
RealPython-中文系列教程-二十-
RealPython 中文系列教程(二十)
原文:RealPython
用 Django 1.6 进行交易管理
原文:https://realpython.com/transaction-management-with-django-1-6/
如果您曾经花了很多时间在 Django 数据库事务管理上,您就会知道这有多么令人困惑。在过去,文档提供了相当多的深度,但是只有通过构建和实验才能理解。
有太多的装修工可以一起工作,比如commit_on_success、commit_manually、commit_unless_managed、rollback_unless_managed、enter_transaction_management、leave_transaction_management等等。幸运的是,有了 Django 1.6,这一切都不复存在了。你现在真的只需要知道几个函数。我们一会儿就会谈到这些。首先,我们将讨论以下主题:
- 什么是事务管理?
- Django 1.6 之前的事务管理有什么问题?
在进入之前:
- Django 1.6 中关于事务管理的正确之处是什么?
然后处理一个详细的例子:
- 条纹示例
- 交易
- 推荐方式
- 使用装饰器
- 每个 HTTP 请求的事务
- 保存点
- 嵌套事务
什么是交易?
根据 SQL-92 ,“一个 SQL 事务(有时简称为“事务”)是 SQL 语句的一个执行序列,它在恢复方面是原子的”。换句话说,所有的 SQL 语句被一起执行和提交。同样,回滚时,所有语句一起回滚。
例如:
# START
note = Note(title="my first note", text="Yay!")
note = Note(title="my second note", text="Whee!")
address1.save()
address2.save()
# COMMIT
所以事务是数据库中的一个工作单元。并且该单个工作单元由开始事务和随后的提交或显式回滚来划分。
Django 1.6 之前的事务管理有什么问题?
为了全面回答这个问题,我们必须解决在数据库、客户程序库和 Django 中如何处理事务。
数据库
数据库中的每条语句都必须在事务中运行,即使事务只包含一条语句。
大多数数据库都有一个AUTOCOMMIT设置,默认情况下通常设置为 True。这个AUTOCOMMIT包装事务中的每个语句,如果语句成功,就立即提交该语句。当然,你可以手动调用类似于START_TRANSACTION的东西,这将暂时中止AUTOCOMMIT,直到你调用COMMIT_TRANSACTION或ROLLBACK。
然而,这里的要点是AUTOCOMMIT设置在每个语句之后应用隐式提交。
客户端库
然后是 Python 客户端库,比如 sqlite3 和 mysqldb,它们允许 Python 程序与数据库本身接口。这种库遵循一套关于如何访问和查询数据库的标准。该标准 DB API 2.0 在 PEP 249 中有描述。虽然这可能会导致一些稍微枯燥的阅读,但重要的是 PEP 249 声明数据库AUTOCOMMIT在默认情况下应该关闭。
这显然与数据库中发生的事情相冲突:
- SQL 语句总是必须在事务中运行,数据库通常通过
AUTOCOMMIT为您打开事务。 - 但是,根据 PEP 249,这种情况应该不会发生。
- 客户端库必须反映数据库中发生的事情,但是由于默认情况下它们不允许打开
AUTOCOMMIT,所以它们只是将 SQL 语句包装在一个事务中,就像数据库一样。
好吧。多陪我一会儿。
姜戈
进入姜戈。 Django 对于交易管理也有话要说。在 Django 1.5 和更早的版本中,Django 基本上运行一个打开的事务,并在您向数据库写入数据时自动提交该事务。所以每次您调用类似于model.save()或model.update()的东西时,Django 都会生成适当的 SQL 语句并提交事务。
同样在 Django 1.5 和更早的版本中,建议使用TransactionMiddleware将事务绑定到 HTTP 请求。每个请求都有一个事务。如果响应返回没有异常,Django 将提交事务,但是如果您的视图函数抛出错误,将调用ROLLBACK。这实际上关闭了AUTOCOMMIT。如果您想要标准的、数据库级的自动提交风格的事务管理,您必须自己管理事务——通常通过在您的视图函数上使用事务装饰器,比如@transaction.commit_manually或@transaction.commit_on_success。
深呼吸。或者两个。
这是什么意思?
是的,那里有很多正在进行的事情,结果是大多数开发人员只是想要标准的数据库级自动提交——这意味着事务留在幕后,做他们的事情,直到您需要手动调整它们。
Django 1.6 中关于事务管理的哪些内容是正确的?
现在,欢迎来到 Django 1.6。尽最大努力忘记我们刚刚谈到的一切,只需记住在 Django 1.6 中,您使用数据库AUTOCOMMIT并在需要时手动管理事务。本质上,我们有一个简单得多的模型,它基本上完成了数据库最初设计的功能。
理论够了。我们编码吧。
条纹示例
这里我们有这个示例视图函数,它处理注册用户并调用 Stripe 进行信用卡处理。
def register(request):
user = None
if request.method == 'POST':
form = UserForm(request.POST)
if form.is_valid():
customer = Customer.create("subscription",
email = form.cleaned_data['email'],
description = form.cleaned_data['name'],
card = form.cleaned_data['stripe_token'],
plan="gold",
)
cd = form.cleaned_data
try:
user = User.create(cd['name'], cd['email'], cd['password'],
cd['last_4_digits'])
if customer:
user.stripe_id = customer.id
user.save()
else:
UnpaidUsers(email=cd['email']).save()
except IntegrityError:
form.addError(cd['email'] + ' is already a member')
else:
request.session['user'] = user.pk
return HttpResponseRedirect('/')
else:
form = UserForm()
return render_to_response(
'register.html',
{
'form': form,
'months': range(1, 12),
'publishable': settings.STRIPE_PUBLISHABLE,
'soon': soon(),
'user': user,
'years': range(2011, 2036),
},
context_instance=RequestContext(request)
)
这个视图首先调用Customer.create,它实际上调用 Stripe 来处理信用卡处理。然后我们创建一个新用户。如果我们从 Stripe 得到响应,我们就用stripe_id更新新创建的客户。如果我们找不到客户(Stripe 已关闭),我们将在新创建的客户电子邮件的UnpaidUsers表中添加一个条目,这样我们可以要求他们稍后重试他们的信用卡详细信息。
这个想法是,即使 Stripe 关闭了,用户仍然可以注册并开始使用我们的网站。我们稍后会再次向他们询问信用卡信息。
我知道这可能是一个有点做作的例子,如果必须的话,我不会用这种方式实现这样的功能,但目的是演示事务。
前进。考虑事务,记住 Django 1.6 默认为我们的数据库提供了AUTOCOMMIT行为,让我们再看一下数据库相关的代码。
cd = form.cleaned_data
try:
user = User.create(
cd['name'], cd['email'],
cd['password'], cd['last_4_digits'])
if customer:
user.stripe_id = customer.id
user.save()
else:
UnpaidUsers(email=cd['email']).save()
except IntegrityError:
# ...
你能发现任何问题吗?嗯,如果UnpaidUsers(email=cd['email']).save()行失败了会发生什么?
你将有一个用户,在系统中注册,系统认为已经验证了他们的信用卡,但实际上他们并没有验证信用卡。
我们只想要两种结果中的一种:
- 用户被创建(在数据库中)并有一个
stripe_id。 - 用户被创建(在数据库中)并且没有一个
stripe_id,并且在UnpaidUsers表中生成一个具有相同电子邮件地址的相关行。
这意味着我们希望两个独立的数据库语句要么都提交,要么都回滚。谦逊交易的完美案例。
首先,让我们编写一些测试来验证事情是否按照我们想要的方式运行。
@mock.patch('payments.models.UnpaidUsers.save', side_effect = IntegrityError)
def test_registering_user_when_strip_is_down_all_or_nothing(self, save_mock):
#create the request used to test the view
self.request.session = {}
self.request.method='POST'
self.request.POST = {'email' : 'python@rocks.com',
'name' : 'pyRock',
'stripe_token' : '...',
'last_4_digits' : '4242',
'password' : 'bad_password',
'ver_password' : 'bad_password',
}
#mock out stripe and ask it to throw a connection error
with mock.patch('stripe.Customer.create', side_effect =
socket.error("can't connect to stripe")) as stripe_mock:
#run the test
resp = register(self.request)
#assert there is no record in the database without stripe id.
users = User.objects.filter(email="python@rocks.com")
self.assertEquals(len(users), 0)
#check the associated table also didn't get updated
unpaid = UnpaidUsers.objects.filter(email="python@rocks.com")
self.assertEquals(len(unpaid), 0)
测试顶部的装饰器是一个模拟,当我们试图保存到UnpaidUsers表时,它将抛出一个‘integrity error’。
这是为了回答“如果UnpaidUsers(email=cd['email']).save()线出现故障会怎么样?”下一段代码只是创建一个模拟会话,其中包含注册函数所需的适当信息。然后,with mock.patch迫使系统认为条带关闭……最后我们进行测试。
resp = register(self.request)
上面的代码只是调用了我们的注册视图函数,并传入了被模仿的请求。然后,我们只需检查以确保表没有被更新:
#assert there is no record in the database without stripe_id.
users = User.objects.filter(email="python@rocks.com")
self.assertEquals(len(users), 0)
#check the associated table also didn't get updated
unpaid = UnpaidUsers.objects.filter(email="python@rocks.com")
self.assertEquals(len(unpaid), 0)
因此,如果我们运行测试,它应该会失败:
======================================================================
FAIL: test_registering_user_when_strip_is_down_all_or_nothing (tests.payments.testViews.RegisterPageTests)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/j1z0/.virtualenvs/django_1.6/lib/python2.7/site-packages/mock.py", line 1201, in patched
return func(*args, **keywargs)
File "/Users/j1z0/Code/RealPython/mvp_for_Adv_Python_Web_Book/tests/payments/testViews.py", line 266, in test_registering_user_when_strip_is_down_all_or_nothing
self.assertEquals(len(users), 0)
AssertionError: 1 != 0
----------------------------------------------------------------------
很好。说起来似乎很可笑,但那正是我们想要的。记住:我们在这里练习 TDD。错误消息告诉我们,用户确实被存储在数据库中——这正是我们不想要的,因为他们没有付费!
拯救交易…
交易
在 Django 1.6 中,实际上有几种创建事务的方法。
我们来看几个。
推荐方式
根据 Django 1.6 文件:
Django 提供了一个 API 来控制数据库事务。[…]原子性是数据库事务的定义属性。atomic 允许我们创建一个代码块,在其中保证数据库的原子性。如果代码块成功完成,更改将提交到数据库。如果出现异常,更改将被回滚。
Atomic 既可以用作装饰器,也可以用作 context_manager。因此,如果我们将它用作上下文管理器,注册函数中的代码将如下所示:
from django.db import transaction
try:
with transaction.atomic():
user = User.create(
cd['name'], cd['email'],
cd['password'], cd['last_4_digits'])
if customer:
user.stripe_id = customer.id
user.save()
else:
UnpaidUsers(email=cd['email']).save()
except IntegrityError:
form.addError(cd['email'] + ' is already a member')
注意第with transaction.atomic()行。该块中的所有代码都将在一个事务中执行。因此,如果我们重新运行我们的测试,他们都应该通过!请记住,事务是一个单一的工作单元,所以当UnpaidUsers调用失败时,上下文管理器中的所有内容都会一起回滚。
使用装饰器
我们还可以尝试添加 atomic 作为装饰器。
@transaction.atomic():
def register(request):
# ...snip....
try:
user = User.create(
cd['name'], cd['email'],
cd['password'], cd['last_4_digits'])
if customer:
user.stripe_id = customer.id
user.save()
else:
UnpaidUsers(email=cd['email']).save()
except IntegrityError:
form.addError(cd['email'] + ' is already a member')
如果我们重新运行我们的测试,它们将会失败,并出现与我们之前相同的错误。
这是为什么呢?为什么事务没有正确回滚?原因是因为transaction.atomic正在寻找某种异常,我们捕捉到了那个错误(即在我们的 try except 块中的IntegrityError,所以transaction.atomic从未发现它,因此标准的AUTOCOMMIT功能接管了它。
当然,移除 try except 将导致异常被抛出调用链,并且很可能在其他地方爆发。所以我们也不能那么做。
因此,技巧是将原子上下文管理器放在 try except 块中,这是我们在第一个解决方案中所做的。再次查看正确的代码:
from django.db import transaction
try:
with transaction.atomic():
user = User.create(
cd['name'], cd['email'],
cd['password'], cd['last_4_digits'])
if customer:
user.stripe_id = customer.id
user.save()
else:
UnpaidUsers(email=cd['email']).save()
except IntegrityError:
form.addError(cd['email'] + ' is already a member')
当UnpaidUsers触发IntegrityError时,transaction.atomic()上下文管理器将捕获它并执行回滚。当我们的代码在异常处理程序中执行时,(即form.addError行),回滚将完成,如果需要,我们可以安全地进行数据库调用。还要注意,无论上下文管理器的最终结果如何,在transaction.atomic()上下文管理器之前或之后的任何数据库调用都不会受到影响。
每个 HTTP 请求的事务
Django 1.6(像 1.5 一样)也允许您以“每个请求一个事务”的模式操作。在这种模式下,Django 会自动将视图函数包装在一个事务中。如果函数抛出异常,Django 将回滚事务,否则将提交事务。
要设置它,你必须在数据库配置中为你想要的每个数据库设置ATOMIC_REQUEST为真。因此,在我们的“settings.py”中,我们进行了如下更改:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(SITE_ROOT, 'test.db'),
'ATOMIC_REQUEST': True,
}
}
实际上,这就像你把装饰器放在我们的视图函数上一样。所以它不符合我们的目的。
然而值得注意的是,使用ATOMIC_REQUESTS和@transaction.atomic装饰器,仍然可以在这些错误从视图中抛出后捕获/处理它们。为了捕捉这些错误,你必须实现一些定制的中间件,或者你可以覆盖 urls.hadler500 或者制作一个500.html 模板。
保存点
尽管事务是原子性的,但它们可以进一步分解成保存点。将保存点视为部分事务。
因此,如果您有一个需要四个 SQL 语句来完成的事务,您可以在第二个语句之后创建一个保存点。一旦创建了保存点,即使第 3 或第 4 条语句失败,您也可以进行部分回滚,去掉第 3 和第 4 条语句,但保留前两条。
因此,这基本上就像将一个事务分割成更小的轻量级事务,允许您进行部分回滚或提交。
但是请记住,如果主事务回滚到哪里(可能是因为一个
IntegrityError被引发而没有被捕获,那么所有保存点也将回滚)。
让我们看一个保存点如何工作的例子。
@transaction.atomic()
def save_points(self,save=True):
user = User.create('jj','inception','jj','1234')
sp1 = transaction.savepoint()
user.name = 'starting down the rabbit hole'
user.stripe_id = 4
user.save()
if save:
transaction.savepoint_commit(sp1)
else:
transaction.savepoint_rollback(sp1)
这里,整个函数都在一个事务中。创建新用户后,我们创建一个保存点,并获取对该保存点的引用。接下来的三个陈述-
user.name = 'starting down the rabbit hole'
user.stripe_id = 4
user.save()
-不是现有保存点的一部分,因此它们有可能成为下一个savepoint_rollback或savepoint_commit的一部分。在使用savepoint_rollback的情况下,行user = User.create('jj','inception','jj','1234')仍然会提交给数据库,即使其余的更新不会提交。
换句话说,以下两个测试描述了保存点的工作方式:
def test_savepoint_rollbacks(self):
self.save_points(False)
#verify that everything was stored
users = User.objects.filter(email="inception")
self.assertEquals(len(users), 1)
#note the values here are from the original create call
self.assertEquals(users[0].stripe_id, '')
self.assertEquals(users[0].name, 'jj')
def test_savepoint_commit(self):
self.save_points(True)
#verify that everything was stored
users = User.objects.filter(email="inception")
self.assertEquals(len(users), 1)
#note the values here are from the update calls
self.assertEquals(users[0].stripe_id, '4')
self.assertEquals(users[0].name, 'starting down the rabbit hole')
同样,在我们提交或回滚保存点之后,我们可以继续在同一个事务中工作。并且该工作不会受到前一个保存点的结果的影响。
例如,如果我们这样更新我们的save_points函数:
@transaction.atomic()
def save_points(self,save=True):
user = User.create('jj','inception','jj','1234')
sp1 = transaction.savepoint()
user.name = 'starting down the rabbit hole'
user.save()
user.stripe_id = 4
user.save()
if save:
transaction.savepoint_commit(sp1)
else:
transaction.savepoint_rollback(sp1)
user.create('limbo','illbehere@forever','mind blown',
'1111')
无论调用的是savepoint_commit还是savepoint_rollback,都将成功创建“中间状态”用户。除非有其他原因导致整个事务回滚。
嵌套交易
除了用savepoint()、savepoint_commit和savepoint_rollback手动指定保存点之外,创建一个嵌套事务将自动为我们创建一个保存点,并在我们遇到错误时回滚。
进一步扩展我们的例子,我们得到:
@transaction.atomic()
def save_points(self,save=True):
user = User.create('jj','inception','jj','1234')
sp1 = transaction.savepoint()
user.name = 'starting down the rabbit hole'
user.save()
user.stripe_id = 4
user.save()
if save:
transaction.savepoint_commit(sp1)
else:
transaction.savepoint_rollback(sp1)
try:
with transaction.atomic():
user.create('limbo','illbehere@forever','mind blown',
'1111')
if not save: raise DatabaseError
except DatabaseError:
pass
这里我们可以看到,在处理完保存点之后,我们使用了transaction.atomic上下文管理器来封装我们的“limbo”用户的创建。当调用该上下文管理器时,它实际上创建了一个保存点(因为我们已经在一个事务中了),该保存点将在退出上下文管理器时被提交或回滚。
因此,以下两个测试描述了它们的行为:
def test_savepoint_rollbacks(self):
self.save_points(False)
#verify that everything was stored
users = User.objects.filter(email="inception")
self.assertEquals(len(users), 1)
#savepoint was rolled back so we should have original values
self.assertEquals(users[0].stripe_id, '')
self.assertEquals(users[0].name, 'jj')
#this save point was rolled back because of DatabaseError
limbo = User.objects.filter(email="illbehere@forever")
self.assertEquals(len(limbo),0)
def test_savepoint_commit(self):
self.save_points(True)
#verify that everything was stored
users = User.objects.filter(email="inception")
self.assertEquals(len(users), 1)
#savepoint was committed
self.assertEquals(users[0].stripe_id, '4')
self.assertEquals(users[0].name, 'starting down the rabbit hole')
#save point was committed by exiting the context_manager without an exception
limbo = User.objects.filter(email="illbehere@forever")
self.assertEquals(len(limbo),1)
所以实际上,您可以使用atomic或savepoint在事务中创建保存点。使用atomic,您不必担心提交/回滚,就像使用savepoint一样,您可以完全控制何时提交/回滚。
结论
如果您以前使用过 Django 事务的早期版本,您会发现事务模型要简单得多。另外,默认打开AUTOCOMMIT是 Django 和 Python 都引以为豪的“正常”默认的一个很好的例子。对于许多系统来说,你不需要直接处理事务,让AUTOCOMMIT做它的工作就行了。但是如果你这样做了,希望这篇文章能给你提供像专家一样管理 Django 交易所需的信息。*****
如何用 Tweepy 用 Python 制作一个 Twitter 机器人
在本文中,您将学习如何使用 Tweepy 用 Python 制作自己的 Twitter 机器人,Tweepy 是一个提供了使用 Twitter API 的非常方便的方法的包。
Twitter 是使用最广泛的社交网络之一。对于许多组织和个人来说,拥有一个伟大的 Twitter 是保持他们的观众参与的关键因素。
拥有一个伟大的 Twitter 存在的一部分包括用新的 tweets 和 retweets 保持你的帐户活跃,关注有趣的帐户,并迅速回复你的追随者的消息。您可以手动完成所有这些工作,但这会花费很多时间。相反,你可以依靠一个推特机器人,一个自动完成你全部或部分推特活动的程序。
在这篇文章中,你将学习如何:
- 改善并自动化您与 Twitter 受众的互动
- 安装 Tweepy
- 注册成为 Twitter 开发者来使用它的 API
- 使用 Tweepy 调用 Twitter API
- 构建 Twitter 机器人
- 使用 Docker 和 AWS 将机器人部署到服务器上
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
你好 Tweepy
首先,你可以使用 Tweepy 创建一条 tweet,说Hello Tweepy:
import tweepy
# Authenticate to Twitter
auth = tweepy.OAuthHandler("CONSUMER_KEY", "CONSUMER_SECRET")
auth.set_access_token("ACCESS_TOKEN", "ACCESS_TOKEN_SECRET")
# Create API object
api = tweepy.API(auth)
# Create a tweet
api.update_status("Hello Tweepy")
这是一个简短的示例,但它显示了所有 Tweepy 程序共有的四个步骤:
- 导入
tweepy包 - 设置身份验证凭据
- 创建一个新的
tweepy.API对象 - 使用
api对象调用 Twitter API
属于tweepy.API类的对象提供了大量的方法,可以用来访问几乎所有的 Twitter 功能。在代码片段中,我们使用了update_status()来创建一条新的 Tweet。
我们将在本文后面看到身份验证是如何工作的,以及如何创建所需的身份验证密钥、令牌和秘密。
这只是用 Tweepy 可以做的一个小例子。通过这篇文章,您将学习如何构建以更加有趣和复杂的方式与 Twitter 交互的程序。
Twitter API
Twitter API 让开发者可以使用 Twitter 的大部分功能。您可以使用 API 来读取和写入与 Twitter 实体相关的信息,比如 tweets、用户和趋势。
从技术上讲,该 API 公开了许多与以下内容相关的 HTTP 端点:
- 小鸟叫声
- 转发
- 喜欢
- 直接消息
- 收藏夹
- 趋势
- 媒体
正如我们将在后面看到的,Tweepy 提供了一种无需处理底层细节就能调用那些 HTTP 端点的方法。
Twitter API 使用 OAuth (一种广泛使用的开放授权协议)来认证所有请求。在调用 Twitter API 之前,您需要创建和配置您的身份验证凭证。在本文的后面,您将找到这方面的详细说明。
您可以利用 Twitter API 来构建不同种类的自动化,例如机器人、分析和其他工具。请记住,Twitter 对使用它的 API 能做什么和不能做什么施加了一定的限制和政策。这样做是为了保证用户有良好的体验。禁止开发垃圾邮件、误导用户等工具。
Twitter API 还对允许调用 API 方法的频率施加了速率限制。如果超过这些限制,您必须等待 5 到 15 分钟才能再次使用该 API。您必须在设计和实现机器人时考虑这一点,以避免不必要的等待。
您可以在其官方文档中找到关于 Twitter API 的政策和限制的更多信息:
什么是 Tweepy?
Tweepy 是一个开源的 Python 包,给你一个非常方便的方法来用 Python 访问 Twitter API。Tweepy 包括一组表示 Twitter 模型和 API 端点的类和方法,它透明地处理各种实现细节,例如:
- 数据编码和解码
- HTTP 请求
- 结果分页
- OAuth 认证
- 费率限制
- 流
如果您没有使用 Tweepy,那么您必须处理与 HTTP 请求、数据序列化、身份验证和速率限制有关的底层细节。这可能很耗时,并且容易出错。相反,由于 Tweepy,您可以专注于您想要构建的功能。
Twitter API 提供的几乎所有功能都可以通过 Tweepy 使用。从 3.7.0 版本开始,目前唯一的限制是,由于 Twitter API 最近的一些变化,直接消息不能正常工作。
使用 Tweepy
在本节中,您将学习如何安装 Tweepy for development、配置身份验证凭证以及与 Twitter API 交互。
安装
Tweepy 可以使用 Python 包管理器 pip 来安装。在本文中,我们将为项目使用一个虚拟环境( virtualenv ),以避免依赖系统范围的软件包。有关虚拟环境和 pip 的更多信息,请查看 Python 虚拟环境:初级读本和什么是 Pip?新蟒蛇指南。
您可以通过创建一个名为tweepy-bots的项目开始。第一步是创建目录和虚拟环境:
$ mkdir tweepy-bots
$ cd tweepy-bots
$ python3 -m venv venv
上面的命令在项目目录中创建虚拟环境。
然后就可以安装 Tweepy 包了。首先,您需要激活新创建的虚拟环境,然后使用 pip 进行安装:
$ source ./venv/bin/activate
$ pip install tweepy
现在 Tweepy 已经安装好了,让我们创建一个包含您的依赖项的名称的requirements.txt文件。您可以使用 pip 命令冻结来完成该任务:
$ pip freeze > requirements.txt
您将在部署项目时使用这个requirements.txt文件。
注意:用于激活虚拟环境的方法可能会有所不同,这取决于您的操作系统和 shell。你可以在 venv 文档中了解更多。
创建 Twitter API 认证证书
正如我们之前看到的,Twitter API 要求所有请求都使用 OAuth 进行身份验证。因此,您需要创建必需的身份验证凭证,以便能够使用 API。这些凭据是四个文本字符串:
- 消费者密钥
- 消费者秘密
- 访问令牌
- 访问机密
如果您已经有了一个 Twitter 用户帐户,那么按照以下步骤创建密钥、令牌和秘密。否则,你必须注册成为 Twitter 用户才能继续。
第一步:申请 Twitter 开发者账户
去 Twitter 开发者网站申请一个开发者账号。在这里,您必须选择负责该帐户的 Twitter 用户。大概应该是你或者你的组织。该页面如下所示:
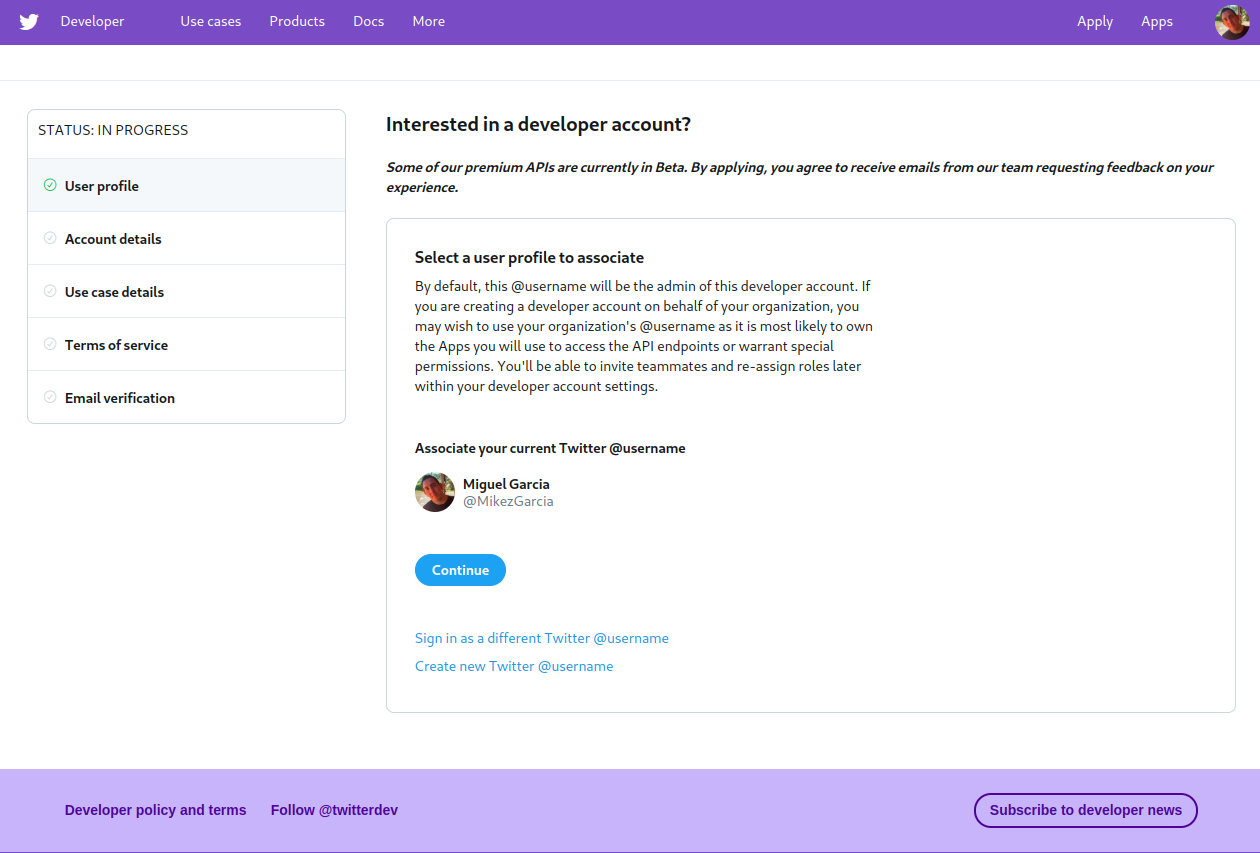
在这种情况下,我选择用自己的账号, @MikezGarcia 。
Twitter 随后会询问一些关于你打算如何使用开发者账户的信息,如下所示:
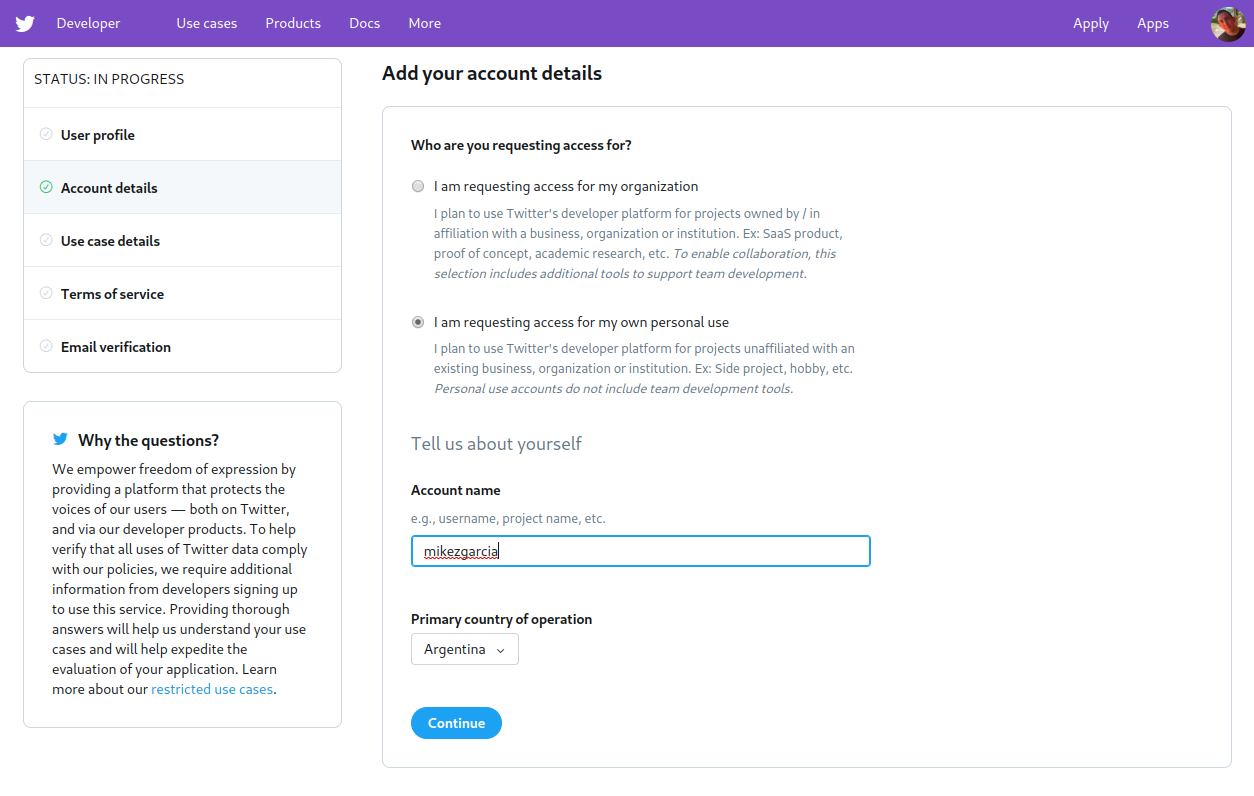
您必须指定开发人员帐户名,以及您计划将其用于个人目的还是用于您的组织。
第二步:创建一个应用程序
Twitter 向应用程序授予认证证书,而不是帐户。一个应用可以是任何使用 Twitter API 的工具或机器人。因此,您需要注册您的应用程序才能进行 API 调用。
要注册你的应用,进入你的 Twitter 应用页面,选择创建应用选项。
你需要提供关于你的应用程序及其用途的以下信息:
- 应用程序名称:用于标识您的应用程序的名称(如 examplebot
- 应用描述:你的应用的目的(比如一个真实 Python 文章的示例 bot
- 您或您的应用程序的网站 URL: 必需,但可以是您的个人网站的 URL,因为机器人不需要 URL 来工作
- app 的使用:用户会如何使用你的 app(比如这个 app 是一个会自动回复用户的 bot
步骤 3:创建认证凭证
要创建认证凭证,请前往您的 Twitter 应用页面。以下是应用页面的外观:

在这里你可以找到你的应用程序的细节按钮。单击此按钮将转到下一页,您可以在此生成凭据。
通过选择密钥和令牌选项卡,您可以生成并复制密钥、令牌和秘密,以便在您的代码中使用它们:
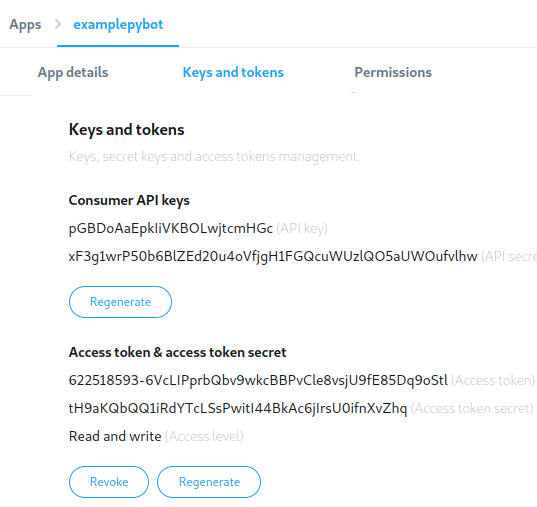
生成凭据后,保存它们以便以后在代码中使用。
您可以使用以下代码片段测试凭据:
import tweepy
# Authenticate to Twitter
auth = tweepy.OAuthHandler("pGBDoAaEpkliVKBOLwjtcmHGc",
"xF3g1wrP50b6BlZEd20u4oVfjgH1FGQcuWUzlQO5aUWOufvlhw")
auth.set_access_token("622518493-6VcLIPprbQbv9wkcBBPvCle8vsjU9fE85Dq9oStl",
"tH9aKQbQQ1iRdYTcLSsPwitl44BkAc6jilrsU0ifnXvZhq")
api = tweepy.API(auth)
try:
api.verify_credentials()
print("Authentication OK")
except:
print("Error during authentication")
在这个代码片段中,使用verify_credentials()测试凭证。如果一切顺利,您应该会看到一条消息,说认证成功。
注意:本文中使用的所有凭据都只是示例,不起作用。你必须生成并使用你自己的凭证。
回顾 Tweepy 功能
Tweepy 为您提供了一个从 Python 访问 Twitter API 的接口。它通过封装 Twitter API 的复杂性,并在其上添加模型层和其他有用的功能来做到这一点。
由于随着时间的推移,各种 Twitter 概念的名称已经发生了变化,一些旧名称仍然在 Tweepy 中使用。因此请记住,在本文的上下文中,这些等价关系成立:
- 一条状态是一条推文。
- 一种友谊是一种追随关系。
- 一个喜欢的是一个喜欢的。
现在你知道 Tweepy 是如何命名事物的了,让我们看看它是如何工作的。
Tweepy 的功能可分为以下几组:
- OAuth
- API 类
- 模型
- 光标
- 流
现在,您将了解这些组,了解每个组提供的功能。
OAuth
Tweepy 负责使用 Twitter API 认证每个请求所需的 OAuth 的所有细节。它提供了一个OAuthHandler类,可以用来设置所有 API 调用中使用的凭证。
这段代码片段展示了如何创建一个OAuthHandler对象,该对象稍后可用于 API 调用:
import tweepy
# Authenticate to Twitter
auth = tweepy.OAuthHandler("CONSUMER_KEY", "CONSUMER_SECRET")
auth.set_access_token("ACCESS_TOKEN", "ACCESS_TOKEN_SECRET")
这里您告诉 Tweepy 使用您在步骤 3:创建认证凭证中创建的凭证。您必须用之前生成的值替换CONSUMER_KEY、CONSUMER_SECRET、ACCESS_TOKEN和ACCESS_TOKEN_SECRET。
API 类
API类有许多方法提供对 Twitter API 端点的访问。使用这些方法,您可以访问 Twitter API 的功能。
下面的代码片段创建了一个API对象,您可以用它来调用 Twitter API 方法。将wait_on_rate_limit和wait_on_rate_limit_notify设置为True会使 API 对象打印一条消息,并在超过速率限制时等待:
import tweepy
# Authenticate to Twitter
auth = tweepy.OAuthHandler("CONSUMER_KEY", "CONSUMER_SECRET")
auth.set_access_token("ACCESS_TOKEN", "ACCESS_TOKEN_SECRET")
# Create API object
api = tweepy.API(auth, wait_on_rate_limit=True,
wait_on_rate_limit_notify=True)
在上面的代码中,我们已经设置了认证凭证并创建了一个api对象。您可以调用该对象的方法来进行任何 API 调用。
API方法可分为以下几类:
- 用户时间线的方法
- 推文的方法
- 用户方法
- 追随者的方法
- 您的帐户的方法
- 喜欢的方法
- 阻止用户的方法
- 搜索方法
- 趋势方法
- 流式传输方法
在下面的小节中,您将回顾不同组的 API 方法。你可以访问 API 类文档来获得所有 API 方法的详细列表。
用户时间线的方法
这些方法处理从你的时间线或任何其他用户的时间线读取推文、提及和转发,只要它是公开的。
此代码片段打印了您的家庭时间轴中最后一条推文的作者和文本:
timeline = api.home_timeline()
for tweet in timeline:
print(f"{tweet.user.name} said {tweet.text}")
home_timeline(),一个 Tweepy API 方法,用于获取你的时间线中的最后 20 个条目。20 是 Tweepy 中的默认值。稍后您将看到如何获得 20 个以上的结果并处理分页的结果。
推文方法
这些方法与创建、获取和转发推文有关。
下面的代码使用 Tweepy 创建一条带有一些文本的 tweet:
api.update_status("Test tweet from Tweepy Python")
我们已经使用update_status()从 Python 字符串创建了一条新的 tweet。
用户方法
该组中的方法使您能够使用过滤标准搜索用户,获取用户详细信息,并列出任何用户的关注者,只要该用户帐户是公共的。
下面的代码片段获取我的用户, @MikezGarcia ,然后打印它的详细信息以及它最近的 20 个关注者:
user = api.get_user("MikezGarcia")
print("User details:")
print(user.name)
print(user.description)
print(user.location)
print("Last 20 Followers:")
for follower in user.followers():
print(follower.name)
get_user()返回一个包含用户详细信息的对象。这个返回的对象也有访问与用户相关的信息的方法。您使用了followers属性来获取关注者列表。
追随者的方法
这组方法处理关注和不关注用户,查询用户的关注者,并列出任何用户正在关注的帐户。
这段代码展示了如何使用 Tweepy 开始跟随 @realpython :
api.create_friendship("realpython")
create_friendship()将 @realpython 添加到您关注的帐户列表中。
您的账户方式
这些方法允许您读取和写入自己的个人资料详细信息。
例如,您可以使用以下代码片段来更新您的个人资料描述:
api.update_profile(description="I like Python")
关键字参数description被传递给update_profile()以将您的个人资料描述更改为"I like Python"。
喜欢的方法
使用这些 API 方法,你可以将任何推文标记为喜欢或者移除喜欢的标记,如果它已经被添加的话。
您可以在您的个人日程表中将最近的推文标记为喜欢的,如下所示:
tweets = api.home_timeline(count=1)
tweet = tweets[0]
print(f"Liking tweet {tweet.id} of {tweet.author.name}")
api.create_favorite(tweet.id)
这段代码使用home_timeline()获取最近的 tweet。然后,tweet.id被传递给create_favorite()以将推文标记为喜欢。
阻止用户的方法
这组方法处理阻止和解除阻止用户,以及列出被阻止的用户。
以下是查看您阻止的用户的方式:
for block in api.blocks():
print(block.name)
此代码遍历您已阻止的帐户列表。你可以用blocks()得到这个列表。
搜索方法
使用这些方法,您可以使用文本、语言和其他过滤器来搜索推文。
例如,您可以尝试使用以下代码来获取最近 10 条包含单词"Python"的英文公共 tweets:
for tweet in api.search(q="Python", lang="en", rpp=10):
print(f"{tweet.user.name}:{tweet.text}")
您使用了search()来过滤符合期望标准的推文。这将搜索任何公开的推文,而不仅仅是你关注的人的推文。
趋势方法
这组方法允许您列出任何地理位置的当前趋势。
例如,以下是如何列出全球热门话题:
trends_result = api.trends_place(1)
for trend in trends_result[0]["trends"]:
print(trend["name"])
使用trends_place(),您可以获得任何地点的趋势列表,将地点 id 作为唯一参数传递。在这里,1的意思是全球范围的。您可以使用api.trends_available()查看可用位置的完整列表。
流式传输的方法
流媒体允许你在实时中主动观看符合特定标准的推文。这意味着当没有任何新的 tweet 符合标准时,程序将等待直到一个新的 tweet 被创建,然后处理它。
要使用流,您必须创建两个对象:
- 流对象使用 Twitter API 获取符合某些标准的推文。这个对象是推文的来源,然后由流监听器处理。
- 流监听器从流中接收 tweets。
你可以这样做:
import json
import tweepy
class MyStreamListener(tweepy.StreamListener):
def __init__(self, api):
self.api = api
self.me = api.me()
def on_status(self, tweet):
print(f"{tweet.user.name}:{tweet.text}")
def on_error(self, status):
print("Error detected")
# Authenticate to Twitter
auth = tweepy.OAuthHandler("CONSUMER_KEY", "CONSUMER_SECRET")
auth.set_access_token("ACCESS_TOKEN", "ACCESS_TOKEN_SECRET")
# Create API object
api = tweepy.API(auth, wait_on_rate_limit=True,
wait_on_rate_limit_notify=True)
tweets_listener = MyStreamListener(api)
stream = tweepy.Stream(api.auth, tweets_listener)
stream.filter(track=["Python", "Django", "Tweepy"], languages=["en"])
你声明了一个新类,MyStreamListener。这个类用于流监听器tweets_listener。通过扩展 Tweepy 的StreamLister,我们重用了所有流监听器通用的代码。来自流的推文由on_status()处理。
我们使用tweepy.Stream创建了流,传递了认证凭证和我们的流监听器。要开始从流中获取推文,您必须调用流的filter(),传递用于过滤推文的标准。然后,对于每个符合标准的新 tweet,流对象调用流监听器的on_status()。
型号
Tweepy 使用自己的模型类封装来自各种 Twitter API 方法的响应。这为您提供了一种使用 API 操作结果的便捷方式。
模型类包括:
UserStatusFriendshipSearchResults
假设您想要获取每条提到您的推文,然后将每条推文标记为喜欢并关注其作者。你可以这样做:
tweets = api.mentions_timeline()
for tweet in tweets:
tweet.favorite()
tweet.user.follow()
因为由mentions_timeline()返回的每个tweet对象都属于Status类,所以可以使用:
favorite()将其标注为名不虚传user取其作者
这个用户属性tweet.user也是一个属于User的对象,因此您可以使用follow()将推文作者添加到您关注的人列表中。
利用 Tweepy 模型使您能够创建简明易懂的代码。
光标
许多 Twitter API 端点使用分页来返回结果。默认情况下,每个方法返回第一页,通常包含几十个项目。
十二游标消除了处理分页结果的部分复杂性。游标被实现为一个名为Cursor的 Tweepy 类。要使用游标,请选择用于提取项目的 API 方法和所需的项目数。Cursor对象负责透明地获取各种结果页面。
这段代码展示了如何通过使用光标,不仅可以从时间轴中获取第一页,还可以获取最后 100 条推文:
for tweet in tweepy.Cursor(api.home_timeline).items(100):
print(f"{tweet.user.name} said: {tweet.text}")
使用tweepy.Cursor创建光标对象。类构造函数接收一个 API 方法作为结果的来源。在这个例子中,我们使用home_timeline()作为源,因为我们想要来自时间轴的 tweets。Cursor对象有一个items()方法,它返回一个 iterable,您可以用它来迭代结果。您可以向items()传递您想要获得的结果项的数量。
如何用 Tweepy 用 Python 制作一个 Twitter 机器人
现在你知道 Tweepy 是如何工作的了,让我们看看如何用 Tweepy 用 Python 制作一个 Twitter 机器人。机器人的工作原理是持续观察的一些 Twitter 活动,然后自动对做出反应。
关注 Twitter 活动
有两种方法可以持续观察 Twitter 活动:
- 使用流:当新内容(比如 tweets)符合特定标准时被通知
- 使用轮询:定期进行 Tweepy API 调用,然后检查它们的结果,看它们是否包含新的内容
选择哪个选项取决于您的用例。使用流是最有效的选择,但你只能观看与推文相关的活动,所以它不太灵活。在本节中,这两个选项都用于构建不同的机器人。
展示示例机器人
在本文中,您将了解如何构建三个不同的机器人来执行自动操作,以对一些 Twitter 事件做出反应:
- 跟随者机器人自动跟随任何跟随你的人。
- 最喜欢的&转发机器人自动喜欢并转发符合特定标准的推文。
- 回复提及机器人会自动回复包含
help或support字样的提及你的推文。
我们将使用一个名为bots的目录来存储项目的所有 Python 文件,如下所示:
tweepy-bots/
│
├── bots/
│ ├── config.py
│ └── followfollowers.py
│ └── favretweet.py
│ └── autoreply.py
│
└── requirements.txt
下一节解释了config模块。
配置模块
我们正在构建的所有机器人都有一些共同的功能。例如,他们需要通过 Twitter API 的认证。
您可以创建一个包含所有机器人通用逻辑的可重用 Python 模块。我们将这个模块命名为config。
该模块从环境变量中读取身份验证凭证,并创建 Tweepy API 对象。通过从环境变量中读取凭证,您可以避免将它们硬编码到源代码中,从而更加安全。
机器人将从这些环境变量中读取凭证:
CONSUMER_KEYCONSUMER_SECRETACCESS_TOKENACCESS_TOKEN_SECRET
稍后,您将看到如何设置这些变量来匹配您之前为 Twitter 应用程序生成的凭证。
下面是config模块的完整源代码。它包含create_api(),一个从环境变量中读取认证凭证并创建 Tweepy API 对象的函数:
# tweepy-bots/bots/config.py
import tweepy
import logging
import os
logger = logging.getLogger()
def create_api():
consumer_key = os.getenv("CONSUMER_KEY")
consumer_secret = os.getenv("CONSUMER_SECRET")
access_token = os.getenv("ACCESS_TOKEN")
access_token_secret = os.getenv("ACCESS_TOKEN_SECRET")
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit=True,
wait_on_rate_limit_notify=True)
try:
api.verify_credentials()
except Exception as e:
logger.error("Error creating API", exc_info=True)
raise e
logger.info("API created")
return api
这段代码使用os.getenv()读取环境变量,然后创建 Tweepy auth对象。然后创建 API 对象。
在创建tweepy.API对象时传递wait_on_rate_limit和wait_on_rate_limit_notify会让 Tweepy 等待,并在超过速率限制时打印一条消息。
在返回 API 对象之前,create_api()调用verify_credentials()来检查凭证是否有效。
这个模块,以及您将在后面看到的机器人源代码,使用logging Python 模块通知错误和信息消息,如果出现任何问题,帮助您调试它们。你可以在 Python 的日志中了解更多信息。
跟随者机器人
这个机器人每分钟从 Twitter 获取你的关注者列表,然后遍历它来关注你还没有关注的每个用户。
Bot 源代码
这是这个机器人的完整源代码。它使用先前创建的config模块、Tweepy API 和游标:
#!/usr/bin/env python
# tweepy-bots/bots/followfollowers.py
import tweepy
import logging
from config import create_api
import time
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
def follow_followers(api):
logger.info("Retrieving and following followers")
for follower in tweepy.Cursor(api.followers).items():
if not follower.following:
logger.info(f"Following {follower.name}")
follower.follow()
def main():
api = create_api()
while True:
follow_followers(api)
logger.info("Waiting...")
