PythonProgramming-net-系列教程-一-
PythonProgramming.net 系列教程(一)
译者:飞龙
PythonProgramming.net Matplotlib 入门教程
译者:飞龙
一、Matplotlib 简介
欢迎阅读 Python 3+ Matplotlib 系列教程。 在本系列中,我们将涉及 Matplotlib 数据可视化模块的多个方面。 Matplotlib 能够创建多数类型的图表,如条形图,散点图,条形图,饼图,堆叠图,3D 图和地图图表。
首先,为了实际使用 Matplotlib,我们需要安装它。
如果你安装了更高版本的 Python,你应该能够打开cmd.exe或终端,然后执行:
pip install matplotlib
注意:如果上面的较短命令不工作,你可能需要执行C:/Python34/Scripts/pip install matplotlib。
如果在导入matplotlib时,你会收到类似『无命名模块』和模块名称的错误,这意味着你还需要安装该模块。 一个常见的问题是缺少名为six的模块。 这意味着你需要使用pip安装six。
或者,你可以前往 Matplotlib.org 并通过访问下载页面下载适当的版本进行安装。 请记住,因为你的操作系统为 64 位,你不一定需要 64 位版本的 Python。 如果你不打算尝试 64 位,你可以使用 32 位。 打开 IDLE 并阅读顶部。 如果它说你是 64 位,你就是 64 位,如果它说是 32 位,那么你就是 32 位。 一旦你安装了 Python,你就做好了准备,你可以编写任何你想要的逻辑。 我喜欢使用 IDLE 来编程,但你可以随意使用任何你喜欢的东西。
import matplotlib.pyplot as plt
这一行导入集成的pyplot,我们将在整个系列中使用它。 我们将pyplot导入为plt,这是使用pylot的 python 程序的传统惯例。
plt.plot([1,2,3],[5,7,4])
接下来,我们调用plot的.plot方法绘制一些坐标。 这个.plot需要许多参数,但前两个是'x'和'y'坐标,我们放入列表。 这意味着,根据这些列表我们拥有 3 个坐标:1,5 2,7和3,4。
plt.plot在后台『绘制』这个绘图,但绘制了我们想要的一切之后,当我们准备好的时候,我们需要把它带到屏幕上。
plt.show()
这样,应该弹出一个图形。 如果没有,有时它可以弹出,或者你可能得到一个错误。 你的图表应如下所示:
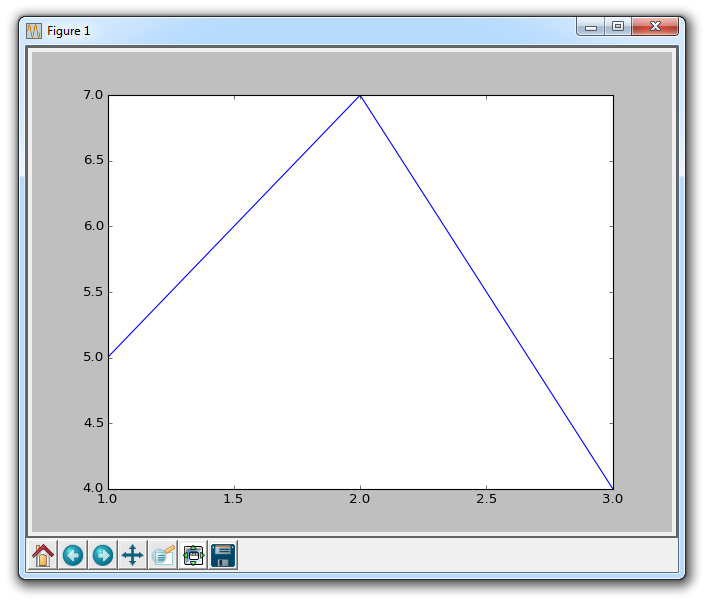
这个窗口是一个 matplotlib 窗口,它允许我们查看我们的图形,以及与它进行交互和访问。 你可以将鼠标悬停在图表上,并查看通常在右下角的坐标。 你也可以使用按钮。 它们可能在不同的位置,但在上图中,这些按钮在左下角。
Home(主页)

一旦你开始浏览你的图表,主页按钮会帮助你。 如果你想要返回原始视图,可以单击它。 在浏览图表之前单击此按钮将不会生效。
Forward/Back(前进/后退)

这些按钮可以像浏览器中的前进和后退按钮一样使用。 你可以单击这些来移回到你之前的位置,或再次前进。
Pan(平移)

你可以点击平移按钮,之后点击并拖拽你的图表。
Zoom(缩放)

缩放按钮可让你单击它,然后单击并拖动出要放大的方形区域。 放大需要左键单击并拖动。 你也可以右键单击并拖动来缩小。
Configure Subplots(配置子图)

此按钮允许你对图形和绘图配置各种间距选项。 点击它会弹出:
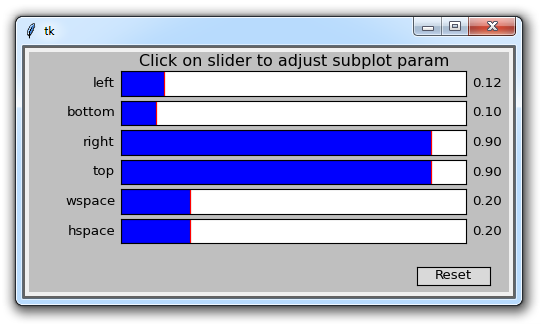
每个蓝色条形都是一个滑块,它允许你调整内边距。 其中有些现在没有任何效果,因为没有任何其他子图。 前四个值调整图形到窗口边缘的边距。 之后wspace和hspace对应于当你绘制多个子图时,它们的水平或竖直间距。
Save(保存)

此按钮允许你以各种形式保存图形。
所以这是 matplotlib 的快速介绍,我们之后会涉及更多。
二、图例、标题和标签
在本教程中,我们将讨论 Matplotlib 中的图例,标题和标签。 很多时候,图形可以不言自明,但是图形带有标题,轴域上的标签和图例,来解释每一行是什么非常必要。
注:轴域(
Axes)即两条坐标轴围城的区域。
从这里开始:
import matplotlib.pyplot as plt
x = [1,2,3]
y = [5,7,4]
x2 = [1,2,3]
y2 = [10,14,12]
这样我们可以画出两个线条,接下来:
plt.plot(x, y, label='First Line')
plt.plot(x2, y2, label='Second Line')
在这里,我们绘制了我们已经看到的东西,但这次我们添加另一个参数label。 这允许我们为线条指定名称,我们以后可以在图例中显示它。 我们的其余代码为:
plt.xlabel('Plot Number')
plt.ylabel('Important var')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
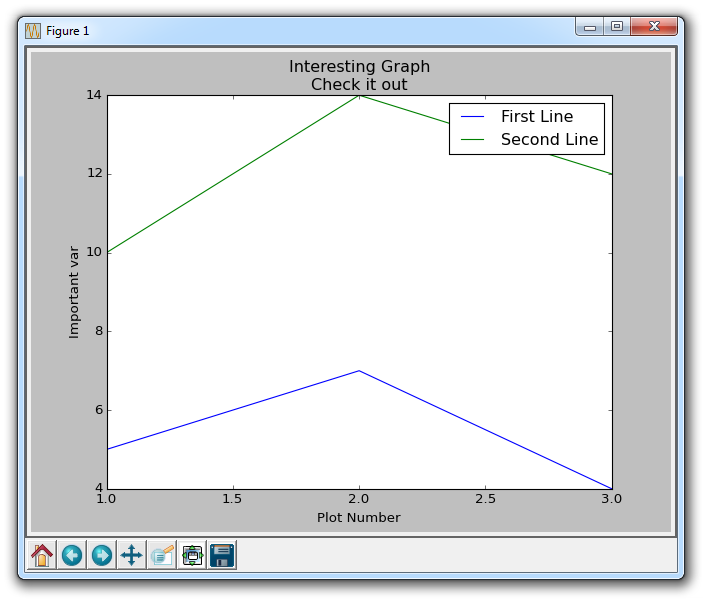
使用plt.xlabel和plt.ylabel,我们可以为这些相应的轴创建标签。 接下来,我们可以使用plt.title创建图的标题,然后我们可以使用plt.legend()生成默认图例。 结果图如下:
三、条形图和直方图
这个教程中我们会涉及条形图和直方图。我们先来看条形图:
import matplotlib.pyplot as plt
plt.bar([1,3,5,7,9],[5,2,7,8,2], label="Example one")
plt.bar([2,4,6,8,10],[8,6,2,5,6], label="Example two", color='g')
plt.legend()
plt.xlabel('bar number')
plt.ylabel('bar height')
plt.title('Epic Graph\nAnother Line! Whoa')
plt.show()
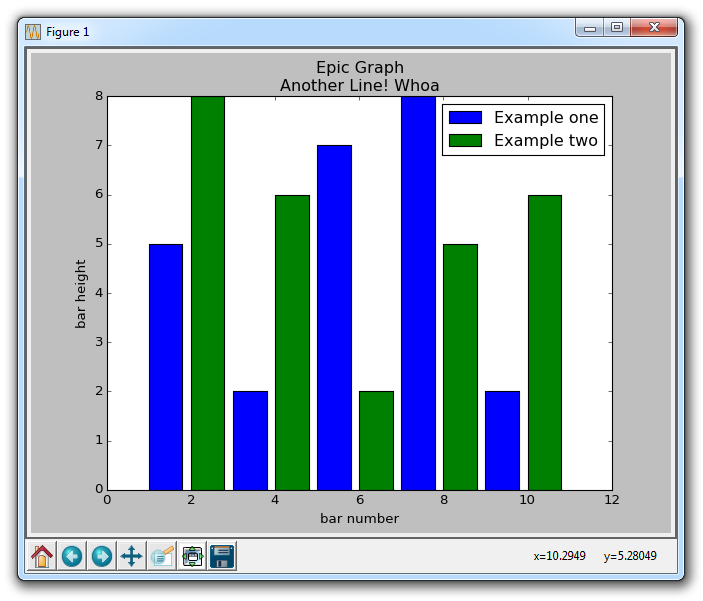
plt.bar为我们创建条形图。 如果你没有明确选择一种颜色,那么虽然做了多个图,所有的条看起来会一样。 这让我们有机会使用一个新的 Matplotlib 自定义选项。 你可以在任何类型的绘图中使用颜色,例如g为绿色,b为蓝色,r为红色,等等。 你还可以使用十六进制颜色代码,如#191970。
接下来,我们会讲解直方图。 直方图非常像条形图,倾向于通过将区段组合在一起来显示分布。 这个例子可能是年龄的分组,或测试的分数。 我们并不是显示每一组的年龄,而是按照 20 ~ 25,25 ~ 30... 等等来显示年龄。 这里有一个例子:
import matplotlib.pyplot as plt
population_ages = [22,55,62,45,21,22,34,42,42,4,99,102,110,120,121,122,130,111,115,112,80,75,65,54,44,43,42,48]
bins = [0,10,20,30,40,50,60,70,80,90,100,110,120,130]
plt.hist(population_ages, bins, histtype='bar', rwidth=0.8)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
产生的图表为:
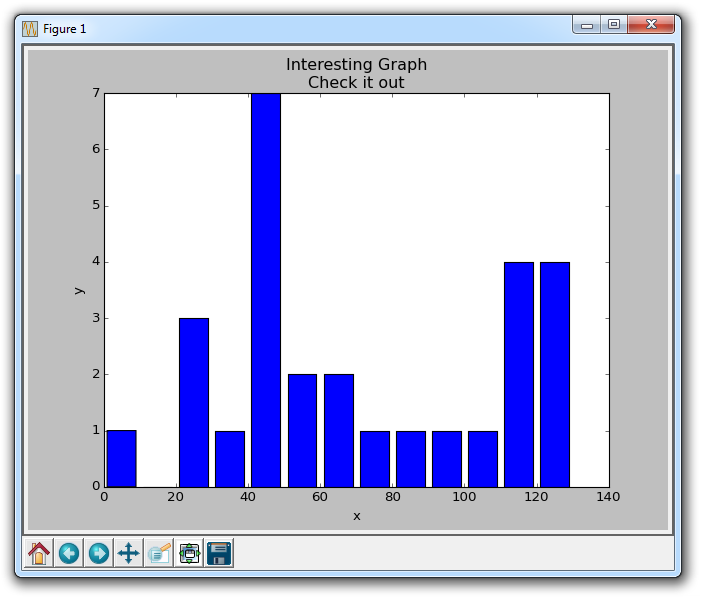
对于plt.hist,你首先需要放入所有的值,然后指定放入哪个桶或容器。 在我们的例子中,我们绘制了一堆年龄,并希望以 10 年的增量来显示它们。 我们将条形的宽度设为 0.8,但是如果你想让条形变宽,或者变窄,你可以选择其他的宽度。
四、散点图
接下来,我们将介绍散点图。散点图通常用于比较两个变量来寻找相关性或分组,如果你在 3 维绘制则是 3 个。
散点图的一些示例代码:
import matplotlib.pyplot as plt
x = [1,2,3,4,5,6,7,8]
y = [5,2,4,2,1,4,5,2]
plt.scatter(x,y, label='skitscat', color='k', s=25, marker="o")
plt.xlabel('x')
plt.ylabel('y')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
结果为:
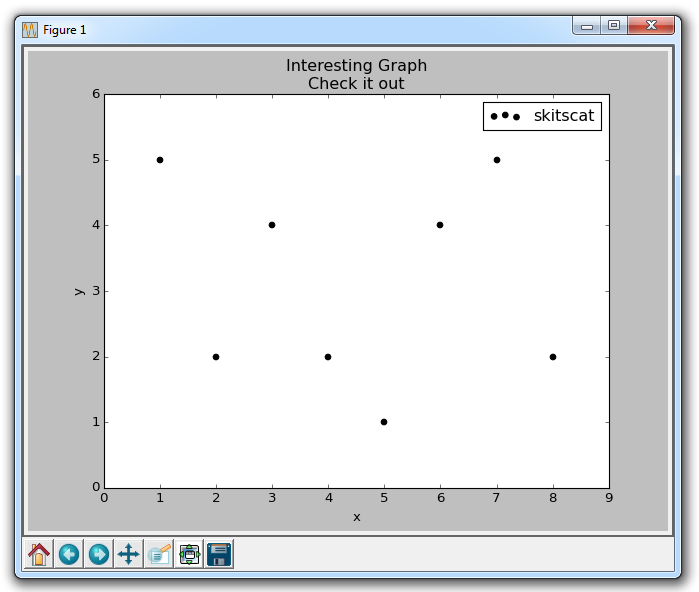
plt.scatter不仅允许我们绘制x和y,而且还可以让我们决定所使用的标记颜色,大小和类型。 有一堆标记选项,请参阅 Matplotlib 标记文档中的所有选项。
五、堆叠图
在这篇 Matplotlib 数据可视化教程中,我们要介绍如何创建堆叠图。 堆叠图用于显示『部分对整体』随时间的关系。 堆叠图基本上类似于饼图,只是随时间而变化。
让我们考虑一个情况,我们一天有 24 小时,我们想看看我们如何花费时间。 我们将我们的活动分为:睡觉,吃饭,工作和玩耍。
我们假设我们要在 5 天的时间内跟踪它,因此我们的初始数据将如下所示:
import matplotlib.pyplot as plt
days = [1,2,3,4,5]
sleeping = [7,8,6,11,7]
eating = [2,3,4,3,2]
working = [7,8,7,2,2]
playing = [8,5,7,8,13]
因此,我们的x轴将包括day变量,即 1, 2, 3, 4 和 5。然后,日期的各个成分保存在它们各自的活动中。 像这样绘制它们:
plt.stackplot(days, sleeping,eating,working,playing, colors=['m','c','r','k'])
plt.xlabel('x')
plt.ylabel('y')
plt.title('Interesting Graph\nCheck it out')
plt.show()
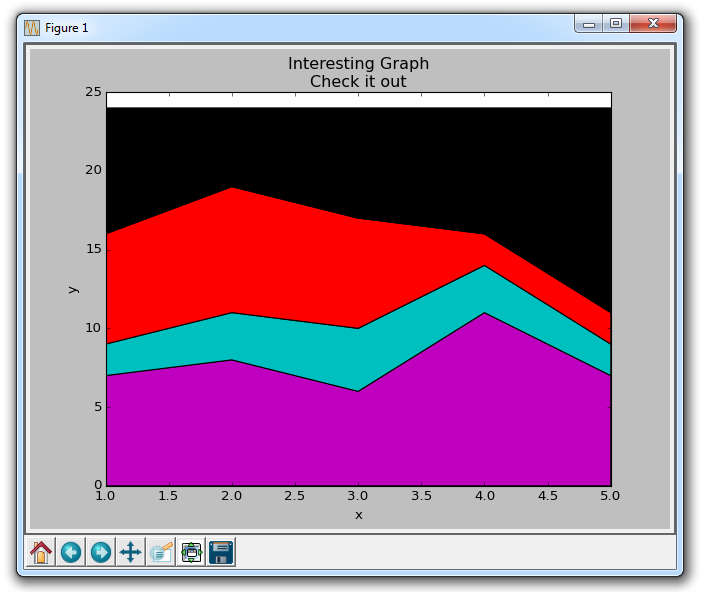
在这里,我们可以至少在颜色上看到,我们如何花费我们的时间。 问题是,如果不回头看代码,我们不知道什么颜色是什么。 下一个问题是,对于多边形来说,我们实际上不能为数据添加『标签』。 因此,在任何不止是线条,带有像这样的填充或堆叠图的地方,我们不能以固有方式标记出特定的部分。 这不应该阻止程序员。 我们可以解决这个问题:
import matplotlib.pyplot as plt
days = [1,2,3,4,5]
sleeping = [7,8,6,11,7]
eating = [2,3,4,3,2]
working = [7,8,7,2,2]
playing = [8,5,7,8,13]
plt.plot([],[],color='m', label='Sleeping', linewidth=5)
plt.plot([],[],color='c', label='Eating', linewidth=5)
plt.plot([],[],color='r', label='Working', linewidth=5)
plt.plot([],[],color='k', label='Playing', linewidth=5)
plt.stackplot(days, sleeping,eating,working,playing, colors=['m','c','r','k'])
plt.xlabel('x')
plt.ylabel('y')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
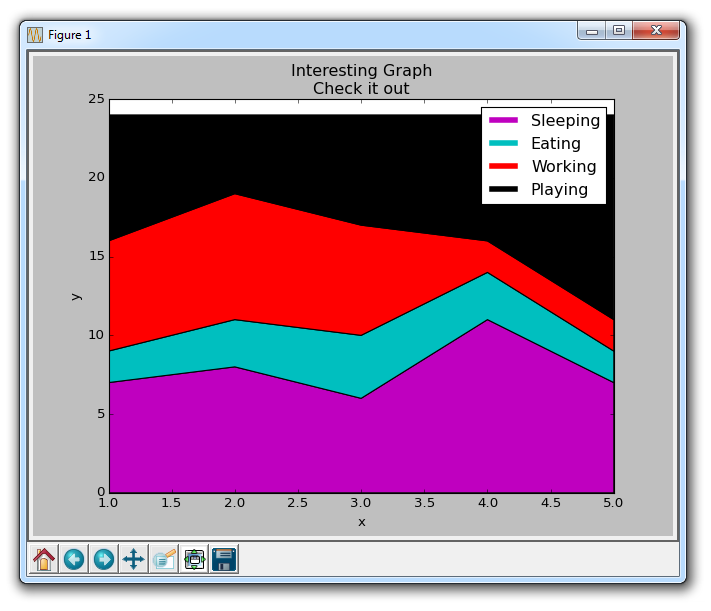
我们在这里做的是画一些空行,给予它们符合我们的堆叠图的相同颜色,和正确标签。 我们还使它们线宽为 5,使线条在图例中显得较宽。 现在,我们可以很容易地看到,我们如何花费我们的时间。
六、饼图
饼图很像堆叠图,只是它们位于某个时间点。 通常,饼图用于显示部分对于整体的情况,通常以%为单位。 幸运的是,Matplotlib 会处理切片大小以及一切事情,我们只需要提供数值。
import matplotlib.pyplot as plt
slices = [7,2,2,13]
activities = ['sleeping','eating','working','playing']
cols = ['c','m','r','b']
plt.pie(slices,
labels=activities,
colors=cols,
startangle=90,
shadow= True,
explode=(0,0.1,0,0),
autopct='%1.1f%%')
plt.title('Interesting Graph\nCheck it out')
plt.show()
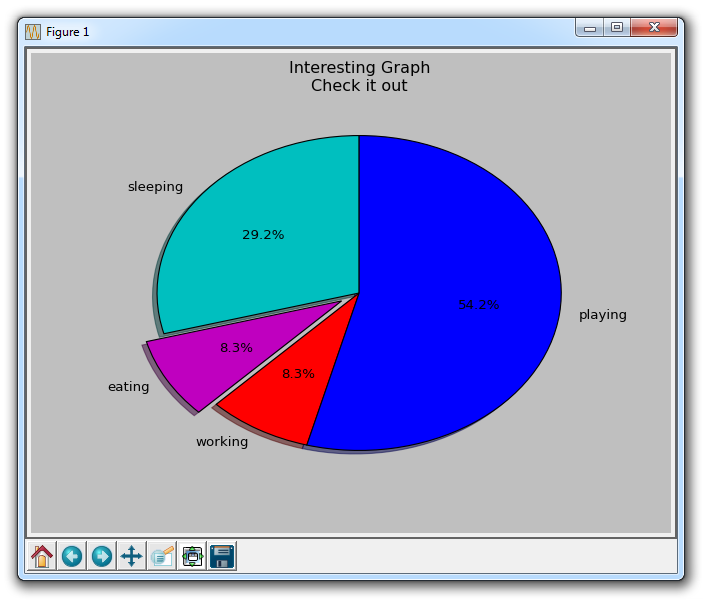
在plt.pie中,我们需要指定『切片』,这是每个部分的相对大小。 然后,我们指定相应切片的颜色列表。 接下来,我们可以选择指定图形的『起始角度』。 这使你可以在任何地方开始绘图。 在我们的例子中,我们为饼图选择了 90 度角,这意味着第一个部分是一个竖直线条。 接下来,我们可以选择给绘图添加一个字符大小的阴影,然后我们甚至可以使用explode拉出一个切片。
我们总共有四个切片,所以对于explode,如果我们不想拉出任何切片,我们传入0,0,0,0。 如果我们想要拉出第一个切片,我们传入0.1,0,0,0。
最后,我们使用autopct,选择将百分比放置到图表上面。
七、从文件加载数据
很多时候,我们想要绘制文件中的数据。 有许多类型的文件,以及许多方法,你可以使用它们从文件中提取数据来图形化。 在这里,我们将展示几种方法。 首先,我们将使用内置的csv模块加载CSV文件,然后我们将展示如何使用 NumPy(第三方模块)加载文件。
import matplotlib.pyplot as plt
import csv
x = []
y = []
with open('example.txt','r') as csvfile:
plots = csv.reader(csvfile, delimiter=',')
for row in plots:
x.append(int(row[0]))
y.append(int(row[1]))
plt.plot(x,y, label='Loaded from file!')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
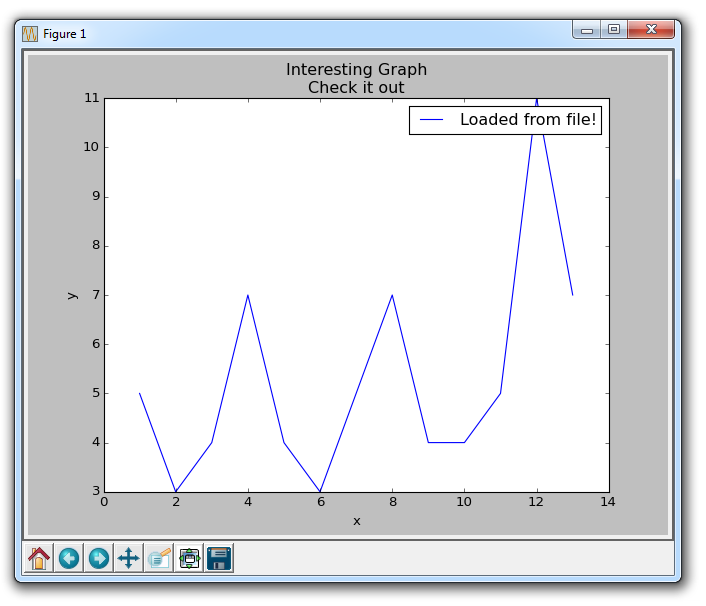
这里,我们打开样例文件,包含以下数据:
1,5
2,3
3,4
4,7
5,4
6,3
7,5
8,7
9,4
10,4
接下来,我们使用csv模块读取数据。 csv读取器自动按行分割文件,然后使用我们选择的分隔符分割文件中的数据。 在我们的例子中,这是一个逗号。 注意:csv模块和csv reader不需要文件在字面上是一个.csv文件。 它可以是任何具有分隔数据的简单的文本文件。
一旦我们这样做了,我们将索引为 0 的元素存储到x列表,将索引为 1 的元素存储到y列表中。 之后,我们都设置好了,准备绘图,然后显示数据。
虽然使用 CSV 模块是完全正常的,但使用 NumPy 模块来加载我们的文件和数据,可能对我们更有意义。 如果你没有 NumPy,你需要按下面的步骤来获取它。 为了了解安装模块的更多信息,请参阅 pip 教程。 大多数人应该都能打开命令行,并执行pip install numpy。
如果不能,请参阅链接中的教程。
一旦你安装了 NumPy,你可以编写如下代码:
import matplotlib.pyplot as plt
import numpy as np
x, y = np.loadtxt('example.txt', delimiter=',', unpack=True)
plt.plot(x,y, label='Loaded from file!')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
结果应该是相同的图表。 稍后,当我们加载数据时,我们可以利用 NumPy 为我们做一些更多的工作,但这是教程未来的内容。 就像csv模块不需要一个特地的.csv一样,loadtxt函数不要求文件是一个.txt文件,它可以是一个.csv,它甚至可以是一个 python 列表对象。
八、从网络加载数据
除了从文件加载数据,另一个流行的数据源是互联网。 我们可以用各种各样的方式从互联网加载数据,但对我们来说,我们只是简单地读取网站的源代码,然后通过简单的拆分来分离数据。
import matplotlib.pyplot as plt
import numpy as np
import urllib
import matplotlib.dates as mdates
def graph_data(stock):
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line:
stock_data.append(line)
这里有很多步骤。首先,我们看到import。 pyplot像往常一样导入,然后导入了numpy,然后是用于访问互联网的urllib,然后导入了matplotlib.dates作为mdates,它对于将日期戳转换为 matplotlib 可以理解的日期很有用。
接下来,我们开始构建我们的graph_data函数。在这里,我们首先定义包含股票数据的网址。之后,我们写一些urllib代码来访问该 URL,然后使用.read读取源代码,之后我们继续解码该数据。如果你使用 Python 2,则不必使用decode。
然后,我们定义一个空列表,这是我们将要放置股票数据的地方,我们也开始使用split_source变量拆分数据,以换行符拆分。
现在,如果你去看源代码,用stock替换 URL 中的+stock+,像 AAPL 那样,你可以看到大多数页面数据确实是股票定价信息,但有一些头信息我们需要过滤掉。为此,我们使用一些基本的过滤,检查它们来确保每行有 6 个数据点,然后确保术语values不在行中。
现在,我们已经解析了数据,并做好了准备。我们将使用 NumPy:
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
# %Y = full year. 2015
# %y = partial year 15
# %m = number month
# %d = number day
# %H = hours
# %M = minutes
# %S = seconds
# 12-06-2014
# %m-%d-%Y
converters={0: bytespdate2num('%Y%m%d')})
我们在这里所做的是,使用numpy的loadtxt函数,并将这六个元素解构到六个变量。 这里的第一个参数是stock_data,这是我们加载的数据。 然后,我们指定delimiter(这里是逗号),然后我们指定我们确实想要在这里解包变量,不是一个变量,而是我们定义的这组变量。 最后,我们使用可选的converters参数来指定我们要转换的元素(0),以及我们打算要怎么做。 我们传递一个名为bytespdate2num的函数,它还不存在,但我们下面会编写它。
九、时间戳的转换
本教程的重点是将来自 Yahoo finance API 的日期转换为 Matplotlib 可理解的日期。 为了实现它,我们要写一个新的函数,bytespdate2num。
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
此函数接受数据,基于编码来解码数据,然后返回它。
将此应用于我们的程序的其余部分:
import matplotlib.pyplot as plt
import numpy as np
import urllib
import matplotlib.dates as mdates
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
# %Y = full year. 2015
# %y = partial year 15
# %m = number month
# %d = number day
# %H = hours
# %M = minutes
# %S = seconds
# 12-06-2014
# %m-%d-%Y
converters={0: bytespdate2num('%Y%m%d')})
plt.plot_date(date, closep,'-', label='Price')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.show()
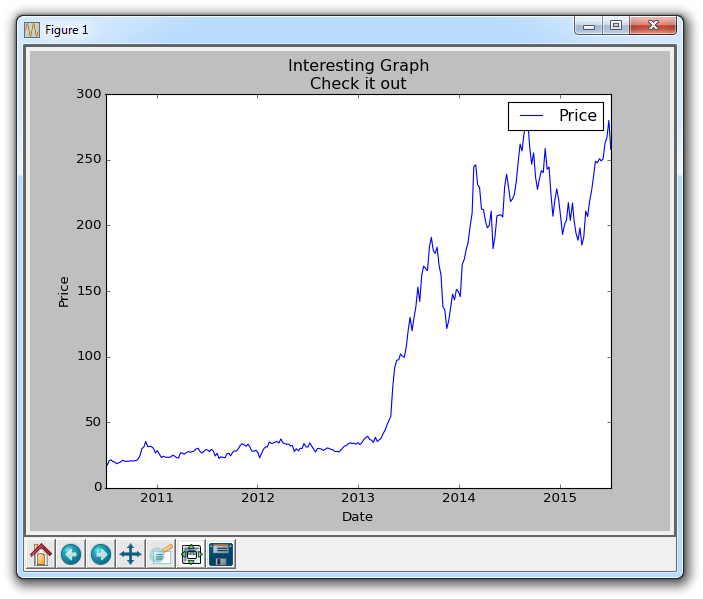
graph_data('TSLA')
如果你绘制 TSLA,结果图应该看起来像这样:
十、基本的自定义
在 Matplotlib 教程中,我们将讨论一些可能的图表自定义。 为了开始修改子图,我们必须定义它们。 我们很快会谈论他们,但有两种定义并构造子图的主要方法。 现在,我们只使用其中一个,但我们会很快解释它们。
现在,修改我们的graph_data函数:
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
为了修改图表,我们需要引用它,所以我们将它存储到变量fig。 然后我们将ax1定义为图表上的子图。 我们在这里使用subplot2grid,这是获取子图的两种主要方法之一。 我们将深入讨论这些东西,但现在,你应该看到我们有 2 个元组,它们提供了(1,1)和(0,0)。 1,1表明这是一个 1×1 网格。 然后0,0表明这个子图的『起点』将为0,0。
接下来,通过我们已经编写的代码来获取和解析数据:
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
下面,我们这样绘制数据:
ax1.plot_date(date, closep,'-', label='Price')
现在,由于我们正在绘制日期,我们可能会发现,如果我们放大,日期会在水平方向上移动。但是,我们可以自定义这些刻度标签,像这样:
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
这将使标签转动到对角线方向。 接下来,我们可以添加一个网格:
ax1.grid(True)
然后,其它东西我们保留默认,但我们也可能需要略微调整绘图,因为日期跑到了图表外面。 记不记得我们在第一篇教程中讨论的configure subplots按钮? 我们不仅可以以这种方式配置图表,我们还可以在代码中配置它们,以下是我们设置这些参数的方式:
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
现在,为了防止我们把你遗留在某个地方,这里是完整的代码:
import matplotlib.pyplot as plt
import numpy as np
import urllib
import matplotlib.dates as mdates
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
ax1.plot_date(date, closep,'-', label='Price')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.grid(True)#, color='g', linestyle='-', linewidth=5)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('TSLA')
结果为:
十一、Unix 时间
在这个 Matplotlib 教程中,我们将介绍如何处理 unix 时间戳的转换,然后在图形中绘制日期戳。 使用 Yahoo Finance API,你会注意到,如果你使用较大的时间间隔,如1y(一年),你会得到我们一直在使用的日期戳,但如果你使用10d(10 天),反之你会得到 unix 时间的时间戳。
Unix 时间是 1970 年 1 月 1 日以后的秒数,它是跨程序的标准化时间表示方法。 也就是说,Matplotlib 并不欢迎 unix 时间戳。 这里是你可以使用 Matplotlib 来处理 unix 时间的方式:
import matplotlib.pyplot as plt
import numpy as np
import urllib
import datetime as dt
import matplotlib.dates as mdates
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10d/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True)
dateconv = np.vectorize(dt.datetime.fromtimestamp)
date = dateconv(date)
## date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
## delimiter=',',
## unpack=True,
## converters={0: bytespdate2num('%Y%m%d')})
ax1.plot_date(date, closep,'-', label='Price')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.grid(True)#, color='g', linestyle='-', linewidth=5)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title('Interesting Graph\nCheck it out')
plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('TSLA')
所以在这里,我们所做的是 unix 时间的写入处理,并注释掉我们以前的代码,因为我们为之后的使用而保存它。 这里的主要区别是:
dateconv = np.vectorize(dt.datetime.fromtimestamp)
date = dateconv(date)
这里,我们将时间戳转换为日期戳,然后将其转换为 Matplotlib 想要的时间。
现在,由于某些原因,我的 unix 时间带有另一行包含 6 个元素的数据,并且它包含了术语label,因此,在我们解析数据的for循环中,我们为你再添加一个需要注意的检查:
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
现在你的图表应该类似:
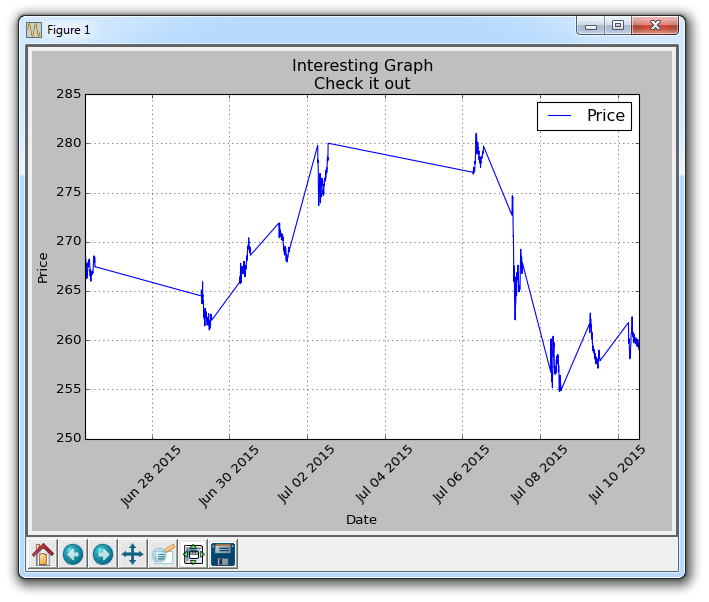
这里的所有扁平线条的原因是市场关闭。 有了这个短期数据,我们可以得到日内数据。 所以交易开放时有很多点,然后市场关闭时就没有了,然后又是一堆,然后又是没有。
十二、颜色和填充
在本教程中,我们将介绍一些更多的自定义,比如颜色和线条填充。
我们要做的第一个改动是将plt.title更改为stock变量。
plt.title(stock)
现在,让我们来介绍一下如何更改标签颜色。 我们可以通过修改我们的轴对象来实现:
ax1.xaxis.label.set_color('c')
ax1.yaxis.label.set_color('r')
如果我们运行它,我们会看到标签改变了颜色,就像在单词中那样。
接下来,我们可以为要显示的轴指定具体数字,而不是像这样的自动选择:
ax1.set_yticks([0,25,50,75])
接下来,我想介绍填充。 填充所做的事情,是在变量和你选择的一个数值之间填充颜色。 例如,我们可以这样:
ax1.fill_between(date, 0, closep)
所以到这里,我们的代码为:
import matplotlib.pyplot as plt
import numpy as np
import urllib
import datetime as dt
import matplotlib.dates as mdates
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
ax1.fill_between(date, 0, closep)
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.grid(True)#, color='g', linestyle='-', linewidth=5)
ax1.xaxis.label.set_color('c')
ax1.yaxis.label.set_color('r')
ax1.set_yticks([0,25,50,75])
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
结果为:
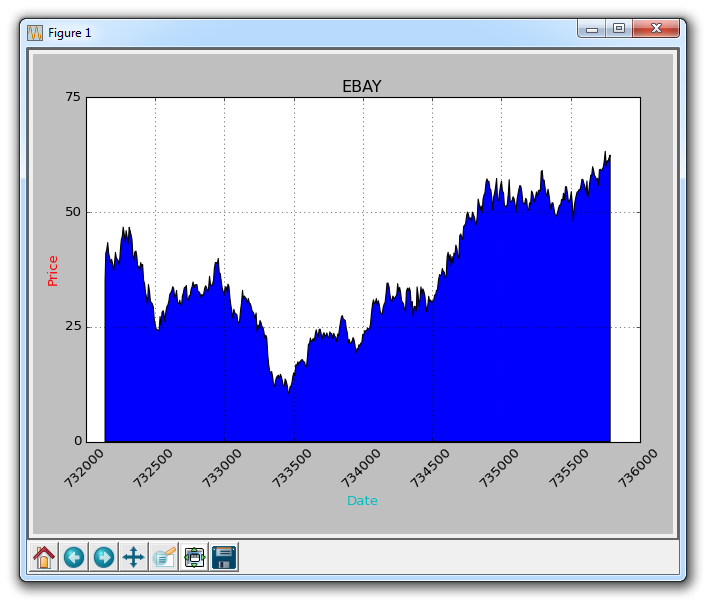
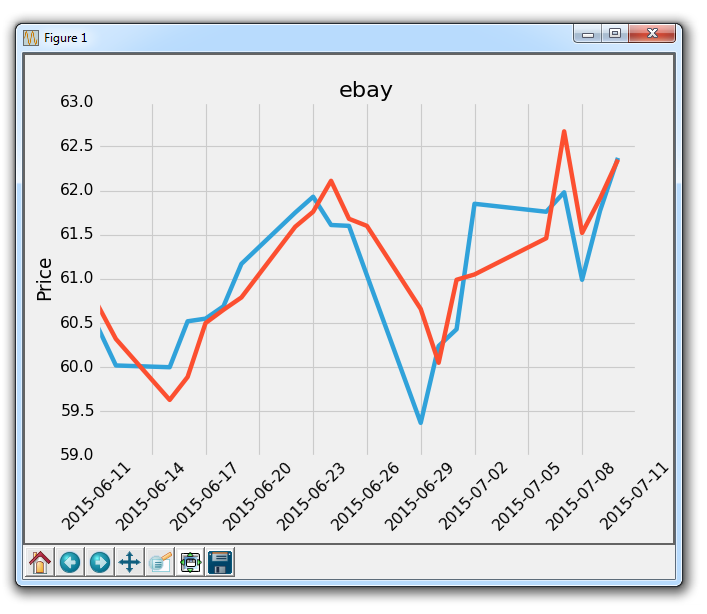
填充的一个问题是,我们可能最后会把东西都覆盖起来。 我们可以用透明度来解决它:
ax1.fill_between(date, 0, closep)
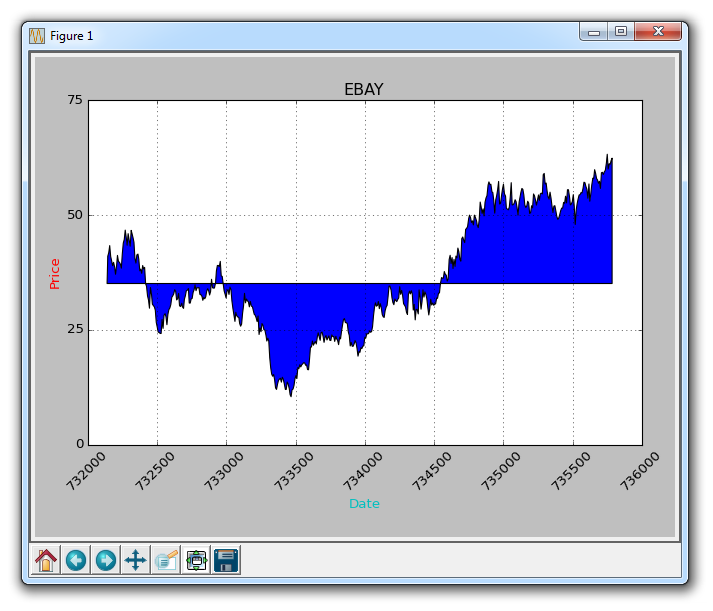
现在,让我们介绍条件填充。 让我们假设图表的起始位置是我们开始买入 eBay 的地方。 这里,如果价格低于这个价格,我们可以向上填充到原来的价格,然后如果它超过了原始价格,我们可以向下填充。 我们可以这样做:
ax1.fill_between(date, closep[0], closep)
会生成:
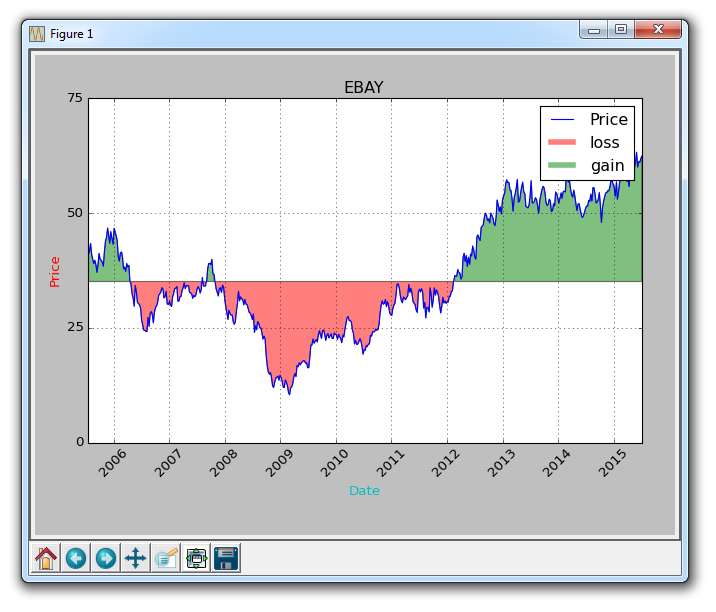
如果我们想用红色和绿色填充来展示收益/损失,那么与原始价格相比,绿色填充用于上升(注:国外股市的颜色和国内相反),红色填充用于下跌? 没问题! 我们可以添加一个where参数,如下所示:
ax1.fill_between(date, closep, closep[0],where=(closep > closep[0]), facecolor='g', alpha=0.5)
这里,我们填充当前价格和原始价格之间的区域,其中当前价格高于原始价格。 我们给予它绿色的前景色,因为这是一个上升,而且我们使用微小的透明度。
我们仍然不能对多边形数据(如填充)应用标签,但我们可以像以前一样实现空线条,因此我们可以:
ax1.plot([],[],linewidth=5, label='loss', color='r',alpha=0.5)
ax1.plot([],[],linewidth=5, label='gain', color='g',alpha=0.5)
ax1.fill_between(date, closep, closep[0],where=(closep > closep[0]), facecolor='g', alpha=0.5)
ax1.fill_between(date, closep, closep[0],where=(closep < closep[0]), facecolor='r', alpha=0.5)
这向我们提供了一些填充,以及用于处理标签的空线条,我们打算将其显示在图例中。这里完整的代码是:
import matplotlib.pyplot as plt
import numpy as np
import urllib
import datetime as dt
import matplotlib.dates as mdates
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
ax1.plot_date(date, closep,'-', label='Price')
ax1.plot([],[],linewidth=5, label='loss', color='r',alpha=0.5)
ax1.plot([],[],linewidth=5, label='gain', color='g',alpha=0.5)
ax1.fill_between(date, closep, closep[0],where=(closep > closep[0]), facecolor='g', alpha=0.5)
ax1.fill_between(date, closep, closep[0],where=(closep < closep[0]), facecolor='r', alpha=0.5)
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.grid(True)#, color='g', linestyle='-', linewidth=5)
ax1.xaxis.label.set_color('c')
ax1.yaxis.label.set_color('r')
ax1.set_yticks([0,25,50,75])
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
现在我们的结果是:
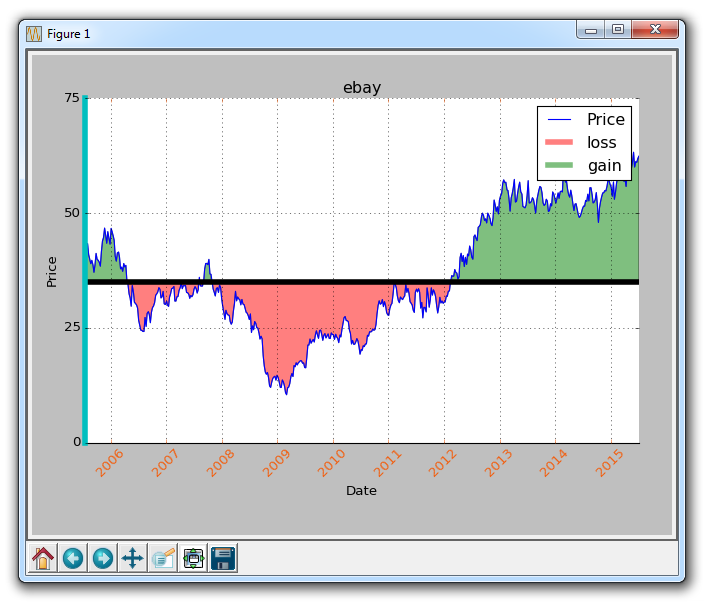
十三、边框和水平线条
欢迎阅读另一个定制教程,在这里我们使用 Matplotlib 讨论边框和水平线条。 有时候你可能想做的事情是改变边框的颜色,或者甚至完全删除它们。
图形的边框基本上是图形的边界,其中有刻度线等东西。为了改变边框的颜色,你可以做一些类似这样的事情:
ax1.spines['left'].set_color('c')
在这里,我们引用了我们的边框字典,表示我们要调整左边框,然后我们使用set_color方法将颜色设置为'c',它是青色。
如果我们想删除所有边框怎么办? 我们可以这样做:
ax1.spines['right'].set_visible(False)
ax1.spines['top'].set_visible(False)
这是非常类似的代码,删除了右边框和上边框。
很难看到我们修改了左边框的颜色,所以让我们通过修改线宽来使它变得很明显:
ax1.spines['left'].set_linewidth(5)
现在,左边框变成了非常粗也非常显眼的青色。 最后,如果我们想修改刻度参数怎么办? 假如不想要黑色的日期,我们想要一些橙色的日期? 没问题!
ax1.tick_params(axis='x', colors='#f06215')
现在我们的日期是橙色了! 接下来,让我们来看看我们如何绘制一条水平线。 你当然可以将你创建的一组新数据绘制成一条水平线,但你不需要这样做。 你可以:
ax1.axhline(closep[0], color='k', linewidth=5)
所以在这里,我们的整个代码是:
import matplotlib.pyplot as plt
import numpy as np
import urllib
import datetime as dt
import matplotlib.dates as mdates
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=10y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
ax1.plot_date(date, closep,'-', label='Price')
ax1.plot([],[],linewidth=5, label='loss', color='r',alpha=0.5)
ax1.plot([],[],linewidth=5, label='gain', color='g',alpha=0.5)
ax1.axhline(closep[0], color='k', linewidth=5)
ax1.fill_between(date, closep, closep[0],where=(closep > closep[0]), facecolor='g', alpha=0.5)
ax1.fill_between(date, closep, closep[0],where=(closep < closep[0]), facecolor='r', alpha=0.5)
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.grid(True)
#ax1.xaxis.label.set_color('c')
#ax1.yaxis.label.set_color('r')
ax1.set_yticks([0,25,50,75])
ax1.spines['left'].set_color('c')
ax1.spines['right'].set_visible(False)
ax1.spines['top'].set_visible(False)
ax1.spines['left'].set_linewidth(5)
ax1.tick_params(axis='x', colors='#f06215')
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('ebay')
结果为:
十四、OHLC K 线图
在 Matplotlib 教程中,我们将介绍如何在 Matplotlib 中创建开,高,低,关(OHLC)的 K 线图。 这些图表用于以精简形式显示时间序列股价信息。 为了实现它,我们首先需要导入一些模块:
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
我们引入了ticker,允许我们修改图表底部的ticker信息。 然后我们从matplotlib.finance模块中引入candlestick_ohlc功能。
现在,我们需要组织我们的数据来和 matplotlib 协作。 如果你刚刚加入我们,我们得到的数据如下:
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
现在,我们需要构建一个 Python 列表,其中每个元素都是数据。 我们可以修改我们的loadtxt函数,使其不解构,但随后我们还是希望引用特定的数据点。 我们可以解决这个问题,但是我们最后可能只拥有两个单独的数据集。 为此,我们执行以下操作:
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
有了这个,我们现在将 OHLC 数据列表存储到我们的变量ohlc。 现在我们可以这样绘制:
candlestick_ohlc(ax1, ohlc)
图表应该是这样:
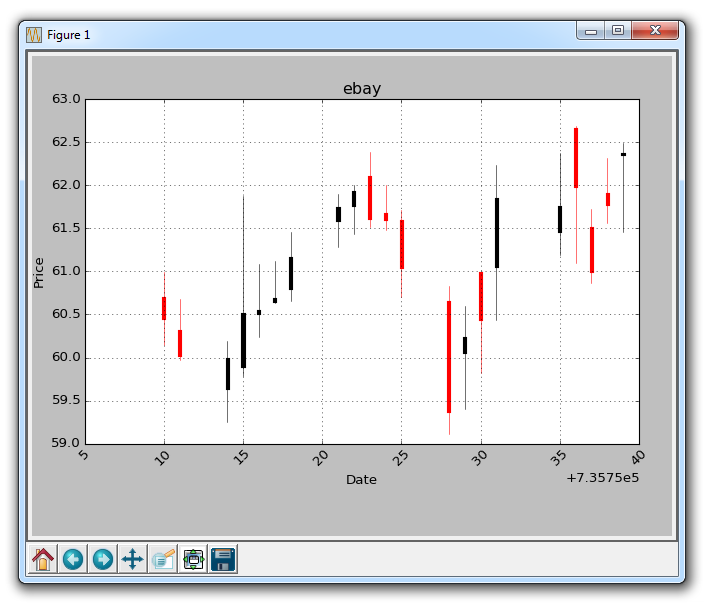
不幸的是,x轴上的datetime数据不是日期戳的形式。 我们可以处理它:
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
此外,红/黑着色依我看不是最好的选择。 我们应该使用绿色表示上升和红色表示下降。 为此,我们可以:
candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
最后,我们可以将x标签设置为我们想要的数量,像这样:
ax1.xaxis.set_major_locator(mticker.MaxNLocator(10))
现在,完整代码现在是这样:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
import numpy as np
import urllib
import datetime as dt
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax1.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax1.grid(True)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
结果为:
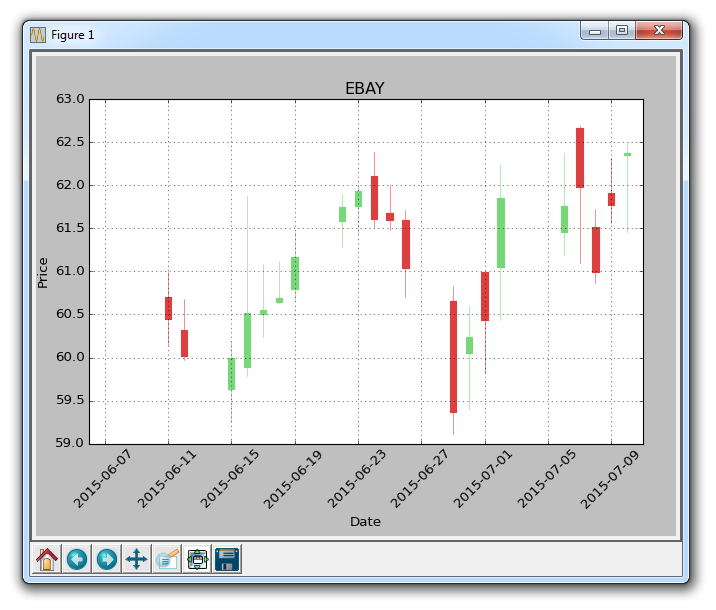
还要注意,我们从前面的教程中删除了大部分ax1的修改。
十五、样式
在这个 Matplotlib 教程中,我们将讨论样式。 我们用于 Matplotlib 的样式非常相似于用于 HTML 页面的 CSS(层叠样式表)。 正如你在这里可以看到的,我们对图形所做的所有修改都会叠加,而且我们目前只有一个轴域。 我们可以使用for循环,至少使代码量降低,但我们也可以在 Matplotlib 中利用这些样式。
样式页的想法是将自定义样式写入文件,然后,为了使用这些更改并将其应用于图形,所有你需要做的就是导入样式,然后使用该特定样式。 这样,让我们假设你发现自己总是改变图形的各种元素。 你不必为每个图表编写 25 ~ 200 行自定义代码,只需将其写入一个样式,然后加载该样式,并以两行应用所有这些更改即可! 让我们开始吧。
from matplotlib import style
接下来,我们指定要使用的样式。 Matplotlib 已经有了几种样式。
我们可以这样来使用样式:
style.use('ggplot')
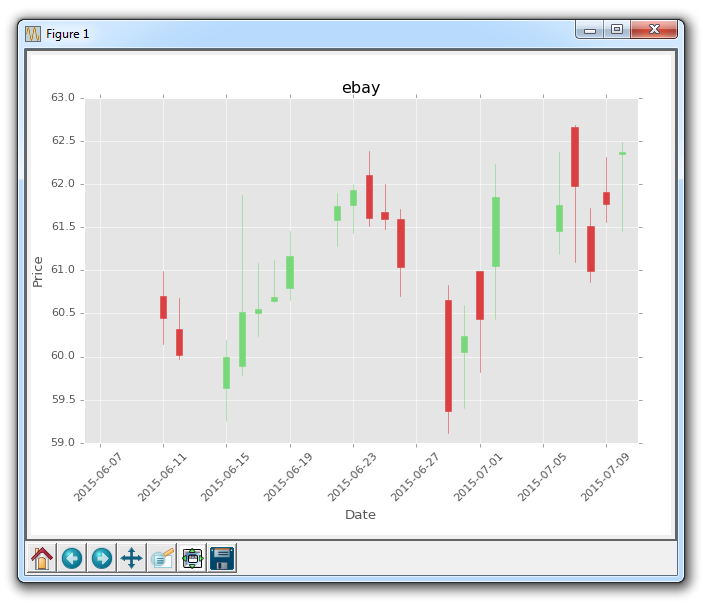
除了标题,标签的颜色是灰色的,轴域的背景是浅灰色,我们可以立即分辨字体是不同的。 我们还注意到,网格实际上是一个白色的实线。 我们的 K 线图保持不变,主要是因为我们在事后定制它。 在样式中加载时,更改会生效,但如果在加载样式后编写新的自定义代码,你的更改也会生效。
因为我们试图展示样式模块,但是让我们继续,简单绘制几行,并暂且注释掉 K 线图:
#candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
ax1.plot(date,closep)
ax1.plot(date,openp)
会生成:
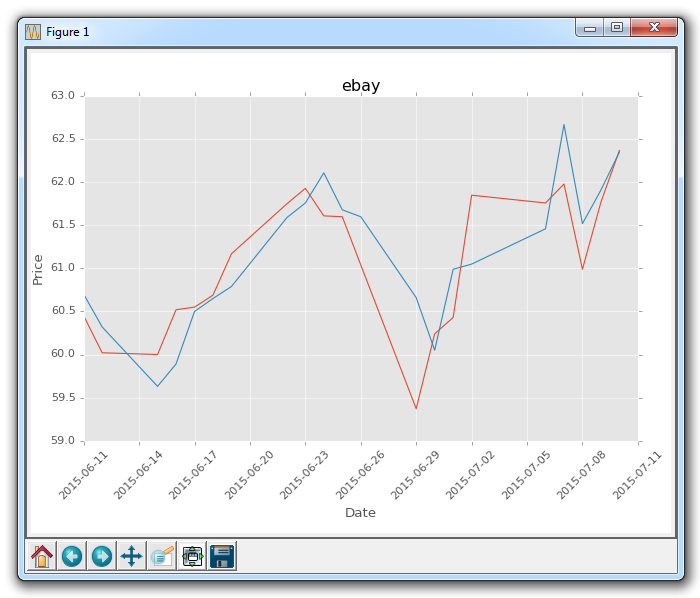
已经比默认值好多了!
样式的另一个例子是fivethirtyeight:
你可以这样查看所有的可用样式:
print(plt.style.available)
我这里它提供了['bmh', 'dark_background', 'ggplot', 'fivethirtyeight', 'grayscale']。
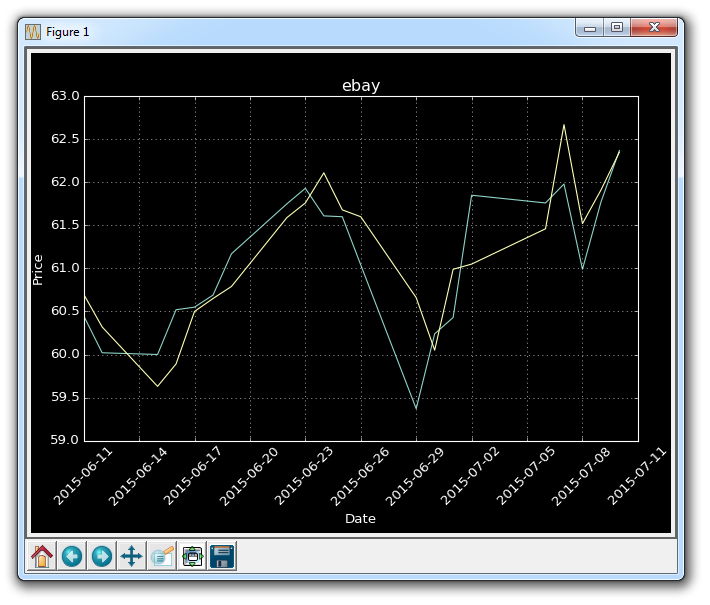
让我们尝试dark_background:
style.use('dark_background')
现在,如果你想制作自己的风格呢? 首先,你需要找到样式目录。 为了实现它,如果你知道它在哪里,你可以前往你的 matplotlib 目录,或者你可以找到该目录。 如果你不知道如何找到该目录,你可以执行以下操作:
print(plt.__file__)
这至少会告诉你pyplot模块的位置。
在 matplotlib 目录中,你需要寻找mpl-data。 然后在那里,你需要寻找stylelib。 在 Windows 上 ,我的完整路径是:C:\Python34\Lib\site-packages\matplotlib\mpl-data\stylelib。
那里应该显示了所有可用的.mplstyle文件。 你可以编辑、复制或重命名它们,然后在那里修改为你想要的东西。 然后,无论你用什么来命名.mplstyle文件,都要放在style.use中。
十六、实时图表
在这篇 Matplotlib 教程中,我们将介绍如何创建实时更新图表,可以在数据源更新时更新其图表。 你可能希望将此用于绘制股票实时定价数据,或者可以将传感器连接到计算机,并且显示传感器实时数据。 为此,我们使用 Matplotlib 的动画功能。
最开始:
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from matplotlib import style
这里,唯一的新增导入是matplotlib.animation as animation。 这是一个模块,允许我们在显示之后对图形进行动画处理。
接下来,我们添加一些你熟悉的代码,如果你一直关注这个系列:
style.use('fivethirtyeight')
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
现在我们编写动画函数:
def animate(i):
graph_data = open('example.txt','r').read()
lines = graph_data.split('\n')
xs = []
ys = []
for line in lines:
if len(line) > 1:
x, y = line.split(',')
xs.append(x)
ys.append(y)
ax1.clear()
ax1.plot(xs, ys)
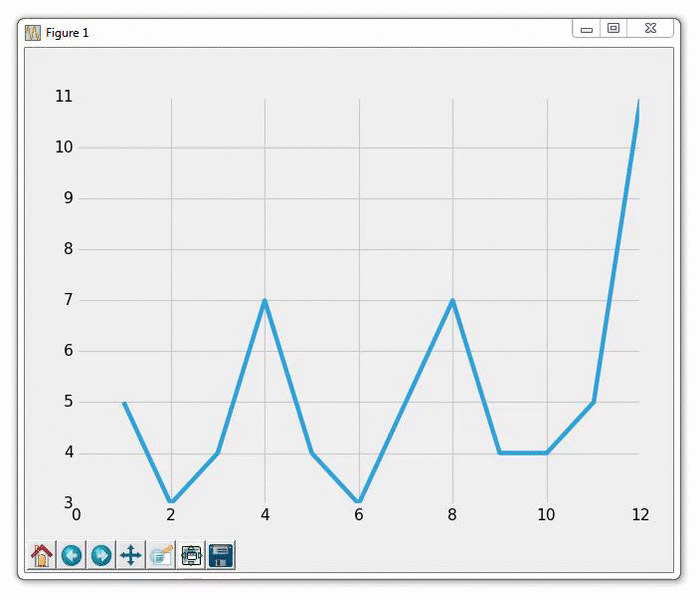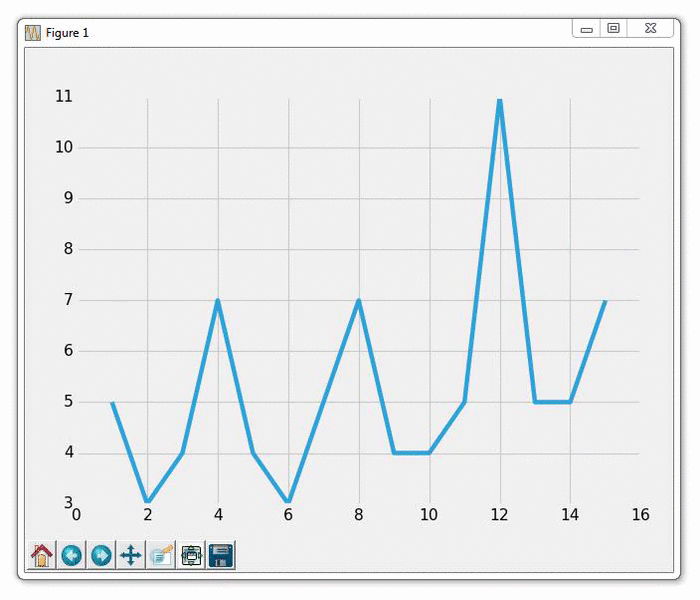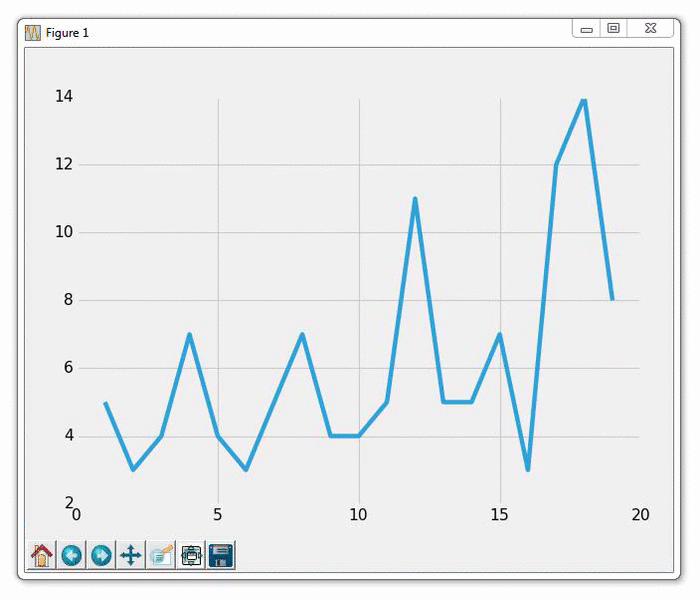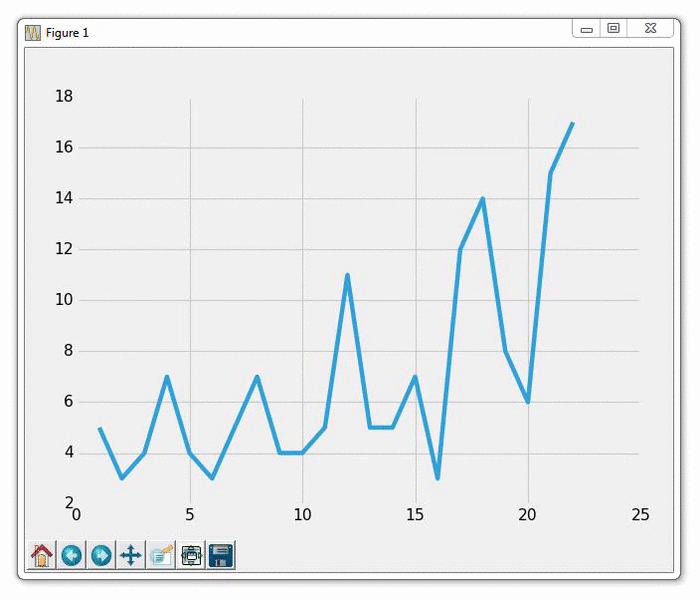
我们在这里做的是构建数据,然后绘制它。 注意我们这里不调用plt.show()。 我们从一个示例文件读取数据,其内容如下:
1,5
2,3
3,4
4,7
5,4
6,3
7,5
8,7
9,4
10,4
我们打开上面的文件,然后存储每一行,用逗号分割成xs和ys,我们将要绘制它。 然后:
ani = animation.FuncAnimation(fig, animate, interval=1000)
plt.show()
我们运行动画,将动画放到图表中(fig),运行animate的动画函数,最后我们设置了 1000 的间隔,即 1000 毫秒或 1 秒。
运行此图表的结果应该像往常一样生成图表。 然后,你应该能够使用新的坐标更新example.txt文件。 这样做会生成一个自动更新的图表,如下:
十七、注解和文本
在本教程中,我们将讨论如何向 Matplotlib 图形添加文本。 我们可以通过两种方式来实现。 一种是将文本放置在图表上的某个位置。 另一个是专门注解图表上的绘图,来引起注意。
这里的起始代码是教程 15,它在这里:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax1.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax1.grid(True)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('ebay')
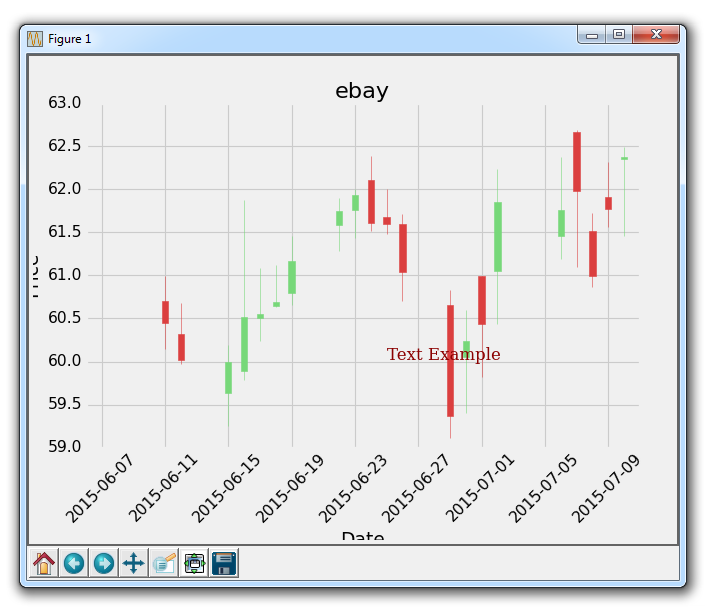
所以这里是 Yahoo Finance API 的 eBay 的 OHLC K 线图。 这里我们要讲解的第一件事是向图形添加文本。
font_dict = {'family':'serif',
'color':'darkred',
'size':15}
ax1.text(date[10], closep[1],'Text Example', fontdict=font_dict)
在这里,我们需要做一些事情。 首先,我们使用ax1.text添加文本。 我们使用我们的数据,以坐标形式给出此文本的位置。 首先给出文本的坐标,然后给出要放置的实际文本。 接下来,我们使用fontdict参数添加一个数据字典,来使用所用的字体。 在我们的字体字典中,我们将字体更改为serif,颜色为『深红色』,然后将字体大小更改为 15。这将全部应用于我们的图表上的文本,如下所示:
太棒了,接下来我们可以做的是,注解某个特定的绘图。 我们希望这样做来给出更多的信息。 在 eBay 的例子中,也许我们想解释某个具体绘图,或给出一些关于发生了什么的信息。 在股价的例子中,也许有一些发生的新闻会影响价格。 你可以注解新闻来自哪里,这将有助于解释定价变化。
ax1.annotate('Bad News!',(date[9],highp[9]),
xytext=(0.8, 0.9), textcoords='axes fraction',
arrowprops = dict(facecolor='grey',color='grey'))
这里,我们用ax1.annotate来注解。 我们首先传递我们想要注解的文本,然后传递我们让这个注解指向的坐标。 我们这样做,是因为当我们注释时,我们可以绘制线条和指向特定点的箭头。 接下来,我们指定xytext的位置。 它可以是像我们用于文本放置的坐标位置,但是让我们展示另一个例子。 它可以为轴域小数,所以我们使用 0.8 和 0.9。 这意味着文本的位置在x轴的80%和y轴的90%处。 这样,如果我们移动图表,文本将保持在相同位置。
执行它,会生成:
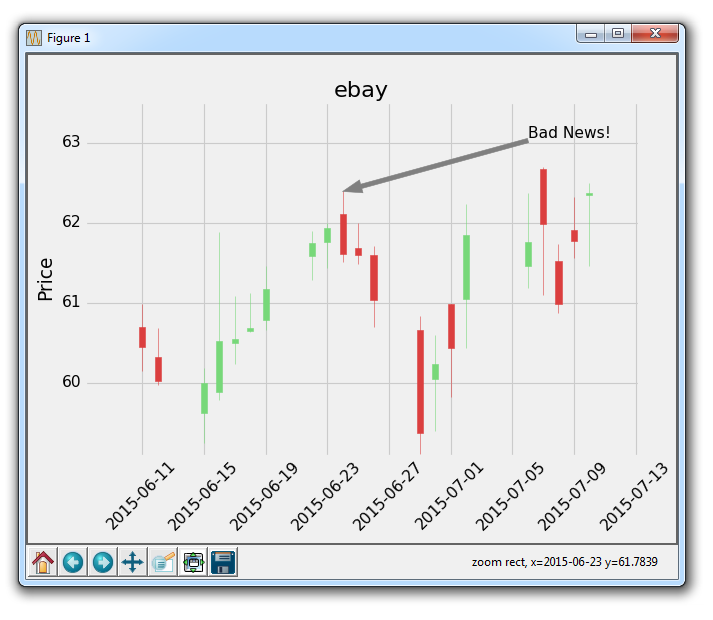
根据你学习这个教程的时间,所指向的点可能有所不同,这只是一个注解的例子,其中有一些合理的想法,即为什么我们需要注解一些东西。
当图表启动时,请尝试单击平移按钮(蓝色十字),然后移动图表。 你会看到文本保持不动,但箭头跟随移动并继续指向我们想要的具体的点。 这很酷吧!
最后一个图表的完整代码:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax1.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax1.grid(True)
ax1.annotate('Bad News!',(date[9],highp[9]),
xytext=(0.8, 0.9), textcoords='axes fraction',
arrowprops = dict(facecolor='grey',color='grey'))
## # Text placement example:
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## ax1.text(date[10], closep[1],'Text Example', fontdict=font_dict)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
#plt.legend()
plt.subplots_adjust(left=0.09, bottom=0.20, right=0.94, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('ebay')
现在,使用注解,我们可以做一些其他事情,如注解股票图表的最后价格。 这就是我们接下来要做的。
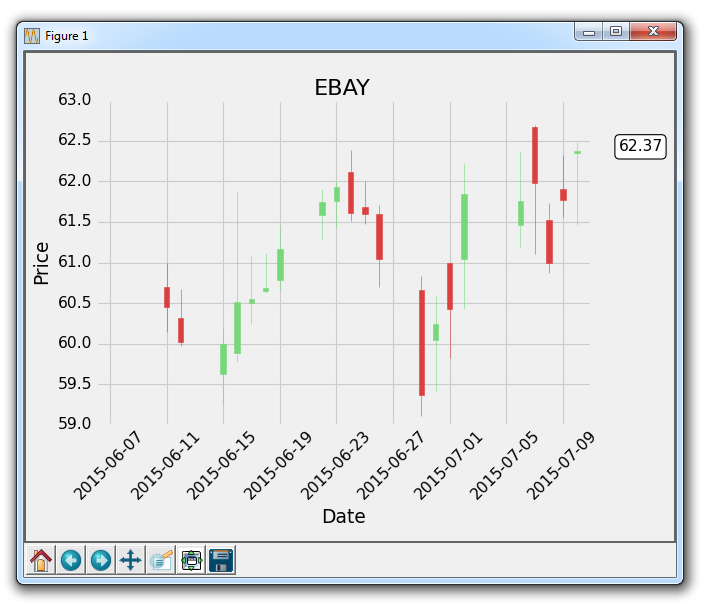
十八、注解股票图表的最后价格
在这个 Matplotlib 教程中,我们将展示如何跟踪股票的最后价格的示例,通过将其注解到轴域的右侧,就像许多图表应用程序会做的那样。
虽然人们喜欢在他们的实时图表中看到历史价格,他们也想看到最新的价格。 大多数应用程序做的是,在价格的y轴高度处注释最后价格,然后突出显示它,并在价格变化时,在框中将其略微移动。 使用我们最近学习的注解教程,我们可以添加一个bbox。
我们的核心代码是:
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax1.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
我们使用ax1.annotate来放置最后价格的字符串值。 我们不在这里使用它,但我们将要注解的点指定为图上最后一个点。 接下来,我们使用xytext将我们的文本放置到特定位置。 我们将它的y坐标指定为最后一个点的y坐标,x坐标指定为最后一个点的x坐标,再加上几个点。我们这样做是为了将它移出图表。 将文本放在图形外面就足够了,但现在它只是一些浮动文本。
我们使用bbox参数在文本周围创建一个框。 我们使用bbox_props创建一个属性字典,包含盒子样式,然后是白色(w)前景色,黑色(k)边框颜色并且线宽为 1。 更多框样式请参阅 matplotlib 注解文档。
最后,这个注解向右移动,需要我们使用subplots_adjust来创建一些新空间:
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.87, top=0.90, wspace=0.2, hspace=0)
这里的完整代码如下:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax1.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax1.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax1.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+3, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax1.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax1.text(date[10], closep[1],'Text Example', fontdict=font_dict)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
#plt.legend()
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.87, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
结果为:
十九、子图
在这个 Matplotlib 教程中,我们将讨论子图。 有两种处理子图的主要方法,用于在同一图上创建多个图表。 现在,我们将从一个干净的代码开始。 如果你一直关注这个教程,那么请确保保留旧的代码,或者你可以随时重新查看上一个教程的代码。
首先,让我们使用样式,创建我们的图表,然后创建一个随机创建示例绘图的函数:
import random
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
fig = plt.figure()
def create_plots():
xs = []
ys = []
for i in range(10):
x = i
y = random.randrange(10)
xs.append(x)
ys.append(y)
return xs, ys
现在,我们开始使用add_subplot方法创建子图:
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(212)
它的工作原理是使用 3 个数字,即:行数(numRows)、列数(numCols)和绘图编号(plotNum)。
所以,221 表示两行两列的第一个位置。222 是两行两列的第二个位置。最后,212 是两行一列的第二个位置。
2x2:
+-----+-----+
| 1 | 2 |
+-----+-----+
| 3 | 4 |
+-----+-----+
2x1:
+-----------+
| 1 |
+-----------+
| 2 |
+-----------+
译者注:原文此处表述有误,译文已更改。
译者注:
221是缩写形式,仅在行数乘列数小于 10 时有效,否则要写成2,2,1。
此代码结果为:
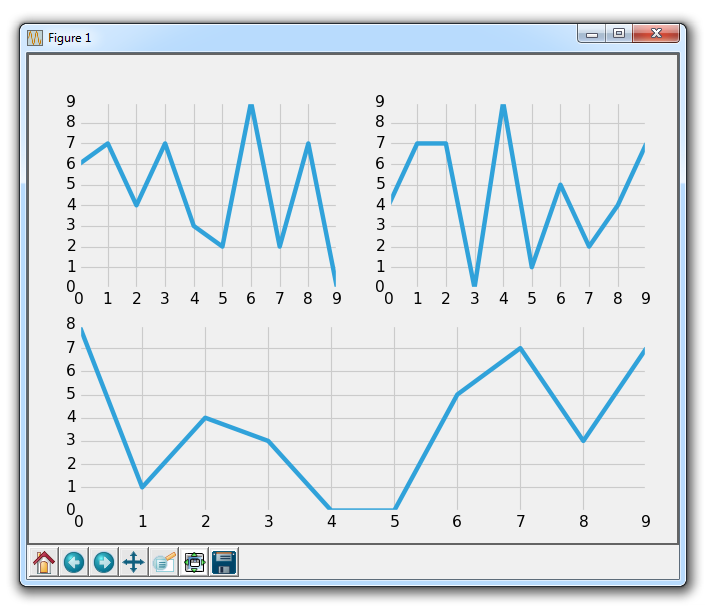
这就是add_subplot。 尝试一些你认为可能很有趣的配置,然后尝试使用add_subplot创建它们,直到你感到满意。
接下来,让我们介绍另一种方法,它是subplot2grid。
删除或注释掉其他轴域定义,然后添加:
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
所以,add_subplot不能让我们使一个绘图覆盖多个位置。 但是这个新的subplot2grid可以。 所以,subplot2grid的工作方式是首先传递一个元组,它是网格形状。 我们传递了(6,1),这意味着整个图表分为六行一列。 下一个元组是左上角的起始点。 对于ax1,这是0,0,因此它起始于顶部。 接下来,我们可以选择指定rowspan和colspan。 这是轴域所占的行数和列数。
6x1:
colspan=1
(0,0) +-----------+
| ax1 | rowspan=1
(1,0) +-----------+
| |
| ax2 | rowspan=4
| |
| |
(5,0) +-----------+
| ax3 | rowspan=1
+-----------+
结果为:
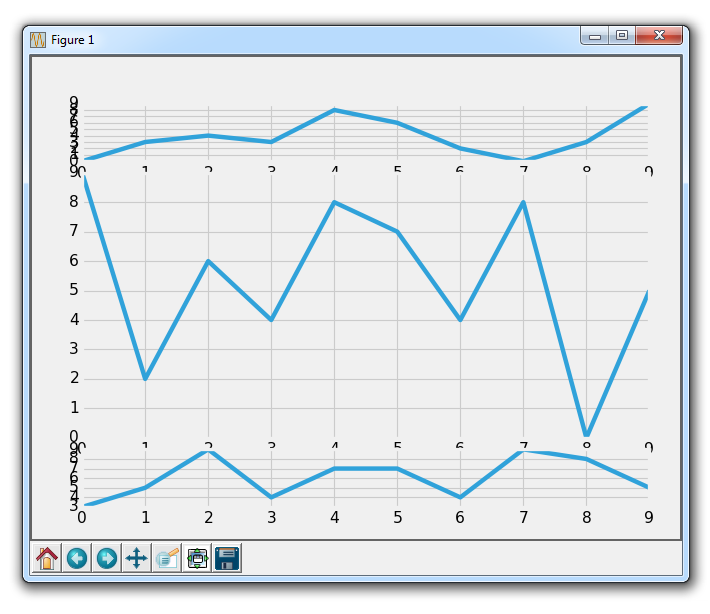
显然,我们在这里有一些重叠的问题,我们可以调整子图来处理它。
再次,尝试构思各种配置的子图,使用subplot2grid制作出来,直到你感到满意!
我们将继续使用subplot2grid,将它应用到我们已经逐步建立的代码中,我们将在下一个教程中继续。
二十、将子图应用于我们的图表
在这个 Matplotlib 教程中,我们将处理我们以前教程的代码,并实现上一个教程中的子图配置。 我们的起始代码是这样:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax1.xaxis.get_ticklabels():
label.set_rotation(45)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax1.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax1.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax1.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax1.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax1.text(date[10], closep[1],'Text Example', fontdict=font_dict)
plt.xlabel('Date')
plt.ylabel('Price')
plt.title(stock)
#plt.legend()
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
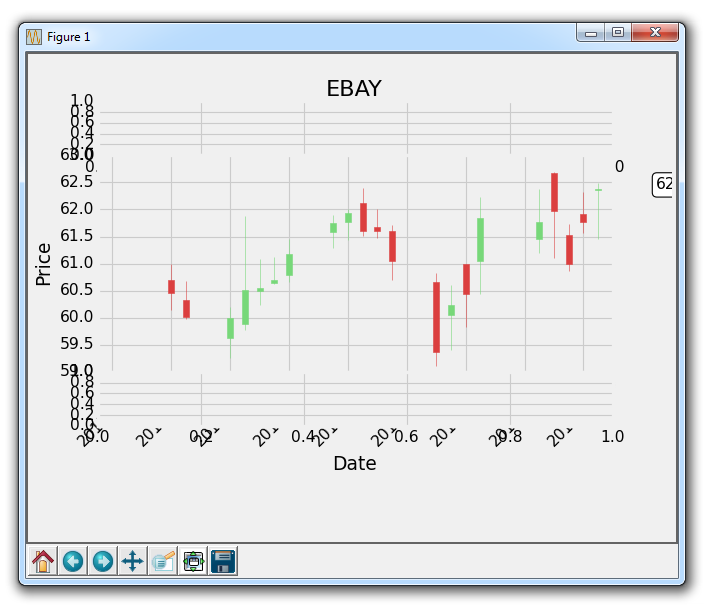
一个主要的改动是修改轴域的定义:
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
plt.xlabel('Date')
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
现在,ax2是我们实际上在绘制的股票价格数据。 顶部和底部图表将作为指标信息。
在我们绘制数据的代码中,我们需要将ax1更改为ax2:
candlestick_ohlc(ax2, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax2.xaxis.get_ticklabels():
label.set_rotation(45)
ax2.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax2.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
更改之后,代码为:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
plt.xlabel('Date')
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1m/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
candlestick_ohlc(ax2, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax2.xaxis.get_ticklabels():
label.set_rotation(45)
ax2.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax2.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax1.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax1.text(date[10], closep[1],'Text Example', fontdict=font_dict)
#
#plt.legend()
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
结果为:
二十一、更多指标数据
在这篇 Matplotlib 教程中,我们介绍了添加一些简单的函数来计算数据,以便我们填充我们的轴域。 一个是简单的移动均值,另一个是简单的价格 HML 计算。
这些新函数是:
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
你不需要太过专注于理解移动均值的工作原理,我们只是对样本数据来计算它,以便可以学习更多自定义 Matplotlib 的东西。
我们还想在脚本顶部为移动均值定义一些值:
MA1 = 10
MA2 = 30
下面,在我们的graph_data函数中:
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
在这里,我们计算两个移动均值和 HML。
我们还定义了一个『起始』点。 我们这样做是因为我们希望我们的数据排成一行。 例如,20 天的移动均值需要 20 个数据点。 这意味着我们不能在第 5 天真正计算 20 天的移动均值。 因此,当我们计算移动均值时,我们会失去一些数据。 为了处理这种数据的减法,我们使用起始变量来计算应该有多少数据。 这里,我们可以安全地使用[-start:]绘制移动均值,并且如果我们希望的话,对所有绘图进行上述步骤来排列数据。
接下来,我们可以在ax1上绘制 HML,通过这样:
ax1.plot_date(date,h_l,'-')
最后我们可以通过这样向ax3添加移动均值:
ax3.plot(date[-start:], ma1[-start:])
ax3.plot(date[-start:], ma2[-start:])
我们的完整代码,包括增加我们所用的时间范围:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
plt.xlabel('Date')
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date,h_l,'-')
candlestick_ohlc(ax2, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax2.xaxis.get_ticklabels():
label.set_rotation(45)
ax2.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax2.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax3.plot(date[-start:], ma1[-start:])
ax3.plot(date[-start:], ma2[-start:])
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
代码效果如图:
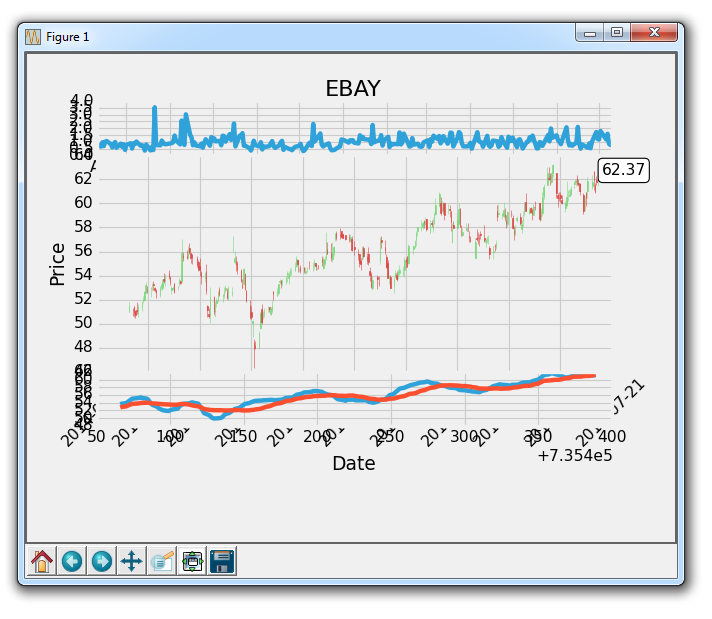
二十二、自定义填充、修剪和清除
欢迎阅读另一个 Matplotlib 教程! 在本教程中,我们将清除图表,然后再做一些自定义。
我们当前的代码是:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
plt.xlabel('Date')
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date,h_l,'-')
candlestick_ohlc(ax2, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
for label in ax2.xaxis.get_ticklabels():
label.set_rotation(45)
ax2.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax2.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax3.plot(date[-start:], ma1[-start:])
ax3.plot(date[-start:], ma2[-start:])
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
现在我认为向我们的移动均值添加自定义填充是一个很好的主意。 移动均值通常用于说明价格趋势。 这个想法是,你可以计算一个快速和一个慢速的移动均值。 一般来说,移动均值用于使价格变得『平滑』。 他们总是『滞后』于价格,但是我们的想法是计算不同的速度。 移动均值越大就越『慢』。 所以这个想法是,如果『较快』的移动均值超过『较慢』的均值,那么价格就会上升,这是一件好事。 如果较快的 MA 从较慢的 MA 下方穿过,则这是下降趋势并且通常被视为坏事。 我的想法是在快速和慢速 MA 之间填充,『上升』趋势为绿色,然后下降趋势为红色。 方法如下:
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] < ma2[-start:]),
facecolor='r', edgecolor='r', alpha=0.5)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] > ma2[-start:]),
facecolor='g', edgecolor='g', alpha=0.5)
下面,我们会碰到一些我们可解决的问题:
ax3.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax3.xaxis.set_major_locator(mticker.MaxNLocator(10))
for label in ax3.xaxis.get_ticklabels():
label.set_rotation(45)
plt.setp(ax1.get_xticklabels(), visible=False)
plt.setp(ax2.get_xticklabels(), visible=False)
这里,我们剪切和粘贴ax2日期格式,然后我们将x刻度标签设置为false,去掉它们!
我们还可以通过在轴域定义中执行以下操作,为每个轴域提供自定义标签:
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
plt.xlabel('Date')
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
接下来,我们可以看到,我们y刻度有许多数字,经常互相覆盖。 我们也看到轴之间互相重叠。 我们可以这样:
ax1.yaxis.set_major_locator(mticker.MaxNLocator(nbins=5, prune='lower'))
所以,这里发生的是,我们通过首先将nbins设置为 5 来修改我们的y轴对象。这意味着我们显示的标签最多为 5 个。然后我们还可以『修剪』标签,因此,在我们这里, 我们修剪底部标签,这会使它消失,所以现在不会有任何文本重叠。 我们仍然可能打算修剪ax2的顶部标签,但这里是我们目前为止的源代码:
当前的源码:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
plt.ylabel('H-L')
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1)
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1)
plt.ylabel('MAvgs')
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date,h_l,'-')
ax1.yaxis.set_major_locator(mticker.MaxNLocator(nbins=5, prune='lower'))
candlestick_ohlc(ax2, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f')
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax3.plot(date[-start:], ma1[-start:], linewidth=1)
ax3.plot(date[-start:], ma2[-start:], linewidth=1)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] < ma2[-start:]),
facecolor='r', edgecolor='r', alpha=0.5)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] > ma2[-start:]),
facecolor='g', edgecolor='g', alpha=0.5)
ax3.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax3.xaxis.set_major_locator(mticker.MaxNLocator(10))
for label in ax3.xaxis.get_ticklabels():
label.set_rotation(45)
plt.setp(ax1.get_xticklabels(), visible=False)
plt.setp(ax2.get_xticklabels(), visible=False)
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
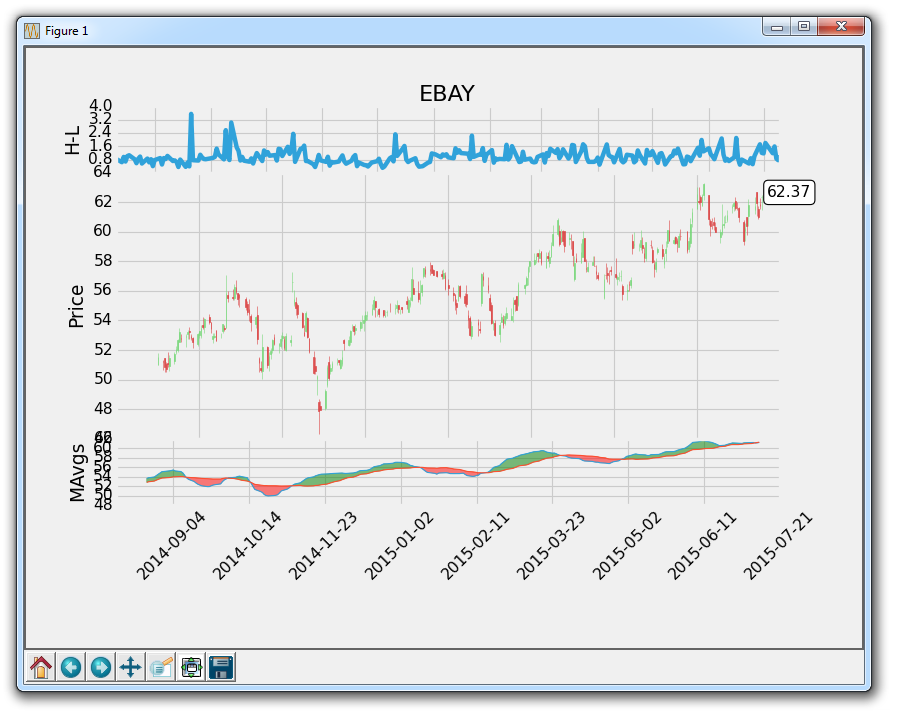
看起来好了一些,但是仍然有一些东西需要清除。
二十三、共享 X 轴
在这个 Matplotlib 数据可视化教程中,我们将讨论sharex选项,它允许我们在图表之间共享x轴。将sharex看做『复制 x』也许更好。
在我们开始之前,首先我们要做些修剪并在另一个轴上设置最大刻度数,如下所示:
ax2.yaxis.set_major_locator(mticker.MaxNLocator(nbins=7, prune='upper'))
以及
ax3.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='upper'))
现在,让我们共享所有轴域之间的x轴。 为此,我们需要将其添加到轴域定义中:
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
plt.ylabel('H-L')
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1, sharex=ax1)
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
plt.ylabel('MAvgs')
上面,对于ax2和ax3,我们添加一个新的参数,称为sharex,然后我们说,我们要与ax1共享x轴。
使用这种方式,我们可以加载图表,然后我们可以放大到一个特定的点,结果将是这样:
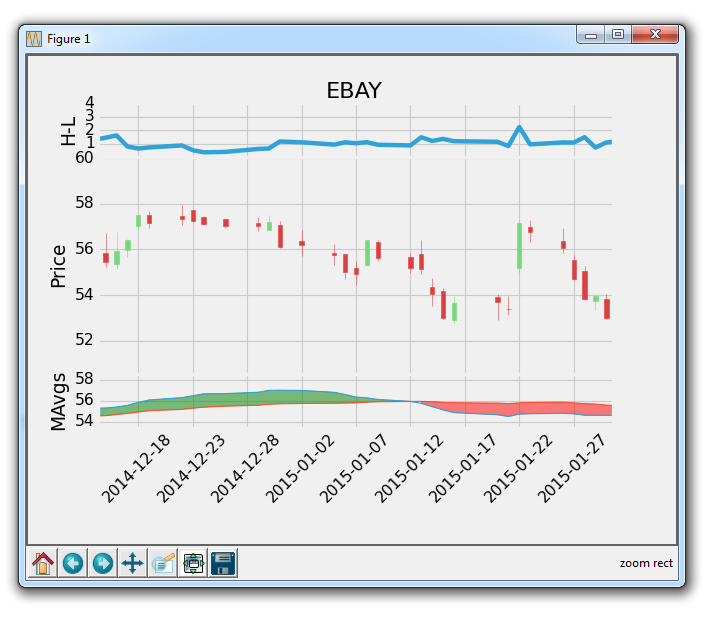
所以这意味着所有轴域沿着它们的x轴一起移动。 这很酷吧!
接下来,让我们将[-start:]应用到所有数据,所以所有轴域都起始于相同地方。 我们最终的代码为:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
plt.ylabel('H-L')
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1, sharex=ax1)
plt.ylabel('Price')
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
plt.ylabel('MAvgs')
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date[-start:],h_l[-start:],'-')
ax1.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='lower'))
candlestick_ohlc(ax2, ohlc[-start:], width=0.4, colorup='#77d879', colordown='#db3f3f')
ax2.yaxis.set_major_locator(mticker.MaxNLocator(nbins=7, prune='upper'))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax3.plot(date[-start:], ma1[-start:], linewidth=1)
ax3.plot(date[-start:], ma2[-start:], linewidth=1)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] < ma2[-start:]),
facecolor='r', edgecolor='r', alpha=0.5)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] > ma2[-start:]),
facecolor='g', edgecolor='g', alpha=0.5)
ax3.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax3.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax3.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='upper'))
for label in ax3.xaxis.get_ticklabels():
label.set_rotation(45)
plt.setp(ax1.get_xticklabels(), visible=False)
plt.setp(ax2.get_xticklabels(), visible=False)
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('EBAY')
下面我们会讨论如何创建多个y轴。
二十四、多个 Y 轴
在这篇 Matplotlib 教程中,我们将介绍如何在同一子图上使用多个 Y 轴。 在我们的例子中,我们有兴趣在同一个图表及同一个子图上绘制股票价格和交易量。
为此,首先我们需要定义一个新的轴域,但是这个轴域是ax2仅带有x轴的『双生子』。
这足以创建轴域了。我们叫它ax2v,因为这个轴域是ax2加交易量。
现在,我们在轴域上定义绘图,我们将添加:
ax2v.fill_between(date[-start:],0, volume[-start:], facecolor='#0079a3', alpha=0.4)
我们在 0 和当前交易量之间填充,给予它蓝色的前景色,然后给予它一个透明度。 我们想要应用幽冥毒,以防交易量最终覆盖其它东西,所以我们仍然可以看到这两个元素。
所以,到现在为止,我们的代码为:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
plt.ylabel('H-L')
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1, sharex=ax1)
plt.ylabel('Price')
ax2v = ax2.twinx()
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
plt.ylabel('MAvgs')
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date[-start:],h_l[-start:],'-')
ax1.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='lower'))
candlestick_ohlc(ax2, ohlc[-start:], width=0.4, colorup='#77d879', colordown='#db3f3f')
ax2.yaxis.set_major_locator(mticker.MaxNLocator(nbins=7, prune='upper'))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax2v.fill_between(date[-start:],0, volume[-start:], facecolor='#0079a3', alpha=0.4)
ax3.plot(date[-start:], ma1[-start:], linewidth=1)
ax3.plot(date[-start:], ma2[-start:], linewidth=1)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] < ma2[-start:]),
facecolor='r', edgecolor='r', alpha=0.5)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] > ma2[-start:]),
facecolor='g', edgecolor='g', alpha=0.5)
ax3.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax3.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax3.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='upper'))
for label in ax3.xaxis.get_ticklabels():
label.set_rotation(45)
plt.setp(ax1.get_xticklabels(), visible=False)
plt.setp(ax2.get_xticklabels(), visible=False)
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('GOOG')
会生成:
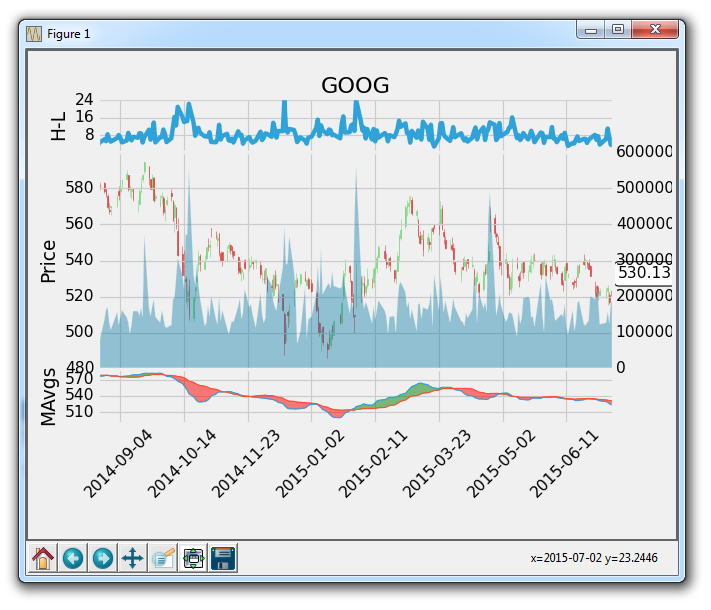
太棒了,到目前为止还不错。 接下来,我们可能要删除新y轴上的标签,然后我们也可能不想让交易量占用太多空间。 没问题:
首先:
ax2v.axes.yaxis.set_ticklabels([])
上面将y刻度标签设置为一个空列表,所以不会有任何标签了。
译者注:所以将标签删除之后,添加新轴的意义是什么?直接在原轴域上绘图就可以了。
接下来,我们可能要将网格设置为false,使轴域上不会有双网格:
ax2v.grid(False)
最后,为了处理交易量占用很多空间,我们可以做以下操作:
ax2v.set_ylim(0, 3*volume.max())
所以这设置y轴显示范围从 0 到交易量的最大值的 3 倍。 这意味着,在最高点,交易量最多可占据图形的33%。 所以,增加volume.max的倍数越多,空间就越小/越少。
现在,我们的图表为:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
plt.ylabel('H-L')
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1, sharex=ax1)
plt.ylabel('Price')
ax2v = ax2.twinx()
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
plt.ylabel('MAvgs')
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date[-start:],h_l[-start:],'-')
ax1.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='lower'))
candlestick_ohlc(ax2, ohlc[-start:], width=0.4, colorup='#77d879', colordown='#db3f3f')
ax2.yaxis.set_major_locator(mticker.MaxNLocator(nbins=7, prune='upper'))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+5, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax2v.fill_between(date[-start:],0, volume[-start:], facecolor='#0079a3', alpha=0.4)
ax2v.axes.yaxis.set_ticklabels([])
ax2v.grid(False)
ax2v.set_ylim(0, 3*volume.max())
ax3.plot(date[-start:], ma1[-start:], linewidth=1)
ax3.plot(date[-start:], ma2[-start:], linewidth=1)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] < ma2[-start:]),
facecolor='r', edgecolor='r', alpha=0.5)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] > ma2[-start:]),
facecolor='g', edgecolor='g', alpha=0.5)
ax3.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax3.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax3.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='upper'))
for label in ax3.xaxis.get_ticklabels():
label.set_rotation(45)
plt.setp(ax1.get_xticklabels(), visible=False)
plt.setp(ax2.get_xticklabels(), visible=False)
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
plt.show()
graph_data('GOOG')
到这里,我们差不多完成了。 这里唯一的缺陷是一个好的图例。 一些线条是显而易见的,但人们可能会好奇移动均值的参数是什么,我们这里是 10 和 30。 添加自定义图例是下一个教程中涉及的内容。
二十五、自定义图例
在这篇 Matplotlib 教程中,我们将讨论自定义图例。 我们已经介绍了添加图例的基础知识。
图例的主要问题通常是图例阻碍了数据的展示。 这里有几个选项。 一个选项是将图例放在轴域外,但是我们在这里有多个子图,这是非常困难的。 相反,我们将使图例稍微小一点,然后应用一个透明度。
首先,为了创建一个图例,我们需要向我们的数据添加我们想要显示在图例上的标签。
ax1.plot_date(date[-start:],h_l[-start:],'-', label='H-L')
...
ax2v.plot([],[], color='#0079a3', alpha=0.4, label='Volume')
...
ax3.plot(date[-start:], ma1[-start:], linewidth=1, label=(str(MA1)+'MA'))
ax3.plot(date[-start:], ma2[-start:], linewidth=1, label=(str(MA2)+'MA'))
请注意,我们通过创建空行为交易量添加了标签。 请记住,我们不能对任何填充应用标签,所以这就是我们添加这个空行的原因。
现在,我们可以在右下角添加图例,通过在plt.show()之前执行以下操作:
ax1.legend()
ax2v.legend()
ax3.legend()
会生成:
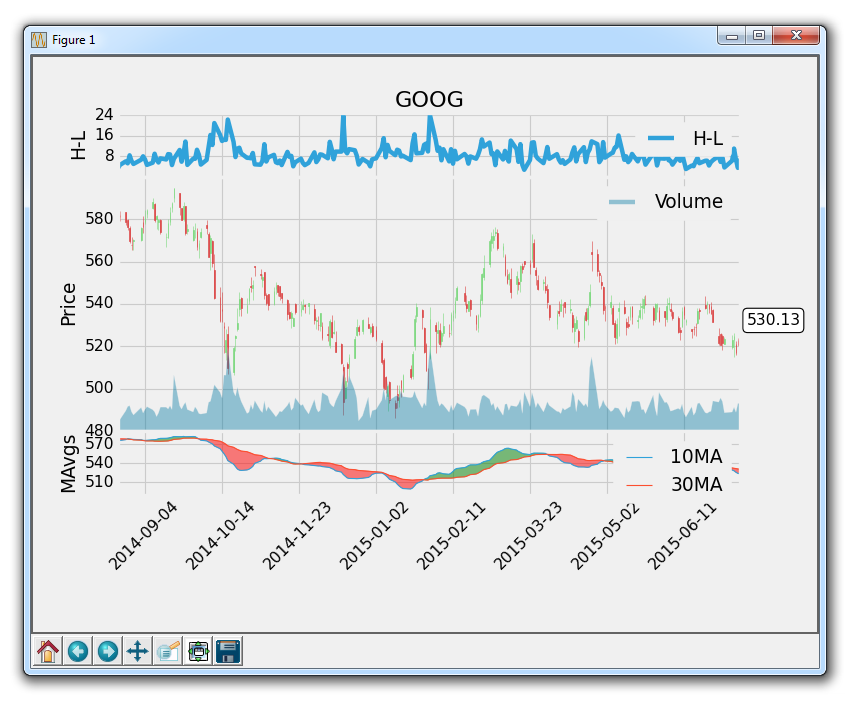
所以,我们可以看到,图例还是占用了一些位置。 让我们更改位置,大小并添加透明度:
ax1.legend()
leg = ax1.legend(loc=9, ncol=2,prop={'size':11})
leg.get_frame().set_alpha(0.4)
ax2v.legend()
leg = ax2v.legend(loc=9, ncol=2,prop={'size':11})
leg.get_frame().set_alpha(0.4)
ax3.legend()
leg = ax3.legend(loc=9, ncol=2,prop={'size':11})
leg.get_frame().set_alpha(0.4)
所有的图例位于位置 9(上中间)。 有很多地方可放置图例,我们可以为参数传入不同的位置号码,来看看它们都位于哪里。 ncol参数允许我们指定图例中的列数。 这里只有一列,如果图例中有 2 个项目,他们将堆叠在一列中。 最后,我们将尺寸规定为更小。 之后,我们对整个图例应用0.4的透明度。
现在我们的结果为:
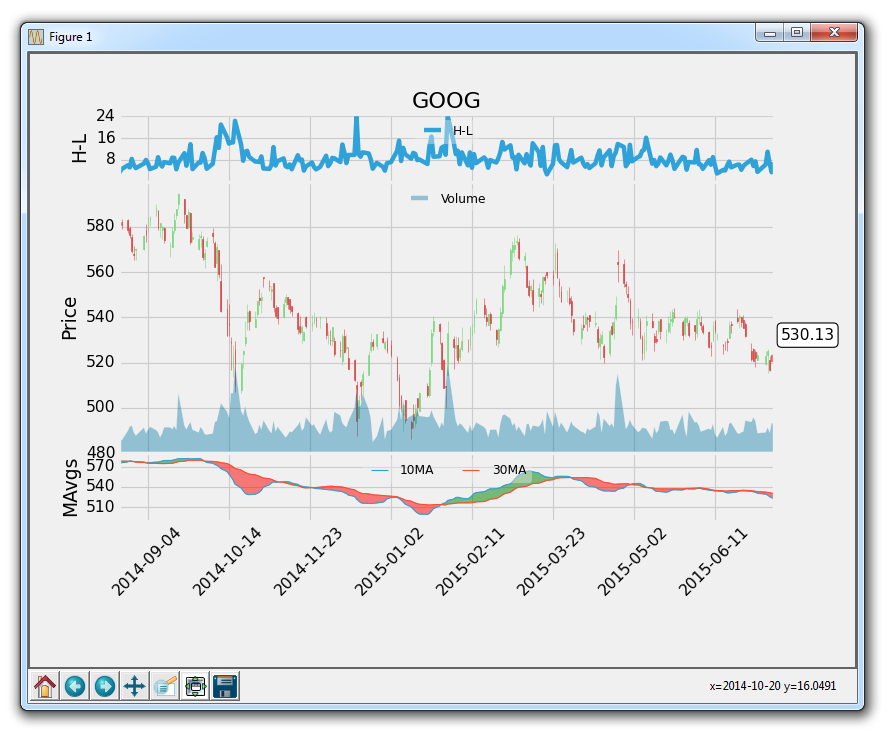
完整的代码为:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.ticker as mticker
from matplotlib.finance import candlestick_ohlc
from matplotlib import style
import numpy as np
import urllib
import datetime as dt
style.use('fivethirtyeight')
print(plt.style.available)
print(plt.__file__)
MA1 = 10
MA2 = 30
def moving_average(values, window):
weights = np.repeat(1.0, window)/window
smas = np.convolve(values, weights, 'valid')
return smas
def high_minus_low(highs, lows):
return highs-lows
def bytespdate2num(fmt, encoding='utf-8'):
strconverter = mdates.strpdate2num(fmt)
def bytesconverter(b):
s = b.decode(encoding)
return strconverter(s)
return bytesconverter
def graph_data(stock):
fig = plt.figure(facecolor='#f0f0f0')
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=1, colspan=1)
plt.title(stock)
plt.ylabel('H-L')
ax2 = plt.subplot2grid((6,1), (1,0), rowspan=4, colspan=1, sharex=ax1)
plt.ylabel('Price')
ax2v = ax2.twinx()
ax3 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
plt.ylabel('MAvgs')
stock_price_url = 'http://chartapi.finance.yahoo.com/instrument/1.0/'+stock+'/chartdata;type=quote;range=1y/csv'
source_code = urllib.request.urlopen(stock_price_url).read().decode()
stock_data = []
split_source = source_code.split('\n')
for line in split_source:
split_line = line.split(',')
if len(split_line) == 6:
if 'values' not in line and 'labels' not in line:
stock_data.append(line)
date, closep, highp, lowp, openp, volume = np.loadtxt(stock_data,
delimiter=',',
unpack=True,
converters={0: bytespdate2num('%Y%m%d')})
x = 0
y = len(date)
ohlc = []
while x < y:
append_me = date[x], openp[x], highp[x], lowp[x], closep[x], volume[x]
ohlc.append(append_me)
x+=1
ma1 = moving_average(closep,MA1)
ma2 = moving_average(closep,MA2)
start = len(date[MA2-1:])
h_l = list(map(high_minus_low, highp, lowp))
ax1.plot_date(date[-start:],h_l[-start:],'-', label='H-L')
ax1.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='lower'))
candlestick_ohlc(ax2, ohlc[-start:], width=0.4, colorup='#77d879', colordown='#db3f3f')
ax2.yaxis.set_major_locator(mticker.MaxNLocator(nbins=7, prune='upper'))
ax2.grid(True)
bbox_props = dict(boxstyle='round',fc='w', ec='k',lw=1)
ax2.annotate(str(closep[-1]), (date[-1], closep[-1]),
xytext = (date[-1]+4, closep[-1]), bbox=bbox_props)
## # Annotation example with arrow
## ax2.annotate('Bad News!',(date[11],highp[11]),
## xytext=(0.8, 0.9), textcoords='axes fraction',
## arrowprops = dict(facecolor='grey',color='grey'))
##
##
## # Font dict example
## font_dict = {'family':'serif',
## 'color':'darkred',
## 'size':15}
## # Hard coded text
## ax2.text(date[10], closep[1],'Text Example', fontdict=font_dict)
ax2v.plot([],[], color='#0079a3', alpha=0.4, label='Volume')
ax2v.fill_between(date[-start:],0, volume[-start:], facecolor='#0079a3', alpha=0.4)
ax2v.axes.yaxis.set_ticklabels([])
ax2v.grid(False)
ax2v.set_ylim(0, 3*volume.max())
ax3.plot(date[-start:], ma1[-start:], linewidth=1, label=(str(MA1)+'MA'))
ax3.plot(date[-start:], ma2[-start:], linewidth=1, label=(str(MA2)+'MA'))
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] < ma2[-start:]),
facecolor='r', edgecolor='r', alpha=0.5)
ax3.fill_between(date[-start:], ma2[-start:], ma1[-start:],
where=(ma1[-start:] > ma2[-start:]),
facecolor='g', edgecolor='g', alpha=0.5)
ax3.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax3.xaxis.set_major_locator(mticker.MaxNLocator(10))
ax3.yaxis.set_major_locator(mticker.MaxNLocator(nbins=4, prune='upper'))
for label in ax3.xaxis.get_ticklabels():
label.set_rotation(45)
plt.setp(ax1.get_xticklabels(), visible=False)
plt.setp(ax2.get_xticklabels(), visible=False)
plt.subplots_adjust(left=0.11, bottom=0.24, right=0.90, top=0.90, wspace=0.2, hspace=0)
ax1.legend()
leg = ax1.legend(loc=9, ncol=2,prop={'size':11})
leg.get_frame().set_alpha(0.4)
ax2v.legend()
leg = ax2v.legend(loc=9, ncol=2,prop={'size':11})
leg.get_frame().set_alpha(0.4)
ax3.legend()
leg = ax3.legend(loc=9, ncol=2,prop={'size':11})
leg.get_frame().set_alpha(0.4)
plt.show()
fig.savefig('google.png', facecolor=fig.get_facecolor())
graph_data('GOOG')
现在我们可以看到图例,但也看到了图例下的任何信息。 还要注意额外函数fig.savefig。 这是自动保存图形的图像的方式。 我们还可以设置所保存的图形的前景色,使背景不是白色的,如我们的例子所示。
这就是目前为止,我想要显示的典型 Matplotlib 图表。 接下来,我们将涉及Basemap,它是一个 Matplotlib 扩展,用于绘制地理位置,然后我打算讲解 Matplotlib 中的 3D 图形。
二十六、Basemap 地理绘图
在这个 Matplotlib 教程中,我们将涉及地理绘图模块Basemap。 Basemap是 Matplotlib 的扩展。
为了使用Basemap,我们首先需要安装它。 为了获得Basemap,你可以从这里获取:http://matplotlib.org/basemap/users/download.html,或者你可以访问http://www.lfd.uci.edu/~gohlke/pythonlibs/。
如果你在安装Basemap时遇到问题,请查看pip安装教程。
一旦你安装了Basemap,你就可以创建地图了。 首先,让我们投影一个简单的地图。 为此,我们需要导入Basemap,pyplot,创建投影,至少绘制某种轮廓或数据,然后我们可以显示图形。
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill')
m.drawcoastlines()
plt.show()
上面的代码结果如下:
这是使用 Miller 投影完成的,这只是许多Basemap投影选项之一。
二十七、Basemap 自定义
在这篇 Matplotlib 教程中,我们继续使用Basemap地理绘图扩展。 我们将展示一些我们可用的自定义选项。
首先,从上一个教程中获取我们的起始代码:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill')
m.drawcoastlines()
plt.show()
我们可以从放大到特定区域来开始:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill',
llcrnrlat = -40,
llcrnrlon = -40,
urcrnrlat = 50,
urcrnrlon = 75)
m.drawcoastlines()
plt.show()
这里的参数是:
llcrnrlat- 左下角的纬度llcrnrlon- 左下角的经度urcrnrlat- 右上角的纬度urcrnrlon- 右上角的经度
此外,坐标需要转换,其中西经和南纬坐标是负值,北纬和东经坐标是正值。
使用这些坐标,Basemap会选择它们之间的区域。
下面,我们要使用一些东西,类似:
m.drawcountries(linewidth=2)
这会画出国家,并使用线宽为 2 的线条生成分界线。
另一个选项是:
m.drawstates(color='b')
这会用蓝色线条画出州。
你也可以执行:
m.drawcounties(color='darkred')
这会画出国家。
所以,我们的代码是:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill',
llcrnrlat = -90,
llcrnrlon = -180,
urcrnrlat = 90,
urcrnrlon = 180)
m.drawcoastlines()
m.drawcountries(linewidth=2)
m.drawstates(color='b')
m.drawcounties(color='darkred')
plt.title('Basemap Tutorial')
plt.show()
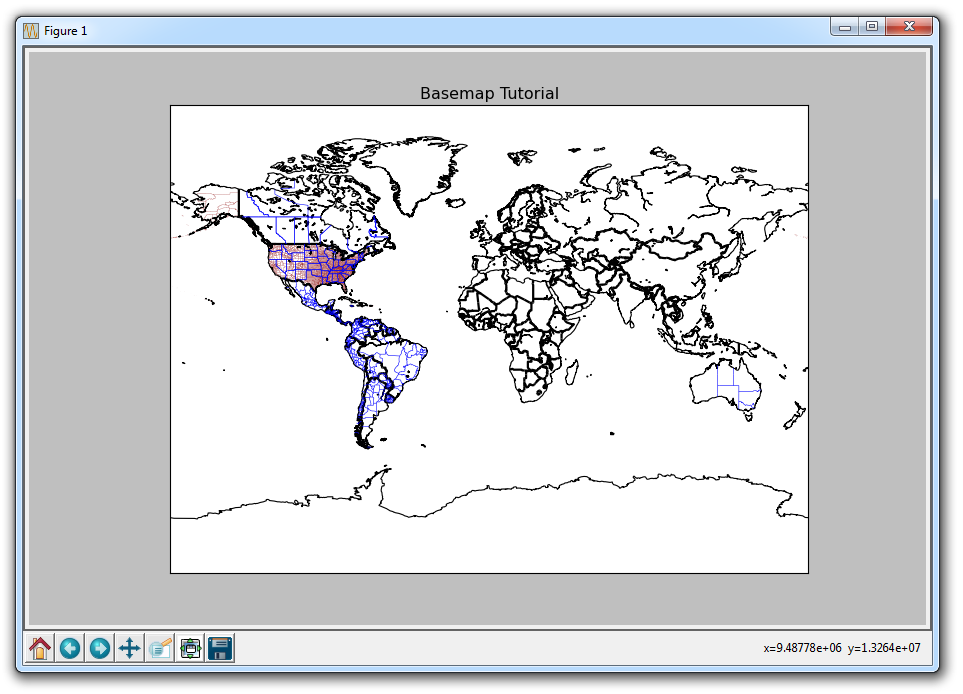
很难说,但我们定义了美国的区县的线条。 我们可以使用放大镜放大Basemap图形,就像其他图形那样,会生成:
另一个有用的选项是Basemap调用中的『分辨率』选项。
m = Basemap(projection='mill',
llcrnrlat = -90,
llcrnrlon = -180,
urcrnrlat = 90,
urcrnrlon = 180,
resolution='l')
分辨率的选项为:
c- 粗糙l- 低h- 高f- 完整
对于更高的分辨率,你应该放大到很大,否则这可能只是浪费。
另一个选项是使用etopo()绘制地形,如:
m.etopo()
使用drawcountries方法绘制此图形会生成:
最后,有一个蓝色的大理石版本,你可以调用:
m.bluemarble()
会生成:
目前为止的代码:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill',
llcrnrlat = -90,
llcrnrlon = -180,
urcrnrlat = 90,
urcrnrlon = 180,
resolution='l')
m.drawcoastlines()
m.drawcountries(linewidth=2)
##m.drawstates(color='b')
##m.drawcounties(color='darkred')
#m.fillcontinents()
#m.etopo()
m.bluemarble()
plt.title('Basemap Tutorial')
plt.show()
二十八、在 Basemap 中绘制坐标
欢迎阅读另一个 Matplotlib Basemap 教程。 在本教程中,我们将介绍如何绘制单个坐标,以及如何在地理区域中连接这些坐标。
首先,我们将从一些基本的起始数据开始:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill',
llcrnrlat = 25,
llcrnrlon = -130,
urcrnrlat = 50,
urcrnrlon = -60,
resolution='l')
m.drawcoastlines()
m.drawcountries(linewidth=2)
m.drawstates(color='b')
接下来,我们可以绘制坐标,从获得它们的实际坐标开始。 记住,南纬和西经坐标需要转换为负值。 例如,纽约市是北纬40.7127西经74.0059。 我们可以在我们的程序中定义这些坐标,如:
NYClat, NYClon = 40.7127, -74.0059
之后我们将这些转换为要绘制的x和y坐标。
xpt, ypt = m(NYClon, NYClat)
注意这里,我们现在已经将坐标顺序翻转为lon, lat(纬度,经度)。 坐标通常以lat, lon顺序给出。 然而,在图形中,lat, long转换为y, x,我们显然不需要。 在某些时候,你必须翻转它们。 不要忘记这部分!
最后,我们可以绘制如下的坐标:
m.plot(xpt, ypt, 'c*', markersize=15)
这个图表上有一个青色的星,大小为 15。更多标记类型请参阅:Matplotlib 标记文档。
接下来,让我们再画一个位置,洛杉矶,加利福尼亚:
LAlat, LAlon = 34.05, -118.25
xpt, ypt = m(LAlon, LAlat)
m.plot(xpt, ypt, 'g^', markersize=15)
这次我们画出一个绿色三角,执行代码会生成:
如果我们想连接这些图块怎么办?原来,我们可以像其它 Matplotlib 图表那样实现它。
首先,我们将那些xpt和ypt坐标保存到列表,类似这样的东西:
xs = []
ys = []
NYClat, NYClon = 40.7127, -74.0059
xpt, ypt = m(NYClon, NYClat)
xs.append(xpt)
ys.append(ypt)
m.plot(xpt, ypt, 'c*', markersize=15)
LAlat, LAlon = 34.05, -118.25
xpt, ypt = m(LAlon, LAlat)
xs.append(xpt)
ys.append(ypt)
m.plot(xpt, ypt, 'g^', markersize=15)
m.plot(xs, ys, color='r', linewidth=3, label='Flight 98')
会生成:
太棒了。有时我们需要以圆弧连接图上的两个坐标。如何实现呢?
m.drawgreatcircle(NYClon, NYClat, LAlon, LAlat, color='c', linewidth=3, label='Arc')
我们的完整代码为:
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
m = Basemap(projection='mill',
llcrnrlat = 25,
llcrnrlon = -130,
urcrnrlat = 50,
urcrnrlon = -60,
resolution='l')
m.drawcoastlines()
m.drawcountries(linewidth=2)
m.drawstates(color='b')
#m.drawcounties(color='darkred')
#m.fillcontinents()
#m.etopo()
#m.bluemarble()
xs = []
ys = []
NYClat, NYClon = 40.7127, -74.0059
xpt, ypt = m(NYClon, NYClat)
xs.append(xpt)
ys.append(ypt)
m.plot(xpt, ypt, 'c*', markersize=15)
LAlat, LAlon = 34.05, -118.25
xpt, ypt = m(LAlon, LAlat)
xs.append(xpt)
ys.append(ypt)
m.plot(xpt, ypt, 'g^', markersize=15)
m.plot(xs, ys, color='r', linewidth=3, label='Flight 98')
m.drawgreatcircle(NYClon, NYClat, LAlon, LAlat, color='c', linewidth=3, label='Arc')
plt.legend(loc=4)
plt.title('Basemap Tutorial')
plt.show()
结果为:
这就是Basemap的全部了,下一章关于 Matplotlib 的 3D 绘图。
二十九、3D 绘图
您好,欢迎阅读 Matplotlib 教程中的 3D 绘图。 Matplotlib 已经内置了三维图形,所以我们不需要再下载任何东西。 首先,我们需要引入一些完整的模块:
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
使用axes3d是因为它需要不同种类的轴域,以便在三维中实际绘制一些东西。 下面:
fig = plt.figure()
ax1 = fig.add_subplot(111, projection='3d')
在这里,我们像通常一样定义图形,然后我们将ax1定义为通常的子图,只是这次使用 3D 投影。 我们需要这样做,以便提醒 Matplotlib 我们要提供三维数据。
现在让我们创建一些 3D 数据:
x = [1,2,3,4,5,6,7,8,9,10]
y = [5,6,7,8,2,5,6,3,7,2]
z = [1,2,6,3,2,7,3,3,7,2]
接下来,我们绘制它。 首先,让我们展示一个简单的线框示例:
ax1.plot_wireframe(x,y,z)
最后:
ax1.set_xlabel('x axis')
ax1.set_ylabel('y axis')
ax1.set_zlabel('z axis')
plt.show()
我们完整的代码是:
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
fig = plt.figure()
ax1 = fig.add_subplot(111, projection='3d')
x = [1,2,3,4,5,6,7,8,9,10]
y = [5,6,7,8,2,5,6,3,7,2]
z = [1,2,6,3,2,7,3,3,7,2]
ax1.plot_wireframe(x,y,z)
ax1.set_xlabel('x axis')
ax1.set_ylabel('y axis')
ax1.set_zlabel('z axis')
plt.show()
结果为(包括所用的样式):
这些 3D 图形可以进行交互。 首先,您可以使用鼠标左键单击并拖动来移动图形。 您还可以使用鼠标右键单击并拖动来放大或缩小。
三十、3D 散点图
欢迎阅读另一个 3D Matplotlib 教程,会涉及如何绘制三维散点图。
绘制 3D 散点图非常类似于通常的散点图以及 3D 线框图。
一个简单示例:
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
fig = plt.figure()
ax1 = fig.add_subplot(111, projection='3d')
x = [1,2,3,4,5,6,7,8,9,10]
y = [5,6,7,8,2,5,6,3,7,2]
z = [1,2,6,3,2,7,3,3,7,2]
x2 = [-1,-2,-3,-4,-5,-6,-7,-8,-9,-10]
y2 = [-5,-6,-7,-8,-2,-5,-6,-3,-7,-2]
z2 = [1,2,6,3,2,7,3,3,7,2]
ax1.scatter(x, y, z, c='g', marker='o')
ax1.scatter(x2, y2, z2, c ='r', marker='o')
ax1.set_xlabel('x axis')
ax1.set_ylabel('y axis')
ax1.set_zlabel('z axis')
plt.show()
结果为:
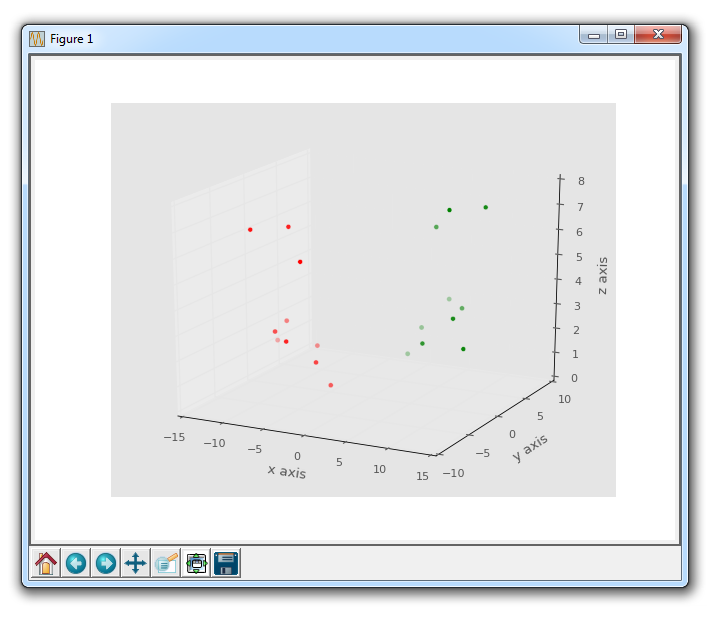
要记住你可以修改这些绘图的大小和标记,就像通常的散点图那样。
三十一、3D 条形图
在这个 Matplotlib 教程中,我们要介绍 3D 条形图。 3D 条形图是非常独特的,因为它允许我们绘制多于 3 个维度。 不,你不能超过第三个维度来绘制,但你可以绘制多于 3 个维度。
对于条形图,你需要拥有条形的起点,条形的高度和宽度。 但对于 3D 条形图,你还有另一个选项,就是条形的深度。 大多数情况下,条形图从轴上的条形平面开始,但是你也可以通过打破此约束来添加另一个维度。 然而,我们会让它非常简单:
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import style
style.use('ggplot')
fig = plt.figure()
ax1 = fig.add_subplot(111, projection='3d')
x3 = [1,2,3,4,5,6,7,8,9,10]
y3 = [5,6,7,8,2,5,6,3,7,2]
z3 = np.zeros(10)
dx = np.ones(10)
dy = np.ones(10)
dz = [1,2,3,4,5,6,7,8,9,10]
ax1.bar3d(x3, y3, z3, dx, dy, dz)
ax1.set_xlabel('x axis')
ax1.set_ylabel('y axis')
ax1.set_zlabel('z axis')
plt.show()
注意这里,我们必须定义x、y和z,然后是 3 个维度的宽度、高度和深度。 这会生成:
三十二、总结
欢迎阅读最后的 Matplotlib 教程。 在这里我们将整理整个系列,并显示一个稍微更复杂的 3D 线框图:
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import style
style.use('ggplot')
fig = plt.figure()
ax1 = fig.add_subplot(111, projection='3d')
x, y, z = axes3d.get_test_data()
print(axes3d.__file__)
ax1.plot_wireframe(x,y,z, rstride = 3, cstride = 3)
ax1.set_xlabel('x axis')
ax1.set_ylabel('y axis')
ax1.set_zlabel('z axis')
plt.show()
如果你从一开始就关注这个教程的话,那么你已经学会了 Matplotlib 提供的大部分内容。 你可能不相信,但Matplotlib 仍然可以做很多其他的事情! 请继续学习,你可以随时访问 Matplotlib.org,并查看示例和图库页面。
如果你发现自己大量使用 Matplotlib,请考虑捐助给 John Hunter Memorial 基金。
注:空间曲面的画法
# 二次抛物面 z = x^2 + y^2 x = np.linspace(-10, 10, 101) y = x x, y = np.meshgrid(x, y) z = x ** 2 + y ** 2 ax = plot.subplot(111, projection='3d') ax.plot_wireframe(x, y, z) plot.show()

