RealPython-中文系列教程-八-
RealPython 中文系列教程(八)
原文:RealPython
熊猫中的设置与拷贝警告:视图与拷贝
NumPy 和 Pandas 是非常全面、高效、灵活的数据操作 Python 工具。这两个库的熟练用户需要理解的一个重要概念是,数据是如何被引用为浅层副本 ( 视图)和深层副本(或者仅仅是副本)。Pandas 有时会发出一个SettingWithCopyWarning来警告用户对视图和副本的潜在不当使用。
在这篇文章中,你将了解到:
- 什么视图和副本在 NumPy 和熊猫
- 如何在 NumPy 和 Pandas 中正确使用视图和副本
- 为什么
SettingWithCopyWarning发生在熊猫身上 - 如何避免在熊猫身上受伤
你首先会看到一个简短的解释什么是SettingWithCopyWarning以及如何避免它。您可能会发现这已经足够满足您的需求,但是您还可以更深入地了解 NumPy 和 Pandas 的细节,以了解更多关于副本和视图的信息。
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
先决条件
为了遵循本文中的例子,您将需要 Python 3.7 或 3.8 ,以及库 NumPy 和 Pandas 。本文是为 NumPy 1 . 18 . 1 版和 Pandas 1 . 0 . 3 版编写的。你可以用pip安装它们:
$ python -m pip install -U "numpy==1.18.*" "pandas==1.0.*"
如果你喜欢 Anaconda T1 或 T2 Miniconda T3 发行版,你可以使用 T4 conda T5 软件包管理系统。要了解关于这种方法的更多信息,请查看在 Windows 上为机器学习设置 Python。现在,在您的环境中安装 NumPy 和 Pandas 就足够了:
$ conda install numpy=1.18.* pandas=1.0.*
现在您已经安装了 NumPy 和 Pandas,您可以导入它们并检查它们的版本:
>>> import numpy as np >>> import pandas as pd >>> np.__version__ '1.18.1' >>> pd.__version__ '1.0.3'就是这样。您已经具备了这篇文章的所有先决条件。您的版本可能略有不同,但下面的信息仍然适用。
注:本文要求你先有一些熊猫知识。对于后面的部分,您还需要一些 NumPy 知识。
要更新您的数字技能,您可以查看以下资源:
为了提醒自己关于熊猫的事情,你可以阅读以下内容:
现在你已经准备好开始学习视图、副本和
SettingWithCopyWarning!
SettingWithCopyWarning的一个例子如果你和熊猫一起工作,你很可能已经看过一次行动。这很烦人,有时很难理解。然而,它的发布是有原因的。
关于
SettingWithCopyWarning你应该知道的第一件事是,它是而不是一个错误。这是一个警告。它警告您,您可能已经做了一些会在代码中导致不想要的行为的事情。让我们看一个例子。你将从创建一个熊猫数据帧开始:
>>> data = {"x": 2**np.arange(5),
... "y": 3**np.arange(5),
... "z": np.array([45, 98, 24, 11, 64])}
>>> index = ["a", "b", "c", "d", "e"]
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
- 键
"x"、"y"和"z",它们将是数据帧的列标签 - 三个 NumPy 数组,保存数据帧的数据
用例程 numpy.arange() 创建前两个数组,用 numpy.array() 创建最后一个数组。要了解更多关于arange()的信息,请查看 NumPy arange():如何使用 np.arange() 。
附加在变量index上的列表包含了字符串 "a"、"b"、"c"、"d"和"e",它们将成为数据帧的行标签。
最后,初始化包含来自data和index的信息的数据帧 df。你可以这样想象:
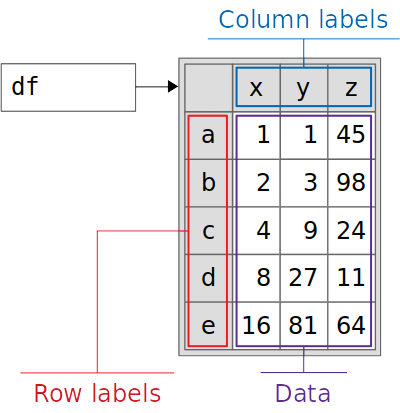
下面是数据帧中包含的主要信息的分类:
- 紫色方框:数据
- 蓝色框:列标签
- 红框:行标签
数据帧存储附加信息或元数据,包括其形状、数据类型等。
现在您已经有了一个数据框架,让我们试着获取一个SettingWithCopyWarning。您将从列z中取出所有小于 50 的值,并用零替换它们。你可以从创建一个遮罩开始,或者用熊猫布尔运算符创建一个滤镜:
>>> mask = df["z"] < 50 >>> mask a True b False c True d True e False Name: z, dtype: bool >>> df[mask] x y z a 1 1 45 c 4 9 24 d 8 27 11
mask是熊猫系列的实例,具有布尔数据和来自df的索引:
True表示df中z的值小于50的行。False表示df中z的值为而非小于50的行。
df[mask]返回来自df的数据帧,其中mask为True。在这种情况下,您会得到行a、c和d。如果您试图通过使用
mask提取行a、c和d来改变df,您将得到一个SettingWithCopyWarning,而df将保持不变:
>>> df[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
如您所见,向列z分配零失败。这张图片展示了整个过程:
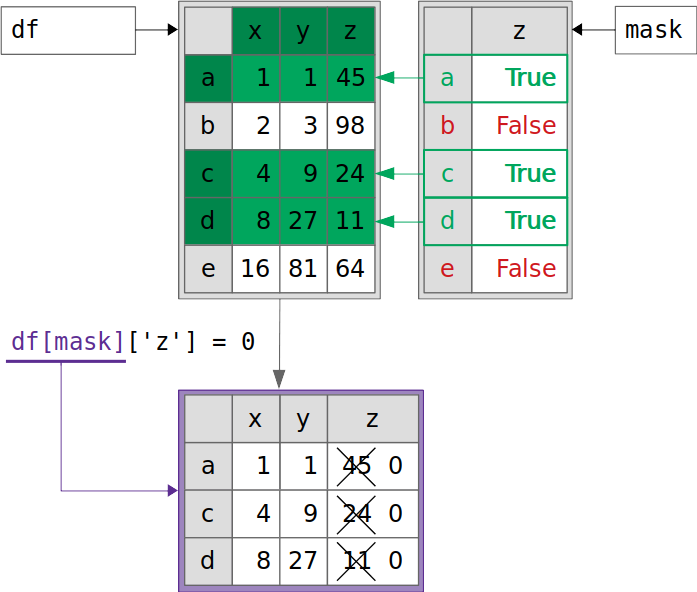
下面是上面代码示例中发生的情况:
df[mask]返回一个全新的数据帧(用紫色标出)。该数据帧保存了来自df的数据的副本,这些数据对应于来自mask的True值(以绿色突出显示)。df[mask]["z"] = 0将新数据帧的列z修改为零,保持df不变。
通常情况下,你不会想要这样的!你想要修改df而不是一些没有被任何变量引用的中间数据结构。这就是为什么熊猫会发出一个SettingWithCopyWarning警告你这个可能的错误。
在这种情况下,修改df的正确方法是应用访问器 .loc[] 、 .iloc[] 、 .at[] 或 .iat[] 中的一个:
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc[mask, "z"] = 0 >>> df x y z a 1 1 0 b 2 3 98 c 4 9 0 d 8 27 0 e 16 81 64这种方法使您能够向为 DataFrame 赋值的单个方法提供两个参数
mask和"z"。解决此问题的另一种方法是更改评估顺序:
>>> df = pd.DataFrame(data=data, index=index)
>>> df["z"]
a 45
b 98
c 24
d 11
e 64
Name: z, dtype: int64
>>> df["z"][mask] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
这个管用!您修改了df。这个过程是这样的:
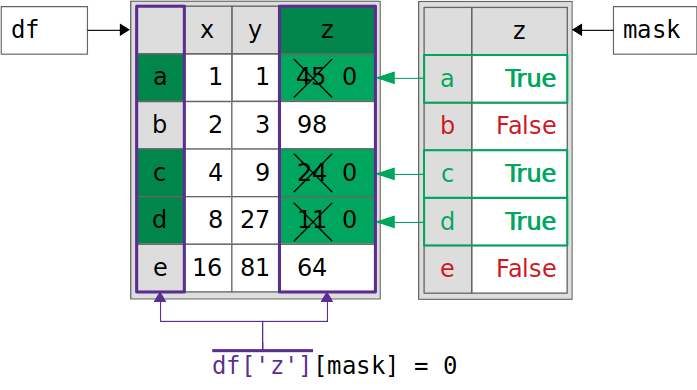
这是图像的分解:
df["z"]返回一个Series对象(用紫色标出),该对象指向与df中的z列相同的数据,而不是其副本。df["z"][mask] = 0通过使用链式赋值将屏蔽值(以绿色突出显示)设置为零来修改此Series对象。df也被修改,因为Series对象df["z"]持有与df相同的数据。
您已经看到df[mask]包含数据的副本,而df["z"]指向与df相同的数据。熊猫用来决定你是否复制的规则非常复杂。幸运的是,有一些简单的方法可以给数据帧赋值并避免SettingWithCopyWarning。
调用访问器通常被认为是比链式赋值更好的实践,原因如下:
- 当你使用单一方法时,修改
df的意图对熊猫来说更加清晰。 - 代码对读者来说更清晰。
- 访问器往往具有更好的性能,尽管在大多数情况下您不会注意到这一点。
然而,使用访问器有时是不够的。他们也可能返回副本,在这种情况下,您可以获得一个SettingWithCopyWarning:
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64在这个例子中,和上一个例子一样,您使用了访问器
.loc[]。赋值失败是因为df.loc[mask]返回一个新的数据帧,其中包含来自df的数据副本。然后df.loc[mask]["z"] = 0修改新的数据帧,而不是df。一般来说,为了避免熊猫出现
SettingWithCopyWarning,你应该做以下事情:
- 避免像
df["z"][mask] = 0和df.loc[mask]["z"] = 0那样结合两个或更多步进操作的链式分配。- 只需像
df.loc[mask, "z"] = 0一样进行一次步进操作,即可应用单次分配。这可能涉及(也可能不涉及)访问器的使用,但它们肯定非常有用,而且通常是首选。有了这些知识,你可以在大多数情况下成功地避免
SettingWithCopyWarning和任何不想要的行为。但是,如果你想更深入地了解 NumPy、Pandas、views、copies 以及与SettingWithCopyWarning相关的问题,那么请继续阅读本文的其余部分。NumPy 和 Pandas 中的视图和副本
理解视图和副本是了解 NumPy 和 Pandas 如何操作数据的重要部分。它还可以帮助您避免错误和性能瓶颈。有时数据从内存的一部分复制到另一部分,但在其他情况下,两个或多个对象可以共享相同的数据,从而节省时间和内存。
了解 NumPy 中的视图和副本
让我们从创建一个 NumPy 数组开始:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr
array([ 1, 2, 4, 8, 16, 32])
现在已经有了arr,可以用它来创建其他数组。我们先把arr ( 2和8)的第二个和第四个元素提取出来作为一个新数组。有几种方法可以做到这一点:
>>> arr[1:4:2] array([2, 8]) >>> arr[[1, 3]] array([2, 8]))如果您不熟悉数组索引,也不用担心。稍后你会学到更多关于这些和其他陈述的内容。现在,重要的是要注意这两个语句都返回
array([2, 8])。然而,他们在表面下有不同的行为:
>>> arr[1:4:2].base
array([ 1, 2, 4, 8, 16, 32])
>>> arr[1:4:2].flags.owndata
False
>>> arr[[1, 3]].base
>>> arr[[1, 3]].flags.owndata
True
乍一看,这似乎很奇怪。不同之处在于,arr[1:4:2]返回一个浅拷贝,而arr[[1, 3]]返回一个深拷贝。理解这种差异不仅对处理SettingWithCopyWarning至关重要,对用 NumPy 和 Pandas 处理大数据也是如此。
在下面几节中,您将了解更多关于 NumPy 和 Pandas 中的浅拷贝和深拷贝。
数字视图
一个浅拷贝或视图是一个没有自己数据的 NumPy 数组。它查看原始数组中包含的数据。您可以使用 .view() 创建一个数组视图:
>>> view_of_arr = arr.view() >>> view_of_arr array([ 1, 2, 4, 8, 16, 32]) >>> view_of_arr.base array([ 1, 2, 4, 8, 16, 32]) >>> view_of_arr.base is arr True您已经获得了数组
view_of_arr,这是原始数组arr的一个视图或简单副本。view_of_arr的属性.base就是arr本身。换句话说,view_of_arr不拥有任何数据——它使用属于arr的数据。您也可以使用属性.flags来验证这一点:
>>> view_of_arr.flags.owndata
False
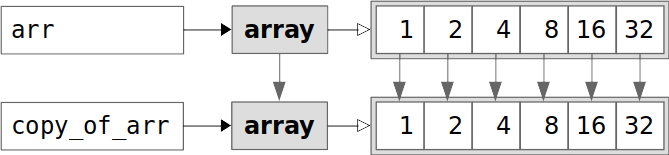
如你所见,view_of_arr.flags.owndata就是False。这意味着view_of_arr并不拥有数据,而是使用它的.base来获取数据:
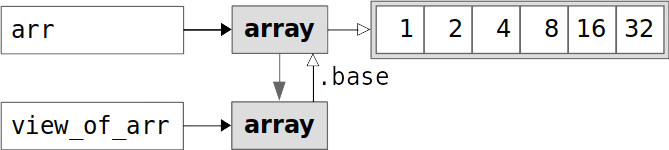
上图显示arr和view_of_arr指向相同的数据值。
份数
NumPy 数组的深度副本,有时也称为副本,是一个独立的 NumPy 数组,拥有自己的数据。深层副本的数据是通过将原始数组的元素复制到新数组中获得的。原件和副本是两个独立的实例。您可以使用 .copy() 创建数组的副本:
>>> copy_of_arr = arr.copy() >>> copy_of_arr array([ 1, 2, 4, 8, 16, 32]) >>> copy_of_arr.base is None True >>> copy_of_arr.flags.owndata True如你所见,
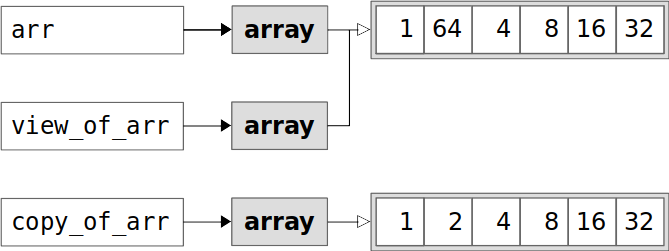
copy_of_arr没有.base。更准确的说,copy_of_arr.base的值是None。属性.flags.owndata是True。这意味着copy_of_arr拥有数据:
上图显示了
arr和copy_of_arr包含数据值的不同实例。视图和副本之间的差异
视图和副本之间有两个非常重要的区别:
- 视图不需要额外的数据存储,但是副本需要。
- 修改原始阵列会影响其视图,反之亦然。然而,修改原始数组将而不是影响它的副本。
为了说明视图和副本之间的第一个区别,让我们比较一下
arr、view_of_arr和copy_of_arr的大小。属性.nbytes返回数组元素消耗的内存:
>>> arr.nbytes
48
>>> view_of_arr.nbytes
48
>>> copy_of_arr.nbytes
48
所有数组的内存量都是一样的:48 字节。每个数组查看 6 个 8 字节(64 位)的整数元素。总共有 48 个字节。
但是,如果您使用 sys.getsizeof() 来获得直接归属于每个数组的内存量,那么您会看到不同之处:
>>> from sys import getsizeof >>> getsizeof(arr) 144 >>> getsizeof(view_of_arr) 96 >>> getsizeof(copy_of_arr) 144
arr和copy_of_arr各保存 144 字节。正如您之前看到的,总共 144 个字节中有 48 个字节是用于数据元素的。剩余的 96 个字节用于其他属性。view_of_arr只保存这 96 个字节,因为它没有自己的数据元素。为了说明视图和副本之间的第二个区别,您可以修改原始数组的任何元素:
>>> arr[1] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> view_of_arr
array([ 1, 64, 4, 8, 16, 32])
>>> copy_of_arr
array([ 1, 2, 4, 8, 16, 32])
如您所见,视图也发生了变化,但副本保持不变。下图显示了该代码:
视图被修改是因为它查看了arr的元素,而它的.base是原始数组。副本是不变的,因为它不与原始文件共享数据,所以对原始文件的更改根本不会影响它。
了解 Pandas 中的视图和副本
Pandas 还区分了视图和副本。您可以使用 .copy() 创建数据帧的视图或副本。参数deep决定您是想要查看(deep=False)还是复制(deep=True)。deep默认为True,所以你可以省略它得到一个副本:
>>> df = pd.DataFrame(data=data, index=index) >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64 >>> view_of_df = df.copy(deep=False) >>> view_of_df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64 >>> copy_of_df = df.copy() >>> copy_of_df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64起初,
df的视图和副本看起来是一样的。但是,如果您比较它们的数字表示,那么您可能会注意到这种微妙的差异:
>>> view_of_df.to_numpy().base is df.to_numpy().base
True
>>> copy_of_df.to_numpy().base is df.to_numpy().base
False
这里, .to_numpy() 返回保存数据帧数据的 NumPy 数组。你可以看到df和view_of_df有相同的.base,共享相同的数据。另一方面,copy_of_df包含不同的数据。
可以通过修改df来验证这一点:
>>> df["z"] = 0 >>> df x y z a 1 1 0 b 2 3 0 c 4 9 0 d 8 27 0 e 16 81 0 >>> view_of_df x y z a 1 1 0 b 2 3 0 c 4 9 0 d 8 27 0 e 16 81 0 >>> copy_of_df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64您已经为
df中的列z的所有元素赋了零。这导致了view_of_df的变化,但是copy_of_df保持不变。行和列标签也表现出相同的行为:
>>> view_of_df.index is df.index
True
>>> view_of_df.columns is df.columns
True
>>> copy_of_df.index is df.index
False
>>> copy_of_df.columns is df.columns
False
df和view_of_df共享相同的行和列标签,而copy_of_df有单独的索引实例。请记住,您不能修改.index和.columns的特定元素。它们是不可变的对象。
熊猫和熊猫的指数和切片
NumPy 中的基本索引和切片类似于列表和元组的索引和切片。但是,NumPy 和 Pandas 都提供了额外的选项来引用对象及其部件并为其赋值。
NumPy 数组和 Pandas 对象 ( DataFrame和Series)实现了的特殊方法,这些方法能够以类似于容器的方式引用、赋值和删除值:
.__getitem__()引用值。.__setitem__()赋值。.__delitem__()删除数值。
当您在类似 Python 容器的对象中引用、分配或删除数据时,通常会调用这些方法:
var = obj[key]相当于var = obj.__getitem__(key)。obj[key] = value相当于obj.__setitem__(key, value)。del obj[key]相当于obj.__delitem__(key)。
参数key代表索引,可以是整数、切片、元组、列表、NumPy 数组等等。
NumPy 中的索引:副本和视图
在索引数组时,NumPy 有一套与副本和视图相关的严格规则。您获得的是原始数据的视图还是副本取决于您用来索引数组的方法:切片、整数索引或布尔索引。
一维数组
切片是 Python 中一种众所周知的操作,用于从数组、列表或元组中获取特定数据。当您对 NumPy 数组进行切片时,您会看到数组的视图:
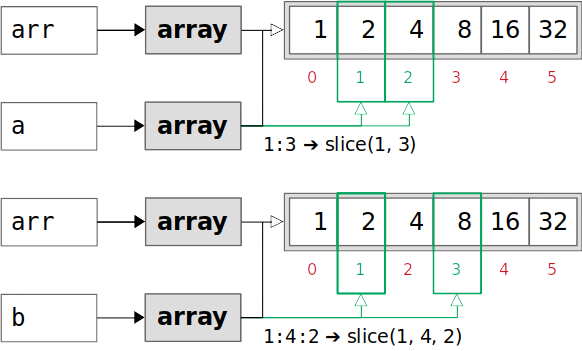
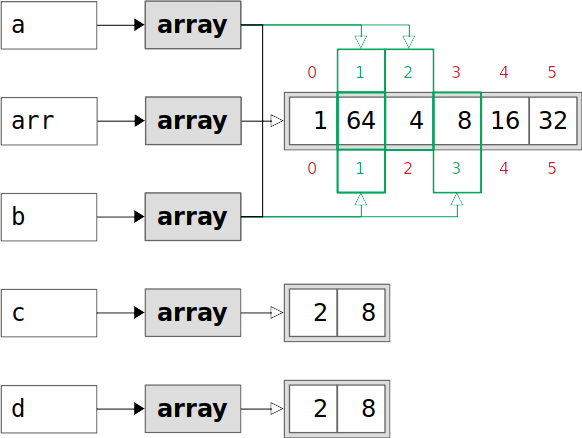
>>> arr = np.array([1, 2, 4, 8, 16, 32]) >>> a = arr[1:3] >>> a array([2, 4]) >>> a.base array([ 1, 2, 4, 8, 16, 32]) >>> a.base is arr True >>> a.flags.owndata False >>> b = arr[1:4:2] >>> b array([2, 8]) >>> b.base array([ 1, 2, 4, 8, 16, 32]) >>> b.base is arr True >>> b.flags.owndata False您已经创建了原始数组
arr,并将其分割成两个更小的数组a和b。a和b都以arr为基准,都没有自己的数据。相反,他们看的是arr的数据:
上图中的绿色指数是通过切片获得的。
a和b都查看绿色矩形中arr的对应元素。注意:当你有一个很大的原始数组,只需要其中的一小部分时,可以切片后调用
.copy(),用del语句删除指向原始的变量。这样,您可以保留副本并从内存中删除原始数组。虽然切片会返回一个视图,但是在其他情况下,从一个数组创建另一个数组实际上会产生一个副本。
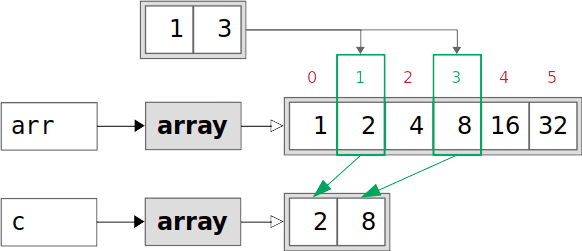
用整数列表索引数组会返回原始数组的副本。副本包含原始数组中的元素,这些元素的索引出现在列表中:
>>> c = arr[[1, 3]]
>>> c
array([2, 8])
>>> c.base is None
True
>>> c.flags.owndata
True
结果数组c包含来自arr的元素,索引为1和3。这些元素具有值2和8。在这种情况下,c是arr的副本,它的.base是None,它有自己的数据:
具有所选索引1和3的arr的元素被复制到新数组c中。复印完成后,arr和c是独立的。
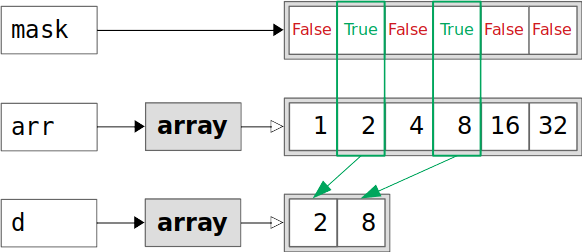
还可以用掩码数组或列表来索引 NumPy 数组。遮罩是与原始形状相同的布尔数组或列表。您将得到一个原始数组的副本,它只包含与掩码的True值相对应的元素:
>>> mask = [False, True, False, True, False, False] >>> d = arr[mask] >>> d array([2, 8]) >>> d.base is None True >>> d.flags.owndata True列表
mask在第二和第四位置具有True值。这就是为什么数组d只包含来自arr的第二个和第四个位置的元素。和c的情况一样,d是副本,它的.base是None,它有自己的数据:
绿色矩形中的
arr元素对应于来自mask的True值。这些元素被复制到新数组d中。复制后,arr和d是独立的。注意:可以用另一个 NumPy 的整数数组代替一个 list,但是不是一个 tuple 。
概括一下,这里是您到目前为止创建的引用
arr的变量:# `arr` is the original array: arr = np.array([1, 2, 4, 8, 16, 32]) # `a` and `b` are views created through slicing: a = arr[1:3] b = arr[1:4:2] # `c` and `d` are copies created through integer and Boolean indexing: c = arr[[1, 3]] d = arr[[False, True, False, True, False, False]]记住,这些例子展示了如何在数组中引用数据。引用数据在切片数组时返回视图,在使用索引和掩码数组时返回副本。另一方面,赋值总是修改数组的原始数据。
现在您已经有了所有这些数组,让我们看看当您改变原始数组时会发生什么:
>>> arr[1] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> a
array([64, 4])
>>> b
array([64, 8])
>>> c
array([2, 8])
>>> d
array([2, 8])
您已经将arr的第二个值从2更改为64。值2也出现在派生数组a、b、c和d中。然而,只有视图a和b被修改:
视图a和b查看arr的数据,包括它的第二个元素。这就是你看到变化的原因。副本c和d保持不变,因为它们与arr没有公共数据。它们独立于arr。
数字中的链式索引
这个带有a和b的行为看起来和之前熊猫的例子有什么相似之处吗?有可能,因为链式索引的概念也适用于 NumPy:
>>> arr = np.array([1, 2, 4, 8, 16, 32]) >>> arr[1:4:2][0] = 64 >>> arr array([ 1, 64, 4, 8, 16, 32]) >>> arr = np.array([1, 2, 4, 8, 16, 32]) >>> arr[[1, 3]][0] = 64 >>> arr array([ 1, 2, 4, 8, 16, 32])这个例子说明了在 NumPy 中使用链式索引时副本和视图之间的区别。
在第一种情况下,
arr[1:4:2]返回一个视图,该视图引用了arr的数据,并包含元素2和8。语句arr[1:4:2][0] = 64将这些元素中的第一个修改为64。这个变化在arr和arr[1:4:2]返回的视图中都是可见的。在第二种情况下,
arr[[1, 3]]返回一个副本,其中也包含元素2和8。但是这些与arr中的元素不同。它们是新的。arr[[1, 3]][0] = 64修改arr[[1, 3]]返回的副本,保持arr不变。这与熊猫产生
SettingWithCopyWarning的行为本质上是一样的,但这种警告在 NumPy 中并不存在。多维数组
引用多维数组遵循相同的原则:
- 分割数组会返回视图。
- 使用索引和掩码数组返回副本。
将索引和掩码数组与切片相结合也是可能的。在这种情况下,你会得到副本。
这里有几个例子:
>>> arr = np.array([[ 1, 2, 4, 8],
... [ 16, 32, 64, 128],
... [256, 512, 1024, 2048]])
>>> arr
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a = arr[:, 1:3] # Take columns 1 and 2
>>> a
array([[ 2, 4],
[ 32, 64],
[ 512, 1024]])
>>> a.base
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a.base is arr
True
>>> b = arr[:, 1:4:2] # Take columns 1 and 3
>>> b
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> b.base
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> b.base is arr
True
>>> c = arr[:, [1, 3]] # Take columns 1 and 3
>>> c
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> c.base
array([[ 2, 32, 512],
[ 8, 128, 2048]])
>>> c.base is arr
False
>>> d = arr[:, [False, True, False, True]] # Take columns 1 and 3
>>> d
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> d.base
array([[ 2, 32, 512],
[ 8, 128, 2048]])
>>> d.base is arr
False
在这个例子中,你从二维数组arr开始。对行应用切片。使用冒号语法(:),相当于slice(None),意味着您想要获取所有行。
当您使用列的切片1:3和1:4:2时,会返回视图a和b。然而,当你应用列表[1, 3]和遮罩[False, True, False, True]时,你会得到副本c和d。
a和b的.base都是arr本身。c和d都有自己与arr无关的基地。
与一维数组一样,当您修改原始数组时,视图会发生变化,因为它们看到的是相同的数据,但副本保持不变:
>>> arr[0, 1] = 100 >>> arr array([[ 1, 100, 4, 8], [ 16, 32, 64, 128], [ 256, 512, 1024, 2048]]) >>> a array([[ 100, 4], [ 32, 64], [ 512, 1024]]) >>> b array([[ 100, 8], [ 32, 128], [ 512, 2048]]) >>> c array([[ 2, 8], [ 32, 128], [ 512, 2048]]) >>> d array([[ 2, 8], [ 32, 128], [ 512, 2048]])您将
arr中的值2更改为100,并修改了视图a和b中的相应元素。副本c和d不能这样修改。要了解更多关于索引 NumPy 数组的信息,可以查看官方快速入门教程和索引教程。
熊猫的索引:拷贝和浏览
您已经了解了如何在 NumPy 中使用不同的索引选项来引用实际数据(一个视图,或浅层副本)或新复制的数据(深层副本,或只是副本)。NumPy 对此有一套严格的规则。
Pandas 非常依赖 NumPy 阵列,但也提供了额外的功能和灵活性。正因为如此,返回视图和副本的规则更加复杂,也不那么简单。它们取决于数据的布局、数据类型和其他细节。事实上,Pandas 通常不保证视图或副本是否会被引用。
注:熊猫的索引是一个非常广泛的话题。正确使用熊猫数据结构是必不可少的。您可以使用多种技术:
- 字典式的符号
- 类属性(点)符号
- 存取器
.loc[]、.iloc[]、.at[]和.iat更多信息,请查看官方文档和熊猫数据框架:让数据工作变得愉快。
在这一节中,您将看到两个熊猫与 NumPy 行为相似的例子。首先,您可以看到用一个切片访问
df的前三行会返回一个视图:
>>> df = pd.DataFrame(data=data, index=index)
>>> df["a":"c"]
x y z
a 1 1 45
b 2 3 98
c 4 9 24
>>> df["a":"c"].to_numpy().base
array([[ 1, 2, 4, 8, 16],
[ 1, 3, 9, 27, 81],
[45, 98, 24, 11, 64]])
>>> df["a":"c"].to_numpy().base is df.to_numpy().base
True
该视图查看与df相同的数据。
另一方面,用标签列表访问df的前两列会返回一个副本:
>>> df = pd.DataFrame(data=data, index=index) >>> df[["x", "y"]] x y a 1 1 b 2 3 c 4 9 d 8 27 e 16 81 >>> df[["x", "y"]].to_numpy().base array([[ 1, 2, 4, 8, 16], [ 1, 3, 9, 27, 81]]) >>> df[["x", "y"]].to_numpy().base is df.to_numpy().base False副本的
.base与df不同。在下一节中,您将找到与索引数据帧和返回视图和副本相关的更多细节。你会看到一些情况,熊猫的行为变得更加复杂,与 NumPy 不同。
在 Pandas 中使用视图和副本
正如您已经了解的,当您试图修改数据的副本而不是原始数据时,Pandas 可以发出一个
SettingWithCopyWarning。这通常遵循链式索引。在本节中,您将看到一些产生
SettingWithCopyWarning的特定案例。您将确定原因并学习如何通过正确使用视图、副本和访问器来避免它们。链式索引
SettingWithCopyWarning和在第一个例子中,你已经看到了
SettingWithCopyWarning如何与链式索引一起工作。让我们详细说明一下。您已经创建了对应于
df["z"] < 50的数据帧和遮罩Series对象:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> mask = df["z"] < 50
>>> mask
a True
b False
c True
d True
e False
Name: z, dtype: bool
你已经知道赋值df[mask]["z"] = 0失败了。在这种情况下,您会得到一个SettingWithCopyWarning:
>>> df[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64赋值失败,因为
df[mask]返回一个副本。更准确地说,分配是在副本上进行的,而df不受影响。你也看到了在熊猫身上,评估顺序很重要。在某些情况下,您可以切换操作顺序以使代码正常工作:
>>> df["z"][mask] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
df["z"][mask] = 0成功,你得到没有SettingWithCopyWarning的修改后的df。
建议使用访问器,但是使用它们也会遇到麻烦:
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64在这种情况下,
df.loc[mask]返回一个副本,赋值失败,Pandas 正确地发出警告。在某些情况下,Pandas 未能发现问题,并且副本上的作业在没有
SettingWithCopyWarning的情况下通过:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[["a", "c", "e"]]["z"] = 0 # Assignment fails, no warning
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
在这里,您不会收到一个SettingWithCopyWarning并且df不会被更改,因为df.loc[["a", "c", "e"]]使用一个索引列表并返回一个副本,而不是一个视图。
在某些情况下,代码是有效的,但 Pandas 还是会发出警告:
>>> df = pd.DataFrame(data=data, index=index) >>> df[:3]["z"] = 0 # Assignment succeeds, with warning __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 0 b 2 3 0 c 4 9 0 d 8 27 11 e 16 81 64 >>> df = pd.DataFrame(data=data, index=index) >>> df.loc["a":"c"]["z"] = 0 # Assignment succeeds, with warning __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 0 b 2 3 0 c 4 9 0 d 8 27 11 e 16 81 64在这两种情况下,选择带有切片的前三行并获取视图。视图和
df上的分配都成功。但是你还是收到一个SettingWithCopyWarning。执行此类操作的推荐方式是避免链式索引。访问器在这方面很有帮助:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask, "z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
这种方法使用一个方法调用,没有链式索引,代码和您的意图都更加清晰。另外,这是一种稍微更有效的分配数据的方式。
数据类型对视图、副本和SettingWithCopyWarning 的影响
在 Pandas 中,创建视图和创建副本之间的区别也取决于所使用的数据类型。在决定是返回视图还是副本时,Pandas 处理单一数据类型的数据帧与处理多种数据类型的数据帧的方式不同。
让我们关注本例中的数据类型:
>>> df = pd.DataFrame(data=data, index=index) >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64 >>> df.dtypes x int64 y int64 z int64 dtype: object您已经创建了包含所有整数列的数据框架。这三列都有相同的数据类型,这一点很重要!在这种情况下,您可以选择带有切片的行并获得视图:
>>> df["b":"d"]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 64
这反映了到目前为止您在本文中看到的行为。df["b":"d"]返回一个视图并允许你修改原始数据。这就是赋值df["b":"d"]["z"] = 0成功的原因。请注意,在这种情况下,无论是否成功更改为df,您都会获得一个SettingWithCopyWarning。
如果您的数据帧包含不同类型的列,那么您可能会得到一个副本而不是一个视图,在这种情况下,相同的赋值将失败:
>>> df = pd.DataFrame(data=data, index=index).astype(dtype={"z": float}) >>> df x y z a 1 1 45.0 b 2 3 98.0 c 4 9 24.0 d 8 27 11.0 e 16 81 64.0 >>> df.dtypes x int64 y int64 z float64 dtype: object >>> df["b":"d"]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 45.0 b 2 3 98.0 c 4 9 24.0 d 8 27 11.0 e 16 81 64.0在这种情况下,您使用了。astype() 创建一个有两个整数列和一个浮点列的 DataFrame。与前面的例子相反,
df["b":"d"]现在返回一个副本,所以赋值df["b":"d"]["z"] = 0失败,df保持不变。当有疑问时,避免混淆,在整个代码中使用
.loc[]、.iloc[]、.at[]和.iat[]访问方法!分层索引
SettingWithCopyWarning和分级索引或多索引,是 Pandas 的一个特性,它使您能够根据层次结构在多个级别上组织行或列索引。这是一个强大的功能,增加了熊猫的灵活性,并使数据能够在两个以上的维度上工作。
使用元组作为行或列标签来创建分层索引:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
现在您有了具有两级列索引的数据框架df:
- 第一级包含标签
powers和random。 - 第二级有标签
x和y,分别属于powers和z,属于random。
表达式df["powers"]将返回一个 DataFrame,其中包含powers下面的所有列,即列x和y。如果你只想得到列x,那么你可以同时通过powers和x。正确的做法是使用表达式df["powers", "x"]:
>>> df["powers"] x y a 1 1 b 2 3 c 4 9 d 8 27 e 16 81 >>> df["powers", "x"] a 1 b 2 c 4 d 8 e 16 Name: (powers, x), dtype: int64 >>> df["powers", "x"] = 0 >>> df powers random x y z a 0 1 45 b 0 3 98 c 0 9 24 d 0 27 11 e 0 81 64在多级列索引的情况下,这是获取和设置列的一种方式。您还可以对多索引数据帧使用访问器来获取或修改数据:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df.loc[["a", "b"], "powers"]
x y
a 1 1
b 2 3
上面的例子使用了.loc[]来返回一个 DataFrame,其中包含行a和b以及列x和y,它们位于powers的下面。您可以类似地获得特定的列(或行):
>>> df.loc[["a", "b"], ("powers", "x")] a 1 b 2 Name: (powers, x), dtype: int64在这个例子中,您指定您想要行
a和b与列x的交集,该列在powers的下面。要获得一个单独的列,可以传递索引元组("powers", "x")并获得一个Series对象作为结果。您可以使用这种方法修改具有分层索引的数据帧的元素:
>>> df.loc[["a", "b"], ("powers", "x")] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 4 9 24
d 8 27 11
e 16 81 64
在上面的例子中,您避免了带访问器(df.loc[["a", "b"], ("powers", "x")])和不带访问器(df["powers", "x"])的链式索引。
正如您之前看到的,链式索引会导致一个SettingWithCopyWarning:
>>> df = pd.DataFrame( ... data={("powers", "x"): 2**np.arange(5), ... ("powers", "y"): 3**np.arange(5), ... ("random", "z"): np.array([45, 98, 24, 11, 64])}, ... index=["a", "b", "c", "d", "e"] ... ) >>> df powers random x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64 >>> df["powers"] x y a 1 1 b 2 3 c 4 9 d 8 27 e 16 81 >>> df["powers"]["x"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df powers random x y z a 0 1 45 b 0 3 98 c 0 9 24 d 0 27 11 e 0 81 64这里,
df["powers"]返回一个带有列x和y的数据帧。这只是一个指向来自df的数据的视图,所以赋值成功并且df被修改。但是熊猫还是发出了SettingWithCopyWarning。如果您重复相同的代码,但是在
df的列中使用不同的数据类型,那么您将得到不同的行为:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers"]["x"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
powers random
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
这次,df的数据类型不止一种,所以df["powers"]返回一个副本,df["powers"]["x"] = 0在这个副本上做了更改,df保持不变,给你一个SettingWithCopyWarning。
修改df的推荐方法是避免链式赋值。您已经了解到访问器非常方便,但是并不总是需要它们:
>>> df = pd.DataFrame( ... data={("powers", "x"): 2**np.arange(5), ... ("powers", "y"): 3**np.arange(5), ... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)}, ... index=["a", "b", "c", "d", "e"] ... ) >>> df["powers", "x"] = 0 >>> df powers random x y z a 0 1 45 b 0 3 98 c 0 9 24 d 0 27 11 e 0 81 64 >>> df = pd.DataFrame( ... data={("powers", "x"): 2**np.arange(5), ... ("powers", "y"): 3**np.arange(5), ... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)}, ... index=["a", "b", "c", "d", "e"] ... ) >>> df.loc[:, ("powers", "x")] = 0 >>> df powers random x y z a 0 1 45.0 b 0 3 98.0 c 0 9 24.0 d 0 27 11.0 e 0 81 64.0在这两种情况下,您都可以获得没有
SettingWithCopyWarning的修改后的数据帧df。改变默认的
SettingWithCopyWarning行为
SettingWithCopyWarning是一个警告,不是一个错误。您的代码在发布时仍然会执行,即使它可能不会像预期的那样工作。要改变这种行为,可以用
pandas.set_option()修改熊猫mode.chained_assignment选项。您可以使用以下设置:
pd.set_option("mode.chained_assignment", "raise")引出一个SettingWithCopyException。pd.set_option("mode.chained_assignment", "warn")发出一个SettingWithCopyWarning。这是默认行为。pd.set_option("mode.chained_assignment", None)抑制警告和错误。例如,这段代码将引发一个
SettingWithCopyException,而不是发出一个SettingWithCopyWarning:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> pd.set_option("mode.chained_assignment", "raise")
>>> df["powers"]["x"] = 0
除了修改默认行为,您还可以使用 get_option() 来检索与mode.chained_assignment相关的当前设置:
>>> pd.get_option("mode.chained_assignment") 'raise'在这种情况下,您得到了
"raise",因为您用set_option()改变了行为。正常情况下,pd.get_option("mode.chained_assignment")返回"warn"。虽然您可以抑制它,但是请记住,
SettingWithCopyWarning在通知您不正确的代码时非常有用。结论
在本文中,您了解了 NumPy 和 Pandas 中的视图和副本,以及它们的行为有何不同。您还看到了什么是
SettingWithCopyWarning以及如何避免它所指向的细微错误。具体来说,您已经了解了以下内容:
- NumPy 和 Pandas 中基于索引的赋值可以返回视图或副本。
- 视图和副本都是有用的,但是它们有不同的行为。
- 必须特别注意避免在副本上设置不需要的值。
- Pandas 中的访问器对于正确分配和引用数据是非常有用的对象。
理解视图和副本是正确使用 NumPy 和 Pandas 的重要要求,尤其是在处理大数据时。现在,您已经对这些概念有了坚实的理解,您已经准备好深入数据科学这个激动人心的世界了!
如果你有任何问题或意见,请写在下面的评论区。******
熊猫排序:Python 数据排序指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用熊猫排序 Python 中的数据
学习 pandas 排序方法是开始或练习使用 Python 进行基本数据分析的好方法。最常见的是,数据分析是用电子表格、 SQL 或熊猫来完成的。使用 pandas 的好处之一是它可以处理大量数据,并提供高性能的数据操作能力。
在本教程中,您将学习如何使用
.sort_values()和.sort_index(),这将使您能够有效地对数据帧中的数据进行排序。本教程结束时,你将知道如何:
- 按照一个或多个列的值对一个 pandas 数据帧进行排序
- 使用
ascending参数改变排序顺序- 使用
.sort_index()按index对数据帧进行排序- 对值排序时组织缺失数据
- 使用设置为
True的inplace将数据帧排序到位置为了跟随本教程,你需要对熊猫数据帧有一个基本的了解,并且对从文件中读取数据有一些熟悉。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
熊猫排序方法入门
快速提醒一下, DataFrame 是一种数据结构,带有行和列的标记轴。您可以按行或列值以及行或列索引对数据帧进行排序。
行和列都有索引,它是数据在数据帧中位置的数字表示。您可以使用数据帧的索引位置从特定的行或列中检索数据。默认情况下,索引号从零开始。您也可以手动分配自己的索引。
准备数据集
在本教程中,您将使用美国环境保护署(EPA)收集的 1984 年至 2021 年间制造的车辆的燃油经济性数据。EPA 燃油经济性数据集非常棒,因为它有许多不同类型的信息可以排序,从文本到数字数据类型。数据集总共包含 83 列。
要继续学习,您需要安装 pandas Python 库。本教程中的代码是使用 pandas 1.2.0 和 Python 3.9.1 执行的。
注意:整个燃油经济性数据集约为 18 MB。将整个数据集读入内存可能需要一两分钟。限制行数和列数将有助于提高性能,但在下载数据之前仍需要几秒钟。
出于分析的目的,您将按品牌、型号、年份和其他车辆属性查看车辆的 MPG(每加仑英里数)数据。您可以指定将哪些列读入数据框架。对于本教程,您只需要个可用列的子集。
以下是将燃油经济性数据集的相关列读入数据帧并显示前五行的命令:
>>> import pandas as pd
>>> column_subset = [
... "id",
... "make",
... "model",
... "year",
... "cylinders",
... "fuelType",
... "trany",
... "mpgData",
... "city08",
... "highway08"
... ]
>>> df = pd.read_csv(
... "https://www.fueleconomy.gov/feg/epadata/vehicles.csv",
... usecols=column_subset,
... nrows=100
... )
>>> df.head()
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
[5 rows x 10 columns]
通过使用数据集 URL 调用.read_csv(),您能够将数据加载到 DataFrame 中。缩小列的范围会导致更快的加载时间和更少的内存使用。为了进一步限制内存消耗并快速获得数据,您可以使用nrows指定加载多少行。
熟悉.sort_values()
您可以使用 .sort_values() 沿任一轴(列或行)对数据帧中的值进行排序。通常,您希望按一列或多列的值对数据帧中的行进行排序:
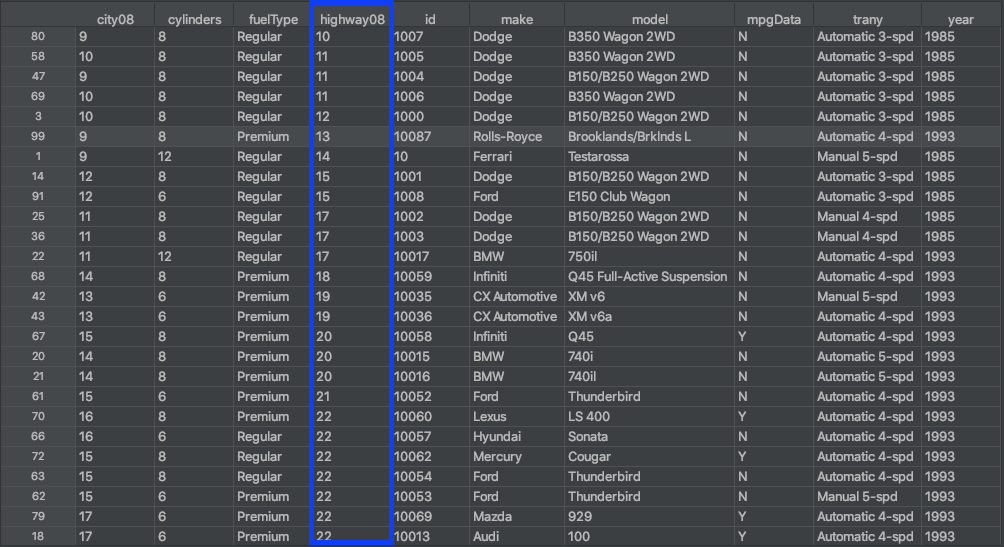
上图显示了使用.sort_values()根据highway08列中的值对数据帧的行进行排序的结果。这类似于使用列对电子表格中的数据进行排序。
熟悉.sort_index()
使用.sort_index()按照行索引或列标签对数据帧进行排序。与使用.sort_values()的不同之处在于,您是基于数据帧的行索引或列名对数据帧进行排序,而不是根据这些行或列中的值:
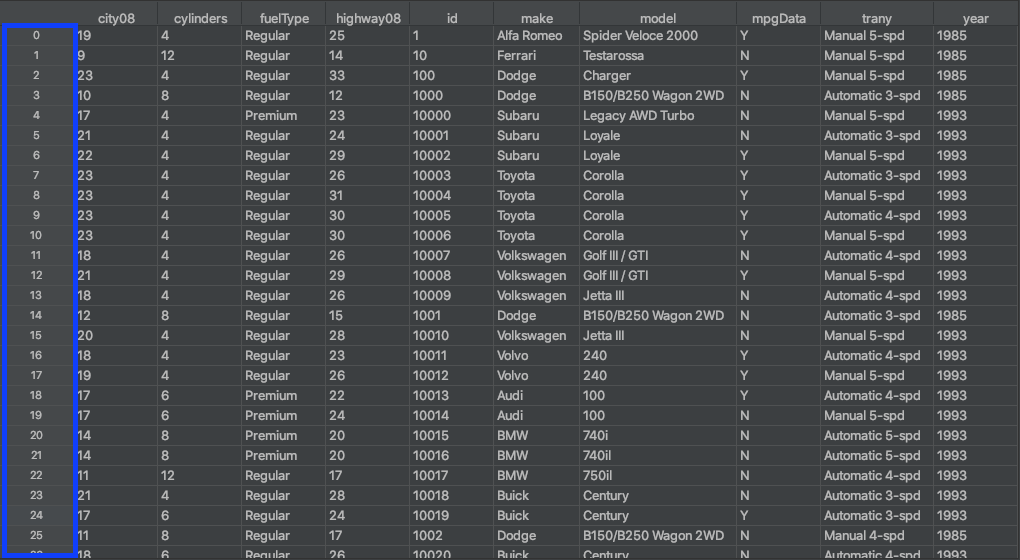
在上图中,数据帧的行索引用蓝色标出。索引不被认为是列,通常只有一个单行索引。行索引可以看作是从零开始的行号。
在单列上对数据帧排序
要根据单个列中的值对 DataFrame 进行排序,您将使用.sort_values()。默认情况下,这将返回一个按升序排序的新数据帧。它不会修改原始数据帧。
按列升序排序
要使用.sort_values(),您可以向方法传递一个参数,该参数包含您想要排序的列的名称。在本例中,您按city08列对数据帧进行排序,该列代表纯燃油汽车的城市 MPG:
>>> df.sort_values("city08") city08 cylinders fuelType ... mpgData trany year 99 9 8 Premium ... N Automatic 4-spd 1993 1 9 12 Regular ... N Manual 5-spd 1985 80 9 8 Regular ... N Automatic 3-spd 1985 47 9 8 Regular ... N Automatic 3-spd 1985 3 10 8 Regular ... N Automatic 3-spd 1985 .. ... ... ... ... ... ... ... 9 23 4 Regular ... Y Automatic 4-spd 1993 8 23 4 Regular ... Y Manual 5-spd 1993 7 23 4 Regular ... Y Automatic 3-spd 1993 76 23 4 Regular ... Y Manual 5-spd 1993 2 23 4 Regular ... Y Manual 5-spd 1985 [100 rows x 10 columns]这将使用
city08中的列值对数据框进行排序,首先显示 MPG 最低的车辆。默认情况下,.sort_values()按照升序对数据进行排序。虽然您没有为传递给.sort_values()的参数指定名称,但是您实际上使用了by参数,这将在下一个示例中看到。改变排序顺序
.sort_values()的另一个参数是ascending。默认情况下.sort_values()已经将ascending设置为True。如果你想让数据帧按降序排序,那么你可以将False传递给这个参数:
>>> df.sort_values(
... by="city08",
... ascending=False
... )
city08 cylinders fuelType ... mpgData trany year
9 23 4 Regular ... Y Automatic 4-spd 1993
2 23 4 Regular ... Y Manual 5-spd 1985
7 23 4 Regular ... Y Automatic 3-spd 1993
8 23 4 Regular ... Y Manual 5-spd 1993
76 23 4 Regular ... Y Manual 5-spd 1993
.. ... ... ... ... ... ... ...
58 10 8 Regular ... N Automatic 3-spd 1985
80 9 8 Regular ... N Automatic 3-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
47 9 8 Regular ... N Automatic 3-spd 1985
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
通过将False传递给ascending,可以颠倒排序顺序。现在,您的数据框架按照在城市条件下测得的平均 MPG 降序排列。MPG 值最高的车辆位于第一排。
选择排序算法
值得注意的是,pandas 允许你选择不同的排序算法用于.sort_values()和.sort_index()。可用的算法有quicksort、mergesort和heapsort。有关这些不同排序算法的更多信息,请查看 Python 中的排序算法。
对单个列排序时默认使用的算法是 quicksort 。要将其更改为稳定的排序算法,请使用 mergesort 。你可以用.sort_values()或.sort_index()中的kind参数来完成,就像这样:
>>> df.sort_values( ... by="city08", ... ascending=False, ... kind="mergesort" ... ) city08 cylinders fuelType ... mpgData trany year 2 23 4 Regular ... Y Manual 5-spd 1985 7 23 4 Regular ... Y Automatic 3-spd 1993 8 23 4 Regular ... Y Manual 5-spd 1993 9 23 4 Regular ... Y Automatic 4-spd 1993 10 23 4 Regular ... Y Manual 5-spd 1993 .. ... ... ... ... ... ... ... 69 10 8 Regular ... N Automatic 3-spd 1985 1 9 12 Regular ... N Manual 5-spd 1985 47 9 8 Regular ... N Automatic 3-spd 1985 80 9 8 Regular ... N Automatic 3-spd 1985 99 9 8 Premium ... N Automatic 4-spd 1993 [100 rows x 10 columns]使用
kind,你设置排序算法为mergesort。前面的输出使用默认的quicksort算法。查看突出显示的索引,您可以看到这些行的顺序不同。这是因为quicksort不是一个稳定的排序算法,但是mergesort是。注意:在熊猫中,当你在多个列或标签上排序时,
kind被忽略。当您对具有相同键的多条记录进行排序时,稳定排序算法将在排序后保持这些记录的原始顺序。因此,如果您计划执行多次排序,那么使用稳定的排序算法是必要的。
在多列上对数据帧进行排序
在数据分析中,通常希望根据多列的值对数据进行排序。假设您有一个包含人们的名字和姓氏的数据集。先按姓再按名排序是有意义的,这样姓相同的人就按名的字母顺序排列。
在第一个例子中,您在一个名为
city08的列上对数据帧进行了排序。从分析的角度来看,城市条件下的 MPG 是决定汽车受欢迎程度的重要因素。除了城市条件下的 MPG,您可能还想看看高速公路条件下的 MPG。要按两个键排序,您可以将列名的列表传递给by:
>>> df.sort_values(
... by=["city08", "highway08"]
... )[["city08", "highway08"]]
city08 highway08
80 9 10
47 9 11
99 9 13
1 9 14
58 10 11
.. ... ...
9 23 30
10 23 30
8 23 31
76 23 31
2 23 33
[100 rows x 2 columns]
通过指定列名city08和highway08的列表,可以使用.sort_values()对两列上的数据帧进行排序。下一个例子将解释如何指定排序顺序,以及为什么注意所使用的列名列表很重要。
按多列升序排序
要对多个列上的数据帧进行排序,必须提供列名列表。例如,要按make和model排序,您应该创建以下列表,然后将其传递给.sort_values():
>>> df.sort_values( ... by=["make", "model"] ... )[["make", "model"]] make model 0 Alfa Romeo Spider Veloce 2000 18 Audi 100 19 Audi 100 20 BMW 740i 21 BMW 740il .. ... ... 12 Volkswagen Golf III / GTI 13 Volkswagen Jetta III 15 Volkswagen Jetta III 16 Volvo 240 17 Volvo 240 [100 rows x 2 columns]现在你的数据帧按
make升序排序。如果有两个或更多相同的品牌,则按model排序。列表中列名的指定顺序与数据帧的排序方式相对应。更改列排序顺序
因为您使用多列进行排序,所以您可以指定列的排序顺序。如果您想改变前面例子中的逻辑排序顺序,那么您可以改变列表中传递给
by参数的列名的顺序:
>>> df.sort_values(
... by=["model", "make"]
... )[["make", "model"]]
make model
18 Audi 100
19 Audi 100
16 Volvo 240
17 Volvo 240
75 Mazda 626
.. ... ...
62 Ford Thunderbird
63 Ford Thunderbird
88 Oldsmobile Toronado
42 CX Automotive XM v6
43 CX Automotive XM v6a
[100 rows x 2 columns]
您的数据帧现在按model列升序排序,如果有两个或更多相同的模型,则按make排序。您可以看到,更改列的顺序也会更改值的排序顺序。
按多列降序排序
到目前为止,您只对多列进行了升序排序。在下一个例子中,您将基于make和model列进行降序排序。要按降序排序,请将ascending设置为False:
>>> df.sort_values( ... by=["make", "model"], ... ascending=False ... )[["make", "model"]] make model 16 Volvo 240 17 Volvo 240 13 Volkswagen Jetta III 15 Volkswagen Jetta III 11 Volkswagen Golf III / GTI .. ... ... 21 BMW 740il 20 BMW 740i 18 Audi 100 19 Audi 100 0 Alfa Romeo Spider Veloce 2000 [100 rows x 2 columns]对于任何具有相同
make的汽车,make列中的值按字母顺序排列,而model列中的值按降序排列。对于文本数据,排序是区分大小写,这意味着大写文本将首先以升序出现,最后以降序出现。按不同排序顺序的多列排序
您可能想知道是否可以使用多列进行排序,并让这些列使用不同的
ascending参数。对于 pandas,您可以通过一个方法调用来实现。如果您想对一些列进行升序排序,对一些列进行降序排序,那么您可以传递一个由布尔值到ascending组成的列表。在本例中,您按照
make、model和city08列对数据帧进行排序,前两列按升序排序,而city08按降序排序。为此,您向by传递一个列名列表,向ascending传递一个布尔值列表:
>>> df.sort_values(
... by=["make", "model", "city08"],
... ascending=[True, True, False]
... )[["make", "model", "city08"]]
make model city08
0 Alfa Romeo Spider Veloce 2000 19
18 Audi 100 17
19 Audi 100 17
20 BMW 740i 14
21 BMW 740il 14
.. ... ... ...
11 Volkswagen Golf III / GTI 18
15 Volkswagen Jetta III 20
13 Volkswagen Jetta III 18
17 Volvo 240 19
16 Volvo 240 18
[100 rows x 3 columns]
现在你的数据帧按照make和model升序排序,但是city08列按照降序排序。这很有帮助,因为它按分类顺序对汽车进行分组,并首先显示 MPG 最高的汽车。
根据索引对数据帧进行排序
在对索引进行排序之前,最好知道索引代表什么。DataFrame 有一个 .index 属性,默认情况下是其行位置的数字表示。您可以将索引视为行号。它有助于快速查找和识别行。
按索引升序排序
您可以使用.sort_index()根据行索引对数据帧进行排序。像前面例子中那样按列值排序会对数据帧中的行进行重新排序,因此索引会变得杂乱无章。当您筛选数据帧或删除或添加行时,也会发生这种情况。
为了说明.sort_index()的用法,首先使用.sort_values()创建一个新的排序数据帧:
>>> sorted_df = df.sort_values(by=["make", "model"]) >>> sorted_df city08 cylinders fuelType ... mpgData trany year 0 19 4 Regular ... Y Manual 5-spd 1985 18 17 6 Premium ... Y Automatic 4-spd 1993 19 17 6 Premium ... N Manual 5-spd 1993 20 14 8 Premium ... N Automatic 5-spd 1993 21 14 8 Premium ... N Automatic 5-spd 1993 .. ... ... ... ... ... ... ... 12 21 4 Regular ... Y Manual 5-spd 1993 13 18 4 Regular ... N Automatic 4-spd 1993 15 20 4 Regular ... N Manual 5-spd 1993 16 18 4 Regular ... Y Automatic 4-spd 1993 17 19 4 Regular ... Y Manual 5-spd 1993 [100 rows x 10 columns]您已经创建了一个使用多个值排序的数据帧。请注意,行索引没有特定的顺序。要将新的数据帧恢复到原来的顺序,可以使用
.sort_index():
>>> sorted_df.sort_index()
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Y Automatic 3-spd 1993
96 17 6 Regular ... N Automatic 4-spd 1993
97 15 6 Regular ... N Automatic 4-spd 1993
98 15 6 Regular ... N Manual 5-spd 1993
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
现在索引是升序排列的。就像.sort_values()一样,.sort_index()中ascending的默认实参是True,通过False可以改成降序。索引排序对数据本身没有影响,因为值是不变的。
当您已经使用 .set_index() 指定了自定义索引时,这尤其有用。如果您想使用make和model列设置一个自定义索引,那么您可以将一个列表传递给.set_index():
>>> assigned_index_df = df.set_index( ... ["make", "model"] ... ) >>> assigned_index_df city08 cylinders ... trany year make model ... Alfa Romeo Spider Veloce 2000 19 4 ... Manual 5-spd 1985 Ferrari Testarossa 9 12 ... Manual 5-spd 1985 Dodge Charger 23 4 ... Manual 5-spd 1985 B150/B250 Wagon 2WD 10 8 ... Automatic 3-spd 1985 Subaru Legacy AWD Turbo 17 4 ... Manual 5-spd 1993 ... ... ... ... ... Pontiac Grand Prix 17 6 ... Automatic 3-spd 1993 Grand Prix 17 6 ... Automatic 4-spd 1993 Grand Prix 15 6 ... Automatic 4-spd 1993 Grand Prix 15 6 ... Manual 5-spd 1993 Rolls-Royce Brooklands/Brklnds L 9 8 ... Automatic 4-spd 1993 [100 rows x 8 columns]使用这种方法,可以用两个轴标签替换默认的基于整数的行索引。这被认为是一个
MultiIndex或一个层次索引。您的数据帧现在由多个关键字索引,您可以使用.sort_index()进行排序:
>>> assigned_index_df.sort_index()
city08 cylinders ... trany year
make model ...
Alfa Romeo Spider Veloce 2000 19 4 ... Manual 5-spd 1985
Audi 100 17 6 ... Automatic 4-spd 1993
100 17 6 ... Manual 5-spd 1993
BMW 740i 14 8 ... Automatic 5-spd 1993
740il 14 8 ... Automatic 5-spd 1993
... ... ... ... ...
Volkswagen Golf III / GTI 21 4 ... Manual 5-spd 1993
Jetta III 18 4 ... Automatic 4-spd 1993
Jetta III 20 4 ... Manual 5-spd 1993
Volvo 240 18 4 ... Automatic 4-spd 1993
240 19 4 ... Manual 5-spd 1993
[100 rows x 8 columns]
首先使用make和model列为数据帧分配一个新的索引,然后使用.sort_index()对索引进行排序。你可以在熊猫文档中阅读更多关于使用 .set_index() 的信息。
按索引降序排序
在下一个示例中,您将按照索引降序对数据帧进行排序。记住,在用.sort_values()对数据帧进行排序时,可以通过将ascending设置为False来颠倒排序顺序。该参数也适用于.sort_index(),因此您可以像这样以相反的顺序对数据帧进行排序:
>>> assigned_index_df.sort_index(ascending=False) city08 cylinders ... trany year make model ... Volvo 240 18 4 ... Automatic 4-spd 1993 240 19 4 ... Manual 5-spd 1993 Volkswagen Jetta III 18 4 ... Automatic 4-spd 1993 Jetta III 20 4 ... Manual 5-spd 1993 Golf III / GTI 18 4 ... Automatic 4-spd 1993 ... ... ... ... ... BMW 740il 14 8 ... Automatic 5-spd 1993 740i 14 8 ... Automatic 5-spd 1993 Audi 100 17 6 ... Automatic 4-spd 1993 100 17 6 ... Manual 5-spd 1993 Alfa Romeo Spider Veloce 2000 19 4 ... Manual 5-spd 1985 [100 rows x 8 columns]现在,您的数据帧按其索引降序排序。使用
.sort_index()和.sort_values()的一个区别是.sort_index()没有by参数,因为默认情况下它在行索引上对数据帧进行排序。探索高级索引排序概念
在数据分析的许多情况下,您希望按照层次索引进行排序。你已经看到了如何在
MultiIndex中使用make和model。对于这个数据集,您还可以使用id列作为索引。将
id列设置为索引可能有助于链接相关数据集。例如,环保署的排放数据集也使用id来表示车辆记录 id。这将排放数据与燃油经济性数据联系起来。在数据帧中对两个数据集的索引进行排序可以使用其他方法加快速度,例如.merge()。要了解更多关于在 pandas 中组合数据的信息,请查看使用 merge()组合 Pandas 中的数据。join()和 concat() 。对数据帧的列进行排序
您还可以使用数据框架的列标签对行值进行排序。使用可选参数
axis设置为1的.sort_index()将按列标签对数据帧进行排序。排序算法应用于轴标签,而不是实际数据。这有助于数据帧的视觉检查。使用数据帧
axis当您使用
.sort_index()而不传递任何显式参数时,它使用axis=0作为默认参数。数据帧的轴是指索引(axis=0)或列(axis=1)。您可以使用两个轴对数据帧中的数据进行索引和选择,以及对数据进行排序。使用列标签进行排序
您也可以使用数据帧的列标签作为
.sort_index()的排序键。将axis设置为1会根据列标签对数据帧的列进行排序:
>>> df.sort_index(axis=1)
city08 cylinders fuelType ... mpgData trany year
0 19 4 Regular ... Y Manual 5-spd 1985
1 9 12 Regular ... N Manual 5-spd 1985
2 23 4 Regular ... Y Manual 5-spd 1985
3 10 8 Regular ... N Automatic 3-spd 1985
4 17 4 Premium ... N Manual 5-spd 1993
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Y Automatic 3-spd 1993
96 17 6 Regular ... N Automatic 4-spd 1993
97 15 6 Regular ... N Automatic 4-spd 1993
98 15 6 Regular ... N Manual 5-spd 1993
99 9 8 Premium ... N Automatic 4-spd 1993
[100 rows x 10 columns]
数据帧的列按字母升序从左到右排序。如果您想按降序对列进行排序,那么您可以使用ascending=False:
>>> df.sort_index(axis=1, ascending=False) year trany mpgData ... fuelType cylinders city08 0 1985 Manual 5-spd Y ... Regular 4 19 1 1985 Manual 5-spd N ... Regular 12 9 2 1985 Manual 5-spd Y ... Regular 4 23 3 1985 Automatic 3-spd N ... Regular 8 10 4 1993 Manual 5-spd N ... Premium 4 17 .. ... ... ... ... ... ... ... 95 1993 Automatic 3-spd Y ... Regular 6 17 96 1993 Automatic 4-spd N ... Regular 6 17 97 1993 Automatic 4-spd N ... Regular 6 15 98 1993 Manual 5-spd N ... Regular 6 15 99 1993 Automatic 4-spd N ... Premium 8 9 [100 rows x 10 columns]使用
.sort_index()中的axis=1,您以升序和降序对数据帧的列进行了排序。这在其他数据集中可能更有用,例如列标签对应于一年中的几个月。在这种情况下,按月升序或降序排列数据是有意义的。在 Pandas 中排序时处理缺失数据
现实世界的数据常常有许多不完美之处。虽然 pandas 有几种方法可以让你在排序前清理你的数据(T2 ),但是有时候在你排序的时候看看哪些数据丢失了会更好。你可以通过
na_position参数来实现。用于本教程的燃油经济性数据子集没有缺失值。为了说明
na_position的用法,首先您需要创建一些缺失的数据。下面这段代码基于现有的mpgData列创建一个新列,映射True,其中mpgData等于Y,而NaN不等于:
>>> df["mpgData_"] = df["mpgData"].map({"Y": True})
>>> df
city08 cylinders fuelType ... trany year mpgData_
0 19 4 Regular ... Manual 5-spd 1985 True
1 9 12 Regular ... Manual 5-spd 1985 NaN
2 23 4 Regular ... Manual 5-spd 1985 True
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
.. ... ... ... ... ... ... ...
95 17 6 Regular ... Automatic 3-spd 1993 True
96 17 6 Regular ... Automatic 4-spd 1993 NaN
97 15 6 Regular ... Automatic 4-spd 1993 NaN
98 15 6 Regular ... Manual 5-spd 1993 NaN
99 9 8 Premium ... Automatic 4-spd 1993 NaN
[100 rows x 11 columns]
现在您有了一个名为mpgData_的新列,它包含了True和NaN值。您将使用该列来查看使用这两种排序方法时na_position的效果。要了解更多关于使用.map()的信息,你可以阅读熊猫项目:用 Python 制作年级册&熊猫。
了解.sort_values() 中的na_position参数
.sort_values()接受一个名为 na_position 的参数,该参数有助于组织正在排序的列中缺少的数据。如果对缺少数据的列进行排序,则缺少值的行将出现在数据框的末尾。无论您是按升序还是降序排序,都会发生这种情况。
当您对缺少数据的列进行排序时,您的数据框架如下所示:
>>> df.sort_values(by="mpgData_") city08 cylinders fuelType ... trany year mpgData_ 0 19 4 Regular ... Manual 5-spd 1985 True 55 18 6 Regular ... Automatic 4-spd 1993 True 56 18 6 Regular ... Automatic 4-spd 1993 True 57 16 6 Premium ... Manual 5-spd 1993 True 59 17 6 Regular ... Automatic 4-spd 1993 True .. ... ... ... ... ... ... ... 94 18 6 Regular ... Automatic 4-spd 1993 NaN 96 17 6 Regular ... Automatic 4-spd 1993 NaN 97 15 6 Regular ... Automatic 4-spd 1993 NaN 98 15 6 Regular ... Manual 5-spd 1993 NaN 99 9 8 Premium ... Automatic 4-spd 1993 NaN [100 rows x 11 columns]要改变这种行为并让丢失的数据首先出现在数据帧中,可以将
na_position设置为first。na_position参数只接受默认值last和first。下面是如何在.sort_values()中使用na_postion:
>>> df.sort_values(
... by="mpgData_",
... na_position="first"
... )
city08 cylinders fuelType ... trany year mpgData_
1 9 12 Regular ... Manual 5-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
5 21 4 Regular ... Automatic 3-spd 1993 NaN
11 18 4 Regular ... Automatic 4-spd 1993 NaN
.. ... ... ... ... ... ... ...
32 15 8 Premium ... Automatic 4-spd 1993 True
33 15 8 Premium ... Automatic 4-spd 1993 True
37 17 6 Regular ... Automatic 3-spd 1993 True
85 17 6 Regular ... Automatic 4-spd 1993 True
95 17 6 Regular ... Automatic 3-spd 1993 True
[100 rows x 11 columns]
现在,用于排序的列中的任何缺失数据都将显示在数据框的顶部。当您第一次开始分析数据,并且不确定是否有缺失值时,这非常有用。
了解.sort_index() 中的na_position参数
.sort_index()也接受na_position。您的数据帧通常不会将NaN值作为其索引的一部分,因此该参数在.sort_index()中用处不大。但是,如果您的数据帧在行索引或列名中确实有NaN,那么您可以使用.sort_index()和na_position快速识别出来。
默认情况下,该参数设置为last,将NaN值放在排序结果的末尾。要改变这种行为,让丢失的数据首先出现在数据帧中,将na_position设置为first。
使用排序方法修改数据帧
在迄今为止您看到的所有示例中,当您调用这些方法时,.sort_values()和.sort_index()都返回了 DataFrame 对象。这是因为在默认情况下,熊猫的排序在位置不工作。一般来说,这是使用 pandas 分析数据的最常见和首选方式,因为它创建了一个新的数据框架,而不是修改原始数据框架。这允许您保留从文件中读取数据时的数据状态。
但是,您可以通过用值True指定可选参数 inplace 来直接修改原始数据帧。大多数熊猫方法都包含了inplace参数。下面,您将看到一些使用inplace=True对数据帧进行排序的例子。
使用.sort_values()就位
当inplace设置为True时,您修改原始数据帧,因此排序方法返回 None 。像第一个例子一样,通过city08列的值对数据帧进行排序,但是将inplace设置为True:
>>> df.sort_values("city08", inplace=True)注意调用
.sort_values()并没有返回数据帧。下面是最初的df的样子:
>>> df
city08 cylinders fuelType ... trany year mpgData_
99 9 8 Premium ... Automatic 4-spd 1993 NaN
1 9 12 Regular ... Manual 5-spd 1985 NaN
80 9 8 Regular ... Automatic 3-spd 1985 NaN
47 9 8 Regular ... Automatic 3-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
.. ... ... ... ... ... ... ...
9 23 4 Regular ... Automatic 4-spd 1993 True
8 23 4 Regular ... Manual 5-spd 1993 True
7 23 4 Regular ... Automatic 3-spd 1993 True
76 23 4 Regular ... Manual 5-spd 1993 True
2 23 4 Regular ... Manual 5-spd 1985 True
[100 rows x 11 columns]
在df对象中,值现在根据city08列按升序排序。您的原始数据帧已被修改,这些更改将持续存在。一般来说,避免使用inplace=True进行分析是个好主意,因为对数据框架的更改是不可撤销的。
使用.sort_index()就位
下一个例子说明了inplace也可以和.sort_index()一起工作。
因为当您将文件读入数据帧时,索引是按升序创建的,所以您可以再次修改您的df对象,使其恢复到初始顺序。使用inplace设置为True的.sort_index()来修改数据帧:
>>> df.sort_index(inplace=True) >>> df city08 cylinders fuelType ... trany year mpgData_ 0 19 4 Regular ... Manual 5-spd 1985 True 1 9 12 Regular ... Manual 5-spd 1985 NaN 2 23 4 Regular ... Manual 5-spd 1985 True 3 10 8 Regular ... Automatic 3-spd 1985 NaN 4 17 4 Premium ... Manual 5-spd 1993 NaN .. ... ... ... ... ... ... ... 95 17 6 Regular ... Automatic 3-spd 1993 True 96 17 6 Regular ... Automatic 4-spd 1993 NaN 97 15 6 Regular ... Automatic 4-spd 1993 NaN 98 15 6 Regular ... Manual 5-spd 1993 NaN 99 9 8 Premium ... Automatic 4-spd 1993 NaN [100 rows x 11 columns]现在您的数据帧已经使用
.sort_index()再次修改。因为您的数据帧仍然有默认索引,所以按升序排序会将数据恢复到原来的顺序。如果你熟悉 Python 的内置函数
sort()和sorted(),那么熊猫排序方法中可用的inplace参数可能感觉非常相似。要了解更多信息,您可以查看如何在 Python 中使用 sorted()和 sort()。结论
您现在知道如何使用 pandas 库的两个核心方法:
.sort_values()和.sort_index()。有了这些知识,您就可以使用数据框架进行基本的数据分析。虽然这两种方法之间有很多相似之处,但看到它们之间的差异,就可以清楚地看出哪种方法适用于不同的分析任务。在本教程中,您已经学会了如何:
- 按照一个或多个列的值对一个 pandas 数据帧进行排序
- 使用
ascending参数改变排序顺序- 使用
.sort_index()按index对数据帧进行排序- 对值排序时组织缺失数据
- 使用设置为
True的inplace将数据帧排序到位置这些方法是精通数据分析的重要组成部分。他们将帮助你建立一个坚实的基础,在此基础上你可以执行更高级的熊猫操作。如果您想看一些 pandas 排序方法的更高级用法的例子,那么 pandas 文档是一个很好的资源。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用熊猫排序 Python 中的数据*****
如何在 Python 中使用 PDF
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 如何用 Python 处理 PDF
可移植文档格式(PDF)是一种文件格式,可用于跨操作系统可靠地呈现和交换文档。虽然 PDF 最初是由 Adobe 发明的,但它现在是由国际标准化组织(ISO)维护的一个开放标准。您可以使用
PyPDF2包来处理 Python 中预先存在的 PDF。
PyPDF2是一个纯 Python 包,可以用于许多不同类型的 PDF 操作。到本文结束时,你将知道如何做以下事情:
- 用 Python 从 PDF 中提取文档信息
- 旋转页面
- 合并 pdf
- 分割 pdf
- 添加水印
- 加密 PDF
我们开始吧!
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
pyPdf、PyPDF2、PyPDF4、T3 的历史最初的
pyPdf套装发布于 2005 年。上一次正式发布pyPdf是在 2010 年。时隔一年左右,一家名为 Phasit 的公司赞助了一款名为PyPDF2的pyPdf叉子。该代码被编写为向后兼容原始代码,并在几年内运行良好,其最后一次发布是在 2016 年。有一个名为
PyPDF3的包的简短系列发布,然后该项目被重命名为PyPDF4。所有这些项目做的都差不多,但是pyPdf和 PyPDF2+之间最大的区别是后者版本增加了 Python 3 支持。Python 3 有一个和原来T3 不一样的 Python 3 分叉,但是那个已经很多年没有维护了。虽然
PyPDF2在 2016 年被废弃,但它在 2022 年被重新启用,目前正在积极维护中。新的PyPDF4并不完全向后兼容PyPDF2。本文中的大多数例子都可以很好地与PyPDF4一起工作,但也有一些不能,这就是为什么PyPDF4在本文中没有被重点介绍的原因。随意用PyPDF4替换PyPDF2的导入,看看它如何为你工作。
pdfrw:替代方案帕特里克·莫平创造了一个名为
pdfrw的包,它可以做很多和PyPDF2一样的事情。您可以使用pdfrw完成所有与您将在本文中学习如何为PyPDF2完成的任务相同的任务,加密是一个明显的例外。最大的不同是它集成了 ReportLab 包,这样你就可以获取一个预先存在的 PDF,并使用部分或全部预先存在的 PDF 构建一个新的。
安装
如果你碰巧用的是 Anaconda 而不是普通的 Python,那么安装
PyPDF2可以用pip或conda来完成。下面是如何安装带有
pip的PyPDF2:$ pip install pypdf2安装非常快,因为
PyPDF2没有任何依赖关系。你可能会花和安装包一样多的时间来下载它。现在让我们继续学习如何从 PDF 中提取一些信息。
如何用 Python 从 PDF 中提取文档信息
您可以使用
PyPDF2从 PDF 中提取元数据和一些文本。当您对预先存在的 PDF 文件进行某些类型的自动化时,这很有用。以下是当前可以提取的数据类型:
- 作者
- 创造者
- 生产者
- 科目
- 标题
- 页数
你需要去找一个 PDF 来用于这个例子。你可以在你的机器上使用任何你手边的 PDF 文件。为了让事情变得简单,我去了 Leanpub 并拿了一本我的书作为这个练习的样本。你要下载的样本叫做
reportlab-sample.pdf。让我们使用该 PDF 编写一些代码,并了解如何访问这些属性:
# extract_doc_info.py from PyPDF2 import PdfFileReader def extract_information(pdf_path): with open(pdf_path, 'rb') as f: pdf = PdfFileReader(f) information = pdf.getDocumentInfo() number_of_pages = pdf.getNumPages() txt = f""" Information about {pdf_path}: Author: {information.author} Creator: {information.creator} Producer: {information.producer} Subject: {information.subject} Title: {information.title} Number of pages: {number_of_pages} """ print(txt) return information if __name__ == '__main__': path = 'reportlab-sample.pdf' extract_information(path)这里您从
PyPDF2包中导入PdfFileReader。PdfFileReader是一个有几个与 PDF 文件交互的方法的类。在这个例子中,您调用.getDocumentInfo(),它将返回一个DocumentInformation的实例。这包含了你感兴趣的大部分信息。您还调用 reader 对象上的.getNumPages(),它返回文档中的页数。注意:最后一个代码块使用 Python 3 新的 f 字符串进行字符串格式化。如果你想了解更多,你可以查看 Python 3 的 f-Strings:一个改进的字符串格式语法(指南)。
information变量有几个实例属性,您可以使用它们从文档中获得想要的其余元数据。你把信息打印出来,然后还回去以备将来使用。虽然
PyPDF2有.extractText(),可以在它的页面对象上使用(在这个例子中没有显示),但是它不能很好地工作。一些 pdf 将返回文本,一些将返回空字符串。当你想从 PDF 中提取文本时,你应该选择PDFMiner项目。PDFMiner更加健壮,专门用于从 pdf 中提取文本。现在您已经准备好了解旋转 PDF 页面。
如何翻页
有时,您会收到包含处于横向模式而非纵向模式页面的 pdf。或者它们甚至是上下颠倒的。当有人将文档扫描成 PDF 或电子邮件时,可能会发生这种情况。您可以将文档打印出来并阅读纸质版本,也可以使用 Python 的强大功能来旋转有问题的页面。
对于这个例子,你可以选择一篇真正的 Python 文章并打印成 PDF。
让我们学习如何用
PyPDF2旋转文章的几页:# rotate_pages.py from PyPDF2 import PdfFileReader, PdfFileWriter def rotate_pages(pdf_path): pdf_writer = PdfFileWriter() pdf_reader = PdfFileReader(pdf_path) # Rotate page 90 degrees to the right page_1 = pdf_reader.getPage(0).rotateClockwise(90) pdf_writer.addPage(page_1) # Rotate page 90 degrees to the left page_2 = pdf_reader.getPage(1).rotateCounterClockwise(90) pdf_writer.addPage(page_2) # Add a page in normal orientation pdf_writer.addPage(pdf_reader.getPage(2)) with open('rotate_pages.pdf', 'wb') as fh: pdf_writer.write(fh) if __name__ == '__main__': path = 'Jupyter_Notebook_An_Introduction.pdf' rotate_pages(path)对于这个例子,除了
PdfFileReader之外,您还需要导入T0 】,因为您将需要写出一个新的 PDF。rotate_pages()获取您想要修改的 PDF 的路径。在这个函数中,您需要创建一个名为pdf_writer的 writer 对象和一个名为pdf_reader的 reader 对象。接下来,您可以使用
.GetPage()来获得想要的页面。这是第 0 页,也就是第一页。然后调用 page 对象的.rotateClockwise()方法,90 度传入。然后对于第二页,你调用.rotateCounterClockwise()并且同样 90 度通过它。注意:
PyPDF2包只允许你以 90 度为增量旋转一页。否则你会收到一个AssertionError。在每次调用旋转方法之后,调用
.addPage()。这将把页面的旋转版本添加到 writer 对象中。添加到 writer 对象的最后一页是第 3 页,没有进行任何旋转。最后,使用
.write()写出新的 PDF。它将一个类似于文件的对象作为它的参数。这个新的 PDF 将包含三页。前两页将向彼此相反的方向旋转,并且是横向的,而第三页是普通页。现在让我们学习如何将多个 pdf 合并成一个。
如何合并 pdf 文件
在许多情况下,您会想要将两个或多个 PDF 合并成一个 PDF。例如,您可能有一个标准的封面,需要转到许多类型的报告。你可以用 Python 来帮你做这类事情。
对于本例,您可以打开一个 PDF,并将页面作为单独的 PDF 打印出来。然后再做一次,但是用不同的页面。这将为您提供一些输入,用于示例目的。
让我们继续编写一些代码,您可以使用它们将 pdf 合并在一起:
# pdf_merging.py from PyPDF2 import PdfFileReader, PdfFileWriter def merge_pdfs(paths, output): pdf_writer = PdfFileWriter() for path in paths: pdf_reader = PdfFileReader(path) for page in range(pdf_reader.getNumPages()): # Add each page to the writer object pdf_writer.addPage(pdf_reader.getPage(page)) # Write out the merged PDF with open(output, 'wb') as out: pdf_writer.write(out) if __name__ == '__main__': paths = ['document1.pdf', 'document2.pdf'] merge_pdfs(paths, output='merged.pdf')当您有想要合并在一起的 pdf 列表时,您可以使用
merge_pdfs()。您还需要知道保存结果的位置,因此这个函数接受一个输入路径列表和一个输出路径。然后循环输入,并为每个输入创建一个 PDF 阅读器对象。接下来,您将遍历 PDF 文件中的所有页面,并使用
.addPage()将这些页面中的每一个添加到它自身。一旦你完成了列表中所有 pdf 的所有页面的迭代,你将在最后写出结果。
我想指出的一点是,如果您不想合并每个 PDF 的所有页面,您可以通过添加一系列要添加的页面来增强这个脚本。如果你喜欢挑战,你也可以使用 Python 的
argparse模块为这个函数创建一个命令行界面。让我们来了解一下如何做与合并相反的事情!
如何分割 pdf 文件
有时,您可能需要将一个 PDF 拆分成多个 PDF。对于包含大量扫描内容的 PDF 来说尤其如此,但是有太多好的理由想要分割 PDF。
以下是如何使用
PyPDF2将 PDF 分割成多个文件:# pdf_splitting.py from PyPDF2 import PdfFileReader, PdfFileWriter def split(path, name_of_split): pdf = PdfFileReader(path) for page in range(pdf.getNumPages()): pdf_writer = PdfFileWriter() pdf_writer.addPage(pdf.getPage(page)) output = f'{name_of_split}{page}.pdf' with open(output, 'wb') as output_pdf: pdf_writer.write(output_pdf) if __name__ == '__main__': path = 'Jupyter_Notebook_An_Introduction.pdf' split(path, 'jupyter_page')在本例中,您再次创建了一个 PDF reader 对象,并对其页面进行循环。对于 PDF 中的每个页面,您将创建一个新的 PDF writer 实例并向其添加一个页面。然后,您将把该页面写出到一个唯一命名的文件中。当脚本运行完成时,您应该将原始 PDF 的每一页分割成单独的 PDF。
现在,让我们花一点时间来学习如何添加水印到您的 PDF。
如何添加水印
水印是印刷和数字文档上的识别图像或图案。有些水印只有在特殊的光照条件下才能看到。水印之所以重要,是因为它允许您保护您的知识产权,如您的图像或 pdf。水印的另一个术语是覆盖。
你可以用 Python 和
PyPDF2给你的文档加水印。您需要一个只包含您的水印图像或文本的 PDF。现在让我们学习如何添加水印:
# pdf_watermarker.py from PyPDF2 import PdfFileWriter, PdfFileReader def create_watermark(input_pdf, output, watermark): watermark_obj = PdfFileReader(watermark) watermark_page = watermark_obj.getPage(0) pdf_reader = PdfFileReader(input_pdf) pdf_writer = PdfFileWriter() # Watermark all the pages for page in range(pdf_reader.getNumPages()): page = pdf_reader.getPage(page) page.mergePage(watermark_page) pdf_writer.addPage(page) with open(output, 'wb') as out: pdf_writer.write(out) if __name__ == '__main__': create_watermark( input_pdf='Jupyter_Notebook_An_Introduction.pdf', output='watermarked_notebook.pdf', watermark='watermark.pdf')
create_watermark()接受三个论点:
input_pdf: 要加水印的 PDF 文件路径output: 您想要保存 PDF 水印版本的路径watermark: 包含水印图像或文本的 PDF在代码中,您打开水印 PDF 并从文档中抓取第一页,因为这是您的水印应该驻留的位置。然后使用
input_pdf和一个通用的pdf_writer对象创建一个 PDF 阅读器对象,用于写出带水印的 PDF。下一步是迭代
input_pdf中的页面。这就是奇迹发生的地方。你需要调用.mergePage()并传递给它watermark_page。当你这样做时,它将覆盖当前页面顶部的watermark_page。然后你把新合并的页面添加到你的pdf_writer对象中。最后,你把新加水印的 PDF 写到磁盘上,你就完成了!
您将了解的最后一个主题是
PyPDF2如何处理加密。如何加密 PDF 文件
PyPDF2目前仅支持将用户密码和所有者密码添加到预先存在的 PDF 中。在 PDF land 中,所有者密码基本上会授予您 PDF 的管理员权限,并允许您设置文档的权限。另一方面,用户密码只允许您打开文档。据我所知,
PyPDF2实际上不允许您在文档上设置任何权限,尽管它允许您设置所有者密码。无论如何,这就是你如何添加密码,这也将固有地加密 PDF:
# pdf_encrypt.py from PyPDF2 import PdfFileWriter, PdfFileReader def add_encryption(input_pdf, output_pdf, password): pdf_writer = PdfFileWriter() pdf_reader = PdfFileReader(input_pdf) for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) pdf_writer.encrypt(user_pwd=password, owner_pwd=None, use_128bit=True) with open(output_pdf, 'wb') as fh: pdf_writer.write(fh) if __name__ == '__main__': add_encryption(input_pdf='reportlab-sample.pdf', output_pdf='reportlab-encrypted.pdf', password='twofish')
add_encryption()接收输入和输出 PDF 路径以及您想要添加到 PDF 的密码。然后像以前一样,它打开一个 PDF writer 和一个 reader 对象。因为您想要加密整个输入 PDF,所以您需要循环所有页面并将它们添加到 writer 中。最后一步是调用
.encrypt(),它接受用户密码、所有者密码以及是否应该添加 128 位加密。默认情况下,打开 128 位加密。如果您将其设置为False,那么将改为应用 40 位加密。注: PDF 加密根据pdflib.com使用 RC4 或 AES(高级加密标准)加密 PDF。
仅仅因为你加密了你的 PDF 并不意味着它一定是安全的。有工具可以删除 pdf 中的密码。如果你想了解更多,卡耐基·梅隆大学有一篇关于主题的有趣的论文。
结论
这个包非常有用,而且通常非常快。您可以使用
PyPDF2来自动化大型工作,并利用其功能来帮助您更好地完成工作!在本教程中,您学习了如何执行以下操作:
- 从 PDF 中提取元数据
- 旋转页面
- 合并和分割 pdf
- 添加水印
- 添加加密
同时也要关注新的
PyPDF4包,因为它可能很快就会取代PyPDF2。你可能还想看看pdfrw,它可以做很多和PyPDF2一样的事情。延伸阅读
如果您想了解更多关于使用 Python 处理 pdf 的信息,您应该查看以下资源以获取更多信息:
PyPDF2网站- Github 页面为
PyPDF4- Github 页面为
pdfrw- 报告实验室网站
- Github 页面为
PDFMiner- 卡米洛特:人类 PDF 表格提取
- 在 Python 中创建和修改 PDF 文件(教程)
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 如何用 Python 处理 PDF***
Pipenv:新 Python 打包工具指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深理解: 与 Pipenv 一起工作
Pipenv 是 Python 的一个打包工具,它使用
pipvirtualenv和传统的requirements.txt解决了一些与典型工作流相关的常见问题。除了解决一些常见问题之外,它还将开发过程整合并简化为一个命令行工具。
本指南将介绍 Pipenv 解决了哪些问题,以及如何用 Pipenv 管理 Python 依赖关系。此外,它还将介绍 Pipenv 如何与之前的包装配送方法相适应。
免费奖励: ,向您展示如何使用 Pip、PyPI、Virtualenv 和需求文件等工具避免常见的依赖管理问题。
Pipenv 解决的问题
为了理解 Pipenv 的好处,了解一下 Python 中当前的打包和依赖管理方法是很重要的。
先说一个处理第三方包的典型情况。然后,我们将构建部署完整 Python 应用程序的方法。
依赖关系管理用
requirements.txt想象一下你正在做一个 Python 项目,它使用了像
flask这样的第三方包。您需要指定该需求,以便其他开发人员和自动化系统可以运行您的应用程序。所以您决定在一个
requirements.txt文件中包含flask依赖项:flask太好了,在本地一切都很好,在你的应用程序上破解了一段时间后,你决定把它转移到生产中。这就是事情变得有点可怕的地方…
上面的
requirements.txt文件没有指定使用哪个版本的flask。在这种情况下,pip install -r requirements.txt会默认安装最新版本。这是可以的,除非在最新的版本中有接口或行为的变化会破坏我们的应用程序。为了这个例子,让我们假设一个新版本的
flask发布了。然而,它并不向后兼容您在开发过程中使用的版本。现在,假设您将应用程序部署到生产环境中,并执行
pip install -r requirements.txt。 Pip 获得最新的、不向后兼容的flask版本,就这样,您的应用程序中断了…生产。“但是,嘿,它在我的机器上工作了!”—我自己也去过,感觉不是很棒。
此时,您知道您在开发期间使用的版本
flask工作正常。所以,为了解决问题,你应该在你的requirements.txt中尽量具体一点。您向flask依赖项添加了一个版本说明符。这也被称为钉住依赖关系:flask==0.12.1将
flask依赖固定到一个特定的版本可以确保一个pip install -r requirements.txt设置你在开发过程中使用的flask的精确版本。但是真的吗?请记住,
flask本身也有依赖项(由pip自动安装)。然而,flask本身并没有为它的依赖项指定确切的版本。比如它允许任何版本的Werkzeug>=0.14。再一次,为了这个例子,让我们假设一个新版本的
Werkzeug发布了,但是它给你的应用程序引入了一个大错误。当您这次在生产中执行
pip install -r requirements.txt时,您将获得flask==0.12.1,因为您已经锁定了那个需求。然而,不幸的是,你将得到最新的,有缺陷的版本Werkzeug。同样,产品在生产中出现故障。这里真正的问题是构建不是确定性的。我的意思是,给定相同的输入(
requirements.txt文件),pip 并不总是产生相同的环境。目前,您无法在生产中轻松复制您的开发机器上的确切环境。这个问题的典型解决方案是使用
pip freeze。此命令允许您获取当前安装的所有第三方库的确切版本,包括自动安装的子依赖项 pip。因此,您可以冻结开发中的一切,以确保您在生产中拥有相同的环境。执行
pip freeze会导致可以添加到requirements.txt的固定依赖关系:click==6.7 Flask==0.12.1 itsdangerous==0.24 Jinja2==2.10 MarkupSafe==1.0 Werkzeug==0.14.1有了这些固定的依赖项,您可以确保安装在生产环境中的包与开发环境中的包完全匹配,这样您的产品就不会意外中断。不幸的是,这种“解决方案”导致了一系列全新的问题。
既然您已经指定了每个第三方包的确切版本,您有责任保持这些版本最新,即使它们是
flask的子依赖项。如果在Werkzeug==0.14.1中发现了一个安全漏洞,包的维护者立即在Werkzeug==0.14.2中打了补丁,那该怎么办?你真的需要升级到Werkzeug==0.14.2,以避免任何由Werkzeug早期未打补丁版本引起的安全问题。首先,你需要意识到你的版本有问题。然后,您需要在有人利用安全漏洞之前,在您的生产环境中获得新版本。因此,您必须手动更改您的
requirements.txt来指定新版本Werkzeug==0.14.2。正如您在这种情况下所看到的,保持必要更新的责任落在了您的身上。事实是,只要不破坏您的代码,您真的不在乎安装了什么版本的
Werkzeug。事实上,您可能希望获得最新版本,以确保您获得错误修复、安全补丁、新功能、更多优化等等。真正的问题是:“您如何在不承担更新子依赖项版本的责任的情况下,允许您的 Python 项目的确定性构建?”
剧透:简单的答案是使用 Pipenv。
开发具有不同依赖关系的项目
让我们稍微转换一下话题,来谈谈当你在多个项目中工作时出现的另一个常见问题。想象一下
ProjectA需要django==1.9,但是ProjectB需要django==1.10。默认情况下,Python 试图将所有第三方包存储在系统范围的位置。这意味着每次你想在
ProjectA和ProjectB之间切换时,你必须确保安装了正确版本的django。这使得在项目之间切换很痛苦,因为您必须卸载并重新安装软件包来满足每个项目的需求。标准的解决方案是使用一个拥有自己的 Python 可执行文件和第三方包存储的虚拟环境。这样,
ProjectA和ProjectB就充分分开了。现在,您可以轻松地在项目之间切换,因为它们不共享同一个包存储位置。PackageA可以在自己的环境中拥有它所需要的django的任何版本,PackageB可以拥有它所需要的完全独立的版本。一个非常常见的工具是virtualenv(或者 Python 3 中的venv)。Pipenv 具有内置的虚拟环境管理功能,因此您只需使用一个工具来管理您的软件包。
依赖性解析
我说的依赖解析是什么意思?假设您有一个类似这样的
requirements.txt文件:package_a package_b假设
package_a有一个子依赖package_c,package_a需要这个包的一个特定版本:package_c>=1.0。反过来,package_b具有相同的子依赖关系,但是需要package_c<=2.0。理想情况下,当你试图安装
package_a和package_b时,安装工具会查看对package_c(即>=1.0和<=2.0)的需求,并选择一个满足这些需求的版本。您希望该工具能够解决依赖性,以便您的程序最终能够正常工作。这就是我所说的“依赖性解决方案”不幸的是,pip 本身目前没有真正的依赖性解决方案,但是有一个开放问题来支持它。
pip 处理上述场景的方式如下:
它安装
package_a并寻找满足第一个需求的package_c版本(package_c>=1.0)。然后 Pip 安装最新版本的
package_c来满足这个需求。假设package_c的最新版本是 3.1。这是麻烦(潜在的)开始的地方。
如果 pip 选择的
package_c版本不符合未来需求(如package_b需要package_c<=2.0,安装将失败。这个问题的“解决方案”是在
requirements.txt文件中指定子依赖项(package_c)所需的范围。这样,pip 可以解决这种冲突,并安装满足这些要求的软件包:package_c>=1.0,<=2.0 package_a package_b就像以前一样,你现在直接关注子依赖项(
package_c)。问题是,如果package_a在你不知道的情况下改变了他们的需求,你指定的需求(package_c>=1.0,<=2.0)可能不再被接受,安装可能会再次失败。真正的问题是,再一次,你要负责保持子依赖的最新需求。理想情况下,您的安装工具应该足够智能,能够安装满足所有需求的包,而无需您显式指定子依赖版本。
Pipenv 简介
现在我们已经解决了这些问题,让我们看看 Pipenv 如何解决它们。
首先,让我们安装它:
$ pip install pipenv一旦你做到了这一点,你就可以有效地忘记
pip,因为 Pipenv 本质上是一个替代品。它还引入了两个新文件,Pipfile(意在取代requirements.txt)和Pipfile.lock(支持确定性构建)。Pipenv 在底层使用了
pip和virtualenv,但是通过一个命令行界面简化了它们的使用。用法示例
让我们从创建令人惊叹的 Python 应用程序开始。首先,在虚拟环境中生成一个 shell 来隔离这个应用程序的开发:
$ pipenv shell如果虚拟环境不存在,这将创建一个虚拟环境。Pipenv 在默认位置创建所有虚拟环境。如果你想改变 Pipenv 的默认行为,有一些环境变量用于配置。
您可以分别使用参数
--two和--three强制创建 Python 2 或 3 环境。否则,Pipenv 将使用virtualenv找到的任何缺省值。旁注:如果您需要一个更具体的 Python 版本,您可以提供一个
--python参数来指定您需要的版本。比如:--python 3.6现在你可以安装你需要的第三方包了,
flask。哦,但是你知道你需要的是版本0.12.1而不是最新的版本,所以请具体说明:$ pipenv install flask==0.12.1您应该会在终端中看到如下内容:
Adding flask==0.12.1 to Pipfile's [packages]... Pipfile.lock not found, creating...您会注意到创建了两个文件,一个
Pipfile和Pipfile.lock。我们一会儿会仔细看看这些。让我们安装另一个第三方软件包,numpy,进行一些数字运算。您不需要特定的版本,所以不要指定:$ pipenv install numpy如果你想直接从版本控制系统(VCS)安装一些东西,你可以!您可以像使用
pip一样指定位置。例如,要从版本控制安装requests库,请执行以下操作:$ pipenv install -e git+https://github.com/requests/requests.git#egg=requests注意上面的
-e参数,使安装可编辑。目前,这是 Pipenv 进行子依赖解析所需要的。假设您也有这个令人敬畏的应用程序的一些单元测试,并且您想要使用
pytest来运行它们。您在生产中不需要pytest,因此您可以使用--dev参数指定该依赖项仅用于开发:$ pipenv install pytest --dev提供
--dev参数将把依赖关系放在Pipfile中的一个特殊的[dev-packages]位置。只有当您用pipenv install指定了--dev参数时,这些开发包才会被安装。不同的部分将开发所需的依赖项与基本代码实际工作所需的依赖项分开。一般来说,这可以通过附加的需求文件来完成,比如
dev-requirements.txt或者test-requirements.txt。现在,所有的事情都整合在一个Pipfile的不同部门下。好了,让我们假设您已经在本地开发环境中做好了一切准备,并准备将其推向生产。要做到这一点,您需要锁定您的环境,以便确保您在生产中拥有相同的环境:
$ pipenv lock这将创建/更新您的
Pipfile.lock,您将永远不需要(也不打算)手动编辑它。您应该始终使用生成的文件。现在,一旦您在生产环境中获得了代码和
Pipfile.lock,您应该安装记录的最后一个成功的环境:$ pipenv install --ignore-pipfile这告诉 Pipenv 忽略
Pipfile进行安装,并使用Pipfile.lock中的内容。给定这个Pipfile.lock,Pipenv 将创建与您运行pipenv lock时完全相同的环境,包括子依赖项和所有内容。锁文件通过获取环境中所有包版本的快照(类似于
pip freeze的结果)来实现确定性构建。现在让我们假设另一个开发人员想要对您的代码进行一些添加。在这种情况下,他们将获得代码,包括
Pipfile,并使用以下命令:$ pipenv install --dev这将安装开发所需的所有依赖项,包括常规依赖项和您在
install期间用--dev参数指定的依赖项。当 Pipfile 中没有指定一个确切的版本时,
install命令为依赖关系(和子依赖关系)提供了更新版本的机会。这是一个重要的注意事项,因为它解决了我们之前讨论的一些问题。为了演示,假设您的一个依赖项的新版本变得可用。因为您不需要这个依赖项的特定版本,所以您不需要在
Pipfile中指定一个确切的版本。当您pipenv install时,新版本的依赖项将被安装到您的开发环境中。现在,您对代码进行更改,并运行一些测试来验证一切仍按预期运行。(你有单元测试,对吗?)现在,就像以前一样,您使用
pipenv lock锁定您的环境,并且将使用依赖关系的新版本生成更新的Pipfile.lock。和以前一样,您可以用锁文件在生产中复制这个新环境。正如您在这个场景中看到的,您不再需要强制使用您并不真正需要的确切版本来确保您的开发和生产环境是相同的。您也不需要一直更新您“不关心”的子依赖项 Pipenv 的这个工作流,结合您出色的测试,解决了手动进行所有依赖管理的问题。
Pipenv 的依赖性解决方法
Pipenv 将尝试安装满足核心依赖项所有要求的子依赖项。但是,如果存在相互冲突的依赖关系(
package_a需要package_c>=1.0,但是package_b需要package_c<1.0),Pipenv 将无法创建锁文件,并将输出如下错误:Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies. You can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation. Could not find a version that matches package_c>=1.0,package_c<1.0正如警告所说,您还可以显示一个依赖关系图来了解您的顶级依赖关系及其子依赖关系:
$ pipenv graph该命令将打印出一个树状结构,显示您的依赖关系。这里有一个例子:
Flask==0.12.1 - click [required: >=2.0, installed: 6.7] - itsdangerous [required: >=0.21, installed: 0.24] - Jinja2 [required: >=2.4, installed: 2.10] - MarkupSafe [required: >=0.23, installed: 1.0] - Werkzeug [required: >=0.7, installed: 0.14.1] numpy==1.14.1 pytest==3.4.1 - attrs [required: >=17.2.0, installed: 17.4.0] - funcsigs [required: Any, installed: 1.0.2] - pluggy [required: <0.7,>=0.5, installed: 0.6.0] - py [required: >=1.5.0, installed: 1.5.2] - setuptools [required: Any, installed: 38.5.1] - six [required: >=1.10.0, installed: 1.11.0] requests==2.18.4 - certifi [required: >=2017.4.17, installed: 2018.1.18] - chardet [required: >=3.0.2,<3.1.0, installed: 3.0.4] - idna [required: >=2.5,<2.7, installed: 2.6] - urllib3 [required: <1.23,>=1.21.1, installed: 1.22]从
pipenv graph的输出中,可以看到我们之前安装的顶层依赖项(Flask、numpy、pytest和requests),下面可以看到它们所依赖的包。此外,您可以反转树来显示需要它的父级的子依赖关系:
$ pipenv graph --reverse当您试图找出冲突的子依赖关系时,这种反向树可能更有用。
Pipfile
Pipfile 打算取代
requirements.txt。Pipenv 目前是使用Pipfile的参考实现。看来很有可能pip本身就能够处理这些文件。还有,值得注意的是 Pipenv 甚至是 Python 自己推荐的官方包管理工具。
Pipfile的语法是 TOML ,文件被分成几个部分。[dev-packages]用于开发包,[packages]用于最低需求包,[requires]用于其他需求,比如特定版本的 Python。请参见下面的示例文件:[[source]] url = "https://pypi.python.org/simple" verify_ssl = true name = "pypi" [dev-packages] pytest = "*" [packages] flask = "==0.12.1" numpy = "*" requests = {git = "https://github.com/requests/requests.git", editable = true} [requires] python_version = "3.6"理想情况下,您的
Pipfile中不应该有任何子依赖项。我的意思是你应该只包含你实际导入和使用的包。不需要仅仅因为chardet是requests的一个子依赖项,就将chardet保留在你的Pipfile中。(Pipenv 会自动安装。)T4 应该传达你的包所需要的顶层依赖关系。Pipfile.lock
该文件通过指定重现环境的确切要求来实现确定性构建。它包含了包和哈希的精确版本,以支持更安全的验证,
pip现在也支持。一个示例文件可能如下所示。注意,这个文件的语法是 JSON,我已经用...排除了文件的一部分:{ "_meta": { ... }, "default": { "flask": { "hashes": [ "sha256:6c3130c8927109a08225993e4e503de4ac4f2678678ae211b33b519c622a7242", "sha256:9dce4b6bfbb5b062181d3f7da8f727ff70c1156cbb4024351eafd426deb5fb88" ], "version": "==0.12.1" }, "requests": { "editable": true, "git": "https://github.com/requests/requests.git", "ref": "4ea09e49f7d518d365e7c6f7ff6ed9ca70d6ec2e" }, "werkzeug": { "hashes": [ "sha256:d5da73735293558eb1651ee2fddc4d0dedcfa06538b8813a2e20011583c9e49b", "sha256:c3fd7a7d41976d9f44db327260e263132466836cef6f91512889ed60ad26557c" ], "version": "==0.14.1" } ... }, "develop": { "pytest": { "hashes": [ "sha256:8970e25181e15ab14ae895599a0a0e0ade7d1f1c4c8ca1072ce16f25526a184d", "sha256:9ddcb879c8cc859d2540204b5399011f842e5e8823674bf429f70ada281b3cc6" ], "version": "==3.4.1" }, ... } }请注意为每个依赖项指定的确切版本。甚至像
werkzeug这样不在我们的Pipfile中的子依赖项也出现在这个Pipfile.lock中。哈希用于确保您检索到的包与开发时相同。再次值得注意的是,您不应该手动更改这个文件。它是用
pipenv lock生成的。Pipenv 额外功能
使用以下命令在默认编辑器中打开第三方包:
$ pipenv open flask这将在默认编辑器中打开
flask包,或者您可以指定一个带有EDITOR环境变量的程序。比如我用崇高文字,所以我只设置EDITOR=subl。这使得深入研究您正在使用的包的内部变得非常简单。
您可以在虚拟环境中运行命令,而无需启动 shell:
$ pipenv run <insert command here>
检查您环境中的安全漏洞(以及 PEP 508 要求):
$ pipenv check
现在,让我们说你不再需要一个包。您可以卸载它:
$ pipenv uninstall numpy此外,假设您想要从虚拟环境中完全清除所有已安装的软件包:
$ pipenv uninstall --all您可以用
--all-dev替换--all来删除开发包。
当顶层目录中存在一个
.env文件时,Pipenv 支持自动加载环境变量。这样,当你pipenv shell打开虚拟环境时,它从文件中加载你的环境变量。.env文件只包含键值对:SOME_ENV_CONFIG=some_value SOME_OTHER_ENV_CONFIG=some_other_value
最后,这里有一些快速的命令来找出东西在哪里。如何找到您的虚拟环境:
$ pipenv --venv如何找到您的项目主页:
$ pipenv --where包装分发
您可能会问,如果您打算将代码作为一个包分发,这一切是如何工作的。
是的,我需要将我的代码打包分发
Pipenv 如何处理
setup.py文件?这个问题有很多微妙之处。首先,当您使用
setuptools作为构建/发布系统时,一个setup.py文件是必要的。这已经成为事实上的标准有一段时间了,但是最近的变化使得setuptools的使用成为可选的。这意味着像 flit 这样的项目可以使用新的
pyproject.toml来指定不需要setup.py的不同构建系统。尽管如此,在不久的将来
setuptools和伴随的setup.py仍将是许多人的默认选择。当您使用
setup.py作为分发包的方式时,以下是推荐的工作流程:
setup.pyinstall_requires关键字应该包括包“最低限度需要正确运行”的任何内容Pipfile- 代表您的包的具体要求
- 通过使用 Pipenv 安装您的软件包,从
setup.py中提取最低要求的依赖项:
- 使用
pipenv install '-e .'- 这将在您的
Pipfile中产生一行类似于"e1839a8" = {path = ".", editable = true}的内容。Pipfile.lock- 从
pipenv lock生成的可再现环境的详细信息澄清一下,把你的最低要求放在
setup.py里,而不是直接用pipenv install。然后使用pipenv install '-e .'命令将你的包安装成可编辑的。这将把所有需求从setup.py放到您的环境中。然后你可以使用pipenv lock来获得一个可复制的环境。我不需要将我的代码作为一个包分发
太好了!如果你正在开发一个不打算发布或安装的应用程序(一个个人网站,一个桌面应用程序,一个游戏,或者类似的),你真的不需要一个
setup.py。在这种情况下,您可以使用
Pipfile/Pipfile.lock组合来管理您与前面描述的流程的依赖关系,以便在生产中部署一个可再现的环境。我已经有一个
requirements.txt。我如何转换成一个Pipfile?如果您运行
pipenv install,它应该会自动检测到requirements.txt并将其转换为Pipfile,输出如下内容:requirements.txt found, instead of Pipfile! Converting… Warning: Your Pipfile now contains pinned versions, if your requirements.txt did. We recommend updating your Pipfile to specify the "*" version, instead.请注意上面的警告。
如果您已经在
requirements.txt文件中固定了精确的版本,那么您可能希望更改Pipfile来指定您真正需要的精确版本。这将让你获得转型的真正好处。例如,假设您有以下内容,但真的不需要确切版本的numpy:[packages] numpy = "==1.14.1"如果您对您的依赖项没有任何特定的版本要求,您可以使用通配符
*告诉 Pipenv 可以安装任何版本:[packages] numpy = "*"如果您对允许任何带有
*的版本感到紧张,通常安全的做法是指定大于或等于您已经使用的版本,这样您仍然可以利用新版本:[packages] numpy = ">=1.14.1"当然,保持与新版本的同步也意味着当包发生变化时,您有责任确保您的代码仍能按预期运行。这意味着,如果您想要确保代码的功能发布,测试套件对于整个 Pipenv 流程是必不可少的。
您允许包更新,运行您的测试,确保它们都通过,锁定您的环境,然后您就可以高枕无忧了,因为您知道您没有引入突破性的变化。如果事情确实因为依赖关系而中断,您需要编写一些回归测试,并且可能对依赖关系的版本有更多的限制。
例如,如果在运行
pipenv install之后安装了numpy==1.15,并且它破坏了您的代码,您希望在开发或测试期间注意到这一点,您有几个选择:
更新您的代码以使用新版本的依赖项。
如果向后兼容以前版本的依赖项是不可能的,那么您还需要在您的
Pipfile中添加您需要的版本:[packages] numpy = ">=1.15"`将
Pipfile中依赖项的版本限制为<刚刚破坏代码的版本:[packages] numpy = ">=1.14.1,<1.15"`首选选项 1,因为它可以确保您的代码使用最新的依赖项。然而,选项 2 花费的时间更少,并且不需要修改代码,只需要限制依赖关系。
您也可以从需求文件安装,使用相同的
-r参数pip:$ pipenv install -r requirements.txt如果您有一个
dev-requirements.txt或类似的东西,您也可以将它们添加到Pipfile中。只需添加--dev参数,使其放在正确的部分:$ pipenv install -r dev-requirements.txt --dev此外,您可以走另一条路,从
Pipfile生成需求文件:$ pipenv lock -r > requirements.txt $ pipenv lock -r -d > dev-requirements.txt下一步是什么?
在我看来,Python 生态系统的一个自然发展将是一个构建系统,当从包索引(如 PyPI)中检索和构建包时,它使用
Pipfile来安装最低要求的依赖项。需要再次注意的是, Pipfile 设计规范仍在开发中,Pipenv 只是一个参考实现。也就是说,我可以预见一个不存在
setup.py的install_requires部分,而引用Pipfile作为最低要求的未来。或者setup.py完全消失,您以不同的方式获得元数据和其他信息,仍然使用Pipfile获得必要的依赖关系。Pipenv 值得一查吗?
绝对的。即使它只是作为一种将您已经使用的工具(
pip&virtualenv)整合到一个单一界面的方式。然而,远不止如此。通过添加Pipfile,您可以只指定您真正需要的依赖项。您不再为仅仅为了确保可以复制您的开发环境而亲自管理所有东西的版本而头痛。有了
Pipfile.lock,你可以安心地发展,因为你知道你可以在任何地方精确地复制你的环境。除此之外,
Pipfile格式似乎很有可能被官方 Python 工具如pip所采用和支持,所以走在游戏的前面是有益的。哦,还要确保你把所有代码都升级到 Python 3:2020 年即将到来。参考资料、进一步阅读、有趣的讨论等等
- 官方 Pipenv 文档
- 官方
Pipfile项目- 关于
Pipfile的问题处理install_requires- 再论
setup.pyvsPipfileT3】- 帖子谈人教版 518
- 贴在 Python 包装上
- 建议使用 Pipenv 的注释
免费奖励: ,向您展示如何使用 Pip、PyPI、Virtualenv 和需求文件等工具避免常见的依赖管理问题。
立即观看本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深理解: 与 Pipenv 一起工作******
用 Python 和 Arcade 构建一个平台游戏
对于许多视频游戏玩家来说,编写游戏的诱惑是学习计算机编程的主要原因。然而,构建一个 2D 平台游戏如矿脉跑者,的陷阱!或超级马里奥兄弟没有合适的工具或指导会让你灰心丧气。幸运的是,Python
arcade库使得许多程序员可以用 Python 创建一个 2D 游戏!如果你还没有听说过,
arcade库是一个现代的 Python 框架,用于制作具有引人注目的图形和声音的游戏。arcade面向对象,为 Python 3.6 及更高版本而构建,为您提供了一套现代的工具来打造出色的游戏体验,包括平台游戏。本教程结束时,你将能够:
- 安装 Python
arcade库- 创建一个基本的 2D 游戏结构
- 找到可用的游戏作品和其他资产
- 使用平铺的地图编辑器构建平台地图
- 定义玩家动作,游戏奖励,以及障碍
- 用键盘和操纵杆输入控制你的玩家
- 播放游戏动作的音效
- 用视窗滚动游戏屏幕,让你的玩家保持在视野中
- 添加标题、指令、暂停画面
- 在屏幕上移动非玩家游戏元素
本教程假设你对编写 Python 程序有的基本理解。你还应该熟练使用
arcade库,熟悉面向对象的 Python ,它在arcade中被广泛使用。您可以通过单击下面的链接下载本教程的所有代码、图像和声音:
获取源代码: 点击此处获取您将在本教程中使用用 Python Arcade 构建平台游戏的源代码。
安装 Python
arcade您可以使用
pip安装arcade及其依赖项:$ python -m pip install arcade完整的安装说明适用于 Windows 、 Mac 和 Linux 。如果你愿意,你甚至可以直接从源代码安装
arcade。本教程通篇使用 Python 3.9 和
arcade2.5.5。设计游戏
在开始编写任何代码之前,制定一个计划是有益的。既然你的目标是写一个 2D 平台游戏,那么准确定义是什么让一个游戏成为平台游戏将是一个好主意。
什么是平台游戏?