time.sleep(60)
if __name__ == "__main__":
main()
main()使用之前创建的config模块中的create_api()创建一个 Tweepy API 对象。然后,在一个循环内部,follow_followers()每分钟被调用一次。
follow_followers()使用 Tweepy 光标和 Tweepy API 方法followers()获取你的关注者列表。此列表包含关注您的每个用户的十二人用户模型。
然后,机器人遍历列表,并使用following来检查您是否已经关注了每个用户。使用follow()关注尚未被关注的用户。
运行机器人
要运行 bot,您必须首先为身份验证凭证创建环境变量。为此,您可以从终端运行以下命令,并用您的实际凭据替换这些值:
$ export CONSUMER_KEY="pGBDoAaEpkliVKBOLwjtcmHGc"
$ export CONSUMER_SECRET="xF3g1wrP50b6BlZEd20u4oVfjgH1FGQcuWUzlQO5aUWOufvlhw"
$ export ACCESS_TOKEN="622518493-6VcLIPprbQbv9wkcBBPvCle8vsjU9fE85Dq9oStl"
$ export ACCESS_TOKEN_SECRET="tH9aKQbQQ1iRdYTcLSsPwitl44BkAc6jilrsU0ifnXvZhq"
注意:这里假设你使用的是 Linux 或 macOS 。如果您使用的是 Windows,那么步骤可能会有所不同。
运行这些命令后,您的环境变量将包含使用 Twitter API 所需的凭证。
接下来,您必须激活您的虚拟环境并运行 bot 的主文件bots/followfollowers.py:
$ source ./venv/bin/activate
$ python bots/followfollowers.py
当它运行时,机器人会跟随任何跟随你的人。你可以通过取消跟踪正在跟踪你的人来测试它是否有效。一分钟后,他们又会被跟踪。你可以使用Ctrl-C来停止这个机器人。
最喜欢的转发机器人
这个机器人使用之前引入的 Tweepy 流来主动观察包含特定关键字的推文。对于每条推文,如果你不是推文作者,它会将推文标记为喜欢,然后转发。
你可以使用这个机器人向你的账户提供与你兴趣相关的内容。
Bot 源代码
下面,你可以看到这个机器人的完整源代码。它使用一个流来过滤包含单词"Python"或"Tweepy"的推文。来自信息流的每条推文都被标记为喜欢并被转发:
#!/usr/bin/env python
# tweepy-bots/bots/favretweet.py
import tweepy
import logging
from config import create_api
import json
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
class FavRetweetListener(tweepy.StreamListener):
def __init__(self, api):
self.api = api
self.me = api.me()
def on_status(self, tweet):
logger.info(f"Processing tweet id {tweet.id}")
if tweet.in_reply_to_status_id is not None or \
tweet.user.id == self.me.id:
# This tweet is a reply or I'm its author so, ignore it
return
if not tweet.favorited:
# Mark it as Liked, since we have not done it yet
try:
tweet.favorite()
except Exception as e:
logger.error("Error on fav", exc_info=True)
if not tweet.retweeted:
# Retweet, since we have not retweeted it yet
try:
tweet.retweet()
except Exception as e:
logger.error("Error on fav and retweet", exc_info=True)
def on_error(self, status):
logger.error(status)
def main(keywords):
api = create_api()
tweets_listener = FavRetweetListener(api)
stream = tweepy.Stream(api.auth, tweets_listener)
stream.filter(track=keywords, languages=["en"])
if __name__ == "__main__":
main(["Python", "Tweepy"])
与前面的 bot 一样,main 函数使用来自config模块的create_api()来创建 Tweepy API 对象。
创建一个 Tweepy 流来过滤英语的 Tweepy,其中包含 main 函数参数中指定的一些关键字,在本例中为"Python"或"Tweepy"。
FavRetweetListener的on_status()处理来自流的推文。该方法接收一个状态对象,并使用favorite()和retweet()将推文标记为喜欢并转发。
为了避免转发和喜欢回复其他推文的推文,on_status()使用一个if来查看in_reply_to_status_id是否不是 None 。此外,代码会检查您是否是推文作者,以避免转发和喜欢您自己的内容。
您可以使用与上一个 bot 相同的指令运行这个 bot,将 Python 程序改为favretweet.py。
的回复提到了 Bot
这个机器人定期获取提到你的推文。如果这条推文不是对另一条推文的回复,并且它包含单词"help"或"support",那么该推文的作者将被跟踪,并且该推文将被另一条推文回复为"Please reach us via DM"。
你可以使用这个机器人来自动化回答你的追随者的问题的初始过程。
Bot 源代码
这是这个机器人的完整源代码。它使用光标获取你的提及:
#!/usr/bin/env python
# tweepy-bots/bots/autoreply.py
import tweepy
import logging
from config import create_api
import time
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger()
def check_mentions(api, keywords, since_id):
logger.info("Retrieving mentions")
new_since_id = since_id
for tweet in tweepy.Cursor(api.mentions_timeline,
since_id=since_id).items():
new_since_id = max(tweet.id, new_since_id)
if tweet.in_reply_to_status_id is not None:
continue
if any(keyword in tweet.text.lower() for keyword in keywords):
logger.info(f"Answering to {tweet.user.name}")
if not tweet.user.following:
tweet.user.follow()
api.update_status(
status="Please reach us via DM",
in_reply_to_status_id=tweet.id,
)
return new_since_id
def main():
api = create_api()
since_id = 1
while True:
since_id = check_mentions(api, ["help", "support"], since_id)
logger.info("Waiting...")
time.sleep(60)
if __name__ == "__main__":
main()
与其他机器人一样,main 函数创建一个 Tweepy API 对象。之后,它用值1初始化变量since_id。该变量仅用于获取在已经处理之后创建的提及。
在一个循环中,check_mentions()每分钟被调用一次。
这个函数使用一个 Tweepy 光标和mentions_timeline()来获取所有提到你的推文,这些推文的id大于since_id变量。
对于每一条提到你的推文,如果你还没有关注它们,就用tweet.user.follow()来关注它的作者。
然后使用update_status()创建对推文的回复,将原始推文的id作为in_reply_to_status_id传递。
check_mentions()返回处理量最大的 tweet id。这些信息将在下一次调用中用作since_id,只查找比已经获取的推文更新的推文。
您可以使用之前使用的相同指令来运行 bot。把 Python 程序改成autoreply.py就行了。
使用 Docker 将机器人部署到服务器
能够在你的本地机器上运行你的 Twitter 机器人对于开发来说很好,但是对于生产来说,你可能需要在服务器上运行你的机器人。本节详细介绍了如何使用 Docker 打包 bot 及其依赖项,然后将其部署到服务器上。
注意:这只是将 Twitter 机器人部署到服务器的一种方式。
Docker 提供了一种将任何应用程序打包到 Docker 映像中的方法,该映像不仅包含应用程序本身,还包含它的所有依赖项。您可以在 Docker in Action 中了解更多关于 Docker 及其设置的信息——更健康、更快乐、更高效
构建 Docker 映像
要打包您的 bot 或应用程序,您必须在项目的根目录中创建一个 Dockerfile 。该文件包含一组指令,用于创建包含您的应用程序的 Docker 映像。
您的项目结构应该是这样的:
tweepy-bots/
│
├── bots/
│ ├── config.py
│ └── followfollowers.py
│ └── favretweet.py
│ └── autoreply.py
│
├── requirements.txt
└── Dockerfile
如您所见,Dockerfile和requirements.txt位于您的项目顶层目录中。
您可以使用下面的 docker 文件为 Fav & Retweet bot 创建图像。它使用Python:3.7-alpine作为基础图像。我们选择这个图像作为基础,因为它非常小,包含 Python3.7 和 pip。然后,这个 Dockerfile 将 bot 代码和requirements.txt文件复制到映像中。最后,使用 pip3 将依赖项安装到映像中:
FROM python:3.7-alpine
COPY bots/config.py /bots/
COPY bots/favretweet.py /bots/
COPY requirements.txt /tmp
RUN pip3 install -r /tmp/requirements.txt
WORKDIR /bots
CMD ["python3", "favretweet.py"]
最后一行说明了使用这个映像时必须运行什么命令。
现在,您可以使用以下命令构建映像:
$ docker build . -t fav-retweet-bot
然后,使用docker images命令,您可以看到新生成的图像的细节。
最后,您可以使用docker run命令来测试图像,向它传递保存认证凭证的环境变量:
$ docker run -it -e CONSUMER_KEY="uDRNy31oWfoiKV9AvPoNavy0I" \
-e CONSUMER_SECRET="lnAL5VAgZLWNspQVpd3X6tEo47PRCmsPEwuxpvLCLSR08DMa4O" \
-e ACCESS_TOKEN="622518593-j7gWSqzQO31ju7Bf7idB47NlZeSENsuADGU9B69I" \
-e ACCESS_TOKEN_SECRET="iutFsxvP5IglRckJ1I1why6017xMNkzxqBID48Azw0GvT" \
fav-retweet-bot
当它运行时,你会在屏幕上看到机器人的日志输出。
同样的过程可以用来为其他机器人创建 Docker 映像。
示例:将 Twitter 机器人部署到亚马逊 AWS
现在 Docker 映像已经准备好了,有很多方法可以部署它在任何服务器上运行。在本节中,您将看到一种方法,可以用来在亚马逊 AWS 的 服务器上部署机器人。这个设置使用一个亚马逊 AWS EC2 实例,就像一个虚拟服务器,来运行 Docker 映像。
注意:你需要一个亚马逊 AWS 账户来执行这些步骤。本文中使用的所有资源都符合 AWS 免费层的条件,所以如果您是 AWS 新手,那么您将不会被收费。
第一步:导出 Docker 图像
在创建 Docker 映像的计算机上,运行这些命令将其导出到文件中并进行压缩。稍后您将使用该文件将图像上传到您的 EC2 实例:
$ docker image save fav-retweet-bot:latest -o fav-retweet-bot.tar
$ gzip fav-retweet-bot.tar
现在图像已经压缩成fav-retweet-bot.tar.gz。
步骤 2:创建一个 Amazon EC2 实例
AWS 的第一步是创建一个新的 EC2 实例。机器人将在这个实例中运行。登录到您的 AWS 控制台,选择 EC2 服务,并选择实例。您会看到类似这样的内容:
点击启动实例按钮,选择 Ubuntu Server 18.04 作为基础镜像:
现在您可以选择实例类型。这个要看你的 bot 需要的计算资源。对于本文中描述的机器人, t2.micro 实例类型是一个很好的起点。选中后点击查看并启动:
在下一页,您可以查看和检查您的配置。然后点击 Launch 按钮开始创建 EC2 实例:
在你点击了 Launch 之后,你将被要求创建一个密钥对。它允许您连接到实例并部署 bot Docker 映像。选择创建新的密钥对,输入密钥对名称,下载密钥对。
记住你在哪里下载密钥对。你以后会需要它的。
然后点击启动实例按钮继续:
您将看到一个页面,显示正在创建您的实例。单击查看实例按钮查看实例的状态:
首先,您的实例状态将是 pending 。你必须等到它过渡到运行:


步骤 3:在 EC2 实例中安装 Docker
现在,您必须使用 SSH 连接到您的实例,以便在其上安装 Docker。
如果在前面的屏幕中,右键单击您的实例,您会发现一个上下文菜单。选择连接选项,查看如何使用 SSH 进行连接:
此对话框显示了如何连接到您的实例:
注意: ec2-3-86-66-73.compute-1.amazonaws.com是 AWS 分配给本文中使用的实例的地址,但对您来说可能会有所不同。
首先,使用以下命令更改密钥对文件的权限。否则,您将无法使用这个密钥对连接到 EC2 实例:
$ chmod 400 mykeypair.pem
然后使用 SSH 连接到您的实例。您可以从连接到您的实例对话框中复制您需要执行的命令:
$ ssh -i "mykeypair.pem" ubuntu@ec2-3-86-66-73.compute-1.amazonaws.com
一旦连接完毕,运行以下命令在实例中安装 Docker:
ubuntu@ip-172-31-44-227:~$ sudo apt-get update
ubuntu@ip-172-31-44-227:~$ sudo apt install docker.io
ubuntu@ip-172-31-44-227:~$ sudo adduser ubuntu docker
ubuntu@ip-172-31-44-227:~$ exit
安装后退出 SSH 会话很重要,这样在下次登录时,您的用户权限将被重新加载。
第四步:上传你的机器人的 Docker 图像
从您的本地计算机,使用scp将 bot Docker 映像上传到您的实例。这可能需要一些时间,具体取决于您的互联网连接:
$ scp -i "mykeypair.pem" fav-retweet-bot.tar.gz \
ubuntu@ec2-3-86-66-73.compute-1.amazonaws.com:/tmp
映像上传完成后,使用 SSH 再次登录到您的实例:
$ ssh -i "mykeypair.pem" ubuntu@ec2-3-86-66-73.compute-1.amazonaws.com
在您的实例中运行以下命令来解压缩和导入 Docker 映像:
ubuntu@ip-172-31-44-227:~$ gunzip /tmp/fav-retweet-bot.tar.gz
ubuntu@ip-172-31-44-227:~$ docker image load -i /tmp/fav-retweet-bot.tar
步骤 5:运行你的机器人的 Docker 镜像
部署 bot 的最后一步是在 EC2 实例中运行 Docker 映像,向它传递身份验证凭证。
您可以使用docker命令来完成此操作。传递标志-d和--restart-always可以确保如果您从 SSH 会话断开连接或者如果实例重新启动,bot 将继续运行:
ubuntu@ip-172-31-44-227:~$ docker run -d --restart always \
-e CONSUMER_KEY="uDRNy31oWfoiKV9AvPoNavy0I" \
-e CONSUMER_SECRET="lnAL5VAgZLWNspQVpd3X6tEo47PRCmsPEwuxpvLCLSR08DMa4O" \
-e ACCESS_TOKEN="622518593-j7gWSqzQO31ju7Bf7idB47NlZeSENsuADGU9B69I" \
-e ACCESS_TOKEN_SECRET="iutFsxvP5IglRckJ1I1why6017xMNkzxqBID48Azw0GvT" \
fav-retweet-bot
使用docker ps,您可以检查 bot 是否正在运行,并找到它的容器id。最后,使用docker logs命令和容器id,您可以检查机器人的输出,看看它是否正常工作:
$ ubuntu@ip-172-31-44-227:~$ docker logs e6aefe73a885
INFO:root:API created
INFO:root:Processing tweet id 1118276911262785538
INFO:root:Processing tweet id 1118276942162214918
INFO:root:Processing tweet id 1118276990853951488
INFO:root:Processing tweet id 1118277032360722433
INFO:root:Processing tweet id 1118277034466324480
现在,即使您从 SSH 会话中断开连接或关闭计算机,bot 将继续在您的 AWS EC2 实例上运行。
免费 AWS 资源
为了节省资源和资金(如果您的 AWS 自由层期已经结束),您可以停止或终止 EC2 实例:
停止它将允许您在将来重新启动它,但是它仍然会消耗一些与您的实例存储相关的资源。相比之下,如果您终止 EC2 实例,那么它的所有资源都将被释放,但是您将无法重新启动它。
使用 AWS 还有很多事情要做,比如创建实例的 AWS 映像,但这超出了本文的范围。
总结
构建自己的 Twitter 机器人可以让你的 Twitter 形象更上一层楼。通过使用机器人,你可以自动创建内容和其他 Twitter 活动。这可以节省你很多时间,给你的观众更好的体验。
Tweepy 包隐藏了许多 Twitter API 的底层细节,允许您专注于 Twitter 机器人的逻辑。
在本文中,您学习了如何:
- 改善并自动化您与 Twitter 受众的互动
- 安装 Tweepy
- 注册成为 Twitter 开发者来使用它的 API
- 使用 Tweepy 调用 Twitter API
- 构建 Twitter 机器人
- 使用 Docker 和 AWS 将机器人部署到服务器上
您可以使用本文中的机器人作为自动化部分 Twitter 活动的起点。不要忘记看一下整个 Tweepy API 文档,并发挥你的想象力来制作对你的用例有意义的更复杂的机器人。
你也可以探索一下聊天机器人、 InstaPy 、 Discord 和 Alexa Skills 的可能性,以了解如何使用 Python 为不同平台制作机器人。********
flask by Example–更新暂存环境
在这一部分中,我们将在 Heroku 上设置 Redis,并了解当我们使用字数统计功能更新暂存环境时,如何在一个 dyno 上运行 web 和 worker 进程。
更新:
- 03/22/2016:升级到 Python 版本 3.5.1 。
- 2015 年 2 月 22 日:添加了 Python 3 支持。
记住:这是我们正在构建的——一个 Flask 应用程序,它根据来自给定 URL 的文本计算词频对。
- 第一部分:建立一个本地开发环境,然后在 Heroku 上部署一个试运行环境和一个生产环境。
- 第二部分:使用 SQLAlchemy 和 Alembic 建立一个 PostgreSQL 数据库来处理迁移。
- 第三部分:添加后端逻辑,使用 requests、BeautifulSoup 和 Natural Language Toolkit (NLTK)库从网页中抓取并处理字数。
- 第四部分:实现一个 Redis 任务队列来处理文本处理。
- 第五部分:在前端设置 Angular,持续轮询后端,看请求是否处理完毕。
- 第六部分:推送到 Heroku 上的临时服务器——建立 Redis 并详细说明如何在一个 Dyno 上运行两个进程(web 和 worker)。(当前 )
- 第七部分:更新前端,使其更加人性化。
- 第八部分:使用 JavaScript 和 D3 创建一个自定义角度指令来显示频率分布图。
需要代码吗?从回购中抢过来。
测试推送
从提升当前状态的代码开始,看看需要修复什么:
$ cd flask-by-example
$ git add -A
$ git commit -m "added angular and the backend worker process"
$ git push stage master
$ heroku open --app wordcount-stage
确保将
wordcount-stage替换为您的应用程序名称。
尝试运行一个快速测试,看看字数统计功能是否有效。什么都不会发生。为什么?
嗯,如果你打开“Chrome 开发者工具”中的“网络”标签,你会看到对/start端点的 post 请求返回了一个 500(内部服务器错误)状态码:
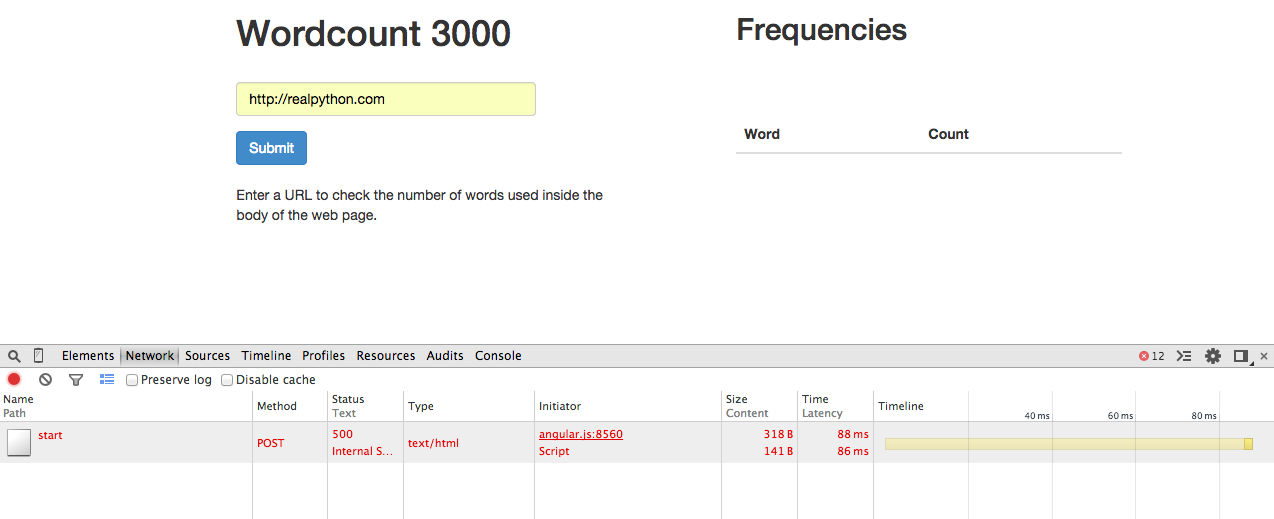
想想我们是如何在本地运行这个应用程序的:我们运行了一个工作进程和 Redis 服务器以及 Flask 开发服务器。同样的事情也需要发生在赫罗库。
再说一遍
首先向 staging 应用程序添加 Redis:
$ heroku addons:create redistogo:nano --app wordcount-stage
您可以使用以下命令进行测试,以确保已经将REDISTOGO_URL设置为环境变量:
$ heroku config --app wordcount-stage | grep REDISTOGO_URL
我们需要确保在我们的代码中链接到 Redis URI,这实际上已经设置好了。打开 worker.py 找到这个代码:
redis_url = os.getenv('REDISTOGO_URL', 'redis://localhost:6379')
这里我们首先尝试使用与环境变量REDISTOGO_URL相关的 URI。如果这个变量不存在(比如在我们的本地环境中),那么我们使用redis://localhost:6379 URI。完美。
请务必查看 Heroku 官方文档,了解更多关于使用 Redis 的信息。
有了 Redis 设置,我们现在只需要启动并运行我们的工作进程。
工人
Heroku 允许你运行一个免费的 dyno。您应该为每个 dyno 运行一个进程。在我们的例子中,web 进程应该在一个 dyno 中运行,而工作进程应该在另一个 dyno 中运行。然而,因为我们正在做一个小项目,所以有一个变通方法可以用来在一个 dyno 上运行这两个过程。请记住,这种方法不推荐用于大型项目,因为流程不会随着流量的增加而适当扩展。
首先,将名为 heroku.sh 的 bash 脚本添加到根目录:
#!/bin/bash
gunicorn app:app --daemon
python worker.py
然后,用以下内容更新 Procfile :
web: sh heroku.sh
现在,web(后台被妖魔化)和 worker(前台)进程都在 Procfile 中的 web 进程下运行。
请注意,在 Heroku 上还有其他免费运行 web 和 worker 的方法。我们将在以后的文章中探讨另一种方法(如果大家感兴趣的话)。
在推送到临时服务器之前,让我们在本地测试一下。在新的终端窗口中,运行 Redis 服务器- redis-server。然后运行 heroku local :
$ heroku local
forego | starting web.1 on port 5000
web.1 | 18:17:00 RQ worker 'rq:worker:Michaels-MacBook-Air.9044' started, version 0.5.6
web.1 | 18:17:00
导航到 http://localhost:5000/ 并测试应用程序。应该能行。
提交您的更改,然后推至 Heroku。测试一下。
结论
作业!虽然我们还有很多工作要做,但是应用程序确实工作了——所以让我们进行一次迭代,让全世界都看到。使用相同的工作流程更新生产环境。
链接:
请在下面留下问题和评论。**
Python 的 urllib.request 用于 HTTP 请求
如果你需要用 Python 发出 HTTP 请求,那么你可能会发现自己被引向了辉煌的 requests 库。虽然它是一个很棒的库,但是您可能已经注意到它不是 Python 的内置部分。无论出于什么原因,如果您喜欢限制依赖项并坚持使用标准库 Python,那么您可以使用urllib.request!
在本教程中,您将:
- 学习如何用
urllib.request制作基本的 HTTP 请求 - 深入了解 HTTP 消息 的具体细节以及
urllib.request如何表示它 - 了解如何处理 HTTP 消息的字符编码
- 探索使用
urllib.request时的一些常见错误,并学习如何解决它们 - 用
urllib.request体验一下认证请求的世界 - 理解为什么
urllib和requests库都存在,以及何时使用其中一个
如果你听说过 HTTP 请求,包括 GET 和 POST ,那么你可能已经准备好学习本教程了。此外,您应该已经使用 Python 对文件进行了读写,最好是使用上下文管理器,至少一次。
最终,你会发现提出请求并不一定是一次令人沮丧的经历,尽管它确实有这样的名声。你可能遇到的许多问题都是由于互联网这个神奇的东西固有的复杂性。好消息是,urllib.request模块可以帮助揭开这种复杂性的神秘面纱。
了解更多: ,获取新的 Python 教程和新闻,让您成为更有效的 Python 爱好者。
带有urllib.request 的基本 HTTP GET 请求
在深入了解什么是 HTTP 请求以及它是如何工作的之前,您将通过向一个示例 URL 发出一个基本的 get 请求来尝试一下。您还将向 mock REST API 请求一些 JSON 数据。如果你对 POST 请求感到疑惑,一旦你对urllib.request有了更多的了解,你将在教程的后面中涉及到它们。
小心:根据你的具体设置,你可能会发现其中一些例子并不适用。如果是,请跳到常见 urllib.request错误部分进行故障排除。
如果你遇到了这里没有涉及的问题,一定要在下面用一个精确的可重复的例子来评论。
首先,您将向www.example.com发出请求,服务器将返回一条 HTTP 消息。确保您使用的是 Python 3 或更高版本,然后使用来自urllib.request的urlopen()函数:
>>> from urllib.request import urlopen >>> with urlopen("https://www.example.com") as response: ... body = response.read() ... >>> body[:15] b'<!doctype html>'在这个例子中,您从
urllib.request导入urlopen()。使用上下文管理器with,你发出一个请求,然后用urlopen()接收一个响应。然后,读取响应的主体并关闭响应对象。这样,您显示了正文的前 15 个位置,注意到它看起来像一个 HTML 文档。原来你在这里!您已成功提出请求,并收到了回复。通过检查内容,您可以知道这可能是一个 HTML 文档。注意正文的打印输出前面有
b。这表示一个字节的文字,你可能需要解码。在本教程的后面,您将学习如何将字节转换成一个字符串,将它们写入一个文件,或者将它们解析成一个字典。如果您想调用 REST APIs 来获取 JSON 数据,这个过程只是略有不同。在以下示例中,您将向{ JSON }占位符请求一些虚假的待办事项数据:
>>> from urllib.request import urlopen
>>> import json
>>> url = "https://jsonplaceholder.typicode.com/todos/1"
>>> with urlopen(url) as response:
... body = response.read()
...
>>> todo_item = json.loads(body)
>>> todo_item
{'userId': 1, 'id': 1, 'title': 'delectus aut autem', 'completed': False}
在这个例子中,您所做的与上一个例子非常相似。但是在这个例子中,您导入了urllib.request 和 json,使用带有body的json.loads()函数将返回的 JSON 字节解码并解析到一个 Python 字典。瞧啊。
如果你足够幸运地使用无错误的端点,比如这些例子中的那些,那么也许以上就是你从urllib.request开始所需要的全部。话说回来,你可能会发现这还不够。
现在,在进行一些urllib.request故障排除之前,您将首先了解 HTTP 消息的底层结构,并学习urllib.request如何处理它们。这种理解将为解决许多不同类型的问题提供坚实的基础。
HTTP 消息的基本要素
为了理解使用urllib.request时可能遇到的一些问题,您需要研究一下urllib.request是如何表示响应的。要做到这一点,您将从什么是 HTTP 消息的高层次概述中受益,这也是您将在本节中得到的内容。
在高级概述之前,先简要说明一下参考源。如果你想进入技术领域,互联网工程任务组(IETF) 有一套广泛的征求意见稿(RFC) 文档。这些文档最终成为诸如 HTTP 消息之类的实际规范。例如,RFC 7230,第 1 部分:消息语法和路由,都是关于 HTTP 消息的。
如果你正在寻找一些比 RFC 更容易理解的参考资料,那么Mozilla Developer Network(MDN)有大量的参考文章。例如,他们关于 HTTP 消息的文章,虽然仍然是技术性的,但是更容易理解。
现在您已经了解了这些参考信息的基本来源,在下一节中,您将获得一个对 HTTP 消息的初学者友好的概述。
了解什么是 HTTP 消息
简而言之,HTTP 消息可以理解为文本,作为一个由字节组成的流传输,其结构遵循 RFC 7230 规定的指导原则。解码后的 HTTP 消息可能只有两行:
GET / HTTP/1.1
Host: www.google.com
这使用HTTP/1.1协议在根(/)指定了一个 GET 请求。唯一需要的头是主机www.google.com。目标服务器有足够的信息来用这些信息作出响应。
响应在结构上类似于请求。HTTP 消息有两个主要部分,元数据和主体。在上面的请求示例中,消息都是元数据,没有正文。另一方面,响应确实有两个部分:****
HTTP/1.1 200 OK
Content-Type: text/html; charset=ISO-8859-1
Server: gws
(... other headers ...)
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage"
...
响应以指定 HTTP 协议HTTP/1.1和状态200 OK的状态行开始。在状态行之后,您会得到许多键值对,比如Server: gws,代表所有的响应头。这是响应的元数据。
在元数据之后,有一个空行,作为标题和正文之间的分隔符。空行之后的一切组成了正文。当你使用urllib.request时,这是被读取的部分。
注:空行在技术上通常被称为换行符。HTTP 消息中的换行符必须是一个 Windows 风格的回车符 ( \r)和一个行结束符 ( \n)。在类似 Unix 的系统上,换行符通常只是一个行尾(\n)。
您可以假设所有的 HTTP 消息都遵循这些规范,但是也有可能有些消息违反了这些规则或者遵循了一个旧的规范。不过,这很少会引起任何问题。所以,把它放在你的脑海里,以防你遇到一个奇怪的 bug!
在下一节中,您将看到urllib.request如何处理原始 HTTP 消息。
理解urllib.request如何表示 HTTP 消息
使用urllib.request时,您将与之交互的 HTTP 消息的主要表示是 HTTPResponse 对象。urllib.request模块本身依赖于底层的http模块,你不需要直接与之交互。不过,你最终还是会使用一些http提供的数据结构,比如HTTPResponse和HTTPMessage。
注意:Python 中表示 HTTP 响应和消息的对象的内部命名可能有点混乱。你通常只与HTTPResponse的实例交互,而请求的事情在内部处理。
你可能认为HTTPMessage是一种基类,它是从HTTPResponse继承而来的,但事实并非如此。HTTPResponse直接继承io.BufferedIOBase,而HTTPMessage类继承 email.message.EmailMessage 。
在源代码中,EmailMessage被定义为一个包含一堆头和一个有效载荷的对象,所以它不一定是一封电子邮件。HTTPResponse仅仅使用HTTPMessage作为其头部的容器。
然而,如果您谈论的是 HTTP 本身而不是它的 Python 实现,那么您将 HTTP 响应视为一种 HTTP 消息是正确的。
当你用urllib.request.urlopen()发出请求时,你得到一个HTTPResponse对象作为回报。花些时间探索带有 pprint() 和 dir() 的HTTPResponse对象,看看属于它的所有不同方法和属性:
>>> from urllib.request import urlopen >>> from pprint import pprint >>> with urlopen("https://www.example.com") as response: ... pprint(dir(response)) ...要显示此代码片段的输出,请单击展开下面的可折叠部分:
['__abstractmethods__', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_abc_impl', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_check_close', '_close_conn', '_get_chunk_left', '_method', '_peek_chunked', '_read1_chunked', '_read_and_discard_trailer', '_read_next_chunk_size', '_read_status', '_readall_chunked', '_readinto_chunked', '_safe_read', '_safe_readinto', 'begin', 'chunk_left', 'chunked', 'close', 'closed', 'code', 'debuglevel', 'detach', 'fileno', 'flush', 'fp', 'getcode', 'getheader', 'getheaders', 'geturl', 'headers', 'info', 'isatty', 'isclosed', 'length', 'msg', 'peek', 'read', 'read1', 'readable', 'readinto', 'readinto1', 'readline', 'readlines', 'reason', 'seek', 'seekable', 'status', 'tell', 'truncate', 'url', 'version', 'will_close', 'writable', 'write', 'writelines']这有很多方法和属性,但是您最终只会使用其中的一小部分。除了
.read()之外,重要的通常包括获得关于报头的信息。检查所有标题的一种方法是访问
HTTPResponse对象的.headers属性。这将返回一个HTTPMessage对象。方便的是,您可以像对待字典一样对待一个HTTPMessage,方法是对它调用.items(),以元组的形式获取所有的头:
>>> with urlopen("https://www.example.com") as response:
... pass
...
>>> response.headers
<http.client.HTTPMessage object at 0x000001E029D9F4F0>
>>> pprint(response.headers.items())
[('Accept-Ranges', 'bytes'),
('Age', '398424'),
('Cache-Control', 'max-age=604800'),
('Content-Type', 'text/html; charset=UTF-8'),
('Date', 'Tue, 25 Jan 2022 12:18:53 GMT'),
('Etag', '"3147526947"'),
('Expires', 'Tue, 01 Feb 2022 12:18:53 GMT'),
('Last-Modified', 'Thu, 17 Oct 2019 07:18:26 GMT'),
('Server', 'ECS (nyb/1D16)'),
('Vary', 'Accept-Encoding'),
('X-Cache', 'HIT'),
('Content-Length', '1256'),
('Connection', 'close')]
现在您可以访问所有的响应头了!您可能不需要这些信息中的大部分,但是请放心,有些应用程序确实会用到它们。例如,您的浏览器可能会使用标题来读取响应、设置 cookies 并确定适当的缓存生命周期。
有一些方便的方法可以从一个HTTPResponse对象中获取标题,因为这是一个非常常见的操作。您可以直接在HTTPResponse对象上调用.getheaders(),这将返回与上面完全相同的元组列表。如果您只对一个头感兴趣,比如说Server头,那么您可以在HTTPResponse上使用单数.getheader("Server"),或者在.headers上使用方括号([])语法,从HTTPMessage:
>>> response.getheader("Server") 'ECS (nyb/1D16)' >>> response.headers["Server"] 'ECS (nyb/1D16)'说实话,您可能不需要像这样直接与标题交互。您最可能需要的信息可能已经有了一些内置的帮助器方法,但是现在您知道了,以防您需要更深入地挖掘!
关闭
HTTPResponse
HTTPResponse对象与文件对象有很多共同之处。像文件对象一样,HTTPResponse类继承了IOBase类,这意味着你必须注意打开和关闭。在简单的程序中,如果你忘记关闭
HTTPResponse对象,你不太可能注意到任何问题。然而,对于更复杂的项目,这可能会显著降低执行速度,并导致难以查明的错误。出现问题是因为输入/输出 (I/O)流受到限制。每个
HTTPResponse都要求一个流在被读取时保持清晰。如果您从不关闭您的流,这将最终阻止任何其他流被打开,并且它可能会干扰其他程序甚至您的操作系统。所以,一定要关闭你的
HTTPResponse对象!为了方便起见,您可以使用上下文管理器,正如您在示例中看到的那样。您也可以通过在响应对象上显式调用.close()来获得相同的结果:
>>> from urllib.request import urlopen
>>> response = urlopen("https://www.example.com")
>>> body = response.read()
>>> response.close()
在这个例子中,您没有使用上下文管理器,而是显式地关闭了响应流。不过,上面的例子仍然有一个问题,因为在调用.close()之前可能会引发一个异常,阻止正确的拆卸。要使这个调用无条件,正如它应该的那样,您可以使用一个带有一个else和一个finally子句的 try … except 块:
>>> from urllib.request import urlopen >>> response = None >>> try: ... response = urlopen("https://www.example.com") ... except Exception as ex: ... print(ex) ... else: ... body = response.read() ... finally: ... if response is not None: ... response.close()在本例中,您通过使用
finally块实现了对.close()的无条件调用,无论出现什么异常,该块都将一直运行。finally块中的代码首先检查response对象是否与is not None一起存在,然后关闭它。也就是说,这正是上下文管理器所做的,并且通常首选
with语法。with语法不仅不那么冗长、可读性更好,而且还能防止令人讨厌的遗漏错误。换句话说,这是防止意外忘记关闭对象的更好的方法:
>>> from urllib.request import urlopen
>>> with urlopen("https://www.example.com") as response:
... response.read(50)
... response.read(50)
...
b'<!doctype html>\n<html>\n<head>\n <title>Example D'
b'omain</title>\n\n <meta charset="utf-8" />\n <m'
在这个例子中,您从urllib.request模块导入urlopen()。您使用带有.urlopen()的with关键字将HTTPResponse对象赋给变量response。然后,读取响应的前 50 个字节,然后读取随后的 50 个字节,所有这些都在with块中。最后,关闭with块,它执行请求并运行其块中的代码行。
使用这段代码,可以显示两组各 50 个字节的内容。一旦退出with块范围,HTTPResponse对象将关闭,这意味着.read()方法将只返回空字节对象:
>>> import urllib.request >>> with urllib.request.urlopen("https://www.example.com") as response: ... response.read(50) ... b'<!doctype html>\n<html>\n<head>\n <title>Example D' >>> response.read(50) b''在这个例子中,读取 50 个字节的第二个调用在
with范围之外。在with块之外意味着HTTPResponse被关闭,即使你仍然可以访问这个变量。如果你试图在HTTPResponse关闭时读取它,它将返回一个空字节对象。另一点需要注意的是,一旦你从头到尾阅读了一遍,你就不能重读一遍:
>>> import urllib.request
>>> with urllib.request.urlopen("https://www.example.com") as response:
... first_read = response.read()
... second_read = response.read()
...
>>> len(first_read)
1256
>>> len(second_read)
0
这个例子表明,一旦你读了一个回复,你就不能再读了。如果您已经完整地读取了响应,那么即使响应没有关闭,后续的尝试也只是返回一个空字节对象。你必须再次提出请求。
在这方面,响应与文件对象不同,因为对于文件对象,可以使用 .seek() 方法多次读取,而HTTPResponse不支持。即使在关闭响应之后,您仍然可以访问头和其他元数据。
探索文本、八位字节和位
在迄今为止的大多数例子中,您从HTTPResponse读取响应体,立即显示结果数据,并注意到它显示为一个字节对象。这是因为计算机中的文本信息不是以字母的形式存储或传输的,而是以字节的形式!
通过网络发送的原始 HTTP 消息被分解成一系列的字节,有时被称为八位字节。字节是 8- 位块。例如,01010101是一个字节。要了解关于二进制、位和字节的更多信息,请查看 Python 中的位运算符。
那么如何用字节表示字母呢?一个字节有 256 种可能的组合,你可以给每种组合分配一个字母。您可以将00000001分配给A,将00000010分配给B,以此类推。 ASCII 字符编码,相当普遍,使用这种类型的系统编码 128 个字符,对于英语这样的语言来说足够了。这非常方便,因为只要一个字节就可以表示所有的字符,还留有空间。
所有标准的英语字符,包括大写字母、标点符号和数字,都适合 ASCII。另一方面,日语被认为有大约五万个标识字符,所以 128 个字符是不够的!即使一个字节理论上有 256 个字符,对日语来说也远远不够。因此,为了适应世界上所有的语言,有许多不同的字符编码系统。
即使有许多系统,你可以依赖的一件事是它们总是被分成字节的事实。大多数服务器,如果不能解析 MIME 类型和字符编码,默认为application/octet-stream,字面意思是字节流。然后,接收消息的人可以计算出字符编码。
处理字符编码
正如您可能已经猜到的那样,问题经常出现,因为有许多不同的潜在字符编码。今天占主导地位的字符编码是 UTF-8 ,它是 Unicode 的一个实现。幸运的是,今天百分之九十八的网页都是用 UTF-8 编码的!
UTF 8 占优势,因为它可以有效地处理数量惊人的字符。它处理 Unicode 定义的所有 1,112,064 个潜在字符,包括中文、日文、阿拉伯文(从右到左书写)、俄文和更多字符集,包括表情符号!
UTF-8 仍然有效,因为它使用可变数量的字节来编码字符,这意味着对于许多字符,它只需要一个字节,而对于其他字符,它可能需要多达四个字节。
注意:要了解更多关于 Python 中的编码,请查看 Python 中的 Unicode &字符编码:无痛指南。
虽然 UTF-8 占主导地位,并且假设 UTF-8 编码通常不会出错,但您仍然会一直遇到不同的编码。好消息是,在使用urllib.request时,你不需要成为编码专家来处理它们。
从字节到字符串
当您使用urllib.request.urlopen()时,响应的主体是一个 bytes 对象。您可能要做的第一件事是将 bytes 对象转换为字符串。也许你想做一些网络搜集。为此,你需要解码字节。要用 Python 解码字节,你只需要找出使用的字符编码。编码,尤其是当提到字符编码时,通常被称为字符集。
如上所述,在 98%的情况下,您可能会安全地默认使用 UTF-8:
>>> from urllib.request import urlopen >>> with urlopen("https://www.example.com") as response: ... body = response.read() ... >>> decoded_body = body.decode("utf-8") >>> print(decoded_body[:30]) <!doctype html> <html> <head>在本例中,您获取从
response.read()返回的 bytes 对象,并使用 bytes 对象的.decode()方法对其进行解码,将utf-8作为参数传入。当你打印decoded_body时,你可以看到它现在是一个字符串。也就是说,听天由命很少是一个好策略。幸运的是,标题是获取字符集信息的好地方:
>>> from urllib.request import urlopen
>>> with urlopen("https://www.example.com") as response:
... body = response.read()
...
>>> character_set = response.headers.get_content_charset()
>>> character_set
'utf-8'
>>> decoded_body = body.decode(character_set)
>>> print(decoded_body[:30])
<!doctype html>
<html>
<head>
在这个例子中,你在response的.headers对象上调用.get_content_charset(),并使用它来解码。这是一个方便的方法,它解析Content-Type头,这样您就可以轻松地将字节解码成文本。
从字节到文件
如果你想把字节解码成文本,现在你可以开始了。但是,如果您想将响应的主体写入文件,该怎么办呢?好吧,你有两个选择:
- 将字节直接写入文件
- 将字节解码成 Python 字符串,然后将字符串编码回文件
第一种方法最简单,但是第二种方法允许您根据需要更改编码。要更详细地了解文件操作,请看一下 Real Python 的用 Python (Guide) 读写文件。
要将字节直接写入文件而无需解码,您需要内置的 open() 函数,并且您需要确保使用写二进制模式:
>>> from urllib.request import urlopen >>> with urlopen("https://www.example.com") as response: ... body = response.read() ... >>> with open("example.html", mode="wb") as html_file: ... html_file.write(body) ... 1256在
wb模式下使用open()绕过了解码或编码的需要,将 HTTP 消息体的字节转储到example.html文件中。写操作后输出的数字表示已经写入的字节数。就是这样!您已经将字节直接写入文件,没有进行任何编码或解码。现在假设您有一个不使用 UTF 8 的 URL,但是您想将内容写入一个使用 UTF 8 的文件。为此,首先将字节解码成字符串,然后将字符串编码成文件,指定字符编码。
谷歌的主页似乎根据你的位置使用不同的编码。在欧洲和美国的大部分地区,它使用 ISO-8859-1 编码:
>>> from urllib.request import urlopen
>>> with urlopen("https://www.google.com") as response:
... body = response.read()
...
>>> character_set = response.headers.get_content_charset()
>>> character_set
'ISO-8859-1'
>>> content = body.decode(character_set)
>>> with open("google.html", encoding="utf-8", mode="w") as file:
... file.write(content)
...
14066
在这段代码中,您获得了响应字符集,并使用它将 bytes 对象解码成一个字符串。然后,您将字符串写入一个文件,使用 UTF-8 编码它。
注意:有趣的是,谷歌似乎有各种各样的检查层,用来决定网页使用何种语言和编码。这意味着你可以指定一个 Accept-Language头,它似乎覆盖了你的 IP 地址。尝试使用不同的区域标识符来看看你能得到什么样的编码!
写入文件后,您应该能够在浏览器或文本编辑器中打开结果文件。大多数现代文本处理器可以自动检测字符编码。
如果存在编码错误,并且您正在使用 Python 读取文件,那么您可能会得到一个错误:
>>> with open("encoding-error.html", mode="r", encoding="utf-8") as file: ... lines = file.readlines() ... UnicodeDecodeError: 'utf-8' codec can't decode bytePython 显式地停止了这个过程并引发了一个异常,但是在一个显示文本的程序中,比如你正在查看这个页面的浏览器,你可能会发现臭名昭著的替换字符:
A Replacement Character 带白色问号的黑色菱形(ᦅ)、正方形(□)和矩形(▯)通常用于替换无法解码的字符。
有时,解码看似可行,但会产生难以理解的序列,如?到-到-到。,这也暗示使用了错误的字符集。在日本,他们甚至有一个词来形容由于字符编码问题而产生的乱码,即 Mojibake ,因为这些问题在互联网时代开始时就困扰着他们。
这样,您现在应该可以用从
urlopen()返回的原始字节编写文件了。在下一节中,您将学习如何使用json模块将字节解析到 Python 字典中。从字节到字典
对于
application/json响应,您通常会发现它们不包含任何编码信息:

>>> from urllib.request import urlopen
>>> with urlopen("https://httpbin.org/json") as response:
... body = response.read()
...