# 半径为 1 的球 t = np.linspace(0, np.pi * 2, 100) s = np.linspace(0, np.pi, 100) t, s = np.meshgrid(t, s) x = np.cos(t) * np.sin(s) y = np.sin(t) * np.sin(s) z = np.cos(s) ax = plot.subplot(111, projection='3d') ax.plot_wireframe(x, y, z) plot.show()

PythonProgramming.net Python 机器学习实战教程
原文:Practical Machine Learning Tutorial with Python Introduction
译者:飞龙
第一部分 回归
二、回归 - 引言和数据
欢迎阅读 Python 机器学习系列教程的回归部分。这里,你应该已经安装了 Scikit-Learn。如果没有,安装它,以及 Pandas 和 Matplotlib。
pip install numpy
pip install scipy
pip install scikit-learn
pip install matplotlib
pip install pandas
除了这些教程范围的导入之外,我们还要在这里使用 Quandl:
pip install quandl
首先,对于我们将其用于机器学习而言,什么是回归呢?它的目标是接受连续数据,寻找最适合数据的方程,并能够对特定值进行预测。使用简单的线性回归,你可以仅仅通过创建最佳拟合直线,来实现它。

这里,我们可以使用这条直线的方程,来预测未来的价格,其中日期是 x 轴。
回归的热门用法是预测股票价格。由于我们会考虑价格随时间的流动,并且使用连续的数据集,尝试预测未来的下一个流动价格,所以可以这样做。
回归是监督的机器学习的一种,也就是说,科学家向其展示特征,之后向其展示正确答案来教会机器。一旦教会了机器,科学家就能够使用一些不可见的数据来测试机器,其中科学家知道正确答案,但是机器不知道。机器的答案会与已知答案对比,并且度量机器的准确率。如果准确率足够高,科学家就会考虑将其算法用于真实世界。
由于回归广泛用于股票价格,我们可以使用一个示例从这里开始。最开始,我们需要数据。有时候数据易于获取,有时你需要出去并亲自收集。我们这里,我们至少能够以简单的股票价格和成交量信息开始,它们来自 Quandl。我们会抓取 Google 的股票价格,它的代码是GOOGL:
import pandas as pd
import quandl
df = quandl.get("WIKI/GOOGL")
print(df.head())
注意:写这篇文章的时候,Quandl 的模块使用大写 Q 引用,但现在是小写 q,所以import quandl。
到这里,我们拥有:
Open High Low Close Volume Ex-Dividend \
Date
2004-08-19 100.00 104.06 95.96 100.34 44659000 0
2004-08-20 101.01 109.08 100.50 108.31 22834300 0
2004-08-23 110.75 113.48 109.05 109.40 18256100 0
2004-08-24 111.24 111.60 103.57 104.87 15247300 0
2004-08-25 104.96 108.00 103.88 106.00 9188600 0
Split Ratio Adj. Open Adj. High Adj. Low Adj. Close \
Date
2004-08-19 1 50.000 52.03 47.980 50.170
2004-08-20 1 50.505 54.54 50.250 54.155
2004-08-23 1 55.375 56.74 54.525 54.700
2004-08-24 1 55.620 55.80 51.785 52.435
2004-08-25 1 52.480 54.00 51.940 53.000
Adj. Volume
Date
2004-08-19 44659000
2004-08-20 22834300
2004-08-23 18256100
2004-08-24 15247300
2004-08-25 9188600
这是个非常好的开始,我们拥有了数据,但是有点多了。
这里,我们有很多列,许多都是多余的,还有些不怎么变化。我们可以看到,常规和修正(Adj)的列是重复的。修正的列看起来更加理想。常规的列是当天的价格,但是股票有个叫做分拆的东西,其中一股突然就变成了两股,所以一股的价格要减半,但是公司的价值不变。修正的列为股票分拆而调整,这使得它们对于分析更加可靠。
所以,让我们继续,削减原始的 DataFrame。
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
现在我们拥有了修正的列,以及成交量。有一些东西需要注意。许多人谈论或者听说机器学习,就像无中生有的黑魔法。机器学习可以突出已有的数据,但是数据需要先存在。你需要有意义的数据。所以你怎么知道是否有意义呢?我的最佳建议就是,仅仅简化你的大脑。考虑一下,历史价格会决定未来价格吗?有些人这么认为,但是久而久之这被证实是错误的。但是历史规律呢?突出的时候会有意义(机器学习会有所帮助),但是还是太弱了。那么,价格变化和成交量随时间的关系,再加上历史规律呢?可能更好一点。所以,你已经能够看到,并不是数据越多越好,而是我们需要使用有用处的数据。同时,原始数据应该做一些转换。
考虑每日波动,例如最高价减最低价的百分比差值如何?每日的百分比变化又如何呢?你觉得Open, High, Low, Close这种简单数据,还是Close, Spread/Volatility, %change daily更好?我觉得后者更好一点。前者都是非常相似的数据点,后者基于前者的统一数据创建,但是带有更加有价值的信息。
所以,并不是你拥有的所有数据都是有用的,并且有时你需要对你的数据执行进一步的操作,并使其更加有价值,之后才能提供给机器学习算法。让我们继续并转换我们的数据:
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
这会创建一个新的列,它是基于收盘价的百分比极差,这是我们对于波动的粗糙度量。下面,我们会计算每日百分比变化:
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
现在我们会定义一个新的 DataFrame:
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
print(df.head())
Adj. Close HL_PCT PCT_change Adj. Volume
Date
2004-08-19 50.170 8.072553 0.340000 44659000
2004-08-20 54.155 7.921706 7.227007 22834300
2004-08-23 54.700 4.049360 -1.218962 18256100
2004-08-24 52.435 7.657099 -5.726357 15247300
2004-08-25 53.000 3.886792 0.990854 9188600
三、回归 - 特征和标签
基于上一篇机器学习回归教程,我们将要对我们的股票价格数据执行回归。目前的代码:
import quandl
import pandas as pd
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
print(df.head())
这里我们已经获取了数据,判断出有价值的数据,并通过操作创建了一些。我们现在已经准备好使用回归开始机器学习的过程。首先,我们需要一些更多的导入。所有的导入是:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
我们会使用numpy模块来将数据转换为 NumPy 数组,它是 Sklearn 的预期。我们在用到preprocessing 和cross_validation 时,会深入谈论他们,但是预处理是用于在机器学习之前,对数据清洗和缩放的模块。交叉验证在测试阶段使用。最后,我们也从 Sklearn 导入了LinearRegression算法,以及svm。它们用作我们的机器学习算法来展示结果。
这里,我们已经获取了我们认为有用的数据。真实的机器学习如何工作呢?使用监督式学习,你需要特征和标签。特征就是描述性属性,标签就是你尝试预测的结果。另一个常见的回归示例就是尝试为某个人预测保险的保费。保险公司会收集你的年龄、驾驶违规行为、公共犯罪记录,以及你的信用评分。公司会使用老客户,获取数据,并得出应该给客户的“理想保费”,或者如果他们觉得有利可图的话,他们会使用实际使用的客户。
所以,对于训练机器学习分类器来说,特征是客户属性,标签是和这些属性相关的保费。
我们这里,什么是特征和标签呢?我们尝试预测价格,所以价格就是标签?如果这样,什么是特征呢?对于预测我们的价格来说,我们的标签,就是我们打算预测的东西,实际上是未来价格。这样,我们的特征实际上是:当前价格、HL 百分比和百分比变化。标签价格是未来某个点的价格。让我们继续添加新的行:
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
这里,我们定义了预测列,之后我们将任何 NaN 数据填充为 -99999。对于如何处理缺失数据,你有一些选择,你不能仅仅将 NaN(不是数值)数据点传给机器学习分类西,你需要处理它。一个主流选项就是将缺失值填充为 -99999。在许多机器学习分类器中,会将其是被为离群点。你也可以仅仅丢弃包含缺失值的所有特征或标签,但是这样你可能会丢掉大量的数据。
真实世界中,许多数据集都很混乱。多数股价或成交量数据都很干净,很少有缺失数据,但是许多数据集会有大量缺失数据。我见过一些数据集,大量的行含有缺失数据。你并不一定想要失去所有不错的数据,如果你的样例数据有一些缺失,你可能会猜测真实世界的用例也有一些缺失。你需要训练、测试并依赖相同数据,以及数据的特征。
最后,我们定义我们需要预测的东西。许多情况下,就像尝试预测客户的保费的案例中,你仅仅需要一个数字,但是对于预测来说,你需要预测指定数量的数据点。我们假设我们打算预测数据集整个长度的 1%。因此,如果我们的数据是 100 天的股票价格,我们需要能够预测未来一天的价格。选择你想要的那个。如果你只是尝试预测明天的价格,你应该选取一天之后的数据,而且也只能一天之后的数据。如果你打算预测 10 天,我们可以为每一天生成一个预测。
我们这里,我们决定了,特征是一系列当前值,标签是未来的价格,其中未来是数据集整个长度的 1%。我们假设所有当前列都是我们的特征,所以我们使用一个简单的 Pnadas 操作添加一个新的列:
df['label'] = df[forecast_col].shift(-forecast_out)
现在我们拥有了数据,包含特征和标签。下面我们在实际运行任何东西之前,我们需要做一些预处理和最终步骤,我们在下一篇教程会关注。
四、回归 - 训练和测试
欢迎阅读 Python 机器学习系列教程的第四部分。在上一个教程中,我们获取了初始数据,按照我们的喜好操作和转换数据,之后我们定义了我们的特征。Scikit 不需要处理 Pandas 和 DataFrame,我出于自己的喜好而处理它,因为它快并且高效。反之,Sklearn 实际上需要 NumPy 数组。Pandas 的 DataFrame 可以轻易转换为 NumPy 数组,所以事情就是这样的。
目前为止我们的代码:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
df = quandl.get("WIKI/GOOGL")
print(df.head())
#print(df.tail())
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
print(df.head())
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
我们之后要丢弃所有仍旧是 NaN 的信息。
df.dropna(inplace=True)
对于机器学习来说,通常要定义X(大写)作为特征,和y(小写)作为对于特征的标签。这样,我们可以定义我们的特征和标签,像这样:
X = np.array(df.drop(['label'], 1))
y = np.array(df['label'])
上面,我们所做的就是定义X(特征),是我们整个的 DataFrame,除了label列,并转换为 NumPy 数组。我们使用drop方法,可以用于 DataFrame,它返回一个新的 DataFrame。下面,我们定义我们的y变量,它是我们的标签,仅仅是 DataFrame 的标签列,并转换为 NumPy 数组。
现在我们就能告一段落,转向训练和测试了,但是我们打算做一些预处理。通常,你希望你的特征在 -1 到 1 的范围内。这可能不起作用,但是通常会加速处理过程,并有助于准确性。因为大家都使用这个范围,它包含在了 Sklearn 的preprocessing模块中。为了使用它,你需要对你的X变量调用 preprocessing.scale。
X = preprocessing.scale(X)
下面,创建标签y:
y = np.array(df['label'])
现在就是训练和测试的时候了。方式就是选取 75% 的数据用于训练机器学习分类器。之后选取剩下的 25% 的数据用于测试分类器。由于这是你的样例数据,你应该拥有特征和一直标签。因此,如果你测试后 25% 的数据,你就会得到一种准确度和可靠性,叫做置信度。有许多方式可以实现它,但是,最好的方式可能就是使用内建的cross_validation,因为它也会为你打乱数据。代码是这样:
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
这里的返回值是特征的训练集、测试集、标签的训练集和测试集。现在,我们已经定义好了分类器。Sklearn 提供了许多通用的分类器,有一些可以用于回归。我们会在这个例子中展示一些,但是现在,让我们使用svm包中的支持向量回归。
clf = svm.SVR()
我们这里仅仅使用默认选项来使事情简单,但是你可以在sklearn.svm.SVR的文档中了解更多。
一旦你定义了分类器,你就可以训练它了。在 Sklearn 中,使用fit来训练。
clf.fit(X_train, y_train)
这里,我们拟合了我们的训练特征和训练标签。
我们的分类器现在训练完毕。这非常简单,现在我们可以测试了。
confidence = clf.score(X_test, y_test)
加载测试,之后:
print(confidence)
# 0.960075071072
所以这里,我们可以看到准确率几乎是 96%。没有什么可说的,让我们尝试另一个分类器,这一次使用LinearRegression:
clf = LinearRegression()
# 0.963311624499
更好一点,但是基本一样。所以作为科学家,我们如何知道,选择哪个算法呢?不久,你会熟悉什么在多数情况下都工作,什么不工作。你可以从 Scikit 的站点上查看选择正确的评估工具。这有助于你浏览一些基本的选项。如果你询问搞机器学习的人,它完全是试验和出错。你会尝试大量的算法并且仅仅选取最好的那个。要注意的另一件事情就是,一些算法必须线性运行,其它的不是。不要把线性回归和线性运行搞混了。所以这些意味着什么呢?一些机器学习算法会一次处理一步,没有多线程,其它的使用多线程,并且可以利用你机器上的多核。你可以深入了解每个算法,来弄清楚哪个可以多线程,或者你可以阅读文档,并查看n_jobs参数。如果拥有n_jobs,你就可以让算法通过多线程来获取更高的性能。如果没有,就很不走运了。所以,如果你处理大量的数据,或者需要处理中等规模的数据,但是需要很高的速度,你就可能想要线程加速。让我们看看这两个算法。
访问sklearn.svm.SVR的文档,并查看参数,看到n_jobs了嘛?反正我没看到,所以它就不能使用线程。你可能会看到,在我们的小型数据集上,差异不大。但是,假设数据集由 20MB,差异就很明显。然后,我们查看LinearRegression算法,看到n_jobs了嘛?当然,所以这里,你可以指定你希望多少线程。如果你传入-1,算法会使用所有可用的线程。
这样:
clf = LinearRegression(n_jobs=-1)
就够了。虽然我让你做了很少的事情(查看文档),让我给你说个事实吧,仅仅由于机器学习算法使用默认参数工作,不代表你可以忽略它们。例如,让我们回顾svm.SVR。SVR 是支持向量回归,在执行机器学习时,它是一种架构。我非常鼓励那些有兴趣学习更多的人,去研究这个主题,以及向比我学历更高的人学习基础。我会尽力把东西解释得更简单,但是我并不是专家。回到刚才的话题,svm.SVR有一个参数叫做kernel。这个是什么呢?核就相当于你的数据的转换。这使得处理过程更加迅速。在svm.SVR的例子中,默认值是rbf,这是核的一个类型,你有一些选择。查看文档,你可以选择'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'或者一个可调用对象。同样,就像尝试不同的 ML 算法一样,你可以做你想做的任何事情,尝试一下不同的核吧。
for k in ['linear','poly','rbf','sigmoid']:
clf = svm.SVR(kernel=k)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(k,confidence)
linear 0.960075071072
poly 0.63712232551
rbf 0.802831714511
sigmoid -0.125347960903
我们可以看到,线性的核表现最好,之后是rbf,之后是poly,sigmoid很显然是个摆设,并且应该移除。
所以我们训练并测试了数据集。我们已经有 71% 的满意度了。下面我们做什么呢?现在我们需要再进一步,做一些预测,下一章会涉及它。
五、预测
欢迎阅读机器学习系列教程的第五章,当前涉及到回归。目前为止,我们收集并修改了数据,训练并测试了分类器。这一章中,我们打算使用我们的分类器来实际做一些预测。我们目前所使用的代码为:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
我会强调,准确率大于 95% 的线性模型并不是那么好。我当然不会用它来交易股票。仍然有一些需要考虑的问题,特别是不同公司有不同的价格轨迹。Google 非常线性,向右上角移动,许多公司不是这样,所以要记住。现在,为了做预测,我们需要一些数据。我们决定预测 1% 的数据,因此我们打算,或者至少能够预测数据集的后 1%。所以我们什么可以这样做呢?我们什么时候可以识别这些数据?我们现在就可以,但是要注意我们尝试预测的数据,并没有像训练集那样缩放。好的,那么做什么呢?是否要对后 1% 调用preprocessing.scale()?缩放方法基于所有给它的已知数据集。理想情况下,你应该一同缩放训练集、测试集和用于预测的数据。这永远是可能或合理的嘛?不是,如果你可以这么做,你就应该这么做。但是,我们这里,我们可以这么做。我们的数据足够小,并且处理时间足够低,所以我们会一次性预处理并缩放数据。
在许多例子中,你不能这么做。想象如果你使用几个 GB 的数据来训练分类器。训练分类器会花费几天,不能在每次想要做出预测的时候都这么做。因此,你可能需要不缩放任何东西,或者单独缩放数据。通常,你可能希望测试这两个选项,并看看那个对于你的特定案例更好。
要记住它,让我们在定义X的时候处理所有行:
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
要注意我们首先获取所有数据,预处理,之后再分割。我们的X_lately变量包含最近的特征,我们需要对其进行预测。目前你可以看到,定义分类器、训练、和测试都非常简单。预测也非常简单:
forecast_set = clf.predict(X_lately)
forecast_set 是预测值的数组,表明你不仅仅可以做出单个预测,还可以一次性预测多个值。看看我们目前拥有什么:
[ 745.67829395 737.55633261 736.32921413 717.03929303 718.59047951
731.26376715 737.84381394 751.28161162 756.31775293 756.76751056
763.20185946 764.52651181 760.91320031 768.0072636 766.67038016
763.83749414 761.36173409 760.08514166 770.61581391 774.13939706
768.78733341 775.04458624 771.10782342 765.13955723 773.93369548
766.05507556 765.4984563 763.59630529 770.0057166 777.60915879] 0.956987938167 30
所以这些就是我们的预测结果,然后呢?已经基本完成了,但是我们可以将其可视化。股票价格是每一天的,一周 5 天,周末没有。我知道这个事实,但是我们打算将其简化,把每个预测值当成每一天的。如果你打算处理周末的间隔(不要忘了假期),就去做吧,但是我这里会将其简化。最开始,我们添加一些新的导入:
import datetime
import matplotlib.pyplot as plt
from matplotlib import style
我导入了datetime来处理datetime对象,Matplotlib 的pyplot包用于绘图,以及style来使我们的绘图更加时髦。让我们设置一个样式:
style.use('ggplot')
之后,我们添加一个新的列,forecast列:
df['Forecast'] = np.nan
我们首先将值设置为 NaN,但是我们之后会填充他。
预测集的标签正好从明天开始。因为我们要预测未来m = 0.1 * len(df)天的数据,相当于把收盘价往前移动m天生成标签。那么数据集的后m个是不能用作训练集和测试集的,因为没有标签。于是我们将后m个数据用作预测集。预测集的第一个数据,也就是数据集的第n - m个数据,它的标签应该是n - m + m = n天的收盘价,我们知道今天在df里面是第n - 1天,那么它就是明天。
我们首先需要抓取 DataFrame 的最后一天,将每一个新的预测值赋给新的日期。我们会这样开始。
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
现在我们拥有了预测集的起始日期,并且一天有 86400 秒。现在我们将预测添加到现有的 DataFrame 中。
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
我们这里所做的是,迭代预测集的标签,获取每个预测值和日期,之后将这些值放入 DataFrame(使预测集的特征为 NaN)。最后一行的代码创建 DataFrame 中的一行,所有元素置为 NaN,然后将最后一个元素置为i(这里是预测集的标签)。我选择了这种单行的for循环,以便在改动 DataFrame 和特征之后,代码还能正常工作。所有东西都做完了吗?将其绘制出来。
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
完整的代码:
import Quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from matplotlib import style
import datetime
style.use('ggplot')
df = Quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
forecast_set = clf.predict(X_lately)
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
结果:

六、保存和扩展
上一篇教程中,我们使用回归完成了对股票价格的预测,并使用 Matplotlib 可视化。这个教程中,我们会讨论一些接下来的步骤。
我记得我第一次尝试学习机器学习的时候,多数示例仅仅涉及到训练和测试的部分,完全跳过了预测部分。对于那些包含训练、测试和预测部分的教程来说,我没有找到一篇解释保存算法的文章。在那些例子中,数据通常非常小,所以训练、测试和预测过程都很快。在真实世界中,数据都非常大,并且花费更长时间来处理。由于没有一篇教程真正谈论到这一重要的过程,我打算包含一些处理时间和保存算法的信息。
虽然我们的机器学习分类器花费几秒来训练,在一些情况下,训练分类器需要几个小时甚至是几天。想象你想要预测价格的每天都需要这么做。这不是必要的,因为我们呢可以使用 Pickle 模块来保存分类器。首先确保你导入了它:
import pickle
使用 Pickle,你可以保存 Python 对象,就像我们的分类器那样。在定义、训练和测试你的分类器之后,添加:
with open('linearregression.pickle','wb') as f:
pickle.dump(clf, f)
现在,再次执行脚本,你应该得到了linearregression.pickle,它是分类器的序列化数据。现在,你需要做的所有事情就是加载pickle文件,将其保存到clf,并照常使用,例如:
pickle_in = open('linearregression.pickle','rb')
clf = pickle.load(pickle_in)
代码中:
import Quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from matplotlib import style
import datetime
import pickle
style.use('ggplot')
df = Quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.1 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
#COMMENTED OUT:
##clf = svm.SVR(kernel='linear')
##clf.fit(X_train, y_train)
##confidence = clf.score(X_test, y_test)
##print(confidence)
pickle_in = open('linearregression.pickle','rb')
clf = pickle.load(pickle_in)
forecast_set = clf.predict(X_lately)
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()

要注意我们注释掉了分类器的原始定义,并替换为加载我们保存的分类器。就是这么简单。
最后,我们要讨论一下效率和保存时间,前几天我打算提出一个相对较低的范式,这就是临时的超级计算机。严肃地说,随着按需主机服务的兴起,例如 AWS、DO 和 Linode,你能够按照小时来购买主机。虚拟服务器可以在 60 秒内建立,所需的模块可以在 15 分钟内安装,所以非常有限。你可以写一个 shell 脚本或者什么东西来给它加速。考虑你需要大量的处理,并且还没有一台顶级计算机,或者你使用笔记本。没有问题,只需要启动一台服务器。
我对这个方式的最后一个注解是,使用任何主机,你通常都可以建立一个非常小型的服务器,加载所需的东西,之后扩展这个服务器。我喜欢以一个小型服务器开始,之后,我准备好的时候,我会改变它的尺寸,给它升级。完成之后,不要忘了注销或者降级你的服务器。
七、回归 - 理论以及工作原理
欢迎阅读第七篇教程。目前为止,你已经看到了线性回归的价值,以及如何使用 Sklearn 来应用它。现在我们打算深入了解它如何计算。虽然我觉得不必要深入到每个机器学习算法数学中(你有没有进入到你最喜欢的模块的源码中,看看它是如何实现的?),线性代数是机器学习的本质,并且对于理解机器学习的构建基础十分实用。
线性代数的目标是计算向量空间中的点的关系。这可以用于很多事情,但是某天,有个人有了个非常狂野的想法,拿他处理数据集的特征。我们也可以。记得之前我们定义数据类型的时候,线性回归处理连续数据吗?这并不是因为使用线性回归的人,而是因为组成它的数学。简单的线性回归可用于寻找数据集的最佳拟合直线。如果数据不是连续的,就不是最佳拟合直线。让我们看看一些示例。
协方差

上面的图像显然拥有良好的协方差。如果你通过估计画一条最佳拟合直线,你应该能够轻易画出来:

如果图像是这样呢?

并不和之前一样,但是是清楚的负相关。你可能能够画出最佳拟合直线,但是更可能画不出来。
最后,这个呢?

啥?的确有最佳拟合直线,但是需要运气将其画出来。
将上面的图像看做特征的图像,所以 X 坐标是特征,Y 坐标是相关的标签。X 和 Y 是否有任何形式的结构化关系呢?虽然我们可以准确计算关系,未来我们就不太可能拥有这么多值了。
在其它图像的案例中,X 和 Y 之间显然存在关系。我们实际上可以探索这种关系,之后沿着我们希望的任何点绘图。我们可以拿 Y 来预测 X,或者拿 X 来预测 Y,对于任何我们可以想到的点。我们也可以预测我们的模型有多少的误差,即使模型只有一个点。我们如何实现这个魔法呢?当然是线性代数。
首先,让我们回到中学,我们在那里复习直线的定义:y = mx + b,其中m是斜率,b是纵截距。这可以是用于求解y的方程,我们可以将其变形来求解x,使用基本的代数原则:x = (y-b)/m。
好的,所以,我们的目标是寻找最佳拟合直线。不是仅仅是拟合良好的直线,而是最好的那条。这条直线的定义就是y = mx + b。y就是答案(我们其他的坐标,或者甚至是我们的特征),所以我们仍然需要m(斜率)和b(纵截距),由于x可能为沿 x 轴的任一点,所以它是已知的。
最佳拟合直线的斜率m定义为:

注:可简写为
m = cov(x, y) / var(x)。
符号上面的横杠代表均值。如果两个符号挨着,就将其相乘。xs 和 ys 是所有已知坐标。所以我们现在求出了y=mx+b最佳拟合直线定义的m(斜率),现在我们仅仅需要b(纵截距)。这里是公式:

好的。整个部分不是个数学教程,而是个编程教程。下一个教程中,我们打算这样做,并且解释为什么我要编程实现它,而不是直接用模块。
八、回归 - 编程计算斜率
欢迎阅读第八篇教程,我们刚刚意识到,我们需要使用 Python 重复编写一些比较重要的算法,来尝试给定数据集的计算最佳拟合直线。
在我们开始之前,为什么我们会有一些小麻烦呢?线性回归是机器学习的构建基础。它几乎用于每个单独的主流机器学习算法之中,所以对它的理解有助于你掌握多数主流机器学习算法。出于我们的热情,理解线性回归和线性代数,是编写你自己的机器学习算法,以及跨入机器学习前沿,使用当前最佳的处理过程的第一步。由于处理过程的优化和硬件架构的改变。用于机器学习的方法论也会改变。最近出现的神经网络,使用大量 GPU 来完成工作。你想知道什么是神经网络的核心吗?你猜对了,线性代数。
如果你能记得,最佳拟合直线的斜率m:

是的,我们会将其拆成片段。首先,进行一些导入:
from statistics import mean
import numpy as np
我们从statistics导入mean,所以我们可以轻易获取列表的均值。下面,我们使numpy as np,所以我们可以其创建 NumPy 数组。我们可以对列表做很多事情,但是我们需要能够做一些简单的矩阵运算,它并不对简单列表提供,所以我们使用 NumPy。我们在这个阶段不会使用太复杂的 NumPy,但是之后 NumPy 就会成为你的最佳伙伴。下面,让我们定义一些起始点吧。
xs = [1,2,3,4,5]
ys = [5,4,6,5,6]
所以这里有一些我们要使用的数据点,xs和ys。你可以认为xs就是特征,ys就是标签,或者他们都是特征,我们想要建立他们的联系。之前提到过,我们实际上把它们变成 NumPy 数组,以便执行矩阵运算。所以让我们修改这两行:
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
现在他们都是 NumPy 数组了。我们也显式声明了数据类型。简单讲一下,数据类型有特性是属性,这些属性决定了数据本身如何储存和操作。现在它不是什么问题,但是如果我们执行大量运算,并希望他们跑在 GPU 而不是 CPU 上就是了。
将其画出来,他们是:

现在我们准备好构建函数来计算m,也就是我们的直线斜率:
def best_fit_slope(xs,ys):
return m
m = best_fit_slope(xs,ys)
好了。开个玩笑,所以这是我们的框架,现在我们要填充了。
我们的第一个逻辑就是计算xs的均值,再乘上ys的均值。继续填充我们的框架:
def best_fit_slope(xs,ys):
m = (mean(xs) * mean(ys))
return m
目前为止还很简单。你可以对列表、元组或者数组使用mean函数。要注意我这里使用了括号。Python 的遵循运算符的数学优先级。所以如果你打算保证顺序,要显式使用括号。要记住你的运算规则。
下面我们需要将其减去x*y的均值。这既是我们的矩阵运算mean(xs*ys)。现在的代码是:
def best_fit_slope(xs,ys):
m = ( (mean(xs)*mean(ys)) - mean(xs*ys) )
return m
我们完成了公式的分子部分,现在我们继续处理的分母,以x的均值平方开始:(mean(xs)*mean(xs))。Python 支持** 2,能够处理我们的 NumPy 数组的float64类型。添加这些东西:
def best_fit_slope(xs,ys):
m = ( ((mean(xs)*mean(ys)) - mean(xs*ys)) /
(mean(xs)**2))
return m
虽然根据运算符优先级,向整个表达式添加括号是不必要的。我这里这样做,所以我可以在除法后面添加一行,使整个式子更加易读和易理解。不这样的话,我们会在新的一行得到语法错误。我们几乎完成了,现在我们只需要将x的均值平方和x的平方均值(mean(xs*xs))相减。全部代码为:
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)**2) - mean(xs*xs)))
return m
好的,现在我们的完整脚本为:
from statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)**2) - mean(xs**2)))
return m
m = best_fit_slope(xs,ys)
print(m)
# 0.3
下面干什么?我们需要计算纵截距b。我们会在下一个教程中处理它,并完成完整的最佳拟合直线计算。它比斜率更佳易于计算,尝试编写你自己的函数来计算它。如果你做到了,也不要跳过下一个教程,我们会做一些别的事情。
九、回归 - 计算纵截距
欢迎阅读第九篇教程。我们当前正在为给定的数据集,使用 Python 计算回归或者最佳拟合直线。之前,我们编写了一个函数来计算斜率,现在我们需要计算纵截距。我们目前的代码是:
from statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
return m
m = best_fit_slope(xs,ys)
print(m)
请回忆,最佳拟合直线的纵截距是:

这个比斜率简单多了。我们可以将其写到同一个函数来节省几行代码。我们将函数重命名为best_fit_slope_and_intercept。
下面,我们可以填充b = mean(ys) - (m*mean(xs)),并返回m, b:
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
现在我们可以调用它:
best_fit_slope_and_intercept(xs,ys)
我们目前为止的代码:
from statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
m, b = best_fit_slope_and_intercept(xs,ys)
print(m,b)
# 0.3, 4.3
现在我们仅仅需要为数据创建一条直线:

要记住y=mx+b,我们能够为此编写一个函数,或者仅仅使用一行的for循环。
regression_line = [(m*x)+b for x in xs]
上面的一行for循环和这个相同:
regression_line = []
for x in xs:
regression_line.append((m*x)+b)
好的,让我们收取我们的劳动果实吧。添加下面的导入:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
我们可以绘制图像,并且不会特备难看。现在:
plt.scatter(xs,ys,color='#003F72')
plt.plot(xs, regression_line)
plt.show()
首先我们绘制了现有数据的散点图,之后我们绘制了我们的回归直线,之后展示它。如果你不熟悉,可以查看 Matplotlib 教程集。
输出:

恭喜恭喜。所以,如何基础这个模型来做一些实际的预测呢?很简单,你拥有了模型,只要填充x就行了。例如,让我们预测一些点:
predict_x = 7
我们输入了数据,也就是我们的特征。那么标签呢?
predict_y = (m*predict_x)+b
print(predict_y)
# 6.4
我们也可以绘制它:
predict_x = 7
predict_y = (m*predict_x)+b
plt.scatter(xs,ys,color='#003F72',label='data')
plt.plot(xs, regression_line, label='regression line')
plt.legend(loc=4)
plt.show()
输出:

我们现在知道了如何创建自己的模型,这很好,但是我们仍旧缺少了一些东西,我们的模型有多精确?这就是下一个教程的话题了。
十、回归 - R 平方和判定系数原理
欢迎阅读第十篇教程。我们刚刚完成了线性模型的创建和处理,现在我们好奇接下来要干什么。现在,我们可以轻易观察数,并决定线性回归模型有多么准确。但是,如果你的线性回归模型是拿神经网络的 20 个层级做出来的呢?不仅仅是这样,你的模型以步骤或者窗口工作,也就是一共 5 百万个数据点,一次只显示 100 个,会怎么样?你需要一些自动化的方式来判断你的最佳拟合直线有多好。
回忆之前,我们展示几个绘图的时候,你已经看到,最佳拟合直线好还是不好。像这样:

与这个相比:

第二张图片中,的确有最佳拟合直线,但是没有人在意。即使是最佳拟合直线也是没有用的。并且,我们想在花费大量计算能力之前就知道它。
检查误差的标准方式就是使用平方误差。你可能之前听说过,这个方法叫做 R 平方或者判定系数。什么叫平方误差呢?

回归直线和数据的y值的距离,就叫做误差,我们将其平方。直线的平方误差是它们的平均或者和。我们简单求和吧。
我们实际上已经解除了平方误差假设。我们的最佳拟合直线方程,用于计算最佳拟合回归直线,就是证明结果。其中回归直线就是拥有最小平方误差的直线(所以它才叫做最小二乘法)。你可以搜索“回归证明”,或者“最佳拟合直线证明”来理解它。它很抑郁理解,但是需要代数变形能力来得出结果。
为啥是平方误差?为什么不仅仅将其加起来?首先,我们想要一种方式,将误差规范化为距离,所以误差可能是 -5,但是,平方之后,它就是正数了。另一个原因是要进一步惩罚离群点。进一步的意思是,它影响误差的程度更大。这就是人们所使用的标准方式。你也可以使用4, 6, 8的幂,或者其他。你也可以仅仅使用误差的绝对值。如果你只有一个挑战,也许就是存在一些离群点,但是你并不打算管它们,你就可以考虑使用绝对值。如果你比较在意离群点,你就可以使用更高阶的指数。我们会使用平方,因为这是大多数人所使用的。
好的,所以我们计算回归直线的平方误差,什么计算呢?这是什么意思?平方误差完全和数据集相关,所以我们不再需要别的东西了。这就是 R 平方引入的时候了,也叫作判定系数。方程是:

y_hat = x * m + b
r_sq = 1 - np.sum((y - y_hat) ** 2) / np.sum((y - y.mean()) ** 2)
这个方程的的本质就是,1 减去回归直线的平方误差,比上 y 平均直线的平方误差。 y 平均直线就是数据集中所有 y 值的均值,如果你将其画出来,它是一个水平的直线。所以,我们计算 y 平均直线,和回归直线的平方误差。这里的目标是识别,与欠拟合的直线相比,数据特征的变化产生了多少误差。
所以判定系数就是上面那个方程,如何判定它是好是坏?我们看到了它是 1 减去一些东西。通常,在数学中,你看到他的时候,它返回了一个百分比,它是 0 ~ 1 之间的数值。你认为什么是好的 R 平方或者判定系数呢?让我们假设这里的 R 平方是 0.8,它是好是坏呢?它比 0.3 是好还是坏?对于 0.8 的 R 平方,这就意味着回归直线的平方误差,比上 y 均值的平方误差是 2 比 10。这就是说回归直线的误差非常小于 y 均值的误差。听起来不错。所以 0.8 非常好。
那么与判定系数的值 0.3 相比呢?这里,它意味着回归直线的平方误差,比上 y 均值的平方误差是 7 比 10。其中 7 比 10 要坏于 2 比 10,7 和 2 都是回归直线的平方误差。因此,目标是计算 R 平方值,或者叫做判定系数,使其尽量接近 1。
十一、回归 - 编程计算 R 平方
欢迎阅读第十一篇教程。既然我们知道了我们寻找的东西,让我们实际在 Python 中计算它吧。第一步就是计算平方误差。函数可能是这样:
def squared_error(ys_orig,ys_line):
return sum((ys_line - ys_orig) * (ys_line - ys_orig))
使用上面的函数,我们可以计算出任何实现到数据点的平方误差。所以我们可以将这个语法用于回归直线和 y 均值直线。也就是说,平方误差只是判定系数的一部分,所以让我们构建那个函数吧。由于平方误差函数只有一行,你可以选择将其嵌入到判定系数函数中,但是平方误差是你在这个函数之外计算的东西,所以我选择将其单独写成一个函数。对于 R 平方:
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = squared_error(ys_orig, ys_line)
squared_error_y_mean = squared_error(ys_orig, y_mean_line)
return 1 - (squared_error_regr/squared_error_y_mean)
我们所做的是,计算 y 均值直线,使用单行的for循环(其实是不必要的)。之后我们计算了 y 均值的平方误差,以及回归直线的平方误差,使用上面的函数。现在,我们需要做的就是计算出 R 平方之,它仅仅是 1 减去回归直线的平方误差,除以 y 均值直线的平方误差。我们返回该值,然后就完成了。组合起来并跳过绘图部分,代码为:
from statistics import mean
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
def squared_error(ys_orig,ys_line):
return sum((ys_line - ys_orig) * (ys_line - ys_orig))
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = squared_error(ys_orig, ys_line)
squared_error_y_mean = squared_error(ys_orig, y_mean_line)
return 1 - (squared_error_regr/squared_error_y_mean)
m, b = best_fit_slope_and_intercept(xs,ys)
regression_line = [(m*x)+b for x in xs]
r_squared = coefficient_of_determination(ys,regression_line)
print(r_squared)
# 0.321428571429
##plt.scatter(xs,ys,color='#003F72',label='data')
##plt.plot(xs, regression_line, label='regression line')
##plt.legend(loc=4)
##plt.show()
这是个很低的值,所以根据这个度量,我们的最佳拟合直线并不是很好。这里的 R 平方是个很好的度量手段吗?可能取决于我们的目标。多数情况下,如果我们关心准确预测未来的值,R 平方的确很有用。如果你对预测动机或者趋势感兴趣,我们的最佳拟合直线实际上已经很好了。R 平方不应该如此重要。看一看我们实际的数据集,我们被一个较低的数值卡住了。值与值之间的变化在某些点上是 20% ~ 50%,这已经非常高了。我们完全不应该感到意外,使用这个简单的数据集,我们的最佳拟合直线并不能描述真实数据。
但是,我们刚才说的是一个假设。虽然我们逻辑上统一这个假设,我们需要提出一个新的方法,来验证假设。到目前为止的算法非常基础,我们现在只能做很少的事情,所以没有什么空间来改进误差了,但是之后,你会在空间之上发现空间。不仅仅要考虑算法本身的层次空间,还有由很多算法层次组合而成的算法。其中,我们需要测试它们来确保我们的假设,关于算法是干什么用的,是正确的。考虑把操作组成成函数由多么简单,之后,从这里开始,将整个验证分解成数千行代码。
我们在下一篇教程所做的是,构建一个相对简单的数据集生成器,根据我们的参数来生成数据。我们可以使用它来按照意愿操作数据,之后对这些数据集测试我们的算法,根据我们的假设修改参数,应该会产生一些影响。我们之后可以将我们的假设和真实情况比较,并希望他们匹配。这里的例子中,假设是我们正确编写这些算法,并且判定系数低的原因是,y 值的方差太大了。我们会在下一个教程中验证这个假设。
十二、为测试创建样例数据集
欢迎阅读第十二篇教程。我们已经了解了回归,甚至编写了我们自己的简单线性回归算法。并且,我们也构建了判定系数算法来检查最佳拟合直线的准确度和可靠性。我们之前讨论和展示过,最佳拟合直线可能不是最好的拟合,也解释了为什么我们的示例方向上是正确的,即使并不准确。但是现在,我们使用两个顶级算法,它们由一些小型算法组成。随着我们继续构造这种算法层次,如果它们之中有个小错误,我们就会遇到麻烦,所以我们打算验证我们的假设。
在编程的世界中,系统化的程序测试通常叫做“单元测试”。这就是大型程序构建的方式,每个小型的子系统都不断检查。随着大型程序的升级和更新,可以轻易移除一些和之前系统冲突的工具。使用机器学习,这也是个问题,但是我们的主要关注点仅仅是测试我们的假设。最后,你应该足够聪明,可以为你的整个机器学习系统创建单元测试,但是目前为止,我们需要尽可能简单。
我们的假设是,我们创建了最贱he直线,之后使用判定系数法来测量。我们知道(数学上),R 平方的值越低,最佳拟合直线就越不好,并且越高(接近 1)就越好。我们的假设是,我们构建了一个这样工作的系统,我们的系统有许多部分,即使是一个小的操作错误都会产生很大的麻烦。我们如何测试算法的行为,保证任何东西都预期工作呢?
这里的理念是创建一个样例数据集,由我们定义,如果我们有一个正相关的数据集,相关性非常强,如果相关性很弱的话,点也不是很紧密。我们用眼睛很容易评测这个直线,但是机器应该做得更好。让我们构建一个系统,生成示例数据,我们可以调整这些参数。
最开始,我们构建一个框架函数,模拟我们的最终目标:
def create_dataset(hm,variance,step=2,correlation=False):
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
我们查看函数的开头,它接受下列参数:
-
hm(how much):这是生成多少个数据点。例如我们可以选择 10,或者一千万。 -
variance:决定每个数据点和之前的数据点相比,有多大变化。变化越大,就越不紧密。 -
step:每个点距离均值有多远,默认为 2。 -
correlation:可以为False、pos或者neg,决定不相关、正相关和负相关。
要注意,我们也导入了random,这会帮助我们生成(伪)随机数据集。
现在我们要开始填充函数了。
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
非常简单,我们仅仅使用hm变量,迭代我们所选的范围,将当前值加上一个负差值到证差值的随机范围。这会产生数据,但是如果我们想要的话,它没有相关性。让我们这样:
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
非常棒了,现在我们定义好了 y 值。下面,让我们创建 x,它更简单,只是返回所有东西。
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
xs = [i for i in range(len(ys))]
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
我们准备好了。为了创建样例数据集,我们所需的就是:
xs, ys = create_dataset(40,40,2,correlation='pos')
让我们将之前线性回归教程的代码放到一起:
from statistics import mean
import numpy as np
import random
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
xs = [i for i in range(len(ys))]
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = sum((ys_line - ys_orig) * (ys_line - ys_orig))
squared_error_y_mean = sum((y_mean_line - ys_orig) * (y_mean_line - ys_orig))
print(squared_error_regr)
print(squared_error_y_mean)
r_squared = 1 - (squared_error_regr/squared_error_y_mean)
return r_squared
xs, ys = create_dataset(40,40,2,correlation='pos')
m, b = best_fit_slope_and_intercept(xs,ys)
regression_line = [(m*x)+b for x in xs]
r_squared = coefficient_of_determination(ys,regression_line)
print(r_squared)
plt.scatter(xs,ys,color='#003F72', label = 'data')
plt.plot(xs, regression_line, label = 'regression line')
plt.legend(loc=4)
plt.show()
执行代码,你会看到:

判定系数是 0.516508576011(要注意你的结果不会相同,因为我们使用了随机数范围)。
不错,所以我们的假设是,如果我们生成一个更加紧密相关的数据集,我们的 R 平方或判定系数应该更好。如何实现它呢?很简单,把范围调低。
xs, ys = create_dataset(40,10,2,correlation='pos')

现在我们的 R 平方值为 0.939865240568,非常不错,就像预期一样。让我们测试负相关:
xs, ys = create_dataset(40,10,2,correlation='neg')

R 平方值是 0.930242442156,跟之前一样好,由于它们参数相同,只是方向不同。
这里,我们的假设证实了:变化越小 R 值和判定系数越高,变化越大 R 值越低。如果是不相关呢?应该很低,接近于 0,除非我们的随机数排列实际上有相关性。让我们测试:
xs, ys = create_dataset(40,10,2,correlation=False)

判定系数为 0.0152650900427。
现在为止,我觉得我们应该感到自信,因为事情都符合我们的预期。
既然我们已经对简单的线性回归很熟悉了,下个教程中我们开始讲解分类。
第二部分 分类
十三、KNN 分类入门
欢迎阅读第十三篇机器学习系列讲义。我们开始了一个全新的部分:分类。这面,我们会涉及两个主要的分类算法:K 最近邻和支持向量机(SVM)。这两个算法都是分类算法,它们的工作方式不同。
首先,让我们考虑一个数据集,创建下面的图像:

直观上,你应该能够看到两个组。但是,分类是监督式机器学习。当我们将数据提供给机器学习算法的时候,我们实际上已经告诉它组的存在,以及哪个数据属于哪个组。一个机器学习的相似形式是聚类,其中你让机器寻找组,但它是非监督机器学习算法,后面我们会降到。所以,使用监督式机器学习,我们需要拥有预置标签的数据用于训练,像这样:

这里我们拥有黑的点和红的点。分类的目标就是拿已知的数据训练机器,就像这样,使机器能够识别新数据的分类(红的还是黑的)。例如,我们会处理乳腺肿瘤的数据,来基于一些属性尝试判断是良性的还是恶性的。我们实现它的方式,就是获取已知的样本属性,例如大小、形状作为特征,标签或者分类就是良性或者恶性。这里,我们可以根据纵六的相同属性来评估未来的肿瘤,并且预测是良性还是恶性。
所以,分类的目标就是识别下面的点属于哪个类:

你可能能猜到它是红的类,但是为什么呢?尝试为自己定义这里有什么参数。下面这种情况呢?

