码保存为testapp.py并尝试用python testapp.py运行它,您会看到如下错误:
Traceback (most recent call last):
File "testapp.py", line 60, in <module>
print_person(final_transformed)
File "testapp.py", line 23, in print_person
parents = "and".join(person_data['parents'])
KeyError: 'parents'
在传递到print_person的person_data中有一个丢失的键。第一步是检查print_person的输入,看看为什么我们期望的输出(打印的消息)没有生成。我们将在调用print_person之前添加一个print函数调用:
final_transformed = final_transform(initial_transformed)
print(final_transformed)
print_person(final_transformed)
这里的工作由print函数完成,在其输出中显示我们没有顶级的parents键,也没有siblings键,但是为了我们的理智起见,我将向您展示pprint,它以更易读的方式打印多级对象。要使用它,将from pprint import pprint添加到你的脚本的顶部。
我们调用pprint(final_transformed)而不是print(final_transformed)来检查我们的对象:
{'address': '123 Main St.\nFL, Anytown 99999',
'city': 'Anytown',
'name': 'John Q. Public',
'relationships': {'parents': ['John Q. Public Sr.', 'Mary S. Public'],
'siblings': ['Michael R. Public', 'Suzy Q. Public']},
'state': 'FL',
'street': '123 Main St.',
'zip': 99999}
将此与上面预期的最终形式进行比较。
因为我们知道final_transform不接触relationships字典,所以是时候看看initial_transform发生了什么。通常,我会使用传统的调试器来逐步完成这个,但是我想向您展示打印调试的另一种用法。
我们可以打印代码中对象的状态,但我们并不局限于此。我们可以打印我们想要的任何东西,所以我们也可以打印标记来查看哪些逻辑分支在什么时候被执行。
因为initial_transform主要是几个循环,并且因为内部字典应该由内部 for 循环处理,我们应该检查那里发生了什么,如果有的话:
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(item) is dict:
print "item is dict!"
pprint(item)
for key in item:
data[key] = item[key]
return data
如果我们在我们的输入data中遇到一个字典,那么我们将在控制台中得到警告,然后我们将看到这个条目看起来像什么。
运行之后,我们的控制台输出没有变化。这很好地证明了我们的if语句没有像预期的那样工作。虽然我们可以继续打印以找到错误,但这是展示使用调试器的优势的一个很好的方式。
不过,作为练习,我建议只使用打印调试来查找这段代码中的错误。这是一个很好的实践,它会迫使你思考所有使用控制台来提醒你代码中发生的不同事情的方法。
总结
何时使用打印调试:
- 简单的物体
- 较短的脚本
- 看似简单的 bug
- 快速检查
潜得更深:
- pprint -美化印刷品
优点:
- 快速测试
- 使用方便
缺点:
- 大多数情况下你必须运行整个程序,否则:
- 您需要添加额外的代码来手动控制流量
- 完成后,您可能会意外地留下测试代码,尤其是在复杂的代码中
使用调试器
当您希望一次一行地单步执行代码并检查整个应用程序状态时,调试器非常有用。当您大致知道错误发生在哪里,但不知道原因时,它们会有所帮助,并且它们可以让您一次清楚地看到应用程序内部发生的所有事情。
有许多调试器,而且通常都带有 ide。Python 还有一个名为pdb 的模块,可以在 REPL 中用来调试代码。在这一节中,我将向您展示如何使用具有常见功能的调试器,例如设置断点和观察器,而不是进入所有可用调试器的特定实现细节。
断点是代码上的标记,告诉调试器在哪里暂停执行,以便检查应用程序的状态。 Watches 是可以在调试会话期间添加的表达式,用于观察变量(以及更多)的值,并在应用程序的执行过程中保持不变。
但是让我们跳回断点。这些将被添加到您希望开始或继续调试会话的位置。因为我们正在调试initial_transform方法,所以我们想在那里放一个。我将用一个(*)来表示断点:
def initial_transform(data):
"""
Flatten nested dicts
"""
(*) for item in list(data):
if type(item) is dict:
for key in item:
data[key] = item[key]
return data
现在,当我们开始调试时,执行将在那一行暂停,你将能够在程序执行的特定点看到变量和它们的类型。我们有几个选择来导航我们的代码:跨过、步入和步出是最常见的。
Step over 是你最常使用的一个——它只是跳转到下一行代码。
进入,尝试深入代码。当你遇到一个你想更深入研究的函数调用时,你会用到它——你会被直接带到那个函数的代码,并且能够检查那里的状态。当你把它和跨过混淆时,你也会经常用到它。幸运的是站出来可以拯救我们,这让我们回到了呼叫者那里。
我们还可以在这里设置一个观察器,类似于type(item) is dict,在大多数 ide 中,你可以在调试会话期间通过“添加观察器”按钮来完成。不管你在代码中的什么位置,现在都会显示True或False。
设置手表,现在移过去,这样你现在暂停在if type(item) is dict:线上。您现在应该能够看到手表的状态、新变量item和对象data。