>>> character_set = response.headers.get_content_charset()
>>> print(character_set)
None
在这个例子中,您使用了 httpbin 的json端点,这个服务允许您试验不同类型的请求和响应。json端点模拟一个返回 JSON 数据的典型 API。请注意,.get_content_charset()方法在其响应中不返回任何内容。
即使没有字符编码信息,也不会全部丢失。根据 RFC 4627 ,UTF-8 的默认编码是application/json规范的绝对要求。这并不是说每一台服务器都遵守规则,但是一般来说,如果 JSON 被传输,它几乎总是使用 UTF-8 编码。
幸运的是,json.loads()在幕后解码字节对象,甚至在它可以处理的不同编码方面有一些余地。因此,json.loads()应该能够处理您扔给它的大多数字节对象,只要它们是有效的 JSON:
>>> import json >>> json.loads(body) {'slideshow': {'author': 'Yours Truly', 'date': 'date of publication', 'slides' : [{'title': 'Wake up to WonderWidgets!', 'type': 'all'}, {'items': ['Why <em>W onderWidgets</em> are great', 'Who <em>buys</em> WonderWidgets'], 'title': 'Ove rview', 'type': 'all'}], 'title': 'Sample Slide Show'}}如您所见,
json模块自动处理解码并生成一个 Python 字典。几乎所有的 API 都以 JSON 的形式返回键值信息,尽管您可能会遇到一些使用 XML 的旧 API。为此,您可能想看看 Python 中 XML 解析器的路线图。有了这些,你应该对字节和编码有足够的了解。在下一节中,您将学习如何对使用
urllib.request时可能遇到的一些常见错误进行故障诊断和修复。常见
urllib.request故障不管你有没有使用
urllib.request,在这个世界狂野的网络上你都会遇到各种各样的问题。在本节中,您将学习如何在开始时处理几个最常见的错误:403错误和 TLS/SSL 证书错误。不过,在查看这些特定的错误之前,您将首先学习如何在使用urllib.request时更普遍地实现错误处理。实施错误处理
在您将注意力转向特定的错误之前,提高您的代码优雅地处理各种错误的能力将会得到回报。Web 开发受到错误的困扰,您可以投入大量时间明智地处理错误。在这里,您将学习在使用
urllib.request时处理 HTTP、URL 和超时错误。HTTP 状态代码伴随着状态行中的每个响应。如果您可以在响应中读取状态代码,那么请求就到达了它的目标。虽然这很好,但是只有当响应代码以
2开头时,您才能认为请求完全成功。例如,200和201代表成功的请求。例如,如果状态码是404或500,则出错了,urllib.request会抛出一个HTTPError。有时会发生错误,提供的 URL 不正确,或者由于其他原因无法建立连接。在这些情况下,
urllib.request会养出一个URLError。最后,有时服务器就是不响应。也许您的网络连接速度慢,服务器关闭,或者服务器被编程为忽略特定的请求。为了处理这个问题,您可以将一个
timeout参数传递给urlopen()以在一定时间后引发一个TimeoutError。处理这些异常的第一步是捕捉它们。您可以利用
HTTPError、URLError和TimeoutError类,用try…except块捕获urlopen()内产生的错误:# request.py from urllib.error import HTTPError, URLError from urllib.request import urlopen def make_request(url): try: with urlopen(url, timeout=10) as response: print(response.status) return response.read(), response except HTTPError as error: print(error.status, error.reason) except URLError as error: print(error.reason) except TimeoutError: print("Request timed out")函数
make_request()将一个 URL 字符串作为参数,尝试用urllib.request从该 URL 获得响应,并捕捉在出错时引发的HTTPError对象。如果 URL 是坏的,它将捕获一个URLError。如果没有任何错误,它将打印状态并返回一个包含主体和响应的元组。回应将在return后关闭。该函数还使用一个
timeout参数调用urlopen(),这将导致在指定的秒数后引发一个TimeoutError。十秒钟通常是等待响应的合适时间,不过和往常一样,这在很大程度上取决于您需要向哪个服务器发出请求。现在,您已经准备好优雅地处理各种错误,包括但不限于您将在接下来讨论的错误。
处理
403错误现在您将使用
make_request()函数向 httpstat.us 发出一些请求,这是一个用于测试的模拟服务器。这个模拟服务器将返回具有您所请求的状态代码的响应。例如,如果你向https://httpstat.us/200发出请求,你应该期待一个200的响应。像 httpstat.us 这样的 API 用于确保您的应用程序能够处理它可能遇到的所有不同的状态代码。httpbin 也有这个功能,但是 httpstat.us 有更全面的状态代码选择。它甚至还有臭名昭著的半官方
418状态码,返回消息我是茶壶!要与您在上一节中编写的
make_request()函数进行交互,请在交互模式下运行该脚本:$ python3 -i request.py使用
-i标志,该命令将在交互模式下运行脚本。这意味着它将执行脚本,然后打开 Python REPL ,因此您现在可以调用您刚刚定义的函数:
>>> make_request("https://httpstat.us/200")
200
(b'200 OK', <http.client.HTTPResponse object at 0x0000023D612660B0>)
>>> make_request("https://httpstat.us/403")
403 Forbidden
在这里,您尝试了 httpstat.us 的200和403端点。200端点按照预期通过并返回响应体和响应对象。403端点只是打印了错误消息,没有返回任何东西,这也是意料之中的。
403 状态意味着服务器理解了请求,但不会执行它。这是一个你会遇到的常见错误,尤其是在抓取网页的时候。在许多情况下,您可以通过传递一个用户代理头来解决这个问题。
注意:有两个密切相关的 4xx 代码有时会引起混淆:
如果用户没有被识别或登录,服务器应该返回401,并且必须做一些事情来获得访问权,比如登录或注册。
如果用户被充分识别,但没有访问资源的权限,则应该返回403状态。例如,如果你登录了一个社交媒体账户,并试图查看一个人的个人资料页面,那么你很可能会获得一个403状态。
也就是说,不要完全信任状态代码。在复杂的分布式服务中,bug 是存在的,也是常见的。有些服务器根本就不是模范公民!
服务器识别谁或什么发出请求的主要方法之一是检查User-Agent头。由urllib.request发送的原始默认请求如下:
GET https://httpstat.us/403 HTTP/1.1
Accept-Encoding: identity
Host: httpstat.us
User-Agent: Python-urllib/3.10
Connection: close
请注意,User-Agent被列为Python-urllib/3.10。你可能会发现一些网站会试图屏蔽网页抓取器,这个User-Agent就是一个很好的例子。也就是说,你可以用urllib.request来设置你自己的User-Agent,尽管你需要稍微修改一下你的函数:
# request.py from urllib.error import HTTPError, URLError -from urllib.request import urlopen +from urllib.request import urlopen, Request -def make_request(url): +def make_request(url, headers=None): + request = Request(url, headers=headers or {}) try: - with urlopen(url, timeout=10) as response: + with urlopen(request, timeout=10) as response: print(response.status) return response.read(), response except HTTPError as error: print(error.status, error.reason) except URLError as error: print(error.reason) except TimeoutError: print("Request timed out")
要定制随请求发出的标题,首先必须用 URL 实例化一个 Request 对象。此外,您可以传入一个headers的关键字参数,它接受一个标准字典来表示您希望包含的任何头。因此,不是将 URL 字符串直接传递给urlopen(),而是传递这个已经用 URL 和头实例化的Request对象。
注意:在上面的例子中,当Request被实例化时,你需要给它传递头文件,如果它们已经被定义的话。否则,传递一个空白对象,比如{}。你不能通过None,因为这会导致错误。
要使用这个修改过的函数,重新启动交互会话,然后调用make_request(),用一个字典将头表示为一个参数:
>>> body, response = make_request( ... "https://www.httpbin.org/user-agent", ... {"User-Agent": "Real Python"} ... ) 200 >>> body b'{\n "user-agent": "Real Python"\n}\n'在这个例子中,您向 httpbin 发出一个请求。这里您使用
user-agent端点来返回请求的User-Agent值。因为您是通过定制用户代理Real Python发出请求的,所以这是返回的内容。不过,有些服务器很严格,只接受来自特定浏览器的请求。幸运的是,可以在网上找到标准的
User-Agent字符串,包括通过用户代理数据库。它们只是字符串,所以您需要做的就是复制您想要模拟的浏览器的用户代理字符串,并将其用作User-Agent头的值。修复 SSL
CERTIFICATE_VERIFY_FAILED错误另一个常见错误是由于 Python 无法访问所需的安全证书。为了模拟这个错误,你可以使用一些已知不良 SSL 证书的模拟网站,由badssl.com提供。您可以向其中一个(如
superfish.badssl.com)发出请求,并直接体验错误:
>>> from urllib.request import urlopen
>>> urlopen("https://superfish.badssl.com/")
Traceback (most recent call last):
(...)
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED]
certificate verify failed: unable to get local issuer certificate (_ssl.c:997)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
(...)
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED]
certificate verify failed: unable to get local issuer certificate (_ssl.c:997)>
这里,用已知的坏 SSL 证书向一个地址发出请求将导致CERTIFICATE_VERIFY_FAILED,它是URLError的一种类型。
SSL 代表安全套接字层。这有点用词不当,因为 SSL 已被弃用,取而代之的是 TLS、传输层安全性。有时旧的术语只是坚持!这是一种加密网络流量的方法,这样一个假想的监听者就无法窃听到通过网络传输的信息。
如今,大多数网站的地址不是以http://开头,而是以https://开头,其中代表安全。 HTTPS 连接必须通过 TLS 加密。urllib.request可以处理 HTTP 和 HTTPS 连接。
HTTPS 的细节远远超出了本教程的范围,但是您可以将 HTTPS 连接想象成包含两个阶段,握手和信息传输。握手确保连接是安全的。有关 Python 和 HTTPS 的更多信息,请查看使用 Python 探索 HTTPS 的。
为了确定特定的服务器是安全的,发出请求的程序依赖于存储的可信证书。握手阶段会验证服务器的证书。Python 使用操作系统的证书库。如果 Python 找不到系统的证书存储库,或者存储库过期,那么您就会遇到这个错误。
注意:在之前的 Python 版本中,urllib.request的默认行为是而不是验证证书,这导致 PEP 476 默认启用证书验证。在 Python 3.4.3 中默认改变。
有时,Python 可以访问的证书存储区已经过期,或者 Python 无法访问它,不管是什么原因。这是令人沮丧的,因为你有时可以从你的浏览器访问 URL,它认为它是安全的,然而urllib.request仍然引发这个错误。
你可能很想选择不验证证书,但这会使你的连接不安全,并且绝对不推荐:
>>> import ssl >>> from urllib.request import urlopen >>> unverified_context = ssl._create_unverified_context() >>> urlopen("https://superfish.badssl.com/", context=unverified_context) <http.client.HTTPResponse object at 0x00000209CBE8F220>这里您导入了
ssl模块,它允许您创建一个未验证的上下文。然后,您可以将这个上下文传递给urlopen()并访问一个已知的坏 SSL 证书。因为没有检查 SSL 证书,所以连接成功通过。在采取这些孤注一掷的措施之前,请尝试更新您的操作系统或 Python 版本。如果失败了,那么您可以从
requests库中取出一个页面并安装certifi:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> .\venv\Scripts\activate (venv) PS> python -m pip install certifi$ python3 -m venv venv $ source venv/bin/activate.sh (venv) $ python3 -m pip install certifi
certifi是一个证书集合,你可以用它来代替你系统的集合。您可以通过使用certifi证书包而不是操作系统的证书包来创建 SSL 上下文:
>>> import ssl
>>> from urllib.request import urlopen
>>> import certifi
>>> certifi_context = ssl.create_default_context(cafile=certifi.where())
>>> urlopen("https://sha384.badssl.com/", context=certifi_context)
<http.client.HTTPResponse object at 0x000001C7407C3490>
在这个例子中,您使用了certifi作为您的 SSL 证书库,并使用它成功地连接到一个具有已知良好 SSL 证书的站点。请注意,您使用的是.create_default_context(),而不是._create_unverified_context()。
这样,您可以保持安全,而不会有太多的麻烦!在下一节中,您将尝试身份验证。
认证请求
认证是一个庞大的主题,如果您正在处理的认证比这里讨论的要复杂得多,这可能是进入requests包的一个很好的起点。
在本教程中,您将只讨论一种身份验证方法,它作为对您的请求进行身份验证所必须进行的调整类型的示例。确实有很多其他功能有助于身份验证,但这不会在本教程中讨论。
最常见的认证工具之一是不记名令牌,由 RFC 6750 指定。它经常被用作 OAuth 的一部分,但也可以单独使用。它也是最常见的标题,您可以在当前的make_request()函数中使用它:
>>> token = "abcdefghijklmnopqrstuvwxyz" >>> headers = { ... "Authorization": f"Bearer {token}" ... } >>> make_request("https://httpbin.org/bearer", headers) 200 (b'{\n "authenticated": true, \n "token": "abcdefghijklmnopqrstuvwxyz"\n}\n', <http.client.HTTPResponse object at 0x0000023D612642E0>)在这个例子中,您向 httpbin
/bearer端点发出一个请求,它模拟了载体认证。它将接受任何字符串作为令牌。它只需要 RFC 6750 指定的正确格式。名字的是Authorization,或者有时是小写的authorization,值的是Bearer,在值和令牌之间有一个空格。注意:如果您使用任何形式的令牌或秘密信息,请确保妥善保护这些令牌。例如,不要将它们提交给 GitHub 库,而是将它们存储为临时的环境变量。
恭喜您,您已经使用不记名令牌成功认证!
另一种形式的认证称为 基本访问认证 ,这是一种非常简单的认证方法,仅比在报头中发送用户名和密码稍微好一点。很没有安全感!
当今最常用的协议之一是 【开放授权】 。如果你曾经使用过谷歌、GitHub 或脸书登录另一个网站,那么你就使用过 OAuth。OAuth 流通常涉及您希望与之交互的服务和身份服务器之间的一些请求,从而产生一个短期的承载令牌。然后,该承载令牌可以与承载认证一起使用一段时间。
大部分身份验证归结于理解目标服务器使用的特定协议,并仔细阅读文档以使其工作。
用
urllib.request发布请求您已经发出了许多 GET 请求,但是有时您想要发送信息。这就是发布请求的来源。要使用
urllib.request进行 POST 请求,您不必显式地更改方法。你可以将一个data对象传递给一个新的Request对象或者直接传递给urlopen()。然而,data对象必须是一种特殊的格式。您将通过添加data参数来稍微修改您的make_request()函数以支持 POST 请求:# request.py from urllib.error import HTTPError, URLError from urllib.request import urlopen, Request -def make_request(url, headers=None): +def make_request(url, headers=None, data=None): - request = Request(url, headers=headers or {}) + request = Request(url, headers=headers or {}, data=data) try: with urlopen(request, timeout=10) as response: print(response.status) return response.read(), response except HTTPError as error: print(error.status, error.reason) except URLError as error: print(error.reason) except TimeoutError: print("Request timed out")在这里,您只是修改了函数来接受一个默认值为
None的data参数,并将该参数传递给了Request实例化。然而,这并不是所有需要做的事情。您可以使用两种不同的格式之一来执行 POST 请求:
- 表格数据 :
application/x-www-form-urlencoded- JSON :
application/json第一种格式是 POST 请求最古老的格式,它涉及到用百分比编码对数据进行编码,也称为 URL 编码。您可能已经注意到键值对 URL 编码为一个查询字符串。键用等号(
=)与值分开,键-值对用&符号(&)分开,空格通常被取消,但可以用加号(+)代替。如果您从 Python 字典开始,要将表单数据格式用于您的
make_request()函数,您需要编码两次:
- 一次对字典进行 URL 编码
- 然后再次将结果字符串编码成字节
对于 URL 编码的第一阶段,您将使用另一个
urllib模块urllib.parse。记得在交互模式下启动你的脚本,这样你就可以使用make_request()功能并在 REPL 上玩它:
>>> from urllib.parse import urlencode
>>> post_dict = {"Title": "Hello World", "Name": "Real Python"}
>>> url_encoded_data = urlencode(post_dict)
>>> url_encoded_data
'Title=Hello+World&Name=Real+Python'
>>> post_data = url_encoded_data.encode("utf-8")
>>> body, response = make_request(
... "https://httpbin.org/anything", data=post_data
... )
200
>>> print(body.decode("utf-8"))
{
"args": {},
"data": "",
"files": {},
"form": { "Name": "Real Python", "Title": "Hello World" }, "headers": {
"Accept-Encoding": "identity",
"Content-Length": "34",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.10",
"X-Amzn-Trace-Id": "Root=1-61f25a81-03d2d4377f0abae95ff34096"
},
"json": null,
"method": "POST", "origin": "86.159.145.119",
"url": "https://httpbin.org/anything"
}
在本例中,您可以:
- 从
urllib.parse模块导入urlencode() - 初始化你的文章数据,从字典开始
- 使用
urlencode()功能对字典进行编码 - 使用 UTF-8 编码将结果字符串编码成字节
- 向
httpbin.org的anything端点发出请求 - 打印 UTF-8 解码响应正文
UTF-8 编码是application/x-www-form-urlencoded类型的规范的一部分。UTF-8 被优先用于解码身体,因为你已经知道httpbin.org可靠地使用 UTF-8。
来自 httpbin 的anything端点充当一种 echo,返回它接收到的所有信息,以便您可以检查您所做请求的细节。在这种情况下,你可以确认method确实是POST,你可以看到你发送的数据列在form下面。
要使用 JSON 发出同样的请求,您将使用json.dumps()将 Python 字典转换成 JSON 字符串,使用 UTF-8 对其进行编码,将其作为data参数传递,最后添加一个特殊的头来指示数据类型是 JSON:
>>> post_dict = {"Title": "Hello World", "Name": "Real Python"} >>> import json >>> json_string = json.dumps(post_dict) >>> json_string '{"Title": "Hello World", "Name": "Real Python"}' >>> post_data = json_string.encode("utf-8") >>> body, response = make_request( ... "https://httpbin.org/anything", ... data=post_data, ... headers={"Content-Type": "application/json"}, ... ) 200 >>> print(body.decode("utf-8")) { "args": {}, "data": "{\"Title\": \"Hello World\", \"Name\": \"Real Python\"}", "files": {}, "form": {}, "headers": { "Accept-Encoding": "identity", "Content-Length": "47", "Content-Type": "application/json", "Host": "httpbin.org", "User-Agent": "Python-urllib/3.10", "X-Amzn-Trace-Id": "Root=1-61f25a81-3e35d1c219c6b5944e2d8a52" }, "json": { "Name": "Real Python", "Title": "Hello World" }, "method": "POST", "origin": "86.159.145.119", "url": "https://httpbin.org/anything" }这次为了序列化字典,您使用
json.dumps()而不是urlencode()。您还显式添加了值为application/json的Content-Type头。有了这些信息,httpbin 服务器可以在接收端反序列化 JSON。在它的回复中,你可以看到列在json键下的数据。注意:有时候需要以纯文本的形式发送 JSON 数据,这种情况下步骤同上,只是你把
Content-Type设置为text/plain; charset=UTF-8。很多这些必需品依赖于你发送数据的服务器或 API,所以一定要阅读文档并进行实验!这样,你现在就可以开始发布请求了。本教程不会详细介绍其他请求方法,比如 PUT 。我只想说,您也可以通过向
Request对象的实例化传递一个method关键字参数来显式设置该方法。请求包生态系统
为了使事情更加完整,本教程的最后一部分将致力于阐明 Python 中 HTTP 请求的包生态系统。因为有很多套餐,没有明确的标准,会比较混乱。也就是说,每个包都有用例,这意味着您有更多的选择!
什么是
urllib2和urllib3?要回答这个问题,你需要追溯到早期的 Python,一直追溯到 1.2 版本,最初的
urllib推出的时候。在 1.6 版本左右,增加了一个改版的urllib2,它与原来的urllib并存。当 Python 3 出现时,最初的urllib被弃用,urllib2放弃了2,取了最初的urllib名称。它也分裂成几部分:那么
urllib3呢?那是在urllib2还在的时候开发的第三方库。它与标准库无关,因为它是一个独立维护的库。有意思的是,requests库居然在遮光罩下使用urllib3,pip也是如此!什么时候应该用
requests而不用urllib.request?主要答案是易用性和安全性。
urllib.request被认为是一个低级的库,它公开了许多关于 HTTP 请求工作的细节。针对urllib.request的 Python 文档毫不犹豫地推荐requests作为更高级的 HTTP 客户端接口。如果您日复一日地与许多不同的 REST APIs 交互,那么强烈推荐使用
requests。requests库标榜自己为“为人类而建”,并成功地围绕 HTTP 创建了一个直观、安全和简单的 API。它通常被认为是最重要的图书馆!如果你想了解更多关于requests库的信息,请查看真正的 Pythonrequests指南。关于
requests如何让事情变得更简单的一个例子是字符编码。你会记得使用urllib.request时,你必须了解编码,并采取一些步骤来确保没有错误的体验。requests包将它抽象出来,并通过使用chardet(一种通用的字符编码检测器)来解析编码,以防有什么有趣的事情发生。如果你的目标是学习更多关于标准 Python 和它如何处理 HTTP 请求的细节,那么
urllib.request是一个很好的方法。你甚至可以更进一步,使用非常低级的http模块。另一方面,你可能只是想将依赖性保持在最低限度,而urllib.request完全有能力做到这一点。为什么
requests不是标准库的一部分?也许你想知道为什么
requests现在还不是核心 Python 的一部分。这是一个复杂的问题,没有简单快速的答案。关于原因有许多猜测,但有两个原因似乎很突出:
requests有其他需要集成的第三方依赖关系。- 需要保持敏捷,并且能够在标准库之外做得更好。
requests库具有第三方依赖性。将requests集成到标准库中也意味着集成chardet、certifi和urllib3等等。另一种选择是从根本上改变requests,只使用 Python 现有的标准库。这不是一项简单的任务!整合
requests也意味着开发这个库的现有团队将不得不放弃对设计和实现的完全控制,让位于 PEP 决策过程。HTTP 规范和建议一直在变化,一个高水平的库必须足够敏捷才能跟上。如果有一个安全漏洞需要修补,或者有一个新的工作流需要添加,
requests团队可以比作为 Python 发布过程的一部分更快地构建和发布。据说曾经有过这样的情况,他们在漏洞被发现 12 小时后发布了一个安全补丁!关于这些问题的有趣概述,请查看向标准库添加请求,其中总结了在 Python 语言峰会上与请求的创建者和维护者 Kenneth Reitz 的讨论。
因为这种敏捷性对于
requests和它的底层urllib3来说是如此的必要,所以经常使用矛盾的说法,即requests对于标准库来说太重要了。这是因为 Python 社区如此依赖于requests及其灵活性,以至于将它集成到核心 Python 中可能会损害它和 Python 社区。在
requests的 GitHub 库问题板上,发布了一个问题,要求将requests包含在标准库中。requests和urllib3的开发者插话说,他们很可能会对自己维护它失去兴趣。一些人甚至说他们将分叉存储库并继续为他们自己的用例开发它们。也就是说,注意
requests库 GitHub 存储库是托管在 Python 软件基金会的账户下的。仅仅因为某些东西不是 Python 标准库的一部分,并不意味着它不是生态系统不可分割的一部分!似乎目前的情况对 Python 核心团队和
requests的维护者都有效。虽然对于新手来说可能有点困惑,但是现有的结构为 HTTP 请求提供了最稳定的体验。同样重要的是要注意 HTTP 请求本质上是复杂的。不要试图掩饰得太多。它公开了 HTTP 请求的许多内部工作方式,这就是它被称为低级模块的原因。您选择
requests还是urllib.request实际上取决于您的特定用例、安全考虑和偏好。结论
现在,您可以使用
urllib.request来发出 HTTP 请求了。现在,您可以在您的项目中使用这个内置模块,让它们在更长时间内保持无依赖性。您还通过使用较低级别的模块,如urllib.request,对 HTTP 有了深入的了解。在本教程中,您已经:
- 学会了如何用
urllib.request制作基本的 HTTP 请求- 探究了一条 HTTP 消息的具体细节,并研究了它是如何被
urllib.request表示的- 弄清楚如何处理 HTTP 消息的字符编码
- 探究使用
urllib.request时的一些常见错误,并学习如何解决它们- 用
urllib.request尝试一下认证请求的世界- 理解了为什么
urllib和requests库都存在,以及何时使用其中一个现在,您已经能够使用
urllib.request发出基本的 HTTP 请求,并且您还拥有使用标准库深入底层 HTTP 领域的工具。最后,你可以选择是使用requests还是urllib.request,这取决于你想要什么或者需要什么。尽情探索网络吧!了解更多: ,获取新的 Python 教程和新闻,让您成为更有效的 Python 爱好者。****************
使用 Angular 4 和 Flask 进行用户验证
原文:https://realpython.com/user-authentication-with-angular-4-and-flask/
在本教程中,我们将演示如何用 Angular 4 和 Flask 设置基于令牌的认证(通过 JSON Web 令牌)。
主要依赖关系:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
授权工作流
以下是完整的用户认证过程:
- 客户端登录,凭据被发送到服务器
- 如果凭证正确,服务器将生成一个令牌,并将其作为响应发送给客户端
- 客户端接收令牌并将其存储在本地存储中
- 然后,客户端在请求标头中的后续请求上向服务器发送令牌
项目设置
从全局安装角度控制器开始:
$ npm install -g @angular/cli@1.3.2然后生成一个新的 Angular 4 项目样板文件:
$ ng new angular4-auth安装完依赖项后启动应用程序:
$ cd angular4-auth $ ng serve编译和构建您的应用程序可能需要一两分钟。完成后,导航到 http://localhost:4200 以确保应用程序启动并运行。
在您最喜欢的代码编辑器中打开项目,然后浏览代码:
├── e2e │ ├── app.e2e-spec.ts │ ├── app.po.ts │ └── tsconfig.e2e.json ├── karma.conf.js ├── package.json ├── protractor.conf.js ├── src │ ├── app │ │ ├── app.component.css │ │ ├── app.component.html │ │ ├── app.component.spec.ts │ │ ├── app.component.ts │ │ └── app.module.ts │ ├── assets │ ├── environments │ │ ├── environment.prod.ts │ │ └── environment.ts │ ├── favicon.ico │ ├── index.html │ ├── main.ts │ ├── polyfills.ts │ ├── styles.css │ ├── test.ts │ ├── tsconfig.app.json │ ├── tsconfig.spec.json │ └── typings.d.ts ├── tsconfig.json └── tslint.json简而言之,客户端代码位于“src”文件夹中,而 Angular 应用程序本身位于“app”文件夹中。
注意 app.module.ts 中的
AppModule。这用于引导 Angular 应用程序。@NgModule装饰器获取元数据,让 Angular 知道如何运行应用程序。我们在本教程中创建的所有东西都将被添加到这个对象中。在继续下一步之前,确保你已经很好地掌握了应用程序的结构。
注:刚入门 Angular 4?查看 Angular Style 指南,因为从 CLI 生成的 app 遵循该指南推荐的结构,以及 Angular4Crud 教程。
您是否注意到 CLI 初始化了一个新的 Git repo?这部分是可选的,但是创建一个新的 Github 存储库并更新 remote 是个好主意:
$ git remote set-url origin <newurl>现在,让我们连接一个新的组件 …
认证组件
首先,使用 CLI 生成一个新的登录组件:
$ ng generate component components/login这将设置组件文件和文件夹,甚至将其连接到 app.module.ts 。接下来,让我们将 login.component.ts 文件修改如下:
import { Component } from '@angular/core'; @Component({ selector: 'login', templateUrl: './login.component.html', styleUrls: ['./login.component.css'] }) export class LoginComponent { test: string = 'just a test'; }如果你以前没有使用过 TypeScript ,那么这段代码可能对你来说很陌生。TypeScript 是 JavaScript 的静态类型超集,编译成普通 JavaScript,它是构建 Angular 4 应用程序的事实上的编程语言。
在 Angular 4 中,我们通过用一个
@Component装饰器包装一个配置对象来定义一个组件。通过导入我们需要的类,我们可以在包之间共享代码;在这种情况下,我们从@angular/core包中导入Component。LoginComponent类是组件的控制器,我们使用export操作符使它可供其他类导入。将以下 HTML 添加到login.component.html中:
<h1>Login</h1> <p>{{test}}</p>接下来,通过 app.module.ts 文件中的 RouterModule 配置路由:
import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { RouterModule } from '@angular/router'; import { AppComponent } from './app.component'; import { LoginComponent } from './components/login/login.component'; @NgModule({ declarations: [ AppComponent, LoginComponent, ], imports: [ BrowserModule, RouterModule.forRoot([ { path: 'login', component: LoginComponent } ]) ], providers: [], bootstrap: [AppComponent] }) export class AppModule { }通过将app.component.html文件中的所有 HTML 替换为
<router-outlet>标签来完成启用路由:<router-outlet></router-outlet>在您的终端中运行
ng serve,如果您还没有运行的话,然后导航到http://localhost:4200/log in。如果一切顺利,您应该会看到just a test文本。自举风格
为了快速添加一些样式,更新index.html,添加引导,并将
<app-root></app-root>包装在容器中:<!doctype html> <html lang="en"> <head> <meta charset="utf-8"> <title>Angular4Auth</title> <base href="/"> <meta name="viewport" content="width=device-width, initial-scale=1"> <link rel="icon" type="image/x-icon" href="favicon.ico"> <link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css"> </head> <body> <div class="container"> <app-root></app-root> </div> </body> </html>你应该看到应用程序自动重新加载,只要你保存。
授权服务
接下来,让我们创建一个全局服务来处理用户登录、注销和注册:
$ ng generate service services/auth编辑 auth.service.ts ,使其具有以下代码:
import { Injectable } from '@angular/core'; @Injectable() export class AuthService { test(): string { return 'working'; } }还记得 Angular 1 中提供者是如何工作的吗?它们是存储单一状态的全局对象。当提供程序中的数据发生变化时,任何注入该提供程序的对象都会收到更新。在 Angular 4 中,提供者保留了它们的特殊行为,它们是用
@Injectable装饰器定义的。健全性检查
在向
AuthService添加任何重要内容之前,让我们确保服务本身被正确连接。为此,在 login.component.ts 中注入服务并调用test()方法:import { Component, OnInit } from '@angular/core'; import { AuthService } from '../../services/auth.service'; @Component({ selector: 'login', templateUrl: './login.component.html', styleUrls: ['./login.component.css'] }) export class LoginComponent implements OnInit { test: string = 'just a test'; constructor(private auth: AuthService) {} ngOnInit(): void { console.log(this.auth.test()); } }我们引入了一些新概念和关键词。
constructor()函数是一个特殊的方法,我们用它来建立一个类的新实例。constructor()是我们传递该类所需的任何参数的地方,包括我们想要注入的任何提供者(即AuthService)。在 TypeScript 中,我们可以用private关键字对外界隐藏变量。在构造函数中传递一个private变量是在类中定义它,然后将参数值赋给它的捷径。请注意auth变量在传递给构造函数后如何被this对象访问。我们实现了
OnInit接口,以确保我们明确定义了一个ngOnInit()函数。实现OnInit确保我们的组件将在第一次变更检测检查后被调用。该函数在组件首次初始化时调用一次,使其成为配置依赖于其他角度类的数据的理想位置。与自动添加的组件不同,服务必须在
@NgModule上手动导入和配置。因此,要让它工作,你还必须导入 app.module.ts 中的AuthService,并将其添加到providers:import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { RouterModule } from '@angular/router'; import { AppComponent } from './app.component'; import { LoginComponent } from './components/login/login.component'; import { AuthService } from './services/auth.service'; @NgModule({ declarations: [ AppComponent, LoginComponent, ], imports: [ BrowserModule, RouterModule.forRoot([ { path: 'login', component: LoginComponent } ]) ], providers: [AuthService], bootstrap: [AppComponent] }) export class AppModule { }运行服务器,然后导航到http://localhost:4200/log in。您应该看到
working被记录到 JavaScript 控制台。用户登录
要处理用户登录,请像这样更新
AuthService:import { Injectable } from '@angular/core'; import { Headers, Http } from '@angular/http'; import 'rxjs/add/operator/toPromise'; @Injectable() export class AuthService { private BASE_URL: string = 'http://localhost:5000/auth'; private headers: Headers = new Headers({'Content-Type': 'application/json'}); constructor(private http: Http) {} login(user): Promise<any> { let url: string = `${this.BASE_URL}/login`; return this.http.post(url, user, {headers: this.headers}).toPromise(); } }我们借助一些内置的 Angular 类,
Headers和Http,来处理我们对服务器的 AJAX 调用。同样,更新 app.module.ts 文件来导入
HttpModule。import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { RouterModule } from '@angular/router'; import { HttpModule } from '@angular/http'; import { AppComponent } from './app.component'; import { LoginComponent } from './components/login/login.component'; import { AuthService } from './services/auth.service'; @NgModule({ declarations: [ AppComponent, LoginComponent, ], imports: [ BrowserModule, HttpModule, RouterModule.forRoot([ { path: 'login', component: LoginComponent } ]) ], providers: [AuthService], bootstrap: [AppComponent] }) export class AppModule { }这里,我们使用 Http 服务向
/user/login端点发送一个 AJAX 请求。这将返回一个承诺对象。注意:确保从
LoginComponent组件上移除console.log(this.auth.test());。用户注册
让我们继续添加注册用户的功能,这类似于让用户登录。更新src/app/services/auth . service . ts,注意
register方法:import { Injectable } from '@angular/core'; import { Headers, Http } from '@angular/http'; import 'rxjs/add/operator/toPromise'; @Injectable() export class AuthService { private BASE_URL: string = 'http://localhost:5000/auth'; private headers: Headers = new Headers({'Content-Type': 'application/json'}); constructor(private http: Http) {} login(user): Promise<any> { let url: string = `${this.BASE_URL}/login`; return this.http.post(url, user, {headers: this.headers}).toPromise(); } register(user): Promise<any> { let url: string = `${this.BASE_URL}/register`; return this.http.post(url, user, {headers: this.headers}).toPromise(); } }现在,为了测试这一点,我们需要设置一个后端…
服务器端设置
对于服务器端,我们将使用上一篇博文中完成的项目,使用 Flask 进行基于令牌的认证。您可以从 flask-jwt-auth 存储库中查看代码。
注意:随意使用自己的服务器,只要确保更新
AuthService中的baseURL即可。在新的终端窗口中克隆项目结构:
$ git clone https://github.com/realpython/flask-jwt-auth按照自述文件中的指示建立项目,确保在继续之前通过测试。一旦完成,用
python manage.py runserver运行服务器,它将监听端口 5000。健全性检查
为了测试,更新
LoginComponent以使用服务中的login和register方法:import { Component, OnInit } from '@angular/core'; import { AuthService } from '../../services/auth.service'; @Component({ selector: 'login', templateUrl: './login.component.html', styleUrls: ['./login.component.css'] }) export class LoginComponent implements OnInit { test: string = 'just a test'; constructor(private auth: AuthService) {} ngOnInit(): void { let sampleUser: any = { email: 'michael@realpython.com' as string, password: 'michael' as string }; this.auth.register(sampleUser) .then((user) => { console.log(user.json()); }) .catch((err) => { console.log(err); }); this.auth.login(sampleUser).then((user) => { console.log(user.json()); }) .catch((err) => { console.log(err); }); } }在浏览器中刷新http://localhost:4200/log in,在用户登录后,您应该在 JavaScript 控制台中看到一个成功,标记为:
{ "auth_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE1M…jozfQ.bPNQb3C98yyNe0LDyl1Bfkp0Btn15QyMxZnBoE9RQMI", "message": "Successfully logged in.", "status": "success" }授权登录
更新login.component.html:
<div class="row"> <div class="col-md-4"> <h1>Login</h1> <hr><br> <form (ngSubmit)="onLogin()" novalidate> <div class="form-group"> <label for="email">Email</label> <input type="text" class="form-control" id="email" placeholder="enter email" [(ngModel)]="user.email" name="email" required> </div> <div class="form-group"> <label for="password">Password</label> <input type="password" class="form-control" id="password" placeholder="enter password" [(ngModel)]="user.password" name="password" required> </div> </form> </div> </div>请注意表格。我们在每个表单输入上使用了
[(ngModel)]指令来捕获控制器中的那些值。同样,当表单被提交时,ngSubmit指令通过触发onLogin()方法来处理事件。现在,让我们更新组件代码,添加
onLogin():import { Component } from '@angular/core'; import { AuthService } from '../../services/auth.service'; import { User } from '../../models/user'; @Component({ selector: 'login', templateUrl: './login.component.html', styleUrls: ['./login.component.css'] }) export class LoginComponent { user: User = new User(); constructor(private auth: AuthService) {} onLogin(): void { this.auth.login(this.user) .then((user) => { console.log(user.json()); }) .catch((err) => { console.log(err); }); } }如果您运行 Angular web 服务器,您应该会在浏览器中看到错误
Cannot find module '../../models/user'。在我们的代码工作之前,我们需要创建一个User模型。$ ng generate class models/user更新 src/app/models/user.ts :
export class User { constructor(email?: string, password?: string) {} }我们的
User模型有两个属性,password。?字符是一个特殊的操作符,表示用显式的password值初始化User是可选的。这相当于 Python 中的以下类:class User(object): def __init__(self, email=None, password=None): self.email = email self.password = password不要忘记更新 auth.service.ts 以使用新对象。
import { Injectable } from '@angular/core'; import { Headers, Http } from '@angular/http'; import { User } from '../models/user'; import 'rxjs/add/operator/toPromise'; @Injectable() export class AuthService { private BASE_URL: string = 'http://localhost:5000/auth'; private headers: Headers = new Headers({'Content-Type': 'application/json'}); constructor(private http: Http) {} login(user: User): Promise<any> { let url: string = `${this.BASE_URL}/login`; return this.http.post(url, user, {headers: this.headers}).toPromise(); } register(user: User): Promise<any> { let url: string = `${this.BASE_URL}/register`; return this.http.post(url, user, {headers: this.headers}).toPromise(); } }最后一件事。我们需要导入 app.module.ts 文件中的
FormsModule。import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { RouterModule } from '@angular/router'; import { HttpModule } from '@angular/http'; import { FormsModule } from '@angular/forms'; import { AppComponent } from './app.component'; import { LoginComponent } from './components/login/login.component'; import { AuthService } from './services/auth.service'; @NgModule({ declarations: [ AppComponent, LoginComponent, ], imports: [ BrowserModule, HttpModule, FormsModule, RouterModule.forRoot([ { path: 'login', component: LoginComponent } ]) ], providers: [AuthService], bootstrap: [AppComponent] }) export class AppModule { }因此,当提交表单时,我们捕获电子邮件和密码,并将它们传递给服务上的
login()方法。用这个测试一下-
- 电子邮件:
michael@realpython.com- 密码:
michael同样,您应该在 javaScript 控制台中看到一个成功的标记。
授权寄存器
就像登录功能一样,我们需要添加一个组件来注册用户。首先生成一个新的寄存器组件:
$ ng generate component components/register更新src/app/components/register/register . component . html:
<div class="row"> <div class="col-md-4"> <h1>Register</h1> <hr><br> <form (ngSubmit)="onRegister()" novalidate> <div class="form-group"> <label for="email">Email</label> <input type="text" class="form-control" id="email" placeholder="enter email" [(ngModel)]="user.email" name="email" required> </div> <div class="form-group"> <label for="password">Password</label> <input type="password" class="form-control" id="password" placeholder="enter password" [(ngModel)]="user.password" name="password" required> </div> </form> </div> </div>然后,更新src/app/components/register/register . component . ts如下:
import { Component } from '@angular/core'; import { AuthService } from '../../services/auth.service'; import { User } from '../../models/user'; @Component({ selector: 'register', templateUrl: './register.component.html', styleUrls: ['./register.component.css'] }) export class RegisterComponent { user: User = new User(); constructor(private auth: AuthService) {} onRegister(): void { this.auth.register(this.user) .then((user) => { console.log(user.json()); }) .catch((err) => { console.log(err); }); } }向 app.module.ts 文件添加一个新的路由处理程序:
RouterModule.forRoot([ { path: 'login', component: LoginComponent }, { path: 'register', component: RegisterComponent } ])通过注册一个新用户来测试它!
本地存储
接下来,让我们通过将src/app/components/log in/log in . component . ts中的
console.log(user.json());替换为localStorage.setItem('token', user.data.token);,将令牌添加到本地存储中进行持久化:onLogin(): void { this.auth.login(this.user) .then((user) => { localStorage.setItem('token', user.json().auth_token); }) .catch((err) => { console.log(err); }); }在src/app/components/register/register . component . ts内做同样的操作:
onRegister(): void { this.auth.register(this.user) .then((user) => { localStorage.setItem('token', user.json().auth_token); }) .catch((err) => { console.log(err); }); }只要该令牌存在,就可以认为用户已经登录。而且,当用户需要发出 AJAX 请求时,可以使用这个令牌。
注意:除了令牌,您还可以将用户 id 和电子邮件添加到本地存储。您只需要更新服务器端,以便在用户登录时发送回该信息。
测试一下。登录后,确保令牌存在于本地存储中。
用户状态
为了测试登录持久性,我们可以添加一个新的视图来验证用户是否登录以及令牌是否有效。
将以下方法添加到
AuthService:ensureAuthenticated(token): Promise<any> { let url: string = `${this.BASE_URL}/status`; let headers: Headers = new Headers({ 'Content-Type': 'application/json', Authorization: `Bearer ${token}` }); return this.http.get(url, {headers: headers}).toPromise(); }记下
Authorization: 'Bearer ' + token。这被称为承载模式,它随请求一起发送。在服务器上,我们只是检查Authorization头,然后检查令牌是否有效。你能在服务器端找到这段代码吗?然后,生成一个新的状态组件:
$ ng generate component components/status创建 HTML 模板,src/app/components/status/status . component . HTML:
<div class="row"> <div class="col-md-4"> <h1>User Status</h1> <hr><br> <p>Logged In? {{isLoggedIn}}</p> </div> </div>并更改src/app/components/status/status . component . ts中的组件代码:
import { Component, OnInit } from '@angular/core'; import { AuthService } from '../../services/auth.service'; @Component({ selector: 'status', templateUrl: './status.component.html', styleUrls: ['./status.component.css'] }) export class StatusComponent implements OnInit { isLoggedIn: boolean = false; constructor(private auth: AuthService) {} ngOnInit(): void { const token = localStorage.getItem('token'); if (token) { this.auth.ensureAuthenticated(token) .then((user) => { console.log(user.json()); if (user.json().status === 'success') { this.isLoggedIn = true; } }) .catch((err) => { console.log(err); }); } } }最后,向 app.module.ts 文件添加一个新的路由处理程序:
RouterModule.forRoot([ { path: 'login', component: LoginComponent }, { path: 'register', component: RegisterComponent }, { path: 'status', component: StatusComponent } ])准备测试了吗?登录,然后导航到http://localhost:4200/status。如果本地存储中有令牌,您应该会看到:
{ "message": "Signature expired. Please log in again.", "status": "fail" }为什么?嗯,如果你在服务器端深入挖掘,你会发现这个令牌在 project/server/models.py 中只有效 5 秒钟:
def encode_auth_token(self, user_id): """ Generates the Auth Token :return: string """ try: payload = { 'exp': datetime.datetime.utcnow() + datetime.timedelta(days=0, seconds=5), 'iat': datetime.datetime.utcnow(), 'sub': user_id } return jwt.encode( payload, app.config.get('SECRET_KEY'), algorithm='HS256' ) except Exception as e: return e将此更新为 1 天:
'exp': datetime.datetime.utcnow() + datetime.timedelta(days=1, seconds=0)然后再测试一次。您现在应该会看到类似这样的内容:
{ "data": { "admin": false, "email": "michael@realpython.com", "registered_on": "Sun, 13 Aug 2017 17:21:52 GMT", "user_id": 4 }, "status": "success" }最后,让我们在用户成功注册或登录后重定向到状态页面。更新src/app/components/log in/log in . component . ts像这样:
import { Component } from '@angular/core'; import { Router } from '@angular/router'; import { AuthService } from '../../services/auth.service'; import { User } from '../../models/user'; @Component({ selector: 'login', templateUrl: './login.component.html', styleUrls: ['./login.component.css'] }) export class LoginComponent { user: User = new User(); constructor(private router: Router, private auth: AuthService) {} onLogin(): void { this.auth.login(this.user) .then((user) => { localStorage.setItem('token', user.json().auth_token); this.router.navigateByUrl('/status'); }) .catch((err) => { console.log(err); }); } }然后更新src/app/components/register/register . component . ts:
import { Component } from '@angular/core'; import { Router } from '@angular/router'; import { AuthService } from '../../services/auth.service'; import { User } from '../../models/user'; @Component({ selector: 'register', templateUrl: './register.component.html', styleUrls: ['./register.component.css'] }) export class RegisterComponent { user: User = new User(); constructor(private router: Router, private auth: AuthService) {} onRegister(): void { this.auth.register(this.user) .then((user) => { localStorage.setItem('token', user.json().auth_token); this.router.navigateByUrl('/status'); }) .catch((err) => { console.log(err); }); } }测试一下!
路线限制
现在,所有的路线都是开放的;因此,无论用户是否登录,他们都可以访问每条路线。如果用户未登录,则应限制某些路由,而如果用户登录,则应限制其他路由:
/-没有限制/login-登录时受限/register-登录时受限/status-未登录时受限为了实现这一点,根据您是希望将用户引导到
status视图还是login视图,向每条路线添加EnsureAuthenticated或LoginRedirect。首先创建两个新服务:
$ ng generate service services/ensure-authenticated $ ng generate service services/login-redirect替换确保-认证.服务. ts 文件中的代码如下:
import { Injectable } from '@angular/core'; import { CanActivate, Router } from '@angular/router'; import { AuthService } from './auth.service'; @Injectable() export class EnsureAuthenticated implements CanActivate { constructor(private auth: AuthService, private router: Router) {} canActivate(): boolean { if (localStorage.getItem('token')) { return true; } else { this.router.navigateByUrl('/login'); return false; } } }并替换log in-redirect . service . ts中的代码,如下所示:
import { Injectable } from '@angular/core'; import { CanActivate, Router } from '@angular/router'; import { AuthService } from './auth.service'; @Injectable() export class LoginRedirect implements CanActivate { constructor(private auth: AuthService, private router: Router) {} canActivate(): boolean { if (localStorage.getItem('token')) { this.router.navigateByUrl('/status'); return false; } else { return true; } } }最后,更新 app.module.ts 文件以导入和配置新服务:
import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { RouterModule } from '@angular/router'; import { HttpModule } from '@angular/http'; import { FormsModule } from '@angular/forms'; import { AppComponent } from './app.component'; import { LoginComponent } from './components/login/login.component'; import { AuthService } from './services/auth.service'; import { RegisterComponent } from './components/register/register.component'; import { StatusComponent } from './components/status/status.component'; import { EnsureAuthenticated } from './services/ensure-authenticated.service'; import { LoginRedirect } from './services/login-redirect.service'; @NgModule({ declarations: [ AppComponent, LoginComponent, RegisterComponent, StatusComponent, ], imports: [ BrowserModule, HttpModule, FormsModule, RouterModule.forRoot([ { path: 'login', component: LoginComponent, canActivate: [LoginRedirect] }, { path: 'register', component: RegisterComponent, canActivate: [LoginRedirect] }, { path: 'status', component: StatusComponent, canActivate: [EnsureAuthenticated] } ]) ], providers: [ AuthService, EnsureAuthenticated, LoginRedirect ], bootstrap: [AppComponent] }) export class AppModule { }请注意我们是如何将我们的服务添加到新的 route 属性中的。路由系统使用
canActivate数组中的服务来确定是否显示请求的 URL 路径。如果路线有LoginRedirect并且用户已经登录,那么他们将被重定向到status视图。如果用户试图访问需要认证的 URL,包含EnsureAuthenticated服务会将用户重定向到login视图。最后测试一次。
下一步是什么?
在本教程中,我们经历了使用 JSON Web 令牌向 Angular 4 + Flask 应用程序添加身份验证的过程。
下一步是什么?
尝试使用以下端点将 Flask 后端切换到不同的 web 框架,如 Django 或 Bottle:
/auth/register/auth/login/auth/logout/auth/user如果您想了解如何使用 Flask 构建完整的 Python web 应用程序,请查看此视频系列:
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
在下面添加问题和/或评论。从 angular4-auth repo 中抓取最终代码。*****
使用 Flask-Login 通过 Flask 进行用户管理
原文:https://realpython.com/using-flask-login-for-user-management-with-flask/
以下是杰夫·克努普、编写惯用 Python 的作者的客座博文。杰夫目前正在 Kickstarter 上开展一个活动,将这本书改编成视频系列——看看吧!
