PythonLibrary-博客中文翻译-一-
PythonLibrary 博客中文翻译(一)
10 年的老鼠大战蟒蛇
原文:https://www.blog.pythonlibrary.org/2018/03/14/10-years-of-mouse-vs-the-python/
十年前的今天,当我第一次开始写这个博客的时候,我从来没有想过我会在十年内写关于 Python 的博客。事实上,第一个帖子甚至不是关于 Python 语言本身,而是关于我去芝加哥的 PyCon。事实上,在我写第一篇类似于教程的文章之前,我写了 7 篇关于第一次 PyCon 事件的文章,那篇文章恰好是关于使用 wxPython 和 PyWin32 读取 OpenVPN 状态的。
坦白地说,如果没有一些读者联系我,告诉我这个博客有多么有用,或者提出文章请求,这个博客根本不会存在。由于这种鼓励,我继续写作,Python 最终成为我的激情之一。事实上,持续的鼓励和建议让我写了我的第一本书,Python 101。
我不知道再过十年博客是否还会流行,但是如果人们继续喜欢我的内容,我会继续写下去。感谢您的支持和快乐编码!
帕克特出版社本周正在出售 Python 书籍
Packt Publishing 最近问我是否有兴趣让我的读者了解他们正在进行的一次销售。大多数时候,我避免向我的读者推销,但 Packt 本周有很多 Python 电子书出售,我想你可能会觉得有用。这是他们的新闻稿(如果适用的话,还有我对这本书的评论的链接):
Packt Publishing 以 10 美元的特价庆祝 10 周年
10 年前,Packt Publishing 开始致力于为 It 专业人士提供有效的学习和信息服务。在此期间,它已经出版了 2000 多种图书,并帮助项目成为家喻户晓的名字,通过其开源项目版税计划奖励了 40 多万美元。
为了庆祝这一巨大的里程碑,Packt 以每本仅 10 美元的价格提供其所有电子书和视频,这一促销活动涵盖了所有图书,客户可以在 7 月 5 日之前购买任意数量的副本。如果您过去已经尝试过 Packt 图书,您会知道这是一个探索新事物并保持您的个人和专业发展的绝佳机会。如果您是 Packt 的新手,那么现在是时候尝试他们广泛的范围了,在他们的 2000 多个标题范围内,您将找到您真正需要的知识,无论是对新兴技术的特定学习,还是在更成熟的技术领域保持领先的关键技能。’
您可以查阅一些 Python 书籍:
Python 中的 Kivy 交互式应用(回顾)
Tkinter GUI 应用程序开发专家(回顾)
即时烧瓶网开发(回顾)
web2py 应用开发食谱(回顾)
Numpy 1.5 初学者指南(复习)
MySQL for Python ( 回顾)
Python 多媒体应用初学者指南(复习)
Python 3 面向对象编程(回顾)
更多信息请访问:http://bit.ly/1mMzRAV
离 Kickstarter +新视频结束还有 47 小时
原文:https://www.blog.pythonlibrary.org/2015/04/22/47-hours-to-end-of-kickstarter-new-video/
我的第二次 Kickstarter 活动还有不到 2 天就要结束了!我仍然没有达到我的目标,但我知道我仍然可以做到。同时,我创作了第 3 集,这是一个关于 Python 的列表、元组和字典的截屏。你可以在这里查看:
https://www.youtube.com/embed/rC6DRJwm4o4?feature=oembed
一定要看看我的 Kickstarter 活动!
来自 Packt 的 5 美元 Python 书籍
原文:https://www.blog.pythonlibrary.org/2014/12/19/5-python-books-from-packt/
Packt Publishing 最近联系我,让我知道他们的网站上所有的电子书和视频都以 5 美元的价格出售。因为他们有很多不同的 Python 和 Python 相关的书籍,我想我的读者可能想知道那次销售。这是他们的新闻稿:

继去年的节日促销活动取得成功后,Packt Publishing 将推出更大的 5 美元促销活动来庆祝节日。从12 月 18 日星期四开始,每本电子书和视频都将在出版商的网站上出售,价格仅为 5 美元。顾客被邀请在 1 月 6 日星期二的优惠结束前尽可能多地购买,这是在 2015 年开始之际尝试新事物或让你的技能更上一层楼的绝佳机会。由于所有 5 美元的产品都有多种格式和无数字版权管理,客户将在今年圣诞节和新年期间在 Packt 的网站上找到他们想要的超值内容。
在 www.packtpub.com/packt5dollar 了解更多信息
从零开始学习 Python 的 5 个技巧
原文:https://www.blog.pythonlibrary.org/2022/03/01/5-tips-on-learning-python-from-zero/
最近,https://www.developrec.net/联系我制作一个关于 Python 的视频。结果如下:
https://www.youtube.com/embed/CK76sOD-wM8?feature=oembed
2015 年前 Python 101 半价优惠
原文:https://www.blog.pythonlibrary.org/2014/12/08/50-off-on-python-101-until-2015/
我已经决定在年底前举办我的书《Python 101》的销售活动。从现在起到 1 月 1 日,如果您使用以下优惠代码,您可以以 50%的价格获得我的书: xmas2014
只需前往https://gumroad.com/products/bppWr并在结账时输入优惠代码。
节日快乐!
Python 101:第 19 集-子流程模块
https://www.youtube.com/embed/BuUSXPKhBNc?feature=oembed
在这个截屏中,我们将学习 Python 子流程模块的基础知识。随意在这里阅读本视频所基于的书:http://python101.pythonlibrary.org/或者在 Leanpub 上购买这本书
一个 bbfreeze 教程——构建二进制系列!
原文:https://www.blog.pythonlibrary.org/2010/08/19/a-bbfreeze-tutorial-build-a-binary-series/
bbfreeze 包也允许我们创建二进制文件,但是只能在 Linux 和 Windows 上。这只是一个简单的安装工具,所以如果您打算按照本文中的示例进行操作,您应该去获取它。bbfreeze 包包含 egg 支持,因此它可以在二进制文件中包含 egg 依赖项,这与 py2exe 不同。你也可以一次冻结多个脚本,包括 Python 解释器等等。根据 bbfreeze 的 PyPI 条目,它只在 Python 2.4-2.5 中测试过,所以要记住这一点。然而,我能够在 Python 2.6 中使用它,没有明显的问题。
bbfreeze 入门
您可以使用 easy_install 下载并安装 bbfreeze,也可以直接从 Python 包索引 (PyPI)下载它的源代码或 egg 文件。在本文中,我们将尝试在一个简单的配置文件生成器脚本中使用它,我们还将在一个蹩脚的 wxPython 程序中使用它。我的测试机器是一台 Windows 7 家庭版 32 位笔记本电脑,安装了 bbfreeze 0.96.5 和 Python 2.6.4。让我们从配置脚本开始:
# config_1.py
import configobj
#----------------------------------------------------------------------
def createConfig(configFile):
"""
Create the configuration file
"""
config = configobj.ConfigObj()
inifile = configFile
config.filename = inifile
config['server'] = "http://www.google.com"
config['username'] = "mike"
config['password'] = "dingbat"
config['update interval'] = 2
config.write()
#----------------------------------------------------------------------
def getConfig(configFile):
"""
Open the config file and return a configobj
"""
return configobj.ConfigObj(configFile)
def createConfig2(path):
"""
Create a config file
"""
config = configobj.ConfigObj()
config.filename = path
config["Sony"] = {}
config["Sony"]["product"] = "Sony PS3"
config["Sony"]["accessories"] = ['controller', 'eye', 'memory stick']
config["Sony"]["retail price"] = "$400"
config.write()
if __name__ == "__main__":
createConfig2("sampleConfig2.ini")
这个脚本有几个没有意义的函数,但是为了便于说明,我们将把它们留在这里。根据 bbfreeze 文档,我们应该能够在命令行中键入以下字符串来创建二进制文件:
bb-freeze config_1.py
这假设您的路径上有“C:\Python26\Scripts”。否则,您需要键入完整的路径(例如“C:\ python 26 \ Scripts \ b B- freeze config _ 1 . py”)。当我运行这个时,我得到了一个错误。这是:
Traceback (most recent call last):
File "C:\Python26\Scripts\bb-freeze-script.py", line 8, in load_entry_point('bbfreeze==0.96.5', 'console_scripts', 'bb-freeze')()
File "C:\Python26\lib\site-packages\bbfreeze-0.96.5-py2.6-win32.egg\bbfreeze\__init__.py", line 18, in main
f()
File "C:\Python26\lib\site-packages\bbfreeze-0.96.5-py2.6-win32.egg\bbfreeze\freezer.py", line 474, in __call__
self.addModule("encodings.*")
File "C:\Python26\lib\site-packages\bbfreeze-0.96.5-py2.6-win32.egg\bbfreeze\freezer.py", line 411, in addModule
self.mf.import_hook(name[:-2], fromlist="*")
File "C:\Python26\lib\site-packages\bbfreeze-0.96.5-py2.6-win32.egg\bbfreeze\modulegraph\modulegraph.py", line 256, in import_hook
modules.update(self.ensure_fromlist(m, fromlist))
File "C:\Python26\lib\site-packages\bbfreeze-0.96.5-py2.6-win32.egg\bbfreeze\modulegraph\modulegraph.py", line 345, in ensure_fromlist
fromlist.update(self.find_all_submodules(m))
File "C:\Python26\lib\site-packages\bbfreeze-0.96.5-py2.6-win32.egg\bbfreeze\modulegraph\modulegraph.py", line 369, in find_all_submodules
for (path, mode, typ) in ifilter(None, imap(moduleInfoForPath, names)):
NameError: global name 'ifilter' is not defined
“modulegraph.py”文件似乎缺少从 Python 中包含的 itertools 库中导入的内容。我编辑了我的“modulegraph.py”副本,在文件的顶部添加了下面一行:“从 itertools 导入 ifilter”。这消除了追溯,但也带来了另一个问题,因为“imap”也没有定义。为了修复第二个错误,我将导入改为“从 itertools 导入 ifilter,imap ”,然后它运行起来没有任何问题,并在“dist”文件夹中生成了一个二进制文件以及其他九个文件(见下面的截图)。

使用 bbfreeze 的高级配置
bbfreeze 的 PyPI 页面(也是它的主页)几乎没有文档。然而,页面上确实说使用 bbfreeze 的首选方式是使用小脚本。我们将尝试使用前面提到的蹩脚的 wxPython 创建一个二进制文件。以下是 wx 代码:
import wx
########################################################################
class DemoPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent)
labels = ["Name", "Address", "City", "State", "Zip",
"Phone", "Email", "Notes"]
mainSizer = wx.BoxSizer(wx.VERTICAL)
lbl = wx.StaticText(self, label="Please enter your information here:")
lbl.SetFont(wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD))
mainSizer.Add(lbl, 0, wx.ALL, 5)
for lbl in labels:
sizer = self.buildControls(lbl)
mainSizer.Add(sizer, 1, wx.EXPAND)
self.SetSizer(mainSizer)
mainSizer.Layout()
#----------------------------------------------------------------------
def buildControls(self, label):
""""""
sizer = wx.BoxSizer(wx.HORIZONTAL)
size = (80,40)
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD)
lbl = wx.StaticText(self, label=label, size=size)
lbl.SetFont(font)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
if label != "Notes":
txt = wx.TextCtrl(self, name=label)
else:
txt = wx.TextCtrl(self, style=wx.TE_MULTILINE, name=label)
sizer.Add(txt, 1, wx.ALL, 5)
return sizer
########################################################################
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, wx.ID_ANY,
"cxFreeze Tutorial",
size=(600,400)
)
panel = DemoPanel(self)
self.Show()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
现在让我们创建一个简单的冻结脚本!
# bb_setup.py
from bbfreeze import Freezer
f = Freezer(distdir="bb-binary")
f.addScript("sampleApp.py")
f()
首先,我们从 bbfreeze 包中导入冷冻器类。Freezer 接受三个参数:一个目标文件夹、一个 includes iterable 和一个 excludes iterable(即一个元组或列表)。为了看看 bbfreeze 只使用它的缺省值有多好,我们省略了包含和排除元组/列表。一旦你有了一个冻结对象,你可以通过调用冻结对象名的 addScript 方法来添加你的脚本。然后你只需要调用对象(即 f())。如果你这样做了,你应该得到一个 14.5 MB 的文件夹,里面有 18 个文件。当我运行 sampleApp.exe 文件时,它运行得很好,主题也很恰当,但是它还有一个控制台屏幕。为了找出正确的语法,我使用了 GUI2Exe 。下面是新代码:
# bb_setup2.py
from bbfreeze import Freezer
includes = []
excludes = ['_gtkagg', '_tkagg', 'bsddb', 'curses', 'email', 'pywin.debugger',
'pywin.debugger.dbgcon', 'pywin.dialogs', 'tcl',
'Tkconstants', 'Tkinter']
bbFreeze_Class = Freezer('dist', includes=includes, excludes=excludes)
bbFreeze_Class.addScript("sampleApp.py", gui_only=True)
bbFreeze_Class.use_compression = 0
bbFreeze_Class.include_py = True
bbFreeze_Class()
如果您运行这个,您应该会得到一个“dist”文件夹,其中包含 18 个文件,大小为 16.6 MB。注意,我们向 addScript 方法添加了第二个参数:gui_only=True。这使得那个烦人的控制台消失了。我们还将压缩设置为零(我认为没有压缩),并包含 Python 解释器。不过,打开压缩只会将结果减少到 14.3 MB。
bbfreeze 包也处理“食谱”,并包括几个例子,但是它们也没有很好地记录,我不知道如何将它们包含在我当前的例子中。你可以自己想办法解决!
包扎
好了,现在你应该知道使用 bbfreeze 从你的程序中创建二进制文件的基本知识了。我希望这能对你有所帮助。本系列的最后一篇文章将讨论 GUI2Exe。快去找吧!
简要的 ConfigObj 教程
原文:https://www.blog.pythonlibrary.org/2010/01/01/a-brief-configobj-tutorial/
Python 附带了一个方便的模块,叫做 ConfigParser 。这对于创建和读取配置文件(又名 INI 文件)很有好处。然而,迈克尔·福德(《T2》的作者)和尼古拉·拉罗萨决定编写他们自己的配置模块,名为 ConfigObj 。在许多方面,它是对标准库模块的改进。当我第一次看 ConfigObj 的主页时,我认为它有很好的文档,但它似乎没有任何完整的功能片段。由于我从 docs plus examples 中学习,我发现在没有示例的情况下开始使用 ConfigObj 会更加困难。当我开始写这篇文章时,我并不知道迈克尔·福德已经就这个主题写了自己的教程;但是我承诺过我会写我自己的,所以这就是你今天要读的!
入门指南
首先,您需要下载 ConfigObj 。一旦你下载并安装,我们可以继续。明白了吗?那我们就看看它能做什么吧!
首先,打开一个文本编辑器,创建一个包含如下内容的文件:
`product = Sony PS3
accessories = controller, eye, memory stick
This is a comment that will be ignored
retail_price = $400`
把它保存在你喜欢的任何地方。我将把我的命名为“config.ini”。现在让我们看看如何使用 ConfigObj 来提取这些信息:
`>>> from configobj import ConfigObj
config = ConfigObj(r"path to config.ini")
config["product"]
'Sony PS3'
config["accessories"]
['controller', 'eye', 'memory stick']
type(config["accessories"])`
可以看到,ConfigObj 使用 Python 的 dict API 来访问它提取的信息。要让 ConfigObj 解析文件,只需将文件的路径传递给 ConfigObj。现在,如果信息在一个部分下(即[Sony]),那么您必须使用["Sony"],像这样:config["Sony"]["product"],预先挂起所有内容。还要注意“附件”部分是作为字符串列表返回的。ConfigObj 将接受任何带有逗号分隔列表的有效行,并将其作为 Python 列表返回。您也可以在配置文件中创建多行字符串,只要用三个单引号或双引号将它们括起来。
如果您需要在文件中创建一个子节,那么使用额外的方括号。比如,[索尼]是顶节,[[Playstation]]是子节,[[[PS3]]]是子节的子节。您可以创建任意深度的子部分。有关文件格式的更多信息,我推荐上面链接的文档。
现在我们将反向操作,以编程方式创建配置文件。
import configobj
def createConfig(path):
config = configobj.ConfigObj()
config.filename = path
config["Sony"] = {}
config["Sony"]["product"] = "Sony PS3"
config["Sony"]["accessories"] = ['controller', 'eye', 'memory stick']
config["Sony"]["retail price"] = "$400"
config.write()
如您所见,只需要 8 行代码。在上面的代码中,我们创建了一个函数,并将配置文件的路径传递给它。然后我们创建一个 ConfigObj 对象并设置它的文件名属性。为了创建这个部分,我们创建一个名为“Sony”的空 dict。然后,我们以同样的方式预处理每一行的内容。最后,我们调用配置对象的 write 方法将数据写入文件。
使用配置规范
ConfigObj 还提供了一种使用 configspec 来验证配置文件的方法。当我提到我将要写这篇文章时,Steven Sproat(Whyteboard的创建者)主动提供了他的 configspec 代码作为例子。我采用了他的规范,并用它来创建一个默认的配置文件。在这个例子中,我们使用 Foord 的 validate 模块来进行验证。我不认为它包含在您的 ConfigObj 下载中,所以您可能也需要下载它。现在,让我们看一下代码:
import configobj, validate
cfg = """
bmp_select_transparent = boolean(default=False)
canvas_border = integer(min=10, max=35, default=15)
colour1 = list(min=3, max=3, default=list('280', '0', '0'))
colour2 = list(min=3, max=3, default=list('255', '255', '0'))
colour3 = list(min=3, max=3, default=list('0', '255', '0'))
colour4 = list(min=3, max=3, default=list('255', '0', '0'))
colour5 = list(min=3, max=3, default=list('0', '0', '255'))
colour6 = list(min=3, max=3, default=list('160', '32', '240'))
colour7 = list(min=3, max=3, default=list('0', '255', '255'))
colour8 = list(min=3, max=3, default=list('255', '165', '0'))
colour9 = list(min=3, max=3, default=list('211', '211', '211'))
convert_quality = option('highest', 'high', 'normal', default='normal')
default_font = string
default_width = integer(min=1, max=12000, default=640)
default_height = integer(min=1, max=12000, default=480)
imagemagick_path = string
handle_size = integer(min=3, max=15, default=6)
language = option('English', 'English (United Kingdom)', 'Russian', 'Hindi', default='English')
print_title = boolean(default=True)
statusbar = boolean(default=True)
toolbar = boolean(default=True)
toolbox = option('icon', 'text', default='icon')
undo_sheets = integer(min=5, max=50, default=10)
"""
def createConfig(path):
"""
Create a config file using a configspec
and validate it against a Validator object
"""
spec = cfg.split("\n")
config = configobj.ConfigObj(path, configspec=spec)
validator = validate.Validator()
config.validate(validator, copy=True)
config.filename = path
config.write()
if __name__ == "__main__":
createConfig("config.ini")
如果你去看看 Steven 的原始 configspec,你会注意到我把他的语言列表缩短了不少。我这样做是为了让代码更容易阅读。无论如何, configspec 允许程序员指定为配置文件中的每一行返回什么类型。它还可以用来设置默认值、最小值和最大值(等等)。如果您运行上面的代码,您会看到在当前工作目录中生成了一个“config.ini”文件,其中只有默认值。如果程序员没有指定默认值,那么这一行甚至不会被添加到配置中。
让我们仔细看看发生了什么,以确保您理解。在 createConfig 函数中,我们通过传入文件路径并设置 configspec 来创建一个 ConfigObj 实例。请注意,configspec 也可以是普通的文本文件或 python 文件,而不是本例中的字符串。接下来,我们创建一个验证器对象。正常的用法是只调用config . validate(validator),但是在这段代码中,我将 copy 参数设置为 True ,这样我就可以创建一个文件。否则,它只会验证我传入的文件是否符合 configspec 的规则。最后,我设置配置的文件名并写出数据。
包扎
现在,您已经了解了 ConfigObj 的来龙去脉。我希望你会和我一样觉得它很有帮助。还有很多东西要学,所以一定要看看下面的一些链接。
注意:所有代码都是在 Windows XP 上用 Python 2.5、ConfigObj 4.6.0 和 Validate 1.0.0 测试的。
延伸阅读
下载源码
PySimpleGUI 简介
原文:https://www.blog.pythonlibrary.org/2019/10/23/a-brief-intro-to-pysimplegui/
创建图形用户界面(GUI)可能很困难。有许多不同的 Python GUI 工具包可供选择。您可能会看到最常提到的前三个是 Tkinter、wxPython 和 PyQt(或 PySide2)。然而,有一个更新的工具包叫做 PySimpleGUI ,旨在使创建 GUI 更容易。
PySimpleGUI 的强大之处在于它是 Tkinter、wxPython 和 PyQt 之上的一个抽象层。您可以将 PySimpleGUI 看作一个包装器。PySimpleGUI 背后的开发人员最近还添加了第四个包装器,它是一个“Python 应用程序的 GUI 库,将应用程序的界面转换成 HTML,以便在 web 浏览器中呈现”。
PySimpleGUI 的一个出名之处是你不需要使用类来创建你的用户界面。这是一种有趣的做事方式,但可能会让该库的一些用户失去兴趣。
安装 PySimpleGUI
如果您知道如何使用 pip,安装 PySimpleGUI 是轻而易举的事情。下面是您应该运行的命令:
pip install pysimplegui
注意,这将把 PySimpleGUI 安装到您的系统 Python 中。您可能希望将其安装到虚拟 Python 环境中。你可以使用 Python 的 venv 模块来实现。看看吧!
Hello PySimpleGUI
当涉及到使用 GUI 时,更容易看到如何自己组装一个 GUI。让我们编写一个小的表单,它有一个字符串和两个按钮:一个 OK 按钮和一个 Cancel 按钮。
这个例子基于 PySimpleGUI 用户手册中的一个例子:
import PySimpleGUI as sg
# Create some elements
layout = [[sg.Text("What's your name?"), sg.InputText()],
[sg.Button('OK'), sg.Button('Cancel')]]
# Create the Window
window = sg.Window('Hello PySimpleGUI', layout)
# Create the event loop
while True:
event, values = window.read()
if event in (None, 'Cancel'):
# User closed the Window or hit the Cancel button
break
print(f'Event: {event}')
print(str(values))
window.close()
在这里,您导入 PySimpleGUI,然后创建一系列小部件,它们在 PySimpleGUI 中被称为“元素”:文本、输入文本和两个按钮。要按行布局元素,您可以将它们添加到列表中。因此,对于第一行元素,您创建一个包含 Text 元素的列表,后跟 InputText 元素。元素从左向右水平添加。要添加第二行,需要添加第二个元素列表,其中包含两个按钮。
在嵌套列表中包含所有元素后,可以创建窗口。这是包含所有其他元素的父元素。它有一个标题,并接受您的嵌套元素列表。
最后,创建一个 while 循环,并调用窗口的 read() 方法来提取用户设置的事件和值。如果用户按下 Cancel 按钮或关闭窗口,您会捕捉到这一点并跳出循环。否则,您将打印出事件和用户输入的任何值。
运行代码时,GUI 应该是这样的:

假设您在文本输入小部件中输入字符串“mike ”,然后点击 OK 按钮。您应该在终端中看到以下输出:
Event: OK {0: 'mike'}
如果可以将 stdout 重定向到 GUI 中的调试窗口,那不是很好吗?PySimpleGUI 实际上有一个简单的方法来做到这一点。您只需将上面代码中的 print 语句更新为以下内容:
sg.Print(f'Event: {event}')
sg.Print(str(values))
现在,当您运行代码并输入一个字符串,然后按 OK,您应该会看到下面的调试窗口:

PySimpleGUI Elements
没有足够的时间来检查 PySimpleGUI 支持的每个元素。然而,您可以通过转到文档的这一部分来查看支持哪些元素。文档中有一个注释提到表格小部件目前有问题。暗示树小部件也有问题,但并没有真正谈到原因。
请注意,PySimpleGUI 已经包装了 Tkinter 中所有可用的小部件,所以您确实有很多小部件可以使用。然而,ttk 中的小部件目前还不被支持。
更新:在与软件包的维护者交谈后,我被告知表格和树元素实际上工作得相当好。
创建多个窗口
我看到许多新程序员都在为在他们选择的 GUI 工具包中打开多个窗口而苦恼。幸运的是,PySimpleGUI 清楚地标明了如何做的方向。他们实际上有两种不同的“设计模式”来做这类事情。
为简洁起见,我将只展示如何操作两个活动窗口:
import PySimpleGUI as sg
# Create some Elements
ok_btn = sg.Button('Open Second Window')
cancel_btn = sg.Button('Cancel')
layout = [[ok_btn, cancel_btn]]
# Create the first Window
window = sg.Window('Window 1', layout)
win2_active = False
# Create the event loop
while True:
event1, values1 = window.read(timeout=100)
if event1 in (None, 'Cancel'):
# User closed the Window or hit the Cancel button
break
if not win2_active and event1 == 'Open Second Window':
win2_active = True
layout2 = [[sg.Text('Window 2')],
[sg.Button('Exit')]]
window2 = sg.Window('Window 2', layout2)
if win2_active:
events2, values2 = window2.Read(timeout=100)
if events2 is None or events2 == 'Exit':
win2_active = False
window2.close()
window.close()
前几行与本文中的第一个例子非常相似。这一次,您将创建只有两个按钮的主应用程序。其中一个按钮用于打开第二个窗口,而另一个按钮用于关闭程序。
接下来,将标志 win2_active 设置为 False,然后开始您的“事件循环”。在事件循环内部,检查用户是否按下了“打开第二个窗口”按钮。如果有,那么你打开第二个窗口,观察它的事件。
就我个人而言,我觉得和这种人一起工作很笨拙。我认为,通过为窗口使用一些类并抽象出主循环,很多事情都可以得到改善。我不想用这种模式创建大量的窗口,因为对我来说这看起来很快就会变得非常复杂。但是我还没有充分使用这个包,不知道是否已经有好的解决方法。
包扎
PySimpleGUI 是一个简洁的库,我喜欢它比 wxPython 和 PyQt 更“Python 化”。当然,如果你正在寻找另一个 GUI 工具包,它使用更 Python 化的方法,而不是 PyQt 和 wxPython 使用的 C++方法,你可能想看看托加或基维。
无论如何,我认为 PySimpleGUI 看起来有很多有趣的功能。小部件集与 Tkinter 相匹配,甚至有所超越。PySimpleGUI 在他们的 Github 上也有很多很酷的演示应用程序。他们还提供了使用 PyInstaller 将您的应用程序转换成 Windows 和 Mac 上的可执行文件的信息,这是您在 GUI 工具包的文档中通常看不到的。
如果您正在寻找一个简单的 GUI 工具包,PySimpleGUI 可能正合您的胃口。
对 sh 包的简单介绍
原文:https://www.blog.pythonlibrary.org/2016/01/20/a-brief-intro-to-the-sh-package/
前几天偶然看到一个有趣的项目叫做 sh ,我相信指的就是 shell(或者终端)。它曾经是 pbs 项目,但是他们为了我还没有弄清楚的原因而重新命名了它。无论如何,sh 包是一个包装子进程的包装器,允许开发人员更简单地调用可执行文件。基本上,它会将你的系统程序映射到 Python 函数。注意,sh 只支持 linux 和 mac,而 pbs 也支持 Windows。
让我们看几个例子。
>>> from sh import ls
>>> ls
>>> ls('/home')
user_one user_two
在上面的代码中,我简单地从 sh 导入了 ls“命令”。然后我在我的 home 文件夹上调用它,它会吐出那里存在哪些用户文件夹。让我们试试运行 Linux 的 which 命令。
>>> import sh
>>> sh.which('python')
'/usr/bin/python'
这次我们只是导入 sh 并使用 sh.which 调用 which 命令。在这种情况下,我们传入我们想知道位置的程序名。换句话说,它的工作方式与常规的 which 程序相同。
多个参数
如果需要向命令传递多个参数,该怎么办?让我们来看看 ping 命令来了解一下吧!
>>> sh.ping('-c', '4', 'www.google.com')
PING www.google.com (74.125.225.17) 56(84) bytes of data.
64 bytes from ord08s12-in-f17.1e100.net (74.125.225.17): icmp_seq=1 ttl=55 time=16.3 ms
64 bytes from ord08s12-in-f17.1e100.net (74.125.225.17): icmp_seq=2 ttl=55 time=15.1 ms
64 bytes from ord08s12-in-f17.1e100.net (74.125.225.17): icmp_seq=3 ttl=55 time=21.3 ms
64 bytes from ord08s12-in-f17.1e100.net (74.125.225.17): icmp_seq=4 ttl=55 time=23.8 ms
--- www.google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3002ms
rtt min/avg/max/mdev = 15.121/19.178/23.869/3.581 ms
在这里,我们调用 ping 并告诉它我们只希望计数为 4。如果我们不这样做,它基本上会一直运行,直到我们告诉它停止,这就把 Python 挂在了我的机器上。
实际上,您也可以使用关键字参数作为传递给被调用程序的参数。这里有一个等价的例子:
>>> sh.ping('www.google.com', c='4')
这有点违背直觉,因为关键字参数在 URL 后面,而在前面的例子中正好相反。然而,这更像是一个 Python 构造,是 sh 包有意为之的。在 Python 中,你毕竟不能让一个关键字参数后跟一个常规参数。
包扎
当我偶然发现这个项目时,我认为这是一个非常好的想法。仅仅使用 Python 的子流程模块真的很难吗?不尽然,但这种方式更有趣,有些人甚至会称 sh 更“Pythonic 化”。不管怎样,我认为值得你花时间去看看。还有一些其他的功能没有在这里介绍,比如“烘焙”,所以如果你想了解更多关于它的其他特性,查看这个项目的文档是个好主意。
附加阅读
- sh PyPI 页面
- sh github 页面
- Python 初学者- 如何在 Python 中使用 sh
一个 cx_Freeze 教程——构建二进制系列!
原文:https://www.blog.pythonlibrary.org/2010/08/12/a-cx_freeze-tutorial-build-a-binary-series/
在本文中,我们将学习 cx_Freeze,这是一组跨平台的脚本,旨在以类似于 py2exe、PyInstaller 等的方式将 Python 脚本“冻结”成可执行文件。我们将冻结一个控制台脚本和一个窗口(即 GUI)脚本,使用本系列前一篇文章中的例子。如果你还没有这样做,你可以在这里得到 CX _ Freeze。我们开始派对吧,好吗?
cx_Freeze 入门
正如 cx_Freeze 网站上提到的,有三种方法可以使用这个脚本。第一种是只使用附带的 cxfreeze 脚本;第二种方法是创建一个 distutils 安装脚本(比如 py2exe ),您可以保存它以备将来使用;第三是使用 cxfreeze 的内部。我们将关注使用 cx_Freeze 的前两种方式。我们将从控制台脚本开始:
import configobj
#----------------------------------------------------------------------
def createConfig(configFile):
"""
Create the configuration file
"""
config = configobj.ConfigObj()
inifile = configFile
config.filename = inifile
config['server'] = "http://www.google.com"
config['username'] = "mike"
config['password'] = "dingbat"
config['update interval'] = 2
config.write()
#----------------------------------------------------------------------
def getConfig(configFile):
"""
Open the config file and return a configobj
"""
return configobj.ConfigObj(configFile)
def createConfig2(path):
"""
Create a config file
"""
config = configobj.ConfigObj()
config.filename = path
config["Sony"] = {}
config["Sony"]["product"] = "Sony PS3"
config["Sony"]["accessories"] = ['controller', 'eye', 'memory stick']
config["Sony"]["retail price"] = "$400"
config.write()
if __name__ == "__main__":
createConfig2("sampleConfig2.ini")
这个脚本所做的就是使用 Michael Foord 的 configobj 模块创建一个非常简单的配置文件。您也可以设置它来读取配置,但是对于这个例子,我们将跳过它。让我们来看看如何用 cx_Freeze 构建一个二进制文件!根据文档,只需在命令行中输入以下字符串(假设您位于正确的目录中):
cxfreeze config_1.py --target-dir dirName
这假设您的路径上有“C:\PythonXX\Scripts”。如果没有,您要么修复它,要么输入完全限定的路径。无论如何,如果 cxfreeze 脚本正确运行,您应该有一个包含以下内容的文件夹:

正如您所看到的,总文件大小应该是 4.81 MB 或者差不多 MB。这很简单。它甚至在我们没有告诉它的情况下就选择了 configobj 模块,这是 PyInstaller 没有做到的。有 18 个命令行参数可以传递给 cx_Freeze 来控制它如何工作。这些功能包括包含或排除哪些模块、优化、压缩、包含 zip 文件、路径操作等等。现在让我们尝试一些更高级的东西。
“高级”cx_Freeze -使用 setup.py 文件
首先,我们需要一个脚本来使用。对此,我们将使用 PyInstaller 文章中的简单 wxPython 脚本:
import wx
########################################################################
class DemoPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent)
labels = ["Name", "Address", "City", "State", "Zip",
"Phone", "Email", "Notes"]
mainSizer = wx.BoxSizer(wx.VERTICAL)
lbl = wx.StaticText(self, label="Please enter your information here:")
lbl.SetFont(wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD))
mainSizer.Add(lbl, 0, wx.ALL, 5)
for lbl in labels:
sizer = self.buildControls(lbl)
mainSizer.Add(sizer, 1, wx.EXPAND)
self.SetSizer(mainSizer)
mainSizer.Layout()
#----------------------------------------------------------------------
def buildControls(self, label):
""""""
sizer = wx.BoxSizer(wx.HORIZONTAL)
size = (80,40)
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD)
lbl = wx.StaticText(self, label=label, size=size)
lbl.SetFont(font)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
if label != "Notes":
txt = wx.TextCtrl(self, name=label)
else:
txt = wx.TextCtrl(self, style=wx.TE_MULTILINE, name=label)
sizer.Add(txt, 1, wx.ALL, 5)
return sizer
########################################################################
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, wx.ID_ANY,
"cxFreeze Tutorial",
size=(600,400)
)
panel = DemoPanel(self)
self.Show()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
现在让我们以 cx_Freeze 风格创建一个 setup.py 文件:
from cx_Freeze import setup, Executable
setup(
name = "wxSampleApp",
version = "0.1",
description = "An example wxPython script",
executables = [Executable("sampleApp.pyw")]
)
如你所见,这是一个非常简单的问题。我们从 cx_Freeze 导入了几个类,并向它们传递了一些参数。在这种情况下,我们给设置类一个名称、版本、描述和可执行文件类。可执行类还获得一个参数,即它将用来创建二进制文件的脚本名。为了构建二进制文件,您需要在命令行上执行以下操作:
python setup.py build
运行此程序后,您应该会看到以下文件夹:“build\exe.win32-2.6”。最后一个文件夹中有 17 个文件,总共 15.3 MB。当你运行 sampleApp.exe 的文件时,你会注意到我们搞砸了一些事情。除了我们的 GUI 之外,还有一个控制台窗口正在加载!!!为了纠正这一点,我们需要稍微修改一下我们的设置文件。看看我们的新产品:
from cx_Freeze import setup, Executable
exe = Executable(
script="sampleApp.pyw",
base="Win32GUI",
)
setup(
name = "wxSampleApp",
version = "0.1",
description = "An example wxPython script",
executables = [exe]
)
首先,我们将可执行类从设置类中分离出来,并将可执行类分配给一个变量。我们还向可执行类添加了第二个参数,这是一个关键参数。那个参数叫做“基数”。通过设置 base="Win32GUI" ,我们能够抑制控制台窗口。了解 cx_Freeze 可以使用的许多其他选项的一个好方法是使用 GUI2Exe 为我们生成 setup.py 文件。cx_Freeze 网站上的文档显示了可执行类采用的许多其他选项。奇怪的是,除了源代码本身之外,我找不到任何关于 setup 类接受什么参数的信息,源代码本身几乎没有注释。祝你好运搞清楚这一点。
包扎
现在你应该知道如何用 cx_Freeze 创建二进制文件了。这很容易做到,而且他们创造了一种跨平台创建二进制文件的方法,这很好。玩得开心!
进一步阅读
代码的一天:Python Kickstarter
原文:https://www.blog.pythonlibrary.org/2020/12/09/a-day-in-code-python-kickstarter/
最近偶然看到一个有趣的 Python Kickstarter,叫做《代码中的一天:Python——用代码写的绘本。

我个人不了解作者或他们的作品,但我真的很喜欢这个想法。我也完全支持独立的内容创作者。你应该去看看这个 Kickstarter,看看它是否是你可能喜欢的东西,或者是你可以为你认识的人得到的东西。
argparse 简介
原文:https://www.blog.pythonlibrary.org/2015/10/08/a-intro-to-argparse/
你有没有想过如何在 Python 中处理命令行参数?是的,有一个模块。它叫做 argparse ,是对 optparse 的替代。在本文中,我们将快速浏览一下这个有用的模块。先说简单的吧!
入门指南
我一直发现解释一个编码概念最简单的方法就是展示一些代码。这就是我们要做的。这里有一个超级简单的例子,它没有做任何事情:
>>> import argparse
>>> parser = argparse.ArgumentParser(
... description="A simple argument parser",
... epilog="This is where you might put example usage"
... )
...
>>> parser.print_help()
usage: _sandbox.py [-h]
A simple argument parser
optional arguments:
-h, --help show this help message and exit
This is where you might put example usage
这里我们只是导入 argparse,给它一个描述,并设置一个用法部分。这里的想法是,当你向你正在创建的程序寻求帮助时,它会告诉你如何使用它。在这种情况下,它打印出一个简单的描述、默认的可选参数(在这种情况下为“-h”)和示例用法。
现在让我们把这个例子变得更具体一些。毕竟,您通常不会从命令行解析参数。因此,我们将代码移动到 Python 文件内的 Python 函数中:
# arg_demo.py
import argparse
#----------------------------------------------------------------------
def get_args():
""""""
parser = argparse.ArgumentParser(
description="A simple argument parser",
epilog="This is where you might put example usage"
)
return parser.parse_args()
if __name__ == '__main__':
get_args()
现在让我们从命令行调用这个脚本:
python arg_demo.py -h
这将打印出我们前面看到的帮助文本。现在让我们了解一下如何添加一些我们自己的自定义参数。
添加参数
让我们编写一些代码,添加我们的解析器可以理解的三个新参数。我们将添加一个必需的参数和两个非必需的参数。我们还将看看如何添加一个默认类型和一个必需类型。代码如下:
# arg_demo2.py
import argparse
#----------------------------------------------------------------------
def get_args():
""""""
parser = argparse.ArgumentParser(
description="A simple argument parser",
epilog="This is where you might put example usage"
)
# required argument
parser.add_argument('-x', action="store", required=True,
help='Help text for option X')
# optional arguments
parser.add_argument('-y', help='Help text for option Y', default=False)
parser.add_argument('-z', help='Help text for option Z', type=int)
print(parser.parse_args())
if __name__ == '__main__':
get_args()
现在让我们运行几次,这样您就可以看到发生了什么:
mike@pc:~/py/argsparsing$ python arg_demo2.py
usage: arg_demo2.py [-h] -x X [-y Y] [-z Z]
arg_demo2.py: error: argument -x is required
mike@pc:~/py/argsparsing$ python arg_demo2.py -x something
Namespace(x='something', y=False, z=None)
mike@pc:~/py/argsparsing$ python arg_demo2.py -x something -y text
Namespace(x='something', y='text', z=None)
mike@pc:~/py/argsparsing$ python arg_demo2.py -x something -z text
usage: arg_demo2.py [-h] -x X [-y Y] [-z Z]
arg_demo2.py: error: argument -z: invalid int value: 'text'
mike@pc:~/py/argsparsing$ python arg_demo2.py -x something -z 10
Namespace(x='something', y=False, z=10)
正如您所看到的,如果您运行代码而不传递任何参数,您将得到一个错误。接下来,我们只传递所需的参数,这样您就可以看到其他两个参数的默认值。然后,我们尝试将“文本”传递给“-y”参数,它会被存储起来,所以我们知道它不需要布尔值。最后两个例子展示了当您向'-z '参数传递一个无效值和一个有效值时会发生什么。
顺便说一下,参数名称的长度不必是一个字符。你可以改变那些更具描述性的东西,如“arg1”或“simulator”或任何你想要的东西。
包扎
您现在知道了如何创建参数解析器的基础。您可能对该模块的许多其他方面感兴趣,例如为要保存的参数定义一个备用目标名称,使用不同的前缀(即使用“+”而不是“-”),创建参数组等等。我建议查看文档(链接如下)了解更多细节。
附加阅读
- 本周 Python 模块: argparse
- 官方文件
- stack overflow-Python arg parse:用 nargs=argparse 组合可选参数。余数
新 Python.org 网站的预览
原文:https://www.blog.pythonlibrary.org/2013/03/17/a-preview-of-the-new-python-org-website/
Python.org 网站终于得到了急需的更新,在 2013 年的 PyCon 上,他们宣布你现在可以预览一下这里将会是什么样子:http://preview.python.org/
在网站的底部有一个对测试者的呼吁,所以如果你想帮助 Python,这里有一个非常简单的方法。他们还在把内容放在网站上,所以会有一段时间会有占位符之类的东西,但我已经喜欢它的外观和感觉了。自己去看看吧,看你怎么想!
一个 py2exe 教程——构建二进制系列!
原文:https://www.blog.pythonlibrary.org/2010/07/31/a-py2exe-tutorial-build-a-binary-series/
我收到了一个请求,要求我写一篇关于如何使用 py2exe 和 wxPython 创建可执行文件的文章。我决定做一个关于包装的系列。亲爱的读者,我打算介绍一下主要的 Windows 二进制构建实用程序,并向您展示如何使用它们来创建可以分发的二进制文件。一旦这些文章完成,我将展示如何使用 Inno 和 NSIS。首先,我们将讨论如何使用 py2exe,这可能是最流行的 Windows 可执行软件包。
我们开始吧
对于本教程,我们将使用一个不做任何事情的 wxPython 脚本。这是一个虚构的例子,但是我们使用 wx 使它比仅仅做一个控制台“Hello World”程序在视觉上更有趣。还要注意我用的是 py2exe 0.6.9,wxPython 2.8.11.0 和 Python 2.6。运行时,最终产品应该是这样的:

现在我们知道了它的样子,下面来看看代码:
import wx
########################################################################
class DemoPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent)
labels = ["Name", "Address", "City", "State", "Zip",
"Phone", "Email", "Notes"]
mainSizer = wx.BoxSizer(wx.VERTICAL)
lbl = wx.StaticText(self, label="Please enter your information here:")
lbl.SetFont(wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD))
mainSizer.Add(lbl, 0, wx.ALL, 5)
for lbl in labels:
sizer = self.buildControls(lbl)
mainSizer.Add(sizer, 1, wx.EXPAND)
self.SetSizer(mainSizer)
mainSizer.Layout()
#----------------------------------------------------------------------
def buildControls(self, label):
""""""
sizer = wx.BoxSizer(wx.HORIZONTAL)
size = (80,40)
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD)
lbl = wx.StaticText(self, label=label, size=size)
lbl.SetFont(font)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
if label != "Notes":
txt = wx.TextCtrl(self, name=label)
else:
txt = wx.TextCtrl(self, style=wx.TE_MULTILINE, name=label)
sizer.Add(txt, 1, wx.ALL, 5)
return sizer
########################################################################
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, wx.ID_ANY,
"Py2Exe Tutorial",
size=(600,400)
)
panel = DemoPanel(self)
self.Show()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
这相当简单,所以我让读者自己去解决。这篇文章说的毕竟是 py2exe。
py2exe setup.py 文件
任何 py2exe 脚本的关键是 setup.py 文件。这个文件控制包含或排除什么,压缩和打包多少,等等!下面是我们可以在上面的 wx 脚本中使用的最简单的设置:
from distutils.core import setup
import py2exe
setup(windows=['sampleApp.py'])
如你所见,我们从 distutils.core 导入 setup 方法,然后导入 py2exe 。接下来,我们用一个 windows 关键字参数调用 setup,并向它传递 python 列表对象中主文件的名称。如果您正在创建一个非 GUI 项目,那么您将使用控制台键而不是窗口。要运行它,打开命令提示符并导航到适当的位置。然后输入“python setup.py py2exe”运行它。这是我第一次运行时得到的结果:

看起来 wxPython 需要“MSVCP90.dll ”,而 Windows 找不到它。快速的谷歌搜索产生了共识,我需要“微软 Visual C++ 2008 可再发行软件包”,在这里找到了。我下载了它,安装了它,并再次尝试 py2exe。同样的错误。如果我使用 Visual Studio 来创建一个 C#程序的 exe,这可能会有效。无论如何,诀窍是在硬盘上搜索文件,然后将其复制到 Python 的 DLL 文件夹中,在我的机器上,该文件夹位于以下位置:C:\ Python 26 \ DLL(根据需要在您的机器上进行调整)。一旦 DLL 在正确的位置,setup.py 文件就可以正常运行了。结果被放入“dist”文件夹,该文件夹包含 17 个文件,重 15.3 MB。我双击“sampleApp.exe”文件,看看我闪亮的新二进制文件是否能工作,它确实工作了!在旧版本的 wxPython 中,您可能需要包含一个清单文件来获得正确的外观(即主题),但在 2.8.10 中(我认为)这一点已经解决了,就像过去需要的并行(SxS)程序集清单文件一样。
注意,对于非 wxPython 脚本,您可能仍然需要弄乱 SxS 清单和其中包含的所有环。你可以在 py2exe 教程中了解更多。
创建高级 setup.py 文件
让我们通过创建一个更复杂的 setup.py 文件来看看 py2exe 为我们创建二进制文件提供了哪些其他选项。
from distutils.core import setup
import py2exe
includes = []
excludes = ['_gtkagg', '_tkagg', 'bsddb', 'curses', 'email', 'pywin.debugger',
'pywin.debugger.dbgcon', 'pywin.dialogs', 'tcl',
'Tkconstants', 'Tkinter']
packages = []
dll_excludes = ['libgdk-win32-2.0-0.dll', 'libgobject-2.0-0.dll', 'tcl84.dll',
'tk84.dll']
setup(
options = {"py2exe": {"compressed": 2,
"optimize": 2,
"includes": includes,
"excludes": excludes,
"packages": packages,
"dll_excludes": dll_excludes,
"bundle_files": 3,
"dist_dir": "dist",
"xref": False,
"skip_archive": False,
"ascii": False,
"custom_boot_script": '',
}
},
windows=['sampleApp.py']
)
这是相当不言自明的,但无论如何让我们解开它。首先,我们设置几个列表,并将其传递给 set up 函数的 options 参数。
- 包含列表是针对您需要特别包含的特殊模块。有时 py2exe 找不到某些模块,所以您需要在这里手动指定它们。
- 排除列表是从程序中排除哪些模块的列表。在这种情况下,我们不需要 Tkinter,因为我们正在使用 wxPython。这个排除列表是 GUI2Exe 默认排除的内容。
- 包列表是要包含的特定包的列表。还是那句话,有时候 py2exe 就是找不到东西。我以前必须在这里包括 email、PyCrypto 或 lxml。请注意,如果排除列表包含您试图包含在包或包含列表中的内容,py2exe 可能会继续排除它们。
- dll_excludes -排除我们项目中不需要的 dll。
在选项字典中,我们还有一些其他的选项可以查看。 compressed 键告诉 py2exe 是否压缩 zip 文件,如果设置了的话。优化键设置优化级别。零表示没有优化,2 表示最高。 bundle_files 键将 dll 捆绑在 zipfile 或 exe 中。 bundle_files 的有效值为:3 =不捆绑(默认)2 =捆绑除 Python 解释器之外的所有内容 1 =捆绑所有内容,包括 Python 解释器。几年前,当我第一次学习 py2exe 时,我在他们的邮件列表上询问最佳选项是什么,因为我对捆绑选项 1 有疑问。有人告诉我,3 可能是最稳定的。我照着做了,不再有随机的问题,所以这是我目前的建议。如果你不喜欢分发多个文件,把它们压缩或者创建一个安装程序。我在这个列表中使用的另外一个选项是 dist_dir 选项。当我不想覆盖我的主要构建时,我用它来试验不同的构建选项或创建自定义构建。你可以在 py2exe 网站上阅读所有其他选项(包括这里没有列出的选项)。通过将 optimize 设置为 2,我们可以将文件夹的大小减少大约一兆字节。
减少 wxPython 脚本的二进制文件大小
wxPython 邮件列表上有一个关于减小二进制文件大小的主题。我联系了 Steven Sproat,其中的一个人,关于他做了什么,这里的诀窍是:设置“bundle_files”选项为 1,zipfile 为 None。结果在你的 dist 文件夹中会有三个文件:MSVCR71.dll,sampleApp.exe 和 w9xpopen.exe。在我的机器上,该文件夹的大小为 5.94 MB(在 Windows XP 机器上测试)。正如我前面提到的,将 bundle_files 设置为 1 会导致一些用户在运行您的应用程序时遇到问题,但这可能已经在 py2exe 的新版本中得到解决。以下是设置了新选项的 setup.py 文件的外观:
from distutils.core import setup
import py2exe
includes = []
excludes = ['_gtkagg', '_tkagg', 'bsddb', 'curses', 'email', 'pywin.debugger',
'pywin.debugger.dbgcon', 'pywin.dialogs', 'tcl',
'Tkconstants', 'Tkinter']
packages = []
dll_excludes = ['libgdk-win32-2.0-0.dll', 'libgobject-2.0-0.dll', 'tcl84.dll',
'tk84.dll']
setup(
options = {"py2exe": {"compressed": 2,
"optimize": 2,
"includes": includes,
"excludes": excludes,
"packages": packages,
"dll_excludes": dll_excludes,
"bundle_files": 1,
"dist_dir": "dist",
"xref": False,
"skip_archive": False,
"ascii": False,
"custom_boot_script": '',
}
},
zipfile = None,
windows=['sampleApp.py']
)
另一种减小文件夹大小的方法是使用压缩程序,这是我的一位读者 ProgMan 指出的。以下是他的结果:

包扎
现在,您已经了解了使用 py2exe 创建二进制文件的基础知识。我希望这对您当前或未来的项目有所帮助。如果有,请在评论中告诉我!
进一步阅读
- py2exe 教程
- 打包 wxPyMail 进行分发
- GUI2Exe
- py2exe 上的 wxPython wiki 页面
PyInstaller 教程——构建二进制系列!
原文:https://www.blog.pythonlibrary.org/2010/08/10/a-pyinstaller-tutorial-build-a-binary-series/
在我们上一篇关于构建二进制文件的文章中,我们了解了一点 py2exe。这一次,我们将共同关注 PyInstaller 的来龙去脉。我们将使用上一篇文章中相同的蹩脚的 wxPython 脚本作为我们的一个例子,但是我们也将尝试一个普通的控制台脚本来看看有什么不同,如果有的话。如果您不知道的话,PyInstaller 可以在 Linux、Windows 和 Mac(实验性的)上运行,并且可以在 Python 1.5-2.6 上运行(除了在 Windows 上,这里有一个关于 2.6 的警告——见下文)。PyInstaller 支持代码签名(Windows)、eggs、隐藏导入、单个可执行文件、单个目录等等!
PyInstaller 入门
关于 Python 2.6 在 Windows 上的注意:如果你仔细阅读 PyInstaller 网站,你会看到一个关于 Python 2.6+不被完全支持的警告。注意到你现在需要安装微软的 CRT 来运行你的可执行文件。这可能指的是 Python 2.6 相对于 Microsoft Visual Studio 2008 引入的并行程序集/清单问题。我们在第一篇文章中已经提到了这个问题。如果你对此一无所知,请查看 py2exe 网站、wxPython wiki 或 Google。
不管怎样,我们继续表演吧。下载 PyInstaller 后,只需将归档文件解压到方便的地方。遵循这三个简单步骤:
- 运行 Configure.py 将一些基本配置数据保存到 a”。dat”文件。这节省了一些时间,因为 PyInstaller 不必动态地重新计算配置。
- 在命令行上运行以下命令:
python makespec.py [opts] <scriptname>其中 scriptname 是您用来运行程序的主 Python 文件的名称。 - 最后,通过命令行运行下面的命令: python Build.py specfile 来构建您的可执行文件。
现在让我们用一个真实的脚本来演示一下。我们将从一个简单的控制台脚本开始,该脚本创建一个伪配置文件。代码如下:
import configobj
#----------------------------------------------------------------------
def createConfig(configFile):
"""
Create the configuration file
"""
config = configobj.ConfigObj()
inifile = configFile
config.filename = inifile
config['server'] = "http://www.google.com"
config['username'] = "mike"
config['password'] = "dingbat"
config['update interval'] = 2
config.write()
#----------------------------------------------------------------------
def getConfig(configFile):
"""
Open the config file and return a configobj
"""
return configobj.ConfigObj(configFile)
def createConfig2(path):
"""
Create a config file
"""
config = configobj.ConfigObj()
config.filename = path
config["Sony"] = {}
config["Sony"]["product"] = "Sony PS3"
config["Sony"]["accessories"] = ['controller', 'eye', 'memory stick']
config["Sony"]["retail price"] = "$400"
config.write()
if __name__ == "__main__":
createConfig2("sampleConfig.ini")
现在让我们创建一个规范文件:
c:\Python25\python c:\Users\Mike\Desktop\pyinstaller-1.4\Makespec.py config_1.py
在我的测试机器上,我安装了 3 个不同的 Python 版本,所以我必须显式地指定 Python 2.5 路径(或者将 Python 2.5 设置为默认路径)。无论如何,这应该会创建一个类似下面的文件(命名为“config_1.spec”):
# -*- mode: python -*-
a = Analysis([os.path.join(HOMEPATH,'support\\_mountzlib.py'), os.path.join(HOMEPATH,'support\\useUnicode.py'), 'config_1.py'],
pathex=['C:\\Users\\Mike\\Desktop\\py2exe_ex', r'C:\Python26\Lib\site-packages'])
pyz = PYZ(a.pure)
exe = EXE(pyz,
a.scripts,
exclude_binaries=1,
name=os.path.join('build\\pyi.win32\\config_1', 'config_1.exe'),
debug=False,
strip=False,
upx=True,
console=True )
coll = COLLECT( exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
name=os.path.join('pyInstDist2', 'config_1'))
对于我们正在使用的 Python 脚本,我们需要在规格文件的分析部分的 configobj.py 的位置添加一个显式路径到 pathex 参数中。如果您不这样做,当您运行生成的可执行文件时,它将打开和关闭一个控制台窗口非常快,您将无法知道它说什么,除非您从命令行运行 exe。我采用了后者来找出问题所在,并发现它找不到 configobj 模块。您还可以在 COLLECT 函数的 name 参数中指定 exe 的输出路径。在这种情况下,我们将 PyInstaller 的输出放在“pyInstDist2”的“config_1”子文件夹中,该文件夹应该与您的原始脚本放在一起。在配置你的规格文件时有很多选项,你可以在这里阅读。
要基于规范文件构建可执行文件,请在命令行上执行以下操作:
c:\Python25\python c:\Users\Mike\Desktop\pyinstaller-1.4\Build.py config_1.spec
在我的机器上,我得到了一个文件夹,里面有 25 个文件,总共 6.7 MB。您应该能够使用分析部分的排除参数和/或压缩来减小大小。
PyInstaller 和 wxPython
现在让我们尝试从一个简单的 wxPython 脚本创建一个二进制文件。以下是 Python 脚本:
import wx
########################################################################
class DemoPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent)
labels = ["Name", "Address", "City", "State", "Zip",
"Phone", "Email", "Notes"]
mainSizer = wx.BoxSizer(wx.VERTICAL)
lbl = wx.StaticText(self, label="Please enter your information here:")
lbl.SetFont(wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD))
mainSizer.Add(lbl, 0, wx.ALL, 5)
for lbl in labels:
sizer = self.buildControls(lbl)
mainSizer.Add(sizer, 1, wx.EXPAND)
self.SetSizer(mainSizer)
mainSizer.Layout()
#----------------------------------------------------------------------
def buildControls(self, label):
""""""
sizer = wx.BoxSizer(wx.HORIZONTAL)
size = (80,40)
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD)
lbl = wx.StaticText(self, label=label, size=size)
lbl.SetFont(font)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
if label != "Notes":
txt = wx.TextCtrl(self, name=label)
else:
txt = wx.TextCtrl(self, style=wx.TE_MULTILINE, name=label)
sizer.Add(txt, 1, wx.ALL, 5)
return sizer
########################################################################
class DemoFrame(wx.Frame):
"""
Frame that holds all other widgets
"""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, wx.ID_ANY,
"PyInstaller Tutorial",
size=(600,400)
)
panel = DemoPanel(self)
self.Show()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = wx.App(False)
frame = DemoFrame()
app.MainLoop()
因为这是一个 GUI,所以我们创建的 spec 文件略有不同:
c:\Python25\python c:\Users\Mike\Desktop\pyinstaller-1.4\Makespec.py -F -w sampleApp.py
请注意-F 和-w 参数。F 命令告诉 PyInstaller 只创建一个可执行文件,而-w 命令告诉 PyInstaller 隐藏控制台窗口。下面是生成的规范文件:
# -*- mode: python -*-
a = Analysis([os.path.join(HOMEPATH,'support\\_mountzlib.py'), os.path.join(HOMEPATH,'support\\useUnicode.py'), 'sampleApp.py'],
pathex=['C:\\Users\\Mike\\Desktop\\py2exe_ex'])
pyz = PYZ(a.pure)
exe = EXE( pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
name=os.path.join('pyInstDist', 'sampleApp.exe'),
debug=False,
strip=False,
upx=True,
console=False )
请注意,最后一行的“console”参数设置为“False”。如果您像使用控制台脚本那样构建它,那么您应该在“pyInstDist”文件夹中得到一个大约 7.1 MB 大小的文件。
包扎
这就结束了我们对 PyInstaller 的快速浏览。我希望这对您的 Python 二进制制作工作有所帮助。PyInstaller 网站上有更多的信息,并且有很好的文档记录,尽管该网站非常简单。一定要试一试,看看 PyInstaller 是多么容易使用!
注意:我在 Windows 7 家庭高级版(32 位)上使用 PyInstaller 1.4 和 Python 2.5 测试了所有这些。
进一步阅读
快速 EasyGui 教程
原文:https://www.blog.pythonlibrary.org/2010/05/22/a-quick-easygui-tutorial/
本周早些时候,我正在阅读沃伦·d·桑德和卡特·桑德所写的《Hello World 》,在关于图形用户界面的章节中,我提到了一个名为 EasyGui 的库。这是我见过的第一个也是唯一一个非事件驱动的 Python GUI 项目。相反,EasyGui 基本上是一组可以按需打开的对话框。这个包对于需要使用对话框从用户那里获取信息的命令行程序来说是很方便的,或者对于教新程序员简单的 GUI 来说也是很方便的。让我们快速看一下 EasyGui 能做什么。我们将使用书中的一些例子。
EasyGui 基于 Tkinter,内置于 Python 中。它也只是一个小的 python 脚本,你可以把它放在 python 路径的某个地方,这样你就可以使用它了。我把我的放在站点包文件夹中。让我们来看几个例子。
easyui msgbox