即使没有手表,我们也能看到这个问题:不是type查看item指向什么,而是查看item本身的类型,这是一个字符串。毕竟,计算机完全按照我们告诉它们的去做。感谢调试器,我们看到了我们的方法的错误,并像这样修正我们的代码:
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(data[item]) is dict:
for key in data[item]:
data[key] = item[key]
return data
我们应该再次通过调试器运行它,并确保代码运行到我们期望的地方。而我们没有,结构现在看起来是这样的:
john_data = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
'relationships': {
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
},
'siblings',
'parents',
}
现在我们已经了解了如何使用可视化调试器,让我们更深入,通过完成下面的练习来测试我们的新知识。
我希望您修改代码,使initial_transform的输出看起来更像这样,只使用调试器:
john_data = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
'relationships': {
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
},
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
}
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(data[item]) is dict:
for key in data[item]:
data[key] = data[item][key]
return data
我们已经讨论了可视化调试器。我们使用了可视化调试器。我们喜欢可视化调试器。不过,这种技术仍然有优点和缺点,您可以在下一节回顾它们。
总结
何时使用 Python 调试器:
- 更复杂的项目
- 很难发现漏洞
- 你需要检查不止一个物体
- 您大概知道哪里发生了错误,但是需要关注它
潜得更深:
- 条件断点
- 调试时计算表达式
优点:
- 程序流程控制
- 应用程序状态的鸟瞰图
- 不需要知道错误发生在哪里
缺点:
- 难以手动观察非常大的物体
- 长时间运行的代码需要很长时间来调试
使用 Pytest 和模拟进行单元测试
如果你想彻底测试输入输出组合,确保你命中代码的每一个分支——特别是当你的应用程序增长时,前面的技术是单调乏味的,并且可能需要改变代码。在我们的例子中,initial_transform的输出看起来仍然不太对。
虽然我们代码中的逻辑相当简单,但它很容易变得更大、更复杂,或者成为整个团队的责任。我们如何以更结构化、更详细、更自动化的方式测试应用程序?
输入单元测试。
单元测试是一种测试技术,它将源代码分解成可识别的单元(通常是方法或函数)并单独测试它们。
本质上,您将编写一个脚本或一组脚本,用不同的输入测试每个方法,以确保每个方法中的每个逻辑分支都得到测试——这被称为代码覆盖率,通常您希望达到 100%的代码覆盖率。这并不总是必要或实际的,但是我们可以把它留到另一篇文章(或教科书)中。
每个测试都将被测试的方法隔离对待:外部调用被一种称为 mocking 的技术覆盖,以给出可靠的返回值,并且在测试之前设置的任何对象在测试之后都被移除。这些技术和其他技术是为了确保被测单元的独立性和隔离性。
可重复性和隔离性是这类测试的关键,即使我们仍然继续我们的主题,比较预期输出和实际输出。现在你已经对单元测试有了全面的了解,你可以快速地绕一圈,看看如何用最小可行测试套件对烧瓶应用程序进行单元测试。
Pytest
既然我们已经深入理论了,让我们看看它在实践中是如何工作的。Python 自带了一个内置的unittest模块,但我相信 pytest 在unittest提供的基础上做得很好。不管怎样,我将只展示单元测试的基础知识,因为单元测试一项就可以占据多篇长文章。
一个常见的惯例是将所有的测试放在项目中的一个test目录中。因为这是一个小脚本,一个与testapp.py同级的文件test_testapp.py就足够了。
我们将为initial_transform编写一个单元测试,展示如何设置一组预期的输入和输出,并确保它们匹配。我使用pytest的基本模式是设置一个夹具,它将获取一些参数,并使用这些参数来生成我想要的测试输入和预期输出。
首先,我将展示 fixture 设置,当您查看代码时,请思考您需要的测试用例,以便找到initial_transform的所有可能的分支:
import pytest
import testapp as app
@pytest.fixture(params=['nodict', 'dict'])
def generate_initial_transform_parameters(request):
在我们生成输入之前,让我们看看这里发生了什么,因为它可能会令人困惑。
首先,我们使用@pytest.fixture decorator 将下面的函数定义声明为 fixture。我们还使用一个命名参数params来和generate_initial_transform_parameters一起使用。
这个函数的巧妙之处在于,无论何时使用修饰函数,它都会与每个参数一起使用,所以只需调用generate_initial_transform_parameters就会调用它两次,一次用nodict作为参数,一次用dict。
为了访问这些参数,我们将 pytest 特殊对象request添加到我们的函数签名中。
现在,让我们构建我们的输入和预期输出:
@pytest.fixture(params=['nodict', 'dict'])
def generate_initial_transform_parameters(request):
test_input = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
}
expected_output = {
'name': 'John Q. Public',
'street': '123 Main St.',
'city': 'Anytown',
'state': 'FL',
'zip': 99999,
}
if request.param == 'dict':
test_input['relastionships'] = {
'siblings': ['Michael R. Public', 'Suzy Q. Public'],
'parents': ['John Q. Public Sr.', 'Mary S. Public'],
}
expected_output['siblings'] = ['Michael R. Public', 'Suzy Q. Public']
expected_output['parents'] = ['John Q. Public Sr.', 'Mary S. Public']
return test_input, expected_output
这里没有什么太令人惊讶的,我们设置了输入和预期输出,如果我们有了'dict'参数,那么我们修改输入和预期输出,允许我们测试if块。
然后我们编写测试。在测试中,我们必须将 fixture 作为参数传递给测试函数来访问它:
def test_initial_transform(generate_initial_transform_parameters):
test_input = generate_initial_transform_parameters[0]
expected_output = generate_initial_transform_parameters[1]
assert app.initial_transform(test_input) == expected_output
测试函数应该以test_为前缀,并且应该基于 assert语句。这里我们断言,通过将输入传递给实函数,我们得到的输出等于我们期望的输出。当你用测试配置在你的 IDE 中或者用 CLI 中的pytest运行它时,你会得到…错误!我们的产出还不完全正确。让我们通过下面的练习来解决这个问题——实践经验是无价的,将你所学付诸实践会让你在将来回忆起来更容易。
我想让你用单元测试来帮助你修复函数,这样它就会像我们期望的那样运行。仅使用单元测试输出来进行这些更改,不要更改单元测试。
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(data[item]) is dict:
for key in data[item]:
data[key] = data[item][key]
data.pop(item)
return data
模拟
模拟是单元测试的另一个重要部分。因为我们只测试单个代码单元,所以我们并不关心其他函数调用做了什么。我们只想从他们那里得到可靠的回报。
让我们给initial_transform添加一个外部函数调用:
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(data[item]) is dict:
for key in data[item]:
data[key] = data[item][key]
data.pop(item)
outside_module.do_something()
return data
我们不想对do_something()进行实时调用,所以我们将在测试脚本中进行模拟。mock 将捕获这个调用,并返回您设置 mock 返回的任何内容。我喜欢在 fixtures 中设置模拟,因为这是测试设置的一部分,我们可以将所有设置代码放在一起:
@pytest.fixture(params=['nodict', 'dict'])
def generate_initial_transform_parameters(request, mocker):
[...]
mocker.patch.object(outside_module, 'do_something')
mocker.do_something.return_value(1)
[...]
现在每次调用initial_transform时,do_something调用都会被拦截,返回 1。您还可以利用 fixture 参数来确定您的 mock 返回什么——当代码分支由外部调用的结果决定时,这一点很重要。
最后一个巧妙的技巧是使用side_effect。除了别的以外,这允许您模拟对同一函数的连续调用的不同返回:
def initial_transform(data):
"""
Flatten nested dicts
"""
for item in list(data):
if type(data[item]) is dict:
for key in data[item]:
data[key] = data[item][key]
data.pop(item)
outside_module.do_something()
outside_module.do_something()
return data
我们像这样设置我们的模拟,将一个输出列表(对于每个连续的调用)传递给side_effect:
@pytest.fixture(params=['nodict', 'dict'])
def generate_initial_transform_parameters(request, mocker):
[...]
mocker.patch.object(outside_module, 'do_something')
mocker.do_something.side_effect([1, 2])
[...]
嘲讽是非常强大的,强大到你甚至可以设置模仿服务器来测试第三方 API,我再次鼓励你自己用mocker更深入地探究嘲讽。
总结
何时使用 Python 单元测试框架:
- 大型复杂项目
- OSS 项目
有用的工具:
优点:
- 自动化运行测试
- 可以捕捉多种类型的错误
- 团队的简单设置和修改
缺点:
- 写起来很乏味
- 必须随着大多数代码的更改而更新
- 不会复制真实的应用程序运行
集成测试
集成测试是这里最简单的测试方法之一,但可以说是最重要的方法之一。这需要在类似生产的环境中使用真实数据端到端地运行您的应用。
无论这是您的家用机器,还是复制生产服务器的测试服务器,或者只是更改从生产服务器到测试数据库的连接,这都让您知道您的更改将在部署时生效。
像所有其他方法一样,您正在检查您的应用程序是否在给定一些输入的情况下生成了预期的输出——除了这次您使用了实际的外部模块(不像在单元测试中,它们被模拟),可能写入实际的数据库或文件,以及在更大的应用程序中,确保您的代码与整个系统很好地集成。
如何做到这一点高度依赖于您的应用程序,例如,我们的测试应用程序可以使用python testapp.py自行运行。然而,让我们假设我们的代码是一个大型分布式应用程序的一部分,比如 ETL 管道——在这种情况下,您必须在测试服务器上运行整个系统,交换您的代码,通过它运行数据,并确保它以正确的形式通过整个系统。在命令行应用程序世界之外,像py waves 这样的工具可以用于集成测试 Django apps 。
这是一个开放式练习。我在代码中留下了一些 bug,运行几次代码,并将您的输出与本教程开始时我们预期的输出进行比较。使用这种方法和你学过的其他方法来查找和修复任何剩余的 bug。
总结
在 Python 中何时使用集成测试:
- 总是;-)
- 一般在其他测试方法之后,如果它们被使用的话。
有用的工具:
- tox 环境和测试自动化管理
优点:
- 了解您的应用程序在真实环境中的运行情况
缺点:
- 较大的应用程序可能很难准确跟踪数据流
- 必须拥有非常接近生产环境的测试环境
将所有这些放在一起
总之,所有 CLI 测试都是在给定一组输入的情况下,将预期输出与实际输出进行比较。我上面讨论的方法都是这样做的,并且在许多方面是互补的。当您继续用 Python 构建命令行应用程序时,这些将是您需要理解的重要工具,但本教程只是一个起点。
Python 有一个非常丰富的生态系统,并且扩展到测试工具和方法学,所以从这里扩展开来,进行更多的研究——你可能会找到我在这里没有提到的你绝对喜欢的工具或技术。如果是这样的话,我很想在评论中听到它!
简单回顾一下,以下是我们今天学到的技巧以及如何运用它们:
- 打印调试——打印出代码中的变量和其他标记,以查看执行流程
- 调试器——控制程序执行以获得应用程序状态和程序流的鸟瞰图
- 单元测试——将一个应用程序分成可单独测试的单元,并测试该单元中的所有逻辑分支
- 集成测试——在更广泛的应用程序环境中测试您的代码变更
现在去测试吧!当你使用这些技术时,一定要在评论中让我知道你是如何使用它们的,哪些是你最喜欢的。
要获得总结了本教程中演示的技术的 Python 测试备忘单,请单击下面的链接:
免费奖励: 点击这里获取我们的 Python 测试备忘单,它总结了本教程中演示的技术。******
Python 代码质量:工具和最佳实践
在本文中,我们将识别高质量的 Python 代码,并向您展示如何提高您自己代码的质量。
我们将分析和比较您可以用来将代码提升到下一个级别的工具。无论您使用 Python 已经有一段时间了,还是刚刚开始,您都可以从这里讨论的实践和工具中受益。
什么是代码质量?
你当然想要高质量的代码,谁不想呢?但是为了提高代码质量,我们必须定义它是什么。
快速的谷歌搜索会产生许多定义代码质量的结果。事实证明,这个词对人们来说有很多不同的含义。
定义代码质量的一种方法是着眼于光谱的一端:高质量的代码。希望您能同意以下高质量的代码标识符:
- 它做它应该做的事情。
- 它不包含缺陷或问题。
- 它易于阅读、维护和扩展。
这三个标识符虽然简单,但似乎得到了普遍认同。为了进一步扩展这些想法,让我们深入了解为什么每一个在软件领域都很重要。
为什么代码质量很重要?
为了确定为什么高质量的代码是重要的,让我们重温一下这些标识符。我们将看到当代码不满足它们时会发生什么。
它没有做它应该做的事情
满足需求是任何产品、软件等的基础。我们制作软件来做一些事情。如果最后,它没有做到…嗯,它肯定不是高质量的。如果达不到基本要求,甚至很难称之为低质量。
是否包含缺陷和问题
如果你正在使用的东西有问题或者给你带来问题,你可能不会称之为高质量。事实上,如果它足够糟糕,你可能会完全停止使用它。
为了不用软件做例子,假设你的吸尘器在普通地毯上效果很好。它能清理所有的灰尘和猫毛。一个灾难性的夜晚,猫打翻了一株植物,把泥土洒得到处都是。当你试图用吸尘器清理这堆脏东西时,它坏了,把脏东西弄得到处都是。
虽然真空吸尘器在某些情况下工作,但它不能有效地处理偶尔的额外负载。因此,你不会称之为高品质的吸尘器。
这是我们希望在代码中避免的问题。如果事情在边缘情况下破裂,缺陷导致不必要的行为,我们就没有高质量的产品。
很难读取、维护或扩展
想象一下:一个客户请求一个新特性。写原始代码的人走了。替换它们的人现在必须理解已经存在的代码。那个人就是你。
如果代码很容易理解,你就能更快地分析问题并提出解决方案。如果代码复杂且令人费解,您可能会花费更长的时间,并可能做出一些错误的假设。
如果能在不破坏原有功能的情况下轻松添加新功能,那也不错。如果代码不容易扩展,你的新特性可能会破坏其他东西。
没有人希望处于必须阅读、维护或扩展低质量代码的位置。这对每个人来说意味着更多的头痛和更多的工作。
你不得不处理低质量的代码已经够糟糕了,但是不要让别人处于同样的情况。您可以提高自己编写的代码的质量。
如果你和一个开发团队一起工作,你可以开始实施一些方法来确保更好的整体代码质量。当然,前提是你有他们的支持。你可能需要赢得一些人的支持(请随意发送这篇文章给他们😃).
如何提高 Python 代码质量
在我们追求高质量代码的过程中,有一些事情需要考虑。首先,这个旅程不是一个纯粹客观的旅程。对于高质量的代码是什么样子,有一些强烈的感觉。
虽然每个人都有希望在上面提到的标识符上达成一致,但是他们实现的方式是一条主观的道路。当您谈到实现可读性、可维护性和可扩展性时,通常会出现一些最固执己见的话题。
所以请记住,虽然本文将试图保持客观,但当涉及到代码时,有一个非常固执己见的世界。
所以,让我们从最固执己见的话题开始:代码风格。
风格指南
啊,是的。古老的问题:空格还是制表符?
不管你个人对如何表示空白有什么看法,可以有把握地假设你至少想要代码的一致性。
风格指南的目的是定义一种一致的方式来编写代码。通常这都是修饰性的,意味着它不会改变代码的逻辑结果。尽管如此,一些文体选择确实避免了常见的逻辑错误。
风格指南有助于实现使代码易于阅读、维护和扩展的目标。
就 Python 而言,有一个广为接受的标准。它部分是由 Python 编程语言本身的作者编写的。
PEP 8 提供了 Python 代码的编码约定。Python 代码遵循这种风格指南是相当常见的。这是一个很好的起点,因为它已经定义好了。
一个姐妹 Python 增强提案, PEP 257 描述了 Python 文档字符串的约定,这些字符串旨在记录模块、类、函数和方法。额外的好处是,如果 docstrings 是一致的,有工具能够直接从代码生成文档。
这些指南所做的就是定义一种样式代码的方式。但是你如何执行它呢?那么代码中的缺陷和问题是什么呢,你如何发现它们呢?这就是棉绒的由来。
棉绒
什么是棉绒?
首先,我们来说说 lint。那些微小的,恼人的小瑕疵不知何故布满了你的衣服。没有那些线头,衣服看起来和感觉都好多了。你的代码没有什么不同。小错误、风格不一致和危险的逻辑不会让你的代码感觉很棒。
但是我们都会犯错。你不能指望自己总能及时抓住他们。输入错误的变量名称,忘记了右括号,Python 中不正确的跳转,用错误数量的参数调用函数,等等。Linters 有助于识别这些问题区域。
此外,大多数编辑器和 ide能够在你输入的时候在后台运行 linters。这就产生了一个能够在运行代码之前突出显示、强调或识别代码中问题区域的环境。这就像是高级的代码拼写检查。它用弯弯曲曲的红线强调问题,就像你最喜欢的文字处理器一样。
Linters 分析代码以检测各种类别的 lint。这些类别可以大致定义如下:
- 逻辑 Lint
- 代码错误
- 具有潜在意外结果的代码
- 危险的代码模式
- 文体线头
- 不符合规定惯例的代码
还有一些代码分析工具可以提供对代码的其他洞察。虽然根据定义可能不是 linters,但是这些工具通常与 linters 一起使用。他们也希望提高代码的质量。
最后,还有一些工具可以自动将代码格式化为某种规格。这些自动化工具确保了我们劣等的人类头脑不会搞乱惯例。
Python 有哪些 Linter 选项?
在深入研究您的选择之前,重要的是要认识到一些“棉绒”只是多个棉绒很好地包装在一起。这些组合棉绒的一些流行例子如下:
Flake8 :能够检测逻辑和风格 lint。它将 pycodestyle 的样式和复杂性检查添加到 PyFlakes 的逻辑 lint 检测中。它结合了以下棉绒:
- PyFlakes
- pycodestyle(以前为 pep8)
- 麦凯布
Pylama :由大量 linters 等工具组成的代码审计工具,用于分析代码。它结合了以下内容:
- pycodestyle(以前为 pep8)
- pydocstyle(原 pep257)
- PyFlakes
- 麦凯布
- Pylint
- 氡
- jslint
以下是一些独立的棉绒分类和简要说明:
| 棉绒 | 种类 | 描述 |
|---|---|---|
| 皮林特 | 逻辑和风格 | 检查错误,尝试执行编码标准,寻找代码味道 |
| PyFlakes | 逻辑学的 | 分析程序并检测各种错误 |
| pycodestyle | 体裁上的 | 对照 PEP 8 中的一些样式约定进行检查 |
| pydocstyle | 体裁上的 | 检查是否符合 Python 文档字符串约定 |
| 土匪 | 逻辑学的 | 分析代码以发现常见的安全问题 |
| MyPy | 逻辑学的 | 检查可选的强制静态类型 |
这里有一些代码分析和格式化工具:
| 工具 | 种类 | 描述 |
|---|---|---|
| 麦凯布 | 分析的 | 检查麦凯布复杂度 |
| 氡 | 分析的 | 分析代码的各种度量(代码行数、复杂性等) |
| 黑色 | 格式程序 | 毫不妥协地格式化 Python 代码 |
| Isort | 格式程序 | 通过按字母顺序排序并分成几个部分来格式化导入 |
比较 Python 短绒
让我们更好地了解不同的棉绒能够捕捉什么以及输出是什么样的。为此,我用默认设置在一些不同的 linters 上运行了相同的代码。
下面是我在 linters 中运行的代码。它包含各种逻辑和风格问题:
1"""
2code_with_lint.py
3Example Code with lots of lint!
4"""
5import io
6from math import *
7
8
9from time import time
10
11some_global_var = 'GLOBAL VAR NAMES SHOULD BE IN ALL_CAPS_WITH_UNDERSCOES'
12
13def multiply(x, y):
14 """
15 This returns the result of a multiplation of the inputs
16 """
17 some_global_var = 'this is actually a local variable...'
18 result = x* y
19 return result
20 if result == 777:
21 print("jackpot!")
22
23def is_sum_lucky(x, y):
24 """This returns a string describing whether or not the sum of input is lucky
25 This function first makes sure the inputs are valid and then calculates the
26 sum. Then, it will determine a message to return based on whether or not
27 that sum should be considered "lucky"
28 """
29 if x != None:
30 if y is not None:
31 result = x+y;
32 if result == 7:
33 return 'a lucky number!'
34 else:
35 return( 'an unlucky number!')
36
37 return ('just a normal number')
38
39class SomeClass:
40
41 def __init__(self, some_arg, some_other_arg, verbose = False):
42 self.some_other_arg = some_other_arg
43 self.some_arg = some_arg
44 list_comprehension = [((100/value)*pi) for value in some_arg if value != 0]
45 time = time()
46 from datetime import datetime
47 date_and_time = datetime.now()
48 return
下面的比较显示了我在分析上述文件时使用的 linters 及其运行时。我应该指出,这些并不完全可比,因为它们服务于不同的目的。例如,PyFlakes 不像 Pylint 那样识别风格错误。
| 棉绒 | 命令 | 时间 |
|---|---|---|
| 皮林特 | pylint code_with_lint.py | 1.16 秒 |
| PyFlakes | pyflakes code_with_lint.py | 0.15 秒 |
| pycodestyle | pycodestyle code_with_lint.py | 0.14 秒 |
| pydocstyle | pydocstyle code_with_lint.py | 0.21 秒 |
有关每个的输出,请参见下面的部分。
Pylint
皮林特是最古老的棉绒之一(大约 2006 年),现在仍然维护得很好。有些人可能会称这个软件久经沙场。它已经存在了足够长的时间,贡献者已经修复了大多数主要的 bug,核心特性也已经开发得很好了。
对 Pylint 的常见抱怨是它很慢,默认情况下过于冗长,并且需要大量的配置才能让它按照您想要的方式工作。除了速度慢之外,其他的抱怨有点像一把双刃剑。啰嗦可以是因为彻底。大量的配置意味着对你的偏好有很大的适应性。
事不宜迟,对上面填充了 lint 的代码运行 Pylint 后的输出:
No config file found, using default configuration
************* Module code_with_lint
W: 23, 0: Unnecessary semicolon (unnecessary-semicolon)
C: 27, 0: Unnecessary parens after 'return' keyword (superfluous-parens)
C: 27, 0: No space allowed after bracket
return( 'an unlucky number!')
^ (bad-whitespace)
C: 29, 0: Unnecessary parens after 'return' keyword (superfluous-parens)
C: 33, 0: Exactly one space required after comma
def __init__(self, some_arg, some_other_arg, verbose = False):
^ (bad-whitespace)
C: 33, 0: No space allowed around keyword argument assignment
def __init__(self, some_arg, some_other_arg, verbose = False):
^ (bad-whitespace)
C: 34, 0: Exactly one space required around assignment
self.some_other_arg = some_other_arg
^ (bad-whitespace)
C: 35, 0: Exactly one space required around assignment
self.some_arg = some_arg
^ (bad-whitespace)
C: 40, 0: Final newline missing (missing-final-newline)
W: 6, 0: Redefining built-in 'pow' (redefined-builtin)
W: 6, 0: Wildcard import math (wildcard-import)
C: 11, 0: Constant name "some_global_var" doesn't conform to UPPER_CASE naming style (invalid-name)
C: 13, 0: Argument name "x" doesn't conform to snake_case naming style (invalid-name)
C: 13, 0: Argument name "y" doesn't conform to snake_case naming style (invalid-name)
C: 13, 0: Missing function docstring (missing-docstring)
W: 14, 4: Redefining name 'some_global_var' from outer scope (line 11) (redefined-outer-name)
W: 17, 4: Unreachable code (unreachable)
W: 14, 4: Unused variable 'some_global_var' (unused-variable)
...
R: 24,12: Unnecessary "else" after "return" (no-else-return)
R: 20, 0: Either all return statements in a function should return an expression, or none of them should. (inconsistent-return-statements)
C: 31, 0: Missing class docstring (missing-docstring)
W: 37, 8: Redefining name 'time' from outer scope (line 9) (redefined-outer-name)
E: 37,15: Using variable 'time' before assignment (used-before-assignment)
W: 33,50: Unused argument 'verbose' (unused-argument)
W: 36, 8: Unused variable 'list_comprehension' (unused-variable)
W: 39, 8: Unused variable 'date_and_time' (unused-variable)
R: 31, 0: Too few public methods (0/2) (too-few-public-methods)
W: 5, 0: Unused import io (unused-import)
W: 6, 0: Unused import acos from wildcard import (unused-wildcard-import)
...
W: 9, 0: Unused time imported from time (unused-import)
请注意,我用省略号对类似的行进行了压缩。这很难理解,但是在这段代码中有很多琐碎的东西。
注意,Pylint 在每个问题区域前面加上了一个R、C、W、E或F,意思是:
- “良好实践”度量违规的因子
- 违反编码标准的规定
- 注意文体问题或小的编程问题
- 重要编程问题的错误(即最有可能的错误)
- [F]防止进一步处理的错误
以上列表直接来自 Pylint 的用户指南。
PyFlakes
Pyflakes“做出一个简单的承诺:它永远不会抱怨风格,它会非常非常努力地尝试永远不会发出误报”。这意味着 Pyflakes 不会告诉您缺少文档字符串或不符合命名风格的参数名称。它主要关注逻辑代码问题和潜在的错误。
这里的好处是速度。PyFlakes 的运行时间是 Pylint 的一小部分。
对上面填充了 lint 的代码运行后的输出:
code_with_lint.py:5: 'io' imported but unused
code_with_lint.py:6: 'from math import *' used; unable to detect undefined names
code_with_lint.py:14: local variable 'some_global_var' is assigned to but never used
code_with_lint.py:36: 'pi' may be undefined, or defined from star imports: math
code_with_lint.py:36: local variable 'list_comprehension' is assigned to but never used
code_with_lint.py:37: local variable 'time' (defined in enclosing scope on line 9) referenced before assignment
code_with_lint.py:37: local variable 'time' is assigned to but never used
code_with_lint.py:39: local variable 'date_and_time' is assigned to but never used
这里的缺点是解析这个输出可能有点困难。各种问题和错误没有按类型进行标记或组织。取决于你如何使用它,这可能根本不是问题。
pycodestyle(原 pep8)
用于检查 PEP8 的一些样式约定。不检查命名约定,也不检查文档字符串。它捕捉到的错误和警告被分类在这个表中。
对上面填充了 lint 的代码运行后的输出:
code_with_lint.py:13:1: E302 expected 2 blank lines, found 1
code_with_lint.py:15:15: E225 missing whitespace around operator
code_with_lint.py:20:1: E302 expected 2 blank lines, found 1
code_with_lint.py:21:10: E711 comparison to None should be 'if cond is not None:'
code_with_lint.py:23:25: E703 statement ends with a semicolon
code_with_lint.py:27:24: E201 whitespace after '('
code_with_lint.py:31:1: E302 expected 2 blank lines, found 1
code_with_lint.py:33:58: E251 unexpected spaces around keyword / parameter equals
code_with_lint.py:33:60: E251 unexpected spaces around keyword / parameter equals
code_with_lint.py:34:28: E221 multiple spaces before operator
code_with_lint.py:34:31: E222 multiple spaces after operator
code_with_lint.py:35:22: E221 multiple spaces before operator
code_with_lint.py:35:31: E222 multiple spaces after operator
code_with_lint.py:36:80: E501 line too long (83 > 79 characters)
code_with_lint.py:40:15: W292 no newline at end of file
这个输出的好处是 lint 是按类别标记的。如果您不在乎遵守特定的约定,也可以选择忽略某些错误。
pydocstyle(原 pep257)
与 pycodestyle 非常相似,除了它不是根据 PEP8 代码样式约定进行检查,而是根据来自 PEP257 的约定检查 docstrings。
对上面填充了 lint 的代码运行后的输出:
code_with_lint.py:1 at module level:
D200: One-line docstring should fit on one line with quotes (found 3)
code_with_lint.py:1 at module level:
D400: First line should end with a period (not '!')
code_with_lint.py:13 in public function `multiply`:
D103: Missing docstring in public function
code_with_lint.py:20 in public function `is_sum_lucky`:
D103: Missing docstring in public function
code_with_lint.py:31 in public class `SomeClass`:
D101: Missing docstring in public class
code_with_lint.py:33 in public method `__init__`:
D107: Missing docstring in __init__
同样,像 pycodestyle 一样,pydocstyle 对它发现的各种错误进行标记和分类。该列表与 pycodestyle 中的任何内容都不冲突,因为所有错误都以 docstring 的D为前缀。这些错误的列表可以在这里找到。
无绒毛代码
您可以根据 linter 的输出来调整之前填充了 lint 的代码,最终会得到如下结果:
1"""Example Code with less lint."""
2
3from math import pi
4from time import time
5from datetime import datetime
6
7SOME_GLOBAL_VAR = 'GLOBAL VAR NAMES SHOULD BE IN ALL_CAPS_WITH_UNDERSCOES'
8
9
10def multiply(first_value, second_value):
11 """Return the result of a multiplation of the inputs."""
12 result = first_value * second_value
13
14 if result == 777:
15 print("jackpot!")
16
17 return result
18
19
20def is_sum_lucky(first_value, second_value):
21 """
22 Return a string describing whether or not the sum of input is lucky.
23
24 This function first makes sure the inputs are valid and then calculates the
25 sum. Then, it will determine a message to return based on whether or not
26 that sum should be considered "lucky".
27 """
28 if first_value is not None and second_value is not None:
29 result = first_value + second_value
30 if result == 7:
31 message = 'a lucky number!'
32 else:
33 message = 'an unlucky number!'
34 else:
35 message = 'an unknown number! Could not calculate sum...'
36
37 return message
38
39
40class SomeClass:
41 """Is a class docstring."""
42
43 def __init__(self, some_arg, some_other_arg):
44 """Initialize an instance of SomeClass."""
45 self.some_other_arg = some_other_arg
46 self.some_arg = some_arg
47 list_comprehension = [
48 ((100/value)*pi)
49 for value in some_arg
50 if value != 0
51 ]
52 current_time = time()
53 date_and_time = datetime.now()
54 print(f'created SomeClass instance at unix time: {current_time}')
55 print(f'datetime: {date_and_time}')
56 print(f'some calculated values: {list_comprehension}')
57
58 def some_public_method(self):
59 """Is a method docstring."""
60 pass
61
62 def some_other_public_method(self):
63 """Is a method docstring."""
64 pass
根据上面的棉绒,该代码是不起毛的。虽然逻辑本身基本上是无意义的,但您可以看到,至少一致性得到了加强。
在上面的例子中,我们在编写完所有代码后运行了 linters。然而,这并不是检查代码质量的唯一方法。
我什么时候可以检查我的代码质量?
您可以检查代码的质量:
- 当你写的时候
- 当它被检入时
- 当你进行测试的时候
让 linters 经常运行你的代码是很有用的。如果没有自动化和一致性,大型团队或项目很容易忽略目标,并开始创建质量较低的代码。当然,这是慢慢发生的。一些写得不好的逻辑,或者一些代码的格式与邻近的代码不匹配。随着时间的推移,所有的棉绒堆积起来。最终,你可能会陷入一些有问题的、难以阅读的、难以修复的、维护起来很痛苦的东西。
为了避免这种情况,经常检查代码质量!
正如你写的
您可以在编写代码时使用 linters,但是配置您的环境这样做可能需要一些额外的工作。这通常是一个为你的 IDE 或编辑器选择插件的问题。事实上,大多数 ide 已经内置了 linters。
以下是为各种编辑提供的关于 Python 林挺的一些一般信息:
在您签入代码之前
如果您正在使用 Git,可以设置 Git 挂钩在提交之前运行您的 linters。其他版本控制系统也有类似的方法,在系统中的某个操作之前或之后运行脚本。您可以使用这些方法来阻止任何不符合质量标准的新代码。
虽然这看起来有些极端,但是强制每一位代码通过 lint 筛选是确保持续质量的重要一步。在代码的前门自动进行筛选可能是避免代码中充满棉绒的最好方法。
运行测试时
你也可以将棉绒直接放入任何你可以用来持续集成的系统中。如果代码不符合质量标准,linters 可以被设置为构建失败。
同样,这似乎是一个极端的步骤,尤其是在现有代码中已经有很多 linter 错误的情况下。为了解决这个问题,一些持续集成系统将允许您选择只有在新代码增加了已经存在的 linter 错误的数量时才使构建失败。这样,您就可以开始提高质量,而无需对现有的代码库进行整体重写。
结论
高质量的代码做它应该做的事情而不会中断。它易于阅读、维护和扩展。它运行起来没有任何问题或缺陷,而且写得便于下一个人一起工作。
希望不言而喻,你应该努力拥有这样高质量的代码。幸运的是,有一些方法和工具可以帮助提高代码质量。
风格指南将为您的代码带来一致性。 PEP8 是 Python 的一个伟大起点。Linters 将帮助您识别问题区域和不一致之处。您可以在整个开发过程中使用 linters,甚至可以自动标记 lint 填充的代码,以免发展太快。
让 linters 抱怨风格也避免了在代码评审期间讨论风格的需要。有些人可能会发现从这些工具而不是团队成员那里更容易得到坦诚的反馈。此外,一些团队成员可能不想在代码评审期间“挑剔”风格。Linters 避免政治,节省时间,并抱怨任何不一致。
此外,本文中提到的所有 linters 都有各种命令行选项和配置,允许您根据自己的喜好定制工具。你可以想多严格就多严格,也可以想多宽松就多宽松,这是要认识到的一件重要的事情。
提高代码质量是一个过程。您可以采取措施改进它,而不完全禁止所有不一致的代码。意识是伟大的第一步。只需要一个人,比如你,首先意识到高质量的代码有多重要。***
如何在 Python 编码面试中脱颖而出
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 编码面试:技巧&最佳实践
您已经通过了与招聘人员的电话沟通,现在是时候展示您知道如何用实际代码解决问题了。无论是 HackerRank 练习、带回家的作业,还是现场白板面试,这都是你证明自己编码面试技巧的时刻。
但是面试不仅仅是为了解决问题:他们也是为了展示你可以写出干净的产品代码。这意味着您对 Python 的内置功能和库有深入的了解。这些知识向公司表明,你可以快速移动,不会仅仅因为你不知道它的存在而复制语言自带的功能。
注意:要了解编码面试的情况并学习编码挑战的最佳实践,请查看视频课程编写并测试 Python 函数:面试实践。
在 Real Python 上,我们集思广益,讨论了在编码面试中我们总是印象深刻的工具。本文将带您领略这些功能的精华,从 Python 的内置开始,然后是 Python 对数据结构的本地支持,最后是 Python 强大的(但往往不被重视的)标准库。
在这篇文章中,你将学习如何:
- 使用
enumerate()迭代索引和值 - 用
breakpoint()调试有问题的代码 - 用 f 字符串有效地格式化字符串
- 使用自定义参数对列表进行排序
- 使用生成器而不是列表理解来节省内存
- 查找字典关键字时定义默认值
- 用
collections.Counter类计数可散列对象 - 使用标准库获得排列和组合列表
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
为作业选择正确的内置功能
Python 有一个很大的标准库,但只有一个很小的内置函数库,这些函数总是可用的,不需要导入。每一个都值得一读,但是在你有机会这样做之前,这里有几个内置函数值得你去理解如何使用,以及在其中一些情况下,用什么替代函数来代替。
用enumerate()代替range() 进行迭代
这种场景在编码面试中出现的次数可能比其他任何场景都多:您有一个元素列表,您需要通过访问索引和值来遍历该列表。
有一个名为 FizzBuzz 的经典编码面试问题可以通过迭代索引和值来解决。在 FizzBuzz 中,给你一个整数列表。你的任务是做以下事情:
- 用
"fizz"替换所有能被3整除的整数 - 用
"buzz"替换所有能被5整除的整数 - 用
"fizzbuzz"替换所有能被3和5整除的整数
通常,开发人员会用range()来解决这个问题:
>>> numbers = [45, 22, 14, 65, 97, 72] >>> for i in range(len(numbers)): ... if numbers[i] % 3 == 0 and numbers[i] % 5 == 0: ... numbers[i] = 'fizzbuzz' ... elif numbers[i] % 3 == 0: ... numbers[i] = 'fizz' ... elif numbers[i] % 5 == 0: ... numbers[i] = 'buzz' ... >>> numbers ['fizzbuzz', 22, 14, 'buzz', 97, 'fizz']Range 允许你通过索引访问
numbers的元素,在某些情况下它是一个有用的工具。但是在这种情况下,如果您希望同时获得每个元素的索引和值,更好的解决方案是使用enumerate():
>>> numbers = [45, 22, 14, 65, 97, 72]
>>> for i, num in enumerate(numbers):
... if num % 3 == 0 and num % 5 == 0:
... numbers[i] = 'fizzbuzz'
... elif num % 3 == 0:
... numbers[i] = 'fizz'
... elif num % 5 == 0:
... numbers[i] = 'buzz'
...
>>> numbers
['fizzbuzz', 22, 14, 'buzz', 97, 'fizz']
对于每个元素,enumerate()返回一个计数器和元素值。计数器默认为0,这也是元素的索引。不想从0开始计算吗?只需使用可选的start参数来设置偏移量:
>>> numbers = [45, 22, 14, 65, 97, 72] >>> for i, num in enumerate(numbers, start=52): ... print(i, num) ... 52 45 53 22 54 14 55 65 56 97 57 72通过使用
start参数,我们从第一个索引开始访问所有相同的元素,但是现在我们的计数从指定的整数值开始。使用列表理解代替
map()和filter()“我认为去掉 filter()和 map()是相当没有争议的。]"
— 吉多·范·罗苏姆,Python 的创造者
他可能错误地认为它没有争议,但是 Guido 有充分的理由想要从 Python 中删除
map()和filter()。一个原因是 Python 支持列表理解,它们通常更容易阅读,并支持与map()和filter()相同的功能。让我们首先来看看我们是如何构造对
map()的调用以及等价的列表理解的:
>>> numbers = [4, 2, 1, 6, 9, 7]
>>> def square(x):
... return x*x
...
>>> list(map(square, numbers))
[16, 4, 1, 36, 81, 49]
>>> [square(x) for x in numbers]
[16, 4, 1, 36, 81, 49]
使用map()和列表理解的两种方法返回相同的值,但是列表理解更容易阅读和理解。
现在我们可以对filter()及其等价的列表理解做同样的事情:
>>> def is_odd(x): ... return bool(x % 2) ... >>> list(filter(is_odd, numbers)) [1, 9, 7] >>> [x for x in numbers if is_odd(x)] [1, 9, 7]就像我们在
map()中看到的那样,filter()和列表理解方法返回相同的值,但是列表理解更容易理解。来自其他语言的开发者可能不同意列表理解比
map()和filter()更容易阅读,但是根据我的经验,初学者能够更直观地理解列表理解。不管怎样,在编码面试中使用列表理解很少会出错,因为它会传达出你知道 Python 中最常见的是什么。
用
breakpoint()代替print()进行调试通过在代码中添加
print()并查看打印出来的内容,你可能已经调试出了一个小问题。这种方法一开始工作得很好,但是很快就变得很麻烦。另外,在编码面试环境中,你很难希望print()调用贯穿你的代码。相反,你应该使用一个调试器。对于重要的 bug,它几乎总是比使用
print()更快,鉴于调试是编写软件的一个重要部分,它表明你知道如何使用工具,让你在工作中快速开发。如果您使用的是 Python 3.7,您不需要导入任何东西,只需在代码中您想要进入调试器的位置调用
breakpoint():# Some complicated code with bugs breakpoint()调用
breakpoint()会让你进入pdb,这是默认的 Python 调试器。在 Python 3.6 和更早的版本中,您可以通过显式导入pdb来完成同样的操作:import pdb; pdb.set_trace()像
breakpoint(),pdb.set_trace()会把你放入pdb调试器。只是不太干净,而且更容易记住。您可能想尝试其他可用的调试器,但是
pdb是标准库的一部分,所以它总是可用的。无论您喜欢哪种调试器,在您进入编码面试环境之前,尝试一下它们以适应工作流都是值得的。用 f 字符串格式化字符串
Python 有很多不同的方法来处理字符串格式,知道使用什么可能很棘手。事实上,我们在两篇独立的文章中深入探讨了格式化:一篇是关于一般的字符串格式化,另一篇是专门针对 f 字符串的。在一次编码面试中,当你(希望)使用 Python 3.6+时,建议的格式化方法是 Python 的 f 字符串。
f-strings 支持使用字符串格式化迷你语言,以及强大的字符串插值。这些特性允许您添加变量,甚至是有效的 Python 表达式,并在将它们添加到字符串之前,在运行时对它们进行评估:
>>> def get_name_and_decades(name, age):
... return f"My name is {name} and I'm {age / 10:.5f} decades old."
...
>>> get_name_and_decades("Maria", 31)
My name is Maria and I'm 3.10000 decades old.
f-string 允许您将Maria放入字符串中,并在一个简洁的操作中添加她的年龄和所需的格式。
需要注意的一个风险是,如果您输出用户生成的值,那么这可能会引入安全风险,在这种情况下,模板字符串可能是更安全的选择。
用sorted() 对复杂列表进行排序
大量的编码面试问题需要某种排序,有多种有效的方法可以对项目进行排序。除非面试官希望你实现自己的排序算法,通常最好用 sorted() 。
你可能见过排序的最简单的用法,比如对数字或者字符串按照升序或者降序排序:
>>> sorted([6,5,3,7,2,4,1]) [1, 2, 3, 4, 5, 6, 7] >>> sorted(['cat', 'dog', 'cheetah', 'rhino', 'bear'], reverse=True) ['rhino', 'dog', 'cheetah', 'cat', 'bear]默认情况下,
sorted()已经按升序对输入进行了排序,而reverse关键字参数使它按降序排序。值得一提的是可选的关键字参数
key,它允许您指定一个函数,在排序之前对每个元素调用这个函数。添加函数允许自定义排序规则,这在您想要对更复杂的数据类型进行排序时尤其有用:
>>> animals = [
... {'type': 'penguin', 'name': 'Stephanie', 'age': 8},
... {'type': 'elephant', 'name': 'Devon', 'age': 3},
... {'type': 'puma', 'name': 'Moe', 'age': 5},
... ]
>>> sorted(animals, key=lambda animal: animal['age'])
[
{'type': 'elephant', 'name': 'Devon', 'age': 3},
{'type': 'puma', 'name': 'Moe', 'age': 5},
{'type': 'penguin', 'name': 'Stephanie, 'age': 8},
]
通过传入一个返回每个元素年龄的 lambda 函数,您可以很容易地根据每个字典的单个值对字典列表进行排序。在这种情况下,字典现在按年龄升序排序。
有效利用数据结构
算法在编码面试中得到很多关注,但数据结构可能更重要。在编码面试环境中,选择正确的数据结构会对性能产生重大影响。
除了理论上的数据结构,Python 在其标准数据结构实现中内置了强大而方便的功能。这些数据结构在编写采访代码时非常有用,因为它们默认为您提供了许多功能,让您可以将时间集中在问题的其他部分。
用集合存储唯一值
您通常需要从现有数据集中移除重复的元素。新开发人员有时会在应该使用集合的时候使用列表,集合强制所有元素的唯一性。
假设你有一个名为get_random_word()的函数。它总是从一小组单词中随机选择:
>>> import random >>> all_words = "all the words in the world".split() >>> def get_random_word(): ... return random.choice(all_words)你应该反复调用
get_random_word()来获得 1000 个随机单词,然后返回一个包含每个唯一单词的数据结构。这里有两种常见的次优方法和一种好方法。错误的方法
get_unique_words()将值存储在列表中,然后将列表转换为集合:
>>> def get_unique_words():
... words = []
... for _ in range(1000):
... words.append(get_random_word())
... return set(words)
>>> get_unique_words()
{'world', 'all', 'the', 'words'}
这种方法并不可怕,但是它不必要地创建了一个列表,然后将它转换成一个集合。面试官几乎总是注意到(并询问)这种类型的设计选择。
更糟糕的方法
为了避免从列表转换到集合,您现在将值存储在列表中,而不使用任何其他数据结构。然后,通过将新值与列表中当前的所有元素进行比较来测试唯一性:
>>> def get_unique_words(): ... words = [] ... for _ in range(1000): ... word = get_random_word() ... if word not in words: ... words.append(word) ... return words >>> get_unique_words() ['world', 'all', 'the', 'words']这比第一种方法更糟糕,因为您必须将每个新单词与列表中已经存在的每个单词进行比较。这意味着随着单词数量的增长,查找的次数以二次方增长。换句话说,时间复杂度以 O(N)的数量级增长。
好方法
现在,您完全跳过使用列表,而是从一开始就使用集合:
>>> def get_unique_words():
... words = set()
... for _ in range(1000):
... words.add(get_random_word())
... return words
>>> get_unique_words()
{'world', 'all', 'the', 'words'}
除了从一开始就使用集合之外,这看起来与其他方法没有太大的不同。如果您考虑在.add()中发生的事情,它甚至听起来像第二种方法:获取单词,检查它是否已经在集合中,如果不是,将它添加到数据结构中。
那么,为什么使用集合不同于第二种方法呢?
这是不同的,因为集合存储元素的方式允许以接近常数的时间检查一个值是否在集合中,不像列表需要线性时间查找。查找时间的差异意味着添加到集合的时间复杂度以 O(N)的速率增长,这在大多数情况下比第二种方法的 O(N)好得多。
使用发电机节省内存
列表理解是方便的工具,但有时会导致不必要的内存使用。
假设你被要求找出前 1000 个完美平方的总和,从 1 开始。您了解列表理解,因此您很快编写了一个可行的解决方案:
>>> sum([i * i for i in range(1, 1001)]) 333833500您的解决方案列出了 1 到 1,000,000 之间的所有完美正方形,并将这些值相加。你的代码返回了正确的答案,但是你的面试官开始增加你需要求和的完美正方形的数量。
起初,你的函数不断弹出正确的答案,但很快它就开始变慢,直到最终这个过程似乎永远停止。这是你在编码面试中最不希望发生的事情。
这是怎么回事?
它会列出你要求的所有完美的正方形,然后把它们加起来。一个包含 1000 个完美方块的列表对计算机来说可能不算大,但 1 亿或 10 亿是相当多的信息,可以很容易地淹没计算机的可用内存资源。这就是这里正在发生的事情。
谢天谢地,有一个快速解决内存问题的方法。您只需用圆括号替换括号:
>>> sum((i * i for i in range(1, 1001)))
333833500
交换括号会将你对列表的理解变成一个生成器表达式。当您知道要从序列中检索数据,但不需要同时访问所有数据时,生成器表达式是最理想的选择。
生成器表达式返回一个generator对象,而不是创建一个列表。该对象知道自己在当前状态中的位置(例如,i = 49),并且只在需要时才计算下一个值。
所以当sum通过反复调用.__next__()来迭代生成器对象时,生成器检查i等于多少,计算i * i,在内部递增i,并将适当的值返回给sum。该设计允许生成器用于大规模数据序列,因为一次只有一个元素存在于内存中。
用.get()和.setdefault() 定义字典中的默认值
最常见的编程任务之一是添加、修改或检索一个可能在字典中也可能不在字典中的条目。Python 字典具有优雅的功能,可以使这些任务变得简单明了,但是开发人员经常在不必要的时候显式地检查值。
假设你有一本名为cowboy的词典,你想得到那个牛仔的名字。一种方法是使用条件显式检查键:
>>> cowboy = {'age': 32, 'horse': 'mustang', 'hat_size': 'large'} >>> if 'name' in cowboy: ... name = cowboy['name'] ... else: ... name = 'The Man with No Name' ... >>> name 'The Man with No Name'这种方法首先检查字典中是否存在
name键,如果存在,则返回相应的值。否则,它将返回默认值。虽然显式检查键确实有效,但是如果使用
.get(),可以很容易地用一行代码替换它:
>>> name = cowboy.get('name', 'The Man with No Name')
执行与第一种方法相同的操作,但现在它们是自动处理的。如果键存在,那么将返回正确的值。否则,将返回默认值。
但是,如果您想在访问name键的同时用默认值更新字典,该怎么办呢?.get()在这里并不能真正帮助您,所以您只能再次显式地检查值:
>>> if 'name' not in cowboy: ... cowboy['name'] = 'The Man with No Name' ... >>> name = cowboy['name']检查值并设置默认值是一种有效的方法,并且易于阅读,但是 Python 同样提供了一种更优雅的方法,使用
.setdefault():
>>> name = cowboy.setdefault('name', 'The Man with No Name')
完成与上面的代码片段完全相同的事情。它检查name是否存在于cowboy中,如果存在,它返回该值。否则,它将cowboy['name']设置为The Man with No Name,并返回新值。
利用 Python 的标准库
默认情况下,Python 附带了许多功能,只需要一个import语句。它本身就很强大,但是知道如何利用标准库可以增强你的编码面试技巧。
很难从所有可用的模块中挑选出最有用的部分,因此本节将只关注其实用函数的一小部分。希望这些能对你编写面试代码有所帮助,并激发你学习更多关于这些和其他模块的高级功能的欲望。
用collections.defaultdict() 处理缺失的字典键
当您为单个键设置默认值时,.get()和.setdefault()工作得很好,但是通常需要为所有可能的未设置键设置默认值,特别是在编码面试环境中编程时。
假设你有一群学生,你需要记录他们的家庭作业成绩。输入值是一个格式为(student_name, grade)的元组列表,但是您想要轻松地查找单个学生的所有成绩,而不需要遍历列表。
存储成绩数据的一种方法是使用一个将学生姓名映射到成绩列表的字典:
>>> student_grades = {} >>> grades = [ ... ('elliot', 91), ... ('neelam', 98), ... ('bianca', 81), ... ('elliot', 88), ... ] >>> for name, grade in grades: ... if name not in student_grades: ... student_grades[name] = [] ... student_grades[name].append(grade) ... >>> student_grades {'elliot': [91, 88], 'neelam': [98], 'bianca': [81]}在这种方法中,迭代学生并检查他们的名字是否已经是字典中的属性。如果没有,您可以将它们添加到字典中,并将空列表作为默认值。然后将他们的实际成绩添加到学生的成绩列表中。
但是还有一种更简洁的方法,使用了一个
defaultdict,它扩展了标准的dict功能,允许您设置一个缺省值,如果键不存在,将对该值进行操作:
>>> from collections import defaultdict
>>> student_grades = defaultdict(list)
>>> for name, grade in grades:
... student_grades[name].append(grade)
在这种情况下,您正在创建一个使用不带参数的list()构造函数作为默认工厂方法的defaultdict。没有参数的list()返回一个空列表,所以如果名字不存在的话defaultdict调用list(),然后允许附加等级。如果你想变得有趣,你也可以使用一个 lambda 函数作为你的工厂值来返回一个任意的常量。
利用defaultdict可以使应用程序代码更加整洁,因为您不必担心键级的默认值。相反,您可以在defaultdict级别处理它们一次,然后表现得好像密钥总是存在一样。有关这种技术的更多信息,请查看使用 Python defaultdict 类型处理丢失键的。
用collections.Counter 计数可散列对象
您有一长串没有标点符号或大写字母的单词,并且您想要计算每个单词出现的次数。
您可以使用字典或defaultdict来增加计数,但是collections.Counter提供了一种更干净、更方便的方式来实现这一点。Counter 是dict的一个子类,它使用0作为任何缺失元素的默认值,并使计算对象的出现次数变得更容易:
>>> from collections import Counter >>> words = "if there was there was but if \ ... there was not there was not".split() >>> counts = Counter(words) >>> counts Counter({'if': 2, 'there': 4, 'was': 4, 'not': 2, 'but': 1})当您将单词列表传递给
Counter时,它会存储每个单词以及该单词在列表中出现的次数。你好奇最常见的两个词是什么吗?只需使用
.most_common():
>>> counts.most_common(2)
[('there', 4), ('was', 4)]
.most_common()是一个方便的方法,简单地通过计数返回最频繁的输入n。
使用string常量访问公共字符串组
现在是问答时间!'A' > 'a'是真还是假?
是假的,因为A的 ASCII 码是 65,但是a是 97,65 不大于 97。
为什么答案很重要?因为如果你想检查一个字符是否是英语字母表的一部分,一个流行的方法是看它是否在A和z之间(ASCII 表上的 65 和 122)。
检查 ASCII 代码是可行的,但在编码面试中很笨拙,很容易搞砸,特别是如果你不记得是小写还是大写的 ASCII 字符先出现。使用定义为 string模块一部分的常量要容易得多。
您可以在is_upper()中看到一个正在使用的,它返回一个字符串中的所有字符是否都是大写字母:
>>> import string >>> def is_upper(word): ... for letter in word: ... if letter not in string.ascii_uppercase: ... return False ... return True ... >>> is_upper('Thanks Geir') False >>> is_upper('LOL') True
is_upper()遍历word中的字母,并检查这些字母是否是string.ascii_uppercase的一部分。如果你打印出string.ascii_uppercase,你会看到它只是一个低级的字符串。该值被设置为文字'ABCDEFGHIJKLMNOPQRSTUVWXYZ'。所有的
string常量都只是被频繁引用的字符串值的字符串。它们包括以下内容:
string.ascii_lettersstring.ascii_uppercasestring.ascii_lowercasestring.digitsstring.hexdigitsstring.octdigitsstring.punctuationstring.printablestring.whitespace这些更容易使用,更重要的是,更容易阅读。
用
itertools生成排列组合面试官喜欢给出真实的生活场景,让编码面试看起来不那么吓人,所以这里有一个人为的例子:你去一个游乐园,决定找出每一对可能一起坐在过山车上的朋友。
除非生成这些配对是面试问题的主要目的,否则生成所有可能的配对很可能只是通向工作算法的冗长乏味的一步。你可以用嵌套的 for 循环自己计算它们,或者你可以使用强大的
itertools库。
itertools有多种工具可以生成可迭代的输入数据序列,但是现在我们只关注两个常见的函数:itertools.permutations()和itertools.combinations()。
itertools.permutations()构建所有排列的列表,这意味着它是长度与count参数匹配的输入值的每个可能分组的列表。r关键字参数让我们指定每个分组中有多少个值:
>>> import itertools
>>> friends = ['Monique', 'Ashish', 'Devon', 'Bernie']
>>> list(itertools.permutations(friends, r=2))
[('Monique', 'Ashish'), ('Monique', 'Devon'), ('Monique', 'Bernie'),
('Ashish', 'Monique'), ('Ashish', 'Devon'), ('Ashish', 'Bernie'),
('Devon', 'Monique'), ('Devon', 'Ashish'), ('Devon', 'Bernie'),
('Bernie', 'Monique'), ('Bernie', 'Ashish'), ('Bernie', 'Devon')]
对于排列,元素的顺序很重要,所以('sam', 'devon')代表与('devon', 'sam')不同的配对,这意味着它们都将包含在列表中。
itertools.combinations()构建组合。这些也是输入值的可能分组,但现在值的顺序无关紧要了。因为('sam', 'devon')和('devon', 'sam')表示同一对,所以它们中只有一个会包含在输出列表中:
>>> list(itertools.combinations(friends, r=2)) [('Monique', 'Ashish'), ('Monique', 'Devon'), ('Monique', 'Bernie'), ('Ashish', 'Devon'), ('Ashish', 'Bernie'), ('Devon', 'Bernie')]因为值的顺序与组合无关,所以对于相同的输入列表,组合比排列要少。同样,因为我们将
r设置为 2,所以每个分组中都有两个名字。
.combinations()和.permutations()只是一个强大的库的小例子,但是当你试图快速解决一个算法问题时,即使这两个函数也非常有用。结论:编码面试超能力
在下一次编码面试中,您现在可以放心地使用 Python 的一些不太常见但更强大的标准特性了。关于这门语言整体上还有很多需要学习,但是这篇文章应该给你一个更深入的起点,同时让你在面试时更有效地使用 Python。
在本文中,您学习了不同类型的标准工具来增强您的编码面试技能:
- 强大的内置功能
- 构建数据结构来处理普通场景,几乎不需要任何代码
- 针对特定问题的功能丰富的解决方案的标准库包,让您更快地编写更好的代码
面试可能不是真实软件开发的最佳近似,但了解如何在任何编程环境中取得成功是值得的,即使是面试。令人欣慰的是,在编码面试中学习如何使用 Python 可以帮助你更深入地理解这门语言,这将在日常开发中带来回报。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 编码面试:技巧&最佳实践******
Windows 上的 Python 编码环境:安装指南
你有兴趣在一台 Windows 机器上写 Python 代码吗?也许你是一个终身的 Windows 用户,开始使用 Python 编程,或者你刚刚开始从 macOS 或 Linux 中脱离出来。在本教程中,您将在 Windows 10 上完成一个简单易用且灵活的 Python 编码设置。
注意:这里的大部分步骤在 Windows 11 上同样适用。
要为 Python 编码设置您的 Windows 机器,您将:
- 清理和更新新的 Windows 安装
- 使用包管理器批量安装关键软件
- 使用内置的
ssh-keygen生成 SSH 密钥并连接到你的 GitHub 账户- 搭建一个开发环境,包括 PowerShell 内核、 pyenv for Windows 、 Python 、 VS 代码
- 检查脚本和工具来自动化设置和安装过程
在这个过程中,您将了解到各种推荐的工具,这些工具用于一个完整的、免费的、大部分开源的 Windows Python 编码设置。您不会了解所有可能的工具,但是您将带着一个对大多数情况足够灵活的设置离开。
如果你是初级到中级 Pythonista,或者你只是想在 Windows 机器上进行设置,而不必考虑所有不同的选项,那么本教程就是为你准备的。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
也许你急着去准备。如果是这种情况,那么您将在关于快速跟踪您的设置的部分中找到您需要的东西,在那里您将研究一个 PowerShell 脚本来几乎完全自动化这个过程。如果你需要快速起床跑步,就跳到那边去。也就是说,浏览一下的第一部分会给你一个很好的清单,确保你不会遇到任何错误。
在 Windows 中设置您的基本 Python 编码环境
假设你正坐在一个全新的 Windows 系统前。在本节中,您将经历在这种情况下应该执行的最初步骤。您将获得一个初始命令行环境设置,通过包管理器安装软件,并为 Python 编码设置配置必要的 Windows 设置。
注意:如果你打算跟着做,你将在整个过程中多次重启电脑。在附近有另一个设备是值得的,不仅是为了保持本教程打开,而且是为了一般的查询、故障排除,以及在等待更新或安装时继续阅读其他真正的 Python 教程的能力。
除了安装您需要的东西,您还将学习如何避开一些可能碍事的微软内置程序。第一步是确保您的 Windows 安装是最新的。
更新您的 Windows 安装
首先,如果你的机器是新的或者你已经禁用了更新,那么你需要确保你的 Windows 安装是最新的。如果你想使用 Windows 子系统 for Linux (WSL) 并拥有 Windows 10,更新就显得尤为重要。这也是对可怕的 Windows 自动重启的一种保护。
安装 Windows 更新可能需要一两个小时,但相对来说是不需要动脑的。因此,如果您从这里开始,请在等待更新完成的同时安排一些其他任务。
要开始更新过程,进入开始菜单并搜索 Windows 更新。到达后,提示 Windows 搜索、下载并安装它能找到的任何更新:
一旦安装了所有的更新,你可能会被提示重新启动计算机。它让你做多少次,你就做多少次。
你可能需要重复更新过程两到三次。一旦安装了第一批更新,并且重新启动了系统,如果你返回到更新屏幕,它可能会说系统是最新的。但是,如果您等待一段时间,然后再次检查更新,它可能会找到更多的安装。
安装完所有更新后,就可以在 Windows Python 编码设置中对命令行环境进行初始设置了。
发现 Windows 终端
如果你一直使用 Windows,那么你可能习惯于通过自己的应用程序使用命令提示符和 PowerShell 。以这种方式打开它们可能会让你认为它们是独立的程序。但是,当您从“开始”菜单运行这些程序时,有两个进程正在运行。一个进程执行命令,另一个进程发送你的输入,显示输出。
打开命令提示符时看到的窗口是显示进程。命令提示符的核心在后台,等待窗口发送的输入。这样,窗口就充当了终端的某种主机。
有关命令解释器和接口之间的差异的更多信息,请查看关于
subprocess模块的文章中的对 shell 的介绍部分。Windows 已经创建了一个新的、开源的 Windows 终端 作为通用的控制台主机。它充当多个 Shell 的接口,允许您启动命令提示符、PowerShell 和任何其他 shell,这些 shell 可能作为同一主机中的不同选项卡提供:
在新的 Windows 终端出现之前,许多人依赖其他主机(也称为模拟器)来管理不同的 shell 会话,如标签、水平和垂直分割。一个流行的选择是 ConEmu。ConEmu 比 Windows 终端拥有更多的功能。然而,Windows 终端正在迎头赶上,并拥有一些 ConEmu 没有的功能,如 Unicode emoji 支持。
注意:本教程不要求您使用 Windows 终端,但建议您使用。似乎在 UNIX 世界中,人们使用命令行更加普遍,这部分是因为终端模拟器的良好特性。
Windows 终端还有一个优势,就是有开源社区和微软的支持。Windows 终端正在以惊人的速度改进和增加功能。至关重要的是,对于本教程来说,Windows 终端比 ConEmu 更容易安装,所以如果您正在学习,请转到下一节安装 Windows 终端。
安装 Windows 终端
对于本教程的设置,您应该从微软商店 安装终端应用程序,可从开始菜单访问。从微软商店安装它有几个好处。一个优点是它确保更新自动到来。另一个优点是安装起来没有痛苦。其他来源似乎打破相对频繁,大概是因为 Windows 终端发展非常迅速。
Windows 终端是唯一一个不需要安装软件包管理器的应用程序,你将在本教程的后面部分看到。也就是说,希望很快你就能在一个包管理器下管理你所有的软件。
一旦你在微软商店安装了 Windows 终端,你应该可以在终端下的开始菜单中找到它。如果,不管什么原因,你不能从微软商店安装它,试试 GitHub 仓库里的发布页面。
当您启动 Windows 终端时,它应该会自动启动一个新的 PowerShell 选项卡:
正确工作后,你将切换齿轮来执行一些常规的窗户调整。
配置常规 Windows 设置
有一些通用的 Windows 设置,你会想要设置,以保持你的理智检查。本节包含一些典型设置,Windows 用户在安装 Windows 时通常会立即更改这些设置。大多数设置都是可选的。确保你做了列出的第一个,接下来。
应用执行别名
应用程序执行别名是 Windows 的一种特殊别名。比如你在命令行输入
python,Windows 会自动询问你是否要安装 Python 的微软商店版本。应用程序执行别名是一个使事情更容易开始的功能,但它们会干扰其他程序。例如,当您安装 pyenv for Windows 并安装几个 Python 版本时,应用程序执行别名将通过不允许您访问这些 Python 版本来进行干扰。
您可以从“开始”菜单中搜索应用程序执行别名控制面板。该条目名为管理应用执行别名。下面是控制面板屏幕截图:
您通常可以关闭所有这些,因为您已经有了
Path环境变量来确保应用程序在命令行上可用。在教程的后面会有更多关于环境变量的内容。必须禁用的是与 Python 相关的。这一小节中的其余设置是可选的,但是对于生活质量是推荐的。
Windows 更新
让 Windows 保持最新是值得的,这不仅是为了安全,也是为了更新所有的开发工具,如 Windows 终端和 WSL。你想避免的一个 Windows 怪癖是自动重启。为此,您可以使用高级 Windows 更新选项控制面板禁用重启设备的选项:
在这里,您需要禁用在安装新的更新后尽快重启设备的选项。这个设置通常会导致可怕的 Windows 自动重启。
不过,禁用自动重启功能仍然不是无懈可击的。为了安全起见,你需要每隔几天或者至少每周重启一次 Windows。如果有一件事 UNIX 系统似乎更擅长,那就是能够长时间不重启。
Windows 资源管理器
为了使非开发人员更容易使用 Windows 资源管理器,它隐藏了一些您可能想看到的信息,因此您应该启用以下功能:
- 显示文件扩展名
- 显示隐藏文件
- 显示受保护的操作系统文件
- 在标题栏中显示完整路径
您可以从文件浏览器中访问这些选项,您可以使用
Win+E打开文件浏览器,点击左上角的文件选项卡,选择更改文件夹和搜索选项。在视图选项卡下,您可以找到这些设置:
调整这些设置后,您将能够看到以前隐藏的文件和文件扩展名。
在 Windows 中管理软件
大多数 Windows 用户在安装软件时的默认选项是访问网站,下载并运行可执行文件。可执行文件通常是扩展名为
.msi的 Windows Installer 包。然后你会看到一个用户账户控制 (UAC)屏幕,询问你是否允许更改你的设备:
如果这还不够,你必须阅读许可协议,点击 OK 很多次,然后关闭安装程序。一定有更好的办法!
在基于 UNIX 的系统上,你会得到一些叫做包管理器的好东西,比如自制软件、、
apt、、dnf、、pacman、。为什么 Windows 不能有那些?嗯,Windows 的确有一些软件包管理器可供选择,其中最受欢迎的是 Chocolatey 。Windows 包管理器不像基于 UNIX 的包管理器那样先进。然而,对于喜欢做事的人来说,这是朝着正确方向迈出的一大步。
微软正在开发它的包管理器,
winget。虽然它很好,而且变得越来越好,但它仍然不是最受欢迎的 Windows 软件包管理器,也没有 Chocolatey 那么多的软件包可供选择。在安装 Chocolatey 之前,您需要先做几件事。
放松您的执行策略
要安装 Chocolatey,您需要首先以管理员身份打开 Windows 终端或您选择的终端程序。
注意:要以管理员身份启动程序,可以在开始菜单中搜索 app,然后右键点击,选择以管理员身份运行。
作为管理员运行一个程序也被称为运行该程序的一个提升的实例。它也可以被称为用提升的特权运行程序。
打开管理员终端会话后,您应该会看到一个 PowerShell 选项卡。
为了能够毫不费力地安装 Chocolatey,并且对于教程后面的自动化脚本,您需要将您的执行策略设置为没有默认的严格。
执行策略设置您的系统对运行来自其他来源的脚本的严格程度。对于本教程,您需要将其设置为
RemoteSigned:PS> Set-ExecutionPolicy RemoteSigned Execution Policy Change The execution policy helps protect you from scripts that you don't trust. ... Do you want to change the execution policy? [Y] Yes [N] No [S] Suspend [?] Help (default is "Y"): y您可能看不到该警告,因为可能已经设置了执行策略。要仔细检查您的设置,您可以运行
Get-ExecutionPolicy。一旦有了正确的执行策略,就可以下载并运行安装 Chocolatey 的脚本了。安装巧克力
要运行 Chocolatey 安装脚本并运行您将在教程稍后的中看到的自动安装脚本,您可以向脚本的托管版本发出请求。
注意:您总是被告知在运行远程脚本之前检查它们的源代码,因为恶意的参与者可以利用这种技术。
例如,如果有人入侵了
community.chocolatey.org/install.ps1URL 并用恶意脚本替换它,这可能会对您的机器造成严重破坏。所以,要小心检查来源没有被破坏。要运行安装脚本的托管版本,您可以运行以下命令:
PS> iwr -useb community.chocolatey.org/install.ps1 | iex
iwr是Invoke-WebRequest的别名,-useb表示使用基本解析,从community.chocolatey.org/install.ps1下载并解析脚本。这样做的结果是脚本文本,然后通过管道将 (|)传输到iex,T5 是运行脚本的Invoke-Expression的别名。该脚本安装 Chocolatey。一旦安装完成,您应该能够从同一个提示符调用
choco。但是,在安装后,该命令并不总是在同一个提示符下可用。在这种情况下,您可以重新启动终端,确保它仍然处于管理员模式,以适应教程中将要出现的内容。如果还是失败,请重新启动系统以刷新环境。使用巧克力
安装了 Chocolatey 后,您就可以用简单的命令管理几乎所有的软件了。请记住,要安装、升级和卸载软件,您需要以管理员身份启动终端会话。
注意:作为管理员启动整个程序可能有点麻烦。通常,你只想以管理员的身份运行一些命令,所以不得不在管理员模式下启动整个程序感觉有点大材小用。
在 UNIX 环境中,有一个方便的
sudo命令,您可以将其添加到任何命令的前面,以提升的权限运行该特定命令。如果这个命令在 Windows 上可用的话,它将是安装包的理想选择。幸运的是,您可以安装一个名为 gsudo 的包,它几乎可以实现这一功能。你仍然需要点击 UAC 屏幕,但是你不需要打开一个全新的程序实例来安装。
然而,安装 gsudo 并不是遵循本教程所必需的。
尝试启动一个提升的终端会话,然后从在线包搜索中安装您选择的包。下面用开源文件归档器 7zip 演示了安装命令:
PS> choco install 7zip 7zip.install v22.0 [Approved] 7zip.install package files install completed. Performing other installation steps. The package 7zip.install wants to run 'chocolateyInstall.ps1'. Note: If you don't run this script, the installation will fail. Note: To confirm automatically next time, use '-y' or consider: choco feature enable -n allowGlobalConfirmation Do you want to run the script?([Y]es/[A]ll - yes to all/[N]o/[P]rint):在确认提示符下,键入
Y并按回车键。然后,Chocolatey 将安装该软件包。如果您想禁用双重检查的行为,那么您可以发送以下命令:PS> choco feature enable -n allowGlobalConfirmation现在安装过程不会提示你烦人的你确定吗?提示类型。也就是说,您也可以通过添加
-y标志为每个安装命令传递这个选项。如果您想从命令行搜索可用的包,那么您可以使用
choco search [keyword]命令。要查看已安装软件包的列表,可以使用带有--local-only标志的choco list命令。最后,升级和卸载也有choco upgrade和choco uninstall命令:PS> choco upgrade [package-name] PS> choco upgrade all # keyword to try upgrade all packages PS> choco uninstall [package-name]请注意,升级所有软件包可能需要一段时间。
现在你已经准备好开始使用 Chocolatey 了,只需安装一小组软件来帮助你清理和卸载任何可能已经预装在你系统上的膨胀软件。
解除你的机器和卸载软件
一旦你有了你的包管理器,你可能想做的第一件事就是清理它。这一部分是可选的,对于您的系统来说可能不是必需的。
如果你已经从微软镜像安装了 Windows,那么可能没有什么需要删除的。如果你的电脑是预装的,那么它可能会被一堆膨胀软件所填充。
例如,制造商通常包括第三方防病毒软件,但可能不会停用 Windows Defender。安装多个防病毒软件可能会导致奇怪的问题,并显著影响您电脑的性能。此外,Windows Defender 或 Microsoft Defender 是安全的,因此如果您出于任何特殊原因不需要额外的防病毒软件,您可以放心,内置的防病毒软件足以保护您的安全。
为了在预装系统上进行完美安装,有些人甚至会完全重置 Windows 安装。通过搜索复位,可通过开始菜单使用该选项。然而,这个核心选项可能会成为一个麻烦,因为您的机器可能需要特殊的驱动程序,而 Windows 安装过程无法访问这些驱动程序。
同样不可避免的是,在某些时候,你会安装一些你不想要的东西。也许这是 Chocolatey 上没有的一个包,或者你只是忘了使用 Chocolatey。或者,令你惊恐的是,你点击了一个可疑的链接并安装了一些持续的间谍软件。
要清理和删除程序,你可能需要一个像样的卸载程序,理想情况下,它可以让你批量卸载,还可以做额外的工作,清理有时留下的文件和文件夹。
间谍软件、恶意软件和广告软件特别擅长留下服务,一旦你卸载了它们,它们就会自动重新安装。
或者 BCU,是一个神奇的开源卸载程序,它会找出各种各样的程序并清除它们:
PS> choco install bulk-crap-uninstaller一旦它安装并打开,它将允许您选择多个程序,并尽可能自动卸载和清理过程:
BCU 将检测哪些卸载过程不能自动化,并卸载那些第一。然后,它会让你知道,所有其余的程序都可以卸载,无需你的干预。
在主要的卸载过程后,BCU 将执行深度清理,显示您可能想要删除的剩余文件、服务和注册表项。
注意:删除注册表项时要小心,因为这会影响其他程序!
其他免费选项也是可用的,比如 Geek 卸载程序,如果你只是想卸载一两个程序,它通常会更快。
注意:如果您看到一些程序已经安装在您的系统上,但有 Chocolatey 软件包可用,那么卸载它们并使用 Chocolatey 重新安装它们可能是值得的。一旦所有程序都在同一个包管理器下,更新和卸载它们就更容易管理了。
有些程序很难卸载,因为它们深深地嵌入了 Windows。如果你想尽量减少他们的出现,那么你可能也想和 Winaero Tweaker 玩玩:
PS> choco install winaero-tweakerWinaero Tweaker 是一个实用程序,允许您更改一系列设置,这些设置要么无法通过设置应用程序访问,要么很难更改。例如,它可以禁用 Cortana 和 OneDrive ,如果你不打算使用它们的话。
注意:安装完浏览器和其他软件后,您可能想要打开默认应用控制面板,也可以从开始菜单中搜索,并将您喜欢的应用设置为默认应用。
一个常见的变化是从 Edge 更改默认浏览器。Windows 将做最后一次尝试来说服你使用 Edge,但如果你更喜欢另一种浏览器,请大胆尝试!
一旦你完成了一般的清理,是时候深入研究和探索 Windows 命令行体验了。
导航 Windows 命令行
经典的 Windows 命令行体验与命令提示符相关,也称为
cmd.exe:
但是时代在发展,现在你会想要使用 PowerShell Core ,这是一个跨平台、面向对象的 Shell,它能做的远不止命令提示符。
PowerShell 是由微软设计的,由布鲁斯·帕耶特掌舵,是一个强大且相对容易理解的工具,可以帮助管理 Windows 机器的各个方面。它是一个外壳、一个脚本环境和一个自动化工具。它可以用于任何事情,从个人脚本到 DevOps 。
PowerShell 确实因为奇怪和冗长而名声不好,但它是一个引人注目的系统,可以完成很多工作。只是需要一点时间去适应。
在 Windows 10 上,默认安装了 Windows PowerShell。然而,更新的 PowerShell 内核却没有。Windows PowerShell 从版本 6 开始成为 PowerShell Core,也就是这个时候它成为了一个跨平台的 Shell 和开源来引导。
由于 PowerShell Core 在默认情况下不附带 Windows 10,所以您会希望安装它。
安装 PowerShell 核心
现在您可以安装最新版本的 PowerShell Core with Chocolatey 了:
PS> choco install powershell-core一旦完成,您现在应该能够调用
pwsh来启动 PowerShell 核心会话。如果不起作用,尝试命令refreshenv,如果失败,重启终端会话:
请注意,当您升级 PowerShell Core 时,您会希望从另一个 shell 进行更新,比如仍然可用的旧 Windows PowerShell,或者命令提示符。试图更换正在使用的 PowerShell 核心可能会有问题。因此,当您升级它时,请确保所有 PowerShell 核心实例都已关闭。
注意:在本教程中,您并不一定需要 PowerShell Core,因为 Windows PowerShell 将适用于您将在此介绍的内容。也就是说,您还不如使用最新的、功能最全的版本。毕竟,业界对 PowerShell 技能的需求越来越大!
现在您已经安装了最新版本的 PowerShell Core,您将能够使用它来完成所有典型的基于 Shell 的任务。
掌握 PowerShell 基础知识
PowerShell Core 有很多功能,但你并不需要全部;见鬼,你甚至不需要它的一部分。以下是导航和管理文件系统的一些最常用命令:
别名 完整的 PowerShell 命令 说明 Bash 等价物 lsGet-ChildItem列出当前工作目录的内容 lscdSet-Location更改您当前的工作目录 cdrmRemove-Item删除项目 rmrm -recurse -foRemove-Item -Recurse -Force递归删除文件夹 rm -rfmkdirNew-Item -ItemType Directory创建新目录 mkdirniNew-Item -ItemType File创建新文件 touchcatGet-Content将文件内容打印到屏幕上 cat您会发现它与典型的 POSIX shell 没有太大的不同,就像您在 Linux 或 macOS 等基于 UNIX 的系统上看到的那样。
如果你对 PowerShell 感到困惑,这种困惑通常源于 PowerShell 像 Python 一样非常面向对象,而大多数 Shell 是纯基于文本的。一旦你开始理解这种变化,它就会变得更有意义。
如果你有兴趣了解更多关于 PowerShell 的知识,Bruce Payette 自己写了Windows PowerShell in Action。尽管这本书使用了 Windows PowerShell,但对于一般的介绍来说还是很棒的。
现在您已经熟悉了命令行,有些事情您可能想给自己起个别名来定制您的体验,使它更适合您的工作流。
定制您的 PowerShell 体验
您在某个时候想要做的一项任务是配置您的 PowerShell 配置文件。这个概要文件不是必需的,但是它是一个可以利用的很好的工具。您的概要文件是一个 PowerShell 脚本,用于配置您的命令行环境——它相当于一个 Bash
.bashrc文件。每当您启动新的 PowerShell 会话时,配置文件脚本都会运行。如果你有多台机器,那么它是一个很好的备份文档,可以在所有机器之间共享。该配置文件对于初始化新机器也非常有用。这样,您可以从一开始就获得所有的快捷方式和自定义功能。
注意: Windows PowerShell 有自己的配置文件位置,不会受到 PowerShell 核心配置文件的影响。
首先,您需要创建配置文件,因为在安装 PowerShell Core 时,默认情况下不会创建它:
PS> ni -Force $PROFILE该命令使用
ni命令,它是New-Item的别名。它使用了$PROFILEPowerShell 变量,该变量指向 PowerShell 查找配置文件的路径。使用-Force标志是因为 PowerShell 可能需要在这个过程中创建一些目录。注意: PowerShell 变量前面有美元符号
$。一旦创建了个人资料,您就可以用 Windows 记事本打开它:
PS> notepad $PROFILE一旦它打开,添加任何您想要的 PowerShell 命令。例如,您可以为经常使用的程序设置别名:
# Microsoft.PowerShell_profile.ps1 Set-Alias n notepad在这种情况下,
n将成为命令notepad的别名。所以如果你想打开记事本,现在你只需输入n。请注意,您对配置文件所做的任何更改只有在您启动的下一个会话中才会显现出来。您还可以将功能添加到您的个人资料中:
# Microsoft.PowerShell_profile.ps1 function grep { $input | out-string -stream | select-string $args }如果你来自 UNIX 背景,那么
grep可能是一个受欢迎的 Windows 实用程序!这是一种过滤多行输出的方法。例如,如果您正在列出一个大型目录,并且希望只显示包含特定字符串的行,那么您可以像这样使用该实用程序:PS> ls large-directory | grep python这个命令列出了一个大目录的内容,并且只显示包含字符串
python的行。注意:另一个工作方式略有不同的后起之秀是 Scoop 。Scoop 主要关注命令行工具。
Scoop 是移植 UNIX 命令行工具的一个很好的来源,比如
grep、less、cowsay等等。因此,如果您来自 UNIX 背景,并且错过了某些命令行工具,Scoop 值得一试。PowerShell 还有一个模块系统来扩展和定制您的命令行体验,在下一节中,您将获得一些关于安装方便的模块的建议。
发现 PowerShell 模块
PowerShell 拥有丰富的可选模块生态系统,您可以安装这些模块来进一步增强您的命令行体验。以下是一些非常有用但完全可选的方法:
- ZLocation :这个模块可以帮助你非常快速地导航到常用的文件夹。
- 哦,我的豪华版:这个模块使得定制你的 PowerShell 提示符变得很容易,看起来很棒,还可以添加一些额外的功能。
- PSFzf :这个模块将搜索工具 fzf 的功能封装在 PowerShell 内部。你需要先安装 fzf,用
choco install fzf就可以了。- posh-git :这个模块允许进一步定制你的提示,但是会给你的 Git 命令带来制表符补全。
你可以用
Install-Module命令安装这些模块,尽管每个链接都有更多关于如何正确安装和设置的信息。您已经为您的 PowerShell 会话设置了一些定制,但是有些东西需要在更深的层次上进行配置。在下一节中,您将讨论环境变量。
配置环境变量
环境变量是通用的键-值对,在操作系统的许多级别上都可用。它们通常包含有关如何运行程序或在哪里找到资源的信息。例如,如果设置或不设置某些环境变量,Python 会以不同的方式运行。
虽然在设置机器的过程中,您不需要在自己的配置方面做太多工作,但在进行故障诊断时,这总是迟早会发生的事情。所以在这个话题上了解自己的方式是值得的。
使用 PowerShell 发现环境变量
PowerShell 可以访问环境变量和许多相关的功能。如果你有兴趣深入了解,微软在 PowerShell 文档中有一个页面专门讨论这些变量。
要查看当前 PowerShell 会话可用的所有环境变量,您可以导航到一个名为
ENV的伪驱动器,就像它是一个类似C或D的驱动器一样:PS> cd ENV: PS> pwd # alias for Get-Location Path ---- Env:\ PS> ls Name Value ---- ----- ALLUSERSPROFILE C:\ProgramData ANSICON 166x32766 (166x66) ANSICON_DEF 7 APPDATA C:\Users\RealPython\AppData\Roaming AZ_ENABLED False ChocolateyInstall C:\ProgramData\chocolatey ...一旦导航到
ENV:伪驱动器,就可以调用ls来列出当前 PowerShell 会话可用的所有环境变量。注意: PowerShell 和一般的 Windows 一样,不区分大小写。所以像
$PROFILE这样的路径或变量也可以用$profile来访问。ENV可以通过env进入。这也适用于文件名和路径。还有一个用于环境变量的图形用户界面(GUI) 控制面板,这将在本节的后面部分介绍。
环境变量不同于像
$PROFILE这样的变量,因为环境变量通常可用于您的用户空间中的所有程序,而$PROFILE是 PowerShell 专用的变量。这个
Env:Path变量特别容易出错,如果你不明白发生了什么,它会令人沮丧。理解
Path环境变量您应该熟悉的环境变量之一是
Path环境变量。Path是一个变量,包含可执行文件所在目录的路径列表。Path由你的系统保存,作为一种让程序总是在手边的方式。例如,无论何时从命令行调用
choco或python,都可以看到Path环境变量的运行。您知道目标可执行文件可能不在当前工作目录中,但 Windows 仍然可以启动它。例如,Chocolatey 在
Path中添加了一个目录,其中放置了您可能希望从命令行调用的可执行文件。它添加到Path环境变量的目录是C:\ProgramData\chocolatey\bin,在这个目录中,您至少可以找到choco.exe。有了这个设置,当你从命令行调用choco时,Windows 将在Path环境变量的每个路径中搜索包含choco可执行文件的文件夹。要查看您的
Path变量中有哪些路径,您可以从 PowerShell 中调用以下命令:PS> (cat ENV:Path) -Split ";"
cat是Get-Content的别名,返回Path变量内容的字符串对象。您可以将该对象放在括号中,以调用-Split操作符来查看单独一行上的每条路径。运行上一个命令后显示的列表是您的系统在评估要运行哪个程序时将查找的位置列表。一旦安装了 Python,就需要添加 Python 可执行文件的位置,这样就可以从任何地方调用
python。注意:注意
Path中任何给定的可执行文件都有多个可能的选择。例如,如果您在Path的两个不同地方有一个python.exe,那么运行的将总是第一个的。有了一些环境变量和
Path变量的知识,您现在可以学习如何在必要时对它们进行修改。设置和更改环境变量
有多种方法可以改变环境变量——最常见的是使用 GUI 控制面板。
打开开始菜单,搜索编辑系统环境变量,打开系统属性窗口。在高级选项卡中,点击按钮环境变量。在那里,您将看到用户和系统变量,您可以编辑这些变量:
https://player.vimeo.com/video/729132627?background=1
如果您是计算机的唯一用户,那么您可以只设置用户变量。如果希望计算机上的所有用户都可以访问该变量,请设置系统变量。
您还可以使用在提升的 PowerShell 提示符下设置环境变量。NET API 方法,像这样:
PS> [Environment]::SetEnvironmentVariable("TEST", "VALUE", "User")该命令设置一个带有关键字
"TEST"的环境变量,其值为"VALUE",作用域为"User"。范围可以是"User"、"Process"或"Machine"。如果希望环境变量对所有用户都可用,可以使用"Machine",而"User"只对当前用户可用。"Process"作用域将只为当前 PowerShell 会话和会话的子进程设置一个变量。您可以使用下面的命令使用 pure PowerShell 创建临时环境变量:
PS> $ENV:TEST = "VALUE"但是 PowerShell 会话上下文之外的程序将无法访问该变量。此外,如果您不将此声明也添加到您的个人资料中,那么它将不会在您的下一次 PowerShell 会话中可用。
如果您需要更改
Path变量,还有一些事情需要记住。更改
Path环境变量因为
Path环境变量是许多路径的列表,所以在修改它的时候需要小心,不要用一个路径覆盖整个Path。通常情况下,如果您打算在 PowerShell 中将它作为一个临时环境变量,那么您将需要使用字符串连接将新值追加到。
PS> $env:Path = "$env:Path;C:\new\path"也许更改
Path环境变量最简单的方法是使用 GUI 控制面板,它让每个Path条目都在自己的行上,这样更容易避免出错。为了使对环境变量的任何更改生效,您通常需要重新启动 shell 会话。Chocolatey 附带了一个实用程序脚本,允许您刷新环境:
PS> refreshenv请注意,如果您在同一个会话中安装了 Chocolatey,这将不起作用。也就是说,有时即使有那个脚本,也需要重启。
既然您已经知道了如何进行一些
Path故障排除,并且对新的命令行设置相对满意,那么是时候安装 Python 和 pyenv for Windows 了。在 Windows 中设置核心 Python 编码软件
现在是时候开始使用几个不同的 Python 版本了。尽管使用最新版本的 Python 是一个好主意,但是遇到无法使用最新最好版本的项目并不罕见。甚至还有程序还在运行 Python 2,毕竟!所以最好准备好安装任意数量的 Python 版本,并且能够在它们之间轻松切换。
使用 pyenv for Windows 安装 Python
pyenv for Windows 是最初的 pyenv 的一个端口,它只运行在基于 UNIX 的系统上。Windows 版本不像 UNIX 版本那样功能齐全,但仍然功能齐全。
使用 Chocolatey,安装 pyenv for Windows 就像安装任何其他软件包一样:
PS> choco install pyenv-win安装 pyenv for Windows 后,您将需要更新可供安装的 Python 版本的本地索引,这需要几分钟时间。更新完成后,您需要安装几个版本的 Python:
PS> pyenv update :: [Info] :: Mirror: https://www.python.org/ftp/python :: [Info] :: Scanned 172 pages and found 563 installers. PS> pyenv install --quiet 3.10.5 3.9.12 :: [Info] :: Mirror: https://www.python.org/ftp/python :: [Downloading] :: 3.10.5 ... ... :: [Installing] :: 3.10.5 ... :: [Downloading] :: 3.9.12 ... ... :: [Installing] :: 3.9.12 ...由于有了
--quiet标志,install命令将安装两个 Python 版本,而无需您的手动干预。您可以使用
pyenv global命令在 Python 版本之间切换,然后使用【T1 for version】标志检查 Python 的活动版本:PS> pyenv global 3.10.5 PS> python -V Python 3.10.5 PS> pyenv global 3.9.12 PS> python -V Python 3.9.12正如您所看到的,在不同的 Python 版本之间切换只是一个命令的问题。
注意:记住,你需要禁用 Python 相关的应用执行别名,pyenv for Windows 才能正常工作。必须禁用它们,因为 Windows 的应用执行别名和 pyenv 都会拦截
python命令。应用程序执行别名似乎优先,因此将在 pyenv for Windows 获得机会之前阻止python命令。如果您有一个项目需要特定版本的 Python,您有几个选项来处理它。您可以使用
pyenv local命令,该命令将在当前工作目录中创建一个文件,以确保您在该目录中始终运行该版本的 Python。或者您可以创建一个虚拟环境,并激活该版本:
PS> pyenv global 3.9.12 PS> python -V Python 3.9.12 PS> python -m venv venv PS> pyenv global 3.10.5 PS> python -V Python 3.10.5 PS> venv/Scripts/activate (venv) PS> python -V Python 3.9.12如果您创建了一个 Python 虚拟环境,并激活了特定版本的 Python,那么该虚拟环境将继续指向该版本的 Python。
关于 pyenv 更深入的信息,请查看上面的专用教程。请注意,由于该教程是针对 UNIX 版本的,有些功能可能无法像在 Windows 上那样工作。在这种情况下,请查看用于 Windows 存储库的pyenv。
现在您已经有了 Python,您将需要一种与其他程序员协作的方式。
在 Windows 上安装 Git
Git 是程序员中最受欢迎和最受支持的 T2 版本控制系统 T3。如果您以前从未使用过版本控制系统,它会管理对项目的更改,允许您回滚到您开始使用版本控制时代码所处的任何状态。
Git 与库一起工作。存储库基本上是一个带有跟踪历史的文件夹。 GitHub 是一个允许你托管你的仓库的网站。一旦存储库被托管,许多人可以在任何地方同时处理这个项目。您可以脱机工作,然后在连接到互联网后同步回主存储库。
Git 很容易与 Chocolatey 一起安装:
PS> choco install git就是这样!现在,您应该能够从 PowerShell 提示符下调用
git。如果这不起作用,你得到一个消息说这个命令不能被识别,尝试refreshenv。如果失败了,那么您可以重新启动 PowerShell 会话或者重启机器。Git 和 PowerShell 一样,也在用户的 home 文件夹中搜索一个配置文件。您可以在根主路径中手动创建它,或者使用一些内置的 Git 命令:
PS> git config --global user.name "John Doe" PS> git config --global user.email john.doe@domain.com也就是说,如果您试图提交,Git 将提示您添加这些信息,这将创建
.gitconfig文件。Git 启动并运行后,您将希望能够从命令行连接 GitHub,但是为此,您需要设置您的 SSH 密钥。
使用 SSH 连接 GitHub
连接 GitHub 的方式是使用 SSH,或者说安全 Shell 。为此,您需要创建一些 SSH 密钥。您将在本节中遵循的过程将生成两个密钥,一个私钥和一个公钥。你将把公开的上传到你的 GitHub 账户。
打开一个 PowerShell 会话,并确保您有默认安装的 Open-SSH :
PS> ssh usage: ssh [-46AaCfGgKkMNnqsTtVvXxYy] [-B bind_interface] [-b bind_address] [-c cipher_spec] [-D [bind_address:]port] [-E log_file] [-e escape_char] [-F configfile] [-I pkcs11] [-i identity_file] [-J [user@]host[:port]] [-L address] [-l login_name] [-m mac_spec] [-O ctl_cmd] [-o option] [-p port] [-Q query_option] [-R address] [-S ctl_path] [-W host:port] [-w local_tun[:remote_tun]] destination [command]如果您没有看到类似的输出,请按照 Windows 文档上的说明安装 Open-SSH。你也可以从一个巧克力包中安装它。
您将首先使用
ssh-keygen创建您的密钥,在每个提示符下按 enter 键以使用默认选项:PS> ssh-keygen -C john.doe@domain.com Generating public/private rsa key pair. Enter file in which to save the key (C:\Users\Real Python/.ssh.id_rsa): Created directory 'c:\Users|Real Python/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in C:\Users\Real Python/.ssh/id_rsa. Your public key has been saved in C:\Users\Real Python/.ssh/id_rsa.pub. The key fingerprint is: SHA256:aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa jondoe@domain.com The key's randomart image is: +---[RSA 3072]----+ | E+===+*++.o. | |..=+=o+O+ o.o | |o+o++.B.o oo | |o+o*oo o o . | | o+o. S . | | o | | | | | | | +----[SHA256]-----+如果你想要额外的保护,你可以添加一个密码短语,但这很方便,你不必每次将你的作品推送到 GitHub 时都输入密码。生成密钥后,输出公钥的内容,以便您可以选择它并将其复制到剪贴板:
PS> cat ~/.ssh/id_rsa.pub最后这个
cat命令的输出是您需要复制到您的 GitHub 帐户中的内容。要将密钥复制到你的 GitHub 帐户,你首先必须确保你已经注册了一个帐户。一旦你注册并登录,如果你去你的 GitHub 设置,你应该找到选项管理你的 SSH 和 GPG 键。在那里,您应该能够看到粘贴 SSH 密钥的位置。
之后,您可以测试连接:
PS> ssh -T git@github.com Hi John Doe! You've successfully authenticated, but GitHub doesn't provide shell access.如果您得到这个成功的认证消息,那么您就可以从命令行使用 GitHub 了。
既然您已经启动并运行了,是时候设置您的代码编辑器了。
设置 VS 代码
VS Code 是一个令人惊讶的可扩展的免费、开源的通用编辑器。它也是最受欢迎的。它可以用于许多语言,但是在本节中,您将为 Python 设置它。
可以用 Chocolatey 安装 VS 代码:
PS> choco install vscode请记住从提升的 PowerShell 提示符运行安装命令。
VS 代码有一个丰富的扩展生态系统来帮助你的生产力。微软官方的 Python 扩展通常是默认安装的,但如果不是,你应该确保安装它。
要安装扩展,请单击活动栏中的扩展图标:
然后使用搜索框搜索上面链接的 Python 扩展。
Python 扩展将为您提供用于 Python 的 IntelliSense ,这是您的编辑器为您提供自动完成建议的一种方式,并将在详细的工具提示中为您提供大量信息。
如果您计划使用 WSL,另一个扩展是 WSL 连接器,它将允许您编辑文件,就像在 Linux 上运行一样。
设置设置同步也是值得的,因为这将把你的 VS 代码设置和你的扩展列表链接到你的 GitHub 或微软账户,负责备份并使其在新机器上快速设置。
设置好 VS 代码后,您就可以测试您的设置了,以确保它能够正常工作。
测试您的设置
恭喜你,你可以走了。在本节中,您将快速测试您的设置,以确保一切正常工作。
在下面的代码片段中,您将测试创建一个文件夹、创建一个虚拟环境、安装一个包、初始化一个 Git 存储库,并确保 VS 代码与该设置相集成:
PS> mkdir test Directory: C:\Users\RealPython Mode LastWriteTime Length Name ---- ------------- ------ ---- d---- 27/06/22 18:19 test PS> cd test PS> pyenv versions * 3.10.5 (set by C:\Users\RealPython\.pyenv\pyenv-win\version) 3.9.12 PS> python -m venv venv PS> venv\Scripts\activate (venv) PS> python -m pip install requests Collecting requests ... Successfully installed certifi charset-normalizer idna requests urllib3 (venv) PS> git init Initialized empty Git repository in C:/Users/RealPython/test/.git/ (venv) PS> ni test.py Directory: C:\Users\RealPython\test Mode LastWriteTime Length Name ---- ------------- ------ ---- -a--- 27/06/22 18:25 0 test.py (venv) PS> code .现在打开了 VS 代码,在右下角,您应该能够看到您所处的 Python 环境:
https://player.vimeo.com/video/729155332?background=1
如果没有显示
venv并且 IntelliSense 没有工作,那么您可以使用Ctrl+Shift+P调用命令面板,并搜索Python:Select Interpreter命令。选择指向虚拟环境路径的选项。选择虚拟环境后,VS 代码应该在 VS 代码窗口的底部显示为 3.10.5 ('venv':venv) 。您还应该能够看到 VS Code 的 Git 集成正在工作。如果您更改了一个文件或添加了一个新文件,那么您将在编辑器窗口和文件资源管理器中看到该更改的指示。
干得好!现在,您在 Windows 上有了一个强大而灵活的设置。虽然使用软件包管理器比手动下载和执行安装程序要有效得多,但也许您正在寻找一种更快的方法。
快速跟踪您的 Windows Python 编码设置
也许这对你来说有点慢,或者你只是想开始自动化这个过程。有一些工具可以在工业规模上实现自动化安装,比如 Boxstarter 和 Ansible ,但是这一部分更多的是针对那些想看看你自己能做什么的修补者。
在本节中,您将快速跟踪您的最小设置,跳过任何额外的步骤,并尽可能快地开始开发。
配置存储库
当第一次尝试自动化一个新的安装时,您通常会遇到将脚本放到新机器上运行它们的问题。文件同步服务可以工作,但它们通常需要很长时间来进行初始同步。
这个问题的一个很好的解决方案是拥有一个包含配置文件和脚本的存储库。有时其他片段也可能包含在其中——有点像编码人员的个人食谱。
在这里,您可以保存您的 PowerShell 配置文件、Git 配置文件、其他配置文件以及您可能需要的任何脚本或注释。一旦你在 GitHub 上托管了文件,你就可以获得它们的原始链接并使用 PowerShell 下载它们:
要获得 raw 链接,导航到您想要在 GitHub 中使用的文件,当您查看文件内容时,您应该能够看到一个按钮,上面写着 Raw 。此按钮会将您带到一个如下所示的 URL:
https://raw.githubusercontent.com/[USER]/[REPO]/[COMMIT_SHA_OR_BRANCH]/path/to/file现在,您可以使用这个 URL 获取内容,并从您的新机器上运行它。你也可以用一个 GitHub Gist 托管单个文件。
更进一步,为了避免必须键入整个链接,您可以通过 URL 缩写器传递它,例如 bitly ,这将缩短链接:
https://bit.ly/xxxxxxx现在是时候进行主要的设置了。有了这个简短的链接,您所要做的就是禁用与 Python 相关的应用程序执行别名,启动提升的 PowerShell 会话,并运行以下命令:
PS> Set-ExecutionPolicy RemoteSigned -Force PS> iwr -useb bit.ly/xxxxxxx | iex然后一切都会为您处理好,您可以在安装过程中跑跑腿。既然您已经选择了托管安装脚本的平台,那么您将需要实际的脚本!
运行设置脚本
在这一节中,您将研究一个示例安装脚本,该脚本将安装一些您可能需要用 Python 编码的最小依赖项,特别是如果您想为 GitHub 上的开源项目做贡献的话。
运行该脚本的先决条件是:
- 将您的执行策略设置为
RemoteSigned- 禁用 Python 相关的应用执行别名
完成这两项任务后,您就可以展开下面的可折叠框并运行脚本了:
# setup.ps1 Write-Output "Downloading and installing Chocolatey" Invoke-WebRequest -useb community.chocolatey.org/install.ps1 | Invoke-Expression Write-Output "Configuring Chocolatey" choco feature enable -n allowGlobalConfirmation Write-Output "Installing Chocolatey Packages" choco install powershell-core choco install vscode choco install git --package-parameters="/NoAutoCrlf /NoShellIntegration" choco install pyenv-win # The Google Chrome package often gets out of sync because it updates so # frequently. Ignoring checksums is a way to force install it. choco install googlechrome --ignore-checksums # Google Chrome auto-updates so you can pin it to prevent Chocolatey from # trying to upgrade it and inadvertently downgrading it. # You could also add VS Code here if you like. choco pin add -n googlechrome refreshenv # The refreshenv command usually doesn't work on first install. # This is a way to make sure that the Path gets updated for the following # operations that require Path to be refreshed. # Source: https://stackoverflow.com/a/22670892/10445017 foreach ($level in "Machine", "User") { [Environment]::GetEnvironmentVariables($level).GetEnumerator() | ForEach-Object { if ($_.Name -match 'Path$') { $combined_path = (Get-Content "Env:$($_.Name)") + ";$($_.Value)" $_.Value = ( ($combined_path -split ';' | Select-Object -unique) -join ';' ) } $_ } | Set-Content -Path { "Env:$($_.Name)" } } Write-Output "Setting up pyenv and installing Python" pyenv update pyenv install --quiet 3.10.5 3.9.12 pyenv global 3.10.5 Write-Output "Generating SSH key" ssh-keygen -C john.doe@domain.com -P '""' -f "$HOME/.ssh/id_rsa" cat $HOME/.ssh/id_rsa.pub | clip Write-Output "Your SSH key has been copied to the clipboard"该脚本将尝试安装 Chocolatey,安装本教程中提到的关键软件,用 pyenv 安装几个 Python 版本,生成您的 SSH 密钥并呈现给您,以便您可以转到 GitHub 并将其添加到您的帐户中。
如果你要使用它,一定要定制你想要安装的软件,并在你的电子邮件中把它放在
ssh-keygen行。确保 Python 应用程序执行别名被禁用,获取 GitHub 上托管的文件的原始内容的缩短链接,如上一节所述,并在提升的 PowerShell 会话中运行以下命令:
PS> Set-ExecutionPolicy RemoteSigned -Force PS> iwr -useb bit.ly/xxxxxxx | iex有了这个,你应该准备好并渴望去!剩下唯一可选的步骤是配置一般的 Windows 设置,也许是解屏蔽并在此过程中设置你的配置文件。
结论
现在,您已经设置了 Windows 机器,可以使用 Python 进行一些开发了。您已经探索了一些现代工具来管理您的软件和不同的 Python 版本。不仅如此,您还参加了 PowerShell 速成班,了解了如何开始自动化安装。
在本教程中,您已经成功:
- 清理和更新新的 Windows 安装
- 使用巧克力批量安装关键软件
- 使用内置的
ssh-keygen生成 SSH 密钥并连接到你的 GitHub 账户- 搭建一个开发环境,包括 PowerShell 内核、 pyenv for Windows 、 Python 、 VS 代码
- 编写一个脚本来尽可能自动化流程。
有了这个 Windows 设置,您就可以开始用 Python 编码了。既然你也连接到 GitHub,你也准备好为开源项目做贡献了。欢迎在评论中分享你一直在做的事情!
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
其他漂亮的 Windows 软件
现在,您已经为 Python 编码设置好了所有的窗口,您可能想让您的生活更加轻松。这里有一些很棒的 Windows 实用程序可以帮助你做到这一点:
- Everything :一个伟大的搜索工具,它利用了 Windows 专用的文件索引工具。它可以作为一个通用的文件查找工具和应用程序启动器。好快啊!
- Linux 的 Windows 子系统:如果你想在 Windows 中拥有一个几乎完全成熟的 Linux 体验,看看 WSL 吧。这不是巧克力包装。
- Autohotkey:一个简单易用且非常流行的自动化工具,仅适用于 Windows。有些人坚持用窗户只是为了 AHK!
安装了这些实用程序后,您就可以应对任何编码挑战了。**********
Python 的集合:专门化数据类型的自助餐
Python 的
collections模块提供了一组丰富的专用容器数据类型,这些数据类型经过精心设计,以 python 化且高效的方式处理特定的编程问题。该模块还提供了包装类,使得创建行为类似于内置类型dict、list和str的定制类更加安全。学习
collections中的数据类型和类将允许你用一套有价值的可靠而有效的工具来扩充你的编程工具包。在本教程中,您将学习如何:
- 用
namedtuple编写可读和显式代码- 使用
deque构建高效队列和堆栈- 用
Counter快速计数物体- 用
defaultdict处理缺失的字典键- 用
OrderedDict保证插入顺序- 使用
ChainMap将多个字典作为一个单元进行管理为了更好地理解
collections中的数据类型和类,你应该知道使用 Python 内置数据类型的基础知识,比如列表、元组和字典。另外,文章的最后一部分需要一些关于 Python 中面向对象编程的基础知识。免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 的
collections入门回到 Python 2.4 , Raymond Hettinger 为标准库贡献了一个名为
collections的新模块。目标是提供各种专门的集合数据类型来解决特定的编程问题。当时,
collections只包含一个数据结构,deque,专门设计为一个双端队列,支持序列两端高效的追加和弹出操作。从这一点开始,标准库中的几个模块利用了deque来提高它们的类和结构的性能。一些突出的例子是queue和threading。随着时间的推移,一些专门的容器数据类型填充了该模块:
数据类型 Python 版本 描述 T2 deque2.4 一个类似序列的集合,支持从序列的任意一端有效地添加和移除项 T2 defaultdict2.5 字典子类,用于为缺失的键构造默认值,并自动将它们添加到字典中 T2 namedtuple()2.6 一个用于创建 tuple子类的工厂函数,提供命名字段,允许通过名称访问项目,同时保持通过索引访问项目的能力T2 OrderedDict2.7 , 3.1 字典子类,根据插入键的时间保持键-值对的顺序 T2 Counter2.7 , 3.1 字典子类,支持对序列或可重复项中的唯一项进行方便的计数 T2 ChainMap3.3 一个类似字典的类,允许将多个映射作为单个字典对象处理 除了这些专门的数据类型,
collections还提供了三个基类来帮助创建定制列表、字典和字符串:
班级 描述 T2 UserDict围绕字典对象的包装类,便于子类化 dictT2 UserList围绕列表对象的包装类,便于子类化 listT2 UserString一个围绕字符串对象的包装类,便于子类化 string对这些包装类的需求部分被相应的标准内置数据类型的子类化能力所掩盖。但是,有时使用这些类比使用标准数据类型更安全,也更不容易出错。
有了对
collections的简要介绍以及本模块中的数据结构和类可以解决的具体用例,是时候更仔细地研究它们了。在此之前,需要指出的是,本教程整体上是对collections的介绍。在接下来的大部分章节中,您会发现一个蓝色的警告框,它会引导您找到关于这个类或函数的专门文章。提高代码可读性:
namedtuple()Python 的
namedtuple()是一个工厂函数,允许你用命名字段创建tuple子类。这些字段使用点符号让您直接访问给定命名元组中的值,就像在obj.attr中一样。之所以需要这个特性,是因为使用索引来访问常规元组中的值很烦人,难以阅读,而且容易出错。如果您正在处理的元组有几个项,并且是在远离您使用它的地方构造的,这一点尤其正确。
注:查看使用 namedtuple 编写 Python 和 Clean 代码,深入了解如何在 Python 中使用
namedtuple。在 Python 2.6 中,开发人员可以用点符号访问带有命名字段的 tuple 子类,这似乎是一个理想的特性。这就是
namedtuple()的由来。如果与常规元组相比,用这个函数构建的元组子类在代码可读性方面是一大优势。为了正确看待代码可读性问题,考虑一下
divmod()。这个内置函数接受两个(非复杂的)数字,并返回一个元组,该元组具有输入值的整数除法的商和余数:
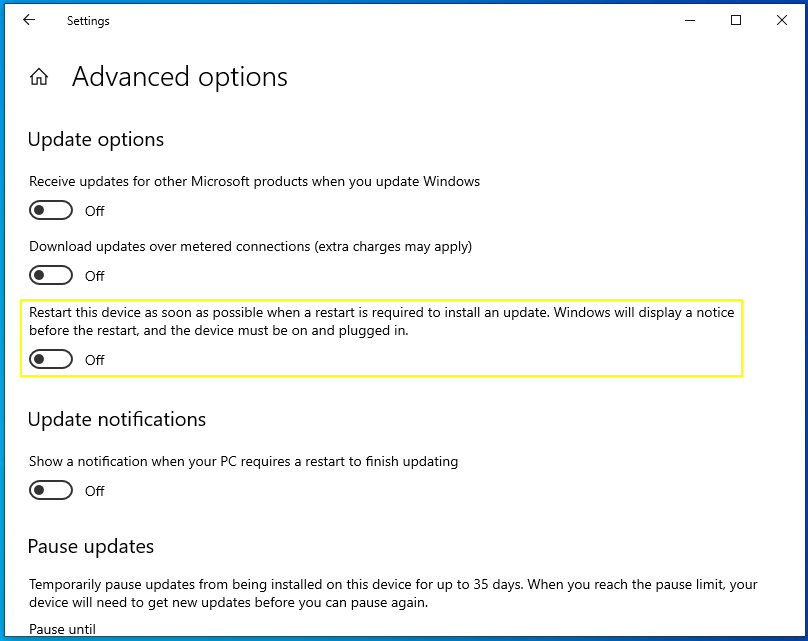
>>> divmod(12, 5)
(2, 2)
它工作得很好。然而,这个结果是否具有可读性?你能说出输出中每个数字的含义吗?幸运的是,Python 提供了一种改进方法。您可以使用namedtuple编写带有显式结果的自定义版本的divmod():
>>> from collections import namedtuple >>> def custom_divmod(x, y): ... DivMod = namedtuple("DivMod", "quotient remainder") ... return DivMod(*divmod(x, y)) ... >>> result = custom_divmod(12, 5) >>> result DivMod(quotient=2, remainder=2) >>> result.quotient 2 >>> result.remainder 2现在你知道结果中每个值的含义了。您还可以使用点符号和描述性字段名称来访问每个独立的值。
要使用
namedtuple()创建新的 tuple 子类,需要两个必需的参数:
typename是您正在创建的类的名称。它必须是一个带有有效 Python 标识符的字符串。field_names是字段名列表,您将使用它来访问结果元组中的项目。它可以是:
- 一个可迭代的字符串,比如
["field1", "field2", ..., "fieldN"]- 由空格分隔的字段名组成的字符串,例如
"field1 field2 ... fieldN"- 用逗号分隔字段名的字符串,如
"field1, field2, ..., fieldN"例如,以下是使用
namedtuple()创建具有两个坐标(x和y)的样本 2DPoint的不同方法:
>>> from collections import namedtuple
>>> # Use a list of strings as field names
>>> Point = namedtuple("Point", ["x", "y"])
>>> point = Point(2, 4)
>>> point
Point(x=2, y=4)
>>> # Access the coordinates
>>> point.x
2
>>> point.y
4
>>> point[0]
2
>>> # Use a generator expression as field names
>>> Point = namedtuple("Point", (field for field in "xy"))
>>> Point(2, 4)
Point(x=2, y=4)
>>> # Use a string with comma-separated field names
>>> Point = namedtuple("Point", "x, y")
>>> Point(2, 4)
Point(x=2, y=4)
>>> # Use a string with space-separated field names
>>> Point = namedtuple("Point", "x y")
>>> Point(2, 4)
Point(x=2, y=4)
在这些例子中,首先使用字段名的list创建Point。然后你实例化Point来制作一个point对象。请注意,您可以通过字段名和索引来访问x和y。
剩下的例子展示了如何用一串逗号分隔的字段名、生成器表达式和一串空格分隔的字段名创建一个等价的命名元组。
命名元组还提供了一系列很酷的特性,允许您定义字段的默认值,从给定的命名元组创建字典,替换给定字段的值,等等:
>>> from collections import namedtuple >>> # Define default values for fields >>> Person = namedtuple("Person", "name job", defaults=["Python Developer"]) >>> person = Person("Jane") >>> person Person(name='Jane', job='Python Developer') >>> # Create a dictionary from a named tuple >>> person._asdict() {'name': 'Jane', 'job': 'Python Developer'} >>> # Replace the value of a field >>> person = person._replace(job="Web Developer") >>> person Person(name='Jane', job='Web Developer')这里,首先使用
namedtuple()创建一个Person类。这一次,您使用一个名为defaults的可选参数,它接受元组字段的一系列默认值。注意namedtuple()将默认值应用于最右边的字段。在第二个例子中,您使用
._asdict()从现有的命名元组创建一个字典。该方法返回一个使用字段名作为键的新字典。最后,你用
._replace()替换job的原始值。这个方法不更新 tuple 的位置,而是返回一个新命名的 tuple,其新值存储在相应的字段中。你知道为什么._replace()返回一个新的命名元组吗?构建高效的队列和堆栈:
dequePython 的
deque是collections中第一个数据结构。这种类似序列的数据类型是对堆栈和队列的概括,旨在支持数据结构两端的高效内存和快速追加和弹出操作。注:字
deque读作“deck”,代表ddouble-eenddqueUE。在 Python 中,在
list对象的开头或左侧进行追加和弹出操作效率很低,时间复杂度O(n)。如果处理大型列表,这些操作的开销会特别大,因为 Python 必须将所有项目移到右边,以便在列表的开头插入新项目。另一方面,列表右侧的 append 和 pop 操作通常是高效的( O (1)),除非 Python 需要重新分配内存来增加底层列表以接受新项。
Python 的
deque就是为了克服这个问题而产生的。在一个deque对象两侧的追加和弹出操作是稳定的和同样有效的,因为 deques 被实现为一个双向链表。这就是为什么 deques 对于创建堆栈和队列特别有用。以一个队列为例。它以先进/先出 ( 先进先出)的方式管理项目。它就像一个管道,你在管道的一端推入新的项目,从另一端弹出旧的项目。将一个项目添加到队列的末尾被称为入队操作。从队列的前面或开始处移除一个项目称为出列。
注:查看 Python 的 dequee:implementing Efficient queue and Stacks以深入探究如何在 Python 代码中使用
deque。现在假设你正在为一个排队买电影票的人建模。你可以用一个
deque来做。每次有新人来,你就让他们排队。当排在队伍前面的人拿到票时,你让他们出队。下面是如何使用一个
deque对象来模拟这个过程:
>>> from collections import deque
>>> ticket_queue = deque()
>>> ticket_queue
deque([])
>>> # People arrive to the queue
>>> ticket_queue.append("Jane")
>>> ticket_queue.append("John")
>>> ticket_queue.append("Linda")
>>> ticket_queue
deque(['Jane', 'John', 'Linda'])
>>> # People bought their tickets
>>> ticket_queue.popleft()
'Jane'
>>> ticket_queue.popleft()
'John'
>>> ticket_queue.popleft()
'Linda'
>>> # No people on the queue
>>> ticket_queue.popleft()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: pop from an empty deque
在这里,首先创建一个空的deque对象来表示人的队列。要让一个人入队,可以使用 .append() ,它将项目添加到队列的右端。要让一个人出列,可以使用 .popleft() ,它移除并返回队列左端的项目。
注意:在 Python 标准库中,你会找到 queue 。该模块实现了多生产者、多消费者队列,有助于在多线程之间安全地交换信息。
deque初始化器有两个可选参数:
iterable持有一个作为初始化器的 iterable。maxlen保存一个指定deque最大长度的整数。
如果你不提供一个iterable,那么你会得到一个空的队列。如果您为 maxlen 提供一个值,那么您的 deque 将只存储最多maxlen个项目。
拥有一个maxlen是一个方便的特性。例如,假设您需要在一个应用程序中实现一个最近文件的列表。在这种情况下,您可以执行以下操作:
>>> from collections import deque >>> recent_files = deque(["core.py", "README.md", "__init__.py"], maxlen=3) >>> recent_files.appendleft("database.py") >>> recent_files deque(['database.py', 'core.py', 'README.md'], maxlen=3) >>> recent_files.appendleft("requirements.txt") >>> recent_files deque(['requirements.txt', 'database.py', 'core.py'], maxlen=3)一旦 dequeue 达到其最大大小(本例中为三个文件),在 dequeue 的一端添加新文件会自动丢弃另一端的文件。如果您不为
maxlen提供一个值,那么 deque 可以增长到任意数量的项目。到目前为止,您已经学习了 deques 的基本知识,包括如何创建 deques 以及如何从给定的 deques 的两端追加和弹出项目。Deques 通过类似列表的界面提供了一些额外的特性。以下是其中的一些:
>>> from collections import deque
>>> # Use different iterables to create deques
>>> deque((1, 2, 3, 4))
deque([1, 2, 3, 4])
>>> deque([1, 2, 3, 4])
deque([1, 2, 3, 4])
>>> deque("abcd")
deque(['a', 'b', 'c', 'd'])
>>> # Unlike lists, deque doesn't support .pop() with arbitrary indices
>>> deque("abcd").pop(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: pop() takes no arguments (1 given)
>>> # Extend an existing deque
>>> numbers = deque([1, 2])
>>> numbers.extend([3, 4, 5])
>>> numbers
deque([1, 2, 3, 4, 5])
>>> numbers.extendleft([-1, -2, -3, -4, -5])
>>> numbers
deque([-5, -4, -3, -2, -1, 1, 2, 3, 4, 5])
>>> # Insert an item at a given position
>>> numbers.insert(5, 0)
>>> numbers
deque([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
在这些例子中,您首先使用不同类型的 iterables 创建 deques 来初始化它们。deque和list的一个区别是deque.pop()不支持弹出给定索引处的项目。
注意,deque为.append()、、.pop()、、.extend()、提供了姊妹方法,并带有后缀left来表示它们在底层 deque 的左端执行相应的操作。
Deques 也支持序列操作:
| 方法 | 描述 |
|---|---|
T2.clear() |
从队列中删除所有元素 |
T2.copy() |
创建一个 deque 的浅层副本 |
T2.count(x) |
计算等于x的双队列元素的数量 |
T2.remove(value) |
删除第一次出现的value |
deques 的另一个有趣的特性是能够使用.rotate()旋转它们的元素:
>>> from collections import deque >>> ordinals = deque(["first", "second", "third"]) >>> ordinals.rotate() >>> ordinals deque(['third', 'first', 'second']) >>> ordinals.rotate(2) >>> ordinals deque(['first', 'second', 'third']) >>> ordinals.rotate(-2) >>> ordinals deque(['third', 'first', 'second']) >>> ordinals.rotate(-1) >>> ordinals deque(['first', 'second', 'third'])该方法向右旋转 deque
n步骤。n的默认值为1。如果给n提供一个负值,那么旋转向左。最后,您可以使用索引来访问 dequee 中的元素,但是您不能对 dequee 进行切片:
>>> from collections import deque
>>> ordinals = deque(["first", "second", "third"])
>>> ordinals[1]
'second'
>>> ordinals[0:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence index must be integer, not 'slice'
Deques 支持索引,但有趣的是,它们不支持切片。当您试图从现有的队列中检索一个切片时,您会得到一个TypeError。这是因为在链表上执行切片操作是低效的,所以该操作不可用。
处理丢失的按键:defaultdict
当你在 Python 中使用字典时,你会面临的一个常见问题是如何处理丢失的键。如果您试图访问一个给定字典中不存在的键,那么您会得到一个KeyError:
>>> favorites = {"pet": "dog", "color": "blue", "language": "Python"} >>> favorites["fruit"] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'fruit'有几种方法可以解决这个问题。比如可以用
.setdefault()。该方法将一个键作为参数。如果字典中存在该键,那么它将返回相应的值。否则,该方法插入该键,为其赋一个默认值,并返回该值:
>>> favorites = {"pet": "dog", "color": "blue", "language": "Python"}
>>> favorites.setdefault("fruit", "apple")
'apple'
>>> favorites
{'pet': 'dog', 'color': 'blue', 'language': 'Python', 'fruit': 'apple'}
>>> favorites.setdefault("pet", "cat")
'dog'
>>> favorites
{'pet': 'dog', 'color': 'blue', 'language': 'Python', 'fruit': 'apple'}
在这个例子中,您使用.setdefault()为fruit生成一个默认值。由于这个键在favorites中不存在,.setdefault()创建了它并赋予它apple的值。如果你用一个存在的键调用.setdefault(),那么这个调用不会影响字典,你的键将保持原始值而不是默认值。
如果给定的键丢失,您也可以使用.get()返回一个合适的默认值:
>>> favorites = {"pet": "dog", "color": "blue", "language": "Python"} >>> favorites.get("fruit", "apple") 'apple' >>> favorites {'pet': 'dog', 'color': 'blue', 'language': 'Python'}这里,
.get()返回apple,因为底层字典中缺少该键。然而,.get()并没有为你创建新的密匙。由于处理字典中丢失的键是一种常见的需求,Python 的
collections也为此提供了一个工具。defaultdict类型是dict的子类,旨在帮助你解决丢失的键。注意:查看使用 Python defaultdict 类型处理丢失的键,深入了解如何使用 Python 的
defaultdict。
defaultdict的构造函数将一个函数对象作为它的第一个参数。当您访问一个不存在的键时,defaultdict自动调用该函数,不带参数,为手边的键创建一个合适的默认值。为了提供其功能,
defaultdict将输入函数存储在.default_factory中,然后覆盖.__missing__()以在您访问任何丢失的键时自动调用该函数并生成默认值。你可以使用任何可调用来初始化你的
defaultdict对象。例如,使用int()您可以创建一个合适的计数器来计数不同的对象:
>>> from collections import defaultdict
>>> counter = defaultdict(int)
>>> counter
defaultdict(<class 'int'>, {})
>>> counter["dogs"]
0
>>> counter
defaultdict(<class 'int'>, {'dogs': 0})
>>> counter["dogs"] += 1
>>> counter["dogs"] += 1
>>> counter["dogs"] += 1
>>> counter["cats"] += 1
>>> counter["cats"] += 1
>>> counter
defaultdict(<class 'int'>, {'dogs': 3, 'cats': 2})
在本例中,您创建了一个空的defaultdict,将int()作为它的第一个参数。当你访问一个不存在的键时,字典自动调用int(),它返回0作为当前键的默认值。这种defaultdict对象在 Python 中计数时非常有用。
defaultdict的另一个常见用例是将事物分组。在这种情况下,方便的工厂函数是list():
>>> from collections import defaultdict >>> pets = [ ... ("dog", "Affenpinscher"), ... ("dog", "Terrier"), ... ("dog", "Boxer"), ... ("cat", "Abyssinian"), ... ("cat", "Birman"), ... ] >>> group_pets = defaultdict(list) >>> for pet, breed in pets: ... group_pets[pet].append(breed) ... >>> for pet, breeds in group_pets.items(): ... print(pet, "->", breeds) ... dog -> ['Affenpinscher', 'Terrier', 'Boxer'] cat -> ['Abyssinian', 'Birman']在这个例子中,您有关于宠物及其品种的原始数据,您需要按照宠物对它们进行分组。为此,在创建
defaultdict实例时,使用list()作为.default_factory。这使您的字典能够自动创建一个空列表([])作为您访问的每个缺失键的默认值。然后你用这个列表来存储你的宠物的品种。最后,你应该注意到由于
defaultdict是dict的子类,它提供了相同的接口。这意味着你可以像使用普通字典一样使用你的defaultdict对象。保持字典有序:
OrderedDict有时,您需要字典来记住键值对的插入顺序。多年来,Python 的常规字典是无序的数据结构。所以,回到 2008 年, PEP 372 引入了给
collections添加一个新字典类的想法。新的类会根据钥匙插入的时间记住项目的顺序。这就是
OrderedDict的由来。
OrderedDict在 Python 3.1 中引入。其应用编程接口(API)与dict基本相同。然而,OrderedDict按照键被第一次插入字典的顺序遍历键和值。如果为现有键分配一个新值,则键-值对的顺序保持不变。如果一个条目被删除并重新插入,那么它将被移动到字典的末尾。注:查看Python 中的 OrderedDict vs dict:工作的正确工具以深入了解 Python 的
OrderedDict以及为什么应该考虑使用它。有几种方法可以创建
OrderedDict对象。它们中的大多数与你如何创建一个普通的字典是一样的。例如,您可以通过实例化不带参数的类来创建一个空的有序字典,然后根据需要插入键值对:
>>> from collections import OrderedDict
>>> life_stages = OrderedDict()
>>> life_stages["childhood"] = "0-9"
>>> life_stages["adolescence"] = "9-18"
>>> life_stages["adulthood"] = "18-65"
>>> life_stages["old"] = "+65"
>>> for stage, years in life_stages.items():
... print(stage, "->", years)
...
childhood -> 0-9
adolescence -> 9-18
adulthood -> 18-65
old -> +65
在这个例子中,您通过实例化不带参数的OrderedDict来创建一个空的有序字典。接下来,像处理常规字典一样,将键值对添加到字典中。
当您遍历字典、life_stages时,您将获得键-值对,其顺序与您将它们插入字典的顺序相同。保证物品的顺序是OrderedDict解决的主要问题。
Python 3.6 引入了一个的新实现dict 。这种实现提供了一个意想不到的新特性:现在普通字典按照它们第一次插入的顺序保存它们的条目。
最初,这个特性被认为是一个实现细节,文档建议不要依赖它。然而,自从 Python 3.7 ,特性正式成为语言规范的一部分。那么,用OrderedDict有什么意义呢?
OrderedDict的一些特性仍然让它很有价值:
- 意图传达:有了
OrderedDict,你的代码会清楚的表明字典中条目的顺序很重要。你清楚地表达了你的代码需要或者依赖于底层字典中的条目顺序。 - 对条目顺序的控制:使用
OrderedDict,您可以访问.move_to_end(),这是一种允许您操纵字典中条目顺序的方法。您还将拥有一个增强的.popitem()变体,允许从底层字典的任意一端移除条目。 - 相等性测试行为:使用
OrderedDict,字典之间的相等性测试会考虑条目的顺序。因此,如果您有两个有序的字典,它们包含相同的条目组,但顺序不同,那么您的字典将被认为是不相等的。
使用OrderedDict : 向后兼容至少还有一个原因。在运行 than 3.6 之前版本的环境中,依靠常规的dict对象来保持项目的顺序会破坏您的代码。
好了,现在是时候看看OrderedDict的一些很酷的功能了:
>>> from collections import OrderedDict >>> letters = OrderedDict(b=2, d=4, a=1, c=3) >>> letters OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3)]) >>> # Move b to the right end >>> letters.move_to_end("b") >>> letters OrderedDict([('d', 4), ('a', 1), ('c', 3), ('b', 2)]) >>> # Move b to the left end >>> letters.move_to_end("b", last=False) >>> letters OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3)]) >>> # Sort letters by key >>> for key in sorted(letters): ... letters.move_to_end(key) ... >>> letters OrderedDict([('a', 1), ('b', 2), ('c', 3), ('d', 4)])在这些例子中,您使用
.move_to_end()来移动项目并重新排序letters。注意,.move_to_end()接受了一个名为last的可选参数,它允许您控制想要将条目移动到词典的哪一端。当您需要对词典中的条目进行排序或者需要以任何方式操纵它们的顺序时,这种方法非常方便。
OrderedDict和普通词典的另一个重要区别是它们如何比较相等性:
>>> from collections import OrderedDict
>>> # Regular dictionaries compare the content only
>>> letters_0 = dict(a=1, b=2, c=3, d=4)
>>> letters_1 = dict(b=2, a=1, d=4, c=3)
>>> letters_0 == letters_1
True
>>> # Ordered dictionaries compare content and order
>>> letters_0 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_1 = OrderedDict(b=2, a=1, d=4, c=3)
>>> letters_0 == letters_1
False
>>> letters_2 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_0 == letters_2
True
这里,letters_1的项目顺序与letters_0不同。当你使用普通的字典时,这种差异并不重要,两种字典比较起来是一样的。另一方面,当你使用有序字典时,letters_0和letters_1并不相等。这是因为有序字典之间的相等测试考虑了内容以及条目的顺序。
一气呵成清点物体:Counter
对象计数是编程中常见的操作。假设你需要计算一个给定的条目在列表或 iterable 中出现了多少次。如果你的清单很短,那么计算清单上的项目会很简单快捷。如果你有一个很长的清单,那么计算清单会更有挑战性。
为了计数对象,你通常使用一个计数器,或者一个初始值为零的整数变量。然后递增计数器以反映给定对象出现的次数。
在 Python 中,你可以使用字典一次计算几个不同的对象。在这种情况下,键将存储单个对象,值将保存给定对象的重复次数,或对象的计数。
这里有一个例子,用一个普通的字典和一个 for循环来计算单词"mississippi"中的字母:
>>> word = "mississippi" >>> counter = {} >>> for letter in word: ... if letter not in counter: ... counter[letter] = 0 ... counter[letter] += 1 ... >>> counter {'m': 1, 'i': 4, 's': 4, 'p': 2}循环遍历
word中的字母。条件语句检查字母是否已经在字典中,并相应地将字母的计数初始化为零。最后一步是随着循环的进行增加字母的计数。正如你已经知道的,
defaultdictobjects 在计数的时候很方便,因为你不需要检查键是否存在。字典保证任何丢失的键都有适当的默认值:
>>> from collections import defaultdict
>>> counter = defaultdict(int)
>>> for letter in "mississippi":
... counter[letter] += 1
...
>>> counter
defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})
在本例中,您创建了一个defaultdict对象,并使用int()对其进行初始化。使用int()作为工厂函数,底层默认字典会自动创建缺失的键,并方便地将其初始化为零。然后增加当前键的值来计算"mississippi"中字母的最终计数。
就像其他常见的编程问题一样,Python 也有一个处理计数问题的有效工具。在collections中,你会发现 Counter ,这是一个专门为计数对象设计的dict子类。
以下是使用Counter编写"mississippi"示例的方法:
>>> from collections import Counter >>> Counter("mississippi") Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})哇!真快!一行代码就完成了。在这个例子中,
Counter遍历"mississippi",生成一个字典,将字母作为键,将它们的频率作为值。注:查看 Python 的计数器:计算对象的 Python 方式深入了解
Counter以及如何使用它高效地计算对象。有几种不同的方法来实例化
Counter。您可以使用列表、元组或任何具有重复对象的 iterables。唯一的限制是你的对象必须是可散列的 T4:
>>> from collections import Counter
>>> Counter([1, 1, 2, 3, 3, 3, 4])
Counter({3: 3, 1: 2, 2: 1, 4: 1})
>>> Counter(([1], [1]))
Traceback (most recent call last):
...
TypeError: unhashable type: 'list'
整数是可散列的,所以Counter可以正常工作。另一方面,列表是不可散列的,所以Counter以一个TypeError失败。
被哈希化意味着你的对象必须有一个哈希值,在它们的生命周期中不会改变。这是一个要求,因为这些对象将作为字典键工作。在 Python 中,不可变的对象也是可散列的。
注:Counter中的,经过高度优化的 C 函数提供计数功能。如果这个函数由于某种原因不可用,那么这个类使用一个等效的但是效率较低的 Python 函数。
由于Counter是dict的子类,所以它们的接口大多相同。但是,也有一些微妙的区别。第一个区别是Counter没有实现 .fromkeys() 。这避免了不一致,比如Counter.fromkeys("abbbc", 2),其中每个字母都有一个初始计数2,而不管它在输入 iterable 中的实际计数。
第二个区别是 .update() 不会用新的计数替换现有对象(键)的计数(值)。它将两个计数相加:
>>> from collections import Counter >>> letters = Counter("mississippi") >>> letters Counter({'i': 4, 's': 4, 'p': 2, 'm': 1}) >>> # Update the counts of m and i >>> letters.update(m=3, i=4) >>> letters Counter({'i': 8, 'm': 4, 's': 4, 'p': 2}) >>> # Add a new key-count pair >>> letters.update({"a": 2}) >>> letters Counter({'i': 8, 'm': 4, 's': 4, 'p': 2, 'a': 2}) >>> # Update with another counter >>> letters.update(Counter(["s", "s", "p"])) >>> letters Counter({'i': 8, 's': 6, 'm': 4, 'p': 3, 'a': 2})在这里,您更新了
m和i的计数。现在这些字母保存了它们初始计数的总和加上你通过.update()传递给它们的值。如果您使用一个不存在于原始计数器中的键,那么.update()会用相应的值创建一个新的键。最后,.update()接受可重复项、映射、关键字参数以及其他计数器。注意:因为
Counter是dict的一个子类,所以对于您可以在计数器的键和值中存储的对象没有限制。键可以存储任何可散列的对象,而值可以存储任何对象。但是,为了在逻辑上作为计数器工作,这些值应该是表示计数的整数。
Counter和dict的另一个区别是,访问丢失的键会返回0,而不是引发KeyError:
>>> from collections import Counter
>>> letters = Counter("mississippi")
>>> letters["a"]
0
这种行为表明计数器中不存在的对象的计数为零。在这个例子中,字母"a"不在原始单词中,所以它的计数是0。
在 Python 中,Counter也可以用来模拟一个多重集或包。多重集类似于集,但是它们允许给定元素的多个实例。一个元素的实例数量被称为它的多重性。例如,您可以有一个类似{1,1,2,3,3,3,4,4}的多重集。
当您使用Counter来模拟多重集时,键代表元素,值代表它们各自的多重性:
>>> from collections import Counter >>> multiset = Counter({1, 1, 2, 3, 3, 3, 4, 4}) >>> multiset Counter({1: 1, 2: 1, 3: 1, 4: 1}) >>> multiset.keys() == {1, 2, 3, 4} True在这里,
multiset的键相当于一个 Python 集合。这些值包含集合中每个元素的多重性。Python'
Counter'提供了一些额外的特性,帮助您将它们作为多重集来使用。例如,您可以用元素及其多重性的映射来初始化您的计数器。您还可以对元素的多重性执行数学运算等等。假设你在当地的宠物收容所工作。你有一定数量的宠物,你需要记录每天有多少宠物被收养,有多少宠物进出收容所。在这种情况下,可以使用
Counter:
>>> from collections import Counter
>>> inventory = Counter(dogs=23, cats=14, pythons=7)
>>> adopted = Counter(dogs=2, cats=5, pythons=1)
>>> inventory.subtract(adopted)
>>> inventory
Counter({'dogs': 21, 'cats': 9, 'pythons': 6})
>>> new_pets = {"dogs": 4, "cats": 1}
>>> inventory.update(new_pets)
>>> inventory
Counter({'dogs': 25, 'cats': 10, 'pythons': 6})
>>> inventory = inventory - Counter(dogs=2, cats=3, pythons=1)
>>> inventory
Counter({'dogs': 23, 'cats': 7, 'pythons': 5})
>>> new_pets = {"dogs": 4, "pythons": 2}
>>> inventory += new_pets
>>> inventory
Counter({'dogs': 27, 'cats': 7, 'pythons': 7})
太棒了!现在你可以用Counter记录你的宠物了。请注意,您可以使用.subtract()和.update()来加减计数或重数。您也可以使用加法(+)和减法(-)运算符。
在 Python 中,您可以将Counter对象作为多重集来做更多的事情,所以请大胆尝试吧!
将字典链接在一起:ChainMap
Python 的ChainMap将多个字典和其他映射组合在一起,创建一个单一对象,其工作方式非常类似于常规字典。换句话说,它接受几个映射,并使它们在逻辑上表现为一个映射。
ChainMap对象是可更新的视图,这意味着任何链接映射的变化都会影响到整个ChainMap对象。这是因为ChainMap没有将输入映射合并在一起。它保留了一个映射列表,并在该列表的顶部重新实现了公共字典操作。例如,关键字查找会连续搜索映射列表,直到找到该关键字。
注意:查看 Python 的 ChainMap:有效管理多个上下文,深入了解如何在 Python 代码中使用ChainMap。
当你使用ChainMap对象时,你可以有几个字典,或者是唯一的或者是重复的键。
无论哪种情况,ChainMap都允许您将所有的字典视为一个字典。如果您的字典中有唯一的键,您可以像使用单个字典一样访问和更新这些键。
如果您的字典中有重复的键,除了将字典作为一个字典管理之外,您还可以利用内部映射列表来定义某种类型的访问优先级。由于这个特性,ChainMap对象非常适合处理多种上下文。
例如,假设您正在开发一个命令行界面(CLI) 应用程序。该应用程序允许用户使用代理服务连接到互联网。设置优先级包括:
- 命令行选项(
--proxy、-p) - 用户主目录中的本地配置文件
- 全局代理配置
如果用户在命令行提供代理,那么应用程序必须使用该代理。否则,应用程序应该使用下一个配置对象中提供的代理,依此类推。这是ChainMap最常见的用例之一。在这种情况下,您可以执行以下操作:
>>> from collections import ChainMap >>> cmd_proxy = {} # The user doesn't provide a proxy >>> local_proxy = {"proxy": "proxy.local.com"} >>> global_proxy = {"proxy": "proxy.global.com"} >>> config = ChainMap(cmd_proxy, local_proxy, global_proxy) >>> config["proxy"] 'proxy.local.com'
ChainMap允许您为应用程序的代理配置定义适当的优先级。一个键查找搜索cmd_proxy,然后是local_proxy,最后是global_proxy,返回当前键的第一个实例。在这个例子中,用户没有在命令行提供代理,所以您的应用程序使用了local_proxy中的代理。一般来说,
ChainMap对象的行为类似于常规的dict对象。但是,它们还有一些附加功能。例如,它们有一个保存内部映射列表的.maps公共属性:
>>> from collections import ChainMap
>>> numbers = {"one": 1, "two": 2}
>>> letters = {"a": "A", "b": "B"}
>>> alpha_nums = ChainMap(numbers, letters)
>>> alpha_nums.maps
[{'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'}]
实例属性.maps允许您访问内部映射列表。该列表可更新。您可以手动添加和删除映射,遍历列表,等等。
另外,ChainMap提供了一个 .new_child() 方法和一个 .parents 属性:
>>> from collections import ChainMap >>> dad = {"name": "John", "age": 35} >>> mom = {"name": "Jane", "age": 31} >>> family = ChainMap(mom, dad) >>> family ChainMap({'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35}) >>> son = {"name": "Mike", "age": 0} >>> family = family.new_child(son) >>> for person in family.maps: ... print(person) ... {'name': 'Mike', 'age': 0} {'name': 'Jane', 'age': 31} {'name': 'John', 'age': 35} >>> family.parents ChainMap({'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35})使用
.new_child(),您创建一个新的ChainMap对象,包含一个新的地图(son),后跟当前实例中的所有地图。作为第一个参数传递的映射成为映射列表中的第一个映射。如果没有传递 map,那么这个方法使用一个空字典。
parents属性返回一个新的ChainMap对象,包含当前实例中除第一个以外的所有地图。当您需要在键查找中跳过第一个映射时,这很有用。在
ChainMap中要强调的最后一个特性是变异操作,比如更新键、添加新键、删除现有键、弹出键和清除字典,作用于内部映射列表中的第一个映射:
>>> from collections import ChainMap
>>> numbers = {"one": 1, "two": 2}
>>> letters = {"a": "A", "b": "B"}
>>> alpha_nums = ChainMap(numbers, letters)
>>> alpha_nums
ChainMap({'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'})
>>> # Add a new key-value pair
>>> alpha_nums["c"] = "C"
>>> alpha_nums
ChainMap({'one': 1, 'two': 2, 'c': 'C'}, {'a': 'A', 'b': 'B'})
>>> # Pop a key that exists in the first dictionary
>>> alpha_nums.pop("two")
2
>>> alpha_nums
ChainMap({'one': 1, 'c': 'C'}, {'a': 'A', 'b': 'B'})
>>> # Delete keys that don't exist in the first dict but do in others
>>> del alpha_nums["a"]
Traceback (most recent call last):
...
KeyError: "Key not found in the first mapping: 'a'"
>>> # Clear the dictionary
>>> alpha_nums.clear()
>>> alpha_nums
ChainMap({}, {'a': 'A', 'b': 'B'})
这些例子表明对一个ChainMap对象的变异操作只影响内部列表中的第一个映射。当您使用ChainMap时,这是一个需要考虑的重要细节。
棘手的是,乍一看,在给定的ChainMap中,任何现有的键值对都有可能发生变异。但是,您只能改变第一个映射中的键-值对,除非您使用.maps来直接访问和改变列表中的其他映射。
自定义内置:UserString、UserList和UserDictT3
有时您需要定制内置类型,如字符串、列表和字典,以添加和修改某些行为。从 Python 2.2 开始,你可以通过直接子类化这些类型来实现。但是,这种方法可能会遇到一些问题,您马上就会看到。
Python 的collections提供了三个方便的包装类,模拟内置数据类型的行为:
UserStringUserListUserDict
通过常规和特殊方法的组合,您可以使用这些类来模拟和定制字符串、列表和字典的行为。
现在,开发人员经常问自己,当他们需要定制内置类型的行为时,是否有理由使用UserString、UserList和UserDict。答案是肯定的。
考虑到的开闭原则,内置类型被设计和实现。这意味着它们对扩展开放,但对修改关闭。允许修改这些类的核心特性可能会破坏它们的不变量。因此,Python 核心开发人员决定保护它们不被修改。
例如,假设您需要一个字典,当您插入键时,它会自动小写。您可以子类化dict并覆盖 .__setitem__() ,这样每当您插入一个键时,字典就会小写这个键名:
>>> class LowerDict(dict): ... def __setitem__(self, key, value): ... key = key.lower() ... super().__setitem__(key, value) ... >>> ordinals = LowerDict({"FIRST": 1, "SECOND": 2}) >>> ordinals["THIRD"] = 3 >>> ordinals.update({"FOURTH": 4}) >>> ordinals {'FIRST': 1, 'SECOND': 2, 'third': 3, 'FOURTH': 4} >>> isinstance(ordinals, dict) True当您使用带有方括号(
[])的字典样式赋值来插入新键时,该字典可以正常工作。然而,当你将一个初始字典传递给类构造函数或者当你使用.update()时,它不起作用。这意味着您需要覆盖.__init__().update(),可能还有其他一些方法来让您的自定义词典正确工作。现在看一下同样的字典,但是使用
UserDict作为基类:
>>> from collections import UserDict
>>> class LowerDict(UserDict):
... def __setitem__(self, key, value):
... key = key.lower()
... super().__setitem__(key, value)
...
>>> ordinals = LowerDict({"FIRST": 1, "SECOND": 2})
>>> ordinals["THIRD"] = 3
>>> ordinals.update({"FOURTH": 4})
>>> ordinals
{'first': 1, 'second': 2, 'third': 3, 'fourth': 4}
>>> isinstance(ordinals, dict)
False
有用!您的自定义词典现在会在将所有新键插入词典之前将其转换为小写字母。注意,因为你不直接从dict继承,你的类不像上面的例子那样返回dict的实例。
UserDict在名为.data的实例属性中存储一个常规字典。然后,它围绕该字典实现它的所有方法。UserList和UserString工作方式相同,但是它们的.data属性分别拥有一个list和一个str对象。
如果您需要定制这些类中的任何一个,那么您只需要覆盖适当的方法并根据需要更改它们的功能。
一般来说,当您需要一个行为与底层包装内置类几乎相同的类,并且您想要定制其标准功能的某个部分时,您应该使用UserDict、UserList和UserString。
使用这些类而不是内置的等价类的另一个原因是访问底层的.data属性来直接操作它。
直接从内置类型继承的能力已经在很大程度上取代了UserDict、UserList和UserString的使用。然而,内置类型的内部实现使得在不重写大量代码的情况下很难安全地从它们继承。在大多数情况下,使用collections中合适的类更安全。这会让你避免一些问题和奇怪的行为。
结论
在 Python 的collections模块中,有几个专门的容器数据类型,可以用来处理常见的编程问题,比如计算对象数量、创建队列和堆栈、处理字典中丢失的键等等。
collections中的数据类型和类被设计成高效和 Pythonic 化的。它们对您的 Python 编程之旅非常有帮助,因此了解它们非常值得您花费时间和精力。
在本教程中,您学习了如何:
- 使用
namedtuple编写可读的和显式的代码 - 使用
deque构建高效队列和堆栈 - 使用
Counter有效地计数对象 - 用
defaultdict处理缺失的字典键 - 记住
OrderedDict键的插入顺序 - 用
ChainMap在单个视图中链接多个字典
您还了解了三个方便的包装器类:UserDict、UserList和UserString。当您需要创建模拟内置类型dict、list和str的行为的定制类时,这些类非常方便。*******
Python 命令行参数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的命令行接口
添加处理 Python 命令行参数的功能为基于文本的命令行程序提供了一个用户友好的界面。它类似于由图形元素或小部件操纵的可视化应用程序的图形用户界面。
Python 公开了一种捕获和提取 Python 命令行参数的机制。这些值可以用来修改程序的行为。例如,如果您的程序处理从文件中读取的数据,那么您可以将该文件的名称传递给您的程序,而不是在您的源代码中硬编码该值。
本教程结束时,你会知道:
- Python 命令行参数的起源
- Python 命令行参数的底层支持
- 指导命令行界面设计的标准
- 手动定制和处理 Python 命令行参数的基础知识
- Python 中可用的库简化了复杂命令行界面的开发
如果您想要一种用户友好的方式向您的程序提供 Python 命令行参数,而不需要导入专用的库,或者如果您想要更好地理解专用于构建 Python 命令行界面的现有库的公共基础,那么请继续阅读!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
命令行界面
命令行界面(CLI) 为用户提供了与运行在基于文本的外壳解释器中的程序进行交互的方式。shell 解释器的一些例子是 Linux 上的 Bash 或 Windows 上的命令提示符。命令行界面由暴露命令提示符的外壳解释器启用。它可以由以下要素来表征:
- 一个命令或程序
- 零个或多个命令行参数
- 代表命令结果的输出
- 称为用法或帮助的文本文档
不是每个命令行界面都提供所有这些元素,但是这个列表也不是详尽的。命令行的复杂性范围很广,从传递单个参数的能力到众多参数和选项,很像一种领域特定语言。例如,一些程序可能从命令行启动 web 文档,或者启动类似 Python 的交互式 shell 解释器。
以下两个 Python 命令示例说明了命令行界面的描述:
$ python -c "print('Real Python')"
Real Python
在第一个例子中,Python 解释器将选项-c用于命令,该命令将选项-c之后的 Python 命令行参数作为 Python 程序来执行。
另一个例子展示了如何用-h调用 Python 来显示帮助:
$ python -h
usage: python3 [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-b : issue warnings about str(bytes_instance), str(bytearray_instance)
and comparing bytes/bytearray with str. (-bb: issue errors)
[ ... complete help text not shown ... ]
在您的终端中尝试一下,以查看完整的帮助文档。
C 遗留问题
Python 命令行参数直接继承自 C 编程语言。正如 Guido Van Rossum 在 1993 年的《Unix/C 程序员 Python 入门》中所写的,C 对 Python 有很大的影响。Guido 提到了文字、标识符、操作符和语句的定义,如break、continue或return。Python 命令行参数的使用也受到 C 语言的强烈影响。
为了说明相似之处,请考虑下面的 C 程序:
1// main.c
2#include <stdio.h> 3
4int main(int argc, char *argv[]) { 5 printf("Arguments count: %d\n", argc); 6 for (int i = 0; i < argc; i++) { 7 printf("Argument %6d: %s\n", i, argv[i]); 8 } 9 return 0; 10}
第 4 行定义了 main() ,是一个 C 程序的入口点。请记下这些参数:
argc是一个表示程序参数个数的整数。argv是一个指向字符的数组,在数组的第一个元素中包含程序的名称,在数组的其余元素中后跟程序的自变量(如果有的话)。
您可以在 Linux 上用gcc -o main main.c编译上面的代码,然后用./main执行以获得以下内容:
$ gcc -o main main.c
$ ./main
Arguments count: 1
Argument 0: ./main
除非在命令行用选项-o明确表示, a.out 是由 gcc 编译器生成的可执行文件的默认名称。它代表汇编器输出,让人想起在旧的 UNIX 系统上生成的可执行文件。注意,可执行文件的名称./main是唯一的参数。
让我们通过向同一个程序传递几个 Python 命令行参数来增加这个例子的趣味:
$ ./main Python Command Line Arguments
Arguments count: 5
Argument 0: ./main
Argument 1: Python
Argument 2: Command
Argument 3: Line
Argument 4: Arguments
输出显示参数的数量是5,参数列表包括程序名main,后面是您在命令行传递的短语"Python Command Line Arguments"的每个单词。
注 : argc代表自变量计数,而argv代表自变量向量。要了解更多信息,请查看一点 C Primer/C 命令行参数。
main.c的编译假设你用的是 Linux 或者 Mac OS 系统。在 Windows 上,您还可以使用以下选项之一编译此 C 程序:
- Windows Subsystem for Linux(WSL):它在一些 Linux 发行版中可用,比如 Ubuntu 、 OpenSUSE 和 Debian 等等。您可以从 Microsoft 商店安装它。
- Windows 构建工具: 这包括 Windows 命令行构建工具,微软 C/C++编译器
cl.exe,以及一个名为clang.exe用于 C/C++的编译器前端。 - 微软 Visual Studio: 这是微软主要的集成开发环境(IDE)。要了解更多关于可用于各种操作系统(包括 Windows)上的 Python 和 C 的 ide,请查看Python ide 和代码编辑器(指南)。
- mingw-64 项目: 这个支持 Windows 上的 GCC 编译器。
如果您已经安装了 Microsoft Visual Studio 或 Windows 构建工具,那么您可以如下编译main.c:
C:/>cl main.c
您将获得一个名为main.exe的可执行文件,您可以这样开始:
C:/>main
Arguments count: 1
Argument 0: main
你可以实现一个 Python 程序main.py,它相当于 C 程序main.c,你可以在上面看到:
# main.py
import sys
if __name__ == "__main__":
print(f"Arguments count: {len(sys.argv)}")
for i, arg in enumerate(sys.argv):
print(f"Argument {i:>6}: {arg}")
你看不到像 C 代码例子中的argc 变量。它在 Python 中不存在,因为sys.argv已经足够了。您可以在sys.argv中解析 Python 命令行参数,而不必知道列表的长度,如果您的程序需要参数的数量,您可以调用内置的 len() 。
另外,请注意, enumerate() 在应用于 iterable 时,会返回一个enumerate对象,该对象可以发出将sys.arg中元素的索引与其相应值相关联的对。这允许循环遍历sys.argv的内容,而不必维护列表中索引的计数器。
如下执行main.py:
$ python main.py Python Command Line Arguments
Arguments count: 5
Argument 0: main.py
Argument 1: Python
Argument 2: Command
Argument 3: Line
Argument 4: Arguments
sys.argv包含与 C 程序中相同的信息:
- 节目名称
main.py是列表的第一项。 - 自变量
Python、Command、Line和Arguments是列表中剩余的元素。
通过对 C 语言一些神秘方面的简短介绍,您现在已经掌握了一些有价值的知识,可以进一步掌握 Python 命令行参数。
来自 Unix 世界的两个实用程序
为了在本教程中使用 Python 命令行参数,您将实现 Unix 生态系统中两个实用程序的部分功能:
在下面几节中,您将对这些 Unix 工具有所熟悉。
sha1sum
sha1sum计算SHA-1T3】哈希,常用于验证文件的完整性。对于给定的输入,一个 哈希函数 总是返回相同的值。输入中的任何微小变化都会导致不同的哈希值。在使用带有具体参数的实用程序之前,您可以尝试显示帮助:
$ sha1sum --help
Usage: sha1sum [OPTION]... [FILE]...
Print or check SHA1 (160-bit) checksums.
With no FILE, or when FILE is -, read standard input.
-b, --binary read in binary mode
-c, --check read SHA1 sums from the FILEs and check them
--tag create a BSD-style checksum
-t, --text read in text mode (default)
-z, --zero end each output line with NUL, not newline,
and disable file name escaping
[ ... complete help text not shown ... ]
显示命令行程序的帮助是命令行界面中公开的一个常见功能。
要计算文件内容的 SHA-1 哈希值,请执行以下操作:
$ sha1sum main.c
125a0f900ff6f164752600550879cbfabb098bc3 main.c
结果显示 SHA-1 哈希值作为第一个字段,文件名作为第二个字段。该命令可以将多个文件作为参数:
$ sha1sum main.c main.py
125a0f900ff6f164752600550879cbfabb098bc3 main.c
d84372fc77a90336b6bb7c5e959bcb1b24c608b4 main.py
由于 Unix 终端的通配符扩展特性,还可以为 Python 命令行参数提供通配符。一个这样的字符是星号或星号(*):
$ sha1sum main.*
3f6d5274d6317d580e2ffc1bf52beee0d94bf078 main.c
f41259ea5835446536d2e71e566075c1c1bfc111 main.py
shell 将main.*转换为main.c和main.py,这是当前目录中与模式main.*匹配的两个文件,并将它们传递给sha1sum。程序计算参数列表中每个文件的 SHA1 散列。您将会看到,在 Windows 上,行为是不同的。Windows 没有通配符扩展,所以程序可能必须适应这一点。您的实现可能需要在内部扩展通配符。
没有任何参数,sha1sum从标准输入中读取。你可以通过在键盘上键入字符向程序输入数据。输入可以包含任何字符,包括回车符 Enter 。要终止输入,必须用 Enter 发出文件结束的信号,后面是顺序 Ctrl + D :
1$ sha1sum
2Real
3Python
487263a73c98af453d68ee4aab61576b331f8d9d6 -
你先输入节目名称,sha1sum,接着是 Enter ,然后是Real和Python,每一个后面还跟着 Enter 。要关闭输入流,您可以键入 Ctrl + D 。结果是为文本Real\nPython\n生成的 SHA1 散列值。文件的名称是-。这是指示标准输入的约定。当您执行以下命令时,哈希值是相同的:
$ python -c "print('Real\nPython\n', end='')" | sha1sum
87263a73c98af453d68ee4aab61576b331f8d9d6 -
$ python -c "print('Real\nPython')" | sha1sum
87263a73c98af453d68ee4aab61576b331f8d9d6 -
$ printf "Real\nPython\n" | sha1sum
87263a73c98af453d68ee4aab61576b331f8d9d6 -
接下来,你会读到一段关于seq的简短描述。
seq
seq 生成一个序列的数字。在其最基本的形式中,如生成从 1 到 5 的序列,您可以执行以下内容:
$ seq 5
1
2
3
4
5
为了获得对seq所揭示的可能性的概述,您可以在命令行显示帮助:
$ seq --help
Usage: seq [OPTION]... LAST
or: seq [OPTION]... FIRST LAST
or: seq [OPTION]... FIRST INCREMENT LAST
Print numbers from FIRST to LAST, in steps of INCREMENT.
Mandatory arguments to long options are mandatory for short options too.
-f, --format=FORMAT use printf style floating-point FORMAT
-s, --separator=STRING use STRING to separate numbers (default: \n)
-w, --equal-width equalize width by padding with leading zeroes
--help display this help and exit
--version output version information and exit
[ ... complete help text not shown ... ]
对于本教程,您将编写几个简化的sha1sum和seq变体。在每个示例中,您将了解 Python 命令行参数的不同方面或特性组合。
在 Mac OS 和 Linux 上,sha1sum和seq应该是预装的,尽管不同系统或发行版的特性和帮助信息有时会略有不同。如果你使用的是 Windows 10,那么最方便的方法就是在安装在 WSL 上的 Linux 环境下运行sha1sum和seq。如果您不能访问公开标准 Unix 实用程序的终端,那么您可以访问在线终端:
- 在 PythonAnywhere 上创建一个免费账户,并启动一个 Bash 控制台。
- 在 repl.it 上创建一个临时 Bash 终端。
这是两个例子,你可能会找到其他的。
sys.argv数组
在探索一些公认的惯例和发现如何处理 Python 命令行参数之前,您需要知道对所有 Python 命令行参数的底层支持是由 sys.argv 提供的。下面几节中的例子向您展示了如何处理存储在sys.argv中的 Python 命令行参数,以及如何克服在您试图访问它们时出现的典型问题。您将了解到:
- 如何访问的内容
sys.argv - 如何减轻全球性质的副作用
sys.argv - 如何处理 Python 命令行参数中的空格
- 在访问 Python 命令行参数时,如何处理错误
- 如何摄取按字节传递的 Python 命令行参数的原始格式
我们开始吧!
显示参数
sys模块公开了一个名为argv的数组,它包括以下内容:
argv[0]包含当前 Python 程序的名称。argv[1:],列表的其余部分,包含任何和所有传递给程序的 Python 命令行参数。
下面的例子演示了sys.argv的内容:
1# argv.py
2import sys
3
4print(f"Name of the script : {sys.argv[0]=}")
5print(f"Arguments of the script : {sys.argv[1:]=}")
下面是这段代码的工作原理:
- 第 2 行导入内部 Python 模块
sys。 - 第 4 行通过访问列表的第一个元素
sys.argv提取程序名。 - 第 5 行通过获取列表
sys.argv的所有剩余元素来显示 Python 命令行参数。
注意:在argv.py中使用的 f 字符串语法利用了 Python 3.8 中新的调试说明符。要了解更多关于 f-string 的新特性和其他特性,请查看 Python 3.8 中的新特性。
如果您的 Python 版本低于 3.8,那么只需删除两个 f 字符串中的等号(=)就可以让程序成功执行。输出将只显示变量的值,而不是它们的名称。
使用如下任意参数列表执行上面的脚本argv.py:
$ python argv.py un deux trois quatre
Name of the script : sys.argv[0]='argv.py'
Arguments of the script : sys.argv[1:]=['un', 'deux', 'trois', 'quatre']
输出确认了sys.argv[0]的内容是 Python 脚本argv.py,并且sys.argv列表的剩余元素包含脚本的参数['un', 'deux', 'trois', 'quatre']。
总而言之,sys.argv包含了所有的argv.py Python 命令行参数。当 Python 解释器执行 Python 程序时,它解析命令行并用参数填充sys.argv。
颠倒第一个论点
现在您已经有了足够的关于sys.argv的背景知识,您将对命令行传递的参数进行操作。示例reverse.py反转在命令行传递的第一个参数:
1# reverse.py
2
3import sys
4
5arg = sys.argv[1]
6print(arg[::-1])
在reverse.py中,通过以下步骤执行反转第一个自变量的过程:
- 第 5 行取出存储在
sys.argv的索引1处的程序的第一个自变量。记住程序名存储在sys.argv的索引0中。 - 第 6 行打印反转的字符串。
args[::-1]是使用切片操作的一种 Pythonic 方式来反转一个列表。
您按如下方式执行脚本:
$ python reverse.py "Real Python"
nohtyP laeR
正如所料,reverse.py对"Real Python"进行运算,并反转输出"nohtyP laeR"的唯一参数。请注意,用引号将多单词字符串"Real Python"括起来可以确保解释器将它作为一个唯一的参数来处理,而不是两个参数。在后面的部分中,您将深入研究参数分隔符。
sys.argv变异
sys.argv对你正在运行的 Python 程序来说是全球可用的吗?流程执行过程中导入的所有模块都可以直接访问sys.argv。这种全球访问可能很方便,但sys.argv不是一成不变的。您可能希望实现一种更可靠的机制,将程序参数公开给 Python 程序中的不同模块,尤其是在具有多个文件的复杂程序中。
观察篡改sys.argv会发生什么:
# argv_pop.py
import sys
print(sys.argv)
sys.argv.pop()
print(sys.argv)
您调用 .pop() 删除并返回sys.argv中的最后一项。
执行上面的脚本:
$ python argv_pop.py un deux trois quatre
['argv_pop.py', 'un', 'deux', 'trois', 'quatre']
['argv_pop.py', 'un', 'deux', 'trois']
注意第四个参数不再包含在sys.argv中。
在一个简短的脚本中,您可以安全地依赖对sys.argv的全局访问,但是在一个更大的程序中,您可能希望将参数存储在一个单独的变量中。前面的示例可以修改如下:
# argv_var_pop.py
import sys
print(sys.argv)
args = sys.argv[1:]
print(args)
sys.argv.pop()
print(sys.argv)
print(args)
这一次,sys.argv虽然失去了最后的元素,args却被安全的保存了下来。args不是全局的,你可以传递它来解析程序逻辑中的参数。Python 包管理器 pip 使用这种方法。下面是pip源代码的简短摘录:
def main(args=None):
if args is None:
args = sys.argv[1:]
在这个取自 pip 源代码的代码片段中, main() 将只包含参数而不包含文件名的sys.argv片段保存到args中。sys.argv保持不变,args也不会受到对sys.argv的任何无意更改的影响。
转义空白字符
在reverse.py的例子中你看到了前面的,第一个也是唯一一个参数是"Real Python",结果是"nohtyP laeR"。参数在"Real"和"Python"之间包含一个空格分隔符,需要对其进行转义。
在 Linux 上,可以通过执行以下操作之一来转义空格:
- 围绕的论点用单引号(
') - 用双引号将括起来(
") - 在每个空格前加一个反斜杠(
\)
如果没有一个转义解决方案,reverse.py将存储两个参数,"Real"在sys.argv[1]中,"Python"在sys.argv[2]中:
$ python reverse.py Real Python
laeR
上面的输出显示脚本只反转了"Real"并且忽略了"Python"。为了确保两个参数都被存储,您需要用双引号(")将整个字符串括起来。
您也可以使用反斜杠(\)来转义空格:
$ python reverse.py Real\ Python
nohtyP laeR
使用反斜杠(\),命令 shell 向 Python 公开一个惟一的参数,然后向reverse.py公开。
在 Unix shells 中,内部字段分隔符(IFS) 定义用作分隔符的字符。通过运行以下命令,可以显示 shell 变量IFS的内容:
$ printf "%q\n" "$IFS"
$' \t\n'
从上面的结果中,' \t\n',您发现了三个分隔符:
- 太空 (
' ') - 标签 (
\t) - 换行 (
\n)
在空格前加上反斜杠(\)会绕过空格作为字符串"Real Python"中分隔符的默认行为。这产生了预期的一个文本块,而不是两个。
注意,在 Windows 上,可以通过使用双引号的组合来管理空白解释。这有点违反直觉,因为在 Windows 终端中,双引号(")被解释为禁用并随后启用特殊字符的开关,如空格、制表符或竖线 ( |)。
因此,当你用双引号将多个字符串括起来时,Windows 终端会将第一个双引号解释为命令忽略特殊字符,将第二个双引号解释为命令解释特殊字符。
考虑到这些信息,可以有把握地认为,用双引号将多个字符串括起来会产生预期的行为,即将一组字符串作为单个参数公开。要确认 Windows 命令行上双引号的这种特殊效果,请观察以下两个示例:
C:/>python reverse.py "Real Python"
nohtyP laeR
在上面的例子中,你可以直观地推断出"Real Python"被解释为单个参数。但是,请意识到当您使用单引号时会发生什么:
C:/>python reverse.py "Real Python
nohtyP laeR
命令提示符将整个字符串"Real Python"作为单个参数传递,就像参数是"Real Python"一样。实际上,Windows 命令提示符将唯一的双引号视为禁用空格作为分隔符的开关,并将双引号后面的任何内容作为唯一参数传递。
关于 Windows 终端中双引号的影响的更多信息,请查看了解 Windows 命令行参数引用和转义的更好方法。
处理错误
Python 命令行参数是松散字符串。很多事情都可能出错,所以为程序的用户提供一些指导是个好主意,以防他们在命令行传递不正确的参数。例如,reverse.py需要一个参数,如果忽略它,就会出现错误:
1$ python reverse.py
2Traceback (most recent call last):
3 File "reverse.py", line 5, in <module>
4 arg = sys.argv[1]
5IndexError: list index out of range
Python 异常 IndexError被引发,对应的回溯显示错误是由表达式arg = sys.argv[1]引起的。例外的消息是list index out of range。你没有在命令行传递参数,所以在索引1的列表sys.argv中没有任何内容。
这是一种常见的模式,可以用几种不同的方法来解决。对于这个初始示例,您将通过在一个try块中包含表达式arg = sys.argv[1]来保持它的简短。按如下方式修改代码:
1# reverse_exc.py
2
3import sys
4
5try:
6 arg = sys.argv[1]
7except IndexError:
8 raise SystemExit(f"Usage: {sys.argv[0]} <string_to_reverse>")
9print(arg[::-1])
第 4 行的表达式包含在try块中。第 8 行引出内置异常 SystemExit 。如果没有参数传递给reverse_exc.py,那么在打印用法之后,流程退出,状态代码为1。请注意错误消息中对sys.argv[0]的整合。它在使用消息中公开程序的名称。现在,当您在没有任何 Python 命令行参数的情况下执行相同的程序时,您可以看到以下输出:
$ python reverse.py
Usage: reverse.py <string_to_reverse>
$ echo $?
1
没有在命令行传递参数。结果,程序引发了带有错误消息的SystemExit。这导致程序以1的状态退出,当你用 echo 打印特殊变量 $? 时显示。
计算sha1sum
您将编写另一个脚本来演示,在类似于 Unix 的系统上,Python 命令行参数是按字节从操作系统传递的。该脚本将一个字符串作为参数,并输出该参数的十六进制 SHA-1 散列:
1# sha1sum.py
2
3import sys
4import hashlib
5
6data = sys.argv[1]
7m = hashlib.sha1()
8m.update(bytes(data, 'utf-8'))
9print(m.hexdigest())
这大致是受sha1sum的启发,但是它有意处理一个字符串,而不是文件的内容。在sha1sum.py中,获取 Python 命令行参数并输出结果的步骤如下:
- 第 6 行将第一个参数的内容存储在
data中。 - 第 7 行举例说明了一个 SHA1 算法。
- 第 8 行用第一个程序参数的内容更新 SHA1 散列对象。注意,
hash.update接受一个字节数组作为参数,因此有必要将data从字符串转换为字节数组。 - 第 9 行打印第 8 行计算的 SHA1 散列的十六进制表示。
当您运行带有参数的脚本时,您会得到以下结果:
$ python sha1sum.py "Real Python"
0554943d034f044c5998f55dac8ee2c03e387565
为了保持示例简短,脚本sha1sum.py不处理缺失的 Python 命令行参数。在这个脚本中,可以像在reverse_exc.py中一样处理错误。
注意:查看 hashlib 了解 Python 标准库中可用散列函数的更多细节。
从sys.argv 文档中,您了解到为了获得 Python 命令行参数的原始字节,您可以使用 os.fsencode() 。通过直接从sys.argv[1]获取字节,你不需要执行data的字符串到字节的转换:
1# sha1sum_bytes.py
2
3import os
4import sys
5import hashlib
6
7data = os.fsencode(sys.argv[1])
8m = hashlib.sha1()
9m.update(data)
10print(m.hexdigest())
sha1sum.py和sha1sum_bytes.py的主要区别在以下几行中突出显示:
- 第 7 行用传递给 Python 命令行参数的原始字节填充
data。 - 第 9 行将
data作为参数传递给m.update(),后者接收一个类似字节的对象。
执行sha1sum_bytes.py比较输出:
$ python sha1sum_bytes.py "Real Python"
0554943d034f044c5998f55dac8ee2c03e387565
SHA1 散列的十六进制值与前面的sha1sum.py示例中的值相同。
Python 命令行参数剖析
既然您已经研究了 Python 命令行参数的几个方面,最著名的是sys.argv,那么您将应用开发人员在实现命令行接口时经常使用的一些标准。
Python 命令行参数是命令行界面的子集。它们可以由不同类型的参数组成:
- 选项修改特定命令或程序的行为。
- 自变量表示要处理的源或目的地。
- 子命令允许程序用相应的选项和参数集定义多个命令。
在深入研究不同类型的参数之前,您将对指导命令行界面和参数设计的公认标准有一个概述。自从 20 世纪 60 年代中期计算机终端问世以来,这些技术已经得到了改进。
标准
一些可用的标准提供了一些定义和指南,以促进实现命令及其参数的一致性。以下是主要的 UNIX 标准和参考资料:
上面的标准为任何与程序和 Python 命令行参数相关的事物定义了指导方针和术语。以下几点摘自这些参考资料:
- POSIX :
- 程序或实用程序后跟选项、选项参数和操作数。
- 所有选项前面都应该有一个连字符或减号(
-)分隔符。 - 选项参数不应该是可选的。
- GNU :
- 所有程序都应该支持两个标准选项,分别是
--version和--help。 - 长名称选项等效于单字母 Unix 样式的选项。一个例子是
--debug和-d。
- 所有程序都应该支持两个标准选项,分别是
- docopt :
- 短选项可以叠加,意思是
-abc相当于-a -b -c。 - 长选项可以在空格或等号(
=)后指定参数。长选项--input=ARG相当于--input ARG。
- 短选项可以叠加,意思是
这些标准定义了有助于描述命令的符号。当您使用选项-h或--help调用特定命令时,可以使用类似的符号来显示该命令的用法。
GNU 标准非常类似于 POSIX 标准,但是提供了一些修改和扩展。值得注意的是,他们添加了长选项,这是一个以两个连字符(--)为前缀的全名选项。例如,要显示帮助,常规选项是-h,长选项是--help。
注意:你不需要严格遵循那些标准。相反,遵循自 UNIX 出现以来已经成功使用多年的惯例。如果你为你或你的团队编写一套实用程序,那么确保你在不同的实用程序之间保持一致。
在接下来的几节中,您将了解更多关于命令行组件、选项、参数和子命令的信息。
选项
一个选项,有时被称为标志或开关,意在修改程序的行为。例如,Linux 上的命令ls列出了给定目录的内容。没有任何参数,它列出了当前目录中的文件和目录:
$ cd /dev
$ ls
autofs
block
bsg
btrfs-control
bus
char
console
我们来补充几个选项。您可以将-l和-s组合成-ls,改变终端显示的信息:
$ cd /dev
$ ls -ls
total 0
0 crw-r--r-- 1 root root 10, 235 Jul 14 08:10 autofs
0 drwxr-xr-x 2 root root 260 Jul 14 08:10 block
0 drwxr-xr-x 2 root root 60 Jul 14 08:10 bsg
0 crw------- 1 root root 10, 234 Jul 14 08:10 btrfs-control
0 drwxr-xr-x 3 root root 60 Jul 14 08:10 bus
0 drwxr-xr-x 2 root root 4380 Jul 14 15:08 char
0 crw------- 1 root root 5, 1 Jul 14 08:10 console
一个选项可以带一个参数,称为一个选项-参数。参见下面的 od 动作示例:
$ od -t x1z -N 16 main
0000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 >.ELF............<
0000020
od 代表八进制转储。该实用程序以不同的可打印表示显示数据,如八进制(默认)、十六进制、十进制和 ASCII。在上面的例子中,它获取二进制文件main并以十六进制格式显示文件的前 16 个字节。选项-t需要一个类型作为选项参数,而-N需要输入的字节数。
在上面的例子中,-t被赋予类型x1,它代表十六进制,每个整数一个字节。接下来是z,在输入行的末尾显示可打印的字符。-N将16作为选项参数,用于将输入字节数限制为 16。
参数
在 POSIX 标准中,参数也被称为操作数或参数。参数表示命令所作用的数据的源或目标。例如,用于将一个或多个文件复制到一个文件或目录的命令 cp 至少有一个源和一个目标:
1$ ls main
2main
3
4$ cp main main2 5
6$ ls -lt
7main
8main2
9...
在第 4 行,cp有两个参数:
main:源文件main2: 目标文件
然后它将main的内容复制到一个名为main2的新文件中。main和main2都是程序cp的参数或操作数。
子命令
在 POSIX 或 GNU 标准中没有记载子命令的概念,但是它确实出现在 docopt 中。标准的 Unix 实用程序是遵循 Unix 理念的小工具。Unix 程序旨在成为做一件事情并且做好这件事情的程序。这意味着不需要子命令。
相比之下,新一代的程序,包括 git 、 go 、 docker 和 gcloud ,有一个稍微不同的范例,包含子命令。它们不一定是 Unix 环境的一部分,因为它们跨越几个操作系统,而且它们部署在一个完整的生态系统中,需要几个命令。
以git为例。它处理几个命令,每个命令可能都有自己的一组选项、选项参数和参数。以下示例适用于 git 子命令branch:
git branch显示本地 git 仓库的分支。git branch custom_python在本地存储库中创建本地分支custom_python。git branch -d custom_python删除本地分支custom_python。git branch --help显示git branch子命令的帮助。
在 Python 生态系统中, pip 也有子命令的概念。一些pip子命令包括list、install、freeze或uninstall。
窗户
在 Windows 上,关于 Python 命令行参数的约定略有不同,特别是关于命令行选项的约定。为了验证这种差异,以tasklist为例,它是一个本地 Windows 可执行文件,显示当前运行的进程列表。类似于 Linux 或者 macOS 系统上的ps。下面是一个如何在 Windows 的命令提示符下执行tasklist的例子:
C:/>tasklist /FI "IMAGENAME eq notepad.exe"
Image Name PID Session Name Session# Mem Usage
========================= ======== ================ =========== ============
notepad.exe 13104 Console 6 13,548 K
notepad.exe 6584 Console 6 13,696 K
注意,选项的分隔符是正斜杠(/),而不是像 Unix 系统的约定那样的连字符(-)。为了可读性,在程序名taskslist和选项/FI之间有一个空格,但是键入taskslist/FI也是一样正确的。
上面的特定示例使用过滤器执行tasklist,只显示当前运行的记事本进程。您可以看到系统有两个正在运行的记事本进程实例。尽管这并不等同,但这类似于在类似 Unix 的系统上的终端中执行以下命令:
$ ps -ef | grep vi | grep -v grep
andre 2117 4 0 13:33 tty1 00:00:00 vi .gitignore
andre 2163 2134 0 13:34 tty3 00:00:00 vi main.c
上面的ps命令显示了所有当前正在运行的vi进程。这种行为与 Unix 哲学一致,因为ps的输出由两个grep过滤器转换。第一个grep命令选择vi的所有出现,第二个grep命令过滤掉grep本身的出现。
随着 Unix 工具在 Windows 生态系统中的出现,非特定于 Windows 的约定也在 Windows 上被接受。
视觉
在 Python 进程开始时,Python 命令行参数分为两类:
-
Python 选项:这些影响 Python 解释器的执行。例如,添加选项
-O是通过删除assert和__debug__语句来优化 Python 程序执行的一种手段。命令行中还有其他的 Python 选项。 -
Python 程序及其参数:跟随 Python 选项(如果有的话),你会找到 Python 程序,它是一个文件名,通常有扩展名
.py,以及它的参数。按照惯例,它们也可以由选项和参数组成。
采用下面的命令来执行程序main.py,它带有选项和参数。注意,在这个例子中,Python 解释器还带了一些选项,分别是 -B 和 -v 。
$ python -B -v main.py --verbose --debug un deux
在上面的命令行中,选项是 Python 命令行参数,组织如下:
- 选项
-B告诉 Python 在导入源模块时不要写.pyc文件。关于.pyc文件的更多细节,请查看章节编译器做什么?在您的 CPython 源代码指南中。 - 选项
-v代表冗长并告诉 Python 跟踪所有导入语句。 - 传递给
main.py的参数是虚构的,代表两个长选项(--verbose和--debug)和两个参数(un和deux)。
Python 命令行参数的这个示例可以用图形方式说明如下:
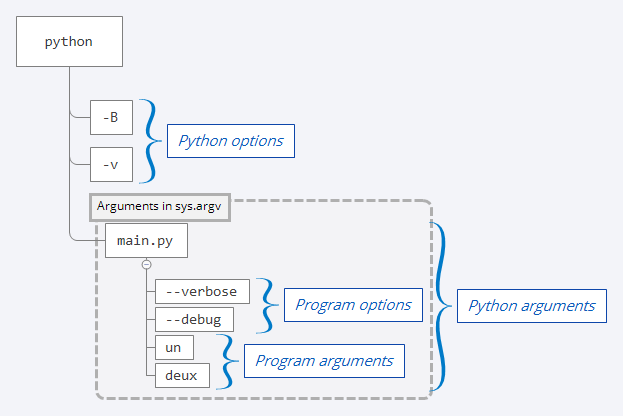
在 Python 程序main.py中,您只能访问 Python 在sys.argv中插入的 Python 命令行参数。Python 选项可能会影响程序的行为,但在main.py中无法访问。
解析 Python 命令行参数的几种方法
现在,您将探索几种理解选项、选项参数和操作数的方法。这是通过解析 Python 命令行参数来完成的。在本节中,您将看到 Python 命令行参数的一些具体方面以及处理它们的技术。首先,您将看到一个例子,它介绍了一种依靠列表理解从参数中收集和分离选项的直接方法。然后你会:
- 使用正则表达式提取命令行的元素
- 学习如何处理命令行传递的文件
- 以与 Unix 工具兼容的方式理解标准输入
- 将程序的正常输出与错误区分开来
- 实现一个定制的解析器来读取 Python 命令行参数
这将为涉及标准库中或外部库中模块的选项做准备,您将在本教程的后面部分了解这些选项。
对于不复杂的情况,下面的模式可能就足够了,它不强制排序,也不处理选项参数:
# cul.py
import sys
opts = [opt for opt in sys.argv[1:] if opt.startswith("-")] args = [arg for arg in sys.argv[1:] if not arg.startswith("-")]
if "-c" in opts:
print(" ".join(arg.capitalize() for arg in args))
elif "-u" in opts:
print(" ".join(arg.upper() for arg in args))
elif "-l" in opts:
print(" ".join(arg.lower() for arg in args))
else:
raise SystemExit(f"Usage: {sys.argv[0]} (-c | -u | -l) <arguments>...")
上面程序的目的是修改 Python 命令行参数的大小写。有三个选项可用:
-c将论据资本化-u将自变量转换为大写-l将自变量转换为小写
代码使用列表理解收集和分离不同的参数类型:
- 第 5 行通过过滤任何以连字符(
-)开头的 Python 命令行参数来收集所有的选项。 - 第 6 行通过过滤选项来组装程序参数。
当您使用一组选项和参数执行上面的 Python 程序时,您会得到以下输出:
$ python cul.py -c un deux trois
Un Deux Trois
这种方法在许多情况下可能已经足够,但在以下情况下会失败:
- 如果顺序很重要,尤其是选项应该出现在参数之前
- 如果需要支持选项参数
- 如果一些参数以连字符(
-)为前缀
在求助于像argparse或click这样的库之前,您可以利用其他选项。
正则表达式
您可以使用一个正则表达式来强制执行特定的顺序、特定的选项和选项参数,甚至是参数的类型。为了说明正则表达式解析 Python 命令行参数的用法,您将实现一个 Python 版本的 seq ,这是一个打印数字序列的程序。遵循 docopt 惯例,seq.py的规范可能是这样的:
Print integers from <first> to <last>, in steps of <increment>.
Usage:
python seq.py --help
python seq.py [-s SEPARATOR] <last>
python seq.py [-s SEPARATOR] <first> <last>
python seq.py [-s SEPARATOR] <first> <increment> <last>
Mandatory arguments to long options are mandatory for short options too.
-s, --separator=STRING use STRING to separate numbers (default: \n)
--help display this help and exit
If <first> or <increment> are omitted, they default to 1\. When <first> is
larger than <last>, <increment>, if not set, defaults to -1.
The sequence of numbers ends when the sum of the current number and
<increment> reaches the limit imposed by <last>.
首先,看一个旨在捕捉上述需求的正则表达式:
1args_pattern = re.compile(
2 r"""
3 ^
4 (
5 (--(?P<HELP>help).*)|
6 ((?:-s|--separator)\s(?P<SEP>.*?)\s)?
7 ((?P<OP1>-?\d+))(\s(?P<OP2>-?\d+))?(\s(?P<OP3>-?\d+))?
8 )
9 $
10""",
11 re.VERBOSE,
12)
为了试验上面的正则表达式,您可以使用记录在正则表达式 101 上的片段。正则表达式捕获并实施了针对seq的需求的几个方面。特别是,该命令可能采用:
- 一个帮助选项,简称
-h或长格式--help,捕获为一个命名组称为HELP - 一个分隔符选项、
-s或--separator,取一个可选参数,并被捕获为命名组、SEP、 - 最多三个整数操作数,分别捕捉为
OP1、OP2、OP3
为了清楚起见,上面的模式args_pattern在第 11 行使用了标志 re.VERBOSE 。这允许您将正则表达式分散在几行中以增强可读性。该模式验证以下内容:
- 参数顺序:选项和参数应该按照给定的顺序排列。例如,参数前应该有选项。
- 选项值 **:只有
--help、-s或--separator被期望作为选项。 - 论据互斥:选项
--help与其他选项或论据不兼容。 - 参数类型:操作数应为正整数或负整数。
为了让正则表达式能够处理这些事情,它需要在一个字符串中看到所有 Python 命令行参数。您可以使用 str.join() 收集它们:
arg_line = " ".join(sys.argv[1:])
这使得arg_line成为一个包含所有参数的字符串,除了程序名,用空格分开。
给定上面的模式args_pattern,您可以使用下面的函数提取 Python 命令行参数:
def parse(arg_line: str) -> Dict[str, str]:
args: Dict[str, str] = {}
if match_object := args_pattern.match(arg_line):
args = {k: v for k, v in match_object.groupdict().items()
if v is not None}
return args
该模式已经处理了参数的顺序、选项和参数之间的互斥性以及参数的类型。parse()是将 re.match() 应用到参数行,以提取适当的值并将数据存储在字典中。
字典包括每个组的名称作为键和它们各自的值。例如,如果arg_line值是--help,那么字典就是{'HELP': 'help'}。如果arg_line是-s T 10,那么字典就变成了{'SEP': 'T', 'OP1': '10'}。您可以展开下面的代码块来查看带有正则表达式的seq的实现。
下面的代码使用正则表达式实现了 seq 的有限版本,以处理命令行解析和验证:
# seq_regex.py
from typing import List, Dict
import re
import sys
USAGE = (
f"Usage: {sys.argv[0]} [-s <separator>] [first [increment]] last"
)
args_pattern = re.compile(
r"""
^
(
(--(?P<HELP>help).*)|
((?:-s|--separator)\s(?P<SEP>.*?)\s)?
((?P<OP1>-?\d+))(\s(?P<OP2>-?\d+))?(\s(?P<OP3>-?\d+))?
)
$
""",
re.VERBOSE,
)
def parse(arg_line: str) -> Dict[str, str]:
args: Dict[str, str] = {}
if match_object := args_pattern.match(arg_line):
args = {k: v for k, v in match_object.groupdict().items()
if v is not None}
return args
def seq(operands: List[int], sep: str = "\n") -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
if len(operands) == 2:
first, last = operands
if first > last:
increment = -1
if len(operands) == 3:
first, increment, last = operands
last = last + 1 if increment > 0 else last - 1
return sep.join(str(i) for i in range(first, last, increment))
def main() -> None:
args = parse(" ".join(sys.argv[1:]))
if not args:
raise SystemExit(USAGE)
if args.get("HELP"):
print(USAGE)
return
operands = [int(v) for k, v in args.items() if k.startswith("OP")]
sep = args.get("SEP", "\n")
print(seq(operands, sep))
if __name__ == "__main__":
main()
您可以通过运行以下命令来执行上面的代码:
$ python seq_regex.py 3
这将输出以下内容:
1
2
3
尝试此命令与其他组合,包括--help选项。
您没有看到此处提供的版本选项。这样做是为了缩短示例的长度。您可以考虑添加版本选项作为扩展练习。作为提示,您可以通过用(--(?P<HELP>help).*)|(--(?P<VER>version).*)|替换行(--(?P<HELP>help).*)|来修改正则表达式。在main()中还需要一个额外的if块。
至此,您已经知道了一些从命令行提取选项和参数的方法。到目前为止,Python 命令行参数只有字符串或整数。接下来,您将学习如何处理作为参数传递的文件。
文件处理
现在是试验 Python 命令行参数的时候了,这些参数应该是文件名。修改sha1sum.py来处理一个或多个文件作为参数。您将得到一个原始sha1sum实用程序的降级版本,它将一个或多个文件作为参数,并显示每个文件的十六进制 SHA1 散列,后跟文件名:
# sha1sum_file.py
import hashlib
import sys
def sha1sum(filename: str) -> str:
hash = hashlib.sha1()
with open(filename, mode="rb") as f:
hash.update(f.read())
return hash.hexdigest()
for arg in sys.argv[1:]:
print(f"{sha1sum(arg)} {arg}")
sha1sum()应用于从命令行传递的每个文件中读取的数据,而不是字符串本身。请注意,m.update()将一个类似于字节的对象作为参数,在用rb模式打开一个文件后调用read()的结果将返回一个 bytes对象。有关处理文件内容的更多信息,请查看用 Python 读写文件的,尤其是使用字节的部分。
sha1sum_file.py从在命令行处理字符串到操作文件内容的演变让您更接近于sha1sum的最初实现:
$ sha1sum main main.c
9a6f82c245f5980082dbf6faac47e5085083c07d main
125a0f900ff6f164752600550879cbfabb098bc3 main.c
使用相同的 Python 命令行参数执行 Python 程序,结果如下:
$ python sha1sum_file.py main main.c
9a6f82c245f5980082dbf6faac47e5085083c07d main
125a0f900ff6f164752600550879cbfabb098bc3 main.c
因为您与 shell 解释器或 Windows 命令提示符进行交互,所以您还可以受益于 shell 提供的通配符扩展。为了证明这一点,您可以重用main.py,它显示每个参数及其值:
$ python main.py main.*
Arguments count: 5
Argument 0: main.py
Argument 1: main.c
Argument 2: main.exe
Argument 3: main.obj
Argument 4: main.py
您可以看到 shell 自动执行通配符扩展,因此任何基本名称与main匹配的文件,不管扩展名是什么,都是sys.argv的一部分。
通配符扩展在 Windows 上不可用。为了获得相同的行为,您需要在代码中实现它。要重构main.py以处理通配符扩展,您可以使用 glob 。下面的例子适用于 Windows,尽管它不如最初的main.py简洁,但同样的代码在不同平台上的表现是相似的:
1# main_win.py
2
3import sys
4import glob
5import itertools
6from typing import List
7
8def expand_args(args: List[str]) -> List[str]:
9 arguments = args[:1]
10 glob_args = [glob.glob(arg) for arg in args[1:]]
11 arguments += itertools.chain.from_iterable(glob_args)
12 return arguments
13
14if __name__ == "__main__":
15 args = expand_args(sys.argv)
16 print(f"Arguments count: {len(args)}")
17 for i, arg in enumerate(args):
18 print(f"Argument {i:>6}: {arg}")
在main_win.py中,expand_args依靠 glob.glob() 来处理 shell 风格的通配符。您可以在 Windows 和任何其他操作系统上验证结果:
C:/>python main_win.py main.*
Arguments count: 5
Argument 0: main_win.py
Argument 1: main.c
Argument 2: main.exe
Argument 3: main.obj
Argument 4: main.py
这解决了使用通配符如星号(*)或问号(?)处理文件的问题,但是stdin如何呢?
如果您不向原始的sha1sum实用程序传递任何参数,那么它将从标准输入中读取数据。这是您在终端输入的文本,当您在类似 Unix 的系统上键入 Ctrl + D 或在 Windows 上键入 Ctrl + Z 时结束。这些控制序列向终端发送文件结束(EOF ),终端停止从stdin读取并返回输入的数据。
在下一节中,您将在代码中添加从标准输入流中读取的功能。
标准输入
当您使用 sys.stdin 修改前面的sha1sumPython 实现来处理标准输入时,您将更接近最初的sha1sum:
# sha1sum_stdin.py
from typing import List
import hashlib
import pathlib
import sys
def process_file(filename: str) -> bytes:
return pathlib.Path(filename).read_bytes()
def process_stdin() -> bytes:
return bytes("".join(sys.stdin), "utf-8")
def sha1sum(data: bytes) -> str:
sha1_hash = hashlib.sha1()
sha1_hash.update(data)
return sha1_hash.hexdigest()
def output_sha1sum(data: bytes, filename: str = "-") -> None:
print(f"{sha1sum(data)} {filename}")
def main(args: List[str]) -> None:
if not args:
args = ["-"]
for arg in args:
if arg == "-":
output_sha1sum(process_stdin(), "-")
else:
output_sha1sum(process_file(arg), arg)
if __name__ == "__main__":
main(sys.argv[1:])
两个惯例适用于这个新的sha1sum版本:
- 在没有任何参数的情况下,程序期望在标准输入中提供数据,
sys.stdin,这是一个可读的文件对象。 - 当在命令行提供一个连字符(
-)作为文件参数时,程序将其解释为从标准输入中读取文件。
尝试这个没有任何参数的新脚本。输入Python 之禅的第一句警句,然后在类 Unix 系统上用键盘快捷键 Ctrl + D 或在 Windows 上用键盘快捷键 Ctrl + Z 完成输入:
$ python sha1sum_stdin.py
Beautiful is better than ugly.
ae5705a3efd4488dfc2b4b80df85f60c67d998c4 -
您还可以将其中一个参数作为stdin与其他文件参数混合,如下所示:
$ python sha1sum_stdin.py main.py - main.c
d84372fc77a90336b6bb7c5e959bcb1b24c608b4 main.py
Beautiful is better than ugly.
ae5705a3efd4488dfc2b4b80df85f60c67d998c4 -
125a0f900ff6f164752600550879cbfabb098bc3 main.c
类 Unix 系统上的另一种方法是提供/dev/stdin而不是-来处理标准输入:
$ python sha1sum_stdin.py main.py /dev/stdin main.c
d84372fc77a90336b6bb7c5e959bcb1b24c608b4 main.py
Beautiful is better than ugly.
ae5705a3efd4488dfc2b4b80df85f60c67d998c4 /dev/stdin
125a0f900ff6f164752600550879cbfabb098bc3 main.c
在 Windows 上没有与/dev/stdin等价的东西,所以使用-作为文件参数可以达到预期的效果。
脚本sha1sum_stdin.py并没有涵盖所有必要的错误处理,但是您将在本教程的后面部分涵盖一些缺失的特性。
标准输出和标准误差
命令行处理可能与stdin有直接关系,以遵守前一节中详述的约定。标准输出虽然不是直接相关的,但如果你想坚持 Unix 哲学 T2,它仍然是一个问题。为了允许组合小程序,您可能必须考虑三个标准流:
stdinstdoutstderr
一个程序的输出成为另一个程序的输入,允许你链接小的实用程序。例如,如果您想要对 Python 的 Zen 的格言进行排序,那么您可以执行以下内容:
$ python -c "import this" | sort
Although never is often better than *right* now.
Although practicality beats purity.
Although that way may not be obvious at first unless you're Dutch.
...
为了更好的可读性,上面的输出被截断了。现在假设您有一个程序,它输出相同的数据,但也打印一些调试信息:
# zen_sort_debug.py
print("DEBUG >>> About to print the Zen of Python")
import this
print("DEBUG >>> Done printing the Zen of Python")
执行上面的 Python 脚本给出了:
$ python zen_sort_debug.py
DEBUG >>> About to print the Zen of Python
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
...
DEBUG >>> Done printing the Zen of Python
省略号 ( ...)表示输出被截断以提高可读性。
现在,如果您想对格言列表进行排序,那么执行如下命令:
$ python zen_sort_debug.py | sort
Although never is often better than *right* now.
Although practicality beats purity.
Although that way may not be obvious at first unless you're Dutch.
Beautiful is better than ugly.
Complex is better than complicated.
DEBUG >>> About to print the Zen of Python
DEBUG >>> Done printing the Zen of Python
Errors should never pass silently.
...
您可能意识到您并不打算将调试输出作为sort命令的输入。为了解决这个问题,您希望将跟踪发送到标准错误流stderr,而不是:
# zen_sort_stderr.py
import sys
print("DEBUG >>> About to print the Zen of Python", file=sys.stderr)
import this
print("DEBUG >>> Done printing the Zen of Python", file=sys.stderr)
执行zen_sort_stderr.py观察以下内容:
$ python zen_sort_stderr.py | sort
DEBUG >>> About to print the Zen of Python
DEBUG >>> Done printing the Zen of Python
Although never is often better than *right* now.
Although practicality beats purity.
Although that way may not be obvious at first unless you're Dutch
....
现在,轨迹显示在终端上,但是它们不用作sort命令的输入。
自定义解析器
如果参数不太复杂,可以依靠正则表达式来实现seq。然而,正则表达式模式可能会很快使脚本的维护变得困难。在尝试从特定的库获得帮助之前,另一种方法是创建一个定制的解析器。解析器是一个循环,它一个接一个地获取每个参数,并根据程序的语义应用定制的逻辑。
处理seq_parse.py的自变量的可能实现如下:
1def parse(args: List[str]) -> Tuple[str, List[int]]:
2 arguments = collections.deque(args)
3 separator = "\n"
4 operands: List[int] = []
5 while arguments:
6 arg = arguments.popleft()
7 if not operands:
8 if arg == "--help":
9 print(USAGE)
10 sys.exit(0)
11 if arg in ("-s", "--separator"):
12 separator = arguments.popleft()
13 continue
14 try:
15 operands.append(int(arg))
16 except ValueError:
17 raise SystemExit(USAGE)
18 if len(operands) > 3:
19 raise SystemExit(USAGE)
20
21 return separator, operands
给parse()一个没有 Python 文件名的参数列表,并使用 collections.deque() 来获得 .popleft() 的好处,从集合的左边移除元素。随着参数列表中各项的展开,您可以应用程序预期的逻辑。在parse()中,您可以观察到以下内容:
while循环是该函数的核心,当没有更多的参数要解析时,当调用帮助时,或者当出现错误时,该循环终止。- 如果检测到
separator选项,那么下一个参数应该是分隔符。 operands存储用于计算序列的整数。应该至少有一个操作数,最多三个。
下面是parse()的完整版本代码:
# seq_parse.py
from typing import Dict, List, Tuple
import collections
import re
import sys
USAGE = (f"Usage: {sys.argv[0]} "
"[--help] | [-s <sep>] [first [incr]] last")
def seq(operands: List[int], sep: str = "\n") -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
if len(operands) == 2:
first, last = operands
if first > last:
increment = -1
if len(operands) == 3:
first, increment, last = operands
last = last + 1 if increment > 0 else last - 1
return sep.join(str(i) for i in range(first, last, increment))
def parse(args: List[str]) -> Tuple[str, List[int]]:
arguments = collections.deque(args)
separator = "\n"
operands: List[int] = []
while arguments:
arg = arguments.popleft()
if not len(operands):
if arg == "--help":
print(USAGE)
sys.exit(0)
if arg in ("-s", "--separator"):
separator = arguments.popleft() if arguments else None
continue
try:
operands.append(int(arg))
except ValueError:
raise SystemExit(USAGE)
if len(operands) > 3:
raise SystemExit(USAGE)
return separator, operands
def main() -> None:
sep, operands = parse(sys.argv[1:])
if not operands:
raise SystemExit(USAGE)
print(seq(operands, sep))
if __name__ == "__main__":
main()
注意,为了保持例子相对简短,一些错误处理方面被保持在最低限度。
这种手动解析 Python 命令行参数的方法对于一组简单的参数可能就足够了。但是,由于以下原因,当复杂性增加时,它很容易出错:
- 大量的论据
- 参数之间的复杂性和相互依赖性
- 验证根据参数执行
定制方法是不可重用的,需要在每个程序中重新发明轮子。到本教程结束时,您将已经改进了这个手工制作的解决方案,并学会了一些更好的方法。
验证 Python 命令行参数的几种方法
您已经在几个例子中对 Python 命令行参数进行了验证,比如seq_regex.py和seq_parse.py。在第一个例子中,您使用了一个正则表达式,在第二个例子中,您使用了一个定制的解析器。
这两个例子都考虑了相同的方面。他们认为预期的选项是短格式(-s)还是长格式(--separator)。他们考虑了参数的顺序,这样选项就不会放在操作数之后。最后,他们考虑类型、操作数的整数和参数的数量,从一个到三个参数。
使用 Python 数据类进行类型验证
下面是一个概念验证,它试图验证在命令行传递的参数的类型。在以下示例中,您将验证参数的数量及其各自的类型:
# val_type_dc.py
import dataclasses
import sys
from typing import List, Any
USAGE = f"Usage: python {sys.argv[0]} [--help] | firstname lastname age]"
@dataclasses.dataclass
class Arguments:
firstname: str
lastname: str
age: int = 0
def check_type(obj):
for field in dataclasses.fields(obj):
value = getattr(obj, field.name)
print(
f"Value: {value}, "
f"Expected type {field.type} for {field.name}, "
f"got {type(value)}"
)
if type(value) != field.type:
print("Type Error")
else:
print("Type Ok")
def validate(args: List[str]):
# If passed to the command line, need to convert
# the optional 3rd argument from string to int
if len(args) > 2 and args[2].isdigit():
args[2] = int(args[2])
try:
arguments = Arguments(*args)
except TypeError:
raise SystemExit(USAGE)
check_type(arguments)
def main() -> None:
args = sys.argv[1:]
if not args:
raise SystemExit(USAGE)
if args[0] == "--help":
print(USAGE)
else:
validate(args)
if __name__ == "__main__":
main()
除非您在命令行传递了--help选项,否则这个脚本需要两到三个参数:
- 一个强制字符串:
firstname - 一个强制字符串:
lastname - 可选整数:
age
因为sys.argv中的所有项都是字符串,所以如果可选的第三个参数是由数字组成的,您需要将它转换为整数。 str.isdigit() 验证字符串中的所有字符是否都是数字。此外,通过用转换后的参数值构造数据类 Arguments,可以获得两个验证:
- 如果参数的数量与
Arguments所期望的强制字段的数量不一致,那么就会出现一个错误。这是最少两个最多三个字段。 - 如果转换后的类型与
Arguments数据类定义中定义的类型不匹配,那么就会出现错误。
您可以通过下面的执行看到这一点:
$ python val_type_dc.py Guido "Van Rossum" 25
Value: Guido, Expected type <class 'str'> for firstname, got <class 'str'>
Type Ok
Value: Van Rossum, Expected type <class 'str'> for lastname, got <class 'str'>
Type Ok
Value: 25, Expected type <class 'int'> for age, got <class 'int'>
Type Ok
在上面的执行中,参数的数量是正确的,每个参数的类型也是正确的。
现在,执行相同的命令,但省略第三个参数:
$ python val_type_dc.py Guido "Van Rossum"
Value: Guido, Expected type <class 'str'> for firstname, got <class 'str'>
Type Ok
Value: Van Rossum, Expected type <class 'str'> for lastname, got <class 'str'>
Type Ok
Value: 0, Expected type <class 'int'> for age, got <class 'int'>
Type Ok
结果也是成功的,因为字段age是用默认值、0定义的,所以数据类Arguments不需要它。
相反,如果第三个参数的类型不正确,比如说,字符串而不是整数,那么就会出现错误:
python val_type_dc.py Guido Van Rossum
Value: Guido, Expected type <class 'str'> for firstname, got <class 'str'>
Type Ok
Value: Van, Expected type <class 'str'> for lastname, got <class 'str'>
Type Ok
Value: Rossum, Expected type <class 'int'> for age, got <class 'str'>
Type Error
期望值Van Rossum没有用引号括起来,所以它被拆分了。姓氏的第二个单词Rossum,是一个作为年龄处理的字符串,应该是一个int。验证失败。
注意:关于 Python 中数据类用法的更多细节,请查看Python 3.7 中数据类的终极指南。
同样,您也可以使用 NamedTuple 来实现类似的验证。你可以用一个从NamedTuple派生的类替换数据类,然后check_type()会如下变化:
from typing import NamedTuple
class Arguments(NamedTuple):
firstname: str
lastname: str
age: int = 0
def check_type(obj):
for attr, value in obj._asdict().items():
print(
f"Value: {value}, "
f"Expected type {obj.__annotations__[attr]} for {attr}, "
f"got {type(value)}"
)
if type(value) != obj.__annotations__[attr]:
print("Type Error")
else:
print("Type Ok")
一个NamedTuple公开了类似于_asdict的函数,这些函数将对象转换成可用于数据查找的字典。它还公开了像__annotations__这样的属性,这是一个为每个字段存储类型的字典,关于__annotations__的更多信息,请查看 Python 类型检查(指南)。
正如在 Python 类型检查(指南)中所强调的,您还可以利用现有的包,如 Enforce 、 Pydantic 和 Pytypes 进行高级验证。
自定义验证
与你之前已经探索过的不同,详细的验证可能需要一些定制的方法。例如,如果您试图使用不正确的文件名作为参数来执行sha1sum_stdin.py,那么您会得到以下结果:
$ python sha1sum_stdin.py bad_file.txt
Traceback (most recent call last):
File "sha1sum_stdin.py", line 32, in <module>
main(sys.argv[1:])
File "sha1sum_stdin.py", line 29, in main
output_sha1sum(process_file(arg), arg)
File "sha1sum_stdin.py", line 9, in process_file
return pathlib.Path(filename).read_bytes()
File "/usr/lib/python3.8/pathlib.py", line 1222, in read_bytes
with self.open(mode='rb') as f:
File "/usr/lib/python3.8/pathlib.py", line 1215, in open
return io.open(self, mode, buffering, encoding, errors, newline,
File "/usr/lib/python3.8/pathlib.py", line 1071, in _opener
return self._accessor.open(self, flags, mode)
FileNotFoundError: [Errno 2] No such file or directory: 'bad_file.txt'
不存在,但程序试图读取它。
重新访问sha1sum_stdin.py中的main(),以处理在命令行传递的不存在的文件:
1def main(args):
2 if not args:
3 output_sha1sum(process_stdin())
4 for arg in args:
5 if arg == "-":
6 output_sha1sum(process_stdin(), "-")
7 continue
8 try: 9 output_sha1sum(process_file(arg), arg) 10 except FileNotFoundError as err: 11 print(f"{sys.argv[0]}: {arg}: {err.strerror}", file=sys.stderr)
要查看这个额外验证的完整示例,请展开下面的代码块:
# sha1sum_val.py
from typing import List
import hashlib
import pathlib
import sys
def process_file(filename: str) -> bytes:
return pathlib.Path(filename).read_bytes()
def process_stdin() -> bytes:
return bytes("".join(sys.stdin), "utf-8")
def sha1sum(data: bytes) -> str:
m = hashlib.sha1()
m.update(data)
return m.hexdigest()
def output_sha1sum(data: bytes, filename: str = "-") -> None:
print(f"{sha1sum(data)} {filename}")
def main(args: List[str]) -> None:
if not args:
output_sha1sum(process_stdin())
for arg in args:
if arg == "-":
output_sha1sum(process_stdin(), "-")
continue
try:
output_sha1sum(process_file(arg), arg)
except (FileNotFoundError, IsADirectoryError) as err:
print(f"{sys.argv[0]}: {arg}: {err.strerror}", file=sys.stderr)
if __name__ == "__main__":
main(sys.argv[1:])
当您执行这个修改后的脚本时,您会得到:
$ python sha1sum_val.py bad_file.txt
sha1sum_val.py: bad_file.txt: No such file or directory
注意,显示到终端的错误被写入stderr,因此它不会干扰读取sha1sum_val.py输出的命令所期望的数据:
$ python sha1sum_val.py bad_file.txt main.py | cut -d " " -f 1
sha1sum_val.py: bad_file.txt: No such file or directory
d84372fc77a90336b6bb7c5e959bcb1b24c608b4
该命令通过管道将sha1sum_val.py的输出传输到 cut 以仅包括第一场。你可以看到cut忽略了错误信息,因为它只接收发送给stdout的数据。
Python 标准库
尽管您采用了不同的方法来处理 Python 命令行参数,但是任何复杂的程序都可能更好地利用现有的库来处理复杂的命令行接口所需的繁重工作。从 Python 3.7 开始,标准库中有三个命令行解析器:
标准库中推荐使用的模块是argparse。标准库也公开了optparse,但是它已经被官方否决了,在这里只是作为参考。在 Python 3.2 中,它被argparse所取代,你不会在本教程中看到对它的讨论。
argparse
你将重访sha1sum的最新克隆sha1sum_val.py,介绍argparse的好处。为此,您将修改main()并添加init_argparse来实例化argparse.ArgumentParser:
1import argparse
2
3def init_argparse() -> argparse.ArgumentParser:
4 parser = argparse.ArgumentParser(
5 usage="%(prog)s [OPTION] [FILE]...",
6 description="Print or check SHA1 (160-bit) checksums."
7 )
8 parser.add_argument(
9 "-v", "--version", action="version",
10 version = f"{parser.prog} version 1.0.0"
11 )
12 parser.add_argument('files', nargs='*')
13 return parser
14
15def main() -> None:
16 parser = init_argparse()
17 args = parser.parse_args()
18 if not args.files:
19 output_sha1sum(process_stdin())
20 for file in args.files:
21 if file == "-":
22 output_sha1sum(process_stdin(), "-")
23 continue
24 try:
25 output_sha1sum(process_file(file), file)
26 except (FileNotFoundError, IsADirectoryError) as err:
27 print(f"{sys.argv[0]}: {file}: {err.strerror}", file=sys.stderr)
与之前的实现相比,只需要多几行代码,就可以获得一种清晰的方法来添加以前不存在的--help和--version选项。对象 argparse.Namespace 的字段files中有所有期望的参数(要处理的文件)。通过调用 parse_args() 在第 17 行填充这个对象。
要查看经过上述修改的完整脚本,请展开下面的代码块:
# sha1sum_argparse.py
import argparse
import hashlib
import pathlib
import sys
def process_file(filename: str) -> bytes:
return pathlib.Path(filename).read_bytes()
def process_stdin() -> bytes:
return bytes("".join(sys.stdin), "utf-8")
def sha1sum(data: bytes) -> str:
sha1_hash = hashlib.sha1()
sha1_hash.update(data)
return sha1_hash.hexdigest()
def output_sha1sum(data: bytes, filename: str = "-") -> None:
print(f"{sha1sum(data)} {filename}")
def init_argparse() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(
usage="%(prog)s [OPTION] [FILE]...",
description="Print or check SHA1 (160-bit) checksums.",
)
parser.add_argument(
"-v", "--version", action="version",
version=f"{parser.prog} version 1.0.0"
)
parser.add_argument("files", nargs="*")
return parser
def main() -> None:
parser = init_argparse()
args = parser.parse_args()
if not args.files:
output_sha1sum(process_stdin())
for file in args.files:
if file == "-":
output_sha1sum(process_stdin(), "-")
continue
try:
output_sha1sum(process_file(file), file)
except (FileNotFoundError, IsADirectoryError) as err:
print(f"{parser.prog}: {file}: {err.strerror}", file=sys.stderr)
if __name__ == "__main__":
main()
为了说明您通过在该程序中引入argparse获得的直接好处,请执行以下操作:
$ python sha1sum_argparse.py --help
usage: sha1sum_argparse.py [OPTION] [FILE]...
Print or check SHA1 (160-bit) checksums.
positional arguments:
files
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
要深入了解argparse的细节,请查看如何用 argparse 在 Python 中构建命令行接口。
getopt
getopt起源于 getopt C 函数。它有助于解析命令行和处理选项、选项参数和参数。从seq_parse.py重游parse到使用getopt:
def parse():
options, arguments = getopt.getopt(
sys.argv[1:], # Arguments
'vhs:', # Short option definitions
["version", "help", "separator="]) # Long option definitions
separator = "\n"
for o, a in options:
if o in ("-v", "--version"):
print(VERSION)
sys.exit()
if o in ("-h", "--help"):
print(USAGE)
sys.exit()
if o in ("-s", "--separator"):
separator = a
if not arguments or len(arguments) > 3:
raise SystemExit(USAGE)
try:
operands = [int(arg) for arg in arguments]
except ValueError:
raise SystemExit(USAGE)
return separator, operands
getopt.getopt() 采取了如下论点:
- 通常的参数列表减去脚本名,
sys.argv[1:] - 定义短选项的字符串
- 长选项的字符串列表
请注意,后跟冒号(:)的短选项需要一个选项参数,后跟等号(=)的长选项需要一个选项参数。
seq_getopt.py的剩余代码与seq_parse.py相同,可在下面折叠的代码块中找到:
# seq_getopt.py
from typing import List, Tuple
import getopt
import sys
USAGE = f"Usage: python {sys.argv[0]} [--help] | [-s <sep>] [first [incr]] last"
VERSION = f"{sys.argv[0]} version 1.0.0"
def seq(operands: List[int], sep: str = "\n") -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
elif len(operands) == 2:
first, last = operands
if first > last:
increment = -1
elif len(operands) == 3:
first, increment, last = operands
last = last - 1 if first > last else last + 1
return sep.join(str(i) for i in range(first, last, increment))
def parse(args: List[str]) -> Tuple[str, List[int]]:
options, arguments = getopt.getopt(
args, # Arguments
'vhs:', # Short option definitions
["version", "help", "separator="]) # Long option definitions
separator = "\n"
for o, a in options:
if o in ("-v", "--version"):
print(VERSION)
sys.exit()
if o in ("-h", "--help"):
print(USAGE)
sys.exit()
if o in ("-s", "--separator"):
separator = a
if not arguments or len(arguments) > 3:
raise SystemExit(USAGE)
try:
operands = [int(arg) for arg in arguments]
except:
raise SystemExit(USAGE)
return separator, operands
def main() -> None:
args = sys.argv[1:]
if not args:
raise SystemExit(USAGE)
sep, operands = parse(args)
print(seq(operands, sep))
if __name__ == "__main__":
main()
接下来,您将看到一些外部包,它们将帮助您解析 Python 命令行参数。
几个外部 Python 包
基于您在本教程中看到的现有约定, Python 包索引(PyPI) 中有一些可用的库,它们需要更多的步骤来简化命令行接口的实现和维护。
以下章节简要介绍了点击和 Python 提示工具包。您将只接触到这些包的非常有限的功能,因为它们都需要完整的教程——如果不是整个系列的话——来公正地对待它们!
点击
在撰写本文时, Click 可能是为 Python 程序构建复杂命令行界面的最先进的库。它被几个 Python 产品使用,最著名的是烧瓶和黑。在尝试下面的例子之前,您需要在一个 Python 虚拟环境或者您的本地环境中安装 Click。如果你不熟悉虚拟环境的概念,那么看看 Python 虚拟环境:初级读本。
要安装 Click,请执行以下步骤:
$ python -m pip install click
那么,Click 如何帮助您处理 Python 命令行参数呢?这里有一个使用 Click 的seq程序的变体:
# seq_click.py
import click
@click.command(context_settings=dict(ignore_unknown_options=True))
@click.option("--separator", "-s",
default="\n",
help="Text used to separate numbers (default: \\n)")
@click.version_option(version="1.0.0")
@click.argument("operands", type=click.INT, nargs=-1)
def seq(operands, separator) -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
elif len(operands) == 2:
first, last = operands
if first > last:
increment = -1
elif len(operands) == 3:
first, increment, last = operands
else:
raise click.BadParameter("Invalid number of arguments")
last = last - 1 if first > last else last + 1
print(separator.join(str(i) for i in range(first, last, increment)))
if __name__ == "__main__":
seq()
将 ignore_unknown_options 设置为True可以确保 Click 不会将负参数解析为选项。负整数是有效的seq参数。
正如你可能已经观察到的,你可以免费得到很多!几个精心雕琢的装饰者就足以埋葬样板代码,让你专注于主要代码,也就是本例中seq()的内容。
注意:要了解更多关于 Python 装饰者的信息,请查看关于 Python 装饰者的入门。
剩下的唯一导入是click。修饰主命令seq()的声明性方法消除了重复的代码。这可能是以下任何一种情况:
- 定义帮助或使用程序
- 处理程序的版本
- 捕捉和设置选项默认值
- 验证参数,包括类型
新的seq实现仅仅触及了表面。Click 提供了许多有助于您打造非常专业的命令行界面的细节:
- 输出着色
- 提示省略参数
- 命令和子命令
- 参数类型验证
- 对选项和参数的回调
- 文件路径验证
- 进度条
还有许多其他功能。查看使用 Click 编写 Python 命令行工具的以查看更多基于 Click 的具体示例。
Python 提示工具包
还有其他流行的 Python 包在处理命令行接口问题,比如 Python 的doc opt。所以,你可能会发现选择提示工具包有点违反直觉。
Python Prompt Toolkit 提供的特性可能会让你的命令行应用偏离 Unix 哲学。然而,它有助于在晦涩难懂的命令行界面和成熟的图形用户界面之间架起一座桥梁。换句话说,它可能有助于使你的工具和程序更加用户友好。
除了像前面的例子中一样处理 Python 命令行参数之外,您还可以使用这个工具,但是这为您提供了一个类似 UI 的方法,而不必依赖于完整的 Python UI 工具包。要使用prompt_toolkit,需要安装pip:
$ python -m pip install prompt_toolkit
您可能会觉得下一个例子有点做作,但是它的目的是激发灵感,让您稍微远离命令行中与您在本教程中看到的约定相关的更严格的方面。
正如您已经看到的这个示例的核心逻辑一样,下面的代码片段只显示了与前面的示例明显不同的代码:
def error_dlg():
message_dialog(
title="Error",
text="Ensure that you enter a number",
).run()
def seq_dlg():
labels = ["FIRST", "INCREMENT", "LAST"]
operands = []
while True:
n = input_dialog(
title="Sequence",
text=f"Enter argument {labels[len(operands)]}:",
).run()
if n is None:
break
if n.isdigit():
operands.append(int(n))
else:
error_dlg()
if len(operands) == 3:
break
if operands:
seq(operands)
else:
print("Bye")
actions = {"SEQUENCE": seq_dlg, "HELP": help, "VERSION": version}
def main():
result = button_dialog(
title="Sequence",
text="Select an action:",
buttons=[
("Sequence", "SEQUENCE"),
("Help", "HELP"),
("Version", "VERSION"),
],
).run()
actions.get(result, lambda: print("Unexpected action"))()
上面的代码涉及交互的方法,可能会引导用户输入预期的输入,并使用三个对话框交互地验证输入:
button_dialogmessage_dialoginput_dialog
Python Prompt Toolkit 公开了许多旨在改善与用户交互的其他特性。对main()中处理程序的调用是通过调用存储在字典中的函数来触发的。如果您以前从未遇到过 Python 习语,请查看 Python 中的仿真 switch/case 语句。
您可以通过展开下面的代码块来查看使用prompt_toolkit的程序的完整示例:
# seq_prompt.py
import sys
from typing import List
from prompt_toolkit.shortcuts import button_dialog, input_dialog, message_dialog
def version():
print("Version 1.0.0")
def help():
print("Print numbers from FIRST to LAST, in steps of INCREMENT.")
def seq(operands: List[int], sep: str = "\n"):
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
elif len(operands) == 2:
first, last = operands
if first > last:
increment = -1
elif len(operands) == 3:
first, increment, last = operands
last = last - 1 if first > last else last + 1
print(sep.join(str(i) for i in range(first, last, increment)))
def error_dlg():
message_dialog(
title="Error",
text="Ensure that you enter a number",
).run()
def seq_dlg():
labels = ["FIRST", "INCREMENT", "LAST"]
operands = []
while True:
n = input_dialog(
title="Sequence",
text=f"Enter argument {labels[len(operands)]}:",
).run()
if n is None:
break
if n.isdigit():
operands.append(int(n))
else:
error_dlg()
if len(operands) == 3:
break
if operands:
seq(operands)
else:
print("Bye")
actions = {"SEQUENCE": seq_dlg, "HELP": help, "VERSION": version}
def main():
result = button_dialog(
title="Sequence",
text="Select an action:",
buttons=[
("Sequence", "SEQUENCE"),
("Help", "HELP"),
("Version", "VERSION"),
],
).run()
actions.get(result, lambda: print("Unexpected action"))()
if __name__ == "__main__":
main()
当您执行上面的代码时,会出现一个对话框提示您采取行动。然后,如果您选择动作序列,将显示另一个对话框。收集完所有必要的数据、选项或参数后,对话框消失,结果在命令行打印出来,如前面的示例所示:
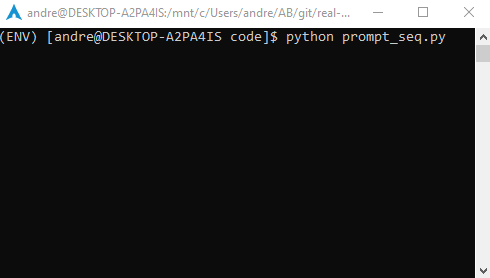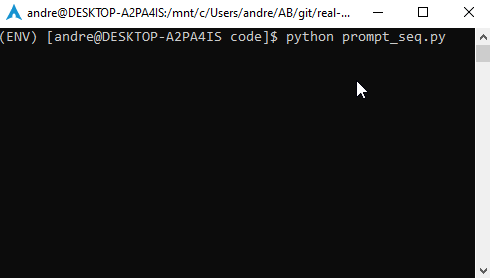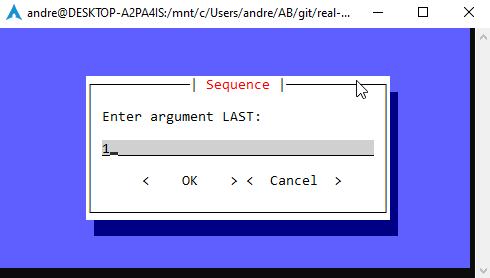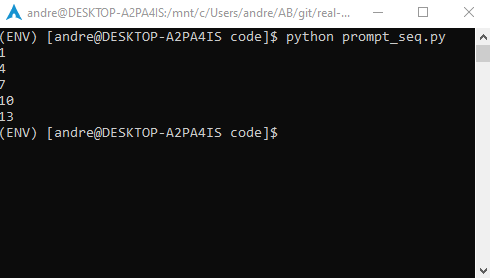
随着命令行的发展,你可以看到一些更有创造性的与用户交互的尝试,其他包如 PyInquirer 也允许你利用一种非常交互式的方法。
为了进一步探索基于文本的用户界面(TUI) 的世界,请查看构建控制台用户界面和您的 Python 打印功能指南中的第三方部分。
如果您有兴趣研究完全依赖图形用户界面的解决方案,那么您可以考虑查看以下资源:
结论
在本教程中,您已经浏览了 Python 命令行参数的许多不同方面。您应该准备好将以下技能应用到您的代码中:
- Python 命令行参数的约定和伪标准
- Python 中
sys.argv的起源 sys.argv的用法提供运行 Python 程序的灵活性- Python 标准库像
argparse或getopt那样抽象命令行处理 - 强大的 Python 包像
click和python_toolkit来进一步提高你的程序的可用性
无论您运行的是小脚本还是复杂的基于文本的应用程序,当您公开一个命令行接口时,您将显著改善 Python 软件的用户体验。事实上,你可能就是这些用户中的一员!
下次使用您的应用程序时,您会感谢您提供的带有--help选项的文档,或者您可以传递选项和参数,而不是修改源代码来提供不同的数据。
额外资源
要进一步了解 Python 命令行参数及其许多方面,您可能希望查阅以下资源:
- 比较 Python 命令行解析库——arg parse、Docopt 和 Click
- Python、Ruby 和 Golang:命令行应用比较
您可能还想尝试其他 Python 库,它们针对相同的问题,同时为您提供不同的解决方案:
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的命令行接口*********
用 Python 编写注释(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 写评论
当用 Python 写代码时,确保你的代码能被其他人容易地理解是很重要的。给变量起一个明显的名字,定义显式函数,以及组织你的代码都是很好的方法。
增加代码可读性的另一个简单又棒的方法是使用注释!
在本教程中,您将了解用 Python 编写注释的一些基础知识。你将学习如何写干净简洁的评论,以及什么时候你可能根本不需要写任何评论。
您还将了解:
- 为什么注释代码如此重要
- 用 Python 编写注释的最佳实践
- 您可能希望避免的评论类型
- 如何练习写更干净的评论
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
为什么注释你的代码如此重要
注释是任何程序不可或缺的一部分。它们可以以模块级文档字符串的形式出现,甚至可以是有助于阐明复杂函数的内联解释。
在深入不同类型的注释之前,让我们仔细看看为什么注释代码如此重要。
考虑下面两种情况,其中一个程序员决定不注释他们的代码。
当读取自己的代码时
客户端 A 想要对他们的 web 服务进行最后的部署。你已经在一个紧张的最后期限,所以你决定让它工作。所有那些“额外”的东西——文档、适当的注释等等——您将在以后添加。
截止日期到了,您准时部署了服务。咻!
你在心里记下回去更新评论,但是在你把它放到你的任务清单上之前,你的老板带着一个你需要立即开始的新项目过来了。几天之内,你已经完全忘记了你应该回去适当地注释你为客户 a 写的代码。
快进六个月,客户端 A 需要为相同的服务构建一个补丁,以符合一些新的要求。维护它是你的工作,因为你是最初建造它的人。你打开你的文本编辑器…
你到底写了什么?!
你花了几个小时解析你的旧代码,但你完全迷失在混乱中。当时你太匆忙了,以至于没有正确命名变量,甚至没有在正确的控制流中设置函数。最糟糕的是,你在脚本中没有任何注释来告诉你什么是什么!
开发人员总是忘记他们自己的代码是做什么的,特别是如果它是很久以前或者在很大压力下写的。当最后期限快到了,在电脑前的几个小时已经导致眼睛充血,双手抽筋,这种压力可以以比平时更混乱的代码形式反映出来。
一旦提交了项目,许多开发人员就懒得回去评论他们的代码了。当以后需要重新审视它的时候,他们会花上几个小时试图解析他们所写的内容。
边走边写注释是防止上述情况发生的好方法。对未来的你好点!
当别人阅读你的代码时
想象一下,你是唯一一个从事小型 Django 项目的开发人员。您非常了解自己的代码,所以您不倾向于使用注释或任何其他类型的文档,并且您喜欢这样。评论是需要时间去写和维护的,你就是看不到重点。
唯一的问题是,到年底,你的“小 Django 项目”已经变成了“20,000 行代码”的项目,你的主管带来了额外的开发人员来帮助维护它。
新的开发人员努力工作以快速达到速度,但是在一起工作的头几天,你已经意识到他们遇到了一些麻烦。您使用了一些古怪的变量名,并用超级简洁的语法编写。新员工花大量时间一行一行地检查你的代码,试图弄清楚它是如何工作的。他们甚至需要几天时间才能帮你维护它!
在你的代码中使用注释可以帮助其他开发者。注释有助于其他开发人员浏览您的代码,并很快理解它是如何工作的。通过选择从项目一开始就对代码进行注释,可以帮助确保平稳的过渡。
如何用 Python 写注释
既然你已经理解了注释你的代码的重要性,让我们回顾一些基础知识,这样你就知道如何正确地做了。
Python 注释基础知识
评论是给开发者看的。它们在必要的地方描述了代码的各个部分,以方便程序员的理解,包括你自己。
要用 Python 写注释,只需在您想要的注释前加上散列符号#:
# This is a comment
Python 会忽略散列标记之后直到行尾的所有内容。您可以将它们插入代码中的任何位置,甚至与其他代码内联:
print("This will run.") # This won't run
当你运行上面的代码时,你只会看到输出This will run.,其他的都被忽略了。
评论应该简短、甜蜜、切中要害。虽然 PEP 8 建议每行代码保持在 79 个字符或更少,但它建议行内注释和文档字符串最多 72 个字符。如果你的评论接近或超过了这个长度,那么你需要把它分散到多行中。
Python 多行注释
不幸的是,Python 无法像其他语言一样编写多行注释,比如 C 、 Java 和 Go:
# So you can't
just do this
in python
在上面的例子中,第一行将被程序忽略,但是其他行将引发一个语法错误。
相比之下,像 Java 这样的语言将允许您非常容易地将注释分散到多行中:
/* You can easily
write multiline
comments in Java */
程序会忽略/*和*/之间的所有内容。
虽然 Python 本身没有多行注释功能,但是您可以在 Python 中创建多行注释。有两种简单的方法可以做到这一点。
第一种方法是在每一行之后按下return键,添加一个新的散列标记,然后从那里继续您的注释:
def multiline_example():
# This is a pretty good example
# of how you can spread comments
# over multiple lines in Python
以散列符号开头的每一行都将被程序忽略。
另一种方法是使用多行字符串,将注释放在一组三重引号中:
"""
If I really hate pressing `enter` and
typing all those hash marks, I could
just do this instead
"""
这就像 Java 中的多行注释,三重引号中的所有内容都将作为注释。
虽然这为您提供了多行功能,但从技术上讲,这并不是注释。它是一个没有赋值给任何变量的字符串,所以你的程序不会调用或引用它。尽管如此,因为它在运行时会被忽略,不会出现在字节码中,所以它可以有效地充当注释。(你可以看看这篇文章来证明这些字符串不会出现在字节码中。)
但是,在放置这些多行“注释”时要小心根据它们在程序中的位置,它们可能会变成文档串,这些文档串是与函数或方法相关联的文档。如果你在一个函数定义后面加上一个坏男孩,那么你原本打算作为注释的东西将会和这个对象相关联。
在使用这些的时候要小心,如果有疑问,就在后面的每一行加上一个散列符号。如果您有兴趣了解更多关于 docstrings 以及如何将它们与模块、类等相关联的信息,请查看我们关于记录 Python 代码的教程。
Python 注释快捷键
每次需要添加注释时,都要键入所有这些散列符号,这可能很乏味。那么,你能做些什么来加快速度呢?这里有几个技巧可以帮助你在评论时摆脱困境。
您可以做的第一件事就是使用多个游标。听起来就是这样:在屏幕上放置多个光标来完成一项任务。只需按住 Ctrl 或 Cmd 键,同时单击鼠标左键,您应该会在屏幕上看到闪烁的线条:

当你需要在几个地方评论同一件事时,这是最有效的。
如果你有一段很长的文本需要注释掉呢?假设您不希望运行一个已定义的函数来检查 bug。点击每一行注释掉它会花费很多时间!在这种情况下,您需要切换注释。只需选择所需代码,在 PC 上按 Ctrl + / ,在 Mac 上按 Cmd + / :
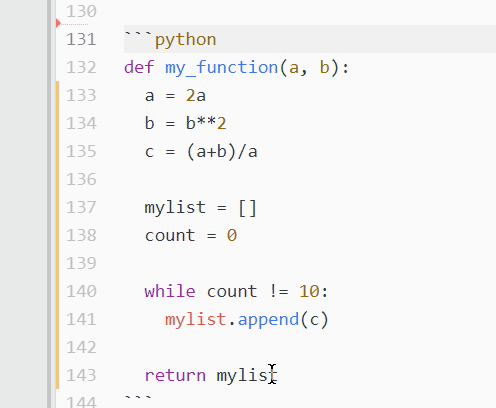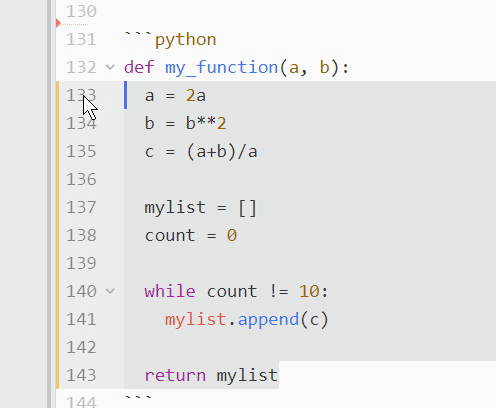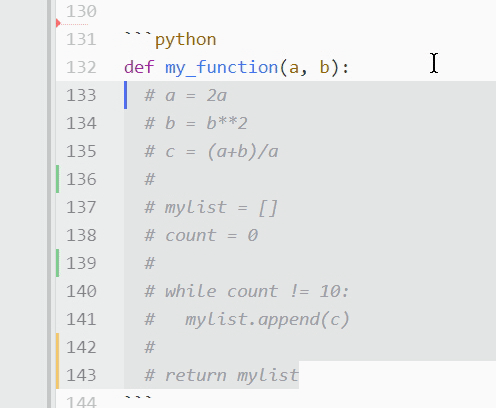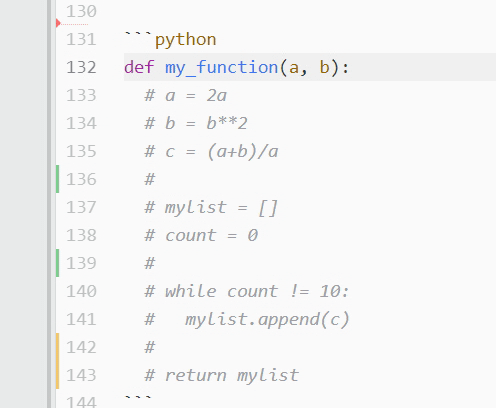
所有突出显示的文本都将加上一个散列标记,并被程序忽略。
如果您的注释变得过于笨拙,或者您正在阅读的脚本中的注释非常长,那么您的文本编辑器可能会让您选择使用左侧的小向下箭头折叠它们:

只需点击箭头隐藏评论。这最适用于多行的长注释,或者占据程序大部分开头的文档字符串。
结合这些技巧将会使你的代码注释变得快速、简单、轻松!
Python 注释最佳实践
虽然知道如何用 Python 写注释是很好的,但确保您的注释可读且易于理解也同样重要。
看看这些提示,帮助你写出真正支持你的代码的注释。
给自己写代码的时候
通过适当地注释您自己的代码,您可以让自己的生活更轻松。即使没有其他人会看到它,你也会看到它,这就足够让它变得正确。毕竟你是一名开发人员,所以你的代码也应该易于理解。
使用注释的一个非常有用的方法是作为代码的大纲。如果你不确定你的程序结果如何,那么你可以使用注释作为一种跟踪剩余工作的方式,或者甚至作为一种跟踪程序高级流程的方式。例如,使用注释来概述伪代码中的函数:
from collections import defaultdict
def get_top_cities(prices):
top_cities = defaultdict(int)
# For each price range
# Get city searches in that price
# Count num times city was searched
# Take top 3 cities & add to dict
return dict(top_cities)
这些评论策划出来get_top_cities()。一旦你确切地知道你想要你的函数做什么,你就可以把它翻译成代码。
使用这样的评论可以帮助你保持头脑清醒。当你浏览你的程序时,你会知道为了有一个功能完整的脚本还需要做什么。在将注释“翻译”成代码之后,记得删除任何多余的注释,这样你的代码就会保持清晰和整洁。
您也可以使用注释作为调试过程的一部分。注释掉旧代码,看看这会如何影响您的输出。如果你同意这个改变,那么不要在你的程序中把代码注释掉,因为这会降低可读性。如果需要恢复它,请删除它并使用版本控制。
最后,使用注释来定义您自己代码中的棘手部分。如果你放下一个项目,几个月或几年后再回来,你会花很多时间试图重新熟悉你写的东西。万一你忘记了你自己的代码是做什么的,那就帮你自己一个忙,把它记下来,这样以后就可以更容易地恢复速度了。
为他人编写代码时
人们喜欢在文本中快速浏览和来回跳转,阅读代码也不例外。你可能一行一行地通读代码的唯一时间是当它不工作的时候,你必须弄清楚发生了什么。
在大多数其他情况下,您将快速浏览一下变量和函数定义,以便获得要点。在这种情况下,用简单的英语来解释正在发生的事情确实可以帮助开发人员。
善待你的开发伙伴,使用注释来帮助他们浏览你的代码。内联注释应该有节制地使用,以清除那些本身不明显的代码。(当然,您的首要任务应该是让您的代码独立存在,但是行内注释在这方面会很有用。)
如果你有一个复杂的方法或函数,它的名字不容易理解,你可能想在def行后面加上一个简短的注释来说明一些问题:
def complicated_function(s):
# This function does something complicated
这可以帮助其他浏览你的代码的开发人员了解这个函数的功能。
对于任何公共函数,您都希望包含一个关联的 docstring,不管它是否复杂:
def sparsity_ratio(x: np.array) -> float:
"""Return a float
Percentage of values in array that are zero or NaN
"""
该字符串将成为函数的.__doc__属性,并正式与该特定方法相关联。PEP 257 docstring 指南将帮助你构建你的 docstring。这些是开发人员在构造文档字符串时通常使用的一组约定。
PEP 257 指南对多行文档字符串也有约定。这些文档字符串出现在文件的顶部,包括对整个脚本及其功能的高级概述:
# -*- coding: utf-8 -*-
"""A module-level docstring
Notice the comment above the docstring specifying the encoding.
Docstrings do appear in the bytecode, so you can access this through
the ``__doc__`` attribute. This is also what you'll see if you call
help() on a module or any other Python object.
"""
像这样的模块级 docstring 将包含开发人员阅读它时需要知道的任何相关信息。当编写一个时,建议列出所有的类、异常和函数,并为每个列出一行摘要。
Python 评论最差实践
正如编写 Python 注释有标准一样,有几种类型的注释不会导致 Python 代码。这里只是几个。
避免:W.E.T .评论
你的评论应该是 D.R.Y .缩写代表编程格言“不要重复自己。”这意味着你的代码应该很少或者没有冗余。你不需要注释一段足以解释它自己的代码,就像这样:
return a # Returns a
我们可以清楚地看到,a被返回,所以没有必要在注释中明确声明这一点。这使得注释成为 W.E.T .,意味着你“每件事都写了两遍。”(或者,对于更愤世嫉俗的人来说,“浪费了每个人的时间。”)
W.E.T .注释可能是一个简单的错误,特别是如果你在写代码之前使用注释来规划代码。但是一旦你让代码运行良好,一定要回去删除那些变得不必要的注释。
忌:臭评论
注释可能是“代码味道”的标志,这意味着您的代码可能存在更深层次的问题。代码味道试图掩盖程序的潜在问题,而注释是试图隐藏这些问题的一种方式。评论应该支持你的代码,而不是试图解释它。如果你的代码写得很差,再多的注释也无法修复它。
让我们举一个简单的例子:
# A dictionary of families who live in each city
mydict = {
"Midtown": ["Powell", "Brantley", "Young"],
"Norcross": ["Montgomery"],
"Ackworth": []
}
def a(dict):
# For each city
for p in dict:
# If there are no families in the city
if not mydict[p]:
# Say that there are no families
print("None.")
这段代码相当难懂。每一行之前都有一个注释来解释代码的作用。通过为变量、函数和集合指定明显的名称,这个脚本可以变得更简单,如下所示:
families_by_city = {
"Midtown": ["Powell", "Brantley", "Young"],
"Norcross": ["Montgomery"],
"Ackworth": [],
}
def no_families(cities):
for city in cities:
if not families_by_city[city]:
print(f"No families in {city}.")
通过使用显而易见的命名约定,我们能够删除所有不必要的注释并减少代码长度!
您的注释应该很少比它们支持的代码长。如果你花了太多时间来解释你做了什么,那么你需要回去重构,使你的代码更加清晰和简洁。
避免:粗鲁的评论
这是在开发团队中工作时可能会遇到的事情。当几个人都在处理同一个代码时,其他人会进去检查你写的东西并进行修改。有时,你可能会碰到有人敢写这样的评论:
# Put this here to fix Ryan's stupid-a** mistake
老实说,不这么做是个好主意。如果是你朋友的代码就没关系,你确定他们不会因此而被冒犯。你永远不知道什么可能会被发布到产品中,如果你不小心把那个评论留在那里,然后被客户发现了,会是什么样子?你是专业人士,在你的评论中包含粗俗的词语不是展示这一点的方式。
如何练习评论
开始写更多 Pythonic 注释的最简单的方法就是去做!
开始用自己的代码为自己写注释。从现在开始,在必要的地方加入简单的评论。为复杂的函数增加一些清晰度,并在所有脚本的顶部放置一个 docstring。
另一个很好的练习方法是回顾你写的旧代码。看看哪些地方可能没有意义,并清理代码。如果它仍然需要一些额外的支持,添加一个简短的注释来帮助阐明代码的目的。
如果你的代码在 GitHub 上,并且人们正在分叉你的回购,这是一个特别好的主意。通过引导他们完成您已经完成的工作来帮助他们开始。
也可以通过评论别人的代码来回馈社区。如果你已经从 GitHub 下载了一些东西,并且在筛选的时候遇到了困难,当你开始理解每段代码是做什么的时候,添加注释。
在您的评论上“签名”您的姓名首字母和日期,然后提交您的更改作为拉请求。如果您的更改被合并,您可能会帮助几十个甚至几百个像您一样的开发人员在他们的下一个项目中取得优势。
结论
学会好好评论是一个很有价值的工具。一般来说,你不仅会学到如何更清晰、更简洁地写作,而且毫无疑问,你也会对 Python 有更深的理解。
知道如何用 Python 写注释可以让所有开发者的生活变得更轻松,包括你自己!他们可以帮助其他开发人员了解你的代码所做的事情,并帮助你重新熟悉你自己的旧代码。
通过注意当你使用注释来尝试和支持写得很差的代码时,你将能够回过头来修改你的代码,使之更加健壮。注释以前编写的代码,无论是您自己的还是其他开发人员的,都是练习用 Python 编写简洁注释的好方法。
随着您对编写代码了解的越来越多,您可以考虑进入下一个文档级别。查看我们的教程记录 Python 代码以采取下一步行动。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 写评论******
python 社区采访黄铁矿的 bob 和 julian
原文:https://realpython.com/python-community-interview-bob-and-julian-pybites/
本周,我和 PyBites 乐队的鲍勃·贝尔德博斯和 T2·朱利安·塞杰拉在一起。Bob 是西班牙甲骨文公司的一名软件开发人员。Julian 是澳大利亚亚马逊网络服务公司的一名数据中心技术人员。
加入我们,一起讨论 PyBites 是如何起步的,以及他们对未来有什么打算。我们还会调查鲍勃对绘画的秘密爱好以及朱利安对好酒的秘密爱好。
里基: 欢迎,鲍勃和朱利安!或者是朱利安和鲍勃?不管是哪种情况,谢谢你参加这次面试。让我们从通常的第一个问题开始。你是怎么进入编程的?你是什么时候开始用 Python 的?