平台游戏与其他类型的游戏有几个不同的特征:
- 玩家在游戏场上的各种平台之间跳跃和攀爬。
- 平台通常具有不平坦的地形和不平坦的高度位置。
- 障碍被放置在玩家的路径上,并且必须被克服以达到目标。
这些只是平台游戏的最低要求,您可以根据需要自由添加其他功能,包括:
- 难度不断增加的多个级别
- 整个游戏中的奖励
- 多玩家生活
- 摧毁游戏障碍的能力
本教程中开发的游戏计划包括增加难度和奖励。
游戏故事
所有好的游戏都有一些背景故事,即使很简单:
- 矿脉运送者中的矿工必须收集所有的黄金。
- 哈利必须在规定的时间内收集 32 件不同的宝物。
- 马里奥的任务是营救毒菌公主。
你的游戏受益于一个故事,这个故事将玩家采取的行动与某个总体目标联系起来。
对于本教程来说,游戏故事是关于一个名叫罗兹的太空旅行者,他在一个外星世界迫降。在他们的飞船坠毁前,罗兹被扔了出去,现在需要找到他们的飞船,修好它,然后回家。
为了做到这一点,罗兹必须从他们目前的位置旅行到每一级的出口,这使他们更接近船。一路上,罗兹可以收集硬币,用来修复受损的飞船。由于罗兹被驱逐出飞船,他们没有任何武器,因此必须避免途中的任何危险障碍。
虽然这个故事看起来很傻,但它服务于告知设计者你的等级和角色的重要目的。这有助于您在实施功能时做出决策:
- 由于罗兹没有武器,所以没有办法射杀可能出现的敌人。
- 罗兹坠毁在一个外星世界,所以敌人可以在任何地方和任何东西。
- 因为这个星球是外星的,重力可能会不同,这可能会影响罗兹的跳跃和移动能力。
- 罗兹需要修复他们损坏的飞船,这需要收集物品来完成。目前,硬币可用,但其他项目可能会在稍后可用。
在设计游戏的时候,你可以根据自己的喜好让故事变得简单或者复杂。
游戏机制
有了粗略的设计,你也可以开始计划如何控制游戏。在游戏场地中移动 Roz 需要一种方法来控制几种不同的移动:
Left和Right在一个平台上移动Up和Down爬平台间的梯子- 跳跃收集硬币,避免敌人,或在平台之间移动
传统上,玩家可以使用四个箭头键进行定向移动,以及
Space进行跳跃。如果你愿意,你也可以使用诸如 IJKL 、 IJKM 或 WASD 这样的键。你也不仅仅局限于键盘输入。
arcade库包括对操纵杆和游戏控制器的支持,您将在后面探索。一旦游戏杆连接到你的电脑上,你就可以通过检查游戏杆的 X 轴和 Y 轴的位置来移动 Roz,并通过检查特定的按钮按压来跳跃。游戏资产
现在你对游戏应该如何运行有了一个想法,你需要对游戏的外观和声音做出一些决定。用于显示乐谱的图像、精灵、声音甚至文本统称为资产。他们在你的球员眼中定义了你的比赛。创建它们可能是一个挑战,比编写实际的游戏代码花费更多的时间。
您可以下载免费或低价的资源在游戏中使用,而不是创建自己的资源。许多艺术家和设计师提供精灵、背景、字体、声音和其他内容供游戏制作者使用。以下是一些音乐、声音和艺术资源,您可以从中搜索有用的内容:
来源 鬼怪;雪碧 艺术品 音乐 音效 OpenGameArt.org X X X X kenney . nlT3】 X X X X 游戏美术 2D X X cc mixterT3】 X X Freesound X X 对于本教程中概述的游戏,你将使用免费提供的地图图片和由 Kenney.nl 创建的精灵。可下载源代码中提供的音效是作者使用 MuseScore 和 Audacity 制作的。
注意:如果您决定使用他人拥有或创建的游戏资产,请务必阅读、理解并遵守所有者规定的任何许可要求。许可证可能要求支付费用或添加适当的归属,并可能对您的游戏施加许可限制。如有疑问,咨询法律专业人士。
开始编写代码前的最后一步是决定如何组织和存储所有内容。
定义程序结构
因为视频游戏由图形和声音资产以及代码组成,所以组织您的项目非常重要。保持游戏资产和代码的合理组织将允许你对游戏的设计或行为进行有针对性的修改,同时将对游戏其他方面的影响降到最低。
该项目使用以下结构:
arcade_platformer/ | ├── arcade_platformer/ | ├── assets/ | | │ ├── images/ | | | │ │ ├── enemies/ | | | │ │ ├── ground/ | | | │ │ ├── HUD/ | | | │ │ ├── items/ | | | │ │ ├── player/ | | | │ │ └── tiles/ | | │ └── sounds/ | └── tests/在项目的根文件夹下有以下子文件夹:
arcade_platformer掌握着游戏的所有 Python 代码。assets由你所有的游戏图像、字体、声音和平铺地图组成。tests包含你可以选择编写的任何测试。虽然还有其他一些游戏决策要做,但这已经足够开始编写代码了。您将从定义基本的
arcade代码结构开始,您可以在其中构建您的平台游戏!在 Python 中定义游戏结构
arcade你的游戏使用了
arcade完整的面向对象功能。为此,您基于arcade.Window定义一个新类,然后覆盖该类中的方法来更新和呈现您的游戏图形。这是一个游戏成品的基本框架。随着游戏的进行,您将在这个框架上构建:
1""" 2Arcade Platformer 3 4Demonstrating the capabilities of arcade in a platformer game 5Supporting the Arcade Platformer article 6at https://realpython.com/platformer-python-arcade/ 7 8All game artwork from www.kenney.nl 9Game sounds and tile maps by author 10""" 11 12import arcade 13 14class Platformer(arcade.Window): 15 def __init__(self): 16 pass 17 18 def setup(self): 19 """Sets up the game for the current level""" 20 pass 21 22 def on_key_press(self, key: int, modifiers: int): 23 """Processes key presses 24 25 Arguments: 26 key {int} -- Which key was pressed 27 modifiers {int} -- Which modifiers were down at the time 28 """ 29 30 def on_key_release(self, key: int, modifiers: int): 31 """Processes key releases 32 33 Arguments: 34 key {int} -- Which key was released 35 modifiers {int} -- Which modifiers were down at the time 36 """ 37 38 def on_update(self, delta_time: float): 39 """Updates the position of all game objects 40 41 Arguments: 42 delta_time {float} -- How much time since the last call 43 """ 44 pass 45 46 def on_draw(self): 47 pass 48 49if __name__ == "__main__": 50 window = Platformer() 51 window.setup() 52 arcade.run()这个基本结构几乎提供了你构建一个 2D 平台游戏所需的一切:
12 号线 进口
arcade库。第 14 行定义了用来运行整个游戏的类。调用该类的方法来更新游戏状态、处理用户输入以及在屏幕上绘制项目。
第 15 行定义
.__init__(),初始化游戏对象。您在这里添加代码来处理只应在游戏首次启动时采取的操作。第 18 行定义了
.setup(),它设置游戏开始玩。您将代码添加到这个方法中,可能需要在整个游戏中重复使用。例如,这是一个成功时初始化新等级或者失败时重置当前等级的好地方。第 22 行和第 30 行定义了
.on_key_press()和.on_key_release(),允许你独立处理键盘输入。arcade将按键和按键释放分开处理,这有助于避免键盘自动重复的问题。第 38 行定义了
.on_update(),在这里你可以更新你的游戏和游戏中所有物体的状态。这是处理对象之间的碰撞、播放大多数声音效果、更新分数和动画精灵的地方。这个方法是游戏中所有事情发生的地方,所以这里通常有很多代码。第 46 行定义了
.on_draw(),游戏中显示的所有东西都画在这里。与.on_update()相比,这种方法通常只包含几行代码。第 49 行到第 52 行定义了游戏的主入口。这是您:
- 基于第 13 行定义的类创建游戏对象
window- 通过调用
window.setup()设置游戏- 通过调用
arcade.run()开始游戏循环这种基本结构对于大多数 Python
arcade游戏来说都工作得很好。注意:在可下载的资料中,这个基本的代码大纲可以在
arcade_platformer/01_game_skeleton.py下找到。随着本教程的深入,您将充实这些方法,并添加新的方法来实现游戏的功能。
添加初始游戏功能
开始游戏的第一件事就是打开游戏窗口。在本节结束时,您的游戏看起来会像这样:
您可以在
arcade_platformer/02_open_game_window.py中看到游戏骨骼的变化:11import arcade 12import pathlib 13 14# Game constants 15# Window dimensions 16SCREEN_WIDTH = 1000 17SCREEN_HEIGHT = 650 18SCREEN_TITLE = "Arcade Platformer" 19 20# Assets path 21ASSETS_PATH = pathlib.Path(__file__).resolve().parent.parent / "assets" 22 23class Platformer(arcade.Window): 24 def __init__(self) -> None: 25 super().__init__(SCREEN_WIDTH, SCREEN_HEIGHT, SCREEN_TITLE) 26 27 # These lists will hold different sets of sprites 28 self.coins = None 29 self.background = None 30 self.walls = None 31 self.ladders = None 32 self.goals = None 33 self.enemies = None 34 35 # One sprite for the player, no more is needed 36 self.player = None 37 38 # We need a physics engine as well 39 self.physics_engine = None 40 41 # Someplace to keep score 42 self.score = 0 43 44 # Which level are we on? 45 self.level = 1 46 47 # Load up our sounds here 48 self.coin_sound = arcade.load_sound( 49 str(ASSETS_PATH / "sounds" / "coin.wav") 50 ) 51 self.jump_sound = arcade.load_sound( 52 str(ASSETS_PATH / "sounds" / "jump.wav") 53 ) 54 self.victory_sound = arcade.load_sound( 55 str(ASSETS_PATH / "sounds" / "victory.wav") 56 )这里有一个细目分类:
第 11 行和第 12 行导入你需要的
arcade和pathlib库。第 16 到 18 行定义了几个游戏窗口常量,用于稍后打开游戏窗口。
第 21 行保存你的
assets文件夹的路径,使用当前文件的路径作为基础。因为你将在整个游戏中使用这些资产,知道它们在哪里是至关重要的。使用pathlib可以确保您的路径在 Windows、Mac 或 Linux 上正常工作。第 25 行使用
super()和上面第 16 到 18 行定义的常量调用父类的.__init__()方法来设置你的游戏窗口。第 28 到 33 行定义了六个不同的精灵列表来保存游戏中使用的各种精灵。没有必要在这里声明和定义它们,因为它们将在后面的
.setup()中被完全正确地定义。声明对象属性是像 C++或 Java 这样的语言的延续。每个级别都有一组不同的对象,这些对象被填充在.setup()中:
coins是罗兹可以在整个游戏中找到的可收集物品。
background物体的呈现只是为了视觉上的兴趣,不与任何东西互动。
walls是罗兹无法穿越的物体。这些包括真正的墙壁和平台,罗兹可以在上面行走和跳跃。
ladders是让 Roz 爬上爬下的物体。
goals是 Roz 要移动到下一关必须找到的对象。
enemies是罗兹在整个游戏中必须避开的对象。与敌人接触将会结束游戏。第 36 行声明了 player 对象,将在
.setup()中正确定义。第 39 行声明了一个用于管理运动和碰撞的物理引擎。
第 42 行定义了一个变量来跟踪当前得分。
第 45 行定义了一个变量来跟踪当前的游戏级别。
第 48 到 56 行使用前面定义的
ASSETS_PATH常量来定位和加载用于收集硬币、跳跃和完成每一关的声音文件。如果你愿意,你可以在这里添加更多,但是记住
.__init__()只在游戏开始时运行。注:上述声音在可下载资料中提供。你可以使用他们提供的或替换你自己的声音。
罗兹需要能够在游戏世界中行走、跳跃和攀爬。管理何时以及如何发生是物理引擎的工作。
什么是物理引擎?
在大多数平台上,用户使用操纵杆或键盘来移动玩家。他们可能会让玩家跳下或带着玩家走下平台。一旦玩家在半空中,用户不需要做任何其他事情来使他们落到更低的平台上。由物理引擎控制玩家可以在哪里行走,以及他们跳下或走下平台后如何摔倒。
在游戏中,物理引擎提供了作用于玩家和其他游戏对象的物理力的近似值。这些力可以传递或影响游戏对象的运动,包括跳跃、攀爬、下落和阻挡运动。
Python
arcade中包含了三个物理引擎:
arcade.PhysicsEngineSimple是一个非常基本的引擎,处理单个玩家精灵和一系列墙壁精灵的移动和交互。这对于自上而下的游戏很有用,因为重力不是一个因素。
arcade.PhysicsEnginePlatformer是为平台游戏量身定制的更复杂的引擎。除了基本的移动,它还提供了一种重力,将物体拉到屏幕底部。它还为玩家提供了一种跳跃和攀爬梯子的方式。
arcade.PymunkPhysicsEngine建立在花栗鼠之上,这是一个使用花栗鼠库的 2D 物理库。Pymunk 使极其真实的物理计算可用于arcade应用。在本教程中,您将使用
arcade.PhysicsEnginePlatformer。为了正确设置
arcade.PhysicsEnginePlatformer,你必须提供玩家精灵以及两个精灵列表,包含玩家与之互动的墙壁和梯子。因为墙和梯子根据等级而变化,所以在等级建立之前,你不能正式定义物理引擎,这发生在.setup()中。说到等级,你是如何定义的呢?和大多数事情一样,完成工作的方法不止一种。
构建游戏关卡
当视频游戏还分布在软盘上时,很难存储一个游戏所需的所有游戏级别数据。许多游戏制造商诉诸于编写代码来创建关卡。虽然这种方法节省了磁盘空间,但是使用命令式代码来生成游戏关卡会限制你以后修改或增加关卡的能力。
随着存储空间变得越来越便宜,游戏通过将更多的资产存储在数据文件中而获益,这些数据文件由代码读取和处理。现在可以在不改变游戏代码的情况下创建和修改游戏关卡,这使得艺术家和游戏设计师无需理解底层代码就可以做出贡献。关卡设计的这种声明式方法允许在设计和开发游戏时有更大的灵活性。
声明式游戏级别设计的缺点是不仅需要定义数据,还需要存储数据。幸运的是,有一个工具可以做到这两点,而且它与
arcade配合得非常好。Tiled 是一个开源的 2D 游戏关卡编辑器,可以生成 Python
arcade可以读取和使用的文件。Tiled 允许你创建一个名为 tileset 的图像集合,用来创建一个 tile map 来定义你游戏的每一关。您可以使用平铺为自上而下、等轴测和侧滚游戏创建平铺地图,包括游戏的关卡:
Tiled 附带了一套很棒的文档和很棒的介绍教程。为了让你开始,并希望激起你更多的欲望,接下来你将通过创建你的第一个地图水平的步骤。
下载并开始平铺
在运行 Tiled 之前,你需要下载它。撰写本文时的当前版本是 Tiled 版本 1.4.3,该版本可用于各种格式的 Windows、Mac 和 Linux。下载时,考虑通过捐赠来支持它的持续维护。
下载完切片后,您可以首次启动它。您将看到以下窗口:
点击新建地图为你的第一关创建地图。将出现以下对话框:
这些默认的磁贴地图属性对于平台游戏来说很棒,代表了
arcade游戏的最佳选项。以下是您可以选择的其他选项的快速分类:
- 方向指定如何显示和编辑地图。
- 正交地图是正方形的,用于自上而下和平台游戏。
arcade与正交贴图配合使用效果最佳。- 等角图地图将视点转换成游戏领域的非直角,提供了 2D 世界的伪 3D 视图。交错等距地图指定地图的顶边是视图的顶边。
- 六边形地图对每个地图拼贴使用六边形而不是正方形(尽管拼贴在编辑器中显示正方形)。
- 切片图层格式指定地图在磁盘上的存储方式。使用 zlib 进行压缩有助于节省磁盘空间。
- 图块渲染顺序指定图块如何存储在文件中,并最终如何由游戏引擎渲染。
- 地图大小设置要存储的地图的大小,以图块为单位。将贴图指定为 Infinite 会告诉 Tiled 根据所做的编辑来确定最终大小。
- 图块尺寸以像素为单位指定每个图块的尺寸。如果您使用来自外部来源的图稿,请将其设定为该组中拼贴的大小。本教程提供的插图使用了 128 × 128 像素的方形精灵。这意味着每个区块由大约 16,000 个像素组成,如果需要,它们可以存储在磁盘和内存中,从而提高游戏性能。
点击另存为保存关卡。既然这是游戏资产,那就存为
arcade_platformer/assets/platform_level_01.tmx。切片地图由放置在特定地图图层上的一组切片组成。要开始为某个级别定义切片贴图,必须首先定义要使用的切片集以及它们出现的图层。
创建 Tileset
用于创建关卡的图块包含在图块集中。tileset 与 tile map 相关联,并提供定义级别所需的所有 sprite 图像。
使用位于平铺窗口右下角的 Tilesets 视图定义 tileset 并与之交互:
点击 New Tileset 按钮定义该级别的 Tileset。Tiled 显示一个对话框,询问有关要创建的新 tileset 的一些信息:
对于新的 tileset,您有以下选项:
- 名称是您的 tileset 的名称。把这个叫做
arcade_platformer。- Type 指定如何定义 tileset:
- 图像集合表示每个图块都包含在磁盘上一个单独的图像中。您应该选择此选项,因为
arcade最适合单独的图块图像。- 基于拼贴设置图像表示所有的拼贴被组合成一个单独的大图像,拼贴需要对其进行处理以定位每个单独的图像。仅当您正在使用的资产需要时,才选择此选项。
- 嵌入贴图告诉 Tiled 将 tileset 存储在贴图中。保持此项未选中,因为您将在多个切片地图中将切片集作为单独的资源保存和使用。
点击另存为,另存为
assets/arcade_platformer.tsx。要在未来的图块地图上重复使用该图块集,选择地图 → 添加外部图块集将其包括在内。定义 Tileset
您的新 tileset 最初是空的,所以您需要用 tiles 填充它。您可以通过定位图块图像并将其添加到集合中来实现这一点。每个图像的尺寸应该与您在创建拼贴贴图时定义的拼贴尺寸相同。
此示例假设您已经下载了本教程的游戏资源。您可以通过单击下面的链接来完成此操作:
获取源代码: 点击此处获取您将在本教程中使用用 Python Arcade 构建平台游戏的源代码。
或者,你可以下载平台包 Redux (360 资产),将
PNG文件夹的内容移动到你的arcade-platformer/assets/images文件夹。请记住,您的平铺地图位于arcade-platformer/assets下,因为这在以后会很重要。在工具栏上,点击蓝色加号(
+)或选择图块设置 → 添加图块开始该过程。您将看到以下对话框:
从这里,导航到下面列出的文件夹,将指定的资源添加到您的 tileset:
文件夹 文件 arcade-platformer/asseimg/ground/Grass所有文件 arcade-platformer/asseimg/HUDhudHeart_empty.pnghudHeart_full.pnghudHeart_half.pnghudX.pngarcade-platformer/asseimg/itemscoinBronze.pngcoinGold.pngcoinSilver.pngflagGreen_down.pngflagGreen1.pngflagGreen2.pngarcade-platformer/asseimg/tilesdoorOpen_mid.pngdoorOpen_top.pnggrass.pngladderMid.pngladderTop.pngsignExit.pngsignLeft.pngsignRight.pngtorch1.pngtorch2.pngwater.pngwaterTop_high.pngwaterTop_low.png添加完文件后,您的 tileset 应该如下所示:
如果您没有看到所有的图块,请单击工具栏上的动态换行图块按钮来显示所有图块。
使用菜单中的
Ctrl+S或文件 → 保存保存您的新图块集,并返回到您的图块地图。您将在平铺界面的右下角看到新的平铺集,准备用于定义您的平铺地图!定义地图图层
一个级别中的每个项目都有特定的用途:
- 地面和墙壁决定了玩家可以移动的位置和方式。
- 硬币和其他可收集的项目得分和解锁成就。
- 梯子允许玩家爬上新的平台,但不会阻碍移动。
- 背景项目提供视觉兴趣,并可能提供信息。
- 敌人为玩家提供了躲避的障碍。
- 目标提供了一个在这个水平上移动的理由。
这些不同的项目类型在
arcade中需要不同的处理。因此,在平铺中定义它们时,将它们分开是有意义的。平铺允许你通过使用地图图层来做到这一点。通过将不同的项目类型放置在不同的地图图层上并分别处理每个图层,可以不同地跟踪和处理每种类型的精灵。要定义一个层,首先打开平铺屏幕右上角的层视图:
已经设置并选择了默认层。点击图层,将该图层重命名为
ground,然后在左侧的属性视图中更改Name。或者,您可以双击名称直接在图层面板中编辑:
这一层将包含您的地面瓷砖,包括玩家不能走过的墙壁。
创建新图层不仅需要定义图层名称,还需要定义图层类型。平铺提供四种类型的图层:
- 图块层允许您将图块从图块集中放置到地图上。放置仅限于网格位置,并且必须按照定义放置瓷砖。
- 对象层允许你在地图上放置对象,例如收藏品或触发器。对象可以是来自图块地图的图块或自由绘制的形状,并且它们可以是可见的或不可见的。每个对象都可以自由定位、缩放和旋转。
- 图像层允许您将图像放置在地图上,用作背景或前景图像。
- 图层组允许您将图层分组,以便于地图管理。
在本教程中,您将使用对象图层在地图上放置硬币,并使用切片图层放置其他东西。
要创建新的平铺层,在层视图中点击新建层,然后选择平铺层:
创建三个名为
ladders、background和goal的新图块层。接下来,创建一个名为
coins的新对象层来保存你的收藏品:
您可以使用层视图底部的箭头按钮以任何您喜欢的顺序排列层。现在你可以开始布置你的关卡了!
设计关卡
在《经典游戏设计一书中,作者兼游戏开发者 Franz Lanzinger 为经典游戏设计定义了八条规则。以下是前三条规则:
- 保持简单。
- 立即开始游戏。
- 由易到难渐变难度。
同样,资深游戏开发者史蒂夫·古德温在他的书《完美游戏开发》中谈到了平衡游戏。他强调好的游戏平衡从第一关开始,这“应该是第一个开发的,也是最后一个完成的。”
有了这些想法,这里有一些设计平台关卡的指导方针:
- 游戏的第一关应该向用户介绍基本的游戏功能和控制。
- 让最初的障碍变得容易克服。
- 使第一批收藏品不可能错过,以后的更难得到。
- 在用户学会如何在世界中导航之前,不要引入需要技巧来克服的障碍。
- 在用户学会克服障碍之前,不要引入敌人。
下面是根据这些指导方针设计的第一级的详细介绍。在可下载的资料中,可以在
assets/platform_level_01.tmx下找到完整的关卡设计:
玩家从左边开始,然后向右边前进,如指向右边的箭头所示。当玩家向右移动时,他们发现一枚铜币,这将增加他们的分数。第二枚铜币稍后被发现悬挂在更高的空中,这向玩家表明硬币可能在任何地方。然后玩家找到一枚金币,它有不同的点值。
然后,玩家爬上一个斜坡,这表明他们上方有更多的世界。山顶上是最后的金币,他们必须跳下去才能拿到。山的另一边是出口,也有标记。
这个简单的关卡有助于向用户展示如何移动和跳跃。说明世界上有值得收藏的物品价值点。它还显示信息性或装饰性的项目,玩家不会与之互动,如箭头标志、出口标志和草丛。最后,它向他们展示目标是什么样的。
完成第一关的艰苦设计后,你现在可以用瓷砖来建造它了。
建造一个关卡
在你放置硬币和目标之前,你需要知道如何到达那里。所以首先要定义的是地面的位置。在平铺模式下选择你的平铺地图,选择
ground层进行构建。注意:在你的磁贴地图上放置磁贴时,确保你选择了正确的图层。否则,
arcade将无法妥善处理您的物品。从您的图块集中,选择
grassCenter图块。然后,单击单幅图块地图底行的任意网格,将该单幅图块放置到位:
使用第一个 tileset,您可以拖动底部的行,将所有内容设置为
grassCenter。然后,选择grassMid图块,绘制穿过第二行的绿色关卡顶部:
继续使用草砖来建造一个两瓦高的山丘,从地球的一半开始。在右边留出四块瓷砖的空间,为玩家提供下山的空间以及出口标志和出口入口。
接下来,切换到
goal层,将出口处的图块从最右边开始放置:
有了基本的平台和目标,就可以放置一些背景物品了。切换到
background层,在左侧放置一个箭头来指引玩家去哪里,并在入口旁边放置一个出口标志。您也可以在地图上的任何位置放置草簇:
现在,您可以定义放置硬币的位置。切换到你的
coins层这样做。请记住,这是一个对象层,所以你不仅限于将硬币放在网格上。选择青铜硬币,并把它靠近开始箭头。将第二枚铜币放在右边稍远一点、稍高一点的地方:
用两枚金币重复这一过程,一枚放在山前,一枚放在山顶,离山顶至少三块瓷砖:
当玩家收集硬币时,不同的硬币应该获得不同的分值。有几种方法可以做到这一点,但在本教程中,您将设置一个自定义属性来跟踪每个硬币的点值。
定义自定义属性
使用对象层的好处之一是能够在该层的对象上设置自定义属性。自定义属性由您定义,代表您希望的任何值。在这种情况下,您将使用它们来指定图层上每个硬币的点数。
选中硬币图层,按
S开始选择对象。然后右键单击您放置的第一枚铜币,并从上下文菜单中选择对象属性查看其属性:
预定义的对象属性显示在对象属性视图的顶部,而自定义属性显示在下方。目前没有自定义属性,因此您需要添加一个。点击对象属性视图底部的蓝色加号,添加一个新的自定义属性:
您可以定义自定义特性的名称和类型。在这种情况下,您将属性设置为
int,将名称设置为point_value。注意:虽然自定义属性名
points似乎是更好的选择,但是arcade在确定碰撞时在内部使用该属性名来定义精灵的形状。定义自定义属性后,您可以在对象属性视图中设置其值:
对关卡中的每枚硬币执行相同的步骤,将铜币的值设置为
10,金币的值设置为20。不要忘记保存关卡,因为接下来你将学习如何将它读入arcade。阅读游戏关卡
用 Tiled 定义游戏关卡很棒,但是除非你能把它读入
arcade,否则用处不大。幸运的是,arcade原生支持读取平铺的平铺地图和处理图层。完成后,您的游戏将如下所示:
读取你的游戏等级完全在
.setup()中处理。这个代码可以在文件arcade_platformer/03_read_level_one.py中找到。注意:如果您在文章进行过程中输入代码,代码块中显示的行号可能与代码中的行号不匹配。
在可能的情况下,添加了额外的上下文,使您能够找到正确的行来添加新代码。
首先,添加几个常量:
# Game constants # Window dimensions SCREEN_WIDTH = 1000 SCREEN_HEIGHT = 650 SCREEN_TITLE = "Arcade Platformer" # Scaling constants MAP_SCALING = 1.0 # Player constants GRAVITY = 1.0 PLAYER_START_X = 65 PLAYER_START_Y = 256这些常量定义了地图的比例因子,以及玩家的起始位置和世界中重力的强度。这些常量用于定义
.setup()中的液位:def setup(self) -> None: """Sets up the game for the current level""" # Get the current map based on the level map_name = f"platform_level_{self.level:02}.tmx" map_path = ASSETS_PATH / map_name # What are the names of the layers? wall_layer = "ground" coin_layer = "coins" goal_layer = "goal" background_layer = "background" ladders_layer = "ladders" # Load the current map game_map = arcade.tilemap.read_tmx(str(map_path)) # Load the layers self.background = arcade.tilemap.process_layer( game_map, layer_name=background_layer, scaling=MAP_SCALING ) self.goals = arcade.tilemap.process_layer( game_map, layer_name=goal_layer, scaling=MAP_SCALING ) self.walls = arcade.tilemap.process_layer( game_map, layer_name=wall_layer, scaling=MAP_SCALING ) self.ladders = arcade.tilemap.process_layer( game_map, layer_name=ladders_layer, scaling=MAP_SCALING ) self.coins = arcade.tilemap.process_layer( game_map, layer_name=coin_layer, scaling=MAP_SCALING ) # Set the background color background_color = arcade.color.FRESH_AIR if game_map.background_color: background_color = game_map.background_color arcade.set_background_color(background_color) # Create the player sprite if they're not already set up if not self.player: self.player = self.create_player_sprite() # Move the player sprite back to the beginning self.player.center_x = PLAYER_START_X self.player.center_y = PLAYER_START_Y self.player.change_x = 0 self.player.change_y = 0 # Load the physics engine for this map self.physics_engine = arcade.PhysicsEnginePlatformer( player_sprite=self.player, platforms=self.walls, gravity_constant=GRAVITY, ladders=self.ladders, )首先,使用当前级别构建当前平铺地图的名称。格式字符串
{self.level:02}产生一个两位数的级别编号,并允许您定义多达 99 个不同的地图级别。接下来,使用
pathlib语法,定义地图的完整路径。这使得arcade能够正确定位你所有的游戏资源。接下来,定义您的层的名称,您将很快使用它。确保这些名称与您在切片中定义的图层名称相匹配。
现在打开切片地图,以便处理之前命名的图层。函数
arcade.tilemap.process_layer()有许多参数,但您将只提供其中的三个:
game_map,包含待加工的层- 要读取和处理的图层的名称
- 应用于拼贴的任何缩放
arcade.tilemap.process_layer()返回一个用代表层中瓷砖的Sprite对象填充的SpriteList。为图块定义的任何自定义属性,例如coins层中图块的point_value,都与Sprite一起存储在名为.properties的字典中。稍后您将看到如何访问它们。您还可以设置级别的背景颜色。您可以使用贴图 → 贴图属性并定义背景颜色属性来定义自己的平铺背景颜色。如果背景颜色未设置为平铺,则使用预定义的
.FRESH_AIR颜色。接下来,检查是否已经创建了一个播放器。如果您调用
.setup()来重新开始该级别或移动到下一个级别,可能会出现这种情况。如果没有,就调用一个方法来创建 player sprite(稍后会详细介绍)。如果有一个玩家,你就把他放到位置上,确保他不动。最后,您可以定义要使用的物理引擎,传入以下参数:
- 玩家精灵
- 一个
SpriteList包含墙壁- 定义重力的常数
- 一个
SpriteList包含梯子墙壁决定了玩家可以移动的位置和跳跃的时间,梯子支持攀爬。重力常数控制着玩家下落的快慢。
当然,现在运行这段代码是行不通的,因为您仍然需要定义播放器。
定义玩家
到目前为止,你的游戏缺少了一个玩家:
在
.setup()中,你调用了一个叫做.create_player_sprite()的方法来定义玩家,如果它还不存在的话。您用单独的方法创建播放器 sprite 有两个主要原因:
- 它将播放器中的任何变化与
.setup()中的其他代码隔离开来。- 它有助于简化游戏设置代码。
在任何游戏中,精灵都可以是静态的或动画的。静态精灵不会随着游戏的进行而改变它们的外观,例如代表你的地面瓷砖、背景物品和硬币的精灵。相比之下,动画精灵会随着游戏的进行而改变它们的外观。为了增加一些视觉趣味,您将使您的播放器精灵动画。
在 Python
arcade中,你通过为每个动画序列定义一系列图像来创建一个动画精灵,这些图像被称为纹理,比如攀爬或行走。随着游戏的进行,arcade从动画序列的列表中选择下一个纹理进行显示。当到达列表的末尾时,arcade又从头开始。通过仔细挑选纹理,您可以在动画精灵中创建运动的幻觉:
因为您的播放器精灵执行许多不同的活动,所以您为以下每一项提供纹理列表:
- 站立,面向左右两边
- 向左向右走
- 爬上爬下梯子
您可以为每个活动提供任意数量的纹理。如果你不想要一个动作动画,你可以提供一个单一的纹理。
文件
arcade_platformer/04_define_player.py包含了.create_player_sprite()的定义,它定义了动画播放器精灵。将这个方法放在您的.setup()下面的Platformer类中:def create_player_sprite(self) -> arcade.AnimatedWalkingSprite: """Creates the animated player sprite Returns: The properly set up player sprite """ # Where are the player images stored? texture_path = ASSETS_PATH / "images" / "player" # Set up the appropriate textures walking_paths = [ texture_path / f"alienGreen_walk{x}.png" for x in (1, 2) ] climbing_paths = [ texture_path / f"alienGreen_climb{x}.png" for x in (1, 2) ] standing_path = texture_path / "alienGreen_stand.png" # Load them all now walking_right_textures = [ arcade.load_texture(texture) for texture in walking_paths ] walking_left_textures = [ arcade.load_texture(texture, mirrored=True) for texture in walking_paths ] walking_up_textures = [ arcade.load_texture(texture) for texture in climbing_paths ] walking_down_textures = [ arcade.load_texture(texture) for texture in climbing_paths ] standing_right_textures = [arcade.load_texture(standing_path)] standing_left_textures = [ arcade.load_texture(standing_path, mirrored=True) ] # Create the sprite player = arcade.AnimatedWalkingSprite() # Add the proper textures player.stand_left_textures = standing_left_textures player.stand_right_textures = standing_right_textures player.walk_left_textures = walking_left_textures player.walk_right_textures = walking_right_textures player.walk_up_textures = walking_up_textures player.walk_down_textures = walking_down_textures # Set the player defaults player.center_x = PLAYER_START_X player.center_y = PLAYER_START_Y player.state = arcade.FACE_RIGHT # Set the initial texture player.texture = player.stand_right_textures[0] return player对于您的游戏,当罗兹行走和攀爬时,您可以设置他们的动画,而不是当他们只是静止不动时。每个动画都有两个独立的图像,您的首要任务是找到这些图像。您可以通过单击下面的链接下载本教程中使用的所有资源和源代码:
获取源代码: 点击此处获取您将在本教程中使用用 Python Arcade 构建平台游戏的源代码。
或者,您可以创建一个名为
asseimg/player的文件夹来存储用于绘制 Roz 的纹理。然后,在您之前下载的Platformer Pack Redux (360 Assets)档案中,找到PNG/Players/128x256/Green文件夹,并将那里的所有图像复制到您的新asseimg/player文件夹中。这个包含玩家纹理的新路径在
texture_path中定义。使用这个路径,你使用列表理解和 f 字符串格式化来创建每个纹理资源的完整路径名。有了这些路径,你就可以使用更多的列表理解,用
arcade.load_texture()创建一个纹理列表。因为 Roz 可以左右行走,所以为每个方向定义不同的列表。图像显示 Roz 指向右边,所以当定义 Roz 面向左边行走或站立的纹理时,使用mirrored参数。向上或向下移动看起来是一样的,所以这些列表的定义是一样的。即使只有一个站立纹理,你仍然需要把它放在一个列表中,这样
arcade就可以正确地处理AnimatedSprite。所有真正困难的工作现在都完成了。您创建实际的
AnimatedWalkingSprite,指定要使用的纹理列表。接下来,设置 Roz 的初始位置和方向,以及要显示的第一个纹理。最后,在方法的末尾返回完整构造的 sprite。现在你有了一个初始地图和一个玩家精灵。如果运行此代码,您应该会看到以下内容:
这可不太有趣。这是因为虽然你已经创造了一切,你目前没有更新或绘制任何东西。是时候解决了!
更新和绘图
更新游戏状态发生在
.on_update()中,大约每秒钟arcade调用 60 次。此方法处理下列操作和事件:
- 移动玩家和敌人精灵
- 检测与敌人或收藏品的碰撞
- 更新分数
- 动画精灵
简而言之,让你的游戏可玩的一切都发生在
.on_update()。更新完所有内容后,arcade调用.on_draw()将所有内容呈现到屏幕上。这种游戏逻辑与游戏显示的分离意味着您可以自由地添加或修改游戏中的特性,而不会影响显示游戏的代码。其实因为游戏逻辑大部分发生在
.on_update()里,所以你的.on_draw()方法往往很短。您可以在可下载的资料中找到下面
arcade_platformer/05_update_and_draw.py中的所有代码。将.on_draw()添加到您的Platformer类中:def on_draw(self) -> None: arcade.start_render() # Draw all the sprites self.background.draw() self.walls.draw() self.coins.draw() self.goals.draw() self.ladders.draw() self.player.draw()在强制调用
arcade.start_render()之后,你调用所有精灵列表中的.draw(),然后是玩家精灵。请注意绘制项目的顺序。你应该从出现在最后面的精灵开始,然后继续向前。现在,当您运行代码时,它应该看起来像这样:
唯一缺少的是正确放置玩家精灵。为什么?因为动画精灵需要更新以选择合适的纹理显示和屏幕上合适的位置,而你还没有更新任何东西。看起来是这样的:
def on_update(self, delta_time: float) -> None: """Updates the position of all game objects Arguments: delta_time {float} -- How much time since the last call """ # Update the player animation self.player.update_animation(delta_time) # Update player movement based on the physics engine self.physics_engine.update() # Restrict user movement so they can't walk off screen if self.player.left < 0: self.player.left = 0 # Check if we've picked up a coin coins_hit = arcade.check_for_collision_with_list( sprite=self.player, sprite_list=self.coins ) for coin in coins_hit: # Add the coin score to our score self.score += int(coin.properties["point_value"]) # Play the coin sound arcade.play_sound(self.coin_sound) # Remove the coin coin.remove_from_sprite_lists() # Now check if we're at the ending goal goals_hit = arcade.check_for_collision_with_list( sprite=self.player, sprite_list=self.goals ) if goals_hit: # Play the victory sound self.victory_sound.play() # Set up the next level self.level += 1 self.setup()为了确保你的游戏以恒定速度运行,无论实际帧速率如何,
.on_update()都采用一个名为delta_time的单一float参数,该参数指示自上次更新以来的时间。首先要做的是动画播放器精灵。根据玩家的动作,
.update_animation()自动选择正确的纹理来使用。接下来,你更新所有可以移动的物体的移动。既然你在
.setup()中定义了一个物理引擎,让它处理运动是有意义的。然而,物理引擎会让玩家跑出游戏地图的左侧,所以你也需要采取措施来防止这种情况。重要:确保你在
PhysicsEnginePlatformer.update()之前打电话给AnimatedSprite.update_animation()。通过首先更新精灵,您可以确保物理引擎将作用于当前精灵设置,而不是前一帧的精灵设置。现在玩家已经移动了,你检查他们是否与硬币相撞。如果是这样,这算作收集硬币,所以您使用您在 Tiled 中定义的
point_value自定义属性来增加玩家的分数。然后你放一个声音,并把硬币从游戏场上拿走。你还要检查玩家是否达到了最终目标。如果是这样,你播放胜利的声音,增加等级,并再次调用
.setup()来加载下一张地图并重置其中的玩家。但是用户如何达到最终目标呢?物理引擎将确保 Roz 不会从地板上摔下来,并且可以跳跃,但它实际上不知道将 Roz 移动到哪里或何时跳跃。这是用户应该决定的事情,你需要为他们提供一种方法来做这件事。
移动玩家精灵
在电脑游戏的早期,唯一可用的输入设备是键盘。即使在今天,许多游戏——包括这个——仍然提供键盘控制。
使用键盘移动播放器可以通过多种方式完成。有许多不同的流行键盘排列,包括:
当然还有很多其他键盘排列可以选择。
因为你需要允许 Roz 向四个方向移动和跳跃,所以在这个游戏中,你将使用箭头键和 IJKL 键移动,使用空格键跳跃:
https://player.vimeo.com/video/530532458?background=1
arcade中的所有键盘输入都由.on_key_press()和.on_key_release()处理。你可以在arcade_platformer/06_keyboard_movement.py中找到通过键盘让 Roz 移动的代码。首先,您需要两个新常数:
23# Player constants 24GRAVITY = 1.0 25PLAYER_START_X = 65 26PLAYER_START_Y = 256 27PLAYER_MOVE_SPEED = 10 28PLAYER_JUMP_SPEED = 20这些常数控制 Roz 移动的速度。
PLAYER_MOVE_SPEED控制他们在梯子上向左、向右和上下移动。PLAYER_JUMP_SPEED表示 Roz 能跳多高。通过将这些值设置为常量,您可以在测试期间调整它们以适应正确的游戏。您在
.on_key_press()中使用这些常量:def on_key_press(self, key: int, modifiers: int) -> None: """Arguments: key -- Which key was pressed modifiers -- Which modifiers were down at the time """ # Check for player left or right movement if key in [arcade.key.LEFT, arcade.key.J]: self.player.change_x = -PLAYER_MOVE_SPEED elif key in [arcade.key.RIGHT, arcade.key.L]: self.player.change_x = PLAYER_MOVE_SPEED # Check if player can climb up or down elif key in [arcade.key.UP, arcade.key.I]: if self.physics_engine.is_on_ladder(): self.player.change_y = PLAYER_MOVE_SPEED elif key in [arcade.key.DOWN, arcade.key.K]: if self.physics_engine.is_on_ladder(): self.player.change_y = -PLAYER_MOVE_SPEED # Check if player can jump elif key == arcade.key.SPACE: if self.physics_engine.can_jump(): self.player.change_y = PLAYER_JUMP_SPEED # Play the jump sound arcade.play_sound(self.jump_sound)该代码有三个主要部分:
您通过检查 IJKL 排列中的
Left和Right箭头以及J和L键来处理水平移动。然后适当地设置.change_x属性。您可以通过检查
Up和Down箭头以及I和K键来处理垂直移动。然而,由于 Roz 只能在梯子上上下移动,所以在上下移动之前,您需要使用.is_on_ladder()来验证。你可以通过
Space键来控制跳跃。为了防止 Roz 在半空中跳跃,您使用.can_jump()检查 Roz 是否能跳跃,只有 Roz 站在墙上时,T1 才返回True。如果是这样,你把播放器上移,播放跳跃声。当你释放一个键,罗兹应该停止移动。您在
.on_key_release()中进行了设置:def on_key_release(self, key: int, modifiers: int) -> None: """Arguments: key -- The key which was released modifiers -- Which modifiers were down at the time """ # Check for player left or right movement if key in [ arcade.key.LEFT, arcade.key.J, arcade.key.RIGHT, arcade.key.L, ]: self.player.change_x = 0 # Check if player can climb up or down elif key in [ arcade.key.UP, arcade.key.I, arcade.key.DOWN, arcade.key.K, ]: if self.physics_engine.is_on_ladder(): self.player.change_y = 0这段代码遵循与
.on_key_press()相似的模式:
- 您检查是否有任何水平移动键被释放。如果是,那么 Roz 的
change_x被设置为 0。- 你检查垂直移动键是否被释放。同样,因为 Roz 需要在梯子上上下移动,所以您也需要在这里检查
.is_on_ladder()。如果没有,玩家可以跳起来,然后按下并释放Up,让罗兹悬在半空中!请注意,您不需要检查是否释放了跳转键。
好了,现在你可以移动罗兹了,但是为什么罗兹只是向右走出窗户?你需要一种方法来保持 Roz 在游戏世界中移动时可见,这就是视口的作用。
滚动视窗
早期的视频游戏将游戏限制在一个窗口中,对玩家来说,这个窗口就是整个世界。然而,现代视频游戏世界可能太大,以至于无法在一个小小的游戏窗口中显示。大多数游戏都实现了滚动视图,向玩家展示游戏世界的一部分。在 Python
arcade中,这种滚动视图被称为视口。它本质上是一个矩形,定义了你在游戏窗口中显示游戏世界的哪一部分:https://player.vimeo.com/video/530532574?background=1
您可以在
arcade_platformer/07_scrolling_view.py下的可下载资料中找到这段代码。要实现滚动视图,需要根据 Roz 的当前位置定义视口。当 Roz 接近游戏窗口的任何边缘时,你在行进的方向上移动视口,这样 Roz 在屏幕上保持舒适。您还可以确保视口不会滚动到可见世界之外。为此,您需要了解一些事情:
- 在视窗滚动之前,Roz 可以移动到游戏窗口边缘多近?这被称为边距,并且对于每个窗口边缘它可以是不同的。
- 当前视口现在在哪里?
- 你的游戏地图有多宽?
- 罗兹现在在哪里?
首先,在代码顶部将边距定义为常量:
# Player constants GRAVITY = 1.0 PLAYER_START_X = 65 PLAYER_START_Y = 256 PLAYER_MOVE_SPEED = 10 PLAYER_JUMP_SPEED = 20 # Viewport margins # How close do we have to be to scroll the viewport? LEFT_VIEWPORT_MARGIN = 50 RIGHT_VIEWPORT_MARGIN = 300 TOP_VIEWPORT_MARGIN = 150 BOTTOM_VIEWPORT_MARGIN = 150注意
LEFT_VIEWPORT_MARGIN和RIGHT_VIEWPORT_MARGIN的区别。这使得罗兹更接近左边缘,而不是右边缘。这样,当 Roz 向右移动时,用户有更多的时间看到障碍物并做出反应。视口是一个矩形,宽度和高度与游戏窗口相同,分别是常量
SCREEN_WIDTH和SCREEN_HEIGHT。因此,要完整地描述视口,只需要知道左下角的位置。通过改变这个角,视口将对 Roz 的移动做出反应。你在你的游戏对象中跟踪这个角,并在.setup()中定义它,就在你将罗兹移动到关卡的开始之后:# Move the player sprite back to the beginning self.player.center_x = PLAYER_START_X self.player.center_y = PLAYER_START_Y self.player.change_x = 0 self.player.change_y = 0 # Reset the viewport self.view_left = 0 self.view_bottom = 0对于本教程,由于每个级别都从同一个地方开始,所以视口的左下角也总是从同一个地方开始。
您可以通过将游戏地图中包含的方块数量乘以每个方块的宽度来计算游戏地图的宽度。在您阅读每张地图并在
.setup()中设置背景颜色后,您可以计算这个值:# Set the background color background_color = arcade.color.FRESH_AIR if game_map.background_color: background_color = game_map.background_color arcade.set_background_color(background_color) # Find the edge of the map to control viewport scrolling self.map_width = ( game_map.map_size.width - 1 ) * game_map.tile_size.width从
game_map.map_size.width中减去1校正平铺使用的平铺索引。最后,通过检查
self.player中的任何位置属性,您可以随时知道 Roz 的位置。以下是如何使用所有这些信息来滚动
.update()中的视窗:
- 更新 Roz 的位置后,计算它们是否在四条边中任何一条边的边距内。
- 如果是这样,您将视口向该方向移动 Roz 在边距内的量。
您可以将这段代码放在
Platformer类的一个单独的方法中,以便于更新:def scroll_viewport(self) -> None: """Scrolls the viewport when the player gets close to the edges""" # Scroll left # Find the current left boundary left_boundary = self.view_left + LEFT_VIEWPORT_MARGIN # Are we to the left of this boundary? Then we should scroll left. if self.player.left < left_boundary: self.view_left -= left_boundary - self.player.left # But don't scroll past the left edge of the map if self.view_left < 0: self.view_left = 0 # Scroll right # Find the current right boundary right_boundary = self.view_left + SCREEN_WIDTH - RIGHT_VIEWPORT_MARGIN # Are we to the right of this boundary? Then we should scroll right. if self.player.right > right_boundary: self.view_left += self.player.right - right_boundary # Don't scroll past the right edge of the map if self.view_left > self.map_width - SCREEN_WIDTH: self.view_left = self.map_width - SCREEN_WIDTH # Scroll up top_boundary = self.view_bottom + SCREEN_HEIGHT - TOP_VIEWPORT_MARGIN if self.player.top > top_boundary: self.view_bottom += self.player.top - top_boundary # Scroll down bottom_boundary = self.view_bottom + BOTTOM_VIEWPORT_MARGIN if self.player.bottom < bottom_boundary: self.view_bottom -= bottom_boundary - self.player.bottom # Only scroll to integers. Otherwise we end up with pixels that # don't line up on the screen. self.view_bottom = int(self.view_bottom) self.view_left = int(self.view_left) # Do the scrolling arcade.set_viewport( left=self.view_left, right=SCREEN_WIDTH + self.view_left, bottom=self.view_bottom, top=SCREEN_HEIGHT + self.view_bottom, )这段代码可能看起来有点混乱,所以看一个具体的例子可能是有用的,比如当 Roz 向右移动并且您需要滚动视口时会发生什么。下面是您将浏览的代码:
# Scroll right # Find the current right boundary right_boundary = self.view_left + SCREEN_WIDTH - RIGHT_VIEWPORT_MARGIN # Are we right of this boundary? Then we should scroll right. if self.player.right > right_boundary: self.view_left += self.player.right - right_boundary # Don't scroll past the right edge of the map if self.view_left > self.map_width - SCREEN_WIDTH: self.view_left = self.map_width - SCREEN_WIDTH以下是一些关键变量的示例值:
- Roz 向右移动,将他们的
self.player.right属性设置为710。- 视口还没变,所以
self.view_left目前是0。- 常数
SCREEN_WIDTH为1000。- 常数
RIGHT_VIEWPORT_MARGIN为300。首先,计算
right_boundary的值,该值确定 Roz 是否在视窗右边缘的边距内:
- 可视视口的右边是
self.view_left + SCREEN_WIDTH,也就是1000。- 从这里减去
RIGHT_VIEWPORT_MARGIN得到700的right_boundary。接下来,检查 Roz 是否已经超过了
right_boundary。因为self.player.right > right_boundary是True,你需要移动视窗,所以你计算移动多远:
- 将
self.player.right - right_boundary计算为10,这是 Roz 移动到右边距的距离。- 由于视口矩形是从左侧测量的,因此将其添加到
self.view_left中,使其成为10。但是,您不希望将视口移出世界的边缘。如果视口一直向右滚动,其左边缘将是小于地图宽度的全屏宽度:
- 检查
self.view_left > self.map_width - SCREEN_WIDTH是否。- 如果是这样,只需将
self.view_left设置为该值来限制视窗移动。对左边界执行相同的步骤。顶部和底部边缘也被检查以更新
self.view_bottom。两个视图变量都更新后,最后要做的是使用arcade.set_viewport()设置视口。因为您将这段代码放在一个单独的方法中,所以在
.on_update()的末尾调用它:if goals_hit: # Play the victory sound self.victory_sound.play() # Set up the next level self.level += 1 self.setup() # Set the viewport, scrolling if necessary self.scroll_viewport()有了这个,你的游戏视图应该随着罗兹向左、向右、向上或向下移动,永远不要让他们离开屏幕!
就这样,你有了一个平台!现在是时候添加一些额外的东西了!
添加额外功能
除了增加越来越复杂的平台,还有一些额外的功能可以让你的游戏脱颖而出。本教程将涵盖其中一些,包括:
- 维护屏幕上的分数
- 使用操纵杆或游戏控制器控制 Roz
- 添加标题、结束游戏、帮助和暂停屏幕
- 自动移动敌人和平台
因为您已经在滚动视图中看到了它的运行,所以让我们从在屏幕上添加跑步得分开始。
屏幕得分
你已经在
self.score中记录了玩家的分数,这意味着你需要做的就是把它画在屏幕上。你可以在.on_draw()中使用arcade.draw_text()来处理这个问题:
你可以在
arcade_platformer/08_on_screen_score.py中找到这段代码。得出分数的代码出现在
.on_draw()的底部,就在self.player.draw()调用之后。你最后画出分数,这样它总是比其他任何东西都清晰可见:def on_draw(self) -> None: arcade.start_render() # Draw all the sprites self.background.draw() self.walls.draw() self.coins.draw() self.goals.draw() self.ladders.draw() self.player.draw() # Draw the score in the lower left score_text = f"Score: {self.score}" # First a black background for a shadow effect arcade.draw_text( score_text, start_x=10 + self.view_left, start_y=10 + self.view_bottom, color=arcade.csscolor.BLACK, font_size=40, ) # Now in white, slightly shifted arcade.draw_text( score_text, start_x=15 + self.view_left, start_y=15 + self.view_bottom, color=arcade.csscolor.WHITE, font_size=40, )首先,构建显示当前分数的字符串。这是后续调用
arcade.draw_text()时将显示的内容。然后,您在屏幕上绘制实际的文本,并传入以下参数:
- 要绘制的文本
start_x和start_y坐标表示开始绘制文本的位置color绘制文本font_size在积分中使用通过将
start_x和start_y参数基于视窗属性self.view_left和self.view_bottom,您可以确保乐谱总是显示在窗口中的相同位置,即使视窗移动时也是如此。您第二次绘制相同的文本,但是稍微移动了一下,颜色变浅,以提供一些对比。
有更多的选项可以与
arcade.draw_text()一起使用,包括指定粗体或斜体文本以及使用游戏特定的字体。查看文档来定制你喜欢的文本。操纵杆和游戏控制器
平台游戏非常适合操纵杆和游戏控制器。控制面板、控制杆和无数的按钮给了你很多机会来最终控制屏幕上的角色。添加操纵杆控制有助于您的游戏脱颖而出。
与键盘控制不同,没有特定的操纵杆方法可以覆盖。相反,
arcade提供了一个设置操纵杆的函数,并公开了来自pyglet的变量和方法来读取实际操纵杆和按钮的状态。您在游戏中使用以下子集:
arcade.get_joysticks()返回连接到系统的操纵杆列表。如果该列表为空,则不存在操纵杆。joystick.x和joystick.y分别返回操纵杆在水平和垂直方向偏转的状态。这些float值的范围从-1.0 到 1.0,需要转换成对你的游戏有用的值。joystick.buttons返回一列指定控制器上所有按钮状态的布尔值。如果按钮被按下,其值将为True。关于可用操纵杆变量和方法的完整列表,请查看
pyglet文档。这方面的代码可以在
arcade_platformer/09_joystick_control.py中找到。在你的玩家可以使用游戏杆之前,你需要验证游戏的
.__init__()方法中是否连接了一个游戏杆。加载游戏声音后会出现以下代码:# Check if a joystick is connected joysticks = arcade.get_joysticks() if joysticks: # If so, get the first one self.joystick = joysticks[0] self.joystick.open() else: # If not, flag it so we won't use it print("There are no Joysticks") self.joystick = None首先,使用
arcade.get_joysticks()枚举所有连接的操纵杆。如果找到,第一个保存为self.joystick。否则,你就设定self.joystick = None。检测并定义了操纵杆后,您可以读取它来为 Roz 提供控制。在任何其他检查之前,在
.on_update()的顶部执行此操作:def on_update(self, delta_time: float) -> None: """Updates the position of all game objects Arguments: delta_time {float} -- How much time since the last call """ # First, check for joystick movement if self.joystick: # Check if we're in the dead zone if abs(self.joystick.x) > DEAD_ZONE: self.player.change_x = self.joystick.x * PLAYER_MOVE_SPEED else: self.player.change_x = 0 if abs(self.joystick.y) > DEAD_ZONE: if self.physics_engine.is_on_ladder(): self.player.change_y = self.joystick.y * PLAYER_MOVE_SPEED else: self.player.change_y = 0 # Did the user press the jump button? if self.joystick.buttons[0]: if self.physics_engine.can_jump(): self.player.change_y = PLAYER_JUMP_SPEED # Play the jump sound arcade.play_sound(self.jump_sound) # Update the player animation self.player.update_animation(delta_time)在阅读游戏杆之前,首先要确保游戏杆已连接。
所有静止的操纵杆都围绕中心值或零值波动。因为
joystick.x和joystick.y返回float值,这些波动可能导致返回值稍微高于或低于零,这将转化为 Roz 在没有任何操纵杆输入的情况下非常轻微地移动。为了解决这个问题,游戏设计者定义了一个操纵杆死区来包含这些小波动。该死区内对
joystick.x或joystick.y的任何更改都会被忽略。您可以通过首先在代码顶部定义一个常量DEAD_ZONE来实现一个死区:# Viewport margins # How close do we have to be to scroll the viewport? LEFT_VIEWPORT_MARGIN = 50 RIGHT_VIEWPORT_MARGIN = 300 TOP_VIEWPORT_MARGIN = 150 BOTTOM_VIEWPORT_MARGIN = 150 # Joystick control DEAD_ZONE = 0.1现在你可以检查操纵杆是否移动超过
DEAD_ZONE。如果不是,你忽略操纵杆输入。否则,你用操纵杆值乘以PLAYER_MOVE_SPEED来移动 Roz。这使得玩家可以根据操纵杆的推动程度来更快或更慢地移动 Roz。记住,在你允许罗兹上下移动之前,你仍然必须检查他是否在梯子上。接下来,你处理跳跃。如果操纵杆上的第一个按钮被按下,也就是我游戏手柄上的
A按钮,你会将其解释为跳转命令,并让 Roz 以与Space相同的方式跳转。就是这样!现在你可以使用任何操作系统支持的操纵杆来控制 Roz!
标题和其他屏幕
一个没有介绍就开始的游戏会让你的用户感觉被抛弃了。除非他们已经知道该做什么,否则在没有标题屏幕或基本说明的情况下直接从 1 级开始游戏会令人不安。你可以在
arcade中使用视图来解决这个问题。在
arcade中的一个视图代表了你想向用户展示的任何东西,无论是静态文本、关卡间的过场动画,还是真实的游戏本身。视图是基于类arcade.View的,可以用来向用户显示信息,也可以让他们玩你的游戏:https://player.vimeo.com/video/530532600?background=1
对于这个游戏,您将定义三个独立的视图:
- 标题视图允许用户开始游戏或查看帮助屏幕。
- 指令视图向用户显示背景故事和基本控件。
- 暂停视图在用户暂停游戏时显示。
为了使一切无缝,你首先需要把你的游戏转换成一个视图,所以你现在要做的就是这个!
PlatformerView修改现有游戏以无缝使用视图需要三个单独的代码更改。您可以在
arcade_platformer/10_view_conversion.py的可下载资料中找到这些变化。您可以通过单击下面的链接下载本教程中使用的所有材料和代码:获取源代码: 点击此处获取您将在本教程中使用用 Python Arcade 构建平台游戏的源代码。
第一个是对您的
Platformer类的一行修改:class PlatformerView(arcade.View): def __init__(self) -> None: super().__init__()为了保持命名的一致性,您可以更改类名和基类名。从功能上来说,
PlatformerView类包含了与最初的Platformer类相同的方法。第二个变化是在
.__init__()中,这里不再传入常量SCREEN_WIDTH、SCREEN_HEIGHT或SCREEN_TITLE。这是因为您的PlatformerView类现在是基于arcade.View的,它不使用这些常量。您的super()调用也会发生变化以反映这一点。为什么不再需要那些常量了?视图不是窗口,所以没有必要传入那些
arcade.Window参数。那么你在哪里定义游戏窗口的大小和外观呢?这发生在最后的更改中,在文件的底部,在
__main__部分:if __name__ == "__main__": window = arcade.Window( width=SCREEN_WIDTH, height=SCREEN_HEIGHT, title=SCREEN_TITLE ) platform_view = PlatformerView() platform_view.setup() window.show_view(platform_view) arcade.run()您显式地创建一个
arcade.Window来显示您的视图。然后创建PlatformerView对象,调用.setup(),并使用window.show_view(platformer_view)来显示它。一旦它是可见的,你像以前一样运行你的游戏。这些改变应该不会对游戏的功能造成影响,所以测试之后,你就可以添加一个标题视图了。
标题视图
任何游戏的标题视图都应该稍微展示一下游戏,并允许玩家在闲暇时开始游戏。虽然动画标题页是可能的,但在本教程中,您将创建一个带有简单菜单的静态标题视图,以允许用户开始游戏或查看帮助屏幕:
https://player.vimeo.com/video/530532600?background=1
这方面的代码可以在
arcade_platformer/11_title_view.py找到。创建标题视图首先要为它定义一个新类:
class TitleView(arcade.View): """Displays a title screen and prompts the user to begin the game. Provides a way to show instructions and start the game. """ def __init__(self) -> None: super().__init__() # Find the title image in the images folder title_image_path = ASSETS_PATH / "images" / "title_image.png" # Load our title image self.title_image = arcade.load_texture(title_image_path) # Set our display timer self.display_timer = 3.0 # Are we showing the instructions? self.show_instructions = False标题视图显示一个简单的静态图像。
注意:此处使用的标题图像仅在可下载材料中提供。你可以使用它提供的或替换你自己的。
您使用
self.display_timer和self.show_instructions属性让一组指令在屏幕上闪烁。这在您在TitleView类中创建的.on_update()中处理:def on_update(self, delta_time: float) -> None: """Manages the timer to toggle the instructions Arguments: delta_time -- time passed since last update """ # First, count down the time self.display_timer -= delta_time # If the timer has run out, we toggle the instructions if self.display_timer < 0: # Toggle whether to show the instructions self.show_instructions = not self.show_instructions # And reset the timer so the instructions flash slowly self.display_timer = 1.0回想一下,
delta_time参数告诉您自从最后一次调用.on_update()以来已经过去了多长时间。每次.on_update()被调用,你就从self.display_timer中减去delta_time。当它超过零时,你触发self.show_instructions并重置计时器。那么这是如何控制指令何时显示的呢?这一切都发生在
.on_draw():def on_draw(self) -> None: # Start the rendering loop arcade.start_render() # Draw a rectangle filled with our title image arcade.draw_texture_rectangle( center_x=SCREEN_WIDTH / 2, center_y=SCREEN_HEIGHT / 2, width=SCREEN_WIDTH, height=SCREEN_HEIGHT, texture=self.title_image, ) # Should we show our instructions? if self.show_instructions: arcade.draw_text( "Enter to Start | I for Instructions", start_x=100, start_y=220, color=arcade.color.INDIGO, font_size=40, )绘制背景图像后,检查是否设置了
self.show_instructions。如果是这样,您使用arcade.draw_text()绘制说明文本。否则,你什么也画不出来。由于.on_update()每秒切换一次self.show_instructions的值,这使得文本在屏幕上闪烁。指令要求玩家打
Enter或者I,所以需要提供一个.on_key_press()的方法:def on_key_press(self, key: int, modifiers: int) -> None: """Resume the game when the user presses ESC again Arguments: key -- Which key was pressed modifiers -- What modifiers were active """ if key == arcade.key.RETURN: game_view = PlatformerView() game_view.setup() self.window.show_view(game_view) elif key == arcade.key.I: instructions_view = InstructionsView() self.window.show_view(instructions_view)如果用户按下
Enter,你创建一个名为game_view的PlatformerView对象,调用game_view.setup(),显示该视图开始游戏。如果用户按下I,你创建一个InstructionsView对象(下面会详细介绍)并显示它。最后,您希望标题屏幕是用户看到的第一样东西,所以您也更新了您的
__main__部分:if __name__ == "__main__": window = arcade.Window( width=SCREEN_WIDTH, height=SCREEN_HEIGHT, title=SCREEN_TITLE ) title_view = TitleView() window.show_view(title_view) arcade.run()那么,指令视图是怎么回事?
说明视图
向用户显示游戏说明可以像完整游戏一样复杂,也可以像标题屏幕一样简单:
https://player.vimeo.com/video/530532487?background=1
在这种情况下,您的说明视图与标题屏幕非常相似:
- 显示带有游戏说明的预生成图像。
- 允许玩家按下
Enter开始游戏。- 如果玩家按下
Esc,则返回标题画面。因为没有计时器,所以只需要实现三个方法:
.__init__()加载指令图像.on_draw()画出图像.on_key_press()处理用户输入你可以在
arcade_platformer/12_instructions_view.py下找到这个代码:class InstructionsView(arcade.View): """Show instructions to the player""" def __init__(self) -> None: """Create instructions screen""" super().__init__() # Find the instructions image in the image folder instructions_image_path = ( ASSETS_PATH / "images" / "instructions_image.png" ) # Load our title image self.instructions_image = arcade.load_texture(instructions_image_path) def on_draw(self) -> None: # Start the rendering loop arcade.start_render() # Draw a rectangle filled with the instructions image arcade.draw_texture_rectangle( center_x=SCREEN_WIDTH / 2, center_y=SCREEN_HEIGHT / 2, width=SCREEN_WIDTH, height=SCREEN_HEIGHT, texture=self.instructions_image, ) def on_key_press(self, key: int, modifiers: int) -> None: """Start the game when the user presses Enter Arguments: key -- Which key was pressed modifiers -- What modifiers were active """ if key == arcade.key.RETURN: game_view = PlatformerView() game_view.setup() self.window.show_view(game_view) elif key == arcade.key.ESCAPE: title_view = TitleView() self.window.show_view(title_view)这样,你就可以向你的玩家显示标题屏幕和说明,并允许他们在屏幕之间移动。
但是如果有人在玩你的游戏,电话响了怎么办?让我们看看如何使用视图来实现暂停特性。
暂停视图
实现暂停功能需要您编写两个新特性:
- 暂停和取消暂停游戏的按键
- 一种指示游戏暂停的方式
当用户暂停时,他们会看到类似这样的内容:
https://player.vimeo.com/video/530532547?background=1
你可以在
arcade_platformer/13_pause_view.py中找到这段代码。您在
PlatformerView.on_keypress()中添加按键,就在检查跳转键之后:# Check if we can jump elif key == arcade.key.SPACE: if self.physics_engine.can_jump(): self.player.change_y = PLAYER_JUMP_SPEED # Play the jump sound arcade.play_sound(self.jump_sound) # Did the user want to pause? elif key == arcade.key.ESCAPE: # Pass the current view to preserve this view's state pause = PauseView(self) self.window.show_view(pause)当玩家点击
Esc时,游戏会创建一个新的PauseView对象并显示出来。由于PlatformerView不再主动显示,它不能处理任何方法调用,如.on_update()或.on_draw()。这有效地停止了游戏的运行。需要注意的一点是创建新的
PauseView对象的那一行。这里你传入了self,它是对当前PlatformerView对象的引用。记住这一点,因为它以后会很重要。现在您可以创建新的
PauseView类。这个类非常类似于您已经实现的TitleView和InstructionView类。最大的区别是视图显示的内容。PauseView显示的不是完全覆盖游戏屏幕的图形,而是覆盖着半透明层的活动游戏屏幕。在这一层上绘制的文本表示游戏暂停,而背景向用户显示游戏暂停的位置。定义暂停视图从定义类及其
.__init__()方法开始:class PauseView(arcade.View): """Shown when the game is paused""" def __init__(self, game_view: arcade.View) -> None: """Create the pause screen""" # Initialize the parent super().__init__() # Store a reference to the underlying view self.game_view = game_view # Store a semitransparent color to use as an overlay self.fill_color = arcade.make_transparent_color( arcade.color.WHITE, transparency=150 )这里,
.__init__()接受一个名为game_view的参数。这是你在创建PauseView对象时传递的对PlatformerView游戏的引用。您需要将这个引用存储在self.game_view中,因为您以后会用到它。为了创建半透明层的效果,你也可以创建一个半透明的颜色来填充屏幕:
def on_draw(self) -> None: """Draw the underlying screen, blurred, then the Paused text""" # First, draw the underlying view # This also calls start_render(), so no need to do it again self.game_view.on_draw() # Now create a filled rect that covers the current viewport # We get the viewport size from the game view arcade.draw_lrtb_rectangle_filled( left=self.game_view.view_left, right=self.game_view.view_left + SCREEN_WIDTH, top=self.game_view.view_bottom + SCREEN_HEIGHT, bottom=self.game_view.view_bottom, color=self.fill_color, ) # Now show the Pause text arcade.draw_text( "PAUSED - ESC TO CONTINUE", start_x=self.game_view.view_left + 180, start_y=self.game_view.view_bottom + 300, color=arcade.color.INDIGO, font_size=40, )注意,这里使用了保存的对当前
PlatformerView对象的引用。通过调用self.game_view.on_draw()首先显示游戏的当前状态。由于self.game_view仍然在内存中并且活跃,这是完全可以接受的。只要self.game_view.on_update()没有被调用,你总是会在暂停键被按下的那一刻画出游戏的静态视图。接下来,绘制一个覆盖整个窗口的矩形,用
.__init__()中定义的半透明颜色填充。因为这发生在游戏已经画出它的物体之后,看起来好像一场雾降临在游戏上。为了清楚地表明游戏已经暂停,您最终通过在屏幕上显示一条消息来通知用户这个事实。
取消暂停游戏使用与暂停相同的
Esc按键,因此您必须处理它:def on_key_press(self, key: int, modifiers: int) -> None: """Resume the game when the user presses ESC again Arguments: key -- Which key was pressed modifiers -- What modifiers were active """ if key == arcade.key.ESCAPE: self.window.show_view(self.game_view)这是保存
self.game_view引用的最后一个原因。当玩家再次按下Esc时,你需要从它停止的地方重新激活游戏。您不需要创建一个新的PlatformerView,只需显示您之前保存的已经激活的视图。使用这些技术,您可以实现任意多的视图。一些扩展的想法包括:
- 游戏结束时的游戏结束视图
- 一个级别结束视图,用于在级别之间转换并允许过场动画
- 如果玩家选择重启关卡,将会显示一个特殊的重启界面
- 一直受欢迎的 boss 键,为工作时玩游戏的玩家提供电子表格覆盖
选择权全在你!
移动敌人和平台
让屏幕上的东西自动移动并不像听起来那么困难。不是根据玩家的输入来移动对象,而是根据内部和游戏状态来移动对象。您将实现两种不同的移动:
- 在封闭区域自由活动的敌人
- 在设定路径上移动的平台
您将首先探索如何让敌人移动。
敌人的动向
您可以在可下载资料的
arcade_platformer/14_enemies.py和assets/platform_level_02.tmx中找到这一部分的代码。它会告诉你如何让你的游戏像这样:https://player.vimeo.com/video/530532447?background=1
在你能让敌人移动之前,你必须有一个敌人。对于本教程,您将在代码中定义您的敌人,这需要一个敌人类:
class Enemy(arcade.AnimatedWalkingSprite): """An enemy sprite with basic walking movement""" def __init__(self, pos_x: int, pos_y: int) -> None: super().__init__(center_x=pos_x, center_y=pos_y) # Where are the player images stored? texture_path = ASSETS_PATH / "images" / "enemies" # Set up the appropriate textures walking_texture_path = [ texture_path / "slimePurple.png", texture_path / "slimePurple_move.png", ] standing_texture_path = texture_path / "slimePurple.png" # Load them all now self.walk_left_textures = [ arcade.load_texture(texture) for texture in walking_texture_path ] self.walk_right_textures = [ arcade.load_texture(texture, mirrored=True) for texture in walking_texture_path ] self.stand_left_textures = [ arcade.load_texture(standing_texture_path, mirrored=True) ] self.stand_right_textures = [ arcade.load_texture(standing_texture_path) ] # Set the enemy defaults self.state = arcade.FACE_LEFT self.change_x = -PLAYER_MOVE_SPEED // 2 # Set the initial texture self.texture = self.stand_left_textures[0]将敌人定义为一个职业遵循了与 Roz 相似的模式。基于
arcade.AnimatedWalkingSprite,敌人继承了一些基本的功能。像罗兹一样,你需要采取以下步骤:
- 定义制作动画时要使用的纹理。
- 定义精灵最初应该面向哪个方向。
- 定义它应该移动的速度。
通过让敌人以罗兹一半的速度移动,你可以确保罗兹跑得比敌人快。
现在你需要创建敌人并把它放在屏幕上。因为每个关卡在不同的地方可能有不同的敌人,所以创建一个
PlatformerView方法来处理这个问题:def create_enemy_sprites(self) -> arcade.SpriteList: """Creates enemy sprites appropriate for the current level Returns: A Sprite List of enemies""" enemies = arcade.SpriteList() # Only enemies on level 2 if self.level == 2: enemies.append(Enemy(1464, 320)) return enemies创建一个
SpriteList来控制你的敌人,确保你可以用与其他屏幕上的对象相似的方式来管理和更新你的敌人。虽然这个例子显示了一个敌人被放置在一个等级的硬编码位置,但是您也可以编写代码来处理不同等级的多个敌人,或者从数据文件中读取敌人的放置信息。您在
.setup()中调用这个方法,就在创建播放器精灵之后和设置视口之前:# Move the player sprite back to the beginning self.player.center_x = PLAYER_START_X self.player.center_y = PLAYER_START_Y self.player.change_x = 0 self.player.change_y = 0 # Set up our enemies self.enemies = self.create_enemy_sprites() # Reset the viewport self.view_left = 0 self.view_bottom = 0现在你的敌人已经被创造出来了,你可以在更新完
.on_update()中的玩家后立即更新他们:# Update the player animation self.player.update_animation(delta_time) # Are there enemies? Update them as well self.enemies.update_animation(delta_time) for enemy in self.enemies: enemy.center_x += enemy.change_x walls_hit = arcade.check_for_collision_with_list( sprite=enemy, sprite_list=self.walls ) if walls_hit: enemy.change_x *= -1物理引擎不会自动管理敌人的移动,所以你必须手动处理。你还需要检查是否有撞墙,如果敌人撞上了墙,就逆转敌人的移动。
你还需要检查罗兹是否与你的任何敌人发生过碰撞。在检查罗兹是否捡起了一枚硬币后,执行以下操作:
for coin in coins_hit: # Add the coin score to our score self.score += int(coin.properties["point_value"]) # Play the coin sound arcade.play_sound(self.coin_sound) # Remove the coin coin.remove_from_sprite_lists() # Has Roz collided with an enemy? enemies_hit = arcade.check_for_collision_with_list( sprite=self.player, sprite_list=self.enemies ) if enemies_hit: self.setup() title_view = TitleView() window.show_view(title_view)这段代码从硬币碰撞检查开始,除了寻找 Roz 和
self.enemies之间的碰撞。然而,如果你与任何敌人相撞,游戏就结束了,所以唯一需要检查的是是否至少有一个敌人被击中。如果是这样,您调用.setup()来重置当前级别并显示一个TitleView。如果你已经在视图上创建了一个游戏,这将是创建和显示它的地方。最后要做的事情是使用与其他精灵列表相同的技术来绘制你的敌人。将以下内容添加到
.on_draw():def on_draw(self) -> None: arcade.start_render() # Draw all the sprites self.background.draw() self.walls.draw() self.coins.draw() self.goals.draw() self.ladders.draw() self.enemies.draw() self.player.draw()你可以扩展这个技巧来创造尽可能多的不同类型的敌人。
现在,您已经准备好启动一些平台了!
移动平台
移动平台给你的游戏带来视觉和战略上的兴趣。它们允许你建立需要思想和技巧去克服的世界和障碍:
https://player.vimeo.com/video/530532499?background=1
您可以在
arcade_platformer/15_moving_platforms.py和assets/platform_level_02.tmx找到该部分的代码。如果你想自己建造移动平台,你可以在assets/platform_level_02_start.tmx找到一个没有现有平台的起点。由于平台在
arcade中被视为墙,所以用 Tiled 来声明性地定义它们通常会更快。在平铺中,打开地图并创建一个名为moving_platforms的新对象层:
在一个对象层上创建移动平台允许你定义属性
arcade来移动平台。在本教程中,您将创建一个移动平台。选中该层后,点击
T添加一个新的图块,并选择将成为新平台的图块。将图块放在您希望它开始或结束的位置附近。看起来完整的单幅图块通常是最佳选择:
一旦放置了移动的牌,点击
Esc停止放置牌。接下来,您将定义自定义特性来设置移动平台运动的速度和限制。使用以下定义的属性将对水平和垂直移动平台的支持内置到
arcade中:
boundary_left和boundary_right限制平台的水平运动。boundary_top和boundary_bottom限制平台的垂直运动。change_x设定水平速度。change_y设定垂直速度。由于该平台将 Roz 水平运送到下方的敌人上方,因此只有
boundary_left、boundary_right和change_x属性被定义为float值:
您可以修改这些属性以适应您的关卡设计。如果您定义了所有六个自定义属性,那么您的平台将以对角线模式移动!
设置好平台及其属性后,就该处理新图层了。在
PlatformerView.setup()中,在处理您的地图图层之后和设置背景颜色之前,添加以下代码:self.coins = arcade.tilemap.process_layer( game_map, layer_name=coin_layer, scaling=MAP_SCALING ) # Process moving platforms moving_platforms_layer_name = "moving_platforms" moving_platforms = arcade.tilemap.process_layer( game_map, layer_name=moving_platforms_layer_name, scaling=MAP_SCALING, ) for sprite in moving_platforms: self.walls.append(sprite)因为你的移动平台位于一个对象层,它们必须与你的其他墙壁分开处理。然而,由于你的玩家需要能够站在它们上面,你将它们添加到
self.walls中,这样物理引擎就可以正确地处理它们。最后,你需要让你的平台动起来。还是你?
记住你已经做了什么:
- 当您在平铺中定义移动平台时,您可以设置自定义属性来定义其移动。
- 当您处理
moving_platforms层时,您将其中的所有内容都添加到了self.walls中。- 当您创建
self.physics_engine时,您将self.walls列表作为参数传递。这都意味着,当你在
.on_update()中调用self.physics_engine.update()时,你所有的平台都会自动移动!任何没有设置自定义属性的墙砖都不会移动。当罗兹站在一个移动的平台上时,物理引擎甚至聪明到可以移动他们:https://player.vimeo.com/video/530532499?background=1
你可以添加任意多的移动平台,来创建任意复杂的世界。
结论
Python
arcade库是一个现代的 Python 框架,非常适合制作具有引人注目的图形和声音的游戏。面向对象,为 Python 3.6 和更高版本而构建,arcade为程序员提供了一套现代的工具,用于打造出色的游戏体验,包括平台游戏。arcade是开源的,随时欢迎投稿。阅读完本教程后,你现在能够:
- 安装 Python
arcade库- 创建一个基本的 2D 游戏结构
- 找到可用的游戏作品和其他资产
- 使用平铺的地图编辑器构建平台地图
- 定义玩家动作,游戏奖励,以及障碍
- 用键盘和操纵杆输入控制你的玩家
- 播放游戏动作的音效
- 用视窗滚动游戏屏幕,让你的玩家保持在视野中
- 添加标题、指令、暂停画面
- 在屏幕上移动非玩家游戏元素
这个游戏还有很多事要做。以下是一些您可以实现的功能想法:
- 在屏幕上添加游戏。
- 动画屏幕上的硬币。
- 添加 Roz 与敌人碰撞时的动画。
- 检测罗兹何时从地图上消失。
- 给罗兹多重生命。
- 添加高分表。
- 使用
arcade.PymunkPhysicsEngine来提供更真实的物理交互。在
arcade图书馆里也有更多值得探索的东西。有了这些技术,你现在完全有能力去做一些很酷的游戏了!您可以通过单击下面的链接下载本教程中使用的所有代码、图像和声音:
获取源代码: 点击此处获取您将在本教程中使用用 Python Arcade 构建平台游戏的源代码。**********
用 Python 播放和录制声音
原文:https://realpython.com/playing-and-recording-sound-python/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 演奏录音
如果您想使用 Python 来播放或录制声音,那么您来对地方了!在本教程中,您将学习如何使用一些最流行的音频库在 Python 中播放和录制声音。您将首先了解播放和录制声音的最直接的方法,然后了解一些提供更多功能的库,以换取几行额外的代码。
本教程结束时,你将知道如何:
- 播放 MP3 和 WAV 文件,以及一系列其他音频格式
- 播放包含声音的 NumPy 和 Python 数组
- 使用 Python 录制声音
- 以一系列不同的文件格式保存您的录音或音频文件
要获得与音频相关的 Python 库的完整列表,请查看 Python 中关于音频的维基页面。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
播放音频文件
下面,您将看到如何使用一系列 Python 库来播放音频文件。其中一些库允许您播放一系列音频格式,包括 MP3 和 NumPy 数组。以下所有库都允许您播放 WAV 文件,有些库比其他库多几行代码:
如果你只是想播放一个 WAV 或 MP3 文件,那么
playsound是最简单的软件包。除了简单的回放,它不提供任何功能。
simpleaudio让你播放 WAV 文件和 NumPy 数组,并给你检查文件是否还在播放的选项。
winsound允许你播放 WAV 文件或者让你的扬声器发出嘟嘟声,但是它只在 Windows 上有效。
python-sounddevice****pyaudio为 PortAudio 库提供绑定,用于跨平台播放 WAV 文件。
pydub需要pyaudio进行音频播放,但安装了ffmpeg后,只需几行代码就能让你播放大范围的音频格式。让我们一个一个的来看看这些用于音频播放的库。
playsound
playsound是一个“纯 Python,跨平台,单一功能模块,对播放声音没有依赖性。”使用这个模块,你可以用一行代码播放一个声音文件:from playsound import playsound playsound('myfile.wav')
playsound的文档声明它已经在 WAV 和 MP3 文件上测试过,但它也可能适用于其他文件格式。这个库最后一次更新是在 2017 年 6 月。在撰写本文时,它似乎工作得很好,但不清楚它是否仍然支持较新的 Python 版本。
simpleaudio
simpleaudio是一个跨平台的库,用于播放(单声道和立体声)WAV 文件,不依赖。以下代码可用于播放 WAV 文件,并在终止脚本之前等待文件播放完毕:import simpleaudio as sa filename = 'myfile.wav' wave_obj = sa.WaveObject.from_wave_file(filename) play_obj = wave_obj.play() play_obj.wait_done() # Wait until sound has finished playingWAV 文件包含一个代表原始音频数据的位序列,以及 RIFF(资源交换文件格式)格式的带有元数据的头。
对于 CD 录音,行业标准是将每个音频样本(与气压相关的单个音频数据点)存储为一个 16 位值,每秒 44100 个样本。
为了减小文件大小,以较低的采样率(例如每秒 8000 个样本)存储一些记录(例如人类语音)可能就足够了,尽管这确实意味着较高的声音频率可能不会被准确地表示。
本教程中讨论的一些库播放和录制
bytes对象,而其他的使用 NumPy 数组来存储原始音频数据。两者都对应于一系列数据点,为了播放声音,可以以指定的采样速率回放这些数据点。对于一个
bytes对象,每个样本存储为一组两个 8 位值,而在 NumPy 数组中,每个元素可以包含一个对应于单个样本的 16 位值。这两种数据类型的一个重要区别是,
bytes对象是不可变的,而 NumPy 数组是可变的,这使得后者更适合生成声音和更复杂的信号处理。关于如何使用 NumPy 的更多信息,请看我们的 NumPy 教程。
simpleaudio允许你使用simpleaudio.play_buffer()来玩 NumPy 和 Python 数组以及bytes对象。确保您已经安装了 NumPy,以便下面的示例以及simpleaudio能够工作。(安装了pip之后,你可以通过从你的控制台运行pip install numpy来完成这个任务。)关于如何使用
pip安装包的更多信息,请看一下 Pipenv:新 Python 打包工具指南。在下面,您将看到如何生成一个对应于 440 赫兹音调的 NumPy 数组,并使用
simpleaudio.play_buffer()进行回放:import numpy as np import simpleaudio as sa frequency = 440 # Our played note will be 440 Hz fs = 44100 # 44100 samples per second seconds = 3 # Note duration of 3 seconds # Generate array with seconds*sample_rate steps, ranging between 0 and seconds t = np.linspace(0, seconds, seconds * fs, False) # Generate a 440 Hz sine wave note = np.sin(frequency * t * 2 * np.pi) # Ensure that highest value is in 16-bit range audio = note * (2**15 - 1) / np.max(np.abs(note)) # Convert to 16-bit data audio = audio.astype(np.int16) # Start playback play_obj = sa.play_buffer(audio, 1, 2, fs) # Wait for playback to finish before exiting play_obj.wait_done()接下来,让我们看看如何使用
winsound在 Windows 机器上播放 WAV 文件。
winsound如果你使用 Windows,你可以使用内置的
winsound模块来访问其基本的声音播放机制。播放 WAV 文件只需几行代码:import winsound filename = 'myfile.wav' winsound.PlaySound(filename, winsound.SND_FILENAME)
winsound不支持播放除 WAV 文件以外的任何文件。它确实允许你使用winsound.Beep(frequency, duration)让你的扬声器发出嘟嘟声。例如,您可以使用以下代码发出 1000 赫兹的提示音 100 毫秒:import winsound winsound.Beep(1000, 100) # Beep at 1000 Hz for 100 ms接下来,您将学习如何使用
python-sounddevice模块进行跨平台音频播放。
python-sounddevice正如其文档中所述,
python-sounddevice“为 PortAudio 库提供绑定和一些方便的函数来播放和录制包含音频信号的 NumPy 数组”。为了播放 WAV 文件,需要安装numpy和soundfile,以 NumPy 数组的形式打开 WAV 文件。安装了
python-sounddevice、numpy和soundfile之后,您现在可以将 WAV 文件作为 NumPy 数组读取并回放:import sounddevice as sd import soundfile as sf filename = 'myfile.wav' # Extract data and sampling rate from file data, fs = sf.read(filename, dtype='float32') sd.play(data, fs) status = sd.wait() # Wait until file is done playing包含
sf.read()的行提取原始音频数据,以及存储在其 RIFF 头中的文件的采样率,sounddevice.wait()确保脚本仅在声音结束播放后终止。接下来,我们将学习如何使用
pydub来播放声音。安装了正确的依赖项后,它允许你播放各种各样的音频文件,并且比python-soundevice提供了更多的音频处理选项。
pydub虽然
pydub可以打开保存 WAV 文件,没有任何依赖关系,但是需要安装音频播放包才能播放音频。强烈推荐simpleaudio,但是pyaudio、ffplay、avplay也是备选方案。下面的代码可以用来播放带有
pydub的 WAV 文件:from pydub import AudioSegment from pydub.playback import play sound = AudioSegment.from_wav('myfile.wav') play(sound)为了播放其他音频类型,如 MP3 文件,应安装
ffmpeg或libav。查看pydub的文档获取说明。作为文档中描述的步骤的替代,ffmpeg-python为ffmpeg提供绑定,可以使用 pip 进行安装:$ pip install ffmpeg-python安装了
ffmpeg之后,回放一个 MP3 文件只需要对我们之前的代码做一点小小的改动:from pydub import AudioSegment from pydub.playback import play sound = AudioSegment.from_mp3('myfile.mp3') play(sound)使用
AudioSegment.from_file(filename, filetype)结构,你可以播放任何类型的ffmpeg支持的音频文件。例如,您可以使用以下内容播放 WMA 文件:sound = AudioSegment.from_file('myfile.wma', 'wma')除了回放声音文件,
pydub还允许您以不同的文件格式保存音频(稍后将详细介绍),分割音频,计算音频文件的长度,淡入或淡出,以及应用交叉淡入淡出。
AudioSegment.reverse()创建倒放的音频片段的副本,文档描述为“对平克·弗洛伊德、鬼混和一些音频处理算法有用。”
pyaudio
pyaudio为跨平台音频 I/O 库 PortAudio 提供绑定。这意味着您可以使用pyaudio在各种平台上播放和录制音频,包括 Windows、Linux 和 Mac。使用pyaudio,通过写入.Stream来播放音频:import pyaudio import wave filename = 'myfile.wav' # Set chunk size of 1024 samples per data frame chunk = 1024 # Open the sound file wf = wave.open(filename, 'rb') # Create an interface to PortAudio p = pyaudio.PyAudio() # Open a .Stream object to write the WAV file to # 'output = True' indicates that the sound will be played rather than recorded stream = p.open(format = p.get_format_from_width(wf.getsampwidth()), channels = wf.getnchannels(), rate = wf.getframerate(), output = True) # Read data in chunks data = wf.readframes(chunk) # Play the sound by writing the audio data to the stream while data != '': stream.write(data) data = wf.readframes(chunk) # Close and terminate the stream stream.close() p.terminate()您可能已经注意到,用
pyaudio播放声音比用您之前看到的库播放声音要复杂一些。这意味着,如果您只想在 Python 应用程序中播放声音效果,它可能不是您的首选。然而,因为
pyaudio给了你更多的底层控制,所以可以获取和设置你的输入和输出设备的参数,并检查你的 CPU 负载和输入或输出延迟。它还允许您在回调模式下播放和录制音频,在回调模式下,当需要新数据进行回放或可用于录制时,会调用指定的回调函数。如果您的音频需求不仅仅是简单的回放,这些选项使
pyaudio成为一个合适的库。既然您已经看到了如何使用许多不同的库来播放音频,那么是时候看看如何使用 Python 来自己录制音频了。
录制音频
python-sounddevice和pyaudio库提供了用 Python 录制音频的方法。python-sounddevice记录到 NumPy 数组,pyaudio记录到bytes对象。这两个都可以分别使用scipy和wave库存储为 WAV 文件。
python-sounddevice
python-sounddevice允许你从你的麦克风记录音频,并将其存储为一个 NumPy 数组。这是一种方便的声音处理数据类型,可以使用scipy.io.wavfile模块将其转换为 WAV 格式进行存储。确保为以下示例(pip install scipy)安装scipy模块。这将自动安装 NumPy 作为其依赖项之一:import sounddevice as sd from scipy.io.wavfile import write fs = 44100 # Sample rate seconds = 3 # Duration of recording myrecording = sd.rec(int(seconds * fs), samplerate=fs, channels=2) sd.wait() # Wait until recording is finished write('output.wav', fs, myrecording) # Save as WAV file
pyaudio在本文前面的中,你通过阅读一首
pyaudio.Stream()学会了如何弹奏声音。可以通过写入此流来录制音频:import pyaudio import wave chunk = 1024 # Record in chunks of 1024 samples sample_format = pyaudio.paInt16 # 16 bits per sample channels = 2 fs = 44100 # Record at 44100 samples per second seconds = 3 filename = "output.wav" p = pyaudio.PyAudio() # Create an interface to PortAudio print('Recording') stream = p.open(format=sample_format, channels=channels, rate=fs, frames_per_buffer=chunk, input=True) frames = [] # Initialize array to store frames # Store data in chunks for 3 seconds for i in range(0, int(fs / chunk * seconds)): data = stream.read(chunk) frames.append(data) # Stop and close the stream stream.stop_stream() stream.close() # Terminate the PortAudio interface p.terminate() print('Finished recording') # Save the recorded data as a WAV file wf = wave.open(filename, 'wb') wf.setnchannels(channels) wf.setsampwidth(p.get_sample_size(sample_format)) wf.setframerate(fs) wf.writeframes(b''.join(frames)) wf.close()现在您已经了解了如何使用
python-sounddevice和pyaudio录制音频,您将学习如何将您的录音(或任何其他音频文件)转换为一系列不同的音频格式。保存和转换音频
您在前面的中看到,您可以使用
scipy.io.wavfile模块将 NumPy 数组存储为 WAV 文件。wavio模块同样可以让你在 WAV 文件和 NumPy 数组之间转换。如果你想以不同的文件格式存储你的音频,pydub和soundfile就派上了用场,因为它们允许你读写一系列流行的文件格式(如 MP3、FLAC、WMA 和 FLV)。
wavio这个模块依赖于
numpy并允许你读取 WAV 文件作为 NumPy 数组,并保存 NumPy 数组为 WAV 文件。要将 NumPy 数组保存为 WAV 文件,可以使用
wavio.write():import wavio wavio.write("myfile.wav", my_np_array, fs, sampwidth=2)在这个例子中,
my_np_array是包含音频的 NumPy 数组,fs是录音的采样率(通常为 44100 或 44800 Hz),sampwidth是音频的采样宽度(每个样本的字节数,通常为 1 或 2 字节)。
soundfile
soundfile库可以读写libsndfile支持的所有文件格式。虽然它不能播放音频,但它允许你在 FLAC、AIFF 和一些不太常见的音频格式之间来回转换。要将 WAV 文件转换为 FLAC,可以使用以下代码:import soundfile as sf # Extract audio data and sampling rate from file data, fs = sf.read('myfile.wav') # Save as FLAC file at correct sampling rate sf.write('myfile.flac', data, fs)类似的代码也可以在
libsndfile支持的其他文件格式之间转换。
pydub
pydub可以让你将音频保存为ffmpeg支持的格式,几乎囊括了你日常生活中可能遇到的所有音频类型。例如,您可以使用以下代码将 WAV 文件转换为 MP3:from pydub import AudioSegment sound = AudioSegment.from_wav('myfile.wav') sound.export('myfile.mp3', format='mp3')使用
AudioSegment.from_file()是一种更通用的加载音频文件的方式。例如,如果您想将文件从 MP3 转换回 WAV,您可以执行以下操作:from pydub import AudioSegment sound = AudioSegment.from_file('myfile.mp3', format='mp3') sound.export('myfile.wav', format='wav')这段代码应该适用于
ffmpeg支持的任何音频文件格式。音频库对比
下表比较了本教程中讨论的库的功能:
图书馆 平台 重放 记录 皈依者 属国 T2 playsound跨平台 WAV,MP3 - - 没有人 T2 simpleaudio跨平台 WAV,数组, bytes- - 没有人 T2 winsoundWindows 操作系统 声音资源文件 - - 没有人 T2 sounddevice跨平台 数字阵列 数字阵列 - numpy,soundfileT2 pydub跨平台 ffmpeg支持的任何类型- ffmpeg支持的任何类型simpleaudio,ffmpegT2 pyaudio跨平台 bytesbytes- waveT2 wavio跨平台 - - WAV,数字阵列 numpy,waveT2 soundfile跨平台 - - libsndfile支持的任何类型CFFI、libsndfile、numpy本教程中包含的库是根据它们的易用性和受欢迎程度而选择的。要获得更全面的 Python 音频库列表,请查看关于 Python 音频的 wiki 页面。
结论:在 Python 中播放和录制声音
在本教程中,您学习了如何使用一些最流行的音频库在 Python 中播放和录制音频。您还了解了如何以各种不同的格式保存音频。
您现在能够:
- 播放多种音频格式,包括 WAV、MP3 和 NumPy 阵列
- 将麦克风中的音频录制到 NumPy 或 Python 数组中
- 储存您录制的各种不同格式的音频,包括 WAV 和 MP3
- 将您的声音文件转换成一系列不同的音频格式
现在,您已经有了所需的信息,可以帮助您决定使用哪些库来开始在 Python 中处理音频。向前迈进,开发一些令人敬畏的音频应用程序!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 Python 演奏录音***
Python 中的指针:有什么意义?
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的指针和对象
如果你曾经使用过像 C 或者 C++ 这样的低级语言,那么你可能听说过指针。指针允许你在部分代码中创造巨大的效率。它们还会给初学者带来困惑,甚至会导致各种内存管理错误,即使对于专家来说也是如此。那么它们在 Python 中的什么位置,如何在 Python 中模拟指针呢?
指针在 C 和 C++中被广泛使用。本质上,它们是保存另一个变量的内存地址的变量。对于指针的复习,你可以考虑看看这篇关于 C 指针的概述。
在本文中,您将更好地理解 Python 的对象模型,并了解为什么 Python 中的指针并不真正存在。对于需要模拟指针行为的情况,您将学习在 Python 中模拟指针的方法,而不会遇到内存管理的噩梦。
在本文中,您将:
- 了解为什么 Python 中的指针不存在
- 探究 C 变量和 Python 名称之间的区别
- 在 Python 中模拟指针
- 使用
ctypes试验真正的指针注意:在本文中,“Python”将指 Python 在 C 中的参考实现,也称为 CPython 。由于本文讨论了该语言的一些内部机制,这些注释对 CPython 3.7 是正确的,但在该语言的未来或过去的迭代中可能不正确。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 为什么没有指针?
事实是我不知道。Python 中的指针可以原生存在吗?可能吧,但是指针似乎违背了 Python 的禅。指针鼓励隐式更改,而不是显式更改。通常,它们是复杂的而不是简单的,尤其是对初学者来说。更糟糕的是,他们会想方设法搬起石头砸自己的脚,或者做一些非常危险的事情,比如读一段你不该读的记忆。
Python 倾向于从用户那里抽象出实现细节,比如内存地址。Python 经常关注可用性而不是速度。因此,Python 中的指针并不真正有意义。不过不用担心,默认情况下,Python 确实给了你一些使用指针的好处。
理解 Python 中的指针需要简单了解一下 Python 的实现细节。具体来说,您需要了解:
- 不可变对象与可变对象
- Python 变量/名称
抓紧你的内存地址,让我们开始吧。
Python 中的对象
在 Python 中,一切都是对象。为了证明这一点,您可以打开 REPL,使用
isinstance()进行探索:

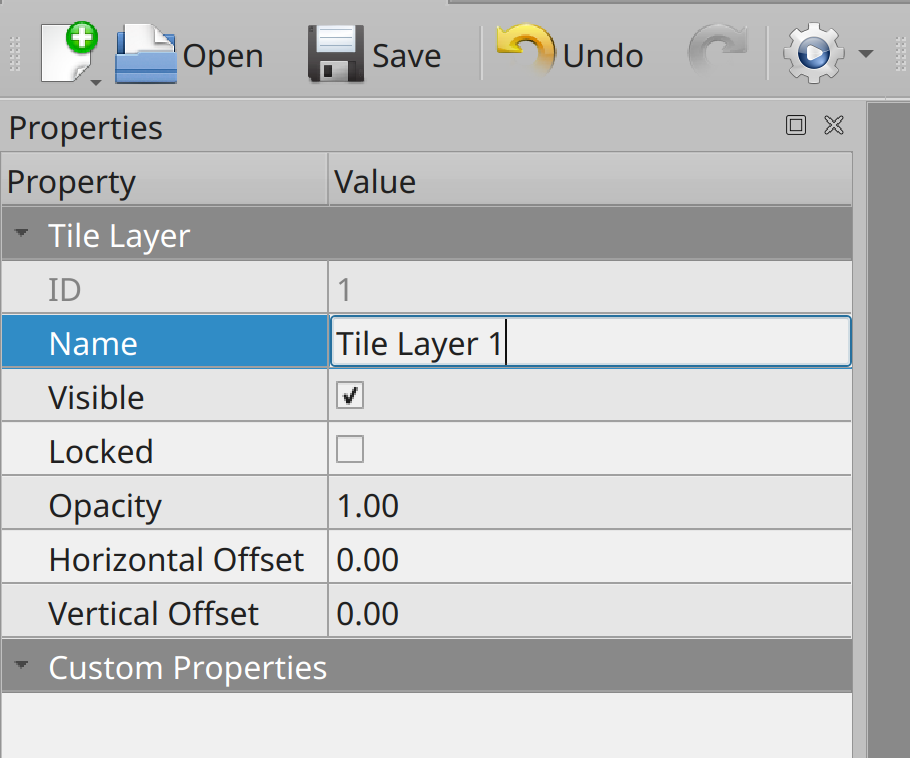
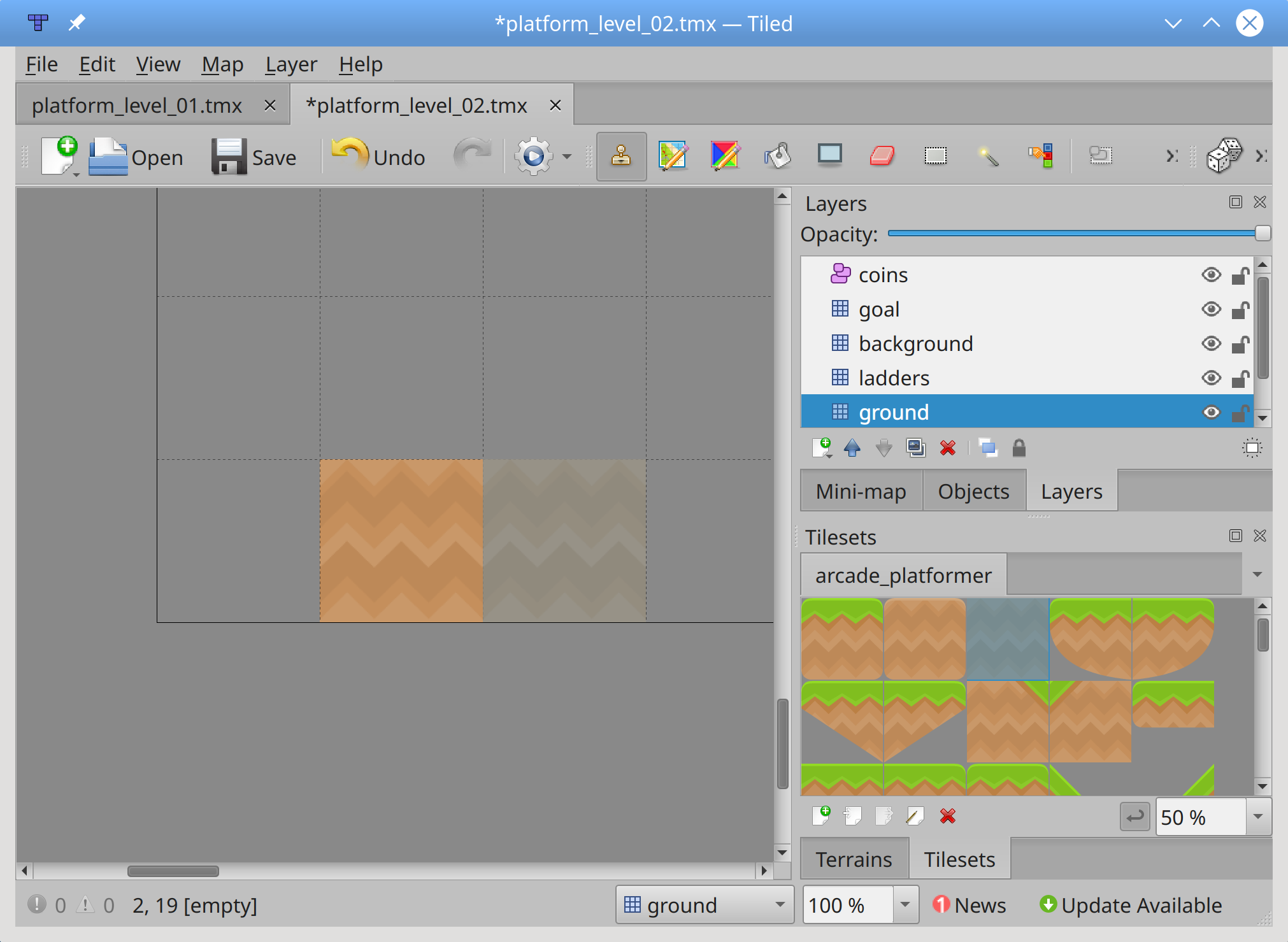
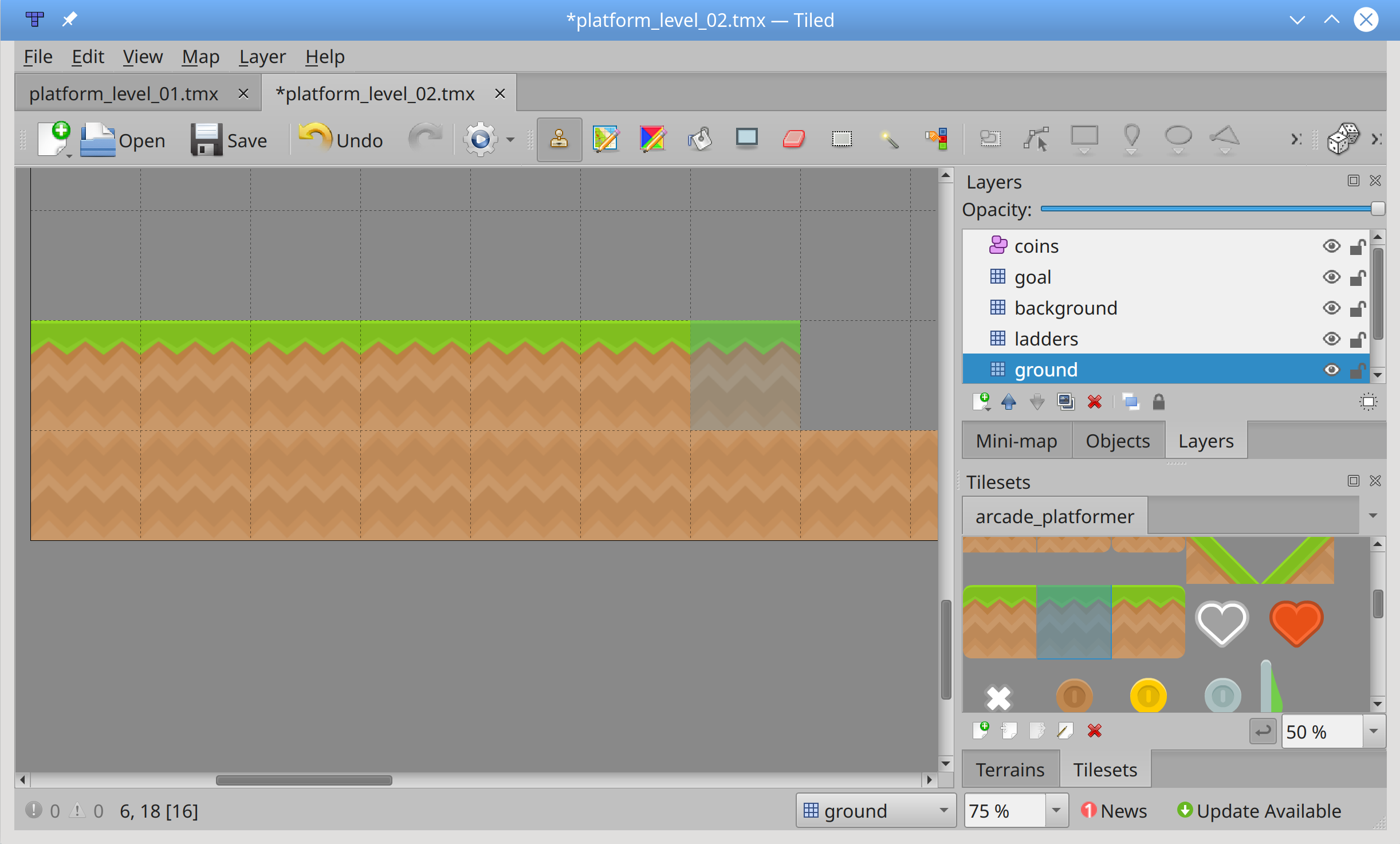
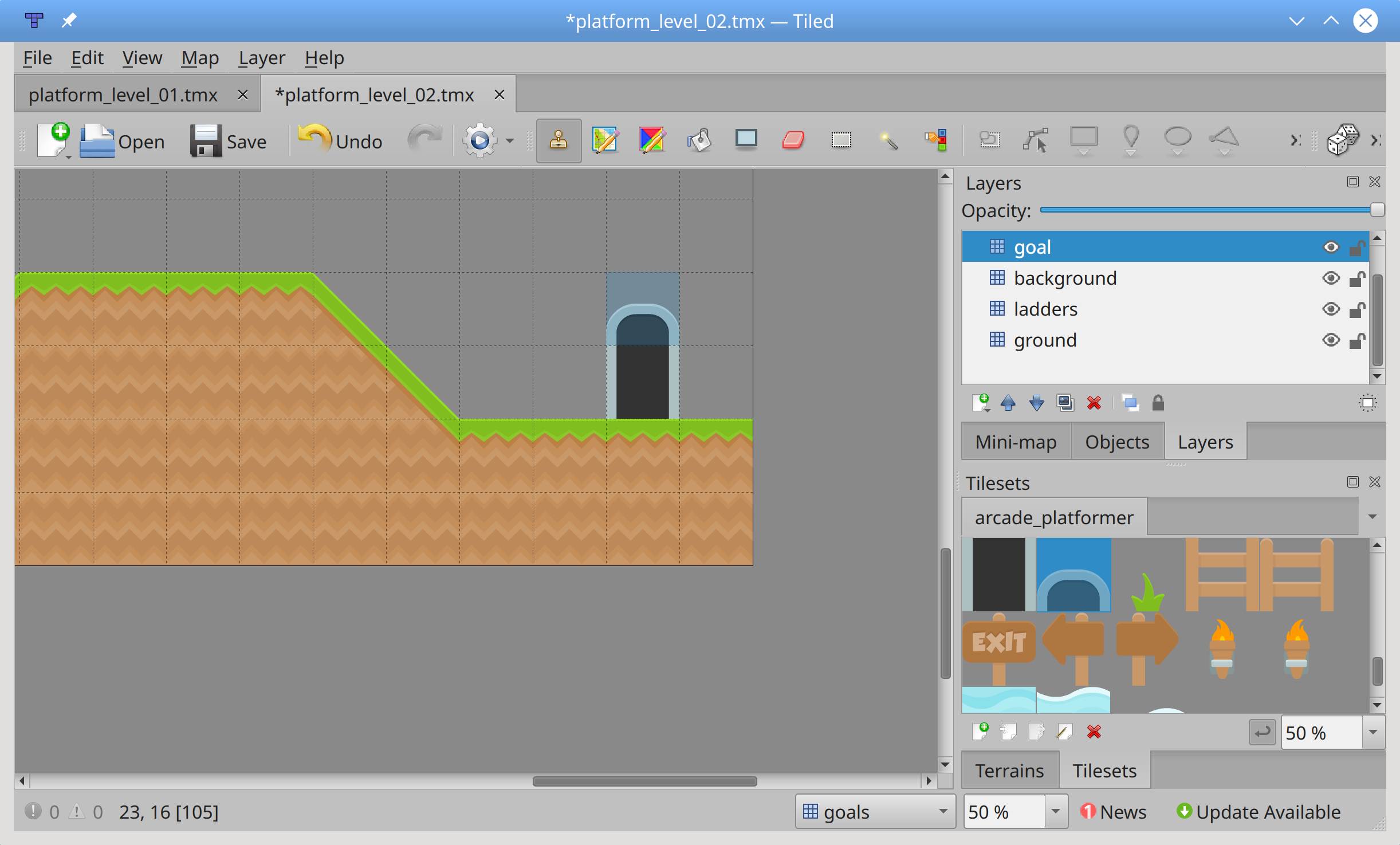
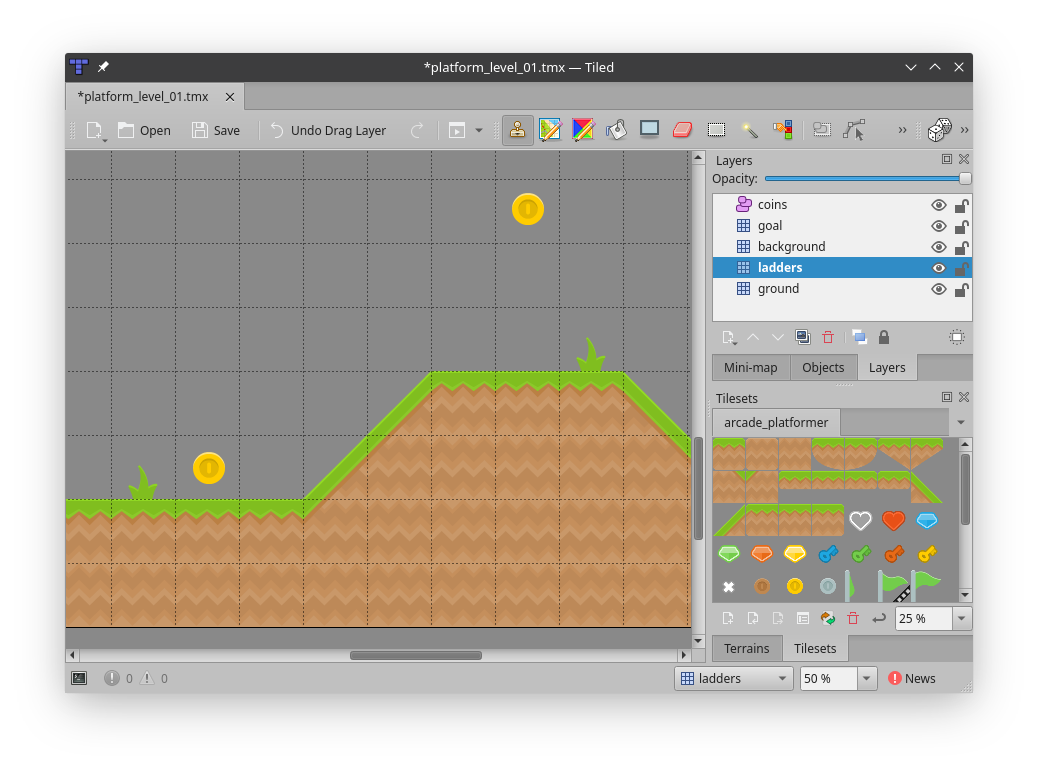

>>> isinstance(1, object)
True
>>> isinstance(list(), object)
True
>>> isinstance(True, object)
True
>>> def foo():
... pass
...