几个月前,我厌倦了用来卖书的数字商品支付服务,决定自己写书。两个小时后,公牛诞生了。这是一个使用 Flask 和 Python 编写的小应用程序,它被证明是实现的一个极好的选择。它从最基本的功能开始:客户可以在一个 Stripe JavaScript 弹出窗口中输入他们的详细信息,
bull会记录他们的电子邮件地址,并为购买创建一个唯一的 id,然后将用户与他们购买的内容相关联。它工作得非常好。而在此之前,潜在客户不仅要输入他们的全名和地址(这两个我都没用过),他们还必须在我的支付处理器网站上创建一个账户。我不确定由于复杂的结账过程我损失了多少销售额,但我确定这是一笔好交易。在 bull 上,从点击图书销售页面上的“立即购买”按钮到真正阅读图书的时间大约是 10 秒钟。顾客喜欢它。
我也很喜欢它,但原因略有不同:由于
bull在我的网络服务器上运行,我可以获得比让客户到第三方网站付款更丰富的分析。这为一系列新的可能性打开了大门:A/B 测试、分析报告、定制销售报告。我很兴奋。免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
添加用户
我决定,至少,我希望
bull能够显示一个“销售概述”页面,其中包含基本的销售数据:交易信息、一段时间内的销售图表等。为了做到这一点(以安全的方式),我需要向我的小 Flask 应用程序添加身份验证和授权。不过,有益的是,我只需要支持一个被授权查看报告的单个“管理员”用户。幸运的是,通常情况下,已经有一个第三方包来处理这个问题。 Flask-login 是一个 Flask 扩展,支持用户认证。所需要的只是一个
User模型和一些简单的函数。让我们看看需要什么。
User型号
bull已经在使用 Flask-sqlalchemy 来创建purchase和product模型,分别捕获关于销售和产品的信息。Flask-login 需要一个具有以下属性的User模型:
- 有一个
is_authenticated()方法,如果用户提供了有效的凭证,该方法将返回True- 有一个
is_active()方法,如果用户的帐户是活动的,该方法返回True- 有一个
is_anonymous()方法,如果当前用户是匿名用户,该方法返回True- 有一个
get_id()方法,给定一个User实例,该方法返回该对象的唯一 ID虽然 Flask-login 提供了一个
UserMixin类,该类提供了所有这些的默认实现,但我只是像这样定义了所有需要的东西:from flask.ext.sqlalchemy import SQLAlchemy db = SQLAlchemy() #... class User(db.Model): """An admin user capable of viewing reports. :param str email: email address of user :param str password: encrypted password for the user """ __tablename__ = 'user' email = db.Column(db.String, primary_key=True) password = db.Column(db.String) authenticated = db.Column(db.Boolean, default=False) def is_active(self): """True, as all users are active.""" return True def get_id(self): """Return the email address to satisfy Flask-Login's requirements.""" return self.email def is_authenticated(self): """Return True if the user is authenticated.""" return self.authenticated def is_anonymous(self): """False, as anonymous users aren't supported.""" return False
user_loaderFlask-login 还要求您定义一个“user_loader”函数,给定一个用户 ID,该函数返回相关的用户对象。
简单:
@login_manager.user_loader def user_loader(user_id): """Given *user_id*, return the associated User object. :param unicode user_id: user_id (email) user to retrieve """ return User.query.get(user_id)
@login_manager.user_loader部分告诉 Flask-login 如何加载给定 id 的用户。我把这个函数放在定义了我的所有路线的文件中,因为它就用在这里。
/reports终点现在,我可以创建一个需要认证的
/reports端点。该端点的代码如下所示:@bull.route('/reports') @login_required def reports(): """Run and display various analytics reports.""" products = Product.query.all() purchases = Purchase.query.all() purchases_by_day = dict() for purchase in purchases: purchase_date = purchase.sold_at.date().strftime('%m-%d') if purchase_date not in purchases_by_day: purchases_by_day[purchase_date] = {'units': 0, 'sales': 0.0} purchases_by_day[purchase_date]['units'] += 1 purchases_by_day[purchase_date]['sales'] += purchase.product.price purchase_days = sorted(purchases_by_day.keys()) units = len(purchases) total_sales = sum([p.product.price for p in purchases]) return render_template( 'reports.html', products=products, purchase_days=purchase_days, purchases=purchases, purchases_by_day=purchases_by_day, units=units, total_sales=total_sales)您会注意到大部分代码与身份验证无关,这正是它应该有的样子。由于装饰器的原因,该函数假设用户已经通过了身份验证,因此有权查看这些数据。只有一个问题:用户如何被“认证”?
登录和注销
当然是通过一个
/login端点!/login和/logout都很简单,几乎可以从 Flask-login 文档中一字不差地提取出来:@bull.route("/login", methods=["GET", "POST"]) def login(): """For GET requests, display the login form. For POSTS, login the current user by processing the form. """ print db form = LoginForm() if form.validate_on_submit(): user = User.query.get(form.email.data) if user: if bcrypt.check_password_hash(user.password, form.password.data): user.authenticated = True db.session.add(user) db.session.commit() login_user(user, remember=True) return redirect(url_for("bull.reports")) return render_template("login.html", form=form) @bull.route("/logout", methods=["GET"]) @login_required def logout(): """Logout the current user.""" user = current_user user.authenticated = False db.session.add(user) db.session.commit() logout_user() return render_template("logout.html")您会注意到,一旦验证了数据库中的
User对象,我们就会更新它们。这是因为从一个请求到下一个请求,每次都会创建一个新的User对象实例,所以我们需要一个地方来存储用户已经验证过的信息。注销也是如此。创建管理员用户
与 Django 的
manage.py非常相似,我需要一种方法来创建一个具有正确登录凭证的管理员用户。我不能只手动向数据库添加一行,因为密码是以加盐散列的形式存储的(而不是纯文本,从安全角度来看,纯文本是愚蠢的)。为此,我创建了下面的脚本create_user.py:#!/usr/bin/env python """Create a new admin user able to view the /reports endpoint.""" from getpass import getpass import sys from flask import current_app from bull import app, bcrypt from bull.models import User, db def main(): """Main entry point for script.""" with app.app_context(): db.metadata.create_all(db.engine) if User.query.all(): print 'A user already exists! Create another? (y/n):', create = raw_input() if create == 'n': return print 'Enter email address: ', email = raw_input() password = getpass() assert password == getpass('Password (again):') user = User( email=email, password=bcrypt.generate_password_hash(password)) db.session.add(user) db.session.commit() print 'User added.' if __name__ == '__main__': sys.exit(main())最后,我有了一种方法来隔离销售站点的一部分,为管理员用户显示销售数据。在我的例子中,我只需要一个用户,但是 Flask-login 显然同时支持许多用户。
烧瓶生态系统
我能够快速地将这个功能添加到站点中,这说明了 Flask 扩展的丰富生态系统。最近,我想创建一个 web 应用程序,其中包括一个论坛。Django 有各种各样的复杂的论坛应用程序,您可以通过大量的努力来使用它们,但是没有一个能很好地与我选择的认证应用程序一起工作;这两个应用程序没有理由耦合在一起,但却是这样。
另一方面,Flask 使得将正交应用程序组合成更大、更复杂的应用程序变得容易,就像在函数式语言中组合函数一样。以烧瓶论坛为例。它在创建论坛时使用了以下 Flask 扩展:
- flask-数据库管理管理员
- 烧瓶-用于资产管理的资产
- 用于调试和分析的 Flask-DebugToolbar。
- 论坛帖子的减价
- 基本命令的脚本
- flask-认证安全性
- 用于数据库查询的 Flask-SQLAlchemy
- 用于表单的 Flask-WTF
有了这么长的列表,几乎令人惊讶的是,所有的应用程序都能够协同工作,而不会相互依赖(或者更确切地说,如果您来自 Django,这是令人惊讶的),但是 Flask 扩展通常遵循“做好一件事”的 Unix 哲学。我还没有遇到过我会认为“臃肿”的烧瓶扩展。
免费奖励: 点击此处获得免费的 Flask + Python 视频教程,向您展示如何一步一步地构建 Flask web 应用程序。
总结
虽然我的用例及实现相当简单,但 Flask 的伟大之处在于它让简单的事情变得简单。如果某件事看起来应该很容易做,不需要花太多时间,用 Flask,这通常是真的。我能够在不到一个小时的时间里在我的支付处理器中添加一个经过认证的管理部分,而且没有任何魔法。我知道所有的东西是如何工作和组合在一起的。
这是一个强大的概念:没有魔法。虽然许多 web 框架为开发人员创建应用程序所需要做的事情如此之少而自豪,但他们没有意识到开发人员只理解自己编写和使用的内容,他们隐藏这么多内容可能对开发人员不利。Flask 将其全部公开,并在此过程中允许 Django 着手创建的应用程序的功能组合。**
Real Python 上现在有视频字幕和文字记录
原文:https://realpython.com/video-subtitles-transcripts-now-available/
你好,
今天我有一个重大的更新要分享:
真正的 Python 视频课程现在有完整的字幕和文字记录!
我认为这将大大提高可访问性,并使您最喜欢的 Python 学习资源更容易查看和搜索。
让我们快速演示一下。视频课程现在配有全字幕,你可以在方便的时候打开和关闭:
在每个视频下方,你还会发现一个互动脚本,它会随视频一起播放动画,向你展示视频当前正在播放的部分:
为了使字幕准确,编辑和润色字幕花费了大量精力。
例如,当代码示例和变量标识符出现在字幕提示文本和抄本中时,我们对它们应用自定义格式:
YouTube 和许多其他在线平台为其视频内容提供自动生成的字幕。
但是对于像我们编程课程这样的高技术材料来说,这还不够好。潦草、不准确的字幕和文字稿让人摸不着头脑。
它们浪费你的时间,减缓你的学习进度。
相反,我们将视频字幕和文字记录视为我们内容库的一等公民:在真正的 Python 上,你会得到高质量的、手工编辑的字幕,你可以相信它们是准确的。
此外,realpython.com 学习平台在访问字幕和文本时为你提供了几个便利的功能。
例如,抄本中的每个句子都是可点击的,因此只需点击抄本中的一个单词,您就可以快速跳转到视频的特定部分:
这使得复习课程的特定部分或查找您以前观看的内容变得非常容易…
您甚至可以通过右键单击文字记录中的一个句子或单词并选择复制链接地址来共享视频中特定时间代码的链接。
这对于向同事和朋友指出视频的某些部分非常有用。
或者,您可以使用我们的网站搜索功能对所有视频字幕进行全文搜索,立即找到对您最有帮助的学习材料。
如果你以 1.5 倍或 2 倍的速度观看视频,或者如果你想训练各种技术和编码缩略语的发音(如 API、RESTful、PyPy、PyPI 等),字幕也会对你有所帮助。)
我们一直在与 RP 社区聊天的成员测试字幕功能,现在它终于可以在所有 realpython.com 账户上使用了:
从第一天起,所有新课程都将有字幕和文字记录。
随着时间的推移,我们还将回顾我们的课程目录,为所有人提供字幕和抄本。
我对这个新功能和它背后的团队努力感到非常自豪。
为了给你带来最高质量的脚本,我扩大了真正的 Python 团队,并聘请了一位字幕专家(对 Sadie 大喊),整个 RP 编辑团队正在不断完善我们的编辑和格式标准。
顺便说一句:
这是对当前真正的 Python 成员的完全免费升级。如果你今天是会员,你将获得所有字幕和课程记录,完全免费。
还不是会员? 加入真正的 Python 并访问我们的整个 Python 视频课程库、互动测验&学习路径、真正的 Python 社区聊天、每周“办公时间”现场问答&等等。
看看新的字幕和文字记录功能是如何工作的:
快乐的蟒蛇!
—丹·巴德,Real Python 的主编
VIM 和 Python–天作之合
原文:https://realpython.com/vim-and-python-a-match-made-in-heaven/
我注意到这一带有人一直在宣扬崇高文本 3 的福音。作为常驻高级开发人员(呃,老古董),我觉得我有责任告诉你你将需要的唯一真正的 Python 开发环境: VIM 。
没错。VIM 无处不在,速度很快,而且从不崩溃。它还可以做任何事情!
不过,从负面来看,配置 VIM 可能会很痛苦,但不用担心。本文将向您展示如何建立一个强大的 VIM 环境,以适应日复一日与 Python 的争论。
注意:为了从本文中获得最大收益,您至少应该对如何使用 VIM 及其命令模式有一个基本的了解。如果你刚刚开始,查看一下的这个资源或者的这个。在继续下一步之前,您将需要花一些时间来学习 VIM 并了解基础知识。
免费奖励: ,其中包含优化 Python 开发设置的技巧和调整。
更新于 2018-06-01
安装
由于 VIM 预装在许多 *nix 系统上,让我们首先检查它是否已安装:
$ vim --version如果安装了它,您应该会看到如下内容:
VIM - Vi IMproved 7.3 (2010 Aug 15, compiled Nov 5 2014 21:00:28) Compiled by root@apple.com Normal version without GUI. Features included (+) or not (-): -arabic +autocmd -balloon_eval -browse +builtin_terms +byte_offset +cindent -clientserver -clipboard +cmdline_compl +cmdline_hist +cmdline_info +comments -conceal +cryptv +cscope +cursorbind +cursorshape +dialog_con +diff +digraphs -dnd -ebcdic -emacs_tags +eval +ex_extra +extra_search -farsi +file_in_path +find_in_path +float +folding -footer +fork() -gettext -hangul_input +iconv +insert_expand +jumplist -keymap -langmap +libcall +linebreak +lispindent +listcmds +localmap -lua +menu +mksession +modify_fname +mouse -mouseshape -mouse_dec -mouse_gpm -mouse_jsbterm -mouse_netterm -mouse_sysmouse +mouse_xterm +multi_byte +multi_lang -mzscheme +netbeans_intg -osfiletype +path_extra -perl +persistent_undo +postscript +printer -profile +python/dyn -python3 +quickfix +reltime -rightleft +ruby/dyn +scrollbind +signs +smartindent -sniff +startuptime +statusline -sun_workshop +syntax +tag_binary +tag_old_static -tag_any_white -tcl +terminfo +termresponse +textobjects +title -toolbar +user_commands +vertsplit +virtualedit +visual +visualextra +viminfo +vreplace +wildignore +wildmenu +windows +writebackup -X11 -xfontset -xim -xsmp -xterm_clipboard -xterm_save system vimrc file: "$VIM/vimrc" user vimrc file: "$HOME/.vimrc" user exrc file: "$HOME/.exrc" fall-back for $VIM: "/usr/share/vim" Compilation: gcc -c -I. -D_FORTIFY_SOURCE=0 -Iproto -DHAVE_CONFIG_H -arch i386 -arch x86_64 -g -Os -pipe Linking: gcc -arch i386 -arch x86_64 -o vim -lncurses此时,您需要检查两件事情:
- VIM 版本应高于 7.3。
- 应该出现在特性列表中,这样你就知道 Python 是受支持的。
如果这两个检查都通过了,那么就直接移动到 VIM 扩展。如果没有,是时候安装/升级了。
马科斯/ OS X
如果你还没有自制软件的话,拿起它,然后运行:
$ brew update $ brew install vimNIX / Linux
对于 Debian 或 Ubuntu,可以尝试:
$ sudo apt-get remove vim-tiny $ sudo apt-get update $ sudo apt-get install vim对于其他版本的 Linux,请查看软件包管理器中的文档。这里有一个链接可以帮助您入门:安装 Vim 。
窗户
在 Windows 上安装 VIM 有许多不同的方法。先从公文说起。
验证您的 VIM 安装
确保您已经安装了支持 Python 的 VIM > 7.3。再次运行
vim --version来验证这一点。如果您想检查 VIM 中使用的 Python 的具体版本,请在 VIM 中运行:python import sys; print(sys.version):2.7.6 (default, Sep 9 2014, 15:04:36) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.39)]这应该会输出您当前的 Python 版本。如果您得到一个错误,那么您没有 Python 支持,如果您从源代码构建,您需要重新安装或重新编译。
安装了 VIM 之后,让我们看看如何为 Python 开发定制 VIM。
VIM 扩展
VIM 可以做很多开发者需要的事情。然而,它也是大规模可扩展的,并且有一些非常棒的扩展使它的行为更像一个“现代”IDE。你首先需要的是一个好的扩展经理。
注意:VIM 中的扩展通常被称为捆绑包或插件。
Vundle
VIM 有几个扩展管理器,但是我强烈推荐的是 Vundle 。可以把它想象成 VIM 的 pip 。它使得安装包和更新包变得很简单。
让我们安装 Vundle:
$ git clone https://github.com/gmarik/Vundle.vim.git ~/.vim/bundle/Vundle.vim这个命令下载 Vundle 插件管理器,并把它放到您的 VIM 包目录中。现在你可以从
.vimrc配置文件中管理你所有的扩展。将文件添加到用户的主目录:
$ touch ~/.vimrc现在,通过在文件顶部添加以下内容,在您的
.vimrc中设置 Vundle:set nocompatible " required filetype off " required " set the runtime path to include Vundle and initialize set rtp+=~/.vim/bundle/Vundle.vim call vundle#begin() " alternatively, pass a path where Vundle should install plugins "call vundle#begin('~/some/path/here') " let Vundle manage Vundle, required Plugin 'gmarik/Vundle.vim' " add all your plugins here (note older versions of Vundle " used Bundle instead of Plugin) " ... " All of your Plugins must be added before the following line call vundle#end() " required filetype plugin indent on " required就是这样。你现在可以使用 Vundle 了。之后,您可以添加想要安装的插件,然后启动 VIM 并运行:
:PluginInstall这个命令告诉 Vundle 发挥它的魔力——下载所有的插件并为你安装/更新它们。
注意:如果你是 Windows 用户,查看 Windows 安装说明。
让我们做一个 IDE
我们不可能列出所有的 VIM 特性,但是让我们快速列出一些非常适合 Python 开发的强大的现成特性。
扔掉鼠标
VIM 最重要的特性可能是它不需要鼠标(除了 VIM 的图形化变体)。起初,这似乎是一个可怕的想法,但是在你投入时间——这确实需要时间——去学习组合键之后,你将会加快你的整个工作流程!
分割布局
如果用
:sp <filename>打开一个文件,则垂直分割布局(在当前文件下打开新文件)。如果您将键反转到:vs <filename>,您会得到一个水平分割(在当前文件的右边打开新文件)。
你也可以嵌套拆分,这样你就可以随心所欲地在拆分中包含水平和垂直的拆分。众所周知,我们在开发的时候经常需要一次看几个文件。
专业提示#1: 确保在键入
:sp后使用制表符补全来查找文件。专业提示#2: 您也可以通过在
.vimrc文件中添加以下几行来指定屏幕上应该出现拆分的不同区域:set splitbelow set splitright专业提示#3: 想不用鼠标就能在拆分之间移动吗?如果您简单地将以下内容添加到
.vimrc中,只需一个组合键,您就可以在拆分之间跳转:"split navigations nnoremap <C-J> <C-W><C-J> nnoremap <C-K> <C-W><C-K> nnoremap <C-L> <C-W><C-L> nnoremap <C-H> <C-W><C-H>关键组合:
Ctrl+J移动到拆分的下方Ctrl+K移动到拆分上面Ctrl+L向右移动拆分Ctrl+H向左移动拆分换句话说,按下
Ctrl加标准 VIM 移动键移动到特定的窗格。但是等等——什么是
nnoremap事情?简而言之,nnoremap将一个组合键重新映射到另一个组合键。no部分意味着在普通模式下重新映射按键,而不是视觉模式。基本上,nnoremap <C-J> <C-W><C-j>说,在正常模式下,当我点击<C-J>时,改为做<C-W><C-j>。更多信息可以在这里找到。缓冲器
虽然 VIM 可以做标签,但许多用户更喜欢缓冲和拆分。你可以把一个缓冲区想象成一个最近打开的文件。VIM 提供了对最近缓冲区的简单访问。只需输入
:b <buffer name or number>就可以切换到一个开放的缓冲区。(自动完成在这里也有效。)也可以使用:ls列出所有缓冲区。Pro 提示#4: 在
:ls输出结束时,VIM 会提示Hit enter to continue。你可以输入:b <buffer number>,在列表显示的时候立即选择缓冲区。这样做将为您节省一次击键,并且您不必记住缓冲区编号。代码折叠
大多数“现代”ide 提供了一种折叠(或折叠)方法和类的方法,只显示类/方法定义行,而不是所有代码。
您可以在
.vimrc中使用下面几行来启用它:" Enable folding set foldmethod=indent set foldlevel=99这可以正常工作,但是您必须键入
za才能折叠(和展开)。空格键会更好。所以也将这一行添加到您的.vimrc文件中:" Enable folding with the spacebar nnoremap <space> za现在,您可以轻松地隐藏您当前没有处理的代码部分。
第一个命令
set foldmethod=indent,根据行缩进创建折叠。然而,这通常会产生比您真正想要的更多的折叠。但是不要害怕!有几个扩展试图纠正这一点。我们推荐simply fold。通过在.vimrc中添加以下行,用 Vundle 安装它:Plugin 'tmhedberg/SimpylFold'注意:别忘了安装插件-
:PluginInstall。Pro Tip #5: 如果你想查看折叠代码的文档字符串,试试这个:
let g:SimpylFold_docstring_preview=1Python 缩进
当然,对于基于缩进的代码折叠,您希望缩进是正确的。同样,VIM 在开箱即用方面有所欠缺,因为它不处理函数定义后的自动缩进。使用缩进可以做两件事:
- 让缩进遵循 PEP 8 标准。
- 更好地处理自动缩进。
PEP 8
要添加正确的 PEP 8 缩进,请将以下内容添加到您的
.vimrc:au BufNewFile,BufRead *.py \ set tabstop=4 \ set softtabstop=4 \ set shiftwidth=4 \ set textwidth=79 \ set expandtab \ set autoindent \ set fileformat=unix当你点击 tab 键时,这将为你提供标准的四个空格,确保你的行长度不超过 80 个字符,并以 Unix 格式存储文件,这样你就不会在签入 GitHub 和/或与其他用户共享时遇到一堆转换问题。
对于全栈开发,您可以对每个文件类型使用另一个
au命令:au BufNewFile,BufRead *.js, *.html, *.css \ set tabstop=2 \ set softtabstop=2 \ set shiftwidth=2这样,不同的文件类型可以有不同的设置。还有一个名为 ftypes 的插件,它允许你为每个你想要维护设置的文件类型创建一个单独的文件,所以如果你觉得合适就使用它。
自动缩进
autoindent将会有所帮助,但是在某些情况下(比如当一个函数签名跨越多行时),它并不总是如你所愿,尤其是在涉及到符合 PEP 8 标准的时候。要解决这个问题,您可以使用 indentpython.vim 扩展:Plugin 'vim-scripts/indentpython.vim'标记不必要的空白
您还希望避免无关的空白。您可以让 VIM 为您标记它,以便于识别和删除:
au BufRead,BufNewFile *.py,*.pyw,*.c,*.h match BadWhitespace /\s\+$/这将把多余的空白标记为坏的,并可能把它涂成红色。
UTF-8 支持
在大多数情况下,使用 Python 时应该使用 UTF-8,尤其是使用 Python 3 时。确保 VIM 知道使用下面的行:
set encoding=utf-8自动完成
Python 自动完成最好的插件是 YouCompleteMe 。同样,使用 Vundle 来安装:
Bundle 'Valloric/YouCompleteMe'在幕后,YouCompleteMe 使用了几个不同的自动完成器(包括 Python 的 Jedi ),它需要安装一些 C 库才能正常工作。文档中有非常好的安装说明,所以我不会在这里重复,但请务必遵循它们。
它开箱即用,但让我们添加一些定制:
let g:ycm_autoclose_preview_window_after_completion=1 map <leader>g :YcmCompleter GoToDefinitionElseDeclaration<CR>第一行确保自动完成窗口在您完成后消失,第二行定义了 goto 定义的快捷方式。
注意:我的 leader 键被映射到空间,所以
space-g将转到我当前所在位置的定义。这在我探索新代码时很有帮助。虚拟支持
上面 goto 定义的一个问题是,默认情况下,VIM 不知道任何关于 virtualenv 的信息,所以您必须通过向
.vimrc添加以下代码行,让 VIM 和 YouCompleteMe 知道您的 virtualenv:"python with virtualenv support py << EOF import os import sys if 'VIRTUAL_ENV' in os.environ: project_base_dir = os.environ['VIRTUAL_ENV'] activate_this = os.path.join(project_base_dir, 'bin/activate_this.py') execfile(activate_this, dict(__file__=activate_this)) EOF这将确定您是否在 virtualenv 中运行,切换到该特定的 virtualenv,然后设置您的系统路径,以便您的 CompleteMe 将找到适当的站点包。
语法检查/高亮显示
您可以让 VIM 使用 syntastic 扩展名在每次保存时检查语法:
Plugin 'vim-syntastic/syntastic'还用这个漂亮的小插件添加了 PEP 8 检查:
Plugin 'nvie/vim-flake8'最后,让你的代码看起来很漂亮:
let python_highlight_all=1 syntax on配色方案
配色方案与您正在使用的基本配色方案一起使用。检查 GUI 模式的日光化,终端模式的 Zenburn :
Plugin 'jnurmine/Zenburn' Plugin 'altercation/vim-colors-solarized'然后,只需添加一点逻辑来定义基于 VIM 模式使用哪个方案:
if has('gui_running') set background=dark colorscheme solarized else colorscheme zenburn endif日晒也有黑暗和光明的主题。为了使它们之间的切换非常容易(通过按
F5)添加:call togglebg#map("<F5>")文件浏览
如果你想要一个合适的文件树,那么 NERDTree 是一个不错的选择:
Plugin 'scrooloose/nerdtree'如果你想使用标签,使用 vim-nerdtree-tabs :
Plugin 'jistr/vim-nerdtree-tabs'想隐藏
.pyc文件?然后添加下面一行:let NERDTreeIgnore=['\.pyc$', '\~$'] "ignore files in NERDTree超级搜索
想在 VIM 上搜索任何东西吗?检查 ctrlP :
Plugin 'kien/ctrlp.vim'如你所料,按下
Ctrl+P将启用搜索,因此你可以直接开始输入。如果您的搜索与您要查找的文件匹配,它会找到它。哦,它不仅仅是文件:它还会找到标签!更多信息,请看这个 YouTube 视频。行号
使用以下选项打开屏幕侧面的行号:
set nuGit 集成
想在不离开 VIM 的情况下执行基本的 git 命令吗?那么vim-逃犯就是要走的路:
Plugin 'tpope/vim-fugitive'
在 VIMcasts 上观看它的运行。
电力线
Powerline 是一个状态栏,显示当前的 virtualenv、git 分支、正在编辑的文件等等。
它是用 Python 编写的,支持许多其他环境,如 zsh、bash、tmux 和 IPython:
Plugin 'Lokaltog/powerline', {'rtp': 'powerline/bindings/vim/'}查看官方文档了解所有配置选项。
系统剪贴板
Vim 通常有自己的剪贴板,并忽略系统键盘,但是有时您可能想要剪切、复制和/或粘贴到 VIM 之外的其他应用程序。在 OS X 上,您可以通过以下命令行访问系统剪贴板:
set clipboard=unnamed外壳中的 VIM
最后,一旦您掌握了 VIM 及其键盘快捷键,您会经常发现自己对 shell 中缺少相同的快捷键感到恼火。不用担心:大多数 shells 都有 VI 模式。要为您的 shell 打开它,请将下面一行添加到
~/.inputrc:set editing-mode vi现在,您不仅可以在 shell 中使用 VIM 组合键,还可以在 Python 解释器和任何其他使用 GNU Readline 的工具(大多数数据库 shell)中使用。现在你到处都有 VIM!
结论
差不多就是这样(至少对于 Python 开发来说)。你可以使用很多其他的扩展,以及这篇文章中详细描述的所有东西的替代品。你最喜欢的扩展是什么?你是如何配置 VIM 来匹配你的个性的?
这是我当前的 VIM 配置的链接。你自己有吗?请分享!
感谢阅读!
资源
免费奖励: ,其中包含优化 Python 开发设置的技巧和调整。
- VIM Tutor 是 VIM 自带的,所以一旦安装了 VIM,只要从命令行输入
vimtutor,程序就会教你如何使用 VIM。- VIMcasts 是描述如何使用 VIM 许多特性的高级教程视频。
- VIM 官方文档
- 打开 Vim
- 艰难地学习 Vimscript非常适合学习 vim script。******
使用 plt.scatter()在 Python 中可视化数据
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 使用 plt.scatter()在 Python 中可视化数据
处理数据的一个重要部分是能够可视化它。Python 有几个第三方模块可以用于数据可视化。最受欢迎的模块之一是 Matplotlib 及其子模块 pyplot ,通常使用别名
plt。Matplotlib 提供了一个名为plt.scatter()的非常通用的工具,允许您创建基本的和更复杂的散点图。下面,您将通过几个例子来展示如何有效地使用该函数。
在本教程中,你将学习如何:
- 使用
plt.scatter()创建散点图- 使用必需和可选的输入参数
- 为基本图和更高级图定制散点图
- 在散点图上表示两个以上的维度
为了从本教程中获得最大收益,你应该熟悉 Python 编程的基础和 NumPy 及其
ndarray对象的基础。你不需要熟悉 Matplotlib 来学习本教程,但如果你想了解更多关于该模块的知识,那么请查看 Python 使用 Matplotlib 绘图(指南)。免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
创建散点图
一个散点图是两个变量如何相互关联的可视化表示。您可以使用散点图来探索两个变量之间的关系,例如通过寻找它们之间的任何相关性。
在本节教程中,您将熟悉如何使用 Matplotlib 创建基本散点图。在后面的章节中,您将学习如何进一步定制您的绘图,以使用两个以上的维度来表示更复杂的数据。
plt.scatter()入门在你开始使用
plt.scatter()之前,你需要安装 Matplotlib。您可以使用 Python 的标准包管理器pip,通过在控制台中运行以下命令来实现:$ python -m pip install matplotlib现在您已经安装了 Matplotlib,考虑下面的用例。一家咖啡馆出售六种不同类型的瓶装橙汁饮料。店主希望了解饮料价格和他销售的每种饮料数量之间的关系,所以他记录了他每天销售的每种饮料的数量。您可以将这种关系形象化,如下所示:
import matplotlib.pyplot as plt price = [2.50, 1.23, 4.02, 3.25, 5.00, 4.40] sales_per_day = [34, 62, 49, 22, 13, 19] plt.scatter(price, sales_per_day) plt.show()在这个 Python 脚本中,您使用别名
plt从 Matplotlib 导入子模块pyplot。这个别名通常用于缩短模块和子模块的名称。然后创建列表,列出六种橙汁饮料的价格和每天的平均销售额。最后,使用
plt.scatter()创建散点图,将两个想要比较的变量作为输入参数。由于您使用的是 Python 脚本,您还需要通过使用plt.show()显式地显示图形。当你在使用一个交互环境时,比如一个控制台或者一个 Jupyter 笔记本,你不需要调用
plt.show()。在本教程中,所有的例子都是脚本的形式,并且包括对plt.show()的调用。下面是这段代码的输出:
该图显示,一般来说,饮料越贵,售出的商品越少。然而,售价 4.02 美元的饮料是一个异常值,这可能表明它是一种特别受欢迎的产品。以这种方式使用散点图时,仔细检查可以帮助您探索变量之间的关系。然后你可以进行进一步的分析,无论是使用线性回归还是其他技术。
比较
plt.scatter()和plt.plot()T2您也可以使用
matplotlib.pyplot中的另一个函数生成如上所示的散点图。Matplotlib 的plt.plot()是一个通用绘图功能,允许您创建各种不同的线条或标记图。使用相同的数据,通过调用
plt.plot(),您可以获得与上一节相同的散点图:plt.plot(price, sales_per_day, "o") plt.show()在这种情况下,您必须包含标记
"o"作为第三个参数,否则plt.plot()将绘制一个线图。你用这段代码创建的图和你之前用plt.scatter()创建的图是一样的。在某些情况下,对于本例中绘制的基本散点图,使用
plt.plot()可能更好。您可以使用timeit模块来比较这两个功能的效率:import timeit import matplotlib.pyplot as plt price = [2.50, 1.23, 4.02, 3.25, 5.00, 4.40] sales_per_day = [34, 62, 49, 22, 13, 19] print( "plt.scatter()", timeit.timeit( "plt.scatter(price, sales_per_day)", number=1000, globals=globals(), ), ) print( "plt.plot()", timeit.timeit( "plt.plot(price, sales_per_day, 'o')", number=1000, globals=globals(), ), )在不同的计算机上,性能会有所不同,但是当您运行这段代码时,您会发现
plt.plot()比plt.scatter()要高效得多。在我的系统上运行上面的例子时,plt.plot()快了 7 倍多。如果您可以使用
plt.plot()创建散点图,而且速度也快得多,那么您为什么还要使用plt.scatter()?你将在本教程的剩余部分找到答案。你将在本教程中学到的大多数定制和高级用法只有在使用plt.scatter()时才有可能。这里有一个你可以使用的经验法则:
- 如果你需要一个基本的散点图,使用
plt.plot(),特别是如果你想优先考虑性能。- 如果您想通过使用更高级的绘图功能自定义散点图,请使用
plt.scatter()。在下一节中,您将开始探索
plt.scatter()更高级的用法。自定义散点图中的标记
通过自定义标记,可以在二维散点图上显示两个以上的变量。散点图中使用的标记有四个主要特征,您可以使用
plt.scatter()进行定制:
- 大小
- 颜色
- 形状
- 透明度
在本节教程中,您将学习如何修改所有这些属性。
改变尺寸
让我们回到你在本教程前面遇到的咖啡馆老板。他卖的不同的橙汁饮料来自不同的供应商,利润率也不同。通过调整标记的大小,可以在散点图中显示这些附加信息。在本例中,利润率以百分比形式给出:
import matplotlib.pyplot as plt import numpy as np price = np.asarray([2.50, 1.23, 4.02, 3.25, 5.00, 4.40]) sales_per_day = np.asarray([34, 62, 49, 22, 13, 19]) profit_margin = np.asarray([20, 35, 40, 20, 27.5, 15]) plt.scatter(x=price, y=sales_per_day, s=profit_margin * 10) plt.show()您可以注意到第一个示例中的一些变化。您现在使用的是 NumPy 数组,而不是列表。您可以为数据使用任何类似数组的数据结构,NumPy 数组通常用在这些类型的应用程序中,因为它们支持有效执行的元素操作。NumPy 模块是 Matplotlib 的一个依赖项,这就是为什么你不需要手动安装它。
您还使用了命名参数作为函数调用中的输入参数。参数
x和y是必需的,但所有其他参数都是可选的。参数
s表示标记的大小。在本例中,您使用利润率作为变量来确定标记的大小,并将其乘以10以更清楚地显示大小差异。您可以在下面看到这段代码创建的散点图:
标记的大小表明每种产品的利润率。销量最大的两种橙汁饮料也是利润率最高的。这对咖啡馆老板来说是个好消息!
改变颜色
咖啡馆的许多顾客都喜欢仔细阅读标签,尤其是为了弄清他们所购买的饮料的含糖量。咖啡馆老板希望在下一次营销活动中强调他对健康食品的选择,因此他根据饮料的含糖量对其进行分类,并使用交通灯系统来指示饮料的低、中或高含糖量。
您可以给散点图中的标记添加颜色,以显示每种饮料的含糖量:
# ... low = (0, 1, 0) medium = (1, 1, 0) high = (1, 0, 0) sugar_content = [low, high, medium, medium, high, low] plt.scatter( x=price, y=sales_per_day, s=profit_margin * 10, c=sugar_content, ) plt.show()您将变量
low、medium和high定义为元组,每个元组包含三个值,依次代表红色、绿色和蓝色分量。这些是 RGB 颜色值。low、medium和high的元组分别代表绿色、黄色和红色。然后您定义了变量
sugar_content来对每种饮料进行分类。您在函数调用中使用可选参数c来定义每个标记的颜色。下面是这段代码生成的散点图:
咖啡馆老板已经决定从菜单上去掉最贵的饮料,因为这种饮料卖得不好,而且含糖量很高。他是否也应该停止储存最便宜的饮料,以提升企业的健康信誉,即使它卖得很好,利润率也很高?
改变形状
咖啡馆老板发现这个练习非常有用,他想调查另一种产品。除了橙汁饮料之外,您现在还将绘制咖啡馆中各种谷物棒的类似数据:
import matplotlib.pyplot as plt import numpy as np low = (0, 1, 0) medium = (1, 1, 0) high = (1, 0, 0) price_orange = np.asarray([2.50, 1.23, 4.02, 3.25, 5.00, 4.40]) sales_per_day_orange = np.asarray([34, 62, 49, 22, 13, 19]) profit_margin_orange = np.asarray([20, 35, 40, 20, 27.5, 15]) sugar_content_orange = [low, high, medium, medium, high, low] price_cereal = np.asarray([1.50, 2.50, 1.15, 1.95]) sales_per_day_cereal = np.asarray([67, 34, 36, 12]) profit_margin_cereal = np.asarray([20, 42.5, 33.3, 18]) sugar_content_cereal = [low, high, medium, low] plt.scatter( x=price_orange, y=sales_per_day_orange, s=profit_margin_orange * 10, c=sugar_content_orange, ) plt.scatter( x=price_cereal, y=sales_per_day_cereal, s=profit_margin_cereal * 10, c=sugar_content_cereal, ) plt.show()在这段代码中,您重构了变量名,以考虑到您现在拥有两种不同产品的数据。然后在一个图形中绘制两个散点图。这将产生以下输出:
不幸的是,您再也无法确定哪些数据点属于橙汁饮料,哪些属于谷物棒。您可以更改其中一个散点图的标记形状:
import matplotlib.pyplot as plt import numpy as np low = (0, 1, 0) medium = (1, 1, 0) high = (1, 0, 0) price_orange = np.asarray([2.50, 1.23, 4.02, 3.25, 5.00, 4.40]) sales_per_day_orange = np.asarray([34, 62, 49, 22, 13, 19]) profit_margin_orange = np.asarray([20, 35, 40, 20, 27.5, 15]) sugar_content_orange = [low, high, medium, medium, high, low] price_cereal = np.asarray([1.50, 2.50, 1.15, 1.95]) sales_per_day_cereal = np.asarray([67, 34, 36, 12]) profit_margin_cereal = np.asarray([20, 42.5, 33.3, 18]) sugar_content_cereal = [low, high, medium, low] plt.scatter( x=price_orange, y=sales_per_day_orange, s=profit_margin_orange * 10, c=sugar_content_orange, ) plt.scatter( x=price_cereal, y=sales_per_day_cereal, s=profit_margin_cereal * 10, c=sugar_content_cereal, marker="d", ) plt.show()您保留橙汁饮料数据的默认标记形状。默认标记为
"o",代表一个点。对于谷物条数据,您将标记形状设置为"d",它代表一个菱形标记。您可以在标记器的文档页面中找到所有可用标记器的列表。这是叠加在同一个图上的两个散点图:
现在,您可以将橙汁饮料的数据点与谷物棒的数据点区分开来。但是,您创建的最后一个图有一个问题,您将在下一节中探索这个问题。
改变透明度
橙汁饮料的一个数据点消失了。应该有六种橙色饮料,但在图中只能看到五个圆形标记。其中一个谷物条数据点隐藏了一个橙汁饮料数据点。
您可以通过使用 alpha 值使数据点部分透明来解决这个可视化问题:
# ... plt.scatter( x=price_orange, y=sales_per_day_orange, s=profit_margin_orange * 10, c=sugar_content_orange, alpha=0.5, ) plt.scatter( x=price_cereal, y=sales_per_day_cereal, s=profit_margin_cereal * 10, c=sugar_content_cereal, marker="d", alpha=0.5, ) plt.title("Sales vs Prices for Orange Drinks and Cereal Bars") plt.legend(["Orange Drinks", "Cereal Bars"]) plt.xlabel("Price (Currency Unit)") plt.ylabel("Average weekly sales") plt.text( 3.2, 55, "Size of marker = profit margin\n" "Color of marker = sugar content", ) plt.show()您已经将两组标记的
alpha值设置为0.5,这意味着它们是半透明的。现在,您可以看到该图中的所有数据点,包括那些重合的数据点:
您还向图中添加了一个标题和其他标签,以便用更多关于正在显示的内容的信息来完成该图。
定制颜色图和样式
在您到目前为止创建的散点图中,您使用了三种颜色来表示饮料和谷物棒的低、中、高含糖量。现在,您将对此进行更改,使颜色直接代表项目的实际含糖量。
首先需要重构变量
sugar_content_orange和sugar_content_cereal,使它们表示含糖量值,而不仅仅是 RGB 颜色值:sugar_content_orange = [15, 35, 22, 27, 38, 14] sugar_content_cereal = [21, 49, 29, 24]现在这些列表包含了每一项中每日推荐糖量的百分比。代码的其余部分保持不变,但是您现在可以选择要使用的颜色图。这会将值映射到颜色:
# ... plt.scatter( x=price_orange, y=sales_per_day_orange, s=profit_margin_orange * 10, c=sugar_content_orange, cmap="jet", alpha=0.5, ) plt.scatter( x=price_cereal, y=sales_per_day_cereal, s=profit_margin_cereal * 10, c=sugar_content_cereal, cmap="jet", marker="d", alpha=0.5, ) plt.title("Sales vs Prices for Orange Drinks and Cereal Bars") plt.legend(["Orange Drinks", "Cereal Bars"]) plt.xlabel("Price (Currency Unit)") plt.ylabel("Average weekly sales") plt.text( 2.7, 55, "Size of marker = profit margin\n" "Color of marker = sugar content", ) plt.colorbar() plt.show()标记的颜色现在基于连续的刻度,并且您还显示了作为标记颜色图例的颜色条。这是最终的散点图:
到目前为止,您绘制的所有图都以本机 Matplotlib 样式显示。您可以使用几个选项中的一个来更改此样式。您可以使用以下命令显示可用的样式:





>>> plt.style.available
[
"Solarize_Light2",
"_classic_test_patch",
"bmh",
"classic",
"dark_background",
"fast",
"fivethirtyeight",
"ggplot",
"grayscale",
"seaborn",
"seaborn-bright",
"seaborn-colorblind",
"seaborn-dark",
"seaborn-dark-palette",
"seaborn-darkgrid",
"seaborn-deep",
"seaborn-muted",
"seaborn-notebook",
"seaborn-paper",
"seaborn-pastel",
"seaborn-poster",
"seaborn-talk",
"seaborn-ticks",
"seaborn-white",
"seaborn-whitegrid",
"tableau-colorblind10",
]
现在,使用 Matplotlib 时,您可以在调用plt.scatter()之前使用以下函数调用来更改绘图样式:
import matplotlib.pyplot as plt
import numpy as np
plt.style.use("seaborn")