朱利安:我们更喜欢用“布尔”不完全是,但是让我们坚持下去。
我第一次被编程错误(双关语!)回到高中,但在 2015 年末真正投身于编程。
我需要一种方法来跟踪我在 Oracle 担任现场工程师时的加班时间,以确保我得到正确的报酬。输入 Python(在 Bob 的推荐下)。
我给自己做了一个 CLI 加班跟踪器,包括一个基本的菜单系统,带有简单的选项来计算我的税后加班工资。这是最基本的,非常有效,让我迷上了 Python。
提示:是真实世界的用例让学习变得更有意义!
与我使用 C++的高中时代相比,Python 的速度和简单性让我着迷。然后我们开始 PyBites,蟒蛇变得真实。(真正的 Python ,懂了吗?)

对我来说,这一切要追溯到 2009 年的太阳微系统公司。我加入了系统支持小组,找到了一个合适的位置来开发一个 web 应用程序来解析诊断输出,我们每个月都会收到数千个这样的输出。这成为支持组织的主要工具,每天为他们节省了无数小时的繁琐工作。
这个诊断工具是 shell 脚本(bash/sed/awk)、Perl、PHP 和一些 jQuery 的混合。企业决定转向服务请求的完全自动化,为此我用 Perl 编写了一个新的框架,这很快成为维护的噩梦,所以我开始寻找其他解决方案。
这是在 2012 年。我偶然发现了 Python 并开始学习它。这是一见钟情:它干净优雅的设计( type import this in your REPL ),没有括号和其他类似 C 的语法,读起来就像英语!学习 Python 的基础很简单,但是在幕后,它是非常通用的。
在 Linux Journal 上有一篇 Eric Raymond 的很棒的文章,题目是 为什么是 Python? ,描述了他从 Perl 转向 Python 时的启示。
我也经历过类似的事情。在用 Python 快速重写自动化框架之后,进行更改变得相对“容易”,并且我们用许多令人兴奋的新特性对其进行了扩展,所有这些都没有大的麻烦。虽然我转换到了另一个角色,但解决方案仍然得到了积极的维护。从那以后,我有幸在几乎所有的工作中使用 Python。
瑞奇: 你们两个都是最出名的(不管是好是坏),因为你们都是皮比特的联合创始人。对于不了解 PyBites 的人来说,它是什么,又是怎么开始的?
PyBites 最初只是一个简单的博客,分享我们在 Python 领域的学习。(我们使用名为鹈鹕的静态站点生成器。)我们热衷于推动自己超越仅仅阅读书籍和观看视频。写博客文章让我们真正深入下去,以确保我们传达的是正确的概念。
它成立后不久,我们就开始试验一些想法。一个是挑战自我,受到诺亚·卡根的咖啡挑战的启发。所以有一天 Bob 提出了一个 Python 练习,让我们在周末之前解决。
我们发现了一个 JavaScript 课程页面,上面有每个视频的mm:ss计时,但没有总时长。任务是浏览网站,把所有的视频时间戳加起来,计算课程的总时长。
在周末(sprint),我们比较了我们的解决方案,回顾了我们的学习成果。我们有“搏击俱乐部时刻”(也许没有那么暴力……)“我们应该找个时间再来一次”,这就是我们的博客/社区代码挑战热线的诞生。
我们研究了 GitHub,为我们建立了一个挑战报告来发布我们的挑战和解决方案,然后创建了一个单独的社区分支,让其他人请求他们的工作。
我们从中获得的动力激发了这个想法,这个想法成为了我们的编码平台: CodeChalleng.es 。它由不断增长的近 200 个 Python 练习(称为 Py 的片段)组成,您可以在自己的浏览器中舒适地编写代码。
对我们来说,另一件大事是完成 #100DaysOfCode 挑战,我们在博客和社交媒体上积极分享了这一挑战。这让我们在 Talk Python 播客上接受了采访,反过来,也让我们与 Michael Kennedy 一起制作了 #100DaysOfCode in Python 课程。
对我们来说,重要的一课是,你只需要开始行动,放弃完美主义。发生的许多令人敬畏的事情不是计划好的,而是因为我们把一些产生兴趣的东西放在那里而来到我们身边,我们在这个过程中根据我们收到的有价值的反馈采取行动!
朱利安,你白天不是程序员,你在亚马逊网络服务公司做数据中心技术员。和像 Bob 这样有成就的人一起学习编程感觉如何?我认为找一个更有经验的人做你的生意伙伴会有帮助?在你学习编码的过程中,有什么让你感到惊讶或感到困难的事情吗?
我和鲍勃之间的鸿沟一直是 PyBites 的基石。实际上,我们认为这会给我们的博客一个独特的旋转!
为此,情况有点复杂。当你和像 Bob 这样有能力的人一起编码时,第一感觉是敬畏。你可以看到他们代码的优雅,以及他们在瞬间解决你花了几个小时解决的问题的能力。真的很励志!
但并不总是如此。很容易陷入冒名顶替综合症的陷阱:
- "我的代码还会一样好吗?"
- “我为什么要烦恼?”
- “他总是会变得更好!”
现实是,总会有更好的人来写代码,总会有更好的人来生活!我很快认识到,与其关注技能差距,我应该关注我自己的代码,为我的成就感到自豪,并拥抱我带来的东西。
有趣的是,这适用于我们两个人,我们在学习和管理代码时遇到的困难可以忽略不计。也就是我们接受它,热爱它。(我现在这样说,但绝不是在当下!)
令人惊讶的困难部分是 PyBites 的实际业务方面!我还要补充一点,我不做专业程序员的日子可能要结束了!(嘘!)
鲍勃,用你自己的话来说,当你在日常工作中“不为男人努力工作”时,你喜欢在业余时间修补和建造项目。你目前有什么样的项目在进行中?
目前,我几乎所有的时间都花在了制作课程内容和通过增加更多练习和功能来改进我们的平台上。随着使用的增加,会有更多的问题和反馈/请求,但是我很喜欢它的每一分钟,因为它提供了一个教授 Python 和指导其他开发人员的好方法,这是我非常喜欢的。
我还参加了 Coursera 应用数据科学专业,因为我热爱数据,并希望在日常工作中更多地融入这些数据。
当这个和我们即将开始的课程(悬念… )完成后,我的默认工作流程仍然是相似的:
- 接受一个新概念(Python 模块、数据、web 技术、自动化机会等等)
- 研究一下
- 做一些很酷的东西,然后写博客/分享这个过程
这是我所热爱的,也是 PyBites 不断增长的内容的一部分。
这实际上是我推荐给任何程序员/开发人员的。简历是遗产。开始建立你的博客/GitHub/品牌,这样你就有一个可以展示的作品集了。它还使您能够在未来的项目中重复使用您所构建的内容,这是一种与他人建立网络/协作的好方法。
里基: 很明显,你们俩都有企业家的基因。(你只要看看鲍勃的书架就能看到证据。)对你来说,创业/副业(PyBites)最困难或最具挑战性的部分是什么?你发现你们各自的才能互相抵消了吗?
最具挑战性的部分无疑是管理我们的优先事项。
我们两个人生活中最重要的事情碰巧非常相似:
- 家人/孩子
- 全职工作
- 学问
- 硫化铁矿
随着 PyBites 的增长,所需的时间投资也在增长。我们不能把这些时间从日常工作或家庭中抽出来,所以这无疑是试图找到一个可接受的平衡的最大障碍。
我们采取的观点是“如果我们有时间看网飞,那么我们就有时间研究俾比特人。”
为此,我们常常有意识地选择不看电视、不玩游戏或不出门,把这些时间变成我们的时间。这听起来没什么,但是在漫长的一天工作和哄孩子睡觉之后,重新使用工具来研究 PyBites 是非常具有挑战性的!
也就是说,我们公开告诉任何愿意倾听的人,如果没有彼此的相互支持,我们就不会有今天。
如果你在做任何有价值的事情,那么给自己找一个负责任的伙伴。我们让对方对我们接手的项目负责,当事情不尽如人意时,我们互相扶持。
我们不同的才能肯定会互相抵消。Julian 更倾向于作家、讲故事者、营销者、业务经理和“代言人”,而 Bob 深入研究代码,构建和维护工具,提出令人难以置信的想法,并在技术上支持社区。结合这两种才能,你就有了一台运转良好的 PyBites 机器。
最好的部分(并且坚持我们的核心信念,即你从实践中学习)是我们互相学习。我们互相推动,不断改进,跳出框框,不断尝试新事物。
里基: 现在我的最后一个问题。你在业余时间还做些什么?除了 Python 和编码,你还有什么其他的爱好和兴趣?
哈哈,Python 和编码是一大块,但除此之外,我喜欢和我的妻子和两个孩子在一起的每一分钟。
我也热衷于坚持每天的健身计划,尤其是当我们的工作需要这么多坐着和看屏幕的时间的时候!我喜欢看书和听播客。当我有更多的空闲时间时,语言学习和绘画是我真正喜欢的另外两件事。
Julian: 好了,切掉编码和 Python,唷!
像鲍勃一样,首要任务是花时间陪伴我的妻子和两个孩子。任何有小孩的人都会知道,在他们结束后,你真的没有太多的时间,所以现在的业余爱好时间是有限的。
当我抓住几分钟不重要的时间时,我喜欢弹电吉他,玩电子游戏,阅读,摆弄我的树莓派和家庭自动化设备。
此外,作为一个交际花,我喜欢和朋友出去玩,喝几杯啤酒。带我去酒吧,给我一杯好酒,我会是你最好的朋友!
(等一下。鲍勃刚才说他喜欢画画吗?)
你有什么项目想和我们的读者分享吗?我们在哪里可以找到更多关于你们的信息以及你们在做什么?

Boolean: 除了博客,我们目前最引以为豪的是我们的在线 Python 编码练习平台。
我们还与 Michael Kennedy 一起在 Python 课程中创建了 #100DaysOfCode】并成为了 Talk Python to Me 培训平台的培训师。同样,这也是我们非常自豪的事情。(更多内容请见此处!)
你可以在下面黑暗的地方找到并跟踪朱利安:
- 推特: @_juliansequeira
- 领英:【https://www.linkedin.com/in/juliansequeira/】T2
- 我还在 Udemy 上创建了一个入门烧瓶课程!
- 个人博客:【https://www.techmoneykids.com/】T2
鲍勃:
谢谢朱利安和鲍勃的有趣采访。如果你最近没有去过 PyBites,那么我鼓励你去看看。如果你想让我采访某个人作为这个系列的一部分,请在下面留下评论。编码快乐!
Python 社区采访教授 Python 的 Kelly 和 Sean
原文:https://realpython.com/python-community-interview-kelly-and-sean-teaching-python/
本周,我和凯利·帕雷德斯和肖恩·蒂博尔一起参加了教学 Python 播客的主持人。加入我们,讨论在代码本身之外学习 Python 的好处,以及当你不打算成为专业开发人员时学习 Python 是什么感觉。那么,事不宜迟,让我们见见凯利和肖恩吧!
瑞奇: 欢迎来到真正的巨蟒,凯利和肖恩。我很高兴你能和我一起参加这次面试。让我们像对待所有客人一样开始吧。你是如何开始编程的,你是什么时候开始使用 Python 的?