>>> isinstance(foo, object)
True
这段代码向您展示了 Python 中的一切确实都是对象。每个对象至少包含三段数据:
- 引用计数
- 类型
- 价值
引用计数用于内存管理。要深入了解 Python 中内存管理的内部机制,可以阅读 Python 中的内存管理。
该类型在 CPython 层使用,以确保运行时的类型安全。最后是值,它是与对象相关联的实际值。
然而,并非所有的对象都是相同的。还有一个你需要理解的重要区别:不可变对象和可变对象。理解对象类型之间的差异确实有助于澄清洋葱的第一层,即 Python 中的指针。
不可变与可变对象
在 Python 中,有两种类型的对象:
- 不可变对象不能改变。
- 可变对象可以改变。
理解这种差异是在 Python 中导航指针景观的第一把钥匙。下面是常见类型的分类,以及它们是可变的还是不可变的:
| 类型 | 不可变? |
|---|---|
int |
是 |
float |
是 |
bool |
是 |
complex |
是 |
tuple |
是 |
frozenset |
是 |
str |
是 |
list |
不 |
set |
不 |
dict |
不 |
如您所见,许多常用的原始类型都是不可变的。你可以自己写一些 Python 来证明这一点。您需要 Python 标准库中的几个工具:
id()返回对象的内存地址。is返回True当且仅当两个对象有相同的内存地址。
同样,您可以在 REPL 环境中使用它们:
>>> x = 5 >>> id(x) 94529957049376在上面的代码中,您将值
5赋给了x。如果你试图用加法修改这个值,你会得到一个新的对象:
>>> x += 1
>>> x
6
>>> id(x)
94529957049408
尽管上面的代码似乎修改了x的值,但是作为响应,您将得到一个新的对象。
str类型也是不可变的:
>>> s = "real_python" >>> id(s) 140637819584048 >>> s += "_rocks" >>> s 'real_python_rocks' >>> id(s) 140637819609424同样,
s在+=操作后以不同的内存地址结束。好处:
+=操作符翻译成各种方法调用。对于一些像
list,+=会翻译成__iadd__()(原地添加)。这将修改self并返回相同的 ID。然而,str和int没有这些方法,导致调用__add__()而不是__iadd__()。有关更多详细信息,请查看 Python 数据模型文档。
试图直接改变字符串
s会导致错误:
>>> s[0] = "R"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
以上代码失败,Python 表明str不支持这种突变,符合str类型不可变的定义。
与可变对象形成对比,如list:
>>> my_list = [1, 2, 3] >>> id(my_list) 140637819575368 >>> my_list.append(4) >>> my_list [1, 2, 3, 4] >>> id(my_list) 140637819575368这段代码显示了这两种对象的主要区别。
my_list原本有一个 id。即使在将4添加到列表中之后,my_list仍然拥有与相同的 id。这是因为list类型是可变的。证明列表可变的另一种方法是赋值:
>>> my_list[0] = 0
>>> my_list
[0, 2, 3, 4]
>>> id(my_list)
140637819575368
在这段代码中,您对my_list进行了变异,并将其第一个元素设置为0。但是,即使在这种赋值之后,它仍然保持相同的 id。随着可变和不可变对象的消失,您通往 Python 启蒙之旅的下一步是理解 Python 的可变生态系统。
理解变量
Python 变量与 C 或 C++中的变量有着本质的不同。其实 Python 连变量都没有。 Python 有名字,没有变量。
这可能看起来很迂腐,但在大多数情况下,的确如此。大多数时候,将 Python 名称视为变量是完全可以接受的,但是理解其中的区别是很重要的。当您在 Python 中导航棘手的指针主题时,尤其如此。
为了帮助理解这种差异,您可以看一看变量在 C 中是如何工作的,它们代表什么,然后将其与 Python 中的名称工作方式进行对比。
C 语言中的变量
假设您有以下定义变量x的代码:
int x = 2337;
这一行代码在执行时有几个不同的步骤:
- 为整数分配足够的内存
- 将值
2337分配给该存储单元 - 表示
x指向该值
在内存的简化视图中,它可能如下所示:

这里,你可以看到变量x有一个假的内存位置0x7f1和值2337。如果在程序的后面,您想要更改x的值,您可以执行以下操作:
x = 2338;
上面的代码给变量x赋了一个新值(2338),从而覆盖了之前的值。这意味着变量x是可变的。更新后的内存布局显示新值:

请注意,x的位置没有改变,只是值本身发生了变化。这是很重要的一点。这意味着x 是内存位置,而不仅仅是它的一个名字。
另一种思考这个概念的方式是从所有权的角度。在某种意义上,x拥有内存位置。x首先是一个空盒子,它只能容纳一个整数,其中可以存储整数值。
当你给x赋值的时候,你就在x拥有的盒子里放了一个值。如果你想引入一个新的变量(y,你可以添加这行代码:
int y = x;
这段代码创建了一个名为y的新框,并将值从x复制到该框中。现在,内存布局将如下所示:

注意y的新位置0x7f5。即使x的值被复制到y,变量y在内存中拥有一些新的地址。因此,您可以覆盖y的值,而不会影响x:
y = 2339;
现在,内存布局将如下所示:

同样,您修改了y处的值,但是没有其位置。此外,您根本没有影响原来的x变量。这与 Python 名称的工作方式形成了鲜明的对比。
Python 中的名称
Python 没有变量。它有名字。是的,这是一个迂腐的观点,你当然可以尽可能多地使用变量这个术语。要知道变量和名字是有区别的,这一点很重要。
让我们从上面的 C 示例中取出等价的代码,并用 Python 编写:
>>> x = 2337与 C 语言非常相似,上面的代码在执行过程中被分解成几个不同的步骤:
- 创建一个
PyObject- 将
PyObject的类型码设置为整数- 将
PyObject的值设置为2337- 创建名为
x的名称- 将
x指向新的PyObject- 将
PyObject的 refcount 增加 1注:的
PyObject和 Python 的object不一样。它特定于 CPython,代表所有 Python 对象的基本结构。
PyObject被定义为 C 结构,所以如果你想知道为什么不能直接调用typecode或refcount,那是因为你不能直接访问这些结构。像sys.getrefcount()这样的方法调用可以帮助获得一些内部消息。在内存中,它可能是这样的:
您可以看到内存布局与以前的 C 布局有很大不同。新创建的 Python 对象拥有
2337所在的内存,而不是x拥有值2337所在的内存块。Python 名字x不像 C 变量x拥有内存中的静态槽那样直接拥有任何内存地址。如果您试图给
x分配一个新值,您可以尝试以下方法:

>>> x = 2338
这里发生的事情与 C 语言的对等用法不同,但与 Python 中最初的 bind 没有太大的不同。
此代码:
- 创建新的
PyObject - 将
PyObject的类型码设置为整数 - 将
PyObject的值设置为2338 - 将
x指向新的PyObject - 将新
PyObject的引用计数增加 1 - 将旧
PyObject的引用计数减 1
现在在内存中,它看起来像这样:

这个图有助于说明x指向一个对象的引用,并且不像以前那样拥有内存空间。它还显示了x = 2338命令不是赋值,而是将名称x绑定到一个引用。
此外,先前的对象(保存了2337值)现在位于内存中,引用计数为 0,并将被垃圾收集器清除。
您可以在混合中引入一个新名称y,如 C 示例所示:
>>> y = x在内存中,您会有一个新的名称,但不一定是一个新的对象:
现在你可以看到一个新的 Python 对象已经而不是被创建,只是一个指向同一个对象的新名字。此外,对象的 refcount 增加了 1。您可以检查对象标识是否相等,以确认它们是否相同:

>>> y is x
True
上面的代码表明x和y是同一个对象。但是不要搞错:y仍然是不可改变的。
例如,您可以在y上执行加法:
>>> y += 1 >>> y is x False在添加调用之后,您将获得一个新的 Python 对象。现在,内存看起来是这样的:
已经创建了一个新对象,
y现在指向新对象。有趣的是,如果您将y直接绑定到2339,这是相同的最终状态:

>>> y = 2339
上述语句导致与加法相同的最终内存状态。概括地说,在 Python 中,不需要给变量赋值。相反,您将名称绑定到引用。
关于 Python 中 Intern 对象的一个注释
现在,您已经了解了 Python 对象是如何创建的,名称是如何绑定到这些对象的,是时候使用扳手了。那把扳手被称为被扣押的物品。
假设您有以下 Python 代码:
>>> x = 1000 >>> y = 1000 >>> x is y True如上所述,
x和y都是指向同一个 Python 对象的名字。但是保存值1000的 Python 对象并不总是保证有相同的内存地址。例如,如果你将两个数相加得到1000,你将得到一个不同的内存地址:
>>> x = 1000
>>> y = 499 + 501
>>> x is y
False
这一次,行x is y返回False。如果这令人困惑,那么不要担心。以下是执行此代码时发生的步骤:
- 创建 Python 对象(
1000) - 将名称
x分配给该对象 - 创建 Python 对象(
499) - 创建 Python 对象(
501) - 将这两个对象相加
- 创建新的 Python 对象(
1000) - 将名称
y分配给该对象
技术提示:只有在 REPL 内部执行这段代码时,上述步骤才会发生。如果您将上面的例子粘贴到一个文件中,并运行该文件,那么您会发现x is y行将返回True。
这是因为编译器很聪明。CPython 编译器试图进行称为窥视孔优化的优化,这有助于尽可能节省执行步骤。有关详细信息,您可以查看 CPython 的窥视孔优化器源代码。
这不是浪费吗?是的,它是,但是那是你为 Python 的所有巨大好处所付出的代价。您永远不必担心清理这些中间对象,甚至不需要知道它们的存在!令人高兴的是,这些操作相对来说很快,直到现在您才需要了解这些细节。
核心的 Python 开发者,凭他们的智慧,也注意到了这种浪费,并决定做一些优化。这些优化会导致新来者感到惊讶的行为:
>>> x = 20 >>> y = 19 + 1 >>> x is y True在本例中,您看到的代码与之前几乎相同,只是这次的结果是
True。这是被拘留对象的结果。Python 在内存中预先创建了对象的某个子集,并将它们保存在全局的名称空间中,以供日常使用。哪些对象依赖于 Python 的实现。CPython 3.7 实习如下:
-5和256之间的整数- 仅包含 ASCII 字母、数字或下划线的字符串
背后的原因是,这些变量极有可能在许多程序中使用。通过扣留这些对象,Python 防止了对一致使用的对象的内存分配调用。
少于 20 个字符并包含 ASCII 字母、数字或下划线的字符串将被保留。这背后的推理是,这些被假定为某种身份:
>>> s1 = "realpython"
>>> id(s1)
140696485006960
>>> s2 = "realpython"
>>> id(s2)
140696485006960
>>> s1 is s2
True
这里可以看到s1和s2都指向内存中的同一个地址。如果您要引入非 ASCII 字母、数字或下划线,那么您会得到不同的结果:
>>> s1 = "Real Python!" >>> s2 = "Real Python!" >>> s1 is s2 False因为这个例子中有一个感叹号(
!),所以这些字符串不会被保留,而是内存中的不同对象。额外收获:如果你真的想让这些对象引用同一个内部对象,那么你可能想检查一下
sys.intern()。文档中概述了此功能的一个用例:保留字符串有助于提高字典查找的性能——如果字典中的键被保留,并且查找键也被保留,则键比较(哈希之后)可以通过指针比较而不是字符串比较来完成。(来源)
被扣留的物品通常是混乱的来源。只要记住,如果你有任何疑问,你总是可以使用
id()和is来确定对象相等。在 Python 中模拟指针
Python 中的指针不是原生存在的,并不意味着你不能获得使用指针的好处。事实上,在 Python 中模拟指针有多种方式。在本节中,您将了解到两个问题:
- 使用可变类型作为指针
- 使用自定义 Python 对象
好了,说重点吧。
使用可变类型作为指针
您已经了解了可变类型。因为这些对象是可变的,所以您可以将它们视为指针来模拟指针行为。假设您想要复制以下 c 代码:
void add_one(int *x) { *x += 1; }这段代码获取一个指向整数(
*x)的指针,然后将该值递增 1。下面是练习代码的一个主要函数:#include <stdio.h> int main(void) { int y = 2337; printf("y = %d\n", y); add_one(&y); printf("y = %d\n", y); return 0; }在上面的代码中,您将
2337赋值给y,打印出当前值,将值递增 1,然后打印出修改后的值。执行这段代码的输出如下:y = 2337 y = 2338在 Python 中复制这种行为的一种方法是使用可变类型。考虑使用列表并修改第一个元素:
>>> def add_one(x):
... x[0] += 1
...
>>> y = [2337]
>>> add_one(y)
>>> y[0]
2338
这里,add_one(x)访问第一个元素,并将其值递增 1。使用一个list意味着最终结果似乎已经修改了值。所以 Python 中的指针确实存在?不,这是唯一可能的,因为list是一个可变类型。如果您试图使用一个tuple,您会得到一个错误:
>>> z = (2337,) >>> add_one(z) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in add_one TypeError: 'tuple' object does not support item assignment上面的代码演示了
tuple是不可变的。因此,它不支持项目分配。list不是唯一的可变类型。另一种在 Python 中模仿指针的常见方法是使用dict。假设您有一个应用程序,您希望跟踪每次发生的有趣事件。实现这一点的一种方法是创建一个
dict,并使用其中一个项目作为计数器:
>>> counters = {"func_calls": 0}
>>> def bar():
... counters["func_calls"] += 1
...
>>> def foo():
... counters["func_calls"] += 1
... bar()
...
>>> foo()
>>> counters["func_calls"]
2
在这个例子中,counters 字典用于跟踪函数调用的次数。在您呼叫foo()之后,计数器已经如预期的那样增加到2。都是因为dict是可变的。
请记住,这只是模拟指针行为,并不直接映射到 C 或 C++中的真正指针。也就是说,这些操作比在 C 或 C++中更昂贵。
使用 Python 对象
dict选项是在 Python 中模拟指针的一种很好的方式,但是有时记住您使用的键名会很麻烦。如果您在应用程序的不同部分使用字典,这一点尤其正确。这就是自定义 Python 类真正有用的地方。
在最后一个例子的基础上,假设您想要跟踪应用程序中的指标。创建一个类是抽象讨厌的细节的好方法:
class Metrics(object):
def __init__(self):
self._metrics = {
"func_calls": 0,
"cat_pictures_served": 0,
}
这段代码定义了一个Metrics类。这个类仍然使用一个dict来保存实际数据,它在_metrics成员变量中。这会给你你需要的可变性。现在,您只需要能够访问这些值。一个很好的方法是使用属性:
class Metrics(object):
# ...
@property
def func_calls(self):
return self._metrics["func_calls"]
@property
def cat_pictures_served(self):
return self._metrics["cat_pictures_served"]
这段代码利用了 @property 。如果你不熟悉 decorator,你可以看看这篇关于 Python decorator 的初级读本。这里的@property装饰器允许您访问func_calls和cat_pictures_served,就像它们是属性一样:
>>> metrics = Metrics() >>> metrics.func_calls 0 >>> metrics.cat_pictures_served 0事实上,您可以将这些名称作为属性来访问,这意味着您抽象了这些值在一个
dict中的事实。您还可以使属性的名称更加明确。当然,您需要能够增加这些值:class Metrics(object): # ... def inc_func_calls(self): self._metrics["func_calls"] += 1 def inc_cat_pics(self): self._metrics["cat_pictures_served"] += 1你介绍了两种新方法:
inc_func_calls()inc_cat_pics()这些方法修改了指标
dict中的值。现在你有了一个类,你可以像修改一个指针一样修改它:
>>> metrics = Metrics()
>>> metrics.inc_func_calls()
>>> metrics.inc_func_calls()
>>> metrics.func_calls
2
在这里,您可以在应用程序的不同地方访问func_calls和调用inc_func_calls(),并在 Python 中模拟指针。当您在应用程序的不同部分需要经常使用和更新度量标准时,这是非常有用的。
注意:特别是在这个类中,使inc_func_calls()和inc_cat_pics()显式而不是使用@property.setter可以防止用户将这些值设置为任意的int或像dict一样的无效值。
下面是Metrics类的完整源代码:
class Metrics(object):
def __init__(self):
self._metrics = {
"func_calls": 0,
"cat_pictures_served": 0,
}
@property
def func_calls(self):
return self._metrics["func_calls"]
@property
def cat_pictures_served(self):
return self._metrics["cat_pictures_served"]
def inc_func_calls(self):
self._metrics["func_calls"] += 1
def inc_cat_pics(self):
self._metrics["cat_pictures_served"] += 1
带ctypes的实指针
好吧,也许 Python 中有指针,特别是 CPython。使用内置的ctypes模块,您可以在 Python 中创建真正的 C 风格指针。如果你对ctypes不熟悉,那么可以看看用 C 库扩展 Python 的和“ctypes”模块。
您使用它的真正原因是,如果您需要对需要指针的 C 库进行函数调用。让我们回到之前的add_one() C 函数:
void add_one(int *x) { *x += 1; }
同样,这段代码将x的值加 1。要使用它,首先把它编译成一个共享对象。假设上述文件存储在add.c中,您可以用gcc来完成:
$ gcc -c -Wall -Werror -fpic add.c
$ gcc -shared -o libadd1.so add.o
第一个命令将 C 源文件编译成一个名为add.o的对象。第二个命令获取未链接的对象文件,并生成一个名为libadd1.so的共享对象。
libadd1.so应该在你当前的目录下。您可以使用ctypes将其加载到 Python 中:
>>> import ctypes >>> add_lib = ctypes.CDLL("./libadd1.so") >>> add_lib.add_one <_FuncPtr object at 0x7f9f3b8852a0>
ctypes.CDLL代码返回一个代表libadd1共享对象的对象。因为您在这个共享对象中定义了add_one(),所以您可以像访问任何其他 Python 对象一样访问它。但是在调用函数之前,应该指定函数签名。这有助于 Python 确保向函数传递正确的类型。在这种情况下,函数签名是一个指向整数的指针。
ctypes将允许您使用以下代码对此进行指定:
>>> add_one = add_lib.add_one
>>> add_one.argtypes = [ctypes.POINTER(ctypes.c_int)]
在这段代码中,您将函数签名设置为与 C 期望的相匹配。现在,如果您试图用错误的类型调用这段代码,您将得到一个很好的警告,而不是未定义的行为:
>>> add_one(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> ctypes.ArgumentError: argument 1: <class 'TypeError'>: \ expected LP_c_int instance instead of intPython 抛出一个错误,解释说
add_one()想要一个指针而不仅仅是一个整数。幸运的是,ctypes有办法传递指向这些函数的指针。首先,声明一个 C 风格的整数:
>>> x = ctypes.c_int()
>>> x
c_int(0)
上面的代码创建了一个 C 风格的整数x,其值为0。ctypes提供了方便的byref()来允许通过引用传递变量。
注意:术语通过引用与通过值传递变量相反。
当通过引用传递时,您传递的是对原始变量的引用,因此修改将反映在原始变量中。通过值传递会产生原始变量的副本,修改不会反映在原始变量中。
有关 Python 中引用传递的更多信息,请查看Python 中的引用传递:背景和最佳实践。
你可以用这个来调用add_one():
>>> add_one(ctypes.byref(x)) 998793640 >>> x c_int(1)不错!您的整数增加了 1。恭喜你,你已经在 Python 中成功使用了实指针。
结论
现在,您对 Python 对象和指针之间的交集有了更好的理解。尽管名称和变量之间的一些区别看起来有些学究气,但是从根本上理解这些关键术语可以扩展您对 Python 如何处理变量的理解。
您还学习了一些在 Python 中模拟指针的优秀方法:
- 利用可变对象作为低开销指针
- 创建易于使用的自定义 Python 对象
- 使用
ctypes模块解锁真实指针这些方法允许您在 Python 中模拟指针,而不会牺牲 Python 提供的内存安全性。
感谢阅读。如果你还有问题,请在评论区或 Twitter 上联系我们。
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的指针和对象******
微软 Power BI 和 Python:两个超级大国的结合
Microsoft Power BI 是一款交互式数据分析和可视化工具,用于商业智能 (BI),您现在可以使用 Python 编写脚本。通过结合这两种技术,您可以扩展 Power BI 的数据摄取、转换、增强和可视化功能。此外,您还可以将 Python 众多的数据科学和机器学习库附带的复杂算法用于增强 BI。
在本教程中,您将学习如何:
- 安装和配置Python 和 Power BI 环境
- 使用 Python 来导入和转换数据
- 使用 Python 制作定制可视化效果
- 重用您现有的 Python 源代码
- 理解在 Power BI 中使用 Python 的限制
无论您是 Power BI、Python 还是两者的新手,您都将学习如何一起使用它们。然而,如果你了解一些 Python 基础知识和 SQL 将有助于从本教程中充分受益。此外,熟悉熊猫和 Matplotlib 库将是一个加号。但是如果你不知道他们,不要担心,因为你会在工作中学到你需要的一切。
虽然 Power BI 在整个商业领域都有潜力,但在本教程中,您将重点关注销售数据。单击以下链接下载将在本教程中使用的样本数据集和 Python 脚本:
源代码: 点击此处获取免费的源代码和数据集,您将使用它们将 Python 和 Power BI 结合起来,获得超强的商业洞察力。
准备您的环境
要学习本教程,你需要 Windows 8.1 或更高版本。如果你目前使用的是 macOS 或 Linux 发行版,那么你可以获得一个免费的虚拟机和一个 Windows 11 开发环境的评估版,你可以通过开源 VirtualBox 或一个商业替代品运行它。
注意:Windows 映像大约重 20 千兆字节,因此下载和安装可能需要很长时间。请注意,在虚拟机中运行另一个操作系统将需要大量的计算机内存。
在本节中,您将安装和配置运行 Python 和 Power BI 所需的所有工具。结束时,您将准备好将 Python 代码集成到您的 Power BI 报告中!
安装微软 Power BI 桌面
Microsoft Power BI 是各种工具和服务的集合,其中一些需要 Microsoft 帐户、订阅计划和互联网连接。幸运的是,在本教程中,您将使用 Microsoft Power BI Desktop ,它完全免费,不需要 Microsoft 帐户,可以像传统的 office 套件一样离线工作。
有几种方法可以在您的计算机上获得并安装 Microsoft Power BI Desktop。推荐的方法,也可以说是最方便的方法,是使用微软商店,可从开始菜单或其基于网络的店面访问:
Power BI Desktop in Microsoft Store 通过从微软商店安装 Power BI Desktop】,您将确保自动快速更新到最新的 Power BI 版本,而无需以系统管理员身份登录。然而,如果这种方法对你不起作用,那么你总是可以尝试从微软下载中心下载安装程序并手动运行它。可执行文件的大小大约为 400 兆字节。
安装 Power BI 桌面应用程序后,启动它,您将看到一个类似于下面的欢迎屏幕:
The Welcome Screen in Power BI Desktop 如果 Power BI 桌面用户界面一开始令人生畏,请不要担心。在学习教程的过程中,您将了解一些基本知识。
安装微软 Visual Studio 代码
Microsoft Power BI Desktop 只提供基本的代码编辑功能,这是可以理解的,因为它主要是一个数据分析工具。它没有针对 Python 的智能上下文建议、自动完成或语法突出显示,而这些在处理代码时都是非常宝贵的。因此,除了在 Power BI 中编写最简单的 Python 脚本之外,您真的应该使用外部的代码编辑器来编写任何东西。
如果您已经使用了像 PyCharm 这样的 IDE,或者如果您的工作流中不需要任何花哨的代码编辑特性,请随意跳过这一步。否则,考虑安装 Visual Studio Code ,这是一个免费的、现代的、非常受欢迎的代码编辑器。因为它是由微软制造的,所以您可以在微软商店中快速找到它:
Visual Studio Code in Microsoft Store 微软 Visual Studio Code,或者有些人喜欢称之为 VS Code ,是一个通用代码编辑器,通过扩展支持许多编程语言。它不理解 Python 的开箱即用。但是当你用 Python 源代码打开一个现有文件或者创建一个新文件,并选择 Python 作为 VS 代码中的语言时,它会提示你安装推荐的 Python 扩展集:
Visual Studio Code Extensions for Python 在您确认并继续之后,VS 代码会要求您指定 Python 解释器的路径。在大多数情况下,它会自动为你检测到一个。如果你还没有在你的电脑上安装 Python,那么看看下一部分,在那里你也将接触到 pandas 和 Matplotlib。
安装 Python、pandas 和 Matplotlib
现在是时候安装 Python 了,还有 Power BI Desktop 所需的几个库,以使您的 Python 脚本在这个数据分析工具中工作。
如果您是一名数据分析师,那么您可能已经在使用 Anaconda ,这是一个流行的 Python 发行版,捆绑了数百个科学库和一个定制的包管理器。数据分析师倾向于选择 Anaconda,而不是标准的 Python 发行版,因为它使他们的环境设置更加方便。具有讽刺意味的是,使用 Power BI Desktop 设置 Anaconda 比使用标准 Python 更麻烦,而且微软甚至不推荐这样做:
需要额外准备环境的发行版(例如 Conda)可能会遇到执行失败的问题。我们建议使用 https://www.python.org/的官方 Python 发行版来避免相关问题。(来源)
Anaconda 通常使用几代以前的 Python 版本,这是如果您想保持领先地位,那么更喜欢标准发行版的另一个原因。也就是说,您将在下一节中找到一些关于如何使用 Anaconda 和 Power BI Desktop 的帮助。
如果你之前没有在电脑上安装过 Python,那么你最好的选择是再次使用微软商店。找到最新的 Python 版本并继续安装:
Python in Microsoft Store 安装完成后,您将在开始菜单中看到几个新条目。它还将使
python命令在命令提示符下立即可用,以及用于安装第三方 Python 包的pip。注意:在本教程中,你将使用 Windows 终端,它默认安装在 Windows 11 上。如果你使用的是 Windows 10 或更低版本,那么花一分钟时间从微软商店手动安装 Windows 终端。简单来说,Windows 终端是一个通用容器,可以托管多个 shell,比如 PowerShell 。
Power BI Desktop 要求您的 Python 安装有两个额外的库, pandas 和 Matplotlib ,除非您使用过 Anaconda,否则它们不会作为标准提供。然而,将第三方包安装到全局或系统范围的 Python 解释器中被认为是一种不好的做法。此外,由于 Windows 上的权限限制,您将无法从 Power BI 运行系统解释程序。相反,您需要一个 Python 虚拟环境。
虚拟环境是一个包含全局 Python 解释器副本的文件夹,你可以随意摆弄。您可以在其中安装额外的库,而不用担心破坏其他可能也依赖于 Python 的程序。在任何时候,您都可以安全地删除包含您的虚拟环境的文件夹,并且之后 Python 仍然在您的计算机上。
PowerShell 默认禁止运行脚本,包括那些用于管理 Python 虚拟环境的脚本,因为有一个受限执行策略。在激活虚拟环境之前,需要进行一些初始设置。进入你的开始菜单,找到 Windows 终端,点击右键,选择以管理员身份运行,点击是确认。接下来,键入以下命令来提升您的执行策略:
PS> Set-ExecutionPolicy RemoteSigned确保您以系统管理员的身份运行该命令,以防出现任何错误。
RemoteSigned 策略将允许您运行本地脚本以及从互联网下载的脚本,只要它们由可信机构签名。这个配置只需要做一次,所以现在可以关闭窗口了。然而,在 Windows 上设置 Python 编码环境还有更多的事情要做,所以如果你感兴趣的话,请随意查看指南。
现在,是时候为您的虚拟环境选择一个父文件夹了。例如,它可能在您的工作区中,用于 Power BI 报告。但是,如果您不确定将它放在哪里,那么您可以使用 Windows 用户的桌面文件夹,这样可以很快找到它。在这种情况下,右击桌面上的任意位置,选择在终端中打开选项。这将打开 Windows 终端,将您的桌面作为当前工作目录。
接下来,使用 Python 的
venv模块在本地文件夹中创建一个新的虚拟环境。您可以将文件夹命名为powerbi-python,以提醒自己以后的用途:PS> python -m venv powerbi-python几秒钟后,你的桌面上会出现一个新文件夹,里面有 Python 解释器的副本。现在,您可以通过运行激活脚本来激活虚拟环境,然后安装 Power BI 所需的两个库。当桌面仍是您的当前工作目录时,键入以下两个命令:
PS> .\powerbi-python\Scripts\activate (powerbi-python) PS> python -m pip install pandas matplotlib激活它之后,您应该在提示中看到您的虚拟环境的名称
powerbi-python。否则,您将在全局 Python 解释器中安装第三方包,这是您首先想要避免的。好了,你差不多准备好了。如果您想在您的环境中添加更多的库,您可以重复激活虚拟环境和使用
pip安装其他第三方包这两个步骤。接下来,您将告诉 Power BI 在您的虚拟环境中哪里可以找到 Python。为 Python 配置 Power BI Desktop】
返回到 Power BI Desktop,或者,如果您已经关闭了它,请再次启动它。点击窗口右上角的 X 图标退出欢迎屏幕,从文件菜单中选择选项和设置。然后,进入选项,它旁边有一个齿轮图标:
Options and Settings in Power BI Desktop 这将显示按类别分组的许多配置选项。点击左侧栏中标有 Python 脚本的组,点击下图所示的浏览按钮,设置 Python 主目录:
Python Options in Power BI Desktop 您必须在虚拟环境中指定到
Scripts子文件夹的路径,该子文件夹包含python.exe可执行文件。如果您将虚拟环境放在桌面文件夹中,那么您的路径应该如下所示:C:\Users\User\Desktop\powerbi-python\Scripts将
User替换为您的用户名。如果指定的路径无效并且不包含虚拟环境,那么您将得到一个合适的错误消息。如果你的电脑上有 Anaconda 或者它的精简版 Miniconda 版本,那么 Power BI Desktop 应该会自动检测到它。不幸的是,为了让它正常工作,您需要从开始菜单启动 Anaconda 提示符,并首先手动创建一个包含两个必需库的独立环境:
(base) C:\Users\User> conda create --name powerbi-python pandas matplotlib这类似于用常规的 Python 发行版建立一个虚拟环境,并使用
pip来安装第三方包。接下来,您会想要列出您的 conda 环境,并记下到您新创建的
powerbi-python环境的路径:(base) C:\Users\User> conda env list # conda environments: # base * C:\Users\User\anaconda3 powerbi-python C:\Users\User\anaconda3\envs\powerbi-python复制相应的路径并将其粘贴到 Power BI 的配置中,以设置 Python 主文件夹选项。注意,对于 conda 环境,您不需要指定任何子文件夹,因为 Python 可执行文件就位于环境的父文件夹中。
虽然仍然在 Python 脚本选项中,你会在下面找到另一个有趣的配置。它允许您指定默认的 Python IDE 或代码编辑器,Power BI 应该在您编写代码片段时为您启动这些编辑器。您可以保留与文件扩展名
.py相关联的操作系统默认程序,也可以指定您选择的特定 Python IDE:
Python IDE Options in Power BI Desktop 要指定您最喜欢的 Python IDE,请从第一个下拉列表中选择 Other ,并浏览到您的代码编辑器的可执行文件,如下所示:
C:\Users\User\AppData\Local\Programs\Microsoft VS Code\Code.exe和以前一样,您计算机上的正确路径可能不同。关于使用带有 Power BI 的外部 Python IDE 的更多细节,请查看在线文档。
恭喜你!这就是 Python 的 Power BI Desktop 的配置。最重要的设置是 Python 虚拟环境的路径,它应该包含 pandas 和 Matplotlib 库。在下一节中,您将看到 Power BI 和 Python 的实际应用。
在 Power BI 中运行 Python
在 Power BI Desktop 中有三种运行 Python 代码的方式,它们与数据分析师的典型工作流程相集成。具体来说,您可以使用 Python 作为一个数据源来加载或生成报表中的数据集。您还可以使用 Python 在 Power BI 中对任何数据集执行清理和其他转换。最后,您可以利用 Python 的绘图库创建数据可视化。现在您将体验所有这些应用程序!
数据来源:导入一个
pandas.DataFrame假设您必须从 Power BI 不支持的专有或遗留系统中获取数据。也许你的数据存储在一个过时的或不太流行的文件格式中。在任何情况下,您都可以编写一个 Python 脚本,通过一个或多个
pandas.DataFrame对象将双方粘在一起。一个数据帧是一种表格数据存储格式,很像关系数据库中的电子表格或表格。它是二维的,由行和列组成,其中每一列通常都有一个关联的数据类型,比如数字或日期。Power BI 可以从保存有熊猫数据帧的 Python 变量中抓取数据,并且可以将带有数据帧的变量注入到你的脚本中。
在本教程中,您将使用 Python 从 SQLite 加载虚假销售数据,SQLite 是一个广泛使用的基于文件的数据库引擎。请注意,在 Power BI Desktop 中直接获取这些数据在技术上是可行的,但前提是安装合适的 SQLite 驱动程序并使用 ODBC 连接器。另一方面,Python 支持 SQLite,所以选择它可能更方便。
在开始编写代码之前,探索一下您的数据集,对您将要处理的内容有所了解会有所帮助。这将是一个由存储在
car_sales.db文件中的二手车经销商数据组成的单一表格。请记住,您可以通过单击下面的链接下载此样本数据集:源代码: 点击此处获取免费的源代码和数据集,您将使用它们将 Python 和 Power BI 结合起来,获得超强的商业洞察力。
表格中有千条记录和十一列,分别代表售出的汽车、它们的购买者以及相应的销售明细。您可以通过使用下面的代码片段将这个样本数据库加载到 pandas 数据帧中,并对 Jupyter 笔记本中的几条记录进行采样,来快速可视化这个样本数据库:
import sqlite3 import pandas as pd with sqlite3.connect(r"C:\Users\User\Desktop\car_sales.db") as connection: df = pd.read_sql_query("SELECT * FROM sales", connection) df.sample(15)请注意,
car_sales.db文件的路径在您的计算机上可能不同。如果你不能使用 Jupyter Notebook,那么试着安装一个像 SQLite Browser 这样的工具,把文件加载进去。无论哪种方式,样本数据都应该表示为类似于下表的表格:
Used Car Sales Dataset 一眼就可以看出,由于底层数据的几个问题,该表需要清理。然而,您将在稍后的 Power Query 编辑器中,在数据转换阶段处理它们中的大部分。现在,专注于将数据加载到 Power BI 中。
只要您还没有关闭 Power BI 中的欢迎屏幕,您就可以点击左边带有圆柱图标的链接 Get data 。或者,您可以在报告的主视图上单击从另一个来源获取数据,因为为数不多的快捷图标中没有一个包含 Python。最后,如果没有帮助,那么使用顶部的菜单,选择主页获取数据更多……,如下所示:
Get Data Menu in Power BI Desktop 这样做将显示一个弹出窗口,其中选择了几个数据源的 Power BI 连接器,包括一个 Python 脚本,您可以通过在搜索框中键入 python 来找到它:
Get Data Pop-Up Window in Power BI Desktop 选中后点击底部的连接按钮确认。之后,您将看到 Python 脚本的一个空白编辑器窗口,您可以在其中键入一个简短的代码片段来将记录加载到 pandas 数据帧中:
Python Editor in Power BI Desktop 请注意,Power BI 内置的编辑器中缺少语法突出显示或智能代码建议。正如您之前了解到的,最好使用外部代码编辑器,比如 VS Code,来测试一切是否按预期运行,然后将您的 Python 代码粘贴到 Power BI。
在继续之前,您可以仔细检查 Power BI 是否使用了正确的虚拟环境,安装了 pandas 和 Matplotlib,方法是阅读编辑器下方的文本。
虽然附加的 SQLite 数据库中只有一个表,但它目前以非规范化的形式保存,这使得关联的数据变得冗余,容易出现各种异常。将单独的实体,如汽车、销售和客户提取到单独的数据框架中,将是朝着正确方向纠正这种情况的良好的第一步。
幸运的是,您的 Python 脚本可以生成任意多的数据帧,Power BI 将允许您选择在最终报告中包含哪些数据帧。例如,您可以通过以下方式使用列子集来提取这三个实体:
import sqlite3 import pandas as pd with sqlite3.connect(r"C:\Users\User\Desktop\car_sales.db") as connection: df = pd.read_sql_query("SELECT * FROM sales", connection) cars = df[ [ "vin", "car", "mileage", "license", "color", "purchase_date", "purchase_price", "investment", ] ] customers = df[["vin", "customer"]] sales = df[["vin", "sale_price", "sale_date"]]首先,通过为
car_sales.db文件指定一个合适的路径来连接到 SQLite 数据库,这个路径在您的计算机上可能看起来不同。接下来,运行一个 SQL 查询,选择sales表中的所有行,并将它们放入一个名为df的新的 pandas 数据帧中。最后,通过挑选特定的列,创建三个额外的数据框架。车辆识别号(VIN) 作为主键绑定相关记录。注意:在 Python 代码中习惯将
pandas缩写为pd。通常,你还会看到变量名df用于一般的、短暂的数据帧。但是,作为一般规则,请为变量选择有意义和描述性的名称,以使代码更具可读性。当您点击 OK 并等待几秒钟时,Power BI 将为您呈现 Python 脚本生成的四个数据帧的可视化表示。假设没有语法错误,并且您指定了数据库的正确文件路径,您应该会看到以下窗口:
Processed DataFrames in Power Query Editor 结果表名对应于您的 Python 变量。当你点击一个,你会看到一个包含数据的快速预览。上面的屏幕截图显示了 customers 表,它只包含两列。
在左边的层级树中选择汽车、客户和销售,同时去掉 df ,因为你不需要那个。现在,您可以通过将选定的数据框架加载到报表中来完成数据导入。然而,您将想要点击一个标记为转换数据的按钮来使用 Power BI 中的熊猫执行数据清理。
注意:有关本节主题的更多详细信息,请查看微软关于如何在 Power BI Desktop 中运行 Python 脚本的文档。
在下一节中,您将学习如何使用 Python 来清理、转换和扩充您在 Power BI 中使用的数据。
超级查询编辑器:转换和扩充数据
如果您遵循了本教程中的步骤,那么您应该已经在 Power Query Editor 中结束,它显示了您之前选择的三个数据帧。在这个视图中,它们被称为查询。但是,如果您已经将数据加载到 Power BI 报告中,而没有应用任何转换,那么不必担心!您可以随时调出同一个编辑器。
点击左侧功能区中间的表格图标,导航至数据透视图,然后从主页菜单中选择转换数据:
Transform Data Menu in Power BI Desktop 或者,您可以在窗口最右侧的数据视图中右键单击其中一个字段,并选择编辑查询以获得相同的效果。一旦 Power Query Editor 窗口再次出现,它将在左侧包含您的数据帧或查询,在右侧包含当前所选数据帧的应用步骤,中间是行和列:
Power Query Editor Window 步骤代表了针对查询以类似流水线的方式从上到下应用的一系列数据转换。每一步都表示为一个幂查询 M 公式。名为 Source 的第一步是调用 Python 脚本,该脚本基于 SQLite 数据库生成四个数据帧。另外两步找出相关的数据帧,然后转换列类型。
注意:通过点击 Source 步骤旁边的齿轮图标,您将显示数据摄取脚本的原始 Python 源代码。您可以使用该特性来访问和编辑嵌入到 Power BI 报告中的 Python 代码,即使是在将其保存为
.pbix文件之后。您可以在管道中插入自定义步骤,以便对数据转换进行更精细的控制。Power BI Desktop 提供了大量内置转换,您可以在 Power Query Editor 的顶部菜单中找到这些转换。但是在本教程中,您将探索运行 Python 脚本转换,这是在 Power BI 中运行 Python 代码的第二种模式:
Run Python Script in Power Query Editor 从概念上讲,它的工作方式与数据接收几乎相同,但也有一些不同。首先,您可以对 Power BI 本机支持的任何数据源使用这种转换,因此这可能是 Python 在您的报告中的唯一用途。其次,您在脚本中得到一个名为
dataset的隐式全局变量,它保存管道中数据的当前状态,表示为 pandas DataFrame。注意:和以前一样,您的脚本可以生成多个数据帧,但是您只能选择一个在转换管道中进行进一步处理。您也可以决定就地修改数据集,而不创建任何新的数据框。
Pandas 允许您使用正则表达式从现有列中提取值到新列中。例如,您的表中的一些客户的姓名旁边有一个用尖括号(
<>)括起来的电子邮件地址,它实际上应该属于一个单独的列。选择客户查询,然后选择最后一个变更类型步骤,并为应用的步骤添加一个运行 Python 脚本转换。当弹出窗口出现时,在其中键入以下代码片段:
# 'dataset' holds the input data for this script dataset = dataset.assign( full_name=dataset["customer"].str.extract(r"([^<]+)"), email=dataset["customer"].str.extract(r"<([^>]+)>") ).drop(columns=["customer"])Power BI 将隐式的
dataset变量注入到您的脚本中,以引用customers数据帧,因此您可以访问它的方法并用转换后的数据覆盖它。或者,您可以为结果数据帧定义一个新变量。在转换过程中,您分配两个新的列,full_name和customer列。点击 OK 并等待几秒钟后,您将看到一个表格,其中包含您的脚本生成的数据帧:
DataFrames Produced by the Python Script 只有一个名为
dataset的数据帧,因为您为新的数据帧重用了 Power BI 提供的隐式全局变量。继续点击值列中的黄色表链接,选择您的数据框架。这将生成应用步骤的新输出:
Dataset Transformed With Python 突然,在您的客户表中出现了两个新列。现在,您可以立即找到没有提供电子邮件地址的客户。如果您愿意,您可以添加更多的转换步骤,例如,将
full_name列拆分为first_name和last_name,假设没有超过两个名称的边缘案例。确保选择了最后一个步骤,并将另一个运行 Python 脚本插入到应用的步骤中。相应的 Python 代码应该如下所示:
# 'dataset' holds the input data for this script dataset[ ["first_name", "last_name"] ] = dataset["full_name"].str.split(n=1, expand=True) dataset.drop(columns=["full_name"], inplace=True)与上一步不同的是,
dataset变量引用了一个有三列的数据帧,vin、full_name和inplace=True参数,它从现有的 DataFrame 中删除了full_name列,而不是返回一个新的对象。您会注意到,Power BI 为应用的步骤给出了通用名称,并在相同步骤的多个实例中为它们附加了连续的数字。幸运的是,您可以通过右键单击一个步骤并从上下文菜单中选择 Rename 来为这些步骤提供更具描述性的名称:
Rename an Applied Step in Power Query Editor 通过编辑属性… ,您还可以用几句话描述给定步骤试图完成的内容。
使用 Power BI 中的 pandas 和 Python 可以做更多的事情来转换数据集!例如,您可以:
- 匿名敏感的个人信息,如信用卡号码
- 从数据集中识别和提取新实体
- 拒绝缺少交易细节的汽车销售
- 删除重复的销售记录
- 根据车辆识别号合成汽车的型号年份
- 统一不一致的购销日期格式
这些只是一些想法。虽然本教程没有足够的空间来涵盖所有内容,但是非常欢迎您自己进行实验并查看额外的资料。注意,在 Power BI 中使用 Python 转换数据的成功将取决于您对 pandas 的了解,Power BI 在幕后使用 pandas。要提高您的技能,请在 Real Python 查看数据科学学习路径的 pandas。
当您完成数据集的转换后,您可以通过从主页功能区中选择关闭&应用或在文件菜单中选择其别名来关闭 Power Query 编辑器:
Apply Pending Changes in the Datasets 这将跨数据集应用所有转换步骤,并返回到 Power BI Desktop 的主窗口。
注意:关于本节主题的更多细节,请查看微软关于如何在 Power Query Editor 中使用 Python 的文档。
接下来,您将学习如何使用 Python 来生成定制的数据可视化。
视觉效果:绘制数据的静态图像
到目前为止,您已经导入并转换了数据。Python 在 Power BI Desktop 中的第三个也是最后一个应用是绘制数据的可视化表示。当创建可视化时,您可以使用任何受支持的 Python 库,只要您已经将它们安装在 Power BI 使用的虚拟环境中。然而,Matplotlib 是绘图的基础,这些库无论如何都要委托给它。
除非 Power BI 已经在转换数据集后将您带到了报告透视图,否则现在通过单击左侧功能区上的图表图标导航到那里。您应该会看到一个空白的报告画布,您将在其中放置您的图表和其他交互式组件,共同命名为视觉效果:
Blank Report Canvas in Power BI Desktop 在右侧的可视化面板中,您会看到许多与可用视觉效果相对应的图标。找到 Python 可视化工具的图标,点击它将可视化工具添加到报告画布中。第一次将 Python 或 R 可视化添加到 Power BI 报告时,它会要求您启用脚本可视化:
Enable Script Visuals Pop-Up Window in Power BI Desktop 事实上,在每次 Power BI 会话中,它都会一直问你同样的问题,因为这没有全局设置。当您打开一个包含使用脚本可视化的已保存报告的文件时,您可以选择在启用它之前检查嵌入的 Python 代码。为什么?简而言之,Power BI 关心您的隐私,因为如果脚本来自不可信的来源,任何脚本都可能泄漏或损坏您的数据。
在右侧的字段工具栏中展开您的汽车表,并将它的
color和vin列拖放到您的视图的值上:
Drag and Drop Data Fields Onto a Visual 这些将成为 Python 脚本中 Power BI 提供的隐式
datasetDataFrame 的 only 列。将这些数据字段添加到 visual 的值中会启用窗口底部的 Python 脚本编辑器。有点令人惊讶的是,这一个确实提供了基本的语法突出显示:
Python Script Editor of a Power BI Visual 但是,如果您已经将 Power BI 配置为使用外部代码编辑器,那么单击小斜箭头图标(
↗)将启动它并打开脚本的整个框架。您可以暂时忽略它的内容,因为您将在接下来的部分中探索它。不幸的是,当您完成编辑后,您必须手动将脚本中自动生成的# Prolog和# Epilog注释之间的部分复制并粘贴回 Power BI。注意:不要忽略 Python 脚本编辑器中的黄色警告栏,它提醒你有重复值的行将被删除。如果您只拖动
color列,那么您将得到与少数几种独特颜色相对应的少数记录。但是,添加vin列通过让颜色在整个表中重复来防止这种情况,这在执行聚合时很有用。为了演示 Python 可视化在 Power BI 中的基本用法,您可以绘制一个条形图,显示涂有给定颜色的汽车数量:
# The following code to create a dataframe and remove duplicated # rows is always executed and acts as a preamble for your script: # dataset = pandas.DataFrame(color, vin) # dataset = dataset.drop_duplicates() # Paste or type your script code here: import matplotlib.pyplot as plt plt.style.use("seaborn") series = dataset[dataset["color"] != ""]["color"].value_counts() series.plot(kind="bar", color=series.index, edgecolor="black") plt.show()你首先启用 Matplotlib 的主题,它模仿了 seaborn 库,与默认的相比,它有一个稍微更吸引人的外观和感觉。接下来,您排除缺少颜色的记录,并计算每个唯一颜色组中剩余的颜色。这将产生一个
pandas.Series对象,您可以使用它的由颜色名称组成的索引对其进行绘图和颜色编码。最后你调用plt.show()渲染剧情。要首次触发此代码,您必须单击 Python 脚本编辑器中的播放图标,因为您尚未在报告中显示任何数据。如果你得到一个关于没有创建图像的错误,那么检查你是否在脚本的末尾调用了
plt.show()。Matplotlib 有必要在默认后端上渲染绘图,这意味着将渲染的 PNG 图像写入磁盘上的文件,Power BI 可以加载并显示该文件。只要一切顺利,您的空白报告应该会增加一些颜色:
Distribution of Car Colors in the Whole Dataset 您可以移动和调整视觉效果以使其变大或更改其比例。或者,您可以通过点击视觉上的相关图标进入聚焦模式,这将扩展它以适应可用空间。
Python 视觉效果自动更新以响应数据、过滤和高亮显示的变化,就像其他 Power BI 视觉效果一样。然而,渲染图像本身是静态的,所以你不能以任何方式与它交互来交叉过滤其他视觉效果。为了测试过滤是如何工作的,在你的汽车的购买日期数据字段旁边添加一个切片器:
Slice the Dataset by Car Purchase Date 它将在您的报告中创建一个交互式滑块小部件,让您调整购车日期的范围。每当您调整这些日期时,Power BI 将重新运行您的 Python 脚本,以生成新的数据静态呈现,这无疑需要一些时间来更新:
Distribution of Car Colors in a Range of Purchase Dates 请注意,视觉上的颜色分布略有变化。除了对数据进行切片,您还可以在 Power BI 中定义一个过滤器,例如,只显示特定品牌的汽车颜色,这由 VIN 前缀决定。
注意:有关本节主题的更多细节,请查看微软关于如何使用 Python 创建 Power BI 视觉效果的文档。
Power BI 中的 Python 视觉效果仅仅是静态图像,分辨率限制在 72 DPI。它们不是交互式的,并且需要一些时间来更新。然而,尽管有这些限制,它们可以丰富 Power BI 中现有的视觉效果。
既然您已经有了在 Power BI Desktop 中使用 Python 的实践经验,那么是时候深入研究了。在下一节中,您将通过深入了解这两种工具的集成是如何工作的。
了解 Power BI 和 Python 的集成
知道如何操作工具能给你带来有价值的技能。然而,工具内部的知识才是让你变得熟练的真正力量。请继续阅读,了解 Power BI Desktop 如何与 Python 和其他脚本语言集成。
截取电力毕的临时文件
Power BI 控制着处理报表数据的整个过程,因此它负责运行 Python 代码并与它双向交互。特别是,Power BI 需要为脚本提供一个要转换或可视化的数据帧,并且需要从该脚本加载数据帧或可视化。
促进外国程序之间的这种接口的最直接的机制是什么?
如果你想一想,那么你可能会意识到你一直在使用那个机制。例如,当您在 Microsoft Excel 或其他软件中制作电子表格时,您将它保存在其他程序可以读取的
.xlsx文件中,前提是它们理解该特定的数据格式。这可能不是跨应用程序共享数据的最有效的方式,但它非常可靠。Power BI 使用类似的方法,利用文件系统与 Python 脚本通信。然而,它是以自动化和稍微结构化的方式来实现的。每次 Power BI 想要执行一个 Python 脚本时,它会在用户文件夹中创建一个具有唯一伪随机名称的临时文件夹,如下所示:
C:\Users\User\PythonScriptWrapper_a6a7009b-1938-471b-b9e4-a1668a38458a │ ├── cars.csv ├── customers.csv ├── df.csv ├── sales.csv ├── input_df_738f5a98-23e4-4873-b00e-0c5780220bb9.csv └── PythonScriptWrapper.PY该文件夹包含一个包装器脚本,其中包含您的 Python 代码。它还可能包含一个带有输入数据集的 CSV 文件,如果相关步骤不是管道中的第一个步骤,脚本会将该文件加载到
dataset变量中。执行后,包装器脚本自动将数据帧转储到以相应全局变量命名的 CSV 文件中。Power BI 将让您选择这些表进行进一步的处理。文件夹及其内容只是临时的,这意味着当不再需要它们时,它们会消失而不留任何痕迹。当脚本完成执行时,Power BI 会删除它们。
包装器脚本包含胶水代码,负责 Power BI 和 Python 之间的数据序列化和反序列化。这里有一个例子:
# Prolog - Auto Generated # import os, pandas, matplotlib matplotlib.use('Agg') import matplotlib.pyplot import sys sys.tracebacklimit = 0 os.chdir(u'C:/Users/User/PythonScriptWrapper_a6a7009b-1938-471b-b9e4-a1668a38458a') dataset = pandas.read_csv('input_df_738f5a98-23e4-4873-b00e-0c5780220bb9.csv') matplotlib.pyplot.show = lambda args=None,kw=None: () POWERBI_GET_USED_VARIABLES = dir # Original Script. Please update your script content here and once completed copy below section back to the original editing window 'dataset' holds the input data for this script # ... # Epilog - Auto Generated # os.chdir(u'C:/Users/User/PythonScriptWrapper_a6a7009b-1938-471b-b9e4-a1668a38458a') for key in POWERBI_GET_USED_VARIABLES(): if (type(globals()[key]) is pandas.DataFrame): (globals()[key]).to_csv(key + '.csv', index = False)突出显示的行是可选的,只会出现在管道的中间或终端步骤中,这些步骤会转换一些现有的数据集。另一方面,对应于第一步的数据摄取脚本不会包含任何要反序列化的输入数据帧,因此 Power BI 不会生成这个隐式变量。
包装器脚本由三部分组成,用 Python 注释分隔:
- Prolog: 将输入 CSV 反序列化为 DataFrame,以及其他管道
- Body: 您的原始代码来自 Power BI Desktop 中的 Python 脚本编辑器
- 结尾:将一个或多个数据帧序列化为 CSV 文件
如您所见,在 Power BI 中使用 Python 时,由于额外的数据整理成本,会产生大量的输入/输出开销。要转换一段数据,必须对其进行四次序列化和反序列化,顺序如下:
- 电源 BI 至 CSV
- CSV 到 Python
- Python 到 CSV
- CSV 至 Power BI
读写文件是昂贵的操作,不能与在同一程序中直接访问共享内存相比。因此,如果您有大型数据集,并且性能对您至关重要,那么您应该更喜欢 Power BI 的内置转换和数据分析表达式(DAX) 公式语言,而不是 Python。同时,如果您有一些想要在 Power BI 中重用的现有代码,使用 Python 可能是您唯一的选择。
使用 Python 绘制 Power BI 视觉效果的包装器脚本看起来非常相似:
# Prolog - Auto Generated # import os, uuid, matplotlib matplotlib.use('Agg') import matplotlib.pyplot import pandas import sys sys.tracebacklimit = 0 os.chdir(u'C:/Users/User/PythonScriptWrapper_0fe352b7-79cf-477a-9e9d-80203fde2a54') dataset = pandas.read_csv('input_df_84e90f47-2386-45a9-90d4-77efca6d4942.csv') matplotlib.pyplot.figure(figsize=(4.03029540114132,3.76640651225243), dpi=72) matplotlib.pyplot.show = lambda args=None,kw=None: matplotlib.pyplot.savefig(str(uuid.uuid1())) # Original Script. Please update your script content here and once completed copy below section back to the original editing window # # The following code to create a dataframe and remove duplicated rows is always executed and acts as a preamble for your script: # dataset = pandas.DataFrame(car) # dataset = dataset.drop_duplicates() # Paste or type your script code here: # ... # Epilog - Auto Generated # os.chdir(u'C:/Users/User/PythonScriptWrapper_0fe352b7-79cf-477a-9e9d-80203fde2a54')生成的代码覆盖了 Matplotlib 的
plt.show()方法,因此绘制数据会将渲染图保存为分辨率为 72 DPI 的 PNG 图像。图像的宽度和高度将取决于您在 Power BI 中的视觉尺寸。输入数据帧可能包含完整数据集的过滤或切片子集。这就是 Power BI Desktop 与 Python 脚本集成的方式。接下来,您将了解 Power BI 在报告中存储 Python 代码和数据的位置。
在 Power BI 报告中查找和编辑 Python 脚本
当您将 Power BI 报告保存为
.pbix文件时,所有相关的 Python 脚本都以压缩二进制形式保留在您的报告中。如果你想的话,你可以在之后编辑这些脚本来更新一些数据集或视觉效果。然而,在 Power BI Desktop 中找到相关的 Python 代码可能很棘手。要显示一个 Python 可视化工具的源代码,当在报告画布上查看它时,单击可视化工具本身。这将在窗口底部显示熟悉的 Python 脚本编辑器,让您可以立即对代码进行更改。当您与其他视觉效果和过滤器交互时,或者当您在 Python 脚本编辑器中单击播放图标时,Power BI 将运行这个新代码。
找到数据摄取或转换脚本的 Python 代码更具挑战性。首先,您必须通过从数据透视图的菜单中选择转换数据来打开 Power Query 编辑器,就像您执行数据转换时所做的那样。一旦到了那里,定位一个对应于运行一段 Python 代码的应用步骤。它通常被命名为 Source 或 Run Python script ,除非你重命名了那个步骤。
然后,点击相应步骤旁边的齿轮图标,或者从上下文菜单中选择编辑设置选项,以显示您的原始 Python 代码。点击 OK 编辑并确认更新后的代码后,您必须指出选择哪个结果表进行进一步处理。当您这样做时,您可能会在 Power BI 中看到以下警告:
Replace the Subsequent Steps Pop-Up Window 当您刚刚编辑的步骤下面有后续步骤时,您会看到此警告。在这种情况下,您的更改可能会影响其余的应用步骤管道。所以,如果你现在点击继续,那么 Power BI 将删除下面的步骤。但是,如果您改变主意,想要放弃待定的更改,那么您仍然可以关闭超级查询编辑器窗口而不应用它们。
当您在 Power Query Editor 中对您的 Python 脚本之一进行更改并应用它时,Power BI 将尝试通过在整个管道中再次推送来刷新相应的数据集。换句话说,您必须能够访问您的原始数据源,比如 SQLite 数据库,否则您会得到一个错误。
注意:除了脚本之外,Power BI 还在
.pbix文件中保存您摄取和转换的数据集。因此,除非您编辑与数据相关的 Python 脚本,否则您可以在打开报表后立即开始与报表进行交互。至此,您知道了在 Power BI 中使用 Python 可以实现什么,以及 T2 如何在较低的层次上集成它们。在本教程的最后一节中,您将进一步了解这种集成带来的一些限制,这可能有助于您做出明智的决定,决定何时在 Power BI 中使用 Python。
考虑到 Python 在 Power BI 中的局限性
在本节中,您将了解在 Power BI Desktop 中使用 Python 的局限性。不过,最严格的限制是关于 Power BI 视觉效果,而不是与数据相关的脚本。
超时和数据大小限制
根据官方文档,您在 Power Query Editor 中定义的数据摄取和转换脚本运行时间不能超过三十分钟,否则它们将超时并出错。然而,Python 视觉效果中的脚本被限制只能执行五分钟。如果您正在处理非常大的数据集,那么这可能是一个问题。
此外,Power BI visuals 中的 Python 脚本受到额外的数据大小限制。最重要的包括以下内容:
- 只能绘制数据集中前 150,000 行或更少的行。
- 输入数据集不能大于 250 兆字节。
- 长度超过 32,766 个字符的字符串将被截断。
运行 Python 脚本时,Power BI 中的时间和内存是有限的。然而,实际的 Python 代码执行也会产生成本,您现在将了解到这一点。
数据整理开销
正如您之前所了解的,Power BI Desktop 通过交换 CSV 文件的方式与 Python 进行通信。因此,您的 Python 脚本必须从一个文本文件中加载数据集,而不是直接操作数据集,Power BI 会在每次运行时创建该文本文件。稍后,脚本将结果保存到另一个文本或图像文件中,供 Power BI 读取。
当处理较大的数据集时,这种冗余的数据整理会导致一个显著的性能瓶颈。这可能是 Python 集成在 Power BI Desktop 中的最大缺点。如果糟糕的性能变得明显,那么您应该考虑使用 Power BI 的内置转换或 Python 上的数据分析表达式(DAX) 公式语言。
或者,您可以尝试通过将多个步骤合并到一个 Python 脚本中来减少数据序列化的数量,该脚本可以批量执行繁重的工作。因此,如果您在本教程开始时使用的示例是一个非常大的数据集,而不是在 Power Query 编辑器中执行多个步骤,那么您最好尝试将它们合并到第一个加载脚本中。
非交互式 Python 视觉效果
使用 Python 代码进行渲染的数据可视化是静态图像,不能与之交互来过滤数据集。但是,Power BI 将触发 Python 视觉效果的更新,以响应与其他视觉效果的交互。此外,由于前面提到的数据封送处理开销以及需要运行 Python 代码来呈现它们,Python 视觉效果的显示时间会稍长一些。
其他轻微滋扰
在 Power BI 中使用 Python 还有其他一些不太重要的限制。例如,如果需要他人安装和配置 Python,您就不能轻易与他人共享您的 Power BI 报告。报告中所有数据集的隐私级别必须设置为公共,Python 脚本才能在 Power BI 服务中正确工作。Power BI 中有有限数量的支持的 Python 库。这样的例子不胜枚举。
要更全面地了解 Python 在 Power BI 中的局限性,请查看如何准备 Python 脚本以及微软文档中 Python 可视化的已知局限性。
结论
即使您以前没有使用过 Python 或 Power BI,现在也可以在您的数据分析工作流中结合使用这两种工具。您使用 Python 成功地将数据从 SQLite 数据库加载到 Power BI 报告中,并利用 pandas 库来转换和扩充您的数据集。最后,您通过用 Python 的 Matplotlib 绘制数据,在 Power BI 中可视化了数据。
在本教程中,您学习了如何:
- 安装和配置Python 和 Power BI 环境
- 使用 Python 来导入和转换数据
- 使用 Python 制作定制可视化效果
- 重用您现有的 Python 源代码
- 理解在 Power BI 中使用 Python 的限制
现在,您已经掌握了利用 Power BI 和 Python 这两项强大技术来转变数据驱动型业务决策方式的知识!
源代码: 点击此处获取免费的源代码和数据集,您将使用它们将 Python 和 Power BI 结合起来,获得超强的商业洞察力。*******
用 Python 防止 SQL 注入攻击
每隔几年,开放 Web 应用安全项目(OWASP)就会对最关键的 web 应用安全风险进行排名。自第一份报告以来,注射风险一直居于首位。在所有注射类型中, SQL 注入是最常见的攻击媒介之一,也可以说是最危险的。由于 Python 是世界上最流行的编程语言之一,知道如何防范 Python SQL 注入是至关重要的。
在本教程中,你将学习:
- 什么是 Python SQL 注入以及如何防范
- 如何用文字和标识符作为参数来组成查询
- 如何在数据库中安全地执行查询
本教程适合所有数据库引擎的用户。这里的例子使用 PostgreSQL,但是结果可以在其他数据库管理系统中重现(比如 SQLite 、 MySQL 、微软 SQL Server、Oracle 等等)。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
了解 Python SQL 注入
SQL 注入攻击是一个如此常见的安全漏洞,以至于传奇人物 xkcd webcomic 专门为此画了一幅漫画:
"Exploits of a Mom" (Image: [xkcd](https://xkcd.com/327/)) 生成和执行 SQL 查询是一项常见的任务。然而,世界各地的公司在编写 SQL 语句时经常犯可怕的错误。虽然 ORM 层通常编写 SQL 查询,但有时您必须自己编写。
当您使用 Python 直接在数据库中执行这些查询时,您有可能会犯错误,危及您的系统。在本教程中,您将学习如何成功实现组成动态 SQL 查询的函数,而不让您的系统面临 Python SQL 注入的风险。
建立数据库
首先,您将建立一个新的 PostgreSQL 数据库,并用数据填充它。在整个教程中,您将使用该数据库直接见证 Python SQL 注入的工作原理。
创建数据库
首先,打开您的 shell 并创建一个新的 PostgreSQL 数据库,归用户
postgres所有:$ createdb -O postgres psycopgtest这里,您使用命令行选项
-O将数据库的所有者设置为用户postgres。您还指定了数据库的名称,即psycopgtest。注意:
postgres是一个的特殊用户,它通常用于管理任务,但是在本教程中,使用postgres也可以。然而,在实际系统中,您应该创建一个单独的用户作为数据库的所有者。您的新数据库已经准备就绪!您可以使用
psql连接到它:$ psql -U postgres -d psycopgtest psql (11.2, server 10.5) Type "help" for help.现在,您以用户
postgres的身份连接到数据库psycopgtest。该用户也是数据库所有者,因此您将拥有数据库中每个表的读取权限。创建包含数据的表格
接下来,您需要创建一个包含一些用户信息的表,并向其中添加数据:
psycopgtest=# CREATE TABLE users ( username varchar(30), admin boolean ); CREATE TABLE psycopgtest=# INSERT INTO users (username, admin) VALUES ('ran', true), ('haki', false); INSERT 0 2 psycopgtest=# SELECT * FROM users; username | admin ----------+------- ran | t haki | f (2 rows)该表有两列:
username和admin。admin列表示用户是否拥有管理权限。你的目标是针对admin领域,并试图滥用它。设置 Python 虚拟环境
现在您已经有了一个数据库,是时候设置您的 Python 环境了。关于如何做到这一点的分步说明,请查看 Python 虚拟环境:初级教程。
在新目录中创建虚拟环境:
(~/src) $ mkdir psycopgtest (~/src) $ cd psycopgtest (~/src/psycopgtest) $ python3 -m venv venv运行该命令后,将创建一个名为
venv的新目录。该目录将存储您在虚拟环境中安装的所有软件包。连接到数据库
要连接到 Python 中的数据库,您需要一个数据库适配器。大多数数据库适配器遵循 Python 数据库 API 规范的 2.0 版本 PEP 249 。每个主要的数据库引擎都有一个领先的适配器:
数据库ˌ资料库 适配器 一种数据库系统 心理战 SQLite sqlite3 神谕 cx_oracle 关系型数据库 MySQLdb 要连接到 PostgreSQL 数据库,您需要安装 Psycopg ,这是 Python 中最流行的 PostgreSQL 适配器。 Django ORM 默认使用它, SQLAlchemy 也支持它。
在您的终端中,激活虚拟环境,使用
pip安装psycopg:(~/src/psycopgtest) $ source venv/bin/activate (~/src/psycopgtest) $ python -m pip install psycopg2>=2.8.0 Collecting psycopg2 Using cached https://.... psycopg2-2.8.2.tar.gz Installing collected packages: psycopg2 Running setup.py install for psycopg2 ... done Successfully installed psycopg2-2.8.2现在,您已经准备好创建到数据库的连接了。以下是 Python 脚本的开头:
import psycopg2 connection = psycopg2.connect( host="localhost", database="psycopgtest", user="postgres", password=None, ) connection.set_session(autocommit=True)您使用了
psycopg2.connect()来创建连接。该函数接受以下参数:
host是你的数据库所在服务器的 IP 地址或者 DNS。在这种情况下,主机是您的本地机器,或localhost。
database是要连接的数据库的名称。您想要连接到您之前创建的数据库,psycopgtest。
user是对数据库有权限的用户。在这种情况下,您希望作为所有者连接到数据库,因此您传递了用户postgres。
password是您在user中指定的任何人的密码。在大多数开发环境中,用户无需密码就可以连接到本地数据库。建立连接后,您用
autocommit=True配置了会话。激活autocommit意味着您不必通过发出commit或rollback来手动管理交易。这是大多数 ORM 的默认 行为。这里也使用这种行为,这样您就可以专注于编写 SQL 查询,而不是管理事务。注意: Django 用户可以从
django.db.connection获取 ORM 使用的连接实例:from django.db import connection执行查询
现在您已经连接到数据库,可以执行查询了:

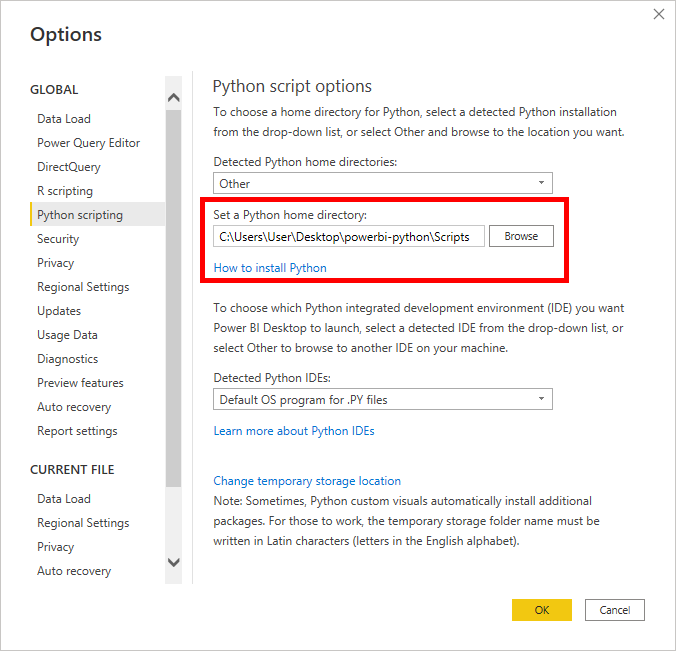
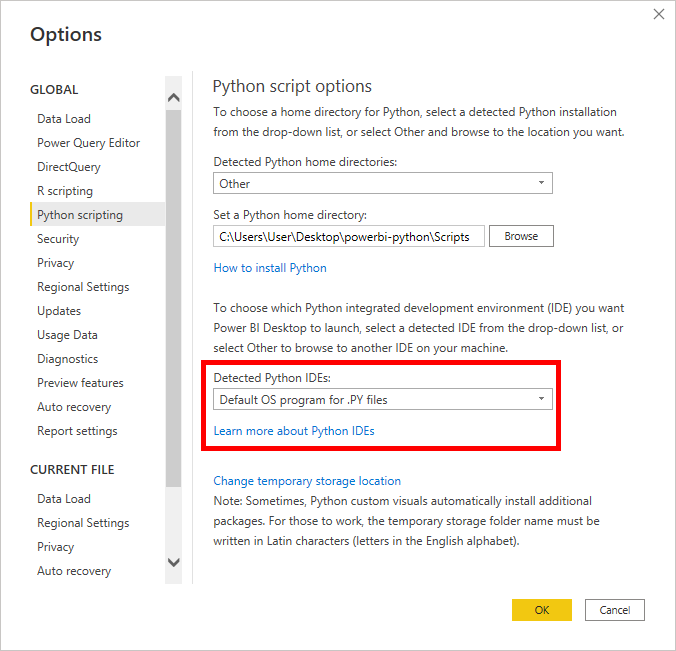
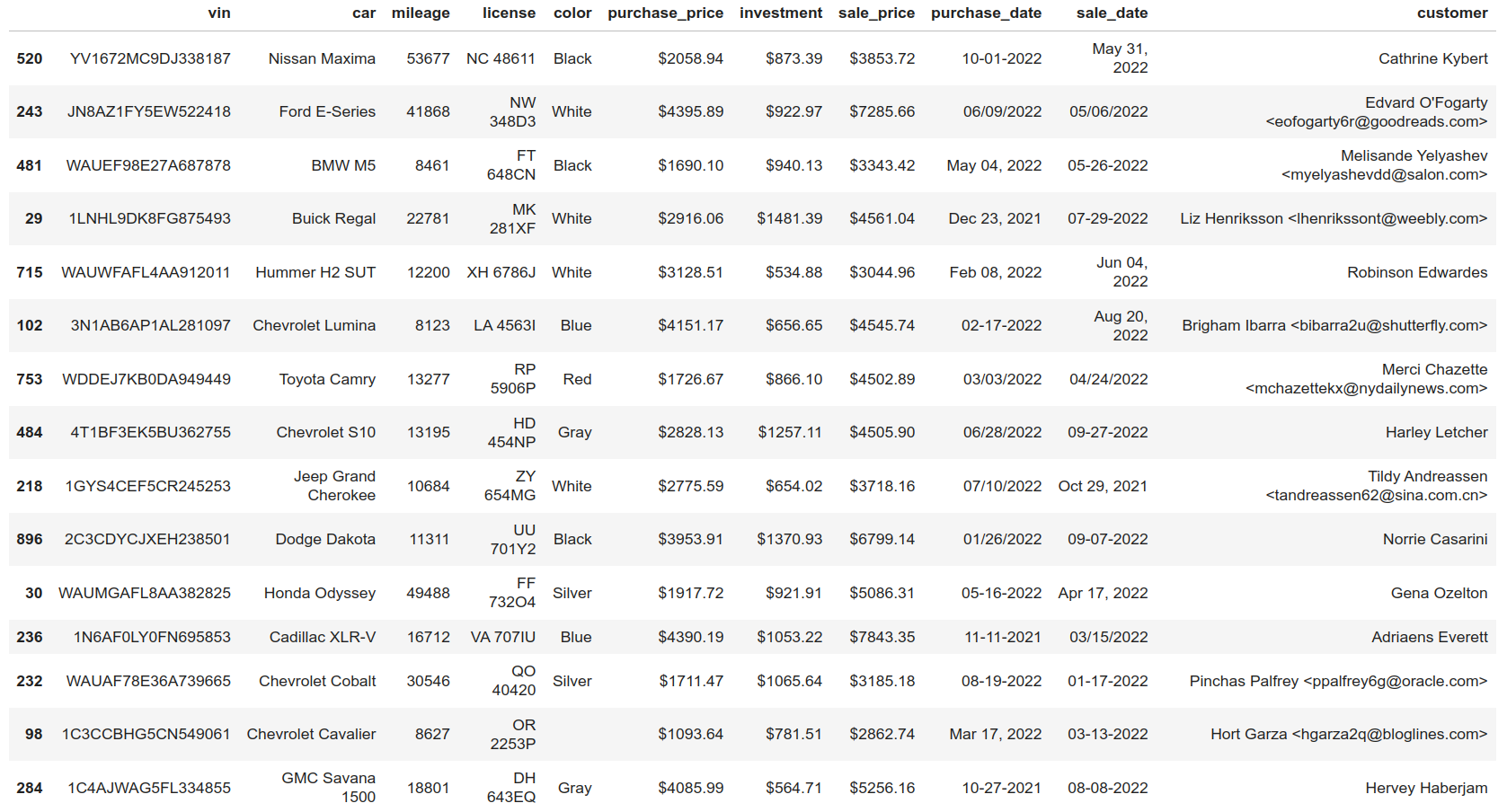
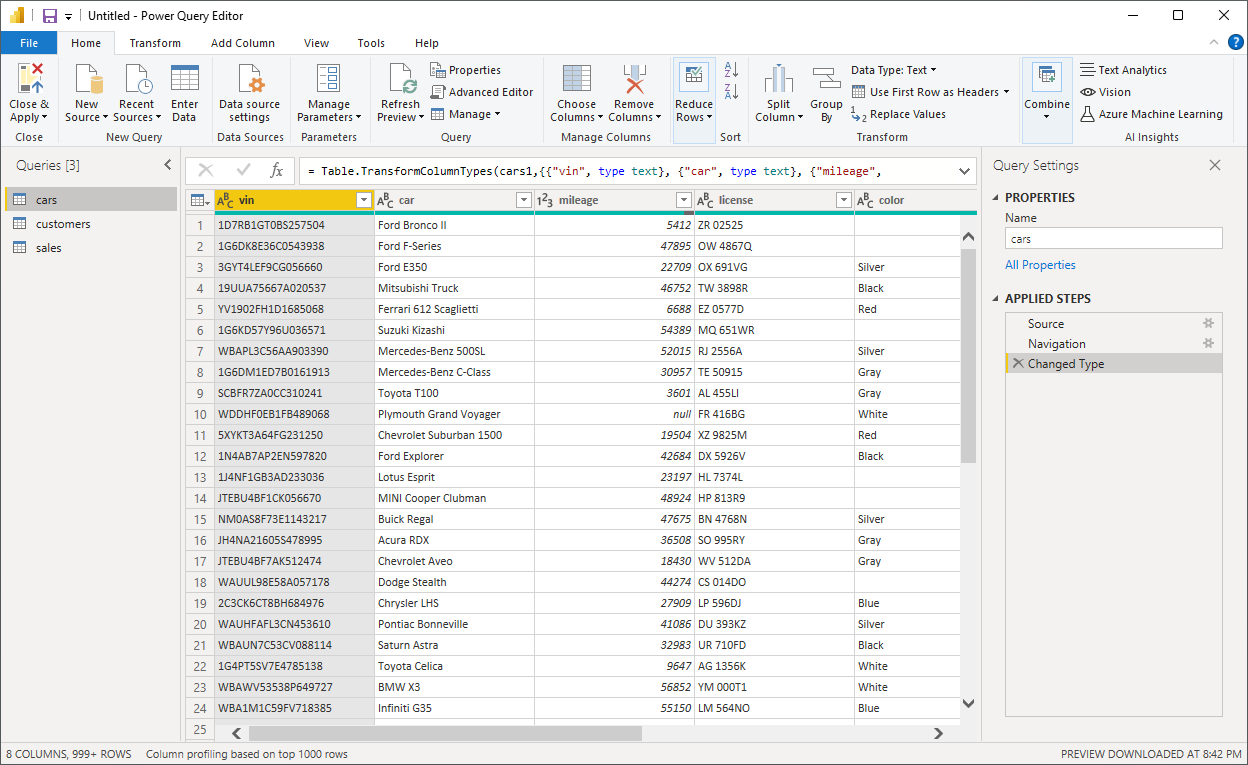

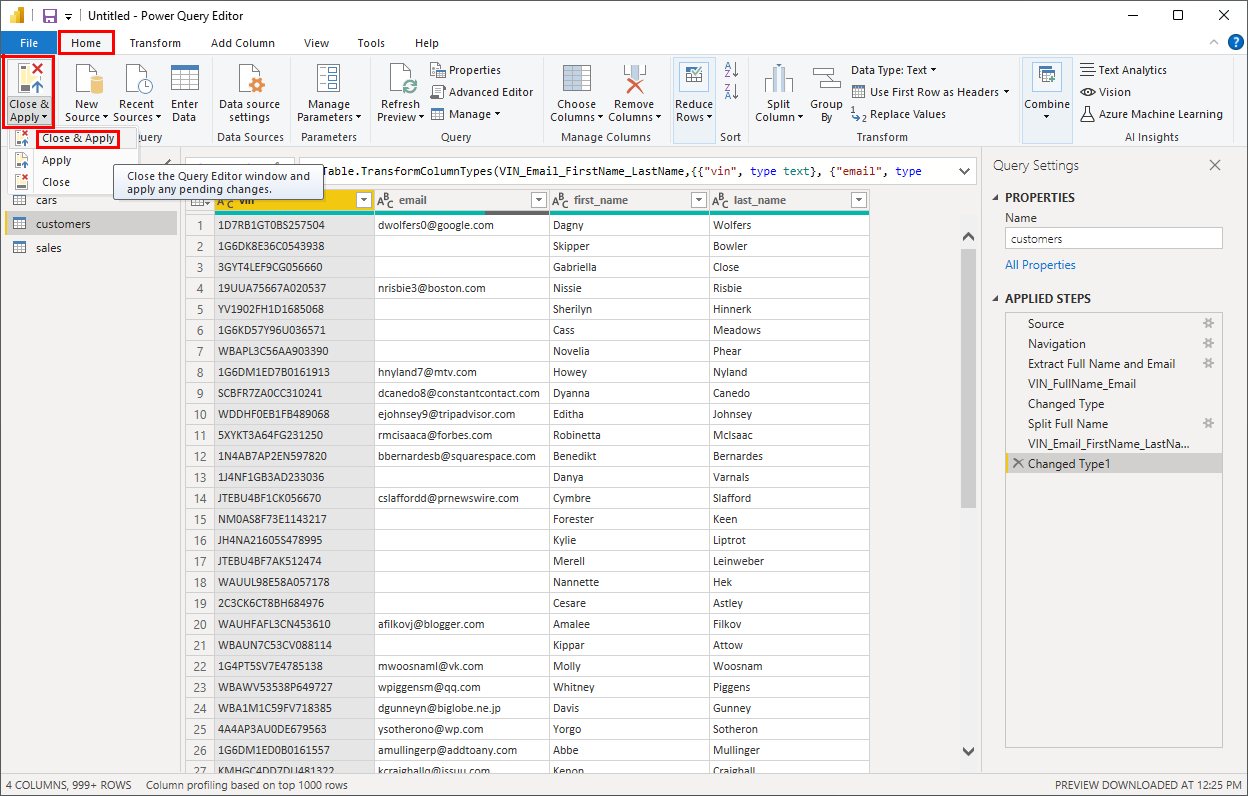
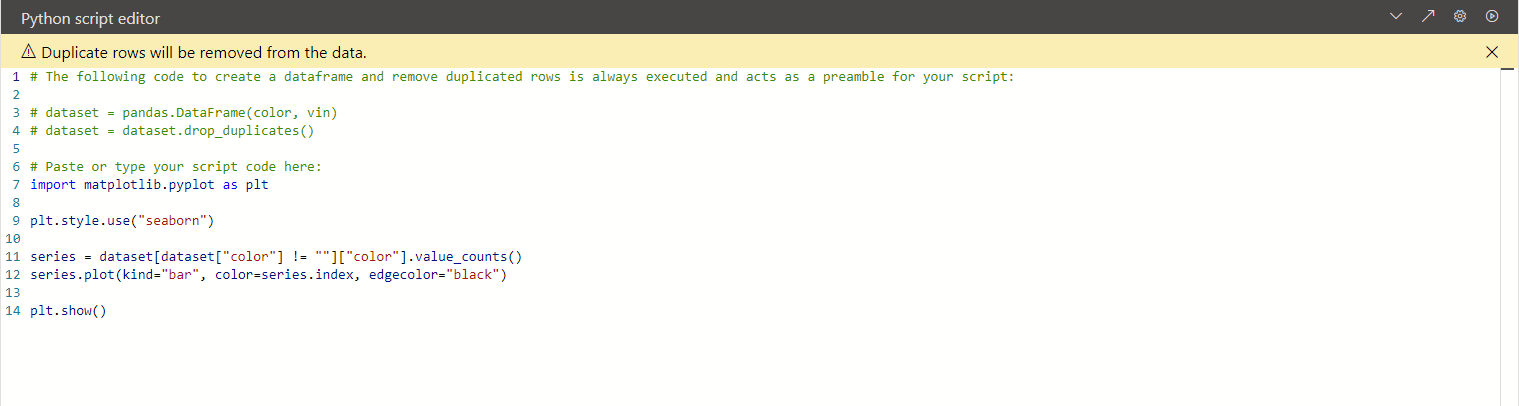
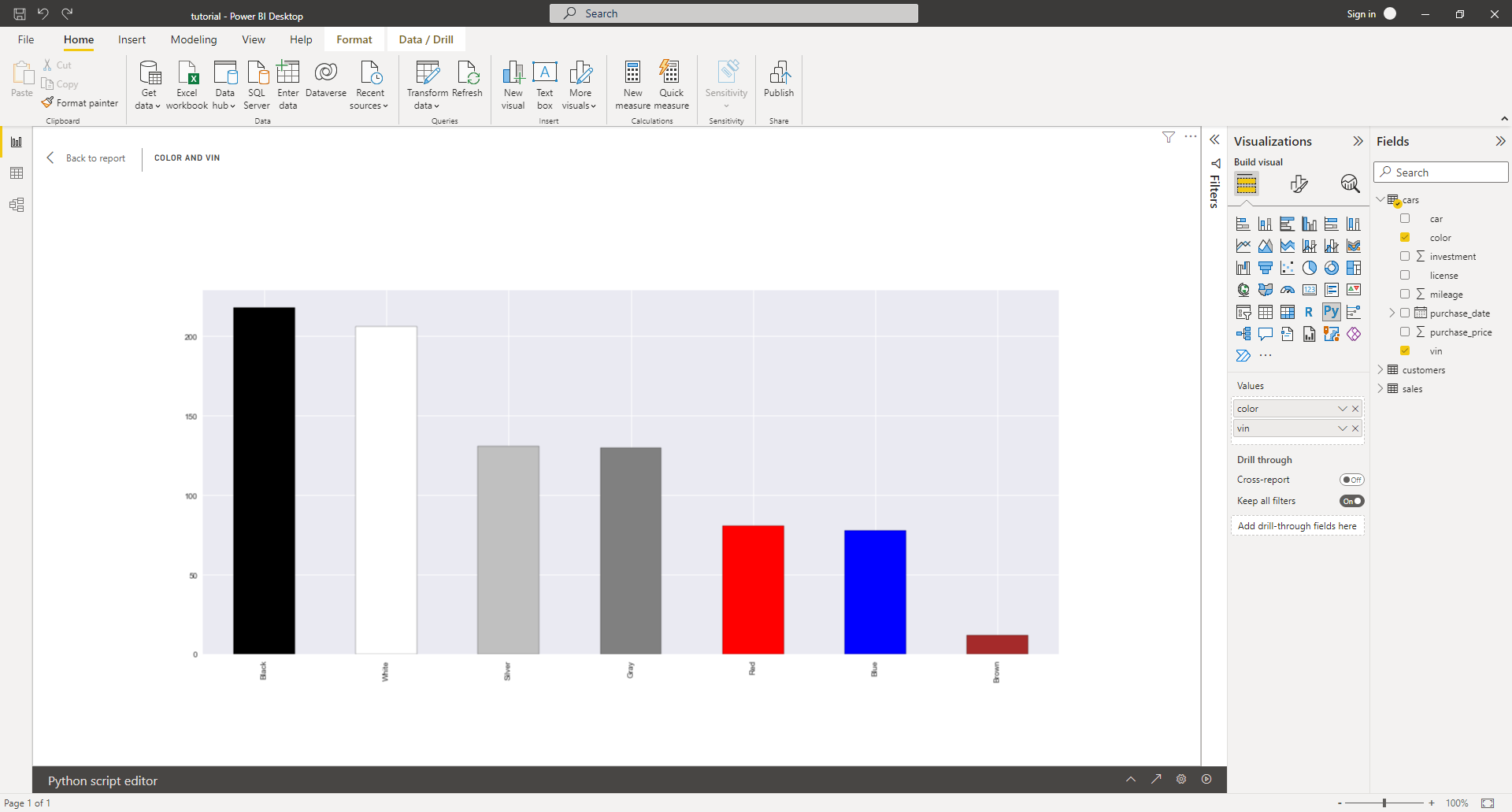
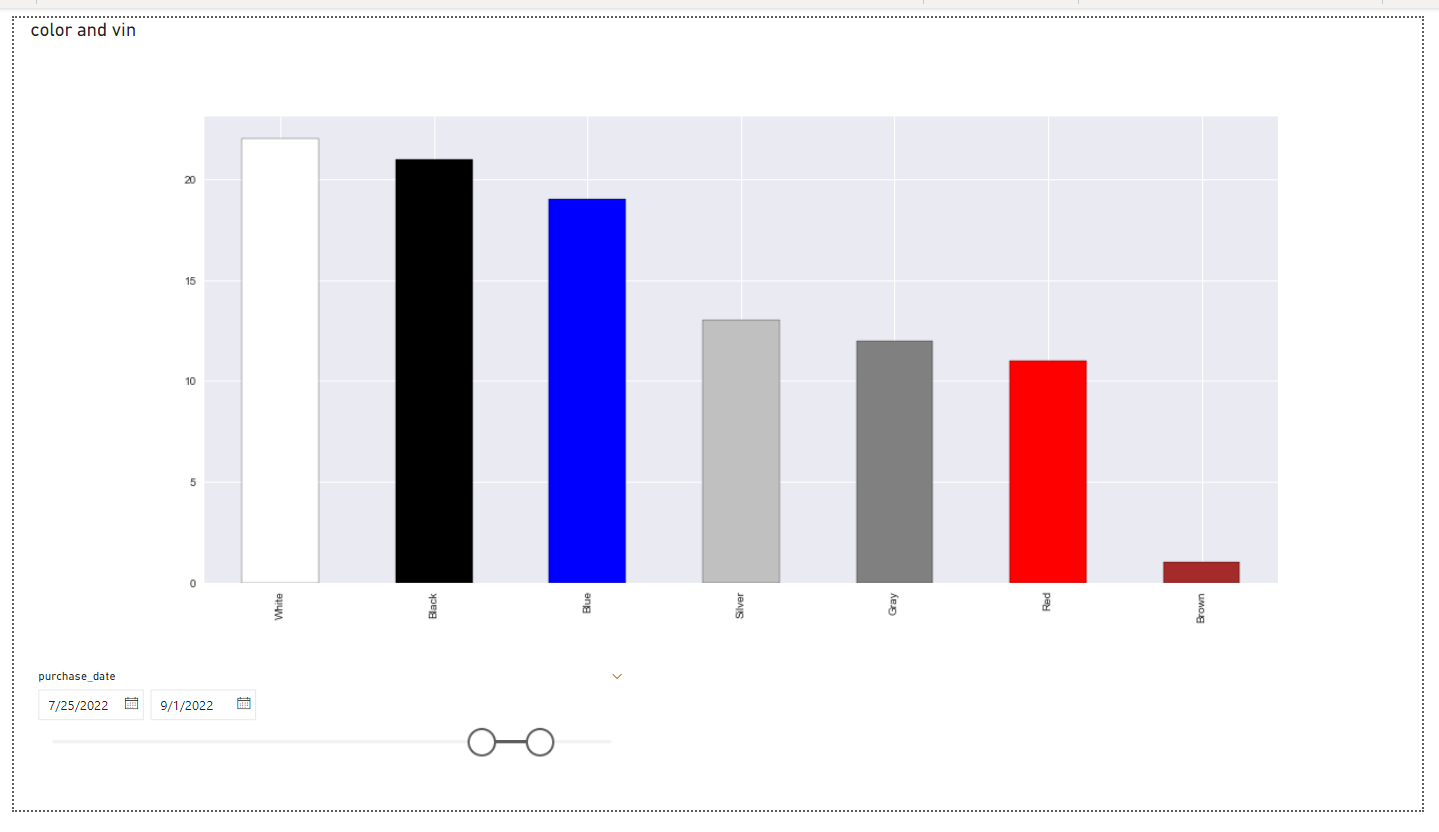
>>> with connection.cursor() as cursor:
... cursor.execute('SELECT COUNT(*) FROM users')
... result = cursor.fetchone()
... print(result)
(2,)
您使用了connection对象来创建一个cursor。就像 Python 中的文件一样,cursor被实现为上下文管理器。当您创建上下文时,会打开一个cursor用于向数据库发送命令。当上下文退出时,cursor关闭,您不能再使用它。
注意:要了解关于上下文管理器的更多信息,请查看 Python 上下文管理器和“with”语句。
在上下文中,您使用了cursor来执行查询并获取结果。在这种情况下,您发出一个查询来计算users表中的行数。为了从查询中获取结果,您执行了cursor.fetchone()并收到了一个元组。因为查询只能返回一个结果,所以您使用了fetchone()。如果查询要返回多个结果,那么您需要迭代cursor或者使用其他 fetch* 方法之一。
在 SQL 中使用查询参数
在上一节中,您创建了一个数据库,建立了到它的连接,并执行了一个查询。您使用的查询是静态。换句话说,它的没有参数。现在,您将开始在查询中使用参数。
首先,您将实现一个检查用户是否是管理员的函数。is_admin()接受用户名并返回该用户的管理员状态:
# BAD EXAMPLE. DON'T DO THIS!
def is_admin(username: str) -> bool:
with connection.cursor() as cursor:
cursor.execute("""
SELECT
admin
FROM
users
WHERE
username = '%s'
""" % username)
result = cursor.fetchone()
admin, = result
return admin
这个函数执行一个查询来获取给定用户名的admin列的值。您使用了fetchone()来返回一个只有一个结果的元组。然后,你将这个元组解包到变量 admin中。要测试您的功能,请检查一些用户名:
>>> is_admin('haki') False >>> is_admin('ran') True到目前为止一切顺利。该函数返回两个用户的预期结果。但是不存在的用户怎么办?看看这个 Python 回溯:
>>> is_admin('foo')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 12, in is_admin
TypeError: cannot unpack non-iterable NoneType object
当用户不存在时,产生一个TypeError。这是因为.fetchone()在没有找到结果时返回 None ,而解包None会引发一个TypeError。唯一可以解包元组的地方是从result填充admin的地方。
为了处理不存在的用户,当result为None时创建一个特例:
# BAD EXAMPLE. DON'T DO THIS!
def is_admin(username: str) -> bool:
with connection.cursor() as cursor:
cursor.execute("""
SELECT
admin
FROM
users
WHERE
username = '%s'
""" % username)
result = cursor.fetchone()
if result is None: # User does not exist return False
admin, = result
return admin
这里,您添加了一个处理None的特例。如果username不存在,那么函数应该返回False。再次在一些用户身上测试该功能:
>>> is_admin('haki') False >>> is_admin('ran') True >>> is_admin('foo') False太好了!该功能现在也可以处理不存在的用户名。
利用 Python SQL 注入开发查询参数
在前面的例子中,您使用了字符串插值来生成一个查询。然后,执行查询并将结果字符串直接发送到数据库。然而,在这个过程中你可能忽略了一些东西。
回想一下您传递给
is_admin()的username参数。这个变量到底代表什么?你可能会认为username只是一个表示真实用户名的字符串。但是,正如您将要看到的,入侵者可以很容易地利用这种疏忽,通过执行 Python SQL 注入造成重大伤害。尝试检查以下用户是否是管理员:
>>> is_admin("'; select true; --")
True
等等…刚刚发生了什么?
让我们再看一下实现。打印出数据库中正在执行的实际查询:
>>> print("select admin from users where username = '%s'" % "'; select true; --") select admin from users where username = ''; select true; --'结果文本包含三个语句。为了准确理解 Python SQL 注入的工作原理,您需要单独检查每个部分。第一个声明如下:
select admin from users where username = '';这是您想要的查询。分号(
;)终止查询,因此这个查询的结果无关紧要。接下来是第二条语句:select true;这份声明是入侵者编造的。它被设计为总是返回
True。最后,您会看到这段简短的代码:
--'这个片段消除了它后面的所有内容。入侵者添加了注释符号(
--),将您可能放在最后一个占位符之后的所有内容都变成了注释。当你用这个参数执行函数时,将总是返回
True。例如,如果您在登录页面中使用这个函数,入侵者可以使用用户名'; select true; --登录,他们将被授予访问权限。如果你认为这很糟糕,它可能会变得更糟!了解您的表结构的入侵者可以使用 Python SQL 注入来造成永久性破坏。例如,入侵者可以注入更新语句来改变数据库中的信息:
>>> is_admin('haki')
False
>>> is_admin("'; update users set admin = 'true' where username = 'haki'; select true; --")
True
>>> is_admin('haki')
True
让我们再分解一下:
';
这个代码片段终止了查询,就像前面的注入一样。下一条语句如下:
update users set admin = 'true' where username = 'haki';
该部分为用户haki将admin更新为true。
最后,有这样一段代码:
select true; --
和前面的例子一样,这段代码返回true并注释掉它后面的所有内容。
为什么会更糟?好吧,如果入侵者设法用这个输入执行函数,那么用户haki将成为管理员:
psycopgtest=# select * from users; username | admin
----------+-------
ran | t
haki | t (2 rows)
入侵者不再需要使用黑客技术。他们可以用用户名haki登录。(如果入侵者真的想要造成伤害,那么他们甚至可以发出DROP DATABASE命令。)
在您忘记之前,将haki恢复到其原始状态:
psycopgtest=# update users set admin = false where username = 'haki'; UPDATE 1
那么,为什么会这样呢?嗯,你对username论点了解多少?您知道它应该是一个表示用户名的字符串,但是您实际上并不检查或强制执行这个断言。这可能很危险!这正是攻击者试图入侵您的系统时所寻找的。
精心制作安全查询参数
在上一节中,您看到了入侵者如何通过使用精心编制的字符串来利用您的系统并获得管理员权限。问题是您允许从客户端传递的值直接执行到数据库,而不执行任何检查或验证。 SQL 注入依赖于这种类型的漏洞。
在数据库查询中使用用户输入的任何时候,SQL 注入都可能存在漏洞。防止 Python SQL 注入的关键是确保该值按照开发人员的意图使用。在前面的例子中,您打算将username用作一个字符串。实际上,它被用作原始 SQL 语句。
为了确保值按预期使用,您需要对值进行转义。例如,为了防止入侵者在字符串参数的位置注入原始 SQL,可以对引号进行转义:
>>> # BAD EXAMPLE. DON'T DO THIS! >>> username = username.replace("'", "''")这只是一个例子。在尝试防止 Python SQL 注入时,有许多特殊字符和场景需要考虑。幸运的是,现代数据库适配器带有内置工具,通过使用查询参数来防止 Python SQL 注入。这些用于代替普通的字符串插值,以构成带有参数的查询。
注意:不同的适配器、数据库、编程语言对查询参数的称呼不同。俗称有绑定变量、替换变量、替代变量。
现在您对漏洞有了更好的理解,可以使用查询参数而不是字符串插值来重写函数了:
1def is_admin(username: str) -> bool: 2 with connection.cursor() as cursor: 3 cursor.execute(""" 4 SELECT 5 admin 6 FROM 7 users 8 WHERE 9 username = %(username)s 10 """, { 11 'username': username 12 }) 13 result = cursor.fetchone() 14 15 if result is None: 16 # User does not exist 17 return False 18 19 admin, = result 20 return admin以下是本例中的不同之处:
在第 9 行,中,您使用了一个命名参数
username来指示用户名应该放在哪里。注意参数username不再被单引号包围。在第 11 行,你将
username的值作为第二个参数传递给了cursor.execute()。在数据库中执行查询时,连接将使用username的类型和值。要测试这个函数,请尝试一些有效和无效的值,包括前面的危险字符串:
>>> is_admin('haki')
False
>>> is_admin('ran')
True
>>> is_admin('foo')
False
>>> is_admin("'; select true; --")
False
太神奇了!该函数返回所有值的预期结果。更有甚者,危险的弦不再起作用。要了解原因,您可以查看由execute()生成的查询:
>>> with connection.cursor() as cursor: ... cursor.execute(""" ... SELECT ... admin ... FROM ... users ... WHERE ... username = %(username)s ... """, { ... 'username': "'; select true; --" ... }) ... print(cursor.query.decode('utf-8')) SELECT admin FROM users WHERE username = '''; select true; --'该连接将
username的值视为一个字符串,并对任何可能终止该字符串并引入 Python SQL 注入的字符进行了转义。传递安全查询参数
数据库适配器通常提供几种传递查询参数的方法。命名占位符通常是可读性最好的,但是一些实现可能会受益于使用其他选项。
让我们快速看一下使用查询参数的一些正确和错误的方法。下面的代码块显示了您希望避免的查询类型:
# BAD EXAMPLES. DON'T DO THIS! cursor.execute("SELECT admin FROM users WHERE username = '" + username + '"); cursor.execute("SELECT admin FROM users WHERE username = '%s' % username); cursor.execute("SELECT admin FROM users WHERE username = '{}'".format(username)); cursor.execute(f"SELECT admin FROM users WHERE username = '{username}'");这些语句中的每一条都将
username从客户端直接传递到数据库,而不执行任何检查或验证。这种代码已经成熟,可以邀请 Python SQL 注入了。相比之下,执行这些类型的查询应该是安全的:
# SAFE EXAMPLES. DO THIS! cursor.execute("SELECT admin FROM users WHERE username = %s'", (username, )); cursor.execute("SELECT admin FROM users WHERE username = %(username)s", {'username': username});在这些语句中,
username作为命名参数传递。现在,当执行查询时,数据库将使用指定的类型和值username,以防止 Python SQL 注入。使用 SQL 组合
到目前为止,您已经为文字使用了参数。文字是数字、字符串和日期等数值。但是,如果您有一个用例需要编写一个不同的查询——其中的参数是其他的东西,比如表或列名,该怎么办呢?
受前面示例的启发,让我们实现一个接受表名并返回该表中行数的函数:
# BAD EXAMPLE. DON'T DO THIS! def count_rows(table_name: str) -> int: with connection.cursor() as cursor: cursor.execute(""" SELECT count(*) FROM %(table_name)s """, { 'table_name': table_name, }) result = cursor.fetchone() rowcount, = result return rowcount尝试在用户表上执行该功能:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 9, in count_rows
psycopg2.errors.SyntaxError: syntax error at or near "'users'"
LINE 5: 'users'
^
该命令无法生成 SQL。正如您已经看到的,数据库适配器将变量视为字符串或文字。然而,表名不是普通的字符串。这就是 SQL 组合的用武之地。
你已经知道使用字符串插值来构造 SQL 是不安全的。幸运的是,Psycopg 提供了一个名为 psycopg.sql 的模块来帮助您安全地编写 SQL 查询。让我们用 psycopg.sql.SQL() 重写函数:
from psycopg2 import sql
def count_rows(table_name: str) -> int:
with connection.cursor() as cursor:
stmt = sql.SQL("""
SELECT
count(*)
FROM
{table_name} """).format(
table_name = sql.Identifier(table_name),
)
cursor.execute(stmt)
result = cursor.fetchone()
rowcount, = result
return rowcount
在这个实现中有两个不同之处。首先,您使用了sql.SQL()来编写查询。然后,您使用sql.Identifier()来注释参数值table_name。(一个标识符是一个列或表名。)
注意:流行包 django-debug-toolbar 的用户可能会在 SQL 面板中得到一个用psycopg.sql.SQL()编写的查询的错误。预计将在版本 2.0 中发布一个修复程序。
现在,尝试执行users表上的函数:
>>> count_rows('users') 2太好了!接下来,让我们看看当表不存在时会发生什么:
>>> count_rows('foo')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 11, in count_rows
psycopg2.errors.UndefinedTable: relation "foo" does not exist
LINE 5: "foo"
^
该函数抛出UndefinedTable异常。在接下来的步骤中,您将使用该异常来表明您的函数不会受到 Python SQL 注入攻击。
注:异常UndefinedTable是在psycopg 2 2.8 版中增加的。如果您使用的是 Psycopg 的早期版本,那么您会得到一个不同的异常。
要将所有这些放在一起,可以添加一个选项来计算表中的行数,直到达到一定的限制。这个特性对于非常大的表可能很有用。要实现这一点,需要在查询中添加一个LIMIT子句,以及限制值的查询参数:
from psycopg2 import sql
def count_rows(table_name: str, limit: int) -> int:
with connection.cursor() as cursor:
stmt = sql.SQL("""
SELECT
COUNT(*)
FROM (
SELECT
1
FROM
{table_name} LIMIT {limit} ) AS limit_query
""").format(
table_name = sql.Identifier(table_name),
limit = sql.Literal(limit), )
cursor.execute(stmt)
result = cursor.fetchone()
rowcount, = result
return rowcount
在这个代码块中,您使用sql.Literal()对limit进行了注释。和前面的例子一样,在使用简单方法时,psycopg会将所有查询参数绑定为文字。然而,当使用sql.SQL()时,您需要使用sql.Identifier()或sql.Literal()显式地注释每个参数。
注意:不幸的是,Python API 规范没有解决标识符的绑定,只解决了文字。Psycopg 是唯一一个流行的适配器,它增加了用文字和标识符安全组合 SQL 的能力。这个事实使得在绑定标识符时更加需要注意。
执行该功能以确保其正常工作:
>>> count_rows('users', 1) 1 >>> count_rows('users', 10) 2既然您已经看到该函数正在工作,请确保它也是安全的:
>>> count_rows("(select 1) as foo; update users set admin = true where name = 'haki'; --", 1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 18, in count_rows
psycopg2.errors.UndefinedTable: relation "(select 1) as foo; update users set admin = true where name = '" does not exist
LINE 8: "(select 1) as foo; update users set adm...
^
这个回溯表明psycopg对该值进行了转义,数据库将其视为表名。因为这个名称的表不存在,所以出现了一个UndefinedTable异常,您没有被攻击!
结论
您已经成功实现了一个组成动态 SQL 的函数,而没有让您的系统面临 Python SQL 注入的风险!您在查询中使用了文字和标识符,而没有损害安全性。
你已经学会:
- 什么是 Python SQL 注入以及如何利用它
- 如何防止 Python SQL 注入使用查询参数
- 如何安全地编写使用文字和标识符作为参数的 SQL 语句
您现在能够创建能够抵御外部攻击的程序。前进,挫败黑客!******
Jinja 模板底漆
模板是全栈 web 开发中的重要组成部分。有了 Jinja ,您可以构建丰富的模板来驱动 Python web 应用程序的前端。
但是您不需要使用 web 框架来体验 Jinja 的功能。当你想创建带有编程内容的文本文件时,Jinja 可以帮助你。
在本教程中,您将学习如何:
- 安装 Jinja 模板引擎
- 创建你的第一个 Jinja 模板
- 在烧瓶中渲染一个 Jinja 模板
- 用
for循环和条件语句搭配 Jinja - 嵌套金佳模板
- 用过滤器修改 Jinja 中的变量
- 使用宏为您的前端添加功能
您将从单独使用 Jinja 开始,了解 Jinja 模板的基础知识。稍后,您将构建一个包含两个页面和一个导航栏的基本 Flask web 项目,以充分利用 Jinja 的潜力。
在整个教程中,您将构建一个示例应用程序,展示 Jinja 的一些广泛功能。要查看它会做什么,请跳到最后一部分。
您也可以通过点击下面的链接找到 web 项目的完整源代码:
源代码: 点击这里下载源代码,你将使用它来探索 Jinja 的能力。
如果你想学习更多关于 Jinja 模板语言的知识,或者如果你正在开始使用 Flask,这篇教程是为你准备的。
金贾入门
金贾不仅是乌干达东部地区的城市和日本寺庙,还是模板引擎。您通常将模板引擎用于 web 模板,这些模板从后端接收动态内容,并在前端将其呈现为静态页面。
但是你可以使用 Jinja,而不需要在后台运行 web 框架。这正是您在本节中要做的。具体来说,您将安装 Jinja 并构建您的第一个模板。
安装金贾
在探索任何新的包之前,创建并激活一个虚拟环境是个好主意。这样,您将在项目的虚拟环境中安装任何项目依赖项,而不是在系统范围内。
在下面选择您的操作系统,并使用您的平台特定命令来设置虚拟环境:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS>
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $
通过上面的命令,您可以使用 Python 的内置venv模块创建并激活一个名为venv的虚拟环境。提示前面venv周围的括号(())表示您已经成功激活了虚拟环境。
创建并激活虚拟环境后,就该用 pip 安装 Jinja 了:
(venv) $ python -m pip install Jinja2
不要忘记包名末尾的2。否则,你将安装一个与 Python 3 不兼容的旧版本。
值得注意的是,虽然当前的主要版本实际上比2更大,但是您将要安装的包仍然叫做Jinja2。你可以通过运行pip list来验证你已经安装了一个现代版的 Jinja:
(venv) $ python -m pip list
Package Version
---------- -------
Jinja2 3.x
...
更混乱的是,在用大写的J安装了 Jinja 之后,还要用 Python 导入小写的j。通过打开交互式 Python 解释器并运行以下命令来尝试一下:
>>> import Jinja2 Traceback (most recent call last): ... ModuleNotFoundError: No module named 'Jinja2' >>> import jinja2 >>> # No error当你试图导入
Jinja2,用你用来安装 Jinja 的大写命名,然后你抛出一个ModuleNotFoundError。要将 Jinja 包导入 Python,必须键入小写的j``jinja2。渲染你的第一个金贾模板
导入 Jinja 后,您可以继续加载和渲染您的第一个模板:
>>> import jinja2
>>> environment = jinja2.Environment()
>>> template = environment.from_string("Hello, {{ name }}!")
>>> template.render(name="World")
'Hello, World!'
Jinja 的核心组件是Environment()级。在本例中,您创建了一个没有任何参数的 Jinja 环境。稍后,您将更改Environment的参数来定制您的环境。在这里,您创建了一个简单的环境,将字符串"Hello, {{ name }}!"作为模板加载。
您刚才所做的可能不会比在普通 Python 中使用格式的字符串更令人印象深刻。然而,这个例子展示了在使用 Jinja 时通常要执行的两个重要步骤:
- 加载模板:加载包含占位符变量的源。默认情况下,它们被包在一对花括号(
{{ }})中。 - 呈现模板:用内容填充占位符。你可以提供一个字典或者关键字参数作为上下文。在本例中,您已经填充了占位符,这样您就可以得到熟悉的
Hello, World!作为输出。
您正在加载的源模板可以是一个文字字符串。但是当您使用文件并提供一个文本文件作为模板时,事情会变得更加有趣。
使用外部文件作为模板
如果您想遵循本教程中的示例,那么您可以继续创建一个新的文件夹来工作。在您的工作目录中,创建一个名为templates/的文件夹。
您可以将任何即将出现的模板存储在templates/文件夹中。现在创建一个名为message.txt的文本文件:
{# templates/message.txt #}
Hello {{ name }}!
I'm happy to inform you that you did very well on today's {{ test_name }}.
You reached {{ score }} out of {{ max_score }} points.
See you tomorrow!
Anke
假设你是一名老师,想把成绩发给表现好的学生。message.txt模板包含了消息的蓝图,您可以复制并粘贴它以便以后发送。就像在Hello, World!的例子中,你可以在你的模板文本中找到花括号({{ }})。
接下来,创建一个名为write_messages.py的 Python 文件:
# write_messages.py
from jinja2 import Environment, FileSystemLoader
max_score = 100
test_name = "Python Challenge"
students = [
{"name": "Sandrine", "score": 100},
{"name": "Gergeley", "score": 87},
{"name": "Frieda", "score": 92},
]
environment = Environment(loader=FileSystemLoader("templates/"))
template = environment.get_template("message.txt")
for student in students:
filename = f"message_{student['name'].lower()}.txt"
content = template.render(
student,
max_score=max_score,
test_name=test_name
)
with open(filename, mode="w", encoding="utf-8") as message:
message.write(content)
print(f"... wrote {filename}")
当你用FileSystemLoader创建一个 Jinja 环境时,你可以传递指向你的模板文件夹的路径。您现在加载message.txt作为模板,而不是传入一个字符串。一旦你的模板被加载,你可以反复使用它来填充内容。在write_messages.py中,你将每个优等生的name和score呈现到一个文本文件中。
注意,students字典的键,连同max_score和test_name,匹配message.txt中的模板变量。如果您没有为模板中的变量提供上下文,它们不会抛出错误。但是它们呈现一个空字符串,这通常是不希望的。
当您调用template.render()时,您将呈现的模板作为字符串返回。与任何其他字符串一样,您可以使用.write()将其写入文件。要查看write_messages.py的运行,运行脚本:
(venv) $ python write_messages.py
... wrote message_sandrine.txt
... wrote message_gergeley.txt
... wrote message_frieda.txt
您刚刚为您的每个学生创建了一个文件。看看message_gergeley.txt吧,比如:
Hello Gergeley!
I'm happy to inform you that you did very well on today's Python Challenge.
You reached 87 out of 100 points.
See you tomorrow!
Anke
您的message.txt模板的变量成功接收了您学生的数据。让 Python 和 Jinja 为您工作是多么好的方式啊!现在,您可以复制并粘贴文本,将其发送给您的学生,并为自己节省一些工作。
控制金贾的流量
到目前为止,您已经向模板文本添加了占位符变量,并向其中呈现了值。在这一节中,您将学习如何将if语句和for循环添加到模板中,以便有条件地呈现内容而无需重复。
使用 if 语句
在上一节的示例中,您以编程方式为优等生创建了定制的消息。现在是时候考虑一下你所有的学生了。在write_messages.py中给students增加两个分数较低的学生:
# write_messages.py
# ...
students = [
{"name": "Sandrine", "score": 100},
{"name": "Gergeley", "score": 87},
{"name": "Frieda", "score": 92},
{"name": "Fritz", "score": 40}, {"name": "Sirius", "score": 75}, ]
# ...
你把弗里茨和小天狼星的分数加到students列表上。与其他学生不同,两人的成绩都低于 80 分。使用80标记在message.txt中创建一个条件语句:
1{# templates/message.txt #}
2
3Hello {{ name }}!
4
5{% if score > 80 %} 6I'm happy to inform you that you did very well on today's {{ test_name }}.
7{% else %} 8I'm sorry to inform you that you did not do so well on today's {{ test_name }}.
9{% endif %} 10You reached {{ score }} out of {{ max_score }} points.
11
12See you tomorrow!