# ...
这将样式更改为另一个第三方可视化包 Seaborn 的样式。通过使用 Seaborn 样式绘制上面显示的最终散点图,您可以看到不同的样式:
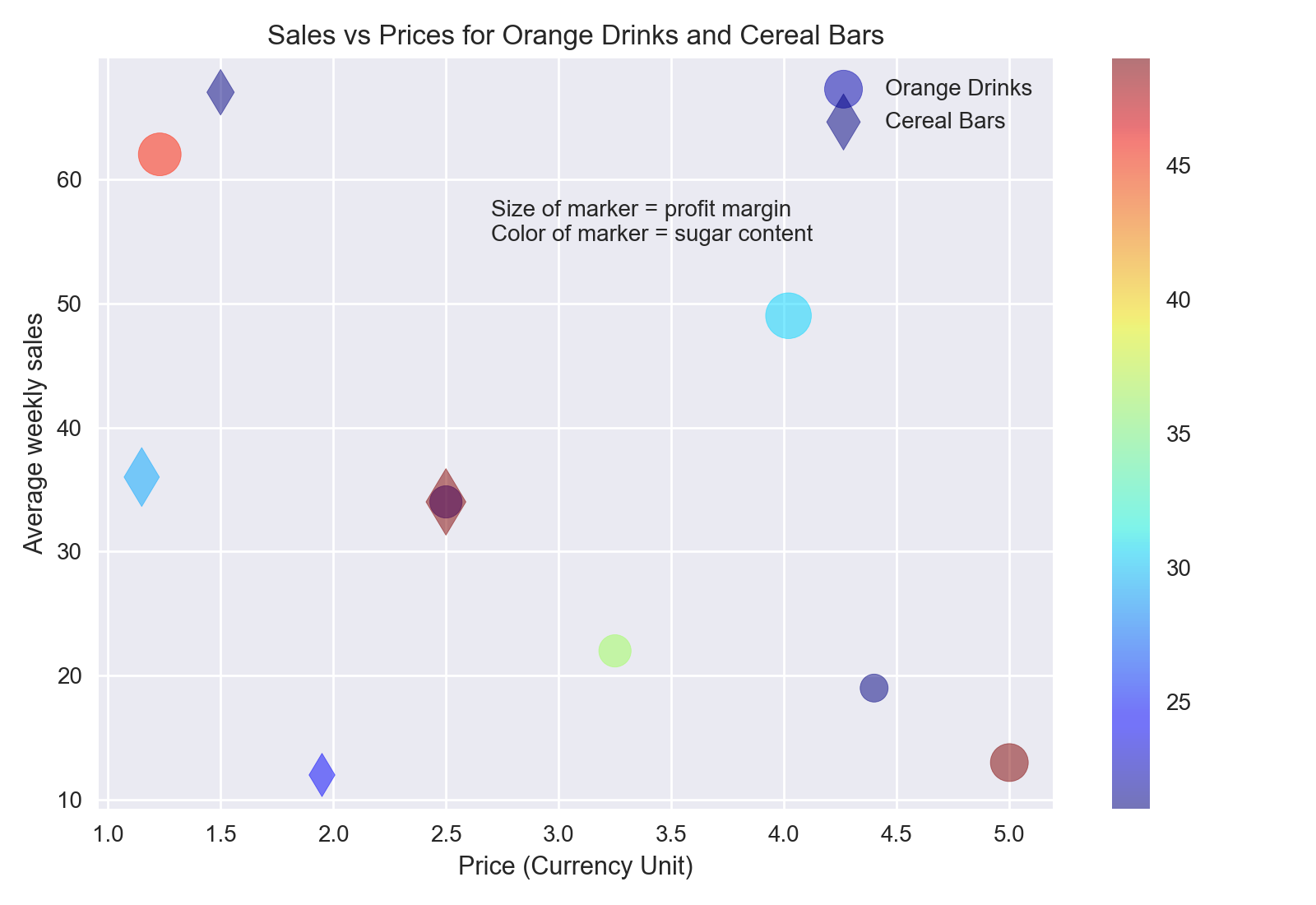
你可以在 Matplotlib 中阅读更多关于定制图的内容,在 Matplotlib 文档页面上也有进一步的教程。
使用plt.scatter()创建散点图可以显示两个以上的变量。以下是本例中的变量:
| 可变的 | 由...代表 |
|---|---|
| 价格 | x 轴 |
| 平均售出数量 | y 轴 |
| 利润率 | 标记大小 |
| 产品类型 | 标记形状 |
| 含糖量 | 标记颜色 |
表示两个以上变量的能力使plt.scatter()成为一个非常强大和通用的工具。
进一步探索plt.scatter(
plt.scatter()在定制散点图方面提供了更大的灵活性。在这一节中,您将通过一个示例探索如何使用 NumPy 数组和散点图来屏蔽数据。在本例中,您将生成随机数据点,然后在同一散点图中将它们分成两个不同的区域。
一位热衷于收集数据的通勤者整理了六个月来她所在的当地公交车站的公交车到站时间。时间表上的到达时间是整点后的 15 分钟和 45 分钟,但她注意到真正的到达时间在这些时间附近遵循正态分布:
这张图显示了一小时内每分钟有一辆公共汽车到达的相对可能性。这个概率分布可以用 NumPy 和 np.linspace() 来表示:
import matplotlib.pyplot as plt
import numpy as np
mean = 15, 45
sd = 5, 7
x = np.linspace(0, 59, 60) # Represents each minute within the hour
first_distribution = np.exp(-0.5 * ((x - mean[0]) / sd[0]) ** 2)
second_distribution = 0.9 * np.exp(-0.5 * ((x - mean[1]) / sd[1]) ** 2)
y = first_distribution + second_distribution
y = y / max(y)
plt.plot(x, y)
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()
您已经创建了两个正态分布,分别以过去一小时的15和45分钟为中心,并将它们相加。通过除以最大值,将最可能的到达时间设置为值1。
现在,您可以使用此分布来模拟公交车到达时间。为此,您可以使用内置的 random 模块创建随机时间和随机相对概率。在下面的代码中,您还将使用列表理解:
import random
import matplotlib.pyplot as plt
import numpy as np
n_buses = 40
bus_times = np.asarray([random.randint(0, 59) for _ in range(n_buses)])
bus_likelihood = np.asarray([random.random() for _ in range(n_buses)])
plt.scatter(x=bus_times, y=bus_likelihood)
plt.title("Randomly chosen bus arrival times and relative probabilities")
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()
您已经模拟了40辆公交车的到达,您可以用下面的散点图对其进行可视化:
由于生成的数据是随机的,所以您的绘图看起来会有所不同。然而,并非所有这些点都可能接近通勤者从她收集和分析的数据中观察到的现实。您可以绘制她从模拟公交车到站数据中获得的分布图:
import random
import matplotlib.pyplot as plt
import numpy as np
mean = 15, 45
sd = 5, 7
x = np.linspace(0, 59, 60)
first_distribution = np.exp(-0.5 * ((x - mean[0]) / sd[0]) ** 2)
second_distribution = 0.9 * np.exp(-0.5 * ((x - mean[1]) / sd[1]) ** 2)
y = first_distribution + second_distribution
y = y / max(y)
n_buses = 40
bus_times = np.asarray([random.randint(0, 59) for _ in range(n_buses)])
bus_likelihood = np.asarray([random.random() for _ in range(n_buses)])
plt.scatter(x=bus_times, y=bus_likelihood)
plt.plot(x, y) plt.title("Randomly chosen bus arrival times and relative probabilities")
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()
这将产生以下输出:
为了保持模拟的真实性,您需要确保随机到达的公交车与数据以及从这些数据中获得的分布相匹配。您可以通过仅保留落在概率分布内的点来过滤随机生成的点。您可以通过为散点图创建一个遮罩来实现这一点:
# ...
in_region = bus_likelihood < y[bus_times]
out_region = bus_likelihood >= y[bus_times]
plt.scatter(
x=bus_times[in_region],
y=bus_likelihood[in_region],
color="green",
)
plt.scatter(
x=bus_times[out_region],
y=bus_likelihood[out_region],
color="red",
marker="x",
)
plt.plot(x, y)
plt.title("Randomly chosen bus arrival times and relative probabilities")
plt.ylabel("Relative probability of bus arrivals")
plt.xlabel("Minutes past the hour")
plt.show()
变量in_region和out_region是包含布尔值的 NumPy 数组,这些布尔值基于随机生成的可能性是高于还是低于分布y。然后绘制两个独立的散点图,一个包含分布范围内的点,另一个包含分布范围外的点。高于分布的数据点不代表真实数据:
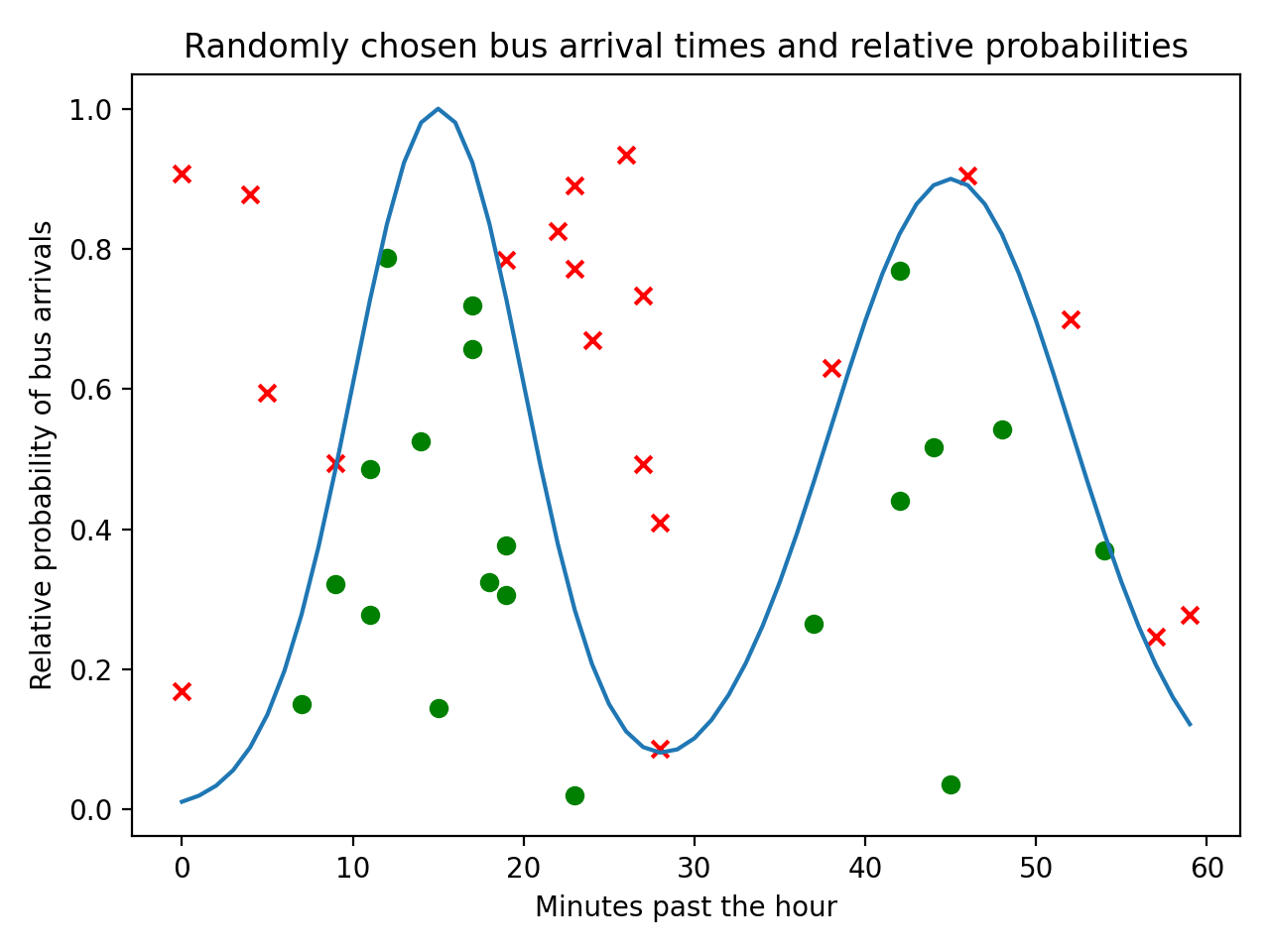
您已经根据原始散点图中的数据点是否在分布范围内对其进行了分割,并使用不同的颜色和标记来标识两组数据。
查看关键输入参数
在上述章节中,您已经了解了创建散点图的主要输入参数。以下是关于主要输入参数需要记住的要点的简要总结:
| 参数 | 描述 |
|---|---|
x和y |
这些参数代表两个主要变量,可以是任何类似数组的数据类型,比如 lists 或 NumPy 数组。这些是必需的参数。 |
s |
此参数定义标记的大小。如果所有标记具有相同的大小,它可以是一个 float ,如果标记具有不同的大小,它可以是一个类似数组的数据结构。 |
c |
此参数表示标记的颜色。它通常是一个颜色数组,比如 RGB 值,或者是一个使用参数cmap映射到颜色图上的值序列。 |
marker |
此参数用于自定义标记的形状。 |
cmap |
如果参数c使用一系列值,则该参数可用于选择值和颜色之间的映射,通常使用标准色图或自定义色图。 |
alpha |
这个参数是一个浮点数,可以取0和1之间的任何值,表示标记的透明度,其中1表示不透明的标记。 |
这些并不是plt.scatter()唯一可用的输入参数。您可以从文档中获得输入参数的完整列表。
结论
现在您已经知道如何使用plt.scatter()创建和定制散点图,您已经准备好开始使用您自己的数据集和示例进行实践了。这种多功能的功能使您能够探索您的数据,并以一种清晰的方式呈现您的发现。
在本教程中,你已经学会了如何:
- 使用
plt.scatter()创建一个散点图 - 使用必需和可选的输入参数
- 为基本图和更高级图定制散点图
- 用
plt.scatter()表示两个维度以上的
通过了解 Matplotlib 中的所有特性以及使用 NumPy 处理数据,您可以充分利用plt.scatter()的可视化功能。
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 使用 plt.scatter()在 Python 中可视化数据******
全栈开发——获取数据,用 D3 可视化,用 Dokku 部署
原文:https://realpython.com/web-development-with-flask-fetching-data-with-requests/
在本教程中,我们将构建一个 web 应用程序来从 NASDAQ-100 中获取数据,并用 D3 将其可视化为气泡图。然后最重要的是,我们将通过 Dokku 在数字海洋上部署它。
注意:气泡图非常适合在一个小空间内可视化数百个值。然而,它们更难阅读,因为很难区分相似大小的圆。如果您只处理几个值,条形图可能是更好的选择,因为它更容易阅读。
本教程使用的主要工具:Python v2.7.8、Flask v0.10.1、 Requests v2.4.1、D3 v3.4.11、Dokku v0.2.3 和 Bower v1.3.9
首先从这个 repo 中找到并下载文件 _app_boilerplate.zip 。这个文件包含一个烧瓶样本。下载完成后,解压文件和文件夹,激活一个 virtualenv,然后用 Pip 安装依赖项:
pip install -r requirements.txt
然后测试以确保它能工作:启动服务器,打开浏览器,并导航到http://localhost:5000/。你应该看到“你好,世界!”盯着你。
获取数据
在 app.py 文件中创建新的路线和查看功能:
@app.route("/data")
def data():
return jsonify(get_data())
更新导入:
from flask import Flask, render_template, jsonify
from stock_scraper import get_data
因此,当调用该路由时,它将返回值从名为get_data()的函数转换为 JSON,然后返回它。这个函数驻留在一个名为 stock_scraper.py 的文件中,这让你大吃一惊!-从纳斯达克 100 指数获取数据。
剧本
将 stock_scraper.py 添加到主目录中。
轮到你了:按照以下步骤,自己创建脚本:
- 从http://www.nasdaq.com/quotes/nasdaq-100-stocks.aspx?下载 CSV 渲染=下载。
- 从 CSV 中获取相关数据:股票名称、股票代码、当前价格、净变化、百分比变化、成交量和价值。
- 将解析后的数据转换为 Python 字典。
- 归还字典。
怎么样了?需要帮助吗?让我们来看一个可能的解决方案:
import csv
import requests
URL = "http://www.nasdaq.com/quotes/nasdaq-100-stocks.aspx?render=download"
def get_data():
r = requests.get(URL)
data = r.text
RESULTS = {'children': []}
for line in csv.DictReader(data.splitlines(), skipinitialspace=True):
RESULTS['children'].append({
'name': line['Name'],
'symbol': line['Symbol'],
'symbol': line['Symbol'],
'price': line['lastsale'],
'net_change': line['netchange'],
'percent_change': line['pctchange'],
'volume': line['share_volume'],
'value': line['Nasdaq100_points']
})
return RESULTS
发生了什么事?
- 这里,我们通过 GET 请求获取 URL,然后将响应对象
r转换为 unicode 。 - 然后我们使用
CSV库将逗号分隔的文本转换成DictReader()类的实例,它将数据映射到字典而不是列表。 - 最后,在遍历数据、创建字典列表(其中每个字典代表不同的股票)之后,我们返回
RESULTSdict。
注意:你也可以使用字典理解来创建个人字典。这是一个更有效的方法,但是你牺牲了可读性。你的电话。
测试的时间:启动服务器,然后导航到http://localhost:5000/data。如果一切顺利,您应该看到一个包含相关股票数据的对象。
有了手头的数据,我们现在可以在前端可视化它。
可视化
除了 HTML 和 CSS ,我们还将使用 Bootstrap 、JavaScript/jQuery 和 D3 来驱动我们的前端。我们还将使用客户端依赖管理工具 Bower 来下载和管理这些库。
轮到你了:按照安装说明在你的机器上设置 Bower。提示:在安装 Bower 之前,您需要安装 Node.js 。
准备好了吗?
鲍尔
需要两个文件来启动 bower-bower . JSON和。bower RCT7】。
后一个文件用于配置 Bower。将其添加到主目录:
{ "directory": "static/bower_components" }
这只是指定我们希望依赖项安装在应用程序的静态目录中的 bower_components 目录(约定)中。
同时,第一个文件 bower.json 存储了 bower 清单——这意味着它包含关于 Bower 组件以及应用程序本身的元数据。该文件可通过bower init命令交互创建。现在就做。接受所有的默认值。
现在,我们可以安装依赖项了。
$ bower install bootstrap#3.2.0 jquery#2.1.1 d3#3.4.11 --save
标志将包添加到 bower.json dependencies 数组中。看看这个。此外,确保 bower.json 中的依赖版本与我们指定的版本相匹配——即bootstrap#3.20。
安装完依赖项后,让我们在应用程序中访问它们。
更新index.htmlT2】*
<!DOCTYPE html>
<html>
<head>
<title>Flask Stock Visualizer</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href={{ url_for('static', filename='./bower_components/bootstrap/dist/css/bootstrap.min.css') }} rel="stylesheet" media="screen">
<link href={{ url_for('static', filename='main.css') }} rel="stylesheet" media="screen">
</head>
<body>
<div class="container">
</div>
<script src={{ url_for('static', filename='./bower_components/jquery/dist/jquery.min.js') }}></script>
<script src={{ url_for('static', filename='./bower_components/bootstrap/dist/js/bootstrap.min.js') }}></script>
<script src={{ url_for('static', filename='./bower_components/d3/d3.min.js') }}></script>
<script src={{ url_for('static', filename='main.js') }}></script>
</body>
</html>
D3
有了这么多的数据可视化框架,为什么还要有 D3 ?D3 是相当低的级别,所以它可以让你构建你想要的框架类型。一旦将数据附加到 DOM,就可以使用 CSS3、HTML5 和 SVG 的组合来创建实际的可视化。然后你可以通过 D3 内置的数据驱动的转换来增加交互性。
平心而论,这个图书馆并不适合所有人。因为你有很大的自由来构建你想要的东西,所以学习曲线相当高。如果你正在寻找一个快速的开始,看看 Python-NVD3 ,它是 D3 的一个包装器,用来使使用 D3 变得非常非常容易。尽管我们在本教程中没有使用它,因为 Python-NVD3 不支持气泡图。
轮到你了:浏览 D3 介绍教程。
现在让我们编码。
设置
将以下代码添加到 main.js 中:
// Custom JavaScript $(function() { console.log('jquery is working!'); createGraph(); }); function createGraph() { // Code goes here }
在这里,在初始页面加载之后,我们记录“jquery 正在工作!”然后启动一个名为createGraph()的函数。测试一下。启动服务器,然后导航到http://localhost:5000/,打开 JavaScript 控制台,刷新页面。您应该看到“jquery 正在工作!”如果一切顺利就发短信。
将以下标记添加到index.html文件中,在具有container的id的<div>标记内(在第 10 行之后),以保存 D3 气泡图:
<div id="chart"></div>
主配置
将以下代码添加到 main.js 中的createGraph()函数中:
var width = 960; // chart width var height = 700; // chart height var format = d3.format(",d"); // convert value to integer var color = d3.scale.category20(); // create ordinal scale with 20 colors var sizeOfRadius = d3.scale.pow().domain([-100,100]).range([-50,50]); // https://github.com/mbostock/d3/wiki/Quantitative-Scales#pow
请务必查阅代码注释和官方 D3 文档。你不明白的地方就去查。程序员必须自力更生!
气泡配置
var bubble = d3.layout.pack() .sort(null) // disable sorting, use DOM tree traversal .size([width, height]) // chart layout size .padding(1) // padding between circles .radius(function(d) { return 20 + (sizeOfRadius(d) * 30); }); // radius for each circle
同样,将上述代码添加到createGraph()函数中,并检查文档中的任何问题。
SVG Config
接下来,将下面的代码添加到createGraph()中,它选择了带有chart的id的元素,然后附加上圆圈和一些属性:
var svg = d3.select("#chart").append("svg") .attr("width", width) .attr("height", height) .attr("class", "bubble");
继续使用createGraph()函数,我们现在需要获取数据,这可以用 D3 异步完成。
请求数据
// REQUEST THE DATA d3.json("/data", function(error, quotes) { var node = svg.selectAll('.node') .data(bubble.nodes(quotes) .filter(function(d) { return !d.children; })) .enter().append('g') .attr('class', 'node') .attr('transform', function(d) { return 'translate(' + d.x + ',' + d.y + ')'}); node.append('circle') .attr('r', function(d) { return d.r; }) .style('fill', function(d) { return color(d.symbol); }); node.append('text') .attr("dy", ".3em") .style('text-anchor', 'middle') .text(function(d) { return d.symbol; }); });
因此,我们点击前面设置的/data端点来返回数据。这段代码的剩余部分只是将气泡和文本添加到 DOM 中。这是标准的样板代码,为我们的数据稍作修改。
工具提示
因为我们在图表上的空间有限,仍然在createGraph()函数中,所以让我们添加一些工具提示来显示每只特定股票的附加信息。
// tooltip config var tooltip = d3.select("body") .append("div") .style("position", "absolute") .style("z-index", "10") .style("visibility", "hidden") .style("color", "white") .style("padding", "8px") .style("background-color", "rgba(0, 0, 0, 0.75)") .style("border-radius", "6px") .style("font", "12px sans-serif") .text("tooltip");
这些只是与工具提示相关的 CSS 样式。我们仍然需要添加实际数据。更新我们将圆圈附加到 DOM 的代码:
node.append("circle") .attr("r", function(d) { return d.r; }) .style('fill', function(d) { return color(d.symbol); }) .on("mouseover", function(d) { tooltip.text(d.name + ": $" + d.price); tooltip.style("visibility", "visible"); }) .on("mousemove", function() { return tooltip.style("top", (d3.event.pageY-10)+"px").style("left",(d3.event.pageX+10)+"px"); }) .on("mouseout", function(){return tooltip.style("visibility", "hidden");});
对此进行测试,导航至http://localhost:5000/。现在,当你用吸尘器清扫一圈时,你会看到一些底层元数据——公司名称和股票价格。
轮到你了:添加更多元数据。你认为还有哪些相关的数据?想想我们在这里展示的——价格的相对变化。您也许可以计算以前的价格并显示:
- 当前价格
- 相对变化
- 先前价格
重构
股票如果我们只是想用修改后的市值加权指数——纳斯达克-100 点列——大于 0.1 来想象股票会怎么样?
向get_data()函数添加一个条件:
def get_data():
r = requests.get(URL)
data = r.text
RESULTS = {'children': []}
for line in csv.DictReader(data.splitlines(), skipinitialspace=True):
if float(line['Nasdaq100_points']) > .01:
RESULTS['children'].append({
'name': line['Name'],
'symbol': line['Symbol'],
'symbol': line['Symbol'],
'price': line['lastsale'],
'net_change': line['netchange'],
'percent_change': line['pctchange'],
'volume': line['share_volume'],
'value': line['Nasdaq100_points']
})
return RESULTS
现在,让我们在 main.js 的气泡配置部分增加每个气泡的半径;相应地修改代码:
// Radius for each circle .radius(function(d) { return 20 + (sizeOfRadius(d) * 60); });
CSS
最后,让我们给 main.css 添加一些基本样式:
body { padding-top: 20px; font: 12px sans-serif; font-weight: bold; }
好看吗?准备部署了吗?
正在部署
Dokku 是一个开源的、类似 Heroku 的平台即服务(PaaS),由 Docker 提供支持。设置完成后,你可以用 Git 把你的应用程序推送到上面。
我们使用数字海洋作为我们的主机。让我们开始吧。
设置数字海洋
如果你还没有帐户,请注册一个帐户。然后按照这个指南添加一个公钥。
创建新的 Droplet -指定名称、大小和位置。对于图像,单击“应用程序”选项卡并选择 Dokku 应用程序。确保选择您的 SSH 密钥。
创建完成后,通过在浏览器中输入新创建的 Droplet 的 IP 来完成设置,这将带您进入 Dokku 设置屏幕。确认公钥是正确的,然后单击“完成设置”。
现在 VPS 可以接受推送了。
部署配置
- 用下面的代码创建一个 proc file:
web: gunicorn app:app。(此文件包含启动 web 进程必须运行的命令。) - 安装 gunicorn:
pip install gunicorn - 更新需求. txt 文件:
pip freeze > requirements.txt - 初始化一个新的本地 Git repo:
git init - 添加遥控器:
git remote add dokku dokku@192.241.208.61:app_name(一定要添加自己的 IP 地址。)
更新 app.py :
if __name__ == '__main__':
port = int(os.environ.get('PORT', 5000))
app.run(host='0.0.0.0', port=port)
所以,我们首先尝试从 app 的环境中抓取端口,如果找不到,默认为端口 5000。
确保也更新导入:
import os
部署!
提交您的更改,然后按:git push dokku master。如果一切顺利,您应该在终端中看到应用程序的 URL:
=====> Application deployed:
http://192.241.208.61:49155
测试一下。导航到http://192.241.208.61:49155(同样,确保添加您自己的 IP 地址和正确的端口。)你应该看看你的直播 app!(预览见本文顶部的图片。)
接下来的步骤
想更进一步吗?向应用程序添加以下功能:
- 错误处理
- 单元测试
- 集成测试
- 持续集成/交付
这些功能(以及更多!)将包含在 2014 年 10 月初推出的下一期真正的 Python 课程中!
如有疑问,请在下方评论。
干杯!*****
用 Scrapy 和 MongoDB 进行网页抓取和抓取
原文:https://realpython.com/web-scraping-and-crawling-with-scrapy-and-mongodb/
上次我们实现了一个基本的网络抓取器,它从 StackOverflow 下载最新的问题,并将结果存储在 MongoDB 中。在这篇文章中,我们将扩展我们的抓取器,使它能够抓取每个页面底部的分页链接,并从每个页面抓取问题(问题标题和 URL)。
免费奖励: ,向您展示如何从 Python 访问 MongoDB。
更新:
在您开始任何刮擦工作之前,请查看网站的使用条款政策,并遵守 robots.txt 文件。此外,要遵守道德规范,不要在短时间内让大量请求涌入网站。对待你刮下的任何地方,就像是你自己的一样。
这是 Real Python 和 Gyö rgy 的合作作品,Gyö rgy 是一名 Python 爱好者和软件开发人员,目前在一家大数据公司工作,同时在寻找一份新工作。可以在 twitter 上问他问题- @kissgyorgy 。
开始使用
有两种可能的方法从我们停止的地方继续。
第一种方法是扩展我们现有的蜘蛛,用一个 xpath 表达式从parse_item方法的响应中提取每个下一页链接,只使用一个对同一个parse_item方法进行回调的yield对象。这样 scrapy 会自动向我们指定的链接发出新的请求。你可以在 Scrapy 文档中找到更多关于这种方法的信息。
另一个更简单的选择是利用不同类型的蜘蛛——即CrawlSpider ( 链接)。这是基本Spider的扩展版本,专为我们的用例而设计。
爬虫
我们将使用上一个教程中相同的 Scrapy 项目,所以如果需要的话,可以从 repo 中获取代码。
创建样板文件
在“stack”目录中,首先由从crawl模板生成蜘蛛样板文件:
$ scrapy genspider stack_crawler stackoverflow.com -t crawl
Created spider 'stack_crawler' using template 'crawl' in module:
stack.spiders.stack_crawler
Scrapy 项目现在应该是这样的:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
├── stack_crawler.py
└── stack_spider.py
并且 stack_crawler.py 文件应该是这样的:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.contrib.spiders import CrawlSpider, Rule
from stack.items import StackItem
class StackCrawlerSpider(CrawlSpider):
name = 'stack_crawler'
allowed_domains = ['stackoverflow.com']
start_urls = ['http://www.stackoverflow.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = StackItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
我们只需要对这个样板文件做一些更新…
更新start_urls列表
首先,将第一页的问题添加到start_urls列表中:
start_urls = [
'http://stackoverflow.com/questions?pagesize=50&sort=newest'
]
更新rules列表
接下来,我们需要通过给rules属性添加一个正则表达式来告诉蜘蛛它可以在哪里找到下一个页面链接:
rules = [
Rule(LinkExtractor(allow=r'questions\?page=[0-9]&sort=newest'),
callback='parse_item', follow=True)
]
Scrapy 现在将根据这些链接自动请求新页面,并将响应传递给parse_item方法以提取问题和标题。
如果你密切关注,这个正则表达式将抓取限制在前 9 页,因为对于这个演示,我们不想抓取所有的 176,234 页!
更新parse_item方法
现在我们只需要写如何用 xpath 解析页面,我们在上一个教程中已经完成了——所以只需要复制它:
def parse_item(self, response):
questions = response.xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
yield item
对蜘蛛来说就是这样,但是不要现在就开始。
添加下载延迟
我们需要通过在 settings.py 中设置下载延迟来善待 StackOverflow(以及任何网站,就此而言):
DOWNLOAD_DELAY = 5
这告诉 Scrapy 在每次新请求之间至少等待 5 秒钟。你本质上是在限制自己的速度。如果你不这样做,StackOverflow 会限制你的流量;如果你继续抓取网站而不设置速率限制,你的 IP 地址可能会被禁止。所以,善待你刮到的任何地方,就像是你自己的一样。
现在只剩下一件事要做——存储数据。
MongoDB
上次我们只下载了 50 个问题,但由于我们这次获取了更多的数据,我们希望避免向数据库中添加重复的问题。我们可以通过使用 MongoDB upsert 来实现,这意味着如果问题标题已经在数据库中,我们就更新它,否则就插入。
修改我们之前定义的MongoDBPipeline:
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
for data in item:
if not data:
raise DropItem("Missing data!")
self.collection.update({'url': item['url']}, dict(item), upsert=True)
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
为了简单起见,我们没有优化查询,也没有处理索引,因为这不是一个生产环境。
测试
启动蜘蛛!
$ scrapy crawl stack_crawler
现在坐好,看着你的数据库充满数据!
$ mongo
MongoDB shell version: 3.0.4
> use stackoverflow
switched to db stackoverflow
> db.questions.count()
447
>
结论
您可以从 Github 资源库下载完整的源代码。带着问题在下面评论。干杯!
免费奖励: ,向您展示如何从 Python 访问 MongoDB。
寻找更多的网页抓取?一定要去看看真正的 Python 课程。想雇一个专业的网页抓取者吗?查看围棋。**
使用 Scrapy 和 MongoDB 进行网页抓取
原文:https://realpython.com/web-scraping-with-scrapy-and-mongodb/
在本文中,我们将为实际的自由职业者构建一个抓取器,其中客户希望 Python 程序从堆栈溢出中抓取数据以获取新问题(问题标题和 URL)。抓取的数据应该存储在 MongoDB 中。值得注意的是,堆栈溢出有一个 API ,可以用来访问完全相同的数据。然而,客户想要一个刮刀,所以他得到了一个刮刀。
免费奖励: ,向您展示如何从 Python 访问 MongoDB。
更新:
- 2014 年 1 月 3 日-重构了蜘蛛。谢谢, @kissgyorgy 。
- 2015 年 2 月 18 日-增加了第二部分的。
- 09/06/2015 -更新至 Scrapy 和 PyMongo 的最新版本-干杯!
一如既往,在开始任何刮擦工作之前,请务必查看网站的使用/服务条款,并尊重 robots.txt 文件。确保遵守道德规范,不要在短时间内让大量请求涌入网站。像对待自己的地盘一样对待你刮的任何地盘。
安装
我们需要 Scrapy 库(v1.0.3)和 PyMongo (v3.0.3)来存储 MongoDB 中的数据。您还需要安装 MongoDB (未涵盖)。
刺儿头
如果你运行的是 OSX 或者 Linux,安装 Scrapy with pip (激活你的 virtualenv):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
如果您在 Windows 机器上,您将需要手动安装一些依赖项。请参考官方文档获取详细说明,以及我创建的这个 Youtube 视频。
设置 Scrapy 后,通过在 Python shell 中运行以下命令来验证您的安装:
>>> import scrapy
如果你没有得到一个错误,那么你就可以走了!
### PyMongo
接下来,用 pip 安装 PyMongo:
```py
$ pip install pymongo
$ pip freeze > requirements.txt
现在我们可以开始构建爬虫了。
零散项目
让我们开始一个新的 Scrapy 项目:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
这将创建许多文件和文件夹,其中包括一个基本的样板文件,便于您快速入门:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
指定数据
items.py 文件用于为我们计划抓取的数据定义存储“容器”。
StackItem()类继承自Item ( 文档),它基本上有许多 Scrapy 已经为我们构建的预定义对象:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
让我们添加一些我们实际上想要收集的物品。对于每个问题,客户需要标题和网址。所以,把 items.py 更新成这样:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
创建蜘蛛
在“spiders”目录下创建一个名为 stack_spider.py 的文件。这就是神奇的地方——例如,我们将告诉 Scrapy 如何找到我们正在寻找的确切的数据。你可以想象,这是特定的给你想要抓取的每一个网页。
首先定义一个继承自 Scrapy 的Spider的类,然后根据需要添加属性:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
name定义了蜘蛛的名称。- 包含允许蜘蛛抓取的域的基本 URL。
- 是蜘蛛开始爬行的 URL 列表。所有后续的 URL 都将从蜘蛛从
start_urls中的 URL 下载的数据开始。
XPath 选择器
接下来,Scrapy 使用 XPath 选择器从网站中提取数据。换句话说,我们可以根据给定的 XPath 选择 HTML 数据的某些部分。正如 Scrapy 的文档中所述,“XPath 是一种在 XML 文档中选择节点的语言,也可以和 HTML 一起使用。”
使用 Chrome 的开发工具可以很容易地找到特定的 Xpath。只需检查特定的 HTML 元素,复制 XPath,然后进行调整(根据需要):
Developer Tools 还让您能够在 JavaScript 控制台中使用$x -即$x("//img")来测试 XPath 选择器:
同样,我们基本上告诉 Scrapy 从哪里开始根据定义的 XPath 查找信息。让我们导航到 Chrome 中的堆栈溢出站点,找到 XPath 选择器。
右键单击第一个问题,选择“检查元素”:
现在获取<div class="summary">、//*[@id="question-summary-27624141"]/div[2]的 XPath,然后在 JavaScript 控制台中测试它:
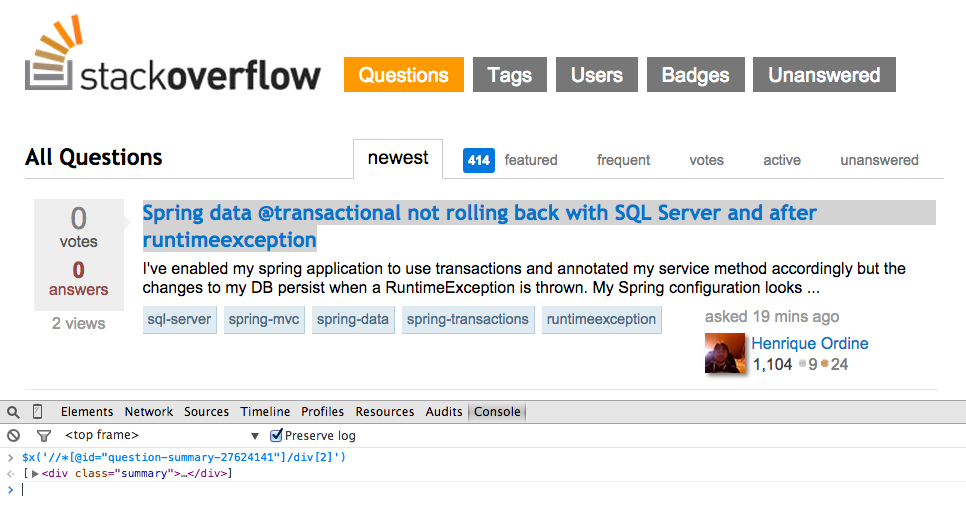
如你所见,它只选择了那个的一个问题。所以我们需要修改 XPath 来获取所有的问题。有什么想法吗?很简单://div[@class="summary"]/h3。这是什么意思?本质上,这个 XPath 声明:获取所有<h3>元素,这些元素是拥有summary 类的<div>的子元素。在 JavaScript 控制台中测试这个 XPath。
请注意,我们并没有使用 Chrome 开发工具的实际 XPath 输出。在大多数情况下,输出只是一个有用的提示,它通常为您指出找到工作 XPath 的正确方向。
现在让我们更新一下 stack_spider.py 脚本:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
提取数据
我们仍然需要解析和抓取我们想要的数据,这属于<div class="summary"><h3>。再次更新 stack_spider.py 像这样:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
`
We are iterating through the questions and assigning the title and url values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., $x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()') and $x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href').
Test
Ready for the first test? Simply run the following command within the "stack" directory:
console
$ scrapy crawl stack
随着 Scrapy 堆栈跟踪,你应该看到 50 个问题的标题和输出的网址。您可以使用这个小命令将输出呈现到 JSON 文件中:
$ scrapy crawl stack -o items.json -t json
我们现在已经根据我们正在寻找的数据实现了我们的蜘蛛。现在我们需要将抓取的数据存储在 MongoDB 中。
将数据存储在 MongoDB
每次返回一个项目时,我们都希望验证数据,然后将其添加到 Mongo 集合中。
第一步是创建数据库,我们计划用它来保存我们所有的抓取数据。打开 settings.py ,指定管道,添加数据库设置:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
管道管理
我们已经设置了爬行和解析 HTML 的蜘蛛,并且设置了数据库设置。现在我们必须通过 pipelines.py 中的管道将两者连接在一起。
连接到数据库
首先,让我们定义一个实际连接到数据库的方法:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
在这里,我们创建了一个类MongoDBPipeline(),我们有一个构造函数,通过定义 Mongo 设置来初始化这个类,然后连接到数据库。
处理数据
接下来,我们需要定义一个方法来处理解析后的数据:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
我们建立到数据库的连接,解包数据,然后保存到数据库。现在我们可以再次测试了!
测试
同样,在“stack”目录中运行以下命令:
$ scrapy crawl stack
注意:确保你有 Mongo 守护进程 -
mongod-运行在不同的终端窗口。
万岁!我们已成功将爬网数据存储到数据库中:
结论
这是一个非常简单的使用 Scrapy 抓取网页的例子。实际的自由职业项目要求脚本遵循分页链接,并使用CrawlSpider ( docs )抓取每一页,这非常容易实现。尝试自己实现它,并在下面留下评论和 Github 库的链接,以便快速查看代码。
需要帮助吗?从这个脚本开始,差不多完成了。然后查看 Part 2 获取完整解决方案!
免费奖励: ,向您展示如何从 Python 访问 MongoDB。
您可以从 Github 资源库下载完整的源代码。带着问题在下面评论。感谢阅读!****
web2py–从 SQLite 迁移到 MySQL
原文:https://realpython.com/web2py-migrating-from-sqlite-to-mysql/
我最近需要将一个基于 web2py 的 CRM 应用程序转换成 T2 MySQL T3,该应用程序托管在一个 Apache 服务器上,并带有一个 SQLite T1 后端。以下是对我有效的步骤。我创建了一个示例应用程序,如果你想继续,你可以在这里下载所有文件。
请注意:我在 Unix 环境下使用 web2py 版本 2.4.7。在开始之前,确保您的系统上安装了 SQLite。你可以用 pip、
pip install sqlite安装它,或者你可以在http://sqlite.org/download.html下载二进制文件。你还需要安装 MySQL。如果你需要帮助,请点击这里的教程。
当前数据库有所有默认的 web2py 表以及一个带有字段 id 、 start_date 和 end_date 的 users 表:
db.define_table(
'users',
Field('start_date','string'),
Field('end_date','string')
)
这段代码遵循 web2py DAL 语法。表格中有 30,000 行数据。
数据清理
下载应用程序的最新 SQLite 数据库。默认情况下,它是“/web 2py/applications/<your_application>/databases/”文件夹下名为 storage.sqlite 的文件。要下载,通过在终端中运行以下命令创建一个数据库转储:</your_application>
$ sqlite3 storage.sqlite .dump > output_before.sql
使用文本编辑器编辑 output_before.sql 文件:
- 删除所有以
PRAGMA、BEGIN TRANSACTION、CREATE TABLE和COMMIT开头的行。 - 删除所有与
sqlite_sequence表相关的行(即DELETE FROM sqlite_sequence;)。 - 对于所有的
INSERT INTO "<table_name>" VALUES(...)语句,将<table_name>前后的双引号(" ")替换为反斜线(INSERT INTOtable_nameVALUES(...)。
最后,在桌面上将文件保存为 output_after.sql 。
MySQL 设置
在远程服务器上创建 MySQL 数据库。记下数据库名称、用户名和密码。您还可以在本地设置数据库进行测试,我将在本教程中使用它:
$ mysql.server start
$ mysql -u root -p
Enter password:
mysql> create database migration;
Query OK, 1 row affected (0.03 sec)
mysql> exit;
配置您的应用程序以使用 MySQL。启动你的 web2py 管理。编辑 db.py :
db = DAL('mysql://<mysql_user>:<mysql_password>@localhost/<mysql_database>')
保存文件。
允许 web2py 初始化 MySQL 数据库:
- 备份
/web2py/applications/<your_application>/databases/文件夹的内容。然后删除文件夹的内容。 - 回到 web2py 管理。单击“数据库管理”按钮,在本地 MySQL 数据库中创建表。
在终端中启动 MySQL 数据库,检查以确保空表已添加到数据库中:
添加数据
导航到保存 output.sql 的位置(应该是您的桌面),然后运行以下命令将数据添加到 MySQL:
$ mysql -u root migration < output_after.sql
这将需要几分钟才能完全执行。
在 web2py admin 中,检查您的数据库和应用程序,确保新数据是可访问的。*
用 Python 可以做什么?
你已经完成了一门课程,或者终于看完了一本书,这本书教你用 Python 编程的基础知识。你已经学习了变量、列表、元组、字典、 for 和 while 循环、条件语句、面向对象概念等等。那么,下一步是什么?现在你能用 Python 做什么?
Python 是一种通用的编程语言,在各种不同的领域有许多用例。如果你已经掌握了 Python 的基础知识,并且渴望用这种语言构建一些东西,那么是时候考虑下一步该怎么做了。
在本文中,您将看到如何使用 Python 来:
- 做一般的软件开发
- 钻研数据科学和数学
- 加速和自动化您的工作流程
- 构建嵌入式系统和机器人
您还将找到实用项目、资源和教程的想法,您可以使用它们立即开始用 Python 构建东西。
免费奖励: 从 Python 基础:Python 3 实用入门中获取一个示例章节,看看如何通过完整的课程(最新的 Python 3.9)从 Python 初学者过渡到中级。
真实世界中的 python
Python 是一种高级通用编程语言。正如这个定义所暗示的,你可以将 Python 用于几个目的,从 web 开发到数据科学、机器学习和机器人。Python 的真实用例是无限的。
你可能想知道哪些人用 Python 成功地构建了。如果你快速浏览一下使用这种语言的公司,你会发现世界级的公司,比如谷歌、YouTube、脸书、Instagram、Spotify、网飞等等。
谷歌从一开始就使用 Python,它已经成为科技巨头的主要服务器端语言之一。Python 的创造者吉多·范·罗苏姆,在那里工作了几年,监督语言的发展。
Instagram 喜欢 Python 简单。服务因运行“完全用 Python 编写的世界上最大的 Django web 框架部署”而闻名
Spotify 使用这种语言进行数据分析和后端服务。据其团队称,Python 的易用性导致了闪电般快速的开发流程。Spotify 执行大量的分析来给用户提供建议,所以它需要一个有效的工具。巨蟒来救援了!
你还会发现 Python 对于科学和太空探索至关重要,在 T2 机器人和硬件控制方面有很多令人兴奋的用例。
在本文中,您将看到如何在广泛的领域中使用 Python 技能。
开发酷软件
Python 的生态系统提供了一套丰富的框架、工具和库,允许你编写几乎任何种类的应用程序。你可以使用 Python 为网络以及桌面和移动平台构建应用程序。你甚至可以用 Python 来创作视频游戏。
网络开发
用 Python 开发 web 应用程序是最受欢迎的技能之一,有很多机会等着你。在这个领域,您会发现一些有用的 Python 框架、库和工具,用于开发很酷的 web 应用程序、API 等等。以下是一些最流行的 Python web 框架:
| 结构 | 描述 |
|---|---|
| 姜戈 | Django 是一个高级框架,它鼓励使用简洁实用的设计来快速开发 web 应用程序。它可以让你专注于编写你的应用程序,而不必重新发明轮子。 |
| FastAPI | FastAPI 是一个用于构建 web APIs 的快速且高性能的 web 框架。它建立在现代 Python 类型提示特性之上,支持异步编程。 |
| 烧瓶 | Flask 是一个用于创建 web 应用程序的轻量级框架。它允许您快速开始,并在需要时扩展到复杂的应用程序。 |
| 龙卷风 | Tornado 是一个 web 框架和异步网络库。它使用非阻塞网络 I/O ,因此您可以编写可以扩展到数万个开放连接的应用程序。 |
要开始 web 开发,请查看:
如果你想要一些实用的项目想法来立即应用你的 web 开发技能,那么你可以用 Django 构建一个 portfolio web 应用程序。有这么多的工作和职业机会,现在拥有一个个人投资组合是一个很好的主意,所以去尝试一下吧。您不需要了解任何关于 Django 的知识,就可以开始学习这个循序渐进的教程。如果你想尝试用 Python 进行 web 开发,这是再好不过的了。
CLI 开发
Python 另一个大放异彩的领域是命令行界面(CLI) 应用程序开发。CLI 应用程序无处不在,它允许您通过为命令行创建大大小小的工具来自动化日常工作中重复而枯燥的任务。
在 Python 中,您有一套令人印象深刻的 CLI 库和框架,可以让您的生活更加愉快,并帮助您快速构建命令行工具:
| 图书馆 | 描述 |
|---|---|
T2argparse |
argprse是一个标准库模块,允许你编写用户友好的命令行界面。您可以在命令行定义想要的参数,并很好地解析它们。它会自动生成帮助和使用信息,并在用户输入无效时发出错误信息。 |
| 点击 | Click 是一个 Python 包,可以用最少的代码创建漂亮的命令行界面。它是高度可配置的,并带有现成的合理默认值。它的目标包括使编写命令行工具的过程变得快速而有趣。 |
| 类型 | Typer 是一个用于构建 CLI 应用程序的库,用户会喜欢使用它,开发人员也会喜欢创建它。它为所有的外壳提供自动帮助消息和自动完成。它最大限度地减少了代码重复,并方便了调试。 |
要开始 CLI 开发,请查看:
此外,如果您想开始构建 CLI 应用程序项目,那么您可以从为您的命令行创建一个目录树生成器工具开始。在这个循序渐进的项目中,您将构建一个命令行工具来生成 ASCII 图,显示文件系统中的目录或文件夹的内容。
对于任何 Python 开发人员来说,创建具有用户友好且直观的命令行界面的应用程序都是一项有价值的技能。
图形用户界面开发
为桌面环境创建传统的图形用户界面(GUI) 应用程序也是 Python 中一个有吸引力的选项。如果您对构建这种应用程序感兴趣,那么 Python 为您提供了广泛的 GUI 库、框架和工具包供您选择:
| 图书馆 | 描述 |
|---|---|
| Kivy | Kivy 是一个用于快速开发具有创新用户界面的应用程序的库,例如多点触摸应用程序。它可以在 Linux、Windows、macOS、Android、iOS 和树莓派上运行。 |
| PyQt | PyQt 是一组用于 Qt 应用程序框架的 Python 绑定。它包括构建 GUI 应用程序的类。它还提供了网络类、线程、 SQL 数据库等等。它支持 Windows、Linux 和 macOS 平台。 |
| PySimpleGUI | PySimpleGUI 是一个库,旨在将 tkinter、Qt、wxPython 和 Remi GUI 框架转换成一个更简单的界面。它使用 Python 核心数据类型来定义窗口和简化事件处理。 |
Qt for Python ( PySide6 ) |
Qt for Python 是一个为 Qt 框架提供官方 Python 绑定集(PySide6)的项目。 |
| tkinter | tkinter 是对 Tk GUI 工具包的标准 Python 接口。它允许您构建 GUI 应用程序,而不需要依赖第三方。它可以在大多数 Unix 平台和 Windows 系统上使用。 |
| wxPython | wxPython 是针对 wxWidgets C++ 库的 Python 绑定。它允许你用一个代码库为 Windows、macOS 和 Linux 创建应用程序。它给了应用一个本地的外观和感觉,因为它使用了平台的本地 API 。 |
开始构建 GUI 应用程序的一个快速方法是使用 tkinter 。这个模块来自 Python 标准库。练习使用tkinter并观察你的视觉在屏幕上实现。一旦你熟悉了,你就可以开始使用其他 Python GUI 工具包了。
要开始 GUI 编程,请查看:
构建后端服务是开发的重要组成部分。但是,你也需要一个前端。创建用户可以有效交互的应用程序至关重要。
如果您想开始创建真实世界的 GUI 应用程序,那么您可以使用 PyQt 构建一个计算器。完成这个计算器项目将帮助你掌握这个全功能 GUI 框架的基本原理,这样你就可以立即开始为你的桌面构建漂亮的东西。
您还可以找到一些其他实用的项目来帮助您完成 GUI 编程之旅。请查看以下资源:
这些项目将引导您完成用 PyQt 和 Python 构建 GUI 应用程序的过程。他们还将帮助您整合各种技能,以创建功能齐全的真实世界的应用程序。
游戏开发
创建电脑游戏不仅是学习如何用 Python 编程的好方法,也是学习如何用其他语言编程的好方法。开发游戏,你需要使用变量、循环、条件语句、函数、面向对象编程等等。游戏开发是整合多种技能的绝佳选择。
电脑游戏在编程中发挥了重要作用。许多人进入编程领域是因为他们热爱游戏,想要重新创作自己喜欢的游戏或者构建自己的游戏。开发电脑游戏可以是一种有趣且有益的冒险,在其中你可以体验玩你刚刚创建的游戏的美妙体验。
您会发现在 Python 生态系统中有几种快速创建游戏的工具、库和框架。这是其中的一个小例子:
| 图书馆 | 描述 |
|---|---|
| 街机 | Arcade 是一个用于创建 2D 视频游戏的 Python 库。它非常适合学习编程的人,因为他们不需要学习复杂的游戏框架来开始创建自己的游戏。 |
| PyGame | PyGame 是一组 Python 模块,设计用于编写视频游戏。它在 SDL 库的基础上增加了功能。它允许你创建全功能的游戏和多媒体程序。这个库是高度可移植的,可以在多种平台和操作系统上运行。 |
| pyglet | pyglet 是一个强大的 Python 库,用于在 Windows、macOS 和 Linux 上创建游戏和其他视觉丰富的应用程序。它支持窗口、用户界面事件处理、 OpenGL 图形、加载图像以及播放视频和音乐。 |
要开始游戏编程,请查看:
- Python 游戏开发教程
- py Game:Python 游戏编程入门
你可以使用 Python 来创建街机游戏、冒险游戏和益智游戏,你可以在几个小时内部署这些游戏。你还可以用你新学到的编程技巧编写经典游戏,比如 hangman、井字游戏、石头剪刀布等等。
如果你想开始构建你的第一个游戏,那么你可以从用 Python 和 PyGame 构建一个小行星游戏开始。如果你想更进一步,构建你的第一个平台游戏,那么看看用街机用 Python 构建一个平台游戏。
深入研究数据科学和数学
数据科学是一个涉及清理、准备和分析数据以从中提取知识的领域。数据科学结合了统计学、数学、编程,以及解题技巧,从数据中提取有用的信息。
Python 在数据科学和数学领域扮演着重要角色。这种语言因其可读性、生产率、灵活性和可移植性而在科学家中流行起来。围绕科学的 Python 生态系统已经有了巨大的发展。你会发现在数学和科学的几乎每个主要领域都有成熟的 Python 解决方案。
Python 包括机器学习(ML) 、人工智能(AI) 、科学计算、数据分析、数据可视化的工具。这种语言还提供了收集、挖掘和操作数据的有效工具。
机器学习
对于对人工智能感兴趣的人来说,机器学习可能是第一步。机器学习研究通过经验学习的算法。这些算法基于训练数据的样本建立模型,进行预测和决策。
机器学习可能是一个令人生畏的领域,因为这个领域是快速和不断变化的。这里总结了一些最流行的使用 Python 进行机器学习的工具:
| 图书馆 | 描述 |
|---|---|
| Keras | Keras 是一个工业强度的深度学习框架,具有为人类设计的 API。它允许你运行新的实验,快速尝试更多的想法。它遵循减少认知负荷的最佳实践。 |
| NLTK | NLTK 是一个平台,用于构建 Python 程序来处理人类语言数据。它提供了用于分类、标记化、词干提取、标记、解析和语义推理的库。 |
| 指针 | PyTorch 是一个开源的机器学习框架,它加速了从研究原型到生产部署的过程。 |
| scikit-learn | scikit-learn 是一个开源的机器学习库,支持监督的和非监督的学习。这是一个高效的预测数据分析工具,每个人都可以使用,并且可以在各种环境中重复使用。 |
| TensorFlow | TensorFlow 是一个机器学习的端到端开源平台。它有一个全面、灵活的工具、库和社区资源生态系统,可以帮助您构建和部署 ML 驱动的应用程序。 |
要开始学习机器,请查看:
科学计算
Python 发挥重要作用的另一个领域是科学计算。科学家们通过超级计算机、计算机集群,甚至台式机和笔记本电脑,使用先进的计算能力来理解和解决复杂的问题。
以下是目前在 Python 中可以用于科学计算的一些库和工具:
| 图书馆 | 描述 |
|---|---|
| NumPy | NumPy 是使用 Python 进行科学计算的基础包。它提供了全面的数学函数,随机数生成器,线性代数例程,傅立叶变换,等等。它提供了一种高级语法,使其易于访问且高效。 |
| 轨道轨道 | SciPy 是一个基于 Python 的数学、科学和工程开源软件集合。 |
| 简单的 | SimPy 是一个基于 Python 的基于流程的离散事件仿真框架。它可以帮助您模拟真实世界的系统,如机场、客户服务、高速公路等。 |
要开始科学计算,请查看:
本节中的库和工具是 Python 中数据科学领域的基础部分。其中一些是用于机器学习、数据分析等的高级库的核心组件。
数据分析和可视化
数据分析是收集、检查、清洗、转换、建模数据,以发现有用信息、做出预测、得出结论、支持决策过程等的过程。数据分析与数据可视化密切相关,后者处理数据的图形表示。
在 Python 中,您还会发现用于数据分析和数据可视化的成熟和完善的库。以下是其中的一些:
| 图书馆 | 描述 |
|---|---|
| 散景 | Bokeh 是一个用于 web 浏览器的交互式数据可视化库。它提供了构建优雅和通用图形的工具。它可以帮助您快速制作交互式绘图、仪表盘和数据应用程序。 |
| 破折号 | Dash 是一个 Python 框架,用于快速构建 web 分析应用程序。它非常适合于构建在浏览器中呈现自定义用户界面的数据可视化应用程序。 |
| Matplotlib | Matplotlib 是一个用于在 Python 中创建静态、动画和交互式数据可视化的库。 |
| 熊猫 | pandas 是一个用于分析和操作数据的强大而灵活的开源工具。它提供了快速、灵活和富有表现力的数据结构来处理关系数据或标签数据。 |
| Seaborn | Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库。它提供了一个高级界面,用于绘制吸引人的信息丰富的统计图形,使您能够探索和理解您的数据。它与 pandas 数据结构紧密集成。 |
要开始数据分析和可视化,请查看:
如果你想通过建立一个实际的项目来提高你的数据分析技能,那么你可以用 Python 和熊猫创建一本成绩册。这个循序渐进的项目将引导您完成创建 Python 脚本的过程,该脚本加载成绩数据并计算一组学生的字母成绩。该项目包括从一个逗号分隔值(CSV)文件加载数据,探索数据,并使用 pandas 计算和绘制分数。
网页抓取
做数据科学最重要的信息来源之一是网络。使用自动化工具(爬虫)从网络上收集和解析原始数据的过程被称为网络抓取。
Python 有一套很好的工具和库,可以从 Web 上抓取数据。以下是其中的一些:
| 图书馆 | 描述 |
|---|---|
| 美汤 | Beautiful Soup 是一个 Python 库,用于将 HTML 和 XML 文件中的数据提取到解析树中。该库提供了导航、搜索、修改和从解析树中提取信息的方法和 Pythonic 习惯用法。 |
T2requests |
requests是一个优雅而强大的HTTPPython 库。它提供了一个为人类设计的直观简洁的 API。 |
| 刺儿头 | Scrapy 是一个快速、高级的 web 爬行和 web 抓取框架。它允许你抓取网站并从网页中提取结构化数据。 |
T2urllib.request |
urllib.request是一个标准的库模块,它定义了函数和类来帮助你打开 URL。它还允许您使用基本和摘要认证、重定向、cookies 等等。 |
要从网上搜集数据,请查看:
一旦你了解了网页抓取的基础知识,你就可以投入到一个实际的项目中,用 Python 和 Beautiful Soup 构建你自己的网页抓取器。完成这个实践项目后,你将能够把同样的过程和工具应用到其他静态网站上。这些技能允许你提取相关信息,并在你的应用程序中使用。来吧,试一试!