第二种情况中我们可能选取黑色。同样,尝试定义为啥这么选择。最后,如果是这样:

这种情况比较复杂,尝试选取一种分类。
大多数人都会选择黑色。无论哪种,考虑为什么你会做出这种选择。多数人会根据近似性对数据集分组。直觉上它是最有意义的。如果你拿尺子画出它到最近的黑色点的直线,之后画出它到最近的红色点的直线,你就会发现黑色点更近一些。与之相似,当数据点距离一个分组比另一个更近时,你就会基于近似性做出判断。因此 KNN 机器学习算法就诞生了。
KNN 是个简单高效的机器学习分类算法。如果这非常简单,就像我们看到的那样,我们为什么需要一个算法,而不是直接拿眼睛看呢?就像回归那样,机器可以计算得更快,处理更大的数据集,扩展,以及更重要的是,处理更多维度,例如 100 维。
它的工作方式就是它的名字。K 就是你选取的数量,近邻就是已知数据中的相邻数据点。我们寻找任意数量的“最近”的相邻点。假设K=3,所以我们就寻找三个最近的相邻点。例如:

上面的图中,我圈出了三个最近的相邻点。这里,所有三个点都是红色分类。KNN 会基于相邻点进行计数。所有三个近邻都是红色,所以它 100% 是红色分类。如果两个近邻都是红色,一个是黑色,我们也将其分类为红色,只是置信度就少了。要注意,由于计数的本质,你会更希望使用奇数 K,否则会产生 50:50 的情况。有一种方式在距离上应用权重,来惩罚那些更远的点,所以你就可以使用偶数的 K 值了。
下一个教程中,我们会涉及到 Scikit 的 KNN 算法,来处理乳腺肿瘤数据,之后我们会尝试自己来编写这个算法。
十四、对数据使用 KNN
欢迎阅读第十四个部分。上一个部分我们介绍了分类,它是一种机器学习的监督算法,并且解释了 KNN 算法的直觉。这个教程中,我们打算使用 Sklearn,讲解一个简单的算法示例,之后在后面的教程中,我们会构建我们自己的算法来更多了解背后的工作原理。
为了使用例子说明分类,我们打算使用乳腺肿瘤数据集,它是 UCI 所贡献的数据集,从威斯康星大学收集。UCI 拥有庞大的机器学习仓库。这里的数据集组织为经常使用的机器学习算法类型、数据类型、属性类型、主题范围以及其它。它们对教学和机器学习算法开发都很实用。我自己经常浏览那里,非常值得收藏。在乳腺肿瘤数据集的页面,选择Data Folder链接。之后,下载breast-cancer-wisconsin.data和breast-cancer-wisconsin.names。这些可能不能下载,而是会在浏览器中展示。如果是这样右键点击“另存为”。
下载之后,打开breast-cancer-wisconsin.names文件。查看文件,向下滚动 100 行,我们就能获取属性(列)的名称、使用这些信息,我们打算手动将这些标签添加到 breast-cancer-wisconsin.data文件中。打开它,并输入新的第一行:
id,clump_thickness,uniform_cell_size,
uniform_cell_shape,marginal_adhesion,
single_epi_cell_size,bare_nuclei,bland_chromation,
normal_nucleoli,mitoses,class
之后,你应该会思考,我们的特征和标签应该是什么。我们尝试对数据进行分类,所以很显然分类就是这些属性会导致良性还是恶性。同样,大多数这些属性看起来都是可用的,但是是否有任何属性与其它属性类似,或者是无用的?ID 属性并不是我们打算扔给分类器的东西。
缺失或者损坏的数据:这个数据集拥有一些缺失数据,我们需要清理。让我们以导入来开始,拉取数据,之后做一些清理:
import numpy as np
from sklearn import preprocessing, cross_validation, neighbors
import pandas as pd
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
在读取数据之后,我们注意到,有一些列存在缺失数据。这些缺失数据以?填充。.names文件告诉了我们,但是我们最终可以通过错误来发现,如果我们尝试将这些信息扔给分类为。这个时候,我们选择将缺失数据填充为 -99999 值。你可以选择你自己的方法来处理缺失数据,但是在真实世界中,你可能发现 50% 或者更多记录,一个或多个列都含有缺失数据。尤其是,如果你使用可扩展的属性来收集数据。-99999 并不完美,但是它足够有效了。下面,我们丢弃了 ID 列。完成之后,我们会注释掉 ID 列的丢弃,只是看看包含他可能有哪些影响。
下面,我们定义我们的特征和标签。
特征X是除了分类的任何东西。调用df.drop会返回一个新的 DataFrame,不带丢弃的列。标签y仅仅是分类列。
现在我们创建训练和测试样本,使用 Sklearn 的cross_validation.train_test_split。
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
定义分类器:
clf = neighbors.KNeighborsClassifier()
这里,我们使用 KNN 分类器。
训练分类器:
clf.fit(X_train, y_train)
测试:
accuracy = clf.score(X_test, y_test)
print(accuracy)
结果应该是 95%,并且开箱即用,无需任何调整。非常棒。让我们展示一下,当我们注释掉 ID 列,包含一些无意义和误导性的数据之后,会发生什么。
import numpy as np
from sklearn import preprocessing, cross_validation, neighbors
import pandas as pd
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
#df.drop(['id'], 1, inplace=True)
X = np.array(df.drop(['class'], 1))
y = np.array(df['class'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = neighbors.KNeighborsClassifier()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print(accuracy)
影响很令人吃惊,准确率从 95% 降到了 60%。在未来,如果 AI 通知了这个星球,要注意你只需要给它一些无意义的属性来智取它。非常有意思,添加噪声是一种损害你的算法的方式。当你和你的机器人霸主较量时,分辨有意义和恶意的噪声会节省你的时间。
下面你可以大致猜测,我们如何做预测,如果你遵循了 Sklearn 的教程。首先,我们需要一些沿革本数据。我们可以自己编。例如,我们会查看样本文件的某一行。你可以添加噪声来执行进一步的分析,假设标准差不是那么离谱。这么做也比较安全,由于你并不在篡改的数据上训练,你仅仅做了测试。我会通过编造一行来手动实现它。
example_measures = np.array([4,2,1,1,1,2,3,2,1])
你可以尽管在文档中搜索特征列表。它不存在。现在你可以:
prediction = clf.predict(example_measures)
print(prediction)
或者取决于你的阅读时间,你可能不能这么做。在这么做的时候,我得到了一个警告:
DeprecationWarning: Passing 1d arrays as data is deprecated in 0.17 and will raise ValueError in 0.19. Reshape your data either using X.reshape(-1, 1) if your data has a single feature or X.reshape(1, -1) if it contains a single sample.
好的,没有问题。我们只拥有一个特征吗?不是。我们只拥有一个记录吗?是的。所以我们使用X.reshape(1, -1)。
example_measures = np.array([4,2,1,1,1,2,3,2,1])
example_measures = example_measures.reshape(1, -1)
prediction = clf.predict(example_measures)
print(prediction)
# 0.95
# [2]
这里的第一个输出是准确率(95%)和预测(2)。这就是我们的伪造数据的建模。
如果我们有两条呢?
example_measures = np.array([[4,2,1,1,1,2,3,2,1],[4,2,1,1,1,2,3,2,1]])
example_measures = example_measures.reshape(2, -1)
prediction = clf.predict(example_measures)
print(prediction)
忽略这个硬编码。如果我们不知道有几何样例会怎么样?
example_measures = np.array([[4,2,1,1,1,2,3,2,1],[4,2,1,1,1,2,3,2,1]])
example_measures = example_measures.reshape(len(example_measures), -1)
prediction = clf.predict(example_measures)
print(prediction)
你可以看到,KNN 算法的实现不仅仅很简单,而且这里也很准确。下一个教程中,我们打算从零构建我们自己的 KNN 算法,而不是使用 Sklearn,来尝试了解更多算法的东西,理解它的工作原理,最重要的是,了解它的陷阱。
十五、对数据使用 KNN
欢迎阅读第十五篇教程,其中我们当前涉及到使用 KNN 算法来分类。上一篇教程中,我们涉及到如何使用 Sklearn 的 KNN 算法来预测良性或者恶性肿瘤,基于肿瘤的属性,准确率有 95%。现在,我们打算深入 KNN 的工作原理,以便完全理解算法本身,来使其更好为我们工作。
我们会回到我们的乳腺肿瘤数据集,对其使用我们自定义 KNN 算法,并将其与 Sklearn 的比较,但是我们打算首先以一个非常简单的理论开始。KNN 基于近似性,不是分组,而是单独的点。所以,所有这种算法所做的,实际上是计算点之间的距离,并且之后选取距离最近的前 K 个点的最常出现的分类。有几种方式来计算平面上的距离,他们中许多都可以在这里使用,但是最常使用的版本是欧氏距离,以欧几里得命名。他是一个著名的数学家,被称为几何之父,他编写了《几何原本》,被称为数学家的圣经。欧氏距离为:

所以这是什么意思?基本上,它是每个点之间距离的平方和的平方根。在 Python 的术语中,是这样:
plot1 = [1,3]
plot2 = [2,5]
euclidean_distance = sqrt( (plot1[0]-plot2[0])**2 + (plot1[1]-plot2[1])**2 )
这里距离是 2.236。
这就是 KNN 背后的基本数学原理了,现在我们仅仅需要构建一个系统来处理算法的剩余部分,例如寻找最近距离,它们的分组,然后是计数。
十六、从零创建 KNN 分类器:第一部分
欢迎阅读第十六个部分,我们现在涉及到 KNN 算法的分类。在上一个教程中,我们涉及到了欧氏距离,现在我们开始使用纯粹的 Python 代码来建立我们自己的简单样例。
最开始,让我们导入下列东西并为 Matplotlib 设置一个样式。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
import warnings
from math import sqrt
from collections import Counter
style.use('fivethirtyeight')
我们打算使用警告来避免使用比分组数量更低的 K 值,至少是最开始(因为我会展示一个更加高效的方法),之后对集合计数来获取出现次数最多的分类。
下面,我们创建一些数据:
dataset = {'k':[[1,2],[2,3],[3,1]], 'r':[[6,5],[7,7],[8,6]]}
new_features = [5,7]
这个数据集只是个 Python 字典,键是点的颜色(将这些看做分类),值是属于这个分类的数据点。如果你回忆我们的乳腺肿瘤数据集,分类都是数字,通常 Sklearn 只能处理数字。例如,向量翻译为任意数字2,而恶性翻译为任意数字4,而不是一个字符串。这是因为,Sklearn 只能使用数字,但是你并不一定要使用数字来代表分类。下面,我们创建简单的数据集5, 7,用于测试。我们可以这样来快速绘图:
[[plt.scatter(ii[0],ii[1],s=100,color=i) for ii in dataset[i]] for i in dataset]
plt.scatter(new_features[0], new_features[1], s=100)
plt.show()

[[plt.scatter(ii[0],ii[1],s=100,color=i) for ii in dataset[i]] for i in dataset]这一行和下面这个相同:
for i in dataset:
for ii in dataset[i]:
plt.scatter(ii[0],ii[1],s=100,color=i)
你可以看到红色和黑色的明显分组,并且我们还有蓝色的点,它是new_features,我们打算对其分类。
我们拥有了数据,现在我们打算创建一些函数,来分类数据。
def k_nearest_neighbors(data, predict, k=3):
return vote_result
这就是我们的框架,从这里开始。我们想要一个函数,它接受要训练的数据,预测的数据,和 K 值,它的默认值为 3。
下面,我们会开始填充函数,首先是一个简单的警告:
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
return vote_result
如果选取的最近邻的数量小于或等于分类数量,那么就给出警告(因为这样会产生偏差)。
现在,如何寻找最近的三个点呢?是否有一些用于搜索的魔法呢?没有,如果有的话,也是很复杂而。为什么呢?KNN 的工作原理是,我们需要将问题中的数据与之前的数据比较,之后才能知道最近的点是什么。因此,如果你的数据越多,KNN 就越慢。我们这里告一段落,但是要考虑是否有方法来加速这个过程。
十七、从零创建 KNN 分类器:第二部分
欢迎阅读第十七个部分,我们正在讲解 KNN 算法的分类。上一个教程中,我们开始构建我们的 KNN 示例,这里我们将其完成。
我处理它的方式,就是首先创建一个 Python 列表,它包含另一个列表,里面包含数据集中每个点的距离和分类。一旦填充完毕,我们就可以根据距离来排序列表,截取列表的前 K 个值,找到出现次数最多的,就找到了答案。
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = sqrt( (features[0]-predict[0])**2 + (features[1]-predict[1])**2 )
distances.append([euclidean_distance,group])
有一种方式来计算欧氏距离,最简洁的方式就是遵循定义。也就是说,使用 NumPy 会更快一点。由于 KNN 是一种机器学习的爆破方法,我们需要我们能得到的所有帮助。因此,我们可以将函数修改一点。一个选项是:
euclidean_distance = np.sqrt(np.sum((np.array(features)-np.array(predict))**2))
print(euclidean_distance)
这还是很清楚,我们刚刚使用了 NumPy 版本。NumPy 使用 C 优化,是个非常高效的库,很多时候允许我们计算更快的算术。也就是说,NumPy 实际上拥有大量的线性代数函数。例如,这是范数:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
print(euclidean_distance)
欧式距离度量两个端点之间的线段长度。欧几里得范数度量向量的模。向量的模就是它的长度,这个是等价的。名称仅仅告诉你你所在的控件。
我打算使用后面那一个,但是我会遵循我的约定,使其易于拆解成代码。如果你不了解 NumPy 的内建功能,你需要去了解如何使用。
现在,for循环之外,我们得到了距离列表,它包含距离和分类的列表。我们打算对列表排序,之后截取前 K 个元素,选取下标 1,它就是分类。
votes = [i[1] for i in sorted(distances)[:k]]
上面,我们遍历了排序后的距离列表的每个列表。排序方法会(首先)基于列表中每个列表的第一个元素。第一个元素是距离,所以执行orted(distances)之后我们就按照从小到大的距离排序了列表。之后我们截取了列表的[:k],因为我们仅仅对前 K 个感兴趣。最后,在for循环的外层,我们选取了i[1],其中i就是列表中的列表,它包含[diatance, class](距离和分类的列表)。按照距离排序之后,我们无需再关心距离,只需要关心分类。
所以现在有三个候选分类了。我们需要寻找出现次数最多的分类。我们会使用 Python 标准库模块collections.Counter。
vote_result = Counter(votes).most_common(1)[0][0]
Collections会寻找最常出现的元素。这里,我们想要一个最常出现的元素,但是你可以寻找前 3 个或者前x个。如果没有[0][0]这部分,你会得到[('r', 3)](元素和计数的元组的列表)。所以[0][0]会给我们元组的第一个元素。你看到的 3 是'r'的计数。
最后,返回预测结果,就完成了。完整的代码是:
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
return vote_result
现在,如果我们打算基于我们之前所选的点,来做预测:
result = k_nearest_neighbors(dataset, new_features)
print(result)
非常肯定,我得到了r,这就是预期的值。让我们绘制它吧。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
import warnings
from math import sqrt
from collections import Counter
style.use('fivethirtyeight')
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
return vote_result
dataset = {'k':[[1,2],[2,3],[3,1]], 'r':[[6,5],[7,7],[8,6]]}
new_features = [5,7]
[[plt.scatter(ii[0],ii[1],s=100,color=i) for ii in dataset[i]] for i in dataset]
# same as:
##for i in dataset:
## for ii in dataset[i]:
## plt.scatter(ii[0],ii[1],s=100,color=i)
plt.scatter(new_features[0], new_features[1], s=100)
result = k_nearest_neighbors(dataset, new_features)
plt.scatter(new_features[0], new_features[1], s=100, color = result)
plt.show()

你可以看到,我们添加了新的点5, 7,它分类为红色的点,符合预期。
这只是小规模的处理,但是如果我们处理乳腺肿瘤数据集呢?我们如何和 Sklearn 的 KNN 算法比较?下一个教程中,我们会将算法用于这个数据集。
十八、测试 KNN 分类器
欢迎阅读第十八篇教程,我们刚刚编写了我们自己的 KNN 分类器算法,现在我们准备好了使用一些真实数据来测试它。开始,我们打算使用之前的乳腺肿瘤数据集。如果你没有它,返回教程 13 并抓取数据。
目前为止,我们的算法像这样处理数据:

其中蓝色的点是位置数据,运行算法,并正确分类数据:

现在,我们打算回顾乳腺肿瘤数据集,它记录肿瘤的属性变将它们按照良性还是恶性分类。Sklearn 的 KNN 分类器有 95% 的准确率,并且我们打算测试我们自己的算法。
我们会以下列代码开始:
import numpy as np
import warnings
from collections import Counter
import pandas as pd
import random
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
return vote_result
这应该看起来很熟悉。要注意我导入了 Pandas 和 random。我已经移除了 Matplotlib 的导入,因为我们不打算绘制任何东西。下面,我们打算加载数据:
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
full_data = df.astype(float).values.tolist()
这里,我们加载了数据,替换掉了问号,丢弃了 ID 列,并且将数据转危为列表的列表。要注意我们显式将 DataFrame 转换为浮点类型。出于一些原因,至少对于我来说,一些数据点仍然是数字,但是字符串数据类型并不是很好。
下面,我们打算把数据打乱,之后将其分割:
Next, we're going to shuffle the data, and then split it up:
random.shuffle(full_data)
test_size = 0.2
train_set = {2:[], 4:[]}
test_set = {2:[], 4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
首先我们打乱了数据(它包含特征和标签)。之后我们为训练和测试集准备了一个字典用于填充。下面,我们指定了哪个是train_data ,哪个是test_data。我们选取前 80% 作为train_data (逻辑是在后 20% 的地方分割),之后我们通过在后 20% 的地方分割,来创建test_data。
现在我们开始填充字典。如果不清楚的话,字典有两个键:2 和 4。2 是良性肿瘤(和实际数据集相同),4 是恶性肿瘤,也和数据集相同。我们将其硬编码,但是其他人可以选取分类,并像这样创建字典,它的键是分类中的唯一值。我们仅仅是使其简单。
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
现在我们填充了字典,我们拥有了测试集,其中键是分类,值是属性。
最后就是训练和测试的时候了。使用 KNN,这些步骤基本就完成了,因为训练步骤就是把点村进内存,测试步骤就是比较距离:
correct = 0
total = 0
for group in test_set:
for data in test_set[group]:
vote = k_nearest_neighbors(train_set, data, k=5)
if group == vote:
correct += 1
total += 1
print('Accuracy:', correct/total)
现在我们首先迭代测试集的分组(分类,2 或者 4,也是字典的键),之后我们遍历每个数据点,将数据点扔给k_nearest_neighbors,以及我们的训练集train_set,之后是我们的 K,它是 5。我选择了 5,纯粹是因为它是 SKlearn 的KNeighborsClassifier的默认值。所以我们的完整代码是:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
import warnings
from collections import Counter
#dont forget this
import pandas as pd
import random
style.use('fivethirtyeight')
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
return vote_result
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
full_data = df.astype(float).values.tolist()
random.shuffle(full_data)
test_size = 0.2
train_set = {2:[], 4:[]}
test_set = {2:[], 4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
correct = 0
total = 0
for group in test_set:
for data in test_set[group]:
vote = k_nearest_neighbors(train_set, data, k=5)
if group == vote:
correct += 1
total += 1
print('Accuracy:', correct/total)
十九、KNN 的最终见解
既然我们了解了它的工作原理,这里我们打算涉及一些 KNN 算法的最终见解,包含 K 值,置信度,速度,以及算法的优点和缺点。
在执行 100 个样例的测试之后,Sklearn 的neighbors.KNeighborsClassifier分类器的准确率是 0.97,我们自己编写的分类器也一样。不要故步自封,因为这个算法非常简单和基础。KNN 分类器的真正价值并不在准确率上,而是它的速度。KNN 分类器的主要缺陷就是就是速度,你可以用它来执行操作。
对于速度,Sklearn 的 KNN 版本的每个周期是 0.044 秒,我们的是 0.55 秒。因此,虽然我们实现了相同的结果,我们比 Sklearn 慢很多。好的消息是,如果你对它们如何实现的感兴趣,你可以查看源代码、我们也提到了,我们也可以使用一个主流方式来提升速度。KNN 并不需要过多的训练。训练仅仅是将数据集加载到内存。你可以将数据集保留在内存中,但是 KNN 分类器的真正痛点就是对比每个数据集来寻找最近的那个。之后,如果你打算对 1000 个数据集分类,会发生什么呢?是的,一个选项是可以并发。串行执行它们没有任何好处。我们的方式是这样,仅仅使用一点点的处理器的能力。但是,我们可以一次性至少计算 100~200 个数据,即使是在便宜的处理器上。如果你打算了解如何并发,看一看这个并发教程。使用 Sklearn,KNN 分类器自带一个并行处理参数n_jobs。你可以将其设置为任何数值,你可以以这个线程数来并发。如果你打算一次运行 100 个操作,n_jobs=100。如果你仅仅打算运行尽可能做的操作,设置n_jobs=-1。阅读最近邻文档,你可以了解更多选项。有几种方式将你的数据与指定半径之内的数据对比,如果你对加速 KNN,以及 Sklearn 的 KNN 版本感兴趣,你可能想要看一看。
最后,我要讲的最后一点就是预测的置信度。有两种方式来度量置信度。一种是比较你预测对了多少个点,另一个是,检查计数的百分比。例如,你的算法准确率可能是 97%,但是对于一些分类,计数可能是 3 比 2。其中 3 是主流,它的占有率是 60%,而不是理想情况下的 100%。但是告诉别人它是否有癌症的话,就像自动驾驶汽车分辨一团土和毛毯上的孩子,你可能更希望是 100%。可能 60% 的计数就是 3% 的不准确度量的一部分。
好的,所以我们刚刚编写了准确率为 97% 的分类器,但是没有把所有事情都做好。KNN 非常拥有,因为它对线性和非线性数据都表现出色。主要的缺陷是规模、离群点和不良数据(要记得 ID 列的无效引入)。
我们仍然专注于监督式机器学习,特别是分类,我们下面打算设计支持向量机。
最后的代码:
import numpy as np
from math import sqrt
import warnings
from collections import Counter
import pandas as pd
import random
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
distances.append([euclidean_distance, group])
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
confidence = Counter(votes).most_common(1)[0][1] / k
return vote_result, confidence
df = pd.read_csv("breast-cancer-wisconsin.data.txt")
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
full_data = df.astype(float).values.tolist()
random.shuffle(full_data)
test_size = 0.4
train_set = {2:[], 4:[]}
test_set = {2:[], 4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
correct = 0
total = 0
for group in test_set:
for data in test_set[group]:
vote,confidence = k_nearest_neighbors(train_set, data, k=5)
if group == vote:
correct += 1
total += 1
print('Accuracy:', correct/total)
二十、支持向量机简介
欢迎阅读第二十篇。我们现在打算深入另一个监督式机器学习和分类的形式:支持向量机。
支持向量机,由 Vladimir Vapnik 在上个世纪 60 年代发明,但是 90 年代之前都被忽视,并且是最热门的机器学习分类器之一。
支持向量的目标就是寻找数据之间的最佳分割边界。在二维空间中,你可以将其看做分隔你的数据集的最佳拟合直线。使用支持向量机,我们在向量空间中处理问题,因此分隔直线实际上是个单独的超平面。最佳的分隔超平面定义为,支持向量之间间距“最宽”的超平面。超平面也可以叫做决策边界。最简单的讲解方式就是图片:

我们会使用上面的数据开始。我们注意到,之前最普遍的直觉就是,你会将一个新的点基于它的近邻来分类,这就是 KNN 的工作原理。这个方式的主要问题是,对于每个数据点,你将其与每个其它数据点比较,来获取距离,因为算法不能很好扩展,尽管准确率上很可靠。支持向量机的目标就是,一次性生成“最佳拟合”直线(实际上是个平面,甚至是个超平面),他可以最优划分数据。一旦计算出了超平面,我们就将其作为决策边界。我们这样做,因为决策边界划分两个分类的数据。一旦我们计算了决策边界,我们就再也不需要计算了,除非我们重新训练数据集。因此,算法易于扩展,不像 KNN 分类器。
好奇之处在于,我们如何找出最佳分隔超平面?我们可以先使用眼睛来找。

这几乎是争取的,但是如何寻找呢?首先寻找支持向量。

一旦你找到了支持向量,你就可以创建直线,最大分隔彼此。这里,我们可以通过计算总宽度来轻易找到决策边界。

一分为二。

你就会得到边界。

现在如果一个点位于决策边界或者分割超平面的左侧,我们就认为它是黑色分类,否则就是红色分类。
值得注意的是,这个方式本质上只能处理线性分隔的数据,如果你的数据是:

这里你能够创建分隔超平面嘛?不能。还有没有办法了?当我们深入支持向量机的时候,我会让你考虑这个问题。这里是使用 Sklearn 非常方便的原因。记得我们之前使用 Sklearn KNN 分类器的代码嘛?这里就是了。
import numpy as np
from sklearn import preprocessing, cross_validation, neighbors
import pandas as pd
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
X = np.array(df.drop(['class'], 1))
y = np.array(df['class'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = neighbors.KNeighborsClassifier()
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
example_measures = np.array([[4,2,1,1,1,2,3,2,1]])
example_measures = example_measures.reshape(len(example_measures), -1)
prediction = clf.predict(example_measures)
print(prediction)
我们只需要改动两个地方,第一个就是从sklearn导入svm。第二个就是使用支持向量分类为,它是svm.SVC。改动之后是:
import numpy as np
from sklearn import preprocessing, cross_validation, neighbors, svm
import pandas as pd
df = pd.read_csv('breast-cancer-wisconsin.data.txt')
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
X = np.array(df.drop(['class'], 1))
y = np.array(df['class'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = svm.SVC()
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence)
example_measures = np.array([[4,2,1,1,1,2,3,2,1]])
example_measures = example_measures.reshape(len(example_measures), -1)
prediction = clf.predict(example_measures)
print(prediction)
# 0.978571428571
# [2]
取决于你爹随机样例,你应该得到 94% 到 99% ,平均值为 97%。同样,对操作计时,要记得我通过 Sklearn 执行 KNN 代码花费了 0.044 秒。使用svm.SVC,执行时间仅仅是 0.00951,在这个非常小的数据集上也有 4.6 倍。
所以我们可以认为,支持向量机似乎有同样的准确度,但是速度更快。要注意如果我们注释掉丢弃 ID 列的代码,准确率会降到 60%。支持向量机通常比 KNN 算法处理大量数据要好,并且处理离群点要好。但是,这个例子中,无意义数据仍然会误导它。我们之前使用默认参数,查看支持向量机的文档,确实有一些参数,我们不知道它们干什么用。在后面的教程中,我们打算深入支持向量机算法,以便我们能够实际理解所有这些参数的含义,以及它们有什么影响。虽然我们在这里告一段落,思考一下:如何处理非线性分隔,多个分类的数据和数据集(由于 SVM 是个二元分类器,也就是它生成直线来划分两个分组)。
二十一、向量基础
欢迎阅读第二十一篇教程,下面就是支持向量机的部分了。这个教程中,我们打算设计一些向量的基础,它们是支持向量机概念的组成部分。
首先,向量拥有模(大小)和方向:

上面的例子中,向量 A(使用字母上面的箭头来表示),向[3, 4]移动。可以将每个坐标看做该维度上的方向。我们这里,有两个维度。我们在第一维里面移动 3 个单位,第二维里面移动 4 个。这就是方向了,那么模是什么呢?我们之前看到过它,它就是欧氏距离,范式,或者是大小。对我们来说,最重要的是,它们的计算方式相同(平方和的平方根)。

我们这里,向量的模是 5。如果你仔细观察图片,你可能会注意一些其它东西:

看起来像是直角三角形的勾股(帕斯卡)定理。的确是相同的公式,只要我们进入更高的维度,它就不是简单的三角形了。
很简单,下面是点积。如果我们对向量计算点积会发生什么呢?假设有两个向量,A 和 B。A 是[1, 3],B 是[4, 2]。我们所做的是,将对应分量相乘再相加。例如:

好的,既然我们知道了这些东西,我们就要讲解支持向量机本身了。我们作为科学家,首先会在机器上做一些断言。
二十二、支持向量断言
欢迎阅读机器学习教程的第二十二章。这个教程中,我们会涉及一些 SVM 的断言。理解这些断言,它们中一些是约束,是是理解 SVM 的数学与美的一部分。
首先,让我们看一看 SVM 的示例目标。它的理念是接受已知数据,之后 SVM 的拟合或者训练是个最优化问题,寻找数据的最佳分隔直线,也就是决策边界,像这样:

我们在二维空间中,所以分隔超平面(决策边界)也就是简单的直线(红色直线)。决策边界分隔了蓝色减号分组,和绿色加号分组。下面,如果我们在图中任意位置放一个点,我们就可以做一个简单的检查,来看看它位于分隔直线的哪一边,我们就会有答案了。是不是很简单?如果我们仅仅停留在二维空间,我们这里的维度是什么呢?每个特征都是一个维度,所有特征组成了我们的特征集。因此,我们可能拥有一条简单的直线,超级简单。我们可以使用线性代数来解决它。但如果我们拥有 63 个特征,也就是 63 维呢?
目前为止还不清楚,但是勾股定理多于二维是没问题的。好的,我们来看看向量空间吧。我们现在在向量空间中了,我们拥有了未知的特征集,记为v。之后,我们有了另一个向量(法向量),和决策边界正交,记为w。看起来是:

现在如何呢?我们可以用眼睛看出来,但是如何用数学表达呢?同样,要记得你需要一个方法,在 2 维和 5902 维都工作。你可以仅仅将向量v和w点乘,并加上一些偏移b(就是超平面的一般式方程),之后观察这个值大于还是小于 0。

好的,尽管我们这里不知道w和b都是什么。
然后就复杂了。
我们有了两个未知变量,并且有个坏消息:我们要求解它们。根据优化来说,这应该是个危险信号,也就是有无限个w和b满足我们的方程,但是我们也知道有一种约束,已经在我们的脑子里定义了逻辑:我们想要最佳的分隔超平面。我们可以大致猜测这是w和b优化的一部分。最开始我们打算设置一些真实的数学约束。
目前为止,我们仅仅看到了分隔超平面,但是分隔超平面在两个超平面之间。所谓的支持向量经过两个超平面,这些支持向量是特征集(图上的数据点),如果移动了它们,就会对最佳分隔超平面有影响。
由于这些支持向量会产生重大影响,我们打算为其设置一个常量值。前面说,分类函数是sign(x·w + b),如果它是 0,那就说明在决策边界上。如果大于零,就是正向分类,如果小于零,就是负向分类。我们打算利用它,并且认为,如果x·w + b为 1,就是正向支持向量,如果为 -1,就是负向支持向量。如果一个未知值是 -0.52,仍然是负向分类,即使它没有超过支持向量的标记 -1。我们简单使用支持向量来帮助我们选取最佳分隔超平面,这就是它们的作用。我们的断言是:

也就是说,第一行,我们让X负向支持向量(这是任何为负向支持向量的特征)点乘向量w再加b等于 -1。我们断言了这个。之后对正向支持向量:X正向支持向量点乘向量w再加b为正一。同样,我们刚开始,没有真正的证明,我们刚刚说这是一个案例。现在,我们打算引入新的值,Yi。

y 在 Python 代码中是我们的分类,这里也是。

我们打算向之前的断言引入它,如果你记得正向和负向支持向量的值:x·w+b=1是正向,x·w+b=-1是负向。我们打算将我们的原始断言相乘:

根据这个新的Yi值,它同样是 -1 或者 1(取决于分类是 -1 还是 1)。当我们将原始断言相乘时,我们就需要将两边都乘Yi,也就是:

我们将Yi的符号留在左边,但是我们实际上将其应用到了右边(1 或者 -1)。这样意味着对于正向支持向量,我们得到了1x1=1,对于负向支持向量,我们得到了(-1)x(-1)=1,也等于 1。我们可以将每个方程的右边设为 0,通过两边都减一,我们就有了相同的方程Yi(Xi·w+b)-1 = 0。

现在我们拥有了约束,下个教程中我们会深入讲解。
二十三、支持向量机基础
欢迎阅读第二十三篇教程。这篇教程中,我们打算为支持向量机的优化来解方程。
我们需要计算的支持向量为:Yi(Xi·w+b)-1 = 0。

现在我们打算讨论一下,我们如何处理这个支持向量机的形式优化问题。特别是,我们如何获取向量w和b的最优解。我们也会涉及一些支持向量机的其它基础。
开始,之前说过超平面的定义为w·x+b。因此,我们断言了该方程中支持向量机的定义,正向类为 1,负向类为 -1。

我们也推测,一旦我们找到了满足约束问题(w的模最小,b最大)的w和b,我们用于未知点的分类决策函数,只需要简单计算x·w+b。如果值为 0.99 呢?它在图中是什么样子?

所以它并不在正向支持向量平面上,但是很接近了。它超过了决策边界没有?是的,决策边界是x·w+b=0。因此,未知数据集的实际决策函数只是sign(x·w+b)。就是它了。如果它是正的,就是+分类,负的就是-分类。现在为了求得这个函数,我们需要w和b。我们的约束函数,Yi(Xi·W+b) >= 1,需要满足每个数据集。我们如何使其大于等于 1 呢?如果不乘 Yi,就仅仅需要我们的已知数据集,如果代入x·w+b大于 1 或者小于 -1,尽管我们之前提到过,0.98 的值也是正向分类。原因就是,新的或者未知的数据可以位于支持向量平面和决策边界之间,但是训练集或已知数据不可以。
于是,我们的目标就是最小化|w|,最大化b,并保持Yi(X·W+b)>=1的约束。

要注意,我们尝试满足向量w的约束,但是我们需要最小化w的模,而不是w,不要混淆。
有许多方式来计算这个带约束的最优化。第一个方式就是支持向量机的传统描述。开始,我们尝试将分隔超平面之间的宽度最大化。

下面,向量之间的距离可以记为:

要注意,这里我们得到了X+和X-,这是两个超平面,我们尝试最大化之间的距离。幸运的是,这里没有b,非常好。那么,X+和X-又是什么呢?我们知道吗?是的,我们知道。

这里就有b了。总有一天我们会将其解出来。无论如何,我们做一些代数,将X+和X-替换为1-b和1+b。

记得你的操作顺序吗?这非常方便,我们就将b移走了,现在我们的方程极大简化了。

为了更好地满足我们未来的要求,我们可以认为,如果我们打算最大化2/|w|,我们就可以最小化|w|,这个之前已经讲过了。由于我们打算最小化|w|,相当于最小化1/2 * |w|^2:

我们的约束是 Yi(Xi·W+b)-1 = 0。因此,所有特征集的和应该也是 0。所以我们引入了拉格朗日乘数法:

在这里求导:

把所有东西放到一起:

于是,如果你没有对求出来的东西不满意,你就到这里了。我们得到了alpha的平方,也就是说,我们需要解决一个平方规划。
很快就变复杂了。
下一篇教程中,我们的兴趣是从零编写 SVM,我们看看是否可以将其简化。
二十四、约束优化
欢迎阅读第二十四篇教程。这个教程中,我们打算深入讨论 SVM 的约束优化。
上一个教程中,我们剩下了 SVM 的形式约束优化问题:

看起来很丑陋,并且由于alpha的平方,我们看到了一个平方规划问题,这不是很容易完成。约束优化不是一个很大的范围吗?有没有别的方式?你怎么问我会很高兴,因为是的,的确存在其他方式。SVM 的优化问题是个凸优化问题,其中凸优化的形状是w的模。

这个凸优化的目标是寻找w的最大模。一种解决凸优化问题的方式就是“下降”,直到你不能再往下走了。一旦你到达了底部,你就能通过其他路径慢慢回去,重复这个步骤,直到你到达了真正的底部。将凸优化问题看做一个碗,求解过程就是沿着碗的边缘扔进去一个球。球会很快滚下边缘,正好达到最中间的位置,之后可能会在另一侧上升,但是会再次下降,沿着另一个路径,可能会重复几次,每次都会移动得更慢,并且距离更短,最终,球会落在碗的底部。
我们会使用 Python 来模拟这个十分相同的问题。我们会专注于向量w,以一个很大的模来开始。之前提到过向量的模就是分量的平方和的平方根。也就是说,向量w为[5,5]或者[-5,5]的模都一样。但是和特征集的点积有很大不同,并且是完全不同的超平面。出于这个原因,我们需要检查每个向量的每个变种。
我们的基本思想就是像一个球那样,快速沿侧壁下降,重复知道我们不能再下降了。这个时候,我们需要重复我们的最后几个步骤。我们以更小的步骤来执行。之后可能将这个步骤重复几次,例如:

首先,我们最开始就像绿色的线,我们用大的步长下降。我们会绕过中心,之后用更小的步长,就像红色的线。之后我们会像蓝色的线。这个方式,我们的步长会越来越小(每一步我们都会计算新的向量w和b)。这样,我们就可以获取最优化的向量w,而不需要一开始就使用较大的步长来完成相同结果,并且在处理时浪费很多时间。
如果我们找到了碗或者凸形状的底部,我们就说我们找到了全局最小值。凸优化问题非常好的原因,就是我们可以使用这个迭代方式来找到底部。如果不是凸优化,我们的形状就是这样:

现在,当从左侧开始时,你可能检测到上升了,所以你返回并找到了局部最小值。

再说一遍,我们在处理一个很好的凸优化问题,所以我们不需要担心错误。我的计划就是给定一个向量,缓慢减小向量的模(也就是讲笑向量中数据的绝对值)。对于每个向量,假设是[10, 10],我们会使用这些东西来变换向量:[1,1],[-1,1],[-1,-1],[1,-1]。这会向我们提供这个向量的所有变种,我们需要检查它们,尽管它们拥有相同的模。这就是下个教程中要做的事情。
二十五、使用 Python 从零开始编写 SVM
欢迎阅读第 25 篇教程,下面就是我们的 SVM 部分了。这个教程中,我们打算从零编写 SVM。
在深入之前,我们会专注于一些选项,用于解决约束优化问题。
首先,约束优化的话题很多,也有很多材料。即使是我们的子话题:凸优化,也是很庞大的。一个不错的起始点是 https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf。对于约束优化,你可以查看 http://www.mit.edu/~dimitrib/Constrained-Opt.pdf。
特别是在 Python 中,CVXOPT 包拥有多种凸优化方法,其中之一就是我们的平方规划问题(cvxopt.solvers.qp)。
同样,也有 libsvm 的 Python 接口,或者 libsvm 包。我们选择不要用这些东西,因为 SVM 的最优化问题几乎就是 SVM 问题的全部了。
现在,为了使用 Python 来开始写 SVM,我们以这些导入来开始。
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
我们使用 Matplotlib 来绘图,NumPy 来处理数组。下面我们会拥有一些起始数据:
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
现在我们打算开始构建我们的 SVM 类。如果你不熟悉面向对象编程,不要害怕。我们这里的例子是个非常基本的 OOP 形式。只要知道 OOP 创建带有对象,类中带有属性、函数(实际上是方法),以及我们使用self变量来代表对象本身。解释再多也没有意义,已经足以开始了。如果你对代码感到疑惑,可以去在线社区提问。
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
类的__init__方法是使用类创建对象时,执行的方法。其它方法只在调用时执行。对于每个方法,我们传入self作为第一个参数,主要是一种约定。下面,我们添加可视化参数。我们想看看 SVM,所以将其设为True。下面米可以看见一些变量,例如self.color和self.visualization。这样做能够让我们在类的其它方法中,引用self.color,最后,如果我们开启了可视化,我们打算绘制我们的图像。
下面,让我们继续并体感家更多方法:fit和predict。
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
pass
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
fit方法会用于训练我们的 SVM。这就是最优化的步骤。一旦我们完成了训练,predict方法会预测新特征集的值,一旦我们知道了w和b,它就是sign(x·w+b)。
目前为止的代码。
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
pass
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
下个教程中,我们会继续并开始处理fit方法。
二十六、支持向量机优化
欢迎阅读第二十六篇教程,下面就是我们的支持向量机章节。这篇教程中,我们打算处理 SVM 的优化方法fit。
目前为止的代码为:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
pass
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
我们开始填充fit方法:
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
要注意这个方法首先传递self(记住这是方法的约定),之后传递data。data就是我们我们打算训练或者优化的数据。我们这里,它是data_dict,我们已经创建好了。
我们将self.data设为该数据。现在,我们可以在类中的任何地方引用这个训练数据了(但是,我们需要首先使用数据来调用这个训练方法,来避免错误)。
下面,我们开始构建最优化字典opt_dict,它包含任何最优化的值。随着我们减小我们的w向量,我们会使用约束函数来测试向量,如果存在的话,寻找最大的满足方程的b,之后将所有数据储存在我们的最华友字典中。字典是{ ||w|| : [w,b] }。当我们完成所有优化时,我们会选择字典中键最小的w和b值。
最后,我们会设置我们的转换。我们已经解释了我们的意图,来确保我们检查了每个可能的向量版本。
下面,我们需要一些匹配数据的起始点。为此,我们打算首先引用我们的训练数据,来选取一些合适的起始值。
# finding values to work with for our ranges.
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
# no need to keep this memory.
all_data=None
我们所做的就是遍历所有数据,寻找最大值和最小值。现在我们打算定义我们的步长。
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# starts getting very high cost after this.
self.max_feature_value * 0.001]
这里我们设置了一些大小的步长,我们打算这样执行。对于我们的第一遍,我们会采取大跨步(10%)。一旦我们使用这些步长找到了最小值,我们就将步长降至 1% 来调优。我们会继续下降,取决于你想要多么精确。我会在这个项目的末尾讨论,如何在程序中判断是否应该继续优化。
下面,我们打算设置一些变量,来帮助我们给b生成步长(用于生成比w更大的步长,因为我们更在意w的精确度),并跟踪最后一个最优值。
# extremely expensive
b_range_multiple = 5
b_multiple = 5
latest_optimum = self.max_feature_value*10
现在我们开始了:
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
pass
这里的思想就是沿着向量下降。开始,我们将optimized设为False,并为我们会在每个主要步骤重置它。optimized变量再我们检查所有步骤和凸形状(我们的碗)的底部之后,会设为True。
我们下个教程中会继续实现这个逻辑,那里我们会实际使用约束问题来检查值,检查我们是否找到了可以保存的值。
目前为止的代码:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
all_data = None
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# point of expense:
self.max_feature_value * 0.001,]
# extremely expensive
b_range_multiple = 5
#
b_multiple = 5
latest_optimum = self.max_feature_value*10
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
pass
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
二十七、支持向量机优化 第二部分
欢迎阅读第二十七篇教程,下面就是支持向量机的部分。这个教程中,我们打算继续使用 Python 代码处理 SVM 优化问题。
在我们停止的地方,我们的代码为:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
all_data = None
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# point of expense:
self.max_feature_value * 0.001,]
# extremely expensive
b_range_multiple = 5
#
b_multiple = 5
latest_optimum = self.max_feature_value*10
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
pass
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
选取while not optimized 部分:
optimized = False
while not optimized:
for b in np.arange(-1*(self.max_feature_value*b_range_multiple),
self.max_feature_value*b_range_multiple,
step*b_multiple):
这里我们开始迭代所有可能的b值,并且现在可以看到,之前设置的b值。这里要注意,我们使用一个固定的步长,直接迭代b。我们也可以拆分b的步长,就像我们对w所做的那样。为了使事情更加准确,你可能打算这样实现。也就是说,出于简洁,我打算跳过这个部分,因为我们要完成近似的结果。而不是尝试获得什么奖项。
继续:
optimized = False
while not optimized:
for b in np.arange(-1*(self.max_feature_value*b_range_multiple),
self.max_feature_value*b_range_multiple,
step*b_multiple):
for transformation in transforms:
w_t = w*transformation
found_option = True
# weakest link in the SVM fundamentally
# SMO attempts to fix this a bit
# yi(xi.w+b) >= 1
#
# #### add a break here later..
for i in self.data:
for xi in self.data[i]:
yi=i
if not yi*(np.dot(w_t,xi)+b) >= 1:
found_option = False
if found_option:
opt_dict[np.linalg.norm(w_t)] = [w_t,b]
现在我们迭代了每个变形,对我们的约束条件测试了每个东西。如果我们数据集中的任何特征集不满足我们的约束,我们就会去掉这个变量,因为它不匹配,并继续。我建议在这里停顿一下。如果仅仅是一个变量不工作,你可能要放弃其余部分,因为一个变量不匹配,就足以扔掉w和b了。你应该在这里停顿,并且处理循环。现在,我们会将代码保持原样,但是我在录制视频的时候,会有所修改。
现在我们完成fit方法,我会贴出完整代码并解释差异:
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
all_data = None
# support vectors yi(xi.w+b) = 1
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# point of expense:
self.max_feature_value * 0.001,]
# extremely expensive
b_range_multiple = 5
# we dont need to take as small of steps
# with b as we do w
b_multiple = 5
latest_optimum = self.max_feature_value*10
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
for b in np.arange(-1*(self.max_feature_value*b_range_multiple),
self.max_feature_value*b_range_multiple,
step*b_multiple):
for transformation in transforms:
w_t = w*transformation
found_option = True
# weakest link in the SVM fundamentally
# SMO attempts to fix this a bit
# yi(xi.w+b) >= 1
#
# #### add a break here later..
for i in self.data:
for xi in self.data[i]:
yi=i
if not yi*(np.dot(w_t,xi)+b) >= 1:
found_option = False
if found_option:
opt_dict[np.linalg.norm(w_t)] = [w_t,b]
if w[0] < 0:
optimized = True
print('Optimized a step.')
else:
w = w - step
norms = sorted([n for n in opt_dict])
#||w|| : [w,b]
opt_choice = opt_dict[norms[0]]
self.w = opt_choice[0]
self.b = opt_choice[1]
latest_optimum = opt_choice[0][0]+step*2
一旦我们越过了w向量的零点,就没有理由继续了,因为我们通过变换测试了负值。所以我们已经完成了这个步长,要么继续下一个步长,要么就完全完成了。如果没有经过 0,那就向下走一步。一旦我们走完了能走的所有步骤,我们就对opt_dict 字典的键数组记性排序(它包含||w|| : [w,b])。我们想要向量w的最小模,所以我们选取列表的第一个元素。我们给这里的self.w和self.b赋值,并设置最后的优化值。之后,我们选取另一个步长,或者完全完成了整个过程(如果没有更多的步长可选取了)。
这里,完整代码是:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
all_data = None
# support vectors yi(xi.w+b) = 1
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# point of expense:
self.max_feature_value * 0.001,]
# extremely expensive
b_range_multiple = 5
# we dont need to take as small of steps
# with b as we do w
b_multiple = 5
latest_optimum = self.max_feature_value*10
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
for b in np.arange(-1*(self.max_feature_value*b_range_multiple),
self.max_feature_value*b_range_multiple,
step*b_multiple):
for transformation in transforms:
w_t = w*transformation
found_option = True
# weakest link in the SVM fundamentally
# SMO attempts to fix this a bit
# yi(xi.w+b) >= 1
#
# #### add a break here later..
for i in self.data:
for xi in self.data[i]:
yi=i
if not yi*(np.dot(w_t,xi)+b) >= 1:
found_option = False
if found_option:
opt_dict[np.linalg.norm(w_t)] = [w_t,b]
if w[0] < 0:
optimized = True
print('Optimized a step.')
else:
w = w - step
norms = sorted([n for n in opt_dict])
#||w|| : [w,b]
opt_choice = opt_dict[norms[0]]
self.w = opt_choice[0]
self.b = opt_choice[1]
latest_optimum = opt_choice[0][0]+step*2
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
现在我们已经准备好可视化以及测试支持向量机的预测了。我们会在下一个教程中完成它们。
二十八、使用我们的 SVM 来可视化和预测
欢迎阅读第二十八篇教程。这个教程中,我们完成我们从零开始的基本 SVM,并使用它来可视化并作出预测。
我们目前为止的代码:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
all_data = None
# support vectors yi(xi.w+b) = 1
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# point of expense:
self.max_feature_value * 0.001,]
# extremely expensive
b_range_multiple = 5
# we dont need to take as small of steps
# with b as we do w
b_multiple = 5
latest_optimum = self.max_feature_value*10
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
for b in np.arange(-1*(self.max_feature_value*b_range_multiple),
self.max_feature_value*b_range_multiple,
step*b_multiple):
for transformation in transforms:
w_t = w*transformation
found_option = True
# weakest link in the SVM fundamentally
# SMO attempts to fix this a bit
# yi(xi.w+b) >= 1
#
# #### add a break here later..
for i in self.data:
for xi in self.data[i]:
yi=i
if not yi*(np.dot(w_t,xi)+b) >= 1:
found_option = False
if found_option:
opt_dict[np.linalg.norm(w_t)] = [w_t,b]
if w[0] < 0:
optimized = True
print('Optimized a step.')
else:
w = w - step
norms = sorted([n for n in opt_dict])
#||w|| : [w,b]
opt_choice = opt_dict[norms[0]]
self.w = opt_choice[0]
self.b = opt_choice[1]
latest_optimum = opt_choice[0][0]+step*2
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
return classification
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
我们已经拥有预测方法了,因为这非常简单。但是现在我们打算添加一些,来处理预测的可视化。
def predict(self,features):
# classifiction is just:
# sign(xi.w+b)
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
# if the classification isn't zero, and we have visualization on, we graph
if classification != 0 and self.visualization:
self.ax.scatter(features[0],features[1],s=200,marker='*', c=self.colors[classification])
else:
print('featureset',features,'is on the decision boundary')
return classification
上面,我们添加了代码来可视化预测,如果存在的话。我们打算一次做一个,但是你可以扩展代码来一次做许多个,就像 Sklearn 那样。
下面,让我们构建visualize方法:
def visualize(self):
#scattering known featuresets.
[[self.ax.scatter(x[0],x[1],s=100,color=self.colors[i]) for x in data_dict[i]] for i in data_dict]
这一行所做的就是,遍历我们的数据,并绘制它和它的相应颜色。
下面,我们打算绘制正向和负向支持向量的超平面,以及决策边界。为此,我们至少需要两个点,来创建“直线”,它就是我们的超平面。
一旦我们知道了w和b,我们就可以使用代数来创建函数,它对x值返回y值来生成直线:
def hyperplane(x,w,b,v):
# w[0] * x + w[1] * y + b = v
# 正向支持超平面 v = 1
# 最佳分隔超平面 v = 0
# 负向支持超平面 v = -1
# y = (v - b - w[0] * x) / w[1]
return (-w[0]*x-b+v) / w[1]
然后,我们创建一些变量,来存放我们打算引用的多种数据:
datarange = (self.min_feature_value*0.9,self.max_feature_value*1.1)
hyp_x_min = datarange[0]
hyp_x_max = datarange[1]
我们的主要目标就是弄清楚为了绘制我们的超平面,我们需要什么值。
现在,让我们绘制正向支持向量超平面。
# w.x + b = 1
# pos sv hyperplane
psv1 = hyperplane(hyp_x_min, self.w, self.b, 1)
psv2 = hyperplane(hyp_x_max, self.w, self.b, 1)
self.ax.plot([hyp_x_min,hyp_x_max], [psv1,psv2], "k")
非常简单,我们获得了x_min和x_max的y值,然后我们绘制了它们。
···
# w.x + b = -1
# negative sv hyperplane
nsv1 = hyperplane(hyp_x_min, self.w, self.b, -1)
nsv2 = hyperplane(hyp_x_max, self.w, self.b, -1)
self.ax.plot([hyp_x_min,hyp_x_max], [nsv1,nsv2], "k")
# w.x + b = 0
# decision
db1 = hyperplane(hyp_x_min, self.w, self.b, 0)
db2 = hyperplane(hyp_x_max, self.w, self.b, 0)
self.ax.plot([hyp_x_min,hyp_x_max], [db1,db2], "g--")
plt.show()
现在,在底部添加一些代码来训练、预测和可视化:
```py
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
class Support_Vector_Machine:
def __init__(self, visualization=True):
self.visualization = visualization
self.colors = {1:'r',-1:'b'}
if self.visualization:
self.fig = plt.figure()
self.ax = self.fig.add_subplot(1,1,1)
# train
def fit(self, data):
self.data = data
# { ||w||: [w,b] }
opt_dict = {}
transforms = [[1,1],
[-1,1],
[-1,-1],
[1,-1]]
all_data = []
for yi in self.data:
for featureset in self.data[yi]:
for feature in featureset:
all_data.append(feature)
self.max_feature_value = max(all_data)
self.min_feature_value = min(all_data)
all_data = None
# support vectors yi(xi.w+b) = 1
step_sizes = [self.max_feature_value * 0.1,
self.max_feature_value * 0.01,
# point of expense:
self.max_feature_value * 0.001,
]
# extremely expensive
b_range_multiple = 2
# we dont need to take as small of steps
# with b as we do w
b_multiple = 5
latest_optimum = self.max_feature_value*10
for step in step_sizes:
w = np.array([latest_optimum,latest_optimum])
# we can do this because convex
optimized = False
while not optimized:
for b in np.arange(-1*(self.max_feature_value*b_range_multiple),
self.max_feature_value*b_range_multiple,
step*b_multiple):
for transformation in transforms:
w_t = w*transformation
found_option = True
# weakest link in the SVM fundamentally
# SMO attempts to fix this a bit
# yi(xi.w+b) >= 1
#
# #### add a break here later..
for i in self.data:
for xi in self.data[i]:
yi=i
if not yi*(np.dot(w_t,xi)+b) >= 1:
found_option = False
#print(xi,':',yi*(np.dot(w_t,xi)+b))
if found_option:
opt_dict[np.linalg.norm(w_t)] = [w_t,b]
if w[0] < 0:
optimized = True
print('Optimized a step.')
else:
w = w - step
norms = sorted([n for n in opt_dict])
#||w|| : [w,b]
opt_choice = opt_dict[norms[0]]
self.w = opt_choice[0]
self.b = opt_choice[1]
latest_optimum = opt_choice[0][0]+step*2
for i in self.data:
for xi in self.data[i]:
yi=i
print(xi,':',yi*(np.dot(self.w,xi)+self.b))
def predict(self,features):
# sign( x.w+b )
classification = np.sign(np.dot(np.array(features),self.w)+self.b)
if classification !=0 and self.visualization:
self.ax.scatter(features[0], features[1], s=200, marker='*', c=self.colors[classification])
return classification
def visualize(self):
[[self.ax.scatter(x[0],x[1],s=100,color=self.colors[i]) for x in data_dict[i]] for i in data_dict]
# hyperplane = x.w+b
# v = x.w+b
# psv = 1
# nsv = -1
# dec = 0
def hyperplane(x,w,b,v):
return (-w[0]*x-b+v) / w[1]
datarange = (self.min_feature_value*0.9,self.max_feature_value*1.1)
hyp_x_min = datarange[0]
hyp_x_max = datarange[1]
# (w.x+b) = 1
# positive support vector hyperplane
psv1 = hyperplane(hyp_x_min, self.w, self.b, 1)
psv2 = hyperplane(hyp_x_max, self.w, self.b, 1)
self.ax.plot([hyp_x_min,hyp_x_max],[psv1,psv2], 'k')
# (w.x+b) = -1
# negative support vector hyperplane
nsv1 = hyperplane(hyp_x_min, self.w, self.b, -1)
nsv2 = hyperplane(hyp_x_max, self.w, self.b, -1)
self.ax.plot([hyp_x_min,hyp_x_max],[nsv1,nsv2], 'k')
# (w.x+b) = 0
# positive support vector hyperplane
db1 = hyperplane(hyp_x_min, self.w, self.b, 0)
db2 = hyperplane(hyp_x_max, self.w, self.b, 0)
self.ax.plot([hyp_x_min,hyp_x_max],[db1,db2], 'y--')
plt.show()
data_dict = {-1:np.array([[1,7],
[2,8],
[3,8],]),
1:np.array([[5,1],
[6,-1],
[7,3],])}
svm = Support_Vector_Machine()
svm.fit(data=data_dict)
predict_us = [[0,10],
[1,3],
[3,4],
[3,5],
[5,5],
[5,6],
[6,-5],
[5,8]]
for p in predict_us:
svm.predict(p)
svm.visualize()
我们的结果:

二十九、核的简介
欢迎阅读第二十九篇教程。这个教程中,我们打算使用机器学习谈论核的概念。
回忆一开始的 SVM 话题,我们的问题是,你可不可以使用 SVM 来处理这样的数据:

至少我们现在为止,它可能吗?不,完全不可能,至少不能是这样。但是一个选择,就是采取新的视角。我们可以通过添加一个新的维度来实现。例如上面的数据中,我们可以添加第三个维度,使用一些函数,比如X3 = X1*X2。在这里可能管用,但是也可以不管用。同样,一些案例,比如图像分析又如何呢?其中你可能有多于几百和维度。它就是性能很重要的场景,并且你是否应该添加一个维度到已经有很多维度的数据中,我们会进一步把事情变慢。
如果我告诉你,你可以在无限的维度上做计算,或者,你可以让那些计算在这些维度上实现,而不需要在这些维度上工作,并且仍然能得到结果呢?
就是这样。我们实际上使用叫做核的东西来实现。相对于 SVM 来说,许多人一开始就接触它了,也可能最后才接触。这可能会让你认为,核主要用于 SVM,但是并不是这样。
核就是相似度函数,它接受两个输出,并使用内积来返回相似度。由于这是个机器学习教程,你们中的一些可能想知道,为什么人们不将核用于机器学习算,以及,我在这里告诉你它们实际上使用了。你不仅仅可以使用核来创建自己的机器学习算法,你可以将现有的机器学习算法翻译为使用核的版本。
核所做的就是允许你,处理许多维度,而不需要花费处理的开销。核的确有个要求:它们依赖于内核。对于这篇教程的目的,“点积”和“内积”可以互相代替。
为了验证我们是否可以使用核,我们需要做的,就是验证我们的特征空间的每个交互,都是内积。我们会从末尾开始,然后返回来确认它。
首先,我们如何在训练之后判断特征的分类呢?

它是不是内积的交互呢?当然是,我们可以将x换成z。

继续,我们打算回顾我们的约束,约束方程为:

这里如何呢?这个交互式内积嘛?当然, yi(xi.w+b)-1 >= 0等价于yi(xi.w+b) >= 1。所以这里我们可以讲义将x_i替换为z_i。
最后,我们的形式优化方程w如何呢?

它是另一个点积或内积。有任何问题吗?这样:

太好了。我们可以使用核。你可能想知道,这个“零开销来计算无穷维度”是什么?好吧,首先我们需要确保我们能这样做。对于零开销的处理,你需要看下一篇教程来了解。
三十、为什么是核
欢迎阅读第三十篇教程。这篇教程中,我们打算继续讨论核,既然我们知道了我们能使用它之后,主要弄清楚如何实际使用它们。
我们之前了解到,我们可以利用核来帮助我们将数据转换为无穷数量的维度,以便找到线性分隔。我们也了解到,核可以让我们处理这些维度,而不需要实际为这些高维度花费开销。通常,核定义为这样:

核函数应用于x和x',并等于z和z'的内积,其中z就是z维度的值(我们新的维度空间)。

z值就是一些function(x)的结果,这些z值点乘在一起就是我们核函数的结果。

我们仍然需要涉及,它如何节省我们的处理步骤。所以看一个例子吧。我们以多项式来开始,并将多项式核的要求,与简单使用我们的向量来创建二阶多项式来比较:

核对x和x'使用相同函数,所以我们对z'也使用相同的东西(x'对二阶多项式)。这里,最终步骤就是计算二者的点积。

所以所有工作就是手动执行一个和核函数类似的操作。幸运的是,我们的起始维度只有两维。现在让我们考虑多项式核:

要注意,这里没有提到z。整个核仅仅使用x来计算。你所需的所有东西,就是使用维度数量n和你想使用的权重p来计算。你的方程是这样:

如果你计算了出来,你的新向量是这样,它对应z空间的向量:

也就是说,你永远不需要继续深入了。你只需要专注于多项式和,它简单返回点积给你,你不需要实际计算向量,之后计算非常大的点积。
也有一些预先创建的核,但是我这里仅仅会展示径向基函数(RBF)核。只是因为它通常是默认使用的核,并且可以将我们带到无限的维度中。

这里的 Gamma 值是后面教程的话题。所以这里以拥有了核,了解了为什么使用它们,如何使用它们,以及它们如何让你处理更大的维度,而不需要花费非常大的处理开销。下一篇教程中,我们打算讨论另一个非线性数据的解决方案,以及数据的过拟合问题。
三十一、软边界 SVM
欢迎阅读第 31 个部分。这篇教程中,我们打算讨论软边界 SVM。
首先,为什么软边界分类器更加优秀,主要有两个原因。一是你的数据可能不是完全线性分隔的,但是很接近了,并且继续使用默认的线性核有更大意义。另一个原因是,即使你使用了某个核,如果你打算使用硬边界的话,你最后也会过拟合。例如,考虑这个:

这里是一个数据案例,当前并不是线性可分的。假设使用硬边界(也就是我们之前看到的那种),我们可能使用核来生成这样的决策边界:

下面,注意我的绘图工具中的缺陷,让我们绘制支持向量平面,并圈出支持向量:

这里,每个正向的数据样例都是支持向量,只有两个负向分类不是支持向量。这个信号就是可能过拟合了,我们应该避免它。因为,当我们用它来预测未来的点时,我们就没有余地了,并且可能会错误分类新的数据。如果我们这样做,会怎么样呢?

我们有一些错误或者误差,由箭头标记,但是这个可能能够更好地为将来的数据集分类。我们这里就拥有了“软边界”分类器,它允许一些误差上的“弹性”,我们可以在优化过程中获得它。

我们的新的优化就是上面的计算,其中弹性大于等于 0。弹性越接近 0,就越接近“硬边界”。弹性越高,边界就越软。如果弹性是 0,我们就得到了一个典型的硬边界分类器。但是你可能能够菜刀,我们希望最小化弹性。为此,我们将其添加到向量w的模的最小值中。

因此,我们实际上打算最小化1/2||w||^2 + C * 所有使用的弹性之和。使用它,我们引入了另一个变量C。C是个系数,关于我们打算让弹性对方程的剩余部分有多少影响。C阅读,弹性的和与向量w的模相比,就越不重要,反之亦然。多数情况下,C的值默认为 1。
所以这里你了解了软边界 SVM,以及为什么打算使用它。下面,我们打算展示一些样例代码,它们由软边界、核和 CVXOPT 组成。
三十二、核、软边界和使用 Python 和 CVXOPT 的平方规划
欢迎阅读第三十二篇机器学习教程。这篇教程中,我们打算展示核、软边界的 Python 版本,并使用 CVXOPT 来解决平方规划问题。
在这个简短的章节中,我打算主要向你分享其它资源,你应该想要使用 Python 和 CVXOPT 深入研究 SVM 或者平方规划。为了开始,你可以阅读 CVXOPT 平方规划文档,来深入了解 Python 中的平方规划。你也可以查看 CVXOPT 平方规划示例。
对于 CVXOPT 的更加深入的平方规划示例,请查看这个 PDF。
最后,我们打算看一看来自 Mathieu Blondel 的博客的一些代码,它由核、软边界 SVM 以及 CVXOPT 平方规划组成。所有代码都优于我写的任何东西。
# Mathieu Blondel, September 2010
# License: BSD 3 clause
# http://www.mblondel.org/journal/2010/09/19/support-vector-machines-in-python/
# visualizing what translating to another dimension does
# and bringing back to 2D:
# https://www.youtube.com/watch?v=3liCbRZPrZA
# Docs: http://cvxopt.org/userguide/coneprog.html#quadratic-programming
# Docs qp example: http://cvxopt.org/examples/tutorial/qp.html
# Nice tutorial:
# https://courses.csail.mit.edu/6.867/wiki/images/a/a7/Qp-cvxopt.pdf
import numpy as np
from numpy import linalg
import cvxopt
import cvxopt.solvers
def linear_kernel(x1, x2):
return np.dot(x1, x2)
def polynomial_kernel(x, y, p=3):
return (1 + np.dot(x, y)) ** p
def gaussian_kernel(x, y, sigma=5.0):
return np.exp(-linalg.norm(x-y)**2 / (2 * (sigma ** 2)))
class SVM(object):
def __init__(self, kernel=linear_kernel, C=None):
self.kernel = kernel
self.C = C
if self.C is not None: self.C = float(self.C)
def fit(self, X, y):
n_samples, n_features = X.shape
# Gram matrix
K = np.zeros((n_samples, n_samples))
for i in range(n_samples):
for j in range(n_samples):
K[i,j] = self.kernel(X[i], X[j])
P = cvxopt.matrix(np.outer(y,y) * K)
q = cvxopt.matrix(np.ones(n_samples) * -1)
A = cvxopt.matrix(y, (1,n_samples))
b = cvxopt.matrix(0.0)
if self.C is None:
G = cvxopt.matrix(np.diag(np.ones(n_samples) * -1))
h = cvxopt.matrix(np.zeros(n_samples))
else:
tmp1 = np.diag(np.ones(n_samples) * -1)
tmp2 = np.identity(n_samples)
G = cvxopt.matrix(np.vstack((tmp1, tmp2)))
tmp1 = np.zeros(n_samples)
tmp2 = np.ones(n_samples) * self.C
h = cvxopt.matrix(np.hstack((tmp1, tmp2)))
# solve QP problem
solution = cvxopt.solvers.qp(P, q, G, h, A, b)
# Lagrange multipliers
a = np.ravel(solution['x'])
# Support vectors have non zero lagrange multipliers
sv = a > 1e-5
ind = np.arange(len(a))[sv]
self.a = a[sv]
self.sv = X[sv]
self.sv_y = y[sv]
print("%d support vectors out of %d points" % (len(self.a), n_samples))
# Intercept
self.b = 0
for n in range(len(self.a)):
self.b += self.sv_y[n]
self.b -= np.sum(self.a * self.sv_y * K[ind[n],sv])
self.b /= len(self.a)
# Weight vector
if self.kernel == linear_kernel:
self.w = np.zeros(n_features)
for n in range(len(self.a)):
self.w += self.a[n] * self.sv_y[n] * self.sv[n]
else:
self.w = None
def project(self, X):
if self.w is not None:
return np.dot(X, self.w) + self.b
else:
y_predict = np.zeros(len(X))
for i in range(len(X)):
s = 0
for a, sv_y, sv in zip(self.a, self.sv_y, self.sv):
s += a * sv_y * self.kernel(X[i], sv)
y_predict[i] = s
return y_predict + self.b
def predict(self, X):
return np.sign(self.project(X))
if __name__ == "__main__":
import pylab as pl
def gen_lin_separable_data():
# generate training data in the 2-d case
mean1 = np.array([0, 2])
mean2 = np.array([2, 0])
cov = np.array([[0.8, 0.6], [0.6, 0.8]])
X1 = np.random.multivariate_normal(mean1, cov, 100)
y1 = np.ones(len(X1))
X2 = np.random.multivariate_normal(mean2, cov, 100)
y2 = np.ones(len(X2)) * -1
return X1, y1, X2, y2
def gen_non_lin_separable_data():
mean1 = [-1, 2]
mean2 = [1, -1]
mean3 = [4, -4]
mean4 = [-4, 4]
cov = [[1.0,0.8], [0.8, 1.0]]
X1 = np.random.multivariate_normal(mean1, cov, 50)
X1 = np.vstack((X1, np.random.multivariate_normal(mean3, cov, 50)))
y1 = np.ones(len(X1))
X2 = np.random.multivariate_normal(mean2, cov, 50)
X2 = np.vstack((X2, np.random.multivariate_normal(mean4, cov, 50)))
y2 = np.ones(len(X2)) * -1
return X1, y1, X2, y2
def gen_lin_separable_overlap_data():
# generate training data in the 2-d case
mean1 = np.array([0, 2])
mean2 = np.array([2, 0])
cov = np.array([[1.5, 1.0], [1.0, 1.5]])
X1 = np.random.multivariate_normal(mean1, cov, 100)
y1 = np.ones(len(X1))
X2 = np.random.multivariate_normal(mean2, cov, 100)
y2 = np.ones(len(X2)) * -1
return X1, y1, X2, y2
def split_train(X1, y1, X2, y2):
X1_train = X1[:90]
y1_train = y1[:90]
X2_train = X2[:90]
y2_train = y2[:90]
X_train = np.vstack((X1_train, X2_train))
y_train = np.hstack((y1_train, y2_train))
return X_train, y_train
def split_test(X1, y1, X2, y2):
X1_test = X1[90:]
y1_test = y1[90:]
X2_test = X2[90:]
y2_test = y2[90:]
X_test = np.vstack((X1_test, X2_test))
y_test = np.hstack((y1_test, y2_test))
return X_test, y_test
def plot_margin(X1_train, X2_train, clf):
def f(x, w, b, c=0):
# given x, return y such that [x,y] in on the line
# w.x + b = c
return (-w[0] * x - b + c) / w[1]
pl.plot(X1_train[:,0], X1_train[:,1], "ro")
pl.plot(X2_train[:,0], X2_train[:,1], "bo")
pl.scatter(clf.sv[:,0], clf.sv[:,1], s=100, c="g")
# w.x + b = 0
a0 = -4; a1 = f(a0, clf.w, clf.b)
b0 = 4; b1 = f(b0, clf.w, clf.b)
pl.plot([a0,b0], [a1,b1], "k")
# w.x + b = 1
a0 = -4; a1 = f(a0, clf.w, clf.b, 1)
b0 = 4; b1 = f(b0, clf.w, clf.b, 1)
pl.plot([a0,b0], [a1,b1], "k--")
# w.x + b = -1
a0 = -4; a1 = f(a0, clf.w, clf.b, -1)
b0 = 4; b1 = f(b0, clf.w, clf.b, -1)
pl.plot([a0,b0], [a1,b1], "k--")
pl.axis("tight")
pl.show()
def plot_contour(X1_train, X2_train, clf):
pl.plot(X1_train[:,0], X1_train[:,1], "ro")
pl.plot(X2_train[:,0], X2_train[:,1], "bo")
pl.scatter(clf.sv[:,0], clf.sv[:,1], s=100, c="g")
X1, X2 = np.meshgrid(np.linspace(-6,6,50), np.linspace(-6,6,50))
X = np.array([[x1, x2] for x1, x2 in zip(np.ravel(X1), np.ravel(X2))])
Z = clf.project(X).reshape(X1.shape)
pl.contour(X1, X2, Z, [0.0], colors='k', linewidths=1, origin='lower')
pl.contour(X1, X2, Z + 1, [0.0], colors='grey', linewidths=1, origin='lower')
pl.contour(X1, X2, Z - 1, [0.0], colors='grey', linewidths=1, origin='lower')
pl.axis("tight")
pl.show()
def test_linear():
X1, y1, X2, y2 = gen_lin_separable_data()
X_train, y_train = split_train(X1, y1, X2, y2)
X_test, y_test = split_test(X1, y1, X2, y2)
clf = SVM()
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
correct = np.sum(y_predict == y_test)
print("%d out of %d predictions correct" % (correct, len(y_predict)))
plot_margin(X_train[y_train==1], X_train[y_train==-1], clf)
def test_non_linear():
X1, y1, X2, y2 = gen_non_lin_separable_data()
X_train, y_train = split_train(X1, y1, X2, y2)
X_test, y_test = split_test(X1, y1, X2, y2)
clf = SVM(polynomial_kernel)
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
correct = np.sum(y_predict == y_test)
print("%d out of %d predictions correct" % (correct, len(y_predict)))
plot_contour(X_train[y_train==1], X_train[y_train==-1], clf)
def test_soft():
X1, y1, X2, y2 = gen_lin_separable_overlap_data()
X_train, y_train = split_train(X1, y1, X2, y2)
X_test, y_test = split_test(X1, y1, X2, y2)
clf = SVM(C=1000.1)
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
correct = np.sum(y_predict == y_test)
print("%d out of %d predictions correct" % (correct, len(y_predict)))
plot_contour(X_train[y_train==1], X_train[y_train==-1], clf)
#test_linear()
#test_non_linear()
test_soft()
如果你想要让我执行这个代码,你可以查看这个视频。我会仅仅提及,你可能不需要使用 CVXOPT。多数人用于 SVM 的库是 LibSVM。
大家都说,这个代码可以让你理解内部的工作原理,并不是为了让你实际创建一个健壮的 SVM,超过你可以自由使用的那个。
下一篇教程中,我们打算再讨论一个 SVM 的概念,它就是当你拥有多于两个分组时,你该怎么做。我们也会在总结中,浏览 Sklearn 的 SVM 的所有参数,因为我们很少涉及这个话题。
第三十三章 支持向量机的参数
译者:飞龙
欢迎阅读第三十三篇教程,这篇教程中,我们打算通过解释如何处理多于 2 个分类,以及卢兰 Sklearn 的 SVM 的参数,来对 SVM 做个收尾,并且让你见识一下用于 SVM 的现代方法论。
首先,你已经学到了,SVM 是个二元分类器。也就是说,任何时候,SVM 的最优化都只能将一个分组与另一个分组分离。之后问题是我们如何对三个或更多分组分类。通常,方法就是“一对其它”(OVR)。这里的理念就是,将每个分组从其余的分组分离。例如,为了分类三个分组(1,2 和 3),你应该首先将 1 从 2 和 3 分离。之后将 2 从 1 和 3。最后将 3 从 1 和 2 分离。这样有一些问题,因为类似置信度的东西,可能对于每个分类边界都不同,以及分隔边界可能有一些缺陷,因为有一些不仅仅是正向和负向的东西,你将一个分组与其它三个比较。假设最开始有一个均衡的数据集,也就是说每个分类的边界可能是不均衡的。

另一个方法是“一对一”(OVO)。这个情况下,考虑你总共拥有三个分组。它的工作方式是,你的边界从 1 分离 3,以及从 1 分离 2,并且对其余分类重复这个过程。这样,边界就会更均衡。

第一个参数是C。它告诉你这是一个软边界分类器。你可以按需调整C,并且可以使C足够高来创建硬边界分类器。C是||w||的软边界优化函数。

C的默认值是 1,并且多数情况下都很好。
下面我们有个kernel的选项。这里默认是rbf核,但是你可以调整为linear,poly(多项式)和sigmoid核,甚至你选择或设计的自定义核。
然后,还有degree值,默认为 3,这个是多项式的阶数,如果你将poly用于kernel参数的话。
gamma是你为rbf核设置 Gamma 值的地方。你应该将其保留为auto。
coef0允许你调整核函数的独立项,但是你应该保留不变,并且它只用于多项式和 sigmoid 核。
probability 参数项可能对你很使用。回忆 KNN 算法不仅仅拥有模型准确度,每个预测还拥有置信度。SVM 本质上没有这个属性,但是你可以使用probability 参数来获取一种形式。这是个开销大的功能,但是可能对你来说足够重要,或者默认值为False。
下面是shrinking布尔值,它默认为True。这个用于表示你是否将启发式用于 SVM 的优化,它使用了序列最小优化(SMO)。你应该将其保留为True,因为它可以极大提升你的性能,并且只损失一点点准确性。
tol参数设置了 SVM 的容差。前面说过yi(xi.w+b)-1 >= 0。对于 SVM 来说,所有值都必须大于等于 0,每一边至少一个值要等于 0,这就是你的支持向量。由于你不可能让值(浮点数)完全等于 0,你需要设置一个容差来获取一些弹性空间。Sklearn 中默认的 tol是1e-3,也就是 0.001。
下一个重要的参数是max_iter,它是你可以为平方规划设置最大迭代次数的地方。默认值为-1,也就是没有限制。
decision_function_shape 是一对一(OVO),或者一对其它(OVR),那就是教程开始讨论的概念。
random_state 用于概率估计中的种子,如果你打算指定的话。
除了这些参数,我们还有几个属性。
support_ 提供了支持向量的索引。support_vectors_ 提供了实际的支持向量。n_support_是支持向量的个数,如果你的数据集有一些统计问题,将它与你的数据集尺寸相比非常实用。最后三个参数是dual_coef_、 coef_和intercept_,如果你打算绘制 SVM,会非常实用。
SVM 就讲完了。下一个话题是聚类。
第三部分 聚类
三十四、聚类简介
欢迎阅读第三十四篇教程。这篇教程是聚类和非监督机器学习的开始。到现在为止,每个我们涉及到的东西都是“监督”机器学习,也就是说,我们科学家,告诉机器特征集有什么分类。但是在非监督机器学习下,科学家的角色就溢出了。首先,我们会涉及聚类,它有两种形式,扁平和层次化的。
对于这两种形式的聚类,机器的任务是,接受仅仅是特征集的数据集,之后搜索分组并分配标签。对于扁平化聚类,科学家告诉机器要寻找多少个分类或簇。对于层次化聚类,机器会自己寻找分组及其数量。
我们为什么要利用聚类呢?聚类的目标就是寻找数据中的关系和含义。多数情况下,我自己看到了,人们将聚类用于所谓的“半监督”机器学习。这里的想法是,你可以使用聚类来定义分类。另一个用途就是特征选取和验证。例如,考虑我们的乳腺肿瘤数据集。我们可能认为,我们选取的特征缺失是描述性并且有意义的。我们拥有的一个选项,就是将数据扔给 KMeans 算法,之后观察数据实际上是否描述了我们跟踪的两个分组,以我们预期的方式。
下面假设,你是个 Amazon 的树科学家。你的 CTO 收集了数据,并且认为可以用于预测顾客是不是买家。它们希望你使用 KMeans 来看看是否 KMeans 正确按照数据来组织用户,CTO 认为这个很有意义。
层次聚类是什么?假设你仍然是那个相同的数据科学家。这一次,你使用层次聚类算法处理看似有意义的数据,例如均值漂移,并且实际上获取了五个分组。在深入分析之后,你意识到访问者实际上不是买家或者非买家,它们实际上是个光谱。实际上有非买家、可能的非买家、低可能的买家、高可能的马甲,和确定的买家。
聚类也可以用于真正的未知数据,来尝试寻找结构。假设你是个探索北美人类文字的外星人。你可能收集了所有手写字符,将其编译为一个大型的特征列表。之后你可能将这个列表扔给层次聚类算法,来看看是否可以寻找特定的分组,以便通过字符解码语言。
“大数据分析”的领域通常是聚类的初始区域。这里有大量的数据,但是如何处理他们,或者如何获取他们的含义,多数公司完全没有概念。聚类可以帮助数据科学家,来分析大量数据集的结构,以及寻找它们的含义。
最后,聚类也可以用于典型的分类,你实际上并不需要将其扔给分类算法,但是如果你在多数主流的分类数据集上使用聚类,你应该能发现,它能够找到分组。
我们第一个算法是 KMeans。KMeans 的思路就是尝试将给定数据集聚类到 K 个簇中。它的工作方式令人印象深刻。并且我们足够幸运,他还非常简单。这个过程是:
-
获取真个数据集,并随机设置 K 个形心。形心就是簇的“中心”。首先,我通常选取前 K 个值,并使用它们来开始,但是你也可以随机选取它们。这应该没关系,但是,如果你不为了一些原因做优化,可能就需要尝试打乱数据并再次尝试。
-
计算每个数据集到形心的距离,1并按照形心的接近程度来分类每个数据集。形心的分类是任意的,你可能将第一个形心命名为 0,第二个为 1,以此类推。
-
一旦已经分类好了数据,现在计算分组的均值,并将均值设为新的形心。
-
重复第二和第三步直到最优。通常,你通过形心的移动来度量优化。有很多方式来这么做,我们仅仅使用百分数比例。
很简单,比 SVM 简单多了。让我们看看一个简短的代码示例。开始,我们拥有这样一些数据:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from sklearn.cluster import KMeans
style.use('ggplot')
#ORIGINAL:
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8],
[8, 8],
[1, 0.6],
[9, 11]])
plt.scatter(X[:, 0],X[:, 1], s=150, linewidths = 5, zorder = 10)
plt.show()
我们的数据是:

太棒了,看起来很简单,所以我们的 KMeans 算法更适于这个东西。首先我们会尝试拟合所有东西:
clf = KMeans(n_clusters=2)
clf.fit(X)
就这么简单,但是我们可能希望看到它。我们之前在 SVM 中看到过,多数 Sklearn 分类器都拥有多种属性。使用 KMeans 算法,我们可以获取形心和标签。
centroids = clf.cluster_centers_
labels = clf.labels_
现在绘制他们:
colors = ["g.","r.","c.","y."]
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(centroids[:, 0],centroids[:, 1], marker = "x", s=150, linewidths = 5, zorder = 10)
plt.show()

下面,我们打算讲 KMeans 算法应用于真实的数据集,并且涉及,如果你的数据含有非数值的信息,会发生什么。
三十五、处理非数值数据
欢迎阅读第三十五篇教程。我们最近开始谈论聚类,但是这个教程中,我们打算涉及到处理非数值数据,它当然不是聚类特定的。
我们打算处理的数据是泰坦尼克数据集。
简单看一下数据和值:
Pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival (0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare (British pound)
cabin Cabin
embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
这个数据集的主要关注点就是survival 一列。在使用监督式机器学习的时候,你要将这一列看做分类,对其训练数据。但是对于聚类,我们让机器生产分组,并自行贴标签。我的第一个兴趣点事,是否分组和任何列相关,尤其是survival 一列。对于我们这个教程,我们现在执行扁平聚类,也就是我们告诉机器想要两个分组,但是之后我们也会让机器决定分组数量。
但是现在,我们要面对另一个问题。如果我们将这个数据加载进 Pandas,我们会看到这样一些东西:
#https://pythonprogramming.net/static/downloads/machine-learning-data/titanic.xls
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
from sklearn.cluster import KMeans
from sklearn import preprocessing, cross_validation
import pandas as pd
'''
Pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival (0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare (British pound)
cabin Cabin
embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
'''
df = pd.read_excel('titanic.xls')
print(df.head())
pclass survived name sex \
0 1 1 Allen, Miss. Elisabeth Walton female
1 1 1 Allison, Master. Hudson Trevor male
2 1 0 Allison, Miss. Helen Loraine female
3 1 0 Allison, Mr. Hudson Joshua Creighton male
4 1 0 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) female
age sibsp parch ticket fare cabin embarked boat body \
0 29.0000 0 0 24160 211.3375 B5 S 2 NaN
1 0.9167 1 2 113781 151.5500 C22 C26 S 11 NaN
2 2.0000 1 2 113781 151.5500 C22 C26 S NaN NaN
3 30.0000 1 2 113781 151.5500 C22 C26 S NaN 135.0
4 25.0000 1 2 113781 151.5500 C22 C26 S NaN NaN
home.dest
0 St Louis, MO
1 Montreal, PQ / Chesterville, ON
2 Montreal, PQ / Chesterville, ON
3 Montreal, PQ / Chesterville, ON
4 Montreal, PQ / Chesterville, ON
pclass survived name sex age sibsp parch ticket fare \
0 1 1 110 0 29.0000 0 0 748 211.3375
1 1 1 839 1 0.9167 1 2 504 151.5500
2 1 0 1274 0 2.0000 1 2 504 151.5500
3 1 0 284 1 30.0000 1 2 504 151.5500
4 1 0 563 0 25.0000 1 2 504 151.5500
cabin embarked boat body home.dest
0 52 1 1 NaN 173
1 44 1 6 NaN 277
2 44 1 0 NaN 277
3 44 1 0 135.0 277
4 44 1 0 NaN 277
问题是,我们得到了非数值的数据。机器学习算法需要数值。我们可以丢弃name列,它对我们没有用。我们是否应该丢弃sex列呢?我不这么看,它看起来是特别重要的列,尤其是我们知道“女士和孩子是有限的”。那么cabin列又如何呢?可能它对于你在船上的位置很重要呢?我猜是这样。可能你从哪里乘船不是很重要,但是这个时候,我们已经知道了我们需要以任何方式处理非数值数据。
有很多方式处理非数值数据,这就是我自己使用的方式。首先,你打算遍历 Pandas 数据帧中的列。对于不是数值的列,你想要寻找它们的唯一元素。这可以简单通过获取列值的set来完成。这里,set中的索引也可以是新的“数值”值,或者文本数据的“id”。
开始:
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
创建函数,获取列,迭代它们。继续:
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
unique_elements = set(column_contents)
这里,我们添加了嵌套函数,将参数值作为键,转换为这个元素在text_digit_vals中的值。我们现在还不使用它,但是也快了。下面,当我们迭代列的时候,我们打算确认是否这一列是np.int64或np.float64。如果不是,我们将这一列转换为值的列表,之后我们获取这一列的set来获取唯一的值。
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
unique_elements = set(column_contents)
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
text_digit_vals[unique] = x
x+=1
df[column] = list(map(convert_to_int, df[column]))
return df
我们继续,对于每个找到的唯一元素,我们创建新的字典,键是唯一元素,值是新的数值。一旦我们迭代了所有的唯一元素,我们就将之前创建的函数映射到这一列上。不知道什么是映射嘛?查看这里。
现在我们添加一些代码:
df = handle_non_numerical_data(df)
print(df.head())
完整代码:
#https://pythonprogramming.net/static/downloads/machine-learning-data/titanic.xls
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
from sklearn.cluster import KMeans
from sklearn import preprocessing, cross_validation
import pandas as pd
'''
Pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival (0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare (British pound)
cabin Cabin
embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
'''
df = pd.read_excel('titanic.xls')
#print(df.head())
df.drop(['body','name'], 1, inplace=True)
df.convert_objects(convert_numeric=True)
df.fillna(0, inplace=True)
#print(df.head())
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
unique_elements = set(column_contents)
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
text_digit_vals[unique] = x
x+=1
df[column] = list(map(convert_to_int, df[column]))
return df
df = handle_non_numerical_data(df)
print(df.head())
输出:
pclass survived sex age sibsp parch ticket fare cabin \
0 1 1 1 29.0000 0 0 767 211.3375 80
1 1 1 0 0.9167 1 2 531 151.5500 149
2 1 0 1 2.0000 1 2 531 151.5500 149
3 1 0 0 30.0000 1 2 531 151.5500 149
4 1 0 1 25.0000 1 2 531 151.5500 149
embarked boat home.dest
0 1 1 307
1 1 27 43
2 1 0 43
3 1 0 43
4 1 0 43
如果df.convert_objects(convert_numeric=True)出现了废弃警告,或者错误,尽管将其注释掉吧。我通常为了清楚而保留它,但是数据帧应该把数值读作数值。出于一些原因,Pandas 会随机将列中的一些行读作字符串,尽管字符串实际上是数值。对我来说没有意义,所以我将将它们转为字符串来保证。
太好了,所以我们得到了数值,现在我们可以继续使用这个数据做扁平聚类了。
三十六、泰坦尼克数据集 KMeans
欢迎阅读第三十六篇教程,另一篇话题为聚类的教程。
之前的教程中,我们涉及了如何处理非数值的数据,这里我们打算实际对泰坦尼克数据集应用 KMeans 算法。KMeans 算法是个扁平聚类算法,也就是说我们需要告诉机器一件事情,应该有多少个簇。我们打算告诉算法有两个分组,之后我们让机器寻找幸存者和遇难者,基于它选取的这两个分组。
我们的代码为:
#https://pythonprogramming.net/static/downloads/machine-learning-data/titanic.xls
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
'''
Pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival (0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare (British pound)
cabin Cabin
embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
'''
df = pd.read_excel('titanic.xls')
#print(df.head())
df.drop(['body','name'], 1, inplace=True)
df.convert_objects(convert_numeric=True)
df.fillna(0, inplace=True)
#print(df.head())
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
unique_elements = set(column_contents)
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
text_digit_vals[unique] = x
x+=1
df[column] = list(map(convert_to_int, df[column]))
return df
df = handle_non_numerical_data(df)
这里,我们可以立即执行聚类:
X = np.array(df.drop(['survived'], 1).astype(float))
y = np.array(df['survived'])
clf = KMeans(n_clusters=2)
clf.fit(X)
好的,现在让我们看看,是否分组互相匹配。你可以注意,这里,幸存者是 0,遇难者是 1。对于聚类算法,机器会寻找簇,但是会给簇分配任意标签,以便寻找它们。因此,幸存者的分组可能是 0 或者 1,取决于随机度。因此,如果你的一致性是 30% 或者 70%,那么你的模型准确度是 70%。让我们看看吧:
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = clf.predict(predict_me)
if prediction[0] == y[i]:
correct += 1
print(correct/len(X))
# 0.4957983193277311
准确度是 49% ~ 51%,不是很好。还记得几篇教程之前,预处理的事情吗?当我们之前使用的时候,看起来不是很重要,但是这里呢?
X = np.array(df.drop(['survived'], 1).astype(float))
X = preprocessing.scale(X)
y = np.array(df['survived'])
clf = KMeans(n_clusters=2)
clf.fit(X)
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = clf.predict(predict_me)
if prediction[0] == y[i]:
correct += 1
print(correct/len(X))
# 0.7081741787624141
预处理看起来很重要。预处理的目的是把你的数据放到 -1 ~ 1 的范围内,这可以使事情更好。我从来没有见过预处理产生很大的负面影响,它至少不会有什么影响,但是这里产生了非常大的正面影响。
好奇的是,我想知道上不上船对它影响多大。我看到机器将人们划分为上船和不上船的。我们可以看到,添加df.drop(['boat'], 1, inplace=True)是否会有很大影响。
0.6844919786096256
并不是很重要,但是有轻微的影响。那么性别呢?你知道这个数据实际上有两个分类:男性和女性。可能这就是它的主要发现?现在我们尝试df.drop(['sex'], 1, inplace=True)。
0.6982429335370511
也不是很重要。
目前的完整代码:
#https://pythonprogramming.net/static/downloads/machine-learning-data/titanic.xls
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
'''
Pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival (0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare (British pound)
cabin Cabin
embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
'''
df = pd.read_excel('titanic.xls')
#print(df.head())
df.drop(['body','name'], 1, inplace=True)
df.convert_objects(convert_numeric=True)
df.fillna(0, inplace=True)
#print(df.head())
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
unique_elements = set(column_contents)
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
text_digit_vals[unique] = x
x+=1
df[column] = list(map(convert_to_int, df[column]))
return df
df = handle_non_numerical_data(df)
df.drop(['sex','boat'], 1, inplace=True)
X = np.array(df.drop(['survived'], 1).astype(float))
X = preprocessing.scale(X)
y = np.array(df['survived'])
clf = KMeans(n_clusters=2)
clf.fit(X)
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = clf.predict(predict_me)
if prediction[0] == y[i]:
correct += 1
print(correct/len(X))
对我来说,这个聚类算法看似自动将这些人归类为幸存者和遇难者。真实有趣。我们没有过多判断,机器认为为什么选取这些分组,但是它们似乎和幸存者有很高的相关度。
下一篇教程中,我们打算进一步,从零创建我们自己的 KMeans 算法。
三十七、使用 Python 从零实现 KMeans
欢迎阅读第三十七篇教程,这是另一篇聚类的教程。
这个教程中,我们打算从零构建我们自己的 KMeans 算法。之前提到过 KMeans 算法的步骤。
- 选择 K 值。
- 随机选取 K 个特征作为形心。
- 计算所有其它特征到形心的距离。
- 将其它特征分类到最近的形心。
- 计算每个分类的均值(分类中所有特征的均值),使均值为新的形心。
- 重复步骤 3 ~ 5,直到最优(形心不再变化)。
最开始,我们:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11]])
plt.scatter(X[:,0], X[:,1], s=150)
plt.show()

我们的簇应该很显然了。我们打算选取K=2。我们开始构建我们的 KMeans 分类:
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
我们刚刚配置了一些起始值,k就是簇的数量,tol就是容差,如果簇的形心移动没有超过这个值,就是最优的。max_iter值用于限制循环次数。
现在我们开始处理fit方法:
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
最开始,我们知道我们仅仅需要传入拟合数据。之后我们以空字典开始,它之后会存放我们的形心。下面,我们开始循环,仅仅将我们的起始形心赋为数据中的前两个样例。如果你打算真正随机选取形心,你应该首先打乱数据,但是这样也不错。
继续构建我们的类:
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
现在我们开始迭代我们的max_iter值。这里,我们以空分类开始,之后创建两个字典的键(通过遍历self.k的范围)。
下面,我们需要遍历我们的特征,计算当前形心个特征的距离,之后分类他们:
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
下面,我们需要创建新的形心,并且度量形心的移动。如果移动小于我们的容差(sel.tol),我们就完成了。包括添加的代码,目前为止的代码为:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11]])
plt.scatter(X[:,0], X[:,1], s=150)
plt.show()
colors = 10*["g","r","c","b","k"]
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
prev_centroids = dict(self.centroids)
for classification in self.classifications:
self.centroids[classification] = np.average(self.classifications[classification],axis=0)
下一篇教程中,我们会完成我们的类,并看看它表现如何。
三十八、完成 KMeans 聚类
欢迎阅读第三十八篇教程,另一篇关于聚类的教程。
我们暂停的地方是,我们开始创建自己的 KMeans 聚类算法。我们会继续,从这里开始:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11]])
##plt.scatter(X[:,0], X[:,1], s=150)
##plt.show()
colors = 10*["g","r","c","b","k"]
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
prev_centroids = dict(self.centroids)
for classification in self.classifications:
self.centroids[classification] = np.average(self.classifications[classification],axis=0)
既然我们拥有了新的形心,以及之前形心的只是,我们关心是否是最优化的。非常简单,我们会向fit方法添加下面的代码:
optimized = True
for c in self.centroids:
original_centroid = prev_centroids[c]
current_centroid = self.centroids[c]
if np.sum((current_centroid-original_centroid)/original_centroid*100.0) > self.tol:
print(np.sum((current_centroid-original_centroid)/original_centroid*100.0))
optimized = False
我们开始假设是最优的,只有选取所有形心,并将它们与之前的形心比较。如果他们符合我们所需的容差,我们就开心了。如果没有,我们将optimized设为False,并继续我们的for i in range(self.max_iter):。我们是否是最优化的呢?
if optimized:
break
我们就完成了fit方法:
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
prev_centroids = dict(self.centroids)
for classification in self.classifications:
self.centroids[classification] = np.average(self.classifications[classification],axis=0)
optimized = True
for c in self.centroids:
original_centroid = prev_centroids[c]
current_centroid = self.centroids[c]
if np.sum((current_centroid-original_centroid)/original_centroid*100.0) > self.tol:
print(np.sum((current_centroid-original_centroid)/original_centroid*100.0))
optimized = False
if optimized:
break
现在我们可以添加一些预测方法。这实际上已经完成了。还记得我们遍历特征集来分配簇的地方吗?
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
这就是我们需要做的所有预测,除了最后一行。
def predict(self,data):
distances = [np.linalg.norm(data-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
return classification
现在我们就完成了整个 KMeans 类:
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
prev_centroids = dict(self.centroids)
for classification in self.classifications:
self.centroids[classification] = np.average(self.classifications[classification],axis=0)
optimized = True
for c in self.centroids:
original_centroid = prev_centroids[c]
current_centroid = self.centroids[c]
if np.sum((current_centroid-original_centroid)/original_centroid*100.0) > self.tol:
print(np.sum((current_centroid-original_centroid)/original_centroid*100.0))
optimized = False
if optimized:
break
def predict(self,data):
distances = [np.linalg.norm(data-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
return classification
现在我们可以这样做了:
clf = K_Means()
clf.fit(X)
for centroid in clf.centroids:
plt.scatter(clf.centroids[centroid][0], clf.centroids[centroid][1],
marker="o", color="k", s=150, linewidths=5)
for classification in clf.classifications:
color = colors[classification]
for featureset in clf.classifications[classification]:
plt.scatter(featureset[0], featureset[1], marker="x", color=color, s=150, linewidths=5)
plt.show()

我们测试下面的预测又如何呢?
clf = K_Means()
clf.fit(X)
for centroid in clf.centroids:
plt.scatter(clf.centroids[centroid][0], clf.centroids[centroid][1],
marker="o", color="k", s=150, linewidths=5)
for classification in clf.classifications:
color = colors[classification]
for featureset in clf.classifications[classification]:
plt.scatter(featureset[0], featureset[1], marker="x", color=color, s=150, linewidths=5)
unknowns = np.array([[1,3],
[8,9],
[0,3],
[5,4],
[6,4],])
for unknown in unknowns:
classification = clf.predict(unknown)
plt.scatter(unknown[0], unknown[1], marker="*", color=colors[classification], s=150, linewidths=5)
plt.show()

如果我们选取我们的预测并将其添加到原始数据集呢?这样会移动形心,并且会不会修改任何数据的新的分类?
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11],
[1,3],
[8,9],
[0,3],
[5,4],
[6,4],])
##plt.scatter(X[:,0], X[:,1], s=150)
##plt.show()
colors = 10*["g","r","c","b","k"]
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in data:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
prev_centroids = dict(self.centroids)
for classification in self.classifications:
self.centroids[classification] = np.average(self.classifications[classification],axis=0)
optimized = True
for c in self.centroids:
original_centroid = prev_centroids[c]
current_centroid = self.centroids[c]
if np.sum((current_centroid-original_centroid)/original_centroid*100.0) > self.tol:
print(np.sum((current_centroid-original_centroid)/original_centroid*100.0))
optimized = False
if optimized:
break
def predict(self,data):
distances = [np.linalg.norm(data-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
return classification
clf = K_Means()
clf.fit(X)
for centroid in clf.centroids:
plt.scatter(clf.centroids[centroid][0], clf.centroids[centroid][1],
marker="o", color="k", s=150, linewidths=5)
for classification in clf.classifications:
color = colors[classification]
for featureset in clf.classifications[classification]:
plt.scatter(featureset[0], featureset[1], marker="x", color=color, s=150, linewidths=5)
##unknowns = np.array([[1,3],
## [8,9],
## [0,3],
## [5,4],
## [6,4],])
##
##for unknown in unknowns:
## classification = clf.predict(unknown)
## plt.scatter(unknown[0], unknown[1], marker="*", color=colors[classification], s=150, linewidths=5)
##
plt.show()

足够了,虽然多数特征集都保留了原来的簇,特征集[5,4]在用作训练集时修改了分组。
这就是 KMeans 了,如果你问我,KMeans 以及另一些扁平聚类算法可能很使用,但是程序员还是要决定 K 是什么。我们下一个话题就是层次聚类,其中机器会寻找多少个簇用于对特征集分组,它更加震撼一点。
我们也会对泰坦尼克数据集测试我们的 KMeans 算法,并将我们的结果与 Sklearn 的输出比较:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from sklearn import preprocessing, cross_validation
import pandas as pd
##X = np.array([[1, 2],
## [1.5, 1.8],
## [5, 8],
## [8, 8],
## [1, 0.6],
## [9, 11]])
##
##
##colors = ['r','g','b','c','k','o','y']
class K_Means:
def __init__(self, k=2, tol=0.001, max_iter=300):
self.k = k
self.tol = tol
self.max_iter = max_iter
def fit(self,data):
self.centroids = {}
for i in range(self.k):
self.centroids[i] = data[i]
for i in range(self.max_iter):
self.classifications = {}
for i in range(self.k):
self.classifications[i] = []
for featureset in X:
distances = [np.linalg.norm(featureset-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
self.classifications[classification].append(featureset)
prev_centroids = dict(self.centroids)
for classification in self.classifications:
self.centroids[classification] = np.average(self.classifications[classification],axis=0)
optimized = True
for c in self.centroids:
original_centroid = prev_centroids[c]
current_centroid = self.centroids[c]
if np.sum((current_centroid-original_centroid)/original_centroid*100.0) > self.tol:
print(np.sum((current_centroid-original_centroid)/original_centroid*100.0))
optimized = False
if optimized:
break
def predict(self,data):
distances = [np.linalg.norm(data-self.centroids[centroid]) for centroid in self.centroids]
classification = distances.index(min(distances))
return classification
# https://pythonprogramming.net/static/downloads/machine-learning-data/titanic.xls
df = pd.read_excel('titanic.xls')
df.drop(['body','name'], 1, inplace=True)
#df.convert_objects(convert_numeric=True)
print(df.head())
df.fillna(0,inplace=True)
def handle_non_numerical_data(df):
# handling non-numerical data: must convert.
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
#print(column,df[column].dtype)
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
#finding just the uniques
unique_elements = set(column_contents)
# great, found them.
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
# creating dict that contains new
# id per unique string
text_digit_vals[unique] = x
x+=1
# now we map the new "id" vlaue
# to replace the string.
df[column] = list(map(convert_to_int,df[column]))
return df
df = handle_non_numerical_data(df)
print(df.head())
# add/remove features just to see impact they have.
df.drop(['ticket','home.dest'], 1, inplace=True)
X = np.array(df.drop(['survived'], 1).astype(float))
X = preprocessing.scale(X)
y = np.array(df['survived'])
#X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.5)
clf = K_Means()
clf.fit(X)
correct = 0
for i in range(len(X)):
predict_me = np.array(X[i].astype(float))
predict_me = predict_me.reshape(-1, len(predict_me))
prediction = clf.predict(predict_me)
if prediction == y[i]:
correct += 1
print(correct/len(X))
我们现在完成了机器学习教程的 KMeans 部分。下面,我们打算涉及均值漂移算法,它不像 KMeans,科学家不需要告诉算法有多少个簇。
三十九、均值漂移,层次聚类
欢迎阅读第三十九篇教程,另一片聚类的教程,我们使用均值漂移算法,继续探讨聚类和非监督机器学习的话题。
均值漂移非常类似于 KMeans 算法,除了一个很重要的因素,你不需要指定分组的数量。均质漂亮算法自己寻找簇。出于这个原因,它比起 KMeans,更加是一种“非监督”的机器学习的算法。
均值漂移的方式就是遍历每个特征集(图上的数据点),并且执行登山的操作。登山就像它的名字,思想是持续底层,或者向上走,直到到达了顶部。我们不确定只有一个局部最大值。我们可能拥有一个,也可能拥有是个。这里我们的“山”就是给定半径内的特征集或数据点数量。半径也叫作贷款,整个窗口就是你的核。窗口中的数据越多,就越好。一旦我们不再执行另一个步骤,来降低半径内的特征集或者数据点的数量时,我们就选取该区域内所有数据的均值,然后就有了簇的中心。我们从每个数据点开始这样做。许多数据点都会产生相同的簇中心,这应该是预料中的,但是其他数据点也可能有完全不同的簇中心。
但是,你应该开始认识到这个操作的主要弊端:规模。规模看似是一个永久的问题。所以我们从每个数据点开始运行这个优化算法,这很糟糕,我们可以使用一些方法来加速这个过程,但是无论怎么样,这个算法仍然开销很大。
虽然这个方法是层次聚类方法,你的核可以是扁平的,或者高斯核。要记住这个核就是你的窗口,在寻找均值时,我们可以让每个特征集拥有相同权重(扁平核),或者通过核中心的接近性来分配权重(高斯核)。
均值漂移用于什么呢?核之前提到的聚类相比,均值漂移在图像分析的跟踪和平滑中很热门。现在,我们打算仅仅专注于我们的特征集聚类。
现在为止,我们涉及了使用 Sklearn 和 Matplotlib 可视化的基础,以及分类器的属性。所以我直接贴出了代码:
import numpy as np
from sklearn.cluster import MeanShift
from sklearn.datasets.samples_generator import make_blobs
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import style
style.use("ggplot")
centers = [[1,1,1],[5,5,5],[3,10,10]]
X, _ = make_blobs(n_samples = 100, centers = centers, cluster_std = 1.5)
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Number of estimated clusters:", n_clusters_)
colors = 10*['r','g','b','c','k','y','m']
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i in range(len(X)):
ax.scatter(X[i][0], X[i][1], X[i][2], c=colors[labels[i]], marker='o')
ax.scatter(cluster_centers[:,0],cluster_centers[:,1],cluster_centers[:,2],
marker="x",color='k', s=150, linewidths = 5, zorder=10)
plt.show()
控制台输出:
[[ 1.26113946 1.24675516 1.04657994]
[ 4.87468691 4.88157787 5.15456168]
[ 2.77026724 10.3096062 10.40855045]]
Number of estimated clusters: 3
绘图:

四十、应用均值漂移的泰坦尼克数据集
欢迎阅读第四十篇机器学习教程,也是另一篇聚类的教程。我们使用均值漂移,继续聚类和非监督学习的话题,这次将其用于我们的泰坦尼克数据集。
这里有一些随机度,所以你的结果可能并不相同,然而你可以重新运行程序来获取相似结果,如果你没有得到相似结果的话。
我们打算通过均值漂移聚类来看一看泰坦尼克数据集。我们感兴趣的是,是否均值漂移能够自动将乘客分离为分组。如果能,检查它创建的分组就很有趣了。第一个明显的兴趣点就是,所发现分组的幸存率,但是,我们也会深入这些分组的属性,来观察我们是否能够理解,均值漂移为什么决定了特定的分组。
首先,我们使用已经看过的代码:
import numpy as np
from sklearn.cluster import MeanShift, KMeans
from sklearn import preprocessing, cross_validation
import pandas as pd
import matplotlib.pyplot as plt
'''
Pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival (0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare (British pound)
cabin Cabin
embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
'''
# https://pythonprogramming.net/static/downloads/machine-learning-data/titanic.xls
df = pd.read_excel('titanic.xls')
original_df = pd.DataFrame.copy(df)
df.drop(['body','name'], 1, inplace=True)
df.fillna(0,inplace=True)
def handle_non_numerical_data(df):
# handling non-numerical data: must convert.
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
#print(column,df[column].dtype)
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
#finding just the uniques
unique_elements = set(column_contents)
# great, found them.
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
# creating dict that contains new
# id per unique string
text_digit_vals[unique] = x
x+=1
# now we map the new "id" vlaue
# to replace the string.
df[column] = list(map(convert_to_int,df[column]))
return df
df = handle_non_numerical_data(df)
df.drop(['ticket','home.dest'], 1, inplace=True)
X = np.array(df.drop(['survived'], 1).astype(float))
X = preprocessing.scale(X)
y = np.array(df['survived'])
clf = MeanShift()
clf.fit(X)
除了两个例外,一个是original_df = pd.DataFrame.copy(df),在我们将csv文件读取到df对象之后。另一个是从sklearn.cluster 导入MeanShift,并且用其作为我们的聚类器。我们生成了副本,以便之后引用原始非数值形式的数据。
既然我们创建了拟合,我们可以从clf对象获取一些属性。
labels = clf.labels_
cluster_centers = clf.cluster_centers_
下面,我们打算向我们的原始数据帧添加新的一项。
original_df['cluster_group']=np.nan
现在,我们可以迭代标签,并向空列添加新的标签。
for i in range(len(X)):
original_df['cluster_group'].iloc[i] = labels[i]
现在我们可以检查每个分组的幸存率:
n_clusters_ = len(np.unique(labels))
survival_rates = {}
for i in range(n_clusters_):
temp_df = original_df[ (original_df['cluster_group']==float(i)) ]
#print(temp_df.head())
survival_cluster = temp_df[ (temp_df['survived'] == 1) ]
survival_rate = len(survival_cluster) / len(temp_df)
#print(i,survival_rate)
survival_rates[i] = survival_rate
print(survival_rates)
如果我们执行它,我们会得到:
{0: 0.3796583850931677, 1: 0.9090909090909091, 2: 0.1}
同样,你可能获得更多分组。我这里获得了三个,但是我在这个数据集上获得过六个分组。现在,我们看到分组 0 的幸存率是 38%,分组 1 是 91%,分组 2 是 10%。这就有些奇怪了,因为我们知道船上有三个真实的“乘客分类”。我想知道是不是 0 就是二等舱,1 就是头等舱, 2 是三等舱。船上的舱是,3 等舱在最底下,头等舱在最上面,底部首先淹没,然后顶部是救生船的地方。我可以深入看一看:
print(original_df[ (original_df['cluster_group']==1) ])
我们获取cluster_group为 1 的original_df 。
打印出来:
pclass survived name \
17 1 1 Baxter, Mrs. James (Helene DeLaudeniere Chaput)
49 1 1 Cardeza, Mr. Thomas Drake Martinez
50 1 1 Cardeza, Mrs. James Warburton Martinez (Charlo...
66 1 1 Chaudanson, Miss. Victorine
97 1 1 Douglas, Mrs. Frederick Charles (Mary Helene B...
116 1 1 Fortune, Mrs. Mark (Mary McDougald)
183 1 1 Lesurer, Mr. Gustave J
251 1 1 Ryerson, Miss. Susan Parker "Suzette"
252 1 0 Ryerson, Mr. Arthur Larned
253 1 1 Ryerson, Mrs. Arthur Larned (Emily Maria Borie)
302 1 1 Ward, Miss. Anna
sex age sibsp parch ticket fare cabin embarked \
17 female 50.0 0 1 PC 17558 247.5208 B58 B60 C
49 male 36.0 0 1 PC 17755 512.3292 B51 B53 B55 C
50 female 58.0 0 1 PC 17755 512.3292 B51 B53 B55 C
66 female 36.0 0 0 PC 17608 262.3750 B61 C
97 female 27.0 1 1 PC 17558 247.5208 B58 B60 C
116 female 60.0 1 4 19950 263.0000 C23 C25 C27 S
183 male 35.0 0 0 PC 17755 512.3292 B101 C
251 female 21.0 2 2 PC 17608 262.3750 B57 B59 B63 B66 C
252 male 61.0 1 3 PC 17608 262.3750 B57 B59 B63 B66 C
253 female 48.0 1 3 PC 17608 262.3750 B57 B59 B63 B66 C
302 female 35.0 0 0 PC 17755 512.3292 NaN C
boat body home.dest cluster_group
17 6 NaN Montreal, PQ 1.0
49 3 NaN Austria-Hungary / Germantown, Philadelphia, PA 1.0
50 3 NaN Germantown, Philadelphia, PA 1.0
66 4 NaN NaN 1.0
97 6 NaN Montreal, PQ 1.0
116 10 NaN Winnipeg, MB 1.0
183 3 NaN NaN 1.0
251 4 NaN Haverford, PA / Cooperstown, NY 1.0
252 NaN NaN Haverford, PA / Cooperstown, NY 1.0
253 4 NaN Haverford, PA / Cooperstown, NY 1.0
302 3 NaN NaN 1.0
很确定了,整个分组就是头等舱。也就是说,这里实际上只有 11 个人。让我们看看分组 0,它看起来有些不同。这一次,我们使用 Pandas 的.describe()方法。
print(original_df[ (original_df['cluster_group']==0) ].describe())
pclass survived age sibsp parch \
count 1288.000000 1288.000000 1027.000000 1288.000000 1288.000000
mean 2.300466 0.379658 29.668614 0.496118 0.332298
std 0.833785 0.485490 14.395610 1.047430 0.686068
min 1.000000 0.000000 0.166700 0.000000 0.000000
25% 2.000000 0.000000 21.000000 0.000000 0.000000
50% 3.000000 0.000000 28.000000 0.000000 0.000000
75% 3.000000 1.000000 38.000000 1.000000 0.000000
max 3.000000 1.000000 80.000000 8.000000 4.000000
fare body cluster_group
count 1287.000000 119.000000 1288.0
mean 30.510172 159.571429 0.0
std 41.511032 97.302914 0.0
min 0.000000 1.000000 0.0
25% 7.895800 71.000000 0.0
50% 14.108300 155.000000 0.0
75% 30.070800 255.500000 0.0
max 263.000000 328.000000 0.0
这里有 1287 个人,我们可以看到平均等级是二等舱,但是这里从头等到三等都有。
让我们检查最后一个分组,2,它的预期是全都是三等舱:
print(original_df[ (original_df['cluster_group']==2) ].describe())
pclass survived age sibsp parch fare \
count 10.0 10.000000 8.000000 10.000000 10.000000 10.000000
mean 3.0 0.100000 39.875000 0.800000 6.000000 42.703750
std 0.0 0.316228 1.552648 0.421637 1.632993 15.590194
min 3.0 0.000000 38.000000 0.000000 5.000000 29.125000
25% 3.0 0.000000 39.000000 1.000000 5.000000 31.303125
50% 3.0 0.000000 39.500000 1.000000 5.000000 35.537500
75% 3.0 0.000000 40.250000 1.000000 6.000000 46.900000
max 3.0 1.000000 43.000000 1.000000 9.000000 69.550000
body cluster_group
count 2.000000 10.0
mean 234.500000 2.0
std 130.814755 0.0
min 142.000000 2.0
25% 188.250000 2.0
50% 234.500000 2.0
75% 280.750000 2.0
max 327.000000 2.0
很确定了,我们是对的,这个分组全是三等舱,所以有最坏的幸存率。
足够有趣,在查看所有分组的时候,分组 2 的票价范围的确是最低的,从 29 到 69 磅。
在我们查看簇 0 的时候,票价最高为 263 磅。这是最大的组,幸存率为 38%。
当我们回顾簇 1 时,它全是头等舱,我们看到这里的票价范围是 247 ~ 512 磅,均值为 350。尽管簇 0 有一些头等舱的乘客,这个分组是最精英的分组。
出于好奇,分组 0 的头等舱的生存率,与整体生存率相比如何呢?
>>> cluster_0 = (original_df[ (original_df['cluster_group']==0) ])
>>> cluster_0_fc = (cluster_0[ (cluster_0['pclass']==1) ])
>>> print(cluster_0_fc.describe())
pclass survived age sibsp parch fare \
count 312.0 312.000000 273.000000 312.000000 312.000000 312.000000
mean 1.0 0.608974 39.027167 0.432692 0.326923 78.232519
std 0.0 0.488764 14.589592 0.606997 0.653100 60.300654
min 1.0 0.000000 0.916700 0.000000 0.000000 0.000000
25% 1.0 0.000000 28.000000 0.000000 0.000000 30.500000
50% 1.0 1.000000 39.000000 0.000000 0.000000 58.689600
75% 1.0 1.000000 49.000000 1.000000 0.000000 91.079200
max 1.0 1.000000 80.000000 3.000000 4.000000 263.000000
body cluster_group
count 35.000000 312.0
mean 162.828571 0.0
std 82.652172 0.0
min 16.000000 0.0
25% 109.500000 0.0
50% 166.000000 0.0
75% 233.000000 0.0
max 307.000000 0.0
>>>
很确定了,它们的幸存率更高,约为 61%,但是仍然低于精英分组(根据票价和幸存率)的 91%。花费一些时间来深入挖掘,看看你是否能发现一些东西。然后我们要到下一章,自己编写均值漂移算法。
四十一、从零编写均值漂移
欢迎阅读第四十一篇教程,这是另一篇聚类教程。
这篇教程中,我们从零开始构建我们自己的均值漂移算法。首先,我们会以一些 37 章中的代码开始,它就是我们开始构建 KMeans 算法的地方。我会向原始原始数据添加更多簇或者分组。你可以添加新的数据,或者保留原样。
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11],
[8,2],
[10,2],
[9,3],])
plt.scatter(X[:,0], X[:,1], s=150)
plt.show()
colors = 10*["g","r","c","b","k"]
运行之后,代码会生成:

就像 KMeans 那部分,这会创建明显的分组。对于 KMeans,我们告诉机器我们想要 K(2)个簇。对于均值漂移,我们希望机器自己识别出来,并且对于我们来说,我们希望有三个分组。
我们开始我们的MeanShift类:
class Mean_Shift:
def __init__(self, radius=4):
self.radius = radius
我们会以半径 4 开始,因为我们可以估计出,半径 4 是有意义的。这就是我们在初始化方法中需要的所有东西。我们来看看fit方法:
def fit(self, data):
centroids = {}
for i in range(len(data)):
centroids[i] = data[i]
这里,我们开始创建起始形心。均值漂移的方法是:
- 让所有数据点都是形心。
- 计算形心半径内的所有数据集,将均值设置为新的形心。
- 重复步骤 2 直至收敛。
目前为止,我们完成了步骤 1,现在需要重复步骤 2 直到收敛。
while True:
new_centroids = []
for i in centroids:
in_bandwidth = []
centroid = centroids[i]
for featureset in data:
if np.linalg.norm(featureset-centroid) < self.radius:
in_bandwidth.append(featureset)
new_centroid = np.average(in_bandwidth,axis=0)
new_centroids.append(tuple(new_centroid))
uniques = sorted(list(set(new_centroids)))
这里,我们开始迭代每个形心,并且找到范围内的所有特征集。这里,我们计算了均值,并将均值设置为新的形心。最后,我们创建unique变量,它跟踪了所有已知形心的排序后的列表。我们这里使用set,因为它们可能重复,重复的形心也就是同一个形心。
我们来完成fit方法:
prev_centroids = dict(centroids)
centroids = {}
for i in range(len(uniques)):
centroids[i] = np.array(uniques[i])
optimized = True
for i in centroids:
if not np.array_equal(centroids[i], prev_centroids[i]):
optimized = False
if not optimized:
break
if optimized:
break
self.centroids = centroids
这里我们注意到之前的形心,之后,我们重置“当前”或者“新的”形心,通过将其去重。最后,我们比较了之前的形心和新的形心,并度量了移动。如果任何形心发生了移动,就不是完全收敛和最优化,我们就需要继续执行另一个循环。如果它是最优化的,我们就终端,之后将centroids属性设置为我们生成的最后一个形心。
我们现在可以将这个第一个部分,以及类包装起来,添加下面这些东西:
clf = Mean_Shift()
clf.fit(X)
centroids = clf.centroids
plt.scatter(X[:,0], X[:,1], s=150)
for c in centroids:
plt.scatter(centroids[c][0], centroids[c][1], color='k', marker='*', s=150)
plt.show()

目前为止的完整代码:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11],
[8,2],
[10,2],
[9,3],])
##plt.scatter(X[:,0], X[:,1], s=150)
##plt.show()
colors = 10*["g","r","c","b","k"]
class Mean_Shift:
def __init__(self, radius=4):
self.radius = radius
def fit(self, data):
centroids = {}
for i in range(len(data)):
centroids[i] = data[i]
while True:
new_centroids = []
for i in centroids:
in_bandwidth = []
centroid = centroids[i]
for featureset in data:
if np.linalg.norm(featureset-centroid) < self.radius:
in_bandwidth.append(featureset)
new_centroid = np.average(in_bandwidth,axis=0)
new_centroids.append(tuple(new_centroid))
uniques = sorted(list(set(new_centroids)))
prev_centroids = dict(centroids)
centroids = {}
for i in range(len(uniques)):
centroids[i] = np.array(uniques[i])
optimized = True
for i in centroids:
if not np.array_equal(centroids[i], prev_centroids[i]):
optimized = False
if not optimized:
break
if optimized:
break
self.centroids = centroids
clf = Mean_Shift()
clf.fit(X)
centroids = clf.centroids
plt.scatter(X[:,0], X[:,1], s=150)
for c in centroids:
plt.scatter(centroids[c][0], centroids[c][1], color='k', marker='*', s=150)
plt.show()
到这里,我们获取了所需的形心,并且我们觉得十分聪明。从此,所有我们所需的就是计算欧氏距离,并且我们拥有了形心和分类。预测就变得简单了。现在只有一个问题:半径。
我们基本上硬编码了半径。我看了数据集之后才决定 4 是个好的数值。这一点也不动态,并且它不像是非监督机器学习。假设如果我们有 50 个维度呢?就不会很简单了。机器能够观察数据集并得出合理的值吗?我们会在下一个教程中涉及它。
四十二、均值漂移的动态权重带宽
欢迎阅读第四十二篇教程,另一篇聚类的教程。我们打算继续处理我们自己的均值漂移算法。
目前为止的代码:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
import numpy as np
X = np.array([[1, 2],
[1.5, 1.8],
[5, 8 ],
[8, 8],
[1, 0.6],
[9,11],
[8,2],
[10,2],
[9,3],])
##plt.scatter(X[:,0], X[:,1], s=150)
##plt.show()
colors = 10*["g","r","c","b","k"]
class Mean_Shift:
def __init__(self, radius=4):
self.radius = radius
def fit(self, data):
centroids = {}
for i in range(len(data)):
centroids[i] = data[i]
while True:
new_centroids = []
for i in centroids:
in_bandwidth = []
centroid = centroids[i]
for featureset in data:
if np.linalg.norm(featureset-centroid) < self.radius:
in_bandwidth.append(featureset)
new_centroid = np.average(in_bandwidth,axis=0)
new_centroids.append(tuple(new_centroid))
uniques = sorted(list(set(new_centroids)))
prev_centroids = dict(centroids)
centroids = {}
for i in range(len(uniques)):
centroids[i] = np.array(uniques[i])
optimized = True
for i in centroids:
if not np.array_equal(centroids[i], prev_centroids[i]):
optimized = False
if not optimized:
break
if optimized:
break
self.centroids = centroids
clf = Mean_Shift()
clf.fit(X)
centroids = clf.centroids
plt.scatter(X[:,0], X[:,1], s=150)
for c in centroids:
plt.scatter(centroids[c][0], centroids[c][1], color='k', marker='*', s=150)
plt.show()
这个代码能够工作,但是我们决定硬编码的半径不好。我们希望做一些更好的事情。首先,我们会修改我们的__init__方法:
def __init__(self, radius=None, radius_norm_step = 100):
self.radius = radius
self.radius_norm_step = radius_norm_step
所以这里的计划时创建大量的半径,但是逐步处理这个半径,就像带宽一样,或者一些不同长度的半径,我们将其称为步骤。如果特征集靠近半径,它就比远离的点有更大的“权重”。唯一的问题就是,这些步骤应该是什么。现在,开始实现我们的方法:
def fit(self, data):
if self.radius == None:
all_data_centroid = np.average(data, axis=0)
all_data_norm = np.linalg.norm(all_data_centroid)
self.radius = all_data_norm / self.radius_norm_step
centroids = {}
for i in range(len(data)):
centroids[i] = data[i]
这里,如果用户没有硬编码半径,我们就打算寻找所有数据的“中心”。之后,我们会计算数据的模,之后假设每个self.radius中的半径都是整个数据长度,再除以我们希望的步骤数量。这里,形心的定义和上面的代码相同。现在我们开始while循环的优化:
weights = [i for i in range(self.radius_norm_step)][::-1]
while True:
new_centroids = []
for i in centroids:
in_bandwidth = []
centroid = centroids[i]
for featureset in data:
#if np.linalg.norm(featureset-centroid) < self.radius:
# in_bandwidth.append(featureset)
distance = np.linalg.norm(featureset-centroid)
if distance == 0:
distance = 0.00000000001
weight_index = int(distance/self.radius)
if weight_index > self.radius_norm_step-1:
weight_index = self.radius_norm_step-1
to_add = (weights[weight_index]**2)*[featureset]
in_bandwidth +=to_add
new_centroid = np.average(in_bandwidth,axis=0)
new_centroids.append(tuple(new_centroid))
uniques = sorted(list(set(new_centroids)))
要注意权重的定义,之后是数据中特征集的改变。
第四部分 神经网络
四十三、神经网络简介
欢迎阅读机器学习系列教程的一个新部分:深度学习和神经网络、以及 TensorFlow。人造的神经网络受生物学启发,用于指导机器学习,刻意模拟你的大脑(生物神经网络)。
人造神经网络是个新的概念,我现在将其用神经网络来指代。这个概念刻意追溯到 20 世纪 40 年代,并且有数次波动,尤其是跟支持向量机来比较。例如,神经网络直到 90 年代中期才流行,同时 SVM 使用一种新公开的技术(技术在应用之前经过了很长时间),“核的技巧”,适用于非线性分隔的数据集。有了它,SVM 再次流行起来,将神经网络和很多有趣的东西遗留在了后面,直到 2011 年。由于大量的可用数据集,以及更加强大的计算机,这个时候神经网络使用新的技巧,开始优于 SVM。
这就是为什么,如果你打算致力于机器学习领域,理解其它模型也是很重要的,因为趋势可以或者的确改变了。既然我们有了一些机器,它们能够实际执行神经网络,我们就有了一个有些有趣的情况,因为人们一直坐着,一直琢磨这个话题已经有十年了。这并不是说,发表神经研究的论文的人很少见,并且有些具体话题的论文在十年前就写完了。
神经网络的模型实际上是个非常简单的概念。这个概念就是模拟神经元(neuron),并且对于一个基本的神经元,它有树突(dendrites)、细胞核、轴突(axon)和轴突末梢(axon terminal)。

然后,对于一个网络,你需要两个神经元。神经元通过树突和轴突末梢之间的突触(synapse)来传递信息。

好的,所以这就是神经元的工作方式。现在计算机科学家认为我们可以用这个。所以我们提出了一个人造神经元的模型:

就是这样。所以你和你的神经元很像了。虽然,我们进一步简化了事情,并且如果你搜索神经网络的图片,你可能看到这个:

那个圆圈就是神经元或者节点,它们带有数据上的函数,并且互相连接的线是所传递的权重或者信息。每一列都是一个层。你的数据的第一层是输入层。之后,除非你的输出就是你的输入,你拥有至少一个隐藏层。如果你只有一个隐藏层,你就有了一个常规的人造神经网络。如果你拥有多个隐藏层,你就有了深度神经网络,是不是很简单呢?至少是概念上。
所以对于这个模型,你拥有输入数据,对其加权,并且将其传给神经元中的函数。神经元中的函数是个阈值函数,也叫作激活函数。基本上,它是使用一个高于或者低于特定值加权之后的总合。如果它是,你就可以得到一个信号(1),或者什么都没有(0)。然后它加权并且转给下一个神经元,并且执行同样的函数。
这就是一个神经网络模型。所以,什么是权重和阈值函数呢?首先,多亏了 1974 的 Paul Werbos,我们去掉了阈值“变量”。我们不将这些阈值处理为另一个要优化的变量,而是选取然后阈值的值,将其权重为 -1,阈值总是为0,。无论阈值有多大,它都会自行消除,并且始终为 0。我们仍然有一个丑陋的步骤函数,因为神经元产生 0 还是 1 的决策是非常混乱的。我们决定使用某种类型的 sigmoid 函数(S 形)来代替。

对于权重,它们只是随机启动,并且它们对于每个输入到节点/神经元是唯一的。 然后,在典型的“前馈”(最基本的类型)神经网络中,你的信息通过你创建的网络直接传递,并使用你的样本数据,将输出与期望输出进行比较。 从这里,你需要调整权重,来帮助你获得与预期输出匹配的输出。 直接通过神经网络发送数据的行为称为前馈神经网络。 我们的数据从输入层到隐藏层,然后是输出层。 当我们向后退,开始调整权重来最小化损失/成本时,这称为反向传播。
这是一个新的优化问题。 回忆一下,几个教程之前的支持向量机优化问题,我们如何解释这是一个很好的凸优化问题。 即使我们有两个变量,我们的优化问题是一个完美的碗形,所以我们可以知道什么时候达到了最优化,同时沿着路径执行了大量的步骤,使处理便宜。 使用神经网络,情况并非如此。 在实际中,你寻找更多成千上万个变量,甚至数百万或更多的变量。这里的原始解决方案是使用随机梯度下降,但还有其他选项,如 AdaGrad 和 Adam Optimizer。无论如何,这是一项巨大的计算任务。