13Anke
除了您之前使用的变量,您现在还使用了一个带有 Jinja 块的条件语句。不用一对双花括号,而是用一个花括号和一个百分号({% %})创建 Jinja 块。
虽然您可以将普通变量看作子字符串,但是 Jinja 块包装了模板的更大部分。这就是为什么你也需要告诉 Jinja 你的街区在哪里结束。要关闭一个块,可以再次使用完全相同的关键字,加上一个end前缀。
在上面的例子中,你在第 5 行开始一个{% if %}块,在第 9 行用{% endif %}关闭它。if语句本身的工作方式类似于 Python 中的条件语句。在第 5 行,你正在检查score是否高于80。如果是这样,那么你正在传递一个快乐的信息。否则,您需要在第 8 行显示一条道歉消息。
在上面的例子中,学生们同意将 80 分作为他们 Python 挑战性能的基准。随意将80改成任何让你和你的学生更舒服的分数。
循环杠杆
您还可以使用for循环来控制模板的流程。例如,您决定为学生创建一个显示所有结果的 HTML 页面。请注意,所有学生都同意在这场友谊赛中公开展示他们的成绩。
在您的templates/目录中创建一个名为results.html的新文件:
{# templates/results.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Results</title>
</head>
<body>
<h1>{{ test_name }} Results</h1>
<ul>
{% for student in students %}
<li>
<em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
</ul>
</body>
</html>
在这里,您创建了一个 HTML 页面,它遍历您的students字典并显示它们的性能。就像用{% if %}块一样,你必须确保用{% endfor %}关闭你的{% for %}块。
您可以结合使用if语句和for循环来进一步控制模板的流程:
{# templates/results.html #}
{# ... #}
{% for student in students %}
<li>
{% if student.score > 80 %}🙂{% else %}🙁{% endif %} <em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
{# ... #}
```py
根据学生的分数,你会显示一个微笑或悲伤的表情符号。请注意,您也可以将块表达式放在一行中。
继续更新`write_messages.py`:
write_messages.py
...
results_filename = "students_results.html"
results_template = environment.get_template("results.html")
context = {
"students": students,
"test_name": test_name,
"max_score": max_score,
}
with open(results_filename, mode="w", encoding="utf-8") as results:
results.write(results_template.render(context))
print(f"... wrote {results_filename}")
除了为每个学生保存消息的`for`循环之外,现在还要编写一个包含该学生所有结果的 HTML 文件。这一次,您将创建一个`context`字典,保存您传递给模板的所有变量。
**注意:**使用`context`作为存储模板变量的集合的名称是一种约定。也就是说,如果你愿意的话,你可以用不同的名字来命名字典。
有了包含模板所有上下文的字典,您就可以用唯一的参数`context`调用`.render()`。当您运行`write_messages.py`时,您还会创建一个 HTML 文件:
>>>
(venv) $ python write_messages.py
... wrote message_sandrine.txt
... wrote message_gergeley.txt
... wrote message_frieda.txt
... wrote message_fritz.txt
... wrote message_sirius.txt
... wrote students_results.html
您可以在代码编辑器中查看呈现的 HTML 文件。但是,由于您现在正在使用 HTML,您也可以在浏览器中查看该文件:
[](https://files.realpython.com/media/jinja-student-results.0fd2e89ad93a.png)
像在 Python 脚本中一样,您可以用`if`语句和`for`循环来控制 Jinja 模板的流程。在 Jinja 中,你使用块来包装内容。当你使用一个`for`块时,该块中的内容会在循环的每一步中呈现。
使用模板,您可以为大型网站创建构建块,而无需复制前端代码。这就是为什么像 Flask 这样的 web 框架利用了 Jinja 模板的力量。在下一节中,您将学习如何使用 Flask 将数据从后端呈现到前端的 web 页面中。
## 将金贾与烧瓶一起使用
很有可能你第一次听说 Jinja 是在你使用像 [Flask](https://flask.palletsprojects.com/) 这样的 web 框架的时候。Jinja 和 Flask 都由[托盘项目](https://palletsprojects.com/)维护,这是一个社区驱动的组织,负责管理为 Flask web 框架提供动力的 Python 库。
在本节中,您将继续前面的示例,为您的学生创建一个基本的 web 应用程序。
[*Remove ads*](/account/join/)
### 安装烧瓶
您可以继续在上一节中创建的相同目录和虚拟环境中工作。当您处于活跃的虚拟环境中时,继续安装 Flask:
(venv) $ python -m pip install flask
安装 Flask 后,继续创建您的第一条路线,以验证 Flask 是否按预期工作。在项目的根目录下创建一个名为`app.py`的文件:
app.py
from flask import Flask
app = Flask(name)
@app.route("/")
def home():
return "Hello, World!"
if name == "main":
app.run(debug=True)
当你把一个`@app.route()` [装饰器](https://realpython.com/primer-on-python-decorators/)放在一个烧瓶**视图**函数的顶部时,你用给定的 URL [规则](https://flask.palletsprojects.com/en/2.1.x/quickstart/#routing)注册它。在这里,您正在建立路由`/`,它返回`Hello, World!`。
要在浏览器中查看您的主页,请启动 Flask development web 服务器:
(venv) $ python app.py
...
- Debug mode: on
- Running on http://127.0.0.1:5000 (Press CTRL+C to quit)
- Restarting with watchdog (fsevents)
- Debugger is active!
现在你的 Flask 应用运行在`debug`模式。在`debug`模式下,如果出现问题,你会得到更有意义的错误信息。此外,每当您更改代码库中的内容时,您的服务器都会自动重启。
要查看您的主页,请访问`http://127.0.0.1:5000`:
[](https://files.realpython.com/media/jinja-flask-hello-world.3a9c3d2d7869.png)
太棒了,你现在有一个跑步烧瓶应用程序了!在下一节中,您将在 Flask 应用程序中实现 Jinja 模板。
### 添加基础模板
到目前为止,您的 Flask 应用程序返回一个字符串。您可以通过添加 HTML 代码来增强您的字符串,Flask 会为您呈现它。但是正如您在上一节中了解到的,使用模板可以让您更方便地呈现内容。
在您的`templates/`目录中创建一个名为`base.html`的新模板:
1{# templates/base.html #}
2
3
4
5
6
7
8
9
10
11
Welcome to {{ title }}!
12
13
在`base.html`中,你有两次使用模板变量的机会:一次在第 7 行,另一次在第 11 行。为了渲染和提供`base.html`,将其作为您在`app.py`的主页加载:
app.py
from flask import Flask, render_template
app = Flask(name)
@app.route("/")
def home():
return render_template("base.html", title="Jinja and Flask")
...
默认情况下,Flask 希望你的模板在一个`templates/`目录中。因此,不需要显式设置模板目录。当你提供`base.html`给`render_template()`时,Flask 知道在哪里寻找你的模板。
**注意:**通常,你会用 [CSS](https://realpython.com/html-css-python/) 改善网站的外观,用 [JavaScript](https://realpython.com/python-vs-javascript/) 添加一些功能。因为您在本教程中关注的是内容结构,所以您的 web 应用程序基本上是无样式的。
如果 Flask development server 还没有自动更新,请重新启动它。然后访问`http://127.0.0.1:5000`并验证 Flask 服务并呈现您的基本模板:
[](https://files.realpython.com/media/jinja-flask-welcome-home.816baca03b8a.png)
Flask 在你的网站标题和欢迎信息中呈现了`title`变量。接下来,您将创建一个页面来显示学生的成绩。
[*Remove ads*](/account/join/)
### 添加另一页
在前面的[章节](#leverage-for-loops)中,您使用`results.html`作为模板来生成一个名为`students_results.html`的文件。现在你已经有了一个 web 应用程序,你可以使用`results.html`来动态渲染你的模板,这次不用保存到一个新文件。
确保`results.html`被放置在`templates/`中,看起来像这样:
1{# templates/results.html #}
2
3
4
5
6
7
9
10
11
{{ test_name }} {{ title }}
12
15 {% if student.score > 80 %}🙂{% else %}🙁{% endif %}
16 {{ student.name }}: {{ student.score }}/{{ max_score }}
17
13 {% for student in students %}
14
18 {% endfor %}
19
20
21
上面突出显示了对早期版本的唯一调整:
* **第 7 行**添加动态页面标题。
* **第 11 行**增强第一个标题。
要在 web 应用程序中访问结果页面,您必须创建路径。将以下代码添加到`app.py`:
app.py
...
max_score = 100
test_name = "Python Challenge"
students = [
{"name": "Sandrine", "score": 100},
{"name": "Gergeley", "score": 87},
{"name": "Frieda", "score": 92},
{"name": "Fritz", "score": 40},
{"name": "Sirius", "score": 75},
]
@app.route("/results")
def results():
context = {
"title": "Results",
"students": students,
"test_name": test_name,
"max_score": max_score,
}
return render_template("results.html", **context)
...
在一个成熟的网络应用程序中,你可能会将数据存储在一个[外部数据库](https://realpython.com/python-mysql/)中。现在,你把`max_score`、`test_name`和`students`放在`results()`旁边。
Flask 的`render_template()`只接受一个[位置参数](https://realpython.com/defining-your-own-python-function/#positional-arguments),即模板名称。任何其他参数都必须是关键字参数。所以你必须[打开你的字典](https://realpython.com/python-kwargs-and-args/#unpacking-with-the-asterisk-operators),在`context`前面加两个星号(`**`)。使用星号操作符,您可以将`context`的条目作为关键字参数传递给`render_template()`。
当您在浏览器中访问`http://127.0.0.1:5000/results`时,Flask 为`results.html`提供呈现的上下文。跳到浏览器上看一看:
[](https://files.realpython.com/media/jinja-flask-student-results.d8afe18f9539.png)
现在,您有了一个主页和一个显示学生成绩的页面。对于 web 应用程序来说,这是一个很好的开始!
在下一节中,您将学习如何通过嵌套模板来更好地利用模板的功能。您还将向项目添加一个导航菜单,以便用户可以方便地从一个页面跳到另一个页面。
## 嵌套您的模板
随着应用程序的增长和不断添加新模板,您必须保持公共代码同步。到目前为止,你的两个模板,`base.html`和`results.html`,看起来非常相似。当多个模板包含相同的代码时,如果您更改了任何公共代码,就需要调整每个模板。
在本节中,您将实现一个父模板和子模板结构,这将使您的代码更易于维护。
### 调整您的基础模板
当您使用 Jinja 的模板继承时,您可以将 web 应用程序的公共结构移动到父**基础模板**,并让**子模板**继承该代码。
您的`base.html`几乎可以作为您的基础模板了。为了使您的基本模板可扩展,向结构中添加一些`{% block %}`标记:
{# templates/base.html #}
<html lang="en"> <head> <meta charset="utf-8"> <title>{% block title %}{{ title }}{% endblock title %}</title> </head> <body> {% block content %} <h1>Welcome to {{ title }}!</h1> {% endblock content %} </body> </html> ```py您使用{% block %}标签来定义您的基本模板的哪些部分可以被子模板覆盖。就像用{% if %}和{% for %}一样,你必须用{% endblock %}关闭你的区块。
请注意,您还命名了您的块。使用title参数,您允许子模板用自己的title块替换{% block title %}和{% endblock title %}之间的代码。你可以用一个content块代替{% block content %}的代码。
注意:内容块的名称在每个模板中必须是唯一的。否则,Jinja 会对选择哪个块进行替换感到困惑。
在base.html中的{% block %}标签之间的内容是一个占位符。每当子模板不包含相应的{% block %}标签时,就会显示回退内容。
您也可以决定不在{% block %}标签之间添加回退内容。和模板中的变量一样,如果你不为它们提供内容,Jinja 也不会抱怨。相反,Jinja 将呈现一个空字符串。
在base.html中,你为你的模板块提供后备内容。因此,你不需要改变你的home()视图中的任何东西。它会像以前一样工作。
在下一节中,您将准备您的子模板来使用base.html。
扩展子模板
您当前有一个独立工作的results.html模板,没有父模板。这意味着你现在可以调整results.html的代码来连接base.html:
1{# templates/results.html #}
2
3{% extends "base.html" %} 4
5{% block content %} 6<h1>{{ test_name }} {{ title }}</h1>
7<ul>
8{% for student in students %}
9 <li>
10 {% if student.score > 80 %}🙂{% else %}🙁{% endif %}
11 <em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
12 </li>
13{% endfor %}
14</ul>
15{% endblock content %}
```py
要将子模板与其父模板连接起来,必须在文件顶部添加一个`{% extends %}`标签。
子模板也包含`{% block %}`标签。通过提供块的名称作为参数,可以将子模板中的块与父模板中的块连接起来。
注意`results.html`不包含`title`块。但是您的页面仍然会显示正确的标题,因为它使用了`base.html`中的回退内容,并且视图提供了一个`title`变量。
你不需要调整你的`results()`视角。当您访问`http://127.0.0.1:5000/results`时,您应该注意不到任何变化。呈现的页面包含`base.html`的根代码和来自`results.html`块的填充。
请记住,子模板块之外的任何内容都不会出现在您呈现的页面上。例如,如果你想给链接回你主页的`results.html`添加导航,那么你必须要么在`base.html`中定义一个新的占位符块,要么给`base.html`的结构添加导航菜单。
### 包括导航菜单
网站的导航通常显示在每个页面上。有了基础和子模板结构,最好将导航菜单的代码添加到`base.html`中。
您可以利用`{% include %}`标签,而不是将导航菜单代码直接添加到`base.html`中。通过用`{% include %}`引用另一个模板,你将整个模板加载到那个位置。
**内含模板**是包含完整 HTML 代码一小部分的部分模板。为了表示要包含一个模板,您可以在它的名称前加一个下划线(`_`)。
遵循基于前缀的命名方案,在您的`templates/`文件夹中创建一个名为`_navigation.html`的新模板:
{# templates/_navigation.html #}
```py请注意,_navigation.html既不包含{% extends %}标签,也不包含任何{% block %}标签。您可以只关注如何呈现导航菜单。
当您使用url_for()时,Flask 会为您创建给定视图的完整 URL。因此,即使当你决定改变路线到你的一个网页,导航菜单仍然会工作。
在base.html中包含_navigation.html以在所有页面上显示导航菜单:
{# templates/base.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{% block title %}{{ title }}{% endblock title %}</title>
</head>
<body>
<header> {% include "_navigation.html" %} </header> {% block content %}
<h1>Welcome to {{ title }}!</h1>
{% endblock content %}
</body>
</html>
```py
你不需要直接在`base.html`中添加导航菜单代码,而是将`_navigation.html`包含在你网站的标题中。由于`results.html`延伸了`base.html`,你可以访问`http://127.0.0.1:5000/results`查看你的新导航菜单:
[](https://files.realpython.com/media/jinja-flask-menu.a642577f578f.png)
您的结果页面从您的基本模板继承代码。当您单击导航菜单中的链接时,地址栏中的 URL 会根据您当前的页面而改变。
[*Remove ads*](/account/join/)
## 应用过滤器
花点时间想一个情况,另一个人负责后端,你的责任是网站的前端。为了避免相互干扰,不允许您调整`app.py`中的任何视图或更改模板中的数据。
在与您的学生交谈后,您同意您的 web 应用程序可以改进。你想出了两个特点:
1. 以大写形式显示导航菜单项。
2. 将你学生的名字按字母顺序排序。
您将使用 Jinja 的**过滤器**功能来实现这两个特性,而无需触及后端。
### 调整您的菜单项
Jinja 提供了一堆[内置滤镜](https://jinja.palletsprojects.com/en/3.1.x/templates/#builtin-filters)。如果你检查它们,你会注意到它们看起来类似于 [Python 的内置函数](https://docs.python.org/3/library/functions.html)和[字符串方法](https://realpython.com/python-strings/#built-in-string-methods)。
在您继续之前,请重温您的`_navigation.html`部分:
{# templates/_navigation.html #}
```py目前,您的菜单项以小写显示,以匹配视图的名称。如果menu_item不是小写,那么这个链接就不起作用。这意味着href属性中的menu_item必须保持原样。
但是,您可以调整<a>标签内menu_item的显示:
{# templates/_navigation.html #}
<nav>
{% for menu_item in ["home", "results"] %}
<a href="{{ url_for(menu_item) }}">{{ menu_item|upper }}</a> {% endfor %}
</nav>
```py
指定变量,然后指定管道符号(`|`),再指定过滤器。在某些情况下,可以在括号中指定参数。
在导航菜单中,您将`menu_item`变量交给`upper`过滤器。像 Python 的`.upper()`字符串方法一样,Jinja 的`upper`过滤器以大写字母返回变量。
访问`http://127.0.0.1:5000`实时查看您的变化:
[](https://files.realpython.com/media/jinja-flask-uppercase-nav.6a897f4c5416.png)
完美,菜单项现在是大写的!您实现了请求列表中的第一个特性。是时候处理下一个特性请求了。
### 对结果列表进行排序
此时,您的学生的结果会按照您在`app.py`中定义的顺序出现。您将使用 Jinja 的`sort`过滤器按照学生的字母顺序对结果列表进行排序。
打开`results.html`,将`sort`滤镜添加到`for`循环中:
{# templates/results.html #}
{# ... #}
{% for student in students|sort(attribute="name") %}
{# ... #}
`sort`滤镜使用 [Python 的`sorted()`](https://realpython.com/python-sort/) 遮光罩下。
您在`results.html`中的`students` iterable 包含每个条目的字典。通过添加`attribute=name`,您告诉 Jinja 根据`name`的值对`students`进行排序。当您想要对字符串列表进行排序时,可以使用不带任何参数的`sort`过滤器。
转到`http://127.0.0.1:5000/results`查看新的分类:
[](https://files.realpython.com/media/jinja-flask-student-results-sorted.57e84ccd5637.png)
您使用 Jinja 的`sort`过滤器将学生的成绩按姓名排序。如果您有同名的学生,那么您可以链接过滤器:
{% for student in students|sort(attribute="name")
|sort(attribute="score", reverse=true) %}
{# ... #}
{% endfor %}
首先,你按名字给你的学生分类。如果有两个学生同名,那么你按他们的分数排序。当然,同名的学生除了他们的分数之外,实际上还需要一些差异,但是对于这个例子来说,这种排序已经足够了。
你颠倒`score`的顺序,将这些学生从最高分到最低分排序。当你的行变得太长时,Jinja 允许你跨多行分布你的语句。
**注意:**与在 Python 中使用[布尔相反](https://realpython.com/python-boolean/),你应该用小写写 Jinja 中的布尔。
您可以使用过滤器独立于后端来转换模板中的数据。将筛选器应用于变量时,您可以为用户更改变量值,而无需更改任何基础数据结构。
查看 [Jinja 的滤镜文档](https://jinja.palletsprojects.com/en/3.1.x/templates/#filters)以了解更多关于模板滤镜的信息。
如果你想在你的模板中加入更多的逻辑,那么你可以利用宏。在下一节中,您将通过在 Flask 应用程序中实现另外三个特性来探索宏。
[*Remove ads*](/account/join/)
## 包括宏
当您包含像导航菜单这样的部分模板时,包含的代码会在父模板的上下文中呈现,无需任何调整。通常,这正是您想要的,但是其他时候您可能想要定制包含的模板的外观。
Jinja 的**宏**可以帮助你创建接受参数的模板片段。就像当[在 Python](https://realpython.com/defining-your-own-python-function/) 中定义自己的函数时,你可以定义宏并将它们导入你的模板。
在本节中,您将向您的 Flask 项目添加另外三个特性:
1. 实现黑暗模式。
2. 突出分数最高的学生。
3. 在导航菜单中标记当前页面。
像以前一样,你不会碰任何后端代码来改进你的 web app。
### 实施黑暗模式
对于一些学生来说,亮暗配色方案在视觉上更有吸引力。为了迎合所有学生,您将添加切换到深色模式的选项,在深色背景上显示浅色文本。
向`templates/`目录添加一个`macros.html`文件:
1{# templates/macros.html #}
2
3{% macro light_or_dark_mode(element) %}
4 {% if request.args.get('mode') == "dark" %}
5 Switch to Light Mode
6
15 {% else %}
16 Switch to Dark Mode
17 {% endif %}
18{% endmacro %}
您使用类似于 Python 中函数定义的`{% macro %}`块来定义宏。您的宏必须有一个名称,并且它可以接受参数。
对于`light_or_dark_mode()`宏,您必须提供一个 HTML 元素名。这将是第 6 行到第 14 行中 CSS 由亮变暗的元素。
为了避免默认情况下提供一个黑暗主题的网站,你应该给你的学生提供切换设计的选项。当他们将`?mode=dark`添加到你 app 的任意路线时,你就激活了黑暗模式。
在第 4 行,您使用 Flask 的 [`request`对象](https://flask.palletsprojects.com/en/2.1.x/reqcontext/)来读取请求参数。默认情况下,`request`对象存在于模板的上下文中。
如果黑暗模式参数存在于 GET 请求中,那么在第 5 行显示一个带有切换到光明模式选项的链接,并将`style`标记添加到模板中。没有任何黑暗模式参数,你显示一个链接切换到黑暗主题。
要使用宏,必须将其导入到基本模板中。就像使用 [Python 的`import`语句](https://realpython.com/python-import/)一样,建议将`{% import %}`块放在模板的顶部:
{# templates/base.html #}
{% import "macros.html" as macros %}
<html lang="en"> <head> <meta charset="utf-8"> <title>{% block title %}{{ title }}{% endblock title %}</title> </head> <body> {# ... #} <footer> {{ macros.light_or_dark_mode("body") }} </footer> </body> </html> ```py根据请求的 GET 参数,您将呈现深色模式,并显示一个切换到其他颜色主题的链接。
通过提供body作为macros.light_or_dark_mode()的参数,您的学生可以切换整个页面的配色方案。访问http://127.0.0.1:5000,体验你的配色方案:
https://player.vimeo.com/video/727335601?background=1
你可以尝试向macros.light_or_dark_mode()提供"h1"而不是"body",然后重新加载页面。因为宏接受参数,所以可以灵活地有条件地呈现模板的各个部分。
突出你最好的学生
将宏引入 Flask 项目的另一个原因是将一些逻辑放入它自己的隔间中。像嵌套模板一样,将功能外包给宏可以整理您的父模板。
为了用星形表情符号突出你最好的学生,清理results.html并引用一个add_badge()宏:
{# templates/results.html #}
{# ... #}
{% for student in students|sort(attribute="name") %}
<li>
{{ macros.add_badge(student, students) }} <em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
{# ... #}
```py
注意不要在`results.html`的顶部导入`macros.html`。您正在扩展`base.html`,其中您已经导入了所有的宏。所以这里不需要再导入了。
不是在`results.html`中向列表项添加更多代码,而是在`for`循环中引用`macros.add_badge()`。你借此机会移除显示快乐或悲伤表情的`if` … `else`状态。这段代码完全符合宏的目的,即给所有学生添加一个徽章。
`add_badge()`宏需要两个参数:
1. 当前的`student`字典
2. 完整的`students`列表
如果你现在访问你的页面,你会得到一个错误,因为 Flask 找不到你引用的宏。继续将您的新宏添加到`macros.html`:
1{# templates/macros.html #}
2
3{# ... #}
4
5{% macro add_badge(student, students) %}
6 {% set high_score = students|map(attribute="score")|max %}
7
8 {% if student.score == high_score %}
9 ⭐️
10 {% elif student.score > 80 %}
11 🙂
12 {% else %}
13 🙁
14 {% endif %}
15{% endmacro %}
Jinja 允许你用`{% set %}`块在模板中定义你自己的变量。当您定义变量时,您还可以为它们的值添加过滤器,甚至将它们链接起来。
在`add_badge`中,首先用`map()`过滤器创建一个所有分数的列表,然后用`max()`挑选最高分,从而定义`high_score`。这两个过滤器的行为类似于 [Python 的`map()`](https://realpython.com/python-map-function/) 或 [`max()`函数](https://realpython.com/python-min-and-max/)。
一旦你知道了你的学生中的最高分,然后你在第 8 到 14 行检查你当前学生的分数。
访问`http://127.0.0.1:5000/results`并查看您的新宏的运行情况:
[](https://files.realpython.com/media/jinja-flask-student-results-star.a19d3ee96cfe.png)
除了您之前展示的微笑或悲伤表情外,您现在还为表现最好的学生展示了一个星形表情。
### 标记当前页面
您将实现的最后一个功能将改进您的导航菜单。目前,导航菜单在任一页面上保持不变。在本节中,您将创建一个用箭头标记当前页面菜单项的宏。
向`macros.html`添加另一个宏:
{# templates/macros.html #}
{# ... #}
{% macro nav_link(menu_item) %}
{% set mode = "?mode=dark" if request.args.get("mode") == "dark" else "" %}
{{ menu_item|upper }}
{% if request.endpoint == menu_item %}
←
{% endif %}
您的`nav_link()`宏将菜单项作为参数。如果`menu_item`匹配当前端点,那么除了菜单项链接之外,宏还会呈现一个箭头。
此外,还要检查颜色模式。如果`"dark"`是 GET 请求的一部分,那么`"?mode=dark"`将被添加到菜单链接中。如果不检查和添加模式,你每次点击链接都会切换到灯光主题,因为`"?mode=dark"`不会是链接的一部分。
用新的宏替换`_navigation.html`中的菜单项链接:
{# templates/_navigation.html #}
```通过添加nav_link()宏到你的导航菜单,你可以保持你的导航模板干净。你把任何条件逻辑交给nav_link()。
访问http://127.0.0.1:5000并查看您已经实现的所有功能:
https://player.vimeo.com/video/727335630?background=1
宏是 Jinja 的一个强大功能。不过,你不应该过度使用它们。在某些情况下,最好将逻辑放在后端,而不是让模板来完成工作。
总会有一些极端的情况,您必须决定是将代码直接添加到模板中,还是将其推迟到包含的模板中,或者创建一个宏。如果你的模板代码与你的数据结构纠缠太多,那么它甚至可能是你的代码逻辑属于你的应用程序后端的一个标志。
结论
Jinja 是一个功能丰富的模板引擎,与 Flask web 框架打包在一起。但是,您也可以独立于 Flask 使用 Jinja 来创建模板,您可以通过编程用内容填充这些模板。
在本教程中,您学习了如何:
- 安装 Jinja 模板引擎
- 创建你的第一个 Jinja 模板
- 在烧瓶中渲染一个 Jinja 模板
- 用
for循环和条件语句搭配 Jinja - 嵌套金佳模板
- 用过滤器修改 Jinja 中的变量
- 使用宏为您的前端添加功能
如果你想把你新学到的关于 Jinja 的知识付诸实践,那么你可以构建一个前端的fast API URL shorter或者部署你的 Flask 应用到 Heroku 。
你也可以考虑使用 Jinja 作为 Django 的模板引擎。要了解更多关于 Jinja 和 Django 的模板引擎之间的区别,请访问 Jinja 关于从其他模板引擎切换到 Jinja 的文档。
您是否有其他利用 Jinja 提供的功能的用例?请在下面的评论中与真正的 Python 社区分享它们!*************
Python 装饰者入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python Decorators 101
在这篇关于装饰者的教程中,我们将看看它们是什么,以及如何创建和使用它们。Decorators 为调用高阶函数提供了简单的语法。
根据定义,装饰器是一个函数,它接受另一个函数并扩展后一个函数的行为,而无需显式修改它。
这听起来令人困惑,但事实并非如此,尤其是在你看过一些装饰者如何工作的例子之后。你可以在本文这里找到所有的例子。
免费奖励: ,它向您展示了三种高级装饰模式和技术,您可以用它们来编写更简洁、更 Python 化的程序。
Decorators Cheat Sheet:点击这里获得一个免费的三页 Python decorators cheat sheet ,它总结了本教程中解释的技术。
Decorators Q &文字记录: 点击此处获取我们 Python decorators Q &的 25 页聊天记录,这是真实 Python 社区 Slack 中的一个会话,我们在这里讨论了常见的 decorator 问题。
更新:
- 08/22/2018: 主要更新增加了更多的例子和更高级的装饰者
- 2016 年 1 月 12 日:更新了 Python 3 (v3.5.1)语法的示例,并添加了一个新示例
- 2015 . 11 . 01:增加了对
functools.wraps()装饰工的简要说明
功能
在理解 decorators 之前,你必须先理解函数是如何工作的。出于我们的目的,函数根据给定的参数返回值。这里有一个非常简单的例子:
>>> def add_one(number): ... return number + 1 >>> add_one(2) 3一般来说,Python 中的函数也可能有副作用,而不仅仅是将输入变成输出。
print()函数就是一个基本的例子:它返回None,同时具有向控制台输出一些东西的副作用。然而,要理解 decorators,只需将函数看作是将给定参数转化为值的东西。注:在函数式编程中,你(几乎)只用纯函数工作,没有副作用。虽然 Python 不是纯粹的函数式语言,但它支持许多函数式编程概念,包括作为一级对象的函数。
一等物体
在 Python 中,函数是一级对象。这意味着函数可以被传递并用作参数,就像任何其他对象(string、int、float、list 等等)一样。考虑以下三个函数:
def say_hello(name): return f"Hello {name}" def be_awesome(name): return f"Yo {name}, together we are the awesomest!" def greet_bob(greeter_func): return greeter_func("Bob")这里,
say_hello()和be_awesome()是常规函数,它们期望一个字符串形式的名称。然而,greet_bob()函数需要一个函数作为它的参数。例如,我们可以传递给它say_hello()或be_awesome()函数:
>>> greet_bob(say_hello)
'Hello Bob'
>>> greet_bob(be_awesome)
'Yo Bob, together we are the awesomest!'
注意,greet_bob(say_hello)指的是两个函数,只是方式不同:greet_bob()和say_hello。say_hello函数的命名不带括号。这意味着只传递对函数的引用。不执行该功能。另一方面,greet_bob()函数是用圆括号写的,所以它将像往常一样被调用。
内部函数
可以在其他函数内定义函数 。这样的函数被称为内部函数。下面是一个包含两个内部函数的函数示例:
def parent():
print("Printing from the parent() function")
def first_child():
print("Printing from the first_child() function")
def second_child():
print("Printing from the second_child() function")
second_child()
first_child()
调用parent()函数会发生什么?考虑一下这个问题。输出如下所示:
>>> parent() Printing from the parent() function Printing from the second_child() function Printing from the first_child() function请注意,内部函数的定义顺序并不重要。像任何其他函数一样,只有在执行内部函数时才会进行打印。
此外,在调用父函数之前,不会定义内部函数。它们的局部范围是
parent():它们只作为局部变量存在于parent()函数中。试着打电话给first_child()。您应该会得到一个错误:Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'first_child' is not defined每当你调用
parent(),内部函数first_child()和second_child()也被调用。但是由于它们的局部作用域,它们在parent()函数之外是不可用的。从函数返回函数
Python 还允许使用函数作为返回值。以下示例从外部
parent()函数返回一个内部函数:def parent(num): def first_child(): return "Hi, I am Emma" def second_child(): return "Call me Liam" if num == 1: return first_child else: return second_child请注意,您返回的是不带括号的
first_child。回想一下,这意味着您正在返回对函数first_child的引用。相反,带括号的first_child()指的是函数求值的结果。这可以从下面的例子中看出:
>>> first = parent(1)
>>> second = parent(2)
>>> first
<function parent.<locals>.first_child at 0x7f599f1e2e18>
>>> second
<function parent.<locals>.second_child at 0x7f599dad5268>
有些晦涩的输出仅仅意味着first变量引用了parent()内部的局部first_child()函数,而second指向了second_child()。
您现在可以像使用常规函数一样使用first和second,即使它们指向的函数不能被直接访问:
>>> first() 'Hi, I am Emma' >>> second() 'Call me Liam'最后,注意在前面的例子中,您在父函数中执行了内部函数,例如
first_child()。然而,在最后一个例子中,您没有在返回时给内部函数first_child添加括号。这样,你就有了将来可以调用的每个函数的引用。有道理吗?简单的装饰者
既然您已经看到了函数就像 Python 中的任何其他对象一样,那么您就可以继续下去,看看 Python 装饰器这个神奇的东西了。让我们从一个例子开始:
def my_decorator(func): def wrapper(): print("Something is happening before the function is called.") func() print("Something is happening after the function is called.") return wrapper def say_whee(): print("Whee!") say_whee = my_decorator(say_whee)你能猜到当你调用
say_whee()时会发生什么吗?试试看:
>>> say_whee()
Something is happening before the function is called.
Whee!
Something is happening after the function is called.
要理解这里发生了什么,回头看看前面的例子。我们实际上只是应用了你到目前为止所学的一切。
所谓的装饰发生在下面这条线上:
say_whee = my_decorator(say_whee)
实际上,名称say_whee现在指向了wrapper()内部函数。记住当你调用my_decorator(say_whee)时,你返回wrapper作为一个函数:
>>> say_whee <function my_decorator.<locals>.wrapper at 0x7f3c5dfd42f0>但是,
wrapper()将原来的say_whee()引用为func,并在对print()的两次调用之间调用那个函数。简单地说:装饰者包装一个函数,修改它的行为。
在继续之前,让我们看第二个例子。因为
wrapper()是一个常规的 Python 函数,装饰者修改函数的方式可以动态改变。为了不打扰邻居,下面的示例将只在白天运行修饰代码:from datetime import datetime def not_during_the_night(func): def wrapper(): if 7 <= datetime.now().hour < 22: func() else: pass # Hush, the neighbors are asleep return wrapper def say_whee(): print("Whee!") say_whee = not_during_the_night(say_whee)如果你试图在就寝时间后打电话给
say_whee(),什么也不会发生:
>>> say_whee()
>>>
句法糖!
你上面装饰的方式有点笨拙。首先,你最终要输入名字say_whee三次。此外,装饰隐藏在函数定义的下面。
相反,Python 允许你以更简单的方式用符号来使用装饰器,有时被称为“派”语法。以下示例与第一个装饰器示例做了完全相同的事情:
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def say_whee():
print("Whee!")
所以,@my_decorator只是say_whee = my_decorator(say_whee)更简单的说法。这就是如何将装饰器应用到函数中。
重用装饰者
回想一下,装饰器只是一个普通的 Python 函数。所有易于重用的常用工具都是可用的。让我们将装饰器移到它自己的模块中,该模块可以在许多其他函数中使用。
用以下内容创建一个名为decorators.py的文件:
def do_twice(func):
def wrapper_do_twice():
func()
func()
return wrapper_do_twice
注意:您可以随意命名您的内部函数,像wrapper()这样的通用名称通常是可以的。你会在这篇文章中看到很多装饰者。为了将它们区分开来,我们将内部函数命名为与装饰器相同的名称,但带有一个wrapper_前缀。
现在,您可以通过常规的导入在其他文件中使用这个新的装饰器:
from decorators import do_twice
@do_twice
def say_whee():
print("Whee!")
当您运行这个示例时,您应该看到原始的say_whee()被执行了两次:
>>> say_whee() Whee! Whee!免费奖励: ,它向您展示了三种高级装饰模式和技术,您可以用它们来编写更简洁、更 Python 化的程序。
用参数装饰函数
假设你有一个接受一些参数的函数。还能装修吗?让我们试试:
from decorators import do_twice @do_twice def greet(name): print(f"Hello {name}")不幸的是,运行这段代码会引发一个错误:
>>> greet("World")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: wrapper_do_twice() takes 0 positional arguments but 1 was given
问题是内部函数wrapper_do_twice()没有任何参数,但是name="World"被传递给了它。您可以通过让wrapper_do_twice()接受一个参数来解决这个问题,但是它对您之前创建的say_whee()函数不起作用。
解决方法是在内部包装函数中使用 *args和**kwargs 。那么它将接受任意数量的位置和关键字参数。将decorators.py改写如下:
def do_twice(func):
def wrapper_do_twice(*args, **kwargs): func(*args, **kwargs) func(*args, **kwargs) return wrapper_do_twice
wrapper_do_twice()内部函数现在接受任意数量的参数,并将它们传递给它修饰的函数。现在你的say_whee()和greet()例子都起作用了:
>>> say_whee() Whee! Whee! >>> greet("World") Hello World Hello World从修饰函数中返回值
修饰函数的返回值会怎么样?嗯,这要由装修工来决定。假设您如下装饰一个简单的函数:
from decorators import do_twice @do_twice def return_greeting(name): print("Creating greeting") return f"Hi {name}"尝试使用它:
>>> hi_adam = return_greeting("Adam")
Creating greeting
Creating greeting
>>> print(hi_adam)
None
糟糕,你的装饰器吃了函数的返回值。
因为do_twice_wrapper()没有显式返回值,所以调用return_greeting("Adam")最终返回了None。
要解决这个问题,你需要确保包装函数返回被修饰函数的返回值。更改您的decorators.py文件:
def do_twice(func):
def wrapper_do_twice(*args, **kwargs):
func(*args, **kwargs)
return func(*args, **kwargs) return wrapper_do_twice
返回上一次执行函数的返回值:
>>> return_greeting("Adam") Creating greeting Creating greeting 'Hi Adam'你到底是谁?
在使用 Python 时,特别是在交互式 shell 中,一个很大的便利是它强大的自省能力。自省是对象在运行时知道自己属性的能力。例如,一个函数知道它自己的名字和文档:
>>> print
<built-in function print>
>>> print.__name__
'print'
>>> help(print)
Help on built-in function print in module builtins:
print(...)
<full help message>
自省也适用于您自己定义的函数:
>>> say_whee <function do_twice.<locals>.wrapper_do_twice at 0x7f43700e52f0> >>> say_whee.__name__ 'wrapper_do_twice' >>> help(say_whee) Help on function wrapper_do_twice in module decorators: wrapper_do_twice()然而,在被装饰之后,
say_whee()对自己的身份变得非常困惑。现在它被报告为do_twice()装饰器中的wrapper_do_twice()内部函数。虽然从技术上讲这是真的,但这并不是非常有用的信息。为了解决这个问题,decorator 应该使用
@functools.wrapsdecorator,它将保存关于原始函数的信息。再次更新decorators.py:import functools def do_twice(func): @functools.wraps(func) def wrapper_do_twice(*args, **kwargs): func(*args, **kwargs) return func(*args, **kwargs) return wrapper_do_twice您不需要对修饰过的
say_whee()函数做任何修改:
>>> say_whee
<function say_whee at 0x7ff79a60f2f0>
>>> say_whee.__name__
'say_whee'
>>> help(say_whee)
Help on function say_whee in module whee:
say_whee()
好多了!现在say_whee()还是装修后的自己。
技术细节:@functools.wraps装饰器使用函数functools.update_wrapper()来更新自检中使用的特殊属性,如__name__和__doc__。
几个真实世界的例子
让我们看几个更有用的装饰者的例子。您会注意到,它们将主要遵循您到目前为止所学的相同模式:
import functools
def decorator(func):
@functools.wraps(func)
def wrapper_decorator(*args, **kwargs):
# Do something before
value = func(*args, **kwargs)
# Do something after
return value
return wrapper_decorator
这个公式对于构建更复杂的装饰器来说是一个很好的样板模板。
注意:在后面的例子中,我们将假设这些装饰器也保存在您的decorators.py文件中。回想一下,你可以下载本教程中的所有例子。
计时功能
让我们从创建一个@timer装饰器开始。它将测量一个函数执行所需的时间,并将持续时间打印到控制台。代码如下:
import functools
import time
def timer(func):
"""Print the runtime of the decorated function"""
@functools.wraps(func)
def wrapper_timer(*args, **kwargs):
start_time = time.perf_counter() # 1
value = func(*args, **kwargs)
end_time = time.perf_counter() # 2
run_time = end_time - start_time # 3
print(f"Finished {func.__name__!r} in {run_time:.4f} secs")
return value
return wrapper_timer
@timer
def waste_some_time(num_times):
for _ in range(num_times):
sum([i**2 for i in range(10000)])
这个装饰器通过存储函数开始运行之前的时间(在标记为# 1的行)和函数结束之后的时间(在# 2)来工作。函数花费的时间就是两者之差(在# 3)。我们使用 time.perf_counter() 函数,它很好地测量了时间间隔。以下是一些计时示例:
>>> waste_some_time(1) Finished 'waste_some_time' in 0.0010 secs >>> waste_some_time(999) Finished 'waste_some_time' in 0.3260 secs自己跑吧。逐行检查代码。确保你明白它是如何工作的。不过,如果你不明白,也不要担心。装修工是高级生物。试着考虑一下或者画一个程序流程图。
注意:如果你只是想了解一下你的函数的运行时,这个
@timer装饰器是很棒的。如果你想对代码进行更精确的测量,你应该考虑标准库中的timeit模块。它暂时禁用垃圾收集,并运行多次试验来去除快速函数调用中的噪声。调试代码
下面的
@debugdecorator 将打印调用函数时使用的参数以及每次调用函数时的返回值:import functools def debug(func): """Print the function signature and return value""" @functools.wraps(func) def wrapper_debug(*args, **kwargs): args_repr = [repr(a) for a in args] # 1 kwargs_repr = [f"{k}={v!r}" for k, v in kwargs.items()] # 2 signature = ", ".join(args_repr + kwargs_repr) # 3 print(f"Calling {func.__name__}({signature})") value = func(*args, **kwargs) print(f"{func.__name__!r} returned {value!r}") # 4 return value return wrapper_debug签名是通过连接所有参数的字符串表示创建的。下表中的数字对应于代码中的编号注释:
- 创建位置参数列表。使用
repr()获得代表每个参数的字符串。- 创建关键字参数列表。 f 字符串将每个参数格式化为
key=value,其中!r说明符意味着repr()用于表示值。- 位置和关键字参数列表被连接在一起成为一个签名字符串,每个参数用逗号分隔。
- 函数执行后,返回值被打印出来。
让我们通过将装饰器应用到一个只有一个位置和一个关键字参数的简单函数来看看它在实践中是如何工作的:
@debug def make_greeting(name, age=None): if age is None: return f"Howdy {name}!" else: return f"Whoa {name}! {age} already, you are growing up!"注意
@debug装饰器如何打印make_greeting()函数的签名和返回值:
>>> make_greeting("Benjamin")
Calling make_greeting('Benjamin')
'make_greeting' returned 'Howdy Benjamin!'
'Howdy Benjamin!'
>>> make_greeting("Richard", age=112)
Calling make_greeting('Richard', age=112)
'make_greeting' returned 'Whoa Richard! 112 already, you are growing up!'
'Whoa Richard! 112 already, you are growing up!'
>>> make_greeting(name="Dorrisile", age=116)
Calling make_greeting(name='Dorrisile', age=116)
'make_greeting' returned 'Whoa Dorrisile! 116 already, you are growing up!'
'Whoa Dorrisile! 116 already, you are growing up!'
这个例子可能看起来不太有用,因为@debug装饰器只是重复你刚刚写的内容。当应用到你自己不直接调用的小便利函数时,它就更强大了。
以下示例计算数学常数eT3的近似值:
import math
from decorators import debug
# Apply a decorator to a standard library function
math.factorial = debug(math.factorial)
def approximate_e(terms=18):
return sum(1 / math.factorial(n) for n in range(terms))
这个例子还展示了如何将装饰器应用到一个已经定义好的函数中。 e 的近似值基于以下级数展开:

当调用approximate_e()函数时,可以看到@debug装饰器在工作:
>>> approximate_e(5) Calling factorial(0) 'factorial' returned 1 Calling factorial(1) 'factorial' returned 1 Calling factorial(2) 'factorial' returned 2 Calling factorial(3) 'factorial' returned 6 Calling factorial(4) 'factorial' returned 24 2.708333333333333在这个例子中,您得到了真实值 e = 2.718281828 的一个不错的近似值,只增加了 5 项。
减速代码
下一个例子可能不太有用。为什么要降低 Python 代码的速度?可能最常见的用例是,您希望对一个连续检查资源(如网页)是否已更改的函数进行速率限制。装饰器在调用被装饰的函数之前会休眠一秒钟:
import functools import time def slow_down(func): """Sleep 1 second before calling the function""" @functools.wraps(func) def wrapper_slow_down(*args, **kwargs): time.sleep(1) return func(*args, **kwargs) return wrapper_slow_down @slow_down def countdown(from_number): if from_number < 1: print("Liftoff!") else: print(from_number) countdown(from_number - 1)要查看
@slow_down装饰器的效果,您真的需要自己运行这个例子:
>>> countdown(3)
3
2
1
Liftoff!
注意:countdown()函数是递归函数。换句话说,它是一个调用自身的函数。要了解更多关于 Python 中递归函数的知识,请参阅我们的指南Python 中的递归思维。
室内设计师总是睡一秒钟。稍后,您将看到如何通过向装饰器传递一个参数来控制速率。
注册插件
装饰者不必包装他们正在装饰的功能。他们也可以简单地注册一个函数的存在,并将其解包返回。例如,这可以用来创建一个轻量级插件架构:
import random
PLUGINS = dict()
def register(func):
"""Register a function as a plug-in"""
PLUGINS[func.__name__] = func
return func
@register
def say_hello(name):
return f"Hello {name}"
@register
def be_awesome(name):
return f"Yo {name}, together we are the awesomest!"
def randomly_greet(name):
greeter, greeter_func = random.choice(list(PLUGINS.items()))
print(f"Using {greeter!r}")
return greeter_func(name)
@register装饰器只是在全局PLUGINS字典中存储一个对被装饰函数的引用。注意,在这个例子中,你不需要写一个内部函数或者使用@functools.wraps,因为你返回的是未修改的原始函数。
randomly_greet()函数随机选择一个注册的函数来使用。注意,PLUGINS字典已经包含了对每个注册为插件的函数对象的引用:
>>> PLUGINS {'say_hello': <function say_hello at 0x7f768eae6730>, 'be_awesome': <function be_awesome at 0x7f768eae67b8>} >>> randomly_greet("Alice") Using 'say_hello' 'Hello Alice'这种简单的插件架构的主要好处是,您不需要维护存在哪些插件的列表。该列表是在插件注册时创建的。这使得添加新插件变得很简单:只需定义函数并用
@register修饰它。如果你熟悉 Python 中的
globals(),你可能会发现插件架构的一些相似之处。globals()允许访问当前作用域中的所有全局变量,包括您的插件:
>>> globals()
{..., # Lots of variables not shown here.
'say_hello': <function say_hello at 0x7f768eae6730>,
'be_awesome': <function be_awesome at 0x7f768eae67b8>,
'randomly_greet': <function randomly_greet at 0x7f768eae6840>}
使用@register装饰器,您可以创建自己的有趣变量列表,有效地从globals()中挑选一些函数。
用户登录了吗?
在转向一些更好的装饰者之前,最后一个例子通常在使用 web 框架时使用。在这个例子中,我们使用 Flask 来建立一个/secret网页,这个网页应该只对已经登录或者通过身份验证的用户可见:
from flask import Flask, g, request, redirect, url_for
import functools
app = Flask(__name__)
def login_required(func):
"""Make sure user is logged in before proceeding"""
@functools.wraps(func)
def wrapper_login_required(*args, **kwargs):
if g.user is None:
return redirect(url_for("login", next=request.url))
return func(*args, **kwargs)
return wrapper_login_required
@app.route("/secret")
@login_required
def secret():
...
虽然这给出了一个关于如何向 web 框架添加身份验证的想法,但是您通常不应该自己编写这些类型的 decorators。对于 Flask,您可以使用 Flask-Login 扩展来代替,这增加了更多的安全性和功能性。
花哨的装饰工
到目前为止,您已经看到了如何创建简单的装饰器。你已经很好的理解了装饰者是什么以及他们是如何工作的。请从这篇文章中抽出一点时间来练习你所学到的一切。
在本教程的第二部分,我们将探索更高级的功能,包括如何使用以下内容:
装饰课
有两种不同的方法可以在类中使用 decorators。第一个非常接近你已经用函数做的:你可以装饰一个类的方法。这是当年引进装修工的动机之一。
一些常用的甚至是 Python 内置的装饰器有 @classmethod、@staticmethod 、 @property 。@classmethod和@staticmethod装饰器用于定义类命名空间内的方法,这些方法不连接到该类的特定实例。@property装饰器用于为类属性定制获取器和设置器。展开下面的方框,看一个使用这些装饰器的例子。
下面的Circle类定义使用了@classmethod、@staticmethod和@property装饰器:
class Circle:
def __init__(self, radius):
self._radius = radius
@property
def radius(self):
"""Get value of radius"""
return self._radius
@radius.setter
def radius(self, value):
"""Set radius, raise error if negative"""
if value >= 0:
self._radius = value
else:
raise ValueError("Radius must be positive")
@property
def area(self):
"""Calculate area inside circle"""
return self.pi() * self.radius**2
def cylinder_volume(self, height):
"""Calculate volume of cylinder with circle as base"""
return self.area * height
@classmethod
def unit_circle(cls):
"""Factory method creating a circle with radius 1"""
return cls(1)
@staticmethod
def pi():
"""Value of π, could use math.pi instead though"""
return 3.1415926535
在本课程中:
.cylinder_volume()是常规方法。.radius是一个可变属性:它可以被设置为不同的值。然而,通过定义 setter 方法,我们可以进行一些错误测试,以确保它没有被设置为无意义的负数。属性作为不带括号的属性来访问。.area是不可变的属性:没有.setter()方法的属性不能被改变。即使它被定义为一个方法,它也可以作为一个没有括号的属性被检索。.unit_circle()是类方法。它并不局限于某个特定的Circle实例。类方法通常用作工厂方法,可以创建类的特定实例。.pi()是静态方法。它并不真正依赖于Circle类,除了它是其名称空间的一部分。静态方法可以在实例或类上调用。
例如,Circle类可以如下使用:
>>> c = Circle(5) >>> c.radius 5 >>> c.area 78.5398163375 >>> c.radius = 2 >>> c.area 12.566370614 >>> c.area = 100 AttributeError: can't set attribute >>> c.cylinder_volume(height=4) 50.265482456 >>> c.radius = -1 ValueError: Radius must be positive >>> c = Circle.unit_circle() >>> c.radius 1 >>> c.pi() 3.1415926535 >>> Circle.pi() 3.1415926535让我们定义一个类,其中我们使用前面中的
@debug和@timer装饰器来装饰它的一些方法:from decorators import debug, timer class TimeWaster: @debug def __init__(self, max_num): self.max_num = max_num @timer def waste_time(self, num_times): for _ in range(num_times): sum([i**2 for i in range(self.max_num)])使用这个类,您可以看到装饰者的效果:
>>> tw = TimeWaster(1000)
Calling __init__(<time_waster.TimeWaster object at 0x7efccce03908>, 1000)
'__init__' returned None
>>> tw.waste_time(999)
Finished 'waste_time' in 0.3376 secs
在类上使用装饰器的另一种方式是用装饰整个类。例如,这是在 Python 3.7 中的新 dataclasses模块中完成的:
from dataclasses import dataclass
@dataclass
class PlayingCard:
rank: str
suit: str
语法的含义类似于函数装饰符。在上面的例子中,你可以通过写PlayingCard = dataclass(PlayingCard)来完成修饰。
类装饰器的一个常见用途是成为元类的一些用例的简单替代。在这两种情况下,您都在动态地更改类的定义。
编写类装饰器与编写函数装饰器非常相似。唯一的区别是装饰者将接收一个类而不是一个函数作为参数。事实上,你在上面看到的所有装饰者都将作为职业装饰者工作。当你在一个类而不是一个函数上使用它们时,它们的效果可能不是你想要的。在下面的例子中,@timer装饰器被应用于一个类:
from decorators import timer
@timer
class TimeWaster:
def __init__(self, max_num):
self.max_num = max_num
def waste_time(self, num_times):
for _ in range(num_times):
sum([i**2 for i in range(self.max_num)])
装饰一个类并不装饰它的方法。回想一下,@timer只是TimeWaster = timer(TimeWaster)的简称。
这里,@timer只测量实例化类所花费的时间:
>>> tw = TimeWaster(1000) Finished 'TimeWaster' in 0.0000 secs >>> tw.waste_time(999)
[稍后](#creating-singletons),你会看到一个定义合适的类装饰器的例子,即`@singleton`,它确保一个类只有一个实例。
[*Remove ads*](/account/join/)
### 嵌套装饰器
你可以将几个装饰器叠加在一起应用于一个功能:
```py
from decorators import debug, do_twice
@debug
@do_twice
def greet(name):
print(f"Hello {name}")
可以把这想象成装饰器按照它们被列出的顺序被执行。换句话说,@debug调用@do_twice,T1 调用greet(),或者debug(do_twice(greet())):
>>> greet("Eva") Calling greet('Eva') Hello Eva Hello Eva 'greet' returned None如果我们改变
@debug和@do_twice的顺序,请观察不同之处:from decorators import debug, do_twice @do_twice @debug def greet(name): print(f"Hello {name}")在这种情况下,
@do_twice也将应用于@debug:
>>> greet("Eva")
Calling greet('Eva')
Hello Eva
'greet' returned None
Calling greet('Eva')
Hello Eva
'greet' returned None
带参数的装饰器
有时候,向你的装饰者传递论点是有用的。例如,@do_twice可以扩展为@repeat(num_times)装饰器。执行修饰函数的次数可以作为一个参数给出。
这将允许您执行如下操作:
@repeat(num_times=4)
def greet(name):
print(f"Hello {name}")
>>> greet("World") Hello World Hello World Hello World Hello World想想你如何能实现这一点。
到目前为止,写在
@后面的名字引用了一个可以用另一个函数调用的函数对象。为了保持一致,您需要repeat(num_times=4)返回一个可以充当装饰器的函数对象。幸运的是,你已经知道如何返回函数!一般来说,您需要类似如下的内容:def repeat(num_times): def decorator_repeat(func): ... # Create and return a wrapper function return decorator_repeat通常,装饰器会创建并返回一个内部包装函数,所以完整地写出这个例子会给你一个内部函数中的内部函数。虽然这可能听起来像是《盗梦空间》电影的编程等价物,但我们马上就会解开这一切:
def repeat(num_times): def decorator_repeat(func): @functools.wraps(func) def wrapper_repeat(*args, **kwargs): for _ in range(num_times): value = func(*args, **kwargs) return value return wrapper_repeat return decorator_repeat这看起来有点乱,但是我们只把你已经见过很多次的装饰器模式放在一个额外的
def中,它处理装饰器的参数。让我们从最里面的函数开始:def wrapper_repeat(*args, **kwargs): for _ in range(num_times): value = func(*args, **kwargs) return value这个
wrapper_repeat()函数接受任意参数并返回修饰函数func()的值。这个包装函数还包含调用装饰函数num_times次的循环。除了使用必须从外部提供的num_times参数之外,这与您看到的早期包装函数没有什么不同。一步之外,您会发现装饰函数:
def decorator_repeat(func): @functools.wraps(func) def wrapper_repeat(*args, **kwargs): ... return wrapper_repeat同样,
decorator_repeat()看起来与您之前编写的装饰函数一模一样,只是名称不同。这是因为我们为最外层的函数保留了基本名称——repeat(),这是用户将调用的函数。正如您已经看到的,最外层的函数返回对装饰函数的引用:
def repeat(num_times): def decorator_repeat(func): ... return decorator_repeat在
repeat()函数中发生了一些微妙的事情:
- 将
decorator_repeat()定义为内部函数意味着repeat()将引用一个函数对象——decorator_repeat。前面我们用没有括号的repeat来指代函数对象。当定义接受参数的装饰器时,添加的括号是必要的。num_times参数似乎没有在repeat()本身中使用。但是通过传递num_times,一个闭包被创建,其中num_times的值被存储,直到它稍后被wrapper_repeat()使用。一切就绪后,让我们看看结果是否如预期的那样:
@repeat(num_times=4) def greet(name): print(f"Hello {name}")
>>> greet("World")
Hello World
Hello World
Hello World
Hello World
这正是我们想要的结果。
两样都要,但不要介意面包
稍加注意,您还可以定义既可以使用参数也可以不使用参数的装饰器。最有可能的是,你不需要这个,但是拥有灵活性是很好的。
正如您在上一节中看到的,当装饰器使用参数时,您需要添加一个额外的外部函数。对您的代码来说,挑战在于判断是否使用参数调用了装饰器。
因为只有在没有参数的情况下调用装饰器时,才直接传递要装饰的函数,所以该函数必须是可选参数。这意味着装饰参数必须全部由关键字指定。您可以使用特殊的*语法来强制实现这一点,这意味着后面的所有参数都是关键字专用的:
def name(_func=None, *, kw1=val1, kw2=val2, ...): # 1
def decorator_name(func):
... # Create and return a wrapper function.
if _func is None:
return decorator_name # 2
else:
return decorator_name(_func) # 3
在这里,_func参数作为一个标记,记录装饰器是否被带参数调用:
- 如果在没有参数的情况下调用了
name,修饰函数将作为_func传入。如果它被带参数调用,那么_func将会是None,并且一些关键字参数可能已经改变了它们的默认值。参数列表中的*表示剩余的参数不能作为位置参数调用。 - 在这种情况下,装饰器是用参数调用的。返回一个可以读取和返回函数的装饰函数。
- 在这种情况下,调用装饰器时没有参数。立即将装饰器应用于函数。
使用上一节中的@repeat装饰器的样板文件,您可以编写以下代码:
def repeat(_func=None, *, num_times=2):
def decorator_repeat(func):
@functools.wraps(func)
def wrapper_repeat(*args, **kwargs):
for _ in range(num_times):
value = func(*args, **kwargs)
return value
return wrapper_repeat
if _func is None: return decorator_repeat else: return decorator_repeat(_func)
把这个和原来的@repeat对比一下。唯一的变化是增加了_func参数和末尾的if - else。
优秀的 Python 食谱的食谱 9.6 展示了使用 functools.partial() 的替代方案。
这些例子表明@repeat现在可以带或不带参数使用:
@repeat
def say_whee():
print("Whee!")
@repeat(num_times=3)
def greet(name):
print(f"Hello {name}")
回想一下num_times的默认值是 2:
>>> say_whee() Whee! Whee! >>> greet("Penny") Hello Penny Hello Penny Hello Penny有状态装饰器
有时候,让一个装饰器跟踪状态是很有用的。作为一个简单的例子,我们将创建一个装饰器来计算一个函数被调用的次数。
注意:在本指南的开头的中,我们讨论了基于给定参数返回值的纯函数。有状态装饰器完全相反,返回值依赖于当前状态和给定的参数。
在下一节中,您将看到如何使用类来保持状态。但是在简单的情况下,您也可以使用功能属性来避免麻烦:
import functools def count_calls(func): @functools.wraps(func) def wrapper_count_calls(*args, **kwargs): wrapper_count_calls.num_calls += 1 print(f"Call {wrapper_count_calls.num_calls} of {func.__name__!r}") return func(*args, **kwargs) wrapper_count_calls.num_calls = 0 return wrapper_count_calls @count_calls def say_whee(): print("Whee!")状态——调用函数的次数——存储在包装函数的函数属性
.num_calls中。下面是使用它的效果:
>>> say_whee()
Call 1 of 'say_whee'
Whee!
>>> say_whee()
Call 2 of 'say_whee'
Whee!
>>> say_whee.num_calls
2
作为装饰者的类
维护状态的典型方式是通过使用类。在这一节中,您将看到如何使用一个类作为装饰器来重写上一节中的@count_calls示例。
回想一下,修饰语法@my_decorator只是一种更简单的说法func = my_decorator(func)。因此,如果my_decorator是一个类,它需要在它的.__init__()方法中将func作为参数。此外,类实例需要是可调用的,这样它就可以代替被修饰的函数。
为了使一个类实例可被调用,需要实现特殊的.__call__()方法:
class Counter:
def __init__(self, start=0):
self.count = start
def __call__(self):
self.count += 1
print(f"Current count is {self.count}")
每次您试图调用该类的实例时,都会执行.__call__()方法:
>>> counter = Counter() >>> counter() Current count is 1 >>> counter() Current count is 2 >>> counter.count 2因此,装饰器类的典型实现需要实现
.__init__()和.__call__():import functools class CountCalls: def __init__(self, func): functools.update_wrapper(self, func) self.func = func self.num_calls = 0 def __call__(self, *args, **kwargs): self.num_calls += 1 print(f"Call {self.num_calls} of {self.func.__name__!r}") return self.func(*args, **kwargs) @CountCalls def say_whee(): print("Whee!")
.__init__()方法必须存储对函数的引用,并且可以进行任何其他必要的初始化。将调用.__call__()方法,而不是被修饰的函数。它做的事情与我们前面例子中的wrapper()函数基本相同。注意,你需要使用functools.update_wrapper()功能,而不是@functools.wraps。这个
@CountCalls装饰器的工作原理与上一节中的相同:
>>> say_whee()
Call 1 of 'say_whee'
Whee!
>>> say_whee()
Call 2 of 'say_whee'
Whee!
>>> say_whee.num_calls
2
更多真实世界的例子
我们已经走了很长一段路,已经知道如何创建各种各样的装饰器。让我们总结一下,将我们新发现的知识用于创建更多可能在现实世界中有用的示例。
放慢代码,重温
如前所述,我们之前的@slow_down 的实现总是休眠一秒钟。现在你知道了如何给装饰器添加参数,所以让我们使用一个可选的rate参数来重写@slow_down,这个参数控制它休眠多长时间:
import functools
import time
def slow_down(_func=None, *, rate=1):
"""Sleep given amount of seconds before calling the function"""
def decorator_slow_down(func):
@functools.wraps(func)
def wrapper_slow_down(*args, **kwargs):
time.sleep(rate)
return func(*args, **kwargs)
return wrapper_slow_down
if _func is None:
return decorator_slow_down
else:
return decorator_slow_down(_func)
我们使用了在中介绍的样板,但是不要介意面包部分,使@slow_down无论有无参数都可以调用。与之前的相同的递归countdown()函数现在在每次计数之间休眠两秒钟:
@slow_down(rate=2) def countdown(from_number):
if from_number < 1:
print("Liftoff!")
else:
print(from_number)
countdown(from_number - 1)
和前面一样,您必须自己运行这个示例来查看装饰器的效果:
>>> countdown(3) 3 2 1 Liftoff!创建单件
singleton 是只有一个实例的类。Python 中有几个你经常使用的单例,包括
None、True和False。事实上,None是一个单例,允许你使用is关键字来比较None,就像你在两者皆请部分看到的那样:if _func is None: return decorator_name else: return decorator_name(_func)使用
is只为完全相同实例的对象返回True。下面的@singletondecorator 通过将一个类的第一个实例存储为一个属性,将该类转化为一个单体。稍后尝试创建实例时,只需返回存储的实例:import functools def singleton(cls): """Make a class a Singleton class (only one instance)""" @functools.wraps(cls) def wrapper_singleton(*args, **kwargs): if not wrapper_singleton.instance: wrapper_singleton.instance = cls(*args, **kwargs) return wrapper_singleton.instance wrapper_singleton.instance = None return wrapper_singleton @singleton class TheOne: pass如您所见,这个类装饰器遵循与我们的函数装饰器相同的模板。唯一的区别是我们使用了
cls而不是func作为参数名来表示它是一个类装饰器。让我们看看它是否有效:
>>> first_one = TheOne()
>>> another_one = TheOne()
>>> id(first_one)
140094218762280
>>> id(another_one)
140094218762280
>>> first_one is another_one
True
很明显,first_one确实是和another_one完全相同的实例。
注意:单例类在 Python 中并不像在其他语言中那样经常使用。单例的效果通常作为模块中的全局变量来实现更好。
缓存返回值
装饰者可以为缓存和记忆提供一个很好的机制。作为一个例子,让我们看看斐波那契数列的递归定义:
from decorators import count_calls
@count_calls
def fibonacci(num):
if num < 2:
return num
return fibonacci(num - 1) + fibonacci(num - 2)
虽然实现很简单,但它的运行时性能很糟糕:
>>> fibonacci(10) <Lots of output from count_calls> 55 >>> fibonacci.num_calls 177为了计算第十个斐波那契数,你应该只需要计算前面的斐波那契数,但是这个实现需要 177 次计算。情况很快变得更糟:对
fibonacci(20)需要 21891 次计算,对第 30 个数需要将近 270 万次计算。这是因为代码不断重新计算已知的斐波那契数。通常的解决方案是使用一个
for循环和一个查找表来实现斐波那契数。然而,简单的计算缓存也能达到目的:import functools from decorators import count_calls def cache(func): """Keep a cache of previous function calls""" @functools.wraps(func) def wrapper_cache(*args, **kwargs): cache_key = args + tuple(kwargs.items()) if cache_key not in wrapper_cache.cache: wrapper_cache.cache[cache_key] = func(*args, **kwargs) return wrapper_cache.cache[cache_key] wrapper_cache.cache = dict() return wrapper_cache @cache @count_calls def fibonacci(num): if num < 2: return num return fibonacci(num - 1) + fibonacci(num - 2)缓存就像一个查找表,所以现在
fibonacci()只做一次必要的计算:
>>> fibonacci(10)
Call 1 of 'fibonacci'
...
Call 11 of 'fibonacci'
55
>>> fibonacci(8)
21
注意,在对fibonacci(8)的最后一次调用中,不需要新的计算,因为已经为fibonacci(10)计算了第八个斐波那契数。
在标准库中,一个最近最少使用的(LRU)缓存可用作 @functools.lru_cache 。
这个装饰器比你上面看到的那个有更多的特性。您应该使用@functools.lru_cache而不是编写自己的缓存装饰器:
import functools
@functools.lru_cache(maxsize=4) def fibonacci(num):
print(f"Calculating fibonacci({num})") if num < 2:
return num
return fibonacci(num - 1) + fibonacci(num - 2)
maxsize参数指定缓存了多少个最近的呼叫。默认值是 128,但是您可以指定maxsize=None来缓存所有的函数调用。但是,请注意,如果您正在缓存许多大型对象,这可能会导致内存问题。
您可以使用.cache_info()方法来查看缓存的性能,如果需要,您可以对其进行调优。在我们的例子中,我们使用一个人为的小maxsize来观察从缓存中删除元素的效果:
>>> fibonacci(10) Calculating fibonacci(10) Calculating fibonacci(9) Calculating fibonacci(8) Calculating fibonacci(7) Calculating fibonacci(6) Calculating fibonacci(5) Calculating fibonacci(4) Calculating fibonacci(3) Calculating fibonacci(2) Calculating fibonacci(1) Calculating fibonacci(0) 55 >>> fibonacci(8) 21 >>> fibonacci(5) Calculating fibonacci(5) Calculating fibonacci(4) Calculating fibonacci(3) Calculating fibonacci(2) Calculating fibonacci(1) Calculating fibonacci(0) 5 >>> fibonacci(8) Calculating fibonacci(8) Calculating fibonacci(7) Calculating fibonacci(6) 21 >>> fibonacci(5) 5 >>> fibonacci.cache_info() CacheInfo(hits=17, misses=20, maxsize=4, currsize=4)添加单元信息
下面的例子有点类似于前面的注册插件的例子,因为它并没有真正改变被修饰函数的行为。相反,它只是添加了
unit作为函数属性:def set_unit(unit): """Register a unit on a function""" def decorator_set_unit(func): func.unit = unit return func return decorator_set_unit以下示例根据圆柱体的半径和高度(以厘米为单位)计算圆柱体的体积:
import math @set_unit("cm^3") def volume(radius, height): return math.pi * radius**2 * height这个
.unit功能属性可以在以后需要时访问:
>>> volume(3, 5)
141.3716694115407
>>> volume.unit
'cm^3'
请注意,您可以使用函数注释实现类似的功能:
import math
def volume(radius, height) -> "cm^3":
return math.pi * radius**2 * height
然而,由于注释用于类型提示,很难将注释这样的单元与静态类型检查结合起来。
当与一个可以在单位之间转换的库连接时,单位变得更加强大和有趣。一个这样的库是 pint 。安装pint(pip install Pint)后,您可以将体积转换为立方英寸或加仑:
>>> import pint >>> ureg = pint.UnitRegistry() >>> vol = volume(3, 5) * ureg(volume.unit) >>> vol <Quantity(141.3716694115407, 'centimeter ** 3')> >>> vol.to("cubic inches") <Quantity(8.627028576414954, 'inch ** 3')> >>> vol.to("gallons").m # Magnitude 0.0373464440537444您也可以修改装饰器以直接返回一个
pintQuantity。这样的一个Quantity是用一个值乘以单位得到的。在pint中,单位必须在UnitRegistry中查找。注册表存储为函数属性,以避免混淆名称空间:def use_unit(unit): """Have a function return a Quantity with given unit""" use_unit.ureg = pint.UnitRegistry() def decorator_use_unit(func): @functools.wraps(func) def wrapper_use_unit(*args, **kwargs): value = func(*args, **kwargs) return value * use_unit.ureg(unit) return wrapper_use_unit return decorator_use_unit @use_unit("meters per second") def average_speed(distance, duration): return distance / duration使用
@use_unit装饰器,转换单位几乎毫不费力:
>>> bolt = average_speed(100, 9.58)
>>> bolt
<Quantity(10.438413361169102, 'meter / second')>
>>> bolt.to("km per hour")
<Quantity(37.578288100208766, 'kilometer / hour')>
>>> bolt.to("mph").m # Magnitude
23.350065679064745
正在验证 JSON
让我们看最后一个用例。快速查看下面的烧瓶路线处理器:
@app.route("/grade", methods=["POST"])
def update_grade():
json_data = request.get_json()
if "student_id" not in json_data:
abort(400)
# Update database
return "success!"
这里我们确保键student_id是请求的一部分。尽管这种验证是有效的,但它并不属于函数本身。另外,也许还有其他途径使用完全相同的验证。所以,让我们保持干燥,用装饰器抽象出任何不必要的逻辑。下面的@validate_json装饰器将完成这项工作:
from flask import Flask, request, abort
import functools
app = Flask(__name__)
def validate_json(*expected_args): # 1
def decorator_validate_json(func):
@functools.wraps(func)
def wrapper_validate_json(*args, **kwargs):
json_object = request.get_json()
for expected_arg in expected_args: # 2
if expected_arg not in json_object:
abort(400)
return func(*args, **kwargs)
return wrapper_validate_json
return decorator_validate_json
在上面的代码中,装饰器将一个可变长度列表作为一个参数,这样我们可以根据需要传入尽可能多的字符串参数,每个参数代表一个用于验证 JSON 数据的键:
- JSON 中必须存在的键列表作为参数提供给装饰器。
- 包装器函数验证 JSON 数据中是否存在每个预期的键。
然后,路由处理程序可以专注于其真正的工作—更新分数—因为它可以安全地假设 JSON 数据是有效的:
@app.route("/grade", methods=["POST"])
@validate_json("student_id")
def update_grade():
json_data = request.get_json()
# Update database.
return "success!"
结论
这是一段不平凡的旅程!本教程开始时,您稍微仔细地研究了函数,特别是如何在其他函数中定义函数,以及如何像其他 Python 对象一样传递函数。然后,您了解了 decorators 以及如何编写它们:
- 它们可以重复使用。
- 它们可以用参数和返回值来修饰函数。
- 他们可以使用
@functools.wraps看起来更像修饰过的函数。
在本教程的第二部分,您看到了更高级的装饰者,并学习了如何:
- 装饰班级
- 鸟巢装饰者
- 向装饰者添加参数
- 在 decorators 中保持状态
- 使用类作为装饰者
您已经看到,为了定义一个装饰器,通常要定义一个返回包装函数的函数。包装函数使用*args和**kwargs将参数传递给修饰函数。如果您希望您的装饰器也接受参数,您需要将包装器函数嵌套在另一个函数中。在这种情况下,你通常以三个return语句结束。
你可以从这个教程在线找到的代码。
延伸阅读
如果你还在寻找更多,我们的书 Python 窍门中有一个关于装饰者的章节,大卫·比兹利和布莱恩·k·琼斯的 Python 食谱也是如此。
要深入探究装饰者应该如何在 Python 中实现的历史讨论,请参见 PEP 318 以及 Python 装饰者维基。更多装饰器的例子可以在 Python 装饰器库中找到。 decorator模块可以简化创建你自己的装饰器,它的文档包含更多的装饰器示例。
此外,我们还为您准备了一份简短的 Python decorators 备忘单:
Decorators Cheat Sheet:点击这里获得一个免费的三页 Python decorators cheat sheet ,它总结了本教程中解释的技术。
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python Decorators 101*********
用于高效 Python 开发的 PyCharm(指南)
作为一名程序员,你应该专注于业务逻辑,为你的用户创建有用的应用程序。在这样做的时候,由 JetBrains 开发的 PyCharm 通过处理日常事务以及简化调试和可视化等其他任务,为您节省了大量时间。
在这篇文章中,你将了解到:
- 安装 PyCharm
- 用 PyCharm 编写代码
- 在 PyCharm 中运行代码
- 在 PyCharm 中调试和测试代码
- 在 PyCharm 中编辑现有项目
- 在 PyCharm 中搜索和导航
- 在 PyCharm 中使用版本控制
- 在 PyCharm 中使用插件和外部工具
- 使用 PyCharm 专业特性,如 Django 支持和科学模式
本文假设您熟悉 Python 开发,并且已经在系统上安装了某种形式的 Python。Python 3.6 将用于本教程。提供的截图和演示是针对 macOS 的。因为 PyCharm 运行在所有主要平台上,所以您可能会看到略有不同的 UI 元素,并且可能需要修改某些命令。
注:
PyCharm 有三个版本:
- PyCharm Edu 是免费的,用于教育目的。
- PyCharm 社区也是免费的,旨在用于纯 Python 开发。
- PyCharm Professional 是付费的,拥有 Community edition 所拥有的一切,并且非常适合 Web 和科学开发,支持 Django 和 Flask、数据库和 SQL 等框架,以及 Jupyter 等科学工具。
要了解更多细节,请查看 JetBrains 的 PyCharm 版本对比矩阵。该公司还有针对学生、教师、开源项目和其他案例的特别优惠。
下载示例项目: 单击此处下载示例项目,您将在本教程中使用来探索 PyCharm 的项目特性。
安装 PyCharm
本文将使用 PyCharm 社区版 2019.1,因为它是免费的,可以在各大平台上使用。只有关于专业特性的部分会使用 py charm Professional Edition 2019.1。
安装 PyCharm 的推荐方式是使用 JetBrains 工具箱应用。在它的帮助下,您将能够安装不同的 JetBrains 产品或同一产品的几个版本,更新,回滚,并在必要时轻松删除任何工具。您还可以在正确的 IDE 和版本中快速打开任何项目。
要安装工具箱应用程序,请参考 JetBrains 的文档。它会根据你的操作系统自动给出正确的指令。如果它不能正确识别您的操作系统,您可以从右上方的下拉列表中找到它:
安装后,启动应用程序并接受用户协议。在工具选项卡下,您将看到可用产品列表。在那里找到 PyCharm 社区,点击安装:

瞧啊。你的机器上有 PyCharm。如果你不想用工具箱 app,那么你也可以做一个单机安装 PyCharm 。
启动 PyCharm,您将看到弹出的导入设置:
PyCharm 将自动检测这是一个全新的安装,并为您选择不要导入设置。点击确定,PyCharm 会让你选择一个键位图方案。保留默认设置,点击右下方的下一步:UI 主题:
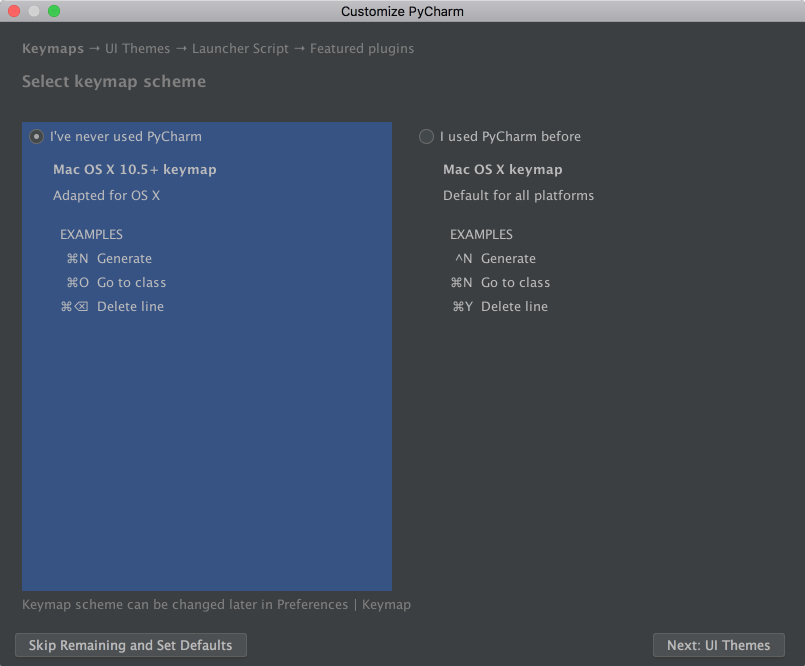
然后 PyCharm 会让你选择一个叫 Darcula 的黑暗主题或者一个光明主题。选择你喜欢的,然后点击下一步:启动器脚本:
我将在整个教程中使用黑暗主题 Darcula。你可以找到并安装其他主题作为插件,或者你也可以导入它们。
在下一页,保留默认设置,点击下一页:特色插件。在那里,PyCharm 将向您显示您可能想要安装的插件列表,因为大多数用户都喜欢使用它们。点击开始使用 PyCharm ,现在你已经准备好写一些代码了!
用 PyCharm 编写代码
在 PyCharm 中,你可以在一个项目的上下文中做任何事情。因此,您需要做的第一件事就是创建一个。
安装并打开 PyCharm 后,您将进入欢迎屏幕。点击新建项目,会弹出新建项目:
指定项目位置并展开项目解释器下拉菜单。在这里,您可以选择创建一个新的项目解释器或者重用一个现有的解释器。使用选择新环境。紧挨着它,你有一个下拉列表来选择一个 Virtualenv 、 Pipenv 或 Conda ,这些工具通过为它们创建隔离的 Python 环境来帮助保持不同项目所需的依赖关系的分离。
你可以自由选择你喜欢的,但是本教程使用的是 Virtualenv 。如果您愿意,您可以指定环境位置并从列表中选择基本解释器,该列表是您的系统上安装的 Python 解释器(如 Python2.7 和 Python3.6)的列表。通常情况下,默认值是好的。然后,您必须选择框来将全局站点包继承到您的新环境中,并使它对所有其他项目可用。不要选择它们。
点击右下方的创建,您将看到新项目被创建:
你还会看到一个小小的日积月累弹出窗口,PyCharm 在这里给你一个每次启动都要学的技巧。继续并关闭此弹出窗口。
现在是时候开始一个新的 Python 程序了。如果您在 Mac 上,请键入 Cmd + N ,如果您在 Windows 或 Linux 上,请键入 Alt + Ins 。然后,选择 Python 文件。您也可以从菜单中选择文件→新建。将新文件命名为guess_game.py,点击确定。您将看到一个类似如下的 PyCharm 窗口:
对于我们的测试代码,让我们快速编写一个简单的猜谜游戏,程序选择一个用户必须猜的数字。对于每一个猜测,该程序将告诉如果用户的猜测是小于或大于秘密数字。当用户猜出数字时,游戏结束。这是游戏的代码:
1from random import randint
2
3def play():
4 random_int = randint(0, 100)
5
6 while True:
7 user_guess = int(input("What number did we guess (0-100)?"))
8
9 if user_guess == random_int:
10 print(f"You found the number ({random_int}). Congrats!")
11 break
12
13 if user_guess < random_int:
14 print("Your number is less than the number we guessed.")
15 continue
16
17 if user_guess > random_int:
18 print("Your number is more than the number we guessed.")
19 continue
20
21
22if __name__ == '__main__':
23 play()
直接键入此代码,而不是复制和粘贴。您会看到类似这样的内容:

如您所见,PyCharm 为智能编码助手提供了代码完成、代码检查、即时错误突出显示和快速修复建议。特别要注意,当您键入main然后点击 tab 时,PyCharm 会自动为您完成整个main子句。
还要注意,如果您忘记在条件前键入if,追加.if,然后点击 Tab ,PyCharm 会为您修复if子句。True.while也是如此。这是 PyCharm 的后缀补全为您工作,帮助您减少向后插入符号跳转。
在 PyCharm 中运行代码
既然你已经编写了游戏代码,现在是你运行它的时候了。
你有三种方式运行这个程序:
- 在 Mac 上使用快捷键
Ctrl+Shift+R或者在 Windows 或 Linux 上使用快捷键Ctrl+Shift+F10。 - 右击背景,从菜单中选择运行‘guess _ game’。
- 因为这个程序有
__main__子句,你可以点击__main__子句左边的绿色小箭头,然后从那里选择运行‘guess _ game’。
使用上面的任何一个选项运行程序,您会看到窗口底部出现运行工具窗格,代码输出显示:
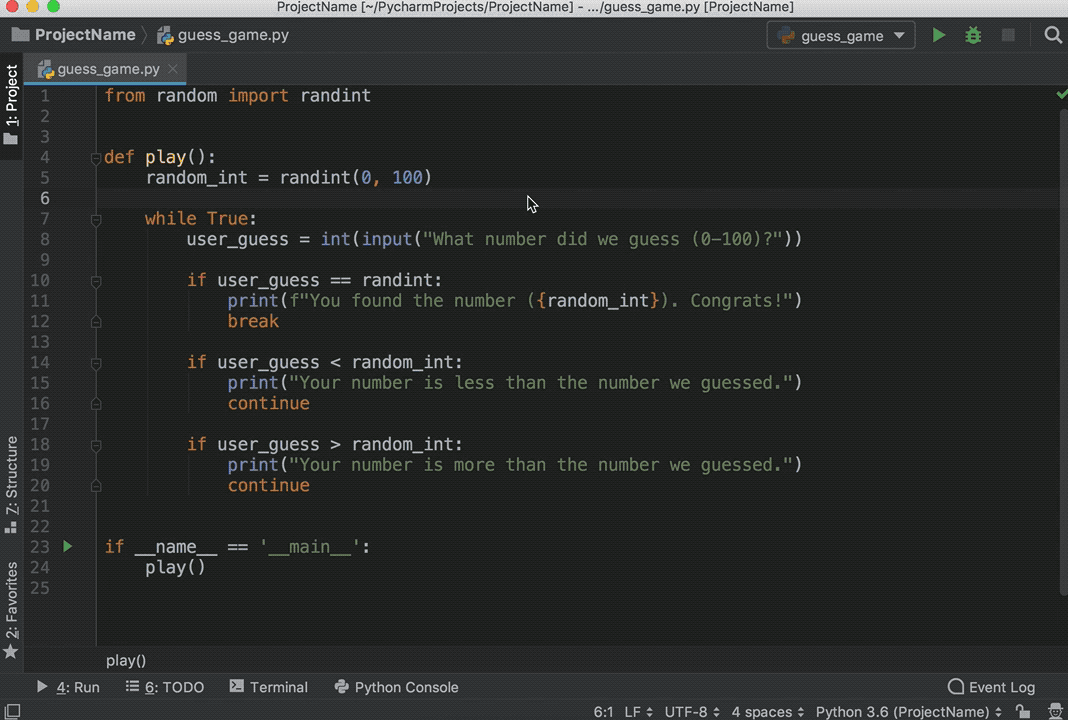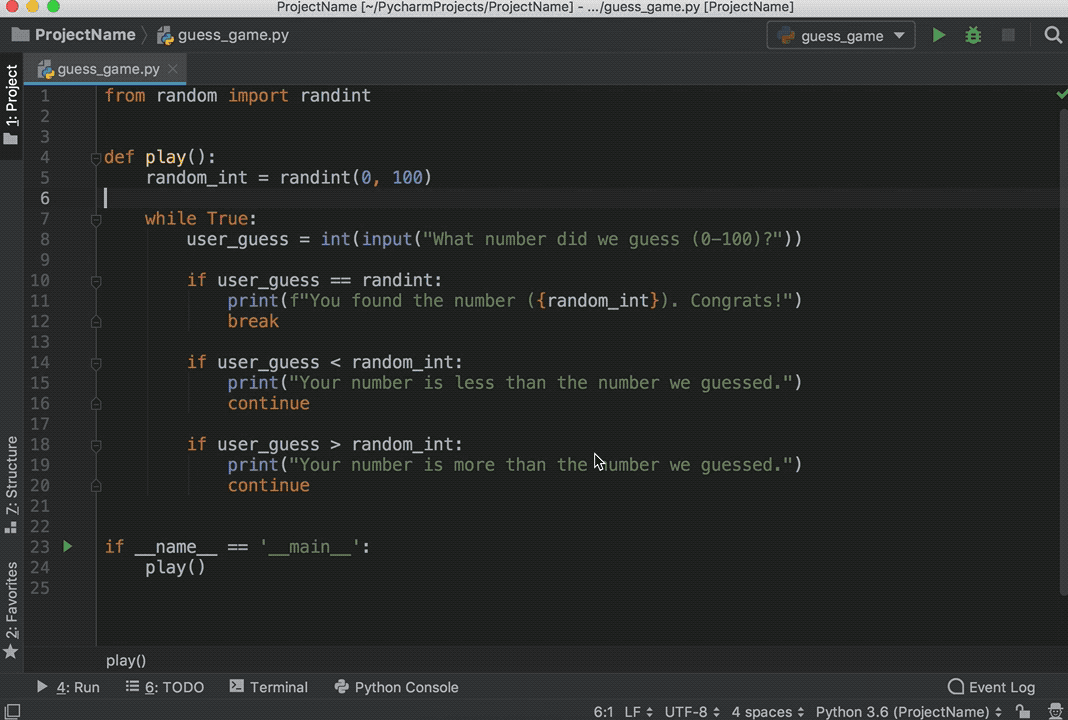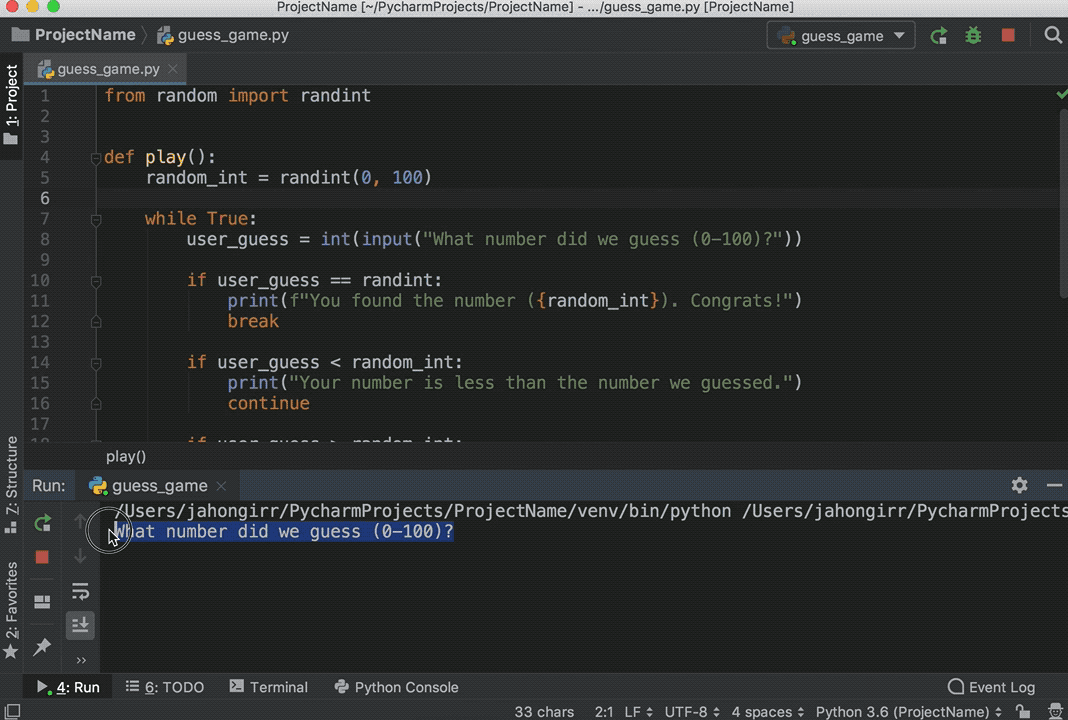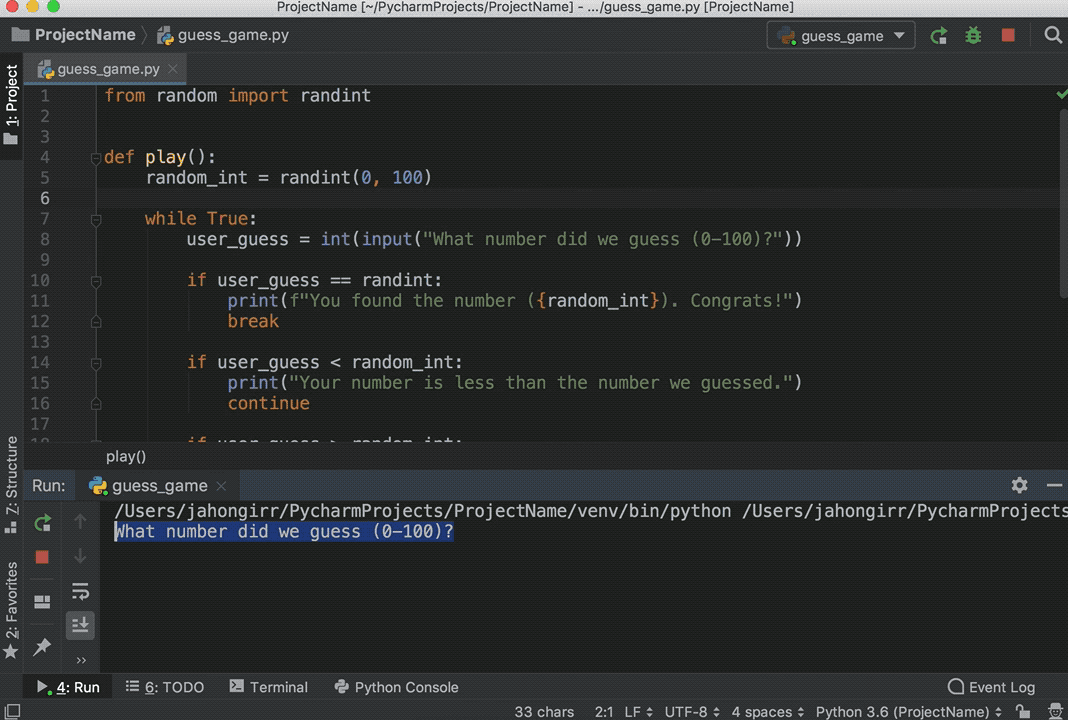
稍微玩一下这个游戏,看看你是否能找到猜对的数字。专业提示:从 50 开始。
在 PyCharm 中调试
你找到号码了吗?如果是这样,你可能在找到号码后看到了一些奇怪的东西。程序似乎重新开始,而不是打印祝贺信息并退出。那是一只虫子。为了找出程序重新开始的原因,现在您将调试程序。
首先,通过单击第 8 行左边的空白处放置一个断点:
这将是程序将被暂停的点,并且您可以从那里开始探索哪里出错了。接下来,选择以下三种方式之一开始调试:
- 在 Mac 上按
Ctrl+Shift+D或者在 Windows 或 Linux 上按Shift++Alt+F9。 - 右击背景,选择调试‘guess _ game’。
- 点击
__main__子句左边的绿色小箭头,并从那里选择Debug‘guess _ game。
之后,你会看到一个调试窗口在底部打开:
按照以下步骤调试程序:
-
请注意,当前行以蓝色突出显示。
-
请注意
random_int及其值在调试窗口中列出。记下这个数字。(图中,数字是 85。) -
点击
F8执行当前行,并跳过进入下一行。如有必要,您也可以使用F7将步进到当前行的功能。当您继续执行语句时,变量中的变化将自动反映在调试器窗口中。
** 请注意,在打开的调试器选项卡旁边有一个控制台选项卡。此控制台选项卡和调试器选项卡是互斥的。在控制台选项卡中,您将与您的程序进行交互,在调试器选项卡中,您将执行调试操作。
* 切换到控制台选项卡,输入您的猜测。
* 键入显示的数字,然后点击 `Enter` 。
* 切换回调试器标签。
* 再次点击 `F8` 来评估 [`if`语句](https://realpython.com/python-conditional-statements/)。注意你现在在第 14 行。但是等一下!为什么不去 11 号线?原因是第 10 行的`if`语句评估为`False`。但是为什么当你输入被选中的数字时,它的值是`False`?
* 仔细看第 10 行,注意我们在比较`user_guess`和错误的东西。我们没有将它与`random_int`进行比较,而是将它与从`random`包中导入的函数`randint`进行比较。
* 将其更改为`random_int`,重新开始调试,并再次执行相同的步骤。你会看到,这一次,它将转到第 11 行,第 10 行将评估为`True`:*
*
恭喜你!你修复了漏洞。
在 PyCharm 中测试
没有单元测试的应用程序是不可靠的。PyCharm 可以帮助您快速舒适地编写和运行它们。默认情况下, unittest 作为测试运行器,但 PyCharm 也支持其他测试框架,如 pytest , nose , doctest , tox , trial 。例如,您可以为您的项目启用 pytest ,如下所示:
- 打开设置/首选项→工具→ Python 集成工具设置对话框。
- 在默认测试流道字段中选择
pytest。 - 点击确定保存设置。
对于这个例子,我们将使用默认的测试运行器unittest。
在同一个项目中,创建一个名为calculator.py的文件,并将下面的Calculator类放入其中:
1class Calculator:
2 def add(self, a, b):
3 return a + b
4
5 def multiply(self, a, b):
6 return a * b
PyCharm 使得为现有代码创建测试变得非常容易。在calculator.py文件打开的情况下,执行以下任意一项操作:
- 在 Mac 上按
Shift+Cmd+T或者在 Windows 或 Linux 上按Ctrl++Shift+T。 - 在课程背景中单击鼠标右键,然后选择转到和测试。
- 在主菜单上,选择导航→测试。
选择创建新测试… ,您将看到以下窗口:
保留默认的目标目录、测试文件名、测试类名。选择两种方法并点击确定。瞧啊。PyCharm 自动创建了一个名为test_calculator.py的文件,并在其中为您创建了以下存根测试:
1from unittest import TestCase
2
3class TestCalculator(TestCase):
4 def test_add(self):
5 self.fail()
6
7 def test_multiply(self):
8 self.fail()
使用以下方法之一运行测试:
- 在 Mac 上按
Ctrl+R或者在 Windows 或 Linux 上按Shift+F10。 - 右键单击背景并选择Run ' Unittests for test _ calculator . py '。
- 点击测试类名左边的绿色小箭头,选择Run ' Unittests for test _ calculator . py '。
您会看到测试窗口在底部打开,所有测试都失败了:
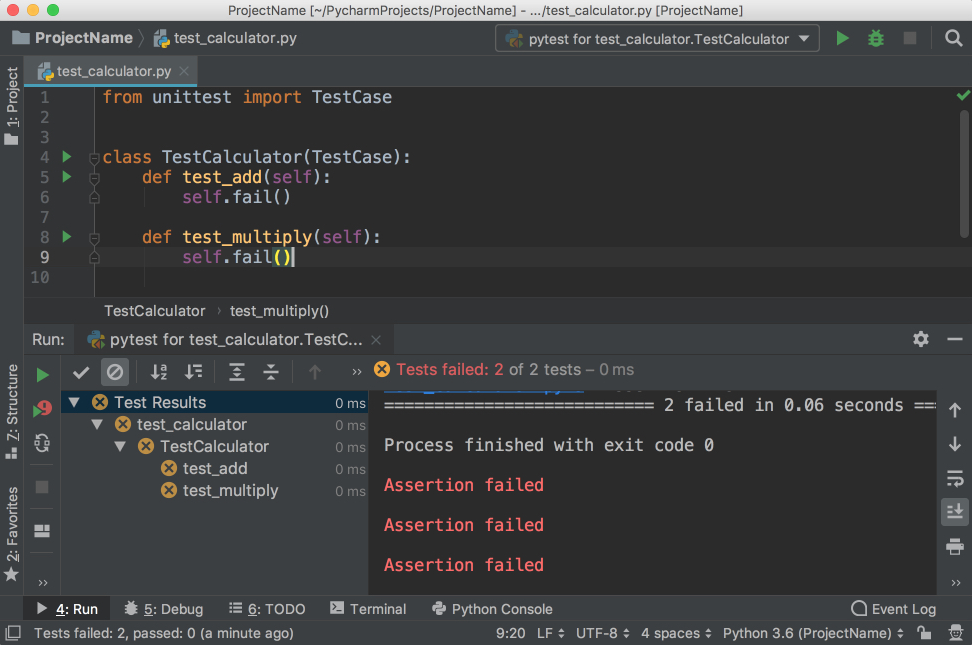
注意,左边是测试结果的层次结构,右边是终端的输出。
现在,通过将代码改为如下来实现test_add:
1from unittest import TestCase
2
3from calculator import Calculator
4
5class TestCalculator(TestCase):
6 def test_add(self):
7 self.calculator = Calculator()
8 self.assertEqual(self.calculator.add(3, 4), 7)
9
10 def test_multiply(self):
11 self.fail()
再次运行测试,您将看到一个测试通过了,另一个测试失败了。浏览选项以显示通过的测试、显示忽略的测试、按字母顺序对测试排序以及按持续时间对测试排序:
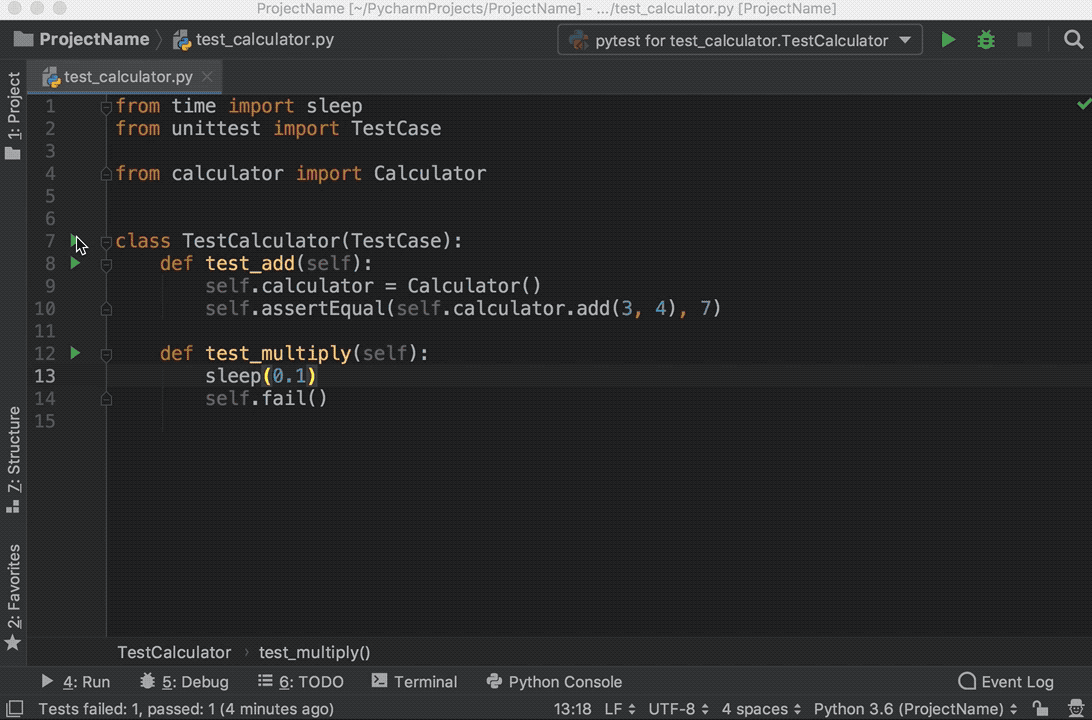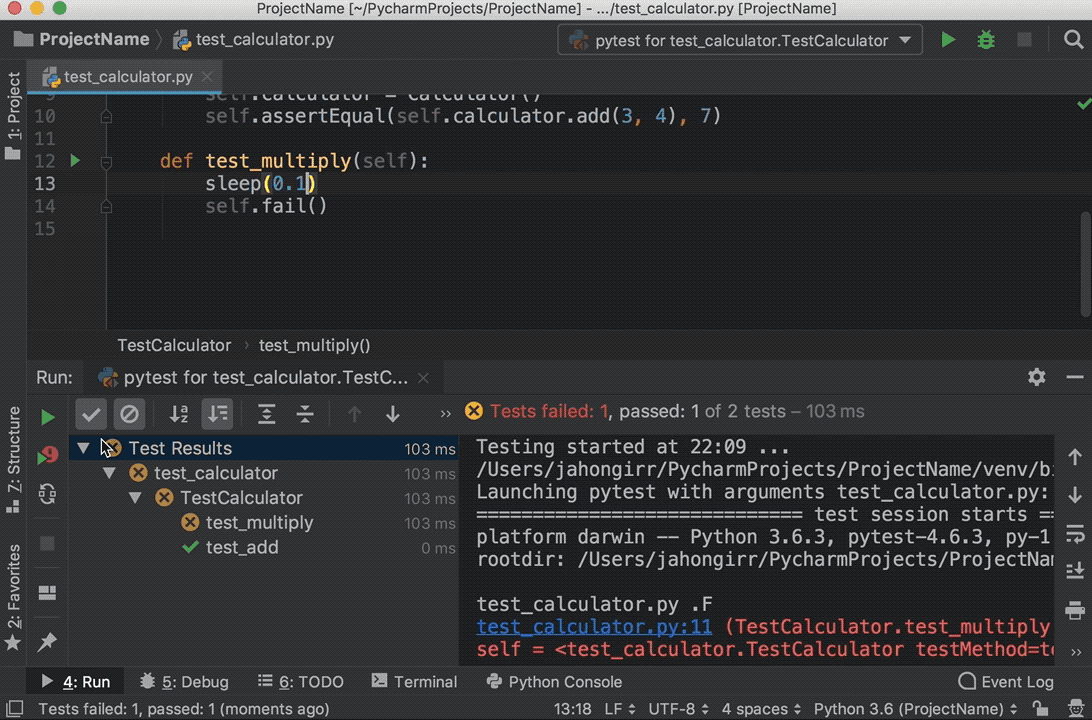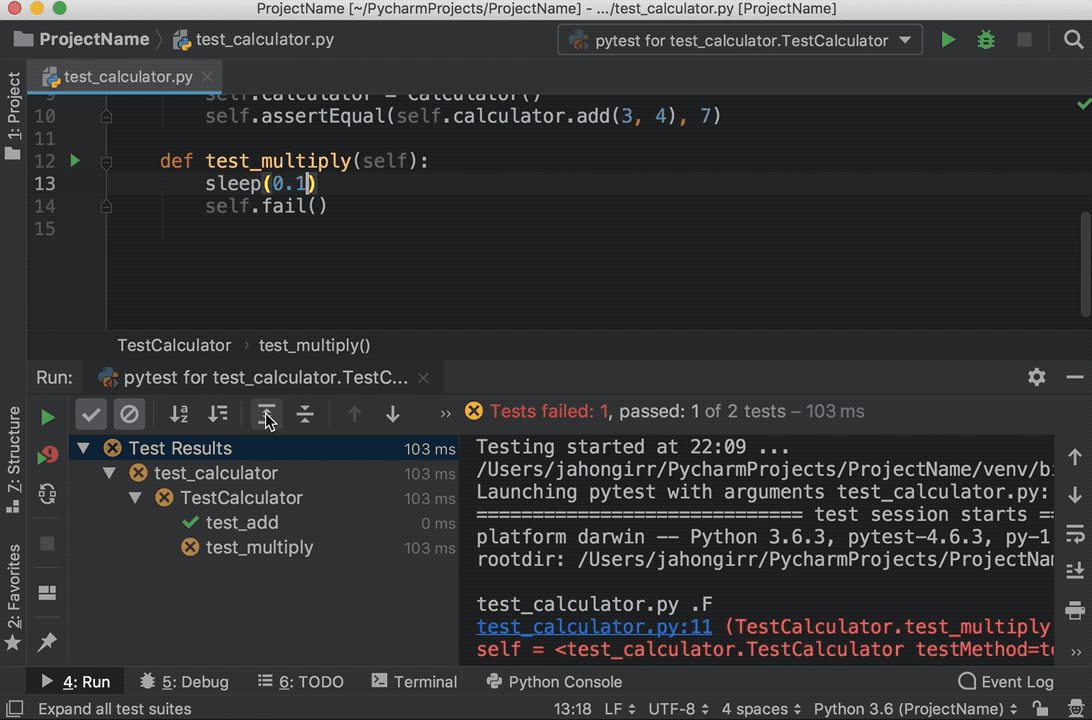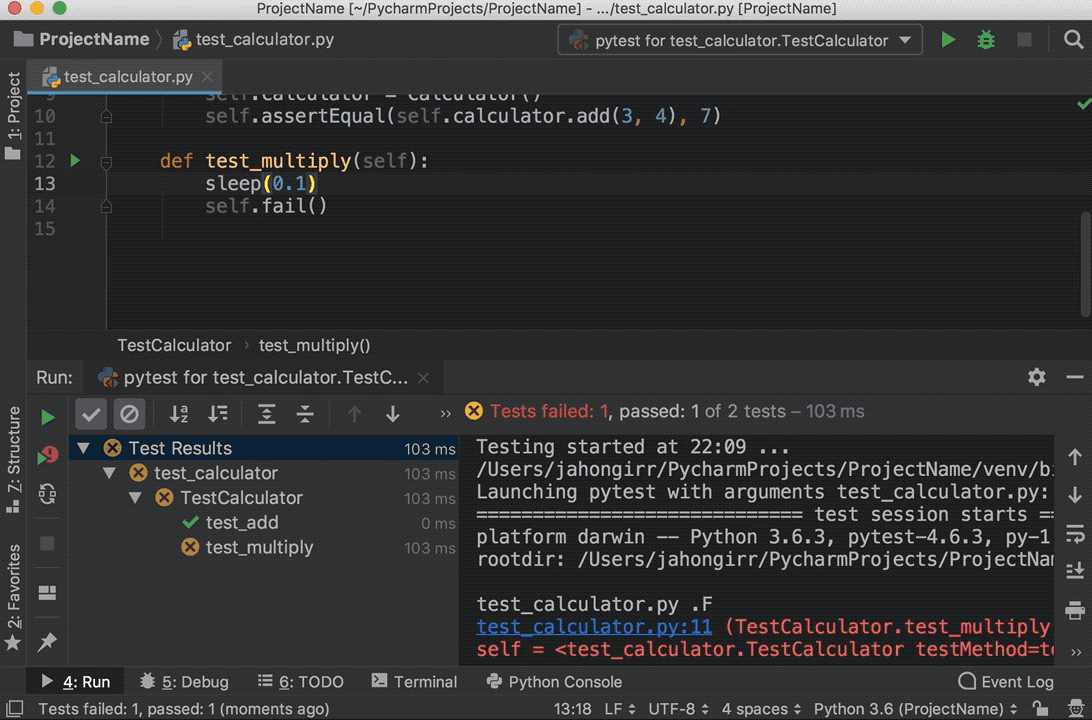
请注意,您在上面的 GIF 中看到的sleep(0.1)方法是有意用来使其中一个测试变慢,以便按持续时间排序。
在 PyCharm 中编辑现有项目
这些单个文件的项目是很好的例子,但是你经常会在更长的时间内处理更大的项目。在这一节中,您将了解 PyCharm 如何处理一个更大的项目。
为了探索 PyCharm 以项目为中心的特性,您将使用为学习目的而构建的 Alcazar web 框架。要继续跟进,请在本地下载示例项目:
下载示例项目: 单击此处下载示例项目,您将在本教程中使用来探索 PyCharm 的项目特性。
在本地下载并解压缩项目后,使用以下方法之一在 PyCharm 中打开它:
- 在主菜单上点击文件→打开。
- 如果你在的话,点击欢迎界面上的打开。
完成上述任一步骤后,在您的计算机上找到包含该项目的文件夹并将其打开。
如果这个项目包含一个虚拟环境,那么 PyCharm 会自动使用这个虚拟环境,并使其成为项目解释器。
如果需要配置不同的virtualenv,那么在 Mac 上通过按 Cmd + , 打开偏好设置,在 Windows 或 Linux 上通过按Ctrl+Alt+S打开设置,找到项目:项目名称部分。打开下拉菜单,选择项目解释器:
从下拉列表中选择virtualenv。如果没有,点击下拉列表右侧的设置按钮,然后选择添加… 。剩下的步骤应该和我们创建新项目时一样。
在 PyCharm 中搜索和导航
在一个大项目中,一个人很难记住所有东西的位置,因此能够快速导航并找到您要找的东西非常重要。皮查姆也在这里保护你。使用您在上一节中打开的项目来练习这些快捷键:
- 在当前文件中查找片段:在 Mac 上按
Cmd+F或者在 Windows 或 Linux 上按Ctrl+F。 - 在整个项目中搜索一个片段:在 Mac 上按
Cmd+Shift+F或者在 Windows 或 Linux 上按Ctrl+Shift+F。 - 搜索类:在 Mac 上按
Cmd+O或者在 Windows 或 Linux 上按Ctrl+N。 - 搜索文件:按
Cmd+Shift+O在 Mac 上或Ctrl+Shift+N在 Windows 或 Linux 上。 - 搜索全部如果你不知道你要找的是文件、类还是代码片段:按两次
Shift。
至于导航,以下快捷方式可能会为您节省大量时间:
- 要去声明一个变量:在 Mac 上按
Cmd或者在 Windows 或 Linux 上按Ctrl,点击变量。 - 查找一个类、一个方法或者任何符号的用法:按
Alt+F7。 - 查看您最近的变更:按
Shift+Alt+C或进入主菜单上的查看→最近变更。 - 查看您最近的文件:在 Mac 上按
Cmd+E或者在 Windows 或 Linux 上按Ctrl+E,或者在主菜单上进入查看→最近的文件。 - 在你跳来跳去之后,在你的导航历史中前进后退:在 Mac 上按
Cmd+[/Cmd+]或者Ctrl+Alt+Left/Ctrl+Alt+Righton
更多详情,参见官方文档。
在 PyCharm 中使用版本控制
诸如 Git 和 Mercurial 这样的版本控制系统是现代软件开发世界中一些最重要的工具。因此,IDE 支持它们是必不可少的。PyCharm 通过整合许多流行的 VC 系统做得很好,如 Git(和 Github )、Mercurial、 Perforce 和 Subversion 。
注意 : Git 用于下面的例子。
配置 VCS
实现 VCS 一体化。进入 VCS → VCS 操作弹出菜单… ,在 Mac 上按 Ctrl + V ,在 Windows 或 Linux 上按 Alt + ```py
。选择启用版本控制集成… 。您将看到以下窗口打开:
从下拉列表中选择 Git ,点击 OK ,您就为您的项目启用了 VCS。请注意,如果您打开了一个已经启用了版本控制的项目,那么 PyCharm 会看到并自动启用它。
现在,如果您转到 VCS 操作弹出窗口… ,您将看到一个不同的弹出窗口,其中包含待办事项选项git add、git stash、git branch、git commit、git push等等:
如果你找不到你需要的东西,你很可能通过从顶部菜单进入 VCS 并选择 Git 来找到它,在那里你甚至可以创建和查看拉请求。
提交和冲突解决
这是我个人非常喜欢使用的 PyCharm 中 VCS 集成的两个特性!假设你已经完成了你的工作,想提交它。进入 VCS → VCS 操作弹出框… →提交… 或者在 Mac 上按 Cmd + K 或者在 Windows 或 Linux 上按 Ctrl + K 。您将看到以下窗口打开:
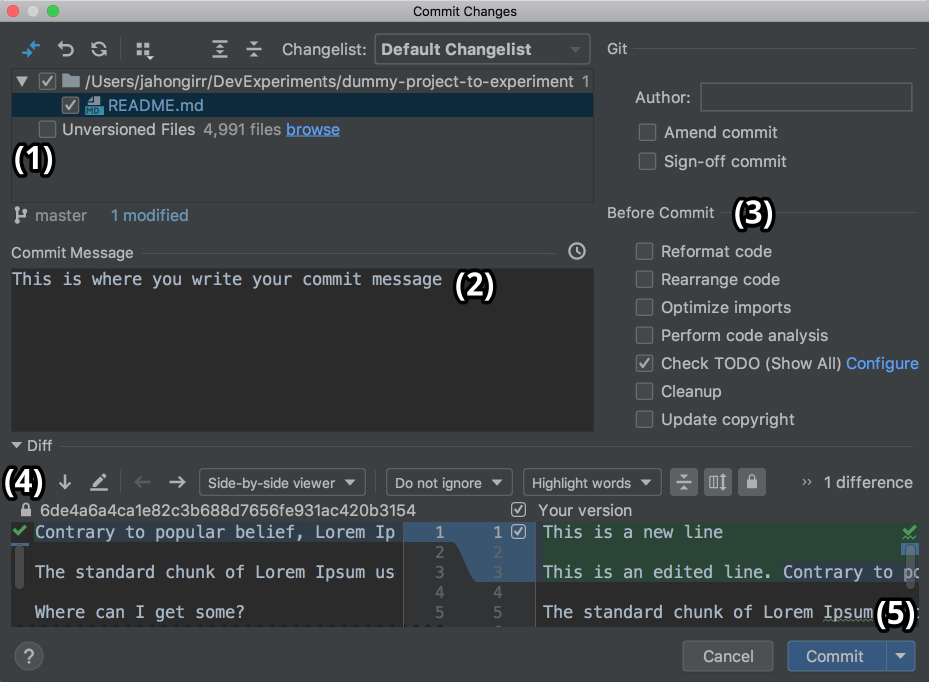
在此窗口中,您可以执行以下操作:
- 选择要提交的文件
- 编写您的提交消息
- 在提交之前做各种检查和清理
- 看到变化的不同
- 按下右下角提交按钮右侧的箭头,选择提交并推送… ,即可提交并推送
它可以感觉神奇和快速,尤其是如果你习惯于在命令行上手动做一切。
当你在团队中工作时,合并冲突确实会发生。当有人提交对你正在处理的文件的更改,但是他们的更改与你的重叠,因为你们两个都更改了相同的行,那么 VCS 将不能决定它应该选择你的更改还是你的队友的更改。所以你会看到这些不幸的箭头和符号:
这看起来很奇怪,很难弄清楚哪些更改应该删除,哪些应该保留。皮查姆来救援了。它有一个更好更干净的解决冲突的方式。进入顶部菜单的 VCS ,选择 Git ,然后选择解决冲突… 。选择您想要解决冲突的文件,点击合并。您将看到以下窗口打开:
在左栏,您将看到您的更改。右边是你的队友所做的改变。最后,在中间的列中,您将看到结果。冲突的线被突出显示,你可以在那些线的右边看到一点点 X 和>>/<<。按箭头接受更改,按 X 拒绝。解决所有这些冲突后,单击应用按钮:

在上面的 GIF 中,对于第一条冲突线,作者谢绝了自己的改动,接受了队友的改动。相反,作者接受了自己的修改,拒绝了队友对第二条冲突线的修改。
使用 PyCharm 中的 VCS 集成,您可以做更多的事情。有关更多详细信息,请参见本文档。
在 PyCharm 中使用插件和外部工具
在 PyCharm 中,您几乎可以找到开发所需的一切。如果你不能,最有可能的是有一个插件添加了你需要的 PyCharm 功能。例如,他们可以:
- 添加对各种语言和框架的支持
- 通过快捷方式提示、文件监视器等提高您的工作效率
- 通过编码练习帮助你学习一门新的编程语言
例如, IdeaVim 将 Vim 仿真添加到 PyCharm 中。如果你喜欢 Vim,这可能是一个很好的组合。
材质主题 UI 将 PyCharm 的外观改为材质设计外观和感觉:
Vue.js 增加对 Vue.js 项目的支持。 Markdown 提供了在 IDE 中编辑 Markdown 文件并在实时预览中查看渲染 HTML 的能力。你可以通过进入 Marketplace 标签下的首选项→插件在 Mac 上或设置→插件在 Windows 或 Linux 上找到并安装所有可用的插件:
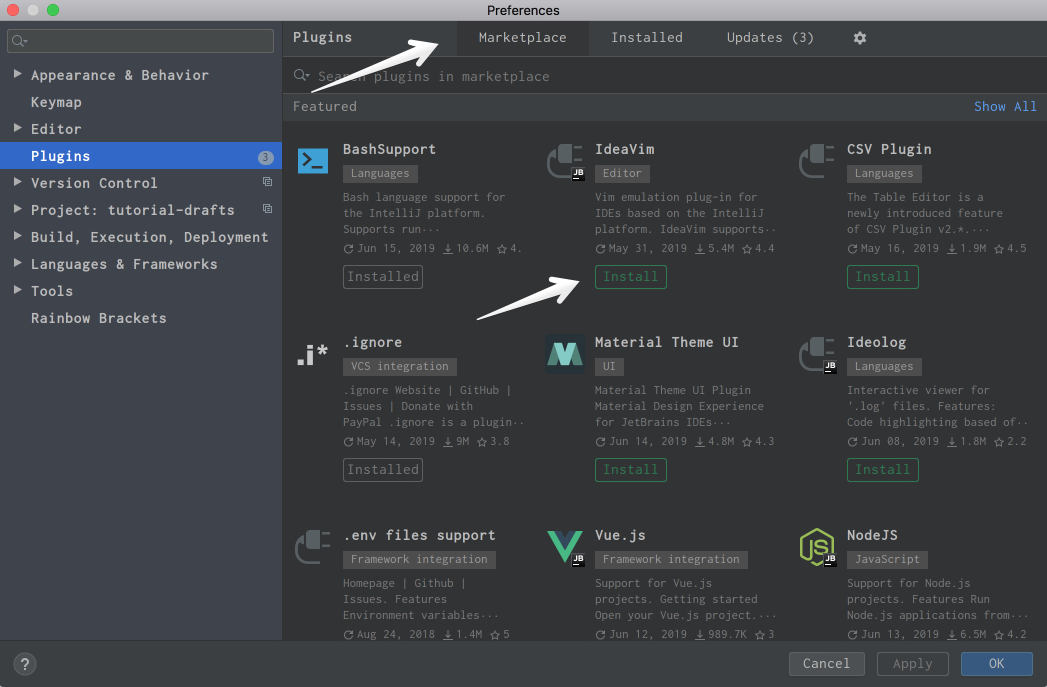
如果找不到自己需要的,甚至可以开发自己的插件。
如果你找不到合适的插件,又不想自己开发,因为 PyPI 里已经有一个包了,那么你可以把它作为外部工具添加到 PyCharm 里。以代码分析器 Flake8 为例。
首先,将flake8安装到你的 virtualenv 中,并在你选择的终端应用程序中安装pip install flake8。您也可以使用集成到 PyCharm 中的那个:
然后,在 Mac 上进入首选项→工具或者在 Windows/Linux 上进入设置→工具,然后选择外部工具。然后点击底部的小 + 按钮(1)。在新的弹出窗口中,插入如下所示的详细信息,并在两个窗口中点击确定:
这里的程序 (2)指的是 Flake8 可执行文件,可以在你的虚拟环境的文件夹 /bin 中找到。 Arguments (3)指的是你想借助 Flake8 分析哪个文件。工作目录是你项目的目录。
您可以在这里硬编码所有东西的绝对路径,但是这意味着您不能在其他项目中使用这个外部工具。您只能在一个文件的一个项目中使用它。
所以你需要使用叫做宏的东西。宏基本上是$name$格式的变量,它根据你的上下文而变化。例如,当你编辑first.py时,$FileName$是first.py,当你编辑second.py时,它是second.py。您可以看到他们的列表,并通过点击插入宏… 按钮插入他们中的任何一个。因为您在这里使用了宏,所以这些值将根据您当前工作的项目而改变,并且 Flake8 将继续正常工作。
为了使用它,创建一个文件example.py并将以下代码放入其中:
1CONSTANT_VAR = 1
2
3
4
5def add(a, b):
6 c = "hello"
7 return a + b
它故意打破了一些规则。右键单击该文件的背景。选择外部工具,然后选择薄片 8 。瞧啊。Flake8 分析的输出将出现在底部:
为了让它更好,你可以为它添加一个快捷方式。在 Mac 上进入偏好设置或者在 Windows 或 Linux 上进入设置。然后,进入键图→外部工具→外部工具。双击薄片 8 并选择添加键盘快捷键。您将看到以下窗口:
在上图中,该工具的快捷方式是Ctrl+Alt+A。在文本框中添加您喜欢的快捷方式,并在两个窗口中单击确定。现在,您可以使用该快捷方式来分析您当前正在使用 Flake8 处理的文件。
PyCharm 专业特色
PyCharm Professional 是 PyCharm 的付费版本,具有更多开箱即用的功能和集成。在这一节中,您将主要看到其主要特性的概述和到官方文档的链接,其中详细讨论了每个特性。请记住,以下功能在社区版中不可用。
Django 支持
PyCharm 对 Django T1 有广泛的支持,Django T1 是最受欢迎和喜爱的 T2 Python web 框架 T3 之一。要确保它已启用,请执行以下操作:
- 在 Mac 上打开偏好设置或者在 Windows 或 Linux 上打开设置。
- 选择语言和框架。
- 选择 Django 。
- 选中复选框启用 Django 支持。
- 应用更改。
既然您已经启用了 Django 支持,那么您在 PyCharm 中的 Django 开发之旅将会容易得多:
- 当创建一个项目时,您将拥有一个专用的 Django 项目类型。这意味着,当您选择这种类型时,您将拥有所有必要的文件和设置。这相当于使用
django-admin startproject mysite。 - 您可以直接在 PyCharm 中运行
manage.py命令。 - 支持 Django 模板,包括:
- 语法和错误突出显示
- 代码完成
- 航行
- 块名的完成
- 自定义标签和过滤器的完成
- 标签和过滤器的快速文档
- 调试它们的能力
- 所有其他 Django 部分的代码完成,比如视图、URL 和模型,以及对 Django ORM 的代码洞察支持。
- Django 模型的模型依赖图。
关于 Django 支持的更多细节,请参见官方文档。
数据库支持
现代数据库开发是一项复杂的任务,需要许多支持系统和工作流。这就是为什么 PyCharm 背后的公司 JetBrains 为此开发了一个名为 DataGrip 的独立 IDE。它是 PyCharm 的独立产品,有单独的许可证。
幸运的是,PyCharm 通过一个名为数据库工具和 SQL 的插件支持 DataGrip 中所有可用的特性,这个插件默认是启用的。有了它的帮助,你可以查询、创建和管理数据库,无论它们是在本地、在服务器上还是在云中工作。该插件支持 MySQL 、PostgreSQL、微软 SQL Server、 SQLite 、MariaDB、Oracle、Apache Cassandra 等。关于你可以用这个插件做什么的更多信息,请查看关于数据库支持的全面文档。
线程并发可视化
Django Channels 、 asyncio ,以及最近出现的类似 Starlette 的框架,都是异步 Python 编程日益增长的趋势的例子。虽然异步程序确实给桌面带来了很多好处,但是众所周知,编写和调试它们也很困难。在这种情况下,线程并发可视化可能正是医生所要求的,因为它可以帮助您完全控制您的多线程应用程序并优化它们。
查看该特性的综合文档以了解更多细节。
Profiler
说到优化,剖析是另一种可以用来优化代码的技术。在它的帮助下,您可以看到代码的哪些部分占用了大部分执行时间。探查器按以下优先级顺序运行:
如果你没有安装vmprof或yappi,那么它将回落到标准的cProfile。是有据可查的,这里就不赘述了。
科学模式
Python 不仅是一种通用和 web 编程语言。在过去的几年里,它也成为了数据科学和机器学习的最佳工具,这要归功于像 NumPy 、 SciPy 、 scikit-learn 、 Matplotlib 、 Jupyter 等库和工具。有了如此强大的库,您需要一个强大的 IDE 来支持所有的功能,比如绘制和分析这些库所具有的功能。PyCharm 提供了您需要的一切,这里有详细的记录。
远程开发
许多应用程序中错误的一个常见原因是开发和生产环境不同。尽管在大多数情况下,不可能为开发提供生产环境的精确副本,但追求它是一个有价值的目标。
使用 PyCharm,您可以使用位于其他计算机上的解释器(如 Linux VM)来调试您的应用程序。因此,您可以使用与生产环境相同的解释器来修复和避免开发和生产环境之间的差异所导致的许多错误。请务必查看官方文档以了解更多信息。
结论
PyCharm 即使不是最好的,也是最好的、全功能的、专用的和通用的 Python 开发 ide 之一。它提供了大量的好处,通过帮助你完成日常任务来节省你的大量时间。现在你知道如何有效利用它了!