注意:在使用你的 Python 技能进行网页抓取之前,你应该检查你的目标网站的使用政策,以确保使用自动化工具抓取网页不违反其使用条款。
你可以马上建立的第二个项目是比特币价格通知服务。自 2021 年 1 月以略高于 4 万美元的价格达到顶峰以来,这种加密货币已经成为数百万人的心头之患。它的价格继续波动,但许多人会认为这是一个值得的投资。
如果你想从虚拟淘金热中获利,并且只需要知道何时出手,那么你需要掌握比特币的价格。这个项目的基础是创建 IFTTT (如果这个那么那个)小程序。您将学习如何使用 requests 发送 HTTP 请求,以及如何使用 webhook 将您的应用程序连接到外部服务。
对于对加密感兴趣的初学者来说,这种比特币价格通知服务是一个完美的起步项目。然后,您可以扩展您将在本教程中构建的服务,以监控其他货币。
多亏了互联网——以及越来越多的物联网——你现在可以访问多年前无法获得的海量数据。
分析是任何与数据打交道的领域的重要组成部分。人们在谈论什么?你能在他们的行为中看到什么样的模式?Twitter 是一个获得这些问题答案的好地方。如果你对数据分析感兴趣,那么一个 Twitter 情绪分析项目是一个利用你的 Python 技能来回答关于你周围世界的问题的好方法。
在这个项目中,你将学习如何在一个 Docker 环境中挖掘 Twitter 数据并分析用户情绪。您将学习如何向 Twitter 注册一个应用程序,为了访问他们的流 API,您需要这样做。您将看到如何使用 Tweepy 来过滤您想要提取的推文, TextBlob 来计算这些推文的情感, Elasticsearch 来分析它们的内容,以及 Kibana 来可视化结果。
加速并自动化您的工作流程
计算机非常擅长执行重复和枯燥的任务。他们可以长时间做同样的事情而不出错。这是一个有价值的功能,可以帮助你让日常工作更加愉快和富有成效。
使用 Python,您可以自动化工作流程中的许多任务。您可以自动化和管理您的 DevOps 操作,构建有效的 Python 开发环境,在您的开发周期中处理打包和部署过程,测试您的软件,管理您的数据库系统,等等。
DevOps
DevOps 包括软件开发和一般 IT 运营。DevOps 允许您处理应用程序和软件产品的整个生命周期。它包括开发、测试、打包和部署以及其他相关操作。
Python 是人们用于 DevOps 的主要技术之一。它的灵活性和可访问性使 Python 非常适合这项工作,使开发团队能够改进他们的工作流程,并变得更加高效和多产。
在 Python 生态系统中,你会发现一些流行的 DevOps 工具都是用 Python 写的。您还会发现,您可以使用 Python 来控制大多数工具。以下是其中的几个例子:
| 图书馆 | 描述 |
|---|---|
| 可回答的 | Ansible 是一个用于软件供应、配置管理和应用部署的工具。它启用代码为的基础设施。 |
| 坞站组成 | Docker Compose 是一个定义和运行多容器 Docker 应用程序的工具。你可以用一个 YAML 文件来配置你的应用服务。然后,只需一个命令,您就可以从您的配置文件中创建并启动所有服务。它致力于生产、试运行、开发、测试等等。 |
要开始使用 DevOps,请查看:
有了这些资源,您将掌握各种技能并学会使用任何使用 Python 的 DevOps 工程师都应该知道的工具和技术。
开发环境
为你和你的队友构建一个高效的环境是软件开发的基础部分。为此,Python 有一套很棒的工具,允许您在每个项目的虚拟环境中隔离您的包、库和 Python 版本。
以下是一些最受欢迎的工具:
| 工具 | 描述 |
|---|---|
T2conda |
conda是一个开源的包和环境管理系统。它允许您快速安装、运行和更新软件包及其依赖项。它帮助您找到并安装软件包。 |
T2pip |
pip是 Python 的包管理工具。它允许你安装来自 PyPI 和其他索引的包。 |
| Pipenv | Pipenv 是一个工具,旨在将所有打包领域的精华引入 Python 世界。它允许您为项目创建和管理虚拟环境。它提供了一种通过统一接口将pip和 virtualenv 一起使用的方式。 |
| pix | pipx 是一个帮助您在隔离环境中安装和运行用 Python 编写的最终用户应用程序的工具。它为每个应用程序及其相关包创建了一个隔离的环境。它使应用程序在命令行或 shell 中可用。 |
| pyenv | pyenv 是一个用于安装和管理多个 Python 版本的工具。它可以让你在它们之间快速切换。它还允许您定义每个项目的 Python 版本。 |
要构建有效的开发环境,请查看:
学习如何为您的开发冒险构建一个有效的 Python 环境将会把您的生产力推向一个新的水平,所以花时间来完善这项技能是很重要的。
软件打包和部署
软件开发周期的另一个关键部分是将你的产品打包、分发和部署到你的最终用户或客户手中。在 Python 中,一种快速且流行的部署应用程序和库的方法是将它们发布到 PyPI。
以下是一些可用于此目的的工具:
| 工具 | 描述 |
|---|---|
| 掠过 | Flit 是一个工具,它提供了一种将 Python 包和模块放到 PyPI 上的快捷方式。它帮助您设置关于您的包的信息,因此您可以用最少的努力将它发布到 PyPI。 |
| 诗歌 | 诗歌是创建、构建、安装和打包 Python 项目的工具。它还允许您将项目发布到 PyPI。它跟踪并解析项目的依赖关系。它使用您当前的虚拟环境或创建新的虚拟环境,将您的包与系统范围的 Python 安装隔离开来。 |
| PyInstaller | PyInstaller 是一个工具,它将 Python 应用程序冻结成可以在 Windows、GNU/Linux、macOS 等环境下运行的独立可执行文件。 |
| 安装工具 | setuptools 是对 Python distutils 的一系列增强,它允许您构建和分发 Python 发行版,尤其是那些依赖于其他包的发行版。 |
| 麻绳 | Twine 是一个在 PyPI 上发布 Python 包的工具。它允许您上传项目的源代码和二进制发行版。 |
要开始,请查看:
有了这些资源,您就可以开始打包 Python 应用程序、库和包并将其部署到最终用户、客户和大学。另外, Python 打包权威提供了很多有用的信息和教程,帮助你用现代工具分发 Python 包。
数据库系统
作为开发人员,您在职业生涯中构建的大多数应用程序都会以某种方式与数据进行交互。这种交互通常通过一个数据库管理系统(DBMS) 进行,它允许您定义、创建、维护和控制对数据库的访问。
要使用 Python 连接和操作数据库,您有几种选择,包括标准库包和第三方包和库。在 Python 中,您还可以选择 SQL 和 NoSQL 数据库。
对象关系映射工具(ORMs) 是另一种重要的工具,你可能会用它来处理 Python 中的数据库。这些工具允许你使用面向对象编程来创建和操作你的数据库。
以下是一些可用于连接和操作数据库的 Python 库:
| 图书馆 | 数据库ˌ资料库 | 描述 |
|---|---|---|
| 蒙戈金 | MongoDB | MongoEngine 是一个文档-对象映射器,用于使用 Python 中的面向对象编程来处理 MongoDB。 |
| MySQL 连接器/Python | MySQL 的实现 | MySQL 连接器是一个独立的 Python 驱动程序,用于与 MySQL 服务器通信。 |
| 心理战 | PostgreSQL | Psycopg 是 Python 编程语言的 PostgreSQL 数据库适配器。 |
| PyMongo | MongoDB | PyMongo 是一个 Python 发行版,包含用于处理 MongoDB 数据库的工具。它为这种类型的数据库系统提供了一个本地 Python 驱动程序。 |
| SQL 语法 | SQL | SQLAlchemy 是用于 SQL 数据库的 Python SQL 工具包和对象关系映射器。 |
T2sqlite3 |
SQLite | sqlite3是一个轻量级的基于磁盘的数据库,不需要单独的服务器进程。它允许您使用 SQL 的非标准变体来访问数据库。它是免费的,来自 Python 标准库。 |
要开始使用数据库,请查看:
创建和使用数据库是在 Python 应用程序中管理数据的一种强大方式。数据库为您的程序增加了重要的功能和多样性,并允许您为您的用户和客户提供令人兴奋的特性。管理数据库是开发人员教育中的一项基本技能。
软件测试
当您开始使用 Python 或编程时,您可能会从创建小程序和脚本开始,您可以运行并手动测试以确保它们如您所愿地工作。然而,当你的程序变得越来越复杂时,手工测试它们几乎是不可能的。这就是自动化测试出现的时候。
不幸的是,开发人员会犯错误,没有代码是完美的。因此,您需要一个测试过程来帮助您识别 bug 并避免将它们投入生产。测试还可以驱动你的代码设计并帮助你检查非功能特性,比如性能、安全性、可用性、法规遵从性等等。因此,测试是软件开发的一个重要组成部分。
谈到测试,Python 有一些最好的工具。您可以使用这些工具来编写一致的测试并自动运行它们。以下是这些工具的一个小例子:
| 工具 | 描述 |
|---|---|
| doctest | doctest 是一个标准模块,它在你的文档字符串中搜索看起来像交互式 Python 会话的文本片段,并执行它们来验证它们是否正常工作。 |
| pytest | pytest 是一个健壮而成熟的测试框架,允许您编写和自动化测试。它可以从小单元测试扩展到应用程序和库的复杂功能测试。 |
| 毒性 | tox 是一个通用的 virtualenv 管理和测试命令行工具。它允许您检查您的包是否在不同的 Python 版本和解释器中正确安装。它可以在每个已配置的环境中运行您的测试。 |
T2unittest |
unittest是 Python 标准库中可用的单元测试框架。它支持测试自动化、测试的设置和拆卸、测试集合的聚合等等。 |
要开始测试,请查看:
作为一名开发人员,您需要编写可靠的、能够正常工作的代码。这意味着每次修改代码或添加新特性时,都需要测试代码。在这些情况下,自动化测试是可行的。
开发嵌入式系统和机器人
为 Web 或桌面编写自己的应用程序很酷,但编写控制硬件系统和机器人如何工作的代码会更酷!随着科技的进步,像物联网、家庭自动化、无人驾驶汽车和机器人这样的领域变得越来越受欢迎。
Python 逐渐进入了传感器、电机、电路、微控制器和机器人的世界。今天,您可以找到几个朝着这个方向发展的 Python 项目。以下是其中的一些:
| 图书馆 | 描述 |
|---|---|
| BBC 微:位 | BBC micro:bit 是一款口袋大小的电脑,向你介绍软件和硬件是如何协同工作的。它可以用 Python 编程。 |
| CircuitPython | CircuitPython 是一种编程语言,旨在简化在低成本微控制器板上进行编码的实验和学习。 |
| MicroPython | MicroPython 是 Python 的一个精简高效的实现。它包括 Python 标准库的一小部分。它针对微控制器和受限环境下的运行进行了优化。 |
| PythonRobotics | PythonRobotics 是各种机器人算法与可视化的汇编。它专注于自主导航。它的目标是让你理解它提供的每个机器人算法背后的基本思想。 |
| 树莓派 | Raspberry Pi 是一种基于 Linux 的通用计算机。它有一个完整的操作系统,带有 GUI 界面,能够同时运行许多不同的程序。Python 内置于树莓派之上。 |
| 俄罗斯语 | rospy 是 ROS(机器人操作系统)的客户端库。它的 API 使 Python 程序员能够快速与 ROS 交互,以创建复杂可靠的机器人行为。 |
要开始使用嵌入式 Python,请查看:
- MicroPython:Python 硬件编程入门
- 第五集:探索电路 Python
- 嵌入式 Python:在 BBC 上构建游戏 micro:bit
如果你想开始用 Python 创建一个硬件相关的项目,那么看看如何在 Raspberry Pi 上用 Python 构建物理项目。在这个项目中,您将学习如何设置一个 Raspberry Pi,在它上面运行 Python 代码,从它的传感器读取输入,向它的电子组件发送信号,等等。
你可能不应该用 Python 做什么
Python 是一种高度通用的语言,你可以用它做很多事情。然而,你不能什么都做。有些事情 Python 根本不太适合。
作为一种解释型语言,Python 很难与低级设备交互,比如设备驱动程序。如果你想用 Python 写一个操作系统,你会遇到一个问题。对于低级应用程序,你最好坚持使用 C 或 C++ 。
然而,即便如此,这种情况也不会持续太久。作为 Python 灵活性的一个证明,有人正在从事将 Python 的可用性扩展到低级交互的项目。MicroPython 和 CircuitPython 只是为 Python 设计底层功能的一些项目。
用 Python 还能做什么?
本教程中的想法列表并不详尽。使用 Python 可以处理无数其他领域。如果你正在寻找 Python 非常适合的实用项目,那么看看为中级 Python 开发者准备的 13 个项目创意来寻找灵感。
你也可以做自己的研究,寻找你感兴趣的项目。如果你不确定从哪里开始,那么在 Twitter 上关注真正的 Python 。你会在那里找到来自社区的又酷又有趣的 Python 项目。也许你会发现一些你迫不及待想要贡献的东西!
结论
对 Python 能做什么有一个基本的了解是你不断提高 Python 技能的关键。您可以在从应用程序开发到机器人技术的各种不同领域使用 Python!
在本文中,您看到了 Python 可以用于:
- 通用软件开发
- 数据科学和数学
- 工作流程加速和自动化
- 嵌入式系统和机器人
您还看到了几个实际项目的想法,您可以构建这些项目来将您的 Python 技能提升到一个新的水平。
接下来的步骤
所以你有它!一个广泛的主题和实践项目列表,帮助您从 Python 初学者成为精通 Python 的人。
无论您选择从哪里开始,您都将为提高您的编程技能开辟无数的途径。挑个东西开始吧!你有一个不在这里的实际项目的想法吗?在下面留下评论吧!你可以为你的程序员同事推荐一个完美的项目。
如果你被困住了,需要一个正确方向的推动,那么看看 11 个学习 Python 编程的初学者技巧来帮助你回到正轨。
另一个摆脱困境的好方法是说出来。编码不一定是一项孤独的活动。如果你需要一种方法来提问并从有知识的 Python 开发者那里快速得到答案,那么考虑加入真正的 Python 成员的 Slack 社区。任何人都受欢迎,不管你有多少经验。你总是能帮助别人,也能得到别人的帮助。******
使用 Python 的 pip 管理项目的依赖关系
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Pip 入门
Python 的标准包管理器是 pip 。它允许你安装和管理不属于 Python 标准库的包。如果你正在寻找关于pip的介绍,那么你来对地方了!
在本教程中,您将学习如何:
- 在您的工作环境中设置
pip - 修复与使用
pip相关的常见错误 - 用
pip安装和卸载软件包 - 使用需求文件管理项目的依赖关系
您可以使用pip做很多事情,但是 Python 社区非常活跃,已经创建了一些简洁的替代方案来代替pip。您将在本教程的后面部分了解这些内容。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
pip 入门
那么,pip到底是做什么的呢? pip 是 Python 的一个包管理器。这意味着它是一个工具,允许您安装和管理不作为标准库的一部分分发的库和依赖项。伊恩·比克在 2008 年引入了 pip 这个名字:
我已经将 pyinstall 重命名为新名称:pip。pip 这个名字是一个缩写和声明:pip 安装软件包。(来源)
包管理是如此重要,以至于 Python 的安装程序从版本 3.4 和 2.7.9 开始就包含了pip,分别针对 Python 3 和 Python 2。许多 Python 项目使用pip,这使得它成为每个 Python 爱好者的必备工具。
如果您来自另一种编程语言,那么您可能对包管理器的概念很熟悉。 JavaScript 使用 npm 进行包管理, Ruby 使用 gem ,而。NET 平台使用 NuGet 。在 Python 中,pip已经成为标准的包管理器。
在您的系统上找到pip
在您的系统上安装 Python 时,Python 3 安装程序为您提供了安装pip的选项。事实上,用 Python 安装pip的选项是默认勾选的,所以安装完 Python 后pip应该就可以使用了。
注意:在 Ubuntu 等一些 Linux (Unix)系统上,pip是一个名为python3-pip的单独的包,你需要用sudo apt install python3-pip来安装。默认情况下,它不会随解释器一起安装。
您可以通过在您的系统上查找pip3可执行文件来验证pip是否可用。从下面选择您的操作系统,并相应地使用特定于平台的命令:
- 视窗
** Linux + macOS*
C:\> where pip3
Windows 上的where命令会告诉你在哪里可以找到pip3的可执行文件。如果 Windows 找不到名为pip3的可执行文件,那么你也可以尝试寻找末尾没有三个(3)的pip。
$ which pip3
Linux 系统和 macOS 上的which命令显示了pip3二进制文件的位置。
在 Windows 和 Unix 系统中,pip3可能位于多个位置。当您安装了多个 Python 版本时,可能会发生这种情况。如果您在系统的任何位置都找不到pip,那么您可以考虑重新安装 pip 。
除了直接运行您的系统pip,您还可以将它作为 Python 模块来运行。在下一节中,您将了解如何操作。
将pip作为模块运行
当你直接运行你的系统pip时,命令本身并不会透露pip属于哪个 Python 版本。不幸的是,这意味着您可以使用pip将一个包安装到旧 Python 版本的站点包中,而不会注意到。为了防止这种情况发生,您可以将pip作为 Python 模块运行:
$ python3 -m pip
注意,您使用了python3 -m来运行pip。-m开关告诉 Python 运行一个模块作为python3解释器的可执行文件。这样,您可以确保您的系统默认 Python 3 版本运行pip命令。如果你想进一步了解这种运行pip的方式,那么你可以阅读 Brett Cannon 关于使用python3 -m pip 的优势的颇有见地的文章。
有时您可能想要更明确地将包限制在特定的项目中。在这种情况下,你应该在一个虚拟环境中运行pip。
在 Python 虚拟环境中使用pip
为了避免将包直接安装到您的系统 Python 安装中,您可以使用一个虚拟环境。虚拟环境为您的项目提供了一个独立的 Python 解释器。您在这个环境中使用的任何包都将独立于您的系统解释器。这意味着您可以将项目的依赖项与其他项目和整个系统分开。
在虚拟环境中使用pip有三个主要优势。您可以:
- 确保您正在为手头的项目使用正确的 Python 版本
- 确信你在运行
pip或pip3时引用的是正确的pip实例 - 在不影响其他项目的情况下,为您的项目使用一个特定的包版本
Python 3 内置了 venv 模块,用于创建虚拟环境。本模块帮助您使用独立的 Python 安装创建虚拟环境。一旦激活了虚拟环境,就可以将软件包安装到该环境中。您安装到一个虚拟环境中的软件包与系统上的所有其他环境是隔离的。
您可以按照以下步骤创建一个虚拟环境,并验证您在新创建的环境中使用了pip模块:
- 视窗
** Linux + macOS*
C:\> python -m venv venv
C:\> venv\Scripts\activate.bat
(venv) C:\> pip3 --version
pip 21.2.3 from ...\lib\site-packages\pip (python 3.10)
(venv) C:\> pip --version
pip 21.2.3 from ...\lib\site-packages\pip (python 3.10)
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ pip3 --version
pip 21.2.3 from .../python3.10/site-packages/pip (python 3.10)
(venv) $ pip --version
pip 21.2.3 from .../python3.10/site-packages/pip (python 3.10)
在这里,您通过使用 Python 的内置venv模块创建一个名为venv的虚拟环境。然后你用source命令激活它。您的venv名字周围的括号(())表示您成功激活了虚拟环境。
最后,检查激活的虚拟环境中的pip3和pip可执行文件的版本。两者都指向同一个pip模块,所以一旦你的虚拟环境被激活,你可以使用pip或者pip3。
出现错误时重新安装pip
当运行pip命令时,在某些情况下可能会出现错误。具体的错误消息取决于您的操作系统:
| 操作系统 | 出错信息 |
|---|---|
| Windows 操作系统 | 'pip' is not recognized as an internal or external command, |
| T1】 | |
| Linux 操作系统 | bash: pip: command not found |
| 马科斯 | zsh: command not found: pip |
类似这样的错误消息表明pip的安装出现了问题。
注意:当pip命令不起作用时,在您开始任何故障排除之前,您可以尝试使用结尾带有三个(3)的pip3命令。
得到如上所示的错误可能会令人沮丧,因为pip对于安装和管理外部包是至关重要的。pip的一些常见问题与该工具在您的系统上的安装方式有关。
尽管不同系统的错误信息不同,但它们都指向同一个问题:您的系统无法在您的 PATH 变量中列出的位置找到pip。在 Windows 上,PATH是系统变量的一部分。在 macOS 和 Linux 上,PATH是环境变量的一部分。你可以用这个命令检查你的PATH变量的内容:
- 视窗
** Linux + macOS*
C:\> echo %PATH%
$ echo $PATH
该命令的输出将显示操作系统在磁盘上查找可执行程序的位置(目录)列表。根据您的系统,位置可以用冒号(:)或分号(;)分隔。
默认情况下,在安装 Python 或创建虚拟环境之后,包含pip可执行文件的目录应该出现在PATH中。然而,失踪的pip是一个常见的问题。两个支持的方法可以帮助你再次安装pip并将其添加到你的PATH中:
ensurepip模块get-pip.py剧本
从 Python 3.4 开始,ensurepip模块就是标准库的一部分。它被添加到中,为你重新安装pip提供了一种直接的方式,例如,如果你在安装 Python 时跳过了它或者在某个时候卸载了pip。在下面选择您的操作系统,并相应地运行ensurepip:
- 视窗
** Linux + macOS*
C:\> python -m ensurepip --upgrade
$ python3 -m ensurepip --upgrade
如果pip还没有安装,那么这个命令会将它安装到您当前的 Python 环境中。如果您在一个活动的虚拟环境中,那么该命令会将pip安装到该环境中。否则,它会在你的系统上全局安装pip。--upgrade选项确保pip版本与ensurepip中声明的版本相同。
注意:ensurepip模块不接入互联网。ensurepip可以安装的最新版本的pip是捆绑在您环境的 Python 安装中的版本。比如用 Python 3.10.0 运行ensurepip,安装pip 21.2.3。如果你想要一个更新的pip版本,那么你需要首先运行ensurepip。之后,您可以手动将pip更新到其最新版本。
另一种修复pip安装的方法是使用get-pip.py脚本。get-pip.py文件包含一个完整的pip副本,作为一个编码的 ZIP 文件。你可以直接从 PyPA 引导页面下载get-pip.py。一旦你在你的机器上有了脚本,你就可以像这样运行 Python 脚本:
- 视窗
** Linux + macOS*
C:\> python get-pip.py
$ python3 get-pip.py
该脚本将在您当前的 Python 环境中安装最新版本的pip、、setuptools、和、wheel、。如果您只想安装pip,那么您可以在您的命令中添加--no-setuptools和--no-wheel选项。
如果以上方法都不起作用,那么可能值得尝试为您当前的平台下载最新的 Python 版本。你可以按照 Python 3 安装&设置指南来确保pip被正确安装并且工作无误。
用pip 安装包
Python 被认为是一门包含电池的语言。这意味着 Python 标准库包含了一套广泛的包和模块来帮助开发者完成他们的编码项目。
同时,Python 有一个活跃的社区,它提供了一组更广泛的包,可以帮助您满足开发需求。这些包被发布到 Python 包索引,也称为 PyPI (读作派豌豆眼)。
PyPI 托管了大量的包,包括开发框架、工具和库。其中许多包都提供了 Python 标准库功能的友好接口。
使用 Python 包索引(PyPI)
PyPI 托管的众多包中有一个叫做 requests 。requests库通过抽象 HTTP 请求的复杂性来帮助与 web 服务交互。你可以在官方的文档网站上了解关于requests的一切。
当您想在项目中使用requests包时,您必须首先将它安装到您的环境中。如果您不想将它安装在您的系统 Python 站点包中,那么您可以首先创建一个虚拟环境,如上所示。
一旦创建并激活了虚拟环境,命令行提示符就会在括号中显示虚拟环境的名称。从现在起,您执行的任何pip命令都将发生在您的虚拟环境中。
为了安装软件包,pip提供了一个install命令。你可以运行它来安装requests包:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install requests
(venv) $ python3 -m pip install requests
在这个例子中,您运行pip,带有install命令,后跟您想要安装的软件包的名称。pip命令在 PyPI 中寻找包,解析它的依赖项,并在当前的 Python 环境中安装所有东西,以确保requests能够工作。
pip install <package>命令总是寻找软件包的最新版本并安装它。它还搜索软件包元数据中列出的依赖项并安装它们,以确保软件包具有它需要的所有要求。
也可以在一个命令中安装多个软件包:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install rptree codetiming
(venv) $ python3 -m pip install rptree codetiming
通过在pip install命令中链接软件包rptree和codetiming,你可以一次安装两个软件包。您可以向pip install命令添加任意数量的包。在这种情况下,一个requirements.txt文件可以派上用场。在本教程的后面,您将学习如何使用一个requirements.txt文件一次安装多个包。
注意:除非软件包的具体版本号与本教程相关,否则您会注意到版本字符串采用了x.y.z的通用形式。这是一种占位符格式,可以代表3.1.4、2.9或任何其他版本号。当您继续操作时,终端中的输出将显示您实际的包版本号。
您可以使用list命令来显示您的环境中安装的软件包,以及它们的版本号:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip list
Package Version
------------------ ---------
certifi x.y.z
charset-normalizer x.y.z
codetiming x.y.z
idna x.y.z
pip x.y.z
requests x.y.z
rptree x.y.z
setuptools x.y.z
urllib3 x.y.z
(venv) $ python3 -m pip list
Package Version
------------------ ---------
certifi x.y.z
charset-normalizer x.y.z
idna x.y.z
pip x.y.z
requests x.y.z
setuptools x.y.z
urllib3 x.y.z
pip list命令呈现一个表格,显示当前环境中所有已安装的软件包。上面的输出显示了使用x.y.z占位符格式的包的版本。当您在您的环境中运行pip list命令时,pip会显示您为每个包安装的特定版本号。
要获得关于特定包的更多信息,您可以通过使用pip中的show命令来查看包的元数据:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip show requests
Name: requests
Version: x.y.z
Summary: Python HTTP for Humans.
...
Requires: certifi, idna, charset-normalizer, urllib3
Required-by:
(venv) $ python3 -m pip show requests
Name: requests
Version: x.y.z
Summary: Python HTTP for Humans.
...
Requires: certifi, idna, charset-normalizer, urllib3
Required-by:
您系统上的这个命令的输出将列出包的元数据。Requires行列出了包,比如certifiidnacharset-normalizerurllib3。安装这些是因为requests依赖它们才能正常工作。
既然已经安装了requests及其依赖项,就可以像 Python 代码中的任何其他常规包一样导入了。启动交互式 Python 解释器,导入requests包;
>>> import requests >>> requests.__version__ "x.y.z"启动交互式 Python 解释器后,您导入了
requests模块。通过调用requests.__version__,您验证了您正在虚拟环境中使用requests模块。使用自定义包索引
默认情况下,
pip使用 PyPI 来查找包。但是pip也给了你定义自定义包索引的选项。当 PyPI 域在您的网络上被阻止时,或者如果您想使用不公开的包,使用带有自定义索引的
pip会很有帮助。有时系统管理员也会创建他们自己的内部包索引,以便更好地控制哪些包版本对公司网络上的pip用户可用。自定义包索引必须符合PEP 503–简单存储库 API 才能与
pip一起工作。您可以通过访问 PyPI 简单索引来了解这样一个 API(应用程序编程接口)是什么样子的——但是要注意这是一个很大的页面,有很多难以解析的内容。任何遵循相同 API 的定制索引都可以使用--index-url选项。除了键入--index-url,你还可以使用-i速记。例如,要从 TestPyPI 包索引中安装
rptree工具,可以运行以下命令:
- 视窗
** Linux + macOS*(venv) C:\> python -m pip install -i https://test.pypi.org/simple/ rptree(venv) $ python3 -m pip install -i https://test.pypi.org/simple/ rptree使用
-i选项,您告诉pip查看不同的包索引,而不是默认的 PyPI。这里,你是从 TestPyPI 而不是从 PyPI 安装rptree。您可以使用 TestPyPI 来微调 Python 包的发布过程,而不会弄乱 PyPI 上的产品包索引。如果需要永久使用替代索引,那么可以在
pip配置文件中设置index-url选项。这个文件叫做pip.conf,您可以通过运行以下命令找到它的位置:
- 视窗
** Linux + macOS*(venv) C:\> python -m pip config list -vv(venv) $ python3 -m pip config list -vv使用
pip config list命令,您可以列出活动配置。只有当您设置了自定义配置时,此命令才会输出一些内容。否则,输出为空。这时,附加的--verbose或-vv选项会有所帮助。当您添加-vv,pip会向您显示它在哪里寻找不同的配置级别。如果你想添加一个
pip.conf文件,那么你可以选择一个pip config list -vv列出的位置。带有自定义包索引的pip.conf文件如下所示:# pip.conf [global] index-url = https://test.pypi.org/simple/当你有一个像这样的
pip.conf文件时,pip将使用定义好的index-url来寻找包。有了这个配置,您不需要在您的pip install命令中使用--index-url选项来指定您只想要可以在 TestPyPI 的简单 API 中找到的包。从你的 GitHub 库安装包
您不局限于托管在 PyPI 或其他包索引上的包。
pip还提供了从 GitHub 库安装包的选项。但是即使一个包托管在 PyPI 上,比如真正的 Python 目录树生成器,你也可以选择从它的 Git 库安装它:
- 视窗
** Linux + macOS*(venv) C:\> python -m pip install git+https://github.com/realpython/rptree(venv) $ python3 -m pip install git+https://github.com/realpython/rptree使用
git+https方案,您可以指向包含可安装包的 Git 存储库。您可以通过运行交互式 Python 解释器并导入rptree来验证您是否正确安装了包:
>>> import rptree
>>> rptree.__version__
"x.y.z"
启动交互式 Python 解释器后,导入rptree模块。通过调用rptree.__version__,您验证了您正在使用基于虚拟环境的rptree模块。
注意:如果你使用的是版本控制系统(VCS)而不是 Git,pip你已经覆盖了。要了解如何将pip与 Mercurial、Subversion 或 Bazaar 一起使用,请查看pip文档的 VCS 支持章节。
如果包不是托管在 PyPI 上,而是有一个远程 Git 存储库,那么从 Git 存储库安装包会很有帮助。您指向的远程存储库甚至可以托管在您公司内部网的内部 Git 服务器上。当您处于防火墙之后或 Python 项目有其他限制时,这可能会很有用。
以可编辑模式安装软件包以简化开发
当处理您自己的包时,以可编辑的模式安装它是有意义的。通过这样做,您可以在处理源代码的同时仍然像在任何其他包中一样使用命令行。典型的工作流程是首先克隆存储库,然后使用pip将其作为可编辑的包安装到您的环境中:
- 视窗
** Linux + macOS*
1C:\> git clone https://github.com/realpython/rptree
2C:\> cd rptree
3C:\rptree> python3 -m venv venv
4C:\rptree> venv\Scripts\activate.bat
5(venv) C:\rptree> python -m pip install -e .
1$ git clone https://github.com/realpython/rptree
2$ cd rptree
3$ python3 -m venv venv
4$ source venv/bin/activate
5(venv) $ python3 -m pip install -e .
使用上面的命令,您安装了作为可编辑模块的rptree包。以下是您刚刚执行的操作的详细步骤:
- 第 1 行克隆了
rptree包的 Git 库。 - 第 2 行将工作目录更改为
rptree/。 - 第 3 行和第 4 行创建并激活了一个虚拟环境。
- 第 5 行将当前目录的内容安装为可编辑包。
-e选项是--editable选项的简写。当你使用-e选项和pip install时,你告诉pip你想在可编辑模式下安装软件包。不使用包名,而是使用一个点(.)将pip指向当前目录。
如果您没有使用-e标志,pip将会把这个包正常安装到您环境的site-packages/文件夹中。当您在可编辑模式下安装软件包时,您会在站点软件包中创建一个到本地项目路径的链接:
~/rptree/venv/lib/python3.10/site-packages/rptree.egg-link
使用带有-e标志的pip install命令只是pip install提供的众多选项之一。你可以在pip文档中查看 pip install示例。在那里你将学习如何安装一个包的特定版本,或者将pip指向一个不同的不是 PyPI 的索引。
在下一节中,您将了解需求文件如何帮助您的pip工作流。
使用需求文件
pip install命令总是安装软件包的最新发布版本,但是有时您的代码需要特定的软件包版本才能正常工作。
您希望创建用于开发和测试应用程序的依赖项和版本的规范,以便在生产中使用应用程序时不会出现意外。
固定要求
当您与其他开发人员共享 Python 项目时,您可能希望他们使用与您相同版本的外部包。也许某个软件包的特定版本包含了您所依赖的新特性,或者您正在使用的软件包版本与以前的版本不兼容。
这些外部依赖也被称为需求。您经常会发现 Python 项目将它们的需求固定在一个名为requirements.txt或类似的文件中。需求文件格式允许您精确地指定应该安装哪些包和版本。
运行pip help显示有一个freeze命令以需求格式输出已安装的包。您可以使用这个命令,将输出重定向到一个文件来生成一个需求文件:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip freeze > requirements.txt
(venv) $ python3 -m pip freeze > requirements.txt
该命令在您的工作目录中创建一个包含以下内容的requirements.txt文件:
certifi==x.y.z
charset-normalizer==x.y.z
idna==x.y.z
requests==x.y.z
urllib3==x.y.z
记住上面显示的x.y.z是包版本的占位符格式。您的requirements.txt文件将包含真实的版本号。
freeze命令将当前安装的软件包的名称和版本转储到标准输出中。您可以将输出重定向到一个文件,稍后您可以使用该文件将您的确切需求安装到另一个系统中。您可以随意命名需求文件。然而,一个广泛采用的惯例是将其命名为requirements.txt。
当您想要在另一个系统中复制环境时,您可以运行pip install,使用-r开关来指定需求文件:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install -r requirements.txt
(venv) $ python3 -m pip install -r requirements.txt
在上面的命令中,您告诉pip将requirements.txt中列出的包安装到您当前的环境中。包版本将匹配requirements.txt文件包含的版本约束。您可以运行pip list来显示您刚刚安装的包,以及它们的版本号:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip list
Package Version
------------------ ---------
certifi x.y.z
charset-normalizer x.y.z
idna x.y.z
pip x.y.z
requests x.y.z
setuptools x.y.z
urllib3 x.y.z
(venv) $ python3 -m pip list
Package Version
------------------ ---------
certifi x.y.z
charset-normalizer x.y.z
idna x.y.z
pip x.y.z
requests x.y.z
setuptools x.y.z
urllib3 x.y.z
现在,您可以分享您的项目了!您可以将requirements.txt提交到 Git 这样的版本控制系统中,并使用它在其他机器上复制相同的环境。但是等等,如果这些包发布了新的更新会怎么样呢?
微调要求
硬编码软件包的版本和依赖关系的问题是,软件包会频繁地更新错误和安全补丁。您可能希望这些更新一发布就加以利用。
需求文件格式允许您使用比较操作符来指定依赖版本,这为您提供了一些灵活性,以确保在定义包的基本版本的同时更新包。
在您最喜欢的编辑器中打开requirements.txt,将等式运算符(==)转换为大于或等于运算符(>=,如下例所示:
# requirements.txt
certifi>=x.y.z
charset-normalizer>=x.y.z
idna>=x.y.z
requests>=x.y.z
urllib3>=x.y.z
您可以将比较运算符改为>=来告诉pip安装一个已经发布的精确或更高版本。当您使用requirements.txt文件设置一个新环境时,pip会寻找满足需求的最新版本并安装它。
接下来,您可以通过运行带有--upgrade开关或-U速记的install命令来升级您的需求文件中的包:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install -U -r requirements.txt
(venv) $ python3 -m pip install -U -r requirements.txt
如果列出的软件包有新版本可用,则该软件包将被升级。
在理想的情况下,新版本的包应该是向后兼容的,并且不会引入新的错误。不幸的是,新版本可能会引入一些会破坏应用程序的变化。为了微调您的需求,需求文件语法支持额外的版本说明符。
假设requests的一个新版本3.0已经发布,但是引入了一个不兼容的变更,导致应用程序崩溃。您可以修改需求文件以防止安装3.0或更高版本:
# requirements.txt
certifi==x.y.z
charset-normalizer==x.y.z
idna==x.y.z
requests>=x.y.z, <3.0 urllib3==x.y.z
更改requests包的版本说明符可以确保任何大于或等于3.0的版本都不会被安装。pip文档提供了关于需求文件格式的大量信息,你可以参考它来了解更多。
分离生产和开发依赖关系
并非所有在应用程序开发过程中安装的包都是生产依赖项。例如,您可能想要测试您的应用程序,因此您需要一个测试框架。一个流行的测试框架是 pytest 。您希望将它安装在您的开发环境中,但不希望将其安装在您的生产环境中,因为它不是生产依赖项。
您创建了第二个需求文件requirements_dev.txt,列出了设置开发环境的附加工具:
# requirements_dev.txt
pytest>=x.y.z
拥有两个需求文件将要求你使用pip来安装它们,requirements.txt和requirements_dev.txt。幸运的是,pip允许您在需求文件中指定额外的参数,因此您可以修改requirements_dev.txt来安装来自生产requirements.txt文件的需求:
# requirements_dev.txt
-r requirements.txt
pytest>=x.y.z
注意,您使用同一个-r开关来安装生产requirements.txt文件。现在,在您的开发环境中,您只需运行这个命令就可以安装所有需求:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install -r requirements_dev.txt
(venv) $ python3 -m pip install -r requirements_dev.txt
因为requirements_dev.txt包含了-r requirements.txt行,所以您不仅要安装pytest,还要安装requirements.txt的固定需求。在生产环境中,只安装生产需求就足够了:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip install -r requirements.txt
(venv) $ python3 -m pip install -r requirements.txt
使用这个命令,您可以安装requirements.txt中列出的需求。与您的开发环境相比,您的生产环境不会安装pytest。
生产冻结要求
您创建了生产和开发需求文件,并将它们添加到源代码控制中。这些文件使用灵活的版本说明符来确保您利用由您的依赖项发布的错误修复。您还测试了您的应用程序,现在准备将它部署到生产环境中。
您知道所有的测试都通过了,并且应用程序使用了您在开发过程中使用的依赖项,因此您可能希望确保您将相同版本的依赖项部署到生产环境中。
当前的版本说明符不能保证相同的版本将被部署到生产中,所以您希望在发布项目之前冻结生产需求。
在您根据当前需求完成开发之后,创建当前项目的新版本的工作流可能如下所示:
| 步骤 | 命令 | 说明 |
|---|---|---|
| one | pytest |
运行您的测试并验证您的代码工作正常。 |
| Two | pip install -U -r requirements.txt |
将您的需求升级到与您的requirements.txt文件中的约束相匹配的版本。 |
| three | pytest |
运行您的测试,并考虑降级任何给代码带来错误的依赖项。 |
| four | pip freeze > requirements_lock.txt |
一旦项目正常工作,将依赖关系冻结到一个requirements_lock.txt文件中。 |
有了这样的工作流,requirements_lock.txt文件将包含精确的版本说明符,并可用于复制您的环境。您已经确保当您的用户将requirements_lock.txt中列出的软件包安装到他们自己的环境中时,他们将使用您希望他们使用的版本。
冻结您的需求是确保您的 Python 项目在您的用户环境中与在您的环境中一样工作的重要一步。
用pip 卸载软件包
偶尔,你需要卸载一个软件包。要么你找到了更好的库来代替它,要么它是你不需要的东西。卸载软件包可能有点棘手。
请注意,当您安装了requests时,您也让pip安装其他依赖项。安装的软件包越多,多个软件包依赖于同一个依赖项的可能性就越大。这就是pip中的show命令派上用场的地方。
在卸载软件包之前,请确保运行该软件包的show命令:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip show requests
Name: requests
Version: 2.26.0
Summary: Python HTTP for Humans.
Home-page: https://requests.readthedocs.io
Author: Kenneth Reitz
Author-email: me@kennethreitz.org
License: Apache 2.0
Location: .../python3.9/site-packages
Requires: certifi, idna, charset-normalizer, urllib3 Required-by:
(venv) $ python3 -m pip show requests
Name: requests
Version: 2.26.0
Summary: Python HTTP for Humans.
Home-page: https://requests.readthedocs.io
Author: Kenneth Reitz
Author-email: me@kennethreitz.org
License: Apache 2.0
Location: .../python3.9/site-packages
Requires: certifi, idna, charset-normalizer, urllib3 Required-by:
注意最后两个字段,Requires和Required-by。show命令告诉你requests需要certifi、idna、charset-normalizer和urllib3。你可能也想卸载它们。注意requests不是任何其他包所必需的。所以卸载它是安全的。
您应该对所有的requests依赖项运行show命令,以确保没有其他库也依赖于它们。一旦理解了要卸载的软件包的依赖顺序,就可以使用uninstall命令删除它们:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip uninstall certifi
(venv) $ python3 -m pip uninstall certifi
uninstall命令显示将要删除的文件并要求确认。如果您确定要删除这个包,因为您已经检查了它的依赖关系,并且知道没有其他东西在使用它,那么您可以传递一个-y开关来抑制文件列表和确认对话框:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip uninstall urllib3 -y
(venv) $ python3 -m pip uninstall urllib3 -y
这里你卸载urllib3。使用-y开关,您抑制询问您是否要卸载该软件包的确认对话框。
在一次调用中,您可以指定要卸载的所有软件包:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip uninstall -y charset-normalizer idna requests
(venv) $ python3 -m pip uninstall -y charset-normalizer idna requests
您可以向pip uninstall命令传递多个包。如果您没有添加任何额外的开关,那么您需要确认卸载每个软件包。通过-y开关,你可以卸载它们,而不需要任何确认对话框。
您也可以通过提供-r <requirements file>选项来卸载需求文件中列出的所有包。该命令将提示对每个包的确认请求,但您可以使用-y开关抑制它:
- 视窗
** Linux + macOS*
(venv) C:\> python -m pip uninstall -r requirements.txt -y
(venv) $ python3 -m pip uninstall -r requirements.txt -y
请记住,始终检查要卸载的软件包的依赖关系。您可能希望卸载所有依赖项,但是卸载其他人使用的包会破坏您的工作环境。因此,您的项目可能不再正常工作。
如果您在虚拟环境中工作,只需创建一个新的虚拟环境就可以减少工作量。然后,您可以安装您需要的软件包,而不是尝试卸载您不需要的软件包。然而,当您需要从您的系统 Python 安装中卸载一个包时,pip uninstall会非常有用。如果您不小心在系统范围内安装了一个软件包,使用pip uninstall是清理系统的好方法。
探索pip的替代品
Python 社区提供了优秀的工具和库供您在pip之外使用。这些包括试图简化和改进包管理的pip的替代方案。
以下是 Python 可用的一些其他包管理工具:
| 工具 | 描述 |
|---|---|
| 康达 | Conda 是许多语言的包、依赖和环境管理器,包括 Python。它来自 Anaconda ,最初是 Python 的一个数据科学包。因此,它被广泛用于数据科学和机器学习应用。Conda 运行自己的索引来托管兼容的包。 |
| 诗歌 | 如果你来自 JavaScript 和 npm ,那么诗歌对你来说会非常熟悉。poem 超越了包管理,帮助您为您的应用程序和库构建发行版,并将它们部署到 PyPI。 |
| Pipenv | Pipenv 是另一个软件包管理工具,它将虚拟环境和包管理合并在一个工具中。 Pipenv:新 Python 打包工具指南是开始学习 Pipenv 及其包管理方法的好地方。 |
只有pip捆绑在标准 Python 安装中。如果您想使用上面列出的任何替代方法,那么您必须遵循文档中的安装指南。有了这么多的选项,您一定会找到适合您编程之旅的工具!