凯利:我可能是你最不典型的编码员/程序员。直到大约一年半以前,我才真正开始接触编程。我小时候玩过一点 MS-DOS,但除了从手册上抄东西之外,我从来没有更进一步。此外,我是一名大学医学预科生,但从未真正上过编码课。
在研究生院期间,我上过一些网页设计课,我喜欢在网上玩,但那是我年轻时做的最多的编码。我后来教学生如何在 Dreamweaver 中用 HTML 制作网站,那时候这在教育界是一件大事。然后,后来我用 EV3 思维风暴软件给乐高机器人编程,和学生们一起玩积木代码。
然而,Python 是我第一门真正的编码语言,从那以后我一直在自学如何编码。我认为 Python 适合新手,因为它的可读性和逻辑组织结构。
Sean: 我是在电脑周围长大的,我想我最早的编码经历是在教室里用 Apple II 电脑。我记得从杂志和书上输入基本程序来解谜和解码密码。
我认真的编程始于大学,在那里我学习信息系统,必须学习数据库以及用 Java 和 PHP 进行 web 编程。我爱上了通过实用代码让事情变得更高效、更优雅的能力。我将这一点应用到我的软件开发和市场营销职业生涯中,总是找到一种方法让代码变得更好,即使当我成为一名经理,不再将编码作为我日常工作的一部分时也是如此。
大约一年半前,我决定转行,开始全职教授计算机科学。我们想用 Python 作为我们基于文本的基础语言,所以我开始自学。由于其优雅的实现和广泛的用途,它已经成为最令人满意的学习、使用和教授语言之一。
瑞奇: 你是 2018 年 12 月开始的教学 Python 播客的共同主持人。对于那些还没有听的人,你为什么开始播客?此外,当你开始的时候,谁是你的目标听众?随着你的进步,这种情况有变化吗?
凯莉:肖恩和我在同一个教室一起工作。我们在一起的九个小时里,大部分时间都在谈论非常酷的事情,比如编码、教育学、课堂管理、课程设计、如何让酷项目进入课堂,以及那天任何能激起我们兴趣的事情。当我们中的一个人在教学的时候,我们经常在一起,当我们可以的时候,我们会一起指导。
我们意识到我们拥有独一无二的东西。我是他的教学导师,因为这是他第一次教学,他是我的 Python 编码导师,因为,嗯,他在编码方面真的很聪明!我们开始这个播客是因为我们注意到很难找到愿意教书的训练有素的软件工程师和愿意学习如何编码的老师。
如果你是一名程序员,你通常不希望开始教书时薪水较低,而且没有多少有丰富编程经验的老师。如果你没有既懂代码又懂教学法的优秀教师,就很难开设计算机科学课程。
我们坚信,来自其他学科领域的好老师也可以成为伟大的计算机科学老师,只需要一点指导和大量的毅力。与此同时,我们希望帮助其他教师学习如何编写代码,这样我们就可以帮助培养能够批判性思考、解决问题的学生,并培养对他们的未来有所帮助的社交和情感技能。
Sean: 我们原本以为我们的许多听众会是专攻计算机科学或相关 STEM 领域的教师。有趣的是,我们发现有如此多的 Python 开发者对教育和向他人展示如何开始将计算思维和问题解决应用到他们周围的世界充满热情!
关于这个播客,我们最喜欢的事情之一是与来自 Python 世界的人们见面,他们正在做着如此有趣而重要的工作。无论是使用代码探索文学概念的英语教师,向理科研究生教授数据科学原理的大学教师,还是向贫困或代表性不足的群体教授课后 Python 程序的忙碌的专业人员,看到 Python 如何被用来让世界变得更美好都是令人鼓舞的。
瑞奇: 你给中学生教 Python。我很想听听它给你个人带来的挑战。与成人相比,你对那个年龄组的教学方法有什么不同?
凯莉:我教了二十多年的中学生。我喜欢这个年龄组,尤其是七年级学生——他们是海绵!如果给他们机会和适当的支持,他们可以完成令人惊奇的事情。
在我看来,教中学生是容易的部分。有时候,向他们的父母解释编码很难,我们在“推动”他们的孩子去做他们认为他们做不到的事情,这才是最难的部分。父母通常不知道如何让他们的孩子挣扎。而且大多数父母自己也不懂编码,所以他们在试图帮助孩子时感到失落。
然而,Sean 和我相信,找到合适的理想困难不仅仅是帮助学生学习如何编码。最后,父母对他们的孩子所取得的成就非常满意!
Sean: 即使在成年人中间工作了这么多年,第一次教中学生还是有点害怕,因为他们通常把老师视为主要的知识来源。我们学校有非常优秀的学生,中学通常是他们寻求大量知识、了解自己和周围世界的时候。
我发现,作为一名教师,我能做的最重要的事情之一就是向他们表明,我并非无所不知。然后,我可以指导他们获取新信息,并将其应用到他们试图解决的问题或他们试图创建的程序中。我必须感谢 Kelly,作为一名新老师,她帮助我如此迅速地理解了这种方法的重要性。
我认为公平地说,并不是你所有的学生将来都会成为软件工程师或类似的人。你的学生在学习 Python 编程和完成项目集的过程中获得了什么好处?
凯莉:我认为公平地说,大多数计算机科学教师并不期望他们的学生成为软件工程师,我们也没有为他们寻找那个目标。我从自己的学习过程中学到的是,“学习如何编码”不仅仅是开发一个很酷的应用程序,或者另一个版本的“猜数字”游戏。
我对自己和如何解决问题有了更多的了解,而我对此一无所知或没有背景知识,甚至没有参考资料。然而,我已经发展了一些技能,帮助我建立自信,提高我的研究技能,让我能够阅读我知道不到 80%词汇的内容,并坚持解决一个有多个解决方案的问题。
我希望我的学生也有同样的经历。我想建立他们的信心,让他们明白在考试中获得“A”是很好的,但是能够解决问题,批判性地思考问题的含义和结果,以及勇于面对未知比获得“A”或成为“程序员”更重要。我们真的希望培养渴望接受任何挑战的终身学习者。
Sean: 我经常告诉学生们,我们很幸运能够用 Python 编程,因为对于初学者来说,它是一种非常棒的语言,而且它还会随着你的成长而解决手边的问题。
我认为公平地说,我们现在教的最不重要的东西是 Python 的语言、语法和词汇。我们真正教授的是研究、解决问题、坚持不懈、应对挫折和失败,以及如何在某方面发展真正的能力。这些特质和技能在许多不同的学科中都是持久的,不仅仅是计算机科学。
用 Kelly 的话来说,我们的学生中只有一小部分人会继续接受传统的计算机科学教育,但所有人都需要思考和解决问题,学习和掌握主题,并在他们选择的领域发展真正的能力。我们的赌注是,知道如何通过代码和技术解决问题将在 21 世纪的职业道路上很好地为他们服务。
里基: 现在,我的最后几个问题。你在业余时间还做些什么?除了教 Python 和编码,你还有什么其他的爱好和兴趣?
Kelly: 在教学,学习如何更好的编码,和录制教学 Python 之间,我不做太多别的!我喜欢和我的两个小男孩在一起,享受南佛罗里达的生活。我们喜欢游泳、去海滩、钓鱼和运动——真的,任何户外运动。然而,我真的很想有一天写一本书,并已经开始了这个过程,但很难用我一天中剩余的时间来完成它。
我还想在我的编码中找到一个点,在那里我可以做出一些真正有用的东西,帮助教师更好地了解他们的学生在学校的学业、情感和社会进步。后面这两个目标都是“近”的未来希望和梦想,我试图保持在我的掌握之中。
Sean: 如果我没有教 Python 或写代码,那么你通常会发现我在和我的孩子玩耍,咨询一些营销客户,或者想办法让我的房子变得更智能。我还试图通过长跑和跆拳道来保持健康,每周至少有几个早上是在上学前。
幸运的是,南佛罗里达全年都有温暖的天气,所以你也可以看到我在运河和湖泊里钓鱼,放飞我的无人机,或者尝试摄影。有时,我甚至可以玩视频游戏或从事一些兼职项目,比如为我的客户进行基于熊猫的 CRM 系统数据科学分析。
感谢凯利和肖恩参加这次采访!很高兴收到你们俩的来信。
你可以在他们的网站上查看教学 Python 播客,或者在你最喜欢的播客播放器中搜索。你也可以在推特上关注凯利和肖恩。一如既往,如果你想让我在未来采访某人,请在下面留下评论或在 Twitter 上给我发消息。
用 Python 简化复数
大多数通用编程语言要么不支持,要么有限支持复数。你的典型选择是学习一些专门的工具,比如 MATLAB 或者找一个第三方库。Python 是一个罕见的例外,因为它内置了复数。
顾名思义,复数并不复杂!它们在处理实际问题时很方便,您将在本教程中体会到这一点。你将探索矢量图形和声音频率分析,但是复数也可以帮助绘制分形,例如曼德尔布罗集合。
在本教程中,您将学习如何:
- 用 Python 中的文字定义复数
- 在直角和极坐标中表示复数
- 在算术表达式中使用复数
- 利用内置的
cmath模块 - 将数学公式直接翻译成 Python 代码
如果你需要快速复习或者对复数理论有一个温和的介绍,那么你可以看看汗学院的视频系列。要下载本教程中使用的示例代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的复数。
在 Python 中创建复数
在 Python 中创建和操作复数与其他内置数据类型没有太大区别,尤其是数值类型。这是可能的,因为这种语言将他们视为一等公民。这意味着你可以用很少的开销来表达包含复数的数学公式。
Python 允许你在算术表达式中使用复数,并对它们调用函数,就像你在 Python 中处理其他数一样。它产生了优雅的语法,读起来几乎像一本数学教科书。
复数文字
在 Python 中定义复数的最快方法是直接在源代码中键入它的文字:
>>> z = 3 + 2j虽然这看起来像一个代数公式,但等号右边的表达式已经是一个固定值,不需要进一步计算。当您检查它的类型时,您将确认它确实是一个复数:
>>> type(z)
<class 'complex'>
这与用加号运算符将两个数字相加有何不同?一个明显的例子是粘在第二个数字上的字母j,它完全改变了表达的意思。如果您删除字母,您将得到一个熟悉的整数结果:
>>> z = 3 + 2 >>> type(z) <class 'int'>顺便说一下,您也可以使用浮点数来创建复数:
>>> z = 3.14 + 2.71j
>>> type(z)
<class 'complex'>
Python 中的复数文字模拟数学符号,也称为复数的标准形式、代数形式,或者有时称为标准形式。在 Python 中,可以在这些文字中使用小写的j或大写的J。
如果你在数学课上学过复数,你可能会看到用i而不是j来表示它们。如果你对 Python 为什么使用j而不是i感到好奇,那么你可以展开下面的可折叠部分来了解更多。
传统的复数符号使用字母i代替j,因为它代表虚数单位。如果你有数学背景,你可能会对 Python 的约定感到有点不舒服。然而,有几个原因可以证明 Python 有争议的选择是正确的:
- 这是工程师已经采用的惯例,以避免与电流的名称冲突,电流用字母
i表示。 - 在计算中,字母
i通常用于循环中的索引变量。 - 字母
i在源代码中很容易与l或1混淆。
这是十多年前 Python 的 bug 追踪器提出来的,Python 的创造者吉多·范·罗苏姆本人用下面的评论结束了这个问题:
这个问题不会得到解决。首先,字母“I”或大写字母“I”看起来太像数字了。语言解析器(在源代码中)或内置函数(int、float、complex)解析数字的方式不应以任何方式进行本地化或配置;这是在自找巨大的失望。如果你想用“I”而不是“j”来解析复数,你已经有很多解决方案了。(来源)
所以你有它。除非你想开始使用 MATLAB,否则你将不得不忍受使用j来表示你的复数。
复数的代数形式遵循代数的标准规则,这便于执行算术运算。例如,加法有一个可交换属性,它允许你交换一个复数文字的两个部分的顺序,而不改变它的值:
>>> 3 + 2j == 2j + 3 True同样,您可以在复数文字中用加法代替减法,因为减号只是等价形式的简写符号:
>>> 3 - 2j == 3 + (-2j)
True
Python 中的复数文字一定要由两个数字组成吗?它能有更多吗?它们被订购了吗?为了回答这些问题,让我们进行一些实验。不出所料,如果您只指定一个数字,没有字母j,那么您将得到一个常规整数或浮点数:
>>> z = 3.14 >>> type(z) <class 'float'>另一方面,将字母
j附加到数字文字会立即将它变成一个复数:
>>> z = 3.14j
>>> type(z)
<class 'complex'>
严格地说,从数学的角度来看,您刚刚创建了一个纯虚数,但是 Python 不能将其表示为独立的数据类型。因此,没有另一部分,它只是一个复数。
反过来呢?要创建一个没有虚数部分的复数,你可以利用零,像这样加或减它:
>>> z = 3.14 + 0j >>> type(z) <class 'complex'>事实上,复数的两个部分总是存在的。当你看不到 1 时,意味着它的值为零。让我们来看看当你尝试把比以前更多的项填入总和时会发生什么:
>>> 2 + 3j + 4 + 5j
(6+8j)
这一次,您的表达式不再是一个文字,因为 Python 将其计算为一个仅包含两部分的复数。请记住,代数的基本规则适用于复数,所以如果您将相似的术语分组并应用组件式加法,那么您将得到6 + 8j。
注意 Python 默认显示复数的方式。它们的文本表示包含一对括号、一个小写字母j,没有空格。此外,虚部次之。
恰好也是纯虚数的复数没有括号,只显示它们的虚部:
>>> 3 + 0j (3+0j) >>> 0 + 3j 3j这有助于区分虚数和大多数由实部和虚部组成的复数。
complex()工厂功能Python 有一个内置函数
complex(),您可以使用它作为复数文字的替代:
>>> z = complex(3, 2)
在这种形式下,它类似于一个元组或者一对有序的普通数字。这个类比并没有那么牵强。复数在笛卡儿坐标系中有一个几何解释,稍后您将对其进行探究。你可以认为复数是二维的。
有趣的事实:在数学中,复数传统上用字母z表示,因为它是字母表中继x和y之后的下一个字母,通常代表坐标。
复数工厂函数接受两个数值参数。第一个代表实部,而第二个代表虚部在你之前看到的字面上用字母j表示:
>>> complex(3, 2) == 3 + 2j True这两个参数都是可选的,默认值为零,这使得定义没有虚部或实部和虚部的复数变得不那么笨拙:
>>> complex(3) == 3 + 0j
True
>>> complex() == 0 + 0j
True
单参数版本在类型转换中很有用。例如,您可以传递一个非数字值,比如一个字符串文本,以获得一个对应的complex对象。请注意,该字符串不能包含任何空格,尽管:
>>> complex("3+2j") (3+2j) >>> complex("3 + 2j") Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: complex() arg is a malformed string稍后,您将了解如何让您的类与这种类型转换机制兼容。有趣的是,当您将一个复数传递给
complex()时,您将得到相同的实例:
>>> z = complex(3, 2)
>>> z is complex(z)
True
这与 Python 中其他类型的数字的工作方式一致,因为它们都是不可变的。要制作一个复数的不同副本,必须再次调用带有两个参数的函数,或者用复数文本声明另一个变量:
>>> z = complex(3, 2) >>> z is complex(3, 2) False当你给函数提供两个参数时,它们必须总是数字,比如
int、float或complex。否则,您会得到一个运行时错误。从技术上讲,bool是int的子类,所以它也可以工作:
>>> complex(False, True) # Booleans, same as complex(0, 1)
1j
>>> complex(3, 2) # Integers
(3+2j)
>>> complex(3.14, 2.71) # Floating-point numbers
(3.14+2.71j)
>>> complex("3", "2") # Strings
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: complex() can't take second arg if first is a string
当您向complex()工厂函数提供复数作为参数时,事情似乎变得更加奇怪。但是,如果只提供第一个参数,它将像以前一样充当代理:
>>> complex(complex(3, 2)) (3+2j)但是,当存在两个参数并且其中至少有一个是复数时,您将得到乍一看可能难以解释的结果:
>>> complex(1, complex(3, 2))
(-1+3j)
>>> complex(complex(3, 2), 1)
(3+3j)
>>> complex(complex(3, 2), complex(3, 2))
(1+5j)
为了得到答案,让我们看一看工厂函数的 docstring 或在线文档,它们解释了当您调用complex(real, imag)时发生了什么:
返回一个值为实数 + imag *1j 的复数,或者将字符串或数字转换为复数。(来源)
在本说明中,real和imag是函数自变量的名称。第二个参数乘以虚数单位j,结果加到第一个参数上。如果还是没有任何意义也不用担心。当你读到复数算术时,你可以回到这一部分。您将学习的规则将使这变得简单明了。
什么时候你想在字面上使用complex()工厂函数?这要视情况而定,但是例如,当您处理动态生成的数据时,调用该函数可能更方便。
了解 Python 复数
在数学中,复数是实数的超集,也就是说每一个实数也是虚数部分等于零的复数。Python 通过一个叫做数字塔的概念来模拟这种关系,在 PEP 3141 中有描述:
>>> import numbers >>> issubclass(numbers.Real, numbers.Complex) True内置的
numbers模块通过抽象类定义了数字类型的层次结构,这些抽象类可用于类型检查和数字分类。例如,要确定一个值是否属于一组特定的数字,可以对它调用isinstance():
>>> isinstance(3.14, numbers.Complex)
True
>>> isinstance(3.14, numbers.Integral)
False
浮点值3.14是一个实数,恰好也是一个复数,但不是整数。请注意,您不能在这样的测试中直接使用内置类型:
>>> isinstance(3.14, complex) False
complex和numbers.Complex的区别在于,它们属于数值型层次树中单独的分支,后者是一个抽象基类,没有任何实现:
Type hierarchy for numbers in Python 抽象基类,在上图中用红色表示,可以通过将不相关的类注册为它们的虚拟子类来绕过常规的继承检查机制。这就是为什么示例中的浮点值看起来是
numbers.Complex的实例,而不是complex的实例。访问实部和虚部
为了在 Python 中获得复数的实部和虚部,您可以使用相应的
.real和.imag属性:
>>> z = 3 + 2j
>>> z.real
3.0
>>> z.imag
2.0
两个属性都是只读的,因为复数是不可变的,所以试图给它们中的任何一个赋值都会失败:
>>> z.real = 3.14 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: readonly attribute因为 Python 中的每个数字都是一个更具体的复数类型,所以在
numbers.Complex中定义的属性和方法也适用于所有数字类型,包括int和float:
>>> x = 42
>>> x.real
42
>>> x.imag
0
这类数字的虚部总是零。
计算复数的共轭
Python 复数只有三个公共成员。除了.real和.imag属性,它们还公开了.conjugate()方法,该方法翻转虚部的符号:
>>> z = 3 + 2j >>> z.conjugate() (3-2j)对于虚数部分等于零的数字,它不会有任何影响:
>>> x = 3.14
>>> x.conjugate()
3.14
这个操作是它自己的逆操作,所以调用它两次将得到开始时的原始数字:
>>> z.conjugate().conjugate() == z True虽然看起来没什么价值,但复共轭有一些有用的算术属性,可以帮助用笔和纸计算两个复数的除法,以及其他许多东西。
复数算术
由于
complex是 Python 中的原生数据类型,您可以将复数插入到算术表达式中,并调用其中的许多内置函数。更高级的复数函数在cmath模块中定义,它是标准库的一部分。在本教程的后面部分,您将会看到对它的介绍。现在,记住一个规则将让你运用小学的算术知识来计算涉及复数的基本运算。需要记住的规则是虚数单位的定义,它满足以下等式:
把
j想成实数看起来不太对,但是不要慌。如果你暂时忽略它,把每一次出现的j2都用-1代替,就好像它是一个常数一样,那么你就设定好了。让我们看看它是如何工作的。加法
两个或更多复数之和相当于将它们的实部和虚部按分量相加:

>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 + z2
(6+8j)
之前,你发现由实数和虚数组成的代数表达式遵循代数的标准规则。当你用代数的方式写下它时,你将能够应用分配性质并通过分解和分组常见术语来简化公式:

当您添加混合数值类型的值时,Python 会自动将操作数提升为complex数据类型:
>>> z = 2 + 3j >>> z + 7 # Add complex to integer (9+3j)这类似于您可能更熟悉的从
int到float的隐式转换。减法
复数的减法类似于复数的加法,这意味着您也可以按元素应用它:
>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 - z2
(-2-2j)
然而,与求和不同的是,操作数的顺序很重要,并且产生不同的结果,就像实数一样:
>>> z1 + z2 == z2 + z1 True >>> z1 - z2 == z2 - z1 False您也可以使用一元减号运算符(-) 来求复数的负数:
>>> z = 3 + 2j
>>> -z
(-3-2j)
这将反转复数的实部和虚部。
乘法运算
两个或更多复数的乘积变得更加有趣:
>>> z1 = 2 + 3j >>> z2 = 4 + 5j >>> z1 * z2 (-7+22j)你究竟是如何在只有正数的情况下得到负数的呢?要回答这个问题,你必须回忆一下虚部的定义,并用实部和虚部改写这个表达式:
要重点观察的是,
j乘以j得出j2,可以用-1代替。这将反转其中一个被加数的符号,而其余的规则保持不变。分部
初看起来,将复数相除可能有些吓人:
>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 / z2
(0.5609756097560976+0.0487804878048781j)
信不信由你,你只用纸和笔就能得到同样的结果!(好吧,一个计算器可能会让你以后不再头疼。)当两个数都以标准形式表示时,技巧是将分子和分母乘以后者的共轭:
分母变成除数的平方模数。稍后你会学到更多关于复数的模数。当你继续推导这个公式时,你会得到:
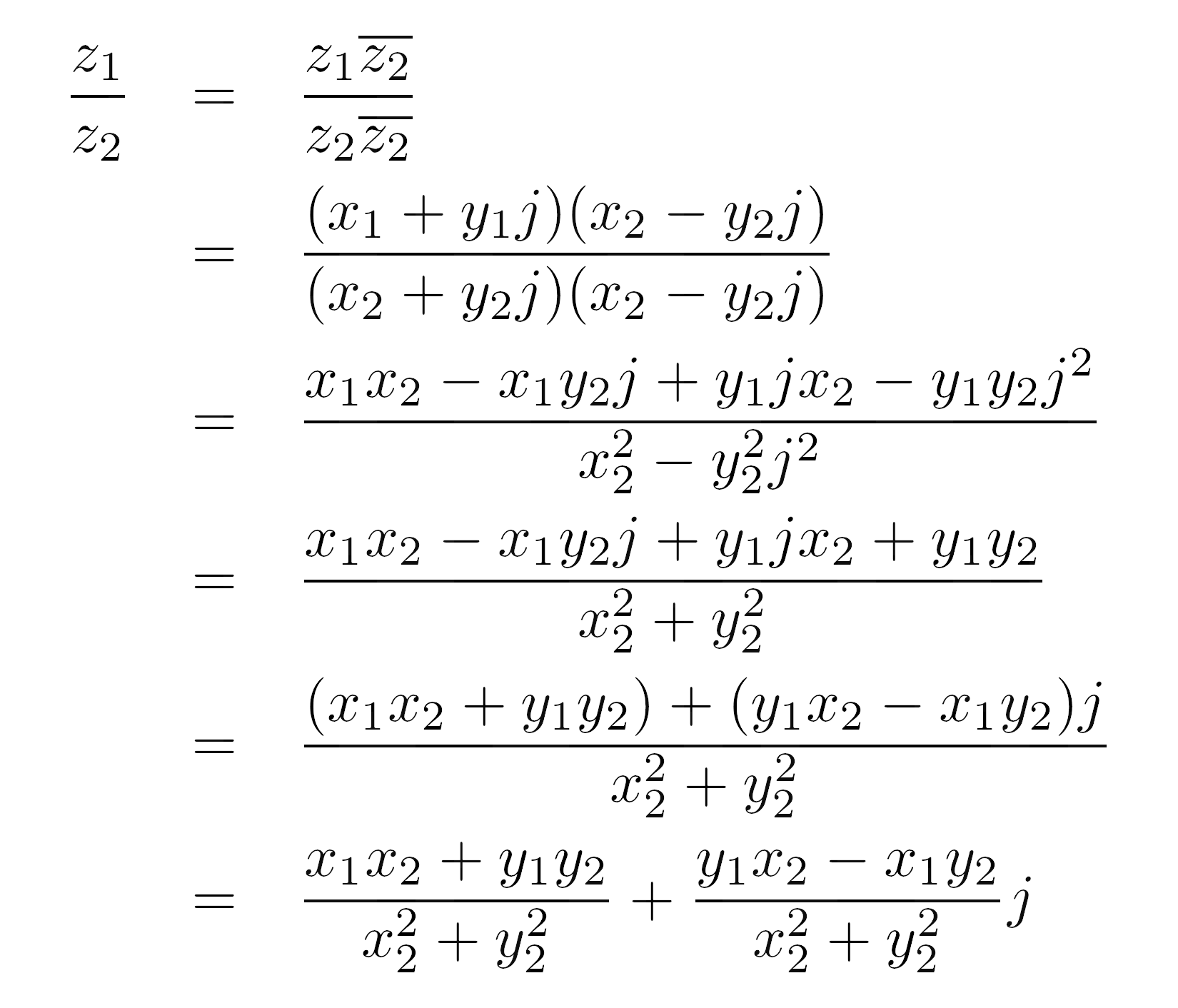
注意,复数不支持底数除法,也称为整数除法:
>>> z1 // z2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't take floor of complex number. >>> z1 // 3.14 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't take floor of complex number.这在 Python 2.x 中曾经有效,但后来为了避免歧义而被删除了。
求幂运算
您可以使用二进制取幂运算符(
**) 或内置的pow()对复数进行幂运算,但不能使用在math模块中定义的运算符,后者仅支持浮点值:
>>> z = 3 + 2j
>>> z**2
(5+12j)
>>> pow(z, 2)
(5+12j)
>>> import math
>>> math.pow(z, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert complex to float
底数和指数可以是任何数字类型,包括整数、浮点、虚数或复数:
>>> 2**z (1.4676557979464138+7.86422192328995j) >>> z**2 (5+12j) >>> z**0.5 (1.8173540210239707+0.5502505227003375j) >>> z**3j (-0.13041489185767086-0.11115341486478239j) >>> z**z (-5.409738793917679-13.410442370412747j)当复数以标准形式表示时,手动求幂变得非常困难。将三角形式中的数字重写,用一些基本的三角学计算幂就方便多了。如果你对所涉及的数学感兴趣,看看德莫维尔的公式,它能让你做到这一点。
使用 Python 复数作为 2D 向量
你可以把复数想象成笛卡尔或 T4 直角坐标系统中欧几里得平面上的点 T1 或 T2 向量 T3:
复平面上的 X 轴,也称为高斯平面或阿甘图,代表一个复数的实部,而 Y 轴代表其虚部。
这个事实导致了 Python 中
complex数据类型最酷的特性之一,它免费实现了二维向量的基本实现。虽然不是所有的运算在两者中都以相同的方式工作,但是向量和复数有许多相似之处。获取坐标
百慕大三角是一个以超自然现象闻名的传奇地区,横跨佛罗里达南端、波多黎各和百慕大小岛。其顶点大致由三个主要城市指定,其地理坐标如下:
- 迈阿密:北纬 25° 45 ' 42.054 英寸,西经 80° 11 ' 30.438 英寸
- 圣胡安:北纬 18° 27 ' 58.8 英寸,西经 66° 6 ' 20.598 英寸
- 汉密尔顿:北纬 32° 17 ' 41.64 ",西经 64° 46 ' 58.908 "
将这些坐标转换成十进制度数后,每个城市将有两个浮点数。您可以使用
complex数据类型来存储有序的数字对。由于纬度是纵坐标,而经度是横坐标,因此按照笛卡尔坐标的传统顺序将它们互换可能会更方便:miami_fl = complex(-80.191788, 25.761681) san_juan = complex(-66.105721, 18.466333) hamilton = complex(-64.78303, 32.2949)负经度值代表西半球,而正纬度值代表北半球。
记住这些是球坐标。为了正确地将它们投影到一个平面上,你需要考虑地球的曲率。地图学中最早使用的地图投影之一是墨卡托投影,它帮助水手们为他们的船只导航。但是让我们忽略所有这些,假设值已经在直角坐标系中表示了。
当你在一个复平面上绘制这些数字时,你会得到百慕大三角的粗略描绘:
在配套资料中,你会发现一个交互式的 Jupyter 笔记本,它使用 Matplotlib 库绘制了百慕大三角。要下载本教程的源代码和材料,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的复数。
如果你不喜欢调用
complex()工厂函数,你可以用一个更合适的名字创建一个类型的别名,或者使用复数的字面形式来节省一些击键次数:CityCoordinates = complex miami_fl = CityCoordinates(-80.191788, 25.761681) miami_fl = -80.191788 + 25.761681j如果您需要在一个城市上打包更多的属性,您可以使用一个名为 tuple 的或者一个数据类或者创建一个自定义类。
计算震级
一个复数的大小,也称为模数或半径,是在一个复平面上描述它的向量的长度:
你可以从勾股定理通过取实部平方和虚部平方之和的平方根来计算:
你可能会认为 Python 会让你用内置的
len()来计算这样一个向量的长度,但事实并非如此。要得到一个复数的大小,你必须调用另一个名为abs()的全局函数,它通常用于计算一个数的绝对值:



>>> len(3 + 2j)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: object of type 'complex' has no len()
>>> abs(3 + 2j)
3.605551275463989
这个函数从您传入的整数中删除符号,但是对于复数,它返回幅度或向量长度:
>>> abs(-42) 42 >>> z = 3 + 2j >>> abs(z) 3.605551275463989 >>> from math import sqrt >>> sqrt(z.real**2 + z.imag**2) 3.605551275463989您可能记得在前面的章节中,一个复数乘以它的共轭会产生它的大小的平方。
求两点间的距离
让我们找到百慕大三角的几何中心和形成其边界的三个城市到它的距离。首先,您需要将所有坐标相加,然后将结果除以它们的数量,得到平均值:
geometric_center = sum([miami_fl, san_juan, hamilton]) / 3这会给你一个位于大西洋的点,在三角形内的某个地方:
现在,您可以创建锚定在城市中并指向三角形几何中心的向量。向量是通过从目标点减去源点得到的:
v1 = geometric_center - miami_fl v2 = geometric_center - san_juan v3 = geometric_center - hamilton因为减去复数,所以每个向量也是由两部分组成的复数。要获得距离,请计算每个矢量的大小:
>>> abs(v1)
9.83488994681275
>>> abs(v2)
8.226809506084367
>>> abs(v3)
8.784732429678444
这些向量长度并不能反映有意义的距离,但对于这样的玩具示例来说是很好的近似值。为了用有形的单位表示精确的结果,你必须首先将坐标从球形转换成矩形,或者使用大圆方法来计算距离。
平移、翻转、缩放和旋转
三角形出现在笛卡尔坐标系的第二个象限可能会困扰你。让我们移动它,使它的几何中心与原点对齐。所有三个顶点将被平移由几何中心指示的矢量长度,但方向相反:
triangle = miami_fl, san_juan, hamilton
offset = -geometric_center
centered_triangle = [vertex + offset for vertex in triangle]
请注意,您将两个复数加在一起,这将执行它们的元素相加。这是一个仿射变换,因为它不会改变三角形的形状或其顶点的相对位置:

围绕实轴或虚轴的三角形的镜像需要反转其顶点中的相应分量。例如,要将水平翻转,您必须使用实数部分的负数,这对应于水平方向。要垂直翻转它,你要取虚部的负值:
flipped_horizontally = [complex(-v.real, v.imag) for v in centered_triangle]
flipped_vertically = [complex(v.real, -v.imag) for v in centered_triangle]
后者本质上与计算复数共轭是一样的,所以你可以在每个顶点上直接调用.conjugate()来为你做这项艰苦的工作:
flipped_vertically = [v.conjugate() for v in centered_triangle]
自然,没有什么可以阻止你在任一方向上或同时在两个方向上应用对称性。在这种情况下,您可以在复数前面使用一元减号运算符来翻转其实部和虚部:
flipped_in_both_directions = [-v for v in centered_triangle]
继续使用可下载资料中的交互式 Jupyter 笔记本摆弄不同的翻盖组合。以下是沿两个轴翻转三角形时的样子:

缩放类似于平移,但不是添加偏移,而是将每个顶点乘以一个常数因子,该常数因子必须是一个实数:
scaled_triangle = [1.5*vertex for vertex in centered_triangle]
这样做的结果是每个复数的两个分量都乘以相同的量。它应该拉伸百慕大三角,使它在图上看起来更大:

另一方面,将三角形的顶点乘以另一个复数,会产生围绕坐标系原点旋转的效果。这与通常的向量相乘有很大的不同。例如,两个向量的点积将产生一个标量,而它们的叉积将返回三维空间中的一个新向量,该向量垂直于它们定义的表面。
注意:两个复数的乘积不代表向量乘法。而是定义为二维向量空间中的矩阵乘法,以 1 和j为标准基。将(x1+y1j)乘以(x2+y2j)对应如下矩阵乘法:

这是左边的旋转矩阵,这使得数学计算很好。
当你把顶点乘以虚数单位时,它会把三角形逆时针旋转 90 度。如果你不断重复,你最终会到达你开始的地方:

如何找到一个特定的复数,当两个复数相乘时,它可以将另一个复数旋转任意角度?首先,看一下下表,它总结了连续旋转 90°的情况:
| 90 度旋转 | 总角度 | 公式 | 指数 | 价值 |
|---|---|---|---|---|
| Zero | 0° | z | j 0 |
one |
| one | 90° | z × j |
j 1 |
j |
| Two | 180° | z × j × j |
j 2 |
-1 |
| three | 270° | z × j × j × j |
j 3 |
- j |
| four | 360° | z × j × j × j × j |
j 4 |
one |
| five | 450° | z×j×j×j×j×j |
j 5 |
j |
| six | 540° | z×j×j×j×j×j×j |
j 6 |
-1 |
| seven | 630° | z×j×j×j×j×j×j×j |
j 7 |
- j |
| eight | 720° | z×j×j×j×j×j×j×j×j |
j 8 |
one |
当你用正整数指数来表示与j的重复乘法时,就会出现一种模式。请注意虚数单位的后续幂如何使其重复循环相同的值。你可以将此推断到分数指数上,并期望它们对应于中间角度。
例如,第一次旋转中途的指数等于 0.5,代表 45 度角:
因此,如果您知道 1 的幂代表直角,并且两者之间的任何值都按比例缩放,那么您就可以推导出任意旋转的通用公式:
def rotate(z: complex, degrees: float) -> complex:
return z * 1j**(degrees/90)
请注意,当您在极坐标中表示复数时,旋转变得更加自然,极坐标已经描述了角度。然后,您可以利用指数形式使计算更加简单明了:
使用极坐标旋转数字有两种方法:
import math, cmath
def rotate1(z: complex, degrees: float) -> complex:
radius, angle = cmath.polar(z)
return cmath.rect(radius, angle + math.radians(degrees))
def rotate2(z: complex, degrees: float) -> complex:
return z * cmath.rect(1, math.radians(degrees))
你可以对角度求和,或者将你的复数乘以一个单位向量。
在下一节中,您将了解到更多关于这些内容的信息。
探索复数的数学模块:cmath
您已经看到了一些内置函数,如abs()和pow()接受复数,而其他的则不接受。例如,你不能round()一个复数,因为这样的运算没有意义:
>>> round(3 + 2j) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: type complex doesn't define __round__ method许多高级数学函数,如三角函数、双曲线函数或对数函数都可以在标准库中找到。可悲的是,即使你对 Python
math模块了如指掌,也无济于事,因为它的函数都不支持复数。您需要将它与cmath模块结合起来,后者为复数定义了相应的函数。
cmath模块重新定义了来自math的所有浮点常量,因此它们唾手可得,无需导入这两个模块:
>>> import math, cmath
>>> for name in "e", "pi", "tau", "nan", "inf":
... print(name, getattr(math, name) == getattr(cmath, name))
...
e True
pi True
tau True
nan False
inf True
注意nan是一个特殊值,它永远不等于任何其他值,包括它本身!这就是为什么你在上面的输出中看到了一个孤独的False。除此之外,cmath还为 NaN (非数字)和 infinity 提供了两个复数对应物,两者的实部都为零:
>>> from cmath import nanj, infj >>> nanj.real, nanj.imag (0.0, nan) >>> infj.real, infj.imag (0.0, inf)
cmath中的功能大约是标准math模块的一半。它们中的大部分模仿了最初的行为,但也有一些是复数所特有的。它们将允许您在两个坐标系之间进行转换,这将在本节中探讨。提取复数的根
代数的基本定理说明一个复系数的次数 n 多项式恰好有 n 复数根。如果你仔细想想,那是相当重要的,所以让它沉淀一会儿。
现在,我们以二次函数 x 2 + 1 为例。从视觉上看,这条抛物线不与 X 轴相交,因为它位于原点上方一个单位处。该函数的判别式为负,这从算术上证实了这一观察结果。同时,它是一个二次多项式,所以它必须有两个复数根,尽管它没有任何实数根!
为了找到这些根,你可以将函数重写为一个二次方程,然后将常数移到右边,取两边的平方根:
在实数域中,平方根仅针对非负输入值定义。因此,在 Python 中调用这个函数将引发一个异常,并显示相应的错误消息:
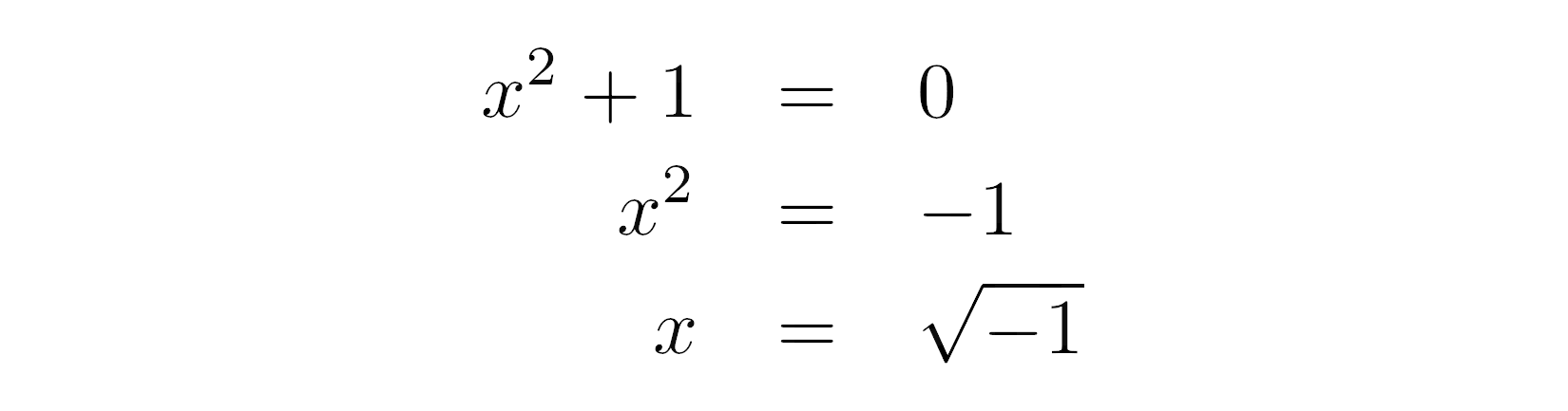
>>> import math
>>> math.sqrt(-1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: math domain error
然而,当您将√-1 视为复数并从cmath模块调用相关函数时,您将获得更有意义的结果:
>>> import cmath >>> cmath.sqrt(-1) 1j有道理。毕竟,二次方程的中间形式 x 2 = -1 正是虚数单位的定义。但是,等一下。另一个复杂的根去了哪里?高次多项式的复根怎么办?
比如一个四次多项式 x 4 + 1,可以写成方程 x 4 = -1,有这四个复数根:
- z0= 2/2+2/2
j- z1= 2/2-√2/2
j- z2=【T2/2+2/2
j- z=【T2/2】-【T2/2】
j将每个根提升到四次幂会得到一个等于-1 + 0
j的复数或一个实数-1:
>>> import cmath
>>> z0 = -cmath.sqrt(2)/2 + cmath.sqrt(2)/2*1j
>>> z0**4
(-1.0000000000000004-0j)
>>> (z0**4).real
-1.0000000000000004
您会注意到,由于浮点运算中的舍入误差,结果值并不完全是-1。为了说明这一点,只要需要判断两个复数的值是否接近,就可以调用cmath.isclose():
>>> cmath.isclose(z0**4, -1) True不幸的是,您不能用纯 Python 计算其他复杂的根,因为正则求幂总是给出一个解:
>>> pow(-1, 1/4)
(0.7071067811865476+0.7071067811865475j)
这只是之前列出的词根之一。寻找所有复数根的数学公式利用了复数的三角形式:

r 和 φ 是复数的极坐标,而 n 是多项式的次数, k 是根的索引,从零开始。好消息是你不需要自己费力地计算这些根。找到它们最快的方法是通过安装一个第三方库,比如 NumPy 和将导入到您的项目中:
>>> import numpy as np >>> np.roots([1, 0, 0, 0, 1]) # Coefficients of the polynomial x**4 + 1 array([-0.70710678+0.70710678j, -0.70710678-0.70710678j, 0.70710678+0.70710678j, 0.70710678-0.70710678j])了解各种复数形式及其坐标系会很有用。如你所见,它有助于解决实际问题,如寻找复杂的根。因此,在下一节中,您将深入研究更多的细节。
在直角坐标和极坐标之间转换
几何上,你可以把一个复数看两遍。一方面,它是一个点,它离原点的水平和垂直距离唯一地标识了它的位置。这些被称为包含实部和虚部的直角坐标。
另一方面,你可以在极坐标中描述同一点,这也让你用两个距离明确地找到它:
- 径向距离是从原点测量的半径长度。
- 角距离是水平轴和半径之间测得的角度。
半径,也被称为模数,对应于复数的幅度,或者矢量的长度。该角度通常被称为复数的相位或幅角。使用三角函数时,用弧度而不是度数来表示角度很有用。
以下是对两个坐标系中的复数的描述:
因此,笛卡尔坐标系中的点(3,2)具有大约 3.6 的半径和大约 33.7 的角度,或者大约π超过 5.4 弧度。
两个坐标系之间的转换可以通过
cmath模块中的几个函数来实现。具体来说,要获得一个复数的极坐标,必须将其传递给cmath.polar():

>>> import cmath
>>> cmath.polar(3 + 2j)
(3.605551275463989, 0.5880026035475675)
它将返回一个元组,其中第一个元素是半径,第二个元素是以弧度表示的角度。注意,半径的值与星等相同,可以通过在复数上调用abs()来计算。相反,如果您只对获取一个复数的角度感兴趣,那么您可以调用cmath.phase():
>>> z = 3 + 2j >>> abs(z) # Magnitude is also the radial distance 3.605551275463989 >>> import cmath >>> cmath.phase(3 + 2j) 0.5880026035475675 >>> cmath.polar(z) == (abs(z), cmath.phase(z)) True由于实部、虚部和幅度一起形成了一个直角三角形,因此可以使用基本的三角学获得角度:
您可以从
math或cmath使用反三角函数,如反正弦,但后者会产生虚部等于零的复数值:

>>> z = 3 + 2j
>>> import math
>>> math.acos(z.real / abs(z))
0.5880026035475675
>>> math.asin(z.imag / abs(z))
0.5880026035475676
>>> math.atan(z.imag / z.real) # Prefer math.atan2(z.imag, z.real)
0.5880026035475675
>>> import cmath
>>> cmath.acos(z.real / abs(z))
(0.5880026035475675-0j)
不过,在使用反正切函数时,有一个小细节需要小心,这导致许多编程语言开发了一个名为 atan2() 的替代实现。计算虚部和实部之间的比率有时会由于例如被零除而产生奇点。此外,在此过程中,两个值的单个符号会丢失,从而无法确定地判断角度:
>>> import math >>> math.atan(1 / 0) Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zero >>> math.atan2(1, 0) 1.5707963267948966 >>> math.atan(1 / 1) == math.atan(-1 / -1) True >>> math.atan2(1, 1) == math.atan2(-1, -1) False注意
atan()是如何无法识别位于坐标系相对象限的两个不同点的。另一方面,atan2()期望两个参数而不是一个参数来保留各个符号,然后再将它们分开,这样也避免了其他问题。要获得角度而不是弧度,您可以再次使用
math模块进行必要的转换:
>>> import math
>>> math.degrees(0.5880026035475675) # Radians to degrees
33.690067525979785
>>> math.radians(180) # Degrees to radians
3.141592653589793
反转该过程(即将极坐标转换为直角坐标)依赖于另一个函数。然而,你不能只传递从cmath.polar()得到的相同的元组,因为cmath.rect()需要两个独立的参数:
>>> cmath.rect(cmath.polar(3 + 2j)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: rect expected 2 arguments, got 1在进行赋值时,最好先解包元组,并给这些元素起一个更具描述性的名字。现在您可以正确地调用
cmath.rect():
>>> radius, angle = cmath.polar(3 + 2j)
>>> cmath.rect(radius, angle)
(3+1.9999999999999996j)
在 Python 进行计算的过程中,您可能会遇到舍入误差。在幕后,它调用三角函数来检索实部和虚部:
>>> import math >>> radius*(math.cos(angle) + math.sin(angle)*1j) (3+1.9999999999999996j) >>> import cmath >>> radius*(cmath.cos(angle) + cmath.sin(angle)*1j) (3+1.9999999999999996j)同样,在这种情况下使用
math还是cmath并不重要,因为结果是一样的。以不同方式表示复数
不管坐标系如何,您都可以用几种数学上等价的形式来表示同一个复数:
- 代数(标准)
- 几何学的
- 三角法的
- 指数的
这个列表并不详尽,因为还有更多表示法,比如复数的矩阵表示法。
拥有选择权可以让你选择最方便的方法来解决给定的问题。例如,在下一节中,您将需要指数形式来计算离散傅立叶变换。使用这种形式也适用于复数的乘除运算。
以下是单个复数形式及其坐标的简要概述:
形式 矩形的 极地的 代数的 z=x+y j- 几何学的 z = ( x , y ) z = ( r ,φ) 三角法的 z= |z|(cos(x/|z|)+ jsin(y/|z|))z=r(cos(φ)+ jsin(φ))指数的 z= |z| e atan2(y/x)jT6】z=r(eT0】φ 当您使用文字指定复数时,代数形式是 Python 固有的。您也可以将它们视为笛卡尔或极坐标系统中欧几里得平面上的点。虽然 Python 中没有三角或指数形式的单独表示,但您可以验证数学原理是否成立。
例如,将欧拉公式代入三角形式,就会变成指数形式。你可以调用
cmath模块的exp()或者提升e常数的幂来得到相同的结果:
>>> import cmath
>>> algebraic = 3 + 2j
>>> geometric = complex(3, 2)
>>> radius, angle = cmath.polar(algebraic)
>>> trigonometric = radius * (cmath.cos(angle) + 1j*cmath.sin(angle))
>>> exponential = radius * cmath.exp(1j*angle)
>>> for number in algebraic, geometric, trigonometric, exponential:
... print(format(number, "g"))
...
3+2j
3+2j
3+2j
3+2j
所有的形式实际上都是同一数字的不同编码方式。但是不能直接比较,因为其间可能会出现舍入误差。使用cmath.isclose()进行安全比较,或者适当地使用 format()作为字符串。在下一节中,您将了解如何格式化这样的字符串。
解释为什么不同形式的复数是等价的需要微积分,远远超出了本教程的范围。然而,如果你对数学感兴趣,那么你会发现由复数表现出来的不同数学领域之间的联系非常迷人。
在 Python 中剖析复数
您已经学习了很多关于 Python 复数的知识,并且已经看到了初步的例子。然而,在进一步讨论之前,有必要讨论一些最终的主题。在这一节中,您将研究比较复数、格式化包含复数的字符串等等。
测试复数的相等性
在数学上,当两个复数具有相同的值时,不管所采用的坐标系如何,它们都等于。然而,极坐标和直角坐标之间的转换通常会在 Python 中引入舍入误差,因此在比较它们时需要注意细微的差异。
例如,当您考虑半径等于 1 且倾斜 60°的单位圆上的一个点时,三角学很好地解决了这个问题,使得用笔和纸进行转换很简单:
>>> import math, cmath >>> z1 = cmath.rect(1, math.radians(60)) >>> z2 = complex(0.5, math.sqrt(3)/2) >>> z1 == z2 False >>> z1.real, z2.real (0.5000000000000001, 0.5) >>> z1.imag, z2.imag (0.8660254037844386, 0.8660254037844386)即使你知道
z1和z2是同一点,Python 也无法确定,因为存在舍入误差。幸运的是, PEP 485 文档定义了近似相等的函数,这些函数在math和cmath模块中可用:
>>> math.isclose(z1.real, z2.real)
True
>>> cmath.isclose(z1, z2)
True
记住在比较复数时一定要使用它们!如果默认容差对您的计算不够好,您可以通过指定附加参数来更改它。
复数排序
如果你熟悉元组,那么你知道 Python 可以对它们进行排序:
>>> planets = [ ... (6, "saturn"), ... (4, "mars"), ... (1, "mercury"), ... (5, "jupiter"), ... (8, "neptune"), ... (3, "earth"), ... (7, "uranus"), ... (2, "venus"), ... ] >>> from pprint import pprint >>> pprint(sorted(planets)) [(1, 'mercury'), (2, 'venus'), (3, 'earth'), (4, 'mars'), (5, 'jupiter'), (6, 'saturn'), (7, 'uranus'), (8, 'neptune')]默认情况下,单个元组从左到右进行比较:
>>> (6, "saturn") < (4, "mars")
False
>>> (3, "earth") < (3, "moon")
True
在第一种情况下,数字6大于4,所以根本不考虑行星名称。不过,它们可以帮助解决平局。然而,复数就不是这样了,因为它们没有定义自然的排序关系。例如,如果您试图比较两个复数,就会得到一个错误:
>>> (3 + 2j) < (2 + 3j) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'complex' and 'complex'虚维度是否应该比实维度更有分量?是否应该比较它们的大小?这取决于你,答案会有所不同。由于不能直接比较复数,所以需要通过指定一个自定义的键函数,比如
abs(),告诉 Python 如何排序:
>>> cities = {
... complex(-64.78303, 32.2949): "Hamilton",
... complex(-66.105721, 18.466333): "San Juan",
... complex(-80.191788, 25.761681): "Miami"
... }
>>> for city in sorted(cities, key=abs, reverse=True):
... print(abs(city), cities[city])
...
84.22818453809096 Miami
72.38647347392259 Hamilton
68.63651945864338 San Juan
这将把复数按大小降序排列。
将复数格式化为字符串
没有任何特定于复数的格式代码,但是您可以使用浮点数的标准代码分别格式化它们的实部和虚部。下面,你会发现一些技术来证明这一点。他们中的一些人实际上将你的格式说明符同时应用到实部和虚部。
注意:字符串格式化可以让你忽略浮点表示错误,假装它不存在:
>>> import cmath >>> z = abs(3 + 2j) * cmath.exp(1j*cmath.phase(3 + 2j)) >>> str(z) '(3+1.9999999999999996j)' >>> format(z, "g") '3+2j'格式说明符中的字母
"g"代表通用格式,它将您的数字四舍五入到要求的精度。默认精度为六位有效数字。让我们以下面的复数为例,将其格式化为两部分都有两位小数:
>>> z = pow(3 + 2j, 0.5)
>>> print(z)
(1.8173540210239707+0.5502505227003375j)
一种快速的方法是用数字格式说明符调用format(),或者创建一个适当格式化的 f 字符串:
>>> format(z, ".2f") '1.82+0.55j' >>> f"{z:.2f}" '1.82+0.55j'如果您想要更多的控制,例如,在加号运算符周围添加额外的填充,那么 f 字符串将是更好的选择:
>>> f"{z.real:.2f} + {z.imag:.2f}j"
'1.82 + 0.55j'
你也可以在一个字符串对象上调用 .format(),并将位置或关键字参数传递给它:
>>> "{0:.2f} + {0:.2f}j".format(z.real, z.imag) '1.82 + 1.82j' >>> "{re:.2f} + {im:.2f}j".format(re=z.real, im=z.imag) '1.82 + 0.55j'位置参数提供了一系列值,而关键字参数允许您通过名称引用它们。类似地,可以将字符串模操作符 (
%)与元组或字典一起使用:
>>> "%.2f + %.2fj" % (z.real, z.imag)
'1.82 + 0.55j'
>>> "%(re).2f + %(im).2fj" % {"re": z.real, "im": z.imag}
'1.82 + 0.55j'
但是,这使用了不同的占位符语法,有点过时。
创建自己的复杂数据类型
Python 数据模型定义了一组特殊的方法,您可以实现这些方法来使您的类与某些内置类型兼容。假设你正在处理点和向量,并且想要得到两个约束向量之间的角度。你可能会计算它们的点积,并做一些三角学。或者,你可以利用复数。
让我们首先定义您的类:
from typing import NamedTuple
class Point(NamedTuple):
x: float
y: float
class Vector(NamedTuple):
start: Point
end: Point
一个Point具有x和y坐标,而一个Vector连接两个点。你可能记得cmath.phase(),它计算一个复数的角距离。现在,如果你将矢量视为复数,并知道它们的相位,那么你可以减去它们,以获得所需的角度。
要让 Python 将向量实例识别为复数,必须在类体中提供.__complex__():
class Vector(NamedTuple):
start: Point
end: Point
def __complex__(self):
real = self.end.x - self.start.x
imag = self.end.y - self.start.y
return complex(real, imag)
里面的代码必须总是返回一个complex数据类型的实例,所以它通常从你的对象中构造一个新的复数。在这里,你减去初始点和终点,得到水平和垂直位移,作为实部和虚部。当您在 vector 实例上调用全局complex()时,该方法将通过委托运行:
>>> vector = Vector(Point(-2, -1), Point(1, 1)) >>> complex(vector) (3+2j)在某些情况下,您不必自己制作这种类型的铸件。让我们看一个实践中的例子:
>>> v1 = Vector(Point(-2, -1), Point(1, 1))
>>> v2 = Vector(Point(10, -4), Point(8, -1))
>>> import math, cmath
>>> math.degrees(cmath.phase(v2) - cmath.phase(v1))
90.0
你有两个向量,由四个不同的点标识。接下来,您将它们直接传递给cmath.phase(),它会将它们转换成复数并返回相位。相位差是两个向量之间的角度。
那不是很美吗?通过使用复数和一点 Python 技巧,您避免了键入大量容易出错的代码。
用复数计算离散傅立叶变换
虽然您可以使用实数通过傅立叶变换来计算周期函数频率的正弦和余弦系数,但通常更方便的是每个频率只处理一个复系数。复域中的离散傅立叶变换由以下公式给出:

对于每个频率仓 k ,它测量信号和以指数形式表示为复数的特定正弦波的相关性。(谢谢你,莱昂哈德·欧拉!)波的角频率可以通过将圆角(2π弧度)乘以离散样本数的 k 来计算:
当您利用complex数据类型时,用 Python 编写这些代码看起来非常简洁:
from cmath import pi, exp
def discrete_fourier_transform(x, k):
omega = 2 * pi * k / (N := len(x))
return sum(x[n] * exp(-1j * omega * n) for n in range(N))
这个函数是上面公式的文字转录。现在,您可以对使用 Python 的wave模块从音频文件加载的声音或从头合成的声音进行频率分析。本教程附带的一个 Jupyter 笔记本可以让您交互式地进行音频合成和分析。
要用 Matplotlib 绘制频谱,你必须知道采样频率,它决定了你的频率仓分辨率以及奈奎斯特极限:
import matplotlib.pyplot as plt
def plot_frequency_spectrum(
samples,
samples_per_second,
min_frequency=0,
max_frequency=None,
):
num_bins = len(samples) // 2
nyquist_frequency = samples_per_second // 2
magnitudes = []
for k in range(num_bins):
magnitudes.append(abs(discrete_fourier_transform(samples, k)))
# Normalize magnitudes
magnitudes = [m / max(magnitudes) for m in magnitudes]
# Calculate frequency bins
bin_resolution = samples_per_second / len(samples)
frequency_bins = [k * bin_resolution for k in range(num_bins)]
plt.xlim(min_frequency, max_frequency or nyquist_frequency)
plt.bar(frequency_bins, magnitudes, width=bin_resolution)
频谱中频段的数量等于样本的一半,而奈奎斯特频率限制了您可以测量的最高频率。该变换返回一个复数,其幅度对应于给定频率的正弦波的振幅,而其角度是相位。
注意:要获得正确的振幅值,必须将数值加倍,并将结果振幅除以样本数。另一方面,如果您只关心频率直方图,那么您可以通过它们的总和或最大频率来归一化幅度。
这是一个声波频率图示例,它包含三个振幅相等的音调,即 440 Hz、1.5 kHz 和 5 kHz:
请注意,这是一个纯粹的学术示例,因为使用嵌套迭代计算离散傅立叶变换具有O(n2)的时间复杂度,这使得它在实践中无法使用。对于实际应用,您希望使用最好在 C 库中实现的快速傅立叶变换(FFT) 算法,例如 SciPy 中的 FFT。
结论
在 Python 中使用复数的便利性使它们成为一个非常有趣和实用的工具。你看到了实际上免费实现的二维向量,多亏了它们,你才能够分析声音频率。复数让你可以优雅地用代码表达数学公式,而没有太多样板语法的阻碍。
在本教程中,您学习了如何:
- 用 Python 中的文字定义复数
- 在直角和极坐标中表示复数
- 在算术表达式中使用复数
- 利用内置的
cmath模块 - 将数学公式直接翻译成 Python 代码
到目前为止,你对 Python 复数有什么体验?你被他们吓倒过吗?你认为他们还会让你解决什么有趣的问题?
您可以单击下面的链接来获得本教程的完整源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的复数。**********
通过并发加速您的 Python 程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用并发加速 Python
如果你听说过很多关于将asyncio 添加到 Python 的讨论,但是很好奇它与其他并发方法相比如何,或者想知道什么是并发以及它如何加速你的程序,那么你来对地方了。
在这篇文章中,你将学到以下内容:
- 什么是并发
- 什么是平行度
- 如何比较一些 Python 的并发方法,包括
threading、asyncio、multiprocessing - 什么时候在你的程序中使用并发以及使用哪个模块
本文假设您对 Python 有基本的了解,并且至少使用 3.6 版本来运行这些示例。你可以从 真实 Python GitHub repo 下载例子。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
参加测验:通过我们的交互式“Python 并发性”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
什么是并发?
并发的字典定义是同时发生。在 Python 中,同时发生的事情有不同的名称(线程、任务、进程),但在高层次上,它们都指的是按顺序运行的指令序列。
我喜欢把它们看作不同的思路。每一个都可以在特定的点停止,处理它们的 CPU 或大脑可以切换到不同的点。每一个的状态都被保存,这样它就可以在被中断的地方重新启动。
您可能想知道为什么 Python 对同一个概念使用不同的词。原来线程、任务、进程只有从高层次来看才是一样的。一旦你开始挖掘细节,它们都代表着略有不同的东西。随着示例的深入,您将会看到更多的不同之处。
现在我们来谈谈这个定义的同时部分。你必须小心一点,因为当你深入到细节时,只有multiprocessing实际上同时运行这些思路。 Threading 和asyncio都运行在一个处理器上,因此一次只运行一个。他们只是巧妙地想办法轮流加速整个过程。即使它们不同时运行不同的思路,我们仍然称之为并发。
线程或任务轮流的方式是threading和asyncio的最大区别。在threading中,操作系统实际上知道每个线程,并可以随时中断它,开始运行不同的线程。这被称为抢先多任务,因为操作系统可以抢先你的线程进行切换。
抢先式多任务处理非常方便,因为线程中的代码不需要做任何事情来进行切换。因为“在任何时候”这个短语,它也可能是困难的。这种切换可能发生在一条 Python 语句的中间,甚至是像x = x + 1这样微不足道的语句。
另一方面,Asyncio使用协同多任务。当任务准备好被切换时,它们必须通过宣布来协作。这意味着任务中的代码必须稍加修改才能实现这一点。
预先做这些额外工作的好处是你总是知道你的任务将在哪里被交换。它不会在 Python 语句中间被换出,除非该语句被标记。稍后您将看到这是如何简化设计的。
什么是并行?
到目前为止,您已经看到了发生在单个处理器上的并发性。你的酷炫新笔记本电脑拥有的所有 CPU 内核呢?你如何利用它们?multiprocessing就是答案。
使用multiprocessing,Python 创建了新的流程。这里的进程可以被认为是一个几乎完全不同的程序,尽管从技术上来说,它们通常被定义为资源的集合,其中的资源包括内存、文件句柄等等。一种思考方式是,每个进程都在自己的 Python 解释器中运行。
因为它们是不同的进程,所以你在多处理程序中的每一个思路都可以在不同的内核上运行。在不同的内核上运行意味着它们实际上可以同时运行,这太棒了。这样做会产生一些复杂的问题,但是 Python 在大多数情况下做得很好。
现在,您已经了解了什么是并发和并行,让我们回顾一下它们的区别,然后我们可以看看它们为什么有用:
| 并发类型 | 转换决策 | 处理器数量 |
|---|---|---|
抢先多任务(threading) |
操作系统决定何时切换 Python 外部的任务。 | one |
协作多任务(asyncio) |
任务决定何时放弃控制权。 | one |
多重处理(multiprocessing) |
这些进程同时在不同的处理器上运行。 | 许多 |
这些并发类型中的每一种都很有用。让我们来看看它们能帮助你加速哪些类型的程序。
并发什么时候有用?
并发性对于两种类型的问题有很大的不同。这些通常被称为 CPU 绑定和 I/O 绑定。
I/O 相关的问题会导致你的程序变慢,因为它经常需要等待来自外部资源的输入/输出。当你的程序处理比你的 CPU 慢得多的东西时,它们经常出现。
比你的 CPU 慢的例子举不胜举,但是谢天谢地你的程序没有和它们中的大部分进行交互。你的程序最常与之交互的是文件系统和网络连接。
让我们看看这是什么样子:
在上图中,蓝框表示程序工作的时间,红框表示等待 I/O 操作完成的时间。这个图不是按比例绘制的,因为互联网上的请求可能比 CPU 指令多花几个数量级的时间,所以你的程序可能会花费大部分时间等待。这是你的浏览器大部分时间在做的事情。
另一方面,有些程序可以在不与网络通信或不访问文件的情况下进行大量计算。这些是 CPU 受限的程序,因为限制程序速度的资源是 CPU,而不是网络或文件系统。
下面是一个 CPU 受限程序的相应图表:
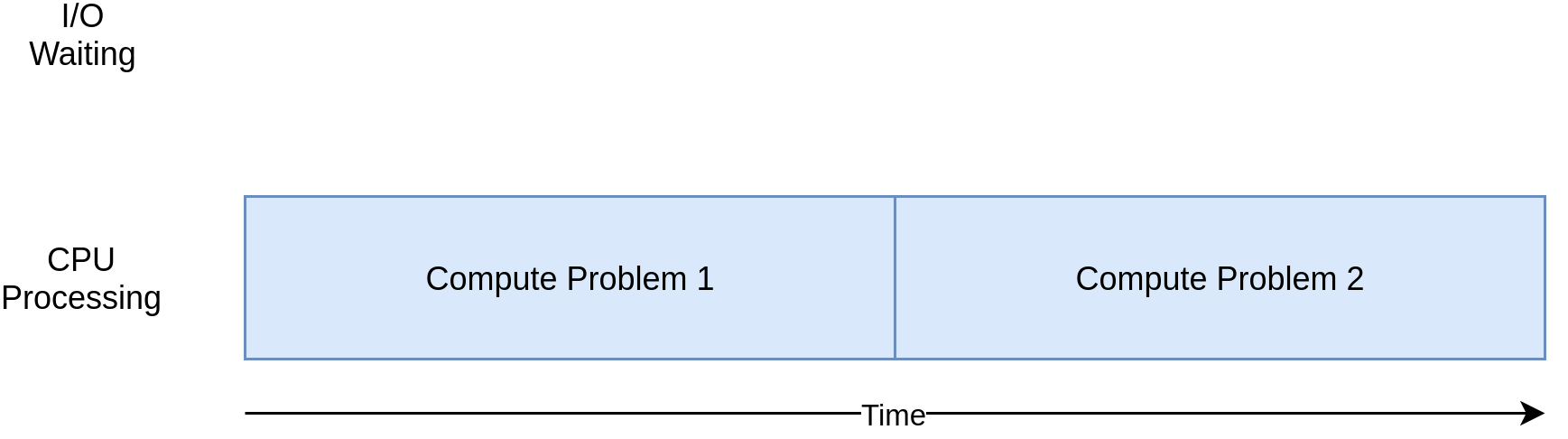
通过下一节中的例子,您将看到不同形式的并发在 CPU 受限和 I/O 受限的程序中工作得更好或更差。向程序中添加并发性会增加额外的代码和复杂性,因此您需要决定潜在的加速是否值得付出额外的努力。到本文结束时,您应该有足够的信息来开始做决定。
这里有一个简短的总结来阐明这个概念:
| 输入输出绑定进程 | CPU 限制的进程 |
|---|---|
| 你的程序大部分时间都在和一个慢速设备对话,比如网络连接,硬盘,或者打印机。 | 你的程序大部分时间都在做 CPU 操作。 |
| 加速包括重叠等待这些设备的时间。 | 加快速度需要找到在相同时间内完成更多计算的方法。 |
您将首先看到 I/O 绑定的程序。然后,您将看到一些处理 CPU 受限程序的代码。
如何加速一个 I/O 绑定的程序
让我们首先关注 I/O 绑定程序和一个常见问题:通过网络下载内容。对于我们的例子,您将从几个站点下载网页,但它实际上可能是任何网络流量。它只是更容易可视化和设置网页。
同步版本
我们将从这个任务的非并发版本开始。注意,这个程序需要 requests 模块。你应该在运行它之前运行pip install requests,可能使用一个虚拟器。这个版本根本不使用并发:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
如你所见,这是一个相当短的程序。从 URL 下载内容并打印尺寸。需要指出的一件小事是,我们使用了来自requests的 Session 对象。
可以简单地直接使用来自requests的get(),但是创建一个Session对象允许requests做一些奇特的网络技巧并真正加速。
download_all_sites()创建Session然后遍历列表中的站点,依次下载每个站点。最后,它打印出这个过程花了多长时间,这样您就可以满意地看到在下面的例子中并发性给我们带来了多大的帮助。
这个程序的处理图看起来很像上一节中的 I/O 绑定图。
注意:网络流量取决于多种因素,这些因素可能会因时而异。我看到由于网络问题,这些测试的次数从一次运行到另一次运行增加了一倍。
为什么同步版摇滚
这个版本的代码的伟大之处在于,它很简单。它相对容易编写和调试。考虑起来也更直截了当。只有一个思路贯穿其中,所以你可以预测下一步是什么,它会如何表现。
同步版本的问题
这里的大问题是,与我们将提供的其他解决方案相比,它相对较慢。下面是我的机器上最终输出的一个例子:
$ ./io_non_concurrent.py
[most output skipped]
Downloaded 160 in 14.289619207382202 seconds
注意:您的结果可能会有很大差异。运行这个脚本时,我看到时间从 14.2 秒到 21.9 秒不等。对于本文,我选择了三次跑步中最快的一次作为时间。这些方法之间的差异仍然很明显。
然而,速度慢并不总是一个大问题。如果您正在运行的程序在同步版本中只需要 2 秒钟,并且很少运行,那么可能不值得添加并发性。你可以停在这里。
如果你的程序经常运行怎么办?如果要跑几个小时呢?让我们通过使用threading重写这个程序来讨论并发性。
threading版本
正如你可能猜到的,编写一个线程化的程序需要更多的努力。然而,对于简单的情况,您可能会惊讶地发现几乎不需要额外的努力。下面是使用threading的相同程序的样子:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
当你添加threading时,整体结构是一样的,你只需要做一些改变。download_all_sites()从每个站点调用一次函数变成了更复杂的结构。
在这个版本中,您正在创建一个ThreadPoolExecutor,这似乎是一件复杂的事情。让我们来分解一下:ThreadPoolExecutor = Thread + Pool + Executor。
你已经知道了Thread部分。那只是我们之前提到的一个思路。Pool部分是开始变得有趣的地方。这个对象将创建一个线程池,每个线程都可以并发运行。最后,Executor是控制池中每个线程如何以及何时运行的部分。它将在池中执行请求。
有益的是,标准库将ThreadPoolExecutor实现为上下文管理器,因此您可以使用with语法来管理Threads池的创建和释放。
一旦你有了一个ThreadPoolExecutor,你就可以使用它方便的.map()方法。该方法在列表中的每个站点上运行传入的函数。最重要的是,它使用自己管理的线程池自动并发运行它们。
那些来自其他语言,甚至 Python 2 的人,可能想知道在处理threading、Thread.start()、Thread.join()和Queue时,管理您习惯的细节的常用对象和函数在哪里。
这些仍然存在,您可以使用它们来实现对线程运行方式的细粒度控制。但是,从 Python 3.2 开始,标准库增加了一个名为Executors的高级抽象,如果您不需要这种细粒度的控制,它可以为您管理许多细节。
我们示例中另一个有趣的变化是每个线程都需要创建自己的requests.Session()对象。当你在看requests的文档时,不一定容易分辨,但是阅读这一期,似乎很清楚你需要为每个线程建立一个单独的会话。
这是关于threading的有趣且困难的问题之一。因为操作系统控制着您的任务何时被中断以及另一个任务何时开始,所以线程之间共享的任何数据都需要受到保护,或者说是线程安全的。不幸的是requests.Session()不是线程安全的。
根据数据是什么以及如何使用数据,有几种策略可以使数据访问线程安全。其中之一是使用线程安全的数据结构,比如 Python 的queue模块中的Queue。
这些对象使用像 threading.Lock 这样的低级原语来确保同一时间只有一个线程可以访问一块代码或一点内存。您通过ThreadPoolExecutor对象间接地使用了这个策略。
这里使用的另一个策略是线程本地存储。创建一个看起来像全局的对象,但却是特定于每个线程的。在您的示例中,这是通过thread_local和get_session()完成的:
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
local()是在threading模块中专门解决这个问题的。这看起来有点奇怪,但是您只想创建这些对象中的一个,而不是为每个线程创建一个。对象本身负责分离不同线程对不同数据的访问。
当调用get_session()时,它查找的session是特定于它运行的特定线程的。所以每个线程在第一次调用get_session()时都会创建一个会话,然后在整个生命周期中的每个后续调用中都会使用这个会话。
最后,关于选择线程数量的一个简短说明。您可以看到示例代码使用了 5 个线程。你可以随意摆弄这个数字,看看总的时间是如何变化的。您可能认为每次下载一个线程是最快的,但至少在我的系统上不是这样。我发现最快的结果出现在 5 到 10 个线程之间。如果超过这个值,那么创建和销毁线程的额外开销会抵消所有节省的时间。
这里很难回答的一个问题是,线程的正确数量对于不同的任务来说并不是一个常数。需要做一些实验。
为什么threading版摇滚
好快啊!这是我最快的一次测试。请记住,非并发版本耗时超过 14 秒:
$ ./io_threading.py
[most output skipped]
Downloaded 160 in 3.7238826751708984 seconds
下面是它的执行时序图:
它使用多线程同时向网站发出多个打开的请求,允许您的程序重叠等待时间并更快地获得最终结果!耶!这就是目标。
版本threading的问题
正如你从例子中看到的,这需要更多的代码来实现,你真的需要考虑一下线程之间共享什么数据。
线程可以以微妙且难以察觉的方式进行交互。这些交互会导致竞争条件,这种竞争条件经常会导致难以发现的随机的、间歇性的错误。那些不熟悉竞争条件概念的人可能想扩展阅读下面的部分。
竞争条件是一整类微妙的错误,在多线程代码中可能并且经常发生。竞争情况的发生是因为程序员没有充分保护数据访问,以防止线程相互干扰。在编写线程代码时,您需要采取额外的步骤来确保事情是线程安全的。
这里发生的事情是操作系统控制你的线程何时运行,何时被换出让另一个线程运行。这种线程交换可以在任何时候发生,甚至在执行 Python 语句的子步骤时。举个简单的例子,看看这个函数:
import concurrent.futures
counter = 0
def increment_counter(fake_value):
global counter
for _ in range(100):
counter += 1
if __name__ == "__main__":
fake_data = [x for x in range(5000)]
counter = 0
with concurrent.futures.ThreadPoolExecutor(max_workers=5000) as executor:
executor.map(increment_counter, fake_data)
这段代码与您在上面的threading示例中使用的结构非常相似。不同之处在于,每个线程都在访问同一个全局变量 counter并递增它。Counter没有受到任何保护,所以它不是线程安全的。
为了增加counter,每个线程需要读取当前值,给它加 1,然后将该值保存回变量。发生在这一行:counter += 1。
因为操作系统对您的代码一无所知,并且可以在执行的任何时候交换线程,所以这种交换可能发生在线程读取值之后,但在它有机会写回值之前。如果正在运行的新代码也修改了counter,那么第一个线程就有了数据的旧拷贝,问题就会随之而来。
可以想象,碰到这种情况是相当罕见的。你可以运行这个程序成千上万次,永远看不到问题。这就是为什么这种类型的问题很难调试,因为它可能很难重现,并可能导致随机出现的错误。
作为进一步的例子,我想提醒你requests.Session()不是线程安全的。这意味着,如果多个线程使用同一个Session,在某些地方可能会发生上述类型的交互。我提出这个问题并不是要诽谤requests,而是要指出这些问题很难解决。
asyncio版本
在您开始研究asyncio示例代码之前,让我们更多地讨论一下asyncio是如何工作的。
asyncio基础知识
这将是asyncio的简化版。这里忽略了许多细节,但它仍然传达了其工作原理。
asyncio的一般概念是,一个称为事件循环的 Python 对象控制每个任务如何以及何时运行。事件循环知道每个任务,并且知道它处于什么状态。实际上,任务可能处于许多状态,但现在让我们想象一个只有两种状态的简化事件循环。
就绪状态将指示任务有工作要做并准备好运行,等待状态意味着任务正在等待一些外部事情完成,例如网络操作。
简化的事件循环维护两个任务列表,每个列表对应一种状态。它选择一个就绪任务,并让它重新开始运行。该任务处于完全控制中,直到它合作地将控制权交还给事件循环。
当正在运行的任务将控制权交还给事件循环时,事件循环会将该任务放入就绪或等待列表中,然后遍历等待列表中的每个任务,以查看它是否在 I/O 操作完成时已就绪。它知道就绪列表中的任务仍然是就绪的,因为它知道它们还没有运行。
一旦所有的任务都被重新排序到正确的列表中,事件循环就会选择下一个要运行的任务,并重复这个过程。简化的事件循环挑选等待时间最长的任务并运行它。这个过程重复进行,直到事件循环结束。
asyncio很重要的一点是,任务永远不会放弃控制,除非有意这样做。他们从不在行动中被打断。这使得我们在asyncio比在threading更容易共享资源。您不必担心使您的代码线程安全。
这是对正在发生的asyncio的高级视图。如果你想要更多的细节,这个 StackOverflow 答案提供了一些很好的细节,如果你想深入挖掘的话。
async和await
现在来说说 Python 中新增的两个关键词:async和await。根据上面的讨论,您可以将await视为允许任务将控制权交还给事件循环的魔法。当您的代码等待函数调用时,这是一个信号,表明调用可能需要一段时间,任务应该放弃控制。
最简单的方法是将async看作 Python 的一个标志,告诉它将要定义的函数使用了await。在某些情况下,这并不完全正确,比如异步发电机,但它适用于许多情况,并在您开始时为您提供一个简单的模型。
您将在下一段代码中看到的一个例外是async with语句,它从您通常等待的对象创建一个上下文管理器。虽然语义略有不同,但想法是一样的:将这个上下文管理器标记为可以被换出的东西。
我相信您可以想象,管理事件循环和任务之间的交互是很复杂的。对于从asyncio开始的开发者来说,这些细节并不重要,但是你需要记住任何调用await的函数都需要用async来标记。否则会出现语法错误。
回码
现在你已经对什么是asyncio有了一个基本的了解,让我们浏览一下示例代码的asyncio版本,并弄清楚它是如何工作的。注意这个版本增加了 aiohttp 。您应该在运行之前运行pip install aiohttp:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")
这个版本比前两个版本稍微复杂一点。它有相似的结构,但是设置任务比创建ThreadPoolExecutor要多一点工作。让我们从示例的顶部开始。
T2download_site()
除了函数定义行上的async关键字和实际调用session.get()时的async with关键字之外,顶部的download_site()几乎与threading版本相同。稍后您将看到为什么Session可以在这里传递,而不是使用线程本地存储。
T2download_all_sites()
download_all_sites()是与threading示例相比最大的变化。
您可以在所有任务之间共享该会话,因此该会话在这里被创建为上下文管理器。这些任务可以共享会话,因为它们都运行在同一个线程上。当会话处于不良状态时,一个任务不可能中断另一个任务。
在上下文管理器中,它使用asyncio.ensure_future()创建了一个任务列表,并负责启动它们。一旦创建了所有的任务,这个函数就使用asyncio.gather()来保持会话上下文活动,直到所有的任务都完成。
threading代码做了一些类似的事情,但是细节在ThreadPoolExecutor中可以方便地处理。目前还没有一个AsyncioPoolExecutor类。
然而,这里的细节隐藏了一个微小但重要的变化。还记得我们如何讨论要创建的线程数量吗?在threading的例子中,线程的最佳数量并不明显。
asyncio的一个很酷的优势是它的伸缩性比threading好得多。与线程相比,创建每个任务需要的资源和时间要少得多,因此创建和运行更多的任务效果会更好。这个例子只是为每个站点创建了一个单独的下载任务,这样做效果很好。
T2__main__
最后,asyncio的性质意味着您必须启动事件循环并告诉它运行哪些任务。文件底部的__main__部分包含了get_event_loop()和run_until_complete()的代码。如果不说别的,他们在命名这些函数方面做得非常好。
如果你已经升级到了 Python 3.7 ,Python 核心开发者为你简化了这个语法。你可以用asyncio.run()代替asyncio.get_event_loop().run_until_complete()绕口令。
为什么asyncio版摇滚
真的很快!在我的机器上进行的测试中,这是最快的代码版本,远远超过其他版本:
$ ./io_asyncio.py
[most output skipped]
Downloaded 160 in 2.5727896690368652 seconds
执行时序图看起来与threading示例中发生的事情非常相似。只是 I/O 请求都是由同一个线程完成的:
缺少像ThreadPoolExecutor这样的包装器使得这段代码比threading的例子要复杂一些。在这种情况下,您必须做一些额外的工作才能获得更好的性能。
还有一个常见的论点是,必须在适当的位置添加async和await会增加额外的复杂性。在某种程度上,这是真的。这个论点的另一面是,它迫使你去思考一个给定的任务什么时候会被交换出去,这可以帮助你创造一个更好、更快的设计。
缩放问题在这里也很突出。用一个线程为每个站点运行上面的threading例子明显比用少量线程运行慢。运行有数百个任务的asyncio示例丝毫没有降低它的速度。
版本asyncio的问题
在这一点上,asyncio有几个问题。你需要特殊的异步版本的库来获得asyncio的全部优势。如果你只是使用requests来下载网站,它会慢得多,因为requests不是用来通知事件循环它被阻止的。随着时间的推移,这个问题越来越小,越来越多的图书馆接受了asyncio。
另一个更微妙的问题是,如果其中一个任务不合作,合作多任务的所有优势都会被抛弃。代码中的一个小错误会导致一个任务停止运行,并长时间占用处理器,使其他需要运行的任务无法运行。如果任务不将控制权交还给它,事件循环就无法中断。
考虑到这一点,让我们采用一种完全不同的方法来实现并发性。
multiprocessing版本
与之前的方法不同,multiprocessing版本的代码充分利用了您的新电脑拥有的多个 CPU。或者,在我的情况下,我的笨重,旧笔记本电脑。让我们从代码开始:
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
这比asyncio的例子短得多,实际上看起来与threading的例子非常相似,但是在我们深入研究代码之前,让我们快速浏览一下multiprocessing为您做了什么。
multiprocessing总而言之
到目前为止,本文中的所有并发示例都只在计算机的单个 CPU 或内核上运行。其原因与 CPython 当前的设计和一种叫做全局解释器锁(或 GIL)的东西有关。
这篇文章不会深入到 GIL 的方式和原因。现在知道这个例子的同步、threading和asyncio版本都运行在单个 CPU 上就足够了。
标准库中的旨在打破这一障碍,并在多个 CPU 上运行您的代码。在高层次上,它通过创建一个新的 Python 解释器实例来运行在每个 CPU 上,然后将程序的一部分移植到它上面来运行。
可以想象,启动一个单独的 Python 解释器不如在当前的 Python 解释器中启动一个新线程快。这是一个重量级的操作,并带有一些限制和困难,但对于正确的问题,它可以产生巨大的差异。
multiprocessing代号
代码与我们的同步版本相比有一些小的变化。第一个在download_all_sites()里。它不是简单地重复调用download_site(),而是创建一个multiprocessing.Pool对象,并让它将download_site映射到可迭代的sites。从threading示例来看,这应该很熟悉。
这里发生的是,Pool创建了许多独立的 Python 解释器进程,并让每个进程对 iterable 中的一些项目运行指定的函数,在我们的例子中,iterable 是站点列表。主进程和其他进程之间的通信由multiprocessing模块为您处理。
创建Pool的行值得你关注。首先,它没有指定在Pool中创建多少个流程,尽管这是一个可选参数。默认情况下,multiprocessing.Pool()会决定你电脑中的 CPU 数量并与之匹配。这通常是最好的答案,对我们来说也是如此。
对于这个问题,增加流程的数量并没有让事情变得更快。它实际上减慢了速度,因为设置和拆除所有这些进程的成本大于并行执行 I/O 请求的好处。
接下来是通话的initializer=set_global_session部分。记住我们的Pool中的每个进程都有自己的内存空间。这意味着他们不能共享像Session对象这样的东西。您不希望每次调用函数时都创建一个新的Session,而是希望为每个进程创建一个。
initializer功能参数就是为这种情况建立的。没有办法将返回值从initializer传递回进程download_site()调用的函数,但是您可以初始化一个全局session变量来保存每个进程的单个会话。因为每个进程都有自己的内存空间,所以每个进程的全局内存空间都是不同的。
这就是事情的全部。代码的其余部分与您之前看到的非常相似。
为什么multiprocessing版摇滚
这个例子的multiprocessing版本很棒,因为它相对容易设置,只需要很少的额外代码。它还充分利用了计算机的 CPU 能力。这段代码的执行时序图如下所示:
版本multiprocessing的问题
这个版本的例子确实需要一些额外的设置,而且全局session对象很奇怪。你必须花一些时间考虑在每个进程中哪些变量将被访问。
最后,它显然比本例中的asyncio和threading版本慢:
$ ./io_mp.py
[most output skipped]
Downloaded 160 in 5.718175172805786 seconds
这并不奇怪,因为 I/O 绑定问题并不是multiprocessing存在的真正原因。当您进入下一节并查看 CPU 相关的示例时,您将会看到更多内容。
如何加速一个 CPU 受限的程序
让我们稍微改变一下思路。到目前为止,这些例子都处理了一个 I/O 绑定的问题。现在,您将研究一个 CPU 相关的问题。正如您所看到的,一个 I/O 绑定的问题大部分时间都在等待外部操作(如网络调用)的完成。另一方面,与 CPU 相关的问题很少进行 I/O 操作,它的总执行时间是它处理所需数据速度的一个因素。
出于我们示例的目的,我们将使用一个有点傻的函数来创建一些需要在 CPU 上运行很长时间的东西。此函数计算从 0 到传入值的每个数字的平方和:
def cpu_bound(number):
return sum(i * i for i in range(number))
您将传入大量的数字,所以这将需要一段时间。请记住,这只是你的代码的占位符,它实际上做了一些有用的事情,需要大量的处理时间,比如计算方程的根或者对大型数据结构进行排序。
CPU 绑定的同步版本
现在让我们来看看这个例子的非并发版本:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")
这段代码调用cpu_bound() 20 次,每次都使用不同的大数。它在单个 CPU 上的单个进程中的单个线程上完成所有这些工作。执行时序图如下所示:
与 I/O 相关的示例不同,CPU 相关的示例通常在运行时相当一致。在我的机器上,这个大约需要 7.8 秒:
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 seconds
显然我们可以做得更好。这一切都在一个 CPU 上运行,没有并发性。让我们看看我们能做些什么来使它变得更好。
threading和asyncio版本
你认为使用threading或asyncio重写这段代码会提高多少速度?
如果你回答“一点也不”,给自己一块饼干。如果你回答“它会让你慢下来”,给自己两块饼干。
原因如下:在上面的 I/O 绑定示例中,总时间的大部分都花在了等待缓慢的操作完成上。threading和asyncio通过让你的等待时间重叠来加快速度,而不是按顺序进行。
然而,在 CPU 受限的问题上,没有等待。中央处理器正在尽可能快地处理这个问题。在 Python 中,线程和任务都在同一个进程的同一个 CPU 上运行。这意味着一个 CPU 负责非并发代码的所有工作,外加设置线程或任务的额外工作。需要超过 10 秒钟:
$ ./cpu_threading.py
Duration 10.407078266143799 seconds
我已经写了这段代码的一个threading版本,并把它和其他示例代码一起放在了 GitHub repo 中,这样你就可以自己去测试了。不过,我们先不要看这个。
受 CPU 限制的multiprocessing版本
现在你终于到达了multiprocessing真正闪耀的地方。与其他并发库不同,multiprocessing被明确设计为在多个 CPU 之间共享繁重的 CPU 工作负载。下面是它的执行时序图:
下面是代码的样子:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")
非并发版本的代码几乎没有什么变化。你不得不import multiprocessing然后从循环遍历数字变成创建一个multiprocessing.Pool对象,并使用它的.map()方法在工人进程空闲时向它们发送单独的数字。
这正是你对 I/O 绑定的multiprocessing代码所做的,但是这里你不需要担心Session对象。
如上所述,multiprocessing.Pool()构造函数的processes可选参数值得注意。您可以指定想要在Pool中创建和管理多少个Process对象。默认情况下,它将确定您的机器中有多少个 CPU,并为每个 CPU 创建一个进程。虽然这对于我们的简单示例来说非常有用,但是您可能希望在生产环境中有更多的控制。
此外,正如我们在第一部分提到的threading,multiprocessing.Pool代码是建立在像Queue和Semaphore这样的构建模块之上的,这对于那些用其他语言编写过多线程和多处理代码的人来说是很熟悉的。
为什么multiprocessing版摇滚
这个例子的multiprocessing版本很棒,因为它相对容易设置,只需要很少的额外代码。它还充分利用了计算机的 CPU 能力。
哎,上次我们看multiprocessing的时候我也是这么说的。最大的不同在于,这一次它显然是最佳选择。在我的机器上需要 2.5 秒:
$ ./cpu_mp.py
Duration 2.5175397396087646 seconds
这比我们看到的其他选项要好得多。
版本multiprocessing的问题
使用multiprocessing有一些缺点。在这个简单的例子中,它们并没有真正显示出来,但是将您的问题分解开来,使每个处理器都可以独立工作,有时会很困难。
此外,许多解决方案需要进程间更多的通信。这会给你的解决方案增加一些非并发程序不需要处理的复杂性。
何时使用并发
您已经讨论了很多内容,所以让我们回顾一些关键的想法,然后讨论一些决策点,这些决策点将帮助您确定您希望在项目中使用哪个并发模块(如果有的话)。
这个过程的第一步是决定你是否应该使用并发模块。虽然这里的例子使每个库看起来都很简单,但是并发总是带来额外的复杂性,并且经常会导致难以发现的错误。
坚持添加并发性,直到您发现一个已知的性能问题,然后再决定您需要哪种类型的并发性。正如 Donald Knuth 所说,“过早优化是编程中所有罪恶(或者至少是大部分罪恶)的根源。”
一旦你决定你应该优化你的程序,弄清楚你的程序是受 CPU 限制的还是受 I/O 限制的是一个很好的下一步。请记住,I/O 绑定的程序是那些花费大部分时间等待事情发生的程序,而 CPU 绑定的程序花费时间尽可能快地处理数据或计算数字。
如您所见,CPU 限制的问题只有通过使用multiprocessing才能真正解决。threading和asyncio对这类问题一点帮助都没有。
对于 I/O 相关的问题,Python 社区有一条通用的经验法则:“尽可能使用asyncio,必要时使用threading”asyncio可以为这种类型的程序提供最好的速度,但有时你会需要尚未移植的关键库来利用asyncio。请记住,任何没有放弃对事件循环的控制的任务都会阻塞所有其他任务。
结论
现在,您已经看到了 Python 中可用的基本并发类型:
threadingasynciomultiprocessing
您已经理解了决定对于给定的问题应该使用哪种并发方法,或者是否应该使用任何一种并发方法!此外,您对使用并发时可能出现的一些问题有了更好的理解。
我希望您从这篇文章中学到了很多,并且在您自己的项目中发现了并发的巨大用途!请务必参加下面链接的“Python 并发性”测验,检查您的学习情况:
参加测验:通过我们的交互式“Python 并发性”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用并发加速 Python********


 浙公网安备 33010602011771号
浙公网安备 33010602011771号