现在你可以看到为什么神经网络几乎已经搁置了半个多世纪。 只是最近,我们才拥有了这种能力和架构的机器,以便执行这些操作,以及用于匹配的适当大小的数据集。 好消息是,我们已经有花个世纪来就这个话题进行哲学思考,而且大量的基础工作已经完成了,只需要实施和测试。
有意思的是,正如我们不完全了解人类大脑一样,我们并不完全理解神经网络为什么或如何实现这样有趣的结果。 通过大量的挖掘和分析,我们可以揭开一些事情,但是由于许多变量和维度,我们实际上并不太了解发生了什么,我们只是看到了很好的结果,并且很开心。 即使是我们的第一个例子,原则上也是非常基本的,但是他做的事情也有惊人的结果。
对于简单的分类任务,神经网络在性能上与其他简单算法相对接近,甚至像 KNN 那样。 神经网络中的真正美丽带来了更大的数据,更复杂的问题,这两个都使其他机器学习模型变得无力。 例如,当前的神经网络可以做出如下回答:
Jack 12 岁,Jane 10 岁,Kate 比 Jane 年长,比 Jack 年轻,Kate 多少岁?
答案是11,一个深度学习模型可以解释出来,无需你在某种程度上教会如何实际完成逻辑部分。 你只需简单地传递原始数据,它是单词,甚至是字符,而神经网络则完成其余部分。 哦,你需要数百万个样例! 以数百万计,我的意思是为了理想的准确度需要约 5 亿。
你在哪里得到数以百万计的样品?你有一些选择。图像数据的一个选择是 ImageNet,它在事物的组织中非常类似于 wordnet。如果你不熟悉,你可以提出一个想法。这里的一切都是免费的。接下来,对于文本数据,第一个站点应该是像维基百科数据转储。这对于更多的深度学习的任务非常有用,而不是标签数据。接下来,对于更多的文本数据,为什么不去已经被爬去和解析的大部分网站呢?如果这听起来很有趣,请查看 CommonCrawl。这个数据集不是一个笑话,但是它的数据是 PB 级的。对于演讲,我并没有很多思路。一个选项是像 Tatoeba,它有标签和一些翻译,这是非常有用的。当一切都失败时,你可以尝试创建自己的数据集,但是大小要求相当有挑战性。另外,你可以随时寻求帮助。根据我的经验,存在任何东西的数据集,你只需要找到它。很多时候,Google 在尝试查找数据集时会失败,但是人们可以帮助你。目前,你可以在机器学习 subreddit 中尝试询问,大概 90% 的内容与神经网络相关,每个人都需要了解大量的数据集。
现在应该比较明显的是,像 Facebook 和 Google 这样的公司,对于 AI 和神经网络的投入如此之大。 他们实际上拥有所需的数据量来做一些非常有趣的事情。
现在我们有这样的方式,我们如何在神经网络上工作? 我们将使用 TensorFlow,这是 Google 的一个相对较新的软件包,在撰写本文时仍然是测试版。 还有其他用于机器学习的包,如 Theano 或 Torch,但它们都以类似的方式工作。 我们真的只需要选一个,我选择 Tensorflow。 在下一个教程中,我们将安装 TensorFlow。 如果你已经安装了 TensorFlow,可以跳过下一个教程(使用侧面导航栏,或者单击下一步,滚动到底部,然后再次单击)。
四十四、为神经网络安装 TensorFlow(可选)
这是一个可选的教程,用于安装 TensorFlow。 如果你有 Mac 或者 Linux,你不需要这个教程,只需访问TensorFlow.org > get started > pip installation。 你只需要运行几个命令,然后就设置好了。 对于 Windows 用户,你需要使用 Docker 或虚拟机来安装 TensorFlow。 我选择虚拟机,因为它很容易,后来可能需要使用双引导。
对于启动,TensorFlow 由 Mac 和 Linux 支持,但 Windows 不支持。 如果需要,可以在 Windows 上使用它们的 Docker 发行包。
你可以随意使用任何你想要的设置,但我个人将在 Windows 机器上的虚拟机上使用 Ubuntu 16.04。 目前,人们要在哪个平台执行机器学习模型,还是比较不清楚的,所以谁也不知道哪个操作系数最终会成为这个领域的王者。 随意使用任何你想要使用的方法,这一点不重要,但我仍然简单通过虚拟机来运行。
首先,下载 Virtualbox。 这将允许你虚拟化各种组件,如一些 CPU,GPU 和磁盘空间。 接下来,你需要一个操作系统。 我选择 Ubuntu 16.04 64bit。 如果你有 64 位处理器,那么你可以运行 64 位的映像,但是你可能需要在 BIOS 设置中启用硬件虚拟化,这在 BIOS 设置的 CPU 部分显示。 每个主板是不同的,所以我不能更具体了。 只需在设置和高级设置中查找 CPU 设置选项。
一旦你安装了 VirtualBox 软件,以及要使用的操作系统映像,请在 VirtualBox 中单击“新建”,为新机器命名,选择操作系统的类型和版本,然后转到下一个选项。
如果你想看到我的实时选项,你可以观看视频。 然而,设置非常简单。 选择一个固定大小的硬盘,至少要有 20 GB 的硬盘。 我选择了 50.VDI。 选择适配内存的东西。 你仍然需要一些内存留给你的主机,所以不要全部都占了。
一旦你完成了,你可以双击虚拟机来尝试启动它,你应该得到一个消息,没有什么可以引导,也没有任何启动驱动器。 从这里可以选择你最近下载的 Ubuntu 安装映像,并开始安装过程。 安装时,你将了解到是否要擦除硬盘驱动器的内容,并替换为 Ubuntu。 可能感觉不舒服,答案是肯定的,那就是你想做的。 这将清除虚拟硬盘上的安装,而不是实际的硬盘驱动器。
安装完成后,系统将提示你重启虚拟机。 重新启动提示似乎对我没有太大意义,所以你可以关闭窗口来关闭电源,或者从 GUI 右键单击你的虚拟机,并选择关闭。
当你关闭虚拟机时,你可以右键单击它,然后进入设置。 在那里,进入系统,并分配多于 cpus(1) 的默认数量。 这些只会在启动时分配给你的虚拟机,而不是所有时间。 你可能还想为视频,给自己一些更多的内存。
现在开机,你可能已经注意到你没有得到很好的解决方案。 你可以运行以下操作来启用可调整大小的屏幕:
sudo apt-get install virtualbox-guest-utils virtualbox-guest-x11 virtualbox-guest-dkms
现在,我们准备好在我们的机器上安装 TensorFlow。 你还需要 Python3,但这是 Ubuntu 16.04 自带的。 前往 TensorFlow.org,点击开始,然后在侧栏上的pip installation。 如果你稍后查看本教程,可能会有所不同。 但是,随着事情的变化,我会尽力更新这个文本的版本。 所以,在pip installation页面上,指南首先让我们运行:
$ sudo apt-get install python3-pip python3-dev
以上在你的终端中运行。 在 Ubuntu 上,你可以按ctrl + alt + t使其在 GUI 桌面上出现。 由于我运行的是 64 位版本的 Linux(Ubuntu),有了 Python 3.5,而且想要 CPU 版本,我选择:
# Ubuntu/Linux 64-bit, CPU only, Python 3.5
$ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.9.0-cp35-cp35m-linux_x86_64.whl
之后执行:
$ sudo pip3 install --upgrade $TF_BINARY_URL
我们完成了。为了测试,我们可以在控制台中输入python3,并尝试导入tensorflow。 如果工作正常,我们就都设置好了!
我使用 Sublime Text 来编辑 Python 文件。 使用任何你喜欢的 编辑器。在 Ubuntu 上,一旦下载了.deb文件,你需要运行:sudo dpkg -i /path/to/deb/file,然后sudo apt-get install -f。
下一篇教程中,我们打算涉及使用 TensorFlow 的基础。
四十五、深度学习和 TensorFlow 简介
欢迎阅读深度学习与神经网络和 TensorFlow 的第二部分,以及机器学习教程系列的第 44 部分。 在本教程中,我们将介绍一些关于 TensorFlow 的基础知识,以及如何开始使用它。
像 TensorFlow 和 Theano 这样的库不仅仅是深入学习库,它们是用于深入学习的库。 他们实际上只是数值处理库,就像 Numpy 一样。 然而,不同的是,像 TensorFlow 这样的软件包使我们能够以高效率执行特定的机器学习数值处理操作,如巨大的矩阵上的求导。 我们也可以轻松地在 CPU 内核,GPU 内核或甚至多个 GPU 等多个设备上分布式处理。 但这不是全部! 我们甚至可以在具有 TensorFlow 的分布式计算机网络上分发计算。 所以,虽然 TensorFlow 主要是与机器学习一起使用,但它实际上在其他领域也有使用,因为它真的只是一个庞大的数组操作库。
什么是张量(tensor)? 到目前为止,在机器学习系列中,我们主要使用向量(numpy 数组),张量可以是一个向量。 最简单的说,一个张量是一个类似数组的对象,正如你所看到的,一个数组可以容纳你的矩阵,你的向量,甚至一个标量。
在这一点上,我们只需要将机器学习问题转化为张量函数,这可以用每一个 ML 算法来实现。 考虑神经网络。 神经网络能够分解成什么?
我们有数据(X),权重(w)和阈值(t)。 所有这些都是张量嘛? X是数据集(一个数组),所以这是一个张量。 权重也是一组权重值,所以它们也是张量。阈值? 与权重相同。 因此,我们的神经网络确实是X,w和``t或f(Xwt)的函数,所以我们准备完全了,当然可以使用 TensorFlow,但是如何呢?
TensorFlow 的工作方式是,首先定义和描述我们的抽象模型,然后在我们准备好的时候,在会话(session)中成为现实。 在 TensorFlow 术语中,该模型的描述是所谓的“计算图形”。 我们来玩一个简单的例子。 首先,我们来构建图:
import tensorflow as tf
# creates nodes in a graph
# "construction phase"
x1 = tf.constant(5)
x2 = tf.constant(6)
所以我们有了一些值。现在,我们可以用这些值做一些事情,例如相乘:
result = tf.mul(x1,x2)
print(result)
要注意输出仍然是个抽象的张量。没有运行实际计算,只能创建操作。我们的计算图中的每个操作或“op”都是图中的“节点”。
要真正看到结果,我们需要运行会话。 一般来说,你首先构建图形,然后“启动”图形:
# defines our session and launches graph
sess = tf.Session()
# runs result
print(sess.run(result))
我们也可以将会话的输出赋给变量:
output = sess.run(result)
print(output)
当你完成了一个会话是,你需要关闭它,来释放所使用的资源。
sess.close()
关闭之后,你仍然可以引用output变量,但是你不能这样做了:
sess.run(result)
这会返回错误另一个选项就是利用 Python 的with语句:
with tf.Session() as sess:
output = sess.run(result)
print(output)
如果你不熟悉这些操作,它在这些语句所在的代码块中使用会话,然后在完成后自动关闭会话,和使用with语句打开文件的方法相同。
你还可以在多个设备上使用 TensorFlow,甚至可以使用多台分布式机器。 在特定 GPU 上运行某些计算的示例是:
with tf.Session() as sess:
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
代码来自:TensorFlow 文档。tf.matmul是矩阵乘法函数。
上述代码将在第二个系统 GPU 上运行计算。 如果你安装了 CPU 版本,那么这不是一个选项,但是你仍然应该意识到这个可能性。 TensorFlow 的 GPU 版本要求正确设置 CUDA(以及需要支持 CUDA 的 GPU)。 我有几个支持 CUDA 的 GPU,并希望最终能够充分使用它们,但这要等到以后了!
现在我们已经有了 TensorFlow 的基础知识了,下一个教程中我会邀请你,创建一个深度神经网络的“兔子洞”。 如果你需要安装 TensorFlow,如果你在 Mac 或 Linux 上,安装过程非常简单。 在 Windows 上,也不是很麻烦。 下一个教程是可选的,它只是用于在 Windows 机器上安装 TensorFlow。
四十六、深度学习和 TensorFlow - 创建神经网络模型
欢迎阅读深度学习与神经网络和 TensorFlow 的第三部分,以及机器学习教程系列的第 45 部分。 在本教程中,我们将通过创建我们自己的深度神经网络(TensorFlow),来进入(下落)的兔子洞。
我们首先使用 MNIST 数据集,该数据集包含 6 万个手写和标记数字训练样本和 10,000 个的测试样本,0 到 9,因此共有 10 个“分类”。 我会注意到,这是一个非常小的数据集,就你在任何现实环境中的工作而言,它也应该足够小到在每个人的电脑上工作。
MNIST 数据集具有图像,我们将使用纯粹的黑色和白色,阈值,图像,总共 28×28 或 784 像素。 我们的特征是每个像素的像素值,阈值。 像素是“空白”(没有什么,0),或有东西(1)。 这些是我们的特征。 我们尝试使用这个非常基本的数据,并预测我们正在查看的数字(0 ~ 9)。 我们希望我们的神经网络,将以某种方式创建像素之间的关系的内在模型,并且能够查看数字的新样例,并且高准确度预测。
虽然这里的代码不会那么长,但如果你不完全了解应该发生的事情,那么我们可以尝试凝结我们迄今为止所学到的知识,以及我们在这里会做什么。
首先,我们传入输入数据,并将其发送到隐藏层1。因此,我们对输入数据加权,并将其发送到层1。在那里将经历激活函数,因此神经元可以决定是否触发,并将一些数据输出到输出层或另一个隐藏层。在这个例子中,我们有三个隐藏层,使之成为深度神经网络。从我们得到的输出中,我们将该输出与预期输出进行比较。我们使用成本函数(或称为损失函数)来确定我们的正确率。最后,我们将使用优化器函数,Adam Optimizer。在这种情况下,最小化损失(我们有多错误)。成本最小化的方法是通过修改权重,目的是希望降低损失。我们要降低损失的速度由学习率决定。学习率越低,我们学习的速度越慢,我们越有可能获得更好的结果。学习率越高,我们学习越快,训练时间更短,也可能会受到影响。当然,这里的收益递减,你不能只是继续降低学习率,并且总是做得更好。
通过我们的网络直接发送数据的行为,意味着我们正在运行前馈神经网络。 向后调整权重是我们的反向传播。
我们这样做是向前和向后传播,但我们想要多次。 这个周期被称为一个迭代(epoch)。 我们可以选择任何数量的迭代,但你可能想要避免太多,这会导致过拟合。
在每个时代之后,我们希望进一步调整我们的权重,降低损失和提高准确性。 当我们完成所有的迭代,我们可以使用测试集进行测试。
清楚了吗?准备开始了!
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
我们导入 TensorFlow 和我们将要使用的样本数据。 请注意one_hot参数。 这个术语来自只有一个元素的点子,在其余元素当中,字面上是“热”的,或者开启的。 这对于我们这里的多类分类任务是有用的(0 ~ 9)。 因此,不是简单的 0 或者 1,我们拥有:
0 = [1,0,0,0,0,0,0,0,0]
1 = [0,1,0,0,0,0,0,0,0]
2 = [0,0,1,0,0,0,0,0,0]
3 = [0,0,0,1,0,0,0,0,0]
...
好的,所以我们有了数据。 我选择使用 MNIST 数据集,因为它是一个合适的起始数据集,实际上,收集原始数据并将其转换为可以使用的东西,比创建机器学习模型本身需要更多的时间,我认为这里大多数人都想学习 神经网络,而不是网页抓取和正则表达式。
现在我们要开始构建模型:
n_nodes_hl1 = 500
n_nodes_hl2 = 500
n_nodes_hl3 = 500
n_classes = 10
batch_size = 100
我们首先指定每个隐藏层将有多少个节点,我们的数据集有多少份额里,以及我们的批量大小。 虽然你理论上可以一次训练整个网络,这是不切实际的。 你们中的许多人可能有可以完全处理 MNIST 数据集的计算机,但是大多数人都没有或可以访问这种计算机,它们可以一次完成实际大小的数据集。 因此,我们进行批量优化。 在这种情况下,我们进行 100 个批次。
x = tf.placeholder('float', [None, 784])
y = tf.placeholder('float')
这些是我们图中某些值的占位符。 回想一下,你只需在 TensorFlow 图中构建模型即可。 在这里,TensorFlow 操纵一切,而你不会。 一旦完成,这将更加明显,你尝试寻找在哪里修改重量! 请注意,我已经使用[None,784]作为第一个占位符中的第二个参数。 这是一个可选参数,然而这样显式指定非常有用。 如果你不显式指定,TensorFlow 会在那里填充任何东西。 如果你的形状是显式的,并且一些不同形状的东西尝试放进这个变量的地方,TensorFlow 将抛出一个错误。
我们现在完成了我们的常量以及其实值。现在我们可以实际构建神经网络模型了:
def neural_network_model(data):
hidden_1_layer = {'weights':tf.Variable(tf.random_normal([784, n_nodes_hl1])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl1]))}
hidden_2_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl1, n_nodes_hl2])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl2]))}
hidden_3_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl2, n_nodes_hl3])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl3]))}
output_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl3, n_classes])),
'biases':tf.Variable(tf.random_normal([n_classes]))}
这里,我们开始定义我们的权重和我们的...等等,这些偏差是什么? 偏差是在通过激活函数之前,与我们的相加的值,不要与偏差节点混淆,偏差节点只是一个总是存在的节点。 这里的偏差的目的主要是,处理所有神经元生成 0 的情况。 偏差使得神经元仍然能够从该层中触发。 偏差与权重一样独特,也需要优化。
我们迄今所做的一切都是为我们的权重和偏差创建一个起始定义。 对于层的矩阵的应有形状,这些定义只是随机值(这是tf.random_normal为我们做的事情,它为我们输出符合形状的随机值)。 还没有发生任何事情,没有发生流动(前馈)。我们开始流程:
l1 = tf.add(tf.matmul(data,hidden_1_layer['weights']), hidden_1_layer['biases'])
l1 = tf.nn.relu(l1)
l2 = tf.add(tf.matmul(l1,hidden_2_layer['weights']), hidden_2_layer['biases'])
l2 = tf.nn.relu(l2)
l3 = tf.add(tf.matmul(l2,hidden_3_layer['weights']), hidden_3_layer['biases'])
l3 = tf.nn.relu(l3)
output = tf.matmul(l3,output_layer['weights']) + output_layer['biases']
return output
在这里,我们将值传入第一层。 这些值是什么? 它们是原始输入数据乘以其唯一权重(从随机开始,但将被优化):tf.matmul(l1,hidden_2_layer['weights'])。 然后,我们添加了tf.add的偏差。 我们对每个隐藏层重复这个过程,直到我们的输出,我们的最终值仍然是输入和权重的乘积,加上输出层的偏差值。
完成后,我们只需返回该输出层。 所以现在,我们已经构建了网络,几乎完成了整个计算图形。 在下一个教程中,我们将构建一个函数,使用 TensorFlow 实际运行并训练网络。
第四十七章 深度学习和 TensorFlow - 神经网络如何运行
原文:Deep Learning with TensorFlow - Creating the Neural Network Model
译者:飞龙
欢迎阅读深度学习与神经网络和 TensorFlow 的第四部分,以及机器学习教程系列的第 46 部分。 在本教程中,我们将在 TensorFlow 中编写会话期间发生的代码。
这里的代码已经更新,以便支持TensorFlow 1.0,但视频有两行需要稍微更新。
在前面的教程中,我们构建了人工神经网络的模型,并用 TensorFlow 建立了计算图表。 现在我们需要实际建立训练过程,这将在 TensorFlow 会话中运行。 继续处理我们的代码:
def train_neural_network(x):
prediction = neural_network_model(x)
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y) )
在新的函数train_neural_network下,我们传入数据。 然后,我们通过我们的neural_network_model产生一个基于该数据输出的预测。 接下来,我们创建一个开销变量,衡量我们有多少错误,而且我们希望通过操纵我们的权重来最小化这个变量。 开销函数是损失函数的代名词。 为了优化我们的成本,我们将使用AdamOptimizer,它是一个流行的优化器,以及其他类似的随机梯度下降和AdaGrad。
optimizer = tf.train.AdamOptimizer().minimize(cost)
在AdamOptimizer()中,您可以选择将learning_rate指定为参数。默认值为 0.001,这在大多数情况下都不错。 现在我们定义了这些东西,我们将启动会话。
hm_epochs = 10
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
首先,我们有一个简单的hm_epochs变量,它将确定有多少个迭代(前馈和后退循环)。 接下来,我们使用上一个教程中讨论的会话开启和关闭的语法。 首先,我们初始化所有的变量。这是主要步骤:
for epoch in range(hm_epochs):
epoch_loss = 0
for _ in range(int(mnist.train.num_examples/batch_size)):
epoch_x, epoch_y = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={x: epoch_x, y: epoch_y})
epoch_loss += c
print('Epoch', epoch, 'completed out of',hm_epochs,'loss:',epoch_loss)
对于每个迭代,对于我们的数据中的每个批次,我们将针对我们数据批次运行优化器和开销。 为了跟踪我们每一步的损失或开销,我们要添加每个迭代的总开销。 对于每个迭代,我们输出损失,每次都应该下降。 这可以用于跟踪,所以随着时间的推移,你可以看到收益递减。 前几个迭代应该有很大的改进,但是在大约 10 或 20 之间,你会看到很小的变化,或者可能会变得更糟。
现在,在循环之外:
correct = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1))
这会告诉我们,我们做了多少个预测,它完美匹配它们的标签。
accuracy = tf.reduce_mean(tf.cast(correct, 'float'))
print('Accuracy:',accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
现在我们拥有了测试集上的最终准确率。现在我们需要:
train_neural_network(x)
在 10 到 20 个迭代的某个地方应该有 95% 的准确度。 95% 的准确度,听起来不错,但比起更主流的方法,实际上被认为非常糟糕。 我实际上认为 95% 的准确性,这个模型是没有什么意外的。 考虑到我们给网络的唯一信息是像素值,就是这样。 我们没有告诉它如何寻找模式,或者说如何从 9 中得到一个4 ,或者从 8 中得到一个 1。网络只是用一个内在的模型来计算出来,纯粹是基于像素值来开始,并且达到了 95% 准确性。 对我来说这是惊人的,虽然最先进的技术超过 99%。
目前为止的完整代码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
n_nodes_hl1 = 500
n_nodes_hl2 = 500
n_nodes_hl3 = 500
n_classes = 10
batch_size = 100
x = tf.placeholder('float', [None, 784])
y = tf.placeholder('float')
def neural_network_model(data):
hidden_1_layer = {'weights':tf.Variable(tf.random_normal([784, n_nodes_hl1])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl1]))}
hidden_2_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl1, n_nodes_hl2])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl2]))}
hidden_3_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl2, n_nodes_hl3])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl3]))}
output_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl3, n_classes])),
'biases':tf.Variable(tf.random_normal([n_classes])),}
l1 = tf.add(tf.matmul(data,hidden_1_layer['weights']), hidden_1_layer['biases'])
l1 = tf.nn.relu(l1)
l2 = tf.add(tf.matmul(l1,hidden_2_layer['weights']), hidden_2_layer['biases'])
l2 = tf.nn.relu(l2)
l3 = tf.add(tf.matmul(l2,hidden_3_layer['weights']), hidden_3_layer['biases'])
l3 = tf.nn.relu(l3)
output = tf.matmul(l3,output_layer['weights']) + output_layer['biases']
return output
def train_neural_network(x):
prediction = neural_network_model(x)
# OLD VERSION:
#cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(prediction,y) )
# NEW:
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y) )
optimizer = tf.train.AdamOptimizer().minimize(cost)
hm_epochs = 10
with tf.Session() as sess:
# OLD:
#sess.run(tf.initialize_all_variables())
# NEW:
sess.run(tf.global_variables_initializer())
for epoch in range(hm_epochs):
epoch_loss = 0
for _ in range(int(mnist.train.num_examples/batch_size)):
epoch_x, epoch_y = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={x: epoch_x, y: epoch_y})
epoch_loss += c
print('Epoch', epoch, 'completed out of',hm_epochs,'loss:',epoch_loss)
correct = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct, 'float'))
print('Accuracy:',accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
train_neural_network(x)
下一篇教程中,我们尝试使用这个准确的模型,并将其应用到一个新的数据集,这对我们来说并没有准备好。
PythonProgramming.net 自然语言处理教程
译者:飞龙
一、使用 NLTK 分析单词和句子
欢迎阅读自然语言处理系列教程,使用 Python 的自然语言工具包 NLTK 模块。
NLTK 模块是一个巨大的工具包,目的是在整个自然语言处理(NLP)方法上帮助你。 NLTK 将为你提供一切,从将段落拆分为句子,拆分词语,识别这些词语的词性,高亮主题,甚至帮助你的机器了解文本关于什么。在这个系列中,我们将要解决意见挖掘或情感分析的领域。
在我们学习如何使用 NLTK 进行情感分析的过程中,我们将学习以下内容:
- 分词 - 将文本正文分割为句子和单词。
- 词性标注
- 机器学习与朴素贝叶斯分类器
- 如何一起使用 Scikit Learn(sklearn)与 NLTK
- 用数据集训练分类器
- 用 Twitter 进行实时的流式情感分析。
- ...以及更多。
为了开始,你需要 NLTK 模块,以及 Python。
如果你还没有 Python,请转到python.org并下载最新版本的 Python(如果你在 Windows上)。如果你在 Mac 或 Linux 上,你应该可以运行apt-get install python3。
接下来,你需要 NLTK 3。安装 NLTK 模块的最简单方法是使用pip。
对于所有的用户来说,这通过打开cmd.exe,bash,或者你使用的任何 shell,并键入以下命令来完成:
pip install nltk
接下来,我们需要为 NLTK 安装一些组件。通过你的任何常用方式打开 python,然后键入:
import nltk
nltk.download()
除非你正在操作无头版本,否则一个 GUI 会弹出来,可能只有红色而不是绿色:
为所有软件包选择下载“全部”,然后单击“下载”。 这会给你所有分词器,分块器,其他算法和所有的语料库。 如果空间是个问题,你可以选择手动选择性下载所有内容。 NLTK 模块将占用大约 7MB,整个nltk_data目录将占用大约 1.8GB,其中包括你的分块器,解析器和语料库。
如果你正在使用 VPS 运行无头版本,你可以通过运行 Python ,并执行以下操作来安装所有内容:
import nltk
nltk.download()
d (for download)
all (for download everything)
这将为你下载一切东西。
现在你已经拥有了所有你需要的东西,让我们敲一些简单的词汇:
- 语料库(Corpus) - 文本的正文,单数。Corpora 是它的复数。示例:
A collection of medical journals。 - 词库(Lexicon) - 词汇及其含义。例如:英文字典。但是,考虑到各个领域会有不同的词库。例如:对于金融投资者来说,
Bull(牛市)这个词的第一个含义是对市场充满信心的人,与“普通英语词汇”相比,这个词的第一个含义是动物。因此,金融投资者,医生,儿童,机械师等都有一个特殊的词库。 - 标记(Token) - 每个“实体”都是根据规则分割的一部分。例如,当一个句子被“拆分”成单词时,每个单词都是一个标记。如果你将段落拆分为句子,则每个句子也可以是一个标记。
这些是在进入自然语言处理(NLP)领域时,最常听到的词语,但是我们将及时涵盖更多的词汇。以此,我们来展示一个例子,说明如何用 NLTK 模块将某些东西拆分为标记。
from nltk.tokenize import sent_tokenize, word_tokenize
EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."
print(sent_tokenize(EXAMPLE_TEXT))
起初,你可能会认为按照词或句子来分词,是一件相当微不足道的事情。 对于很多句子来说,它可能是。 第一步可能是执行一个简单的.split('. '),或按照句号,然后是空格分割。 之后也许你会引入一些正则表达式,来按照句号,空格,然后是大写字母分割。 问题是像Mr. Smith这样的事情,还有很多其他的事情会给你带来麻烦。 按照词分割也是一个挑战,特别是在考虑缩写的时候,例如we和we're。 NLTK 用这个看起来简单但非常复杂的操作为你节省大量的时间。
上面的代码会输出句子,分成一个句子列表,你可以用for循环来遍历。
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and Python is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard."]
所以这里,我们创建了标记,它们都是句子。让我们这次按照词来分词。
print(word_tokenize(EXAMPLE_TEXT))
['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']
这里有几件事要注意。 首先,注意标点符号被视为一个单独的标记。 另外,注意单词shouldn't分隔为should和n't。 最后要注意的是,pinkish-blue确实被当作“一个词”来对待,本来就是这样。很酷!
现在,看着这些分词后的单词,我们必须开始思考我们的下一步可能是什么。 我们开始思考如何通过观察这些词汇来获得含义。 我们可以想清楚,如何把价值放在许多单词上,但我们也看到一些基本上毫无价值的单词。 这是一种“停止词”的形式,我们也可以处理。 这就是我们将在下一个教程中讨论的内容。
二、NLTK 与停止词
自然语言处理的思想,是进行某种形式的分析或处理,机器至少可以在某种程度上理解文本的含义,表述或暗示。
这显然是一个巨大的挑战,但是有一些任何人都能遵循的步骤。然而,主要思想是电脑根本不会直接理解单词。令人震惊的是,人类也不会。在人类中,记忆被分解成大脑中的电信号,以发射模式的神经组的形式。对于大脑还有很多未知的事情,但是我们越是把人脑分解成基本的元素,我们就会发现基本的元素。那么,事实证明,计算机以非常相似的方式存储信息!如果我们要模仿人类如何阅读和理解文本,我们需要一种尽可能接近的方法。一般来说,计算机使用数字来表示一切事物,但是我们经常直接在编程中看到使用二进制信号(True或False,可以直接转换为 1 或 0,直接来源于电信号存在(True, 1)或不存在(False, 0))。为此,我们需要一种方法,将单词转换为数值或信号模式。将数据转换成计算机可以理解的东西,这个过程称为“预处理”。预处理的主要形式之一就是过滤掉无用的数据。在自然语言处理中,无用词(数据)被称为停止词。
我们可以立即认识到,有些词语比其他词语更有意义。我们也可以看到,有些单词是无用的,是填充词。例如,我们在英语中使用它们来填充句子,这样就没有那么奇怪的声音了。一个最常见的,非官方的,无用词的例子是单词umm。人们经常用umm来填充,比别的词多一些。这个词毫无意义,除非我们正在寻找一个可能缺乏自信,困惑,或者说没有太多话的人。我们都这样做,有...呃...很多时候,你可以在视频中听到我说umm或uhh。对于大多数分析而言,这些词是无用的。
我们不希望这些词占用我们数据库的空间,或占用宝贵的处理时间。因此,我们称这些词为“无用词”,因为它们是无用的,我们希望对它们不做处理。 “停止词”这个词的另一个版本可以更书面一些:我们停在上面的单词。
例如,如果你发现通常用于讽刺的词语,可能希望立即停止。讽刺的单词或短语将因词库和语料库而异。就目前而言,我们将把停止词当作不含任何含义的词,我们要把它们删除。
你可以轻松地实现它,通过存储你认为是停止词的单词列表。 NLTK 用一堆他们认为是停止词的单词,来让你起步,你可以通过 NLTK 语料库来访问它:
from nltk.corpus import stopwords
这里是这个列表:
>>> set(stopwords.words('english'))
{'ourselves', 'hers', 'between', 'yourself', 'but', 'again', 'there', 'about', 'once', 'during', 'out', 'very', 'having', 'with', 'they', 'own', 'an', 'be', 'some', 'for', 'do', 'its', 'yours', 'such', 'into', 'of', 'most', 'itself', 'other', 'off', 'is', 's', 'am', 'or', 'who', 'as', 'from', 'him', 'each', 'the', 'themselves', 'until', 'below', 'are', 'we', 'these', 'your', 'his', 'through', 'don', 'nor', 'me', 'were', 'her', 'more', 'himself', 'this', 'down', 'should', 'our', 'their', 'while', 'above', 'both', 'up', 'to', 'ours', 'had', 'she', 'all', 'no', 'when', 'at', 'any', 'before', 'them', 'same', 'and', 'been', 'have', 'in', 'will', 'on', 'does', 'yourselves', 'then', 'that', 'because', 'what', 'over', 'why', 'so', 'can', 'did', 'not', 'now', 'under', 'he', 'you', 'herself', 'has', 'just', 'where', 'too', 'only', 'myself', 'which', 'those', 'i', 'after', 'few', 'whom', 't', 'being', 'if', 'theirs', 'my', 'against', 'a', 'by', 'doing', 'it', 'how', 'further', 'was', 'here', 'than'}
以下是结合使用stop_words集合,从文本中删除停止词的方法:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = "This is a sample sentence, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
我们的输出是:
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words', 'filtration', '.']
我们的数据库感谢了我们。数据预处理的另一种形式是“词干提取(Stemming)”,这就是我们接下来要讨论的内容。
三、NLTK 词干提取
词干的概念是一种规范化方法。 除涉及时态之外,许多词语的变体都具有相同的含义。
我们提取词干的原因是为了缩短查找的时间,使句子正常化。
考虑:
I was taking a ride in the car.
I was riding in the car.
这两句话意味着同样的事情。 in the car(在车上)是一样的。 I(我)是一样的。 在这两种情况下,ing都明确表示过去式,所以在试图弄清这个过去式活动的含义的情况下,是否真的有必要区分riding和taking a ride?
不,并没有。
这只是一个小例子,但想象英语中的每个单词,可以放在单词上的每个可能的时态和词缀。 每个版本有单独的字典条目,将非常冗余和低效,特别是因为一旦我们转换为数字,“价值”将是相同的。
最流行的瓷感提取算法之一是 Porter,1979 年就存在了。
首先,我们要抓取并定义我们的词干:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()
现在让我们选择一些带有相似词干的单词,例如:
example_words = ["python","pythoner","pythoning","pythoned","pythonly"]
下面,我们可以这样做来轻易提取词干:
for w in example_words:
print(ps.stem(w))
我们的输出:
python
python
python
python
pythonli
现在让我们尝试对一个典型的句子,而不是一些单词提取词干:
new_text = "It is important to by very pythonly while you are pythoning with python. All pythoners have pythoned poorly at least once."
words = word_tokenize(new_text)
for w in words:
print(ps.stem(w))
现在我们的结果为:
It
is
import
to
by
veri
pythonli
while
you
are
python
with
python
.
All
python
have
python
poorli
at
least
onc
.
接下来,我们将讨论 NLTK 模块中一些更高级的内容,词性标注,其中我们可以使用 NLTK 模块来识别句子中每个单词的词性。
四、NLTK 词性标注
NLTK模块的一个更强大的方面是,它可以为你做词性标注。 意思是把一个句子中的单词标注为名词,形容词,动词等。 更令人印象深刻的是,它也可以按照时态来标记,以及其他。 这是一列标签,它们的含义和一些例子:
POS tag list:
CC coordinating conjunction
CD cardinal digit
DT determiner
EX existential there (like: "there is" ... think of it like "there exists")
FW foreign word
IN preposition/subordinating conjunction
JJ adjective 'big'
JJR adjective, comparative 'bigger'
JJS adjective, superlative 'biggest'
LS list marker 1)
MD modal could, will
NN noun, singular 'desk'
NNS noun plural 'desks'
NNP proper noun, singular 'Harrison'
NNPS proper noun, plural 'Americans'
PDT predeterminer 'all the kids'
POS possessive ending parent's
PRP personal pronoun I, he, she
PRP$ possessive pronoun my, his, hers
RB adverb very, silently,
RBR adverb, comparative better
RBS adverb, superlative best
RP particle give up
TO to go 'to' the store.
UH interjection errrrrrrrm
VB verb, base form take
VBD verb, past tense took
VBG verb, gerund/present participle taking
VBN verb, past participle taken
VBP verb, sing. present, non-3d take
VBZ verb, 3rd person sing. present takes
WDT wh-determiner which
WP wh-pronoun who, what
WP$ possessive wh-pronoun whose
WRB wh-abverb where, when
我们如何使用这个? 当我们处理它的时候,我们要讲解一个新的句子标记器,叫做PunktSentenceTokenizer。 这个标记器能够无监督地进行机器学习,所以你可以在你使用的任何文本上进行实际的训练。 首先,让我们获取一些我们打算使用的导入:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
现在让我们创建训练和测试数据:
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
一个是 2005 年以来的国情咨文演说,另一个是 2006 年以来的乔治·W·布什总统的演讲。
接下来,我们可以训练 Punkt 标记器,如下所示:
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
之后我们可以实际分词,使用:
tokenized = custom_sent_tokenizer.tokenize(sample_text)
现在我们可以通过创建一个函数,来完成这个词性标注脚本,该函数将遍历并标记每个句子的词性,如下所示:
def process_content():
try:
for i in tokenized[:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
print(tagged)
except Exception as e:
print(str(e))
process_content()
输出应该是元组列表,元组中的第一个元素是单词,第二个元素是词性标签。 它应该看起来像:
[('PRESIDENT', 'NNP'), ('GEORGE', 'NNP'), ('W.', 'NNP'), ('BUSH', 'NNP'), ("'S", 'POS'), ('ADDRESS', 'NNP'), ('BEFORE', 'NNP'), ('A', 'NNP'), ('JOINT', 'NNP'), ('SESSION', 'NNP'), ('OF', 'NNP'), ('THE', 'NNP'), ('CONGRESS', 'NNP'), ('ON', 'NNP'), ('THE', 'NNP'), ('STATE', 'NNP'), ('OF', 'NNP'), ('THE', 'NNP'), ('UNION', 'NNP'), ('January', 'NNP'), ('31', 'CD'), (',', ','), ('2006', 'CD'), ('THE', 'DT'), ('PRESIDENT', 'NNP'), (':', ':'), ('Thank', 'NNP'), ('you', 'PRP'), ('all', 'DT'), ('.', '.')] [('Mr.', 'NNP'), ('Speaker', 'NNP'), (',', ','), ('Vice', 'NNP'), ('President', 'NNP'), ('Cheney', 'NNP'), (',', ','), ('members', 'NNS'), ('of', 'IN'), ('Congress', 'NNP'), (',', ','), ('members', 'NNS'), ('of', 'IN'), ('the', 'DT'), ('Supreme', 'NNP'), ('Court', 'NNP'), ('and', 'CC'), ('diplomatic', 'JJ'), ('corps', 'NNS'), (',', ','), ('distinguished', 'VBD'), ('guests', 'NNS'), (',', ','), ('and', 'CC'), ('fellow', 'JJ'), ('citizens', 'NNS'), (':', ':'), ('Today', 'NN'), ('our', 'PRP$'), ('nation', 'NN'), ('lost', 'VBD'), ('a', 'DT'), ('beloved', 'VBN'), (',', ','), ('graceful', 'JJ'), (',', ','), ('courageous', 'JJ'), ('woman', 'NN'), ('who', 'WP'), ('called', 'VBN'), ('America', 'NNP'), ('to', 'TO'), ('its', 'PRP$'), ('founding', 'NN'), ('ideals', 'NNS'), ('and', 'CC'), ('carried', 'VBD'), ('on', 'IN'), ('a', 'DT'), ('noble', 'JJ'), ('dream', 'NN'), ('.', '.')] [('Tonight', 'NNP'), ('we', 'PRP'), ('are', 'VBP'), ('comforted', 'VBN'), ('by', 'IN'), ('the', 'DT'), ('hope', 'NN'), ('of', 'IN'), ('a', 'DT'), ('glad', 'NN'), ('reunion', 'NN'), ('with', 'IN'), ('the', 'DT'), ('husband', 'NN'), ('who', 'WP'), ('was', 'VBD'), ('taken', 'VBN'), ('so', 'RB'), ('long', 'RB'), ('ago', 'RB'), (',', ','), ('and', 'CC'), ('we', 'PRP'), ('are', 'VBP'), ('grateful', 'JJ'), ('for', 'IN'), ('the', 'DT'), ('good', 'NN'), ('life', 'NN'), ('of', 'IN'), ('Coretta', 'NNP'), ('Scott', 'NNP'), ('King', 'NNP'), ('.', '.')] [('(', 'NN'), ('Applause', 'NNP'), ('.', '.'), (')', ':')] [('President', 'NNP'), ('George', 'NNP'), ('W.', 'NNP'), ('Bush', 'NNP'), ('reacts', 'VBZ'), ('to', 'TO'), ('applause', 'VB'), ('during', 'IN'), ('his', 'PRP$'), ('State', 'NNP'), ('of', 'IN'), ('the', 'DT'), ('Union', 'NNP'), ('Address', 'NNP'), ('at', 'IN'), ('the', 'DT'), ('Capitol', 'NNP'), (',', ','), ('Tuesday', 'NNP'), (',', ','), ('Jan', 'NNP'), ('.', '.')]
到了这里,我们可以开始获得含义,但是还有一些工作要做。 我们将要讨论的下一个话题是分块(chunking),其中我们跟句单词的词性,将单词分到,有意义的分组中。
五、NLTK 分块
现在我们知道了词性,我们可以注意所谓的分块,把词汇分成有意义的块。 分块的主要目标之一是将所谓的“名词短语”分组。 这些是包含一个名词的一个或多个单词的短语,可能是一些描述性词语,也可能是一个动词,也可能是一个副词。 这个想法是把名词和与它们有关的词组合在一起。
为了分块,我们将词性标签与正则表达式结合起来。 主要从正则表达式中,我们要利用这些东西:
+ = match 1 or more
? = match 0 or 1 repetitions.
* = match 0 or MORE repetitions
. = Any character except a new line
如果你需要正则表达式的帮助,请参阅上面链接的教程。 最后需要注意的是,词性标签中用<和>表示,我们也可以在标签本身中放置正则表达式,来表达“全部名词”(<N.*>)。
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
结果是这样的:
这里的主要一行是:
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
把这一行拆分开:
<RB.?>*:零个或多个任何时态的副词,后面是:
<VB.?>*:零个或多个任何时态的动词,后面是:
<NNP>+:一个或多个合理的名词,后面是:
<NN>?:零个或一个名词单数。
尝试玩转组合来对各种实例进行分组,直到你觉得熟悉了。
视频中没有涉及,但是也有个合理的任务是实际访问具体的块。 这是很少被提及的,但根据你在做的事情,这可能是一个重要的步骤。 假设你把块打印出来,你会看到如下输出:
(S
(Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP)
'S/POS
(Chunk
ADDRESS/NNP
BEFORE/NNP
A/NNP
JOINT/NNP
SESSION/NNP
OF/NNP
THE/NNP
CONGRESS/NNP
ON/NNP
THE/NNP
STATE/NNP
OF/NNP
THE/NNP
UNION/NNP
January/NNP)
31/CD
,/,
2006/CD
THE/DT
(Chunk PRESIDENT/NNP)
:/:
(Chunk Thank/NNP)
you/PRP
all/DT
./.)
很酷,这可以帮助我们可视化,但如果我们想通过我们的程序访问这些数据呢? 那么,这里发生的是我们的“分块”变量是一个 NLTK 树。 每个“块”和“非块”是树的“子树”。 我们可以通过像chunked.subtrees的东西来引用它们。 然后我们可以像这样遍历这些子树:
for subtree in chunked.subtrees():
print(subtree)
接下来,我们可能只关心获得这些块,忽略其余部分。 我们可以在chunked.subtrees()调用中使用filter参数。
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
现在,我们执行过滤,来显示标签为“块”的子树。 请记住,这不是 NLTK 块属性中的“块”...这是字面上的“块”,因为这是我们给它的标签:chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""。
如果我们写了一些东西,类似chunkGram = r"""Pythons: {<RB.?>*<VB.?>*<NNP>+<NN>?}""",那么我们可以通过"Pythons."标签来过滤。 结果应该是这样的:
-
(Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP)
(Chunk
ADDRESS/NNP
BEFORE/NNP
A/NNP
JOINT/NNP
SESSION/NNP
OF/NNP
THE/NNP
CONGRESS/NNP
ON/NNP
THE/NNP
STATE/NNP
OF/NNP
THE/NNP
UNION/NNP
January/NNP)
(Chunk PRESIDENT/NNP)
(Chunk Thank/NNP)
完整的代码是:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
print(chunked)
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
六、 NLTK 添加缝隙(Chinking)
你可能会发现,经过大量的分块之后,你的块中还有一些你不想要的单词,但是你不知道如何通过分块来摆脱它们。 你可能会发现添加缝隙是你的解决方案。
添加缝隙与分块很像,它基本上是一种从块中删除块的方法。 你从块中删除的块就是你的缝隙。
代码非常相似,你只需要用}{来代码缝隙,在块后面,而不是块的{}。
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
使用它,你得到了一些东西:
现在,主要的区别是:
}<VB.?|IN|DT|TO>+{
这意味着我们要从缝隙中删除一个或多个动词,介词,限定词或to这个词。
现在我们已经学会了,如何执行一些自定义的分块和添加缝隙,我们来讨论一下 NLTK 自带的分块形式,这就是命名实体识别。
七、NLTK 命名实体识别
自然语言处理中最主要的分块形式之一被称为“命名实体识别”。 这个想法是让机器立即能够拉出“实体”,例如人物,地点,事物,位置,货币等等。
这可能是一个挑战,但 NLTK 是为我们内置了它。 NLTK 的命名实体识别有两个主要选项:识别所有命名实体,或将命名实体识别为它们各自的类型,如人物,地点,位置等。
这是一个例子:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=True)
namedEnt.draw()
except Exception as e:
print(str(e))
process_content()
在这里,选择binary = True,这意味着一个东西要么是命名实体,要么不是。 将不会有进一步的细节。 结果是:
如果你设置了binary = False,结果为:
你可以马上看到一些事情。 当binary是假的时候,它也选取了同样的东西,但是把White House这样的术语分解成White和House,就好像它们是不同的,而我们可以在binary = True的选项中看到,命名实体的识别 说White House是相同命名实体的一部分,这是正确的。
根据你的目标,你可以使用binary 选项。 如果你的binary 为false,这里是你可以得到的,命名实体的类型:
NE Type and Examples
ORGANIZATION - Georgia-Pacific Corp., WHO
PERSON - Eddy Bonte, President Obama
LOCATION - Murray River, Mount Everest
DATE - June, 2008-06-29
TIME - two fifty a m, 1:30 p.m.
MONEY - 175 million Canadian Dollars, GBP 10.40
PERCENT - twenty pct, 18.75 %
FACILITY - Washington Monument, Stonehenge
GPE - South East Asia, Midlothian
无论哪种方式,你可能会发现,你需要做更多的工作才能做到恰到好处,但是这个功能非常强大。
在接下来的教程中,我们将讨论类似于词干提取的东西,叫做“词形还原”(lemmatizing)。
八、NLTK 词形还原
与词干提权非常类似的操作称为词形还原。 这两者之间的主要区别是,你之前看到了,词干提权经常可能创造出不存在的词汇,而词形是实际的词汇。
所以,你的词干,也就是你最终得到的词,不是你可以在字典中查找的东西,但你可以查找一个词形。
有时你最后会得到非常相似的词语,但有时候,你会得到完全不同的词语。 我们来看一些例子。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("cats"))
print(lemmatizer.lemmatize("cacti"))
print(lemmatizer.lemmatize("geese"))
print(lemmatizer.lemmatize("rocks"))
print(lemmatizer.lemmatize("python"))
print(lemmatizer.lemmatize("better", pos="a"))
print(lemmatizer.lemmatize("best", pos="a"))
print(lemmatizer.lemmatize("run"))
print(lemmatizer.lemmatize("run",'v'))
在这里,我们有一些我们使用的词的词形的例子。 唯一要注意的是,lemmatize 接受词性参数pos。 如果没有提供,默认是“名词”。 这意味着,它将尝试找到最接近的名词,这可能会给你造成麻烦。 如果你使用词形还原,请记住!
在接下来的教程中,我们将深入模块附带的 NTLK 语料库,查看所有优秀文档,他们在那里等待着我们。
九、 NLTK 语料库
在本教程的这一部分,我想花一点时间来深入我们全部下载的语料库! NLTK 语料库是各种自然语言数据集,绝对值得一看。
NLTK 语料库中的几乎所有文件都遵循相同的规则,通过使用 NLTK 模块来访问它们,但是它们没什么神奇的。 这些文件大部分都是纯文本文件,其中一些是 XML 文件,另一些是其他格式文件,但都可以通过手动或模块和 Python 访问。 让我们来谈谈手动查看它们。
根据你的安装,你的nltk_data目录可能隐藏在多个位置。 为了找出它的位置,请转到你的 Python 目录,也就是 NLTK 模块所在的位置。 如果你不知道在哪里,请使用以下代码:
import nltk
print(nltk.__file__)
运行它,输出将是 NLTK 模块__init__.py的位置。 进入 NLTK 目录,然后查找data.py文件。
代码的重要部分是:
if sys.platform.startswith('win'):
# Common locations on Windows:
path += [
str(r'C:\nltk_data'), str(r'D:\nltk_data'), str(r'E:\nltk_data'),
os.path.join(sys.prefix, str('nltk_data')),
os.path.join(sys.prefix, str('lib'), str('nltk_data')),
os.path.join(os.environ.get(str('APPDATA'), str('C:\\')), str('nltk_data'))
]
else:
# Common locations on UNIX & OS X:
path += [
str('/usr/share/nltk_data'),
str('/usr/local/share/nltk_data'),
str('/usr/lib/nltk_data'),
str('/usr/local/lib/nltk_data')
]
在那里,你可以看到nltk_data的各种可能的目录。 如果你在 Windows 上,它很可能是在你的appdata中,在本地目录中。 为此,你需要打开你的文件浏览器,到顶部,然后输入%appdata%。
接下来点击roaming,然后找到nltk_data目录。 在那里,你将找到你的语料库文件。 完整的路径是这样的:
C:\Users\yourname\AppData\Roaming\nltk_data\corpora
在这里,你有所有可用的语料库,包括书籍,聊天记录,电影评论等等。
现在,我们将讨论通过 NLTK 访问这些文档。 正如你所看到的,这些主要是文本文档,所以你可以使用普通的 Python 代码来打开和阅读文档。 也就是说,NLTK 模块有一些很好的处理语料库的方法,所以你可能会发现使用他们的方法是实用的。 下面是我们打开“古腾堡圣经”,并阅读前几行的例子:
from nltk.tokenize import sent_tokenize, PunktSentenceTokenizer
from nltk.corpus import gutenberg
# sample text
sample = gutenberg.raw("bible-kjv.txt")
tok = sent_tokenize(sample)
for x in range(5):
print(tok[x])
其中一个更高级的数据集是wordnet。 Wordnet 是一个单词,定义,他们使用的例子,同义词,反义词,等等的集合。 接下来我们将深入使用 wordnet。
十、 NLTK 和 Wordnet
WordNet 是英语的词汇数据库,由普林斯顿创建,是 NLTK 语料库的一部分。
你可以一起使用 WordNet 和 NLTK 模块来查找单词含义,同义词,反义词等。 我们来介绍一些例子。
首先,你将需要导入wordnet:
from nltk.corpus import wordnet
之后我们打算使用单词program来寻找同义词:
syns = wordnet.synsets("program")
一个同义词的例子:
print(syns[0].name())
# plan.n.01
只是单词:
print(syns[0].lemmas()[0].name())
# plan
第一个同义词的定义:
print(syns[0].definition())
# a series of steps to be carried out or goals to be accomplished
单词的使用示例:
print(syns[0].examples())
# ['they drew up a six-step plan', 'they discussed plans for a new bond issue']
接下来,我们如何辨别一个词的同义词和反义词? 这些词形是同义词,然后你可以使用.antonyms找到词形的反义词。 因此,我们可以填充一些列表,如:
synonyms = []
antonyms = []
for syn in wordnet.synsets("good"):
for l in syn.lemmas():
synonyms.append(l.name())
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(set(synonyms))
print(set(antonyms))
'''
{'beneficial', 'just', 'upright', 'thoroughly', 'in_force', 'well', 'skilful', 'skillful', 'sound', 'unspoiled', 'expert', 'proficient', 'in_effect', 'honorable', 'adept', 'secure', 'commodity', 'estimable', 'soundly', 'right', 'respectable', 'good', 'serious', 'ripe', 'salutary', 'dear', 'practiced', 'goodness', 'safe', 'effective', 'unspoilt', 'dependable', 'undecomposed', 'honest', 'full', 'near', 'trade_good'} {'evil', 'evilness', 'bad', 'badness', 'ill'}
'''
你可以看到,我们的同义词比反义词更多,因为我们只是查找了第一个词形的反义词,但是你可以很容易地平衡这个,通过也为bad这个词执行完全相同的过程。
接下来,我们还可以很容易地使用 WordNet 来比较两个词的相似性和他们的时态,把 Wu 和 Palmer 方法结合起来用于语义相关性。
我们来比较名词ship和boat:
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('boat.n.01')
print(w1.wup_similarity(w2))
# 0.9090909090909091
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('car.n.01')
print(w1.wup_similarity(w2))
# 0.6956521739130435
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('cat.n.01')
print(w1.wup_similarity(w2))
# 0.38095238095238093
接下来,我们将讨论一些问题并开始讨论文本分类的主题。
十一、NLTK 文本分类
现在我们熟悉 NLTK 了,我们来尝试处理文本分类。 文本分类的目标可能相当宽泛。 也许我们试图将文本分类为政治或军事。 也许我们试图按照作者的性别来分类。 一个相当受欢迎的文本分类任务是,将文本的正文识别为垃圾邮件或非垃圾邮件,例如电子邮件过滤器。 在我们的例子中,我们将尝试创建一个情感分析算法。
为此,我们首先尝试使用属于 NLTK 语料库的电影评论数据库。 从那里,我们将尝试使用词汇作为“特征”,这是“正面”或“负面”电影评论的一部分。 NLTK 语料库movie_reviews数据集拥有评论,他们被标记为正面或负面。 这意味着我们可以训练和测试这些数据。 首先,让我们来预处理我们的数据。
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
print(documents[1])
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
print(all_words.most_common(15))
print(all_words["stupid"])
运行此脚本可能需要一些时间,因为电影评论数据集有点大。 我们来介绍一下这里发生的事情。
导入我们想要的数据集后,你会看到:
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
基本上,用简单的英文,上面的代码被翻译成:在每个类别(我们有正向和独享),选取所有的文件 ID(每个评论有自己的 ID),然后对文件 ID存储word_tokenized版本(单词列表),后面是一个大列表中的正面或负面标签。
接下来,我们用random 来打乱我们的文件。这是因为我们将要进行训练和测试。如果我们把他们按序排列,我们可能会训练所有的负面评论,和一些正面评论,然后在所有正面评论上测试。我们不想这样,所以我们打乱了数据。
然后,为了你能看到你正在使用的数据,我们打印出documents[1],这是一个大列表,其中第一个元素是一列单词,第二个元素是pos或neg标签。
接下来,我们要收集我们找到的所有单词,所以我们可以有一个巨大的典型单词列表。从这里,我们可以执行一个频率分布,然后找出最常见的单词。正如你所看到的,最受欢迎的“词语”其实就是标点符号,the,a等等,但是很快我们就会得到有效词汇。我们打算存储几千个最流行的单词,所以这不应该是一个问题。
print(all_words.most_common(15))
以上给出了15个最常用的单词。 你也可以通过下面的步骤找出一个单词的出现次数:
print(all_words["stupid"])
接下来,我们开始将我们的单词,储存为正面或负面的电影评论的特征。
十二、使用 NLTK 将单词转换为特征
在本教程中,我们在以前的视频基础上构建,并编撰正面评论和负面评论中的单词的特征列表,来看到正面或负面评论中特定类型单词的趋势。
最初,我们的代码:
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:3000]
几乎和以前一样,只是现在有一个新的变量,word_features,它包含了前 3000 个最常用的单词。 接下来,我们将建立一个简单的函数,在我们的正面和负面的文档中找到这些前 3000 个单词,将他们的存在标记为是或否:
def find_features(document):
words = set(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
下面,我们可以打印出特征集:
print((find_features(movie_reviews.words('neg/cv000_29416.txt'))))
之后我们可以为我们所有的文档做这件事情,通过做下列事情,保存特征存在性布尔值,以及它们各自的正面或负面的类别:
featuresets = [(find_features(rev), category) for (rev, category) in documents]
真棒,现在我们有了特征和标签,接下来是什么? 通常,下一步是继续并训练算法,然后对其进行测试。 所以,让我们继续这样做,从下一个教程中的朴素贝叶斯分类器开始!
十三、NLTK 朴素贝叶斯分类器
现在是时候选择一个算法,将我们的数据分成训练和测试集,然后启动!我们首先要使用的算法是朴素贝叶斯分类器。这是一个非常受欢迎的文本分类算法,所以我们只能先试一试。然而,在我们可以训练和测试我们的算法之前,我们需要先把数据分解成训练集和测试集。
你可以训练和测试同一个数据集,但是这会给你带来一些严重的偏差问题,所以你不应该训练和测试完全相同的数据。为此,由于我们已经打乱了数据集,因此我们将首先将包含正面和负面评论的 1900 个乱序评论作为训练集。然后,我们可以在最后的 100 个上测试,看看我们有多准确。
这被称为监督机器学习,因为我们正在向机器展示数据,并告诉它“这个数据是正面的”,或者“这个数据是负面的”。然后,在完成训练之后,我们向机器展示一些新的数据,并根据我们之前教过计算机的内容询问计算机,计算机认为新数据的类别是什么。
我们可以用以下方式分割数据:
# set that we'll train our classifier with
training_set = featuresets[:1900]
# set that we'll test against.
testing_set = featuresets[1900:]
下面,我们可以定义并训练我们的分类器:
classifier = nltk.NaiveBayesClassifier.train(training_set)
首先,我们只是简单调用朴素贝叶斯分类器,然后在一行中使用.train()进行训练。
足够简单,现在它得到了训练。 接下来,我们可以测试它:
print("Classifier accuracy percent:",(nltk.classify.accuracy(classifier, testing_set))*100)
砰,你得到了你的答案。 如果你错过了,我们可以“测试”数据的原因是,我们仍然有正确的答案。 因此,在测试中,我们向计算机展示数据,而不提供正确的答案。 如果它正确猜测我们所知的答案,那么计算机是正确的。 考虑到我们所做的打乱,你和我可能准确度不同,但你应该看到准确度平均为 60-75%。
接下来,我们可以进一步了解正面或负面评论中最有价值的词汇:
classifier.show_most_informative_features(15)
这对于每个人都不一样,但是你应该看到这样的东西:
Most Informative Features
insulting = True neg : pos = 10.6 : 1.0
ludicrous = True neg : pos = 10.1 : 1.0
winslet = True pos : neg = 9.0 : 1.0
detract = True pos : neg = 8.4 : 1.0
breathtaking = True pos : neg = 8.1 : 1.0
silverstone = True neg : pos = 7.6 : 1.0
excruciatingly = True neg : pos = 7.6 : 1.0
warns = True pos : neg = 7.0 : 1.0
tracy = True pos : neg = 7.0 : 1.0
insipid = True neg : pos = 7.0 : 1.0
freddie = True neg : pos = 7.0 : 1.0
damon = True pos : neg = 5.9 : 1.0
debate = True pos : neg = 5.9 : 1.0
ordered = True pos : neg = 5.8 : 1.0
lang = True pos : neg = 5.7 : 1.0
这个告诉你的是,每一个词的负面到正面的出现几率,或相反。 因此,在这里,我们可以看到,负面评论中的insulting一词比正面评论多出现 10.6 倍。Ludicrous是 10.1。
现在,让我们假设,你完全满意你的结果,你想要继续,也许使用这个分类器来预测现在的事情。 训练分类器,并且每当你需要使用分类器时,都要重新训练,是非常不切实际的。 因此,你可以使用pickle模块保存分类器。 我们接下来做。
十四、使用 NLTK 保存分类器
训练分类器和机器学习算法可能需要很长时间,特别是如果你在更大的数据集上训练。 我们的其实很小。 你可以想象,每次你想开始使用分类器的时候,都要训练分类器吗? 这么恐怖! 相反,我们可以使用pickle模块,并序列化我们的分类器对象,这样我们所需要做的就是简单加载该文件。
那么,我们该怎么做呢? 第一步是保存对象。 为此,首先需要在脚本的顶部导入pickle,然后在使用.train()分类器进行训练后,可以调用以下几行:
save_classifier = open("naivebayes.pickle","wb")
pickle.dump(classifier, save_classifier)
save_classifier.close()
这打开了一个pickle文件,准备按字节写入一些数据。 然后,我们使用pickle.dump()来转储数据。 pickle.dump()的第一个参数是你写入的东西,第二个参数是你写入它的地方。
之后,我们按照我们的要求关闭文件,这就是说,我们现在在脚本的目录中保存了一个pickle或序列化的对象!
接下来,我们如何开始使用这个分类器? .pickle文件是序列化的对象,我们现在需要做的就是将其读入内存,这与读取任何其他普通文件一样简单。 这样做:
classifier_f = open("naivebayes.pickle", "rb")
classifier = pickle.load(classifier_f)
classifier_f.close()
在这里,我们执行了非常相似的过程。 我们打开文件来读取字节。 然后,我们使用pickle.load()来加载文件,并将数据保存到分类器变量中。 然后我们关闭文件,就是这样。 我们现在有了和以前一样的分类器对象!
现在,我们可以使用这个对象,每当我们想用它来分类时,我们不再需要训练我们的分类器。
虽然这一切都很好,但是我们可能不太满意我们所获得的 60-75% 的准确度。 其他分类器呢? 其实,有很多分类器,但我们需要 scikit-learn(sklearn)模块。 幸运的是,NLTK 的员工认识到将 sklearn 模块纳入 NLTK 的价值,他们为我们构建了一个小 API。 这就是我们将在下一个教程中做的事情。
十五、NLTK 和 Sklearn
现在我们已经看到,使用分类器是多么容易,现在我们想尝试更多东西! Python 的最好的模块是 Scikit-learn(sklearn)模块。
如果你想了解 Scikit-learn 模块的更多信息,我有一些关于 Scikit-Learn 机器学习的教程。
幸运的是,对于我们来说,NLTK 背后的人们更看重将 sklearn 模块纳入NLTK分类器方法的价值。 就这样,他们创建了各种SklearnClassifier API。 要使用它,你只需要像下面这样导入它:
from nltk.classify.scikitlearn import SklearnClassifier
从这里开始,你可以使用任何sklearn分类器。 例如,让我们引入更多的朴素贝叶斯算法的变体:
from sklearn.naive_bayes import MultinomialNB,BernoulliNB
之后,如何使用它们?结果是,这非常简单。
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
print("MultinomialNB accuracy percent:",nltk.classify.accuracy(MNB_classifier, testing_set))
BNB_classifier = SklearnClassifier(BernoulliNB())
BNB_classifier.train(training_set)
print("BernoulliNB accuracy percent:",nltk.classify.accuracy(BNB_classifier, testing_set))
就是这么简单。让我们引入更多东西:
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
现在,我们所有分类器应该是这样:
print("Original Naive Bayes Algo accuracy percent:", (nltk.classify.accuracy(classifier, testing_set))*100)
classifier.show_most_informative_features(15)
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
print("MNB_classifier accuracy percent:", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)
BernoulliNB_classifier = SklearnClassifier(BernoulliNB())
BernoulliNB_classifier.train(training_set)
print("BernoulliNB_classifier accuracy percent:", (nltk.classify.accuracy(BernoulliNB_classifier, testing_set))*100)
LogisticRegression_classifier = SklearnClassifier(LogisticRegression())
LogisticRegression_classifier.train(training_set)
print("LogisticRegression_classifier accuracy percent:", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)
SGDClassifier_classifier = SklearnClassifier(SGDClassifier())
SGDClassifier_classifier.train(training_set)
print("SGDClassifier_classifier accuracy percent:", (nltk.classify.accuracy(SGDClassifier_classifier, testing_set))*100)
SVC_classifier = SklearnClassifier(SVC())
SVC_classifier.train(training_set)
print("SVC_classifier accuracy percent:", (nltk.classify.accuracy(SVC_classifier, testing_set))*100)
LinearSVC_classifier = SklearnClassifier(LinearSVC())
LinearSVC_classifier.train(training_set)
print("LinearSVC_classifier accuracy percent:", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)
NuSVC_classifier = SklearnClassifier(NuSVC())
NuSVC_classifier.train(training_set)
print("NuSVC_classifier accuracy percent:", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)
运行它的结果应该是这样:
Original Naive Bayes Algo accuracy percent: 63.0
Most Informative Features
thematic = True pos : neg = 9.1 : 1.0
secondly = True pos : neg = 8.5 : 1.0
narrates = True pos : neg = 7.8 : 1.0
rounded = True pos : neg = 7.1 : 1.0
supreme = True pos : neg = 7.1 : 1.0
layered = True pos : neg = 7.1 : 1.0
crappy = True neg : pos = 6.9 : 1.0
uplifting = True pos : neg = 6.2 : 1.0
ugh = True neg : pos = 5.3 : 1.0
mamet = True pos : neg = 5.1 : 1.0
gaining = True pos : neg = 5.1 : 1.0
wanda = True neg : pos = 4.9 : 1.0
onset = True neg : pos = 4.9 : 1.0
fantastic = True pos : neg = 4.5 : 1.0
kentucky = True pos : neg = 4.4 : 1.0
MNB_classifier accuracy percent: 66.0
BernoulliNB_classifier accuracy percent: 72.0
LogisticRegression_classifier accuracy percent: 64.0
SGDClassifier_classifier accuracy percent: 61.0
SVC_classifier accuracy percent: 45.0
LinearSVC_classifier accuracy percent: 68.0
NuSVC_classifier accuracy percent: 59.0
所以,我们可以看到,SVC 的错误比正确更常见,所以我们可能应该丢弃它。 但是呢? 接下来我们可以尝试一次使用所有这些算法。 一个算法的算法! 为此,我们可以创建另一个分类器,并根据其他算法的结果来生成分类器的结果。 有点像投票系统,所以我们只需要奇数数量的算法。 这就是我们将在下一个教程中讨论的内容。
十六、使用 NLTK 组合算法
现在我们知道如何使用一堆算法分类器,就像糖果岛上的一个孩子,告诉他们只能选择一个,我们可能会发现很难只选择一个分类器。 好消息是,你不必这样! 组合分类器算法是一种常用的技术,通过创建一种投票系统来实现,每个算法拥有一票,选择得票最多分类。
为此,我们希望我们的新分类器的工作方式像典型的 NLTK 分类器,并拥有所有方法。 很简单,使用面向对象编程,我们可以确保从 NLTK 分类器类继承。 为此,我们将导入它:
from nltk.classify import ClassifierI
from statistics import mode
我们也导入mode(众数),因为这将是我们选择最大计数的方法。
现在,我们来建立我们的分类器类:
class VoteClassifier(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
我们把我们的类叫做VoteClassifier,我们继承了 NLTK 的ClassifierI。 接下来,我们将传递给我们的类的分类器列表赋给self._classifiers。
接下来,我们要继续创建我们自己的分类方法。 我们打算把它称为.classify,以便我们可以稍后调用.classify,就像传统的 NLTK 分类器那样。
def classify(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
return mode(votes)
很简单,我们在这里所做的就是,遍历我们的分类器对象列表。 然后,对于每一个,我们要求它基于特征分类。 分类被视为投票。 遍历完成后,我们返回mode(votes),这只是返回投票的众数。
这是我们真正需要的,但是我认为另一个参数,置信度是有用的。 由于我们有了投票算法,所以我们也可以统计支持和反对票数,并称之为“置信度”。 例如,3/5 票的置信度弱于 5/5 票。 因此,我们可以从字面上返回投票比例,作为一种置信度指标。 这是我们的置信度方法:
def confidence(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
choice_votes = votes.count(mode(votes))
conf = choice_votes / len(votes)
return conf
现在,让我们把东西放到一起:
import nltk
import random
from nltk.corpus import movie_reviews
from nltk.classify.scikitlearn import SklearnClassifier
import pickle
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from nltk.classify import ClassifierI
from statistics import mode
class VoteClassifier(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
def classify(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
return mode(votes)
def confidence(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
choice_votes = votes.count(mode(votes))
conf = choice_votes / len(votes)
return conf
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:3000]
def find_features(document):
words = set(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
#print((find_features(movie_reviews.words('neg/cv000_29416.txt'))))
featuresets = [(find_features(rev), category) for (rev, category) in documents]
training_set = featuresets[:1900]
testing_set = featuresets[1900:]
#classifier = nltk.NaiveBayesClassifier.train(training_set)
classifier_f = open("naivebayes.pickle","rb")
classifier = pickle.load(classifier_f)
classifier_f.close()
print("Original Naive Bayes Algo accuracy percent:", (nltk.classify.accuracy(classifier, testing_set))*100)
classifier.show_most_informative_features(15)
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
print("MNB_classifier accuracy percent:", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)
BernoulliNB_classifier = SklearnClassifier(BernoulliNB())
BernoulliNB_classifier.train(training_set)
print("BernoulliNB_classifier accuracy percent:", (nltk.classify.accuracy(BernoulliNB_classifier, testing_set))*100)
LogisticRegression_classifier = SklearnClassifier(LogisticRegression())
LogisticRegression_classifier.train(training_set)
print("LogisticRegression_classifier accuracy percent:", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)
SGDClassifier_classifier = SklearnClassifier(SGDClassifier())
SGDClassifier_classifier.train(training_set)
print("SGDClassifier_classifier accuracy percent:", (nltk.classify.accuracy(SGDClassifier_classifier, testing_set))*100)
##SVC_classifier = SklearnClassifier(SVC())
##SVC_classifier.train(training_set)
##print("SVC_classifier accuracy percent:", (nltk.classify.accuracy(SVC_classifier, testing_set))*100)
LinearSVC_classifier = SklearnClassifier(LinearSVC())
LinearSVC_classifier.train(training_set)
print("LinearSVC_classifier accuracy percent:", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)
NuSVC_classifier = SklearnClassifier(NuSVC())
NuSVC_classifier.train(training_set)
print("NuSVC_classifier accuracy percent:", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)
voted_classifier = VoteClassifier(classifier,
NuSVC_classifier,
LinearSVC_classifier,
SGDClassifier_classifier,
MNB_classifier,
BernoulliNB_classifier,
LogisticRegression_classifier)
print("voted_classifier accuracy percent:", (nltk.classify.accuracy(voted_classifier, testing_set))*100)
print("Classification:", voted_classifier.classify(testing_set[0][0]), "Confidence %:",voted_classifier.confidence(testing_set[0][0])*100)
print("Classification:", voted_classifier.classify(testing_set[1][0]), "Confidence %:",voted_classifier.confidence(testing_set[1][0])*100)
print("Classification:", voted_classifier.classify(testing_set[2][0]), "Confidence %:",voted_classifier.confidence(testing_set[2][0])*100)
print("Classification:", voted_classifier.classify(testing_set[3][0]), "Confidence %:",voted_classifier.confidence(testing_set[3][0])*100)
print("Classification:", voted_classifier.classify(testing_set[4][0]), "Confidence %:",voted_classifier.confidence(testing_set[4][0])*100)
print("Classification:", voted_classifier.classify(testing_set[5][0]), "Confidence %:",voted_classifier.confidence(testing_set[5][0])*100)
所以到了最后,我们对文本运行一些分类器示例。我们所有输出:
Original Naive Bayes Algo accuracy percent: 66.0
Most Informative Features
thematic = True pos : neg = 9.1 : 1.0
secondly = True pos : neg = 8.5 : 1.0
narrates = True pos : neg = 7.8 : 1.0
layered = True pos : neg = 7.1 : 1.0
rounded = True pos : neg = 7.1 : 1.0
supreme = True pos : neg = 7.1 : 1.0
crappy = True neg : pos = 6.9 : 1.0
uplifting = True pos : neg = 6.2 : 1.0
ugh = True neg : pos = 5.3 : 1.0
gaining = True pos : neg = 5.1 : 1.0
mamet = True pos : neg = 5.1 : 1.0
wanda = True neg : pos = 4.9 : 1.0
onset = True neg : pos = 4.9 : 1.0
fantastic = True pos : neg = 4.5 : 1.0
milos = True pos : neg = 4.4 : 1.0
MNB_classifier accuracy percent: 67.0
BernoulliNB_classifier accuracy percent: 67.0
LogisticRegression_classifier accuracy percent: 68.0
SGDClassifier_classifier accuracy percent: 57.99999999999999
LinearSVC_classifier accuracy percent: 67.0
NuSVC_classifier accuracy percent: 65.0
voted_classifier accuracy percent: 65.0
Classification: neg Confidence %: 100.0
Classification: pos Confidence %: 57.14285714285714
Classification: neg Confidence %: 57.14285714285714
Classification: neg Confidence %: 57.14285714285714
Classification: pos Confidence %: 57.14285714285714
Classification: pos Confidence %: 85.71428571428571
十七、使用 NLTK 调查偏差
在本教程中,我们将讨论一些问题。最主要的问题是我们有一个相当有偏差的算法。你可以通过注释掉文档的打乱,然后使用前 1900 个进行训练,并留下最后的 100 个(所有正面)评论来测试它。测试它,你会发现你的准确性很差。
相反,你可以使用前 100 个数据进行测试,所有的数据都是负面的,并且使用后 1900 个训练。在这里你会发现准确度非常高。这是一个不好的迹象。这可能意味着很多东西,我们有很多选择来解决它。
也就是说,我们所考虑的项目建议我们继续,并使用不同的数据集,所以我们会这样做。最后,我们会发现这个新的数据集仍然存在一些偏差,那就是它更经常选择负面的东西。原因是负面评论的负面往往比正面评论的正面程度更大。这个可以用一些简单的加权来完成,但是它也可以变得很复杂。也许是另一天的教程。现在,我们要抓取一个新的数据集,我们将在下一个教程中讨论这个数据集。
十八、使用 NLTK 改善情感分析的训练数据
所以现在是时候在新的数据集上训练了。 我们的目标是分析 Twitter 的情绪,所以我们希望数据集的每个正面和负面语句都有点短。 恰好我有 5300+ 个正面和 5300 + 个负面电影评论,这是短得多的数据集。 我们应该能从更大的训练集中获得更多的准确性,并且把 Twitter 的推文拟合得更好。
我在这里托管了这两个文件,你可以通过下载简短的评论来找到它们。 将这些文件保存为positive.txt和negative.txt。
现在,我们可以像以前一样建立新的数据集。 需要改变什么呢?
我们需要一种新的方法来创建我们的“文档”变量,然后我们还需要一种新的方法来创建all_words变量。 真的没问题,我是这么做的:
short_pos = open("short_reviews/positive.txt","r").read()
short_neg = open("short_reviews/negative.txt","r").read()
documents = []
for r in short_pos.split('\n'):
documents.append( (r, "pos") )
for r in short_neg.split('\n'):
documents.append( (r, "neg") )
all_words = []
short_pos_words = word_tokenize(short_pos)
short_neg_words = word_tokenize(short_neg)
for w in short_pos_words:
all_words.append(w.lower())
for w in short_neg_words:
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
接下来,我们还需要调整我们的特征查找功能,主要是按照文档中的单词进行标记,因为我们的新样本没有漂亮的.words()特征。 我继续并增加了最常见的词语:
word_features = list(all_words.keys())[:5000]
def find_features(document):
words = word_tokenize(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
featuresets = [(find_features(rev), category) for (rev, category) in documents]
random.shuffle(featuresets)
除此之外,其余的都是一样的。 这是完整的脚本,以防万一你或我错过了一些东西:
这个过程需要一段时间..你可能想要干些别的。 我花了大约 30-40 分钟来全部运行完成,而我在 i7 3930k 上运行它。 在我写这篇文章的时候(2015),一般处理器可能需要几个小时。 不过这是一次性的过程。
import nltk
import random
from nltk.corpus import movie_reviews
from nltk.classify.scikitlearn import SklearnClassifier
import pickle
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from nltk.classify import ClassifierI
from statistics import mode
from nltk.tokenize import word_tokenize
class VoteClassifier(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
def classify(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
return mode(votes)
def confidence(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
choice_votes = votes.count(mode(votes))
conf = choice_votes / len(votes)
return conf
short_pos = open("short_reviews/positive.txt","r").read()
short_neg = open("short_reviews/negative.txt","r").read()
documents = []
for r in short_pos.split('\n'):
documents.append( (r, "pos") )
for r in short_neg.split('\n'):
documents.append( (r, "neg") )
all_words = []
short_pos_words = word_tokenize(short_pos)
short_neg_words = word_tokenize(short_neg)
for w in short_pos_words:
all_words.append(w.lower())
for w in short_neg_words:
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:5000]
def find_features(document):
words = word_tokenize(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
#print((find_features(movie_reviews.words('neg/cv000_29416.txt'))))
featuresets = [(find_features(rev), category) for (rev, category) in documents]
random.shuffle(featuresets)
# positive data example:
training_set = featuresets[:10000]
testing_set = featuresets[10000:]
##
### negative data example:
##training_set = featuresets[100:]
##testing_set = featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(training_set)
print("Original Naive Bayes Algo accuracy percent:", (nltk.classify.accuracy(classifier, testing_set))*100)
classifier.show_most_informative_features(15)
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
print("MNB_classifier accuracy percent:", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)
BernoulliNB_classifier = SklearnClassifier(BernoulliNB())
BernoulliNB_classifier.train(training_set)
print("BernoulliNB_classifier accuracy percent:", (nltk.classify.accuracy(BernoulliNB_classifier, testing_set))*100)
LogisticRegression_classifier = SklearnClassifier(LogisticRegression())
LogisticRegression_classifier.train(training_set)
print("LogisticRegression_classifier accuracy percent:", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)
SGDClassifier_classifier = SklearnClassifier(SGDClassifier())
SGDClassifier_classifier.train(training_set)
print("SGDClassifier_classifier accuracy percent:", (nltk.classify.accuracy(SGDClassifier_classifier, testing_set))*100)
##SVC_classifier = SklearnClassifier(SVC())
##SVC_classifier.train(training_set)
##print("SVC_classifier accuracy percent:", (nltk.classify.accuracy(SVC_classifier, testing_set))*100)
LinearSVC_classifier = SklearnClassifier(LinearSVC())
LinearSVC_classifier.train(training_set)
print("LinearSVC_classifier accuracy percent:", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)
NuSVC_classifier = SklearnClassifier(NuSVC())
NuSVC_classifier.train(training_set)
print("NuSVC_classifier accuracy percent:", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)
voted_classifier = VoteClassifier(
NuSVC_classifier,
LinearSVC_classifier,
MNB_classifier,
BernoulliNB_classifier,
LogisticRegression_classifier)
print("voted_classifier accuracy percent:", (nltk.classify.accuracy(voted_classifier, testing_set))*100)
输出:
Original Naive Bayes Algo accuracy percent: 66.26506024096386
Most Informative Features
refreshing = True pos : neg = 13.6 : 1.0
captures = True pos : neg = 11.3 : 1.0
stupid = True neg : pos = 10.7 : 1.0
tender = True pos : neg = 9.6 : 1.0
meandering = True neg : pos = 9.1 : 1.0
tv = True neg : pos = 8.6 : 1.0
low-key = True pos : neg = 8.3 : 1.0
thoughtful = True pos : neg = 8.1 : 1.0
banal = True neg : pos = 7.7 : 1.0
amateurish = True neg : pos = 7.7 : 1.0
terrific = True pos : neg = 7.6 : 1.0
record = True pos : neg = 7.6 : 1.0
captivating = True pos : neg = 7.6 : 1.0
portrait = True pos : neg = 7.4 : 1.0
culture = True pos : neg = 7.3 : 1.0
MNB_classifier accuracy percent: 65.8132530120482
BernoulliNB_classifier accuracy percent: 66.71686746987952
LogisticRegression_classifier accuracy percent: 67.16867469879519
SGDClassifier_classifier accuracy percent: 65.8132530120482
LinearSVC_classifier accuracy percent: 66.71686746987952
NuSVC_classifier accuracy percent: 60.09036144578314
voted_classifier accuracy percent: 65.66265060240963
是的,我敢打赌你花了一段时间,所以,在下一个教程中,我们将谈论pickle所有东西!
十九、使用 NLTK 为情感分析创建模块
有了这个新的数据集和新的分类器,我们可以继续前进。 你可能已经注意到的,这个新的数据集需要更长的时间来训练,因为它是一个更大的集合。 我已经向你显示,通过pickel或序列化训练出来的分类器,我们实际上可以节省大量的时间,这些分类器只是对象。
我已经向你证明了如何使用pickel来实现它,所以我鼓励你尝试自己做。 如果你需要帮助,我会粘贴完整的代码...但要注意,自己动手!
这个过程需要一段时间..你可能想要干些别的。 我花了大约 30-40 分钟来全部运行完成,而我在 i7 3930k 上运行它。 在我写这篇文章的时候(2015),一般处理器可能需要几个小时。 不过这是一次性的过程。
import nltk
import random
#from nltk.corpus import movie_reviews
from nltk.classify.scikitlearn import SklearnClassifier
import pickle
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from nltk.classify import ClassifierI
from statistics import mode
from nltk.tokenize import word_tokenize
class VoteClassifier(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
def classify(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
return mode(votes)
def confidence(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
choice_votes = votes.count(mode(votes))
conf = choice_votes / len(votes)
return conf
short_pos = open("short_reviews/positive.txt","r").read()
short_neg = open("short_reviews/negative.txt","r").read()
# move this up here
all_words = []
documents = []
# j is adject, r is adverb, and v is verb
#allowed_word_types = ["J","R","V"]
allowed_word_types = ["J"]
for p in short_pos.split('\n'):
documents.append( (p, "pos") )
words = word_tokenize(p)
pos = nltk.pos_tag(words)
for w in pos:
if w[1][0] in allowed_word_types:
all_words.append(w[0].lower())
for p in short_neg.split('\n'):
documents.append( (p, "neg") )
words = word_tokenize(p)
pos = nltk.pos_tag(words)
for w in pos:
if w[1][0] in allowed_word_types:
all_words.append(w[0].lower())
save_documents = open("pickled_algos/documents.pickle","wb")
pickle.dump(documents, save_documents)
save_documents.close()
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:5000]
save_word_features = open("pickled_algos/word_features5k.pickle","wb")
pickle.dump(word_features, save_word_features)
save_word_features.close()
def find_features(document):
words = word_tokenize(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
featuresets = [(find_features(rev), category) for (rev, category) in documents]
random.shuffle(featuresets)
print(len(featuresets))
testing_set = featuresets[10000:]
training_set = featuresets[:10000]
classifier = nltk.NaiveBayesClassifier.train(training_set)
print("Original Naive Bayes Algo accuracy percent:", (nltk.classify.accuracy(classifier, testing_set))*100)
classifier.show_most_informative_features(15)
###############
save_classifier = open("pickled_algos/originalnaivebayes5k.pickle","wb")
pickle.dump(classifier, save_classifier)
save_classifier.close()
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
print("MNB_classifier accuracy percent:", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)
save_classifier = open("pickled_algos/MNB_classifier5k.pickle","wb")
pickle.dump(MNB_classifier, save_classifier)
save_classifier.close()
BernoulliNB_classifier = SklearnClassifier(BernoulliNB())
BernoulliNB_classifier.train(training_set)
print("BernoulliNB_classifier accuracy percent:", (nltk.classify.accuracy(BernoulliNB_classifier, testing_set))*100)
save_classifier = open("pickled_algos/BernoulliNB_classifier5k.pickle","wb")
pickle.dump(BernoulliNB_classifier, save_classifier)
save_classifier.close()
LogisticRegression_classifier = SklearnClassifier(LogisticRegression())
LogisticRegression_classifier.train(training_set)
print("LogisticRegression_classifier accuracy percent:", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)
save_classifier = open("pickled_algos/LogisticRegression_classifier5k.pickle","wb")
pickle.dump(LogisticRegression_classifier, save_classifier)
save_classifier.close()
LinearSVC_classifier = SklearnClassifier(LinearSVC())
LinearSVC_classifier.train(training_set)
print("LinearSVC_classifier accuracy percent:", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)
save_classifier = open("pickled_algos/LinearSVC_classifier5k.pickle","wb")
pickle.dump(LinearSVC_classifier, save_classifier)
save_classifier.close()
##NuSVC_classifier = SklearnClassifier(NuSVC())
##NuSVC_classifier.train(training_set)
##print("NuSVC_classifier accuracy percent:", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)
SGDC_classifier = SklearnClassifier(SGDClassifier())
SGDC_classifier.train(training_set)
print("SGDClassifier accuracy percent:",nltk.classify.accuracy(SGDC_classifier, testing_set)*100)
save_classifier = open("pickled_algos/SGDC_classifier5k.pickle","wb")
pickle.dump(SGDC_classifier, save_classifier)
save_classifier.close()
现在,你只需要运行一次。 如果你希望,你可以随时运行它,但现在,你已经准备好了创建情绪分析模块。 这是我们称为sentiment_mod.py的文件:
#File: sentiment_mod.py
import nltk
import random
#from nltk.corpus import movie_reviews
from nltk.classify.scikitlearn import SklearnClassifier
import pickle
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from nltk.classify import ClassifierI
from statistics import mode
from nltk.tokenize import word_tokenize
class VoteClassifier(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
def classify(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
return mode(votes)
def confidence(self, features):
votes = []
for c in self._classifiers:
v = c.classify(features)
votes.append(v)
choice_votes = votes.count(mode(votes))
conf = choice_votes / len(votes)
return conf
documents_f = open("pickled_algos/documents.pickle", "rb")
documents = pickle.load(documents_f)
documents_f.close()
word_features5k_f = open("pickled_algos/word_features5k.pickle", "rb")
word_features = pickle.load(word_features5k_f)
word_features5k_f.close()
def find_features(document):
words = word_tokenize(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
featuresets_f = open("pickled_algos/featuresets.pickle", "rb")
featuresets = pickle.load(featuresets_f)
featuresets_f.close()
random.shuffle(featuresets)
print(len(featuresets))
testing_set = featuresets[10000:]
training_set = featuresets[:10000]
open_file = open("pickled_algos/originalnaivebayes5k.pickle", "rb")
classifier = pickle.load(open_file)
open_file.close()
open_file = open("pickled_algos/MNB_classifier5k.pickle", "rb")
MNB_classifier = pickle.load(open_file)
open_file.close()
open_file = open("pickled_algos/BernoulliNB_classifier5k.pickle", "rb")
BernoulliNB_classifier = pickle.load(open_file)
open_file.close()
open_file = open("pickled_algos/LogisticRegression_classifier5k.pickle", "rb")
LogisticRegression_classifier = pickle.load(open_file)
open_file.close()
open_file = open("pickled_algos/LinearSVC_classifier5k.pickle", "rb")
LinearSVC_classifier = pickle.load(open_file)
open_file.close()
open_file = open("pickled_algos/SGDC_classifier5k.pickle", "rb")
SGDC_classifier = pickle.load(open_file)
open_file.close()
voted_classifier = VoteClassifier(
classifier,
LinearSVC_classifier,
MNB_classifier,
BernoulliNB_classifier,
LogisticRegression_classifier)
def sentiment(text):
feats = find_features(text)
return voted_classifier.classify(feats),voted_classifier.confidence(feats)
所以在这里,除了最终的函数外,其实并没有什么新东西,这很简单。 这个函数是我们从这里开始与之交互的关键。 这个我们称之为“情感”的函数带有一个参数,即文本。 在这里,我们用我们早已创建的find_features函数,来分解这些特征。 现在我们所要做的就是,使用我们的投票分类器返回分类,以及返回分类的置信度。
有了这个,我们现在可以将这个文件,以及情感函数用作一个模块。 以下是使用该模块的示例脚本:
import sentiment_mod as s
print(s.sentiment("This movie was awesome! The acting was great, plot was wonderful, and there were pythons...so yea!"))
print(s.sentiment("This movie was utter junk. There were absolutely 0 pythons. I don't see what the point was at all. Horrible movie, 0/10"))
正如预期的那样,带有python的电影的评论显然很好,没有任何python的电影是垃圾。 这两个都有 100% 的置信度。
我花了大约 5 秒钟的时间导入模块,因为我们保存了分类器,没有保存的话可能要花 30 分钟。 多亏了pickle 你的时间会有很大的不同,取决于你的处理器。如果你继续下去,我会说你可能也想看看joblib。
现在我们有了这个很棒的模块,它很容易就能工作,我们可以做什么? 我建议我们去 Twitter 上进行实时情感分析!
二十、NLTK Twitter 情感分析
现在我们有一个情感分析模块,我们可以将它应用于任何文本,但最好是短小的文本,比如 Twitter! 为此,我们将把本教程与 Twitter 流式 API 教程结合起来。
该教程的初始代码是:
from tweepy import Stream
from tweepy import OAuthHandler
from tweepy.streaming import StreamListener
#consumer key, consumer secret, access token, access secret.
ckey="fsdfasdfsafsffa"
csecret="asdfsadfsadfsadf"
atoken="asdf-aassdfs"
asecret="asdfsadfsdafsdafs"
class listener(StreamListener):
def on_data(self, data):
print(data)
return(True)
def on_error(self, status):
print status
auth = OAuthHandler(ckey, csecret)
auth.set_access_token(atoken, asecret)
twitterStream = Stream(auth, listener())
twitterStream.filter(track=["car"])
这足以打印包含词语car的流式实时推文的所有数据。 我们可以使用json模块,使用json.loads(data)来加载数据变量,然后我们可以引用特定的tweet:
tweet = all_data["text"]
既然我们有了一条推文,我们可以轻易将其传入我们的sentiment_mod 模块。
from tweepy import Stream
from tweepy import OAuthHandler
from tweepy.streaming import StreamListener
import json
import sentiment_mod as s
#consumer key, consumer secret, access token, access secret.
ckey="asdfsafsafsaf"
csecret="asdfasdfsadfsa"
atoken="asdfsadfsafsaf-asdfsaf"
asecret="asdfsadfsadfsadfsadfsad"
from twitterapistuff import *
class listener(StreamListener):
def on_data(self, data):
all_data = json.loads(data)
tweet = all_data["text"]
sentiment_value, confidence = s.sentiment(tweet)
print(tweet, sentiment_value, confidence)
if confidence*100 >= 80:
output = open("twitter-out.txt","a")
output.write(sentiment_value)
output.write('\n')
output.close()
return True
def on_error(self, status):
print(status)
auth = OAuthHandler(ckey, csecret)
auth.set_access_token(atoken, asecret)
twitterStream = Stream(auth, listener())
twitterStream.filter(track=["happy"])
除此之外,我们还将结果保存到输出文件twitter-out.txt中。
接下来,什么没有图表的数据分析是完整的? 让我们再结合另一个教程,从 Twitter API 上的情感分析绘制实时流式图。
二十一,使用 NLTK 绘制 Twitter 实时情感分析
现在我们已经从 Twitter 流媒体 API 获得了实时数据,为什么没有显示情绪趋势的活动图呢? 为此,我们将结合本教程和 matplotlib 绘图教程。
如果你想了解代码工作原理的更多信息,请参阅该教程。 否则:
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from matplotlib import style
import time
style.use("ggplot")
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
def animate(i):
pullData = open("twitter-out.txt","r").read()
lines = pullData.split('\n')
xar = []
yar = []
x = 0
y = 0
for l in lines[-200:]:
x += 1
if "pos" in l:
y += 1
elif "neg" in l:
y -= 1
xar.append(x)
yar.append(y)
ax1.clear()
ax1.plot(xar,yar)
ani = animation.FuncAnimation(fig, animate, interval=1000)
plt.show()
二十二、斯坦福 NER 标记器与命名实体识别
Chuck Dishmon 的客座文章。
斯坦福 NER 标记器提供了 NLTK 的命名实体识别(NER)分类器的替代方案。这个标记器在很大程度上被看作是命名实体识别的标准,但是由于它使用了先进的统计学习算法,它的计算开销比 NLTK 提供的选项更大。
斯坦福 NER 标记器的一大优势是,为我们提供了几种不同的模型来提取命名实体。我们可以使用以下任何一个:
- 三类模型,用于识别位置,人员和组织
- 四类模型,用于识别位置,人员,组织和杂项实体
- 七类模型,识别位置,人员,组织,时间,金钱,百分比和日期
为了继续,我们需要下载模型和jar文件,因为 NER 分类器是用 Java 编写的。这些可从斯坦福自然语言处理小组免费获得。 NTLK 为了使我们方便,NLTK 提供了斯坦福标记器的包装,所以我们可以用最好的语言(当然是 Python)来使用它!
传递给StanfordNERTagger类的参数包括:
- 分类模型的路径(以下使用三类模型)
- 斯坦福标记器
jar文件的路径 - 训练数据编码(默认为 ASCII)
以下是我们设置它来使用三类模型标记句子的方式:
# -*- coding: utf-8 -*-
from nltk.tag import StanfordNERTagger
from nltk.tokenize import word_tokenize
st = StanfordNERTagger('/usr/share/stanford-ner/classifiers/english.all.3class.distsim.crf.ser.gz',
'/usr/share/stanford-ner/stanford-ner.jar',
encoding='utf-8')
text = 'While in France, Christine Lagarde discussed short-term stimulus efforts in a recent interview with the Wall Street Journal.'
tokenized_text = word_tokenize(text)
classified_text = st.tag(tokenized_text)
print(classified_text)
一旦我们按照单词分词,并且对句子进行分类,我们就会看到标记器产生了如下的元组列表:
[('While', 'O'), ('in', 'O'), ('France', 'LOCATION'), (',', 'O'), ('Christine', 'PERSON'), ('Lagarde', 'PERSON'), ('discussed', 'O'), ('short-term', 'O'), ('stimulus', 'O'), ('efforts', 'O'), ('in', 'O'), ('a', 'O'), ('recent', 'O'), ('interview', 'O'), ('with', 'O'), ('the', 'O'), ('Wall', 'ORGANIZATION'), ('Street', 'ORGANIZATION'), ('Journal', 'ORGANIZATION'), ('.', 'O')]
太好了! 每个标记都使用PERSON,LOCATION,ORGANIZATION或O标记(使用我们的三类模型)。 O只代表其他,即非命名的实体。
这个列表现在可以用于测试已标注数据了,我们将在下一个教程中介绍。
二十三、测试 NLTK 和斯坦福 NER 标记器的准确性
Chuck Dishmon 的客座文章。
我们知道了如何使用两个不同的 NER 分类器! 但是我们应该选择哪一个,NLTK 还是斯坦福大学的呢? 让我们做一些测试来找出答案。
我们需要的第一件事是一些已标注的参考数据,用来测试我们的 NER 分类器。 获取这些数据的一种方法是查找大量文章,并将每个标记标记为一种命名实体(例如,人员,组织,位置)或其他非命名实体。 然后我们可以用我们所知的正确标签,来测试我们单独的 NER 分类器。
不幸的是,这是非常耗时的! 好消息是,有一个手动标注的数据集可以免费获得,带有超过 16,000 英语句子。 还有德语,西班牙语,法语,意大利语,荷兰语,波兰语,葡萄牙语和俄语的数据集!
这是一个来自数据集的已标注的句子:
Founding O
member O
Kojima I-PER
Minoru I-PER
played O
guitar O
on O
Good I-MISC
Day I-MISC
, O
and O
Wardanceis I-MISC
cover O
of O
a O
song O
by O
UK I-LOC
post O
punk O
industrial O
band O
Killing I-ORG
Joke I-ORG
. O
让我们阅读,分割和操作数据,使其成为用于测试的更好格式。
import nltk
from nltk.tag import StanfordNERTagger
from nltk.metrics.scores import accuracy
raw_annotations = open("/usr/share/wikigold.conll.txt").read()
split_annotations = raw_annotations.split()
# Amend class annotations to reflect Stanford's NERTagger
for n,i in enumerate(split_annotations):
if i == "I-PER":
split_annotations[n] = "PERSON"
if i == "I-ORG":
split_annotations[n] = "ORGANIZATION"
if i == "I-LOC":
split_annotations[n] = "LOCATION"
# Group NE data into tuples
def group(lst, n):
for i in range(0, len(lst), n):
val = lst[i:i+n]
if len(val) == n:
yield tuple(val)
reference_annotations = list(group(split_annotations, 2))
好的,看起来不错! 但是,我们还需要将这些数据的“整洁”形式粘贴到我们的 NER 分类器中。 让我们来做吧。
pure_tokens = split_annotations[::2]
这读入数据,按照空白字符分割,然后以二的增量(从第零个元素开始),取split_annotations中的所有东西的子集。 这产生了一个数据集,类似下面的(小得多)例子:
['Founding', 'member', 'Kojima', 'Minoru', 'played', 'guitar', 'on', 'Good', 'Day', ',', 'and', 'Wardanceis', 'cover', 'of', 'a', 'song', 'by', 'UK', 'post', 'punk', 'industrial', 'band', 'Killing', 'Joke', '.']
让我们继续并测试 NLTK 分类器:
tagged_words = nltk.pos_tag(pure_tokens)
nltk_unformatted_prediction = nltk.ne_chunk(tagged_words)
由于 NLTK NER 分类器产生树(包括 POS 标签),我们需要做一些额外的数据操作来获得用于测试的适当形式。
#Convert prediction to multiline string and then to list (includes pos tags)
multiline_string = nltk.chunk.tree2conllstr(nltk_unformatted_prediction)
listed_pos_and_ne = multiline_string.split()
# Delete pos tags and rename
del listed_pos_and_ne[1::3]
listed_ne = listed_pos_and_ne
# Amend class annotations for consistency with reference_annotations
for n,i in enumerate(listed_ne):
if i == "B-PERSON":
listed_ne[n] = "PERSON"
if i == "I-PERSON":
listed_ne[n] = "PERSON"
if i == "B-ORGANIZATION":
listed_ne[n] = "ORGANIZATION"
if i == "I-ORGANIZATION":
listed_ne[n] = "ORGANIZATION"
if i == "B-LOCATION":
listed_ne[n] = "LOCATION"
if i == "I-LOCATION":
listed_ne[n] = "LOCATION"
if i == "B-GPE":
listed_ne[n] = "LOCATION"
if i == "I-GPE":
listed_ne[n] = "LOCATION"
# Group prediction into tuples
nltk_formatted_prediction = list(group(listed_ne, 2))
现在我们可以测试 NLTK 的准确率。
nltk_accuracy = accuracy(reference_annotations, nltk_formatted_prediction)
print(nltk_accuracy)
哇,准确率为.8971!
现在让我们测试斯坦福分类器。 由于此分类器以元组形式生成输出,因此测试不需要更多的数据操作。
st = StanfordNERTagger('/usr/share/stanford-ner/classifiers/english.all.3class.distsim.crf.ser.gz',
'/usr/share/stanford-ner/stanford-ner.jar',
encoding='utf-8')
stanford_prediction = st.tag(pure_tokens)
stanford_accuracy = accuracy(reference_annotations, stanford_prediction)
print(stanford_accuracy)
.9223的准确率!更好!
如果你想绘制这个,这里有一些额外的代码。 如果你想深入了解这如何工作,查看 matplotlib 系列:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
N = 1
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars
fig, ax = plt.subplots()
stanford_percentage = stanford_accuracy * 100
rects1 = ax.bar(ind, stanford_percentage, width, color='r')
nltk_percentage = nltk_accuracy * 100
rects2 = ax.bar(ind+width, nltk_percentage, width, color='y')
# add some text for labels, title and axes ticks
ax.set_xlabel('Classifier')
ax.set_ylabel('Accuracy (by percentage)')
ax.set_title('Accuracy by NER Classifier')
ax.set_xticks(ind+width)
ax.set_xticklabels( ('') )
ax.legend( (rects1[0], rects2[0]), ('Stanford', 'NLTK'), bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0. )
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x()+rect.get_width()/2., 1.02*height, '%10.2f' % float(height),
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
plt.show()
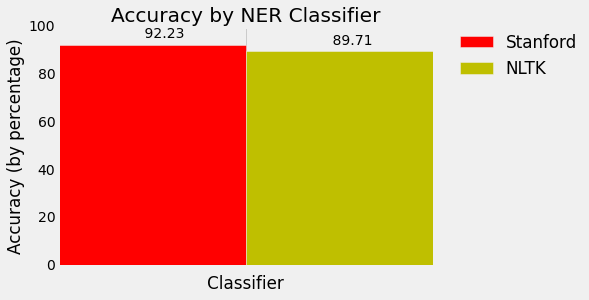
二十四、测试 NLTK 和斯坦福 NER 标记器的速度
Chuck Dishmon 的客座文章。
我们已经测试了我们的 NER 分类器的准确性,但是在决定使用哪个分类器时,还有更多的问题需要考虑。 接下来我们来测试速度吧!
我们知道我们正在比较同一个东西,我们将在同一篇文章中进行测试。 使用 NBC 新闻里的这个片段吧:
House Speaker John Boehner became animated Tuesday over the proposed Keystone Pipeline, castigating the Obama administration for not having approved the project yet.
Republican House Speaker John Boehner says there's "nothing complex about the Keystone Pipeline," and that it's time to build it.
"Complex? You think the Keystone Pipeline is complex?!" Boehner responded to a questioner. "It's been under study for five years! We build pipelines in America every day. Do you realize there are 200,000 miles of pipelines in the United States?"
The speaker went on: "And the only reason the president's involved in the Keystone Pipeline is because it crosses an international boundary. Listen, we can build it. There's nothing complex about the Keystone Pipeline -- it's time to build it."
Boehner said the president had no excuse at this point to not give the pipeline the go-ahead after the State Department released a report on Friday indicating the project would have a minimal impact on the environment.
Republicans have long pushed for construction of the project, which enjoys some measure of Democratic support as well. The GOP is considering conditioning an extension of the debt limit on approval of the project by Obama.
The White House, though, has said that it has no timetable for a final decision on the project.
首先,我们执行导入,通过阅读和分词来处理文章。
# -*- coding: utf-8 -*-
import nltk
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
from nltk import pos_tag
from nltk.tag import StanfordNERTagger
from nltk.tokenize import word_tokenize
style.use('fivethirtyeight')
# Process text
def process_text(txt_file):
raw_text = open("/usr/share/news_article.txt").read()
token_text = word_tokenize(raw_text)
return token_text
很棒! 现在让我们写一些函数来拆分我们的分类任务。 因为 NLTK NEG 分类器需要 POS 标签,所以我们会在我们的 NLTK 函数中加入 POS 标签。
# Stanford NER tagger
def stanford_tagger(token_text):
st = StanfordNERTagger('/usr/share/stanford-ner/classifiers/english.all.3class.distsim.crf.ser.gz',
'/usr/share/stanford-ner/stanford-ner.jar',
encoding='utf-8')
ne_tagged = st.tag(token_text)
return(ne_tagged)
# NLTK POS and NER taggers
def nltk_tagger(token_text):
tagged_words = nltk.pos_tag(token_text)
ne_tagged = nltk.ne_chunk(tagged_words)
return(ne_tagged)
每个分类器都需要读取文章,并对命名实体进行分类,所以我们将这些函数包装在一个更大的函数中,使计时变得简单。
def stanford_main():
print(stanford_tagger(process_text(txt_file)))
def nltk_main():
print(nltk_tagger(process_text(txt_file)))
当我们调用我们的程序时,我们调用这些函数。 我们将在os.times()函数调用中包装我们的stanford_main()和nltk_main()函数,取第四个索引,它是经过的时间。 然后我们将图绘制我们的结果。
if __name__ == '__main__':
stanford_t0 = os.times()[4]
stanford_main()
stanford_t1 = os.times()[4]
stanford_total_time = stanford_t1 - stanford_t0
nltk_t0 = os.times()[4]
nltk_main()
nltk_t1 = os.times()[4]
nltk_total_time = nltk_t1 - nltk_t0
time_plot(stanford_total_time, nltk_total_time)
对于我们的绘图,我们使用time_plot()函数:
def time_plot(stanford_total_time, nltk_total_time):
N = 1
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars
stanford_total_time = stanford_total_time
nltk_total_time = nltk_total_time
fig, ax = plt.subplots()
rects1 = ax.bar(ind, stanford_total_time, width, color='r')
rects2 = ax.bar(ind+width, nltk_total_time, width, color='y')
# Add text for labels, title and axes ticks
ax.set_xlabel('Classifier')
ax.set_ylabel('Time (in seconds)')
ax.set_title('Speed by NER Classifier')
ax.set_xticks(ind+width)
ax.set_xticklabels( ('') )
ax.legend( (rects1[0], rects2[0]), ('Stanford', 'NLTK'), bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0. )
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x()+rect.get_width()/2., 1.02*height, '%10.2f' % float(height),
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
plt.show()
哇,NLTK 像闪电一样快! 看来斯坦福更准确,但 NLTK 更快。 当平衡我们偏爱的精确度,和所需的计算资源时,这是需要知道的重要信息。
但是等等,还是有问题。我们的输出比较丑陋! 这是斯坦福大学的一个小样本:
[('House', 'ORGANIZATION'), ('Speaker', 'O'), ('John', 'PERSON'), ('Boehner', 'PERSON'), ('became', 'O'), ('animated', 'O'), ('Tuesday', 'O'), ('over', 'O'), ('the', 'O'), ('proposed', 'O'), ('Keystone', 'ORGANIZATION'), ('Pipeline', 'ORGANIZATION'), (',', 'O'), ('castigating', 'O'), ('the', 'O'), ('Obama', 'PERSON'), ('administration', 'O'), ('for', 'O'), ('not', 'O'), ('having', 'O'), ('approved', 'O'), ('the', 'O'), ('project', 'O'), ('yet', 'O'), ('.', 'O')
以及 NLTK:
(S
(ORGANIZATION House/NNP)
Speaker/NNP
(PERSON John/NNP Boehner/NNP)
became/VBD
animated/VBN
Tuesday/NNP
over/IN
the/DT
proposed/VBN
(PERSON Keystone/NNP Pipeline/NNP)
,/,
castigating/VBG
the/DT
(ORGANIZATION Obama/NNP)
administration/NN
for/IN
not/RB
having/VBG
approved/VBN
the/DT
project/NN
yet/RB
./.
让我们在下个教程中,将它们转为可读的形式。
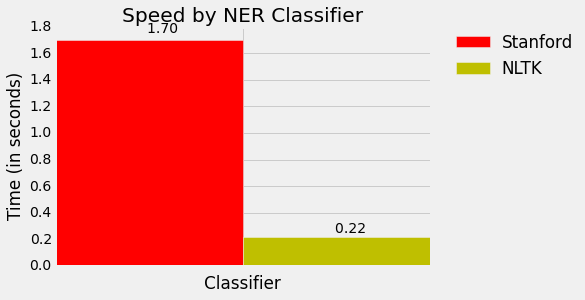
使用 BIO 标签创建可读的命名实体列表
Chuck Dishmon 的客座文章。
现在我们已经完成了测试,让我们将我们的命名实体转为良好的可读格式。
再次,我们将使用来自 NBC 新闻的同一篇新闻:
House Speaker John Boehner became animated Tuesday over the proposed Keystone Pipeline, castigating the Obama administration for not having approved the project yet.
Republican House Speaker John Boehner says there's "nothing complex about the Keystone Pipeline," and that it's time to build it.
"Complex? You think the Keystone Pipeline is complex?!" Boehner responded to a questioner. "It's been under study for five years! We build pipelines in America every day. Do you realize there are 200,000 miles of pipelines in the United States?"
The speaker went on: "And the only reason the president's involved in the Keystone Pipeline is because it crosses an international boundary. Listen, we can build it. There's nothing complex about the Keystone Pipeline -- it's time to build it."
Boehner said the president had no excuse at this point to not give the pipeline the go-ahead after the State Department released a report on Friday indicating the project would have a minimal impact on the environment.
Republicans have long pushed for construction of the project, which enjoys some measure of Democratic support as well. The GOP is considering conditioning an extension of the debt limit on approval of the project by Obama.
The White House, though, has said that it has no timetable for a final decision on the project.
我们的 NTLK 输出已经是树了(只需要最后一步),所以让我们来看看我们的斯坦福输出。 我们将对标记进行 BIO 标记,B 分配给命名实体的开始,I 分配给内部,O 分配给其他。 例如,如果我们的句子是Barack Obama went to Greece today,我们应该把它标记为Barack-B Obama-I went-O to-O Greece-B today-O。 为此,我们将编写一系列条件来检查当前和以前的标记的O标签。
# -*- coding: utf-8 -*-
import nltk
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
from nltk import pos_tag
from nltk.tag import StanfordNERTagger
from nltk.tokenize import word_tokenize
from nltk.chunk import conlltags2tree
from nltk.tree import Tree
style.use('fivethirtyeight')
# Process text
def process_text(txt_file):
raw_text = open("/usr/share/news_article.txt").read()
token_text = word_tokenize(raw_text)
return token_text
# Stanford NER tagger
def stanford_tagger(token_text):
st = StanfordNERTagger('/usr/share/stanford-ner/classifiers/english.all.3class.distsim.crf.ser.gz',
'/usr/share/stanford-ner/stanford-ner.jar',
encoding='utf-8')
ne_tagged = st.tag(token_text)
return(ne_tagged)
# NLTK POS and NER taggers
def nltk_tagger(token_text):
tagged_words = nltk.pos_tag(token_text)
ne_tagged = nltk.ne_chunk(tagged_words)
return(ne_tagged)
# Tag tokens with standard NLP BIO tags
def bio_tagger(ne_tagged):
bio_tagged = []
prev_tag = "O"
for token, tag in ne_tagged:
if tag == "O": #O
bio_tagged.append((token, tag))
prev_tag = tag
continue
if tag != "O" and prev_tag == "O": # Begin NE
bio_tagged.append((token, "B-"+tag))
prev_tag = tag
elif prev_tag != "O" and prev_tag == tag: # Inside NE
bio_tagged.append((token, "I-"+tag))
prev_tag = tag
elif prev_tag != "O" and prev_tag != tag: # Adjacent NE
bio_tagged.append((token, "B-"+tag))
prev_tag = tag
return bio_tagged
现在我们将 BIO 标记后的标记写入树中,因此它们与 NLTK 输出格式相同。
# Create tree
def stanford_tree(bio_tagged):
tokens, ne_tags = zip(*bio_tagged)
pos_tags = [pos for token, pos in pos_tag(tokens)]
conlltags = [(token, pos, ne) for token, pos, ne in zip(tokens, pos_tags, ne_tags)]
ne_tree = conlltags2tree(conlltags)
return ne_tree
遍历并解析出所有命名实体:
# Parse named entities from tree
def structure_ne(ne_tree):
ne = []
for subtree in ne_tree:
if type(subtree) == Tree: # If subtree is a noun chunk, i.e. NE != "O"
ne_label = subtree.label()
ne_string = " ".join([token for token, pos in subtree.leaves()])
ne.append((ne_string, ne_label))
return ne
在我们的调用中,我们把所有附加函数聚到一起。
def stanford_main():
print(structure_ne(stanford_tree(bio_tagger(stanford_tagger(process_text(txt_file))))))
def nltk_main():
print(structure_ne(nltk_tagger(process_text(txt_file))))
之后调用这些函数:
if __name__ == '__main__':
stanford_main()
nltk_main()
这里是来自斯坦福的看起来不错的输出:
[('House', 'ORGANIZATION'), ('John Boehner', 'PERSON'), ('Keystone Pipeline', 'ORGANIZATION'), ('Obama', 'PERSON'), ('Republican House', 'ORGANIZATION'), ('John Boehner', 'PERSON'), ('Keystone Pipeline', 'ORGANIZATION'), ('Keystone Pipeline', 'ORGANIZATION'), ('Boehner', 'PERSON'), ('America', 'LOCATION'), ('United States', 'LOCATION'), ('Keystone Pipeline', 'ORGANIZATION'), ('Keystone Pipeline', 'ORGANIZATION'), ('Boehner', 'PERSON'), ('State Department', 'ORGANIZATION'), ('Republicans', 'MISC'), ('Democratic', 'MISC'), ('GOP', 'MISC'), ('Obama', 'PERSON'), ('White House', 'LOCATION')]
以及来自 NLTK 的:
[('House', 'ORGANIZATION'), ('John Boehner', 'PERSON'), ('Keystone Pipeline', 'PERSON'), ('Obama', 'ORGANIZATION'), ('Republican', 'ORGANIZATION'), ('House', 'ORGANIZATION'), ('John Boehner', 'PERSON'), ('Keystone Pipeline', 'ORGANIZATION'), ('Keystone Pipeline', 'ORGANIZATION'), ('Boehner', 'PERSON'), ('America', 'GPE'), ('United States', 'GPE'), ('Keystone Pipeline', 'ORGANIZATION'), ('Listen', 'PERSON'), ('Keystone', 'ORGANIZATION'), ('Boehner', 'PERSON'), ('State Department', 'ORGANIZATION'), ('Democratic', 'ORGANIZATION'), ('GOP', 'ORGANIZATION'), ('Obama', 'PERSON'), ('White House', 'FACILITY')]
分块在一起,可读性强。不错!
PythonProgramming.net 图像和视频分析
译者:飞龙
一、Python OpenCV 入门

欢迎阅读系列教程,内容涵盖 OpenCV,它是一个图像和视频处理库,包含 C ++,C,Python 和 Java 的绑定。 OpenCV 用于各种图像和视频分析,如面部识别和检测,车牌阅读,照片编辑,高级机器人视觉,光学字符识别等等。
你将需要两个主要的库,第三个可选:python-OpenCV,Numpy 和 Matplotlib。
Windows 用户:
python-OpenCV:有其他的方法,但这是最简单的。 下载相应的 wheel(.whl)文件,然后使用pip进行安装。 观看视频来寻求帮助。
pip install numpy
pip install matplotlib
不熟悉使用pip? 请参阅pip安装教程来获得帮助。
Linux/Mac 用户
pip3 install numpy
或者
apt-get install python3-numpy
你可能需要apt-get来安装python3-pip。
pip3 install matplotlib
或者
apt-get install python3-matplotlib
apt-get install python-OpenCV
Matplotlib 是用于展示来自视频或图像的帧的可选选项。 我们将在这里展示几个使用它的例子。 Numpy 被用于“数值和 Python”的所有东西。 我们主要利用 Numpy 的数组功能。 最后,我们使用python-OpenCV,它是 Python 特定的 OpenCV 绑定。
OpenCV 有一些操作,如果没有完整安装 OpenCV (大小约 3GB),你将无法完成,但是实际上你可以用 python-OpenCV 最简安装。 我们将在本系列的后续部分中使用 OpenCV 的完整安装,如果你愿意的话,你可以随意获得它,但这三个模块将使我们忙碌一段时间!
通过运行 Python 并执行下列命令来确保你安装成功:
import cv2
import matplotlib
import numpy
如果你没有错误,那么你已经准备好了。好了嘛?让我们下潜吧!
首先,在图像和视频分析方面,我们应该了解一些基本的假设和范式。对现在每个摄像机的记录方式来说,记录实际上是一帧一帧地显示,每秒 30-60 次。但是,它们的核心是静态帧,就像图像一样。因此,图像识别和视频分析大部分使用相同的方法。有些东西,如方向跟踪,将需要连续的图像(帧),但像面部检测或物体识别等东西,在图像和视频中代码几乎完全相同。
接下来,大量的图像和视频分析归结为尽可能简化来源。这几乎总是起始于转换为灰度,但也可以是彩色滤镜,渐变或这些的组合。从这里,我们可以对来源执行各种分析和转化。一般来说,这里发生的事情是转换完成,然后是分析,然后是任何覆盖,我们希望应用在原始来源上,这就是你可以经常看到,对象或面部识别的“成品”在全色图像或视频上显示。然而,数据实际上很少以这种原始形式处理。有一些我们可以在基本层面上做些什么的例子。所有这些都使用基本的网络摄像头来完成,没有什么特别的:
背景提取

颜色过滤

边缘检测
用于对象识别的特征匹配

一般对象识别

在边缘检测的情况下,黑色对应于(0,0,0)的像素值,而白色线条是(255,255,255)。视频中的每个图片和帧都会像这样分解为像素,并且像边缘检测一样,我们可以推断,边缘是基于白色与黑色像素对比的地方。然后,如果我们想看到标记边缘的原始图像,我们记录下白色像素的所有坐标位置,然后在原始图像或视频上标记这些位置。
到本教程结束时,你将能够完成上述所有操作,并且能够训练你的机器识别你想要的任何对象。就像我刚开始说的,第一步通常是转换为灰度。在此之前,我们需要加载图像。因此,我们来做吧!在整个教程中,我极力鼓励你使用你自己的数据来玩。如果你有摄像头,一定要使用它,否则找到你认为很有趣的图像。如果你有麻烦,这是一个手表的图像:

import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('watch.jpg',cv2.IMREAD_GRAYSCALE)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
首先,我们正在导入一些东西,我已经安装了这三个模块。接下来,我们将img定义为cv2.read(image file, parms)。默认值是IMREAD_COLOR,这是没有任何 alpha 通道的颜色。如果你不熟悉,alpha 是不透明度(与透明度相反)。如果你需要保留 Alpha 通道,也可以使用IMREAD_UNCHANGED。很多时候,你会读取颜色版本,然后将其转换为灰度。如果你没有网络摄像机,这将是你在本教程中使用的主要方法,即加载图像。
你可以不使用IMREAD_COLOR ...等,而是使用简单的数字。你应该熟悉这两种选择,以便了解某个人在做什么。对于第二个参数,可以使用-1,0或1。颜色为1,灰度为0,不变为-1。因此,对于灰度,可以执行cv2.imread('watch.jpg', 0)。
一旦加载完成,我们使用cv2.imshow(title,image)来显示图像。从这里,我们使用cv2.waitKey(0)来等待,直到有任何按键被按下。一旦完成,我们使用cv2.destroyAllWindows()来关闭所有的东西。
正如前面提到的,你也可以用 Matplotlib 显示图像,下面是一些如何实现的代码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('watch.jpg',cv2.IMREAD_GRAYSCALE)
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # to hide tick values on X and Y axis
plt.plot([200,300,400],[100,200,300],'c', linewidth=5)
plt.show()
请注意,你可以绘制线条,就像任何其他 Matplotlib 图表一样,使用像素位置作为坐标的。 不过,如果你想绘制你的图片,Matplotlib 不是必需的。 OpenCV 为此提供了很好的方法。 当你完成修改后,你可以保存,如下所示:
cv2.imwrite('watchgray.png',img)
将图片导入 OpenCV 似乎很容易,加载视频源如何? 在下一个教程中,我们将展示如何加载摄像头或视频源。
二、加载视频源
在这个 Python OpenCV 教程中,我们将介绍一些使用视频和摄像头的基本操作。 除了起始行,处理来自视频的帧与处理图像是一样的。 我们来举例说明一下:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
首先,我们导入numpy和cv2,没有什么特别的。 接下来,我们可以cap = cv2.VideoCapture(0)。 这将从你计算机上的第一个网络摄像头返回视频。 如果你正在观看视频教程,你将看到我正在使用1,因为我的第一个摄像头正在录制我,第二个摄像头用于实际的教程源。
while(True):
ret, frame = cap.read()
这段代码启动了一个无限循环(稍后将被break语句打破),其中ret和frame被定义为cap.read()。 基本上,ret是一个代表是否有返回的布尔值,frame是每个返回的帧。 如果没有帧,你不会得到错误,你会得到None。
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
在这里,我们定义一个新的变量gray,作为转换为灰度的帧。 注意这个BGR2GRAY。 需要注意的是,OpenCV 将颜色读取为 BGR(蓝绿色红色),但大多数计算机应用程序读取为 RGB(红绿蓝)。 记住这一点。
cv2.imshow('frame',gray)
请注意,尽管是视频流,我们仍然使用imshow。 在这里,我们展示了转换为灰色的源。 如果你想同时显示,你可以对原始帧和灰度执行imshow,将出现两个窗口。
if cv2.waitKey(1) & 0xFF == ord('q'):
break
这个语句每帧只运行一次。 基本上,如果我们得到一个按键,那个键是q,我们将退出while循环,然后运行:
cap.release()
cv2.destroyAllWindows()
这将释放网络摄像头,然后关闭所有的imshow()窗口。
在某些情况下,你可能实际上需要录制,并将录制内容保存到新文件中。 以下是在 Windows 上执行此操作的示例:
import numpy as np
import cv2
cap = cv2.VideoCapture(1)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi',fourcc, 20.0, (640,480))
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
out.write(frame)
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()
这里主要要注意的是正在使用的编解码器,以及在while循环之前定义的输出信息。 然后,在while循环中,我们使用out.write()来输出帧。 最后,在while循环之外,在我们释放摄像头之后,我们也释放out。
太好了,现在我们知道如何操作图像和视频。 如果你没有网络摄像头,你可以使用图像甚至视频来跟随教程的其余部分。 如果你希望使用视频而不是网络摄像头作为源,则可以为视频指定文件路径,而不是摄像头号码。
现在我们可以使用来源了,让我们来展示如何绘制东西。 此前你已经看到,你可以使用 Matplotlib 在图片顶部绘制,但是 Matplotlib 并不真正用于此目的,特别是不能用于视频源。 幸运的是,OpenCV 提供了一些很棒的工具,来帮助我们实时绘制和标记我们的源,这就是我们将在下一个教程中讨论的内容。
三、在图像上绘制和写字
在这个 Python OpenCV 教程中,我们将介绍如何在图像和视频上绘制各种形状。 想要以某种方式标记检测到的对象是相当普遍的,所以我们人类可以很容易地看到我们的程序是否按照我们的希望工作。 一个例子就是之前显示的图像之一:
对于这个临时的例子,我将使用下面的图片:
鼓励你使用自己的图片。 像往常一样,我们的起始代码可以是这样的:
import numpy as np
import cv2
img = cv2.imread('watch.jpg',cv2.IMREAD_COLOR)
下面,我们可以开始绘制,这样:
cv2.line(img,(0,0),(150,150),(255,255,255),15)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.line()接受以下参数:图片,开始坐标,结束坐标,颜色(bgr),线条粗细。
结果在这里:
好吧,很酷,让我们绘制更多形状。 接下来是一个矩形:
cv2.rectangle(img,(15,25),(200,150),(0,0,255),15)
这里的参数是图像,左上角坐标,右下角坐标,颜色和线条粗细。
圆怎么样?
cv2.circle(img,(100,63), 55, (0,255,0), -1)
这里的参数是图像/帧,圆心,半径,颜色和。 注意我们粗细为-1。 这意味着将填充对象,所以我们会得到一个圆。
线条,矩形和圆都很酷,但是如果我们想要五边形,八边形或十八边形? 没问题!
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
# OpenCV documentation had this code, which reshapes the array to a 1 x 2. I did not
# find this necessary, but you may:
#pts = pts.reshape((-1,1,2))
cv2.polylines(img, [pts], True, (0,255,255), 3)
首先,我们将坐标数组称为pts(点的简称)。 然后,我们使用cv2.polylines来画线。 参数如下:绘制的对象,坐标,我们应该连接终止的和起始点,颜色和粗细。
你可能想要做的最后一件事是在图像上写字。 这可以这样做:
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCV Tuts!',(0,130), font, 1, (200,255,155), 2, cv2.LINE_AA)
目前为止的完整代码:
import numpy as np
import cv2
img = cv2.imread('watch.jpg',cv2.IMREAD_COLOR)
cv2.line(img,(0,0),(200,300),(255,255,255),50)
cv2.rectangle(img,(500,250),(1000,500),(0,0,255),15)
cv2.circle(img,(447,63), 63, (0,255,0), -1)
pts = np.array([[100,50],[200,300],[700,200],[500,100]], np.int32)
pts = pts.reshape((-1,1,2))
cv2.polylines(img, [pts], True, (0,255,255), 3)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCV Tuts!',(10,500), font, 6, (200,255,155), 13, cv2.LINE_AA)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果:
在下一个教程中,我们将介绍我们可以执行的基本图像操作。
四、图像操作
在 OpenCV 教程中,我们将介绍一些我们可以做的简单图像操作。 每个视频分解成帧。 然后每一帧,就像一个图像,分解成存储在行和列中的,帧/图片中的像素。 每个像素都有一个坐标位置,每个像素都由颜色值组成。 让我们列举访问不同的位的一些例子。
我们将像往常一样读取图像(如果可以,请使用自己的图像,但这里是我在这里使用的图像):
import cv2
import numpy as np
img = cv2.imread('watch.jpg',cv2.IMREAD_COLOR)
现在我们可以实际引用特定像素,像这样:
px = img[55,55]
下面我们可以实际修改像素:
img[55,55] = [255,255,255]
之后重新引用:
px = img[55,55]
print(px)
现在应该不同了,下面我们可以引用 ROI,图像区域:
px = img[100:150,100:150]
print(px)
我们也可以修改 ROI,像这样:
img[100:150,100:150] = [255,255,255]
我们可以引用我们的图像的特定特征:
print(img.shape)
print(img.size)
print(img.dtype)
我们可以像这样执行操作:
watch_face = img[37:111,107:194]
img[0:74,0:87] = watch_face
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
这会处理我的图像,但是可能不能用于你的图像,取决于尺寸。这是我的输出:
这些是一些简单的操作。 在下一个教程中,我们将介绍一些我们可以执行的更高级的图像操作。
五、图像算术和逻辑运算
欢迎来到另一个 Python OpenCV 教程,在本教程中,我们将介绍一些简单算术运算,我们可以在图像上执行的,并解释它们的作用。 为此,我们将需要两个相同大小的图像来开始,然后是一个较小的图像和一个较大的图像。 首先,我将使用:
和
首先,让我们看看简单的加法会做什么:
import cv2
import numpy as np
# 500 x 250
img1 = cv2.imread('3D-Matplotlib.png')
img2 = cv2.imread('mainsvmimage.png')
add = img1+img2
cv2.imshow('add',add)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果:
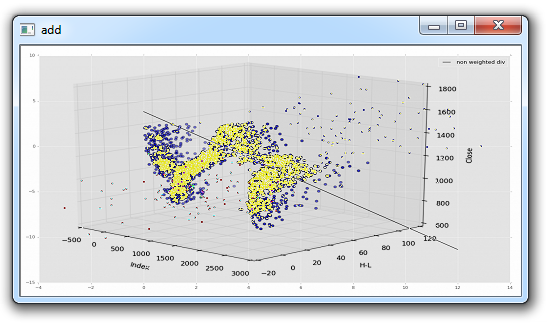
你不可能想要这种混乱的加法。 OpenCV 有一个“加法”方法,让我们替换以前的“加法”,看看是什么:
add = cv2.add(img1,img2)
结果:
这里可能不理想。 我们可以看到很多图像是非常“白色的”。 这是因为颜色是 0-255,其中 255 是“全亮”。 因此,例如:(155,211,79) + (50, 170, 200) = 205, 381, 279...转换为(205, 255,255)。
接下来,我们可以添加图像,并可以假设每个图像都有不同的“权重”。 这是如何工作的:
import cv2
import numpy as np
img1 = cv2.imread('3D-Matplotlib.png')
img2 = cv2.imread('mainsvmimage.png')
weighted = cv2.addWeighted(img1, 0.6, img2, 0.4, 0)
cv2.imshow('weighted',weighted)
cv2.waitKey(0)
cv2.destroyAllWindows()
对于addWeighted方法,参数是第一个图像,权重,第二个图像,权重,然后是伽马值,这是一个光的测量值。 我们现在就把它保留为零。
这些是一些额外的选择,但如果你真的想将一个图像添加到另一个,最新的重叠在哪里? 在这种情况下,你会从最大的开始,然后添加较小的图像。 为此,我们将使用相同的3D-Matplotlib.png图像,但使用一个新的 Python 标志:

现在,我们可以选取这个标志,并把它放在原始图像上。 这很容易(基本上使用我们在前一个教程中使用的相同代码,我们用一个新的东西替换了图像区域(ROI)),但是如果我们只想要标志部分而不是白色背景呢? 我们可以使用与之前用于 ROI 替换相同的原理,但是我们需要一种方法来“去除”标志的背景,使得白色不会不必要地阻挡更多背景图像。 首先我将显示完整的代码,然后解释:
import cv2
import numpy as np
# Load two images
img1 = cv2.imread('3D-Matplotlib.png')
img2 = cv2.imread('mainlogo.png')
# I want to put logo on top-left corner, So I create a ROI
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols ]
# Now create a mask of logo and create its inverse mask
img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
# add a threshold
ret, mask = cv2.threshold(img2gray, 220, 255, cv2.THRESH_BINARY_INV)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv2.bitwise_and(roi,roi,mask = mask_inv)
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(img2,img2,mask = mask)
dst = cv2.add(img1_bg,img2_fg)
img1[0:rows, 0:cols ] = dst
cv2.imshow('res',img1)
cv2.waitKey(0)
cv2.destroyAllWindows()
这里发生了很多事情,出现了一些新的东西。 我们首先看到的是一个新的阈值:ret, mask = cv2.threshold(img2gray, 220, 255, cv2.THRESH_BINARY_INV)。
我们将在下一个教程中介绍更多的阈值,所以请继续关注具体内容,但基本上它的工作方式是根据阈值将所有像素转换为黑色或白色。 在我们的例子中,阈值是 220,但是我们可以使用其他值,或者甚至动态地选择一个,这是ret变量可以使用的值。 接下来,我们看到:mask_inv = cv2.bitwise_not(mask)。 这是一个按位操作。 基本上,这些操作符与 Python 中的典型操作符非常相似,除了一点,但我们不会在这里触及它。 在这种情况下,不可见的部分是黑色的地方。 然后,我们可以说,我们想在第一个图像中将这个区域遮住,然后将空白区域替换为图像 2 的内容。
下个教程中,我们深入讨论阈值。
六、阈值
欢迎阅读另一个 OpenCV 教程。在本教程中,我们将介绍图像和视频分析的阈值。阈值的思想是进一步简化视觉数据的分析。首先,你可以转换为灰度,但是你必须考虑灰度仍然有至少 255 个值。阈值可以做的事情,在最基本的层面上,是基于阈值将所有东西都转换成白色或黑色。比方说,我们希望阈值为 125(最大为 255),那么 125 以下的所有内容都将被转换为 0 或黑色,而高于 125 的所有内容都将被转换为 255 或白色。如果你像平常一样转换成灰度,你会变成白色和黑色。如果你不转换灰度,你会得到二值化的图片,但会有颜色。
虽然这听起来不错,但通常不是。我们将在这里介绍多个示例和不同类型的阈值来说明这一点。我们将使用下面的图片作为我们的示例图片,但可以随意使用你自己的图片:

这个书的图片就是个很好的例子,说明为什么一个人可能需要阈值。 首先,背景根本没有白色,一切都是暗淡的,而且一切都是变化的。 有些部分很容易阅读,另一部分则非常暗,需要相当多的注意力才能识别出来。 首先,我们尝试一个简单的阈值:
retval, threshold = cv2.threshold(img, 10, 255, cv2.THRESH_BINARY)
二元阈值是个简单的“是或不是”的阈值,其中像素为 255 或 0。在很多情况下,这是白色或黑色,但我们已经为我们的图像保留了颜色,所以它仍然是彩色的。 这里的第一个参数是图像。 下一个参数是阈值,我们选择 10。下一个是最大值,我们选择为 255。最后是阈值类型,我们选择了THRESH_BINARY。 通常情况下,10 的阈值会有点差。 我们选择 10,因为这是低光照的图片,所以我们选择低的数字。 通常 125-150 左右的东西可能效果最好。
import cv2
import numpy as np
img = cv2.imread('bookpage.jpg')
retval, threshold = cv2.threshold(img, 12, 255, cv2.THRESH_BINARY)
cv2.imshow('original',img)
cv2.imshow('threshold',threshold)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果:
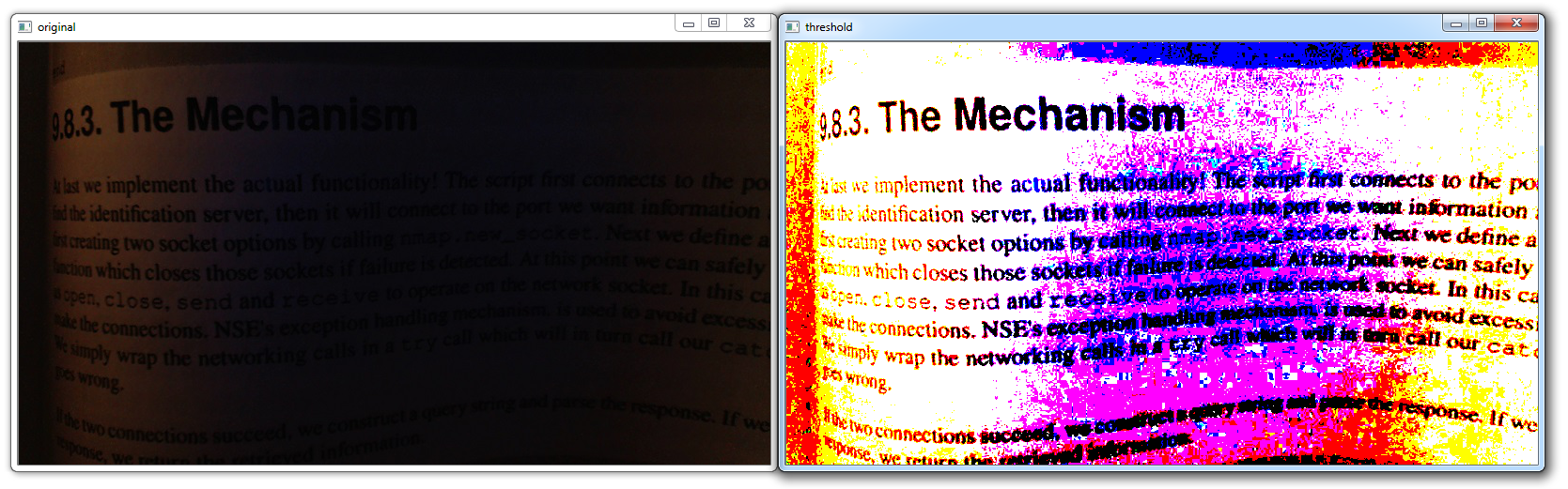
现在的图片稍微更便于阅读了,但还是有点乱。 从视觉上来说,这样比较好,但是仍然难以使用程序来分析它。 让我们看看我们是否可以进一步简化。
首先,让我们灰度化图像,然后使用一个阈值:
import cv2
import numpy as np
grayscaled = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
retval, threshold = cv2.threshold(grayscaled, 10, 255, cv2.THRESH_BINARY)
cv2.imshow('original',img)
cv2.imshow('threshold',threshold)
cv2.waitKey(0)
cv2.destroyAllWindows()
更简单,但是我们仍然在这里忽略了很多背景。 接下来,我们可以尝试自适应阈值,这将尝试改变阈值,并希望弄清楚弯曲的页面。
import cv2
import numpy as np
th = cv2.adaptiveThreshold(grayscaled, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 115, 1)
cv2.imshow('original',img)
cv2.imshow('Adaptive threshold',th)
cv2.waitKey(0)
cv2.destroyAllWindows()

还有另一个版本的阈值,可以使用,叫做大津阈值。 它在这里并不能很好发挥作用,但是:
retval2,threshold2 = cv2.threshold(grayscaled,125,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
cv2.imshow('original',img)
cv2.imshow('Otsu threshold',threshold2)
cv2.waitKey(0)
cv2.destroyAllWindows()
七、颜色过滤
在这个 Python OpenCV 教程中,我们将介绍如何创建一个过滤器,回顾按位操作,其中我们将过滤特定的颜色,试图显示它。或者,你也可以专门筛选出特定的颜色,然后将其替换为场景,就像我们用其他方法替换ROI(图像区域)一样,就像绿屏的工作方式。
为了像这样过滤,你有几个选项。通常,你可能会将你的颜色转换为 HSV,即“色调饱和度纯度”。例如,这可以帮助你根据色调和饱和度范围,使用变化的值确定一个更具体的颜色。如果你希望的话,你可以实际生成基于 BGR 值的过滤器,但是这会有点困难。如果你很难可视化 HSV,不要感到失落,查看维基百科页面上的 HSV,那里有一个非常有用的图形让你可视化它。我最好亲自描述颜色的色调饱和度和纯度。现在让我们开始:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
cv2.imshow('frame',frame)
cv2.imshow('mask',mask)
cv2.imshow('res',res)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()
这只是一个例子,以红色为目标。 它的工作方式是,我们所看到的是我们范围内的任何东西,基本上是 30-255,150-255 和 50-180。 它用于红色,但可以随便尝试找到自己的颜色。 HSV 在这里效果最好的原因是,我们想要范围内的颜色,这里我们通常需要相似的颜色。 很多时候,典型的红色仍然会有一些绿色和蓝色分量,所以我们必须允许一些绿色和蓝色,但是我们会想要几乎全红。 这意味着我们会在这里获得所有颜色的低光混合。
为了确定 HSV 的范围,我认为最好的方法就是试错。 OpenCV 内置了将 BGR 转换为 HSV 的方法。 如果你想挑选单一的颜色,那么 BGR 到 HSV 将会很好用。 为了教学,下面是这个代码的一个例子:
dark_red = np.uint8([[[12,22,121]]])
dark_red = cv2.cvtColor(dark_red,cv2.COLOR_BGR2HSV)
这里的结果是一个 HSV 值,与dark_red值相同。这很棒...但是,同样...你遇到了颜色范围和 HSV 范围的基本问题。他们根本不同。你可能合理使用 BGR 范围,它们仍然可以工作,但是对于检测一种“颜色”,则无法正常工作。
回到主代码,然而,我们首先要把帧转换成 HSV。那里没什么特别的。接下来,我们为红色指定一些 HSV 值。我们使用inRange函数,为我们的特定范围创建掩码。这是真或假,黑色或白色。接下来,我们通过执行按位操作来“恢复”我们的红色。基本上,我们显示了frame and mask。掩码的白色部分是红色范围,被转换为纯白色,而其他一切都变成黑色。最后我们展示所有东西。我选择了显示原始真,掩码和最终结果,以便更好地了解发生的事情。
在下一个教程中,我们将对这个主题做一些介绍。你可能看到了,我们在这里还是有一些“噪音”。东西有颗粒感,红色中的黑点很多,还有许多其他的小色点。我们可以做一些事情,试图通过模糊和平滑来缓解这个问题,接下来我们将讨论这个问题。
八、模糊和平滑
在这个 Python OpenCV 教程中,我们将介绍如何尝试从我们的过滤器中消除噪声,例如简单的阈值,或者甚至我们以前的特定的颜色过滤器:
正如你所看到的,我们有很多黑点,其中我们喜欢红色,还有很多其他的色点散落在其中。 我们可以使用各种模糊和平滑技术来尝试弥补这一点。 我们可以从一些熟悉的代码开始:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
现在,让我们应用一个简单的平滑,我们计算每个像素块的均值。 在我们的例子中,我们使用15x15正方形,这意味着我们有 225 个总像素。
kernel = np.ones((15,15),np.float32)/225
smoothed = cv2.filter2D(res,-1,kernel)
cv2.imshow('Original',frame)
cv2.imshow('Averaging',smoothed)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()
这个很简单,但是结果牺牲了很多粒度。 接下来,让我们尝试一些高斯模糊:
blur = cv2.GaussianBlur(res,(15,15),0)
cv2.imshow('Gaussian Blurring',blur)
另一个选项是中值模糊:
median = cv2.medianBlur(res,15)
cv2.imshow('Median Blur',median)

最后一个选项是双向模糊:
bilateral = cv2.bilateralFilter(res,15,75,75)
cv2.imshow('bilateral Blur',bilateral)
所有模糊的对比:

至少在这种情况下,我可能会使用中值模糊,但是不同的照明,不同的阈值/过滤器,以及其他不同的目标和目标可能会决定你使用其中一个。
在下一个教程中,我们将讨论形态变换。
九、形态变换
在这个 Python OpenCV 教程中,我们将介绍形态变换。 这些是一些简单操作,我们可以基于图像形状执行。
我们要谈的第一对是腐蚀和膨胀。 腐蚀是我们将“腐蚀”边缘。 它的工作方式是使用滑块(核)。 我们让滑块滑动,如果所有的像素是白色的,那么我们得到白色,否则是黑色。 这可能有助于消除一些白色噪音。 另一个版本是膨胀,它基本上是相反的:让滑块滑动,如果整个区域不是黑色的,就会转换成白色。 这是一个例子:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
kernel = np.ones((5,5),np.uint8)
erosion = cv2.erode(mask,kernel,iterations = 1)
dilation = cv2.dilate(mask,kernel,iterations = 1)
cv2.imshow('Original',frame)
cv2.imshow('Mask',mask)
cv2.imshow('Erosion',erosion)
cv2.imshow('Dilation',dilation)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()
结果:
下一对是“开放”和“关闭”。 开放的目标是消除“假阳性”。 有时在背景中,你会得到一些像素“噪音”。 “关闭”的想法是消除假阴性。 基本上就是你检测了你的形状,例如我们的帽子,但物体仍然有一些黑色像素。 关闭将尝试清除它们。
cap = cv2.VideoCapture(1)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
closing = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
cv2.imshow('Original',frame)
cv2.imshow('Mask',mask)
cv2.imshow('Opening',opening)
cv2.imshow('Closing',closing)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()

另外两个选项是tophat和blackhat,对我们的案例并不有用:
# It is the difference between input image and Opening of the image
cv2.imshow('Tophat',tophat)
# It is the difference between the closing of the input image and input image.
cv2.imshow('Blackhat',blackhat)
在下一个教程中,我们将讨论图像渐变和边缘检测。
十、边缘检测和渐变
欢迎阅读另一个 Python OpenCV 教程。 在本教程中,我们将介绍图像渐变和边缘检测。 图像渐变可以用来测量方向的强度,边缘检测就像它所说的:它找到了边缘! 我敢打赌你肯定没看到。
首先,我们来展示一些渐变的例子:
import cv2
import numpy as np
cap = cv2.VideoCapture(1)
while(1):
# Take each frame
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
laplacian = cv2.Laplacian(frame,cv2.CV_64F)
sobelx = cv2.Sobel(frame,cv2.CV_64F,1,0,ksize=5)
sobely = cv2.Sobel(frame,cv2.CV_64F,0,1,ksize=5)
cv2.imshow('Original',frame)
cv2.imshow('Mask',mask)
cv2.imshow('laplacian',laplacian)
cv2.imshow('sobelx',sobelx)
cv2.imshow('sobely',sobely)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()

如果你想知道什么是cv2.CV_64F,那就是数据类型。 ksize是核大小。 我们使用 5,所以每次查询5×5的渔区。
虽然我们可以使用这些渐变转换为纯边缘,但我们也可以使用 Canny 边缘检测!
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
cv2.imshow('Original',frame)
edges = cv2.Canny(frame,100,200)
cv2.imshow('Edges',edges)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()
这真是太棒了! 但是,这并不完美。 注意阴影导致了边缘被检测到。 其中最明显的是蓝狗窝发出的阴影。
在下一个 OpenCV 教程中,我们将讨论如何在其他图像中搜索和查找相同的图像模板。
十一、模板匹配
欢迎阅读另一个 Python OpenCV 教程,在本教程中,我们将介绍对象识别的一个基本版本。 这里的想法是,给出一定的阈值,找到匹配我们提供的模板图像的相同区域。 对于具体的对象匹配,具有精确的照明/刻度/角度,这可以工作得很好。 通常会遇到这些情况的例子就是计算机上的任何 GUI。 按钮等东西总是相同的,所以你可以使用模板匹配。 结合模板匹配和一些鼠标控制,你已经实现了一个基于 Web 的机器人!
首先,你需要一个主要图像和一个模板。 你应该从你正在图像中查找的“东西”选取你的模板。 我将提供一个图像作为例子,但随意使用你最喜爱的网站的图像或类似的东西。
主要图像:

我们要搜索的模板:

这只是其中一个端口,但我们很好奇,看看我们是否可以匹配任何其他端口。 我们确实要选择一个阈值,其中某种东西可能是 80% 匹配,那么我们说这就匹配。 所以,我们将开始加载和转换图像:
import cv2
import numpy as np
img_rgb = cv2.imread('opencv-template-matching-python-tutorial.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('opencv-template-for-matching.jpg',0)
w, h = template.shape[::-1]
到目前为止,我们加载了两个图像,转换为灰度。 我们保留原始的 RGB 图像,并创建一个灰度版本。 我之前提到过这个,但是我们这样做的原因是,我们在灰度版本上执行所有的处理,然后在彩色图像上使用相同的标签来标记。
对于主要图像,我们只有彩色版本和灰度版本。 我们加载模板并记下尺寸。
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
在这里,我们用img_gray(我们的主图像),模板,和我们要使用的匹配方法调用matchTemplate,并将返回值称为res。 我们指定一个阈值,这里是 80%。 然后我们使用逻辑语句,找到res大于或等于 80% 的位置。
最后,我们使用灰度图像中找到的坐标,标记原始图像上的所有匹配:
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,255,255), 2)
cv2.imshow('Detected',img_rgb)

所以我们得到了几个匹配。也许需要降低阈值?我们试试 0.7。

这里有一些假阳性。 你可以继续调整门槛,直到你达到 100%,但是如果没有假阳性,你可能永远不会达到它。 另一个选择就是使用另一个模板图像。 有时候,使用相同对象的多个图像是有用的。 这样,你可以使阈值足够高的,来确保你的结果准确。
在下一个教程中,我们将介绍前景提取。
十二、GrabCut 前景提取
欢迎阅读 Python OpenCV 前景提取教程。 这里的想法是找到前景,并删除背景。 这很像绿屏,只是这里我们实际上不需要绿屏。
首先,我们将使用一个图像:

随意使用你自己的。
让我们加载图像并定义一些东西:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('opencv-python-foreground-extraction-tutorial.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (161,79,150,150)
到目前为止,我们已经导入了cv2,numpy和matplotlib。 然后我们加载图像,创建一个掩码,指定算法内部使用的背景和前景模型。 真正重要的部分是我们定义的矩形。 这是rect = (start_x, start_y, width, height)。
这是包围我们的主要对象的矩形。 如果你正在使用我的图片,那就是要使用的矩阵。 如果你使用自己的,找到适合你的图像的坐标。
下面:
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img)
plt.colorbar()
plt.show()
所以在这里我们使用了cv2.grabCut,它用了很多参数。 首先是输入图像,然后是掩码,然后是主要对象的矩形,背景模型,前景模型,要运行的迭代量以及使用的模式。
这里改变了掩码,使得所有像素 0 和 2 转换为背景,而像素 1 和 3 现在是前景。 从这里,我们乘以输入图像,得到我们的最终结果:
下个教程中,我们打算讨论如何执行角点检测。
十三、角点检测
欢迎阅读 Python OpenCV 角点检测教程。 检测角点的目的是追踪运动,做 3D 建模,识别物体,形状和角色等。
对于本教程,我们将使用以下图像:
我们的目标是找到这个图像中的所有角点。 我会注意到,在这里我们有一些别名问题(斜线的锯齿),所以,如果我们允许的话,会发现很多角点,而且是正确的。 和往常一样,OpenCV 已经为我们完成了难题,我们需要做的就是输入一些参数。 让我们开始加载图像并设置一些参数:
import numpy as np
import cv2
img = cv2.imread('opencv-corner-detection-sample.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
corners = cv2.goodFeaturesToTrack(gray, 100, 0.01, 10)
corners = np.int0(corners)
到目前为止,我们加载图像,转换为灰度,然后是float32。 接下来,我们用goodFeaturesToTrack函数检测角点。 这里的参数是图像,检测到的最大角点数量,品质和角点之间的最小距离。 如前所述,我们在这里的锯齿问题将允许找到许多角点,所以我们对其进行了限制。 下面:
for corner in corners:
x,y = corner.ravel()
cv2.circle(img,(x,y),3,255,-1)
cv2.imshow('Corner',img)
现在我们遍历每个角点,在我们认为是角点的每个点上画一个圆。
在下一个教程中,我们将讨论功能匹配/单映射。
十四、特征匹配(单映射)爆破
欢迎阅读 Python OpenCV 特征匹配教程。 特征匹配将是稍微更令人印象深刻的模板匹配版本,其中需要一个完美的,或非常接近完美的匹配。
我们从我们希望找到的图像开始,然后我们可以在另一幅图像中搜索这个图像。 这里的完美是图像不需要相同的光照,角度,旋转等。 特征只需要匹配。
首先,我们需要一些示例图像。 我们的“模板”,或者我们将要尝试匹配的图像:

之后是我们用于搜索这个模板的图像:

在这里,我们的模板图像在模板中,比在我们要搜索的图像中要小一些。 它的旋转也不同,阴影也有些不同。
现在我们将使用一种“爆破”匹配的形式。 我们将在这两个图像中找到所有特征。 然后我们匹配这些特征。 然后,我们可以绘制我们想要的,尽可能多的匹配。 但是要小心。 如果你绘制 500 个匹配,你会有很多误报。 所以只绘制绘制前几个。
import numpy as np
import cv2
import matplotlib.pyplot as plt
img1 = cv2.imread('opencv-feature-matching-template.jpg',0)
img2 = cv2.imread('opencv-feature-matching-image.jpg',0)
到目前为止,我们已经导入了要使用的模块,并定义了我们的两个图像,即模板(img1)和用于搜索模板的图像(img2)。
orb = cv2.ORB_create()
这是我们打算用于特征的检测器。
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
在这里,我们使用orb探测器找到关键点和他们的描述符。
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
这就是我们的BFMatcher对象。
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)
这里我们创建描述符的匹配,然后根据它们的距离对它们排序。
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:10],None, flags=2)
plt.imshow(img3)
plt.show()
这里我们绘制了前 10 个匹配。输出:

十五、MOG 背景减弱
在这个 Python OpenCV 教程中,我们将要讨论如何通过检测运动来减弱图像的背景。 这将要求我们回顾视频的使用,或者有两个图像,一个没有你想要追踪的人物/物体,另一个拥有人物/物体。 如果你希望,你可以使用你的摄像头,或者使用如下的视频:
这里的代码实际上很简单,就是我们现在知道的:
import numpy as np
import cv2
cap = cv2.VideoCapture('people-walking.mp4')
fgbg = cv2.createBackgroundSubtractorMOG2()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
cv2.imshow('fgmask',frame)
cv2.imshow('frame',fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
结果:
https://pythonprogramming.net/static/images/opencv/opencv-python-foreground.mp4
这里的想法是从静态背景中提取移动的前景。 你也可以使用这个来比较两个相似的图像,并立即提取它们之间的差异。
在我们的例子中,我们可以看到我们确实已经检测到了一些人,但是我们确实有一些“噪音”,噪音实际上是树叶在周围的风中移动了一下。 只要我们知道一种减少噪音的方法。 等一下! 我们的确知道! 一个疯狂的挑战已经出现了你面前!
接下来的教程开始让我们远离滤镜或变换的应用,并让我们使用 Haar Cascades 来检测一般对象,例如面部检测等等。
十六、Haar Cascade 面部检测
在这个 Python OpenCV 教程中,我们将讨论 Haar Cascades 对象检测。我们将从脸部和眼睛检测来开始。为了使用层叠文件进行对象识别/检测,首先需要层叠文件。对于非常流行的任务,这些已经存在。检测脸部,汽车,笑脸,眼睛和车牌等东西都是非常普遍的。
首先,我会告诉你如何使用这些层叠文件,然后我将告诉你如何开始创建你自己的层叠,这样你就可以检测到任何你想要的对象,这很酷!
你可以使用 Google 来查找你可能想要检测的东西的各种 Haar Cascades。对于找到上述类型,你应该没有太多的麻烦。我们将使用面部层叠和眼睛层叠。你可以在 Haar Cascades 的根目录找到更多。请注意用于使用/分发这些 Haar Cascades 的许可证。
让我们开始我们的代码。我假设你已经从上面的链接中下载了haarcascade_eye.xml和haarcascade_frontalface_default.xml,并将这些文件放在你项目的目录中。
import numpy as np
import cv2
# multiple cascades: https://github.com/Itseez/opencv/tree/master/data/haarcascades
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_eye.xml
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
cap = cv2.VideoCapture(0)
在这里,我们从导入cv2和numpy开始,然后加载我们的脸部和眼部的层叠。 目前为止很简单。
while 1:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
现在我们开始我们的典型循环,这里唯一的新事物就是脸部的创建。 更多信息请访问detectMultiScale函数的文档。 基本上,它找到了面部! 我们也想找到眼睛,但是在一个假阳性的世界里,在面部里面寻找眼睛,从逻辑上来说是不是很明智? 我们希望我们不寻找不在脸上的眼睛! 严格来说,“眼睛检测”可能不会找到闲置的眼球。 大多数眼睛检测使用周围的皮肤,眼睑,眼睫毛,眉毛也可以用于检测。 因此,我们的下一步就是先去拆分面部,然后才能到达眼睛:
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
在这里,我们找到了面部,它们的大小,绘制矩形,并注意 ROI。 接下来,我们找了一些眼睛:
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
如果我们找到这些,我们会继续绘制更多的矩形。 接下来我们完成:
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
完整代码:
import numpy as np
import cv2
# multiple cascades: https://github.com/Itseez/opencv/tree/master/data/haarcascades
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_eye.xml
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
cap = cv2.VideoCapture(0)
while 1:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
不错。你可能会注意到我不得不取下我的眼镜。这些造成了一些麻烦。我的嘴也经常被检测为眼睛,有时甚至是一张脸,但你明白了。面部毛发和其他东西经常可以欺骗基本面部检测,除此之外,皮肤的颜色也会造成很大的麻烦,因为我们经常试图尽可能简化图像,从而失去了很多颜色值。甚至还有一个小型行业,可以避免人脸检测和识别。CVDazzle 网站就是一个例子。其中有些非常古怪,但他们很有效。你也可以总是走完整的面部重建手术的路线,以避免自动跟踪和检测,所以总是这样,但是这更永久。做个发型比较短暂也容易做到。
好吧,检测面部,眼睛和汽车是可以的,但我们是程序员。我们希望能够做任何事情。事实证明,事情会变得相当混乱,建立自己的 Haar Cascades 有一定的难度,但是其他人也这么做......你也可以!这就是在下一个教程中所讨论的。
十七、创建自己的 Haar Cascade
欢迎使用 Python OpenCV 对象检测教程。在本教程中,你将看到如何创建你自己的 Haar Cascades,以便你可以跟踪任何你想要的对象。由于这个任务的本质和复杂性,本教程将比平时稍长一些,但奖励是巨大的。
虽然你可以在 Windows 中完成,我不会建议这样。因此,对于本教程,我将使用 Linux VPS,并且我建议你也这样做。你可以尝试使用 Amazon Web Services 提供的免费套餐,但对你来说可能太痛苦了,你可能需要更多的内存。你还可以从 Digital Ocean 获得低至五美元/月的 VPS。我推荐至少 2GB 的内存用于我们将要做的事情。现在大多数主机按小时收费,包括 DO。因此,你可以购买一个 20 美元/月的服务器,使用它一天,获取你想要的文件,然后终止服务器,并支付很少的钱。你需要更多的帮助来设置服务器?如果是的话,看看这个具体的教程。
一旦你的服务器准备就绪,你会打算获取实际的 OpenCV 库。
将目录更改到服务器的根目录,或者你想放置工作区的地方:
cd ~
sudo apt-get update
sudo apt-get upgrade
首先,让我们为自己制作一个漂亮的工作目录:
mkdir opencv_workspace
cd opencv_workspace
既然我们完成了,让我们获取 OpenCV。
sudo apt-get install git
git clone https://github.com/Itseez/opencv.git
我们这里克隆了 OpenCV 的最新版本。现在获取一些必需品。
编译器:sudo apt-get install build-essential
库:sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
Python 绑定:sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
最后,让我们获取 OpenCV 开发库:
sudo apt-get install libopencv-dev
现在,我们该如何完成这个过程呢?所以当你想建立一个 Haar Cascade 时,你需要“正片”图像和“底片”图像。 “正片”图像是包含要查找的对象的图像。这可以是具有对象的主要图像,也可以是包含对象的图像,并指定对象所在的 ROI(兴趣区域)。有了这些正片图像,我们建立一个矢量文件,基本上是所有这些东西放在一起。正片图像的一个好处是,你可以实际只有一个你想要检测的对象的图像,然后有几千个底片图像。是的,几千。底片图像可以是任何东西,除了他们不能包含你的对象。
在这里,使用你的底片图像,你可以使用opencv_createsamples命令来创建一堆正片的示例。你的正片图像将叠加在这些底片上,而且会形成各种各样的角度。它实际上可以工作得很好,特别是如果你只是在寻找一个特定的对象。但是,如果你正在寻找所有螺丝刀,则需要拥有数千个螺丝刀的独特图像,而不是使用opencv_createsamples为你生成样品。我们将保持简单,只使用一个正片图像,然后用我们的底片创建一堆样本。
我们的正片图像:

这是另外一个场景,如果你使用自己的图像,你可能会更喜欢这个。如果事情出错了,试试看我的,但是我建议你自己画一下。保持较小。 50x50像素应该可以。
好吧,获得正片图像是没有问题的!只有一个问题。我们需要成千上万的底片图像。可能在未来,我们也可能需要成千上万的正片图像。我们可以在世界的哪个地方实现它?基于 WordNet 的概念,有一个非常有用的站点叫做 ImageNet。从这里,你可以找到几乎任何东西的图像。我们这里,我们想要手表,所以搜索手表,你会发现大量种类的手表。让我们检索电子表。真棒!看看下载标签!存在用于所有电子表手表的 URL!很酷。好吧,但我说过我们只会使用一个正片,所以我们只是检测一个手表。如果你想检测“全部”手表,需要准备获取多余 50,000 个手表图像,至少 25000 个“底片”的图像。之后,准备足够的服务器,除非你想要你的 Haar Cascade 训练花一个星期。那么我们如何得到底片? ImageNet 的全部重点是图像训练,所以他们的图像非常具体。因此,如果我们搜索人,汽车,船只,飞机......无论什么,都不会有手表。你可能会看到一些人或类似的东西,但你明白了。既然你可能看到人周围或上面的手表,我其实认为你也会得到人的图像。我的想法是寻找做运动的人,他们可能没有戴电子表。所以,我们来找一些批量图片的 URL 链接。我发现体育/田径链接有 1,888 张图片,但你会发现很多这些都是完全损坏的。让我们再来找一个:
好吧,我们拥有所有这些图片,现在呢?那么,首先,我们希望所有这些大小都相同,而且要小很多!天哪,只要我们知道一个方法来操作图像...嗯...哦,这是一个 OpenCV 教程!我们可以处理它。所以,首先,我们要做的就是编写一个简单的脚本,访问这些 URL 列表,获取链接,访问链接,拉取图像,调整大小,保存它们,然后重复,直到完成。当我们的目录充满图像时,我们还需要一种描述图像的描述文件。对于正片,手动创建这个文件特别痛苦,因为你需要指定你的对象,每个图像的具体的兴趣区域。幸运的是,create_samples方法将图像随机放置,并为我们做了所有工作。我们只需要一个用于底片的简单描述符,但是这不是问题,在拉伸和操作图像时我们可以实现。
https://www.youtube.com/embed/z_6fPS5tDNU?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
在任何你喜欢的地方随意运行这个代码。 我要在我的主机上运行它,因为它应该快一点。 你可以在你的服务器上运行。 如果你想使用cv2模块,请执行sudo apt-get install python-OpenCV。 目前,我不知道在 Linux 上为 Python 3 获得这些绑定的好方法。 我将要写的脚本是 Python 3,所以记住这一点。 主要区别是Urllib处理。
# download-image-by-link.py
import urllib.request
import cv2
import numpy as np
import os
def store_raw_images():
neg_images_link = '//image-net.org/api/text/imagenet.synset.geturls?wnid=n00523513'
neg_image_urls = urllib.request.urlopen(neg_images_link).read().decode()
pic_num = 1
if not os.path.exists('neg'):
os.makedirs('neg')
for i in neg_image_urls.split('\n'):
try:
print(i)
urllib.request.urlretrieve(i, "neg/"+str(pic_num)+".jpg")
img = cv2.imread("neg/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE)
# should be larger than samples / pos pic (so we can place our image on it)
resized_image = cv2.resize(img, (100, 100))
cv2.imwrite("neg/"+str(pic_num)+".jpg",resized_image)
pic_num += 1
except Exception as e:
print(str(e))
很简单,这个脚本将访问链接,抓取网址,并继续访问它们。从这里,我们抓取图像,转换成灰度,调整大小,然后保存。我们使用一个简单的计数器来命名图像。继续运行它。你可能看到,有很多确实的图片等。没关系。这些错误图片中的一些更有问题。基本上都是白色,带有一些文本,说他们不再可用,而不是服务和 HTTP 错误。现在,我们有几个选择。我们可以忽略它们,或者修复它。嘿,这是一个没有手表的图像,所以什么是对的呢?当然,你可以采取这种观点,但如果你为正片使用这种拉取方式的话,这肯定是一个问题。你可以手动删除它们...或者我们可以使用我们新的图像分析知识,来检测这些愚蠢的图像,并将其删除!
我继续生成了一个新的目录,称之为“uglies(丑陋)”。在那个目录中,我点击并拖动了所有丑陋的图像版本(只是其中之一)。在底片中我只发现了一个主犯,所以我只有一个。让我们编写一个脚本来查找这个图像的所有实例并删除它。
https://www.youtube.com/embed/t0HOVLK30xQ?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
def find_uglies():
match = False
for file_type in ['neg']:
for img in os.listdir(file_type):
for ugly in os.listdir('uglies'):
try:
current_image_path = str(file_type)+'/'+str(img)
ugly = cv2.imread('uglies/'+str(ugly))
question = cv2.imread(current_image_path)
if ugly.shape == question.shape and not(np.bitwise_xor(ugly,question).any()):
print('That is one ugly pic! Deleting!')
print(current_image_path)
os.remove(current_image_path)
except Exception as e:
print(str(e))
现在我们只有底片,但是我留下了空间让你轻易在那里添加'pos'(正片)。 你可以运行它来测试,但我不介意先抓住更多的底片。 让我们再次运行图片提取器,仅仅使用这个 url://image-net.org/api/text/imagenet.synset.geturls?wnid=n07942152。 最后一张图像是#952,所以让我们以 953 开始pic_num,并更改网址。
def store_raw_images():
neg_images_link = '//image-net.org/api/text/imagenet.synset.geturls?wnid=n07942152'
neg_image_urls = urllib.request.urlopen(neg_images_link).read().decode()
pic_num = 953
if not os.path.exists('neg'):
os.makedirs('neg')
for i in neg_image_urls.split('\n'):
try:
print(i)
urllib.request.urlretrieve(i, "neg/"+str(pic_num)+".jpg")
img = cv2.imread("neg/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE)
# should be larger than samples / pos pic (so we can place our image on it)
resized_image = cv2.resize(img, (100, 100))
cv2.imwrite("neg/"+str(pic_num)+".jpg",resized_image)
pic_num += 1
except Exception as e:
print(str(e))
现在我们有超过2000张照片。 最后一步是,我们需要为这些底片图像创建描述符文件。 我们将再次使用一些代码!
def create_pos_n_neg():
for file_type in ['neg']:
for img in os.listdir(file_type):
if file_type == 'pos':
line = file_type+'/'+img+' 1 0 0 50 50\n'
with open('info.dat','a') as f:
f.write(line)
elif file_type == 'neg':
line = file_type+'/'+img+'\n'
with open('bg.txt','a') as f:
f.write(line)
运行它,你有了个bg.txt文件。 现在,我知道有些人的互联网连接可能不是最好的,所以我做个好人,在这里上传底片图片和描述文件。 你应该通过这些步骤。 如果你对本教程感到困扰,则需要知道如何执行这部分。 好吧,所以我们决定我们将一个图像用于正片前景图像。 因此,我们需要执行create_samples。 这意味着,我们需要将我们的neg目录和bg.txt文件移动到我们的服务器。 如果你在服务器上运行所有这些代码,不要担心。
https://www.youtube.com/embed/eay7CgPlCyo?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
如果你是一个术士,并已经想出了如何在 Windows 上运行create_samples等,恭喜! 回到服务器的领地,我的文件现在是这样的:
opencv_workspace
--neg
----negimages.jpg
--opencv
--info
--bg.txt
--watch5050.jpg
你可能没有info目录,所以继续并mkdir info。 这是我们放置所有正片图像的地方。
我们现在准备根据watch5050.jpg图像创建一些正片样本。 为此,请在工作区中通过终端运行以下命令:
opencv_createsamples -img watch5050.jpg -bg bg.txt -info info/info.lst -pngoutput info -maxxangle 0.5 -maxyangle 0.5 -maxzangle 0.5 -num 1950
这样做是基于我们指定的img创建样本,bg是背景信息,我们将输出info.list(很像bg.txt文件)的信息,然后-pngoutput就是我们想要放置新生成的图像的任何地方。 最后,我们有一些可选的参数,使我们的原始图像更加动态一些,然后用= num来表示我们想要创建的样本数量。 太棒了,让我们来运行它。 现在你的info目录应该有约 2,000 个图像,还有一个名为info.lst的文件。 这个文件基本上是你的“正片”文件。 打开它,并且看看它怎么样:
0001_0014_0045_0028_0028.jpg 1 14 45 28 28
首先你有文件名,之后是图像中有多少对象,其次是它们的所有位置。 我们只有一个,所以它是图像中对象矩形的x,y,宽度和高度。 这是一个图像:

很难看到它,但如果你很难看到,手表就是这个图像。 图像中最左侧人物的左下方。 因此,这是一个“正片”图像,从另外一个“底片”图像创建,底片图像也将用于训练。 现在我们有了正片图像,现在我们需要创建矢量文件,这基本上是一个地方,我们将所有正片图像拼接起来。我们会再次为此使用opencv_createsamples!
opencv_createsamples -info info/info.lst -num 1950 -w 20 -h 20 -vec positives.vec
这是我们的矢量文件。 在这里,我们只是让它知道信息文件的位置,我们想要在文件中包含多少图像,在这个矢量文件中图像应该是什么尺寸,然后才能输出结果。 如果你愿意的话,你可以做得更大一些,20×20可能足够好了,你做的越大,训练时间就会越长。 继续,我们现在只需要训练我们的层叠。
首先,我们要把输出放在某个地方,所以让我们创建一个新的数据目录:
mkdir data,你的工作空间应该如下所示:
opencv_workspace
--neg
----negimages.jpg
--opencv
--info
--data
--positives.vec --bg.txt
--watch5050.jpg
现在让我们运行训练命令:
opencv_traincascade -data data -vec positives.vec -bg bg.txt -numPos 1800 -numNeg 900 -numStages 10 -w 20 -h 20
在这里,我们表明了,我们想要数据去的地方,矢量文件的位置,背景文件的位置,要使用多少个正片图像和底片图像,多少个阶段以及宽度和高度。请注意,我们使用的numPos比我们少得多。这是为了给阶段腾出空间。
有更多的选择,但这些就够了。这里主要是正片和底片的数量。一般认为,对于大多数实践,你需要 2:1 比例的正片和底片图像。有些情况可能会有所不同,但这是人们似乎遵循的一般规则。接下来,我们拥有阶段。我们选择了 10 个。你至少要 10-20 个,越多需要的时间越长,而且是指数级的。第一阶段通常很快,第五阶段要慢得多,第五十个阶段永远不会做完!所以,我们现在执行 10 个阶段。这里不错的事情是你可以训练 10 个阶段,稍后再回来,把数字改成 20,然后在你离开的地方继续。同样的,你也可以放一些像 100 个阶段的东西,上床睡觉,早上醒来,停下来,看看你有多远,然后用这些阶段“训练”,你会立即得到一个层叠文件。你可能从最后一句话中得出,这个命令的结果确实很棒,是个不错的层叠文件。我们希望能检测到我的手表,或者你决定检测的任何东西。我所知道的是,在输出这一段的时候,我还没有完成第一阶段的工作。如果你真的想要在一夜之间运行命令,但不想让终端打开,你可以使用nohup:
nohup opencv_traincascade -data data -vec positives.vec -bg bg.txt -numPos 1800 -numNeg 900 -numStages 10 -w 20 -h 20 &
这使命令即使在关闭终端之后也能继续运行。 你可以使用更多,但你可能会或可能不会用完你的 2GB RAM。
https://www.youtube.com/embed/-Mhy-5YNcG4?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
在我的 2GB DO 服务器上,10 个阶段花了不到 2 个小时的时间。 所以,要么有一个cascade.xml文件,要么停止脚本运行。 如果你停止运行,你应该在你的data目录下有一堆stageX.xml文件。 打开它,看看你有多少个阶段,然后你可以使用这些阶段,再次运行opencv_traincascade,你会立即得到一个cascade.xml文件。 这里,我只想说出它是什么,以及有多少个阶段。 对我来说,我做了 10 个阶段,所以我将它重命名为watchcascade10stage.xml。 这就是我们所需的,所以现在将新的层次文件传回主计算机,放在工作目录中,让我们试试看!
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
#this is the cascade we just made. Call what you want
watch_cascade = cv2.CascadeClassifier('watchcascade10stage.xml')
cap = cv2.VideoCapture(0)
while 1:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# add this
# image, reject levels level weights.
watches = watch_cascade.detectMultiScale(gray, 50, 50)
# add this
for (x,y,w,h) in watches:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,255,0),2)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
你可能注意到,手表的方框很小。 它似乎并没有达到整个手表。 回想一下我们的训练规模是20x20。 因此,我们最多有个20x20的方框。 你可以做100x100,但是,要小心,这将需要很长时间来训练。 因此,我们不绘制方框,而是,为什么不在手表上写字或什么东西? 这样做相对简单。 我们不在手表上执行cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),2),我们可以执行:
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'Watch',(x-w,y-h), font, 0.5, (11,255,255), 2, cv2.LINE_AA)
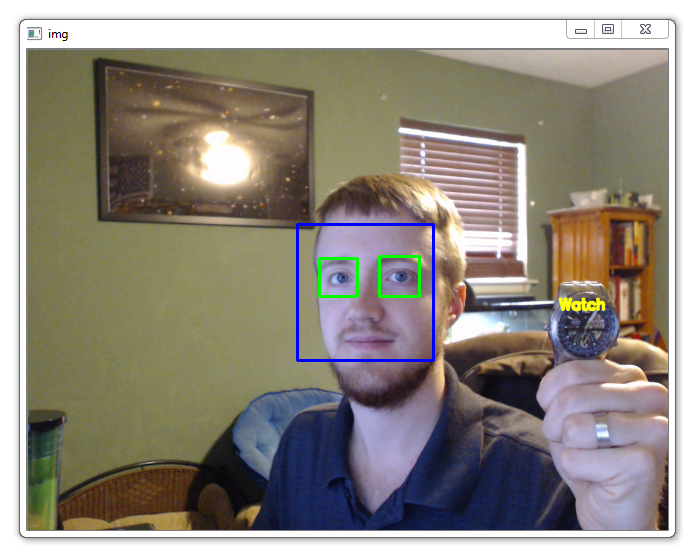
很酷! 所以你可能没有使用我的手表,你是怎么做的? 如果遇到麻烦,请尝试使用与我完全相同的所有内容。 检测图像,而不是检测摄像头,这里是一个:

在图像上运行检测会给你:
我不了解你,但一旦我最终使其工作,我非常兴奋!最让我印象深刻的是,跟踪对象所需的数据大小。Haar Cascades 往往是 100-2000 KB 的大小。大于等于 2,000 KB 的 Haar Cascades 应该非常准确。考虑你的情况,你可能会遇到约 5000 个一般物体。考虑 Haar Cascades 平均可能是约 500 KB。我们需要:0.5 MB * 5,000 = 2,500 MB或 2.5 GB。你需要 2.5 GB 的内存来识别 5000 个对象,并且可能是你在一天中遇到的最多对象。这让我着迷。考虑到我们可以访问所有的 image-net,并可以立即拉取很大范围的对象的一般图像。考虑 image-net 上的大多数图像,基本上都是 100% 的“跟踪”对象,因此,你可以通过手动标注位置,并仅使用 0,0 和图像的全部大小来得到正确的结果。这里你可以做的事情有巨大可能...好吧,那就是现在。我将来可能会用 OpenCV 做一些字符识别。如果你有任何其他要求,请发送电子邮件,在社区中提出建议,或张贴在视频上。
享受你的新力量。好好利用它们。
PythonProgramming.net Python 和 Pandas 数据分析教程
原文:Data Analysis with Python and Pandas Tutorial Introduction
译者:飞龙
大家好,欢迎阅读 Python 和 Pandas 数据分析系列教程。 Pandas 是一个 Python 模块,Python 是我们要使用的编程语言。Pandas 模块是一个高性能,高效率,高水平的数据分析库。
它的核心就像操作一个电子表格的无头版本,比如 Excel。你使用的大多数数据集将是所谓的数据帧(DataFrame)。你可能已经熟悉这个术语,它也用于其他语言,但是如果没有,数据帧通常就像电子表格一样,拥有列和行,这就是它了!从这里开始,我们可以利用 Pandas 以闪电般的速度操作我们的数据集。
Pandas 还与许多其他数据分析库兼容,如用于机器学习的 Scikit-Learn,用于图形的 Matplotlib,NumPy,因为它使用 NumPy ,以及其他。这些是非常强大和宝贵的。如果你发现自己使用 Excel 或者一般电子表格来执行各种计算任务,那么他们可能需要一分钟或者一小时来运行,Pandas 将会改变你的生活。我甚至已经看到机器学习的版本,如 K-Means 聚类在 Excel 上完成。这真的很酷,但是我的 Python 会为你做得更快,这也将使你对参数要求更严格,拥有更大的数据集,并且能够完成更多的工作。
还有一个好消息。你可以很容易加载和输出xls或xlsx格式的文件,所以,即使你的老板想用旧的方式来查看,他们也可以。Pandas 还可以兼容文本文件,csv,hdf文件,xml,html等等,其 IO 非常强大。
如果你刚刚入门 Python,那么你应该可以继续学习,而不必精通 Python,这甚至可以让你入门 Python 。最重要的是,如果你有问题,问问他们!如果你为每一个困惑的领域寻找答案,并为此做好每件事,那么最终你会有一个完整的认识。你的大部分问题都可以通过 Google 解决。不要害怕 Google 你的问题,它不会嘲笑你,我保证。我仍然 Google 了我的很多目标,看看是否有人有一些示例代码,做了我想做的事情,所以不要仅仅因为你这样做了,而觉得你是个新手。
如果我还没有把 Pandas 推销给你,那么电梯演讲就是:电子表格式数据的闪电般的数据分析,具有非常强大的输入/输出机制,可以处理多种数据类型,甚至可以转换数据类型。
好的,你被推销了。现在让我们获取 Pandas!首先,我将假设有些人甚至还没有 Python。到目前为止,最简单的选择是使用预编译的 Python 发行版,比如 ActivePython,它是个快速简单的方式,将数据科学所需的所有包和依赖关系都集中在一起,而不需要一个接一个安装它们,特别是在 64 位 Windows 上。我建议获取最新版本的 64 位 Python。仅在这个系列中,我们使用 Pandas ,它需要 Numpy。我们还将使用 Matplotlib 和 Scikit-Learn,所有这些都是 ActivePython 自带的,预先编译和优化的 MKL。你可以从这里下载一个配置完整的 Python 发行版。
如果你想手动安装 Python,请转到Python.org,然后下载 Python 3+ 或更高版本。不要仅仅获取2.X。记下你下载的位版本。因为你的操作系统是 64 位的,这并是你的 Python 版本,默认总是 32 位。选择你想要的。 64 位可能有点头疼,所以如果你是新手,我不会推荐它,但 64 位是数据科学的理想选择,所以你不会被锁定在最大 2GB 的 RAM 上。如果你想装 64 位,查看pip安装教程可能有帮助,其中介绍了如何处理常规安装以及更棘手的 64 位软件包。如果你使用 32 位,那么现在不用担心这个教程。
所以你已经安装了 Python。接下来,转到你的终端或cmd.exe,然后键入:pip install pandas。你有没有得到pip is not a recognized command或类似的东西?没问题,这意味着pip不在你的PATH中。pip是一个程序,但是你的机器不知道它在哪里,除非它在你的PATH中。如果你愿意,你可以搜索如何添加一些东西到你的PATH中,但是你总是可以显式提供你想要执行的程序的路径。例如,在 Windows 上,Python 的pip位于C:/Python34/Scripts/pip中。 Python34的意思是 Python 3.4。如果你拥有 Python 3.6,那么你需要使用Python36,以此类推。
因此,如果常规的pip install pandas不起作用,那么你可以执行C:/Python34/Scripts/pip install pandas。
到了这里,人们争论的另一个重点是他们选择的编辑器。编辑器在事物的宏观层面中并不重要。你应该尝试多个编辑器,并选择最适合你的编辑器。无论哪个,只要你感到舒适,而且你的工作效率很高,这是最重要的。一些雇主也会迫使你最终使用编辑器 X,Y 或 Z,所以你可能不应该依赖编辑器功能。因此,我更喜欢简单的 IDLE,这就是我将用于编程的东西。再次,你可以在 Wing,emacs,Nano,Vim,PyCharm,IPython 中编程,你可以随便选一个。要打开 IDLE,只需访问开始菜单,搜索 IDLE,然后选择它。在这里,File > New,砰的一下,你就有了带高亮的文本编辑器和其他一些小东西。我们将在进行中介绍一些这些次要的事情。
现在,无论你使用哪种编辑器,都可以打开它,让我们编写一些简单的代码来查看数据帧。
通常,DataFrame最接近 Python Dictionary 数据结构。如果你不熟悉字典,这里有一个教程。我将在视频中注明类似的东西,并且在描述中,以及在PythonProgramming.net上的文本版教程中有链接。
首先,我们来做一些简单的导入:
import pandas as pd
import datetime
import pandas.io.data as web
在这里,我们将pandas导入为pd。 这只是导入pandas模块时使用的常用标准。 接下来,我们导入datetime,我们稍后将使用它来告诉 Pandas 一些日期,我们想要拉取它们之间的数据。 最后,我们将pandas.io.data导入为web,因为我们将使用它来从互联网上获取数据。 接下来:
start = datetime.datetime(2010, 1, 1)
end = datetime.datetime(2015, 8, 22)
在这里,我们创建start和end变量,这些变量是datetime对象,获取 2010 年 1 月 1 日到 2015 年 8 月 22 日的数据。现在,我们可以像这样创建数据帧:
df = web.DataReader("XOM", "yahoo", start, end)
这从雅虎财经 API 获取 Exxon 的数据,存储到我们的df变量。 将你的数据帧命名为df不是必需的,但是它页是用于 Pandas 的非常主流的标准。 它只是帮助人们立即识别活动数据帧,而无需追溯代码。
所以这给了我们一个数据帧,我们怎么查看它? 那么,可以打印它,就像这样:
print(df)
所以这是很大一个空间。 数据集的中间被忽略,但仍然是大量输出。 相反,大多数人只会这样做:
print(df.head())
输出:
Open High Low Close Volume Adj Close
Date
2010-01-04 68.720001 69.260002 68.190002 69.150002 27809100 59.215446
2010-01-05 69.190002 69.449997 68.800003 69.419998 30174700 59.446653
2010-01-06 69.449997 70.599998 69.339996 70.019997 35044700 59.960452
2010-01-07 69.900002 70.059998 69.419998 69.800003 27192100 59.772064
2010-01-08 69.690002 69.750000 69.220001 69.519997 24891800 59.532285
这打印了数据帧的前 5 行,并且对于调试很有用,只查看了数据帧的外观。 当你执行分析等,看看你想要的东西是否实际发生了,就很有用。 不过,我们稍后会深入它。
我们可以在这里停止介绍,但还有一件事:数据可视化。 我之前说过,Pandas 和其他模块配合的很好,Matplotlib 就是其中之一。 让我们来看看! 打开你的终端或cmd.exe,并执行pip install matplotlib。 你安装完 Pandas,我确信你应该已经获取了它,但我们要证实一下。 现在,在脚本的顶部,和其他导入一起,添加:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
Pyplot 是 matplotlib 的基本绘图模块。 Style 帮助我们快速美化图形,style.use让我们选择风格。 有兴趣了解 Matplotlib 的更多信息吗? 查看 Matplotlib 的深入系列教程!
接下来,在我们的print(df.head())下方,我们可以执行如下操作:
df['High'].plot()
plt.legend()
plt.show()
很酷! 这里有个 pandas 的快速介绍,但一点也不可用。 在这个系列中,我们将会涉及更多 Pandas 的基础知识,然后转到导航和处理数据帧。 从这里开始,我们将更多地介绍可视化,多种数据格式的输入和输出,基本和进阶数据分析和操作,合并和组合数据帧,重复取样等等。
如果你迷茫,困惑,或需要澄清,请不要犹豫,给对应的视频提问。
二、Pandas 基础
在这个 Python 和 Pandas 数据分析教程中,我们将弄清一些 Pandas 的基础知识。 加载到 Pandas 数据帧之前,数据可能有多种形式,但通常需要是以行和列组成的数据集。 所以也许是这样的字典:
web_stats = {'Day':[1,2,3,4,5,6],
'Visitors':[43,34,65,56,29,76],
'Bounce Rate':[65,67,78,65,45,52]}
我们可以将这个字典转换成数据帧,通过这样:
import pandas as pd
web_stats = {'Day':[1,2,3,4,5,6],
'Visitors':[43,34,65,56,29,76],
'Bounce Rate':[65,67,78,65,45,52]}
df = pd.DataFrame(web_stats)
现在我们可以做什么?之前看到,你可以通过这样来查看简单的起始片段:
print(df.head())
Bounce Rate Day Visitors
0 65 1 43
1 67 2 34
2 78 3 65
3 65 4 56
4 45 5 29
你也可以查看后几行。为此,你需要这样做:
print(df.tail())
Bounce Rate Day Visitors
1 67 2 34
2 78 3 65
3 65 4 56
4 45 5 29
5 52 6 76
最后,你也可以传入头部和尾部数量,像这样:
print(df.tail(2))
Bounce Rate Day Visitors
4 45 5 29
5 52 6 76
你可以在这里看到左边有这些数字,0,1,2,3,4,5等等,就像行号一样。 这些数字实际上是你的“索引”。 数据帧的索引是数据相关,或者数据按它排序的东西。 一般来说,这将是连接所有数据的变量。 这里,我们从来没有为此目的定义任何东西,知道这个变量是什么,对于 Pandas 是个挑战。 因此,当你没有定义索引时,Pandas 会像这样为你生成一个。 现在看数据集,你能看到连接其他列的列吗?
Day列适合这个东西! 一般来说,如果你有任何日期数据,日期将成为“索引”,因为这就是所有数据点的关联方式。 有很多方法可以识别索引,更改索引等等。 我们将在这里介绍一些。 首先,在任何现有的数据帧上,我们可以像这样设置一个新的索引:
df.set_index('Day', inplace=True)
输出:
Bounce Rate Visitors
Day
1 65 43
2 67 34
3 78 65
4 65 56
5 45 29
现在你可以看到这些行号已经消失了,同时也注意到Day比其他列标题更低,这是为了表示索引。 有一点需要注意的是inplace = True的使用。 这允许我们原地修改数据帧,意味着我们实际上修改了变量本身。 没有inplace = True,我们需要做一些事情:
df = df.set_index('Day')
你也可以设置多个索引,但这是以后的更高级的主题。 你可以很容易做到这一点,但它的原因相当合理。
一旦你有了合理的索引,是一个日期时间或数字,那么它将作为一个 X 轴。 如果其他列也是数值数据,那么你可以轻松绘图。 就像我们之前做的那样,继续并执行:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
然后,在底部,你可以绘图。 还记得我们之前引用了特定的列嘛?也许你注意到了,但是我们可以像这样,引用数据帧中的特定项目:
print(df['Visitors'])
Day
1 43
2 34
3 65
4 56
5 29
6 76
Name: Visitors, dtype: int64
你也可以像对象一样引用数据帧的部分,只要没有空格,就可以这样做:
print(df.Visitors)
Day
1 43
2 34
3 65
4 56
5 29
6 76
Name: Visitors, dtype: int64
所以我们可以像这样绘制单列:
df['Visitors'].plot()
plt.show()
我们也可以绘制整个数据帧。 只要数据是规范化的或者在相同的刻度上,效果会很好。 这是一个例子:
df.plot()
plt.show()
注意图例如何自动添加。 你可能会喜欢的另一个很好的功能是,图例也自动为实际绘制的直线让路。 如果你是 Python 和 Matplotlib 的新手,这可能对你来说并不重要,但这不是一个正常的事情。
最后,在我们离开之前,你也可以一次引用多个列,就像这样(我们只有两列,但是多列相同):
print(df[['Visitors','Bounce Rate']])
所以这是括起来的列标题列表。 你也可以绘制这个。
这些是一些方法,你可以直接与数据帧进行交互,引用数据框的各个方面,带有一个示例,绘制了这些特定的方面。
三、IO 基础
欢迎阅读 Pandas 和 Python 数据分析第三部分。在本教程中,我们将开始讨论 Pandas IO 即输入/输出,并从一个实际的用例开始。为了得到充分的实践,一个非常有用的网站是 Quandl。 Quandl 包含大量的免费和付费数据源。这个站点的好处在于数据通常是标准化的,全部在一个地方,提取数据的方法是一样的。如果你使用的是 Python,并且通过它们的简单模块访问 Quandl 数据,那么数据将自动以数据帧返回。出于本教程的目的,我们将仅仅出于学习的目的而手动下载一个 CSV 文件,因为并不是每个数据源都会有一个完美的模块用于提取数据集。
假设我们有兴趣,在德克萨斯州的奥斯汀购买或出售房屋。那里的邮政编码是 77006。我们可以访问当地的房源清单,看看目前的价格是多少,但这并不能真正为我们提供任何真实的历史信息,所以我们只是试图获得一些数据。让我们来查询“房屋价值指数 77006”。果然,我们可以在这里看到一个索引。有顶层,中层,下层,三居室,等等。比方说,当然,我们有一个三居室的房子。我们来检查一下。原来 Quandl 已经提供了图表,但是我们还是要抓取数据集,制作自己的图表,或者做一些其他的分析。访问“下载”,并选择 CSV。Pandas 的 IO 兼容 csv,excel 数据,hdf,sql,json,msgpack,html,gbq,stata,剪贴板和 pickle 数据,并且列表不断增长。查看 IO 工具文档的当前列表。将该 CSV 文件移动到本地目录(你正在使用的目录/这个.py脚本所在的目录)。
以这个代码开始,将 CSV 加载进数据帧就是这样简单:
import pandas as pd
df = pd.read_csv('ZILL-Z77006_3B.csv')
print(df.head())
输出:
Date Value
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700
注意我们又没有了合适的索引。我们可以首先这样做来修复:
df.set_index('Date', inplace = True)
现在,让我们假设,我们打算将它转回 CSV,我们可以:
df.to_csv('newcsv2.csv')
我们仅仅有了一列,但是如果你有很多列,并且仅仅打算转换一列,你可以:
df['Value'].to_csv('newcsv2.csv')
要记住我们如何绘制多列,但是并不是所有列。看看你能不能猜出如何保存多列,但不是所有列。
现在,让我们读取新的 CSV:
df = pd.read_csv('newcsv2.csv')
print(df.head())
输出:
Date Value
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700
该死,我们的索引又没了! 这是因为 CSV 没有像我们的数据帧那样的“索引”属性。 我们可以做的是,在导入时设置索引,而不是导入之后设置索引。 像这样:
df = pd.read_csv('newcsv2.csv', index_col=0)
print(df.head())
输出:
Value
Date
2015-06-30 502300
2015-05-31 501500
2015-04-30 500100
2015-03-31 495800
2015-02-28 492700
现在,我不了解你,但“价值”这个名字是毫无价值的。 我们可以改变这个吗? 当然,有很多方法来改变列名,一种方法是:
df.columns = ['House_Prices']
print(df.head())
输出:
House_Prices
Date
2015-06-30 502300
2015-05-31 501500
2015-04-30 500100
2015-03-31 495800
2015-02-28 492700
下面,我们可以尝试这样保存为 CSV:
df.to_csv('newcsv3.csv')
如果你看看 CSV,你应该看到它拥有标题。如果不想要标题怎么办呢?没问题!
df.to_csv('newcsv4.csv', header=False)
如果文件没有标题呢?没问题!
df = pd.read_csv('newcsv4.csv', names = ['Date','House_Price'], index_col=0)
print(df.head())
输出:
House_Price
Date
2015-06-30 502300
2015-05-31 501500
2015-04-30 500100
2015-03-31 495800
2015-02-28 492700
这些是IO的基本知识,在输入和输出时有一些选项。
一个有趣的事情是使用 Pandas 进行转换。 所以,也许你是从 CSV 输入数据,但你真的希望在你的网站上,将这些数据展示为 HTML。 由于 HTML 是数据类型之一,我们可以将其导出为 HTML,如下所示:
df.to_html('example.html')
现在我们有了 HTML 文件。打开它,然后你就有了 HTML 中的一个表格:
| House_Prices | |
|---|---|
| Date | |
| 2015-06-30 | 502300 |
| 2015-05-31 | 501500 |
| 2015-04-30 | 500100 |
| 2015-03-31 | 495800 |
| 2015-02-28 | 492700 |
| 2015-01-31 | 493000 |
| 2014-12-31 | 494200 |
| 2014-11-30 | 490900 |
| 2014-10-31 | 486000 |
| 2014-09-30 | 479800 |
| 2014-08-31 | 473900 |
| 2014-07-31 | 467100 |
| 2014-06-30 | 461400 |
| 2014-05-31 | 455400 |
| 2014-04-30 | 450500 |
| 2014-03-31 | 450300 |
注意,这个表自动分配了dataframe类。 这意味着你可以自定义 CSS 来处理数据帧特定的表!
当我有用数据的 SQL 转储时,我特别喜欢使用 Pandas。 我倾向于将数据库数据直接倒入 Pandas 数据帧中,执行我想要执行的操作,然后将数据显示在图表中,或者以某种方式提供数据。
最后,如果我们想重新命名其中一列,该怎么办? 之前,你已经看到了如何命名所有列,但是也许你只是想改变一个列,而不必输入所有的列。 足够简单:
print(df.head())
df.rename(columns={'House_Price':'Prices'}, inplace=True)
print(df.head())
输出:
Date House_Price
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700
Date Prices
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700
所以在这里,我们首先导入了无头文件,提供了列名Date和House_Price。 然后,我们决定,我们打算用Price代替House_Price。 因此,我们使用df.rename,指定我们要重命名的列,然后在字典形式中,键是原始名称,值是新名称。 我们最终使用inplace = True,以便修改原始对象。
四、构件数据集
在 Python 和 Pandas 数据分析系列教程的这一部分中,我们将扩展一些东西。让我们想想,我们是亿万富豪,还是千万富豪,但成为亿万富豪则更有趣,我们正在努力使我们的投资组合尽可能多样化。我们希望拥有所有类型的资产类别,所以我们有股票,债券,也许是一个货币市场帐户,现在我们正在寻找坚实的不动产。你们都看过广告了吗?你买了 60 美元的 CD,参加了 500 美元的研讨会,你开始把你的 6 位数字投资到房地产,对吧?
好吧,也许不是,但是我们肯定要做一些研究,并有一些购买房地产的策略。那么,什么统治了房价,我们是否需要进行研究才能找到答案?一般来说,不,你并不需要那么做,我们知道这些因素。房价的因素受经济,利率和人口统计的影响。这是房地产价格总体上的三大影响。现在当然,如果你买土地,其他的事情很重要,它的水平如何,我们是否需要在土地上做一些工作,才能真正奠定基础,如何排水等等。那么我们还有更多的因素,比如屋顶,窗户,暖气/空调,地板,地基等等。我们可以稍后考虑这些因素,但首先我们要从宏观层面开始。你会看到我们的数据集在这里膨胀得有多快,它会爆炸式增长。
所以,我们的第一步是收集数据。 Quandl 仍然是良好的起始位置,但是这一次让我们自动化数据抓取。我们将首先抓取 50 个州的住房数据,但是我们也试图收集其他数据。我们绝对不想手动抓取这个数据。首先,如果你还没有帐户,你需要得到一个帐户。这将给你一个 API 密钥和免费数据的无限的 API 请求,这真棒。
一旦你创建了一个账户,访问your account / me,不管他们这个时候叫什么,然后找到标有 API 密钥的部分。这是你所需的密钥。接下来,我们要获取 Quandl 模块。我们实际上并不需要模块来生成请求,但它是一个非常小的模块,他能给我们带来一些小便利,所以不妨试试。打开你的终端或cmd.exe并且执行pip install quandl(再一次,如果pip不能识别,记得指定pip的完整路径)。
接下来,我们做好了开始的准备,打开一个新的编辑器。开始:
import Quandl
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
df = Quandl.get("FMAC/HPI_TX", authtoken=api_key)
print(df.head())
如果你愿意的话,你可以只存储你的密钥的纯文本版本,我只隐藏了我的密钥,因为它是我发布的教程。这是我们需要做的,来获得德克萨斯州的房价指数。我们抓取的实际指标可以在任何页面上找到,无论你什么时候访问,只要在网站上点击你使用的库,我们这里是 Python,然后需要输入的查询就会弹出。
随着你的数据科学事业的发展,你将学习到各种常数,因为人们是合乎逻辑和合理的。我们这里,我们需要获取所有州的数据。我们如何做到呢?我们是否需要手动抓取每个指标?不,看看这个代码,我们看到FMAC/HPI_TX。我们可以很容易地把这个解码为FMAC = Freddie Mac。 HPI = House Price Index(房价指数)。TX是德克萨斯州,它的常用两字母缩写。从这里,我们可以安全地假设所有的代码都是这样构建的,所以现在我们只需要一个州缩写的列表。我们搜索它,作出选择,就像这个 50 个州的列表。怎么办?
我们可以通过多种方式提取这些数据。这是一个 Pandas 教程,所以如果我们可以 Pandas 熊猫,我们就这样。让我们来看看 Pandas 的read_html。它不再被称为“实验性”的,但我仍然会将其标记为实验性的。其他 IO 模块的标准和质量非常高并且可靠。read_html并不是很好,但我仍然说这是非常令人印象深刻有用的代码,而且很酷。它的工作方式就是简单地输入一个 URL,Pandas 会从表中将有价值的数据提取到数据帧中。这意味着,与其他常用的方法不同,read_html最终会读入一些列数据帧。这不是唯一不同点,但它是不同的。首先,为了使用read_html,我们需要html5lib。打开cmd.exe或你的终端,并执行:pip install html5lib。现在,我们可以做我们的第一次尝试:
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
print(fiddy_states)
它的输出比我要在这里发布的更多,但你明白了。 这些数据中至少有一部分是我们想要的,看起来第一个数据帧是一个很好的开始。 那么让我们执行:
print(fiddy_states[0])
0 1 2 3
0 Abbreviation State name Capital Became a state
1 AL Alabama Montgomery December 14, 1819
2 AK Alaska Juneau January 3, 1959
3 AZ Arizona Phoenix February 14, 1912
4 AR Arkansas Little Rock June 15, 1836
5 CA California Sacramento September 9, 1850
6 CO Colorado Denver August 1, 1876
7 CT Connecticut Hartford January 9, 1788
8 DE Delaware Dover December 7, 1787
9 FL Florida Tallahassee March 3, 1845
10 GA Georgia Atlanta January 2, 1788
11 HI Hawaii Honolulu August 21, 1959
12 ID Idaho Boise July 3, 1890
13 IL Illinois Springfield December 3, 1818
14 IN Indiana Indianapolis December 11, 1816
15 IA Iowa Des Moines December 28, 1846
16 KS Kansas Topeka January 29, 1861
17 KY Kentucky Frankfort June 1, 1792
18 LA Louisiana Baton Rouge April 30, 1812
19 ME Maine Augusta March 15, 1820
20 MD Maryland Annapolis April 28, 1788
21 MA Massachusetts Boston February 6, 1788
22 MI Michigan Lansing January 26, 1837
23 MN Minnesota Saint Paul May 11, 1858
24 MS Mississippi Jackson December 10, 1817
25 MO Missouri Jefferson City August 10, 1821
26 MT Montana Helena November 8, 1889
27 NE Nebraska Lincoln March 1, 1867
28 NV Nevada Carson City October 31, 1864
29 NH New Hampshire Concord June 21, 1788
30 NJ New Jersey Trenton December 18, 1787
31 NM New Mexico Santa Fe January 6, 1912
32 NY New York Albany July 26, 1788
33 NC North Carolina Raleigh November 21, 1789
34 ND North Dakota Bismarck November 2, 1889
35 OH Ohio Columbus March 1, 1803
36 OK Oklahoma Oklahoma City November 16, 1907
37 OR Oregon Salem February 14, 1859
38 PA Pennsylvania Harrisburg December 12, 1787
39 RI Rhode Island Providence May 19, 1790
40 SC South Carolina Columbia May 23, 1788
41 SD South Dakota Pierre November 2, 1889
42 TN Tennessee Nashville June 1, 1796
43 TX Texas Austin December 29, 1845
44 UT Utah Salt Lake City January 4, 1896
45 VT Vermont Montpelier March 4, 1791
46 VA Virginia Richmond June 25, 1788
47 WA Washington Olympia November 11, 1889
48 WV West Virginia Charleston June 20, 1863
49 WI Wisconsin Madison May 29, 1848
50 WY Wyoming Cheyenne July 10, 1890
是的,这看起来不错,我们想要第零列。所以,我们要遍历fiddy_states[0]的第零列。 请记住,现在fiddy_states是一个数帧列表,而fiddy_states[0]是第一个数据帧。 为了引用第零列,我们执行fiddy_states[0][0]。 一个是列表索引,它返回一个数据帧。 另一个是数据帧中的一列。 接下来,我们注意到第零列中的第一项是abbreviation,我们不想要它。 当我们遍历第零列中的所有项目时,我们可以使用[1:]排除掉它。 因此,我们的缩写列表是fiddy_states[0][0][1:],我们可以像这样迭代:
for abbv in fiddy_states[0][0][1:]:
print(abbv)
AL
AK
AZ
AR
CA
CO
CT
DE
FL
GA
HI
ID
IL
IN
IA
KS
KY
LA
ME
MD
MA
MI
MN
MS
MO
MT
NE
NV
NH
NJ
NM
NY
NC
ND
OH
OK
OR
PA
RI
SC
SD
TN
TX
UT
VT
VA
WA
WV
WI
WY
完美! 现在,我们回忆这样做的原因:我们正在试图用州名缩写建立指标,来获得每个州的房价指数。 好的,我们可以建立指标:
for abbv in fiddy_states[0][0][1:]:
#print(abbv)
print("FMAC/HPI_"+str(abbv))
FMAC/HPI_AL
FMAC/HPI_AK
FMAC/HPI_AZ
FMAC/HPI_AR
FMAC/HPI_CA
FMAC/HPI_CO
FMAC/HPI_CT
FMAC/HPI_DE
FMAC/HPI_FL
FMAC/HPI_GA
FMAC/HPI_HI
FMAC/HPI_ID
FMAC/HPI_IL
FMAC/HPI_IN
FMAC/HPI_IA
FMAC/HPI_KS
FMAC/HPI_KY
FMAC/HPI_LA
FMAC/HPI_ME
FMAC/HPI_MD
FMAC/HPI_MA
FMAC/HPI_MI
FMAC/HPI_MN
FMAC/HPI_MS
FMAC/HPI_MO
FMAC/HPI_MT
FMAC/HPI_NE
FMAC/HPI_NV
FMAC/HPI_NH
FMAC/HPI_NJ
FMAC/HPI_NM
FMAC/HPI_NY
FMAC/HPI_NC
FMAC/HPI_ND
FMAC/HPI_OH
FMAC/HPI_OK
FMAC/HPI_OR
FMAC/HPI_PA
FMAC/HPI_RI