在本文中,您了解了很多内容,包括:
- 安装 PyCharm
- 用 PyCharm 编写代码
- 在 PyCharm 中运行代码
- 在 PyCharm 中调试和测试代码
- 在 PyCharm 中编辑现有项目
- 在 PyCharm 中搜索和导航
- 在 PyCharm 中使用版本控制
- 在 PyCharm 中使用插件和外部工具
- 使用 PyCharm 专业特性,如 Django 支持和科学模式
如果你有什么想问或分享的,请在下面的评论中联系我们。在 PyCharm 网站上还有更多信息供你探索。
下载示例项目: 单击此处下载示例项目,您将在本教程中使用来探索 PyCharm 的项目特性。********
PyCon Africa 2019(摘要)
PyCon Africa 是一场精彩、鼓舞人心、极具技术启发性的会议,于 2019 年 8 月 6 日至 10 日在加纳阿克拉的加纳大学举行。这次会议是第一次为 Python 开发者举办的泛非会议,来自 26 个不同国家的 323 名 Python 爱好者参加了会议。大多数与会者来自非洲各国,一些发言者来自美国、荷兰、德国、巴西和意大利。
Python 在全球变得越来越受欢迎。在非洲,Python 为自己赢得了一个特殊的位置,在那里它被广泛用于网络开发和数据科学。非洲企业正在寻找在这些领域拥有 Python 技能的开发人员,在非洲拥有一个PyCon为帮助支持非洲程序员提供了基础。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
在 PyCon Africa 发生了什么
在主会议开始的前一天,与会者需要一些时间来适应。那些刚刚开始使用 Python 的人参加了由 Joey Darko 主持的初学者日会议,帮助他们为 Python 开发设置他们的计算机。我加入了另一个国际旅游团,去加纳的阿克拉旅游。我们参观了许多旅游景点,如独立广场、文化中心和一些当地市场,感受加纳的生活方式。

第二天是研讨会,上午和下午同时举行两场研讨会。Django 女孩讲习班向妇女和 Django 初学者介绍了 Django 的发展。其他研讨会关注的是数据可视化、测试和迭代器等概念。
主会议
主要会议于 8 月 8 日开始,开幕式以加纳传统舞蹈和 Python 非洲主席 Marlene Mhangami 的欢迎辞为特色。会议的每一天都有开幕和闭幕主题演讲。

让我们来看看在会议的两天里所做的一些演讲。
穆斯塔法·西塞:通过人工智能产生积极影响的潜力
穆斯塔法·西塞是位于阿克拉的谷歌人工智能中心的负责人,他在主要会议的第一天发表了开幕主题演讲。穆斯塔法的演讲是关于非洲技术专家如何利用技术解决非洲问题。在他的演讲中,他讨论了他在谷歌和人工智能领域参与的一些工作,如使用人工智能进行疾病预测,以及使用卫星图像收集信息和统计数据进行人工智能洪水预测。

Meili Triantafyllidi:柏林皮拉迪斯 6 年的经验教训
Meili Triantafyllidi 是 PyLadies Berlin 的联合创始人。在非洲有许多以女性为中心的 Python 用户群。这些小组正在做许多令人惊叹的工作,但是就像生活中的任何事情一样,总有改进的空间。
Meili Triantafyllidi 做了一个及时的演讲,讲述了她在管理柏林皮拉迪斯的六年中所学到的经验。在她的演讲中,她分享了使活动更具包容性、可及性和安全性的技巧和最佳实践。她的演讲还涵盖了如何举办活动、找到合适的演讲者以及提高公共演讲技巧的信息。

梅丽会谈后,召开了皮拉第斯会议。会议确立了支持非洲女性程序员的共同目标和计划,包括通过在皮拉迪斯松弛小组中创建一个专门的皮拉迪斯非洲频道。
坎迪·特里西亚·科利韦:网络虚拟现实和 A-Frame
Mozilla 技术发言人 Candy Khohliwe 发表了一篇关于 WebVR 的演讲,这是一项开放的技术,无论你使用什么设备,都可以在浏览器中体验虚拟现实。Candy 演讲的焦点是 A-Frame ,一个使用 HTML 创建 3D 和网络虚拟现实体验的网络框架。从这个内容丰富的讲座中,我学会了如何使用 A-Frame 来创建和绘制 WebVR 组件。我期待在未来的项目中尝试它!

尼古拉斯·德尔·格罗索:解开意大利面条(重构代码的技巧)
尼克·德尔·格罗索做了一个关于重构代码的演讲。他解释了项目代码是如何变得混乱的,并带我们安全地完成了重构过程。他还讨论了识别死代码、选择好的变量名以及使用工具帮助重构代码的策略。

杰西卡·乌帕尼:Python 真的有用吗?
来自纳米比亚 Python 社区的 Jessica Upani 就纳米比亚不同的 Python 社区团体进行了富有启发性的演讲。她讨论了他们克服的挑战,以及其他非洲 Python 社区可以从他们身上学到什么。

Kelvin Oyana:弥合 Python 社区和行业之间的人才差距
Kelvin 的演讲是关于公司对开发者的期望和开发者实际能做的之间的鸿沟。他还提出了社区和个人开发者如何弥合这一差距的见解。

丹尼尔·普罗奇达:世界上最简单、最便宜的绘图仪
Daniele Procida 是 Django 的核心开发人员,也是 PyCon Africa 组织团队的成员之一。在他的演讲中,丹尼尔展示了一个有趣的项目:他用纸板、一个 Rasberry Pi、一些伺服电机和 Python 软件制作了一个简单的笔式绘图仪。他的项目体现了非洲企业特有的足智多谋和创新精神。

Ewa Jodlowska:主题演讲
Python 软件基金会(PSF) 的执行董事 Ewa Jodlowska 做了一个关于 PSF、它如何与全球社区合作及其未来计划的主题演讲。Ewa 进一步阐述了 PSF 为促进 Python 社区的发展而开展的不同项目,例如赞助项目和南美的 Python 大使项目。

安娜·马卡鲁泽:非洲开发者如何增加技术多样性
安娜·马卡鲁泽在主要会议的第一天作了闭幕主旨发言。她是 brite core(PyCon Africa 的钻石赞助商之一)的软件工程师,Django 软件基金会的副主席,以及 T2 Django 女孩基金会的筹款协调员。Anna 利用她在这些组织中的经验,讨论了会议、组织和个人开发人员如何提高技术领域的多样性。

小组讨论:非洲 Python 开发者在社区中的角色
商业、技术和社区发展领域的领导人进行了小组讨论。Marlene Manghami 主持了关于非洲 Python 社区在全球技术空间中的作用的讨论。她的小组成员是所罗门·阿彭亚、丹尼尔·罗伊·格林菲尔德和詹姆斯·扬卡。
Solomon Apenya 是 Andela 公司的高级顾问,该公司在非洲寻找并建立分布式工程团队。丹尼尔·罗伊·格林菲尔德是《T2:Django 的两个独家新闻》的合著者,也是 T4 brite core 的执行工程副总裁。詹姆斯·扬卡是布朗普顿集团的总经理,这是一家提供招聘、培训、管理、后勤和安全服务的公司。

安东尼·肖:在 2000 万开发者中脱颖而出
在会议的最后一天,我有幸见到并聆听了安东尼·肖(Anthony Shaw)的演讲。Anthony 做了一个针对新开发人员的演讲,帮助他们在开发生涯中取得成功。在的演讲中,Anthony 讨论了如何获得成功,增长技能,学习新技术,以及对抗怀疑和冒名顶替综合症。最后,他给出了如何完成技术面试的建议。

闭幕主题演讲:Kojo Idrissa
DjangoCon 的组织者和 Django Events Foundation North America(DEFNA)大使 Kojo Idrissa 在会议的最后一天发表了闭幕主题演讲。Kojo 反思了过去的教训以及非洲移民对我们所有人的影响。

短跑日
主发布会的后一天是专门用来冲刺的!这是人们聚集在一起从事各种开源 Python 项目的地方。我是团队中的一员,参与了饼干切割器和其他相关项目。我提交了一份合并到项目中的 PR,还帮助指导了其他团队成员。
我强烈推荐任何以前没有参加过短跑的人参加!这是一个很好的方式来练习你的技能,为一个开源项目做贡献,并会见参与该项目的开发人员。

总结
PyCon Africa 取得了巨大的成功,简直棒极了!对于非洲社区来说,这是一个良好的开端,因为它第一次将来自不同非洲 Python 社区的 Python 开发人员聚集在一起。这也让我们能够听到 PSF 代表关于 Python 社区是如何组织和资助的。对许多人来说,这是来自不同社区的人在多年的在线合作后第一次见面。

对我来说,这种经历的牺牲和花费是值得的,因为我见到了来自世界各地的人,并与他们交谈,了解他们如何在工作或学习中使用 Python。我做了一个简短的演讲,讲述了如何使用 Python 和其他 Linux 自带的工具从 Python 脚本发送桌面通知。
参加 PyCon Africa 的另一个亮点是,我见到了我们的许多读者,他们中的许多人将他们的成功归功于他们在这里的 Real Python 上阅读的许多内容。安东尼·肖和我还赠送了许多真蟒贴纸。这是我们和爱迪生,一个朋友和真正的 Python 读者的合影:

组织者面临的一个问题是让尽可能多的人负担得起这次会议。对许多非洲人来说,在非洲旅行既昂贵又困难。例如,仅加纳的入境签证就要花费 100 至 200 美元。再加上旅行和住宿的费用,这个活动对许多有兴趣参加的人来说是遥不可及的。
来自个人的自愿捐款和来自 Real Python、BriteCore、Andela 和其他几家赞助商的公司赞助帮助那些需要的人支付了门票、住宿和旅行的费用。如果你想让更多的非洲人参与 Python,那么考虑支持未来在非洲的 Python 活动,并雇佣非洲开发者在你的团队中远程工作。
在撰写本文时,会议的视频还没有公开,但有一个精彩视频,其中也包括对一些与会者的采访。你也可以阅读来自会议组织者的官方报告。如果你想参加附近的 PyCon,那么看看如何充分利用 PyCon 。***
如何充分利用 PyCon US
恭喜你!你要骗我们!
不管这是不是你的第一次,参加一个满是和你爱好相同的人的会议总是一种有趣的经历。PyCon 不仅仅是一群人在谈论 Python 语言,这对于第一次参加的人来说可能有点吓人。本指南将帮助您浏览 PyCon 的所有景点和活动。
PyCon US 是围绕 Python 语言的最大会议。这个会议最初于 2003 年发起,现在已经成指数级增长,甚至在世界各地催生了其他几个pycon 和工作坊。
每个参加 PyCon 的人都会有不同的体验,这也是会议真正与众不同的地方。本指南旨在帮助你,但你不必严格遵守。
到本文结束时,你会知道:
- PyCon 如何由教程、会议和冲刺组成
- 去之前做什么
*** 在 PyCon 期间做什么*** PyCon 之后做什么*** 如何拥有一个伟大的 PyCon*****
***本指南将有专门针对 PyCon 2022 的链接,但对未来的 PyCon 也应该有用。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
PyCon 涉及什么
在考虑如何充分利用 PyCon 之前,首先了解 PyCon 涉及的内容是很重要的。
PyCon 分为三个阶段:
-
教程: PyCon 从两天三小时的课程开始,在此期间,您可以在导师的指导下深入学习。这些都是很好的去处,因为班级规模很小,你可以向老师提问。如果可以的话,你应该考虑至少参加其中的一个,但是他们每节课都有 150 美元的额外费用。
-
接下来,PyCon 将提供为期三天的讲座。每场演讲持续 30 到 45 分钟,大约有五场演讲同时进行,包括西班牙语的 charlas 曲目。但这还不是全部:还有开放空间,赞助商,闪电谈话,晚宴,等等。
-
冲刺:在这个阶段,你可以学以致用!这是一个为期两天的练习,在这个练习中,人们分组从事与 Python 相关的各种开源项目。如果你有时间,参加 sprints 是一个很好的方式,可以实践你所学的知识,参与开源项目,和非常聪明有才华的人交流。在今年早些时候的博客文章中了解更多关于短跑的知识。
由于大多数 PyCon 与会者都参加了会议部分,这将是本文的重点。然而,如果可能的话,不要让这阻止你参加教程或短跑!
你甚至可以通过参加辅导课而不是听讲座来学习更多的技术技能。短跑对于人际关系网和应用你已经掌握的技能很有帮助,同时也能从你的同事那里学到新的技能。
去之前做什么
一般来说,你对某事准备得越充分,你的体验就会越好。这同样适用于 PyCon。
提前计划和准备真的很有帮助,你已经通过阅读这篇文章做到了!
浏览一下会谈时间表,看看哪些会谈你听起来最感兴趣。这并不意味着你需要计划好你将要看到的所有演讲,在每一个可能的时段,但是它有助于你了解将要展示的主题,这样你就可以决定你最感兴趣的是什么。
获得旅行指南应用将帮助你计划你的时间表。这个应用程序可以让你查看会谈的时间表,并为你想参加的会谈添加提醒。如果你很难选择去参加哪个讲座,你可以准备好你需要解决的问题。这样做可以帮助你专注于对你来说重要的话题。
如果可以,提前一天来报到,参加开幕酒会。第一天登记的队伍总是很长,所以如果你在前一天登记,你会节省时间。那天晚上通常还会有一个开幕招待会,这样你就可以见到其他与会者和演讲者,也有机会去看看各个赞助商和他们的展位。
如果你是 PyCon 的新手,那么新人培训可以帮助你了解会议内容以及如何参与。
由于 COVID 疫情,导致 PyCon 2020 和 PyCon 2021 变得遥远,今年的 PyCon 大会有额外的健康和安全指南。确保你有资格参加,并在去之前填写必要的文件。注意安全!
回顾:以下是你出发前要做的事情:
在 PyCon 做什么
如果你在会议的第一天感到紧张或兴奋也没关系。
会有很多来自各行各业的人,这就是它如此伟大的原因。你可能会看到一些你的 Python 英雄,比如吉多·范·罗苏姆,并且有机会走上前去和他们打招呼。

Python 社区非常欢迎!但也有一些指定的安静房间,在那里发言者和其他人将平静地工作。你应该避免和那些房间里的任何人说话,给他们一个安全的空间。
你可以将会议分解成一些关键要素,看看如何最大限度地利用它们:
- 会谈
- 空地
- 赞助商
- 志愿服务机会
- 下班后的活动,包括闪电谈话
- 属于你自己的时间
会谈
想去多少场讲座就去多少场,但你不需要去所有的讲座。当你从一个房间跑到另一个房间时,你只会发现自己越来越紧张。相反,要确保你在来之前就选择了演讲。虽然这种情况很少发生,但是时间表是可以改变的,所以每天查看时间表来发现任何变化。

如果你真的想去的两个讲座之间有冲突,记住每个讲座都被记录下来并上传到 YouTube 上。有时候,它们甚至在同一天就可以买到!选择一个与你的情况最相关,并且对你来说最有趣的话题。然后记下你错过的演讲,并在当天晚上或第二天有空的时候观看。
尽管所有的讲座都可以在网上找到,但实际去听讲座仍然是有价值的。如果你参加,你会更好地记住信息,而且你将有机会直接向演讲者提问。
请记住,你不需要看到所有所谓的名人发言人。这些演讲者在 Python 社区得到了很多关注,因此看起来更值得一提。但是,在 PyCon 上让一个演讲获得批准的过程是严格的,并确保所有的演讲者和主题都值得一听。
事实上,有时候去看一些不太出名的演讲者会更好,因为你可以得到更好的座位,也有更多的机会提问。
当你去参加一个讲座时,记得关掉你的手机和电脑。噪音会让听众和演讲者分心。把你所有的设备放在一边,用便笺簿和纸简单地听或者记笔记可能会有帮助。
试着想一想你可能对正在讨论的内容有什么疑问。通常情况下,最后会分配时间给观众提问。如果这种情况没有发生,主持人通常会很乐意在之后的大厅里回答问题。
回顾:以下是你需要了解的关于 PyCon 的演讲:
- 你不需要去参加所有的讲座,你可以在 YouTube 上观看。
- 所有的演讲和演讲者都很棒。
- 在谈话时把噪音降到最低。
- 想好要问的问题。
- 之后与演讲者交谈。
开放空间
开放空间是可以被与会者预订的房间。全天都有一个小时的时段,任何人都可以使用。这些房间被用作教授人们、举行聚会、甚至是瑜伽课的地方。它们对任何你需要它们的活动开放,当然,只要你遵守行为准则。

有时你可能想去这些开放的地方,而不是去演讲或赞助商的展位。请务必每天查看开放空间公告板,因为它会不断变化。拍一张板子的照片供以后参考可能会有帮助。
随意创造你自己的开放空间。还记得您寻求帮助的那个问题或特定问题吗?注册一个房间,并就该主题寻求建议!你永远不知道谁会出现帮忙。
我们在 Real Python 主持了 PyCon 2019 的一个开放空间。对于现有成员和不太了解我们的人来说,这是一个非常棒的时刻。今年我们也将举办一个开放空间。来加入我们,一起讨论我们对未来的展望吧!你应该可以在空地板上找到时间,或者你可以到我们的展位来问我们。
如果你是一个专家,或者对你想分享的话题知之甚少,也可以随意地为它找一个开放的空间!这些空间是你想要和需要的,所以不要羞于使用它们。
回顾:以下是您需要了解的关于 PyCon 露天场地的信息:
- 开放空间可以是你想要的任何样子。
- 利用空位寻求帮助。
- 利用空位教别人。
赞助商
拜访赞助商是了解一些在日常工作流程中使用 Python 的公司的好方法。有一些非常大的名字几乎每年都会出现:微软、JetBrains 和谷歌,仅举几例。PyCon 2022 大概有一百个赞助商!去赞助商的展台有很多好处,不仅仅是因为每个人都送出了精美的礼品。以下是我们的一些例子:

赞助商在那里最大的好处是你可以和你使用的工具和软件的实际开发者交流。假设您在 Windows 环境中遇到了 Anaconda 安装问题。你可以直接去蟒蛇展台问问题!这是一个和你所使用的工具的开发者和创造者交流的好机会。
你遇到的不仅仅是开发人员。也有作者和内容创作者来。 O'Reilly 通常每天会有一两个作者在展台前与你见面聊天。今年,我们将有自己的真正的 Python 展台,在那里你可以见到一些作者和课程创建者!
最后,与赞助商会面可能会带来一个工作机会。许多赞助商也在寻找有才华的 Python 开发人员,你可以在展位或招聘会期间直接向他们申请,招聘会在会议快结束时举行。如果你没有在找工作,看看外面有什么,这些公司在寻找什么技能来帮助你选择学习的重点仍然很好。
回顾:以下是您需要了解的关于 PyCon 赞助商的信息:
- 得到赞助商的赠品很棒。
- 与开发者和内容创建者见面就更好了。
- 你可以去应聘,或者看看公司在找什么技能。
志愿服务机会
你是否曾希望自己能为 Python 社区做出贡献或回报?嗯,你可以在 PyCon。
举办一次会议需要做很多工作,如果没有志愿者,这一切都是不可能的。2022 年 PyCon 大会正在寻找超过 300 个现场志愿者小时!
这听起来很多,但你仍然可以有所作为。一两个小时的时间会很有帮助,而且不会占用你的学习时间。作为一名志愿者,你也永远不知道你会和谁接触。你可以在现场志愿者的电话中了解更多帮助信息。每个人都有一点小礼物。
回顾:以下是你需要了解的关于 PyCon 志愿者的信息:
- 去做吧。
- 真的,照做就是了!
下班后的活动
尽管会议在傍晚结束,但在会议结束后还有更多事情要做。
你首先应该检查的是闪电对话,即使只是一小会儿。这是五分钟的时间段,任何人都可以分享他们对某个主题的知识。这些讲座涵盖了广泛的话题:从新的开源项目到社会评论再到慈善事业。你知道吗 Docker 是在一次 PyCon 闪电对话中首次公开宣布的?闪电会谈已经成为定期与会者的热门话题。
也要留意和他们公司成员一起做赞助晚餐的赞助商。这是一个建立你的人际网络的好方法,也是一顿免费晚餐。PyCon 确实在晚上举办晚宴,但这些都要花钱,而且通常很快就会卖光。
即使您没有参加正式的 PyCon 晚宴或赞助晚宴,在会议附近也有很多值得一去的地方。每个会议地点的选择部分是因为附近有趣的事情。当你为会议做准备的时候,找一些好玩的地方吃饭。
回顾:以下是你需要了解的关于 PyCon 会后活动的信息:
- 看看闪电谈话。
- 如果有空位,报名参加一个正式的 PyCon 晚宴。
- 尽早并经常检查任何赞助的晚餐。
- 享受探索当地美食和文化的乐趣。
新朋友
去 PyCon 的最好建议之一就是每天交一个新朋友。

在 PyCon 认识一个人的最好时间是午餐和小吃休息时间。不要试图找一张空桌子坐下,找一张已经坐了一两个人的桌子,问问你是否可以加入他们。
开始一段对话,谈论他们迄今为止最喜欢的话题,或者他们如何在日常活动中使用 Python。很快你就会交到新朋友。你可以做一些笔记,无论是精神上的还是文字上的,这样你就可以在以后记住那个人。
为了与您遇到的人保持联系,您可能需要制作一些名片,上面有您想要共享的联系信息。确保更新你与他人分享的个人资料,如 LinkedIn 或 GitHub。
回顾:以下是你在 PyCon 结交新朋友需要知道的事情:
- 接受挑战,每天至少认识一个新的人。
- 记下那个人是谁,这样你就不会忘记。
- 带上名片,与你遇到的人分享。
PyCon 之后做什么
一旦会议结束,你还有很多事情可以做。首先,如果你有时间,还有 sprints,这是一个很好的机会让你磨练自己的技能,甚至作为一名 Python 开发人员获得新的技能。会议结束后会持续两天,但是你不需要一直呆在这里。想呆多久就呆多久,不管是几个小时还是一整天。
回家后,一定要看看 YouTube 上你错过或想重新观看的演讲视频。在 YouTube 上,你还可以查看所有的教程、主题演讲,甚至闪电演讲。全年都有足够的时间让你得到你的 PyCon fix。
PyCon 最大的好处就是有一种社区归属感。只有回馈 Python 社区的优秀人士才能做到这一点,你也可以成为他们中的一员!
你可以通过很多方式回馈这个伟大的社区:
- 为使用 Python 的开源项目做贡献。
- 加入当地的 Python meetup 群组。没有吗?创建一个!
- 与他人分享你所学到的东西。
- 为明年的 PyCon 提交一份报告或海报。
终于可以开始准备下一次 PyCon 了。当你提前买票时,你会得到一个折扣价格,但是那些票也很快就卖完了。为了准备选择在下一次 PyCon 上检查的演讲,你也可以开始记下任何你找不到答案的问题。
回顾:以下是你需要知道的会后要做的事情:
- 如果你有时间,留下来看短跑。
- 看看你错过或喜欢的 YouTube 视频。
- 用你学到的知识为 Python 社区做贡献。
- 开始看明年的 PyCon。
欢迎来到最伟大的社区!
恭喜你!你即将参加一个最伟大的技术会议,你已经准备好充分利用你在那里的时间。
在本文中,您学习了:
- 什么是 PyCon所有关于
- 在来到 PyCon 之前你可以做什么
- 在 PyCon 上可以做什么
- 在 PyCon 之后你能做什么
根据这篇文章中的建议,你将会拥有一个很棒的 PyCon。我们期待在那里见到您!********
PyGame:Python 游戏编程入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 PyGame 制作一个 2D 侧滚游戏
当我在上个千年后期开始学习计算机编程时,是受我编写计算机游戏的愿望驱使的。我试图弄清楚如何用我学过的每一种语言和每一个平台(包括 Python)用写游戏。我就是这样发现了 pygame ,并学会了如何用它来编写游戏和其他图形程序。当时我真的很想要一本pygame的入门书。
本文结束时,你将能够:
- 在屏幕上绘制项目
- 播放音效和音乐
- 处理用户输入
- 实现事件循环
- 描述游戏编程与标准的程序化 Python 编程有何不同
这本初级读本假设你对编写 Python 程序有的基本了解,包括用户自定义函数、导入、循环和条件。您还应该熟悉如何在您的平台上打开文件。对面向对象的 Python 的基本理解也是有帮助的。pygame适用于大多数版本的 Python,但本文通篇推荐使用 Python 3.6。
您可以阅读本文中的所有代码:
示例代码: 单击此处下载本教程中使用的 PyGame 示例项目的源代码。
背景和设置
pygame是 SDL 库的 Python 包装器,代表简单 DirectMedia 层。SDL 提供对系统底层多媒体硬件组件的跨平台访问,如声音、视频、鼠标、键盘和操纵杆。pygame开始作为停滞不前的 PySDL 项目的替代品。SDL 和pygame的跨平台特性意味着你可以为每一个支持它们的平台编写游戏和丰富的多媒体 Python 程序!
要在您的平台上安装pygame,使用适当的 pip 命令:
$ pip install pygame
您可以通过加载库附带的示例之一来验证安装:
$ python3 -m pygame.examples.aliens
如果出现游戏窗口,那么pygame安装正确!如果你遇到问题,那么入门指南概述了所有平台的一些已知问题和警告。
基本 PyGame 程序
在进入细节之前,让我们看一下一个基本的pygame程序。这个程序创建一个窗口,用白色填充背景,并在中间画一个蓝色的圆圈:
1# Simple pygame program
2
3# Import and initialize the pygame library
4import pygame
5pygame.init()
6
7# Set up the drawing window
8screen = pygame.display.set_mode([500, 500])
9
10# Run until the user asks to quit
11running = True
12while running:
13
14 # Did the user click the window close button?
15 for event in pygame.event.get():
16 if event.type == pygame.QUIT:
17 running = False
18
19 # Fill the background with white
20 screen.fill((255, 255, 255))
21
22 # Draw a solid blue circle in the center
23 pygame.draw.circle(screen, (0, 0, 255), (250, 250), 75)
24
25 # Flip the display
26 pygame.display.flip()
27
28# Done! Time to quit.
29pygame.quit()
当你运行这个程序时,你会看到一个类似这样的窗口:
让我们一段一段地分解这段代码:
-
4 号线和 5 号线导入并初始化
pygame库。没有这些线,就没有pygame。 -
第 8 行设置程序的显示窗口。您可以提供一个列表或一个元组来指定要创建的窗口的宽度和高度。这个程序使用一个列表来创建一个每边 500 像素的正方形窗口。
-
第 11 行和第 12 行建立了一个游戏循环来控制程序何时结束。在本教程的后面,你将会谈到游戏循环。
-
第 15 至 17 行扫描并处理游戏循环中的事件。你也会晚一点参加活动。在这种情况下,唯一处理的事件是
pygame.QUIT,它在用户单击窗口关闭按钮时发生。 -
第 20 行用纯色填充窗口。
screen.fill()接受指定颜色 RGB 值的列表或元组。自从提供了(255, 255, 255)后,窗口被填充为白色。 -
第 23 行使用以下参数在窗口中画一个圆:
screen: 要绘制的窗口(0, 0, 255): 包含 RGB 颜色值的元组(250, 250): 指定圆的中心坐标的元组75: 以像素为单位绘制的圆的半径
-
第 26 行更新屏幕显示的内容。如果没有这个调用,窗口中什么都不会出现!
-
29 号线出站
pygame。这只有在循环结束时才会发生。
这是“你好,世界”的pygame版本现在让我们更深入地挖掘一下这些代码背后的概念。
PyGame 概念
由于 SDL 库可以跨不同的平台和设备移植,它们都需要定义和处理各种硬件现实的抽象。理解这些概念和抽象将帮助你设计和开发你自己的游戏。
初始化和模块
pygame库是由许多 Python 构造组成的,其中包括几个不同的模块。这些模块提供了对系统上特定硬件的抽象访问,以及使用该硬件的统一方法。例如,display允许统一访问你的视频显示,而joystick允许抽象控制你的操纵杆。
在上例中导入了pygame库之后,你做的第一件事就是使用pygame.init()初始化 PyGame 。该函数调用所有包含的pygame模块的独立init()函数。因为这些模块是特定硬件的抽象,所以这个初始化步骤是必需的,这样您就可以在 Linux、Windows 和 Mac 上使用相同的代码。
显示器和表面
除了这些模块,pygame还包括几个 Python 类,它们封装了与硬件无关的概念。其中一个是 Surface ,它最基本的定义了一个你可以在上面画画的矩形区域。Surface在pygame中,宾语用在很多语境中。稍后您将看到如何将一幅图像加载到Surface中并显示在屏幕上。
在pygame中,一切都在单个用户创建的 display 上查看,可以是窗口,也可以是全屏。使用 .set_mode() 创建显示,返回代表窗口可见部分的Surface。就是这个Surface你传入 pygame.draw.circle() 这样的绘图函数,当你调用 pygame.display.flip() 的时候那个Surface的内容就被推送到显示器上。
图像和矩形
你的基本pygame程序直接在显示器的Surface上画出一个形状,但是你也可以处理磁盘上的图像。 image模块允许你加载和保存各种流行格式的图像。图像被加载到Surface对象中,然后可以用多种方式操作和显示。
如上所述,Surface对象由矩形表示,pygame中的许多其他对象也是如此,比如图像和窗口。矩形被大量使用,以至于有一个专用的Rect类来处理它们。你将在游戏中使用Rect物体和图像来绘制玩家和敌人,并管理他们之间的冲突。
好了,理论到此为止。让我们设计并编写一个游戏吧!
基础游戏设计
在你开始写任何代码之前,做一些适当的设计总是一个好主意。由于这是一个教程游戏,让我们也为它设计一些基本的游戏玩法:
- 游戏的目标是避免即将到来的障碍:
- 玩家从屏幕左侧开始。
- 障碍物随机从右侧进入,然后沿直线向左移动。
- 玩家可以向左、向右、向上或向下移动来避开障碍物。
- 玩家不能离开屏幕。
- 游戏要么在玩家被障碍物击中时结束,要么在用户关闭窗口时结束。
当他描述软件项目时,我的一个前同事曾经说过,“你不知道你做什么,直到你知道你不做什么。”记住这一点,以下是本教程中不会涉及的一些内容:
- 没有多重生命
- 不计分
- 没有玩家攻击能力
- 没有升级级别
- 没有老板角色
您可以自由尝试将这些和其他特性添加到您自己的程序中。
我们开始吧!
导入并初始化 PyGame
导入pygame后,您还需要初始化它。这允许pygame将其抽象连接到您的特定硬件:
1# Import the pygame module
2import pygame
3
4# Import pygame.locals for easier access to key coordinates
5# Updated to conform to flake8 and black standards
6from pygame.locals import (
7 K_UP,
8 K_DOWN,
9 K_LEFT,
10 K_RIGHT,
11 K_ESCAPE,
12 KEYDOWN,
13 QUIT,
14)
15
16# Initialize pygame
17pygame.init()
除了模块和类之外,pygame库还定义了许多东西。它还为按键、鼠标移动和显示属性定义了一些本地常量。使用语法pygame.<CONSTANT>引用这些常量。通过从pygame.locals导入特定的常量,您可以使用语法<CONSTANT>来代替。这将为您节省一些击键次数,并提高整体可读性。
设置显示屏
现在你需要一些可以借鉴的东西!创建一个屏幕作为整体画布:
1# Import the pygame module
2import pygame
3
4# Import pygame.locals for easier access to key coordinates
5# Updated to conform to flake8 and black standards
6from pygame.locals import (
7 K_UP,
8 K_DOWN,
9 K_LEFT,
10 K_RIGHT,
11 K_ESCAPE,
12 KEYDOWN,
13 QUIT,
14)
15
16# Initialize pygame
17pygame.init()
18
19# Define constants for the screen width and height 20SCREEN_WIDTH = 800 21SCREEN_HEIGHT = 600 22
23# Create the screen object 24# The size is determined by the constant SCREEN_WIDTH and SCREEN_HEIGHT 25screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))
您通过调用pygame.display.set_mode()并传递一个具有所需宽度和高度的元组或列表来创建要使用的屏幕。在这种情况下,窗口是 800x600,由第 20 行和第 21 行的常量SCREEN_WIDTH和SCREEN_HEIGHT定义。这将返回一个代表窗口内部尺寸的Surface。这是您可以控制的窗口部分,而操作系统控制窗口边框和标题栏。
如果你现在运行这个程序,那么你会看到一个窗口短暂弹出,然后随着程序的退出而立即消失。不要眨眼,否则你可能会错过它!在下一节中,您将关注游戏的主循环,以确保您的程序只有在得到正确的输入时才退出。
设置游戏循环
从 Pong 到堡垒之夜的每个游戏都使用一个游戏循环来控制游戏性。游戏循环做了四件非常重要的事情:
- 处理用户输入
- 更新所有游戏对象的状态
- 更新显示和音频输出
- 保持游戏的速度
游戏循环的每个周期都被称为一个帧,每个周期你做事情越快,你的游戏就会运行得越快。帧继续出现,直到满足退出游戏的某些条件。在您的设计中,有两种情况可以结束游戏循环:
- 玩家撞上了一个障碍物。(您将在后面讨论碰撞检测。)
- 玩家关闭窗口。
游戏循环做的第一件事是处理用户输入,允许玩家在屏幕上移动。因此,您需要一些方法来捕获和处理各种输入。您可以使用pygame事件系统来做到这一点。
处理事件
按键、鼠标移动、甚至操纵杆移动是用户可以提供输入的一些方式。所有用户输入都导致产生一个事件。事件可以在任何时候发生,并且经常(但不总是)起源于程序之外。pygame中的所有事件都放在事件队列中,然后可以访问和操作。处理事件被称为处理它们,这样做的代码被称为事件处理程序。
pygame中的每个事件都有一个与之关联的事件类型。对于您的游戏,您将关注的事件类型是按键和窗口关闭。按键事件具有事件类型KEYDOWN,窗口关闭事件具有类型QUIT。不同的事件类型也可能有与之相关的其他数据。例如,KEYDOWN事件类型也有一个名为key的变量来指示哪个键被按下了。
您可以通过调用pygame.event.get()来访问队列中所有活动事件的列表。然后,循环遍历该列表,检查每个事件类型,并做出相应的响应:
27# Variable to keep the main loop running
28running = True
29
30# Main loop
31while running:
32 # Look at every event in the queue
33 for event in pygame.event.get():
34 # Did the user hit a key?
35 if event.type == KEYDOWN:
36 # Was it the Escape key? If so, stop the loop.
37 if event.key == K_ESCAPE:
38 running = False
39
40 # Did the user click the window close button? If so, stop the loop.
41 elif event.type == QUIT:
42 running = False
让我们仔细看看这个游戏循环:
-
第 28 行为游戏循环设置一个控制变量。要退出循环和游戏,您需要设置
running = False。游戏循环从第 29 行开始。 -
第 31 行启动事件处理程序,遍历当前事件队列中的每个事件。如果没有事件,那么列表是空的,处理程序不会做任何事情。
-
第 35 到 38 行检查当前
event.type是否为KEYDOWN事件。如果是,那么程序通过查看event.key属性来检查哪个键被按下了。如果键是Esc键,用K_ESCAPE表示,则通过设置running = False退出游戏循环。 -
第 41 行和第 42 行对名为
QUIT的事件类型进行类似的检查。该事件仅在用户单击窗口关闭按钮时发生。用户也可以使用任何其他操作系统动作来关闭窗口。
当您将这些行添加到前面的代码中并运行它时,您将看到一个空白或黑屏的窗口:
直到您按下 Esc 键,或者通过关闭窗口触发QUIT事件,窗口才会消失。
在屏幕上绘图
在示例程序中,您使用两个命令在屏幕上绘图:
screen.fill()填充背景pygame.draw.circle()画一个圆
现在你将学习第三种在屏幕上绘图的方法:使用Surface。
回想一下, Surface 是一个长方形的物体,你可以在上面画画,就像一张白纸。screen对象是一个Surface,你可以在显示屏之外创建你自己的Surface对象。让我们看看它是如何工作的:
44# Fill the screen with white
45screen.fill((255, 255, 255))
46
47# Create a surface and pass in a tuple containing its length and width
48surf = pygame.Surface((50, 50))
49
50# Give the surface a color to separate it from the background
51surf.fill((0, 0, 0))
52rect = surf.get_rect()
在屏幕第 45 行填满白色后,在第 48 行创建一个新的Surface。这个Surface宽 50 像素,高 50 像素,分配给surf。在这一点上,你对待它就像对待screen一样。所以在第 51 行,你用黑色填充。你也可以使用.get_rect()来访问它的底层Rect。这被存储为rect以备后用。
使用.blit()和.flip()
仅仅创建一个新的Surface不足以在屏幕上看到它。要做到这一点,你需要把这个Surface放到另一个Surface上。术语blit代表块传输,.blit()是你如何将一个Surface的内容复制到另一个。你只能从一个Surface到另一个.blit(),但既然屏幕只是另一个Surface,那就不是问题。下面是你在屏幕上画surf的方法:
54# This line says "Draw surf onto the screen at the center"
55screen.blit(surf, (SCREEN_WIDTH/2, SCREEN_HEIGHT/2))
56pygame.display.flip()
第 55 行的.blit()调用有两个参数:
Surface画画- 在源上绘制的位置
Surface
坐标(SCREEN_WIDTH/2, SCREEN_HEIGHT/2)告诉你的程序将surf放在屏幕的正中央,但是看起来并不是这样:
图像看起来偏离中心的原因是.blit()将surf的左上角放在给定的位置。如果你想让surf居中,那么你必须做一些数学运算来把它向左上方移动。你可以通过从屏幕的宽度和高度中减去surf的宽度和高度,除以 2 来确定中心,然后将这些数字作为参数传递给screen.blit():
54# Put the center of surf at the center of the display
55surf_center = (
56 (SCREEN_WIDTH-surf.get_width())/2,
57 (SCREEN_HEIGHT-surf.get_height())/2
58)
59
60# Draw surf at the new coordinates
61screen.blit(surf, surf_center)
62pygame.display.flip()
注意在调用blit()之后调用 pygame.display.flip() 。这将使用自上次翻转以来绘制的所有内容更新整个屏幕。没有对.flip()的调用,什么也不显示。
精灵
在你的游戏设计中,玩家从左边开始,障碍物从右边进来。你可以用Surface对象来表示所有的障碍,以使绘制一切变得更容易,但是你如何知道在哪里绘制它们呢?如何知道障碍物是否与玩家发生了碰撞?当障碍物飞出屏幕时会发生什么?如果你想画也会移动的背景图片怎么办?如果你想让你的图片变成动画,该怎么办?你可以用精灵处理所有这些情况甚至更多。
用编程术语来说,一个精灵是屏幕上某个东西的 2D 表示。本质上是一张图片。pygame提供了一个 Sprite类,它被设计用来保存你想要在屏幕上显示的任何游戏对象的一个或几个图形表示。为了使用它,你创建一个扩展Sprite的新类。这允许您使用它的内置方法。
玩家
以下是如何在当前游戏中使用Sprite对象来定义玩家。在第 18 行后插入以下代码:
20# Define a Player object by extending pygame.sprite.Sprite
21# The surface drawn on the screen is now an attribute of 'player'
22class Player(pygame.sprite.Sprite):
23 def __init__(self):
24 super(Player, self).__init__()
25 self.surf = pygame.Surface((75, 25))
26 self.surf.fill((255, 255, 255))
27 self.rect = self.surf.get_rect()
首先通过在第 22 行扩展pygame.sprite.Sprite来定义Player。然后.__init__()用.super()调用Sprite的.__init__()方法。关于为什么这是必要的更多信息,你可以阅读用 Python super() 增强你的类。
接下来,您定义并初始化.surf来保存要显示的图像,它目前是一个白盒。您还定义并初始化了.rect,稍后您将使用它来绘制播放器。要使用这个新类,您需要创建一个新对象并更改绘图代码。展开下面的代码块以查看所有内容:
1# Import the pygame module
2import pygame
3
4# Import pygame.locals for easier access to key coordinates
5# Updated to conform to flake8 and black standards
6from pygame.locals import (
7 K_UP,
8 K_DOWN,
9 K_LEFT,
10 K_RIGHT,
11 K_ESCAPE,
12 KEYDOWN,
13 QUIT,
14)
15
16# Define constants for the screen width and height
17SCREEN_WIDTH = 800
18SCREEN_HEIGHT = 600
19
20# Define a player object by extending pygame.sprite.Sprite 21# The surface drawn on the screen is now an attribute of 'player' 22class Player(pygame.sprite.Sprite): 23 def __init__(self): 24 super(Player, self).__init__() 25 self.surf = pygame.Surface((75, 25)) 26 self.surf.fill((255, 255, 255)) 27 self.rect = self.surf.get_rect() 28
29# Initialize pygame
30pygame.init()
31
32# Create the screen object
33# The size is determined by the constant SCREEN_WIDTH and SCREEN_HEIGHT
34screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))
35
36# Instantiate player. Right now, this is just a rectangle. 37player = Player() 38
39# Variable to keep the main loop running
40running = True
41
42# Main loop
43while running:
44 # for loop through the event queue
45 for event in pygame.event.get():
46 # Check for KEYDOWN event
47 if event.type == KEYDOWN:
48 # If the Esc key is pressed, then exit the main loop
49 if event.key == K_ESCAPE:
50 running = False
51 # Check for QUIT event. If QUIT, then set running to false.
52 elif event.type == QUIT:
53 running = False
54
55 # Fill the screen with black
56 screen.fill((0, 0, 0))
57
58 # Draw the player on the screen 59 screen.blit(player.surf, (SCREEN_WIDTH/2, SCREEN_HEIGHT/2)) 60
61 # Update the display
62 pygame.display.flip()
运行这段代码。您会在屏幕的大致中间位置看到一个白色矩形:
![]()
如果把 59 行改成screen.blit(player.surf, player.rect),你觉得会怎么样?试试看:
55# Fill the screen with black
56screen.fill((0, 0, 0))
57
58# Draw the player on the screen
59screen.blit(player.surf, player.rect) 60
61# Update the display
62pygame.display.flip()
当你传递一个Rect到.blit()的时候,它会用左上角的坐标来绘制曲面。稍后您将使用它来让您的玩家移动!
用户输入
到目前为止,你已经学会了如何设置pygame并在屏幕上绘制对象。现在,真正的乐趣开始了!您将使用键盘来控制播放器。
之前,您看到pygame.event.get()返回了事件队列中的事件列表,您在其中扫描KEYDOWN事件类型。嗯,这不是读取按键的唯一方法。pygame还提供pygame.event.get_pressed(),返回包含队列中所有当前KEYDOWN事件的字典。
把这个放在你的游戏循环中,就在事件处理循环之后。这将返回一个字典,其中包含在每一帧开始时按下的键:
54# Get the set of keys pressed and check for user input
55pressed_keys = pygame.key.get_pressed()
接下来,在Player中编写一个方法来接受字典。这将基于被按下的键定义精灵的行为。这可能是这样的:
29# Move the sprite based on user keypresses
30def update(self, pressed_keys):
31 if pressed_keys[K_UP]:
32 self.rect.move_ip(0, -5)
33 if pressed_keys[K_DOWN]:
34 self.rect.move_ip(0, 5)
35 if pressed_keys[K_LEFT]:
36 self.rect.move_ip(-5, 0)
37 if pressed_keys[K_RIGHT]:
38 self.rect.move_ip(5, 0)
K_UP、K_DOWN、K_LEFT、K_RIGHT对应键盘上的箭头键。如果该键的字典条目是True,那么该键被按下,并且你在正确的方向上移动播放器.rect。这里使用.move_ip(),代表 移动到位 ,移动当前Rect。
然后,您可以在每一帧调用.update()来移动播放器精灵以响应按键。在对.get_pressed()的呼叫后立即添加此呼叫:
52# Main loop
53while running:
54 # for loop through the event queue
55 for event in pygame.event.get():
56 # Check for KEYDOWN event
57 if event.type == KEYDOWN:
58 # If the Esc key is pressed, then exit the main loop
59 if event.key == K_ESCAPE:
60 running = False
61 # Check for QUIT event. If QUIT, then set running to false.
62 elif event.type == QUIT:
63 running = False
64
65 # Get all the keys currently pressed
66 pressed_keys = pygame.key.get_pressed()
67
68 # Update the player sprite based on user keypresses 69 player.update(pressed_keys) 70
71 # Fill the screen with black
72 screen.fill((0, 0, 0))
现在你可以用箭头键在屏幕上移动你的球员矩形:
您可能会注意到两个小问题:
- 如果按住一个键,玩家矩形可以快速移动。你过会儿将在那上工作。
- 玩家矩形可以移出屏幕。我们现在来解决这个问题。
为了让玩家留在屏幕上,你需要添加一些逻辑来检测rect是否会移出屏幕。为此,您需要检查rect坐标是否已经超出了屏幕的边界。如果是,那么你指示程序将它移回边缘:
25# Move the sprite based on user keypresses
26def update(self, pressed_keys):
27 if pressed_keys[K_UP]:
28 self.rect.move_ip(0, -5)
29 if pressed_keys[K_DOWN]:
30 self.rect.move_ip(0, 5)
31 if pressed_keys[K_LEFT]:
32 self.rect.move_ip(-5, 0)
33 if pressed_keys[K_RIGHT]:
34 self.rect.move_ip(5, 0)
35
36 # Keep player on the screen 37 if self.rect.left < 0: 38 self.rect.left = 0 39 if self.rect.right > SCREEN_WIDTH: 40 self.rect.right = SCREEN_WIDTH 41 if self.rect.top <= 0: 42 self.rect.top = 0 43 if self.rect.bottom >= SCREEN_HEIGHT: 44 self.rect.bottom = SCREEN_HEIGHT
这里不使用.move(),直接改变.top、.bottom、.left或.right的对应坐标即可。测试这个,你会发现玩家矩形不再能离开屏幕。
现在让我们添加一些敌人!
敌人
没有敌人的游戏算什么?你将使用你已经学过的技术创建一个基本的敌人职业,然后创建许多敌人让你的玩家躲避。首先,导入random库:
4# Import random for random numbers
5import random
然后创建一个名为Enemy的新 sprite 类,遵循用于Player的相同模式:
55# Define the enemy object by extending pygame.sprite.Sprite
56# The surface you draw on the screen is now an attribute of 'enemy'
57class Enemy(pygame.sprite.Sprite):
58 def __init__(self):
59 super(Enemy, self).__init__()
60 self.surf = pygame.Surface((20, 10))
61 self.surf.fill((255, 255, 255))
62 self.rect = self.surf.get_rect(
63 center=(
64 random.randint(SCREEN_WIDTH + 20, SCREEN_WIDTH + 100),
65 random.randint(0, SCREEN_HEIGHT),
66 )
67 )
68 self.speed = random.randint(5, 20)
69
70 # Move the sprite based on speed
71 # Remove the sprite when it passes the left edge of the screen
72 def update(self):
73 self.rect.move_ip(-self.speed, 0)
74 if self.rect.right < 0:
75 self.kill()
Enemy和Player有四个显著的区别:
-
在第 62 到 67 行上,你将
rect更新为沿着屏幕右边缘的一个随机位置。矩形的中心刚好在屏幕之外。它位于距离右边缘 20 到 100 像素之间的某个位置,在顶部和底部边缘之间的某个位置。 -
在第 68 行,你将
.speed定义为 5 到 20 之间的一个随机数。这指定了这个敌人向玩家移动的速度。 -
在第 73 到 76 行,你定义
.update()。这不需要争论,因为敌人会自动移动。相反,.update()将敌人移向屏幕左侧的.speed,这个位置是在敌人被创建时定义的。 -
在第 74 行,你检查敌人是否已经离开屏幕。为了确保
Enemy完全离开屏幕,并且不会在它仍然可见时就消失,你要检查.rect的右侧是否已经越过了屏幕的左侧。一旦敌人离开屏幕,你呼叫.kill()阻止它被进一步处理。
那么,.kill()是做什么的呢?要想弄清楚这一点,你必须知道雪碧集团。
精灵组
pygame提供的另一个超级有用的类是 Sprite Group 。这是一个包含一组Sprite对象的对象。那么为什么要用呢?你不能在列表中跟踪你的Sprite对象吗?嗯,可以,但是使用Group的优势在于它公开的方法。这些方法有助于检测是否有任何Enemy与Player冲突,这使得更新更加容易。
让我们看看如何创建精灵组。您将创建两个不同的Group对象:
- 第一个
Group将持有游戏中的每一个Sprite。 - 第二个
Group将只保存Enemy对象。
代码看起来是这样的:
82# Create the 'player'
83player = Player()
84
85# Create groups to hold enemy sprites and all sprites 86# - enemies is used for collision detection and position updates 87# - all_sprites is used for rendering 88enemies = pygame.sprite.Group() 89all_sprites = pygame.sprite.Group() 90all_sprites.add(player) 91
92# Variable to keep the main loop running
93running = True
当您调用.kill()时,Sprite将从它所属的每个Group中删除。这也删除了对Sprite的引用,允许 Python 的垃圾收集器在必要时回收内存。
现在你有了一个all_sprites组,你可以改变对象的绘制方式。您可以迭代all_sprites中的所有内容,而不是只在Player上调用.blit():
117# Fill the screen with black
118screen.fill((0, 0, 0))
119
120# Draw all sprites 121for entity in all_sprites: 122 screen.blit(entity.surf, entity.rect) 123
124# Flip everything to the display
125pygame.display.flip()
现在,放入all_sprites的任何东西都会随着每一帧画出来,不管是敌人还是玩家。
只有一个问题…你没有任何敌人!你可以在游戏开始时创造一堆敌人,但几秒钟后当他们都离开屏幕时,游戏会很快变得无聊。相反,让我们探索如何随着游戏的进展保持稳定的敌人供应。
自定义事件
这个设计要求敌人定期出现。这意味着在设定的时间间隔内,您需要做两件事:
- 创建新的
Enemy。 - 添加到
all_sprites和enemies中。
您已经有了处理随机事件的代码。事件循环旨在寻找每一帧中发生的随机事件,并适当地处理它们。幸运的是,pygame没有限制您只能使用它定义的事件类型。你可以定义你自己的事件来处理你认为合适的。
让我们看看如何创建每隔几秒钟生成一次的自定义事件。您可以通过命名来创建自定事件:
78# Create the screen object
79# The size is determined by the constant SCREEN_WIDTH and SCREEN_HEIGHT
80screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))
81
82# Create a custom event for adding a new enemy 83ADDENEMY = pygame.USEREVENT + 1 84pygame.time.set_timer(ADDENEMY, 250) 85
86# Instantiate player. Right now, this is just a rectangle.
87player = Player()
pygame内部将事件定义为整数,所以需要用唯一的整数定义一个新的事件。保留的最后一个事件pygame被称为USEREVENT,因此在第 83 行定义ADDENEMY = pygame.USEREVENT + 1可以确保它是唯一的。
接下来,您需要在整个游戏中以固定的间隔将这个新事件插入到事件队列中。这就是 time 模块的用武之地。第 84 行每 250 毫秒触发一次新的ADDENEMY事件,即每秒四次。你在游戏循环之外调用.set_timer(),因为你只需要一个定时器,但是它会在整个游戏中触发。
添加处理新事件的代码:
100# Main loop
101while running:
102 # Look at every event in the queue
103 for event in pygame.event.get():
104 # Did the user hit a key?
105 if event.type == KEYDOWN:
106 # Was it the Escape key? If so, stop the loop.
107 if event.key == K_ESCAPE:
108 running = False
109
110 # Did the user click the window close button? If so, stop the loop.
111 elif event.type == QUIT:
112 running = False
113
114 # Add a new enemy? 115 elif event.type == ADDENEMY: 116 # Create the new enemy and add it to sprite groups 117 new_enemy = Enemy() 118 enemies.add(new_enemy) 119 all_sprites.add(new_enemy) 120
121 # Get the set of keys pressed and check for user input
122 pressed_keys = pygame.key.get_pressed()
123 player.update(pressed_keys)
124
125 # Update enemy position 126 enemies.update()
每当事件处理程序在第 115 行看到新的ADDENEMY事件时,它就创建一个Enemy并将它添加到enemies和all_sprites中。因为Enemy在all_sprites里,所以每一帧都会被画出来。您还需要调用第 126 行的enemies.update(),它更新enemies中的所有内容,以确保它们正确移动:
然而,这并不是仅仅为enemies而成立团体的唯一原因。
碰撞检测
你的游戏设计要求每当敌人与玩家发生冲突时游戏就结束。检查碰撞是游戏编程的基本技术,通常需要一些非平凡的数学来确定两个精灵是否会相互重叠。
这就是像pygame这样的框架派上用场的地方!编写碰撞检测代码很繁琐,但是pygame有很多碰撞检测方法可供您使用。
对于本教程,您将使用一个名为 .spritecollideany() 的方法,读作“sprite collide any”这个方法接受一个Sprite和一个Group作为参数。它查看Group中的每个对象,并检查其.rect是否与Sprite的.rect相交。如果是,那么它返回True。否则返回False。这对这个游戏来说是完美的,因为你需要检查单个player是否与enemies中的一个Group碰撞。
代码看起来是这样的:
130# Draw all sprites
131for entity in all_sprites:
132 screen.blit(entity.surf, entity.rect)
133
134# Check if any enemies have collided with the player 135if pygame.sprite.spritecollideany(player, enemies): 136 # If so, then remove the player and stop the loop 137 player.kill() 138 running = False
第 135 行测试player是否与enemies中的任何物体发生碰撞。如果是这样,那么player.kill()被调用来从它所属的每个组中删除它。由于唯一被渲染的对象在all_sprites中,player将不再被渲染。一旦玩家被杀死,你也需要退出游戏,所以你在第 138 行设置running = False来退出游戏循环。
至此,您已经具备了游戏的基本要素:
现在,让我们稍微打扮一下,让它更具可玩性,并添加一些高级功能来帮助它脱颖而出。
精灵图像
好吧,你有一个游戏,但是说实话……它有点丑。玩家和敌人只是黑色背景上的白色方块。当 Pong 还是新产品的时候,这是最先进的技术,但现在已经不再适用了。让我们用一些更酷的图片来取代那些无聊的白色矩形,让游戏看起来像一个真实的游戏。
前面,您已经了解到,在image模块的帮助下,磁盘上的图像可以加载到Surface中。在本教程中,我们为玩家制作了一架小型喷气式飞机,为敌人制作了一些导弹。欢迎你使用这种艺术,画你自己的,或者下载一些免费游戏艺术资产来使用。您可以单击下面的链接下载本教程中使用的图片:
示例代码: 单击此处下载本教程中使用的 PyGame 示例项目的源代码。
改变对象构造函数
在使用图像来表示玩家和敌人的精灵之前,您需要对它们的构造函数进行一些更改。下面的代码替换了以前使用的代码:
7# Import pygame.locals for easier access to key coordinates
8# Updated to conform to flake8 and black standards
9# from pygame.locals import *
10from pygame.locals import (
11 RLEACCEL, 12 K_UP,
13 K_DOWN,
14 K_LEFT,
15 K_RIGHT,
16 K_ESCAPE,
17 KEYDOWN,
18 QUIT,
19)
20
21# Define constants for the screen width and height
22SCREEN_WIDTH = 800
23SCREEN_HEIGHT = 600
24
25
26# Define the Player object by extending pygame.sprite.Sprite
27# Instead of a surface, use an image for a better-looking sprite
28class Player(pygame.sprite.Sprite):
29 def __init__(self):
30 super(Player, self).__init__()
31 self.surf = pygame.image.load("jet.png").convert() 32 self.surf.set_colorkey((255, 255, 255), RLEACCEL) 33 self.rect = self.surf.get_rect()
让我们打开第 31 行的包装。pygame.image.load()从磁盘加载图像。你把文件的路径传递给它。它返回一个Surface,.convert()调用优化了Surface,使得未来的.blit()调用更快。
第 32 行使用.set_colorkey()表示颜色pygame将呈现为透明。在这种情况下,您选择白色,因为这是 jet 图像的背景色。 RLEACCEL 常量是一个可选参数,帮助pygame在非加速显示器上更快地渲染。这被添加到第 11 行的pygame.locals导入语句中。
其他都不需要改变。图像仍然是一个Surface,只不过现在上面画了一张图片。你仍然用同样的方式使用它。
下面是与Enemy类似的变化:
59# Define the enemy object by extending pygame.sprite.Sprite
60# Instead of a surface, use an image for a better-looking sprite
61class Enemy(pygame.sprite.Sprite):
62 def __init__(self):
63 super(Enemy, self).__init__()
64 self.surf = pygame.image.load("missile.png").convert() 65 self.surf.set_colorkey((255, 255, 255), RLEACCEL) 66 # The starting position is randomly generated, as is the speed
67 self.rect = self.surf.get_rect(
68 center=(
69 random.randint(SCREEN_WIDTH + 20, SCREEN_WIDTH + 100),
70 random.randint(0, SCREEN_HEIGHT),
71 )
72 )
73 self.speed = random.randint(5, 20)
现在运行程序应该会显示这是你以前玩过的同一个游戏,除了现在你已经添加了一些漂亮的图形皮肤和图像。但是为什么仅仅让玩家和敌人的精灵看起来漂亮呢?让我们添加一些经过的云,给人一种喷气机飞过天空的感觉。
添加背景图像
对于背景云,你使用与Player和Enemy相同的原则:
- 创建
Cloud类。 - 给它添加一个云的图像。
- 创建一个方法
.update(),将cloud向屏幕左侧移动。 - 创建一个自定义事件和处理程序,以在设定的时间间隔创建新的
cloud对象。 - 将新创建的
cloud对象添加到名为clouds的新Group中。 - 更新并绘制游戏循环中的
clouds。
下面是Cloud的样子:
83# Define the cloud object by extending pygame.sprite.Sprite
84# Use an image for a better-looking sprite
85class Cloud(pygame.sprite.Sprite):
86 def __init__(self):
87 super(Cloud, self).__init__()
88 self.surf = pygame.image.load("cloud.png").convert()
89 self.surf.set_colorkey((0, 0, 0), RLEACCEL)
90 # The starting position is randomly generated
91 self.rect = self.surf.get_rect(
92 center=(
93 random.randint(SCREEN_WIDTH + 20, SCREEN_WIDTH + 100),
94 random.randint(0, SCREEN_HEIGHT),
95 )
96 )
97
98 # Move the cloud based on a constant speed
99 # Remove the cloud when it passes the left edge of the screen
100 def update(self):
101 self.rect.move_ip(-5, 0)
102 if self.rect.right < 0:
103 self.kill()
这看起来应该很熟悉。和Enemy差不多。
要让云以一定的间隔出现,您将使用与创建新敌人类似的事件创建代码。放在敌人创造事件的正下方:
116# Create custom events for adding a new enemy and a cloud
117ADDENEMY = pygame.USEREVENT + 1
118pygame.time.set_timer(ADDENEMY, 250)
119ADDCLOUD = pygame.USEREVENT + 2 120pygame.time.set_timer(ADDCLOUD, 1000)
这意味着在创建下一个cloud之前要等待 1000 毫秒,或者一秒钟。
接下来,创建一个新的Group来保存每个新创建的cloud:
125# Create groups to hold enemy sprites, cloud sprites, and all sprites
126# - enemies is used for collision detection and position updates
127# - clouds is used for position updates
128# - all_sprites is used for rendering
129enemies = pygame.sprite.Group()
130clouds = pygame.sprite.Group() 131all_sprites = pygame.sprite.Group()
132all_sprites.add(player)
接下来,在事件处理程序中为新的ADDCLOUD事件添加一个处理程序:
137# Main loop
138while running:
139 # Look at every event in the queue
140 for event in pygame.event.get():
141 # Did the user hit a key?
142 if event.type == KEYDOWN:
143 # Was it the Escape key? If so, then stop the loop.
144 if event.key == K_ESCAPE:
145 running = False
146
147 # Did the user click the window close button? If so, stop the loop.
148 elif event.type == QUIT:
149 running = False
150
151 # Add a new enemy?
152 elif event.type == ADDENEMY:
153 # Create the new enemy and add it to sprite groups
154 new_enemy = Enemy()
155 enemies.add(new_enemy)
156 all_sprites.add(new_enemy)
157
158 # Add a new cloud? 159 elif event.type == ADDCLOUD: 160 # Create the new cloud and add it to sprite groups 161 new_cloud = Cloud() 162 clouds.add(new_cloud) 163 all_sprites.add(new_cloud)
最后,确保每一帧都更新clouds:
167# Update the position of enemies and clouds
168enemies.update()
169clouds.update() 170
171# Fill the screen with sky blue
172screen.fill((135, 206, 250))
第 172 行更新了原来的screen.fill(),用令人愉快的天蓝色填充屏幕。你可以把这个颜色换成别的颜色。也许你想要一个紫色天空的外星世界,霓虹绿色的有毒荒地,或者红色的火星表面!
注意,每个新的Cloud和Enemy都被添加到all_sprites以及clouds和enemies中。这样做是因为每个组都有单独的用途:
- 渲染是用
all_sprites完成的。 - 位置更新使用
clouds和enemies完成。 - 碰撞检测使用
enemies完成。
您可以创建多个组,以便可以更改精灵移动或行为的方式,而不会影响其他精灵的移动或行为。
游戏速度
在测试游戏的时候,你可能已经注意到敌人移动的有点快。如果没有,那也没关系,因为不同的机器在这一点上会看到不同的结果。
原因是游戏循环以处理器和环境允许的最快速度处理帧。由于所有精灵每帧移动一次,它们每秒可以移动数百次。每秒处理的帧数被称为帧率,正确处理这一点是一个可玩的游戏和一个可遗忘的游戏之间的区别。
通常情况下,你想要尽可能高的帧率,但对于这个游戏,你需要放慢一点速度,让游戏可以玩。幸运的是,模块time包含一个 Clock 正是为此目的而设计的。
使用Clock来建立一个可播放的帧速率只需要两行代码。第一个在游戏循环开始前创建一个新的Clock:
106# Setup the clock for a decent framerate
107clock = pygame.time.Clock()
第二个调用.tick()通知pygame程序已经到达帧的末尾:
188# Flip everything to the display
189pygame.display.flip()
190
191# Ensure program maintains a rate of 30 frames per second 192clock.tick(30)
传递给.tick()的参数确定了所需的帧速率。为此,.tick()根据所需的帧速率,计算每帧应该花费的毫秒数。然后,它将这个数字与上次调用.tick()以来经过的毫秒数进行比较。如果没有经过足够的时间,那么.tick()延迟处理,以确保它永远不会超过指定的帧速率。
传入较小的帧速率会导致每帧有更多的时间用于计算,而较大的帧速率会提供更流畅(也可能更快)的游戏体验:
玩玩这个数字,看看什么最适合你!
音效
到目前为止,你已经专注于游戏性和游戏的视觉方面。现在让我们来探索给你的游戏一些听觉的味道。pygame提供了 mixer 来处理所有与声音相关的活动。您将使用这个模块的类和方法为各种动作提供背景音乐和声音效果。
名字mixer指的是该模块将各种声音混合成一个有凝聚力的整体。使用 music 子模块,您可以以多种格式传输单个声音文件,例如 MP3 、 Ogg 和 Mod 。你也可以使用Sound来保存一个要播放的音效,无论是 Ogg 还是未压缩的 WAV 格式。所有回放都在后台进行,因此当您播放一个Sound时,该方法会在声音播放时立即返回。
注意:pygame文档声明 MP3 支持是有限的,不支持的格式会导致系统崩溃。本文中引用的声音已经过测试,我们建议在发布游戏之前彻底测试所有声音。
和大多数东西pygame一样,使用mixer从一个初始化步骤开始。幸运的是,这已经由pygame.init()处理了。如果您想更改默认值,只需调用pygame.mixer.init():
106# Setup for sounds. Defaults are good. 107pygame.mixer.init() 108
109# Initialize pygame
110pygame.init()
111
112# Set up the clock for a decent framerate
113clock = pygame.time.Clock()
pygame.mixer.init()接受一些参数,但是默认参数在大多数情况下工作良好。注意,如果你想改变默认值,你需要在调用pygame.init()之前调用pygame.mixer.init()。否则,无论您如何更改,默认值都将生效。
系统初始化后,您可以设置声音和背景音乐:
135# Load and play background music
136# Sound source: http://ccmixter.org/files/Apoxode/59262
137# License: https://creativecommons.org/licenses/by/3.0/
138pygame.mixer.music.load("Apoxode_-_Electric_1.mp3")
139pygame.mixer.music.play(loops=-1)
140
141# Load all sound files
142# Sound sources: Jon Fincher
143move_up_sound = pygame.mixer.Sound("Rising_putter.ogg")
144move_down_sound = pygame.mixer.Sound("Falling_putter.ogg")
145collision_sound = pygame.mixer.Sound("Collision.ogg")
第 138 和 139 行加载一个背景声音剪辑并开始播放。您可以通过设置命名参数loops=-1来告诉声音剪辑循环播放并且永不结束。
第 143 行到第 145 行加载了三种你将用于各种音效的声音。前两个是上升和下降的声音,当玩家向上或向下移动时播放。最后是每当发生碰撞时使用的声音。你也可以添加其他声音,比如创建Enemy时的声音,或者游戏结束时的最后声音。
那么,你是如何使用音效的呢?您希望在某个事件发生时播放每个声音。比如船往上走,你想玩move_up_sound。因此,无论何时处理该事件,都要添加对.play()的调用。在设计中,这意味着为Player添加以下对.update()的调用:
26# Define the Player object by extending pygame.sprite.Sprite
27# Instead of a surface, use an image for a better-looking sprite
28class Player(pygame.sprite.Sprite):
29 def __init__(self):
30 super(Player, self).__init__()
31 self.surf = pygame.image.load("jet.png").convert()
32 self.surf.set_colorkey((255, 255, 255), RLEACCEL)
33 self.rect = self.surf.get_rect()
34
35 # Move the sprite based on keypresses
36 def update(self, pressed_keys):
37 if pressed_keys[K_UP]:
38 self.rect.move_ip(0, -5)
39 move_up_sound.play() 40 if pressed_keys[K_DOWN]:
41 self.rect.move_ip(0, 5)
42 move_down_sound.play()
对于玩家和敌人之间的碰撞,当检测到碰撞时播放声音:
201# Check if any enemies have collided with the player
202if pygame.sprite.spritecollideany(player, enemies):
203 # If so, then remove the player
204 player.kill()
205
206 # Stop any moving sounds and play the collision sound
207 move_up_sound.stop() 208 move_down_sound.stop() 209 collision_sound.play() 210
211 # Stop the loop
212 running = False
在这里,您首先停止任何其他声音效果,因为在碰撞中玩家不再移动。然后播放碰撞声,从那里继续执行。
最后,当游戏结束时,所有的声音都应该停止。无论游戏是因为碰撞而结束,还是用户手动退出,都是如此。为此,请在循环后的程序末尾添加以下行:
220# All done! Stop and quit the mixer.
221pygame.mixer.music.stop()
222pygame.mixer.quit()
从技术上讲,最后几行是不需要的,因为程序在这之后就结束了。然而,如果你决定在游戏中添加一个介绍界面或者退出界面,那么在游戏结束后可能会有更多的代码运行。
就是这样!再次测试,您应该会看到类似这样的内容:
关于来源的说明
您可能已经注意到在加载背景音乐时第 136-137 行的注释,列出了音乐的来源和到 Creative Commons 许可证的链接。这样做是因为声音的创造者需要它。许可证要求声明,为了使用声音,必须提供正确的属性和到许可证的链接。
以下是一些音乐、声音和艺术资源,您可以从中搜索有用的内容:
- OpenGameArt.org: 声音、音效、精灵和其他作品
- Kenney.nl: 声音、音效、精灵和其他作品
- 玩家艺术 2D: 小妖精和其他艺术品
- CC Mixter: 声音和音效
- Freesound: 声音和音效
当您制作游戏和使用从其他来源下载的内容(如艺术、音乐或代码)时,请确保您遵守这些来源的许可条款。
结论
在本教程中,你已经了解了用pygame进行游戏编程与标准程序编程的不同之处。您还学习了如何:
- 实现事件循环
- 在屏幕上绘制项目
- 播放音效和音乐
- 处理用户输入
为此,您使用了pygame模块的子集,包括display、mixer和music、time、image、event和key模块。您还使用了几个pygame类,包括Rect、Surface、Sound和Sprite。但是这些仅仅触及了pygame所能做的事情的表面!查看官方pygame文档以获得可用模块和类的完整列表。
您可以通过单击下面的链接找到本文的所有代码、图形和声音文件:
示例代码: 单击此处下载本教程中使用的 PyGame 示例项目的源代码。
欢迎在下面留下你的评论。快乐的蟒蛇!
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 用 PyGame 制作一个 2D 侧滚游戏********
使用 PyInstaller 轻松发布 Python 应用程序
原文:# t0]https://realython . com/pyinstaller-python/
你是否嫉妒开发人员构建一个可执行程序并轻松地将其发布给用户?如果你的用户不需要安装任何东西就可以运行你的应用程序,这不是很好吗?这就是梦想,而 PyInstaller 是在 Python 生态系统中实现梦想的一种方式。
关于如何建立虚拟环境、管理依赖关系、避免依赖陷阱以及发布到 PyPI 有无数的教程,这在你创建 Python 库时很有用。对于构建 Python 应用程序的开发者来说,信息少得多。本教程是为那些想将应用程序分发给用户的开发人员编写的,这些用户可能是也可能不是 Python 开发人员。
在本教程中,您将学习以下内容:
- PyInstaller 如何简化应用程序分发
- 如何在自己的项目中使用 PyInstaller
- 如何调试 PyInstaller 错误
- PyInstaller 做不到的
PyInstaller 让你能够创建一个文件夹或可执行文件,用户无需额外安装就可以立即运行。为了充分理解 PyInstaller 的强大功能,回顾一下 PyInstaller 帮助您避免的一些发行版问题是很有用的。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
分配问题
建立一个 Python 项目可能会令人沮丧,尤其是对于非开发人员来说。通常,设置从打开终端开始,这对于一大群潜在用户来说是不可能的。这个障碍甚至在安装指南深入研究虚拟环境、Python 版本和无数潜在依赖项的复杂细节之前就阻止了用户。
考虑一下在为 Python 开发设置一台新机器时通常会经历什么。大概是这样的:
- 下载并安装特定版本的 Python
- 设置 pip
- 设置虚拟环境
- 获取代码的副本
- 安装依赖项
停下来想一想,如果你不是开发人员,更不用说 Python 开发人员,上述步骤是否有意义。大概不会。
如果您的用户足够幸运地到达安装的依赖部分,这些问题就会爆发。随着 wheels 的流行,这在过去几年中已经变得更好了,但是一些依赖项仍然需要 C/C++甚至 FORTRAN 编译器!
如果你的目标是让尽可能多的用户使用一个应用程序,那么这个门槛太高了。正如 Raymond Hettinger 在他的精彩演讲中经常说的,“一定有更好的方法。”
PyInstaller
PyInstaller 通过找到你所有的依赖项并把它们捆绑在一起,从用户那里抽象出这些细节。你的用户甚至不会知道他们正在运行一个 Python 项目,因为 Python 解释器本身就捆绑在你的应用程序中。再见复杂的安装说明!
PyInstaller 通过自省您的 Python 代码,检测您的依赖项,然后根据您的操作系统将它们打包成合适的格式,来完成这一惊人的壮举。
关于 PyInstaller 有很多有趣的细节,但是现在您将学习它如何工作以及如何使用它的基础知识。如果您想了解更多细节,您可以随时参考优秀的 PyInstaller 文档。
此外,PyInstaller 可以为 Windows、Linux 或 macOS 创建可执行文件。这意味着 Windows 用户将获得一个.exe,Linux 用户将获得一个常规的可执行文件,macOS 用户将获得一个.app包。对此有一些警告。更多信息参见限制部分。
准备您的项目
PyInstaller 要求您的应用程序符合一些最小的结构,即您有一个 CLI 脚本来启动您的应用程序。通常,这意味着在你的 Python 包的之外创建一个小脚本,它简单地导入你的包并运行main()。
入口点脚本是一个 Python 脚本。从技术上讲,您可以在入口点脚本中做任何您想做的事情,但是您应该避免使用显式相对导入。如果您喜欢的话,您仍然可以在应用程序的其余部分使用相对导入。
注意:入口点是启动项目或应用程序的代码。
您可以在自己的项目中尝试一下,或者跟随 Real Python feed reader 项目。关于阅读器项目的更多详细信息,请查看关于在 PyPI 上发布包的教程。
构建该项目的可执行版本的第一步是添加入口点脚本。幸运的是,feed reader 项目结构良好,所以你只需要在包外面有一个简短的脚本来运行它。例如,您可以使用以下代码在 reader 包旁边创建一个名为cli.py的文件:
from reader.__main__ import main
if __name__ == '__main__':
main()
这个cli.py脚本调用main()来启动提要阅读器。
当您在自己的项目中工作时,创建这个入口点脚本很简单,因为您对代码很熟悉。然而,找到另一个人的代码的入口点并不容易。在这种情况下,你可以从查看第三方项目中的setup.py文件开始。
在项目的setup.py中查找对entry_points参数的引用。例如,这是读者项目的setup.py:
setup(
name="realpython-reader",
version="1.0.0",
description="Read the latest Real Python tutorials",
long_description=README,
long_description_content_type="text/markdown",
url="https://github.com/realpython/reader",
author="Real Python",
author_email="info@realpython.com",
license="MIT",
classifiers=[
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 3",
],
packages=["reader"],
include_package_data=True,
install_requires=[
"feedparser", "html2text", "importlib_resources", "typing"
],
entry_points={"console_scripts": ["realpython=reader.__main__:main"]},
)
如您所见,入口点cli.py脚本调用了entry_points参数中提到的同一个函数。
更改之后,reader 项目目录应该如下所示,假设您将它签出到一个名为reader的文件夹中:
reader/
|
├── reader/
| ├── __init__.py
| ├── __main__.py
| ├── config.cfg
| ├── feed.py
| └── viewer.py
|
├── cli.py
├── LICENSE
├── MANIFEST.in
├── README.md
├── setup.py
└── tests
注意,阅读器代码本身没有变化,只是一个名为cli.py的新文件。这个入口点脚本通常是在 PyInstaller 中使用您的项目所必需的。
然而,您还需要注意在函数内部使用__import__()或导入。在 PyInstaller 术语中,这些被称为隐藏导入。
如果在您的应用程序中更改导入非常困难,您可以手动指定隐藏的导入来强制 PyInstaller 包含这些依赖项。在本教程的后面,您将看到如何做到这一点。
一旦您可以在包的之外使用 Python 脚本启动您的应用程序,您就可以尝试让 PyInstaller 创建一个可执行文件了。
使用 PyInstaller
第一步是从 PyPI 安装 PyInstaller。你可以像使用其他 Python 包一样使用pip来完成这项工作:
$ pip install pyinstaller
pip将安装 PyInstaller 的依赖项以及一个新命令:pyinstaller。PyInstaller 可以导入到 Python 代码中,并作为一个库使用,但您可能只会将它用作 CLI 工具。
如果你创建你自己的钩子文件,你将使用库接口。
如果您只有纯 Python 依赖,您将增加 PyInstaller 默认创建可执行文件的可能性。然而,如果你对 C/C++扩展有更复杂的依赖,不要太紧张。
PyInstaller 支持许多流行的软件包,如 NumPy 、 PyQt 和 Matplotlib ,而不需要您做任何额外的工作。通过参考 PyInstaller 文档,可以看到更多关于 PyInstaller 官方支持的包列表。
如果您的一些依赖项没有列在官方文档中,也不用担心。许多 Python 包工作良好。事实上,PyInstaller 非常受欢迎,许多项目都解释了如何使用 PyInstaller。
简而言之,你的项目打破常规的几率很高。
要尝试使用所有默认设置创建可执行文件,只需给 PyInstaller 主入口点脚本的名称。
首先,将cd放入带有您的入口点的文件夹中,并将其作为参数传递给安装 PyInstaller 时添加到您的 PATH 中的pyinstaller命令。
例如,如果您正在跟踪 feed reader 项目,请在顶层reader目录中的cd之后键入以下内容:
$ pyinstaller cli.py
如果您在构建可执行文件时看到大量输出,不要惊慌。默认情况下,PyInstaller 是冗长的,可以通过调试来提高冗长度,稍后您将看到这一点。
挖掘 PyInstaller 工件
PyInstaller 很复杂,会产生大量输出。所以,知道先关注什么很重要。也就是可以分发给用户的可执行文件和潜在的调试信息。默认情况下,pyinstaller命令会创建一些感兴趣的东西:
- 一个
*.spec文件 - 一个
build/文件夹 - 一个
dist/文件夹
规格文件
默认情况下,规范文件将以您的 CLI 脚本命名。继续我们之前的例子,您会看到一个名为cli.spec的文件。在对cli.py文件运行 PyInstaller 之后,默认的 spec 文件看起来是这样的:
# -*- mode: python -*-
block_cipher = None
a = Analysis(['cli.py'],
pathex=['/Users/realpython/pyinstaller/reader'],
binaries=[],
datas=[],
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
[],
exclude_binaries=True,
name='cli',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=True )
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
name='cli')
该文件将由pyinstaller命令自动创建。您的版本将有不同的路径,但大多数应该是相同的。
不要担心,您不需要理解上面的代码就可以有效地使用 PyInstaller!
这个文件可以修改,并在以后创建可执行文件时重用。通过向pyinstaller命令提供这个 spec 文件而不是入口点脚本,可以使未来的构建更快一些。
PyInstaller 规范文件有一些特定的用例。然而,对于简单的项目,您不需要担心这些细节,除非您想要大量定制您的项目是如何构建的。
构建文件夹
文件夹build/是 PyInstaller 放置大部分元数据和内部簿记的地方,用于构建您的可执行文件。默认内容如下所示:
build/
|
└── cli/
├── Analysis-00.toc
├── base_library.zip
├── COLLECT-00.toc
├── EXE-00.toc
├── PKG-00.pkg
├── PKG-00.toc
├── PYZ-00.pyz
├── PYZ-00.toc
├── warn-cli.txt
└── xref-cli.html
build 文件夹对于调试很有用,但是除非您遇到问题,否则这个文件夹很大程度上可以被忽略。在本教程的后面,您将了解更多关于调试的内容。
Dist Folder
构建完成后,您将得到一个类似如下的dist/文件夹:
dist/
|
└── cli/
└── cli
dist/文件夹包含您想要发送给用户的最终工件。在dist/文件夹中,有一个以您的入口点命名的文件夹。所以在这个例子中,您将有一个dist/cli文件夹,其中包含我们应用程序的所有依赖项和可执行文件。运行的可执行文件是dist/cli/cli或dist/cli/cli.exe,如果你在 Windows 上的话。
根据您的操作系统,您还会发现许多扩展名为.so、.pyd和.dll的文件。这些共享库代表 PyInstaller 创建和收集的项目的依赖项。
注意:如果您使用git进行版本控制,您可以将*.spec、build/和dist/添加到您的.gitignore文件中,以保持git status的整洁。Python 项目的默认 GitHub gitignore 文件已经为您完成了这项工作。
您将希望分发整个dist/cli文件夹,但是您可以将cli重命名为任何适合您的名称。
此时,如果您遵循提要阅读器示例,您可以尝试运行dist/cli/cli可执行文件。
您会注意到,运行可执行文件会导致提及version.txt文件的错误。这是因为提要阅读器及其依赖项需要一些 PyInstaller 不知道的额外数据文件。要解决这个问题,您必须告诉 PyInstaller 需要version.txt,您将在测试您的新可执行文件时了解到这一点。
定制您的构建
PyInstaller 附带了许多选项,可以作为规范文件或普通 CLI 选项提供。下面,你会发现一些最常见和最有用的选项。
--name
更改可执行文件的名称。
这是一种避免您的可执行文件、规范文件和构建工件文件夹以您的入口点脚本命名的方法。如果您像我一样习惯于将您的入口点脚本命名为类似于cli.py的名称,那么--name是非常有用的。
您可以使用如下命令从cli.py脚本构建一个名为realpython的可执行文件:
$ pyinstaller cli.py --name realpython
--onefile
将整个应用程序打包成一个可执行文件。
默认选项创建一个依赖项和以及可执行文件的文件夹,而--onefile通过只创建和一个可执行文件来简化发布。
该选项没有参数。要将您的项目捆绑到一个文件中,您可以使用如下命令进行构建:
$ pyinstaller cli.py --onefile
使用上面的命令,您的dist/文件夹将只包含一个可执行文件,而不是一个包含所有独立文件的文件夹。
--hidden-import
列出 PyInstaller 无法自动检测的多个顶级导入。
这是使用import内部函数和__import__()解决代码问题的一种方法。你也可以在同一个命令中多次使用--hidden-import。
此选项需要您要包含在可执行文件中的包的名称。例如,如果您的项目在一个函数中导入了请求库,那么 PyInstaller 不会自动将requests包含在您的可执行文件中。您可以使用以下命令强制包含requests:
$ pyinstaller cli.py --hiddenimport=requests
您可以在构建命令中多次指定该选项,每个隐藏导入指定一次。
--add-data和--add-binary
指示 PyInstaller 将附加数据或二进制文件插入到您的构建中。
当您想要捆绑配置文件、示例或其他非代码数据时,这很有用。如果您一直关注 feed reader 项目,稍后将会看到一个这样的例子。
--exclude-module
从可执行文件中排除一些模块
这有助于排除开发人员专用的需求,如测试框架。这是一个让你给用户的工件尽可能小的好方法。例如,如果您使用 pytest ,您可能希望将其从您的可执行文件中排除:
$ pyinstaller cli.py --exclude-module=pytest
-w
避免自动打开控制台窗口进行
stdout记录。
这只有在构建支持 GUI 的应用程序时才有用。通过允许用户永远看不到终端,这有助于隐藏实现的细节。
类似于--onefile选项,-w没有参数:
$ pyinstaller cli.py -w
.spec file
如前所述,您可以重用自动生成的.spec文件来进一步定制您的可执行文件。.spec文件是一个普通的 Python 脚本,它隐式地使用 PyInstaller 库 API。
因为它是一个普通的 Python 脚本,所以你可以在里面做任何事情。你可以参考官方的 PyInstaller 规范文档来获得更多关于这个 API 的信息。
测试新的可执行文件
测试新的可执行文件的最好方法是在一台新机器上。新机器应该与您的构建机器具有相同的操作系统。理想情况下,这台机器应该尽可能与你的用户使用的相似。这并不总是可能的,所以下一个最好的方法是在您自己的机器上进行测试。
关键是在没有激活开发环境的情况下运行生成的可执行文件。这意味着在没有virtualenv、conda或任何其他能够访问您的 Python 安装的环境的情况下运行。记住,PyInstaller 创建的可执行文件的主要目标之一是让用户不需要在他们的机器上安装任何东西。
以提要阅读器为例,您会注意到在dist/cli文件夹中运行默认的cli可执行文件会失败。幸运的是,这个错误指出了问题所在:
FileNotFoundError: 'version.txt' resource not found in 'importlib_resources'
[15110] Failed to execute script cli
importlib_resources包需要一个version.txt文件。您可以使用--add-data选项将这个文件添加到构建中。下面是如何包含所需的version.txt文件的示例:
$ pyinstaller cli.py \
--add-data venv/reader/lib/python3.6/site-packages/importlib_resources/version.txt:importlib_resources
这个命令告诉 PyInstaller 将importlib_resources文件夹中的version.txt文件包含在您的构建中一个名为importlib_resources的新文件夹中。
注意:pyinstaller命令使用\字符使命令更容易阅读。如果您使用相同的路径,您可以在自己运行命令时省略\,或者复制并粘贴下面的命令。
您需要调整上述命令中的路径,以匹配安装提要阅读器依赖项的位置。
现在运行新的可执行文件将导致一个关于config.cfg文件的新错误。
这个文件是 feed reader 项目所必需的,因此您需要确保将它包含在您的构建中:
$ pyinstaller cli.py \
--add-data venv/reader/lib/python3.6/site-packages/importlib_resources/version.txt:importlib_resources \
--add-data reader/config.cfg:reader
同样,您需要根据 feed reader 项目所在的位置来调整文件的路径。
此时,您应该有一个可以直接提供给用户的工作可执行文件了!
调试 PyInstaller 可执行文件
正如您在上面看到的,您可能会在运行可执行文件时遇到问题。根据项目的复杂程度,修复可以简单到包括像提要阅读器示例这样的数据文件。然而,有时你需要更多的调试技巧。
以下是一些常见的策略,排名不分先后。通常情况下,这些策略中的一个或一个组合会在艰难的调试过程中带来突破。
使用终端
首先,尝试从终端运行可执行文件,这样就可以看到所有的输出。
记得移除-w构建标志,以便在控制台窗口中查看所有的stdout。通常,如果缺少依赖项,您会看到ImportError异常。
调试文件
检查build/cli/warn-cli.txt文件是否有问题。PyInstaller 创建了大量的输出来帮助你理解它到底在创建什么。在build/文件夹中挖掘是一个很好的起点。
单一目录构建
使用--onedir分发模式创建分发文件夹,而不是单个可执行文件。同样,这是默认模式。用--onedir构建让你有机会检查所有包含的依赖项,而不是所有东西都隐藏在一个可执行文件中。
--onedir对于调试很有用,但是--onefile通常更容易让用户理解。调试之后,你可能想切换到--onefile模式来简化发布。
其他 CLI 选项
PyInstaller 还可以控制构建过程中打印的信息量。使用 PyInstaller 的--log-level=DEBUG选项重新构建可执行文件,并查看输出。
当用--log-level=DEBUG增加详细程度时,PyInstaller 将创建大量的输出。将此输出保存到一个文件中很有用,您可以稍后参考,而不是在您的终端中滚动。为此,您可以使用您的 shell 的重定向功能。这里有一个例子:
$ pyinstaller --log-level=DEBUG cli.py 2> build.txt
通过使用上面的命令,您将拥有一个名为build.txt的文件,其中包含许多额外的DEBUG消息。
注意:带>的标准重定向是不够的。PyInstaller 打印到stderr流,而不是 stdout。这意味着您需要将stderr流重定向到一个文件,这可以使用前面命令中的2来完成。
下面是您的build.txt文件的一个示例:
67 INFO: PyInstaller: 3.4
67 INFO: Python: 3.6.6
73 INFO: Platform: Darwin-18.2.0-x86_64-i386-64bit
74 INFO: wrote /Users/realpython/pyinstaller/reader/cli.spec
74 DEBUG: Testing for UPX ...
77 INFO: UPX is not available.
78 DEBUG: script: /Users/realptyhon/pyinstaller/reader/cli.py
78 INFO: Extending PYTHONPATH with paths
['/Users/realpython/pyinstaller/reader',
'/Users/realpython/pyinstaller/reader']
这个文件包含了很多详细的信息,比如你的构建中包含了什么,为什么没有包含什么,以及可执行文件是如何打包的。
除了使用--log-level选项获取更多信息之外,您还可以使用--debug选项重新构建您的可执行文件。
注意:-y和--clean选项在重建时很有用,尤其是在最初配置您的构建或者用持续集成构建时。这些选项删除了旧的构建,并且在构建过程中不需要用户输入。
附加 PyInstaller 文档
PyInstaller GitHub Wiki 有很多有用的链接和调试技巧。最值得注意的是关于确保所有东西都正确包装和如果事情出错该怎么做的部分。
协助依赖性检测
如果 PyInstaller 不能正确地检测到所有的依赖项,您将看到的最常见的问题是ImportError异常。如前所述,如果你正在使用__import__(),函数内部的导入,或者其他类型的隐藏导入,就会发生这种情况。
许多这类问题可以通过使用--hidden-import PyInstaller CLI 选项来解决。这告诉 PyInstaller 包含一个模块或包,即使它没有自动检测到它。这是在你的应用程序中解决大量动态导入魔法的最简单的方法。
另一种解决问题的方法是钩子文件。这些文件包含帮助 PyInstaller 打包依赖项的附加信息。您可以编写自己的钩子,并告诉 PyInstaller 通过--additional-hooks-dir CLI 选项来使用它们。
钩子文件是 PyInstaller 内部工作的方式,所以你可以在 PyInstaller 源代码中找到很多钩子文件的例子。
局限性
PyInstaller 非常强大,但是它也有一些限制。前面已经讨论过一些限制:入口点脚本中的隐藏导入和相对导入。
PyInstaller 支持为 Windows、Linux 和 macOS 制作可执行文件,但是它不能交叉编译。因此,您不能从一个操作系统创建针对另一个操作系统的可执行文件。因此,要为多种类型的操作系统分发可执行文件,您需要为每种支持的操作系统创建一台构建机器。
与交叉编译限制相关,知道 PyInstaller 在技术上不完全捆绑您的应用程序运行所需的一切是有用的。您的可执行文件仍然依赖于用户的 glibc 。通常情况下,您可以通过构建每一个目标操作系统的最老版本来绕过glibc限制。
例如,如果您想要针对各种各样的 Linux 机器,那么您可以构建一个旧版本的 CentOS 。这将使您能够兼容比您构建的版本更新的大多数版本。这与 PEP 0513 中描述的策略相同,也是 PyPA 对制造兼容车轮的建议。
事实上,您可能希望使用 PyPA 的 manylinux docker 映像来研究您的 linux 构建环境。您可以从基本映像开始,然后安装 PyInstaller 以及所有的依赖项,并拥有一个支持大多数 Linux 变体的构建映像。
结论
PyInstaller 可以使复杂的安装文档变得不必要。相反,您的用户可以简单地运行您的可执行文件来尽快开始。PyInstaller 工作流可以总结为执行以下操作:
- 创建一个调用主函数的入口点脚本。
- 安装 PyInstaller。
- 在您的入口点上运行 PyInstaller。
- 测试新的可执行文件。
- 将生成的
dist/文件夹发送给用户。
您的用户根本不需要知道您使用的是哪个版本的 Python,或者您的应用程序使用的是 Python!******
如何将开源 Python 包发布到 PyPI
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 如何将自己的 Python 包发布到 PyPI
Python 以自带电池而闻名,标准库中提供了许多复杂的功能。然而,为了释放这种语言的全部潜力,你也应该利用社区在PyPI:Python 打包索引上的贡献。
PyPI,通常读作 pie-pee-eye ,是一个包含几十万个包的仓库。这些范围从琐碎的 Hello, World 实现到高级的深度学习库。在本教程中,您将学习如何将自己的包上传到 PyPI 。发布项目比以前更容易了。然而,仍然有几个步骤。
在本教程中,您将学习如何:
- 准备您的 Python 包以供发布
- 处理您的包的版本控制
- 构建你的包,上传到 PyPI
- 理解并使用不同的构建系统
在本教程中,您将使用一个示例项目:一个reader包,可以用来在您的控制台中阅读真正的 Python 教程。在深入了解如何发布这个包之前,您将得到一个关于这个项目的快速介绍。点击下面的链接访问包含reader完整源代码的 GitHub 库:
获取源代码: 单击此处获取您将在本教程中使用的真正的 Python 提要阅读器的源代码。
了解 Python 打包
对于新手和经验丰富的老手来说,用 Python 打包看起来很复杂。你会在互联网上找到相互矛盾的建议,曾经被认为是好的做法现在可能会被人反对。
造成这种情况的主要原因是 Python 是一种相当古老的编程语言。事实上,Python 的第一个版本是在 1991 年发布的,那时,万维网还没有面向大众。自然,在 Python 的早期版本中,没有包括甚至没有计划一个现代的、基于网络的包分发系统。
相反,Python 的打包生态系统在过去几十年中随着用户需求的明确和技术提供新的可能性而有机地发展。第一个打包支持出现在 2000 年秋天,Python 1.6 和 2.0 中包含了 distutils 库。Python 打包索引(PyPI) 于 2003 年上线,最初是作为现有包的纯索引,没有任何托管能力。
注: PyPI 参照巨蟒剧团著名的奶酪店小品,常被称为巨蟒奶酪店。时至今日, cheeseshop.python.org 重定向到 PyPI。
在过去的十年里,许多倡议已经改善了包装景观,把它从蛮荒的西部和一个相当现代和有能力的系统。这主要是通过 Python 增强提案 (PEPs)来完成的,这些提案由 Python 打包管理局 (PyPA)工作组审查和实施。
定义 Python 打包如何工作的最重要的文档是以下 pep:
- PEP 427 描述了车轮应该如何包装。
- PEP 440 描述了如何解析版本号。
- PEP 508 描述了如何指定依赖关系。
- PEP 517 描述了一个构建后端应该如何工作。
- PEP 518 描述了如何指定一个构建系统。
- PEP 621 描述了项目元数据应该如何编写。
- PEP 660 描述了可编辑安装应该如何执行。
你不需要研究这些技术文件。在本教程中,您将在发布自己的包的过程中学习所有这些规范在实践中是如何结合在一起的。
为了更好地概述 Python 打包的历史,请查看 Thomas Kluyver 在 PyCon UK 2019 上的演讲: Python 打包:我们是如何来到这里的,我们要去哪里?您还可以在 PyPA 网站上找到更多演示。
创建一个小的 Python 包
在这一节中,您将了解一个小的 Python 包,它可以作为一个发布到 PyPI 的例子。如果你已经有了自己想要发布的包,那么请随意浏览这一部分,并在下一部分再次加入。
你在这里看到的这个包叫做reader。它既可以作为一个库来下载您自己代码中的真正 Python 教程,也可以作为一个应用程序来阅读您控制台中的教程。
注意:本节中显示和解释的源代码是真正的 Python 提要阅读器的简化版,但功能齐全。与目前在 PyPI 上发布的版本相比,这个版本缺少一些错误处理和额外的选项。
首先看一下reader的目录结构。这个包完全位于一个可以命名为任何名称的目录中。在本例中,它被命名为realpython-reader/。源代码被包装在一个src/目录中。这并不是绝对必要的,但通常是个好主意。
注意:在构建包时使用额外的src/目录已经成为 Python 社区中讨论的焦点好几年了。一般来说,平面目录结构更容易上手,但是随着项目的增长,src/结构提供了几个优势。
内部的src/reader/目录包含了你所有的源代码:
realpython-reader/
│
├── src/
│ └── reader/
│ ├── __init__.py
│ ├── __main__.py
│ ├── config.toml
│ ├── feed.py
│ └── viewer.py
│
├── tests/
│ ├── test_feed.py
│ └── test_viewer.py
│
├── LICENSE
├── MANIFEST.in
├── README.md
└── pyproject.toml
这个包的源代码和一个配置文件在一个src/子目录中。在单独的tests/子目录中有一些测试。测试本身不会在本教程中讨论,但是稍后你会学到如何处理测试目录。你可以在的 Python 测试入门和的 Pytest 有效 Python 测试中了解更多关于测试的知识。
如果您正在使用自己的包,那么您可以使用不同的结构或者在您的包目录中有其他文件。 Python 应用布局讨论了几种不同的选项。以下发布到 PyPI 的步骤将独立于您使用的布局。
在本节的剩余部分,您将看到reader包是如何工作的。在的下一节中,您将了解更多关于发布您的包所需的特殊文件,如LICENSE、MANIFEST.in、README.md和pyproject.toml。
使用真正的 Python 阅读器
reader是一个基本的 web feed 阅读器,可以从真实 Python feed 下载最新的真实 Python 教程。
在这一节中,您将首先看到几个可以从reader得到的输出示例。您还不能自己运行这些示例,但是它们应该会让您对该工具的工作原理有所了解。
注意:如果您已经下载了reader的源代码,那么您可以先创建一个虚拟环境,然后在这个虚拟环境中本地安装这个包:
(venv) $ python -m pip install -e .
在整个教程中,当您运行这个命令时,您将会了解到更多的事情。
第一个示例使用阅读器获取最新文章的列表:
$ python -m reader
The latest tutorials from Real Python (https://realpython.com/)
0 How to Publish an Open-Source Python Package to PyPI
1 The Real Python Podcast – Episode #110
2 Build a URL Shortener With FastAPI and Python
3 Using Python Class Constructors
4 Linear Regression in Python
5 The Real Python Podcast – Episode #109
6 pandas GroupBy: Your Guide to Grouping Data in Python
7 Deploying a Flask Application Using Heroku
8 Python News: What's New From April 2022
9 The Real Python Podcast – Episode #108
10 Top Python Game Engines
11 Testing Your Code With pytest
12 Python's min() and max(): Find Smallest and Largest Values
13 Real Python at PyCon US 2022
14 Why Is It Important to Close Files in Python?
15 Combining Data in Pandas With merge(), .join(), and concat()
16 The Real Python Podcast – Episode #107
17 Python 3.11 Preview: Task and Exception Groups
18 Building a Django User Management System
19 How to Get the Most Out of PyCon US
此列表显示了最新的教程,因此您的列表可能与上面看到的有所不同。尽管如此,请注意每篇文章都有编号。要阅读一个特定的教程,可以使用相同的命令,但是也要包括教程的编号。
注意:真正的 Python 提要包含有限的文章预览。因此,你将无法用reader阅读完整的教程。
在这种情况下,要阅读如何向 PyPI 发布开源 Python 包,您需要在命令中添加0:
$ python -m reader 0
How to Publish an Open-Source Python Package to PyPI
Python is famous for coming with batteries included, and many sophisticated
capabilities are available in the standard library. However, to unlock the
full potential of the language, you should also take advantage of the
community contributions at PyPI: the Python Packaging Index.
PyPI, typically pronounced pie-pee-eye, is a repository containing several
hundred thousand packages. These range from trivial Hello, World
implementations to advanced deep learning libraries. In this tutorial,
you'll learn how to upload your own package to PyPI. Publishing your
project is easier than it used to be. Yet, there are still a few
steps involved.
[...]
这将使用减价格式将文章打印到控制台。
注意: python -m是用来执行一个模块或者一个包。对于模块和常规脚本,它的工作方式类似于python。比如python module.py和python -m module大多是等价的。
当你用-m运行一个包时,包内的文件 __main__.py 被执行。更多信息参见致电读者。
现在,您需要从src/目录中运行python -m reader命令。稍后,您将学习如何从任何工作目录运行该命令。
通过在命令行上更改数字,您可以阅读任何可用的教程。
理解阅读器代码
对于本教程来说,reader如何工作的细节并不重要。但是,如果您有兴趣了解关于实现的更多信息,那么您可以扩展下面的部分。该包包含五个文件:
config.toml是一个配置文件,用于指定真实 Python 教程的提要的 URL。这是一个可以被第三方库 tomli 读取的文本文件:
# config.toml [feed] url = "https://realpython.com/atom.xml"
一般来说,TOML 文件包含被分成几个部分或表格的键值对。这个特定的文件只包含一个区段feed,以及一个关键字url。
注意:对于这个简单的包,一个配置文件可能是多余的。您可以直接在源代码中将 URL 定义为模块级常量。这里包含的配置文件演示了如何使用非代码文件。
TOML 是一种最近流行起来的配置文件格式。Python 将它用于pyproject.toml文件,稍后您将了解到和。要深入探究 TOML,请查看 Python 和 TOML:新的最好的朋友。
对读取 TOML 文件的支持将添加到 Python 3.11 的标准库中,新增 tomllib 库。在此之前,可以使用第三方 tomli 包。
您将看到的第一个源代码文件是__main__.py。双下划线表示这个文件在 Python 中有一个特殊的含义。事实上,当像前面一样用python -m执行一个包时,Python 会运行__main__.py的内容。
换句话说,__main__.py充当程序的入口点,负责主流程,根据需要调用其他部分:
1# __main__.py
2
3import sys
4
5from reader import feed, viewer
6
7def main():
8 """Read the Real Python article feed"""
9
10 # If an article ID is given, then show the article
11 if len(sys.argv) > 1:
12 article = feed.get_article(sys.argv[1])
13 viewer.show(article)
14
15 # If no ID is given, then show a list of all articles
16 else:
17 site = feed.get_site()
18 titles = feed.get_titles()
19 viewer.show_list(site, titles)
20
21if __name__ == "__main__":
22 main()
注意最后一行调用了main()。如果不调用main(),那么程序什么都不会做。正如您之前看到的,该程序可以列出所有教程,也可以打印一个特定的教程。这由第 11 至 19 行的if … else模块处理。
下一个文件是__init__.py。同样,文件名中的双下划线告诉您这是一个特殊的文件。__init__.py代表你的包的根。它通常应该非常简单,但是它是放置包常量、文档等的好地方:
# __init__.py
from importlib import resources
try:
import tomllib
except ModuleNotFoundError:
import tomli as tomllib
# Version of the realpython-reader package
__version__ = "1.0.0"
# Read URL of the Real Python feed from config file
_cfg = tomllib.loads(resources.read_text("reader", "config.toml"))
URL = _cfg["feed"]["url"]
特殊变量__version__是 Python 中向包中添加版本号的约定。它是在 PEP 396 中引入的。稍后你会学到更多关于版本控制的知识。
注意:您可以使用 importlib.metadata 来检查您已经安装的任何软件包的版本:
>>> from importlib import metadata >>> metadata.version("realpython-reader") '1.0.0'
importlib.metadata通过包的 PyPI 名来识别包,这就是为什么你要查找realpython-reader而不是reader。稍后你会学到更多关于你的项目的不同名字。严格地说,没有必要指定
__version__。importlib.metadata机制使用项目元数据来查找版本号。然而,这仍然是一个有用的约定,像 Setuptools 和 Flit 这样的工具可以使用它来自动更新您的包元数据。要从配置文件中读取提要的 URL,可以使用
tomllib或tomli来获得 TOML 支持。如上所述使用try…except可以确保在tomllib可用时使用它,如果不可用时退回到到tomli。
importlib.resources用于从一个包中导入非代码或资源文件,而不必找出它们的完整文件路径。当您将您的包发布到 PyPI 并且不能完全控制包的安装位置和使用方式时,这尤其有用。资源文件甚至可能在 zip 存档中结束。
importlib.resources在 Python 3.7 中成为 Python 标准库的一部分。更多信息,请参见 Barry Warsaw 在 2018 年PyCon 上的演讲。在
__init__.py中定义的变量成为包名称空间中的变量:
>>> import reader
>>> reader.__version__
'1.0.0'
>>> reader.URL
'https://realpython.com/atom.xml'
您可以直接在reader上访问作为属性的包常量。
在__main__.py中,您导入两个模块feed和viewer,并使用它们从提要中读取并显示结果。这些模块完成了大部分实际工作。
首先考虑feed.py。这个文件包含了从一个 web 提要中读取并解析结果的函数。幸运的是,已经有很好的库可以做到这一点。feed.py依赖于 PyPI 上已经有的两个模块: feedparser 和 html2text 。
feed.py由几个功能组成。你会一次看一个。
阅读网络订阅源可能需要一些时间。为了避免从 web 提要中读取不必要的内容,可以在提要第一次被读取时使用@cache到缓存:
# feed.py
from functools import cache
import feedparser
import html2text
import reader
@cache
def _get_feed(url=reader.URL):
"""Read the web feed, use caching to only read it once"""
return feedparser.parse(url)
从网上读取一个 feed,并以一种看起来像字典的结构返回。为了避免多次下载提要,函数用@cache修饰了,它会记住_get_feed()返回的值,并在以后的调用中重用它。
注:@cache装饰器是在 Python 3.9 中引入到functools的。在老版本的 Python 上,可以用 @lru_cache 代替。
您在_get_feed()前面加了一个下划线,表示它是一个支持函数,并不意味着您的软件包的用户可以直接使用它。
通过查看.feed元数据,您可以获得关于提要的一些基本信息。下面的函数挑选出包含提要的网站的标题和链接:
# feed.py
# ...
def get_site(url=reader.URL):
"""Get name and link to website of the feed"""
feed = _get_feed(url).feed
return f"{feed.title} ({feed.link})"
除了.title和.link之外,属性像.subtitle、.updated、.id也可以。
提要中可用的文章可以在.entries列表中找到。文章标题可以通过列表理解找到:
# feed.py
# ...
def get_titles(url=reader.URL):
"""List titles in the feed"""
articles = _get_feed(url).entries
return [a.title for a in articles]
.entries按时间顺序列出提要中的文章,因此最新的文章是.entries[0]。
为了获得一篇特定文章的内容,您使用它在.entries中的索引作为文章 ID:
# feed.py
# ...
def get_article(article_id, url=reader.URL):
"""Get article from feed with the given ID"""
articles = _get_feed(url).entries
article = articles[int(article_id)]
html = article.content[0].value
text = html2text.html2text(html)
return f"# {article.title}\n\n{text}"
从.entries中选择正确的文章后,您找到 HTML 格式的文章文本,并将其存储为article。接下来,html2text出色地将 HTML 翻译成可读性更好的降价文本。HTML 不包含文章标题,所以标题是在文章文本返回之前添加的。
最后的模块是viewer.py。它由两个小函数组成。实际上,你可以在__main__.py中直接使用print(),而不是调用viewer函数。然而,将功能分离出来使得以后用更高级的东西替换它变得更加简单。
这里,您使用简单的 print() 语句向用户显示内容。作为一种改进,也许你想给你的阅读器添加更丰富的格式或 GUI 界面。为此,您只需替换以下两个函数:
# viewer.py
def show(article):
"""Show one article"""
print(article)
def show_list(site, titles):
"""Show list of article titles"""
print(f"The latest tutorials from {site}")
for article_id, title in enumerate(titles):
print(f"{article_id:>3} {title}")
show()打印一篇文章到控制台,而show_list()打印标题列表。后者还创建文章 id,在选择阅读一篇特定文章时使用。
除了这些源代码文件,您还需要添加一些特殊的文件,然后才能发布您的包。您将在后面的章节中讨论这些文件。
召唤读者
当你的项目越来越复杂时,一个挑战就是让你的用户知道他们如何使用你的项目。由于reader由四个不同的源代码文件组成,用户如何知道执行哪个文件才能使用应用程序?
