RealPython-中文系列教程-二-
RealPython 中文系列教程(二)
原文:RealPython
如何用 Python 实现二分搜索法
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 创建二分搜索法
二分搜索法是计算机科学中的经典算法。它经常出现在编程竞赛和技术面试中。实现二分搜索法被证明是一项具有挑战性的任务,即使您理解了这个概念。除非你很好奇或者有特定的任务,否则你应该总是利用现有的库来用 Python 或者任何其他语言做二分搜索法。
在本教程中,您将学习如何:
- 使用
bisect模块在 Python 中做一个二分搜索法 - 在 Python 中递归地实现二分搜索法和迭代地实现 T2
- 识别并修复二分搜索法 Python 实现中的缺陷
- 分析二分搜索法算法的时空复杂度
- 搜索甚至比二分搜索法还要快
本教程假设你是一名学生或对算法和数据结构感兴趣的中级程序员**。最起码要熟悉 Python 的内置数据类型,比如列表和元组。此外,熟悉一下递归、类、数据类和 lambdas 将有助于你更好地理解本教程中的概念。*
*在下面,您将找到贯穿本教程的示例代码的链接,它需要 Python 3.7 或更高版本才能运行:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的二分搜索法。
基准测试
在本教程的下一部分,您将使用互联网电影数据库(IMDb) 的子集来测试一些搜索算法的性能。这个数据集对于个人和非商业用途是免费的。它以一堆压缩的制表符分隔值(TSV) 文件的形式分发,这些文件每天更新。
为了让您的生活更轻松,您可以使用示例代码中包含的 Python 脚本。它会自动从 IMDb 获取相关文件,解压缩,并提取有趣的部分:
$ python download_imdb.py
Fetching data from IMDb...
Created "names.txt" and "sorted_names.txt"
请注意,这将下载和提取大约 600 MB 的数据,并产生两个额外的文件,其大小约为该文件的一半。下载和处理这些数据可能需要一两分钟的时间。
下载 IMDb
要手动获取数据,请在网络浏览器中导航至https://datasets.imdbws.com/,并获取名为name.basics.tsv.gz的文件,其中包含演员、导演、编剧等的记录。当您解压缩文件时,您会看到以下内容:
nconst primaryName birthYear deathYear (...)
nm0000001 Fred Astaire 1899 1987 (...)
nm0000002 Lauren Bacall 1924 2014 (...)
nm0000003 Brigitte Bardot 1934 \N (...)
nm0000004 John Belushi 1949 1982 (...)
它有一个标题,第一行是列名,随后的每一行是数据记录。每个记录包含一个唯一的标识符、全名、出生年份和一些其他属性。这些都用制表符分隔。
有数百万条记录,所以不要试图用常规的文本编辑器打开文件,以免让你的电脑崩溃。即使是专门的软件,如电子表格,也很难打开它。相反,例如,您可以利用包含在 JupyterLab 中的高性能数据网格查看器。
读取制表符分隔的值
有几种方法可以解析 TSV 文件。例如,你可以用 Pandas 阅读它,使用一个专用的应用程序,或者利用一些命令行工具。但是,建议您使用示例代码中包含的简单 Python 脚本。
注意:根据经验,您应该避免手动解析文件,因为您可能会忽略边缘情况。例如,在其中一个字段中,可以在引号内使用分隔制表符,这会破坏列数。只要有可能,尽量在标准库中或者值得信赖的第三方库中找到相关的模块。
最终,您希望得到两个文本文件供您使用:
names.txtsorted_names.txt
其中一个将包含一个通过从原始 TSV 文件中剪切第二列而获得的姓名列表:
Fred Astaire
Lauren Bacall
Brigitte Bardot
John Belushi
Ingmar Bergman
...
第二个将是这个的排序版本。
一旦两个文件都准备好了,就可以使用这个函数将它们加载到 Python 中:
def load_names(path):
with open(path) as text_file:
return text_file.read().splitlines()
names = load_names('names.txt')
sorted_names = load_names('sorted_names.txt')
这段代码返回一个从给定文件中提取的名字列表。注意,对产生的字符串调用.splitlines()会移除每行的尾部换行符。或者,您可以调用text_file.readlines(),但是这样会保留不需要的换行符。
测量执行时间
要评估特定算法的性能,可以根据 IMDb 数据集测量其执行时间。这通常是借助内置的 time 或 timeit 模块来完成的,这些模块对于计时一段代码很有用。
如果你愿意,你也可以定义一个定制的装饰器来计时一个函数。提供的示例代码使用了 Python 3.7 中引入的 time.perf_counter_ns() ,因为它提供了纳秒级的高精度。
理解搜索算法
搜索无处不在,是计算机科学的核心。你可能今天一个人就进行了几次网络搜索,但是你有没有想过搜索到底是什么意思?
搜索算法有许多不同的形式。例如,您可以:
在本教程中,您将学习如何在排序的项目列表(如电话簿)中搜索元素。当您搜索这样的元素时,您可能会问以下问题之一:
| 问题 | 回答 |
|---|---|
| 在那里吗? | 是 |
| 它在哪里? | 在第 42 页 |
| 是哪一个? | 一个叫约翰·多伊的人 |
第一个问题的答案告诉你一个元素是否存在于集合中。它总是保持真或假。第二个答案是集合中某个元素的位置,如果该元素丢失,则可能无法使用。最后,第三个答案是元素本身,或者说缺少它。
注:由于重复或相似的项目,有时可能会有不止一个正确答案。例如,如果您有几个同名的联系人,那么他们都符合您的搜索条件。在其他时候,可能只有一个大概的答案或者根本没有答案。
在最常见的情况下,您将通过值进行搜索,它将集合中的元素与您作为引用提供的元素进行比较。换句话说,您的搜索条件是整个元素,比如一个数字、一个字符串或一个像人这样的对象。即使两个被比较的元素之间的微小差异也不会导致匹配。
另一方面,通过选择元素的某些属性,比如一个人的姓氏,可以使搜索标准更加细化。这被称为通过键的搜索,因为您选择一个或多个属性进行比较。在深入研究 Python 中的二分搜索法之前,让我们快速浏览一下其他搜索算法,以获得更全面的了解,并理解它们是如何工作的。
随机搜索
你会怎样在背包里找东西?你可能只是把手伸进去,随便挑一件,看看它是不是你想要的。如果你运气不好,你就把它放回去,冲洗,然后重复。这个例子很好的理解了随机搜索,这是效率最低的搜索算法之一。这种方法的低效源于这样一个事实,即你冒着多次选择同样错误的东西的风险。
注意:有趣的是,理论上来说,如果你非常幸运或者收藏的元素数量很少,这个策略可能是最有效的。**
该算法的基本原理可以用以下 Python 代码片段来表达:
import random
def find(elements, value):
while True:
random_element = random.choice(elements)
if random_element == value:
return random_element
该函数循环,直到在随机选择的某个元素与作为输入给出的值匹配。然而,这不是很有用,因为函数要么隐式返回 None ,要么返回它已经在参数中收到的相同值。您可以在下面的链接下载的示例代码中找到完整的实现:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的二分搜索法。
对于微观数据集,随机搜索算法似乎工作得相当快:
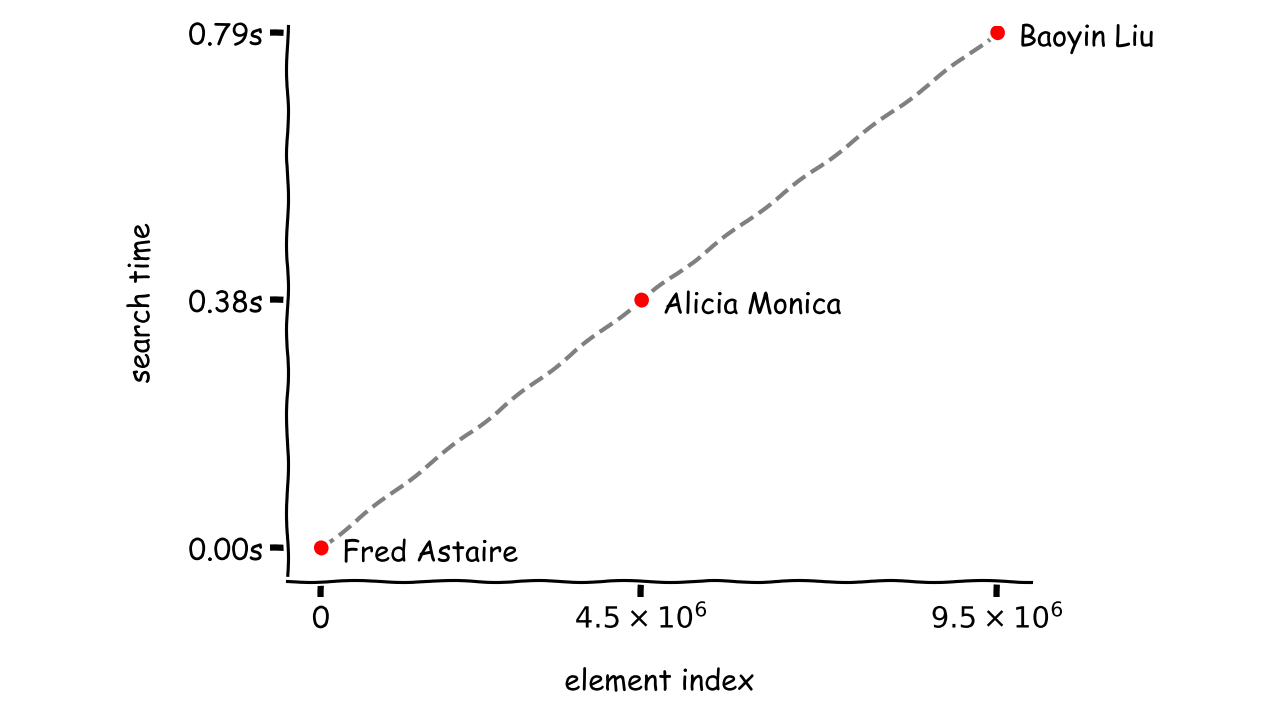
>>> from search.random import * # Sample code to download >>> fruits = ['orange', 'plum', 'banana', 'apple'] >>> contains(fruits, 'banana') True >>> find_index(fruits, 'banana') 2 >>> find(fruits, key=len, value=4) 'plum'然而,想象一下,必须像这样在百万个元素中搜索!下面是对 IMDb 数据集进行的性能测试的简要介绍:
搜索术语 元素索引 最佳时间 平均时间 最糟糕的时候 弗雷德·阿斯泰尔 00.74s21.69s43.16s艾丽西娅·莫妮卡 4,500,0001.02s26.17s66.34sBaoyin Liu 9,500,0000.11s17.41s51.03s失踪 N/A5m 16s5m 40s5m 54s特别选择了不同存储位置的独特元素以避免偏差。考虑到算法的随机性和其他因素,如垃圾收集或在后台运行的系统进程,每个术语都被搜索了十次。
注意:如果你想自己进行这个实验,那么回头参考本教程介绍中的说明。为了测量代码的性能,你可以使用内置的
time和timeit模块,或者你可以使用自定义的装饰器来计时函数。该算法具有非确定性性能。虽然找到一个元素的平均时间不取决于它的位置,但最好和最差的时间相差两到三个数量级。它也遭受不一致的行为。考虑拥有一个包含一些重复元素的元素集合。因为该算法随机选取元素,所以在随后的运行中,它将不可避免地返回不同的副本。
你如何改进这一点?一次解决这两个问题的方法是使用线性搜索。
线性搜索
当你决定午餐吃什么时,你可能会乱翻菜单,直到有什么吸引你的目光。或者,你可以采取一种更系统的方法,从上到下浏览菜单,并按照顺序仔细检查每一个项目。简而言之,这就是线性搜索。要在 Python 中实现它,您可以使用
enumerate()元素来跟踪当前元素的索引:def find_index(elements, value): for index, element in enumerate(elements): if element == value: return index该函数以预定义且一致的顺序在元素集合上循环。当找到元素时,或者当没有更多元素要检查时,它停止。这种策略保证没有一个元素会被访问一次以上,因为您是按
index的顺序遍历它们的。让我们看看线性搜索如何处理您之前使用的 IMDb 数据集:
搜索术语 元素索引 最佳时间 平均时间 最糟糕的时候 弗雷德·阿斯泰尔 0491ns1.17µs6.1µs艾丽西娅·莫妮卡 4,500,0000.37s0.38s0.39sBaoyin Liu 9,500,0000.77s0.79s0.82s失踪 N/A0.79s0.81s0.83s单个元素的查找时间几乎没有任何差异。平均时间实际上与最好和最差的时间相同。因为元素总是以相同的顺序浏览,所以查找相同元素所需的比较次数不会改变。
但是,查找时间会随着集合中元素索引的增加而增加。元素离列表的开头越远,需要进行的比较就越多。在最坏的情况下,当一个元素丢失时,必须检查整个集合才能给出明确的答案。
当您将实验数据投影到图上并连接这些点时,您将立即看到元素位置与找到它所需的时间之间的关系:
所有样本都位于一条直线上,可以用一个线性函数来描述,这也是算法名字的由来。您可以假设,平均而言,使用线性搜索查找任何元素所需的时间将与集合中所有元素的数量成比例。随着要搜索的数据量的增加,它们不能很好地扩展。
例如,如果使用线性搜索,一些机场的生物扫描仪不会在几秒钟内识别乘客。另一方面,线性搜索算法可能是较小数据集的一个好选择,因为它不需要对数据进行预处理。在这种情况下,预处理的好处无法补偿它的成本。
Python 已经提供了线性搜索,所以没有必要自己编写。例如,
list数据结构公开了一个方法,该方法将返回元素的索引,否则将引发异常:
>>> fruits = ['orange', 'plum', 'banana', 'apple']
>>> fruits.index('banana')
2
>>> fruits.index('blueberry')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'blueberry' is not in list
这也可以告诉您该元素是否存在于集合中,但是一种更具python 式的方式是使用通用的in操作符:
>>> 'banana' in fruits True >>> 'blueberry' in fruits False值得注意的是,尽管使用了线性搜索,但这些内置函数和操作符会让您的实现大吃一惊。这是因为它们是用纯 C 编写的,可以编译成本机代码。无论你如何努力,标准的 Python 解释器都不是它的对手。
使用
timeit模块进行的快速测试显示,Python 实现的运行速度可能比同等的本地实现慢十倍:
>>> import timeit
>>> from search.linear import contains
>>> fruits = ['orange', 'plum', 'banana', 'apple']
>>> timeit.timeit(lambda: contains(fruits, 'blueberry'))
1.8904765040024358
>>> timeit.timeit(lambda: 'blueberry' in fruits)
0.22473459799948614
然而,对于足够大的数据集,即使是本机代码也会达到其极限,唯一的解决方案将是重新思考算法。
注意:in操作符并不总是进行线性搜索。例如,当您在set上使用它时,它会进行基于哈希的搜索。操作员可以使用任何可重复的**,包括tuple、list、set、dict和str。通过实现魔法方法 .__contains__()来定义底层逻辑,你甚至可以用它来支持你的定制类。*
*在现实生活中,通常应该避免使用线性搜索算法。例如,有一段时间,我不能在兽医诊所注册我的猫,因为他们的系统总是崩溃。医生告诉我,他最终必须升级他的电脑,因为向数据库中添加更多的记录会使它运行得越来越慢。
我记得当时我心里想,写那个软件的人显然不知道二分搜索法算法!
二分搜索法
单词二进制一般与数字 2 联系在一起。在这个上下文中,它指的是将一个元素集合分成两半,并在算法的每一步丢弃其中的一个。这可以极大地减少查找元素所需的比较次数。但是有一个问题——集合中的元素必须先排序为。
其背后的想法类似于在书中寻找一页的步骤。首先,你通常会把书翻到完全随机的一页,或者至少是接近你认为你想要的那一页的那一页。
偶尔,你会幸运地在第一次尝试时找到那个页面。然而,如果页码太低,那么你知道这一页一定是在右边。如果您在下一次尝试时超过了,并且当前页码高于您正在查找的页面,那么您肯定知道它一定在两者之间。
重复这个过程,但不是随机选择一个页面,而是检查位于新范围中间的页面。这最大限度地减少了尝试的次数。类似的方法可以用在数字猜谜游戏中。如果您没有听说过这个游戏,那么您可以在互联网上查找,以获得大量用 Python 实现的示例。
注:有时,如果数值是均匀分布的,可以用线性插值计算中间指数,而不是取平均值。该算法的这种变化将需要更少的步骤。
限制要搜索的页面范围的页码称为下限和上限。在二分搜索法,通常从第一页开始作为下界,最后一页作为上界。您必须在进行过程中更新这两个边界。例如,如果你翻到的那一页比你要找的那一页低,那就是你新的下限。
假设您要在一组按大小升序排列的水果中寻找一颗草莓:
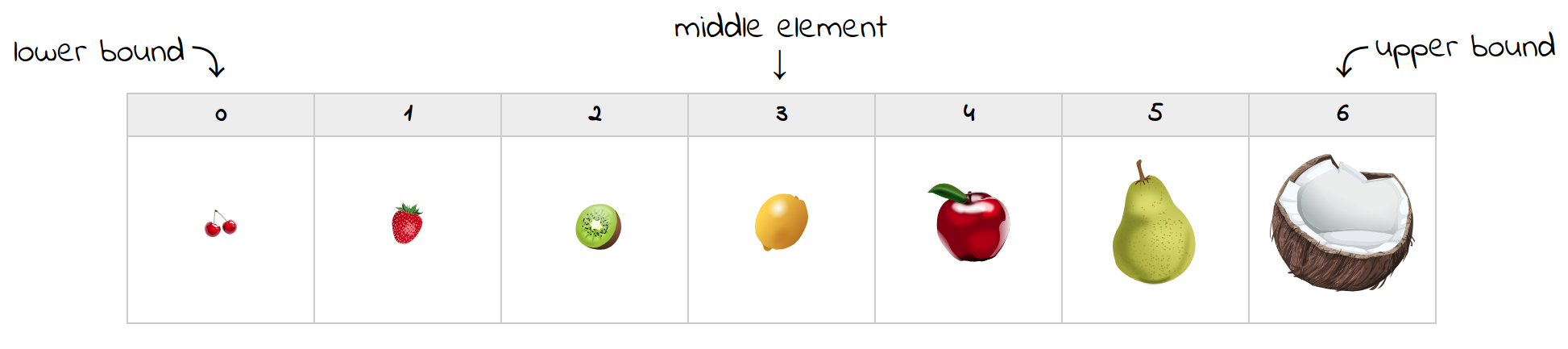
第一次尝试时,中间的元素恰好是一个柠檬。因为它比草莓大,你可以丢弃右边的所有元素,包括柠檬。您将把上限移动到一个新位置,并更新中间索引:
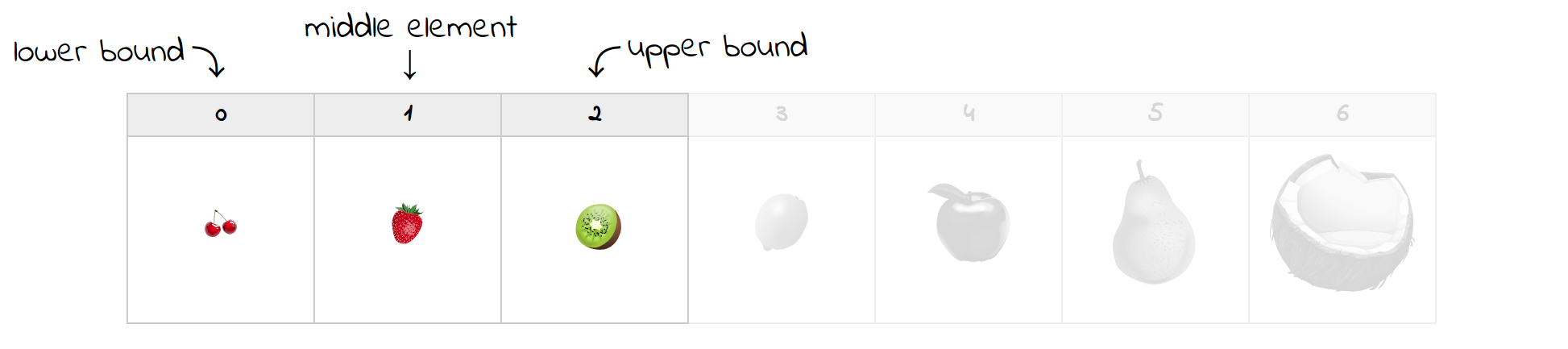
现在,你只剩下一半的水果了。当前的中间元素确实是您正在寻找的草莓,这结束了搜索。如果不是,那么你只需要相应地更新边界,并继续下去,直到它们通过对方。例如,在草莓和猕猴桃之间寻找一个丢失的李子,将得到以下结果:
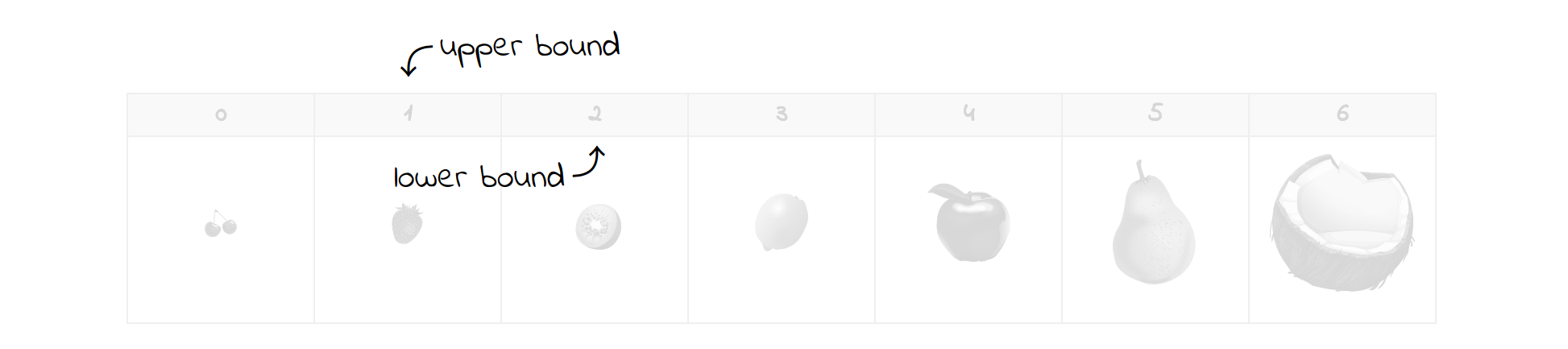
请注意,为了找到想要的元素,不必进行太多的比较。这就是二分搜索法的魅力。即使您正在处理一百万个元素,您最多只需要少量的检查。这个数不会因为减半而超过元素总数的对数底数 2。换句话说,剩余元素的数量在每一步减少一半。
这是可能的,因为元素已经按大小排序。但是,如果您想通过另一个关键字(比如颜色)来查找水果,那么您必须再次对整个集合进行排序。为了避免昂贵的排序开销,您可以尝试预先计算同一集合的不同视图。这有点类似于创建一个数据库索引。
考虑一下如果在集合中添加、删除或更新一个元素会发生什么。为了让二分搜索法继续工作,您需要保持正确的排序顺序。这可以通过bisect模块来完成,您将在下一节中读到。
在本教程的后面,你将看到如何用 Python 实现二分搜索法算法。现在,让我们用 IMDb 数据集来面对它。请注意,现在要搜索的人与以前不同。这是因为数据集必须针对二分搜索法进行排序,这会对元素进行重新排序。新元素的位置与之前大致相同,以保持测量的可比性:
| 搜索术语 | 元素索引 | 平均时间 | 比较 |
|---|---|---|---|
| (…)准备好了 | 0 |
6.52µs |
Twenty-three |
| 乔纳森·萨姆万埃特 | 4,499,997 |
6.99µs |
Twenty-four |
| 黑曲霉 | 9,500,001 |
6.5µs |
Twenty-three |
| 失踪 | N/A |
7.2µs |
Twenty-three |
答案几乎是即时的。在一般情况下,二分搜索法只需要几微秒就能在九百万个元素中找到一个!除此之外,所选元素的比较次数几乎保持不变,这符合以下公式:
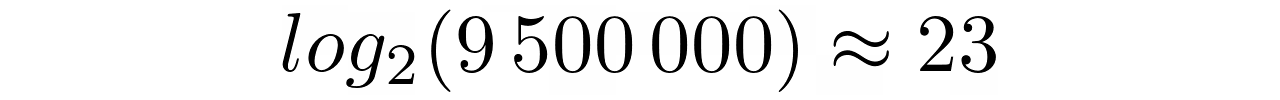
找到大多数元素将需要最大数量的比较,这可以从集合大小的对数中得出。相反,中间只有一个元素可以在第一次比较中找到。
二分搜索法是“分而治之”技术的一个很好的例子,这种技术将一个问题分成一堆同类的小问题。然后将各个解决方案组合起来,形成最终答案。这种技术的另一个众所周知的例子是快速排序算法。
注:不要把各个击破和 动态编程 混为一谈,这是有点类似的手法。
与其他搜索算法不同,二分搜索法不仅可以用于搜索。例如,它允许集合成员测试、查找最大值或最小值、查找目标值的最近邻、执行范围查询等等。
如果速度是重中之重,那么二分搜索法并不总是最好的选择。甚至还有更快的算法可以利用基于散列的数据结构。然而,这些算法需要大量额外的内存,而二分搜索法提供了一个很好的时空权衡。
基于哈希的搜索
为了更快的搜索,你需要缩小问题空间。二分搜索法通过将每一级的候选人数减半来实现这一目标。这意味着,即使您有一百万个元素,如果所有元素都已排序,那么最多需要二十次比较才能确定该元素是否存在。
最快的搜索方法是知道在哪里可以找到你要找的东西。如果您知道一个元素的确切内存位置,那么您将直接访问它,而不需要首先进行搜索。将一个元素或者(更常见的)它的一个键映射到内存中的元素位置被称为散列。
您可以认为散列不是搜索特定的元素,而是基于元素本身计算索引。这是一个 哈希函数 的工作,它需要保存某些数学属性。一个好的散列函数应该:
*同时,它不应该在计算上太昂贵,否则它的成本会超过收益。哈希函数也用于数据完整性验证和加密。
使用这个概念将键映射为值的数据结构被称为映射、散列表、字典或关联数组。
注意: Python 有两个内置的数据结构,分别是set和dict,依靠 hash 函数寻找元素。当一个set散列它的元素时,一个dict对元素键使用散列函数。要弄清楚dict是如何在 Python 中实现的,请查看 Raymond Hettinger 关于现代 Python 词典的会议演讲。
另一种可视化散列的方式是想象相似元素的所谓的桶被分组到它们各自的键下。例如,您可以根据颜色将水果收获到不同的桶中:

椰子和猕猴桃被放入标有棕色标签的桶中,而苹果则被放入标有红色标签的桶中,以此类推。这允许你快速浏览一小部分元素。理想情况下,你希望每个桶里只有一个水果。否则,你会得到所谓的碰撞,这会导致额外的工作。
注意:桶及其内容通常没有特定的顺序。
让我们将 IMDb 数据集中的名字放入字典中,这样每个名字就成为一个键,相应的值就成为它的索引:
>>> from benchmark import load_names # Sample code to download >>> names = load_names('names.txt') >>> index_by_name = { ... name: index for index, name in enumerate(names) ... }在将文本名称加载到平面列表中之后,您可以将它放入字典理解(T2)中来创建映射。现在,检查元素是否存在以及获取其索引非常简单:
>>> 'Guido van Rossum' in index_by_name
False
>>> 'Arnold Schwarzenegger' in index_by_name
True
>>> index_by_name['Arnold Schwarzenegger']
215
感谢在幕后使用的哈希函数,你根本不用实现任何搜索!
以下是基于哈希的搜索算法在 IMDb 数据集上的表现:
| 搜索术语 | 元素索引 | 最佳时间 | 平均时间 | 最糟糕的时候 |
|---|---|---|---|---|
| 弗雷德·阿斯泰尔 | 0 |
0.18µs |
0.4µs |
1.9µs |
| 艾丽西娅·莫妮卡 | 4,500,000 |
0.17µs |
0.4µs |
2.4µs |
| Baoyin Liu | 9,500,000 |
0.17µs |
0.4µs |
2.6µs |
| 失踪 | N/A |
0.19µs |
0.4µs |
1.7µs |
不仅平均时间比已经很快的二分搜索法 Python 实现快了一个数量级,而且无论元素在哪里,这种速度在所有元素中都保持不变。
这种收益的代价是 Python 进程多消耗了大约 0.5 GB 的内存,加载时间变慢,并且需要保持额外的数据与字典的内容一致。反过来,查找非常快,而更新和插入比列表稍慢。
字典对关键字的另一个约束是它们必须是可散列的,并且它们的散列值不能随时间改变。您可以通过对特定数据类型调用hash()来检查它在 Python 中是否是可散列的:
>>> key = ['round', 'juicy'] >>> hash(key) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list'可变集合——如
list、set和dict—是不可散列的。实际上,字典键应该是不可变的,因为它们的哈希值通常取决于键的一些属性。如果一个可变集合是可散列的,并且可以用作一个键,那么它的散列值在每次内容改变时都会不同。考虑一下,如果一个特定的水果由于成熟而改变了颜色,会发生什么。你找错桶了!散列函数还有许多其他用途。例如,它用在密码学中以避免以纯文本形式存储密码,以及用于数据完整性验证。
使用
bisect模块Python 中的二分搜索法可以使用内置的
bisect模块来执行,这也有助于按排序顺序保存列表。它基于求函数根的二分法。该模块有六个功能,分为两类:
查找索引 插入元素 bisect()insort()bisect_left()insort_left()bisect_right()insort_right()这些函数允许您查找一个元素的索引或者在正确的位置添加一个新元素。第一行中的那些只是分别用于
bisect_right()和insort_right()的别名。实际上,你只需要处理四个功能。注意:在将列表传递给某个函数之前,您有责任对其进行排序。如果元素没有排序,那么您很可能会得到不正确的结果。
事不宜迟,让我们看看
bisect模块的运行情况。寻找元素
要在排序列表中查找现有元素的索引,您需要
bisect_left():
>>> import bisect
>>> sorted_fruits = ['apple', 'banana', 'orange', 'plum']
>>> bisect.bisect_left(sorted_fruits, 'banana')
1
输出告诉您香蕉是列表中的第二种水果,因为它是在索引1处找到的。但是,如果缺少一个元素,您仍然可以获得它的预期位置:
>>> bisect.bisect_left(sorted_fruits, 'apricot') 1 >>> bisect.bisect_left(sorted_fruits, 'watermelon') 4尽管这些水果还没有列在清单上,但你可以知道把它们放在哪里。例如,杏应该出现在苹果和香蕉之间,而西瓜应该成为最后一个元素。通过评估两个条件,您将知道是否找到了元素:
索引是否在列表大小内?
元素的值是想要的值吗?
这可以转化为通过值查找元素的通用函数:
def find_index(elements, value): index = bisect.bisect_left(elements, value) if index < len(elements) and elements[index] == value: return index当有匹配时,该函数将返回相应的元素索引。否则,它将隐式返回
None。要按键搜索,您必须维护一个单独的键列表。因为这会导致额外的成本,所以预先计算这些键并尽可能多地重用它们是值得的。您可以定义一个助手类,以便能够通过不同的键进行搜索,而不会引入太多的代码重复:
class SearchBy: def __init__(self, key, elements): self.elements_by_key = sorted([(key(x), x) for x in elements]) self.keys = [x[0] for x in self.elements_by_key]密钥是作为第一个参数传递给
__init__()的函数。一旦有了它,就可以创建一个键-值对的排序列表,以便以后能够从它的键中检索元素。用元组表示对保证了每对的第一个元素将被排序。在下一步中,您将提取键来创建一个适合您的二分搜索法 Python 实现的平面列表。还有通过键查找元素的实际方法:
class SearchBy: def __init__(self, key, elements): ... def find(self, value): index = bisect.bisect_left(self.keys, value) if index < len(self.keys) and self.keys[index] == value: return self.elements_by_key[index][1]这段代码将排序后的键列表一分为二,通过键获得元素的索引。如果这样的键存在,那么它的索引可以用来从以前计算的键-值对列表中获得相应的对。该对中的第二个元素是期望值。
注:这只是一个说明性的例子。使用官方文件中提到的推荐食谱,你会感觉更好。
如果你有多个香蕉,那么
bisect_left()将返回最左边的实例:
>>> sorted_fruits = [
... 'apple',
... 'banana', 'banana', 'banana',
... 'orange',
... 'plum'
... ]
>>> bisect.bisect_left(sorted_fruits, 'banana')
1
可以预见,要获得最右边的香蕉,您需要调用bisect_right()或它的别名bisect()。但是,这两个函数从实际最右边的香蕉返回一个索引,这对于查找新元素的插入点很有用:
>>> bisect.bisect_right(sorted_fruits, 'banana') 4 >>> bisect.bisect(sorted_fruits, 'banana') 4 >>> sorted_fruits[4] 'orange'当你组合代码时,你可以看到你有多少香蕉:
>>> l = bisect.bisect_left(sorted_fruits, 'banana')
>>> r = bisect.bisect_right(sorted_fruits, 'banana')
>>> r - l
3
如果缺少一个元素,那么bisect_left()和bisect_right()将返回相同的索引,没有香蕉。
插入新元素
模块的另一个实际应用是维护已经排序的列表中元素的顺序。毕竟,你不会想在每次需要插入内容的时候对整个列表进行排序。在大多数情况下,这三种功能可以互换使用:
>>> import bisect >>> sorted_fruits = ['apple', 'banana', 'orange'] >>> bisect.insort(sorted_fruits, 'apricot') >>> bisect.insort_left(sorted_fruits, 'watermelon') >>> bisect.insort_right(sorted_fruits, 'plum') >>> sorted_fruits ['apple', 'apricot', 'banana', 'orange', 'plum', 'watermelon']直到你的列表中有个重复的时,你才会看到任何不同。但即使这样,只要这些重复项是简单的值,它就不会变得明显。再往左边加一根香蕉,效果和往右边加一样。
要注意这种差异,您需要一种数据类型,其对象可以有个唯一标识,尽管有个相等的值。让我们使用 Python 3.7 中引入的 @dataclass 装饰器来定义一个
Person类型:from dataclasses import dataclass, field @dataclass class Person: name: str number: int = field(compare=False) def __repr__(self): return f'{self.name}({self.number})'一个人有一个
name和一个任意的number分配给它。通过从相等测试中排除number字段,您使两个人相等,即使他们具有不同的属性值:
>>> p1 = Person('John', 1)
>>> p2 = Person('John', 2)
>>> p1 == p2
True
另一方面,这两个变量指的是完全独立的实体,这使您可以区分它们:
>>> p1 is p2 False >>> p1 John(1) >>> p2 John(2)变量
p1和p2确实是不同的对象。请注意,默认情况下,数据类的实例是不可比较的,这使得您无法对它们使用二分法:
>>> alice, bob = Person('Alice', 1), Person('Bob', 1)
>>> alice < bob
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'Person' and 'Person'
Python 不知道对alice和bob排序,因为它们是自定义类的对象。传统上,你要在你的类中实现神奇的方法.__lt__(),它代表小于,告诉解释器如何比较这些元素。然而,@dataclass装饰器接受一些可选的布尔标志。其中之一是order,当设置为True时,会自动生成用于比较的神奇方法:
@dataclass(order=True) class Person:
...
反过来,这允许你比较两个人,并决定谁先来:
>>> alice < bob True >>> bob < alice False最后,您可以利用
name和number属性来观察各种函数向列表中插入新成员的位置:
>>> sorted_people = [Person('John', 1)]
>>> bisect.insort_left(sorted_people, Person('John', 2))
>>> bisect.insort_right(sorted_people, Person('John', 3))
>>> sorted_people
[John(2), John(1), John(3)]
名称后括号中的数字表示插入顺序。最开始的时候,只有一个John,他得到的号码是1。然后,你把它的复制品加到左边,后来又在右边加了一个。
用 Python 实现二分搜索法
请记住,除非有充分的理由,否则您可能不应该实现该算法。你将节省时间,不需要重新发明轮子。库代码很有可能是成熟的,已经在生产环境中被真实用户测试过,并且具有由多个贡献者交付的广泛功能。
也就是说,有时候卷起袖子自己动手是有意义的。由于许可或安全问题,您的公司可能有禁止某些开源库的政策。也许由于内存或网络带宽的限制,您无法承受另一种依赖。最后,自己编写代码可能是一个很好的学习工具!
您可以通过两种方式实现大多数算法:
- 迭代
- 递归
然而,这一规则也有例外。一个显著的例子是阿克曼函数,它只能用递归来表示。
在进一步学习之前,请确保您已经很好地掌握了二分搜索法算法。你可以参考本教程前面的部分来快速复习。
迭代
该算法的迭代版本包含一个循环,它将重复一些步骤,直到满足停止条件。让我们从实现一个函数开始,这个函数将通过值搜索元素并返回它们的索引:
def find_index(elements, value):
...
稍后您将重用这个函数。
假设所有的元素都被排序,你可以在序列的两端设置上下边界:
def find_index(elements, value):
left, right = 0, len(elements) - 1
现在,您希望识别中间的元素,以查看它是否具有所需的值。计算中间指数可以通过取两个边界的平均值来完成:
def find_index(elements, value):
left, right = 0, len(elements) - 1
middle = (left + right) // 2
注意一个整数除法是如何通过对结果进行地板处理来帮助处理有界范围内的奇数和偶数元素的。根据你如何更新边界和定义停止条件,你也可以使用上限函数。
接下来,您要么完成序列,要么将序列一分为二,并继续在结果的一半中搜索:
def find_index(elements, value):
left, right = 0, len(elements) - 1
middle = (left + right) // 2
if elements[middle] == value: return middle
if elements[middle] < value: left = middle + 1 elif elements[middle] > value: right = middle - 1
如果中间的元素是匹配的,那么返回它的索引。否则,如果它太小,那么你需要向上移动下边界。如果它太大,那么你需要把上限下移。
要继续前进,您必须将大部分步骤封闭在一个循环中,当下边界超过上边界时,循环将停止:
def find_index(elements, value):
left, right = 0, len(elements) - 1
while left <= right: middle = (left + right) // 2
if elements[middle] == value:
return middle
if elements[middle] < value:
left = middle + 1
elif elements[middle] > value:
right = middle - 1
换句话说,只要下边界低于或等于上边界,您就希望迭代。否则,没有匹配,函数隐式返回None。
通过关键字搜索可以归结为查看一个对象的属性,而不是它的文字值。例如,关键字可以是水果名称中的字符数。您可以修改find_index()以接受并使用一个key参数:
def find_index(elements, value, key):
left, right = 0, len(elements) - 1
while left <= right:
middle = (left + right) // 2
middle_element = key(elements[middle])
if middle_element == value:
return middle
if middle_element < value:
left = middle + 1
elif middle_element > value:
right = middle - 1
但是,您还必须记住使用您将要搜索的相同的key对列表进行排序:
>>> fruits = ['orange', 'plum', 'watermelon', 'apple'] >>> fruits.sort(key=len) >>> fruits ['plum', 'apple', 'orange', 'watermelon'] >>> fruits[find_index(fruits, key=len, value=10)] 'watermelon' >>> print(find_index(fruits, key=len, value=3)) None在上面的例子中,
watermelon被选中是因为它的名字正好是十个字符长,而列表中没有水果的名字是由三个字母组成的。这很好,但同时,您也失去了按值搜索的能力。为了解决这个问题,你可以给
key分配一个默认值None,然后检查它是否被给定。然而,在一个更简化的解决方案中,您总是希望调用key。默认情况下,它是一个返回元素本身的标识函数:def identity(element): return element def find_index(elements, value, key=identity): ...或者,您可以使用匿名的 lambda 表达式来定义 identity 函数:
def find_index(elements, value, key=lambda x: x): ...只回答一个问题。还有另外两个,分别是“在吗?”以及“这是什么?”要回答这两个问题,您可以在此基础上构建:
def find_index(elements, value, key): ... def contains(elements, value, key=identity): return find_index(elements, value, key) is not None def find(elements, value, key=identity): index = find_index(elements, value, key) return None if index is None else elements[index]有了这三个函数,您几乎可以了解一个元素的所有信息。然而,在您的实现中,您仍然没有解决重复的问题。如果你有一群人,其中一些人有共同的名字或姓氏,那会怎么样?例如,人们中可能有一个
Smith家庭或几个叫John的人:people = [ Person('Bob', 'Williams'), Person('John', 'Doe'), Person('Paul', 'Brown'), Person('Alice', 'Smith'), Person('John', 'Smith'), ]要对
Person类型建模,您可以修改前面定义的数据类:from dataclasses import dataclass @dataclass(order=True) class Person: name: str surname: str请注意使用了
order属性来自动生成神奇的方法,以便通过所有字段来比较该类的实例。或者,您可能更喜欢利用namedtuple,它的语法更短:from collections import namedtuple Person = namedtuple('Person', 'name surname')这两种定义都很好,可以互换。每个人都有一个
name和一个surname属性。要按其中一个进行排序和搜索,您可以使用内置operator模块中的attrgetter()方便地定义关键功能:
>>> from operator import attrgetter
>>> by_surname = attrgetter('surname')
>>> people.sort(key=by_surname)
>>> people
[Person(name='Paul', surname='Brown'),
Person(name='John', surname='Doe'),
Person(name='Alice', surname='Smith'),
Person(name='John', surname='Smith'),
Person(name='Bob', surname='Williams')]
注意现在人们是如何按照姓氏升序排列的。有John Smith和Alice Smith,但是对Smith姓氏进行二进制搜索目前只会给出一个任意的结果:
>>> find(people, key=by_surname, value='Smith') Person(name='Alice', surname='Smith')为了模仿前面显示的
bisect模块的特性,您可以编写自己版本的bisect_left()和bisect_right()。在找到重复元素的最左边的和实例之前,您需要确定是否存在这样的元素:def find_leftmost_index(elements, value, key=identity): index = find_index(elements, value, key) if index is not None: ... return index如果已经找到了某个索引,那么您可以向左看并继续移动,直到您遇到具有不同键的元素或者不再有元素:
def find_leftmost_index(elements, value, key=identity): index = find_index(elements, value, key) if index is not None: while index >= 0 and key(elements[index]) == value: index -= 1 index += 1 return index一旦越过最左边的元素,就需要将索引向右移动一个位置。
找到最右边的实例非常相似,但是您需要翻转条件:
def find_rightmost_index(elements, value, key=identity): index = find_index(elements, value, key) if index is not None: while index < len(elements) and key(elements[index]) == value: index += 1 index -= 1 return index现在你不是向左走,而是向右走,直到列表结束。使用这两个函数,您可以找到重复项目的所有出现次数:
def find_all_indices(elements, value, key=identity): left = find_leftmost_index(elements, value, key) right = find_rightmost_index(elements, value, key) if left and right: return set(range(left, right + 1)) return set()这个函数总是返回一个集合。如果没有找到元素,那么集合将是空的。如果元素是唯一的,那么集合将只由一个索引组成。否则,集合中会有多个索引。
最后,您可以定义更抽象的函数来完善您的二分搜索法 Python 库:
def find_leftmost(elements, value, key=identity): index = find_leftmost_index(elements, value, key) return None if index is None else elements[index] def find_rightmost(elements, value, key=identity): index = find_rightmost_index(elements, value, key) return None if index is None else elements[index] def find_all(elements, value, key=identity): return {elements[i] for i in find_all_indices(elements, value, key)}这不仅允许您精确定位列表中元素的确切位置,还允许您检索这些元素。你可以问非常具体的问题:
在那里吗? 它在哪里? 这是什么? contains()find_index()find()find_leftmost_index()find_leftmost()find_rightmost_index()find_rightmost()find_all_indices()find_all()二分搜索法 Python 库的完整代码可以在下面的链接中找到:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的二分搜索法。
递归
为了简单起见,我们只考虑
contains()的递归版本,它告诉我们是否找到了一个元素。注意:我最喜欢的关于递归的定义是在关于 JavaScript 函数式编程的Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun Fun
"递归是当一个函数调用它自己,直到它不调用为止."
-mattias Petter Johansson的缩写
最直接的方法是采用二分搜索法的迭代版本,并使用切片操作符来分割列表:
def contains(elements, value): left, right = 0, len(elements) - 1 if left <= right: middle = (left + right) // 2 if elements[middle] == value: return True if elements[middle] < value: return contains(elements[middle + 1:], value) elif elements[middle] > value: return contains(elements[:middle], value) return False不是循环,而是检查一次条件,有时在一个较小的列表上调用相同的函数。那会有什么问题呢?事实证明,切片会生成元素引用的副本,这会产生显著的内存和计算开销。
为了避免复制,您可以重用同一个列表,但在必要时将不同的边界传递给函数:
def contains(elements, value, left, right): if left <= right: middle = (left + right) // 2 if elements[middle] == value: return True if elements[middle] < value: return contains(elements, value, middle + 1, right) elif elements[middle] > value: return contains(elements, value, left, middle - 1) return False缺点是每次你想调用那个函数时,你必须通过初始边界,确保它们是正确的:
>>> sorted_fruits = ['apple', 'banana', 'orange', 'plum']
>>> contains(sorted_fruits, 'apple', 0, len(sorted_fruits) - 1)
True
如果你犯了一个错误,那么它可能找不到那个元素。您可以通过使用默认的函数参数或引入一个助手函数来改进这一点,该助手函数委托给递归函数:
def contains(elements, value):
return recursive(elements, value, 0, len(elements) - 1)
def recursive(elements, value, left, right):
...
更进一步,您可能更喜欢将一个函数嵌套在另一个函数中,以隐藏技术细节并利用外部作用域的变量重用:
def contains(elements, value):
def recursive(left, right):
if left <= right:
middle = (left + right) // 2
if elements[middle] == value:
return True
if elements[middle] < value:
return recursive(middle + 1, right)
elif elements[middle] > value:
return recursive(left, middle - 1)
return False
return recursive(0, len(elements) - 1)
recursive() 内部函数可以访问elements和value参数,即使它们是在封闭范围内定义的。Python 中变量的生命周期和可见性由所谓的 LEGB 规则决定,该规则告诉解释器按以下顺序查找符号:
- 本地范围
- 封闭范围
- 全局范围
- 内置符号
这允许从嵌套的代码块中访问外部作用域中定义的变量。
迭代和递归实现之间的选择通常是性能考虑、便利性以及个人喜好的最终结果。然而,递归也有一定的风险,这是下一节的主题之一。
掩盖棘手的细节
以下是《计算机编程的艺术》 的作者对实现二分搜索法算法的看法:
“尽管二分搜索法的基本思想相对来说比较简单,但细节可能出人意料地复杂,许多优秀的程序员在第一次尝试时就做错了。”
—唐纳德·克努特
如果这还不足以阻止你自己编写算法的想法,那么这个可能会。Java 中的标准库在实现二分搜索法时有一个微妙的错误,这个错误十年来都没有被发现!但是臭虫本身的根源要比这早得多。
注:我曾经在一次技术筛选中成为二分搜索法算法的受害者。有几个编码难题需要解决,包括一个二分搜索法难题。猜猜我哪一个没完成?是啊。
下面的列表并不详尽,但同时,它也没有谈到像忘记对列表排序这样的常见错误。
整数溢出
这就是刚刚提到的 Java bug。如果您还记得,二分搜索法 Python 算法检查排序集合中有界范围的中间元素。但是中间元素究竟是如何选择的呢?通常,取上下边界的平均值来寻找中间指数:
middle = (left + right) // 2
这种计算平均值的方法在绝大多数情况下都很好。但是,一旦元素集合变得足够大,两个边界的总和就不适合整数数据类型。它将大于整数允许的最大值。
在这种情况下,一些编程语言可能会引发错误,从而立即停止程序执行。不幸的是,情况并非总是如此。比如 Java 默默的忽略了这个问题,让值翻转过来变成了某个看似随机的数字。只有当结果恰好是负数时,您才会知道这个问题,这会抛出一个IndexOutOfBoundsException。
这里有一个例子演示了在 jshell 中的这种行为,它有点像 Java 的交互式解释器:
jshell> var a = Integer.MAX_VALUE a ==> 2147483647 jshell> a + 1 $2 ==> -2147483648
找到中间索引的更安全的方法是首先计算偏移量,然后将其添加到下边界:
middle = left + (right - left) // 2
即使两个值都达到最大值,上面公式中的和也永远不会是。还有一些方法,但好消息是您不需要担心这些,因为 Python 没有整数溢出错误。除了内存之外,整数的大小没有上限:
>>> 2147483647**7 210624582650556372047028295576838759252690170086892944262392971263然而,有一个问题。当您从库中调用函数时,代码可能会受到 C 语言的约束,仍然会导致溢出。Python 中有很多基于 C 语言的库。你甚至可以构建自己的 C 扩展模块,或者使用
ctypes将动态链接库加载到 Python 中。堆栈溢出
从理论上讲,堆栈溢出问题可能与二分搜索法的递归实现有关。大多数编程语言对嵌套函数调用的数量都有限制。每个调用都与存储在堆栈中的返回地址相关联。在 Python 中,此类调用的默认限制是几千级:
>>> import sys
>>> sys.getrecursionlimit()
3000
这对许多递归函数来说是不够的。然而,由于其对数性质,Python 中的二分搜索法不太可能需要更多。你需要收集 2 的 3000 次方个元素。那是一个超过九百位数的数字!
然而,如果停止条件由于一个 bug 而被错误地陈述,那么无限递归错误仍然有可能出现。在这种情况下,无限递归将最终导致堆栈溢出。
注意:****堆栈溢出错误在手动内存管理的语言中非常常见。人们经常会在谷歌上搜索这些错误,看看其他人是否也有类似的问题,这就给一个流行的程序员网站Q&A起了个名字。
您可以临时提高或降低递归限制来模拟堆栈溢出错误。请注意,由于 Python 运行时环境必须调用的函数,有效限制将会更小:
>>> def countup(limit, n=1): ... print(n) ... if n < limit: ... countup(limit, n + 1) ... >>> import sys >>> sys.setrecursionlimit(7) # Actual limit is 3 >>> countup(10) 1 2 3 Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 4, in countup File "<stdin>", line 4, in countup File "<stdin>", line 2, in countup RecursionError: maximum recursion depth exceeded while calling a Python object在堆栈饱和之前,递归函数被调用了三次。剩下的四个调用肯定是由交互式解释器发出的。如果您在 PyCharm 或其他 Python shell 中运行相同的代码,那么您可能会得到不同的结果。
重复元素
您知道列表中有重复元素的可能性,并且知道如何处理它们。这只是为了强调 Python 中传统的二分搜索法可能不会产生确定性的结果。根据列表的排序方式或元素数量,您会得到不同的答案:
>>> from search.binary import *
>>> sorted_fruits = ['apple', 'banana', 'banana', 'orange']
>>> find_index(sorted_fruits, 'banana')
1
>>> sorted_fruits.append('plum')
>>> find_index(sorted_fruits, 'banana')
2
单子上有两个香蕉。起初,对find_index()的调用返回左边的。然而,在列表的末尾添加一个完全不相关的元素会使相同的调用产生不同的banana。
同样的原理,被称为算法稳定性,适用于排序算法。有些是稳定的,意味着它们不会改变等价元素的相对位置。其他人不做这样的保证。如果您需要根据多个标准对元素进行排序,那么您应该总是从最不重要的键开始,以保持稳定性。
浮点舍入
到目前为止,你只搜索了水果或人,但数字呢?他们应该没什么不同,对吧?让我们使用列表理解来制作一个以0.1为增量的浮点数列表:
>>> sorted_numbers = [0.1*i for i in range(1, 4)]该列表应包含数字:十分之一的、十分之二的和十分之三的。令人惊讶的是,这三个数字中只有两个可以找到:
>>> from search.binary import contains
>>> contains(sorted_numbers, 0.1)
True
>>> contains(sorted_numbers, 0.2)
True
>>> contains(sorted_numbers, 0.3)
False
这不是一个与 Python 中的二分搜索法严格相关的问题,因为内置的线性搜索与它是一致的:
>>> 0.1 in sorted_numbers True >>> 0.2 in sorted_numbers True >>> 0.3 in sorted_numbers False这甚至不是 Python 的问题,而是浮点数如何在计算机内存中表示的问题。这是由 IEEE 754 浮点运算标准定义的。不深入细节,一些十进制数没有二进制形式的有限表示。由于内存有限,这些数字被舍入,导致浮点舍入错误。
注意:如果你需要最大的精度,那么避开浮点数。它们非常适合工程用途。但是,对于货币操作,您不希望舍入误差累积。建议将所有价格和金额缩小到最小单位,如美分或便士,并将它们视为整数。
或者,许多编程语言都支持定点数,比如 Python 中的十进制类型。这使您可以控制舍入发生的时间和方式。
如果您确实需要处理浮点数,那么您应该用一个近似比较来代替精确匹配。让我们考虑两个值略有不同的变量:
>>> a = 0.3
>>> b = 0.1 * 3
>>> b
0.30000000000000004
>>> a == b
False
虽然两个值几乎相同,但常规比较会得出否定结果。幸运的是,Python 提供了一个函数来测试两个值在某个小邻域内是否接近:
>>> import math >>> math.isclose(a, b) True该邻域是值之间的最大距离,可根据需要进行调整:
>>> math.isclose(a, b, rel_tol=1e-16)
False
您可以通过以下方式使用该函数在 Python 中进行二分搜索法:
import math
def find_index(elements, value):
left, right = 0, len(elements) - 1
while left <= right:
middle = (left + right) // 2
if math.isclose(elements[middle], value): return middle
if elements[middle] < value:
left = middle + 1
elif elements[middle] > value:
right = middle - 1
另一方面,Python 中二分搜索法的这种实现仅特定于浮点数。你不能用它来搜索其他任何东西而不出错。
解析二分搜索法的时空复杂性
接下来的部分将不包含代码和一些数学概念。
在计算中,你可以以增加内存使用为代价来优化几乎任何算法的性能。例如,您看到了基于哈希的 IMDb 数据集搜索需要额外的 0.5 GB 内存来实现无与伦比的速度。
相反,为了节省带宽,您会在通过网络发送视频流之前对其进行压缩,这增加了工作量。这种现象被称为时空权衡,在评估算法的复杂度时非常有用。
时空复杂度
计算复杂度是一种相对的度量,用来衡量一个算法完成它的工作需要多少资源。资源包括计算时间以及它使用的内存量。比较各种算法的复杂性可以让你在给定的情况下做出明智的决定。
注意:不需要分配比其输入数据已经消耗的内存更多的内存的算法被称为就地,或就地,算法。这导致原始数据的变异,有时可能会产生不必要的副作用。
您了解了一些搜索算法以及它们在大型数据集上的平均性能。从这些测量中可以明显看出,二分搜索法比线性搜索更快。你甚至可以通过什么因素来判断。
然而,如果你在不同的环境中进行相同的测量,你可能会得到稍微不同或者完全不同的结果。有一些看不见的因素会影响你的测试。此外,这样的测量并不总是可行的。那么,如何快速客观地比较时间复杂度呢?
第一步是将算法分解成更小的部分,并找到做最多工作的部分。很可能会有一些基本操作被多次调用,并且持续花费相同的时间来运行。对于搜索算法,这样的操作可能是两个元素的比较。
建立了这一点,现在可以分析算法了。要找到时间复杂度,您需要描述执行的基本操作数量与输入大小之间的关系。形式上,这样的关系是一个数学函数。然而,你对寻找它的精确代数公式不感兴趣,而是估计它的整体形状。
有几个众所周知的函数类适合大多数算法。一旦您根据其中一个算法对其进行分类,您就可以将它放在一个标尺上:
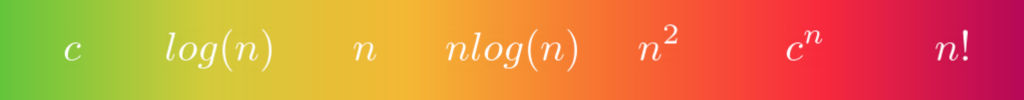
这些类告诉您基本操作的数量是如何随着输入大小的增加而增加的。从左至右分别是:
- 常数
- 对数的
- 线性的
- 拟线性的
- 二次的
- 指数的
- 阶乘
这可以让你对你正在考虑的算法的性能有一个概念。不管输入大小如何,恒定的复杂度是最理想的。对数复杂度仍然很好,表明分而治之的技术正在使用。在这个标度上,越靠右,算法的复杂性越差,因为它有更多的工作要做。
当你谈论时间复杂度时,你通常指的是渐近复杂度,它描述了在非常大的数据集下的行为。这简化了函数公式,消除了所有项和系数,只保留了增长速度最快的项和系数(例如,n 的平方)。
然而,单个函数并不能提供足够的信息来准确地比较两种算法。时间复杂度可能因数据量而异。例如,二分搜索法算法就像一个涡轮增压发动机,它在准备输出功率之前就建立了压力。另一方面,线性搜索算法从一开始就很快,但很快达到其峰值功率,并最终输掉比赛:
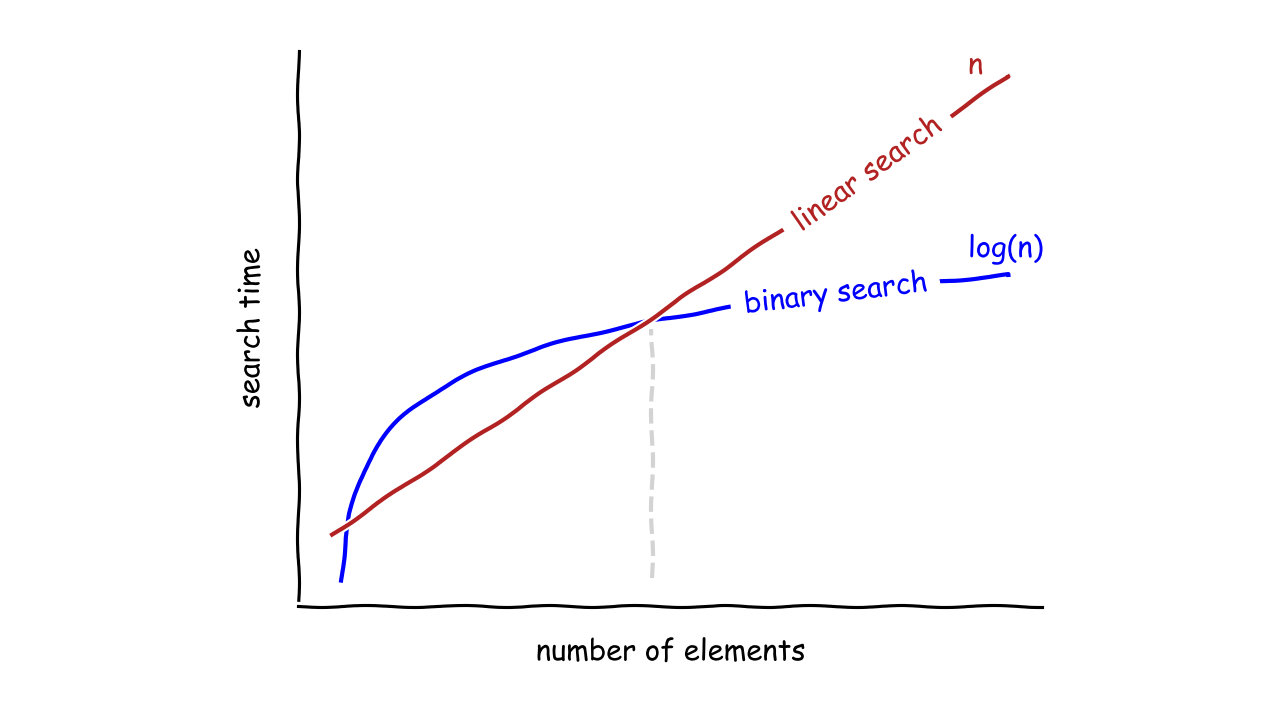
就速度而言,当集合中有一定数量的元素时,二分搜索法算法开始超过线性搜索。对于较小的集合,线性搜索可能是更好的选择。
注意:注意,同一个算法可能有不同的乐观、悲观、平均时间复杂度。例如,在最好的情况下,线性搜索算法将在运行一次比较后,找到第一个索引处的元素。
另一方面,它必须将一个参考值与集合中的所有元素进行比较。实际上,你想知道一个算法的悲观复杂度。
渐近复杂性有一些数学符号,用于比较算法。到目前为止,最流行的是大 O 符号。
大 O 符号
大 O 符号 代表渐近复杂的最坏情况。虽然这听起来有点吓人,但是您不需要知道正式的定义。直观地说,这是对描述复杂性的函数尾部增长率的一个非常粗略的度量。你把它读成某个东西的“大哦”:
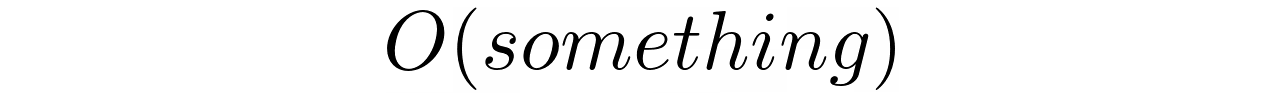
“某样东西”通常是数据大小的函数,或者只是代表常数的数字“1”。例如,线性搜索算法的时间复杂度为O(n),而基于哈希的搜索的时间复杂度为O(1)。
注意:当你说某个算法有复杂度O(f(n)),其中n是输入数据的大小,那么就意味着函数f(n)是那个复杂度的图的一个上界。换句话说,当n接近无穷大时,该算法的实际复杂度不会比f(n)乘以某个常数增长得更快。
在现实生活中,大 O 符号不太正式地用作上界和下界。这对于算法的分类和比较很有用,不用担心精确的函数公式。
二分搜索法的复杂性
您将通过确定作为输入大小的函数的最坏情况下(元素缺失时)的比较次数来估计二分搜索法的渐近时间复杂度。你可以用三种不同的方法来解决这个问题:
- 扁平的
- 图解的
- 分析的
表格方法是收集经验数据,将其放入表格中,并通过目测采样值来猜测公式:
| 元素数量 | 比较次数 |
|---|---|
| Zero | Zero |
| one | one |
| Two | Two |
| three | Two |
| four | three |
| five | three |
| six | three |
| seven | three |
| eight | four |
随着集合中元素数量的增加,比较的次数也会增加,但是增加的速度比线性函数要慢。这表明有一个好的算法可以根据数据进行扩展。
如果那对你没有帮助,你可以试试图形化方法,它通过绘制一个图形来可视化采样数据:
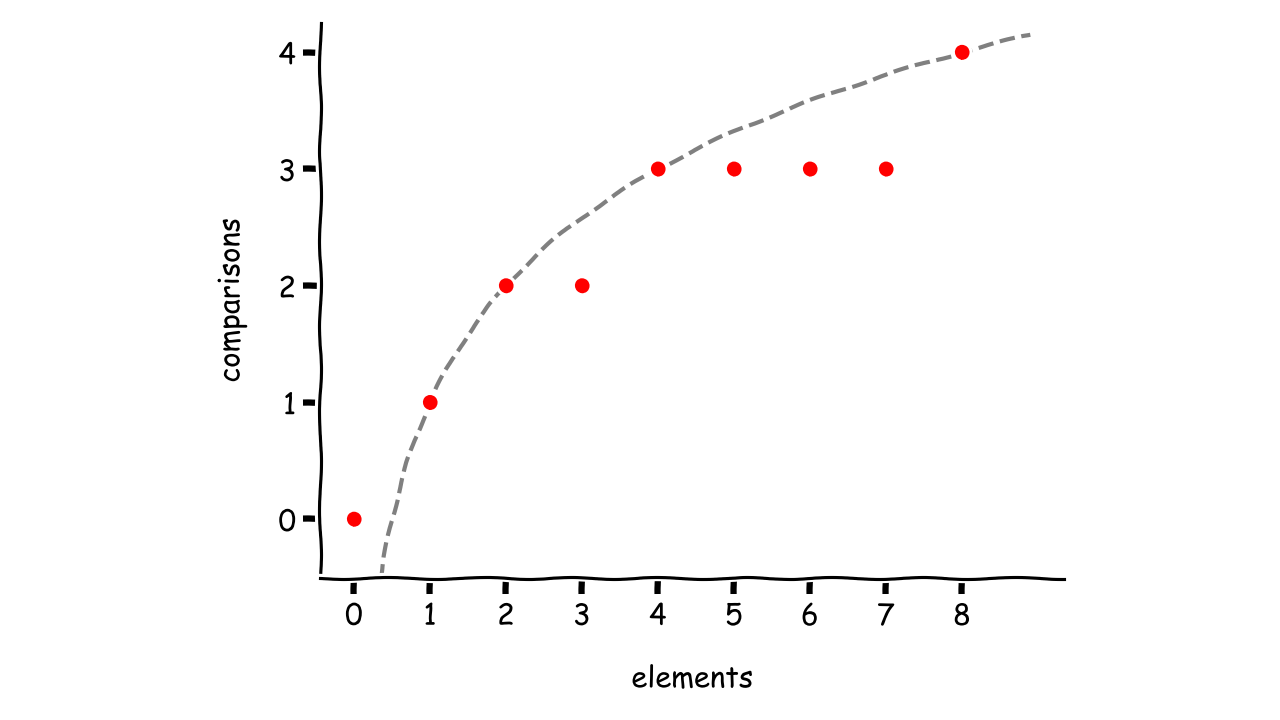
数据点似乎与曲线重叠,但您没有足够的信息来提供结论性的答案。它可以是一个多项式,对于较大的输入,其图形上下翻转。
采用分析方法,你可以选择一些关系并寻找模式。例如,您可以研究在算法的每一步中元素的数量是如何减少的:
| 比较 | 元素数量 |
|---|---|
| - | n |
| 第一 | n/2 |
| 第二 | n/4 |
| 第三 | n/8 |
| ⋮ | ⋮ |
| k-th | n/2 k |
在开始的时候,你从所有的 n 元素开始。第一次比较后,你只剩下一半了。接下来,你有 25 美分,以此类推。从这个观察中产生的模式是,在第 k 个比较之后,有第 n/2 个第 k 个 个元素。变量 k 是基本运算的预期次数。
在所有的 k 比较之后,就不会再剩下元素了。然而,当你后退一步,也就是 k - 1 ,就只剩下一个元素了。这给了你一个方便的等式:
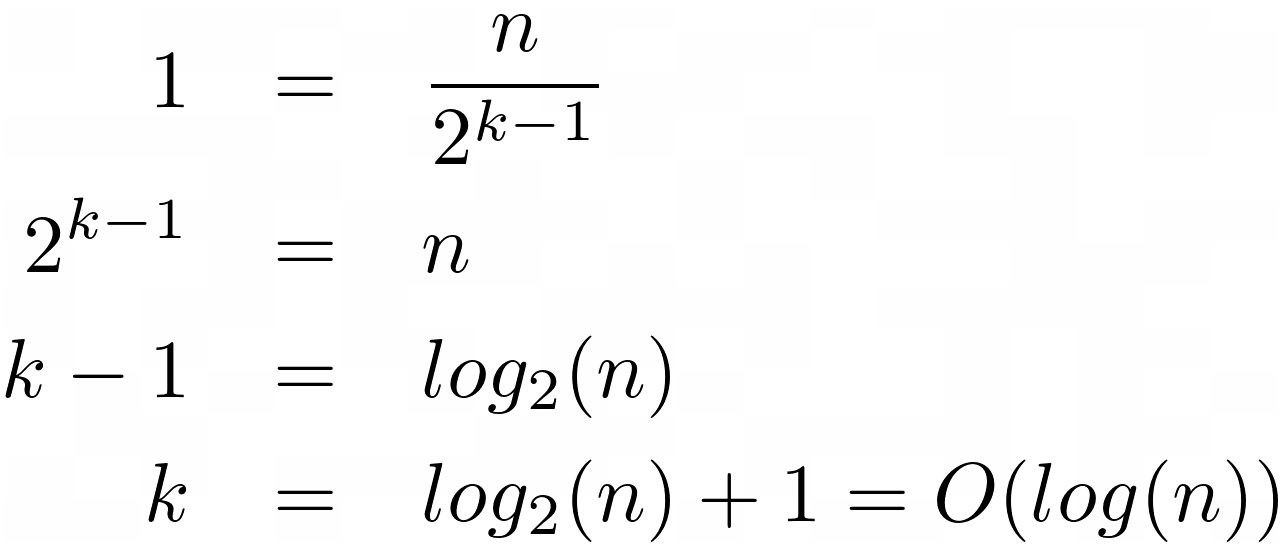
将等式两边乘以分母,然后取结果的以 2 为底的对数,并将剩余的常数向右移动。你刚刚找到了二分搜索法复杂度的公式,其数量级为O(log(n))。
结论
现在你对二分搜索法算法了如指掌。您可以自己完美地实现它,或者利用 Python 中的标准库。了解了时空复杂性的概念后,你就能够为给定的情况选择最佳的搜索算法。
现在你可以:
- 使用
bisect模块在 Python 中做一个二分搜索法 - 在 Python 中递归地实现二分搜索法和迭代地实现 T2
*** 识别并修复二分搜索法 Python 实现中的缺陷* 分析二分搜索法算法的时空复杂度* 搜索甚至比二分搜索法还要快*
*有了这些知识,你将会在 编程面试 中大显身手!不管二分搜索法算法是不是一个特定问题的最佳解决方案,你都有工具自己找出答案。你不需要一个计算机科学学位来做到这一点。
您可以通过下面的链接获得本教程中的所有代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的二分搜索法。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 创建二分搜索法*****************
探索 bpython:具有类似 IDE 特性的 Python REPL
标准的 Python 解释器让你从文件中运行脚本或者在所谓的读取-评估-打印循环(REPL) 中动态交互执行代码。虽然这是一个通过对代码输入的即时反馈来探索语言和发现其库的强大工具,但 Python 附带的默认 REPL 有几个限制。幸运的是,像 bpython 这样的替代品提供了一种对程序员更加友好和方便的体验。
您可以使用 bpython 来试验您的代码或快速测试一个想法,而无需在不同程序之间切换上下文,就像在集成开发环境(IDE) 中一样。此外,bpython 可能是虚拟或物理教室中一个有价值的教学工具。
在本教程中,您将学习如何:
- 安装并使用 bpython 作为您的替代 Python REPL
- 由于 bpython 的独特特性,提高您的生产力
- 调整 bpython 的配置和它的颜色主题
- 使用通用的键盘快捷键更快地编码
- 在 GitHub 上为 bpython 的开源项目做出贡献
在开始本教程之前,请确保您已经熟悉了 Python 基础知识,并且知道如何在命令行中启动标准的 Python REPL。此外,你应该能够用pip安装包,理想情况下进入一个虚拟环境。
要下载您将在本教程中使用的配置文件和示例脚本,请单击下面的链接:
源代码: 点击这里下载免费的源代码,您将使用它来驾驭 bpython 的力量。
开始使用 bpython
与独立的 python 发行版不同,例如 CPython 、 PyPy 或 Anaconda 、 bpython 仅仅是一个纯 Python 包,作为所选 Python 解释器的轻量级包装器。因此,您可以在任何特定的 python 发行版、版本甚至虚拟环境上使用 bpython,这为您提供了很大的灵活性。
注意:bpython 中的字母 b 代表鲍勃·法雷尔,他是该工具的原作者和维护者。
与此同时,bpython 仍然是一个熟悉的 Python REPL,只有一些基本特性,如语法高亮和自动完成,是从成熟的Python ide借鉴来的。这种极简方法与 IPython 等工具形成对比,后者是标准 Python REPL 的另一种替代方案,在数据科学界很流行。IPython 引入了许多定制命令和其他额外的功能,这些功能在 vanilla Python 中是没有的。
有几种方法可以在您的计算机上安装 bpython。像家酿或 APT 这样的包管理器为你的操作系统提供预构建版本的 bpython。然而,它们很可能已经过时,并被硬连接到系统范围的 Python 解释器中。虽然您可以手工从其源代码构建最新的 bpython 版本,但最好将其安装到一个带有 pip 的 虚拟环境 :
(venv) $ python -m pip install bpython
在许多虚拟环境中,将 bpython 安装在多个副本中是很常见的,这很好。这允许您将 bpython 包装在您最初用来创建虚拟环境的特定 python 解释器周围。
注意:不幸的是,bpython 在 Windows 上没有本地支持,因为它依赖于 curses 库,而这个库只在类似 Unix 的系统上可用,比如 macOS 和 Linux。官方文档提到了一个变通办法,它依赖于一个非官方的 Windows 二进制文件,但似乎不再管用了。如果您使用的是 Windows,那么您最好的选择是安装 Windows 子系统 for Linux (WSL) 并从那里使用 bpython。
安装完成后,您可以使用以下两个命令之一启动 bpython:
bpythonpython -m bpython
最好选择更明确的第二个命令,它将 bpython 作为一个可运行的 python 模块来调用。这样,您将确保运行安装在当前活动虚拟环境中的 bpython 程序。
另一方面,使用简单的bpython命令可以悄悄地回到全局安装的程序,如果有的话。它也可以在您的 shell 中别名为不同的可执行文件,优先于本地bpython模块。
下面是一个示例,展示了如何针对封装在隔离虚拟环境中的几个不同的 python 解释器使用 bpython:
(py2.7) $ python -m bpython
bpython version 0.20.1 on top of Python 2.7.18
⮑ /home/realpython/py2.7/bin/python WARNING: You are using `bpython` on Python 2\. Support for Python 2
⮑ has been deprecated in version 0.19 and might disappear
⮑ in a future version.
>>> import platform
>>> platform.python_version()
'2.7.18'
>>> platform.python_implementation()
'CPython'
(py3.11) $ python -m bpython
bpython version 0.23 on top of Python 3.11.0
⮑ /home/realpython/py3.11/bin/python >>> import platform
>>> platform.python_version()
'3.11.0'
>>> platform.python_implementation()
'CPython'
(pypy) $ python -m bpython
bpython version 0.23 on top of Python 3.9.12
⮑ /home/realpython/pypy/bin/python >>> import platform
>>>> platform.python_version()
'3.9.12'
>>> platform.python_implementation()
'PyPy'
注意,您使用相同的命令从不同的虚拟环境运行 bpython。每一个突出显示的行都指出了解释器版本以及 bpython 在当前 REPL 会话中包装的 Python 可执行文件的路径。可以通过标准库中的 platform 模块确认 Python 版本及其实现。
注意:Django web 框架可以检测到安装在虚拟环境中的 bpython。当您执行 shell 命令来调用 python 交互式解释器以及模块搜索路径上的项目文件时,框架将自动运行 bpython。
好了,现在你已经学习了如何安装和运行 bpython 作为一个替代 Python REPL ,是时候探索它的关键特性了。在接下来的几节中,无论您的技能水平如何,您都将发现 bpython 可以提高您作为 python 程序员的生产率的几种方式。
一眼看出错别字

加入我们,访问数以千计的教程和 Pythonistas 专家社区。
*已经是会员了?签到
全文仅供会员阅读。加入我们,访问数以千计的教程和 Pythonistas 专家社区。
已经是会员了?签到*
Brython:浏览器中的 Python
如果你是一个喜欢编写 Python 而不是 JavaScript 的 web 开发人员,那么运行在浏览器中的 Python 实现 Brython 可能是一个有吸引力的选择。
JavaScript 是前端 web 开发的事实语言。复杂的 JavaScript 引擎是所有现代互联网浏览器的固有部分,自然会驱使开发人员用 JavaScript 编写前端 web 应用程序。 Brython 通过让 Python 成为浏览器中的一级公民语言,并可以访问浏览器中所有现有的 JavaScript 库和 API,提供了两个世界的最佳选择。
在本教程中,您将学习如何:
- 在您的本地环境中安装 Brython
- 在浏览器中使用Python
- 编写与 JavaScript 交互的 Python 代码
*** 使用您的 web 应用程序部署 Python* 用 Python 创建浏览器扩展* 将 Brython 与 web 应用程序的其他 Python 实现进行比较*
*作为一名熟悉 web 开发的中级 Python 开发人员,如果你还具备一些 HTML 和 JavaScript 的知识,你将从本教程中获益匪浅。对于 JavaScript 复习者,请查看Python vs . Python istas 的 JavaScript。
您可以通过单击下面的链接下载本教程中示例的源材料:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Brython 在浏览器中运行 Python。
在浏览器中运行 Python:好处
尽管 JavaScript 是前端 web 开发中无处不在的语言,但以下几点可能适用于您:
- 你可能不喜欢用 JavaScript 写代码。
- 您可能想要利用您的 Python 技能。
- 您可能不想花时间学习 JavaScript 来探索浏览器技术。
- 您可能不喜欢被迫学习和使用 JavaScript 来实现 web 应用程序。
不管是什么原因,许多开发人员更喜欢使用基于 Python 的替代方案来利用浏览器的功能,而不是 JavaScript。
在浏览器中运行 Python 有几个好处。它允许您:
- 在服务器和浏览器中执行相同的 Python 代码
- 使用 Python 与各种浏览器 API 协同工作
- 用 Python 操作文档对象模型(DOM)
- 使用 Python 与现有的 JavaScript 库如 Vue.js 和 jQuery 进行交互
- 使用 Brython 编辑器向 Python 学生教授 Python 语言
- 用 Python 编程时保持趣味性
与 JavaScript 中的相同代码相比,在浏览器中使用 Python 的一个副作用是性能损失。然而,这个缺点并没有超过上面概述的任何好处。
实现同构 Web 开发
同构 JavaScript ,或者说通用 JavaScript ,强调 JavaScript 应用要同时运行在客户端和服务器端。这是假设后端是基于 JavaScript 的,即一个节点服务器。使用 Flask 或 Django 的 Python 开发者也可以将同构原理应用于 Python,前提是他们可以在浏览器中运行 Python。
Brython 允许您用 Python 构建前端,并在客户机和服务器之间共享模块。例如,您可以共享验证函数,如以下代码,该代码对美国电话号码进行规范化和验证:
1import re
2
3def normalize_us_phone(phone: str) -> str:
4 """Extract numbers and digits from a given phone number"""
5 return re.sub(r"[^\da-zA-z]", "", phone)
6
7def is_valid_us_phone(phone: str) -> bool:
8 """Validate 10-digit phone number"""
9 normalized_number = normalize_us_phone(phone)
10 return re.match(r"^\d{10}$", normalized_number) is not None
normalize_us_phone()消除任何非字母数字字符,而如果输入字符串恰好包含十位数字且不包含字母字符,则is_valid_us_phone()返回True。相同的代码可以在 Python 服务器上运行的进程和使用 Brython 构建的客户端之间共享。
访问网络应用编程接口
互联网浏览器将标准化的 web APIs 暴露给 JavaScript。这些标准是 T2 HTML 生活标准 T3 的一部分。一些 web API 示例包括:
Brython 允许您使用 web APIs 并与 JavaScript 交互。您将在后面的章节中使用一些 web APIs。
原型和 JavaScript 库
Python 经常被用于构建代码片段、语言结构或更大想法的原型。有了 Brython,这种常见的编码实践在您的浏览器中变得可用。例如,你可以使用 Brython 控制台或交互式编辑器来试验一段代码。
打开在线编辑器,键入以下代码:
1from browser import ajax
2
3def on_complete(req):
4 print(req.text)
5
6language = "fr"
7
8ajax.get(f"https://fourtonfish.com/hellosalut/?lang={language}",
9 blocking=True,
10 oncomplete=on_complete)
下面是这段代码的工作原理:
- 线 1 进口
ajax模块。 - 第 3 行定义了
on_complete(),得到ajax.get()响应后调用的回调函数。 - 第 6 行使用 HelloSalut API 调用
ajax.get()来检索法语中“hello”的翻译。注意,当您在 Brython 编辑器中执行这段代码时,blocking可以是True或False。如果您在 Brython 控制台中执行相同的代码,则需要使用True。
点击输出窗格上方的运行以查看以下结果:
{"code":"fr","hello":"Salut"} <completed in 5.00 ms>
尝试将语言从fr修改为es并观察结果。该 API 支持的语言代码在 HelloSalut 文档中列出。
注 : HelloSalut 是互联网上可用的公共 API 之一,列在公共 APIs GitHub 项目中。
您可以在在线编辑器中修改代码片段,以使用不同的公共 API。例如,尝试从公共 API 项目中获取一个随机公共 API :
1from browser import ajax
2
3def on_complete(req):
4 print(req.text)
5
6ajax.get("https://api.publicapis.org/random",
7 blocking=True,
8 oncomplete=on_complete)
将上面的代码复制到在线 Brython 编辑器中,然后单击 Run 来显示结果。下面是一个 JSON 格式的例子:
{ "count": 1, "entries": [ { "API": "Open Government, USA", "Description": "United States Government Open Data", "Auth": "", "HTTPS": true, "Cors": "unknown", "Link": "https://www.data.gov/", "Category": "Government" } ] }
因为端点获取一个随机项目,所以您可能会得到不同的结果。有关 JSON 格式的更多信息,请查看在 Python 中使用 JSON 数据的。
您可以像在 Python 解释器中一样,使用原型来尝试常规的 Python 代码。因为您是在浏览器环境中,所以 Brython 还提供了以下方法:
作为一种快捷方式,您可以通过打开 Brython 网站上的控制台或编辑器来利用上述大多数功能。这不需要您在本地计算机上安装或运行任何东西。相反,它为您提供了一个与 Python 和 web 技术互动的在线平台。
向学生教授 Python
Brython 既是 Python 编译器,也是用 JavaScript 编写的解释器。因此,您可以在浏览器中编译和运行 Python 代码。Brython 网站上的在线编辑器展示了这一特性的一个很好的例子。
使用在线编辑器,Python 在浏览器中运行。不需要在机器上安装 Python ,也不需要发送代码到服务器执行。对于用户来说,反馈是即时的,这种方法不会将后端暴露给恶意脚本。学生们可以在任何装有工作浏览器的设备上使用 Python 进行实验,比如手机或 Chromebooks,即使是在网络连接不稳定的情况下。
将性能考虑在内
Brython 网站指出,该实现的执行速度与 CPython 相当。但是 Brython 是在浏览器中执行的,这个环境中的引用是烘焙到浏览器引擎中的 JavaScript。因此,预计 Brython 会比手写的、经过良好调整的 JavaScript 慢。
Brython 将 Python 代码编译成 JavaScript,然后执行生成的代码。这些步骤对整体性能有影响,并且 Brython 可能不总是满足您的性能要求。在某些情况下,您可能需要将一些代码执行委托给 JavaScript,甚至是 WebAssembly 。在关于 WebAssembly 的一节中,您将看到如何构建 WebAssembly 以及如何使用 Python 中的结果代码。
但是,不要让感知到的性能影响您使用 Brython。例如,导入 Python 模块可能会导致从服务器下载相应的模块。为了说明这种情况,请打开 Brython 控制台并执行以下代码:
>>> import uuid直到显示提示的延迟(在测试机器上为 390 ms)是明显的。这是因为 Brython 必须下载
uuid及其依赖项,然后编译下载的资源。然而,从那一点开始,在执行uuid中可用的功能时没有延迟。例如,您可以用下面的代码生成一个随机通用唯一标识符,UUID 版本 4:
>>> uuid.uuid4()
UUID('291930f9-0c79-4c24-85fd-f76f2ada0b2a')
调用uuid.uuid4()生成一个 UUID 对象,其字符串表示打印在控制台中。调用uuid.uuid4()会立即返回,比最初导入uuid模块要快得多。
玩得开心
如果您正在阅读本教程,那么您可能对在浏览器中编写 Python 代码感兴趣。对于大多数 Python 爱好者来说,看到 Python 代码在浏览器中执行是令人兴奋的,它唤醒了一种乐趣和无尽的可能性。
Brython 的作者 Pierre Quentel 和该项目的贡献者们在承担使这种语言与网络浏览器兼容的巨大任务的同时,也牢记着 Python 的乐趣。
为了证明这一点,将您的浏览器指向 Brython 交互式控制台,并在 Python 提示符下键入以下内容:
import this
与 Python 在本地机器上的体验类似,Brython 动态编译并执行指令,并打印出 Python 的禅。它发生在浏览器中,Python 代码的执行不需要与后端服务器进行任何交互:

您还可以在相同的浏览器环境中使用以下代码尝试另一个经典 Python 复活节彩蛋:
import antigravity
Brython 包含了与 Python 参考实现中相同的幽默。
现在您已经熟悉了使用 Brython 的基础知识,您将在下面的小节中探索更多的高级特性。
安装 Brython
尝试 Brython 的在线控制台是一个好的开始,但它不允许您部署 Python 代码。在本地环境中安装 Brython 有几种不同的选择:
下面列出了每种方法的说明,但是如果你已经做了决定,可以直接跳到你喜欢的方法。
CDN 安装
内容交付网络(CDN) 是一个服务器网络,可以提高在线内容的性能和下载速度。您可以从几个不同的 cdn 安装 Brython 库:
如果您想部署一个静态网站,并以最小的开销向您的页面添加一些动态行为,您可以选择此安装。除了使用 Python 而不是 JavaScript 之外,您可以将此选项视为对 jQuery 的替代。
为了说明 Brython 和 CDN 的用法,我们将使用 CDNJS。使用以下 HTML 代码创建一个文件:
1<!doctype html>
2<html>
3 <head>
4 <script
5 src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.js"> 6 </script>
7 </head>
8 <body onload="brython()"> 9 <script type="text/python"> 10 import browser 11 browser.alert("Hello Real Python!") 12 </script>
13 </body>
14</html>
以下是该 HTML 页面的关键元素:
-
线 5 从 CDNJS 装载
brython.js。 -
第 8 行在文件加载完成后执行
brython()。brython()读取当前作用域内的 Python 代码,编译成 JavaScript。更多细节请参见了解 Brython 如何工作一节。 -
第 9 行设置脚本的类型为
text/python。这向 Brython 表明需要编译和执行哪些代码。 -
第 10 行导入了
browser,这是一个 Brython 模块,它公开了允许与浏览器交互的对象和函数。 -
第 11 行调用
alert(),显示一个消息框,文本为"Hello Real Python!"
将文件另存为index.html,然后双击该文件,用默认的互联网浏览器打开它。浏览器显示一个消息框,点击确定关闭消息框:
为了减小下载文件的大小,尤其是在生产中,请考虑使用最小化版本的brython.js:
1<script
2 src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.min.js"> 3</script>
从用户的角度来看,最小化版本将减少下载时间和感知延迟。在了解 Brython 如何工作中,您将了解浏览器如何加载 Brython 以及如何执行上面的 Python 代码。
GitHub 安装
GitHub 安装与 CDN 安装非常相似,但是它允许您使用最新的开发版本实现 Brython 应用程序。您可以复制前面的示例,并修改head元素中的 URL,以获得下面的index.html:
<!doctype html>
<html>
<head>
<script
src="https://raw.githack.com/brython-dev/brython/master/www/src/brython.js"> </script>
</head>
<body onload="brython()">
<script type="text/python"> import browser browser.alert("Hello Real Python!") </script>
</body>
</html>
将该文件保存到本地目录后,双击index.html在浏览器中呈现您在安装 CDN 时获得的相同页面。
PyPI 安装
到目前为止,您还不需要在本地环境中安装任何东西。相反,您已经在 HTML 文件中指出了浏览器可以在哪里找到 Brython 包。当浏览器打开页面时,它会从适当的环境(CDN 或 GitHub)下载 Brython JavaScript 文件。
Brython 也可以本地安装在 PyPI 上。PyPI 安装适合您,如果:
- 在指向 CDN 文件时,您需要对 Brython 环境进行更多的控制和定制。
- 你的背景是 Python,你熟悉
pip。 - 您希望在开发过程中进行本地安装以最小化网络延迟。
- 您希望以更细粒度的方式管理您的项目和可交付成果。
从 PyPI 安装 Brython 会安装brython_cli,这是一个命令行工具,您可以使用它来自动化一些功能,例如生成项目模板或打包和捆绑模块,以简化 Brython 项目的部署。
要了解更多细节,您可以查阅本地安装文档,查看安装后brython-cli在您的环境中可用的功能。brython-cli仅适用于这种类型的安装。如果您从 CDN 或使用 npm 安装,则它不可用。在本教程的后面,你将看到brython-cli的实际应用。
在安装 Brython 之前,您需要为这个项目创建一个 Python 虚拟环境。
在 Linux 或 macOS 上,执行以下命令:
$ python3 -m venv .venv --prompt brython
$ source .venv/bin/activate
(brython) $ python -m pip install --upgrade pip
Collecting pip
Downloading pip-20.2.4-py2.py3-none-any.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 1.3 MB/s
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 20.2.3
Uninstalling pip-20.2.3:
Successfully uninstalled pip-20.2.3
在 Windows 上,您可以进行如下操作:
> python3 -m venv .venv --prompt brython
> .venv\Scripts\activate
(brython) > python -m pip install --upgrade pip
Collecting pip
Downloading pip-20.2.4-py2.py3-none-any.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 1.3 MB/s
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 20.2.3
Uninstalling pip-20.2.3:
Successfully uninstalled pip-20.2.3
您已经为您的项目创建了一个专用的 Python 环境,并用最新版本更新了pip。
在接下来的步骤中,您将安装 Brython 并创建一个默认项目。这些命令在 Linux、macOS 和 Windows 上是相同的:
(brython) $ python -m pip install brython
Collecting brython
Downloading brython-3.9.0.tar.gz (1.2 MB)
|████████████████████████████████| 1.2 MB 1.4 MB/s
Using legacy 'setup.py install' for brython, since package 'wheel'
is not installed.
Installing collected packages: brython
Running setup.py install for brython ... done
(brython) $ mkdir web
(brython) $ cd web
(brython) $ brython-cli --install
Installing Brython 3.9.0
done
您已经从 PyPI 安装了 Brython,创建了一个名为web的空文件夹,并通过执行安装期间在虚拟环境中复制的brython-cli生成了默认的项目框架。
在web文件夹中,brython-cli --install创建了一个项目模板,并生成了以下文件:
| 文件 | 描述 |
|---|---|
README.txt |
关于如何运行 Python HTTP 服务器并打开demo.html的文档 |
brython.js |
核心 Brython 引擎(编译器、运行时和浏览器界面) |
brython_stdlib.js |
布里森标准图书馆 |
demo.html |
Brython 演示 HTML 页面的源代码 |
index.html |
可以用作项目起始页的基本示例 |
unicode.txt |
unicodedata 使用的 Unicode 字符数据库(UCD) |
为了测试这个新创建的 web 项目,您可以使用以下命令启动一个本地 Python web 服务器:
(brython) $ python -m http.server
Serving HTTP on :: port 8000 (http://[::]:8000/) ...
当您执行python -m http.server时,Python 在端口 8000 上启动一个 web 服务器。期望的默认页面是index.html。将您的互联网浏览器指向http://localhost:8000,显示一个带有文本Hello的页面:
更完整的例子,你可以把浏览器地址栏里的网址改成http://localhost:8000/demo.html。您应该会看到一个类似于 Brython 演示页面的页面:
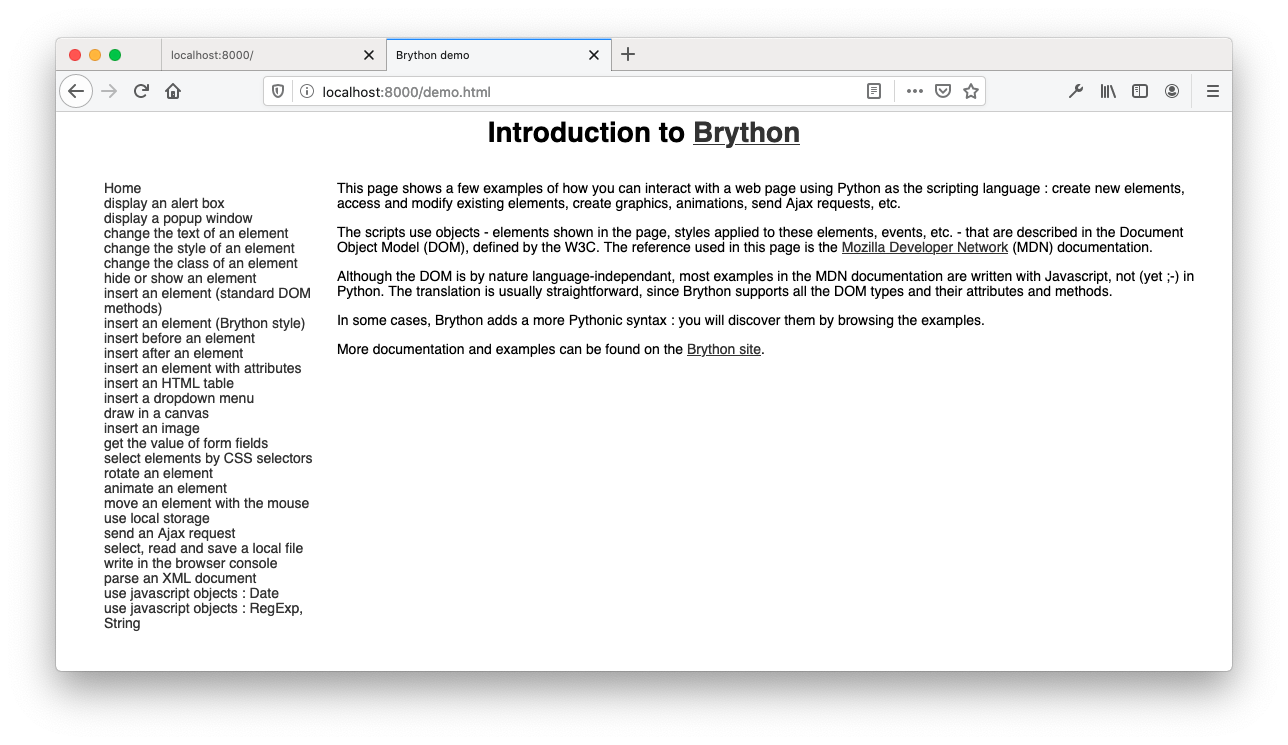
使用这种方法,Brython JavaScript 文件直接从本地环境加载。注意index.html的head元素中的src属性:
1<!doctype html>
2<html>
3 <head>
4 <meta charset="utf-8">
5 <script type="text/javascript" src="brython.js"></script>
6 <script type="text/javascript" src="brython_stdlib.js"></script> 7 </head>
8 <body onload="brython(1)"> 9 <script type="text/python"> 10 from browser import document 11 document <= "Hello" 12 </script>
13 </body>
14</html>
上面的 HTML 是缩进的,以增强本教程的可读性。命令brython_cli --install不缩进它生成的初始 HTML 模板。
HTML 文件引入了一些新的 Brython 特性:
-
第 6 行加载
brython_stdlib.js,编译成 JavaScript 的 Python 标准库。 -
第 8 行用参数
1调用brython()将错误信息打印到浏览器控制台。 -
10 号线从
browser导入document模块。访问 DOM 的函数在document中可用。 -
第 11 行显示了作为语法糖添加到 Python 中的新符号(
<=)。在这个例子中,document <= "Hello"是document.body.appendChild(document.createTextNode("Hello"))的替代品。关于这些 DOM 函数的详细信息,请查看Document.createTextNode。
操作符<=用于向 DOM 元素添加子节点。您将在的 Brython 的 DOM API 中看到关于使用特定于 Brython 的操作符的更多细节。
npm 安装
如果你精通 JavaScript 生态系统,那么 npm 安装可能会吸引你。在执行此安装之前,需要 Node.js 和 npm 。
使用 npm 安装将使 JavaScript Brython 模块像其他 JavaScript 模块一样在您的项目中可用。然后,您将能够利用您最喜欢的 JavaScript 工具来测试、打包和部署 Brython 解释器和库。如果您已经在 npm 中安装了现有的 JavaScript 库,那么这种安装是理想的。
注意:如果您的系统上没有安装 Node.js 和 npm,那么考虑阅读本节的剩余部分,因为您可以安全地跳过安装本身。对于任何示例,本教程的其余部分都不依赖于 npm 安装方法。
假设您的系统上安装了 npm,通过调用空目录中的npm init --yes创建一个默认的 package.json文件:
$ npm init --yes
Wrote to /Users/john/projects/brython/npm_install/package.json:
{
"name": "npm_install",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
要将 Brython 集成到您的项目中,请执行以下命令:
$ npm install brython
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN npm_install@1.0.0 No description
npm WARN npm_install@1.0.0 No repository field.
+ brython@3.9.0
added 1 package from 1 contributor and audited 1 package in 1.778s
found 0 vulnerabilities
您可以忽略这些警告,并注意到 Brython 已添加到您的项目中。要确认,打开package.json并确保有一个dependencies属性指向一个包含brython条目的对象:
1{ 2 "name": "npm_install", 3 "version": "1.0.0", 4 "description": "", 5 "main": "index.js", 6 "scripts": { 7 "test": "echo \"Error: no test specified\" && exit 1" 8 }, 9 "author": "", 10 "license": "ISC", 11 "dependencies": { 12 "brython": "^3.9.0" 13 } 14}
至于前面的例子,你可以创建下面的index.html并用浏览器打开它。这个例子不需要 web 服务器,因为浏览器能够在本地加载 JavaScript 文件node_modules/brython/brython.js:
1<!doctype html>
2<html>
3<head>
4 <meta charset="utf-8">
5 <script
6 type="text/javascript"
7 src="node_modules/brython/brython.js" defer> 8 </script>
9</head>
10<body onload="brython()">
11<script type="text/python"> 12from browser import document 13document <= "Hello" 14</script>
15</body>
16</html>
浏览器渲染index.html并从index.html中的script URL 加载brython.js。在本例中,您看到了一种利用 JavaScript 生态系统安装 Brython 的不同方式。在本教程的剩余部分,您将编写依赖于 CDN 安装或 PyPI 安装的代码。
概述 Brython 安装选项
Brython 一只脚涉足 Python 世界,另一只脚涉足 JavaScript。不同的安装选项说明了这种跨技术的情况。根据你的背景,选择最吸引你的装置。
下表为您提供了一些指导:
| 安装类型 | 语境 |
|---|---|
| CDN | 您希望部署一个静态网站,并以最小的开销向页面添加一些动态行为。除了使用 Python 而不是 JavaScript 之外,您可以将此选项视为 jQuery 的替代品。 |
| GitHub | 这类似于 CDN 安装,但是您想要试验最先进的 Brython 版本。 |
| 黑桃 | 你的背景是 Python。您熟悉pip以及如何创建 Python 虚拟环境。您的项目可能需要一些您想要在本地环境或源代码存储库中维护的定制。您希望对将要分发的包有更多的控制权。您希望在无法访问互联网的封闭环境中进行部署。 |
| npm | 你的背景是 JavaScript。您熟悉 JavaScript 工具,尤其是 Node.js 和 npm。您的项目可能需要一些您想要在本地环境或源代码存储库中维护的定制。你想对你要分发的包有更多的控制权。您希望在无法访问互联网的封闭环境中进行部署。 |
下表总结了您可以使用的不同安装选项。在下一节中,您将了解更多关于 Brython 的工作原理。
了解 Brython 如何工作
您对安装 Brython 的不同方法的浏览为您提供了一些关于实现如何工作的高级线索。以下是到目前为止您在本教程中发现的一些特征的总结:
- 它是 JavaScript 中的 Python 实现。
- 它是 Python 到 JavaScript 的翻译器,是在浏览器中执行的运行时。
- 它公开了两个主要的 JavaScript 文件库:
brython.js是 Brython 语言的核心,详见 Brython 核心组件。brython_stdlib.js就是布里森标准库。
- 它调用
brython(),用text/python类型编译包含在script标签中的 Python 代码。
在接下来的几节中,您将更详细地了解 Brython 是如何工作的。
Brython 核心组件
Brython 的核心包含在brython.js或brython.min.js中,是 Brython 引擎的最小化版本。两者都包括以下关键组件:
-
brython()是 JavaScript 全局名称空间中暴露的主要 JavaScript 函数。如果不调用这个函数,就不能执行任何 Python 代码。这是唯一需要显式调用的 JavaScript 函数。 -
__BRYTHON__是一个 JavaScript 全局对象,保存运行 Python 脚本所需的所有内部对象。当您编写 Brython 应用程序时,不会直接使用该对象。如果您查看 Brython 代码,包括 JavaScript 和 Python,那么您会看到定期出现的__BRYTHON__。您不需要使用此对象,但是当您看到错误或想要在浏览器控制台中调试代码时,您应该知道它。 -
内置类型是 JavaScript 中 Python 内置类型的实现。比如 py_int.js 、 py_string.js 和 py_dicts.js 分别是
int、str和dict的实现。 -
browser是浏览器模块,它公开了前端 web 应用程序中常用的 JavaScript 对象,如使用document的 DOM 接口和使用window对象的浏览器窗口。
在学习本教程中的示例时,您将看到这些组件的运行。
布里森标准库
现在您已经对核心 Brython 文件brython.js有了一个总体的概念,接下来您将学习它的配套文件brython_stdlib.js。
brython_stdlib.js公开 Python 标准库。当生成这个文件时,Brython 将 Python 标准库编译成 JavaScript,并将结果连接成包brython_stdlib.js。
Brython 旨在尽可能接近 Python 参考实现 CPython 。关于 CPython 的更多信息,请查看CPython 源代码指南和 CPython 内部指南。
由于 Brython 是在 web 浏览器的环境中运行的,所以它有一些限制。例如,浏览器不允许直接访问文件系统,所以用os.open()打开文件是不可能的。与 web 浏览器无关的功能可能无法实现。例如,下面的代码运行在 Brython 环境中:
>>> import os >>> os.unlink() Traceback (most recent call last): File <string>, line 1, in <module> NotImplementedError: posix.unlink is not implemented
os.unlink()引发了一个异常,因为从浏览器环境中删除一个本地文件是不安全的,而文件和目录条目 API 只是一个提议草案。Brython 只支持原生 Python 模块。它不支持用 C 构建的 Python 模块,除非它们已经用 JavaScript 重新实现了。比如
hashlib在 CPython 中用 C 编写,在 Brython 中用 JavaScript 实现。您可以参考 Brython 发行版中的模块列表,与 CPython 实现进行比较。您需要包含
brython_stdlib.js或brython_stdlib.min.js来从 Python 标准库中导入模块。布里森在行动
此时,您可能想知道 Brython 在只知道其 JavaScript 引擎的浏览器中的行为。重用前面的示例和浏览器中可用的工具,您将了解在浏览器中执行 Python 代码的过程。
在 CDN 服务器安装部分,您看到了以下示例:
1<!doctype html> 2<html> 3 <head> 4 <script 5 src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.js"> 6 </script> 7 </head> 8 <body onload="brython()"> 9 <script type="text/python"> 10 import browser 11 browser.alert("Hello Real Python!") 12 </script> 13 </body> 14</html>加载并解析 HTML 页面后,
brython()采取以下步骤:
- 读取元素
<script type="text/python">中包含的 Python 代码- 将 Python 代码编译成等效的 JavaScript
- 用
eval()评估生成的 JavaScript 代码在上面的示例中,Python 代码嵌入在 HTML 文件中:
<script type="text/python"> import browser browser.alert("Hello Real Python!") </script>另一种选择是从单独的文件下载 Python 代码:
<head> <script src="https://www.example.com/main.py" type="text/python"></script> </head>在这种情况下,Python 文件如下所示:
import browser browser.alert("Hello Real Python!")将 Python 代码从 HTML 代码中分离出来是一种更简洁的方法,并且允许您利用代码编辑器的优势和功能。大多数编辑器支持 HTML 中的嵌入式 JavaScript,但不支持 HTML 中的内联 Python。
Brython 的内部结构
本节将深入探讨将 Python 代码转换为 JavaScript 的过程。如果你对这些细节不感兴趣,那么可以跳过这一节,因为这不是理解本教程其余部分所必需的。为了演示这个过程并了解 Brython 的内部情况,请执行以下步骤:
- 打开 Brython 主页。
- 在 Mac 上用
Cmd+Alt+I或者在 Windows 和 Linux 上用Ctrl+Shift+I打开 web 控制台。在浏览器 JavaScript REPL 中,键入并执行以下代码:
> eval(__BRYTHON__.python_to_js("import browser; browser.console.log('Hello Brython!')"));
python_to_js()将提供的 Python 代码解析编译成 JavaScript,然后在 web 浏览器中执行 JavaScript。您应该会得到以下结果:
将
eval()应用到 Brython 代码会在浏览器控制台中打印出"Hello Brython!"。 JavaScript 函数返回undefined,这是 JavaScript 中函数的默认返回值。当您构建一个 Brython 应用程序时,您不需要显式调用 JavaScript 模块中的函数。提供这个示例只是为了演示 Brython 如何在幕后操作。意识到
__BRYTHON__可以帮助你阅读 Brython 代码,甚至在你获得更多经验时为项目做出贡献。它还将帮助您更好地理解浏览器控制台中可能显示的异常。JavaScript
__BRYTHON__对象在 JavaScript 全局范围内可用,您可以通过浏览器 JavaScript 控制台访问它。在浏览器中使用 Brython
至此,您已经对 Brython 有了足够的了解,可以使用更详细的示例了。在本节中,您将实现一个 Base64 计算器,在浏览器中使用 DOM API 和其他通常只能从 JavaScript 获得的功能进行实验。
您可以通过单击下面的链接下载本教程中示例的源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Brython 在浏览器中运行 Python。
您将从学习如何使用 Python 和 HTML 操作 DOM 开始。
Brython 中的 DOM API
为了试验 Brython 中可用的 DOM 操作,您将构建一个表单来将一个字符串编码为 Base64 。完成后的表单将如下所示:
创建以下 HTML 文件,并将其命名为
index.html:1<!-- index.html --> 2<!DOCTYPE html > 3<html> 4 <head> 5 <meta charset="utf-8"/> 6 <link rel="stylesheet" 7 href="https://cdnjs.cloudflare.com/ajax/libs/pure/2.0.3/pure-min.css" /> 8 <script 9 src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.min.js"> 10 </script> 11 <script 12 src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython_stdlib.min.js"> 13 </script> 14 <script src="main.py" type="text/python" defer></script> 15 <style>body { padding: 30px; }</style> 16 </head> 17 <body onload="brython()"> 18 <form class="pure-form" onsubmit="return false;"> 19 <fieldset> 20 <legend>Base64 Calculator</legend> 21 <input type="text" id="text-src" placeholder="Text to Encode" /> 22 <button 23 type="submit" id="submit" 24 class="pure-button pure-button-primary" 25 autocomplete="off">Ok</button> 26 27 </fieldset> 28 </form> 29 <div id="b64-display"></div> 30 </body> 31</html>上面的 HTML 加载静态资源,定义 UI 布局,并启动 Python 编译:
第 7 行加载了 PureCSS 样式表来改进默认的 HTML 样式。这对于 Brython 的工作是不必要的。
第 9 行加载最小化版本的 Brython 引擎。
第 12 行加载最小化版本的 Brython 标准库。
第 14 行加载
main.py,处理这个静态 HTML 页面的动态逻辑。注意defer的用法。它有助于同步资源的加载和评估,有时需要确保 Brython 和任何 Python 脚本在执行brython()之前被完全加载。第 21 行描述了一个
input字段。该字段将要编码的字符串作为参数。第 22 到 25 行定义了触发页面主要逻辑的默认
button。你可以在下面的main.py中看到这个逻辑的实现。第 26 行定义了一个
button来清理页面上的数据和元素。这在下面的main.py中实现。第 29 行声明了一个
div来作为表格的占位符。相关的 Python 代码
main.py如下:1from browser import document, prompt, html, alert 2import base64 3 4b64_map = {} 5 6def base64_compute(_): 7 value = document["text-src"].value 8 if not value: 9 alert("You need to enter a value") 10 return 11 if value in b64_map: 12 alert(f"'The base64 value of '{value}' already exists: '{b64_map[value]}'") 13 return 14 b64data = base64.b64encode(value.encode()).decode() 15 b64_map[value] = b64data 16 display_map() 17 18def clear_map(_) -> None: 19 b64_map.clear() 20 document["b64-display"].clear() 21 22def display_map() -> None: 23 table = html.TABLE(Class="pure-table") 24 table <= html.THEAD(html.TR(html.TH("Text") + html.TH("Base64"))) 25 table <= (html.TR(html.TD(key) + html.TD(b64_map[key])) for key in b64_map) 26 base64_display = document["b64-display"] 27 base64_display.clear() 28 base64_display <= table 29 document["text-src"].value = "" 30 31document["submit"].bind("click", base64_compute) 32document["clear-btn"].bind("click", clear_map)Python 代码显示了回调函数的定义和操纵 DOM 的机制:
第 1 行导入用于与 DOM 交互的模块和
brython.min.js中的浏览器 API 代码。第 2 行导入
base64,在 Brython 标准库中有brython_stdlib.min.js。第 4 行声明了一个字典,您将使用它在 HTML 页面的生命周期中存储数据。
第 6 行定义了事件处理程序
base64_compute(),它对 ID 为text-src的输入字段中输入的文本的 Base64 值进行编码。这是一个回调函数,将事件作为参数。该参数不在函数中使用,但在 Brython 中是必需的,在 JavaScript 中是可选的。按照惯例,您可以使用_作为虚拟占位符。在谷歌 Python 风格指南中描述了这种用法的一个例子。第 7 行检索用
text-src标识的 DOM 元素的值。第 18 行定义了事件处理程序
clear_map(),该事件处理程序清除该页面上的数据以及数据的显示。第 22 行定义了
display_map(),它取b64_map中包含的数据并显示在页面的表单下。第 26 行检索 ID 为
text-src的 DOM 元素。第 29 行清除 ID 为
text-src的 DOM 元素的值。第 31 行将
submit按钮的onclick事件绑定到base64_compute()。第 32 行将
clear-btn按钮的onclick事件绑定到clear_map()。为了操作 DOM,Brython 使用了两个操作符:
<=是 Brython 特有的新操作符,用于向节点添加子节点。你可以在第 22 行定义的display_map()中看到一些这种用法的例子。
+是Element.insertAdjacentHTML('afterend')的替代,增加了同级节点。您可以在取自
display_map()的以下语句中看到这两个运算符:table <= html.THEAD(html.TR(html.TH("Text") + html.TH("Base64")))您可以将上面的代码理解为“向表格元素添加一个表格标题元素,其中包含一个由两个相邻的表格数据单元格元素组成的表格行元素。它在浏览器中呈现为以下 HTML 代码:
<table> <thead><tr><th>Text</th><th>Base64</th></tr></thead> </table>HTML 代码显示了表格元素标题行的嵌套结构。下面是相同代码的一种更具可读性的格式:
<table> <thead> <tr> <th>Text</th> <th>Base64</th> </tr> </thead> </table>要在 Brython 控制台中观察结果,可以输入以下代码块:
>>> from browser import html
>>> table = html.TABLE()
>>> table <= html.THEAD(html.TR(html.TH("Text") + html.TH("Base64")))
>>> table.outerHTML
'<table><thead><tr><th>Text</th><th>Base64</th></tr></thead></table>'
要执行全部代码,您需要启动一个 web 服务器。和前面一样,您在与两个文件index.html和main.py相同的目录中启动内置的 Python web 服务器:
$ python3 -m http.server
Serving HTTP on :: port 8000 (http://[::]:8000/) ...
启动 web 服务器后,将浏览器指向http://localhost:8000。页面看起来像这样:
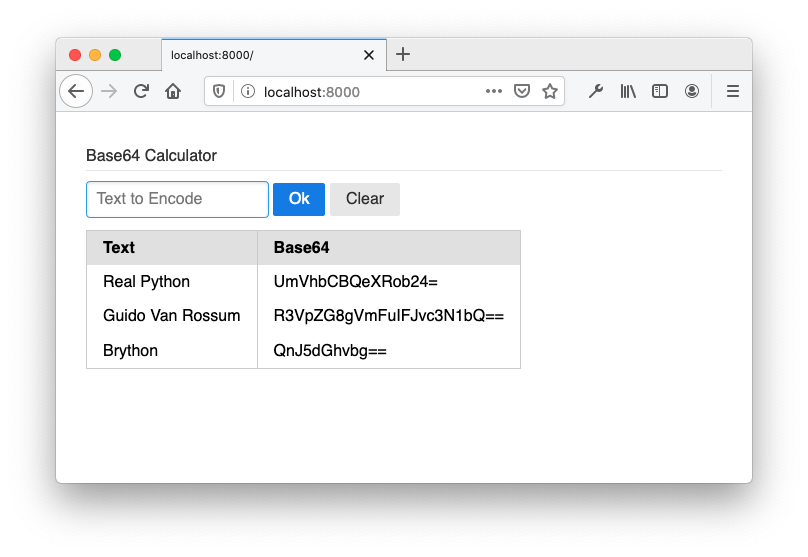
您将在 Browser Web API 一节中扩展这个示例,允许在页面重新加载之间存储数据。
导入到 Brython
可以使用import访问编译成 JavaScript 的 Python 模块或 Brython 模块。
Python 模块是项目根文件夹中扩展名为.py的文件,或者对于 Python 包,是包含__init__.py文件的子文件夹中的文件。要在 Brython 代码中导入 Python 模块,需要启动一个 web 服务器。关于 Python 模块的更多信息,请查看 Python 模块和包——简介。
要探索如何将 Python 模块导入到您的 Brython 代码中,请遵循关于使用 PyPI 安装一节中描述的说明,创建并激活一个 Python 虚拟环境,安装 Brython,并修改index.html,如下所示:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<script type="text/javascript" src="brython.js"></script>
<script type="text/javascript" src="brython_stdlib.js"></script>
</head>
<body onload="brython()">
<script type="text/python"> from browser import document, html, window import sys import functional selection = functional.take(10, range(10000)) numbers = ', '.join([str(x) for x in selection]) document <= html.P(f"{sys.version=}") document <= html.P(f"{numbers=}") </script>
</body>
</html>
上面的 HTML 文件公开了从核心引擎(browser)、标准库(sys)和本地 Python 模块(functional)导入的模块。下面是functional.py的内容:
import itertools
def take(n, iterable):
"Return first n items of the iterable as a list"
return list(itertools.islice(iterable, n))
该模块实现 itertools配方之一的take()。take()返回给定 iterable 的前 n 个元素。就靠itertools.slice()了。
如果您试图用浏览器从文件系统中打开index.html,那么您将在浏览器控制台中得到以下错误:
Traceback (most recent call last):
File file:///Users/andre/brython/code/import/index.html/__main__
line 3, in <module>
import functional
ModuleNotFoundError: functional
导入 Python 模块需要启动本地 web 服务器。启动本地 web 服务器,将浏览器指向http://localhost:8000。您应该会看到以下 HTML 页面:
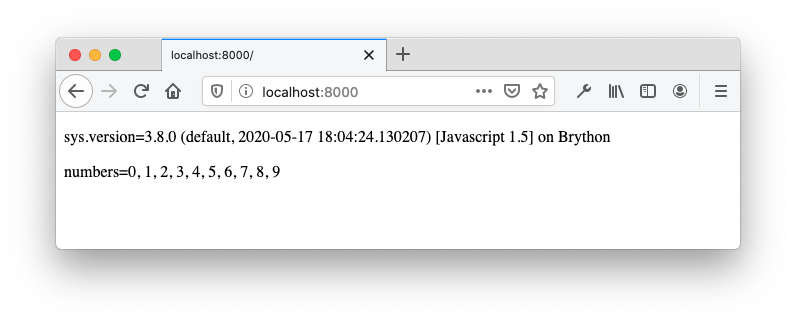
对于正在运行的 web 服务器,当执行import functional时,浏览器能够获取模块functional.py。两个值sys.version和numbers的结果由嵌入的 Python 脚本的最后两行插入到 HTML 文件中,并由浏览器呈现。
减少导入大小
在前一个示例的项目目录中,为了减小导入的 JavaScript 模块的大小并将 Python 模块预编译成 JavaScript,您可以使用带有选项--modules的brython-cli:
$ brython-cli --modules
Create brython_modules.js with all the modules used by the application
searching brython_stdlib.js...
finding packages...
script in html index.html
这将生成brython_modules.js,你可以修改index.html的head元素如下:
1<head>
2<meta charset="utf-8">
3<script type="text/javascript" src="brython.js"></script>
4<script type="text/javascript" src="brython_modules.js"></script> 5</head>
第 4 行将原始脚本源从brython_stdlib.js更改为brython_modules.js。
用浏览器打开index.html或将浏览器指向本地服务器会呈现相同的 HTML 页面。请注意以下几点:
- 您可以在浏览器中呈现 HTML 页面,而无需运行 web 服务器。
- 您不需要分发
functional.py,因为代码已经被转换成 JavaScript 并捆绑在brython_modules.js中。 - 不需要加载
brython_stdlib.js。
命令行工具brython-cli --modules提供了从标准库中删除不必要代码的解决方案,并将您的 python 模块编译成 JavaScript 代码。这有助于打包您的应用程序,从而减少资源下载量。
注意:与导入 Python 模块类似,加载带有 HTML script元素的 Python 模块需要您启动一个 web 服务器。考虑下面的 HTML script元素:
<script src="main.py" type="text/python"></script>
当 Brython 函数被执行并加载一个指向 Python 文件的script内容时,它试图执行一个 Ajax 调用,这只能在 web 服务器运行时才能完成。如果您尝试从文件系统中打开该文件,浏览器 JavaScript 控制台中将显示类似以下内容的错误:
IOError: can't load external script at file:///project/main.py
(Ajax calls not supported with protocol file:///)
安全保护阻止您从本地文件系统加载main.py。您可以通过运行本地文件服务器来解决此问题。有关此行为的更多信息,请参见 Brython 文档。
与 JavaScript 交互
Brython 允许 Python 代码与 JavaScript 代码进行交互。最常见的模式是从 Brython 访问 JavaScript。反过来,虽然可能,但并不常见。在 JavaScript 单元测试一节中,您将看到一个 JavaScript 调用 Python 函数的例子。
JavaScript
到目前为止,您已经经历了一些 Python 代码与 JavaScript 代码交互的场景。特别是,您已经能够通过调用browser.alert()来显示消息框。
在 Brython 控制台中运行的以下三个示例中,您可以看到alert正在运行,而不是在标准的 CPython 解释器 shell 中:
>>> import browser >>> browser.alert("Real Python")或者你可以使用
window:
>>> from browser import window
>>> window.alert("Real Python")
或者你可以使用this:
>>> from javascript import this >>> this().alert("Real Python")由于 Brython 暴露的新层以及
alert()和window的全局性质,你可以在browser.window甚至在javascript.this上调用alert。以下是允许访问 JavaScript 函数的主要 Brython 模块:
模块 语境 例子 browser包含内置名称和模块 browser.alert()browser.document访问 DOM document.getElementById("element-id")T1】 browser.html创建 HTML 元素 html.H1("This is the title")browser.window访问 Window函数和对象window.navigatorT1】 javascript访问 JavaScript 中定义的对象 javascript.this()T1】 除了浏览器中可用的 JavaScript 函数和 API,您还可以访问自己编写的 JavaScript 函数。以下示例演示了如何从 Brython 访问自定义 JavaScript 函数:
1<!doctype html> 2<html> 3 <head> 4 <meta charset="utf-8"> 5 <script 6 src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.js"> 7 </script> 8 <script type="text/javascript"> 9 function myMessageBox(name) { 10 window.alert(`Hello ${name}!`); 11 } 12 </script> 13 </head> 14 <body onload="brython()"> 15 <script type="text/python"> 16 from browser import window 17 window.myMessageBox("Jon") 18 </script> 19 </body> 20</html>它是这样工作的:
- 第 9 行定义了 JavaScript 块中的自定义函数
myMessageBox()。- 第十七行调用
myMessageBox()。您可以使用相同的特性来访问 JavaScript 库。在 Web UI 框架一节中,您将看到如何与 Vue.js 交互,这是一个流行的 Web UI 框架。
浏览器 Web API
浏览器公开了可以从 JavaScript 访问的 web APIs,Brython 也可以访问相同的 API。在本节中,您将扩展 Base64 计算器来存储浏览器页面重新加载之间的数据。
允许此功能的 web API 是 Web 存储 API 。它包括两种机制:
在接下来的例子中,您将使用
localStorage。正如您在前面所学的,Base64 计算器创建一个字典,其中包含映射到该字符串的 Base64 编码值的输入字符串。页面加载后,数据会保留在内存中,但在重新加载页面时会被清除。将数据保存到
localStorage将在页面重新加载之间保留字典。localStorage是一个键值存储。要访问
localStorage,需要导入storage。为了接近最初的实现,您将把字典数据以 JSON 格式加载并保存到localStorage。保存和获取数据的键将是b64data。修改后的代码包括新的导入和一个load_data()函数:from browser.local_storage import storage import json, base64 def load_data(): data = storage.get("b64data") if data: return json.loads(data) else: storage["b64data"] = json.dumps({}) return {}加载 Python 代码时执行
load_data()。它从localStorage获取 JSON 数据,并填充一个 Python 字典,该字典将用于在页面生命周期内在内存中保存数据。如果在localStorage中没有找到b64data,那么在localStorage中为关键字b64data创建一个空字典,并返回一个空字典。你可以通过展开下面的方框来查看包含
load_data()的完整 Python 代码。它展示了如何使用localStorageweb API 作为持久存储,而不是依赖短暂的内存存储,就像本例前面的实现一样。以下代码显示了如何使用浏览器
localStorage管理数据:1from browser import document, prompt, html, alert 2from browser.local_storage import storage 3import json, base64 4 5def load_data(): 6 data = storage.get("b64data") 7 if data: 8 return json.loads(data) 9 else: 10 storage["b64data"] = json.dumps({}) 11 return {} 12 13def base64_compute(evt): 14 value = document["text-src"].value 15 if not value: 16 alert("You need to enter a value") 17 return 18 if value in b64_map: 19 alert(f"'{value}' already exists: '{b64_map[value]}'") 20 return 21 b64data = base64.b64encode(value.encode()).decode() 22 b64_map[value] = b64data 23 storage["b64data"] = json.dumps(b64_map) 24 display_map() 25 26def clear_map(evt): 27 b64_map.clear() 28 storage["b64data"] = json.dumps({}) 29 document["b64-display"].clear() 30 31def display_map(): 32 if not b64_map: 33 return 34 table = html.TABLE(Class="pure-table") 35 table <= html.THEAD(html.TR(html.TH("Text") + html.TH("Base64"))) 36 table <= (html.TR(html.TD(key) + html.TD(b64_map[key])) for key in b64_map) 37 base64_display = document["b64-display"] 38 base64_display.clear() 39 base64_display <= table 40 document["text-src"].value = "" 41 42b64_map = load_data() 43display_map() 44document["submit"].bind("click", base64_compute) 45document["clear-btn"].bind("click", clear_map)新行将突出显示。当文件在调用
brython()时被加载和处理时,全局字典b64_map由load_data()填充。当页面重新加载时,从localStorage中获取数据。每次计算新的 Base64 值时,
b64_map的内容被转换为 JSON 并存储在本地存储器中。存储的关键是b64data。您可以从
browser和其他子模块访问所有 web API 函数。关于访问 web API 的高级文档可以在 Brython 文档中找到。更多细节,你可以参考 web API 文档并使用 Brython 控制台来试验 web API。在某些情况下,您可能需要在熟悉的 Python 函数和 web APIs 函数之间做出选择。例如,在上面的代码中,您使用了 Python Base64 编码,
base64.b64encode(),但是您也可以使用 JavaScript 的btoa():
>>> from browser import window
>>> window.btoa("Real Python")
'UmVhbCBQeXRob24='
您可以在在线控制台中测试这两种变体。使用window.btoa()只能在 Brython 上下文中工作,而base64.b64encode()可以用常规的 Python 实现来执行,如 CPython 。注意,在 CPython 版本中,base64.b64encode()采用一个 bytearray 作为参数类型,而 JavaScript window.btoa()采用一个字符串。
如果性能是一个问题,那么考虑使用 JavaScript 版本。
Web UI 框架
像 Angular 、 React 、 Vue.js 或 Svelte 等流行的 JavaScript UI 框架已经成为前端开发人员工具包的重要组成部分,Brython 与其中一些框架无缝集成。在本节中,您将使用 Vue.js 版本 3 和 Brython 构建一个应用程序。
您将构建的应用程序是一个计算字符串的散列值的表单。下面是正在运行的 HTML 页面的屏幕截图:
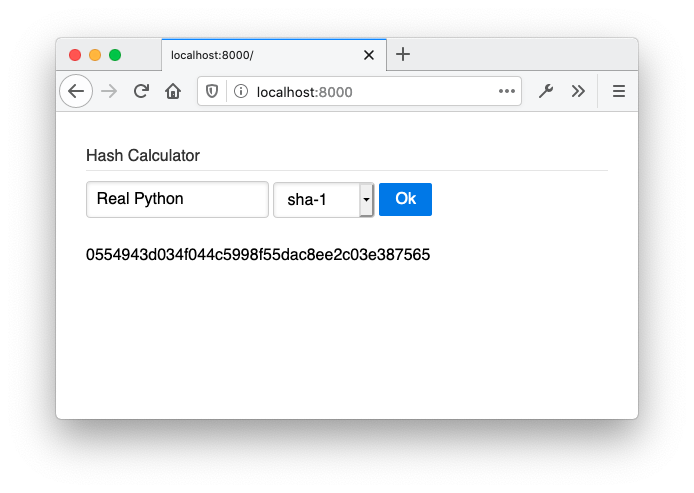
HTML 页面的body以声明方式定义了绑定和模板:
<!DOCTYPE html >
<html>
<head>
<meta charset="utf-8"/>
<link
rel="stylesheet"
href="https://cdnjs.cloudflare.com/ajax/libs/pure/2.0.3/pure-min.min.css"/>
<script src="https://cdnjs.cloudflare.com/ajax/libs/vue/3.0.2/vue.global.prod.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython_stdlib.min.js"></script>
<script src="main.py" type="text/python"></script>
<style> body { padding: 30px; } [v-cloak] { visibility: hidden; } </style>
</head>
<body onload="brython(1)">
<div id="app">
<form class="pure-form" onsubmit="return false;">
<fieldset>
<legend>Hash Calculator</legend>
<input type="text" v-model.trim="input_text"
placeholder="Text to Encode" autocomplete="off"/>
<select v-model="algo" v-cloak>
<option v-for="name in algos" v-bind:value="name">
</option>
</select>
<button @click="compute_hash" type="submit"
class="pure-button pure-button-primary">Ok</button>
</fieldset>
</form>
<p v-cloak></p>
</div>
</body>
如果您不熟悉 Vue,那么您可以快速了解下面的一些内容,但是请随意查阅官方文档以获取更多信息:
- Vue.js 指令 是特殊的属性值,以
v-为前缀,提供 DOM 和 Vue.js 组件的值之间的动态行为和数据映射:v-model.trim="input_text"将输入值绑定到 Vue 模型input_text并修剪该值。v-model="algo"将下拉列表的值绑定到algo。v-for="name in algos"将选项值绑定到name。
- Vue 模板 用双花括号括起来的变量表示。Vue.js 用 Vue 组件中的相应值替换相应的占位符:
- T2
hash_value - T2
name
- T2
- 事件处理程序 用一个 at 符号(
@)标识,就像在@click="compute_hash"中一样。
相应的 Python 代码描述了 Vue 和附加的业务逻辑:
1from browser import alert, window
2from javascript import this
3import hashlib
4
5hashes = {
6 "sha-1": hashlib.sha1,
7 "sha-256": hashlib.sha256,
8 "sha-512": hashlib.sha512,
9}
10
11Vue = window.Vue 12
13def compute_hash(evt):
14 value = this().input_text 15 if not value:
16 alert("You need to enter a value")
17 return
18 hash_object = hashes[this().algo]()
19 hash_object.update(value.encode())
20 hex_value = hash_object.hexdigest()
21 this().hash_value = hex_value 22
23def created():
24 for name in hashes:
25 this().algos.append(name) 26 this().algo = next(iter(hashes)) 27
28app = Vue.createApp(
29 {
30 "el": "#app",
31 "created": created,
32 "data": lambda _: {"hash_value": "", "algos": [], "algo": "", "input_text": ""},
33 "methods": {"compute_hash": compute_hash},
34 }
35)
36
37app.mount("#app")
Vue.js 的声明性质显示在带有 Vue 指令和模板的 HTML 文件中。这也在 Python 代码中用第 11 行和第 28 到 35 行的 Vue 组件声明进行了演示。这种声明性技术将 DOM 的节点值与 Vue 数据连接起来,允许框架的反应性行为。
这消除了您在前一个示例中必须编写的一些样板代码。例如,请注意,您不必用类似于document["some_id"]的表达式从 DOM 中选择元素。创建 Vue 应用程序并调用app.mount()处理 Vue 组件到相应 DOM 元素的映射以及 JavaScript 函数的绑定。
在 Python 中,访问 Vue 对象字段需要使用javascript.this()引用 Vue 对象:
- 第 14 行获取组件字段
this().input_text的值。 - 第 21 行更新数据成分
this().hash_value。 - 第 25 行向列表
this().algos添加一个算法。 - 第 26 行用
hashes{}的第一个键实例化this().algo。
如果结合 Brython 的 Vue 介绍激发了您的兴趣,那么您可能想看看 vuepy 项目,它为 Vue.js 提供了完整的 Python 绑定,并使用 Brython 在浏览器中运行 Python。
网络组装
在某些情况下,可以使用 WebAssembly 来提高 Brython 甚至 JavaScript 的性能。 WebAssembly ,或 Wasm ,是所有主流浏览器都支持的二进制代码。它可以在浏览器中提供比 JavaScript 更好的性能,并且是像 C 、 C++ 和 Rust 这样的语言的编译目标。如果你没有使用 Rust 或 Wasm,那么你可以跳过这一节。
在下面演示 WebAssembly 使用方法的示例中,您将在 Rust 中实现一个函数,并从 Python 中调用它。
这不是一个彻底的生锈教程。它只是触及了表面。关于 Rust 的更多细节,请查看 Rust 文档。
从使用rustup安装防锈的开始。要编译 Wasm 文件,还需要添加 wasm32目标:
$ rustup target add wasm32-unknown-unknown
使用 cargo 创建一个项目,在 Rust 安装时安装:
$ cargo new --lib op
上面的命令在名为op的文件夹中创建一个框架项目。在这个文件夹中,您将找到Cargo.toml,Rust build 配置文件,您需要修改它以表明您想要创建一个动态库。您可以通过添加突出显示的部分来做到这一点:
[package] name = "op" version = "0.1.0" authors = ["John <john@example.com>"] edition = "2018" [lib] crate-type=["cdylib"]
[dependencies]
修改src/lib.rs,将其内容替换为以下内容:
#[no_mangle] pub extern fn double_first_and_add(x: u32, y: u32) -> u32 { (2 * x) + y }
在项目的根目录中,即Cargo.toml所在的位置,编译您的项目:
$ cargo build --target wasm32-unknown-unknown
接下来,用下面的index.html创建一个web目录:
1<!-- index.html -->
2<!DOCTYPE html>
3<html>
4<head>
5 <script src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.min.js"></script>
6 <script src="main.py" type="text/python"></script> 7</head>
8<body onload="brython()">
9
10<form class="pure-form" onsubmit="return false;">
11 <h2>Custom Operation using Wasm + Brython</h2>
12 <fieldset>
13 <legend>Multiply first number by 2 and add result to second number</legend>
14 <input type="number" value="0" id="number-1" placeholder="1st number"
15 autocomplete="off" required/>
16 <input type="number" value="0" id="number-2" placeholder="2nd number"
17 autocomplete="off" required/>
18 <button type="submit" id="submit" class="pure-button pure-button-primary">
19 Execute
20 </button>
21 </fieldset>
22</form>
23
24<br/>
25<div id="result"></div>
26</body>
27</html>
上面的第 6 行从同一个目录加载了下面的main.py:
1from browser import document, window
2
3double_first_and_add = None
4
5def add_rust_fn(module): 6 global double_first_and_add
7 double_first_and_add = module.instance.exports.double_first_and_add 8
9def add_numbers(evt):
10 nb1 = document["number-1"].value or 0
11 nb2 = document["number-2"].value or 0
12 res = double_first_and_add(nb1, nb2)
13 document["result"].innerHTML = f"Result: ({nb1} * 2) + {nb2} = {res}"
14
15document["submit"].bind("click", add_numbers)
16window.WebAssembly.instantiateStreaming(window.fetch("op.wasm")).then(add_rust_fn)
突出显示的线条是允许 Brython 访问 Rust 函数double_first_and_add()的粘合剂:
- 第 16 行使用
WebAssembly读取op.wasm,然后在 Wasm 文件下载时调用add_rust_fn()。 - 第 5 行实现
add_rust_fn(),以 Wasm 模块为参数。 - 第 7 行将
double_first_and_add()赋予本地double_first_and_add名称,使其对 Python 可用。
在同一个web目录下,从target/wasm32-unknown-unknown/debug/op.wasm复制op.wasm:
$ cp target/wasm32-unknown-unknown/debug/op.wasm web
项目文件夹布局如下所示:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
├── target
│ ...
└── web
├── index.html
├── main.py
└── op.wasm
这显示了用cargo new创建的 Rust 项目的文件夹结构。为了清楚起见,target被部分省略。
现在在web中启动一个服务器:
$ python3 -m http.server
Serving HTTP on :: port 8000 (http://[::]:8000/) ...
最后,将你的网络浏览器指向http://localhost:8000。您的浏览器应该呈现如下所示的页面:
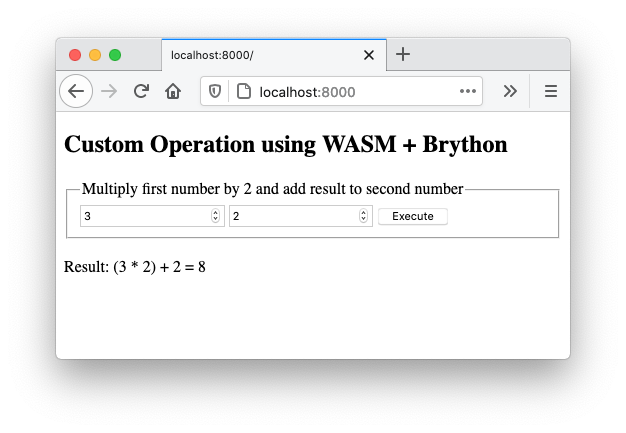
这个项目展示了如何创建一个可以在 JavaScript 或 Brython 中使用的 WebAssembly。由于构建 Wasm 文件会产生很大的开销,这不应该是解决特定问题的首选方法。
如果 JavaScript 不能满足您的性能需求,那么 Rust 可能是一个选项。如果您已经有 Wasm 代码可以与之交互,无论是您构建的代码还是现有的 Wasm 库,这都非常有用。
使用 Rust 生成 WebAssembly 的另一个好处是它可以访问 Python 或 JavaScript 中不存在的库。如果您想使用用 C 编写的 Python 库,而该库不能与 Brython 一起使用,那么它也很有用。如果 Rust 中存在这样一个库,那么您可以考虑构建一个 Wasm 文件来与 Brython 一起使用。
在 Brython 中应用异步开发
同步编程可能是你最熟悉的计算行为。例如,当执行三个语句 A、B 和 C 时,一个程序首先执行 A,然后执行 B,最后执行 C,每个语句在将程序传递给下一个语句之前都会阻塞程序流。
想象一种技术,首先执行 A,调用 B 但不立即执行,然后执行 C。你可以把 B 想成是未来被执行的承诺。因为 B 是非阻塞的,所以它被认为是异步的。要了解异步编程的更多背景知识,您可以查看Python中的异步特性入门。
JavaScript 是单线程的,并且依赖于异步处理,尤其是在涉及网络通信的时候。例如,获取 API 的结果不需要阻塞其他 JavaScript 函数的执行。
使用 Brython,您可以通过许多组件访问异步特性:
随着 JavaScript 的发展,回调逐渐被承诺或异步函数所取代。在本教程中,您将学习如何使用 Brython 的 promises 以及如何使用browser.ajax和browser.aio模块,这两个模块利用了 JavaScript 的异步特性。
CPython 库中的 asyncio模块不能在浏览器上下文中使用,在 Brython 中被替换为browser.aio。
JavaScript 在 Brython 中承诺
在 JavaScript 中, promise 是一个可能在未来某个时候产生结果的对象。完成时产生的值将是错误的值或原因。
下面的例子说明了如何使用 Brython 的 JavaScript Promise对象。您可以在在线控制台中使用此示例:
1>>> from browser import timer, window 2>>> def message_in_future(success, error): 3... timer.set_timeout(lambda: success("Message in the future"), 3000) 4... 5>>> def show_message(msg): 6... window.alert(msg) 7... 8>>> window.Promise.new(message_in_future).then(show_message) 9<Promise object>在 web 控制台中,您可以获得关于 Python 代码执行的即时反馈:
- 第 1 行导入
timer来设置超时,导入window来访问Promise对象。- 第 2 行定义了一个执行器,
message_in_future(),当承诺成功时,在超时结束时返回一条消息。- 第 5 行定义了一个显示警告的函数
show_message()。- 第 8 行创建一个与执行人的承诺,用一个
then块链接,允许访问承诺的结果。在上面的例子中,超时模拟了一个长时间运行的函数。承诺的真正用途可能涉及网络呼叫。在
3秒后,承诺成功完成,值为"Message in the future"。如果 executor 函数
message_in_future()检测到一个错误,那么它可以调用error(),将错误原因作为参数。您可以用一个新的链接方法.catch()在Promise对象上实现它,如下所示:
>>> window.Promise.new(message_in_future).then(show_message).catch(show_message)
您可以在下图中看到成功完成承诺的行为:
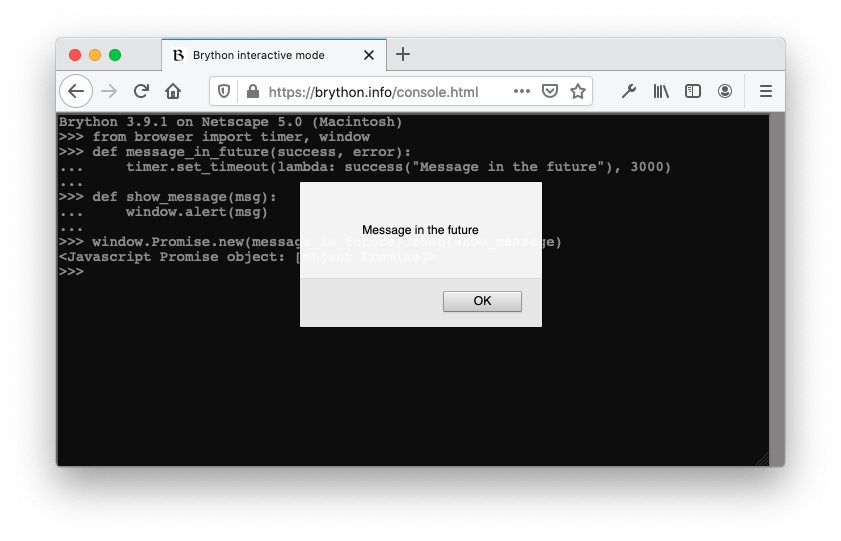
当您在控制台中运行代码时,您可以看到首先创建了Promise对象,然后,在超时之后,显示消息框。
Brython 中的 Ajax
当函数被限定为 I/O 绑定时,异步函数特别有用。这与 CPU 绑定的函数形成了对比。一个 I/O 绑定的函数是一个主要花费时间等待输入或输出完成的函数,而一个 CPU 绑定的函数是计算。通过网络调用 API 或查询数据库是 I/O 绑定的执行,而计算素数序列是 CPU 绑定的。
Brython 的browser.ajax公开了像get()和post()这样的 HTTP 函数,默认情况下,它们是异步的。这些函数采用一个可以设置为True的blocking参数来同步呈现相同的函数。
要异步调用HTTPGETT3,调用ajax.get()如下:
ajax.get(url, oncomplete=on_complete)
要以阻塞模式获取 API,请将blocking参数设置为True:
ajax.get(url, blocking=True, oncomplete=on_complete)
以下代码显示了阻塞 Ajax 调用和非阻塞 Ajax 调用之间的区别:
1from browser import ajax, document
2import javascript
3
4def show_text(req):
5 if req.status == 200:
6 log(f"Text received: '{req.text}'")
7 else:
8 log(f"Error: {req.status} - {req.text}")
9
10def log(message):
11 document["log"].value += f"{message} \n"
12
13def ajax_get(evt): 14 log("Before async get")
15 ajax.get("/api.txt", oncomplete=show_text)
16 log("After async get")
17
18def ajax_get_blocking(evt): 19 log("Before blocking get")
20 try:
21 ajax.get("/api.txt", blocking=True, oncomplete=show_text)
22 except Exception as exc:
23 log(f"Error: {exc.__name__} - Did you start a local web server?")
24 else:
25 log("After blocking get")
26
27document["get-btn"].bind("click", ajax_get)
28document["get-blocking-btn"].bind("click", ajax_get_blocking)
上面的代码演示了同步和异步两种行为:
-
第 13 行定义了
ajax_get(),它使用ajax.get()从远程文件中获取文本。ajax.get()的默认行为是异步的。ajax_get()返回,分配给参数oncomplete的show_text()在收到远程文件/api.txt后被回调。 -
第 18 行定义了
ajax_get_blocking(),演示了如何将ajax.get()用于阻塞行为。在这个场景中,show_text()在ajax_get_blocking()返回之前被调用。
当您运行完整的示例并单击异步获取和阻塞获取时,您将看到以下屏幕:
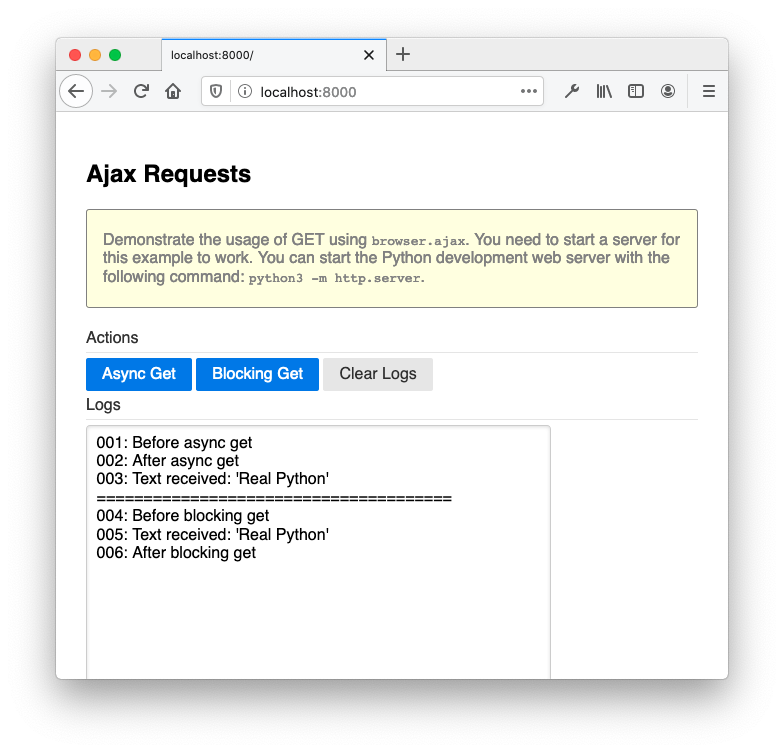
您可以看到,在第一个场景中,ajax_get()被完全执行,API 调用的结果异步发生。在第二种情况下,在从ajax_get_blocking()返回之前显示 API 调用的结果。
Brython 中的异步 IO
随着 asyncio ,Python 3.4 开始暴露新的异步能力。在 Python 3.5 中,异步支持增加了 async / await语法。由于与浏览器事件循环不兼容,Brython 实现了 browser.aio 作为标准asyncio的替代。
Brython 模块browser.aio和 Python 模块asyncio都支持使用async和await关键字,并共享通用函数,如run()和sleep()。两个模块都实现了其他不同的功能,这些功能与它们各自的执行上下文有关,CPython 上下文环境用于asyncio,浏览器环境用于browser.aio。
协程程序
你可以使用run()和sleep()来创建协程。为了说明在 Brython 中实现的协同程序的行为,您将实现一个在 CPython 文档中可用的协同程序示例的变体:
1from browser import aio as asyncio 2import time
3
4async def say_after(delay, what): 5 await asyncio.sleep(delay) 6 print(what)
7
8async def main(): 9 print(f"started at {time.strftime('%X')}")
10
11 await say_after(1, 'hello')
12 await say_after(2, 'world')
13
14 print(f"finished at {time.strftime('%X')}")
15
16asyncio.run(main())
除了第一行import之外,代码与您在 CPython 文档中找到的一样。它演示了关键字async和await的用法,并展示了run()和sleep()的实际应用:
- 第 1 行使用
asyncio作为browser.aio的别名。尽管它隐藏了aio,但它保持代码接近 Python 文档示例,以便于比较。 - 第 4 行声明协程
say_after()。注意async的使用。 - 第 5 行用
await调用asyncio.sleep(),以便当前函数将控制权让给另一个函数,直到sleep()完成。 - 第 8 行声明了另一个协程,该协程本身将调用协程
say_after()两次。 - 第 9 行调用
run(),这是一个非阻塞函数,它将一个协程(本例中为main())作为参数。
注意,在浏览器的上下文中,aio.run()利用了内部 JavaScript 事件循环。这与 CPython 中的相关函数asyncio.run()不同,后者完全管理事件循环。
要执行这段代码,将其粘贴到在线 Brython 编辑器中,然后单击 Run 。您应该会得到类似以下屏幕截图的输出:
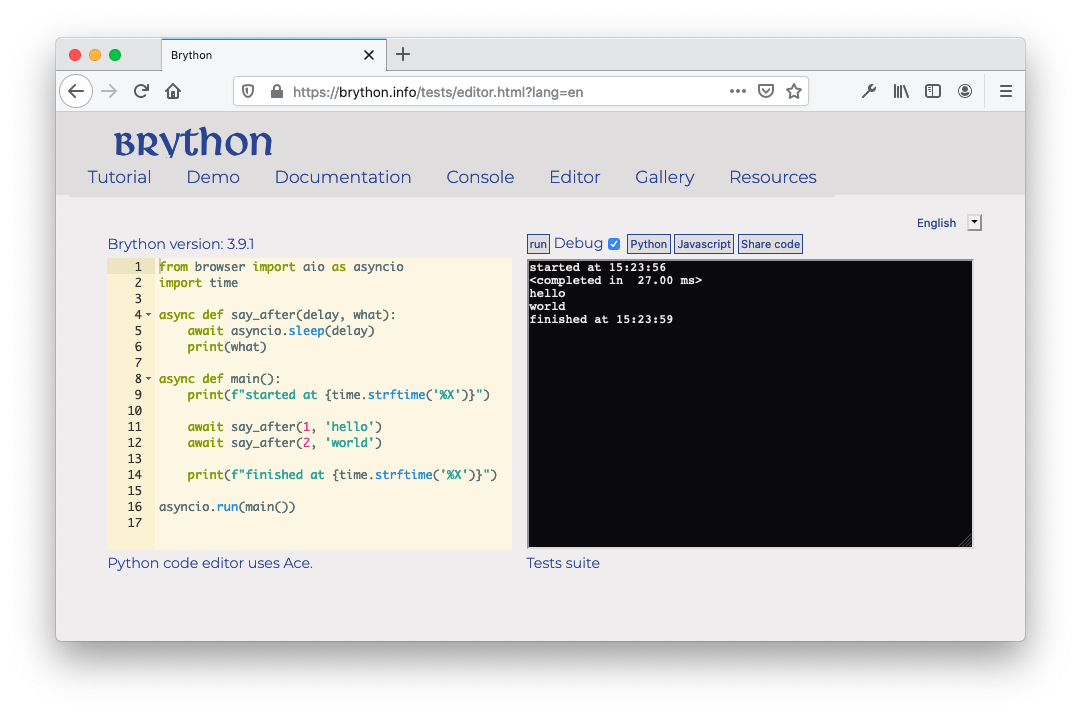
首先执行脚本,然后显示"hello",最后显示"world"。
关于 Python 中协同程序的更多细节,可以查看 Python 中的异步 IO:完整演练。
异步 I/O 的一般概念适用于所有采用这种模式的平台。在 JavaScript 中,事件循环本质上是环境的一部分,而在 CPython 中,这是使用由asyncio公开的函数来管理的。
上面的例子是一个有意的练习,目的是保持代码完全如 Python 文档示例所示。使用 Brython 在浏览器中编码时,建议显式使用browser.aio,您将在下一节中看到。
网络特定功能
如前一节所述,要对 API 发出异步调用,您可以编写如下函数:
async def process_get(url):
req = await aio.get(url)
注意关键字async和await的使用。该功能需要定义为async才能使用await呼叫。在执行该函数期间,当到达对await aio.get(url)的调用时,该函数将控制权交还给主事件循环,同时等待网络调用aio.get()完成。程序执行的其余部分不会被阻塞。
下面是一个如何调用process_get()的例子:
aio.run(process_get("/some_api"))
函数aio.run()执行协程process_get()。它是非阻塞的。
一个更完整的代码示例展示了如何使用关键字async和await以及aio.run()和aio.get()是如何互补的:
1from browser import aio, document
2import javascript
3
4def log(message):
5 document["log"].value += f"{message} \n"
6
7async def process_get(url): 8 log("Before await aio.get")
9 req = await aio.get(url) 10 log(f"Retrieved data: '{req.data}'")
11
12def aio_get(evt):
13 log("Before aio.run")
14 aio.run(process_get("/api.txt")) 15 log("After aio.run")
16
17document["get-btn"].bind("click", aio_get)
在 Python 3 的最新版本中,您可以使用async和await关键字:
- 第 7 行用关键字
async定义process_get()。 - 第 9 行用关键字
await调用aio.get()。使用await需要用async定义封闭函数。 - 第 14 行展示了如何使用
aio.run(),它将被调用的async函数作为参数。
要运行完整的示例,您需要启动一个 web 服务器。可以用python3 -m http.server启动 Python 开发 web 服务器。它在端口 8000 和默认页面index.html上启动一个本地 web 服务器:
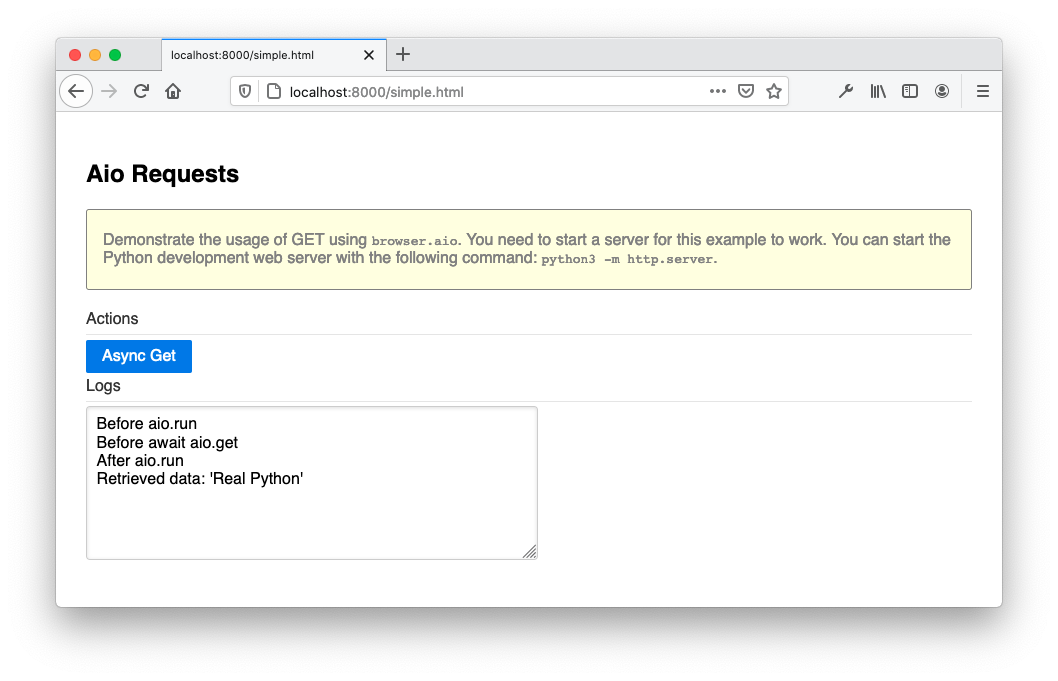
截图显示了点击异步获取后执行的步骤顺序。使用aio模块和关键字async和await的组合展示了如何拥抱 JavaScript 提倡的异步编程模型。
分发和打包一个 Brython 项目
您用来安装 Brython 的方法可能会影响您部署 Brython 项目的方式和位置。特别是,要部署到 PyPI,最好的选择是首先从 PyPI 安装 Brython,然后用brython-cli创建您的项目。但是到私有服务器或云提供商的典型 web 部署可以利用您选择的任何安装方法。
您有几个部署选项:
- 手动和自动部署
- 部署到 PyPI
- 部署到 CDN
在接下来的几节中,您将探索其中的每一个。
手动和自动 Web 部署
您的应用程序包含您的网站所需的所有静态依赖项、CSS、JavaScript、Python 和图像文件。Brython 是 JavaScript 文件的一部分。所有文件都可以按原样部署在您选择的提供者上。你可以参考 Web 开发教程和用 Fabric 和 Ansible 实现 Django 部署自动化来了解关于部署你的 Brython 应用的细节。
如果您决定使用brython-cli --modules来预编译您的 Python 代码,那么您部署的文件将没有任何 Python 源代码,只有brython.js和brython_modules.js。你也不会包含brython_stdlib.js,因为所需的模块已经包含在brython_modules.js中了。
部署到 PyPI
当您从 PyPI 安装 Brython 时,您可以使用brython-cli创建一个可以部署到 PyPI 的包。创建这样一个包的目的是扩展默认的 Brython 模板作为定制项目的基础,并使 Brython 网站可以从 PyPI 获得。
按照从 PyPI 安装一节中的说明,在您的新web项目中执行以下命令:
$ brython-cli --make_dist
系统会提示您回答几个旨在创建brython_setup.json的问题,您可以稍后修改这些问题。该命令完成后,您将拥有一个名为__dist__的目录,其中包含创建可安装包所需的文件。
您可以在本地测试这个新包的安装,如下所示:
$ pip install -e __dist__
随后,您还可以通过执行以下命令来确认新命令与web包一起部署在本地:
$ python -m web --help
usage: web.py [-h] [--install]
optional arguments:
-h, --help show this help message and exit
--install Install web in an empty directory
请注意,web命令的行为与 Brython 在初始安装后的行为完全一样。您刚刚创建了一个可定制安装的 Brython 包,它可以部署到 PyPI。关于如何将包部署到 PyPI 的完整描述,请查看如何将开源 Python 包发布到 PyPI 。
一旦部署到 PyPI,您就可以在一个 Python 虚拟环境中安装带有pip的 Brython 包。您将能够使用您创建的新命令创建新的定制应用程序:
$ python -m <application_name> --install
总而言之,下面是部署到 PyPI 的步骤:
- 从 PyPI 安装 Brython。
- 用
brython-cli --install创建一个项目。 - 用
brython-cli --make-dist从你的项目创建一个可安装的包。 - 将这个包部署到 PyPI。
其他安装方法——CDN、GitHub 和 NPM——不包括brython-cli,因此不太适合准备 PyPI 包。
部署到 CDN
正如brython.js和brython_stdlibs.js在 CDN 服务器上可用一样,您也可以将您的静态资产、图像、样式和 JavaScript 文件,包括您的 Python 文件或brython_modules.js部署到 CDN。cdn 的示例包括:
如果你的应用是开源的,那么你可以获得免费的 CDN 支持。例子包括 CDNJS 和 jsDelivr 。
创建谷歌浏览器扩展
Chrome 扩展是利用网络技术构建的组件,集成到 Chrome 中以定制你的浏览环境。通常,这些扩展的图标会出现在 Chrome 窗口的顶部,地址栏的右边。
在 Chrome 网上商店上可以获得公共扩展。为了学习,您将从本地文件安装 Google Chrome 扩展:
![]()
在 Brython 中实现 Google Chrome 扩展之前,您将首先实现一个 JavaScript 版本,然后将其翻译成 Brython。
JS 中的 Hello World 扩展
首先,您将实现一个执行以下操作的扩展:
- 点击扩展图标时打开一个弹出窗口
- 单击弹出窗口按钮时打开提示消息
- 将您输入的消息附加到初始弹出窗口的底部
下面的屏幕截图说明了这种行为:
在空文件夹中,创建文件manifest.json来配置扩展名:
1// manifest.json 2{ 3 "name": "JS Hello World", 4 "version": "1.0", 5 "description": "Hello World Chrome Extension in JavaScript", 6 "manifest_version": 2, 7 "browser_action": { 8 "default_popup": "popup.html" 9 }, 10 "permissions": ["declarativeContent", "storage", "activeTab"] 11}
本例中的重要字段是默认弹出文件popup.html,您也必须创建该文件。关于其他字段和更多的信息,你可以参考清单文件格式文档。
在同一个文件夹中,创建用于定义用户界面扩展的popup.html文件:
1<!-- popup.html -->
2<!DOCTYPE html>
3<html>
4 <head>
5 <script src="popup.js" defer></script>
6 </head>
7 <body>
8
9 <div id="hello"></div>
10 </body>
11</html>
HTML 文件包含一个到扩展的 JavaScript 业务逻辑的链接,并描述了它的用户界面:
- 第 5 行指的是
popup.js,里面包含了扩展的逻辑。 - 第 8 行定义了一个
button,它将被绑定到popup.js中的一个处理程序。 - 第 9 行声明了一个由 JavaScript 代码用来显示一些文本的字段。
您还需要创建popup.js:
1// popup.js 2'use strict'; 3
4let helloButton = document.getElementById("hello-btn"); 5
6helloButton.onclick = function (element) { 7 const defaultName = "Real JavaScript"; 8 let name = prompt("Enter your name:", defaultName); 9 if (!name) { 10 name = defaultName; 11 } 12 document.getElementById("hello").innerHTML = `Hello, ${name}!`; 13};
JavaScript 代码的主要逻辑包括声明一个绑定到 HTML 容器的字段hello-btn的onclick处理程序:
- 第 2 行调用脚本模式,该模式在 JavaScript 中启用更严格的验证来揭示 JavaScript 错误。
- 第 4 行选择由
popup.html中的hello-btn标识的字段,并将其赋给一个变量。 - 第 6 行定义了当用户点击按钮时处理事件的处理器。这个事件处理程序提示用户输入他们的名字,然后将用
hello标识的<div>的内容更改为提供的名字。
安装此扩展之前,请执行以下步骤:
- 打开屏幕右侧的谷歌 Chrome 菜单。
- 打开子菜单更多工具。
- 点击扩展。
屏幕将显示您当前安装的扩展,如果有的话。它可能看起来像这样:
要安装新的扩展,您需要采取以下步骤:
- 确保在屏幕的右上角启用了开发人员模式。
- 点击加载解包。
- 选择包含您刚刚创建的所有文件的文件夹。
如果在安装过程中没有出现错误,那么您现在应该会在浏览器地址栏的右侧看到一个带有 J 的新图标。要测试您的扩展,请单击下面显示的工具栏的 J 图标:

如果在安装或执行过程中出现任何错误,您应该会在扩展卡的移除按钮右侧看到一个红色错误按钮:
您可以点击错误来显示错误并确定根本原因。更正后,通过单击扩展卡右下角的圆形箭头重新加载该扩展,然后重复该过程,直到它按预期工作。
要测试新安装的扩展,可以点击浏览器工具栏右侧显示的 J 图标。如果图标没有显示,那么点击扩展列出已安装的扩展,并选择与您刚刚安装的 JS Hello World 扩展对齐的图钉按钮。
Python 中的 Hello World 扩展
如果你已经到了这一步,那么你已经完成了最困难的步骤,主要是熟悉创建和安装 Chrome 扩展的过程。这些步骤与 Brython 类似,您将在本节中了解到一些不同之处。
清单文件将是不同的,具有不同的扩展名,并且为了更好地衡量,具有不同的描述:
1// manifest.json 2{ 3 "name": "Py Hello World", 4 "version": "1.0", 5 "description": "Hello World Chrome Extension in Python", 6 "manifest_version": 2, 7 "browser_action": { 8 "default_popup": "popup.html" 9 }, 10 "content_security_policy": "script-src 'self' 'unsafe-eval';object-src 'self'", 11 "permissions": ["declarativeContent", "storage", "activeTab"] 12}
注意,你还必须包括一个新的属性, content_security_policy 。这是需要的,以便在 chrome 扩展系统中可以放松针对eval() 的策略。记住 Brython 使用eval() 。
这不是你在 Brython 中引入和控制的东西。如果你想使用 Brython 作为浏览器扩展的语言,你需要启用 using eval()。如果您不将unsafe-eval添加到content_security_policy,那么您将会看到以下错误:
Uncaught EvalError: Refused to evaluate a string as JavaScript because
'unsafe-eval' is not an allowed source of script in the following Content
Security Policy directive: "script-src 'self' blob: filesystem:".
HTML 文件也将有一些更新,如下所示:
1<!-- popup.html -->
2<!DOCTYPE html>
3<html>
4 <head>
5 <script src="brython.min.js" defer></script> 6 <script src="init_brython.js" defer></script> 7 <script src="popup.py" type="text/python" defer></script> 8 </head>
9 <body> 10
11 <div id="hello"></div>
12 </body>
13</html>
HTML 代码与您用 JavaScript 创建 Chrome 扩展的代码非常相似。一些细节值得注意:
- 线 5 从本地包装载
brython.min.js。出于安全原因,只加载本地脚本,你不能从 CDN 之类的外部来源加载。 - 第 6 行加载
init_brython.js,调用brython()。 - 7 号线加载
popup.py。 - 第 9 行宣告
body没有通常的onload="brython()"。
另一个安全约束阻止您在body标签的onload事件中调用brython()。解决方法是在文档中添加一个监听器,并指示浏览器在文档内容加载后执行brython():
// init_brython.js document.addEventListener('DOMContentLoaded', function () { brython(); });
最后,您可以在下面的 Python 代码中看到该应用程序的主要逻辑:
# popup.py
from browser import document, prompt
def hello(evt):
default = "Real Python"
name = prompt("Enter your name:", default)
if not name:
name = default
document["hello"].innerHTML = f"Hello, {name}!"
document["hello-btn"].bind("click", hello)
这样,您就可以像处理 JavaScript chrome 扩展一样继续安装和测试了。
测试和调试 Brython
目前没有方便的库用于单元测试 Brython 代码。随着 Brython 的发展,您将看到更多在浏览器中测试和调试 Python 代码的选项。可以利用 Python 单元测试框架开发一个可以在浏览器之外使用的独立 Python 模块。在浏览器中,带有浏览器驱动程序的 Selenium 是一个不错的选择。调试也是有限的,但也是可能的。
Python 单元测试
Python 的单元测试框架,像内置的 unittest 和 pytest ,在浏览器中不工作。您可以将这些框架用于 Python 模块,这些模块也可以在 CPython 的上下文中执行。任何像browser这样的特定于 Brython 的模块都不能在命令行用这样的工具进行测试。有关 Python 单元测试的更多信息,请查看Python 测试入门。
硒
Selenium 是一个自动化浏览器的框架。它与浏览器中使用的语言无关,无论是 JavaScript、 Elm 、Wasm 还是 Brython,因为它使用了 WebDriver 的概念,就像用户与浏览器交互一样。你可以查看使用 Python 和 Selenium 的现代 Web 自动化来获得关于这个框架的更多信息。
JavaScript 单元测试
有许多专注于 JavaScript 的测试框架,如 Mocha 、 Jasmine 和 QUnit ,它们在完整的 JavaScript 生态系统中表现良好。但是它们不一定非常适合在浏览器中运行的单元测试 Python 代码。一个选项要求将 Brython 函数全局暴露给 JavaScript,这违背了最佳实践。
为了说明将 Brython 函数暴露给 JavaScript 的选项,您将使用 QUnit ,这是一个 JavaScript 单元测试套件,可以在 HTML 文件中独立运行:
1<!-- index.html -->
2<!DOCTYPE html >
3<html>
4
5<head>
6 <meta charset="utf-8">
7 <meta name="viewport" content="width=device-width">
8 <title>Test Suite</title>
9 <link rel="stylesheet" href="https://code.jquery.com/qunit/qunit-2.13.0.css">
10 <script src="https://cdnjs.cloudflare.com/ajax/libs/brython/3.9.0/brython.min.js"></script>
11 <script src="https://code.jquery.com/qunit/qunit-2.13.0.js"></script> 12</head>
13
14<body onload="brython()">
15<div id="qunit"></div>
16<div id="qunit-fixture"></div>
17<script type="text/python"> 18from browser import window 19
20def python_add(a, b): 21 return a + b 22
23window.py_add = python_add 24</script>
25
26<script> 27const js_add = (a, b) => a + b; 28QUnit.module('js_add_test', function() { 29 QUnit.test('should add two numbers', function(assert) { 30 assert.equal(js_add(1, 1), 2, '1 + 1 = 2 (javascript'); 31 }); 32}); 33
34QUnit.module('py_add_test', function() { 35 QUnit.test('should add two numbers in Brython', function(assert) { 36 assert.equal(py_add(2, 3), 5, '2 + 3 = 5 (python)'); 37 }); 38}); 39
40QUnit.module('py_add_failed_test', function() { 41 QUnit.test('should add two numbers in Brython (failure)', function(assert) { 42 assert.equal(py_add(2, 3), 6, '2 + 3 != 6 (python)'); 43 }); 44}); 45</script>
46
47</body>
48</html>
在一个 HTML 文件中,您编写了 Python 代码、JavaScript 代码和 JavaScript 测试来验证在浏览器中执行的两种语言的函数:
- 第 11 行导入 QUnit 框架。
- 第 23 行将
python_add()暴露给 JavaScript。 - 第 28 行定义了
js_add_test来测试 JavaScript 函数js_add()。 - 第 34 行定义了
py_add_test来测试 Python 函数python_add()。 - 第 40 行定义了
py_add_failed_test来测试有错误的 Python 函数python_add()。
您不需要启动 web 服务器来执行单元测试。在浏览器中打开index.html,您应该看到以下内容:
该页面显示了两个成功的测试js_add_test()和py_add_test(),以及一个失败的测试py_add_failed_test()。
向 JavaScript 公开 Python 函数展示了如何使用 JavaScript 单元测试框架在浏览器中执行 Python。尽管可以进行测试,但通常不建议这样做,因为它可能会与现有的 JavaScript 名称冲突。
在 Brython 中调试
在撰写本文时,还没有调试 Brython 应用程序的用户友好工具。您无法生成一个允许您在浏览器开发工具中逐步调试的源映射文件。
这不应该阻止你使用 Brython。以下是一些有助于调试和排除 Brython 代码故障的提示:
- 使用
print()或browser.console.log()或在浏览器的开发者工具控制台中打印变量值。 - 使用 f-string 调试,如中所述,Python 3.8 中的酷新特性。
- 使用开发者工具偶尔清除浏览器的索引数据库。
- 在开发过程中,通过选中浏览器开发工具的网络选项卡中的禁用缓存复选框,禁用浏览器缓存。
- 将选项添加到
brython()中,使额外的调试信息能够显示在 JavaScript 控制台中。 - 在本地复制
brython.js和brython_stdlib.min.js以加快开发时的重装速度。 - 启动本地服务器当你
importPython 代码。 - 对 Chrome 扩展进行故障诊断时,从扩展打开检查器。
Python 的一个优点是 REPL(读取-评估-打印循环)。在线 Brython 控制台提供了一个实验、测试和调试一些代码片段行为的平台。
探索布里森的替代品
Brython 并不是在浏览器中编写 Python 代码的唯一选择。有几种选择:
每个实现都从不同的角度处理这个问题。Brython 试图通过提供与 JavaScript 相同的 web API 和 DOM 操作来替代 JavaScript,但它具有 Python 语法和习惯用法的吸引力。与一些可能有不同目标的替代方案相比,它被打包成一个小下载。
注:在 PyCon US 2022 上,一个新的替代方案亮相: PyScript !关于这个新框架的指南,您可以在 Web 浏览器中查看一下 PyScript:Python。
这些框架相比如何?
雕塑
Skulpt 在浏览器中将 Python 代码编译成 JavaScript。编译发生在页面加载之后,而在 Brython 中,编译发生在页面加载期间。
虽然它没有内置的函数来操作 DOM,但 Skulpt 在应用程序上非常接近 Brython。这包括教育用途和成熟的 Python 应用,正如 Anvil 所展示的。
Skulpt 是一个向 Python 3 迁移的维护项目。对于与浏览器中的执行兼容的模块,Brython 基本上与 CPython 3.9 相当。
转加密
Transcrypt 包含一个命令行工具,可以将 Python 代码编译成 JavaScript 代码。据说提前编译的是(AOT)。然后可以将生成的代码加载到浏览器中。Transcrypt 占用空间很小,大约 100KB。速度很快,支持 DOM 操作。
Skulpt 和 Brython 的区别在于,在下载并在浏览器中使用 Transcrypt 之前,先用 Transcrypt 编译器将 Transcrypt 编译成 JavaScript。这实现了速度和小尺寸。然而,它阻止了 Transcrypt 像其他平台一样被用作教育平台。
Pyodide
Pyodide 是 CPython 解释器的 WebAssembly 编译。它在浏览器中解释 Python 代码。没有 JavaScript 编译阶段。虽然 Pyodide 和 PyPy.js 一样,需要你下载大量数据,但它装载了科学库,如 NumPy 、 Pandas 、 Matplotlib 等等。
你可以把 Pyodide 看作是一个完全在浏览器中运行的 Jupyter 笔记本环境,而不是由后端服务器提供服务。你可以用一个活生生的例子来试验 Pyodide。
pypy . js〔t0〕
PyPy.js 使用 PyPy Python 解释器,用 emscripten 编译成 JavaScript,使其兼容在浏览器中运行。
除了项目当前的休眠状态之外,PyPy.js 还是一个很大的包,大约 10 MB,这对于典型的 web 应用程序来说是禁止的。打开 PyPy.js 主页,仍然可以在浏览器中使用 PyPy.js 作为学习 Python 的平台。
PyPy.js 用 emscripten 编译成 JavaScript。Pyodide 更进一步,特别是利用 emscripten 和 Wasm 来编译 Python C 扩展,如 WebAssembly 的 NumPy 。
在撰写本文时,PyPy.js 似乎没有得到维护。关于编译过程的类似情况,可以考虑 Pyodide。
结论
在本教程中,您已经深入了解了在浏览器中编写 Python 代码的几个方面。这可能会让您对尝试 Python 进行前端开发产生一些兴趣。
在本教程中,您已经学会了如何:
- 在本地环境中安装和使用 Brython
- 在你的前端网络应用中用 Python 替换 JavaScript
- 操纵 DOM
- 与 JavaScript 交互
- 创建浏览器扩展
- 比较 Brython 的备选方案
除了访问通常为 JavaScript 保留的特性之外,Brython 的最佳用途之一是作为学习和教学工具。你可以访问运行在浏览器中的 Python 编辑器和控制台,开始探索如今 Brython 的许多用途。
要查看您在本教程中看到的示例,您可以通过单击下面的链接下载源代码:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Brython 在浏览器中运行 Python。************
用 Python 构建一个聊天机器人
原文:https://realpython.com/build-a-chatbot-python-chatterbot/
聊天机器人可以提供实时客户支持,因此是许多行业的宝贵资产。当你理解了聊天机器人库的基础知识,你就可以用几行 Python 代码来构建和训练一个自学聊天机器人。
在第一步中,你将立即启动并运行基本的聊天机器人,但最有趣的部分是学习阶段,这时你开始训练你的聊天机器人。您的训练数据的质量和准备情况将对您的聊天机器人的性能产生很大影响。
为了模拟真实世界中创建行业相关聊天机器人的过程,您将学习如何定制聊天机器人的响应。你可以通过准备 WhatsApp 聊天数据来训练聊天机器人。您可以应用类似的过程,从任何领域特定主题的不同对话数据中训练您的机器人。
在本教程中,您将学习如何:
- 用聊天机器人构建一个命令行聊天机器人
- 训练聊天机器人定制它的反应
- 导出您的 WhatsApp 聊天记录
- 使用正则表达式对聊天导出执行数据清理
- 用特定行业的数据重新训练聊天机器人
您还将了解 ChatterBot 如何存储您的训练数据,您将找到关于下一步的建议和指针,因此您可以开始收集真实的用户数据,并让 chatter bot 从中学习。
总的来说,在本教程中,您将快速浏览使用 ChatterBot 创建聊天机器人的基础知识,并了解 Python 如何让您在无需编写大量代码的情况下获得有趣且有用的结果。
源代码: 点击这里下载免费的源代码,你将使用它来构建一个聊天机器人。
演示
在本教程结束时,您将拥有一个命令行聊天机器人,它可以用半有意义的回复来响应您的输入:
https://player.vimeo.com/video/751629412
你将通过准备 WhatsApp 聊天数据并使用它来训练聊天机器人来实现这一点。除了从你的自动化训练中学习,聊天机器人还会随着时间的推移而改进,因为它从用户互动中获得了更多的问题和回答。
项目概述
ChatterBot 库结合了语言语料库、文本处理、机器学习算法以及数据存储和检索,允许您构建灵活的聊天机器人。
你可以通过用相关数据训练它来构建一个特定行业的聊天机器人。此外,聊天机器人会记住用户的响应,并继续构建其内部的图结构,以改进它可以给出的响应。
注意:虽然 ChatterBot 仍然是一个流行的用 Python 构建聊天机器人的开源解决方案,但它已经有一段时间没有得到积极的维护,因此积累了大量的问题。
该项目的多个分支实现了对现有代码库的修复和更新,但是您必须亲自挑选实现您正在寻找的解决方案的分支,然后直接从 GitHub 安装它。叉子也可能带有附加安装说明。
然而,开始时,你不会用叉子。相反,您将使用库的特定固定版本,如分布在 PyPI 上的。你会在第一步中找到更多关于安装聊天机器人的信息。
在本教程中,您将从一个未经训练的聊天机器人开始,展示使用 Python 的 ChatterBot 创建一个交互式聊天机器人有多快。你也会注意到未经训练的聊天机器人的词汇量有多小。
接下来,您将学习如何训练这样一个聊天机器人,并检查略有改善的结果。你的训练数据越丰富、质量越高,你的聊天机器人的反应就越好。
因此,您可以获取您的 WhatsApp 聊天记录,或者使用提供的chat.txt文件,您可以从这里下载:
源代码: 点击这里下载免费的源代码,你将使用它来构建一个聊天机器人。
输入数据很少以您需要的形式出现,因此您将清理聊天导出数据,使其成为有用的输入格式。此过程将向您展示一些可用于数据清理的工具,这可能有助于您准备其他输入数据以提供给您的聊天机器人。
数据清理后,您将重新训练您的聊天机器人,并让它再次旋转以体验改进的性能。
当您从头到尾完成这个过程时,您将会很好地理解如何使用 ChatterBot 库构建和训练 Python 聊天机器人,以便它能够提供与相关回复的交互体验。
先决条件
在开始之前,确保您有一个适用于这个 ChatterBot 项目的 Python 版本。您需要的 Python 版本取决于您的操作系统:
**您需要使用低于 3.8 的 Python 版本才能成功使用本教程中推荐的 ChatterBot 版本。使用pyenv-win 可以安装 Python 3.7.9。
您应该能够使用各种 Python 版本在 Ubuntu Linux 上运行该项目。但是,如果你碰到任何问题,那么你可以尝试安装 Python 3.7.9 ,例如使用 pyenv 。
您可以使用各种 Python 版本运行该项目。聊天机器人是用 Python 3.10.7 版本构建和测试的,但也应该可以在旧版本的 Python 上运行。
如果您已经为您的操作系统安装了正确的 Python 版本,那么您就可以开始了。在学习本教程的过程中,您将接触到一些 Python 概念:
如果您对这些概念感到满意,那么您可能会对编写本教程的代码感到满意。如果您在开始本教程之前没有掌握所有的必备知识,那也没关系!事实上,你可以通过前进和开始来学习更多。如果遇到困难,您可以随时停下来查看此处链接的资源。
步骤 1:使用 Python 聊天机器人创建一个聊天机器人
在这一步中,您将设置一个虚拟环境并安装必要的依赖项。您还将创建一个可以回复您的命令行聊天机器人——但是它还没有非常有趣的回复。
要开始你的聊天机器人项目,创建并激活一个虚拟环境,然后安装chatterbot和pytz:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> venv\Scripts\activate
(venv) PS> python -m pip install chatterbot==1.0.4 pytz
$ python -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install chatterbot==1.0.4 pytz
在终端应用程序中运行这些命令会将 ChatterBot 及其依赖项安装到一个新的 Python 虚拟环境中。
注:在撰写本文的时候,的 ChatterBot 库已经有一段时间没怎么维护了。因此,它面临着一些很快就会变得恼人的问题。
对于本教程,您将使用 ChatterBot 1.0.4,它也适用于 macOS 和 Linux 上的新 Python 版本。在 Windows 上,你必须使用低于 3.8 的 Python 版本。ChatterBot 1.0.4 附带了一些本项目不需要的依赖项。然而,如果您尝试使用 ChatterBot 的新版本或删除一些依赖项,您将很快遇到更多问题。
所以,只要放松到这个选定的版本,给它一个旋转。如果你已经迷上了,并且需要更多,那么你可以在以后切换到一个新的版本。
安装完成后,运行python -m pip freeze应该会显示已安装的依赖项列表,类似于您可以在提供的示例代码的requirements.txt文件中找到的内容:
源代码: 点击这里下载免费的源代码,你将使用它来构建一个聊天机器人。
安装完成后,忽略该库目前存在的一些问题,您就可以开始了!创建一个新的 Python 文件,将其命名为bot.py,并添加启动和运行基本聊天机器人所需的代码:
1# bot.py
2
3from chatterbot import ChatBot
4
5chatbot = ChatBot("Chatpot")
6
7exit_conditions = (":q", "quit", "exit")
8while True:
9 query = input("> ")
10 if query in exit_conditions:
11 break
12 else:
13 print(f"🪴 {chatbot.get_response(query)}")
```py
在第 3 行导入`ChatBot`之后,您在第 5 行创建了一个`ChatBot`的实例。唯一需要的参数是一个名字,您称这个为`"Chatpot"`。不,这不是打字错误——在本教程中,您将实际构建一个健谈的花盆聊天机器人!你很快就会注意到,花盆可能并不是最好的谈话对象。
在第 8 行,您创建了一个 [`while`循环](https://realpython.com/python-while-loop/),它将一直循环下去,除非您输入第 7 行定义的退出条件之一。最后,在第 13 行,您在之前创建的`ChatBot`实例上调用`.get_response()`,并将您在第 9 行收集并分配给`query`的用户输入传递给它。
短脚本最后一行对`.get_response()`的调用是与您的`chatbot`的唯一交互。然而,你有一个可以运行的命令行聊天机器人,你可以带着它转一圈。
当您运行`bot.py`时,ChatterBot 可能会下载一些与 [NLTK 项目](https://realpython.com/python-nltk-sentiment-analysis/)相关的数据和语言模型。它会将一些相关信息打印到您的控制台上。Python 不会在后续运行中再次下载这些数据。
**注意:**NLTK 项目[将 ChatterBot 使用的数据](https://www.nltk.org/data)安装到操作系统的默认位置:
* **视窗:** `C:\nltk_data\`
* **Linux:**T0】
* **macOS:** `/Users/<username>/nltk_data/`
NLTK 会在你的聊天机器人第一次运行时自动创建目录。
如果您准备好与您新开发的`Chatpot`进行交流,那么您可以继续运行 Python 文件:
$ python bot.py
在建立语言模型之后,您将看到您在`bot.py`中定义的大于号(`>`)作为您的输入提示。您现在可以开始与您的聊天锅互动了:
hello
🪴 hello
are you a plant?
🪴 hello
can you chat, pot?
🪴 hello
嗯……你的聊天室正在*响应*,但是它真的很难扩展。很难对盆栽植物有更多的期望——毕竟,它从未见过世面!
**注意:**在 Windows PowerShell 上,盆栽植物表情符号(🪴)可能无法正确显示。您可以随意用您喜欢的任何其他提示来替换它。
即使你的聊天锅还没有太多的话要说,它已经在学习和成长。要对此进行测试,请停止当前会话。您可以通过键入退出条件之一来实现这一点— `":q"`、`"quit"`或`"exit"`。那就另找时间启动聊天机器人。输入不同的信息,您会注意到聊天机器人会记住您在上次运行时输入的内容:
hi
🪴 hello
what's up?
🪴 are you a plant?
在第一次运行期间,ChatterBot 创建了一个 [SQLite](https://www.sqlite.org/about.html) 数据库文件,其中存储了您的所有输入并将它们与可能的响应联系起来。您的工作目录中应该会弹出三个新文件:
./
├── bot.py
├── db.sqlite3 ├── db.sqlite3-shm └── db.sqlite3-wal
ChatterBot 使用默认的`SQLStorageAdapter`和[创建一个 SQLite 文件数据库](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/storage/sql_storage.py#L31),除非你指定一个不同的[存储适配器](https://chatterbot.readthedocs.io/en/stable/storage/index.html)。
**注:**主数据库文件为`db.sqlite3`,另外两个以 [`-wal`](https://www.sqlite.org/tempfiles.html#write_ahead_log_wal_files) 和 [`-shm`](https://www.sqlite.org/tempfiles.html#shared_memory_files) 结尾的是临时支持文件。
因为你在聊天开始时既说了*你好*又说了*嗨*,所以你的聊天室知道它可以互换使用这些信息。这意味着如果你和你的新聊天机器人聊很多,它会逐渐给你更好的回复。但是手动改进它的响应听起来是一个漫长的过程!
现在,您已经创建了一个可用的命令行聊天机器人,您将学习如何训练它,以便您可以进行稍微更有趣的对话。
[*Remove ads*](/account/join/)
## 第二步:开始训练你的聊天机器人
在上一步中,您构建了一个可以从命令行与之交互的聊天机器人。聊天机器人是从一张白纸开始的,和它聊天并不有趣。
在这一步中,您将使用`ListTrainer`训练您的聊天机器人,让它从一开始就变得更聪明。您还将了解 ChatterBot 自带的内置训练器,包括它们的局限性。
你的聊天机器人不必从头开始,ChatterBot 为你提供了一个快速训练你的机器人的方法。您将使用[聊天机器人的`ListTrainer`](https://chatterbot.readthedocs.io/en/stable/training.html#training-via-list-data) 提供一些对话示例,让您的聊天机器人有更多的发展空间:
1# bot.py
2
3from chatterbot import ChatBot
4from chatterbot.trainers import ListTrainer 5
6chatbot = ChatBot("Chatpot")
7
8trainer = ListTrainer(chatbot) 9trainer.train([ 10 "Hi", 11 "Welcome, friend 🤗", 12]) 13trainer.train([ 14 "Are you a plant?", 15 "No, I'm the pot below the plant!", 16]) 17
18exit_conditions = (":q", "quit", "exit")
19while True:
20 query = input("> ")
21 if query in exit_conditions:
22 break
23 else:
24 print(f"🪴 {chatbot.get_response(query)}")
在第 4 行,导入`ListTrainer`,在第 8 行将`chatbot`传递给它以创建`trainer`。
在第 9 到 12 行,您设置了第一轮训练,在这里您将两个字符串的列表传递给`trainer.train()`。使用`.train()`将条目注入到数据库中,以构建 ChatterBot 用来选择可能回复的图结构。
**注意:**如果你向`ListTrainer.train()`传递一个正好有两个项目的 iterable,那么 ChatterBot 认为第一个项目是一个语句,第二个项目是一个可接受的响应。
您可以运行多个培训会话,因此在第 13 到 16 行中,您向 chatbot 的数据库添加了另一条语句和另一条回复。
如果您现在使用`python bot.py`再次运行交互式聊天机器人,您可以从它那里得到与以前略有不同的响应:
hi
🪴 Welcome, friend 🤗
hello
🪴 are you a plant?
me?
🪴 are you a plant?
yes
🪴 hi
are you a plant?
🪴 No, I'm the pot below the plant!
cool
🪴 Welcome, friend 🤗
对话还不够流畅,以至于你想进行第二次约会,但是有额外的背景,你以前没有!当你用更多的数据训练你的聊天机器人时,它会更好地响应用户的输入。
聊天机器人库附带了一些语料库,你可以用它们来训练你的聊天机器人。然而,在撰写本文时,如果您试图直接使用这些资源,就会出现一些问题。
**注意:**问题来自于依赖项版本之间的不匹配,以及您使用的 Python 版本。你*可以*绕过他们,但这需要你自己做一些调整。
或者,您可以使用`pyYAML` 自己解析语料库文件[,因为它们被](https://realpython.com/python-yaml/)[存储为 YAML 文件](https://github.com/gunthercox/chatterbot-corpus/blob/master/chatterbot_corpus/data/english/computers.yml)。
虽然提供的语料库可能对你来说足够了,但在本教程中,你将完全跳过它们,而是学习如何使用 ChatterBot 的`ListTrainer`来调整你自己的对话输入数据。
为了训练你的聊天机器人回答与行业相关的问题,你可能需要使用自定义数据,例如来自你公司的现有支持请求或聊天记录。
接下来,您将逐步完成将 WhatsApp 对话中的聊天数据转换为可用于训练您的聊天机器人的格式。如果你自己的资源是 WhatsApp 的对话数据,那么你可以直接使用这些步骤。如果您的数据来自其他地方,那么您可以调整这些步骤以适应您的特定文本格式。
首先,您将学习如何从 WhatsApp 聊天对话中导出数据。
## 第三步:导出 WhatsApp 聊天记录
在这一步结束时,您将下载一个包含 WhatsApp 对话的聊天历史的 TXT 文件。如果你没有 WhatsApp 帐户或者不想使用自己的对话数据,那么你可以下载下面的聊天导出示例:
**源代码:** [点击这里下载免费的源代码](https://realpython.com/bonus/build-a-chatbot-python-chatterbot-code/),你将使用它来构建一个聊天机器人。
如果您要使用提供的聊天历史示例,您可以跳到下一部分,在那里您将[清理您的聊天导出](#step-4-clean-your-chat-export)。
要导出您在 WhatsApp 上的对话历史,您需要在手机上打开该对话。进入对话屏幕后,您可以访问导出菜单:
1. 点击右上角的三个点(⋮)打开主菜单。
2. 选择*更多*调出附加菜单选项。
3. 选择*导出聊天*创建您的对话的 TXT 导出。
在下面拼接在一起的截图中,你可以看到三个连续的步骤编号并用红色标出:
[](https://files.realpython.com/media/whatsapp-export-instructions.851f28025997.jpeg)
一旦你点击了*导出聊天*,你需要决定是否包括媒体,如照片或音频信息。因为你的聊天机器人只处理文本,选择没有媒体的*。然后,您可以声明要将文件发送到哪里。
同样,你可以在两张拼接在一起的 WhatsApp 截图中看到这些后续步骤的示例,下面有红色数字和轮廓:
[](https://files.realpython.com/media/whatsapp-export-instructions-2.9035f97fd000.jpg)
在本例中,您将聊天导出文件保存到名为 *Chat exports* 的 Google Drive 文件夹中。你必须在你的 Google Drive 中设置这个文件夹,然后才能选择它作为一个选项。当然,你不需要使用 Google Drive。只要您保存或发送您的聊天导出文件,以便您可以在您的计算机上访问它,您就可以开始了。
一旦完成,切换回你的电脑。找到您保存的文件,并将其下载到您的机器上。
具体来说,您应该将文件保存到也包含`bot.py`的文件夹中,并将其重命名为`chat.txt`。然后,用[你最喜欢的文本编辑器](https://realpython.com/python-ides-code-editors-guide/)打开它,检查你收到的数据:
9/15/22, 14:50 - Messages and calls are end-to-end encrypted.
⮑ No one outside of this chat, not even WhatsApp, can read
⮑ or listen to them. Tap to learn more.
9/15/22, 14:49 - Philipp: Hi Martin, Philipp here!
9/15/22, 14:50 - Philipp: I'm ready to talk about plants!
9/15/22, 14:51 - Martin: Oh that's great!
9/15/22, 14:52 - Martin: I've been waiting for a good convo about
⮑ plants for a long time
9/15/22, 14:52 - Philipp: We all have.
9/15/22, 14:52 - Martin: Did you know they need water to grow?
...
如果您还记得 ChatterBot 是如何处理训练数据的,那么您会发现这种格式并不适合用于训练。
当聊天机器人回复用户消息时,聊天机器人使用完整的行作为消息。在这个聊天导出的例子中,它将包含所有的消息元数据。这意味着你的友好锅将研究日期,时间和用户名!不是很好的谈话肥料。
为了避免这个问题,在使用聊天导出数据训练您的聊天机器人之前,您需要清理它。
[*Remove ads*](/account/join/)
## 第四步:清理你的聊天导出
在这一步中,您将清理 WhatsApp 聊天导出数据,以便您可以使用它作为输入,就特定于行业的主题训练您的聊天机器人。在这个例子中,主题将是…室内植物!
你用来训练聊天机器人的大多数数据在产生有用的结果之前都需要某种清理。就像老话说的那样:
> 垃圾输入,垃圾输出([来源](https://en.wikipedia.org/wiki/Garbage_in,_garbage_out)
花些时间浏览您正在处理的数据,并确定潜在的问题:
9/15/22, 14:50 - Messages and calls are end-to-end encrypted.
⮑ No one outside of this chat, not even WhatsApp, can read
⮑ or listen to them. Tap to learn more.
...
9/15/22, 14:50 - Philipp: I'm ready to talk about plants!
...
9/16/22, 06:34 - Martin:
...
例如,您可能注意到所提供的聊天导出的第一行不是对话的一部分。此外,每条实际消息都以元数据开始,包括日期、时间和消息发送者的用户名。
如果您进一步向下滚动对话文件,您会发现一些行不是真正的消息。因为你没有在聊天导出中包含媒体文件,WhatsApp 用文本`<Media omitted>`替换了这些文件。
所有这些数据都会干扰你的聊天机器人的输出,而且肯定会让它听起来不太像对话。因此,删除这些数据是个好主意。
在将数据提交给 ChatterBot 进行训练之前,打开一个新的 Python 文件对数据进行预处理。首先读入文件内容并删除聊天元数据:
1# cleaner.py
2
3import re
4
5def remove_chat_metadata(chat_export_file):
6 date_time = r"(\d+/\d+/\d+,\s\d+:\d+)" # e.g. "9/16/22, 06:34"
7 dash_whitespace = r"\s-\s" # " - "
8 username = r"([\w\s]+)" # e.g. "Martin"
9 metadata_end = r":\s" # ": "
10 pattern = date_time + dash_whitespace + username + metadata_end
11
12 with open(chat_export_file, "r") as corpus_file:
13 content = corpus_file.read()
14 cleaned_corpus = re.sub(pattern, "", content)
15 return tuple(cleaned_corpus.split("\n"))
16
17if name == "main":
18 print(remove_chat_metadata("chat.txt"))
该函数使用[内置的`re`模块](https://docs.python.org/3/library/re.html)从聊天导出文件中删除与对话无关的消息元数据,该模块允许您[使用正则表达式](https://realpython.com/regex-python/):
* **三号线**进口`re`。
* **第 6 到 9 行**定义了多个正则表达式模式。构建多个模式有助于您跟踪匹配的内容,并让您能够灵活地使用单独的[捕获组](https://realpython.com/regex-python/#capturing-groups)在以后应用进一步的预处理。例如,通过访问`username`,你可以通过合并同一用户连续发送的消息来进行分组对话。
* **第 10 行**将您在第 6 到 9 行中定义的正则表达式模式连接成一个模式。完整模式匹配您想要移除的所有元数据。
* **第 12 行和第 13 行**打开聊天导出文件并将数据读入内存。
* **第 14 行**使用`re.sub()`将您在`pattern`中定义的模式的每一次出现替换为一个空字符串(`""`),有效地将其从字符串中删除。
* **第 15 行**首先使用`.split("\n")`将文件内容字符串分割成列表项。这将`cleaned_corpus`分解成一个列表,其中每行代表一个单独的项目。然后,你将这个列表转换成一个元组,并从`remove_chat_metadata()`返回它。
* **第 17 行和第 18 行**使用 Python 的[名-main 习语](https://realpython.com/if-name-main-python/)以`"chat.txt"`为参数调用`remove_chat_metadata()`,这样你就可以在运行脚本时检查输出了。
最终,您将使用`cleaner`作为一个模块,并将功能直接导入到`bot.py`中。但是当您开发脚本时,检查中间输出是有帮助的,例如用一个`print()`调用,如第 18 行所示。
**注意:**在你开发代码的时候,经常运行你的脚本是个好主意。作为打印输出的替代方法,您可以使用`breakpoint()`到[用`pdb`](https://realpython.com/python-debugging-pdb/) 检查您的代码。如果你使用诸如`pdb`这样的调试器,那么你可以与代码对象交互,而不仅仅是打印一个静态的表示。
从每一行中删除消息元数据后,您还需要删除几行与对话无关的完整内容。为此,在数据清理脚本中创建第二个函数:
1# cleaner.py
2
3# ...
4
5def remove_non_message_text(export_text_lines):
6 messages = export_text_lines[1:-1]
7
8 filter_out_msgs = ("
9 return tuple((msg for msg in messages if msg not in filter_out_msgs))
10
11if name == "main":
12 message_corpus = remove_chat_metadata("chat.txt")
13 cleaned_corpus = remove_non_message_text(message_corpus)
14 print(cleaned_corpus)
在`remove_non_message_text()`中,您已经编写了允许您从对话语料库中删除无关行的代码:
* **第 6 行**删除每个 WhatsApp 聊天导出自带的第一个介绍行,以及文件末尾的空行。
* **第 8 行**创建一个元组,您可以在其中定义要从数据中排除哪些字符串,以便进行训练。现在,它只包含一个字符串,但是如果您想删除其他内容,您可以快速地将更多的字符串作为条目添加到这个元组中。
* **第 9 行**使用一个[生成器表达式](https://realpython.com/introduction-to-python-generators/)过滤`filter_out_msgs`中定义的字符串`messages`,在返回之前将它转换成一个元组。
最后,您还修改了第 12 行到第 14 行。您现在在变量`message_corpus`中收集第一个函数调用的返回值,然后将它用作`remove_non_message_text()`的参数。您保存对`cleaned_corpus`的函数调用的结果,并将该值打印到控制台的第 14 行。
因为您想将`cleaner`视为一个模块并在`bot.py`中运行清理代码,所以现在最好将 name-main 习语中的代码重构为一个主函数,然后您可以在`bot.py`中导入并调用它:
1# cleaner.py
2
3import re
4
5def clean_corpus(chat_export_file):
6 message_corpus = remove_chat_metadata(chat_export_file)
7 cleaned_corpus = remove_non_message_text(message_corpus)
8 return cleaned_corpus
9
10# ...
11
12# Deleted: if name == "main":
您通过将函数调用从 name-main 习语移动到一个专用函数`clean_corpus()`中来重构您的代码,这个函数是您在文件顶部定义的。在第 6 行中,您用参数`chat_export_file`替换了`"chat.txt"`,使其更加通用。您将在调用函数时提供文件名。`clean_corpus()`函数返回清理过的语料库,你可以用它来训练你的聊天机器人。
在创建了你的清理模块之后,你现在可以返回到`bot.py`并将代码集成到你的管道中。
[*Remove ads*](/account/join/)
## 第五步:用自定义数据训练你的聊天机器人,并开始聊天
在这一步中,您将使用在上一步中清理的 WhatsApp 对话数据来训练您的聊天机器人。你最终将拥有一个聊天机器人,你已经对特定行业的对话数据进行了训练,你将能够与机器人聊天——关于室内植物!
打开`bot.py`,在代码中包含对你的清理函数的调用:
1# bot.py
2
3from chatterbot import ChatBot
4from chatterbot.trainers import ListTrainer
5from cleaner import clean_corpus 6
7CORPUS_FILE = "chat.txt" 8
9chatbot = ChatBot("Chatpot")
10
11trainer = ListTrainer(chatbot)
12cleaned_corpus = clean_corpus(CORPUS_FILE) 13trainer.train(cleaned_corpus) 14
15exit_conditions = (":q", "quit", "exit")
16while True:
17 query = input("> ")
18 if query in exit_conditions:
19 break
20 else:
21 print(f"🪴 {chatbot.get_response(query)}")
您不需要在这个文件中做很多额外的工作,因为您已经准备好了您的清理函数:
* **五号线**从`cleaner`进口`clean_corpus()`。
* **第 7 行**定义了你的聊天导出文件的文件名。在这个例子中,假设它叫做`"chat.txt"`,它和`bot.py`位于同一个目录中。如果你需要更高级的路径处理,那么看看 [Python 的`pathlib`](https://realpython.com/python-pathlib/) 模块。
* **第 12 行**将您的清理代码应用到聊天历史文件,并返回一组清理过的消息,您称之为`cleaned_corpus`。
* **第 13 行**最后使用这些数据作为`.train()`的输入,用 WhatsApp 的对话数据有效地训练你的聊天机器人。
很重要的一点是,ChatterBot 对待包含两个以上项目的 iterable 的方式与只有两个项目的情况略有不同,就像您在之前的训练中遇到的情况一样:
> 如果您提供更长的培训对话列表,那么这将把列表中的每个项目建立为对列表中其前一个项目的可能响应。([来源](https://chatterbot.readthedocs.io/en/stable/training.html#training-via-list-data))
根据您的输入数据,这可能是也可能不是您想要的。对于所提供的 WhatsApp 聊天导出数据,这并不理想,因为并不是每一行都代表一个问题和一个答案。
为了解决这个问题,您可以对您的数据应用额外的预处理,您可能希望将同一个人发送的所有消息分组到一行中,或者按照时间和日期将聊天导出分块。这样,在特定时间段内发送的消息可以被视为单个对话。
总是有更多的东西需要清理,以改善您的输入数据!然而,在本教程中,是时候让对话式室内植物聊天机器人再试一次了。运行`bot.py`并与你的健谈锅聊天,测试它的反应如何因训练而改变:
hi
🪴 Welcome, friend 🤗
thanks for the green welcome
🪴 I let you
you let me be here?
🪴 It's a monsters!
did you mean monstera?
🪴 The leafs are getting dryer and dryer. But she's growing new ones
who?
🪴 Do raindrops touch their leaves?
very philosophical!
🪴 Lol
😉
🪴 I don't grow any crop at home
no crops in pots
🪴 Ah, gotcha!
ah, I just thought you meant that
🪴 But water makes sense
yes, water in pots
🪴 Do you have any plant care pro tips?
water.
🪴 I always thought that love and music was more than enough
haha
🪴 Well, no. Just the balcony. This worked best
ok, balcony is notes
🪴 I let you
您的聊天机器人根据您提供给它的训练数据增加了它的反应范围。正如你可能注意到的,当你和你的聊天机器人互动时,回应并不总是很有意义。
ChatterBot 使用完整的句子作为回复,而你只是在一个很小的会话数据样本上训练它。小规模的训练数据意味着它没有一个大的回复池可供选择。因为数据是会话式的,所以并不是所有的句子作为回答都非常有用。但是`Chatpot`正在尽一切努力为你输入的任何新邮件找到最佳匹配的回复!
为了选择对输入的响应,默认情况下,ChatterBot 使用`BestMatch` [逻辑适配器](https://chatterbot.readthedocs.io/en/stable/logic/index.html#logic-adapters)。这个逻辑适配器使用 [Levenshtein 距离](https://en.wikipedia.org/wiki/Levenshtein_distance)来比较输入字符串和数据库中的所有语句。然后,它选择最接近输入字符串的语句回复。
如果您使用结构良好的输入数据,那么 ChatterBot 的默认设置会为您提供良好的开箱即用结果。如果你准备做一些额外的工作来得到你想要的,那么你很幸运!ChatterBot 允许进行大量的定制,并提供一些指导来引导您朝着正确的方向前进:
| 主题 | 方法 | 说明 |
| --- | --- | --- |
| 培养 | 继承自 [`Trainer`](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/trainers.py) | [创建新的培训课程](https://chatterbot.readthedocs.io/en/stable/training.html?highlight=graph#creating-a-new-training-class) |
| 输入预处理 | 写一个函数,[取并返回一个`Statement`](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/preprocessors.py) | [创建新的预处理器](https://chatterbot.readthedocs.io/en/stable/preprocessors.html#creating-new-preprocessors) |
| 选择响应 | 继承自 [`LogicAdapter`](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/logic/logic_adapter.py) | [创建一个新的逻辑适配器](https://chatterbot.readthedocs.io/en/stable/logic/create-a-logic-adapter.html) |
| 存储数据 | 继承自 [`StorageAdapter`](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/storage/storage_adapter.py) | [创建新的存储适配器](https://chatterbot.readthedocs.io/en/stable/storage/create-a-storage-adapter.html) |
| 比较语句 | 编写一个函数,它采用两个语句并返回一个介于 0 和 1 之间的数字 | [创建新的比较函数](https://chatterbot.readthedocs.io/en/stable/comparisons.html#use-your-own-comparison-function) |
ChatterBot 为您提供了合理的默认值。但是如果你想定制这个过程的任何部分,那么它给你所有的自由去做。
在本节中,您将所有东西放回一起,并使用从 WhatsApp 对话聊天导出的干净语料库来训练您的聊天机器人。在这一点上,你已经可以和你的聊天机器人进行有趣的对话了,尽管它们可能有些荒谬。根据你的训练数据的数量和质量,你的聊天机器人可能已经或多或少有用了。
## 结论
恭喜你,你已经使用 ChatterBot 库构建了一个 Python 聊天机器人!你的聊天机器人还不是一个智能工厂,但每个人都必须从某个地方开始。你已经通过从 WhatsApp 聊天导出的预处理对话数据来训练聊天机器人,从而帮助它成长。
**在本教程中,您学习了如何:**
* 用聊天机器人构建一个命令行聊天机器人
* 训练聊天机器人定制它的回答
* **导出**您的 WhatsApp 聊天记录
* 使用**正则表达式**对聊天导出执行**数据清理**
* 用特定行业的数据重新训练聊天机器人
因为所提供的 WhatsApp 聊天导出中特定行业的聊天数据集中在室内植物上,`Chatpot`现在对室内植物护理有了一些看法。如果你问起,它会很乐意与你分享——或者真的,当你问起*任何*的事情时。
大数据带来大成果!你可以想象,用更多的输入数据,尤其是更相关的数据来训练你的聊天机器人,会产生更好的结果。
[*Remove ads*](/account/join/)
## 接下来的步骤
ChatterBot 提供了一种将库安装为 Django 应用程序的方式。下一步,你可以[将 ChatterBot 集成到你的 Django 项目](https://chatterbot.readthedocs.io/en/stable/django/index.html)中,[将其部署为 web 应用](https://realpython.com/django-hosting-on-heroku/)。
您还可以通过使用不同的存储适配器来交换数据库后端,并将您的 Django ChatterBot 连接到生产就绪的数据库。
完成设置后,您部署的聊天机器人可以根据来自世界各地的用户反馈不断改进。
即使您现在继续在 CLI 上运行 chatbot,也有许多方法可以改进项目并继续了解 ChatterBot 库:
* **处理更多边缘情况:**您的正则表达式模式可能无法捕获所有 WhatsApp 用户名。当[为你的代码](https://realpython.com/python-hash-table/#build-a-hash-table-prototype-in-python-with-tdd)构建测试时,你可以抛出一些边缘案例来提高解析的稳定性。
* **改进对话:**将您的输入数据分组为对话,以便您的训练输入将同一用户在一小时内发送的连续消息视为一条消息。
* **解析 ChatterBot 语料库:**跳过依赖冲突,[直接安装`PyYAML`](https://realpython.com/python-yaml/) ,自己解析 [chatterbot-corpus](https://github.com/gunthercox/chatterbot-corpus/) 中提供的部分训练语料库。使用其中的一个或多个来继续训练您的聊天机器人。
* **构建自定义预处理器:** ChatterBot 可以在将用户输入发送到逻辑适配器之前对其进行修改。您可以使用内置的预处理程序,例如删除空白。构建一个[定制预处理器](https://chatterbot.readthedocs.io/en/stable/preprocessors.html#creating-new-preprocessors),它可以[替换用户输入中的脏话](https://realpython.com/replace-string-python/)。
* **包含额外的逻辑适配器:** ChatterBot 自带了几个预装的[逻辑适配器](https://chatterbot.readthedocs.io/en/stable/logic/index.html),比如用于[数学求值的](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/logic/mathematical_evaluation.py)和[时间逻辑](https://github.com/gunthercox/ChatterBot/blob/1.0/chatterbot/logic/time_adapter.py)。将这些逻辑适配器添加到您的聊天机器人,以便它可以执行计算并告诉您当前时间。
* **编写一个定制的逻辑适配器:**创建一个[定制的逻辑适配器](https://chatterbot.readthedocs.io/en/stable/logic/create-a-logic-adapter.html),它在特定的用户输入时触发,例如当你的用户要求一个笑话时。
* **合并一个 API 调用:**构建一个逻辑适配器,它可以[与 API 服务](https://chatterbot.readthedocs.io/en/stable/logic/create-a-logic-adapter.html#interacting-with-services)进行交互,例如通过重新调整你的[天气 CLI 项目](https://realpython.com/build-a-python-weather-app-cli/)的用途,以便它可以在你的聊天机器人中工作。
你可以做很多事情!查看您的聊天机器人的建议:
what should i do next?
🪴 Yeah! I want them to be strong and take care of themselves at some point
很棒的建议!或者…至少它看起来像是你的聊天机器人在告诉你,你应该帮助它变得更加自给自足?
为了让你的聊天机器人更好地处理输入,下一步要做的就是加入更多更好的训练数据。如果你这样做了,并且利用了 ChatterBot 提供的所有定制特性,那么你就可以创建一个比这里的`🪴 Chatpot`反应更及时的聊天机器人。
如果你对室内植物不感兴趣,那么选择你自己的聊天机器人想法,用独特的数据进行训练。重复您在本教程中学习的过程,但是清理并使用您自己的数据进行训练。
你决定让你的聊天机器人适应一个特定的用例了吗?你和它进行过哲学对话吗?还是你的聊天机器人一直在以一种有趣的方式切换话题?在下面的评论里分享你的经验吧!************
# 用 Python 构建内容聚合器
> 原文:<https://realpython.com/build-a-content-aggregator-python/>
在这个基于项目的教程中,您将使用 Python 和流行的框架 **Django** 从头开始构建一个**内容聚合器**。
每天都有如此多的内容出现在网上,去多个网站和来源获取关于你最喜欢的主题的信息是非常耗时的。这就是内容聚合器如此受欢迎和强大的原因,因为你可以使用它们在一个地方查看所有最新的新闻和内容。
无论你是在寻找一个**投资组合项目**还是寻找将未来项目扩展到简单的 [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) 能力之外的方法,本教程都会有你想要的。
在本教程中,您将学习:
* 如何使用 **RSS 源**
* 如何创建 Django **自定义管理命令**
* 如何按照**计划**自动运行您的自定义命令
* 如何使用**单元测试**来测试你的 Django 应用的功能
单击下面的链接下载该项目的代码,并跟随您构建自己的内容聚合器:
**获取源代码:** [点击此处获取您将在本教程中使用](https://realpython.com/bonus/content-aggregator-project-code/)用 Django 和 Python 构建内容聚合器的源代码。
## 演示:您将构建什么
您将使用 Python 构建自己的播客内容聚合器,名为 **pyCasts!**从头到尾遵循本教程。
该应用程序将是一个单一的网页,显示从[真正的 Python 播客](https://realpython.com/podcasts/rpp/)和[跟我说 Python 播客](https://talkpython.fm/)的最新 Python 播客片段。完成本教程后,您可以通过向应用程序添加更多的播客来实践您所学到的内容。
这里有一个快速演示视频,展示了它的实际效果:
[https://player.vimeo.com/video/640030974](https://player.vimeo.com/video/640030974)
幕后有许多活动的部分,使这一工作以自动化的方式高效和有效地进行。在本教程中,您将了解所有这些内容。准备钻研吧。
[*Remove ads*](/account/join/)
## 项目概述
为了能够向最终用户显示内容,您需要遵循几个步骤:
1. [设置项目](#step-1-setting-up-your-project)
2. [建立播客模型](#step-2-building-your-podcast-model)
3. [创建主页视图](#step-3-creating-your-homepage-view)
4. [解析播客 RSS 提要](#step-4-parsing-podcast-rss-feeds)
5. [创建 Django 自定义命令](#step-5-creating-a-django-custom-command)
6. [添加额外的饲料](#step-6-adding-additional-feeds-to-your-python-content-aggregator)
7. [用 django-APS scheduler 安排任务](#step-7-scheduling-tasks-with-django-apscheduler)
在本教程的课程中,您将逐步了解这些内容。现在,您将看到您将为上述步骤使用哪些技术和框架。
为了将播客 RSS 提要获取到您的应用程序中并解析它们,您将学习如何使用 [feedparser](https://feedparser.readthedocs.io/en/latest/) 库。您将使用这个库从提要中仅提取最新的剧集数据,您将[将这些数据](https://en.wikipedia.org/wiki/Marshalling_(computer_science))整理到一个`Episode`模型中,并用 Django ORM 保存到数据库中。
您可以将这段代码添加到脚本中,并定期手动运行它,但是这样会使使用聚合器来节省时间的目的落空。相反,您将学习如何使用一个名为[定制管理命令](https://docs.djangoproject.com/en/3.1/howto/custom-management-commands/)的内置 Django 工具。为了解析和保存数据,您将从 Django 内部运行代码。
在 [django-apscheduler](https://github.com/jcass77/django-apscheduler) 库的帮助下,你将**为你的函数调用设置一个调度**,这也被称为**作业**。然后,您可以使用 Django 管理面板来查看哪些作业在何时运行。这将确保自动获取和解析提要,而不需要管理员干预。
然后,您将使用 [Django 模板引擎](https://docs.djangoproject.com/en/3.1/topics/templates/#the-django-template-language)向用户显示查询的上下文——换句话说,最新的剧集。
## 先决条件
为了充分利用本教程,您应该熟悉以下概念和技术:
* [Python 基础知识](https://realpython.com/learning-paths/python3-introduction/)
* [虚拟环境](https://realpython.com/python-virtual-environments-a-primer/)设置和使用
* HTML 和 CSS 的基本层次[和](https://realpython.com/html-css-python/)
* Django 基础知识,比如它的[文件夹结构](https://realpython.com/python-application-layouts/#django)、 [URL 路由](https://docs.djangoproject.com/en/3.1/topics/http/urls/)、[迁移](https://realpython.com/django-migrations-a-primer/),以及如何[创建项目和 app](https://realpython.com/django-setup/)
你可能还会发现有一些使用 [Bootstrap 4](https://getbootstrap.com/) 的经验会有所帮助。
如果在开始本教程之前,你还没有掌握所有的必备知识,那也没关系!事实上,你可以通过继续学习和开始学习来学到更多。如果遇到困难,你可以随时停下来复习上面链接的资源。
## 步骤 1:设置您的项目
到这一步结束时,您已经设置好了您的环境,安装了您的依赖项,并完成了 Django 的启动和运行。
首先创建项目目录,然后将目录切换到其中:
```py
$ mkdir pycasts
$ cd pycasts
现在您已经进入了项目目录,您应该创建您的虚拟环境并激活它。使用任何让你最开心的工具来做这件事。这个例子使用了venv:
$ python3 -m venv .venv
$ source .venv/bin/activate
(.venv) $ python -m pip install --upgrade pip
现在您的环境已经激活并且pip已经升级,您需要安装所需的依赖项来完成项目。您可以在本教程的可下载源代码中找到一个requirements.txt文件:
获取源代码: 点击此处获取您将在本教程中使用用 Django 和 Python 构建内容聚合器的源代码。
打开source_code_setup/文件夹并安装固定的依赖项。确保用下载文件的实际路径替换<path_to_requirements.txt>:
(.venv) $ python -m pip install -r <path_to_requirements.txt>
现在您应该已经安装了 Django、 feedparser 、 django-apscheduler ,以及它们的子依赖项。
现在您已经拥有了启动和运行所需的所有工具,您可以设置 Django 并开始构建了。要完成这一步的构建,您需要做以下四件事:
- 在当前工作目录下创建 Django 项目,
/pycasts - 创建一个 Django 应用程序
- 运行初始迁移
- 创建超级用户
因为您已经熟悉了 Django,所以您不会详细探究这些步骤。您可以继续运行以下命令:
(.venv) $ django-admin startproject content_aggregator .
(.venv) $ python manage.py startapp podcasts
(.venv) $ python manage.py makemigrations && python manage.py migrate
(.venv) $ python manage.py createsuperuser
如果您确实需要更深入地理解这些终端命令,您可以查看 Django 第 1 部分的入门。
一旦你按照 Django 的提示完成创建你的超级用户帐号,在测试应用程序工作之前,你还有一个改动要做。尽管应用程序没有它也能运行,但不要忘记将新的podcasts应用程序添加到settings.py文件中:
# content_aggregator/settings.py
# ...
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
# My Apps "podcasts.apps.PodcastsConfig", ]
你在INSTALLED_APPS中将你的新应用列为"podcasts.apps.PodcastsConfig"。
注意:如果你对为什么使用冗长的podcasts.apps.PodcastsConfig而不是podcasts感到好奇,那么你可以在 Django 官方文档中阅读更多关于配置应用程序的内容。
TLDR;版本是,虽然使用应用程序名称,podcasts,*对于这个小应用程序应该工作良好,但使用完整的 AppConfig 名称被认为是最佳实践。
是时候带着你的 Django 新项目转一圈了。启动 Django 服务器:
(.venv) $ python manage.py runserver
在浏览器中导航到localhost:8000,您应该会看到 Django 的默认成功页面:
现在您已经设置了项目,并且让 Django 工作,继续下一步。
第二步:建立你的播客模型
此时,您应该已经设置好了您的环境,安装了您的依赖项,并且 Django 已经成功运行。到这一步结束时,您已经为播客剧集定义并测试了一个模型,并将该模型迁移到了数据库中。
你的Episode模型不应该仅仅反映你作为开发者想要获取的信息。它还应该反映用户希望看到的信息。跳入代码并立即开始编写模型很有诱惑力,但这可能是一个错误。如果你这样做,你可能很快就会忘记你的用户的观点。毕竟,应用程序是为用户服务的,甚至是像您或其他开发人员这样的用户。
在这一点上,拿出一支笔和纸可能是有用的,但是你应该做任何对你有用的事情。问问你自己,“作为一个用户,我想做什么?”反复回答这个问题,直到你穷尽了所有的想法。然后你可以问问自己,作为一名开发人员,你想要什么。
在编写数据库模型时,这可能是一个很好的策略,它可以让您不必在以后添加额外的字段和运行不必要的迁移。
注意:你可能有一个与下面不同的列表,这没关系。作为本教程的作者,我将分享我想到的东西,这也是你将在本项目的其余部分使用的东西。
但是如果您觉得缺少某个字段或属性,那么在本教程结束时,您可以随意扩展应用程序来添加它。毕竟这是你的项目。把它变成你自己的!
从用户和开发人员的角度列出项目的需求:
As a user, I would like to:
- Know the title of an episode
- Read a description of the episode
- Know when an episode was published
- Have a clickable URL so I can listen to the episode
- See an image of the podcast so I can scroll to look
for my favorite podcasts
- See the podcast name
As a developer, I would like to:
- Have a uniquely identifiable attribute for each episode
so I can avoid duplicating episodes in the database
你会在本教程的第 4 步中看到更多关于这最后一点的内容。
根据您列出的要求,您的podcasts应用程序中的Episode模型应该如下所示:
# podcasts/models.py
from django.db import models
class Episode(models.Model):
title = models.CharField(max_length=200)
description = models.TextField()
pub_date = models.DateTimeField()
link = models.URLField()
image = models.URLField()
podcast_name = models.CharField(max_length=100)
guid = models.CharField(max_length=50)
def __str__(self) -> str:
return f"{self.podcast_name}: {self.title}"
Django 最强大的部分之一是内置的管理区。将剧集存储在数据库中是一件事,但是您也希望能够在管理区与它们进行交互。您可以通过替换您的podcasts/admin.py文件中的代码来告诉 Django 管理员您想要显示您的剧集数据:
# podcasts/admin.py
from django.contrib import admin
from .models import Episode
@admin.register(Episode)
class EpisodeAdmin(admin.ModelAdmin):
list_display = ("podcast_name", "title", "pub_date")
在将模型迁移到数据库之前,您还需要做一件事情。在 Django 3.2 中,你现在可以定制自动创建的主键的类型。新的缺省值是BigAutoField,而不是 Django 以前版本中的缺省值Integer。如果您现在运行迁移,您会看到以下错误:
(models.W042) Auto-created primary key used when not defining
a primary key type, by default 'django.db.models.AutoField'.
HINT: Configure the DEFAULT_AUTO_FIELD setting or the
PodcastsConfig.default_auto_field attribute to point to a subclass
of AutoField, e.g. 'django.db.models.BigAutoField'.
您可以通过在app.py文件中的PodcastsConfig类中添加额外的一行来确保您不会看到这个错误:
# podcasts/app.py
from django.apps import AppConfig
class PodcastsConfig(AppConfig):
default_auto_field = "django.db.models.AutoField" name = "podcasts"
现在,您的应用程序已配置为自动向所有模型添加主键。你也有一张你的数据应该是什么样子的图片,并且你在一个模型中表现它。您现在可以运行 Django 迁移来将您的Episode表包含在数据库中:
(.venv) $ python manage.py makemigrations
(.venv) $ python manage.py migrate
既然您已经迁移了更改,那么是时候测试它了!
本教程已经涵盖了很多内容,所以为了简单起见,您将使用 Django 的内置测试框架进行单元测试。完成本教程中的项目后,如果你愿意,可以随意用 pytest 或其他测试框架重写单元测试。
在您的podcasts/tests.py文件中,您可以添加:
# podcasts/tests.py
from django.test import TestCase
from django.utils import timezone
from .models import Episode
class PodCastsTests(TestCase):
def setUp(self):
self.episode = Episode.objects.create(
title="My Awesome Podcast Episode",
description="Look mom, I made it!",
pub_date=timezone.now(),
link="https://myawesomeshow.com",
image="https://image.myawesomeshow.com",
podcast_name="My Python Podcast",
guid="de194720-7b4c-49e2-a05f-432436d3fetr",
)
def test_episode_content(self):
self.assertEqual(self.episode.description, "Look mom, I made it!")
self.assertEqual(self.episode.link, "https://myawesomeshow.com")
self.assertEqual(
self.episode.guid, "de194720-7b4c-49e2-a05f-432436d3fetr"
)
def test_episode_str_representation(self):
self.assertEqual(
str(self.episode), "My Python Podcast: My Awesome Podcast Episode"
)
在上面的代码中,您使用.setUp()来定义一个示例Episode对象。
现在,您可以测试一些Episode属性,以确认模型如预期的那样工作。从您的模型中测试字符串表示总是一个好主意,这是您在Episode.__str__()中定义的。字符串表示是您在调试代码时将看到的内容,如果它准确地显示了您期望看到的信息,将使调试变得更容易。
现在您可以运行您的测试了:
(.venv) $ python manage.py test
如果您的测试成功运行,那么恭喜您!现在,您已经有了内容聚合器的良好基础,并且有了定义良好的数据模型。第三步的时间到了。
第三步:创建你的主页视图
到目前为止,您应该已经有了一个带有您的Episode模型的工作 Django 应用程序,并且通过了单元测试。在这一步中,您将为主页构建 HTML 模板,添加所需的 CSS 和资产,将主页添加到您的 views.py文件,并测试主页是否正确呈现。
注意:编写 HTML 和 CSS 超出了本教程的范围,所以你不会涉及这些的原因和方法。然而,如果你对 HTML 或 CSS 有任何不理解或有疑问,你可以在评论中寻求来自真实 Python 社区的见解。
在你之前下载的source_code_setup/文件夹中,你会发现一个名为static的文件夹和一个名为templates的文件夹。您应该将这些文件夹复制到您的项目根文件夹中,pycasts/。确保将<source_code_setup_path>替换为您保存在本地机器上的实际路径,并且不要忘记将点(.)复制到当前工作目录中:
(.venv) $ cp -r <source_code_setup_path>/static .
(.venv) $ cp -r <source_code_setup_path>/templates .
既然在项目根中已经有了 HTML 模板和静态文件的文件夹,那么是时候把所有东西都连接起来了,以便 Django 知道它们的存在。
前往主content_aggregator应用程序中的settings.py文件。向下滚动直到到达TEMPLATES部分,并将之前创建的templates/目录添加到DIRS列表中。本教程使用 Django 3,它使用pathlib作为文件路径:
# content_aggregator/settings.py
# ...
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
"DIRS": [
BASE_DIR / "templates", ],
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
"django.template.context_processors.debug",
"django.template.context_processors.request",
"django.contrib.auth.context_processors.auth",
"django.contrib.messages.context_processors.messages",
],
},
},
]
您还需要将static/文件夹添加到您的设置中。你可以通过向下滚动到你的settings.py文件的STATIC部分,并包含到你新创建的static/文件夹的路径:
# content_aggregator/settings.py
# ...
STATIC_URL = "/static/"
STATICFILES_DIRS = [
BASE_DIR / "static", ]
Django 现在知道您的静态资产和模板存在,但是您还没有完成。为了把你目前已经完成的事情联系起来,你还有几项任务要完成:
- 创建主页查看
views.py中的 - 创建 URL 路径
- 添加更多的单元测试
创建 URL 路径和主页视图的顺序并不重要。这两项都需要完成,应用程序才能正常工作,但是您可以从列表的顶部开始,首先创建您的视图类。
在您的podcasts应用程序中,打开您的views.py文件,并用以下代码替换内容:
1# podcasts/views.py
2
3from django.views.generic import ListView
4
5from .models import Episode
6
7class HomePageView(ListView):
8 template_name = "homepage.html"
9 model = Episode
10
11 def get_context_data(self, **kwargs):
12 context = super().get_context_data(**kwargs)
13 context["episodes"] = Episode.objects.filter().order_by("-pub_date")[:10]
14 return context
你可能对 Django 中基于函数的视图很熟悉,但是 Django 也有内置的基于类的视图。这非常方便,可以减少您需要编写的代码量。
在上面的代码片段中,您利用基于类的视图将播客剧集发送到主页:
- 第 7 行:你继承了
ListView类,这样你就可以迭代剧集。默认情况下,它将遍历第 9 行model = Episode定义的所有剧集。 - 第 11 行到第 14 行:您覆盖了
context的数据,并根据由发布日期pub_date确定的最近十集进行过滤。你想在这里过滤,因为,否则,可能有数百-如果不是数千-集传递到主页。
现在是时候给你的主页一个网址了。您首先需要在您的podcasts应用程序中创建一个urls.py文件:
(.venv) $ touch podcasts/urls.py
现在您可以为HomePageView类添加一个路径:
# podcasts/urls.py
from django.urls import path
from .views import HomePageView
urlpatterns = [
path("", HomePageView.as_view(), name="homepage"),
]
在当前状态下,应用程序仍然不会显示你的主页,因为主content_aggregator应用程序不知道podcasts/urls.py中的 URL 路径。两行代码应该可以解决这个问题。在您的content_aggregator/urls.py文件中,添加突出显示的代码,将两者连接在一起:
# podcasts/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("", include("podcasts.urls")), ]
走了这么远,干得好!你现在应该能够启动你的应用程序,并看到主页。就像之前一样,用python manage.py runserver启动你的应用,然后前往localhost:8000:

可以看到首页作品,但是没有内容。即使没有它,您仍然可以通过使用单元测试来测试内容是否会正确显示。
在步骤 2 中,您为模型创建了一个单元测试。您还创建了.setUp(),它创建了一个用于测试的Episode对象。您可以使用相同的测试集数据来测试您的主页模板是否按预期工作。
除了测试主页是否正确呈现剧集之外,测试是否使用了正确的模板以及导航到其 URL 是否返回了有效的 HTTP 状态代码也是一个很好的做法。
对于像这样的单页面应用程序,这可能看起来有点过分——事实也可能如此。但是,随着任何应用程序的增长,您都希望确保未来的变化不会破坏您的工作代码。此外,如果你把这个项目作为一个作品集,那么你应该表明你知道最佳实践。
下面突出显示的代码是添加到您的podcasts/tests.py文件中的新测试代码:
# podcasts/tests.py
from django.test import TestCase
from django.utils import timezone
from django.urls.base import reverse
from datetime import datetime
from .models import Episode
class PodCastsTests(TestCase):
def setUp(self):
self.episode = Episode.objects.create(
title="My Awesome Podcast Episode",
description="Look mom, I made it!",
pub_date=timezone.now(),
link="https://myawesomeshow.com",
image="https://image.myawesomeshow.com",
podcast_name="My Python Podcast",
guid="de194720-7b4c-49e2-a05f-432436d3fetr",
)
def test_episode_content(self):
self.assertEqual(self.episode.description, "Look mom, I made it!")
self.assertEqual(self.episode.link, "https://myawesomeshow.com")
self.assertEqual(
self.episode.guid, "de194720-7b4c-49e2-a05f-432436d3fetr"
)
def test_episode_str_representation(self):
self.assertEqual(
str(self.episode), "My Python Podcast: My Awesome Podcast Episode"
)
def test_home_page_status_code(self): response = self.client.get("/") self.assertEqual(response.status_code, 200) def test_home_page_uses_correct_template(self): response = self.client.get(reverse("homepage")) self.assertTemplateUsed(response, "homepage.html") def test_homepage_list_contents(self): response = self.client.get(reverse("homepage")) self.assertContains(response, "My Awesome Podcast Episode")
和以前一样,您可以使用python manage.py test运行您的单元测试。如果您的所有测试都通过了,那么恭喜您!
在这一步中,您成功地创建了 HTML 模板和资产,构建了视图类,并连接了所有的 URL 路由。你也写了更多的通过单元测试。现在你已经准备好进入下一步了。
步骤 4:解析播客 RSS 提要
此时,您的应用程序应该看起来相当不错!您已经具备了开始添加内容所需的一切。到这一步结束时,您应该对使用 feedparser 库解析 RSS 提要并提取您需要的数据感到满意了。
在开始解析之前,什么是 RSS 提要?你为什么用它来获取播客数据?
首先,所有播客都有一个 RSS 提要。这是播客应用程序获取并向您显示播客数据和剧集的基本方式。您经常可以在 podcast 网站上找到提要 URL 链接。
此外,播客 RSS 源需要看起来都一样。这意味着,当一个播客创作者将他们的提要提交给一个平台,如苹果播客或 T2 谷歌播客时,提要必须符合 T4 RSS 2.0 规范。
这一要求对您有两方面的好处:
- 所有的提要都有相同的属性,所以你可以重用代码为任何给定的播客提取相同的数据,这使得你的代码更容易维护并且更加简洁。
- 每一集都必须分配一个
guid,这使得提要中的每一集都是唯一的。
您要解析的第一个提要是真正的 Python 播客提要。在您的浏览器中导航到 https://realpython.com/podcasts/rpp/feed 的查看提要的外观。如果你觉得难以阅读,你可以安装几个浏览器插件来美化它。Chrome 插件的一个例子是 XML Tree ,但是还有很多其他的插件。
要用 feedparser 解析一个提要,可以使用parse():
>>> import feedparser >>> feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed")获取提要并将其自动解析成可用的 Python 对象。然后,您可以使用标准点标记来访问提要标签,如 podcast 标题:
>>> podcast_title = feed.channel.title
>>> podcast_title
'The Real Python Podcast'
您还可以使用括号符号来访问标记中的属性:
>>> podcast_image = feed.channel.image["href"] >>> podcast_image 'https://files.realpython.com/media/real-python-logo-square.28474fda9228.png'在使用 feedparser 解析的提要中,您还可以访问一个名为
.entries的特殊属性。这允许遍历提要中的每个<item>元素。在你用播客剧集填充了你的数据库之后,你将能够使用.entries来检查提要上每个播客剧集的guid,并查看它是否存在于你的数据库中。注意:暂时不要实现下面的代码片段。读一遍就好了。下一步,当您创建一个 Django 定制命令并将其用于您的项目时,您将编写类似的代码。现在,只需浏览一下这段代码,就可以了解如何使用 feedparser。
值得注意的是,您需要将来自 RSS 提要的发布日期转换成一个
datetime对象,以便将其保存到数据库中。您将使用dateutil库来完成这项工作:# Example import feedparser from dateutil import parser from podcasts.models import Episode feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed") podcast_title = feed.channel.title podcast_image = feed.channel.image["href"] for item in feed.entries: if not Episode.objects.filter(guid=item.guid).exists(): episode = Episode( title=item.title, description=item.description, pub_date=parser.parse(item.published), link=item.link, image=podcast_image, podcast_name=podcast_title, guid=item.guid, ) episode.save()您还没有将这段代码放到文件中的原因是,您没有一个好的方法在 Django 中运行它。既然您已经掌握了如何使用 feedparser,那么您将探索如何使用自定义命令来运行您的解析函数。
步骤 5:创建 Django 定制命令
在最后一步中,您学习了如何使用 feedparser,但是没有合理的方法来运行与 Django ORM 交互的代码。在这一步中,您将介绍如何使用一个定制命令在您的项目中执行脚本,以便您可以在 Django 服务器或生产服务器运行时与之交互。
定制命令利用
manage.py文件来运行您的代码。当您运行manage.py时,Django 会将management/commands/目录中的任何模块注册为可用的命令。注意:如果你想深入研究,请前往 Django 官方文档,获取更多关于定制管理命令的信息。
首先创建适当的目录和文件来存储您的命令:
(.venv) $ mkdir -p podcasts/management/commands (.venv) $ touch podcasts/management/commands/startjobs.py您几乎可以将这个文件命名为您喜欢的任何名称,但是请注意,如果它以下划线开头,
manage.py将不会注册它。稍后在步骤 7 中,您将使用 django-apscheduler 向该文件添加作业,这就是您将该文件命名为startjobs.py的原因。为了测试您的设置,您将创建一个将
"It works!"打印到您的终端的基本命令。每个命令都应该有一个
Command类。那个类需要一个.handle()方法,你可以把它想象成你的类的主方法。.handle()方法保存您想要执行的代码:# podcasts/management/commands/startjobs.py from django.core.management.base import BaseCommand class Command(BaseCommand): def handle(self, *args, **options): print("It works!")现在从您的终端运行您的新命令:
(.venv) $ python manage.py startjobs如果你看到了
It works!打印到终端上,恭喜你!您创建了第一个自定义命令。现在是时候加入上一步中的 RSS 解析代码了,看看是否可以向数据库中添加一些项目。继续更新您的
startjobs.py代码:# podcasts/management/commands/startjobs.py from django.core.management.base import BaseCommand import feedparser from dateutil import parser from podcasts.models import Episode class Command(BaseCommand): def handle(self, *args, **options): feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed") podcast_title = feed.channel.title podcast_image = feed.channel.image["href"] for item in feed.entries: if not Episode.objects.filter(guid=item.guid).exists(): episode = Episode( title=item.title, description=item.description, pub_date=parser.parse(item.published), link=item.link, image=podcast_image, podcast_name=podcast_title, guid=item.guid, ) episode.save()这一次,当您运行自定义命令时,没有任何内容打印到屏幕上,但是您现在应该可以在主页上显示来自真实 Python 播客的播客片段。去试试吧。
你得到了什么?如果您还没有浏览过,现在请访问您的主页:
你有没有看到类似这张图片的东西?如果是的话,恭喜你。成功了。
既然您已经探索了如何使用定制命令,并且已经设置了第一个提要并使其工作,那么您将在下一步中学习如何添加额外的提要。
步骤 6:向 Python 内容聚合器添加额外的提要
至此,您应该有了一个可以解析真正的 Python 播客提要的定制命令。在这一步结束时,您将学会如何向自定义命令添加更多的提要。
现在您已经用自定义命令成功解析了一个 podcast 提要,您可能想为每个提要一遍又一遍地重复相同的代码。然而,这不是好的编码实践。你想要易于维护的干代码。
您可能认为可以遍历一个提要 URL 列表,并对每个条目使用解析代码,通常这是可行的。然而,由于 django-apscheduler 的工作方式,这并不是一个可行的解决方案。在下一步的中会有更多的介绍。
相反,您需要重构您的代码,为您需要解析的每个提要提供一个解析函数和一个单独的函数。现在,您将分别调用这些方法。
注意:正如本教程开始时提到的,目前您只关注两个提要。一旦你完成了教程,并且知道了如何添加更多,你就可以通过选择更多的 RSS 源来自己动手练习了。
与此同时,与我谈论 Python播客中的 Michael Kennedy 已经好心地允许在本教程中使用他的播客提要。谢谢你,迈克尔!
现在,您将开始探索这在您的代码中会是什么样子:
1# podcasts/management/commands/startjobs.py 2 3from django.core.management.base import BaseCommand 4 5import feedparser 6from dateutil import parser 7 8from podcasts.models import Episode 9 10def save_new_episodes(feed): 11 """Saves new episodes to the database. 12 13 Checks the episode GUID against the episodes currently stored in the 14 database. If not found, then a new `Episode` is added to the database. 15 16 Args: 17 feed: requires a feedparser object 18 """ 19 podcast_title = feed.channel.title 20 podcast_image = feed.channel.image["href"] 21 22 for item in feed.entries: 23 if not Episode.objects.filter(guid=item.guid).exists(): 24 episode = Episode( 25 title=item.title, 26 description=item.description, 27 pub_date=parser.parse(item.published), 28 link=item.link, 29 image=podcast_image, 30 podcast_name=podcast_title, 31 guid=item.guid, 32 ) 33 episode.save() 34 35def fetch_realpython_episodes(): 36 """Fetches new episodes from RSS for The Real Python Podcast.""" 37 _feed = feedparser.parse("https://realpython.com/podcasts/rpp/feed") 38 save_new_episodes(_feed) 39 40def fetch_talkpython_episodes(): 41 """Fetches new episodes from RSS for the Talk Python to Me Podcast.""" 42 _feed = feedparser.parse("https://talkpython.fm/episodes/rss") 43 save_new_episodes(_feed) 44 45class Command(BaseCommand): 46 def handle(self, *args, **options): 47 fetch_realpython_episodes() 48 fetch_talkpython_episodes()如前所述,您将解析代码从单独的提要中分离出来,使其可重用。对于您添加的每个额外的提要,您需要添加一个新的顶级函数。在这个例子中,您已经通过分别使用
fetch_realpython_episodes()和fetch_talkpython_episodes()在真正的 Python 播客和 Talk Python to Me 播客中做到了这一点。现在,您已经知道了如何向应用程序添加额外的提要,您可以继续下一步,看看如何自动运行定制命令并定义运行它的时间表。
第七步:用
django-apscheduler安排任务此时,您应该有两个或更多的 RSS 提要,并准备好在每次运行新的定制命令时进行解析。
在最后一步中,您将:
- 设置django-APS scheduler
- 为自定义命令添加一个时间表
- 将任务日志添加到您的应用程序中
- 有机会在 Django 管理中查看您的预定工作
django-apscheduler 包是 apscheduler 库的 django 实现。
注意:有关 APS scheduler 和所有可用设置的详细信息,请查看官方 APS scheduler 文档。你也可以在该项目的 GitHub repo 上了解更多关于 django-apscheduler 的信息。
您的虚拟环境中已经安装了 django-apscheduler。要将它安装到您的应用程序中,您还需要将它添加到您的
settings.py文件中的INSTALLED_APPS:# content_aggregator/settings.py # ... INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", # My Apps "podcasts.apps.PodcastsConfig", # Third Party Apps "django_apscheduler", ]要创建 django-apscheduler 模型,您需要运行数据库迁移命令:
(.venv) $ python manage.py migrate这个命令应用 django-apscheduler 正常工作所必需的数据库迁移。
注意:不需要先运行
makemigrations,因为 django-apscheduler 包包含了自己的迁移文件。现在 django-apscheduler 已经安装到您的应用程序中,您将简要地探索它是如何工作的。更详细的解释请见正式文件。
您想要在自定义命令中运行的每个任务被称为一个任务。您的应用程序中总共有三个作业:一个用于您希望解析的每个 podcast 提要,第三个用于从数据库中删除旧作业。
django-apscheduler 包将您的作业存储在数据库中,它还将存储所有成功和不成功的作业运行。作为开发人员或站点管理员,拥有这一历史记录对您来说非常有用,因为您可以监控是否有任何任务失败。但是如果这些没有定期从数据库中清除,您的数据库将很快填满,所以从数据库中清除旧的历史记录是一个好习惯。这也将按计划完成。
尽管作业历史将存储在数据库中,但是如果出现任何错误,最好将其记录下来以便调试。通过将以下代码添加到
settings.py中,您可以将一些基本的日志设置添加到您的应用程序中:# content_aggregator/settings.py # ... LOGGING = { "version": 1, "disable_existing_loggers": False, "handlers": { "console": { "class": "logging.StreamHandler", }, }, "root": { "handlers": ["console"], "level": "INFO", }, }现在您已经添加了日志记录的设置,您需要在
startjobs.py文件中实例化它。现在您将在startjobs.py中包含一些导入,稍后您将详细介绍这些导入。添加日志记录和调度程序需要的一些其他导入语句:1# podcasts/management/commands/startjobs.py 2 3# Standard Library 4import logging 5 6# Django 7from django.conf import settings 8from django.core.management.base import BaseCommand 9 10# Third Party 11import feedparser 12from dateutil import parser 13from apscheduler.schedulers.blocking import BlockingScheduler 14from apscheduler.triggers.cron import CronTrigger 15from django_apscheduler.jobstores import DjangoJobStore 16from django_apscheduler.models import DjangoJobExecution 17 18# Models 19from podcasts.models import Episode 20 21logger = logging.getLogger(__name__)一次添加大量的 import 语句可能会太多,所以让我们挑选出需要一些解释的类:
- 第 13 行:
BlockingScheduler是运行您的作业的调度程序。它是阻塞,所以它将是进程中唯一运行的东西。- 第 14 行:
CronTrigger是您将用于计划的触发器类型。- 第 15 行:
DjangoJobStore将决定如何存储作业。在这种情况下,您希望它们在数据库中。- 第 16 行:你将使用
DjangoJobExecution运行刚才提到的清理功能。接下来,您需要使用所有的导入语句并设置调度器、触发器和作业存储。
你已经写好了三个工作职能中的两个,现在是时候添加第三个了。在你的
Command类之上,添加你的工作职能:# podcasts/management/commands/startjobs.py # ... def delete_old_job_executions(max_age=604_800): """Deletes all apscheduler job execution logs older than `max_age`.""" DjangoJobExecution.objects.delete_old_job_executions(max_age)
max_age参数是以整数表示的秒数。注意 604800 秒等于 1 周。下一步是在自定义命令的
.handle()函数中创建作业存储和调度程序实例。你也可以在你的第一份工作中加入:1# podcasts/management/commands/startjobs.py 2 3# ... 4 5def handle(self, *args, **options): 6 scheduler = BlockingScheduler(timezone=settings.TIME_ZONE) 7 scheduler.add_jobstore(DjangoJobStore(), "default") 8 9 scheduler.add_job( 10 fetch_realpython_episodes, 11 trigger="interval", 12 minutes=2, 13 id="The Real Python Podcast", 14 max_instances=1, 15 replace_existing=True, 16 ) 17 logger.info("Added job: The Real Python Podcast.")您将在上面看到,您已经成功地创建了您的
scheduler实例并添加了作业存储。然后你创建了你的第一份工作——真正的 Python 播客。
.add_job()方法需要几个参数来成功创建一个作业:
- 第 10 行:第一个参数需要一个函数,所以您将之前创建的
fetch_realpython_episodes函数对象传递给它。注意它在被传递时没有调用括号。- 第 11 行和第 12 行:你必须设置一个触发器。对于本教程,您将设置执行间隔为两分钟。这只是为了让您可以测试并看到它为自己工作。然而,它应该绝对不会在生产环境中如此频繁地使用。您还可以将
seconds和hours作为参数传递,这样,如果您在实际环境中托管这个应用程序,就可以设置一个更现实的更新间隔。- 第 13 行:所有的工作必须有一个 ID。Django 管理员也将使用 ID,所以选择一个可读且有意义的名称。
- 第 15 行:
replace_existing关键字参数替换现有的作业,并在重启应用程序时防止重复。你可以查看官方的 APScheduler 文档,获得
.add_job()接受的所有参数的完整列表。既然您已经安排了第一个作业,那么您可以继续将最后两个作业添加到
.handle()中,并添加对scheduler.start()和scheduler.shutdown()的调用。哦,让我们也加入一些伐木。您的自定义命令类现在应该如下所示:
# podcasts/management/commands/startjobs.py # ... class Command(BaseCommand): help = "Runs apscheduler." def handle(self, *args, **options): scheduler = BlockingScheduler(timezone=settings.TIME_ZONE) scheduler.add_jobstore(DjangoJobStore(), "default") scheduler.add_job( fetch_realpython_episodes, trigger="interval", minutes=2, id="The Real Python Podcast", max_instances=1, replace_existing=True, ) logger.info("Added job: The Real Python Podcast.") scheduler.add_job( fetch_talkpython_episodes, trigger="interval", minutes=2, id="Talk Python Feed", max_instances=1, replace_existing=True, ) logger.info("Added job: Talk Python Feed.") scheduler.add_job( delete_old_job_executions, trigger=CronTrigger( day_of_week="mon", hour="00", minute="00" ), # Midnight on Monday, before start of the next work week. id="Delete Old Job Executions", max_instances=1, replace_existing=True, ) logger.info("Added weekly job: Delete Old Job Executions.") try: logger.info("Starting scheduler...") scheduler.start() except KeyboardInterrupt: logger.info("Stopping scheduler...") scheduler.shutdown() logger.info("Scheduler shut down successfully!")您可能还记得,这个调度程序使用
BlockingScheduler在自己的进程中运行。在一个终端中,您可以像以前一样使用python manage.py startjobs运行自定义命令。在一个单独的终端进程中,启动 Django 服务器。当您查看您的管理控制面板时,您现在可以看到您的作业已经注册,并且您可以查看历史记录:
在这最后一步中发生了很多事情,但是你已经用一个功能正常的应用程序完成了!您已经成功地导航了如何使用 django-apscheduler 按照定义的时间表自动运行您的定制命令。不小的成就。干得好!
从头开始构建一个像内容聚合器这样的项目从来都不是一个快速或简单的任务,你应该为自己能够坚持到底而感到自豪。做一些新的事情,推动你一点点,只会帮助你成长为一名开发人员,不管你有多高级。
结论
在这个基于项目的教程中,您已经介绍了很多内容。干得好!
在本教程中,您已经学习了:
- 如何使用 feed parser处理 RSS 提要
- 如何创建和使用自定义管理命令
- 如何使用 django-apscheduler 在个性化的时间表上自动化你的定制命令
- 如何将基本的单元测试添加到 Django 应用程序中
如果您还没有这样做,请单击下面的链接下载本教程的代码,这样您就可以使用 Python 构建自己的内容聚合器:
获取源代码: 点击此处获取您将在本教程中使用用 Django 和 Python 构建内容聚合器的源代码。
接下来的步骤
作为一名开发人员,有许多方法可以定制和修改这个应用程序,尤其是当您计划将它作为一个作品集时。让这个项目更上一层楼,将有助于你在未来的求职申请中脱颖而出。
以下是一些让你的项目更上一层楼的想法:
- 添加更多饲料!对数据科学感兴趣?查看数据科学播客的终极列表。
- 改变内容的类型。如果播客不是你的菜,也许足球新闻是?或者你可能喜欢听财经播客?无论你的兴趣是什么,用这个项目作为垫脚石,为你的激情之一创建一个聚合器。
- 添加用户账户以便用户可以订阅他们感兴趣的提要。然后在一天结束时,给他们发一封电子邮件,告诉他们订阅的新内容。查看关于 Django 视图授权的教程以获得帮助。
- 给
Episode模型添加一个is_published布尔标志,这样管理员可以手动策划和确认主页上显示的剧集。- 给
Episode模型添加一个featured字段,这样你就可以在主页上高亮显示选中的播客。- 重新设计应用程序让它成为你自己的应用程序。定制 CSS 或者撕掉 Bootstrap 4 以利于顺风 CSS 。世界是你的。
- 将应用部署到生产环境中——例如,通过在 Heroku 上托管你的 Django 应用。
- 定制 Django 管理和增强你的 Django 管理体验。
无论你是使用以上其中一种思路,还是用自己的方式定制 app,请分享!在下面发表评论,告诉其他读者你是如何把它变成你自己的。如果你把它推向生产,删除一个链接!*******
用 FastAPI 和 Python 构建一个 URL 缩短器
原文:https://realpython.com/build-a-python-url-shortener-with-fastapi/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 FastAPI 和 Python 构建网址缩短器
在本教程中,您将使用 Python 和 FastAPI 构建一个 URL 缩短器。URL 可能会非常长,而且对用户不友好。这就是网址缩写可以派上用场的地方。URL 缩写减少了 URL 中的字符数,使其更容易阅读、记忆和共享。
通过这个循序渐进的项目,您将使用 Python 和 FastAPI 构建一个 URL 缩短器。在本教程结束时,你将拥有一个全功能的 API 驱动的 web 应用,它可以创建缩短的 URL 并转发给目标 URL。
在本教程中,您将学习如何:
- 用 FastAPI 创建一个 REST API
- 使用uvicon运行开发 web 服务器
- 建模一个 SQLite 数据库
- 调查自动生成的 API 文档
- 通过 CRUD 动作与数据库交互
- 通过重构代码来优化你的应用
这个 URL shortener 项目是为中级 Python 程序员设计的,他们想尝试一下 FastAPI 并学习 API 设计、CRUD 和与数据库的交互。如果您熟悉处理 HTTP 请求的基础知识,将会有所帮助。如果你需要重温 FastAPI,使用 FastAPI 构建 Python Web API是一个很好的介绍。
获取源代码: 点击此处获取源代码,您将使用 FastAPI 构建您的 Python URL shortener。
演示:你的 Python 网址缩写器
在这个循序渐进的项目中,您将构建一个 API 来创建和管理缩短的 URL。这个 API 的主要目的是接收一个完整的目标 URL 并返回一个缩短的 URL。为了测试您的 API 端点,您将利用 FastAPI 自动创建的文档:
https://player.vimeo.com/video/709517464?background=1
当你向 URL shortener 应用程序发布一个目标 URL 时,你会得到一个缩短的 URL 和一个密钥。缩短的 URL 包含转发到目标 URL 的随机密钥。您可以使用密钥来查看缩短的 URL 的统计数据或删除转发。
项目概述
您的 URL shortener Python 项目将提供能够接收不同的 HTTP 请求类型的 API 端点。每个端点将执行您指定的操作。以下是您的 URL shortener 的 API 端点的摘要:
端点 HTTP 动词 请求正文 行动 /GET返回一个 Hello, World!字符串/urlPOST您的目标 URL 显示创建的 url_key和附加信息,包括一个secret_key/{url_key}GET转发到您的目标 URL /admin/{secret_key}GET显示您的简短网址的管理信息 /admin/{secret_key}DELETE你的秘密钥匙 删除您缩短的 URL 您将在本教程中编写的代码侧重于首先让应用程序工作。然而,拥有一个工作的应用程序并不总是意味着它背后的代码是完美的。这就是为什么你会在本教程中找到一个步骤来重构你的应用程序的一部分。
注意:本教程的主要目标是展示使用 FastAPI 快速设置 REST API 服务器的基础知识,而不涉及更高级的主题,如 Python 中的异步 IO或考虑性能。
如果您想充分利用 FastAPI 的全部性能,您应该以异步方式使用 FastAPI。
如果你想了解更多关于编写异步代码以及 FastAPI 如何处理并发,那么你可以查看 FastAPI 文档。
如果您想看看最终的源代码,请继续下载:
获取源代码: 点击此处获取源代码,您将使用 FastAPI 构建您的 Python URL shortener。
这个项目是用更多功能扩展您的 API 的一个很好的起点。在本教程的结尾,你会发现下一步要构建什么的想法。
先决条件
为了充分利用本教程,您应该熟悉以下概念:
链接的资源将帮助您更好地理解您在本教程中编写的代码。然而,在本教程中,您将逐步构建您的应用程序。所以即使你不熟悉上面的概念,你也能理解。
步骤 1:准备您的环境
在这一步中,您将为 FastAPI 应用程序准备开发环境。首先,您将为应用程序创建文件夹结构。然后,您将创建一个虚拟环境,并安装您的项目所需的所有项目依赖项。最后,您将学习如何在代码之外存储环境变量,以及如何将这些变量加载到您的应用程序中。
创建项目的文件夹结构
在本节中,您将创建您的项目结构。您可以随意命名项目的根文件夹。例如,您可以将其命名为
url_shortener_project/。根文件夹将是您的工作目录。您将从当前所在的根文件夹中运行应用程序的命令。您将创建的文件和文件夹将位于此文件夹或您稍后将创建的应用程序文件夹中。
虽然您可以单独选取项目文件夹的名称,但给应用程序文件夹命名
shortener_app/很重要。当您在项目文件夹中时,创建一个名为shortener_app/的子文件夹:$ mkdir shortener_app
shortener_app/文件夹将是你的应用程序所在的位置。稍后,您将把应用程序的源代码添加到这个shortener_app/目录中的不同文件中。你的 URL shortener Python 应用程序将是一个名为
shortener_app的包,它将包含不同的模块。要使用shortener_app作为一个包,创建一个__init__.py文件:
- 视窗
** Linux + macOS*PS> ni shortener_app\__init__.py$ touch shortener_app/__init__.py您可以通过在目录中添加一个
__init__.py文件来创建一个包。在本教程中,__init__.py文件将保持为空。它唯一的工作就是告诉 Python 你的shortener_app/目录是一个包。注意:如果没有
__init__.py文件,您将创建一个命名空间包,而不是一个常规包。当将包拆分到多个目录时,名称空间包会很方便,但是在这个项目中并没有拆分包。查看 Python import:高级技术和技巧以了解更多关于包的信息。包结构就绪后,继续下一部分,在这里您将创建一个虚拟环境并添加项目的依赖项。
添加项目依赖关系
依赖项是您的 FastAPI 项目需要工作的 Python 包。在用
pip安装它们之前,创建一个虚拟环境是个不错的主意。这样,您不是在系统范围内安装依赖项,而是只在项目的虚拟环境中安装。在下面选择您的操作系统,并使用您的平台特定命令来设置虚拟环境:
- 视窗
** Linux + macOS*PS> python -m venv venv PS> .\venv\Scripts\activate (venv) PS> python -m pip --version pip 21.2.3 from ...\lib\site-packages\pip (python 3.10)$ python3 -m venv venv $ source venv/bin/activate (venv) $ python -m pip --version pip 21.2.3 from .../python3.10/site-packages/pip (python 3.10)使用上面显示的命令,您可以通过使用 Python 的内置
venv模块创建一个名为venv的虚拟环境。然后你用source命令激活它。您的venv名字周围的括号(())表示您成功激活了虚拟环境。创建并激活虚拟环境后,就该安装 URL shortener Python 应用程序所需的依赖项了:
(venv) $ python -m pip install fastapi==0.75.0 uvicorn==0.17.6您将使用 FastAPI web 框架来构建 API。所以
fastapi是你项目的第一个需求也就不足为奇了。要运行 API,您需要一个 web 服务器。这就是
uvicorn的作用。uvicon是 Python 的 web 服务器实现,它提供了异步服务器网关接口(ASGI) 。Web 服务器网关接口(WSGI)指定了 web 服务器如何与 web 应用程序通信。像 Gunicorn 这样的传统 WSGI 实现需要运行多个进程来并发处理网络流量。相反,ASGI 可以在单线程上处理异步事件循环,只要您可以避免调用任何阻塞函数。
FastAPI 利用了 ASGI 标准,并且您使用了能够处理异步功能的
uvicornweb 服务器。但是正如你将在本教程中看到的,你不必编写异步代码来使用 FastAPI。注意:如果你想了解更多关于 Python 中的异步 IO 以及 FastAPI 如何处理并行性,那么你可以查看 FastAPI 文档的并发和异步/等待页面。
安装好 web 框架和 web 服务器后,将
sqlalchemy添加到组合中:(venv) $ python -m pip install sqlalchemy==1.4.32SQLAlchemy 是一个 Python SQL 工具包,帮助您与数据库进行通信。您可以使用 SQLAlchemy 的对象关系映射器(ORM) ,而不是编写原始的 SQL 语句。ORM 为您提供了一种更加用户友好的方式来声明您的应用程序和您将使用的 SQLite 数据库的交互。
您的应用程序也将依赖于环境变量。在本教程的后面,您将了解更多关于环境变量的内容。现在,确保安装
python-dotenv来从外部文件加载它们:(venv) $ python -m pip install python-dotenv==0.19.2
python-dotenv包帮助您从外部文件读取键值对,并将它们设置为环境变量。最后,您将使用一个包来验证 URL:
(venv) $ python -m pip install validators==0.18.2顾名思义,
validators库可以帮助你验证像电子邮件地址、IP 地址,甚至是芬兰社会安全号码这样的值。您将使用validators来验证用户想要在您的项目中缩短的 URL。注意:上面的
pip install命令被挑选出来解释为什么需要它们。您可以通过链接软件包名称,在一个命令中安装所有依赖项。现在,您已经安装了 FastAPI 项目需要使用的所有项目依赖项。安装需求在您的开发过程中至关重要,因为它为您的工作环境做准备。在下一节中,您将定义存储应用程序设置的环境变量。
定义环境变量
您目前正在本地计算机上开发 Python URL shortener。但是一旦你想让它对你的用户可用,你可能想把它部署到网络上。
对不同的环境使用不同的设置是有意义的。您的本地开发环境可能使用与在线生产环境不同名称的数据库。
为了灵活起见,您将这些信息存储在特殊的变量中,您可以针对每个环境对这些变量进行调整。虽然在本教程中,您不会采取步骤来在线托管您的应用程序,但是您将构建您的应用程序,以便将来能够将其部署到云中。
注意:如果你想了解更多关于部署的信息,请查看 Python Web 应用程序:将你的脚本部署为 Flask 应用程序或使用 Heroku 部署 Python Flask 示例应用程序。
首先用默认设置创建一个
config.py文件:1# shortener_app/config.py 2 3from pydantic import BaseSettings 4 5class Settings(BaseSettings): 6 env_name: str = "Local" 7 base_url: str = "http://localhost:8000" 8 db_url: str = "sqlite:///./shortener.db" 9 10def get_settings() -> Settings: 11 settings = Settings() 12 print(f"Loading settings for: {settings.env_name}") 13 return settings在第 3 行,您正在导入
pydantic。当你用pip安装fastapi的时候,你就自动安装了 pydantic。pydantic 是一个使用类型注释来验证数据和管理设置的库。您在第 5 行定义的
Settings类是BaseSettings的子类。BaseSettings类在应用程序中定义环境变量非常方便。您只需要定义您想要使用的变量,pydantic 会处理剩下的事情。换句话说,如果 pydantic 没有找到相应的环境变量,它将自动采用这些默认值。在这种情况下,您在第 6 到第 8 行定义了
env_name、base_url和db_url的默认设置。稍后,您将使用外部环境变量替换它们的值:
设置变量 环境变量 价值 env_nameENV_NAME您当前环境的名称 base_urlBASE_URL您的应用程序的域 db_urlDB_URL您的数据库的地址 让
env_name、base_url和db_url使用默认值是一个好的开始。但是,由于您当前环境的值、应用程序的域和数据库的地址取决于您正在工作的环境,因此您稍后将从外部环境变量加载这些值。要在加载设置后显示一条消息,可以在第 10 到 13 行创建
get_settings()。get_settings()函数返回你的Settings类的一个实例,并为你提供缓存你的设置的选项。但是在研究为什么需要缓存之前,在交互式 Python 解释器中运行get_settings():

>>> from shortener_app.config import get_settings
>>> get_settings().base_url
Loading settings for: Local
'http://localhost:8000'
>>> get_settings().db_url
Loading settings for: Local
'sqlite:///./shortener.db'
当您调用get_settings()时,您的设置被正确加载。但是,您可以进一步优化设置的检索。
注意:如果您在运行上面的命令时遇到错误,那么您应该确保您是从项目的根目录启动交互式 Python 解释器的:
- 视窗
** Linux + macOS*
(venv) PS> ls
shortener_app/ venv/
(venv) $ ls
shortener_app/ venv/
当在您的终端中运行ls命令时,您应该看到shortener_app/是一个子目录。如果列出了您的应用程序目录,那么您当前位于项目的根目录中。*** 运行应用程序时,您不能更改应用程序的设置。尽管如此,每次调用get_settings()时,你都要一遍又一遍地加载你的设置。但是您可以利用get_settings()作为一个函数来实现一个最近最少使用(LRU)* 策略。
当你启动应用程序时,加载你的设置,然后缓存数据是有意义的。缓存是一种优化技术,您可以在应用程序中使用它来将最近或经常使用的数据保存在内存中。您可以实现一个 LRU 缓存策略来完成这一行为:
# shortener_app/config.py
from functools import lru_cache
from pydantic import BaseSettings
class Settings(BaseSettings):
env_name: str = "Local"
base_url: str = "http://localhost:8000"
db_url: str = "sqlite:///./shortener.db"
@lru_cache def get_settings() -> Settings:
settings = Settings()
print(f"Loading settings for: {settings.env_name}")
return settings
您在第 3 行从 Python 的functools模块导入lru_cache。@lru_cache 装饰器允许你使用 LRU 策略缓存get_settings()的结果。运行以下命令,查看缓存是如何工作的:
>>> from shortener_app.config import get_settings >>> get_settings().base_url Loading settings for: Local 'http://localhost:8000' >>> get_settings().db_url 'sqlite:///./shortener.db'现在,你只能看到你的信息一次。这意味着您的设置已成功缓存。通过添加
@lru_cache装饰器,您可以在降低计算资源负载的同时提高应用程序的速度。您将实现的另一个改进是加载外部环境变量。首先在项目的根目录下创建一个外部
.env文件,然后添加以下内容:# .env ENV_NAME="Development" BASE_URL="http://127.0.0.1:8000" DB_URL="sqlite:///./shortener.db"通过将您的环境变量存储在外部,您正在遵循十二因素应用程序方法。十二要素应用方法论陈述了十二条原则,使开发者能够构建可移植和可伸缩的网络应用。一个原则是将应用程序的配置存储在环境中:
一个应用程序的配置是在不同的部署之间可能会发生变化的一切(登台、生产、开发者环境等。).这包括:
- 数据库、Memcached 和其他后台服务的资源句柄
- 亚马逊 S3 或 Twitter 等外部服务的凭证
- 每个部署的值,例如部署的规范主机名
十二要素原则要求配置与代码严格分离。配置在不同的部署中有很大的不同,而代码则没有。(来源)
对于不同的环境,建议使用不同的
.env文件。此外,你不应该将.env文件添加到你的版本控制系统中,因为你的环境变量可能会存储敏感信息。注意:如果你与其他开发者共享你的代码,那么你可能想在你的库中展示他们的
.env文件应该是什么样子。在这种情况下,您可以将.env_sample添加到版本控制系统中。在.env_sample中,您可以存储带有占位符值的键。为了帮助你自己和你的开发伙伴,不要忘记在你的README.md文件中写下关于如何重命名.env_sample和在文件中存储正确值的说明。您在
Settings类中使用的配置变量是外部环境变量的后备。在.env文件中,您为您的开发环境声明了相同的变量。当您将应用程序部署到 web 时,您为每个环境声明了环境变量。要加载您的外部
.env文件,请调整您的config.py文件中的Settings类:# shortener_app/config.py # ... class Settings(BaseSettings): env_name: str = "Local" base_url: str = "http://localhost:8000" db_url: str = "sqlite:///./shortener.db" class Config: env_file = ".env" # ...当您将带有到您的
env_file的路径的Config类添加到您的设置中时,pydantic 从.env文件中加载您的环境变量。通过运行以下命令测试外部环境变量:
>>> from shortener_app.config import get_settings
>>> get_settings().base_url
Loading settings for: Development
'http://127.0.0.1:8000'
>>> get_settings().db_url
'sqlite:///./shortener.db'
太棒了,这些值就是您在.env文件中声明的值!现在你的应用程序可以处理外部变量了。
比较您的项目设置
如果您遵循了上面的说明,那么您的目录树应该如下所示:
url_shortener_project/
│
├── shortener_app/
│ │
│ ├── __init__.py
│ └── config.py
│
├── venv/
│
└── .env
您的url_shortener_project/目录包含了shortener_app/文件夹。到目前为止,有一个空的__init__.py文件和一个config.py文件,其中保存了你的应用程序的设置。您可以从您在项目目录的根目录下创建的外部.env文件中加载您的设置。
除此之外,您可能有一个包含虚拟环境的venv文件夹。项目结构就绪后,您就可以实现 URL shortener 应用程序的主要功能了。
步骤 2:设置你的 Python 网址缩写器
现在你已经准备好了你的开发环境,是时候设置你的 URL shortener 应用程序了。只需几行代码,您就可以用第一个 API 端点创建一个 FastAPI 应用程序。
一旦应用程序运行,您将定义您的应用程序应该能够做什么。您将把数据模式建模到数据库中。在这一步结束时,您将能够缩短一个 URL,并查看您的应用程序如何将该 URL 转发到其目标。
创建您的 FastAPI 应用程序
从 FastAPI 的一个Hello, World!实现开始。这个实现是一个有一个端点的 FastAPI 应用程序。在shortener_app/文件夹中创建一个名为main.py的文件,并添加以下代码:
1# shortener_app/main.py
2
3from fastapi import FastAPI
4
5app = FastAPI()
6
7@app.get("/")
8def read_root():
9 return "Welcome to the URL shortener API :)"
在第 3 行,您导入了FastAPI。通过实例化FastAPI类,在第 5 行定义了app。app变量是创建 API 的主要交互点。在本教程中,您将多次引用它。
在第 7 行,您使用了一个路径操作装饰器,通过在 FastAPI 中注册它来将您的根路径与read_root()相关联。现在,FastAPI 监听根路径并将所有传入的 GET 请求 委托给你的read_root()函数。
最后,在第 9 行返回一个字符串。当您向 API 的根路径发送请求时,会显示此字符串。
您刚刚添加到main.py的代码是您的应用程序的开始。要运行你的应用,你需要一个服务器。如上所述,您已经安装了uvicorn作为您的服务器。
使用uvicorn运行实时服务器:
(venv) $ uvicorn shortener_app.main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000
INFO: (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.
你用上面的命令告诉uvicorn运行你的shortener_app包的main.py文件的app。--reload标志确保当你保存应用程序代码时,你的服务器会自动重新加载。自动重新加载将非常方便,因为你不需要在编码时反复停止和重启你的服务器。相反,您可以在后台保持此终端窗口打开。
现在您的服务器正在运行,测试您的 API 端点的响应。在浏览器中打开http://127.0.0.1:8000:

当您在浏览器中导航到http://127.0.0.1:8000时,您正在向 FastAPI 应用程序的根目录发送 GET 请求。响应是您定义的欢迎消息。恭喜你,你的应用成功了!
注意:您的浏览器可能会将响应显示为无格式文本。您可以为您的浏览器安装一个 JSON 格式化程序扩展来很好地呈现 API 响应。
FastAPI 的一个优点是,框架会自动为您创建 API 端点的文档。请点击http://127.0.0.1:8000/docs在您的浏览器中查看:
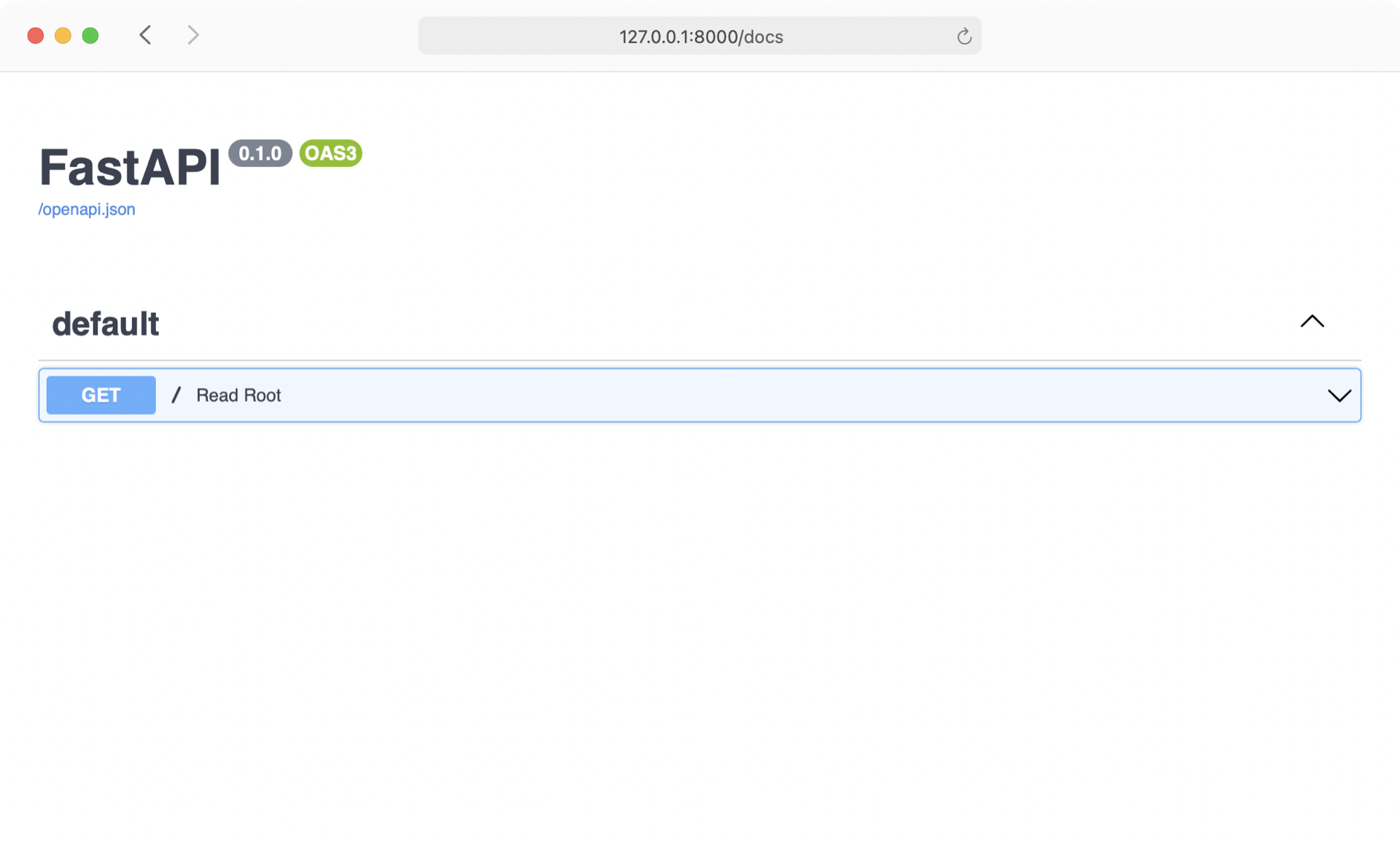
这是 FastAPI 为您创建的 Swagger UI 文档。 Swagger UI 不仅给你一个 API 端点的概述,你还可以用它来测试你的 API。在本教程的剩余部分中,您将利用这一功能来监视 API 的行为。
您也可以在http://127.0.0.1:8000/redoc查看替代文档。但是在本教程中,您只会看到在/docs端点上可以找到的 Swagger UI 文档的截图。
决定你的应用能做什么
在向应用程序添加更多代码之前,请记住 URL 缩写程序的端点和操作:
| 端点 | HTTP 动词 | 请求正文 | 行动 |
|---|---|---|---|
/ |
GET |
返回一个Hello, World!字符串 |
|
/url |
POST |
您的目标 URL | 显示创建的url_key和附加信息,包括一个secret_key |
/{url_key} |
GET |
转发到您的目标 URL | |
/admin/{secret_key} |
GET |
显示您的简短网址的管理信息 | |
/admin/{secret_key} |
DELETE |
你的秘密钥匙 | 删除您缩短的 URL |
当用户发布他们想要缩短的目标 URL 时,您的应用程序应该发送一条消息,确认该操作有效。为了让您的用户能够管理缩短的 URL,您将向客户端发送一个包含一些附加信息的响应。下面是一个响应正文的示例:
{ "target_url": "https://realpython.com", "is_active": true, "clicks": 0, "url": "JNPGB", "admin_url": "MIZJZYVA" }
您的模式说明了 API 对请求体的期望,以及客户端对响应体的期望。您将实现类型提示来验证请求和响应是否匹配您定义的数据类型。
首先在一个schemas.py文件中为您的 API 请求和响应主体创建基本模型:
1# shortener_app/schemas.py
2
3from pydantic import BaseModel
4
5class URLBase(BaseModel):
6 target_url: str
7
8class URL(URLBase):
9 is_active: bool
10 clicks: int
11
12 class Config:
13 orm_mode = True
14
15class URLInfo(URL):
16 url: str
17 admin_url: str
在schemas.py文件中,您使用 pydantic 的BaseModel来定义您的URLBase类。第 5 行的URLBase类包含字段target_url,它需要一个字符串。您将使用target_url来存储您的简短 URL 转发到的 URL。
第 8 行的URL类从URLBase继承了target_url字段。在第 9 行和第 10 行,您将布尔字段is_active和整数字段clicks添加到该类中。is_active字段允许您禁用缩短的 URL。使用clicks,你将会计算一个被缩短的网址被访问了多少次。
就像在您的config.py文件中一样,您在第 12 行使用Config类向 pydantic 提供配置。在这种情况下,您告诉 pydantic 和orm_mode = True一起使用数据库模型。ORM 代表对象关系映射,它使用面向对象的方法提供了与数据库交互的便利。在下一节中,您将看到 ORM 如何工作,以及URL类如何与urls数据库表相关联。
在第 15 行,您定义了URLInfo。这通过需要两个额外的弦url和admin_url来增强URL。你也可以添加两根弦url和admin_url到URL。但是通过将url和admin_url添加到URLInfo子类中,您可以在 API 中使用数据,而无需将数据存储在数据库中。
返回到main.py以在 POST 端点中使用URLBase模式:
1# shortener_app/main.py
2
3import validators
4from fastapi import FastAPI, HTTPException
5
6from . import schemas
7
8# ...
9
10def raise_bad_request(message):
11 raise HTTPException(status_code=400, detail=message)
12
13# ...
14
15@app.post("/url")
16def create_url(url: schemas.URLBase):
17 if not validators.url(url.target_url):
18 raise_bad_request(message="Your provided URL is not valid")
19 return f"TODO: Create database entry for: {url.target_url}"
在第 3 到 6 行,您从fastapi导入HTTPException,以及validators和您刚刚创建的schemas模块。第 10 行中的raise_bad_request()函数将message作为参数,并使用状态代码 400 引发一个HTTPException。当提供的 URL 无效时,您将在第 18 行引发它。在本教程的后面,您将重用raise_bad_request(),这就是为什么您将HTTPException放入它自己的函数中。
在第 16 行,您定义了create_url端点,它期望一个 URL 字符串作为 POST 请求主体。您用第 15 行中的@app.post装饰器将这个端点定义为 POST 请求端点。create_url端点的 URL 是/url。
虽然 pydantic 确保 URL 是一个字符串,但它不会检查该字符串是否是一个有效的 URL。这就是你在本教程开始时安装的validators包的工作。在第 17 行,检查url.target_url是否是有效的 URL。如果提供的target_url无效,那么调用raise_bad_request()。目前,您只在第 19 行给自己返回了一条消息。稍后,如果target_url有效,您将创建一个数据库条目。
现在,main.py中已经有了与schemas.py中定义的模式一起工作的函数。您可以向 API 端点发送请求并获得响应,但是到目前为止还没有发生任何事情。在下一部分,您将通过将您的应用程序与数据库连接起来,为您的项目注入一些活力。
准备您的 SQLite 数据库
尽管您可以到达您的 API 端点来缩短 URL,但是在后端中还没有发生任何事情。在本节中,您将创建数据库并将其连接到代码库。
首先,将数据库连接所需的代码存储在一个名为database.py的文件中:
1# shortener_app/database.py
2
3from sqlalchemy import create_engine
4from sqlalchemy.ext.declarative import declarative_base
5from sqlalchemy.orm import sessionmaker
6
7from .config import get_settings
8
9engine = create_engine(
10 get_settings().db_url, connect_args={"check_same_thread": False}
11)
12SessionLocal = sessionmaker(
13 autocommit=False, autoflush=False, bind=engine
14)
15Base = declarative_base()
在前面的一节中,您学习了如何使用 SQLAlchemy 与数据库通信。特别是,您将使用在第 3 行导入的create_engine(),在第 9 行定义您的engine。您可以将engine视为数据库的入口点。第一个参数是数据库 URL,它是从第 7 行导入的设置的db_url中获得的。
您将check_same_thread设置为False,因为您正在使用 SQLite 数据库。通过这个连接参数,SQLite 允许一次有多个请求与数据库通信。
您使用在第 5 行导入的sessionmaker,在第 12 行创建SessionLocal类。稍后实例化SessionLocal时,您将创建一个工作数据库会话。
您在第 4 行中导入的declarative_base函数返回一个类,该类将数据库引擎连接到模型的 SQLAlchemy 功能。你把第 15 行的declarative_base()赋值给Base。Base将是数据库模型在models.py文件中继承的类。
当database.py包含关于数据库连接的信息时,models.py文件将描述数据库的内容。若要继续,请创建models.py:
1# shortener_app/models.py
2
3from sqlalchemy import Boolean, Column, Integer, String
4
5from .database import Base
6
7class URL(Base):
8 __tablename__ = "urls"
9
10 id = Column(Integer, primary_key=True)
11 key = Column(String, unique=True, index=True)
12 secret_key = Column(String, unique=True, index=True)
13 target_url = Column(String, index=True)
14 is_active = Column(Boolean, default=True)
15 clicks = Column(Integer, default=0)
您添加到models.py中的代码看起来类似于您在schemas.py中编写的代码。在schemas.py中,您定义了 API 期望从客户机和服务器获得什么数据。在models.py中,您声明您的数据应该如何存储在数据库中。
您正在第 7 行创建一个名为URL的数据库模型。URL模型是Base的子类,您在第 5 行导入它。
给你的模型取一个单一的名字,给你的数据库表取多个名字是很常见的。这就是为什么您在第 7 行将模型命名为URL,并在第 8 行提供特殊变量__tablename__。
在第 10 行,您将id定义为数据库的主键。通过将primary_key参数设置为True,您不需要提供unique参数,因为它默认为主键的True。
您在第 11 行和第 12 行中定义的key和secret_key列也将包含唯一的条目。key字段将包含随机字符串,这将是缩短的 URL 的一部分。使用secret_key,您可以向用户提供一个密钥来管理他们缩短的 URL 并查看统计数据。
在第 13 行,您定义了列target_url来存储 URL 字符串,您的应用程序为这些字符串提供了缩短的 URL。重要的是,不要将你的target_url列设置为unique=True。如果您只接受这个数据库字段的唯一值,那么您可以防止不同的用户转发到同一个 URL。
您的应用程序的预期行为是,任何用户都可以为任何目标 URL 创建一个缩短的 URL,而不知道这样的转发是否已经存在。因此,虽然您将提供一个独特的缩短网址,多个缩短网址可能会转发到同一个网站。
稍后您将会看到,当用户想要删除一个缩短的 URL 时,第 14 行的is_active 布尔型列将会派上用场。您将使条目处于非活动状态,而不是赋予用户直接删除数据库条目的权力。这样,您就有了一个关键操作的安全网,如果用户无意中触发了删除,您就可以撤销删除。
在第 15 行,您定义了从零开始的clicks列。后来,每当有人点击缩短的链接时,该字段将增加整数和。
连接您的数据库
有了数据库模型,您现在可以将应用程序链接到数据库。现在,您将把与数据库通信的大部分代码添加到main.py:
1# shortener_app/main.py
2
3import secrets 4
5import validators
6from fastapi import Depends, FastAPI, HTTPException 7from sqlalchemy.orm import Session 8
9from . import models, schemas 10from .database import SessionLocal, engine 11
12app = FastAPI()
13models.Base.metadata.create_all(bind=engine) 14
15def get_db(): 16 db = SessionLocal() 17 try: 18 yield db 19 finally: 20 db.close() 21
22# ...
23
24@app.post("/url", response_model=schemas.URLInfo) 25def create_url(url: schemas.URLBase, db: Session = Depends(get_db)):
26 if not validators.url(url.target_url):
27 raise_bad_request(message="Your provided URL is not valid")
28
29 chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
30 key = "".join(secrets.choice(chars) for _ in range(5))
31 secret_key = "".join(secrets.choice(chars) for _ in range(8))
32 db_url = models.URL(
33 target_url=url.target_url, key=key, secret_key=secret_key
34 )
35 db.add(db_url)
36 db.commit()
37 db.refresh(db_url)
38 db_url.url = key
39 db_url.admin_url = secret_key
40
41 return db_url
现在main.py发生了很多事情。这是一行一行发生的事情:
- 第 3 行到第 7 行从外部模块导入函数和类。
- 线 9 导入你的内部模块
models和schemas。 - 第 10 行从你的
database模块导入SessionLocal和engine。 - 第 12 行保持不变。在这里你定义你的 FastAPI 应用。
- 第 13 行将您的数据库引擎与
models.Base.metadata.create_all()绑定。如果您在engine中定义的数据库还不存在,那么当您第一次运行您的应用程序时,将会创建一个包含所有建模表的数据库。 - 第 15 到 20 行定义了
get_db()函数,该函数将为每个请求创建和yield新的数据库会话。请求完成后,您用db.close()关闭会话。您可以使用try…finally块在任何情况下关闭数据库连接,即使在请求过程中出现错误。 - 第 24 行是路径操作装饰器,确保下面的
create_url()函数响应/url路径上的任何 POST 请求。 - 第 25 行定义了
create_url(),它需要一个URLBase模式作为参数,并且依赖于数据库会话。通过将get_db传递给Depends(),您为请求建立了一个数据库会话,并在请求完成时关闭会话。 - 第 26 行和第 27 行确保提供的
target_url数据是有效的 URL。如果 URL 无效,那么调用raise_bad_request()。 - 第 29 到 31 行为
key和secret_key提供随机字符串。 - 第 32 到 37 行为你的
target_url创建一个数据库条目。 - 第 38 行和第 39 行将
key和secret_key添加到db_url中,以匹配需要在函数结束时返回的URLInfo模式。
您可能会觉得刚刚添加的代码覆盖了create_url()函数的范围。你的直觉是正确的。事实上,您可能会找到更好的地方来创建随机字符串和执行数据库操作。但是不马上变得完美也没关系。首先,在解决缺点之前,检查你的应用程序是否如预期那样工作。
如果您的 live 服务器尚未重新启动,请重新启动它:
(venv) $ uvicorn shortener_app.main:app --reload
当服务器重新启动时,sqlalchemy自动在您在DB_URL环境变量中定义的位置创建您的数据库。如果你用sqlite:///./shortener.db作为DB_URL的值,那么现在你的项目根目录下应该有一个名为shortener.db的文件。那是你的 SQLite 数据库!
到目前为止,数据库包含您在models.py中定义的表,但是它不包含任何数据。要查看一下,启动您的 Python 解释器并按照下面显示的命令操作:
1>>> from shortener_app.database import SessionLocal 2Loading settings for: Development 3>>> db = SessionLocal() 4 5>>> from shortener_app.models import URL 6>>> db.query(URL).all() 7[]首先,在第 1 行导入
SessionLocal,在第 3 行实例化一个数据库连接。在第 5 行,您导入了您的URL模型。您在第 6 行使用URL作为数据库查询的参数,请求URL的所有数据库条目。第 7 行返回的列表是空的,因为您的urls表还没有包含任何数据。暂时保持这个会话打开,然后跳到您的浏览器。打开
http://127.0.0.1:8000/docs并使用您的POST端点创建一些 URL:https://player.vimeo.com/video/709517390?background=1
这是可行的,因为您的 API 使用您在
schemas.py中定义的数据进行响应:{ "target_url": "https://realpython.com", "is_active": true, "clicks": 0, "url": "JNPGB", "admin_url": "MIZJZYVA" }一旦使用了应用程序的
POST端点,验证请求是否相应地创建了数据库条目:
>>> db.query(URL).all()
[<shortener_app.models.URL object at 0x104c65cc0>, ...]
使用db.query(URL).all()查询URL表中的所有条目。作为回报,您将获得一个由发送到 API 的 POST 请求创建的所有数据库条目的列表。
现在,您可以将数据存储在数据库中,并且它会在多个用户的会话中保持不变。这是你的网址缩写的一个重要的里程碑!
作为后端开发人员,这可能会让您感到高兴。但是为了让你的用户满意,你需要添加转发到目标 URL 的重要特性。在下一节中,您将增强您的应用程序,以将缩短的 URL 转发到其 URL 目标。
转发一个缩短的网址
您的 Python URL shortener 应用程序旨在提供转发到目标 URL 的缩短 URL。例如,如果你想分享一张图片,那么你就不必依赖一个笨拙的长链接。相反,你可以使用 URL shortener 应用程序来创建一个短链接。
这意味着你的应用需要有一个转发到目标 URL 的路由。用更专业的术语来说,转发行为意味着您需要将带有URL.key的 HTTP 请求重定向到URL.target_url地址。
更新main.py以实现一个RedirectResponse:
1# shortener_app/main.py
2
3# ...
4
5from fastapi import Depends, FastAPI, HTTPException, Request
6from fastapi.responses import RedirectResponse
7
8# ...
9
10def raise_not_found(request):
11 message = f"URL '{request.url}' doesn't exist"
12 raise HTTPException(status_code=404, detail=message)
13
14# ...
15
16@app.get("/{url_key}")
17def forward_to_target_url(
18 url_key: str,
19 request: Request,
20 db: Session = Depends(get_db)
21 ):
22 db_url = (
23 db.query(models.URL)
24 .filter(models.URL.key == url_key, models.URL.is_active)
25 .first()
26 )
27 if db_url:
28 return RedirectResponse(db_url.target_url)
29 else:
30 raise_not_found(request)
对于您的应用程序需要的重定向行为,您使用在第 5 行和第 6 行中导入的Request和RedirectResponse类。RedirectResponse返回一个转发客户端请求的 HTTP 重定向。
还记得你之前创建的raise_bad_request()函数吗?您在第 10 行添加了一个类似的名为raise_not_found()的函数。如果提供的URL.key与数据库中的任何 URL 都不匹配,您将在第 30 行使用raise_not_found()。不像在raise_bad_request()中传递消息,raise_not_found()总是返回你在第 11 行定义的相同消息。通常,您在HTTPException中发回 404 HTTP 状态代码。
在第 17 行,您用第 16 行的@app.get()装饰函数创建了forward_to_target_url()函数。当您使用@app.get()装饰器时,您允许对作为参数提供的 URL 进行 GET 请求。使用"/{url_key}"参数,每当客户端请求与主机和密钥模式匹配的 URL 时,就会调用forward_to_target_url()函数。
在第 22 到 26 行,您在数据库中寻找一个带有提供的url_key的活动 URL 条目。如果找到一个数据库条目,那么在第 28 行返回带有target_url的RedirectResponse。如果没有找到匹配的数据库条目,那么就引发HTTPException。
在您的浏览器中,尝试您刚刚实现的行为:
https://player.vimeo.com/video/709517744?background=1
首先,转到您在http://127.0.0.1:8000/docs的文档,并为您的create_url端点创建一个 POST 请求。作为一个目标 URL,你使用https://realpython.com。复制您在响应中收到的key,并尝试转发。在上例中,http://127.0.0.1:8000/JNPGB成功转发到https://realpython.com。
那几乎是完美的!为什么只有差点?虽然代码有效,但是create_url()和forward_to_target_url()都有缺点。在下一节中,您将在为 Python URL shortener 应用程序创建更多功能和端点之前清理代码。
步骤 3:整理你的代码
在最后一步中,您将 URL shortener API 与数据库连接起来。您编写的代码可以工作,但是它有一些缺点。如果你现在花一些时间整理你的代码,那么从长远来看,你会使实现新特性变得更加方便。
在这一步结束时,您不仅会有一个可以正确构建的代码库。但是你也会有更干净的代码,甚至可能会带来一些快乐。
找出代码中的缺陷
重构你的代码包含着永无止境的风险。就像在一幅画中,你不断地擦除来完善你的线条,你可以花无限的时间在你的代码库中寻找改进。
限制重构过程的范围是个好主意。你可以通过浏览你的代码并列出你想消除的缺陷来做到这一点。
不要被吓倒!总的来说,你的代码是可行的,而且是有效的。然而,正如您在最后一步中发现的,您的main.py文件中的create_url()和forward_to_target_url()函数还不理想。
注意:随时回顾你的代码,写下你发现的任何缺点。然后,您可以将您的列表项目与您将在下面找到的项目进行比较。
首先来看看create_url()的当前状态:
1# shortener_app/main.py
2
3@app.post("/url", response_model=schemas.URLInfo)
4def create_url(url: schemas.URLBase, db: Session = Depends(get_db)):
5 if not validators.url(url.target_url):
6 raise_bad_request(message="Your provided URL is not valid")
7
8 chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
9 key = "".join(secrets.choice(chars) for _ in range(5))
10 secret_key = "".join(secrets.choice(chars) for _ in range(8))
11 db_url = models.URL(
12 target_url=url.target_url, key=key, secret_key=secret_key
13 )
14 db.add(db_url)
15 db.commit()
16 db.refresh(db_url)
17 db_url.url = key
18 db_url.admin_url = secret_key
19
20 return db_url
在第 8 行,您将字母表硬编码为值chars。如果您还想在字符串中添加数字,那么输入数字会很麻烦。
你可能听说过保持代码整洁的不要重复自己(干)原则。第 9 行和第 10 行看起来几乎相同。您构造key和secret_key变量的方式是非干代码的一个完美例子。
在第 11 到 16 行,您正在与数据库进行交互。这个动作不应该是create_url()的直接关注点。在create_url()中,您想要定义您的端点期望什么数据以及端点应该返回什么。理想情况下,您应该将任何数据计算外包给其他函数。
在第 17 行和第 18 行的函数末尾,您与数据库对象混合在一起创建了schemas.URLInfo响应。您没有试图将这一部分保存到数据库中,因此没有任何危害。但是在上面几行中,应该有更明显的数据库交互分离。
总之,create_url()函数加载了太多不同的动作。当你阅读代码时,很难理解函数的用途。
接下来看forward_to_target_url()。同样,先花点时间自己找出问题所在。然后继续阅读,了解问题所在:
1# shortener_app/main.py
2
3@app.get("/{url_key}")
4def forward_to_target_url(
5 url_key: str,
6 request: Request,
7 db: Session = Depends(get_db)
8 ):
9 db_url = (
10 db.query(models.URL)
11 .filter(models.URL.key == url_key, models.URL.is_active)
12 .first()
13 )
14 if db_url:
15 return RedirectResponse(db_url.target_url)
16 else:
17 raise_not_found(request)
在第 9 到 13 行,您执行了一个数据库操作。就像在create_url()中,你在定义一个 API 端点的函数中与数据库交互,感觉不太对。
接下来,你将找出你在create_url()和forward_to_target_url()中发现的缺陷,并逐一修复它们。
重构你的代码
在本节中,您将创建两个新文件来分离您的应用程序的关注点。在这个过程中,您将定义函数来挑选出职责。你最终会得到一个更清晰、可读性更强的文档。
首先创建一个名为keygen.py的新文件。这个文件将包含为您的项目生成密钥的所有帮助器函数。这是为您的.url和.admin_url属性创建随机字符串的最佳位置:
# shortener_app/keygen.py
import secrets
import string
def create_random_key(length: int = 5) -> str:
chars = string.ascii_uppercase + string.digits
return "".join(secrets.choice(chars) for _ in range(length))
您不用对字母 A 到 Z 进行硬编码,而是使用string模块并将所有 ASCII 大写字符和数字组合成chars。然后您使用secrets模块从chars中随机选择五个字符并返回选择。
像前面一样,您可以通过使用random模块来完成类似的结果。然而,在创建用作密钥的随机字符串时,推荐使用secrets模块。 PEP 506 引入了secrets作为生成加密安全随机字节和字符串的标准 Python 模块。查看用 Python 生成随机数据指南以了解更多关于生成随机数据的信息。
通过将随机字符串创建模块化到它自己的函数中,您可以在 Python 解释器中方便地测试它:
>>> from shortener_app.keygen import create_random_key >>> create_random_key() '81I5B' >>> create_random_key(length=8) 'WAT3K9VQ'当你在没有任何参数的情况下调用
create_random_key()时,你会得到一个包含五个字符的字符串。在您的情况下,该字符串可能与上面示例中的字符串不同。但是它应该包含大写字母和/或数字。接下来,创建一个
crud.py文件。您的crud.py文件将包含对数据库中的创建、读取、更新和删除(CRUD) 项目执行操作的函数。继续添加create_db_url():# shortener_app/crud.py from sqlalchemy.orm import Session from . import keygen, models, schemas def create_db_url(db: Session, url: schemas.URLBase) -> models.URL: key = keygen.create_random_key() secret_key = keygen.create_random_key(length=8) db_url = models.URL( target_url=url.target_url, key=key, secret_key=secret_key ) db.add(db_url) db.commit() db.refresh(db_url) return db_url在详细介绍这段代码之前,请注意这段代码实现中的一个问题。请记住,数据库条目的
key值必须是唯一的。虽然几率很小,但是keygen.create_random_key()有可能返回一个已经存在的键。所以您需要确保没有相同的
key条目。首先,定义一个函数,告诉您数据库中是否已经存在一个键:# shortener_app/crud.py # ... def get_db_url_by_key(db: Session, url_key: str) -> models.URL: return ( db.query(models.URL) .filter(models.URL.key == url_key, models.URL.is_active) .first() )该函数返回
None或一个带有给定关键字的数据库条目。现在,您可以创建一个函数来确保生成一个惟一的键。移回
keygen.py并添加create_unique_random_key():# shortener_app/keygen.py # ... from sqlalchemy.orm import Session from . import crud # ... def create_unique_random_key(db: Session) -> str: key = create_random_key() while crud.get_db_url_by_key(db, key): key = create_random_key() return key
while循环是create_unique_random_key()最关键的部分。如果key已经存在于您的数据库中,您将再次调用create_random_key()。使用这种逻辑可以确保每个缩短的 URL 只存在一次。有了这个函数,在
crud.py中更新您的create_db_url()函数:1# shortener_app/crud.py 2 3# ... 4 5def create_db_url(db: Session, url: schemas.URLBase) -> models.URL: 6 key = keygen.create_unique_random_key(db) 7 secret_key = f"{key}_{keygen.create_random_key(length=8)}" 8 db_url = models.URL( 9 target_url=url.target_url, key=key, secret_key=secret_key 10 ) 11 db.add(db_url) 12 db.commit() 13 db.refresh(db_url) 14 return db_url在第 6 行,您调用
keygen.create_unique_random_key()来为您的简短 URL 的key获取一个唯一的字符串。通过调用keygen.create_unique_random_key(),可以确保数据库中没有两个重复的键。注意,您在第 7 行调用了
keygen.create_random_key()来构造secret_key字符串。正如你之前所学的,keygen.create_random_key()只创建一个随机的字符串,但是你不检查它是否存在于数据库中。尽管如此,您仍然可以确定
secret_key是唯一的,因为您在字符串前面加上了值key。因此,即使keygen.create_random_key()返回一个已经在之前的某个时间点创建的字符串,那么将唯一键放在前面会使整个字符串唯一。这样创建
secret_key有两个好处:
key前缀表示缩短的 URLsecret_key属于哪一个。- 当创建另一个随机字符串时,您不会再次访问数据库。
返回
main.py并更新create_url()以使用crud.create_db_url():1# shortener_app/main.py 2 3# ... 4 5from . import crud, models, schemas 6 7# ... 8 9@app.post("/url", response_model=schemas.URLInfo) 10def create_url(url: schemas.URLBase, db: Session = Depends(get_db)): 11 if not validators.url(url.target_url): 12 raise_bad_request(message="Your provided URL is not valid") 13 14 db_url = crud.create_db_url(db=db, url=url) 15 db_url.url = db_url.key 16 db_url.admin_url = db_url.secret_key 17 18 return db_url首先,删除
secrets模块的导入。因为在main.py中不直接使用secrets,所以不需要在main.py中导入模块。在第 14 行,你调用
crud.create_db_url()。您取回了数据库对象db_url,并且可以在第 15 行和第 16 行使用它的字段db_url.key和db_url.secret_key。接下来,利用
get_db_url_by_key()的创建并更新forward_to_target_url():1# shortener_app/main.py 2 3# ... 4 5@app.get("/{url_key}") 6def forward_to_target_url( 7 url_key: str, 8 request: Request, 9 db: Session = Depends(get_db) 10 ): 11 if db_url := crud.get_db_url_by_key(db=db, url_key=url_key): 12 return RedirectResponse(db_url.target_url) 13 else: 14 raise_not_found(request)在第 11 行,您正在更新
forward_to_target_url()以使用crud.get_db_url_by_key()。这是一个使用赋值表达式 (:=)和精简if语句的好机会。操作符
:=俗称海象操作符,它为在表达式中间分配变量提供了一种新的语法。如果
db_url是一个数据库条目,那么在第 12 行将RedirectResponse返回给target_url。否则你调用 14 线的raise_not_found()。有了所有这些更新,是时候检查一下您的 Python URL shortener 是否仍然像预期的那样工作了。转到
http://127.0.0.1:8000/docs并在浏览器中试用您的 API 端点:https://player.vimeo.com/video/709517672?background=1
您的 API 的功能与上一步结束时的功能相同。但是你的代码现在干净多了。
注意:如果你想看重构的另一个例子,那么看看真正的 Python 代码对话重构:准备你的代码以获得帮助。
尽管如此,你并没有像属性
.url和.admin_url所暗示的那样返回 URL。相反,你只需要归还钥匙。在下一节中,您将创建适当的 URL,您还将添加一些功能来让您的用户管理他们缩短的 URL。第四步:管理你的网址
在上一节中,您通过创建新的文件和函数清理了代码。现在,你将建立在你的改进之上。在这一步结束时,您将能够通过访问 API 的安全端点来管理您的 URL。
获取有关您的 URL 的信息
创建缩短的 URL 时,您会在响应正文中收到如下所示的信息:
{ "target_url": "https://realpython.com", "is_active": true, "clicks": 0, "url": "81I5B", "admin_url": "81I5B_WAT3K9VQ" }在本节中,您将创建一个
admin端点,这样您以后还可以看到关于您的 URL 的信息。只有知道secret_key的用户才能访问该端点。首先在您的
crud.py文件中创建get_db_url_by_secret_key():# shortener_app/crud.py # ... def get_db_url_by_secret_key(db: Session, secret_key: str) -> models.URL: return ( db.query(models.URL) .filter(models.URL.secret_key == secret_key, models.URL.is_active) .first() )您的
get_db_url_by_secret_key()函数使用提供的secret_key检查数据库中的活动数据库条目。如果找到一个数据库条目,则返回该条目。否则,你返回None。您在
main.py中处理get_url_info()中返回的数据:1# shortener_app/main.py 2 3# ... 4 5@app.get( 6 "/admin/{secret_key}", 7 name="administration info", 8 response_model=schemas.URLInfo, 9) 10def get_url_info( 11 secret_key: str, request: Request, db: Session = Depends(get_db) 12): 13 if db_url := crud.get_db_url_by_secret_key(db, secret_key=secret_key): 14 db_url.url = db_url.key 15 db_url.admin_url = db_url.secret_key 16 return db_url 17 else: 18 raise_not_found(request)在第 5 行,您在
/admin/{secret_key}URL 定义了一个新的 API 端点。您还将这个端点命名为"administration info",以便以后更容易引用它。作为response_model,您期望第 8 行有一个URLInfo模式。在您获得第 13 行中的数据库条目
crud.get_db_url_by_secret_key()后,您将它分配给db_url并立即检查它。这一行的if语句使用了赋值表达式。但是等一下!是不是也有 14、15 号线看着眼熟的感觉?这些正是您在
create_url()中编写的代码行,因此您有机会在同一个文件中进行重构会话:1# shortener_app/main.py 2 3# ... 4 5from starlette.datastructures import URL 6 7# ... 8 9from .config import get_settings 10 11# ... 12 13def get_admin_info(db_url: models.URL) -> schemas.URLInfo: 14 base_url = URL(get_settings().base_url) 15 admin_endpoint = app.url_path_for( 16 "administration info", secret_key=db_url.secret_key 17 ) 18 db_url.url = str(base_url.replace(path=db_url.key)) 19 db_url.admin_url = str(base_url.replace(path=admin_endpoint)) 20 return db_url 21 22# ...在
get_admin_info()中,你甚至比仅仅获得.url和.admin_url属性更进一步。您还可以利用 FastAPI 附带的starlette包中的URL类。为了在第 14 行创建base_url,您从设置中传递base_url来初始化URL类。之后,您可以使用.replace()方法构建一个完整的 URL。之前你只自行返回了
key和secret_key。如果你想访问其中一个端点,那么你必须自己把它添加到你的基本 URL 中。你的应用程序现在更加用户友好,因为
URLInfo返回转发url和admin_url的完整 URL。有了这个函数,您可以更新
create_url()和get_url_info():1# shortener_app/main.py 2 3# ... 4 5@app.post("/url", response_model=schemas.URLInfo) 6def create_url(url: schemas.URLBase, db: Session = Depends(get_db)): 7 if not validators.url(url.target_url): 8 raise_bad_request(message="Your provided URL is not valid") 9 db_url = crud.create_db_url(db=db, url=url) 10 return get_admin_info(db_url) 11 12 13# ... 14 15@app.get( 16 "/admin/{secret_key}", 17 name="administration info", 18 response_model=schemas.URLInfo, 19) 20def get_url_info( 21 secret_key: str, request: Request, db: Session = Depends(get_db) 22): 23 if db_url := crud.get_db_url_by_secret_key(db, secret_key=secret_key): 24 return get_admin_info(db_url) 25 else: 26 raise_not_found(request)删除设置
.url和.admin_url属性的行。在第 10 行和第 24 行,您现在从get_admin_info()返回URLInfo模式,而不是返回db_url。你清理了
create_url()并且有一个端点来查看你的 URL 信息。在浏览器中尝试一下。在响应中,您现在会收到转发 URL 和管理 URL 的完整 URL:{ "target_url": "https://realpython.com", "is_active": true, "clicks": 0, "url": "http://127.0.0.1:8000/81I5B", "admin_url": "http://127.0.0.1:8000/81I5B_WAT3K9VQ" }目前看起来不错。您可能已经在网络中共享了缩短的 URL。但是虽然网址被点击了多次,但是
clicks值仍然是0。在下一节中,您将实现查看 URL 被访问频率的功能。更新您的访客数量
当您访问
"administration info"端点时,响应主体包含关于您的缩短 URL 的数据。回复正文的一个数据点是你的简短 URL 被点击的频率。到目前为止,该计数仍然为零。要计算访问您的简短 URL 时的点击次数,请向您的
crud.py文件添加一个新函数:1# shortener_app/crud.py 2 3# ... 4 5def update_db_clicks(db: Session, db_url: schemas.URL) -> models.URL: 6 db_url.clicks += 1 7 db.commit() 8 db.refresh(db_url) 9 return db_url
update_db_clicks()函数将db_url作为第 5 行的参数。这意味着您可以在函数中预期一个现有的数据库条目。在第 6 行,您将clicks值增加 1。使用第 7 行和第 8 行中的.commit()和.refresh()方法,您将更新保存在数据库中。注:方法
.commit()和.refresh()来自db,不是db_url。当您转发到一个目标 URL 时,您调用刚刚创建的
update_db_clicks()函数。因此,您需要调整main.py中的forward_to_target_url()功能:1# shortener_app/main.py 2 3# ... 4 5@app.get("/{url_key}") 6def forward_to_target_url( 7 url_key: str, 8 request: Request, 9 db: Session = Depends(get_db) 10 ): 11 if db_url := crud.get_db_url_by_key(db=db, url_key=url_key): 12 crud.update_db_clicks(db=db, db_url=db_url) 13 return RedirectResponse(db_url.target_url) 14 else: 15 raise_not_found(request) 16 17# ...在第 12 行插入
crud.update_db_clicks()函数调用。每当一个朋友使用你的短网址,点击量就会增加。您可以使用点击次数来查看链接被访问的频率。在某些时候,您可能会决定删除转发 URL。请继续阅读,在您的应用中实现停用端点。
删除一个网址
您的 Python URL shortener 应用程序非常适合与朋友共享链接。一旦您的朋友访问了该链接,您可能希望再次删除缩短的 URL。
就像使用
update_db_clicks()函数一样,首先在crud.py中创建一个新函数:1# shortener_app/crud.py 2 3# ... 4 5def deactivate_db_url_by_secret_key(db: Session, secret_key: str) -> models.URL: 6 db_url = get_db_url_by_secret_key(db, secret_key) 7 if db_url: 8 db_url.is_active = False 9 db.commit() 10 db.refresh(db_url) 11 return db_url首先,注意你调用的是函数
deactivate_db_url_by_secret_key()而不是delete_db_url_by_secret_key()。因此,您将第 8 行中的.is_active属性设置为False,而不是完全删除数据库条目。请记住,您请求 URL 对象的数据库查询包含过滤器,即 URL 必须是活动的。这意味着任何停用的 URL 都不会在数据库调用中返回。对用户来说,这看起来像是 URL 被删除了,但是只有你作为超级管理员才能真正完成删除操作。这样做的主要好处是,如果用户改变主意禁用 URL,您可以恢复停用的 URL。
第 5 行的
deactivate_db_url_by_secret_key()函数将secret_key作为参数。只有缩短网址的创建者知道这个secret_key。当只有创建者才能禁用 URL 时,这是一个很好的安全措施。现在,唯一缺少的函数是调用
deactivate_db_url_by_secret_key()的端点。最后一次打开main.py,增加一个delete_url()功能:1# shortener_app/main.py 2 3# ... 4 5@app.delete("/admin/{secret_key}") 6def delete_url( 7 secret_key: str, request: Request, db: Session = Depends(get_db) 8): 9 if db_url := crud.deactivate_db_url_by_secret_key(db, secret_key=secret_key): 10 message = f"Successfully deleted shortened URL for '{db_url.target_url}'" 11 return {"detail": message} 12 else: 13 raise_not_found(request)您在第 5 行使用了
@app.delete()装饰器来表示delete_url()接受删除请求。然而,只有当请求体包含适当的secret_key时,才允许这个删除操作。这个secret_key必须是 URL 的一部分,如第 5 行所示,它是您在第 6 行定义的delete_url()函数的一个参数。
delete_url()的身体现在可能看起来很熟悉。您在第 9 行使用了一个赋值表达式(:=)来给第 10 行的crud.deactivate_db_url_by_secret_key()的返回结果db_url赋值。如果具有所提供的secret_key的数据库条目存在并且被停用,那么在第 11 行返回成功消息。否则,您触发第 13 行的raise_not_found()。现在,您还可以停用不再需要的 URL。继续使用您的 URL 缩写程序创建一个简短的 URL:
当一个短网址被激活时,它会把你转到目标网址。但是,一旦你停用你的网址缩短,转发到目标网址将不再工作。完美,这意味着你已经创建了一个全功能的网址缩写!
结论
您已经使用 FastAPI 构建了一个 web 应用程序来创建和管理缩短的 URL。有了 URL shortener,你现在可以将长 URL 转换成小的、可共享的链接。当有人点击你的短网址时,你的短网址应用程序会将他们转发到目标网址。
在本教程中,您学习了如何:
- 用 FastAPI 创建一个 REST API
- 使用uvicon运行开发 web 服务器
- 建模一个 SQLite 数据库
- 调查自动生成的 API 文档
- 通过 CRUD 动作与数据库交互
你写的代码主要是让应用程序先工作。但你并没有就此止步。你花时间检查你的代码库,发现机会重构你的代码。现在,您可以考虑扩展您的 Python URL shortener 了。
要查看您已经创建的内容,请查看完整的源代码:
获取源代码: 点击此处获取源代码,您将使用 FastAPI 构建您的 Python URL shortener。
接下来的步骤
现在,您可以调用自己的全功能 Python URL shortener。通过遵循这个循序渐进的教程,您为您的应用程序添加了大量功能。虽然您已经完成了本教程,但仍有一些功能可以添加到您的应用程序中。
以下是一些关于附加功能的想法:
- 自定义 URL 键:让您的用户创建自定义 URL 键,而不是随机字符串。
- Peek URL: 为您的用户创建一个端点来检查哪个目标 URL 在一个缩短的 URL 后面。
- 优雅转发:转发前检查网站是否存在。
当你觉得准备好了,那么在 Heroku 上托管你的项目是一个很好的下一步。如果你想让你的 URL shortener Python 项目更加用户友好,那么你可以考虑添加一个前端。有了前端,你可以为你的用户提供一个好看的界面,所以他们不需要知道任何 API 端点本身。
无论你朝哪个方向发展你的网址缩短器,一定要在下面的评论中推广它。加分,如果你张贴一个简短的链接,转发到你的托管项目!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 FastAPI 和 Python 构建网址缩短器******************
外面下雨了?使用 Python 构建天气 CLI 应用程序
你又因为暴雨被困在里面了!您想知道来自真正 Python 社区的朋友们居住的那个遥远城市的天气如何。您宁愿呆在命令行界面(CLI)中,也不愿在浏览器中查找。如果这听起来像是你想通过只使用 Python 标准库构建命令行天气应用程序来完成的任务,那么本教程就是为你准备的。
在本教程中,您将学习如何:
- 仅使用 Python 标准库模块构建功能性天气查找工具
- 构建一个 Python CLI app 使用
argparse- 使用
configparser到处理 API 秘密- 从您的 Python 脚本中进行 API 调用
- 使用 ANSI 转义码、表情符号、 f 字符串和 Python 的字符串迷你语言,创建视觉上吸引人的 CLI 输出
向窗外望去证实了你的决定。下着雨,今天没法在草地上玩耍了。是时候编写一个 Python 天气应用程序,并从您的 CLI 梦想遥远的地方了!沿途你甚至会发现几个令人惊讶的城市名称。
获取源代码: 点击此处获取源代码,您将使用构建您的天气应用程序。
演示
当你等待窗外出现彩虹时,你可以将自己的颜色添加到天气应用程序中。为此,您将使用一些格式化技巧,使 CLI 输出比纯文本更有趣:
https://player.vimeo.com/video/644506117?background=1
如果您喜欢这个命令行应用程序的外观,并且希望在使用标准库的同时训练您的 Python 编码技能,那么您来对地方了!
注:这个 app 是在 macOS 上为 Zsh 外壳开发的。根据您的设置,您使用某些颜色显示和表情符号的里程数可能会有所不同。在 Windows , PowerShell 显示格式相当不错,如果你使用的是更新版本的操作系统,你应该会看到使用 Windows 终端的默认设置的良好效果。
如果你喜欢另一种配色方案,或者想在你自己的应用程序中使用不同的表情符号,你可以在学习本教程的同时自定义它。
项目概述
在您开始编写任何代码之前,考虑一下您计划构建的程序的规范通常是一个好主意。首先,拿出纸和笔,写下你对完美天气应用的想法。一旦你记下了你的想法,你可以点击下面的标题来阅读你在学习本教程时要考虑的规范:
您将在本教程中构建的天气应用程序将:
- 将城市名称作为必填输入
- 如果需要,可以选择一个标志以华氏温度而不是摄氏温度来显示输出
- 调用在线天气 API 来获取天气数据
- 显示城市名称、当前天气状况和当前温度
- 使用颜色、间距和表情符号直观地格式化输出
有了这些快速笔记,你就有了一个关于你要构建什么的粗略计划,并且你已经定义了应用程序能够做什么的范围。
如果你有不同的或额外的功能,那么就把你的笔记放在身边,一旦你完成了这个初始版本,就在你的天气应用上实现它们。
注意:编写优秀的命令行界面可能具有挑战性。你希望你的应用程序是用户友好的,并且仍然提供你需要的所有功能。使用更高级别的库可能会使您更容易构建应用程序。
在本教程中,您将使用 Python 内置的
argparse模块,它可以帮助您创建用户友好的 CLI 应用程序,例如通过提供一个现成的有用的--help选项。使用来自 OpenWeather 的天气 API ,你将获得来自世界各地的城市名称的当前天气数据。这个应用编程接口(API) 是免费使用的,有丰厚的 API 调用额度。然而,您将需要创建一个个人 API 密匙来发出请求,这将在一会儿完成。
在你开始钻研之前,再看一下预期的先决条件,这样你就知道你可以在哪里提高自己的技能,以防中途遇到困难。
先决条件
要完成本教程,您应该熟悉以下概念:
- 使用
argparse构建命令行界面- 使用 API 从互联网读取公共数据
- 在 Python 代码中集成 APIs】
- 使用 JSON 数据
- 导入模块和库
- 定义自己的功能
- 用 Python 异常处理错误
- 使用 f 字符串格式化您的文本
- 使用条件表达式
对于来自 OpenWeather 的天气 API,您还需要一个 API 键,并且您将在下一节中学习如何访问它。
如果您在开始本教程之前没有掌握所有的必备知识,那也没关系!事实上,你可以通过前进和开始来学习更多。如果遇到困难,您可以随时停下来查看此处链接的资源。
步骤 1:获取合适的天气 API
在这一步中,您将为您的项目选择一个合适的天气 API,您将获得对您个人 API 密钥的访问权,并且您将学习如何从 API 请求信息。您还将理解作为对天气 API 调用的响应而获得的数据的形状和内容。
获取一个 OpenWeather API 密钥
OpenWeather 的团队希望免费分享他们的技术。为了提供这种服务,他们需要监控每个人打来的电话,为此他们要求你使用 API 密匙。你需要在他们的平台上注册来获得你的个人 API 密匙。
导航至 OpenWeather 的注册页面并输入您的信息:
成功注册后,您将收到一封包含 API 密钥的确认电子邮件。您现在还可以登录到 OpenWeather web 界面,通过导航到您的帐户页面的 API 密钥选项卡来查看您的 API 密钥:
The API key isn't shown on this image. Never share your API keys with anyone! 在这个页面上,您可以查看您的 API 密钥。复制现有的,名称为默认为。在下一节中,您将使用它从浏览器中调用天气 API。
发出 API 请求并检查数据
您将为您的 Python 天气应用程序使用当前天气数据端点,并且您将允许您的用户通过向您的 CLI 传递一个城市名称来调用它。
注意:注册后,您的 API 密钥可能需要几个小时才能激活。
在您开始编写任何代码之前,请确保您可以调用 API 并查看它返回的数据是什么样子的。OpenWeather 网站上的 API 文档显示了您可以向其端点发出请求以接收天气数据的示例:
api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}您需要用您的输入替换花括号(
{})中显示的两个变量:
- 将
{city name}替换为vienna,或其他城市名称。- 用您之前复制的 API 密钥替换
{API key}。替换这两个值后,您可以将 URL 粘贴到浏览器中,并查看 API 响应:
在您的浏览器中,您将看到类似于上面截图中所示的文本。这个文本是 OpenWeather 对您的请求的 JSON API 响应。如果没有格式化,响应的内容很难阅读。展开下面的块,获得格式化的、可读性更强的 JSON 响应:
1{ 2 "coord": { 3 "lon": 16.3721, 4 "lat": 48.2085 5 }, 6 "weather": [ 7 { 8 "id": 801, 9 "main": "Clouds", 10 "description": "few clouds", 11 "icon": "02d" 12 } 13 ], 14 "base": "stations", 15 "main": { 16 "temp": 287.72, 17 "feels_like": 286.98, 18 "temp_min": 285.99, 19 "temp_max": 290.48, 20 "pressure": 1028, 21 "humidity": 67 22 }, 23 "visibility": 10000, 24 "wind": { 25 "speed": 1.34, 26 "deg": 100, 27 "gust": 1.34 28 }, 29 "clouds": { 30 "all": 20 31 }, 32 "dt": 1635333309, 33 "sys": { 34 "type": 2, 35 "id": 2037452, 36 "country": "AT", 37 "sunrise": 1635312722, 38 "sunset": 1635349469 39 }, 40 "timezone": 7200, 41 "id": 2761369, 42 "name": "Vienna", 43 "cod": 200 44}检查您在 JSON 响应中收到的数据,并确定您希望从中选择哪些信息用于您的天气应用程序的初始版本。
您之前决定至少要显示三个项目:
- 城市名称
- 气象条件
- 温度
如果您在提供的 JSON 响应中搜索这些信息,您会看到它们都在那里:
- 第 42 行显示
"name"键下的城市名称"Vienna"。- 第 10 行在关键字
"weather"和子项"description"下保存详细的天气信息。- 第 16 行可让您访问键
"main"和子项"temp"下的温度信息。温度信息看起来是不是很热?如果你回头查看一下 API 文档,你会发现默认的温标是开尔文。然而,在你的天气应用程序中,你会希望你的温标默认为摄氏度。
注意:如果你来自美国,喜欢用英制单位表示温度,你可能会选择华氏温度作为默认温度。但是沉住气,坚持使用教程!稍后,您将实现一个可选标志来显示华氏温度。如果您愿意,可以替换掉默认设置。
继续编辑 URL 中的查询参数以获得相同的结果,但是温度显示为摄氏度:
api.openweathermap.org/data/2.5/weather?q=vienna&units=metric&appid={API key}如果您将查询参数
&units=metric添加到 URL,您将收到以摄氏度显示的温度结果:"main": { "temp": 14.57, "feels_like": 13.83, "temp_min": 12.84, "temp_max": 17.33, "pressure": 1028, "humidity": 67 },这看起来更冷,但也更现实。当您为 Python 天气应用程序构建代码时,默认情况下,您将把
units查询参数指向metric,但是您还将为希望以华氏温度显示温度的用户添加一个可选标志。在这一步中,您在 OpenWeather 注册了一个帐户,以获得一个免费的 API 密钥。然后,使用这个 API 键从浏览器中向 OpenWeather API 发出请求。您检查了 API 返回的 JSON 数据,并确定了您希望用于 Python weather CLI 应用程序的数据。
在下一步中,您将设置 Python 项目的基本结构,通过配置文件处理 API 键,并编写必要的代码以从 Python 脚本中访问该信息。
步骤 2:处理代码中的秘密
在这一步中,您将完成项目结构的设置,包括您将使用的大多数文件。您还将把 API 键添加到一个配置文件中,并编写代码将其导入到主脚本中。作为避免意外将 API 键推给版本控制的措施,您将创建一个
.gitignore文件。简而言之,到这一步结束时,您就可以开始编写 Python 天气应用程序的主要逻辑了。
创建您的项目文件夹结构
正如本教程开始时提到的,这个 CLI 项目不需要任何外部包。你所需要的只是 Python 的安装。确认您拥有 Python 3.6 或更高版本,因为您将在本教程的后面使用 Python f-strings 进行字符串格式化。Python 从 3.6 版开始支持这种格式化技术。
一旦在系统上安装了现代 Python 版本,您就可以选择下面的操作系统并设置项目文件夹结构了:
- 视窗
** Linux + macOS*PS C:\> New-Item weather-app -ItemType Directory PS C:\> Set-Location weather-app PS C:\> New-Item .gitignore, secrets.ini, weather.py$ mkdir weather-app && cd weather-app $ touch .gitignore secrets.ini weather.py如果您在 shell 中运行这些命令,您将创建一个名为
weather-app/的文件夹,其中包含三个文件:
.gitignore将防止您意外地将 API 密钥提交给版本控制。secrets.ini会持有你的 API 密钥。weather.py将包含 Python 天气应用程序的主要代码逻辑。您可以在您最喜欢的代码编辑器或 IDE 中打开项目文件夹,它应该具有如下所示的结构:
weather-app/ ├── .gitignore ├── secrets.ini └── weather.py您将在
weather.py中构建大部分 CLI 应用程序。然而,在开始编写代码逻辑之前,您需要确保您可以访问 Python 脚本中的 OpenWeather API 密钥,并且它是安全的,不会意外泄露到开源世界的广阔领域中。保护您的 API 密钥
您将使用
secrets.ini来存储这个项目所需的 API 密匙。为了确保你不会不小心把它提交给开源,首先打开你的.gitignore文件,把secrets.ini添加到被忽略的文件中:# .gitignore secrets.ini通过添加配置文件的名称
secrets.ini,作为空的.gitignore文件中的新行,您已经抢先让 Git 知道您不希望它在版本控制下记录该配置文件。只有当您决定使用 Git 来跟踪您的项目时,这种保护才会有效。尽管如此,它还是有助于防止您意外地将 API 密钥注册到版本控制,并将其推送到 GitHub。注意:一定要确保你的 API 密匙、密码和其他秘密远离公共存储库和版本控制。一旦你把一个 API 密匙推送到 GitHub,你就应该认为它被破坏了,删除它,然后创建一个新的。
即使你开始在本地开发你的项目,你可能以后会选择与全世界分享它。如果您将 API 键放在主脚本之外,并且不将配置文件注册到版本控制中,就不太可能意外泄漏 API 键。
在 Python 代码中访问 API 密钥
在您设置了安全屏障之后,您可以将您在第一步中创建的 API 密钥添加到您的
secrets.ini文件中。打开文件并添加信息,遵循 INI 文件格式:; secrets.ini [openweather] api_key=<YOUR-OPENWEATHER-API-KEY>通过这个设置,您已经创建了一个名为
openweather的部分,以及一个名为api_key的属性,其值就是您的 OpenWeather API 密钥。接下来,您需要使用 Python 的
configparser模块来访问您的weather.py文件中的 API 键:1# weather.py 2 3from configparser import ConfigParser 4 5def _get_api_key(): 6 """Fetch the API key from your configuration file. 7 8 Expects a configuration file named "secrets.ini" with structure: 9 10 [openweather] 11 api_key=<YOUR-OPENWEATHER-API-KEY> 12 """ 13 config = ConfigParser() 14 config.read("secrets.ini") 15 return config["openweather"]["api_key"]您已经创建了一个名为
_get_api_key()的模块非公共函数,它封装了用于访问您的 OpenWeather API 密钥的代码逻辑:
- 第 3 行从 Python 的
configparser模块导入ConfigParser。- 第 5 行定义了
_get_api_key(),以下划线(_)字符开始命名。这种命名约定表明该函数应该被认为是非公共的。- 第 6 行到第 12 行组成了该函数的文档串。
- 第 13 行实例化了一个被你命名为
config的ConfigParser对象。- 第 14 行使用
.read()将您在secrets.ini中保存的信息加载到您的 Python 脚本中。- 第 15 行通过使用方括号符号访问字典值来返回 API 键的值。
您可能会注意到,
configparser将secrets.ini文件的节名和属性名都变成了具有嵌套结构的字典键。如果您调用
_get_api_key(),它现在将返回您的 OpenWeather API 键的值,该值已准备好用于您的 API 请求。同时,API 键的值在您的主代码文件之外,这意味着您不太可能意外地破坏它。在这一步中,您已经学习了如何使用 Python 的
configparser模块从 INI 配置文件中读取信息。通过在您的.gitignore文件中注册您的secrets.ini配置文件,您已经抢先将其从版本控制中排除。在本教程的下一步中,您将为 Python 天气应用程序创建启用 CLI 交互的代码。
步骤 3:为你的 Python 天气应用创建一个 CLI
在这一步中,您将编写一个命令行输入解析器,该解析器接受用户提供的城市信息和一个关于使用何种温度等级的可选参数。为了构建这个功能,你将使用 Python 的
argparse模块。设置一个参数解析器
首先要记住你决定从用户那里收集什么信息:
- 城市名称
- 温标,默认值为摄氏度
要通过命令行界面收集这两个值并在 Python 天气应用程序中使用它们,您将使用 Python 的内置
argparse模块。您将添加的代码还不会显示用户输入,但它会收集用户输入:1# weather.py 2 3import argparse 4from configparser import ConfigParser 5 6def read_user_cli_args(): 7 """Handles the CLI user interactions. 8 9 Returns: 10 argparse.Namespace: Populated namespace object 11 """ 12 parser = argparse.ArgumentParser( 13 description="gets weather and temperature information for a city" 14 ) 15 return parser.parse_args() 16 17# ... 18 19if __name__ == "__main__": 20 read_user_cli_args()在第 3 行导入
argparse之后,从第 6 行开始定义read_user_cli_args():
- 第 12 到 14 行创建了一个
argparse.ArgumentParser的实例,您可以在第 13 行向其传递解析器的可选描述。- 第 15 行返回调用
.parse_args()的结果,这些结果最终将是用户输入的值。- 第 19 行在检查了 Python 的
"__main__"命名空间后打开一个条件块,它允许你定义当你作为脚本执行weather.py时应该运行的代码。- 第 20 行调用
read_user_cli_args(),有效地运行您编写的 CLI 解析代码逻辑。如果你在这个阶段给你的脚本一个旋转,它会毫无怨言地执行。然而,也不会有任何输出:
$ python weather.py $如果你试图将一个城市名传递给你的 CLI 应用程序,Python 会报错,你的脚本会退出,但你也会得到一个免费的帮助消息,其中包含你在
read_user_cli_args()中编写的ArgumentParser的最小设置:$ python weather.py vienna usage: weather.py [-h] weather.py: error: unrecognized arguments: viennaPython 首先将使用信息打印到您的控制台。该信息暗示了
ArgumentParser提供的内置帮助(-h)。然后,它告诉您,您的解析器没有识别出您使用 CLI 传递给程序的参数。由于您还没有在read_user_cli_args()中设置任何参数,您不能因为 Python 的抱怨而生气。解析输入参数
当然,如果你允许用户输入一个城市并选择他们选择的温度范围,你的应用会更有帮助。为此,您将向之前创建的解析器添加两个参数:
1# weather.py 2 3import argparse 4from configparser import ConfigParser 5 6def read_user_cli_args(): 7 """Handles the CLI user interactions. 8 9 Returns: 10 argparse.Namespace: Populated namespace object 11 """ 12 parser = argparse.ArgumentParser( 13 description="gets weather and temperature information for a city" 14 ) 15 parser.add_argument( 16 "city", nargs="+", type=str, help="enter the city name" 17 ) 18 parser.add_argument( 19 "-i", 20 "--imperial", 21 action="store_true", 22 help="display the temperature in imperial units", 23 ) 24 return parser.parse_args() 25 26# ... 27 28if __name__ == "__main__": 29 read_user_cli_args()通过向
.add_argument()添加这两个调用,您已经设置了解析器来收集通过 CLI 提交的用户输入:
第 15 到 17 行定义了
"city"参数,它将接受一个或多个由空格分隔的输入。通过将参数数量(nargs)设置为"+",您允许用户传递由多个单词组成的城市名称,例如 New York 。第 18 到 23 行定义了可选的布尔参数
imperial。您将action关键字参数设置为"store_true",这意味着如果用户添加了可选标志,则imperial的值将为True,如果用户没有添加,则为False。两个添加的参数都有一个关键字参数
help,您用它来定义帮助文本,然后argparse通过-h标志使其可用:1$ python weather.py -h 2usage: weather.py [-h] [-i] city [city ...] 3 4gets weather and temperature information for a city 5 6positional arguments: 7 city enter the city name 8 9optional arguments: 10 -h, --help show this help message and exit 11 -i, --imperial display the temperature in imperial units在这个控制台输出中,您可以在第 4 行看到解析器的描述文本,而每个参数的帮助文本分别显示在第 7 行或第 11 行的描述旁边。
但是,如果您运行该脚本并将一个城市名作为输入传递给它,您仍然看不到显示回控制台的任何输出。回到
weather.py,编辑文件底部条件代码块中的代码:# weather.py # ... if __name__ == "__main__": user_args = read_user_cli_args() print(user_args.city, user_args.imperial)现在,您已经在
user_args变量中捕获了read_user_cli_args()的返回值,并添加了对print()的调用,以便将用户输入的值显示回控制台:$ python weather.py vienna ['vienna'] False $ python weather.py new york -i ['new', 'york'] True $ python weather.py ho chi minh city --imperial ['ho', 'chi', 'minh', 'city'] True现在,您可以将组成城市名称的多个单词传递给 CLI,它会正确地将它们作为字符串收集到一个列表中。此外,您可以选择传递
-i或--imperial标志来保存True作为user_args.imperial的值。您的 Python weather CLI 应用程序已经设置好收集您需要的用户输入!在本节中,您已经使用了
argparse来接收和处理您的用户将通过他们的命令行界面传递的信息。您确保了城市名称可以由多个单词组成,并且有一种方法可以选择请求英制单位的温度。虽然你的用户现在可以输入城市名称和温度等级偏好,但你目前没有对他们的输入做任何事情。在下一步中,您将使用它们提交的值来调用 OpenWeather API 并获取特定城市的天气信息。
第四步:获取天气信息
外面天气怎么样?还在下雨吗?如果你足够幸运,附近有个窗户,你可以看一看。但是你家里的任何真实窗口都比你的下一个终端窗口要远,所以是时候使用 Python 脚本从最近的窗口获取天气信息了。
在这一步,您将将用户输入连接到一个有效的 URL,您将使用该 URL 向 OpenWeather 的 API 发送 API 请求。您还将把所有必要的代码逻辑封装到公共和非公共函数中,以遵循最佳实践并添加异常处理,这样您的用户就不会遇到意外错误。
构建 URL
如果您回想一下步骤一,您可能还记得您使用浏览器成功调用 API 时使用的 URL:
api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}您将在 Python 代码中执行的操作与此类似,因此您需要一个像这样的有效 URL。传递任何查询参数之前的基本 URL 对于对此端点的任何调用都是相同的。
注意:您可能会注意到,URL 包含一个数字
2.5,它表示编写本文时 API 的版本。如果 API 获得了更新,这个数字将会不同。检查 API 的当前版本,并在您的 URL 中确认您正在使用您想要使用的版本。因为 URL 的基数对于所有调用都保持不变,所以最好在代码的顶部将其定义为一个常量:
# weather.py import argparse from configparser import ConfigParser BASE_WEATHER_API_URL = "http://api.openweathermap.org/data/2.5/weather" # ...通过这一行代码,您已经添加了所有 API 调用将共享的基本 URL 作为一个常量。
注意:记住 Python 常量在技术上不是常量,因为你可以随时改变它们的值。然而,你可以通过将一个值全部格式化成大写字母来表明你不希望在你的程序中改变它,正如PEP 8-Python 代码风格指南中所描述的。
但是
BASE_WEATHER_API_URL中的 URL 并不完整,到目前为止,在一个由一个或多个字符串组成的列表中,只有一个城市名和一个布尔值。是时候根据您可以获得的输入创建一个完整的 URL 了:1# weather.py 2 3import argparse 4from configparser import ConfigParser 5from urllib import parse 6 7BASE_WEATHER_API_URL = "http://api.openweathermap.org/data/2.5/weather" 8 9def read_user_cli_args(): 10 # ... 11 12def build_weather_query(city_input, imperial=False): 13 """Builds the URL for an API request to OpenWeather's weather API. 14 15 Args: 16 city_input (List[str]): Name of a city as collected by argparse 17 imperial (bool): Whether or not to use imperial units for temperature 18 19 Returns: 20 str: URL formatted for a call to OpenWeather's city name endpoint 21 """ 22 api_key = _get_api_key() 23 city_name = " ".join(city_input) 24 url_encoded_city_name = parse.quote_plus(city_name) 25 units = "imperial" if imperial else "metric" 26 url = ( 27 f"{BASE_WEATHER_API_URL}?q={url_encoded_city_name}" 28 f"&units={units}&appid={api_key}" 29 ) 30 return url 31 32# ...您首先在第 5 行添加了一个新的 import 语句。您将在第 24 行使用来自
urllib.parse模块的函数来帮助净化用户输入,以便 API 可以安全地使用它。在第 12 行,您已经定义了
build_weather_query(),它接受两个输入,这两个输入对应于您通过 CLI 收集的用户输入:
city_input是您在user_args.city中收集的字符串列表。imperial是一个布尔值,它决定是用摄氏度还是华氏温度来显示温度。该参数的默认值是False。您编写的函数由几行代码组成,带有一个描述性的文档字符串:
第 22 行调用
_get_api_key()从你的配置文件中获取 OpenWeather API 密匙并保存为api_key。第 23 行使用
str.join()将组成城市名称的单词与空白字符(" ")连接起来,如果一个城市名称由多个单词组成。第 24 行将
city_name传递给parse.quote_plus(),它对字符串进行编码,以便您可以向 API 发出有效的 HTTP 请求。除了通过 UTF-8 编码转换某些字符之外,这个函数还将空白字符转换成加号(+),这是正确调用这个 API 所必需的 URL 编码的一种形式。第 25 行使用一个条件表达式将
"imperial"或"metric"分配给units,这取决于imperial参数是True还是False。第 26 到 29 行构建了一个完整的 URL,您可以使用它来进行一次成功的 API 调用。您正在使用 f-string 从
BASE_WEATHER_API_URL和您在前面几行中分配的变量组成 URL。第 30 行最后返回完整格式的 URL。
调用
build_weather_query()返回一个 URL,您可以使用它对 OpenWeather 提供的天气 API 的特定端点进行有效的 API 调用。如果您调用weather.py底部的函数,那么您可以生成并显示 URL:# weather.py # ... if __name__ == "__main__": user_args = read_user_cli_args() query_url = build_weather_query(user_args.city, user_args.imperial) print(query_url)如果您在应用这些更改后执行
weather.py并传递您的程序所期望的 CLI 参数,它将打印一个到您的控制台的 URL,您可以复制并粘贴到您的浏览器中,以进行 API 调用,就像您在第一步中所做的那样:$ python weather.py bee http://api.openweathermap.org/data/2.5/weather?q=bee&units=metric&appid=<YOUR-OPENWEATHER-API-KEY> $ python weather.py zap -i http://api.openweathermap.org/data/2.5/weather?q=zap&units=imperial&appid=<YOUR-OPENWEATHER-API-KEY>试一试,将脚本生成的 URL 粘贴到浏览器搜索栏中。请记住,
<YOUR-OPENWEATHER-API-KEY>应该保存您的脚本从您的secrets.ini配置文件中获取的 API 键值。是的,蜜蜂和 zap 都是 OpenWeather 提供天气信息的真实城市名称:)既然您已经知道可以生成有效的 URL,那么是时候让 Python 来发出请求,而不必再将 URL 复制粘贴到您的浏览器中了。
用 Python 发出 HTTP 请求
您将使用 Python 的
urllib模块向 weather API 端点发出一个 HTTP GET 请求,该请求使用由build_weather_query()和您的用户的 CLI 输入生成的 URL。您将需要 Python 标准库中的一些额外的内置模块来构建这一步的代码逻辑:# weather.py import argparse import json from configparser import ConfigParser from urllib import parse, request # ...您将使用
urllib.request发出请求,并使用json将 API 响应的数据转换成 Python 字典:1# weather.py 2 3# ... 4 5def get_weather_data(query_url): 6 """Makes an API request to a URL and returns the data as a Python object. 7 8 Args: 9 query_url (str): URL formatted for OpenWeather's city name endpoint 10 11 Returns: 12 dict: Weather information for a specific city 13 """ 14 response = request.urlopen(query_url) 15 data = response.read() 16 return json.loads(data) 17 18 19if __name__ == "__main__": 20 user_args = read_user_cli_args() 21 query_url = build_weather_query(user_args.city, user_args.imperial) 22 weather_data = get_weather_data(query_url) 23 print(weather_data)通过添加此代码,您已经将之前通过浏览器处理的所有功能都移到了 Python 脚本中:
第 5 行定义了
get_weather_data(),这是您将用来向 weather API 端点发出请求的函数。第 6 行到第 13 行组成了该函数的 docstring。
第 14 行使用
urllib.request.urlopen()向query_url参数发出 HTTP GET 请求,并将结果保存为response。第 15 行从响应中提取数据。
第 16 行以
data为参数返回对json.loads()的调用。该函数返回一个保存从query_url获取的 JSON 信息的 Python 对象。第 22 行调用
get_weather_data()传递你用build_weather_query()生成的query_url,然后将字典保存到weather_data。第 23 行最后将天气数据打印到你的控制台上。
如果您在添加此代码后运行您的 weather CLI 应用程序,您将看到类似于之前在浏览器中得到的输出:
$ python weather.py antananarivo {'coord': {'lon': 47.5361, 'lat': -18.9137}, 'weather': [{'id': 500, 'main': 'Rain', 'description': 'light rain', 'icon': '10d'}], 'base': 'stations', 'main': {'temp': 21.98, 'feels_like': 21.8, 'temp_min': 21.98, 'temp_max': 21.98, 'pressure': 1016, 'humidity': 60}, 'visibility': 10000, 'wind': {'speed': 4.12, 'deg': 120}, 'rain': {'1h': 0.15}, 'clouds': {'all': 75}, 'dt': 1635501615, 'sys': {'type': 1, 'id': 2136, 'country': 'MG', 'sunrise': 1635473461, 'sunset': 1635519356}, 'timezone': 10800, 'id': 1070940, 'name': 'Antananarivo', 'cod': 200}但是如果你太有创意,输入了一个 OpenWeather 没有任何天气数据的城市名称,会发生什么呢?尝试将以下一些城市名称传递到您的 CLI:
- 常态
- One thousand seven hundred and seventy
- 为什么
- 真相还是后果
- 没有别的地方
- 奶酪地震
虽然列表中的所有城市都存在,但谁会想到呢?—最后一个是 Cheesequake ,它没有可以通过这个 API 访问的天气数据:
$ python weather.py cheesequake Traceback (most recent call last): ... urllib.error.HTTPError: HTTP Error 404: Not Found如果你的 Python weather CLI 应用程序在每次你的用户变得太有创造力时都会带来大量的堆栈跟踪,那么它就不会非常用户友好。您可以通过在代码中添加一些异常处理来改进这一点。
处理代码中的异常
当您使用命令行应用程序时,您遇到了一个
HTTPError。这不利于良好的用户体验。因为您已经知道要捕获哪个错误,所以可以在代码中添加一个特定的异常:1# weather.py 2 3import argparse 4import json 5import sys 6from configparser import ConfigParser 7from urllib import error, parse, request 8 9# ... 10 11def get_weather_data(query_url): 12 13 # ... 14 15 try: 16 response = request.urlopen(query_url) 17 except error.HTTPError: 18 sys.exit("Can't find weather data for this city.") 19 20 data = response.read() 21 return json.loads(data) 22 23# ...通过添加这些额外的代码行并创建一个
try…except块,您现在可以成功地处理请求 API 中没有城市数据的城市所产生的错误:
第 5 行导入了内置的
sys模块,该模块允许您优雅地退出程序而不进行回溯,您在第 18 行执行了这一操作。7 号线从
urllib进口增加error。第 15 行启动了
try…except块,您已经将执行 HTTP 请求的代码行移到了第 16 行的try块中。第 17 行捕捉第 16 行 HTTP 请求期间发生的任何
error.HTTPError。它打开了一个except块。第 18 行调用
sys.exit()来优雅地退出应用程序,如果 HTTP 错误发生的话。您还传递了一条描述性消息,当没有为用户输入找到天气数据时,您的 CLI 将显示这条消息。这对您的 Python 天气应用程序的用户体验来说已经是一项重大改进:
$ python weather.py why not Can't find weather data for this city.天气 API 没有一个叫做的城市的数据,为什么没有,有了这个描述性的消息,你的用户就会明白了。
虽然在这种情况下消息是正确的,但是您的应用程序目前还会捕捉属于
HTTPError子类的其他异常。例如,如果您的 API 密钥过期或者您忘记提供一个,它会显示相同的消息。发生这种混淆是因为如果你发送一个没有有效 API 密钥的请求,weather API 将返回一个 HTTP 错误,状态码为 401 Unauthorized 。通过使您的消息更具体地针对不同的 HTTP 错误代码,您可以改进您的异常处理:
1# weather.py 2 3# ... 4 5def get_weather_data(query_url): 6 7 # ... 8 9 try: 10 response = request.urlopen(query_url) 11 except error.HTTPError as http_error: 12 if http_error.code == 401: # 401 - Unauthorized 13 sys.exit("Access denied. Check your API key.") 14 elif http_error.code == 404: # 404 - Not Found 15 sys.exit("Can't find weather data for this city.") 16 else: 17 sys.exit(f"Something went wrong... ({http_error.code})") 18 19 data = response.read() 20 return json.loads(data) 21 22# ...通过添加这些内容,您可以更深入地研究在将 HTTP 错误响应作为
except块中的http_error提供后从 API 收到的 HTTP 错误响应:
第 12 行到第 13 行捕捉 HTTP 401 未授权错误,这些错误表明您的 API 密钥已经过期或者您没有正确提供它。
第 14 到 15 行捕捉到 HTTP 404 Not Found 错误,通知您天气 API 找不到您输入的城市名称的任何数据。
第 16 到 17 行捕获所有其他可能发生的 HTTP 错误,然后退出程序并打印一条包含 HTTP 错误代码的消息。
您对 HTTP 错误的错误处理现在比以前更加精细了。这将帮助您的用户更好地识别他们遇到的问题。
此外,您将添加另一个
try…except块来处理 API 可能发送给您的可能格式错误的 JSON:# weather.py # ... def get_weather_data(query_url): # ... try: response = request.urlopen(query_url) except error.HTTPError as http_error: if http_error.code == 401: # 401 - Unauthorized sys.exit("Access denied. Check your API key.") elif http_error.code == 404: # 404 - Not Found sys.exit("Can't find weather data for this city.") else: sys.exit(f"Something went wrong... ({http_error.code})") data = response.read() try: return json.loads(data) except json.JSONDecodeError: sys.exit("Couldn't read the server response.") # ...在这里,您已经将试图解码 JSON 响应的代码包装到另一个
try…except块中,以处理可能在此阶段弹出的JSONDecodeError异常。如果 Python 无法将服务器的 JSON 响应转换成有效的 Python 对象,就会引发这个异常。如果发生这种情况,您现在可以优雅地退出程序,并向用户显示一条描述性消息。注意:有了这些新功能,你已经使你的 Python 天气应用程序对开发者和非开发者来说都更加舒适!
在本节中,您编写了 Python 代码,使用
urllib模块从脚本中发出 web 请求。为此,首先构建有效 API 请求所需的 URL,然后在get_weather_data()中使用它来发出请求并接收 JSON 响应。您将 JSON 响应转换为 Python 字典,并将其显示回您的控制台。您还添加了异常处理以避免显示冗长的错误消息,而是给出描述性的反馈,并且您至少遇到了一个您以前从未听说过的新城市名称!
此时,您可能想知道如何找到重复城市名称的天气信息:
如果你住在加拿大安大略省的伦敦,你可能会担心你将永远看不到你家乡城市的天气,因为你的城市名同胞是英国伦敦的 T2。OpenWeather API 对此有一个解决方案!您可以将 ISO 3166-1 国家代码标准的 alpha-2 代码作为逗号分隔值传递给城市名称 API 调用:
$ python weather.py london, ca在你的控制台上旋转一下吧!你将会看到,对于名为伦敦的城市,你会得到不同的结果,这取决于你是否通过了代表加拿大的 alpha-2 代码 ca 。
虽然您可以访问世界上许多城市的天气信息,包括几个不同的伦敦,但您的 CLI 应用程序的输出仍然难以阅读。一次有太多的信息,而且格式也不好。在下一步中,您将隔离要点,并学习如何以更漂亮的方式将它们显示到控制台。
步骤 5:显示你的 Python 天气应用的输出
在这一步中,您将对天气数据进行过滤,筛选出要在输出中使用的基本信息。您还将使用
pprint、f-strings 和 Python 的字符串格式化迷你语言来使输出更具可读性。识别相关数据
Python 天气应用程序的当前状态已经收集了用户输入并将现有城市的天气信息返回到终端:
$ python weather.py boring {'coord': {'lon': -76.8223, 'lat': 39.5316}, 'weather': [{'id': 501, 'main': 'Rain', 'description': 'moderate rain', 'icon': '10n'}], 'base': 'stations', 'main': {'temp': 11.78, 'feels_like': 11.36, 'temp_min': 10.69, 'temp_max': 13.25, 'pressure': 993, 'humidity': 90}, 'visibility': 10000, 'wind': {'speed': 1.34, 'deg': 136, 'gust': 3.58}, 'rain': {'1h': 1.83}, 'clouds': {'all': 90}, 'dt': 1635497629, 'sys': {'type': 2, 'id': 2032439, 'country': 'US', 'sunrise': 1635507144, 'sunset': 1635545363}, 'timezone': -14400, 'id': 4347790, 'name': 'Boring', 'cod': 200}但是这可能很难阅读,考虑到外面雷雨造成的昏暗光线——或者可能只是太无聊而无法通过?您可以使用 Python 的
pprint模块在您的终端中获得更清晰的表示:# weather.py from pprint import pp # ... if __name__ == "__main__": # ... pp(weather_data)通过添加 import 语句并调用
pp()而不是print(),您已经告诉 Python 很好地为您格式化输出并使其更具可读性:$ python weather.py bat cave {'coord': {'lon': -82.2871, 'lat': 35.4515}, 'weather': [{'id': 803, 'main': 'Clouds', 'description': 'broken clouds', 'icon': '04n'}], 'base': 'stations', 'main': {'temp': 10.99, 'feels_like': 10.7, 'temp_min': 8.64, 'temp_max': 12.96, 'pressure': 997, 'humidity': 98}, 'visibility': 10000, 'wind': {'speed': 0.9, 'deg': 245, 'gust': 1.05}, 'clouds': {'all': 65}, 'dt': 1635498584, 'sys': {'type': 2, 'id': 2017496, 'country': 'US', 'sunrise': 1635508089, 'sunset': 1635547041}, 'timezone': -14400, 'id': 4456121, 'name': 'Bat Cave', 'cod': 200}嗯,那就更刺激一点了!谁知道天气现象会在蝙蝠洞里发生?!
嵌套字典的这种可读性更强的显示方式使得识别您想要从 API 响应中收集的三条信息成为可能:
- 城市名称至
weather_data['name']- 天气描述到
weather_data['weather'][0]['description']- 温度至
weather_data['main']['temp']回到你的主脚本文件,去掉
pprint的使用。然后从weather_data字典中选择您感兴趣的数据,这样您就可以只打印相关信息:# weather.py # Removed: from pprint import pp # ... if __name__ == "__main__": # ... print( f"{weather_data['name']}: " f"{weather_data['weather'][0]['description']} " f"({weather_data['main']['temp']})" )您用对
print()的标准调用替换了pp(),并添加了三个 f 字符串来过滤weather_data中您感兴趣的信息,并将其显示回您的控制台:$ python weather.py zig zag Zig Zag: light rain (12.95)这个输出看起来比以前可读性更好!然而,目前仍然很难知道温度信息是用摄氏度还是华氏温度。您可以在这里将适当的符号添加到您的
print()调用中,但是因为您最终会将更多样式添加到您的 CLI 输出中,所以创建一个用于打印结果的专用函数是一个好主意。您将在下一部分解决这个问题。建立显示功能
在
weather.py中,滚动到文件的底部。上面的if __name__ == "__main__":正是创建这个新功能的好地方:1# weather.py 2 3# ... 4 5def display_weather_info(weather_data, imperial=False): 6 """Prints formatted weather information about a city. 7 8 Args: 9 weather_data (dict): API response from OpenWeather by city name 10 imperial (bool): Whether or not to use imperial units for temperature 11 12 More information at https://openweathermap.org/current#name 13 """ 14 city = weather_data["name"] 15 weather_description = weather_data["weather"][0]["description"] 16 temperature = weather_data["main"]["temp"] 17 18 print(f"{city}", end="") 19 print(f"\t{weather_description.capitalize()}", end=" ") 20 print(f"({temperature}°{'F' if imperial else 'C'})") 21 22 23if __name__ == "__main__": 24 25 # ... 26 27 display_weather_info(weather_data, user_args.imperial)在这个函数中,您首先为想要显示的数据创建了变量,然后将之前传递给
print()的字符串参数分成三个单独的对print()的调用:
第 5 行用两个参数
weather_data和imperial定义display_weather_info()。第二个参数默认为False。第 14 行到第 16 行从
weather_data字典中为city、weather_description和temperature选取相关数据,并将其赋给变量。第 18 行打印 API 调用返回的城市名称。通过传递一个空字符串(
"")而不是默认的换行符(\n)来防止换行。因此,下一次调用print()将继续在同一行显示文本。第 19 行打印关于当前天气的信息,以制表符(
\t)开始,将其与之前的输出分开。您还可以调用.capitalize()来将 weather API 返回的字符串信息大写,默认情况下,这些信息都是小写的。最后,使用end=" "将最后一个字符设置为空白字符,而不是默认的换行符。第 20 行从打印温度信息开始,然后使用依赖于布尔值
imperial的条件表达式来决定是打印华氏度的F还是摄氏度的C。第 27 行用对
display_weather_info()的调用替换了之前对print()的调用,并传递给它必要的参数。您已经将对
print()的调用分成三个不同的函数调用,分别位于不同的行上。您可以像这样将它们分开,以便为稍后添加的代码留出空间,这些代码将改变它们之间的显示颜色。如果您通过从命令行运行 Python 天气应用程序来运行更新后的显示功能,您将看到信息仍然整齐地显示在一行输出中:
$ python weather.py bitter end -i Bitter End Scattered clouds (27.93°F)您还会注意到,您的应用程序现在可以根据您是否通过了
-i标志来正确选择合适的温度范围。您在城市名称后使用的制表符将有助于保持信息显示的一致性,即使您查找的城市名称长度不同:$ python weather.py antananarivo Antananarivo Scattered clouds (29.98°C) $ python weather.py double trouble -i Double Trouble Clear sky (37.11°F)现在天气输出很好地对齐了!但是,这并不适用于所有城市名称,当城市名称的长度变成另一个制表符时,您的天气信息将显示在不同的位置:
$ python weather.py gotham -i Gotham Broken clouds (49.8°F) $ python weather.py national city -i National City Few clouds (46.65°F)您可以通过使用 Python 的格式规范小型语言向输出字符串添加字符串填充来改进这一点,接下来您将会这样做。
将字符串填充添加到您的输出中
Python 提供了一种内置的迷你语言,允许您在一个格式的字符串中应用规范。
为了使您的
city和weather_description字符串在一致的字符长度内居中,您可以在变量名后添加一个冒号(:),后跟一个对齐选项字符(^)和一个定义总长度的整数,例如20:print(f"{city:^20}", end="") print( f"\t{weather_description.capitalize():^20}", end=" ", ) print(f"({temperature}°{'F' if imperial else 'C'})")通过这一添加,您告诉 Python 将字符串输出保持在 20 个字符的一致长度,并在任何较短的字符串的左右两边填充空格:
$ python weather.py antananarivo Antananarivo Scattered clouds (23.98°C) $ python weather.py eureka -i Eureka Scattered clouds (9.85°C)找到了,成功了!长城市名 Antananarivo 和短城市名 Eureka 都在 20 个字符的填充范围内。现在,制表符将两个城市的天气描述对齐到 CLI 输出中的同一点。
然而,20 个字符似乎只是一些适合这些城市名称的数字。当您对天气应用程序进行最后润色时,您可能需要更改填充。因此,最好避免添加 20 作为一个幻数,而是在脚本的顶部将其定义为一个常数:
# weather.py import argparse import json import sys from configparser import ConfigParser from urllib import error, parse, request BASE_WEATHER_API_URL = "http://api.openweathermap.org/data/2.5/weather" PADDING = 20 # ... def display_weather_info(weather_data, imperial=False): # ... print(f"{city:^{PADDING}}", end="") print( f"\t{weather_description.capitalize():^{PADDING}}", end=" ", ) print(f"({temperature}°{'F' if imperial else 'C'})")通过将可视填充的值作为常量添加到代码中,您将能够快速地交换它,直到找到 Python 天气应用程序精美可视显示的最佳填充。
你在这个项目上走了很长的路,忍受了干旱和雷暴,建立了这个功能齐全的 Python 天气应用程序。如果您想将您编写的代码与项目当前状态的快照进行比较,您可以点击展开
weather.py的完整代码:# weather.py import argparse import json import sys from configparser import ConfigParser from urllib import error, parse, request BASE_WEATHER_API_URL = "http://api.openweathermap.org/data/2.5/weather" PADDING = 20 def read_user_cli_args(): """Handles the CLI user interactions. Returns: argparse.Namespace: Populated namespace object """ parser = argparse.ArgumentParser( description="gets weather and temperature information for a city" ) parser.add_argument( "city", nargs="+", type=str, help="enter the city name" ) parser.add_argument( "-i", "--imperial", action="store_true", help="display the temperature in imperial units", ) return parser.parse_args() def build_weather_query(city_input, imperial=False): """Builds the URL for an API request to OpenWeather's weather API. Args: city_input (List[str]): Name of a city as collected by argparse imperial (bool): Whether or not to use imperial units for temperature Returns: str: URL formatted for a call to OpenWeather's city name endpoint """ api_key = _get_api_key() city_name = " ".join(city_input) url_encoded_city_name = parse.quote_plus(city_name) units = "imperial" if imperial else "metric" url = ( f"{BASE_WEATHER_API_URL}?q={url_encoded_city_name}" f"&units={units}&appid={api_key}" ) return url def _get_api_key(): """Fetch the API key from your configuration file. Expects a configuration file named "secrets.ini" with structure: [openweather] api_key=<YOUR-OPENWEATHER-API-KEY> """ config = ConfigParser() config.read("secrets.ini") return config["openweather"]["api_key"] def get_weather_data(query_url): """Makes an API request to a URL and returns the data as a Python object. Args: query_url (str): URL formatted for OpenWeather's city name endpoint Returns: dict: Weather information for a specific city """ try: response = request.urlopen(query_url) except error.HTTPError as http_error: if http_error.code == 401: # 401 - Unauthorized sys.exit("Access denied. Check your API key.") elif http_error.code == 404: # 404 - Not Found sys.exit("Can't find weather data for this city.") else: sys.exit(f"Something went wrong... ({http_error.code})") data = response.read() try: return json.loads(data) except json.JSONDecodeError: sys.exit("Couldn't read the server response.") def display_weather_info(weather_data, imperial=False): """Prints formatted weather information about a city. Args: weather_data (dict): API response from OpenWeather by city name imperial (bool): Whether or not to use imperial units for temperature More information at https://openweathermap.org/current#name """ city = weather_data["name"] weather_description = weather_data["weather"][0]["description"] temperature = weather_data["main"]["temp"] print(f"{city:^{PADDING}}", end="") print( f"\t{weather_description.capitalize():^{PADDING}}", end=" ", ) print(f"({temperature}°{'F' if imperial else 'C'})") if __name__ == "__main__": user_args = read_user_cli_args() query_url = build_weather_query(user_args.city, user_args.imperial) weather_data = get_weather_data(query_url) display_weather_info(weather_data, user_args.imperial)恭喜你!你的剧本看起来很棒,而且你花了很多时间来创作。也许是时候出去走走了?不,看起来外面还在下雨。
这让你有时间改进应用程序输出的外观和风格。添加一些天气表情符号来增加活力,用彩虹色取代单调的黑白文本怎么样?
步骤 6:对天气应用的输出进行样式化
此时,您的 Python weather CLI 应用程序以可读和可理解的方式显示所有相关信息。不过输出看起来还是有点风化。
在这一步中,你将为你的天气应用添加颜色和华丽的表情符号,使其流行起来。您的应用程序将以各种颜色显示不同的符号和文本,具体取决于您正在查询的地方的当前天气。
更改终端输出颜色
您可以更改打印到 CLI 的文本的颜色和其他显示方式。您将使用特殊字符序列通过反转颜色来突出显示城市名称:
# weather.py # ... PADDING = 20 REVERSE = "\033[;7m" RESET = "\033[0m" # ... def display_weather_info(weather_data, imperial=False): # ... city = weather_data["name"] weather_description = weather_data["weather"][0]["description"] temperature = weather_data["main"]["temp"] print(f"{REVERSE}{city:^{PADDING}}{RESET}", end="") print( f"\t{weather_description.capitalize():^{PADDING}}", end=" ", ) print(f"({temperature}°{'F' if imperial else 'C'})") # ...您在文件的顶部定义了两个新的常量,
REVERSE和RESET。这些字符串以 ASCII 转义字符\033开头,后面是方括号([),最后是一些 SGR 参数。注意:如果你想进一步了解 ANSI 转义码是如何工作的,你也可以暂时接受这种语法,并在网上找到一个颜色代码列表来玩。
您在上述代码片段中定义的两个序列会反转终端颜色,并将它们分别重置为默认值:
\033[;7m反转终端背景和前景色。\033[0m将一切重置为默认值。然后,在传递给
print()的字符串中使用这些字符序列。在第一个序列中,您在 CLI 应用程序打印城市名称之前反转颜色。对于第二个序列,在它打印出城市名称后,您可以重置它。如果你旋转一下,你会看到城市名称被突出显示,比以前更加突出:
https://player.vimeo.com/video/644463159?background=1
哇!这看起来不错,接下来您可能会急于给输出添加一些颜色。你可能想在你的 Python 天气应用程序中加入各种各样的风格和天赋,这可能会很快失控。因此,在开始之前,您会希望将所有与样式相关的设置和颜色定义保存在一个单独的 Python 文件中,您将称之为
style.py。在下面选择您的操作系统以重构代码:
- 视窗
** Linux + macOS*PS C:\> Get-Location Path ---- C:\path\to\weather-app PS C:\> New-Item style.py PS C:\> Get-ChildItem Directory: C:\path\to\weather-app Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 12/2/2021 08:55 11 .gitignore -a---- 12/2/2021 08:55 48 secrets.ini -a---- 12/2/2021 08:55 5131 weather.py -a---- 12/2/2021 14:31 0 style.py$ pwd /Users/user/path/to/weather-app $ touch style.py $ ls -a . .. .gitignore secrets.ini style.py weather.py打开刚刚在
weather-app/目录中创建的新的空 Python 文件,添加用于向 CLI 输出添加样式的代码,以及之前定义的PADDING:# style.py PADDING = 20 REVERSE = "\033[;7m" RESET = "\033[0m" def change_color(color): print(color, end="")您已经将样式相关的常量从
weather.py移动到新文件style.py。您还预计到您可能想要对print()进行大量调用来改变您的输出颜色,所以您编写了change_color()来为您处理这些。现在,您可以返回到
weather.py并重构您的主应用程序代码,以反映您的新项目组织,其中您将样式相关的代码保存在一个单独的style模块中:1# weather.py 2 3import argparse 4import json 5import sys 6from configparser import ConfigParser 7from urllib import error, request 8 9import style 10 11BASE_WEATHER_API_URL = "http://api.openweathermap.org/data/2.5/weather" 12# Remove: PADDING = 20 13# Remove: REVERSE = "\033[;7m" 14# Remove: RESET = "\033[0m" 15 16# ... 17 18def display_weather_info(weather_data, imperial=False): 19 20 # ... 21 22 city = weather_data["name"] 23 weather_description = weather_data["weather"][0]["description"] 24 temperature = weather_data["main"]["temp"] 25 26 style.change_color(style.REVERSE) 27 print(f"{city:^{style.PADDING}}", end="") 28 style.change_color(style.RESET) 29 print( 30 f"\t{weather_description.capitalize():^{style.PADDING}}", 31 end=" ", 32 ) 33 print(f"({temperature}°{'F' if imperial else 'C'})") 34 35# ...通过这个重构,您导入了新的
style模块,并移除了之前在weather.py中定义的与样式相关的常量。然后您重构了对print()的调用,以使用您在新模块中定义的描述性的style.change_color()。您在第 27 行和第 30 行用
style.PADDING替换了提到的两个PADDING,这样它们就引用了该值的更新位置。您还通过使用它们的描述性名称空间将移动到
style.py的常量传递到change_color()。现在,所有与风格相关的探索都有了一个指定的位置,您已经准备好在输出中加入一些颜色了。在
style.py中,添加额外的颜色标识符:# style.py PADDING = 20 RED = "\033[1;31m" BLUE = "\033[1;34m" CYAN = "\033[1;36m" GREEN = "\033[0;32m" YELLOW = "\033[33m" WHITE = "\033[37m" REVERSE = "\033[;7m" RESET = "\033[0m" def change_color(color): print(color, end="")有了它,您可以用醒目的红色格式化天气描述,然后在显示温度之前将其重置为默认值:
# weather.py # ... def display_weather_info(weather_data, imperial=False): # ... city = weather_data["name"] weather_description = weather_data["weather"][0]["description"] temperature = weather_data["main"]["temp"] style.change_color(style.REVERSE) print(f"{city:^{style.PADDING}}", end="") style.change_color(style.RESET) style.change_color(style.RED) print( f"\t{weather_description.capitalize():^{style.PADDING}}", end=" ", ) style.change_color(style.RESET) print(f"({temperature}°{'F' if imperial else 'C'})") # ...使用与更改城市名称显示时相同的方法,您成功地将天气描述的字体颜色更改为红色:
https://player.vimeo.com/video/644473762?background=1
在你的天气应用程序中加入一些颜色当然很好,但是如果这种颜色不仅仅是看起来漂亮,还能包含一些意义,那不是更好吗?接下来,您将使用天气 ID 以不同的颜色格式化不同的天气类型。
用不同的颜色格式化天气类型
与 HTTP 响应代码类似,weather API 为每个响应提供一个天气条件代码。该代码将天气状况分成由一系列 ID 号定义的组。
您可以使用此信息,根据响应所属的天气条件组来选择显示颜色。例如,您可以用蓝色显示下雨的情况,用黄色显示晴朗的情况。
为此,首先需要在脚本中描述天气条件代码的范围:
# weather.py import argparse import json import sys from configparser import ConfigParser from urllib import error, parse, request import style BASE_WEATHER_API_URL = "http://api.openweathermap.org/data/2.5/weather" # Weather Condition Codes # https://openweathermap.org/weather-conditions#Weather-Condition-Codes-2 THUNDERSTORM = range(200, 300) DRIZZLE = range(300, 400) RAIN = range(500, 600) SNOW = range(600, 700) ATMOSPHERE = range(700, 800) CLEAR = range(800, 801) CLOUDY = range(801, 900) # ...请注意,这些范围中的每一个都涵盖了多个单独的天气条件。您可以使用范围来描述较大的组。这似乎是一个很好的折衷办法,给每一个组一个合适的颜色,而不是分别处理每个 ID。
现在,您可以从响应字典中选择天气条件代码,并根据该值做出决策:
1# weather.py 2 3# ... 4 5def display_weather_info(weather_data, imperial=False): 6 7 # ... 8 9 city = weather_data["name"] 10 weather_id = weather_data["weather"][0]["id"] 11 weather_description = weather_data["weather"][0]["description"] 12 temperature = weather_data["main"]["temp"] 13 14 style.change_color(style.REVERSE) 15 print(f"{city:^{style.PADDING}}", end="") 16 style.change_color(style.RESET) 17 18 if weather_id in THUNDERSTORM: 19 style.change_color(style.RED) 20 elif weather_id in DRIZZLE: 21 style.change_color(style.CYAN) 22 elif weather_id in RAIN: 23 style.change_color(style.BLUE) 24 elif weather_id in SNOW: 25 style.change_color(style.WHITE) 26 elif weather_id in ATMOSPHERE: 27 style.change_color(style.BLUE) 28 elif weather_id in CLEAR: 29 style.change_color(style.YELLOW) 30 elif weather_id in CLOUDY: 31 style.change_color(style.WHITE) 32 else: # In case the API adds new weather codes 33 style.change_color(style.RESET) 34 print( 35 f"\t{weather_description.capitalize():^{style.PADDING}}", 36 end=" ", 37 ) 38 style.change_color(style.RESET) 39 40 print(f"({temperature}°{'F' if imperial else 'C'})") 41 42# ...现在,您从响应字典中选择天气条件代码,并将其分配给第 10 行的
weather_id。然后,在上面代码块中从第 18 行到第 33 行的大量条件语句中,根据weather_id所属的天气条件组来改变显示颜色。注意:如果你使用的是 3.10 以上的 Python 版本,你可以尝试一个替代的实现,包括
match…case语句,而不是这个冗长的条件语句。如果您在进行这些调整后再旋转一下您的天气应用程序,您会看到您的终端将以不同的颜色显示不同的天气状况:
https://player.vimeo.com/video/644484744?background=1
这款吸引人的终端用户界面让您爱不释手!然而,将条件代码块添加到
display_weather_info()中并不是那么美好。因此,您将进一步重构代码,并将条件语句移到一个单独的非公共函数中。同时,你还将添加一些与天气相关的表情符号,以结束你一直在酝酿的视觉风暴!
重构你的代码并添加表情符号
首先,将用于为每个天气描述选择显示颜色的条件语句移到一个单独的非公共函数中:
# weather.py # ... def display_weather_info(weather_data, imperial=False): # ... city = weather_data["name"] weather_id = weather_data["weather"][0]["id"] weather_description = weather_data["weather"][0]["description"] temperature = weather_data["main"]["temp"] style.change_color(style.REVERSE) print(f"{city:^{style.PADDING}}", end="") style.change_color(style.RESET) color = _select_weather_display_params(weather_id) style.change_color(color) print( f"\t{weather_description.capitalize():^{style.PADDING}}", end=" ", ) style.change_color(style.RESET) print(f"({temperature}°{'F' if imperial else 'C'})") def _select_weather_display_params(weather_id): if weather_id in THUNDERSTORM: color = style.RED elif weather_id in DRIZZLE: color = style.CYAN elif weather_id in RAIN: color = style.BLUE elif weather_id in SNOW: color = style.WHITE elif weather_id in ATMOSPHERE: color = style.BLUE elif weather_id in CLEAR: color = style.YELLOW elif weather_id in CLOUDY: color = style.WHITE else: # In case the API adds new weather codes color = style.RESET return color # ...通过这一更改,您将条件语句移到了
_select_weather_display_params()中,并添加了对该函数的调用作为对display_weather_info()的替换。通过这种方式,您可以保持信息更加集中和细化,并且这种变化也使您可以清楚地在哪里添加其他与样式相关的显示参数。你将通过添加表情符号来练习以这种包含的方式改善你的输出风格:
1# weather.py 2 3# ... 4 5def display_weather_info(weather_data, imperial=False): 6 7 # ... 8 9 city = weather_data["name"] 10 weather_id = weather_data["weather"][0]["id"] 11 weather_description = weather_data["weather"][0]["description"] 12 temperature = weather_data["main"]["temp"] 13 14 style.change_color(style.REVERSE) 15 print(f"{city:^{style.PADDING}}", end="") 16 style.change_color(style.RESET) 17 18 weather_symbol, color = _select_weather_display_params(weather_id) 19 20 style.change_color(color) 21 print(f"\t{weather_symbol}", end=" ") 22 print( 23 f"{weather_description.capitalize():^{style.PADDING}}", 24 end=" ", 25 ) 26 style.change_color(style.RESET) 27 28 print(f"({temperature}°{'F' if imperial else 'C'})") 29 30def _select_weather_display_params(weather_id): 31 if weather_id in THUNDERSTORM: 32 display_params = ("💥", style.RED) 33 elif weather_id in DRIZZLE: 34 display_params = ("💧", style.CYAN) 35 elif weather_id in RAIN: 36 display_params = ("💦", style.BLUE) 37 elif weather_id in SNOW: 38 display_params = ("⛄️", style.WHITE) 39 elif weather_id in ATMOSPHERE: 40 display_params = ("🌀", style.BLUE) 41 elif weather_id in CLEAR: 42 display_params = ("🔆", style.YELLOW) 43 elif weather_id in CLOUDY: 44 display_params = ("💨", style.WHITE) 45 else: # In case the API adds new weather codes 46 display_params = ("🌈", style.RESET) 47 return display_params 48 49# ...在这次更新中,您为每个天气 ID 添加了一个表情符号,并在一个元组中总结了两个显示参数。在第 47 行,在
_select_weather_display_params()的末尾,你返回了这个元组。当您在第 18 行调用
_select_weather_display_params()时,您使用元组解包来将它包含的两个值分别赋给weather_symbol和color。最后,您在第 21 行添加了对显示
weather_symbol的print()的新调用,并将制表符从第 23 行移动到第 21 行。这样,您通过在输出字符串中包含weather_symbol将表情符号添加到了 CLI 输出中。注意:通过添加空白、不同的填充或额外的制表符,您可以随意更改格式。还有一系列有趣的与天气相关的表情符号可供选择,所以请随意选择不同的表情符号。你可以在下面的评论中分享你最喜欢的天气相关表情符号!
在 Python 天气应用程序中设置了最后一项更改后,您就完成了 CLI 工具的构建。你现在可以去你最喜欢的搜索引擎,寻找一些有趣的城市名称,并在这个雨天的剩余时间里找到一个你可以梦想度过下一个假期的地方。
结论
您已经取得了很大的进步,构建了一个巧妙的命令行应用程序,可以在您的终端上显示世界上数千个城市的重要天气信息。为此,您使用了来自 OpenWeather 的 weather API 和一系列 Python 标准库模块。额外的收获是,你可能已经开始头脑风暴一趟世界各地独特命名的城市之旅。
在本教程中,您学习了如何:
- 仅使用 Python 标准库模块构建功能性天气查找工具
- 构建一个 Python CLI app 使用
argparse- 使用
configparser到处理 API 秘密- 从您的 Python 脚本中进行 API 调用
- 使用 ANSI 转义码、表情符号、 f 字符串和 Python 的字符串迷你语言,创建视觉上吸引人的 CLI 输出
如果您想查看源代码,可以点击下面的链接:
获取源代码: 点击此处获取源代码,您将使用构建您的天气应用程序。
与此同时,看起来太阳终于又出来了!当你开心的时候,时间过得多快啊。但是等等,在你出去之前——所有这些地方的天气是如何变化的?
接下来的步骤
如果你所在的地方雷暴不会平息,并且你想继续这个项目,你可以考虑以下想法,让你的天气应用程序更上一层楼:
- 定制风格,使之符合你的个人口味。
- 用来自 JSON 响应数据的更多信息丰富您的天气报告。
- 使用 Typer 重构 CLI。
- 安装一个 3.10 以上的 Python 版本,将
_select_weather_display_params()中的代码替换为match…case语句。- 使用 Python 的
zipapp打包 CLI 进行分发,或者创建一个可以发布到 PyPI 的包。你还能想出什么其他的主意来扩展这个项目?要有创意,要有乐趣!****************
构建 Python C 扩展模块
有几种方法可以扩展 Python 的功能。其中之一就是用 C 或者 C++ 写你的 Python 模块。这个过程可以提高性能,更好地访问 C 库函数和系统调用。在本教程中,您将了解如何使用 Python API 编写 Python C 扩展模块。
您将学习如何:
- 从 Python 内部调用 C 函数
- 从 Python 向 C 传递参数,并相应地解析它们
- 从 C 代码中引发异常,并在 C 中创建自定义 Python 异常
- 在 C 中定义全局常量,并使它们在 Python 中可访问
- 测试、打包和分发您的 Python C 扩展模块
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
扩展你的 Python 程序
Python 的一个鲜为人知但非常强大的特性是它能够调用用 C 或 C++等编译语言定义的函数和库。这允许您将程序的功能扩展到 Python 的内置特性之外。
有许多语言可供选择来扩展 Python 的功能。那么,为什么要用 C 呢?以下是您可能决定构建 Python C 扩展模块的几个原因:
实现新的内置对象类型:可以用 C 编写一个 Python 类,然后实例化并扩展 Python 本身的类。这样做的原因可能有很多,但更多的时候,性能是驱动开发人员转向 c 的主要原因。这种情况很少见,但知道 Python 可以扩展到什么程度是很好的。
调用 C 库函数和系统调用:很多编程语言都提供了最常用的系统调用的接口。尽管如此,可能还有其他较少使用的系统调用只能通过 c 来访问。Python 中的
os模块就是一个例子。这并不是一个详尽的列表,但是它给了您在使用 C 或任何其他语言扩展 Python 时可以做什么的要点。
要用 C 语言编写 Python 模块,你需要使用 Python API ,它定义了允许 Python 解释器调用你的 C 代码的各种函数、宏和变量。所有这些工具和更多的工具都打包在
Python.h头文件中。用 C 编写 Python 接口
在本教程中,您将为一个 C 库函数编写一个小包装器,然后您将从 Python 中调用它。自己实现一个包装器会让你更好地了解何时以及如何使用 C 来扩展你的 Python 模块。
理解
fputs()是您将要包装的 C 库函数:
int fputs(const char *, FILE *)该函数有两个参数:
const char *是一个字符数组。FILE *是一个文件流指针。
fputs()将字符数组写入文件流指定的文件,并返回一个非负值。如果操作成功,则该值将表示写入文件的字节数。如果有错误,那么它返回EOF。你可以在手册页条目中阅读更多关于这个 C 库函数及其其他变体的信息。编写 C 函数为
fputs()这是一个基本的 C 程序,使用
fputs()将字符串写入文件流:#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main() { FILE *fp = fopen("write.txt", "w"); fputs("Real Python!", fp); fclose(fp); return 1; }这段代码可以总结如下:
- 打开文件
write.txt。- 将字符串
"Real Python!"写入文件。注意:本文中的 C 代码应该构建在大多数系统上。它已经在 GCC 上测试过,没有使用任何特殊的标志。
在下一节中,您将为这个 C 函数编写一个包装器。
包装
fputs()在解释其工作原理之前看到完整的代码可能有点奇怪。然而,花一点时间检查最终产品将补充您在以下部分的理解。下面的代码块显示了 C 代码的最终包装版本:
1#include <Python.h> 2 3static PyObject *method_fputs(PyObject *self, PyObject *args) { 4 char *str, *filename = NULL; 5 int bytes_copied = -1; 6 7 /* Parse arguments */ 8 if(!PyArg_ParseTuple(args, "ss", &str, &filename)) { 9 return NULL; 10 } 11 12 FILE *fp = fopen(filename, "w"); 13 bytes_copied = fputs(str, fp); 14 fclose(fp); 15 16 return PyLong_FromLong(bytes_copied); 17}这段代码引用了三个在
Python.h中定义的对象结构:
PyObjectPyArg_ParseTuple()PyLong_FromLong()这些用于 Python 语言的数据类型定义。现在,您将逐一了解它们。
PyObject
PyObject是一个对象结构,用于为 Python 定义对象类型。所有 Python 对象共享少量使用PyObject结构定义的字段。所有其他对象类型都是这种类型的扩展。
PyObject告诉 Python 解释器将指向一个对象的指针视为一个对象。例如,将上述函数的返回类型设置为PyObject定义了 Python 解释器所需的公共字段,以便将其识别为有效的 Python 类型。再看一下 C 代码的前几行:
1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4 5 /* Snip */在第 2 行,声明希望从 Python 代码中接收的参数类型:
char *str是你要写入文件流的字符串。char *filename是要写入的文件的名称。PyArg_ParseTuple()
PyArg_ParseTuple()将从 Python 程序接收的参数解析成局部变量:1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args, "ss", &str, &filename)) { 7 return NULL; 8 } 9 10 /* Snip */如果你看第 6 行,你会看到
PyArg_ParseTuple()有以下参数:
args属于PyObject类型。
"ss"是指定要解析的参数的数据类型的格式说明符。(你可以查看官方文档以获得完整参考。)
&str和&filename是指向局部变量的指针,解析后的值将被分配给这些变量。失败时,
PyArg_ParseTuple()评估为false。如果失败,那么函数将返回NULL并且不再继续。
fputs()正如您之前看到的,
fputs()有两个参数,其中一个是FILE *对象。因为您不能使用 C 中的 Python API 解析 PythontextIOwrapper对象,所以您必须使用一种变通方法:1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args, "ss", &str, &filename)) { 7 return NULL; 8 } 9 10 FILE *fp = fopen(filename, "w"); 11 bytes_copied = fputs(str, fp); 12 fclose(fp); 13 14 return PyLong_FromLong(bytes_copied); 15}下面是这段代码的详细内容:
- 在第 10 行,你正在传递你将用来创建一个
FILE *对象的文件名,并把它传递给函数。- 在第 11 行,你用下面的参数调用
fputs():
str是你要写入文件的字符串。fp是您在第 10 行定义的FILE *对象。然后将
fputs()的返回值存储在bytes_copied中。这个整数变量将被返回给 Python 解释器中的fputs()调用。
PyLong_FromLong(bytes_copied)
PyLong_FromLong()返回一个PyLongObject,在 Python 中表示整数对象。您可以在 C 代码的最末尾找到它:1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args, "ss", &str, &filename)) { 7 return NULL; 8 } 9 10 FILE *fp = fopen(filename, "w"); 11 bytes_copied = fputs(str, fp); 12 fclose(fp); 13 14 return PyLong_FromLong(bytes_copied); 15}第 14 行为
bytes_copied生成一个PyLongObject,这是在 Python 中调用函数时返回的变量。你必须从你的 Python C 扩展模块返回一个PyObject*给 Python 解释器。编写初始化函数
您已经编写了构成 Python C 扩展模块核心功能的代码。但是,仍然有一些额外的函数是启动和运行您的模块所必需的。您需要编写模块及其包含的方法的定义,如下所示:
static PyMethodDef FputsMethods[] = { {"fputs", method_fputs, METH_VARARGS, "Python interface for fputs C library function"}, {NULL, NULL, 0, NULL} }; static struct PyModuleDef fputsmodule = { PyModuleDef_HEAD_INIT, "fputs", "Python interface for the fputs C library function", -1, FputsMethods };这些函数包括 Python 解释器将使用的模块的元信息。让我们浏览一下上面的每个结构,看看它们是如何工作的。
PyMethodDef为了调用在你的模块中定义的方法,你需要首先告诉 Python 解释器它们。为此,可以使用
PyMethodDef。这是一个有 4 个成员的结构,代表模块中的一个方法。理想情况下,在您的 Python C 扩展模块中会有不止一个您希望可以从 Python 解释器中调用的方法。这就是为什么您需要定义一组
PyMethodDef结构:static PyMethodDef FputsMethods[] = { {"fputs", method_fputs, METH_VARARGS, "Python interface for fputs C library function"}, {NULL, NULL, 0, NULL} };该结构的每个成员都包含以下信息:
"fputs"是用户为了调用这个特定功能而写的名字。
method_fputs是要调用的 C 函数的名称。
METH_VARARGS是一个标志,告诉解释器该函数将接受两个PyObject*类型的参数:
self是模块对象。args是一个包含函数实际参数的元组。如前所述,这些参数是使用PyArg_ParseTuple()解包的。最后一个字符串是表示方法 docstring 的值。
PyModuleDef正如
PyMethodDef保存关于 Python C 扩展模块中方法的信息一样,PyModuleDef结构保存关于模块本身的信息。它不是结构的数组,而是用于模块定义的单个结构:static struct PyModuleDef fputsmodule = { PyModuleDef_HEAD_INIT, "fputs", "Python interface for the fputs C library function", -1, FputsMethods };此结构中共有 9 个成员,但并非所有成员都是必需的。在上面的代码块中,您初始化了以下五个:
PyModuleDef_HEAD_INIT是类型PyModuleDef_Base的成员,建议只有这一个值。
"fputs"是你的 Python C 扩展模块的名字。字符串是代表你的模块 docstring 的值。您可以使用
NULL没有 docstring,或者您可以通过传递一个const char *来指定一个 docstring,如上面的代码片段所示。它属于Py_ssize_t类型。您还可以使用PyDoc_STRVAR()为您的模块定义一个 docstring。
-1是存储你的程序状态所需的内存量。当您的模块在多个子解释器中使用时,这很有帮助,它可以有以下值:
- 负值表示这个模块不支持子解释器。
- 非负值启用模块的重新初始化。它还指定了要在每个子解释器会话上分配的模块的内存需求。
T3】
FputsMethods是指你的方法表。这是您之前定义的PyMethodDef结构的数组。有关更多信息,请查看关于
PyModuleDef的官方 Python 文档。
PyMODINIT_FUNC现在您已经定义了 Python C 扩展模块和方法结构,是时候使用它们了。当 Python 程序第一次导入你的模块时,它会调用
PyInit_fputs():PyMODINIT_FUNC PyInit_fputs(void) { return PyModule_Create(&fputsmodule); }
PyMODINIT_FUNC当被声明为函数返回类型时,隐含地做 3 件事:
- 它隐式设置函数的返回类型为
PyObject*。- 它声明任何特殊的链接。
- 它将函数声明为 extern“C”。如果您使用 C++,它会告诉 C++编译器不要对符号进行名称管理。
PyModule_Create()将返回一个类型为PyObject *的新模块对象。对于参数,您将传递您之前已经定义的方法结构的地址,fputsmodule。注意:在 Python 3 中,你的 init 函数必须返回一个
PyObject *类型。然而,如果您使用 Python 2,那么PyMODINIT_FUNC将函数返回类型声明为void。将所有这些放在一起
现在,您已经编写了 Python C 扩展模块的必要部分,让我们后退一步,看看它们是如何组合在一起的。下图显示了模块的组件以及它们如何与 Python 解释器交互:
当您导入 Python C 扩展模块时,
PyInit_fputs()是第一个被调用的方法。然而,在将引用返回给 Python 解释器之前,该函数会对PyModule_Create()进行后续调用。这将初始化结构PyModuleDef和PyMethodDef,它们保存了关于你的模块的元信息。准备好它们是有意义的,因为您将在 init 函数中使用它们。一旦完成,对模块对象的引用最终返回给 Python 解释器。下图显示了模块的内部流程:
由
PyModule_Create()返回的模块对象有一个对模块结构PyModuleDef的引用,模块结构又有一个对方法表PyMethodDef的引用。当您调用 Python C 扩展模块中定义的方法时,Python 解释器使用模块对象及其携带的所有引用来执行特定的方法。(虽然这并不完全是 Python 解释器在幕后处理事情的方式,但它会让您了解它是如何工作的。)同样,您可以访问模块的各种其他方法和属性,如模块 docstring 或方法 docstring。这些是在它们各自的结构中定义的。
现在您已经知道当您从 Python 解释器调用
fputs()时会发生什么了。解释器使用你的模块对象以及模块和方法引用来调用方法。最后,让我们看看解释器如何处理 Python C 扩展模块的实际执行:
一旦
method_fputs()被调用,程序执行以下步骤:
- 用
PyArg_ParseTuple()解析您从 Python 解释器传递的参数- 将这些参数传递给构成模块核心的 C 库函数
fputs()- 使用
PyLong_FromLong返回来自fputs()的值要查看代码中的这些相同步骤,再看一下
method_fputs():1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args, "ss", &str, &filename)) { 7 return NULL; 8 } 9 10 FILE *fp = fopen(filename, "w"); 11 bytes_copied = fputs(str, fp); 12 fclose(fp); 13 14 return PyLong_FromLong(bytes_copied); 15}概括地说,您的方法将解析传递给模块的参数,将它们发送给
fputs(),并返回结果。打包您的 Python C 扩展模块
在导入新模块之前,首先需要构建它。您可以通过使用 Python 包
distutils来实现这一点。你需要一个名为
setup.py的文件来安装你的应用程序。对于本教程,您将关注 Python C 扩展模块特有的部分。对于完整的初级读本,请查看如何向 PyPI 发布开源 Python 包。您的模块的最小
setup.py文件应该如下所示:from distutils.core import setup, Extension def main(): setup(name="fputs", version="1.0.0", description="Python interface for the fputs C library function", author="<your name>", author_email="your_email@gmail.com", ext_modules=[Extension("fputs", ["fputsmodule.c"])]) if __name__ == "__main__": main()上面的代码块显示了传递给
setup()的标准参数。仔细看看最后一个位置参数,ext_modules。这需要一个Extensions类的对象列表。Extensions类的对象描述了安装脚本中的单个 C 或 C++扩展模块。这里,您将两个关键字参数传递给它的构造函数,即:
name是模块的名称。[filename]是源代码文件的路径列表,相对于安装脚本。构建您的模块
既然已经有了
setup.py文件,就可以用它来构建 Python C 扩展模块了。强烈建议您使用虚拟环境来避免与您的 Python 环境冲突。导航到包含
setup.py的目录并运行以下命令:$ python3 setup.py install这个命令将在当前目录中编译并安装 Python C 扩展模块。如果有任何错误或警告,那么你的程序将抛出它们。确保在尝试导入模块之前修复这些问题。
默认情况下,Python 解释器使用
clang来编译 C 代码。如果您想使用gcc或任何其他 C 编译器来完成这项工作,那么您需要相应地设置CC环境变量,要么在设置脚本中,要么直接在命令行中。例如,您可以告诉 Python 解释器使用gcc以这种方式编译和构建您的模块:$ CC=gcc python3 setup.py install然而,如果
clang不可用,Python 解释器将自动退回到gcc。运行您的模块
现在一切都准备好了,是时候看看您的模块的运行情况了!一旦成功构建,启动解释器来测试运行 Python C 扩展模块:
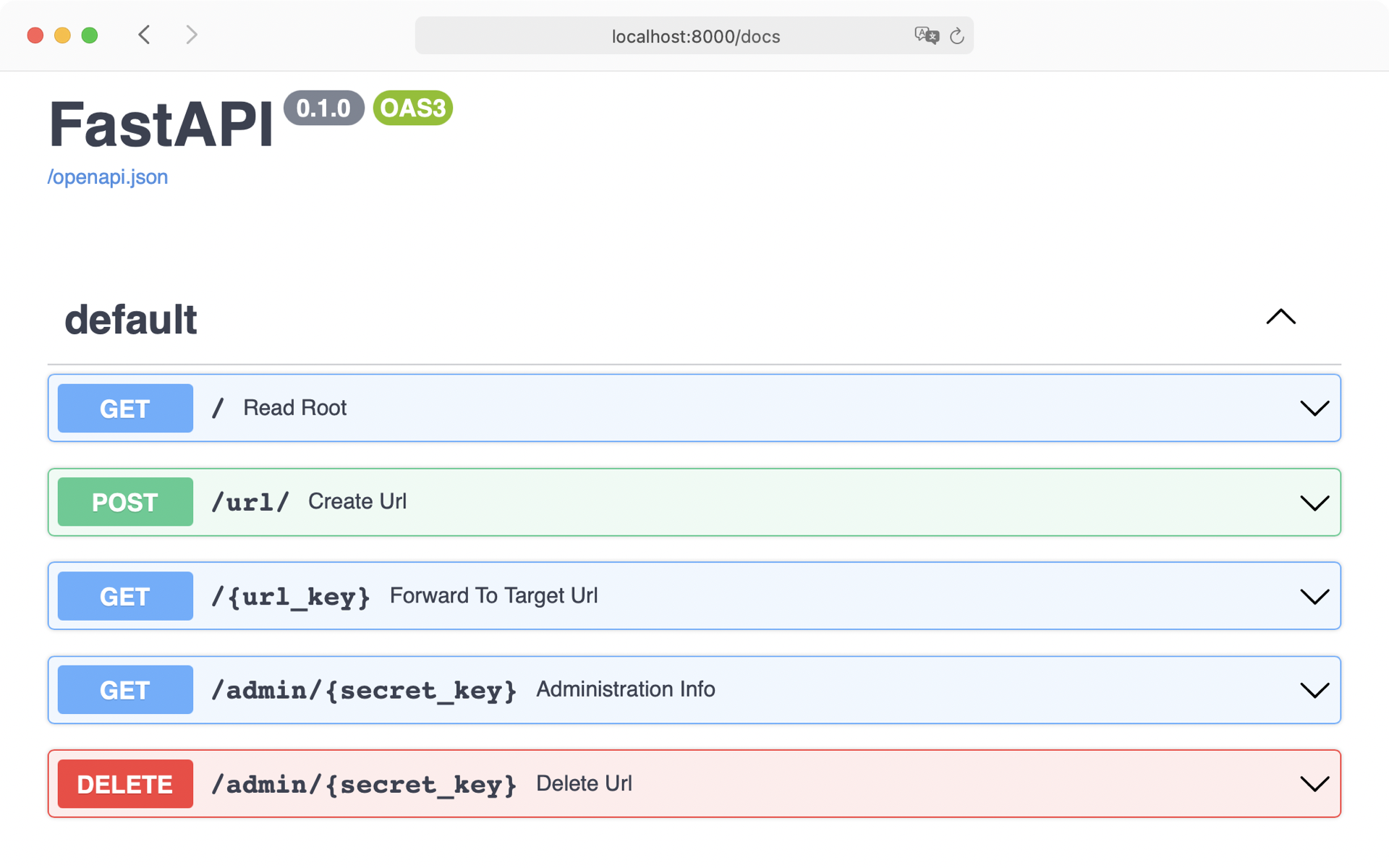