FMAC/HPI_SC
FMAC/HPI_SD
FMAC/HPI_TN
FMAC/HPI_TX
FMAC/HPI_UT
FMAC/HPI_VT
FMAC/HPI_VA
FMAC/HPI_WA
FMAC/HPI_WV
FMAC/HPI_WI
FMAC/HPI_WY
我们已经得到了指标,现在我们已经准备好提取数据帧了。 但是,一旦我们拿到他们,我们会做什么? 我们将使用 50 个独立的数据帧? 听起来像一个愚蠢的想法,我们需要一些方法来组合他们。 Pandas 背后的优秀人才看到了这一点,并为我们提供了多种组合数据帧的方法。 我们将在下一个教程中讨论这个问题。
五、连接(concat)和附加数据帧
欢迎阅读 Python 和 Pandas 数据分析系列教程第五部分。在本教程中,我们将介绍如何以各种方式组合数据帧。
在我们的房地产投资案例中,我们希望使用房屋数据获取 50 个数据帧,然后把它们全部合并成一个数据帧。我们这样做有很多原因。首先,将这些组合起来更容易,更有意义,也会减少使用的内存。每个数据帧都有日期和值列。这个日期列在所有数据帧中重复出现,但实际上它们应该全部共用一个,实际上几乎减半了我们的总列数。
在组合数据帧时,你可能会考虑相当多的目标。例如,你可能想“附加”到他们,你可能会添加到最后,基本上就是添加更多的行。或者,也许你想添加更多的列,就像我们的情况一样。有四种主要的数据帧组合方式,我们现在开始介绍。四种主要的方式是:连接(Concatenation),连接(Join),合并和附加。我们将从第一种开始。这里有一些初始数据帧:
df1 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2001, 2002, 2003, 2004])
df2 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2005, 2006, 2007, 2008])
df3 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'Low_tier_HPI':[50, 52, 50, 53]},
index = [2001, 2002, 2003, 2004])
注意这些之间有两个主要的变化。 df1和df3具有相同的索引,但它们有一些不同的列。 df2和df3有不同的索引和一些不同的列。 通过连接(concat),我们可以讨论将它们结合在一起的各种方法。 我们来试一下简单的连接(concat):
concat = pd.concat([df1,df2])
print(concat)
HPI Int_rate US_GDP_Thousands
2001 80 2 50
2002 85 3 55
2003 88 2 65
2004 85 2 55
2005 80 2 50
2006 85 3 55
2007 88 2 65
2008 85 2 55
很简单。 这两者之间的主要区别仅仅是索引的延续,但是它们共享同一列。 现在他们已经成为单个数据帧。 然而我们这里,我们对添加列而不是行感到好奇。 当我们将一些共有的和一些新列组合起来:
concat = pd.concat([df1,df2,df3])
print(concat)
HPI Int_rate Low_tier_HPI US_GDP_Thousands
2001 80 2 NaN 50
2002 85 3 NaN 55
2003 88 2 NaN 65
2004 85 2 NaN 55
2005 80 2 NaN 50
2006 85 3 NaN 55
2007 88 2 NaN 65
2008 85 2 NaN 55
2001 80 2 50 NaN
2002 85 3 52 NaN
2003 88 2 50 NaN
2004 85 2 53 NaN
不错,我们有一些NaN(不是数字),因为那个索引处不存在数据,但是我们所有的数据确实在这里。
这些就是基本的连接(concat),接下来,我们将讨论附加。 附加就像连接的第一个例子,只是更加强大一些,因为数据帧会简单地追加到行上。 我们通过一个例子来展示它的工作原理,同时也展示它可能出错的地方:
df4 = df1.append(df2)
print(df4)
HPI Int_rate US_GDP_Thousands
2001 80 2 50
2002 85 3 55
2003 88 2 65
2004 85 2 55
2005 80 2 50
2006 85 3 55
2007 88 2 65
2008 85 2 55
这就是我们期望的附加。 在大多数情况下,你将要做这样的事情,就像在数据库中插入新行一样。 我们并没有真正有效地附加数据帧,它们更像是根据它们的起始数据来操作,但是如果你需要,你可以附加。 当我们附加索引相同的数据时会发生什么?
df4 = df1.append(df3)
print(df4)
HPI Int_rate Low_tier_HPI US_GDP_Thousands
2001 80 2 NaN 50
2002 85 3 NaN 55
2003 88 2 NaN 65
2004 85 2 NaN 55
2001 80 2 50 NaN
2002 85 3 52 NaN
2003 88 2 50 NaN
2004 85 2 53 NaN
好吧,这很不幸。 有人问为什么连接(concat )和附加都退出了。 这就是原因。 因为共有列包含相同的数据和相同的索引,所以组合这些数据帧要高效得多。 一个另外的例子是附加一个序列。 鉴于append的性质,你可能会附加一个序列而不是一个数据帧。 至此我们还没有谈到序列。 序列基本上是单列的数据帧。 序列确实有索引,但是,如果你把它转换成一个列表,它将仅仅是这些值。 每当我们调用df ['column']时,返回值就是一个序列。
s = pd.Series([80,2,50], index=['HPI','Int_rate','US_GDP_Thousands'])
df4 = df1.append(s, ignore_index=True)
print(df4)
HPI Int_rate US_GDP_Thousands
0 80 2 50
1 85 3 55
2 88 2 65
3 85 2 55
4 80 2 50
在附加序列时,我们必须忽略索引,因为这是规则,除非序列拥有名称。
在这里,我们已经介绍了 Pandas 中的连接(concat)和附加数据帧。 接下来,我们将讨论如何连接(join)和合并数据帧。
六、连接(join)和合并数据帧
欢迎阅读 Python 和 Pandas 数据分析系列教程的第六部分。 在这一部分种,我们将讨论连接(join)和合并数据帧,作为组合数据框的另一种方法。 在前面的教程中,我们介绍了连接(concat)和附加。
首先,我们将从以前的一些示例数据帧开始,带有一点更改:
import pandas as pd
df1 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2001, 2002, 2003, 2004])
df2 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2005, 2006, 2007, 2008])
df3 = pd.DataFrame({'HPI':[80,85,88,85],
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53]},
index = [2001, 2002, 2003, 2004])
唯一的变化是df3,我们把Int_rate变成了unemployment。 首先,我们来讨论合并。
print(pd.merge(df1,df3, on='HPI'))
HPI Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
0 80 2 50 50 7
1 85 3 55 52 8
2 85 3 55 53 6
3 85 2 55 52 8
4 85 2 55 53 6
5 88 2 65 50 9
所以,在这里,我们看到了一个共有列(HPI)。 你可以共有多个列,这里有一个例子:
print(pd.merge(df1,df2, on=['HPI','Int_rate']))
HPI Int_rate US_GDP_Thousands_x US_GDP_Thousands_y
0 80 2 50 50
1 85 3 55 55
2 88 2 65 65
3 85 2 55 55
注意这里有US_GDP_Thousands的两个版本。这是因为我们没有共享这些列,所以都保留下来,使用另外一个字母来区分。记得之前我说过,Pandas 是一个很好的模块,与类似 MySQL 的数据库结合。这就是原因。
通常,对于数据库,你希望使其尽可能轻量化,以便在其上运行的查询执行得尽可能快。
假设你运营像pythonprogramming.net这样的网站,在那里你有用户,所以你必须跟踪用户名和加密的密码散列,所以这肯定是两列。也许那么你有登录名,用户名,密码,电子邮件和注册日期。所以这已经是基本数据点的五列。如果你有一个论坛,那么也许你有一些东西,像用户设置,帖子。那么也许你希望有像管理员,主持人,普通用户的设置。
列表可以继续。如果你在字面上只有一个巨大的表,这可以工作,但把表分开也可能更好,因为许多操作将更快,更高效。 合并之后,你可能会设置新的索引。像这样的东西:
df4 = pd.merge(df1,df3, on='HPI')
df4.set_index('HPI', inplace=True)
print(df4)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
HPI
80 2 50 50 7
85 3 55 52 8
85 3 55 53 6
85 2 55 52 8
85 2 55 53 6
88 2 65 50 9
现在,如果HPI已经是索引了呢? 或者,在我们的情况下,我们可能会按照日期连接,但日期可能是索引。 在这种情况下,我们可能会使用连接(join)。
df1.set_index('HPI', inplace=True)
df3.set_index('HPI', inplace=True)
joined = df1.join(df3)
print(joined)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
HPI
80 2 50 50 7
85 3 55 52 8
85 3 55 53 6
85 2 55 52 8
85 2 55 53 6
88 2 65 50 9
现在,我们考虑连接(join)和合并略有不同的索引。 让我们重新定义df1和df3数据帧,将它们变成:
df1 = pd.DataFrame({
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55],
'Year':[2001, 2002, 2003, 2004]
})
df3 = pd.DataFrame({
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53],
'Year':[2001, 2003, 2004, 2005]})
这里,我们现在有相似的年份列,但日期不同。 df3有 2005 年,但没有 2002 年,df1相反。 现在,当我们合并时会发生什么?
merged = pd.merge(df1,df3, on='Year')
print(merged)
Int_rate US_GDP_Thousands Year Low_tier_HPI Unemployment
0 2 50 2001 50 7
1 2 65 2003 52 8
2 2 55 2004 50 9
现在,更实用一些:
merged = pd.merge(df1,df3, on='Year')
merged.set_index('Year', inplace=True)
print(merged)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2003 2 65 52 8
2004 2 55 50 9
注意 2005 年和 2002 年完全失踪了。 合并只会合并现有/共有的数据。 我们能对其做些什么呢? 事实证明,合并时有一个参数how。 此参数表明合并选择,它来自数据库的合并。 你有以下选择:左、右、外部、内部。
- 左 - SQL 左外连接 - 仅使用左侧数据帧中的键
- 右 - SQL 右外连接 - 仅使用右侧数据帧中的键
- 外部 - 全外联接 - 使用键的并集
- 内部 - 使用键的交集
merged = pd.merge(df1,df3, on='Year', how='left')
merged.set_index('Year', inplace=True)
print(merged)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2002 3 55 NaN NaN
2003 2 65 52 8
2004 2 55 50 9
左侧合并实际上在左边的数据帧上。 我们有df1,df3,左边的是第一个,df1。 所以,我们最终得到了一个与左侧数据帧(df1)相同的索引。
merged = pd.merge(df1,df3, on='Year', how='right')
merged.set_index('Year', inplace=True)
print(merged)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2003 2 65 52 8
2004 2 55 50 9
2005 NaN NaN 53 6
我们选择了右侧,所以这次索引来源于右侧(df3)。
merged = pd.merge(df1,df3, on='Year', how='outer')
merged.set_index('Year', inplace=True)
print(merged)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2002 3 55 NaN NaN
2003 2 65 52 8
2004 2 55 50 9
2005 NaN NaN 53 6
这次,我们选择了外部,它是键的并集。也就是会展示所有索引。
merged = pd.merge(df1,df3, on='Year', how='inner')
merged.set_index('Year', inplace=True)
print(merged)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2003 2 65 52 8
2004 2 55 50 9
最后,“内部”是键的交集,基本上就是所有集合之间共有的东西。 这些都有其自己的逻辑,但是,正如你所看到的,默认选项是“内部”。
现在我们可以检查连接(join),这会按照索引连接,所以我们可以做这样的事情:
df1.set_index('Year', inplace=True)
df3.set_index('Year', inplace=True)
joined = df1.join(df3, how="outer")
print(joined)
Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2002 3 55 NaN NaN
2003 2 65 52 8
2004 2 55 50 9
2005 NaN NaN 53 6
好吧,我想我们已经足以涵盖了数据帧的组合。 让我们回到我们的房地产投资,使用我们的新知识,并建立自己的史诗数据集。
七、Pickle
欢迎阅读 Python 和 Pandas 数据分析系列教程第七部分。 在最近的几个教程中,我们学习了如何组合数据集。 在本教程中,我们将恢复我们是房地产巨头的假设。 我们希望通过拥有多元化的财富来保护我们的财富,其中一个组成部分就是房地产。 在第 4部分 中,我们建立了以下代码:
import Quandl
import pandas as pd
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
for abbv in fiddy_states[0][0][1:]:
#print(abbv)
print("FMAC/HPI_"+str(abbv))
这个代码用来获得 50 个州,遍历他们,并产生适当的 Quandl 查询,来按州返回房价指数。 由于我们将在这里生成 50 个数据帧,我们宁愿把它们全部合并成一个。 为此,我们可以使用前面教程中学到的.join。 在这种情况下,我们将使用.join,因为 Quandl 模块将数据返回给我们,实际索引为Date。 通常情况下,你可能不会得到这个,它只是索引为常规数字的数据帧。 在这种情况下,你可以使用连接,on ='Date'。
现在,为了运行并收集所有的数据,我们可以做以下的改变:
import Quandl
import pandas as pd
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
main_df = pd.DataFrame()
for abbv in fiddy_states[0][0][1:]:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
注意:Quandl 已经改变了数据集的返回值,如果返回值只有一列(或者我认为是这样),那么该列的标题就是value。那么,这很麻烦,但我们可以解决它。在for循环中,将数据帧的列重命名为我们的缩写。如果没有做这个改变,你可能会看到:ValueError: columns overlap but no suffix specified: Index([u'Value'], dtype='object')。
太好了,但是每一次你想运行它时,你会发现这个过程可能需要 30 秒到几分钟。这很烦人。现在,你的短期目标是实现它,但接下来呢?我们将继续在此基础上进行研究,每次我们进行测试或者其他东西时,我们都必须忍受这个无意义的东西!因此,我们要保存这些数据。现在,这是一个数据分析和 Pandas 教程。有了 Pandas,我们可以简单地将数据输出到 CSV,或者我们希望的任何数据类型,包括我们要谈论的内容。但是,你可能并不总是可以将数据输出到简单文件。在任何情况下,我们都希望将这些数据保存到一个文件中,所以我们只需要执行一次这个操作,然后我们就可以在它顶上建立。
举个例子来说,就是机器学习。你通常会训练一个分类器,然后你可以立即开始,然后快速使用该分类器进行分类。问题是,分类器不能保存到.txt或.csv文件。这是一个对象。幸运的是,以编程的方式,有各种各样的东西,用于将二进制数据保存到可以稍后访问的文件。在 Python 中,这被称为 Pickle。你可能知道它是序列化的,或者甚至别的东西。 Python 有一个名为 Pickle 的模块,它将把你的对象转换成一个字节流,或者反过来转换它。这让我们做的是保存任何 Python 对象。那机器学习分类器呢?可以。字典?可以。数据帧?可以!现在,Pandas 在 IO 模块中已经有了 Pickle,但是你真的应该知道如何使用和不使用 Pandas 来实现它,所以让我们这样做吧!
首先,我们来谈谈常规的 Pickle。你可以用你想要的任何 Python 对象来这样做,它不需要是一个数据帧,但我们会用我们的数据帧来实现。
首先,在脚本的顶部导入pickle:
import pickle
下面:
pickle_out = open('fiddy_states.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
首先我们打开一个.pickle文件,打算写一些字节。 然后,我们执行pickle.dump来转储我们想要保存的数据,之后是转储它的地方(我们刚才打开的文件)。 最后,我们关闭任何文件。 完成了,我们保存了pickle。
不过,我希望现在组织这些代码。 我们不希望每次都运行这个代码,但是我们仍然需要时常引用状态列表。 我们来清理一下:
import Quandl
import pandas as pd
import pickle
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
grab_initial_state_data()
现在,我们可以在任何需要状态列表的时候,引用state_list,然后我们只需要为HPI基线调用grab_initial_state_data,真的比较快,并且我们已经将这些数据保存到了pickle文件中。
现在,再次获取这些数据,我们只需要做:
pickle_in = open('fiddy_states.pickle','rb')
HPI_data = pickle.load(pickle_in)
print(HPI_data)
输出比我想要粘贴的更多,但是你应该得到一个约 462 行 x50 列的数据帧。 你有了它。 部分对象是它是一个数据帧,这是我们“保存”变量的方式。 很酷! 你可以在 Python 的任何地方用pickle模块来这样做,但是 Pandas 也有自己的pickle,所以我们可以展示:
HPI_data.to_pickle('pickle.pickle')
HPI_data2 = pd.read_pickle('pickle.pickle')
print(HPI_data2)
再次,输出有点多,不能粘贴在这里,但你应该得到同样的东西。 如果你和我一样,你可能会想“如果所有的 Python 已经有 Pickle 并且工作得很好,为什么 Pandas 有自己的 Pickle 选项?” 我真的不知道。 显然,Pandas 有时可以更快地处理海量数据。
现在我们已经得到了数据的pickle,我们已经准备好在下一篇教程中继续深入研究。
八、百分比变化和相关表
欢迎阅读 Python 和 Pandas 数据分析系列教程的第八部分。 在这一部分中,我们将对数据进行一些初步的操作。 我们到目前为止的脚本是:
import Quandl
import pandas as pd
import pickle
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
HPI_data = pd.read_pickle('fiddy_states.pickle')
现在我们可以像这样修改列:
HPI_data['TX2'] = HPI_data['TX'] * 2
print(HPI_data[['TX','TX2']].head())
TX TX2
Date
1975-01-31 32.617930 65.235860
1975-02-28 33.039339 66.078677
1975-03-31 33.710029 67.420057
1975-04-30 34.606874 69.213747
1975-05-31 34.864578 69.729155
我们我们也可以不创建新的列,只是重新定义原来的TX。 从我们的脚本中删除整个TX2的代码,让我们看看我们现在有什么。 在脚本的顶部:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
之后:
HPI_data.plot()
plt.legend().remove()
plt.show()
输出:
嗯,有趣,发生了什么事? 所有这些价格似乎在 2000 年完美汇合!这正是指数从 100.0% 开始的时候。 我们可以得到它,但我根本不喜欢。 那么某种百分比变化呢? 事实证明,Pandas 在这里覆盖了各种“滚动”统计量。 我们可以用一个基本的,就像这样:
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df = df.pct_change()
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states2.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
grab_initial_state_data()
主要是,你要注意:df = df.pct_change(),我们将重新运行它,保存到fiddy_states2.pickle。 值得注意的是,我们也可以尝试修改原来的 Pickle,而不是重新构建。 毕竟,这就是 Pickle 的要点。 如果我没有事后偏见,我可能会同意你的看法。
HPI_data = pd.read_pickle('fiddy_states2.pickle')
HPI_data.plot()
plt.legend().remove()
plt.show()
输出:
不幸的是,我不是那么想的。 我想要一个传统的百分比变化图。 这是距离上次报告值的百分比变化。 我们可以增加它,做一些事情,类似于过去 10 个值的滚动百分比,但仍然不是我想要的。 我们来试试其他的东西:
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
grab_initial_state_data()
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data.plot()
plt.legend().remove()
plt.show()
好的,这就是我要找的! 这是每个州 HPI 自身的百分比变化。 出于各种原因,第一个百分比变化仍然有用。 我们可能会结合使用这个结果,或者取而代之,但是现在,我们最开始坚持使用典型的百分比变化。
现在,我们可能想要引入其他数据集,但是让我们看看我们是否可以自己到达任何地方。 首先,我们可以检查某种“基准”。 对于这个数据,这个基准将是美国的房价指数。 我们可以收集:
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
之后:
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
benchmark = HPI_Benchmark()
HPI_data.plot(ax=ax1)
benchmark.plot(color='k',ax=ax1, linewidth=10)
plt.legend().remove()
plt.show()
输出:
从这个数据来看,似乎是所有的市场都是相对密切地服从彼此和整体房价指数。这里确实存在一些平均偏差,但基本上每个市场似乎都遵循了非常相似的趋势。其中最大的偏差是从 200% 的增长到 800% 的增长,显然我们有很大的偏差,但是在过去的 30 年里,均值从 400% 增长到 500%。
我们如何接近市场呢?之后,我们可以考虑人口统计和利率来预测未来,但不是每个人都对投机游戏感兴趣。有些人想要更安全,更安全的投资。在这里看来,像房地产市场从来没有真正在国家层面失败。如果我们买房子,显然我们的计划可能会失败,之后我们发现了巨大白蚁危害,并可能在任何时候倒塌。
保持宏观,我很清楚,我们可以在这里进行一个非常明显,安全的交易。我们可以使用 Pandas 很容易地收集相关性和协方差信息。相关性和协方差是两个非常相似的话题,经常被混淆。相关不是因果关系,相关性几乎总是包含在协方差计算中用于归一化。相关性衡量了两个资产相对于彼此移动的程度。协方差是衡量两个资产如何一起变化的指标。注意相关性是对“程度”的一种度量。协方差不是。如果我自己的理解不正确,这是重要的区别。
我们来创建一个关联表。这将为我们做的事情,是历史回顾,衡量每个州与其他州的移动之间的相关性。那么,当两个通常高度相关的州开始出现不一致的时候,我们可以考虑出售正在上升的州的房地产,并购买正在下降的州的房地产作为一种市场中性策略,其中我们仅仅从差距中获益,而不是做一些预测未来的尝试。相互接壤的州更有可能比远离的州更相似,但是我们会看到数字说了些什么。
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_State_Correlation = HPI_data.corr()
print(HPI_State_Correlation)
输出是 50 行 x50 列,这里是一些输出。
AL AK AZ AR CA CO CT \
AL 1.000000 0.944603 0.927361 0.994896 0.935970 0.979352 0.953724
AK 0.944603 1.000000 0.893904 0.965830 0.900621 0.949834 0.896395
AZ 0.927361 0.893904 1.000000 0.923786 0.973546 0.911422 0.917500
AR 0.994896 0.965830 0.923786 1.000000 0.935364 0.985934 0.948341
CA 0.935970 0.900621 0.973546 0.935364 1.000000 0.924982 0.956495
CO 0.979352 0.949834 0.911422 0.985934 0.924982 1.000000 0.917129
CT 0.953724 0.896395 0.917500 0.948341 0.956495 0.917129 1.000000
DE 0.980566 0.939196 0.942273 0.975830 0.970232 0.949517 0.981177
FL 0.918544 0.887891 0.994007 0.915989 0.987200 0.905126 0.926364
GA 0.973562 0.880261 0.939715 0.960708 0.943928 0.959500 0.948500
HI 0.946054 0.930520 0.902554 0.947022 0.937704 0.903461 0.938974
ID 0.982868 0.944004 0.959193 0.977372 0.944342 0.960975 0.923099
IL 0.984782 0.905512 0.947396 0.973761 0.963858 0.968552 0.955033
IN 0.981189 0.889734 0.881542 0.973259 0.901154 0.971416 0.919696
IA 0.985516 0.943740 0.894524 0.987919 0.914199 0.991455 0.913788
KS 0.990774 0.957236 0.910948 0.995230 0.926872 0.994866 0.936523
KY 0.994311 0.938125 0.900888 0.992903 0.923429 0.987097 0.941114
LA 0.967232 0.990506 0.909534 0.982454 0.911742 0.972703 0.907456
ME 0.972693 0.935850 0.923797 0.972573 0.965251 0.951917 0.989180
MD 0.964917 0.943384 0.960836 0.964943 0.983677 0.940805 0.969170
MA 0.966242 0.919842 0.921782 0.966962 0.962672 0.959294 0.986178
MI 0.891205 0.745697 0.848602 0.873314 0.861772 0.900040 0.843032
MN 0.971967 0.926352 0.952359 0.972338 0.970661 0.983120 0.945521
MS 0.996089 0.962494 0.927354 0.997443 0.932752 0.985298 0.945831
MO 0.992706 0.933201 0.938680 0.989672 0.955317 0.985194 0.961364
MT 0.977030 0.976840 0.916000 0.983822 0.923950 0.971516 0.917663
NE 0.988030 0.941229 0.896688 0.990868 0.912736 0.992179 0.920409
NV 0.858538 0.785404 0.965617 0.846968 0.948143 0.837757 0.866554
NH 0.953366 0.907236 0.932992 0.952882 0.969574 0.941555 0.990066
NJ 0.968837 0.934392 0.943698 0.967477 0.975258 0.944460 0.989845
NM 0.992118 0.967777 0.934744 0.993195 0.934720 0.968001 0.946073
NY 0.973984 0.940310 0.921126 0.973972 0.959543 0.949474 0.989576
NC 0.998383 0.934841 0.915403 0.991863 0.928632 0.977069 0.956074
ND 0.936510 0.973971 0.840705 0.957838 0.867096 0.942225 0.882938
OH 0.966598 0.855223 0.883396 0.954128 0.901842 0.957527 0.911510
OK 0.944903 0.984550 0.881332 0.967316 0.882199 0.960694 0.879854
OR 0.981180 0.948190 0.949089 0.978144 0.944542 0.971110 0.916942
PA 0.985357 0.946184 0.915914 0.983651 0.950621 0.956316 0.975324
RI 0.950261 0.897159 0.943350 0.945984 0.984298 0.926362 0.988351
SC 0.998603 0.945949 0.929591 0.994117 0.942524 0.980911 0.959591
SD 0.983878 0.966573 0.889405 0.990832 0.911188 0.984463 0.924295
TN 0.998285 0.946858 0.919056 0.995949 0.931616 0.983089 0.953009
TX 0.963876 0.983235 0.892276 0.981413 0.902571 0.970795 0.919415
UT 0.983987 0.951873 0.926676 0.982867 0.909573 0.974909 0.900908
VT 0.975210 0.952370 0.909242 0.977904 0.949225 0.951388 0.973716
VA 0.972236 0.956925 0.950839 0.975683 0.977028 0.954801 0.970366
WA 0.988253 0.948562 0.950262 0.982877 0.956434 0.968816 0.941987
WV 0.984364 0.964846 0.907797 0.990264 0.924300 0.979467 0.925198
WI 0.990190 0.930548 0.927619 0.985818 0.943768 0.987609 0.936340
WY 0.944600 0.983109 0.892255 0.960336 0.897551 0.950113 0.880035
所以现在我们可以看到,每两个州之间的 HPI 移动的相关性。 非常有趣,显而易见,所有这些都非常高。 相关性的范围从 -1 到 1。1 是个完美的正相关,-1 是个完美的负相关。 协方差没有界限。 想知道更多的统计量嘛? Pandas 有一个非常漂亮的描述方法:
print(HPI_State_Correlation.describe())
AL AK AZ AR CA CO \
count 50.000000 50.000000 50.000000 50.000000 50.000000 50.000000
mean 0.969114 0.932978 0.922772 0.969600 0.938254 0.958432
std 0.028069 0.046225 0.031469 0.029532 0.031033 0.030502
min 0.858538 0.745697 0.840705 0.846968 0.861772 0.837757
25% 0.956262 0.921470 0.903865 0.961767 0.916507 0.949485
50% 0.976120 0.943562 0.922784 0.976601 0.940114 0.964488
75% 0.987401 0.957159 0.943081 0.989234 0.961890 0.980550
max 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000
CT DE FL GA ... SD \
count 50.000000 50.000000 50.000000 50.000000 ... 50.000000
mean 0.938752 0.963892 0.920650 0.945985 ... 0.959275
std 0.035402 0.028814 0.035204 0.030631 ... 0.039076
min 0.843032 0.846668 0.833816 0.849962 ... 0.794846
25% 0.917541 0.950417 0.899680 0.934875 ... 0.952632
50% 0.941550 0.970461 0.918904 0.949980 ... 0.972660
75% 0.960920 0.980587 0.944646 0.964282 ... 0.982252
max 1.000000 1.000000 1.000000 1.000000 ... 1.000000
TN TX UT VT VA WA \
count 50.000000 50.000000 50.000000 50.000000 50.000000 50.000000
mean 0.968373 0.944410 0.953990 0.959094 0.963491 0.966678
std 0.029649 0.039712 0.033818 0.035041 0.029047 0.025752
min 0.845672 0.791177 0.841324 0.817081 0.828781 0.862245
25% 0.955844 0.931489 0.936264 0.952458 0.955986 0.954070
50% 0.976294 0.953301 0.956764 0.968237 0.970380 0.974049
75% 0.987843 0.967444 0.979966 0.976644 0.976169 0.983541
max 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000
WV WI WY
count 50.000000 50.000000 50.000000
mean 0.961813 0.965621 0.932232
std 0.035339 0.026125 0.048678
min 0.820529 0.874777 0.741663
25% 0.957074 0.950046 0.915386
50% 0.974099 0.973141 0.943979
75% 0.984067 0.986954 0.961900
max 1.000000 1.000000 1.000000
[8 rows x 50 columns]
这告诉我们,对于每个州,最低的相关性是什么,平均相关性是什么,标准差是什么,前 25%,中间值(中位数/ 50%)等等。显然他们最大都为 1.0,因为他们是完全相关的。然而,最重要的是,我们在这里看到的所有这些州(50 列中的一些被跳过,我们从 GA 到 SD)与其他所有州的相关度平均上高于 90%。怀俄明州与一个州的相关度低至 74%,在看了我们的表后,它就是密歇根州。正因为如此,如果密歇根州上升,我们可能不想在怀俄明州投资,或者因为怀俄明州正在陷入困境而,出售我们在密歇根州的房子。
我们不仅可以从整体指数中看到任何偏差,还可以从个别市场中寻找偏差。正如你所看到的,我们有每个州的标准差数字。当市场低于标准偏差时,我们可以尝试投资于房地产,或者当市场高于标准偏差时卖出。在我们到达那里之前,让我们在下一个教程中讨论平滑数据以及重采样的概念。
九、重采样
欢迎阅读另一个 Python 和 Pandas 数据分析教程。在本教程中,我们将讨论通过消除噪音来平滑数据。有两种主要的方法来实现。所使用的最流行的方法是称为重采样,但可能具有许多其他名称。这是我们有一些数据,以一定的比例抽样。对我们来说,我们的房屋价格指数是按一个月抽样的,但是我们可以每周,每一天,每一分钟或更多时间对 HPI 进行抽样,但是我们也可以每年,每隔 10 年重新抽样。
例如,重新抽样经常出现的另一个环境就是股价。股票价格是二手数据。所发生的事情是,对于免费数据,股票价格通常最低被重新采样为分钟数据。但是,你可以购买实时数据。从长远来看,数据通常会每天采样,甚至每 3-5 天采样一次。这通常是为了使传输数据的大小保持较小。例如,在一年的过程中,二手数据通常是几个 GB,并且一次全部传输是不合理的,人们将等待几分钟或几小时来加载页面。
使用我们目前每个月抽样一次的数据,我们怎样才能每六个月或两年抽样一次呢?试着想想如何亲自编写一个能执行这个任务的函数,这是一个相当具有挑战性的函数,但是它可以完成。也就是说,这是一个计算效率相当低的工作,但 Pandas 会帮助我们,并且速度非常快。让我们来看看。我们现在的起始脚本:
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_State_Correlation = HPI_data.corr()
首先,让我们更简单一点,首先参考德克萨斯州的信息,然后重新抽样:
TX1yr = HPI_data['TX'].resample('A')
print(TX1yr.head())
Date
1975-12-31 4.559105
1976-12-31 11.954152
1977-12-31 23.518179
1978-12-31 41.978042
1979-12-31 64.700665
Freq: A-DEC, Name: TX, dtype: float64
我们以A重新采样,这会每年重新采样(年终)。 你可以在这里找到所有的resample选项:http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases,但这里是我写这篇教程时的最新版本:
Resample rule:
xL for milliseconds
xMin for minutes
xD for Days
Alias Description
B business day frequency
C custom business day frequency (experimental)
D calendar day frequency
W weekly frequency
M month end frequency
BM business month end frequency
CBM custom business month end frequency
MS month start frequency
BMS business month start frequency
CBMS custom business month start frequency
Q quarter end frequency
BQ business quarter endfrequency
QS quarter start frequency
BQS business quarter start frequency
A year end frequency
BA business year end frequency
AS year start frequency
BAS business year start frequency
BH business hour frequency
H hourly frequency
T minutely frequency
S secondly frequency
L milliseonds
U microseconds
N nanoseconds
How:
mean, sum, ohlc
现在我们可以比较两个数据集:
HPI_data['TX'].plot(ax=ax1)
TX1yr.plot(color='k',ax=ax1)
plt.legend().remove()
plt.show()
你可以看到,从月度数据变为年度数据并没有真正向我们隐藏趋势线本身的任何信息,但是至少在德克萨斯州,有一件有趣的事情需要注意,你觉得月度数据中的那些扭曲看起来有些模式化?我反正是。你可以将鼠标悬停在所有峰值上,然后开始查看出现峰值的一年中的月份。大部分峰值出现在 6 月左右,几乎每个最低值都在 12 月左右。许多州都有这种模式,而且在美国的 HPI 中也是如此。也许我们会玩玩这些趋势,并完成整个教程!我们现在是专家!
好的不完全是,我想我们会继续教程。所以通过重新采样,我们可以选择间隔,以及我们希望“如何”重新采样。默认是按照均值,但也有一个时期的总和。如果我们按年份重采样,使用how=sum,那么收益就是这一年所有 HPI 值的总和。最后是 OHLC,这是高开低收。这将返回这个期间的起始值,最高值,最低值和最后一个值。
我认为我们最好坚持使用月度数据,但重新采样绝对值得在任何 Pandas 教程中涵盖。现在,你可能想知道,为什么我们为重采样创建了一个新的数据帧,而不是将其添加到现有的数据帧中。原因是它会创建大量的NaN数据。有时候,即使只是原始的重采样也会包含NaN数据,特别是如果你的数据不按照统一的时间间隔更新的话。处理丢失的数据是一个主要的话题,但是我们将在下一个教程中试图广泛地介绍它,包括处理丢失数据的思路,以及如何通过程序处理你的选择。
十、处理缺失数据
欢迎阅读 Python 和 Pandas 数据分析教程的第 10 部分。在这一部分中,我们将讨论缺失或不可用的数据。考虑到缺失数据的存在,我们有几个选择。
- 忽略它 - 只把它留在那里
- 删除它 - 删除所有的情况。完全从数据中删除。这意味着放弃整行数据。
- 向前或向后填充 - 这意味着只是采用之前或之后的值填充。
- 将其替换为静态的东西 - 例如,用
-9999替换所有的NaN数据。
由于各种原因,这些选项各有其优点。忽略它不需要我们更多的工作。你可能会出于法律原因选择忽略丢失的数据,或者保留数据的最大完整性。缺失数据也可能是非常重要的数据。例如,也许你的分析的一部分是调查服务器的信号丢失。在这种情况下,缺失数据可能非常重要,需要保持在集合中。
接下来,我们可以删除它。在这里你有另外两个选择。如果行中包含任意数量的NaN数据,或者如果该行完全是NaN数据,则可以删除这些行。通常,充满NaN数据的行来自你在数据集上执行的计算,并且数据没有真的丢失,只是你的公式不可用。在大多数情况下,你至少需要删除所有完全是NaN的行,并且在很多情况下,你只希望删除任何具有NaN数据的行。我们该怎么做呢?我们将从以下脚本开始(请注意,现在通过在HPI_data数据帧中添加一个新列,来完成重新采样)。
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
##fig = plt.figure()
##ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX1yr'] = HPI_data['TX'].resample('A')
print(HPI_data[['TX','TX1yr']])
##HPI_data['TX'].plot(ax=ax1)
##HPI_data['TX1yr'].plot(color='k',ax=ax1)
##
##plt.legend().remove()
##plt.show()
我们现在注释了绘图的东西,但是我们稍后会回顾它。
输出:
TX TX1yr
Date
1975-01-31 0.000000 NaN
1975-02-28 1.291954 NaN
1975-03-31 3.348154 NaN
1975-04-30 6.097700 NaN
1975-05-31 6.887769 NaN
1975-06-30 5.566434 NaN
1975-07-31 4.710613 NaN
1975-08-31 4.612650 NaN
1975-09-30 4.831876 NaN
1975-10-31 5.192504 NaN
1975-11-30 5.832832 NaN
1975-12-31 6.336776 4.559105
1976-01-31 6.576975 NaN
1976-02-29 7.364782 NaN
1976-03-31 9.579950 NaN
1976-04-30 12.867197 NaN
1976-05-31 14.018165 NaN
1976-06-30 12.938501 NaN
1976-07-31 12.397848 NaN
1976-08-31 12.388581 NaN
1976-09-30 12.638779 NaN
1976-10-31 13.341849 NaN
1976-11-30 14.336404 NaN
1976-12-31 15.000798 11.954152
1977-01-31 15.555243 NaN
1977-02-28 16.921638 NaN
1977-03-31 20.118106 NaN
1977-04-30 25.186161 NaN
1977-05-31 26.260529 NaN
1977-06-30 23.430347 NaN
... ... ...
2011-01-31 280.574891 NaN
2011-02-28 281.202150 NaN
2011-03-31 282.772390 NaN
2011-04-30 284.374537 NaN
2011-05-31 286.518910 NaN
2011-06-30 288.665880 NaN
2011-07-31 288.232992 NaN
2011-08-31 285.507223 NaN
2011-09-30 283.408865 NaN
2011-10-31 282.348926 NaN
2011-11-30 282.026481 NaN
2011-12-31 282.384836 284.001507
2012-01-31 283.248573 NaN
2012-02-29 285.790368 NaN
2012-03-31 289.946517 NaN
2012-04-30 294.803887 NaN
2012-05-31 299.670256 NaN
2012-06-30 303.575682 NaN
2012-07-31 305.478743 NaN
2012-08-31 305.452329 NaN
2012-09-30 305.446084 NaN
2012-10-31 306.424497 NaN
2012-11-30 307.557154 NaN
2012-12-31 308.404771 299.649905
2013-01-31 309.503169 NaN
2013-02-28 311.581691 NaN
2013-03-31 315.642943 NaN
2013-04-30 321.662612 NaN
2013-05-31 328.279935 NaN
2013-06-30 333.565899 NaN
[462 rows x 2 columns]
我们有很多NaN数据。 如果我们取消所有绘图代码的注释,会发生什么? 原来,我们没有得到包含NaN数据的图表! 这是一个偷懒,所以首先我们想,好吧,让我们丢掉所有有NaN数据的行。 这仅仅是出于教程的目的。 在这个例子中,这将是一个非常糟糕的主意。 相反,你会想要做我们原来做的事情,这是为重采样数据创建一个新的数据帧。 并不意味着你可以总是这样做,但在这种情况下,你可以这样做。 无论如何,让我们删除包含任何na数据的所有行。 这很简单:
HPI_data.dropna(inplace=True)
print(HPI_data[['TX','TX1yr']])
TX TX1yr
Date
1975-12-31 6.336776 4.559105
1976-12-31 15.000798 11.954152
1977-12-31 30.434104 23.518179
1978-12-31 51.029953 41.978042
1979-12-31 75.975953 64.700665
1980-12-31 89.979964 85.147662
1981-12-31 108.121926 99.016599
1982-12-31 118.210559 114.589927
1983-12-31 127.233791 122.676432
1984-12-31 133.599958 131.033359
1985-12-31 132.576673 133.847016
1986-12-31 126.581048 131.627647
1987-12-31 109.829893 119.373827
1988-12-31 104.602726 107.930502
1989-12-31 108.485926 107.311348
1990-12-31 109.082279 108.727174
1991-12-31 114.471725 113.142303
1992-12-31 121.427564 119.650162
1993-12-31 129.817931 127.009907
1994-12-31 135.119413 134.279735
1995-12-31 141.774551 139.197583
1996-12-31 146.991204 145.786792
1997-12-31 155.855049 152.109010
1998-12-31 170.625043 164.595301
1999-12-31 188.404171 181.149544
2000-12-31 206.579848 199.952853
2001-12-31 217.747701 215.692648
2002-12-31 230.161877 226.962219
2003-12-31 236.946005 235.459053
2004-12-31 248.031552 245.225988
2005-12-31 267.728910 260.589093
2006-12-31 288.009470 281.876293
2007-12-31 296.154296 298.094138
2008-12-31 288.081223 296.999508
2009-12-31 291.665787 292.160280
2010-12-31 281.678911 291.357967
2011-12-31 282.384836 284.001507
2012-12-31 308.404771 299.649905
没有带有缺失数据的行了!
现在我们可以绘制它:
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX1yr'] = HPI_data['TX'].resample('A')
HPI_data.dropna(inplace=True)
print(HPI_data[['TX','TX1yr']])
HPI_data['TX'].plot(ax=ax1)
HPI_data['TX1yr'].plot(color='k',ax=ax1)
plt.legend().remove()
plt.show()
好的,太好了。 现在只是出于教程的目的,我们如何编写代码,只在整行是NaN时才删除行?
HPI_data.dropna(how='all',inplace=True)
对于how参数,你可以选择any或all。 all需要该行中的所有数据为NaN,才能将其删除。 你也可以选择any,然后设置一个阈值。 该阈值将要求存在许多非na值,才能接受该行。 更多信息,请参阅dropna的Pandas文档。
好吧,所以这就是dropna,接下来我们可以填充它。 使用填充,我们又有两个主要的选择,是向前还是向后。 另一个选择是仅仅替换数据,但我们称这是一个单独的选择。 碰巧相同函数可以用于实现它,fillna。
修改我们原来的代码块,主要改变:
HPI_data.fillna(method='ffill',inplace=True)
变为:
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX1yr'] = HPI_data['TX'].resample('A')
HPI_data.fillna(method='ffill',inplace=True)
HPI_data.dropna(inplace=True)
print(HPI_data[['TX','TX1yr']])
HPI_data['TX'].plot(ax=ax1)
HPI_data['TX1yr'].plot(color='k',ax=ax1)
plt.legend().remove()
plt.show()
ffill,或者“前向填充”所做的就是,将数据向前扫描,填充到缺失的数据中。 把它看作是一个扫描动作,其中你可以从过去获取数据,将其转移到缺失的数据中。 任何缺失数据的情况都会以最近的非缺失数据填入。 Bfill或后向填充是相反的:
HPI_data.fillna(method='bfill',inplace=True)
这从未来获取数据,并向后扫描来填充缺失。
现在,对于最后一种方法,替换数据。 NaN数据是相对毫无价值的数据,但它可以污染我们的其余数据。以机器学习为例,其中每行是一个特征集,每列是一个特征。数据对我们来说价值非常高,如果我们有大量的NaN数据,那么放弃所有的数据是非常糟糕的。出于这个原因,你可能实际上使用替换。对于大多数机器学习分类器来说,最终的异常值通常被忽略为自己的数据点。正因为如此,很多人会做的是获取任何NaN数据,并用-99999的值代替它。这是因为在数据预处理之后,通常需要将所有特征转换为-1到1的范围。对于几乎任何分类器来说,数据点-99999是一个明显的异常值。但是NaN的数据,根本无法处理!因此,我们可以通过执行以下操作来替换数据:
HPI_data.fillna(value=-99999,inplace=True)
现在,在我们的情况下,这是一个毫无用处的操作,但它确实在某些形式的数据分析中占有一席之地。
现在我们已经介绍了处理缺失数据的基础知识,我们准备继续。 在下一篇教程中,我们将讨论另一种平滑数据的方法,这些方法可以让我们保留月度数据:滚动统计量。 这对于平滑我们的数据,以及在它上面收集一些基本的统计量是有用的。
十一、滚动统计量
欢迎阅读另一个 Python 和 Pandas 数据分析系列教程,这里面我们成为了房地产大亨。在本教程中,我们将讨论各种滚动统计量在我们的数据帧中的应用。
其中较受欢迎的滚动统计量是移动均值。这需要一个移动的时间窗口,并计算该时间段的均值作为当前值。在我们的情况下,我们有月度数据。所以 10 移动均值就是当前值加上前 9 个月的数据的均值,之后我们的月度数据将有 10 个移动均值。Pandas 做这个是非常快的。Pandas 带有一些预先制作的滚动统计量,但也有一个叫做rolling_apply。这使我们可以编写我们自己的函数,接受窗口数据并应用我们想要的任何合理逻辑。这意味着,即使Pandas 没有处理你想要的东西的正式函数,他们已经覆盖了你,让你准确地编写你需要的东西。让我们从基本的移动均值开始,或者 Pandas 叫它rolling_mean。你可以查看 Pandas 文档中的所有移动/滚动统计量。
前面的教程涵盖了我们的起始脚本,如下所示:
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
plt.show()
现在,在定义HPI_data之后,我们可以添加一些新的数据,如下所示:
HPI_data['TX12MA'] = pd.rolling_mean(HPI_data['TX'], 12)
这给了我们一个新列,我们命名为TX12MA来表示得克萨斯和 12 移动平均。 我们将这个应用到pd.rolling_mean()中,该函数接受 2 个主要参数,我们正在应用的数据以及我们打算执行的周期/窗口。
使用滚动统计量,开头将生成NaN数据。 考虑执行 10 移动均值。 在#3行,我们根本没有 10 个以前的数据点。 因此会形成NaN数据。 你可以把它留在那里,或者用前面的教程中的dropna()来删除它。
另一个有趣的是滚动标准差。 我们需要把它放在自己的图表上,但我们可以这样做:
ig = plt.figure()
ax1 = plt.subplot2grid((2,1), (0,0))
ax2 = plt.subplot2grid((2,1), (1,0), sharex=ax1)
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX12MA'] = pd.rolling_mean(HPI_data['TX'], 12)
HPI_data['TX12STD'] = pd.rolling_std(HPI_data['TX'], 12)
HPI_data['TX'].plot(ax=ax1)
HPI_data['TX12MA'].plot(ax=ax1)
HPI_data['TX12STD'].plot(ax=ax2)
plt.show()
这里发生了一些事情,让我们快速谈论它们。
ax1 = plt.subplot2grid((2,1), (0,0))
ax2 = plt.subplot2grid((2,1), (1,0), sharex=ax1)
在这里,我们定义了第二个轴,并改变我们的大小。 我们说这个子图的网格是2×1(高 2,宽 1),那么我们说ax1从0,0开始,ax2从1,0开始,它和ax1共享x轴。 这使我们可以放大一个图形,而另一个图形也放大到同一点。 仍然对 Matplotlib 感到困惑? 使用 Matplotlib 系列教程查看完整的数据可视化。
接下来,我们计算移动标准差:
HPI_data['TX12STD'] = pd.rolling_std(HPI_data['TX'], 12)
然后,我们绘制所有东西。
另一个有趣的可视化是比较得克萨斯HPI与整体HPI。 然后计算他们两个之间的滚动相关性。 假设是,相关性下降时,很快就会出现逆转。 如果相关性下降,这意味着得克萨斯HPI和整体HPI是不一致的。 比方说,美国整体的HPI在上面,TX_HPI在下面产生分歧。 在这种情况下,我们可能会选择投资德克萨斯州的房地产。 另一个选择是使用TX和另一个高度相关的区域。 例如,德克萨斯州与阿拉斯加的相关系数为0.983235。 让我们看看我们的计划看起来怎么样。 最后一块应该现在看起来是这样:
fig = plt.figure()
ax1 = plt.subplot2grid((2,1), (0,0))
ax2 = plt.subplot2grid((2,1), (1,0), sharex=ax1)
HPI_data = pd.read_pickle('fiddy_states3.pickle')
TX_AK_12corr = pd.rolling_corr(HPI_data['TX'], HPI_data['AK'], 12)
HPI_data['TX'].plot(ax=ax1, label="TX HPI")
HPI_data['AK'].plot(ax=ax1, label="AK HPI")
ax1.legend(loc=4)
TX_AK_12corr.plot(ax=ax2)
plt.show()
每当相关性下降时,你理论上应该在上涨的地方出售房地产,然后你应该购买正在下降的地区的房地产。这个想法是,这两个地区是高度相关的,我们可以非常确信,相关性最终会回到0.98左右。因此,当相关系数为-0.5时,我们可以非常有把握地决定采取这样的行动,因为结果可能是下面的结果之一:HPI永远是这样的分歧,永远不会恢复(不太可能),下降的地区上升并遇到上升的地区,这样我们赢了,上升的地区下降并遇到另一个下降的地区,在这种情况下,我们发了一笔大财,或者双方都重新一致,在这种情况下,我们肯定赢了。 HPI不可能完全背离这些市场。我们可以清楚地看到,这完全不会发生,我们有 40 年的数据支持。
在接下来的教程中,我们将讨论异常值检测,不管是错误与否,还包括了如何处理这些数据背后的一些哲理。
十二、将比较操作应用于数据帧
欢迎阅读 Python 和 Pandas 数据分析系列教程第 12 部分。 在本教程中,我们将简要讨论如何处理错误/异常数据。 仅仅因为数据是异常的,并不意味着它是错误的。 很多时候,离群数据点可以使一个假设无效,所以去除它的必要性可能会很高,但这不是我们在这里讨论的。
错误的异常值是多少? 我喜欢使用的一个例子是测量诸如桥梁之类的波动。 由于桥梁承载重量,他们可以移动一点。 在风浪中,可以稍微摆动一下,就会有一些自然的运动。 随着时间的推移,支撑力量减弱,桥梁可能会移动太多,最终需要加固。 也许我们有一个不断测量桥梁高度波动的系统。
一些距离传感器使用激光,另一些则反弹声波。 无论你想假装我们正在使用哪个,都没关系。 我们会假装声波。 它们的工作方式是从触发器发出声波,然后在前面物体处反弹,返回到接收器。 从这里开始,整个操作发生的时间被考虑在内。 由于音速是一个常数,我们可以从这个过程的时间推断出声波传播的距离。 问题是,这只衡量声波传播了多远。 例如他们去了桥梁和背部,没有 100% 的确定性。 也许一片树叶在测量时掉落,并在信号回到接收器之前反弹了信号,谁知道呢。 比方说,举个例子,你有以下的桥梁读数:
bridge_height = {'meters':[10.26, 10.31, 10.27, 10.22, 10.23, 6212.42, 10.28, 10.25, 10.31]}
我们可以可视化:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
bridge_height = {'meters':[10.26, 10.31, 10.27, 10.22, 10.23, 6212.42, 10.28, 10.25, 10.31]}
df = pd.DataFrame(bridge_height)
df.plot()
plt.show()
那么桥是不是被外星人动过了? 由于此后我们有更多的正常读数,6212.42更可能是一个不好的读数。 我们可以直观地看出这是一个异常,但是我们怎么能通过我们的程序检测到这一点?
我们意识到这是一个异常值,因为它与其他价有很大的不同,以及它比其他任何值都突然上升或下降的事实。 听起来我们可以仅仅应用标准差。 我们用它来自动检测这个不好的读数。
df['STD'] = pd.rolling_std(df['meters'], 2)
print(df)
meters STD
0 10.26 NaN
1 10.31 0.035355
2 10.27 0.028284
3 10.22 0.035355
4 10.23 0.007071
5 6212.42 4385.610607
6 10.28 4385.575252
7 10.25 0.021213
8 10.31 0.042426
注:两个数的标准差就是
|a - b|/2。
接下来,我们可以获得整个集合的标准差,如:
df_std = df.describe()
print(df_std)
df_std = df.describe()['meters']['std']
print(df_std)
meters STD
count 9.000000 8.000000
mean 699.394444 1096.419446
std 2067.384584 2030.121949
min 10.220000 0.007071
25% 10.250000 0.026517
50% 10.270000 0.035355
75% 10.310000 1096.425633
max 6212.420000 4385.610607
2067.38458357
首先,我们得到所有的描述。 显示了大部分,所以你看我们如何处理数据。 然后,我们直接查看米的标准差,这是 2067 和一些变化。 这是一个相当高的数字,但仍然远低于主要波动(4385)的标准差。 现在,我们可以遍历并删除所有标准差高于这个值的数据。
这使我们能够学习一项新技能:在逻辑上修改数据帧! 我们可以这样做:
df = df[ (df['STD'] < df_std) ]
print(df)
meters STD
1 10.31 0.035355
2 10.27 0.028284
3 10.22 0.035355
4 10.23 0.007071
7 10.25 0.021213
8 10.31 0.042426
之后我们可以绘制所有东西:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
bridge_height = {'meters':[10.26, 10.31, 10.27, 10.22, 10.23, 6212.42, 10.28, 10.25, 10.31]}
df = pd.DataFrame(bridge_height)
df['STD'] = pd.rolling_std(df['meters'], 2)
print(df)
df_std = df.describe()
print(df_std)
df_std = df.describe()['meters']['std']
print(df_std)
df = df[ (df['STD'] < df_std) ]
print(df)
df['meters'].plot()
plt.show()
输出:
我们刚学到的新行是df = df[ (df['STD'] < df_std) ]。 这是如何工作的? 首先,我们一开始重新定义df。 我们说现在df等于df,其中df['STD']小于我们之前计算的整体df_std。 因此,这里唯一剩下的数据将是标准差小于 2067 的数据。
再次,当我们知道这些数据错误的,我们应该删除它。 因为数据不“适合”你而删除,几乎总是一个坏主意。
十三、30 年抵押贷款利率
欢迎阅读 Python 和 Pandas 数据分析第 13 部分,以房地产投资为例。到了这里,我们已经了解了 Pandas 能提供给我们的东西,我们会在这里面对一些挑战!正如我们到目前为止所介绍的那样,我们可以根据高度相关的州对之间的分歧,做出风险相对较低的投资,可能做得很好。稍后我们将介绍测试这个策略,但是现在让我们来看看获取包含房屋价值的其他必要数据:利率。现在,抵押贷款利率有很多不同的类型,既有利息收入,也有贷款的时间表。这些年来,意见有所不同,根据目前的市场情况,是否需要 10 年,15 年或 30 年的抵押贷款。那么你必须考虑你是否想要可调整的利率,或者在半路上再决定为你的房子付费的方式。
在数据的最后,所有这些数据都是有限的,但最终可能会有点过于嘈杂。现在,让我们简单介绍一下 30 年的传统抵押贷款利率。现在,这个数据应该与房价指数(HPI)非常负相关。在这个低吗之前,我会自动假设并期望相关性不会非常强,就像高于 90% 的HPI相关性,它肯定低于-0.9,而且应该比-0.5大。利率当然很重要,但是整个HPI的相关性非常强,因为这些数据非常相似。利率当然是相关的,但并不像其他HPI值或美国HPI那样直接。
首先,我们抓取这些数据。我们将开始创建一个新的函数:
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
print(df.head())
return df
mortgage_30y()
Value
Date
1975-01-01 0.000000
1975-02-01 -3.393425
1975-03-01 -5.620361
1975-04-01 -6.468717
1975-05-01 -5.514316
这里有几个要点。 首先,注意添加到Quandl.get()的新参数,它是trim_start。 这使我们能够在特定的日期启动数据。 我们之所以选择 1975 年 1 月 1 日,是因为那是我们的房价指数数据开始的时候。 从这里,我们打印数据头部,我们有了第一个问题:这是某月的第一天,而不是月底。 当我们将这个数据帧加入到其他数据帧时,这会造成麻烦。 那么现在怎么办? 我们已经学会了如何重新采样,如果我们只是使用M来进行典型的重新采样,这意味着月末,会怎么样呢? 也许这会把数据移动到第 31 天,因为这个月只有一个值。
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('M')
print(df.head())
return df
mortgage_30y()
Value
Date
1975-01-31 NaN
1975-02-28 NaN
1975-03-31 NaN
1975-04-30 NaN
1975-05-31 NaN
好吧,这并没有那么好。 我们可能需要多个数据点才能进行计算,那么我们该怎么做? 我们可以尝试调整日期列或别的,或者我们可以做一些黑魔法。 如果我们只是按天抽样呢? 如果我们这样做的话,那么这个数字将在整个月份里持续重复。 然后,我们可以重采样到月末,然后一切都应该有效。
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('1D')
df=df.resample('M')
print(df.head())
return df
mortgage_30y()
Value
Date
1975-01-31 0.000000
1975-02-28 -3.393425
1975-03-31 -5.620361
1975-04-30 -6.468717
1975-05-31 -5.514316
我们赢了! 接下来,我们可以获取所有的数据,将这个新的数据集添加到数据帧中,现在我们真的上路了。 为了防止你刚刚加入我们,或者你半路走丢了,这里是目前为止的代码:
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('1D')
df=df.resample('M')
return df
现在我们可以做一些事情,例如:
HPI_data = pd.read_pickle('fiddy_states3.pickle')
m30 = mortgage_30y()
HPI_Bench = HPI_Benchmark()
m30.columns=['M30']
HPI = HPI_Bench.join(m30)
print(HPI.head())
United States M30
Date
1975-01-31 0.000000 0.000000
1975-02-28 0.594738 -3.393425
1975-03-31 1.575473 -5.620361
1975-04-30 2.867177 -6.468717
1975-05-31 3.698896 -5.514316
下面,我们可以立即计算一个简单的相关性:
print(HPI.corr())
United States M30
United States 1.000000 -0.740009
M30 -0.740009 1.000000
这是我们的预期。 -0.74是相当强的负值。 很明显,各州之间的联系并不是很好,但这显然是一个有用的指标。 接下来,我们可以在所有州上检查这个指标:
state_HPI_M30 = HPI_data.join(m30)
print(state_HPI_M30.corr())
AL AK AZ AR CA CO CT \
AL 1.000000 0.944603 0.927361 0.994896 0.935970 0.979352 0.953724
AK 0.944603 1.000000 0.893904 0.965830 0.900621 0.949834 0.896395
AZ 0.927361 0.893904 1.000000 0.923786 0.973546 0.911422 0.917500
AR 0.994896 0.965830 0.923786 1.000000 0.935364 0.985934 0.948341
CA 0.935970 0.900621 0.973546 0.935364 1.000000 0.924982 0.956495
CO 0.979352 0.949834 0.911422 0.985934 0.924982 1.000000 0.917129
CT 0.953724 0.896395 0.917500 0.948341 0.956495 0.917129 1.000000
DE 0.980566 0.939196 0.942273 0.975830 0.970232 0.949517 0.981177
FL 0.918544 0.887891 0.994007 0.915989 0.987200 0.905126 0.926364
GA 0.973562 0.880261 0.939715 0.960708 0.943928 0.959500 0.948500
HI 0.946054 0.930520 0.902554 0.947022 0.937704 0.903461 0.938974
ID 0.982868 0.944004 0.959193 0.977372 0.944342 0.960975 0.923099
IL 0.984782 0.905512 0.947396 0.973761 0.963858 0.968552 0.955033
IN 0.981189 0.889734 0.881542 0.973259 0.901154 0.971416 0.919696
IA 0.985516 0.943740 0.894524 0.987919 0.914199 0.991455 0.913788
KS 0.990774 0.957236 0.910948 0.995230 0.926872 0.994866 0.936523
KY 0.994311 0.938125 0.900888 0.992903 0.923429 0.987097 0.941114
LA 0.967232 0.990506 0.909534 0.982454 0.911742 0.972703 0.907456
ME 0.972693 0.935850 0.923797 0.972573 0.965251 0.951917 0.989180
MD 0.964917 0.943384 0.960836 0.964943 0.983677 0.940805 0.969170
MA 0.966242 0.919842 0.921782 0.966962 0.962672 0.959294 0.986178
MI 0.891205 0.745697 0.848602 0.873314 0.861772 0.900040 0.843032
MN 0.971967 0.926352 0.952359 0.972338 0.970661 0.983120 0.945521
MS 0.996089 0.962494 0.927354 0.997443 0.932752 0.985298 0.945831
MO 0.992706 0.933201 0.938680 0.989672 0.955317 0.985194 0.961364
MT 0.977030 0.976840 0.916000 0.983822 0.923950 0.971516 0.917663
NE 0.988030 0.941229 0.896688 0.990868 0.912736 0.992179 0.920409
NV 0.858538 0.785404 0.965617 0.846968 0.948143 0.837757 0.866554
NH 0.953366 0.907236 0.932992 0.952882 0.969574 0.941555 0.990066
NJ 0.968837 0.934392 0.943698 0.967477 0.975258 0.944460 0.989845
NM 0.992118 0.967777 0.934744 0.993195 0.934720 0.968001 0.946073
NY 0.973984 0.940310 0.921126 0.973972 0.959543 0.949474 0.989576
NC 0.998383 0.934841 0.915403 0.991863 0.928632 0.977069 0.956074
ND 0.936510 0.973971 0.840705 0.957838 0.867096 0.942225 0.882938
OH 0.966598 0.855223 0.883396 0.954128 0.901842 0.957527 0.911510
OK 0.944903 0.984550 0.881332 0.967316 0.882199 0.960694 0.879854
OR 0.981180 0.948190 0.949089 0.978144 0.944542 0.971110 0.916942
PA 0.985357 0.946184 0.915914 0.983651 0.950621 0.956316 0.975324
RI 0.950261 0.897159 0.943350 0.945984 0.984298 0.926362 0.988351
SC 0.998603 0.945949 0.929591 0.994117 0.942524 0.980911 0.959591
SD 0.983878 0.966573 0.889405 0.990832 0.911188 0.984463 0.924295
TN 0.998285 0.946858 0.919056 0.995949 0.931616 0.983089 0.953009
TX 0.963876 0.983235 0.892276 0.981413 0.902571 0.970795 0.919415
UT 0.983987 0.951873 0.926676 0.982867 0.909573 0.974909 0.900908
VT 0.975210 0.952370 0.909242 0.977904 0.949225 0.951388 0.973716
VA 0.972236 0.956925 0.950839 0.975683 0.977028 0.954801 0.970366
WA 0.988253 0.948562 0.950262 0.982877 0.956434 0.968816 0.941987
WV 0.984364 0.964846 0.907797 0.990264 0.924300 0.979467 0.925198
WI 0.990190 0.930548 0.927619 0.985818 0.943768 0.987609 0.936340
WY 0.944600 0.983109 0.892255 0.960336 0.897551 0.950113 0.880035
M30 -0.762343 -0.678591 -0.614237 -0.747709 -0.680250 -0.747269 -0.726121
DE FL GA ... TN TX UT \
AL 0.980566 0.918544 0.973562 ... 0.998285 0.963876 0.983987
AK 0.939196 0.887891 0.880261 ... 0.946858 0.983235 0.951873
AZ 0.942273 0.994007 0.939715 ... 0.919056 0.892276 0.926676
AR 0.975830 0.915989 0.960708 ... 0.995949 0.981413 0.982867
CA 0.970232 0.987200 0.943928 ... 0.931616 0.902571 0.909573
CO 0.949517 0.905126 0.959500 ... 0.983089 0.970795 0.974909
CT 0.981177 0.926364 0.948500 ... 0.953009 0.919415 0.900908
DE 1.000000 0.947876 0.954346 ... 0.977213 0.943323 0.952441
FL 0.947876 1.000000 0.933753 ... 0.910359 0.881164 0.908197
GA 0.954346 0.933753 1.000000 ... 0.970564 0.920372 0.943421
HI 0.976226 0.909336 0.887794 ... 0.941823 0.916708 0.925630
ID 0.971421 0.947140 0.953024 ... 0.976012 0.943472 0.989533
IL 0.978133 0.948851 0.986683 ... 0.980145 0.925778 0.961563
IN 0.941916 0.873664 0.972737 ... 0.982888 0.928735 0.956452
IA 0.954993 0.888359 0.948792 ... 0.987924 0.959989 0.980798
KS 0.964387 0.903659 0.961825 ... 0.993486 0.978622 0.980113
KY 0.968469 0.895461 0.966719 ... 0.996549 0.961847 0.975918
LA 0.949931 0.899010 0.911625 ... 0.968690 0.989803 0.975590
ME 0.993413 0.932706 0.949576 ... 0.973697 0.946992 0.935993
MD 0.993728 0.968700 0.938240 ... 0.960881 0.935619 0.945962
MA 0.978758 0.931237 0.964604 ... 0.969053 0.943613 0.923883
MI 0.846668 0.846085 0.952179 ... 0.891484 0.806632 0.855976
MN 0.966800 0.955992 0.976933 ... 0.970940 0.944605 0.955689
MS 0.975673 0.917084 0.963318 ... 0.996444 0.977670 0.987812
MO 0.978316 0.936293 0.986001 ... 0.991835 0.958853 0.969655
MT 0.968166 0.909331 0.917504 ... 0.976586 0.967914 0.985605
NE 0.951875 0.888425 0.962706 ... 0.991270 0.966743 0.976138
NV 0.881209 0.971601 0.911678 ... 0.845672 0.791177 0.841324
NH 0.975576 0.943501 0.959112 ... 0.954165 0.930112 0.908947
NJ 0.995132 0.952767 0.950385 ... 0.967025 0.940268 0.935497
NM 0.980594 0.925001 0.949564 ... 0.989390 0.972216 0.986413
NY 0.993814 0.928749 0.947804 ... 0.974697 0.950417 0.937078
NC 0.977472 0.906887 0.976190 ... 0.998354 0.959839 0.976901
ND 0.926355 0.833816 0.849962 ... 0.944451 0.964373 0.942833
OH 0.927542 0.878248 0.980012 ... 0.966237 0.900707 0.935392
OK 0.917902 0.868255 0.893142 ... 0.947590 0.992422 0.951925
OR 0.969869 0.940983 0.945712 ... 0.977083 0.943652 0.991080
PA 0.994948 0.919264 0.946609 ... 0.984959 0.954439 0.956809
RI 0.984731 0.959567 0.951973 ... 0.947561 0.907964 0.906497
SC 0.983353 0.922779 0.976778 ... 0.997851 0.966682 0.979527
SD 0.963422 0.883479 0.931010 ... 0.987597 0.973825 0.979387
TN 0.977213 0.910359 0.970564 ... 1.000000 0.967678 0.982384
TX 0.943323 0.881164 0.920372 ... 0.967678 1.000000 0.956718
UT 0.952441 0.908197 0.943421 ... 0.982384 0.956718 1.000000
VT 0.992088 0.914969 0.929674 ... 0.976577 0.955538 0.947708
VA 0.994223 0.957210 0.939416 ... 0.970906 0.952162 0.953655
WA 0.985085 0.945027 0.956455 ... 0.983588 0.950234 0.984835
WV 0.968813 0.901690 0.931330 ... 0.985509 0.967845 0.983636
WI 0.970690 0.925943 0.974086 ... 0.988615 0.946572 0.977972
WY 0.938938 0.884962 0.869454 ... 0.945079 0.963628 0.965801
M30 -0.758073 -0.627997 -0.706512 ... -0.770422 -0.669410 -0.737147
VT VA WA WV WI WY M30
AL 0.975210 0.972236 0.988253 0.984364 0.990190 0.944600 -0.762343
AK 0.952370 0.956925 0.948562 0.964846 0.930548 0.983109 -0.678591
AZ 0.909242 0.950839 0.950262 0.907797 0.927619 0.892255 -0.614237
AR 0.977904 0.975683 0.982877 0.990264 0.985818 0.960336 -0.747709
CA 0.949225 0.977028 0.956434 0.924300 0.943768 0.897551 -0.680250
CO 0.951388 0.954801 0.968816 0.979467 0.987609 0.950113 -0.747269
CT 0.973716 0.970366 0.941987 0.925198 0.936340 0.880035 -0.726121
DE 0.992088 0.994223 0.985085 0.968813 0.970690 0.938938 -0.758073
FL 0.914969 0.957210 0.945027 0.901690 0.925943 0.884962 -0.627997
GA 0.929674 0.939416 0.956455 0.931330 0.974086 0.869454 -0.706512
HI 0.979103 0.976083 0.963950 0.952790 0.928536 0.935530 -0.755064
ID 0.955898 0.970393 0.994442 0.975239 0.977441 0.956742 -0.721927
IL 0.958711 0.968271 0.982702 0.962100 0.992079 0.911345 -0.753583
IN 0.937365 0.928187 0.955000 0.958981 0.982614 0.889497 -0.773100
IA 0.960204 0.955724 0.976571 0.990479 0.991509 0.955104 -0.785584
KS 0.967734 0.964949 0.977117 0.988007 0.989477 0.956913 -0.748138
KY 0.970702 0.962244 0.977386 0.985453 0.992035 0.938804 -0.785726
LA 0.958907 0.962746 0.967991 0.982913 0.957145 0.988894 -0.683956
ME 0.993570 0.990376 0.969212 0.963035 0.963999 0.929516 -0.769778
MD 0.983851 0.997558 0.981974 0.962220 0.960073 0.945807 -0.729642
MA 0.975046 0.975432 0.953441 0.947520 0.964247 0.904811 -0.758192
MI 0.817081 0.828781 0.862245 0.843538 0.918028 0.741663 -0.686146
MN 0.952722 0.969721 0.973082 0.961230 0.987026 0.927507 -0.723314
MS 0.974975 0.973635 0.986430 0.989047 0.986738 0.961005 -0.750756
MO 0.968741 0.972720 0.980907 0.974606 0.993691 0.930004 -0.747344
MT 0.974065 0.976197 0.985994 0.993622 0.972195 0.990517 -0.756735
NE 0.954657 0.949766 0.969023 0.981915 0.988942 0.938583 -0.761330
NV 0.828018 0.882206 0.882127 0.820529 0.874777 0.779155 -0.543798
NH 0.966338 0.972531 0.944892 0.930573 0.949941 0.892414 -0.722957
NJ 0.987844 0.992944 0.971273 0.956438 0.960854 0.928928 -0.743508
NM 0.977351 0.978702 0.988594 0.985877 0.976586 0.966689 -0.729704
NY 0.994142 0.989544 0.968541 0.962209 0.961359 0.929946 -0.770619
NC 0.973354 0.965901 0.981436 0.978326 0.987338 0.931717 -0.770820
ND 0.957772 0.944229 0.935840 0.972698 0.921882 0.977003 -0.763102
OH 0.912974 0.910193 0.939052 0.933308 0.974849 0.852217 -0.753133
OK 0.930105 0.933030 0.937180 0.959298 0.932422 0.969641 -0.621887
OR 0.959889 0.973285 0.995502 0.984262 0.984121 0.968156 -0.749370
PA 0.997231 0.989277 0.982052 0.978963 0.972162 0.945319 -0.779589
RI 0.970213 0.980550 0.953760 0.930845 0.950360 0.890562 -0.732558
SC 0.977946 0.975200 0.987828 0.982315 0.989425 0.943358 -0.754808
SD 0.976071 0.967219 0.976170 0.994328 0.979649 0.971496 -0.794906
TN 0.976577 0.970906 0.983588 0.985509 0.988615 0.945079 -0.770422
TX 0.955538 0.952162 0.950234 0.967845 0.946572 0.963628 -0.669410
UT 0.947708 0.953655 0.984835 0.983636 0.977972 0.965801 -0.737147
VT 1.000000 0.991347 0.975016 0.976666 0.961824 0.951637 -0.779342
VA 0.991347 1.000000 0.983402 0.973592 0.966393 0.956771 -0.745763
WA 0.975016 0.983402 1.000000 0.984210 0.984955 0.962198 -0.750646
WV 0.976666 0.973592 0.984210 1.000000 0.981398 0.977070 -0.770068
WI 0.961824 0.966393 0.984955 0.981398 1.000000 0.939200 -0.776679
WY 0.951637 0.956771 0.962198 0.977070 0.939200 1.000000 -0.702034
M30 -0.779342 -0.745763 -0.750646 -0.770068 -0.776679 -0.702034 1.000000
[51 rows x 51 columns]
我们感兴趣的主要一列是 M30 与其它东西的对比,所以我们这样做:
print(state_HPI_M30.corr()['M30'])
AL -0.762343
AK -0.678591
AZ -0.614237
AR -0.747709
CA -0.680250
CO -0.747269
CT -0.726121
DE -0.758073
FL -0.627997
GA -0.706512
HI -0.755064
ID -0.721927
IL -0.753583
IN -0.773100
IA -0.785584
KS -0.748138
KY -0.785726
LA -0.683956
ME -0.769778
MD -0.729642
MA -0.758192
MI -0.686146
MN -0.723314
MS -0.750756
MO -0.747344
MT -0.756735
NE -0.761330
NV -0.543798
NH -0.722957
NJ -0.743508
NM -0.729704
NY -0.770619
NC -0.770820
ND -0.763102
OH -0.753133
OK -0.621887
OR -0.749370
PA -0.779589
RI -0.732558
SC -0.754808
SD -0.794906
TN -0.770422
TX -0.669410
UT -0.737147
VT -0.779342
VA -0.745763
WA -0.750646
WV -0.770068
WI -0.776679
WY -0.702034
M30 1.000000
Name: M30, dtype: float64
看起来亚利桑那(AZ)的负相关最弱,为-0.614237。 我们可以通过以下方式快速获取更多数据:
print(state_HPI_M30.corr()['M30'].describe())
count 51.000000
mean -0.699445
std 0.247709
min -0.794906
25% -0.762723
50% -0.748138
75% -0.722442
max 1.000000
Name: M30, dtype: float64
这里的均值在-0.7以下,这与我们以前的发现非常一致,这里并没有太多的延展。这在逻辑上应该是显而易见的,但数据明确地反映了,抵押贷款利率在房价中起着重要的作用。到目前为止,我所发现的有趣之处是,我们所看到的变化是多么的微小。有一些州存在分歧,但不是很多。大多数州严格保持在一条直线上,带有非常简单的规则。在深入局部地区之前,我们的第三个主要因素,是整体经济。从这里开始,我们可以开始关注州的人口统计数据,同时我们深入到县甚至社区。但是,我想知道,鉴于迄今为止这样可靠的值,我们已经很容易为HPI制定一个公式。如果不是一个基本的公式,我怀疑我们可以在一个随机森林分类器中使用这些数据,并做得很好。现在,让我们继续看看整体经济。我们希望看到0.5以上的相关性。我们在下一个教程中介绍一下。
十四、添加其它经济指标
大家好,欢迎阅读我们的 Python 和 Pandas 数据分析(和地产投资)系列教程的第14部分。我们在这里已经走了很长一段路,我们想要在这里采取的下一个,最后一大步骤是研究宏观经济指标,看看它们对房价或HPI的影响。
SP500 (股票市场)和国内生产总值(GDP)是两个主要的经济指标。我怀疑 SP500 比国内生产总值相关性更高,但 GDP 总体来说是一个较好的整体经济指标,所以我可能是错的。以及,我怀疑在这里可能有价值的宏观指标是失业率。如果你失业了,你可能不能得到抵押贷款。我们会验证。我们已经完成了添加更多数据点的流程,所以把你拖入这个过程没有多少意义。但是会有一个新的东西需要注意。在HPI_Benchmark()函数中,我们将United States列更改为US_HPI。当我们现在引入其他值时,这会更有意义。
对于国内生产总值,我找不到一个包含所有时间的东西。我相信你可以使用这个数据在某个地方,甚至在 Quandl 上找到一个数据集。有时你必须做一些挖掘。我也很难找到一个很好的长期月失业率。我确实找到了一个失业率水平,但我们真的不仅仅想要百分比/比例,否则我们需要把失业水平除以人口。如果我们确定失业率值得拥有,我们可以这样做,但我们需要首先处理我们得到的东西。
将 Pandas 和 Quandl 代码更新为 2016 年 8 月 1 日的最新版本:
import quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = quandl.get(query, authtoken=api_key)
df.rename(columns={'Value': abbv}, inplace=True)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df.rename(columns={'United States':'US_HPI'}, inplace=True)
return df
def mortgage_30y():
df = quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('1D').mean()
df=df.resample('M').mean()
return df
def sp500_data():
df = quandl.get("YAHOO/INDEX_GSPC", trim_start="1975-01-01", authtoken=api_key)
df["Adjusted Close"] = (df["Adjusted Close"]-df["Adjusted Close"][0]) / df["Adjusted Close"][0] * 100.0
df=df.resample('M').mean()
df.rename(columns={'Adjusted Close':'sp500'}, inplace=True)
df = df['sp500']
return df
def gdp_data():
df = quandl.get("BCB/4385", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('M').mean()
df.rename(columns={'Value':'GDP'}, inplace=True)
df = df['GDP']
return df
def us_unemployment():
df = quandl.get("ECPI/JOB_G", trim_start="1975-01-01", authtoken=api_key)
df["Unemployment Rate"] = (df["Unemployment Rate"]-df["Unemployment Rate"][0]) / df["Unemployment Rate"][0] * 100.0
df=df.resample('1D').mean()
df=df.resample('M').mean()
return df
grab_initial_state_data()
HPI_data = pd.read_pickle('fiddy_states3.pickle')
m30 = mortgage_30y()
sp500 = sp500_data()
gdp = gdp_data()
HPI_Bench = HPI_Benchmark()
unemployment = us_unemployment()
m30.columns=['M30']
HPI = HPI_Bench.join([m30,sp500,gdp,unemployment])
HPI.dropna(inplace=True)
print(HPI.corr())
US_HPI M30 sp500 GDP Unemployment Rate
US_HPI 1.000000 -0.738364 0.738395 0.543507 0.033925
M30 -0.738364 1.000000 -0.625544 -0.714845 -0.395650
sp500 0.738395 -0.625544 1.000000 0.470505 -0.262561
GDP 0.543507 -0.714845 0.470505 1.000000 0.551058
Unemployment Rate 0.033925 -0.395650 -0.262561 0.551058 1.000000
在这里,我们看到 SP500 与US_HPI强相关,30 年抵押贷款利率显然也是如此。其次,GDP 不是最可靠的。这是正值,但我更像看> 70的东西。最后,失业率更低。几乎中立!我对此感到非常惊讶。有了这些信息,我想说 SP500 和 30 年抵押贷款利率可以用来预测房屋市场。这很好,因为这些数字都可以不间断地获得。我很惊讶地看到 SP500 与 HPI 之间的 0.738 相关性。大多数人认为股票和住房是多元化的。很多人都记得房地产危机,而且既然股市和房屋都一起下跌,可能就不会有这样的感觉了,但是传统的智慧依然表明人们通过持有股票和房地产来多样化。 40 年的数据似乎并不完全一致。
向前看,我提倡考虑宏观市场,使用美国房价指数(US_HPI),30 年抵押贷款利率(M30)和标准普尔 500 指数(SP500)。
我们将使用这些值来涵盖本系列的最后一部分:结合其他主要数据科学库。我们这里,我们将结合 Scikit Learn,看看我们是否能预测 HPI 的合理轨迹。这样做只是一个开始,但是之后要求我们使用类似的策略来继续下去,直到我们实际购买的房产的微观层面。无论如何,我们还是亿万富翁,生活是美好的。在我们继续之前,我们将最后一次运行这个代码,将其保存到一个pickle中,这样我们就不需要继续运行代码了。为了保存到pickle,只需把它放在脚本的末尾:
HPI.to_pickle('HPI.pickle')
十五、滚动应用和预测函数
这个 Python 和 Pandas 数据分析教程将涵盖两个主题。首先,在机器学习的背景下,我们需要一种方法,为我们的数据创建“标签”。其次,我们将介绍 Pandas 的映射函数和滚动应用功能。
创建标签对监督式机器学习过程至关重要,因为它用于“教给”或训练机器与特征相关的正确答案。
Pandas 数据帧映射函数到非常有用,可用于编写自定义公式,将其应用于整个数据帧,特定列或创建新列。如果你回想一下,我们生成了一些新列,比如df['Column2'] = df['Column1']*1.5,等等。如果你想创建更多的逻辑密集操作,但是,你会希望写一个函数。我们将展示如何实现它。
由于映射函数是两种方法之一,用户可以极大地定制 Pandas 可以做的事情,我们也会涵盖第二种主要方式,即使用rolling_apply。这使我们可以应用函数的移动窗口。我们刚刚写了一个移动平均函数,但是你可以做任何你想要的。
首先,我们有一些代码:
import Quandl
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from statistics import mean
style.use('fivethirtyeight')
housing_data = pd.read_pickle('HPI.pickle')
housing_data = housing_data.pct_change()
首先,我们要加载数据集,然后将所有列转换为百分比变化。 这将帮助我们规范所有的数据。
下面:
housing_data.replace([np.inf, -np.inf], np.nan, inplace=True)
housing_data['US_HPI_future'] = housing_data['United States'].shift(-1)
在这里,我们先用nan值代替无穷值。 接下来,我们创建一个新的列,其中包含未来的 HPI。 我们可以用一个新的方法来实现:.shift()。 这种方法将会改变有问题的列。 移动-1意味着我们正在向下移动,所以下一个点的值会移动回来。 这是我们的方法,用于快速获得当前值,以及下一时期同一行上的值,用于比较。
接下来,在百分比变化应用和移动中,我们有一些NaN数据,所以我们需要做以下工作:
new_column = list(map( function_to_map, parameter1, parameter2, ... ))
这就是它的一切,你可以继续添加更多的参数。
print(housing_data.head())
AL AK AZ AR CA CO \
Date
1990-03-31 0.003628 0.062548 -0.003033 0.005570 0.007152 0.000963
1990-04-30 0.006277 0.095081 -0.002126 0.005257 0.005569 -0.000318
1990-05-31 0.007421 0.112105 0.001513 0.005635 0.002409 0.004512
1990-06-30 0.004930 0.100642 0.004353 0.006238 0.003569 0.007884
1990-07-31 0.000436 0.067064 0.003322 0.006173 0.004351 0.004374
CT DE FL GA ... WV WI \
Date ...
1990-03-31 -0.009234 0.002786 -0.001259 -0.007290 ... 0.013441 0.015638
1990-04-30 -0.010818 0.000074 0.002675 -0.002477 ... 0.015765 0.015926
1990-05-31 -0.010963 -0.000692 0.004656 0.002808 ... 0.017085 0.012106
1990-06-30 -0.007302 -0.001542 0.003710 0.002857 ... 0.016638 0.010545
1990-07-31 -0.003439 -0.004680 0.003116 0.002276 ... 0.011129 0.009425
WY United States M30 Unemployment Rate GDP \
Date
1990-03-31 0.009831 0.004019 0.090909 0.035714 -0.234375
1990-04-30 0.016868 0.004957 0.119048 -0.068966 4.265306
1990-05-31 0.026130 0.005260 0.117021 0.000000 -1.092539
1990-06-30 0.029359 0.005118 -0.304762 0.074074 3.115183
1990-07-31 0.023640 0.003516 -0.164384 -0.103448 0.441476
sp500 US_HPI_future label
Date
1990-03-31 0.030790 0.004957 1
1990-04-30 -0.001070 0.005260 1
1990-05-31 0.045054 0.005118 0
1990-06-30 0.036200 0.003516 0
1990-07-31 -0.001226 0.000395 0
[5 rows x 57 columns]
接下来,让我们展示一个自定义方式,来应用移动窗口函数。 我们仅仅执行一个简单的移动平均示例:
def moving_average(values):
ma = mean(values)
return ma
这就是我们的功能,请注意,我们只是传递了values参数。 我们不需要编写任何类型的“窗口”或“时间框架”处理,Pandas 将为我们处理。
现在,你可以使用rolling_apply:
housing_data['ma_apply_example'] = pd.rolling_apply(housing_data['M30'], 10, moving_average)
print(housing_data.tail())
AL AK AZ AR CA CO \
Date
2011-07-31 -0.003545 -0.004337 0.002217 0.003215 -0.005579 0.004794
2011-08-31 -0.006886 -0.007139 0.004283 0.000275 -0.007782 0.001058
2011-09-30 -0.011103 -0.007609 0.003190 0.000505 -0.006537 -0.004569
2011-10-31 -0.013189 -0.007754 0.000541 0.001059 -0.005390 -0.009231
2011-11-30 -0.008055 -0.006551 0.005119 -0.000856 -0.003570 -0.010812
CT DE FL GA ... \
Date ...
2011-07-31 -0.002806 -0.001084 -0.001531 -0.003036 ...
2011-08-31 -0.010243 -0.002133 0.001438 -0.006488 ...
2011-09-30 -0.012240 -0.004171 0.002307 -0.013116 ...
2011-10-31 -0.013075 -0.006204 -0.001566 -0.021542 ...
2011-11-30 -0.012776 -0.008252 -0.006211 -0.022371 ...
WI WY United States M30 Unemployment Rate \
Date
2011-07-31 -0.002068 0.001897 -0.000756 -0.008130 0.000000
2011-08-31 -0.006729 -0.002080 -0.005243 0.057377 0.000000
2011-09-30 -0.011075 -0.006769 -0.007180 0.031008 -0.100000
2011-10-31 -0.015025 -0.008818 -0.008293 0.007519 -0.111111
2011-11-30 -0.014445 -0.006293 -0.008541 0.014925 -0.250000
GDP sp500 US_HPI_future label ma_apply_example
Date
2011-07-31 0.024865 0.031137 -0.005243 0 -0.003390
2011-08-31 0.022862 -0.111461 -0.007180 0 -0.000015
2011-09-30 -0.039361 -0.010247 -0.008293 0 0.004432
2011-10-31 0.018059 0.030206 -0.008541 0 0.013176
2011-11-30 0.000562 0.016886 -0.009340 0 0.015728
[5 rows x 58 columns]
十六、Scikit Learn 交互
在这个 Pandas 和 Python 数据分析系列教程中,我们将展示如何快速将 Pandas 数据集转换为数据帧,并将其转换为 numpy 数组,然后可以传给各种其他 Python 数据分析模块。 我们要在这里使用的例子是 Scikit-Learn,也就是 SKlearn。 为了这样做,你需要安装它:
pip install sklearn
从这里开始,我们几乎已经完成了。 对于机器学习来说,至少在监督的形式下,我们只需要几件事情。 首先,我们需要“特征”。 在我们的例子中,特征是像当前的 HPI,也许是 GDP 等等。 之后你需要“标签”。 标签被分配到特征“集”,其中对于任何给定的“标签”,特征集是任何 GDP,HPI 等等的集合。 这里,我们的标签是 1 或 0,其中 1 表示 HPI 未来增加,0 表示没有。
可能不用说,但我会提醒你:你不应该将“未来的 HPI”列包括为一个特征。 如果你这样做,机器学习算法将认识到这一点,并且准确性非常高,在现实世界中不可能实际有用。
前面教程的代码是这样的:
import Quandl
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from statistics import mean
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def create_labels(cur_hpi, fut_hpi):
if fut_hpi > cur_hpi:
return 1
else:
return 0
def moving_average(values):
return mean(values)
housing_data = pd.read_pickle('HPI.pickle')
housing_data = housing_data.pct_change()
housing_data.replace([np.inf, -np.inf], np.nan, inplace=True)
housing_data['US_HPI_future'] = housing_data['United States'].shift(-1)
housing_data.dropna(inplace=True)
#print(housing_data[['US_HPI_future','United States']].head())
housing_data['label'] = list(map(create_labels,housing_data['United States'], housing_data['US_HPI_future']))
#print(housing_data.head())
housing_data['ma_apply_example'] = pd.rolling_apply(housing_data['M30'], 10, moving_average)
print(housing_data.tail())
下面,我们打算添加一些新的导入:
from sklearn import svm, preprocessing, cross_validation
我们将使用 svm(支持向量机)库作为我们的机器学习分类器。 预处理用来调整我们的数据集。 通常情况下,如果你的特征介于 -1 和 1 之间,则机器学习会更精确一些。 这并不意味着永远是真的,检查是否缩放总是一个好主意,以便万无一失。 cross_validation是一个库,我们将用来创建我们的训练和测试集。 这只是一个很好的方法,可以自动随机抽取数据,用于训练和测试。
现在,我们可以创建我们的特征和标签来进行训练/测试:
X = np.array(housing_data.drop(['label','US_HPI_future'], 1))
X = preprocessing.scale(X)
一般来说,对于特征和标签,你有了X,y。 大写字母X用来表示一个特征集。 y是标签。 我们在这里所做的是,将特征集定义为housing_data 数据帧内容的 numpy 数组(这只是将数据帧的内容转换为多维数组),同时删除了label和US_HPI_future列。
y = np.array(housing_data['label'])
现在我们的标签已经定义好了,我们已经准备好,将我们的数据分解成训练和测试集。 我们可以自己做,但是我们将使用之前的cross_validation导入:
注:
cross_validation会打乱数据,最好不要在时序数据上使用这个方法,反之应该以一个位置分割数据。
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
它所做的就是将你的特征(X)和标签(y)随机分解为训练和测试集。 正如你所看到的,返回值是训练集特征,测试集特征,训练集标签和测试集标签。 然后,我们将这些解构到X_train,X_test,y_train,y_test中。 cross_validation.train_test_split接受你的特征和标签作为参数,然后你也可以指定测试集的大小(test_size),我们已经指定为 0.2,意思是 20%。
现在,我们可以建立我们打算使用的分类器:
clf = svm.SVC(kernel='linear')
在这个例子中,我们将使用线性核的支持向量分类器。 在这里更多了解sklearn.svm.SVC。
接下来,我们要训练我们的分类器:
clf.fit(X_train, y_train)
最后,我们从这里可以继续并进行预测,但是让我们来测试分类器在已知数据上的准确性:
print(clf.score(X_test, y_test))
0.792452830189
我的平均准确度约为 70%。 你可能会得到不同的结果。 有许多地方用于机器学习调参。 我们可以改变一些默认参数,我们可以查看一些其他算法,但是现在这样做还不错。
PythonProgramming.net Python 金融教程
一、入门和获取股票数据
您好,欢迎来到 Python 金融系列教程。在本系列中,我们将使用 Pandas 框架来介绍将金融(股票)数据导入 Python 的基础知识。从这里开始,我们将操纵数据,试图搞出一些公司的投资系统,应用一些机器学习,甚至是一些深度学习,然后学习如何回溯测试一个策略。我假设你知道 Python 基础。如果您不确定,请点击基础链接,查看系列中的一些主题,并进行判断。如果在任何时候你卡在这个系列中,或者对某个主题或概念感到困惑,请随时寻求帮助,我将尽我所能提供帮助。
我被问到的一个常见问题是,我是否使用这些技术投资或交易获利。我主要是为了娱乐,并且练习数据分析技巧而玩财务数据,但实际上这也影响了我今天的投资决策。在写这篇文章的时候,我并没有用编程来进行实时算法交易,但是我已经有了实际的盈利,但是在算法交易方面还有很多工作要做。最后,如何操作和分析财务数据,以及如何测试交易状态的知识已经为我节省了大量的金钱。
这里提出的策略都不会使你成为一个超富有的人。如果他们愿意,我可能会把它们留给自己!然而,知识本身可以为你节省金钱,甚至可以使你赚钱。
好吧,让我们开始吧。首先,我正在使用 Python 3.5,但你应该能够获取更高版本。我会假设你已经安装了Python。如果你没有 64 位的 Python,但有 64 位的操作系统,去获取 64 位的 Python,稍后会帮助你。如果你使用的是 32 位操作系统,那么我对你的情况感到抱歉,不过你应该没问题。
用于启动的所需模块:
- NumPy
- Matplotlib
- Pandas
- Pandas-datareader
- BeautifulSoup4
- scikit-learn / sklearn
这些是现在做的,我们会在其他模块出现时处理它们。 首先,让我们介绍一下如何使用 pandas,matplotlib 和 Python 处理股票数据。
如果您想了解 Matplotlib 的更多信息,请查看 Matplotlib 数据可视化系列教程。
如果您想了解 Pandas 的更多信息,请查看 Pandas 数据分析系列教程。
首先,我们将执行以下导入:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
Datetime让我们很容易处理日期,matplotlib用于绘图,Pandas 用于操纵数据,pandas_datareader是我写这篇文章时最新的 Pandas io 库。
现在进行一些启动配置:
style.use('ggplot')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
我们正在设置一个风格,所以我们的图表看起来并不糟糕。 在金融领域,即使你亏本,你的图表也是非常重要的。 接下来,我们设置一个开始和结束datetime 对象,这将是我们要获取股票价格信息的日期范围。
现在,我们可以从这些数据中创建一个数据帧:
df = web.DataReader('TSLA', "yahoo", start, end)
如果您目前不熟悉DataFrame对象,可以查看 Pandas 的教程,或者只是将其想象为电子表格或存储器/ RAM 中的数据库表。 这只是一些行和列,并带有一个索引和列名乘。 在我们的这里,我们的索引可能是日期。 索引应该是与所有列相关的东西。
web.DataReader('TSLA', "yahoo", start, end)这一行,使用pandas_datareader包,寻找股票代码TSLA(特斯拉),从 yahoo 获取信息,从我们选择的起始和结束日期起始或结束。 以防你不知道,股票是公司所有权的一部分,代码是用来在证券交易所引用公司的“符号”。 大多数代码是 1-4 个字母。
所以现在我们有一个Pandas.DataFrame对象,它包含特斯拉的股票交易信息。 让我们看看我们在这里有啥:
print(df.head())
Open High Low Close Volume Adj Close
Date
2010-06-29 19.000000 25.00 17.540001 23.889999 18766300 23.889999
2010-06-30 25.790001 30.42 23.299999 23.830000 17187100 23.830000
2010-07-01 25.000000 25.92 20.270000 21.959999 8218800 21.959999
2010-07-02 23.000000 23.10 18.709999 19.200001 5139800 19.200001
2010-07-06 20.000000 20.00 15.830000 16.110001 6866900 16.110001
.head()是可以用Pandas DataFrames做的事情,它会输出前n行,其中n是你传递的可选参数。如果不传递参数,则默认值为 5。我们绝对会使用.head()来快速浏览一下我们的数据,以确保我们在正路上。看起来很棒!
以防你不知道:
- 开盘价 - 当股市开盘交易时,一股的价格是多少?
- 最高价 - 在交易日的过程中,那一天的最高价是多少?
- 最低价 - 在交易日的过程中,那一天的最低价是多少?
- 收盘价 - 当交易日结束时,最终的价格是多少?
- 成交量 - 那一天有多少股交易?
调整收盘价 - 这一个稍微复杂一些,但是随着时间的推移,公司可能决定做一个叫做股票拆分的事情。例如,苹果一旦股价超过 1000 美元就做了一次。由于在大多数情况下,人们不能购买股票的一小部分,股票价格 1000 美元相当限制投资者。公司可以做股票拆分,他们说每股现在是 2 股,价格是一半。任何人如果以 1,000 美元买入 1 股苹果股份,在拆分之后,苹果的股票翻倍,他们将拥有 2 股苹果(AAPL),每股价值 500 美元。调整收盘价是有帮助的,因为它解释了未来的股票分割,并给出分割的相对价格。出于这个原因,调整价格是你最有可能处理的价格。
二、处理数据和绘图
欢迎阅读 Python 金融系列教程的第 2 部分。 在本教程中,我们将使用我们的股票数据进一步拆分一些基本的数据操作和可视化。 我们将使用的起始代码(在前面的教程中已经介绍过)是:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
start = dt.datetime(2000,1,1)
end = dt.datetime(2016,12,31)
df = web.DataReader('TSLA', 'yahoo', start, end)
我们可以用这些DataFrame做些什么? 首先,我们可以很容易地将它们保存到各种数据类型中。 一个选项是csv:
df.to_csv('TSLA.csv')
我们也可以将数据从 CSV 文件读取到DataFrame中,而不是将数据从 Yahoo 财经 API 读取到DataFrame中:
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
现在,我们可以绘制它:
df.plot()
plt.show()
很酷,尽管我们真正能看到的唯一的东西就是成交量,因为它比股票价格大得多。 我们怎么可能仅仅绘制我们感兴趣的东西?
df['Adj Close'].plot()
plt.show()
你可以看到,你可以在DataFrame中引用特定的列,如:df['Adj Close'],但是你也可以一次引用多个,如下所示:
df[['High','Low']]
在下一个教程中,我们将介绍这些数据的一些基本操作,以及一些更基本的可视化。
三、基本的股票数据操作
欢迎阅读 Python 金融系列教程的第 3 部分。 在本教程中,我们将使用我们的股票数据进一步拆分一些基本的数据操作和可视化。 我们将要使用的起始代码(在前面的教程中已经介绍过)是:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
Pandas 模块配备了一堆可用的内置函数,以及创建自定义 Pandas 函数的方法。 稍后我们将介绍一些自定义函数,但现在让我们对这些数据执行一个非常常见的操作:移动均值。
简单移动均值的想法是选取时间窗口,并计算该窗口内的均值。 然后我们把这个窗口移动一个周期,然后再做一次。 在我们这里,我们将计算 100 天滚动均值。 因此,这将选取当前价格和过去 99 天的价格,加起来,除以 100,之后就是当前的 100 天移动均值。 然后我们把窗口移动一天,然后再做同样的事情。 在 Pandas 中这样做很简单:
df['100ma'] = df['Adj Close'].rolling(window=100).mean()
如果我们有一列叫做100ma,执行df['100ma']允许我们重新定义包含现有列的内容,否则创建一个新列,这就是我们在这里做的。 我们说df['100ma']列等同于应用滚动方法的df['Adj Close']列,窗口为 100,这个窗口将是 mean()(均值)操作。
现在,我们执行:
print(df.head())
Date Open High Low Close Volume \
Date
2010-06-29 2010-06-29 19.000000 25.00 17.540001 23.889999 18766300
2010-06-30 2010-06-30 25.790001 30.42 23.299999 23.830000 17187100
2010-07-01 2010-07-01 25.000000 25.92 20.270000 21.959999 8218800
2010-07-02 2010-07-02 23.000000 23.10 18.709999 19.200001 5139800
2010-07-06 2010-07-06 20.000000 20.00 15.830000 16.110001 6866900
Adj Close 100ma
Date
2010-06-29 23.889999 NaN
2010-06-30 23.830000 NaN
2010-07-01 21.959999 NaN
2010-07-02 19.200001 NaN
2010-07-06 16.110001 NaN
发生了什么? 在100ma列中,我们只看到NaN。 我们选择了 100 移动均值,理论上需要 100 个之前的数据点进行计算,所以我们在这里没有任何前 100 行的数据。 NaN的意思是“不是一个数字”。 有了 Pandas,你可以决定对缺失数据做很多事情,但现在,我们只需要改变最小周期参数:
Date Open High Low Close Volume \
Date
2010-06-29 2010-06-29 19.000000 25.00 17.540001 23.889999 18766300
2010-06-30 2010-06-30 25.790001 30.42 23.299999 23.830000 17187100
2010-07-01 2010-07-01 25.000000 25.92 20.270000 21.959999 8218800
2010-07-02 2010-07-02 23.000000 23.10 18.709999 19.200001 5139800
2010-07-06 2010-07-06 20.000000 20.00 15.830000 16.110001 6866900
Adj Close 100ma
Date
2010-06-29 23.889999 23.889999
2010-06-30 23.830000 23.860000
2010-07-01 21.959999 23.226666
2010-07-02 19.200001 22.220000
2010-07-06 16.110001 20.998000
好吧,可以用,现在我们想看看它! 但是我们已经看到了简单的图表,那么稍微复杂一些呢?
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1,sharex=ax1)
如果你想了解subplot2grid的更多信息,请查看 Matplotlib 教程的子图部分。
基本上,我们说我们想要创建两个子图,而这两个子图都在6x1的网格中,我们有 6 行 1 列。 第一个子图从该网格上的(0,0)开始,跨越 5 行,并跨越 1 列。 下一个子图也在6x1网格上,但是从(5,0)开始,跨越 1 行和 1 列。 第二个子图带有sharex = ax1,这意味着ax2的x轴将始终与ax1的x轴对齐,反之亦然。 现在我们只是绘制我们的图形:
ax1.plot(df.index, df['Adj Close'])
ax1.plot(df.index, df['100ma'])
ax2.bar(df.index, df['Volume'])
plt.show()
在上面,我们在第一个子图中绘制了的close和100ma,第二个图中绘制volume。 我们的结果:
到这里的完整代码:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
df['100ma'] = df['Adj Close'].rolling(window=100, min_periods=0).mean()
print(df.head())
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
ax1.plot(df.index, df['Adj Close'])
ax1.plot(df.index, df['100ma'])
ax2.bar(df.index, df['Volume'])
plt.show()
在接下来的几个教程中,我们将学习如何通过 Pandas 数据重采样制作烛台图,并学习更多使用 Matplotlib 的知识。
四、更多股票操作
欢迎阅读 Python 金融教程系列的第 4 部分。 在本教程中,我们将基于Adj Close列创建烛台/ OHLC 图,我将介绍重新采样和其他一些数据可视化概念。
名为烛台图的 OHLC 图是一个图表,将开盘价,最高价,最低价和收盘价都汇总成很好的格式。 并且它使用漂亮的颜色,还记得我告诉你有关漂亮的图表的事情嘛?
之前的教程中,目前为止的起始代码:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
不幸的是,即使创建 OHLC 数据是这样,Pandas 没有内置制作烛台图的功能。 有一天,我确信这个图表类型将会可用,但是,现在不是。 没关系,我们会实现它! 首先,我们需要做两个新的导入:
from matplotlib.finance import candlestick_ohlc
import matplotlib.dates as mdates
第一个导入是来自 matplotlib 的 OHLC 图形类型,第二个导入是特殊的mdates类型,它在对接中是个麻烦,但这是 matplotlib 图形的日期类型。 Pandas 自动为你处理,但正如我所说,我们没有那么方便的烛台。
首先,我们需要适当的 OHLC 数据。 我们目前的数据确实有 OHLC 值,除非我错了,特斯拉从未有过拆分,但是你不会总是这么幸运。 因此,我们将创建我们自己的 OHLC 数据,这也将使我们能够展示来自 Pandas 的另一个数据转换:
df_ohlc = df['Adj Close'].resample('10D').ohlc()
我们在这里所做的是,创建一个新的数据帧,基于df ['Adj Close']列,使用 10 天窗口重采样,并且重采样是一个 OHLC(开高低关)。我们也可以用.mean()或.sum()计算 10 天的均值,或 10 天的总和。请记住,这 10 天的均值是 10 天均值,而不是滚动均值。由于我们的数据是每日数据,重采样到 10 天的数据有效地缩小了我们的数据大小。这就是你规范多个数据集的方式。有时候,您可能会在每个月的第一天记录一次数据,在每个月末记录其他数据,最后每周记录一些数据。您可以将该数据帧重新采样到月底,并有效地规范化所有东西!这是一个更先进的 Padas 功能,如果你喜欢,你可以更多了解 Pandas 的序列。
我们想要绘制烛台数据以及成交量数据。我们不需要将成交量数据重采样,但是我们应该这样做,因为与我们的10D价格数据相比,这个数据太细致了。
df_volume = df['Volume'].resample('10D').sum()
我们在这里使用sum,因为我们真的想知道在这 10 天内交易总量,但也可以用平均值。 现在如果我们这样做:
print(df_ohlc.head())
open high low close