注意:单个 Python 文件通常被称为脚本或T5】模块 。你可以把一个 包 看成是模块的集合。
最常见的是,你通过提供文件名来运行 Python 脚本。例如,如果您有一个名为hello.py的脚本,那么您可以如下运行它:
$ python hello.py
Hi there!
当您运行这个假想的脚本时,它会将Hi there!打印到您的控制台上。同样,您可以使用python解释程序的-m选项,通过指定其模块名而不是文件名来运行脚本:
$ python -m hello
Hi there!
对于当前目录中的模块,模块名与文件名相同,只是省略了后缀.py。
使用-m的一个好处是它允许你调用所有在你的 Python 路径中的模块,包括那些内置在 Python 中的模块。一个例子是称 antigravity :
$ python -m antigravity
Created new window in existing browser session.
如果你想运行一个没有-m的内置模块,那么你需要首先查找它在你的系统中的存储位置,然后用它的完整路径调用它。
使用-m的另一个优点是它既适用于模块也适用于包。正如您前面所学的,只要在您的工作目录中有reader/目录,您就可以用-m调用reader包:
$ cd src/
$ python -m reader
因为reader是一个包,所以名字只指一个目录。Python 如何决定运行该目录中的哪个代码?它寻找一个名为__main__.py的文件。如果这样的文件存在,那么它被执行。如果它不存在,则会打印一条错误消息:
$ python -m urllib
python: No module named urllib.__main__; 'urllib' is a package and
cannot be directly executed
错误信息显示标准库的 urllib包没有定义__main__.py文件。
如果你正在创建一个应该被执行的包,那么你应该包含一个__main__.py文件。你也可以效仿里奇的好例子,用python -m rich向展示你的软件包的功能。
稍后,您将看到如何为您的包创建入口点,其行为类似于常规命令行程序。这些对于您的最终用户来说会更容易使用。
准备您的软件包以供发布
您有一个想要发布的包。可能你抄袭了reader,也可能你有自己的包。在这一节中,您将看到在将您的包上传到 PyPI 之前需要采取哪些步骤。
将您的包命名为
第一步——可能也是最难的一步——是为你的包取一个好名字。PyPI 上的所有包都需要有唯一的名称。现在 PyPI 上有几十万个包,所以你最喜欢的名字可能已经被使用了。
举个例子,PyPI 上已经有一个名为reader的包。使包名唯一的一种方法是在名字前添加一个可识别的前缀。在这个例子中,您将使用realpython-reader作为reader包的 PyPI 名称。
无论您为您的包选择哪个 PyPI 名称,这都是您在使用pip安装它时将使用的名称:
$ python -m pip install realpython-reader
请注意,PyPI 名称不需要与包名称匹配。这里,包仍然被命名为reader,这是您在导入包时需要使用的名称:
>>> import reader >>> reader.__version__ '1.0.0' >>> from reader import feed >>> feed.get_titles() ['How to Publish an Open-Source Python Package to PyPI', ...]有时你需要为你的包使用不同的名字。但是,如果包名和 PyPI 名相同,那么对用户来说事情就简单多了。
请注意,尽管软件包名称不需要像 PyPI 名称那样是全局唯一的,但是它需要在您运行它的环境中是唯一的。
如果你用相同的包名安装了两个包,例如
reader和realpython-reader,那么像import reader这样的声明是有歧义的。Python 通过导入它在导入路径中首先找到的包来解决这个问题。通常,这将是按字母顺序排列名称时的第一个包。但是,你不应该依赖这种行为。通常,您会希望您的包名尽可能地唯一,同时用一个简短而简洁的名称来平衡这一点。
realpython-reader是一个专门的提要阅读器,而 PyPI 上的reader则更加通用。出于本教程的目的,没有理由两者都需要,所以使用非唯一名称的折衷可能是值得的。配置您的软件包
为了准备在 PyPI 上发布您的包,您需要提供一些关于它的信息。通常,您需要指定两种信息:
- 构建系统的配置
- 包的配置
一个构建系统负责创建你将上传到 PyPI 的实际文件,通常是以轮或源代码分发(sdist) 格式。很长一段时间,这都是由
distutils或者setuptools来完成的。然而, PEP 517 和 PEP 518 引入了一种指定定制构建系统的方法。注意:您可以选择在您的项目中使用哪个构建系统。不同构建系统之间的主要区别在于如何配置包,以及运行哪些命令来构建和上传包。
本教程将重点介绍如何使用
setuptools作为构建系统。不过,稍后你会学到如何使用 Flit 和诗歌这样的替代品。每个 Python 项目都应该使用一个名为
pyproject.toml的文件来指定它的构建系统。您可以通过将后面的添加到pyproject.toml来使用setuptools:# pyproject.toml [build-system] requires = ["setuptools>=61.0.0", "wheel"] build-backend = "setuptools.build_meta"这指定了您使用
setuptools作为构建系统,以及 Python 必须安装哪些依赖项来构建您的包。通常,你选择的构建系统的文档会告诉你如何在pyproject.toml中写build-system表。您需要提供的更有趣的信息与您的包本身有关。 PEP 621 定义了关于你的包的元数据如何被包含在
pyproject.toml中,在不同的构建系统中以一种尽可能统一的方式。注意:历史上,Setuptools 使用
setup.py来配置你的包。因为这是一个在安装时运行的实际 Python 脚本,所以它非常强大,并且在构建复杂的包时可能仍然需要它。然而,使用声明性配置文件来表达如何构建您的包通常更好,因为它更容易推理,并且需要担心的缺陷更少。使用
setup.cfg是配置 Setuptools 最常见的方式。然而,Setuptools 是按照 PEP 621 的规定,将移向使用
pyproject.toml。在本教程中,您将对所有的包配置使用pyproject.toml。
reader包的一个相当简单的配置如下所示:# pyproject.toml [build-system] requires = ["setuptools>=61.0.0", "wheel"] build-backend = "setuptools.build_meta" [project] name = "realpython-reader" version = "1.0.0" description = "Read the latest Real Python tutorials" readme = "README.md" authors = [{ name = "Real Python", email = "info@realpython.com" }] license = { file = "LICENSE" } classifiers = [ "License :: OSI Approved :: MIT License", "Programming Language :: Python", "Programming Language :: Python :: 3", ] keywords = ["feed", "reader", "tutorial"] dependencies = [ "feedparser >= 5.2.0", "html2text", 'tomli; python_version < "3.11"', ] requires-python = ">=3.9" [project.optional-dependencies] dev = ["black", "bumpver", "isort", "pip-tools", "pytest"] [project.urls] Homepage = "https://github.com/realpython/reader" [project.scripts] realpython = "reader.__main__:main"这些信息大部分是可选的,还有其他设置可以使用,但没有包括在本例中。查看文档了解所有细节。
您必须在
pyproject.toml中包含的最基本信息如下:
name指定将出现在 PyPI 上的包的名称。version设置你的包的当前版本。如上例所示,您可以包含更多的信息。
pyproject.toml中的其他几个键解释如下:
classifiers使用一列分类器描述你的项目。你应该使用它们,因为它们使你的项目更容易被搜索到。dependencies列出您的包对第三方库的所有依赖关系。reader取决于feedparser、html2text、tomli,所以在此列出。project.urls添加链接,您可以使用这些链接向用户展示有关您的软件包的附加信息。你可以在这里包括几个链接。project.scripts创建命令行脚本来调用你的包中的函数。这里,新的realpython命令调用reader.__main__模块中的main()。
project.scripts表是可以处理入口点的三个表之一。还可以包含project.gui-scripts和project.entry-points,分别指定 GUI 应用和插件。所有这些信息的目的是让你的包在 PyPI 上更有吸引力,更容易被找到。查看 PyPI 上的
realpython-reader项目页面,并与上面的pyproject.toml信息进行比较:
PyPI 上的所有信息都来自
pyproject.toml和README.md。比如版本号是以project.toml中的台词version = "1.0.0"为准,而阅读最新的真正 Python 教程则是抄袭description。此外,项目描述是从您的
README.md文件中提取的。在侧边栏中,您可以找到来自项目链接部分的project.urls以及来自元部分的license和authors的信息。您在classifiers中指定的值可以在侧边栏的底部看到。有关所有按键的详细信息,请参见 PEP 621 。在下一小节中,您将了解更多关于
dependencies和project.optional-dependencies的内容。指定您的软件包依赖关系
您的包可能依赖于不属于标准库的第三方库。您应该在
pyproject.toml的dependencies列表中指定这些。在上例中,您执行了以下操作:dependencies = [ "feedparser >= 5.2.0", "html2text", 'tomli; python_version < "3.11"', ]这指定了
reader依赖于feedparser、html2text和tomli。此外,它说:
feedparser必须是 5.2.0 或更高版本。html2text可以是任何版本。tomli可以是任何版本,但仅在 Python 3.10 或更早版本上是必需的。这展示了在指定依赖项时可以使用的几种可能性,包括版本说明符和环境标记。您可以使用后者来说明不同的操作系统、Python 版本等等。
但是,请注意,您应该努力只指定库或应用程序工作所需的最低要求。这个列表将被
pip用来在任何时候安装你的包时解析依赖关系。通过保持这个列表的最小化,您可以确保您的包尽可能地兼容。你可能听说过你应该固定你的依赖关系。那就是伟大的建议!然而,它在这种情况下不成立。您固定您的依赖项,以确保您的环境是可复制的。另一方面,您的包应该有望跨许多不同的 Python 环境工作。
向
dependencies添加包时,您应该遵循这些经验法则:
- 只列出你的直接依赖。例如,
reader导入了feedparser、html2text和tomli,所以这些都列出来了。另一方面,feedparser依赖于sgmllib3k,但是reader没有直接使用这个库,所以没有指定。- 永远不要用
==把你的依赖固定在一个特定的版本上。- 如果您依赖于在您的依赖关系的特定版本中添加的功能,使用
>=来添加一个下限。- 如果您担心在主要版本升级中依赖关系可能会破坏兼容性,请使用
<添加上限。在这种情况下,您应该努力测试这样的升级,并在可能的情况下移除或增加上限。请注意,当您配置一个可供他人使用的包时,这些规则也适用。如果您正在部署您的包,那么您应该将您的依赖项固定在一个虚拟环境中。
pip-tools 项目是管理固定依赖关系的好方法。它附带了一个
pip-compile命令,可以创建或更新依赖项的完整列表。例如,假设您正在将
reader部署到虚拟环境中。然后,您可以使用 pip-tools 创建一个可复制的环境。事实上,pip-compile可以直接与你的pyproject.toml文件一起工作:(venv) $ python -m pip install pip-tools (venv) $ pip-compile pyproject.toml feedparser==6.0.8 via realpython-reader (pyproject.toml) html2text==2020.1.16 via realpython-reader (pyproject.toml) sgmllib3k==1.0.0 via feedparser tomli==2.0.1 ; python_version < "3.11" via realpython-reader (pyproject.toml)
pip-compile创建一个详细的requirements.txt文件,其内容类似于上面的输出。您可以使用pip install或pip-sync将这些依赖项安装到您的环境中:(venv) $ pip-sync Collecting feedparser==6.0.8 ... Installing collected packages: sgmllib3k, tomli, html2text, feedparser Successfully installed feedparser-6.0.8 html2text-2020.1.16 sgmllib3k-1.0.0 tomli-2.0.1更多信息参见 pip-tools 文档。
您还可以在一个名为
project.optional-dependencies的单独的表中指定软件包的可选依赖项。您经常使用它来指定您在开发或测试过程中使用的依赖项。但是,您也可以指定用于支持软件包中某些功能的额外依赖项。在上面的示例中,您包括了以下部分:
[project.optional-dependencies] dev = ["black", "bumpver", "isort", "pip-tools", "pytest"]这将添加一组可选依赖项
dev。您可以有几个这样的组,您可以根据需要命名这些组。默认情况下,安装软件包时不包括可选的依赖项。但是,通过在运行
pip时在方括号中添加组名,您可以手动指定应该安装它们。例如,您可以通过执行以下操作来安装reader的额外dev依赖项:(venv) $ python -m pip install realpython-reader[dev]通过使用
--extra命令行选项,您还可以在使用pip-compile固定您的依赖关系时包含可选的依赖关系:(venv) $ pip-compile --extra dev pyproject.toml attrs==21.4.0 via pytest black==22.3.0 via realpython-reader (pyproject.toml) ... tomli==2.0.1 ; python_version < "3.11" via black pytest realpython-reader (pyproject.toml)这将创建一个包含常规依赖项和开发依赖项的固定的
requirements.txt文件。记录您的包
你应该在向全世界发布你的软件包之前添加一些文档。根据您的项目,您的文档可以小到单个
README文件,也可以大到包含教程、示例库和 API 参考的完整网页。至少,您应该在项目中包含一个
README文件。一个好的README应该快速描述你的项目,以及解释如何安装和使用你的软件包。通常,你想在pyproject.toml的readme键中引用你的README。这也将在 PyPI 项目页面上显示信息。您可以使用 Markdown 或 reStructuredText 作为项目描述的格式。PyPI 根据文件扩展名判断出你使用的是哪种格式。如果您不需要 reStructuredText 的任何高级特性,那么您通常最好对您的
README使用 Markdown。它更简单,在 PyPI 之外有更广泛的支持。对于较大的项目,您可能希望提供比单个文件所能容纳的更多的文档。在这种情况下,你可以把你的文档放在类似于 GitHub 或的网站上,阅读文档并从 PyPI 项目页面链接到它。
您可以通过在
pyproject.toml中的project.urls表中指定链接到其他 URL。在示例中,URL 部分用于链接到readerGitHub 存储库。测试您的软件包
当你开发你的包时,测试是有用的,你应该包括它们。如前所述,本教程中不会涉及测试,但是您可以看看
tests/源代码目录中reader的测试。你可以在用 Pytest 进行有效的 Python 测试中了解更多关于测试的知识,在用测试驱动开发(TDD)构建 Python 中的哈希表和 Python 练习题:解析 CSV 文件中获得一些测试驱动开发(TDD)的实践经验。
在准备要出版的包时,您应该意识到测试所扮演的角色。它们通常只对开发人员感兴趣,所以它们应该而不是包含在您通过 PyPI 发布的包中。
Setuptools 的更高版本在代码发现方面非常出色,通常会将您的源代码包含在软件包发行版中,但会省略您的测试、文档和类似的开发工件。
您可以通过使用
pyproject.toml中的find指令来精确控制您的包中包含的内容。更多信息参见设置工具文档。版本化您的软件包
您的包需要有一个版本。此外,PyPI 只允许你上传一次特定版本的包。换句话说,如果你想在 PyPI 上更新你的包,那么你首先需要增加版本号。这是一件好事,因为它有助于保证可再现性:具有相同版本的给定包的两个环境应该表现相同。
您可以使用许多不同的版本控制方案。对于 Python 项目, PEP 440 给出了一些建议。但是,为了灵活起见,PEP 中的描述比较复杂。对于一个简单的项目,您应该坚持使用简单的版本控制方案。
语义版本化是一个很好的默认使用方案,尽管它并不完美。您将版本指定为三个数字部分,例如
1.2.3。这些组件分别称为主要组件、次要组件和修补组件。以下是关于何时增加每个组件的建议:
- When making incompatible API changes, add the major version.
- When adding features in a backward compatible way, add minor versions.
- Add patch version when making backward compatible bug fixes. ( source )
当你增加 MINOR 时,你应该重置 PATCH 到
0,当你增加 MAJOR 时,重置 PATCH 和 MINOR 到0。日历版本化是语义版本化的一种替代方案,越来越受欢迎,被像 Ubuntu 、 Twisted 、 Black 和
pip这样的项目所使用。日历版本也由几个数字组成,但其中一个或几个与当前的年、月或周相关联。通常,您希望在项目的不同文件中指定版本号。例如,
reader包中的pyproject.toml和reader/__init__.py都提到了版本号。为了帮助你确保版本号保持一致,你可以使用像 BumpVer 这样的工具。BumpVer 允许你将版本号直接写入你的文件,然后根据需要更新这些版本号。例如,您可以安装 BumpVer 并将其集成到您的项目中,如下所示:
(venv) $ python -m pip install bumpver (venv) $ bumpver init WARNING - Couldn't parse pyproject.toml: Missing version_pattern Updated pyproject.toml
bumpver init命令在您的pyproject.toml中创建一个部分,允许您为您的项目配置工具。根据您的需要,您可能需要更改许多默认设置。对于reader,你可能会得到如下结果:[tool.bumpver] current_version = "1.0.0" version_pattern = "MAJOR.MINOR.PATCH" commit_message = "Bump version {old_version} -> {new_version}" commit = true tag = true push = false [tool.bumpver.file_patterns] "pyproject.toml" = ['current_version = "{version}"', 'version = "{version}"'] "src/reader/__init__.py" = ["{version}"]为了让 BumpVer 正常工作,您必须在
file_patterns小节中指定包含您的版本号的所有文件。请注意,BumpVer 与 Git 配合得很好,可以在更新版本号时自动提交、标记和推送。注: BumpVer 与您的版本控制系统集成。如果你的存储库中有未提交的变更,它会拒绝更新你的文件。
设置好配置后,您可以用一个命令在所有文件中添加版本。例如,要增加
reader的次要版本,您需要执行以下操作:(venv) $ bumpver update --minor INFO - Old Version: 1.0.0 INFO - New Version: 1.1.0这将把
pyproject.toml和__init__.py中的版本号从 1.0.0 更改为 1.1.0。您可以使用--dry标志来查看 BumpVer 会做出哪些更改,而无需实际执行它们。将资源文件添加到您的包中
有时,您的包中会有一些不是源代码文件的文件。示例包括数据文件、二进制文件、文档,以及(如本例中所示的)配置文件。
为了确保在生成项目时包含这些文件,可以使用清单文件。对于许多项目,您不需要担心清单:默认情况下,Setuptools 在构建中包含所有源代码文件和
README文件。如果您有其他资源文件并且需要更新清单,那么您需要在项目的基本目录中的
pyproject.toml旁边创建一个名为MANIFEST.in的文件。该文件指定包括和排除哪些文件的规则:# MANIFEST.in include src/reader/*.toml这个例子将包括
src/reader/目录中的所有.toml文件。实际上,这是配置文件。参见文档获取更多关于设置你的清单的信息。检查清单工具对于使用
MANIFEST.in也很有用。许可您的软件包
如果您正在与他人共享您的软件包,那么您需要在您的软件包中添加一个许可证,解释如何允许他人使用您的软件包。例如,
reader是根据 MIT license 发布的。许可证是法律文件,你通常不想写你自己的。相反,你应该从众多可用的执照中选择一个。
您应该将一个名为
LICENSE的文件添加到您的项目中,该文件包含您选择的许可文本。然后您可以在pyproject.toml中引用这个文件,使许可证在 PyPI 上可见。在本地安装您的软件包
您已经为您的包完成了所有必要的设置和配置。在下一节的中,您将了解如何最终在 PyPI 上获得您的包裹。不过,首先,您将了解可编辑安装。这是一种使用
pip在本地安装你的包的方式,让你在安装后编辑你的代码。注意:正常情况下,
pip会做一个常规安装,将一个包放到你的site-packages/文件夹中。如果你安装你的本地项目,那么源代码将被复制到site-packages/。这样做的结果是,您以后所做的更改将不会生效。您需要首先重新安装您的软件包。在开发过程中,这可能既无效又令人沮丧。可编辑安装通过直接链接到您的源代码来解决这个问题。
可编辑安装已经在 PEP 660 中正式化。这些在您开发软件包时非常有用,因为您可以测试软件包的所有功能并更新源代码,而无需重新安装。
通过添加
-e或--editable标志,您可以使用pip在可编辑模式下安装您的软件包:(venv) $ python -m pip install -e .注意命令末尾的句点(
.)。这是该命令的必要部分,它告诉pip您想要安装位于当前工作目录中的软件包。一般来说,这应该是包含您的pyproject.toml文件的目录的路径。注意:您可能会得到一条错误消息,说“项目文件有一个‘py Project . toml’并且它的构建后端缺少‘build _ editable’钩子。”这是由于 PEP 660 的 Setuptools 支持中的限制。您可以通过添加包含以下内容的名为
setup.py的文件来解决这个问题:# setup.py from setuptools import setup setup()该填充程序将可编辑安装的工作委托给 Setuptools 的遗留机制,直到对 PEP 660 的本机支持可用。
一旦成功安装了项目,它就可以在您的环境中使用,独立于您的当前目录。此外,您的脚本已经设置好,因此您可以运行它们。回想一下,
reader定义了一个名为realpython的脚本:(venv) $ realpython The latest tutorials from Real Python (https://realpython.com/) 0 How to Publish an Open-Source Python Package to PyPI [...]您也可以从任何目录使用
python -m reader,或者从 REPL 或另一个脚本导入您的包:
>>> from reader import feed
>>> feed.get_titles()
['How to Publish an Open-Source Python Package to PyPI', ...]
在开发过程中以可编辑模式安装您的包会让您的开发体验更加愉快。这也是定位某些 bug 的好方法,在这些 bug 中,您可能不自觉地依赖于当前工作目录中可用的文件。
这需要一些时间,但是这已经完成了您需要为您的包做的准备工作。在下一节中,您将学习如何实际发布它!
将您的包发布到 PyPI
您的软件包终于准备好迎接计算机外部的世界了!在本节中,您将学习如何构建您的包并将其上传到 PyPI。
如果你还没有 PyPI 账户,那么现在是时候在 PyPI 上注册你的账户了。同时,你也应该在 TestPyPI 上注册一个账户。TestPyPI 很有用!如果你搞砸了,你可以尝试发布一个包的所有步骤而不会有任何后果。
要构建您的包并上传到 PyPI,您将使用两个工具,称为构建和缠绕。您可以像往常一样使用pip安装它们:
(venv) $ python -m pip install build twine
在接下来的小节中,您将学习如何使用这些工具。
构建您的软件包
PyPI 上的包不是以普通源代码的形式发布的。相反,它们被打包成分发包。发行包最常见的格式是源文件和 Python wheels 。
注:车轮是参照奶酪车轮而命名为的,是奶酪店里最重要的物品。
源档案由你的源代码和任何支持文件组成,它们被打包成一个 tar文件。类似地,轮子本质上是一个包含代码的 zip 存档。您应该为您的包提供源档案和轮子。对于您的最终用户来说,Wheels 通常更快、更方便,而源归档提供了一种灵活的备份替代方案。
要为您的包创建一个源归档文件和一个轮子,您可以使用 Build:
(venv) $ python -m build
[...]
Successfully built realpython-reader-1.0.0.tar.gz and
realpython_reader-1.0.0-py3-none-any.whl
正如输出的最后一行所说,这创建了一个源档案和一个轮子。您可以在新创建的dist目录中找到它们:
realpython-reader/
│
└── dist/
├── realpython_reader-1.0.0-py3-none-any.whl
└── realpython-reader-1.0.0.tar.gz
.tar.gz文件是您的源档案,而.whl文件是您的车轮。这些是您将上传到 PyPI 的文件,并且pip将在以后安装您的软件包时下载它们。
确认您的软件包版本
在上传新构建的分发包之前,您应该检查它们是否包含您期望的文件。车轮文件实际上是一个扩展名不同的 ZIP 文件。您可以按如下方式解压缩并检查其内容:
- 视窗
** Linux + macOS*
(venv) PS> cd .\dist
(venv) PS> Copy-Item .\realpython_reader-1.0.0-py3-none-any.whl reader-whl.zip
(venv) PS> Expand-Archive reader-whl.zip
(venv) PS> tree .\reader-whl\ /F
C:\REALPYTHON-READER\DIST\READER-WHL
├───reader
│ config.toml
│ feed.py
│ viewer.py
│ __init__.py
│ __main__.py
│
└───realpython_reader-1.0.0.dist-info
entry_points.txt
LICENSE
METADATA
RECORD
top_level.txt
WHEEL
您首先重命名 wheel 文件,使其具有一个.zip扩展名,以便您可以扩展它。
(venv) $ cd dist/
(venv) $ unzip realpython_reader-1.0.0-py3-none-any.whl -d reader-whl
(venv) $ tree reader-whl/
reader-whl/
├── reader
│ ├── config.toml
│ ├── feed.py
│ ├── __init__.py
│ ├── __main__.py
│ └── viewer.py
└── realpython_reader-1.0.0.dist-info
├── entry_points.txt
├── LICENSE
├── METADATA
├── RECORD
├── top_level.txt
└── WHEEL
2 directories, 11 files
您应该看到列出了所有的源代码,以及一些已经创建的新文件,这些文件包含您在pyproject.toml中提供的信息。特别要确保所有的子包和支持文件像config.toml都包含在内。
你也可以看看源文件的内部,因为它被打包成一个焦油球。然而,如果您的轮子包含您期望的文件,那么源归档也应该是好的。
Twine 还可以检查你的包描述是否会在 PyPI 上正确呈现。您可以对在dist中创建的文件运行twine check:
(venv) $ twine check dist/*
Checking distribution dist/realpython_reader-1.0.0-py3-none-any.whl: Passed
Checking distribution dist/realpython-reader-1.0.0.tar.gz: Passed
这不会捕捉到您可能遇到的所有问题,但这是很好的第一道防线。
上传您的包
现在您已经准备好将您的包上传到 PyPI 了。为此,您将再次使用 Twine 工具,告诉它上传您已经构建的分发包。
首先,您应该上传到 TestPyPI 以确保一切按预期运行:
(venv) $ twine upload -r testpypi dist/*
Twine 会要求您输入用户名和密码。
注意:如果您以reader包为例按照教程进行操作,那么前面的命令可能会失败,并显示一条消息,告诉您不允许上传到realpython-reader项目。
你可以把pyproject.toml中的name改成独特的,比如test-<your-username>。然后再次构建项目,并将新构建的文件上传到 TestPyPI。
如果上传成功,那么您可以快速前往 TestPyPI ,向下滚动,查看您的项目在新版本中自豪地展示!点击你的包裹,确保一切正常。
如果您一直在使用reader包,那么本教程到此结束!虽然您可以尽情地使用 TestPyPI,但是您不应该仅仅为了测试而将示例包上传到 PyPI。
注意: TestPyPI 对于检查您的包上传是否正确以及您的项目页面看起来是否如您所愿非常有用。您也可以尝试从 TestPyPI 安装您的软件包:
(venv) $ python -m pip install -i https://test.pypi.org/simple realpython-reader
但是,请注意,这可能会失败,因为不是所有的依赖项在 TestPyPI 上都可用。这不是问题。当你上传到 PyPI 的时候,你的包应该还能工作。
如果您有自己的软件包要发布,那么这一时刻终于到来了!所有准备工作就绪后,最后一步很简单:
(venv) $ twine upload dist/*
要求时提供您的用户名和密码。就是这样!
前往 PyPI 查看你的包裹。你既可以通过搜索,也可以通过查看你的项目页面的T5,或者直接进入你的项目的网址:pypi.org/project/your-package-name/。
恭喜你!你的包裹发布在 PyPI 上!
安装您的软件包
花点时间沐浴在 PyPI 网页的蓝色光芒中,向你的朋友吹嘘。
然后再打开一个终端。还有一个更大的回报!
随着你的包上传到 PyPI,你也可以用pip来安装它。首先,创建一个新的虚拟环境并激活它。然后运行以下命令:
(venv) $ python -m pip install your-package-name
用您为包选择的名称替换your-package-name。例如,要安装reader包,您需要执行以下操作:
(venv) $ python -m pip install realpython-reader
看到自己的代码由pip安装——就像任何其他第三方库一样——是一种美妙的感觉!
探索其他构建系统
在本教程中,您已经使用 Setuptools 构建了您的包。无论好坏,Setuptools 都是创建包的长期标准。虽然它被广泛使用和信任,但它也有很多可能与你无关的特性。
有几个可供选择的构建系统可以用来代替 Setuptools。在过去的几年里,Python 社区已经完成了标准化 Python 打包生态系统的重要工作。这使得在不同的构建系统之间移动变得更加简单,并使用最适合您的工作流和包的构建系统。
在本节中,您将简要了解两种可用于创建和发布 Python 包的备选构建系统。除了 Flit 和诗歌,你接下来会学到,你还可以看看 pbr 、 enscons 和孵卵。此外, pep517 包为创建您自己的构建系统提供了支持。
掠过
Flit 是一个伟大的小项目,目的是在打包时“让简单的事情变得简单”(来源)。Flit 不支持像那些创建 C 扩展的高级包,一般来说,它在设置你的包时不会给你很多选择。相反,Flit 赞同应该有一个明显的工作流来发布一个包的理念。
注意:你不能同时用 Setuptools 和 Flit 配置你的包。为了测试这一部分中的工作流,您应该将您的 Setuptools 配置安全地存储在您的版本控制系统中,然后删除pyproject.toml中的build-system和project部分。
首先用pip安装 Flit:
(venv) $ python -m pip install flit
尽可能多地,Flit 自动完成你需要用你的包做的准备工作。要开始配置新的软件包,请运行flit init:
(venv) $ flit init
Module name [reader]:
Author: Real Python
Author email: info@realpython.com
Home page: https://github.com/realpython/reader
Choose a license (see http://choosealicense.com/ for more info)
1\. MIT - simple and permissive
2\. Apache - explicitly grants patent rights
3\. GPL - ensures that code based on this is shared with the same terms
4\. Skip - choose a license later
Enter 1-4: 1
Written pyproject.toml; edit that file to add optional extra info.
flit init命令将根据您对几个问题的回答创建一个pyproject.toml文件。在使用这个文件之前,您可能需要稍微编辑一下。对于reader项目,Flit 的pyproject.toml文件看起来如下:
# pyproject.toml [build-system] requires = ["flit_core >=3.2,<4"] build-backend = "flit_core.buildapi" [project] name = "realpython-reader" authors = [{ name = "Real Python", email = "info@realpython.com" }] readme = "README.md" license = { file = "LICENSE" } classifiers = [ "License :: OSI Approved :: MIT License", "Programming Language :: Python :: 3", ] dynamic = ["version", "description"] [project.urls] Home = "https://github.com/realpython/reader" [project.scripts] realpython = "reader.__main__:main"
请注意,大多数project项目与您原来的pyproject.toml完全相同。不过,一个不同之处是version和description是在dynamic字段中指定的。Flit 实际上通过使用__version__和__init__.py文件中定义的 docstring 自己解决了这些问题。 Flit 的文档解释了关于pyproject.toml文件的一切。
Flit 可以构建您的包并将其发布到 PyPI。您不需要使用构建和缠绕。要构建您的包,只需执行以下操作:
(venv) $ flit build
这创建了一个源档案和一个轮子,类似于您之前对python -m build所做的。如果您愿意,也可以使用 Build。
要将您的包上传到 PyPI,您可以像前面一样使用 Twine。但是,您也可以直接使用 Flit:
(venv) $ flit publish
如果需要的话,publish命令将构建您的包,然后将文件上传到 PyPI,提示您输入用户名和密码。
要查看 Flit 的早期但可识别的版本,请查看来自 EuroSciPy 2017 的 Thomas Kluyver 的闪电谈话。演示展示了如何在两分钟内配置、编译并发布到 PyPI。
诗歌
诗歌是另一个工具,你可以用它来构建和上传你的包。与 Flit 相比,poem 有更多的特性可以帮助你开发包,包括强大的依赖管理。
在你使用诗歌之前,你需要安装它。用pip装诗是可以的。然而,的维护者建议使用定制的安装脚本来避免潜在的依赖冲突。参见文档中的说明。
注意:你不能同时用设置工具和诗歌来配置你的软件包。为了测试这一部分中的工作流,您应该将您的 Setuptools 配置安全地存储在您的版本控制系统中,然后删除pyproject.toml中的build-system和project部分。
安装完诗歌后,您可以通过一个init命令开始使用它,类似于 Flit:
(venv) $ poetry init
This command will guide you through creating your pyproject.toml config.
Package name [code]: realpython-reader
Version [0.1.0]: 1.0.0
Description []: Read the latest Real Python tutorials
...
这将基于您对关于您的包的问题的回答创建一个pyproject.toml文件。
注意:诗歌目前不支持 PEP 621,因此pyproject.toml内部的实际规格目前在诗歌和其他工具之间有所不同。
对于诗歌,pyproject.toml文件最终看起来如下:
# pyproject.toml [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api" [tool.poetry] name = "realpython-reader" version = "1.0.0" description = "Read the latest Real Python tutorials" authors = ["Real Python <info@realpython.com>"] readme = "README.md" homepage = "https://github.com/realpython/reader" license = "MIT" [tool.poetry.dependencies] python = ">=3.9" feedparser = "^6.0.8" html2text = "^2020.1.16" tomli = "^2.0.1" [tool.poetry.scripts] realpython = "reader.__main__:main"
您应该能从前面的pyproject.toml讨论中认出所有这些项目,尽管这些部分的名称不同。
需要注意的一点是,poems 会根据您指定的许可和 Python 版本自动添加分类器。诗歌也要求你明确你的依赖版本。事实上,依赖管理是诗歌的优点之一。
就像 Flit 一样,诗歌可以构建包并上传到 PyPI。build命令创建一个源档案和一个轮子:
(venv) $ poetry build
这将在dist子目录中创建两个常用文件,您可以像前面一样使用 Twine 上传它们。您也可以使用诗歌发布到 PyPI:
(venv) $ poetry publish
这将把你的包上传到 PyPI。除了有助于建设和出版,诗歌可以帮助你在这个过程的早期。诗歌可以帮助你用new命令启动一个新项目。它还支持使用虚拟环境。详见诗歌的文档。
除了配置文件略有不同,Flit 和 poem 的工作方式非常相似。诗歌的范围更广,因为它也旨在帮助依赖管理,而 Flit 已经存在了一段时间。
结论
您现在知道了如何准备您的项目并将其上传到 PyPI,以便其他人可以安装和使用它。虽然您需要完成一些步骤,但是在 PyPI 上看到您自己的包是一个很大的回报。让别人发现你的项目有用就更好了!
在本教程中,您已经学习了如何通过以下方式发布自己的包:
- 为你的包裹找到一个好名字
- 使用
pyproject.toml配置您的软件包 - 大厦你的包裹
- 上传您的包到 PyPI
此外,您还了解了 Python 打包社区中标准化工具和流程的计划。
如果你还有问题,请在下面的评论区联系我们。另外, Python 打包用户指南提供了比你在本教程中看到的更多的详细信息。
获取源代码: 单击此处获取您将在本教程中使用的真正的 Python 提要阅读器的源代码。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 如何将自己的 Python 包发布到 PyPI************
PyPy:用最少的努力更快的 Python
Python 是开发人员中最流行的编程语言之一,但它有一定的局限性。例如,根据应用的不同,它可以比一些低级语言慢 100 倍。这就是为什么一旦 Python 的速度成为用户的瓶颈,许多公司就会用另一种语言重写他们的应用程序。但是,如果有一种方法既能保留 Python 的出色特性,又能提高它的速度,那会怎么样呢?输入 PyPy 。
PyPy 是一个非常兼容的 Python 解释器,是 CPython 2.7、3.6 以及即将到来的 3.7 的有价值的替代品。通过使用它安装和运行您的应用程序,您可以获得显著的速度提升。您将看到多少改进取决于您运行的应用程序。
在本教程中,您将学习:
- 如何用 PyPy 安装并运行你的代码
- PyPy 在速度方面与 CPython 相比如何
- PyPy 的特性是什么,它们如何让你的 Python 代码运行更快
- PyPy 的限制是什么
本教程中的例子使用 Python 3.6,因为这是 PyPy 兼容的 Python 的最新版本。
Python 和 PyPy
Python 语言规范在许多实现中使用,如 CPython (用 C 编写)、Jython(用 Java 编写)、IronPython(用。NET),还有 PyPy(用 Python 写的)。
CPython 是 Python 的原始实现,是迄今为止最受欢迎和维护最多的。当人们提到 Python 时,他们通常指的是 CPython。你可能正在使用 CPython !
但是因为是高级解释语言,CPython 有一定的局限性,不会因为速度而得什么奖牌。这就是 PyPy 可以派上用场的地方。由于它符合 Python 语言规范,PyPy 不需要对您的代码库进行任何更改,并且由于您将在下面看到的特性,它可以提供显著的速度改进。
现在,您可能想知道为什么 CPython 不实现 PyPy 的出色功能,如果它们使用相同的语法。原因是实现这些特性需要对源代码进行巨大的修改,这将是一项艰巨的任务。
不要深入理论,让我们看看 PyPy 的行动。
安装
您的操作系统可能已经提供了 PyPy 包。比如在 macOS 上,你可以借助家酿来安装:
$ brew install pypy3
如果没有,您可以下载一个预构建的二进制文件用于您的操作系统和架构。完成下载后,只需解压缩 tarball 或 ZIP 文件。然后,您可以执行 PyPy,而不需要在任何地方安装它:
$ tar xf pypy3.6-v7.3.1-osx64.tar.bz2
$ ./pypy3.6-v7.3.1-osx64/bin/pypy3
Python 3.6.9 (?, Jul 19 2020, 21:37:06)
[PyPy 7.3.1 with GCC 4.2.1]
Type "help", "copyright", "credits" or "license" for more information.
在执行上面的代码之前,您需要进入下载二进制文件的文件夹。参考安装文件获取完整说明。
PyPy 在行动
现在,您已经安装了 PyPy,并准备好查看它的运行情况了!为此,创建一个名为script.py的 Python 文件,并将以下代码放入其中:
1total = 0
2for i in range(1, 10000):
3 for j in range(1, 10000):
4 total += i + j
5
6print(f"The result is {total}")
这是一个脚本,在两个嵌套的 for循环中,将从1到9,999的数字相加,打印结果。
要查看运行该脚本需要多长时间,请编辑它以添加突出显示的行:
1import time 2
3start_time = time.time() 4
5total = 0
6for i in range(1, 10000):
7 for j in range(1, 10000):
8 total += i + j
9
10print(f"The result is {total}") 11
12end_time = time.time() 13print(f"It took {end_time-start_time:.2f} seconds to compute")
代码现在执行以下操作:
- 第 3 行保存当前时间到变量
start_time。 - 线 5 到线 8 运行循环。
- 第 10 行打印结果。
- 第 12 行保存当前时间到
end_time。 - 第 13 行打印出
start_time和end_time之间的差异,以显示运行脚本花了多长时间。
尝试用 Python 运行它。这是我在 2015 年 MacBook Pro 上得到的结果:
$ python3.6 script.py
The result is 999800010000
It took 20.66 seconds to compute
现在用 PyPy 运行它:
$ pypy3 script.py
The result is 999800010000
It took 0.22 seconds to compute
在这个小的合成基准测试中,PyPy 的速度大约是 Python 的 94 倍!
对于更严肃的基准测试,您可以看看 PyPy 速度中心,在那里开发人员使用不同的可执行文件运行夜间基准测试。
请记住,PyPy 如何影响代码的性能取决于您的代码在做什么。在某些情况下,PyPy 实际上要慢一些,稍后您会看到。但是,在几何平均上,它是 Python 的 4.3 倍。
PyPy 及其特性
历史上,PyPy 提到了两件事:
- 用于生成动态语言解释器的动态语言框架
- 使用该框架的 Python 实现
通过安装 PyPy 并使用它运行一个小脚本,您已经看到了第二种含义。你用的 Python 实现是用一个叫做 RPython 的动态语言框架写的,就像 CPython 是用 C 写的,Jython 是用 Java 写的。
但是之前不是告诉你 PyPy 是用 Python 写的吗?嗯,这有点简化了。PyPy 之所以被称为用 Python(而不是用 RPython)编写的 Python 解释器,是因为 RPython 使用与 Python 相同的语法。
为了澄清一切,下面是 PyPy 的生产过程:
-
源代码是用 RPython 写的。
-
将 RPython 翻译工具链应用于代码,这基本上使代码更加高效。它还将代码编译成机器码,这就是为什么 Mac、Windows 和 Linux 用户必须下载不同版本的代码。
-
生成二进制可执行文件。这是您用来运行小脚本的 Python 解释器。
请记住,使用 PyPy 不需要经历所有这些步骤。该可执行文件已经可供您安装和使用。
此外,由于在框架和实现中使用同一个词非常令人困惑,PyPy 背后的团队决定不再使用这种双重用法。现在,PyPy 仅指 Python 实现。该框架被称为 RPython 翻译工具链。
接下来,您将了解在某些情况下使 PyPy 比 Python 更好更快的特性。
实时(JIT)编译器
在进入什么是 JIT 编译之前,让我们后退一步,回顾一下 C 等编译的语言和 JavaScript 等解释的语言的属性。
编译过的编程语言性能更好,但是更难移植到不同的 CPU 架构和操作系统。解释型编程语言的可移植性更强,但性能却比编译型语言差很多。这是光谱的两个极端。
还有像 Python 这样的混合编译和解释的编程语言。具体来说,Python 首先被编译成一个中间字节码,然后由 CPython 解释。这使得代码比用纯解释编程语言编写的代码性能更好,并且保持了可移植性的优势。
然而,其性能仍然与编译版本相差甚远。原因是编译后的代码可以做很多优化,而字节码是不可能做到的。
这就是实时(JIT)编译器的用武之地。它试图通过编译成机器码和一些解释来获得两个世界的更好的部分。简而言之,以下是 JIT 编译提供更快性能的步骤:
- 确定代码中最常用的部分,例如循环中的函数。
- 在运行时将这些部分转换成机器代码。
- 优化生成的机器码。
- 用优化的机器码版本替换以前的实现。
还记得教程开头的两个嵌套循环吗?PyPy 检测到相同的操作被反复执行,将其编译成机器码,优化机器码,然后交换实现。这就是为什么你会看到速度有如此大的提高。
垃圾收集
每当你创建变量、函数或任何其他对象时,你的计算机都会给它们分配内存。最终,这些对象中的一些将不再需要。如果你不清理它们,那么你的计算机可能会耗尽内存,使你的程序崩溃。
在 C 和 C++等编程语言中,通常要手动处理这个问题。Python 和 Java 等其他编程语言会自动为您完成这项工作。这被称为自动垃圾收集,有几种技术可以实现它。
CPython 使用一种叫做引用计数的技术。本质上,Python 对象的引用计数在对象被引用时递增,在对象被取消引用时递减。当引用计数为零时,CPython 会自动调用该对象的内存释放函数。这是一种简单有效的技术,但是有一个问题。
当一个大对象树的引用计数变为零时,所有相关对象都被释放。结果,你有一个潜在的长暂停,在此期间你的程序根本没有进展。
此外,在一个用例中,引用计数根本不起作用。考虑以下代码:
1class A(object):
2 pass
3
4a = A()
5a.some_property = a
6del a
在上面的代码中,您定义了新的类。然后,创建该类的一个实例,并将其分配为自身的一个属性。最后,删除实例。
此时,该实例不再可访问。但是,引用计数不会从内存中删除实例,因为它有对自身的引用,所以引用计数不为零。这个问题叫做引用周期,用引用计数是解决不了的。
这就是 CPython 使用另一个叫做循环垃圾收集器的工具的地方。它从已知的根开始遍历内存中的所有对象,比如type对象。然后,它识别所有可到达的对象,并释放不可到达的对象,因为它们已经不存在了。这解决了参考循环问题。但是,当内存中有大量对象时,它会造成更明显的停顿。
另一方面,PyPy 不使用引用计数。相反,它只使用第二种技术,即循环查找器。也就是说,它周期性地从根开始遍历活的对象。这使得 PyPy 比 CPython 有一些优势,因为它不需要进行引用计数,使得花在内存管理上的总时间比 CPython 少。
此外,PyPy 不是像 CPython 那样在一个主要的项目中做所有的事情,而是将工作分成可变数量的部分,并运行每个部分,直到一个也不剩。这种方法在每次小的收集后只增加几毫秒,而不是像 CPython 那样一次性增加数百毫秒。
垃圾收集很复杂,并且有更多的细节超出了本教程的范围。您可以在文档中找到关于 PyPy 垃圾收集的更多信息。
PyPy 的局限性
PyPy 不是灵丹妙药,可能并不总是最适合您的任务的工具。它甚至可能使您的应用程序执行速度比 CPython 慢得多。这就是为什么记住以下限制很重要。
它不能很好地与 C 扩展一起工作
PyPy 最适合纯 Python 应用程序。无论何时你使用一个 C 扩展模块,它的运行速度都比在 CPython 中慢得多。原因是 PyPy 不能优化 C 扩展模块,因为它们不被完全支持。此外,PyPy 必须模拟这部分代码的引用计数,这使得它更慢。
在这种情况下,PyPy 团队建议去掉 CPython 扩展,用一个纯 Python 版本替换它,这样 JIT 就可以看到它并进行优化。如果这不是一个选项,那么您将不得不使用 CPython。
也就是说,核心团队正在开发 C 扩展。有些包已经移植到 PyPy 上,运行速度也一样快。
它只适用于长时间运行的程序
假设你想去一家离家很近的商店。你可以步行去,也可以开车去。
你的车显然比你的脚快得多。然而,想想它会要求你做什么:
- 去你的车库。
- 发动你的车。
- 把车预热一下。
- 开车去商店。
- 找个停车位。
- 回来的路上重复这个过程。
开车有很多开销,如果你想去的地方就在附近,那就不值得了!
现在想想如果你想去五十英里外的邻近城市会发生什么。开车去那里而不是步行肯定是值得的。
虽然速度上的差异不像上面的类比那样明显,但是 PyPy 和 CPython 也是如此。
当你用 PyPy 运行一个脚本时,它会做很多事情来使你的代码运行得更快。如果脚本太小,那么开销会导致脚本运行速度比在 CPython 中慢。另一方面,如果您有一个长时间运行的脚本,那么这种开销可以带来显著的性能收益。
要亲自查看,请在 CPython 和 PyPy 中运行以下小脚本:
1import time
2
3start_time = time.time()
4
5for i in range(100):
6 print(i)
7
8end_time = time.time()
9print(f"It took {end_time-start_time:.10f} seconds to compute")
当你用 PyPy 运行它时,开始会有一点延迟,而 CPython 会立即运行它。确切地说,在 2015 款 MacBook Pro 上运行它需要0.0004873276秒,在 PyPy 上运行它需要0.0019447803秒。
它不做提前编译
正如您在本教程开始时看到的,PyPy 不是一个完全编译的 Python 实现。它编译 Python 代码,但它不是 Python 代码的编译器。由于 Python 固有的动态性,不可能将 Python 编译成独立的二进制文件并重用它。
PyPy 是一个运行时解释器,它比完全解释的语言快,但比完全编译的语言如 c 慢。
结论
PyPy 是 CPython 的快速而强大的替代品。通过用它来运行您的脚本,您可以在不对代码做任何改动的情况下获得很大的速度提升。但这不是银弹。它有一些限制,您需要测试您的程序,看看 PyPy 是否能有所帮助。
在本教程中,您学习了:
- 什么是 PyPy
- 如何安装 PyPy 和用它运行你的脚本
- PyPy 在速度方面与 CPython 相比如何
- PyPy 有什么特性以及它如何提高你程序的速度
- PyPy 有哪些限制使它不适合某些情况
如果您的 Python 脚本需要一点速度提升,那么试试 PyPy 吧。根据你的程序,你可能会得到一些明显的速度提高!
如果你有任何问题,请在下面的评论区联系我们。****
Web 浏览器中的 PyScript: Python 初探
PyScript 是一个全新的框架,当 Anaconda,Inc. 的首席执行官兼联合创始人王蒙杰在 PyCon US 2022 的主题演讲中透露时,它引起了很多兴奋。虽然这个项目只是一个早期开发阶段的实验,但社交媒体上的人们似乎已经爱上了它。本教程将帮助您快速掌握 PyScript,而官方文档仍在制作中。
在本教程中,您将学习如何:
- 使用 Python 和 JavaScript 构建交互式前端应用
- 在网络浏览器中运行现有的 Python 代码
- 在后端和前端上重用相同的代码
- 从 JavaScript 调用 Python 函数,反之亦然
- 分发零依赖的 Python 程序
为了从本教程中获得最大收益,你最好对 JavaScript 和前端编程有所了解。同时,即使你以前从未做过任何网站开发,你也能很好地跟上进度。毕竟,这是 PyScript 背后的全部思想!
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
声明:PyScript 是一个实验项目!
本教程是在 PyScript 正式发布后的几周内发布的。在撰写本文时,您会发现框架主页上醒目地显示了以下警告:
请注意,PyScript 是非常 alpha 化的,正在大量开发中。有许多已知的问题,从可用性到加载时间,你应该预料到事情会经常改变。我们鼓励人们使用 PyScript 进行游戏和探索,但目前我们不建议将其用于生产。(来源)
这一点怎么强调都不为过。在您开始之前,请做好准备,不要像本教程中介绍的那样工作。当你读到这篇文章的时候,有些事情可能根本不起作用,而有些问题可能已经以这样或那样的方式解决了。
鉴于 PyScript 相对较短的历史,这并不奇怪。因为是开源软件,你可以在 GitHub 上一窥它的 Git 提交历史。当你这样做的时候,你会发现来自 Anaconda 的法比奥·普利格,PyScript 的创建者和技术负责人,在 2022 年 2 月 21 日做出了初始承诺。那离 4 月 30 日公开向世界公布也就两个多月!
这就是 PyScript 的现状。如果你准备好冒这个险,想尝试一下这个框架,那么请继续阅读。
PyScript 入门
在本节结束时,您将对框架及其构建块有一个大致的了解,包括它们如何一起将 Python 引入您的浏览器。您将知道如何挑选所需的文件并在本地托管 PyScript,而不依赖于互联网连接。
用你的头脑思考 PyScript
您可能会问自己 PyScript 到底是什么。这个名字可能是一个聪明的尝试,将它作为浏览器中 JavaScript 的替代品进行营销,但这样的解释不会给你完整的画面。以下是 PyScript 目前在其 Twitter 个人资料上的宣传方式:
PyScript -为 99%的人编程(来源
PyScript 的目标之一是让网络成为任何想学习编码的人的友好场所,包括孩子。除了现有的文本编辑器和浏览器之外,该框架不需要任何安装或配置过程就可以实现这一目标。一个副作用是 PyScript 简化了与他人共享您的工作。
当您查看 PyScript 的 README 文件时,您会发现以下摘要和更长的描述:
PyScript 是 Scratch、JSFiddle 和其他“易于使用”的编程框架的 Pythonic 替代品,其目标是使 web 成为一个友好的、可黑客攻击的地方,任何人都可以在那里创作有趣的交互式应用程序。
(…)
PyScript 是一个元项目,旨在将多种开放技术结合到一个框架中,允许用户使用 Python 创建复杂的浏览器应用程序。它与 DOM 在浏览器中的工作方式无缝集成,并允许用户以 web 和 Python 开发人员都感觉自然的方式添加 Python 逻辑( Source )
Scratch 是一种相对简单的可视化编程语言,孩子们在学校学习它来构建简单的游戏和有趣的动画。 JSFiddle 是 JavaScript 的在线编辑器,通常用于在像 StackOverflow 这样的论坛上演示给定问题的解决方案。
此外,PyScript 的主页包含以下标语:
PyScript 是一个框架,允许用户使用 HTML 的界面和 Pyodide、WASM 和现代 web 技术的力量在浏览器中创建丰富的 Python 应用程序。PyScript 框架为各种经验水平的用户提供了一种富于表现力、易于学习的编程语言,以及无数的应用程序。(来源)
换句话说,PyScript 允许您使用 Python,不管有没有 JavaScript,来构建不一定要与服务器通信的交互式网站。这里的主要好处是,您可以利用现有的 Python 知识进入前端开发的世界,降低进入门槛,使其更容易获得。但是使用 PyScript 还有许多其他好处,稍后您将会了解到。
在稍微更技术的层面上,PyScript 是一个使用 Svelte 框架用 TypeScript 编写的单页应用程序(SPA) ,样式为 Tailwind CSS ,捆绑 rollup.js 。根据早期 Git commit中的一条评论,该项目基于 Sascha Aeppli 在博客文章中提到的模板,该模板结合了这些工具。
如果不建立在最近版本的 Pyodide 之上,PyScript 是不可能的——这是一个用 emscripten 到 WebAssembly 编译的 CPython 解释器,使 Python 能够在浏览器中运行。PyScript 通过封装所需的样板代码在 Pyodide 上提供了一个薄的抽象层,否则您必须使用 JavaScript 自己输入。
如果您不熟悉 Pyodide 和 WebAssembly,请单击展开下面的可折叠部分:
已经有很多在浏览器中运行 Python 代码的尝试,取得了不同程度的成功。主要的挑战是,直到最近,JavaScript 还是 web 浏览器唯一能理解的编程语言。
在浏览器中运行 Python 代码有一些额外的困难要克服。例如,trans crypttrans piles将一段 Python 代码转换成类似的 JavaScript 代码片段,而 Brython 是一个用 JavaScript 实现的流线型 Python 解释器。这些和类似的工具并不理想,因为它们依赖于假装是真正的 Python 运行时的东西。
Pyodide 与众不同,因为它利用了 WebAssembly,这是一个由现代 web 浏览器支持的相当新的标准,旨在实现接近本机代码的执行速度。你可以把 WebAssembly 看作浏览器现在理解的第二种“编程语言”。
WebAssembly 是一个成熟的虚拟机,能够运行可移植的字节码,你可以通过编译几乎任何编程语言的源代码来实现。然而,当你查看与 WebAssembly 兼容的语言的列表时,你不会在那里找到 Python。你能猜到原因吗?
Python 是一种解释型语言,它没有针对 WebAssembly 的标准编译器。Pyodide 所做的是将整个 CPython 解释器编译到 WebAssembly 中,让它位于浏览器中并解释 Python 代码,就像它是常规的 Python 解释器一样。
当您忘记了浏览器沙箱及其安全策略的某些限制时,通过 CPython 或 Pyodide 运行代码应该没有功能上的区别,只有性能上的微小差异。Pyodide 和 WebAssembly 使 web 浏览器成为分发 Python 程序的绝佳场所。
为了使 Python 和 web 浏览器之间的集成更加简单,PyScript 定义了几个 Web 组件和定制元素,比如<py-script>和<py-button>,您可以将它们直接嵌入到 HTML 中。如果您对这些自定义标记名称中的连字符感到困扰,那么不要责怪 PyScript。HTML 规范强制执行它,以避免 Web 组件和未来 HTML 元素之间的名称冲突。
事不宜迟,是时候用 PyScript 写出你的第一个 Hello, World! 了!
写下你的第一句“你好,世界!”在 PyScript 中
开始使用 PyScript 的最快方法是创建一个最小 HTML5 文档,将其保存在一个本地文件中,比如hello.html,并利用 PyScript 主页上的两个必需文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello, World!</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" /> <script defer src="https://pyscript.net/alpha/pyscript.js"></script> </head>
<body>
<py-script>print("Hello, World!")</py-script> </body>
</html>
第一个文件pyscript.css,为 PyScript 的可视组件提供了默认样式,稍后您将探索这些组件,以及加载器闪屏。第二个文件pyscript.js,包含引导 Python 运行时的 JavaScript,并添加了像<py-script>这样的定制元素,它可以保存 Python 指令,比如对 print() 函数的调用。
有了这个设置,你不需要启动网络服务器来访问你的 HTML 内容。自己看吧!继续,将 HTML 文档保存到本地文件,并直接在您喜欢的 web 浏览器中打开它:
恭喜你!您刚刚创建了第一个 PyScript 应用程序,它可以在任何现代网络浏览器上工作,甚至可以在早期的 Chromebook 上工作,而不需要安装 Python 解释器。你可以将你的 HTML 文件复制到 USB 拇指驱动器上,然后交给朋友,即使他们的机器上没有安装 Python,他们也可以运行你的代码。
注意: PyScript 只在谷歌 Chrome 上测试过。不幸的是,这意味着您的代码在不同的 web 浏览器上的行为可能会有一些小的差异,这在传统的 Python 开发中是从来没有过的。
接下来,您将了解当您在 web 浏览器中打开该文件时发生了什么。
从互联网上获取 Python 运行时
当你在网络浏览器中打开你的 HTML 文件时,在显示 Hello,World!在橱窗里。PyScript 必须从 jsDelivr CDN ,JavaScript 的免费内容交付网络为开源项目获取一打额外的资源。这些资源组成了 Pyodide 运行时,解压缩后总重量超过 20 兆字节。
幸运的是,您的浏览器会将这些资源的大部分缓存在内存或磁盘上,这样,在将来,加载时间会明显加快。只要你至少打开过一次 HTML 文件,你就可以不依赖网络连接而离线工作。
依靠 CDN 来交付您的依赖无疑是方便的,但它有时会很脆弱。过去有已知的 cdn 宕机案例,导致大型在线业务中断。因为 PyScript 处于最前沿,所以 CDN 总是提供最新的 alpha 版本,这有时会带来突破性的变化。相反,CDN 可能偶尔需要时间来跟上 GitHub,所以它可能提供过时的代码。
总是请求特定版本的 PyScript 不是更好吗?
下载 PyScript 进行离线开发
如果您不想依赖 PyScript 的托管服务,那么您需要下载在浏览器中运行 Python 所需的所有文件,并自己托管它们。出于开发目的,您可以通过在包含您要托管的文件的目录中发出以下命令来启动一个内置在 Python 中的本地 HTTP 服务器:
- 视窗
** Linux + macOS*
PS> python -m http.server
Serving HTTP on :: port 8000 (http://[::]:8000/) ...
$ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
默认情况下,它会启动一个服务器监听所有网络接口上的 HTTP 请求,包括本地主机,端口号为 8000。如果需要,您可以使用可选参数调整地址和端口号。例如,这将允许您在http://localhost:8000/hello.html访问 PyScript 应用程序。
然而,在这样做之前,您需要将pyscript.css、pyscript.js和pyscript.py下载到您的 HTML 文档所在的文件夹中。为此,您可以使用 Wget 命令行工具,它在 Windows 上的 PowerShell 中有对应的功能,或者手动下载文件:
- 视窗
** Linux + macOS*
PS> foreach ($ext in "css", "js", "py") {
>> wget "https://pyscript.net/alpha/pyscript.$ext" -o "pyscript.$ext"
>> }
$ wget https://pyscript.net/alpha/pyscript.{css,js,py}
这将一次性下载所有三个文件。助手 Python 模块包含 PyScript 和 Pyodide 所需的粘合代码。您需要下载pyscript.py,因为引导脚本将试图从它自己的域地址中获取它,这个地址将是您的本地主机地址。
注意:或者,您可以使用可选的源地图来获取引导脚本的缩小版,以进一步减少下载量。源代码映射可以让您从缩小的形式恢复源代码,这在调试过程中很有帮助。
不要忘记更新 HTML 中的 CSS 和 JavaScript 路径,以便它们指向本地文件,而不是在线托管的文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello, World!</title>
<link rel="stylesheet" href="/pyscript.css" /> <script defer src="/pyscript.js"></script> </head>
<body>
<py-script>print("Hello, World!")</py-script>
</body>
</html>
这里,您假设这些资源文件放置在 HTML 文件的旁边,但是您也可以为这些资源创建一个或多个子文件夹以保持有序。
你就快到了。但是,如果您现在将浏览器导航到您的本地服务器,那么它仍然会尝试从 CDN 而不是您的本地 HTTP 服务器获取一些资源。您将在下一节中解决这个问题。
下载特定的 Pyodide 版本
既然您已经使 PyScript 脱机工作,那么是时候对 Pyodide 执行类似的步骤了。在 PyScript 的早期,带有 Pyodide 的 URL 是硬编码的,但是开发人员最近引入了另一个名为<py-config>的定制元素,它允许您指定带有所需 Pyodide 版本的 URL:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello, World!</title>
<link rel="stylesheet" href="/pyscript.css" />
<script defer src="/pyscript.js"></script>
<py-config>
- autoclose_loader: true
- runtimes:
-
src: "/pyodide.js" name: pyodide-0.20
lang: python
</py-config>
</head>
<body>
<py-script>print("Hello, World!")</py-script>
</body>
</html>
这个可选标签里面的内容是一段 YAML 的配置。您可以使用src属性提供一个包含在线托管的具体 Pyodide 版本的 URL,或者一个您稍后将下载的本地文件。在上面的代码块中,"/pyodide.js"表示相对于本地 HTTP 服务器的根地址的路径,例如,可以扩展为http://localhost:8000/pyodide.js。
要获得浏览器将从 CDN 下载或从其缓存加载的剩余文件的最新列表,您可以在刷新页面之前前往 web 开发工具并切换到网络标签。然而,有可能您最终会需要更多的文件,或者它们的名称将来可能会改变,因此检查网络流量很快就会变成一件麻烦的事情。
出于开发的目的,下载所有一个 Pyodide 版本的文件,然后决定你的应用程序真正需要的文件,这可能更方便。因此,如果你不介意下载几百兆字节,那么从 GitHub 中抓取发布版 tarball ,并将其解压到你的Hello, World!应用程序的文件夹中:
- 视窗
** Linux + macOS*
PS> $VERSION='0.20.0'
PS> $TARBALL="pyodide-build-$VERSION.tar.bz2"
PS> $GITHUB_URL='https://github.com/pyodide/pyodide/releases/download'
PS> wget "$GITHUB_URL/$VERSION/$TARBALL"
PS> tar -xf "$TARBALL" --strip-components=1 pyodide
$ VERSION='0.20.0'
$ TARBALL="pyodide-build-$VERSION.tar.bz2"
$ GITHUB_URL='https://github.com/pyodide/pyodide/releases/download'
$ wget "$GITHUB_URL/$VERSION/$TARBALL"
$ tar -xf "$TARBALL" --strip-components=1 pyodide
如果上面的命令在您的操作系统上不起作用,也不用担心。您可以下载归档文件并手动提取其pyodide/子文件夹的内容。
注意: Pyodide 的 release tarball 如此之大是因为它捆绑了许多流行的第三方库,在数据科学中特别有用,这些库是为 WebAssembly 预编译的。
只要一切顺利,您的应用程序文件夹中至少应该有这 14 个文件:
hello-world/
│
├── distutils.tar
├── hello.html
├── micropip-0.1-py3-none-any.whl
├── packages.json
├── packaging-21.3-py3-none-any.whl
├── pyodide.asm.data
├── pyodide.asm.js
├── pyodide.asm.wasm
├── pyodide.js
├── pyodide_py.tar
├── pyparsing-3.0.7-py3-none-any.whl
├── pyscript.css
├── pyscript.js
└── pyscript.py
如您所见,PyScript 是 Python、JavaScript、WebAssembly、CSS 和 HTML 的混合体。在实践中,您将使用 Python 完成大部分 PyScript 编程。
您在本节中采用的方法使您能够更精细地控制 Pyodide 和底层 Python 解释器的版本。要通过 Pyodide 查看哪些 Python 版本可用,可以查看 changelog 。例如,本教程中使用的 Pyodide 0.20.0 是在 CPython 3.10.2 之上构建的。
如果有疑问,您可以亲自验证浏览器中运行的 Python 版本,您将在接下来了解到这一点。
验证您的 Pyodide 和 Python 版本
要检查您的 Pyodide 版本,您需要的只是一行代码。回到您的代码编辑器,用下面的代码片段替换Hello, World!代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello, World!</title>
<link rel="stylesheet" href="/pyscript.css" />
<script defer src="/pyscript.js"></script>
<py-config>
- autoclose_loader: true
- runtimes:
-
src: "/pyodide.js"
name: pyodide-0.20
lang: python
</py-config>
</head>
<body>
<py-script>import pyodide_js; print(pyodide_js.version)</py-script> </body>
</html>
它依赖于自动注入 PyScript 的pyodide_js模块。如果 PyScript 没有为给定的特性提供自己的抽象层,您可以使用它直接从 Python 访问 Pyodide 的 JavaScript API。
在 PyScript 中检查 Python 版本看起来与在标准 CPython 解释器中一样:
<py-script>import sys; print(f"Python {sys.version}")</py-script>
您从标准库中导入sys模块来检查sys.version常量,然后用 f 字符串打印它。当您在 web 浏览器中刷新页面并让它重新加载时,它应该会生成一个以如下内容开头的字符串:
Python 3.10.2 (main,2022 年 4 月 9 日,20:52:01) […]
这是您在命令行中运行交互式 Python 解释器时通常会看到的。在这种情况下,Pyodide 并没有落后于最新的 CPython 版本,在撰写本教程时是 3.10.4。
顺便说一下,你注意到上面例子中的分号(;)了吗?在 Python 中,分号分隔出现在一行中的多个语句,这在您编写单行脚本或受到约束时会很有用,例如,受到 timeit 模块的设置字符串的约束。
在 Python 代码中很少使用分号,而且经验丰富的 Python 爱好者通常不赞成使用分号。然而,这个不受欢迎的符号有助于回避 Python 的重要空格的问题,这在 PyScript 中有时会变得混乱。在下一节中,您将学习如何处理嵌入在 HTML 中的块缩进和 Python 代码格式。
处理 Python 代码格式化
当你在一个 HTML 文档中嵌入一段 CSS、JavaScript,甚至是一个 SVG 图像时,网络浏览器不会有误解相关代码的风险,因为它们都是自由格式语言的例子,忽略多余的空格。在这些语言中,您可以随意设置代码的格式,例如,通过删除换行符,而不会丢失任何信息。这使得 JavaScript 的小型化成为可能。
不幸的是,这对 Python 来说并不正确,它的语法遵循了越位规则,其中每个空格字符都有效。因为 PyScript 是一项如此新颖的技术,今天大多数的自动代码格式化器很可能会做出错误的假设,并通过折叠重要的空白来破坏包含在<py-script>标签中的 Python 代码。如果发生这种情况,您可能会得到类似于下面的错误:
Traceback (most recent call last):
...
File "<exec>", line 2
print(f"Python {sys.version}")
IndentationError: unexpected indent
在这种情况下,Pyodide 无法解析嵌入在 HTML 中的 Python 代码片段,因为缩进被破坏了。您将在文档正文和 web 开发人员控制台中看到这个异常和相关的回溯。
但这还不是全部。如果你在 Python 代码中声明了一个看起来像 HTML 标签的字符串文字,那么浏览器会把它识别为 HTMLUnknownElement 并去掉它,只留下里面的文本。以解析 XML 为例:
<py-script>
import xml.etree.ElementTree as ET
ET.fromstring("<person>John Doe</person>")
</py-script>
上面的代码使用 Python 标准库中的 ElementTree API 来解析一个字符串,该字符串包含一个人的 XML 格式的数据记录。但是,传入函数的实际参数将只有"John Doe"而没有周围的标签。
注意,从 web 浏览器的角度来看,<person>看起来像是嵌套在<py-script>父元素下的另一个 HTML 标签。为了避免这种歧义,您可以将尖括号(<和>)替换为它们的对应编码,称为 HTML 实体:
<py-script>
import xml.etree.ElementTree as ET
ET.fromstring("<person>John Doe</person>")
</py-script>
<实体代表“小于”(<)字符,而>代替了“大于”(>)字符。字符实体允许浏览器按字面意思呈现文本,否则文本会被解释为 HTML 元素。这在 PyScript 中可以工作,但是不能解决缩进问题。
注意:在 XML 文档中,您可以将内容包装在一对字符数据(CDATA) 标记中,作为使用 HTML 实体的替代方法。不幸的是,大多数 HTML 解析器忽略了 CDATA。
除非您只是在玩 PyScript,否则通常最好将 Python 代码提取到一个单独的文件中,而不是与 HTML 混合在一起。您可以通过在<py-script>元素上指定可选的src属性来实现这一点,它看起来类似于 JavaScript 的标准<script>标记:
<py-script src="/custom_script.py"></py-script>
页面一准备好,就会加载并立即运行你的 Python 脚本。如果您只想将一个定制模块加载到 PyScript 运行时中,以使其可用于导入,那么在下一节中用<py-env>检查依赖管理。
注意:由于网络浏览器强制实施的跨来源资源共享(CORS) 政策,当您将页面作为本地文件打开时,您将无法从外部文件加载 Python 脚本。您需要通过 web 服务器托管带有相关资源的 HTML,比如前面提到的 Python 内置的http.server。
你的页面上可以有多个<py-script>标签,只要它们出现在页面的<head>或<body>中。PyScript 会将它们放到一个队列中,并按顺序运行它们。
现在您知道了如何在浏览器中使用 PyScript 运行 Python 代码。然而,大多数实际应用程序需要一个或多个依赖项。在下一节中,您将了解如何利用 Python 现有的“电池”、在 PyPI 或其他地方发布的第三方库,以及您自己的 Python 模块。
在 PyScript 中管理 Python 依赖关系
到目前为止,您已经看到了框架提供的<py-script>和<py-config>定制标签。另一个你经常想使用的元素是<py-env>,它有助于管理你的项目依赖,类似于 Python 的pip工具。
Python 标准库中缺少的模块
Python 自带了包含的电池,这意味着它的标准库模块已经解决了你在软件开发中可能面临的常见问题。您会发现这些模块中的大多数都有现成的 Pyodide 和 PyScript 版本,让您可以立即导入和使用它们。例如,您已经看到了利用xml.etree包解析 XML 文档的代码片段。
然而,由于 web 浏览器的限制和减少下载大小的努力,有一些值得注意的例外。任何与浏览器环境无关的东西都从当前的 Pyodide 版本中删除了。具体而言,这些包括但不限于以下模块和包:
你可以在 Pyodide 的文档页面上查看已移除包的完整列表。
除此之外,一些包作为占位符保留,一旦 WebAssembly 在未来发展,它们最终可能会得到适当的支持。今天,您可以导入它们,以及依赖于它们的 urllib.request 等模块,但它们无法工作:
一般来说,不能启动新的进程、线程,或者打开低级别的网络连接。也就是说,在本教程的后面,你会学到一些缓解措施。
在 PyScript 中使用外部库怎么样,您通常将这些库与 pip 一起安装到您的虚拟环境中?
与 Pyodide 捆绑的第三方库
Pyodide 是 Mozilla 发起的现已停止的碘化物母项目的衍生项目。它的目标是以类似于 Jupyter 笔记本的方式提供在网络浏览器中进行科学计算的工具,但不需要与服务器通信来运行 Python 代码。因此,研究人员将能够以有限的计算能力为代价,更容易地共享和重用他们的工作。
因为 PyScript 是 Pyodide 的包装器,所以您可以访问许多流行的第三方库,这些库是用 Pyodide 为 WebAssembly 编译的,甚至是那些部分用 C 和 Fortran 编写的库。例如,您会在那里找到以下软件包:
- 美汤
- 散景
- Matplotlib
- NLTK
- NumPy
- 熊猫
- 枕头
- 轨道轨道
- SQL 语法
- scikit-learn
实际的列表要长得多,并且不仅限于严格为数据科学设计的库。在撰写本教程时,有将近 100 个库捆绑了 Pyodide。你可以查看 Pyodide 官方文档中的完整列表或者前往相应 GitHub 存储库中的包/ 文件夹查看最新状态。
即使这些外部库是 Pyodide 版本的一部分,它们也不会自动加载到 Python 运行时中。请记住,每个单独的 Python 模块都必须通过网络获取到您的 web 浏览器中,这需要花费宝贵的时间和资源。当 PyScript 启动时,您的环境只有解释 Python 代码所需的最低限度。
要导入 Python 标准库中不存在的模块,必须通过在<py-env>元素中声明它们的名称来显式请求它们:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Sine Wave</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
</head>
<body>
<py-env> - matplotlib - numpy </py-env> <py-script>
import matplotlib.pyplot as plt
import numpy as np
time = np.linspace(0, 2 * np.pi, 100)
plt.plot(time, np.sin(time))
plt
</py-script>
</body>
</html>
<py-env>元素包含一个 YAML 列表,其中包含要按需获取的库的名称。当你在你的网络开发工具中查看网络标签时,你会注意到浏览器从 CDN 服务器或者你的本地 HTTP 服务器下载 NumPy 和 Matplotlib。它还提取了 Matplotlib 所需的几个可传递的依赖项,总计超过 12 兆字节!
注意:您可以将<py-env>元素放在文档的标题或正文中。尽管 PyScript 中的一些示例将这个自定义元素放在了的标题和正文之间,但这似乎并不正确,可能并不适用于所有的 web 浏览器。
或者,您可以在 Python 中以编程方式安装依赖关系,因为 PyScript 公开了 Pyodide 的 micropip 工具,它是pip的精简版本:
<py-script>
# Run this using "asyncio"
async def main():
await micropip.install(["matplotlib", "numpy"])
await loop.run_until_complete(main())
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 100)
plt.plot(x, np.sin(x))
plt
</py-script>
在 PyScript 的全局名称空间中,可以使用代表默认异步事件循环的micropip模块和隐式loop变量,而无需导入它们。
请注意,您必须通过 Python 的 asyncio 包异步调用模块的.install()方法来挂钩到 web 浏览器的 Fetch API 以供 micropip 使用。此外,虽然 imports style guide 建议将您的import语句放在文件的顶部,但是它们必须放在这里的await语句之后,以确保所需的库已经被 micropip 首先获取并安装。
注意:如果单词asyncio出现在代码中的任何地方,包括注释中,那么 PyScript 将使用 Pyodide 的 .runPythonAsync() 方法异步运行 Python。否则,它会调用同步的 .runPython() 对应物,而不让你使用await关键字。
如果 Pyodide 在它的捆绑包中没有找到所需的库,那么它将尝试从 Python 包索引(PyPI)中下载它。然而,由于某些运行时限制,并不是所有的库都这样工作。
从 PyPI 下载的纯 Python 轮子
假设您想要创建一个 PyScript 应用程序,它使用 untangle 库来解析 XML,这个库既没有与 Pyodide 捆绑在一起,也没有与标准库一起分发。您将以下声明添加到<py-env>元素,并在浏览器中重新加载您的页面:
<py-env>
- untangle
</py-env>
Pyodide 联系 PyPI 获取相关联的 JSON 元数据,并得出结论,该库没有以预期的 Python wheel 格式构建和上传。它只能作为源代码发行版(sdist) 使用,这可能需要一个额外的编译步骤。如果库只包含纯 Python 代码也没关系。在这种情况下,Pyodide 需要一个车轮档案,它可以提取并立即开始使用。
有点失望,您用另一个名为 xmltodict 的 XML 解析库试试运气,它将文档转换成 Python 字典而不是对象:
<py-env>
- xmltodict
</py-env>
这一次,库的元数据表明一个纯 Python 的 wheel 档案是可用的,所以 Pyodide 继续获取它。如果库有自己的依赖项,那么 Pyodide 也会尝试获取它们。然而,在 micropip 中实现的依赖关系解析机制是非常初级的。从现在开始,xmltodict库可以导入到 PyScript 应用程序中。
然而,如果您尝试获取一个非纯 Python 库,比如 PostgreSQL 数据库的二进制驱动程序,那么 Pyodide 会拒绝将其加载到您的运行时中。即使它是为各种平台构建的 Python 轮子,也没有一个适合 WebAssembly。在相应页面点击 下载文件 可以查看任意给定库上传到 PyPI 的车轮。
注意:通过在<py-env>元素中提供包的 URL,您可以有选择地从 PyPI 以外的远程服务器请求包,只要它们是纯 Python 的:
<py-env>
- http://local-pypi.org:8001/xmltodict-0.13.0-py2.py3-none-any.whl
</py-env>
托管这些轮子的服务器必须配置为返回 CORS 头,例如Access-Control-Allow-Origin。否则,浏览器将拒绝从不同的来源(协议、域、端口号)获取数据,并根据其安全策略阻止连接。
此外,依赖关系解析机制对上面的自定义 URL 不起作用。
综上所述,<py-env>中列出的第三方库必须是纯 Python 的,并且使用 wheel 格式分发才能被拾取,除非它已经为 WebAssembly 构建并与 Pyodide 捆绑在一起。将一个定制的非纯 Python 库放入 PyScript 是很棘手的。
为 WebAssembly 编译的 c 扩展模块
许多 Python 库包含用 C 或其他语言编写的代码,以提高性能,并利用纯 Python 中不可用的特定系统调用。有几种方法可以与这样的代码交互,但通常的做法是将它封装在一个 Python C 扩展模块中,该模块可以编译成您平台的本机代码,并在运行时动态加载。
使用 emscripten 编译器,您可以将 WebAssembly 作为目标,而不是特定的计算机体系结构和操作系统。然而,这样做并不容易。即使你知道如何为 Pyodide 运行时构建一个 Python 轮子,并且你没有被这个过程吓倒,PyScript 的<py-env>标签总是期望一个纯 Python 轮子或者一个与 Pyodide 捆绑在一起的包。
要安装包含 WebAssembly 代码的轮子,可以使用前面提到的 Pyodide 的 Python 接口pyodide_js调用其 loadPackage() 函数。你也可以在 JavaScript 中直接使用 Pyodide 的 API,但是它会启动一个独立的运行时,而不是连接到 PyScript 已经创建的运行时。因此,带有 WebAssembly 代码的自定义模块在 PyScript 中是不可见的。
加载定制的 C 扩展模块最终会变得更加简单。在此之前,你最好的选择似乎是耐心等待 Pyodide 发布所需的库。或者,您可以使用额外的交叉编译库从源代码构建自己的 Pyodide 运行时。有一个名为 pyodide-build 的命令行工具,可以自动完成一些相关步骤。
目前,您可能希望坚持手工编写定制的 Python 模块。
定制 Python 模块和数据文件
您可以使用<py-env>或 micropip 使您的定制模块可导入 PyScript 应用程序。假设您制作了一个名为waves.py的助手模块,它位于src/子文件夹中:
# src/waves.py
import numpy as np
def wave(frequency, amplitude=1, phase=0):
def _wave(time):
return amplitude * np.sin(2 * np.pi * frequency * time + phase)
return _wave
你的模块名称使用复数形式,避免与标准库中 wave 模块冲突,用于读写波形音频文件格式(WAV) 。您的模块定义了一个名为wave()的函数,它返回一个闭包。闭包所基于的内部函数 _wave()使用 NumPy 生成一个具有给定频率、振幅和相位的纯正弦波。
在您可以从内联或源代码脚本将您的模块导入到一个<py-script>标签中之前,您需要通过在 YAML 指定一个特殊的paths属性,用<py-env>将它获取到您的 web 浏览器中:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Sine Wave</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
</head>
<body>
<py-env>
- matplotlib
- numpy
- paths: - src/waves.py </py-env>
<py-script>
import matplotlib.pyplot as plt
import numpy as np
import waves
time = np.linspace(0, 2 * np.pi, 100)
plt.plot(time, waves.wave(440)(time)) plt
</py-script>
</body>
</html>
文件路径相对于您的 HTML 页面。和以前一样,由于 CORS 政策,你必须通过网络服务器托管你的文件,该政策不允许通过 file:// 协议获取额外的文件。
注意:不能用paths加载 Python 包,只能用模块。如果你有一个纯 Python 包,那么构建一个轮子分发版,并把它和你的其他文件放在一起,或者把它上传到 PyPI 。
从好的方面来说,值得注意的是,虽然您不能将一个目录加载到 PyScript 中,但是您可以滥用paths属性将几乎任何文件加载到其中。这包括数据文件,如文本 CSV 文件或二进制 SQLite 数据库:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Loading Data</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
</head>
<body>
<py-env>
- paths:
- data/people.csv
- data/people.sql
</py-env>
<py-script>
with open("people.csv") as file:
print(file.read())
</py-script>
<py-script>
import sqlite3
with sqlite3.connect("people.sql") as connection:
cursor = connection.cursor()
cursor.execute("SELECT * FROM people")
for row in cursor.fetchall():
print(row)
</py-script>
</body>
</html>
请注意,当您使用<py-env>获取文件时,您会丢失关于其原始目录结构的信息,因为所有文件都在一个目标目录中结束。当您打开一个文件时,您只指定了它的名称而没有路径,这意味着您的文件必须唯一命名。稍后您将了解如何通过在 Pyodide 中写入虚拟文件系统来缓解这个问题。
好吧。既然您已经知道如何将您的 Python 代码或其他人的代码导入 PyScript,那么您应该学习如何更有效地使用这个框架。
效仿 Python REPL 和 Jupyter 的笔记本
学习 Python 或其任何底层库的一个快速而有趣的方法是在一个实时解释器会话中试用它们,也称为读取-评估-打印-循环(REPL) 。通过与代码交互,你可以探索哪些函数和类可用,以及你应该如何使用它们。和 PyScript 没什么区别。
因为 PyScript 的环境需要一段时间来加载,所以每次编辑完代码都刷新页面并不能解决问题。幸运的是,该框架还附带了另一个名为<py-repl>的定制元素,它允许您执行小代码片段,而无需重新加载页面。您可以在 HTML 中包含任意数量的这些内容,将它们留空或预先填充一些初始 Python 代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>PyScript REPL</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
<py-env>
- matplotlib
- numpy
</py-env>
</head>
<body>
<py-repl>
import matplotlib.pyplot as plt
import numpy as np
</py-repl>
<py-repl>
def wave(frequency, amplitude=1, phase=0):
def _wave(time):
return amplitude * np.sin(2 * np.pi * frequency * time + phase)
return _wave
</py-repl>
<py-repl></py-repl>
</body>
</html>
与您已经探索过的元素不同,<py-repl>有一个建立在 CodeMirror 编辑器之上的可视化表示,它支持主题化语法高亮、自动完成、代码折叠等等。只要已经包含了 PyScript 提供的默认 CSS 样式表,这个新元素在浏览器中呈现时应该是这样的:
<py-repl>的每个实例都类似于 Jupyter 笔记本中的一个单元格。您可以在单元格中键入多行 Python 代码,然后单击右下角的绿色播放按钮来执行您的代码。你也可以使用 Shift + Enter 组合键来达到类似的效果。下面是 CodeMirror 提供的几个额外的键盘快捷键:
| 行动 | 马科斯 | Windows 和 Linux |
|---|---|---|
| 搜索 | Cmd + F |
Ctrl + F |
| 选择范围 | Cmd + I |
Ctrl + I |
| 选择线 | Ctrl + L |
Alt + L |
| 删除行 | Cmd+Shift+K |
Ctrl+Shift+K |
| 在下面插入一行 | Cmd + Enter |
Ctrl + Enter |
| 向上移动选择 | Alt + Up |
Alt + Up |
| 向下移动选择 | Alt + Down |
Alt + Down |
| 转到匹配的括号 | Cmd+Shift+\ |
Ctrl+Shift+\ |
| 缩进 | Cmd + ] |
Ctrl + ] |
| 德登特 | Cmd + [ |
Ctrl + [ |
上表显示了默认键映射,可以调整它来模仿 Emacs 、 Vim 或 Sublime Text 。
如果单元格中的最后一行包含有效的 Python 表达式,那么 PyScript 会将其表示形式追加到单元格的正下方。例如,它可以呈现用 Matplotlib 绘制的图形。当您在浏览器中查看这样的网页时,它确实开始看起来像一个 Jupyter 笔记本。
然而,与 Jupyter 笔记本不同,默认情况下,执行<py-repl>不会插入新的单元格。如果您想启用这样的行为,那么将元素的auto-generate属性设置为 true:
<py-repl auto-generate="true"></py-repl>
现在,当您第一次在这样的单元格中运行代码时,它会在页面底部插入另一个代码。然而,随后的运行不会。这个新单元格本身将具有auto-generate属性。
<py-repl>元素的另一个默认行为是为 Python 输出和回溯添加新的 <div> 容器。您可以有选择地将标准输出和标准错误流重定向到页面上单独的自定义元素,让您在浏览器中设计一个类似 IDE 的环境:
下面是上面截图中描述的网页代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>PyScript Playground</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
<style> body { background-color: #eee; } .container { display: grid; grid-template-columns: 1fr 1fr; grid-auto-rows: minmax(200px, auto); grid-gap: 1em; margin-top: 1em; } .container > div:first-child { grid-row: 1/3; } .container > div { background-color: #fff; box-shadow: 0px 5px 10px #ccc; padding: 10px; } </style>
<py-env>
- matplotlib
- numpy
</py-env>
</head>
<body>
<div class="container">
<div>
<py-repl std-out="output" std-err="errors"></py-repl> </div>
<div>
<b>Output</b><hr>
<div id="output"></div>
</div>
<div>
<b>Errors and Warnings</b><hr>
<div id="errors"></div>
</div>
</div>
</body>
</html>
使用std-out和std-err属性来指定相应的目标元素 id。如果您想将这两个流合并到一个元素中,那么您可以使用output属性。同样的属性也适用于您之前看到的<py-script>元素。
PyScript 目前提供的其余元素是可视组件,也称为小部件,它们简化了 HTML 和 Python 的工作。现在您将探索它们。
探索 PyScript 的可视化组件
PyScript 提供的可视化组件是 HTML 元素的方便包装器,这对于没有太多 web 开发经验的初学者可能很有帮助,尤其是在客户端。然而,这些小部件是高度实验性的,功能有限,将来可能会被删除。有时,它们在 Pyodide 完全初始化之前加载得太快,这会导致错误。使用它们需要您自担风险!
PyTitle
使用 PyTitle 元素,您可以快速地将一个文本头添加到您的网页中,如果您链接了 PyScript 附带的默认 CSS 样式表,它将以大写字母出现并水平居中。下面是如何在 HTML 代码中使用这个小部件:
<py-title>PyScript Playground</py-title>
它是一个纯粹的可视化组件,没有额外的属性或行为,只接受开始和结束标记之间的纯文本内容。
宝盒〔t0〕
PyBox 是一个容器元素,可以使用CSS FlexboxT5】布局模型在水平方向排列其子元素。它目前使用 Tailwind CSS 宽度类,如w-1、w-1/2或w-full,来定义列宽。
注意:当你读到这里的时候, Tailwind 很可能已经被 PyScript 中的纯 CSS 所取代,所以下面的代码可能无法工作,或者可能需要一些调整。这一步的主要动机是减少各种资源的下载量。
您可以通过<py-box>父元素的可选widths属性来指定子元素的宽度:
<py-box widths="2/3;1/6;1/6">
<div>Wide Column</div>
<div>Narrow Column</div>
<div>Narrow Column</div>
</py-box>
请注意,您只提供了 CSS 类名中位于前缀w-之后的部分,并且使用分号(;)来分隔宽度。在上面的例子中,第一个<div>将占据该行可用空间的三分之二(⅔),而其他两个元素合起来将占三分之一(⅙ + ⅙ = ⅓).)如果你跳过widths属性,那么所有的子节点将被拉伸到相同的大小。
PyButton
PyButton 是 PyScript 中第一个交互式小部件,它允许您调用 Python 函数来响应用户操作,比如单击鼠标按钮。为了处理 JavaScript 的点击事件,在<py-button>元素中定义一个名为on_click()的内嵌函数:
<py-button label="Click me" styles="btn big">
def on_click(event):
print(event)
</py-button>
这个函数是一个回调,它接受一个指针事件对象,不返回任何内容。虽然不可能附加一个在别处定义的回调,但是你总是可以委托给一些帮助函数。如果您不喜欢 PyButton 的默认外观,那么您可以通过styles属性用一个或多个 CSS 类覆盖它。
PyButton 支持的另一个事件是焦点事件,您可以通过定义on_focus()函数来监听它。它将接收 FocusEvent 对象作为参数。
可悲的是,由于 PyScript 和 Pyodide 的开发速度太快,后者在 0.19 版本中通过修复一个内存泄漏引入了一个突破性的变化,意外地使 PyButton 停止工作。同样的问题也适用于 PyInputBox,您将在接下来了解它。希望在你读到这篇文章的时候,这两个小部件都已经被修复了。
查询输入盒
PyInputBox 是 PyScript 中目前可用的最后一个小部件,它包装了 HTML 的输入元素,并允许您在其上监听按键事件:
<py-inputbox>
def on_keypress(event):
print(event)
</py-inputbox>
请注意,keypress 事件已被弃用,取而代之的是 PyInputBox 尚不支持的 keydown 事件。因此,您可能会发现直接从 PyScript 访问和操作标准 HTML 元素不那么麻烦,因为没有可能会中断的额外抽象层。
使用 PyScript 查找和操作 HTML 元素
WebAssembly 目前不允许与文档对象模型(DOM) 直接交互,这通常会让您访问 HTML 的底层元素。相反,您必须使用 JavaScript 来查询和遍历 DOM 树。由于 Pyodide 的代理对象,访问 Python 中的 JavaScript 对象成为可能,这促进了两种语言之间的翻译。在 PyScript 中,有两种方法可以将它们用于 DOM 操作。
用于 JavaScript 代理的 PyScript 适配器
对于琐碎的用例,当您很着急并且不介意缺少额外的附加功能时,您可以尝试一下 PyScript 的Element类。它已经在您的全局名称空间中,这意味着您不必导入它。类允许您仅通过 ID 查找 HTML 元素,并在有限的范围内修改它们的内容。
考虑下面的 HTML 文档示例:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>DOM API in PyScript</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
<style> .crossed { text-decoration: line-through; } </style>
</head>
<body>
<div id="shopping-list">
<p>Shopping List</p>
<ul>
<li class="crossed">milk</li>
<li class="crossed">eggs</li>
<li>bread</li>
</ul>
<input id="new-item" type="text" placeholder="Add new item">
</div>
<py-repl></py-repl>
</body>
</html>
这是一个购物清单,上面有一些划掉的项目,底部有一个输入框,用于添加要购买的新项目。当您在 web 浏览器中打开这个页面时,<py-repl>元素将允许您交互式地测试和使用 PyScript API。
假设您想要确定用户在输入框中输入了哪个新的购物项目,然后您想要清除它。这里有一段 Python 代码,当它被放在<py-script>或<py-repl>标签中时,就能做到这一点:
input_new_item = Element("new-item")
print(input_new_item.value)
input_new_item.clear()
首先,通过调用带有 HTML id属性"new-item"作为参数的Element() 类构造函数,获取对<input>元素的引用。然后,打印元素的.value属性,并调用.clear()来重置它的值。在看到任何结果之前,您需要在输入框中键入一些内容。
Element类还有其他有价值的属性,它们是只读的,还有一些方法可以调用来改变元素的样式或状态:
| 成员 | 描述 |
|---|---|
.element |
JavaScript 的 HTML 元素的代理对象 |
.id |
HTML 元素的id属性的字符串值(如果存在) |
.value |
HTML 元素的.value属性的字符串值(如果存在) |
.add_class() |
添加一个或多个 CSS 类 |
.remove_class() |
移除一个或多个 CSS 类 |
.write() |
更新.innerHTML属性或添加一个全新的<div>元素 |
.clear() |
清除.value或.innerHTML属性 |
.clone() |
克隆元素并将其深层副本插入到 DOM 树中 |
.select() |
使用 CSS 选择器找到一个后代Element |
在任何时候,您都可以通过.element属性深入到 PyScript 包装的实际 HTMLElement 代理。.select()方法是一个有趣的方法,因为它允许您使用任何 CSS 选择器而不仅仅是普通的 ID 来查找嵌套在容器元素中的后代元素。例如,您可以找到第一个被划掉的列表项并从中删除crossed CSS 类,同时将它添加到列表的最后一个元素:
shopping_list = Element("shopping-list")
shopping_list.select("ul > li.crossed").remove_class("crossed")
shopping_list.select("ul > li:last-child").add_class("crossed")
当您通过 PyScript REPL 运行这段代码时,牛奶将不再被删除,而面包将被删除。下次运行时,蛋也会变得不交叉。
注意:学习 CSS 选择器语法有时会令人沮丧,但也不尽然!掌握它的最好方法是通过练习和获得快速的视觉反馈。有许多有趣的互动游戏,带你一步步地完成这个过程。最受欢迎的是 CSS Diner ,它紧扣烹饪主题。
这就是用 PyScript 的Element类可以做的所有事情。为了最终控制 DOM 树和您的设备,您需要使用代理对象本身。
Pyodide 的 JavaScript 代理
首先在 PyScript 代码中导入 Pyodide 提供的js模块:
import js
print(js.window.innerWidth)
print(js.document.title)
js.console.log("Hello from Python!")
这个模块打开了 JavaScript 的全局名称空间,展示了您的函数和变量,以及 web 浏览器隐式提供的对象。其中包括 window 和 document 对象,以及HTMLElement数据类型,这是您在操作 DOM 时最感兴趣的。
注意,为了方便起见,PyScript 已经将一些东西从js模块导入到 Python 的全局名称空间中。特别是, console 和document对象已经存在:
<py-script>
console.log("This looks like JavaScript, but it's Python!")
console.log(document.title)
</py-script>
您不必再自己导入它们或者在它们的名称前加上js模块,这使得 Python 在您眯着眼睛看的时候看起来很像 JavaScript。
好的,根据输入框的值,将前面部分中的新商品添加到购物列表中怎么样?下面是如何利用 PyScript 中的 DOM API 来实现这一点:
input_new_item = document.querySelector("#new-item")
if input_new_item.value:
child = document.createElement("li")
child.innerText = input_new_item.value
parent = document.querySelector("#shopping-list ul")
parent.appendChild(child)
input_new_item.value = ""
这对于以前使用纯 JavaScript 构建过 web 用户界面的人来说应该很熟悉。使用 CSS 选择器在整个 HTML 文档中查询<input>元素。如果用户在输入框中输入了一些值,那么创建一个新的列表项元素(<li>)并使用.innerText属性填充它。接下来,找到父元素<ul>并追加子元素。最后,清除输入框。
注:人们通常将纯 JavaScript 称为香草 JavaScript。这个术语是由 Eric Wastl 创造的,他是代码的降临的创造者,他创建了 Vanilla JS 网站,作为一个笑话来强调你不需要像 React 这样的框架来创建前端应用程序。
在 PyScript 中使用document对象可以更疯狂。例如,通过结合 Python 和 JavaScript 的 API,可以编写看起来像两者混合的代码:
from random import choice, randint
colors = ["azure", "beige", "khaki", "linen", "skyblue"]
for li in document.querySelectorAll("#shopping-list li"):
if not li.hasAttribute("data-price"):
li.dataset.price = randint(1, 15)
li.classList.toggle("crossed")
li.style.backgroundColor = choice(colors)
在这种情况下,您从 Python 标准库中导入一些函数来生成随机值,并且您还利用了 Python 语法,例如,迭代一个包装在代理对象中的 JavaScript 数组。该循环遍历购物清单项目,有条件地为每个项目分配一个随机价格,切换它们的 CSS 类,并选择一个随机的背景颜色。
web 浏览器公开的 DOM API 太丰富了,不适合本教程,但是可以随意展开下面的可折叠部分,快速参考HTMLElement类最重要的属性和方法:
在 JavaScript 中,每个 HTML 元素都有以下属性:
| 属性 | 描述 |
|---|---|
.classList |
一个类似列表的对象,带有元素的 CSS 类名 |
.className |
带有元素的class属性值的字符串 |
.dataset |
一个类似字典的对象,带有自定义的键值对 |
.innerHTML |
在开始和结束标记之间有 HTML 内容的字符串 |
.innerText |
在开始和结束标记之间有文本内容的字符串 |
.style |
包含 CSS 样式声明的对象 |
.tagName |
HTML 元素标记的大写名称 |
这些属性大多支持读写。除此之外,您还可以找到与当前元素相关的 DOM 树遍历相关的属性:
| 属性 | 描述 |
|---|---|
.parentElement |
此元素的父元素 |
.children |
直接子元素的类似列表的对象 |
.firstElementChild |
第一个子元素 |
.lastElementChild |
最后一个子元素 |
.nextElementSibling |
同一树级别上的下一个元素 |
.previousElementSibling |
同一树级别上的前一个元素 |
要操作此处未列出的通用属性,可以对元素调用以下方法:
| 方法 | 描述 |
|---|---|
.hasAttribute() |
检查元素是否有给定的属性 |
.getAttribute() |
返回给定属性的值 |
.setAttribute() |
分配或覆盖属性值 |
.removeAttribute() |
从元素中删除属性 |
一旦有了对某个元素的对象引用,您可能希望通过使用 CSS 选择器查找它的后代来缩小搜索空间,同时忽略文档中的其余分支:
| 方法 | 描述 |
|---|---|
.querySelector() |
返回匹配给定 CSS 选择器的嵌套元素 |
.querySelectorAll() |
返回匹配给定 CSS 选择器的嵌套元素的类似列表的对象 |
这两个方法的工作方式与它们在document对象中的对应方法相同。此外,您将能够使用以下方便的方法修改 DOM 树的结构:
| 方法 | 描述 |
|---|---|
.cloneNode() |
创建元素的浅层或深层副本 |
.appendChild() |
添加一个新元素作为最后一个子元素 |
.insertBefore() |
在指定的子元素之前插入新元素 |
.removeChild() |
移除给定的子元素 |
.replaceChild() |
用另一个元素替换给定的子元素 |
最后,您将希望通过使元素响应 DOM 事件(通常由用户操作引起)来为元素添加行为:
| 方法 | 描述 |
|---|---|
.addEventListener() |
注册给定事件类型的回调 |
.removeEventListener() |
注销给定事件类型的回调 |
要使用它们,您需要了解如何在 PyScript 中创建回调函数,接下来您将了解这一点。
为了让购物清单变得有用,它需要变得具有交互性。但是在 PyScript 中如何处理 DOM 事件,比如鼠标点击?答案是你注册了一个回调函数!
Python 事件回调代理
您已经编写了基于输入框中的值创建新列表项的代码。然而,它不依赖于页面上的任何可视组件,因为您必须通过<py-repl>元素手动运行它。如果点击添加按钮为你触发代码就好了。
首先,您需要将现有代码封装在一个函数中,该函数将 DOM 事件作为参数。在 JavaScript 中,您可以跳过不需要的参数,但是因为您正在编写 Python 函数,所以它的签名必须更加明确:
def on_add_click(event):
# ...
event参数将不会被使用和忽略,但没关系。假设你已经准备好了你的函数,是时候告诉浏览器什么时候调用它了。您可以通过向一个应该触发动作的元素添加一个事件监听器来实现。在这种情况下,该元素是按钮,您可以使用适当的 CSS 选择器找到它,事件名称是"click":
button = document.querySelector("button")
button.addEventListener("click", on_add_click)
上面代码块中的第二行添加了侦听器,它似乎可以工作而不会发出任何错误。然而,当你尝试点击浏览器中的按钮时,什么也不会发生。
注意:每当浏览器没有按预期运行时,您都有可能在开发工具控制台中找到错误的更多细节,因此在开发时保持它打开是一个好主意。
web 浏览器需要一个 JavaScript 回调,但是您给了它一个 Python 函数。为了解决这个问题,您可以通过使用pyodide模块中的相关函数,从 Python callable 中创建一个代理对象:
from pyodide import create_proxy
button = document.querySelector("button") button.addEventListener("click", create_proxy(on_add_click))
就是这样!现在,您可以用一个包含完整 Python 代码的<py-script>标签替换您的<py-repl>标签,并且您可以开始享受您的第一个交互式 PyScript 应用程序了。下面是生成的 HTML 文档结构:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>DOM API in PyScript</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
<style> .crossed { text-decoration: line-through; } </style>
</head>
<body>
<div id="shopping-list">
<p>Shopping List</p>
<ul>
<li class="crossed">milk</li>
<li class="crossed">eggs</li>
<li>bread</li>
</ul>
<input id="new-item" type="text" placeholder="Add new item">
</div>
<py-script> from pyodide import create_proxy def on_add_click(event):
input_new_item = document.querySelector("#new-item") if input_new_item.value: child = document.createElement("li") child.innerText = input_new_item.value parent = document.querySelector("#shopping-list ul") parent.appendChild(child) input_new_item.value = "" button = document.querySelector("button") button.addEventListener("click", create_proxy(on_add_click))
</py-script>
</body>
</html>
由于调用相同的 API,等效的 JavaScript 代码将占用相同的空间。一方面,使用代理对象增加了更多的字符,但另一方面,Python 不需要像 JavaScript 那样用花括号来分隔每个代码块。
注意:根据经验,您应该倾向于从 web 服务器上托管的单独文件中获取 Python 代码,以避免缩进问题。如果没有,记得在<py-script>标签中正确缩进内联代码。只要您将这样的代码与行首对齐,并且不运行任何代码格式化工具,那么 PyScript 解析它应该没有问题。
除了使用 DOM API 查找和操作 HTML 元素之外,您还可以在 PyScript 中做更多与 web 浏览器相关的酷事情。在下一节中,您将仔细查看前端编程的一些剩余元素,这些元素通常必须用 JavaScript 编写。
通过 Python 与网络浏览器接口
在传统的前端开发中,你对 JavaScript 引擎的依赖程度不亚于你的执行环境提供的 T2 API 集,它们是等式的两个独立部分。虽然 JavaScript 的核心相对较小,并且在不同的供应商中表现得相当一致,但是 API 的前景可能会因目标平台的不同而有很大的不同。
您可以将 JavaScript 用于在 Node.js 中运行的服务器端代码、在 web 浏览器中执行的客户端代码,甚至是支持移动应用的代码。顺便说一句,利用一些独特的 API,在后端 Node.js 中运行 PyScript 在技术上是可能的。然而,在这一节中,您将关注浏览器 API。
饼干
在没有任何外部库的帮助下,使用普通 JavaScript 中的HTTP cookie会变得笨拙,因为它迫使您解析一个包含给定域中所有 cookie 的完整信息的长字符串。相反,在 JavaScript 中定义一个新的 cookie 需要手动连接一个字符串和所需的属性。幸运的是,PyScript 允许您使用 Python,它附带了电池。
触手可及的电池之一是 http.cookies 模块,它可以为您完成 cookie 字符串解析和编码。要解析 JavaScript 的document.cookie属性,使用 Python 中可用的SimpleCookie类:
from http.cookies import SimpleCookie
for cookie in SimpleCookie(document.cookie).values():
print(f"🍪 {cookie.key} = {cookie.value}")
```py
Python helper 类能够解析服务器通常发送给浏览器的带有 cookie 属性的整个字符串。然而,在 JavaScript 中,您只能看到非 HttpOnly cookies 的名称和相应的值,而看不到它们的属性。
使用下面的代码片段为当前域指定一个将在一年后过期的新 cookie。作为一个好公民,您还应该显式设置 [SameSite](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Set-Cookie/SameSite) 属性,以避免依赖默认行为,默认行为因浏览器及其版本而异:
from datetime import timedelta
from http.cookies import SimpleCookie
cookies = SimpleCookie()
cookies["dark_theme"] = "true"
cookies["dark_theme"] |= {
"expires": int(timedelta(days=365).total_seconds()),
"samesite": "Lax"
}
document.cookie = cookies["dark_theme"].OutputString()
诚然,这个模块的界面看起来相当过时,不符合[python 风格](https://realpython.com/learning-paths/writing-pythonic-code/),但它完成了工作。当您运行这段代码并检查您的浏览器 cookie 时,您会看到一个新的设置为 true 的`dark_theme` cookie。您可以调整秒数,看看您的浏览器是否在指定时间后删除了 cookie。
您可以选择生成一个带有附加属性的 [`Set-Cookie`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Set-Cookie) 头字符串,其中一些属性在 JavaScript 中是不允许的:
from http.cookies import SimpleCookie
cookies = SimpleCookie()
cookies["session_id"] = "1ddb897c43fc5f1b773cc5af6cfbe4cf"
cookies["session_id"] |= {
"httponly": True,
"secure": True,
"samesite": "Strict",
"domain": "your-domain.org",
"path": "/",
"max-age": str(int(timedelta(hours=8).total_seconds())),
}
print(cookies["session_id"])
上面的代码将产生下面一长行代表 HTTP 头的文本,它被分割以适合您的屏幕并避免水平滚动:
Set-Cookie: session_id=1ddb897c43fc5f1b773cc5af6cfbe4cf;
⮑ Domain=your-domain.org;
⮑ HttpOnly;
⮑ Max-Age=28800;
⮑ Path=/;
⮑ SameSite=Strict;
⮑ Secure
您不能自己设置这样的 cookie,因为它指定了 JavaScript 中不允许的某些属性,但是在获取一些数据时,从 web 服务器接收一个 cookie 是可能的。
[*Remove ads*](/account/join/)
### 获取 API
当用 JavaScript 从 web 浏览器发出 HTTP 请求时,您会受到几个**安全策略**的约束,这给不了您作为后端开发人员所习惯的自由。此外,JavaScript 固有的[异步模型](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Asynchronous/Introducing)不能很好地与 Python 的同步功能进行网络连接。因此,像`urllib.request`或`socket`这样的模块在 PyScript 中毫无用处。
Pyodide 建议用 web API 编写 HTTP 客户端,比如基于承诺的[Fetch API。为了使从 Python 调用 API 更加简单,Pyodide 提供了`pyfetch()`包装函数,它在异步上下文中工作。](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Asynchronous/Promises)
如果你想发出一个 [REST API](https://realpython.com/api-integration-in-python/) 请求,比如用用户名和密码验证你自己,那么你可以调用`pyfetch()`,它的签名类似于 JavaScript 的`fetch()`函数:
1# Run this using "asyncio"
2
3import json
4
5from pyodide.http import pyfetch
6from pyodide import JsException
7
8async def login(email, password):
9 try:
10 response = await pyfetch(
11 url="https://reqres.in/api/login",
12 method="POST",
13 headers={"Content-Type": "application/json"},
14 body=json.dumps({"email": email, "password": password})
15 )
16 if response.ok:
17 data = await response.json()
18 return data.get("token")
19 except JsException:
20 return None
21
22token = await loop.run_until_complete(
23 login("eve.holt@reqres.in", "cityslicka")
24)
25print(token)
单词`asyncio`出现在上面代码片段顶部的注释中,它告诉 PyScript 异步运行这段代码,以便您可以在底部等待事件循环。请记住,您可以将这个神奇的单词放在代码中的任何位置来触发相同的动作,这在当前就像是施法一样。也许最终会有一种更明确的方式来切换这种行为——例如,通过`<py-script>`标签上的属性。
当您用电子邮件地址和密码调用`login()` [协程](https://docs.python.org/3/glossary.html#term-coroutine)时,您向在线托管的[假 API](https://reqres.in/) 发出 HTTP POST 请求。注意,在 Python 中,使用`json`模块而不是 JavaScript 的`JSON`对象将有效负载序列化为 [JSON。](https://realpython.com/python-json/)
你也可以使用`pyfetch()`下载文件,然后保存到 Pyodide 的 emscripten 提供的[虚拟文件系统](https://pyodide.org/en/latest/usage/file-system.html)。请注意,这些文件只能通过 I/O 界面在您当前的浏览器会话中看到,但您不会在磁盘上的`Downloads/`文件夹中找到它们:
Run this using "asyncio"
from pathlib import Path
from pyodide.http import pyfetch
from pyodide import JsException
async def download(url, filename=None):
filename = filename or Path(url).name
try:
response = await pyfetch(url)
if response.ok:
with open(filename, mode="wb") as file:
file.write(await response.bytes())
except JsException:
return None
else:
return filename
filename = await loop.run_until_complete(
download("https://placekitten.com/500/900", "cats.jpg")
)
除非您想以不同的名称保存文件,否则您可以使用 [`pathlib`](https://realpython.com/python-pathlib/) 模块从您的函数将返回的 URL 中提取文件名。由`pyfetch()`返回的响应对象有一个[可修改的](https://docs.python.org/3/glossary.html#term-awaitable) `.bytes()`方法,您可以用它将二进制内容保存到一个新文件中。
**注意:**您试图下载文件的服务器必须配置为返回适当的 CORS 头,否则浏览器将阻止您的获取请求。
稍后,您可以从虚拟文件系统中读取下载的文件,并将其显示在 HTML 中的一个`<img>`元素上:
import base64
data = base64.b64encode(open(filename, "rb").read()).decode("utf-8")
src = f"data:image/jpeg;charset=utf-8;base64,{data}"
document.querySelector("img").setAttribute("src", src)
您需要使用 [Base64](https://en.wikipedia.org/wiki/Base64) 编码将原始字节转换成文本,然后将结果字符串格式化为一个[数据 URL](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Data_URLs) ,然后将其分配给图像元素的`src`属性。
作为替代,您可以使用 PyScript 中的完全同步函数通过网络获取数据。唯一的问题是`open_url()`不能读取二进制数据:
from pyodide.http import open_url
pep8_url = "https://raw.githubusercontent.com/python/peps/main/pep-0008.txt"
pep8_text = open_url(pep8_url).getvalue()
import json
user = json.load(open_url("https://jsonplaceholder.typicode.com/users/2"))
svg = open_url("https://www.w3.org/Icons/SVG/svg-logo-v.svg")
print(svg.getvalue())
对`open_url()`的第一次调用获取了 [PEP 8](https://peps.python.org/pep-0008/) 文档的原始文本,它存储在一个变量中。第二个调用与 REST API 端点通信,该端点返回 JSON 格式的用户对象,然后将该对象反序列化为 Python 字典。第三个调用下载官方的 SVG 徽标,因为 SVG 是基于文本的格式,所以可以在浏览器中呈现。
当你从因特网上获取数据时,你通常想把它存储起来以备后用。浏览器提供了几个[网络存储](https://developer.mozilla.org/en-US/docs/Web/API/Web_Storage_API)区域供选择,这取决于你想要的信息范围和生命周期。如果您想永久存储数据,本地存储是您的最佳选择。
### 本地存储
在下面的代码片段中,您用一条显示在[警告](https://developer.mozilla.org/en-US/docs/Web/API/Window/alert)框中的欢迎消息问候用户,用之前保存在浏览器的[本地存储](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage)中的名称称呼他们。如果用户是第一次访问您的页面,那么您会显示一个[提示](https://developer.mozilla.org/en-US/docs/Web/API/Window/prompt)对话框,要求输入用户名:
from js import alert, prompt, localStorage, window
if not (name := localStorage.getItem("name")):
name = prompt("What's your name?", "Anonymous")
localStorage.setItem("name", name)
alert(f"Welcome to {window.location}, {name}!")
为了获得本地存储,您从 JavaScript 导入`localStorage`引用,并使用它的`.getItem()`和`.setItem()`方法来持久化键值对。您还利用了 Python 3.8 中引入的 [Walrus 运算符(`:=` )](https://realpython.com/python-walrus-operator/) ,使代码更加简洁,并且您显示了浏览器窗口的 URL 地址。
好吧,来点更刺激的怎么样?