结论
许多 Python 项目使用pip包管理器来管理它们的依赖关系。它包含在 Python 安装程序中,是 Python 中依赖性管理的基本工具。
在本教程中,您学习了如何:
- 在您的工作环境中设置并运行
pip - 修复与使用
pip相关的常见错误 - 用
pip安装和卸载软件包 - 为您的项目和应用定义需求
- 需求文件中的引脚依赖关系
此外,您还了解了保持依赖关系最新的重要性,以及可以帮助您管理这些依赖关系的pip的替代方案。
通过仔细查看pip,您已经探索了 Python 开发工作流中的一个基本工具。使用pip,你可以安装和管理你在 PyPI 上找到的任何额外的包。您可以使用其他开发人员的外部包作为需求,并专注于使您的项目独一无二的代码。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Pip 入门*********************************************************************************
为什么在 Python 中关闭文件很重要?
在 Python 编码之旅的某个时候,您了解到应该使用上下文管理器来打开文件。Python 上下文管理器可以让你轻松地关闭你的文件:
with open("hello.txt", mode="w") as file:
file.write("Hello, World!")
with语句启动上下文管理器。在这个例子中,只要上下文是活动的,上下文管理器就打开文件hello.txt,并且管理文件资源。通常,缩进块中的所有代码都依赖于打开的文件对象。一旦缩进块结束或引发异常,文件就会关闭。
如果您没有使用上下文管理器或者您正在使用不同的语言,那么您可以使用 try … finally方法显式关闭文件:
try:
file = open("hello.txt", mode="w")
file.write("Hello, World!")
finally:
file.close()
关闭文件的finally块无条件运行,不管try块成功还是失败。虽然这种语法有效地关闭了文件,但是 Python 上下文管理器提供了更简洁、更直观的语法。此外,它比简单地用try … finally包装你的代码更加灵活。
您可能已经使用了上下文管理器来管理文件,但是您有没有想过为什么大多数教程和五分之四的牙医建议这样做?总之,为什么在 Python 中关闭文件很重要?
在本教程中,您将深入探讨这个问题。首先,您将了解文件句柄是如何成为有限资源的。然后你将体验不关闭文件的后果。
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
简而言之:文件是受操作系统限制的资源
Python 将文件操作委托给 操作系统 。操作系统是 进程 之间的中介,比如 Python,以及所有的系统资源,比如硬盘、RAM、CPU 时间。
当你用open()打开一个文件时,你向操作系统发出一个 系统调用 来定位硬盘上的那个文件,并准备读或写。然后,操作系统将返回一个无符号整数,在 Windows 上称为文件句柄,在类似 UNIX 的系统上称为文件描述符,包括 Linux 和 macOS:
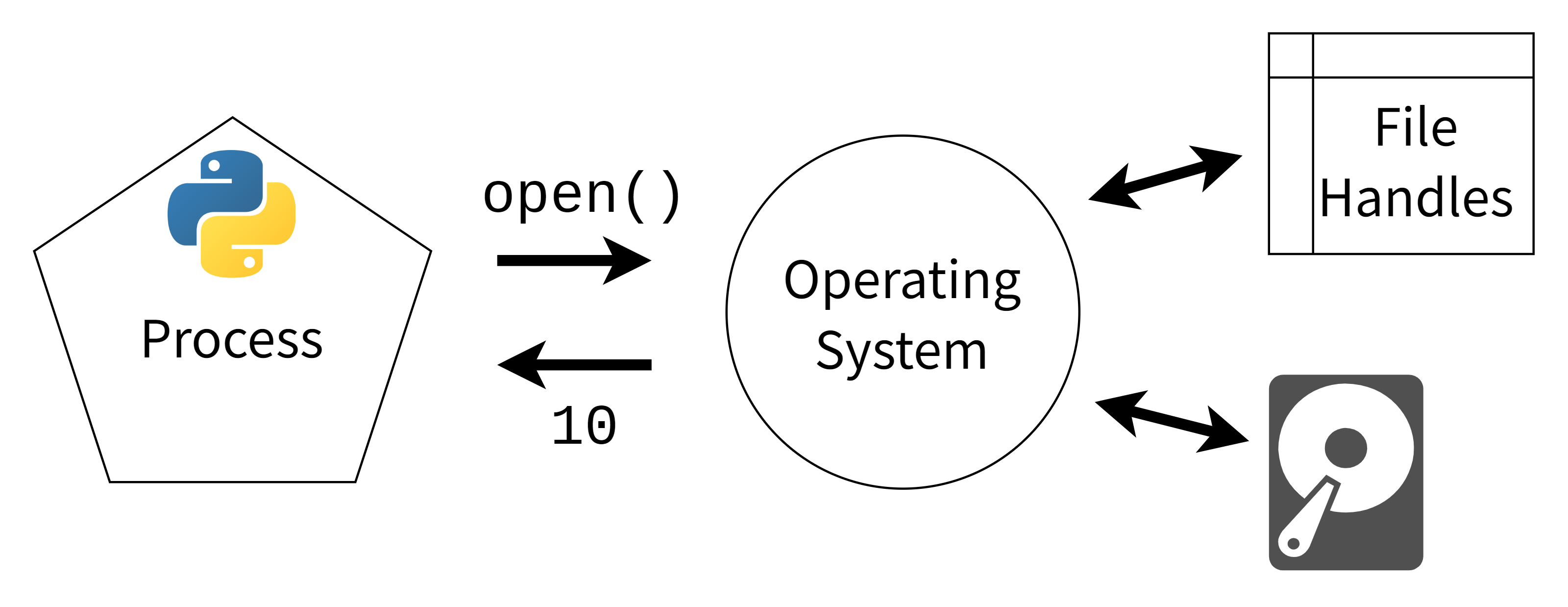
一旦你有了与文件相关的编号,你就准备好进行读或写操作。每当 Python 想读、写或关闭文件时,它会发出另一个系统调用,提供文件句柄号。Python 文件对象有一个.fileno()方法,您可以使用它来查找文件句柄:
>>> with open("test_file.txt", mode="w") as file: ... file.fileno() ... 4打开的文件对象上的
.fileno()方法将返回操作系统使用的整数作为文件描述符。就像使用 ID 字段从数据库中获取记录一样,Python 会在每次操作系统读取或写入文件时向操作系统提供这个数字。操作系统限制任何单个进程可以打开的文件数量。这个数字通常以千计。操作系统设置这个限制是因为如果一个进程试图打开数千个文件描述符,那么这个进程可能有问题。尽管数千个文件看起来很多,但仍有可能达到极限。
除了运行到极限的风险之外,保持文件打开会使你容易丢失数据。总的来说,Python 和操作系统努力保护你不丢失数据。但是如果你的程序或者电脑崩溃了,通常的程序可能无法运行,打开的文件可能会被破坏。
注意:有些库有特定的方法和函数,似乎不用上下文管理器就能打开文件。比如 pathlib 库有
.write_text(),pandas 有read_csv()。但是,它们确实在幕后正确地管理资源,所以在这些情况下,您不需要使用上下文管理器。最好参考您正在使用的库的文档,看看您是否需要上下文管理器。
简而言之,让上下文管理器管理您的文件是一种防御技术,易于实践,并能使您的代码更好——所以您不妨这样做。就像系安全带一样。你可能不需要它,但是没有它的代价会很高。
在本教程的其余部分,您将更深入地了解不关闭文件的限制、后果和危险。在下一节中,您将探索
Too many open files错误。打开太多文件会怎么样?
在本节中,您将探索当您遇到文件限制时会发生什么。您将通过尝试一个代码片段来实现这一点,该代码片段将创建一个打开文件的负载并引发一个
OSError。注意:正如
OSError中的OS所暗示的,这个限制是由操作系统而不是 Python 强制执行的。然而,理论上,操作系统可以处理更多的文件描述符。稍后,你会学到更多关于为什么操作系统限制文件句柄。您可以通过尝试一次打开数千个文件来测试操作系统上每个进程的文件限制。您将把文件对象存储在一个列表中,这样它们就不会被自动清除。但是首先,您需要做一些整理工作,以确保不会在不需要的地方创建大量文件:
$ mkdir file_experiment $ cd file_experiment创建一个可以转储文件的文件夹,然后导航到该文件夹就足够了。然后,您可以打开一个 Python REPL,尝试创建数千个文件:
>>> files = [open(f"file-{n}.txt", mode="w") for n in range(10_000)]
Traceback (most recent call last):
...
OSError: [Errno 24] Too many open files: 'file-1021.txt'
这个代码片段试图打开一万个文件,并将它们保存在一个列表中。操作系统开始创建文件,但一旦达到极限,就会往回推。如果您在新创建的目录中列出文件,您会注意到,即使列表理解最终失败,操作系统也创建了许多文件——只是不是您要求的一万个文件。
您遇到的限制因操作系统而异,在 Windows 中默认情况下似乎更大。根据操作系统的不同,有一些方法可以提高每个进程的文件数限制。但是,你应该问问自己是否真的需要。选择这种解决方案只有几个合理的用例。
一个合理的场景是服务器。服务器与套接字一起工作,它们被视为很像文件。操作系统使用文件句柄跟踪文件表中的套接字。服务器可能需要为它们所连接的每个客户机打开许多套接字。另外,一台服务器可能会与几台客户机通信。这种情况会导致需要数千个文件句柄。
有趣的是,尽管某些应用程序可能会要求提高操作系统对打开文件的限制,但通常正是这些应用程序需要特别注意关闭文件!
也许你认为你不会马上面临极限。尽管如此,请继续读下去,因为在下一节中,您将更仔细地了解意外达到该限制的一些后果。
遇到文件限制的现实后果是什么?
如果您在 Python 中打开文件而从不关闭它们,您可能不会注意到任何区别,尤其是如果您正在处理一个文件脚本或小项目。然而,随着你从事的项目变得越来越复杂,你会越来越多地暴露在有问题的情况下。
想象一下,你在一个大型团队中处理一个巨大的代码库。然后,有一天你达到了打开文件的极限。有趣的是,限制的错误信息不会告诉你问题在哪里。它将是你之前看到的通用 OSError ,它只告诉你Too many open files。
你的代码库中可能有成千上万个打开文件的地方。想象一下寻找代码不能正确处理文件的地方。想象一下,代码在函数之间传递文件对象,您不能立即判断任何给定的文件对象最终是否关闭。那可不是好玩的时候。
如果您感兴趣,有一些方法可以探索您系统的打开文件句柄。展开以下模块进行探索:
- 视窗
** Linux + macOS
**安装进程黑客:
PS> choco install processhacker
打开应用程序并点击查找句柄或 dll按钮。勾选 regex 复选框,键入.*查看所有文件句柄及附带信息。
微软官方版本的 process hacker 是 Sysinternals 工具的一部分,即进程监视器和进程浏览器。
您可能需要安装 lsof ,这是一个 Linux 实用程序,用于lIstopenffiles。使用此实用程序,您可以获得信息并计算有多少个打开的文件:
$ lsof | head
$ lsof | wc -l
lsof命令为每个打开的文件打印一个新行,其中包含该文件的基本信息。通过管道将其输入到head命令中,将会显示输出的开始,包括列名。
lsof的输出可以通过管道进入wc或字数统计命令。-l开关意味着它只会计算换行符。这个数字很可能是几十万。
您可以将lsof的输出通过管道传输到grep中,以查找包含类似于python的字符串的行。您还可以传入一个进程 ID,如果您想寻找文件描述符,这可能会很有帮助:
$ lsof | grep python
该命令将过滤掉所有不包含grep之后的术语的行,在本例中为python。
如果您对系统上文件的理论限制感到好奇,可以通过研究一个特殊文件的内容,在基于 UNIX 的系统上探索这个问题:
$ cat /proc/sys/fs/file-max
这个数字非常依赖于平台,但它可能是巨大的。系统几乎肯定会在达到这个限制之前耗尽其他资源。*** *不过,你可能想知道为什么操作系统会限制文件。据推测,它可以处理比它允许的更多的文件句柄,对吗?在下一节中,您将发现操作系统为什么关心这个问题。
为什么操作系统会限制文件句柄?
一个操作系统可以同时打开的文件数量的实际限制是巨大的。你说的是数百万份文件。但实际上达到这个极限并给它设定一个固定的数字并不明确。通常,系统会在用完文件句柄之前用完其他资源。
从操作系统的角度来看,这个限制是保守的,但从大多数程序的角度来看,这个限制已经足够了。从操作系统的角度来看,任何达到限制的进程都可能会泄漏文件句柄和其他资源。
资源泄漏可能是由于编程不当或恶意程序试图攻击系统造成的。这就是操作系统设置限制的原因——保护你免受他人和你自己的伤害!
另外,对于大多数应用程序来说,打开这么多文件是没有意义的。一个硬盘上最多只能同时发生一个读写操作,所以如果你只是处理文件,它不会让事情变得更快。
好了,你知道打开很多文件是有问题的,但是在 Python 中不关闭文件还有其他的缺点,即使你只打开了一小部分。
如果不关闭文件,Python 崩溃了会怎么样?
在本节中,您将进行模拟崩溃的实验,并了解它如何影响打开的文件。您可以在os模块中使用一个特殊的函数,它将在不执行 Python 通常执行的任何清理的情况下退出,但是首先,您将看到事情通常是如何被清理的。
对每个命令执行写操作可能是昂贵的。出于这个原因,Python 默认使用一个收集写操作的缓冲区。当缓冲区变满时,或者当文件被显式关闭时,缓冲区被刷新,写操作完成。
Python 努力清理自身。在大多数情况下,它会主动刷新和关闭文件:
# write_hello.py
file = open("hello.txt", mode="w")
file.write("Hello, world!")
运行这段代码时,操作系统会创建文件。即使您从未在代码中实际刷新或关闭文件,操作系统也会写入内容。这种刷新和关闭由 Python 将在执行结束时执行的清理例程负责。
不过,有时候出口并没有受到如此严格的控制,崩溃最终可能会绕过这种清理:
# crash_hello.py
import os
file = open("crash.txt", mode="w")
file.write("Hello, world!")
os._exit(1)
运行上面的代码片段后,您可以使用cat来检查您刚刚创建的文件的内容:
$ cat crash.txt
$ # No output!
您将会看到,尽管操作系统已经创建了该文件,但它没有任何内容。输出不足是因为 os._exit() 绕过了通常的 Python 退出例程,模拟了一次崩溃。也就是说,即使这种类型的模拟也是相对可控的,因为它假设 Python 而不是您的操作系统崩溃了。
在幕后,一旦 Python 完成,操作系统也将执行自己的清理,关闭进程打开的所有文件描述符。崩溃可能发生在许多级别,并干扰操作系统的清理,使文件句柄悬空。
例如,在 Windows 上,悬挂文件句柄可能会有问题,因为任何打开文件的进程都会锁定它。在该文件关闭之前,另一个进程无法打开它。Windows 用户可能很熟悉不让你打开或删除文件的流氓程序。
什么可能比被锁定在文件之外更糟糕?泄漏的文件句柄会带来安全风险,因为与文件相关的权限有时会混淆。
注意:Python 最常见的实现 CPython ,在清理悬空文件句柄方面比你想象的更进一步。它使用引用计数进行垃圾收集,这样文件一旦不再被引用就会被关闭。也就是说,其他实现,如 PyPy ,使用不同的策略,在清理未使用的文件句柄时可能不那么激进。
事实上,有些实现可能不会像 CPython 那样有效地清理,这是始终使用上下文管理器的另一个理由!
文件句柄泄漏和内容在缓冲区中丢失已经够糟了,但是中断文件操作的崩溃也会导致文件损坏。这大大增加了数据丢失的可能性。同样,这些都是不太可能的情况,但它们可能代价高昂。
您永远无法完全避免崩溃,但是您可以通过使用上下文管理器来减少风险。上下文管理器的语法自然会引导您以这样一种方式编码,即只在需要的时候才打开文件。
结论
你已经学习了为什么在 Python 中关闭文件很重要。因为文件是由操作系统管理的有限资源,所以确保文件在使用后关闭将防止难以调试的问题,如用完文件句柄或遇到损坏的数据。最好的防御是始终用上下文管理器打开文件。
深入了解一下,您已经看到了当您打开太多文件时会发生什么,并且您已经引起了导致文件内容丢失的崩溃。要了解更多关于打开文件的信息,请参见用 Python 读取和写入文件。要深入了解上下文管理器,请查看上下文管理器和 Python 的with语句。
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。*****
和姜戈还有弗拉斯克一起研究氮气。超正析象管(Image Orthicon)
原文:https://realpython.com/working-with-django-and-flask-on-nitrous-io/
这是我们来自 Nitrous 的朋友 Greg McKeever 的客座博文。IO 。
氮气。IO 是一个平台,允许您在云中快速启动自己的开发环境。这里有几个在氮气上编码的主要优点。IO :
-
为开发而设置 Windows 或 Mac OS 节省无数小时(或数天)的时间。您的 Nitrous box 预装了许多工具和解释器,因此您可以立即开始编码。
-
您的代码可以从任何计算机或移动设备上访问。通过 Web IDE、SSH 或本地同步编辑代码,并使用您最喜欢的文本编辑器。
-
协作:Nitrous 提供了一种与其他用户共享开发环境的方式。如果您在项目中遇到任何问题,需要帮助,您可以邀请一位朋友到您的 Nitrous box 来编辑和运行您的代码。
开始使用
要开始,请在 Nitrous 注册。IO 。一旦你的账户被确认,导航到框页面并创建一个新的 Python/Django 框。

Nitrous box 中包含了许多工具和解释器,在撰写本文时,您的开发环境中将包含 Python 2.7.3 和 Django 1.5.1。如果这是你想要开始工作的,那么一切都准备好了!
如果您想使用不同版本的 Python、Django,或者利用另一个框架,比如 Flask,请继续阅读。
用 Virtualenv 设置 Python 2.7
Virtualenv 允许您创建一个隔离的环境,以便安装特定版本的 Python、Django,还可以安装其他框架,如 Flask,而不需要 root 访问权限。由于氮盒不提供根在这个时候,这是最好的路线。
要查看可用的 Python 版本,请在控制台中运行ls /usr/bin/python*。通过运行以下命令,使用 Python 2.7 创建一个新环境:
$ virtualenv -p /usr/bin/python2.7 py27env
您现在想要连接到此环境:
$ source py27env/bin/activate
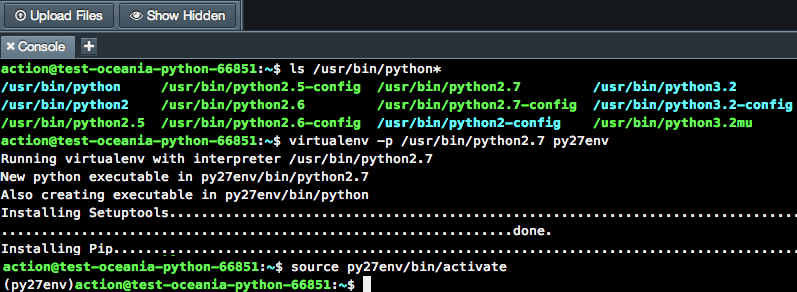
如果您决定在任何时候从这个环境断开连接,请在控制台中键入
deactivate。
因为您是在一个隔离的环境中,所以您需要安装 Django 和任何其他在您的环境之外可用的依赖项。可以用pip freeze查看安装了哪些模块。
安装 Django
要安装 Django 的最新官方版本,您需要使用 pip:
$ pip install Django
安装砂箱
安装 Flask 就像用 pip 安装 Django 一样简单。运行以下命令安装最新的官方版本:
$ pip install Flask
就是这样!您可以通过运行命令pip freeze来验证安装,并在列表中找到 Flask。你现在已经准备好在 RealPython 开始你的课程了。
需要记住的一点是,你总是可以通过在控制台中运行deactivate来断开与 Virtualenv 的连接。如果您将 Virtualenv 会话命名为‘py 27 env ’,那么您总是可以通过运行source py27env/bin/activate来重新连接。*
在 Python 中使用文件
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 处理文件的实用菜谱
Python 有几个处理文件的内置模块和函数。这些功能分布在几个模块上,例如os、os.path、shutil和pathlib等等。本文集中了在 Python 中对文件执行最常见操作所需的许多函数。
在本教程中,您将学习如何:
- 检索文件属性
- 创建目录
- 匹配文件名中的模式
- 遍历目录树
- 创建临时文件和目录
- 删除文件和目录
- 复制、移动或重命名文件和目录
- 创建和提取 ZIP 和 TAR 归档文件
- 使用
fileinput模块打开多个文件
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 的“with open(…) as …”模式
使用 Python 读写数据非常简单。为此,您必须首先以适当的模式打开文件。下面是如何使用 Python 的“with open(…) as …”模式打开文本文件并读取其内容的示例:
with open('data.txt', 'r') as f:
data = f.read()
open()以文件名和模式作为参数。r以只读模式打开文件。要将数据写入文件,请将w作为参数传入:
with open('data.txt', 'w') as f:
data = 'some data to be written to the file'
f.write(data)
在上面的例子中,open()打开文件进行读取或写入,并返回一个文件句柄(在本例中为f),它提供了可用于读取或写入文件数据的方法。查看在 Python 中读写文件和在 Python 中使用文件 I/O,了解更多关于如何读写文件的信息。
获取目录列表
假设您当前的工作目录有一个名为my_directory的子目录,该子目录包含以下内容:
my_directory/
|
├── sub_dir/
| ├── bar.py
| └── foo.py
|
├── sub_dir_b/
| └── file4.txt
|
├── sub_dir_c/
| ├── config.py
| └── file5.txt
|
├── file1.py
├── file2.csv
└── file3.txt
内置的os模块有许多有用的功能,可以用来列出目录内容和过滤结果。要获得文件系统中特定目录下所有文件和文件夹的列表,在 Python 的旧版本中使用os.listdir()或在 Python 3.x 中使用os.scandir()。如果您还想获得文件和目录属性,如文件大小和修改日期,最好使用os.scandir()方法。
传统 Python 版本中的目录列表
在 Python 3 之前的 Python 版本中,os.listdir()是用于获取目录列表的方法:
>>> import os >>> entries = os.listdir('my_directory/')
os.listdir()返回一个 Python 列表,其中包含由 path 参数给出的目录中的文件和子目录的名称:
>>> os.listdir('my_directory/')
['sub_dir_c', 'file1.py', 'sub_dir_b', 'file3.txt', 'file2.csv', 'sub_dir']
像那样的目录列表不容易阅读。使用循环打印出对os.listdir()的调用输出有助于清理:
>>> entries = os.listdir('my_directory/') >>> for entry in entries: ... print(entry) ... ... sub_dir_c file1.py sub_dir_b file3.txt file2.csv sub_dir现代 Python 版本中的目录列表
在现代版本的 Python 中,
os.listdir()的一个替代方法是使用os.scandir()和pathlib.Path()。
os.scandir()是在 Python 3.5 中引入的,在 PEP 471 中有记载。os.scandir()调用时返回迭代器,而不是列表:
>>> import os
>>> entries = os.scandir('my_directory/')
>>> entries
<posix.ScandirIterator object at 0x7f5b047f3690>
ScandirIterator指向当前目录中的所有条目。您可以循环遍历迭代器的内容并打印出文件名:
import os
with os.scandir('my_directory/') as entries:
for entry in entries:
print(entry.name)
这里,os.scandir()与with语句一起使用,因为它支持上下文管理器协议。使用上下文管理器关闭迭代器,并在迭代器用尽后自动释放获取的资源。结果是打印出my_directory/中的文件名,就像您在os.listdir()示例中看到的一样:
sub_dir_c
file1.py
sub_dir_b
file3.txt
file2.csv
sub_dir
获取目录列表的另一种方法是使用pathlib模块:
from pathlib import Path
entries = Path('my_directory/')
for entry in entries.iterdir():
print(entry.name)
根据操作系统的不同,Path返回的对象或者是PosixPath或者是WindowsPath对象。
pathlib.Path()对象有一个.iterdir()方法,用于创建一个目录中所有文件和文件夹的迭代器。由.iterdir()生成的每个条目包含关于文件或目录的信息,比如它的名称和文件属性。pathlib最初是在 Python 3.4 中引入的,是对 Python 的一个很好的补充,为文件系统提供了一个面向对象的接口。
在上面的例子中,您调用pathlib.Path()并传递一个路径参数给它。接下来是对.iterdir()的调用,以获取my_directory中所有文件和目录的列表。
以一种简单的、面向对象的方式,提供了一组以路径上大多数常见操作为特色的类。使用pathlib比使用os中的函数更有效。使用pathlib而不是os的另一个好处是,它减少了操作文件系统路径所需的导入次数。更多信息,请阅读 Python 3 的 pathlib 模块:驯服文件系统。
运行上面的代码会产生以下结果:
sub_dir_c
file1.py
sub_dir_b
file3.txt
file2.csv
sub_dir
使用pathlib.Path()或os.scandir()而不是os.listdir()是获取目录列表的首选方式,尤其是当您处理需要文件类型和文件属性信息的代码时。pathlib.Path()提供了很多在os和shutil中找到的文件和路径处理功能,它的方法比这些模块中的一些更有效。我们将很快讨论如何获取文件属性。
下面是目录列表函数:
| 功能 | 描述 |
|---|---|
os.listdir() |
返回目录中所有文件和文件夹的列表 |
os.scandir() |
返回目录中所有对象的迭代器,包括文件属性信息 |
pathlib.Path.iterdir() |
返回目录中所有对象的迭代器,包括文件属性信息 |
这些函数返回目录中所有内容的列表,包括子目录。这可能并不总是你想要的行为。下一节将向您展示如何从目录列表中过滤结果。
列出目录中的所有文件
本节将向您展示如何使用os.listdir()、os.scandir()和pathlib.Path()打印出目录中的文件名。要从os.listdir()生成的目录列表中过滤出目录并仅列出文件,请使用os.path:
import os
# List all files in a directory using os.listdir
basepath = 'my_directory/'
for entry in os.listdir(basepath):
if os.path.isfile(os.path.join(basepath, entry)):
print(entry)
这里,对os.listdir()的调用返回指定路径中所有内容的列表,然后这个列表被os.path.isfile()过滤,只打印出文件而不是目录。这会产生以下输出:
file1.py
file3.txt
file2.csv
列出目录中的文件的一种更简单的方法是使用os.scandir()或pathlib.Path():
import os
# List all files in a directory using scandir()
basepath = 'my_directory/'
with os.scandir(basepath) as entries:
for entry in entries:
if entry.is_file():
print(entry.name)
使用os.scandir()比使用os.listdir()有看起来更干净、更容易理解的优点,尽管它比使用os.listdir()多了一行代码。如果对象是文件,对ScandirIterator中的每一项调用entry.is_file()将返回True。打印出目录中所有文件的名称会得到以下输出:
file1.py
file3.txt
file2.csv
下面是如何使用pathlib.Path()列出目录中的文件:
from pathlib import Path
basepath = Path('my_directory/')
files_in_basepath = basepath.iterdir()
for item in files_in_basepath:
if item.is_file():
print(item.name)
在这里,您对由.iterdir()产生的每个条目调用.is_file()。产生的输出是相同的:
file1.py
file3.txt
file2.csv
如果将 for循环和 if语句组合成一个生成器表达式,上面的代码会更简洁。Dan Bader 有一篇关于生成器表达式和列表理解的优秀文章。
修改后的版本如下所示:
from pathlib import Path
# List all files in directory using pathlib
basepath = Path('my_directory/')
files_in_basepath = (entry for entry in basepath.iterdir() if entry.is_file())
for item in files_in_basepath:
print(item.name)
这与之前的示例产生了完全相同的输出。本节展示了使用os.scandir()和pathlib.Path()过滤文件或目录比结合使用os.listdir()和os.path感觉更直观,看起来更干净。
列出子目录
要列出子目录而不是文件,请使用下面的方法之一。下面是如何使用os.listdir()和os.path():
import os
# List all subdirectories using os.listdir
basepath = 'my_directory/'
for entry in os.listdir(basepath):
if os.path.isdir(os.path.join(basepath, entry)):
print(entry)
当您多次调用os.path.join()时,以这种方式操作文件系统路径会变得很麻烦。在我的计算机上运行该程序会产生以下输出:
sub_dir_c
sub_dir_b
sub_dir
下面是如何使用os.scandir():
import os
# List all subdirectories using scandir()
basepath = 'my_directory/'
with os.scandir(basepath) as entries:
for entry in entries:
if entry.is_dir():
print(entry.name)
与文件列表示例一样,这里您对由os.scandir()返回的每个条目调用.is_dir()。如果条目是一个目录,.is_dir()返回True,并打印出目录名。输出与上面相同:
sub_dir_c
sub_dir_b
sub_dir
下面是如何使用pathlib.Path():
from pathlib import Path
# List all subdirectory using pathlib
basepath = Path('my_directory/')
for entry in basepath.iterdir():
if entry.is_dir():
print(entry.name)
在basepath迭代器的每个条目上调用.is_dir(),检查条目是文件还是目录。如果条目是一个目录,它的名称将打印到屏幕上,并且产生的输出与上一个示例中的输出相同:
sub_dir_c
sub_dir_b
sub_dir
获取文件属性
Python 使得检索文件属性(如文件大小和修改时间)变得很容易。这是通过os.stat()、os.scandir()或pathlib.Path()完成的。
os.scandir()和pathlib.Path()检索结合了文件属性的目录列表。这可能比使用os.listdir()列出文件,然后获取每个文件的文件属性信息更有效。
下面的例子显示了如何获取my_directory/中的文件最后被修改的时间。输出以秒为单位:
>>> import os >>> with os.scandir('my_directory/') as dir_contents: ... for entry in dir_contents: ... info = entry.stat() ... print(info.st_mtime) ... 1539032199.0052035 1539032469.6324475 1538998552.2402923 1540233322.4009316 1537192240.0497339 1540266380.3434134
os.scandir()返回一个ScandirIterator对象。一个ScandirIterator对象中的每一个条目都有一个.stat()方法来检索关于它所指向的文件或目录的信息。.stat()提供文件大小和上次修改时间等信息。在上面的例子中,代码打印出了st_mtime属性,这是文件内容最后一次被修改的时间。
pathlib模块有相应的方法来检索文件信息,得到相同的结果:
>>> from pathlib import Path
>>> current_dir = Path('my_directory')
>>> for path in current_dir.iterdir():
... info = path.stat()
... print(info.st_mtime)
...
1539032199.0052035
1539032469.6324475
1538998552.2402923
1540233322.4009316
1537192240.0497339
1540266380.3434134
在上面的例子中,代码遍历由.iterdir()返回的对象,并通过对目录列表中每个文件的.stat()调用来检索文件属性。st_mtime属性返回一个浮点值,表示从纪元开始的秒。为了显示的目的,要转换由st_mtime返回的值,您可以编写一个助手函数来将秒转换成一个datetime对象:
from datetime import datetime
from os import scandir
def convert_date(timestamp):
d = datetime.utcfromtimestamp(timestamp)
formated_date = d.strftime('%d %b %Y')
return formated_date
def get_files():
dir_entries = scandir('my_directory/')
for entry in dir_entries:
if entry.is_file():
info = entry.stat()
print(f'{entry.name}\t Last Modified: {convert_date(info.st_mtime)}')
这将首先获得my_directory中文件及其属性的列表,然后调用convert_date()将每个文件的最后修改时间转换成人类可读的形式。convert_date()使用.strftime()将秒的时间转换成字符串。
传递给.strftime()的参数如下:
%d: 一月中的某一天%b: 月份,缩写形式%Y: 年份
这些指令一起产生如下所示的输出:
>>> get_files() file1.py Last modified: 04 Oct 2018 file3.txt Last modified: 17 Sep 2018 file2.txt Last modified: 17 Sep 2018将日期和时间转换成字符串的语法可能会很混乱。要了解更多信息,请查看上面的官方文档。另一个容易记住的方便参考是 http://strftime.org/的 T2。
制作目录
迟早,你写的程序将不得不创建目录来存储数据。
os和pathlib包括创建目录的功能。我们会考虑这些:
功能 描述 os.mkdir()创建一个子目录 pathlib.Path.mkdir()创建单个或多个目录 os.makedirs()创建多个目录,包括中间目录 创建单个目录
要创建单个目录,请将该目录的路径作为参数传递给
os.mkdir():import os os.mkdir('example_directory/')如果一个目录已经存在,
os.mkdir()引发FileExistsError。或者,您可以使用pathlib创建一个目录:from pathlib import Path p = Path('example_directory/') p.mkdir()如果路径已经存在,
mkdir()会引发一个FileExistsError:
>>> p.mkdir()
Traceback (most recent call last):
File '<stdin>', line 1, in <module>
File '/usr/lib/python3.5/pathlib.py', line 1214, in mkdir
self._accessor.mkdir(self, mode)
File '/usr/lib/python3.5/pathlib.py', line 371, in wrapped
return strfunc(str(pathobj), *args)
FileExistsError: [Errno 17] File exists: '.'
[Errno 17] File exists: '.'
为了避免这样的错误,在错误发生时捕获错误,并让您的用户知道:
from pathlib import Path
p = Path('example_directory')
try:
p.mkdir()
except FileExistsError as exc:
print(exc)
或者,您可以通过将exist_ok=True参数传递给.mkdir()来忽略FileExistsError:
from pathlib import Path
p = Path('example_directory')
p.mkdir(exist_ok=True)
如果目录已经存在,这不会引发错误。
创建多个目录
os.makedirs()类似于os.mkdir()。两者的区别在于,os.makedirs()不仅可以创建单独的目录,还可以用来创建目录树。换句话说,它可以创建任何必要的中间文件夹,以确保完整路径的存在。
os.makedirs()类似于在 Bash 中运行mkdir -p。例如,要创建一组类似于2018/10/05的目录,您所要做的就是以下这些:
import os
os.makedirs('2018/10/05')
这将创建一个包含文件夹 2018、10 和 05 的嵌套目录结构:
.
|
└── 2018/
└── 10/
└── 05/
.makedirs()用默认权限创建目录。如果您需要创建具有不同权限的目录,请调用.makedirs()并传递您希望创建目录的模式:
import os
os.makedirs('2018/10/05', mode=0o770)
这将创建2018/10/05目录结构,并授予所有者和组用户读、写和执行权限。默认模式为0o777,现有父目录的文件权限位不变。关于文件权限以及如何应用模式的更多细节,参见文档。
运行tree以确认应用了正确的权限:
$ tree -p -i .
.
[drwxrwx---] 2018
[drwxrwx---] 10
[drwxrwx---] 05
这将打印出当前目录的目录树。tree通常用于以树状格式列出目录的内容。向它传递-p和-i参数会在一个垂直列表中打印出目录名及其文件权限信息。-p打印出文件权限,-i让tree产生一个没有缩进线的垂直列表。
如您所见,所有目录都有770权限。创建目录的另一种方法是使用来自pathlib.Path的.mkdir():
import pathlib
p = pathlib.Path('2018/10/05')
p.mkdir(parents=True)
将parents=True传递给Path.mkdir()会让它创建目录05和任何使路径有效所需的父目录。
默认情况下,如果目标目录已经存在,os.makedirs()和Path.mkdir()会引发一个OSError。在调用每个函数时,通过将exist_ok=True作为关键字参数传递,可以覆盖这种行为(从 Python 3.2 开始)。
运行上面的代码会一次性生成如下所示的目录结构:
.
|
└── 2018/
└── 10/
└── 05/
我更喜欢在创建目录时使用pathlib,因为我可以使用相同的函数来创建单个或嵌套的目录。
文件名模式匹配
使用上述方法之一获得目录中的文件列表后,您很可能想要搜索与特定模式匹配的文件。
以下是您可以使用的方法和功能:
endswith()和startswith()字符串方法fnmatch.fnmatch()glob.glob()pathlib.Path.glob()
下面将逐一讨论。本节中的示例将在名为some_directory的目录上执行,该目录具有以下结构:
.
|
├── sub_dir/
| ├── file1.py
| └── file2.py
|
├── admin.py
├── data_01_backup.txt
├── data_01.txt
├── data_02_backup.txt
├── data_02.txt
├── data_03_backup.txt
├── data_03.txt
└── tests.py
如果您正在使用 Bash shell,您可以使用以下命令创建上面的目录结构:
$ mkdir some_directory
$ cd some_directory/
$ mkdir sub_dir
$ touch sub_dir/file1.py sub_dir/file2.py
$ touch data_{01..03}.txt data_{01..03}_backup.txt admin.py tests.py
这将创建some_directory/目录,进入该目录,然后创建sub_dir。下一行在sub_dir中创建file1.py和file2.py,最后一行使用扩展创建所有其他文件。要了解关于 shell 扩展的更多信息,请访问这个站点。
使用字符串方法
Python 有几个用于修改和操作字符串的内置方法。当您在文件名中搜索模式时,.startswith()和.endswith()这两种方法非常有用。为此,首先获取一个目录列表,然后遍历它:
>>> import os >>> # Get .txt files >>> for f_name in os.listdir('some_directory'): ... if f_name.endswith('.txt'): ... print(f_name)上面的代码找到了
some_directory/中的所有文件,遍历它们并使用.endswith()打印出扩展名为.txt的文件名。在我的计算机上运行该程序会产生以下输出:data_01.txt data_03.txt data_03_backup.txt data_02_backup.txt data_02.txt data_01_backup.txt使用
fnmatch进行简单的文件名模式匹配字符串方法的匹配能力有限。
fnmatch具有更高级的模式匹配功能和方法。我们将考虑fnmatch.fnmatch(),一个支持使用通配符如*和?来匹配文件名的函数。例如,为了使用fnmatch找到一个目录中的所有.txt文件,您可以执行以下操作:
>>> import os
>>> import fnmatch
>>> for file_name in os.listdir('some_directory/'):
... if fnmatch.fnmatch(file_name, '*.txt'):
... print(file_name)
这将遍历some_directory中的文件列表,并使用.fnmatch()对扩展名为.txt的文件执行通配符搜索。
更高级的模式匹配
让我们假设您想要找到符合特定标准的.txt文件。例如,您可能只对查找文件名中包含单词data、一组下划线之间的数字和单词backup的.txt文件感兴趣。类似于data_01_backup、data_02_backup或者data_03_backup的东西。
使用fnmatch.fnmatch(),你可以这样做:
>>> for filename in os.listdir('.'): ... if fnmatch.fnmatch(filename, 'data_*_backup.txt'): ... print(filename)这里,您只打印与
data_*_backup.txt模式匹配的文件名。模式中的星号将匹配任何字符,因此运行该命令将找到文件名以单词data开头并以backup.txt结尾的所有文本文件,正如您从下面的输出中看到的:data_03_backup.txt data_02_backup.txt data_01_backup.txt文件名模式匹配使用
glob模式匹配的另一个有用模块是
glob。
glob模块中的.glob()就像fnmatch.fnmatch()一样工作,但与fnmatch.fnmatch()不同,它把以句点(.)开头的文件视为特殊文件。UNIX 和相关系统将带有通配符
?和*的名称模式转换成文件列表。这叫做 globbing。例如,在 UNIX shell 中键入
mv *.py python_files/会将扩展名为.py的所有文件从当前目录移动(mv)到目录python_files。*字符是一个通配符,表示“任意数量的字符”,而*.py是 glob 模式。此外壳功能在 Windows 操作系统中不可用。glob模块在 Python 中增加了这个功能,使得 Windows 程序能够使用这个特性。下面是一个如何使用
glob在当前目录中搜索所有 Python (.py)源文件的例子:
>>> import glob
>>> glob.glob('*.py')
['admin.py', 'tests.py']
glob.glob('*.py')在当前目录中搜索所有扩展名为.py的文件,并将它们作为列表返回。glob还支持 shell 风格的通配符来匹配模式:
>>> import glob >>> for name in glob.glob('*[0-9]*.txt'): ... print(name)这将查找文件名中包含数字的所有文本(
.txt)文件:data_01.txt data_03.txt data_03_backup.txt data_02_backup.txt data_02.txt data_01_backup.txt
glob也使得在子目录中递归搜索文件变得容易:
>>> import glob
>>> for file in glob.iglob('**/*.py', recursive=True):
... print(file)
这个例子使用glob.iglob()在当前目录和子目录中搜索.py文件。将recursive=True作为参数传递给.iglob(),使其在当前目录和任何子目录中搜索.py文件。glob.iglob()和glob.glob()的区别在于.iglob()返回的是迭代器而不是列表。
运行上面的程序会产生以下结果:
admin.py
tests.py
sub_dir/file1.py
sub_dir/file2.py
pathlib包含制作灵活文件列表的类似方法。下面的例子展示了如何使用.Path.glob()来列出以字母p开头的文件类型:
>>> from pathlib import Path >>> p = Path('.') >>> for name in p.glob('*.p*'): ... print(name) admin.py scraper.py docs.pdf调用
p.glob('*.p*')返回一个生成器对象,该对象指向当前目录中所有文件扩展名以字母p开头的文件。
Path.glob()类似于上面讨论的os.glob()。正如你所看到的,pathlib将os、os.path和glob模块的许多最好的特性结合到一个单独的模块中,这使得它使用起来非常有趣。概括来说,下面是我们在本节中介绍的功能的表格:
功能 描述 startswith()测试字符串是否以指定的模式开始,并返回 True或Falseendswith()测试字符串是否以指定的模式结束,并返回 True或Falsefnmatch.fnmatch(filename, pattern)测试文件名是否与模式匹配,并返回 True或Falseglob.glob()返回与模式匹配的文件名列表 pathlib.Path.glob()查找路径名中的模式并返回一个生成器对象 遍历目录和处理文件
一个常见的编程任务是遍历目录树并处理树中的文件。让我们来探索如何使用内置的 Python 函数
os.walk()来实现这一点。os.walk()用于通过自顶向下或自底向上遍历目录树来生成目录树中的文件名。出于本节的目的,我们将操作以下目录树:. | ├── folder_1/ | ├── file1.py | ├── file2.py | └── file3.py | ├── folder_2/ | ├── file4.py | ├── file5.py | └── file6.py | ├── test1.txt └── test2.txt下面的例子展示了如何使用
os.walk()列出目录树中的所有文件和目录。
os.walk()默认以自顶向下的方式遍历目录:# Walking a directory tree and printing the names of the directories and files for dirpath, dirnames, files in os.walk('.'): print(f'Found directory: {dirpath}') for file_name in files: print(file_name)
os.walk()在循环的每次迭代中返回三个值:
当前文件夹的名称
当前文件夹中的文件夹列表
当前文件夹中的文件列表
在每次迭代中,它打印出找到的子目录和文件的名称:
Found directory: . test1.txt test2.txt Found directory: ./folder_1 file1.py file3.py file2.py Found directory: ./folder_2 file4.py file5.py file6.py要以自下而上的方式遍历目录树,请向
os.walk()传递一个topdown=False关键字参数:for dirpath, dirnames, files in os.walk('.', topdown=False): print(f'Found directory: {dirpath}') for file_name in files: print(file_name)传递
topdown=False参数将使os.walk()首先打印出它在子目录中找到的文件:Found directory: ./folder_1 file1.py file3.py file2.py Found directory: ./folder_2 file4.py file5.py file6.py Found directory: . test1.txt test2.txt如您所见,该程序首先列出子目录的内容,然后列出根目录的内容。这在您想要递归删除文件和目录的情况下非常有用。您将在下面几节中学习如何做到这一点。默认情况下,
os.walk不会进入解析到目录的符号链接。这个行为可以通过用一个followlinks=True参数调用它来覆盖。制作临时文件和目录
Python 为创建临时文件和目录提供了一个方便的模块
tempfile。
tempfile可用于在程序运行时打开数据并将其临时存储在文件或目录中。当你的程序处理完临时文件时,处理它们的删除。下面是创建临时文件的方法:
from tempfile import TemporaryFile # Create a temporary file and write some data to it fp = TemporaryFile('w+t') fp.write('Hello universe!') # Go back to the beginning and read data from file fp.seek(0) data = fp.read() # Close the file, after which it will be removed fp.close()第一步是从
tempfile模块导入TemporaryFile。接下来,使用TemporaryFile()方法创建一个类似文件的对象,方法是调用它并传递您想要打开文件的模式。这将创建并打开一个可用作临时存储区域的文件。在上面的例子中,模式是
'w+t',这使得tempfile以写模式创建一个临时文本文件。不需要给临时文件一个文件名,因为它会在脚本运行后被销毁。写入文件后,您可以读取它,并在完成处理后关闭它。一旦文件关闭,它将从文件系统中删除。如果您需要命名使用
tempfile生成的临时文件,请使用tempfile.NamedTemporaryFile()。使用
tempfile创建的临时文件和目录存储在用于存储临时文件的特殊系统目录中。Python 搜索一个标准的目录列表,以找到一个用户可以在其中创建文件的目录。在 Windows 上,这些目录依次为
C:\TEMP、C:\TMP、\TEMP和\TMP。在所有其他平台上,目录依次为/tmp、/var/tmp和/usr/tmp。作为最后的手段,tempfile会在当前目录下保存临时文件和目录。
.TemporaryFile()也是一个上下文管理器,所以它可以与with语句结合使用。使用上下文管理器可以在文件被读取后自动关闭和删除文件:with TemporaryFile('w+t') as fp: fp.write('Hello universe!') fp.seek(0) fp.read() # File is now closed and removed这将创建一个临时文件并从中读取数据。一旦文件的内容被读取,临时文件就被关闭并从文件系统中删除。
tempfile也可以用来创建临时目录。让我们看看如何使用tempfile.TemporaryDirectory()来实现这一点:
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmpdir:
... print('Created temporary directory ', tmpdir)
... os.path.exists(tmpdir)
...
Created temporary directory /tmp/tmpoxbkrm6c
True
>>> # Directory contents have been removed
...