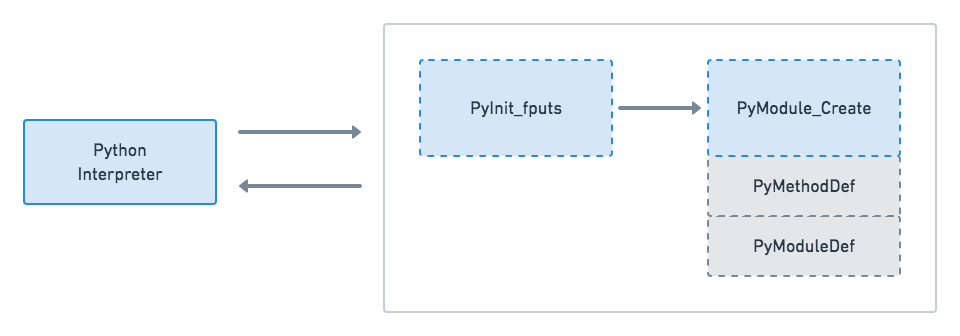

>>> import fputs
>>> fputs.__doc__
'Python interface for the fputs C library function'
>>> fputs.__name__
'fputs'
>>> # Write to an empty file named `write.txt`
>>> fputs.fputs("Real Python!", "write.txt")
13
>>> with open("write.txt", "r") as f:
>>> print(f.read())
'Real Python!'
您的函数按预期执行!你传递一个字符串"Real Python!"和一个文件来写这个字符串,write.txt。对fputs()的调用返回写入文件的字节数。您可以通过打印文件内容来验证这一点。
还记得您是如何将某些参数传递给PyModuleDef和PyMethodDef结构的。从这个输出中可以看到,Python 使用这些结构来分配函数名和文档字符串等内容。
至此,您已经有了模块的基本版本,但是您还可以做更多的事情!您可以通过添加自定义异常和常量来改进您的模块。
引发异常
Python 异常与 C++异常非常不同。如果您想从 C 扩展模块中引发 Python 异常,那么您可以使用 Python API 来实现。Python API 为异常引发提供的一些函数如下:
| 功能 | 描述 |
|---|---|
PyErr_SetString(PyObject *type, |
|
| T1】 | 接受两个参数:指定异常类型的类型参数和显示给用户的定制消息 |
PyErr_Format(PyObject *type, |
|
| T1】 | 接受两个参数:一个指定异常类型的PyObject *类型参数,以及一个显示给用户的格式化定制消息 |
PyErr_SetObject(PyObject *type, |
|
| T1】 | 接受两个类型都为PyObject *的参数:第一个指定异常的类型,第二个将任意 Python 对象设置为异常值 |
您可以使用其中任何一个来引发异常。但是,使用哪一种以及何时使用完全取决于您的需求。Python API 将所有的标准异常预定义为PyObject类型。
从 C 代码中引发异常
虽然您不能在 C 中引发异常,但是 Python API 将允许您从 Python C 扩展模块中引发异常。让我们通过在代码中添加PyErr_SetString()来测试这个功能。每当要写入的字符串长度小于 10 个字符时,这将引发异常:
1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4
5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args, "ss", &str, &fd)) { 7 return NULL; 8 } 9
10 if (strlen(str) < 10) { 11 PyErr_SetString(PyExc_ValueError, "String length must be greater than 10"); 12 return NULL; 13 } 14
15 fp = fopen(filename, "w"); 16 bytes_copied = fputs(str, fp); 17 fclose(fp); 18
19 return PyLong_FromLong(bytes_copied); 20}
在这里,您在解析参数之后和调用fputs()之前立即检查输入字符串的长度。如果用户传递的字符串少于 10 个字符,那么您的程序将发出一个带有自定义消息的ValueError。一旦出现异常,程序执行就会停止。
注意method_fputs()在引发异常后如何返回NULL。这是因为每当您使用PyErr_*()引发异常时,它会自动在异常表中设置一个内部条目并返回它。不要求调用函数随后再次设置该条目。因此,调用函数返回一个指示失败的值,通常是NULL或-1。(这也应该解释了为什么在使用PyArg_ParseTuple()解析method_fputs()中的参数时需要返回NULL。)
引发自定义异常
您还可以在 Python C 扩展模块中引发自定义异常。然而,事情有点不同。以前,在PyMODINIT_FUNC中,你只是简单地返回由PyModule_Create返回的实例,然后就结束了。但是为了让模块的用户可以访问您的自定义异常,您需要在返回它之前将您的自定义异常添加到模块实例中:
static PyObject *StringTooShortError = NULL; PyMODINIT_FUNC PyInit_fputs(void) { /* Assign module value */ PyObject *module = PyModule_Create(&fputsmodule); /* Initialize new exception object */ StringTooShortError = PyErr_NewException("fputs.StringTooShortError", NULL, NULL); /* Add exception object to your module */ PyModule_AddObject(module, "StringTooShortError", StringTooShortError); return module; }
和前面一样,首先创建一个模块对象。然后使用PyErr_NewException创建一个新的异常对象。这将采用一个形式为module.classname的字符串作为您希望创建的异常类的名称。选择一些描述性的东西,让用户更容易理解到底出了什么问题。
接下来,使用PyModule_AddObject将它添加到模块对象中。这将您的模块对象、正在添加的新对象的名称以及自定义异常对象本身作为参数。最后,您返回您的模块对象。
现在,您已经为您的模块定义了一个要引发的定制异常,您需要更新method_fputs()以便它引发适当的异常:
1static PyObject *method_fputs(PyObject *self, PyObject *args) { 2 char *str, *filename = NULL; 3 int bytes_copied = -1; 4
5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args, "ss", &str, &fd)) { 7 return NULL; 8 } 9
10 if (strlen(str) < 10) { 11 /* Passing custom exception */ 12 PyErr_SetString(StringTooShortError, "String length must be greater than 10"); 13 return NULL; 14 } 15
16 fp = fopen(filename, "w"); 17 bytes_copied = fputs(str, fp); 18 fclose(fp); 19
20 return PyLong_FromLong(bytes_copied); 21}
使用新的更改生成模块后,您可以通过尝试编写长度小于 10 个字符的字符串来测试自定义异常是否按预期工作:
>>> import fputs >>> # Custom exception >>> fputs.fputs("RP!", fp.fileno()) Traceback (most recent call last): File "<stdin>", line 1, in <module> fputs.StringTooShortError: String length must be greater than 10当您尝试编写少于 10 个字符的字符串时,您的自定义异常会引发一条解释错误原因的消息。
定义常数
有些情况下,您会希望在 Python C 扩展模块中使用或定义常量。这与您在上一节中定义自定义异常的方式非常相似。您可以定义一个新的常量,并使用
PyModule_AddIntConstant()将其添加到您的模块实例中:PyMODINIT_FUNC PyInit_fputs(void) { /* Assign module value */ PyObject *module = PyModule_Create(&fputsmodule); /* Add int constant by name */ PyModule_AddIntConstant(module, "FPUTS_FLAG", 64); /* Define int macro */ #define FPUTS_MACRO 256 /* Add macro to module */ PyModule_AddIntMacro(module, FPUTS_MACRO); return module; }此 Python API 函数采用以下参数:
- 你的模块的实例
- 常量的名
- 常数的值
您可以使用
PyModule_AddIntMacro()对宏进行同样的操作:PyMODINIT_FUNC PyInit_fputs(void) { /* Assign module value */ PyObject *module = PyModule_Create(&fputsmodule); /* Add int constant by name */ PyModule_AddIntConstant(module, "FPUTS_FLAG", 64); /* Define int macro */ #define FPUTS_MACRO 256 /* Add macro to module */ PyModule_AddIntMacro(module, FPUTS_MACRO); return module; }该函数采用以下参数:
- 你的模块的实例
- 已经定义的宏的名
注意:如果你想给你的模块添加字符串常量或者宏,那么你可以分别使用
PyModule_AddStringConstant()和PyModule_AddStringMacro()。打开 Python 解释器,查看您的常量和宏是否按预期工作:
>>> import fputs
>>> # Constants
>>> fputs.FPUTS_FLAG
64
>>> fputs.FPUTS_MACRO
256
在这里,您可以看到这些常量可以从 Python 解释器中访问。
测试您的模块
您可以像测试任何其他 Python 模块一样测试您的 Python C 扩展模块。这可以通过为 pytest 编写一个小的测试函数来演示:
import fputs
def test_copy_data():
content_to_copy = "Real Python!"
bytes_copied = fputs.fputs(content_to_copy, 'test_write.txt')
with open('test_write.txt', 'r') as f:
content_copied = f.read()
assert content_copied == content_to_copy
在上面的测试脚本中,您使用fputs.fputs()将字符串"Real Python!"写入一个名为test_write.txt的空文件。然后,你读入这个文件的内容,并使用一个 assert语句将其与你最初写的内容进行比较。
您可以运行这个测试套件来确保您的模块按预期工作:
$ pytest -q
test_fputs.py [100%]
1 passed in 0.03 seconds
要获得更深入的介绍,请查看Python 测试入门。
考虑替代方案
在本教程中,您已经为 C 库函数构建了一个接口,以理解如何编写 Python C 扩展模块。然而,有时您需要做的只是调用一些系统调用或一些 C 库函数,并且您希望避免编写两种不同语言的开销。在这些情况下,可以使用 ctypes 或者 cffi 等 Python 库。
这些是 Python 的外部函数库,提供对 C 库函数和数据类型的访问。尽管社区本身在哪个图书馆最好的问题上存在分歧,但两者都有各自的优点和缺点。换句话说,对于任何给定的项目来说,这两种方法都是不错的选择,但是当您需要在两者之间做出选择时,需要记住一些事情:
-
Python 标准库中包含了
ctypes库。如果你想避免外部依赖,这是非常重要的。它允许你用 Python 为其他语言编写包装器。 -
cffi库尚未包含在标准库中。这可能会成为你特定项目的绊脚石。总的来说,它本质上更像蟒蛇,但是它不为你处理预处理。
有关这些库的更多信息,请查看用 C 库扩展 Python 和“ctypes”模块和Python 和 C 的接口:CFFI 模块。
注:除了ctypes和cffi之外,还有其他各种工具可用。例如,你也可以使用swig和boost::Py。
结论
在本教程中,你已经学习了如何使用 Python API 用 C 编程语言编写一个 Python 接口。您为fputs() C 库函数编写了一个 Python 包装器。在构建和测试模块之前,您还向模块添加了自定义异常和常量。
Python API 为用 C 编程语言编写复杂的 Python 接口提供了许多特性。同时,像cffi或ctypes这样的库可以降低编写 Python C 扩展模块的开销。确保你在做决定之前权衡了所有的因素!******
使用协同过滤构建推荐引擎
原文:https://realpython.com/build-recommendation-engine-collaborative-filtering/
协同过滤是构建智能推荐系统时最常用的技术,随着用户信息的收集,该系统可以学习给出更好的推荐。
像亚马逊、YouTube 和网飞这样的大多数网站都使用协同过滤作为他们复杂推荐系统的一部分。您可以使用这种技术来构建推荐器,根据相似用户的好恶向用户提供建议。
在这篇文章中,你将了解到:
- 协同过滤及其类型
- 构建推荐器所需的数据
- Python 中可用于构建推荐器的库
- 协同过滤的使用案例和挑战
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
什么是协同过滤?
协同过滤是一种可以根据相似用户的反应过滤出用户可能喜欢的项目的技术。
它的工作原理是搜索一大群人,找到与特定用户口味相似的一小群用户。它会查看他们喜欢的项目,并将它们组合在一起,创建一个经过排序的建议列表。
有许多方法可以确定哪些用户是相似的,并结合他们的选择来创建一个推荐列表。本文将向您展示如何使用 Python 来实现这一点。
数据集
为了试验推荐算法,你需要包含一组项目和一组用户的数据,这些用户已经对一些项目做出了反应。
反应可以是显性(从 1 到 5 的等级,喜欢或不喜欢)或隐性(查看一件商品,将其添加到愿望清单,花在一件商品上的时间)。
在处理这些数据时,您通常会看到一个由一组用户对一组项目中的一些项目的反应组成的矩阵。每一行包含用户给出的评级,每一列包含一个项目收到的评级。包含五个用户和五个项目的矩阵可能如下所示:
该矩阵显示了五个用户,他们用 1 到 5 的等级对一些项目进行了评级。例如,第一用户对第三个项目给出了评级 4。
在大多数情况下,矩阵中的单元格是空的,因为用户只对几个项目进行评分。让每个用户对每个可用的项目进行评价或做出反应是极不可能的。单元格大部分为空的矩阵称为稀疏矩阵,与之相反的矩阵(大部分为填充矩阵)称为稠密矩阵。
已经收集了许多数据集,并提供给公众用于研究和基准测试。这里有一个高质量数据源的列表,你可以从中选择。
最好从 GroupLens Research 收集的 MovieLens 数据集开始。特别是, MovieLens 100k 数据集是一个稳定的基准数据集,由 943 个用户对 1682 部电影给出了 100,000 个评级,每个用户至少对 20 部电影进行了评级。
这个数据集由许多文件组成,这些文件包含关于电影、用户以及用户对他们所观看的电影的评级的信息。感兴趣的有以下几个:
u.item: 电影列表u.data: 用户给出的评分列表
包含评级的文件u.data是一个制表符分隔的列表,包含用户 ID、项目 ID、评级和时间戳。文件的前几行如下所示:
如上所示,该文件告诉用户对特定电影的评价。该文件包含 100,000 个这样的评级,这些评级将用于预测用户未观看的电影的评级。
协同过滤涉及的步骤
要构建一个可以根据其他用户的喜好自动向用户推荐物品的系统,第一步就是找到相似的用户或物品。第二步是预测用户尚未评级的项目的评级。所以,你需要这些问题的答案:
- 如何确定哪些用户或项目彼此相似?
- 假设您知道哪些用户是相似的,那么您如何根据相似用户的评分来确定用户对某个项目的评分呢?
- 你如何衡量你计算的评分的准确性?
前两个问题没有单一答案。协同过滤是一系列算法,其中有多种方法来找到相似的用户或项目,并且有多种方法来基于相似用户的评级来计算评级。根据您所做的选择,您最终会得到一种协作过滤方法。在本文中,您将看到寻找相似性和预测评分的各种方法。
要记住的一件重要事情是,在纯粹基于协作过滤的方法中,相似性不是使用诸如用户年龄、电影类型或任何其他关于用户或项目的数据等因素来计算的。它只根据用户对某个项目的评分(显性或隐性)来计算。例如,尽管两个用户的年龄相差很大,但是如果他们对十部电影给出相同的评级,则可以认为他们是相似的。
第三个问题是如何衡量你的预测的准确性,这个问题也有多个答案,其中包括可以在许多地方使用的误差计算技术,而不仅仅是基于协同过滤的推荐器。
衡量结果准确性的一种方法是均方根误差(RMSE ),在这种方法中,您可以预测评分值已知的用户-项目对测试数据集的评分。已知值和预测值之间的差异就是误差。对测试集的所有误差值求平方,找到平均值,然后求该平均值的平方根,得到 RMSE。
另一个测量精度的指标是平均绝对误差(MAE ),通过找出误差的绝对值,然后取所有误差值的平均值,就可以得到误差的大小。
在这一点上,您不需要担心 RMSE 或梅的细节,因为它们是 Python 中各种包的一部分,您将在本文后面看到它们。
现在让我们看看协同过滤家族中不同类型的算法。
基于内存的
第一类包括基于记忆的算法,其中统计技术应用于整个数据集来计算预测。
为了找到用户 U 将给予项目 I 的评级 R ,该方法包括:
- 找到与对项目 I 评分的 U 相似的用户
- 基于上一步中找到的用户评级计算评级 R
在接下来的部分中,您将会看到它们中的每一个。
如何在评分的基础上找到相似用户
为了理解相似性的概念,让我们首先创建一个简单的数据集。
数据包括四个用户 A 、 B 、 C 、 D ,他们对两部电影进行了评分。分级存储在列表中,每个列表包含两个数字来表示每部电影的分级:
- A 的评分是
[1.0, 2.0]。 - B 的评分是
[2.0, 4.0]。 - C 的评分是
[2.5, 4.0]。 - 由 D 给出的评分是
[4.5, 5.0]。
从视觉线索开始,将用户给出的两部电影的评分标绘在图上,并寻找一种模式。图表看起来像这样:

在上图中,每个点代表一个用户,并根据他们对两部电影的评分来绘制。
看点与点之间的距离似乎是估计相似度的好方法,对吗?您可以使用两点之间的欧几里德距离公式来计算距离。您可以使用 scipy 中的功能,如下图所示:
>>> from scipy import spatial >>> a = [1, 2] >>> b = [2, 4] >>> c = [2.5, 4] >>> d = [4.5, 5] >>> spatial.distance.euclidean(c, a) 2.5 >>> spatial.distance.euclidean(c, b) 0.5 >>> spatial.distance.euclidean(c, d) 2.23606797749979如上图,可以用
scipy.spatial.distance.euclidean计算两点之间的距离。用它来计算 A 、 B 、 D 与 C 的评分之间的距离可以看出,就距离而言, C 的评分最接近 B 的评分。你可以看到用户 C 与 B 最接近,即使是通过查看图表。但是在 A 和 D 之外,谁和 C 更接近呢?
就距离而言,你可以说 C 更接近 D 。但是看一下排名,似乎 C 的选择更倾向于 A 而不是 D 因为 A 和 C 喜欢第二部电影的程度几乎是他们喜欢第一部电影的两倍,但是 D 对两部电影的喜欢程度是一样的。
那么,你能用什么来识别欧几里德距离不能识别的模式呢?连接点到原点的线之间的角度可以用来做决定吗?您可以查看连接图形原点和相应点的直线之间的角度,如下所示:
该图显示了将每个点连接到原点的四条线。 A 和 B 的直线重合,使它们之间的角度为零。
你可以考虑一下,如果线与线之间的角度增大,那么相似度降低,如果角度为零,那么用户非常相似。
要使用角度来计算相似性,您需要一个函数来返回较低角度的较高相似性或较小距离,以及较高角度的较低相似性或较大距离。角度的余弦是一个函数,随着角度从 0°增加到 180°,余弦值从 1 减小到-1。
你可以用角度的余弦来找出两个用户的相似度。角度越高,余弦越低,因此用户的相似度越低。您还可以求角度余弦值的倒数,从 1 中减去该值,得到用户之间的余弦距离。
scipy具有计算矢量的余弦距离的功能。对于更大的角度,它返回更大的值:

>>> from scipy import spatial
>>> a = [1, 2]
>>> b = [2, 4]
>>> c = [2.5, 4]
>>> d = [4.5, 5]
>>> spatial.distance.cosine(c,a)
0.004504527406047898
>>> spatial.distance.cosine(c,b)
0.004504527406047898
>>> spatial.distance.cosine(c,d)
0.015137225946083022
>>> spatial.distance.cosine(a,b)
0.0
矢量 C 和 A 之间的较小角度给出了较小的余弦距离值。如果你想以这种方式排列用户相似度,使用余弦距离。
注:上例中只考虑了两部电影,这样更容易将评分向量二维可视化。这样做只是为了便于解释。
具有多个项目的真实用例在评定向量中会涉及更多的维度。你可能也想进入余弦相似度的数学领域。
注意,用户 A 和 B 在余弦相似性度量中被认为是绝对相似的,尽管具有不同的评级。这在现实世界中其实是很常见的,像用户 A 这样的用户就是你所谓的强硬评分者。一个例子是一个电影评论家,他给出的评分总是低于平均水平,但他们列表中的项目的排名与平均评分者的排名相似,如。
要考虑到这些个人用户的偏好,你需要通过消除他们的偏见,让所有的用户达到相同的水平。您可以通过从该用户对每个项目的评分中减去该用户对所有项目的平均评分来实现这一点。下面是它的样子:
- 对于用户 A ,评价向量
[1, 2]具有平均值1.5。从每个评分中减去1.5会得到向量[-0.5, 0.5]。 - 对于用户 B ,评分向量
[2, 4]具有平均值3。从每个评分中减去3会得到向量[-1, 1]。
通过这样做,您已经将每个用户给出的平均评分值更改为 0。试着对用户 C 和 D 做同样的事情,你会看到评级现在被调整为所有用户的平均值为 0,这使他们处于相同的水平,并消除了他们的偏见。
调整后的向量之间的夹角余弦称为中心余弦。这种方法通常用在向量中有很多缺失值的时候,你需要放置一个公共值来填充缺失值。
用随机值填充评级矩阵中缺失的值可能会导致不准确。填充缺失值的一个很好的选择可以是每个用户的平均评级,但是用户 A 和 B 的原始平均值分别是1.5和3,用1.5填充 A 的所有空值以及用3填充 B 的所有空值将使他们成为不同的用户。
但是在调整值之后,两个用户的以为中心的平均值为0,这允许您更准确地捕捉项目高于或低于两个用户平均值的想法,其中两个用户向量中所有缺失的值都具有相同的值0。
欧几里德距离和余弦相似性是可以用来查找彼此相似的用户甚至是彼此相似的项目的一些方法。(上面使用的函数计算余弦距离。要计算余弦相似度,从 1 中减去距离。)
注:中心余弦的公式与皮尔逊相关系数的公式相同。你会发现推荐器上很多资源和库都把中心余弦的实现称为皮尔逊相关。
如何计算收视率
在你确定了一个类似于用户 U 的用户列表后,你需要计算 U 会给某个项目 I 的评分 R 。同样,就像相似性一样,你可以通过多种方式来实现。
你可以预测一个用户对一个物品 I 的评分 R 将会接近与 U 最相似的前 5 或前 10 名用户给予 I 的评分的平均值。由 n 用户给出的平均评分的数学公式如下:

这个公式表明, n 个相似用户给出的平均评分等于他们给出的评分之和除以相似用户数,即为 n 。
会有这样的情况,你找到的 n 个相似用户与目标用户 U 不完全相似。他们中的前 3 名可能非常相似,其余的可能不像前 3 名那样与 U 相似。在这种情况下,您可以考虑一种方法,其中最相似用户的评级比第二相似用户更重要,依此类推。加权平均可以帮助我们实现这一目标。
在加权平均方法中,您将每个评级乘以一个相似性因子(它表明用户有多相似)。通过乘以相似性因子,您可以为评级增加权重。权重越大,评级就越重要。
充当权重的相似性因子应该是上面讨论的距离的倒数,因为距离越小意味着相似性越高。例如,您可以从 1 中减去余弦距离来获得余弦相似度。
利用与目标用户 U 相似的每个用户的相似性因子 S ,可以使用以下公式计算加权平均值:

在上面的公式中,每个评级都乘以给出该评级的用户的相似性因子。用户 U 的最终预测评级将等于加权评级的总和除以权重的总和。
注意:如果你想知道为什么加权评分的总和除以权重的总和,而不是除以 n ,考虑一下这个:在之前的平均值公式中,你除以 n ,权重的值是 1。
在求平均值时,分母总是权重之和,在正常平均值的情况下,权重为 1 意味着分母等于 n 。
使用加权平均,您可以按照相似性的顺序更多地考虑相似用户的评级。
现在,你知道如何找到相似的用户,以及如何根据他们的评分计算评分。还有一种协同过滤,通过找到彼此相似的项目而不是用户并计算评分来预测评分。您将在下一节中读到这种变化。
基于用户与基于项目的协同过滤
上面解释的例子中的技术被称为基于用户或用户-用户协同过滤,其中评级矩阵被用于基于用户给出的评级来寻找相似的用户。如果你使用评分矩阵根据用户给他们的评分来寻找相似的项目,那么这种方法就叫做基于项目或项目-项目协同过滤。
这两种方法在数学上非常相似,但在概念上有所不同。以下是两者的对比:
-
基于用户:对于一个用户 U ,基于给定的物品评分组成的评分向量确定一组相似用户,通过从相似度列表中挑出 N 个已经对物品 I 进行了评分的用户,并基于这 N 个评分计算出该物品 I 的评分。
-
基于条目:对于一个条目 I ,基于接收到的用户评分组成的评分向量确定一组相似条目,通过从相似列表中挑选出 N 个已经被 U 评分的条目,并基于这 N 个评分计算出评分,从而得到一个尚未对其进行评分的用户 U 的评分。
基于项目的协同过滤是由亚马逊开发的。在用户多于项目的系统中,基于项目的过滤比基于用户的过滤更快更稳定。这是有效的,因为通常情况下,一个项目收到的平均评分不会像用户对不同项目给出的平均评分那样快速变化。众所周知,当评分矩阵稀疏时,它比基于用户的方法执行得更好。
虽然,基于项目的方法对于具有浏览或娱乐相关项目(如电影镜头)的数据集表现不佳,其中它给出的推荐对于目标用户来说似乎非常明显。这种数据集使用矩阵分解技术会得到更好的结果,您将在下一节中看到,或者使用混合推荐器,它也通过使用基于内容的过滤来考虑数据的内容,如流派。
你可以使用库 Surprise 快速试验不同的推荐算法。(您将在本文的后面看到更多关于这方面的内容。)
基于模型
第二类包括基于模型的方法,包括减少或压缩大而稀疏的用户项目矩阵的步骤。对于理解这一步,对降维的基本理解会很有帮助。
维度缩减
在用户-项目矩阵中,有两个维度:
- 用户数量
- 项目的数量
如果矩阵大部分是空的,则降低维数可以在空间和时间方面提高算法的性能。您可以使用各种方法,如矩阵分解或自动编码器来做到这一点。
矩阵分解可以看作是将一个大矩阵分解成多个小矩阵的乘积。这类似于整数的因式分解,其中12可以写成6 x 2或4 x 3。在矩阵的情况下,一个维数为m x n的矩阵 A 可以简化为两个维数分别为m x p和p x n的矩阵 X 和 Y 的乘积。
注:在矩阵乘法中,一个矩阵 X 只有在 X 中的列数等于 Y 中的行数时,才能乘以 Y 。因此,两个简化的矩阵具有共同的维数 p 。
根据用于维数缩减的算法,缩减矩阵的数量也可以多于两个。
简化的矩阵实际上分别代表用户和项目。第一个矩阵中的 m 行代表 m 用户,而 p 列告诉您用户的特征或特性。具有 n 个项目和 p 个特性的项目矩阵也是如此。下面是矩阵分解的一个例子:
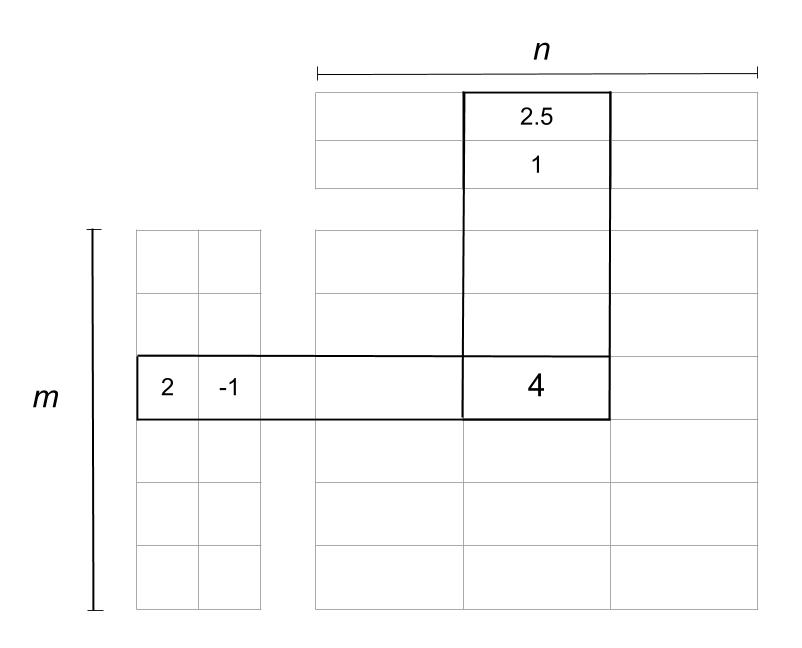
在上图中,矩阵被简化为两个矩阵。左边的是有 m 个用户的用户矩阵,上面的是有 n 个条目的条目矩阵。评级4被降低或分解为:
- 用户向量
(2, -1) - 一个项目向量
(2.5, 1)
用户矩阵中的两列和项目矩阵中的两行被称为潜在因素,并且是关于用户或项目的隐藏特征的指示。因子分解的一种可能解释如下:
-
假设在一个用户向量
(u, v)中,u代表用户有多喜欢恐怖片,而v代表他们有多喜欢言情片。 -
因此,用户向量
(2, -1)表示喜欢恐怖电影并对其进行正面评价,不喜欢浪漫电影并对其进行负面评价的用户。 -
假设在一个项目向量
(i, j)中,i表示一部电影属于恐怖片的程度,j表示该电影属于言情片的程度。 -
电影
(2.5, 1)的恐怖等级为2.5,浪漫等级为1。使用矩阵乘法规则将其乘以用户向量得到(2 * 2.5) + (-1 * 1) = 4。 -
所以,这部电影属于恐怖片类型,用户本来可以给它评分
5,但是稍微包含了浪漫的成分导致最终评分降到了4。
因素矩阵可以提供关于用户和项目的这种洞察力,但是实际上它们通常比上面给出的解释复杂得多。这些因素的数量可以是从一个到数百个甚至数千个。这个数字是模型训练过程中需要优化的东西之一。
在这个例子中,你有两个电影类型的潜在因素,但是在真实的场景中,这些潜在因素不需要太多的分析。这些是数据中的模式,无论你是否理解它们的潜在含义,它们都会自动发挥作用。
潜在因素的数量以这样的方式影响推荐,其中因素的数量越多,推荐变得越个性化。但是太多的因素会导致模型中的过度拟合。
注意: 过度拟合发生在模型训练得太适合训练数据,以至于在新数据下表现不佳的时候。
矩阵分解算法
分解矩阵的流行算法之一是奇异值分解 (SVD)算法。当矩阵分解在网飞奖竞赛中表现出色时,奇异值分解成为人们关注的焦点。其他算法还有 PCA 及其变种、 NMF 等等。如果你想使用神经网络,自动编码器也可以用于降维。
您可以在 Python 的各种库中找到这些算法的实现,因此此时您不需要担心细节。但万一你想多读点,书中关于降维的章节 挖掘海量数据集 值得一读。
使用 Python 构建推荐器
Python 中有相当多的库和工具包提供了各种算法的实现,您可以用它们来构建推荐器。但是在理解推荐系统的时候,你应该尝试的是惊喜。
令人惊讶的是一个 Python SciKit ,它带有各种推荐算法和相似性度量,使构建和分析推荐器变得容易。
下面是如何使用 pip 安装它:
$ pip install numpy
$ pip install scikit-surprise
以下是如何使用 conda 安装它:
$ conda install -c conda-forge scikit-surprise
注意:安装熊猫也是推荐的,如果你想跟随例子。
-
Dataset模块用于从文件中加载数据,熊猫数据帧,甚至是可用于实验的内置数据集。(MovieLens 100k 是惊喜内置数据集之一。)要加载数据集,一些可用的方法有:Dataset.load_builtin()Dataset.load_from_file()Dataset.load_from_df()
-
Reader类用于解析包含评级的文件。它接受数据的默认格式是每个等级按照顺序user item rating存储在单独的行中。该顺序和分隔符可以使用参数进行配置:line_format是一个字符串,它存储数据的顺序,字段名用空格隔开,就像在"item user rating"中一样。sep用于指定字段之间的分隔符,如','。rating_scale用于指定评级尺度。默认为(1, 5)。skip_lines用来表示文件开头要跳过的行数。默认为0。
这里有一个程序,你可以用它从熊猫数据帧或内置的电影镜头 100k 数据集加载数据:
# load_data.py
import pandas as pd
from surprise import Dataset
from surprise import Reader
# This is the same data that was plotted for similarity earlier
# with one new user "E" who has rated only movie 1
ratings_dict = {
"item": [1, 2, 1, 2, 1, 2, 1, 2, 1],
"user": ['A', 'A', 'B', 'B', 'C', 'C', 'D', 'D', 'E'],
"rating": [1, 2, 2, 4, 2.5, 4, 4.5, 5, 3],
}
df = pd.DataFrame(ratings_dict)
reader = Reader(rating_scale=(1, 5))
# Loads Pandas dataframe
data = Dataset.load_from_df(df[["user", "item", "rating"]], reader)
# Loads the builtin Movielens-100k data
movielens = Dataset.load_builtin('ml-100k')
在上面的程序中,数据存储在一个字典中,该字典被加载到一个 Pandas 数据帧中,然后从 Surprise 加载到一个 Dataset 对象中。
基于 K 近邻的算法
推荐器功能的算法选择取决于您想要使用的技术。对于上面讨论的基于记忆的方法,符合要求的算法是中心 k-NN ,因为该算法非常接近上面解释的中心余弦相似性公式。惊喜中有了KNNWithMeans。
要找到相似性,只需通过将字典作为参数传递给推荐器函数来配置该函数。字典应该具有所需的键,例如:
name包含要使用的相似性度量。选项有cosine、msd、pearson或pearson_baseline。默认为msd。user_based是一个boolean,它告诉我们该方法是基于用户还是基于项目。默认值是True,这意味着将使用基于用户的方法。min_support是用户之间考虑相似性所需的最少共同项目数。对于基于项目的方法,这对应于两个项目的公共用户的最小数量。
以下程序配置KNNWithMeans功能:
# recommender.py
from surprise import KNNWithMeans
# To use item-based cosine similarity
sim_options = {
"name": "cosine",
"user_based": False, # Compute similarities between items
}
algo = KNNWithMeans(sim_options=sim_options)
上述程序中的推荐器功能被配置为使用余弦相似性,并使用基于项目的方法来寻找相似的项目。
要试用这个推荐器,您需要从data创建一个Trainset。Trainset是使用相同的数据构建的,但包含更多关于数据的信息,例如算法使用的用户和项目(n_users、n_items)的数量。您可以使用全部数据或部分数据来创建它。您还可以将数据分成多个文件夹,其中一些数据将用于训练,一些用于测试。
注:仅使用一对训练和测试数据通常是不够的。当您将原始数据集分割成训练和测试数据时,您应该创建不止一对,以允许在测试数据的训练中有变化的多个观察。
应该使用多重折叠对算法进行交叉验证。通过使用不同的配对,你会看到推荐者给出的不同结果。MovieLens 100k 提供了五种不同的训练和测试数据分割:u1.base、u1.test、u2.base、u2.test … u5.base、u5.test,用于 5 重交叉验证
这里有一个例子来了解用户 E 会如何评价电影 2:
>>> from load_data import data >>> from recommender import algo >>> trainingSet = data.build_full_trainset() >>> algo.fit(trainingSet) Computing the cosine similarity matrix... Done computing similarity matrix. <surprise.prediction_algorithms.knns.KNNWithMeans object at 0x7f04fec56898> >>> prediction = algo.predict('E', 2) >>> prediction.est 4.15该算法预测用户 E 会给电影评分 4.15,这可能高到足以作为推荐播放。
你应该尝试不同的基于 k-NN 的算法以及不同的相似性选项和矩阵分解算法在惊喜库中可用。在 MovieLens 数据集上尝试它们,看看是否可以超越一些基准。下一节将介绍如何使用 Surprise 来检查哪些参数最适合您的数据。
调整算法参数
Surprise 提供了一个类似于来自
scikit-learn的 GridSearchCV 的GridSearchCV类。对于所有参数中的一个
dict,GridSearchCV尝试所有参数组合,并报告任何精度测量的最佳参数例如,您可以在基于内存的方法中检查哪种相似性度量最适合您的数据:
from surprise import KNNWithMeans from surprise import Dataset from surprise.model_selection import GridSearchCV data = Dataset.load_builtin("ml-100k") sim_options = { "name": ["msd", "cosine"], "min_support": [3, 4, 5], "user_based": [False, True], } param_grid = {"sim_options": sim_options} gs = GridSearchCV(KNNWithMeans, param_grid, measures=["rmse", "mae"], cv=3) gs.fit(data) print(gs.best_score["rmse"]) print(gs.best_params["rmse"])上述程序的输出如下:
0.9434791128171457 {'sim_options': {'name': 'msd', 'min_support': 3, 'user_based': False}}因此,对于 MovieLens 100k 数据集,如果您采用基于项目的方法,并使用 msd 作为最小支持度为 3 的相似性度量,则中心 KNN 算法效果最佳。
类似地,对于基于模型的方法,我们可以使用
Surprise来检查以下因素的哪些值效果最好:
n_epochs是 SGD 的迭代次数,基本上是统计学中用来最小化一个函数的迭代方法。lr_all是所有参数的学习率,是决定每次迭代调整参数多少的参数。reg_all是所有参数的正则化项,是为防止过拟合而添加的惩罚项。注意:请记住,在矩阵分解算法中不会有任何相似性度量,因为潜在因素负责用户或项目之间的相似性。
以下程序将检查 SVD 算法的最佳值,该算法是一种矩阵分解算法:
from surprise import SVD from surprise import Dataset from surprise.model_selection import GridSearchCV data = Dataset.load_builtin("ml-100k") param_grid = { "n_epochs": [5, 10], "lr_all": [0.002, 0.005], "reg_all": [0.4, 0.6] } gs = GridSearchCV(SVD, param_grid, measures=["rmse", "mae"], cv=3) gs.fit(data) print(gs.best_score["rmse"]) print(gs.best_params["rmse"])上述程序的输出如下:
0.9642278631521038 {'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}因此,对于 MovieLens 100k 数据集,如果使用 10 个历元并使用 0.005 的学习率和 0.4 的正则化,
SVD算法效果最佳。在
Surprise中可用的其他基于矩阵分解的算法有 SVD++ 和 NMF 。根据这些示例,您可以深入研究这些算法中可以使用的所有参数。你绝对应该看看它们背后的数学原理。因为你不必一开始就担心算法的实现,所以推荐器是进入机器学习领域并在此基础上构建应用程序的好方法。
协同过滤什么时候可以用?
协作过滤围绕用户与项目的交互进行。这些交互有助于发现商品或用户数据本身无法发现的模式。以下几点可以帮助你决定是否可以使用协同过滤:
协同过滤不需要知道关于项目或用户的特征。它适用于一组不同类型的项目,例如,超市的库存,其中可以添加各种类别的项目。但是,在一组类似的项目中,比如书店,像作者和流派这样的已知特征可能是有用的,并且可能受益于基于内容的或混合的方法。
协同过滤可以帮助推荐者在用户的简档中不过度专业化,推荐与他们之前所见完全不同的项目。如果你希望你的推荐者不会向刚刚买了另一双类似运动鞋的人推荐一双运动鞋,那么尝试在你的推荐者咒语中加入协同过滤。
尽管协同过滤在推荐器中非常常用,但在使用它时面临的一些挑战如下:
协同过滤会导致一些问题,比如添加到列表中的新项目冷启动。直到有人评价他们,他们才被推荐。
数据稀疏会影响基于用户的推荐器的质量,并且还会增加上述冷启动问题。
对于不断增长的数据集,扩展可能是一个挑战,因为复杂性可能会变得太大。当数据集很大时,基于项目的推荐器比基于用户的推荐器更快。
通过一个简单的实现,您可能会发现这些推荐已经很流行了,而来自长尾部分的项目可能会被忽略。
每种类型的推荐算法都有自己的优缺点,通常是混合推荐器来解决这个问题。多个算法协同工作或在一个管道中工作的好处可以帮助您设置更准确的推荐器。事实上,网飞奖得主的解决方案也是多种算法的复杂混合。
结论
您现在知道了协同过滤型推荐器需要进行哪些计算,以及如何在您的数据集上快速尝试各种类型的算法,以确定协同过滤是否可行。即使它看起来不太符合您的数据,但所讨论的一些用例可能会帮助您以一种混合的方式进行长期规划。
这里有一些关于协作过滤和其他推荐算法的更多实现和进一步阅读的资源。
图书馆:
- light FM:Python 中的一种混合推荐算法
- Python-recsys : 用于实现推荐系统的 Python 库
研究论文:
- 基于项目的协同过滤推荐算法 : 第一篇关于基于项目推荐器的论文发表
- 用协同过滤编织一幅信息织锦 : 首次使用术语协同过滤
书籍:
用 Bottle、SQLAlchemy 和 Twitter API 构建一个简单的 Web 应用
原文:https://realpython.com/building-a-simple-web-app-with-bottle-sqlalchemy-twitter-api/
去年 10 月,我们向 PyBites 的观众发出挑战,要求他们制作一个网络应用程序,以便更好地浏览每日 Python 提示提要。在这篇文章中,我将分享我一路构建和学习到的东西。
在本文中,您将了解到:
- 如何克隆项目回购,设置 app?
- 如何通过 Tweepy 模块使用 Twitter API 加载推文。
- 如何使用 SQLAlchemy 来存储和管理数据(提示和标签)。
- 如何使用类似 Flask 的微型 web 框架 Bottle 构建一个简单的 web 应用程序。
- 如何使用 pytest 框架添加测试?
- 更好的 Code Hub 指南如何带来更易维护的代码。
如果你想继续下去,详细阅读代码(并可能有所贡献),我建议你分叉repo。让我们开始吧。
项目设置
首先,名称空间是一个非常棒的想法,所以让我们在一个虚拟环境中工作。使用 Anaconda,我像这样创建它:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip在 Postgres 中创建生产和测试数据库:
$ psql psql (9.6.5, server 9.6.2) Type "help" for help. # create database pytip; CREATE DATABASE # create database pytip_test; CREATE DATABASE我们需要证书来连接到数据库和 Twitter API ( 首先创建一个新的应用)。根据最佳实践,配置应该存储在环境中,而不是代码中。将以下 env 变量放在~/virtualenvs/py tip/bin/activate的末尾,该脚本处理虚拟环境的激活/停用,确保为您的环境更新这些变量:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip' # twitter export CONSUMER_KEY='xyz' export CONSUMER_SECRET='xyz' export ACCESS_TOKEN='xyz' export ACCESS_SECRET='xyz' # if deploying it set this to 'heroku' export APP_LOCATION=local在同一个脚本的 deactivate 函数中,我取消了它们的设置,因此在停用(离开)虚拟环境时,我们将事情排除在 shell 范围之外:
unset DATABASE_URL unset CONSUMER_KEY unset CONSUMER_SECRET unset ACCESS_TOKEN unset ACCESS_SECRET unset APP_LOCATION现在是激活虚拟环境的好时机:
$ source ~/virtualenvs/pytip/bin/activate克隆存储库,在启用虚拟环境的情况下,安装要求:
$ git clone https://github.com/pybites/pytip && cd pytip $ pip install -r requirements.txt接下来,我们导入包含以下内容的推文集合:
$ python tasks/import_tweets.py然后,验证表是否已创建,tweets 是否已添加:
$ psql \c pytip pytip=# \dt List of relations Schema | Name | Type | Owner --------+----------+-------+---------- public | hashtags | table | postgres public | tips | table | postgres (2 rows) pytip=# select count(*) from tips; count ------- 222 (1 row) pytip=# select count(*) from hashtags; count ------- 27 (1 row) pytip=# \q现在让我们运行测试:
$ pytest ========================== test session starts ========================== platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0 rootdir: realpython/pytip, inifile: collected 5 items tests/test_tasks.py . tests/test_tips.py .... ========================== 5 passed in 0.61 seconds ==========================最后,运行瓶子应用程序:
$ python app.py浏览到 http://localhost:8080 ,瞧:你应该会看到按受欢迎程度降序排列的提示。点击左边的标签链接,或者使用搜索框,你可以很容易地过滤它们。在这里我们看到了熊猫的提示举例:
我用 MUI 做的设计——一个轻量级 CSS 框架,遵循 Google 的材料设计准则。
实施细节
DB 和 SQLAlchemy
我使用 SQLAlchemy 与数据库接口,以避免不得不编写大量(冗余的) SQL 。
在 tips/models.py 中,我们定义了我们的模型-
Hashtag和Tip-SQLAlchemy 将映射到 DB 表:from sqlalchemy import Column, Sequence, Integer, String, DateTime from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class Hashtag(Base): __tablename__ = 'hashtags' id = Column(Integer, Sequence('id_seq'), primary_key=True) name = Column(String(20)) count = Column(Integer) def __repr__(self): return "<Hashtag('%s', '%d')>" % (self.name, self.count) class Tip(Base): __tablename__ = 'tips' id = Column(Integer, Sequence('id_seq'), primary_key=True) tweetid = Column(String(22)) text = Column(String(300)) created = Column(DateTime) likes = Column(Integer) retweets = Column(Integer) def __repr__(self): return "<Tip('%d', '%s')>" % (self.id, self.text)在 tips/db.py 中,我们导入了这些模型,现在很容易使用 db,例如与
Hashtag模型接口:def get_hashtags(): return session.query(Hashtag).order_by(Hashtag.name.asc()).all()并且:
def add_hashtags(hashtags_cnt): for tag, count in hashtags_cnt.items(): session.add(Hashtag(name=tag, count=count)) session.commit()查询 Twitter API
我们需要从 Twitter 上检索数据。为此,我创建了tasks/import _ tweets . py。我将它打包在任务下,因为它应该在每日 cronjob 中运行,以寻找新的提示并更新现有推文的统计数据(点赞和转发的数量)。为了简单起见,我每天都重新创建表格。如果我们开始依赖与其他表的 FK 关系,我们肯定应该选择 update 语句而不是 delete+add。
我们在项目设置中使用了这个脚本。让我们更详细地看看它是做什么的。
首先,我们创建一个 API 会话对象,并将其传递给 tweepy。光标。API 的这个特性非常好:它处理分页,遍历时间轴。对于小费的数量——在我写这篇文章的时候是 222 英镑——这真的很快。
exclude_replies=True和include_rts=False参数很方便,因为我们只想要每日 Python Tip 自己的推文(而不是转发推文)。从提示中提取标签只需要很少的代码。
首先,我为标签定义了一个正则表达式:
TAG = re.compile(r'#([a-z0-9]{3,})')然后,我用
findall获取所有标签。我把它们交给了收藏。计数器,它返回一个类似 dict 的对象,标签作为键,并作为值计数,按值降序排列(最常见)。我排除了太常见的 python 标记,它会扭曲结果。
def get_hashtag_counter(tips): blob = ' '.join(t.text.lower() for t in tips) cnt = Counter(TAG.findall(blob)) if EXCLUDE_PYTHON_HASHTAG: cnt.pop('python', None) return cnt最后,tasks/import _ tweets . py中的
import_*函数实际导入 tweets 和 hashtags,调用 tips 目录/包的add_*DB 方法。用瓶子做一个简单的 web 应用
有了这些准备工作,制作一个 web 应用程序变得异常简单(如果你以前使用过 Flask 的话,这并不奇怪)。
首先认识瓶:
Bottle 是一个快速、简单、轻量级的 WSGI 微型 web 框架,用于 Python 。它作为一个单独的文件模块发布,除了 Python 标准库之外,没有任何依赖关系。
很好。最终的 web 应用程序由< 30 LOC and can be found in app.py 组成。
对于这个简单的应用程序,只需要一个带有可选标记参数的方法。类似于 Flask,路由是由 decorators 处理的。如果用标签调用,它过滤标签上的提示,否则显示所有提示。视图装饰器定义要使用的模板。像 Flask(和 Django)一样,我们返回一个用于模板的字典。
@route('/') @route('/<tag>') @view('index') def index(tag=None): tag = tag or request.query.get('tag') or None tags = get_hashtags() tips = get_tips(tag) return {'search_tag': tag or '', 'tags': tags, 'tips': tips}根据文档,要处理静态文件,您需要在导入之后的顶部添加以下代码片段:
@route('/static/<filename:path>') def send_static(filename): return static_file(filename, root='static')最后,我们希望确保我们只在本地主机上以调试模式运行,因此我们在项目设置中定义了
APP_LOCATIONenv 变量:if os.environ.get('APP_LOCATION') == 'heroku': run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000))) else: run(host='localhost', port=8080, debug=True, reloader=True)瓶子模板
Bottle 自带了一个快速、强大、易学的内置模板引擎,名为 SimpleTemplate 。
在视图子目录中,我定义了一个 header.tpl 、 index.tpl 和 footer.tpl 。对于标签云,我使用了一些简单的内联 CSS 来增加标签大小,参见 header.tpl :
% for tag in tags: <a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a> % end在 index.tpl 中我们循环了一下提示:
% for tip in tips: <div class='tip'> <pre>{{ !tip.text }}</pre> <div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div> </div> % end如果你熟悉 Flask 和 Jinja2,这应该看起来很熟悉。嵌入 Python 甚至更容易,输入更少—
(% ...vs{% ... %}。所有的 css、图片(和 JS,如果我们会用到的话)都放在 static 子文件夹中。
这就是用 Bottle 制作一个基本 web 应用程序的全部内容。一旦正确定义了数据层,事情就简单多了。
用 pytest 添加测试
现在,让我们通过添加一些测试来使这个项目更健壮一点。测试 DB 需要更深入地研究 pytest 框架,但是我最终使用了 pytest.fixture decorator 来建立和拆除一个包含一些测试 tweets 的数据库。
我没有调用 Twitter API,而是使用了 tweets.json 中提供的一些静态数据。并且,我没有使用 live DB,而是在 tips/db.py 中,检查 pytest 是否是调用者(
sys.argv[0])。如果是这样,我使用测试数据库。我可能会对此进行重构,因为 Bottle 支持使用配置文件。hashtag 部分更容易测试(
test_get_hashtag_counter),因为我可以在多行字符串中添加一些 hash tag。不需要固定装置。代码质量很重要——更好的代码中枢
更好的代码中枢指导你写,嗯,更好的代码。在编写测试之前,项目得分为 7:
不错,但我们可以做得更好:
结论和学习
我们的代码挑战#40 提供了一些好的实践:
- 我建立了一个有用的应用程序,可以扩展(我想添加一个 API)。
- 我用了一些很酷的值得探索的模块: Tweepy ,SQLAlchemy,和 Bottle。
- 我学习了更多的 pytest,因为我需要夹具来测试与数据库的交互。
- 最重要的是,必须使代码可测试,应用程序变得更加模块化,这使得它更容易维护。更好的 Code Hub 在这个过程中帮助很大。
- 我使用我们的分步指南将应用程序部署到 Heroku 。
我们挑战你
学习和提高你的编码技能的最好方法是练习。在 PyBites,我们通过组织 Python 代码挑战巩固了这一概念。查看我们的成长收藏、叉回购,获取编码!
通过对你的作品提出拉取请求,让我们知道你是否创造了一些很酷的东西。我们已经看到人们在这些挑战中竭尽全力,我们也是如此。
编码快乐!***
用 Python 和 PyQt 构建一个批量文件重命名工具
假设您需要使用特定的命名模式来重命名个人文件夹中的多个文件。手动操作既耗时又容易出错。因此,您正在考虑通过使用 Python 构建自己的批量文件重命名工具来自动化文件重命名过程。如果是这样,那么这篇教程就是为你准备的。
在本教程中,您将学习如何:
- 使用 Qt Designer 和 PyQt 为批量文件重命名工具创建 GUI
- 使用 PyQt 线程卸载文件重命名过程,防止 GUI 冻结
- 使用
pathlib管理系统路径和重命名文件- 根据重命名过程更新 GUI 状态
通过完成本教程中的项目,您将能够应用与 PyQt、Qt Designer、PyQt 线程以及使用 Python 的
pathlib处理文件系统路径相关的大量技能。您可以通过单击下面的链接下载您将在本教程中构建的批量文件重命名工具的最终源代码:
获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
演示:使用 Python 和 PyQt 的批量文件重命名工具
在本教程中,您将构建一个批量文件重命名工具来自动重命名您的文件系统中给定目录下的多个文件。要构建这个应用程序,您将使用 Python 的
pathlib来管理文件重命名过程,并使用 PyQt 来构建应用程序的图形用户界面(GUI)。这是你的批量文件重命名工具在本教程结束后的外观和工作方式:
https://player.vimeo.com/video/521010353?background=1
完成应用程序的构建后,您将能够重命名文件系统中的多个文件,这是组织个人文件和文件夹时的一项常见任务。在本例中,应用程序主要关注图像和 Python 文件,但是您可以随时添加其他文件类型。
项目概述
您将在本教程中构建的项目由一个 GUI 应用程序组成,该应用程序从给定的目录中加载多个文件,并允许您使用预定义的文件名前缀和连续数字一次性重命名所有这些文件。在本节中,您将首先了解问题和可能的解决方案。您还将了解如何设计项目。
布置项目
为了构建您的批量文件重命名工具,您将创建几个模块和包,并将它们组织成一个连贯的 Python 应用程序布局。项目的根目录将如下所示:
./rprename_project/ │ ├── rprename/ │ │ │ ├── ui/ │ │ ├── __init__.py │ │ ├── window.py │ │ └── window.ui │ │ │ ├── __init__.py │ ├── app.py │ ├── rename.py │ └── views.py │ ├── README.md ├── requirements.txt └── rprenamer.py这里,
rprename_project/是项目的根目录,您将在这里创建以下文件:
README.md提供了项目的一般描述以及安装和运行应用程序的说明。为您的项目准备一个README.md文件被认为是编程中的最佳实践,尤其是如果您计划将其作为开源解决方案发布的话。requirements.txt为项目提供了外部依赖列表。rprenamer.py提供了运行应用程序的入口点脚本。然后是
rprename/目录,该目录将包含一个包含以下模块的 Python 包:
__init__.py启用rprename/作为 Python 包。app.py提供了 PyQt 的骨骼应用。rename.py提供了文件重命名功能。views.py提供了应用程序的 GUI 和相关功能。
ui/子目录将提供一个包来存储 GUI 相关的代码。它将包含以下文件和模块:
__init__.py启用ui/作为 Python 包。window.py包含应用程序主窗口的 Python 代码。你将看到如何使用pyuic5生成这个文件。window.ui保存一个 Qt 设计器文件,该文件包含应用程序主窗口的代码,格式为XML。继续用除了
window.ui和window.py之外的所有文件和模块创建这个目录结构。在本教程的后面,你将看到如何用 Qt Designer 和pyuic5创建这两个文件。要下载项目的目录结构,请单击下面的链接:
获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
概述解决方案
您的批量文件重命名工具将是一个功能齐全的 GUI 应用程序。它将允许你从一个现有的目录中加载几个文件,并使用一个描述性的文件名前缀和连续的数字来重命名它们。要构建应用程序,您需要采取以下步骤:
- 创建应用程序的 GUI。
- 提供加载和重命名多个文件的功能。
- 根据文件重命名过程的进度更新应用程序的 GUI。
要创建应用程序的 GUI,您将使用 Qt Designer。该工具提供了一个用户友好的界面,通过在空白表单上拖放图形组件(窗口小部件)来创建 GUI。有了这个工具,您的 GUI 创建过程将变得快速而高效。
谈到用 Python 管理文件和目录,在标准库中有几个选项。例如,您可以使用
os.path来处理文件系统路径,使用os来使用操作系统功能,例如使用os.rename()来重命名文件。然而,在本教程中,您将使用pathlib来完成这两个任务。注: Python 3.4 在标准库中增加了
pathlib。这个模块提供了表示文件系统路径的类,并允许对它们进行操作。通常,您将使用
pathlib.Path来管理应用程序中的文件和目录路径。一旦有了一个指向物理文件或目录的Path对象,就可以在该对象上调用.rename()来重命名相关的文件或目录。接下来,您需要编写功能代码,将多个文件加载到您的应用程序中,并一次性重命名它们。根据需要重命名的文件数量,该操作可能需要相当长的时间。这可能会导致应用程序的 GUI 冻结。为了防止 GUI 冻结问题,您将使用
QThread将重命名过程卸载给一个工作线程。文件重命名过程需要与应用程序的 GUI 连接,以便用户知道在任何给定的时间发生了什么。在本例中,您将设置一个进度条来反映操作进度。
您还将编写一些代码来确保 GUI 根据文件重命名进度和状态进行更新。至少有两种管理 GUI 更新的通用策略:
- 使用条件语句检查状态并相应地采取行动
- 根据应用程序的状态启用和禁用小部件。
在这个项目中,您将使用第二种方法,这种方法可能更加直观和用户友好,提供更好的用户体验。
先决条件
要完成本教程并从中获得最大收益,您应该熟悉以下概念:
- 用 Python 和 PyQt 创建 GUI 应用程序
- 使用 Qt Designer 创建图形用户界面
- 使用 PyQt
QThread卸载长时间运行的任务并防止 GUI 冻结- 使用
pathlib管理系统路径和重命名文件如果你没有掌握所有需要的知识,那也没关系!您可以随时开始学习本教程,花些时间查看以下资源:
- Python 和 PyQt:构建 GUI 桌面计算器
- Qt Designer 和 Python:更快地构建您的 GUI 应用程序
- 使用 PyQt 的 QThread 来防止 GUI 冻结
- Python 3 的 pathlib 模块:驯服文件系统
此外,您可以查看以下资源:
- Python 和 PyQt:创建菜单、工具栏和状态栏
- PyQt 布局:创建专业外观的 GUI 应用程序
- Python 3 中的面向对象编程(OOP)
- 模型-视图-控制器(MVC)解释-用乐高
- PyQt 文档
就外部软件依赖性而言,你的批量文件重命名工具依赖于 PyQt v5.15.12 。您可以照常使用
pip从 PyPI 安装这个库:$ python -m pip install pyqt5最后,您应该创建一个虚拟环境,按照 Python 最佳实践的建议隔离项目的依赖关系。之后,是时候开始开发你自己的批量文件重命名工具了!
步骤 1:构建批量文件重命名工具的 GUI
在本节中,您将使用 Qt Designer 快速创建批量文件重命名工具的 GUI。在这一步的最后,您将拥有一个 Qt Designer 的
.ui文件,它提供了以下窗口所需的代码:
您还将学习如何自动将您的
.ui文件翻译成 Python 代码。您将使用该代码为应用程序的主窗口提供 GUI。若要下载这些文件以及您将在本节中编写的所有代码,请单击下面的链接:
获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
用 Qt Designer 创建 GUI
要开始使用批量文件重命名工具的 GUI,请启动 Qt Designer。然后创建一个基于小部件的表单,并运行以下视频中显示的步骤:
https://player.vimeo.com/video/518785883
以上视频中的步骤如下:
- 使用新表单对话框中的小部件模板创建一个新表单,并将其标题设置为 RP 重命名器。
- 添加一个标签,并将其文本设置为最后一个源目录:。
- 添加一个行编辑来保存所选目录的路径,并将其
.readOnly属性设置为True。- 添加一个按钮并将其文本设置为 &加载文件。
- 添加两个文本为的标签,分别重命名和重命名的文件,并将它们的字体样式设置为加粗。
- 添加两个列表小部件,分别显示要重命名的文件和已重命名的文件。
- 为标签及其相应的列表小部件设置垂直布局。
- 使用拆分器连接两种排列。
- 添加一个标签并将其文本设置为文件名前缀:。
- 添加一个行编辑来获取用户的文件名前缀,并将其占位符文本设置为将文件重命名为… 。
- 添加一个标签并将其文本设置为。jpg 。
- 添加一个按钮,并将其文本设置为 &重命名。
- 添加一个进度条并将其值设置为
0。- 调整标签、线条编辑和按钮的
minimumSize和maximumSize属性,以便在用户调整窗口大小时提供一致的调整行为。- 将网格布局设置为表单的顶级布局。
完成后,将表单保存为
rprename/ui/目录下的window.ui。不要关闭 Qt Designer。继续更改以下对象的.objectName属性:
目标 价值 FormWindowlineEditdirEditpushButtonloadFilesButtonlistWdgetsrcFileListlistWidget_2dstFileListlineEdit_2prefixEditlabel_5extensionLabelpushButton_2renameFilesButton为此,您可以在对象检查器中选择对象,并在属性编辑器中更改属性值:
您需要更改对象名称,因为您将在 Python 代码中使用这些名称,因此它们应该更具描述性和可读性。现在继续点击 Qt Designer 工具栏上的保存,让新的对象名持久保存在你的
window.ui文件中。您也可以通过按键盘上的Ctrl+S来保存文件。一旦你完成了批量文件重命名工具的 GUI 构建,你可以关闭 Qt Designer,因为你不再需要它了。接下来,您需要将刚刚创建的
.ui文件的内容翻译成 Python 代码。这就是你在下一节要做的。将 Qt Designer 的输出转换成 Python 代码
一旦您有了一个适合您的应用程序的 GUI 的
.ui文件,您需要将这个文件的内容转换成 Python 代码,以便您可以在最终的应用程序中加载 GUI。PyQt 提供了一个名为pyuic5的命令行工具,允许您执行这种转换。注意:您也可以使用
uic.loadUi()将.ui文件的内容直接加载到您的应用程序中。然而,这种策略主要被推荐用于小对话。如果你看一下你的
window.ui文件的内容,那么你会看到它包含了XML代码。这些代码定义了应用程序 GUI 的所有图形组件。下面是文件内容的一个片段:<?xml version="1.0" encoding="UTF-8"?> <ui version="4.0"> <class>Window</class> <widget class="QWidget" name="Window"> <property name="geometry"> <rect> <x>0</x> <y>0</y> <width>720</width> <height>480</height> </rect> </property> <property name="windowTitle"> <string>RP Renamer</string> </property> <!-- Snip... -->在这个小片段中,
Window的定义是顶级类。这个类代表你的主窗口。然后XML代码定义其他类并设置它们的属性。由于 PyQt 提供了pyuic5来自动将这个XML代码翻译成 Python 代码,所以您不需要担心您的.ui文件的内容。你只需要知道如何使用pyuic5。现在,在您的
rprename/ui/目录下打开一个终端并运行以下命令:$ pyuic5 -o window.py window.ui这个命令从
window.ui文件生成一个名为window.py的 Python 模块,并将其放在您的rprename/ui/目录中。该模块包含批量文件重命名工具 GUI 的 Python 代码。下面是代码的一个小样本:# -*- coding: utf-8 -*- # Form implementation generated from reading ui file 'window.ui' # # Created by: PyQt5 UI code generator 5.14.1 # # WARNING! All changes made in this file will be lost! from PyQt5 import QtCore, QtGui, QtWidgets class Ui_Window(object): def setupUi(self, Window): Window.setObjectName("Window") Window.resize(720, 480) # Snip... def retranslateUi(self, Window): _translate = QtCore.QCoreApplication.translate Window.setWindowTitle(_translate("Window", "RP Renamer")) # Snip...
Ui_Window提供了生成批量文件重命名工具 GUI 的所有代码。在这种情况下,.setupUi()包含创建所有需要的小部件并在 GUI 上展示它们的代码,而.retranslateUi()包含用于国际化和本地化的代码,这超出了本教程的范围。因为您正在使用
pyuic5从现有的.ui文件中自动生成 Python 代码,所以您不需要担心window.py的内容。与文件状态顶部的WARNING!注释一样,如果使用 Qt Designer 更新 GUI 并重新生成 Python 代码,您对该文件所做的所有更改都将消失。拥有一个包含 GUI 特定代码的模块强烈鼓励 GUI 逻辑与业务逻辑的分离,这是模型-视图-控制器模式中的一个基本原则。
至此,您的项目布局已经完成。您已经拥有了创建批量文件重命名工具所需的所有文件。现在是时候使用刚刚创建的贵由构建 PyQt 应用程序的框架了。
步骤 2:创建 PyQt 框架应用程序
到目前为止,您已经使用 Qt Designer 为批量文件重命名工具构建了一个 GUI。您还使用了
pyuic5来自动将.ui文件内容翻译成 Python 代码,以便您可以在应用程序中使用它。最后,您将代码保存到rprename/ui/目录下的window.py中。在本节中,您将创建一个 PyQt 框架应用程序,并将其主窗口设置为使用您在
window.py中拥有的 GUI 代码。要下载您将在本节中编写的文件和所有代码,请单击下面的链接:获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
设置批量文件重命名工具的窗口
要为批量文件重命名工具创建框架 PyQt 应用程序,首先需要创建应用程序的主窗口。首先,启动你最喜欢的代码编辑器或 IDE ,打开
rprename/__init__.py文件。添加以下内容:# -*- coding: utf-8 -*- # rprename/__init__.py """This module provides the rprename package.""" __version__ = "0.1.0"除了一些注释和模块 docstring ,上面的文件定义了一个名为
__version__的顶级常量来保存应用程序的版本号。接下来,打开
rprename/views.py,将以下内容写入其中:# -*- coding: utf-8 -*- # rprename/views.py """This module provides the RP Renamer main window.""" from PyQt5.QtWidgets import QWidget from .ui.window import Ui_Window class Window(QWidget, Ui_Window): def __init__(self): super().__init__() self._setupUI() def _setupUI(self): self.setupUi(self)在
views.py中,你先从PyQt5.QtWidgets中导入QWidget。然后你从ui.window进口Ui_Window。正如您之前看到的,这个类为您的批量文件重命名工具提供了 GUI。接下来,创建一个名为
Window的新类。这个类使用多重继承。它继承自QWidget,也继承自你的 GUI 类Ui_Window。QWidget启用基本 GUI 功能,Ui_Window为该应用程序提供您想要的特定 GUI 排列。注意:你也可以使用合成来为你的
Window创建 GUI。例如,您可以这样定义
Window:# rprename/views.py # Snip... class Window(QWidget): def __init__(self): super().__init__() self.ui = Ui_Window() self._setupUI() def _setupUI(self): self.ui.setupUi(self)在这种情况下,您创建
.ui作为Ui_Window的实例。从现在开始,您需要使用.ui来访问应用程序 GUI 上的小部件。在本教程中,您使用多重继承方法,因为它使得所有用户界面组件都可以直接访问,而不需要使用
.ui属性。要更深入地了解这个主题,请在您的应用程序中使用设计器 UI 文件来查看。
Window的初始化器使用super()调用基类初始化器。它还调用了._setupUI(),这是一个非公共的方法,将收集生成和设置 GUI 所需的所有代码。至此,._setupUI(self)只调用了第二个父类Ui_Window提供的.setupUi()。注意: Python 不区分私有和公共属性。上一段中的术语非公共指的是那些不打算在包含类之外使用的属性。这种属性的 Python 命名约定是在名称中使用前导下划线(
_)。准备好初始版本的
Window后,您可以继续为您的批量文件重命名工具创建一个 PyQt 框架应用程序。创建 PyQt 框架应用程序
既然您已经准备好了应用程序的主窗口,那么是时候编写创建 PyQt 应用程序所需的样板代码了。回到代码编辑器,打开
rprename/app.py文件。然后添加以下代码:# -*- coding: utf-8 -*- # rprename/app.py """This module provides the RP Renamer application.""" import sys from PyQt5.QtWidgets import QApplication from .views import Window def main(): # Create the application app = QApplication(sys.argv) # Create and show the main window win = Window() win.show() # Run the event loop sys.exit(app.exec())在此模块中,您导入
sys来访问exit()。该函数允许您在用户关闭主窗口时干净地退出应用程序。然后你从PyQt5.QtWidgets导入QApplication,从views导入Window。最后一步是将main()定义为应用程序的主函数。在
main()中,你实例化了QApplication和Window。然后你在Window上呼叫.show()。最后,使用.exec()运行应用程序的主循环或事件循环。编写应用程序的入口点脚本
有了 PyQt 框架应用程序,就可以创建合适的入口点脚本,以便快速运行应用程序。从根目录打开
rprenamer.py文件,并在其中键入以下代码:#!/usr/bin/env python3 # -*- coding: utf-8 -*- # rprenamer.py """This module provides the RP Renamer entry-point script.""" from rprename.app import main if __name__ == "__main__": main()这个脚本相当小。您首先从您的
app.py模块导入main()。然后使用传统的 Python 条件语句,如果用户将模块作为 Python 脚本运行,该语句将调用main()。现在你可以打开一个终端并运行脚本来启动应用程序。您将在屏幕上看到以下窗口:
酷!您的批量文件重命名工具有一个漂亮的 GUI,它提供了一个按钮来加载您想要重命名的文件。第一行编辑将显示源目录的路径。左侧的列表小部件将显示要重命名的文件列表,右侧的列表小部件将显示重命名的文件。
要开始文件重命名过程,用户需要提供一个文件名前缀,然后单击重命名。底部的进度条将显示文件重命名进度。
在下一节中,您将编写所需的代码来提供应用程序的主要功能,一次性重命名多个文件。因此,请关闭应用程序窗口,继续添加功能。
第 3 步:用
pathlib和 PyQt 线程重命名文件为了实现批量文件重命名工具的文件重命名功能,您将使用 Python 的
pathlib和 PyQtQThread。使用pathlib,你可以管理文件系统路径和重命名文件。另一方面,使用QThread,您将在单独的执行线程中重命名文件。为什么?嗯,根据您要重命名的文件的数量,重命名过程可能需要相当长的时间。在应用程序的主线程中启动一个长时间运行的任务可能会冻结 GUI,从而导致糟糕的用户体验。
为了避免 GUI 冻结问题,您可以创建一个 worker
QThread来卸载文件重命名过程,并使您的应用程序响应迅速。同样,您可以通过单击下面的链接下载您将在本节中编写的所有代码:
获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
加载并显示目标文件
要开始重命名文件,您首先需要一种将这些文件加载到应用程序中的方法。PyQt 提供了一个名为
QFileDialog的类,允许您使用预定义的对话框从文件系统中选择文件或目录。一旦选择了要重命名的文件,就需要将它们的路径存储在一个方便的数据结构中。回到
rprename/views.py并像这样更新代码:# -*- coding: utf-8 -*- # rprename/views.py """This module provides the RP Renamer main window.""" from collections import deque from pathlib import Path from PyQt5.QtWidgets import QFileDialog, QWidget from .ui.window_ui import Ui_Window FILTERS = ";;".join( ( "PNG Files (*.png)", "JPEG Files (*.jpeg)", "JPG Files (*.jpg)", "GIF Files (*.gif)", "Text Files (*.txt)", "Python Files (*.py)", ) ) class Window(QWidget, Ui_Window): # Snip...这里,你先从
collections导入deque。Deques 是对栈和队列的概括。它们支持从队列的任意一端进行有效的追加和弹出操作。在这种情况下,您将使用一个 deque 来存储需要重命名的文件的路径。你也从
pathlib导入Path。这个类可以表示文件系统中具体的文件或目录路径。您将使用这个类对文件和目录执行不同的操作。在本教程中,您将使用Path.rename()来重命名硬盘中的物理文件。然后你从
PyQt5.QtWidgets导入QFileDialog。这个类提供了一个合适的对话框来从给定的目录中选择文件。FILTER常量以字符串形式指定不同的文件过滤器。这些过滤器允许您在将文件加载到应用程序时从不同的文件类型中进行选择。保持
views.py打开,像这样更新Window:1# rprename/views.py 2# Snip... 3 4class Window(QWidget, Ui_Window): 5 def __init__(self): 6 super().__init__() 7 self._files = deque() 8 self._filesCount = len(self._files) 9 self._setupUI() 10 self._connectSignalsSlots() 11 12 def _setupUI(self): 13 self.setupUi(self) 14 15 def _connectSignalsSlots(self): 16 self.loadFilesButton.clicked.connect(self.loadFiles) 17 18 def loadFiles(self): 19 self.dstFileList.clear() 20 if self.dirEdit.text(): 21 initDir = self.dirEdit.text() 22 else: 23 initDir = str(Path.home()) 24 files, filter = QFileDialog.getOpenFileNames( 25 self, "Choose Files to Rename", initDir, filter=FILTERS 26 ) 27 if len(files) > 0: 28 fileExtension = filter[filter.index("*") : -1] 29 self.extensionLabel.setText(fileExtension) 30 srcDirName = str(Path(files[0]).parent) 31 self.dirEdit.setText(srcDirName) 32 for file in files: 33 self._files.append(Path(file)) 34 self.srcFileList.addItem(file) 35 self._filesCount = len(self._files)下面是新添加的代码的作用:
第 7 行创建
._files作为一个队列对象。该属性将存储您想要重命名的文件的路径。第 8 行定义了
._filesCount来存储要重命名的文件数量。10 号线呼叫
._connectSignalsSlots()。第 15 行定义
._connectSignalsSlots()。该方法将在一个地方收集几个信号和插槽连接。至此,该方法将加载文件按钮的.clicked()信号与.loadFiles()插槽连接。这使得每次用户点击按钮时触发.loadFiles()成为可能。然后您定义
.loadFiles()来加载您想要重命名的文件。它是这样做的:
第 19 行在用户每次点击加载文件时清除
.dstFileList列表小部件。第 20 到 23 行定义了一个条件语句,检查最后一个源目录行编辑当前是否显示任何目录路径。如果是,那么
if代码块设置初始目录initDir来保存该路径。否则,初始目录被设置为Path.home(),返回当前用户主文件夹的路径。您将使用initDir为QFileOpen对象提供一个初始化目录。第 24 行到第 26 行在
QFileDialog上调用.getOpenFileNames()。这个静态方法接受几个参数,创建一个对话框以允许用户选择一个或多个文件,并返回所选文件的基于字符串的路径列表。它还返回当前使用的文件过滤器。在这种情况下,可以使用以下参数:
parent持有拥有对话框的小部件,在本例中是self或当前的Window对象。
caption保存着对话框的标题或题注。在这个例子中使用了字符串"Choose Files to Rename"。
dir保存着初始化目录的路径。换句话说,就是打开对话框的目录的路径。在这个例子中,您使用initDir来初始化对话框。
filter拥有一个文件类型过滤器,只有符合过滤器的文件才会显示在对话框中。例如,如果您将过滤器设置为"*.jpg",则对话框会显示与此格式匹配的文件。第 27 行定义了一个条件语句,如果用户从
QFileDialog中选择了至少一个文件,该语句将运行一系列语句。第 28 行切片当前过滤字符串提取文件扩展名。
第 29 行将
.extensionLabel对象的文本设置为第 28 行提取的文件扩展名。第 30 行获取包含所选文件的目录路径。为此,使用所选文件列表中第一个文件的路径创建一个
Path对象。.parent属性保存包含目录的路径。第 31 行将
.dirEdit行编辑的文本设置为您在第 30 行得到的目录路径。第 32 到 34 行定义了一个
for循环,该循环遍历所选文件的列表,为每个文件创建一个Path对象,并将其附加到._files。第 34 行将每个文件添加到.srcFileList列表小部件,以便用户可以在应用程序的 GUI 上看到当前选择的文件。第 35 行用列表中文件的当前数量更新
._filesCount。如果您现在运行该应用程序,您将获得以下行为:
https://player.vimeo.com/video/519724506?background=1
现在,您可以通过点击加载文件将多个文件加载到您的批量文件重命名工具中。请注意,您可以从选择要重命名的文件对话框中的几个文件过滤器中选择,指定您想要加载到应用程序中的文件类型。
注意:上述代码和本教程中其余代码示例中的行号是为了便于解释。它们与最终模块或脚本中的行顺序不匹配。
酷!您的项目已经支持加载不同类型的文件。继续并关闭应用程序以继续编码。在下一节中,您将实现文件重命名功能。
重命名一个工作器中的多个文件
QThread要执行文件重命名过程,您将使用一个
QThread对象。创建和设置一个工作线程允许您从应用程序的主线程中卸载文件重命名过程。这样,当您选择大量文件进行重命名时,可以防止可能出现的 GUI 冻结问题。工作线程将使用
pathlib.rename()执行文件重命名。它还会发出自定义信号来与主线程通信,并更新应用程序的 GUI。继续在代码编辑器中打开rprename/rename.py文件。键入以下代码:1# -*- coding: utf-8 -*- 2# rprename/rename.py 3 4"""This module provides the Renamer class to rename multiple files.""" 5 6import time 7from pathlib import Path 8 9from PyQt5.QtCore import QObject, pyqtSignal 10 11class Renamer(QObject): 12 # Define custom signals 13 progressed = pyqtSignal(int) 14 renamedFile = pyqtSignal(Path) 15 finished = pyqtSignal() 16 17 def __init__(self, files, prefix): 18 super().__init__() 19 self._files = files 20 self._prefix = prefix 21 22 def renameFiles(self): 23 for fileNumber, file in enumerate(self._files, 1): 24 newFile = file.parent.joinpath( 25 f"{self._prefix}{str(fileNumber)}{file.suffix}" 26 ) 27 file.rename(newFile) 28 time.sleep(0.1) # Comment this line to rename files faster. 29 self.progressed.emit(fileNumber) 30 self.renamedFile.emit(newFile) 31 self.progressed.emit(0) # Reset the progress 32 self.finished.emit()下面是这段代码的作用:
第 9 行从
PyQt5.QtCore导入QObject和pyqtSignal()。QObject允许您创建带有自定义信号和功能的子类。使用pyqtSignal(),您可以创建自定义信号,以便在给定事件发生时发出它们。第 11 行定义了
QObject的一个子类,称为Renamer。第 13 至 15 行定义了三个自定义信号:
.progressed()会在每次类重命名新文件时发出。它返回一个整数,代表当前重命名文件的编号。您将使用这个数字来更新应用程序 GUI 中的进度条。
.renamedFile()会在类重命名文件时发出。在这种情况下,信号返回重命名文件的路径。您将使用这个路径来更新应用程序 GUI 中的重命名文件列表。当文件重命名过程完成时,会发出
.finished()。第 17 行的类初始化器有两个必需的参数:
files保存着选中文件的列表。每个文件由其对应的Path表示。
prefix保存文件名前缀,您将使用它来重命名文件。然后定义执行文件重命名过程的方法
.renameFiles()。下面是其工作原理的总结:
第 23 行定义了一个
for循环来遍历所选文件的列表。随着循环的进行,循环使用enumerate()生成一个文件号。第 24 行使用文件名前缀
fileNumber和文件扩展名.suffix构建新文件名。然后,它将新文件名与父目录路径连接起来,创建手边文件的路径,newFile。第 27 行通过用
newFile作为参数调用当前file上的.rename()来重命名当前文件。第 28 行是对
time.sleep()的一个可选调用,它减缓了文件重命名的过程,以便你能看到它是如何进行的。您可以随意删除这一行,以正常速度运行应用程序。线 29 和 30 发出
.progressed()和.renamedFile()信号。在下一节中,您将使用这些信号来更新应用程序的 GUI。第 31 行使用
0作为参数发出.progressed()。完成文件重命名过程后,您将使用该值重置进度条。32 线在文件重命名过程结束时发出
.finished()信号。一旦你编写了
Renamer,你就可以开始重命名文件了。为此,您需要创建并设置一个工作线程。但是首先,回到rprename/views.py,像这样更新它的导入部分:# rprename/views.py # Snip... from PyQt5.QtCore import QThread from PyQt5.QtWidgets import QFileDialog, QWidget from .rename import Renamer from .ui.window import Ui_Window # Snip...在第一个突出显示的行中,您从
PyQt5.QtCore导入QThread。这个类允许您在 PyQt 应用程序中创建和管理工作线程。在第二个突出显示的行中,您从您的rename模块导入Renamer。现在在你的
views.py文件中向下滚动一点,像这样更新Window:1# rprename/views.py 2# Snip... 3 4class Window(QWidget, Ui_Window): 5 # Snip... 6 def _connectSignalsSlots(self): 7 self.loadFilesButton.clicked.connect(self.loadFiles) 8 self.renameFilesButton.clicked.connect(self.renameFiles) 9 10 def loadFiles(self): 11 # Snip.. 12 13 def renameFiles(self): 14 self._runRenamerThread() 15 16 def _runRenamerThread(self): 17 prefix = self.prefixEdit.text() 18 self._thread = QThread() 19 self._renamer = Renamer( 20 files=tuple(self._files), 21 prefix=prefix, 22 ) 23 self._renamer.moveToThread(self._thread) 24 # Rename 25 self._thread.started.connect(self._renamer.renameFiles) 26 # Update state 27 self._renamer.renamedFile.connect(self._updateStateWhenFileRenamed) 28 # Clean up 29 self._renamer.finished.connect(self._thread.quit) 30 self._renamer.finished.connect(self._renamer.deleteLater) 31 self._thread.finished.connect(self._thread.deleteLater) 32 # Run the thread 33 self._thread.start() 34 35 def _updateStateWhenFileRenamed(self, newFile): 36 self._files.popleft() 37 self.srcFileList.takeItem(0) 38 self.dstFileList.addItem(str(newFile))这里,首先将重命名按钮的
.clicked()连接到.renameFiles()。这个方法调用._runRenamerThread()来创建、设置和运行工作线程。它是这样工作的:
第 17 行检索文件名前缀行编辑中的文本。用户需要提供这个文件名前缀。
第 18 行创建一个新的
QThread对象来卸载文件重命名过程。第 19 到 22 行实例化
Renamer,将文件列表和文件名前缀作为参数传递给类构造函数。在这种情况下,您将._files变成一个元组,以防止线程修改主线程上的底层队列。第 23 行在
Renamer实例上调用.moveToThread()。顾名思义,这个方法将给定的对象移动到不同的执行线程。在这种情况下,它使用._thread作为目标线程。第 25 行连接线程的
.started()信号和Renamer实例上的.renameFiles()。这使得在线程启动时启动文件重命名过程成为可能。线 27 连接
Renamer实例的.renamedFile()信号和._updateStateWhenFileRenamed()。一会儿你会看到这个方法做了什么。第 29 行和第 30 行将
Renamer实例的.finished()信号连接到两个插槽:
线程的
.quit()槽,一旦文件重命名过程完成就退出线程
Renamer实例的.deleteLater()槽,用于调度对象以便以后删除线 31 连接线程的
.finished()信号与.deleteLater()。这使得删除线程成为可能,但只能在它完成任务之后。第 33 行启动工作线程。
最后一段代码定义了
._updateStateWhenFileRenamed()。重命名文件时,方法从要重命名的文件列表中移除该文件。然后,该方法在应用程序的 GUI 上更新重命名为的文件列表以及重命名为的文件列表。下面是该应用程序现在的工作方式:
https://player.vimeo.com/video/520025279?background=1
就是这样!您的批量文件重命名工具已经完成了它的工作。它允许您加载几个文件,提供一个新的文件名前缀,并重命名所有选定的文件。干得好!
现在,您可以关闭应用程序,继续开发过程。在下一节中,您将学习如何根据文件重命名进度更新应用程序的 GUI。
步骤 4:根据重命名进度更新 GUI 状态
到目前为止,您的批量文件重命名工具提供了它的主要功能。您已经可以使用该工具来重命名文件系统中的多个文件。但是,如果用户在重命名过程中点击了 Rename 会发生什么?此外,如果用户忘记提供适当的文件名前缀怎么办?
另一个更明显的问题是为什么应用程序的进度条不能反映文件重命名的进度。
所有这些问题都与在任何给定时间根据应用程序的状态更新 GUI 有关。在本节中,您将编写所需的代码来修复或防止上述问题。您将从进度条开始。
您可以通过单击下面的链接下载您将在本节中编写的代码:
获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
更新进度条
在 GUI 应用程序中,通常使用进度条来通知用户长时间运行任务的进度。如果用户没有得到应用程序当前正在做什么的反馈,那么他们可能会认为应用程序被冻结了,卡住了,或者有一些内部问题。
在本项目中,您将使用进度条来提供在任何给定时间文件重命名过程的反馈。为此,返回到代码编辑器中的
rprename/views.py,像这样更新它:1# rprename/views.py 2# Snip... 3 4class Window(QWidget, Ui_Window): 5 # Snip... 6 def _runRenamerThread(self): 7 # Update state 8 self._renamer.renamedFile.connect(self._updateStateWhenFileRenamed) 9 self._renamer.progressed.connect(self._updateProgressBar) 10 # Snip... 11 12 def _updateStateWhenFileRenamed(self, newFile): 13 # Snip... 14 15 def _updateProgressBar(self, fileNumber): 16 progressPercent = int(fileNumber / self._filesCount * 100) 17 self.progressBar.setValue(progressPercent)下面是新添加的代码的作用:
- 线 9 连接
Renamer实例的.progressed()信号和._updateProgressBar()。- 第 15 行定义
._updateProgressBar()。该方法将一个fileNumber作为参数。注意,每次文件被重命名时,.progressed()都会提供这个文件号。- 第 16 行计算文件重命名进度占文件总数的百分比,可在
._filesCount中获得。- 第 17 行使用带有
progressPercent的.setValue()作为参数来更新进度条上的.value属性。就是这样!继续运行您的应用程序。它是这样工作的:
https://player.vimeo.com/video/520061171?background=1
在对
Window进行了这些添加之后,你的批量文件重命名工具的进度条反映了文件重命名操作的进度,这很好,改善了你的用户体验。启用和禁用 GUI 组件
当您构建 GUI 应用程序时,您会意识到 GUI 上的某些操作仅在特定情况下可用。例如,在您的批量文件重命名工具中,如果没有文件已经加载到应用程序中,或者如果用户没有提供文件名前缀,则允许用户单击重命名是没有意义的。
处理这种情况至少有两种方法:
- 让所有的小部件一直处于启用状态,并确保它们不会触发任何在上下文中没有意义的动作。
- 根据应用程序的状态启用和禁用小部件。
要实现第一种方法,您可以使用条件语句来确保给定的操作在给定的时刻有意义。另一方面,要实现第二种方法,您需要找出应用程序可能遇到的所有状态,并提供相应的方法来更新 GUI。
注意:当您禁用一个 PyQt 小部件或图形组件时,这个库会将手边的小部件变灰,并使它对用户的事件(比如单击和按键)没有响应。
在本教程中,您将使用第二种方法,这可能更加直观和用户友好。为此,您需要找出应用程序可能会遇到的状态。这是解决这个问题的第一种方法:
状态 描述 方法 没有加载文件 应用程序正在运行,要重命名的文件列表为空。 ._updateStateWhenNoFiles()加载的文件 要重命名的文件列表包含一个或多个文件。 ._updateStateWhenFilesLoaded()准备重命名文件 要重命名的文件列表包含一个或多个文件,并且用户已经提供了文件名前缀。 ._updateStateWhenReady()重命名文件 用户点击重命名,文件重命名过程开始。 ._updateStateWhileRenaming()重命名完成 文件重命名过程已经完成,没有剩余文件需要重命名。 ._updateStateWhenNoFiles()因为上表中的第一个和最后一个状态非常相似,所以您将使用相同的方法来更新 GUI。这意味着您只需要实现四个方法。
要开始编写这些方法,请返回到
views.py并将以下代码添加到Window:1# rprename/views.py 2# Snip... 3 4class Window(QWidget, Ui_Window): 5 # Snip... 6 def _setupUI(self): 7 self.setupUi(self) 8 self._updateStateWhenNoFiles() 9 10 def _updateStateWhenNoFiles(self): 11 self._filesCount = len(self._files) 12 self.loadFilesButton.setEnabled(True) 13 self.loadFilesButton.setFocus(True) 14 self.renameFilesButton.setEnabled(False) 15 self.prefixEdit.clear() 16 self.prefixEdit.setEnabled(False) 17 18 # Snip... 19 def _runRenamerThread(self): 20 # Snip... 21 self._renamer.progressed.connect(self._updateProgressBar) 22 self._renamer.finished.connect(self._updateStateWhenNoFiles) 23 # Snip...以下是此更新的工作方式:
- 第 8 行从
._setupUI()内部调用._updateStateWhenNoFiles()。这将在您启动应用程序时更新 GUI。- 第 10 行定义
._updateStateWhenNoFiles()。- 第 11 行更新文件总数。在这种状态下,
len(self._files)返回0。- 第 12 行启用加载文件按钮,以便接受用户的事件。
- 第 13 行将焦点移动到加载文件按钮。这样,用户可以按键盘上的
Space将文件加载到应用程序中。- 第 14 行禁用重命名按钮。该按钮呈灰色且无响应。
- 第 15 行清除文件名前缀行编辑。这将删除任何以前提供的文件名前缀。
- 第 16 行禁用文件名前缀行编辑。这样,如果应用程序中没有文件,用户将无法键入文件名前缀。
- 线 22 连接
Renamer实例的.finished()信号和._updateStateWhenNoFiles()。这将在文件重命名过程完成后更新 GUI。当您运行应用程序时,您可以按键盘上的
Space来启动对话框并选择您想要重命名的文件。另外,文件名前缀行编辑和重命名按钮被禁用,因此您不能对它们执行操作。现在,您可以编写方法,以便在将文件加载到应用程序中时更新 GUI。将以下代码添加到
Window:# rprename/views.py # Snip... class Window(QWidget, Ui_Window): # Snip... def loadFiles(self): if len(files) > 0: # Snip... self._updateStateWhenFilesLoaded() def _updateStateWhenFilesLoaded(self): self.prefixEdit.setEnabled(True) self.prefixEdit.setFocus(True)当您将一个或多个文件加载到应用程序中时,
.loadFiles()调用._updateStateWhenFilesLoaded()。该方法启用文件名前缀行编辑,这样您可以输入一个前缀用于重命名文件。它还将焦点移到该小部件上,这样您就可以立即提供文件名前缀。接下来,当应用程序准备重命名一堆文件时,您可以编写方法来处理 GUI 更新。将以下代码添加到
Window:# rprename/views.py # Snip... class Window(QWidget, Ui_Window): # Snip... def _connectSignalsSlots(self): # Snip... self.prefixEdit.textChanged.connect(self._updateStateWhenReady) def _updateStateWhenReady(self): if self.prefixEdit.text(): self.renameFilesButton.setEnabled(True) else: self.renameFilesButton.setEnabled(False)这里,首先将文件名前缀行编辑的
.textChanged()信号与._updateStateWhenReady()连接。该方法根据文件名前缀行编辑的内容启用或禁用重命名按钮。这样,当行编辑为空时,按钮被禁用,否则它被启用。最后,当应用程序重命名文件时,您需要编写方法来处理 GUI 更新。继续将以下代码添加到
Window:class Window(QWidget, Ui_Window): # Snip... def renameFiles(self): self._runRenamerThread() self._updateStateWhileRenaming() def _updateStateWhileRenaming(self): self.loadFilesButton.setEnabled(False) self.renameFilesButton.setEnabled(False)当用户点击重命名时,应用程序启动文件重命名过程,并调用
._updateStateWhileRenaming()相应地更新 GUI。该方法禁用加载文件和重命名按钮,因此在重命名过程运行时用户不能点击它们。就是这样!如果您现在运行该应用程序,您将获得以下行为:
https://player.vimeo.com/video/521071061?background=1
您的批量文件重命名工具的 GUI 现在可以随时反映应用程序的状态。这允许你为你的用户提供一个直观的,没有挫败感的体验。干得好!
结论
当您整理个人文件和文件夹时,自动重命名多个文件是一个常见问题。在本教程中,您构建了一个真实的 GUI 应用程序来快速有效地执行这项任务。通过构建这个工具,您应用了与使用 PyQt 和 Qt Designer 创建 GUI 应用程序相关的大量技能。您还使用 Python 的
pathlib处理了文件。在本教程中,您学习了如何:
- 使用 Qt Designer 构建批量文件重命名工具的 GUI
- 使用 PyQt 线程来卸载批量文件重命名过程
- 用
pathlib管理系统路径和重命名文件- 根据文件重命名过程更新 GUI 状态
您可以通过单击下面的链接下载批量文件重命名项目的最终源代码:
获取源代码: 点击此处获取您将在本教程中使用用 Python 构建一个批量文件重命名工具的源代码。
接下来的步骤
到目前为止,您已经构建了一个真实的应用程序来自动化重命名多个文件的过程。尽管该应用程序提供了一组最少的功能,但它是您继续添加功能和学习的良好起点。这将帮助您将 Python 和 PyQt GUI 应用程序的技能提升到一个新的水平。
以下是一些你可以用来继续改进项目的想法:
添加对其他文件类型的支持:您可以添加对新文件类型的支持,例如
.bmp、.docx、.xlsx,或者您需要处理的任何其他文件类型。为此,您可以扩展FILTERS常量。生成基于日期或随机的文件名后缀:你也可以改变你生成文件名后缀的方式。不使用连续的整数,可以使用
datetime提供基于日期的后缀,也可以提供随机的后缀。为应用程序生成可执行文件:您可以使用 PyInstaller 或任何其他工具为您的批量文件重命名工具生成可执行文件。这样,您就可以与您的朋友和同事共享该应用程序。
这些只是如何继续向批量文件重命名工具添加功能的一些想法。接受挑战,创造令人惊叹的东西!*******
Python 程序员的 c 语言
本教程的目的是让一个有经验的 Python 程序员快速掌握 C 语言的基础知识,以及如何在 CPython 源代码中使用它。它假设您已经对 Python 语法有了初步的了解。
也就是说,C 是一种相当有限的语言,它在 CPython 中的大部分使用都属于一小组语法规则。与能够有效地编写 C 语言相比,理解代码是很小的一步。本教程针对的是第一个目标,而不是第二个目标。
在本教程中,您将学习:
- C 预处理器是什么,它在构建 C 程序中起什么作用
- 如何使用预处理指令来操作源文件
- C 语法与 Python 语法相比如何
- 如何在 C 语言中创建循环、函数、字符串以及其他特性
Python 和 C 之间最突出的区别之一是 C 预处理器。你先看看那个。
注:本教程改编自 CPython 内部:你的 Python 解释器指南 中的附录《Python 程序员 C 语言入门》。
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
C 预处理器
预处理程序,顾名思义,是在编译器运行之前在源文件上运行的。它的能力非常有限,但是您可以在构建 C 程序时充分利用它们。
预处理器生成一个新文件,这是编译器实际处理的内容。预处理程序的所有命令都从一行的开头开始,以一个
#符号作为第一个非空白字符。预处理程序的主要目的是在源文件中做文本替换,但是也会用
#if或者类似的语句做一些基本的条件代码。您将从最常用的预处理程序指令开始:
#include。
#include
#include用于将一个文件的内容拉进当前源文件。#include没什么高深的。它从文件系统中读取一个文件,对该文件运行预处理器,并将结果放入输出文件。对于每个#include指令,这是通过递归完成的。例如,如果您查看 CPython 的
Modules/_multiprocessing/semaphore.c文件,那么在顶部附近您会看到下面一行:#include "multiprocessing.h"这告诉预处理器获取
multiprocessing.h的全部内容,并将它们放入输出文件的这个位置。您会注意到
#include语句的两种不同形式。其中一个使用引号("")来指定包含文件的名称,另一个使用尖括号(<>)。不同之处在于在文件系统中查找文件时搜索的路径。如果您使用
<>作为文件名,那么预处理器将只查看系统包含文件。相反,在文件名周围使用引号会迫使预处理程序首先在本地目录中查找,然后返回到系统目录。
#define
#define允许您进行简单的文本替换,也适用于您将在下面看到的#if指令。最基本的是,
#define允许您定义一个新符号,在预处理程序输出中用一个文本字符串替换它。继续进入
semphore.c,你会发现这一行:#define SEM_FAILED NULL这告诉预处理器在代码被发送到编译器之前,用文字字符串
NULL替换该点下面的每个SEM_FAILED实例。
#define项目也可以像在这个特定于 Windows 版本的SEM_CREATE中一样接受参数:#define SEM_CREATE(name, val, max) CreateSemaphore(NULL, val, max, NULL)在这种情况下,预处理器会期望
SEM_CREATE()看起来像一个函数调用,并且有三个参数。这通常被称为宏。它会直接将三个参数的文本替换到输出代码中。例如,在
semphore.c的第 460 行,SEM_CREATE宏是这样使用的:handle = SEM_CREATE(name, value, max);当您为 Windows 编译时,该宏将被展开,如下所示:
handle = CreateSemaphore(NULL, value, max, NULL);在后面的部分中,您将看到这个宏在 Windows 和其他操作系统上的不同定义。
#undef该指令从
#define中删除任何先前的预处理器定义。这使得#define只对文件的一部分有效成为可能。
#if预处理器还允许条件语句,允许您根据特定条件包含或排除文本部分。条件语句以
#endif指令结束,也可以利用#elif和#else进行微调。您将在 CPython 源代码中看到三种基本形式的
#if:
#ifdef <macro>如果定义了指定的宏,则包括后续的文本块。你也可以把它写成#if defined(<macro>)。- 如果指定的宏是而不是定义的,
#ifndef <macro>包括随后的文本块。- 如果宏定义了和,则
#if <macro>包括后续的文本块,其计算结果为True。注意使用“文本”而不是“代码”来描述文件中包含或排除的内容。预处理器对 C 语法一无所知,也不关心指定的文本是什么。
#pragma编译指令是对编译器的指令或提示。一般来说,在阅读代码时可以忽略这些,因为它们通常处理的是代码如何编译,而不是代码如何运行。
#error最后,
#error显示一条消息并使预处理器停止执行。同样,在阅读 CPython 源代码时,您可以安全地忽略这些。Python 程序员的基本 C 语法
本节不会涵盖 C 语言的所有方面,也不会教你如何编写 C 语言。它将集中在 Python 开发人员第一次看到 C 语言时感到不同或困惑的方面。
常规
与 Python 不同,空白对于 C 编译器并不重要。编译器并不关心你是否将语句跨行拆分,或者将整个程序挤在一个很长的行中。这是因为它对所有语句和块使用分隔符。
当然,解析器有非常具体的规则,但是一般来说,只要知道每个语句都以分号(
;)结尾,并且所有代码块都用花括号({})括起来,您就能够理解 CPython 源代码。这个规则的例外是,如果一个块只有一条语句,那么可以省略花括号。
C 中的所有变量都必须由声明为,这意味着需要有一个单独的语句来指示该变量的类型。注意,与 Python 不同,单个变量可以容纳的数据类型是不能改变的。
这里有几个例子:
/* Comments are included between slash-asterisk and asterisk-slash */ /* This style of comment can span several lines - so this part is still a comment. */ // Comments can also come after two slashes // This type of comment only goes until the end of the line, so new // lines must start with double slashes (//). int x = 0; // Declares x to be of type 'int' and initializes it to 0 if (x == 0) { // This is a block of code int y = 1; // y is only a valid variable name until the closing } // More statements here printf("x is %d y is %d\n", x, y); } // Single-line blocks do not require curly brackets if (x == 13) printf("x is 13!\n"); printf("past the if block\n");一般来说,您会看到 CPython 代码的格式非常简洁,并且通常在给定的模块中坚持单一的风格。
if报表在 C 语言中,
if通常像在 Python 中一样工作。如果条件为真,则执行下面的块。Python 程序员应该足够熟悉else和else if语法。注意,Cif语句不需要endif,因为块是由{}分隔的。C 语言中有一种简写
if…else语句的方法,叫做三元运算符:condition ? true_result : false_result您可以在
semaphore.c中找到它,对于 Windows,它为SEM_CLOSE()定义了一个宏:#define SEM_CLOSE(sem) (CloseHandle(sem) ? 0 : -1)如果函数
CloseHandle()返回true,则该宏的返回值为0,否则返回-1。注意:部分 CPython 源代码支持并使用布尔变量类型,但它们不是原始语言的一部分。c 使用一个简单的规则解释二元条件:
0或NULL为假,其他都为真。
switch报表与 Python 不同,C 也支持
switch。使用switch可视为扩展if…elseif链的快捷方式。这个例子来自semaphore.c:switch (WaitForSingleObjectEx(handle, 0, FALSE)) { case WAIT_OBJECT_0: if (!ReleaseSemaphore(handle, 1, &previous)) return MP_STANDARD_ERROR; *value = previous + 1; return 0; case WAIT_TIMEOUT: *value = 0; return 0; default: return MP_STANDARD_ERROR; }这将对来自
WaitForSingleObjectEx()的返回值执行切换。如果值为WAIT_OBJECT_0,则执行第一个程序块。WAIT_TIMEOUT值产生第二个块,其他任何东西都匹配default块。注意,被测试的值,在这种情况下是来自
WaitForSingleObjectEx()的返回值,必须是整数值或枚举类型,并且每个case必须是常量值。循环
C 语言中有三种循环结构:
for循环while循环do…while循环循环的语法与 Python 完全不同:
for ( <initialization>; <condition>; <increment>) { <code to be looped over> }除了要在循环中执行的代码之外,还有三个控制
for循环的代码块:
当循环开始时,
<initialization>段恰好运行一次。它通常用于将循环计数器设置为初始值(也可能用于声明循环计数器)。
<increment>代码在每次通过循环的主程序块后立即运行。传统上,这将增加循环计数器。最后,
<condition>在<increment>之后运行。将计算此代码的返回值,当此条件返回 false 时,循环中断。这里有一个来自
Modules/sha512module.c的例子:for (i = 0; i < 8; ++i) { S[i] = sha_info->digest[i]; }该循环将运行
8次,其中i从0增加到7,并且将在条件被检查并且i为8时终止。
while循环实际上与它们的 Python 对应物相同。然而,do…while的语法有点不同。在第一次执行循环体之后的之前,不会检查do…while循环的条件。CPython 代码库中有很多
for循环和while循环的实例,但是do…while没有使用。功能
C 语言中函数的语法类似于 Python 中的,但是必须指定返回类型和参数类型。C 语法看起来像这样:
<return_type> function_name(<parameters>) { <function_body> }返回类型可以是 C 语言中的任何有效类型,包括像
int和double这样的内置类型,以及像PyObject这样的自定义类型,如本例中的semaphore.c所示:static PyObject * semlock_release(SemLockObject *self, PyObject *args) { <statements of function body here> }这里您可以看到一些 C 语言特有的特性。首先,记住空白不重要。许多 CPython 源代码将函数的返回类型放在函数声明的其余部分之上。这就是
PyObject *部分。稍后您将仔细查看*的用法,但是现在重要的是要知道您可以对函数和变量使用几个修饰符。
static就是这些修饰语之一。修改器的操作有一些复杂的规则。例如,static修饰符在这里的意思和你把它放在变量声明前面的意思完全不同。幸运的是,在试图阅读和理解 CPython 源代码时,通常可以忽略这些修饰符。
函数的参数列表是逗号分隔的变量列表,类似于 Python 中使用的列表。同样,C 要求每个参数都有特定的类型,所以
SemLockObject *self说第一个参数是一个指向SemLockObject的指针,被称为self。请注意,C 中的所有参数都是位置性的。让我们来看看该语句的“指针”部分是什么意思。
举个例子,传递给 C 函数的参数都是通过值传递的,这意味着函数操作的是值的副本,而不是调用函数中的原始值。为了解决这个问题,函数会频繁地传入它可以修改的一些数据的地址。
这些地址被称为指针,并且有类型,所以
int *是一个指向整数值的指针,与double *是不同的类型,后者是一个指向双精度浮点数的指针。指针
如上所述,指针是保存值的地址的变量。这些在 C 中经常使用,如下例所示:
static PyObject * semlock_release(SemLockObject *self, PyObject *args) { <statements of function body here> }这里,
self参数将保存SemLockObject值的地址,或指向的指针。还要注意,该函数将返回一个指向PyObject值的指针。注:要深入了解如何在 Python 中模拟指针,请查看Python 中的指针:有什么意义?
C 语言中有一个特殊的值叫做
NULL,它表示指针没有指向任何东西。在整个 CPython 源代码中,您将看到分配给NULL的指针,并对照NULL进行检查。这一点很重要,因为指针的取值没有什么限制,访问不属于程序的内存位置会导致非常奇怪的行为。另一方面,如果你试图在
NULL访问内存,那么你的程序将立即退出。这可能看起来不太好,但是如果访问了NULL,通常比修改随机内存地址更容易发现内存错误。字符串
c 没有字符串类型。有一个惯例,许多标准库函数都是围绕这个惯例编写的,但是没有实际的类型。相反,C 语言中的字符串存储为由
char(对于 ASCII)或wchar(对于 Unicode)值组成的数组,每个数组保存一个字符。字符串用一个空终止符标记,其值为0,通常在代码中显示为\\0。像
strlen()这样的基本字符串操作依靠这个空终止符来标记字符串的结尾。因为字符串只是值的数组,所以不能直接复制或比较。标准库有
strcpy()和strcmp()函数(以及它们的wchar表兄弟)来完成这些操作以及更多。支柱
C 语言迷你之旅的最后一站是如何在 C: structs 中创建新类型。
struct关键字允许您将一组不同的数据类型组合成一个新的自定义数据类型:struct <struct_name> { <type> <member_name>; <type> <member_name>; ... };这个局部的例子从
Modules/arraymodule.c展示了一个struct的声明:struct arraydescr { char typecode; int itemsize; ... };这创建了一个名为
arraydescr的新数据类型,它有许多成员,前两个是char typecode和int itemsize。结构经常被用作
typedef的一部分,它为名字提供了一个简单的别名。在上面的例子中,所有新类型的变量都必须用全名struct arraydescr x;声明。您会经常看到这样的语法:
typedef struct { PyObject_HEAD SEM_HANDLE handle; unsigned long last_tid; int count; int maxvalue; int kind; char *name; } SemLockObject;这将创建一个新的自定义结构类型,并将其命名为
SemLockObject。要声明这种类型的变量,只需使用别名SemLockObject x;。结论
这就结束了您对 C 语法的快速浏览。虽然这个描述仅仅触及了 C 语言的表面,但是您现在已经有足够的知识来阅读和理解 CPython 源代码了。
在本教程中,您学习了:
- C 预处理器是什么,它在构建 C 程序中起什么作用
- 如何使用预处理指令来操作源文件
- C 语法与 Python 语法相比如何
- 如何在 C 语言中创建循环、函数、字符串以及其他特性
既然您已经熟悉了 C,那么您可以通过探索 CPython 源代码来加深对 Python 内部工作方式的了解。快乐的蟒蛇!
注意:如果你喜欢从CPython Internals:Your Guide to the Python Interpreter中学到的东西,那么一定要看看本书的其余部分。*****
用 Redis 在 Django 缓存
原文:# t0]https://realython . com/cache-in-django-with-redis/
应用性能对产品的成功至关重要。在一个用户期望网站响应时间少于一秒的环境中,缓慢的应用程序的后果可以用金钱来衡量。即使你不卖任何东西,快速的页面加载也能改善访问你网站的体验。
从收到请求到返回响应,服务器上发生的所有事情都会增加加载页面的时间。根据一般经验,服务器上可以消除的处理越多,应用程序的执行速度就越快。处理完数据后缓存数据,然后在下次请求时从缓存中提供数据,这是减轻服务器压力的一种方式。在本教程中,我们将探索一些阻碍你应用的因素,我们将演示如何用 Redis 实现缓存来抵消它们的影响。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
什么是里兹?
Redis 是一个内存中的数据结构存储,可以用作缓存引擎。因为 Redis 将数据保存在 RAM 中,所以它可以非常快速地传递数据。Redis 不是我们可以用于缓存的唯一产品。 Memcached 是另一个流行的内存缓存系统,但是很多人都认为 Redis 在大多数情况下优于 Memcached 。就个人而言,我们喜欢为其他目的设置和使用 Redis 的简单性,例如 Redis Queue 。
开始使用
我们创建了一个示例应用程序,向您介绍缓存的概念。我们的应用程序使用:
安装应用程序
在克隆存储库之前,安装 virtualenvwrapper ,如果你还没有的话。这是一个允许您安装项目所需的特定 Python 依赖项的工具,允许您单独针对应用程序所需的版本和库。
接下来,将目录更改为保存项目的位置,并克隆示例应用程序存储库。完成后,将目录更改为克隆的存储库,然后使用
mkvirtualenv命令为示例应用程序创建一个新的虚拟环境:$ mkvirtualenv django-redis (django-redis)$注意:用
mkvirtualenv创建一个虚拟环境也会激活它。用
pip安装所有需要的 Python 依赖项,然后签出下面的标签:(django-redis)$ git checkout tags/1通过构建数据库并用示例数据填充它来完成示例应用程序的设置。确保创建一个超级用户,这样您就可以登录到管理站点。遵循下面的代码示例,然后尝试运行应用程序,以确保它正常工作。访问浏览器中的管理页面,确认数据已正确加载。
(django-redis)$ python manage.py makemigrations cookbook (django-redis)$ python manage.py migrate (django-redis)$ python manage.py createsuperuser (django-redis)$ python manage.py loaddata cookbook/fixtures/cookbook.json (django-redis)$ python manage.py runserver运行 Django 应用程序后,继续安装 Redis。
安装 Redis
使用文档中提供的说明下载并安装 Redis 。或者,你可以根据你的操作系统使用包管理器安装 Redis,比如 apt-get 或者 homebrew 。
从新的终端窗口运行 Redis 服务器。
$ redis-server接下来,在不同的终端窗口中启动 Redis 命令行界面(CLI ),并测试它是否连接到 Redis 服务器。我们将使用 Redis CLI 来检查我们添加到缓存中的键。
$ redis-cli ping PONGRedis 提供了一个带有各种命令的 API ,开发者可以使用这些命令来操作数据存储。Django 使用 django-redis 在 redis 中执行命令。
在文本编辑器中查看我们的示例应用程序,我们可以在 settings.py 文件中看到 Redis 配置。我们使用内置的 django-redis 缓存作为我们的后端,用
CACHES设置定义一个默认缓存。Redis 默认运行在端口 6379 上,我们在设置中指向这个位置。最后要提到的是 django-redis 在键名后面附加一个前缀和一个版本,以帮助区分相似的键。在这种情况下,我们将前缀定义为“example”。CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379/1", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient" }, "KEY_PREFIX": "example" } }注意:虽然我们已经配置了缓存后端,但是没有一个视图函数实现了缓存。
应用性能
正如我们在本教程开始时提到的,服务器处理请求所做的一切都会减缓应用程序的加载时间。运行业务逻辑和呈现模板的处理开销可能很大。网络延迟会影响查询数据库所需的时间。每当客户端向服务器发送 HTTP 请求时,这些因素就会发挥作用。当用户每秒发起许多请求时,当服务器处理所有请求时,对性能的影响变得很明显。
当我们实现缓存时,我们让服务器处理一次请求,然后将它存储在我们的缓存中。当我们的应用程序收到对同一个 URL 的请求时,服务器从缓存中提取结果,而不是每次都重新处理它们。通常,我们为缓存的结果设置一个生存时间,以便可以定期刷新数据,这是实现的一个重要步骤,以避免提供过时的数据。
当下列情况为真时,您应该考虑缓存请求的结果:
- 呈现页面涉及大量数据库查询和/或业务逻辑,
- 您的用户经常访问该页面,
- 每个用户的数据都是一样的,
- 并且数据不会经常改变。
从测量绩效开始
首先测试应用程序中每个页面的速度,测试应用程序在收到请求后返回响应的速度。
为了实现这一点,我们将使用 HTTP 负载生成器 loadtest 向每个页面发送大量请求,然后密切关注请求率。访问上面的链接进行安装。安装后,根据
/cookbook/URL 路径测试结果:$ loadtest -n 100 -k http://localhost:8000/cookbook/请注意,我们每秒处理大约 16 个请求:
Requests per second: 16当我们看到代码在做什么时,我们可以决定如何做出改变来提高性能。应用程序对数据库进行 3 次网络调用,每次请求到
/cookbook/,每次调用都需要时间来打开连接和执行查询。在您的浏览器中访问/cookbook/URL,并展开 Django 调试工具栏选项卡来确认这一行为。找到标有“SQL”的菜单,并读取查询数:
cookbook/services.py
from cookbook.models import Recipe def get_recipes(): # Queries 3 tables: cookbook_recipe, cookbook_ingredient, # and cookbook_food. return list(Recipe.objects.prefetch_related('ingredient_set__food'))cookbook/views.py
from django.shortcuts import render from cookbook.services import get_recipes def recipes_view(request): return render(request, 'cookbook/recipes.html', { 'recipes': get_recipes() })该应用程序还使用一些潜在的昂贵逻辑来呈现模板。
<html> <head> <title>Recipes</title> </head> <body> {% for recipe in recipes %} <h1>{{ recipe.name }}</h1> <p>{{ recipe.desc }}</p> <h2>Ingredients</h2> <ul> {% for ingredient in recipe.ingredient_set.all %} <li>{{ ingredient.desc }}</li> {% endfor %} </ul> <h2>Instructions</h2> <p>{{ recipe.instructions }}</p> {% endfor %} </body> </html>实现缓存
想象一下当用户开始访问我们的站点时,我们的应用程序将发出的网络调用的总数。如果 1000 个用户点击检索食谱的 API,那么我们的应用程序将查询数据库 3000 次,每次请求都会呈现一个新的模板。这个数字只会随着我们应用程序的扩展而增长。幸运的是,这个视图非常适合缓存。烹饪书中的食谱很少改变,如果有的话。此外,由于查看食谱是应用程序的中心主题,检索食谱的 API 肯定会被频繁调用。
在下面的例子中,我们修改了视图函数来使用缓存。当该函数运行时,它检查视图键是否在缓存中。如果键存在,那么应用程序从缓存中检索数据并返回它。如果没有,Django 查询数据库,然后将结果和视图键一起保存在缓存中。第一次运行这个函数时,Django 会查询数据库并呈现模板,然后还会对 Redis 进行网络调用,将数据存储在缓存中。对该函数的每个后续调用都将完全绕过数据库和业务逻辑,并查询 Redis 缓存。
example/settings.py
# Cache time to live is 15 minutes. CACHE_TTL = 60 * 15cookbook/views.py
from django.conf import settings from django.core.cache.backends.base import DEFAULT_TIMEOUT from django.shortcuts import render from django.views.decorators.cache import cache_page from cookbook.services import get_recipes CACHE_TTL = getattr(settings, 'CACHE_TTL', DEFAULT_TIMEOUT) @cache_page(CACHE_TTL) def recipes_view(request): return render(request, 'cookbook/recipes.html', { 'recipes': get_recipes() })注意,我们已经向视图函数添加了
@cache_page()装饰器,以及生存时间。再次访问/cookbook/URL 并检查 Django 调试工具栏。我们看到进行了 3 次数据库查询,并对缓存进行了 3 次调用,以检查密钥,然后保存它。Django 保存了两个键(一个键用于标题,一个键用于呈现的页面内容)。重新加载页面,观察页面活动如何变化。第二次,对数据库进行了 0 次调用,对缓存进行了 2 次调用。我们的页面现在从缓存中提供服务!当我们重新运行我们的性能测试时,我们看到我们的应用程序加载得更快了。
$ loadtest -n 100 -k http://localhost:8000/cookbook/缓存改善了总负载,我们现在每秒处理 21 个请求,比基线多 5 个:
Requests per second: 21使用命令行界面检查 Redis】
此时,我们可以使用 Redis CLI 来查看 Redis 服务器上存储了什么。在 Redis 命令行中,输入
keys *命令,该命令返回匹配任何模式的所有键。应该会看到一个名为“example:1:views . decorators . cache . cache _ page”的键。记住,“example”是我们的键前缀,“1”是版本,“views . decorators . cache . cache _ page”是 Django 给键起的名字。复制密钥名并用get命令输入。您应该会看到呈现的 HTML 字符串。$ redis-cli -n 1 127.0.0.1:6379[1]> keys * 1) "example:1:views.decorators.cache.cache_header" 2) "example:1:views.decorators.cache.cache_page" 127.0.0.1:6379[1]> get "example:1:views.decorators.cache.cache_page"注意:在 Redis CLI 上运行
flushall命令,清除数据存储中的所有密钥。然后,您可以再次运行本教程中的步骤,而不必等待缓存过期。总结
处理 HTTP 请求的成本很高,而且随着应用程序越来越受欢迎,这种成本还会增加。在某些情况下,通过实现缓存,可以大大减少服务器的处理量。本教程介绍了 Django 中使用 Redis 进行缓存的基础知识,但它只是触及了一个复杂主题的表面。
在健壮的应用程序中实现缓存有许多陷阱和问题。控制缓存什么以及缓存多长时间是很困难的。缓存失效是计算机科学中的难题之一。确保私有数据只能由目标用户访问是一个安全问题,在缓存时必须小心处理。
免费奖励: 点击此处获取免费的 Django 学习资源指南(PDF) ,该指南向您展示了构建 Python + Django web 应用程序时要避免的技巧和窍门以及常见的陷阱。
在示例应用程序中试验源代码,当您继续使用 Django 开发时,请记住始终将性能放在心上。***
缓存外部 API 请求
有没有发现自己对一个外部 API 发出完全相同的请求,使用完全相同的参数并返回完全相同的结果?如果是这样,那么您应该缓存这个请求来限制 HTTP 请求的数量,以帮助提高性能。
让我们看一个使用请求包的例子。
Github API
从 Github repo 中抓取代码(或者下载 zip )。基本上,我们一遍又一遍地搜索 Github API,根据位置和编程语言寻找相似的开发者:
url = "https://api.github.com/search/users?q=location:{0}+language:{1}".format(first, second) response_dict = requests.get(url).json()现在,在初始搜索之后,如果用户再次搜索(例如,不改变参数),应用程序将执行完全相同的搜索,一次又一次地点击 Github API。由于这是一个昂贵的过程,它减慢了我们的最终用户的应用程序。此外,通过像这样打几个电话,我们可以很快用完我们的速率限制。
幸运的是,有一个简单的解决方法。
请求-缓存
为了实现缓存,我们可以使用一个名为 Requests-cache 的简单包,它是一个“用于请求的透明持久缓存”。
请记住,您可以将这个包用于任何 Python 框架,而不仅仅是 Flask 或脚本,只要您将它与 requests 包结合使用。
首先安装软件包:
$ pip install --upgrade requests-cache然后将导入添加到 app.py 以及
install_cache()方法中:requests_cache.install_cache(cache_name='github_cache', backend='sqlite', expire_after=180)现在无论何时使用
requests,响应都会被自动缓存。此外,您可以看到我们正在定义几个选项。注意expire_after选项,它被设置为 180 秒。由于 Github API 经常更新,我们希望确保交付最新的结果。因此,在初始缓存发生 180 秒后,请求将重新触发并缓存一组新的结果,提供更新的结果。更多选项,请查看官方文档。
所以您的 app.py 文件现在应该是这样的:
import requests import requests_cache from flask import Flask, render_template, request, jsonify app = Flask(__name__) requests_cache.install_cache('github_cache', backend='sqlite', expire_after=180) @app.route('/', methods=['GET', 'POST']) def home(): if request.method == 'POST': first = request.form.get('first') second = request.form.get('second') url = "https://api.github.com/search/users?q=location:{0}+language:{1}".format(first, second) response_dict = requests.get(url).json() return jsonify(response_dict) return render_template('index.html') if __name__ == '__main__': app.run(debug=True)测试!
启动应用程序,搜索开发者。在“app”目录中,应该创建一个名为 github_cache.sqlite 的 SQLite 数据库。现在,如果您继续使用相同的位置和编程语言进行搜索,
requests实际上不会进行调用。相反,它将使用来自 SQLite 数据库的缓存响应。让我们确保缓存确实过期了。像这样更新
home()视图功能:@app.route('/', methods=['GET', 'POST']) def home(): if request.method == 'POST': first = request.form.get('first') second = request.form.get('second') url = "https://api.github.com/search/users?q=location:{0}+language:{1}".format(first, second) now = time.ctime(int(time.time())) response = requests.get(url) print "Time: {0} / Used Cache: {1}".format(now, response.from_cache) return jsonify(response.json()) return render_template('index.html')因此,这里我们只是使用
from_cache属性来查看响应是否来自缓存。让我们来测试一下。尝试新的搜索。然后打开你的终端:Time: Fri Nov 28 13:34:25 2014 / Used Cache: False所以你可以看到我们在 13:34:25 向 Github API 发出了初始请求,由于
False被输出到屏幕上,所以没有使用缓存。再次尝试搜索。Time: Fri Nov 28 13:35:28 2014 / Used Cache: True现在您可以看到使用了缓存。多试几次。
Time: Fri Nov 28 13:36:10 2014 / Used Cache: True Time: Fri Nov 28 13:37:59 2014 / Used Cache: False Time: Fri Nov 28 13:39:09 2014 / Used Cache: True所以您可以看到缓存过期了,我们在 13:37:59 进行了一个新的 API 调用。之后就用缓存了。简单吧?
当您更改请求中的参数时会发生什么?试试看。输入新的位置和编程语言。这里发生了什么?因为参数改变了,Requests-cache 把它当作不同的请求,不使用缓存。
平衡-同花顺与性能
同样,在上面的示例中,我们在 180 秒后终止缓存(通常称为刷新),以便向最终用户交付最新的数据。想一想。
真的有必要那么定时冲吗?大概不会。在这个应用程序中,我们可以将这个时间更改为 5 分钟或 10 分钟,因为如果我们偶尔错过一些添加到 API 中的新用户,这并不是什么大问题。
也就是说,当数据对时间敏感并且对应用程序的核心功能至关重要时,您确实需要密切关注刷新。
例如,如果您从一个每分钟更新几次的 API(如地震活动 API )中提取数据,并且您的最终用户必须拥有最新的数据,那么您可能希望每隔 30 或 60 秒左右使其过期。
平衡刷新频率和调用时间也很重要。如果您的 API 调用相当昂贵——可能需要一到五秒——那么您希望增加刷新之间的时间来提高性能。
结论
缓存是一个强大的工具。在这种情况下,我们通过限制外部 HTTP 请求的数量来提高应用程序的性能。我们从实际的 HTTP 请求本身中去掉了延迟。
在很多情况下,你不仅仅是在提出请求。您还必须处理请求,这可能涉及访问数据库、执行某种过滤等。因此,缓存也可以减少请求处理的延迟。
想要本教程的代码吗?抓住它这里。干杯!**
使用 AWS Lambda 和 API 网关进行代码评估
原文:https://realpython.com/code-evaluation-with-aws-lambda-and-api-gateway/
本教程详细介绍了如何使用 AWS Lambda 和 API Gateway 开发一个简单的代码评估 API,最终用户通过 AJAX 表单提交代码,然后由 Lambda 函数安全执行。
点击查看您将要构建的内容的现场演示。
警告:本教程中的代码用于构建一个玩具应用程序,作为概念验证的原型,而不是用于生产。
本教程假设你已经在 AWS 设置了一个账户。同样,我们将使用
US East (N. Virginia)/us-east-1区域。请随意使用您选择的地区。有关更多信息,请查看地区和可用区域指南。目标
本教程结束时,您将能够…
- 解释什么是 AWS Lambda 和 API Gateway,以及为什么要使用它们
- 讨论使用 AWS Lambda 函数的好处
- 用 Python 创建一个 AWS Lambda 函数
- 用 API 网关开发一个 RESTful API 端点
- 从 API 网关触发 AWS Lambda 函数
什么是 AWS Lambda?
Amazon Web Services (AWS) Lambda 是一种按需计算服务,允许您运行代码来响应事件或 HTTP 请求。
使用案例:
事件 行动 图像已添加到 S3 图像已处理 通过 API 网关的 HTTP 请求 HTTP 响应 添加到 Cloudwatch 的日志文件 分析日志 预定事件 备份文件 预定事件 文件同步 有关更多示例,请查看来自 AWS 的如何使用 AWS Lambda 指南的示例。
在一个看似无限可扩展的环境中,您可以运行脚本和应用程序,而不必配置或管理服务器,您只需为使用付费。这就是坚果壳中的“无服务器”计算。出于我们的目的,AWS Lambda 是快速、安全、廉价地运行用户提供的代码的完美解决方案。
截至发稿,Lambda 支持用 JavaScript (Node.js)、Python、Java 和 C#编写的代码。
项目设置
从克隆基础项目开始:
$ git clone https://github.com/realpython/aws-lambda-code-execute \ --branch v1 --single-branch $ cd aws-lambda-code-execute然后,检查主分支的 v1 标签:
$ git checkout tags/v1 -b master在您选择的浏览器中打开index.html文件:
然后,在您最喜欢的代码编辑器中打开项目:
├── README.md ├── assets │ ├── main.css │ ├── main.js │ └── vendor │ ├── bootstrap │ │ ├── css │ │ │ ├── bootstrap-grid.css │ │ │ ├── bootstrap-grid.min.css │ │ │ ├── bootstrap-reboot.css │ │ │ ├── bootstrap-reboot.min.css │ │ │ ├── bootstrap.css │ │ │ └── bootstrap.min.css │ │ └── js │ │ ├── bootstrap.js │ │ └── bootstrap.min.js │ ├── jquery │ │ ├── jquery.js │ │ └── jquery.min.js │ └── popper │ ├── popper.js │ └── popper.min.js └── index.html让我们快速回顾一下代码。本质上,我们只有一个简单的 HTML 表单,样式为 Bootstrap 。输入字段被替换为 Ace ,一个可嵌入的代码编辑器,它提供了基本的语法高亮显示。最后,在 assets/main.js 中,连接了一个 jQuery 事件处理程序,以便在提交表单时从 Ace 编辑器中获取代码,并通过 AJAX 请求将数据发送到某个地方(最终发送到 API 网关)。
λ设置
在 AWS 控制台中,导航到主 Lambda 页面并点击“创建功能”:
创建功能
步骤…
选择蓝图:点击“从头开始创作”开始一个空白功能:
T4】
配置触发器:我们稍后将设置 API 网关集成,因此只需单击“下一步”跳过这一部分。
配置功能:命名功能
execute_python_code,增加一个基本描述-Execute user-supplied Python code。在“运行时”下拉列表中选择“Python 3.6”。
T4】
在内联代码编辑器中,用以下内容更新
lambda_handler函数定义:import sys from io import StringIO def lambda_handler(event, context): # Get code from payload code = event['answer'] test_code = code + '\nprint(sum(1,1))' # Capture stdout buffer = StringIO() sys.stdout = buffer # Execute code try: exec(test_code) except: return False # Return stdout sys.stdout = sys.stdout # Check if int(buffer.getvalue()) == 2: return True return False`这里,在 Lambda 的默认入口点
lambda_handler中,我们解析 JSON 请求体,将提供的代码和一些测试代码 -sum(1,1)-传递给 exec 函数-该函数将字符串作为 Python 代码执行。然后,我们只需确保实际结果与预期结果相同——例如,2——并返回适当的响应。
T4】
在“Lambda 函数处理程序和角色”下,保留默认处理程序,然后从下拉列表中选择“从模板创建新角色”。输入一个“角色名”,如
api_gateway_access,并为“策略模板”选择“简单微服务权限”,它提供对 API 网关的访问。
T4】
点击“下一步”。
回顾:快速回顾后创建函数。
测试
接下来,单击“Test”按钮执行新创建的 Lambda:
使用“Hello World”事件模板,将示例替换为:
{ "answer": "def sum(x,y):\n return x+y" }
单击模式底部的“保存并测试”按钮运行测试。完成后,您应该会看到类似如下的内容:
这样,我们可以继续配置 API 网关,从用户提交的 POST 请求中触发 Lambda
API 网关设置
API 网关用于定义和托管 API。在我们的例子中,我们将创建一个 HTTP POST 端点,当接收到一个 HTTP 请求时触发 Lambda 函数,然后用 Lambda 函数的结果
true或false进行响应。步骤:
- 创建 API
- 手动测试
- 启用 CORS
- 部署 API
- 通过卷曲测试
创建 API
首先,从 API 网关页面,点击“开始”按钮创建一个新的 API:
T4】
选择“新 API”,然后提供一个描述性名称,如
code_execute_api:
T4】
然后,创建 API。
从“操作”下拉列表中选择“创建资源”。
T4】
将资源命名为
execute,然后点击“创建资源”。
T4】
突出显示资源后,从“操作”下拉列表中选择“创建方法”。
T4】
从方法下拉列表中选择“过帐”。单击它旁边的复选标记。
T4】
在“Setup”步骤中,选择“Lambda Function”作为“Integration type”,在下拉列表中选择“us-east-1”地区,并输入您刚刚创建的 Lambda 函数的名称。
T4】
单击“保存”,然后单击“确定”授予 API 网关运行 Lambda 函数的权限。
手动测试
要进行测试,请点击显示“测试”的闪电图标。
向下滚动到“请求体”输入,添加我们在 Lambda 函数中使用的相同 JSON 代码:
{ "answer": "def sum(x,y):\n return x+y" }点击“测试”。您应该会看到类似如下的内容:
启用 CORS
接下来,我们需要启用 CORS ,这样我们就可以从另一个域发布到 API 端点。
突出显示资源后,从“操作”下拉列表中选择“启用 CORS ”:
因为我们还在测试 API,所以现在保持默认值。单击“启用 CORS 并替换现有的 CORS 标题”按钮。
部署 API
最后,要进行部署,请从“操作”下拉列表中选择“部署 API ”:
创建一个名为“v1”的新“部署阶段”:
API gateway 将为 API 端点 URL 生成一个随机子域,并将阶段名添加到 URL 的末尾。现在,您应该能够向类似的 URL 发出发布请求:
https://c0rue3ifh4.execute-api.us-east-1.amazonaws.com/v1/execute
通过卷曲测试
$ curl -H "Content-Type: application/json" -X POST \ -d '{"answer":"def sum(x,y):\n return x+y"}' \ https://c0rue3ifh4.execute-api.us-east-1.amazonaws.com/v1/execute更新表格
现在,为了更新表单,使其将 POST 请求发送到 API 网关端点,首先将 URL 添加到 assets/main.js 中的
grade函数:function grade(payload) { $.ajax({ method: 'POST', url: 'https://c0rue3ifh4.execute-api.us-east-1.amazonaws.com/v1/execute', dataType: 'json', contentType: 'application/json', data: JSON.stringify(payload) }) .done((res) => { console.log(res); }) .catch((err) => { console.log(err); }); }然后,更新
.done和.catch()函数,如下所示:function grade(payload) { $.ajax({ method: 'POST', url: 'https://c0rue3ifh4.execute-api.us-east-1.amazonaws.com/v1/execute', dataType: 'json', contentType: 'application/json', data: JSON.stringify(payload) }) .done((res) => { let message = 'Incorrect. Please try again.'; if (res) { message = 'Correct!'; } $('.answer').html(message); console.log(res); console.log(message); }) .catch((err) => { $('.answer').html('Something went terribly wrong!'); console.log(err); }); }现在,如果请求成功,适当的消息将通过 jQuery html 方法添加到一个具有类
answer的 html 元素中。添加这个元素,就在 HTML 表单的下面,在index.html内:<h5 class="answer"></h5>让我们给 assets/main.css 文件添加一些样式:
.answer { padding-top: 30px; color: #dc3545; font-style: italic; }测试一下!
接下来的步骤
- 生产:想想一个更健壮的、生产就绪的应用程序需要什么——HTTPS、身份验证,可能还有数据存储。你将如何在 AWS 中实现这些?您可以/会使用哪些 AWS 服务?
- 动态:目前 Lambda 函数只能用来测试
sum函数。你如何使这(更)动态,以便它可以被用来测试任何代码挑战(甚至可能在任何语言中)?尝试向 DOM 添加一个数据属性,这样当用户提交一个练习时,测试代码和解决方案会随 POST 请求一起发送——即<some-html-element data-test="\nprint(sum(1,1))" data-results"2" </some-html-element>。- 堆栈跟踪:当答案不正确时,不只是用
true或false响应,而是发送回整个堆栈跟踪,并将其添加到 DOM 中。感谢阅读。在下面添加问题和/或评论。从AWS-lambda-code-executerepo 中抓取最终代码。干杯!****
用 Python 的 argparse 构建命令行界面
原文:https://realpython.com/command-line-interfaces-python-argparse/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 argparse 构建命令行接口
命令行应用在普通用户的空间中可能并不常见,但它们存在于开发、数据科学、系统管理和许多其他操作中。每个命令行应用程序都需要一个用户友好的命令行界面(CLI) ,这样你就可以与应用程序本身进行交互。在 Python 中,可以用标准库中的
argparse模块创建全功能 CLI。在这篇文章中,你将学习如何:
- 从命令行界面开始
- 组织和用 Python 布局一个命令行 app 项目
- 用 Python 的
argparse创建命令行界面- 使用
argparse的一些强大功能深度定制您的 CLI为了充分利用本教程,您应该熟悉 Python 编程,包括诸如面向对象编程、脚本开发和执行以及 Python 包和模块等概念。如果您熟悉与使用命令行或终端相关的一般概念和主题,这也会很有帮助。
源代码: 点击这里下载源代码,您将使用它来构建与
argparse的命令行界面。了解命令行界面
自从计算机发明以来,人类一直需要并找到与这些机器交互和共享信息的方法。信息交换在人类、计算机软件和硬件组件之间流动。这些元素中的任何两个之间的共享边界一般被称为接口。
在软件开发中,接口是给定软件的一个特殊部分,它允许计算机系统的组件之间进行交互。当涉及到人和软件的交互时,这个重要的组件被称为用户界面。
你会在编程中发现不同类型的用户界面。大概,图形用户界面(GUI)是当今最常见的。然而,你也会发现为用户提供命令行界面(CLIs) 的应用和程序。在本教程中,您将了解 CLI 以及如何用 Python 创建它们。
命令行界面
命令行界面允许你通过操作系统命令行、终端或控制台与应用程序或程序进行交互。
要理解命令行界面及其工作原理,请考虑这个实际的例子。假设您有一个名为
sample的目录,其中包含三个示例文件。如果您使用的是类似于 Unix 的操作系统,比如 Linux 或 macOS,那么在父目录中打开一个命令行窗口或终端,然后执行以下命令:$ ls sample/ hello.txt lorem.md realpython.md
lsUnix 命令列出了目标目录下包含的文件和子目录,默认为当前工作目录。上面的命令调用没有显示太多关于sample内容的信息。它只在屏幕上显示文件名。注意:如果你在 Windows 上,那么你会有一个
ls命令,它的工作方式类似于 Unix 的ls命令。但是,在普通形式下,该命令会显示不同的输出:PS> ls .\sample\ Directory: C:\sample Mode LastWriteTime Length Name ---- ------------- ------ ---- -a--- 11/10/2022 10:06 AM 88 hello.txt -a--- 11/10/2022 10:06 AM 2629 lorem.md -a--- 11/10/2022 10:06 AM 429 realpython.mdPowerShell
ls命令发出一个表,其中包含目标目录下每个文件和子目录的详细信息。因此,接下来的例子在 Windows 系统上不会像预期的那样工作。假设您想要关于您的目录及其内容的更丰富的信息。在这种情况下,你不需要四处寻找除了
ls之外的程序,因为这个命令有一个全功能的命令行界面,它有一组有用的选项,你可以用它来定制命令的行为。例如,使用
-l选项继续执行ls:$ ls -l sample/ total 24 -rw-r--r--@ 1 user staff 83 Aug 17 22:15 hello.txt -rw-r--r--@ 1 user staff 2609 Aug 17 22:15 lorem.md -rw-r--r--@ 1 user staff 428 Aug 17 22:15 realpython.md现在
ls的输出已经大不一样了。该命令显示了关于sample中文件的更多信息,包括权限、所有者、组、日期和大小。它还显示这些文件在您的计算机磁盘上使用的总空间。注意:要获得作为 CLI 一部分的
ls提供的所有选项的详细列表,请在命令行或终端中运行man ls命令。这个更丰富的输出来自于使用
-l选项,它是 Unixls命令行界面的一部分,支持详细的输出格式。命令、自变量、选项、参数和子命令
在本教程中,你将学习到命令和子命令。您还将了解命令行参数、选项和参数,因此您应该将这些术语纳入您的技术词汇表:
命令:在命令行或终端窗口运行的程序或例程。您通常会用底层程序或例程的名称来标识命令。
参数:命令用来执行其预期动作的必需或可选信息。命令通常接受一个或多个参数,您可以在命令行中以空格分隔或逗号分隔的列表形式提供这些参数。
选项,也称为标志或开关:修改命令行为的可选参数。选项使用特定的名称传递给命令,就像前面例子中的
-l。参数:选项用来执行其预定操作或动作的自变量。
子命令:预定义的名称,可以传递给应用程序来运行特定的动作。
考虑上一节中的示例命令结构:
$ ls -l sample/在此示例中,您组合了 CLI 的以下组件:
ls:命令名或应用名-l:启用详细输出的选项、开关或标志sample:为命令的执行提供附加信息的参数现在考虑下面的命令结构,它展示了 Python 的包管理器的 CLI,称为
pip:$ pip install -r requirements.txt这是一个常见的
pip命令结构,您可能以前见过。它允许您使用一个requirements.txt文件来安装给定 Python 项目的需求。在本例中,您使用了以下 CLI 组件:
pip:命令的名称install:一条pip子命令的名称-r:是install子命令的一个选项requirements.txt:实参,具体是-r选项的一个参数现在你知道什么是命令行界面,它们的主要部分或组件是什么。是时候学习如何用 Python 创建自己的 CLI 了。
Python 中的 CLIs 入门:
sys.argvvsargparsePython 附带了一些工具,您可以使用它们为您的程序和应用程序编写命令行界面。如果你需要为一个小程序快速创建一个最小化的 CLI,那么你可以使用
sys模块中的argv属性。该属性自动存储您在命令行传递给给定程序的参数。使用
sys.argv构建一个最小的 CLI作为使用
argv创建最小 CLI 的例子,假设您需要编写一个小程序,列出给定目录中的所有文件,类似于ls所做的。在这种情况下,你可以这样写:# ls_argv.py import sys from pathlib import Path if (args_count := len(sys.argv)) > 2: print(f"One argument expected, got {args_count - 1}") raise SystemExit(2) elif args_count < 2: print("You must specify the target directory") raise SystemExit(2) target_dir = Path(sys.argv[1]) if not target_dir.is_dir(): print("The target directory doesn't exist") raise SystemExit(1) for entry in target_dir.iterdir(): print(entry.name)这个程序通过手动处理命令行提供的参数来实现一个最小的 CLI,这些参数自动存储在
sys.argv中。sys.argv中的第一项总是程序名。第二项将是目标目录。app 不应该接受一个以上的目标目录,所以args_count不能超过2。检查完
sys.argv的内容后,创建一个pathlib.Path对象来存储目标目录的路径。如果这个目录不存在,那么你通知用户并退出应用程序。for循环列出了目录内容,每行一个条目。如果您从命令行运行脚本,那么您将得到以下结果:
$ python ls_argv.py sample/ hello.txt lorem.md realpython.md $ python ls_argv.py You must specify the target directory $ python ls_argv.py sample/ other_dir/ One argument expected, got 2 $ python ls_argv.py non_existing/ The target directory doesn't exist您的程序将一个目录作为参数,并列出其内容。如果您运行不带参数的命令,那么您会得到一条错误消息。如果在多个目标目录下运行该命令,也会出现错误。使用不存在的目录运行该命令会产生另一条错误消息。
即使您的程序运行良好,使用
sys.argv属性手动解析命令行参数对于更复杂的 CLI 应用程序来说也不是一个可伸缩的解决方案。如果您的应用程序需要更多的参数和选项,那么解析sys.argv将是一项复杂且容易出错的任务。你需要更好的东西,你可以在 Python 的argparse模块中得到它。使用
argparse和创建 CLI用 Python 创建 CLI 应用程序的一个更方便的方法是使用
argparse模块,它来自标准库。这个模块最初是在 PEP 389 的 Python 3.2 中发布的,是一种在 Python 中创建 CLI 应用程序的快捷方式,无需安装第三方库,如 Typer 或 Click 。这个模块是作为旧的
getopt和optparse模块的替代品发布的,因为它们缺少一些重要的功能。Python 的
argparse模块允许您:
- 解析命令行参数和选项
- 在单个选项中取一个可变数量的参数
- 在您的 CLI 中提供子命令
这些特性将
argparse变成了一个强大的 CLI 框架,您可以在创建 CLI 应用程序时放心地依赖它。要使用 Python 的argparse,您需要遵循四个简单的步骤:
- 导入
argparse。- 通过实例化
ArgumentParser创建一个参数解析器。- 使用
.add_argument()方法将参数和选项添加到解析器中。- 在解析器上调用
.parse_args()来得到Namespace的参数。举个例子,你可以用
argparse来改进你的ls_argv.py脚本。继续用下面的代码创建ls.py:# ls.py v1 import argparse from pathlib import Path parser = argparse.ArgumentParser() parser.add_argument("path") args = parser.parse_args() target_dir = Path(args.path) if not target_dir.exists(): print("The target directory doesn't exist") raise SystemExit(1) for entry in target_dir.iterdir(): print(entry.name)随着
argparse的引入,您的代码发生了显著的变化。与前一版本最显著的不同是,检查用户提供的参数的条件语句不见了。那是因为argparse会自动检查参数的存在。在这个新的实现中,首先导入
argparse并创建一个参数解析器。要创建解析器,可以使用ArgumentParser类。接下来,定义一个名为path的参数来获取用户的目标目录。下一步是调用
.parse_args()来解析输入参数,并获得一个包含所有用户参数的Namespace对象。请注意,现在args变量持有一个Namespace对象,该对象拥有从命令行收集的每个参数的属性。在这个例子中,你只有一个参数,叫做
path。Namespace对象允许你使用args上的点符号来访问path。代码的其余部分与第一个实现中的一样。现在继续从命令行运行这个新脚本:
$ python ls.py sample/ lorem.md realpython.md hello.txt $ python ls.py usage: ls.py [-h] path ls.py: error: the following arguments are required: path $ python ls.py sample/ other_dir/ usage: ls.py [-h] path ls.py: error: unrecognized arguments: other_dir/ $ python ls.py non_existing/ The target directory doesn't exist第一个命令打印与原始脚本
ls_argv.py相同的输出。相比之下,第二个命令显示的输出与ls_argv.py中的完全不同。程序现在显示一条用法信息,并发出一个错误,告诉你必须提供path参数。在第三个命令中,您传递两个目标目录,但是应用程序没有为此做好准备。因此,它会再次显示用法信息,并抛出一个错误,让您了解潜在的问题。
最后,如果您使用一个不存在的目录作为参数来运行脚本,那么您会得到一个错误,告诉您目标目录不存在,因此程序无法工作。
您现在可以使用一个新的隐式功能。现在你的程序接受一个可选的
-h标志。来吧,试一试:$ python ls.py -h usage: ls.py [-h] path positional arguments: path options: -h, --help show this help message and exit太好了,现在你的程序自动响应
-h或--help标志,为你显示一个帮助信息和使用说明。这是一个非常好的特性,您可以通过在代码中引入argparse来免费获得它!有了这个用 Python 创建 CLI 应用程序的快速介绍,您现在就可以更深入地研究
argparse模块及其所有很酷的特性了。用 Python 的
argparse创建命令行界面您可以使用
argparse模块为您的应用程序和项目编写用户友好的命令行界面。此模块允许您定义应用程序需要的参数和选项。然后,argparse将负责为您解析sys.argv的那些参数和选项。
argparse的另一个很酷的特性是它会自动为你的 CLI 应用程序生成用法和帮助信息。该模块还会发出错误以响应无效的参数等。在深入研究
argparse之前,您需要知道模块的文档识别两种不同类型的命令行参数:
- 位置自变量,也就是你所知道的自变量
- 可选参数,即选项、标志或开关
在
ls.py示例中,path是一个位置自变量。这样的参数被称为位置,因为它在命令结构中的相对位置定义了它的用途。可选的参数不是强制的。它们允许您修改命令的行为。在
lsUnix 命令示例中,-l标志是一个可选参数,它使命令显示详细的输出。有了这些清晰的概念,你就可以开始用 Python 和
argparse构建你自己的 CLI 应用了。创建命令行参数解析器
命令行参数解析器是任何
argparseCLI 中最重要的部分。您在命令行中提供的所有参数和选项都将通过这个解析器,它将为您完成繁重的工作。要用
argparse创建命令行参数解析器,需要实例化ArgumentParser类:









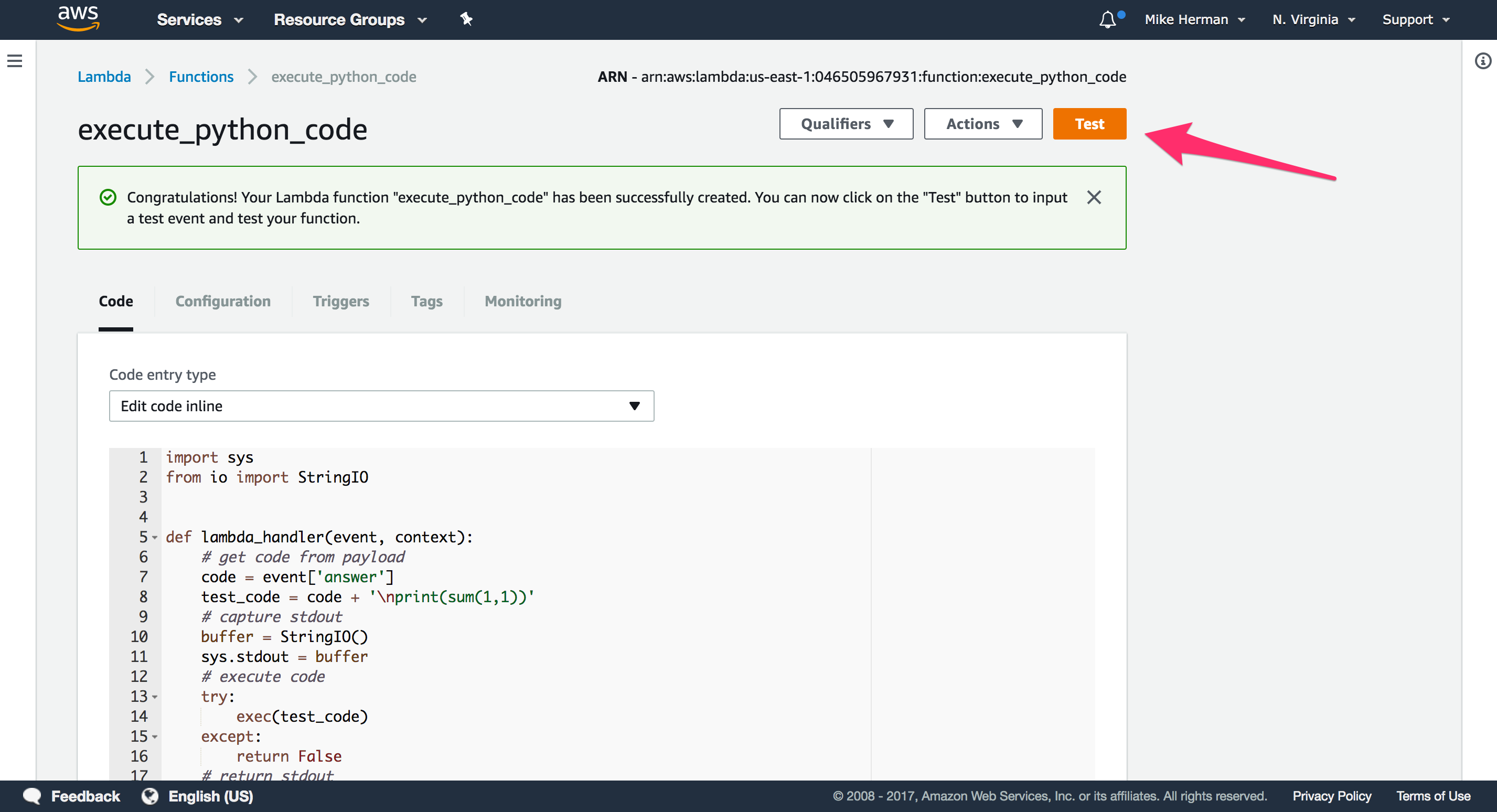







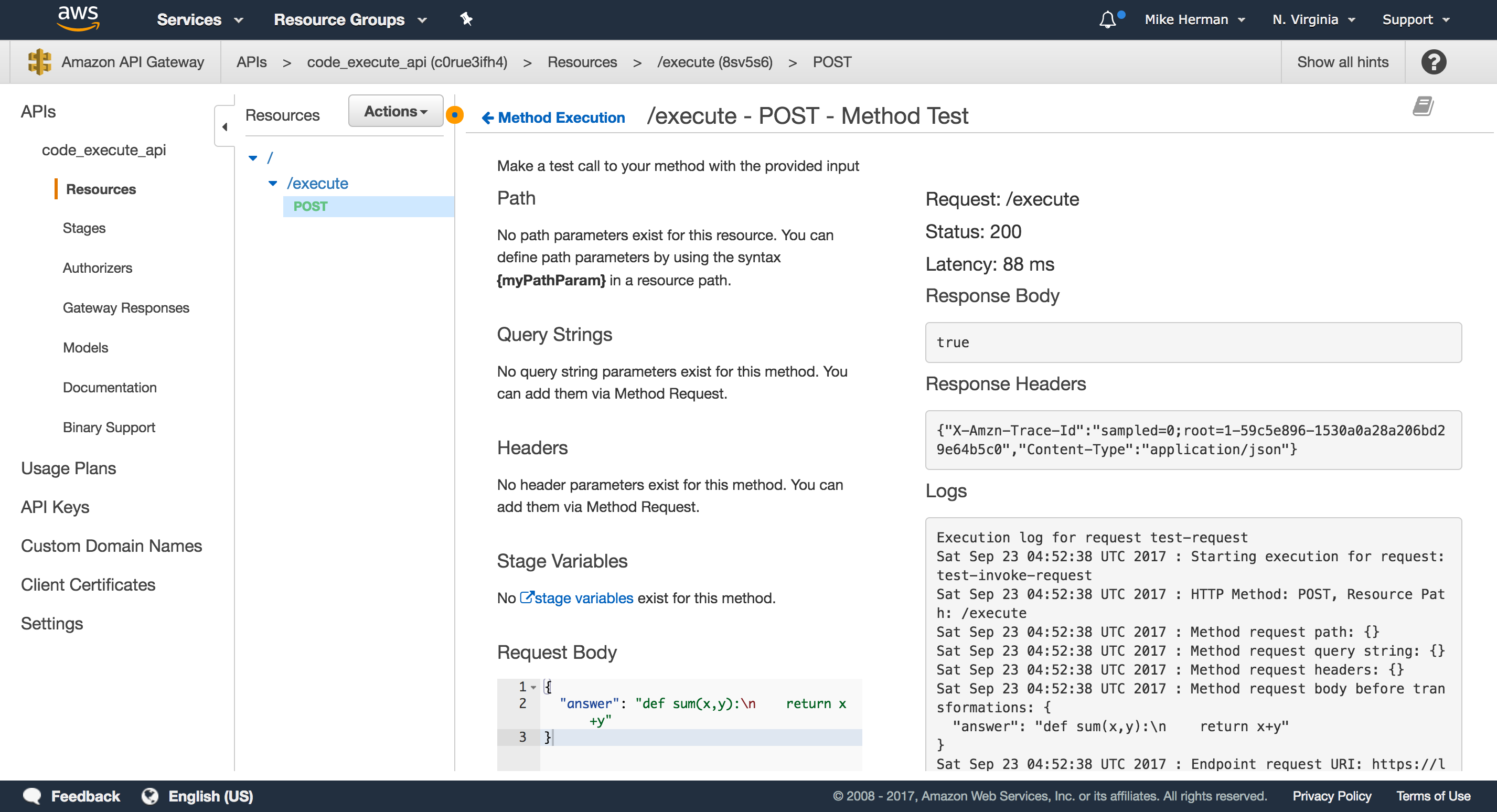






>>> from argparse import ArgumentParser
>>> parser = ArgumentParser()
>>> parser
ArgumentParser(
prog='',
usage=None,
description=None,
formatter_class=<class 'argparse.HelpFormatter'>,
conflict_handler='error',
add_help=True
)
ArgumentParser的构造器接受许多不同的参数,您可以用它们来调整您的 CLI 的一些特性。它的所有参数都是可选的,所以您可以创建的最简单的解析器是通过实例化没有任何参数的ArgumentParser得到的。
在本教程中,你会学到更多关于ArgumentParser构造函数的参数,尤其是在关于定制参数解析器的部分。现在,您可以使用argparse处理创建 CLI 的下一步。这一步是通过解析器对象添加参数和选项。
添加参数和选项
要向一个argparse CLI 添加参数和选项,您将使用您的ArgumentParser实例的 .add_argument() 方法。请注意,该方法对于参数和选项是通用的。请记住,在argparse术语中,参数被称为位置参数,选项被称为可选参数。
.add_argument()方法的第一个参数设置了参数和选项之间的区别。该自变量被标识为 name或flag 。所以,如果你提供一个name,那么你将定义一个参数。相反,如果你使用一个flag,那么你将增加一个选项。
您已经在argparse中使用了命令行参数。因此,考虑下面的定制ls命令的增强版本,它向 CLI 添加了一个-l选项:
1# ls.py v2
2
3import argparse
4import datetime
5from pathlib import Path
6
7parser = argparse.ArgumentParser()
8
9parser.add_argument("path")
10
11parser.add_argument("-l", "--long", action="store_true") 12
13args = parser.parse_args()
14
15target_dir = Path(args.path)
16
17if not target_dir.exists():
18 print("The target directory doesn't exist")
19 raise SystemExit(1)
20
21def build_output(entry, long=False): 22 if long:
23 size = entry.stat().st_size
24 date = datetime.datetime.fromtimestamp(
25 entry.stat().st_mtime).strftime(
26 "%b %d %H:%M:%S"
27 )
28 return f"{size:>6d} {date} {entry.name}"
29 return entry.name
30
31for entry in target_dir.iterdir():
32 print(build_output(entry, long=args.long))
在这个例子中,第 11 行创建了一个带有标志-l和--long的选项。参数和选项在语法上的区别在于,选项名以-开头表示简写标志,以--开头表示长标志。
注意,在这个特定的例子中,设置为"store_true"的action参数伴随着-l或--long选项,这意味着这个选项将存储一个布尔值。如果您在命令行提供选项,那么它的值将是True。如果你错过了选项,那么它的值将是False。您将在设置选项后面的动作一节中了解关于.add_argument()的action参数的更多信息。
当long为True时,第 21 行上的build_output()函数向返回详细输出,否则返回最小输出。详细的输出将包含目标目录中所有条目的大小、修改日期和名称。它使用的工具有 Path.stat() 和一个 datetime.datetime 对象,带有自定义的字符串格式。
继续在sample执行您的程序,检查-l选项是如何工作的:
$ python ls.py -l sample/
2609 Oct 28 14:07:04 lorem.md
428 Oct 28 14:07:04 realpython.md
83 Oct 28 14:07:04 hello.txt
新的-l选项允许您生成并显示关于目标目录内容的更详细的输出。
既然您已经知道了如何向 CLI 添加命令行参数和选项,那么是时候开始解析这些参数和选项了。这就是您将在下一节中探索的内容。
解析命令行参数和选项
解析命令行参数是任何基于argparse的 CLI 应用程序的另一个重要步骤。一旦解析了参数,就可以开始响应它们的值采取行动了。在您的定制ls命令示例中,参数解析发生在包含args = parser.parse_args()语句的行上。
该语句调用 .parse_args() 方法,并将其返回值赋给args变量。.parse_args()的返回值是一个 Namespace 对象,包含命令行提供的所有参数和选项及其对应的值。
考虑下面的玩具例子:
>>> from argparse import ArgumentParser >>> parser = ArgumentParser() >>> parser.add_argument("site") _StoreAction(...) >>> parser.add_argument("-c", "--connect", action="store_true") _StoreTrueAction(...) >>> args = parser.parse_args(["Real Python", "-c"]) >>> args Namespace(site='Real Python', connect=True) >>> args.site 'Real Python' >>> args.connect True在命令行参数解析器上调用
.parse_args()产生的Namespace对象通过使用点符号让您可以访问所有的输入参数、选项及其相应的值。这样,您可以检查输入参数和选项的列表,以响应用户在命令行中的选择。您将在应用程序的主代码中使用这个
Namespace对象。这就是您在自定义的ls命令示例中的for循环下所做的。至此,您已经了解了创建
argparseCLI 的主要步骤。现在,您可以花一些时间来学习如何用 Python 组织和构建 CLI 应用程序的基础知识。设置您的 CLI 应用程序的布局和构建系统
在继续你的
argparse学习冒险之前,你应该停下来想想你将如何组织你的代码和设计一个 CLI 项目。首先,你应该注意以下几点:
- 你可以创建模块和包来组织你的代码。
- 您可以用应用程序本身来命名 Python 应用程序的核心包。
- 您将根据特定的内容或功能来命名每个 Python 模块。
- 如果您想让这个包直接可执行,您可以在任何 Python 包中添加一个
__main__.py模块。记住这些想法,并考虑到模型-视图-控制器(MVC) 模式是构建应用程序的有效方式,您可以在设计 CLI 项目时使用以下目录结构:
hello_cli/ │ ├── hello_cli/ │ ├── __init__.py │ ├── __main__.py │ ├── cli.py │ └── model.py │ ├── tests/ │ ├── __init__.py │ ├── test_cli.py │ └── test_model.py │ ├── pyproject.toml ├── README.md └── requirements.txt
hello_cli/目录是项目的根目录。在那里,您将放置以下文件:
pyproject.toml是一个 TOML 文件,指定了项目的构建系统和其他配置。README.md为安装和运行应用程序提供项目描述和指令。向您的项目添加一个描述性的详细的README.md文件是编程中的最佳实践,尤其是如果您计划将项目作为开源解决方案发布的话。requirements.txt提供了一个常规文件,列出了项目的外部依赖。您将使用这个文件通过使用带有-r选项的pip来自动安装依赖项。然后是保存应用核心包的
hello_cli/目录,它包含以下模块:
__init__.py启用hello_cli/作为 Python 包。__main__.py提供了应用程序的入口点脚本或者可执行文件。cli.py提供了应用程序的命令行界面。这个文件中的代码将在基于 MVC 的架构中扮演视图控制器的角色。model.py包含支持应用程序主要功能的代码。这段代码将在你的 MVC 布局中扮演模型的角色。你还会有一个
tests/包,其中包含对你的应用组件进行单元测试的文件。在这个特定的项目布局示例中,您有test_cli.py用于检查 CLI 功能的单元测试,还有test_model.py用于检查模型代码的单元测试。
pyproject.toml文件允许您定义应用程序的构建系统以及许多其他通用配置。下面是如何为您的示例hello_cli项目填写该文件的一个简单示例:# pyproject.toml [build-system] requires = ["setuptools>=64.0.0", "wheel"] build-backend = "setuptools.build_meta" [project] name = "hello_cli" version = "0.0.1" description = "My awesome Hello CLI application" readme = "README.md" authors = [{ name = "Real Python", email = "info@realpython.com" }] [project.scripts] hello_cli = "hello_cli.__main__:main"
[build-system]表头将setuptools设置为你的应用的构建系统,并指定 Python 需要安装哪些依赖项来构建你的应用。[project]头为你的应用程序提供了通用的元数据。当您想要将您的应用发布到 Python 包索引( PyPI )时,这些元数据非常有用。最后,[project.scripts]标题定义了应用程序的入口点。通过快速浏览布局和构建 CLI 项目,您可以继续学习
argparse,尤其是如何定制您的命令行参数解析器。定制您的命令行参数解析器
在前面的章节中,您学习了使用 Python 的
argparse为您的程序或应用程序实现命令行接口的基础知识。您还学习了如何按照 MVC 模式组织和布局 CLI 应用程序项目。在接下来的几节中,您将深入了解
argparse的许多其他优秀特性。具体来说,您将学习如何在ArgumentParser构造函数中使用一些最有用的参数,这将允许您定制 CLI 应用程序的一般行为。调整程序的帮助和使用内容
向您的 CLI 应用程序的用户提供使用说明和帮助是一种最佳实践,它将使您的用户的生活更加愉快,带来出色的用户体验(UX) 。在本节中,您将了解如何利用
ArgumentParser的一些参数来微调您的 CLI 应用程序如何向用户显示帮助和使用消息。您将学习如何:
- 设置程序的名称
- 定义程序的描述和结尾信息
- 显示参数和选项的分组帮助
首先,您将设置程序的名称,并指定该名称在帮助或用法消息的上下文中的外观。
设置程序名
默认情况下,
argparse使用sys.argv中的第一个值来设置程序的名称。第一项保存了您刚刚执行的 Python 文件的名称。这个文件名在使用信息中看起来很奇怪。例如,继续运行带有
-h选项的自定义ls命令:$ python ls.py -h usage: ls.py [-h] [-l] path positional arguments: path options: -h, --help show this help message and exit -l, --long命令输出中突出显示的一行显示了
argparse正在使用文件名ls.py作为程序的名称。这看起来很奇怪,因为应用程序名称在使用信息中显示时很少包含文件扩展名。幸运的是,您可以通过使用
prog参数来指定程序的名称,如下面的代码片段所示:# ls.py v3 import argparse import datetime from pathlib import Path parser = argparse.ArgumentParser(prog="ls") # ... for entry in target_dir.iterdir(): print(build_output(entry, long=args.long))使用
prog参数,您可以指定将在用法消息中使用的程序名。在这个例子中,您使用了"ls"字符串。现在,继续运行您的应用程序:$ python ls.py -h usage: ls [-h] [-l] path positional arguments: path options: -h, --help show this help message and exit -l, --long太好了!此输出的第一行中的应用程序使用信息显示程序名称为
ls,而不是ls.py。除了设置程序的名称,
argparse让你定义应用程序的描述和结束信息。在下一节中,您将学习如何做到这两点。定义程序的描述和结尾消息
您还可以为您的应用程序定义一个一般描述和一个结尾或结束消息。为此,您将分别使用
description和epilog参数。继续更新ls.py文件,在ArgumentParser构造函数中添加以下内容:# ls.py v4 import argparse import datetime from pathlib import Path parser = argparse.ArgumentParser( prog="ls", description="List the content of a directory", epilog="Thanks for using %(prog)s! :)", ) # ... for entry in target_dir.iterdir(): print(build_output(entry, long=args.long))在此更新中,
description允许您为您的应用程序提供一个通用描述。此描述将显示在帮助消息的开头。epilog参数允许你定义一些文本作为你的应用程序的结尾或结束消息。注意,您可以使用旧式的字符串格式化操作符(%) 将prog参数插入到结束字符串中。注:帮助消息支持
%(specifier)s格式的格式说明符。这些说明符使用字符串格式化操作符%,而不是流行的 f 字符串。这是因为 f 字符串在运行时会立即用它们的值替换名称。因此,在上面对
ArgumentParser的调用中,将prog插入到epilog中,如果使用 f 字符串,将会失败,并出现NameError。如果您再次运行该应用程序,您将得到如下输出:
$ python ls.py -h usage: ls [-h] [-l] path List the content of a directory positional arguments: path options: -h, --help show this help message and exit -l, --long Thanks for using ls! :)现在,输出在用法消息之后显示描述消息,在帮助文本的末尾显示结束消息。
显示参数和选项的分组帮助
帮助小组是
argparse的另一个有趣的特色。它们允许您将相关的命令和参数分组,这将帮助您组织应用程序的帮助信息。要创建这些帮助组,您将使用ArgumentParser的.add_argument_group()方法。例如,考虑以下定制
ls命令的更新版本:# ls.py v5 # ... parser = argparse.ArgumentParser( prog="ls", description="List the content of a directory", epilog="Thanks for using %(prog)s! :)", ) general = parser.add_argument_group("general output") general.add_argument("path") detailed = parser.add_argument_group("detailed output") detailed.add_argument("-l", "--long", action="store_true") args = parser.parse_args() # ... for entry in target_dir.iterdir(): print(build_output(entry, long=args.long))在此更新中,您将为显示常规输出的参数和选项创建一个帮助组,并为显示详细输出的参数和选项创建另一个帮助组。
注意:在这个具体的例子中,像这样对参数进行分组似乎是不必要的。然而,如果你的应用有几个参数和选项,那么使用帮助组可以显著改善你的用户体验。
如果您在命令行运行带有
-h选项的应用程序,那么您将得到以下输出:python ls.py -h usage: ls [-h] [-l] path List the content of a directory options: -h, --help show this help message and exit general output: path detailed output: -l, --long Thanks for using ls! :)现在,您的应用程序的参数和选项被方便地分组在帮助消息的描述性标题下。这个简洁的功能将帮助你为你的用户提供更多的上下文,并提高他们对应用程序如何工作的理解。
为参数和选项提供全局设置
除了定制用法和帮助信息,
ArgumentParser还允许你对你的 CLI 应用程序进行一些其他有趣的调整。这些调整包括:
- 为参数和选项定义全局默认值
- 从外部文件加载参数和选项
- 允许或禁止选项缩写
有时,你可能需要为你的应用程序的参数和选项指定一个单一的全局默认值。您可以通过在调用
ArgumentParser构造函数时将默认值传递给argument_default来做到这一点。此功能可能很少有用,因为参数和选项通常具有不同的数据类型或含义,并且很难找到满足所有要求的值。
然而,
argument_default的一个常见用例是当您想要避免向Namespace对象添加参数和选项时。在这种情况下,可以使用SUPPRESS常量作为默认值。这个默认值将使得只有命令行提供的参数和选项最终存储在参数Namespace中。例如,继续修改您的定制
ls命令,如下面的代码片段所示:# ls.py v6 import argparse import datetime from pathlib import Path parser = argparse.ArgumentParser( prog="ls", description="List the content of a directory", epilog="Thanks for using %(prog)s! :)", argument_default=argparse.SUPPRESS, ) # ... for entry in target_dir.iterdir(): try: long = args.long except AttributeError: long = False print(build_output(entry, long=long))通过将
SUPPRESS传递给ArgumentParser构造函数,可以防止未提供的参数存储在参数Namespace对象中。这就是为什么你要在调用build_output()之前检查-l或者--long选项是否真的通过了。否则,您的代码将因AttributeError而中断,因为long不会出现在args中。
ArgumentParser的另一个很酷的特性是它允许你从外部文件中加载参数值。当您的应用程序具有很长或复杂的命令行结构,并且希望自动加载参数值时,这种可能性就很方便了。在这种情况下,您可以将参数值存储在一个外部文件中,并要求您的程序从中加载它们。要尝试这个特性,请继续创建以下 toy CLI 应用程序:
# fromfile.py import argparse parser = argparse.ArgumentParser(fromfile_prefix_chars="@") parser.add_argument("one") parser.add_argument("two") parser.add_argument("three") args = parser.parse_args() print(args)这里,您将
@符号传递给ArgumentParser的fromfile_prefix_chars参数。然后创建三个必须在命令行提供的参数。现在假设您经常使用具有相同参数值集的应用程序。为了方便和简化您的工作,您可以创建一个包含所有必要参数的适当值的文件,每行一个,如下面的
args.txt文件所示:first second third有了这个文件,您现在可以调用您的程序,并指示它从
args.txt文件加载值,如下面的命令运行所示:$ python fromfile.py @args.txt Namespace(one='first', two='second', three='third')在这个命令的输出中,你可以看到
argparse已经读取了args.txt的内容,并依次给你的fromfile.py程序的每个参数赋值。所有参数及其值都成功地存储在Namespace对象中。接受缩写选项名的能力是
argparseCLIs 的另一个很酷的特性。默认情况下,这个特性是启用的,当您的程序有很长的选项名时,这个特性会很方便。例如,考虑下面的程序,它打印出您在命令行的--argument-with-a-long-name选项下指定的值:# abbreviate.py import argparse parser = argparse.ArgumentParser() parser.add_argument("--argument-with-a-long-name") args = parser.parse_args() print(args.argument_with_a_long_name)这个程序打印您传递的任何内容作为
--argument-with-a-long-name选项的参数。继续运行以下命令,检查 Pythonargparse模块如何为您处理缩写:$ python abbreviate.py --argument-with-a-long-name 42 42 $ python abbreviate.py --argument 42 42 $ python abbreviate.py --a 42 42这些例子展示了如何简化
--argument-with-a-long-name选项的名称,并且仍然让应用程序正常工作。默认情况下,此功能处于启用状态。如果您想禁用它并禁止缩写,那么您可以使用allow_abbrev参数到ArgumentParser:# abbreviate.py import argparse parser = argparse.ArgumentParser(allow_abbrev=False) parser.add_argument("--argument-with-a-long-name") args = parser.parse_args() print(args.argument_with_a_long_name)将
allow_abbrev设置为False会禁用命令行选项中的缩写。从现在开始,您必须提供完整的选项名称,程序才能正常工作。否则,您会得到一个错误:$ python abbreviate.py --argument-with-a-long-name 42 42 $ python abbreviate.py --argument 42 usage: abbreviate.py [-h] [--argument-with-a-long-name ...] abbreviate.py: error: unrecognized arguments: --argument 42第二个例子中的错误消息告诉您,
--argument选项没有被识别为有效选项。要使用该选项,您需要提供它的全名。微调您的命令行参数和选项
到目前为止,您已经学习了如何定制
ArgumentParser类的几个特性来改善 CLI 的用户体验。现在你知道如何调整应用程序的用法和帮助信息,以及如何微调命令行参数和选项的一些全局方面。在本节中,您将了解如何自定义 CLI 命令行参数和选项的其他几个功能。在这种情况下,您将使用
.add_argument()方法及其一些最相关的参数,包括actiontypenargsdefaulthelp,以及其他一些参数。设置选项后的动作
当您向命令行界面添加一个选项或标志时,您通常需要定义如何在调用
.parse_args()得到的Namespace对象中存储选项的值。为此,您将对.add_argument()使用action参数。action参数默认为"store",这意味着为当前选项提供的值将按原样存储在Namespace中。
action参数可以取几个可能值中的一个。以下是这些可能值及其含义的列表:
容许值 描述 store将输入值存储到 Namespace对象store_const当指定选项时,存储一个常数值 store_true当选项被指定时存储 True布尔值,否则存储Falsestore_false指定选项时存储 False,否则存储Trueappend每次提供选项时,将当前值追加到列表 append_const每次提供选项时,将常数值追加到列表中 count存储当前选项被提供的次数 version显示应用程序的版本并终止执行 在此表中,名称中包含
_const后缀的值要求您在调用.add_argument()方法时使用const参数提供所需的常数值。类似地,version动作要求您通过将version参数传递给.add_argument()来提供应用程序的版本。您还应该注意到,只有store和append动作可以而且必须在命令行接受参数。要尝试这些操作,您可以使用以下实现创建一个玩具应用程序:
# actions.py import argparse parser = argparse.ArgumentParser() parser.add_argument( "--name", action="store" ) # Equivalent to parser.add_argument("--name") parser.add_argument("--pi", action="store_const", const=3.14) parser.add_argument("--is-valid", action="store_true") parser.add_argument("--is-invalid", action="store_false") parser.add_argument("--item", action="append") parser.add_argument("--repeated", action="append_const", const=42) parser.add_argument("--add-one", action="count") parser.add_argument( "--version", action="version", version="%(prog)s 0.1.0" ) args = parser.parse_args() print(args)该程序为上面讨论的每种类型的
action实现了一个选项。然后程序打印结果参数Namespace。下面总结了这些选项的工作方式:
--name将存储传递的值,无需任何进一步考虑。当提供选项时,
--pi将自动存储目标常数。
--is-valid将在提供时存储True,否则存储False。如果您需要相反的行为,在本例中使用类似于--is-invalid的store_false动作。
--item将让你创建一个所有值的列表。您必须为每个值重复该选项。在底层,argparse会将项目添加到一个以选项本身命名的列表中。
--repeated的工作方式与--item相似。然而,它总是附加相同的常量值,您必须使用const参数提供该常量值。
--add-one统计选项在命令行传递的次数。当您想在程序中实现几个详细级别时,这种类型的选项非常有用。例如,-v可以表示详细程度的第一级,-vv可以表示详细程度的第二级,等等。
--version显示应用的版本并立即终止执行。注意,您必须预先提供版本号,这可以在使用.add_argument()创建选项时通过使用version参数来实现。继续运行带有以下命令结构的脚本,尝试所有这些选项:
- 视窗
** Linux + macOS*PS> python actions.py ` > --name Python ` > --pi ` > --is-valid ` > --is-invalid ` > --item 1 --item 2 --item 3 ` > --repeat --repeat --repeat ` > --add-one --add-one --add-one Namespace( name='Python', pi=3.14, is_valid=True, is_invalid=False, item=['1', '2', '3'], repeated=[42, 42, 42], add_one=3 ) PS> python actions.py --version actions.py 0.1.0$ python actions.py \ --name Python \ --pi \ --is-valid \ --is-invalid \ --item 1 --item 2 --item 3 \ --repeat --repeat --repeat \ --add-one --add-one --add-one Namespace( name='Python', pi=3.14, is_valid=True, is_invalid=False, item=['1', '2', '3'], repeated=[42, 42, 42], add_one=3 ) $ python actions.py --version actions.py 0.1.0使用这个命令,您可以展示所有动作是如何工作的,以及它们是如何存储在最终的
Namespace对象中的。version动作是您使用的最后一个动作,因为这个选项只是显示程序的版本,然后结束执行。它不会存储在Namespace对象中。即使默认的动作集已经很完整了,你也可以通过子类化
argparse.Action类来创建自定义的动作。如果您决定这样做,那么您必须覆盖.__call__()方法,该方法将实例转换成可调用的对象。或者,您可以根据需要覆盖.__init__()和.format_usage()方法。要覆盖
.__call__()方法,您需要确保该方法的签名包括parser、namespace、values和option_string参数。在以下示例中,您实现了一个最小且详细的
store操作,您可以在构建 CLI 应用程序时使用该操作:# custom_action.py import argparse class VerboseStore(argparse.Action): def __call__(self, parser, namespace, values, option_string=None): print(f"Storing {values} in the {option_string} option...") setattr(namespace, self.dest, values) parser = argparse.ArgumentParser() parser.add_argument("-n", "--name", action=VerboseStore) args = parser.parse_args() print(args)在这个例子中,您定义了从
argparse.Action继承而来的VerboseStore。然后重写.__call__()方法来打印信息性消息,并在命令行参数的名称空间中设置目标选项。最后,应用程序打印名称空间本身。继续运行以下命令来尝试您的自定义操作:
$ python custom_action.py --name Python Storing Python in the --name option... Namespace(name='Python')太好了!您的程序现在在命令行存储提供给
--name选项的值之前打印出一条消息。像上面例子中的自定义动作允许你微调程序选项的存储方式。为了继续微调您的
argparseCLI,您将在下一节学习如何定制命令行参数和选项的输入值。自定义参数和选项中的输入值
构建 CLI 应用程序时的另一个常见需求是自定义参数和选项在命令行接受的输入值。例如,您可能要求给定的参数接受整数值、值列表、字符串等。
默认情况下,命令行中提供的任何参数都将被视为字符串。幸运的是,
argparse有内部机制来检查给定的参数是否是有效的整数、字符串、列表等等。在本节中,您将学习如何定制
argparse处理和存储输入值的方式。具体来说,您将学习如何:
- 设置参数和选项输入值的数据类型
- 在参数和选项中取多个输入值
- 为参数和选项提供默认值
- 为参数和选项定义一系列允许的输入值
首先,您将从定制您的参数和选项在命令行接受的数据类型开始。
设置输入值的类型
创建
argparseCLI 时,您可以定义在Namespace对象中存储命令行参数和选项时要使用的类型。为此,您可以使用.add_argument()的type参数。例如,假设您想编写一个用于划分两个数字的示例 CLI 应用程序。该应用程序将采用两个选项,
--dividend和--divisor。这些选项在命令行中只接受整数:# divide.py import argparse parser = argparse.ArgumentParser() parser.add_argument("--dividend", type=int) parser.add_argument("--divisor", type=int) args = parser.parse_args() print(args.dividend / args.divisor)在本例中,您将
--dividend和--divisor的类型设置为int。此设置将使您的选项只接受有效的整数值作为输入。如果输入值不能被转换成int类型而不丢失信息,那么您将得到一个错误:$ python divide.py --dividend 42 --divisor 2 21.0 $ python divide.py --dividend "42" --divisor "2" 21.0 $ python divide.py --dividend 42 --divisor 2.0 usage: divide.py [-h] [--dividend DIVIDEND] [--divisor DIVISOR] divide.py: error: argument --divisor: invalid int value: '2.0' $ python divide.py --dividend 42 --divisor two usage: divide.py [-h] [--dividend DIVIDEND] [--divisor DIVISOR] divide.py: error: argument --divisor: invalid int value: 'two'前两个示例工作正常,因为输入值是整数。第三个示例失败并出现错误,因为除数是浮点数。最后一个例子也失败了,因为
two不是一个数值。取多个输入值
在一些 CLI 应用程序中,可能需要在参数和选项中采用多个值。默认情况下,
argparse假设每个参数或选项都有一个值。您可以使用.add_argument()的nargs参数修改此行为。
nargs参数告诉argparse底层参数可以接受零个或多个输入值,这取决于分配给nargs的特定值。如果您希望参数或选项接受固定数量的输入值,那么您可以将nargs设置为一个整数。如果你需要更灵活的行为,那么nargs已经满足了你,因为它也接受以下价值观:
容许值 意义 ?接受单个输入值,这可以是可选的 *接受零个或多个输入值,这些值将存储在一个列表中 +接受一个或多个输入值,这些值将存储在一个列表中 argparse.REMAINDER收集命令行中剩余的所有值 值得注意的是,
nargs的允许值列表对命令行参数和选项都有效。要开始尝试
nargs的允许值,请使用以下代码创建一个point.py文件:# point.py import argparse parser = argparse.ArgumentParser() parser.add_argument("--coordinates", nargs=2) args = parser.parse_args() print(args)在这个小应用程序中,您创建了一个名为
--coordinates的命令行选项,它接受两个输入值,分别代表笛卡尔坐标x和y。准备好这个脚本后,继续运行以下命令:$ python point.py --coordinates 2 3 Namespace(coordinates=['2', '3']) $ python point.py --coordinates 2 usage: point.py [-h] [--coordinates COORDINATES COORDINATES] point.py: error: argument --coordinates: expected 2 arguments $ python point.py --coordinates 2 3 4 usage: point.py [-h] [--coordinates COORDINATES COORDINATES] point.py: error: unrecognized arguments: 4 $ python point.py --coordinates usage: point.py [-h] [--coordinates COORDINATES COORDINATES] point.py: error: argument --coordinates: expected 2 arguments在第一个命令中,您将两个数字作为输入值传递给
--coordinates。在这种情况下,程序正常工作,将值存储在Namespace对象的coordinates属性下的列表中。在第二个示例中,您传递了一个输入值,程序失败了。错误消息告诉您应用程序需要两个参数,但您只提供了一个。第三个例子非常相似,但是在这种情况下,您提供了比所需更多的输入值。
最后一个例子也失败了,因为您根本没有提供输入值,而
--coordinates选项需要两个值。在本例中,两个输入值是必需的。要测试
nargs的*值,假设您需要一个 CLI 应用程序,它在命令行中获取一系列数字并返回它们的总和:# sum.py import argparse parser = argparse.ArgumentParser() parser.add_argument("numbers", nargs="*", type=float) args = parser.parse_args() print(sum(args.numbers))因为已经将
nargs设置为*,所以numbers参数在命令行接受零个或多个浮点数。这个脚本是这样工作的:$ python sum.py 1 2 3 6.0 $ python sum.py 1 2 3 4 5 6 21.0 $ python sum.py 0前两个命令显示
numbers在命令行接受不确定数量的值。这些值将存储在一个以Namespace对象中的参数命名的列表中。如果你没有传递任何值给sum.py,那么对应的值列表将会是空的,总和将会是0。接下来,你可以用另一个小例子试试
nargs的+值。这一次,假设您需要一个在命令行接受一个或多个文件的应用程序。您可以像下面的例子一样编写这个应用程序:# files.py import argparse parser = argparse.ArgumentParser() parser.add_argument("files", nargs="+") args = parser.parse_args() print(args)本例中的
files参数将在命令行接受一个或多个值。您可以通过运行以下命令来尝试一下:$ python files.py hello.txt Namespace(files=['hello.txt']) $ python files.py hello.txt realpython.md README.md Namespace(files=['hello.txt', 'realpython.md', 'README.md']) $ python files.py usage: files.py [-h] files [files ...] files.py: error: the following arguments are required: files前两个例子表明
files在命令行接受不确定数量的文件。最后一个例子表明,如果不提供文件,就不能使用files,因为会出错。这种行为迫使您至少向files参数提供一个文件。
nargs的最终允许值是REMAINDER。此常数允许您捕获命令行中提供的其余值。如果你把这个值传递给nargs,那么底层的参数将像一个袋子一样收集所有额外的输入值。作为一个练习,你可以自己编写一个小应用程序,探索一下REMAINDER是如何工作的。尽管
nargs参数为您提供了很大的灵活性,但有时在多个命令行选项和参数中正确使用该参数是相当具有挑战性的。例如,在同一个 CLI 中,当nargs设置为*、+或REMAINDER时,很难可靠地组合参数和选项:# cooking.py import argparse parser = argparse.ArgumentParser() parser.add_argument("veggies", nargs="+") parser.add_argument("fruits", nargs="*") args = parser.parse_args() print(args)在这个例子中,
veggies参数将接受一种或多种蔬菜,而fruits参数应该在命令行接受零种或多种水果。不幸的是,这个例子并不像预期的那样工作:$ python cooking.py pepper tomato apple banana Namespace(veggies=['pepper', 'tomato', 'apple', 'banana'], fruits=[])该命令的输出显示所有提供的输入值都存储在了
veggies属性中,而fruits属性保存了一个空列表。发生这种情况是因为argparse解析器没有可靠的方法来确定哪个值属于哪个参数或选项。在这个特定的示例中,您可以通过将两个参数转换为选项来解决问题:# cooking.py import argparse parser = argparse.ArgumentParser() parser.add_argument("--veggies", nargs="+") parser.add_argument("--fruits", nargs="*") args = parser.parse_args() print(args)通过这个小的更新,您可以确保解析器有一个安全的方法来解析命令行提供的值。继续运行以下命令来确认这一点:
$ python cooking.py --veggies pepper tomato --fruits apple banana Namespace(veggies=['pepper', 'tomato'], fruits=['apple', 'banana'])现在每个输入值都已经存储在结果
Namespace的正确列表中。argparse解析器已经使用选项名来正确解析每个提供的值。为了避免类似于上例中讨论的问题,当试图将参数和选项与设置为
*、+或REMAINDER的nargs组合时,您应该始终小心。提供默认值
.add_argument()方法可以接受一个default参数,该参数允许您为各个参数和选项提供适当的默认值。当您需要目标参数或选项始终有一个有效值,以防止用户在命令行中不提供任何输入时,此功能会很有用。例如,回到您的定制
ls命令,当用户没有提供目标目录时,您需要让命令列出当前目录的内容。您可以通过将default设置为"."来实现这一点,如下面的代码所示:# ls.py v7 import argparse import datetime from pathlib import Path # ... general = parser.add_argument_group("general output") general.add_argument("path", nargs="?", default=".") # ...这段代码中突出显示的一行很神奇。在对
.add_argument()的调用中,您使用带问号(?)的nargs作为它的值。您需要这样做,因为argparse中的所有命令行参数都是必需的,将nargs设置为?、*或+是跳过所需输入值的唯一方法。在这个具体的例子中,您使用?,因为您需要一个输入值或者不需要。然后将
default设置为代表当前工作目录的"."字符串。有了这些更新,你现在可以运行ls.py而不需要提供目标目录。它会列出默认目录的内容。要进行试验,请继续运行以下命令:$ cd sample/ $ python ../ls.py lorem.md realpython.md hello.txt现在,如果您没有在命令行中提供目标目录,您的定制
ls命令会列出当前目录的内容。是不是很酷?指定允许输入值的列表
在
argparseCLIs 中另一个有趣的可能性是,您可以为特定的参数或选项创建一个允许值的域。您可以通过使用.add_argument()的choices参数提供一个可接受值的列表来做到这一点。下面是一个带有
--size选项的小应用程序的例子,它只接受几个预定义的输入值:# size.py import argparse parser = argparse.ArgumentParser() parser.add_argument("--size", choices=["S", "M", "L", "XL"], default="M") args = parser.parse_args() print(args)在这个例子中,您使用
choices参数为--size选项提供一个允许值的列表。此设置将导致该选项仅接受预定义的值。如果您尝试使用不在列表中的值,则会出现错误:$ python size.py --size S Namespace(size='S') $ python choices.py --size A usage: choices.py [-h] [--size {S,M,L,XL}] choices.py: error: argument --size: invalid choice: 'A' (choose from 'S', 'M', 'L', 'XL')如果您使用允许值列表中的输入值,那么您的应用程序可以正常工作。如果您使用一个无关的值,那么应用程序将失败并出现错误。
choices参数可以保存允许值的列表,这些值可以是不同的数据类型。对于整数值,一个有用的技巧是使用一系列可接受的值。为此,您可以使用range(),如下例所示:# weekdays.py import argparse my_parser = argparse.ArgumentParser() my_parser.add_argument("--weekday", type=int, choices=range(1, 8)) args = my_parser.parse_args() print(args)在本例中,命令行提供的值将自动对照作为
choices参数提供的range对象进行检查。继续运行以下命令,尝试一下这个示例:$ python days.py --weekday 2 Namespace(weekday=2) $ python days.py --weekday 6 Namespace(weekday=6) $ python days.py --weekday 9 usage: days.py [-h] [--weekday {1,2,3,4,5,6,7}] days.py: error: argument --weekday: invalid choice: 9 (choose from 1, 2, 3, 4, 5, 6, 7)前两个示例工作正常,因为输入数字在允许的值范围内。然而,如果输入的数字超出了定义的范围,就像上一个例子,那么你的应用程序就会失败,显示使用和错误信息。
在参数和选项中提供和定制帮助消息
正如你已经知道的,
argparse的一个伟大特性是它为你的应用程序自动生成使用和帮助信息。您可以使用任何argparseCLI 中默认包含的-h或--help标志来访问这些消息。至此,您已经了解了如何为您的应用程序提供描述和 epilog 消息。在本节中,您将通过为各个命令行参数和选项提供增强的消息来继续改进应用程序的帮助和使用消息。为此,您将使用
.add_argument()的help和metavar参数。回到您的自定义
ls命令,使用-h开关运行脚本,检查其当前输出:$ python ls.py -h usage: ls [-h] [-l] [path] List the content of a directory options: -h, --help show this help message and exit general output: path detailed output: -l, --long Thanks for using ls! :)这个输出看起来不错,是一个很好的例子,说明了
argparse如何通过提供现成的用法和帮助消息来节省您的大量工作。注意,只有
-h或--help选项显示描述性帮助信息。相比之下,您自己的参数path和-l或--long不会显示帮助信息。要解决这个问题,您可以使用help参数。打开您的
ls.py并更新它,如以下代码所示:# ls.py v8 import argparse import datetime from pathlib import Path # ... general = parser.add_argument_group("general output") general.add_argument( "path", nargs="?", default=".", help="take the path to the target directory (default: %(default)s)", ) detailed = parser.add_argument_group("detailed output") detailed.add_argument( "-l", "--long", action="store_true", help="display detailed directory content", ) # ...在这次对
ls.py的更新中,您使用.add_argument()的help参数来为您的参数和选项提供特定的帮助消息。注意:正如你已经知道的,帮助消息支持像
%(prog)s这样的格式说明符。您可以使用add_argument()的大多数参数作为格式说明符。例如,%(default)s,%(type)s等等。现在继续运行带有
-h标志的应用程序:$ python ls.py -h usage: ls [-h] [-l] [path] List the content of a directory options: -h, --help show this help message and exit general output: path take the path to the target directory (default: .) detailed output: -l, --long display detailed directory content Thanks for using ls! :)现在,当你运行带有
-h标志的应用时,path和-l都会显示描述性的帮助信息。请注意,path在它的帮助消息中包含了它的默认值,这为您的用户提供了有价值的信息。另一个期望的特性是在你的 CLI 应用程序中有一个好的和可读的使用信息。
argparse的默认使用信息已经很不错了。不过,你可以用.add_argument()的metavar论证稍微改进一下。当命令行参数或选项接受输入值时,
metavar参数就派上了用场。它允许您给这个输入值一个描述性的名称,解析器可以用它来生成帮助消息。作为何时使用
metavar的示例,回到您的point.py示例:# point.py import argparse parser = argparse.ArgumentParser() parser.add_argument("--coordinates", nargs=2) args = parser.parse_args() print(args)如果您使用
-h开关从命令行运行这个应用程序,那么您将得到如下所示的输出:$ python point.py -h usage: point.py [-h] [--coordinates COORDINATES COORDINATES] options: -h, --help show this help message and exit --coordinates COORDINATES COORDINATES默认情况下,
argparse使用命令行选项的原始名称来指定它们在用法和帮助消息中对应的输入值,正如您在突出显示的行中所看到的。在这个具体的例子中,复数形式的名称COORDINATES可能会引起混淆。你的用户应该提供点的坐标两次吗?您可以通过使用
metavar参数来消除这种歧义:# point.py import argparse parser = argparse.ArgumentParser() parser.add_argument( "--coordinates", nargs=2, metavar=("X", "Y"), help="take the Cartesian coordinates %(metavar)s", ) args = parser.parse_args() print(args)在这个例子中,您使用一个元组作为
metavar的值。元组包含人们通常用来指定一对笛卡尔坐标的两个坐标名称。您还为--coordinates,提供了一个定制的帮助消息,包括一个带有metavar参数的格式说明符。如果您运行带有
-h标志的脚本,那么您将得到以下输出:$ python coordinates.py -h usage: coordinates.py [-h] [--coordinates X Y] options: -h, --help show this help message and exit --coordinates X Y take the Cartesian coordinates ('X', 'Y')现在,你的应用程序的用法和帮助信息比以前更加清晰。现在您的用户将立即知道他们需要提供两个数值,
X和Y,以便--coordinates选项正确工作。定义互斥的参数和选项组
另一个有趣的特性是,您可以将它整合到您的
argparseCLI 中,创建互斥的参数和选项组。当参数或选项不能在同一个命令结构中共存时,这个特性就很方便了。考虑以下 CLI 应用程序,它具有不能在同一个命令调用中共存的
--verbose和--silent选项:# groups.py import argparse parser = argparse.ArgumentParser() group = parser.add_mutually_exclusive_group(required=True) group.add_argument("-v", "--verbose", action="store_true") group.add_argument("-s", "--silent", action="store_true") args = parser.parse_args() print(args)对
--verbose和--silent使用互斥的组使得不可能在同一个命令调用中使用这两个选项:$ python groups.py -v -s usage: groups.py [-h] (-v | -s) groups.py: error: argument -s/--silent: not allowed with argument -v/--verbose不能在同一个命令调用中指定
-v和-s标志。如果您尝试这样做,那么您会得到一个错误,告诉您不允许同时使用这两个选项。请注意,应用程序的使用消息显示,
-v和-s是互斥的,使用竖线符号(|)来分隔它们。这种呈现选项的方式必须解释为使用-v或-s,而不能同时解释为。向您的 CLI 添加子命令
一些命令行应用程序利用子命令来提供新的特性和功能。像
pip、 pyenv 、poems和git这些在 Python 开发者中相当流行的应用程序,大量使用了子命令。例如,如果您使用
--help开关运行pip,那么您将获得应用程序的使用和帮助消息,其中包括子命令的完整列表:$ pip --help Usage: pip <command> [options] Commands: install Install packages. download Download packages. uninstall Uninstall packages. ...要使用其中一个子命令,您只需将其列在应用程序名称之后。例如,以下命令将列出您在当前 Python 环境中安装的所有包:
$ pip list Package Version ---------- ------- pip x.y.z setuptools x.y.z ...在 CLI 应用程序中提供子命令是一个非常有用的特性。幸运的是,
argparse也提供了实现这个特性所需的工具。如果你想用子命令武装你的命令行程序,那么你可以使用ArgumentParser的.add_subparsers()方法。作为使用
.add_subparsers()的一个例子,假设您想要创建一个 CLI 应用程序来执行基本的算术运算,包括加、减、乘和除。您希望在应用程序的 CLI 中将这些操作作为子命令来实现。要构建这个应用程序,首先要编写应用程序的核心功能,或者算术运算本身。然后,将相应的参数添加到应用程序的 CLI 中:
1# calc.py 2 3import argparse 4 5def add(a, b): 6 return a + b 7 8def sub(a, b): 9 return a - b 10 11def mul(a, b): 12 return a * b 13 14def div(a, b): 15 return a / b 16 17global_parser = argparse.ArgumentParser(prog="calc") 18subparsers = global_parser.add_subparsers( 19 title="subcommands", help="arithmetic operations" 20) 21 22arg_template = { 23 "dest": "operands", 24 "type": float, 25 "nargs": 2, 26 "metavar": "OPERAND", 27 "help": "a numeric value", 28} 29 30add_parser = subparsers.add_parser("add", help="add two numbers a and b") 31add_parser.add_argument(**arg_template) 32add_parser.set_defaults(func=add) 33 34sub_parser = subparsers.add_parser("sub", help="subtract two numbers a and b") 35sub_parser.add_argument(**arg_template) 36sub_parser.set_defaults(func=sub) 37 38mul_parser = subparsers.add_parser("mul", help="multiply two numbers a and b") 39mul_parser.add_argument(**arg_template) 40mul_parser.set_defaults(func=mul) 41 42div_parser = subparsers.add_parser("div", help="divide two numbers a and b") 43div_parser.add_argument(**arg_template) 44div_parser.set_defaults(func=div) 45 46args = global_parser.parse_args() 47 48print(args.func(*args.operands))下面是代码的工作原理:
第 5 行到第 15 行定义了执行加、减、乘、除基本算术运算的四个函数。这些函数将提供应用程序的每个子命令背后的操作。
第 17 行照常定义命令行参数解析器。
第 18 到 20 行通过调用
.add_subparsers()定义了一个子参数。在这个调用中,您提供一个标题和一条帮助消息。第 22 到 28 行为您的命令行参数定义了一个模板。这个模板是一个字典,包含了必需参数
.add_argument()的敏感值。每个参数将被称为operands,并将由两个浮点值组成。定义此模板可以让您在创建命令行参数时避免重复代码。第 30 行给 subparser 对象添加一个解析器。这个子命令的名字是
add,它将代表加法操作的子命令。help参数特别为这个解析器定义了一个帮助消息。第 31 行使用带有参数模板的
.add_argument()将operands命令行参数添加到add子参数中。注意,您需要使用字典解包操作符(**) 从arg_template中提取参数模板。第 32 行使用
.set_defaults()将add()回调函数分配给add子用户或子命令。第 34 行到第 44 行执行类似于第 30 行到第 32 行的操作,用于其余的三个子命令,
sub、mul和div。最后,第 48 行从args调用func属性。该属性将自动调用与子命令相关联的函数。继续运行以下命令,试用您的新 CLI 计算器:
$ python calc.py add 3 8 11.0 $ python calc.py sub 15 5 10.0 $ python calc.py mul 21 2 42.0 $ python calc.py div 12 2 6.0 $ python calc.py -h usage: calc [-h] {add,sub,mul,div} ... options: -h, --help show this help message and exit subcommands: {add,sub,mul,div} arithmetic operations add add two numbers a and b sub subtract two numbers a and b mul multiply two numbers a and b div divide two numbers a and b $ python calc.py div -h usage: calc div [-h] OPERAND OPERAND positional arguments: OPERAND a numeric value options: -h, --help show this help message and exit酷!您所有的子命令都像预期的那样工作。它们接受两个数字,并用它们执行目标算术运算。请注意,现在您已经有了应用程序和每个子命令的用法和帮助消息。
处理您的 CLI 应用程序的执行如何终止
创建 CLI 应用程序时,您会发现由于错误或异常而需要终止应用程序执行的情况。在这种情况下,常见的做法是退出应用程序,同时发出一个错误代码或退出状态,以便其他应用程序或操作系统可以了解应用程序因执行错误而终止。
通常,如果命令以零代码退出,那么它已经成功。同时,非零退出状态表示失败。这个系统的缺点是,虽然你有一个单一的、定义明确的方式来表示成功,但你有各种方式来表示失败,这取决于手头的问题。
不幸的是,错误代码或退出状态没有明确的标准。操作系统和编程语言使用不同的风格,包括十进制或十六进制数字、字母数字代码,甚至描述错误的短语。Unix 程序通常使用
2表示命令行语法错误,使用1表示所有其他错误。在 Python 中,通常使用整数值来指定 CLI 应用程序的系统退出状态。如果你的代码返回
None,那么退出状态为零,这被认为是成功终止。任何非零值表示异常终止。大多数系统要求退出代码在从0到127的范围内,否则会产生未定义的结果。用
argparse构建 CLI apps 时,不需要担心返回成功操作的退出代码。然而,当你的应用程序由于一个错误而不是命令语法错误突然终止执行时,你应该返回一个适当的退出代码,在这种情况下argparse为你做了开箱即用的工作。
argparse模块,特别是ArgumentParser类,有两个专用的方法来在出现问题时终止应用程序:
方法 描述 T2 .exit(status=0, message=None)终止应用程序,返回指定的 status并打印message(如果给定)T2 .error(message)打印包含所提供的 message的使用信息,并使用状态代码2终止应用程序两种方法都直接打印到专用于错误报告的标准错误流。当您需要完全控制返回哪个状态代码时,
.exit()方法是合适的。另一方面,.error()方法由argparse在内部用于处理命令行语法错误,但是您可以在必要和适当的时候使用它。作为何时使用这些方法的示例,考虑对您的自定义
ls命令的以下更新:# ls.py v9 import argparse import datetime from pathlib import Path # ... target_dir = Path(args.path) if not target_dir.exists(): parser.exit(1, message="The target directory doesn't exist") # ...在检查目标目录是否存在的条件语句中,不使用
raise SystemExit(1),而是使用ArgumentParser.exit()。这使得你的代码更加关注于所选择的技术栈,也就是argparse框架。要检查您的应用程序现在的行为,请继续运行以下命令:
- 视窗
** Linux + macOS*PS> python ls.py .\non_existing\ The target directory doesn't exist PS> echo $LASTEXITCODE 1$ python ls.py non_existing/ The target directory doesn't exist $ echo $? 1当目标目录不存在时,应用程序立即终止执行。如果你在一个类似 Unix 的系统上,比如 Linux 或 macOS,那么你可以检查
$?shell 变量来确认你的应用程序已经返回了1来通知它执行中的一个错误。如果你在 Windows 上,那么你可以检查$LASTEXITCODE变量的内容。在您的 CLI 应用程序中提供一致的状态代码是一种最佳实践,它将允许您和您的用户成功地将您的应用程序集成到他们的 shell 脚本和命令管道中。
结论
现在您知道了什么是命令行界面,以及它的主要组件是什么,包括参数、选项和子命令。您还学习了如何使用 Python 标准库中的
argparse模块创建全功能的 CLI 应用程序。在本教程中,您已经学会了如何:
- 从命令行界面开始
- 组织和用 Python 布置一个命令行项目
- 使用 Python 的
argparse创建命令行界面- 使用
argparse的一些强大功能定制 CLI 的大多数方面作为开发人员,知道如何编写有效且直观的命令行界面是一项非常重要的技能。为你的应用程序编写好的 CLI 可以让你在与你的应用程序交互时给你的用户一个愉快的用户体验。
源代码: 点击这里下载源代码,您将使用它来构建与
argparse的命令行界面。立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 argparse 构建命令行接口***************
通过真正的 Python Slack 社区提升您的技能
真正的 Python 社区 Slack 是一个以英语为媒介的 Python 社区,成员遍布世界各地。这是一个受欢迎的小组,你可以自由地讨论你可能有的任何问题,庆祝你的进步,或者在虚拟饮水机旁与社区一起闲逛。
如果你想:
- 充分利用真正的 Python Slack 社区
- 浏览 Slack 最有价值的功能
- 让其他真正的 Python 成员回答您的个问题
- 学习该做什么和不该做什么以保持事情平稳发展
欢迎您提出任何建议或问题。你可以在 Slack 或者下面的评论里和管理员分享。在 Slack 上,你可以通过名字旁边真正的 Python 符号来判断某人是否是管理员。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
享受自己,保持好奇心,提出问题,尊重他人
真正的 Python Slack 社区中的人都是友好的人,他们喜欢回答问题和闲逛。对于初学者和希望扩展知识和建立友谊的更高级的 python 爱好者来说,这是一个极好的资源。
没有愚蠢的问题——没有这样的事情存在!有趣的是,初学者的问题往往会引发关于 Python 和编程的最激动人心、最深入的讨论。所以拜托,问吧!
真正的 Python Slack 社区不是一个敌对的论坛——每个人都在这里学习,人们也乐于提供帮助。所以听和互相优秀。你会交到一些朋友的!
当然,网上交流面临着人们面对面交流时没有的挑战。如果您有任何问题,请随时联系我们的管理员:
- 初学者巴塔哥尼亚
- Geir Arne Hjelle
- 伊恩·库里
- 莱奥达尼丝井树枝
- 马丁·布鲁斯
- 菲利普·阿克萨尼
他们会很乐意尽可能地帮助你。
如果您想知道如何浏览社区、从中受益以及为社区做出贡献,那么您可以继续阅读一些有用的提示和指南。在本指南的其余部分,您将掌握一些该做和不该做的事情,以保持事情顺利进行。
找到提问的最佳渠道
有几个空闲的频道供你提问。大多数频道专注于一个特定的主题或专业。当你加入 Slack 时,你会自动被添加到一些常规频道。你也可以自由——并被鼓励——加入社区 Slack 中存在的任何其他渠道。
点击频道菜单旁边的 + 图标,即可找到可用频道列表。选择您希望加入的频道,点击加入按钮。例如,如果你对这些主题感兴趣,你可能想加入#网络开发、#数据科学和#职业频道:
This may look slightly different depending on the platform where you're using Slack. 一旦你加入了几个频道,你就可以在与你的问题最相关的频道提出你的问题。如果你的问题不属于某一特定类别,那么#编码问题就是你的渠道。
花些时间构思你的问题
当你遇到一个问题并且很急的时候,很容易就会跳到 Slack 上,粘贴你所有的代码,并且写下它不工作。不幸的是,这是一个让人们忽略你的问题的万全之策。知道如何提问很难!
这些天,每个人都很忙,很匆忙。想象一下,你打断了一位同事的工作,请他们帮你解决一个问题。你不会带着你的笔记本电脑,把它放在他们面前,然后说它坏了。你向他们提出这个问题,这样可能会得到有益的回应:
- 总结问题
- 为问题提供一些背景信息
- 提供一个最小的可重复示例
- 提及你迄今为止尝试过的事情
- 检查拼写、语法和格式
你的问题越复杂,你就越有可能不知道答案,并且可能认为这个问题是他们不知道的。代码很难读懂——无论你的技能水平如何,都需要时间和努力。
花些时间收集你的想法,在一篇文章中提出具体的问题和代码。
总结你的问题
用一两句话概括问题可以帮助人们更好地帮助你——糟糕的总结会让人失去兴趣:
- 不要:这段代码不起作用。
- Do :当我所有的输入都是整数时,为什么用
float代替int会给我不同的结果?每个人都很忙,所以如果你能在第一句话中总结你的问题,人们会更容易了解情况并迅速提供帮助。
有时候,你可能会得到一些似乎没有直接解决你所面临的问题的回复。不要对你的同事感到沮丧,考虑一下你的总结是否清楚准确地指出了问题所在。如果你需要的话,恭敬地感谢社区的回应,然后在你的原始帖子的帖子里发布一个更新的摘要。
给出你的问题的背景
给出背景和总体目标有助于防止 XY 问题。如果你有一个关于解决方案的想法,并询问如何实现它,而没有提供原始问题,这往往会发生。原来的问题可能有另一个你没有想到的解决方案。离开背景,不描述你最初的问题,会导致你和决定帮助你的人白费力气。
例如,您想用 Python 运行一个 shell 脚本,但是您不知道如何导航到正确的文件夹来运行它。有人花了很多时间教你如何运行文件,以及如何用 Python 运行 shell 脚本。然后,您发现 shell 脚本所做的只是删除文件,对此,提供帮助的人会问:为什么不放弃 shell 脚本,用 Python 来做这件事呢?
问题的背景——你面临的实际问题——往往比你尝试的解决方案更重要。所以当你问问题的时候,一定要提供一些背景。
提供一个最小的可重复示例
请尝试提供一个最小可重现示例。提供一个最小的可再现的例子意味着提供足够的代码和指令,以便有人可以再现您的环境并再现您正在经历的不想要的行为。
当代码不起作用的时候,尤其是代码超过十行的时候,光靠阅读就很难发现 bug 了。自己运行并调整代码来发现问题要高效得多。这种效率就是为什么一个最小的可重复的例子如此实用——这就像让一群专家围着你的计算机修补你的代码。
如果你的问题与你的环境密切相关,那么就要明确。清楚地说明这对于其他人来说是不可复制的。也就是说,你必须接受这个问题对其他人来说很难调试。
提供追溯
宣称某样东西不起作用并不能提供多少信息。另一方面,Python 生成的回溯或错误消息提供了大量信息。
然而,追溯可能很难破译,阅读追溯是一项需要数年才能掌握的技能。同样,总是提供代码的错误消息或输出。输出给出了关于哪里出错的基本线索,更有经验的编码人员可能能够破译。
不要跨帖
一般来说,请不要将您的问题交叉发布到几个渠道。在一个地方发帖可以确保人们有一个明确的地方来回答你的问题。如果你交叉发布,那么你可能会让成员花时间回答你的问题,而其他人已经在其他地方回答了这个问题。
如果您因为不小心交叉发布而需要删除您的问题,请参见删除和编辑您的帖子。
尝试自己解决问题
真正的 Python 社区喜欢帮助和回答问题,但他们不会替你做你的工作。他们不会完成你的家庭作业!他们是来帮助你学习的,而最好的学习方式就是做。
Eric Lippert 有一篇关于如何调试小程序的经典文章,这是一篇关于调试时应采取的一般方法的优秀指南。
如果你是初学者,那么你也应该看看了解 Python 回溯。该教程将帮助您更好地理解代码中发生的事情,这将帮助您在社区 Slack 中提出更好的问题。
不过,不要打破你的头——如果你被卡住了,也没什么丢人的。请提问!只要包括你到目前为止已经尝试过的。
处理未回答的问题
你的问题得不到回答会令人沮丧。如果你发现你的问题没有得到回答,那么也许有必要问自己几个问题:
- 多少时间过去了?
- 我是否包括了所有相关信息?
- 我是否发布到了最合适的渠道?
当你问自己已经过了多少时间,如果答案只是几个小时,那就多给它一些时间。大多数成员都有全职工作,只有当他们有空闲时间来学习 Python 技能时,才会检查 Slack。
时区也是一个重要因素。最终会回答你问题的人,可能在你发帖的时候正在睡觉。所以,睡一觉吧——这不仅会让你的大脑有时间下意识地解决这个问题,而且你可能会醒来找到一个有用的答案。
你也应该回顾一下这个指南的注意事项,看看你是否遗漏了什么。你包括你的回溯或者错误信息了吗?所有的相关代码包括和格式正确吗?这些都可能影响成员的帮助能力,所以如果你能修改你的问题,让别人更容易理解,这是值得一看的。
当你是一个初学者时,很难知道哪些信息应该包含,哪些应该省略,这没关系。通过练习会变得更容易。遵循上面的指导方针,不要让怀疑阻止你发布你的问题。真正的 Python 社区充满了热情、慷慨的人,他们会尽一切努力帮助你。
如果你已经等了足够长的时间,并且确信你的问题是清晰的和描述性的,那么你可能还会考虑你是否在正确的地方问了你的问题。它是否更适合不同的渠道?如果是这样,您可以变通交叉发布指南,在另一个渠道与分享您的问题的链接:
提供原始问题的链接可以确保仍然只有一个地方可以提供答案。它还将人们链接到可能在原始问题中发生的任何先前的讨论。
如果你已经穷尽了所有这些选择,那么你可以考虑在会员专用的办公时间问你的问题。在#办公时间频道上发布一个与你的问题相关的链接,主持人就会收到。
最后,如果以上都没有结果,那么直接联系 Slack 的一个管理员。他们既可以帮你找到解决方案,也可以给你指明正确的方向。
不要放弃
一个好的程序员的一部分是坚韧。继续尝试,即使你的问题没有得到任何回应。也许这是非常具体或困难的事情,以至于没有人觉得他们能帮上忙。
当你最终解决了你的问题,社区会乐于听到你的胜利和解决方案。所以请分享,让社区加入你的学习之旅。
将您的回答按线索分组
如果您想回复其他成员的帖子,请使用回复主题按钮。使用线程将关于该主题的整个对话保持在一个地方,从而可以跟踪对话:
https://player.vimeo.com/video/462868900?background=1
线程特性是确保对话不会混乱的一个很好的方法。它使交换对未来的用户来说是可读的,他们可能会从中学到一些东西。它还可以作为一个方便的指示器来查看是否有任何问题没有任何响应,从而进一步增加所有问题得到答案的机会。
记住,每个人都是来学习的,每个人都是从某个地方开始的。在你的回应中要尊重他人。
注意拼写、语法和格式
同样,每个人都很忙——阅读有结构的东西要容易得多,因为代码的格式是适当的。这适用于问题和回答。阅读松弛时间格式指南以获得更多关于如何格式化消息的松弛时间特定信息。
使用浏览器的集成拼写检查器,花些时间让你的书写清晰。如果语法跟不上你学校老师告诉你的,不要担心,尤其是如果英语不是你的第一语言。
然而,格式的重要性在于代码。如前所述,代码很难阅读。所以你能做的每一件让代码更容易阅读的小事都将大有帮助。有四种方式可以在 Slack 上共享格式化代码:
每种方法都有其用例,但是最常用的方法应该是使用代码片段。
内嵌代码
内联代码用于格式化您想在问题或评论中提到的小代码。这主要是为了突出显示您问题中的特定变量和对象:
单词
Flask、ModuleNotFoundError和pip install flask被格式化为内联代码。要将内联代码添加到您的问题中,请用反斜杠( ` )将您的变量或对象名称括起来,或者单击消息编辑器上的代码格式按钮:
只需选择要格式化为代码的文本,然后按下按钮。
代码块
您可以将代码块用于小代码示例,如单个函数、和终端输出,以及简短的代码摘录。
下面是一个使用内联代码后跟代码块的示例问题:
问题本身使用对象和变量名的内联代码,后面是显示问题代码的代码块。要创建代码块,请用三个反斜杠( ```
)将代码括起来,或者在 Slack 消息编辑器中单击代码块按钮:
代码块非常适合显示十行或更少的代码。代码块不适合较长的代码,原因如下:
- 没有语法高亮,这使得大段代码更难阅读。
- 它充满了屏幕,这意味着其他成员的问题可能会被埋没或错过。
- 对于任何浏览提要的人来说,这会带来不愉快的阅读体验。
如果您需要共享更大部分的代码,那么有一个更好的方法:代码片段!
代码片段——共享代码的最佳方式
代码片段让在 Slack 中分享和阅读大部分代码成为一种更加愉快的体验。代码片段应该是你分享大部分代码的首选方法。你所需要做的就是在你的邮件中附上一个
.py文件!注:根据你的系统,以及你是从 web 客户端、桌面应用还是移动应用与 Slack 交互,你可能只需将文件拖放到 Slack 窗口中。否则,您可以使用以下步骤附加文件。
您可以在代码片段消息中使用内联代码和代码块。这种灵活性意味着您可以在一条消息中共享您的代码和回溯。
下面是一个代码片段示例:
使用代码片段的一个重要好处是它们支持几乎所有编程语言的代码语法高亮显示。它们也是可折叠的,使得长代码样本更少干扰。感兴趣的成员可以展开并点击阅读整个片段。
另一个很大的优势是它们也是可以下载的,所以任何帮助你的人都可以下载这个文件。能够下载该文件可以更快地重现您的问题。
要创建代码片段,单击 Slack 消息区域中的
+按钮,就像要添加附件一样。然后,您可以附加任何代码文件,该文件将显示为代码片段。您也可以搜索名为的快捷方式,创建一个文本片段,这将打开一个覆盖图,您可以在其中键入您的问题并将您的代码复制到内容区域。您可以为代码片段指定一个标题(可以将其视为文件名),并选择语法高亮显示的语言。
下面是如何创建代码片段的快速演示:
https://player.vimeo.com/video/462868891?background=1
代码片段是在 Slack 上共享代码的最好方式!
如果你有任何关于在 Slack 中格式化代码的问题,请在下面的评论中写下你的想法,或者联系真正的 Python 社区 Slack 的管理员。
GitHub
如果用不到 30 行代码制作一个可重复的例子很复杂,或者帮助你的人需要访问你的所有代码,那么请分享你项目的 T2 Git 库 T3 的链接。您可以创建一个新的存储库,并复制重现问题所需的最少代码:
https://player.vimeo.com/video/711127424?background=1
如果有任何设置说明,则将它们记录在一个
README.md文件中。这样,有人就能快速复制你的工作环境。GitHub 允许你拥有无限的公共存储库,所以这是一个很好的地方来存放一次性存储库,你可以在找到解决方案后删除它们。
如果创建一个完整的存储库似乎太多了,那么一个中间的解决方案是使用 GitHub Gists :
https://player.vimeo.com/video/711127464?background=1
Gists 允许您共享一个或多个文件,而不需要整个存储库的额外样板文件。
删除和编辑您的帖子
最初发布后,您可以在有限的时间内编辑您的帖子,但过一会儿,您将无法更改它们。你可以在帖子下面的帖子里发布更多的上下文、澄清或更正,没有任何限制。
如果你的帖子已经过时,或者你犯了一个错误,你真的必须从头开始,请联系管理员,他们可以帮你删除帖子。但是,他们将无法编辑您的问题。
这一限制主要是因为人们在得到答案后删除他们的问题是很常见的。虽然这是可以理解的,但即使你没有参与,也有问答主题阅读是有价值的。旧线是整个社区的宝贵资源。
总结
作为一名开发人员,加入像 Real Python Slack 这样充满活力的社区会给你的旅程带来巨大的好处。在本指南中,您了解了如何充分利用真正的 Python Slack。
学习如何交流你的技术问题是成为一名熟练开发人员的重要一步。本指南将帮助你实现这一点,这样你就可以开始利用真正的 Python 成员丰富的知识库。
真正的 Python 社区是多样化的,来自全球各地的成员有着不同的背景和经历。与真正的 Python 社区联系将增强你的技术技能,让你接触新的感兴趣的领域,并扩展你的社交网络。
与你的同龄人交往也不仅仅是一项在线活动。Real Python 在 PyCon 2022 上获得了一个展位,并会见了许多会员。有聚会和开放的空间,成员可以问问题和闲逛。
也许你还不是真正的 Python 成员,不能利用 Slack 社区的好处。立即注册账户,与您的同行交流,开始提升您的 Python 知识和职业生涯!*****
比较 Python 命令行解析库 Argparse、Docopt 和 Click
原文:https://realpython.com/comparing-python-command-line-parsing-libraries-argparse-docopt-click/
大约一年前,我开始了一项构建命令行应用程序是家常便饭的工作。那时我已经用了 argparse 很多次,并想探索一下还有什么其他的选择。
我发现最受欢迎的选择是 click 和 docopt 。在我的探索过程中,我还发现除了每个库的“为什么使用我”部分之外,没有太多关于这三个库的完整比较。现在有了——这篇博文!
如果您愿意,您可以直接前往源,尽管如果没有本文中介绍的比较和逐步构建,它真的没有多大用处。
本文使用以下版本的库:
$ python --version Python 3.4.3 # argparse is a Python core library $ pip list | grep click click (5.1) $ pip list | grep docopt docopt (0.6.2) $ pip list | grep invoke invoke (0.10.1)(暂时忽略
invoke,这是给后面的特别惊喜!)命令行示例
我们正在创建的命令行应用程序将具有以下界面:
python [file].py [command] [options] NAME基本用法*
$ python [file].py hello Kyle Hello, Kyle! $ python [file].py goodbye Kyle Goodbye, Kyle!带选项(标志)的用法
$ python [file].py hello --greeting=Wazzup Kyle Whazzup, Kyle! $ python [file].py goodbye --greeting=Later Kyle Later, Kyle! $ python [file].py hello --caps Kyle HELLO, KYLE! $ python [file].py hello --greeting=Wazzup --caps Kyle WAZZUP, KYLE!本文将比较实现以下特性的每种库方法:
- 命令(
hello,goodbye)- 参数(名称)
- 选项/标志(
--greeting=<str>,--caps)附加功能:
- 版本打印(
-v/--version)- 自动帮助消息
- 错误处理
正如您所料, argparse 、 docopt 和 click 实现了所有这些特性(就像任何完整的命令行库一样)。这个事实意味着我们将比较的是这些特性的实际实现。每个库都采用了非常不同的方法,这带来了一个非常有趣的比较- argparse=standard , docopt=docstrings , click=decorators 。
奖金部分
- 我一直对使用像 fabric 这样的任务运行器库感到好奇,它是 python3 的替代品 invoke 来创建简单的命令行接口,所以我将尝试把相同的接口与 invoke 放在一起。
- 打包命令行应用程序时需要一些额外的步骤,所以我也将介绍这些步骤!
命令
让我们从为每个库建立基本框架(没有参数或选项)开始。
抱怨吗
import argparse parser = argparse.ArgumentParser() subparsers = parser.add_subparsers() hello_parser = subparsers.add_parser('hello') goodbye_parser = subparsers.add_parser('goodbye') if __name__ == '__main__': args = parser.parse_args()这样我们现在有了两个命令(
hello和goodbye)和一个内置的帮助消息。请注意,当作为 hello 命令上的一个选项运行时,帮助消息会发生变化。$ python argparse/commands.py --help usage: commands.py [-h] {hello,goodbye} ... positional arguments: {hello,goodbye} optional arguments: -h, --help show this help message and exit $ python argparse/commands.py hello --help usage: commands.py hello [-h] optional arguments: -h, --help show this help message and exitDocopt
"""Greeter. Usage: commands.py hello commands.py goodbye commands.py -h | --help Options: -h --help Show this screen. """ from docopt import docopt if __name__ == '__main__': arguments = docopt(__doc__)同样,我们有两个命令(
hello、goodbye)和一个内置的帮助消息。注意,当作为hello命令的一个选项运行时,帮助信息没有改变。此外,我们不需要在Options部分明确指定commands.py -h | --help来获得帮助命令。但是,如果我们不这样做,它们将不会作为选项出现在输出帮助消息中。$ python docopt/commands.py --help Greeter. Usage: commands.py hello commands.py goodbye commands.py -h | --help Options: -h --help Show this screen. $ python docopt/commands.py hello --help Greeter. Usage: commands.py hello commands.py goodbye commands.py -h | --help Options: -h --help Show this screen.点击
import click @click.group() def greet(): pass @greet.command() def hello(**kwargs): pass @greet.command() def goodbye(**kwargs): pass if __name__ == '__main__': greet()这样我们现在有了两个命令(
hello、goodbye)和一个内置的帮助消息。注意,当作为hello命令的一个选项运行时,帮助信息会发生变化。$ python click/commands.py --help Usage: commands.py [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: goodbye hello $ python click/commands.py hello --help Usage: commands.py hello [OPTIONS] Options: --help Show this message and exit.即使在这一点上,你可以看到我们有非常不同的方法来构建一个基本的命令行应用程序。接下来让我们添加 NAME 参数,以及从每个工具输出结果的逻辑。
参数
在这一节中,我们将向上一节中显示的相同代码添加新的逻辑。我们将在新行中添加注释,说明它们的用途。参数(也称为位置参数)是命令行应用程序的必需输入。在本例中,我们添加了一个必需的
name参数,这样工具就可以问候一个特定的人。抱怨吗
为了给子命令添加一个参数,我们使用了
add_argument方法。为了执行正确的逻辑,当一个命令被调用时,我们使用set_defaults方法来设置一个默认函数。最后,在运行时解析参数后,我们通过调用args.func(args)来执行默认函数。import argparse def hello(args): print('Hello, {0}!'.format(args.name)) def goodbye(args): print('Goodbye, {0}!'.format(args.name)) parser = argparse.ArgumentParser() subparsers = parser.add_subparsers() hello_parser = subparsers.add_parser('hello') hello_parser.add_argument('name') # add the name argument hello_parser.set_defaults(func=hello) # set the default function to hello goodbye_parser = subparsers.add_parser('goodbye') goodbye_parser.add_argument('name') goodbye_parser.set_defaults(func=goodbye) if __name__ == '__main__': args = parser.parse_args() args.func(args) # call the default function$ python argparse/arguments.py hello Kyle Hello, Kyle! $ python argparse/arguments.py hello --help usage: arguments.py hello [-h] name positional arguments: name optional arguments: -h, --help show this help message and exitDocopt
为了添加一个选项,我们向 docstring 添加了一个
<name>。<>用于指定位置参数。为了执行正确的逻辑,我们必须检查命令(作为参数处理)在运行时是否是True``if arguments['hello']:,然后调用正确的函数。"""Greeter. Usage: basic.py hello <name> basic.py goodbye <name> basic.py (-h | --help) Options: -h --help Show this screen. """ from docopt import docopt def hello(name): print('Hello, {0}'.format(name)) def goodbye(name): print('Goodbye, {0}'.format(name)) if __name__ == '__main__': arguments = docopt(__doc__) # if an argument called hello was passed, execute the hello logic. if arguments['hello']: hello(arguments['<name>']) elif arguments['goodbye']: goodbye(arguments['<name>'])$ python docopt/arguments.py hello Kyle Hello, Kyle $ python docopt/arguments.py hello --help Greeter. Usage: basic.py hello <name> basic.py goodbye <name> basic.py (-h | --help) Options: -h --help Show this screen.请注意,帮助消息并不特定于子命令,而是程序的整个文档字符串。
点击
为了给点击命令添加一个参数,我们使用了
@click.argument装饰器。在这种情况下,我们只是传递参数名,但是还有更多选项,其中一些我们稍后会用到。因为我们用参数来修饰逻辑(函数),所以我们不需要做任何事情来设置或调用正确的逻辑。import click @click.group() def greet(): pass @greet.command() @click.argument('name') # add the name argument def hello(**kwargs): print('Hello, {0}!'.format(kwargs['name'])) @greet.command() @click.argument('name') def goodbye(**kwargs): print('Goodbye, {0}!'.format(kwargs['name'])) if __name__ == '__main__': greet()$ python click/arguments.py hello Kyle Hello, Kyle! $ python click/arguments.py hello --help Usage: arguments.py hello [OPTIONS] NAME Options: --help Show this message and exit.标志/选项
在本节中,我们将再次向上一节中显示的相同代码添加新的逻辑。我们将在新行中添加注释来说明目的。选项是非必需的输入,可以用来改变命令行应用程序的执行。标志仅是选项的布尔(
True/False)子集。例如:--foo=bar将传递bar作为foo选项的值,如果给定选项,则--baz(如果定义为标志)将传递True的值,否则传递False。对于本例,我们将添加
--greeting=[greeting]选项和--caps标志。greeting选项将有默认值Hello和Goodbye,并允许用户传入自定义的问候。例如,给定--greeting=Wazzup,工具将响应Wazzup, [name]!。如果给出的话,--caps标志将大写整个响应。例如,给定--caps,工具将响应HELLO, [NAME]!。抱怨吗
import argparse # since we are now passing in the greeting # the logic has been consolidated to a single greet function def greet(args): output = '{0}, {1}!'.format(args.greeting, args.name) if args.caps: output = output.upper() print(output) parser = argparse.ArgumentParser() subparsers = parser.add_subparsers() hello_parser = subparsers.add_parser('hello') hello_parser.add_argument('name') # add greeting option w/ default hello_parser.add_argument('--greeting', default='Hello') # add a flag (default=False) hello_parser.add_argument('--caps', action='store_true') hello_parser.set_defaults(func=greet) goodbye_parser = subparsers.add_parser('goodbye') goodbye_parser.add_argument('name') goodbye_parser.add_argument('--greeting', default='Goodbye') goodbye_parser.add_argument('--caps', action='store_true') goodbye_parser.set_defaults(func=greet) if __name__ == '__main__': args = parser.parse_args() args.func(args)$ python argparse/options.py hello --greeting=Wazzup Kyle Wazzup, Kyle! $ python argparse/options.py hello --caps Kyle HELLO, KYLE! $ python argparse/options.py hello --greeting=Wazzup --caps Kyle WAZZUP, KYLE! $ python argparse/options.py hello --help usage: options.py hello [-h] [--greeting GREETING] [--caps] name positional arguments: name optional arguments: -h, --help show this help message and exit --greeting GREETING --capsDocopt
一旦我们遇到添加默认选项的情况,我们就遇到了在 docopt 中命令的基本实现的障碍。让我们继续来说明这个问题。
"""Greeter. Usage: basic.py hello <name> [--caps] [--greeting=<str>] basic.py goodbye <name> [--caps] [--greeting=<str>] basic.py (-h | --help) Options: -h --help Show this screen. --caps Uppercase the output. --greeting=<str> Greeting to use [default: Hello]. """ from docopt import docopt def greet(args): output = '{0}, {1}!'.format(args['--greeting'], args['<name>']) if args['--caps']: output = output.upper() print(output) if __name__ == '__main__': arguments = docopt(__doc__) greet(arguments)现在,看看当我们运行以下命令时会发生什么:
$ python docopt/options.py hello Kyle Hello, Kyle! $ python docopt/options.py goodbye Kyle Hello, Kyle!什么?!因为我们只能为
--greeting选项设置一个缺省值,所以我们的Hello和Goodbye命令现在都用Hello, Kyle!来响应。为了让我们完成这项工作,我们需要遵循 docopt 提供的 git 示例。重构后的代码如下所示:"""Greeter. Usage: basic.py hello <name> [--caps] [--greeting=<str>] basic.py goodbye <name> [--caps] [--greeting=<str>] basic.py (-h | --help) Options: -h --help Show this screen. --caps Uppercase the output. --greeting=<str> Greeting to use [default: Hello]. Commands: hello Say hello goodbye Say goodbye """ from docopt import docopt HELLO = """usage: basic.py hello [options] [<name>] -h --help Show this screen. --caps Uppercase the output. --greeting=<str> Greeting to use [default: Hello]. """ GOODBYE = """usage: basic.py goodbye [options] [<name>] -h --help Show this screen. --caps Uppercase the output. --greeting=<str> Greeting to use [default: Goodbye]. """ def greet(args): output = '{0}, {1}!'.format(args['--greeting'], args['<name>']) if args['--caps']: output = output.upper() print(output) if __name__ == '__main__': arguments = docopt(__doc__, options_first=True) if arguments['<command>'] == 'hello': greet(docopt(HELLO)) elif arguments['<command>'] == 'goodbye': greet(docopt(GOODBYE)) else: exit("{0} is not a command. \ See 'options.py --help'.".format(arguments['<command>']))如你所见,
hello|goodbye子命令现在有了自己的文档字符串,与变量HELLO和GOODBYE相关联。当这个工具被执行时,它使用一个新的参数command来决定解析哪个。这不仅纠正了我们只有一个默认值的问题,而且我们现在还有子命令特定的帮助消息。$ python docopt/options.py --help usage: greet [--help] <command> [<args>...] options: -h --help Show this screen. commands: hello Say hello goodbye Say goodbye $ python docopt/options.py hello --help usage: basic.py hello [options] [<name>] -h --help Show this screen. --caps Uppercase the output. --greeting=<str> Greeting to use [default: Hello]. $ python docopt/options.py hello Kyle Hello, Kyle! $ python docopt/options.py goodbye Kyle Goodbye, Kyle!此外,我们所有的新选项/标志都工作正常:
$ python docopt/options.py hello --greeting=Wazzup Kyle Wazzup, Kyle! $ python docopt/options.py hello --caps Kyle HELLO, KYLE! $ python docopt/options.py hello --greeting=Wazzup --caps Kyle WAZZUP, KYLE!点击
为了添加
greeting和caps选项,我们使用了@click.option装饰器。同样,因为我们现在有了默认的问候,所以我们将逻辑提取到一个函数中(def greeter(**kwargs):)。import click def greeter(**kwargs): output = '{0}, {1}!'.format(kwargs['greeting'], kwargs['name']) if kwargs['caps']: output = output.upper() print(output) @click.group() def greet(): pass @greet.command() @click.argument('name') # add an option with 'Hello' as the default @click.option('--greeting', default='Hello') # add a flag (is_flag=True) @click.option('--caps', is_flag=True) # the application logic has been refactored into a single function def hello(**kwargs): greeter(**kwargs) @greet.command() @click.argument('name') @click.option('--greeting', default='Goodbye') @click.option('--caps', is_flag=True) def goodbye(**kwargs): greeter(**kwargs) if __name__ == '__main__': greet()$ python click/options.py hello --greeting=Wazzup Kyle Wazzup, Kyle! $ python click/options.py hello --greeting=Wazzup --caps Kyle WAZZUP, KYLE! $ python click/options.py hello --caps Kyle HELLO, KYLE!版本选项(
--version)在这一节中,我们将展示如何给每个工具添加一个
--version参数。为了简单起见,我们将把版本号硬编码为 1.0.0 。请记住,在生产应用程序中,您会希望从已安装的应用程序中提取它。实现这一点的一种方法是使用这个简单的过程:


>>> import pkg_resources
>>> # Replace click with the name of your tool:
>>> pkg_resources.get_distribution("click").version
>>> '5.1'
确定版本的第二种选择是,当发布新版本时,让自动版本碰撞软件改变文件中定义的版本号。这可以通过 bumpversion 实现。但是不推荐这种方法,因为它很容易失去同步。通常,最好的做法是在尽可能少的地方保存版本号。
由于添加硬编码版本选项的实现相当简单,我们将使用...来表示从上一部分代码中跳过的部分。
抱怨吗
对于 argparse ,我们再次需要使用add_argument方法,这一次传递了action='version'参数和version的值。我们将这个方法应用于根解析器(而不是hello或goodbye子解析器)。
...
parser = argparse.ArgumentParser()
parser.add_argument('--version', action='version', version='1.0.0')
...
$ python argparse/version.py --version
1.0.0
docopt
为了将--version添加到 docopt 中,我们将它作为一个选项添加到主 docstring 中。此外,我们将version参数添加到对 docopt 的第一次调用中(解析主 docstring)。
"""usage: greet [--help] <command> [<args>...]
options:
-h --help Show this screen.
--version Show the version.
commands:
hello Say hello
goodbye Say goodbye
"""
from docopt import docopt
...
if __name__ == '__main__':
arguments = docopt(__doc__, options_first=True, version='1.0.0')
...
$ python docopt/version.py --version
1.0.0
点击
点击为我们提供了一个方便的@click.version_option装饰器。为了增加这一点,我们修饰了我们的greet函数(主@click.group函数)。
...
@click.group()
@click.version_option(version='1.0.0')
def greet():
...
$ python click/version.py --version
version.py, version 1.0.0
改善帮助(-h / --help )
完成我们的应用程序的最后一步是改进每个工具的帮助文档。我们要确保我们可以访问关于-h和--help的帮助,并且每个参数和选项都有一定程度的描述。
抱怨吗
默认情况下 argparse 为我们提供了-h和--help,所以我们不需要为此添加任何东西。然而,我们当前的子命令帮助文档缺少关于--caps和--greeting做什么以及name参数是什么的信息。
$ python argparse/version.py hello -h
usage: version.py hello [-h] [--greeting GREETING] [--caps] name
positional arguments:
name
optional arguments:
-h, --help show this help message and exit
--greeting GREETING
--caps
为了添加更多的信息,我们使用了add_argument方法的help参数。
...
hello_parser = subparsers.add_parser('hello')
hello_parser.add_argument('name', help='name of the person to greet')
hello_parser.add_argument('--greeting', default='Hello', help='word to use for the greeting')
hello_parser.add_argument('--caps', action='store_true', help='uppercase the output')
hello_parser.set_defaults(func=greet)
goodbye_parser = subparsers.add_parser('goodbye')
goodbye_parser.add_argument('name', help='name of the person to greet')
goodbye_parser.add_argument('--greeting', default='Hello', help='word to use for the greeting')
goodbye_parser.add_argument('--caps', action='store_true', help='uppercase the output')
...
现在,当我们提供帮助标志时,我们会得到一个更加完整的结果:
$ python argparse/help.py hello -h
usage: help.py hello [-h] [--greeting GREETING] [--caps] name
positional arguments:
name name of the person to greet
optional arguments:
-h, --help show this help message and exit
--greeting GREETING word to use for the greeting
--caps uppercase the output
Docopt
这部分是 docopt 的亮点。因为我们将文档编写为命令行界面本身的定义,所以我们已经完成了帮助文档。此外,已经提供了-h和--help。
$ python docopt/help.py hello -h
usage: basic.py hello [options] [<name>]
-h --help Show this screen.
--caps Uppercase the output.
--greeting=<str> Greeting to use [default: Hello].
点击
向点击添加帮助文档与 argparse 非常相似。我们需要向所有的@click.option装饰器添加help参数。
...
@greet.command()
@click.argument('name')
@click.option('--greeting', default='Hello', help='word to use for the greeting')
@click.option('--caps', is_flag=True, help='uppercase the output')
def hello(**kwargs):
greeter(**kwargs)
@greet.command()
@click.argument('name')
@click.option('--greeting', default='Goodbye', help='word to use for the greeting')
@click.option('--caps', is_flag=True, help='uppercase the output')
def goodbye(**kwargs):
greeter(**kwargs)
...
但是,点击T5 默认不提供给我们-h。我们需要使用context_settings参数来覆盖默认的help_option_names。
import click
CONTEXT_SETTINGS = dict(help_option_names=['-h', '--help'])
...
@click.group(context_settings=CONTEXT_SETTINGS)
@click.version_option(version='1.0.0')
def greet():
pass
现在点击帮助文档已经完成。
$ python click/help.py hello -h
Usage: help.py hello [OPTIONS] NAME
Options:
--greeting TEXT word to use for the greeting
--caps uppercase the output
-h, --help Show this message and exit.
错误处理
错误处理是任何应用程序的重要组成部分。本节将探讨每个应用程序的默认错误处理,并在需要时实现附加逻辑。我们将探讨三种错误情况:
- 没有给出足够的必需参数。
- 给定的选项/标志无效。
- 给出了一个带有值的标志。
抱怨吗
$ python argparse/final.py hello
usage: final.py hello [-h] [--greeting GREETING] [--caps] name
final.py hello: error: the following arguments are required: name
$ python argparse/final.py --badoption hello Kyle
usage: final.py [-h] [--version] {hello,goodbye} ...
final.py: error: unrecognized arguments: --badoption
$ python argparse/final.py hello --caps=notanoption Kyle
usage: final.py hello [-h] [--greeting GREETING] [--caps] name
final.py hello: error: argument --caps: ignored explicit argument 'notanoption'
不是很令人兴奋,因为 argparse 开箱即用地处理我们所有的错误案例。
Docopt
$ python docopt/final.py hello
Hello, None!
$ python docopt/final.py hello --badoption Kyle
usage: basic.py hello [options] [<name>]
不幸的是,我们需要做一些工作来让 docopt 达到可接受的最低错误处理水平。在 docopt 中推荐的验证方法是模式模块。*确保安装- pip install schema。此外,它们还提供了一个非常基本的验证示例。下面是我们的模式验证应用程序:
...
from schema import Schema, SchemaError, Optional
...
schema = Schema({
Optional('hello'): bool,
Optional('goodbye'): bool,
'<name>': str,
Optional('--caps'): bool,
Optional('--help'): bool,
Optional('--greeting'): str
})
def validate(args):
try:
args = schema.validate(args)
return args
except SchemaError as e:
exit(e)
if arguments['<command>'] == 'hello':
greet(validate(docopt(HELLO)))
elif arguments['<command>'] == 'goodbye':
greet(validate(docopt(GOODBYE)))
...
有了这个验证,我们现在得到一些错误消息。
$ python docopt/validation.py hello
None should be instance of <class 'str'>
$ python docopt/validation.py hello --greeting Kyle
None should be instance of <class 'str'>
$ python docopt/validation.py hello --caps=notanoption Kyle
--caps must not have an argument
usage: basic.py hello [options] [<name>]
虽然这些消息不是非常具有描述性,并且对于较大的应用程序来说,可能很难调试,但总比没有验证好。schema 模块确实提供了其他机制来添加更具描述性的错误消息,但是我们不会在这里讨论这些。
点击
$ python click/final.py hello
Usage: final.py hello [OPTIONS] NAME
Error: Missing argument "name".
$ python click/final.py hello --badoption Kyle
Error: no such option: --badoption
$ python click/final.py hello --caps=notanoption Kyle
Error: --caps option does not take a value
和 argparse 一样, click 默认处理错误输入。
至此,我们已经完成了我们要构建的命令行应用程序的构建。在我们结束之前,让我们看看另一个可能的选择。
调用
我们可以使用简单的任务运行库 invoke 来构建欢迎命令行应用程序吗?让我们来了解一下!
首先,让我们从最简单的欢迎界面开始:
tasks.py
from invoke import task
@task
def hello(name):
print('Hello, {0}!'. format(name))
@task
def goodbye(name):
print('Goodbye, {0}!'.format(name))
通过这个非常简单的文件,我们得到了两个任务和非常少的帮助。从与 tasks.py 相同的目录中,我们得到以下结果:
$ invoke -l
Available tasks:
goodbye
hello
$ invoke hello Kyle
Hello, Kyle!
$ invoke goodbye Kyle
Goodbye, Kyle!
现在让我们添加我们的选项/标志- --greeting和--caps。此外,我们可以将问候逻辑提取到它自己的功能中,就像我们对其他工具所做的那样。
from invoke import task
def greet(name, greeting, caps):
output = '{0}, {1}!'.format(greeting, name)
if caps:
output = output.upper()
print(output)
@task
def hello(name, greeting='Hello', caps=False):
greet(name, greeting, caps)
@task
def goodbye(name, greeting='Goodbye', caps=False):
greet(name, greeting, caps)
现在我们实际上拥有了我们在开始时指定的完整接口!
$ invoke hello Kyle
Hello, Kyle!
$ invoke hello --greeting=Wazzup Kyle
Wazzup, Kyle!
$ invoke hello --greeting=Wazzup --caps Kyle
WAZZUP, KYLE!
$ invoke hello --caps Kyle
HELLO, KYLE!
帮助文档
为了与 argparse 、 docopt 和 click 竞争,我们还需要能够添加完整的帮助文档。幸运的是,这也可以在 invoke 中通过使用@task装饰器的help参数并向被装饰的函数添加文档字符串来实现。
...
HELP = {
'name': 'name of the person to greet',
'greeting': 'word to use for the greeting',
'caps': 'uppercase the output'
}
@task(help=HELP)
def hello(name, greeting='Hello', caps=False):
"""
Say hello.
"""
greet(name, greeting, caps)
@task(help=HELP)
def goodbye(name, greeting='Goodbye', caps=False):
"""
Say goodbye.
"""
greet(name, greeting, caps)
$ invoke --help hello
Usage: inv[oke] [--core-opts] hello [--options] [other tasks here ...]
Docstring:
Say hello.
Options:
-c, --caps uppercase the output
-g STRING, --greeting=STRING word to use for the greeting
-n STRING, --name=STRING name of the person to greet
-v, --version
版本选项
实现一个--version选项并不那么简单,并且有一个警告。基本的是,我们将添加version=False作为每个任务的选项,如果True调用新的print_version函数。为了实现这一点,我们不能有任何没有默认值的位置参数,否则我们会得到:
$ invoke hello --version
'hello' did not receive all required positional arguments!
还要注意,我们在命令hello和goodbye上调用--version,因为调用本身有一个版本命令:
$ invoke --version
Invoke 0.10.1
版本命令的完整实现如下:
...
def print_version():
print('1.0.0')
exit(0)
@task(help=HELP)
def hello(name='', greeting='Hello', caps=False, version=False):
"""
Say hello.
"""
if version:
print_version()
greet(name, greeting, caps)
...
现在,我们能够请求 invoke 提供我们工具的版本:
$ invoke hello --version
1.0.0
结论
回顾一下,让我们看看我们创建的每个工具的最终版本。
抱怨吗
import argparse
def greet(args):
output = '{0}, {1}!'.format(args.greeting, args.name)
if args.caps:
output = output.upper()
print(output)
parser = argparse.ArgumentParser()
parser.add_argument('--version', action='version', version='1.0.0')
subparsers = parser.add_subparsers()
hello_parser = subparsers.add_parser('hello')
hello_parser.add_argument('name', help='name of the person to greet')
hello_parser.add_argument('--greeting', default='Hello', help='word to use for the greeting')
hello_parser.add_argument('--caps', action='store_true', help='uppercase the output')
hello_parser.set_defaults(func=greet)
goodbye_parser = subparsers.add_parser('goodbye')
goodbye_parser.add_argument('name', help='name of the person to greet')
goodbye_parser.add_argument('--greeting', default='Hello', help='word to use for the greeting')
goodbye_parser.add_argument('--caps', action='store_true', help='uppercase the output')
goodbye_parser.set_defaults(func=greet)
if __name__ == '__main__':
args = parser.parse_args()
args.func(args)
Docopt
"""usage: greet [--help] <command> [<args>...]
options:
-h --help Show this screen.
--version Show the version.
commands:
hello Say hello
goodbye Say goodbye
"""
from docopt import docopt
from schema import Schema, SchemaError, Optional
HELLO = """usage: basic.py hello [options] [<name>]
-h --help Show this screen.
--caps Uppercase the output.
--greeting=<str> Greeting to use [default: Hello].
"""
GOODBYE = """usage: basic.py goodbye [options] [<name>]
-h --help Show this screen.
--caps Uppercase the output.
--greeting=<str> Greeting to use [default: Goodbye].
"""
def greet(args):
output = '{0}, {1}!'.format(args['--greeting'],
args['<name>'])
if args['--caps']:
output = output.upper()
print(output)
if __name__ == '__main__':
arguments = docopt(__doc__, options_first=True, version='1.0.0')
schema = Schema({
Optional('hello'): bool,
Optional('goodbye'): bool,
'<name>': str,
Optional('--caps'): bool,
Optional('--help'): bool,
Optional('--greeting'): str
})
def validate(args):
try:
args = schema.validate(args)
return args
except SchemaError as e:
exit(e)
if arguments['<command>'] == 'hello':
greet(validate(docopt(HELLO)))
elif arguments['<command>'] == 'goodbye':
greet(validate(docopt(GOODBYE)))
else:
exit("{0} is not a command. See 'options.py --help'.".format(arguments['<command>']))
点击
import click
CONTEXT_SETTINGS = dict(help_option_names=['-h', '--help'])
def greeter(**kwargs):
output = '{0}, {1}!'.format(kwargs['greeting'],
kwargs['name'])
if kwargs['caps']:
output = output.upper()
print(output)
@click.group(context_settings=CONTEXT_SETTINGS)
@click.version_option(version='1.0.0')
def greet():
pass
@greet.command()
@click.argument('name')
@click.option('--greeting', default='Hello', help='word to use for the greeting')
@click.option('--caps', is_flag=True, help='uppercase the output')
def hello(**kwargs):
greeter(**kwargs)
@greet.command()
@click.argument('name')
@click.option('--greeting', default='Goodbye', help='word to use for the greeting')
@click.option('--caps', is_flag=True, help='uppercase the output')
def goodbye(**kwargs):
greeter(**kwargs)
if __name__ == '__main__':
greet()
引起
from invoke import task
def greet(name, greeting, caps):
output = '{0}, {1}!'.format(greeting, name)
if caps:
output = output.upper()
print(output)
HELP = {
'name': 'name of the person to greet',
'greeting': 'word to use for the greeting',
'caps': 'uppercase the output'
}
def print_version():
print('1.0.0')
exit(0)
@task(help=HELP)
def hello(name='', greeting='Hello', caps=False, version=False):
"""
Say hello.
"""
if version:
print_version()
greet(name, greeting, caps)
@task(help=HELP)
def goodbye(name='', greeting='Goodbye', caps=False, version=False):
"""
Say goodbye.
"""
if version:
print_version()
greet(name, greeting, caps)
我的建议
现在,为了解决这个问题,我的个人首选库是 click 。去年我一直在大型、多命令、复杂的界面上使用它。(感谢 @kwbeam 把我介绍给点击)。我更喜欢装饰方法,认为它提供了一个非常干净、可组合的界面。话虽如此,还是让我们公平地评价一下每个选项吧。
抱怨吗
arperse是用于创建命令行实用程序的标准库(包含在 Python 中)。就这一点而言,它可以说是本文研究的最常用的工具。Argparse 使用起来也非常简单,因为大量的魔法(在幕后发生的隐式工作)被用来构建接口。例如,参数和选项都是使用add_arguments方法定义的,并且 argparse 在幕后判断出哪个是哪个。
Docopt
如果你认为写文档很棒, docopt 适合你!此外 docopt 有很多其他语言的实现——这意味着你可以学习一个库并在多种语言中使用它。docopt 的缺点是它非常结构化,你必须定义你的命令行界面。(有人可能会说这是好事!)
点击
我已经说过我非常喜欢 click 并且已经在生产中使用了一年多。我鼓励你阅读非常完整的为什么点击?文献资料。事实上,正是这些文档激发了这篇博文的灵感! click 的装饰风格实现使用起来非常简单,因为你正在装饰你想要执行的函数,这使得阅读代码和判断将要执行什么变得非常容易。此外, click 支持回调、命令嵌套等高级功能。 Click 基于现已废弃的 optparse 库的一个分支。
引起
Invoke 这个对比让我很惊讶。我认为一个为任务执行而设计的库可能无法轻松匹配完整的命令行库——但它做到了!也就是说,我不建议在这种类型的工作中使用它,因为对于比这里给出的例子更复杂的事情,您肯定会遇到限制。
奖励:包装
由于不是每个人都用 setuptools (或其他解决方案)打包 python 源代码,我们决定不把它作为本文的核心部分。此外,我们不想将包装作为一个完整的话题。如果你想了解更多关于 setuptools 包装的信息,请点击这里或者 conda 包装的信息,请点击这里或者你可以阅读我之前关于 conda 包装的博文。我们将在这里介绍如何使用 entry_points 选项使命令行应用程序成为安装时的可执行命令。
入口点基础知识
一个入口点本质上是你的代码中一个单一函数的映射,这个函数将在你的系统路径上被给予一个命令。入口点的形式为- command = package.module:function
解释这一点的最佳方式是查看我们的 click 示例并添加一个入口点。
打包点击命令
单击使打包变得简单,因为默认情况下,我们在执行程序时调用一个函数:
if __name__ == '__main__':
greet()
除了其余的 setup.py (此处未涉及)之外,我们将添加以下内容来为我们的 click 应用程序创建一个入口点。
假设以下目录结构-
greeter/
├── greet
│ ├── __init__.py
│ └── cli.py <-- the same as our final.py
└── setup.py
-我们将创建以下入口点:
entry_points={
'console_scripts': [
'greet=greet.cli:greet', # command=package.module:function
],
},
当用户安装用这个入口点创建的包时, setuptools 会创建下面的可执行脚本(名为greet)并放在用户系统的路径上。
#!/usr/bin/python
if __name__ == '__main__':
import sys
from greet.cli import greet
sys.exit(greet())
安装后,用户现在可以运行以下程序:
$ greet --help
Usage: greet [OPTIONS] COMMAND [ARGS]...
Options:
--version Show the version and exit.
-h, --help Show this message and exit.
Commands:
goodbye
hello
打包 Argparse 命令
我们需要做的唯一不同于 click 的事情是将所有的应用程序初始化都放到一个函数中,我们可以在我们的入口点中调用这个函数。
这个:
if __name__ == '__main__':
args = parser.parse_args()
args.func(args)
变成了:
def greet():
args = parser.parse_args()
args.func(args)
if __name__ == '__main__':
greet()
现在我们可以为点击定义的入口点使用相同的模式。
打包 Docopt 命令
打包 docopt 命令需要与 argparse 相同的过程。
这个:
if __name__ == '__main__':
arguments = docopt(__doc__, options_first=True, version='1.0.0')
if arguments['<command>'] == 'hello':
greet(docopt(HELLO))
elif arguments['<command>'] == 'goodbye':
greet(docopt(GOODBYE))
else:
exit("{0} is not a command. See 'options.py --help'.".format(arguments['<command>']))
变成了:
def greet():
arguments = docopt(__doc__, options_first=True, version='1.0.0')
if arguments['<command>'] == 'hello':
greet(docopt(HELLO))
elif arguments['<command>'] == 'goodbye':
greet(docopt(GOODBYE))
else:
exit("{0} is not a command. See 'options.py --help'.".format(arguments['<command>']))
if __name__ == '__main__':
greet()
如何将 Python 字符串转换成 int
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 将一个 Python 字符串转换成 int
整数是整数。换句话说,它们没有小数部分。Python 中可以用来存储整数的两种数据类型是 int 和 str 。这些类型为在不同环境下处理整数提供了灵活性。在本教程中,您将学习如何将 Python 字符串转换为int。您还将学习如何将int转换成字符串。
本教程结束时,您将了解:
- 如何使用
str和int存储整数 - 如何将 Python 字符串转换成
int - 如何将 Python
int转换成字符串
我们开始吧!
Python 中途站:本教程是一个快速和实用的方法来找到你需要的信息,所以你会很快回到你的项目!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
用 Python 表示整数
整数可以用不同的类型存储。表示整数的两种可能的 Python 数据类型是:
例如,您可以使用字符串文字来表示整数:
>>> s = "110"在这里,Python 理解您的意思是希望将整数
110存储为字符串。您可以对整数数据类型执行相同的操作:
>>> i = 110
在上面的例子中,考虑一下"110"和110的具体含义是很重要的。作为一个一生都在使用十进制数字系统的人,很明显你指的是数字一百一十。不过还有其他几个数制,比如二进制和十六进制,用不同的基来表示一个整数。
比如你可以把数字一百一十用二进制和十六进制分别表示为 1101110 和 6e 。
您还可以使用str和int数据类型用 Python 中的其他数字系统来表示您的整数:
>>> binary = 0b1010 >>> hexadecimal = "0xa"注意
binary和hexadecimal使用前缀来标识数字系统。所有的整数前缀都是以0?的形式出现,在这个形式中,您用一个表示数字系统的字符替换?:
- b: 二进制(基数 2)
- o: 八进制(基数 8)
- d: decimal (base 10)
- x: 十六进制(基数 16)
技术细节:当前缀可以被推断时,它在整数或字符串表示中都不是必需的。
int假设文字整数为十进制:
>>> decimal = 303
>>> hexadecimal_with_prefix = 0x12F
>>> hexadecimal_no_prefix = 12F
File "<stdin>", line 1
hexadecimal_no_prefix = 12F
^
SyntaxError: invalid syntax
整数的字符串表示形式更加灵活,因为字符串包含任意文本数据:
>>> decimal = "303" >>> hexadecimal_with_prefix = "0x12F" >>> hexadecimal_no_prefix = "12F"这些字符串中的每一个都代表同一个整数。
现在您已经有了一些关于如何使用
str和int表示整数的基础知识,您将学习如何将 Python 字符串转换成int。将 Python 字符串转换为
int如果您有一个表示为字符串的十进制整数,并且您想要将 Python 字符串转换为
int,那么您只需将该字符串传递给int(),它将返回一个十进制整数:
>>> int("10")
10
>>> type(int("10"))
<class 'int'>
默认情况下,int()假定字符串参数表示十进制整数。然而,如果您将一个十六进制字符串传递给int(),那么您将看到一个ValueError:
>>> int("0x12F") Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: invalid literal for int() with base 10: '0x12F'错误消息指出该字符串不是有效的十进制整数。
注:
重要的是要认识到向
int()传递字符串的两种失败结果之间的区别:
- 语法错误:当
int()不知道如何使用提供的基数(默认为 10)解析字符串时,会出现ValueError。- 逻辑错误:
int()确实知道如何解析字符串,但不是你预期的方式。这是一个逻辑错误的例子:
>>> binary = "11010010"
>>> int(binary) # Using the default base of 10, instead of 2
11010010
在本例中,您希望结果是 210 ,这是二进制字符串的十进制表示。不幸的是,因为您没有指定这种行为,int()假定该字符串是一个十进制整数。
对此行为的一个很好的保护措施是始终使用显式基来定义字符串表示:
>>> int("0b11010010") Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: invalid literal for int() with base 10: '0b11010010'这里,您得到一个
ValueError,因为int()不知道如何将二进制字符串解析为十进制整数。当您将一个字符串传递给
int()时,您可以指定用来表示整数的数字系统。指定数字系统的方法是使用base:
>>> int("0x12F", base=16)
303
现在,int()知道您传递的是一个十六进制字符串,而期望的是一个十进制整数。
技术细节:你传递给base的参数不限于 2、8、10、16:
>>> int("10", base=3) 3太好了!现在您已经熟悉了将 Python 字符串转换成
int的细节,您将学习如何进行相反的操作。将 Python
int转换成字符串在 Python 中,可以使用
str()将 Pythonint转换成字符串:
>>> str(10)
'10'
>>> type(str(10))
<class 'str'>
默认情况下,str()的行为类似于int(),因为它产生十进制表示:
>>> str(0b11010010) '210'在这个例子中,
str()足够聪明,可以解释二进制文本并将其转换为十进制字符串。如果您希望一个字符串在另一个数字系统中表示一个整数,那么您可以使用一个格式化的字符串,比如一个 f-string (在 Python 3.6+中),以及一个指定基数的选项:
>>> octal = 0o1073
>>> f"{octal}" # Decimal
'571'
>>> f"{octal:x}" # Hexadecimal
'23b'
>>> f"{octal:b}" # Binary
'1000111011'
str是一种在各种不同的数字系统中表示整数的灵活方式。
结论
恭喜你!您已经学习了很多关于整数的知识,以及如何在 Python 字符串和int数据类型之间表示和转换它们。
在本教程中,您学习了:
- 如何使用
str和int存储整数 - 如何为整数表示指定显式数字系统
- 如何将 Python 字符串转换成
int - 如何将 Python
int转换成字符串
现在你已经知道了这么多关于str和int的知识,你可以学习更多关于使用 float() 、 hex() 、 oct() 、 bin() 来表示数值类型的知识!
立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 将一个 Python 字符串转换成 int***
Python 对象的浅层与深层复制
Python 中的赋值语句并不创建对象的副本,它们只是将名字绑定到一个对象上。对于不可变的对象,这通常没什么区别。
但是对于处理可变对象或可变对象的集合,您可能需要寻找一种方法来创建这些对象的“真实副本”或“克隆”。
本质上,你有时会想要可以修改的副本,而不需要同时自动修改原件。在本文中,我将向您简要介绍如何在 Python 3 中复制或“克隆”对象,以及一些相关的注意事项。
注意:本教程是在考虑 Python 3 的情况下编写的,但是在复制对象方面,Python 2 和 Python 3 几乎没有区别。当有不同之处时,我会在文中指出来。
让我们先来看看如何复制 Python 的内置集合。Python 内置的可变集合,如列表、字典和集合可以通过在现有集合上调用它们的工厂函数来复制:
new_list = list(original_list)
new_dict = dict(original_dict)
new_set = set(original_set)
然而,这个方法对定制对象不起作用,除此之外,它只创建了浅拷贝。对于像列表、字典、集合这样的复合对象来说,浅和深复制有一个重要的区别:
-
一个浅拷贝意味着构造一个新的集合对象,然后用在原始对象中找到的子对象的引用填充它。从本质上来说,一个浅的副本只比深一级。复制过程不会递归,因此不会创建子对象本身的副本。
-
一个深度复制使得复制过程递归。它意味着首先构造一个新的集合对象,然后用原始集合中找到的子对象的副本递归地填充它。以这种方式复制对象会遍历整个对象树,从而创建原始对象及其所有子对象的完全独立的克隆。
我知道,这有点拗口。因此,让我们看一些例子来说明深层拷贝和浅层拷贝之间的差异。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
制作浅拷贝
在下面的例子中,我们将创建一个新的嵌套列表,然后用list()工厂函数简单地复制它:
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] >>> ys = list(xs) # Make a shallow copy这意味着
ys现在将是一个新的独立对象,其内容与xs相同。您可以通过检查两个对象来验证这一点:
>>> xs
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> ys
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
为了证实ys真的独立于原始数据,让我们设计一个小实验。您可以尝试向原始列表(xs)添加一个新的子列表,然后检查以确保这个修改没有影响副本(ys):
>>> xs.append(['new sublist']) >>> xs [[1, 2, 3], [4, 5, 6], [7, 8, 9], ['new sublist']] >>> ys [[1, 2, 3], [4, 5, 6], [7, 8, 9]]如您所见,这达到了预期的效果。在“肤浅”的层次上修改复制的列表没有任何问题。
然而,因为我们只创建了原始列表的浅层副本,
ys仍然包含对存储在xs中的原始子对象的引用。这些孩子不是被复制的。它们只是在复制的列表中被再次引用。
因此,当你修改
xs中的一个子对象时,这个修改也会反映在ys中——这是因为两个列表共享相同的子对象。该副本只是一个浅的、一级深的副本:
>>> xs[1][0] = 'X'
>>> xs
[[1, 2, 3], ['X', 5, 6], [7, 8, 9], ['new sublist']]
>>> ys
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
在上面的例子中,我们(似乎)只对xs做了一个修改。但结果是在xs 和 ys中索引为 1 的子列表都被修改了。同样,这是因为我们只创建了原始列表的一个浅层副本。
如果我们在第一步中创建了xs的深度副本,那么这两个对象将是完全独立的。这就是对象的浅拷贝和深拷贝的实际区别。
现在您知道了如何创建一些内置集合类的浅层拷贝,并且知道了浅层拷贝和深层拷贝的区别。我们仍然希望得到答案的问题是:
- 如何创建内置集合的深层副本?
- 如何创建任意对象(包括自定义类)的副本(浅层和深层)?
这些问题的答案就在 Python 标准库中的copy模块中。这个模块为创建任意 Python 对象的浅层和深层副本提供了一个简单的接口。
制作深层副本
让我们重复前面的列表复制示例,但是有一个重要的区别。这次我们将使用在copy模块中定义的deepcopy()函数创建一个深度副本:
>>> import copy >>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] >>> zs = copy.deepcopy(xs)当你检查我们用
copy.deepcopy()创建的xs和它的克隆zs时,你会看到它们看起来又是一样的——就像前面的例子一样:
>>> xs
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> zs
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
然而,如果您对原始对象(xs)中的一个子对象进行修改,您将会看到该修改不会影响深层副本(zs)。
两个对象,原始对象和副本,这次是完全独立的。xs被递归克隆,包括它的所有子对象:
>>> xs[1][0] = 'X' >>> xs [[1, 2, 3], ['X', 5, 6], [7, 8, 9]] >>> zs [[1, 2, 3], [4, 5, 6], [7, 8, 9]]现在,您可能想花些时间坐下来和 Python 解释器一起研究这些例子。当您直接体验和使用这些示例时,就更容易理解如何复制对象。
顺便说一下,您还可以使用
copy模块中的函数创建浅层副本。copy.copy()函数创建对象的浅层副本。如果您需要清楚地表明您正在代码中的某个地方创建一个浅层副本,这是非常有用的。使用
copy.copy()可以让你指出这个事实。然而,对于内置集合,简单地使用 list、dict 和 set factory 函数来创建浅层副本被认为是更 Pythonic 化的。复制任意 Python 对象
我们仍然需要回答的问题是,我们如何创建任意对象的副本(浅层和深层),包括自定义类。现在让我们来看看。
再次
copy模块来救我们了。它的copy.copy()和copy.deepcopy()功能可以用来复制任何对象。同样,理解如何使用这些的最好方法是通过一个简单的实验。我将以前面的列表复制示例为基础。让我们从定义一个简单的 2D 点类开始:
class Point: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return f'Point({self.x!r}, {self.y!r})'我希望你同意这很简单。我添加了一个
__repr__()实现,这样我们可以很容易地在 Python 解释器中检查从这个类创建的对象。注意:上面的例子使用了一个 Python 3.6 f-string 来构造
__repr__返回的字符串。在 Python 2 和 Python 3.6 之前的版本中,您可以使用不同的字符串格式表达式,例如:`def __repr__(self): return 'Point(%r, %r)' % (self.x, self.y)`接下来,我们将创建一个
Point实例,然后使用copy模块(浅显地)复制它:
>>> a = Point(23, 42)
>>> b = copy.copy(a)
如果我们检查原始Point对象及其(浅层)克隆的内容,我们会看到我们所期望的:
>>> a Point(23, 42) >>> b Point(23, 42) >>> a is b False还有一些事情需要记住。因为我们的 point 对象使用不可变类型(int)作为它的坐标,所以在这种情况下,浅拷贝和深拷贝没有区别。但是我马上会扩展这个例子。
让我们来看一个更复杂的例子。我将定义另一个类来表示 2D 矩形。我将以一种允许我们创建一个更复杂的对象层次的方式来完成它——我的矩形将使用
Point对象来表示它们的坐标:class Rectangle: def __init__(self, topleft, bottomright): self.topleft = topleft self.bottomright = bottomright def __repr__(self): return (f'Rectangle({self.topleft!r}, ' f'{self.bottomright!r})')同样,首先我们将尝试创建一个矩形实例的浅层副本:
rect = Rectangle(Point(0, 1), Point(5, 6)) srect = copy.copy(rect)如果您检查原始矩形和它的副本,您将看到
__repr__()覆盖工作得多么好,并且浅层复制过程如预期那样工作:
>>> rect
Rectangle(Point(0, 1), Point(5, 6))
>>> srect
Rectangle(Point(0, 1), Point(5, 6))
>>> rect is srect
False
还记得上一个 list 例子是如何说明深层和浅层拷贝之间的区别的吗?我将在这里使用相同的方法。我将修改对象层次中更深层次的对象,然后您将看到这一变化也反映在(浅层)副本中:
>>> rect.topleft.x = 999 >>> rect Rectangle(Point(999, 1), Point(5, 6)) >>> srect Rectangle(Point(999, 1), Point(5, 6))我希望这是你所期望的。接下来,我将创建一个原始矩形的深度副本。然后,我将应用另一个修改,您将看到哪些对象受到影响:
>>> drect = copy.deepcopy(srect)
>>> drect.topleft.x = 222
>>> drect
Rectangle(Point(222, 1), Point(5, 6))
>>> rect
Rectangle(Point(999, 1), Point(5, 6))
>>> srect
Rectangle(Point(999, 1), Point(5, 6))
瞧啊。这一次深层拷贝(drect)完全独立于原始拷贝(rect)和浅层拷贝(srect)。
我们在这里已经讨论了很多内容,但是仍然有一些关于复制对象的细节。
深入是值得的(哈!)关于这个话题,所以你可能要好好研究一下 copy模块文档。例如,对象可以通过定义特殊的方法__copy__()和__deepcopy__()来控制它们如何被复制。
需要记住的 3 件事
- 制作对象的浅层副本不会克隆子对象。因此,副本并不完全独立于原件。
- 对象的深层副本将递归克隆子对象。克隆完全独立于原始副本,但是创建深层副本的速度较慢。
- 您可以使用
copy模块复制任意对象(包括自定义类)。
如果您想更深入地了解其他中级 Python 编程技术,请查看这个免费赠品:
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。**
CPython 内部:平装本现已上市!
经过近两年的编写、审查和测试,我们很高兴地宣布 CPython Internals:您的 Python 3 解释器指南现在已经有了平装本!
Python 的某些部分看起来像魔术吗?一旦您看到 Python 在解释器级别是如何工作的,您将能够优化您的应用程序并充分利用 Python 的力量。
在 CPython 内部中,你将解开 Python 语言的内部工作,学习如何从源代码中编译Python解释器,并涵盖你需要知道的内容,以便自信地开始为 CPython** 做贡献!**
在这篇文章中,你会看到:
- 如何通过 CPython 内部将您的 Python 技能提升到下一个级别
- 其他的蟒蛇是如何做到的
要直接跳到精彩内容并得到这本书,请单击下面的链接:
可以得到平装版的 CPython Internals!
终于来了!读者一直在向我们展示他们的副本,让我们知道他们的想法:

这本书是 CPython 内部的“失踪手册”,我们期待 Python 社区从这个独特的资源中获得大量的知识和技能。我们对最终产品非常满意,因此作者安东尼·肖将带您了解这本书的平装本:
https://player.vimeo.com/video/547764410
在发布后的最初几天,观看 CPython Internals 在亚马逊排行榜上攀升,并迅速成为 Python 编程的 #1 畅销书简直是一场疯狂之旅:
这本书迅速成为畅销书排行榜第一的事实本身就足以值得庆祝了!但看到它迄今为止收到的评论都是非常积极的,这也是令人难以置信的收获:

得知如此多的学习者正在使用这本书更深入地学习 Python,以便他们能够从仅仅使用 Python 到实际自己构建 Python,这确实是令人鼓舞的。我们希望在您亲自借阅这本书时收到您的来信。
谁应该阅读 CPython 内部?
如果你想解开 Python 语言的内部工作原理,从源代码编译 Python 解释器,或者参与 CPython 的开发,那么 CPython Internals 将会给你你需要的实用技能和知识。
Python 的创造者吉多·范·罗苏姆甚至亲自推荐了这本书:
我可以向任何想在 CPython 上开始学习黑客技术的人推荐 CPython 的内部知识。(来源)
— 吉多·范·罗苏姆,Python 的创造者
他在最近的一次采访中分享了自己的想法:
https://player.vimeo.com/video/556300076
通过这篇 CPython 内部指南,深入理解 Python 变得前所未有的简单。
想了解 Python 3 解释器的源代码?
如果您想理解 CPython 3.x 解释器的源代码,那么您将深入了解列表、字典和生成器等概念的内部工作原理。在动手练习和平易近人的解释的帮助下,您将对 Python 的实际工作原理有一个深刻的理解:
幕后之旅……
本指南是一个非常简单的介绍,深入到 Python 的核心解释器是如何工作的。对我来说,它在介绍 Python 如何工作和思考方面做得非常好,并且打开了许多探索和学习 Python 如何工作以及为什么工作的地方。
非常高兴我得到了这个,因为它为我打开了许多理解的大门。我仍然需要多读几遍才能真正理解它,但作为一个片段的游览,以及它们为什么在那里和如何一起工作,这是非常受欢迎的。(⭐⭐⭐⭐⭐)
— 艾伦·墨菲(通过亚马逊)
想从头开始制作自己版本的 Python 吗?
如果您想修改 Python 的语法并从头编译您自己的版本,那么您将通过添加新功能来定制 Python 的核心数据类型,然后运行 CPython 的自动化测试套件。您将有能力塑造 Python 来满足您的需求:
详细翔实的阅读!
超赞的书!非常描述 CPython 的内部。无论你是希望定制 Python 解释器和添加新的语言特性,还是仅仅为了更好地理解语言的内部原理,这都是一本很棒的书!虽然是技术性的,但对于那些对 Python 感兴趣的人来说,这并不是一本枯燥的读物。(⭐⭐⭐⭐⭐)
——达斯汀·雷德蒙(通过亚马逊)
想为 CPython 做贡献?
如果您想参与 CPython 的开发,那么您将学习如何为 Python 解释器和标准库的未来版本做出贡献。作为 Python 核心开发人员,您将有一种新的方式参与 Python 社区:
真详细
好书。如果你想更深入地了解 Python 知识的话,非常详细。还包括环境设置,这对于没有 C 语言背景的人来说可能很好。非常友好地深入 Python 的二元性。不要以为你需要擅长 C 才能拿起这本书。老实说,任何与真正的 Python 团队相关的东西都是笨蛋。(⭐⭐⭐⭐⭐)
— Js (通过亚马逊)
这本书写得很清楚,将为那些寻找这类信息的人打开一个新的世界!
你还需要知道什么?
在内容上,印刷版与真蟒网上商店上的数字版完全相同。亚马逊还为这本书提供了强大的 30 天退款保证,所以对你来说零风险。要获取打印副本,请单击下面的按钮:
点击该按钮应该会自动将您重定向到您当地的亚马逊商店。或者您可以使用下面的直接链接:
如果您当地的亚马逊商店没有在这里列出,那么尝试在图书部分搜索“CPython Internals”或 ISBN 1775093344,它应该会出现。
如果你得到了平装本,那么你仍然可以获得数字版本中包含的所有额外资料。因此,通过可下载的示例代码和范例,您将获得与数字版用户相同的出色体验。
如果亚马逊没有送货到你的地址,那么你应该可以通过给他们 ISBN 码1775093344从任何一家当地书店订购这本书。这本书可能需要一段时间才能上市,因为我们刚刚出版了它,但它不仅限于在亚马逊上销售。只是亚马逊是最大的分销渠道,所以这是我们现在推出的重点。
使用 CPython 内部组件将您的 Python 提升到一个新的水平!
听说读者已经从这本书中获益良多,这是很值得的,我们也很乐意收到你的来信!我们从 Python 社区得到的反馈是无价的——我们都对最终的书的结果非常满意。感谢您的支持!要获得这本书,请单击下面的链接:
一旦你拿到了这本书,如果你能在亚马逊上添加你自己的评论和评级,那将是一个巨大的帮助。请随时直接联系我们,让我们知道您的 Python 之旅进展如何,以及您需要什么样的学习资源来迈出下一大步。**
CPython 源代码指南
Python 的某些部分看起来很神奇吗?比如说,字典怎么会比遍历一个列表来查找一个条目快得多。每次生成一个值时,生成器是如何记住变量的状态的?为什么你从来不需要像其他语言一样分配内存?事实证明,最流行的 Python 运行时 CPython 是用人类可读的 C 和 Python 代码编写的。本教程将带您浏览 CPython 源代码。
您将涉及到 CPython 内部背后的所有概念,它们是如何工作的,以及可视化的解释。
您将学习如何:
- 阅读并浏览源代码
- 从源代码编译 CPython
- 浏览并理解列表、字典和生成器等概念的内部工作原理
- 运行测试套件
- 修改或升级 CPython 库的组件,以便在将来的版本中使用它们
是的,这是一篇很长的文章。如果你刚为自己泡了一杯新鲜的茶、咖啡或你最喜欢的饮料,那么在第一部分结束时,它会变凉。
本教程分为五个部分。花点时间学习每一部分,并确保尝试演示和交互式组件。你可以感受到一种成就感,那就是你掌握了 Python 的核心概念,可以让你成为更好的 Python 程序员。
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
第 1 部分:CPython 简介
当你在控制台键入python或者安装来自python.org的 Python 发行版时,你正在运行 CPython 。CPython 是众多 Python 运行时之一,由不同的开发团队维护和编写。您可能听说过的其他一些运行时是 PyPy 、 Cython 和 Jython 。
CPython 的独特之处在于它包含了运行时和所有 Python 运行时都使用的共享语言规范。CPython 是 Python 的“官方”或参考实现。
Python 语言规范是描述 Python 语言的文档。例如,它说assert是一个保留关键字,而[]用于索引、切片和创建空列表。
考虑一下您希望在您的计算机上的 Python 发行版中包含什么:
- 当你在没有文件或模块的情况下键入
python时,它会给出一个交互式提示。 - 可以像
json一样从标准库中导入内置模块。 - 您可以使用
pip从互联网安装软件包。 - 您可以使用内置的
unittest库测试您的应用程序。
这些都是 CPython 发行版的一部分。不仅仅是一个编译器。
注:本文是针对 CPython 源代码的 3.8.0b4 版本编写的。
源代码里有什么?
CPython 源代码发行版附带了一整套工具、库和组件。我们将在本文中探讨这些问题。首先,我们将关注编译器。
要下载 CPython 源代码的副本,您可以使用 git 将最新版本下载到本地的工作副本中:
$ git clone https://github.com/python/cpython
$ cd cpython
$ git checkout v3.8.0b4
注意:如果你没有 Git 可用,你可以直接从 GitHub 网站下载一个 ZIP 文件的源代码。
在新下载的cpython目录中,您会发现以下子目录:
cpython/
│
├── Doc ← Source for the documentation
├── Grammar ← The computer-readable language definition
├── Include ← The C header files
├── Lib ← Standard library modules written in Python
├── Mac ← macOS support files
├── Misc ← Miscellaneous files
├── Modules ← Standard Library Modules written in C
├── Objects ← Core types and the object model
├── Parser ← The Python parser source code
├── PC ← Windows build support files
├── PCbuild ← Windows build support files for older Windows versions
├── Programs ← Source code for the python executable and other binaries
├── Python ← The CPython interpreter source code
└── Tools ← Standalone tools useful for building or extending Python
接下来,我们将从源代码编译 CPython。这一步需要一个 C 编译器和一些构建工具,这取决于您使用的操作系统。
编译 CPython (macOS)
在 macOS 上编译 CPython 很简单。您首先需要基本的 C 编译器工具包。命令行开发工具是一款可以通过 App Store 在 macOS 中更新的应用。您需要在终端上执行初始安装。
要在 macOS 中打开一个终端,进入 Launchpad,然后选择其他然后选择终端应用。你会想把这个应用程序保存到你的 Dock,所以右击图标,选择保留在 Dock 。
现在,在终端中,通过运行以下命令安装 C 编译器和工具包:
$ xcode-select --install
这个命令将弹出一个下载和安装一组工具的提示,包括 Git、Make 和 GNU C 编译器。
你还需要一个 OpenSSL 的工作副本,用于从 PyPi.org 网站获取包。如果您以后计划使用这个版本来安装额外的包,SSL 验证是必需的。
在 macOS 上安装 OpenSSL 最简单的方法是使用自制软件。如果已经安装了 HomeBrew,可以用brew install命令安装 CPython 的依赖项:
$ brew install openssl xz zlib
既然有了依赖项,就可以运行configure脚本,通过发现 HomeBrew 安装的位置并启用调试挂钩--with-pydebug来启用 SSL 支持:
$ CPPFLAGS="-I$(brew --prefix zlib)/include" \
LDFLAGS="-L$(brew --prefix zlib)/lib" \
./configure --with-openssl=$(brew --prefix openssl) --with-pydebug
这将在存储库的根中生成一个Makefile,您可以使用它来自动化构建过程。./configure步骤只需要运行一次。您可以通过运行以下命令来构建 CPython 二进制文件:
$ make -j2 -s
-j2标志允许make同时运行两个任务。如果你有 4 个核心,你可以把这个改成 4。-s标志阻止Makefile打印它运行到控制台的每个命令。您可以删除它,但是输出非常冗长。
在构建过程中,您可能会收到一些错误,在摘要中,它会通知您并非所有的包都可以构建。例如,_dbm、_sqlite3、_uuid、nis、ossaudiodev、spwd和_tkinter将无法使用这组指令进行构建。如果您不打算针对这些包进行开发,那也没关系。如果是,那么请访问开发指南网站了解更多信息。
构建需要几分钟,并生成一个名为python.exe的二进制文件。每次修改源代码时,您都需要使用相同的标志重新运行make。python.exe二进制文件是 CPython 的调试二进制文件。执行python.exe查看工作中的 REPL:
$ ./python.exe
Python 3.8.0b4 (tags/v3.8.0b4:d93605de72, Aug 30 2019, 10:00:03)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
注:对,没错,macOS build 有一个文件扩展名为.exe。这是而不是,因为它是 Windows 二进制文件。因为 macOS 有一个不区分大小写的文件系统,当处理二进制文件时,开发人员不希望人们意外地引用目录Python/,所以添加了.exe以避免歧义。如果您稍后运行make install或make altinstall,它会将文件重新命名为python。
编译 CPython (Linux)
对于 Linux,第一步是下载并安装make、gcc、configure和pkgconfig。
对于 Fedora Core、RHEL、CentOS 或其他基于 yum 的系统:
$ sudo yum install yum-utils
对于 Debian、Ubuntu 或其他基于apt的系统:
$ sudo apt install build-essential
然后为 Fedora Core、RHEL、CentOS 或其他基于 yum 的系统安装所需的软件包:
$ sudo yum-builddep python3
对于 Debian、Ubuntu 或其他基于apt的系统:
$ sudo apt install libssl-dev zlib1g-dev libncurses5-dev \
libncursesw5-dev libreadline-dev libsqlite3-dev libgdbm-dev \
libdb5.3-dev libbz2-dev libexpat1-dev liblzma-dev libffi-dev
既然有了依赖关系,就可以运行configure脚本,启用调试钩子--with-pydebug:
$ ./configure --with-pydebug
查看输出以确保 OpenSSL 支持被标记为YES。否则,请检查您的发行版以获得安装 OpenSSL 头文件的说明。
接下来,您可以通过运行生成的Makefile来构建 CPython 二进制文件:
$ make -j2 -s
在构建过程中,您可能会收到一些错误,在摘要中,它会通知您并非所有的包都可以构建。如果您不打算针对这些包进行开发,那也没关系。如果是的话,请访问开发指南网站了解更多信息。
构建需要几分钟,并生成一个名为python的二进制文件。这是 CPython 的调试二进制文件。执行./python查看工作中的 REPL:
$ ./python
Python 3.8.0b4 (tags/v3.8.0b4:d93605de72, Aug 30 2019, 10:00:03)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
编译 CPython (Windows)
PC 文件夹中有一个 Visual Studio 项目文件,用于构建和探索 CPython。若要使用此功能,您需要在 PC 上安装 Visual Studio。
Visual Studio 的最新版本 Visual Studio 2019 更容易使用 Python 和 CPython 源代码,因此建议在本教程中使用。如果你已经安装了 Visual Studio 2017,那也可以。
编译 CPython 或本教程不需要任何付费功能。可以使用 Visual Studio 的社区版,可以从微软的 Visual Studio 网站免费获得。
下载安装程序后,会要求您选择要安装的组件。本教程的最低要求是:
- Python 开发工作量
- 可选的 Python 原生开发工具
- Python 3 64 位(3.7.2)(如果已经安装了 Python 3.7,可以取消选择)
如果您想更谨慎地使用磁盘空间,可以取消选择任何其他可选功能:
安装程序将下载并安装所有需要的组件。安装可能需要一个小时,所以您可能想继续阅读并回到这一部分。
一旦安装程序完成,点击启动按钮启动 Visual Studio。系统将提示您登录。如果您有 Microsoft 帐户,您可以登录,或者跳过这一步。
Visual Studio 启动后,将提示您打开一个项目。开始 Git 配置和克隆 CPython 的一个快捷方式是选择克隆或检出代码选项:

对于项目 URL,键入https://github.com/python/cpython进行克隆:
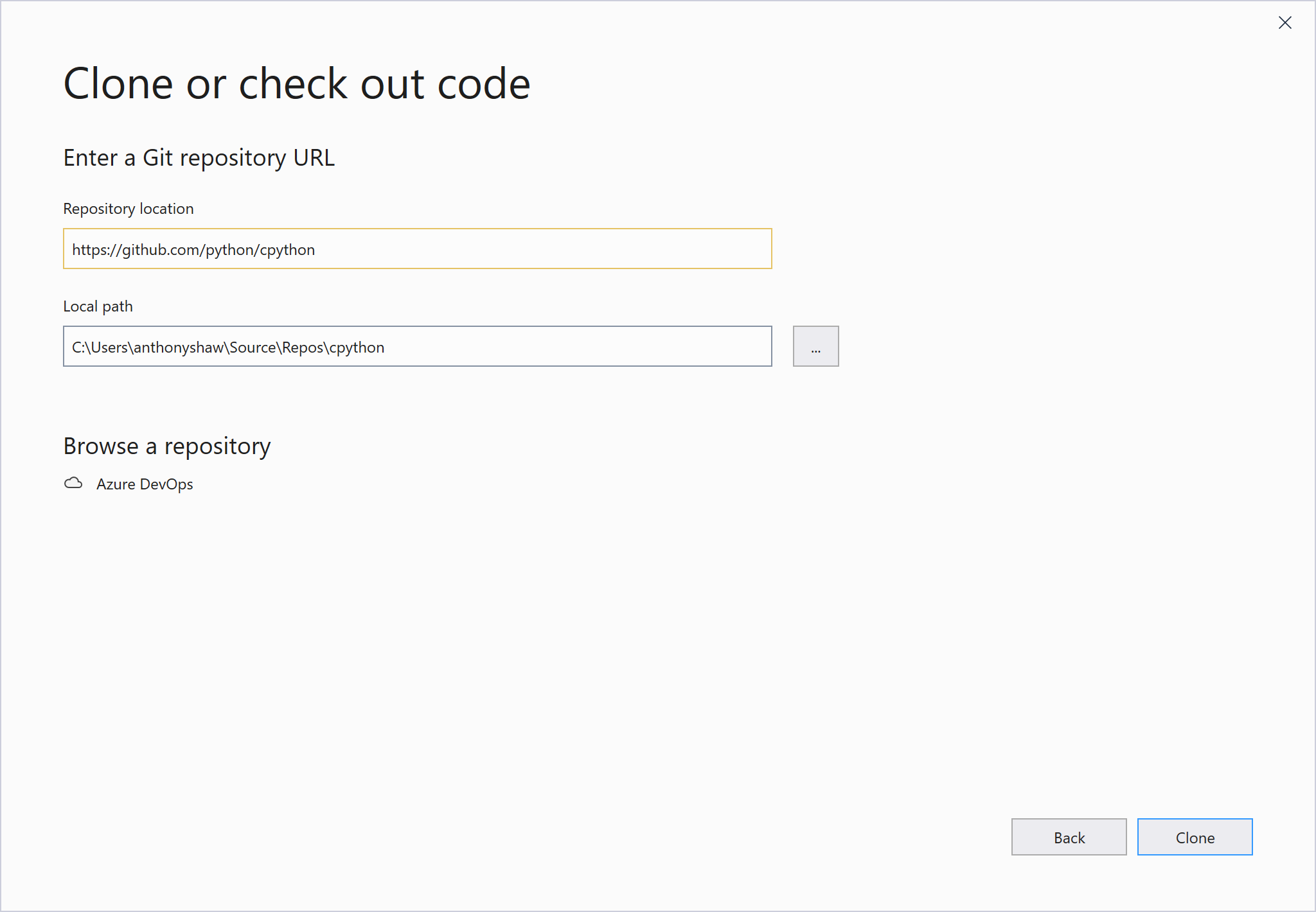
然后,Visual Studio 将使用 Visual Studio 捆绑的 Git 版本从 GitHub 下载一份 CPython。这一步也省去了在 Windows 上安装 Git 的麻烦。下载可能需要 10 分钟。
一旦项目下载完毕,您需要点击解决方案和项目并选择pcbuild.sln,将它指向 pcbuild 解决方案文件:
当加载解决方案时,它会提示您将解决方案中的项目重定向到已安装的 C/C++编译器版本。Visual Studio 还将针对您已安装的 Windows SDK 版本。
确保将 Windows SDK 版本更改为最新安装的版本,并将平台工具集更改为最新版本。如果您错过了这个窗口,您可以在解决方案和项目窗口中右键单击该解决方案,然后单击重定向解决方案。
一旦完成,您需要下载一些源文件来构建整个 CPython 包。在PCBuild文件夹中有一个.bat文件可以自动完成这个任务。打开下载的PCBuild中的命令行提示符,运行get_externals.bat:
> get_externals.bat
Using py -3.7 (found 3.7 with py.exe)
Fetching external libraries...
Fetching bzip2-1.0.6...
Fetching sqlite-3.21.0.0...
Fetching xz-5.2.2...
Fetching zlib-1.2.11...
Fetching external binaries...
Fetching openssl-bin-1.1.0j...
Fetching tcltk-8.6.9.0...
Finished.
接下来,回到 Visual Studio 中,通过按下Ctrl+Shift+B或者从顶部菜单中选择构建解决方案来构建 CPython。如果您收到任何关于 Windows SDK 丢失的错误,请确保您在重定目标解决方案窗口中设置了正确的目标设置。您还应该在开始菜单中看到 Windows 工具包,在该菜单中看到 Windows 软件开发工具包。
第一次构建阶段可能需要 10 分钟或更长时间。构建完成后,您可能会看到一些警告,您可以忽略这些警告并最终完成构建。
要启动 CPython 的调试版本,按下 F5 ,CPython 将以调试模式直接进入 REPL:

一旦完成,您可以通过将构建配置从顶部菜单栏上的 Debug 更改为 Release 来运行发布构建,并再次运行构建解决方案。现在在PCBuild\win32\中已经有了 CPython 二进制文件的调试版本和发布版本。
通过从顶部菜单中选择Tools->-Python->-Python Environments-,可以将 Visual Studio 设置为能够使用发布版本或调试版本打开 REPL:

然后点击添加环境,然后针对调试或发布二进制。调试二进制会以_d.exe结尾,比如python_d.exe和pythonw_d.exe。您很可能希望使用调试二进制文件,因为它附带了 Visual Studio 中的调试支持,对本教程很有用。
在添加环境窗口中,将python_d.exe文件作为PCBuild/win32中的解释器,将pythonw_d.exe作为窗口解释器:

现在,您可以通过单击 Python 环境窗口中的打开交互窗口来启动 REPL 会话,您将看到 Python 编译版本的 REPL:

在本教程中,将有示例命令的 REPL 会话。我鼓励您使用调试二进制文件来运行这些 REPL 会话,以防您想要在代码中放置任何断点。
最后,为了更容易地浏览代码,在解决方案视图中,单击 Home 图标旁边的切换按钮切换到文件夹视图:

现在您已经有了一个编译好的 CPython 版本,让我们看看 CPython 编译器是如何工作的。
编译器做什么?
编译器的目的是把一种语言转换成另一种语言。把编译器想象成翻译器。你会雇一个翻译听你说英语,然后说日语:

一些编译器会编译成可以直接在系统上执行的低级机器码。其他编译器将编译成中间语言,由虚拟机执行。
选择编译器时要做的一个重要决定是系统可移植性要求。 Java 和。NET CLR 将编译成一种中间语言,这样编译后的代码可以跨多个系统架构移植。C、Go、C++和 Pascal 将编译成一个低级可执行文件,该文件只能在与它被编译的系统相似的系统上运行。
因为 Python 应用程序通常以源代码的形式发布,所以 Python 运行时的作用是转换 Python 源代码并在一个步骤中执行它。在内部,CPython 运行时会编译您的代码。一个流行的误解是 Python 是一种解释型语言。它实际上是编译的。
Python 代码不会被编译成机器代码。它被编译成一种特殊的低级中介语言,叫做字节码,只有 CPython 理解。这段代码存储在隐藏目录中的.pyc文件中,并被缓存以供执行。如果在不改变源代码的情况下运行同一个 Python 应用程序两次,第二次总会快得多。这是因为它加载编译后的字节码并直接执行。
为什么 CPython 是用 C 写的而不是 Python?
CPython 中的 C 是对 C 编程语言的引用,暗示这个 Python 发行版是用 C 语言编写的。
这种说法在很大程度上是正确的:CPython 中的编译器是用纯 C 编写的。然而,许多标准库模块是用纯 Python 或 C 和 Python 的组合编写的。
那么为什么 CPython 是用 C 而不是 Python 写的呢?
答案就在编译器是如何工作的。有两种类型的编译器:
如果你正在从头开始编写一门新的编程语言,你需要一个可执行的应用程序来编译你的编译器!你需要一个编译器来执行任何事情,所以当开发新的语言时,它们通常首先用一种更老、更成熟的语言来编写。
一个很好的例子就是 Go 编程语言。第一个 Go 编译器是用 C 写的,后来一旦 Go 可以编译了,编译器就用 Go 重写了。
CPython 保留了它的 C 遗产:许多标准库模块,如ssl模块或sockets模块,都是用 C 编写的,以访问低级操作系统 API。Windows 和 Linux 内核中用于创建网络套接字、处理文件系统或与显示器交互的 API 都是用 C 语言编写的。Python 的可扩展性层专注于 C 语言是有意义的。在本文的后面,我们将介绍 Python 标准库和 C 模块。
有一个用 Python 写的 Python 编译器叫做 PyPy 。PyPy 的标志是一只大毒蛇,代表编译器的自托管特性。
Python 交叉编译器的另一个例子是 Jython。Jython 用 Java 编写,从 Python 源代码编译成 Java 字节码。与 CPython 使从 Python 导入和使用 C 库变得容易一样,Jython 也使导入和引用 Java 模块和类变得容易。
Python 语言规范
包含在 CPython 源代码中的是 Python 语言的定义。这是所有 Python 解释器使用的参考规范。
该规范有人类可读和机器可读两种格式。文档中详细解释了 Python 语言,什么是允许的,以及每个语句应该如何表现。
文档
位于Doc/reference目录中的是对 Python 语言中每个特性的 reStructuredText 解释。这就形成了 docs.python.org 的官方 Python 参考指南。
目录中有您理解整个语言、结构和关键字所需的文件:
cpython/Doc/reference
|
├── compound_stmts.rst
├── datamodel.rst
├── executionmodel.rst
├── expressions.rst
├── grammar.rst
├── import.rst
├── index.rst
├── introduction.rst
├── lexical_analysis.rst
├── simple_stmts.rst
└── toplevel_components.rst
在复合语句的文档compound_stmts.rst中,您可以看到一个定义 with语句的简单示例。
在 Python 中可以以多种方式使用with语句,最简单的是上下文管理器和嵌套代码块的实例化:
with x():
...
您可以使用as关键字将结果赋给一个变量:
with x() as y:
...
您还可以用逗号将上下文管理器链接在一起:
with x() as y, z() as jk:
...
接下来,我们将探索 Python 语言的计算机可读文档。
语法
文档包含人类可读的语言规范,机器可读的规范存放在一个文件中, Grammar/Grammar 。
语法文件是用一种叫做巴克斯-诺尔形式(BNF) 的上下文符号编写的。BNF 不是 Python 特有的,它经常被用作许多其他语言的语法符号。
编程语言中语法结构的概念是受 20 世纪 50 年代诺姆·乔姆斯基关于句法结构的工作的启发!
Python 的语法文件使用带有正则表达式语法的扩展 BNF (EBNF)规范。所以,在语法文件中你可以使用:
*为重复+为至少重复一次[]为可选零件|为替代品()进行分组
如果您在语法文件中搜索with语句,在第 80 行左右,您会看到with语句的定义:
with_stmt: 'with' with_item (',' with_item)* ':' suite
with_item: test ['as' expr]
引号中的任何内容都是字符串文字,这就是关键字的定义方式。因此with_stmt被指定为:
- 从单词
with开始 - 后面跟着一个
with_item,它是一个test和(可选),单词as,以及一个表达式 - 跟随一个或多个项目,每个项目用逗号分隔
- 以
:结尾 - 后面跟着一个
suite
这两行中引用了其他一些定义:
suite指带有一条或多条语句的代码块test指被评价的简单陈述expr指简单的表情
如果您想详细研究这些内容,可以在这个文件中定义整个 Python 语法。
如果你想看看最近一个如何使用语法的例子,在 PEP 572 中,冒号等于操作符被添加到了这个 Git 提交的语法文件中。
使用pgen
Python 编译器从不使用语法文件本身。取而代之的是使用一个名为pgen的工具创建的解析表。pgen读取语法文件并将其转换成一个解析器表。如果您对语法文件进行了更改,您必须重新生成解析器表并重新编译 Python。
注:pgen应用在 Python 3.8 中从 C 重写为纯 Python 。
为了看到pgen的运行,让我们改变 Python 语法的一部分。在第 51 行你会看到一个 pass语句的定义:
pass_stmt: 'pass'
更改该行以接受关键字'pass'或'proceed'作为关键字:
pass_stmt: 'pass' | 'proceed'
现在您需要重建语法文件。在 macOS 和 Linux 上,运行make regen-grammar对修改后的语法文件运行pgen。对于 Windows,没有官方支持的运行方式pgen。然而,您可以从PCBuild目录中克隆 my fork 并运行build.bat --regen。
您应该会看到类似这样的输出,显示新的Include/graminit.h和Python/graminit.c文件已经生成:
# Regenerate Doc/library/token-list.inc from Grammar/Tokens
# using Tools/scripts/generate_token.py
...
python3 ./Tools/scripts/update_file.py ./Include/graminit.h ./Include/graminit.h.new
python3 ./Tools/scripts/update_file.py ./Python/graminit.c ./Python/graminit.c.new
注: pgen的工作原理是将 EBNF 语句转换成非确定性有限自动机(NFA) ,然后再转换成确定性有限自动机(DFA) 。解析器使用 DFA 以 CPython 特有的特殊方式解析表。这项技术由斯坦福大学开发,开发于 20 世纪 80 年代,就在 Python 出现之前。
使用重新生成的解析器表,您需要重新编译 CPython 来查看新的语法。对您的操作系统使用与前面相同的编译步骤。
如果代码编译成功,您可以执行新的 CPython 二进制文件并启动 REPL。
在 REPL 中,您现在可以尝试定义一个函数,而不是使用pass语句,而是使用您编译到 Python 语法中的proceed关键字替代:
Python 3.8.0b4 (tags/v3.8.0b4:d93605de72, Aug 30 2019, 10:00:03)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> def example():
... proceed
...
>>> example()
干得好!您已经更改了 CPython 语法并编译了您自己版本的 CPython。装运它!
接下来,我们将探索标记及其与语法的关系。
代币
在Grammar文件夹中的语法文件旁边是一个 Tokens 文件,它包含在解析树中作为叶节点发现的每个唯一类型。我们将在后面深入讨论解析器树。每个令牌还有一个名称和一个生成的唯一 ID。这些名称是用来简化在记号赋予器中的引用。
注意:Tokens文件是 Python 3.8 中的新特性。
比如左括号叫LPAR,分号叫SEMI。您将在本文后面看到这些令牌:
LPAR '('
RPAR ')'
LSQB '['
RSQB ']'
COLON ':'
COMMA ','
SEMI ';'
和Grammar文件一样,如果你改变了Tokens文件,你需要再次运行pgen。
要查看令牌的运行情况,可以使用 CPython 中的tokenize模块。创建一个名为test_tokens.py的简单 Python 脚本:
# Hello world!
def my_function():
proceed
在本教程的其余部分,./python.exe将引用 CPython 的编译版本。但是,实际的命令将取决于您的系统。
对于 Windows:
> python.exe
对于 Linux:
> ./python
对于 macOS:
> ./python.exe
然后将这个文件传递给标准库中内置的一个名为tokenize的模块。您将看到按行和字符排列的标记列表。使用-e标志输出确切的令牌名称:
$ ./python.exe -m tokenize -e test_tokens.py
0,0-0,0: ENCODING 'utf-8'
1,0-1,14: COMMENT '# Hello world!'
1,14-1,15: NL '\n'
2,0-2,3: NAME 'def'
2,4-2,15: NAME 'my_function'
2,15-2,16: LPAR '('
2,16-2,17: RPAR ')'
2,17-2,18: COLON ':'
2,18-2,19: NEWLINE '\n'
3,0-3,3: INDENT ' '
3,3-3,7: NAME 'proceed'
3,7-3,8: NEWLINE '\n'
4,0-4,0: DEDENT ''
4,0-4,0: ENDMARKER ''
在输出中,第一列是行/列坐标的范围,第二列是标记的名称,最后一列是标记的值。
在输出中,tokenize模块暗示了一些不在文件中的标记。用于utf-8的ENCODING标记,末尾有一个空行,给DEDENT关闭函数声明,给ENDMARKER结束文件。
最佳实践是在 Python 源文件的末尾有一个空行。如果您省略了它,CPython 会为您添加它,但性能会稍有下降。
tokenize模块是用纯 Python 编写的,位于 CPython 源代码内的 Lib/tokenize.py 。
重要提示:CPython 源代码中有两个标记器:一个用 Python 编写,这里演示一下,另一个用 C 编写,用 Python 编写的标记器是一个实用程序,用 C 编写的标记器是供 Python 编译器使用的。它们有相同的输出和行为。用 C 写的版本是为性能设计的,Python 中的模块是为调试设计的。
要查看 C tokenizer 的详细读数,可以使用-d标志运行 Python。使用您之前创建的test_tokens.py脚本,通过以下命令运行它:
$ ./python.exe -d test_tokens.py
Token NAME/'def' ... It's a keyword
DFA 'file_input', state 0: Push 'stmt'
DFA 'stmt', state 0: Push 'compound_stmt'
DFA 'compound_stmt', state 0: Push 'funcdef'
DFA 'funcdef', state 0: Shift.
Token NAME/'my_function' ... It's a token we know
DFA 'funcdef', state 1: Shift.
Token LPAR/'(' ... It's a token we know
DFA 'funcdef', state 2: Push 'parameters'
DFA 'parameters', state 0: Shift.
Token RPAR/')' ... It's a token we know
DFA 'parameters', state 1: Shift.
DFA 'parameters', state 2: Direct pop.
Token COLON/':' ... It's a token we know
DFA 'funcdef', state 3: Shift.
Token NEWLINE/'' ... It's a token we know
DFA 'funcdef', state 5: [switch func_body_suite to suite] Push 'suite'
DFA 'suite', state 0: Shift.
Token INDENT/'' ... It's a token we know
DFA 'suite', state 1: Shift.
Token NAME/'proceed' ... It's a keyword
DFA 'suite', state 3: Push 'stmt'
...
ACCEPT.
在输出中,可以看到它突出显示了proceed作为关键字。在下一章,我们将看到执行 Python 二进制代码是如何到达记号赋予器的,以及从那里执行代码会发生什么。
现在您已经对 Python 语法以及标记和语句之间的关系有了一个大致的了解,现在有一种方法可以将pgen输出转换成交互式图形。
下面是 Python 3.8a2 语法的截图:

用于生成此图的 Python 包instaviz,将在后面的章节中介绍。
CPython 中的内存管理
在整篇文章中,你会看到对一个 PyArena 对象的引用。arena 是 CPython 的内存管理结构之一。代码在Python/pyarena.c中,包含一个包装 C 的内存分配和释放函数的包装器。
在传统编写的 C 程序中,开发人员应该在写入数据之前为数据结构分配内存。这种分配将内存标记为属于操作系统的进程。
当分配的内存不再被使用时,由开发人员解除分配或“释放”它,并将其返回到操作系统的空闲内存块表中。如果一个进程为一个变量分配内存,比如在一个函数或循环中,当该函数完成时,内存不会自动交还给 C 中的操作系统,因此,如果它没有在 C 代码中被显式释放,就会导致内存泄漏。每次该函数运行时,该进程将继续占用更多的内存,直到最终系统耗尽内存并崩溃!
Python 将这一职责从程序员手中夺走,并使用两种算法:一个引用计数器和一个垃圾收集器。
每当解释器被实例化时,一个 PyArena 被创建并附加到解释器中的一个字段。在 CPython 解释器的生命周期中,可以分配许多领域。它们由一个链表连接。arena 将指向 Python 对象的指针列表存储为一个PyListObject。每当创建一个新的 Python 对象时,使用 PyArena_AddPyObject() 添加一个指向它的指针。这个函数调用在竞技场的列表中存储一个指针,a_objects。
即使 Python 没有指针,也有一些有趣的技术来模拟指针的行为。
PyArena的第二个功能是分配和引用原始内存块列表。例如,如果您添加了数千个额外的值,一个PyList将需要额外的内存。PyList对象的 C 代码不直接分配内存。该对象通过从PyObject调用 PyArena_Malloc() 从PyArena获取所需内存大小的原始内存块。这个任务由Objects/obmalloc.c中的另一个抽象完成。在对象分配模块中,可以为 Python 对象分配、释放和重新分配内存。
arena 内部存储了一个已分配内存块的链表,这样当一个解释器停止时,可以使用 PyArena_Free() 一次性释放所有托管内存块。
以PyListObject为例。如果你把一个对象放在一个 Python 列表的末尾,你不需要事先重新分配现有列表中使用的内存。.append()方法调用 list_resize() 来处理列表的内存分配。每个 list 对象保存一个分配的内存量的列表。如果要追加的项可以容纳在现有的空闲内存中,就简单地添加它。如果列表需要更多的内存空间,它会被扩展。列表的长度扩展为 0、4、8、16、25、35、46、58、72、88。
PyMem_Realloc() 被调用来扩展链表中分配的内存。 PyMem_Realloc() 是 pymalloc_realloc() 的 API 包装器。
Python 还为 C 调用malloc()提供了一个特殊的包装器,它设置内存分配的最大大小,以帮助防止缓冲区溢出错误(参见 PyMem_RawMalloc() )。
总而言之:
- 原始存储块的分配通过
PyMem_RawAlloc()完成。 - 指向 Python 对象的指针存储在
PyArena中。 PyArena还存储分配内存块的链表。
关于 API 的更多信息详见 CPython 文档。
参考计数
要在 Python 中创建一个变量,您必须给一个唯一的命名的变量赋予一个值:
my_variable = 180392
在 Python 中,每当给变量赋值时,都会在局部变量和全局变量范围内检查变量名,看它是否已经存在。
因为my_variable已经不在locals()或globals()字典中,所以这个新对象被创建,并且其值被指定为数值常量180392。
现在有一个对my_variable的引用,因此my_variable的引用计数器增加 1。
你会在 CPython 的整个 C 源代码中看到函数调用 Py_INCREF() 和 Py_DECREF() 。这些函数递增和递减对该对象的引用计数。
当变量超出其声明范围时,对对象的引用将减少。Python 中的作用域可以指一个函数或方法,一个理解,或者一个λ函数。这些是一些更字面的作用域,但是还有许多其他的隐式作用域,比如将变量传递给函数调用。
基于语言的递增和递减引用的处理内置在 CPython 编译器和核心执行循环ceval.c中,我们将在本文后面详细介绍。
每当Py_DECREF()被调用,并且计数器变为 0,则 PyObject_Free() 函数被调用。对于这个对象, PyArena_Free() 被调用用于所有被分配的内存。
垃圾收集
你的垃圾多久被收集一次?每周一次,还是两周一次?
当你用完某样东西时,你把它扔掉,扔进垃圾桶。但是垃圾不会马上被收集。你需要等垃圾车来拿走它。
CPython 有相同的原理,使用垃圾收集算法。默认情况下,CPython 的垃圾收集器是启用的,它发生在后台,用于释放已被不再使用的对象使用的内存。
因为垃圾收集算法比引用计数器复杂得多,所以它不会一直发生,否则,它会消耗大量的 CPU 资源。在一定数量的操作之后,它周期性地发生。
CPython 的标准库附带了一个 Python 模块来与 arena 和垃圾收集器接口,即gc模块。以下是如何在调试模式下使用gc模块:
>>> import gc >>> gc.set_debug(gc.DEBUG_STATS)这将在垃圾收集器运行时打印统计数据。
您可以通过调用
get_threshold()获得垃圾收集器运行的阈值:
>>> gc.get_threshold()
(700, 10, 10)
您还可以获得当前阈值计数:
>>> gc.get_count() (688, 1, 1)最后,您可以手动运行收集算法:
>>> gc.collect()
24
这将调用包含垃圾收集器算法实现的Modules/gcmodule.c文件中的 collect() 。
结论
在第 1 部分中,您介绍了源代码库的结构、如何从源代码编译以及 Python 语言规范。在第 2 部分中,当您更深入地研究 Python 解释器过程时,这些核心概念将是至关重要的。
第 2 部分:Python 解释器过程
既然您已经看到了 Python 语法和内存管理,那么您可以遵循从键入python到执行代码部分的过程。
有五种方法可以调用python二进制文件:
- 用
-c和一个 Python 命令运行一个命令 - 用
-m和模块名启动模块 - 使用文件名运行文件
- 使用外壳管道运行
stdin输入 - 启动 REPL 并一次执行一个命令
Python 有如此多的方法来执行脚本,这可能有点让人不知所措。如果你想了解更多,Darren Jones 整理了一个关于运行 Python 脚本的很棒的课程。
您需要检查的三个源文件是:
Programs/python.c是一个简单的切入点。Modules/main.c包含了将整个过程集合在一起的代码,加载配置,执行代码,清理内存。Python/initconfig.c从系统环境加载配置,并将其与任何命令行标志合并。
下图显示了这些函数的调用方式:

执行模式由配置决定。
CPython 源代码风格:
与 Python 代码的 PEP8 风格指南类似,CPython C 代码也有一个官方风格指南,最初设计于 2001 年,并为现代版本进行了更新。
导航源代码时,有一些命名标准会有所帮助:
-
对公共函数使用前缀
Py,不要对静态函数使用前缀。前缀Py_是为像Py_FatalError这样的全局服务例程保留的。特定的例程组(比如特定的对象类型 API)使用更长的前缀,比如字符串函数的PyString_。 -
公共函数和变量使用带下划线的 MixedCase,像这样:
PyObject_GetAttr,Py_BuildValue,PyExc_TypeError。 -
有时候,一个“内部”函数必须对加载程序可见。我们为此使用了
_Py前缀,例如_PyObject_Dump。 -
宏应该有一个 MixedCase 前缀,然后使用大写字母,例如
PyString_AS_STRING、Py_PRINT_RAW。
建立运行时配置
在泳道中,您可以看到在执行任何 Python 代码之前,运行时首先建立配置。运行时的配置是在Include/cpython/initconfig.h中定义的数据结构,命名为 PyConfig 。
配置数据结构包括以下内容:
- 调试和优化模式等各种模式的运行时标志
- 执行模式,如是否传递了文件名,
stdin是否提供了或模块名称 - 扩展选项,由
-X <option>指定 - 运行时设置的环境变量
CPython 运行时主要使用配置数据来启用和禁用各种功能。
Python 还附带了几个命令行接口选项。在 Python 中,可以使用-v标志启用详细模式。在详细模式下,Python 会在加载模块时将消息打印到屏幕上:
$ ./python.exe -v -c "print('hello world')"
# installing zipimport hook
import zipimport # builtin
# installed zipimport hook
...
您将会看到一百行或者更多的用户站点包和系统环境中的任何东西的导入。
你可以在Include/cpython/initconfig.h内看到这个标志的定义struct为 PyConfig :
/* --- PyConfig ---------------------------------------------- */ typedef struct { int _config_version; /* Internal configuration version,
used for ABI compatibility */ int _config_init; /* _PyConfigInitEnum value */ ... /* If greater than 0, enable the verbose mode: print a message each time a
module is initialized, showing the place (filename or built-in module)
from which it is loaded.
If greater or equal to 2, print a message for each file that is checked
for when searching for a module. Also provides information on module
cleanup at exit.
Incremented by the -v option. Set by the PYTHONVERBOSE environment
variable. If set to -1 (default), inherit Py_VerboseFlag value. */ int verbose;
在Python/initconfig.c中,建立了从环境变量和运行时命令行标志中读取设置的逻辑。
在config_read_env_vars功能中,环境变量被读取并用于为配置设置赋值:
static PyStatus config_read_env_vars(PyConfig *config) { PyStatus status; int use_env = config->use_environment; /* Get environment variables */ _Py_get_env_flag(use_env, &config->parser_debug, "PYTHONDEBUG"); _Py_get_env_flag(use_env, &config->verbose, "PYTHONVERBOSE"); _Py_get_env_flag(use_env, &config->optimization_level, "PYTHONOPTIMIZE"); _Py_get_env_flag(use_env, &config->inspect, "PYTHONINSPECT");
对于详细设置,如果找到了PYTHONVERBOSE,可以看到PYTHONVERBOSE的值被用来设置&config->verbose的值。如果环境变量不存在,那么将保留默认值-1。
然后在initconfig.c内的 config_parse_cmdline 中,命令行标志用于设置该值,如果提供:
static PyStatus config_parse_cmdline(PyConfig *config, PyWideStringList *warnoptions, Py_ssize_t *opt_index) { ... switch (c) { ... case 'v': config->verbose++; break; ... /* This space reserved for other options */ default: /* unknown argument: parsing failed */ config_usage(1, program); return _PyStatus_EXIT(2); } } while (1);
这个值稍后被 _Py_GetGlobalVariablesAsDict 函数复制到一个全局变量Py_VerboseFlag。
在 Python 会话中,您可以使用名为 tuple 的sys.flags来访问运行时标志,比如详细模式、安静模式。-X标志都可以在sys._xoptions字典中找到:
$ ./python.exe -X dev -q >>> import sys >>> sys.flags sys.flags(debug=0, inspect=0, interactive=0, optimize=0, dont_write_bytecode=0, no_user_site=0, no_site=0, ignore_environment=0, verbose=0, bytes_warning=0, quiet=1, hash_randomization=1, isolated=0, dev_mode=True, utf8_mode=0) >>> sys._xoptions {'dev': True}除了
initconfig.h中的运行时配置,还有构建配置,它位于根文件夹中的pyconfig.h内。这个文件是在构建过程的configure步骤中动态创建的,或者是由 Visual Studio for Windows 系统创建的。您可以通过运行以下命令来查看构建配置:
$ ./python.exe -m sysconfig读取文件/输入
一旦 CPython 有了运行时配置和命令行参数,它就可以确定需要执行什么。
这个任务由
Modules/main.c中的pymain_main函数处理。根据新创建的config实例,CPython 现在将执行通过几个选项提供的代码。通过
-c输入最简单的方法是为 CPython 提供一个带有
-c选项的命令和一个用引号括起来的 Python 程序。例如:
$ ./python.exe -c "print('hi')" hi以下是这一过程的完整流程图:
首先,
Modules/main.c内部执行pymain_run_command()函数,将-c中传递的命令作为 C 类型wchar_t*中的参数。由于类型的大小可以存储 UTF8 字符,wchar_t*类型通常被用作整个 CPython 中 Unicode 数据的低级存储类型。当将
wchar_t*转换成 Python 字符串时,Objects/unicodeobject.c文件有一个助手函数PyUnicode_FromWideChar(),它返回一个PyObject,类型为str。然后由 Pythonstr对象上的PyUnicode_AsUTF8String()完成 UTF8 编码,将其转换成 Pythonbytes对象。一旦完成,
pymain_run_command()将把 Python 字节对象传递给PyRun_SimpleStringFlags()来执行,但是首先把bytes再次转换成str类型:static int pymain_run_command(wchar_t *command, PyCompilerFlags *cf) { PyObject *unicode, *bytes; int ret; unicode = PyUnicode_FromWideChar(command, -1); if (unicode == NULL) { goto error; } if (PySys_Audit("cpython.run_command", "O", unicode) < 0) { return pymain_exit_err_print(); } bytes = PyUnicode_AsUTF8String(unicode); Py_DECREF(unicode); if (bytes == NULL) { goto error; } ret = PyRun_SimpleStringFlags(PyBytes_AsString(bytes), cf); Py_DECREF(bytes); return (ret != 0); error: PySys_WriteStderr("Unable to decode the command from the command line:\n"); return pymain_exit_err_print(); }将
wchar_t*转换为 Unicode、字节,然后是字符串大致相当于以下内容:unicode = str(command) bytes_ = bytes(unicode.encode('utf8')) # call PyRun_SimpleStringFlags with bytes_
PyRun_SimpleStringFlags()功能是Python/pythonrun.c的一部分。它的目的是将这个简单的命令转换成 Python 模块,然后发送出去执行。因为 Python 模块需要有__main__作为独立模块执行,所以它会自动创建:int PyRun_SimpleStringFlags(const char *command, PyCompilerFlags *flags) { PyObject *m, *d, *v; m = PyImport_AddModule("__main__"); if (m == NULL) return -1; d = PyModule_GetDict(m); v = PyRun_StringFlags(command, Py_file_input, d, d, flags); if (v == NULL) { PyErr_Print(); return -1; } Py_DECREF(v); return 0; }一旦
PyRun_SimpleStringFlags()创建了一个模块和一个字典,它就调用PyRun_StringFlags(),后者创建一个假文件名,然后调用 Python 解析器从字符串创建一个 AST 并返回一个模块,mod:PyObject * PyRun_StringFlags(const char *str, int start, PyObject *globals, PyObject *locals, PyCompilerFlags *flags) { ... mod = PyParser_ASTFromStringObject(str, filename, start, flags, arena); if (mod != NULL) ret = run_mod(mod, filename, globals, locals, flags, arena); PyArena_Free(arena); return ret;在下一节中,您将深入研究 AST 和解析器代码。
通过
-m输入执行 Python 命令的另一种方式是使用带有模块名称的
-m选项。一个典型的例子是python -m unittest运行标准库中的 unittest 模块。能够像脚本一样执行模块最初是在 PEP 338 中提出的,然后在 PEP366 中定义了显式相对导入的标准。
使用
-m标志意味着在模块包中,您想要执行__main__中的任何内容。这也意味着您想要在sys.path中搜索指定的模块。这种搜索机制就是为什么您不需要记住
unittest模块存储在文件系统中的什么位置。在
Modules/main.c内部,有一个函数在命令行运行时使用-m标志调用。模块的名称作为modname参数传递。CPython 将导入一个标准库模块
runpy,并使用PyObject_Call()执行它。使用位于Python/import.c文件中的 C API 函数PyImport_ImportModule()完成导入:static int pymain_run_module(const wchar_t *modname, int set_argv0) { PyObject *module, *runpy, *runmodule, *runargs, *result; runpy = PyImport_ImportModule("runpy"); ... runmodule = PyObject_GetAttrString(runpy, "_run_module_as_main"); ... module = PyUnicode_FromWideChar(modname, wcslen(modname)); ... runargs = Py_BuildValue("(Oi)", module, set_argv0); ... result = PyObject_Call(runmodule, runargs, NULL); ... if (result == NULL) { return pymain_exit_err_print(); } Py_DECREF(result); return 0; }在这个函数中,你还会看到另外两个 C API 函数:
PyObject_Call()和PyObject_GetAttrString()。因为PyImport_ImportModule()返回一个PyObject*,核心对象类型,需要调用特殊函数来获取属性并调用它。在 Python 中,如果你有一个对象并想获得一个属性,那么你可以调用
getattr()。在 C API 中,这个调用是PyObject_GetAttrString(),在Objects/object.c中可以找到。如果你想运行一个可调用函数,你可以给它加上括号,或者你可以在任何 Python 对象上运行__call__()属性。__call__()方法在Objects/object.c内部实现:hi = "hi!" hi.upper() == hi.upper.__call__() # this is the same
runpy模块是纯 Python 写的,位于Lib/runpy.py。执行
python -m <module>相当于运行python -m runpy <module>。创建runpy模块是为了抽象在操作系统上定位和执行模块的过程。
runpy运行目标模块需要做一些事情:
- 为您提供的模块名调用
__import__()- 将
__name__(模块名)设置为名为__main__的名称空间- 在
__main__名称空间内执行模块
runpy模块还支持执行目录和 zip 文件。通过文件名输入
如果
python的第一个参数是文件名,比如python test.py,那么 CPython 将打开一个文件句柄,类似于在 Python 中使用open(),并将句柄传递给Python/pythonrun.c内的PyRun_SimpleFileExFlags()。该函数有 3 条路径可供选择:
- 如果文件路径是一个
.pyc文件,它将调用run_pyc_file()。- 如果文件路径是一个脚本文件(
.py),它将运行PyRun_FileExFlags()。- 如果因为用户运行了
command | python而导致文件路径为stdin,那么将stdin视为文件句柄并运行PyRun_FileExFlags()。int PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) { ... m = PyImport_AddModule("__main__"); ... if (maybe_pyc_file(fp, filename, ext, closeit)) { ... v = run_pyc_file(pyc_fp, filename, d, d, flags); } else { /* When running from stdin, leave __main__.__loader__ alone */ if (strcmp(filename, "<stdin>") != 0 && set_main_loader(d, filename, "SourceFileLoader") < 0) { fprintf(stderr, "python: failed to set __main__.__loader__\n"); ret = -1; goto done; } v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d, closeit, flags); } ... return ret; }用
PyRun_FileExFlags()和通过文件输入对于
stdin和基本脚本文件,CPython 会将文件句柄传递给位于pythonrun.c文件中的PyRun_FileExFlags()。
PyRun_FileExFlags()的用途类似于PyRun_SimpleStringFlags()用于-c输入。CPython 会将文件句柄加载到PyParser_ASTFromFileObject()中。我们将在下一节讨论解析器和 AST 模块。因为这是一个完整的脚本,所以不需要-c使用的PyImport_AddModule("__main__");步骤:PyObject * PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals, PyObject *locals, int closeit, PyCompilerFlags *flags) { ... mod = PyParser_ASTFromFileObject(fp, filename, NULL, start, 0, 0, flags, NULL, arena); ... ret = run_mod(mod, filename, globals, locals, flags, arena); }与
PyRun_SimpleStringFlags()相同,一旦PyRun_FileExFlags()从文件中创建了一个 Python 模块,就将其发送给run_mod()执行。在
Python/pythonrun.c内找到run_mod(),将模块发送给 AST 编译成代码对象。代码对象是一种用于存储字节码操作的格式,也是保存在.pyc文件中的格式;static PyObject * run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags, PyArena *arena) { PyCodeObject *co; PyObject *v; co = PyAST_CompileObject(mod, filename, flags, -1, arena); if (co == NULL) return NULL; if (PySys_Audit("exec", "O", co) < 0) { Py_DECREF(co); return NULL; } v = run_eval_code_obj(co, globals, locals); Py_DECREF(co); return v; }我们将在下一节讨论 CPython 编译器和字节码。对
run_eval_code_obj()的调用是一个简单的包装函数,它调用Python/eval.c文件中的PyEval_EvalCode()。PyEval_EvalCode()函数是 CPython 的主要评估循环,它遍历每个字节码语句并在本地机器上执行。通过用
run_pyc_file()编译的字节码输入在
PyRun_SimpleFileExFlags()中有一个为用户提供一个.pyc文件的文件路径的子句。如果文件路径以.pyc结尾,那么它将假定.pyc文件包含一个写入磁盘的代码对象,而不是将文件作为纯文本文件加载并解析。然后,
Python/pythonrun.c中的run_pyc_file()函数使用文件句柄从.pyc文件中封送代码对象。编组是一个技术术语,用于将文件的内容复制到内存中,并将其转换为特定的数据结构。磁盘上的代码对象数据结构是 CPython 编译器缓存编译后的代码的方式,这样就不需要在每次调用脚本时都解析它:static PyObject * run_pyc_file(FILE *fp, const char *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags) { PyCodeObject *co; PyObject *v; ... v = PyMarshal_ReadLastObjectFromFile(fp); ... if (v == NULL || !PyCode_Check(v)) { Py_XDECREF(v); PyErr_SetString(PyExc_RuntimeError, "Bad code object in .pyc file"); goto error; } fclose(fp); co = (PyCodeObject *)v; v = run_eval_code_obj(co, globals, locals); if (v && flags) flags->cf_flags |= (co->co_flags & PyCF_MASK); Py_DECREF(co); return v; }一旦代码对象被整理到内存中,它就被发送到
run_eval_code_obj(),后者调用Python/ceval.c来执行代码。词法分析和语法分析
在读取和执行 Python 文件的探索中,我们深入到解析器和 AST 模块,函数调用
PyParser_ASTFromFileObject()。在
Python/pythonrun.c中,PyParser_ASTFromFileObject()函数将获取一个文件句柄、编译器标志和一个PyArena实例,并使用PyParser_ParseFileObject()将文件对象转换为节点对象。对于节点对象,它将使用 AST 函数
PyAST_FromNodeObject()将其转换为模块:mod_ty PyParser_ASTFromFileObject(FILE *fp, PyObject *filename, const char* enc, int start, const char *ps1, const char *ps2, PyCompilerFlags *flags, int *errcode, PyArena *arena) { ... node *n = PyParser_ParseFileObject(fp, filename, enc, &_PyParser_Grammar, start, ps1, ps2, &err, &iflags); ... if (n) { flags->cf_flags |= iflags & PyCF_MASK; mod = PyAST_FromNodeObject(n, flags, filename, arena); PyNode_Free(n); ... return mod; }对于
PyParser_ParseFileObject(),我们切换到Parser/parsetok.c和 CPython 解释器的解析器-标记器阶段。该功能有两个重要任务:
- 使用
Parser/tokenizer.c中的PyTokenizer_FromFile()实例化一个分词器状态tok_state- 使用
Parser/parsetok.c中的parsetok()将令牌转换成具体的解析树(一个node列表)node * PyParser_ParseFileObject(FILE *fp, PyObject *filename, const char *enc, grammar *g, int start, const char *ps1, const char *ps2, perrdetail *err_ret, int *flags) { struct tok_state *tok; ... if ((tok = PyTokenizer_FromFile(fp, enc, ps1, ps2)) == NULL) { err_ret->error = E_NOMEM; return NULL; } ... return parsetok(tok, g, start, err_ret, flags); }
tok_state(在Parser/tokenizer.h中定义)是存储由分词器生成的所有临时数据的数据结构。当parsetok()需要数据结构来开发具体的语法树时,它被返回给解析器-标记器。在
parsetok()内部,它将使用tok_state结构,并循环调用tok_get(),直到文件用尽,再也找不到令牌。
tok_get(),在Parser/tokenizer.c中定义的行为类似迭代器。它将不断返回解析树中的下一个标记。
tok_get()是整个 CPython 代码库中最复杂的函数之一。它有 640 多行,包括几十年的边缘案例,新的语言功能和语法的遗产。一个更简单的例子是将换行符转换成换行符的部分:
static int tok_get(struct tok_state *tok, char **p_start, char **p_end) { ... /* Newline */ if (c == '\n') { tok->atbol = 1; if (blankline || tok->level > 0) { goto nextline; } *p_start = tok->start; *p_end = tok->cur - 1; /* Leave '\n' out of the string */ tok->cont_line = 0; if (tok->async_def) { /* We're somewhere inside an 'async def' function, and we've encountered a NEWLINE after its signature. */ tok->async_def_nl = 1; } return NEWLINE; } ... }在这种情况下,
NEWLINE是一个令牌,其值在Include/token.h中定义。所有的令牌都是常量int值,而Include/token.h文件是在我们运行make regen-grammar时生成的。由
PyParser_ParseFileObject()返回的node类型将是下一阶段的关键,将解析树转换成抽象语法树(AST):typedef struct _node { short n_type; char *n_str; int n_lineno; int n_col_offset; int n_nchildren; struct _node *n_child; int n_end_lineno; int n_end_col_offset; } node;由于 CST 是一个由语法、标记 id 和符号组成的树,编译器很难基于 Python 语言做出快速决策。
这就是为什么下一步是将 CST 转变为 AST,一个更高级别的结构。这个任务由
Python/ast.c模块执行,它既有 C 又有 Python API。在进入 AST 之前,有一种方法可以访问解析器阶段的输出。CPython 有一个标准的库模块
parser,它用 Python API 公开了 C 函数。该模块被记录为 CPython 的一个实现细节,因此您不会在其他 Python 解释器中看到它。此外,函数的输出也不容易阅读。
输出将采用数字形式,使用由
make regen-grammar级生成的令牌和符号数,存储在Include/token.h中:
>>> from pprint import pprint
>>> import parser
>>> st = parser.expr('a + 1')
>>> pprint(parser.st2list(st))
[258,
[332,
[306,
[310,
[311,
[312,
[313,
[316,
[317,
[318,
[319,
[320,
[321, [322, [323, [324, [325, [1, 'a']]]]]],
[14, '+'],
[321, [322, [323, [324, [325, [2, '1']]]]]]]]]]]]]]]]],
[4, ''],
[0, '']]
为了更容易理解,您可以将symbol和token模块中的所有数字放入一个字典中,然后递归地将parser.st2list()输出中的值替换为名称:
import symbol
import token
import parser
def lex(expression):
symbols = {v: k for k, v in symbol.__dict__.items() if isinstance(v, int)}
tokens = {v: k for k, v in token.__dict__.items() if isinstance(v, int)}
lexicon = {**symbols, **tokens}
st = parser.expr(expression)
st_list = parser.st2list(st)
def replace(l: list):
r = []
for i in l:
if isinstance(i, list):
r.append(replace(i))
else:
if i in lexicon:
r.append(lexicon[i])
else:
r.append(i)
return r
return replace(st_list)
您可以用一个简单的表达式运行lex(),比如a + 1,看看这是如何表示为一个解析树的:
>>> from pprint import pprint >>> pprint(lex('a + 1')) ['eval_input', ['testlist', ['test', ['or_test', ['and_test', ['not_test', ['comparison', ['expr', ['xor_expr', ['and_expr', ['shift_expr', ['arith_expr', ['term', ['factor', ['power', ['atom_expr', ['atom', ['NAME', 'a']]]]]], ['PLUS', '+'], ['term', ['factor', ['power', ['atom_expr', ['atom', ['NUMBER', '1']]]]]]]]]]]]]]]]], ['NEWLINE', ''], ['ENDMARKER', '']]在输出中,可以看到小写的符号,比如
'test',大写的记号,比如'NUMBER'。抽象语法树
CPython 解释器的下一步是将解析器生成的 CST 转换成更符合逻辑的可执行内容。该结构是代码的高级表示,称为抽象语法树(AST)。
ast 是通过 CPython 解释器过程内联生成的,但是您也可以使用标准库中的
ast模块在 Python 中生成它们,也可以通过 C API 生成它们。在深入 AST 的 C 实现之前,理解一段简单的 Python 代码中的 AST 是什么样子是很有用的。
要做到这一点,这里有一个简单的应用程序称为
instaviz本教程。它在 Web UI 中显示 AST 和字节码指令(我们将在后面介绍)。要安装
instaviz:$ pip install instaviz然后,通过在命令行不带参数地运行
python来打开一个 REPL:
>>> import instaviz
>>> def example():
a = 1
b = a + 1
return b
>>> instaviz.show(example)
您将在命令行上看到一个通知,说明 web 服务器已经在端口8080上启动。如果您将该端口用于其他用途,您可以通过调用instaviz.show(example, port=9090)或其他端口号来更改它。
在网络浏览器中,您可以看到您的功能的详细分解:

左下图是您在 REPL 中声明的函数,表示为抽象语法树。树中的每个节点都是 AST 类型。它们位于ast模块中,并且都继承自_ast.AST。
一些节点具有将它们链接到子节点的属性,这与 CST 不同,CST 具有一般的子节点属性。
例如,如果您单击中间的 Assign 节点,这将链接到行b = a + 1:
它有两个属性:
targets是要分配的名称列表。这是一个列表,因为您可以使用解包用一个表达式给多个变量赋值value是要赋值的值,在本例中是一个BinOp语句,a + 1。
如果你点击BinOp语句,它显示相关性的属性:
left: 运算符左边的节点op: 运算符,在本例中,一个Add节点(+)用于加法right: 操作员右边的节点

用 C 编译 AST 不是一项简单的任务,所以Python/ast.c模块有 5000 多行代码。
有几个入口点,构成了 AST 公共 API 的一部分。在关于词法分析器和解析器的上一节中,当您到达对 PyAST_FromNodeObject() 的调用时,您停止了操作。到这个阶段,Python 解释器进程已经以node *树的格式创建了一个 CST。
然后跳转到Python/ast.c里面的 PyAST_FromNodeObject() ,你可以看到它接收了node *树、文件名、编译器标志和PyArena。
该函数返回的类型为 mod_ty ,在Include/Python-ast.h中定义。mod_ty是 Python 中 5 种模块类型之一的容器结构:
ModuleInteractiveExpressionFunctionTypeSuite
在Include/Python-ast.h中,您可以看到一个Expression类型需要一个字段body,这是一个expr_ty类型。expr_ty类型也在Include/Python-ast.h中定义:
enum _mod_kind {Module_kind=1, Interactive_kind=2, Expression_kind=3, FunctionType_kind=4, Suite_kind=5}; struct _mod { enum _mod_kind kind; union { struct { asdl_seq *body; asdl_seq *type_ignores; } Module; struct { asdl_seq *body; } Interactive; struct { expr_ty body; } Expression; struct { asdl_seq *argtypes; expr_ty returns; } FunctionType; struct { asdl_seq *body; } Suite; } v; };
AST 类型都在Parser/Python.asdl中列出。您将看到模块类型、语句类型、表达式类型、操作符和理解都列出来了。本文档中的类型名称与 AST 生成的类以及在ast标准模块库中命名的相同类相关。
Include/Python-ast.h中的参数和名称与Parser/Python.asdl中指定的参数和名称直接相关:
-- ASDL's 5 builtin types are:
-- identifier, int, string, object, constant
module Python
{
mod = Module(stmt* body, type_ignore *type_ignores)
| Interactive(stmt* body)
| Expression(expr body) | FunctionType(expr* argtypes, expr returns)
C 头文件和结构就在那里,这样Python/ast.c程序可以快速生成指向相关数据的结构。
查看 PyAST_FromNodeObject() 可以发现,它本质上是围绕来自TYPE(n)的结果的switch语句。TYPE()是 AST 用来确定具体语法树中节点类型的核心函数之一。在 PyAST_FromNodeObject() 的情况下只是看第一个节点,所以只能是定义为Module、Interactive、Expression、FunctionType的模块类型之一。
TYPE()的结果将是一个符号或记号类型,这是我们在这个阶段非常熟悉的。
对于file_input,结果应该是一个Module。模块是一系列语句,有几种类型。遍历n的子节点并创建语句节点的逻辑在 ast_for_stmt() 内。如果模块中只有一条语句,则调用此函数一次;如果有多条语句,则在循环中调用。然后用PyArena返回结果Module。
对于eval_input,结果应该是一个Expression。来自CHILD(n ,0)的结果被传递给 ast_for_testlist() ,后者返回一个expr_ty类型。这个expr_ty和 PyArena 一起被发送到Expression()以创建一个表达式节点,然后返回结果:
mod_ty PyAST_FromNodeObject(const node *n, PyCompilerFlags *flags, PyObject *filename, PyArena *arena) { ... switch (TYPE(n)) { case file_input: stmts = _Py_asdl_seq_new(num_stmts(n), arena); if (!stmts) goto out; for (i = 0; i < NCH(n) - 1; i++) { ch = CHILD(n, i); if (TYPE(ch) == NEWLINE) continue; REQ(ch, stmt); num = num_stmts(ch); if (num == 1) { s = ast_for_stmt(&c, ch); if (!s) goto out; asdl_seq_SET(stmts, k++, s); } else { ch = CHILD(ch, 0); REQ(ch, simple_stmt); for (j = 0; j < num; j++) { s = ast_for_stmt(&c, CHILD(ch, j * 2)); if (!s) goto out; asdl_seq_SET(stmts, k++, s); } } } /* Type ignores are stored under the ENDMARKER in file_input. */ ... res = Module(stmts, type_ignores, arena); break; case eval_input: { expr_ty testlist_ast; /* XXX Why not comp_for here? */ testlist_ast = ast_for_testlist(&c, CHILD(n, 0)); if (!testlist_ast) goto out; res = Expression(testlist_ast, arena); break; } case single_input: ... break; case func_type_input: ... ... return res; }
在 ast_for_stmt() 函数中,对于每种可能的语句类型(simple_stmt、compound_stmt等等)都有另一个switch语句,以及确定节点类参数的代码。
其中一个更简单的函数是幂表达式,即2**4是 2 的 4 次方。这个函数从获取 ast_for_atom_expr() 开始,在我们的例子中是数字2,然后如果它有一个孩子,它返回原子表达式。如果它有多个子节点,它将得到右边(数字4)并返回一个BinOp(二元运算),运算符为Pow(幂),左边为e (2),右边为f (4):
static expr_ty ast_for_power(struct compiling *c, const node *n) { /* power: atom trailer* ('**' factor)*
*/ expr_ty e; REQ(n, power); e = ast_for_atom_expr(c, CHILD(n, 0)); if (!e) return NULL; if (NCH(n) == 1) return e; if (TYPE(CHILD(n, NCH(n) - 1)) == factor) { expr_ty f = ast_for_expr(c, CHILD(n, NCH(n) - 1)); if (!f) return NULL; e = BinOp(e, Pow, f, LINENO(n), n->n_col_offset, n->n_end_lineno, n->n_end_col_offset, c->c_arena); } return e; }
如果您向instaviz模块发送一个短函数,您可以看到这样的结果:
>>> def foo(): 2**4 >>> import instaviz >>> instaviz.show(foo)
在用户界面中,您还可以看到相应的属性:
总之,每个语句类型和表达式都有一个相应的
ast_for_*()函数来创建它。参数在Parser/Python.asdl中定义,并通过标准库中的ast模块公开。如果一个表达式或语句有孩子,那么它将在深度优先遍历中调用相应的ast_for_*子函数。结论
CPython 的多功能性和低级执行 API 使其成为嵌入式脚本引擎的理想候选。你会看到 CPython 被用在很多 UI 应用中,比如游戏设计、3D 图形和系统自动化。
解释器过程灵活而高效,现在你已经了解了它是如何工作的,你已经准备好理解编译器了。
第 3 部分:CPython 编译器和执行循环
在第 2 部分中,您看到了 CPython 解释器如何接受输入,比如文件或字符串,并将其转换成逻辑抽象语法树。我们还没有到可以执行这段代码的阶段。接下来,我们必须更深入地将抽象的语法树转换为 CPU 可以理解的一组顺序命令。
编译
现在,解释器有了一个 AST,其中包含每个操作、函数、类和名称空间所需的属性。编译器的工作就是把 AST 转换成 CPU 能够理解的东西。
该编译任务分为两部分:
- 遍历树并创建一个控制流图,它表示执行的逻辑顺序
- 将 CFG 中的节点转换成更小的可执行语句,称为字节码
之前,我们看了文件是如何执行的,以及
Python/pythonrun.c中的PyRun_FileExFlags()函数。在这个函数中,我们将FILE句柄转换为mod,类型为mod_ty。这个任务由PyParser_ASTFromFileObject()完成,它依次调用tokenizer、parser-tokenizer和 AST:PyObject * PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals, PyObject *locals, int closeit, PyCompilerFlags *flags) { ... mod = PyParser_ASTFromFileObject(fp, filename, NULL, start, 0, 0, ... ret = run_mod(mod, filename, globals, locals, flags, arena); }调用的结果模块被发送到仍在
Python/pythonrun.c中的run_mod()。这是一个小函数,它从PyAST_CompileObject()中获取一个PyCodeObject,并将其发送到run_eval_code_obj()。您将在下一节处理run_eval_code_obj():static PyObject * run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags, PyArena *arena) { PyCodeObject *co; PyObject *v; co = PyAST_CompileObject(mod, filename, flags, -1, arena); if (co == NULL) return NULL; if (PySys_Audit("exec", "O", co) < 0) { Py_DECREF(co); return NULL; } v = run_eval_code_obj(co, globals, locals); Py_DECREF(co); return v; }
PyAST_CompileObject()函数是 CPython 编译器的主要入口点。它将一个 Python 模块作为其主要参数,还有文件名、全局变量、局部变量和前面在解释器过程中创建的PyArena。我们现在开始进入 CPython 编译器的内部,它背后有几十年的开发和计算机科学理论。不要被这种语言吓跑。一旦我们将编译器分解成逻辑步骤,就有意义了。
在编译器启动之前,会创建一个全局编译器状态。这个类型
compiler在Python/compile.c中定义,包含编译器用来记住编译器标志、堆栈和PyArena的属性:struct compiler { PyObject *c_filename; struct symtable *c_st; PyFutureFeatures *c_future; /* pointer to module's __future__ */ PyCompilerFlags *c_flags; int c_optimize; /* optimization level */ int c_interactive; /* true if in interactive mode */ int c_nestlevel; int c_do_not_emit_bytecode; /* The compiler won't emit any bytecode if this value is different from zero. This can be used to temporarily visit nodes without emitting bytecode to check only errors. */ PyObject *c_const_cache; /* Python dict holding all constants, including names tuple */ struct compiler_unit *u; /* compiler state for current block */ PyObject *c_stack; /* Python list holding compiler_unit ptrs */ PyArena *c_arena; /* pointer to memory allocation arena */ };在
PyAST_CompileObject()中,有 11 个主要步骤发生:
- 如果模块不存在,则创建一个空的
__doc__属性。- 如果模块不存在,则创建一个空的
__annotations__属性。- 将全局编译器状态的文件名设置为 filename 参数。
- 将编译器的内存分配区域设置为解释器使用的区域。
- 将模块中的任何
__future__标志复制到编译器中的未来标志。- 合并命令行或环境变量提供的运行时标志。
- 启用编译器中的任何
__future__特性。- 将优化级别设置为提供的参数或默认值。
- 从模块对象建立一个符号表。
- 使用编译器状态运行编译器,并返回代码对象。
- 由编译器释放所有分配的内存。
PyCodeObject * PyAST_CompileObject(mod_ty mod, PyObject *filename, PyCompilerFlags *flags, int optimize, PyArena *arena) { struct compiler c; PyCodeObject *co = NULL; PyCompilerFlags local_flags = _PyCompilerFlags_INIT; int merged; PyConfig *config = &_PyInterpreterState_GET_UNSAFE()->config; if (!__doc__) { __doc__ = PyUnicode_InternFromString("__doc__"); if (!__doc__) return NULL; } if (!__annotations__) { __annotations__ = PyUnicode_InternFromString("__annotations__"); if (!__annotations__) return NULL; } if (!compiler_init(&c)) return NULL; Py_INCREF(filename); c.c_filename = filename; c.c_arena = arena; c.c_future = PyFuture_FromASTObject(mod, filename); if (c.c_future == NULL) goto finally; if (!flags) { flags = &local_flags; } merged = c.c_future->ff_features | flags->cf_flags; c.c_future->ff_features = merged; flags->cf_flags = merged; c.c_flags = flags; c.c_optimize = (optimize == -1) ? config->optimization_level : optimize; c.c_nestlevel = 0; c.c_do_not_emit_bytecode = 0; if (!_PyAST_Optimize(mod, arena, c.c_optimize)) { goto finally; } c.c_st = PySymtable_BuildObject(mod, filename, c.c_future); if (c.c_st == NULL) { if (!PyErr_Occurred()) PyErr_SetString(PyExc_SystemError, "no symtable"); goto finally; } co = compiler_mod(&c, mod); finally: compiler_free(&c); assert(co || PyErr_Occurred()); return co; }未来标志和编译器标志
在编译器运行之前,有两种类型的标志来切换编译器内部的特性。这些来自两个地方:
- 解释器状态,可能是命令行选项,在
pyconfig.h中设置或通过环境变量设置- 在模块的实际源代码中使用
__future__语句为了区分这两种类型的标志,考虑到特定模块中的语法或特性,需要使用
__future__标志。例如,Python 3.7 通过annotationsfuture 标志引入了类型提示的延迟求值:from __future__ import annotations该语句后的代码可能使用未解析的类型提示,因此需要使用
__future__语句。否则,模块不会导入。手动请求导入模块的人启用这个特定的编译器标志是不可维护的。其他编译器标志是特定于环境的,因此它们可能会改变代码执行的方式或编译器运行的方式,但它们不应该像
__future__语句那样链接到源代码。编译器标志的一个例子是用于优化使用
assert语句的-O标志。该标志禁用任何assert语句,这些语句可能已经被放入代码中用于调试目的。也可以通过PYTHONOPTIMIZE=1环境变量设置启用。符号表
在
PyAST_CompileObject()中,引用了一个symtable并调用了要执行的模块的PySymtable_BuildObject()。符号表的目的是为编译器提供一个命名空间、全局变量和局部变量的列表,用于引用和解析范围。
Include/symtable.h中的symtable结构有很好的文档记录,所以每个字段的用途很清楚。编译器应该有一个 symtable 实例,所以命名空间变得很重要。如果在一个模块中创建了一个名为
resolve_names()的函数,并在另一个模块中声明了另一个同名的函数,那么您需要确定调用的是哪个函数。symtable 服务于这个目的,并确保在狭窄范围内声明的变量不会自动变成全局变量(毕竟,这不是 JavaScript):struct symtable { PyObject *st_filename; /* name of file being compiled, decoded from the filesystem encoding */ struct _symtable_entry *st_cur; /* current symbol table entry */ struct _symtable_entry *st_top; /* symbol table entry for module */ PyObject *st_blocks; /* dict: map AST node addresses * to symbol table entries */ PyObject *st_stack; /* list: stack of namespace info */ PyObject *st_global; /* borrowed ref to st_top->ste_symbols */ int st_nblocks; /* number of blocks used. kept for consistency with the corresponding compiler structure */ PyObject *st_private; /* name of current class or NULL */ PyFutureFeatures *st_future; /* module's future features that affect the symbol table */ int recursion_depth; /* current recursion depth */ int recursion_limit; /* recursion limit */ };一些符号表 API 通过标准库中的模块
symtable暴露出来。您可以提供一个表达式或模块来接收一个symtable.SymbolTable实例。你可以提供一个带有 Python 表达式的字符串和
"eval"的compile_type,或者一个模块、函数或类和"exec"的compile_mode来得到一个符号表。循环浏览表中的元素,我们可以看到一些公共和私有字段及其类型:


>>> import symtable
>>> s = symtable.symtable('b + 1', filename='test.py', compile_type='eval')
>>> [symbol.__dict__ for symbol in s.get_symbols()]
[{'_Symbol__name': 'b', '_Symbol__flags': 6160, '_Symbol__scope': 3, '_Symbol__namespaces': ()}]
这背后的 C 代码都在Python/symtable.c中,主要接口是 PySymtable_BuildObject() 函数。
类似于我们之前介绍的顶级 AST 函数, PySymtable_BuildObject() 函数在mod_ty可能的类型(模块、表达式、交互、套件、函数类型)之间切换,并访问其中的每个语句。
记住,mod_ty是一个 AST 实例,所以现在将递归地浏览树的节点和分支,并将条目添加到符号表中:
struct symtable * PySymtable_BuildObject(mod_ty mod, PyObject *filename, PyFutureFeatures *future) { struct symtable *st = symtable_new(); asdl_seq *seq; int i; PyThreadState *tstate; int recursion_limit = Py_GetRecursionLimit(); ... st->st_top = st->st_cur; switch (mod->kind) { case Module_kind: seq = mod->v.Module.body; for (i = 0; i < asdl_seq_LEN(seq); i++) if (!symtable_visit_stmt(st, (stmt_ty)asdl_seq_GET(seq, i))) goto error; break; case Expression_kind: ... case Interactive_kind: ... case Suite_kind: ... case FunctionType_kind: ... } ... }
所以对于一个模块, PySymtable_BuildObject() 会循环遍历模块中的每一条语句,并调用 symtable_visit_stmt() 。 symtable_visit_stmt() 是一个巨大的switch语句,每个语句类型都有一个案例(在Parser/Python.asdl中定义)。
对于每种语句类型,都有特定的逻辑。例如,函数定义具有特定的逻辑,用于:
- 如果递归深度超出限制,则引发递归深度错误
- 要作为局部变量添加的函数的名称
- 要解析的顺序参数的默认值
- 要解析的关键字参数的默认值
- 解析参数或返回类型的任何注释
- 任何函数装饰器都被解析
- 在
symtable_enter_block()中访问包含函数内容的代码块 - 论据被访问
- 函数体被访问
注意:如果你曾经想知道为什么 Python 的默认参数是可变的,原因就在这个函数里。你可以看到它们是指向符号表中变量的指针。不需要做额外的工作来将任何值复制到一个不可变的类型。
static int symtable_visit_stmt(struct symtable *st, stmt_ty s) { if (++st->recursion_depth > st->recursion_limit) { // 1. PyErr_SetString(PyExc_RecursionError, "maximum recursion depth exceeded during compilation"); VISIT_QUIT(st, 0); } switch (s->kind) { case FunctionDef_kind: if (!symtable_add_def(st, s->v.FunctionDef.name, DEF_LOCAL)) // 2. VISIT_QUIT(st, 0); if (s->v.FunctionDef.args->defaults) // 3. VISIT_SEQ(st, expr, s->v.FunctionDef.args->defaults); if (s->v.FunctionDef.args->kw_defaults) // 4. VISIT_SEQ_WITH_NULL(st, expr, s->v.FunctionDef.args->kw_defaults); if (!symtable_visit_annotations(st, s, s->v.FunctionDef.args, // 5. s->v.FunctionDef.returns)) VISIT_QUIT(st, 0); if (s->v.FunctionDef.decorator_list) // 6. VISIT_SEQ(st, expr, s->v.FunctionDef.decorator_list); if (!symtable_enter_block(st, s->v.FunctionDef.name, // 7. FunctionBlock, (void *)s, s->lineno, s->col_offset)) VISIT_QUIT(st, 0); VISIT(st, arguments, s->v.FunctionDef.args); // 8. VISIT_SEQ(st, stmt, s->v.FunctionDef.body); // 9. if (!symtable_exit_block(st, s)) VISIT_QUIT(st, 0); break; case ClassDef_kind: { ... } case Return_kind: ... case Delete_kind: ... case Assign_kind: ... case AnnAssign_kind: ...
一旦生成的符号表被创建,它就被发送回去供编译器使用。
核心编译过程
既然 PyAST_CompileObject() 有了编译器状态、符号表和 AST 形式的模块,实际的编译就可以开始了。
核心编译器的目的是:
- 将状态、符号表和 AST 转换成一个控制流图(CFG)
- 通过捕捉任何逻辑和代码错误并在此引发它们,保护执行阶段免受运行时异常的影响
通过调用内置函数compile(),可以用 Python 代码调用 CPython 编译器。它返回一个code object实例:
>>> compile('b+1', 'test.py', mode='eval') <code object <module> at 0x10f222780, file "test.py", line 1>与
symtable()函数一样,一个简单的表达式应该有一个'eval'模式,一个模块、函数或类应该有一个'exec'模式。编译后的代码可以在 code 对象的
co_code属性中找到:
>>> co.co_code
b'e\x00d\x00\x17\x00S\x00'
标准库中还有一个dis模块,它反汇编字节码指令,可以在屏幕上打印出来或者给你一个Instruction实例的列表。
如果你导入dis并给dis()函数代码对象的co_code属性,它会反汇编它并在 REPL 上打印指令:
>>> import dis >>> dis.dis(co.co_code) 0 LOAD_NAME 0 (0) 2 LOAD_CONST 0 (0) 4 BINARY_ADD 6 RETURN_VALUE
LOAD_NAME、LOAD_CONST、BINARY_ADD、RETURN_VALUE都是字节码指令。它们被称为字节码,因为在二进制形式中,它们是一个字节长。然而,自从 Python 3.6 之后,存储格式变成了word,所以现在它们在技术上是字代码,而不是字节码。Python 的每个版本都有完整的字节码指令列表,并且不同版本之间会有所不同。例如,在 Python 3.7 中,引入了一些新的字节码指令来加速特定方法调用的执行。
在前面的部分中,我们探索了
instaviz包。这包括通过运行编译器来可视化代码对象类型。它还显示了代码对象内部的字节码操作。再次执行 instaviz,查看在 REPL 上定义的函数的代码对象和字节码:
>>> import instaviz
>>> def example():
a = 1
b = a + 1
return b
>>> instaviz.show(example)
如果我们现在跳转到 compiler_mod() ,一个用来根据模块类型切换不同编译器功能的函数。我们假设mod是一个Module。该模块被编译成编译器状态,然后运行 assemble() 创建一个 PyCodeObject 。
新的代码对象返回到 PyAST_CompileObject() 并继续执行:
static PyCodeObject * compiler_mod(struct compiler *c, mod_ty mod) { PyCodeObject *co; int addNone = 1; static PyObject *module; ... switch (mod->kind) { case Module_kind: if (!compiler_body(c, mod->v.Module.body)) { compiler_exit_scope(c); return 0; } break; case Interactive_kind: ... case Expression_kind: ... case Suite_kind: ... ... co = assemble(c, addNone); compiler_exit_scope(c); return co; }
compiler_body() 函数有一些优化标志,然后循环遍历模块中的每条语句并访问它,类似于symtable函数的工作方式:
static int compiler_body(struct compiler *c, asdl_seq *stmts) { int i = 0; stmt_ty st; PyObject *docstring; ... for (; i < asdl_seq_LEN(stmts); i++) VISIT(c, stmt, (stmt_ty)asdl_seq_GET(stmts, i)); return 1; }
语句类型是通过调用 asdl_seq_GET() 函数确定的,该函数查看 AST 节点的类型。
通过一些智能宏,VISIT为每种语句类型调用Python/compile.c中的函数:
#define VISIT(C, TYPE, V) {\
if (!compiler_visit_ ## TYPE((C), (V))) \
return 0; \
}
对于一个stmt(语句的类别),编译器将进入 compiler_visit_stmt() 并在Parser/Python.asdl中找到的所有潜在语句类型之间切换:
static int compiler_visit_stmt(struct compiler *c, stmt_ty s) { Py_ssize_t i, n; /* Always assign a lineno to the next instruction for a stmt. */ c->u->u_lineno = s->lineno; c->u->u_col_offset = s->col_offset; c->u->u_lineno_set = 0; switch (s->kind) { case FunctionDef_kind: return compiler_function(c, s, 0); case ClassDef_kind: return compiler_class(c, s); ... case For_kind: return compiler_for(c, s); ... } return 1; }
举个例子,让我们关注一下For语句,在 Python 中是:
for i in iterable:
# block
else: # optional if iterable is False
# block
如果语句是For类型,则调用 compiler_for() 。所有的语句和表达式类型都有一个等价的compiler_*()函数。更简单的类型内联创建字节码指令,一些更复杂的语句类型调用其他函数。
许多语句可以有子语句。一个 for循环有一个主体,但是在赋值和迭代器中也可以有复杂的表达式。
编译器的compiler_语句将块发送到编译器状态。这些块包含指令,Python/compile.c中的指令数据结构有操作码、任何参数和目标块(如果这是跳转指令),它还包含行号。
对于跳转语句,它们可以是绝对跳转语句,也可以是相对跳转语句。跳转语句用于从一个操作“跳转”到另一个操作。绝对跳转语句指定编译的代码对象中的确切操作号,而相对跳转语句指定相对于另一个操作的跳转目标:
struct instr { unsigned i_jabs : 1; unsigned i_jrel : 1; unsigned char i_opcode; int i_oparg; struct basicblock_ *i_target; /* target block (if jump instruction) */ int i_lineno; };
因此一个帧块(类型为basicblock)包含以下字段:
- 一个
b_list指针,指向编译器状态块列表的链接 - 指令列表
b_instr,包括分配的列表大小b_ialloc,以及使用的数量b_iused - 这一块之后的下一块
b_next - 深度优先遍历时,汇编程序是否“看到”了该块
- 如果这个块有一个
RETURN_VALUE操作码(b_return - 进入该块时堆栈的深度(
b_startdepth) - 汇编程序的指令偏移量
typedef struct basicblock_ { /* Each basicblock in a compilation unit is linked via b_list in the
reverse order that the block are allocated. b_list points to the next
block, not to be confused with b_next, which is next by control flow. */ struct basicblock_ *b_list; /* number of instructions used */ int b_iused; /* length of instruction array (b_instr) */ int b_ialloc; /* pointer to an array of instructions, initially NULL */ struct instr *b_instr; /* If b_next is non-NULL, it is a pointer to the next
block reached by normal control flow. */ struct basicblock_ *b_next; /* b_seen is used to perform a DFS of basicblocks. */ unsigned b_seen : 1; /* b_return is true if a RETURN_VALUE opcode is inserted. */ unsigned b_return : 1; /* depth of stack upon entry of block, computed by stackdepth() */ int b_startdepth; /* instruction offset for block, computed by assemble_jump_offsets() */ int b_offset; } basicblock;
就复杂性而言,For语句处于中间位置。用for <target> in <iterator>:语法编译For语句有 15 个步骤:
- 创建一个名为
start的新代码块,它分配内存并创建一个basicblock指针 - 创建一个名为
cleanup的新代码块 - 创建一个名为
end的新代码块 - 将类型为
FOR_LOOP的帧块推入堆栈,其中start为入口块,end为出口块 - 访问迭代器表达式,它为迭代器添加了任何操作
- 将
GET_ITER操作添加到编译器状态 - 切换到
start块 - 调用
ADDOP_JREL,它调用compiler_addop_j()来添加带有cleanup块参数的FOR_ITER操作 - 访问
target并向start块添加任何特殊代码,比如元组解包 - 访问 for 循环体中的每条语句
- 调用
ADDOP_JABS,它调用compiler_addop_j()来添加JUMP_ABSOLUTE操作,这表示在执行完主体后,跳回到循环的开始 - 移动到
cleanup块 - 将
FOR_LOOP帧块弹出堆栈 - 访问 for 循环的
else部分中的语句 - 使用
end块
回头参考basicblock结构。您可以看到在 for 语句的编译中,各种块是如何被创建并推入编译器的框架块和堆栈中的:
static int compiler_for(struct compiler *c, stmt_ty s) { basicblock *start, *cleanup, *end; start = compiler_new_block(c); // 1. cleanup = compiler_new_block(c); // 2. end = compiler_new_block(c); // 3. if (start == NULL || end == NULL || cleanup == NULL) return 0; if (!compiler_push_fblock(c, FOR_LOOP, start, end)) // 4. return 0; VISIT(c, expr, s->v.For.iter); // 5. ADDOP(c, GET_ITER); // 6. compiler_use_next_block(c, start); // 7. ADDOP_JREL(c, FOR_ITER, cleanup); // 8. VISIT(c, expr, s->v.For.target); // 9. VISIT_SEQ(c, stmt, s->v.For.body); // 10. ADDOP_JABS(c, JUMP_ABSOLUTE, start); // 11. compiler_use_next_block(c, cleanup); // 12.
compiler_pop_fblock(c, FOR_LOOP, start); // 13.
VISIT_SEQ(c, stmt, s->v.For.orelse); // 14. compiler_use_next_block(c, end); // 15. return 1; }
根据操作的类型,需要不同的参数。比如我们这里用的ADDOP_JABS和ADDOP_JREL,分别是指“加O 操作带 J ump 到 REL 原点位置”和“加O 操作带 J ump 到 ABS 原点位置”。这是指调用compiler_addop_j(struct compiler *c, int opcode, basicblock *b, int absolute)并将absolute参数分别设置为 0 和 1 的APPOP_JREL和ADDOP_JABS宏。
还有一些其他的宏,比如ADDOP_I调用 compiler_addop_i() 添加一个整数参数的操作,或者ADDOP_O调用 compiler_addop_o() 添加一个PyObject参数的操作。
一旦这些阶段完成,编译器有一个框架块列表,每个包含一个指令列表和一个指向下一个块的指针。
装配
在编译器状态下,汇编程序对程序块进行“深度优先搜索”,并将指令合并成一个字节码序列。汇编状态在Python/compile.c中声明:
struct assembler { PyObject *a_bytecode; /* string containing bytecode */ int a_offset; /* offset into bytecode */ int a_nblocks; /* number of reachable blocks */ basicblock **a_postorder; /* list of blocks in dfs postorder */ PyObject *a_lnotab; /* string containing lnotab */ int a_lnotab_off; /* offset into lnotab */ int a_lineno; /* last lineno of emitted instruction */ int a_lineno_off; /* bytecode offset of last lineno */ };
assemble()功能有几个任务:
- 计算内存分配的块数
- 确保每个落在末尾的块都返回
None,这就是为什么每个函数都返回None,不管return语句是否存在 - 解决任何被标记为相对的跳转语句偏移量
- 调用
dfs()执行块的深度优先搜索 - 向编译器发出所有指令
- 用编译器状态调用
makecode()来生成PyCodeObject
static PyCodeObject * assemble(struct compiler *c, int addNone) { basicblock *b, *entryblock; struct assembler a; int i, j, nblocks; PyCodeObject *co = NULL; /* Make sure every block that falls off the end returns None.
XXX NEXT_BLOCK() isn't quite right, because if the last
block ends with a jump or return b_next shouldn't set.
*/ if (!c->u->u_curblock->b_return) { NEXT_BLOCK(c); if (addNone) ADDOP_LOAD_CONST(c, Py_None); ADDOP(c, RETURN_VALUE); } ... dfs(c, entryblock, &a, nblocks);
/* Can't modify the bytecode after computing jump offsets. */ assemble_jump_offsets(&a, c);
/* Emit code in reverse postorder from dfs. */ for (i = a.a_nblocks - 1; i >= 0; i--) { b = a.a_postorder[i]; for (j = 0; j < b->b_iused; j++) if (!assemble_emit(&a, &b->b_instr[j])) goto error; } ... co = makecode(c, &a); error: assemble_free(&a); return co; }
深度优先搜索由Python/compile.c中的 dfs() 函数执行,该函数跟随每个块中的b_next指针,通过切换b_seen将它们标记为可见,然后以相反的顺序将它们添加到汇编器**a_postorder列表中。
该函数循环遍历汇编程序的后序列表,对于每个块,如果有跳转操作,递归调用 dfs() 进行跳转:
static void dfs(struct compiler *c, basicblock *b, struct assembler *a, int end) { int i, j; /* Get rid of recursion for normal control flow.
Since the number of blocks is limited, unused space in a_postorder
(from a_nblocks to end) can be used as a stack for still not ordered
blocks. */ for (j = end; b && !b->b_seen; b = b->b_next) { b->b_seen = 1; assert(a->a_nblocks < j); a->a_postorder[--j] = b; } while (j < end) { b = a->a_postorder[j++]; for (i = 0; i < b->b_iused; i++) { struct instr *instr = &b->b_instr[i]; if (instr->i_jrel || instr->i_jabs) dfs(c, instr->i_target, a, j); } assert(a->a_nblocks < j); a->a_postorder[a->a_nblocks++] = b; } }
创建代码对象
makecode() 的任务是通过调用 PyCode_New() 来遍历编译器状态、汇编器的一些属性并把这些放入PyCodeObject:

变量名、常量作为属性放入代码对象:
static PyCodeObject * makecode(struct compiler *c, struct assembler *a) { ... consts = consts_dict_keys_inorder(c->u->u_consts); names = dict_keys_inorder(c->u->u_names, 0); varnames = dict_keys_inorder(c->u->u_varnames, 0); ... cellvars = dict_keys_inorder(c->u->u_cellvars, 0); ... freevars = dict_keys_inorder(c->u->u_freevars, PyTuple_GET_SIZE(cellvars)); ... flags = compute_code_flags(c); if (flags < 0) goto error; bytecode = PyCode_Optimize(a->a_bytecode, consts, names, a->a_lnotab); ... co = PyCode_NewWithPosOnlyArgs(posonlyargcount+posorkeywordargcount, posonlyargcount, kwonlyargcount, nlocals_int,
maxdepth, flags, bytecode, consts, names, varnames, freevars, cellvars, c->c_filename, c->u->u_name, c->u->u_firstlineno, a->a_lnotab); ... return co; }
您可能还注意到,字节码在被发送到 PyCode_NewWithPosOnlyArgs() 之前被发送到 PyCode_Optimize() 。这个函数是Python/peephole.c中字节码优化过程的一部分。
窥视孔优化器检查字节码指令,在某些情况下,用其他指令替换它们。例如,有一个名为“常量展开”的优化器,因此如果您将以下语句放入脚本中:
a = 1 + 5
它优化了这一点,以:
a = 6
因为 1 和 5 是常量值,所以结果应该总是相同的。
结论
我们可以通过 instaviz 模块将所有这些阶段整合在一起:
import instaviz
def foo():
a = 2**4
b = 1 + 5
c = [1, 4, 6]
for i in c:
print(i)
else:
print(a)
return c
instaviz.show(foo)
将生成 AST 图:
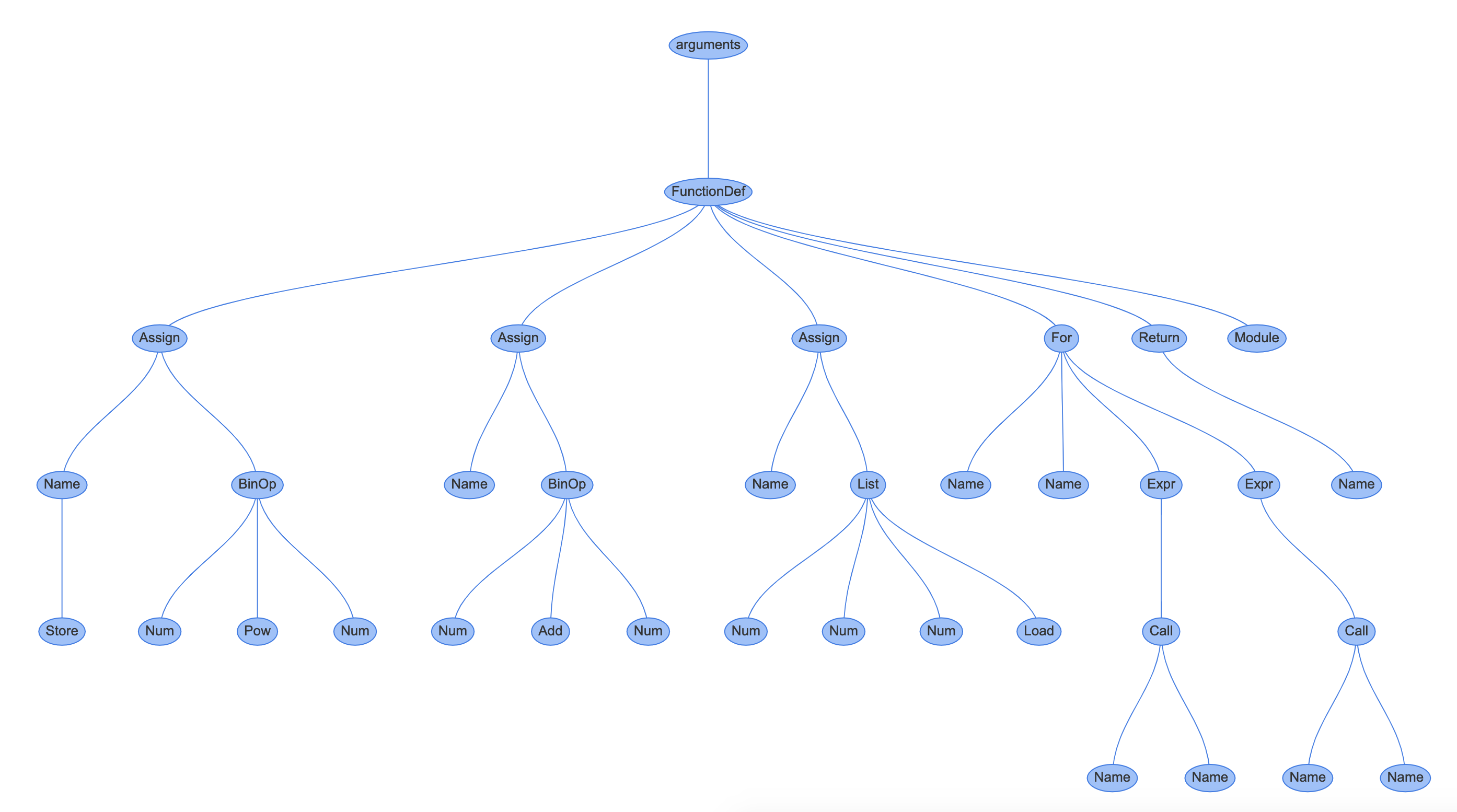
字节码指令按顺序排列:

同样,带有变量名、常量和二进制的代码对象co_code:
执行
就在Python/pythonrun.c我们爆发之前,召唤来了 run_eval_code_obj() 。
这个调用接受一个代码对象,这个代码对象要么是从编组的.pyc文件中获取的,要么是通过 AST 和编译器阶段编译的。
run_eval_code_obj() 会通全局、局部、PyArena,并编译成PyCodeObject到 PyEval_EvalCode() 中的Python/ceval.c。
这个阶段构成了 CPython 的执行组件。每个字节码操作都使用基于系统的“堆栈框架”来获取和执行。
什么是栈帧?
堆栈帧是许多运行时使用的数据类型,不仅仅是 Python,它允许调用函数和在函数之间返回变量。堆栈帧还包含参数、局部变量和其他状态信息。
通常,每个函数调用都有一个堆栈框架,它们是按顺序堆叠的。任何时候异常未被处理并且堆栈被打印在屏幕上,你都可以看到 CPython 的帧堆栈。
PyEval_EvalCode() 是评估一个代码对象的公共 API。评估逻辑分为 _PyEval_EvalCodeWithName() 和 _PyEval_EvalFrameDefault() 两种,都在ceval.c中。
公共 API PyEval_EvalCode() 会通过调用 _PyEval_EvalCodeWithName() 从栈顶构造一个执行帧。
第一个执行框架的构建有许多步骤:
- 关键字和位置参数被解析。
- 解决了函数定义中
*args和**kwargs的使用问题。 - 参数作为局部变量添加到范围中。
- 创建协同例程和生成器,包括异步生成器。
框架对象如下所示:

让我们浏览一下这些序列。
1.构建线程状态
在执行帧之前,需要从线程中引用它。CPython 可以在一个解释器中同时运行多个线程。解释器状态包括作为链表的那些线程的列表。线程结构叫做 PyThreadState ,贯穿ceval.c的引用很多。
下面是线程状态对象的结构:

2.构建帧
输入到 PyEval_EvalCode() ,因此 _PyEval_EvalCodeWithName() 有自变量为:
_co: 一PyCodeObjectglobals: 一个PyDict以变量名为关键字及其值locals: 一个PyDict以变量名为关键字及其值
其他参数是可选的,不用于基本 API:
args: aPyTuple按顺序排列位置参数值,argcount表示值的个数kwnames: 关键字参数名称列表kwargs: 关键字参数值的列表,kwcount表示它们的数量defs: 位置参数的默认值列表,defcount表示长度kwdefs: 以默认值为关键字参数的字典closure: 一个带字符串的元组要合并到代码对象的co_freevars字段中name: 该评估语句的名称为字符串qualname: 字符串形式的该评估语句的限定名
PyObject * _PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals, PyObject *const *args, Py_ssize_t argcount, PyObject *const *kwnames, PyObject *const *kwargs, Py_ssize_t kwcount, int kwstep, PyObject *const *defs, Py_ssize_t defcount, PyObject *kwdefs, PyObject *closure, PyObject *name, PyObject *qualname) { ... PyThreadState *tstate = _PyThreadState_GET(); assert(tstate != NULL); if (globals == NULL) { _PyErr_SetString(tstate, PyExc_SystemError, "PyEval_EvalCodeEx: NULL globals"); return NULL; } /* Create the frame */ f = _PyFrame_New_NoTrack(tstate, co, globals, locals); if (f == NULL) { return NULL; } fastlocals = f->f_localsplus; freevars = f->f_localsplus + co->co_nlocals;
3.将关键字参数转换成字典
如果函数定义包含关键字参数的**kwargs样式的总括,那么创建一个新的字典,并且值被复制。然后将kwargs名设置为变量,如下例所示:
def example(arg, arg2=None, **kwargs):
print(kwargs['extra']) # this would resolve to a dictionary key
创建关键字参数字典的逻辑在_ pye val _ EvalCodeWithName()的下一部分:
/* Create a dictionary for keyword parameters (**kwargs) */ if (co->co_flags & CO_VARKEYWORDS) { kwdict = PyDict_New(); if (kwdict == NULL) goto fail; i = total_args; if (co->co_flags & CO_VARARGS) { i++; } SETLOCAL(i, kwdict); } else { kwdict = NULL; }
如果找到任何关键字参数,kwdict变量将引用一个PyDictObject。
4.将位置参数转换成变量
接下来,将每个位置参数(如果提供的话)设置为局部变量:
/* Copy all positional arguments into local variables */ if (argcount > co->co_argcount) { n = co->co_argcount; } else { n = argcount; } for (j = 0; j < n; j++) { x = args[j]; Py_INCREF(x); SETLOCAL(j, x); }
在循环的最后,你会看到一个对 SETLOCAL() 的调用,带有一个值,所以如果一个位置参数是用一个值定义的,那么在这个范围内是可用的:
def example(arg1, arg2):
print(arg1, arg2) # both args are already local variables.
此外,这些变量的引用计数器是递增的,所以垃圾收集器不会删除它们,直到帧已经求值。
5.将位置参数打包到*args和
与**kwargs类似,可以设置一个带有*前缀的函数参数来捕捉所有剩余的位置参数。这个参数是一个元组,*args名被设置为一个局部变量:
/* Pack other positional arguments into the *args argument */ if (co->co_flags & CO_VARARGS) { u = _PyTuple_FromArray(args + n, argcount - n); if (u == NULL) { goto fail; } SETLOCAL(total_args, u); }
6.加载关键字参数
如果该函数是用关键字参数和值调用的,那么在第 4 步中创建的kwdict字典现在将填充调用者传递的任何未解析为命名参数或位置参数的剩余关键字参数。
例如,e参数既不是位置参数也不是命名参数,所以它被添加到**remaining:
>>> def my_function(a, b, c=None, d=None, **remaining): print(a, b, c, d, remaining) >>> my_function(a=1, b=2, c=3, d=4, e=5) (1, 2, 3, 4, {'e': 5})仅位置参数是 Python 3.8 中的新特性。在 PEP570 中引入,仅位置参数是一种阻止 API 用户使用带有关键字语法的位置参数的方法。
例如,这个简单的函数将 Farenheit 转换为 Celcius。注意,
/作为一个特殊参数的使用将位置参数与其他参数分开。def to_celcius(farenheit, /, options=None): return (farenheit-31)*5/9所有位于
/左侧的参数只能作为位置参数调用,而位于右侧的参数可以作为位置参数或关键字参数调用:
>>> to_celcius(110)
使用关键字参数调用仅位置参数的函数将引发一个TypeError:
>>> to_celcius(farenheit=110) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: to_celcius() got some positional-only arguments passed as keyword arguments: 'farenheit'关键字参数字典值的解析在所有其他参数解包之后进行。PEP570 仅位置参数通过在
co_posonlyargcount开始关键字参数循环来显示。如果在第三个参数上使用了/符号,co_posonlyargcount的值将是2。为每个剩余的参数调用PyDict_SetItem()以将其添加到locals字典中,因此在执行时,每个关键字参数都是局部变量:for (i = 0; i < kwcount; i += kwstep) { PyObject **co_varnames; PyObject *keyword = kwnames[i]; PyObject *value = kwargs[i]; ... /* Speed hack: do raw pointer compares. As names are normally interned this should almost always hit. */ co_varnames = ((PyTupleObject *)(co->co_varnames))->ob_item; for (j = co->co_posonlyargcount; j < total_args; j++) { PyObject *name = co_varnames[j]; if (name == keyword) { goto kw_found; } } if (kwdict == NULL) { if (co->co_posonlyargcount && positional_only_passed_as_keyword(tstate, co, kwcount, kwnames)) { goto fail; } _PyErr_Format(tstate, PyExc_TypeError, "%U() got an unexpected keyword argument '%S'", co->co_name, keyword); goto fail; } if (PyDict_SetItem(kwdict, keyword, value) == -1) { goto fail; } continue; kw_found: ... Py_INCREF(value); SETLOCAL(j, value); } ...在循环结束时,您将看到对
SETLOCAL()的调用,其值为。如果关键字参数定义了一个值,则该值在此范围内可用:def example(arg1, arg2, example_kwarg=None): print(example_kwarg) # example_kwarg is already a local variable.7.添加缺少的位置参数
提供给函数调用的不在位置参数列表中的任何位置参数都被添加到一个
*args元组中。如果该元组不存在,则引发一个失败:/* Add missing positional arguments (copy default values from defs) */ if (argcount < co->co_argcount) { Py_ssize_t m = co->co_argcount - defcount; Py_ssize_t missing = 0; for (i = argcount; i < m; i++) { if (GETLOCAL(i) == NULL) { missing++; } } if (missing) { missing_arguments(co, missing, defcount, fastlocals); goto fail; } if (n > m) i = n - m; else i = 0; for (; i < defcount; i++) { if (GETLOCAL(m+i) == NULL) { PyObject *def = defs[i]; Py_INCREF(def); SETLOCAL(m+i, def); } } }8.添加缺少的关键字参数
提供给函数调用的任何不在命名关键字参数列表中的关键字参数都被添加到一个
**kwargs字典中。如果该字典不存在,则会出现一个错误:/* Add missing keyword arguments (copy default values from kwdefs) */ if (co->co_kwonlyargcount > 0) { Py_ssize_t missing = 0; for (i = co->co_argcount; i < total_args; i++) { PyObject *name; if (GETLOCAL(i) != NULL) continue; name = PyTuple_GET_ITEM(co->co_varnames, i); if (kwdefs != NULL) { PyObject *def = PyDict_GetItemWithError(kwdefs, name); ... } missing++; } ... }9.折叠闭包
任何闭包名都被添加到代码对象的自由变量名列表中:
/* Copy closure variables to free variables */ for (i = 0; i < PyTuple_GET_SIZE(co->co_freevars); ++i) { PyObject *o = PyTuple_GET_ITEM(closure, i); Py_INCREF(o); freevars[PyTuple_GET_SIZE(co->co_cellvars) + i] = o; }10.创建生成器、协程和异步生成器
如果被评估的代码对象有一个标志,表明它是一个生成器、协同程序或异步生成器,则使用生成器、协同程序或异步库中的一个唯一方法创建一个新的帧,并将当前帧作为一个属性添加。
然后返回新帧,不计算原始帧。仅当调用 generator/coroutine/async 方法来执行其目标时,才评估帧:
/* Handle generator/coroutine/asynchronous generator */ if (co->co_flags & (CO_GENERATOR | CO_COROUTINE | CO_ASYNC_GENERATOR)) { ... /* Create a new generator that owns the ready to run frame * and return that as the value. */ if (is_coro) { gen = PyCoro_New(f, name, qualname); } else if (co->co_flags & CO_ASYNC_GENERATOR) { gen = PyAsyncGen_New(f, name, qualname); } else { gen = PyGen_NewWithQualName(f, name, qualname); } ... return gen; }最后,
PyEval_EvalFrameEx()用新帧来称呼:retval = PyEval_EvalFrameEx(f,0); ... }帧执行
如编译器和 AST 章节中所述,code 对象包含要执行的字节码的二进制编码。它还包含一个变量列表和一个符号表。
局部和全局变量是在运行时根据函数、模块或块的调用方式确定的。该信息通过
_PyEval_EvalCodeWithName()功能添加到帧中。框架还有其他的用法,比如协程装饰器,它动态地生成一个以目标为变量的框架。公共 API,
PyEval_EvalFrameEx()调用解释器在eval_frame属性中配置的帧评估函数。框架评估在 Python 3.7 中用 PEP 523 做成可插的。
_PyEval_EvalFrameDefault()是默认函数,除此之外很少使用其他函数。帧在
_PyEval_EvalFrameDefault()内的主执行循环中执行。这个函数是中心函数,它将所有的东西集合在一起,让你的代码充满活力。它包含了几十年的优化,因为即使是一行代码也会对整个 CPython 的性能产生重大影响。在 CPython 中执行的所有东西都要经过这个函数。
注意:阅读
ceval.c时你可能会注意到,C 宏被使用了多少次。c 宏是一种没有函数调用开销的干膜兼容代码的方式。编译器将宏转换成 C 代码,然后编译生成的代码。如果你想看到扩展的代码,你可以在 Linux 和 macOS 上运行
gcc -E:$ gcc -E Python/ceval.c或者,一旦安装了正式的 C/C++扩展, Visual Studio 代码可以进行内联宏扩展:
在 Python 3.7 及更高版本中,我们可以通过在当前线程上启用 tracing 属性来逐步执行帧。
这个代码示例将全局跟踪函数设置为一个名为
trace()的函数,该函数从当前帧获取堆栈,将反汇编的操作码打印到屏幕上,以及一些用于调试的额外信息:import sys import dis import traceback import io def trace(frame, event, args): frame.f_trace_opcodes = True stack = traceback.extract_stack(frame) pad = " "*len(stack) + "|" if event == 'opcode': with io.StringIO() as out: dis.disco(frame.f_code, frame.f_lasti, file=out) lines = out.getvalue().split('\n') [print(f"{pad}{l}") for l in lines] elif event == 'call': print(f"{pad}Calling {frame.f_code}") elif event == 'return': print(f"{pad}Returning {args}") elif event == 'line': print(f"{pad}Changing line to {frame.f_lineno}") else: print(f"{pad}{frame} ({event} - {args})") print(f"{pad}----------------------------------") return trace sys.settrace(trace) # Run some code for a demo eval('"-".join([letter for letter in "hello"])')这将打印每个堆栈中的代码,并在执行前指向下一个操作。当框架返回值时,将打印 return 语句:
完整的指令列表可在
dis模块文档中找到。值堆栈
在核心评估循环中,会创建一个值堆栈。这个堆栈是指向连续的
PyObject实例的指针列表。一种思考价值堆栈的方法是,把它想象成一个木桩,你可以在上面堆叠圆柱体。一次只能添加或删除一个项目。这是使用
PUSH(a)宏完成的,其中a是一个指向PyObject的指针。例如,如果您创建了一个值为 10 的
PyLong,并将其推送到值堆栈上:PyObject *a = PyLong_FromLong(10); PUSH(a);此操作将产生以下效果:
在下一个操作中,为了获取该值,您将使用
POP()宏从堆栈中获取顶部的值:PyObject *a = POP(); // a is PyLongObject with a value of 10此操作将返回顶部值,并以空值堆栈结束:
如果要向堆栈中添加 2 个值:
PyObject *a = PyLong_FromLong(10); PyObject *b = PyLong_FromLong(20); PUSH(a); PUSH(b);它们将按照添加的顺序结束,因此
a将被推到堆栈中的第二个位置:
如果你要获取栈顶的值,你会得到一个指向
b的指针,因为它在栈顶:
如果需要在不弹出的情况下获取指向栈顶值的指针,可以使用
PEEK(v)操作,其中v是栈的位置:PyObject *first = PEEK(0);0 表示堆栈的顶部,1 是第二个位置:
要克隆堆栈顶部的值,可以使用
DUP_TWO()宏,或者使用DUP_TWO操作码:DUP_TOP();此操作将复制顶部的值,以形成指向同一对象的 2 个指针:
有一个旋转宏
ROT_TWO交换第一个和第二个值:
每个操作码都有一个预定义的“堆栈效果”,由
Python/compile.c中的stack_effect()函数计算。这个函数返回每个操作码在堆栈中的值的数量的增量。示例:向列表添加项目
在 Python 中,当您创建一个列表时,list 对象上的
.append()方法是可用的:my_list = [] my_list.append(obj)其中
obj是一个对象,你想追加到列表的末尾。此操作涉及 2 个操作。
LOAD_FAST,将对象obj从框架中的locals列表中加载到值堆栈的顶部,LIST_APPEND添加对象。第一次探索
LOAD_FAST,有 5 个步骤:
指向
obj的指针从GETLOCAL()加载,其中要加载的变量是操作参数。变量指针列表存储在fastlocals中,它是 PyFrame 属性f_localsplus的副本。操作参数是一个数字,指向fastlocals数组指针中的索引。这意味着局部变量的加载只是指针的一个副本,而不是必须查找变量名。如果变量不再存在,将引发未绑定局部变量错误。
value(在我们的例子中为obj)的参考计数器增加 1。指向
obj的指针被推到值堆栈的顶部。调用
FAST_DISPATCH宏,如果启用了跟踪,循环再次遍历(所有跟踪),如果没有启用跟踪,调用goto到fast_next_opcode,它跳回到循环的顶部进行下一条指令。... case TARGET(LOAD_FAST): { PyObject *value = GETLOCAL(oparg); // 1. if (value == NULL) { format_exc_check_arg( PyExc_UnboundLocalError, UNBOUNDLOCAL_ERROR_MSG, PyTuple_GetItem(co->co_varnames, oparg)); goto error; // 2. } Py_INCREF(value); // 3. PUSH(value); // 4. FAST_DISPATCH(); // 5. } ...现在指向
obj的指针位于值堆栈的顶部。运行下一条指令LIST_APPEND。许多字节码操作都引用了基本类型,比如 PyUnicode、PyNumber。例如,
LIST_APPEND将一个对象追加到列表的末尾。为此,它从值堆栈中弹出指针,并将指针返回到堆栈中的最后一个对象。宏是以下操作的快捷方式:PyObject *v = (*--stack_pointer);现在指向
obj的指针被存储为v。列表指针从PEEK(oparg)加载。然后为
list和v调用 Python 列表的 C API。这个的代码在Objects/listobject.c里面,我们将在下一章讨论。对
PREDICT进行调用,推测下一个操作将是JUMP_ABSOLUTE。PREDICT宏为每个潜在操作的case语句提供了编译器生成的goto语句。这意味着 CPU 可以跳转到该指令,而不必再次通过循环:... case TARGET(LIST_APPEND): { PyObject *v = POP(); PyObject *list = PEEK(oparg); int err; err = PyList_Append(list, v); Py_DECREF(v); if (err != 0) goto error; PREDICT(JUMP_ABSOLUTE); DISPATCH(); } ...操作码预测:一些操作码倾向于成对出现,这样就有可能在第一个代码运行时预测第二个代码。例如,
COMPARE_OP后面经常跟着POP_JUMP_IF_FALSE或者POP_JUMP_IF_TRUE。验证预测需要对寄存器变量和常量进行一次高速测试。如果配对是好的,那么处理器自己的内部分支预测就有很高的成功可能性,导致到下一个操作码的几乎零开销的转换。成功的预测节省了评估环路的行程,包括其不可预测的开关情况分支。结合处理器的内部分支预测,成功的预测可以使两个操作码运行起来,就好像它们是一个新的操作码,其主体组合在一起。”
如果收集操作码统计信息,您有两种选择:
- 保持预测打开,并解释结果,就像一些操作码已经结合
- 关闭预测,以便操作码频率计数器更新两个操作码
操作码预测被线程代码禁用,因为后者允许 CPU 为每个操作码记录单独的分支预测信息。
有些操作,如
CALL_FUNCTION、CALL_METHOD,有一个引用另一个编译函数的操作参数。在这些情况下,将另一个帧推入线程中的帧堆栈,并为该函数运行求值循环,直到该函数完成。每当一个新的帧被创建并被推送到堆栈上时,在新的帧被创建之前,该帧的f_back的值被设置为当前帧。当您看到堆栈跟踪时,这种帧嵌套很明显,以下面的脚本为例:
def function2(): raise RuntimeError def function1(): function2() if __name__ == '__main__': function1()在命令行上调用这个命令将会得到:
$ ./python.exe example_stack.py Traceback (most recent call last): File "example_stack.py", line 8, in <module> function1() File "example_stack.py", line 5, in function1 function2() File "example_stack.py", line 2, in function2 raise RuntimeError RuntimeError在
traceback.py中,用于打印回溯的walk_stack()功能:def walk_stack(f): """Walk a stack yielding the frame and line number for each frame. This will follow f.f_back from the given frame. If no frame is given, the current stack is used. Usually used with StackSummary.extract. """ if f is None: f = sys._getframe().f_back.f_back while f is not None: yield f, f.f_lineno f = f.f_back这里你可以看到当前帧,通过调用
sys._getframe()和父帧的父帧被设置为帧,因为你不想在回溯中看到对walk_stack()或print_trace()的调用,所以那些函数帧被跳过。然后
f_back指针跟随到顶部。
sys._getframe()是获取当前线程的frame属性的 Python API。下面是框架堆栈的外观,其中有 3 个框架,每个框架都有其代码对象和一个指向当前框架的线程状态:
结论
在这一部分中,您探索了 CPython 中最复杂的元素:编译器。Python 的原作者吉多·范·罗苏姆认为,CPython 的编译器应该是“哑的”,这样人们才能理解它。
通过将编译过程分解成小的逻辑步骤,理解起来要容易得多。
在下一章中,我们将编译过程与所有 Python 代码的基础
object联系起来。第 4 部分:CPython 中的对象
CPython 附带了一组基本类型,如字符串、列表、元组、字典和对象。
所有这些类型都是内置的。您不需要导入任何库,甚至不需要从标准库中导入。此外,这些内置类型的实例化有一些方便的快捷方式。
例如,要创建新列表,您可以调用:
lst = list()或者,您可以使用方括号:
lst = []可以使用双引号或单引号从字符串文字实例化字符串。我们前面探讨了导致编译器将双引号解释为字符串文字的语法定义。
Python 中的所有类型都继承自
object,一个内置的基本类型。偶数字符串、元组、列表继承自object。在浏览 C 代码的过程中,您已经阅读了许多对PyObject*的引用,这是一个object的 C-API 结构。因为 C 不像 Python 那样面向对象,所以 C 中的对象不会相互继承。
PyObject是 Python 对象内存开始的数据结构。许多基础对象 API 都是在
Objects/object.c中声明的,比如函数PyObject_Repr,其中内置了repr()函数。你还会发现PyObject_Hash()等 API。通过在 Python 对象上实现“dunder”方法,可以在自定义对象中覆盖所有这些函数:
class MyObject(object): def __init__(self, id, name): self.id = id self.name = name def __repr__(self): return "<{0} id={1}>".format(self.name, self.id)这段代码在
Objects/object.c里面的PyObject_Repr()中实现。目标对象的类型,v将通过调用Py_TYPE()来推断,如果设置了tp_repr字段,则调用函数指针。如果没有设置tp_repr字段,即对象没有声明自定义的__repr__方法,那么运行默认行为,即返回带有类型名和 ID 的"<%s object at %p>":PyObject * PyObject_Repr(PyObject *v) { PyObject *res; if (PyErr_CheckSignals()) return NULL; ... if (v == NULL) return PyUnicode_FromString("<NULL>"); if (Py_TYPE(v)->tp_repr == NULL) return PyUnicode_FromFormat("<%s object at %p>", v->ob_type->tp_name, v); ... }给定
PyObject*的 ob_type 字段将指向在Include/cpython/object.h中定义的数据结构PyTypeObject。这个数据结构列出了所有的内置函数,作为它们应该接收的字段和参数。以
tp_repr为例:typedef struct _typeobject { PyObject_VAR_HEAD const char *tp_name; /* For printing, in format "<module>.<name>" */ Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation */ /* Methods to implement standard operations */ ... reprfunc tp_repr;其中
reprfunc是PyObject *(*reprfunc)(PyObject *);的一个typedef,这个函数取 1 个指针指向PyObject(self)。有些 dunder APIs 是可选的,因为它们只适用于某些类型,比如数字:
/* Method suites for standard classes */ PyNumberMethods *tp_as_number; PySequenceMethods *tp_as_sequence; PyMappingMethods *tp_as_mapping;类似于列表的序列将实现以下方法:
typedef struct { lenfunc sq_length; // len(v) binaryfunc sq_concat; // v + x ssizeargfunc sq_repeat; // for x in v ssizeargfunc sq_item; // v[x] void *was_sq_slice; // v[x:y:z] ssizeobjargproc sq_ass_item; // v[x] = z void *was_sq_ass_slice; // v[x:y] = z objobjproc sq_contains; // x in v binaryfunc sq_inplace_concat; ssizeargfunc sq_inplace_repeat; } PySequenceMethods;所有这些内置函数被称为 Python 数据模型。Python 数据模型的一个很好的资源是卢西亚诺·拉马尔霍的“流畅的 Python”。
基础对象类型
在
Objects/object.c中,object类型的基础实现被写成纯 C 代码。有一些基本逻辑的具体实现,比如浅层比较。并非 Python 对象中的所有方法都是数据模型的一部分,因此 Python 对象可以包含属性(类或实例属性)和方法。
思考 Python 对象的一个简单方法是由两件事组成:
- 核心数据模型,带有指向编译函数的指针
- 具有任何自定义属性和方法的字典
核心数据模型在
PyTypeObject中定义,函数在:
Objects/object.c对于内置方法Objects/boolobject.c为bool类型Objects/bytearrayobject.c为byte[]类型Objects/bytesobjects.c为bytes类型Objects/cellobject.c为cell类型Objects/classobject.c为抽象的class类型,用于元编程Objects/codeobject.c用于内置的code对象类型Objects/complexobject.c对于复杂的数值类型Objects/iterobject.c对于迭代器Objects/listobject.c为list类型Objects/longobject.c为long数值型Objects/memoryobject.c为基本记忆类型Objects/methodobject.c为类方法类型Objects/moduleobject.c对于模块类型Objects/namespaceobject.c对于命名空间类型Objects/odictobject.c对于有序字典类型Objects/rangeobject.c对于量程发生器Objects/setobject.c为set类型Objects/sliceobject.c对于切片参考类型Objects/structseq.c为一种struct.Struct类型Objects/tupleobject.c为tuple类型Objects/typeobject.c为type类型Objects/unicodeobject.c为str类型Objects/weakrefobject.c为一个weakref对象我们将深入探讨其中的三种类型:
- 布尔运算
- 整数
- 发电机
布尔和整数有很多共同点,所以我们将首先讨论它们。
Bool 和长整型
bool类型是内置类型最直接的实现。从long继承而来,有预定义的常量,Py_True和Py_False。这些常量是不可变的实例,创建于 Python 解释器的实例化之上。在
Objects/boolobject.c中,您可以看到 helper 函数从一个数字创建一个bool实例:PyObject *PyBool_FromLong(long ok) { PyObject *result; if (ok) result = Py_True; else result = Py_False; Py_INCREF(result); return result; }该函数使用数值类型的 C 评估将
Py_True或Py_False赋值给一个结果,并递增引用计数器。实现了
and、xor和or的数字函数,但是加法、减法和除法是从基本 long 类型中取消引用的,因为将两个布尔值相除没有意义。对一个
bool值的and的实现检查a和b是否为布尔值,然后检查它们对Py_True的引用,否则,被转换为数字,并且对这两个数字运行and操作:static PyObject * bool_and(PyObject *a, PyObject *b) { if (!PyBool_Check(a) || !PyBool_Check(b)) return PyLong_Type.tp_as_number->nb_and(a, b); return PyBool_FromLong((a == Py_True) & (b == Py_True)); }
long类型有点复杂,因为内存需求很大。在从 Python 2 到 3 的过渡中,CPython 放弃了对int类型的支持,转而使用long类型作为主要的整数类型。Python 的long类型非常特殊,因为它可以存储一个可变长度的数字。最大长度是在编译的二进制文件中设置的。Python
long的数据结构由PyObject头和一列数字组成。数字列表,ob_digit最初设置为一位数,但后来在初始化时扩展为更长的长度:struct _longobject { PyObject_VAR_HEAD digit ob_digit[1]; };内存通过
_PyLong_New()分配给新的long。该函数采用固定长度,并确保其小于MAX_LONG_DIGITS。然后它为ob_digit重新分配内存以匹配长度。要将 C
long类型转换为 Pythonlong类型,需要将long转换为一列数字,为 Pythonlong分配内存,然后设置每个数字。因为long在ob_digit的长度已经为 1 的情况下被初始化,如果该数字小于 10,则在没有分配存储器的情况下设置该值:PyObject * PyLong_FromLong(long ival) { PyLongObject *v; unsigned long abs_ival; unsigned long t; /* unsigned so >> doesn't propagate sign bit */ int ndigits = 0; int sign; CHECK_SMALL_INT(ival); ... /* Fast path for single-digit ints */ if (!(abs_ival >> PyLong_SHIFT)) { v = _PyLong_New(1); if (v) { Py_SIZE(v) = sign; v->ob_digit[0] = Py_SAFE_DOWNCAST( abs_ival, unsigned long, digit); } return (PyObject*)v; } ... /* Larger numbers: loop to determine number of digits */ t = abs_ival; while (t) { ++ndigits; t >>= PyLong_SHIFT; } v = _PyLong_New(ndigits); if (v != NULL) { digit *p = v->ob_digit; Py_SIZE(v) = ndigits*sign; t = abs_ival; while (t) { *p++ = Py_SAFE_DOWNCAST( t & PyLong_MASK, unsigned long, digit); t >>= PyLong_SHIFT; } } return (PyObject *)v; }要将一个双点浮点转换成一个 Python
long,PyLong_FromDouble()会为您计算:PyObject * PyLong_FromDouble(double dval) { PyLongObject *v; double frac; int i, ndig, expo, neg; neg = 0; if (Py_IS_INFINITY(dval)) { PyErr_SetString(PyExc_OverflowError, "cannot convert float infinity to integer"); return NULL; } if (Py_IS_NAN(dval)) { PyErr_SetString(PyExc_ValueError, "cannot convert float NaN to integer"); return NULL; } if (dval < 0.0) { neg = 1; dval = -dval; } frac = frexp(dval, &expo); /* dval = frac*2**expo; 0.0 <= frac < 1.0 */ if (expo <= 0) return PyLong_FromLong(0L); ndig = (expo-1) / PyLong_SHIFT + 1; /* Number of 'digits' in result */ v = _PyLong_New(ndig); if (v == NULL) return NULL; frac = ldexp(frac, (expo-1) % PyLong_SHIFT + 1); for (i = ndig; --i >= 0; ) { digit bits = (digit)frac; v->ob_digit[i] = bits; frac = frac - (double)bits; frac = ldexp(frac, PyLong_SHIFT); } if (neg) Py_SIZE(v) = -(Py_SIZE(v)); return (PyObject *)v; }
longobject.c中其余的实现函数都有实用程序,比如用PyLong_FromUnicodeObject()将 Unicode 字符串转换成数字。发电机类型综述
Python 生成器是返回一个
yield语句的函数,可以被不断调用以生成更多的值。通常,它们被用作在大型数据块(如文件、数据库或网络)中循环值的一种内存效率更高的方法。
当使用
yield而不是return时,返回生成器对象来代替值。生成器对象由yield语句创建,并返回给调用者。让我们用 4 个常量值创建一个简单的生成器:







>>> def example():
... lst = [1,2,3,4]
... for i in lst:
... yield i
...
>>> gen = example()
>>> gen
<generator object example at 0x100bcc480>
如果您浏览生成器对象的内容,您可以看到一些以gi_开头的字段:
>>> dir(gen) [ ... 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw']
PyGenObject类型在Include/genobject.h中定义,有 3 种类型:
- 生成器对象
- 协同程序对象
- 异步生成器对象
所有这 3 个都共享生成器中使用的相同字段子集,并且具有相似的行为:
首先关注发生器,您可以看到字段:
gi_frame链接到生成器的PyFrameObject,在前面的执行章节中,我们探讨了在帧的值堆栈中使用局部变量和全局变量。这就是生成器记住局部变量的最后一个值的方式,因为帧在调用之间是持久的gi_running如果发电机当前正在运行,设置为 0 或 1gi_code用生成生成器的编译函数链接到一个PyCodeObject,这样它就可以被再次调用gi_weakreflist链接到生成器函数中对象的弱引用列表gi_name作为发电机的名称gi_qualname作为发电机的限定名- 如果生成器调用引发异常,则作为异常数据元组
协同程序和异步发生器具有相同的字段,但是分别带有
cr和ag前缀。如果在生成器对象上调用
__next__(),将产生下一个值,直到最终引发一个StopIteration:

>>> gen.__next__()
1
>>> gen.__next__()
2
>>> gen.__next__()
3
>>> gen.__next__()
4
>>> gen.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
每次调用__next__()时,generators gi_code字段中的代码对象作为一个新的帧被执行,返回值被推送到值堆栈。
通过导入dis模块并反汇编其中的字节码,还可以看到gi_code是生成器函数的编译代码对象:
>>> gen = example() >>> import dis >>> dis.disco(gen.gi_code) 2 0 LOAD_CONST 1 (1) 2 LOAD_CONST 2 (2) 4 LOAD_CONST 3 (3) 6 LOAD_CONST 4 (4) 8 BUILD_LIST 4 10 STORE_FAST 0 (l) 3 12 SETUP_LOOP 18 (to 32) 14 LOAD_FAST 0 (l) 16 GET_ITER >> 18 FOR_ITER 10 (to 30) 20 STORE_FAST 1 (i) 4 22 LOAD_FAST 1 (i) 24 YIELD_VALUE 26 POP_TOP 28 JUMP_ABSOLUTE 18 >> 30 POP_BLOCK >> 32 LOAD_CONST 0 (None) 34 RETURN_VALUE每当在生成器对象上调用
__next__()时,用生成器实例调用gen_iternext(),生成器实例立即调用Objects/genobject.c内的gen_send_ex()。
gen_send_ex()是将生成器对象转换成下一个生成结果的函数。你会发现在Python/ceval.c中从一个代码对象构造框架的方式有很多相似之处,因为这些函数有相似的任务。
gen_send_ex()函数由生成器、协程程序和异步生成器共享,具有以下步骤:
获取当前线程状态
从生成器对象中获取帧对象
如果调用
__next__()时发电机正在运行,则发出ValueError如果发电机内部的框架位于堆栈顶部:
- 在协程的情况下,如果协程还没有被标记为关闭,则引发
RuntimeError- 如果这是一台异步发电机,则发出
StopAsyncIteration- 对于标准发生器,产生一个
StopIteration。如果帧中的最后一条指令(
f->f_lasti)仍然是-1,因为它刚刚被启动,并且这是一个协同程序或异步生成器,那么一个非 None 值不能作为参数传递,所以会引发一个异常否则,这是它第一次被调用,参数是允许的。参数的值被推送到框架的值堆栈中
框架的
f_back字段是返回值被发送到的调用者,所以它被设置为线程中的当前框架。这意味着返回值被发送给调用者,而不是生成器的创建者发电机被标记为正在运行
生成器异常信息中的最后一个异常是从线程状态中的最后一个异常复制来的
线程状态异常信息被设置为生成器异常信息的地址。这意味着,如果调用方在生成器的执行过程中输入一个断点,堆栈跟踪将遍历生成器,并清除有问题的代码
发生器内部的帧在
Python/ceval.c主执行循环中执行,并返回值线程状态最后一个异常被重置为调用帧之前的值
发电机被标记为未运行
接下来的情况将匹配返回值以及对生成器的调用所引发的任何异常。请记住,生成器应该在耗尽资源时引发一个
StopIteration,要么手动引发,要么不产生值。协同程序和异步生成器不应该:* 如果没有从帧中返回结果,为发生器产生一个`StopIteration`,为异步发生器产生一个`StopAsyncIteration` * 如果一个`StopIteration`被显式引发,但这是一个协同程序或异步生成器,则引发一个`RuntimeError`,因为这是不允许的 * 如果一个`StopAsyncIteration`被显式引发,并且这是一个异步生成器,则引发一个`RuntimeError`,因为这是不允许的
- 最后,结果被返回给
__next__()的调用者static PyObject * gen_send_ex(PyGenObject *gen, PyObject *arg, int exc, int closing) { PyThreadState *tstate = _PyThreadState_GET(); // 1. PyFrameObject *f = gen->gi_frame; // 2. PyObject *result; if (gen->gi_running) { // 3. const char *msg = "generator already executing"; if (PyCoro_CheckExact(gen)) { msg = "coroutine already executing"; } else if (PyAsyncGen_CheckExact(gen)) { msg = "async generator already executing"; } PyErr_SetString(PyExc_ValueError, msg); return NULL; } if (f == NULL || f->f_stacktop == NULL) { // 4. if (PyCoro_CheckExact(gen) && !closing) { /* `gen` is an exhausted coroutine: raise an error, except when called from gen_close(), which should always be a silent method. */ PyErr_SetString( PyExc_RuntimeError, "cannot reuse already awaited coroutine"); // 4a. } else if (arg && !exc) { /* `gen` is an exhausted generator: only set exception if called from send(). */ if (PyAsyncGen_CheckExact(gen)) { PyErr_SetNone(PyExc_StopAsyncIteration); // 4b. } else { PyErr_SetNone(PyExc_StopIteration); // 4c. } } return NULL; } if (f->f_lasti == -1) { if (arg && arg != Py_None) { // 5. const char *msg = "can't send non-None value to a " "just-started generator"; if (PyCoro_CheckExact(gen)) { msg = NON_INIT_CORO_MSG; } else if (PyAsyncGen_CheckExact(gen)) { msg = "can't send non-None value to a " "just-started async generator"; } PyErr_SetString(PyExc_TypeError, msg); return NULL; } } else { // 6. /* Push arg onto the frame's value stack */ result = arg ? arg : Py_None; Py_INCREF(result); *(f->f_stacktop++) = result; } /* Generators always return to their most recent caller, not * necessarily their creator. */ Py_XINCREF(tstate->frame); assert(f->f_back == NULL); f->f_back = tstate->frame; // 7. gen->gi_running = 1; // 8. gen->gi_exc_state.previous_item = tstate->exc_info; // 9. tstate->exc_info = &gen->gi_exc_state; // 10. result = PyEval_EvalFrameEx(f, exc); // 11. tstate->exc_info = gen->gi_exc_state.previous_item; // 12. gen->gi_exc_state.previous_item = NULL; gen->gi_running = 0; // 13. /* Don't keep the reference to f_back any longer than necessary. It * may keep a chain of frames alive or it could create a reference * cycle. */ assert(f->f_back == tstate->frame); Py_CLEAR(f->f_back); /* If the generator just returned (as opposed to yielding), signal * that the generator is exhausted. */ if (result && f->f_stacktop == NULL) { // 14a. if (result == Py_None) { /* Delay exception instantiation if we can */ if (PyAsyncGen_CheckExact(gen)) { PyErr_SetNone(PyExc_StopAsyncIteration); } else { PyErr_SetNone(PyExc_StopIteration); } } else { /* Async generators cannot return anything but None */ assert(!PyAsyncGen_CheckExact(gen)); _PyGen_SetStopIterationValue(result); } Py_CLEAR(result); } else if (!result && PyErr_ExceptionMatches(PyExc_StopIteration)) { // 14b. const char *msg = "generator raised StopIteration"; if (PyCoro_CheckExact(gen)) { msg = "coroutine raised StopIteration"; } else if PyAsyncGen_CheckExact(gen) { msg = "async generator raised StopIteration"; } _PyErr_FormatFromCause(PyExc_RuntimeError, "%s", msg); } else if (!result && PyAsyncGen_CheckExact(gen) && PyErr_ExceptionMatches(PyExc_StopAsyncIteration)) // 14c. { /* code in `gen` raised a StopAsyncIteration error: raise a RuntimeError. */ const char *msg = "async generator raised StopAsyncIteration"; _PyErr_FormatFromCause(PyExc_RuntimeError, "%s", msg); } ... return result; // 15. }回到调用函数或模块时代码对象的评估,在
_PyEval_EvalCodeWithName()中有一个生成器、协同程序和异步生成器的特例。该函数检查代码对象上的CO_GENERATOR、CO_COROUTINE和CO_ASYNC_GENERATOR标志。当使用
PyCoro_New()创建一个新的协程时,使用PyAsyncGen_New()创建一个新的异步生成器,或者使用PyGen_NewWithQualName()创建一个生成器。这些对象是提前返回的,而不是返回一个已求值的帧,这就是为什么在用 yield 语句调用函数后会得到一个 generator 对象:PyObject * _PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals, ... ... /* Handle generator/coroutine/asynchronous generator */ if (co->co_flags & (CO_GENERATOR | CO_COROUTINE | CO_ASYNC_GENERATOR)) { PyObject *gen; PyObject *coro_wrapper = tstate->coroutine_wrapper; int is_coro = co->co_flags & CO_COROUTINE; ... /* Create a new generator that owns the ready to run frame * and return that as the value. */ if (is_coro) { gen = PyCoro_New(f, name, qualname); } else if (co->co_flags & CO_ASYNC_GENERATOR) { gen = PyAsyncGen_New(f, name, qualname); } else { gen = PyGen_NewWithQualName(f, name, qualname); } ... return gen; } ...代码对象中的标志由编译器在遍历 AST 并看到
yield或yield from语句或看到coroutine装饰器后注入。
PyGen_NewWithQualName()将用生成的帧调用gen_new_with_qualname(),然后用NULL值和编译后的代码对象创建PyGenObject:static PyObject * gen_new_with_qualname(PyTypeObject *type, PyFrameObject *f, PyObject *name, PyObject *qualname) { PyGenObject *gen = PyObject_GC_New(PyGenObject, type); if (gen == NULL) { Py_DECREF(f); return NULL; } gen->gi_frame = f; f->f_gen = (PyObject *) gen; Py_INCREF(f->f_code); gen->gi_code = (PyObject *)(f->f_code); gen->gi_running = 0; gen->gi_weakreflist = NULL; gen->gi_exc_state.exc_type = NULL; gen->gi_exc_state.exc_value = NULL; gen->gi_exc_state.exc_traceback = NULL; gen->gi_exc_state.previous_item = NULL; if (name != NULL) gen->gi_name = name; else gen->gi_name = ((PyCodeObject *)gen->gi_code)->co_name; Py_INCREF(gen->gi_name); if (qualname != NULL) gen->gi_qualname = qualname; else gen->gi_qualname = gen->gi_name; Py_INCREF(gen->gi_qualname); _PyObject_GC_TRACK(gen); return (PyObject *)gen; }综上所述,您可以看到生成器表达式是一个强大的语法,其中一个关键字
yield触发整个流程来创建一个惟一的对象,复制一个编译的代码对象作为属性,设置一个框架,并在局部范围内存储一个变量列表。对于生成器表达式的用户来说,这一切看起来像是魔术,但实际上并没有那么复杂。
结论
现在您已经了解了一些内置类型,您可以探索其他类型。
在探索 Python 类时,重要的是要记住有用 C 编写的内置类型和从这些类型继承的用 Python 或 C 编写的类。
有些库的类型是用 C 编写的,而不是从内置类型中继承。一个例子是
numpy,一个用于数字数组的库。nparray类型是用 C 写的,高效且高性能。在下一部分中,我们将探索标准库中定义的类和函数。
第 5 部分:CPython 标准库
Python 总是“包括电池”这个声明意味着,在一个标准的 CPython 发行版中,有用于处理文件、线程、网络、网站、音乐、键盘、屏幕、文本和各种实用程序的库。
CPython 附带的一些电池更像 AA 电池。它们对任何事情都有用,比如
collections模块和sys模块。其中一些比较晦涩难懂,比如一块小小的手表电池,你永远不知道它什么时候会有用。CPython 标准库中有两种类型的模块:
- 那些用纯 Python 编写的代码提供了一个实用程序
- 那些用 Python 包装器用 C 写的
我们将探索这两种类型。
Python 模块
纯 Python 写的模块都位于源代码中的
Lib/目录下。一些较大的模块在子文件夹中有子模块,比如一个简单的模块是
colorsys模块。只有几百行 Python 代码。你可能以前没遇到过。colorsys模块具有一些转换色标的实用功能。当您从源代码安装 Python 发行版时,标准库模块会从
Lib文件夹复制到发行版文件夹中。当你启动 Python 时,这个文件夹总是你的路径的一部分,所以你可以import模块而不用担心它们在哪里。例如:
>>> import colorsys
>>> colorsys
<module 'colorsys' from '/usr/shared/lib/python3.7/colorsys.py'>
>>> colorsys.rgb_to_hls(255,0,0)
(0.0, 127.5, -1.007905138339921)
我们可以在Lib/colorsys.py里面看到rgb_to_hls()的源代码:
# HLS: Hue, Luminance, Saturation
# H: position in the spectrum
# L: color lightness
# S: color saturation
def rgb_to_hls(r, g, b):
maxc = max(r, g, b)
minc = min(r, g, b)
# XXX Can optimize (maxc+minc) and (maxc-minc)
l = (minc+maxc)/2.0
if minc == maxc:
return 0.0, l, 0.0
if l <= 0.5:
s = (maxc-minc) / (maxc+minc)
else:
s = (maxc-minc) / (2.0-maxc-minc)
rc = (maxc-r) / (maxc-minc)
gc = (maxc-g) / (maxc-minc)
bc = (maxc-b) / (maxc-minc)
if r == maxc:
h = bc-gc
elif g == maxc:
h = 2.0+rc-bc
else:
h = 4.0+gc-rc
h = (h/6.0) % 1.0
return h, l, s
这个函数没什么特别的,就是标准的 Python。您会发现所有纯 Python 标准库模块都有类似的情况。它们只是用普通的 Python 编写的,布局合理,易于理解。您甚至可以发现改进或缺陷,因此您可以对它们进行更改,并将其贡献给 Python 发行版。我们将在这篇文章的结尾讨论这个问题。
Python 和 C 模块
其余的模块用 C 或 Python 和 C 的组合编写。这些模块的源代码在 Python 组件的Lib/中,在 C 组件的Modules/中。这个规则有两个例外,在Python/sysmodule.c中的sys模块和在Python/bltinmodule.c中的__builtins__模块。
Python 将import * from __builtins__解释器实例化后,所有的函数如print()chr()format()等都会被实例化。都是在Python/bltinmodule.c内找到的。
因为sys模块对于解释器和 CPython 的内部是如此的特殊,所以可以直接在Python中找到。它还被标记为 CPython 的“实现细节”,在其他发行版中找不到。
内置的print()函数可能是你在 Python 中学会做的第一件事。那么当你输入print("hello world!")时会发生什么?
- 编译器将参数
"hello world"从字符串常量转换为PyUnicodeObject builtin_print()用 1 个参数执行,NULLkwnamesfile变量被设置为系统的stdout句柄PyId_stdout- 每个参数被发送到
file - 换行,
\n被发送到file
static PyObject * builtin_print(PyObject *self, PyObject *const *args, Py_ssize_t nargs, PyObject *kwnames) { ... if (file == NULL || file == Py_None) { file = _PySys_GetObjectId(&PyId_stdout); ... } ... for (i = 0; i < nargs; i++) { if (i > 0) { if (sep == NULL) err = PyFile_WriteString(" ", file); else err = PyFile_WriteObject(sep, file, Py_PRINT_RAW); if (err) return NULL; } err = PyFile_WriteObject(args[i], file, Py_PRINT_RAW); if (err) return NULL; } if (end == NULL) err = PyFile_WriteString("\n", file); else err = PyFile_WriteObject(end, file, Py_PRINT_RAW); ... Py_RETURN_NONE; }
用 C 写的一些模块的内容暴露了操作系统功能。因为 CPython 源代码需要编译到 macOS、Windows、Linux 和其他基于*nix 的操作系统,所以有一些特殊情况。
time模块就是一个很好的例子。Windows 在操作系统中保持和存储时间的方式与 Linux 和 macOS 有着本质的不同。这也是为什么不同操作系统的时钟功能精度不同的原因之一。
在Modules/timemodule.c中,基于 Unix 系统的操作系统时间函数从<sys/times.h>导入:
#ifdef HAVE_SYS_TIMES_H
#include <sys/times.h> #endif
... #ifdef MS_WINDOWS
#define WIN32_LEAN_AND_MEAN
#include <windows.h> #include "pythread.h" #endif /* MS_WINDOWS */ ...
在文件的后面,time_process_time_ns()被定义为_PyTime_GetProcessTimeWithInfo()的包装器:
static PyObject * time_process_time_ns(PyObject *self, PyObject *unused) { _PyTime_t t; if (_PyTime_GetProcessTimeWithInfo(&t, NULL) < 0) { return NULL; } return _PyTime_AsNanosecondsObject(t); }
_PyTime_GetProcessTimeWithInfo() 是在源代码中以多种不同的方式实现的,但只有某些部分被编译成二进制用于模块,这取决于操作系统。Windows 系统将调用GetProcessTimes(),Unix 系统将调用clock_gettime()。
对于同一个 API 有多个实现的其他模块是线程模块,文件系统模块和网络模块。因为操作系统的行为不同,所以 CPython 源代码尽可能实现相同的行为,并使用一致的抽象 API 来公开它。
CPython 回归测试套件
CPython 有一个强大而广泛的测试套件,涵盖了核心解释器、标准库、工具以及 Windows 和 Linux/macOS 的发行版。
测试套件位于Lib/test中,几乎完全用 Python 编写。
完整的测试套件是一个 Python 包,所以可以使用您编译的 Python 解释器来运行。将目录切换到Lib目录,运行python -m test -j2,其中j2表示使用 2 个 CPU。
在 Windows 上,使用 PCBuild 文件夹中的rt.bat脚本,确保您已经提前从 Visual Studio 构建了版本配置:
$ cd PCbuild
$ rt.bat -q
C:\repos\cpython\PCbuild>"C:\repos\cpython\PCbuild\win32\python.exe" -u -Wd -E -bb -m test
== CPython 3.8.0b4
== Windows-10-10.0.17134-SP0 little-endian
== cwd: C:\repos\cpython\build\test_python_2784
== CPU count: 2
== encodings: locale=cp1252, FS=utf-8
Run tests sequentially
0:00:00 [ 1/420] test_grammar
0:00:00 [ 2/420] test_opcodes
0:00:00 [ 3/420] test_dict
0:00:00 [ 4/420] test_builtin
...
在 Linux 上:
$ cd Lib
$ ../python -m test -j2
== CPython 3.8.0b4
== macOS-10.14.3-x86_64-i386-64bit little-endian
== cwd: /Users/anthonyshaw/cpython/build/test_python_23399
== CPU count: 4
== encodings: locale=UTF-8, FS=utf-8
Run tests in parallel using 2 child processes
0:00:00 load avg: 2.14 [ 1/420] test_opcodes passed
0:00:00 load avg: 2.14 [ 2/420] test_grammar passed
...
在 macOS 上:
$ cd Lib
$ ../python.exe -m test -j2
== CPython 3.8.0b4
== macOS-10.14.3-x86_64-i386-64bit little-endian
== cwd: /Users/anthonyshaw/cpython/build/test_python_23399
== CPU count: 4
== encodings: locale=UTF-8, FS=utf-8
Run tests in parallel using 2 child processes
0:00:00 load avg: 2.14 [ 1/420] test_opcodes passed
0:00:00 load avg: 2.14 [ 2/420] test_grammar passed
...
一些测试需要某些标志;否则它们将被跳过。例如,许多空闲测试需要一个 GUI。
要查看配置中的测试套件列表,使用--list-tests标志:
$ ../python.exe -m test --list-tests
test_grammar
test_opcodes
test_dict
test_builtin
test_exceptions
...
您可以通过将测试套件作为第一个参数来运行特定的测试:
$ ../python.exe -m test test_webbrowser
Run tests sequentially
0:00:00 load avg: 2.74 [1/1] test_webbrowser
== Tests result: SUCCESS ==
1 test OK.
Total duration: 117 ms
Tests result: SUCCESS
您还可以看到使用-v参数执行的测试结果的详细列表:
$ ../python.exe -m test test_webbrowser -v
== CPython 3.8.0b4
== macOS-10.14.3-x86_64-i386-64bit little-endian
== cwd: /Users/anthonyshaw/cpython/build/test_python_24562
== CPU count: 4
== encodings: locale=UTF-8, FS=utf-8
Run tests sequentially
0:00:00 load avg: 2.36 [1/1] test_webbrowser
test_open (test.test_webbrowser.BackgroundBrowserCommandTest) ... ok
test_register (test.test_webbrowser.BrowserRegistrationTest) ... ok
test_register_default (test.test_webbrowser.BrowserRegistrationTest) ... ok
test_register_preferred (test.test_webbrowser.BrowserRegistrationTest) ... ok
test_open (test.test_webbrowser.ChromeCommandTest) ... ok
test_open_new (test.test_webbrowser.ChromeCommandTest) ... ok
...
test_open_with_autoraise_false (test.test_webbrowser.OperaCommandTest) ... ok
----------------------------------------------------------------------
Ran 34 tests in 0.056s
OK (skipped=2)
== Tests result: SUCCESS ==
1 test OK.
Total duration: 134 ms
Tests result: SUCCESS
如果您希望对 CPython 进行更改,理解如何使用测试套件并检查您已经编译的版本的状态是非常重要的。在您开始进行更改之前,您应该运行整个测试套件,并确保一切都通过。
安装定制版本
从您的源代码库中,如果您对您的更改感到满意,并且希望在您的系统中使用它们,那么您可以将它安装为一个定制版本。
对于 macOS 和 Linux,您可以使用altinstall命令,它不会为python3创建符号链接并安装一个独立版本:
$ make altinstall
对于 Windows,您必须将构建配置从Debug更改为Release,然后将打包的二进制文件复制到您计算机上的一个目录中,该目录是系统路径的一部分。
CPython 源代码:结论
恭喜你,你成功了!你的茶凉了吗?给你自己再来一杯。你应得的。
现在,您已经看到了 CPython 源代码、模块、编译器和工具,您可能希望进行一些更改,并将它们反馈给 Python 生态系统。
官方开发指南包含大量的初学者资源。您已经迈出了第一步,了解了源代码,知道了如何更改、编译和测试 CPython 应用程序。
回想一下您在这篇文章中学到的关于 CPython 的所有东西。你所学到的所有魔法的秘密。旅程不止于此。
这可能是学习更多 Python 和 c 语言的好时机,谁知道呢:您可能会为 CPython 项目做出越来越多的贡献!另外,请务必在 Real Python 上查看新的 CPython 内部书籍:
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。**********
用 Pyramid 和 Ramses 在几分钟内创建一个 REST API
原文:https://realpython.com/create-a-rest-api-in-minutes-with-pyramid-and-ramses/
这是来自的基斯·哈特布兰迪德的客座博文——一位来自伟大城市蒙特娄的技术专家。
本教程是为初学者准备的。如果你在前进的道路上遇到困难,试着克服它,它可能会成功。如果你有什么不明白的或者需要帮助的,给 info@brandicted.com 发电子邮件或者在下面留下评论。
简介
制作一个 API 可能需要大量的工作。开发人员需要处理诸如序列化、URL 映射、验证、认证、授权、版本控制、测试、数据库、模型和视图的定制代码等细节。像 Firebase 和 Parse 这样的服务的存在使得这种方式变得更容易。使用后端即服务,开发人员可以更加专注于构建独特的用户体验。
使用第三方后端提供商的一些缺点包括缺乏对后端代码的控制、不能自托管、没有知识产权等..控制代码和利用 BaaS 节省时间的便利性是理想的,但是大多数 REST API 框架仍然需要大量的样板文件。一个流行的例子是令人惊叹的笨重的 Django Rest 框架。另一个伟大的项目是Flask-restful(强烈推荐),它需要更少的样板文件,并使构建 API 变得超级简单。但是我们想去掉所有的样板文件,包括通常需要为视图编写的数据库查询。
进入 Ramses,这是一种从 YAML 文件生成强大后端的简单方法(实际上是 REST APIs 的一种方言,称为 RAML )。在这篇文章中,我们将向你展示如何在几分钟内从零到你自己的生产就绪后端。
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
想要密码吗?Github 上的拉姆西斯
引导一个新产品 API
先决条件
我们假设你在一个新的虚拟 Python 环境中工作,并且使用默认配置运行 T2 的弹性搜索和 T4 的 postgresql。我们使用 httpie 与 API 交互,但是你也可以使用 curl 或者其他 http 客户端。
如果任何时候你遇到困难或者想看本教程代码的最终工作版本,可以在这里找到。
场景:一家制作美味披萨的工厂

我们想为我们的新比萨店创建一个 API。我们的后端应该知道所有不同的配料、奶酪、酱料和可以使用的面包皮,以及它们的不同组合来制作各种披萨风格。
$ pip install ramses
$ pcreate -s ramses_starter pizza_factory
安装程序将询问您想要使用哪个数据库后端。选择选项“1”以使用 SQLAlchemy。
换到新创建的目录,环顾四周。
$ cd pizza_factory
所有端点都可以通过 URI/API/端点名称/项目 id 进行访问。默认情况下,内置服务器运行在端口 6543 上。通读一下 local.ini ,看看它是否有意义。然后运行服务器,开始与新的后端交互。
$ pserve local.ini
查看 api.raml 以了解如何指定端点。
#%RAML 0.8 --- title: pizza_factory documentation: - title: pizza_factory REST API content: | Welcome to the pizza_factory API. baseUri: http://localhost:6543/api mediaType: application/json protocols: [HTTP] /items: displayName: Collection of items get: description: Get all item post: description: Create a new item body: application/json: schema: !include items.json /{id}: displayName: Collection-item get: description: Get a particular item delete: description: Delete a particular item patch: description: Update a particular item
如您所见,我们在/api/items 中有一个资源,它是由 items.json 中的模式定义的。
$ http :6543/api/items
HTTP/1.1 200 OK
Cache-Control: max-age=0, must-revalidate, no-cache, no-store
Content-Length: 73
Content-Type: application/json; charset=UTF-8
Date: Tue, 02 Jun 2015 16:02:09 GMT
Expires: Tue, 02 Jun 2015 16:02:09 GMT
Last-Modified: Tue, 02 Jun 2015 16:02:09 GMT
Pragma: no-cache
Server: waitress
{
"count": 0,
"data": [],
"fields": "",
"start": 0,
"took": 1,
"total": 0
}
数据建模
模式!
模式描述了数据的结构。
我们需要为制作披萨的每一种不同的配料制作它们。Ramses 的默认模式是 items.json 中的一个基本示例。
因为我们的项目中会有多个模式,所以让我们创建一个新目录,并将默认模式移入其中,以保持整洁。
$ mkdir schemas
$ mv items.json schemas/
$ cd schemas/
将 items.json 重命名为 pizzas.json 并在文本编辑器中打开它。然后将其内容复制到同一目录下的新文件中,文件名分别为 toppings.json 、 cheeses.json 、 sauces.json 和 crusts.json 。
├── cheeses.json
├── crusts.json
├── pizzas.json
├── sauces.json
└── toppings.json
在每个新的模式中,为被描述的不同种类的事物更新"title"字段的值(例如"title": "Pizza schema"、"title": "Topping schema"等)。).
让我们编辑 pizzas.json 模式,将配料连接到给定风格的比萨饼中。
在"description"字段后,添加以下与配料的关系:
... "toppings": { "required": false, "type": "relationship", "args": { "document": "Topping", "ondelete": "NULLIFY", "backref_name": "pizza", "backref_ondelete": "NULLIFY" } }, "cheeses": { "required": false, "type": "relationship", "args": { "document": "Cheese", "ondelete": "NULLIFY", "backref_name": "pizza", "backref_ondelete": "NULLIFY" } }, "sauce_id": { "required": false, "type": "foreign_key", "args": { "ref_document": "Sauce", "ref_column": "sauce.id", "ref_column_type": "id_field" } }, "crust_id": { "required": true, "type": "foreign_key", "args": { "ref_document": "Crust", "ref_column": "crust.id", "ref_column_type": "id_field" } } ...
关系 101
我们需要对每一种配料做同样的工作,将它们与需要它们的比萨饼风格的食谱联系起来。在 toppings.json 和 cheeses.json 中,我们需要一个"foreign_key"字段,指向每种浇头将用于的特定披萨风格(同样,将它放在"description"字段之后):
... "pizza_id": { "required": false, "type": "foreign_key", "args": { "ref_document": "Pizza", "ref_column": "pizza.id", "ref_column_type": "id_field" } } ...
然后,在 sauces.json 和 crusts.json 中,我们进行了反向(通过指定"relationship"字段而不是"foreign_key"字段),因为这两种配料被调用它们的比萨饼风格的特定实例所引用:
... "pizzas": { "required": false, "type": "relationship", "args": { "document": "Pizza", "ondelete": "NULLIFY", "backref_name": "sauce", "backref_ondelete": "NULLIFY" } } ...
对于 crusts.json ,只要确保将"backref_name"的值设置为"crust"即可。
这里要注意的一件事是,如果你仔细考虑了很久,你会发现做一个比萨饼只需要一层皮。也许在这一点上我们不得不称之为面包,但我们不要太哲学化。
还要注意的是我们有两个不同的“方向”披萨和配料的关系。比萨饼有许多配料和奶酪。这些都是“一(披萨)对多(食材)”的关系。尽管比萨饼只有一种调味汁和一层皮。每种酱料或皮可能被许多不同的比萨饼风格所需要。当谈到比萨饼时,我们说这是一种“多(比萨饼)对一(酱/皮)”的关系。无论你想称之为哪个“方向”,都只是你所谈论的作为参考点的实体的问题。
一对多关系在“一”方有一个relationship字段,在“多”方有一个foreign_key字段,例如披萨(如 pizzas.json 中所述)有多个"toppings":
... "toppings": { "required": false, "type": "relationship", "args": { "document": "Topping", "ondelete": "NULLIFY", "backref_name": "pizza", "backref_ondelete": "NULLIFY" } ...
…每种浇头(如 toppings.json 中所述)都是由某些特定的披萨("pizza_id")要求的:
... "pizza_id": { "required": false, "type": "foreign_key", "args": { "ref_document": "Pizza", "ref_column": "pizza.id", "ref_column_type": "id_field" } } ...
多对一关系在“多”端有一个foreign_key字段,在一端有一个relationship字段。这就是为什么浇头有一个指向特定披萨的foreign_key字段,而披萨有一个指向所有浇头的relationship字段。
Backref & ondelete 参数
要详细了解关系数据库概念的使用,请参考 SQLAlchemy 文档。 非常简要:
一个backref参数告诉数据库,当一个模型被另一个模型引用时,“引用”模型(它有一个foreign_key字段)也将提供对“被引用”模型的“向后”访问。
一个ondelete参数告诉数据库,当被引用模型的实例被删除时,要相应地改变引用字段的值。NULLIFY表示该值将被设置为null。
创建端点
至此,我们的厨房差不多准备好了。为了真正开始制作比萨饼,我们需要连接一些 API 端点来访问我们刚刚创建的数据模型。
让我们编辑 api.raml ,替换每个资源的默认“items”端点,如下所示:
#%RAML 0.8 --- title: pizza_factory API documentation: - title: pizza_factory REST API content: | Welcome to the pizza_factory API. baseUri: http://{host}:{port}/{version} version: v1 mediaType: application/json protocols: [HTTP] /toppings: displayName: Collection of ingredients for toppings get: description: Get all topping ingredients post: description: Create a topping ingredient body: application/json: schema: !include schemas/toppings.json /{id}: displayName: A particular topping ingredient get: description: Get a particular topping ingredient delete: description: Delete a particular topping ingredient patch: description: Update a particular topping ingredient /cheeses: displayName: Collection of different cheeses get: description: Get all cheeses post: description: Create a new cheese body: application/json: schema: !include schemas/cheeses.json /{id}: displayName: A particular cheese ingredient get: description: Get a particular cheese delete: description: Delete a particular cheese patch: description: Update a particular cheese /pizzas: displayName: Collection of pizza styles get: description: Get all pizza styles post: description: Create a new pizza style body: application/json: schema: !include schemas/pizzas.json /{id}: displayName: A particular pizza style get: description: Get a particular pizza style delete: description: Delete a particular pizza style patch: description: Update a particular pizza style /sauces: displayName: Collection of different sauces get: description: Get all sauces post: description: Create a new sauce body: application/json: schema: !include schemas/sauces.json /{id}: displayName: A particular sauce get: description: Get a particular sauce delete: description: Delete a particular sauce patch: description: Update a particular sauce /crusts: displayName: Collection of different crusts get: description: Get all crusts post: description: Create a new crust body: application/json: schema: !include schemas/crusts.json /{id}: displayName: A particular crust get: description: Get a particular crust delete: description: Delete a particular crust patch: description: Update a particular crust
注意端点定义的顺序。/pizzas放在/toppings和/cheeses之后,因为它与它们相关。/sauces和/crusts放在/pizzas之后,因为它们与之相关。如果您在启动服务器时得到任何类型的关于内容丢失或未定义的错误,请检查定义的顺序。
现在我们可以创造自己的配料和比萨饼风格!
重启服务器并开始烹饪。
$ pserve local.ini
让我们从制作夏威夷式披萨开始:
$ http POST :6543/api/toppings name=ham
HTTP/1.1 201 Created...
$ http POST :6543/api/toppings name=pineapple
HTTP/1.1 201 Created...
$ http POST :6543/api/cheeses name=mozzarella
HTTP/1.1 201 Created...
$ http POST :6543/api/sauces name=tomato
HTTP/1.1 201 Created...
$ http POST :6543/api/crusts name=plain
HTTP/1.1 201 Created...
$ http POST :6543/api/pizzas name=hawaiian toppings:=[1,2] cheeses:=[1] sauce=1 crust=1
给你!*
*
这是它所有油腻的荣耀:
HTTP/1.1 201 Created
Cache-Control: max-age=0, must-revalidate, no-cache, no-store
Content-Length: 373
Content-Type: application/json; charset=UTF-8
Date: Fri, 05 Jun 2015 18:47:53 GMT
Expires: Fri, 05 Jun 2015 18:47:53 GMT
Last-Modified: Fri, 05 Jun 2015 18:47:53 GMT
Location: http://localhost:6543/api/pizzas/1
Pragma: no-cache
Server: waitress
{
"data": {
"_type": "Pizza",
"_version": 0,
"cheeses": [
1
],
"crust": 1,
"crust_id": 1,
"description": null,
"id": 1,
"name": "hawaiian",
"sauce": 1,
"sauce_id": 1,
"self": "http://localhost:6543/api/pizzas/1",
"toppings": [
1,
2
],
"updated_at": null
},
"explanation": "",
"id": "1",
"message": null,
"status_code": 201,
"timestamp": "2015-06-05T18:47:53Z",
"title": "Created"
}
种子数据
加分的最后一步是导入一堆现有的配料记录,让事情变得更有趣。
首先在 pizza_factory 项目中创建一个seeds/目录,并下载种子数据:
$ mkdir seeds
$ cd seeds/
$ http -d https://raw.githubusercontent.com/chrstphrhrt/ramses-tutorial/master/pizza_factory/seeds/crusts.json
$ http -d https://raw.githubusercontent.com/chrstphrhrt/ramses-tutorial/master/pizza_factory/seeds/sauces.json
$ http -d https://raw.githubusercontent.com/chrstphrhrt/ramses-tutorial/master/pizza_factory/seeds/cheeses.json
$ http -d https://raw.githubusercontent.com/chrstphrhrt/ramses-tutorial/master/pizza_factory/seeds/toppings.json
现在,使用内置的 post2api 脚本将所有成分加载到您的 api 中。
$ nefertari.post2api -f crusts.json -u http://localhost:6543/api/crusts
$ nefertari.post2api -f sauces.json -u http://localhost:6543/api/sauces
$ nefertari.post2api -f cheeses.json -u http://localhost:6543/api/cheeses
$ nefertari.post2api -f toppings.json -u http://localhost:6543/api/toppings
你现在可以很容易地列出不同的成分。
$ http :6543/api/toppings
或者按名称搜索成分。
$ http :6543/api/toppings?name=chicken
HTTP/1.1 200 OK
Cache-Control: max-age=0, must-revalidate, no-cache, no-store
Content-Length: 934
Content-Type: application/json; charset=UTF-8
Date: Fri, 05 Jun 2015 19:58:48 GMT
Etag: "fd29d8eda6441cebdd632960a21c8136"
Expires: Fri, 05 Jun 2015 19:58:48 GMT
Last-Modified: Fri, 05 Jun 2015 19:58:48 GMT
Pragma: no-cache
Server: waitress
{
"count": 4,
"data": [
{
"_score": 2.3578677,
"_type": "Topping",
"_version": 0,
"description": null,
"id": 28,
"name": "Chicken Tikka",
"pizza": null,
"pizza_id": null,
"self": "http://localhost:6543/api/toppings/28",
"updated_at": null
},
{
"_score": 2.3578677,
"_type": "Topping",
"_version": 0,
"description": null,
"id": 27,
"name": "Chicken Masala",
"pizza": null,
"pizza_id": null,
"self": "http://localhost:6543/api/toppings/27",
"updated_at": null
},
{
"_score": 2.0254436,
"_type": "Topping",
"_version": 0,
"description": null,
"id": 14,
"name": "BBQ Chicken",
"pizza": null,
"pizza_id": null,
"self": "http://localhost:6543/api/toppings/14",
"updated_at": null
},
{
"_score": 2.0254436,
"_type": "Topping",
"_version": 0,
"description": null,
"id": 19,
"name": "Cajun Chicken",
"pizza": null,
"pizza_id": null,
"self": "http://localhost:6543/api/toppings/19",
"updated_at": null
}
],
"fields": "",
"start": 0,
"took": 3,
"total": 4
}
所以,让我们通过寻找原料来做最后一个披萨。这次吃素食怎么样?
可能有一点菠菜、意大利乳清干酪、晒干的番茄酱和全麦面包皮。首先我们找到我们的 id(你的可能不同)..
$ http :6543/api/toppings?name=spinach
...
"id": 88,
"name": "Spinach",
...
$ http :6543/api/cheeses?name=ricotta
...
"id": 18,
"name": "Ricotta",
...
$ http :6543/api/sauces?name=sun
...
"id": 18,
"name": "Sun Dried Tomato",
...
$ http :6543/api/crusts?name=whole
...
"id": 13,
"name": "Whole Wheat",
...
烘烤 0 秒钟,然后..
$ http POST :6543/api/pizzas name="Veggie Delight" toppings:=[88] cheeses:=[18] sauce=18 crust=13
HTTP/1.1 201 Created
Cache-Control: max-age=0, must-revalidate, no-cache, no-store
Content-Length: 382
Content-Type: application/json; charset=UTF-8
Date: Fri, 05 Jun 2015 20:17:26 GMT
Expires: Fri, 05 Jun 2015 20:17:26 GMT
Last-Modified: Fri, 05 Jun 2015 20:17:26 GMT
Location: http://localhost:6543/api/pizzas/2
Pragma: no-cache
Server: waitress
{
"data": {
"_type": "Pizza",
"_version": 0,
"cheeses": [
18
],
"crust": 13,
"crust_id": 13,
"description": null,
"id": 2,
"name": "Veggie Delight",
"sauce": 18,
"sauce_id": 18,
"self": "http://localhost:6543/api/pizzas/2",
"toppings": [
88
],
"updated_at": null
},
"explanation": "",
"id": "2",
"message": null,
"status_code": 201,
"timestamp": "2015-06-05T20:17:26Z",
"title": "Created"
}
祝你用餐愉快!
如果你想了解更多关于使用 Python 进行 RESTful API 设计的知识,请查看我们的(免费)迷你指南:
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
在 Readthedocs 上查看完整的 Ramses 文档,在 Github 上查看更高级的示例项目。***
用 Django Tastypie 创建一个超级基础的 REST API
原文:https://realpython.com/create-a-super-basic-rest-api-with-django-tastypie/
让我们用 Django Tastypie 建立一个 RESTful API 。
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
更新:
项目设置
要么按照下面的步骤创建您的示例项目,要么从 Github 克隆 repo。
创建一个新的项目目录,创建并激活一个 virtualenv,安装 Django 和所需的依赖项:
$ mkdir django-tastypie-tutorial
$ cd django-tastypie-tutorial
$ pyvenv-3.5 env
$ source env/bin/activate
$ pip install Django==1.9.7
$ pip install django-tastypie==0.13.3
$ pip install defusedxml==0.4.1
$ pip install lxml==3.6.0
创建一个基本 Django 项目和应用程序:
$ django-admin.py startproject django19
$ cd django19
$ python manage.py startapp whatever
确保将应用添加到 settings.py 中的INSTALLED_APPS部分:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'whatever',
]
在 settings.py 中添加对 SQLite (或者您选择的 RDBMS)的支持:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'test.db'),
}
}
更新您的 models.py 文件:
from django.db import models
class Whatever(models.Model):
title = models.CharField(max_length=200)
body = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.title
创建迁移:
$ python manage.py makemigrations
现在迁移它们:
$ python manage.py migrate --fake-initial
注意:如果您必须对现有迁移进行故障排除,则
fake-initial可选参数是必需的。如果不存在迁移,请忽略。
启动 Django Shell 并填充数据库:
$ python manage.py shell >>> from whatever.models import Whatever >>> w = Whatever(title="What Am I Good At?", body="What am I good at? What is my talent? What makes me stand out? These are the questions we ask ourselves over and over again and somehow can not seem to come up with the perfect answer. This is because we are blinded, we are blinded by our own bias on who we are and what we should be. But discovering the answers to these questions is crucial in branding yourself.") >>> w.save() >>> w = Whatever(title="Charting Best Practices: Proper Data Visualization", body="Charting data and determining business progress is an important part of measuring success. From recording financial statistics to webpage visitor tracking, finding the best practices for charting your data is vastly important for your company’s success. Here is a look at five charting best practices for optimal data visualization and analysis.") >>> w.save() >>> w = Whatever(title="Understand Your Support System Better With Sentiment Analysis", body="There’s more to evaluating success than monitoring your bottom line. While analyzing your support system on a macro level helps to ensure your costs are going down and earnings are rising, taking a micro approach to your business gives you a thorough appreciation of your business’ performance. Sentiment analysis helps you to clearly see whether your business practices are leading to higher customer satisfaction, or if you’re on the verge of running clients away.") >>> w.save()完成后退出 shell。
任务类型设置
在你的应用中创建一个名为 api.py 的新文件。
from tastypie.resources import ModelResource from tastypie.constants import ALL from whatever.models import Whatever class WhateverResource(ModelResource): class Meta: queryset = Whatever.objects.all() resource_name = 'whatever' filtering = {'title': ALL}更新 urls.py :
from django.conf.urls import url, include from django.contrib import admin from django19.api import WhateverResource whatever_resource = WhateverResource() urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/', include(whatever_resource.urls)), ]开始吧!
- 启动服务器。
- 导航到http://localhost:8000/API/whatever/?format=json 获取 json 格式的数据
- 导航到http://localhost:8000/API/whatever/?format=xml 获取 xml 格式的数据
还记得我们放在
WhateverResource类上的过滤器吗?filtering = {'title': ALL}嗯,我们可以按标题过滤对象。尝试各种关键词:
- http://localhost:8000/API/whatever/?格式=json &标题 _ _ 包含=什么
- http://localhost:8000/API/whatever/?格式=json &标题 _ _ 包含=测试
简单,对!?!
免费奖励: ,并获得 Python + REST API 原则的实际操作介绍以及可操作的示例。
Tastypie 可以配置的东西太多了。查看官方文档了解更多信息。如有疑问,请在下方评论。
同样,您可以从 repo 下载代码。*
如何在 Django 中创建索引而不停机
原文:https://realpython.com/create-django-index-without-downtime/
在任何软件项目中,管理数据库迁移都是一个巨大的挑战。幸运的是,从 1.7 版本开始, Django 提供了一个内置的迁移框架。该框架在管理数据库变化方面非常强大和有用。但是框架提供的灵活性需要一些妥协。为了理解 Django 迁移的局限性,您将处理一个众所周知的问题:在 Django 中创建一个索引,并且不停机。
在本教程中,您将学习:
- Django 如何以及何时产生新的迁移
- 如何检查 Django 生成的执行迁移的命令
- 如何安全地修改迁移以满足您的需求
这篇中级教程是为已经熟悉 Django 迁移的读者设计的。关于这个主题的介绍,请查看 Django 迁移:初级读本。
免费奖励: ,您可以用它们来加深您的 Python web 开发技能。
Django 迁移中创建索引的问题
当应用程序存储的数据增长时,通常需要进行的一个常见更改是添加索引。索引用于加快查询速度,让你的应用程序感觉更快、响应更快。
在大多数数据库中,添加索引需要表上的排他锁。创建索引时,一个排他锁会阻止数据修改(DML)操作,如
UPDATE、INSERT和DELETE。当执行某些操作时,数据库会隐式获取锁。例如,当用户登录你的应用时,Django 会更新
auth_user表中的last_login字段。要执行更新,数据库必须首先获得该行的锁。如果该行当前被另一个连接锁定,那么您可能会得到一个数据库异常。当需要在迁移期间保持系统可用时,锁定表可能会带来问题。表越大,创建索引所需的时间就越长。创建索引的时间越长,系统不可用或对用户无响应的时间就越长。
一些数据库供应商提供了一种在不锁定表的情况下创建索引的方法。例如,要在 PostgreSQL 中创建索引而不锁定表,可以使用
CONCURRENTLY关键字:CREATE INDEX CONCURRENTLY ix ON table (column);在 Oracle 中,有一个
ONLINE选项允许在创建索引时对表进行 DML 操作:CREATE INDEX ix ON table (column) ONLINE;在生成迁移时,Django 不会使用这些特殊的关键字。按原样运行迁移将使数据库获得表上的排他锁,并在创建索引时阻止 DML 操作。
同时创建索引有一些注意事项。提前了解特定于数据库后端的问题非常重要。例如,PostgreSQL中的一个警告是,并发创建索引需要更长时间,因为它需要额外的表扫描。
在本教程中,您将使用 Django 迁移在大型表上创建索引,而不会导致任何停机。
注意:要学习本教程,建议您使用 PostgreSQL 后端、Django 2.x 和 Python 3。
也可以使用其他数据库后端。在使用 PostgreSQL 独有的 SQL 特性的地方,更改 SQL 以匹配您的数据库后端。
设置
你将在名为
app的应用中使用一个虚构的Sale模型。在现实生活中,像Sale这样的模型是数据库中的主表,它们通常会非常大,存储大量数据:# models.py from django.db import models class Sale(models.Model): sold_at = models.DateTimeField( auto_now_add=True, ) charged_amount = models.PositiveIntegerField()要创建表,请生成初始迁移并应用它:
$ python manage.py makemigrations Migrations for 'app': app/migrations/0001_initial.py - Create model Sale $ python manage migrate Operations to perform: Apply all migrations: app Running migrations: Applying app.0001_initial... OK一段时间后,销售表变得非常大,用户开始抱怨速度慢。在监控数据库时,您注意到许多查询都使用了
sold_at列。为了加快速度,您决定在列上需要一个索引。要在
sold_at上添加索引,您需要对模型进行以下更改:# models.py from django.db import models class Sale(models.Model): sold_at = models.DateTimeField( auto_now_add=True, db_index=True, ) charged_amount = models.PositiveIntegerField()如果您照原样运行这个迁移,那么 Django 将在表上创建索引,并且在索引完成之前它将被锁定。在一个非常大的表上创建索引可能需要一段时间,并且您希望避免停机。
在具有小数据集和很少连接的本地开发环境中,这种迁移可能感觉是瞬间的。但是,在具有许多并发连接的大型数据集上,获取锁和创建索引可能需要一段时间。
在接下来的步骤中,您将修改 Django 创建的迁移,以便在不导致任何停机的情况下创建索引。
假移民
第一种方法是手动创建索引。您将生成迁移,但实际上并不打算让 Django 应用它。相反,您将在数据库中手动运行 SQL,然后让 Django 认为迁移已经完成。
首先,生成迁移:
$ python manage.py makemigrations --name add_index_fake Migrations for 'app': app/migrations/0002_add_index_fake.py - Alter field sold_at on sale使用
sqlmigrate命令查看 Django 将用于执行该迁移的 SQL:$ python manage.py sqlmigrate app 0002 BEGIN; -- -- Alter field sold_at on sale -- CREATE INDEX "app_sale_sold_at_b9438ae4" ON "app_sale" ("sold_at"); COMMIT;您希望在不锁定表的情况下创建索引,因此需要修改命令。添加
CONCURRENTLY关键字并在数据库中执行:app=# CREATE INDEX CONCURRENTLY "app_sale_sold_at_b9438ae4" ON "app_sale" ("sold_at"); CREATE INDEX请注意,您执行了不带
BEGIN和COMMIT部分的命令。省略这些关键字将在没有数据库事务的情况下执行命令。我们将在本文后面讨论数据库事务。执行该命令后,如果您尝试应用迁移,将会出现以下错误:
$ python manage.py migrate Operations to perform: Apply all migrations: app Running migrations: Applying app.0002_add_index_fake...Traceback (most recent call last): File "venv/lib/python3.7/site-packages/django/db/backends/utils.py", line 85, in _execute return self.cursor.execute(sql, params) psycopg2.ProgrammingError: relation "app_sale_sold_at_b9438ae4" already existsDjango 抱怨说索引已经存在,所以它不能继续迁移。您刚刚在数据库中直接创建了索引,所以现在您需要让 Django 认为已经应用了迁移。
如何伪造移民
Django 提供了一种内置的方法来将迁移标记为已执行,而不是实际执行它们。要使用此选项,请在应用迁移时设置
--fake标志:$ python manage.py migrate --fake Operations to perform: Apply all migrations: app Running migrations: Applying app.0002_add_index_fake... FAKEDDjango 这次没有出错。事实上,Django 并没有真正应用任何迁移。它只是将它标记为已执行(或
FAKED)。以下是伪造迁移时需要考虑的一些问题:
手动命令必须等同于 Django 生成的 SQL:你需要确保你执行的命令等同于 Django 生成的 SQL。使用
sqlmigrate生成 SQL 命令。如果命令不匹配,那么可能会导致数据库和模型状态之间的不一致。其他未申请的迁移也会造假:当你有多个未申请的迁移时,都会造假。在应用迁移之前,务必确保只有您想要伪造的迁移未被应用。否则,您可能会以不一致而告终。另一个选项是指定您想要伪造的确切迁移。
需要直接访问数据库:需要在数据库中运行 SQL 命令。这并不总是一个选项。此外,在生产数据库中直接执行命令是危险的,应该尽可能避免。
自动化部署流程可能需要调整:如果您自动化部署流程(使用 CI、CD 或其他自动化工具),那么您可能需要更改流程以模拟迁移。这并不总是可取的。
清理
在进入下一节之前,您需要将数据库恢复到初始迁移后的状态。为此,请迁移回初始迁移:
$ python manage.py migrate 0001 Operations to perform: Target specific migration: 0001_initial, from app Running migrations: Rendering model states... DONE Unapplying app.0002_add_index_fake... OKDjango 没有应用第二次迁移中所做的更改,所以现在也可以安全地删除文件了:
$ rm app/migrations/0002_add_index_fake.py为了确保您做的一切都是正确的,请检查迁移:
$ python manage.py showmigrations app app [X] 0001_initial已应用初始迁移,没有未应用的迁移。
在迁移中执行原始 SQL
在上一节中,您直接在数据库中执行 SQL 并伪造了迁移。这就完成了工作,但是还有一个更好的解决方案。
Django 提供了一种使用
RunSQL在迁移中执行原始 SQL 的方法。让我们尝试使用它,而不是直接在数据库中执行命令。首先,生成一个新的空迁移:
$ python manage.py makemigrations app --empty --name add_index_runsql Migrations for 'app': app/migrations/0002_add_index_runsql.py接下来,编辑迁移文件并添加一个
RunSQL操作:# migrations/0002_add_index_runsql.py from django.db import migrations, models class Migration(migrations.Migration): atomic = False dependencies = [ ('app', '0001_initial'), ] operations = [ migrations.RunSQL( 'CREATE INDEX "app_sale_sold_at_b9438ae4" ' 'ON "app_sale" ("sold_at");', ), ]运行迁移时,您将获得以下输出:
$ python manage.py migrate Operations to perform: Apply all migrations: app Running migrations: Applying app.0002_add_index_runsql... OK这看起来不错,但有一个问题。让我们再次尝试生成迁移:
$ python manage.py makemigrations --name leftover_migration Migrations for 'app': app/migrations/0003_leftover_migration.py - Alter field sold_at on saleDjango 再次产生了同样的迁移。为什么会这样?
清理
在我们回答这个问题之前,您需要清理并撤消您对数据库所做的更改。从删除最后一次迁移开始。它未被应用,因此可以安全地删除:
$ rm app/migrations/0003_leftover_migration.py接下来,列出
app应用的迁移:$ python manage.py showmigrations app app [X] 0001_initial [X] 0002_add_index_runsql第三次迁移没有了,但是应用了第二次迁移。您希望在初始迁移后立即恢复状态。尝试像您在上一节中所做的那样迁移回初始迁移:
$ python manage.py migrate app 0001 Operations to perform: Target specific migration: 0001_initial, from app Running migrations: Rendering model states... DONE Unapplying app.0002_add_index_runsql...Traceback (most recent call last): NotImplementedError: You cannot reverse this operationDjango 无法逆转迁移。
反向迁移操作
为了逆转迁移,Django 对每个操作执行相反的操作。在这种情况下,与添加索引相反的是删除索引。正如您已经看到的,当迁移是可逆的时,您可以取消应用它。就像您可以在 Git 中使用
checkout一样,如果您对早期的迁移执行migrate,您可以逆转迁移。许多内置迁移操作已经定义了反向操作。例如,添加字段的相反操作是删除相应的列。创建模型的相反操作是删除相应的表。
有些迁移操作是不可逆的。例如,移除字段或删除模型没有相反的操作,因为一旦应用了迁移,数据就消失了。
在上一节中,您使用了
RunSQL操作。当您尝试反转迁移时,遇到了错误。根据该错误,迁移中的某个操作无法反转。Django 默认情况下不能反转原始 SQL。因为 Django 不知道操作执行了什么,所以它不能自动生成相反的动作。如何使迁移可逆
要使迁移可逆,其中的所有操作都必须可逆。不可能逆转部分迁移,因此单个不可逆操作将使整个迁移不可逆。
要使
RunSQL操作可逆,您必须提供 SQL 以便在操作可逆时执行。反向 SQL 在reverse_sql参数中提供。与添加索引相反的操作是删除索引。要使您的迁移可逆,请提供
reverse_sql来删除索引:# migrations/0002_add_index_runsql.py from django.db import migrations, models class Migration(migrations.Migration): atomic = False dependencies = [ ('app', '0001_initial'), ] operations = [ migrations.RunSQL( 'CREATE INDEX "app_sale_sold_at_b9438ae4" ' 'ON "app_sale" ("sold_at");', reverse_sql='DROP INDEX "app_sale_sold_at_b9438ae4";', ), ]现在尝试反向迁移:
$ python manage.py showmigrations app app [X] 0001_initial [X] 0002_add_index_runsql $ python manage.py migrate app 0001 Operations to perform: Target specific migration: 0001_initial, from app Running migrations: Rendering model states... DONE Unapplying app.0002_add_index_runsql... OK $ python manage.py showmigrations app app [X] 0001_initial [ ] 0002_add_index_runsql第二次迁移逆转,指数被 Django 掉了。现在可以安全地删除迁移文件了:
$ rm app/migrations/0002_add_index_runsql.py提供
reverse_sql总是个好主意。在撤销原始 SQL 操作不需要任何操作的情况下,您可以使用特殊标记migrations.RunSQL.noop将操作标记为可撤销:migrations.RunSQL( sql='...', # Your forward SQL here reverse_sql=migrations.RunSQL.noop, ),了解模型状态和数据库状态
在您之前使用
RunSQL手工创建索引的尝试中,Django 一次又一次地生成相同的迁移,即使索引是在数据库中创建的。要理解 Django 为什么这样做,首先需要理解 Django 如何决定何时生成新的迁移。当 Django 生成新的迁移时
在生成和应用迁移的过程中,Django 在数据库状态和模型状态之间进行同步。例如,当您向模型中添加一个字段时,Django 会向表中添加一列。当您从模型中删除一个字段时,Django 会从表中删除该列。
为了在模型和数据库之间同步,Django 维护一个表示模型的状态。为了将数据库与模型同步,Django 生成迁移操作。迁移操作转换成可以在数据库中执行的特定于供应商的 SQL。当执行所有迁移操作时,数据库和模型应该是一致的。
为了获得数据库的状态,Django 汇总了过去所有迁移的操作。当迁移的聚合状态与模型状态不一致时,Django 会生成一个新的迁移。
在前面的示例中,您使用原始 SQL 创建了索引。Django 不知道您创建了索引,因为您没有使用熟悉的迁移操作。
当 Django 汇总所有的迁移并与模型的状态进行比较时,它发现缺少一个索引。这就是为什么即使手动创建了索引,Django 仍然认为它丢失了,并为它生成了一个新的迁移。
如何在迁移中分离数据库和状态
由于 Django 不能按照您想要的方式创建索引,所以您希望提供自己的 SQL,但仍然让 Django 知道是您创建的。
换句话说,您需要在数据库中执行一些操作,并为 Django 提供迁移操作来同步其内部状态。为此,Django 为我们提供了一个名为
SeparateDatabaseAndState的特殊迁移操作。这种操作并不广为人知,应该保留给像这样的特殊情况。编辑迁移比从头开始编写迁移要容易得多,所以从生成迁移开始,通常的方式是:
$ python manage.py makemigrations --name add_index_separate_database_and_state Migrations for 'app': app/migrations/0002_add_index_separate_database_and_state.py - Alter field sold_at on sale这是 Django 生成的迁移内容,和以前一样:
# migrations/0002_add_index_separate_database_and_state.py from django.db import migrations, models class Migration(migrations.Migration): dependencies = [ ('app', '0001_initial'), ] operations = [ migrations.AlterField( model_name='sale', name='sold_at', field=models.DateTimeField( auto_now_add=True, db_index=True, ), ), ]Django 在字段
sold_at上生成了一个AlterField操作。该操作将创建一个索引并更新状态。我们希望保留这个操作,但是提供一个不同的命令在数据库中执行。再次使用 Django 生成的 SQL 来获得命令:
$ python manage.py sqlmigrate app 0002 BEGIN; -- -- Alter field sold_at on sale -- CREATE INDEX "app_sale_sold_at_b9438ae4" ON "app_sale" ("sold_at"); COMMIT;在适当的位置添加
CONCURRENTLY关键字:CREATE INDEX CONCURRENTLY "app_sale_sold_at_b9438ae4" ON "app_sale" ("sold_at");接下来,编辑迁移文件并使用
SeparateDatabaseAndState来提供修改后的 SQL 命令以供执行:# migrations/0002_add_index_separate_database_and_state.py from django.db import migrations, models class Migration(migrations.Migration): dependencies = [ ('app', '0001_initial'), ] operations = [ migrations.SeparateDatabaseAndState( state_operations=[ migrations.AlterField( model_name='sale', name='sold_at', field=models.DateTimeField( auto_now_add=True, db_index=True, ), ), ], database_operations=[ migrations.RunSQL(sql=""" CREATE INDEX CONCURRENTLY "app_sale_sold_at_b9438ae4" ON "app_sale" ("sold_at"); """, reverse_sql=""" DROP INDEX "app_sale_sold_at_b9438ae4"; """), ], ), ],迁移操作
SeparateDatabaseAndState接受两个操作列表:
- state_operations 是应用于内部模型状态的操作。它们不会影响数据库。
- database_operations 是应用于数据库的操作。
你在
state_operations中保留了 Django 生成的原始操作。当使用SeparateDatabaseAndState时,这是你通常想要做的。请注意,db_index=True参数被提供给了该字段。这个迁移操作将让 Django 知道字段上有一个索引。您使用了 Django 生成的 SQL 并添加了
CONCURRENTLY关键字。您使用了特殊动作RunSQL来执行迁移中的原始 SQL。如果您尝试运行迁移,您将获得以下输出:
$ python manage.py migrate app Operations to perform: Apply all migrations: app Running migrations: Applying app.0002_add_index_separate_database_and_state...Traceback (most recent call last): File "/venv/lib/python3.7/site-packages/django/db/backends/utils.py", line 83, in _execute return self.cursor.execute(sql) psycopg2.InternalError: CREATE INDEX CONCURRENTLY cannot run inside a transaction block非原子迁移
在 SQL 中,
CREATE、DROP、ALTER、TRUNCATE操作被称为数据定义语言 (DDL)。在支持事务性 DDL,的数据库中,比如 PostgreSQL ,Django 默认在数据库事务内部执行迁移。但是,根据上面的错误,PostgreSQL 不能在事务块中同时创建索引。为了能够在迁移中同时创建索引,您需要告诉 Django 不要在数据库事务中执行迁移。为此,通过将
atomic设置为False,将迁移标记为非原子:# migrations/0002_add_index_separate_database_and_state.py from django.db import migrations, models class Migration(migrations.Migration): atomic = False dependencies = [ ('app', '0001_initial'), ] operations = [ migrations.SeparateDatabaseAndState( state_operations=[ migrations.AlterField( model_name='sale', name='sold_at', field=models.DateTimeField( auto_now_add=True, db_index=True, ), ), ], database_operations=[ migrations.RunSQL(sql=""" CREATE INDEX CONCURRENTLY "app_sale_sold_at_b9438ae4" ON "app_sale" ("sold_at"); """, reverse_sql=""" DROP INDEX "app_sale_sold_at_b9438ae4"; """), ], ), ],将迁移标记为非原子后,您可以运行迁移:
$ python manage.py migrate app Operations to perform: Apply all migrations: app Running migrations: Applying app.0002_add_index_separate_database_and_state... OK您刚刚执行了迁移,没有造成任何停机。
以下是使用
SeparateDatabaseAndState时需要考虑的一些问题:
数据库操作必须等同于状态操作:数据库和模型状态之间的不一致会导致很多麻烦。一个好的起点是将 Django 生成的操作保存在
state_operations中,并编辑sqlmigrate的输出以在database_operations中使用。非原子迁移在出现错误时无法回滚:如果迁移过程中出现错误,您将无法回滚。您必须回滚迁移或手动完成迁移。将非原子迁移中执行的操作保持在最低限度是一个好主意。如果您在迁移中有其他操作,请将它们移到新的迁移中。
迁移可能是特定于供应商的:Django 生成的 SQL 是特定于项目中使用的数据库后端的。它可能适用于其他数据库后端,但这不能保证。如果您需要支持多个数据库后端,您需要对这种方法进行一些调整。
结论
您以一个大表和一个问题开始了本教程。你想让你的应用程序对你的用户来说更快,你想在不给他们造成任何停机的情况下做到这一点。
到本教程结束时,您已经成功地生成并安全地修改了一个 Django 迁移来实现这个目标。在这个过程中,您处理了不同的问题,并使用迁移框架提供的内置工具成功地克服了这些问题。
在本教程中,您学习了以下内容:
- Django 迁移如何使用模型和数据库状态在内部工作,以及何时生成新的迁移
- 如何使用
RunSQL动作在迁移中执行定制 SQL- 什么是可逆迁移,以及如何使
RunSQL操作可逆- 什么是原子迁移,以及如何根据您的需要更改默认行为
- 如何在 Django 中安全地执行复杂的迁移
模型和数据库状态之间的分离是一个重要的概念。一旦您理解了它以及如何利用它,您就可以克服内置迁移操作的许多限制。想到的一些用例包括添加已经在数据库中创建的索引,以及为 DDL 命令提供特定于供应商的参数。*****
用 Python 创建和修改 PDF 文件
知道如何在 Python 中创建和修改 PDF 文件真的很有用。 PDF 或 P 或表格 D 文档 F 格式,是在互联网上共享文档最常见的格式之一。pdf可以包含文本、图像、表格、表单以及视频和动画等富媒体,所有这些都在一个文件中。
如此丰富的内容类型会使处理 pdf 变得困难。当打开一个 PDF 文件时,有许多不同种类的数据要解码!幸运的是,Python 生态系统有一些很棒的包,可以用来读取、操作和创建 PDF 文件。
在本教程中,您将学习如何:
- 阅读 PDF 中的文本
- 将一个 PDF 文件分割成多个文件
- 串联和合并 PDF 文件
- 旋转和裁剪 PDF 文件中的页面
- 用密码加密和解密 PDF 文件
- 从头开始创建PDF 文件
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“创建和修改 PDF 文件”一章。
这本书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互,因此在整个教程中你会偶尔看到对 IDLE 的引用。但是,从您选择的编辑器和环境中运行示例代码应该没有问题。
在这个过程中,您将有几次机会通过跟随示例来加深理解。您可以点击下面的链接下载示例中使用的材料:
下载示例材料: 单击此处获取您将在本教程中使用学习创建和修改 PDF 文件的材料。
从 PDF 中提取文本
在本节中,您将学习如何阅读 PDF 文件并使用
PyPDF2包提取文本。不过,在你这么做之前,你需要用pip安装:$ python3 -m pip install PyPDF2通过在终端中运行以下命令来验证安装:
$ python3 -m pip show PyPDF2 Name: PyPDF2 Version: 1.26.0 Summary: PDF toolkit Home-page: http://mstamy2.github.com/PyPDF2 Author: Mathieu Fenniak Author-email: biziqe@mathieu.fenniak.net License: UNKNOWN Location: c:\\users\\david\\python38-32\\lib\\site-packages Requires: Required-by:请特别注意版本信息。在撰写本文时,
PyPDF2的最新版本是1.26.0。如果你有 IDLE open,那么你需要重启它才能使用PyPDF2包。打开 PDF 文件
让我们先打开一个 PDF 文件,阅读一些相关信息。您将使用位于配套存储库中的
practice_files/文件夹中的Pride_and_Prejudice.pdf文件。打开 IDLE 的交互窗口,从
PyPDF2包中导入类PdfFileReader:
>>> from PyPDF2 import PdfFileReader
要创建一个新的PdfFileReader类的实例,您将需要您想要打开的 PDF 文件的路径。现在让我们使用pathlib模块来获取:
>>> from pathlib import Path >>> pdf_path = ( ... Path.home() ... / "creating-and-modifying-pdfs" ... / "practice_files" ... / "Pride_and_Prejudice.pdf" ... )
pdf_path变量现在包含了简·奥斯汀的傲慢与偏见的 PDF 版本的路径。注意:您可能需要更改
pdf_path,使其对应于您计算机上creating-and-modifying-pdfs/文件夹的位置。现在创建
PdfFileReader实例:
>>> pdf = PdfFileReader(str(pdf_path))
您将pdf_path转换为字符串,因为PdfFileReader不知道如何从pathlib.Path对象中读取。
回想一下第 12 章“文件输入和输出”,在程序终止之前所有打开的文件都应该关闭。对象为你做了所有这些,所以你不需要担心打开或关闭 PDF 文件!
现在您已经创建了一个PdfFileReader实例,您可以使用它来收集关于 PDF 的信息。例如,.getNumPages()返回 PDF 文件中包含的页数:
>>> pdf.getNumPages() 234注意
.getNumPages()是用 mixedCase 写的,而不是像 PEP 8 中推荐的 lower _ case _ with _ 下划线。记住,PEP 8 是一套指导方针,而不是规则。就 Python 而言,mixedCase 是完全可以接受的。注:
PyPDF2改编自pyPdf包。pyPdf写于 2005 年,仅在 PEP 8 出版后四年。当时,许多 Python 程序员正在从 mixedCase 更常见的语言中迁移。
您还可以使用
.documentInfo属性访问一些文档信息:
>>> pdf.documentInfo
{'/Title': 'Pride and Prejudice, by Jane Austen', '/Author': 'Chuck',
'/Creator': 'Microsoft® Office Word 2007',
'/CreationDate': 'D:20110812174208', '/ModDate': 'D:20110812174208',
'/Producer': 'Microsoft® Office Word 2007'}
由.documentInfo返回的对象看起来像一个字典,但它实际上不是同一个东西。您可以将.documentInfo中的每个项目作为属性进行访问。
例如,要获得标题,使用.title属性:
>>> pdf.documentInfo.title 'Pride and Prejudice, by Jane Austen'
.documentInfo对象包含 PDF 元数据,它在创建 PDF 时设置。
PdfFileReader类提供了访问 PDF 文件中的数据所需的所有方法和属性。让我们来探索一下您可以用 PDF 文件做什么,以及如何做!从页面中提取文本
PDF 页面在
PyPDF2中用PageObject类表示。您可以使用PageObject实例与 PDF 文件中的页面进行交互。您不需要直接创建自己的PageObject实例。相反,你可以通过PdfFileReader对象的.getPage()方法来访问它们。从单个 PDF 页面中提取文本有两个步骤:
- 用
PdfFileReader.getPage()得到一个PageObject。- 用
PageObject实例的.extractText()方法将文本提取为字符串。
Pride_and_Prejudice.pdf有234页。每一页在0和233之间都有一个索引。通过将页面的索引传递给PdfFileReader.getPage(),可以获得代表特定页面的PageObject:
>>> first_page = pdf.getPage(0)
.getPage()返回一个PageObject:
>>> type(first_page) <class 'PyPDF2.pdf.PageObject'>您可以使用
PageObject.extractText()提取页面文本:
>>> first_page.extractText()
'\\n \\nThe Project Gutenberg EBook of Pride and Prejudice, by Jane
Austen\\n \\n\\nThis eBook is for the use of anyone anywhere at no cost
and with\\n \\nalmost no restrictions whatsoever. You may copy it,
give it away or\\n \\nre\\n-\\nuse it under the terms of the Project
Gutenberg License included\\n \\nwith this eBook or online at
www.gutenberg.org\\n \\n \\n \\nTitle: Pride and Prejudice\\n \\n
\\nAuthor: Jane Austen\\n \\n \\nRelease Date: August 26, 2008
[EBook #1342]\\n\\n[Last updated: August 11, 2011]\\n \\n \\nLanguage:
Eng\\nlish\\n \\n \\nCharacter set encoding: ASCII\\n \\n \\n***
START OF THIS PROJECT GUTENBERG EBOOK PRIDE AND PREJUDICE ***\\n \\n
\\n \\n \\n \\nProduced by Anonymous Volunteers, and David Widger\\n
\\n \\n \\n \\n \\n \\n \\nPRIDE AND PREJUDICE \\n \\n \\nBy Jane
Austen \\n \\n\\n \\n \\nContents\\n \\n'
请注意,此处显示的输出已经过格式化,以更好地适应此页面。您在电脑上看到的输出格式可能会有所不同。
每个PdfFileReader对象都有一个.pages属性,您可以使用它来按顺序遍历 PDF 中的所有页面。
例如,下面的 for循环打印傲慢与偏见 PDF 中每一页的文本:
>>> for page in pdf.pages: ... print(page.extractText()) ...让我们结合你所学的一切,编写一个程序,从
Pride_and_Prejudice.pdf文件中提取所有文本,并保存到.txt文件中。将所有这些放在一起
在空闲状态下打开一个新的编辑器窗口,并键入以下代码:
from pathlib import Path from PyPDF2 import PdfFileReader # Change the path below to the correct path for your computer. pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice-files" / "Pride_and_Prejudice.pdf" ) # 1 pdf_reader = PdfFileReader(str(pdf_path)) output_file_path = Path.home() / "Pride_and_Prejudice.txt" # 2 with output_file_path.open(mode="w") as output_file: # 3 title = pdf_reader.documentInfo.title num_pages = pdf_reader.getNumPages() output_file.write(f"{title}\\nNumber of pages: {num_pages}\\n\\n") # 4 for page in pdf_reader.pages: text = page.extractText() output_file.write(text)让我们来分解一下:
首先,将一个新的
PdfFileReader实例分配给pdf_reader变量。您还创建了一个新的Path对象,它指向您的主目录中的文件Pride_and_Prejudice.txt,并将它赋给变量output_file_path。接下来,以写模式打开
output_file_path,并将.open()返回的文件对象赋给变量output_file。你在第 12 章“文件输入和输出”中了解到的with语句确保当with块退出时文件被关闭。然后,在
with块中,使用output_file.write()将 PDF 标题和页数写入文本文件。最后,使用一个
for循环迭代 PDF 中的所有页面。在循环的每一步,下一个PageObject被分配给page变量。用page.extractText()提取每页的文本,并写入output_file。当您保存并运行该程序时,它将在您的主目录中创建一个名为
Pride_and_Prejudice.txt的新文件,其中包含了Pride_and_Prejudice.pdf文档的全文。打开看看吧!检查你的理解能力
展开下面的方框,检查您的理解程度:
在本文的配套存储库中的
practice_files/文件夹中,有一个名为zen.pdf的文件。创建一个读取 PDF 的PdfFileReader实例,并使用它打印第一页的文本。您可以展开下面的方框查看解决方案:
设置 PDF 文件的路径:
# First, import the needed classes and libraries from pathlib import Path from PyPDF2 import PdfFileReader # Then create a `Path` object to the PDF file. # You might need to change this to match the path # on your computer. pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "zen.pdf" )现在您可以创建
PdfFileReader实例了:pdf_reader = PdfFileReader(str(pdf_path))记住
PdfFileReader对象只能用路径字符串实例化,不能用Path对象实例化!现在使用
.getPage()来获得第一页:first_page = pdf_reader.getPage(0)记住,页面索引是从 0 开始的!
然后使用
.extractText()提取文本:text = first_page.extractText()最后,打印文本:
print(text)当你准备好了,你可以进入下一部分。
从 PDF 中提取页面
在上一节中,您学习了如何从 PDF 文件中提取所有文本并保存到一个
.txt文件中。现在,您将了解如何从现有 PDF 中提取一个页面或一系列页面,并将它们保存到新的 PDF 中。您可以使用
PdfFileWriter创建一个新的 PDF 文件。让我们探索这个课程,学习使用PyPDF2创建 PDF 所需的步骤。使用
PdfFileWriter类
PdfFileWriter类创建新的 PDF 文件。在 IDLE 的交互窗口中,导入PdfFileWriter类并创建一个名为pdf_writer的新实例:
>>> from PyPDF2 import PdfFileWriter
>>> pdf_writer = PdfFileWriter()
对象就像空白的 PDF 文件。在将它们保存到文件之前,您需要向它们添加一些页面。
继续给pdf_writer添加一个空白页:
>>> page = pdf_writer.addBlankPage(width=72, height=72)
width和height参数是必需的,它们以称为点的单位确定页面的尺寸。一点等于 1/72 英寸,所以上面的代码为pdf_writer添加了一个一英寸见方的空白页。
.addBlankPage()返回一个新的PageObject实例,代表您添加到PdfFileWriter中的页面:
>>> type(page)
<class 'PyPDF2.pdf.PageObject'>
在这个例子中,您已经将由.addBlankPage()返回的PageObject实例赋给了page变量,但是实际上您通常不需要这样做。也就是说,您通常调用.addBlankPage()而不将返回值赋给任何东西:
>>> pdf_writer.addBlankPage(width=72, height=72)要将
pdf_writer的内容写入 PDF 文件,以二进制写入模式将文件对象传递给pdf_writer.write():
>>> from pathlib import Path
>>> with Path("blank.pdf").open(mode="wb") as output_file:
... pdf_writer.write(output_file)
...
这将在当前工作目录中创建一个名为blank.pdf的新文件。如果你用 PDF 阅读器打开文件,比如 Adobe Acrobat,你会看到一个只有一个一英寸见方的空白页面的文档。
技术细节:注意,您保存 PDF 文件的方法是将 file 对象传递给PdfFileWriter对象的.write()方法,将而不是传递给 file 对象的.write()方法。
特别是,下面的代码将不起作用:
>>> with Path("blank.pdf").open(mode="wb") as output_file: ... output_file.write(pdf_writer)对于许多新程序员来说,这种方法似乎是倒退的,所以确保你避免这个错误!
PdfFileWriter对象可以写入新的 PDF 文件,但是除了空白页之外,不能从头开始创建新的内容。这似乎是一个大问题,但是在许多情况下,您不需要创建新的内容。通常,您会处理从 PDF 文件中提取的页面,这些文件是用
PdfFileReader实例打开的。注意:您将在下面的“从头创建 PDF 文件”一节中学习如何从头创建 PDF 文件
在上面的例子中,使用
PyPDF2创建一个新的 PDF 文件有三个步骤:
- 创建一个
PdfFileWriter实例。- 向
PdfFileWriter实例添加一个或多个页面。- 使用
PdfFileWriter.write()写入文件。随着您学习向
PdfFileWriter实例添加页面的各种方法,您将会一遍又一遍地看到这种模式。从 PDF 中提取单个页面
让我们重温一下你在上一节处理过的傲慢与偏见 PDF。您将打开 PDF,提取第一页,并创建一个新的 PDF 文件,其中只包含一个提取的页面。
打开 IDLE 的交互窗口,从
PyPDF2导入PdfFileReader和PdfFileWriter,从pathlib模块导入Path类;
>>> from pathlib import Path
>>> from PyPDF2 import PdfFileReader, PdfFileWriter
现在用一个PdfFileReader实例打开Pride_and_Prejudice.pdf文件:
>>> # Change the path to work on your computer if necessary >>> pdf_path = ( ... Path.home() ... / "creating-and-modifying-pdfs" ... / "practice_files" ... / "Pride_and_Prejudice.pdf" ... ) >>> input_pdf = PdfFileReader(str(pdf_path))将索引
0传递给.getPage()以获得代表 PDF 第一页的PageObject:
>>> first_page = input_pdf.getPage(0)
现在创建一个新的PdfFileWriter实例,并用.addPage()将first_page添加到其中:
>>> pdf_writer = PdfFileWriter() >>> pdf_writer.addPage(first_page)与
.addBlankPage()一样,.addPage()方法将页面添加到pdf_writer对象的页面集中。不同的是,它需要一个已有的PageObject。现在将
pdf_writer的内容写入一个新文件:
>>> with Path("first_page.pdf").open(mode="wb") as output_file:
... pdf_writer.write(output_file)
...
您现在有一个新的 PDF 文件保存在您当前的工作目录中,名为first_page.pdf,它包含了Pride_and_Prejudice.pdf文件的封面。相当整洁!
从 PDF 中提取多个页面
让我们从Pride_and_Prejudice.pdf中提取第一章并保存到一个新的 PDF 中。
如果你用 PDF 浏览器打开Pride_and_Prejudice.pdf,那么你可以看到第一章在 PDF 的第二、第三和第四页。因为页面是从0开始索引的,所以您需要提取索引1、2和3处的页面。
您可以通过导入所需的类并打开 PDF 文件来设置所有内容:
>>> from PyPDF2 import PdfFileReader, PdfFileWriter >>> from pathlib import Path >>> pdf_path = ( ... Path.home() ... / "creating-and-modifying-pdfs" ... / "practice_files" ... / "Pride_and_Prejudice.pdf" ... ) >>> input_pdf = PdfFileReader(str(pdf_path))您的目标是提取索引为
1、2和3的页面,将它们添加到一个新的PdfFileWriter实例,然后将它们写入一个新的 PDF 文件。一种方法是在从
1开始到3结束的数字范围内循环,在循环的每一步提取页面并将其添加到PdfFileWriter实例:
>>> pdf_writer = PdfFileWriter()
>>> for n in range(1, 4):
... page = input_pdf.getPage(n)
... pdf_writer.addPage(page)
...
因为range(1, 4)不包括右边的端点,所以循环迭代数字1、2和3。在循环的每一步,使用.getPage()提取当前索引处的页面,并使用.addPage()将其添加到pdf_writer。
现在pdf_writer有三页,你可以用.getNumPages()检查:
>>> pdf_writer.getNumPages() 3最后,您可以将提取的页面写入新的 PDF 文件:
>>> with Path("chapter1.pdf").open(mode="wb") as output_file:
... pdf_writer.write(output_file)
...
现在你可以打开当前工作目录中的chapter1.pdf文件来阅读傲慢与偏见的第一章。
另一种从 PDF 中提取多页的方法是利用PdfFileReader.pages支持切片标记的事实。让我们使用.pages重复前面的例子,而不是在一个 range对象上循环。
首先初始化一个新的PdfFileWriter对象:
>>> pdf_writer = PdfFileWriter()现在从开始于
1结束于4的索引开始循环一段.pages:
>>> for page in input_pdf.pages[1:4]:
... pdf_writer.addPage(page)
...
请记住,切片中的值范围是从切片中第一个索引处的项目到切片中第二个索引处的项目,但不包括这两个项目。所以.pages[1:4]返回一个包含索引为1、2和3的页面的 iterable。
最后,将pdf_writer的内容写入输出文件:
>>> with Path("chapter1_slice.pdf").open(mode="wb") as output_file: ... pdf_writer.write(output_file) ...现在打开当前工作目录中的
chapter1_slice.pdf文件,并将其与通过循环range对象创建的chapter1.pdf文件进行比较。它们包含相同的页面!有时你需要从 PDF 中提取每一页。您可以使用上面举例说明的方法来做到这一点,但是
PyPDF2提供了一个快捷方式。PdfFileWriter实例有一个.appendPagesFromReader()方法,可以用来从PdfFileReader实例追加页面。要使用
.appendPagesFromReader(),向方法的reader参数传递一个PdfFileReader实例。例如,以下代码将傲慢与偏见 PDF 中的每一页复制到PdfFileWriter实例中:
>>> pdf_writer = PdfFileWriter()
>>> pdf_writer.appendPagesFromReader(pdf_reader)
pdf_writer现在包含了pdf_reader中的每一页!
检查你的理解能力
展开下面的方框,检查您的理解程度:
从Pride_and_Prejudice.pdf文件中提取最后一页,并将其保存到主目录中一个名为last_page.pdf的新文件中。
您可以展开下面的方框查看解决方案:
设置Pride_and_Prejudice.pdf文件的路径:
# First, import the needed classes and libraries
from pathlib import Path
from PyPDF2 import PdfFileReader, PdfFileWriter
# Then create a `Path` object to the PDF file.
# You might need to change this to match the path
# on your computer.
pdf_path = (
Path.home()
/ "creating-and-modifying-pdfs"
/ "practice_files"
/ "Pride_and_Prejudice.pdf"
)
现在您可以创建PdfFileReader实例了:
pdf_reader = PdfFileReader(str(pdf_path))
记住PdfFileReader对象只能用路径字符串实例化,不能用Path对象实例化!
使用.pages属性获取 PDF 中所有页面的 iterable。最后一页可以用索引-1访问:
last_page = pdf_reader.pages[-1]
现在您可以创建一个PdfFileWriter实例,并将最后一个页面添加到其中:
pdf_writer = PdfFileWriter()
pdf_writer.addPage(last_page)
最后,将pdf_writer的内容写入主目录中的文件last_page.pdf:
output_path = Path.home() / "last_page.pdf"
with output_path.open(mode="wb") as output_file:
pdf_writer.write(output_file)
当你准备好了,你可以进入下一部分。
连接和合并 pdf 文件
处理 PDF 文件时的两个常见任务是将几个 PDF 连接并合并到一个文件中。
当您连接两个或更多 pdf 时,您将文件一个接一个地合并成一个文档。例如,一家公司可能会在月末将几份每日报告合并成一份月度报告。
合并两个 pdf 也会合并成一个文件。但是合并允许您在第一个 PDF 的特定页面之后插入它,而不是将第二个 PDF 连接到第一个 PDF 的末尾。然后,它将插入点之后的第一个 PDF 的所有页面推到第二个 PDF 的结尾。
在本节中,您将学习如何使用PyPDF2包的PdfFileMerger来连接和合并 pdf。
使用PdfFileMerger类
PdfFileMerger类很像您在上一节中了解的PdfFileWriter类。您可以使用这两个类来编写 PDF 文件。在这两种情况下,都将页添加到类的实例中,然后将它们写入文件。
两者的主要区别在于,PdfFileWriter只能将页面追加或连接到已经包含在编写器中的页面列表的末尾,而PdfFileMerger可以在任何位置插入或合并页面。
继续创建您的第一个PdfFileMerger实例。在 IDLE 的交互窗口中,键入以下代码以导入PdfFileMerger类并创建一个新实例:
>>> from PyPDF2 import PdfFileMerger >>> pdf_merger = PdfFileMerger()对象第一次实例化时是空的。在对对象进行任何操作之前,您需要向对象添加一些页面。
有几种方法可以将页面添加到
pdf_merger对象,使用哪一种取决于您需要完成的任务:
.append()将现有 PDF 文档中的每一页连接到当前PdfFileMerger中页面的末尾。.merge()将现有 PDF 文档中的所有页面插入到PdfFileMerger中的特定页面之后。在本节中,您将从
.append()开始查看这两种方法。将 pdf 与
.append()连接
practice_files/文件夹有一个名为expense_reports的子目录,其中包含名为 Peter Python 的雇员的三份费用报告。Peter 需要将这三个 PDF 文件连接起来,作为一个 PDF 文件提交给他的雇主,这样他就可以报销一些与工作相关的费用。
首先,您可以使用
pathlib模块获取expense_reports/文件夹中三份费用报告的Path对象列表:
>>> from pathlib import Path
>>> reports_dir = (
... Path.home()
... / "creating-and-modifying-pdfs"
... / "practice_files"
... / "expense_reports"
... )
导入Path类后,您需要构建到expense_reports/目录的路径。请注意,您可能需要修改上面的代码,以便在您的计算机上获得正确的路径。
一旦将expense_reports/目录的路径分配给了reports_dir变量,您就可以使用.glob()来获取目录中 PDF 文件的路径。
看看目录中有什么:
>>> for path in reports_dir.glob("*.pdf"): ... print(path.name) ... Expense report 1.pdf Expense report 3.pdf Expense report 2.pdf列出了三个文件的名称,但它们没有按顺序排列。此外,您在计算机输出中看到的文件顺序可能与此处显示的输出不一致。
一般来说,
.glob()返回的路径顺序是不确定的,所以你需要自己排序。您可以通过创建一个包含三个文件路径的列表,然后在该列表上调用.sort()来实现:
>>> expense_reports = list(reports_dir.glob("*.pdf"))
>>> expense_reports.sort()
记住.sort()就地对列表进行排序,所以不需要将返回值赋给变量。在.list()被调用后,expense_reports列表将按文件名的字母顺序排序。
为了确认排序成功,再次循环expense_reports并打印出文件名:
>>> for path in expense_reports: ... print(path.name) ... Expense report 1.pdf Expense report 2.pdf Expense report 3.pdf看起来不错!
现在您可以连接这三个 pdf 文件。为此,您将使用
PdfFileMerger.append(),它需要一个表示 PDF 文件路径的字符串参数。当您调用.append()时,PDF 文件中的所有页面都会被追加到PdfFileMerger对象中的页面集合中。让我们来看看实际情况。首先,导入
PdfFileMerger类并创建一个新实例:
>>> from PyPDF2 import PdfFileMerger
>>> pdf_merger = PdfFileMerger()
现在遍历排序后的expense_reports列表中的路径,并将它们附加到pdf_merger:
>>> for path in expense_reports: ... pdf_merger.append(str(path)) ...注意,
expense_reports/中的每个Path对象在被传递给pdf_merger.append()之前都被转换成一个带有str()的字符串。将
expense_reports/目录中的所有 PDF 文件连接到pdf_merger对象中,您需要做的最后一件事就是将所有内容写入一个输出 PDF 文件。PdfFileMerger实例有一个.write()方法,就像PdfFileWriter.write()一样工作。以二进制写模式打开一个新文件,然后将 file 对象传递给
pdf_merge.write()方法:
>>> with Path("expense_reports.pdf").open(mode="wb") as output_file:
... pdf_merger.write(output_file)
...
您现在在当前工作目录中有一个名为expense_reports.pdf的 PDF 文件。用 PDF 阅读器打开它,您会发现所有三份费用报告都在同一个 PDF 文件中。
使用.merge()和合并 pdf
要合并两个或多个 pdf,请使用PdfFileMerger.merge()。该方法类似于.append(),除了您必须指定在输出 PDF 中的什么位置插入您正在合并的 PDF 中的所有内容。
看一个例子。Goggle,Inc .准备了一份季度报告,但忘记包括目录。Peter Python 注意到了这个错误,并很快创建了一个缺少目录的 PDF。现在,他需要将 PDF 文件合并到原始报告中。
报告 PDF 和目录 PDF 都可以在practice_files文件夹的quarterly_report/子文件夹中找到。报告在名为report.pdf的文件中,目录在名为toc.pdf的文件中。
在 IDLE 的交互窗口中,导入PdfFileMerger类,为report.pdf和toc.pdf文件创建Path对象:
>>> from pathlib import Path >>> from PyPDF2 import PdfFileMerger >>> report_dir = ( ... Path.home() ... / "creating-and-modifying-pdfs" ... / "practice_files" ... / "quarterly_report" ... ) >>> report_path = report_dir / "report.pdf" >>> toc_path = report_dir / "toc.pdf"您要做的第一件事是使用
.append()将报告 PDF 附加到一个新的PdfFileMerger实例:
>>> pdf_merger = PdfFileMerger()
>>> pdf_merger.append(str(report_path))
现在pdf_merger中已经有了一些页面,您可以将目录 PDF 合并到它的正确位置。如果您用 PDF 阅读器打开report.pdf文件,那么您会看到报告的第一页是一个标题页。第二个是简介,其余的页面包含不同的报告部分。
您希望在标题页之后、简介部分之前插入目录。由于 PDF 页面索引从PyPDF2中的0开始,您需要在索引0处的页面之后和索引1处的页面之前插入目录。
为此,用两个参数调用pdf_merger.merge():
- 整数
1,表示应该插入目录的页面索引 - 包含目录的 PDF 文件路径的字符串
看起来是这样的:
>>> pdf_merger.merge(1, str(toc_path))目录 PDF 中的每一页都在索引
1处的页面之前插入。因为目录 PDF 只有一页,所以它被插入到索引1处。当前在索引1的页面然后被转移到索引2。当前在索引2的页面被转移到索引3,等等。现在将合并的 PDF 写入输出文件:
>>> with Path("full_report.pdf").open(mode="wb") as output_file:
... pdf_merger.write(output_file)
...
您现在在当前工作目录中有一个full_report.pdf文件。用 PDF 阅读器打开它,检查目录是否插入正确的位置。
连接和合并 pdf 是常见的操作。虽然本节中的示例确实有些做作,但是您可以想象一个程序对于合并成千上万的 pdf 或自动化日常任务是多么有用,否则这些任务将需要花费大量的时间来完成。
检查你的理解能力
展开下面的方框,检查您的理解程度:
在本文的配套存储库中的practice_files/文件夹中,有两个名为merge1.pdf和merge2.pdf的文件。
使用一个PdfFileMerge实例,通过.append()连接两个文件。如果您的计算机的主目录,将连接的 pdf 保存到一个名为concatenated.pdf的新文件中。
您可以展开下面的方框查看解决方案:
设置 PDF 文件的路径:
# First, import the needed classes and libraries
from pathlib import Path
from PyPDF2 import PdfFileMerger
# Then create a `Path` objects to the PDF files.
# You might need to change this to match the path
# on your computer.
BASE_PATH = (
Path.home()
/ "creating-and-modifying-pdfs"
/ "practice_files"
)
pdf_paths = [BASE_PATH / "merge1.pdf", BASE_PATH / "merge2.pdf"]
现在您可以创建PdfFileMerger实例了:
pdf_merger = PdfFileMerger()
现在将每个文件的pdf_paths和.append()中的路径循环到pdf_merger:
for path in pdf_paths:
pdf_merger.append(str(path))
最后,将pdf_merger的内容写入主目录中名为concatenated.pdf的文件:
output_path = Path.home() / "concatenated.pdf"
with output_path.open(mode="wb") as output_file:
pdf_merger.write(output_file)
当你准备好了,你可以进入下一部分。
旋转和裁剪 PDF 页面
到目前为止,您已经学习了如何从 PDF 中提取文本和页面,以及如何连接和合并两个或多个 PDF 文件。这些都是 pdf 的常见操作,但是PyPDF2还有许多其他有用的特性。
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“创建和修改 PDF 文件”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
在本节中,您将学习如何旋转和裁剪 PDF 文件中的页面。
旋转页面
您将从学习如何翻页开始。对于这个例子,您将使用practice_files文件夹中的ugly.pdf文件。这个ugly.pdf文件包含了安徒生的丑小鸭的可爱版本,除了每一个奇数页都被逆时针旋转了 90 度。
让我们解决这个问题。在一个新的空闲交互窗口中,开始从PyPDF2导入PdfFileReader和PdfFileWriter类,以及从pathlib模块导入Path类:
>>> from pathlib import Path >>> from PyPDF2 import PdfFileReader, PdfFileWriter现在为
ugly.pdf文件创建一个Path对象:
>>> pdf_path = (
... Path.home()
... / "creating-and-modifying-pdfs"
... / "practice_files"
... / "ugly.pdf"
... )
最后,创建新的PdfFileReader和PdfFileWriter实例:
>>> pdf_reader = PdfFileReader(str(pdf_path)) >>> pdf_writer = PdfFileWriter()您的目标是使用
pdf_writer创建一个新的 PDF 文件,其中所有页面都具有正确的方向。PDF 中偶数页的方向已经正确,但是奇数页逆时针旋转了 90 度。要纠正这个问题,您将使用
PageObject.rotateClockwise()。该方法采用一个整数参数,以度数为单位,将页面顺时针旋转该度数。例如,.rotateClockwise(90)顺时针旋转 PDF 页面 90 度。注:除了
.rotateClockwise(),PageObject类还有逆时针旋转页面的.rotateCounterClockwise()。有几种方法可以在 PDF 中旋转页面。我们将讨论做这件事的两种不同方法。它们都依赖于
.rotateClockwise(),但是它们采用不同的方法来决定哪些页面被旋转。第一种技术是遍历 PDF 中页面的索引,并检查每个索引是否对应于需要旋转的页面。如果是这样,那么您将调用
.rotateClockwise()来旋转页面,然后将页面添加到pdf_writer。看起来是这样的:
>>> for n in range(pdf_reader.getNumPages()):
... page = pdf_reader.getPage(n)
... if n % 2 == 0:
... page.rotateClockwise(90)
... pdf_writer.addPage(page)
...
请注意,如果索引是偶数,页面会旋转。这可能看起来很奇怪,因为 PDF 中奇数页是旋转不正确的页面。但是,PDF 中的页码以1开始,而页面索引以0开始。这意味着奇数编号的 PDF 页面具有偶数索引。
如果这让你头晕,不要担心!即使在多年处理这类事情之后,职业程序员仍然会被这类事情绊倒!
注意:当你执行上面的for循环时,你会在 IDLE 的交互窗口看到一堆输出。这是因为.rotateClockwise()返回了一个PageObject实例。
您现在可以忽略这个输出。当你从 IDLE 的编辑器窗口执行程序时,这个输出是不可见的。
现在您已经旋转了 PDF 中的所有页面,您可以将pdf_writer的内容写入一个新文件,并检查一切是否正常:
>>> with Path("ugly_rotated.pdf").open(mode="wb") as output_file: ... pdf_writer.write(output_file) ...现在,在当前工作目录中应该有一个名为
ugly_rotated.pdf的文件,来自ugly.pdf文件的页面都被正确旋转。您刚刚使用的旋转
ugly.pdf文件中页面的方法的问题是,它依赖于提前知道哪些页面需要旋转。在现实世界中,浏览整个 PDF 并注意要旋转哪些页面是不现实的。事实上,您可以在没有先验知识的情况下确定哪些页面需要旋转。嗯,有时候你可以。
让我们看看如何从一个新的
PdfFileReader实例开始:
>>> pdf_reader = PdfFileReader(str(pdf_path))
您需要这样做,因为您通过旋转页面改变了旧的PdfFileReader实例中的页面。所以,通过创建一个新的实例,你可以从头开始。
实例维护一个包含页面信息的值字典:
>>> pdf_reader.getPage(0) {'/Contents': [IndirectObject(11, 0), IndirectObject(12, 0), IndirectObject(13, 0), IndirectObject(14, 0), IndirectObject(15, 0), IndirectObject(16, 0), IndirectObject(17, 0), IndirectObject(18, 0)], '/Rotate': -90, '/Resources': {'/ColorSpace': {'/CS1': IndirectObject(19, 0), '/CS0': IndirectObject(19, 0)}, '/XObject': {'/Im0': IndirectObject(21, 0)}, '/Font': {'/TT1': IndirectObject(23, 0), '/TT0': IndirectObject(25, 0)}, '/ExtGState': {'/GS0': IndirectObject(27, 0)}}, '/CropBox': [0, 0, 612, 792], '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Type': '/Page', '/StructParents': 0}呀!混杂在这些看起来毫无意义的东西中的是一个名为
/Rotate的键,您可以在上面的第四行输出中看到它。这个键的值是-90。您可以使用下标符号访问
PageObject上的/Rotate键,就像您可以访问 Pythondict对象一样:
>>> page = pdf_reader.getPage(0)
>>> page["/Rotate"]
-90
如果您查看pdf_reader中第二页的/Rotate键,您会看到它的值为0:
>>> page = pdf_reader.getPage(1) >>> page["/Rotate"] 0这意味着索引
0处的页面旋转值为-90度。换句话说,它逆时针旋转了 90 度。索引1处的页面旋转值为0,因此根本没有旋转。如果使用
.rotateClockwise()旋转第一页,则/Rotate的值从-90变为0:
>>> page = pdf_reader.getPage(0)
>>> page["/Rotate"]
-90
>>> page.rotateClockwise(90)
>>> page["/Rotate"]
0
现在您已经知道如何检查/Rotate键,您可以使用它来旋转ugly.pdf文件中的页面。
你需要做的第一件事是重新初始化你的pdf_reader和pdf_writer对象,这样你就有了一个新的开始:
>>> pdf_reader = PdfFileReader(str(pdf_path)) >>> pdf_writer = PdfFileWriter()现在编写一个循环,遍历
pdf_reader.pagesiterable 中的页面,检查/Rotate的值,如果该值为-90,则旋转页面:
>>> for page in pdf_reader.pages:
... if page["/Rotate"] == -90:
... page.rotateClockwise(90)
... pdf_writer.addPage(page)
...
这个循环不仅比第一个解决方案中的循环稍短,而且它不依赖于需要旋转哪些页面的任何先验知识。您可以使用这样的循环来旋转任何 PDF 中的页面,而不必打开它查看。
要完成解决方案,将pdf_writer的内容写入一个新文件:
>>> with Path("ugly_rotated2.pdf").open(mode="wb") as output_file: ... pdf_writer.write(output_file) ...现在您可以打开当前工作目录中的
ugly_rotated2.pdf文件,并将其与您之前生成的ugly_rotated.pdf文件进行比较。它们应该看起来一样。注意:关于
/Rotate键的一个警告:它不能保证存在于页面中。如果
/Rotate键不存在,那么通常意味着页面没有被旋转。然而,这并不总是一个安全的假设。如果一个
PageObject没有/Rotate键,那么当你试图访问它的时候会出现一个KeyError。你可以用一个try...except块来捕捉这个异常。
/Rotate的值可能不总是你所期望的。例如,如果您将页面逆时针旋转 90 度来扫描纸质文档,那么 PDF 的内容将会旋转。然而,/Rotate键可能具有值0。这是使处理 PDF 文件令人沮丧的许多怪癖之一。有时你只需要在 PDF 阅读器程序中打开一个 PDF,然后手动解决问题。
裁剪页面
pdf 的另一个常见操作是裁剪页面。您可能需要这样做来将单个页面分割成多个页面,或者只提取页面的一小部分,例如签名或图形。
例如,
practice_files文件夹包含一个名为half_and_half.pdf的文件。这个 PDF 包含了安徒生的小美人鱼的一部分。此 PDF 中的每一页都有两栏。让我们把每一页分成两页,每一栏一页。
首先,从
PyPDF2导入PdfFileReader和PdfFileWriter类,从pathlib模块导入Path类:
>>> from pathlib import Path
>>> from PyPDF2 import PdfFileReader, PdfFileWriter
现在为half_and_half.pdf文件创建一个Path对象:
>>> pdf_path = ( ... Path.home() ... / "creating-and-modifying-pdfs" ... / "practice_files" ... / "half_and_half.pdf" ... )接下来,创建一个新的
PdfFileReader对象并获取 PDF 的第一页:
>>> pdf_reader = PdfFileReader(str(pdf_path))
>>> first_page = pdf_reader.getPage(0)
要裁剪页面,您首先需要对页面的结构有更多的了解。像first_page这样的PageObject实例有一个.mediaBox属性,代表一个定义页面边界的矩形区域。
您可以使用 IDLE 的交互窗口浏览.mediaBox,然后使用它裁剪页面:
>>> first_page.mediaBox RectangleObject([0, 0, 792, 612])
.mediaBox属性返回一个RectangleObject这个对象在PyPDF2包中定义,代表页面上的一个矩形区域。输出中的列表
[0, 0, 792, 612]定义了矩形区域。前两个数字是矩形左下角的 x 和 y 坐标。第三和第四个数字分别代表矩形的宽度和高度。所有数值的单位都是磅,等于 1/72 英寸。
RectangleObject([0, 0, 792, 612])表示一个矩形区域,左下角为原点,宽度为792点,即 11 英寸,高度为 612 点,即 8.5 英寸。这是一个标准信纸大小的横向页面的尺寸,用于《小美人鱼的 PDF 示例。纵向的信纸大小的 PDF 页面将返回输出RectangleObject([0, 0, 612, 792])。一个
RectangleObject有四个返回矩形角坐标的属性:.lowerLeft、.lowerRight、.upperLeft和.upperRight。就像宽度和高度值一样,这些坐标以磅为单位给出。你可以使用这四个属性来获得
RectangleObject的每个角的坐标:
>>> first_page.mediaBox.lowerLeft
(0, 0)
>>> first_page.mediaBox.lowerRight
(792, 0)
>>> first_page.mediaBox.upperLeft
(0, 612)
>>> first_page.mediaBox.upperRight
(792, 612)
每个属性返回一个 tuple 包含指定角的坐标。您可以像访问任何其他 Python 元组一样,使用方括号访问各个坐标:
>>> first_page.mediaBox.upperRight[0] 792 >>> first_page.mediaBox.upperRight[1] 612您可以通过给一个属性分配一个新的元组来改变一个
mediaBox的坐标:
>>> first_page.mediaBox.upperLeft = (0, 480)
>>> first_page.mediaBox.upperLeft
(0, 480)
当您更改.upperLeft坐标时,.upperRight属性会自动调整以保持矩形形状:
>>> first_page.mediaBox.upperRight (792, 480)当您更改由
.mediaBox返回的RectangleObject的坐标时,您有效地裁剪了页面。first_page对象现在只包含新RectangleObject边界内的信息。继续将裁剪后的页面写入新的 PDF 文件:
>>> pdf_writer = PdfFileWriter()
>>> pdf_writer.addPage(first_page)
>>> with Path("cropped_page.pdf").open(mode="wb") as output_file:
... pdf_writer.write(output_file)
...
如果你打开当前工作目录中的cropped_page.pdf文件,你会看到页面的顶部已经被移除。
如何裁剪页面,以便只看到页面左侧的文本?你需要将页面的水平尺寸减半。您可以通过改变.mediaBox对象的.upperRight坐标来实现这一点。让我们看看它是如何工作的。
首先,您需要获得新的PdfFileReader和PdfFileWriter对象,因为您刚刚修改了pdf_reader中的第一页并将其添加到pdf_writer:
>>> pdf_reader = PdfFileReader(str(pdf_path)) >>> pdf_writer = PdfFileWriter()现在获取 PDF 的第一页:
>>> first_page = pdf_reader.getPage(0)
这一次,让我们使用第一页的副本,这样您刚刚提取的页面保持不变。您可以通过从 Python 的标准库中导入copy模块并使用deepcopy()来制作页面的副本:
>>> import copy >>> left_side = copy.deepcopy(first_page)现在你可以改变
left_side而不改变first_page的属性。这样,你可以稍后使用first_page来提取页面右侧的文本。现在你需要做一点数学。您已经知道需要将
.mediaBox的右上角移动到页面的顶部中央。为此,您将创建一个新的tuple,其第一个组件等于原始值的一半,并将其赋给.upperRight属性。首先,获取
.mediaBox右上角的当前坐标。
>>> current_coords = left_side.mediaBox.upperRight
然后创建一个新的tuple,其第一个坐标是当前坐标的一半,第二个坐标与原始坐标相同:
>>> new_coords = (current_coords[0] / 2, current_coords[1])最后,将新坐标分配给
.upperRight属性:
>>> left_side.mediaBox.upperRight = new_coords
现在,您已经裁剪了原始页面,只包含左侧的文本!接下来让我们提取页面的右侧。
首先获取first_page的新副本:
>>> right_side = copy.deepcopy(first_page)移动
.upperLeft角而不是.upperRight角:
>>> right_side.mediaBox.upperLeft = new_coords
这会将左上角设置为提取页面左侧时将右上角移动到的相同坐标。所以,right_side.mediaBox现在是一个矩形,它的左上角在页面的顶部中心,它的右上角在页面的右上角。
最后,将left_side和right_side页面添加到pdf_writer,并将其写入一个新的 PDF 文件:
>>> pdf_writer.addPage(left_side) >>> pdf_writer.addPage(right_side) >>> with Path("cropped_pages.pdf").open(mode="wb") as output_file: ... pdf_writer.write(output_file) ...现在用 PDF 阅读器打开
cropped_pages.pdf文件。您应该看到一个有两页的文件,第一页包含原始第一页左侧的文本,第二页包含原始第二页右侧的文本。检查你的理解能力
展开下面的方框,检查您的理解程度:
在本文的配套存储库中的
practice_files/文件夹中,有一个名为split_and_rotate.pdf的文件。在您计算机的主目录中创建一个名为
rotated.pdf的新文件,其中包含来自split_and_rotate.pdf的所有页面,但是每一页都逆时针旋转 90 度。您可以展开下面的方框查看解决方案:
设置 PDF 文件的路径:
# First, import the needed classes and libraries from pathlib import Path from PyPDF2 import PdfFileReader # Then create a `Path` object to the PDF file. # You might need to change this to match the path # on your computer. pdf_path = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" / "split_and_rotate.pdf" )现在您可以创建
PdfFileReader和PdfFileWriter实例:pdf_reader = PdfFileReader(str(pdf_path)) pdf_writer = PdfFileWriter()循环浏览
pdf_reader中的页面,使用.rotateCounterClockwise()将其全部旋转 90 度,并添加到pdf_writer:for page in pdf_reader.pages: rotated_page = page.rotateCounterClockwise(90) pdf_writer.addPage(rotated_page)最后,将
pdf_writer的内容写入计算机主目录中名为rotated.pdf的文件:output_path = Path.home() / "rotated.pdf" with output_path.open(mode="wb") as output_file: pdf_writer.write(output_file)加密和解密 pdf
有时 PDF 文件受密码保护。使用
PyPDF2包,您可以处理加密的 PDF 文件,并为现有的 PDF 文件添加密码保护。注:本教程改编自 Python 基础知识:Python 实用入门 3 中“创建和修改 PDF 文件”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
加密 pdf
您可以使用
PdfFileWriter()实例的.encrypt()方法为 PDF 文件添加密码保护。它有两个主要参数:
user_pwd设置用户密码。这允许打开和阅读 PDF 文件。owner_pwd设置所有者密码。这使得打开 PDF 没有任何限制,包括编辑。让我们使用
.encrypt()为 PDF 文件添加密码。首先,打开practice_files目录下的newsletter.pdf文件:
>>> from pathlib import Path
>>> from PyPDF2 import PdfFileReader, PdfFileWriter
>>> pdf_path = (
... Path.home()
... / "creating-and-modifying-pdfs"
... / "practice_files"
... / "newsletter.pdf"
... )
>>> pdf_reader = PdfFileReader(str(pdf_path))
现在创建一个新的PdfFileWriter实例,并将来自pdf_reader的页面添加到其中:
>>> pdf_writer = PdfFileWriter() >>> pdf_writer.appendPagesFromReader(pdf_reader)接下来,用
pdf_writer.encrypt()添加密码"SuperSecret":
>>> pdf_writer.encrypt(user_pwd="SuperSecret")
当您只设置了user_pwd时,owner_pwd参数默认为相同的字符串。因此,上面的代码行设置了用户和所有者密码。
最后,将加密的 PDF 写到主目录中的输出文件newsletter_protected.pdf:
>>> output_path = Path.home() / "newsletter_protected.pdf" >>> with output_path.open(mode="wb") as output_file: ... pdf_writer.write(output_file)当您使用 PDF 阅读器打开 PDF 时,系统会提示您输入密码。输入
"SuperSecret"打开 PDF。如果您需要为 PDF 设置单独的所有者密码,那么将第二个字符串传递给
owner_pwd参数:
>>> user_pwd = "SuperSecret"
>>> owner_pwd = "ReallySuperSecret"
>>> pdf_writer.encrypt(user_pwd=user_pwd, owner_pwd=owner_pwd)
在本例中,用户密码是"SuperSecret",所有者密码是"ReallySuperSecret"。
当您使用密码加密 PDF 文件并试图打开它时,您必须提供密码才能查看其内容。这种保护扩展到在 Python 程序中读取 PDF。接下来我们来看看如何用PyPDF2解密 PDF 文件。
解密 pdf 文件
要解密加密的 PDF 文件,请使用PdfFileReader实例的.decrypt()方法。
.decrypt()有一个名为password的参数,可以用来提供解密的密码。您在打开 PDF 时拥有的权限取决于您传递给password参数的参数。
让我们打开您在上一节中创建的加密的newsletter_protected.pdf文件,并使用PyPDF2来解密它。
首先,用受保护 PDF 的路径创建一个新的PdfFileReader实例:
>>> from pathlib import Path >>> from PyPDF2 import PdfFileReader, PdfFileWriter >>> pdf_path = Path.home() / "newsletter_protected.pdf" >>> pdf_reader = PdfFileReader(str(pdf_path))在您解密 PDF 之前,请检查如果您尝试获取第一页会发生什么:
>>> pdf_reader.getPage(0)
Traceback (most recent call last):
File "/Users/damos/github/realpython/python-basics-exercises/venv/
lib/python38-32/site-packages/PyPDF2/pdf.py", line 1617, in getObject
raise utils.PdfReadError("file has not been decrypted")
PyPDF2.utils.PdfReadError: file has not been decrypted
出现一个PdfReadError异常,通知您 PDF 文件还没有被解密。
注:上述追溯已被缩短以突出重要部分。你在电脑上看到的回溯会更长。
现在开始解密文件:
>>> pdf_reader.decrypt(password="SuperSecret") 1
.decrypt()返回一个表示解密成功的整数:
0表示密码不正确。1表示用户密码匹配。2表示主人密码被匹配。解密文件后,您可以访问 PDF 的内容:
>>> pdf_reader.getPage(0)
{'/Contents': IndirectObject(7, 0), '/CropBox': [0, 0, 612, 792],
'/MediaBox': [0, 0, 612, 792], '/Parent': IndirectObject(1, 0),
'/Resources': IndirectObject(8, 0), '/Rotate': 0, '/Type': '/Page'}
现在你可以提取文本和作物或旋转页面到你的心的内容!
检查你的理解能力
展开下面的方框,检查您的理解程度:
在本文的配套存储库中的practice_files/文件夹中,有一个名为top_secret.pdf的文件。
使用PdfFileWriter.encrypt(),用用户密码Unguessable加密文件。将加密文件保存为电脑主目录中的top_secret_encrypted.pdf。
您可以展开下面的方框查看解决方案:
设置 PDF 文件的路径:
# First, import the needed classes and libraries
from pathlib import Path
from PyPDF2 import PdfFileReader
# Then create a `Path` object to the PDF file.
# You might need to change this to match the path
# on your computer.
pdf_path = (
Path.home()
/ "creating-and-modifying-pdfs"
/ "practice_files"
/ "top_secret.pdf"
)
现在创建PdfFileReader和PdfFileWriter实例:
pdf_reader = PdfFileReader(str(pdf_path))
pdf_writer = PdfFileWriter()
您可以使用.appendPagesFromReader()添加从pdf_reader到pdf_writer的所有页面:
pdf_writer.appendPagesFromReader(pdf_reader)
现在使用encrypt()将用户密码设置为"Unguessable":
pdf_writer.encrypt(user_pwd="Unguessable")
最后,将pdf_writer的内容写入计算机主目录中名为top_secret_encrypted.pdf的文件:
output_path = Path.home() / "top_secret_encrypted.pdf"
with output_path.open(mode="wb") as output_file:
pdf_writer.write(output_file)
从头开始创建 PDF 文件
PyPDF2包非常适合阅读和修改现有的 PDF 文件,但是它有一个主要的限制:你不能用它来创建一个新的 PDF 文件。在本节中,您将使用 ReportLab 工具包从头开始生成 PDF 文件。
ReportLab 是用于创建 pdf 的全功能解决方案。有一个付费使用的商业版本,但也有一个功能有限的开源版本。
注意:这一部分并不是对 ReportLab 的详尽介绍,而是一个可能的示例。
更多示例,请查看 ReportLab 的代码片段页面。
安装reportlab
要开始使用,您需要安装带有pip的reportlab:
$ python3 -m pip install reportlab
您可以使用pip show来验证安装:
$ python3 -m pip show reportlab
Name: reportlab
Version: 3.5.34
Summary: The Reportlab Toolkit
Home-page: http://www.reportlab.com/
Author: Andy Robinson, Robin Becker, the ReportLab team
and the community
Author-email: reportlab-users@lists2.reportlab.com
License: BSD license (see license.txt for details),
Copyright (c) 2000-2018, ReportLab Inc.
Location: c:\users\davea\venv\lib\site-packages
Requires: pillow
Required-by:
在撰写本文时,reportlab的最新版本是 3.5.34。如果你有 IDLE open,那么你需要重新启动它才能使用reportlab包。
使用Canvas类
用reportlab创建 pdf 的主界面是Canvas类,它位于reportlab.pdfgen.canvas模块中。
打开一个新的空闲交互窗口,键入以下内容导入Canvas类:
>>> from reportlab.pdfgen.canvas import Canvas当您创建一个新的
Canvas实例时,您需要提供一个字符串,其中包含您正在创建的 PDF 的文件名。继续为文件hello.pdf创建一个新的Canvas实例:
>>> canvas = Canvas("hello.pdf")
现在您有了一个Canvas实例,它被赋予了变量名canvas,并且与当前工作目录中的一个名为hello.pdf的文件相关联。但是文件hello.pdf还不存在。
让我们给 PDF 添加一些文本。为此,您可以使用.drawString():
>>> canvas.drawString(72, 72, "Hello, World")传递给
.drawString()的前两个参数决定了文本在画布上的书写位置。第一个指定距画布左边缘的距离,第二个指定距下边缘的距离。传递给
.drawString()的值以磅为单位。因为一个点等于 1/72 英寸,所以.drawString(72, 72, "Hello, World")将字符串"Hello, World"绘制在页面左侧一英寸和底部一英寸处。要将 PDF 保存到文件,请使用
.save():
>>> canvas.save()
您现在在当前工作目录中有一个名为hello.pdf的 PDF 文件。可以用 PDF 阅读器打开,看到页面底部的文字Hello, World!
对于您刚刚创建的 PDF,有一些事情需要注意:
- 默认页面尺寸是 A4,这与标准的美国信函页面尺寸不同。
- 字体默认为 Helvetica,字号为 12 磅。
你不会被这些设置束缚住。
设置页面尺寸
当实例化一个Canvas对象时,可以用可选的pagesize参数改变页面大小。该参数接受一个由浮点值组成的元组,以磅为单位表示页面的宽度和高度。
例如,要将页面大小设置为宽8.5英寸,高11英寸,您可以创建下面的Canvas:
canvas = Canvas("hello.pdf", pagesize=(612.0, 792.0))
(612, 792)代表信纸大小的纸张,因为8.5次72是612,而11次72是792。
如果你不喜欢计算将磅转换成英寸或厘米,那么你可以使用reportlab.lib.units模块来帮助你转换。.units模块包含几个助手对象,比如inch和cm,它们简化了你的转换。
继续从reportlab.lib.units模块导入inch和cm对象:
>>> from reportlab.lib.units import inch, cm现在,您可以检查每个对象,看看它们是什么:
>>> cm
28.346456692913385
>>> inch
72.0
cm和inch都是浮点值。它们代表每个单元中包含的点数。inch是72.0点,cm是28.346456692913385点。
要使用单位,请将单位名称乘以要转换为点的单位数。例如,下面是如何使用inch将页面尺寸设置为8.5英寸宽乘11英寸高:
>>> canvas = Canvas("hello.pdf", pagesize=(8.5 * inch, 11 * inch))通过向
pagesize传递一个 tuple,您可以创建任意大小的页面。然而,reportlab包有一些更容易使用的标准内置页面大小。页面尺寸位于
reportlab.lib.pagesizes模块中。例如,要将页面大小设置为 letter,可以从pagesizes模块导入LETTER对象,并在实例化Canvas时将其传递给pagesize参数:
>>> from reportlab.lib.pagesizes import LETTER
>>> canvas = Canvas("hello.pdf", pagesize=LETTER)
如果您检查LETTER对象,那么您会看到它是一个浮点元组:
>>> LETTER (612.0, 792.0)
reportlab.lib.pagesize模块包含许多标准页面尺寸。以下是一些尺寸:
页面大小 规模 A4210 毫米 x 297 毫米 LETTER8.5 英寸 x 11 英寸 LEGAL8.5 英寸 x 14 英寸 TABLOID11 英寸 x 17 英寸 除此之外,该模块还包含所有 ISO 216 标准纸张尺寸的定义。
设置字体属性
当您向
Canvas写入文本时,您还可以更改字体、字体大小和字体颜色。要更改字体和字体大小,可以使用
.setFont()。首先,用文件名font-example.pdf和信纸大小创建一个新的Canvas实例:
>>> canvas = Canvas("font-example.pdf", pagesize=LETTER)
然后将字体设置为 Times New Roman,大小为18磅:
>>> canvas.setFont("Times-Roman", 18)最后,将字符串
"Times New Roman (18 pt)"写入画布并保存:
>>> canvas.drawString(1 * inch, 10 * inch, "Times New Roman (18 pt)")
>>> canvas.save()
使用这些设置,文本将被写在离页面左侧 1 英寸,离页面底部 10 英寸的地方。打开当前工作目录中的font-example.pdf文件并检查它!
默认情况下,有三种字体可用:
"Courier""Helvetica""Times-Roman"
每种字体都有粗体和斜体两种变体。以下是reportlab中所有可用字体的列表:
"Courier""Courier-Bold"Courier-BoldOblique""Courier-Oblique""Helvetica""Helvetica-Bold""Helvetica-BoldOblique""Helvetica-Oblique""Times-Bold""Times-BoldItalic"Times-Italic""Times-Roman"
您也可以使用.setFillColor()设置字体颜色。在下面的示例中,您创建了一个名为font-colors.pdf的带有蓝色文本的 PDF 文件:
from reportlab.lib.colors import blue
from reportlab.lib.pagesizes import LETTER
from reportlab.lib.units import inch
from reportlab.pdfgen.canvas import Canvas
canvas = Canvas("font-colors.pdf", pagesize=LETTER)
# Set font to Times New Roman with 12-point size
canvas.setFont("Times-Roman", 12)
# Draw blue text one inch from the left and ten
# inches from the bottom
canvas.setFillColor(blue)
canvas.drawString(1 * inch, 10 * inch, "Blue text")
# Save the PDF file
canvas.save()
blue是从reportlab.lib.colors模块导入的对象。这个模块包含几种常见的颜色。完整的颜色列表可以在 reportlab源代码中找到。
本节中的例子强调了使用Canvas对象的基础。但你只是触及了表面。使用reportlab,您可以从头开始创建表格、表单,甚至高质量的图形!
ReportLab 用户指南包含了大量如何从头开始生成 PDF 文档的例子。如果您有兴趣了解更多关于使用 Python 创建 pdf 的内容,这是一个很好的起点。
检查你的理解能力
展开下面的方框,检查您的理解程度:
在您计算机的主目录中创建一个名为realpython.pdf的 PDF,其中包含文本"Hello, Real Python!"的信纸大小的页面放置在距离页面左边缘 2 英寸和下边缘 8 英寸的位置。
您可以展开下面的方框查看解决方案:
用信纸大小的页面设置Canvas实例:
from reportlab.lib.pagesizes import LETTER
from reportlab.lib.units import inch
from reportlab.pdfgen.canvas import Canvas
canvas = Canvas("font-colors.pdf", pagesize=LETTER)
现在画一条线"Hello, Real Python!",距离左边两英寸,距离底部八英寸:
canvas.drawString(2 * inch, 8 * inch, "Hello, Real Python!")
最后,保存canvas来编写 PDF 文件:
canvas.save()
当你准备好了,你可以进入下一部分。
结论:用 Python 创建和修改 PDF 文件
在本教程中,您学习了如何使用PyPDF2和reportlab包创建和修改 PDF 文件。如果您想了解刚才看到的示例,请务必点击下面的链接下载材料:
下载示例材料: 单击此处获取您将在本教程中使用学习创建和修改 PDF 文件的材料。
通过PyPDF2,你学会了如何:
- 读取 PDF 文件,使用
PdfFileReader类提取文本 - 使用
PdfFileWriter类编写新的 PDF 文件 - 连接和使用
PdfFileMerger类合并 PDF 文件 - 旋转和裁剪 PDF 页面
- 用密码加密和解密 PDF 文件
您还了解了如何使用reportlab包从头开始创建 PDF 文件。你学会了如何:
- 使用
Canvas类 - 用
.drawString()写文本到Canvas - 用
.setFont()设置字体和字体大小 - 用
.setFillColor()改变字体颜色
reportlab是一个强大的 PDF 创建工具,而你只是触及了它的表面。如果你喜欢在这个例子中从 Python 基础知识:Python 3 实用介绍中学到的东西,那么一定要看看本书的其余部分。
编码快乐!**********


 浙公网安备 33010602011771号
浙公网安备 33010602011771号