### 传感器 API
在平板电脑或智能手机等移动设备上运行的网络浏览器会暴露出[传感器 API](https://developer.mozilla.org/en-US/docs/Web/API/Sensor_APIs) ,这使得 JavaScript 程序员可以访问设备的加速度计、环境光传感器、陀螺仪或磁力计(如果配备了一个的话)。此外,通过组合来自多个物理传感器的信号,可以在软件中模拟一些传感器,从而降低噪声。重力传感器就是一个很好的例子。
你可以在 PyScript 中查看一个演示重力传感器用法的现场演示。确保在移动设备上打开链接。一旦您改变手机或平板电脑的方向,您将会看到屏幕上显示以下信息之一:
* 逆时针水平
* 水平顺时针
* 垂直直立
* 垂直颠倒
* 屏幕向上
* 向端线方向作掩护
* 倾斜的
如果您的设备没有重力传感器,或者您正在通过未加密的连接访问该网站,您将通过弹出窗口获得通知。或者,您可能只会看到一个空白屏幕。
**注意:**确保通过安全的 [HTTPS 协议](https://realpython.com/python-https/)托管您的 HTML 文件,以使用传感器 API。对于通过普通 HTTP 提供的内容,Web 浏览器会阻止这个 JavaScript API。您可以查看如何[发布您的 PyScript 应用程序](#publishing-your-pyscript-application-on-github-pages)以了解更多细节。
为了连接到设备上的传感器,您需要编写一点 JavaScript 粘合代码,因为 PyScript 目前没有将它创建的 Pyodide 实例导出到 JavaScript 的全局名称空间中。如果是的话,那么您可以获取一个并以 JavaScript 访问 Python 代理对象,这样会稍微容易一些。现在,您将从 Python 中调用一个 JavaScript 函数来进行相反的操作。
创建一个新的`index.html`文件,并不断向其中添加内容。首先,在 HTML 网页中定义一个`<script>`标记,并用下面的 JavaScript 代码填充它:
该函数接受回调,回调将是 Python 函数的 JavaScript 代理。然后检查您的浏览器是否支持 GravitySensor 界面,并以每秒六十次的采样频率创建一个新的传感器实例。单个传感器读数是代表重力方向和大小的三维向量。
接下来,使用 PyScript 在浏览器中实现并注册 Python 回调:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>PyScript Gravity Sensor</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
</head>
<body>
<span></span> <script> function addGravityListener(callback) { if ("GravitySensor" in window) { const sensor = new GravitySensor({frequency: 60}) sensor.addEventListener("reading", () => callback(sensor.x, sensor.y, sensor.z) ) sensor.start() } else { alert("Gravity sensor unavailable") } } </script>
<py-script> from js import addGravityListener from pyodide import create_proxy span = document.querySelector("span") def callback(x, y, z):
span.innerText = f"{x:.1f}, {y:.1f}, {z:.1f}" addGravityListener(create_proxy(callback))
</py-script> </body>
</html>
```py
假设您的页面上有一个`<span>`元素,您使用 CSS 选择器找到它的引用,然后在获取传感器读数后,将重力向量的三个分量写入一个格式化字符串。请注意,在将 Python 回调注册为监听器之前,需要将其封装在 JavaScript 代理中。
**注意:**在移动设备上测试网页变得很困难,因为你无法使用常用的 web 开发工具和控制台。为了帮助自己,你可以[在你的 Android 设备上启用 USB 调试](https://developer.android.com/studio/debug/dev-options#enable),并利用谷歌 Chrome 中的[远程调试](https://developer.chrome.com/docs/devtools/remote-debugging/)。iOS 设备不支持此功能。
知道重力矢量的方向将会告诉你一些关于你的手机方向的信息,例如,当你想拍摄水平照片或检测你何时从桌子上拿起设备时,这可能是有用的。重力矢量的大小就是地球的加速度,你可以用它来粗略估计高度。
为了让这个例子更有趣,继续使用 NumPy 来检测设备的各种方向:
def callback(x, y, z):
span.innerText = orientation(x, y, z)
def orientation(x, y, z):
gravity = np.array([x, y, z]) v = list(np.round(gravity / np.linalg.norm(gravity)).astype(int)) if v == [ 1, 0, 0]: return "Horizontal counterclockwise" if v == [-1, 0, 0]: return "Horizontal clockwise" if v == [ 0, 1, 0]: return "Vertical upright" if v == [ 0, -1, 0]: return "Vertical upside down" if v == [ 0, 0, 1]: return "Screen up" if v == [ 0, 0, -1]: return "Screen down" return "Tilted"
addGravityListener(create_proxy(callback))
添加<py-env>声明,将 NumPy 提取到 PyScript 环境中。然后,在现有的<py-script>标签的顶部导入库,并让回调将处理委托给一个助手函数。新的orientation()功能将你的重力向量归一化并四舍五入,以便与设备坐标系中沿轴的几个单位向量进行比较。
如果您的设备不支持重力传感器,请尝试识别其他工作的传感器,然后为另一个应用程序想一个主意,并相应地修改此示例中显示的代码。你可以在下面的评论区分享你的酷想法!
定时器功能
JavaScript 通常使用所谓的计时器函数来安排回调在未来运行一次,或者每隔指定的毫秒数定期运行一次。后者对页面上的内容制作动画或者 T2 轮询服务器获取快速变化数据的最新快照非常有用。
如果您打算延迟一次性功能的执行——例如,在特定时间后显示提醒通知或弹出窗口——那么可以考虑使用create_once_callable()来创建一个代理对象。完成后,Pyodide 会自动处理它:
from js import alert, setTimeout
from pyodide import create_once_callable
setTimeout(
create_once_callable(
lambda: alert("Reminder: Meeting in 10 minutes")
),
3000 # Delay in milliseconds
)
```py
您使用 JavaScript 中的`setTimeout()`函数,它需要一个可调用的对象,比如一个包装在代理中的 [Python lambda 函数](https://realpython.com/python-lambda/),以及在运行您的可调用对象之前等待的毫秒数。在这里,您会在三秒钟后显示一个带有提醒的警告框。
您会注意到,在运行上面的代码后,PyScript 将一个数值打印到 HTML 文档中。这是`setTimeout()`函数的返回值,它提供了超时的唯一标识符,您可以选择用相应的`clearTimeout()`函数取消它:
from js import alert, setTimeout, clearTimeout from pyodide import create_once_callable
timeout_id = setTimeout(
create_once_callable(
lambda: alert("Reminder: Meeting in 10 minutes")
),
3000 # Delay in milliseconds
)
clearTimeout(timeout_id)
在这种情况下,您可以在安排回调后立即使用其唯一标识符取消超时,因此它永远不会运行。
有一对类似的 JavaScript 函数,名为`setInterval()`和`clearInterval()`,它们的工作方式基本相同。但是,对回调函数的调用将每隔一段时间重复一次,例如,每隔三秒减去函数的执行时间。如果你的函数需要更长的时间来执行,那么下次它会尽快运行,没有延迟。
要在 PyScript 中使用`setInterval()`,你需要记住用对`create_proxy()`而不是`create_once_callable()`的调用来包装你的回调函数,以防止 Pyodide 在第一次运行后处理它:
from random import randint
from js import alert, setInterval, setTimeout, clearInterval
from pyodide import create_once_callable, create_proxy
def callback():
r, g, b = randint(0, 255), randint(0, 255), randint(0, 255)
document.body.style.backgroundColor = f"rgb({r}, {b}, {b})"
interval_id = setInterval(create_proxy(callback), 1000)
_ = setTimeout(
create_once_callable(
lambda: clearInterval(interval_id)
),
10_000
)
这里发生了一些事情。您注册了一个每秒运行一次的回调,它将文档的背景设置为随机颜色。然后,十秒钟后,通过清除各自的间隔来停止它。最后,为了防止 PyScript 显示超时的标识符,您将返回值`setTimeout()`赋给一个用下划线(`_`)表示的占位符变量,这是 Python 中的标准约定。
好吧。这些是你可以在 JavaScript 中使用的网络浏览器界面的基本部分,多亏了 PyScript,现在你可以在 Python 中使用它们了。接下来,您将有机会使用 web 浏览器的一些功能来增强您动手操作的 PyScript 项目。
## 结合 Python 和 JavaScript 库的力量
PyScript 的优势之一是能够结合使用 Python 和 JavaScript 编写的现有库。Python 有许多奇妙的数据科学库,但没有那么多 JavaScript 等价物。另一方面,JavaScript 总是自然而然地适合在浏览器中构建有吸引力的用户界面。
在本节中,您将构建一个 PyScript 应用程序,它将 Python 和 JavaScript 库结合在一起,在浏览器中创建一个交互式用户界面。更具体地说,您将模拟两个略有不同频率的正弦波干扰,在声学上称为 T2 节拍。最后,您将拥有以下客户端应用程序:
[https://player.vimeo.com/video/714968549?background=1](https://player.vimeo.com/video/714968549?background=1)
<figcaption class="figure-caption text-center">Sine Wave Interference</figcaption>
有两个滑块,让您微调频率,还有一个`<canvas>`元素描绘波形图,它是由两个信号叠加而成的。移动滑块会导致绘图实时更新。
您将在 Python 的 NumPy 库中执行计算,并使用 JavaScript 的开源 [Chart.js](https://www.chartjs.org/) 库绘制结果。值得注意的是,Chart.js 不如一些付费的竞争对手快,但它是免费的,使用起来相当简单,所以你现在要坚持使用它。
### HTML 和 CSS
作为第一步,你需要搭建你的 [HTML 文档](https://realpython.com/html-css-python/#create-your-first-html-file)结构,[用 CSS](https://realpython.com/html-css-python/#style-your-content-with-css) 样式化它,并包含一些必要的样板代码。因为这个例子比您在本教程前面看到的例子稍微复杂一些,所以将 Python、JavaScript 和 CSS 代码保存在单独的文件中并在 HTML 中链接它们是有意义的。将以下代码保存在名为`index.html`的新文件中:
您可以在 HTML 头中包含常见的 PyScript 文件、jsDelivr CDN 提供的 Chart.js 库,以及您将在本地托管的自定义 CSS 样式表。您还在一个<py-env>标签中列出了 NumPy 和一个自定义助手模块,它们是您在之前构建的,作为您的依赖项。在文档的底部,您可以找到核心 Python 模块和 JavaScript 中的绘图代码。
您的自定义 CSS 样式表确保文档正文周围有一些填充,并给画布一个固定的大小:
/* theme.css */ body { padding: 10px; } canvas { max-width: 800px; max-height: 400px; }
```py
请记住将您的自定义样式规则放在 HTML 中的 PyScript 样式表之后,这样才会有效果。因为浏览器从上到下读取文档,所以接下来的内容可能会覆盖前面的规则。
表示层已经不存在了,现在是时候将注意力转移到绘图代码上了。
### JavaScript 代码
要使用 Chart.js,您需要创建一个`Chart`实例,并在某个时候将您的数据传递给它。虽然您只需要制作一次图表,但是您将会多次更新数据,因此您可以定义一个回调函数来重用该逻辑:
// src/plotting.js const chart = new Chart("chart", { type: "line", data: { datasets: [{ borderColor: "#007cfb", backgroundColor: "#0062c5", } ] }, options: { plugins: { legend: {display: false}, tooltip: {enabled: false}, }, scales: { x: {display: false}, y: {display: false} }, } }) function updateChart(xValues, yValues) { chart.data.labels = xValues chart.data.datasets[0].data = yValues chart.update() }
图表的构造函数需要一个`<canvas>`元素的`id`属性和一个描述图表外观的配置对象。回调函数也接受两个参数,即要绘制的数据系列的 x 和 y 值。这些数据点来自您的 Python 代码,现在您将检查这些代码。
### Python 代码
这个应用程序中有两个带有 Python 源代码的文件。一种是具有辅助功能的实用模块,可以生成具有所需频率、振幅和相位的波函数。同时,另一个 Python 文件是你的应用程序的[控制器层](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller),它导入了前者。
为了方便起见,这里再次描述了实用程序模块:
src/waves.py
import numpy as np
def wave(frequency, amplitude=1, phase=0):
def _wave(time):
return amplitude * np.sin(2 * np.pi * frequency * time + phase)
return _wave
虽然您以前已经使用过这个函数,但是控制器模块可能需要一些解释,因为它包含相当多的代码:
1# src/controls.py
2
3import numpy as np
4from pyodide import create_proxy, to_js
5
6from js import updateChart
7from waves import wave
8
9range1 = document.querySelector("#range1")
10range2 = document.querySelector("#range2")
11
12sampling_frequency = 800
13seconds = 1.5
14time = np.linspace(0, seconds, int(seconds * sampling_frequency))
15
16def on_range_update(event):
17 label = event.currentTarget.nextElementSibling
18 label.innerText = event.currentTarget.value
19 plot_waveform()
20
21def plot_waveform():
22 frequency1 = float(range1.value)
23 frequency2 = float(range2.value)
24
25 waveform = wave(frequency1)(time) + wave(frequency2)(time)
26 updateChart(to_js(time), to_js(waveform))
27
28proxy = create_proxy(on_range_update)
29range1.addEventListener("input", proxy)
30range2.addEventListener("input", proxy)
31
32plot_waveform()
下面是这段代码的逐行分解:
* **第 3 行和第 4 行**从所需的第三方库中导入代码。
* **第 6 行和第 7 行**从您之前在 HTML 中链接的 Python 和 JavaScript 实用程序模块中导入您的自定义函数。
* **第 9 行和第 10 行**用 CSS 选择器查询 HTML 文档,找到两个 slider 元素,并将它们保存在变量中以备后用。
* **第 12 行到第 14 行**计算你的时间序列的 x 值,这个时间序列的持续时间是一秒半,每秒钟采样 800 次。
* **第 16 行到第 19 行**定义了一个回调函数来响应你的一个滑块的值的变化,它代表波的频率。该函数更新 HTML 中的相应标签,并调用另一个函数来重新计算波形并更新绘图。
* **第 21 到 26 行**定义了一个辅助函数,它从滑块中读取当前频率值,生成新的波函数,并在指定的持续时间内将它们相加。接下来,helper 函数使用 Pyodide 的`to_js()`将结果 x 和 y 值转换成 JavaScript 代理,并将它们传递给 JavaScript 模块中定义的回调函数。
* **第 28 到 30 行**将您的`on_range_update()`事件监听器包装在一个 JavaScript 代理中,并在两个滑块中将其注册为回调,这样当您更改滑块的值时,web 浏览器将调用它。
* **第 32 行**调用`plot_waveform()`辅助函数来显示页面加载时波形的初始图。
或者,如果您希望使用 Matplotlib 进行绘图,以消除代码中的 JavaScript,那么您可以创建一个图形并使用 PyScript 的`Element.write()`方法,如下所示:
import matplotlib.pyplot as plt
fig, _ = plt.subplots()
...
Element("panel").write(fig)
`Element()`类构造函数接受 HTML 元素的`id`属性,通常是一个`<div>`。
随意增强这个项目——例如,通过将生成的声波转换成[音频流](https://developer.mozilla.org/en-US/docs/Web/API/AudioContext)并在您的浏览器中播放。它有一种奇怪的声音!另一方面,如果您对项目当前的形式感到满意,那么您将学习如何与世界上的任何人免费共享它,即使他们的计算机上没有安装 Python 解释器。
## 在 GitHub 页面上发布您的 PyScript 应用程序
因为 PyScript 允许您完全在客户端的 web 浏览器中运行代码,所以您不需要后端服务器来为您执行代码。因此,分发 PyScript 应用程序可以归结为托管一堆静态文件**供浏览器使用。 [GitHub Pages](https://pages.github.com/) 是一种快速简单的方法,可以将你的任何 Git 仓库免费变成一个网站。**
您将重用前一节中的代码,所以在继续之前,请确保您有以下目录结构:
sine-wave-interference/
│
├── src/
│ ├── controls.py
│ ├── plotting.js
│ └── waves.py
│
├── index.html
└── theme.css
要开始使用 GitHub 页面,[登录](https://github.com/login)到你的 GitHub 账户,创建一个名为`sine-wave-interference`的新的**公共存储库**,保留所有默认选项。您不希望 GitHub 在这个阶段为您创建任何文件,因为它们会与您计算机上已有的代码冲突。之后记下您唯一的存储库 URL。它应该是这样的:
git@github.com:your-username/sine-wave-interference.git
现在,打开终端,将您的工作目录更改为项目[根文件夹](https://en.wikipedia.org/wiki/Root_directory)。然后,初始化一个新的本地 Git 存储库,进行第一次提交,并使用您的惟一 URL 将文件推送到 GitHub 上的远程存储库:
$ cd sine-wave-interference/
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin git@github.com:your-username/sine-wave-interference.git
$ git push -u origin master
现在,您可以转到 GitHub 存储库设置,通过选择要托管的分支和文件夹来启用 GitHub 页面。因为您只有`master`分支,所以您想从下拉菜单中选择它。你也应该选择根文件夹`/`,点击*保存*按钮确认。当你这样做,GitHub 将需要几分钟,直到你可以查看你的网站。
您的存储库的公共 URL 地址将与此类似:
https://your-username.github.io/sine-wave-interference/
恭喜你!您现在可以与任何拥有现代 web 浏览器的人共享此 URL,他们将能够在线使用您的 PyScript 应用程序。达到这一步后,下一步是将缩小的资源包含在您的存储库中,并更新 HTML 文档中的相对路径,以使加载时间稍微快一些。
## 参与 PyScript
参与开源项目可能会令人生畏。然而,因为 PyScript 是一个如此年轻的框架,挖掘其源代码并对其进行修改实际上并不困难。您所需要的只是一个 Git 客户机、一个最新版本的 Node.js 和`npm`包管理器。
**注意:**可以通过[节点版本管理器](https://github.com/nvm-sh/nvm/)安装 Node.js,类似于 Python 中的 [pyenv](https://realpython.com/intro-to-pyenv/) 。
配置好这三个工具后,首先从 GitHub 克隆 [PyScript 库](https://github.com/pyscript/pyscript/),并将所需的依赖项安装到本地`node_modules/`文件夹中:
$ git clone git@github.com:pyscript/pyscript.git
$ cd pyscript/pyscriptjs/
$ npm install --global rollup
$ npm install
您将只运行这些命令一次,因为您不会向项目添加任何新的依赖项。接下来,在`src/`子文件夹中找到名为`main.ts`的文件,在您最喜欢的代码编辑器中打开它,并将与`PyScript`类相关联的自定义`<py-script>` HTML 标记重命名为例如`<real-python>`:
- const xPyScript = customElements.define('py-script', PyScript); + const xPyScript = customElements.define('real-python', PyScript);
请记住,自定义标记名必须包含一个连字符,以区别于常规标记名。然后,在您的终端中,将当前工作目录更改为克隆项目中的`pyscriptjs/`子文件夹,并运行 build 命令:
$ npm run build
这将产生一个新的`pyscript.js`文件,你可以把它放在本地,而不是链接到 CDN 上的官方版本。当您这样做时,您将能够在新的闪亮标签中嵌入 Python 代码:
厉害!现在,你可以在 GitHub 上分叉这个,并打开一个拉取请求。开个玩笑!这是一个玩具示例,但它很好地演示了在较低层次上使用 PyScript 的一些基本步骤。即使您不打算对 PyScript 做任何贡献,浏览它的源代码可能会让您更好地理解它的内部工作方式。
结论
现在您对 PyScript 是什么、它是如何工作的以及它能提供什么有了一个很好的了解。您可以减轻它当前的一些缺点,甚至根据您的喜好对它进行定制。此外,您已经看到了几个演示框架特性和实际应用的实际例子。
在本教程中,您学习了如何:
- 使用 Python 和 JavaScript 构建交互式前端应用
- 在网络浏览器中运行现有的 Python 代码
- 在后端和前端上重用相同的代码
- 从 JavaScript 调用 Python 函数,反之亦然
- 分发零依赖的 Python 程序
PyScript 无疑是一项令人兴奋的新技术,由于有了 Pyodide 和 WebAssembly ,它可以让你在网络浏览器中运行 Python 代码。虽然在这方面已经有过早期的尝试,但 PyScript 是第一个在浏览器中运行真正的 CPython 解释器的框架,使得重用现有的 Python 程序几乎不需要修改成为可能。
免费下载: 从 CPython Internals:您的 Python 3 解释器指南获得一个示例章节,向您展示如何解锁 Python 语言的内部工作机制,从源代码编译 Python 解释器,并参与 CPython 的开发。
你对 PyScript 有什么看法?它真的会取代浏览器中的 JavaScript 吗?你打算在你的下一个项目中尝试一下吗?下面留言评论!*********************
PySimpleGUI:用 Python 创建 GUI 的简单方法
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 PySimpleGUI 简化 Python GUI 开发
创建一个跨多个平台工作的简单图形用户界面(GUI)可能很复杂。但不一定非要这样。您可以使用 Python 和 PySimpleGUI 包来创建您和您的用户都会喜欢的好看的用户界面!PySimpleGUI 是一个新的 Python GUI 库,最近引起了很多人的兴趣。
在本教程中,您将学习如何:
- 安装 PySimpleGUI 包
- 用 PySimpleGUI 创建基本的用户界面元素
- 创建应用程序,比如 PySimpleGUI 图像查看器
- 集成 PySimpleGUI 和 Matplotlib
- 在 PySimpleGUI 中使用计算机视觉
- 为 Windows 打包您的 PySimpleGUI 应用程序
现在是时候开始了!
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
PySimpleGUI 入门
PySimpleGUI 于 2018 年推出,因此与 wxPython 或 PyQt 相比,它是一个相对较新的包。
PySimpleGUI 有四个端口:
PySimpleGUI 包装了这些其他包的一部分,使它们更容易使用。但是,每个端口都必须单独安装。
PySimpleGUI 封装了 Python 自带的全部 Tkinter。PySimpleGUI 已经包装了 PySide2 的大部分,但只包装了 wxPython 的一小部分。当您安装 PySimpleGUI 时,默认情况下您会得到 Tkinter 变量。有关 Tkinter 的更多信息,请查看使用 Tkinter 的 Python GUI 编程。
根据您使用的 PySimpleGUI 的不同版本,您用 PySimpleGUI 创建的应用程序可能看起来不是其平台的原生程序。但是不要让这阻止您尝试 PySimpleGUI。PySimpleGUI 仍然非常强大,只需做一点工作就可以完成大多数事情。
安装 PySimpleGUI
如果使用 pip ,安装 PySimpleGUI 很容易。出于本教程的目的,您将学习如何安装常规的 PySimpleGUI 端口,它是 Tkinter 的变体。
以下是如何做到这一点:
$ python -m pip install pysimplegui
这将把 PySimpleGUI 安装到 Python 设置的任何系统中。您还可以将 PySimpleGUI 安装到 Python 虚拟环境中。如果你不熟悉 Python 虚拟环境,那么你应该读一下 Python 虚拟环境:入门。
如果您喜欢尝试 PyQt 变体,那么您可以使用pip install PySimpleGUIQt来代替。现在您已经安装了 PySimpleGUI,是时候了解如何使用它了!
在 PySimpleGUI 中创建基本 UI 元素
如果你以前用过 GUI 工具包,那么你可能听说过术语 widgets 。小部件是一个通用术语,用于描述组成用户界面(UI)的元素,如按钮、标签、窗口等。在 PySimpleGUI 中,小部件被称为元素,有时您可能会在别处看到大写的元素。
PySimpleGUI 的基本构件之一是Window()。要创建一个Window(),您可以执行以下操作:
# hello_world.py
import PySimpleGUI as sg
sg.Window(title="Hello World", layout=[[]], margins=(100, 50)).read()
需要很多不同的参数——太多了,无法在此列出。然而,对于这个例子,你可以给Window()一个title和一个layout,并设置margins,这是用户界面窗口的像素大小。
read()将Window()中触发的任何事件作为字符串和values 字典返回。在本教程的后面部分,您将了解更多关于这些的内容。
当您运行这段代码时,您应该会看到类似这样的内容:
这个例子除了可能向用户显示一条消息之外,实际上没有做什么。
通常,你的应用程序中除了一个Window()还有其他元素,所以让我们添加一些文本和一个按钮。
创建一个名为hello_psg.py的新文件,并添加以下代码:
# hello_psg.py
import PySimpleGUI as sg
layout = [[sg.Text("Hello from PySimpleGUI")], [sg.Button("OK")]]
# Create the window
window = sg.Window("Demo", layout)
# Create an event loop
while True:
event, values = window.read()
# End program if user closes window or
# presses the OK button
if event == "OK" or event == sg.WIN_CLOSED:
break
window.close()
大多数 GUI 工具包允许你使用绝对定位或者允许 GUI 动态布局元素。例如,wxPython 使用Sizers来动态布局元素。如果你想了解更多关于 wxPython 的知识,那么看看如何用 wxPython 构建一个 Python GUI 应用程序。
PySimpleGUI 使用嵌套的 Python 列表来布局元素。在这种情况下,添加一个Text()元素和一个Button()元素。然后创建window,并传入您的自定义layout。
最后一块代码是事件循环。图形用户界面需要在一个循环中运行,并等待用户做一些事情。例如,用户可能需要按下用户界面中的按钮或者用键盘输入一些东西。当他们这样做时,这些事件由事件循环处理。
当您使用 PySimpleGUI 时,您通过创建一个无限的 while循环来从window对象中读取事件,从而创建一个事件循环。如果用户按下OK按钮或退出按钮,那么你希望程序结束。为了实现这一点,你break退出循环,close()退出window。
上面的代码创建了一个如下所示的应用程序:

现在您已经准备好创建一个实际的应用程序了!
创建简单的应用程序
您可以使用 PySimpleGUI 创建各种不同的跨平台 GUI。该包中包含的演示非常广泛。您可以创建任何东西,从桌面小部件到成熟的用户界面。
在接下来的几节中,您将看到使用 PySimpleGUI 的几种不同方式。然而,除了一个单独的教程所涵盖的内容之外,您还可以做更多的事情。如果您想了解更多细节,请务必查看 PySimpleGUI 中包含的其他演示。
创建 PySimpleGUI 图像查看器
PySimpleGUI 的 GitHub 页面上的演示之一是图像查看器。能够用 Python 编写自己的自定义图像查看器很有趣。您可以使用此代码来查看您自己的照片,或者合并它来查看您从数据库下载或读取的照片。
为了简单起见,您将使用 PySimpleGUI 的内置Image()元素来查看图像。遗憾的是,Image()元素在 PySimpleGUI 的常规版本中只能显示 PNG 和 GIF 格式。
如果你希望能够打开其他图像文件类型,那么你可以下载 Pillow ,它支持 TIFF、JPG 和 BMP 格式。查看 GitHub 上的 PySimpleGUI demo 文件夹,以获得演示如何做到这一点的示例。
另一方面,如果您安装了 PySimpleGUIQt 端口,那么您会发现 Qt 比 Tkinter 支持更多现成的图像格式。
这里有一个图像查看器最终应该是什么样子的模型:
这个例子会有很多代码,但是不要担心。之后你会把它分成小块来看。
您可以在您选择的 Python 编辑器中创建一个名为img_viewer.py的文件。然后添加以下代码:
1# img_viewer.py
2
3import PySimpleGUI as sg
4import os.path
5
6# First the window layout in 2 columns
7
8file_list_column = [
9 [
10 sg.Text("Image Folder"),
11 sg.In(size=(25, 1), enable_events=True, key="-FOLDER-"),
12 sg.FolderBrowse(),
13 ],
14 [
15 sg.Listbox(
16 values=[], enable_events=True, size=(40, 20), key="-FILE LIST-"
17 )
18 ],
19]
20
21# For now will only show the name of the file that was chosen
22image_viewer_column = [
23 [sg.Text("Choose an image from list on left:")],
24 [sg.Text(size=(40, 1), key="-TOUT-")],
25 [sg.Image(key="-IMAGE-")],
26]
27
28# ----- Full layout -----
29layout = [
30 [
31 sg.Column(file_list_column),
32 sg.VSeperator(),
33 sg.Column(image_viewer_column),
34 ]
35]
36
37window = sg.Window("Image Viewer", layout)
38
39# Run the Event Loop
40while True:
41 event, values = window.read()
42 if event == "Exit" or event == sg.WIN_CLOSED:
43 break
44 # Folder name was filled in, make a list of files in the folder
45 if event == "-FOLDER-":
46 folder = values["-FOLDER-"]
47 try:
48 # Get list of files in folder
49 file_list = os.listdir(folder)
50 except:
51 file_list = []
52
53 fnames = [
54 f
55 for f in file_list
56 if os.path.isfile(os.path.join(folder, f))
57 and f.lower().endswith((".png", ".gif"))
58 ]
59 window["-FILE LIST-"].update(fnames)
60 elif event == "-FILE LIST-": # A file was chosen from the listbox
61 try:
62 filename = os.path.join(
63 values["-FOLDER-"], values["-FILE LIST-"][0]
64 )
65 window["-TOUT-"].update(filename)
66 window["-IMAGE-"].update(filename=filename)
67
68 except:
69 pass
70
71window.close()
唷!这相当多行代码!让我们一条一条地过一遍。
下面是最初的几行:
1# img_viewer.py
2
3import PySimpleGUI as sg
4import os.path
5
6# First the window layout in 2 columns
7
8file_list_column = [
9 [
10 sg.Text("Image Folder"),
11 sg.In(size=(25, 1), enable_events=True, key="-FOLDER-"),
12 sg.FolderBrowse(),
13 ],
14 [
15 sg.Listbox(
16 values=[], enable_events=True, size=(40, 20), key="-FILE LIST-"
17 )
18 ],
19]
在这里,在的第 3 行和第 4 行,您导入了PySimpleGUI和 Python 的os模块。然后,在的第 8 行到第 19 行,创建一个嵌套的元素列表,表示用户界面的一个垂直列。这将创建一个浏览按钮,您将使用它来查找包含图像的文件夹。
key参数很重要。这是您用来在 GUI 中标识特定元素的内容。对于In()输入文本控件,您给它一个标识"-FOLDER-"。稍后您将使用它来访问元素的内容。您可以通过enable_events参数打开或关闭每个元素的事件。
元素将显示图像的路径列表,您可以从中选择要显示的图像。您可以通过传入一个字符串列表来用值预先填充Listbox()。
当您第一次加载您的用户界面时,您希望Listbox()是空的,所以您传递给它一个空列表。您打开这个元素的事件,设置它的size,并像处理 input 元素一样给它一个惟一的标识符。
现在,您可以查看右边的元素栏:
21# For now will only show the name of the file that was chosen
22image_viewer_column = [
23 [sg.Text("Choose an image from list on left:")],
24 [sg.Text(size=(40, 1), key="-TOUT-")],
25 [sg.Image(key="-IMAGE-")],
26]
第 22 到 26 行的列表列表创建了三个元素。第一个元素告诉用户他们应该选择一个图像来显示。第二个元素显示选定文件的名称。第三个显示Image()。
请注意,Image()元素也有一个key集合,这样您以后可以很容易地引用该元素。有关Image()元素的更多信息,请查看文档。
下一段代码定义了您的布局:
28# ----- Full layout -----
29layout = [
30 [
31 sg.Column(file_list_column),
32 sg.VSeperator(),
33 sg.Column(image_viewer_column),
34 ]
35]
第 29 到 35 行的最后一个列表包含了控制元素如何在屏幕上布局的代码。这段代码包含两个Column()元素,它们之间有一个VSeperator()。VSeperator()是VerticalSeparator()的别名。通过阅读各自的文档页面,您可以了解更多关于 Column() 和 VSeperator() 如何工作的信息。
要将layout添加到window中,您可以这样做:
37window = sg.Window("Image Viewer", layout)
现在您已经弄清楚了用户界面,您可以查看事件循环代码了。这是第一部分:
39while True:
40 event, values = window.read()
41 if event == "Exit" or event == sg.WIN_CLOSED:
42 break
事件循环包含程序的逻辑。在这里,您从window中提取事件和values。event将是用户与之交互的任何元素的key字符串。values 变量包含一个 Python 字典,它将元素key映射到一个值。例如,如果用户选择一个文件夹,那么"-FOLDER-"将映射到文件夹路径。
条件语句用于控制发生的事情。如果event等于"Exit"或者用户关闭了window,那么你就退出了循环。
现在,您可以看看循环中下一个条件语句的第一部分:
44# Folder name was filled in, make a list of files in the folder
45if event == "-FOLDER-":
46 folder = values["-FOLDER-"]
47 try:
48 # Get list of files in folder
49 file_list = os.listdir(folder)
50 except:
51 file_list = []
52
53 fnames = [
54 f
55 for f in file_list
56 if os.path.isfile(os.path.join(folder, f))
57 and f.lower().endswith((".png", ".gif"))
58 ]
59 window["-FILE LIST-"].update(fnames)
这一次您对照"-FOLDER-" key检查event,后者指的是您之前创建的In()元素。如果事件存在,那么您知道用户已经选择了一个文件夹,并且您使用os.listdir()来获得一个文件列表。然后过滤列表,只列出扩展名为".png"或".gif"的文件。
注意:如前所述,您可以通过使用 Pillow 或 PySimpleGUIQt 来避免缩小图像文件类型。
现在你可以看看条件语句的下一部分:
60elif event == "-FILE LIST-": # A file was chosen from the listbox
61 try:
62 filename = os.path.join(
63 values["-FOLDER-"], values["-FILE LIST-"][0]
64 )
65 window["-TOUT-"].update(filename)
66 window["-IMAGE-"].update(filename=filename)
67 except:
68 pass
如果event等于"-FILE LIST-",那么您知道用户已经在Listbox()中选择了一个文件,并且您想要更新Image()元素以及在右侧显示所选filename的Text()元素。
最后一段代码是如何结束程序的:
71window.close()
当用户按下退出按钮时,应用程序必须关闭。为此,您可以使用window.close()。
从技术上讲,您可以从代码中删除这一行,Python 仍然会结束程序,但是在您完成之后进行清理总是一个好主意。此外,如果您正在使用 PySimpleGUI 的 web 端口,并且没有正确关闭窗口,那么您最终会让一个端口处于打开状态。
现在运行代码,您应该会看到这样的界面:
您可以使用 Browse 按钮在您的计算机上找到一个包含图像的文件夹,以便您可以试用此代码。或者您可以将文件的路径复制并粘贴到Text()元素中。
查看完图像后,您就可以学习如何通过 PySimpleGUI 使用 Matplotlib 了。
集成 Matplotlib 和 PySimpleGUI
创建图表是与同事共享信息的好方法。Python 最流行的绘图包之一是 Matplotlib。Matplotlib 可以创建各种不同的图形。如果你想了解更多,请查看 Python 绘图与 Matplotlib(指南)。
Matplotlib 可以与 PySimpleGUI 集成,因此如果您已经知道如何使用 Matplotlib,您可以相当容易地将图形添加到您的 GUI 中。
如果你没有安装 Matplotlib,那么你可以使用 pip 来安装:
$ python -m pip install matplotlib
对于这个例子,您使用的是 PySimpleGUI 的一个演示。Matplotlib 使用了 NumPy ,所以你也要安装它:
$ python -m pip install numpy
现在您已经拥有了编写代码所需的所有部分,您可以创建一个新文件并将其命名为psg_matplotlib.py。
演示代码有点长,所以您可以从下面开始分段添加代码:
import numpy as np
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
import PySimpleGUI as sg
import matplotlib
fig = matplotlib.figure.Figure(figsize=(5, 4), dpi=100)
t = np.arange(0, 3, .01)
fig.add_subplot(111).plot(t, 2 * np.sin(2 * np.pi * t))
这些是使代码工作所需的导入。这段代码还设置了 Matplotlib Figure()并使用add_subplot()添加了一个绘图。更多细节,你可能想参考文档。PySimpleGUIQt 端口目前不能以同样的方式工作,但是正在为将来的版本而努力。
在 PySimpleGUI 和 Tkinter 中,都使用Canvas()元素进行绘制。你可以在文档中读到更多关于这个元素的内容。
现在您可以创建一个助手函数来在 PySimpleGUI 的Canvas()上绘制图形。一个助手函数是你不想写多次的重复代码。看一看:
matplotlib.use("TkAgg")
def draw_figure(canvas, figure):
figure_canvas_agg = FigureCanvasTkAgg(figure, canvas)
figure_canvas_agg.draw()
figure_canvas_agg.get_tk_widget().pack(side="top", fill="both", expand=1)
return figure_canvas_agg
您将使用figure_canvas_agg.draw()来绘制 PySimpleGUI 的Canvas()元素的图。
要使用 PySimpleGUI 的Canvas(),需要将它和 Matplotlib figure对象一起传递给FigureCanvasTkAgg()。FigureCanvasTkAgg()来自 Matplotlib,由 Tkinter 用于在 PySimpleGUI 中嵌入绘图。如果您使用的是 PySimpleGUIQt,这将会有所不同。
最后一步是用 PySimpleGUI 编写用户界面:
# Define the window layout
layout = [
[sg.Text("Plot test")],
[sg.Canvas(key="-CANVAS-")],
[sg.Button("Ok")],
]
# Create the form and show it without the plot
window = sg.Window(
"Matplotlib Single Graph",
layout,
location=(0, 0),
finalize=True,
element_justification="center",
font="Helvetica 18",
)
# Add the plot to the window
draw_figure(window["-CANVAS-"].TKCanvas, fig)
event, values = window.read()
window.close()
要创建用户界面,您只需要一个Text()元素、一个Canvas()元素和一个Button()元素。然后你将所有这些添加到一个Window()中,并调用你的draw_figure()辅助函数来绘制图表。
这里不需要事件循环,因为您不会与这个用户界面中的元素进行交互。
图表看起来是这样的:
PySimpleGUI 中还包含了其他 Matplotlib 演示程序,您应该去看看。
现在您可以学习如何通过 PySimpleGUI 使用 OpenCV。
集成 OpenCV 和 PySimpleGUI
计算机视觉是现在的热门话题。Python 允许你通过使用 opencv-python 包进入计算机视觉领域,该包是流行的 OpenCV 应用程序的包装器。如果你有兴趣学习更多关于计算机视觉的知识,那么看看用 Python 实现的人脸识别,不到 25 行代码。
PySimpleGUI 具有与 OpenCV 库直接集成的特性。然而,您首先需要使用pip安装 OpenCV:
$ python -m pip install opencv-python
现在你已经安装了 OpenCV,你可以写一个有趣的应用程序了!
您将看到另一个 PySimpleGUI 演示,它使用 OpenCV 和您计算机的网络摄像头。这个应用程序可以让你将一些常用的滤镜实时应用到你的视频中。
这个例子的代码很长,但是不用担心。稍后会分小块解释。继续创建一个名为psg_opencv.py的文件,并添加以下代码:
1import PySimpleGUI as sg
2import cv2
3import numpy as np
4
5def main():
6 sg.theme("LightGreen")
7
8 # Define the window layout
9 layout = [
10 [sg.Text("OpenCV Demo", size=(60, 1), justification="center")],
11 [sg.Image(filename="", key="-IMAGE-")],
12 [sg.Radio("None", "Radio", True, size=(10, 1))],
13 [
14 sg.Radio("threshold", "Radio", size=(10, 1), key="-THRESH-"),
15 sg.Slider(
16 (0, 255),
17 128,
18 1,
19 orientation="h",
20 size=(40, 15),
21 key="-THRESH SLIDER-",
22 ),
23 ],
24 [
25 sg.Radio("canny", "Radio", size=(10, 1), key="-CANNY-"),
26 sg.Slider(
27 (0, 255),
28 128,
29 1,
30 orientation="h",
31 size=(20, 15),
32 key="-CANNY SLIDER A-",
33 ),
34 sg.Slider(
35 (0, 255),
36 128,
37 1,
38 orientation="h",
39 size=(20, 15),
40 key="-CANNY SLIDER B-",
41 ),
42 ],
43 [
44 sg.Radio("blur", "Radio", size=(10, 1), key="-BLUR-"),
45 sg.Slider(
46 (1, 11),
47 1,
48 1,
49 orientation="h",
50 size=(40, 15),
51 key="-BLUR SLIDER-",
52 ),
53 ],
54 [
55 sg.Radio("hue", "Radio", size=(10, 1), key="-HUE-"),
56 sg.Slider(
57 (0, 225),
58 0,
59 1,
60 orientation="h",
61 size=(40, 15),
62 key="-HUE SLIDER-",
63 ),
64 ],
65 [
66 sg.Radio("enhance", "Radio", size=(10, 1), key="-ENHANCE-"),
67 sg.Slider(
68 (1, 255),
69 128,
70 1,
71 orientation="h",
72 size=(40, 15),
73 key="-ENHANCE SLIDER-",
74 ),
75 ],
76 [sg.Button("Exit", size=(10, 1))],
77 ]
78
79 # Create the window and show it without the plot
80 window = sg.Window("OpenCV Integration", layout, location=(800, 400))
81
82 cap = cv2.VideoCapture(0)
83
84 while True:
85 event, values = window.read(timeout=20)
86 if event == "Exit" or event == sg.WIN_CLOSED:
87 break
88
89 ret, frame = cap.read()
90
91 if values["-THRESH-"]:
92 frame = cv2.cvtColor(frame, cv2.COLOR_BGR2LAB)[:, :, 0]
93 frame = cv2.threshold(
94 frame, values["-THRESH SLIDER-"], 255, cv2.THRESH_BINARY
95 )[1]
96 elif values["-CANNY-"]:
97 frame = cv2.Canny(
98 frame, values["-CANNY SLIDER A-"], values["-CANNY SLIDER B-"]
99 )
100 elif values["-BLUR-"]:
101 frame = cv2.GaussianBlur(frame, (21, 21), values["-BLUR SLIDER-"])
102 elif values["-HUE-"]:
103 frame = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
104 frame[:, :, 0] += int(values["-HUE SLIDER-"])
105 frame = cv2.cvtColor(frame, cv2.COLOR_HSV2BGR)
106 elif values["-ENHANCE-"]:
107 enh_val = values["-ENHANCE SLIDER-"] / 40
108 clahe = cv2.createCLAHE(clipLimit=enh_val, tileGridSize=(8, 8))
109 lab = cv2.cvtColor(frame, cv2.COLOR_BGR2LAB)
110 lab[:, :, 0] = clahe.apply(lab[:, :, 0])
111 frame = cv2.cvtColor(lab, cv2.COLOR_LAB2BGR)
112
113 imgbytes = cv2.imencode(".png", frame)[1].tobytes()
114 window["-IMAGE-"].update(data=imgbytes)
115
116 window.close()
117
118main()
那是一段很长的代码!让我们一次检查一个例子:
1import PySimpleGUI as sg
2import cv2
3import numpy as np
4
5def main():
6 sg.theme("LightGreen")
7
8 # Define the window layout
9 layout = [
10 [sg.Text("OpenCV Demo", size=(60, 1), justification="center")],
11 [sg.Image(filename="", key="-IMAGE-")],
12 [sg.Radio("None", "Radio", True, size=(10, 1))],
13 [
14 sg.Radio("threshold", "Radio", size=(10, 1), key="-THRESH-"),
15 sg.Slider(
16 (0, 255),
17 128,
18 1,
19 orientation="h",
20 size=(40, 15),
21 key="-THRESH SLIDER-",
22 ),
23 ],
第 1 行到第 3 行是您需要的 Python 库的导入。然后你把theme设置在线 6 上。
下一步,从第 9 行开始,为 GUI 中的所有元素创建一个layout。第一组元素包括一个Text()元素、一个Image()元素和一个Radio()元素。您将Image元素的标识符键设置为"-IMAGE-"。您还可以嵌套一个Radio()元素和一个Slider()元素,并将它们的标识符键分别设置为"-THRESH-"和"-THRESH SLIDER-"。
现在您将向layout添加更多的元素:
24[
25 sg.Radio("canny", "Radio", size=(10, 1), key="-CANNY-"),
26 sg.Slider(
27 (0, 255),
28 128,
29 1,
30 orientation="h",
31 size=(20, 15),
32 key="-CANNY SLIDER A-",
33 ),
34 sg.Slider(
35 (0, 255),
36 128,
37 1,
38 orientation="h",
39 size=(20, 15),
40 key="-CANNY SLIDER B-",
41 ),
42],
在第 24 行到第 42 行上,您添加了另一个Radio()元素和两个Slider()元素来控制用户界面的 canny 边缘检测。您还可以适当地设置标识符。
现在,您将添加一种模糊图像的方法:
43[
44 sg.Radio("blur", "Radio", size=(10, 1), key="-BLUR-"),
45 sg.Slider(
46 (1, 11),
47 1,
48 1,
49 orientation="h",
50 size=(40, 15),
51 key="-BLUR SLIDER-",
52 ),
53],
在这里,你只需要添加几个元素来控制图像模糊,这也被称为图像平滑。你可以在 OpenCV 文档中读到更多关于这项技术的内容。
您只需再添加两组控件。接下来,您将添加色调控制:
54[
55 sg.Radio("hue", "Radio", size=(10, 1), key="-HUE-"),
56 sg.Slider(
57 (0, 225),
58 0,
59 1,
60 orientation="h",
61 size=(40, 15),
62 key="-HUE SLIDER-",
63 ),
64],
这些元素允许您在不同的色彩空间之间转换。色彩空间超出了本教程的范围,但是你可以在 OpenCV 网站上的改变色彩空间教程中了解更多。
最后要添加的元素用于控制对比度:
65 [
66 sg.Radio("enhance", "Radio", size=(10, 1), key="-ENHANCE-"),
67 sg.Slider(
68 (1, 255),
69 128,
70 1,
71 orientation="h",
72 size=(40, 15),
73 key="-ENHANCE SLIDER-",
74 ),
75 ],
76 [sg.Button("Exit", size=(10, 1))],
77]
78
79# Create the window and show it without the plot
80window = sg.Window("OpenCV Integration", layout, location=(800, 400))
81
82cap = cv2.VideoCapture(0)
这最后几个元素将允许您使用对比度受限的自适应直方图均衡化算法来增强视频流的对比度。
这就完成了layout。然后您将您的layout传递给Window(),这样您就可以在屏幕上看到您的 UI。
最后,您使用cv2.VideoCapture(0)来访问您机器上的网络摄像头。您可能会看到一个弹出窗口,询问您是否允许使用您的相机。如果你这样做,那么你需要授予许可,否则这段代码将无法工作。
现在看一下代码的其余部分:
84 while True:
85 event, values = window.read(timeout=20)
86 if event == "Exit" or event == sg.WIN_CLOSED:
87 break
88
89 ret, frame = cap.read()
90
91 if values["-THRESH-"]:
92 frame = cv2.cvtColor(frame, cv2.COLOR_BGR2LAB)[:, :, 0]
93 frame = cv2.threshold(
94 frame, values["-THRESH SLIDER-"], 255, cv2.THRESH_BINARY
95 )[1]
96 elif values["-CANNY-"]:
97 frame = cv2.Canny(
98 frame, values["-CANNY SLIDER A-"], values["-CANNY SLIDER B-"]
99 )
100 elif values["-BLUR-"]:
101 frame = cv2.GaussianBlur(frame, (21, 21), values["-BLUR SLIDER-"])
102 elif values["-HUE-"]:
103 frame = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
104 frame[:, :, 0] += int(values["-HUE SLIDER-"])
105 frame = cv2.cvtColor(frame, cv2.COLOR_HSV2BGR)
106 elif values["-ENHANCE-"]:
107 enh_val = values["-ENHANCE SLIDER-"] / 40
108 clahe = cv2.createCLAHE(clipLimit=enh_val, tileGridSize=(8, 8))
109 lab = cv2.cvtColor(frame, cv2.COLOR_BGR2LAB)
110 lab[:, :, 0] = clahe.apply(lab[:, :, 0])
111 frame = cv2.cvtColor(lab, cv2.COLOR_LAB2BGR)
112
113 imgbytes = cv2.imencode(".png", frame)[1].tobytes()
114 window["-IMAGE-"].update(data=imgbytes)
115
116 window.close()
117
118main()
这是 PySimpleGUI 接口的事件循环。当您更改 UI 中的滑块时,PySimpleGUI 将获取event和values,并使用它们来确定将哪个 OpenCV 函数应用于您的网络摄像头流。
这段代码与您看到的其他代码有些不同,因为它封装在一个main()函数中。这种类型的函数被用作程序的主入口点。要了解这个主题的更多信息,请查看用 Python 定义主函数的。
下面是 GUI 外观的一个示例:
现在是时候学习如何为 Windows 创建应用程序的可执行文件了。
为 Windows 打包您的 PySimpleGUI 应用程序
有许多不同的 Python 包可以用来把你的 Python 代码转换成 Windows 的可执行文件。其中最受欢迎的是 PyInstaller 。
您可以使用pip安装 PyInstaller:
$ python -m pip install pyinstaller
要了解更多关于如何使用 PyInstaller 的信息,请查看使用 PyInstaller 轻松分发 Python 应用程序。
您将使用 PyInstaller 将之前创建的图像查看器应用程序转换为可执行文件。
$ pyinstaller img_viewer.py
当您运行此命令时,您会看到类似于以下内容的大量输出:
177 INFO: PyInstaller: 3.6
178 INFO: Python: 3.8.2
179 INFO: Platform: Windows-10-10.0.10586-SP0
186 INFO: wrote C:\Users\mike\OneDrive\Documents\image_viewer_psg.spec
192 INFO: UPX is not available.
221 INFO: Extending PYTHONPATH with paths
---- output snipped ----
13476 INFO: Building COLLECT because COLLECT-00.toc is non existent
13479 INFO: Building COLLECT COLLECT-00.toc
25851 INFO: Building COLLECT COLLECT-00.toc completed successfully.
由于 PyInstaller 非常冗长,所以这个输出是缩写的。完成后,您将在包含img_viewer.py的同一个文件夹中拥有一个名为dist的子文件夹。你可以进入dist文件夹找到img_viewer.exe并尝试运行它。
在dist文件夹中会有很多可执行文件使用的其他文件。
如果您希望只有一个可执行文件,那么您可以使用--onefile标志重新运行该命令:
$ pyinstaller --onefile img_viewer.py
这仍然会生成dist文件夹,但是这一次应该只有一个可执行文件。
注意:如果您使用--onefile标志,Windows Defender 可能会将您的可执行文件标记为有病毒。如果是这样,那么您需要向 Windows 安全添加一个排除项以使其运行。这是因为在 Windows 10 中,Windows 可执行文件需要签名。
当您运行可执行文件时,除了您的用户界面之外,您还会看到一个控制台窗口。要移除控制台,可以在运行 PyInstaller 时使用--noconsole或--windowed标志。
结论
您在本教程中学到了很多关于 PySimpleGUI 包的知识!最重要的是,您已经熟悉了使用 PySimpleGUI 创建应用程序的基础知识。
在本教程中,您学习了如何:
- 安装 PySimpleGUI 包
- 用 PySimpleGUI 创建基本的用户界面元素
- 用 PySimpleGUI 创建一些应用程序,比如一个图像浏览器
- 集成 PySimpleGUI 和 Matplotlib
- 在 PySimpleGUI 中使用计算机视觉
- 为 Windows 打包您的 PySimpleGUI 应用程序
您可以使用在本教程中学到的知识来创建自己的有趣且有用的应用程序。
PySimpleGUI 包提供了更多的示例演示,您可以使用它们来培养自己的技能,并发现如何更有效地使用库中的所有工具。一定要看看它们,你很快就会发现自己正在创建自己的跨平台 GUI 应用程序
如果您想了解关于 PySimpleGUI 的更多信息,那么您可以查看以下资源:
- PySimpleGUI 文档
- PySimpleGUI 食谱
- PySimpleGUI 演示程序
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 PySimpleGUI 简化 Python GUI 开发******
PySpark 和大数据处理的第一步
面对数据量太大而无法在单台机器上处理的情况越来越常见。幸运的是,Apache Spark、Hadoop 和其他技术已经被开发出来解决这个问题。使用 PySpark 可以直接从 Python 中利用这些系统的能力!
高效地处理千兆字节甚至更多的数据集是任何 Python 开发人员都能够做到的事情,无论你是数据科学家、web 开发人员,还是介于两者之间的任何人。
在本教程中,您将学习:
- 哪些 Python 概念可以应用于大数据
- 如何使用 Apache Spark 和 PySpark
- 如何编写基本的 PySpark 程序
- 如何在本地小数据集上运行 PySpark 程序
- 将您的 PySpark 技能带到分布式系统的下一步该去哪里
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 中的大数据概念
尽管作为只是一种脚本语言而广受欢迎,Python 公开了几种编程范例,如面向数组编程、面向对象编程、异步编程以及许多其他编程范例。有抱负的大数据专业人士特别感兴趣的一个范例是函数式编程。
在处理大数据时,函数式编程是一种常见的范式。以函数的方式编写会导致令人尴尬的并行代码。这意味着更容易获得代码,并让它在几个 CPU 上运行,甚至在完全不同的机器上运行。通过同时在多个系统上运行,您可以避开单个工作站的物理内存和 CPU 限制。
这就是 PySpark 生态系统的强大之处,它允许您获取功能代码,并自动将其分发到整个计算机集群。
幸运的是,对于 Python 程序员来说,函数式编程的许多核心思想都可以在 Python 的标准库和内置库中找到。您可以学习大数据处理所需的许多概念,而无需离开 Python 的舒适环境。
函数式编程的核心思想是数据应该由函数操作,而不需要维护任何外部状态。这意味着你的代码避免了全局变量,并且总是返回新数据,而不是就地操作数据。
函数式编程中另一个常见的想法是匿名函数。Python 使用 lambda关键字公开匿名函数,不要与 AWS Lambda 函数混淆。
现在您已经了解了一些术语和概念,您可以探索这些概念是如何在 Python 生态系统中体现的。
λ函数
Python 中的 lambda 函数是内联定义的,仅限于单个表达式。你可能在使用内置的 sorted() 函数时见过lambda函数:
>>> x = ['Python', 'programming', 'is', 'awesome!'] >>> print(sorted(x)) ['Python', 'awesome!', 'is', 'programming'] >>> print(sorted(x, key=lambda arg: arg.lower())) ['awesome!', 'is', 'programming', 'Python']为可迭代中的每一项调用
sorted的key参数。这使得排序不区分大小写,在排序发生之前,将所有的字符串都变成小写的。这是
lambda函数的常见用例,小型匿名函数不维护外部状态。Python 中还存在其他常见的函数式编程函数,如
filter()、、map()、和reduce()。所有这些功能都可以以类似的方式使用lambda功能或用def定义的标准功能。
filter()、map()、reduce()、T3】内置的
filter()、map()、reduce()函数都是函数式编程中常见的。您将很快看到这些概念可以构成 PySpark 程序功能的重要部分。在核心 Python 上下文中理解这些函数很重要。然后,您将能够将这些知识转化为 PySpark 程序和 Spark API。
filter()根据条件从 iterable 中过滤出项目,通常表示为lambda函数:
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(filter(lambda arg: len(arg) < 8, x)))
['Python', 'is']
filter()接受一个 iterable,对每个项目调用lambda函数,并返回lambda返回True的项目。
注意:调用list()是必需的,因为filter()也是可迭代的。filter()只给出你循环时的值。list()将所有项目一次强制存入内存,而不是使用循环。
你可以想象使用filter()来替换一个常见的 for循环模式,如下所示:
def is_less_than_8_characters(item):
return len(item) < 8
x = ['Python', 'programming', 'is', 'awesome!']
results = []
for item in x:
if is_less_than_8_characters(item):
results.append(item)
print(results)
这段代码收集所有少于 8 个字符的字符串。代码比filter()示例更加冗长,但是它执行相同的功能,得到相同的结果。
filter()的另一个不太明显的好处是它返回一个 iterable。这意味着filter()不需要你的计算机有足够的内存来一次保存 iterable 中的所有条目。对于可以快速增长到几千兆字节大小的大数据集来说,这变得越来越重要。
map()与filter()的相似之处在于,它将函数应用于 iterable 中的每一项,但它总是产生原始项的一对一映射。map()返回的新 iterable 将始终具有与原始 iterable 相同数量的元素,而filter()则不是这样:
>>> x = ['Python', 'programming', 'is', 'awesome!'] >>> print(list(map(lambda arg: arg.upper(), x))) ['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME!']
map()自动调用所有项目上的lambda函数,有效地取代了如下的for循环:results = [] x = ['Python', 'programming', 'is', 'awesome!'] for item in x: results.append(item.upper()) print(results)
for循环的结果与map()示例相同,它以大写形式收集所有项目。然而,与filter()的例子一样,map()返回一个 iterable,这又使得处理大到无法完全放入内存的大型数据集成为可能。最后,Python 标准库中最后一个函数三重奏是
reduce()。与filter()和map()一样,reduce()将函数应用于 iterable 中的元素。同样,所应用的函数可以是使用
def关键字创建的标准 Python 函数,也可以是lambda函数。然而,
reduce()并不返回新的 iterable。相反,reduce()使用名为的函数将 iterable 简化为一个值:
>>> from functools import reduce
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(reduce(lambda val1, val2: val1 + val2, x))
Pythonprogrammingisawesome!
这段代码将 iterable 中的所有项目从左到右组合成一个项目。这里没有对list()的调用,因为reduce()已经返回了一个条目。
注: Python 3.x 将内置的reduce()函数移到了functools包中。
lambda、map()、filter()和reduce()是存在于许多语言中的概念,可以在常规的 Python 程序中使用。很快,您将看到这些概念扩展到 PySpark API 来处理大量数据。
设置
集合是标准 Python 中的另一个常见功能,在大数据处理中非常有用。集合与列表非常相似,只是它们没有任何顺序,并且不能包含重复值。你可以把集合想象成类似于 Python 字典中的键。
PySpark 的 hello World
如同任何优秀的编程教程一样,您会希望从一个Hello World示例开始。下面是 PySpark 当量:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())
先不要担心所有的细节。主要思想是记住 PySpark 程序与常规 Python 程序没有太大区别。
注意:如果您还没有安装 PySpark 或者没有指定的copyright文件,这个程序可能会在您的系统上引发一个异常,稍后您将看到如何做。
你很快就会了解到这个程序的所有细节,不过还是好好看看吧。该程序计算总行数和在名为copyright的文件中包含单词python的行数。
请记住,PySpark 程序与常规 Python 程序没有太大的不同,但是的执行模型可能与常规 Python 程序有很大的不同,尤其是当您在集群上运行时。
如果您在一个集群上,在后台可能会发生许多事情,将处理分布在多个节点上。但是,现在,请将该程序视为使用 PySpark 库的 Python 程序。
既然您已经看到了 Python 中存在的一些常见函数概念以及一个简单的 PySpark 程序,那么是时候更深入地研究 Spark 和 PySpark 了。
什么是火花?
Apache Spark 是由几个组件组成的,所以描述它可能会很困难。从本质上来说,Spark 是一个通用的 T2 引擎,用于处理大量数据。
Spark 用 Scala 编写,运行在 JVM 上。Spark 内置了用于处理流数据、机器学习、图形处理甚至通过 SQL 与数据交互的组件。
在本指南中,您将仅了解用于处理大数据的核心 Spark 组件。然而,所有其他组件,比如机器学习、SQL 等等,都可以通过 PySpark 用于 Python 项目。
PySpark 是什么?
Spark 是在 Scala 中实现的,Scala 是一种在 JVM 上运行的语言,那么如何通过 Python 访问所有这些功能呢?
PySpark 就是答案。
PySpark 的当前版本是 2.4.3,可以与 Python 2.7、3.3 和更高版本一起工作。
您可以将 PySpark 视为 Scala API 之上的一个基于 Python 的包装器。这意味着您有两套文档可供参考:
PySpark API 文档中有一些例子,但是通常你会想要参考 Scala 文档,并为你的 PySpark 程序将代码翻译成 Python 语法。幸运的是,Scala 是一种可读性很强的基于函数的编程语言。
PySpark 通过 Py4J 库与基于 Spark Scala 的 API 通信。Py4J 不是 PySpark 或 Spark 特有的。Py4J 允许任何 Python 程序与基于 JVM 的代码对话。
PySpark 基于函数范式有两个原因:
- Spark 的原生语言 Scala 是基于函数的。
- 功能代码更容易并行化。
另一种看待 PySpark 的方式是一个允许在单台机器或一组机器上处理大量数据的库。
在 Python 环境中,想想 PySpark 有一种处理并行处理的方法,不需要threading或multiprocessing模块。所有线程、进程甚至不同 CPU 之间复杂的通信和同步都由 Spark 处理。
PySpark API 和数据结构
要与 PySpark 交互,您需要创建称为弹性分布式数据集 (RDDs)的专用数据结构。
如果您在集群上运行,rdd 隐藏了调度程序在多个节点之间自动转换和分发数据的所有复杂性。
为了更好地理解 PySpark 的 API 和数据结构,回想一下前面提到的Hello World程序:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())
任何 PySpark 程序的入口点都是一个SparkContext对象。该对象允许您连接到 Spark 集群并创建 rdd。local[*]字符串是一个特殊的字符串,表示您正在使用一个本地集群,也就是说您正在单机模式下运行。*告诉 Spark 在你的机器上创建和逻辑内核一样多的工作线程。
当您使用集群时,创建一个SparkContext会更加复杂。要连接到 Spark 集群,您可能需要处理认证和其他一些特定于集群的信息。您可以按如下方式设置这些详细信息:
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)
一旦有了SparkContext,就可以开始创建 rdd。
可以用多种方式创建 rdd,但一种常见的方式是 PySpark parallelize()函数。parallelize()可以将一些 Python 数据结构(如列表和元组)转换成 rdd,这为您提供了使它们容错和分布式的功能。
为了更好地理解 rdd,考虑另一个例子。下面的代码创建了一个包含 10,000 个元素的迭代器,然后使用parallelize()将数据分布到两个分区中:
>>> big_list = range(10000) >>> rdd = sc.parallelize(big_list, 2) >>> odds = rdd.filter(lambda x: x % 2 != 0) >>> odds.take(5) [1, 3, 5, 7, 9]
parallelize()将迭代器转换成一个分布式数字集,并为您提供 Spark 基础设施的所有功能。请注意,这段代码使用了 RDD 的
filter()方法,而不是 Python 的内置filter(),您在前面已经看到了。结果是一样的,但是幕后发生的事情却截然不同。通过使用 RDDfilter()方法,该操作以分布式方式在几个 CPU 或计算机上进行。再一次,把这想象成 Spark 为你做
multiprocessing工作,所有这些都封装在 RDD 数据结构中。
take()是查看 RDD 内容的一种方式,但只是一个很小的子集。take()将数据子集从分布式系统拉到一台机器上。
take()对于调试很重要,因为在一台机器上检查整个数据集是不可能的。rdd 针对大数据进行了优化,因此在现实世界中,一台机器可能没有足够的 RAM 来容纳整个数据集。注意:在 shell 中运行这样的例子时,Spark 会暂时将信息打印到
stdout中,您很快就会看到如何做了。您的stdout可能会暂时显示类似于[Stage 0:> (0 + 1) / 1]的内容。
stdout文本演示了 Spark 如何将 rdd 拆分,并跨不同的 CPU 和机器将您的数据处理成多个阶段。创建 rdd 的另一种方法是用
textFile()读入一个文件,这在前面的例子中已经看到过。rdd 是使用 PySpark 的基础数据结构之一,因此 API 中的许多函数都返回 rdd。rdd 和其他数据结构之间的一个关键区别是处理被延迟,直到请求结果。这类似于一个 Python 生成器。Python 生态系统中的开发人员通常使用术语懒惰评估来解释这种行为。
您可以在同一个 RDD 上堆叠多个转换,而不进行任何处理。这个功能是可能的,因为 Spark 维护了一个转换的有向无环图。底层图形只有在请求最终结果时才被激活。在前面的例子中,在您通过调用
take()请求结果之前,不会进行任何计算。有多种方法可以从自动 RDD 获取结果。通过在 RDD 上使用
collect(),您可以显式地请求对结果进行评估并收集到单个集群节点。您还可以通过各种方式隐式请求结果,其中一种方式是使用前面看到的count()。注意:使用这些方法时要小心,因为它们会将整个数据集拉入内存,如果数据集太大而无法放入单台机器的 RAM 中,这种方法就不起作用。
再次,参考 PySpark API 文档以获得更多关于所有可能功能的细节。
安装 PySpark
通常,您将在 Hadoop 集群上运行 PySpark 程序,但是也支持其他集群部署选项。你可以阅读 Spark 的集群模式概述了解更多详情。
注意:设置其中一个集群可能会很困难,这超出了本指南的范围。理想情况下,你的团队有一些向导开发人员工程师来帮助工作。如果没有,Hadoop 发布了指南来帮助你。
在本指南中,您将看到在本地机器上运行 PySpark 程序的几种方法。这对于测试和学习非常有用,但是您很快就会想要使用新程序并在集群上运行它们,以真正处理大数据。
有时,由于所有必需的依赖项,单独设置 PySpark 也很有挑战性。
PySpark 运行在 JVM 之上,需要大量底层的 Java 基础设施才能运行。也就是说,我们生活在码头工人的时代,这使得 PySpark 的实验更加容易。
更好的是, Jupyter 背后令人惊叹的开发人员已经为您完成了所有繁重的工作。他们发布了一个 Dockerfile ,其中包含了所有 PySpark 依赖项以及 Jupyter。所以,你可以直接在 Jupyter 笔记本上做实验!
注: Jupyter 笔记本的功能很多。查看 Jupyter 笔记本:简介了解更多关于如何有效使用笔记本的细节。
首先,你需要安装 Docker。看看 Docker 的运行——更健康、更快乐、更有效率,如果你还没有安装 Docker 的话。
注意:Docker 图像可能会非常大,所以请确保您可以使用大约 5gb 的磁盘空间来使用 PySpark 和 Jupyter。
接下来,您可以运行以下命令来下载并自动启动一个 Docker 容器,其中包含一个预构建的 PySpark 单节点设置。这个命令可能需要几分钟,因为它直接从 DockerHub 下载图像以及 Spark、PySpark 和 Jupyter 的所有要求:
$ docker run -p 8888:8888 jupyter/pyspark-notebook一旦该命令停止打印输出,您就拥有了一个正在运行的容器,其中包含了在单节点环境中测试 PySpark 程序所需的一切。
要停止你的容器,在你输入
docker run命令的同一个窗口中输入Ctrl+C。现在终于要运行一些程序了!
运行 PySpark 程序
执行 PySpark 程序的方法有很多种,这取决于您喜欢命令行还是更直观的界面。对于命令行界面,您可以使用
spark-submit命令、标准 Python shell 或专门的 PySpark shell。首先,你会看到 Jupyter 笔记本更直观的界面。
Jupyter 笔记型电脑
您可以在 Jupyter 笔记本中运行您的程序,方法是运行以下命令来启动您之前下载的 Docker 容器(如果它尚未运行):
$ docker run -p 8888:8888 jupyter/pyspark-notebook Executing the command: jupyter notebook [I 08:04:22.869 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret [I 08:04:25.022 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab [I 08:04:25.022 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab [I 08:04:25.027 NotebookApp] Serving notebooks from local directory: /home/jovyan [I 08:04:25.028 NotebookApp] The Jupyter Notebook is running at: [I 08:04:25.029 NotebookApp] http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437 [I 08:04:25.029 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 08:04:25.037 NotebookApp] To access the notebook, open this file in a browser: file:///home/jovyan/.local/share/jupyter/runtime/nbserver-6-open.html Or copy and paste one of these URLs: http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437现在您有了一个运行 PySpark 的容器。注意,
docker run命令输出的结尾提到了一个本地 URL。注意:
docker命令的输出在每台机器上会略有不同,因为令牌、容器 id 和容器名称都是随机生成的。您需要使用该 URL 在 web 浏览器中连接到运行 Jupyter 的 Docker 容器。将 URL 从您的输出中直接复制并粘贴到您的网络浏览器中。以下是您可能会看到的 URL 示例:
$ http://127.0.0.1:8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437以下命令中的 URL 在您的计算机上可能会稍有不同,但是一旦您在浏览器中连接到该 URL,您就可以访问 Jupyter 笔记本环境,该环境应该类似于以下内容:
从 Jupyter 笔记本页面,您可以使用最右边的新建按钮来创建一个新的 Python 3 shell。然后你可以测试一些代码,就像之前的
Hello World例子:import pyspark sc = pyspark.SparkContext('local[*]') txt = sc.textFile('file:////usr/share/doc/python/copyright') print(txt.count()) python_lines = txt.filter(lambda line: 'python' in line.lower()) print(python_lines.count())下面是 Jupyter 笔记本中运行该代码的样子:
这里的幕后发生了很多事情,所以您的结果可能需要几秒钟才能显示。单击单元格后,答案不会立即出现。
命令行界面
命令行界面提供了多种提交 PySpark 程序的方式,包括 PySpark shell 和
spark-submit命令。要使用这些 CLI 方法,首先需要连接到安装了 PySpark 的系统的 CLI。要连接到 Docker 设置的 CLI,您需要像以前一样启动容器,然后连接到该容器。同样,要启动容器,您可以运行以下命令:
$ docker run -p 8888:8888 jupyter/pyspark-notebook一旦运行了 Docker 容器,就需要通过 shell 而不是 Jupyter 笔记本来连接它。为此,运行以下命令来查找容器名称:
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4d5ab7a93902 jupyter/pyspark-notebook "tini -g -- start-no…" 12 seconds ago Up 10 seconds 0.0.0.0:8888->8888/tcp kind_edison这个命令将显示所有正在运行的容器。找到运行
jupyter/pyspark-notebook映像的容器的CONTAINER ID,用它连接到容器内的bash外壳:$ docker exec -it 4d5ab7a93902 bash jovyan@4d5ab7a93902:~$现在你应该连接到容器内的
bash提示。您可以验证事情正在运行,因为您的 shell 的提示符将变成类似于jovyan@4d5ab7a93902的东西,但是使用您的容器的惟一 ID。注意:用您机器上使用的
CONTAINER ID替换4d5ab7a93902。集群
您可以使用与 Spark 一起安装的
spark-submit命令,通过命令行向集群提交 PySpark 代码。该命令采用 PySpark 或 Scala 程序,并在集群上执行。这可能是您执行真正的大数据处理工作的方式。注意:这些命令的路径取决于 Spark 的安装位置,并且可能只在使用引用的 Docker 容器时才起作用。
要使用正在运行的 Docker 容器运行
Hello World示例(或任何 PySpark 程序),首先如上所述访问 shell。一旦你进入容器的外壳环境,你可以使用纳米文本编辑器创建文件。要在当前文件夹中创建文件,只需使用您想要创建的文件名启动
nano:$ nano hello_world.py键入
Hello World示例的内容,并通过键入Ctrl+X并按照保存提示保存文件:
最后,您可以使用
pyspark-submit命令通过 Spark 运行代码:$ /usr/local/spark/bin/spark-submit hello_world.py默认情况下,这个命令会导致大量的输出,所以可能很难看到你程序的输出。通过改变
SparkContext变量的级别,可以在 PySpark 程序内部控制日志的详细程度。为此,请将这一行放在脚本顶部附近:sc.setLogLevel('WARN')这将省略
spark-submit输出中的部分,这样你可以更清楚地看到你程序的输出。然而,在真实的场景中,您会希望将任何输出放入文件、数据库或其他存储机制中,以便于以后的调试。幸运的是,PySpark 程序仍然可以访问 Python 的所有标准库,因此将结果保存到文件中不成问题:
import pyspark sc = pyspark.SparkContext('local[*]') txt = sc.textFile('file:////usr/share/doc/python/copyright') python_lines = txt.filter(lambda line: 'python' in line.lower()) with open('results.txt', 'w') as file_obj: file_obj.write(f'Number of lines: {txt.count()}\n') file_obj.write(f'Number of lines with python: {python_lines.count()}\n')现在,您的结果保存在一个名为
results.txt的单独文件中,以便于以后参考。注意:上面的代码使用了 f 串,这是在 Python 3.6 中引入的。
PySpark 外壳
另一种特定于 PySpark 的运行程序的方式是使用 PySpark 本身提供的 shell。同样,使用 Docker 设置,您可以如上所述连接到容器的 CLI。然后,您可以使用以下命令运行专门的 Python shell:
$ /usr/local/spark/bin/pyspark Python 3.7.3 | packaged by conda-forge | (default, Mar 27 2019, 23:01:00) [GCC 7.3.0] :: Anaconda, Inc. on linux Type "help", "copyright", "credits" or "license" for more information. Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.1 /_/ Using Python version 3.7.3 (default, Mar 27 2019 23:01:00) SparkSession available as 'spark'.现在您处于 Docker 容器中的 Pyspark shell 环境,您可以测试类似于 Jupyter 笔记本示例的代码:
>>> txt = sc.textFile('file:////usr/share/doc/python/copyright')
>>> print(txt.count())
316
现在,您可以在 Pyspark shell 中工作,就像使用普通 Python shell 一样。
注意:您不必在 Pyspark shell 示例中创建一个SparkContext变量。PySpark shell 自动创建一个变量sc,在单节点模式下将您连接到 Spark 引擎。
当用spark-submit或 Jupyter 笔记本提交真正的 PySpark 程序时,你必须创建你自己的 SparkContext。
只要 PySpark 安装在 Python 环境中,您也可以使用标准的 Python shell 来执行您的程序。您一直在使用的 Docker 容器没有为标准 Python 环境启用 PySpark。因此,您必须使用前面的方法之一在 Docker 容器中使用 PySpark。
将 PySpark 与其他工具结合使用
正如您已经看到的,PySpark 附带了额外的库来完成机器学习和大型数据集的 SQL 式操作。然而,你也可以使用其他常见的科学图书馆,如 NumPy 和 Pandas 。
您必须在每个集群节点上的相同环境中安装它们,然后您的程序可以照常使用它们。然后,你可以自由地使用你已经知道的所有熟悉的惯用熊猫把戏。
记住: 熊猫数据帧被急切地评估,所以所有的数据将需要在一台机器上适合内存。
真正大数据处理的后续步骤
在学习 PySpark 基础知识后不久,您肯定会想要开始分析大量数据,这些数据在您使用单机模式时可能无法工作。安装和维护 Spark cluster 超出了本指南的范围,它本身可能是一项全职工作。
因此,现在可能是时候拜访您办公室的 it 部门,或者研究托管的 Spark 集群解决方案了。一个潜在的托管解决方案是数据块。
Databricks 允许你用微软 Azure 或 AWS 托管你的数据,并有14 天免费试用。
有了一个工作的 Spark 集群后,您会希望将所有数据放入该集群进行分析。Spark 有多种导入数据的方法:
- 亚马逊 S3
- Apache Hive 数据仓库
- 任何带有 JDBC 或 ODBC 接口的数据库
您甚至可以直接从网络文件系统中读取数据,这就是前面的例子的工作方式。
无论您是使用 Databricks 这样的托管解决方案还是您自己的机器集群,都不缺少访问所有数据的方法。
结论
PySpark 是大数据处理的一个很好的切入点。
在本教程中,您了解到,如果您熟悉一些函数式编程概念,如map()、filter()和 basic Python ,那么您就不必花很多时间预先学习。事实上,您可以在 PySpark 程序中直接使用所有您已经知道的 Python,包括熟悉的工具,如 NumPy 和 Pandas。
您现在能够:
- 了解适用于大数据的内置 Python 概念
- 编写基本 PySpark 程序
- 使用本地机器在小型数据集上运行 PySpark 程序
- 探索更强大的大数据解决方案,如 Spark 集群或其他定制的托管解决方案*******
使用 Pytest 进行有效的 Python 测试
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 pytest 测试你的代码
测试你的代码会带来各种各样的好处。它增加了您对代码如您所期望的那样运行的信心,并确保对代码的更改不会导致回归。编写和维护测试是一项艰苦的工作,所以您应该利用您可以使用的所有工具,尽可能地使它变得轻松。 pytest 是你可以用来提高测试效率的最好工具之一。
在本教程中,您将学习:
- 福利
pytest提供什么 - 如何确保你的测试是无状态的
- 如何让重复测试更容易理解
- 如何按名称或自定义组运行测试的子集
- 如何创建和维护可重用的测试工具
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
如何安装pytest
为了跟随本教程中的一些例子,您需要安装pytest。和大多数 Python 包一样,pytest在 PyPI 上可用。你可以使用 pip 在虚拟环境中安装它:
- 视窗
** Linux + macOS*
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS> python -m pip install pytest
$ python -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install pytest
pytest命令现在可以在您的安装环境中使用。
是什么让pytest如此有用?
如果你以前为你的 Python 代码编写过单元测试,那么你可能用过 Python 内置的 unittest 模块。unittest提供了构建测试套件的坚实基础,但是它有一些缺点。
许多第三方测试框架试图解决一些关于unittest的问题,而pytest已经被证明是最受欢迎的一个。pytest是一个功能丰富、基于插件的生态系统,用于测试你的 Python 代码。
如果你还没有享受过使用pytest的乐趣,那你就等着享受吧!它的理念和特性将使您的测试体验更加高效和愉快。使用pytest,普通任务需要更少的代码,高级任务可以通过各种节省时间的命令和插件来完成。它甚至可以运行你现有的测试,包括那些用unittest编写的测试。
与大多数框架一样,当您第一次开始使用pytest时,一些有意义的开发模式可能会随着您的测试套件的增长而开始带来痛苦。本教程将帮助你理解pytest提供的一些工具,这些工具可以在测试扩展时保持测试的效率和效果。
更少的样板文件
大多数功能测试遵循排列-动作-断言模型:
- 安排测试的条件
- 通过调用一些函数或方法来执行
- 断言某个结束条件为真
测试框架通常与测试的断言挂钩,这样它们就可以在断言失败时提供信息。例如,unittest提供了许多现成的有用的断言实用程序。然而,即使是一小组测试也需要相当数量的样板代码。
想象一下,你想写一个测试套件来确保unittest在你的项目中正常工作。您可能希望编写一个总是通过的测试和一个总是失败的测试:
# test_with_unittest.py
from unittest import TestCase
class TryTesting(TestCase):
def test_always_passes(self):
self.assertTrue(True)
def test_always_fails(self):
self.assertTrue(False)
然后,您可以使用unittest的discover选项从命令行运行这些测试:
(venv) $ python -m unittest discover
F.
======================================================================
FAIL: test_always_fails (test_with_unittest.TryTesting)
----------------------------------------------------------------------
Traceback (most recent call last):
File "...\effective-python-testing-with-pytest\test_with_unittest.py",
line 10, in test_always_fails
self.assertTrue(False)
AssertionError: False is not true
----------------------------------------------------------------------
Ran 2 tests in 0.006s
FAILED (failures=1)
不出所料,一个测试通过,一个失败。你已经证明了unittest是有效的,但是看看你必须做什么:
- 从
unittest导入TestCase类 - 创建
TryTesting,一个TestCase的子类 - 在
TryTesting中为每个测试编写一个方法 - 使用来自
unittest.TestCase的self.assert*方法之一进行断言
这需要编写大量的代码,因为这是任何测试所需的最少代码,所以你最终会一遍又一遍地编写相同的代码。pytest通过允许您直接使用普通函数和 Python 的assert关键字,简化了工作流程:
# test_with_pytest.py
def test_always_passes():
assert True
def test_always_fails():
assert False
就是这样。您不必处理任何导入或类。您所需要做的就是包含一个带有前缀test_的函数。因为您可以使用assert关键字,所以您也不需要学习或记住unittest中所有不同的self.assert*方法。如果你能写出一个你期望评价给True的表达式,然后pytest会为你测试。
pytest不仅消除了许多样板文件,还为您提供了更详细、更易读的输出。
漂亮的输出
您可以使用项目顶层文件夹中的pytest命令来运行您的测试套件:
(venv) $ pytest
============================= test session starts =============================
platform win32 -- Python 3.10.5, pytest-7.1.2, pluggy-1.0.0
rootdir: ...\effective-python-testing-with-pytest
collected 4 items
test_with_pytest.py .F [ 50%]
test_with_unittest.py F. [100%]
================================== FAILURES ===================================
______________________________ test_always_fails ______________________________
def test_always_fails():
> assert False
E assert False
test_with_pytest.py:7: AssertionError
________________________ TryTesting.test_always_fails _________________________
self = <test_with_unittest.TryTesting testMethod=test_always_fails>
def test_always_fails(self):
> self.assertTrue(False)
E AssertionError: False is not true
test_with_unittest.py:10: AssertionError
=========================== short test summary info ===========================
FAILED test_with_pytest.py::test_always_fails - assert False
FAILED test_with_unittest.py::TryTesting::test_always_fails - AssertionError:...
========================= 2 failed, 2 passed in 0.20s =========================
pytest显示的测试结果与unittest不同,test_with_unittest.py文件也被自动包含在内。报告显示:
- 系统状态,包括 Python、
pytest的版本,以及您已经安装的任何插件 rootdir,或者在其中搜索配置和测试的目录- 跑步者发现的测试次数
这些项目出现在输出的第一部分:
============================= test session starts =============================
platform win32 -- Python 3.10.5, pytest-7.1.2, pluggy-1.0.0
rootdir: ...\effective-python-testing-with-pytest
collected 4 items
然后,输出使用类似于unittest的语法指示每个测试的状态:
- 一个圆点(
.) 表示测试通过。 F表示测试失败。- An
E表示测试引发了意外异常。
特殊字符显示在名称旁边,测试套件的整体进度显示在右侧:
test_with_pytest.py .F [ 50%]
test_with_unittest.py F. [100%]
对于失败的测试,报告给出了失败的详细分类。在这个例子中,测试失败是因为assert False总是失败:
================================== FAILURES ===================================
______________________________ test_always_fails ______________________________
def test_always_fails():
> assert False
E assert False
test_with_pytest.py:7: AssertionError
________________________ TryTesting.test_always_fails _________________________
self = <test_with_unittest.TryTesting testMethod=test_always_fails>
def test_always_fails(self):
> self.assertTrue(False)
E AssertionError: False is not true
test_with_unittest.py:10: AssertionError
这个额外的输出在调试时会非常方便。最后,报告给出了测试套件的总体状态报告:
=========================== short test summary info ===========================
FAILED test_with_pytest.py::test_always_fails - assert False
FAILED test_with_unittest.py::TryTesting::test_always_fails - AssertionError:...
========================= 2 failed, 2 passed in 0.20s =========================
与 unittest 相比,pytest输出的信息量更大,可读性更强。
在下一节中,您将仔细看看pytest如何利用现有的assert关键字。
少学
能够使用 assert 关键字也很强大。如果你以前用过,那就没什么新东西可学了。这里有几个断言示例,因此您可以了解可以进行的测试类型:
# test_assert_examples.py
def test_uppercase():
assert "loud noises".upper() == "LOUD NOISES"
def test_reversed():
assert list(reversed([1, 2, 3, 4])) == [4, 3, 2, 1]
def test_some_primes():
assert 37 in {
num
for num in range(2, 50)
if not any(num % div == 0 for div in range(2, num))
}
它们看起来非常像普通的 Python 函数。所有这些都使得pytest的学习曲线比unittest要浅,因为你不需要学习新的构造来开始。
注意,每个测试都很小,并且是独立的。这很常见——你会看到很长的函数名,而在一个函数中不会发生很多事情。这主要是为了让你的测试相互隔离,这样如果有什么东西坏了,你就知道问题出在哪里了。一个很好的副作用是输出中的标签更好。
要查看与主项目一起创建测试套件的项目示例,请查看使用 TDD 在 Python 中构建哈希表教程。此外,当为下一次面试或解析 CSV 文件做准备时,你可以解决 Python 实践问题,亲自尝试测试驱动开发。
在下一节中,您将检查 fixtures,这是一个很好的 pytest 特性,可以帮助您管理测试输入值。
更易于管理状态和依赖关系
你的测试将经常依赖于数据类型或者模拟你的代码可能遇到的对象的测试加倍,比如字典或者 JSON 文件。
使用unittest,您可以将这些依赖项提取到.setUp()和.tearDown()方法中,这样类中的每个测试都可以使用它们。使用这些特殊的方法是好的,但是随着你的测试类变得越来越大,你可能会无意中使测试的依赖完全隐含。换句话说,通过孤立地看众多测试中的一个,你可能不会立即看到它依赖于其他东西。
随着时间的推移,隐式依赖可能会导致复杂的代码混乱,您必须展开代码才能理解您的测试。测试应该有助于让你的代码更容易理解。如果测试本身难以理解,那么你可能会有麻烦!
pytest采取不同的方法。它将您引向显式依赖声明,由于夹具的可用性,这些依赖声明仍然是可重用的。pytestfixture 是可以为测试套件创建数据、测试双精度或初始化系统状态的功能。任何想要使用 fixture 的测试都必须显式地使用这个 fixture 函数作为测试函数的参数,因此依赖关系总是在前面声明:
# fixture_demo.py
import pytest
@pytest.fixture
def example_fixture():
return 1
def test_with_fixture(example_fixture):
assert example_fixture == 1
查看测试函数,您可以立即看出它依赖于一个 fixture,而不需要检查整个文件中的 fixture 定义。
注意:你通常想要把你的测试放在你的项目的根层的一个名为tests的文件夹中。
有关构建 Python 应用程序的更多信息,请查看关于该主题的视频课程。
固定设备也可以利用其他固定设备,同样是通过将它们显式声明为依赖关系。这意味着,随着时间的推移,你的设备会变得庞大和模块化。尽管将夹具插入到其他夹具中的能力提供了巨大的灵活性,但是随着测试套件的增长,这也使得管理依赖关系变得更加困难。
在本教程的后面,您将学习更多关于夹具的知识,并尝试一些应对这些挑战的技巧。
易于过滤的测试
随着您的测试套件的增长,您可能会发现您想要对一个特性只运行几个测试,并保存整个套件以备后用。pytest提供了几种方法:
- 基于名称的过滤:您可以将
pytest限制为只运行那些完全限定名与特定表达式匹配的测试。您可以使用-k参数来实现这一点。 - 目录范围:默认情况下,
pytest将只运行那些在当前目录下的测试。 - 测试分类 :
pytest可以包含或排除您定义的特定类别的测试。您可以使用-m参数来实现这一点。
特别是测试分类是一个微妙而强大的工具。pytest使您能够为您喜欢的任何测试创建标记,或自定义标签。一个测试可能有多个标签,您可以使用它们对要运行的测试进行粒度控制。在本教程的后面,你将看到一个关于如何使用pytest标记的例子,并学习如何在大型测试套件中使用它们。
允许测试参数化
当您测试处理数据或执行一般转换的函数时,您会发现自己编写了许多类似的测试。它们可能只是在被测试代码的输入或输出上有所不同。这需要复制测试代码,这样做有时会掩盖您试图测试的行为。
提供了一种将几个测试集合成一个的方法,但是它们不会在结果报告中显示为单独的测试。如果一个测试失败了,而其余的通过了,那么整个组仍然会返回一个失败的结果。pytest提供自己的解决方案,每个测试都可以独立通过或失败。在本教程的后面,你会看到如何用pytest参数化测试。
拥有基于插件的架构
pytest最漂亮的特性之一是它对定制和新特性的开放性。几乎程序的每一部分都可以被破解和修改。结果,pytest用户开发了一个丰富的有用插件生态系统。
虽然有些pytest插件专注于特定的框架,比如 Django ,但是其他的插件适用于大多数测试套件。在本教程的后面你会看到一些特定插件的细节。
夹具:管理状态和依赖关系
夹具是为你的测试提供数据、测试副本或状态设置的一种方式。Fixtures 是可以返回大量值的函数。每个依赖于 fixture 的测试必须明确地接受 fixture 作为参数。
何时创建夹具
在本节中,您将模拟一个典型的测试驱动开发 (TDD)工作流。
假设您正在编写一个函数format_data_for_display(),来处理 API 端点返回的数据。该数据表示一个人员列表,每个人都有一个名、姓和职务。该函数应该输出一个字符串列表,其中包括每个人的全名(他们的given_name后跟他们的family_name)、一个冒号和他们的title:
# format_data.py
def format_data_for_display(people):
... # Implement this!
在好的 TDD 方式中,您将希望首先为它编写一个测试。为此,您可以编写以下代码:
# test_format_data.py
def test_format_data_for_display():
people = [
{
"given_name": "Alfonsa",
"family_name": "Ruiz",
"title": "Senior Software Engineer",
},
{
"given_name": "Sayid",
"family_name": "Khan",
"title": "Project Manager",
},
]
assert format_data_for_display(people) == [
"Alfonsa Ruiz: Senior Software Engineer",
"Sayid Khan: Project Manager",
]
在编写这个测试时,您会想到可能需要编写另一个函数来将数据转换成逗号分隔的值,以便在 Excel 中使用:
# format_data.py
def format_data_for_display(people):
... # Implement this!
def format_data_for_excel(people):
... # Implement this!
你的待办事项越来越多!那就好!TDD 的优势之一是它帮助你提前计划好工作。对format_data_for_excel()函数的测试看起来与format_data_for_display()函数非常相似:
# test_format_data.py
def test_format_data_for_display():
# ...
def test_format_data_for_excel():
people = [
{
"given_name": "Alfonsa",
"family_name": "Ruiz",
"title": "Senior Software Engineer",
},
{
"given_name": "Sayid",
"family_name": "Khan",
"title": "Project Manager",
},
]
assert format_data_for_excel(people) == """given,family,title
Alfonsa,Ruiz,Senior Software Engineer
Sayid,Khan,Project Manager
"""
值得注意的是,两个测试都必须重复people变量的定义,这相当于几行代码。
如果你发现自己写了几个测试,都使用了相同的底层测试数据,那么你的未来可能会有一个夹具。您可以将重复的数据放入用@pytest.fixture修饰的单个函数中,以表明该函数是一个pytest fixture:
# test_format_data.py
import pytest
@pytest.fixture
def example_people_data():
return [
{
"given_name": "Alfonsa",
"family_name": "Ruiz",
"title": "Senior Software Engineer",
},
{
"given_name": "Sayid",
"family_name": "Khan",
"title": "Project Manager",
},
]
# ...
您可以通过将函数引用作为参数添加到测试中来使用 fixture。注意,您没有调用 fixture 函数。会处理好的。您将能够使用 fixture 函数的返回值作为 fixture 函数的名称:
# test_format_data.py
# ...
def test_format_data_for_display(example_people_data):
assert format_data_for_display(example_people_data) == [ "Alfonsa Ruiz: Senior Software Engineer",
"Sayid Khan: Project Manager",
]
def test_format_data_for_excel(example_people_data):
assert format_data_for_excel(example_people_data) == """given,family,title Alfonsa,Ruiz,Senior Software Engineer
Sayid,Khan,Project Manager
"""
每个测试现在都明显缩短了,但仍然有一条清晰的路径返回到它所依赖的数据。一定要给你的固定装置起一个具体的名字。这样,您可以在将来编写新测试时快速确定是否要使用它!
当你第一次发现固定物的力量时,总是使用它们是很诱人的,但是和所有事情一样,需要保持平衡。
何时避开夹具
Fixtures 对于提取您在多个测试中使用的数据或对象非常有用。然而,对于要求数据有细微变化的测试,它们并不总是那么好。在测试套件中乱放固定装置并不比乱放普通数据或对象好。由于增加了间接层,情况可能会更糟。
与大多数抽象一样,需要一些实践和思考来找到夹具使用的正确级别。
尽管如此,夹具很可能是测试套件中不可或缺的一部分。随着项目范围的扩大,规模的挑战开始显现。任何一种工具面临的挑战之一是如何处理大规模使用,幸运的是,pytest有一系列有用的功能可以帮助您管理增长带来的复杂性。
如何大规模使用夹具
随着您从测试中提取更多的装置,您可能会看到一些装置可以从进一步的抽象中受益。在pytest中,夹具是模块化。模块化意味着夹具可以导入,可以导入其他模块,并且可以依赖和导入其他夹具。所有这些都允许您为您的用例构建一个合适的夹具抽象。
例如,您可能会发现两个独立文件中的装置,或模块,共享一个公共的依赖关系。在这种情况下,您可以将 fixture 从测试模块移动到更一般的 fixture 相关模块中。这样,您可以将它们重新导入到任何需要它们的测试模块中。当您发现自己在整个项目中反复使用夹具时,这是一个很好的方法。
如果你想让一个 fixture 对你的整个项目可用而不需要导入它,一个叫做 conftest.py 的特殊配置模块将允许你这样做。
pytest在每个目录中寻找一个conftest.py模块。如果您将通用夹具添加到conftest.py模块,那么您将能够在整个模块的父目录和任何子目录中使用该夹具,而不必导入它。这是放置你最常用的灯具的好地方。
fixtures 和conftest.py的另一个有趣的用例是保护对资源的访问。假设您已经为处理 API 调用的代码编写了一个测试套件。您希望确保测试套件不会进行任何真正的网络调用,即使有人不小心编写了这样的测试。
pytest提供了一个 monkeypatch 夹具来替换价值观和行为,你可以用它来产生很大的效果:
# conftest.py
import pytest
import requests
@pytest.fixture(autouse=True)
def disable_network_calls(monkeypatch):
def stunted_get():
raise RuntimeError("Network access not allowed during testing!")
monkeypatch.setattr(requests, "get", lambda *args, **kwargs: stunted_get())
通过将disable_network_calls()放在conftest.py中并添加autouse=True选项,您可以确保在套件的每个测试中禁用网络调用。任何执行代码调用requests.get()的测试都将引发一个RuntimeError,表明一个意外的网络调用将会发生。
您的测试套件在数量上正在增长,这给了您很大的信心来进行更改,而不是意外地破坏。也就是说,随着测试套件的增长,它可能会花费很长时间。即使不需要那么长时间,也许你正在关注一些核心行为,这些行为会慢慢渗透并破坏大多数测试。在这些情况下,您可能希望将测试运行程序限制在特定的测试类别中。
标记:分类测试
在任何大型测试套件中,当你试图快速迭代一个新特性时,最好避免运行所有的测试。除了默认行为pytest运行当前工作目录中的所有测试,或者过滤功能,您可以利用标记。
使您能够为您的测试定义类别,并在您运行套件时提供包括或排除类别的选项。您可以用任意数量的类别来标记测试。
标记测试对于按子系统或依赖项对测试进行分类很有用。例如,如果您的一些测试需要访问数据库,那么您可以为它们创建一个@pytest.mark.database_access标记。
专家提示:因为你可以给你的标记取任何你想要的名字,所以很容易打错或记错标记的名字。pytest将警告您测试输出中无法识别的标记。
您可以对pytest命令使用--strict-markers标志,以确保您的测试中的所有标记都注册到您的pytest配置文件pytest.ini中。它会阻止你运行你的测试,直到你注册任何未知的标记。
有关注册商标的更多信息,请查看 pytest文档。
到了运行测试的时候,您仍然可以使用pytest命令默认运行所有的测试。如果您只想运行那些需要数据库访问的测试,那么您可以使用pytest -m database_access。要运行除了那些需要数据库访问的测试之外的所有测试,您可以使用pytest -m "not database_access"。您甚至可以使用一个autouse夹具来限制对那些标有database_access的测试的数据库访问。
一些插件通过添加自己的防护来扩展标记的功能。例如, pytest-django 插件提供了一个django_db标记。任何没有这个标记的试图访问数据库的测试都将失败。试图访问数据库的第一个测试将触发 Django 的测试数据库的创建。
添加django_db标记的要求促使你明确地陈述你的依赖关系。毕竟这就是pytest哲学!这也意味着你可以更快地运行不依赖于数据库的测试,因为pytest -m "not django_db"会阻止测试触发数据库创建。节省的时间真的越来越多,特别是如果你勤于频繁地运行测试。
pytest提供了一些现成的标志:
skip无条件跳过一次考试。skipif如果传递给它的表达式计算结果为True,则跳过测试。xfail表示测试预计会失败,因此如果测试和失败,整个套件仍然会导致通过状态。parametrize用不同的值作为自变量创建测试的多个变量。你很快会了解到更多关于这个标记的信息。
您可以通过运行pytest --markers来查看pytest知道的所有标记的列表。
关于参数化的话题,这是接下来要讲的。
参数化:组合测试
在本教程的前面,您已经看到了如何使用pytestfixture 通过提取公共依赖来减少代码重复。当您有几个输入和预期输出略有不同的测试时,Fixtures 就没那么有用了。在这些情况下,您可以用 参数化 一个单一的测试定义,然后pytest会用您指定的参数为您创建测试的变体。
假设你写了一个函数来判断一个字符串是否是回文。最初的一组测试可能如下所示:
def test_is_palindrome_empty_string():
assert is_palindrome("")
def test_is_palindrome_single_character():
assert is_palindrome("a")
def test_is_palindrome_mixed_casing():
assert is_palindrome("Bob")
def test_is_palindrome_with_spaces():
assert is_palindrome("Never odd or even")
def test_is_palindrome_with_punctuation():
assert is_palindrome("Do geese see God?")
def test_is_palindrome_not_palindrome():
assert not is_palindrome("abc")
def test_is_palindrome_not_quite():
assert not is_palindrome("abab")
除了最后两个测试,所有这些测试都具有相同的形状:
def test_is_palindrome_<in some situation>():
assert is_palindrome("<some string>")
这开始有点像样板文件了。到目前为止,它已经帮你摆脱了样板文件,现在也不会让你失望。您可以使用@pytest.mark.parametrize()用不同的值填充这个形状,从而大大减少您的测试代码:
@pytest.mark.parametrize("palindrome", [
"",
"a",
"Bob",
"Never odd or even",
"Do geese see God?",
])
def test_is_palindrome(palindrome):
assert is_palindrome(palindrome)
@pytest.mark.parametrize("non_palindrome", [
"abc",
"abab",
])
def test_is_palindrome_not_palindrome(non_palindrome):
assert not is_palindrome(non_palindrome)
parametrize()的第一个参数是一个逗号分隔的参数名称字符串。正如您在本例中看到的,您不必提供多个名称。第二个参数是代表参数值的元组或单个值的列表。您可以进一步进行参数化,将所有测试合并成一个:
@pytest.mark.parametrize("maybe_palindrome, expected_result", [
("", True),
("a", True),
("Bob", True),
("Never odd or even", True),
("Do geese see God?", True),
("abc", False),
("abab", False),
])
def test_is_palindrome(maybe_palindrome, expected_result):
assert is_palindrome(maybe_palindrome) == expected_result
尽管这缩短了您的代码,但重要的是要注意,在这种情况下,您实际上丢失了原始函数的一些更具描述性的特性。确保你没有将你的测试套件参数化到不可理解的程度。您可以使用参数化将测试数据从测试行为中分离出来,这样就可以清楚地知道测试在测试什么,也可以使不同的测试用例更容易阅读和维护。
持续时间报告:对抗缓慢测试
每次您将上下文从实现代码切换到测试代码时,您都会招致一些开销。如果你的测试一开始就很慢,那么开销会导致摩擦和挫折。
您在前面读到过在运行套件时使用标记来过滤掉缓慢的测试,但是在某些时候您将需要运行它们。如果你想提高测试的速度,那么知道哪些测试可能提供最大的改进是很有用的。pytest可以自动为您记录测试持续时间,并报告排名靠前的违规者。
使用pytest命令的--durations选项在您的测试结果中包含一个持续时间报告。--durations期望一个整数值n,并将报告最慢的n测试次数。您的测试报告中将包含一个新的部分:
(venv) $ pytest --durations=5
...
============================= slowest 5 durations =============================
3.03s call test_code.py::test_request_read_timeout
1.07s call test_code.py::test_request_connection_timeout
0.57s call test_code.py::test_database_read
(2 durations < 0.005s hidden. Use -vv to show these durations.)
=========================== short test summary info ===========================
...
durations 报告中显示的每个测试都是一个很好的加速对象,因为它花费了高于平均水平的总测试时间。请注意,默认情况下,短持续时间是隐藏的。如报告中所述,您可以增加报告的详细程度,并通过将-vv和--durations一起传递来显示这些内容。
请注意,一些测试可能会有不可见的设置开销。您在前面已经了解了标记有django_db的第一个测试将如何触发 Django 测试数据库的创建。durations报告反映了在触发数据库创建的测试中设置数据库所花费的时间,这可能会产生误导。
您正在朝着全面测试覆盖的方向前进。接下来,你将看到丰富的pytest插件生态系统中的一些插件。
有用的pytest插件
在本教程的前面,你已经了解了一些有价值的pytest插件。在这一节中,您将更深入地探索这些和其他一些插件——从像pytest-randomly这样的实用插件到像 Django 那样的特定于库的插件。
pytest-randomly
通常,测试的顺序并不重要,但是随着代码库的增长,您可能会无意中引入一些副作用,如果这些副作用不按顺序运行,可能会导致一些测试失败。
pytest-randomly 强制你的测试以随机的顺序运行。pytest总是在运行测试之前收集它能找到的所有测试。pytest-randomly只是在执行之前打乱测试列表。
这是发现依赖于以特定顺序运行的测试的好方法,这意味着它们对其他一些测试有一个状态依赖。如果您在pytest中从头开始构建您的测试套件,那么这是不太可能的。这更有可能发生在您迁移到pytest的测试套件中。
该插件将在配置描述中打印一个种子值。您可以使用该值按照尝试修复问题时的顺序运行测试。
pytest-cov
如果你想测量你的测试覆盖你的实现代码有多好,那么你可以使用覆盖率包。 pytest-cov 集成了覆盖率,所以你可以运行pytest --cov来查看测试覆盖率报告,并在你的项目首页吹嘘它。
pytest-django
pytest-django 提供了一些有用的夹具和标记来处理 Django 测试。您在本教程的前面看到了django_db标记。rf fixture 提供了对 Django 的 RequestFactory 实例的直接访问。settings夹具提供了一种快速设置或覆盖 Django 设置的方法。这些插件极大地提高了 Django 测试的效率!
如果你有兴趣了解更多关于在 Django 中使用pytest的信息,那么看看如何在 Pytest 中为 Django 模型提供测试夹具。
pytest-bdd
pytest可用于运行传统单元测试范围之外的测试。行为驱动开发 (BDD)鼓励用简单的语言描述用户可能的行为和期望,然后你可以用它来决定是否实现一个给定的特性。pytest-bdd 帮助你使用小黄瓜为你的代码编写特性测试。
你可以通过第三方插件的列表来查看pytest还有哪些可用的插件。
结论
提供了一套核心的生产力特性来过滤和优化您的测试,以及一个灵活的插件系统来进一步扩展其价值。无论你是有一个庞大的遗产unittest套件,还是从头开始一个新项目,pytest都能为你提供一些东西。
在本教程中,您学习了如何使用:
- 用于处理测试依赖、状态和可重用功能的夹具
- 标记,用于对测试进行分类并限制对外部资源的访问
- 参数化用于减少测试之间的重复代码
- 持续时间来识别你最慢的测试
- 用于集成其他框架和测试工具的插件
安装pytest试试看。你会很高兴你做了。测试愉快!
如果你正在寻找一个用pytest构建的示例项目,那么看看关于用 TDD 构建哈希表的教程,它不仅能让你跟上pytest的速度,还能帮助你掌握哈希表!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 pytest 测试你的代码********
如何在 Python 中求绝对值
绝对值通常用于数学、物理和工程中。尽管学校对绝对值的定义可能看起来很简单,但实际上你可以从许多不同的角度来看待这个概念。如果您打算在 Python 中使用绝对值,那么您来对地方了。
在本教程中,您将学习如何:
- 从头开始执行绝对值功能
- 使用 Python 中的内置
abs()函数 - 计算数字的绝对值
- 在数字阵列和熊猫系列上调用
abs() - 自定义对象上
abs()的行为
如果你对绝对值函数的数学知识有点生疏也不用担心。在深入研究 Python 代码之前,您将首先刷新您的记忆。也就是说,请随意跳过下一部分,直接进入接下来的基本细节。
示例代码: 单击此处下载示例代码,您将使用它在 Python 中查找绝对值。
定义绝对值
绝对值让你决定一个物体的大小或大小,比如一个数字或一个向量,而不管它的方向。当你忽略零时,实数可以有两个方向:正数或负数。另一方面,复数和向量可以有更多的方向。
注意:当你取一个数的绝对值时,你会丢失它的符号信息,或者更一般地说,它的方向信息。
以温度测量为例。如果温度计显示零下 12 摄氏度,你就可以说是零下 12 摄氏度。注意你是如何把最后一句话中的温度分解成一个量级,十二,和一个符号的。短语在冰点以下的意思和零摄氏度以下一样。温度的大小或绝对值与高得多的+12 摄氏度的绝对值相同。
使用数学符号,您可以将𝑥的绝对值定义为一个分段函数,它根据输入值的范围表现不同。绝对值的常用符号由两条垂直线组成:

此函数返回大于或等于零的值,不做任何修改。另一方面,小于零的值的符号从负号变为正号。从代数上来说,这相当于求一个数的平方的平方根:

当你对一个实数求平方时,你总是得到一个正的结果,即使这个数一开始是负的。例如,12 的平方和 12 的平方具有相同的值,等于 144。后来,当你计算 144 的平方根时,你只会得到没有负号的 12。
从几何学上讲,你可以把绝对值想象成离原点的距离,在之前温度读数的情况下,该距离在数字线上为零:
要计算这个距离,可以从温度读数中减去原点(-12°C-0°C =-12°C)或者反过来(0°C-(-12°C)=+12°C),然后去掉结果的符号。这里减去零并没有太大的区别,但参考点有时可能会发生偏移。对于束缚在空间固定点上的向量来说就是这样,空间固定点就是向量的原点。
向量就像数字一样,传达关于物理量的方向和大小的信息,但是是在多个维度上。例如,您可以将下落的雪花的速度表示为一个三维向量:
https://player.vimeo.com/video/734381007?background=1
该向量表示雪花相对于坐标系原点的当前位置。它还显示了雪花在空间中运动的方向和速度。向量越长,雪花的速度越大。只要向量的起点和终点的坐标是以米表示的,计算它的长度就会得到雪花在单位时间内以米测量的速度。
注意:看一个向量有两种方法。一个束缚向量是空间中一对有序的固定点,而一个自由向量只告诉你从 A 点到 B 点的坐标位移,而不透露它们的绝对位置。以下面的代码片段为例:
>>> A = [1, 2, 3] >>> B = [3, 2, 1] >>> bound_vector = [A, B] >>> bound_vector [[1, 2, 3], [3, 2, 1]] >>> free_vector = [b - a for a, b in zip(A, B)] >>> free_vector [2, 0, -2]一个边界向量包围了这两个点,提供了相当多的信息。相比之下,自由向量只代表从 A 到 b 的移动。你可以通过从终点 b 减去起点 A 来计算自由向量。一种方法是用列表理解迭代连续的坐标对。
自由向量本质上是一个平移到坐标系原点的约束向量,所以它从零开始。
一个矢量的长度,也就是它的大小,是它的起点和终点𝐴和𝐵之间的距离,你可以用欧几里德范数来计算:
The Length of a Bound Vector as a Euclidean Norm 该公式计算𝑛-dimensional 向量𝐴𝐵的长度,方法是对𝑖.索引的每个维度上的点𝐴和𝐵的坐标之差的平方求和对于自由向量,初始点𝐴成为坐标系的原点(或零点),这简化了公式,因为您只需要对向量的坐标求平方。
回想一下绝对值的代数定义。对于数字,它是数字平方的平方根。现在,当你在方程中增加更多的维度时,你最终得到了欧几里德范数的公式,如上所示。所以,向量的绝对值等于它的长度!
好吧。既然您已经知道了绝对值何时可能有用,那么是时候在 Python 中实现它们了!