>>> tmpdir
'/tmp/tmpoxbkrm6c'
>>> os.path.exists(tmpdir)
False
调用tempfile.TemporaryDirectory()在文件系统中创建一个临时目录,并返回一个表示这个目录的对象。在上面的例子中,目录是使用上下文管理器创建的,目录名存储在tmpdir中。第三行打印出临时目录的名称,os.path.exists(tmpdir)确认该目录是否确实是在文件系统中创建的。
在上下文管理器脱离上下文之后,临时目录被删除,对os.path.exists(tmpdir)的调用返回False,这意味着目录被成功删除。
删除文件和目录
您可以使用os、shutil和pathlib模块中的方法删除单个文件、目录和整个目录树。以下各节介绍了如何删除不再需要的文件和目录。
在 Python 中删除文件
要删除单个文件,使用pathlib.Path.unlink()、os.remove()。或者os.unlink()。
os.remove()和os.unlink()语义相同。要使用os.remove()删除文件,请执行以下操作:
import os
data_file = 'C:\\Users\\vuyisile\\Desktop\\Test\\data.txt'
os.remove(data_file)
使用os.unlink()删除文件类似于使用os.remove()删除文件:
import os
data_file = 'C:\\Users\\vuyisile\\Desktop\\Test\\data.txt'
os.unlink(data_file)
在文件上调用.unlink()或.remove()会从文件系统中删除该文件。如果传递给这两个函数的路径指向一个目录而不是一个文件,它们将抛出一个OSError。为了避免这种情况,您可以检查您试图删除的实际上是一个文件,如果是就删除它,或者您可以使用异常处理来处理OSError:
import os
data_file = 'home/data.txt'
# If the file exists, delete it
if os.path.isfile(data_file):
os.remove(data_file)
else:
print(f'Error: {data_file} not a valid filename')
os.path.isfile()检查data_file是否实际上是一个文件。如果是,则通过调用os.remove()将其删除。如果data_file指向一个文件夹,一条错误信息被打印到控制台。
下面的示例显示了如何使用异常处理来处理删除文件时的错误:
import os
data_file = 'home/data.txt'
# Use exception handling
try:
os.remove(data_file)
except OSError as e:
print(f'Error: {data_file} : {e.strerror}')
上面的代码试图在检查文件类型之前先删除文件。如果data_file实际上不是一个文件,抛出的OSError在except子句中被处理,一条错误消息被打印到控制台。使用 Python f-strings 格式化打印出来的错误消息。
最后,您还可以使用pathlib.Path.unlink()删除文件:
from pathlib import Path
data_file = Path('home/data.txt')
try:
data_file.unlink()
except IsADirectoryError as e:
print(f'Error: {data_file} : {e.strerror}')
这创建了一个名为data_file的Path对象,它指向一个文件。在data_file上呼叫.remove()会删除home/data.txt。如果data_file指向一个目录,则产生一个IsADirectoryError。值得注意的是,上面的 Python 程序与运行它的用户拥有相同的权限。如果用户没有删除文件的权限,就会引发一个PermissionError。
删除目录
标准库提供以下删除目录的功能:
os.rmdir()pathlib.Path.rmdir()shutil.rmtree()
要删除单个目录或文件夹,使用os.rmdir()或pathlib.rmdir()。这两个功能只有在你试图删除的目录为空时才有效。如果目录不为空,就会引发一个OSError。以下是删除文件夹的方法:
import os
trash_dir = 'my_documents/bad_dir'
try:
os.rmdir(trash_dir)
except OSError as e:
print(f'Error: {trash_dir} : {e.strerror}')
这里,trash_dir目录通过将其路径传递给os.rmdir()而被删除。如果目录不为空,屏幕上会显示一条错误消息:
Traceback (most recent call last): File '<stdin>', line 1, in <module> OSError: [Errno 39] Directory not empty: 'my_documents/bad_dir'或者,您可以使用
pathlib删除目录:from pathlib import Path trash_dir = Path('my_documents/bad_dir') try: trash_dir.rmdir() except OSError as e: print(f'Error: {trash_dir} : {e.strerror}')在这里,您创建了一个指向要删除的目录的
Path对象。在Path对象上调用.rmdir()将删除它,如果它是空的。删除整个目录树
为了删除非空目录和整个目录树,Python 提供了
shutil.rmtree():import shutil trash_dir = 'my_documents/bad_dir' try: shutil.rmtree(trash_dir) except OSError as e: print(f'Error: {trash_dir} : {e.strerror}')当调用
shutil.rmtree()时,trash_dir中的所有内容都会被删除。有些情况下,您可能希望递归删除空文件夹。你可以结合os.walk()使用上面讨论的方法之一:import os for dirpath, dirnames, files in os.walk('.', topdown=False): try: os.rmdir(dirpath) except OSError as ex: pass这将遍历目录树,并尝试删除它找到的每个目录。如果目录不为空,则引发
OSError并跳过该目录。下表列出了本节涵盖的功能:
功能 描述 os.remove()删除文件,但不删除目录 os.unlink()与 os.remove()相同,删除一个文件pathlib.Path.unlink()删除文件,不能删除目录 os.rmdir()删除一个空目录 pathlib.Path.rmdir()删除一个空目录 shutil.rmtree()删除整个目录树,并可用于删除非空目录 复制、移动和重命名文件和目录
Python 附带了
shutil模块。shutil是 shell utilities 的简称。它提供了许多对文件的高级操作,以支持文件和目录的复制、存档和删除。在本节中,您将学习如何移动和复制文件和目录。用 Python 复制文件
shutil提供了几个复制文件的功能。最常用的功能是shutil.copy()和shutil.copy2()。要使用shutil.copy()将文件从一个位置复制到另一个位置,请执行以下操作:import shutil src = 'path/to/file.txt' dst = 'path/to/dest_dir' shutil.copy(src, dst)
shutil.copy()相当于基于 UNIX 的系统中的cp命令。shutil.copy(src, dst)会将文件src复制到dst指定的位置。如果dst是一个文件,该文件的内容将被替换为src的内容。如果dst是一个目录,那么src将被复制到那个目录中。shutil.copy()仅复制文件的内容和文件的权限。文件的创建和修改时间等其他元数据不会被保留。要在复制时保留所有文件元数据,请使用
shutil.copy2():import shutil src = 'path/to/file.txt' dst = 'path/to/dest_dir' shutil.copy2(src, dst)使用
.copy2()保存文件的细节,比如最后访问时间、许可位、最后修改时间和标志。复制目录
虽然
shutil.copy()只复制单个文件,但是shutil.copytree()会复制整个目录以及其中包含的所有内容。shutil.copytree(src, dest)有两个参数:一个源目录和文件和文件夹将被复制到的目标目录。以下是如何将一个文件夹的内容复制到不同位置的示例:
>>> import shutil
>>> shutil.copytree('data_1', 'data1_backup')
'data1_backup'
在这个例子中,.copytree()将data_1的内容复制到一个新位置data1_backup,并返回目标目录。目标目录不能已经存在。它将被创建并丢失父目录。shutil.copytree()是备份文件的好方法。
移动文件和目录
要将文件或目录移动到另一个位置,使用shutil.move(src, dst)。
src是要移动的文件或目录,dst是目的地:
>>> import shutil >>> shutil.move('dir_1/', 'backup/') 'backup'如果
backup/存在,则shutil.move('dir_1/', 'backup/')将dir_1/移动到backup/。如果backup/不存在,dir_1/将被重命名为backup。重命名文件和目录
Python 包含用于重命名文件和目录的
os.rename(src, dst):
>>> os.rename('first.zip', 'first_01.zip')
上面的行将first.zip重命名为first_01.zip。如果目标路径指向一个目录,它将引发一个OSError。
重命名文件或目录的另一种方法是使用pathlib模块中的rename():
>>> from pathlib import Path >>> data_file = Path('data_01.txt') >>> data_file.rename('data.txt')要使用
pathlib重命名文件,首先要创建一个pathlib.Path()对象,其中包含要替换的文件的路径。下一步是调用 path 对象上的rename(),并为要重命名的文件或目录传递一个新文件名。存档
归档是将几个文件打包成一个文件的便捷方式。两种最常见的归档类型是 ZIP 和 TAR。您编写的 Python 程序可以创建、读取和提取档案中的数据。在本节中,您将学习如何读写这两种归档格式。
读取 ZIP 文件
zipfile模块是一个低级模块,是 Python 标准库的一部分。zipfile具有打开和解压 ZIP 文件的功能。要读取一个 ZIP 文件的内容,首先要做的是创建一个ZipFile对象。ZipFile对象类似于使用open()创建的文件对象。ZipFile也是一个上下文管理器,因此支持with语句:import zipfile with zipfile.ZipFile('data.zip', 'r') as zipobj:在这里,您创建了一个
ZipFile对象,传入以读取模式打开的 ZIP 文件的名称。打开一个 ZIP 文件后,可以通过zipfile模块提供的函数访问关于档案的信息。上例中的data.zip归档文件是从名为data的目录中创建的,该目录总共包含 5 个文件和 1 个子目录:. | ├── sub_dir/ | ├── bar.py | └── foo.py | ├── file1.py ├── file2.py └── file3.py要获得归档中的文件列表,请对
ZipFile对象调用namelist():import zipfile with zipfile.ZipFile('data.zip', 'r') as zipobj: zipobj.namelist()这会产生一个列表:
['file1.py', 'file2.py', 'file3.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py']
.namelist()返回档案中文件和目录的名称列表。要检索归档中文件的信息,请使用.getinfo():import zipfile with zipfile.ZipFile('data.zip', 'r') as zipobj: bar_info = zipobj.getinfo('sub_dir/bar.py') bar_info.file_size以下是输出结果:
15277
.getinfo()返回一个ZipInfo对象,该对象存储关于档案中一个成员的信息。要获得档案中某个文件的信息,可以将其路径作为参数传递给.getinfo()。使用getinfo(),您可以检索关于归档成员的信息,比如文件的最后修改日期、压缩大小和完整文件名。访问.file_size以字节为单位获取文件的原始大小。以下示例显示了如何在 Python REPL 中检索有关归档文件的更多详细信息。假设
zipfile模块已经被导入,并且bar_info是您在前面的例子中创建的同一个对象:
>>> bar_info.date_time
(2018, 10, 7, 23, 30, 10)
>>> bar_info.compress_size
2856
>>> bar_info.filename
'sub_dir/bar.py'
bar_info包含关于bar.py的细节,比如压缩时的大小和完整路径。
第一行显示了如何检索文件的最后修改日期。下一行显示了如何获得压缩后文件的大小。最后一行显示了归档文件中bar.py的完整路径。
ZipFile支持上下文管理器协议,这就是为什么您可以将它与with语句一起使用。这样做可以在你完成后自动关闭ZipFile对象。试图从关闭的ZipFile对象中打开或提取文件将导致错误。
解压压缩文件
zipfile模块允许您通过.extract()和.extractall()从 ZIP 存档中提取一个或多个文件。
默认情况下,这些方法将文件提取到当前目录。它们都带有一个可选的path参数,允许您指定一个不同的目录来提取文件。如果该目录不存在,则会自动创建。要从归档中提取文件,请执行以下操作:
>>> import zipfile >>> import os >>> os.listdir('.') ['data.zip'] >>> data_zip = zipfile.ZipFile('data.zip', 'r') >>> # Extract a single file to current directory >>> data_zip.extract('file1.py') '/home/terra/test/dir1/zip_extract/file1.py' >>> os.listdir('.') ['file1.py', 'data.zip'] >>> # Extract all files into a different directory >>> data_zip.extractall(path='extract_dir/') >>> os.listdir('.') ['file1.py', 'extract_dir', 'data.zip'] >>> os.listdir('extract_dir') ['file1.py', 'file3.py', 'file2.py', 'sub_dir'] >>> data_zip.close()第三行代码是对
os.listdir()的调用,显示当前目录只有一个文件data.zip。接下来,在读取模式下打开
data.zip,并调用.extract()从中提取file1.py。.extract()返回提取文件的完整文件路径。由于没有指定路径,.extract()将file1.py提取到当前目录。下一行打印一个目录列表,显示当前目录除了原始归档文件之外,还包括提取的文件。之后的一行显示了如何将整个归档文件提取到
zip_extract目录中。.extractall()创建extract_dir并将data.zip的内容提取到其中。最后一行关闭 ZIP 存档。从受密码保护的档案中提取数据
zipfile支持提取密码保护的拉链。要提取受密码保护的 ZIP 文件,请将密码作为参数传递给.extract()或.extractall()方法:
>>> import zipfile
>>> with zipfile.ZipFile('secret.zip', 'r') as pwd_zip:
... # Extract from a password protected archive
... pwd_zip.extractall(path='extract_dir', pwd='Quish3@o')
这将在读取模式下打开secret.zip档案。向.extractall()提供密码,并将档案内容提取到extract_dir。由于使用了with语句,在提取完成后,归档会自动关闭。
创建新的 ZIP 存档文件
要创建一个新的 ZIP 存档,您需要以写模式(w)打开一个ZipFile对象,并添加您想要存档的文件:
>>> import zipfile >>> file_list = ['file1.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py'] >>> with zipfile.ZipFile('new.zip', 'w') as new_zip: ... for name in file_list: ... new_zip.write(name)在本例中,
new_zip以写模式打开,file_list中的每个文件都被添加到归档文件中。当with语句组完成后,new_zip关闭。以写入模式打开 ZIP 文件会删除归档文件的内容,并创建一个新的归档文件。要将文件添加到现有档案中,在追加模式下打开一个
ZipFile对象,然后添加文件:
>>> # Open a ZipFile object in append mode
>>> with zipfile.ZipFile('new.zip', 'a') as new_zip:
... new_zip.write('data.txt')
... new_zip.write('latin.txt')
在这里,您在 append 模式下打开您在前一个例子中创建的new.zip档案。在追加模式下打开ZipFile对象允许您在不删除当前内容的情况下向 ZIP 文件添加新文件。在将文件添加到 ZIP 文件后,with语句脱离上下文并关闭 ZIP 文件。
打开 TAR 档案
TAR 文件是像 ZIP 一样的未压缩文件存档。它们可以使用 gzip、bzip2 和 lzma 压缩方法进行压缩。TarFile类允许读写 TAR 文档。
执行此操作以从归档中读取:
import tarfile
with tarfile.open('example.tar', 'r') as tar_file:
print(tar_file.getnames())
对象像大多数类似文件的对象一样打开。他们有一个open()函数,它采用一种模式来决定文件如何打开。
使用'r'、'w'或'a'模式分别打开一个未压缩的 TAR 文件进行读取、写入和附加。要打开压缩的 TAR 文件,向tarfile.open()传递一个模式参数,格式为filemode[:compression]。下表列出了打开 TAR 文件的可能模式:
| 方式 | 行动 |
|---|---|
r |
使用透明压缩打开档案进行读取 |
r:gz |
使用 gzip 压缩打开存档文件进行阅读 |
r:bz2 |
使用 bzip2 压缩打开存档文件进行阅读 |
r:xz |
使用 lzma 压缩打开档案进行读取 |
w |
打开归档文件进行未压缩的写入 |
w:gz |
打开归档文件进行 gzip 压缩写入 |
w:xz |
为 lzma 压缩写打开存档 |
a |
打开归档文件进行无压缩附加 |
.open()默认为'r'模式。要读取一个未压缩的 TAR 文件并检索其中的文件名,使用.getnames():
>>> import tarfile >>> tar = tarfile.open('example.tar', mode='r') >>> tar.getnames() ['CONTRIBUTING.rst', 'README.md', 'app.py']这将返回一个包含归档内容名称的列表。
注意:为了向您展示如何使用不同的
tarfile对象方法,示例中的 TAR 文件是在交互式 REPL 会话中手动打开和关闭的。通过这种方式与 TAR 文件交互,您可以看到运行每个命令的输出。通常,您会希望使用上下文管理器来打开类似文件的对象。
可以使用特殊属性访问归档中每个条目的元数据:
>>> for entry in tar.getmembers():
... print(entry.name)
... print(' Modified:', time.ctime(entry.mtime))
... print(' Size :', entry.size, 'bytes')
... print()
CONTRIBUTING.rst
Modified: Sat Nov 1 09:09:51 2018
Size : 402 bytes
README.md
Modified: Sat Nov 3 07:29:40 2018
Size : 5426 bytes
app.py
Modified: Sat Nov 3 07:29:13 2018
Size : 6218 bytes
在这个例子中,您遍历由.getmembers()返回的文件列表,并打印出每个文件的属性。由.getmembers()返回的对象具有可以以编程方式访问的属性,比如档案中每个文件的名称、大小和最后修改时间。在读取或写入归档文件后,必须将其关闭以释放系统资源。
从 TAR 存档中提取文件
在本节中,您将学习如何使用以下方法从 TAR 归档中提取文件:
.extract().extractfile().extractall()
要从 TAR 归档文件中提取一个文件,使用extract(),传入文件名:
>>> tar.extract('README.md') >>> os.listdir('.') ['README.md', 'example.tar']
README.md文件从归档文件中提取到文件系统中。调用os.listdir()确认README.md文件被成功提取到当前目录。要从归档中解压或提取所有内容,请使用.extractall():
>>> tar.extractall(path="extracted/")
.extractall()有一个可选的path参数来指定提取的文件应该放在哪里。在这里,归档文件被解压到extracted目录中。以下命令显示归档文件已成功提取:
$ ls
example.tar extracted README.md
$ tree
.
├── example.tar
├── extracted
| ├── app.py
| ├── CONTRIBUTING.rst
| └── README.md
└── README.md
1 directory, 5 files
$ ls extracted/
app.py CONTRIBUTING.rst README.md
要提取一个文件对象来读或写,使用.extractfile(),它接受一个文件名或要提取的TarInfo对象作为参数。.extractfile()返回一个可以读取和使用的类似文件的对象:
>>> f = tar.extractfile('app.py') >>> f.read() >>> tar.close()打开的档案在被读取或写入后应该关闭。要关闭一个归档文件,调用归档文件句柄上的
.close(),或者在创建tarfile对象时使用with语句,以便在完成后自动关闭归档文件。这将释放系统资源,并将您对归档文件所做的任何更改写入文件系统。创建新的 TAR 归档文件
你可以这样做:
>>> import tarfile
>>> file_list = ['app.py', 'config.py', 'CONTRIBUTORS.md', 'tests.py']
>>> with tarfile.open('packages.tar', mode='w') as tar:
... for file in file_list:
... tar.add(file)
>>> # Read the contents of the newly created archive
>>> with tarfile.open('package.tar', mode='r') as t:
... for member in t.getmembers():
... print(member.name)
app.py
config.py
CONTRIBUTORS.md
tests.py
首先,列出要添加到归档中的文件列表,这样就不必手动添加每个文件。
下一行使用with上下文管理器以写模式打开一个名为packages.tar的新档案。以写模式('w')打开一个归档文件,使您能够向归档文件写入新文件。归档中的任何现有文件都将被删除,并创建一个新的归档。
在创建并填充归档文件后,with上下文管理器自动关闭它并将其保存到文件系统中。最后三行打开您刚刚创建的归档文件,并打印出其中包含的文件名。
要向现有档案添加新文件,请在追加模式('a')下打开档案:
>>> with tarfile.open('package.tar', mode='a') as tar: ... tar.add('foo.bar') >>> with tarfile.open('package.tar', mode='r') as tar: ... for member in tar.getmembers(): ... print(member.name) app.py config.py CONTRIBUTORS.md tests.py foo.bar在追加模式下打开归档文件允许您在不删除已有文件的情况下向其中添加新文件。
使用压缩档案
tarfile还可以读写使用 gzip、bzip2 和 lzma 压缩的 TAR 文件。要读取或写入压缩的归档文件,使用tarfile.open(),为压缩类型传入适当的模式。例如,要读取或写入使用 gzip 压缩的 TAR 归档文件,分别使用
'r:gz'或'w:gz'模式:
>>> files = ['app.py', 'config.py', 'tests.py']
>>> with tarfile.open('packages.tar.gz', mode='w:gz') as tar:
... tar.add('app.py')
... tar.add('config.py')
... tar.add('tests.py')
>>> with tarfile.open('packages.tar.gz', mode='r:gz') as t:
... for member in t.getmembers():
... print(member.name)
app.py
config.py
tests.py
'w:gz'模式打开存档进行 gzip 压缩写入,而'r:gz'打开存档进行 gzip 压缩读取。无法在附加模式下打开压缩档案。要将文件添加到压缩的归档文件中,您必须创建一个新的归档文件。
创建档案的简单方法
Python 标准库还支持使用shutil模块中的高级方法创建 TAR 和 ZIP 归档。shutil中的归档工具允许您创建、读取和提取 ZIP 和 TAR 归档文件。这些实用程序依赖于较低级别的tarfile和zipfile模块。
使用shutil.make_archive()处理档案
shutil.make_archive()至少有两个参数:归档文件的名称和归档文件的格式。
默认情况下,它将当前目录中的所有文件压缩成在format参数中指定的存档格式。您可以传入一个可选的root_dir参数来压缩不同目录中的文件。.make_archive()支持zip、tar、bztar和gztar存档格式。
这就是如何使用shutil创建 TAR 归档文件:
import shutil
# shutil.make_archive(base_name, format, root_dir)
shutil.make_archive('data/backup', 'tar', 'data/')
这将复制data/中的所有内容,并在文件系统中创建一个名为backup.tar的归档文件,并返回其名称。要提取存档文件,请调用.unpack_archive():
shutil.unpack_archive('backup.tar', 'extract_dir/')
调用.unpack_archive()并传入一个档案名称和目标目录,将backup.tar的内容提取到extract_dir/中。可以用同样的方式创建和解压缩 ZIP 存档。
读取多个文件
Python 支持通过fileinput模块从多个输入流或文件列表中读取数据。这个模块允许你快速简单地循环一个或多个文本文件的内容。下面是使用fileinput的典型方式:
import fileinput
for line in fileinput.input()
process(line)
默认情况下,fileinput从传递给sys.argv的命令行参数中获取输入。
使用fileinput循环多个文件
让我们使用fileinput构建一个普通 UNIX 实用程序cat的原始版本。cat实用程序按顺序读取文件,将它们写入标准输出。当在命令行参数中给出多个文件时,cat将连接文本文件并在终端中显示结果:
# File: fileinput-example.py
import fileinput
import sys
files = fileinput.input()
for line in files:
if fileinput.isfirstline():
print(f'\n--- Reading {fileinput.filename()} ---')
print(' -> ' + line, end='')
print()
对我当前目录中的两个文本文件运行此命令会产生以下输出:
$ python3 fileinput-example.py bacon.txt cupcake.txt
--- Reading bacon.txt ---
-> Spicy jalapeno bacon ipsum dolor amet in in aute est qui enim aliquip,
-> irure cillum drumstick elit.
-> Doner jowl shank ea exercitation landjaeger incididunt ut porchetta.
-> Tenderloin bacon aliquip cupidatat chicken chuck quis anim et swine.
-> Tri-tip doner kevin cillum ham veniam cow hamburger.
-> Turkey pork loin cupidatat filet mignon capicola brisket cupim ad in.
-> Ball tip dolor do magna laboris nisi pancetta nostrud doner.
--- Reading cupcake.txt ---
-> Cupcake ipsum dolor sit amet candy I love cheesecake fruitcake.
-> Topping muffin cotton candy.
-> Gummies macaroon jujubes jelly beans marzipan.
fileinput允许您检索每一行的更多信息,例如它是否是第一行(.isfirstline())、行号(.lineno())和文件名(.filename())。你可以在这里了解更多关于的信息。
结论
您现在知道如何使用 Python 对文件和文件组执行最常见的操作。您已经了解了用于读取、查找和操作它们的不同内置模块。
现在,您已经准备好使用 Python 来:
- 获取目录内容和文件属性
- 创建目录和目录树
- 在文件名中查找模式
- 创建临时文件和目录
- 移动、重命名、复制和删除文件或目录
- 从不同类型的档案中读取和提取数据
- 使用
fileinput同时读取多个文件
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 处理文件的实用菜谱*********
使用 Pandas 在 Python 中读取大型 Excel 文件
原文:https://realpython.com/working-with-large-excel-files-in-pandas/
在本教程中,你将学习如何在 Pandas 中处理大型 Excel 文件,重点是读取和分析 xls 文件,然后处理原始数据的子集。
免费奖励: 向您展示了如何读取大型 Excel 文件。
本教程利用了 Python(用 64 位版本的 v2.7.9 和 v3.4.3 测试过), Pandas (v0.16.1),和 XlsxWriter (v0.7.3)。我们推荐使用 Anaconda 发行版来快速入门,因为它预装了所有需要的库。
读取文件
我们要处理的第一个文件是从 1979 年到 2004 年英国所有车祸的汇编,提取 2000 年发生在伦敦的所有车祸。
Excel
首先从data.gov.uk下载源 ZIP 文件,并提取内容。然后尝试在 Excel 中打开incidents 7904 . CSV。小心。如果你没有足够的内存,这很可能会使你的电脑崩溃。
会发生什么?
您应该会看到一个“文件没有完全加载”的错误,因为 Excel 一次只能处理一百万行。
我们在 LibreOffice 中对此也进行了测试,并收到了类似的错误——“数据无法完全加载,因为超出了每张工作表的最大行数。”
为了解决这个问题,我们可以在 Pandas 中打开文件。在我们开始之前,源代码在 Github 上。
熊猫
在一个新的项目目录中,激活一个 virtualenv,然后安装 Pandas:
$ pip install pandas==0.16.1
现在让我们构建脚本。创建一个名为 pandas_accidents.py 的文件,并添加以下代码:
import pandas as pd
# Read the file
data = pd.read_csv("Accidents7904.csv", low_memory=False)
# Output the number of rows
print("Total rows: {0}".format(len(data)))
# See which headers are available
print(list(data))
在这里,我们导入 Pandas,读入文件——这可能需要一些时间,取决于您的系统有多少内存——并输出文件的总行数以及可用的标题(例如,列标题)。
运行时,您应该看到:
Total rows: 6224198
['\xef\xbb\xbfAccident_Index', 'Location_Easting_OSGR', 'Location_Northing_OSGR',
'Longitude', 'Latitude', 'Police_Force', 'Accident_Severity', 'Number_of_Vehicles',
'Number_of_Casualties', 'Date', 'Day_of_Week', 'Time', 'Local_Authority_(District)',
'Local_Authority_(Highway)', '1st_Road_Class', '1st_Road_Number', 'Road_Type',
'Speed_limit', 'Junction_Detail', 'Junction_Control', '2nd_Road_Class',
'2nd_Road_Number', 'Pedestrian_Crossing-Human_Control',
'Pedestrian_Crossing-Physical_Facilities', 'Light_Conditions', 'Weather_Conditions',
'Road_Surface_Conditions', 'Special_Conditions_at_Site', 'Carriageway_Hazards',
'Urban_or_Rural_Area', 'Did_Police_Officer_Attend_Scene_of_Accident',
'LSOA_of_Accident_Location']
所以,有超过 600 万行!难怪 Excel 噎着了。请注意标题列表,特别是第一个标题:
'\xef\xbb\xbfAccident_Index',
这应该是Accident_Index。开头多出来的\xef\xbb\xbf是怎么回事?嗯,\x其实是指值为十六进制,是一个字节顺序标志,表示文本为 Unicode 。
为什么这对我们很重要?
你不能假定你阅读的文件是干净的。它们可能包含像这样的额外符号,会影响你的脚本。
这个文件是好的,因为它在其他方面是干净的——但是许多文件有丢失的数据、内部格式不一致的数据等等..所以任何时候你有一个文件要分析,你必须做的第一件事就是清理它。打扫了多少?足以让你做一些分析。遵循吻的原则。
你可能需要什么样的清理工作?
- 确定日期/时间。同一个文件可能有不同格式的日期,比如美国(mm-dd-yy)或欧洲(dd-mm-yy)格式。这些需要纳入一个共同的格式。
- 删除任何空值。文件可能有空白的列和/或行,在 Pandas 中这将显示为 NaN (不是一个数字)。Pandas 提供了一个简单的方法来删除这些:函数
dropna()。我们在上一篇博文中看到了这样的例子。 - 删除任何进入数据的垃圾值。这些值没有意义(就像我们之前看到的字节顺序标记)。有时候,也许可以绕过他们。例如,可能有一个数据集将年龄作为浮点数输入(误输入)。然后可以使用
int()函数来确保所有年龄都是整数格式。
分析
对于熟悉 SQL 的人来说,可以使用带有不同关键字的 SELECT、WHERE 和/或语句来优化搜索。我们可以在熊猫身上做同样的事情,而且是以一种对程序员更友好的方式。
首先,让我们找出星期天发生的所有事故。查看上面的标题,有一个Day_of_Weeks字段,我们将使用它。
在您下载的 ZIP 文件中,有一个名为Road-Accident-Safety-Data-Guide-1979-2004 . xls的文件,其中包含了所使用代码的额外信息。如果你打开它,你会看到星期日有代码1。
print("\nAccidents")
print("-----------")
# Accidents which happened on a Sunday
accidents_sunday = data[data.Day_of_Week == 1]
print("Accidents which happened on a Sunday: {0}".format(
len(accidents_sunday)))
就是这么简单。
在这里,我们以Day_of_Weeks字段为目标,返回一个数据帧,其中包含我们检查的条件- day of week == 1。
当尤然应该看到:
Accidents
-----------
Accidents which happened on a Sunday: 693847
如你所见,周日发生了 693,847 起事故。
让我们把我们的查询变得更复杂一些:找出发生在星期天的所有事故,涉及 20 多辆汽车:
# Accidents which happened on a Sunday, > 20 cars
accidents_sunday_twenty_cars = data[
(data.Day_of_Week == 1) & (data.Number_of_Vehicles > 20)]
print("Accidents which happened on a Sunday involving > 20 cars: {0}".format(
len(accidents_sunday_twenty_cars)))
运行脚本。现在我们有 10 起事故:
Accidents
-----------
Accidents which happened on a Sunday: 693847
Accidents which happened on a Sunday involving > 20 cars: 10
我们再加一个条件:天气。
打开道路-事故-安全-数据-指南-1979-2004.xls,转到天气单。你会看到代码2的意思是,“没有大风的雨”。
添加到我们的查询:
# Accidents which happened on a Sunday, > 20 cars, in the rain
accidents_sunday_twenty_cars_rain = data[
(data.Day_of_Week == 1) & (data.Number_of_Vehicles > 20) &
(data.Weather_Conditions == 2)]
print("Accidents which happened on a Sunday involving > 20 cars in the rain: {0}".format(
len(accidents_sunday_twenty_cars_rain)))
因此,在一个星期天发生了四起事故,涉及 20 多辆汽车,当时正在下雨:
Accidents
-----------
Accidents which happened on a Sunday: 693847
Accidents which happened on a Sunday involving > 20 cars: 10
Accidents which happened on a Sunday involving > 20 cars in the rain: 4
如果需要,我们可以继续把它变得越来越复杂。现在,我们将停止,因为我们的主要兴趣是看看伦敦的事故。
如果你再看道路-事故-安全-数据-指南-1979-2004.xls ,有一张表叫警队。1的代码写着,“伦敦警察厅”。这就是通常所说的苏格兰场,也是负责伦敦大部分地区(尽管不是全部)的警察力量。对于我们的例子来说,这已经足够了,我们可以像这样提取信息:
# Accidents in London on a Sunday
london_data = data[data['Police_Force'] == 1 & (data.Day_of_Week == 1)]
print("\nAccidents in London from 1979-2004 on a Sunday: {0}".format(
len(london_data)))
运行脚本。这为“伦敦警察厅”从 1979 年到 2004 年的一个周日处理的事故创建了一个新的数据框架:
Accidents
-----------
Accidents which happened on a Sunday: 693847
Accidents which happened on a Sunday involving > 20 cars: 10
Accidents which happened on a Sunday involving > 20 cars in the rain: 4
Accidents in London from 1979-2004 on a Sunday: 114624
如果您想创建一个只包含 2000 年事故的新数据框架,该怎么办?
我们需要做的第一件事是使用pd.to_datetime() 函数将日期格式转换成 Python 可以理解的格式。它接受任何格式的日期,并将其转换为我们可以理解的格式( yyyy-mm-dd )。然后我们可以创建另一个只包含 2000 年事故的数据框架:
# Convert date to Pandas date/time
london_data_2000 = london_data[
(pd.to_datetime(london_data['Date'], coerce=True) >
pd.to_datetime('2000-01-01', coerce=True)) &
(pd.to_datetime(london_data['Date'], coerce=True) <
pd.to_datetime('2000-12-31', coerce=True))
]
print("Accidents in London in the year 2000 on a Sunday: {0}".format(
len(london_data_2000)))
运行时,您应该看到:
Accidents which happened on a Sunday: 693847
Accidents which happened on a Sunday involving > 20 cars: 10
Accidents which happened on a Sunday involving > 20 cars in the rain: 4
Accidents in London from 1979-2004 on a Sunday: 114624
Accidents in London in the year 2000 on a Sunday: 3889
所以,这一开始有点混乱。通常,要过滤一个数组,你只需使用一个带有条件的for循环:
for data in array:
if data > X and data < X:
# Do something
然而,你真的不应该定义自己的循环,因为许多高性能的库,比如 Pandas,都有助手函数。在这种情况下,上面的代码循环遍历所有元素,过滤掉设定日期之外的数据,然后返回日期范围内的数据点。
不错!
转换
很有可能,在使用 Pandas 的同时,您组织中的其他人都在使用 Excel。想要与使用 Excel 的人共享数据框架吗?
首先,我们需要做一些清理工作。还记得我们之前看到的字节顺序标记吗?这在将这些数据写入 Excel 文件时会导致问题——Pandas 抛出一个 UnicodeDecodeError 。为什么?因为文本的其余部分被解码为 ASCII,但十六进制值不能用 ASCII 表示。
我们可以把所有东西都写成 Unicode,但是记住这个字节顺序标记是多余的(对我们来说),我们不想要或者不需要。因此,我们将通过重命名列标题来消除它:
london_data_2000.rename(
columns={'\xef\xbb\xbfAccident_Index': 'Accident_Index'},
inplace=True)
这是在熊猫中重命名列的方法;老实说,有点复杂。因为我们想要修改现有的结构,而不是创建一个副本,这是 Pandas 默认做的。
现在我们可以将数据保存到 Excel:
# Save to Excel
writer = pd.ExcelWriter(
'London_Sundays_2000.xlsx', engine='xlsxwriter')
london_data_2000.to_excel(writer, 'Sheet1')
writer.save()
确保在运行前安装 XlsxWriter :
$ pip install XlsxWriter==0.7.3
如果一切顺利,这应该会创建一个名为 London_Sundays_2000.xlsx 的文件,然后将我们的数据保存到 Sheet1 中。在 Excel 或 LibreOffice 中打开该文件,并确认数据是正确的。
结论
那么,我们完成了什么?嗯,我们拿了一个 Excel 打不开的很大的文件,用熊猫来-
- 打开文件。
- 对数据执行类似 SQL 的查询。
- 用原始数据的子集创建一个新的 XLSX 文件。
请记住,尽管这个文件将近 800MB,但在大数据时代,它仍然很小。如果你想打开一个 4GB 的文件呢?即使你有 8GB 或更多的内存,那也是不可能的,因为你的大部分内存是为操作系统和其他系统进程保留的。事实上,我的笔记本电脑在第一次读取 800MB 文件时死机了几次。如果我打开一个 4GB 的文件,它会心脏病发作。
免费奖励: 向您展示了如何读取大型 Excel 文件。
那么我们该如何进行呢?
诀窍是不要一次打开整个文件。这就是我们将在下一篇博文中关注的内容。在那之前,分析你自己的数据。请在下面留下问题或评论。你可以从 repo 中获取本教程的代码。***
8 家使用 Python 的世界级软件公司
原文:https://realpython.com/world-class-companies-using-python/
目前有 500 多种编程语言,而且每天都在增加。不可否认的是,这些方法中的大多数是重叠的,而且很多从来都不是为了在理论或实验室环境之外使用。但是对于日常编码和商业中使用的编程语言,你必须做出选择。你应该学习什么语言,你为什么要花时间学习它们?
由于这是一个专门研究 Python 的网站,我们已经告诉你为什么 Python 是一门很好的学习语言。你可能知道 Python 可能是树莓派最喜欢的语言(因为大多数都预装了它)。知道了这一点,你就知道你可以用一个 Pi 工具包和一点点聪明才智做什么惊人的事情。虽然很容易看出如何修补 Python,但您可能想知道这如何转化为实际的业务和现实世界的应用程序。
我们现在要做的是告诉你你所知道的使用 Python 的八家顶级公司。通过这种方式,您可以看到 Python 开发人员在现实世界中有多么大的机会。
工业光魔
工业光魔(ILM)是特效工作室,由乔治·卢卡斯于 1975 年创建,为《星球大战》创造特效。从那时起,他们就成了 FX 的代名词,因为他们在电影和商业中的工作赢得了多个奖项。
在早期,ILM 专注于实际效果,但很快意识到计算机生成的效果是 FX 的未来。他们的 CGI 部门成立于 1979 年,他们的第一个效果是《星际迷航 II:可汗之怒》中创世纪项目的爆炸场景。
最初,ILM 的 CGI 工作室运行在 Unix shell 上,但这只是处理相对较少的工作量。因为工作室预见了 CGI 的未来,他们开始寻找一个可以处理他们在未来看到的积极向上扩展的系统。
ILM 选择了 Python 1.4 而不是 Perl 和 Tcl,选择使用 Python 是因为它可以更快地集成到他们现有的基础设施中。因为 Python 与 C 和 C++ 的简单互操作性,ILM 很容易将 Python 导入他们专有的照明软件。这让他们可以将 Python 放在更多的地方,用它来包装软件组件并扩展他们的标准图形应用程序。
工作室已经在他们工作的多个其他方面使用了 Python。开发人员使用 Python 来跟踪和审计管道功能,维护为每部电影制作的每张图像的数据库。随着越来越多的 ILM 程序由 Python 控制,它创建了一个更简单的统一工具集,允许更有效的生产管道。对于现实世界的例子,只要看看 ILM 使用的一种高清文件格式 OpenEXR 就知道了。作为软件包的一部分, PyIlmBase 被包含在内(尽管它有一个 Boost 依赖项)。
尽管有许多评论,ILM 仍然认为 Python 是满足其需求的最佳解决方案。开源代码与支持更改的能力相结合,确保 Python 将在很长一段时间内继续满足 ILM 的需求。
谷歌
谷歌几乎从一开始就是 Python 的支持者。一开始,Google 的创始人做出了“Python 在我们能做的地方,C++在我们必须做的地方”的决定。这意味着 C++被用在内存控制是必要的,并且需要低延迟的地方。在其他方面,Python 支持易于维护和相对快速的交付。
即使用 Perl 或 Bash 为 Google 编写了其他脚本,这些脚本也经常被重新编码到 Python 中。原因是因为易于部署以及 Python 的维护非常简单。事实上,根据《在 Plex》的作者 Steven Levy 所说,谷歌的第一个网络爬行蜘蛛最初是用 Java 1.0 的版本编写的,因为太难了,所以他们把它改写成了 Python。
Python 现在是官方的 Google 服务器端语言之一——c++、Java 和 Go 是另外三种——允许部署到生产中。如果你不确定 Python 对谷歌有多重要,Python 的 BDFL吉多·范·罗苏姆从 2005 年到 2012 年在谷歌工作。
最重要的是,彼得·诺维格说:
“Python 从一开始就是 Google 的重要组成部分,并且随着系统的成长和发展而保持不变。如今,数十名谷歌工程师使用 Python,我们正在寻找更多掌握这种语言的人。”
脸书
脸书的制作工程师非常热衷于 Python,这使它成为社交媒体巨头中第三大最受欢迎的语言(仅次于 C++和他们专有的 PHP 方言 Hack)。平均而言,脸书有超过 5,000 项公用事业和服务承诺,管理基础架构、二进制分发、硬件映像和运营自动化。
Python 库的易用性意味着生产工程师不必编写或维护太多代码,让他们可以专注于实时改进。这也确保了脸书的基础设施能够高效地扩展。
根据脸书 2016 年的一篇帖子,Python 目前负责基础设施管理中的多种服务。其中包括使用 TORconfig 处理网络交换机设置和映像,使用 FBOSS 处理白盒交换机 CLI,使用 Dapper 调度和执行维护工作。
脸书发布了许多为 Py3 编写的开源 Python 项目,包括一个脸书 Ads API 和一个 Python 异步 IRCbot 框架。脸书目前正在将其基础设施和装卸机从 2 升级到 3.4,AsyncIO 正在帮助他们的工程师进行升级。
2016 年,Instagram 工程团队夸口说,他们正在运行完全用 Python 编写的 Django web 框架的全球最大部署。这可能在今天仍然适用。Instagram 的软件工程师闵妮这样描述他们对 Python 的生产使用:
“我们最初选择使用 Python 是因为它简单实用的名声,这与我们‘先做简单的事情’的理念非常吻合。”"
从那时起,Instagram 的工程团队投入了时间和资源,以保持他们的 Python 部署在大规模( ~8 亿月活跃用户)下的可行性,他们正在运营:
“通过我们为 Instagram 的网络服务构建效率框架的工作,我们有信心继续使用 Python 扩展我们的服务基础设施。我们也开始在 Python 语言本身上投入更多,并开始探索将我们的 Python 从版本 2 迁移到版本 3。”
2017 年,Instagram 将其大部分 Python 代码库从 Python 2.7 迁移到 Python 3 。您可以观看郭美孜和丁辉的 PyCon 2017 主题演讲,了解他们在大规模代码迁移方面的经验:
Spotify
这家音乐流媒体巨头是 Python 的大力支持者,主要将这种语言用于数据分析和后端服务。在后端,有大量的服务都通过 0MQ 或 ZeroMQ 进行通信,这是一个用 Python 和 C++(以及其他语言)编写的开源网络库和框架。
之所以用 Python 编写服务,是因为 Spotify 喜欢用 Python 编写和编码时开发管道的速度。Spotify 架构的最新更新一直在使用 gevent ,它提供了一个带有高级同步 API 的快速事件循环。
为了向用户提供建议和推荐,Spotify 依赖于大量的分析。为了解释这些,Spotify 使用了与 Hadoop 同步的 Python 模块 Luigi 。这个开源模块处理库如何协同工作,并快速合并错误日志,以便进行故障排除和重新部署。
总的来说,Spotify 使用超过 6000 个单独的 Python 进程,这些进程在 Hadoop 集群的节点上协同工作。
Quora
这个庞大的众包问答平台想了很久很久,想用什么语言来实现他们的想法。Quora 的创始人之一 Charlie Cheever ,将他们的选择缩小到 Python、C#、Java 和 Scala。他们使用 Python 的最大问题是缺乏类型检查,而且相对较慢。
据 Adam D'Angelo 说,他们决定不使用 C# 因为这是微软的专有语言,他们不想受制于任何未来的变化。此外,任何开源代码充其量只能得到二等支持。
Java 比 Python 更难写,而且它不像 Python 那样适合非 Java 程序。当时,Java 还处于起步阶段,所以他们担心未来的支持以及这种语言是否会继续发展。
取而代之的是,Quora 的创始人效仿 Google,选择使用 Python,因为它易于编写且可读性强,并为性能关键部分实现了 C++。他们通过编写单元测试来完成同样的事情,从而避开了 Python 缺乏类型检查的缺陷。
使用 Python 的另一个关键考虑是当时存在几个好的框架,包括 Django 和 Pylons。此外,因为他们知道 Quora 将涉及服务器/客户端交互,不一定是全页面加载,让 Python 和 JS 如此好地合作是一个巨大的优势。
网飞
网飞使用 Python 的方式与 Spotify 非常相似,依靠 Python 语言在服务器端进行数据分析。然而,它并不止于此。网飞允许他们的软件工程师选择用什么语言来编码,并且已经注意到 Python 应用程序的数量有了很大的增长。
接受调查时,网飞的工程师提到了标准库、非常活跃的开发社区和丰富多样的第三方库,它们可以解决几乎任何给定的问题。此外,由于 Python 非常容易开发,它已经成为网飞许多其他服务的关键。
使用 Python 的主要场所之一是中央警报网关。这个 RESTful web 应用程序处理来自任何地方的警报,然后将它们发送给需要看到它们的人或团体。此外,该应用程序有能力抑制已经处理过的重复警报,并在某些情况下,执行自动解决方案,如重新启动进程或终止看起来开始不稳定的事情。考虑到警报的绝对数量,这个应用程序对网飞来说是一个巨大的胜利。智能地处理它们意味着开发人员和工程师不会被多余的调用淹没。
Python 在网飞的另一个应用领域是用于跟踪安全变化和历史的 monkey 应用程序。这些猴子用于跟踪和警告任何组中 EC2 安全相关策略的任何变化,跟踪这些环境中的任何变化。它们还用于确保跟踪网飞多个域附带的数十个 SSL 证书。从追踪数据来看,自 2012 年以来,网飞的意外到期率从四分之一降至零。
收存箱
这个基于云的存储系统在其桌面客户端使用 Python。如果你对 Dropbox 在 Python 上的投入有任何疑问,那就想想 2012 年,他们成功说服了 Python 的创造者、仁慈的终身独裁者吉多·范·罗苏姆离开谷歌,加入 Dropbox。
Rossum 加入 Dropbox 的条件是他将成为一名工程师,而不是一名领导,甚至不是一名经理。在第一年,他帮助 Dropbox 社区中的其他用户实现了共享数据存储的能力。
虽然 Dropbox 的许多库和内部都是专有的,而不是开源的,但该公司已经发布了用 python 编写的非常有效的 API,让你可以看到他们的工程师是如何思考的。当你阅读对 Dropbox 工程师的采访,了解到他们的服务器端代码有很大一部分是 Python 时,你也可以从字里行间体会到这一点。
有趣的是,虽然客户端程序是用 Python 编写的,但是它们利用 Mac 和 Windows 机器上的各种库来提供统一的体验。这是因为 Python 不是预装在 Windows 上的,根据您的 Mac,您的 Python 版本会有所不同。
Reddit " t0 "号
该网站在 2017 年每月有 5.42 亿访客,使其成为美国第四大访问量网站和世界第七大访问量网站。2015 年有 7315 万次投稿,825.4 亿次浏览量。在这一切的背后,形成软件主干的是 Python。
Reddit 最初是用 Lisp 编码的,但是在 2005 年 12 月,也就是它上线 6 个月后,这个网站被重新编码成 Python。这种变化的主要原因是 Python 拥有更广泛的代码库,在开发上更加灵活。最初运行该网站的 web 框架 web.py 现在是一个开源项目。
在 2009 年的一次采访中,Steve Huffman 和 Alexis Ohanian 在 Pycon 上被问到为什么 Reddit 仍然使用 Python 作为它的框架。根据霍夫曼的说法,第一个原因与变化的原因相同:
“什么都有一个图书馆。我们一直在学习这些技术和架构。因此,当我不理解连接池时,我可以找到一个库,直到我自己更好地理解它并编写我们自己的库。我不理解 web 框架,所以我们将使用其他人的,直到我们做出自己的……Python 有一个这样的强大支撑。”
Reddit 坚持使用 Python 的第二个原因是贯穿所有使用 Python 开发的公司的一条共同主线。根据 Huffman 的说法,是代码的可读性:
“当我们雇佣新员工时……我认为我们还没有雇佣懂 Python 的员工。我只是说,‘你写的所有东西都需要用 Python 来写。’这样我就可以读了。这太棒了,因为我可以从房间的另一边看到他们的屏幕,不管他们的代码是好是坏。因为好的 Python 代码有非常明显的结构。
这让我的生活轻松多了。[……]它极具表现力、可读性和可写性。这让生活变得更加顺畅”
更新:是的,现在有 9 家世界级的公司在生产中使用 Python。最初我们没有单独统计 Instagram,因为该公司为脸书所有。但鉴于 Instagram 团队令人印象深刻的运营规模,我们认为给他们一个单独的要点是有意义的。
还有人吗?
在这篇文章中,我们关注了八家在生产中使用 Python 的世界级成功软件公司。但他们不是唯一的。截至 2018 年,Python 的采用达到了一个新的高峰,并继续攀升。
我们有没有漏掉名单上的人?在下面留下评论,让我们知道你最喜欢的 Python 商店!***


 浙公网安备 33010602011771号
浙公网安备 33010602011771号