Date
2010-06-29 23.889999 23.889999 15.800000 17.459999
2010-07-09 17.400000 20.639999 17.049999 20.639999
2010-07-19 21.910000 21.910000 20.219999 20.719999
2010-07-29 20.350000 21.950001 19.590000 19.590000
2010-08-08 19.600000 19.600000 17.600000 19.150000
这是预期,但是,我们现在要将这些信息移动到 matplotlib,并将日期转换为mdates版本。 由于我们只是要在 Matplotlib 中绘制列,我们实际上不希望日期成为索引,所以我们可以这样做:
df_ohlc = df_ohlc.reset_index()
现在dates 只是一个普通的列。 接下来,我们要转换它:
df_ohlc['Date'] = df_ohlc['Date'].map(mdates.date2num)
现在我们打算配置图形:
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1,sharex=ax1)
ax1.xaxis_date()
除了ax1.xaxis_date()之外,你已经看到了一切。 这对我们来说,是把轴从原始的mdate数字转换成日期。
现在我们可以绘制烛台图:
candlestick_ohlc(ax1, df_ohlc.values, width=2, colorup='g')
之后是成交量:
ax2.fill_between(df_volume.index.map(mdates.date2num),df_volume.values,0)
fill_between函数将绘制x,y,然后填充之间的内容。 在我们的例子中,我们选择 0。
plt.show()
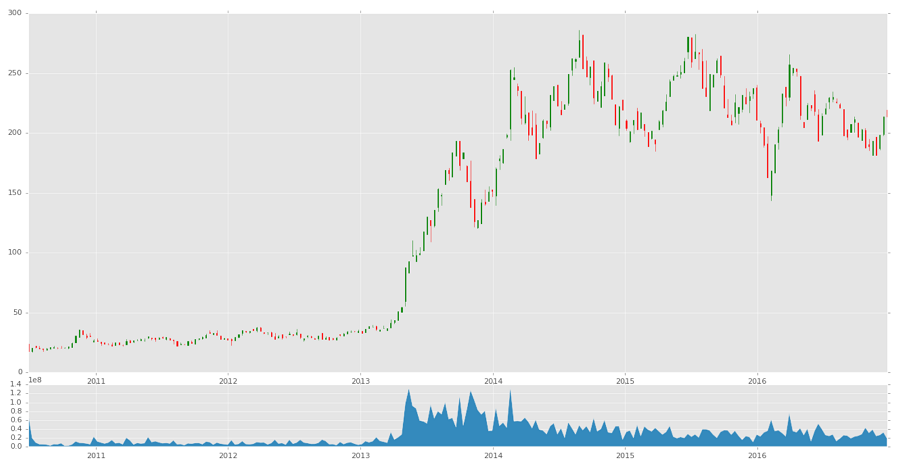
这个教程的完整代码:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
from matplotlib.finance import candlestick_ohlc
import matplotlib.dates as mdates
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
df_ohlc = df['Adj Close'].resample('10D').ohlc()
df_volume = df['Volume'].resample('10D').sum()
df_ohlc.reset_index(inplace=True)
df_ohlc['Date'] = df_ohlc['Date'].map(mdates.date2num)
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
ax1.xaxis_date()
candlestick_ohlc(ax1, df_ohlc.values, width=5, colorup='g')
ax2.fill_between(df_volume.index.map(mdates.date2num), df_volume.values, 0)
plt.show()
在接下来的几个教程中,我们将把可视化留到后面一些,然后专注于获取并处理数据。
五、自动获取 SP500 列表
欢迎阅读 Python 金融教程系列的第 5 部分。在本教程和接下来的几章中,我们将着手研究如何能够获取大量价格信息,以及如何一次处理所有这些数据。
首先,我们需要一个公司名单。我可以给你一个清单,但实际上获得股票清单可能只是你可能遇到的许多挑战之一。在我们的案例中,我们需要一个 SP500 公司的 Python 列表。
无论您是在寻找道琼斯公司,SP500 指数还是罗素 3000 指数,这些公司的信息都有可能在某个地方发布。您需要确保它是最新的,但是它可能还不是完美的格式。在我们的例子中,我们将从维基百科获取这个列表:http://en.wikipedia.org/wiki/List_of_S%26P_500_companies。
维基百科中的代码/符号组织在一张表里面。为了解决这个问题,我们将使用 HTML 解析库,Beautiful Soup。如果你想了解更多,我有一个使用 Beautiful Soup 进行网页抓取的简短的四部分教程。
首先,我们从一些导入开始:
import bs4 as bs
import pickle
import requests
bs4是 Beautiful Soup,pickle 是为了我们可以很容易保存这个公司的名单,而不是每次我们运行时都访问维基百科(但要记住,你需要及时更新这个名单!),我们将使用 requests 从维基百科页面获取源代码。
这是我们函数的开始:
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
首先,我们访问维基百科页面,并获得响应,其中包含我们的源代码。 为了处理源代码,我们想要访问.text属性,我们使用 BeautifulSoup 将其转为soup。 如果您不熟悉 BeautifulSoup 为您所做的工作,它基本上将源代码转换为一个 BeautifulSoup 对象,马上就可以看做一个典型的 Python 对象。
有一次维基百科试图拒绝 Python 的访问。 目前,在我写这篇文章的时候,代码不改变协议头也能工作。 如果您发现原始源代码(resp.text)似乎不返回相同的页面,像您在家用计算机上看到的那样,请添加以下内容并更改resp var代码:
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.27 Safari/537.17'}
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies',
headers=headers)
一旦我们有了soup,我们可以通过简单地搜索wikitable sortable类来找到股票数据表。 我知道指定这个表的唯一原因是,因为我之前在浏览器中查看了源代码。 可能会有这样的情况,你想解析一个不同的网站的股票列表,也许它是在一个表中,也可能是一个列表,或者可能是一些div标签。 这都是一个非常具体的解决方案。 从这里开始,我们仅仅遍历表格:
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
对于每一行,在标题行之后(这就是为什么我们要执行[1:]),我们说股票是“表格数据”(td),我们抓取它的.text, 将此代码添加到我们的列表中。
现在,如果我们可以保存这个列表,那就好了。 我们将使用pickle模块来为我们序列化 Python 对象。
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
我们希望继续并保存它,因此我们无需每天多次请求维基百科。 在任何时候,我们可以更新这个清单,或者我们可以编程一个月检查一次...等等。
目前为止的完整代码:
import bs4 as bs
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
save_sp500_tickers()
现在我们已经知道了代码,我们已经准备好提取所有的信息,这是我们将在下一个教程中做的事情。
六、获取 SP500 中所有公司的价格数据
欢迎阅读 Python 金融教程系列的第 6 部分。 在之前的 Python 教程中,我们介绍了如何获取我们感兴趣的公司名单(在我们的案例中是 SP500),现在我们将获取所有这些公司的股票价格数据。
目前为止的代码:
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
我们打算添加一些新的导入:
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
我们将使用datetime为 Pandas datareader指定日期,os用于检查并创建目录。 你已经知道 Pandas 干什么了!
我们的新函数的开始:
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
在这里,我将展示一个简单示例,可以处理是否重新加载 SP500 列表。 如果我们让它这样,这个程序将重新抓取 SP500,否则将只使用我们的pickle。 现在我们准备抓取数据。
现在我们需要决定我们要处理的数据。 我倾向于尝试解析网站一次,并在本地存储数据。 我不会事先知道我可能用数据做的所有事情,但是我知道如果我不止一次地抓取它,我还可以保存它(除非它是一个巨大的数据集,但不是)。 因此,对于每一种股票,我们抓取所有雅虎可以返回给我们的东西,并保存下来。 为此,我们将创建一个新目录,并在那里存储每个公司的股票数据。 首先,我们需要这个初始目录:
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
您可以将这些数据集存储在与您的脚本相同的目录中,但在我看来,这会变得非常混乱。 现在我们准备好提取数据了。 你已经知道如何实现,我们在第一个教程中完成了!
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
你可能想要为这个函数传入force_data_update参数,因为现在它不会重新提取它已经访问的数据。 由于我们正在提取每日数据,所以您最好至少重新提取最新的数据。 也就是说,如果是这样的话,最好对每个公司使用数据库而不是表格,然后从 Yahoo 数据库中提取最新的值。 但是现在我们会保持简单!
目前为止的代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
#save_sp500_tickers()
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
get_data_from_yahoo()
运行它。如果雅虎阻拦你的话,你可能想添加import time和time.sleep(0.5)或一些东西。 在我写这篇文章的时候,雅虎并没有阻拦我,我能够毫无问题地完成这个任务。 但是这可能需要你一段时间,尤其取决于你的机器。 好消息是,我们不需要再做一遍! 同样在实践中,因为这是每日数据,但是您可能每天都执行一次。
另外,如果你的互联网速度很慢,你不需要获取所有的代码,即使只有 10 个就足够了,所以你可以用ticker [:10]或者类似的东西来加快速度。
在下一个教程中,一旦你下载了数据,我们将把我们感兴趣的数据编译成一个大的 PandasDataFrame。
七、将所有 SP500 价格组合到一个DataFrame
欢迎阅读 Python 金融系列教程的第 7 部分。 在之前的教程中,我们抓取了整个 SP500 公司的雅虎财经数据。 在本教程中,我们将把这些数据放在一个DataFrame中。
目前为止的代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
虽然我们拥有了所有的数据,但是我们可能要一起评估数据。 为此,我们将把所有的股票数据组合在一起。 目前的每个股票文件都带有:开盘价,最高价,最低价,收盘价,成交量和调整收盘价。 至少在最开始,我们现在几乎只对调整收盘价感兴趣。
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
首先,我们获取我们以前生成的代码,并从一个叫做main_df的空DataFrame开始。 现在,我们准备读取每个股票的数据帧:
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
您不需要在这里使用 Python 的enumerate ,我只是使用它,以便知道我们在读取所有数据的过程中的哪里。 你可以迭代代码。 到了这里,我们可以使用有趣的数据来生成额外的列,如:
df['{}_HL_pct_diff'.format(ticker)] = (df['High'] - df['Low']) / df['Low']
df['{}_daily_pct_chng'.format(ticker)] = (df['Close'] - df['Open']) / df['Open']
但是现在,我们不会因此而烦恼。 只要知道这可能是一条遵循之路。 相反,我们真的只是对Adj Close列感兴趣:
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
现在我们已经得到了这一列(或者像上面那样的额外列,但是请记住,在这个例子中,我们没有计算HL_pct_diff或daily_pct_chng)。 请注意,我们已将Adj Close列重命名为任何股票名称。 我们开始构建共享数据帧:
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
如果main_df中没有任何内容,那么我们将从当前的df开始,否则我们将使用 Pandas 的join。
仍然在这个for循环中,我们将添加两行:
if count % 10 == 0:
print(count)
这将只输出当前的股票数量,如果它可以被 10 整除。count % 10计算被除数除以 10 的余数。所以,如果我们计算count % 10 == 0,并且如果当前计数能被 10 整除,余数为零,我们只有看到if语句为真。
我们完成了for循环的时候:
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
目前为止的函数及其调用:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
目前为止的完整代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
在下一个教程中,我们将尝试查看,是否可以快速找到数据中的任何关系。
八、创建大型 SP500 公司相关性表
欢迎阅读 Python 金融教程系列的第 8 部分。 在之前的教程中,我们展示了如何组合 SP500 公司的所有每日价格数据。 在本教程中,我们将看看是否可以找到任何有趣的关联数据。 为此,我们希望将其可视化,因为它是大量数据。 我们将使用 Matplotlib,以及 Numpy。
目前为止的代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
现在我们打算添加下列导入并设置样式:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
下面我们开始构建 Matplotlib 函数:
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
到了这里,我们可以绘制任何公司:
df['AAPL'].plot()
plt.show()
...但是我们没有浏览所有东西,就绘制单个公司! 相反,让我们来看看所有这些公司的相关性。 在 Pandas 中建立相关性表实际上是非常简单的:
df_corr = df.corr()
print(df_corr.head())
这就是它了。.corr()会自动查看整个DataFrame,并确定每列与每列的相关性。 我已经看到付费的网站也把它做成服务。 所以,如果你需要一些副业的话,那么你可以用它!
我们当然可以保存这个,如果我们想要的话:
df_corr.to_csv('sp500corr.csv')
相反,我们要绘制它。 为此,我们要生成一个热力图。 Matplotlib 中没有内置超级简单的热力图,但我们有工具可以制作。 为此,首先我们需要实际的数据来绘制:
data1 = df_corr.values
这会给我们这些数值的 NumPy 数组,它们是相关性的值。 接下来,我们将构建我们的图形和坐标轴:
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
现在我们使用pcolor来绘制热力图:
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
这个热力图使用一系列的颜色来制作,这些颜色可以是任何东西到任何东西的范围,颜色比例由我们使用的cmap生成。 你可以在这里找到颜色映射的所有选项。 我们将使用RdYlGn,它是一个颜色映射,低端为红色,中间为黄色,较高部分为绿色,这将负相关表示为红色,正相关为绿色,无关联为黄色。 我们将添加一个边栏,是个作为“比例尺”的颜色条:
fig1.colorbar(heatmap1)
接下来,我们将设置我们的x和y轴刻度,以便我们知道哪个公司是哪个,因为现在我们只是绘制了数据:
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
这样做只是为我们创建刻度。 我们还没有任何标签。
现在我们添加:
ax1.invert_yaxis()
ax1.xaxis.tick_top()
这会翻转我们的yaxis,所以图形更容易阅读,因为x和y之间会有一些空格。 一般而言,matplotlib 会在图的一端留下空间,因为这往往会使图更容易阅读,但在我们的情况下,却没有。 然后我们也把xaxis翻转到图的顶部,而不是传统的底部,同样使这个更像是相关表应该的样子。 现在我们实际上将把公司名称添加到当前没有名字的刻度中:
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
在这里,我们可以使用两边完全相同的列表,因为column_labels和row_lables应该是相同的列表。 但是,对于所有的热力图而言,这并不总是正确的,所以我决定将其展示为,数据帧的任何热力图的正确方法。 最后:
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
我们旋转xticks,这实际上是代码本身,因为通常他们会超出区域。 我们在这里有超过 500 个标签,所以我们要将他们旋转 90 度,所以他们是垂直的。 这仍然是一个图表,它太大了而看不清所有东西,但没关系。 heatmap1.set_clim(-1,1)那一行只是告诉colormap,我们的范围将从-1变为正1。应该已经是这种情况了,但是我们想确定一下。 没有这一行,它应该仍然是你的数据集的最小值和最大值,所以它本来是非常接近的。
所以我们完成了! 到目前为止的函数:
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
visualize_data()
以及目前为止的完整代码:
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
visualize_data()
我们的劳动果实:

这是很大一个果实。
所以我们可以使用放大镜来放大:

如果你单击它,你可以单击并拖动要放大的框。 这个图表上的框很难看清楚,只知道它在那里。 点击,拖动,释放,你应该放大了,看到像这样的东西:
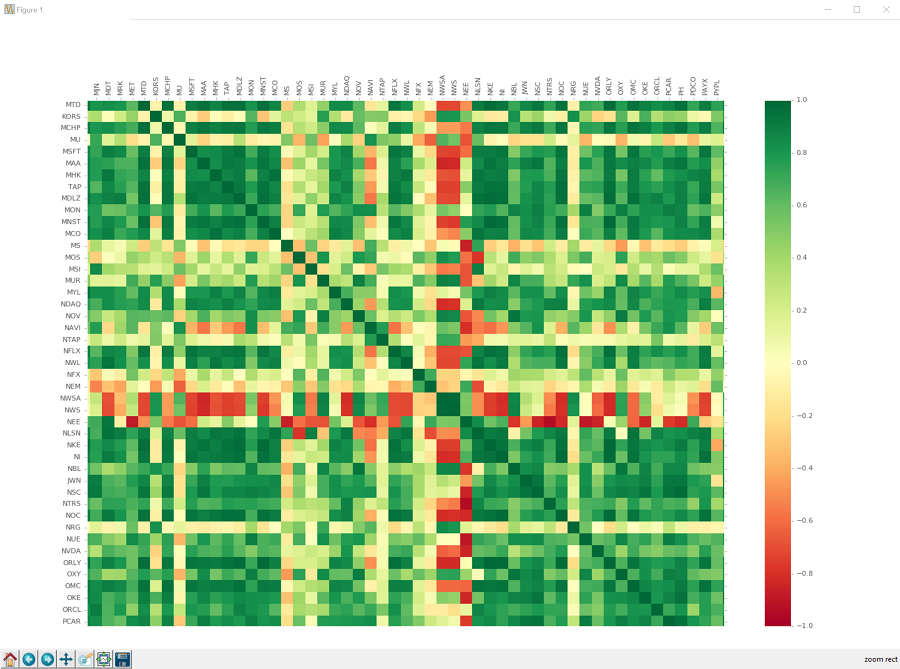
你可以从这里移动,使用十字箭头按钮:
您也可以通过点击主屏幕按钮返回到原始的完整图形。您也可以使用前进和后退按钮“前进”和“后退”到前一个视图。您可以通过点击软盘来保存它。我想知道我们使用软盘的图像来描绘保存东西,有多久了。多久之后人们完全不知道软盘是什么?
好吧,看看相关性,我们可以看到有很多关系。毫不奇怪,大多数公司正相关。有相当多的公司与其他公司有很强的相关性,还有相当多的公司是非常负相关的。甚至有一些公司与大多数公司呈负相关。我们也可以看到有很多公司完全没有关联。机会就是,投资于一群长期以来没有相关性的公司,将是一个多元化的合理方式,但我们现在还不知道。
不管怎样,这个数据已经有很多关系了。人们必须怀疑,一台机器是否能够纯粹依靠这些关系来识别和交易。我们可以轻松成为百万富豪吗?!我们至少可以试试!
九、处理数据,为机器学习做准备
欢迎阅读 Python 金融教程系列的第 9 部分。在之前的教程中,我们介绍了如何拉取大量公司的股票价格数据,如何将这些数据合并为一个大型数据集,以及如何直观地表示所有公司之间的一种关系。现在,我们将尝试采用这些数据,并做一些机器学习!
我们的想法是,看看如果我们获得所有当前公司的数据,并把这些数据扔给某种机器学习分类器,会发生什么。我们知道,随着时间的推移,各个公司彼此有着不同的练习,所以,如果机器能够识别并且拟合这些关系,那么我们可以从今天的价格变化中,预测明天会发生什么事情。咱们试试吧!
首先,所有机器学习都是接受“特征集”,并尝试将其映射到“标签”。无论我们是做 K 最近邻居还是深度神经网络学习,这都是一样的。因此,我们需要将现有的数据转换为特征集和标签。
我们的特征可以是其他公司的价格,但是我们要说的是,特征是所有公司当天的价格变化。我们的标签将是我们是否真的想买特定公司。假设我们正在考虑 Exxon(XOM)。我们要做的特征集是,考虑当天所有公司的百分比变化,这些都是我们的特征。我们的标签将是 Exxon(XOM)在接下来的x天内涨幅是否超过x%,我们可以为x选择任何我们想要的值。首先,假设一家公司在未来 7 天内价格上涨超过 2%,如果价格在这 7 天内下跌超过 2%,那么就卖出。
这也是我们可以比较容易做出的一个策略。如果算法说了买入,我们可以买,放置 2% 的止损(基本上告诉交易所,如果价格跌破这个数字/或者如果你做空公司,价格超过这个数字,那么退出我的位置)。否则,公司一旦涨了 2% 就卖掉,或者保守地在 1% 卖掉,等等。无论如何,你可以比较容易地从这个分类器建立一个策略。为了开始,我们需要为我们的训练数据放入未来的价格。
我将继续编写我们的脚本。如果这对您是个问题,请随时创建一个新文件并导入我们使用的函数。
目前为止的完整代码:
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
继续,让我们开始处理一些数据,这将帮助我们创建我们的标签:
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
这个函数接受一个参数:问题中的股票代码。 每个模型将在一家公司上训练。 接下来,我们想知道我们需要未来多少天的价格。 我们在这里选择 7。 现在,我们将读取我们过去保存的所有公司的收盘价的数据,获取现有的代码列表,现在我们将为缺失值数据填入 0。 这可能是你将来要改变的东西,但是现在我们将用 0 来代替。 现在,我们要抓取未来 7 天的百分比变化:
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
这为我们的特定股票创建新的数据帧的列,使用字符串格式化创建自定义名称。 我们获得未来值的方式是使用.shift,这基本上会使列向上或向下移动。 在这里,我们移动一个负值,这将选取该列,如果你可以看到它,它会把这个列向上移动i行。 这给了我们未来值,我们可以计算百分比变化。
最后:
df.fillna(0, inplace=True)
return tickers, df
我们在这里准备完了,我们将返回代码和数据帧,并且我们正在创建一些特征集,我们的算法可以用它来尝试拟合和发现关系。
我们的完整处理函数:
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
在下一个教程中,我们将介绍如何创建我们的“标签”。
十、十一、为机器学习标签创建目标
欢迎阅读 Python 金融系列教程的第 10 部分(和第 11 部分)。 在之前的教程中,我们开始构建我们的标签,试图使用机器学习和 Python 来投资。 在本教程中,我们将使用我们上一次教程的内容,在准备就绪时实际生成标签。
目前为止的代码:
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
现在我们要创建一个创建标签的函数。 我们在这里有很多选择。 你可能希望有一些东西,它们指导购买,出售或持有,或者只是买或卖。 我要让我们实现前者。 基本上,如果价格在未来 7 天上涨超过 2%,那么我们会说这是买入。 如果在接下来的 7 天内下跌超过 2%,这是卖出。 如果这两者都不是,那么它就没有足够的动力,我们将会坚持我们的位置。 如果我们有这个公司的股份,我们什么都不做,我们坚持我们的位置。 如果我们没有该公司的股份,我们什么都不做,我们只是等待。 我们的函数是:
def buy_sell_hold(*args):
cols = [c for c in args]
requirement = 0.02
for col in cols:
if col > requirement:
return 1
if col < -requirement:
return -1
return 0
我们在这里使用args,所以我们可以在这里接受任意数量的列。 这里的想法是我们要把这个函数映射到 Pandas DataFrame的列,这个列将成为我们的“标签”。 -1是卖出,0 是持有,1 是买入。 *args将是那些未来的价格变化列,我们感兴趣的是,是否我们能看到超过 2% 的双向移动。 请注意,这不是一个完美的函数。 例如,价格可能上涨 2%,然后下降 2%,我们可能没有为此做好准备,但现在就这样了。
那么,让我们来生成我们的特征和标签! 对于这个函数,我们将添加下面的导入:
from collections import Counter
这将让我们在我们的数据集和算法预测中,看到类别的分布。 我们不想将高度不平衡的数据集扔给机器学习分类器,我们也想看看我们的分类器是否只预测一个类别。 我们下一函数是:
def extract_featuresets(ticker):
tickers, df = process_data_for_labels(ticker)
df['{}_target'.format(ticker)] = list(map( buy_sell_hold,
df['{}_1d'.format(ticker)],
df['{}_2d'.format(ticker)],
df['{}_3d'.format(ticker)],
df['{}_4d'.format(ticker)],
df['{}_5d'.format(ticker)],
df['{}_6d'.format(ticker)],
df['{}_7d'.format(ticker)] ))
这个函数将接受任何股票代码,创建所需的数据集,并创建我们的“目标”列,这是我们的标签。 根据我们的函数和我们当如的列,目标列将为每行设置一个-1,0或1。 现在,我们可以得到分布:
vals = df['{}_target'.format(ticker)].values.tolist()
str_vals = [str(i) for i in vals]
print('Data spread:',Counter(str_vals))
清理我们的数据:
df.fillna(0, inplace=True)
df = df.replace([np.inf, -np.inf], np.nan)
df.dropna(inplace=True)
我们可能有一些完全丢失的数据,我们将用 0 代替。接下来,我们可能会有一些无限的数据,特别是如果我们计算了从 0 到任何东西的百分比变化。 我们将把无限值转换为NaN,然后我们将放弃NaN。 我们几乎已经准备好了,但现在我们的“特征”就是当天股票的价格。 只是静态的数字,真的没有什么可说的。 相反,更好的指标是当天每个公司的百分比变化。 这里的想法是,有些公司的价格会先于其他公司变化,而我们也可能从中获利。 我们会将股价转换为百分比变化:
df_vals = df[[ticker for ticker in tickers]].pct_change()
df_vals = df_vals.replace([np.inf, -np.inf], 0)
df_vals.fillna(0, inplace=True)
再次,小心无限的数字,然后填充其他缺失的数据,现在,最后,我们准备创建我们的特征和标签:
X = df_vals.values
y = df['{}_target'.format(ticker)].values
return X,y,df
大写字母X包含我们的特征集(SP500 中每个公司的每日变化百分比)。 小写字母y是我们的“目标”或我们的“标签”。 基本上我们试图将我们的特征集映射到它。
好吧,我们有了特征和标签,我们准备做一些机器学习,这将在下一个教程中介绍。
十二、SP500 上的机器学习
欢迎阅读 Python 金融系列教程的第 12 部分。 在之前的教程中,我们介绍了如何获取数据并创建特征集和标签,然后我们可以将其扔给机器学习算法,希望它能学会将一家公司的现有价格变化关系映射到未来的价格变化。
在我们开始之前,我们目前为止的起始代码到:
import bs4 as bs
from collections import Counter
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
def buy_sell_hold(*args):
cols = [c for c in args]
requirement = 0.02
for col in cols:
if col > requirement:
return 1
if col < -requirement:
return -1
return 0
def extract_featuresets(ticker):
tickers, df = process_data_for_labels(ticker)
df['{}_target'.format(ticker)] = list(map( buy_sell_hold,
df['{}_1d'.format(ticker)],
df['{}_2d'.format(ticker)],
df['{}_3d'.format(ticker)],
df['{}_4d'.format(ticker)],
df['{}_5d'.format(ticker)],
df['{}_6d'.format(ticker)],
df['{}_7d'.format(ticker)] ))
vals = df['{}_target'.format(ticker)].values.tolist()
str_vals = [str(i) for i in vals]
print('Data spread:',Counter(str_vals))
df.fillna(0, inplace=True)
df = df.replace([np.inf, -np.inf], np.nan)
df.dropna(inplace=True)
df_vals = df[[ticker for ticker in tickers]].pct_change()
df_vals = df_vals.replace([np.inf, -np.inf], 0)
df_vals.fillna(0, inplace=True)
X = df_vals.values
y = df['{}_target'.format(ticker)].values
return X,y,df
我们打算添加以下导入:
from sklearn import svm, cross_validation, neighbors
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
Sklearn 是一个机器学习框架。 如果你没有它,请确保你下载它:pip install scikit-learn。svm import是支持向量机,cross_validation可以让我们轻松地创建打乱的训练和测试样本,neighbors是 K 最近邻。 然后,我们引入了VotingClassifier和RandomForestClassifier。投票分类器正是它听起来的样子。 基本上,这是一个分类器,它可以让我们结合许多分类器,并允许他们分别对他们认为的特征集的类别进行“投票”。 随机森林分类器只是另一个分类器。 我们将在投票分类器中使用三个分类器。
我们现在准备做一些机器学习,所以让我们开始我们的函数:
def do_ml(ticker):
X, y, df = extract_featuresets(ticker)
我们已经有了我们的特征集和标签,现在我们想把它们打乱,训练,然后测试:
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y,
test_size=0.25)
这对我们来说是在打乱我们的数据(所以它没有任何特定的顺序),然后为我们创建训练和测试样本。 我们不想在我们相同的训练数据上“测试”这个算法。 如果我们这样做了,我们可能会比现实中做得更好。 我们想要在从来没有见过的数据上测试算法,看看我们是否真的有了一个可行的模型。
现在我们可以从我们想要的任何分类器中进行选择,现在让我们选择 K 最近邻:
clf = neighbors.KNeighborsClassifier()
现在我们可以在我们的数据上fit(训练)分类器:
clf.fit(X_train, y_train)
这行会接受我们的X数据,拟合我们的Y数据,对于我们拥有的每一对X和Y。 一旦完成,我们可以测试它:
confidence = clf.score(X_test, y_test)
这将需要一些特征集X_test来预测,并查看它是否与我们的标签y_test相匹配。 它会以小数形式返回给我们百分比精度,其中1.0是 100%,0.1是 10% 准确。 现在我们可以输出一些更有用的信息:
print('accuracy:',confidence)
predictions = clf.predict(X_test)
print('predicted class counts:',Counter(predictions))
print()
print()
这将告诉我们准确性是什么,然后我们可以得到X_testdata的准确度,然后输出分布(使用Counter),所以我们可以看到我们的模型是否只是对一个类进行分类,这是很容易发生的事情。
如果这个模型确实是成功的,我们可以用pickle保存它,并随时加载它,为它提供一些特征集,并用clf.predict得到一个预测结果,这将从单个特征集预测单个值, 从特征集列表中预测值列表。
好的,我们已经准备好了! 我们的目标是什么? 随机挑选的东西应该是 33% 左右,因为我们在理论上总共有三选择,但实际上我们的模型是不可能真正平衡的。 让我们看一些例子,然后运行:
do_ml('XOM')
do_ml('AAPL')
do_ml('ABT')
Data spread: Counter({'1': 1713, '-1': 1456, '0': 1108})
accuracy: 0.375700934579
predicted class counts: Counter({0: 404, -1: 393, 1: 273})
Data spread: Counter({'1': 2098, '-1': 1830, '0': 349})
accuracy: 0.4
predicted class counts: Counter({-1: 644, 1: 339, 0: 87})
Data spread: Counter({'1': 1690, '-1': 1483, '0': 1104})
accuracy: 0.33738317757
predicted class counts: Counter({-1: 383, 0: 372, 1: 315})
所以这些都比 33% 好,但是训练数据也不是很完美。 例如,我们可以看看第一个:
Data spread: Counter({'1': 1713, '-1': 1456, '0': 1108})
accuracy: 0.375700934579
predicted class counts: Counter({0: 404, -1: 393, 1: 273})
在这种情况下,如果模型只预测“买不买”? 这应该是 1,713 正确比上 4,277,这实际上是比我们得到的更好的分数。 那另外两个呢? 第二个是 AAPL,如果只是预测购买,至少在训练数据上是 49%。 如果只是在训练数据上预测购买与否,ABT 的准确率为 37%。
所以,虽然我们的表现比 33% 好,但目前还不清楚这种模型是否比只说“购买”更好。 在实际交易中,这一切都可以改变。 例如,如果这种模型说了某件事是买入的话,期望在 7 天内上涨 2%,但是直到 8 天才会出现 2% 的涨幅,并且,该算法一直说买入或者 持有,那么这个模型就会受到惩罚。 在实际交易中,这样做还是可以的。 如果这个模型结果非常准确,情况也是如此。 实际上,交易模型完全可以是完全不同的东西。
接下来,让我们尝试一下投票分类器。 所以,不是clf = neighbors.KNeighborsClassifier(),我们这样做:
clf = VotingClassifier([('lsvc',svm.LinearSVC()),
('knn',neighbors.KNeighborsClassifier()),
('rfor',RandomForestClassifier())])
新的输出:
Data spread: Counter({'1': 1713, '-1': 1456, '0': 1108})
accuracy: 0.379439252336
predicted class counts: Counter({-1: 487, 1: 417, 0: 166})
Data spread: Counter({'1': 2098, '-1': 1830, '0': 349})
accuracy: 0.471028037383
predicted class counts: Counter({1: 616, -1: 452, 0: 2})
Data spread: Counter({'1': 1690, '-1': 1483, '0': 1104})
accuracy: 0.378504672897
predicted class counts: Counter({-1: 524, 1: 394, 0: 152})
在所有股票上,我们都有改进! 这很好看。 我们还特别注意,使用所有算法的默认值。 这些算法中的每一个都有相当多的参数,我们可以花一些时间来调整,来获得更高的效果,并且至少可以打败“对一切东西都预测买入”。 也就是说,机器学习是一个巨大的话题,需要花费几个月时间才能讲完所有东西。 如果你想自己学习更多的算法,以便你可以调整它们,看看机器学习系列教程。 我们涵盖了一堆机器学习算法,它们背后是如何工作的,如何应用它们,然后如何使用原始的 Python 自己制作它们。 在你完成整个系列课程的时候,你应该能够很好地配置机器学习来应对各种挑战。
目前为止的所有代码:
import bs4 as bs
from collections import Counter
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
from sklearn import svm, cross_validation, neighbors
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
def buy_sell_hold(*args):
cols = [c for c in args]
requirement = 0.02
for col in cols:
if col > requirement:
return 1
if col < -requirement:
return -1
return 0
def extract_featuresets(ticker):
tickers, df = process_data_for_labels(ticker)
df['{}_target'.format(ticker)] = list(map( buy_sell_hold,
df['{}_1d'.format(ticker)],
df['{}_2d'.format(ticker)],
df['{}_3d'.format(ticker)],
df['{}_4d'.format(ticker)],
df['{}_5d'.format(ticker)],
df['{}_6d'.format(ticker)],
df['{}_7d'.format(ticker)] ))
vals = df['{}_target'.format(ticker)].values.tolist()
str_vals = [str(i) for i in vals]
print('Data spread:',Counter(str_vals))
df.fillna(0, inplace=True)
df = df.replace([np.inf, -np.inf], np.nan)
df.dropna(inplace=True)
df_vals = df[[ticker for ticker in tickers]].pct_change()
df_vals = df_vals.replace([np.inf, -np.inf], 0)
df_vals.fillna(0, inplace=True)
X = df_vals.values
y = df['{}_target'.format(ticker)].values
return X,y,df
def do_ml(ticker):
X, y, df = extract_featuresets(ticker)
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y,
test_size=0.25)
#clf = neighbors.KNeighborsClassifier()
clf = VotingClassifier([('lsvc',svm.LinearSVC()),
('knn',neighbors.KNeighborsClassifier()),
('rfor',RandomForestClassifier())])
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print('accuracy:',confidence)
predictions = clf.predict(X_test)
print('predicted class counts:',Counter(predictions))
print()
print()
return confidence
# examples of running:
do_ml('XOM')
do_ml('AAPL')
do_ml('ABT')
你也可以在所有代码上运行它:
from statistics import mean
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
accuracies = []
for count,ticker in enumerate(tickers):
if count%10==0:
print(count)
accuracy = do_ml(ticker)
accuracies.append(accuracy)
print("{} accuracy: {}. Average accuracy:{}".format(ticker,accuracy,mean(accuracies)))
这将需要一段时间。 我继续做下去,结果平均准确率为 46.279%。 不错,但是从我这里看,结果对于任何形式的策略仍然是可疑的。
在接下来的教程中,我们将深入测试交易策略。
十三、使用 Quantopian 测试交易策略
欢迎阅读 Python 金融系列教程的第 13 部分。在本教程中,我们将开始谈论策略回测。回测领域和正确执行的要求是相当大的。基本上,我们需要创建一个系统,接受历史价格数据并在该环境中模拟交易,然后给我们结果。这听起来可能很简单,但为了分析策略,我们需要跟踪一系列指标,比如我们卖出什么,什么时候交易,我们的 Beta 和 Alpha 是什么,以及其他指标如 drawdown,夏普比,波动率,杠杆等等。除此之外,我们通常希望能够看到所有这些。所以,我们可以自己写所有这些,也可以用一个平台来帮助我们...
这就是为什么我们要介绍 Quantopian,这是一个平台,可以让我们轻松地使用 Python 编写和回测交易策略。
Quantopian 所做的是,在 Python 的 Zipline 回测库之上增加了一个 GUI 层,也带有大量的数据源,其中很多都是完全免费的。如果您符合特定标准,您还可以通过将您的策略授权给他们,从 Quantopian 获得资金。一般来说,-0.3到+0.3之间的 β 值是一个很好的起点,但是您还需要有其他健康的指标来竞争。稍后再介绍一下 Quantopian 的基础知识。由于 Quantopian 主要由 Zipline,Alphalens 和 Pyfolio 等开源库支持,如果您愿意,还可以在本地运行类似 Quantopian 的平台。我发现大多数人都对此感兴趣,来保持其算法的私密性。 Quantopian 不会查看您的算法,除非您授予他们权限,而社区只有在您分享算法时才会看到您的算法。我强烈建议你把自己和 Quantopian 的关系看作是一种合作关系,而不是竞争关系。如果您想出了一些高质量的策略,Quantopian 非常乐意与您合作,并且用资金投资您。在这种关系中,Quantopian 将平台,资金和其他专家带到这个领域来帮助你,在我看来这是一个相当不错的交易。
首先,前往quantopian.com,如果你没有帐户就创建一个,并登录。随意点一点鼠标。 Quantopian 社区论坛是吸收一些知识的好地方。 Quantopian 也经常举办带现金奖励的比赛。我们将从算法开始。到了那里,选择蓝色的“新算法”按钮。现在,我们将把我们大部分时间花在两个地方,这可以在“我的代码”按钮下找到。首先,我们将访问算法,并使用蓝色的“新算法”按钮创建一个新的算法。
当你创建算法时,你应该被带到你的实时编辑算法页面,并带有克隆的算法,看起来像这样(除了彩色框),以及 UI 的一些可能的更改。
Python编辑器 - 这是您为算法编写 Python 逻辑的地方。
构建算法结果 - 当您构建算法时,图形结果将在这里出现。
日志/错误输出 - 任何控制台输出/日志信息将在这里。 您的程序通常会输出各种文本来调试,或者只是为了获取更多信息。
构建算法 - 使用它来快速测试你写的东西。 结果不会被保存,但是您可以在“内置算法结果”部分看到结果。
完整的回测 - 这将根据您当前的算法运行完整的回测。 完整的回测会提供更多分析,结果将被保存,并且生成这些结果的算法也会被保存,所以您可以返回去浏览回测,并查看生成特定结果的具体代码。
起始示例代码如下所示:
"""
This is a template algorithm on Quantopian for you to adapt and fill in.
"""
from quantopian.algorithm import attach_pipeline, pipeline_output
from quantopian.pipeline import Pipeline
from quantopian.pipeline.data.builtin import USEquityPricing
from quantopian.pipeline.factors import AverageDollarVolume
def initialize(context):
"""
Called once at the start of the algorithm.
"""
# Rebalance every day, 1 hour after market open.
schedule_function(my_rebalance, date_rules.every_day(), time_rules.market_open(hours=1))
# Record tracking variables at the end of each day.
schedule_function(my_record_vars, date_rules.every_day(), time_rules.market_close())
# Create our dynamic stock selector.
attach_pipeline(make_pipeline(), 'my_pipeline')
def make_pipeline():
"""
A function to create our dynamic stock selector (pipeline). Documentation on
pipeline can be found here: https://www.quantopian.com/help#pipeline-title
"""
# Create a dollar volume factor.
dollar_volume = AverageDollarVolume(window_length=1)
# Pick the top 1% of stocks ranked by dollar volume.
high_dollar_volume = dollar_volume.percentile_between(99, 100)
pipe = Pipeline(
screen = high_dollar_volume,
columns = {
'dollar_volume': dollar_volume
}
)
return pipe
def before_trading_start(context, data):
"""
Called every day before market open.
"""
context.output = pipeline_output('my_pipeline')
# These are the securities that we are interested in trading each day.
context.security_list = context.output.index
def my_assign_weights(context, data):
"""
Assign weights to securities that we want to order.
"""
pass
def my_rebalance(context,data):
"""
Execute orders according to our schedule_function() timing.
"""
pass
def my_record_vars(context, data):
"""
Plot variables at the end of each day.
"""
pass
def handle_data(context,data):
"""
Called every minute.
"""
pass
这很好,但是可能还差一点才能开始。如果您的帐户是新的,Quantopian 还提供了一些示例算法。随意查看一下,但你可能会发现他们令人困惑。每个算法中只需要两个函数:initialize和handle_data。初始化函数在脚本开始时运行一次。您将使用它来设置全局,例如规则,稍后使用的函数以及各种参数。接下来是handle_data函数,在市场数据上每分钟运行一次。
让我们编写我自己的简单策略来熟悉 Quantopian。我们将要实现一个简单的移动均值交叉策略,看看它是如何实现的。
如果你不熟悉移动均值,他们所做的就是获取一定数量的“窗口”数据。在每日价格的情况下,一个窗口将是一天。如果你计算 20 移动均值,这意味着 20 日均值。从这里来看,我们假设你有 20 移动均值和 50 移动均值。在一个图上绘制它可能看起来像这样:
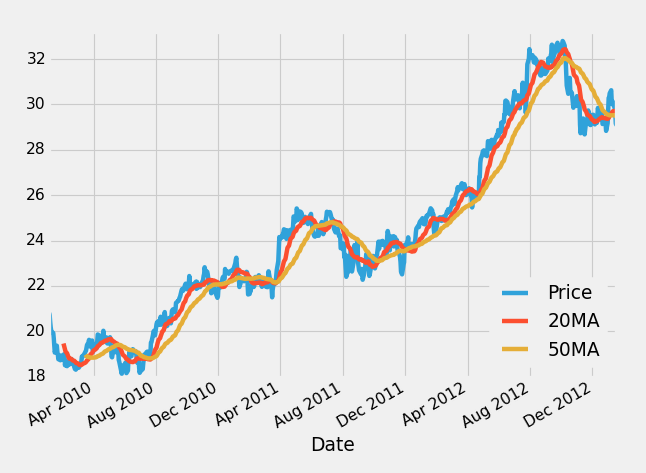
在这里,蓝线是股价,红线是 20 移动均值,黄线是 50 移动均值。这个想法是,20 个移动均值反应更快,当它移动到 50 移动均值上面时,这意味着价格可能会上涨,我们可能要投资。相反,如果 20 移动均值跌到 50 移动平均线下面,这可能意味着价格正在下降,我们可能要么出售或投资,甚至卖空公司,这是你打赌的地方。
就我们的目的而言,让我们在 2015 年 10 月 7 日至 2016 年 10 月 7 日之间,对苹果公司(AAPL)应用移动均值交叉策略。在此期间,AAPL 股价下跌,随后上涨,净变化很小。我们的交叉策略应该随着价格的下跌而保持远离或者做空(押注),然后在价格上涨的时候扑上来。做空公司需要向其他人借入股票,然后出售,然后几天之后再重新买入股份。你的希望是股价下跌,你重新买回会便宜得多,并将股份还给原来的所有者,赚取差价。首先,我们来构建初始化方法:
def initialize(context):
context.aapl = sid(24)
现在,我们只是要定义我们的苹果股票。如果你真的开始输入sid(,Quantopian 有很好的自动补全功能,你可以开始输入公司名称或代码来找到他们的sid。使用sid的原因是,因为公司代码可以在一段时间内改变。这是一种方法,确保你得到你想要得到的代码,你也可以使用symbol()来使用代码,并且让你的代码更容易阅读,但这不推荐,因为股票代码可以改变。
每次用 Zipline 或 Quantopian 创建算法时,都需要有initialize和handle_data方法。
初始化方法在算法启动时运行一次(或者如果您正在实时运行算法,则每天运行一次)。 handle_data每分钟运行一次。
在我们的初始化方法中,我们传递这个上下文参数。上下文是一个 Python 字典,我们将使用它来跟踪,我们将全局变量用于什么。简而言之,上下文变量用于跟踪我们当前的投资环境,例如我们的投资组合和现金。
接下来,我们仍然需要我们的handle_data函数。该函数将context 和data作为参数。
上下文参数已解释了,数据变量用于跟踪实际投资组合之外的环境。它跟踪股票价格和其他我们可能投资的公司的信息,但是他们是我们正在跟踪的公司。
handle_data函数的开头:
def handle_data(context,data):
# prices for aapl for the last 50 days, in 1 day intervals
hist = data.history(context.aapl,'price', 50, '1d')
我们可以使用.history方法,获取过去的 50 天内苹果公司的历史价格,间隔为 1 天。 现在我们可以执行:
# mean of the entire 200 day history
sma_50 = hist.mean()
# mean of just the last 50 days
sma_20 = hist[-20:].mean()
sma_50值就是我们刚刚拉取的历史数据的均值。 sma_20是数据的最后 20 天。 请注意,这包含在handle_data方法中,该方法在每个周期运行,所以我们只需要跟踪 50 和 20 简单移动均值每天的值。
在下一个教程中,我们将讨论下订单。
十四、使用 Quantopian 下达交易订单
欢迎阅读 Python 金融系列教程的第 14 部分,使用 Quantopian。 在本教程中,我们将介绍如何实际下单(股票/卖出/做空)。
到目前为止,我们有以下代码:
def initialize(context):
context.aapl = sid(24)
def handle_data(context,data):
# prices for aapl for the last 50 days, in 1 day intervals
hist = data.history(context.aapl,'price', 50, '1d')
# mean of the entire 50 day history
sma_50 = hist.mean()
# mean of just the last 50 days
sma_20 = hist[-20:].mean()
我们到目前为止所做的,定义了什么是context.aapl,然后我们抓取了 AAPL 的历史价格,并且使用这些价格生成了一些代码,在每个时间间隔计算 50 和 20 简单移动均值。 我们的计划是制定一个简单的移动均值交叉策略,我们几乎准备完毕了。 逻辑应该简单:如果 20SMA 大于 50SMA,那么价格在上涨,我们想在这时候买入! 如果 20SMA 低于 50SMA,那么价格将下跌,我们想做空这个公司(下注)。 让我们建立一个订单系统来反映这一点:
if sma_20 > sma_50:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
order_target_percent(context.aapl, -1.0)
order_target_percent函数用于让我们将一定比例的投资组合投资到一家公司。 在这种情况下,我们唯一考虑的公司是 Apple(AAPL),所以我们使用了 1.0(100%)。 下单有很多方法,这只是其中的一个。 我们可以做市场订单,订特定的金额,订百分比,订目标价值,当然也可以取消未成交的订单。 在这种情况下,我们期望在每一步都简单地买入/卖出 100% 的股份。 如果我们运行它,我们会得到:
太棒了!我们会变富!
只是没有用这个策略。
当你第一次写一个算法,特别是在开始时,这样的事情很可能发生。也许这对你有利,或者你失去了 1000% 的起始资金,你想知道发生了什么。在这种情况下,很容易发现它。首先,我们的回报是不可能的,而且,根据 Quantopian 的基本读数,我们可以看到,当我们启动资金是 100 万美元时,我们现在正在做的交易达到数千万美元,甚至数亿美元。
那么这里发生了什么? Quantopian 是为了让你做任何你想做的事情而建立的,对“贷款”没有任何限制。当你借贷在金融世界投资时,通常被称为杠杆。这个帐户的杠杆严重,这正是我们所要求的。
学习如何诊断它,并在未来避免它非常重要!
第一步几乎总是记录杠杆。现在我们来做:
def initialize(context):
context.aapl = sid(24)
def handle_data(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
if sma_20 > sma_50:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
order_target_percent(context.aapl, -1.0)
record(leverage = context.account.leverage)
有了记录,我们可以跟踪五个值。 这里,我们仅仅选择一个。 我们正在查看我们的帐户的杠杆,我们在context.account.leverage中自动跟踪它。 你可以看到其他选项,只需通过context。 或context.account, 等等,来使用自动完成查看你的选择是什么。 您也可以使用记录来跟踪其他值,这仅仅是一个例子。
只要运行一下,我们就能看到杠杆确实无法控制:
好的,所以我们已经杠杆过多。 究竟发生了什么? 好吧,对于一个人,这个handle_data函数每分钟都运行。 因此,我们每分钟都可以合理下单,在这里,它下单了投资组合的 100%。 我们认为我们是安全的,因为我们正在下单一个目标百分比。 如果目标百分比是 100%,那么我们为什么会得到这么多呢? 问题是,订单实际填充可能需要时间。 因此,一个订单正在等待填充,另一个正在同时进行!
我们可能想要避免的第一件事,就是使用get_open_orders()方法,如下所示:
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
现在,在每个订单之前,我们检查是否有这个公司的未完成订单。 让我们来运行它。
需要注意的一点是,除非您阅读文档,否则确实没有办法知道存在get_open_orders()。 我会告诉你很多方法和函数,但是我当然不会把它们全部涵盖。 一定要确保你浏览了 Quantopian API 文档,看看你有什么可用的。 你不需要全部阅读,只需浏览一遍,并阅读注意到的函数。 函数/方法是红色的,所以当你浏览的时候很容易捕捉它们。
这次运行的结果:
你看到的偏差是1 +/- 0.0001。 正如我们所希望的那样,在这次的所有时间中,我们有效使杠杆保持为 1,但是......呃......那个回报不是非常好!
通过点击左侧导航栏中的“交易详情”,我们可以看到一件事情,那就是我们每天都在做很多交易。 我们可以看到我们的一些交易量也相当大,有时差不多有 1000 万美元。 这里发生了什么事? 我们也认为我们最好每天只进行一次交易。
相反,handle_data函数每分钟运行一次,所以,我们实际上仍然可能每分钟进行一次交易。 如果我们希望做的事情,不是每分钟都在评估市场的话,我们实际上可能打算调度这个函数。 幸运的是,我们可以这样做,这是下一个教程的主题!
十五、在 Quantopian 上调度函数
欢迎来到 Python 金融系列教程的第 15 部分,使用 Quantopian 和 Zipline。 在本教程中,我们将介绍schedule_function。
在我们的案例中,我们实际上只打算每天交易一次,而不是一天交易多次。 除了简单的交易之外,另一种通常的做法是及时“重新平衡”投资组合。 也许每周,也许每天,也许每个月你想适当平衡,或“多元化”你的投资组合。 这个调度功能可以让你实现它! 为了调度函数,可以在initialize方法中调用schedule_function函数。
def initialize(context):
context.aapl = sid(24)
schedule_function(ma_crossover_handling, date_rules.every_day(), time_rules.market_open(hours=1))
在这里,我们要说的是,我们希望调度这个函数,every_day(每天)在market_open后一个小时运行。 像往常一样,这里有很多选择。 您可以在市场收盘前x小时(仍然使用正值)运行。 例如,如果您想在market_close之前 1 小时运行它,那将是time_rules.market_close(hours=1)。 您也可以在几分钟内调度,如:time_rules.market_close(hours=0, minutes=1),这意味着在市场收盘前 1 分钟运行这个函数。
现在,我们要做的是从handle_data函数中获取以下代码:
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
...cut it and place it under a new function ma_crossover_handling
def ma_crossover_handling(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
请注意,我们在这里传递上下文和数据。现在,运行完整的回测,您应该注意到这比以前要快得多。这是因为我们实际上并不是每分钟重新计算移动均值,而是现在每天计算一次。这为我们节省了大量的计算。
但是请注意,我们的一些交易栏表明,我们正在买卖近 200 万美元的股票,当时我们的资本应该是 100 万美元,而我们做得还不够好,已经翻了一番。
做空会造成这种情况。当我们在 Quantopian 上做空公司时,我们的股票是负的。例如,我们假设我们卖空 100 股苹果。这意味着我们在苹果有 -100 的股份。然后考虑我们想改变我们的股份,持有 100 股苹果。实际上我们需要购买 100 股,来达到 0 股,之后再买 100 股达到+100。从+100到-100也是如此。这就是为什么我们拥有这些看似双倍的交易,没有杠杆。所以通过买入(长期)我们大约是-7%,并且根据移动平均交叉做空苹果。如果我们只是买和卖,而不是买和做空,会发生什么?
def initialize(context):
context.aapl = sid(24)
schedule_function(ma_crossover_handling, date_rules.every_day(), time_rules.market_open(hours=1))
def handle_data(context,data):
record(leverage=context.account.leverage)
def ma_crossover_handling(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 0.0)
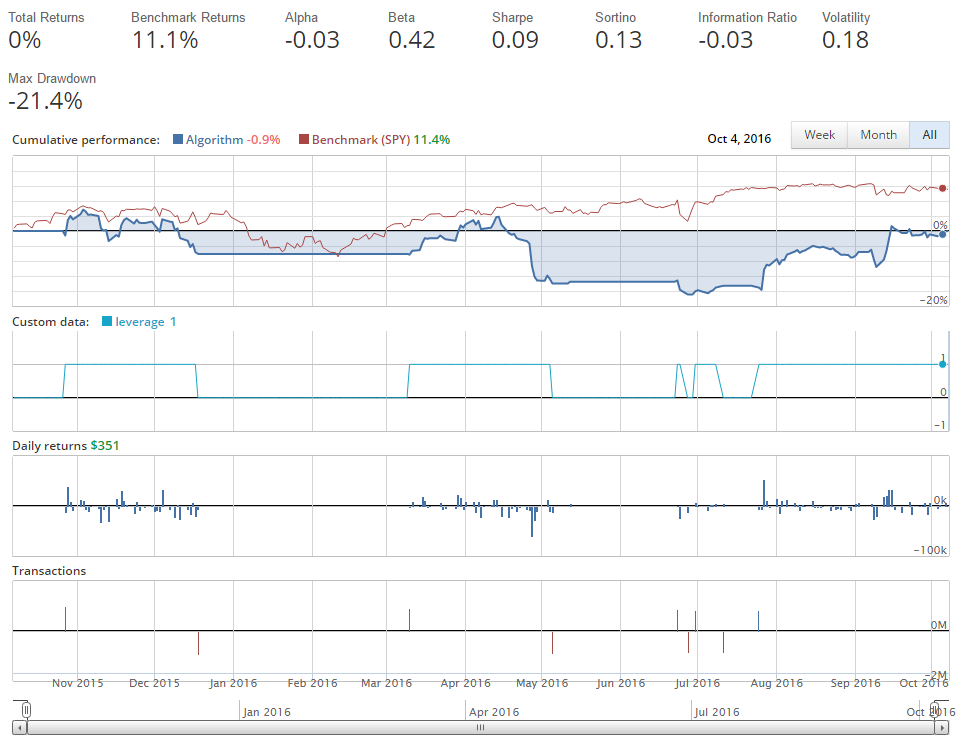
我们基本上原地运行。 通常在这个时候,人们开始考虑调整移动均值。 也许是 10 和 50,或者 2 和 50!
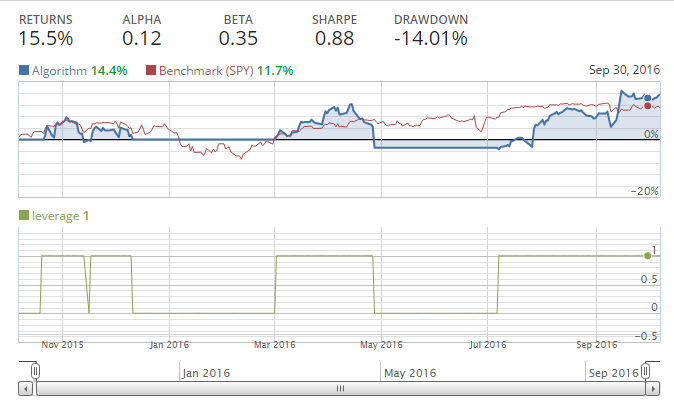
是的,2 和 50 是魔数!我们击败了市场。问题是,我们没有这些随机数字的真正理由,除了我们特地使我们的回测保持运行,直到我们成功。这是一种数据监听的形式,是一个常见的陷阱,也是你想避免的。例如,选择特定的移动均值来“最好地拟合”历史数据,可能会导致未来的问题,因为这些数字用于历史数据,而不是新的,没有见过的数据。考虑一下苹果公司多年来的变化。它从一个电脑公司,变成知名公司,MP3 播放器公司,再变成电话和电脑公司。由于公司本身也在变化,股票的行为可能会在未来持续变化。
相反,我们需要看看我们的策略,并意识到移动平均交叉策略是不好的。我们需要别的东西,而且我们需要一些有意义的东西作为策略,然后我们使用回测来验证是否可行。我们不希望发现自己不断地调整我们的策略,并好奇地回测,看看我们能否找到一些魔数。这对我们来说不太可能在未来好转。
十六、Quantopian 研究入门
接下来的几篇教程将使用 Jamie McCorriston 的“如何获得分配:为 Quantopian 投资管理团队网络研讨会代码编写算法”的稍微修改版本。
第一部分:研究环境入门
from quantopian.interactive.data.sentdex import sentiment
上面,我们导入了 Sentdex 情绪数据集。 情绪数据集提供了大约 500 家公司从 2013 年 6 月开始的情绪数据,1 个月前可以在 Quantopian 上免费使用。 Sentdex 数据提供的信号范围是 -3 到正 6,其中正 6 的程度和 -3 一样,我个人认为正值的粒度更小。
PythonProgramming.net TensorFlow 聊天机器人
原文:Creating a Chatbot with Deep Learning, Python, and TensorFlow
译者:飞龙
一、使用深度学习创建聊天机器人
你好,欢迎阅读 Python 聊天机器人系列教程。 在本系列中,我们将介绍如何使用 Python 和 TensorFlow 创建一个能用的聊天机器人。 以下是一些 chatbot 的实例:
I use Google and it works.
— Charles the AI (@Charles_the_AI) November 24, 2017
I prefer cheese.
— Charles the AI (@Charles_the_AI) November 24, 2017
The internet
— Charles the AI (@Charles_the_AI) November 24, 2017
I'm not sure . I'm just a little drunk.
— Charles the AI (@Charles_the_AI) November 24, 2017
我的目标是创建一个聊天机器人,可以实时与 Twitch Stream 上的人交谈,而不是听起来像个白痴。为了创建一个聊天机器人,或者真的做任何机器学习任务,当然,你的第一个任务就是获取训练数据,之后你需要构建并准备,将其格式化为“输入”和“输出”形式,机器学习算法可以消化它。可以说,这就是做任何机器学习时的实际工作。建立模型和训练/测试步骤简单的部分!
为了获得聊天训练数据,你可以查看相当多的资源。例如,康奈尔电影对话语料库似乎是最受欢迎的语料之一。还有很多其他来源,但我想要的东西更加......原始。有些没有美化的东西,有一些带有为其准备的特征。自然,这把我带到了 Reddit。起初,我认为我会使用 Python Reddit API 包装器,但 Reddit 对抓取的限制并不是最友好的。为了收集大量的数据,你必须打破一些规则。相反,我发现了一个 17 亿个 Reddit 评论的数据转储。那么,应该使用它!
Reddit 的结构是树形的,不像论坛,一切都是线性的。父评论是线性的,但父评论的回复是个分支。以防有些人不熟悉:
-Top level reply 1
--Reply to top level reply 1
--Reply to top level reply 1
---Reply to reply...
-Top level reply 2
--Reply to top level reply 1
-Top level reply 3
我们需要用于深度学习的结构是输入输出。 所以我们实际上通过评论和回复偶对的方式,试图获得更多的东西。 在上面的例子中,我们可以使用以下作为评论回复偶对:
-Top level reply 1 and --Reply to top level reply 1
--Reply to top level reply 1 and ---Reply to reply...
所以,我们需要做的是获取这个 Reddit 转储,并产生这些偶对。 接下来我们需要考虑的是,每个评论应该只有 1 个回复。 尽管许多单独的评论可能会有很多回复,但我们应该只用一个。 我们可以只用第一个,或者我们可以用最顶上那个。 稍后再说。 我们的第一个任务是获取数据。 如果你有存储限制,你可以查看一个月的 Reddit 评论,这是 2015 年 1 月。否则,你可以获取整个转储:
magnet:?xt=urn:btih:7690f71ea949b868080401c749e878f98de34d3d&dn=reddit%5Fdata&tr=http%3A%2F%2Ftracker.pushshift.io%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80
我只下载过两次这个种子,但根据种子和对等的不同,下载速度可能会有很大差异。
最后,你还可以通过 Google BigQuery 查看所有 Reddit 评论。 BigQuery 表似乎随着时间的推移而更新,而 torrent 不是,所以这也是一个不错的选择。 我个人将会使用 torrent,因为它是完全免费的,所以,如果你想完全遵循它,就需要这样做,但如果你愿意的话,可以随意改变主意,使用 Google BigQuery 的东西!
由于数据下载可能需要相当长的时间,我会在这里中断。 一旦你下载了数据,继续下一个教程。 你可以仅仅下载2015-01文件来跟随整个系列教程,你不需要整个 17 亿个评论转储。 一个月的就足够了。
二、聊天数据结构
欢迎阅读 Python 和 TensorFlow 聊天机器人系列教程的第二部分。现在,我假设你已经下载了数据,或者你只是在这里观看。对于大多数机器学习,你需要获取数据,并且某些时候需要输入和输出。对于神经网络,这表示实际神经网络的输入层和输出层。对于聊天机器人来说,这意味着我们需要将东西拆成评论和回复。评论是输入,回复是所需的输出。现在使用 Reddit,并不是所有的评论都有回复,然后很多评论会有很多回复!我们需要挑一个。
我们需要考虑的另一件事是,当我们遍历这个文件时,我们可能会发现一个回复,但随后我们可能会找到更好的回复。我们可以使用一种方法是看看得票最高的。我们可能也只想要得票最高的回应。我们可以考虑在这里很多事情,按照你的希望随意调整!
首先,我们的数据格式,如果我们走了 torrent 路线:
{"author":"Arve","link_id":"t3_5yba3","score":0,"body":"Can we please deprecate the word \"Ajax\" now? \r\n\r\n(But yeah, this _is_ much nicer)","score_hidden":false,"author_flair_text":null,"gilded":0,"subreddit":"reddit.com","edited":false,"author_flair_css_class":null,"retrieved_on":1427426409,"name":"t1_c0299ap","created_utc":"1192450643","parent_id":"t1_c02999p","controversiality":0,"ups":0,"distinguished":null,"id":"c0299ap","subreddit_id":"t5_6","downs":0,"archived":true}
每一行就像上面那样。我们并不需要这些数据的全部,但是我们肯定需要body,comment_id和parent_id。如果你下载完整的 torrent 文件,或者正在使用 BigQuery 数据库,那么可以使用样例数据,所以我也将使用score。我们可以为分数设定限制。我们也可以处理特定的subreddit,来创建一个说话风格像特定 subreddit 的 AI。现在,我会处理所有 subreddit。
现在,即使一个月的评论也可能超过 32GB,我也无法将其纳入 RAM,我们需要通过数据进行缓冲。我的想法是继续并缓冲评论文件,然后将我们感兴趣的数据存储到 SQLite 数据库中。这里的想法是我们可以将评论数据插入到这个数据库中。所有评论将按时间顺序排列,所有评论最初都是“父节点”,自己并没有父节点。随着时间的推移,会有回复,然后我们可以存储这个“回复”,它将在数据库中有父节点,我们也可以按照 ID 拉取,然后我们可以检索一些行,其中我们拥有父评论和回复。
然后,随着时间的推移,我们可能会发现父评论的回复,这些回复的投票数高于目前在那里的回复。发生这种情况时,我们可以使用新信息更新该行,以便我们可以最终得到通常投票数较高的回复。
无论如何,有很多方法可以实现,让我们开始吧!首先,让我们进行一些导入:
import sqlite3
import json
from datetime import datetime
我们将为我们的数据库使用sqlite3,json用于从datadump加载行,然后datetime实际只是为了记录。 这不完全必要。
所以 torrent 转储带有一大堆目录,其中包含实际的json数据转储,按年和月(YYYY-MM)命名。 他们压缩为.bz2。 确保你提取你打算使用的那些。 我们不打算编写代码来做,所以请确保你完成了!
下面,我们以一些变量开始:
timeframe = '2015-05'
sql_transaction = []
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
timeframe值将成为我们将要使用的数据的年份和月份。 你也可以把它列在这里,然后如果你喜欢,可以遍历它们。 现在,我将只用 2015 年 5 月的文件。 接下来,我们有sql_transaction。 所以在 SQL 中的“提交”是更昂贵的操作。 如果你知道你将要插入数百万行,你也应该知道你真的不应该一一提交。 相反,你只需在单个事务中构建语句,然后执行全部操作,然后提交。 接下来,我们要创建我们的表。 使用 SQLite,如果数据库尚不存在,连接时会创建数据库。
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
在这里,我们正在准备存储parent_id,comment_id,父评论,回复(评论),subreddit,时间,然后最后是评论的评分(得票)。
接下来,我们可以开始我们的主代码块:
if __name__ == '__main__':
create_table()
目前为止的完整代码:
import sqlite3
import json
from datetime import datetime
timeframe = '2015-05'
sql_transaction = []
connection = sqlite3.connect('{}2.db'.format(timeframe))
c = connection.cursor()
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
if __name__ == '__main__':
create_table()
一旦我们建立完成,我们就可以开始遍历我们的数据文件并存储这些信息。 我们将在下一个教程中开始这样做!
三、缓冲数据
你好,欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 3 部分。 在上一篇教程中,我们讨论了数据的结构并创建了一个数据库来存放我们的数据。 现在我们准备好开始处理数据了!
目前为止的代码:
import sqlite3
import json
from datetime import datetime
timeframe = '2015-05'
sql_transaction = []
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
if __name__ == '__main__':
create_table()
现在,让我们开始缓冲数据。 我们还将启动一些跟踪时间进度的计数器:
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
for row in f:
row_counter会不时输出,让我们知道我们在迭代的文件中走了多远,然后paired_rows会告诉我们有多少行数据是成对的(意味着我们有成对的评论和回复,这是训练数据)。 请注意,当然,你的数据文件的实际路径将与我的路径不同。
接下来,由于文件太大,我们无法在内存中处理,所以我们将使用buffering参数,所以我们可以轻松地以小块读取文件,这很好,因为我们需要关心的所有东西是一次一行。
现在,我们需要读取json格式这一行:
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
for row in f:
row_counter += 1
row = json.loads(row)
parent_id = row['parent_id']
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['name']
subreddit = row['subreddit']
请注意format_data函数调用,让我们创建:
def format_data(data):
data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")
return data
我们将引入这个来规范平凡并将换行符转换为一个单词。
我们可以使用json.loads()将数据读取到 python 对象中,这只需要json对象格式的字符串。 如前所述,所有评论最初都没有父级,也就是因为它是顶级评论(父级是 reddit 帖子本身),或者是因为父级不在我们的文档中。 然而,在我们浏览文档时,我们会发现那些评论,父级确实在我们数据库中。 发生这种情况时,我们希望将此评论添加到现有的父级。 一旦我们浏览了一个文件或者一个文件列表,我们就会输出数据库并作为训练数据,训练我们的模型,最后有一个我们可以聊天的朋友! 所以,在我们把数据输入到数据库之前,我们应该看看能否先找到父级!
parent_data = find_parent(parent_id)
现在我们需要寻找find_parent函数:
def find_parent(pid):
try:
sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
有可能存在实现他的更有效的方法,但是这样管用。 所以,如果我们的数据库中存在comment_id匹配另一个评论的parent_id,那么我们应该将这个新评论与我们已经有的父评论匹配。 在下一个教程中,我们将开始构建确定是否插入数据所需的逻辑以及方式。
四、插入逻辑
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 4 部分。 目前为止,我们已经获得了我们的数据,并开始遍历。 现在我们准备开始构建用于输入数据的实际逻辑。
首先,我想对全部评论加以限制,不管是否有其他评论,那就是我们只想处理毫无意义的评论。 基于这个原因,我想说我们只想考虑两票或以上的评论。 目前为止的代码:
import sqlite3
import json
from datetime import datetime
timeframe = '2015-05'
sql_transaction = []
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
def format_data(data):
data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")
return data
def find_parent(pid):
try:
sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
for row in f:
row_counter += 1
row = json.loads(row)
parent_id = row['parent_id']
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['name']
subreddit = row['subreddit']
parent_data = find_parent(parent_id)
现在让我们要求票数是两个或更多,然后让我们看看是否已经有了父级的回复,以及票数是多少:
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
for row in f:
row_counter += 1
row = json.loads(row)
parent_id = row['parent_id']
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['name']
subreddit = row['subreddit']
parent_data = find_parent(parent_id)
# maybe check for a child, if child, is our new score superior? If so, replace. If not...
if score >= 2:
existing_comment_score = find_existing_score(parent_id)
现在我们需要创建find_existing_score函数:
def find_existing_score(pid):
try:
sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
如果有现有评论,并且我们的分数高于现有评论的分数,我们想替换它:
if score >= 2:
existing_comment_score = find_existing_score(parent_id)
if existing_comment_score:
if score > existing_comment_score:
接下来,很多评论都被删除,但也有一些评论非常长,或者很短。 我们希望确保评论的长度适合于训练,并且评论未被删除:
def acceptable(data):
if len(data.split(' ')) > 50 or len(data) < 1:
return False
elif len(data) > 1000:
return False
elif data == '[deleted]':
return False
elif data == '[removed]':
return False
else:
return True
好了,到了这里,我们已经准备好开始插入数据了,这就是我们将在下一个教程中做的事情。
五、构建数据库
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 5 部分。 在本教程之前,我们一直在处理我们的数据,准备插入数据的逻辑,现在我们已经准备好开始插入了。 目前为止的代码:
import sqlite3
import json
from datetime import datetime
timeframe = '2015-05'
sql_transaction = []
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
def format_data(data):
data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")
return data
def acceptable(data):
if len(data.split(' ')) > 50 or len(data) < 1:
return False
elif len(data) > 1000:
return False
elif data == '[deleted]':
return False
elif data == '[removed]':
return False
else:
return True
def find_parent(pid):
try:
sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
def find_existing_score(pid):
try:
sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
for row in f:
row_counter += 1
row = json.loads(row)
parent_id = row['parent_id']
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['name']
subreddit = row['subreddit']
parent_data = find_parent(parent_id)
if score >= 2:
existing_comment_score = find_existing_score(parent_id)
现在,如果有现有的评论分数,这意味着已经存在一个评论,所以这需要更新语句。 如果你还不知道 SQL,那么你可能需要阅读 SQLite 教程。 所以我们的逻辑最初是:
if score >= 2:
existing_comment_score = find_existing_score(parent_id)
if existing_comment_score:
if score > existing_comment_score:
if acceptable(body):
sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
现在,我们需要构建sql_insert_replace_comment函数:
def sql_insert_replace_comment(commentid,parentid,parent,comment,subreddit,time,score):
try:
sql = """UPDATE parent_reply SET parent_id = ?, comment_id = ?, parent = ?, comment = ?, subreddit = ?, unix = ?, score = ? WHERE parent_id =?;""".format(parentid, commentid, parent, comment, subreddit, int(time), score, parentid)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
这涵盖了评论已经与父级配对的情况,但我们还需要处理没有父级的评论(但可能是另一个评论的父级!),以及确实有父级,并且它们的父级没有回复的评论。 我们可以进一步构建插入块:
if score >= 2:
existing_comment_score = find_existing_score(parent_id)
if existing_comment_score:
if score > existing_comment_score:
if acceptable(body):
sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
else:
if acceptable(body):
if parent_data:
sql_insert_has_parent(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
paired_rows += 1
else:
sql_insert_no_parent(comment_id,parent_id,body,subreddit,created_utc,score)
现在我们需要构建sql_insert_has_parent和sql_insert_no_parent函数:
def sql_insert_has_parent(commentid,parentid,parent,comment,subreddit,time,score):
try:
sql = """INSERT INTO parent_reply (parent_id, comment_id, parent, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}","{}",{},{});""".format(parentid, commentid, parent, comment, subreddit, int(time), score)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def sql_insert_no_parent(commentid,parentid,comment,subreddit,time,score):
try:
sql = """INSERT INTO parent_reply (parent_id, comment_id, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}",{},{});""".format(parentid, commentid, comment, subreddit, int(time), score)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
所以为了看到我们在遍历期间的位置,我们将在每 10 万行数据输出一些信息:
if row_counter % 100000 == 0:
print('Total Rows Read: {}, Paired Rows: {}, Time: {}'.format(row_counter, paired_rows, str(datetime.now())))
最后,我们现在需要的代码的最后一部分是,我们需要构建transaction_bldr函数。 这个函数用来构建插入语句,并以分组的形式提交它们,而不是一个接一个地提交。 这样做会快得多:
def transaction_bldr(sql):
global sql_transaction
sql_transaction.append(sql)
if len(sql_transaction) > 1000:
c.execute('BEGIN TRANSACTION')
for s in sql_transaction:
try:
c.execute(s)
except:
pass
connection.commit()
sql_transaction = []
是的,我用了个全局变量。
目前为止的代码:
import sqlite3
import json
from datetime import datetime
timeframe = '2015-05'
sql_transaction = []
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
def format_data(data):
data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")
return data
def transaction_bldr(sql):
global sql_transaction
sql_transaction.append(sql)
if len(sql_transaction) > 1000:
c.execute('BEGIN TRANSACTION')
for s in sql_transaction:
try:
c.execute(s)
except:
pass
connection.commit()
sql_transaction = []
def sql_insert_replace_comment(commentid,parentid,parent,comment,subreddit,time,score):
try:
sql = """UPDATE parent_reply SET parent_id = ?, comment_id = ?, parent = ?, comment = ?, subreddit = ?, unix = ?, score = ? WHERE parent_id =?;""".format(parentid, commentid, parent, comment, subreddit, int(time), score, parentid)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def sql_insert_has_parent(commentid,parentid,parent,comment,subreddit,time,score):
try:
sql = """INSERT INTO parent_reply (parent_id, comment_id, parent, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}","{}",{},{});""".format(parentid, commentid, parent, comment, subreddit, int(time), score)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def sql_insert_no_parent(commentid,parentid,comment,subreddit,time,score):
try:
sql = """INSERT INTO parent_reply (parent_id, comment_id, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}",{},{});""".format(parentid, commentid, comment, subreddit, int(time), score)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def acceptable(data):
if len(data.split(' ')) > 50 or len(data) < 1:
return False
elif len(data) > 1000:
return False
elif data == '[deleted]':
return False
elif data == '[removed]':
return False
else:
return True
def find_parent(pid):
try:
sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
def find_existing_score(pid):
try:
sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
for row in f:
row_counter += 1
row = json.loads(row)
parent_id = row['parent_id']
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['name']
subreddit = row['subreddit']
parent_data = find_parent(parent_id)
if score >= 2:
existing_comment_score = find_existing_score(parent_id)
if existing_comment_score:
if score > existing_comment_score:
if acceptable(body):
sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
else:
if acceptable(body):
if parent_data:
sql_insert_has_parent(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
paired_rows += 1
else:
sql_insert_no_parent(comment_id,parent_id,body,subreddit,created_utc,score)
if row_counter % 100000 == 0:
print('Total Rows Read: {}, Paired Rows: {}, Time: {}'.format(row_counter, paired_rows, str(datetime.now())))
现在你可以开始运行它了。随着时间的输出应该是:
Total Rows Read: 100000, Paired Rows: 3221, Time: 2017-11-14 15:14:33.748595
Total Rows Read: 200000, Paired Rows: 8071, Time: 2017-11-14 15:14:55.342929
Total Rows Read: 300000, Paired Rows: 13697, Time: 2017-11-14 15:15:18.035447
Total Rows Read: 400000, Paired Rows: 19723, Time: 2017-11-14 15:15:40.311376
Total Rows Read: 500000, Paired Rows: 25643, Time: 2017-11-14 15:16:02.045075
遍历所有的数据将取决于起始文件的大小。 随着数据量增大插入会减慢。 为了处理 2015 年 5 月的整个文件,可能需要 5-10 个小时。
一旦你遍历了你想要的文件,我们已经准备好,将训练数据转换为我们的模型,这就是我们将在下一个教程中做的事情。
如果你正在训练更大的数据集,你可能会发现我们需要处理的数据有很大的膨胀。 这是因为只有大约 10% 的配对评论,所以我们的数据库中很大一部分并没有被实际使用。 我使用下面的附加代码:
if row_counter % cleanup == 0:
print("Cleanin up!")
sql = "DELETE FROM parent_reply WHERE parent IS NULL"
c.execute(sql)
connection.commit()
c.execute("VACUUM")
connection.commit()
它在另一个计数器之下。这需要新的cleanup变量,它规定了“清理”之前的多少航。这将消除我们的数据库膨胀,并使插入速度保持相当高。每个“清理”似乎移除 2K 对,几乎无论你放在哪里。如果每 100K 行一次,那么每 100K 行去掉 2K 对。我选择 100 万。另一个选项是每 100 万行清理一次,但不清理最后一百万行,而是清理最后 110 万行到第 100 万行,因为看起来这些 2K 对在最后的 100K 中。即使这样做,你仍然会失去一些偶对。我觉得每 100 万行中,100K 对中的 2K 对并不重要。我还添加了一个start_row变量,所以我可以在尝试提高速度的同时,启动和停止数据库插入。 c.execute("VACUUM")是一个 SQL 命令,用于将数据库的大小缩小到应该的值。实际上这可能不是必需的,你可能只想在最后完成此操作。我没有测试这个操作需要多长时间。我是这样做的,所以我可以在删除后立即看到数据库的大小。
完整代码是:
import sqlite3
import json
from datetime import datetime
import time
timeframe = '2017-03'
sql_transaction = []
start_row = 0
cleanup = 1000000
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
def format_data(data):
data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")
return data
def transaction_bldr(sql):
global sql_transaction
sql_transaction.append(sql)
if len(sql_transaction) > 1000:
c.execute('BEGIN TRANSACTION')
for s in sql_transaction:
try:
c.execute(s)
except:
pass
connection.commit()
sql_transaction = []
def sql_insert_replace_comment(commentid,parentid,parent,comment,subreddit,time,score):
try:
sql = """UPDATE parent_reply SET parent_id = ?, comment_id = ?, parent = ?, comment = ?, subreddit = ?, unix = ?, score = ? WHERE parent_id =?;""".format(parentid, commentid, parent, comment, subreddit, int(time), score, parentid)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def sql_insert_has_parent(commentid,parentid,parent,comment,subreddit,time,score):
try:
sql = """INSERT INTO parent_reply (parent_id, comment_id, parent, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}","{}",{},{});""".format(parentid, commentid, parent, comment, subreddit, int(time), score)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def sql_insert_no_parent(commentid,parentid,comment,subreddit,time,score):
try:
sql = """INSERT INTO parent_reply (parent_id, comment_id, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}",{},{});""".format(parentid, commentid, comment, subreddit, int(time), score)
transaction_bldr(sql)
except Exception as e:
print('s0 insertion',str(e))
def acceptable(data):
if len(data.split(' ')) > 1000 or len(data) < 1:
return False
elif len(data) > 32000:
return False
elif data == '[deleted]':
return False
elif data == '[removed]':
return False
else:
return True
def find_parent(pid):
try:
sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
def find_existing_score(pid):
try:
sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)
c.execute(sql)
result = c.fetchone()
if result != None:
return result[0]
else: return False
except Exception as e:
#print(str(e))
return False
if __name__ == '__main__':
create_table()
row_counter = 0
paired_rows = 0
#with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:
with open('/home/paperspace/reddit_comment_dumps/RC_{}'.format(timeframe), buffering=1000) as f:
for row in f:
#print(row)
#time.sleep(555)
row_counter += 1
if row_counter > start_row:
try:
row = json.loads(row)
parent_id = row['parent_id'].split('_')[1]
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['id']
subreddit = row['subreddit']
parent_data = find_parent(parent_id)
existing_comment_score = find_existing_score(parent_id)
if existing_comment_score:
if score > existing_comment_score:
if acceptable(body):
sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
else:
if acceptable(body):
if parent_data:
if score >= 2:
sql_insert_has_parent(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
paired_rows += 1
else:
sql_insert_no_parent(comment_id,parent_id,body,subreddit,created_utc,score)
except Exception as e:
print(str(e))
if row_counter % 100000 == 0:
print('Total Rows Read: {}, Paired Rows: {}, Time: {}'.format(row_counter, paired_rows, str(datetime.now())))
if row_counter > start_row:
if row_counter % cleanup == 0:
print("Cleanin up!")
sql = "DELETE FROM parent_reply WHERE parent IS NULL"
c.execute(sql)
connection.commit()
c.execute("VACUUM")
connection.commit()
六、训练数据集
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 6 部分。 在这一部分,我们将着手创建我们的训练数据。 在本系列中,我正在考虑使用两种不同的整体模型和工作流程:我所知的一个方法(在开始时展示并在 Twitch 流上实时运行),另一个可能会更好,但我仍在探索它。 无论哪种方式,我们的训练数据设置都比较相似。 我们需要创建文件,基本上是“父级”和“回复”文本,每一行都是一个样本。 因此,父级文件中的第15行是父评论,然后在回复文件中的第 15 行是父文件中第 15 行的回复。
要创建这些文件,我们只需要从数据库中获取偶对,然后将它们附加到相应的训练文件中。 让我们以这个开始:
import sqlite3
import pandas as pd
timeframes = ['2015-05']
for timeframe in timeframes:
对于这里的运行,我只在单个月上运行,只创建了一个数据库,但是你可能想创建一个数据库,里面的表是月份和年份,或者你可以创建一堆 sqlite 数据库 ,表类似于我们这些,然后遍历它们来创建你的文件。 无论如何,我只有一个,所以我会把timeframes 作为一个单一的项目列表。 让我们继续构建这个循环:
for timeframe in timeframes:
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
limit = 5000
last_unix = 0
cur_length = limit
counter = 0
test_done = False
第一行只是建立连接,然后我们定义游标,然后是limit。 限制是我们要从数据库中一次抽取的块的大小。 同样,我们正在处理的数据比我们拥有的RAM大得多。 我们现在要将限制设为 5000,所以我们可以有一些测试数据。 我们可以稍后产生。 我们将使用last_unix来帮助我们从数据库中提取数据,cur_length会告诉我们什么时候我们完成了,counter会允许我们显示一些调试信息,而test_done用于我们完成构建测试数据的时候。
while cur_length == limit:
df = pd.read_sql("SELECT * FROM parent_reply WHERE unix > {} and parent NOT NULL and score > 0 ORDER BY unix ASC LIMIT {}".format(last_unix,limit),connection)
last_unix = df.tail(1)['unix'].values[0]
cur_length = len(df)
只要cur_length与我们的限制相同,我们就仍然有更多的工作要做。 然后,我们将从数据库中提取数据并将其转换为数据帧。 目前,我们对数据帧没有做太多的工作,但是之后我们可以用它对我们想要考虑的数据类型设置更多限制。 我们存储了last_unix,所以我们知道之后提取什么时候的。 我们也注意到回报的长度。 现在,建立我们的训练/测试文件。 我们将从测试开始:
if not test_done:
with open('test.from','a', encoding='utf8') as f:
for content in df['parent'].values:
f.write(content+'\n')
with open('test.to','a', encoding='utf8') as f:
for content in df['comment'].values:
f.write(str(content)+'\n')
test_done = True
现在,如果你希望,你也可以在这个时候提高限制。 在test_done = True之后,你也可以重新将limit定义为 100K 之类的东西。 现在,我们来为训练编写代码:
else:
with open('train.from','a', encoding='utf8') as f:
for content in df['parent'].values:
f.write(content+'\n')
with open('train.to','a', encoding='utf8') as f:
for content in df['comment'].values:
f.write(str(content)+'\n')
我们可以通过把它做成一个函数,来使这个代码更简单更好,所以我们不会复制和粘贴基本相同的代码。 但是...相反...让我们继续:
counter += 1
if counter % 20 == 0:
print(counter*limit,'rows completed so far')
这里,我们每 20 步就会看到输出,所以如果我们将限制保持为 5,000,每 100K 步也是。
目前的完整代码:
import sqlite3
import pandas as pd
timeframes = ['2015-05']
for timeframe in timeframes:
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
limit = 5000
last_unix = 0
cur_length = limit
counter = 0
test_done = False
while cur_length == limit:
df = pd.read_sql("SELECT * FROM parent_reply WHERE unix > {} and parent NOT NULL and score > 0 ORDER BY unix ASC LIMIT {}".format(last_unix,limit),connection)
last_unix = df.tail(1)['unix'].values[0]
cur_length = len(df)
if not test_done:
with open('test.from','a', encoding='utf8') as f:
for content in df['parent'].values:
f.write(content+'\n')
with open('test.to','a', encoding='utf8') as f:
for content in df['comment'].values:
f.write(str(content)+'\n')
test_done = True
else:
with open('train.from','a', encoding='utf8') as f:
for content in df['parent'].values:
f.write(content+'\n')
with open('train.to','a', encoding='utf8') as f:
for content in df['comment'].values:
f.write(str(content)+'\n')
counter += 1
if counter % 20 == 0:
print(counter*limit,'rows completed so far')
好的,运行它,当你准备好数据的时候,我就会看到。
七、训练模型
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 7 部分。 在这里,我们将讨论我们的模型。 你可以提出和使用无数的模型,或在网上找到并适配你的需求。 我的主要兴趣是 Seq2Seq 模型,因为 Seq2Seq 可以用于聊天机器人,当然也可以用于其他东西。 基本上,生活中的所有东西都可以简化为序列到序列的映射,所以我们可以训练相当多的东西。 但是对于现在:我想要一个聊天机器人。
当我开始寻找聊天机器人的时候,我偶然发现了原来的 TensorFlow seq2seq 翻译教程,它把专注于英语到法语的翻译上,并做了能用的工作。不幸的是,由于 seq2seq 的一些变化,现在这个模型已经被弃用了。有一个传统的 seq2seq,你可以在最新的 TensorFlow 中使用,但我从来没有让它有效。相反,如果你想使用这个模型,你可能需要降级 TF(pip install tensorflow-gpu==1.0.0)。或者,你可以使用 TensorFlow 中最新,最好的 seq2seq 查看最新的神经机器翻译(NMT)模型。最新的 NMT 教程和来自 TensorFlow 的代码可以在这里找到:神经机器翻译(seq2seq)教程。
我们打算使用一个项目,我一直与我的朋友丹尼尔合作来从事它。
该项目的位置是:NMT 机器人,它是构建在 TensorFlow 的 NMT 代码之上的一组工具。
该项目可能会发生变化,因此你应该检查 README,在撰写本文时,该文件写了:
$ git clone --recursive https://github.com/daniel-kukiela/nmt-chatbot
$ cd nmt-chatbot
$ pip install -r requirements.txt
$ cd setup
(optional) edit settings.py to your liking. These are a decent starting point for ~4gb of VRAM, you should first start by trying to raise vocab if you can.
(optional) Edit text files containing rules in setup directory
Place training data inside "new_data" folder (train.(from|to), tst2012.(from|to)m tst2013(from|to)). We have provided some sample data for those who just want to do a quick test drive.
$ python prepare_data.py ...Run setup/prepare_data.py - new folder called "data" will be created with prepared training data
$ cd ../
$ python train.py Begin training
所以让我们用它!我们将首先设置它,让它运行,然后我将解释你应该理解的主要概念。
如果你需要更多的处理能力,用这个 10 美元的折扣来查看 Paperspace,这会给你足够的时间来获得一些像样的东西。我一直在使用它们,并且非常喜欢我能够快速启动“ML-in-a-Box”选项并立即训练模型。
确保递归下载软件包,或者手动获取 nmt 软件包,或者从我们的仓库派生,或者从官方的 TensorFlow 源文件派生。我们的派生只是版本检查的一次更改,至少在那个时候,它需要非常特殊的 1.4.0 版本,而这实际上并不是必需的。这可能会在你那个时候被修复,但是我们也可能会对 NMT 核心代码做进一步的修改。
一旦下载完成,编辑setup/settings.py。如果你真的不知道自己在做什么,那没关系,你不需要修改任何东西。预设设置将需要约 4GB 的 VRAM,但至少仍然应该产生不错的模型。 Charles v2 用以下设置训练,'vocab_size': 100000,(在脚本的前面设置):
hparams = {
'attention': 'scaled_luong',
'src': 'from',
'tgt': 'to',
'vocab_prefix': os.path.join(train_dir, "vocab"),
'train_prefix': os.path.join(train_dir, "train"),
'dev_prefix': os.path.join(train_dir, "tst2012"),
'test_prefix': os.path.join(train_dir, "tst2013"),
'out_dir': out_dir,
'num_train_steps': 500000,
'num_layers': 2,
'num_units': 512,
'override_loaded_hparams': True,
'learning_rate':0.001,
# 'decay_factor': 0.99998,
'decay_steps': 1,
# 'residual': True,
'start_decay_step': 1,
'beam_width': 10,
'length_penalty_weight': 1.0,
'optimizer': 'adam',
'encoder_type': 'bi',
'num_translations_per_input': 30
}
我手动降低了学习率,因为 Adam 真的不需要逐渐衰减(亚当的ada代表自适应,m是时刻,所以adam就是自适应时刻)。 我以 0.001 开始,然后减半到 0.0005,然后 0.00025,然后 0.0001。 根据你拥有的数据量,你不希望在每个设定的步骤上衰减。 当使用 Adam 时,我会建议每 1-2 个迭代衰减一次。 默认的批量大小是 128,因此如果你想要将其设置为自动衰减,则可以计算出你的迭代的迭代步数。 如果你使用 SGD 优化器,那么注释掉衰减因子没有问题,并且你可能希望学习率从 1 开始。
一旦你完成了所有的设置,在主目录(utils,tests和setup目录)中,把你的train.to和train.from以及匹配的tst2012和tst2013文件放到new_data目录中。 现在cd setup 来运行prepare_data.py文件:
$ python3 prepare_data.py
最后cd ../,之后:
$ python3 train.py
在下一个教程中,我们将更深入地讨论模型的工作原理,参数以及训练涉及的指标。
八、探索我们的 NMT 模型的概念和参数
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 8 部分。在这里,我们将讨论我们的模型。
对你来说,最主要的区别就是分桶(bucketing),填充(padding) 和更多的注意机制。在我们开始之前,先简单地谈谈这些事情。首先,如果你熟悉神经网络,请考虑 seq2seq 之类的任务,其中序列长度不完全相同。我们可以在聊天机器人范围内考虑这一点,但也可以考虑其他领域。在聊天机器人的情况下,一个单词的语句可以产生 20 个单词的回复,而长的语句可以返回单个单词的回复,并且每个输入在字符,单词等方面不同于输出。单词本身将被分配任意或有意义的 ID(通过单词向量),但是我们如何处理可变长度?一个答案就是使所有的单词串都是 50 个单词(例如)。然后,当语句长度为 35 个单词时,我们可以填充另外 15 个单词。超过 50 个单词的任何数据,我们可以不用于训练或截断。
不幸的是,这可能会让训练变得困难,特别是对于可能最为常见的较短回复,并且大多数单词/标记只是填充。原始的 seq2seq(英语到法语)的例子使用分桶来解决这个问题,并用 4 个桶训练。 5-10,10-15,20-25 和 40-50,我们最终将训练数据放入适合输入和输出的最小桶中,但这不是很理想。
然后,我们有了 NMT 代码,处理可变输入,没有分桶或填充!接下来,这段代码还包含对注意机制的支持,这是一种向循环神经网络添加长期记忆的尝试。最后,我们还将使用双向递归神经网络(BRNN)。我们来谈谈这些事情。
一般来说,一个 LSTM 可以很好地记住,长度达到 10-2 0的标记的正确序列。然而,在此之后,性能下降,网络忘记了最初的标记,为新的标记腾出空间。在我们的例子中,标记是词语,所以基本的 LSTM 应该能够学习 10-20 个单词长度的句子,但是,当我们比这更长的时候,输出可能不会那么好。注意机制就引入了,提供了更长的“注意力跨度”,这有助于网络达到更多单词,像 30,40 甚至 80 个,例如。想象一下,如果只能用 3-10 个字来处理和回应其他人的话,对于你来说有多困难,在这 10 个字的标记中,你会变得很草率,像它一样。在前面的句子中,你只需要想象一下,如果你...在你需要以至少 10 个单词开始建立你的回答之前,对你来说有多难。滑动一下,你会得到:如果你只能这样做,那么这将是很难的,而这又不是真正有意义的,并且会很难做出很好的回应。即使你确实知道你需要想象一些事情,想象什么?你必须等待,看看未来的元素,知道你打算想象什么...但是,当我们获得了这些未来的元素,哦,亲爱的,我们早已错过了我们打算想象它的部分。这是双向递归神经网络(BRNN)引入的地方。
在许多 seq2seq 的任务中,比如语言翻译,我们可以通过就地转换单词,学习简单的语法规律,因为许多语言在语法上是相似的。 随着自然语言和交际的发展,以及英语到日语等一些翻译形式的出现,在语境,流动等方面也越来越重要。 还有更多的事情要做。 双向递归神经网络(BRNN)假定现在,过去和未来的数据在输入序列中都是重要的。 双向递归神经网络(BRNN)的“双向”部分具有很好的描述性。 输入序列是双向的。 一个向前,另一个向后。 为了说明这一点:
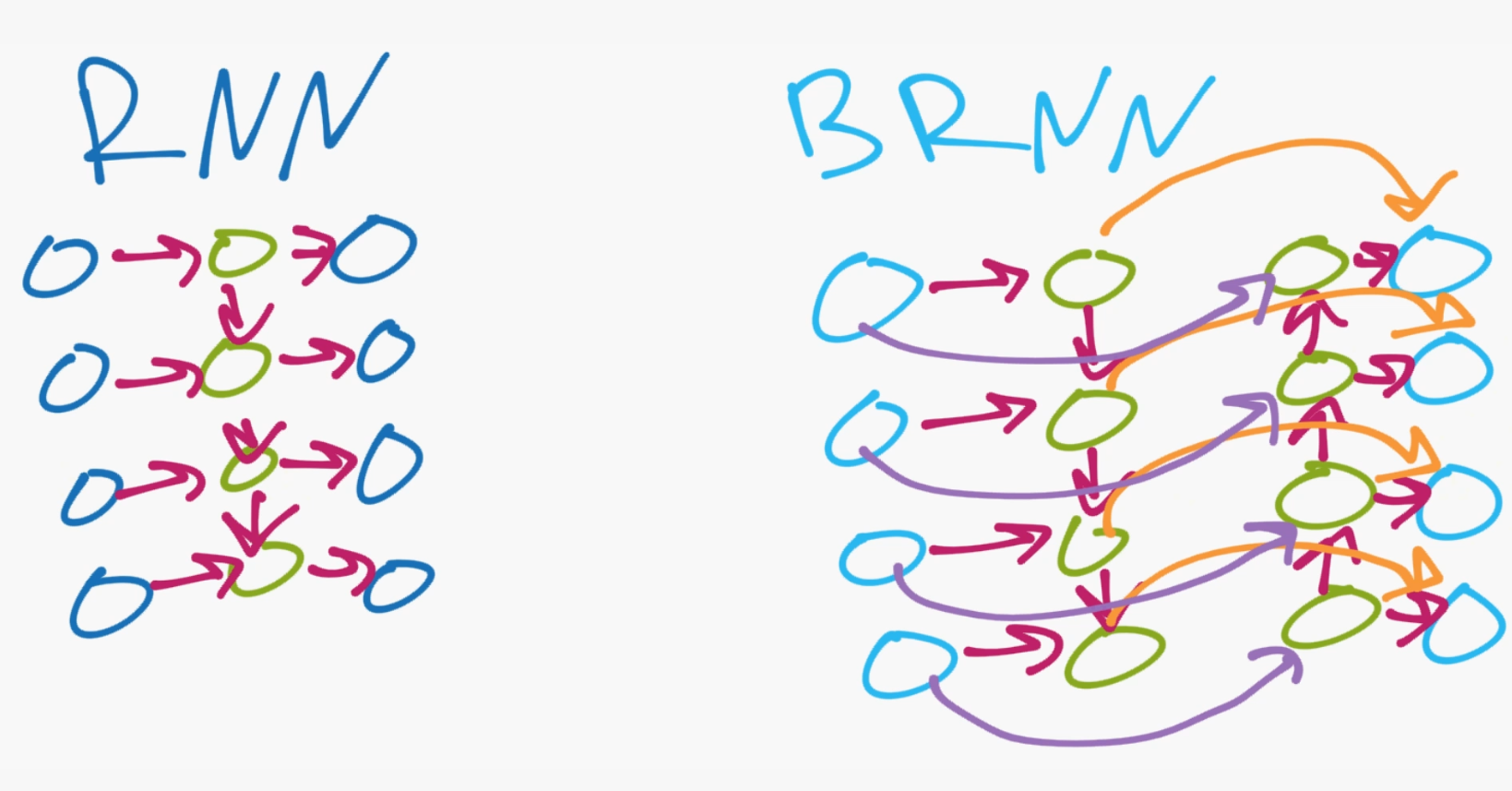
在简单的RNN上,你有输入层,你的输出层,然后我们只有一个隐藏层。然后,你从输入层连接到隐藏层,隐藏层中的每个节点也向下传递到下一个隐藏层节点,这就是我们如何得到我们的“时间”,以及来自循环神经网络的非静态特性,因为之前的输入允许在隐藏层上向下和向下传播。相反在 BRNN 上,你的隐藏层由相反方向的节点组成,所以你有输入和输出层,然后你会有你的隐藏层。然而,与基本的 RNN 不同,隐藏层向上和向下传递数据(或者向前和向后传递,取决于谁在绘制图片),这使得网络能够基于历史上发生的事情,以及我们传给序列的未来发生的事情,理解发生了什么。
下一个加入我们的网络是一个注意机制,因为尽管数据向前和向后传递,但是我们的网络不能一次记住更长的序列(每次最多 3-10 个标记)。如果你正在给我们所用的单词加上标记,那么这意味着每次最多只有 3 到 10 个单词,但是对于字符级别的模型来说,这个问题甚至更加棘手,你最多可以记住 3-10 个字符。但是,如果你做一个字符模型,你的词汇数可能低得多。
有了注意机制,我们可以处理序列中的 30, 40, 80+个标记。下面是一个描述 BLEU 的图片,其中包含或不包含注意机制:
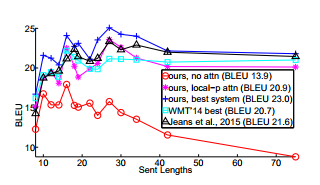
BLEU代表“双语评估替代”,它可能是我们确定翻译算法总体有效性的最佳方式。然而,重要的是,BLEU 将与我们正在翻译的序列有关。例如,我们的英语到法语的 BLEU 成绩远远,很可能高于英语到日语,甚至德语,或者单词,思想或短语没有任何直接翻译的语言。在我们的例子中,我们正在将序列翻译成序列,两个都是英文序列,所以我们应该看到一个非常高的 BLEU?可能不是。有了语言翻译,对于一个输入,经常存在“确切”或至少一些“完美”的匹配(同样,有些东西不能完美翻译,但这不会是多数)。有了对话数据,对于某些陈述真的有一个“确切”的答案吗?绝对不是。我们应该期待看到,BLEU 随着时间的推移缓慢上升,但不期望看到 BLEU 得分与语言翻译任务类似的。
注意机制不仅帮助我们处理更长的序列,而且还改善了短的。注意机制也允许学习比我们需要的聊天机器的更复杂。他们的主要驱动力似乎不仅是语言,在英语和法语之间进行翻译相对比较容易,但像日语这样的语言结构需要更多的注意。你可能真的需要看看 100 个单词的日语句子的结尾,来辨别第一个英文单词应该是什么,反之亦然。通过我们的聊天机器人,我们面临类似的困扰。我们没有将词翻译为词,将名词短语翻译为名词短语。相反,输入序列的结束可以并且通常完全确定输出序列应该是什么。我稍后可能会更深入地关注注意机制,但现在,这对于大体思路已经足够了。
除了 BLEU,你也要看看 Perplexity,通常是缩写为“PPL”。Perplexity 是另一个有用的方法,衡量模型的有效性。与 BLEU 不同的是,它越低越好,因为它是模型预测样本输出效果的概率分布。同样,对于语言翻译。
有了 BLEU 和 PPL,有了翻译,只要 BLEU 上升,PPL 下降,你通常可以训练一个模型。然而,如果一个聊天机器人从来没有或者从来不应该是一个“正确”的答案,那么只要 BLEU 和 PPL 上升,我就会警告不要继续训练,因为这样可能会产生更多的机器人似的反应,而不是高度多样的。我们还有其他方法可以解决这个问题,以后我们可以解决。
我希望这不是你第一个机器学习教程,但是,如果是这样,你也应该知道什么是损失。基本上损失是一个度量,衡量你的神经网络输出层与样本数据的“接近”程度。损失越低越好。
我想提到的最后一个概念是 Beam Search。使用这个,我们可以从我们的模型中查看一系列顶级翻译,而不仅仅是最顶端的一个而不考虑其他的。这样做会导致翻译时间更长,但在我看来,翻译模型必须这样,因为我们会发现,我们的模型仍然很有可能产生我们不想要的输出,但是对训练这些输出可能会导致其他地方的过拟合。允许多种翻译将有助于训练和生产。
好的,在下一个教程中,我们将讨论如何开始与聊天机器人进行交互。
九、与聊天机器人交互
欢迎阅读 Python Tensorflow 和深度学习聊天机器人系列教程的第 9 部分。 在本教程中,我们将讨论如何与我们的模型进行交互,甚至可能将其推入生产环境。
在训练你的模型时,默认情况下每 1,000 步将保存一个检查点文件。 如果你需要或想要停止你的训练,你可以安全地这样做,并选择最近的检查点的备份。 每个检查点的保存数据包含各种日志记录参数,还包括模型的完整权重/偏差等。 这意味着你可以选取这些检查点/模型文件,并使用它们继续训练或在生产中使用它们。
检查点默认保存在模型目录中。 你应该看到名为translate.ckpt-XXXXX的文件,其中X对应于步骤序号。 你应该有.data,.index和一个.meta文件,以及检查点文件。 如果你打开检查点文件,你会看到它看起来像:
model_checkpoint_path: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-225000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-221000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-222000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-223000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-224000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-225000"
这仅仅让你的模型知道使用哪些文件。 如果你想使用一个特定的,较老的模型,你可以编辑它。
因此,为了加载模型,我们需要 4 个文件。 假设我们的步骤是 22.5 万。 这意味着我们需要以下内容来运行我们的模型,或者加载它来继续训练:
checkpoint
translate.ckpt-225000.meta
translate.ckpt-225000.index
translate.ckpt-225000.data-00000-of-00001
因此,如果你转移到云中的某台计算机上,无论是用于训练还是生产,这些都是你需要的文件。
除了每隔 1000 步保存检查点外,我们还会做一些更多的示例(来自我们的tst.to和tst.from文件)。 这些数据每千步输出一次,并进入模型目录以及output_dev和output_test。 你可以使用这些文件查看每隔 1000 个步骤在控制台中完成的单个示例。 这些输出文件纯粹是测试文件的,顶级输出语句的结果响应。 既然你可以在你的测试文件中添加你想要的任何示例,那么这是你可以与聊天机器人进行交互的第一种方式,或者至少可以看到交互。 我写了一个简单的配对脚本,来输出测试文件和输出文件的评论响应偶对。
例如,假设你已经有了你的tst2013.from文件:
Aren ' t they streaming it for free online ... ?
try to get loud please
I ' m trying to eat a fajita here
E
It ' s been 3 innings and Spanton almost hit a dong .
Looks - wise yes , play - wise no
But we ' d both pay $ 9 . 9 9 to see that . newlinechar newlinechar Isn ' t he doing stuff for CZW ? Aren ' t they like extreme stuff , they should do a Punjabi Prison Match with CJ Parker .
' I simply feel as though the game is not for me . ' * Zaffre states , turning back to Ambrose , a frown on his face . *
The fire escape is there . You hear wood splintering , and look to see that a raptor has managed to break a hole in the top of the door , just above the dresser . Its head pokes through , then disappears . There ' s another thud , and the dresser moves forward a few inches .
[ ] ( / fritteehee ) I wonder how I ' ll make the eyes all red ...
3 6 0 , 6 7 8
I like the idea ... have an upvote !
who talks trash about Giannis ?
C
I ' m pretty sure that ' s the peace music .
Did well on my quiz today , am now eating ice cream . Good day .
之后是你的output_dev文件:
Yes they are .
I don ' t think I ' ve ever heard of this . I ' ll have to check it out .
<unk>
R
It ' s been a while since I ' ve seen it , but it ' s been a while since I ' ve seen it .
I don ' t think I ' ve ever played - wise .
I don ' t think he ' s doing anything for <unk> . I ' m sure he ' ll be fine .
' I don ' t feel as though the game is for me . '
That ' s what I was thinking as well .
[ ] ( / <unk> ) I don ' t know .
3 6 0 , 6 7 9
Thank you !
I don ' t think that ' s what he ' s talking about .
K
You ' re right , it ' s the peace music .
Good day .
我们可以手动前后移动,但这可能很乏味,所以我已经做了一个快速配对脚本:
output_file_location = 'output_dev'
tst_file_location = 'tst2013.from'
if __name__ == '__main__':
with open(output_file_location,"r") as f:
content = f.read()
to_data = content.split('\n')
with open(tst_file_location,"r") as f:
content = f.read()
from_data = content.split('\n')
for n, _ in enumerate(to_data[:-1]):
print(30*'_')
print('>',from_data[n])
print()
print('Reply:',to_data[n])
输出应该是:
> Aren ' t they streaming it for free online ... ?
Reply: Yes they are .
接下来,你可能希望实际与你的机器人通信,这是推理脚本的用途。
如果你运行这个,你可以和你的机器人交互,提出问题。在写这篇文章的时候,我们仍然在修改评分结果和调整内容。你可能对这里的结果感到满意,或者你可能想用你自己的方法来选择“正确”的答案。举个例子,到目前为止,我训练过的聊天机器人有问题,例如只是重复问题,或者有时在回复完成之前没有完成一个想法。而且,如果机器人遇到不属于他们词汇表的词语,则会产生 UNK 标记,所以我们可能不想要这些标记。
如果你想从推理脚本获得 10 个以上合理的输出结果,你可以将beam_width和num_translations_per_input从 10 增加到 30,或者如果你喜欢,可以增加更多。
如果你想在 Twitter 上实现类似于 Charles AI 的东西,那么你可以稍微修改这个推理脚本。例如,我打开这个脚本,然后,在True循环内,我检查数据库是否有任何新的社交媒体输入。如果还没有任何回应,我使用该模型创建一个回应并将其存储到数据库中。然后使用 Twitter/Twitch/Reddit API,我实际上会产生一个回应。
你还需要“挑选”一个回应。你可以用机器人的第一个回应,但是由于光束 beam search,你可以看到不少的选择,不妨使用它们!如果你运行推理,你会看到有很多输出:
每个聊天机器人可能会有所不同,但如前所述,我们在这里可能经常会看到许多输出问题。例如,<UNK>标记看起来比较丑陋和不友好,也是我的机器人经常喜欢重复问题或没有完成的想法,因此我们可能会使用一个小型自然语言处理,试图挑最好的答案,我们 可以。 在写这篇文章的时候,我已经写了一个评分脚本,用来评价 Daniel 所做的评分,你可以在sentdex_lab目录中找到它。 基本上,如果你想使用它们,这里的所有文件都需要放在根目录中。 如果你这样做,你可以按照你的喜好调整scoring.py。 然后,你可以运行modded-inference.py,并获得单个最高分结果,例如:
好吧,现在已经够了。 这个时候,你需要做很多调整,然后和它玩玩。 我仍然在讨论各种模型的大小,希望通过更好的方法来表达数据,从而使输出的词汇量可能更大。 我也有兴趣选取一个通用的模型,传入主要是讽刺的数据,看看我是否可以使用迁移学习,实现一个“有态度的查尔斯”类型的机器人,但我们会看看。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号