在 Python 中实现绝对值函数
要在 Python 中实现绝对值函数,您可以采用早期的数学定义之一,并将其翻译成代码。例如,分段函数可能如下所示:
def absolute_value(x): if x >= 0: return x else: return -x您使用一个条件语句来检查用字母
x表示的给定数字是否大于或等于零。如果是,那么你返回相同的数字。否则,你翻转数字的符号。因为这里只有两种可能的结果,你可以用一个适合单行的条件表达式重写上面的函数:def absolute_value(x): return x if x >= 0 else -x这与之前的行为完全相同,只是以稍微紧凑的方式实现。当您没有很多逻辑进入代码中的两个可选分支时,条件表达式非常有用。
注意:或者,您可以依靠 Python 内置的
max()函数来更简洁地编写,该函数返回最大的参数:def absolute_value(x): return max(x, -x)如果数字𝑥是负数,那么这个函数将返回它的正值。否则,它会返回𝑥本身。
绝对值的代数定义在 Python 中实现起来也非常简单:
from math import sqrt def absolute_value(x): return sqrt(pow(x, 2))首先,从
math模块导入平方根函数,然后在给定的 2 次方数字上调用它。这个函数内置在 Python 中,所以你不需要导入它。或者,您可以通过利用 Python 的取幂运算符(**) )来完全避免import语句,它可以模拟平方根函数:def absolute_value(x): return (x**2) ** 0.5这是一种数学技巧,因为使用分数指数等同于计算一个数的 𝑛th 根。在这种情况下,你取一个平方数的二分之一(0.5)或二分之一( ),这与计算平方根是一样的。注意,基于代数定义的两种 Python 实现都有一点不足:

>>> def absolute_value(x):
... return (x**2) ** 0.5
>>> absolute_value(-12)
12.0
>>> type(12.0)
<class 'float'>
你总是以一个浮点数结束,即使你以一个整数开始。因此,如果您想保留数字的原始数据类型,那么您可能更喜欢基于分段的实现。
只要您使用整数和浮点数,您还可以通过利用 Python 中数字的文本表示来编写绝对值函数的一个有点傻的实现:
def absolute_value(x):
return float(str(x).lstrip("-"))
使用内置的str()函数将函数的参数x转换成一个 Python 字符串。这允许您用一个空字符串去掉前导减号(如果有)。然后,用float()将结果转换成浮点数。注意这个实现总是将整数转换成浮点数。
用 Python 从头实现绝对值函数是一项值得学习的工作。然而,在实际应用中,您应该利用 Python 自带的内置abs()函数。您将在下一节中找到原因。
使用内置的abs()函数和数字
上面实现的最后一个函数可能是效率最低的一个,因为数据转换和字符串操作通常比直接的数字操作要慢。但事实上,与语言内置的abs()函数相比,你所有手工实现的绝对值都相形见绌。那是因为abs()被编译成高速的机器码,而你的纯 Python 代码不是。
比起你的自定义函数,你应该总是更喜欢abs()。它的运行速度要快得多,当您有大量数据要处理时,这一优势会非常明显。此外,它的用途更加广泛,您将会发现这一点。
整数和浮点数
abs()函数是属于 Python 语言的内置函数之一。这意味着您可以立即开始使用它,而无需导入:
>>> abs(-12) 12 >>> abs(-12.0) 12.0如您所见,
abs()保留了原始的数据类型。在第一种情况下,您传递了一个整数文本并得到了一个整数结果。当用浮点数调用时,该函数返回一个 Pythonfloat。但是这两种数据类型并不是唯一可以调用abs()的数据类型。abs()知道如何处理的第三个数字类型是 Python 的complex数据类型,它表示复数。复数
你可以把一个复数想象成由两个浮点值组成的一对,俗称实部和虚部。在 Python 中定义复数的一种方法是调用内置的
complex()函数:
>>> z = complex(3, 2)
它接受两个参数。第一个代表实部,第二个代表虚部。在任何时候,您都可以访问复数的.real和.imag属性来取回这些部分:
>>> z.real 3.0 >>> z.imag 2.0它们都是只读的,并且总是表示为浮点值。还有,
abs()返回的复数的绝对值恰好是浮点数:
>>> abs(z)
3.605551275463989
这可能会让您感到惊讶,直到您发现复数有一个类似于固定在坐标系原点的二维向量的视觉表示:
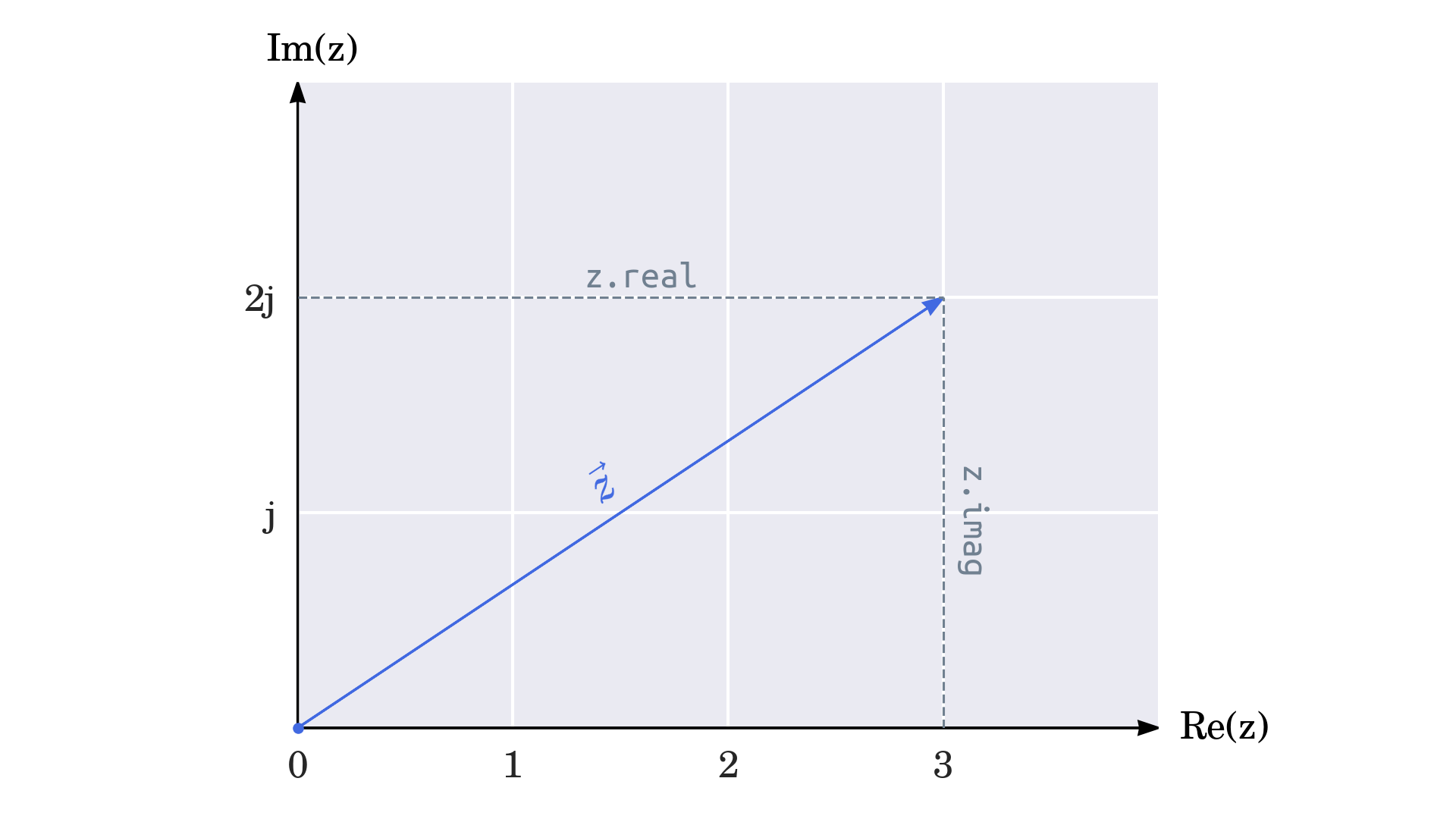
您已经知道了计算这样一个向量的长度的公式,在本例中,它与abs()返回的数字一致。注意,复数的绝对值通常被称为复数的幅度、模数或半径。
虽然整数、浮点数和复数是 Python 本身支持的唯一数字类型,但是在 Python 的标准库中,您会发现另外两种数字类型。它们也可以与abs()函数互操作。
分数和小数
Python 中的abs()函数接受所有可用的数字数据类型,包括鲜为人知的分数和小数。例如,您可以将三分之一或负四分之三的绝对值定义为Fraction实例:
>>> from fractions import Fraction >>> abs(Fraction("1/3")) Fraction(1, 3) >>> abs(Fraction("-3/4")) Fraction(3, 4)在这两种情况下,您都获得了另一个
Fraction对象,但是它是无符号的。如果您打算继续计算分数,这会很方便,因为分数比浮点数精度更高。如果你在金融领域工作,那么你可能想要使用
Decimal对象来帮助减轻浮点表示错误。幸运的是,您可以获得这些对象的绝对值:
>>> from decimal import Decimal
>>> abs(Decimal("0.3333333333333333"))
Decimal('0.3333333333333333')
>>> abs(Decimal("-0.75"))
Decimal('0.75')
同样,abs()函数方便地返回与您提供的数据类型相同的数据类型,但是它给了您一个适当的正值。
哇,abs()可以处理多种多样的数字数据类型!但事实证明abs()比那更聪明。您甚至可以在第三方库提供的一些对象上调用它,这将在下一节中尝试。
在其他 Python 对象上调用abs()
假设您想要计算一段时间内日平均温度读数的绝对值。不幸的是,当您试图用这些数字在 Python 列表上调用abs()时,您会得到一个错误:
>>> temperature_readings = [1, -5, 1, -4, -1, -8, 0, -7, 3, -5, 2] >>> abs(temperature_readings) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: bad operand type for abs(): 'list'那是因为
abs()不知道怎么处理一串数字。要解决这个问题,您可以使用列表理解或调用 Python 的map()函数,如下所示:
>>> [abs(x) for x in temperature_readings]
[1, 5, 1, 4, 1, 8, 0, 7, 3, 5, 2]
>>> list(map(abs, temperature_readings))
[1, 5, 1, 4, 1, 8, 0, 7, 3, 5, 2]
这两种实现都完成了工作,但是需要一个额外的步骤,这可能并不总是令人满意的。如果您想减少额外的步骤,那么您可以查看改变abs()行为的外部库。这就是您将在下面探讨的内容。
数字阵列和熊猫系列
用高性能数组和矩阵扩展 Python 的最流行的库之一是 NumPy 。它的𝑛-dimensional 数组数据结构ndarray,是 Python 中数值计算的基石,所以很多其他库都以它为基础。
一旦用np.array()将常规 Python 列表转换成 NumPy 数组,就可以调用一些内置函数,包括结果中的abs():
>>> import numpy as np >>> temperature_readings = np.array([1, -5, 1, -4, -1, -8, 0, -7, 3, -5, 2]) >>> abs(temperature_readings) array([1, 5, 1, 4, 1, 8, 0, 7, 3, 5, 2])作为对在 NumPy 数组上调用
abs()的响应,您将获得另一个包含原始元素绝对值的数组。就好像您自己迭代温度读数列表,并对每个元素单独应用abs()函数,就像您之前对列表理解所做的一样。如果您觉得更合适,可以将 NumPy 数组转换回 Python 列表:
>>> list(abs(temperature_readings))
[1, 5, 1, 4, 1, 8, 0, 7, 3, 5, 2]
但是,请注意 NumPy 数组共享大部分 Python 列表接口。例如,他们支持索引和切片,他们的方法类似于普通列表,所以大多数人通常只是坚持使用 NumPy 数组,而从来没有回头看列表。
pandas 是另一个广泛用于数据分析的第三方库,这要归功于它的Series和DataFrame对象。系列是一系列观察值或一列,而数据帧就像一个表格或一组列。你可以给他们俩都打电话abs()。
假设您有一个 Python 字典,它将一个城市名称映射到一年中每月观察到的最低平均温度:
>>> lowest_temperatures = { ... "Reykjav\xedk": [-3, -2, -2, 1, 4, 7, 9, 8, 6, 2, -1, -2], ... "Rovaniemi": [-16, -14, -10, -3, 3, 8, 12, 9, 5, -1, -6, -11], ... "Valetta": [9, 9, 10, 12, 15, 19, 21, 22, 20, 17, 14, 11], ... }每个城市有 12 个温度读数,时间跨度从 1 月到 12 月。现在,你可以把那本字典变成一个熊猫
DataFrame对象,这样你就可以得出一些有趣的见解:
>>> import calendar
>>> import pandas as pd
>>> df = pd.DataFrame(lowest_temperatures, index=calendar.month_abbr[1:])
>>> df
Reykjavík Rovaniemi Valetta
Jan -3 -16 9
Feb -2 -14 9
Mar -2 -10 10
Apr 1 -3 12
May 4 3 15
Jun 7 8 19
Jul 9 12 21
Aug 8 9 22
Sep 6 5 20
Oct 2 -1 17
Nov -1 -6 14
Dec -2 -11 11
您的数据框架不是使用默认的从零开始的索引,而是通过缩写的月份名称进行索引,这是您在 calendar 模块的帮助下获得的。数据帧中的每一列都有来自原始字典的温度序列,表示为一个Series对象:
>>> df["Rovaniemi"] Jan -16 Feb -14 Mar -10 Apr -3 May 3 Jun 8 Jul 12 Aug 9 Sep 5 Oct -1 Nov -6 Dec -11 Name: Rovaniemi, dtype: int64 >>> type(df["Rovaniemi"]) <class 'pandas.core.series.Series'>通过使用方括号(
[])语法和罗瓦涅米这样的城市名称,您可以从 DataFrame 中提取单个Series对象,并缩小显示的信息量。pandas,就像 NumPy 一样,让你在它的对象上调用 Python 的许多内置函数,包括它的
DataFrame和Series对象。具体来说,可以调用abs()来一次计算多个绝对值:
>>> abs(df)
Reykjavík Rovaniemi Valetta
Jan 3 16 9
Feb 2 14 9
Mar 2 10 10
Apr 1 3 12
May 4 3 15
Jun 7 8 19
Jul 9 12 21
Aug 8 9 22
Sep 6 5 20
Oct 2 1 17
Nov 1 6 14
Dec 2 11 11
>>> abs(df["Rovaniemi"])
Jan 16
Feb 14
Mar 10
Apr 3
May 3
Jun 8
Jul 12
Aug 9
Sep 5
Oct 1
Nov 6
Dec 11
Name: Rovaniemi, dtype: int64
在整个数据帧上调用abs()会将该函数应用于每一列中的每个元素。也可以在单个列上调用abs()。
NumPy 和 pandas 是如何在不修改其底层代码的情况下改变 Python 内置abs()函数的行为的?嗯,这是可能的,因为该函数在设计时就考虑到了这种扩展。如果您正在寻找abs()的高级用法,那么请继续阅读,创建您自己的数据类型,它将很好地与该函数配合使用。
您自己的数据类型
根据数据类型的不同,Python 会以不同的方式处理绝对值的计算。
当你在一个整数上调用abs()时,它将使用一个定制的代码片段,类似于你的分段函数。然而,为了提高效率,这个功能将用 C 编程语言来实现。如果你传递一个浮点数,那么 Python 会把这个调用委托给 C 的 fabs() 函数。在复数的情况下,它会调用 hypot() 函数来代替。
像 DataFrames、series 和 arrays 这样的容器对象呢?
可以理解的是,当您在 Python 中定义一个新的数据类型时,它不会与abs()函数一起工作,因为它的默认行为是未知的。但是,您可以通过使用纯 Python 实现特殊的 .__abs__() 方法,针对您的类实例定制abs()的行为。Python 中有一组有限的预定义的特殊方法,可以让你覆盖某些函数和操作符应该如何工作。
考虑下面的类,它表示在欧几里得空间中的一个自由𝑛-dimensional 向量:
>>> import math >>> class Vector: ... def __init__(self, *coordinates): ... self.coordinates = coordinates ... ... def __abs__(self): ... origin = [0] * len(self.coordinates) ... return math.dist(origin, self.coordinates)这个类接受一个或多个坐标值,描述从坐标系原点在每个维度上的位移。你的特殊的
.__abs__()方法根据你在本教程开始时学到的欧几里德范数定义计算到原点的距离。为了测试你的新类,你可以创建一个三维的速度向量,比如一片落下的雪花,看起来像这样:
>>> snowflake_velocity = Vector(0.42, 1.5, 0.87)
>>> abs(snowflake_velocity)
1.7841804841439108
注意在你的Vector类实例上调用abs()如何返回正确的绝对值,大约等于 1.78。只要雪花的位移是在相隔一秒钟的两个不同时刻以米为单位测量的,速度单位将以米/秒表示。换句话说,雪花从 A 点到 b 点需要一秒钟。
使用上面提到的公式会迫使您定义原点。然而,因为您的Vector类表示自由向量而不是约束向量,所以您可以通过使用 Python 的math.hypot()函数计算多维斜边来简化您的代码:
>>> import math >>> class Vector: ... def __init__(self, *coordinates): ... self.coordinates = coordinates ... ... def __abs__(self): ... return math.hypot(*self.coordinates) >>> snowflake_velocity = Vector(0.42, 1.5, 0.87) >>> abs(snowflake_velocity) 1.7841804841439108您可以用更少的代码行获得相同的结果。注意,
hypot()是一个接受可变数量参数的变量函数,因此您必须使用星号运算符(*)将坐标元组解包到这些参数中。厉害!您现在可以实现自己的库,Python 的内置
abs()函数将知道如何使用它。您将获得与 NumPy 或 pandas 类似的功能!结论
用 Python 实现绝对值公式轻而易举。然而,Python 已经提供了多功能的
abs()函数,它允许您计算各种类型数字的绝对值,包括整数、浮点数、复数等等。您还可以在自定义类和第三方库对象的实例上使用abs()。在本教程中,您学习了如何:
- 从头开始执行绝对值功能
- 使用 Python 中的内置
abs()函数- 计算数字的绝对值
- 在数字阵列和熊猫系列上调用
abs()- 自定义对象上
abs()的行为有了这些知识,您就拥有了在 Python 中计算绝对值的有效工具。
示例代码: 单击此处下载示例代码,您将使用它在 Python 中查找绝对值。****
代码的出现:用 Python 解决你的难题
《降临代码》是一个在线的降临日历,在那里你可以找到从 12 月 1 日到 25 日每天提供的新的编程难题。虽然你可以在任何时候解谜,但当新的谜题解开时,那种兴奋真的很特别。您可以参与任何编程语言的“代码降临”——包括 Python!
在本教程的帮助下,你将准备好开始解谜并获得你的第一颗金星。
在本教程中,您将学习:
- 什么是在线降临节日历
- 解决谜题如何提高你的编程技能
- 你如何参与代码的出现
- 当解决降临代码难题时,你如何组织你的代码和测试
- 如何在解谜时使用测试驱动开发
代码难题的来临被设计为对解决问题感兴趣的任何人接近。不需要厚重的计算机科学背景也能参与。相反,《代码的出现》是学习新技能和测试 Python 新特性的绝佳舞台。
源代码: 点击此处下载免费源代码,向您展示如何用 Python 解决代码难题。
编程中的困惑?
玩拼图似乎是浪费你的编程时间。毕竟,看起来你并没有真正产生任何有用的东西,也没有推进你当前的项目。
然而,花些时间练习编程难题有几个好处:
编程难题通常比你的常规工作任务更具体、更有内容。它们为你提供了一个机会来练习逻辑思维,解决比你日常工作中通常需要处理的问题更简单的问题。
你可以经常用几个类似的谜题来挑战自己。这允许你建立程序性记忆,就像肌肉记忆一样,并获得构建某种代码的经验。
谜题的设计往往着眼于解决问题。它们允许你学习和应用经过试验和测试的算法,并且是任何程序员工具箱的重要组成部分。
对于一些难题的解决方案,如果算法效率低下,即使是最伟大的超级计算机也会太慢。您可以分析您的解决方案的性能,并获得经验来帮助您理解什么时候简单的方法足够快,什么时候需要更优化的程序。
大多数编程语言非常适合解决编程难题。这给了你一个很好的机会比较不同任务的不同编程语言。谜题也是了解一门新的编程语言或者尝试你最喜欢的语言的一些最新特性的好方法。
最重要的是,用一个编程难题挑战自己通常是非常有趣的!当你把这些都加起来时,留出一些时间玩拼图会很有收获。
探索在线解决编程难题的选项
幸运的是,有许多网站可以让你找到编程难题并尝试解决它们。这些网站呈现的问题类型、你如何提交你的解决方案以及这些网站能提供什么样的反馈和社区通常都有所不同。因此,你应该花些时间四处看看,找到那些最吸引你的。
在本教程中,你将了解代码的出现,包括你可以在那里找到什么样的谜题,以及你可以使用哪些工具和技巧来解决它们。但是,您也可以从其他地方开始解决编程难题:
exercisem 拥有多种不同编程语言的学习轨迹。每条学习路线都提供了编码挑战、关于不同编程概念的小教程,以及为您提供解决方案反馈的导师。
欧拉项目由来已久。该网站提供了数百个谜题,通常是数学问题。你可以用任何编程语言解决问题,一旦你解决了一个难题,你就可以进入一个社区线程,在那里你可以和其他人讨论你的解决方案。
代码大战提供了大量的编码挑战,他们称之为卡塔斯。您可以用许多不同的编程语言通过它们内置的编辑器和自动化测试来解决难题。之后,你可以将你的解决方案与其他人的进行比较,并在论坛中讨论策略。
如果你在找工作,HackerRank 有很棒的功能。他们提供许多不同技能的认证,包括解决问题和 Python 编程,以及一个工作板,让你在求职申请中展示你的解谜技能。
还有许多其他网站可以让你练习解谜技巧。在本教程的其余部分,您将重点关注代码时代提供了什么。
为《代码降临》做准备:圣诞节的 25 个新鲜谜题
代码时代到了!它是由 Eric Wastl 在 2015 年创办的。从那以后,每年 12 月都会出版一个新的降临节日历,里面有 25 个新的编程难题。这些年来,谜题变得越来越受欢迎。超过 235,000 人已经解决了至少一个 2021 年的谜题。
注:传统上,降临节日历是用来计算等待圣诞节时降临节的日子的日历。多年来,降临节日历变得越来越商业化,已经失去了一些与基督教的联系。
大多数降临节日历开始于 12 月 1 日,结束于 12 月 24 日,平安夜,或 12 月 25 日,圣诞节。现在有各种各样的降临节日历,包括乐高日历、茶叶日历和化妆品日历。
在传统的降临节日历中,你每天打开一扇门来展示里面的东西。《代码降临》模拟了这一点,从 12 月 1 日到 12 月 25 日,每天给你一个新的谜题。对于你解决的每一个难题,你将获得属于你的金色星星。
在这一节中,您将更加熟悉《代码的来临》,并初步了解您的第一个难题。稍后,你将看到如何解决这些难题的细节,并练习自己解决一些难题。
代码拼图的出现
代码降临节是一个在线降临节日历,从 12 月 1 日到 12 月 25 日每天发布一个新的谜题。每个谜题在美国东部时间午夜开始发售。代码难题的出现有几个典型特征:
- 每个谜题都由两部分组成,但是第二部分直到你完成第一部分才会显示出来。
- 每完成一个部分,你将获得一个金星(⭐)。这意味着,如果你在一年内解决了所有的谜题,你每天可以获得两颗星星和五十颗星星。
- 这个难题对每个人来说都是一样的,但是你需要根据你从 Code site 的出现中获得的个性化输入来解决它。这意味着你对一个谜题的回答会和别人的不一样,即使你用同样的代码来计算。
你可以参加全球竞赛成为第一个解决每个难题的人。然而,这里通常挤满了高技能、有竞争力的程序员。如果你把《代码的来临》作为自己的练习,或者如果你向你的朋友和同事发起一场小型的友好比赛,它可能会让变得更有趣。
为了感受一下代码拼图是如何出现的,请考虑一下 2020 年的第一天拼图:
在你离开之前,会计的精灵们只需要你搞定你的费用报告(你的拼图输入);显然,有些事情不太对劲。
具体来说,他们需要你找到加起来等于
2020的两个条目,然后将这两个数字相乘。每年,都有一个非常愚蠢的背景故事将谜题结合在一起。2020 年的故事描述了你在连续几年拯救圣诞节后,试图去度一个当之无愧的假期。这个故事通常对谜题没有影响,但是继续下去还是很有趣的。
在故事的情节元素之间,你会发现谜题本身。在本例中,您在难题输入中寻找两个总计为 2,020 的条目。在描述问题的解释之后,您通常会找到一个示例,显示您需要进行的计算:
例如,假设您的费用报告包含以下内容:
`1721 979 366 299 675 1456`在这个列表中,总计为
2020的两个条目是1721和299。将它们相乘产生1721 * 299 = 514579,所以正确答案是514579。这个例子显示了这个特定数字列表的答案。如果你准备开始解决这个难题,你现在应该开始考虑如何在任何有效的数字列表中找到这两个条目。然而,在深入这个难题之前,您将探索如何使用代码站点的出现。
如何参与代码降临
您已经看到了一个代码难题出现的例子。接下来,您将了解如何提交您的答案。你从来没有提交任何代码来解决难题。您只需提交答案,答案通常是一个数字或一个文本字符串。
一般来说,你会按照一系列的步骤来解决网站上的一个难题:
在网站登陆。您可以通过使用来自 GitHub、Google、Twitter 或 Reddit 等其他服务的凭据来实现这一点。
阅读谜题文本,特别注意给出的例子。您应该确保了解示例数据的解决方案。
下载您对谜题的个性化输入。你需要这个输入来找到你对这个问题的唯一答案。
编写您的解决方案。这是有趣的部分,在本教程的剩余部分中,您将得到大量的练习。
在谜题页面上输入您对谜题的答案。如果你的答案是正确的,那么你将获得一颗金星,谜题的第二部分开始了。
对拼图的第二部分重复步骤 2 和 4。这第二部分与第一部分相似,但是它通常增加了一个转折,要求您修改代码。
在拼图页面上输入您的第二个答案,赢取您的第二颗星并完成拼图。
记住,你不需要提交任何代码,只需要你的谜题答案。这意味着任何编程语言都可以解决代码难题。许多人利用《代码的来临》来练习和学习一种新的编程语言。《降临代码》的创作者 Eric Wastl 在 2019 年做了一次演讲,他谈到了参与者的不同背景和动机,以及其他一些事情。
注意:有一个排行榜用于代码的出现。一般来说,你应该忽略这个排行榜!它只显示谁在谜题出现后提交了前 100 个答案。要想有机会加入排行榜,你需要大量的准备、奉献和有竞争力的编程经验。
相反,你应该看看私人排行榜。这些在你登录后就变成了可用,它们给你一个邀请你的朋友和同事到一个更轻松的社区的机会。你可以选择根据解决谜题的或者简单地根据人们解决的谜题数量来给你的私人排行榜打分。
您还可以将您在私人排行榜中的名字链接到您的 GitHub 帐户,这样您就可以与朋友分享您的解决方案。登录后,您可以通过点击代码网站出现菜单中的设置进行设置。
Advent of Code 是完全免费使用的,但是仍然有一些不同的方式可以支持这个项目:
- 在你的社交媒体上分享关于代码出现的信息,让大家知道。
- 通过参加 r/adventofcode 子编辑或其他论坛来帮助他人。
- 邀请您的朋友参加《代码降临》,在私人排行榜上分享您的成果。
- 捐赠给《代码降临》。如果你这样做了,那么在网站上你的名字旁边会有一个 AoC++ 徽章。
在接下来的章节中,您将看到一些关于如何准备用 Python 解决代码问题的建议。还有一个很棒的列表你可以查看与《代码的来临》相关的许多不同资源的链接,包括其他几个人的解决方案。
用 Python 解决代码的出现
代码的出现已经成为世界各地许多编码人员的年度亮点。2021 年,超过 235,000 人提交了他们的解决方案。自 2015 年代码问世以来,程序员已经收集了超过一千万颗星星。许多参与者用 Python 来解谜。
好了,现在轮到你了!前往降临代码网站,看看最新的谜题。然后,回到本教程来获得一些提示,并帮助开始用 Python 解决降临代码难题。
一个谜题的剖析
在这一节中,您将探索代码难题出现的典型剖析。此外,您将了解一些可以用来与之交互的工具。
每次出现的代码难题被分成两部分。当你开始拼图时,你只能看到第一部分。一旦你提交了第一部分的正确答案,第二部分就会解锁。这通常是对您在第一部分中解决的问题的一种扭曲。有时,你会发现有必要重构第一部分的解决方案,而其他时候,你可以基于已经完成的工作快速解决第二部分。
两个部分总是使用相同的难题输入。您可以从当天的谜题页面下载您的谜题输入。你会在谜题描述后找到一个链接。
注:如前所述,你的谜题输入是个性化的。这意味着如果你和其他人讨论解决方案,他们的最终答案可能会和你的不同。
为了提交你的谜题解决方案,你需要做的一切——除了实际解决谜题——你都可以从代码的出现网站上做。你应该用它来提交你的第一个解决方案,这样你就可以熟悉流程了。
稍后,您可以使用几个工具来组织代码设置并更有效地工作。例如,您可以使用
advent-of-code-data包下载数据。是一个可以用pip安装的 Python 包:$ python -m pip install advent-of-code-data你可以使用
advent-of-code-data通过它的aocd工具在命令行上下载一个特定的谜题输入集。另一个有趣的可能性是在 Python 代码中自动下载和缓存您的个性化谜题输入:
>>> from aocd.models import Puzzle
>>> puzzle = Puzzle(year=2020, day=1)
>>> # Personal input data. Your data will be different.
>>> puzzle.input_data[:20]
'1753\n1858\n1860\n1978\n'
在使用advent-of-code-data下载您的个性化数据之前,您需要在环境变量或文件中设置您的会话 ID 。你会在文档中找到对此的解释。如果你感兴趣,那么你也可以使用advent-of-code-data或aocd来提交你的解决方案并回顾你之前的回答。
作为谜题文本的一部分,您还会发现一个或几个示例,这些示例通常基于比您的个性化输入数据更小的数据进行计算。您应该仔细阅读这些示例,并确保在开始编码之前您理解了要求您做的事情。
您可以使用示例为您的代码设置测试。一种方法是对示例数据手动运行您的解决方案,并确认您得到了预期的答案。或者,你可以使用类似 pytest 的工具来自动化这个过程。
注意: 测试驱动开发(TDD) 是你在实现代码之前编写测试的过程。因为《代码的出现》为你提供了小例子的预期答案,它给你一个很好的机会去尝试你自己的测试驱动开发。
当你试着自己解决一些难题时,你会学到更多关于 TDD 的知识。
你可以用普通的 Python 和标准库解决所有的代码难题。但是,在您整理解决方案时,有几个软件包可以帮助您:
advent-of-code-data可以下载您输入的数据并提交您的解决方案。advent-of-code-ocr可以将一些谜题的 ASCII 艺术解答转换成字符串。pytest可以自动检查你对例题数据的解答。parse可以用比正则表达式更简单的语法解析字符串。numpy可以有效地计算带有数组的数字。colorama可以在终端中动画显示您的解决方案。rich可以让你的终端输出更具视觉吸引力。
如果你创建一个虚拟环境并安装这些包,那么你将拥有一个非常坚实的工具箱来迎接代码冒险的到来。稍后,你会看到如何使用parse、numpy和colorama来解谜的例子。
解决方案的结构
在上一节中,您已经熟悉了如何阅读和理解代码难题的降临。在本节中,您将了解如何解决这些问题。在解决代码难题之前,您不需要做大量的设置。
你想过如何解决你之前看到的谜题吗?回想一下,您正在查找列表中两个数字的乘积,其总和为 2,020。在继续之前,想一想——也许可以编码一下——如何找到下面列表中哪两个条目的总数是 2,020:
>>> numbers = [1721, 979, 366, 299, 675, 1456]以下脚本显示了解决 2020 年第一天谜题的第一部分的一种方法:
1>>> for num1 in numbers:
2... for num2 in numbers:
3... if num1 < num2 and num1 + num2 == 2020: 4... print(num1 * num2)
5...
6514579
嵌套的for循环从列表中查找两个数字的所有组合。第 3 行的测试实际上比它需要的要稍微复杂一些:您只需要测试这些数字的总和是 2,020。然而,通过添加条件,即num1应该小于num2,可以避免两次找到解。
在这个例子中,一个解看起来像num1 = 1721和num2 = 299,但是因为你可以以任何顺序添加数字,这意味着num1 = 299和num2 = 1721也形成了一个解。通过额外的检查,只报告后一种组合。
一旦你有了这个解决方案,你就可以将你的个性化输入数据复制到numbers列表中,并计算出你的谜题答案。
注:有比尝试所有可能性更高效的方法来计算这个答案。然而,从基本方法开始通常是个好主意。引用乔·阿姆斯特朗的话说:
让它工作,然后让它漂亮,然后如果你真的,真的有必要,让它快。90%的时候,如果你把它做得漂亮,它已经很快了。所以真的,把它做漂亮就好!(来源)
— 乔·阿姆斯特朗
现在你已经看到了这个难题的解决方案,你能把它变漂亮吗?
随着您处理更多的难题,您可能会开始觉得将数据复制到代码中并将其重写为有效的 Python 变得令人厌倦。类似地,在代码中添加一些函数会给你带来更多的灵活性。例如,您可以使用它们向代码中添加测试。
Python 有许多解析字符串的强大功能。从长远来看,最好让输入数据保持下载时的样子,让 Python 将它们解析成可用的数据结构。事实上,将代码分成两个功能通常是有益的。一个函数将解析字符串输入,另一个函数将解决这个难题。基于这些原则,您可以重写您的代码:
1# aoc202001.py
2
3import pathlib
4import sys
5
6def parse(puzzle_input):
7 """Parse input."""
8 return [int(line) for line in puzzle_input.split()]
9
10def part1(numbers):
11 """Solve part 1."""
12 for num1 in numbers:
13 for num2 in numbers:
14 if num1 < num2 and num1 + num2 == 2020:
15 return num1 * num2
16
17if __name__ == "__main__":
18 for path in sys.argv[1:]:
19 print(f"\n{path}:")
20 puzzle_input = pathlib.Path(path).read_text().strip()
21
22 numbers = parse(puzzle_input)
23 print(part1(numbers))
在第 12 到 15 行,你会发现你之前的解决方案。首先,您已经将它包装在一个函数中。这使得以后向您的代码中添加自动测试变得更加容易。您还添加了一个parse()函数,可以将多行字符串转换成一系列数字。
在第 20 行,使用 pathlib 将文件内容作为文本读取,并去掉末尾的任何空白行。循环通过 sys.argv 给你所有在命令行输入的文件名。
这些变化使您在处理解决方案时更加灵活。假设您已经将示例数据存储在名为example.txt的文件中,并将您的个性化输入数据存储在名为input.txt的文件中。然后,通过在命令行上提供它们的名称,您可以在其中任何一个甚至两个服务器上运行您的解决方案:
$ python aoc202001.py example.txt input.txt
example.txt:
514579
input.txt:
744475
514579确实是使用示例输入数据时的问题答案。请记住,您的个性化输入数据的解决方案将与上面显示的不同。
现在是时候给代码网站的出现一个旋转了!前往 2020 年降临代码日历并找到第一天的谜题。如果你还没有,下载你的输入数据并计算你的解谜方案。然后,在网站上输入您的解决方案,点击提交。
恭喜你!你刚刚赢得了你的第一颗星!
一个起始模板
正如你在上面看到的,代码谜题的出现遵循一个固定的结构。因此,为自己创建一个模板是有意义的,当您开始编写解决方案时,可以将它作为一个起点。在这样的模板中,你到底想要多少结构是个人喜好的问题。首先,您将探索一个基于您在上一节中看到的原则的模板示例:
1# aoc_template.py
2
3import pathlib
4import sys
5
6def parse(puzzle_input):
7 """Parse input."""
8
9def part1(data):
10 """Solve part 1."""
11
12def part2(data):
13 """Solve part 2."""
14
15def solve(puzzle_input):
16 """Solve the puzzle for the given input."""
17 data = parse(puzzle_input)
18 solution1 = part1(data)
19 solution2 = part2(data)
20
21 return solution1, solution2
22
23if __name__ == "__main__":
24 for path in sys.argv[1:]:
25 print(f"{path}:")
26 puzzle_input = pathlib.Path(path).read_text().strip()
27 solutions = solve(puzzle_input)
28 print("\n".join(str(solution) for solution in solutions))
该模板具有单独的功能,用于解析输入以及解决谜题的两个部分。15 到 28 行根本不需要碰。它们负责从输入文件中读取文本,调用parse()、part1()和part2(),然后向控制台报告解决方案。
您可以创建一个类似的模板来测试您的解决方案。
注意:正如您之前所了解的,示例数据对于创建测试非常有用,因为它们代表了具有相应解决方案的已知数据。
下面的模板使用pytest作为测试运行器。它是为几个不同的测试准备的,测试每一个功能parse()、part1()和part2():
1# test_aoc_template.py
2
3import pathlib
4import pytest
5import aoc_template as aoc
6
7PUZZLE_DIR = pathlib.Path(__file__).parent
8
9@pytest.fixture
10def example1():
11 puzzle_input = (PUZZLE_DIR / "example1.txt").read_text().strip()
12 return aoc.parse(puzzle_input)
13
14@pytest.fixture
15def example2():
16 puzzle_input = (PUZZLE_DIR / "example2.txt").read_text().strip()
17 return aoc.parse(puzzle_input)
18
19@pytest.mark.skip(reason="Not implemented")
20def test_parse_example1(example1):
21 """Test that input is parsed properly."""
22 assert example1 == ...
23
24@pytest.mark.skip(reason="Not implemented")
25def test_part1_example1(example1):
26 """Test part 1 on example input."""
27 assert aoc.part1(example1) == ...
28
29@pytest.mark.skip(reason="Not implemented")
30def test_part2_example1(example1):
31 """Test part 2 on example input."""
32 assert aoc.part2(example1) == ...
33
34@pytest.mark.skip(reason="Not implemented")
35def test_part2_example2(example2):
36 """Test part 2 on example input."""
37 assert aoc.part2(example2) == ...
稍后您将看到如何使用这个模板的示例。在那之前,有几件事你应该注意:
- 如第 1 行所示,您应该用前缀
test_来命名您的pytest文件。 - 类似地,每个测试都在一个以前缀
test_命名的函数中实现。您可以在第 20、25、30 和 35 行看到这样的例子。 - 您应该更改第 5 行的 import 来导入您的解决方案代码。
- 该模板假设示例数据存储在名为
example1.txt和example2.txt的文件中。 - 当您准备开始测试时,您应该删除第 19、24、29 和 34 行上的跳过标记。
- 根据示例数据和相应的解决方案,您需要填写第 22、27、32 和 37 行上的省略号(
...)。
例如,如果您要将此模板改编为前一节中第一部分 2020 年 1 月 1 日谜题的重写解决方案,那么您需要创建一个文件example1.txt,包含以下内容:
1721
979
366
299
675
1456
接下来,您将删除前两个测试的跳过标记,并按如下方式实现它们:
# test_aoc202001.py
def test_parse_example1(example1):
"""Test that input is parsed properly."""
assert example1 == [1721, 979, 366, 299, 675, 1456]
def test_part1_example1(example1):
"""Test part 1 on example input."""
assert aoc.part1(example1) == 514579
最后,您需要确保您正在导入您的解决方案。如果您使用了文件名aoc202001.py,那么您应该将第 5 行改为导入aoc202001:
1# test_aoc202001.py
2
3import pathlib
4import pytest
5import aoc202001 as aoc 6
7# ...
然后运行pytest来检查您的解决方案。如果您正确地实现了您的解决方案,那么您会看到类似这样的内容:
$ pytest
====================== test session starts =====================
collected 4 items
test_aoc202001.py ..ss [100%]
================= 2 passed, 2 skipped in 0.02s =================
注意ss前面的两个点(..)。它们代表两个通过的测试。如果测试失败了,你会看到F而不是每个点,以及对错误的详细解释。
像 Cookiecutter 和 Copier 这样的工具使得使用这样的模板更加容易。如果你安装了复印机,那么你可以使用一个模板,类似于你在这里看到的,通过运行以下命令:
$ copier gh:gahjelle/template-aoc-python advent_of_code
这将在您计算机上的advent_of_code目录的子目录中为一个特定的谜题设置模板。
解决策略
代码难题的出现是非常多样的。随着时间的推移,你会解决许多不同的问题,并发现许多不同的解决策略。
其中一些策略非常通用,可以应用于任何难题。如果你发现自己被困在了一个难题上,这里有一些你可以尝试摆脱困境的方法:
- 重读描述。代码难题的出现通常被很好地指定,但是它们中的一些可能是相当信息密集的。确保你没有遗漏谜题的重要部分。
- 主动使用示例数据。确保您理解这些结果是如何实现的,并检查您的代码是否能够重现这些示例。
- 有些谜题可能会有点复杂。将问题分解成更小的步骤,分别实现和测试每一步。
- 如果您的代码适用于示例数据,但不适用于您的个性化输入数据,那么您可以基于您能够手动计算的数字来构建额外的测试用例,以查看您的代码是否覆盖了所有的极限情况。
- 如果你仍然被困住了,那就联系一些致力于《代码降临》的论坛上的你的朋友和其他解谜者,询问他们是如何解谜的。
随着你做越来越多的谜题,你会开始认识到一些反复出现的一般类型的谜题。
一些谜题涉及文本和密码。Python 有几个操作文本字符串的强大工具,包括许多字符串方法。为了读取和解析字符串,了解一下正则表达式的基础知识是很有帮助的。但是,您也可以经常使用第三方的 parse 库。
例如,假设您有一个字符串"shiny gold bags contain 2 dark red bags.",并且想要从中解析相关信息。您可以使用parse及其模式语法:
>>> import parse >>> PATTERN = parse.compile( ... "{outer_color} bags contain {num:d} {inner_color} bags." ... ) >>> match = PATTERN.search("shiny gold bags contain 2 dark red bags.") >>> match.named {'outer_color': 'shiny gold', 'num': 2, 'inner_color': 'dark red'}在后台,
parse构建一个正则表达式,但是您使用一个更简单的语法,类似于 f 字符串使用的语法。在其中一些文本问题中,你被明确要求使用代码和解析器,通常构建一个小的定制汇编语言。解析完代码后,经常需要运行给定的程序。实际上,这意味着你要构建一个小型的状态机,它可以跟踪它的当前状态,包括它的内存内容。
您可以使用类将状态和行为放在一起。在 Python 中,数据类对于快速建立状态机非常有用。在以下示例中,您实现了一个可以处理两条不同指令的小型状态机:
1# aoc_state_machine.py 2 3from dataclasses import dataclass 4 5@dataclass 6class StateMachine: 7 memory: dict[str, int] 8 program: list[str] 9 10 def run(self): 11 """Run the program.""" 12 current_line = 0 13 while current_line < len(self.program): 14 instruction = self.program[current_line] 15 16 # Set a register to a value 17 if instruction.startswith("set "): 18 register, value = instruction[4], int(instruction[6:]) 19 self.memory[register] = value 20 21 # Increase the value in a register by 1 22 elif instruction.startswith("inc "): 23 register = instruction[4] 24 self.memory[register] += 1 25 26 # Move the line pointer 27 current_line += 1两条指令
set和inc在.run()内被解析和处理。请注意,第 7 行和第 8 行的类型提示使用了一个更新的语法,该语法只适用于 Python 3.9 和更高版本。如果你使用的是旧版本的 Python,那么你可以从typing导入Dict和List。要运行你的状态机,你首先要用一个初始内存初始化它,然后把程序加载到机器中。接下来,你调用
.run()。程序完成后,您可以检查.memory以查看机器的新状态:
>>> from aoc_state_machine import StateMachine
>>> state_machine = StateMachine(
... memory={"g": 0}, program=["set g 45", "inc g"]
... )
>>> state_machine.run()
>>> state_machine.memory
{'g': 46}
这个程序首先将g设置为45的值,然后增加它,保持它的最终值46。
一些有趣的谜题涉及网格和迷宫。如果你的网格有固定的大小,那么你可以使用 NumPy 来获得它的有效表示。迷宫通常有助于形象化。您可以使用 Colorama 在您的终端中直接绘图:
# aoc_grid.py
import numpy as np
from colorama import Cursor
grid = np.array(
[
[1, 1, 1, 1, 1],
[1, 0, 0, 0, 1],
[1, 1, 1, 0, 1],
[1, 0, 0, 2, 1],
[1, 1, 1, 1, 1],
]
)
num_rows, num_cols = grid.shape
for row in range(num_rows):
for col in range(num_cols):
symbol = " *o"[grid[row, col]]
print(f"{Cursor.POS(col + 1, row + 2)}{symbol}")
这个脚本展示了一个使用 NumPy 数组存储网格的例子,然后使用 Colorama 中的Cursor.POS将光标定位在终端中以打印出网格。当您运行这个脚本时,您将看到如下输出:
$ python aoc_grid.py
*****
* *
*** *
* o*
*****
在代码运行时可视化代码可能会很有趣,也会给你一些好的见解。当你调试时,不太明白发生了什么,它也是一个无价的帮助。
到目前为止,在本教程中,您已经获得了一些关于如何使用降临代码谜题的一般提示。在接下来的部分中,你将会得到更明确的答案,并解答早年的三个谜题。
练习降临代码:2019 年第 1 天
你将尝试自己解决的第一个谜题是 2019 年第一天的,名为火箭方程的暴政。这是一个典型的第一天难题,因为解决方案并不复杂。这是一个很好的练习,可以让你习惯如何使用 Advent Code,并检查你的环境是否设置正确。
第一部分:谜题描述
在 2019 年的故事线中,你正在营救被困在太阳系边缘的圣诞老人。在第一个谜题中,你正在准备发射火箭:
精灵们很快把你装进飞船,准备发射。
在第一次去/不去投票中,每个 Elf 都去,直到燃料计数器上升。他们还没有确定所需的燃料量。
发射给定的模块所需的燃料基于其质量。具体来说,要找到一个模块所需的燃料,取其质量,除以 3,四舍五入,然后减去 2。
示例数据如下所示:
- For the mass of
12, divide by 3 and round down to get4, and subtract 2 to get2.- For an object with mass
14, divide by 3 and round down to get4, so the required fuel is also2.- For the mass of
1969, the required fuel is654.- For an object with mass
100756, the required fuel is33583.
你需要计算你的宇宙飞船的总燃料需求:
燃料计数器-Upper 需要知道总的燃料需求。要找到它,单独计算每个模块的质量所需的燃料(您的难题输入),然后将所有的燃料值加在一起。
你飞船上所有模块的燃料需求总和是多少?
现在是时候尝试自己解决这个难题了!下载您的个性化输入数据并在代码发布时检查您的解决方案可能是最有趣的事情,这样您就可以获得奖励。但是,如果您还没有准备好登录《降临代码》,请根据上面提供的示例数据来解决这个难题。
第 1 部分:解决方案
完成拼图并获得星星后,您可以展开折叠块来查看拼图解决方案的讨论:
这个解决方案的讨论比解谜所需的要复杂一些。我们的目标是在第一个解决方案中探索一些额外的细节,以便为下一个谜题做更好的准备。
本节分为两部分:
- 一个简短的关于整数除法的讨论以及它是如何帮助我们的。
- 这个难题的简单解决方案。
然后,在下一节中,您将看到另一个解决方案,它使用了您之前看到的解决方案和测试的模板。
要返回到当前的谜题,请再次查看要求您执行的计算:
[要]找到一个模块所需的燃料,取其质量,除以 3,四舍五入,然后减去 2。
您可以一个接一个地执行这些步骤:
>>> mass = 14 >>> mass / 3 4.666666666666667 >>> int(mass / 3) 4 >>> int(mass / 3) - 2 2对于正数,可以用
int()到向下舍入。如果你的数字可能是负数,那么你应该用math.floor()来代替。Python 和许多其他编程语言都支持一步完成除法和舍入。这被称为整数除法,由整数除法运算符 (
//)完成。然后,您可以重写之前的计算:
>>> mass = 14
>>> mass // 3
4
>>> mass // 3 - 2
2
使用mass // 3除以三并一步向下舍入。现在,您可以计算每个质量的燃料,并将它们相加,以解决这个难题:
>>> masses = [12, 14, 1969, 100756] >>> total_fuel = 0 >>> for mass in masses: ... total_fuel += mass // 3 - 2 ... >>> total_fuel 34241四个示例模块总共需要
34241个燃料单元。在谜题描述中,它们分别被列为需要2、2、654和33583燃料单元。把这些加起来,你得到34241,这证实了你的计算。您可以用您的个性化输入数据替换masses列表中的数字,以获得您自己的谜题答案。
>>> masses = [12, 14, 1969, 100756]
>>> sum(mass // 3 - 2 for mass in masses)
34241
有了sum(),你就不需要手动把每个燃料需求加起来。相反,您可以用一行代码解决当前的难题。
你现在已经解决了谜题的第一部分。然而,在进入谜题的第二部分之前,下一部分将展示在解决这个问题时,如何使用之前看到的模板。
第 1 部分:使用模板的解决方案
展开下面的折叠块,查看 2019 年第一天代码拼图第一部分的另一个解决方案——这次使用您之前看到的模板来组织您的代码并简化测试:
如果你要做几个降临代码谜题,那么把你的解决方案组织到文件夹中是个好主意。这允许你将所有与拼图相关的文件放在一起。保持整洁的一个好方法是为代码出现的每一年建立一个文件夹,并且在每年的文件夹中为每一天建立文件夹。
对于这个谜题,你可以这样设置:
advent_of_code/
│
└── 2019/
└── 01_the_tyranny_of_the_rocket_equation/
├── aoc201901.py
├── input.txt
├── example1.txt
└── test_aoc201901.py
您将您的个性化输入数据存储在input.txt中,而example1.txt包含来自谜题描述的示例数据:
12
14
1969
100756
然后,您可以使用这些数据来设置您的第一个测试。从前面的测试模板开始,填写解析输入和解决第一部分的测试:
1# test_aoc201901.py
2
3import pathlib
4import pytest
5import aoc201901 as aoc 6
7PUZZLE_DIR = pathlib.Path(__file__).parent
8
9@pytest.fixture
10def example1():
11 puzzle_input = (PUZZLE_DIR / "example1.txt").read_text().strip()
12 return aoc.parse(puzzle_input)
13
14@pytest.fixture
15def example2():
16 puzzle_input = (PUZZLE_DIR / "example2.txt").read_text().strip()
17 return aoc.parse(puzzle_input)
18
19def test_parse_example1(example1):
20 """Test that input is parsed properly."""
21 assert example1 == [12, 14, 1969, 100756] 22
23def test_part1_example1(example1):
24 """Test part 1 on example input."""
25 assert aoc.part1(example1) == 2 + 2 + 654 + 33583 26
27@pytest.mark.skip(reason="Not implemented")
28def test_part2_example1(example1):
29 """Test part 2 on example input."""
30 assert aoc.part2(example1) == ...
31
32@pytest.mark.skip(reason="Not implemented")
33def test_part2_example2(example2):
34 """Test part 2 on example input."""
35 assert aoc.part2(example2) == ...
您希望解析器读取文本文件并将每一行转换成列表中的一个数字。您在第 21 行指定这个值作为test_parse_example1()中的期望值。test_part1_example1()的期望值是文中提到的四种燃油需求的总和。
最后,根据解决方案模板添加aoc201901.py:
1# aoc201901.py
2
3import pathlib
4import sys
5
6def parse(puzzle_input):
7 """Parse input."""
8
9def part1(data):
10 """Solve part 1."""
11
12def part2(data):
13 """Solve part 2."""
14
15def solve(puzzle_input):
16 """Solve the puzzle for the given input."""
17 data = parse(puzzle_input)
18 solution1 = part1(data)
19 solution2 = part2(data)
20
21 return solution1, solution2
22
23if __name__ == "__main__":
24 for path in sys.argv[1:]:
25 print(f"{path}:")
26 puzzle_input = pathlib.Path(path).read_text().strip()
27 solutions = solve(puzzle_input)
28 print("\n".join(str(solution) for solution in solutions))
在您开始将您的解决方案添加到模板之前,花一分钟运行pytest来确认测试确实失败了。在很多细节之间,你应该得到这样的东西:
$ pytest
test_aoc201901.py FFss [100%]
===================== short test summary info =====================
FAILED test_parse_example1 - assert None == [12, 14, 1969, 100756]
FAILED test_part1_example1 - assert None == (((2 + 2) + 654) + 33583)
================== 2 failed, 2 skipped in 0.09s ===================
请注意,正如所料,您有两个测试失败了。这种工作方式被称为测试驱动开发(TDD) 。您首先编写您的测试,并确保它们失败。之后,您实现必要的代码来使它们通过。对于这个谜题来说,这似乎有些矫枉过正,但对于更具挑战性的问题来说,这可能是一个非常有用的习惯。
是时候将您的解决方案添加到aoc201901.py中了。首先,解析输入数据。它们作为由换行符 ( \n)分隔的数字文本串被传递给parse(),并且应该被转换成一个整数列表:
# aoc201901.py
# ...
def parse(puzzle_input):
"""Parse input."""
return [int(line) for line in puzzle_input.split("\n")]
列表理解将这些行组装成一个列表,并将它们转换成整数。再次运行pytest并确认您的第一个测试test_parse_example1()不再失败。
接下来,将您的解决方案添加到拼图中:
# aoc201901.py
# ...
def part1(module_masses):
"""Solve part 1."""
return sum(mass // 3 - 2 for mass in module_masses)
正如上一节所讨论的,您正在通过使用sum()来解决第一部分。您还可以将通用参数data的名称改为更具体的名称。由于数据描述了每个火箭模块的质量,你称这个参数为module_masses。
通过再次运行pytest确认您的解决方案是正确的:
$ pytest
test_aoc201901.py ..ss [100%]
================== 2 passed, 2 skipped in 0.01s ===================
测试通过后,您可以通过对input.txt运行程序来解决个性化输入数据的难题:
$ python aoc201901.py input.txt
input.txt:
3550236
None
你自己的答案会和这里显示的不一样,3550236。底部的None输出表示第二部分的解决方案,您还没有实现它。现在可能是看第二部分的好时机了!
你现在可以进入拼图的第二部分了。你准备好扭转了吗?
第二部分:谜题描述
每次出现的代码难题都由两部分组成,其中第二部分只有在您解决第一部分后才会显示。第二部分总是与第一部分相关,并将使用相同的输入数据。然而,你可能经常需要重新思考你的方法来解决前半部分的难题,以便解释后半部分。
展开下面的折叠块,查看 2019 年第一天代码拼图的第二部分:
你让火箭起飞的任务还在继续:
在第二次“去/不去”投票中,负责火箭方程式复核的 Elf 停止发射程序。显然,你忘了把额外的燃料包括在你刚刚添加的燃料中。
燃料本身就像一个模块一样需要燃料——取其质量,除以 3,四舍五入,然后减去 2。然而,那个燃料也需要燃料,而那个燃料也需要燃料,以此类推。任何需要负燃料的质量应被视为需要零燃料;剩余的质量,如果有的话,则由许愿真的很难处理,它没有质量,不在这个计算范围内。
当然,给你的飞船添加所有的燃料会使它更重。考虑到增加的重量,你需要添加更多的燃料,但是燃料也是需要考虑的。要了解这在实践中是如何工作的,请看下面的例子:
所以,对于每个模块的质量,计算它的燃料并加到总数中。然后,将刚刚计算的燃油量作为输入质量,重复该过程,直到燃油需求为零或负值。例如:
- 质量为
14的模块需要2燃料。这种燃料不需要更多的燃料(2 除以 3 并向下舍入为0,这将要求负燃料),因此所需的总燃料仍然只是2。- 首先,一个质量为
1969的模块需要654燃料。然后,这种燃料需要216更多的燃料(654 / 3 - 2)。216然后需要70更多的燃料,这需要21燃料,这需要5燃料,这不需要更多的燃料。因此,一个质量为1969的模块所需的总燃料是654 + 216 + 70 + 21 + 5 = 966。- 一个质量为
100756的模块所需的燃料及其燃料为:33583 + 11192 + 3728 + 1240 + 411 + 135 + 43 + 12 + 2 = 50346。
示例仍然使用与第一部分相同的数字。质量为12的模块所需的燃料没有规定,但是你可以通过使用与质量为14的模块相同的计算方法来计算出它将是2。你需要回答的问题是一样的:
考虑到添加燃料的质量,你们飞船上所有模块的燃料需求总量是多少?(分别计算每个模块的燃料需求,然后在最后将它们全部相加。)
试着解决这个问题。你能获得第二颗星吗?
在下一节中,您将看到第二部分的一个可能的解决方案。但是,先试着自己解决这个难题。如果你需要一个开始的提示,然后展开下面的框:
像这部分谜题中的重复计算通常很适合递归。
你做得怎么样?你的火箭准备好发射了吗?
第 2 部分:解决方案
本节将展示如何解决第二部分,继续使用您在上面看到的模板:
继续测试驱动的开发工作流,从向测试文件添加新的例子开始。示例使用了与第一部分相同的数字,因此您可以使用相同的example1.txt文件。因此,您可以从您的测试代码中移除example2()夹具和test_part2_example2()测试。接下来,移除跳过标记并执行test_part2_example1():
# test_aoc201901.py
# ...
def test_part2_example1(example1):
"""Test part 2 on example input."""
assert aoc.part2(example1) == 2 + 2 + 966 + 50346
像以前一样,运行pytest来确认您的测试失败了。
注意: pytest有一个很好的选项-k,您可以使用它来运行您的测试的一个子集。使用-k,您可以过滤测试名称。例如,为了只运行与第二部分相关的测试,您可以使用pytest -k part2。这也是使用一致的和描述性的测试名称的一个很好的激励。
接下来,是实际执行的时候了。因为你被要求重复计算燃料,你可能想要达到递归。
一个递归函数是一个调用自身的函数。当实现一个递归函数时,你应该注意包含一个停止条件:什么时候函数应该停止调用自己?在这个例子中,停止条件在谜题描述中被非常明确地提到。当燃油变为零或负值时,您应该停止。
随着您的解决方案变得越来越复杂,使用助手函数是个好主意。例如,您可以添加一个函数来计算一个模块所需的所有燃料。助手函数的一个好处是你可以独立于难题解决方案来测试它们。
在您的aoc201901.py解决方案文件中添加以下新函数:
# aoc201901.py
# ...
def all_fuel(mass):
"""Calculate fuel while taking mass of the fuel into account.
## Example:
>>> all_fuel(1969)
966
"""
您已经在 docstring 中添加了一个 doctest 。您可以通过添加--doctest-modules标志来告诉pytest运行文档测试:
$ pytest --doctest-modules
aoc201901.py F [ 20%]
test_aoc201901.py ..F [100%]
___________________ [doctest] aoc201901.all_fuel __________________
023 Calculate fuel while taking mass of the fuel into account.
024
025 ## Example:
026
027 >>> all_fuel(1969)
Expected:
966
Got nothing
作为来自pytest的输出的一部分,您将看到一个提示,说明all_fuel() doctest 失败了。添加 doctests 是确保您的助手函数如您所愿的一个好方法。注意,这个测试不依赖于任何输入文件。相反,您可以直接检查上面给出的一个例子。
接下来,执行燃料计算:
1# aoc201901.py
2
3# ...
4
5def all_fuel(mass):
6 """Calculate fuel while taking mass of the fuel into account.
7
8 ## Example:
9
10 >>> all_fuel(1969)
11 966
12 """
13 fuel = mass // 3 - 2
14 if fuel <= 0:
15 return 0
16 else:
17 return fuel + all_fuel(mass=fuel)
第 14 行实现停止条件,而第 17 行执行递归调用。您可以运行测试来检查计算是否按预期工作。
在继续解决整个难题之前,请注意,您可以使用 walrus 操作符 ( :=)来更简洁地编写函数:
# aoc201901.py
# ...
def all_fuel(mass):
"""Calculate fuel while taking mass of the fuel into account.
## Example:
>>> all_fuel(1969)
966
"""
return 0 if (fuel := mass // 3 - 2) < 0 else fuel + all_fuel(fuel)
虽然代码更短,但也更密集。你是否觉得最终结果更具可读性,这是一个品味和经验的问题。
为了完成这个难题,您还需要实现part2()。您的all_fuel()函数计算每个模块所需的燃料,所以剩下的就是将所有模块的燃料加在一起:
# aoc201901.py
# ...
def part2(module_masses):
"""Solve part 2."""
return sum(all_fuel(mass) for mass in module_masses)
part2()的实现最终与part1()非常相似。你只需要改变每个质量的燃料计算。
最后,运行pytest来确认一切正常。然后根据您的输入运行您的程序,以获得最终的谜题答案:
$ python aoc201901.py input.txt
input.txt:
3550236
5322455
回到 Code 网站问世,输入自己的答案,会和上面的不一样。你的第二颗星星在等着你!
在完全离开这个难题之前,请注意,不使用递归也可以解决第二部分。你可以使用循环来做同样的计算。这里有一个可能的实现:
# aoc201901.py
# ...
def part2(module_masses):
"""Solve part 2."""
total_fuel = 0
for mass in module_masses:
while (mass := mass // 3 - 2) > 0:
total_fuel += mass
return total_fuel
对于每个质量,while循环计算所有需要的燃料,并将其添加到运行的总燃料计数中。
用编程难题挑战自己的一个有趣的事情是,它们给了你一个很好的机会来尝试不同的问题解决方案并进行比较。
恭喜你!你现在已经解决了整个代码难题。你准备好迎接更具挑战性的挑战了吗?
练习代码降临:2020 年第 5 天
你将尝试解决的第二个谜题是 2020 年第五天的谜题,叫做二进制登机。这个谜题比前一个更具挑战性,但是最终的解决方案不需要很多代码。首先看看第一部分的拼图描述。
第一部分:谜题描述
2020 年,你正努力去你应得的度假胜地。第五天,你正要登机,这时麻烦来了:
你登上飞机,却发现了一个新问题:你的登机牌掉了!你不确定哪个座位是你的,所有的空乘人员都忙于应付突然通过护照检查的人群。
你写一个快速的程序,用你手机的摄像头扫描附近所有的登机牌(你的字谜输入);也许你可以通过排除法找到你的位置。
这家航空公司使用二进制空间分割为乘客提供座位,而不是区域或分组。可以像
FBFBBFFRLR一样指定座位,其中F表示“前面”,B表示“后面”,L表示“左边”,R表示“右边”。前 7 个字符将是
F或B;这些精确地指定了飞机上 128 行中的一行(编号为0到127)。每个字母告诉你给定的座位在哪个半个区域。从整个行列表开始;第一个字母表示座位是在前面 (
0到63)还是在后面 (64到127)。下一个字母表示该座位位于该区域的哪一半,以此类推,直到只剩下一行。例如,只考虑
FBFBBFFRLR的前七个字符:
- 首先考虑整个范围,从第
0行到第127行。F表示取下半部,保留行0到63。B表示取上半部,保留行32到63。F表示取下半部,保留行32到47。B表示取上半部,保留行40到47。B保持从44到47的行。F保持从44到45的行。- 最后的
F保持两者中较低的,排44。最后三个字符将是
L或R;这些精确地指定了飞机上 8 列座位中的一列(编号为0到7)。再次进行与上述相同的过程,这次只有三个步骤。L表示保留下半部,而R表示保留上半部。例如,只考虑
FBFBBFFRLR的最后 3 个字符:
- 首先考虑整个范围,从列
0到7。R表示取上半部,保留列4至7。L表示取下半部,保留4至5列。- 最后的
R保持两者的上位,列5。于是,解码
FBFBBFFRLR发现是在行44,列5的座位。每个座位都有一个唯一的座位 ID :将行乘以 8,然后添加列。在本例中,座位的 ID 为
44 * 8 + 5 =357。以下是其他一些登机牌:
BFFFBBFRRR:行70,列7,座位号567。FFFBBBFRRR:行14,列7,座位号119。BBFFBBFRLL:行102,列4,座位号820。作为一个理智的检查,看看你的登机牌清单。登机牌上最高的座位号是多少?
这个谜题描述里有很多信息!然而,它最关心的是二进制空间划分如何为这家特定的航空公司工作。
现在,试着自己解决这个难题吧!请记住,如果从正确的角度考虑,从登机牌规格到座位 ID 的转换并不像一开始看起来那么复杂。如果你发现你正在努力完成这一部分,那么请展开下面的方框,查看如何开始的提示:
登机牌规格是基于二进制,只是伪装了不同的字符。你能把登机牌翻译成二进制数字吗?
当你完成了你的解决方案,看看下一部分,看看关于这个难题的讨论。
第 1 部分:解决方案
既然您已经亲自尝试过了,那么您可以继续并展开下面的模块,看看您可以解决这个难题的一种方法:
您可以根据文本中的描述实现座位 id 的计算。以下函数采取与示例相同的步骤:
# aoc202005.py
# ...
def decode(string):
"""Decode a boarding pass string into a number."""
start, end = 0, 2 ** len(string)
for char in string:
if char in {"F", "L"}:
end -= (end - start) // 2
elif char in {"B", "R"}:
start += (end - start) // 2
return start
您可以通过start和end限制可能的行或列的范围。start在范围内,end不在。这使得数学更容易,因为它在整个计算过程中保持了end - start的差可以被 2 整除。降低每个F或L的上限,增加每个B或R的下限start。您可以检查该函数是否给出与示例相同的结果:
>>> decode("FBFBBFF") 44 >>> decode("RLR") 5 >>> decode("FBFBBFFRLR") 357使用
decode(),您可以计算登机牌的行、列和座位 ID。然而,Python 已经有内置工具来为您执行相同的计算。这个谜题的名字,二进制寄宿,以及提到二进制空间分割,意在让你开始思考(或阅读)T2 双星系统。二进制是由
0和1两位数字组成的数字系统,而不是传统的十位数。拼图中,登机牌规格真的是二进制数。不同的是,他们用
F或L代替0,用B和R代替1。比如FBFBBFFRLR可以翻译成二进制数 0101100101 2 。您可以使用 Python 将其转换为常规的十进制数:
>>> int("0101100101", base=2)
357
你认识那个答案吗?357确实是FBFBBFFRLR的座位 ID。换句话说,为了计算座位 id,你需要将F、L、B、R翻译成它们各自的二进制数字。有几种方法可以做到这一点,但是 Python 的标准库中的 str.translate() 可能是最方便的。它是这样工作的:
>>> mapping = str.maketrans({"F": "0", "L": "0", "B": "1", "R": "1"}) >>> "FBFBBFFRLR".translate(mapping) '0101100101'
.translate()方法使用类似70的字符代码,而不是类似"F"的字符串。不过,您可以使用方便的功能str.maketrans()来设置基于字符串的翻译。现在,您可以使用这些工具通过三个步骤来解决这个难题:
- 将登机牌规格转换为二进制数。
- 计算二进制数的十进制值以获得座位 id。
- 找到最大的座位号。
设置新拼图的模板,其中
input.txt包含您的个性化拼图输入:advent_of_code/ │ └── 2020/ └── 05_binary_boarding/ ├── aoc202005.py ├── input.txt ├── example1.txt └── test_aoc202005.py您可以像往常一样将工作示例添加到
example1.txt中:FBFBBFFRLR BFFFBBFRRR FFFBBBFRRR BBFFBBFRLL接下来,你要准备第一部分的测试。在这样做之前,您应该考虑如何解析难题输入。
一种选择是将输入文件解析成字符串列表。但是,您也可以将从登机牌规格到座位 ID 的转换视为解析过程的一部分。需要考虑的一个因素是,您是否认为稍后需要原始的登机牌字符串,也就是在第二部分。
您决定抓住这个机会,并立即解析座位 id。如果在第二部分中需要登机牌字符串,那么您可以随时返回并重构代码。将以下测试添加到测试文件中:
# test_aoc202005.py # ... def test_parse_example1(example1): """Test that input is parsed properly.""" assert example1 == [357, 567, 119, 820] def test_part1_example1(example1): """Test part 1 on example input.""" assert aoc.part1(example1) == 820像往常一样,运行
pytest来确认您的测试失败了。那么是时候开始实施你的解决方案了。从解析开始:# aoc202005.py # ... BP2BINARY = str.maketrans({"F": "0", "B": "1", "L": "0", "R": "1"}) def parse(puzzle_input): """Parse input.""" return [ int(bp.translate(BP2BINARY), base=2) for bp in puzzle_input.split("\n") ]您设置了登机牌字符串和二进制数字之间的转换表。然后使用
.translate()将输入的每个登机牌转换成二进制数字,使用int()将二进制数字转换成座位 ID。查找最高座位 ID 现在很简单:
# aoc202005.py # ... def part1(seat_ids): """Solve part 1.""" return max(seat_ids)Python 内置的
max()找到一个列表中的最高值。现在,您可以运行您的测试来确认您的解决方案是否有效,然后根据您的个性化输入运行您的代码来得到您对这个难题的答案。是时候进入拼图的第二部分了。你能登机吗?
第二部分:谜题描述
当你准备好拼图的第二部分时,展开下面的部分:
与第一部分相比,第二部分的描述非常简短:
丁!“系好安全带”的指示灯已经亮起。该去找你的座位了。
这是一个完全满员的航班,所以你的座位应该是你的名单中唯一缺少的登机牌。然而,有一个问题:飞机最前面和最后面的一些座位在这架飞机上不存在,所以它们也会从你的列表中消失。
不过,你的座位不在最前面或最后面;您的 id 为+1 和-1 的座位将出现在您的列表中。
你的座位号是多少?
你能找到你的座位吗?
慢慢来,努力解决第二部分的问题。
第 2 部分:解决方案
当您准备好将您的解决方案与另一个进行比较时,请打开下面的盒子:
在谜题的第二部分,你要在数字列表中寻找一个缺失的数字。
有几种方法可以解决这个问题。例如,您可以对所有数字进行排序,并比较排序列表中的连续项目。另一种选择是使用 Python 强大的集合。您可以首先创建完整的有效座位 id。然后,您可以计算这个完整集合与您列表上的座位 id 集合之间的集合差。
但是,在开始实现之前,您应该为它添加一个测试。在这种情况下,示例数据实际上不适合用于测试。他们有许多座位 id 丢失,而不是像字谜文本指定的那样只有一个。您最好手动创建一个小测试。有一种方法可以做到:
# test_aoc202005.py # ... def test_part2(): """Test part 2 on example input.""" seat_ids = [3, 9, 4, 8, 5, 10, 7, 11] assert aoc.part2(seat_ids) == 6列表
[3, 9, 4, 8, 5, 10, 7, 11]包含从 3 到 11 的所有座位 id,6 除外。这个小例子满足了这个难题的条件。因此,您的解决方案应该能够找出丢失的座位 ID。在这个实现中,您将使用
set()方法:1# aoc202005.py 2 3# ... 4 5def part2(seat_ids): 6 """Solve part 2.""" 7 all_ids = set(range(min(seat_ids), max(seat_ids) + 1)) 8 return (all_ids - set(seat_ids)).pop()在第 7 行,您创建了所有有效的座位 id。这些是数据集中最小座位 ID 和最大座位 ID 之间的数字,包括这两个数字。为了找到您的座位 ID,您将您的座位 ID 列表转换为一个集合,将其与所有 ID 的集合进行比较,并弹出剩余的一个座位 ID。
太好了,你又完成了一个谜题!为了使事情圆满,请尝试 2021 年的一个谜题。
练习代码降临:2021 年第 5 天
作为第三个密码难题出现的例子,你将仔细观察 2021 年第五天。这个谜题叫做热液冒险,将带你进行一次深海探险。解决方案会比前两个谜题更复杂一些。看看拼图的描述。
第一部分:谜题描述
2021 年的故事线始于精灵们不小心将圣诞老人雪橇的钥匙掉进了海里。为了拯救圣诞节,你最终在一艘潜水艇里搜寻他们。第五天,你会遇到海底的一片热液喷口。
事实证明,这些通风口对你的潜艇有害,你需要绘制出该区域的地图,以避开最危险的区域:
它们倾向于形成线;潜水艇会很有帮助地列出附近的喷口线(你的拼图输入)供你查看。例如:
`0,9 -> 5,9 8,0 -> 0,8 9,4 -> 3,4 2,2 -> 2,1 7,0 -> 7,4 6,4 -> 2,0 0,9 -> 2,9 3,4 -> 1,4 0,0 -> 8,8 5,5 -> 8,2`每一排通风口以格式
x1,y1 -> x2,y2给出一个线段,其中x1、y1是线段一端的坐标,x2、y2是另一端的坐标。这些线段包括两端的点。换句话说:
- 类似于
1,1 -> 1,3的条目覆盖了点1,1、1,2和1,3。- 类似于
9,7 -> 7,7的条目覆盖了点9,7、8,7和7,7。目前,只考虑水平线和垂直线:或者
x1 = x2或者y1 = y2的线。该示例显示了难题输入如何描述给定坐标处的线。你的工作是找到这些线重叠的地方:
为了避开最危险的区域,你需要确定至少两条线重叠的点的数量。在上例中,这是[……]共
5分。只考虑水平线和垂直线。至少有两条线在多少点上重叠?
和上一个谜题一样,谜题文本中有很多信息。这些信息主要是关于你应该如何解释你的字谜输入。
注:在全拼图描述中还有一些附加信息。特别是,有一个图表显示了网格上绘制的所有线条。
试着自己解决这个难题。完成后,继续下一节,看看一个可能的解决方案。
第 1 部分:输入解析
有许多方法可以解决这个难题。展开下面的块,开始处理输入数据:
你的任务是计算两条线或多条线覆盖了多少个点。最直接的方法可能如下:
- 将有问题的每条线转换成组成该线的点集。
- 计算每个点在所有线条中出现的次数。
- 计算出现两次或更多次的点数。
在开始编码之前,你应该考虑如何表示点和线。这可能是使用专用的
Point和Line类的一个很好的用例,在数据类的帮助下实现。然而,在这个解决方案中,您将选择一个基本的表示,对每个点使用一个 2 元组整数,对每条线使用一个 4 元组整数。例如,
(0, 9)代表点0,9,(0, 9, 5, 9)代表线0,9 -> 5,9。如果可以简化计算,从简单的数据结构开始,并准备好转向更复杂的解决方案通常是好的。您的第一个任务是解析输入数据。设置好模板后,您应该添加一些示例数据。
您可以使用给定的示例数据,但是从创建一个更简单的数据集开始可能会更容易。将以下内容添加到
example1.txt:2,0 -> 0,2 0,2 -> 2,2 0,0 -> 0,2 0,0 -> 2,2这些数据代表四条线:两条对角线、一条水平线和一条垂直线。为了完整起见,您也可以将谜题描述中给出的示例数据添加到
example2.txt中。接下来,您将手工拼写出您想要如何在您的测试文件中表示这四行:# test_aoc202105.py # ... def test_parse_example1(example1): """Test that input is parsed properly.""" assert example1 == [ (2, 0, 0, 2), (0, 2, 2, 2), (0, 0, 0, 2), (0, 0, 2, 2), ]像往常一样,您应该运行
pytest来确认您的测试失败。有几种方法可以解析输入,因为您希望从每行中提取四个数字。例如,您可以使用一个正则表达式。在这里,您将重复使用 string.split()方法:1# aoc202105.py 2 3# ... 4 5def parse(puzzle_input): 6 """Parse input.""" 7 return [ 8 tuple( 9 int(xy) 10 for points in line.split(" -> ") 11 for xy in points.split(",") 12 ) 13 for line in puzzle_input.split("\n") 14 ]这当然是一个拗口的问题。为了理解解析是如何工作的,从第 13 行开始。这就建立了一个主循环,它通过在新行上拆分谜题输入来查看每一行。
接下来,将第 8 到 12 行的元组理解应用到每一行。它首先拆分箭头符号(
->)上的每一行,然后拆分逗号(,)上的每一对结果数字。最后,用int()将每个数字从字符串转换成整数。运行您的测试来确认
parse()如预期的那样解析您的输入。即使您的代码可以工作,您也可能希望避免大量嵌套的理解。例如,您可以将其重写如下:
# aoc202105.py # ... def parse(puzzle_input): """Parse input.""" lines = [] for line in puzzle_input.split("\n"): point1, point2 = line.split(" -> ") x1, y1 = point1.split(",") x2, y2 = point2.split(",") lines.append((int(x1), int(y1), int(x2), int(y2))) return lines在这个版本中,您将显式地构建行列表。对于每一行,首先将字符串分成两个点,然后将每个点分成单独的 x 和 y 坐标。
一旦你用一个你能处理的结构表示了数据,那么你就可以继续解决这个难题了。
第 1 部分:解决方案
你将继续拼图的第一部分。下面的解决方案利用了 Python 3.10 中引入的结构模式匹配特性。展开折叠部分以阅读详细信息:
这个难题的主要挑战是将每条线从它当前的表示转换成一个单独点的列表。接下来你会解决这个问题。首先添加一个函数的签名,该函数可以将一条线转换成一系列点,包括一个记录预期输出的 doctest:
# aoc202105.py # ... def points(line): """List all points making up a line. ## Examples: >>> points((0, 3, 3, 3)) # Horizontal line [(0, 3), (1, 3), (2, 3), (3, 3)] >>> points((3, 4, 3, 0)) # Vertical line [(3, 4), (3, 3), (3, 2), (3, 1), (3, 0)] """您希望该函数返回一个点列表,您可以在以后对其进行计数。现在,你需要考虑水平线和垂直线。您已经为这两种情况添加了测试。
谜题描述提示你如何识别水平线和垂直线,因为其中一个坐标是恒定的。你可以用一个
if测试来找到这些。但是,您也可以利用这个机会练习使用 Python 3.10 中引入的match…case语句:1# aoc202105.py 2 3# ... 4 5def points(line): 6 """List all points making up a line. 7 8 ## Examples: 9 10 >>> points((0, 3, 3, 3)) # Horizontal line 11 [(0, 3), (1, 3), (2, 3), (3, 3)] 12 >>> points((3, 4, 3, 0)) # Vertical line 13 [(3, 4), (3, 3), (3, 2), (3, 1), (3, 0)] 14 """ 15 match line: 16 case (x1, y1, x2, y2) if x1 == x2: 17 return [(x1, y) for y in range(y1, y2 + 1)] 18 case (x1, y1, x2, y2) if y1 == y2: 19 return [(x, y1) for x in range(x1, x2 + 1)]这个
match…case结构非常有表现力,但是如果你以前没有使用过它,可能会觉得有点神奇。每个
case都试图匹配line的结构。所以在第 16 行,你要寻找一个 4 元组。此外,您将 4 元组的值分别解包到变量x1、y1、x2和y2中。最后,通过要求x1和x2必须相等来保证匹配。实际上,这代表一条垂直线。类似地,第 18 行的
case语句挑选出水平线。对于每一行,使用range()列出每一个点,注意要包括端点。现在,做你的测试。如果您包括文档测试,那么您会注意到有些地方不太对劲:
$ pytest --doctest-modules ___________________ [doctest] aoc202105.points ___________________ List all points making up a line ## Examples: >>> points((0, 3, 3, 3)) # Horizontal line [(0, 3), (1, 3), (2, 3), (3, 3)] >>> points((3, 4, 3, 0)) # Vertical line Expected: [(3, 4), (3, 3), (3, 2), (3, 1), (3, 0)] Got: []竖线示例返回一个空列表。随着您的研究,您意识到这个例子调用了
range(4, 1),这是一个空的范围,因为1小于4,并且您正在使用默认的步骤1。为了解决这个问题,你可以引入一个更复杂的range()表达式。为了避免在
points()中放入更多的逻辑,您决定创建一个新的助手函数来处理必要的range()逻辑:# aoc202105.py # ... def coords(start, stop): """List coordinates between start and stop, inclusive.""" step = 1 if start <= stop else -1 return range(start, stop + step, step)如果
start大于stop,那么你要确保使用一个-1的步长。您现在可以更新points()以使用新功能:# aoc202105.py # ... def points(line): """List all points making up a line. ## Examples: >>> points((0, 3, 3, 3)) # Horizontal line [(0, 3), (1, 3), (2, 3), (3, 3)] >>> points((3, 4, 3, 0)) # Vertical line [(3, 4), (3, 3), (3, 2), (3, 1), (3, 0)] """ match line: case (x1, y1, x2, y2) if x1 == x2: return [(x1, y) for y in coords(y1, y2)] case (x1, y1, x2, y2) if y1 == y2: return [(x, y1) for x in coords(x1, x2)]通过用
coords()替换range(),你应该能够处理所有的水平线和垂直线。运行您的测试以确认您的代码现在工作正常。现在,您可以将线转换为单独的点。计划的下一步是计算每个点是多少条线的一部分。您可以遍历所有点并显式计数,但是 Python 的标准库中有许多强大的工具。在这种情况下,您可以使用
collections模块中的Counter:1# aoc202105.py 2 3import collections 4 5# ... 6 7def count_overlaps(lines): 8 """Count overlapping points between a list of lines. 9 10 ## Example: 11 12 >>> count_overlaps( 13 ... [(3, 3, 3, 5), (3, 3, 6, 3), (6, 6, 6, 3), (4, 5, 6, 5)] 14 ... ) 15 3 16 """ 17 overlaps = collections.Counter( 18 point for line in lines for point in points(line) 19 ) 20 return sum(num_points >= 2 for num_points in overlaps.values())在第 16 行,你循环每一行中的每一点,并将所有点传递给
Counter。产生的计数器本质上是一个字典,其值指示每个键出现的次数。要找到两条线或多条线重叠的点的数量,您可以查看您的计数器中有多少个点被看到两次或更多次。
您几乎已经完成了第 1 部分。你只需要用
count_overlaps()连接谜题输入,并确保你按照要求去做——只“考虑水平线和垂直线”您可以通过使用更多的理解来过滤所有的行:
# aoc202105.py # ... def part1(lines): """Solve part 1.""" vertical = [(x1, y1, x2, y2) for x1, y1, x2, y2 in lines if x1 == x2] horizontal = [(x1, y1, x2, y2) for x1, y1, x2, y2 in lines if y1 == y2] return count_overlaps(vertical + horizontal)你只通过那些坐标不变的线。在您的个人输入上运行您的代码以计算您的解决方案,并提交它以获得您的下一颗星。
唷!你已经完成了拼图的第一部分。是时候看看第 2 部分为您准备了什么。
第二部分:谜题描述
展开以下部分,阅读 2021 年第 5 天谜题的第二部分:
你可能已经怀疑你不能永远忽略那些对角线:
不幸的是,只考虑水平线和垂直线并不能给你全貌;你还需要考虑对角线。
由于热液喷口绘图系统的限制,你的列表中的线只能是水平的、垂直的或正好 45 度的对角线。换句话说:
- 类似于
1,1 -> 3,3的条目覆盖了点1,1、2,2和3,3。- 类似于
9,7 -> 7,9的条目覆盖了点9,7、8,8和7,9。你仍然需要确定至少两条线重叠的点的数量。在上例中,这是[……]现在共有的
12点。考虑所有的线。至少有两条线在多少点上重叠?
您可能可以重用第 1 部分中所做的大量工作。但是,你怎么能把那些对角线考虑进去呢?
摆弄第二部分,试着自己解决。一旦你完成了,看看下一部分可能的解决方案。
第 2 部分:解决方案
当您准备好查看解决方案并与您自己的解决方案进行比较时,请点击以显示以下解决方案:
第二部分的变化是你需要把对角线考虑进去。这个问题仍然要求你计算两条线或多条线的点数。换句话说,您仍然可以在第二部分中使用
count_overlaps(),但是您需要扩展points()以便它可以处理对角线。幸运的是,所有对角线都正好是 45 度。这样做的实际结果是,这些线中的点的坐标仍然具有连续的整数坐标。
例如,
5,5 -> 8,2涵盖了5,5、6,4、7,3、8,2等穴位。注意,x 坐标是5、6、7和8,而 y 坐标是5、4、3和2。您可以在网格上手动绘制直线,如下所示:123456789 x 1 ......... 2 .......#. 3 ......#.. 4 .....#... 5 ....#.... 6 ......... y上面的数字代表 x 坐标,而左边的数字代表 y 坐标。点(
.)代表网格,线的点用散列符号(#)标注。为了完成您的解决方案,您需要对当前代码进行两处调整:
- 更改
points()使其也能转换对角线。- 使用完整的行列表调用
count_overlaps()。先从适应
points()开始。第一个很好的改变是更新 doctest 以包含一个对角线的例子:# aoc202105.py # ... def points(line): """List all points making up a line. ## Examples: >>> points((0, 3, 3, 3)) # Horizontal line [(0, 3), (1, 3), (2, 3), (3, 3)] >>> points((3, 4, 3, 0)) # Vertical line [(3, 4), (3, 3), (3, 2), (3, 1), (3, 0)] >>> points((1, 2, 3, 4)) # Diagonal line [(1, 2), (2, 3), (3, 4)] """ # ...你已经添加了线
1,2 -> 3,4,它覆盖了点1,2、2,3和3,4。运行您的测试来确认对角线还没有被处理。您需要在您的
match…case陈述中添加一个新案例。case报表从上到下一次检查一个。如果您在现有语句下面添加新代码,那么您将知道您正在处理对角线。因此,你不需要警卫:# aoc202105.py # ... def points(line): """List all points making up a line. ## Examples: >>> points((0, 3, 3, 3)) # Horizontal line [(0, 3), (1, 3), (2, 3), (3, 3)] >>> points((3, 4, 3, 0)) # Vertical line [(3, 4), (3, 3), (3, 2), (3, 1), (3, 0)] >>> points((1, 2, 3, 4)) # Diagonal line [(1, 2), (2, 3), (3, 4)] """ match line: case (x1, y1, x2, y2) if x1 == x2: return [(x1, y) for y in coords(y1, y2)] case (x1, y1, x2, y2) if y1 == y2: return [(x, y1) for x in coords(x1, x2)] case (x1, y1, x2, y2): return [(x, y) for x, y in zip(coords(x1, x2), coords(y1, y2))]第三个
case语句通过同时改变 x 和 y 坐标来处理对角线。在这里,你也从创建coords()中获得了一些回报,因为直接使用range()绘制对角线要比水平和垂直线条复杂得多。现在,您可以将对角线转换为单独的点,剩下的唯一任务是计算重叠的数量。由于
count_overlaps()委托给了points(),它现在也可以处理对角线了。您可以用一行代码实现第二部分的解决方案:# aoc202105.py # ... def part2(lines): """Solve part 2.""" return count_overlaps(lines)您应该运行您的测试,以确保一切按预期运行。然后计算你对第二部分的答案,并在《代码的来临》网站上提交。
恭喜你!到目前为止,你已经解决了至少三个降临密码难题。幸运的是,还有上百个等着你!
结论
代码的来临是有趣的编程难题的一个伟大的资源!你可以用它来练习你的解决问题的能力,挑战你的朋友来一场有趣的比赛和共同的学习经历。在下一集的真实 Python 播客中,你可以听到更多关于代码降临的内容:用 Python 解决代码降临难题。
如果你还没有这样做,那就去代码网站试试一些新的谜题。
在本教程中,您已经学习了:
- 解决谜题如何提高你的编程技能
- 你如何参与代码的出现
- 你如何解决不同种类的谜题
- 当解决降临代码难题时,你如何组织你的代码和测试
- 如何在解谜时使用测试驱动开发
Real Python 拥有一个私人排行榜和一个关于代码问世的社区论坛。成为真正的 Python 成员,加入
#advent-of-codeSlack 频道即可访问。源代码: 点击此处下载免费源代码,向您展示如何用 Python 解决代码难题。*********
Python AI:如何构建神经网络并进行预测
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 构建神经网络&用 Python AI 做预测
如果你刚刚开始进入人工智能(AI)世界,那么 Python 是一门很好的学习语言,因为大多数工具都是用它构建的。深度学习是一种利用数据进行预测的技术,它严重依赖于神经网络。今天,你将学习如何从头开始建立一个神经网络。
在生产环境中,你会使用像 TensorFlow 或 PyTorch 这样的深度学习框架,而不是建立自己的神经网络。也就是说,了解一些神经网络如何工作是有帮助的,因为你可以用它来更好地构建你的深度学习模型。
在本教程中,您将学习:
- 什么是人工智能
- 机器学习和深度学习如何在 AI 中发挥作用
- 一个神经网络如何在内部运行
- 如何使用 Python 从头开始构建神经网络
我们开始吧!
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
人工智能概述
用基本术语来说,使用人工智能的目标是让计算机像人类一样思考。这似乎是新的东西,但这个领域诞生于 20 世纪 50 年代。
想象一下,你需要编写一个 Python 程序,使用 AI 来解决一个数独问题。实现这一点的一个方法是编写条件语句,并检查约束条件,看看是否可以在每个位置放置一个数字。嗯,这个 Python 脚本已经是 AI 的一个应用了,因为你给计算机编程解决了一个问题!
机器学习(ML)****深度学习(DL) 也是解决问题的途径。这些技术与 Python 脚本的区别在于,ML 和 DL 使用训练数据而不是硬编码的规则,但它们都可以用来解决使用 AI 的问题。在接下来的部分中,您将了解更多关于这两种技术的区别。
机器学习
机器学习是一种技术,在这种技术中,你训练系统来解决问题,而不是显式地编程规则。回到上一节中的数独示例,为了使用机器学习来解决问题,您将从已解决的数独游戏中收集数据,并训练一个统计模型。统计模型是一种数学上形式化的方法,用来近似一种现象的行为。
一个常见的机器学习任务是监督学习,其中你有一个带有输入和已知输出的数据集。任务是使用该数据集来训练模型,该模型根据输入来预测正确的输出。下图显示了使用监督学习训练模型的工作流程:
Workflow to train a machine learning model 训练数据与机器学习算法的结合创建了模型。然后,使用这个模型,您可以对新数据进行预测。
注: scikit-learn 是一个流行的 Python 机器学习库,提供了许多监督和非监督学习算法。要了解更多信息,请查看用 scikit-learn 的 train_test_split() 分割数据集。
监督学习任务的目标是对新的、看不见的数据进行预测。为此,假设这些看不见的数据遵循一个类似于训练数据集分布的概率分布。如果将来这种分布发生变化,那么您需要使用新的训练数据集再次训练您的模型。
特征工程
当您使用不同种类的数据作为输入时,预测问题会变得更加困难。数独问题相对简单,因为你直接和数字打交道。如果你想训练一个模型来预测一个句子中的情绪呢?或者,如果你有一个图像,你想知道它是否描绘了一只猫?
输入数据的另一个名称是特征,特征工程是从原始数据中提取特征的过程。当处理不同种类的数据时,您需要找出表示这些数据的方法,以便从中提取有意义的信息。
特征工程技术的一个例子是词汇化,在这种技术中,你可以从一个句子中的单词中去除音调变化。例如,动词“watch”的屈折形式,如“watches”、“watching”和“watched”,将被简化为它们的词条,或基本形式:“watch”
如果您使用数组来存储语料库中的每个单词,那么通过应用词汇化,您最终会得到一个不太稀疏的矩阵。这可以提高一些机器学习算法的性能。下图展示了使用单词袋模型进行词汇化和表示的过程:
Creating features using a bag-of-words model 首先,每个单词的屈折形式被简化为它的引理。然后,计算该单词出现的次数。结果是一个包含文本中每个单词出现次数的数组。
深度学习
深度学习是一种技术,在这种技术中,你让神经网络自己找出哪些特征是重要的,而不是应用特征工程技术。这意味着,通过深度学习,你可以绕过特征工程过程。
不必处理特征工程是件好事,因为随着数据集变得越来越复杂,这个过程会变得越来越困难。例如,给定一个人的脸部照片,你如何提取数据来预测她的情绪?有了神经网络,你就不需要担心了,因为网络可以自己学习特征。在接下来的部分中,您将深入研究神经网络,以更好地理解它们是如何工作的。
神经网络:主要概念
神经网络是一个通过以下步骤学习如何进行预测的系统:
- 获取输入数据
- 做一个预测
- 将预测与期望输出进行比较
- 调整其内部状态以正确预测下一次
向量、层和线性回归是神经网络的一些构建模块。数据存储为向量,使用 Python 可以将这些向量存储在数组中。每一层都转换来自前一层的数据。您可以将每一层视为一个特征工程步骤,因为每一层都提取了先前数据的一些表示。
关于神经网络层的一件很酷的事情是,同样的计算可以从任何种类的数据中提取信息。这意味着无论您使用的是图像数据还是文本数据都没有关系。提取有意义的信息和训练深度学习模型的过程对于两种场景都是相同的。
在下图中,您可以看到一个具有两层的网络架构示例:
A neural network with two layers 每一层都通过应用一些数学运算来转换来自前一层的数据。
训练神经网络的过程
训练一个神经网络类似于试错的过程。想象你第一次玩飞镖。在你的第一次投掷中,你试图击中镖靶的中心点。通常,第一枪只是为了感受一下你的手的高度和速度是如何影响结果的。如果你看到镖高于中心点,那么你调整你的手扔低一点,以此类推。
以下是尝试击中镖靶中心的步骤:
Steps to hit the center of a dartboard 请注意,您一直通过观察飞镖落地的位置来评估错误(步骤 2)。你继续前进,直到你最终击中镖靶的中心。
对于神经网络,过程非常相似:你从一些随机的权重和偏差向量开始,进行预测,将其与期望的输出进行比较,并调整向量以在下一次更准确地预测。该过程继续,直到预测和正确目标之间的差异最小。
知道何时停止训练以及设定什么精度目标是训练神经网络的一个重要方面,主要是因为过拟合和欠拟合场景。
向量和权重
使用神经网络包括对向量进行运算。你把向量表示成多维数组。向量在深度学习中很有用,主要是因为一个特殊的操作:点积。两个向量的点积告诉你它们在方向上有多相似,并且由两个向量的大小来决定。
神经网络中的主要向量是权重和偏差向量。不严格地说,你希望你的神经网络做的是检查一个输入是否与它已经看到的其他输入相似。如果新的输入与先前看到的输入相似,那么输出也将相似。这就是你得到预测结果的方式。
线性回归模型
当你需要估计一个因变量和两个或多个自变量之间的关系时,使用回归。线性回归是一种将变量之间的关系近似为线性的方法。该方法可追溯到十九世纪,是最流行的回归方法。
注:****线性关系是自变量和因变量之间有直接关系的关系。
通过将变量之间的关系建模为线性,您可以将因变量表示为自变量的加权和。所以,每个独立变量都会乘以一个叫做
weight的向量。除了权重和自变量,您还添加了另一个向量:偏差**。当所有其他独立变量都等于零时,它设置结果。**作为如何构建线性回归模型的真实示例,假设您想要训练一个模型来根据面积和房屋的年龄预测房屋的价格。您决定使用线性回归来模拟这种关系。以下代码块显示了如何用伪代码为所述问题编写线性回归模型:
price = (weights_area * area) + (weights_age * age) + bias上例中有两个权重:
weights_area和weights_age。训练过程包括调整权重和偏差,以便模型可以预测正确的价格值。为此,您需要计算预测误差并相应地更新权重。这些是神经网络机制如何工作的基础。现在是时候看看如何使用 Python 应用这些概念了。
Python AI:开始构建你的第一个神经网络
建立神经网络的第一步是从输入数据生成输出。你可以通过创建变量的加权和来实现。您需要做的第一件事是用 Python 和 NumPy 表示输入。
用 NumPy 包装神经网络的输入
您将使用 NumPy 将网络的输入向量表示为数组。但是在使用 NumPy 之前,最好使用纯 Python 中的矢量来更好地理解发生了什么。
在第一个例子中,您有一个输入向量和另外两个权重向量。目标是在考虑方向和大小的情况下,找出哪个权重与输入更相似。如果你画出这些向量,这就是它们的样子:
Three vectors in a cartesian coordinate plane
weights_2更类似于输入向量,因为它指向相同的方向,大小也相似。那么如何使用 Python 找出哪些向量是相似的呢?首先,定义三个向量,一个用于输入,另外两个用于权重。然后你计算
input_vector和weights_1有多相似。为此,您将应用 点积 。因为所有的向量都是二维向量,所以步骤如下:
- 将
input_vector的第一个索引乘以weights_1的第一个索引。- 将
input_vector的第二个指数乘以weights_2的第二个指数。- 将两次乘法的结果相加。
你可以使用 IPython 控制台或 Jupyter 笔记本跟随。每次开始一个新的 Python 项目时,创建一个新的虚拟环境是一个很好的实践,所以你应该首先这样做。
venvPython 3.3 版及以上版本自带,方便创建虚拟环境:$ python -m venv ~/.my-env $ source ~/.my-env/bin/activate使用上面的命令,首先创建虚拟环境,然后激活它。现在是时候使用
pip安装 IPython 控制台了。因为你还需要 NumPy 和 Matplotlib ,安装它们也是个好主意:(my-env) $ python -m pip install ipython numpy matplotlib (my-env) $ ipython现在您已经准备好开始编码了。这是计算
input_vector和weights_1的点积的代码:



In [1]: input_vector = [1.72, 1.23]
In [2]: weights_1 = [1.26, 0]
In [3]: weights_2 = [2.17, 0.32]
In [4]: # Computing the dot product of input_vector and weights_1
In [5]: first_indexes_mult = input_vector[0] * weights_1[0]
In [6]: second_indexes_mult = input_vector[1] * weights_1[1]
In [7]: dot_product_1 = first_indexes_mult + second_indexes_mult
In [8]: print(f"The dot product is: {dot_product_1}")
Out[8]: The dot product is: 2.1672
点积的结果是2.1672。现在你知道了如何计算点积,是时候使用 NumPy 的np.dot()了。下面是如何使用np.dot()计算dot_product_1:
In [9]: import numpy as np In [10]: dot_product_1 = np.dot(input_vector, weights_1) In [11]: print(f"The dot product is: {dot_product_1}") Out[11]: The dot product is: 2.1672做了和以前一样的事情,但是现在你只需要指定两个数组作为参数。现在让我们计算
input_vector和weights_2的点积:
In [10]: dot_product_2 = np.dot(input_vector, weights_2)
In [11]: print(f"The dot product is: {dot_product_2}")
Out[11]: The dot product is: 4.1259
这一次,结果是4.1259。作为一种思考点积的不同方式,您可以将向量坐标之间的相似性视为一个开关。如果乘法结果是0,那么你会说坐标是而不是相似。如果结果不是0,那么你会说它们和相似。
这样,您可以将点积视为向量之间相似性的松散度量。每次乘法结果都是0,最后的点积会有一个较低的结果。回到例子的向量,由于input_vector和weights_2的点积是4.1259,而4.1259大于2.1672,这意味着input_vector更类似于weights_2。你将在你的神经网络中使用同样的机制。
注意:如果需要复制粘贴,点击每个代码块右上角的提示(> > >)。
在本教程中,您将训练一个模型来做出只有两种可能结果的预测。输出结果可以是0或1。这是一个分类问题,一个监督学习问题的子集,其中你有一个带有输入和已知目标的数据集。这些是数据集的输入和输出:
| 输入向量 | 目标 |
|---|---|
| [1.66, 1.56] | one |
| [2, 1.5] | Zero |
目标是你要预测的变量。在本例中,您正在处理一个由数字组成的数据集。这在真实的生产场景中并不常见。通常,当需要深度学习模型时,数据会以文件的形式呈现,如图像或文本。
做出你的第一个预测
由于这是您的第一个神经网络,您将保持事情简单明了,建立一个只有两层的网络。到目前为止,您已经看到在神经网络中使用的唯一两个操作是点积和求和。两者都是线性运算。
如果您添加更多的图层,但一直只使用线性运算,那么添加更多的图层将不会有任何效果,因为每一个图层总是与前一个图层的输入有一些关联。这意味着,对于具有多个图层的网络,总会有一个具有较少图层的网络预测相同的结果。
您想要的是找到一种操作,使中间层有时与输入相关,有时不相关。
您可以通过使用非线性函数来实现这一行为。这些非线性函数称为激活函数。有许多类型的激活功能。例如, ReLU(整流线性单元)是将所有负数转换为零的功能。这意味着如果权重为负,网络可以“关闭”权重,从而增加非线性。
您正在构建的网络将使用s 形激活功能。你将在最后一层使用它,layer_2。数据集中仅有的两个可能输出是0和1,sigmoid 函数将输出限制在0和1之间的范围内。这是表示 sigmoid 函数的公式:

e 是一个叫做欧拉数的数学常数,你可以用np.exp(x)来计算 eˣ 。
概率函数给你一个事件的可能结果发生的概率。数据集仅有的两个可能输出是0和1,而伯努利分布也是一个有两个可能结果的分布。如果你的问题遵循伯努利分布,sigmoid 函数是一个很好的选择,所以这就是为什么你在神经网络的最后一层使用它。
因为该函数将输出限制在0到1的范围内,所以您将使用它来预测概率。如果输出大于0.5,那么你会说预测是1。如果它低于0.5,那么你会说预测是0。这是你正在构建的网络内部的计算流程:

黄色六边形代表函数,蓝色矩形代表中间结果。现在是时候将这些知识转化为代码了。您还需要用 NumPy 数组包装向量。这是应用上图所示功能的代码:
In [12]: # Wrapping the vectors in NumPy arrays In [13]: input_vector = np.array([1.66, 1.56]) In [14]: weights_1 = np.array([1.45, -0.66]) In [15]: bias = np.array([0.0]) In [16]: def sigmoid(x): ...: return 1 / (1 + np.exp(-x)) In [17]: def make_prediction(input_vector, weights, bias): ...: layer_1 = np.dot(input_vector, weights) + bias ...: layer_2 = sigmoid(layer_1) ...: return layer_2 In [18]: prediction = make_prediction(input_vector, weights_1, bias) In [19]: print(f"The prediction result is: {prediction}") Out[19]: The prediction result is: [0.7985731]原始预测结果为
0.79,高于0.5,因此输出为1。网络做出了正确的预测。现在尝试使用另一个输入向量np.array([2, 1.5])。这个输入的正确结果是0。您只需要更改input_vector变量,因为所有其他参数保持不变:
In [20]: # Changing the value of input_vector
In [21]: input_vector = np.array([2, 1.5])
In [22]: prediction = make_prediction(input_vector, weights_1, bias)
In [23]: print(f"The prediction result is: {prediction}")
Out[23]: The prediction result is: [0.87101915]
这一次,网络做出了错误的预测。结果应该小于0.5,因为这个输入的目标是0,但是原始结果是0.87。它做了一个错误的猜测,但是错误有多严重呢?下一步是找到一种评估的方法。
训练你的第一个神经网络
在训练神经网络的过程中,您首先评估误差,然后相应地调整权重。为了调整权重,您将使用梯度下降和反向传播算法。应用梯度下降来寻找方向和速率以更新参数。
在对网络进行任何更改之前,您需要计算误差。这是您将在下一部分中执行的操作。
计算预测误差
要了解误差的大小,您需要选择一种方法来测量它。用于测量误差的函数被称为成本函数,或损失函数。在本教程中,您将使用均方差(MSE) 作为您的成本函数。计算 MSE 分两步:
- 计算预测值和目标值之间的差异。
- 将结果本身相乘。
网络可能会因输出高于或低于正确值的值而出错。因为 MSE 是预测和正确结果之间的平方差,使用这个度量,您将总是以正值结束。
这是计算上一次预测误差的完整表达式:
In [24]: target = 0 In [25]: mse = np.square(prediction - target) In [26]: print(f"Prediction: {prediction}; Error: {mse}") Out[26]: Prediction: [0.87101915]; Error: [0.7586743596667225]在上面的例子中,错误是
0.75。将差异乘以自身的一个含义是,较大的误差具有更大的影响,而较小的误差随着它们的减少而变得越来越小。了解如何减少误差
目标是改变权重和偏差变量,这样可以减少误差。为了理解这是如何工作的,您将只更改权重变量,并暂时保持偏差不变。也可以去掉 sigmoid 函数,只使用
layer_1的结果。剩下要做的就是找出如何修改权重,从而降低误差。你通过做
error = np.square(prediction - target)来计算 MSE。如果你把(prediction - target)看成一个单变量x,那么你就有了error = np.square(x),它是一个二次函数。如果你画出这个函数,它看起来是这样的:
Plot of a quadratic function 误差由 y 轴给出。如果你在点
A上,想要将误差减小到 0,那么你需要降低x的值。另一方面,如果你在点B上,想要减少误差,那么你需要提高x的值。为了知道你应该往哪个方向减少误差,你将使用导数。导数精确地解释了一个模式将如何变化。导数的另一个词是梯度。梯度下降是用于寻找方向和速率以更新网络参数的算法的名称。
注意:要了解更多关于梯度下降背后的数学知识,请查看使用 Python 和 NumPy 的随机梯度下降算法。
在本教程中,你不会关注导数背后的理论,所以你将简单地对你将遇到的每个函数应用导数规则。幂法则表明 xⁿ 的导数是 nx ⁽ ⁿ ⁻ ⁾.所以
np.square(x)的导数是2 * x,x的导数是1。记住错误表达式是
error = np.square(prediction - target)。当你把(prediction - target)当成单变量x时,误差的导数就是2 * x。通过对这个函数求导,你想知道你应该在什么方向改变x以使error的结果为零,从而减少误差。当涉及到你的神经网络时,导数会告诉你应该采取什么方向来更新权重变量。如果它是一个正数,那么你预测得太高了,你需要降低权重。如果是负数,那么你预测的太低了,你需要增加权重。
现在是时候写代码弄清楚如何为之前的错误预测更新
weights_1了。如果均方差是0.75,那么应该增加还是减少权重?由于导数是2 * x,你只需要将预测值和目标值之差乘以2:

In [27]: derivative = 2 * (prediction - target)
In [28]: print(f"The derivative is {derivative}")
Out[28]: The derivative is: [1.7420383]
结果是1.74,一个正数,所以你需要减少权重。你可以通过减去权重向量的导数结果来实现。现在您可以相应地更新weights_1并再次预测,以查看它如何影响预测结果:
In [29]: # Updating the weights In [30]: weights_1 = weights_1 - derivative In [31]: prediction = make_prediction(input_vector, weights_1, bias) In [32]: error = (prediction - target) ** 2 In [33]: print(f"Prediction: {prediction}; Error: {error}") Out[33]: Prediction: [0.01496248]; Error: [0.00022388]误差降到差不多
0!很漂亮,对吧?在这个例子中,导数结果很小,但是在某些情况下,导数结果太高。以二次函数的图像为例。高增量是不理想的,因为你可以从点A一直到点B,永远不会接近零。为了解决这个问题,您可以用导数结果的一部分来更新权重。要定义更新权重的分数,您可以使用 alpha 参数,也称为学习速率。如果你降低学习率,那么增量就更小。如果你增加它,那么步骤是更高的。你怎么知道最佳学习率值是多少?通过猜测和实验。
注:传统默认学习率值为
0.1、0.01、0.001。如果你用新的权重,用第一个输入向量做预测,你会发现现在它对那个向量做了错误的预测。如果你的神经网络对训练集中的每个实例都做出了正确的预测,那么你可能有一个过度拟合的模型,其中该模型只记得如何对实例进行分类,而不是学习注意数据中的特征。
有一些技术可以避免这种情况,包括正则化随机梯度下降。在本教程中,你将使用在线随机梯度下降。
既然你知道了如何计算误差以及如何相应地调整权重,那么是时候回去继续构建你的神经网络了。
应用链式法则
在你的神经网络中,你需要更新权重和偏差向量。您用来测量误差的函数取决于两个独立变量,权重和偏差。由于权重和偏差是独立变量,您可以改变和调整它们以获得您想要的结果。
您正在构建的网络有两层,由于每层都有自己的功能,您正在处理一个功能组合。这意味着误差函数仍然是
np.square(x),但是现在x是另一个函数的结果。重申一下问题,现在你想知道如何改变
weights_1和bias来减少误差。你已经看到,你可以用导数来做这个,但不是一个只有和的函数,现在你有一个函数,它用其他函数来产生结果。既然现在你已经有了这个函数组合,要对关于参数的误差求导,你需要使用微积分中的链式法则。利用链式法则,你得到每个函数的偏导数,对它们求值,然后把所有的偏导数相乘,得到你想要的导数。
现在你可以开始更新权重了。你想知道如何改变权重来减少误差。这意味着您需要计算误差相对于重量的导数。由于误差是通过组合不同的函数来计算的,所以需要对这些函数求偏导数。
以下是如何应用链式法则计算误差相对于权重的导数的直观表示:
A diagram showing the partial derivatives inside the neural network 红色粗体箭头显示您想要的导数,
derror_dweights。你将从红色的六边形开始,采取与预测相反的方式,计算每个函数的偏导数。在上图中,每个函数用黄色六边形表示,偏导数用左边的灰色箭头表示。应用链式法则,
derror_dweights的值如下:derror_dweights = ( derror_dprediction * dprediction_dlayer1 * dlayer1_dweights )为了计算导数,将所有偏导数相乘,这些偏导数沿着从误差六边形(红色的那个)到找到权重的六边形(最左边的绿色的那个)的路径。
你可以说
y = f(x)的导数就是f相对于x的导数。使用这个术语,对于derror_dprediction,您想要知道计算相对于预测值的误差的函数的导数。这个反向路径被称为反向路径。在每次反向传递中,计算每个函数的偏导数,用变量的值替换变量,最后将所有值相乘。
这个“取偏导数、求值、相乘”的部分就是你如何应用链式法则。这种更新神经网络参数的算法被称为反向传播。
用反向传播调整参数
在本节中,您将一步一步地完成反向传播过程,从如何更新偏差开始。你想对误差函数求关于偏差的导数。然后你会继续往回走,求偏导数,直到找到
bias变量。因为你是从终点开始往回走,你首先需要对预测的误差求偏导数。这就是下图中的
derror_dprediction:
A diagram showing the partial derivatives to compute the bias gradient 产生误差的函数是平方函数,这个函数的导数是
2 * x,你前面看到了。您应用了一阶偏导数(derror_dprediction),但仍然没有得到偏差,因此您需要再后退一步,对前一层dprediction_dlayer1的预测进行求导。该预测是 sigmoid 函数的结果。你可以通过把
sigmoid(x)和1 - sigmoid(x)相乘来得到 sigmoid 函数的导数。这个求导公式非常方便,因为你可以使用已经计算过的 sigmoid 结果来计算它的导数。然后你取这个偏导数,继续往回走。现在你要对
layer_1的偏差求导。这就是了——你终于找到了!bias变量是自变量,所以应用幂法则后的结果是1。酷,现在你已经完成了这个反向传递,你可以把所有东西放在一起计算derror_dbias:


In [36]: def sigmoid_deriv(x):
...: return sigmoid(x) * (1-sigmoid(x))
In [37]: derror_dprediction = 2 * (prediction - target)
In [38]: layer_1 = np.dot(input_vector, weights_1) + bias
In [39]: dprediction_dlayer1 = sigmoid_deriv(layer_1)
In [40]: dlayer1_dbias = 1
In [41]: derror_dbias = (
...: derror_dprediction * dprediction_dlayer1 * dlayer1_dbias ...: )
要更新权重,您需要遵循相同的过程,回溯并获取偏导数,直到得到权重变量。因为你已经计算了一些偏导数,你只需要计算dlayer1_dweights。点积的导数是第一个向量乘以第二个向量的导数,加上第二个向量乘以第一个向量的导数。
创建神经网络类
现在,您知道如何编写表达式来更新权重和偏差。是时候为神经网络创建一个类了。类是面向对象编程(OOP) 的主要构建块。NeuralNetwork类为权重和偏差变量生成随机初始值。
当实例化一个NeuralNetwork对象时,需要传递learning_rate参数。你将使用predict()来做一个预测。方法_compute_derivatives()和_update_parameters()包含您在本节中学到的计算。这是最后一节NeuralNetwork课:
class NeuralNetwork:
def __init__(self, learning_rate):
self.weights = np.array([np.random.randn(), np.random.randn()])
self.bias = np.random.randn()
self.learning_rate = learning_rate
def _sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def _sigmoid_deriv(self, x):
return self._sigmoid(x) * (1 - self._sigmoid(x))
def predict(self, input_vector):
layer_1 = np.dot(input_vector, self.weights) + self.bias
layer_2 = self._sigmoid(layer_1)
prediction = layer_2
return prediction
def _compute_gradients(self, input_vector, target): layer_1 = np.dot(input_vector, self.weights) + self.bias layer_2 = self._sigmoid(layer_1) prediction = layer_2 derror_dprediction = 2 * (prediction - target) dprediction_dlayer1 = self._sigmoid_deriv(layer_1) dlayer1_dbias = 1 dlayer1_dweights = (0 * self.weights) + (1 * input_vector) derror_dbias = ( derror_dprediction * dprediction_dlayer1 * dlayer1_dbias ) derror_dweights = ( derror_dprediction * dprediction_dlayer1 * dlayer1_dweights ) return derror_dbias, derror_dweights
def _update_parameters(self, derror_dbias, derror_dweights):
self.bias = self.bias - (derror_dbias * self.learning_rate)
self.weights = self.weights - (
derror_dweights * self.learning_rate
)
这就是你的第一个神经网络的代码。恭喜你!这段代码只是将您到目前为止看到的所有部分组合在一起。如果您想做一个预测,首先您创建一个NeuralNetwork()的实例,然后您调用.predict():
In [42]: learning_rate = 0.1 In [43]: neural_network = NeuralNetwork(learning_rate) In [44]: neural_network.predict(input_vector) Out[44]: array([0.79412963])上面的代码做了一个预测,但是现在你需要学习如何训练网络。目标是让网络在训练数据集上推广。这意味着您希望它适应新的、看不见的数据,这些数据遵循与训练数据集相同的概率分布。这是您将在下一部分中执行的操作。
用更多数据训练网络
您已经为一个数据实例调整了权重和偏差,但目标是使网络在整个数据集上进行概化。随机梯度下降是一种技术,在每次迭代中,模型根据随机选择的训练数据进行预测,计算误差,并更新参数。
现在是时候创建你的
NeuralNetwork类的train()方法了。您将保存每 100 次迭代的所有数据点的误差,因为您想要绘制一个图表来显示这个指标如何随着迭代次数的增加而变化。这是你的神经网络的最终train()方法:1class NeuralNetwork: 2 # ... 3 4 def train(self, input_vectors, targets, iterations): 5 cumulative_errors = [] 6 for current_iteration in range(iterations): 7 # Pick a data instance at random 8 random_data_index = np.random.randint(len(input_vectors)) 9 10 input_vector = input_vectors[random_data_index] 11 target = targets[random_data_index] 12 13 # Compute the gradients and update the weights 14 derror_dbias, derror_dweights = self._compute_gradients( 15 input_vector, target 16 ) 17 18 self._update_parameters(derror_dbias, derror_dweights) 19 20 # Measure the cumulative error for all the instances 21 if current_iteration % 100 == 0: 22 cumulative_error = 0 23 # Loop through all the instances to measure the error 24 for data_instance_index in range(len(input_vectors)): 25 data_point = input_vectors[data_instance_index] 26 target = targets[data_instance_index] 27 28 prediction = self.predict(data_point) 29 error = np.square(prediction - target) 30 31 cumulative_error = cumulative_error + error 32 cumulative_errors.append(cumulative_error) 33 34 return cumulative_errors上面的代码块中发生了很多事情,所以下面是一行一行的分解:
第 8 行从数据集中随机选取一个实例。
第 14 到 16 行计算偏导数并返回偏差和权重的导数。他们使用您之前定义的
_compute_gradients()。第 18 行使用
_update_parameters()更新偏差和权重,这是您在前面的代码块中定义的。第 21 行检查当前迭代索引是否是
100的倍数。这样做是为了观察误差在每一次100迭代中是如何变化的。第 24 行开始遍历所有数据实例的循环。
第 28 行计算
prediction结果。第 29 行为每个实例计算
error。第 31 行是使用
cumulative_error变量累加误差总和的地方。你这样做是因为你想为所有的数据实例绘制一个有误差的点。然后,在第 32 行,您将error添加到cumulative_errors中,这是存储错误的数组。您将使用这个数组来绘制图形。简而言之,从数据集中选取一个随机实例,计算梯度,并更新权重和偏差。您还可以计算每 100 次迭代的累积误差,并将这些结果保存在一个数组中。您将绘制该数组,以直观显示训练过程中误差的变化。
注意:如果你在 Jupyter 笔记本上运行代码,那么你需要在将
train()添加到NeuralNetwork类后重启内核。为了使事情不那么复杂,您将使用一个只有八个实例的数据集,即
input_vectors数组。现在您可以调用train()并使用 Matplotlib 来绘制每次迭代的累积误差:
In [45]: # Paste the NeuralNetwork class code here
...: # (and don't forget to add the train method to the class)
In [46]: import matplotlib.pyplot as plt
In [47]: input_vectors = np.array(
...: [
...: [3, 1.5],
...: [2, 1],
...: [4, 1.5],
...: [3, 4],
...: [3.5, 0.5],
...: [2, 0.5],
...: [5.5, 1],
...: [1, 1],
...: ]
...: )
In [48]: targets = np.array([0, 1, 0, 1, 0, 1, 1, 0])
In [49]: learning_rate = 0.1
In [50]: neural_network = NeuralNetwork(learning_rate)
In [51]: training_error = neural_network.train(input_vectors, targets, 10000)
In [52]: plt.plot(training_error)
In [53]: plt.xlabel("Iterations")
In [54]: plt.ylabel("Error for all training instances")
In [54]: plt.savefig("cumulative_error.png")
再次实例化NeuralNetwork类,并使用input_vectors和target值调用train()。您指定它应该运行10000次。下图显示了神经网络实例的误差:

整体误差在减小,这就是你想要的。该映像是在运行 IPython 的同一个目录中生成的。在最大程度的减少之后,误差从一个交互到另一个交互保持快速上升和下降。这是因为数据集是随机的,非常小,所以神经网络很难提取任何特征。
但是,使用这一指标来评估性能并不是一个好主意,因为您是使用网络已经看到的数据实例来评估性能的。这可能导致过度拟合,此时模型与训练数据集拟合得如此之好,以至于不能推广到新数据。
向神经网络添加更多层
出于学习目的,本教程中的数据集很小。通常,深度学习模型需要大量的数据,因为数据集更复杂,有很多细微差别。
由于这些数据集包含更复杂的信息,仅使用一两个图层是不够的。这就是深度学习模型被称为“深度”的原因。它们通常有许多层。
通过添加更多的层和使用激活函数,您可以增加网络的表达能力,并可以进行非常高水平的预测。这种类型的预测的一个例子是面部识别,例如当你用手机拍摄面部照片时,如果手机识别出图像是你,它就会解锁。
结论
恭喜你!今天,您使用 NumPy 从头开始构建了一个神经网络。有了这些知识,您就可以更深入地研究 Python 中的人工智能世界了。
在本教程中,您学习了:
- 什么是深度学习以及它与机器学习的区别
- 如何用 NumPy 表示向量
- 什么是激活函数以及为什么在神经网络中使用它们
- 什么是反向传播算法以及它是如何工作的
- 如何训练一个神经网络并做出预测
训练神经网络的过程主要包括对向量进行运算。今天,您仅仅使用 NumPy 作为依赖项,从头开始完成了这项工作。在生产环境中不建议这样做,因为整个过程可能是低效的并且容易出错。这就是像 Keras 、 PyTorch 和 TensorFlow 这样的深度学习框架如此受欢迎的原因之一。
延伸阅读
有关本教程所涵盖主题的更多信息,请查看以下资源:
- 看 Ma,无 For 循环:用 NumPy 进行数组编程
- Python 中的线性回归
- 用 Python 和 Keras 进行实用文本分类
- 纯 Python vs NumPy vs TensorFlow 性能对比
- PyTorch vs TensorFlow 为您的 Python 深度学习项目
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 构建神经网络&用 Python AI 做预测*********


 浙公网安备 33010602011771号
浙公网安备 33010602011771号