消息框对于让用户了解他们的程序状态非常有用。这是你做一个的方法:
import easygui
easygui.msgbox("Hello, world!")
EasyGui enterbox

enterbox 对话框允许程序员提示用户输入一串文本。
import easygui
flavor = easygui.enterbox("What is your favorite ice cream flavor?")
easygui.msgbox ("You entered " + flavor)
easyui 按钮盒

向 buttonbox 对话框传递一个字符串列表,以创建一组表示为按钮的选项。
import easygui
flavor = easygui.buttonbox("What is your favorite ice cream flavor?",
choices = ['Vanilla', 'Chocolate', 'Strawberry'] )
easygui.msgbox ("You picked " + flavor)
包扎
EasyGui 提供了更多这里没有涉及的对话框。查看它的文档以获得更多信息。
pdfrw 快速介绍
原文:https://www.blog.pythonlibrary.org/2012/07/07/a-quick-intro-to-pdfrw/
我一直在寻找 Python PDF 库,前几天我偶然发现了 pdfrw 。它看起来像是 pyPDF 的替代品,因为它可以读写 PDF,连接 pdf,并可以使用 Reportlab 进行连接和水印等操作。这个项目看起来也有点死气沉沉,因为它的最后一次更新是在 2011 年,但话又说回来,pyPDF 的最后一次更新是在 2010 年,所以它有点新鲜。在本文中,我们将对 pdfrw 进行一点测试,看看它是否有用。快来凑热闹吧!
安装注意:遗憾的是没有 setup.py 脚本,所以你必须从谷歌代码中检查它,只需将 pdfrw 文件夹复制到 site-packages 或你的 virtualenv。
使用 pdfrw 将 pdf 连接在一起
使用 pdfrw 将两个 PDF 文件合并成一个文件实际上非常简单。见下文:
from pdfrw import PdfReader, PdfWriter
pages = PdfReader(r'C:\Users\mdriscoll\Desktop\1.pdf', decompress=False).pages
other_pages = PdfReader(r'C:\Users\mdriscoll\Desktop\2.pdf', decompress=False).pages
writer = PdfWriter()
writer.addpages(pages)
writer.addpages(other_pages)
writer.write(r'C:\Users\mdriscoll\Desktop\out.pdf')
我觉得有趣的是,在写出文件之前,你还可以通过这样的方式对文件进行元数据:
writer.trailer.Info = IndirectPdfDict(
Title = 'My Awesome PDF',
Author = 'Mike',
Subject = 'Python Rules!',
Creator = 'myscript.py',
)
还有一个包含的示例显示了如何使用 pdfrw 和 reportlab 组合 pdf。我在这里重复一下:
# http://code.google.com/p/pdfrw/source/browse/trunk/examples/rl1/subset.py
import sys
import os
from reportlab.pdfgen.canvas import Canvas
import find_pdfrw
from pdfrw import PdfReader
from pdfrw.buildxobj import pagexobj
from pdfrw.toreportlab import makerl
def go(inpfn, firstpage, lastpage):
firstpage, lastpage = int(firstpage), int(lastpage)
outfn = 'subset_%s_to_%s.%s' % (firstpage, lastpage, os.path.basename(inpfn))
pages = PdfReader(inpfn, decompress=False).pages
pages = [pagexobj(x) for x in pages[firstpage-1:lastpage]]
canvas = Canvas(outfn)
for page in pages:
canvas.setPageSize(tuple(page.BBox[2:]))
canvas.doForm(makerl(canvas, page))
canvas.showPage()
canvas.save()
if __name__ == '__main__':
inpfn, firstpage, lastpage = sys.argv[1:]
go(inpfn, firstpage, lastpage)
我只是觉得这很酷。无论如何,它为您提供了 pyPDF 编写器的几种替代方案。这个包中还有许多其他有趣的例子,包括
- 如何使用 pdf(第一页)作为所有其他页面的背景。
- 如何添加一个水印
我认为这个项目有潜力。希望我们能产生足够的兴趣来再次启动这个项目,或者可能得到一些新的东西。
Python 网页抓取的简单介绍
原文:https://www.blog.pythonlibrary.org/2016/08/04/a-simple-intro-to-web-scraping-with-python/
Web 抓取是程序员编写应用程序来下载网页并从中解析出特定信息的地方。通常当你抓取数据时,你需要让你的应用程序以编程的方式导航网站。在这一章中,我们将学习如何从互联网上下载文件,并在需要时解析它们。我们还将学习如何创建一个简单的蜘蛛,我们可以用它来抓取网站。
刮痧技巧
在我们开始刮之前,有几个提示我们需要复习一下。
- 在你刮之前,一定要检查网站的条款和条件。他们通常有条款限制你刮的频率或者你能刮多少
- 因为你的脚本运行的速度会比人类浏览的速度快得多,所以确保你不要用大量的请求来敲打他们的网站。这甚至可能包含在网站的条款和条件中。
- 如果你让一个网站过载了你的请求,或者你试图以违反你同意的条款和条件的方式使用它,你会陷入法律麻烦。
- 网站一直在变,所以你的刮刀总有一天会坏掉。知道这一点:如果你想让你的铲运机继续工作,你必须维护它。
- 不幸的是,你从网站上获得的数据可能会很混乱。与任何数据解析活动一样,您需要清理它以使它对您有用。
解决了这个问题,我们开始刮吧!
准备刮
在我们开始刮之前,我们需要弄清楚我们想要做什么。我们将使用我的博客作为这个例子。我们的任务是抓取这个博客首页上的文章的标题和链接。你可以使用 Python 的 urllib2 模块下载我们需要解析的 HTML,或者你可以使用请求库。对于这个例子,我将使用请求。
如今大多数网站都有相当复杂的 HTML。幸运的是,大多数浏览器都提供了一些工具来找出网站元素的琐碎之处。例如,如果你在 chrome 中打开我的博客,你可以右击任何文章标题,然后点击检查菜单选项(如下所示):

点击后,你会看到一个侧边栏,突出显示包含标题的标签。看起来是这样的:

Mozilla Firefox 浏览器有开发者工具,你可以在每页的基础上启用,包括一个检查器,你可以像在 Chrome 中一样使用它。无论您最终使用哪种浏览器,您都会很快发现 h1 标签是我们需要寻找的。现在我们知道了我们想要解析什么,我们可以学习如何这样做!
2021 年 8 月更新:最初,鼠标 vs Python 使用 h1 标签作为文章标题,但现在它使用 h2 。
美丽的声音
Python 最流行的 HTML 解析器之一叫做 BeautifulSoup 。它已经存在了一段时间,并以能够很好地处理畸形的 HTML 而闻名。要为 Python 3 安装它,您只需做以下事情:
pip install beautifulsoup4
如果一切正常,您现在应该已经安装了 BeautifulSoup。当传递 BeautifulSoup 一些 HTML 来解析时,可以指定一个树构建器。对于这个例子,我们将使用 html.parser ,因为它包含在 Python 中。如果你想要更快的,你可以安装 lxml。
让我们来看看一些代码,看看这一切是如何工作的:
import requests
from bs4 import BeautifulSoup
url = 'https://www.blog.pythonlibrary.org/'
def get_articles():
"""
Get the articles from the front page of the blog
"""
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
pages = soup.findAll('h2')
articles = {i.a['href']: i.text.strip()
for i in pages if i.a}
for article in articles:
s = '{title}: {url}'.format(
title=articles[article],
url=article)
print(s)
return articles
if __name__ == '__main__':
articles = get_articles()
在这里,我们进行导入,并设置我们将要使用的 URL。然后我们创建一个函数,魔法就在这里发生。我们使用请求库获取 URL,然后使用请求对象的 text 属性将 HTML 作为字符串提取出来。然后我们将 HTML 传递给 BeautifulSoup,后者将它转换成一个漂亮的对象。之后,我们要求 BeautifulSoup 找到所有的 h1 的实例,然后使用字典理解来提取标题和 URL。然后,我们将该信息打印到 stdout 并返回字典。
我们试着再刮一个网站。这次我们将看看 Twitter,并使用我的博客的帐户:mousevspython。我们会努力收集我最近发的微博。你需要像以前一样,通过右键点击一条推文并检查它来找出我们需要做什么。在这种情况下,我们需要寻找‘Li’标记和 js-stream-item 类。让我们来看看:
import requests
from bs4 import BeautifulSoup
url = 'https://twitter.com/mousevspython'
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
tweets = soup.findAll('li', 'js-stream-item')
for item in range(len(soup.find_all('p', 'TweetTextSize'))):
tweet_text = tweets[item].get_text()
print(tweet_text)
dt = tweets[item].find('a', 'tweet-timestamp')
print('This was tweeted on ' + dt)
和以前一样,我们使用 BeautifulSoup 的 findAll 命令获取所有符合我们搜索标准的实例。然后,我们还寻找段落标签(即“p”)和 TweetTextSize 类,并循环结果。你会注意到我们在这里使用了 find_all 。我们要明确的是,findAll 是 find_all 的别名,所以它们做完全相同的事情。无论如何,我们循环这些结果,获取 tweet 文本和 tweet 时间戳并打印出来。
你可能会认为可能有一种更简单的方法来做这类事情,而且确实有。一些网站提供了开发者 API,您可以使用它来访问他们网站的数据。Twitter 有一个很好的要求消费者密钥和秘密的方法。实际上,我们将在下一章研究如何使用这个 API 和其他一些 API。
让我们继续学习如何写一个蜘蛛!
Scrapy
Scrapy 是一个框架,你可以用它来抓取网站和提取(即抓取)数据。它还可以用于通过网站的 API 提取数据,或者作为通用网络爬虫。要安装 Scrapy,您需要的只是 pip:
pip install scrapy
根据 Scrapy 的文档,您还需要安装 lxml 和 OpenSSL。我们将使用 Scrapy 来做与我们使用 BeautifulSoup 相同的事情,即抓取我博客首页上文章的标题和链接。首先,你需要做的就是打开一个终端,将目录切换到你想要存储我们项目的目录。然后运行以下命令:
scrapy startproject blog_scraper
这将在当前目录中创建一个名为 blog_scraper 的目录,其中包含以下项目:
- 另一个嵌套的 blog_scraper 文件夹
- scrapy.cfg
第二个 blog_scraper 文件夹里面是好东西:
- 蜘蛛文件夹
- init.py
- items.py
- pipelines.py
- settings.py
除了 items.py 之外,我们可以使用默认设置。因此,在您最喜欢的 Python 编辑器中打开 items.py ,并添加以下代码:
import scrapy
class BlogScraperItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
我们在这里所做的是创建一个类来模拟我们想要捕获的内容,在这个例子中是一系列的标题和链接。这有点像 SQLAlchemy 的模型系统,其中我们会创建一个数据库模型。在 Scrapy 中,我们创建一个我们想要收集的数据的模型。
接下来我们需要创建一个蜘蛛,因此将目录更改为spider目录,并在那里创建一个 Python 文件。姑且称之为 blog.py 。将以下代码放入新创建的文件中:
from scrapy.spider import BaseSpider
from scrapy.selector import Selector
from ..items import BlogScraperItem
class MyBlogSpider(BaseSpider):
name = 'mouse'
start_urls = ['https://www.blog.pythonlibrary.org']
def parse(self, response):
selector = Selector(response)
blog_titles = selector.xpath("//h1[@class='entry-title']")
selections = []
for data in blog_titles:
selection = BlogScraperItem()
selection['title'] = data.xpath("a/text()").extract()
selection['link'] = data.xpath("a/@href").extract()
selections.append(selection)
return selections
这里我们只导入了 BaseSpider 类和一个选择器类。我们还导入了之前创建的 BlogScraperItem 类。然后我们子类化 BaseSpider 并将我们的蜘蛛命名为鼠标,因为我的博客的名字是鼠标 Vs Python。我们还给它一个开始 URL。请注意,这是一个列表,这意味着你可以给这个蜘蛛多个开始网址。最重要的部分是我们的解析函数。它将从网站获取响应并解析它们。
Scrapy 支持使用 CSS 表达式或 XPath 来选择 HTML 文档的某些部分。这基本上告诉 Scrapy 我们想要刮的是什么。XPath 有点难懂,但是它也是最强大的,所以我们将在这个例子中使用它。为了获取标题,我们可以使用 Google Chrome 的 Inspector 工具找出标题位于一个类名为 entry-title 的 h1 标签中。
选择器返回一个我们可以迭代的 a SelectorList 实例。这允许我们继续对这个特殊列表中的每一项进行 xpath 查询,因此我们可以提取标题文本和链接。我们还创建了 BlogScraperItem 的一个新实例,并将提取的标题和链接插入到这个新对象中。最后,我们将新收集的数据添加到一个列表中,完成后返回该列表。
要运行此代码,请返回到包含嵌套 blog_scraper 文件夹和配置文件的顶级文件夹,并运行以下命令:
scrapy crawl mouse
你会注意到我们告诉 Scrapy 使用我们创建的鼠标蜘蛛爬行。该命令将导致大量输出打印到您的屏幕上。幸运的是,Scrapy 支持将数据导出为各种格式,如 CSV、JSON 和 XML。让我们使用 CSV 格式导出我们收集的数据:
scrapy crawl mouse -o articles.csv -t csv
您仍然会看到许多输出被生成到 stdout,但是标题和链接将被保存到磁盘上一个名为 articles.csv 的文件中。
大多数爬虫被设置为跟随链接并爬行整个网站或一系列网站。这个网站的爬虫并不是这样创建的,但是这将是一个有趣的增强,你可以自己添加。
包扎
从互联网上搜集数据既有挑战性又很有趣。Python 有许多库可以让这项工作变得非常简单。我们了解了如何使用 BeautifulSoup 从博客和 Twitter 上收集数据。然后我们了解了用 Python 创建网络爬虫/抓取器最流行的库之一:Scrapy。我们仅仅触及了这些库的皮毛,所以我们鼓励您花些时间阅读它们各自的文档以了解更多的细节。
相关阅读
- 白痴在里面- 从谷歌 Play 商店获得安卓应用下载量和评分
- Scrapy Hub-用 Scrapy 和 Python 3 进行数据提取
- Dan Nguyen - Python 3 公共数据网络抓取示例
- 第一次刮网教程
- Python 网页抓取入门指南(使用 BeautifulSoup)
- Greg Reda - 使用 Python 的网络抓取 101
- Miguel Grinberg - 使用 Python 轻松抓取网页
- Python 的搭便车指南- HTML 抓取
- 真正的 Python - 用 Scrapy 和 MongoDB 进行网页抓取和抓取
一个简单的 SqlAlchemy 0.7 / 0.8 教程
原文:https://www.blog.pythonlibrary.org/2012/07/01/a-simple-sqlalchemy-0-7-0-8-tutorial/
几年前,我写了一篇关于 SQLAlchemy 的相当有缺陷的教程。我决定是时候从头开始重新做这个教程了,希望这次能做得更好。因为我是一个音乐迷,我们将创建一个简单的数据库来存储专辑信息。没有一些关系的数据库就不是数据库,所以我们将创建两个表并将它们连接起来。以下是我们将要学习的其他一些东西:
- 向每个表中添加数据
- 修改数据
- 删除数据
- 基本查询
但是首先我们需要实际制作数据库,所以我们将从那里开始我们的旅程。注意 SQLAlchemy 是一个第三方包,所以如果你想继续的话,你需要安装它。
如何创建数据库
用 SQLAlchemy 创建数据库真的很容易。他们现在已经完全采用了他们的声明式方法来创建数据库,所以我们不会讨论旧的学校方法。您可以在这里阅读代码,然后我们将在清单后面解释它。如果你想查看你的 SQLite 数据库,我推荐火狐的 SQLite 管理器插件。或者你可以使用我一个月前创建的简单 wxPython 应用程序。
# table_def.py
from sqlalchemy import create_engine, ForeignKey
from sqlalchemy import Column, Date, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, backref
engine = create_engine('sqlite:///mymusic.db', echo=True)
Base = declarative_base()
########################################################################
class Artist(Base):
""""""
__tablename__ = "artists"
id = Column(Integer, primary_key=True)
name = Column(String)
#----------------------------------------------------------------------
def __init__(self, name):
""""""
self.name = name
########################################################################
class Album(Base):
""""""
__tablename__ = "albums"
id = Column(Integer, primary_key=True)
title = Column(String)
release_date = Column(Date)
publisher = Column(String)
media_type = Column(String)
artist_id = Column(Integer, ForeignKey("artists.id"))
artist = relationship("Artist", backref=backref("albums", order_by=id))
#----------------------------------------------------------------------
def __init__(self, title, release_date, publisher, media_type):
""""""
self.title = title
self.release_date = release_date
self.publisher = publisher
self.media_type = media_type
# create tables
Base.metadata.create_all(engine)
如果您运行这段代码,那么您应该会看到发送到 stdout 的以下输出:
2012-06-27 16:34:24,479 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("artists")
2012-06-27 16:34:24,479 INFO sqlalchemy.engine.base.Engine ()
2012-06-27 16:34:24,480 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("albums")
2012-06-27 16:34:24,480 INFO sqlalchemy.engine.base.Engine ()
2012-06-27 16:34:24,480 INFO sqlalchemy.engine.base.Engine
CREATE TABLE artists (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
2012-06-27 16:34:24,483 INFO sqlalchemy.engine.base.Engine ()
2012-06-27 16:34:24,558 INFO sqlalchemy.engine.base.Engine COMMIT
2012-06-27 16:34:24,559 INFO sqlalchemy.engine.base.Engine
CREATE TABLE albums (
id INTEGER NOT NULL,
title VARCHAR,
release_date DATE,
publisher VARCHAR,
media_type VARCHAR,
artist_id INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(artist_id) REFERENCES artists (id)
)
2012-06-27 16:34:24,559 INFO sqlalchemy.engine.base.Engine ()
2012-06-27 16:34:24,615 INFO sqlalchemy.engine.base.Engine COMMIT
为什么会这样?因为当我们创建引擎对象时,我们将其 echo 参数设置为 True。引擎是数据库连接信息所在的地方,它包含了所有的 DBAPI 内容,使得与数据库的通信成为可能。您会注意到我们正在创建一个 SQLite 数据库。从 Python 2.5 开始,该语言就支持 SQLite。如果您想连接到其他数据库,那么您需要编辑连接字符串。以防你对我们正在谈论的内容感到困惑,这里是有问题的代码:
engine = create_engine('sqlite:///mymusic.db', echo=True)
字符串 'sqlite:///mymusic.db' ,是我们的连接字符串。接下来,我们创建声明性基类的一个实例,这是我们的表类所基于的。接下来我们有两个类,艺术家和专辑,它们定义了我们的数据库表的外观。您会注意到我们有列,但是没有列名。SQLAlchemy 实际上使用变量名作为列名,除非您在列定义中特别指定一个。您会注意到我们在两个类中都使用了一个“id”整数字段作为主键。该字段将自动递增。在使用外键之前,其他列都是不言自明的。在这里你会看到我们将 artist_id 绑定到 Artist 表中的 id。关系指令告诉 SQLAlchemy 将专辑类/表绑定到艺术家表。由于我们设置 ForeignKey 的方式,relationship 指令告诉 SQLAlchemy 这是一个多对一关系,这正是我们想要的。一位艺术家的多张专辑。你可以在这里阅读更多关于表关系的内容。
脚本的最后一行将在数据库中创建表。如果您多次运行这个脚本,它在第一次之后不会做任何新的事情,因为表已经创建好了。您可以添加另一个表,然后它会创建一个新表。
如何向表格中插入/添加数据
除非数据库中有一些数据,否则它没有多大用处。在这一节中,我们将向您展示如何连接到您的数据库并将一些数据添加到这两个表中。看一看一些代码然后解释它要容易得多,所以我们就这么做吧!
import datetime
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from table_def import Album, Artist
engine = create_engine('sqlite:///mymusic.db', echo=True)
# create a Session
Session = sessionmaker(bind=engine)
session = Session()
# Create an artist
new_artist = Artist("Newsboys")
new_artist.albums = [Album("Read All About It",
datetime.date(1988,12,1),
"Refuge", "CD")]
# add more albums
more_albums = [Album("Hell Is for Wimps",
datetime.date(1990,7,31),
"Star Song", "CD"),
Album("Love Liberty Disco",
datetime.date(1999,11,16),
"Sparrow", "CD"),
Album("Thrive",
datetime.date(2002,3,26),
"Sparrow", "CD")]
new_artist.albums.extend(more_albums)
# Add the record to the session object
session.add(new_artist)
# commit the record the database
session.commit()
# Add several artists
session.add_all([
Artist("MXPX"),
Artist("Kutless"),
Artist("Thousand Foot Krutch")
])
session.commit()
首先,我们需要从前面的脚本中导入我们的表定义。然后,我们用引擎连接到数据库,并创建新的东西,即会话对象。会话是数据库的句柄,让我们与它交互。我们用它来创建、修改和删除记录,我们还用会话来查询数据库。接下来,我们创建一个艺术家对象并添加一个相册。您会注意到,要添加一个相册,您只需创建一个相册对象列表,并将 artist 对象的“albums”属性设置为该列表,或者您可以扩展它,如示例的第二部分所示。在脚本的最后,我们使用 add_all 添加了三个额外的艺术家。您可能已经注意到,您需要使用会话对象的提交方法将数据写入数据库。现在是时候把注意力转向修改数据了。
关于 init 的一个注意事项:正如我的一些敏锐的读者指出的,对于表定义,您实际上不需要 init 构造函数。我把它们留在那里是因为官方文档仍然在使用它们,我没有意识到我可以把它们漏掉。无论如何,如果您在声明性表定义中不考虑 init 的话,那么在创建记录时您将需要使用关键字参数。例如,您应该执行以下操作,而不是上一个示例中显示的操作:
new_artist = Artist(name="Newsboys")
new_artist.albums = [Album(title="Read All About It",
release_date=datetime.date(1988,12,01),
publisher="Refuge", media_type="CD")]
如何用 SQLAlchemy 修改记录
如果你保存了一些错误的数据会发生什么。例如,你打错了你最喜欢的专辑的名字,或者你弄错了你的粉丝版本的发行日期?你需要学习如何修改那个记录!这实际上是我们学习 SQLAlchemy 查询的起点,因为您需要找到需要更改的记录,这意味着您需要为它编写一个查询。下面的一些代码向我们展示了这种方法:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from table_def import Album, Artist
engine = create_engine('sqlite:///mymusic.db', echo=True)
# create a Session
Session = sessionmaker(bind=engine)
session = Session()
# querying for a record in the Artist table
res = session.query(Artist).filter(Artist.name=="Kutless").first()
print(res.name)
# changing the name
res.name = "Beach Boys"
session.commit()
# editing Album data
artist, album = session.query(Artist, Album).filter(Artist.id==Album.artist_id).filter(Album.title=="Thrive").first()
album.title = "Step Up to the Microphone"
session.commit()
我们的第一个查询使用过滤器方法通过名字查找艺术家。的”。first()"告诉 SQLAlchemy 我们只想要第一个结果。我们本来可以用”。all()"如果我们认为会有多个结果,并且我们想要所有的结果。无论如何,这个查询返回一个我们可以操作的 Artist 对象。正如你所看到的,我们把的名字从“无裤袜”改成了“沙滩男孩”,然后进行了修改。
查询连接表稍微复杂一点。这一次,我们编写了一个查询来查询我们的两个表。它使用艺术家 id 和专辑标题进行过滤。它返回两个对象:艺术家和专辑。一旦我们有了这些,我们可以很容易地改变专辑的标题。那不是很容易吗?此时,我们可能应该注意到,如果我们错误地向会话添加了内容,我们可以通过使用 session.rollback() 回滚我们的更改/添加/删除。说到删除,让我们来解决这个问题吧!
如何删除 SQLAlchemy 中的记录
有时候你只需要删除一条记录。无论是因为你卷入了一场掩盖活动,还是因为你不想让人们知道你对布兰妮音乐的喜爱,你都必须清除证据。在本节中,我们将向您展示如何做到这一点!幸运的是,SQLAlchemy 让删除记录变得非常容易。看看下面的代码就知道了!
# deleting_data.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from table_def import Album, Artist
engine = create_engine('sqlite:///mymusic.db', echo=True)
# create a Session
Session = sessionmaker(bind=engine)
session = Session()
res = session.query(Artist).filter(Artist.name=="MXPX").first()
session.delete(res)
session.commit()
如您所见,您所要做的就是创建另一个 SQL 查询来查找您想要删除的记录,然后调用 session.delete(res) 。在这种情况下,我们删除了我们的 MXPX 记录。有人觉得朋克永远不死,但一定不认识什么 DBA!我们已经看到了运行中的查询,但是让我们更仔细地看一看,看看我们是否能学到新的东西。
SQLAlchemy 的基本 SQL 查询
SQLAlchemy 提供了您可能需要的所有查询。我们将花一点时间来看一些基本的,比如几个简单的选择,一个连接的选择和使用 LIKE 查询。您还将了解到哪里去获取其他类型查询的信息。现在,让我们看一些代码:
# queries.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from table_def import Album, Artist
engine = create_engine('sqlite:///mymusic.db', echo=True)
# create a Session
Session = sessionmaker(bind=engine)
session = Session()
# how to do a SELECT * (i.e. all)
res = session.query(Artist).all()
for artist in res:
print artist.name
# how to SELECT the first result
res = session.query(Artist).filter(Artist.name=="Newsboys").first()
# how to sort the results (ORDER_BY)
res = session.query(Album).order_by(Album.title).all()
for album in res:
print album.title
# how to do a JOINed query
qry = session.query(Artist, Album)
qry = qry.filter(Artist.id==Album.artist_id)
artist, album = qry.filter(Album.title=="Thrive").first()
print
# how to use LIKE in a query
res = session.query(Album).filter(Album.publisher.like("S%a%")).all()
for item in res:
print item.publisher
我们运行的第一个查询将获取数据库中的所有艺术家(SELECT )并打印出他们的每个姓名字段。接下来,您将看到如何查询特定的艺术家并返回第一个结果。第三个查询显示了如何在相册表中选择并按相册标题对结果进行排序。第四个查询与我们在编辑部分使用的查询相同(对一个连接的查询),只是我们对它进行了分解,以更好地适应关于行长度的标准。分解长查询的另一个原因是,如果你搞砸了,它们会变得更易读,更容易修复。最后一个查询使用 LIKE,它允许我们进行模式匹配或查找与指定字符串“相似”的内容。在这种情况下,我们希望找到出版商以大写字母“S”、某个字符“a”以及其他任何字母开头的任何记录。例如,这将匹配发行商 Sparrow 和 Star。
SQLAlchemy 还支持 IN、IS NULL、NOT、AND、OR 以及大多数 DBA 使用的所有其他过滤关键字。SQLAlchemy 还支持文字 SQL、标量等。
包扎
此时,您应该对 SQLAlchemy 有足够的了解,可以放心地开始使用它。该项目也有很好的文档,你应该能够用它来回答你需要知道的任何事情。如果您遇到困难,SQLAlchemy 用户组/邮件列表会对新用户做出积极响应,甚至主要开发人员也会在那里帮助您解决问题。
源代码
进一步阅读
- SQLAlchemy 官方文档
- wxPython 和 SQLAlchemy: 加载随机 SQLite 数据库以供查看
- SqlAlchemy: 连接到预先存在的数据库
- wxPython 和 SqlAlchemy:MVC 和 CRUD 简介
- 另一个循序渐进的 SqlAlchemy 教程(第 1 部分,共 2 部分)
一个简单的分步报告实验室教程
原文:https://www.blog.pythonlibrary.org/2010/03/08/a-simple-step-by-step-reportlab-tutorial/
这篇文章的副标题很可能是“如何用 Python 创建 pdf”,但是 WordPress 不支持这个。无论如何,Python 中首要的 PDF 库是 Reportlab 。它没有随标准库一起发布,所以如果您想运行本教程中的示例,您需要下载它。还会有至少一个如何将图像放入 PDF 的例子,这意味着你还需要枕头包 (PIL)。
|  | 想了解更多关于使用 Python 处理 pdf 的信息吗?
| 想了解更多关于使用 Python 处理 pdf 的信息吗?
ReportLab:用 Python 处理 PDF
Leanpub立即购买 |
装置
Reportlab 支持大多数常规 Python 安装方法。对于旧的 Reportlab 2.x 版本,您可以选择下载源代码并运行“python setup.py install”或运行二进制安装程序(在 Windows 上)。
对于较新的 Reportlab 3.x ,您现在可以在所有平台上使用 pip:
pip install reportlab
注意,Reportlab 3.x 只支持 Python 2.7 和 Python 3.3+ 。如果您使用的是旧版本的 Python 2,那么您必须使用 Reportlab 2.x。
创建简单的 PDF
Reportlab 有不错的文档。我的意思是,文档给了你足够的开始,但是当你发现有一些稍微复杂的事情要做的时候,你可以自己解决。就在最近,他们在自己的网站上增加了一个代码片段部分,有望成为一本很酷的技巧和诀窍的食谱,也有助于改善这个问题。不过,说够了。让我们来看看如何实际创造一些东西!
在 Reportlab 中,最底层的组件是来自 pdfgen 包的 canvas 对象。这个包中的函数允许你用你的文本、图像、线条或任何东西来“画”一个文档。我听过有人形容这是写后记。我怀疑真的有那么糟糕。根据我的经验,这实际上很像使用 GUI 工具包在特定位置布局小部件。让我们看看画布对象是如何工作的:
from reportlab.pdfgen import canvas
c = canvas.Canvas("hello.pdf")
c.drawString(100,750,"Welcome to Reportlab!")
c.save()
您应该最终得到一个看起来像这样的 PDF:

关于这段代码要注意的第一件事是,如果我们想要保存 PDF,我们需要为 Canvas 对象提供一个文件名。这可以是绝对路径,也可以是相对路径。在本例中,它应该在运行脚本的同一位置创建 PDF。下一个难题是拉绳方法。这将绘制文本,无论你告诉它。当使用 canvas 对象时,它从页面的左下方开始,因此对于本例,我们告诉它从左边距 100 磅,从页面底部 750 磅(1 磅= 1/72 英寸)处绘制字符串。您可以在 Canvas 构造函数中通过向 bottomup 关键字参数传递一个零来更改这个默认值。然而,我不确定如果你这样做将会发生什么,因为 Reportlab 用户指南在这个主题上并不清楚。我认为它会改变起点到左上角。上面代码的最后一部分是保存您的 PDF。
那很容易!您刚刚创建了一个非常简单的 PDF!注意,默认的画布大小是 A4,所以如果你碰巧是美国人,你可能会想把它改成 letter 大小。这在 Reportlab 中很容易做到。你只需要做以下事情:
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
canvas = canvas.Canvas('myfile.pdf', pagesize=letter)
width, height = letter
获取宽度和高度的主要原因是,您可以使用它们进行计算,以决定何时添加分页符或帮助定义边距。让我们快速看一下 Canvas 对象的构造函数,看看我们还有哪些其他选项:
def __init__(self,filename,
pagesize=letter,
bottomup = 1,
pageCompression=0,
encoding=rl_config.defaultEncoding,
verbosity=0
encrypt=None):
以上内容直接摘自 Reportlab 用户指南,第 11 页。如果你想了解全部细节,你可以阅读他们指南中的其他选项。
现在让我们做一些稍微复杂和有用的事情。
一点形式,一点功能

在本例中,我们将创建一个部分可打印的表单。据我所知,Reportlab 不支持几年前添加到 Adobe 产品中的可填充表单。无论如何,让我们来看看一些代码!
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
canvas = canvas.Canvas("form.pdf", pagesize=letter)
canvas.setLineWidth(.3)
canvas.setFont('Helvetica', 12)
canvas.drawString(30,750,'OFFICIAL COMMUNIQUE')
canvas.drawString(30,735,'OF ACME INDUSTRIES')
canvas.drawString(500,750,"12/12/2010")
canvas.line(480,747,580,747)
canvas.drawString(275,725,'AMOUNT OWED:')
canvas.drawString(500,725,"$1,000.00")
canvas.line(378,723,580,723)
canvas.drawString(30,703,'RECEIVED BY:')
canvas.line(120,700,580,700)
canvas.drawString(120,703,"JOHN DOE")
canvas.save()
这是基于我在工作中创建的实际收据。这个例子和上一个例子的主要区别是 canvas.line 代码。通过传递两个 X/Y 对,您可以使用它在文档上画线。我已经用这个功能创建了网格,尽管它很乏味。这段代码中其他有趣的地方包括 setLineWidth(.3)命令,它告诉 Reportlab 线条应该有多粗或多细;以及 setFont('Helvetica ',12)命令,它允许我们指定特定的字体和磅值。
我们的下一个例子将建立在我们到目前为止所学的基础上,但是也向我们介绍了“流动”的概念。
随波逐流

如果你从事广告或任何与格式信函有关的工作,那么 Reportlab 是你的一个很好的补充。我们用它来为有过期停车罚单的人创建套用信函。以下示例基于我为该应用程序编写的一些代码,尽管这封信有很大不同。(注意,如果没有 Python 图像库,下面的代码将无法运行)
import time
from reportlab.lib.enums import TA_JUSTIFY
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.lib.units import inch
doc = SimpleDocTemplate("form_letter.pdf",pagesize=letter,
rightMargin=72,leftMargin=72,
topMargin=72,bottomMargin=18)
Story=[]
logo = "python_logo.png"
magName = "Pythonista"
issueNum = 12
subPrice = "99.00"
limitedDate = "03/05/2010"
freeGift = "tin foil hat"
formatted_time = time.ctime()
full_name = "Mike Driscoll"
address_parts = ["411 State St.", "Marshalltown, IA 50158"]
im = Image(logo, 2*inch, 2*inch)
Story.append(im)
styles=getSampleStyleSheet()
styles.add(ParagraphStyle(name='Justify', alignment=TA_JUSTIFY))
ptext = '%s' % formatted_time
Story.append(Paragraph(ptext, styles["Normal"]))
Story.append(Spacer(1, 12))
# Create return address
ptext = '%s' % full_name
Story.append(Paragraph(ptext, styles["Normal"]))
for part in address_parts:
ptext = '%s' % part.strip()
Story.append(Paragraph(ptext, styles["Normal"]))
Story.append(Spacer(1, 12))
ptext = 'Dear %s:' % full_name.split()[0].strip()
Story.append(Paragraph(ptext, styles["Normal"]))
Story.append(Spacer(1, 12))
ptext = 'We would like to welcome you to our subscriber base for %s Magazine! \
You will receive %s issues at the excellent introductory price of $%s. Please respond by\
%s to start receiving your subscription and get the following free gift: %s.' % (magName,
issueNum,
subPrice,
limitedDate,
freeGift)
Story.append(Paragraph(ptext, styles["Justify"]))
Story.append(Spacer(1, 12))
ptext = 'Thank you very much and we look forward to serving you.'
Story.append(Paragraph(ptext, styles["Justify"]))
Story.append(Spacer(1, 12))
ptext = 'Sincerely,'
Story.append(Paragraph(ptext, styles["Normal"]))
Story.append(Spacer(1, 48))
ptext = 'Ima Sucker'
Story.append(Paragraph(ptext, styles["Normal"]))
Story.append(Spacer(1, 12))
doc.build(Story)
这比我们之前的例子包含的代码要多得多。我们需要慢慢看一遍,以了解正在发生的一切。当你准备好了,就继续读。
我们需要了解的第一部分是新的导入:
from reportlab.lib.enums import TA_JUSTIFY
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.lib.units import inch
从 enums 中,我们导入“TA_JUSTIFY ”,这允许我们的字符串具有对齐的格式。我们可以导入许多其他的常量,让我们可以左右对齐文本,还可以做其他有趣的事情。接下来是 platypus(代表使用脚本的页面布局和排版)模块。它包含了很多模块,但可能其中最重要的是可流动的,比如段落。一个流动者通常有以下能力:缠绕,绘制,有时分割。它们用来使在多页上写段落、表格和其他结构变得更容易。
SimpleDocTemplate 类允许我们在一个地方为文档设置边距、页面大小、文件名和一系列其他设置。间隔符适用于添加一行空格,如段落分隔符。Image 类利用 Python 图像库在 PDF 中轻松插入和操作图像。
getSampleStyleSheet 获得了一组我们可以在 PDF 中使用的默认样式。在这个例子中,ParagraphStyle 用于设置段落的文本对齐方式,但是它可以做更多的事情(参见用户指南第 67 页)。最后,英寸是一个测量单位,有助于在 PDF 上定位项目。你可以在我们放置 logo: Image(logo,2inch,2inch)的地方看到这一点。这意味着徽标将离顶部两英寸,离左侧两英寸。
我不记得 Reportlab 的示例使用故事列表的原因,但这也是我们在这里要做的。基本上,你可以创建一行文本、一个表格、一幅图片或者其他任何东西,然后把它添加到故事列表中。你会在整个例子中看到。我们第一次使用它是在添加图像的时候。在我们看下一个实例之前,我们需要看看如何向 styles 对象添加样式:
styles.add(ParagraphStyle(name='Justify', alignment=TA_JUSTIFY))
这一点很重要,因为您可以使用样式列表将各种段落对齐设置(以及更多)应用到文档中的文本。在上面的代码中,我们创建了一个名为“Justify”的 ParagraphStyle。它所做的只是证明我们的文本。在本文后面你会看到一个例子。现在,让我们看一个简单的例子:
ptext = '%s' % formatted_time
Story.append(Paragraph(ptext, styles["Normal"]))
对于我们的第一行文本,我们使用段落类。如您所见,Paragraph 类接受一些类似 HTML 的标签。在这种情况下,我们将字体的磅值设置为 12,并使用正常样式(除其他外,它是左对齐的)。这个例子的其余部分基本相同,只是在这里和那里加入了间隔。最后,我们调用 doc.build 来创建文档。
包扎
现在您已经了解了使用 Reportlab 在 Python 中创建 pdf 的基础知识。我们甚至还没有触及 Reportlab 的皮毛。一些例子包括表格、图表、分页、彩色套印、超链接、图形等等。我强烈建议您下载该模块及其用户指南,并尝试一下!
延伸阅读
Python 的 itertools 库之旅
原文:https://www.blog.pythonlibrary.org/2021/12/07/a-tour-of-pythons-itertools-library/
Python 为创建自己的迭代器提供了一个很好的模块。我所指的模块是 itertools 。itertools 提供的工具速度快,内存效率高。您将能够利用这些构建块来创建您自己的专用迭代器,这些迭代器可用于高效的循环。
在本文中,您将会看到每个构建块的示例,这样到最后您就会理解如何在自己的代码库中使用它们。
让我们从看一些无限迭代器开始吧!
无限迭代器
itertools 包附带了三个迭代器,可以无限迭代。这意味着当你使用它们的时候,你需要
理解你最终将需要脱离这些迭代器,否则你将会有一个无限循环。
例如,这对于生成数字或在未知长度的迭代上循环很有用。让我们开始了解这些有趣的项目吧!
计数(开始=0,步进=1)
count 迭代器将从您作为起始参数传入的数字开始返回等距值。Count 也接受一个步长参数。
让我们看一个简单的例子:
>>> from itertools import count
>>> for i in count(10):
... if i > 20:
... break
... else:
... print(i)
...
10
11
12
13
14
15
16
17
18
19
20
在这里,您从 itertools 导入计数,并为循环创建一个。您添加了一个条件检查,如果迭代器超过 20,它将中断循环,否则,它将打印出您在迭代器中的位置。您会注意到输出从 10 开始,因为这是您传递来作为起始值计数的值。
限制这个无限迭代器输出的另一种方法是使用来自 itertools 的另一个名为 islice 的子模块。
方法如下:
>>> from itertools import islice
>>> for i in islice(count(10), 5):
... print(i)
...
10
11
12
13
14
在本例中,您导入了 islice 并循环遍历 count ,从 10 开始,在 5 个项目后结束。你可能已经猜到了, islice 的第二个参数是何时停止迭代。但这并不意味着“当我到达数字 5 时停止”。相反,它意味着“当你达到五次迭代时停止”。
周期(可迭代)
itertools 中的循环迭代器允许你创建一个迭代器,它将无限循环遍历一系列值。让我们给它传递一个 3 个字母的字符串,看看会发生什么:
>>> from itertools import cycle
>>> count = 0
>>> for item in cycle('XYZ'):
... if count > 7:
... break
... print(item)
... count += 1
...
X
Y
Z
X
Y
Z
X
在这里,您为循环创建了一个来循环三个字母:XYZ 的无限循环。当然,您不希望实际上永远循环下去,所以您添加了一个简单的计数器来打破循环。
您还可以使用 Python 的 next 内置函数来迭代您用 itertools 创建的迭代器:
>>> polys = ['triangle', 'square', 'pentagon', 'rectangle']
>>> iterator = cycle(polys)
>>> next(iterator)
'triangle'
>>> next(iterator)
'square'
>>> next(iterator)
'pentagon'
>>> next(iterator)
'rectangle'
>>> next(iterator)
'triangle'
>>> next(iterator)
'square'
在上面的代码中,您创建了一个简单的多边形列表,并将它们传递给循环。你把我们新的迭代器保存到一个变量中,然后把这个变量传递给下一个函数。每次调用 next,它都会返回迭代器中的下一个值。因为这个迭代器是无限的,所以你可以整天调用 next,永远不会用完所有的条目。
重复(对象)
repeat 迭代器将一次又一次地返回一个对象,除非你设置它的 times 参数。它与 cycle 非常相似,只是它不重复循环一组值。
让我们看一个简单的例子:
>>> from itertools import repeat
>>> repeat(5, 5)
repeat(5, 5)
>>> iterator = repeat(5, 5)
>>> next(iterator)
5
>>> next(iterator)
5
>>> next(iterator)
5
>>> next(iterator)
5
>>> next(iterator)
5
>>> next(iterator)
Traceback (most recent call last):
Python Shell, prompt 21, line 1
builtins.StopIteration:
这里你导入重复并告诉它重复数字 5 五次。然后在我们的新迭代器上调用 next 六次,看看它是否工作正常。当您运行这段代码时,您会看到 StopIteration 被抛出,因为您已经用完了迭代器中的值。
终止的迭代器
用 itertools 创建的大多数迭代器都不是无限的。在本节中,您将学习 itertools 的有限迭代器。为了获得可读的输出,您将使用 Python 内置的列表类型。
如果你不使用列表,那么你只会得到一个 itertools 对象的打印结果。
累积(可迭代)
accumulate 迭代器将返回累加和或一个双参数函数的累加结果,您可以传递给 accumulate。accumulate 的默认值是加法,所以让我们快速尝试一下:
>>> from itertools import accumulate
>>> list(accumulate(range(10)))
[0, 1, 3, 6, 10, 15, 21, 28, 36, 45]
这里我们导入 accumulate 并传递给它一个范围为 0-9 的 10 个数字。它依次将它们相加,因此第一个是 0,第二个是 0+1,第三个是 1+2,依此类推。
现在让我们导入操作符模块,并将其添加到 mix 中:
>>> import operator
>>> list(accumulate(range(1, 5), operator.mul))
[1, 2, 6, 24]
这个函数接受两个要相乘的参数。因此,对于每次迭代,它都是乘法而不是加法(1x1=1,1x2=2,2x3=6,等等)。
accumulate 的文档显示了一些其他有趣的例子,如贷款的分期偿还或混乱的递归关系。你一定要看看这些例子,因为它们非常值得你花时间去做。
链(*iterables)
链迭代器将接受一系列可迭代对象,并基本上将它们展平成一个长的可迭代对象。事实上,我最近正在帮助的一个项目需要它的帮助。基本上,您有一个已经包含一些项目的列表和两个想要添加到原始列表中的其他列表,但是您只想将每个列表中的项目添加到原始列表中,而不是创建一个列表列表。
最初我尝试这样做:
>>> my_list = ['foo', 'bar']
>>> numbers = list(range(5))
>>> cmd = ['ls', '/some/dir']
>>> my_list.extend(cmd, numbers)
>>> my_list
['foo', 'bar', ['ls', '/some/dir'], [0, 1, 2, 3, 4]]
嗯,这并不完全是我想要的方式。 itertools 模块提供了一种更加优雅的方式,使用链将这些列表整合成一个列表:
>>> from itertools import chain
>>> my_list = list(chain(['foo', 'bar'], cmd, numbers))
>>> my_list
['foo', 'bar', 'ls', '/some/dir', 0, 1, 2, 3, 4]
我的更敏锐的读者可能会注意到,实际上有另一种方法可以在不使用 itertools 的情况下完成同样的事情。您可以这样做来获得相同的效果:
>>> my_list = ['foo', 'bar']
>>> my_list += cmd + numbers
>>> my_list
['foo', 'bar', 'ls', '/some/dir', 0, 1, 2, 3, 4]
这两种方法当然都是有效的,在我了解 chain 之前,我可能会走这条路,但我认为在这种特殊情况下, chain 是更优雅、更容易理解的解决方案。
chain.from_iterable(iterable)
你也可以使用一种叫做的链的方法 from_iterable 。这种方法与直接使用链条略有不同。不是传入一系列的 iterables,而是传入一个嵌套的 list。
让我们来看看:
>>> from itertools import chain
>>> numbers = list(range(5))
>>> cmd = ['ls', '/some/dir']
>>> chain.from_iterable(cmd, numbers)
Traceback (most recent call last):
Python Shell, prompt 66, line 1
builtins.TypeError: from_iterable() takes exactly one argument (2 given)
>>> list(chain.from_iterable([cmd, numbers]))
['ls', '/some/dir', 0, 1, 2, 3, 4]
在这里,您像以前一样导入链。您尝试传入我们的两个列表,但最终得到的是一个 TypeError !为了解决这个问题,您稍微修改一下您的调用,将 cmd 和 numbers 放在一个列表中,然后将这个嵌套列表传递给 from_iterable 。这是一个微妙的区别,但仍然易于使用!
压缩(数据,选择器)
compress 子模块对于过滤第一个 iterable 和第二个 iterable 非常有用。这是通过使第二个 iterable 成为一个布尔列表(或者等同于同一事物的 1 和 0)来实现的。
它是这样工作的:
>>> from itertools import compress
>>> letters = 'ABCDEFG'
>>> bools = [True, False, True, True, False]
>>> list(compress(letters, bools))
['A', 'C', 'D']
在本例中,您有一组七个字母和一个五个布尔的列表。然后将它们传递给压缩函数。compress 函数将遍历每个相应的 iterable,并对照第二个 iterable 检查第一个 iterable。如果第二个有匹配的 True,那么它将被保留。如果它是假的,那么这个项目将被删除。
因此,如果你研究上面的例子,你会注意到在第一、第三和第四个位置上有一个 True,分别对应于 A、C 和 d。
dropwhile(谓词,可迭代)
itertools 中有一个简洁的小迭代器,叫做 dropwhile 。这个有趣的小迭代器将删除元素,只要过滤标准是真。因此,在谓词变为 False 之前,您不会看到这个迭代器的任何输出。这可能会使启动时间变得很长,因此需要注意这一点。
让我们看看 Python 文档中的一个例子:
>>> from itertools import dropwhile
>>> list(dropwhile(lambda x: x<5, [1,4,6,4,1]))
[6, 4, 1]
在这里,您导入 dropwhile ,然后传递给它一个简单的 lambda 语句。如果 x 小于 5,该函数将返回真值。否则将返回假。 dropwhile 函数将遍历列表并将每个元素传递给 lambda。如果 lambda 返回 True,那么该值将被删除。一旦你到达数字 6,lambda 返回 False ,你保留数字 6 和它后面的所有值。
当我学习新东西时,我发现在λ上使用常规函数很有用。所以让我们颠倒一下,创建一个函数,如果数字大于 5,返回 True 。
>>> from itertools import dropwhile
>>> def greater_than_five(x):
... return x > 5
...
>>> list(dropwhile(greater_than_five, [6, 7, 8, 9, 1, 2, 3, 10]))
[1, 2, 3, 10]
这里您在 Python 的解释器中创建了一个简单的函数。这个函数是你的谓词或过滤器。如果你传递给它的值是真的,那么它们将被丢弃。一旦您找到一个小于 5 的值,那么在该值之后的所有值(包括该值)都将被保留,您可以在上面的示例中看到这一点。
filterfalse(谓词,可迭代)
来自 itertools 的 filterfalse 函数与 dropwhile 非常相似。然而, filterfalse 将只返回那些被评估为 false 的值,而不是删除与 True 匹配的值。
让我们使用上一节中的函数来说明:
>>> from itertools import filterfalse
>>> def greater_than_five(x):
... return x > 5
...
>>> list(filterfalse(greater_than_five, [6, 7, 8, 9, 1, 2, 3, 10]))
[1, 2, 3]
在这里,你传递给你的函数和一个整数列表。如果整数小于 5,则保留该整数。否则,就扔掉。你会注意到我们的结果只有 1,2 和 3。与 dropwhile 不同, filterfalse 将根据我们的谓词检查每一个值。
groupby(iterable,key=None)
groupby 迭代器将从 iterable 中返回连续的键和组。如果没有例子,你很难理解这一点。所以我们来看一个吧!
将以下代码放入您的解释器或保存在文件中:
from itertools import groupby
vehicles = [('Ford', 'Taurus'), ('Dodge', 'Durango'),
('Chevrolet', 'Cobalt'), ('Ford', 'F150'),
('Dodge', 'Charger'), ('Ford', 'GT')]
sorted_vehicles = sorted(vehicles)
for key, group in groupby(sorted_vehicles, lambda make: make[0]):
for make, model in group:
print('{model} is made by {make}'.format(model=model,
make=make))
print ("**** END OF GROUP ***\n")
在这里,您导入 groupby ,然后创建一个元组列表。然后你对数据进行排序,这样当你输出它时更有意义,它也让 groupby 实际上正确地对项目进行分组。接下来,你实际上循环遍历由 groupby 返回的迭代器,它给你键和组。最后,循环遍历该组并打印出其中的内容。
如果您运行这段代码,您应该会看到类似这样的内容:
Cobalt is made by Chevrolet
**** END OF GROUP ***
Charger is made by Dodge
Durango is made by Dodge
**** END OF GROUP ***
F150 is made by Ford
GT is made by Ford
Taurus is made by Ford
**** END OF GROUP ***
只是为了好玩,试着修改代码,让你传入 vehicles 而不是 sorted_vehicles。如果您这样做,您将很快了解为什么应该在通过 groupby 运行数据之前对其进行排序。
islice(可迭代、启动、停止)
你实际上早在计数部分就已经知道了。但是在这里你会看得更深入一点。islice 是一个迭代器,它从 iterable 中返回选定的元素。这是一种不透明的说法。
基本上 islice 所做的是通过 iterable(你迭代的对象)的索引获取一个切片,并以迭代器的形式返回所选择的项目。实际上, islice 有两个实现。有 itertools.islice(iterable,stop) 还有更接近常规 Python 切片的 islice 版本: islice(iterable,start,stop[,step]) 。
让我们看看第一个版本,看看它是如何工作的:
>>> from itertools import islice
>>> iterator = islice('123456', 4)
>>> next(iterator)
'1'
>>> next(iterator)
'2'
>>> next(iterator)
'3'
>>> next(iterator)
'4'
>>> next(iterator)
Traceback (most recent call last):
Python Shell, prompt 15, line 1
builtins.StopIteration:
在上面的代码中,您将一个由六个字符组成的字符串连同数字 4(即停止参数)一起传递给了 islice 。这意味着 islice 返回的迭代器将包含字符串中的前 4 项。您可以通过在迭代器上调用 next 四次来验证这一点,就像上面所做的那样。Python 足够聪明,知道如果只有两个参数传递给 islice ,那么第二个参数就是 stop 参数。
让我们试着给它三个参数,来证明你可以给它一个开始参数和一个停止参数。来自 itertools 的计数工具可以帮助我们说明这个概念:
>>> from itertools import islice
>>> from itertools import count
>>> for i in islice(count(), 3, 15):
... print(i)
...
3
4
5
6
7
8
9
10
11
12
13
14
在这里,您只需调用 count 并告诉 islice 从数字 3 开始,到 15 时停止。这就像做切片一样,只不过你是对迭代器做切片,然后返回一个新的迭代器!
星图(函数,可迭代)
工具将创建一个迭代器,它可以使用提供的函数和 iterable 进行计算。正如文档中提到的,“T2 地图()和 T4 星图()之间的区别类似于 T6 函数(a,b) 和 T8 函数(*c) ”
让我们看一个简单的例子:
>>> from itertools import starmap
>>> def add(a, b):
... return a+b
...
>>> for item in starmap(add, [(2,3), (4,5)]):
... print(item)
...
5
9
这里您创建了一个简单的加法函数,它接受两个参数。接下来,创建一个 for 循环,调用 starmap ,将函数作为第一个参数,并为 iterable 提供一个元组列表。然后, starmap 函数会将每个元组元素传递到函数中,并返回结果的迭代器,结果将打印出来。
takewhile(谓词,可迭代)
takewhile 函数基本上与您之前看到的 dropwhile 迭代器相反。 takewhile 将创建一个迭代器,只要我们的谓词或过滤器为真,它就从 iterable 返回元素。
让我们尝试一个简单的例子来看看它是如何工作的:
>>> from itertools import takewhile
>>> list(takewhile(lambda x: x<5, [1,4,6,4,1]))
[1, 4]
在这里,您使用一个λ函数和一个链表来运行 takewhile 。输出只是 iterable 的前两个整数。原因是 1 和 4 都小于 5,但 6 更大。因此,一旦 takewhile 看到 6,条件就变为假,它将忽略 iterable 中的其余项。
三通(可迭代,n=2)
函数将从一个 iterable 创建 n 个迭代器。这意味着你可以从一个 iterable 创建多个迭代器。让我们来看一些解释其工作原理的代码:
>>> from itertools import tee
>>> data = 'ABCDE'
>>> iter1, iter2 = tee(data)
>>> for item in iter1:
... print(item)
...
A
B
C
D
E
>>> for item in iter2:
... print(item)
...
A
B
C
D
E
在这里,您创建了一个 5 个字母的字符串,并将其传递给 tee。因为 tee 默认为 2,所以使用多重赋值来获取从 tee 返回的两个迭代器。最后,循环遍历每个迭代器并打印出它们的内容。如你所见,它们的内容是一样的。
zip_longest(*iterables,fillvalue=None)
zip_longest 迭代器可以用来将两个可迭代对象压缩在一起。如果可重复项的长度不同,那么你也可以传入一个填充值。让我们看一个基于这个函数的文档的愚蠢的例子:
>>> from itertools import zip_longest
>>> for item in zip_longest('ABCD', 'xy', fillvalue='BLANK'):
... print (item)
...
('A', 'x')
('B', 'y')
('C', 'BLANK')
('D', 'BLANK')
在这段代码中,您导入 zip_longest,然后向它传递两个字符串以压缩在一起。您可以看到第一个字符串有 4 个字符长,而第二个只有 2 个字符长。您还将填充值设置为“空白”。当您循环并打印出来时,您会看到返回了元组。
前两个元组分别是每个字符串的第一个和第二个字母的组合。最后两个插入了您的填充值。
应该注意的是,如果传递给 zip_longest 的 iterable 有可能是无限的,那么你应该用类似于 islice 的东西来包装这个函数,以限制调用的次数。
组合生成器
itertools 库包含四个迭代器,可用于创建数据的组合和排列。在本节中,您将会看到这些有趣的迭代器。
组合(iterable,r)
如果您需要创建组合,Python 已经为您提供了 itertools.combinations 。组合允许你做的是从一个一定长度的可迭代对象创建一个迭代器。
让我们来看看:
>>> from itertools import combinations
>>> list(combinations('WXYZ', 2))
[('W', 'X'), ('W', 'Y'), ('W', 'Z'), ('X', 'Y'), ('X', 'Z'), ('Y', 'Z')]
当您运行它时,您可能会注意到组合返回元组。为了使这个输出更具可读性,让我们循环遍历迭代器,并将元组连接成一个字符串:
>>> for item in combinations('WXYZ', 2):
... print(''.join(item))
...
WX
WY
WZ
XY
XZ
YZ
现在更容易看到各种组合了。注意,combinations 函数的组合是按字典顺序排序的,所以如果 iterable 排序了,那么组合元组也会排序。同样值得注意的是,如果所有输入元素都是唯一的,组合不会在组合中产生重复值。
combinations with _ replacement(iterable,r)
combinations _ with _ replacement迭代器与组合非常相似。唯一的区别是,它实际上会创建元素重复的组合。让我们用上一节中的一个例子来说明:
>>> from itertools import combinations_with_replacement
>>> for item in combinations_with_replacement('WXYZ', 2):
... print(''.join(item))
...
WW
WX
WY
WZ
XX
XY
XZ
YY
YZ
ZZ
如您所见,现在我们的输出中有四个新条目:WW、XX、YY 和 ZZ。
产品(*iterables,repeat=1)
itertools 包有一个简洁的小函数,可以从一系列输入的可迭代对象中创建笛卡尔乘积。是的,那个功能是产品。
让我们看看它是如何工作的!
>>> from itertools import product
>>> arrays = [(-1,1), (-3,3), (-5,5)]
>>> cp = list(product(*arrays))
>>> cp
[(-1, -3, -5),
(-1, -3, 5),
(-1, 3, -5),
(-1, 3, 5),
(1, -3, -5),
(1, -3, 5),
(1, 3, -5),
(1, 3, 5)]
在这里,您导入产品,然后设置一个元组列表,并将其分配给变量数组。接下来,使用这些数组调用 product。你会注意到你用*数组来调用它。这将导致列表被“展开”或按顺序应用于产品功能。这意味着你要传入三个参数而不是一个。如果你愿意的话,试着在数组前面加上星号来调用它,看看会发生什么。
排列
itertools 的置换子模块将从你给定的 iterable 返回连续 r 长度的元素置换。与组合函数非常相似,排列是按照字典排序顺序发出的。
让我们来看看:
>>> from itertools import permutations
>>> for item in permutations('WXYZ', 2):
... print(''.join(item))
...
WX
WY
WZ
XW
XY
XZ
YW
YX
YZ
ZW
ZX
ZY
您会注意到输出比组合的输出要长得多。当您使用置换时,它将遍历字符串的所有置换,但是如果输入元素是唯一的,它不会重复值。
包扎
itertools 是一套非常通用的创建迭代器的工具。您可以使用它们来创建您自己的迭代器,无论是单独使用还是相互组合使用。Python 文档中有很多很棒的例子,您可以研究这些例子来了解如何使用这个有价值的库。
wxPython Sizers 教程
原文:https://www.blog.pythonlibrary.org/2008/05/18/a-wxpython-sizers-tutorial/
我自愿在 wxPython 中写一些关于常见 GUI 布局的教程。下面的例子来自 Malcolm, wxPython 用户组的成员之一。
示例:简单的数据收集表单,其中图标和文本沿冒号的纵轴右对齐。
icon - title separator icon - text: - single line input control icon - text: - single line input control icon - text: - single line input control icon - text: - multi-line text/list control that stretches vertically separator ok - cancel
首先,我们将创建一个 wx。框架来包含所有的部件,我们将创建一个 wx。面板来“修饰”框架,使其在所有平台上看起来都正常。
import wx
class MyForm(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, wx.ID_ANY, title='My Form')
# Add a panel so it looks correct on all platforms
self.panel = wx.Panel(self, wx.ID_ANY)
if __name__ == '__main__':
app = wx.PySimpleApp()
frame = MyForm().Show()
app.MainLoop()
下一步是弄清楚如何创建一个图标。我将使用 wx。因为它提供了通用的跨平台位图/图标,我将把位图放在一个 wx 中。StaticBitmap 小工具。查看下面的示例代码:
bmp = wx。ArtProvider.GetBitmap(wx。艺术 _ 信息,wx。ART_OTHER,(16,16))
titleIco = wxStaticBitmap(self.panel,wx。ID_ANY,bmp)
我们来看看这里发生了什么。GetBitmap 的第一个参数是 art id,第二个是客户端(比如 wx。ART_TOOLBAR 或 wx。ART_MENU)第三个是图标的大小。StaticBitmap 的参数几乎是不言自明的。您也可以在 wxPython 演示中看到两者的运行。
接下来,我们将把所有的代码放在一起,并把它们放在 sizers 中。我将只在这个例子中使用 BoxSizer。
import wx
class MyForm(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, wx.ID_ANY, title='My Form')
# Add a panel so it looks correct on all platforms
self.panel = wx.Panel(self, wx.ID_ANY)
bmp = wx.ArtProvider.GetBitmap(wx.ART_INFORMATION, wx.ART_OTHER, (16, 16))
titleIco = wx.StaticBitmap(self.panel, wx.ID_ANY, bmp)
title = wx.StaticText(self.panel, wx.ID_ANY, 'My Title')
bmp = wx.ArtProvider.GetBitmap(wx.ART_TIP, wx.ART_OTHER, (16, 16))
inputOneIco = wx.StaticBitmap(self.panel, wx.ID_ANY, bmp)
labelOne = wx.StaticText(self.panel, wx.ID_ANY, 'Input 1')
inputTxtOne = wx.TextCtrl(self.panel, wx.ID_ANY, '')
inputTwoIco = wx.StaticBitmap(self.panel, wx.ID_ANY, bmp)
labelTwo = wx.StaticText(self.panel, wx.ID_ANY, 'Input 2')
inputTxtTwo = wx.TextCtrl(self.panel, wx.ID_ANY, '')
inputThreeIco = wx.StaticBitmap(self.panel, wx.ID_ANY, bmp)
labelThree = wx.StaticText(self.panel, wx.ID_ANY, 'Input 3')
inputTxtThree = wx.TextCtrl(self.panel, wx.ID_ANY, '')
inputFourIco = wx.StaticBitmap(self.panel, wx.ID_ANY, bmp)
labelFour = wx.StaticText(self.panel, wx.ID_ANY, 'Input 4')
inputTxtFour = wx.TextCtrl(self.panel, wx.ID_ANY, '')
okBtn = wx.Button(self.panel, wx.ID_ANY, 'OK')
cancelBtn = wx.Button(self.panel, wx.ID_ANY, 'Cancel')
self.Bind(wx.EVT_BUTTON, self.onOK, okBtn)
self.Bind(wx.EVT_BUTTON, self.onCancel, cancelBtn)
topSizer = wx.BoxSizer(wx.VERTICAL)
titleSizer = wx.BoxSizer(wx.HORIZONTAL)
inputOneSizer = wx.BoxSizer(wx.HORIZONTAL)
inputTwoSizer = wx.BoxSizer(wx.HORIZONTAL)
inputThreeSizer = wx.BoxSizer(wx.HORIZONTAL)
inputFourSizer = wx.BoxSizer(wx.HORIZONTAL)
btnSizer = wx.BoxSizer(wx.HORIZONTAL)
titleSizer.Add(titleIco, 0, wx.ALL, 5)
titleSizer.Add(title, 0, wx.ALL, 5)
inputOneSizer.Add(inputOneIco, 0, wx.ALL, 5)
inputOneSizer.Add(labelOne, 0, wx.ALL, 5)
inputOneSizer.Add(inputTxtOne, 1, wx.ALL|wx.EXPAND, 5)
inputTwoSizer.Add(inputTwoIco, 0, wx.ALL, 5)
inputTwoSizer.Add(labelTwo, 0, wx.ALL, 5)
inputTwoSizer.Add(inputTxtTwo, 1, wx.ALL|wx.EXPAND, 5)
inputThreeSizer.Add(inputThreeIco, 0, wx.ALL, 5)
inputThreeSizer.Add(labelThree, 0, wx.ALL, 5)
inputThreeSizer.Add(inputTxtThree, 1, wx.ALL|wx.EXPAND, 5)
inputFourSizer.Add(inputFourIco, 0, wx.ALL, 5)
inputFourSizer.Add(labelFour, 0, wx.ALL, 5)
inputFourSizer.Add(inputTxtFour, 1, wx.ALL|wx.EXPAND, 5)
btnSizer.Add(okBtn, 0, wx.ALL, 5)
btnSizer.Add(cancelBtn, 0, wx.ALL, 5)
topSizer.Add(titleSizer, 0, wx.CENTER)
topSizer.Add(wx.StaticLine(self.panel), 0, wx.ALL|wx.EXPAND, 5)
topSizer.Add(inputOneSizer, 0, wx.ALL|wx.EXPAND, 5)
topSizer.Add(inputTwoSizer, 0, wx.ALL|wx.EXPAND, 5)
topSizer.Add(inputThreeSizer, 0, wx.ALL|wx.EXPAND, 5)
topSizer.Add(inputFourSizer, 0, wx.ALL|wx.EXPAND, 5)
topSizer.Add(wx.StaticLine(self.panel), 0, wx.ALL|wx.EXPAND, 5)
topSizer.Add(btnSizer, 0, wx.ALL|wx.CENTER, 5)
self.panel.SetSizer(topSizer)
topSizer.Fit(self)
def onOK(self, event):
# Do something
print 'onOK handler'
def onCancel(self, event):
self.closeProgram()
def closeProgram(self):
self.Close()
# Run the program
if __name__ == '__main__':
app = wx.PySimpleApp()
frame = MyForm().Show()
app.MainLoop()
如果您运行这段代码,您应该会看到类似这样的内容:

那么,这些分级器到底是如何工作的呢?让我们来看看。这是基本风格:
mySizer。添加(窗口、比例、标志、边框、用户数据)
第一个参数可以是窗口/小部件、sizer 或 size。第二个是比例,它允许开发人员指定当父窗口调整大小时一个项目拉伸多少。第三个是控制对齐、边框和调整大小的一个或一系列标志。第四个参数是边框,它是已经添加的小部件周围空白的像素数量。最后一个是 userData,我从来不用。然而,根据“wxPython in Action”一书的说法,它被用来为 sizer 的算法传递额外的数据。
我使用的三个位标志是 wx。全部,wx。展开和 wx。中心:wx。ALL 用于在小工具的所有边上放置 x 个像素;wx。EXPAND 告诉 sizer 当父窗口被拉伸时允许小部件扩展或拉伸;wx。居中将使小部件在小部件内水平和垂直居中。
如您所见,我为任何两个或更多需要水平对齐的小部件创建了一个单独的 BoxSizer。我还创建了一个垂直方向的主 BoxSizer,以便我可以在其中“堆叠”其他 Sizer。我也卡在了两个 wx 里。StaticLine 小部件在适当的位置作为分隔符。
最后,我使用 SetSizer()方法将面板连接到 topSizer。我还决定使用 sizer 的 Fit()方法来告诉 sizer 根据窗口(即框架)计算大小。您还可以通过使用 SetMinSize()方法设置包含小部件的最小大小来设置它。
现在您已经学习了使用 BoxSizers 设置表单的基本知识。
下载: wxPythonSizer 教程
延伸阅读:
将 EXIF 浏览器添加到图像浏览器
原文:https://www.blog.pythonlibrary.org/2010/04/10/adding-an-exif-viewer-to-the-image-viewer/
前几天,我们创建了一个简单的图像查看器。今天,我们将创建一个辅助对话框来显示图像的 EXIF 数据,如果有的话。我们将这样做,当我们使用酷的发布模块改变图片时,这个窗口将会更新。对于这个应用程序,我们将使用 wxPython 中包含的版本,但是也可以随意使用独立版本。
展示 EXIF:简单的方式

首先,我们将创建一个非常简单的新框架,用于显示图像的 EXIF 数据。它只有 11 条数据,包括文件名和文件大小。一旦我们了解了代码的工作原理,我们将添加显示从 EXIF 解析器返回的所有数据的功能。我们开始吧!
import os
import wx
from wx.lib.pubsub import Publisher
pil_flag = False
pyexif_flag = False
try:
import exif
pyexif_flag = True
except ImportError:
try:
from PIL import Image
from PIL.ExifTags import TAGS
pil_flag = True
except ImportError:
pass
#----------------------------------------------------------------------
def getExifData(photo):
"""
Extracts the EXIF information from the provided photo
"""
if pyexif_flag:
exif_data = exif.parse(photo)
elif pil_flag:
exif_data = {}
i = Image.open(photo)
info = i._getexif()
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
exif_data[decoded] = value
else:
raise Exception("PyExif and PIL not found!")
return exif_data
#----------------------------------------------------------------------
def getPhotoSize(photo):
"""
"""
photo_size = os.path.getsize(photo)
photo_size = photo_size / 1024.0
if photo_size > 1000:
# photo is larger than 1 MB
photo_size = photo_size / 1024.0
size = "%0.2f MB" % photo_size
else:
size = "%d KB" % photo_size
return size
########################################################################
class Photo:
""""""
#----------------------------------------------------------------------
def __init__(self, photo):
"""Constructor"""
self.exif_data = getExifData(photo)
self.filename = os.path.basename(photo)
self.filesize = getPhotoSize(photo)
########################################################################
class MainPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent, photo):
"""Constructor"""
wx.Panel.__init__(self, parent)
# dict of Exif keys and static text labels
self.photo_data = {"ApertureValue":"Aperture", "DateTime":"Creation Date",
"ExifImageHeight":"Height", "ExifImageWidth":"Width",
"ExposureTime":"Exposure", "FNumber":"F-Stop",
"Flash":"Flash", "FocalLength":"Focal Length",
"ISOSpeedRatings":"ISO", "Model":"Camera Model",
"ShutterSpeedValue":"Shutter Speed"}
# TODO: Display filesize too!
self.exif_data = photo.exif_data
self.filename = photo.filename
self.filesize = photo.filesize
Publisher().subscribe(self.updatePanel, ("update"))
self.mainSizer = wx.BoxSizer(wx.VERTICAL)
self.layoutWidgets()
self.SetSizer(self.mainSizer)
#----------------------------------------------------------------------
def layoutWidgets(self):
"""
"""
ordered_widgets = ["Model", "ExifImageWidth", "ExifImageHeight",
"DateTime", "static_line",
"ApertureValue", "ExposureTime", "FNumber",
"Flash", "FocalLength", "ISOSpeedRatings",
"ShutterSpeedValue"
]
self.buildRow("Filename", self.filename, "Filename")
self.buildRow("File Size", self.filesize, "FileSize")
for key in ordered_widgets:
if key not in self.exif_data and key != "static_line":
continue
if (key != "static_line"):
self.buildRow(self.photo_data[key], self.exif_data[key], key)
else:
print "Adding staticLine"
self.mainSizer.Add(wx.StaticLine(self), 0, wx.ALL|wx.EXPAND, 5)
#----------------------------------------------------------------------
def buildRow(self, label, value, txtName):
""""""
sizer = wx.BoxSizer(wx.HORIZONTAL)
lbl = wx.StaticText(self, label=label, size=(75, -1))
txt = wx.TextCtrl(self, value=value, size=(150,-1),
style=wx.TE_READONLY, name=txtName)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
sizer.Add(txt, 0, wx.ALL, 5)
self.mainSizer.Add(sizer)
#----------------------------------------------------------------------
def updatePanel(self, msg):
""""""
photo = msg.data
self.exif_data = photo.exif_data
children = self.GetChildren()
for child in children:
if isinstance(child, wx.TextCtrl):
self.update(photo, child)
#----------------------------------------------------------------------
def update(self, photo, txtWidget):
""""""
key = txtWidget.GetName()
if key in self.exif_data:
value = self.exif_data[key]
else:
value = "No Data"
if key == "Filename":
txtWidget.SetValue(photo.filename)
elif key == "FileSize":
txtWidget.SetValue(photo.filesize)
else:
txtWidget.SetValue(value)
########################################################################
class PhotoInfo(wx.Frame):
""""""
#----------------------------------------------------------------------
def __init__(self, photo_path):
"""Constructor"""
wx.Frame.__init__(self, None, title="Image Information")
photo = Photo(photo_path)
panel = MainPanel(self, photo)
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(panel, 1, wx.EXPAND)
self.SetSizer(sizer)
sizer.Fit(self)
Publisher().subscribe(self.updateDisplay, ("update display"))
self.Show()
#----------------------------------------------------------------------
def updateDisplay(self, msg):
"""
"""
photo = msg.data
new_photo = Photo(photo)
Publisher().sendMessage(("update"), new_photo)
#----------------------------------------------------------------------
if __name__ == "__main__":
import wx.lib.inspection
app = wx.PySimpleApp()
photo = "path/to/test/photo.jpg"
frame = PhotoInfo(photo)
wx.lib.inspection.InspectionTool().Show()
app.MainLoop()
有很多代码需要检查,所以我们只讨论感兴趣的部分。首先,我们需要导入一些 Python EXIF 库。我更喜欢 pyexif,因为它很容易上手,但如果失败了,我会检查 Python 图像库(PIL)并导入它。如果您有其他喜欢的库,可以根据需要随意修改代码。一旦我们得到了想要加载的库,我们就设置一个标志,我们将在我们的 getExifData 函数中使用它。这个函数所做的就是解析传入的照片以获取其 EXIF 数据(如果有的话),然后将该数据作为一个 dict 返回。我们还有一个 getPhotoSize 函数,用来计算照片的文件大小。最后,在我们进入 wxPython 代码之前的最后一部分是 Photo 类。我们使用这个类来使照片数据的传递变得更加容易。每个照片实例将具有以下三个属性:
- exif_data
- 文件名
- filesize
当我第一次开始编写这段代码时,我试图传递一堆关于文件的数据,这变得非常烦人和混乱。这要干净得多,尽管如果我们将这些函数放在 Photo 类本身中可能会更好。不过,我将把它留给读者作为练习。
在我们的 MainPanel 类中,我们创建了一个 photo_data 字典,其中保存了可能对用户最有用的 EXIF 数据。如果你认为应该有更多的,你可以根据需要修改字典。总之,dict 的键对应于从 exif 转储中返回的一些键。这些值将成为标签。在 layoutWidgets 方法中,我们迭代 dict 的键并创建由两个小部件组成的“行”:一个标签(wx。StaticText)和一个文本控件(wx。TextCtrl)。我们使用 TextCtrls 的 name 参数的键。这在用户切换图片时更新数据时很重要。
updatePanel 和 update 方法显然是用来在用户更改主控件中的照片时更新面板的小部件。这通过我们在主面板的 init 中创建的 pubsub 接收器来实现。在这种情况下,我们实际上使用了 PhotoInfo frame 对象中的 pubsub 接收器来调用主面板的接收器。这主要是为了确保我们在正确的点上创建了一个新的照片实例,但是再看一下代码,我认为我们可以去掉框架中的第二个接收器,在面板的方法中做所有的事情。亲爱的读者,你还有一个有趣的学习项目。
显示 EXIF 数据:使用笔记本!

如果我们就此打住,就会忽略很多数据。然而,有太多的额外数据,它不太适合这种大小的对话框。一个简单的解决方案是将数据放在一个可滚动的面板上,但是我们打算用一个笔记本小部件来代替,因为很多人不喜欢滚动。当然,您可以自由地进行一次冒险,单独使用 ScrolledPanel 小部件或将其与 notebook 的想法结合使用。不过现在,让我们来看看这个复杂的野兽:
import os
import wx
from wx.lib.pubsub import Publisher
pil_flag = False
pyexif_flag = False
try:
import exif
pyexif_flag = True
except ImportError:
try:
from PIL import Image
from PIL.ExifTags import TAGS
pil_flag = True
except ImportError:
pass
#----------------------------------------------------------------------
def getExifData(photo):
"""
Extracts the EXIF information from the provided photo
"""
if pyexif_flag:
exif_data = exif.parse(photo)
elif pil_flag:
exif_data = {}
i = Image.open(photo)
info = i._getexif()
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
exif_data[decoded] = value
else:
raise Exception("PyExif and PIL not found!")
return exif_data
#----------------------------------------------------------------------
def getPhotoSize(photo):
"""
Takes a photo path and returns the size of the photo
"""
photo_size = os.path.getsize(photo)
photo_size = photo_size / 1024.0
if photo_size > 1000:
# photo is larger than 1 MB
photo_size = photo_size / 1024.0
size = "%0.2f MB" % photo_size
else:
size = "%d KB" % photo_size
return size
########################################################################
class Photo:
"""
Class to hold information about the passed in photo
"""
#----------------------------------------------------------------------
def __init__(self, photo):
"""Constructor"""
self.exif_data = getExifData(photo)
self.filename = os.path.basename(photo)
self.filesize = getPhotoSize(photo)
########################################################################
class NBPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent, photo, panelOne=False):
"""Constructor"""
wx.Panel.__init__(self, parent)
self.panelOne = panelOne
# dict of Exif keys and static text labels
self.photo_data = {"ApertureValue":"Aperture", "DateTime":"Creation Date",
"ExifImageHeight":"Height", "ExifImageWidth":"Width",
"ExposureTime":"Exposure", "FNumber":"F-Stop",
"Flash":"Flash", "FocalLength":"Focal Length",
"ISOSpeedRatings":"ISO", "Model":"Camera Model",
"ShutterSpeedValue":"Shutter Speed"}
self.exif_data = photo.exif_data
self.filename = photo.filename
self.filesize = photo.filesize
Publisher().subscribe(self.updatePanel, ("update"))
self.mainSizer = wx.BoxSizer(wx.VERTICAL)
self.layoutWidgets()
self.SetSizer(self.mainSizer)
#----------------------------------------------------------------------
def layoutWidgets(self):
"""
Create and layout the various widgets on the panel
"""
ordered_widgets = ["Model", "ExifImageWidth", "ExifImageHeight",
"DateTime", "static_line",
"ApertureValue", "ExposureTime", "FNumber",
"Flash", "FocalLength", "ISOSpeedRatings",
"ShutterSpeedValue"
]
if self.panelOne:
self.buildRow("Filename", self.filename, "Filename")
self.buildRow("File Size", self.filesize, "FileSize")
for key in ordered_widgets:
if key not in self.exif_data:
continue
if key != "static_line":
self.buildRow(self.photo_data[key], self.exif_data[key], key)
else:
keys = self.exif_data.keys()
keys.sort()
print "keys for second panel:"
print keys
for key in keys:
if key not in self.exif_data:
continue
if key not in ordered_widgets and "Tag" not in key:
self.buildRow(key, self.exif_data[key], key)
#----------------------------------------------------------------------
def buildRow(self, label, value, txtName):
"""
Build a two widget row and add it to the main sizer
"""
sizer = wx.BoxSizer(wx.HORIZONTAL)
if self.panelOne:
lbl = wx.StaticText(self, label=label, size=(75, -1))
else:
lbl = wx.StaticText(self, label=label, size=(150, -1))
txt = wx.TextCtrl(self, value=value, size=(150,-1),
style=wx.TE_READONLY, name=txtName)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
sizer.Add(txt, 0, wx.ALL, 5)
self.mainSizer.Add(sizer)
#----------------------------------------------------------------------
def updatePanel(self, msg):
"""
Iterate over the children widgets in the panel and update the
text control's values via the "update" method
"""
photo = msg.data
self.exif_data = photo.exif_data
children = self.GetChildren()
for child in children:
if isinstance(child, wx.TextCtrl):
self.update(photo, child)
#----------------------------------------------------------------------
def update(self, photo, txtWidget):
"""
Updates the text control's values
"""
key = txtWidget.GetName()
if key in self.exif_data:
value = self.exif_data[key]
else:
value = "No Data"
if self.panelOne:
if key == "Filename":
txtWidget.SetValue(photo.filename)
elif key == "FileSize":
txtWidget.SetValue(photo.filesize)
else:
txtWidget.SetValue(value)
else:
txtWidget.SetValue(value)
########################################################################
class InfoNotebook(wx.Notebook):
""""""
#----------------------------------------------------------------------
def __init__(self, parent, photo):
"""Constructor"""
wx.Notebook.__init__(self, parent, style=wx.BK_BOTTOM)
self.tabOne = NBPanel(self, photo, panelOne=True)
self.tabTwo = NBPanel(self, photo)
self.AddPage(self.tabOne, "Main Info")
self.AddPage(self.tabTwo, "More Info")
Publisher().subscribe(self.updateDisplay, ("update display"))
#----------------------------------------------------------------------
def updateDisplay(self, msg):
"""
Catches the PubSub's "event", creates a new photo instance and
passes that info to the panel so it can update
"""
photo = msg.data
new_photo = Photo(photo)
Publisher().sendMessage(("update"), new_photo)
########################################################################
class PhotoInfo(wx.Frame):
""""""
#----------------------------------------------------------------------
def __init__(self, photo_path):
"""Constructor"""
wx.Frame.__init__(self, None, title="Image Information")
photo = Photo(photo_path)
panel = wx.Panel(self)
notebook = InfoNotebook(panel, photo)
mainSizer = wx.BoxSizer(wx.VERTICAL)
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(notebook, 1, wx.EXPAND)
panel.SetSizer(sizer)
mainSizer.Add(panel)
self.SetSizer(mainSizer)
mainSizer.Fit(self)
self.Show()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = wx.PySimpleApp()
photo = r'path/to/photo.jpg'
frame = PhotoInfo(photo)
app.MainLoop()
这段代码可以做一个很好的重构,但它工作得很好。让我们来看看这个版本和上一个版本之间的区别。首先,我们将主面板改为次面板,因为它现在将是一个笔记本面板/选项卡。我们还向 init 添加了一个额外的参数,以允许我们使第一个面板不同于第二个面板(即 panelOne )。然后在 layoutWidgets 方法中,我们使用 panelOne 标志将 ordered_widgets 放在第一个选项卡上,将剩余的 EXIF 数据放在第二个选项卡上。我们还以大致相同的方式更改了更新方法。最后,我们添加了 InfoNotebook 类来创建笔记本小部件,并将它的一个实例放在框架上。如果您经常处理 EXIF 数据,那么您会知道有几个字段相当长。我们应该把它们放在多行文本控件中。这里有一种方法,通过稍微改变我们的 buildRow 方法:
def buildRow(self, label, value, txtName):
"""
Build a two widget row and add it to the main sizer
"""
sizer = wx.BoxSizer(wx.HORIZONTAL)
if self.panelOne:
lbl = wx.StaticText(self, label=label, size=(75, -1))
else:
lbl = wx.StaticText(self, label=label, size=(150, -1))
if len(value) < 40:
txt = wx.TextCtrl(self, value=value, size=(150,-1),
style=wx.TE_READONLY, name=txtName)
else:
txt = wx.TextCtrl(self, value=value, size=(150,60),
style=wx.TE_READONLY|wx.TE_MULTILINE,
name=txtName)
sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
sizer.Add(txt, 0, wx.ALL, 5)
self.mainSizer.Add(sizer)
在这个代码片段中,我们只是添加了一个 IF 语句来检查值的长度是否少于 40 个字符。如果是这样,我们创建了一个普通的文本控件;否则我们创建了一个多行文本控件。这不是很容易吗?下面是第二个选项卡现在的样子:

包扎
我们需要查看的最后一部分是主程序中需要更改的内容。基本上,我们只需要添加一个信息按钮,实例化我们的 EXIF 浏览器,并在按钮的事件处理程序中显示它。类似这样的事情会起作用:
frame = photoInfo.PhotoInfo(self.currentPicturePath)
frame.Show()
要更新 EXIF 浏览器,我们需要向它发送一条 Pubsub 消息。我们可以在 previous 和 next 按钮事件中发送消息,但是我们必须在两个地方维护代码。相反,我们将把新代码放在 loadImage 方法中,并像这样发送消息:
Publisher().sendMessage("update display", self.currentPicturePath)
这就是全部了。我在下面的下载小节中包含了完整的源代码。希望这有助于您了解向 GUI 项目添加新特性是多么容易,以及如何使用 wxPython 显示 EXIF 数据。
下载
在 pandas 中向空数据框添加数据
原文:https://www.blog.pythonlibrary.org/2022/08/09/adding-data-to-empty-dataframes-in-pandas/
最流行的第三方 Python 包之一叫做 pandas 。熊猫包“是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,建立在 Python 编程语言之上。”它被世界各地的数据科学家和软件工程师所使用。
在本教程中,您将学习一些关于使用 pandas 创建不同类型的空或部分空数据帧的知识。然后,您将学习向该数据帧添加数据的几种不同方法。
具体来说,您将了解以下内容:
- 创建空数据帧并添加数据
- 创建包含列的空数据框架并添加数据
- 创建包含列和索引的空数据帧并添加数据
在 pandas 中创建空数据帧
有时您只需要创建一个空的数据框架,就像有时您需要创建一个空的 Python 字典或列表一样。
下面是一个用熊猫创建一个完全空的数据帧的例子:
>>> import pandas as pd
>>> df = pd.DataFrame()
>>> df
Empty DataFrame
Columns: []
Index: []
当然,空的数据帧不是特别有用。因此,让我们在数据框架中添加一些数据!
>>> import pandas as pd
>>> df = pd.DataFrame()
>>> df
Empty DataFrame
Columns: []
Index: []
>>> df["Name"] = ["Mike", "Steve", "Rodrigo"]
>>> df["Jobs"] = ["Engineer", "Core Dev", "Content Creator"]
>>> df
Name Jobs
0 Mike Engineer
1 Steve Core Dev
2 Rodrigo Content Creator
这个例子演示了如何在 pandas 中指定列并向这些列添加数据。
现在让我们学习如何创建一个包含列但不包含数据的空 DataFrame!
创建包含列的空数据框架
下一个例子将向您展示如何创建一个包含列但不包含索引或列数据的 pandas DataFrame。
让我们来看看:
>>> import pandas as pd
>>> df = pd.DataFrame(columns=["Name", "Job"])
>>> df
Empty DataFrame
Columns: [Name, Job]
Index: []
# Add some data using append()
>>> df = df.append({"Name": "Mike", "Job": "Blogger"}, ignore_index=True)
>>> df
Name Job
0 Mike Blogger
>>> df = df.append({"Name": "Luciano", "Job": "Author"}, ignore_index=True)
>>> df
Name Job
0 Mike Blogger
1 Luciano Author
嗯,这比一个完全空的数据框要好!在本例中,您还将学习如何使用 DataFrame 的 append() 方法向每一列添加数据。
当您使用 append() 时,它接受一个列名和值的字典。您还将 ignore_index 设置为 True ,这将让熊猫自动为您更新索引。
现在让我们看看如何用熊猫创建另一种类型的空数据帧!
创建包含列和索引的空数据框架
对于这个例子,您将学习如何创建一个有两列和三个命名行或索引的 pandas 数据帧。
这是如何做到的:
>>> import pandas as pd
>>> df = pd.DataFrame(columns = ["Name", "Job"], index = ["a", "b", "c"])
>>> df
Name Job
a NaN NaN
b NaN NaN
c NaN NaN
当您打印出 DataFrame 时,可以看到所有列都包含 NaN,它代表“不是一个数字”。NaN 有点像 Python 中的 None。
在 pandas 中向该数据帧添加数据的一种方法是使用 loc 属性:
>>> df.loc["a"] = ["Mike", "Engineer"]
>>> df
Name Job
a Mike Engineer
b NaN NaN
c NaN NaN
>>> df.loc["b"] = ["Steve", "Core Dev"]
>>> df
Name Job
a Mike Engineer
b Steve Core Dev
c NaN NaN
>>> df.loc["c"] = ["Rodrigo", "Content Creator"]
>>> df
Name Job
a Mike Engineer
b Steve Core Dev
c Rodrigo Content Creator
当您使用 loc 属性时,您使用类似字典的语法来设置一个值列表的特定索引。上面的例子显示了如何添加三行数据。
包扎
这篇教程甚至还没有开始触及你能对熊猫做些什么的皮毛。但是不应该这样。这就是书的作用。在这里,您学习了如何创建三种不同类型的空数据帧。
具体来说,您学到了以下内容:
- 创建空数据帧并添加数据
- 创建包含列的空数据框架并添加数据
- 创建包含列和索引的空数据帧并添加数据
希望你会发现这些例子对你的熊猫之旅有用。编码快乐!
向长期运行的 Jupyter 笔记本单元格添加通知
如果您使用 Jupyter Notebook 运行长时间运行的流程,如机器学习培训,那么您可能想知道细胞何时完成执行。有一个很棒的浏览器插件可以帮助你解决这个问题,它叫做 jupyter-notify 。它将允许您在单元格执行完毕时让浏览器发送一条弹出消息。
通知将类似于以下内容:

让我们了解一下如何将此通知添加到您的 Jupyter 笔记本中!
装置
你需要做的第一件事是安装 Jupyter 笔记本,如果你还没有这样做。下面是如何使用 pip 实现这一点:
pip install jupyter
一旦安装完毕,您将需要安装 jupyter-notify :
pip install jupyternotify
现在你已经安装了所有的包,让我们来试试吧!
使用 Jupyter-Notify
要使用 jupyter-notify,您需要运行 Jupyter Notebook。在终端中,运行这个命令: jupyter notebook
现在,在笔记本的第一个单元格中输入以下文本:
%load_ext jupyternotify
这将加载 jupyter-notify 扩展。运行那个单元。您可能会看到浏览器要求您允许笔记本发出通知。您将希望允许通知程序正常工作。
现在,您需要将以下代码添加到笔记本的下一个单元格中:
%%notify
import time
time.sleep(10)
print('Finished!')
您的笔记本现在应该看起来像这样:

现在运行第二个单元。它将调用 time.sleep() ,这将使代码暂停执行您指定的秒数。在这种情况下,您希望暂停执行 10 秒钟,然后打印出一条消息,说明该单元“已完成!”。当单元格完成执行时,您应该会看到一个弹出通知,如下所示:
如果您想定制 jupyter-notify 发出的消息,那么您可以将第二个单元格更改为:
%%notify -m "The cell has finished running"
import time
time.sleep(10)
print('Finished!')
请注意,第一行已经更改为接受一个标志和一个消息字符串。如果您愿意,您可以在单元格内发送多条消息。只需在代码中多次放置 %%notify -m "some message" 。
例如,您可以将上面的代码改为:
import time
time.sleep(10)
%notify -m "The cell finished sleeping"
print('Finished!')
%notify -m "All done!"
为了让这段代码工作,您需要确保 %notify 只有百分之一(%)符号,而不是两个,因为这是 Jupyter 笔记本中的线条魔术。
包扎
jupyter-notify 包非常简洁,但是如果你被同事打断,很容易错过通知。一个解决方案是你可以使用它 py-toolbox ,它有一个 Notify 对象,当一个函数或单元格完成时,你可以用它给自己发电子邮件。
无论哪种方式,如果您想让 Jupyter 笔记本在处理完成时通知您,都有解决方案可供您使用。
就个人而言,如果我有一个长时间运行的进程,我可能会将它放入 Python 脚本文件中,而不是放入 Jupyter 笔记本中,因为这样会使我的代码更容易测试和调试。但是,如果你喜欢使用 Jupyter 笔记本,这些软件包可能是正确的选择!
使用 Python 和 ReportLab 向 pdf 添加 SVG
原文:https://www.blog.pythonlibrary.org/2018/04/12/adding-svg-files-in-reportlab/
ReportLab 支持生成 SVG,但不支持在 pdf 中嵌入 SVG。幸运的是,Dinu Gherman 创建了 svglib 包,这是一个纯 Python 包,可以读取 SVG 文件并将其转换为 ReportLab 可以使用的其他格式。svglib 的官方网站在 Github 上。
svglib 包可以在 Linux、Mac OS 和 Windows 上运行。该网站声称它适用于 Python 2.7 - 3.5,但也应该适用于较新版本的 Python。
您可以使用 svglib 读取现有的 SVG giles,并将它们转换为 ReportLab Drawing 对象。svglib 包还有一个命令行工具, svg2pdf ,可以将 svg 文件转换成 pdf。
属国
svglib 包依赖于 ReportLab 和 lxml 。您可以使用 pip 安装这两个软件包:
pip install reportlab lxml
装置
svglib 软件包可以使用三种方法之一进行安装。
安装最新版本
如果您想安装 Python 打包索引的最新版本,那么您可以按正常方式使用 pip:
pip install svglib
从源代码管理的最新版本安装
如果您想使用最新版本的代码(例如,bleeding edge / alpha builds),那么您可以使用 pip 直接从 Github 安装,如下所示:
pip install git+https://github.com/deeplook/svglib
手动安装
大多数时候,使用 pip 是可行的方法。但是如果您愿意,也可以从 Python 打包索引下载 tarball 并自动完成 pip 为您完成的所有步骤。只需在您的终端中依次运行以下三个命令:
tar xfz svglib-0.8.1.tar.gz
cd svglib-0.8.1
python setup.py install
现在我们已经安装了 svglib,让我们来学习如何使用它!
使用
在 ReportLab 中使用 svglib 实际上相当容易。你所需要做的就是从 svglib.svglib 导入 svg2rlg ,并给它你的 svg 文件的路径。让我们来看看:
# svg_demo.py
from reportlab.graphics import renderPDF, renderPM
from svglib.svglib import svg2rlg
def svg_demo(image_path, output_path):
drawing = svg2rlg(image_path)
renderPDF.drawToFile(drawing, output_path)
renderPM.drawToFile(drawing, 'svg_demo.png', 'PNG')
if __name__ == '__main__':
svg_demo('snakehead.svg', 'svg_demo.pdf')
在给 svg2rlg 你的路径到 svg 文件后,它将返回一个绘图对象。然后你可以用这个对象把它写成 PDF 或者 PNG。您可以继续使用这个脚本来创建您自己的 SVG 到 PNG 转换实用程序!
在画布上画画
就我个人而言,我不喜欢像前面的例子那样创建只有一个图像的一次性 pdf。相反,我希望能够插入图像,并写出文本和其他东西。幸运的是,您可以通过使用绘图对象在画布上绘画来非常容易地做到这一点。这里有一个例子:
# svg_on_canvas.py
from reportlab.graphics import renderPDF
from reportlab.pdfgen import canvas
from svglib.svglib import svg2rlg
def add_image(image_path):
my_canvas = canvas.Canvas('svg_on_canvas.pdf')
drawing = svg2rlg(image_path)
renderPDF.draw(drawing, my_canvas, 0, 40)
my_canvas.drawString(50, 30, 'My SVG Image')
my_canvas.save()
if __name__ == '__main__':
image_path = 'snakehead.svg'
add_image(image_path)
这里我们创建一个画布。画布对象,然后创建我们的 SVG 绘图对象。现在您可以使用 renderPDF.draw 在画布上的特定 x/y 坐标处绘制您的图形。我们在图片下面画出一些小的文字,然后保存下来。结果应该是这样的:

将 SVG 添加到可流动的
ReportLab 中的绘图通常可以作为可流动列表添加,并使用文档模板构建。svglib 的网站上说,它的绘图对象与 ReportLab 的可流动系统兼容。让我们在这个例子中使用一个不同的 SVG。我们将使用维基百科上的古巴国旗。svglib 测试在他们的测试中下载了大量的 flag SVGs,所以我们将尝试他们使用的一个图像。您可以在此处获得:
https://upload.wikimedia.org/wikipedia/commons/b/bd/Flag_of_Cuba.svg
一旦保存了图像,我们就可以看看代码了:
# svg_demo2.py
import os
from reportlab.graphics import renderPDF, renderPM
from reportlab.platypus import SimpleDocTemplate
from svglib.svglib import svg2rlg
def svg_demo(image_path, output_path):
drawing = svg2rlg(image_path)
doc = SimpleDocTemplate(output_path)
story = []
story.append(drawing)
doc.build(story)
if __name__ == '__main__':
svg_demo('Flag_of_Cuba.svg', 'svg_demo2.pdf')
这工作得很好,虽然旗帜在右边被切掉了。以下是输出结果:

实际上,我在这个例子中遇到了一些麻烦。ReportLab 或 svglib 似乎对 SVG 的格式或大小非常挑剔。根据我使用的 SVG,我会以一个 AttributeError 或一个空白文档结束,或者我会成功。所以你的里程可能会有所不同。我要说的是,我与一些核心开发人员交谈过,他们提到SimpleDocTemplate不能让您对绘图进入的框架进行足够的控制,因此您可能需要创建自己的框架或页面模板来使 SVG 正确显示。让 snakehead.svg 工作的一个变通方法是将左右边距设置为零:
# svg_demo3.py
from reportlab.platypus import SimpleDocTemplate
from svglib.svglib import svg2rlg
def svg_demo(image_path, output_path):
drawing = svg2rlg(image_path)
doc = SimpleDocTemplate(output_path,
rightMargin=0,
leftMargin=0)
story = []
story.append(drawing)
doc.build(story)
if __name__ == '__main__':
svg_demo('snakehead.svg', 'svg_demo3.pdf')
在 ReportLab 中缩放 SVG
默认情况下,使用 svglib 创建的 SVG 绘图不会缩放。所以你需要写一个函数来帮你做这件事。让我们来看看:
# svg_scaled_on_canvas.py
from reportlab.graphics import renderPDF
from reportlab.pdfgen import canvas
from svglib.svglib import svg2rlg
def scale(drawing, scaling_factor):
"""
Scale a reportlab.graphics.shapes.Drawing()
object while maintaining the aspect ratio
"""
scaling_x = scaling_factor
scaling_y = scaling_factor
drawing.width = drawing.minWidth() * scaling_x
drawing.height = drawing.height * scaling_y
drawing.scale(scaling_x, scaling_y)
return drawing
def add_image(image_path, scaling_factor):
my_canvas = canvas.Canvas('svg_scaled_on_canvas.pdf')
drawing = svg2rlg(image_path)
scaled_drawing = scale(drawing, scaling_factor=scaling_factor)
renderPDF.draw(scaled_drawing, my_canvas, 0, 40)
my_canvas.drawString(50, 30, 'My SVG Image')
my_canvas.save()
if __name__ == '__main__':
image_path = 'snakehead.svg'
add_image(image_path, scaling_factor=0.5)
这里我们有两个函数。第一个函数将使用缩放因子来缩放我们的图像。在这种情况下,我们使用 0.5 作为缩放因子。然后我们对我们的绘图对象做一些数学运算,并告诉它自己缩放。最后,我们用和上一个例子一样的方法把它拉出来。
结果如下:

在 ReportLab 中使用 matplotlib 中的 SVG 图
在之前的文章中,我们学习了如何仅使用 ReportLab 工具包来创建图表。不过,最流行的 2D Python 绘图包之一是 matplotlib 。你可以在这里阅读所有关于 matplotlib 的内容:【https://matplotlib.org/。我在本文中提到 matplotlib 的原因是它支持 SVG 作为其输出格式之一。因此,我们将了解如何使用 matplotlib 创建一个图,并将其插入 ReportLab。
要安装 matplotlib,最流行的方法是使用 pip:
pip install matplotlib
现在我们已经安装了 matplotlib,我们可以创建一个简单的绘图并将其导出为 SVG。让我们看看这是如何工作的:
import matplotlib.pyplot as pyplot
def create_matplotlib_svg(plot_path):
pyplot.plot(list(range(5)))
pyplot.title = 'matplotlib SVG + ReportLab'
pyplot.ylabel = 'Increasing numbers'
pyplot.savefig(plot_path, format='svg')
if __name__ == '__main__':
from svg_demo import svg_demo
svg_path = 'matplot.svg'
create_matplotlib_svg(svg_path)
svg_demo(svg_path, 'matplot.pdf')
在这段代码中,我们从 matplotlib 导入了 pyplot 子库。接下来,我们创建一个简单的函数,它采用我们想要保存绘图的路径。对于这个简单的图,我们为其中一个轴创建了一个简单的五个数字的范围。当我们添加标题和 y 标签时。最后,我们将绘图作为 SVG 保存到磁盘。
最后一步是在代码底部的 if 语句中。这里我们导入了本文前面的 svg_demo 代码。我们创建 oru SVG 图像,然后通过我们的演示代码将它转换成 PDF。
结果看起来像这样:

使用 svg2pdf
当您安装 svglib 时,您还会得到一个名为 svg2pdf 的命令行工具。顾名思义,您可以使用该工具将 SVG 文件转换为 PDF 文件。让我们看几个例子:
svg2pdf /path/to/plot.svg
这个命令只接受您想要转换成 PDF 的 SVG 文件的路径。它会自动将输出重命名为与输入文件相同的名称,但带有 PDF 扩展名。不过,您可以指定输出名称:
svg2pdf -o /path/to/output.pdf /path/to/plot.svg
-o 标志告诉 svg2pdf 要求您传入输出 pdf 路径,后跟输入 svg 路径。
该文档还提到,您可以使用如下命令将所有 SVG 文件转换为 pdf:
svg2pdf -o "%(base)s.pdf" path/to/file*.svg
这将为指定文件夹中的每个 SVG 文件将输出 PDF 重命名为与输入 SVG 文件相同的名称。
包扎
在写这本书的时候,svglib 是向 ReportLab 添加 SVG 的主要方法。虽然它不是全功能的,但它工作得很好,API 也很好。我们还学习了如何插入通过流行的 matplotlib 包创建的 plot SVG。最后,我们看了如何使用 svg2pdf 命令行工具将 svg 转换成 pdf。
相关阅读
- 简单的分步报告实验室教程
- ReportLab 101: 文本对象
- ReportLab - 如何添加图表和图形
- 用 Python 提取 PDF 元数据和文本
高级 Python——如何动态加载模块或类
时不时地,你会发现自己需要动态地加载模块或类。换句话说,您希望能够在事先不知道要导入哪个模块的情况下导入模块。在本文中,我们将研究用 Python 实现这一壮举的两种方法。
使用 import Magic 方法
做这类事情最简单的方法是使用“神奇”的方法 import。事实上,如果你在谷歌上搜索这个话题,这可能是你找到的第一个方法。下面是基本的方法:
module = __import__(module_name)
my_class = getattr(module, class_name)
instance = my_class()
在上面的代码中,模块名和类名都必须是字符串。如果您正在导入的类需要一些传递给它的参数,那么您也必须添加那个逻辑。这里有一个更具体的例子来帮助你理解这是如何工作的:
########################################################################
class DynamicImporter:
""""""
#----------------------------------------------------------------------
def __init__(self, module_name, class_name):
"""Constructor"""
module = __import__(module_name)
my_class = getattr(module, class_name)
instance = my_class()
print instance
if __name__ == "__main__":
DynamicImporter("decimal", "Context")
如果运行这段代码,您应该会在 stdout 中看到类似下面的输出:
Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999999, Emax=999999999, capitals=1, flags=[], traps=[DivisionByZero, Overflow, InvalidOperation])
这表明代码像预期的那样工作,它导入了十进制的并返回了上下文类的一个实例。那是非常直接的。让我们看看另一种方法!
使用 Python 的 imp 模块
使用 imp 模块稍微复杂一点。您最终需要做一点递归调用,并且您还希望将所有东西都包装在异常处理程序中。让我们看一下代码,然后我会解释为什么:
import imp
import sys
#----------------------------------------------------------------------
def dynamic_importer(name, class_name):
"""
Dynamically imports modules / classes
"""
try:
fp, pathname, description = imp.find_module(name)
except ImportError:
print "unable to locate module: " + name
return (None, None)
try:
example_package = imp.load_module(name, fp, pathname, description)
except Exception, e:
print e
try:
myclass = imp.load_module("%s.%s" % (name, class_name), fp, pathname, description)
print myclass
except Exception, e:
print e
return example_package, myclass
if __name__ == "__main__":
module, modClass = dynamic_importer("decimal", "Context")
imp 模块带有一个 find_module 方法,它将为您查找模块。虽然我不能让它总是可靠地工作,所以我把它包在一个尝试/例外中。例如,它根本找不到 SQLAlchemy,当我试图找到 wx 时。相框,我拿到了,但不是那个。我不知道后一个问题是 wxPython 还是 imp 的问题。无论如何,在 imp 找到模块后,它会返回一个打开的文件处理程序、imp 找到的模块的路径以及排序的描述(参见下面的文档或 PyMOTW 文章)。接下来,您需要加载该模块,使其“导入”。如果你想在模块中取出一个类,那么你可以再次使用 load_module 。此时,您应该拥有与第一个方法中相同的对象。
更新:我已经有一个评论者完全否定了这篇文章。所以作为回应,我想澄清一些事情。首先,简单的尝试/例外通常是不好的。我修正了代码,但是我总是在博客上,在产品代码中,甚至在书中看到它。这是个好主意吗?不。如果您知道会出现什么错误,您应该处理它们或重新引发错误。其次,有人告诉我“import”不是一个“方法”。确实如此。它实际上是 Python 内部的一个函数。然而,我见过的 Python 中的每一个双下划线函数都被称为“神奇方法”。参见福德的书或者这个的博客,上面列出了一堆关于这个主题的其他资源。最后,我的 IDE (Wingware,如果有人关心的话)自己给类和函数/方法添加了一些愚蠢的东西,比如空的 docstring 或者在 init docstring 中,它会添加“构造函数”。
附加阅读
- StackOverflow :动态导入模块中类的字符串名的 Python 动态实例化
- StackOverflow :只有在运行时才知道包名的情况下,如何使用 import()导入包?
- PyMOTW:imp-模块导入机制的接口
- imp 模块的 Python 官方文档
代码 2020 的出现:第一天
原文:https://www.blog.pythonlibrary.org/2020/12/03/advent-of-code-2020-day-1/
我决定今年尝试一下代码挑战的来临。《代码降临》是一系列每天一次的挑战。你可以用任何你想要的编程语言来解决它们。一旦你有了解决方案,你就在网站上输入它来赚取积分。在今年的情况下,你正在赚取星星。每天可以赚两星。
注意:代码的降临不会运行你的代码。它不知道你用的是什么编程语言。它只关心挑战发布后你回答问题的速度。如果你恰好在挑战发布后 5 分钟内回答了问题,你会比那些在挑战出现 5 小时后回答的人得到更好的分数。
我不知道我是否会完成所有的挑战,甚至不知道我能不能完成。如果这些挑战花费了我太多的时间,那么我将不得不放弃它们,因为我还有很多其他的项目要做。但是对于那些我完成的,我会在这里写下来。如果你自己正在解决挑战,你不想看到我的答案,你应该停止阅读!
!!!前方剧透!!!
第一部分
每天分为两个问题。问题详述这里。问题的第一部分是给你一个每行有一个数字的文件。你会发现 t 两个数相加等于 2020 。然后把这两个数相乘就得到答案了。
当我看到这个问题时,我的第一个想法是使用 Python 的 itertools 库,它有一个方便的组合函数。
利用这一点,我想出了以下代码:
from itertools import combinations
result = [pair for pair in combinations(numbers, 2)
if sum(pair) == 2020]
这给了我想要的一对数字,尽管输出看起来像这样:[(number_1,number_2)]
我从中提取了两个数字,将它们相乘,得到了降临节问题第一部分的答案。
第二部分
问题的下一部分是,现在他们希望你接受相同的输入,但是找到加起来是 2020 的唯一的三个数字。然后将这些数字相乘得到答案。
你可以修改组合来寻找两个以上我在上面硬编码的数字。你只是传了 3 个而不是 2 个。
为了让代码更智能,我还导入了 Python 的 math 模块,并使用其 prod() 函数对结果进行乘法运算。
以下是完整的代码:
import math
from itertools import combinations
def get_answer(numbers: list[int], combos: int = 2) -> int:
result = [pair for pair in combinations(numbers, combos)
if sum(pair) == 2020]
multiplied = math.prod(result[0])
print(f"The answer is {multiplied}")
return multiplied
if __name__ == '__main__':
with open('input.txt') as f:
numbers = [int(item.strip()) for item in f.readlines()]
get_answer(numbers, combos=3)
我所有的代码也在 Github 上,一些答案包括单元测试。我现在有一些非常基本的测试来应对这个挑战。
代码 2020 的来临:第二天
原文:https://www.blog.pythonlibrary.org/2020/12/04/advent-of-code-2020-day-2/
《代码 2020》问世的第二天是关于验证密码的。它为您提供一系列密码策略和密码,然后要求您确定这些密码中有多少是有效的。
对于这个挑战,我选择不使用 Python 库,只进行文本解析。
!!!前方剧透!!!
如果你还没有解决这个难题,你应该停止阅读!
第一部分
对于我的解决方案,我最终创建了两个函数。一个用于验证密码,一个用于计算有效密码的数量。这些本来是可以合并的,但是我的最佳编码实践接管了它,我阻止自己在一个函数中放太多东西。
代码如下:
def verify_password(line: str) -> bool:
policy, password = [item.strip() for item in line.split(':')]
bounds = policy[:-2]
letter = policy[-1]
low, high = [int(item) for item in bounds.split('-')]
letter_count = password.count(letter)
if low <= letter_count <= high:
return True
return False
def count_good_passwords(data: list) -> int:
good_passwords = 0
for line in data:
if verify_password(line):
good_passwords += 1
print(f'Number of good password: {good_passwords}')
return good_passwords
if __name__ == "__main__":
data = []
with open('passwords.txt') as f:
for line in f:
data.append(line.strip())
count_good_passwords(data)
这段代码将解决问题的第一部分。在这里打开文件,提取每一行,去掉两端的空格。一旦你有了字符串列表,你就把它们传递给你的函数,这个函数计算好的密码的数量。
操作的大脑在verify_password()中,它使用列表理解将行分解成密码策略和密码本身。然后你根据策略做一些检查,如果好就返回真,如果不好就返回假。
第二部分
在第 2 部分中,必须对密码策略进行不同的解释。与其在这里重复问题陈述,你应该去检查一下,看看两者有何不同。
为了实现这一点,我更新了两个函数,以接受一个版本的参数:
def verify_password(line: str, version: int = 1) -> bool:
policy, password = [item.strip() for item in line.split(':')]
bounds = policy[:-2]
letter = policy[-1]
low, high = [int(item) for item in bounds.split('-')]
if version == 1:
letter_count = password.count(letter)
if low <= letter_count <= high:
return True
elif version == 2:
letters = [password[low-1], password[high-1]]
if letters.count(letter) == 1:
return True
return False
def count_good_passwords(data: list, version: int = 1) -> int:
good_passwords = 0
for line in data:
if verify_password(line, version):
good_passwords += 1
print(f'Number of good password: {good_passwords}')
return good_passwords
if __name__ == "__main__":
data = []
with open('passwords.txt') as f:
for line in f:
data.append(line.strip())
count_good_passwords(data, version=2)
代码基本相同,只是现在它使用一个条件语句以不同的方式检查密码策略。第一个版本对字母进行计数,而第二个版本检查字母的位置。
总的来说,这是一个非常直接的变化。
我所有的代码也在 Github 上,这个包含了几个单元测试,你可以去看看。
代码 2020 的来临:第三天-滑降轨迹
原文:https://www.blog.pythonlibrary.org/2020/12/07/advent-of-code-2020-day-3-toboggan-trajectory/
当我读到代码出现的第三天的描述时,我以为它在要求我创建某种寻路算法。这个挑战背后的想法是计算出你滑下格子时会撞到多少棵树。
你应该去检查一下描述,这样你就会明白这个问题了。
!!!前方剧透!!!
如果你还没有解决这个难题,你应该停止阅读!
第一部分
挑战的第一部分是计算你最终会撞上多少棵树。你的斜率看起来像这样:
..##.......
#...#...#..
.#....#..#.
..#.#...#.#
.#...##..#.
..#.##.....
.#.#.#....#
.#........#
#.##...#...
#...##....#
.#..#...#.#
您的输入文件告诉您如何沿着斜坡向下行进。所以第一行可能说你向右走 3,向下走 2,而第二行可能说你只向右走 1,向下走 1。树木用“#”标记。
我最终强行得到了答案:
def detect_trees(data: list, right: int = 3, down: int = 1) -> int:
pos = 0
trees = 0
first_row = True
for line in data[::down]:
line = line * 100
if pos != 0:
char = line[:pos][-1]
if first_row:
pos += right+1
first_row = False
continue
else:
pos += right
if char == "#":
trees += 1
print(f"Number of trees: {trees}")
return trees
虽然我知道这不是很好的代码,甚至没有效率,但我的目标是快速解决这个难题,并基本上放在一个或两个私人排行榜上。
总之,我在这里做的是循环遍历数据文件中的行,并相应地改变我的位置。我用一个小程序告诉我是否在第一行,这帮助我从我想去的地方开始。
每当我最后一个字符是一个“#”的时候,我就增加我的树计数器。这在总体上运行得相当好,即使这是一个相当蹩脚的解决方案。
第二部分
第 2 部分与第 1 部分非常相似,只不过这一次,您需要获得每个斜率的答案,然后将这些答案相乘。为此,我创建了一个新的函数,并使用上面提供的斜率调用了我的函数。
def multiply_slopes(data: list) -> int:
first = detect_trees(data, right=1, down=1)
second = detect_trees(data, right=3, down=1)
third = detect_trees(data, right=5, down=1)
fourth = detect_trees(data, right=7, down=1)
fifth = detect_trees(data, right=1, down=2)
multiplied = first * second * third * fourth * fifth
print(f'Slopes multiplied: {multiplied}')
return multiplied
然后我把结果相乘,打印出来,还回去。回想起来,我本可以在这里使用 math.prod() 来执行乘法步骤,并使代码稍微少一些。
其他解决方案
Matt Harrison (作者和专业 Python 培训师)正在做一个视频,回顾代码出现的每一天。他在文章中包含了很多关于 Python 的技巧。你应该看看这些视频这里随着价格的上涨,大多数视频被添加。
在写出我的解决方案后,我还发现我可以使用模数运算符来简化整个过程:
https://www.youtube.com/embed/PBI6rGv9Utw?feature=oembed
那家伙不到 3 分钟就解决了挑战!我喜欢这个解决方案的简洁,尽管这不是我能想到的。
代码的出现:第 4 天-护照处理
原文:https://www.blog.pythonlibrary.org/2020/12/09/advent-of-code-day-4-passport-processing/
顾名思义, Day 4 都是办理护照。您将看到以下字段,您必须使用这些字段执行一些验证步骤:
byr (Birth Year)
iyr (Issue Year)
eyr (Expiration Year)
hgt (Height)
hcl (Hair Color)
ecl (Eye Color)
pid (Passport ID)
cid (Country ID)
!!!前方剧透!!!
如果你还没有解决这个难题,你应该停止阅读!
第一部分
挑战的第一部分是验证所有字段都存在。您将检查输入文件并统计所有有效护照。
我对这个问题相当简单的解决方案如下:
def process(lines: str) -> bool:
"""
Part 1
"""
d = lines.split(' ')
dd = dict([item.split(':') for item in d if item])
keys = ['byr', 'iyr', 'eyr', 'hgt', 'hcl', 'ecl', 'pid']
for key in keys:
if key not in dd:
return False
return True
def count_passports(data: str) -> int:
pport = {}
s = ''
count = 0
passports = []
for line in data.split('\n'):
line = line.strip()
if line == '':
# process
count += bool(process(s))
passports.append(s)
s = ''
s += ' ' + line
print(f"Valid passports: {count}")
return count
if __name__ == '__main__':
with open('input.txt') as f:
data = f.read()
count_passports(data)
在这里,我解析了这一行,并在我的 process() 函数中将它转换成一个 Python 字典。然后我检查了所有的钥匙,确认所有需要的都在。如果任何一个键不存在,那么我返回 False。
第二部分
挑战的这一部分要复杂得多。现在,我必须对以下内容进行代码验证:
byr (Birth Year) - four digits; at least 1920 and at most 2002.
iyr (Issue Year) - four digits; at least 2010 and at most 2020.
eyr (Expiration Year) - four digits; at least 2020 and at most 2030.
hgt (Height) - a number followed by either cm or in:
If cm, the number must be at least 150 and at most 193.
If in, the number must be at least 59 and at most 76.
hcl (Hair Color) - a # followed by exactly six characters 0-9 or a-f.
ecl (Eye Color) - exactly one of: amb blu brn gry grn hzl oth.
pid (Passport ID) - a nine-digit number, including leading zeroes.
cid (Country ID) - ignored, missing or not.
对于这个问题,我采用了最直接的方法,并使用了一系列条件语句:
def process2(lines: str) -> bool:
"""
Part 2
"""
d = lines.split(' ')
dd = dict([item.split(':') for item in d if item])
keys = ['byr', 'iyr', 'eyr', 'hgt', 'hcl', 'ecl', 'pid']
for key in keys:
if key not in dd:
return False
if not any([dd[key] != 4 for key in ['byr', 'iyr', 'eyr']]):
return False
if '1920' > dd['byr'] or dd['byr'] > '2002':
return False
if dd['iyr'] < "2010" or dd['iyr'] > "2020":
return False
if dd['eyr'] < "2020" or dd['eyr'] > "2030":
return False
if not any(['in' in dd['hgt'], 'cm' in dd['hgt']]):
return False
if 'cm' in dd['hgt']:
height = int(dd['hgt'][:-2])
if height < 150 or height > 193:
return False
if 'in' in dd['hgt']:
height = int(dd['hgt'][:-2])
if height < 59 or height > 76:
return False
if '#' not in dd['hcl']:
return False
hcl = dd['hcl'].split('#')[-1]
if len(hcl) != 6:
return False
try:
int(hcl, 16)
except ValueError:
return False
eye_colors = ['amb', 'blu', 'brn', 'gry', 'grn', 'hzl', 'oth']
if dd['ecl'] not in eye_colors:
return False
if len(dd['pid']) != 9:
return False
if dd['pid'] == '182693366':
print()
return True
def count_passports(data: str) -> int:
pport = {}
s = ''
count = 0
passports = []
for line in data.split('\n'):
line = line.strip()
if line == '':
# process
count += bool(process2(s))
passports.append(s)
s = ''
s += ' ' + line
print(f"Valid passports: {count}")
return count
if __name__ == '__main__':
with open('input.txt') as f:
data = f.read()
count_passports(data)
这是可行的,但这绝对是一个无聊的解决方案。我看到其他人使用华丽的包来创建一个模式,然后用它来验证一切。您还可以创建一个也执行验证步骤的类。
如果你想看的话,我所有的代码也在 Github 上。
aiohttp 简介
原文:https://www.blog.pythonlibrary.org/2016/11/09/an-intro-to-aiohttp/
Python 3.5 增加了一些新的语法,允许开发人员更容易地创建异步应用程序和包。一个这样的包是 aiohttp,它是 asyncio 的 http 客户端/服务器。基本上,它允许你编写异步客户端和服务器。aiohttp 包还支持服务器 WebSockets 和客户端 WebSockets。您可以使用 pip 安装 aiohttp:
pip install aiohttp
现在我们已经安装了 aiohttp,让我们来看看他们的一个例子!
获取网页
aiohtpp 的文档中有一个有趣的例子,展示了如何获取网页的 HTML。让我们来看看它是如何工作的:
import aiohttp
import asyncio
import async_timeout
async def fetch(session, url):
with async_timeout.timeout(10):
async with session.get(url) as response:
return await response.text()
async def main(loop):
async with aiohttp.ClientSession(loop=loop) as session:
html = await fetch(session, 'https://www.blog.pythonlibrary.org')
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
在这里,我们只需导入 aiohttp、Python 的 asyncio 和 async_timeout,这使我们能够使协程超时。我们在代码底部创建事件循环,并调用 main()函数。它将创建一个 ClientSession 对象,我们将这个对象和要获取的 URL 一起传递给 fetch()函数。最后,在 fetch()函数中,我们使用 our timeout 并尝试获取 URL 的 HTML。如果一切正常,没有超时,您将会看到大量文本涌入 stdout。
用 aiohttp 下载文件
开发人员要做的一个相当常见的任务是使用线程或进程下载文件。我们也可以使用协程下载文件!让我们来看看如何实现:
import aiohttp
import asyncio
import async_timeout
import os
async def download_coroutine(session, url):
with async_timeout.timeout(10):
async with session.get(url) as response:
filename = os.path.basename(url)
with open(filename, 'wb') as f_handle:
while True:
chunk = await response.content.read(1024)
if not chunk:
break
f_handle.write(chunk)
return await response.release()
async def main(loop):
urls = ["http://www.irs.gov/pub/irs-pdf/f1040.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040a.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040ez.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040es.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040sb.pdf"]
async with aiohttp.ClientSession(loop=loop) as session:
for url in urls:
await download_coroutine(session, url)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
您会注意到我们在这里导入了几个新项目: aiohttp 和 async_timeout 。后者实际上是 aiohttp 的依赖项之一,允许我们创建超时上下文管理器。让我们从代码的底部开始,一步步向上。在底部的条件语句中,我们开始异步事件循环,并调用我们的 main 函数。在 main 函数中,我们创建了一个 ClientSession 对象,并将其传递给我们的 download 协程函数,用于我们想要下载的每个 URL。在 download_coroutine 中,我们创建了一个 async_timeout.timeout() 上下文管理器,它基本上创建了一个 X 秒的计时器。当秒数用完时,上下文管理器结束或超时。在这种情况下,超时时间为 10 秒。接下来,我们调用会话的 get() 方法,该方法为我们提供了一个响应对象。现在我们到了有点不可思议的部分。当您使用响应对象的内容属性时,它返回一个 aiohttp 的实例。StreamReader 允许我们下载任何大小的文件。当我们读取文件时,我们把它写到本地磁盘上。最后我们调用响应的 release() 方法,这将完成响应处理。
根据 aiohttp 的文档,因为响应对象是在上下文管理器中创建的,所以它在技术上隐式地调用 release()。但是在 Python 中,显式通常更好,文档中有一个注释,我们不应该依赖于正在消失的连接,所以我认为在这种情况下最好是释放它。
这里仍有一部分被阻塞,这是实际写入磁盘的代码部分。当我们写文件的时候,我们仍然在阻塞。还有另一个名为 aiofiles 的库,我们可以用它来尝试使文件写异步,我们接下来会看到它。
注意:上面的部分来自我以前的文章。
使用 aiofiles 进行异步写入
你将需要安装 aiofiles 来完成这项工作。让我们弄清楚这一点:
pip install aiofiles
现在我们有了所有需要的项目,我们可以更新我们的代码了!注意,这段代码只在 Python 3.6 或更高版本中有效。
import aiofiles
import aiohttp
import asyncio
import async_timeout
import os
async def download_coroutine(session, url):
with async_timeout.timeout(10):
async with session.get(url) as response:
filename = os.path.basename(url)
async with aiofiles.open(filename, 'wb') as fd:
while True:
chunk = await response.content.read(1024)
if not chunk:
break
await fd.write(chunk)
return await response.release()
async def main(loop, url):
async with aiohttp.ClientSession(loop=loop) as session:
await download_coroutine(session, url)
if __name__ == '__main__':
urls = ["http://www.irs.gov/pub/irs-pdf/f1040.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040a.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040ez.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040es.pdf",
"http://www.irs.gov/pub/irs-pdf/f1040sb.pdf"]
loop = asyncio.get_event_loop()
loop.run_until_complete(
asyncio.gather(
*(main(loop, url) for url in urls)
)
)
唯一的变化是为 aiofiles 添加一个导入,然后改变我们打开文件的方式。你会注意到现在是
async with aiofiles.open(filename, 'wb') as fd:
我们使用 await 来编写代码:
await fd.write(chunk)
除此之外,代码是相同的。这里提到的一些可移植性问题你应该知道。
包扎
现在你应该对如何使用 aiohttp 和 aiofiles 有了一些基本的了解。这两个项目的文档都值得一看,因为本教程实际上只是触及了这些库的皮毛。
相关阅读
Python 中的上下文管理器简介(视频)
原文:https://www.blog.pythonlibrary.org/2022/06/07/an-intro-to-context-managers-video/
上下文管理器是打开和关闭文件、对话框、线程锁等等的便捷方式!查看这篇简短的教程,它向您介绍了 Mike Driscoll 的上下文管理器的概念
https://www.youtube.com/embed/3zsgzG8kXvE?feature=oembed
相关文章
- 带语句和上下文管理器的 Python
- Python 3.10 - 带括号的上下文管理器
- wxPython 的上下文管理器
- Python 201 - 上下文管理器简介
coverage.py 简介
原文:https://www.blog.pythonlibrary.org/2016/07/20/an-intro-to-coverage-py/
Coverage.py 是 Python 的第三方工具,用于测量你的代码覆盖率。它最初是由内德·巴切尔德创作的。在编程界,术语“覆盖率”通常用于描述测试的有效性,以及测试实际覆盖了多少代码。您可以将 coverage.py 与 Python 2.6 以及 Python 3 的当前版本一起使用。
pip install coverage
现在我们已经安装了 coverage.py,我们需要一些代码来使用它。让我们创建一个名为 mymath.py 的模块,代码如下:
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(numerator, denominator):
return float(numerator) / denominator
现在我们需要一个测试。让我们创建一个测试 add 函数的程序。让我们将我们的测试命名为: test_mymath.py 。继续操作,并将其保存在与上一模块相同的位置。然后将以下代码添加到我们的测试中:
# test_mymath.py
import mymath
import unittest
class TestAdd(unittest.TestCase):
"""
Test the add function from the mymath library
"""
def test_add_integers(self):
"""
Test that the addition of two integers returns the correct total
"""
result = mymath.add(1, 2)
self.assertEqual(result, 3)
def test_add_floats(self):
"""
Test that the addition of two floats returns the correct result
"""
result = mymath.add(10.5, 2)
self.assertEqual(result, 12.5)
def test_add_strings(self):
"""
Test the addition of two strings returns the two string as one
concatenated string
"""
result = mymath.add('abc', 'def')
self.assertEqual(result, 'abcdef')
if __name__ == '__main__':
unittest.main()
现在我们有了所有的片段,我们可以使用测试运行 coverage.py。打开一个终端,导航到包含 mymath 模块和我们编写的测试代码的文件夹。现在我们可以像这样调用 coverage.py:
coverage run test_mymath.py
注意,我们需要调用 run 来获取 coverage.py 以运行该模块。如果您的模块接受参数,您可以像平常一样传递这些参数。当您这样做时,您将看到测试的输出,就像您自己运行它一样。你还会在目录中找到一个名为的新文件。覆盖范围(注意开头的句号)。要从该文件中获取信息,您需要运行以下命令:
coverage report -m
执行此命令将产生以下输出:
Name Stmts Miss Cover Missing
----------------------------------------------
mymath.py 9 3 67% 9, 13, 17
test_mymath.py 14 0 100%
----------------------------------------------
TOTAL
-m 标志告诉 coverage.py 您希望它在输出中包含缺失的列。如果您省略了 -m ,那么您将只得到前四列。您在这里看到的是覆盖率运行了测试代码,并确定我的单元测试只覆盖了 67%的 mymath 模块。“缺失”栏告诉我哪些代码行仍然需要覆盖。如果您查看 coverage.py 指出的行,您会很快发现我的测试代码没有测试减法、乘法或除法函数。
在我们尝试添加更多的测试覆盖之前,让我们学习如何让 coverage.py 生成一个 HTML 报告。为此,您只需运行以下命令:
coverage html
该命令将创建一个名为 htmlcov 的文件夹,其中包含各种文件。导航到那个文件夹,试着在你选择的浏览器中打开 index.html。在我的机器上,它加载了这样一个页面:
**
你实际上可以点击列出的模块来加载一个带注释的网页,向你显示哪些代码部分没有被覆盖。因为 mymath.py 模块显然没有被很好地覆盖,所以让我们单击它。您最终应该会看到如下所示的内容:

这个截图清楚地显示了我们最初的单元测试中没有覆盖的代码部分。现在我们已经明确知道了我们的测试覆盖中缺少什么,让我们为我们的 subtract 函数添加一个单元测试,看看这是如何改变事情的!
打开您的 test_mymath.py 副本,并向其中添加以下类:
class TestSubtract(unittest.TestCase):
"""
Test the subtract function from the mymath library
"""
def test_subtract_integers(self):
"""
Test that subtracting integers returns the correct result
"""
result = mymath.subtract(10, 8)
self.assertEqual(result, 2)
现在我们需要根据更新的测试重新运行覆盖率。你需要做的就是重新运行这个命令:覆盖率运行 test_mymath.py 。输出将显示四个测试已经成功通过。现在重新运行覆盖率 html 并重新打开“index.html”文件。您现在应该看到我们的覆盖率达到了 78%:

这是 11%的进步!让我们继续为乘法和除法函数添加一个简单的测试,看看我们是否能达到 100%的覆盖率!
class TestMultiply(unittest.TestCase):
"""
Test the multiply function from the mymath library
"""
def test_subtract_integers(self):
"""
Test that multiplying integers returns the correct result
"""
result = mymath.multiply(5, 50)
self.assertEqual(result, 250)
class TestDivide(unittest.TestCase):
"""
Test the divide function from the mymath library
"""
def test_divide_by_zero(self):
"""
Test that multiplying integers returns the correct result
"""
with self.assertRaises(ZeroDivisionError):
result = mymath.divide(8, 0)
现在,您可以像以前一样重新运行相同的命令,并重新加载“index.html”文件。当您这样做时,应该会看到如下所示的内容:

正如你所看到的,我们已经达到了完整的测试覆盖率!当然,在这种情况下,完全覆盖意味着每个功能都由我们的测试套件来执行。这样做的问题是,我们对加法函数的测试次数是其他函数的三倍,但是 coverage.py 没有给我们任何这方面的数据。然而,它会给我们一个基本覆盖的好主意,即使它不能告诉我们,我们是否已经测试了每一个可能的论点排列。
附加说明
我只是想提一下 coverage.py 的其他一些特性,而不想涉及太多细节。首先,coverage.py 支持配置文件。配置文件格式是你的经典”。ini”文件,文件的各个部分用方括号括起来(即[my_section])。您可以使用以下#或;将注释添加到配置文件中。(分号)。
Coverage.py 还允许您通过我们前面提到的配置文件来指定您希望它分析哪些源文件。一旦您按照您想要的方式设置了配置,那么您就可以运行 coverage.py 了。最后,您可以使用“- include”和“- omit”开关来包含或排除文件名模式列表。这些开关具有匹配的配置值,您也可以将其添加到您的配置文件中。
最后要提的一点是,coverage.py 支持插件。可以自己写或者下载安装别人的插件来增强覆盖率. py。
包扎
现在您已经了解了 coverage.py 的基础知识以及这个特殊包的用途。py 允许您检查您的测试,并在您的测试覆盖中找到漏洞。如果你不确定你的代码已经被正确测试了,这个包将帮助你确定漏洞在哪里,如果它们存在的话。当然,你仍然有责任写出好的测试。如果您的测试是无效的,但是它们还是通过了,那么 coverage.py 不会帮助您。**
EasyGUI_Qt 简介
原文:https://www.blog.pythonlibrary.org/2015/02/18/an-intro-to-easygui_qt/
最近偶然发现一个有趣的小项目,叫做 EasyGUI_Qt 。除了使用 PyQt4 而不是 Tkinter 之外,它基本上和 EasyGUI 是一样的。这两个包背后的想法是允许开发者使用对话框向用户提出简单的问题。
在本文中,我们将通过几个例子花一些时间来学习如何使用这个包。注意,虽然 EasyGUI_Qt 的主要目标是 Python 3,但它可以与 Python 2 和 3 一起工作。文档指出 Python 2 中的 unicode 可能存在一些问题,但除此之外,小部件应该工作正常。
入门指南
您需要确保您已经安装了一份 PyQt4 的副本,然后才能安装使用该模块。安装好之后,您可以使用 pip(或 easy_install)来安装 EasyGUI_Qt:
pip install easygui_qt
现在你已经安装了,我们可以学习如何实际做一些事情!
创建消息框

创建一个简单的消息框来告诉用户一些事情是非常容易的。让我们告诉他们一些关于 Python 的事情:
import easygui_qt as easy
easy.set_font_size(18)
easy.show_message(message="Python rocks!", title="EasyGUI_Qt")
这里我们导入 easygui_qt ,设置字体为 18 磅并显示我们的消息。请注意,字体大小的更改将影响对话框中的文本和按钮上的文本。
获取字符串
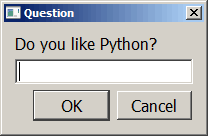
问用户一个问题也很容易。让我们来看看:
>>> import easygui_qt as easy
>>> answer = easy.get_string("Do you like Python?", title="Question")
>>> answer
'Yes!'
那也很简单。让我们看看如何从用户那里获得一种颜色。
获得颜色

EasyGUI_Qt 实际上提供了两种获取颜色的方法。您可以获得十六进制值或 rgb 值。这两种情况下的对话框看起来是一样的。它是这样工作的:
>>> import easygui_qt as easy
>>> easy.get_color_hex()
'#ffffff'
如果你想得到 rgb 值,那么你可以调用 get_color_rgb 来代替。
获取用户名/密码
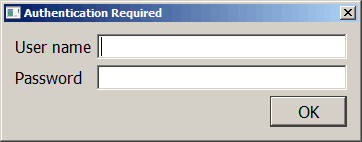
这可能是从用户那里获得身份验证信息的最好方式之一。EasyGUI_Qt 允许我们显示一个对话框来获取用户的用户名和密码。代码如下:
>>> import easygui_qt as easy
>>> easy.get_username_password(title="Authentication Required")
OrderedDict([('User name', ''), ('Password', '')])
请注意,它返回一个 OrderedDict。我们最后要看的是如何运行 EasyGUI_Qt 的演示。
运行 EasyGUI_Qt 演示
我们将从运行主演示开始,它允许你看到你能向用户显示的所有对话框以及它们返回的内容。让我们来看看:
>>> from easygui_qt.demos import launcher
>>> launcher.main()
EasyGUI_Qt 还提供了一点猜谜游戏演示。下面是运行它的方法:
>>> from easygui_qt.demos.guessing_game import guessing_game
>>> guessing_game()
这将显示一系列对话框,演示包的一些对话框。有点意思,但是很短。
包扎
至此,您应该能够使用 EasyGUI_Qt 了。这个包对于控制台程序很有用,在这种程序中,您希望使用 GUI 而不仅仅是控制台提示符从用户那里获得信息。如果您想编写一个成熟的 GUI,那么您应该看看 PyQt 本身或 wxPython。
相关阅读
- EasyGUI_Qt 进展顺利
- EasyGUI_Qt 文件
- 快速简易 Gui 教程
Flake8 简介
原文:https://www.blog.pythonlibrary.org/2019/08/13/an-intro-to-flake8/
Python 有几个 linters,可以用来帮助您找到代码中的错误或关于样式的警告。例如,最彻底的棉绒之一是 Pylint 。
Flake8 被描述为一种用于样式指南实施的工具。它也是围绕 PyFlakes 、 pycodestyle 和内德·巴奇尔德麦凯布剧本的包装。您可以使用 Flake8 作为一种 lint 您的代码并强制 PEP8 合规性的方法。
装置
使用 pip 时,安装 Flake8 相当容易。如果您想将 flake8 安装到默认的 Python 位置,可以使用以下命令:
python -m pip install flake8
既然安装了 Flake8,那就来学习一下如何使用吧!
入门指南
下一步是在您的代码基础上使用 Flake8。让我们写一小段代码来运行 Flake8。
将以下代码放入名为hello.py:的文件中
from tkinter import *
class Hello:
def __init__(self, parent):
self.master = parent
parent.title("Hello Tkinter")
self.label = Label(parent, text="Hello there")
self.label.pack()
self.close_button = Button(parent, text="Close",
command=parent.quit)
self.close_button.pack()
def greet(self):
print("Greetings!")
root = Tk()
my_gui = Hello(root)
root.mainloop()
在这里,您使用 Python 的 tkinter 库编写了一个小型 GUI 应用程序。网上很多 tkinter 代码用的是from tkinter import * pattern, which is something that you should normally avoid. The reason being that you don't know everything you are importing and you could accidentally overwrite an import with your own variable name.
让我们针对这个代码示例运行 Flake8。
打开您的终端并运行以下命令:
flake8 hello.py
您应该会看到以下输出:
tkkkk.py:1:1: F403 'from tkinter import *' used; unable to detect undefined names tkkkk.py:3:1: E302 expected 2 blank lines, found 1 tkkkk.py:8:22: F405 'Label' may be undefined, or defined from star imports: tkinter tkkkk.py:11:29: F405 'Button' may be undefined, or defined from star imports: tkinter tkkkk.py:18:1: E305 expected 2 blank lines after class or function definition, found 1 tkkkk.py:18:8: F405 'Tk' may be undefined, or defined from star imports: tkinter tkkkk.py:20:16: W292 no newline at end of file
以“F”开头的项目是 PyFlake 错误代码,指出代码中的潜在错误。其他错误来自 pycodestyle 。您应该查看这两个链接,以了解完整的错误代码列表及其含义。
您还可以针对一个文件目录运行 Flake8,而不是一次运行一个文件。
如果您想要限制要捕获的错误类型,可以执行如下操作:
flake8 --select E123 my_project_dir
这将只显示在指定目录中的任何文件的 E123 错误,而忽略所有其他类型的错误。
要获得 Flake8 可以使用的命令行参数的完整列表,请查看它们的文档。
最后,Flake8 允许你改变它的配置。例如,你的公司可能只遵循 PEP8 的部分内容,所以你不希望 Flake8 标记你的公司不关心的东西。Flake8 也支持使用插件。
包扎
Flake8 可能就是您用来帮助保持代码整洁和没有错误的工具。如果你使用持续集成系统,比如 TravisCI 或 Jenkins,你可以将 Flake8 和 Black 结合起来,自动格式化你的代码并标记错误。
这绝对是一个值得一试的工具,而且比 PyLint 噪音小得多。试试看,看你怎么想!
相关阅读
- Flake8 网站
- py flakes "Python 程序的被动检查器
- Black 简介不妥协的 Python 代码格式化程序
- PyLint: 分析 Python 代码
Wand / ImageMagick 和 Python 图像处理简介
ImageMagick 是一个开源工具,你可以用它来创建、编辑、合成或转换数字图像。它支持 200 多种图像格式。根据其网站,ImageMagick 可以调整大小,翻转,镜像,旋转,扭曲,剪切和变换图像,调整图像颜色,应用各种特殊效果,或绘制文本,线条,多边形,椭圆和贝塞尔曲线。
更多关于 ImageMagick 的信息,你应该去他们的网站。
Wand 是 ImageMagick 周围的 Python 包装器。Wand 和 Pillow 有很多相似的功能,是最接近枕头的替代品。魔杖很容易与 pip 一起安装:
python3 -m pip install wand
你还必须安装 ImageMagick。根据您使用的操作系统,您可能还需要设置一个环境变量。如果您在安装或配置 Wand 时有任何问题,请参见 Wand 的文档。
Wand 可以完成许多不同的图像处理任务。在接下来的几节中,您将看到它的能力。您将从了解 Wand 的图像效果开始!
用魔杖应用图像效果
Wand 内置了几种不同的图像效果。以下是完整列表:
- 虚化
- 去除斑点
- 边缘
- 装饰
- Kuwahara
- 阴影
- 尖锐
- 传播
这些影响有些存在于枕头中,有些不存在。例如,枕头没有斑点或 Kuwahara。
为了了解如何使用这些效果,您将使用这张小鸭子照片:

你将尝试 Wand 的edge()方法。创建一个新的 Python 文件,将其命名为wand_edger.py。然后输入以下代码:
# wand_edger.py
from wand.image import Image
def edge(input_image_path, output_path):
with Image(filename=input_image_path) as img:
img.transform_colorspace("gray")
img.edge(radius=3)
img.save(filename=output_path)
if __name__ == "__main__":
edge("ducklings.jpg", "edged.jpg")
这里的第一个新条目是 import: from wand.image import Image。Image类是你在 Wand 中处理照片的主要方法。接下来,创建一个edge()函数,打开小鸭子的照片。然后你把图像改成灰度。然后应用edge(),它接受一个radius参数。半径是一个类似光圈的设置。
当您运行此代码时,输出将如下所示:

您应该为radius尝试不同的值。它改变了结果。
现在我们来看看 Wand 提供的特效。
特殊效果
Wand 支持很多其他的特效,他们称之为“特效”。以下是当前支持的列表:
- 添加噪声
- 蓝移
- 木炭
- 彩色矩阵
- 使…变成彩色
- 效果
- 内向坍塌
- 偏振片
- 棕褐色调
- 素描
- 使…过度曝光
- 多边形
- 漩涡
- 色彩
- 小插图
- 波浪
- 小波去噪
其中一些很有趣。文档中有所有这些例子的前后照片。
您将尝试使用作者的照片在本节中使用插图:

迈克尔·德里斯科尔
创建一个名为wand_vignette.py的新文件,并将以下代码添加到其中:
# wand_vignette.py
from wand.image import Image
def vignette(input_image_path, output_path):
with Image(filename=input_image_path) as img:
img.vignette(x=10, y=10)
img.save(filename=output_path)
if __name__ == "__main__":
vignette("author.jpg", "vignette.jpg")
在这个例子中,你调用vignette()。它需要几个不同的参数,但是你只需要提供x和y。这些参数控制要添加晕影的图像周围的边缘数量。
当您运行此代码时,您将获得以下输出:

看起来不错。这是一种有趣的方式,让你的照片看起来独特而优雅。用你的一些照片试试吧!
现在你已经准备好学习如何用魔杖修剪了。
用魔杖裁剪
用魔杖进行作物种植类似于枕头作物。可以传入四个坐标(左、上、右、下)或者(左、上、宽、高)。你将使用小鸭子的照片,并找出如何裁剪照片下来,只有鸟。
创建一个新文件,命名为wand_crop.py。然后添加以下代码:
# wand_crop.py
from wand.image import Image
def crop(input_image_path, output_path, left, top, width, height):
with Image(filename=input_image_path) as img:
img.crop(left, top, width=width, height=height)
img.save(filename=output_path)
if __name__ == "__main__":
crop("ducklings.jpg", "cropped.jpg", 100, 800, 800, 800)
对于这个例子,您提供了left、top、width和height。当您运行此代码时,照片将被裁剪成如下所示:

您可以尝试不同的值,看看它如何影响作物。
Wand 能做的远不止这一节所展示的。它可以做和枕头一样的事情,甚至更多。Pillow 相对于 Wand 的主要优势是 Pillow 是用 Python 编写的,不像 Wand 那样需要外部二进制文件(即 ImageMagick)。
包扎
魔杖包相当厉害。它能做大多数和 T2 枕头包一样事情,也能做一些它不能做的事情。当然,Pillow 还有 Wand 没有的功能。你一定要看看这两个包,看看哪个更适合你正在做的事情。
这两个包都是用 Python 编辑和操作图像的好方法。给 Wand 一个尝试,并使用它的许多其他效果,看看它是多么强大!
基维布局介绍(视频)
原文:https://www.blog.pythonlibrary.org/2022/06/23/an-intro-to-kivy-layouts-video/
了解如何在 Python 的移动 GUI 框架 Kivy 中布局小部件。Kivy 是一个跨平台的 GUI 框架,也可以在 iOS 和 Android 上工作。
这个视频中的例子是基于 Kivy 101 的代码:如何使用 box layoutsT3
https://www.youtube.com/embed/gDqA5qH4BRw?feature=oembed
Mercurial 简介
原文:https://www.blog.pythonlibrary.org/2012/07/23/an-intro-to-mercurial/
Mercurial 是一个免费的分布式源代码控制版本工具,类似于 git 或 bazaar。有些人甚至会把它比作 CVS 或 Subversion (SVN ),尽管它们不是分布式版本控制系统。几年前,Python 编程核心开发团队选择从 SVN 转向 Mercurial,许多其他知名的第三方 Python 项目也是如此。有许多项目也在使用 Git。在本教程中,我们将学习使用 Mercurial 的基础知识。如果你需要更深入的信息,有一个相当详尽的指南和一个在线 Mercurial book 应该可以满足你的需求。
入门指南
首先,您可能需要安装 Mercurial。按照他们的网站上的指示。真的很好做。现在我们可以使用它了。如果安装正确,您应该能够打开一个终端(即命令行)窗口,并创建一个新的存储库或签出一个。在本文中,您将学习如何做到这两点。我们将从头开始创建我们自己的存储库。
首先,在你的机器上创建一个新的文件夹。我们将使用“C:\ repo”(Windows)。当然,你的道路会有所不同。然后在你的终端中,将目录切换到 repo 文件夹。现在键入以下内容:
hg init
等等!那个“hg”是什么意思?“hg”是水银的化学符号。您将始终使用“hg”命令与 Mercurial 存储库(又名:repos)进行交互。您的文件夹现在应该有一个。hg 文件夹,其中将包含一个空的存储文件夹,一个 changelog 文件(某种虚拟文件)和一个需要的文件。在大多数情况下,您并不真正关心中有什么。hg 文件夹,因为它存在的目的是存储回购信息,以便 Mercurial 可以恢复到以前的版本并跟踪历史。
当然,如果存储库是空的,它就没有多大用处,所以让我们在其中放一个文件。事实上,我们将使用以前的文章中的愚蠢的数学包,这样我们将有几个文件和一个文件夹。现在输入汞状态(或“汞 st”)。您应该会看到类似这样的内容:
C:\repo>hg st
? __init__.py
? add.py
? adv\__init__.py
? adv\fib.py
? adv\sqrt.py
? divide.py
? mods_packs.wpr
? mods_packs.wpu
? multiply.py
? subtract.py
这是我们可能添加到回购中的文件列表。问号表示尚未添加。你会注意到我不小心把一些 Wingware IDE 文件留在了存档中,这些文件的扩展名是 wpr 或 wpu。如果你有翅膀,这些就很方便。如果你没有,那你就不会在乎。假设我们有 Wing,但是我们不想共享我们的 Wing 配置文件。我们需要一种方法将它们从存储库中排除。
从 Mercurial 中排除文件
Mercurial 包含一个名为的特殊文件。hgignore 放在我们的根目录中,Mercurial 将查看它以获得关于忽略什么的指示。您可以使用正则表达式或 glob(或者您可以选择)来告诉 Mercurial 忽略什么。在 Windows 上,您可能需要使用记事本或类似的文本编辑器来创建文件,因为 Windows 资源管理器很笨,不允许您以句点开头命名文件。无论如何,要设置类型(glob 或 regex),您需要在它前面加上“syntax:”这个词。这里有一个例子可以特别清楚地说明这一点:
# use glob syntax.
syntax: glob
*.pyc
*.wpr
*.wpu
这告诉 Mercurial 忽略任何带有以下扩展名的文件:pyc、wpr 或 wpu。它还使用了 glob 语法。如果您重新运行 hg st 命令,您将不会再看到这些 Wing 文件。现在我们已经准备好向回购添加文件了!
如何将文件/目录添加到您的 Mercurial 存储库中
向 Mercurial 添加文件也非常简单。你要做的就是输入: hg add 。下面是我运行它时得到的结果:
C:\repo>hg status
A .hgignore
A __init__.py
A add.py
A adv\__init__.py
A adv\fib.py
A adv\sqrt.py
A divide.py
A multiply.py
A subtract.py
注意每个项目前面的大写字母“A”。这意味着它已经被添加,但是没有提交到存储库中。如果它没有被提交,那么它还没有保存在您的版本控制中。我们应该这么做!你所要做的就是输入 hg commit 或 hg com ,它会打开一个文本编辑器让你输入关于你提交的评论。嗯,实际上这就是应该发生的事情,但是除非你已经建立了一个配置文件,否则你可能会得到这个神秘的消息:提交没有用户名提供。这就是事情变得有趣的地方。您需要为 Mercurial 创建一个配置文件。
如何创建 Mercurial 配置文件
Mercurial 在几个地方查找配置文件。下面是他们文档中列出的顺序:
/.hg/hgrc
(Unix) $HOME/.hgrc
(Windows) %USERPROFILE%\.hgrc
(Windows) %USERPROFILE%\Mercurial.ini
(Windows) %HOME%\.hgrc
(Windows) %HOME%\Mercurial.ini
请注意,如果您创建一个每回购配置文件(第一个示例),hgrc 文件不会以句点开头。否则,在创建带句点的配置时,您会创建一个系统范围的配置,并将它放在上面指定的位置(或者创建一个 Mercurial.ini 文件)。我们将创建一个简单的 repo 配置文件,并将其放在我们的。hg 文件夹。以下是一些示例内容:
[ui]
username = Mike Driscoll
现在,如果您保存它并重试 commit 命令,它应该会工作。在 Windows 上,它会弹出一个记事本实例,你可以在其中写下你正在做的事情的简短评论。如果你不在里面放东西,那么提交会中止,你不会保存任何东西到回购。一旦你提交了它,你可以再次运行 hg st ,它不会返回任何东西。现在,无论何时你在 repo 中编辑一个文件,你都可以运行 hg st ,你会看到一个所有已更改文件的列表。只需让他们添加变更即可。如果你想检查别人的代码呢?很高兴你问了。我们接下来会谈到这个问题!
如何签出 Mercurial 存储库
假设我们想从 bitbucket 查看我的旧 wxPython 音乐播放器项目。为此,您应该键入以下内容:
hg clone https://bitbucket.org/driscollis/mamba
这将在您的硬盘上创建一个 mamba 文件夹,无论您当前在文件系统中的什么位置。因此,如果您已经将目录更改到您的桌面,则该文件夹将放在那里。请注意关键字克隆,后跟一个 URL。这是另一个例子:
hg clone http://hg.python.org/cpython
如果你想对 Python 编程语言的开发有所帮助,这就是检验 Python 编程语言的方法。如果你是一个 Windows 用户,你想要更多的信息,你可以在这里阅读更多的信息。这是一个检验一个共享库的例子。在您上传更改之前,它可能会更改。所以你应该总是做一个拉来确保在你把你的变更推回共享回购之前你有最新的副本。当我想更新我的本地 Python 库时,我会这样做:
C:\Users\mdriscoll\cpython>hg pull
pulling from http://hg.python.org/cpython
searching for changes
adding changesets
adding manifests
adding file changes
added 58 changesets with 109 changes to 36 files
(run 'hg update' to get a working copy)
C:\Users\mdriscoll\cpython>hg update
654 files updated, 0 files merged, 276 files removed, 0 files unresolved
因此,当您下载更改时,您必须进行更新来更新您的本地存储库。然后,当您想要将您的更改发送回服务器存储库时,您可以执行一个 hg 推送。大多数情况下,它会要求您输入用户名和密码,或者您可以在配置文件中设置用户名,然后您只需输入密码。一些存储库也要求 pull 请求的凭证,但是这种情况并不常见。您还可以使用 hg update - rev 来指定要更新到哪个版本。与 log 命令结合使用,找出有哪些修订。
使用 Mercurial 创建补丁
通常,在获得特权之前,你是不允许为开源项目做贡献的,所以你必须创建补丁。幸运的是,Mercurial 让创建补丁变得超级简单!只需克隆(或获取最新的更改)存储库并编辑您需要的文件。然后这样做:
hg diff > example.patch
您可能应该以您更改的文件来命名补丁,但这毕竟是一个示例。如果你在修复一个 bug 的过程中提交了同一个东西的多个补丁,你可能会想通过在每个补丁的末尾添加一个递增的数字来重命名它,这样就很容易分辨哪个是最新的补丁。你可以在这里阅读更多关于向 Python 提交补丁的信息。
其他零碎的东西
还有其他几个命令我们没有时间介绍。可能最需要了解的是 merge ,它允许您将两个存储库合并在一起。你应该阅读他们的文档了解更多。这里列出了你最常看到的典型命令,你只需输入 hg 就能得到:
C:\Users\mdriscoll\cpython>hg
Mercurial Distributed SCM
basic commands:
add add the specified files on the next commit
annotate show changeset information by line for each file
clone make a copy of an existing repository
commit commit the specified files or all outstanding changes
diff diff repository (or selected files)
export dump the header and diffs for one or more changesets
forget forget the specified files on the next commit
init create a new repository in the given directory
log show revision history of entire repository or files
merge merge working directory with another revision
phase set or show the current phase name
pull pull changes from the specified source
push push changes to the specified destination
remove remove the specified files on the next commit
serve start stand-alone webserver
status show changed files in the working directory
summary summarize working directory state
update update working directory (or switch revisions)
use "hg help" for the full list of commands or "hg -v" for details
包扎
现在,您应该已经了解了足够的知识,可以开始在自己的工作中使用 Mercurial 了。这是存储代码和返回到以前版本的一个很好的方法。Mercurial 还使协作变得更加容易。对于那些喜欢点击的人来说,有命令行工具和一直流行的乌龟图形用户界面。祝你好运!
进一步阅读
peewee 介绍——另一种 Python ORM
原文:https://www.blog.pythonlibrary.org/2014/07/17/an-intro-to-peewee-another-python-orm/
我认为除了 SQLAlchemy 之外,尝试一些不同的 Python 对象关系映射器(ORM)会很有趣。我最近偶然发现了一个名为 peewee 的项目。对于这篇文章,我们将从我的 SQLAlchemy 教程中提取例子,并将其移植到 peewee,看看它是如何站起来的。peewee 项目支持 sqlite、postgres 和 MySQL 开箱即用,虽然没有 SQLAlchemy 灵活,但也不错。你也可以通过一个方便的 Flask-peewee 插件在 Flask web 框架中使用 peewee。
无论如何,让我们开始玩这个有趣的小图书馆吧!
入门指南
首先,你得去找皮威。幸运的是,如果您安装了 pip,这真的很容易:
pip install peewee
一旦安装完毕,我们就可以开始了!
创建数据库
用 peewee 创建数据库非常容易。事实上,在 peewee 中创建数据库比在 SQLAlchemy 中更容易。你所需要做的就是调用 peewee 的 SqliteDatabase 方法,如果你想要一个内存中的数据库,把文件的路径或者“:memory:”传递给它。让我们创建一个数据库来保存我们音乐收藏的信息。我们将创建两个表:艺术家和专辑。
# models.py
import peewee
database = peewee.SqliteDatabase("wee.db")
########################################################################
class Artist(peewee.Model):
"""
ORM model of the Artist table
"""
name = peewee.CharField()
class Meta:
database = database
########################################################################
class Album(peewee.Model):
"""
ORM model of album table
"""
artist = peewee.ForeignKeyField(Artist)
title = peewee.CharField()
release_date = peewee.DateTimeField()
publisher = peewee.CharField()
media_type = peewee.CharField()
class Meta:
database = database
if __name__ == "__main__":
try:
Artist.create_table()
except peewee.OperationalError:
print "Artist table already exists!"
try:
Album.create_table()
except peewee.OperationalError:
print "Album table already exists!"
这段代码非常简单。我们在这里所做的就是创建两个定义表的类。我们设置字段(或列),并通过嵌套类 Meta 将数据库连接到模型。然后我们直接调用这个类来创建表。这有点奇怪,因为您通常不会像这样直接调用一个类,而是创建该类的一个实例。然而,这是根据 peewee 的文档推荐的程序,并且效果很好。现在我们准备学习如何向我们的数据库添加一些数据。
如何向表格中插入/添加数据
事实证明,将数据插入我们的数据库也非常容易。让我们来看看:
# add_data.py
import datetime
import peewee
from models import Album, Artist
new_artist = Artist.create(name="Newsboys")
album_one = Album(artist=new_artist,
title="Read All About It",
release_date=datetime.date(1988,12,01),
publisher="Refuge",
media_type="CD")
album_one.save()
albums = [{"artist": new_artist,
"title": "Hell is for Wimps",
"release_date": datetime.date(1990,07,31),
"publisher": "Sparrow",
"media_type": "CD"
},
{"artist": new_artist,
"title": "Love Liberty Disco",
"release_date": datetime.date(1999,11,16),
"publisher": "Sparrow",
"media_type": "CD"
},
{"artist": new_artist,
"title": "Thrive",
"release_date": datetime.date(2002,03,26),
"publisher": "Sparrow",
"media_type": "CD"}
]
for album in albums:
a = Album(**album)
a.save()
bands = ["MXPX", "Kutless", "Thousand Foot Krutch"]
for band in bands:
artist = Artist.create(name=band)
artist.save()
这里我们调用该类的 create 方法来添加乐队或唱片。该类也支持一个 insert_many 方法,但是每当我试图通过 save() 方法保存数据时,我都会收到一个 OperationalError 消息。如果你碰巧知道如何做到这一点,请在评论中给我留言,我会更新这篇文章。作为一种变通方法,我只是循环遍历一个字典列表,并以这种方式添加记录。
更新:《peewee》的作者在 reddit 上回复了我,给了我这个一次添加多条记录的解决方案:
albums = [{"artist": new_artist,
"title": "Hell is for Wimps",
"release_date": datetime.date(1990,07,31),
"publisher": "Sparrow",
"media_type": "CD"
},
{"artist": new_artist,
"title": "Love Liberty Disco",
"release_date": datetime.date(1999,11,16),
"publisher": "Sparrow",
"media_type": "CD"
},
{"artist": new_artist,
"title": "Thrive",
"release_date": datetime.date(2002,03,26),
"publisher": "Sparrow",
"media_type": "CD"}
]
Album.insert_many(albums).execute()
现在我们准备学习如何修改数据库中的记录!
使用基本查询通过 peewee 修改记录
在数据库世界中,修改记录是很常见的事情。peewee 项目使修改数据变得非常容易。下面是一些演示如何操作的代码:
# edit_data.py
import peewee
from models import Album, Artist
band = Artist.select().where(Artist.name=="Kutless").get()
print band.name
# shortcut method
band = Artist.get(Artist.name=="Kutless")
print band.name
# change band name
band.name = "Beach Boys"
band.save()
album = Album.select().join(Artist).where(
(Album.title=="Thrive") & (Artist.name == "Newsboys")
).get()
album.title = "Step Up to the Microphone"
album.save()
基本上,我们只需查询这些表,以获得我们想要修改的艺术家或专辑。前两个查询做同样的事情,但是一个比另一个短。这是因为 peewee 提供了一种快捷的查询方法。要实际更改记录,我们只需将返回对象的属性设置为其他值。在这种情况下,我们把乐队的名字从“无裤”改成了“沙滩男孩”。
最后一个查询演示了如何创建一个 SQL 连接,它允许我们在两个表之间进行匹配。如果您碰巧拥有两张同名的 CD,但您只想让查询返回与名为“Newsboys”的乐队相关联的专辑,那么这就很好了。
这些查询有点难以理解,所以您可以将它们分成更小的部分。这里有一个例子:
query = Album.select().join(Artist)
qry_filter = (Album.title=="Step Up to the Microphone") & (Artist.name == "Newsboys")
album = query.where(qry_filter).get()
这更容易跟踪和调试。您也可以对 SQLAlchemy 的查询使用类似的技巧。
如何删除 peewee 中的记录
在 peewee 中从表中删除记录只需要很少的代码。看看这个:
# del_data.py
from models import Artist
band = Artist.get(Artist.name=="MXPX")
band.delete_instance()
我们所要做的就是查询我们想要删除的记录。一旦我们有了实例,我们就调用它的 delete_instance 方法,这样就删除了记录。真的就这么简单!
包扎
peewee 项目很酷。它最大的缺点是它支持的数据库后端数量有限。然而,该项目比 SQLAlchemy 更容易使用,我认为这很神奇。peewee 项目的文档非常好,值得一读,以了解本教程中没有涉及的所有其他功能。试试看,看你怎么想!
额外资源
pyfpdf 简介——一个简单的 Python PDF 生成库
今天我们将看到一个简单的 PDF 生成库,名为 pyfpdf ,它是一个 php 库 FPDF 的一个端口。这不是 Reportlab 的替代品,但它确实为您提供了创建简单 pdf 的足够能力,并且可能满足您的需求。让我们来看看它能做什么!
注:不再维护 PyFPDF。已经换成了fpdf 2
安装 pyfpdf
您可以只使用 pip 来安装 pyfpdf:
pip install pyfpdf
试用 pyfpdf
与任何新的库一样,您需要实际编写一些代码来查看它是如何工作的。下面是创建 PDF 的最简单的脚本之一:
import pyfpdf
pdf = pyfpdf.FPDF(format='letter')
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.cell(200, 10, txt="Welcome to Python!", align="C")
pdf.output("tutorial.pdf")
注意,当我们初始化我们的 FPDF 对象时,我们需要告诉它我们希望结果是“字母”大小。默认为“A4”。接下来,我们需要添加一个页面,设置字体,并把一些文本。 pdf.cell 调用有点不直观。前两个参数是宽度和高度,指定了传入文本的位置。 align 参数只接受单个字母缩写,您必须查看源代码才能弄清楚。在这种情况下,我们通过传递一个“C”来使文本居中。最后一行接受两个参数:pdf 名称和目的地。如果没有目的地,那么 PDF 将输出到脚本运行的目录。
如果您想添加另一行呢?如果你编辑单元格的大小,然后创建另一个单元格,你可以在末尾添加更多的文本。如果您需要换行符,那么您可以将代码更改为以下内容:
import pyfpdf
pdf = pyfpdf.FPDF(format='letter')
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.cell(200, 10, txt="Welcome to Python!", ln=1, align="C")
pdf.cell(200,10,'Powered by FPDF',0,1,'C')
pdf.output("tutorial.pdf")
这产生了下面的 PDF:tutorial.pdf
添加页眉、页脚和分页符
pyfpdf 的 Google 代码站点上的教程展示了如何做页眉、页脚和分页符。它不能运行是因为一个方法名肯定已经改变了,而且代码是用“this”而不是“self”写的,所以我重写了它并稍微清理了一下。代码如下:
import pyfpdf
########################################################################
class MyPDF(pyfpdf.FPDF):
""""""
#----------------------------------------------------------------------
def header(self):
"""
Header on each page
"""
# insert my logo
self.image("logo.png", x=10, y=8, w=23)
# position logo on the right
self.cell(w=80)
# set the font for the header, B=Bold
self.set_font("Arial", style="B", size=15)
# page title
self.cell(40,10, "Python Rules!", border=1, ln=0, align="C")
# insert a line break of 20 pixels
self.ln(20)
#----------------------------------------------------------------------
def footer(self):
"""
Footer on each page
"""
# position footer at 15mm from the bottom
self.set_y(-15)
# set the font, I=italic
self.set_font("Arial", style="I", size=8)
# display the page number and center it
pageNum = "Page %s/{nb}" % self.page_no()
self.cell(0, 10, pageNum, align="C")
#----------------------------------------------------------------------
if __name__ == "__main__":
pdf = MyPDF()
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font("Times", size=12)
# put some lines on the page
for i in range(1, 50):
pdf.cell(0, 10, "Line number %s" % i, border=0, ln=1)
pdf.output("tutorial2.pdf")
这创建了下面的 PDF:tutorial2.pdf
这一次,我们创建了 FPDF 的一个子类,并覆盖了它的 header 和 footer 方法,因为它们实际上不做任何事情(也就是说,它们是存根)。在我们的头中,我们创建一个图像对象,并传入一个徽标文件以及徽标的 x/y 位置和宽度(23)。如果你关心保持长宽比正常,你也可以通过一个高度。然后我们定位它,并为标题插入一串文本。最后,我们放入一个换行符。
页脚设置为距离底部 15 毫米。它也是 8 磅的 Arial 斜体。官方教程的错误是它调用了 self。PageNo(),但那并不存在。然而有一个 page_no 方法似乎可以替代它,所以我使用了它。然后在脚本的底部,我们实际上创建了我们的 pdf 对象,并告诉它写一串行。如果您运行这个脚本,您应该得到一个 3 页的文档。
使用 pyfpdf 从 HTML 生成 pdf
我的一个读者指出 pyfpdf 也可以从基本 HTML 生成 pdf。我不知道我怎么没发现,但这是真的!你可以!你可以在该项目的维基上读到它。我在下面复制一个稍加修改的例子:
html = """
html2fpdf
基本用法
您现在可以轻松打印文本,同时混合不同的样式:粗体、斜体、下划线或 一次全部 !
也可以插入类似这样的超链接 www.mousevspython.comg ,或者在图片中包含超链接。只需点击下面的一个。
样本列表
- 选项 3
标题 1 标题 2
单元格 1 单元格 2
细胞 2 细胞 3
"""从 pyfpdf 导入 fpdf,HTMLMixin 类 my pdf(FPDF,html mixin):pass pdf = my pdf()# First page pdf . add _ page()pdf . write _ html(html)pdf . output(' html . pdf ',' F ')
这将创建以下 PDF:html.pdf
包扎
他们的网站上还有一个关于颜色和换行符的教程,但我会把它留给你作为练习。我在这里没有看到任何关于绘图、插入表格或图形、自定义字体嵌入或 Reportlab 中可用的许多其他功能的内容,但这应该是一个简单的 PDF 生成库。如果您需要更高级的特性,那么您当然应该看看 Reportlab,甚至是基于它的一些分支项目(我想到了 rst2pdf 或 xhtml2pdf)。
进一步阅读
源代码
PyPDF2 简介
原文:https://www.blog.pythonlibrary.org/2018/06/07/an-intro-to-pypdf2/
PyPDF2 包是一个纯 Python 的 PDF 库,你可以用它来分割、合并、裁剪和转换你的 PDF 文件中的页面。根据 PyPDF2 网站,你也可以使用 PyPDF2 添加数据,查看选项和密码。最后,您可以使用 PyPDF2 从 PDF 中提取文本和元数据。
PyPDF2 实际上是 Mathiew Fenniak 编写并于 2005 年发布的原始 PyPDF 的派生版本。然而,最初的 pyPdf 的最后一次发布是在 2014 年。一家名为 Phaseit,Inc .的公司与 Mathieu 进行了对话,并最终赞助 PyPDF2 作为 PyPDF 的一个分支
在撰写本书时,PyPDF2 包自 2016 年以来一直没有发布。然而,它仍然是一个可靠而有用的包,值得你花时间去学习。
下面列出了我们将在本文中学到的内容:
- 提取元数据
- 拆分文档
- 将 2 个 PDF 文件合并为 1 个
- 旋转页面
- 覆盖/水印页面
- 加密/解密
让我们从学习如何安装 PyPDF2 开始!
装置
PyPDF2 是一个纯 Python 包,所以您可以使用 pip 安装它(假设 pip 在您的系统路径中):
python -m pip install pypdf2
通常,您应该将第三方 Python 包安装到 Python 虚拟环境中,以确保它按照您想要的方式工作。
从 pdf 中提取元数据
您可以使用 PyPDF2 从任何 PDF 中提取大量有用的数据。例如,您可以了解文档的作者、标题和主题以及有多少页。让我们从 Leanpub 下载这本书的样本来找出答案。我下载的样本名为“reportlab-sample.pdf”。我将把这个 PDF 文件包含在 Github 源代码中,供您使用。
代码如下:
# get_doc_info.py
from PyPDF2 import PdfFileReader
def get_info(path):
with open(path, 'rb') as f:
pdf = PdfFileReader(f)
info = pdf.getDocumentInfo()
number_of_pages = pdf.getNumPages()
print(info)
author = info.author
creator = info.creator
producer = info.producer
subject = info.subject
title = info.title
if __name__ == '__main__':
path = 'reportlab-sample.pdf'
get_info(path)
这里我们从 PyPDF2 导入 PdfFileReader 类。这个类让我们能够使用各种访问器方法读取 PDF 并从中提取数据。我们做的第一件事是创建我们自己的 get_info 函数,它接受 PDF 文件路径作为唯一的参数。然后,我们以只读二进制模式打开文件。接下来,我们将该文件处理程序传递给 PdfFileReader,并创建它的一个实例。
现在我们可以通过使用 getDocumentInfo 方法从 PDF 中提取一些信息。这将返回一个pypdf 2 . pdf . document information的实例,它具有以下有用的属性:
- 作者
- 创造者
- 生产者
- 科目
- 标题
如果打印出 DocumentInformation 对象,您将看到以下内容:
{'/Author': 'Michael Driscoll',
'/CreationDate': "D:20180331023901-00'00'",
'/Creator': 'LaTeX with hyperref package',
'/Producer': 'XeTeX 0.99998',
'/Title': 'ReportLab - PDF Processing with Python'}
我们还可以通过调用 getNumPages 方法来获得 PDF 中的页数。
从 pdf 中提取文本
PyPDF2 对从 PDF 中提取文本的支持有限。不幸的是,它没有提取图像的内置支持。我在 StackOverflow 上看到过一些使用 PyPDF2 提取图像的菜谱,但是代码示例似乎很随意。
让我们尝试从上一节下载的 PDF 的第一页中提取文本:
# extracting_text.py
from PyPDF2 import PdfFileReader
def text_extractor(path):
with open(path, 'rb') as f:
pdf = PdfFileReader(f)
# get the first page
page = pdf.getPage(1)
print(page)
print('Page type: {}'.format(str(type(page))))
text = page.extractText()
print(text)
if __name__ == '__main__':
path = 'reportlab-sample.pdf'
text_extractor(path)
您会注意到,这段代码的开始方式与我们之前的示例非常相似。我们仍然需要创建一个 PdfFileReader 的实例。但是这一次,我们使用 getPage 方法抓取页面。PyPDF2 是从零开始的,很像 Python 中的大多数东西,所以当你给它传递一个 1 时,它实际上抓取了第二页。在这种情况下,第一页只是一个图像,所以它不会有任何文本。
有趣的是,如果你运行这个例子,你会发现它没有返回任何文本。相反,我得到的是一系列换行符。不幸的是,PyPDF2 对提取文本的支持非常有限。即使它能够提取文本,它也可能不会按照您期望的顺序排列,并且间距也可能不同。
要让这个示例代码工作,您需要尝试在不同的 PDF 上运行它。我在美国国税局的网站上找到了一个:https://www.irs.gov/pub/irs-pdf/fw9.pdf
这是为个体经营者或合同工准备的 W9 表格。它也可以用在其他场合。无论如何,我下载了它作为w9.pdf。如果您使用 PDF 文件而不是示例文件,它会很高兴地从第 2 页中提取一些文本。我不会在这里复制输出,因为它有点长。
分割 pdf
PyPDF2 包让您能够将一个 PDF 分割成多个 PDF。你只需要告诉它你想要多少页。在这个例子中,我们将打开上一个例子中的 W9 PDF,并遍历它的所有六个页面。我们将分裂出每一页,把它变成自己的独立的 PDF 文件。
让我们来看看如何实现:
# pdf_splitter.py
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
def pdf_splitter(path):
fname = os.path.splitext(os.path.basename(path))[0]
pdf = PdfFileReader(path)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf.getPage(page))
output_filename = '{}_page_{}.pdf'.format(
fname, page+1)
with open(output_filename, 'wb') as out:
pdf_writer.write(out)
print('Created: {}'.format(output_filename))
if __name__ == '__main__':
path = 'w9.pdf'
pdf_splitter(path)
对于这个例子,我们需要导入 PdfFileReader 和pdffilerwriter。然后我们创建一个有趣的小函数,叫做 pdf_splitter 。它接受输入 PDF 的路径。这个函数的第一行将获取输入文件的名称,减去扩展名。接下来,我们打开 PDF 并创建一个 reader 对象。然后我们使用 reader 对象的 getNumPages 方法遍历所有页面。
在循环的内部,我们创建了一个 PdfFileWriter 的实例。然后,我们使用其 addPage 方法向 writer 对象添加一个页面。这个方法接受一个 page 对象,所以为了获取 page 对象,我们调用 reader 对象的 getPage 方法。现在我们已经向 writer 对象添加了一个页面。下一步是创建一个唯一的文件名,我们使用原始文件名加上单词“page”加上页码+ 1。我们添加 1 是因为 PyPDF2 的页码是从零开始的,所以第 0 页实际上是第 1 页。
最后,我们以写入二进制模式打开新文件名,并使用 PDF writer 对象的 write 方法将对象的内容写入磁盘。
将多个 pdf 合并在一起
现在我们有了一堆 pdf 文件,让我们学习如何把它们合并在一起。这样做的一个有用的用例是企业将他们的日报合并成一个 PDF。为了工作和娱乐,我需要合并 pdf。我脑海中浮现的一个项目是扫描文档。根据您使用的扫描仪,您可能最终会将一个文档扫描成多个 pdf,因此能够将它们再次合并在一起会非常棒。
当最初的 PyPdf 问世时,让它将多个 Pdf 合并在一起的唯一方法是这样的:
# pdf_merger.py
import glob
from PyPDF2 import PdfFileWriter, PdfFileReader
def merger(output_path, input_paths):
pdf_writer = PdfFileWriter()
for path in input_paths:
pdf_reader = PdfFileReader(path)
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
with open(output_path, 'wb') as fh:
pdf_writer.write(fh)
if __name__ == '__main__':
paths = glob.glob('w9_*.pdf')
paths.sort()
merger('pdf_merger.pdf', paths)
这里我们创建了一个 PdfFileWriter 对象和几个 PdfFileReader 对象。对于每个 PDF 路径,我们创建一个 PdfFileReader 对象,然后遍历它的页面,将每个页面添加到我们的 writer 对象中。然后,我们将 writer 对象的内容写到磁盘上。
PyPDF2 通过创建一个 PdfFileMerger 类使这变得简单了一点:
# pdf_merger2.py
import glob
from PyPDF2 import PdfFileMerger
def merger(output_path, input_paths):
pdf_merger = PdfFileMerger()
file_handles = []
for path in input_paths:
pdf_merger.append(path)
with open(output_path, 'wb') as fileobj:
pdf_merger.write(fileobj)
if __name__ == '__main__':
paths = glob.glob('fw9_*.pdf')
paths.sort()
merger('pdf_merger2.pdf', paths)
这里我们只需要创建 PdfFileMerger 对象,然后遍历 PDF 路径,将它们添加到我们的合并对象中。PyPDF2 将自动追加整个文档,因此您不需要自己遍历每个文档的所有页面。然后我们把它写到磁盘上。
PdfFileMerger 类也有一个可以使用的合并方法。它的代码定义如下:
def merge(self, position, fileobj, bookmark=None, pages=None,
import_bookmarks=True):
"""
Merges the pages from the given file into the output file at the
specified page number.
:param int position: The *page number* to insert this file. File will
be inserted after the given number.
:param fileobj: A File Object or an object that supports the standard
read and seek methods similar to a File Object. Could also be a
string representing a path to a PDF file.
:param str bookmark: Optionally, you may specify a bookmark to be
applied at the beginning of the included file by supplying the
text of the bookmark.
:param pages: can be a :ref:`Page Range ` or a
``(start, stop[, step])`` tuple
to merge only the specified range of pages from the source
document into the output document.
:param bool import_bookmarks: You may prevent the source
document's bookmarks from being imported by specifying this as
``False``.
"""
基本上,merge 方法允许您通过页码告诉 PyPDF 将页面合并到哪里。因此,如果您已经创建了一个包含 3 页的合并对象,您可以告诉合并对象在特定位置合并下一个文档。这允许开发者做一些非常复杂的合并操作。试试看,看看你能做什么!
旋转页面
PyPDF2 让您能够旋转页面。但是,您必须以 90 度的增量旋转。您可以顺时针或逆时针旋转 PDF 页面。这里有一个简单的例子:
# pdf_rotator.py
from PyPDF2 import PdfFileWriter, PdfFileReader
def rotator(path):
pdf_writer = PdfFileWriter()
pdf_reader = PdfFileReader(path)
page1 = pdf_reader.getPage(0).rotateClockwise(90)
pdf_writer.addPage(page1)
page2 = pdf_reader.getPage(1).rotateCounterClockwise(90)
pdf_writer.addPage(page2)
pdf_writer.addPage(pdf_reader.getPage(2))
with open('pdf_rotator.pdf', 'wb') as fh:
pdf_writer.write(fh)
if __name__ == '__main__':
rotator('reportlab-sample.pdf')
这里,我们像以前一样创建 PDF 阅读器和编写器对象。然后我们得到传入的 PDF 的第一页和第二页。然后我们将第一页顺时针或向右旋转 90 度。然后我们将第二页逆时针旋转 90 度。最后,我们将第三页以正常方向添加到 writer 对象中,并写出新的 3 页 PDF 文件。
如果您打开 PDF,您会发现前两页现在以彼此相反的方向旋转,第三页以正常方向旋转。
覆盖/水印页面
PyPDF2 还支持将 PDF 页面合并在一起,或者将页面相互叠加。如果您想要为 PDF 中的页面添加水印,这将非常有用。例如,我使用的一个电子书分销商会在我的书的 PDF 版本上“水印”购买者的电子邮件地址。我见过的另一个用例是在页面边缘添加打印机控制标记,以告知打印机某个文档何时到达其结尾。
对于这个例子,我们将采用我在博客中使用的一个徽标“鼠标与 Python”,并将其覆盖在前面的 W9 表单之上:
# watermarker.py
from PyPDF2 import PdfFileWriter, PdfFileReader
def watermark(input_pdf, output_pdf, watermark_pdf):
watermark = PdfFileReader(watermark_pdf)
watermark_page = watermark.getPage(0)
pdf = PdfFileReader(input_pdf)
pdf_writer = PdfFileWriter()
for page in range(pdf.getNumPages()):
pdf_page = pdf.getPage(page)
pdf_page.mergePage(watermark_page)
pdf_writer.addPage(pdf_page)
with open(output_pdf, 'wb') as fh:
pdf_writer.write(fh)
if __name__ == '__main__':
watermark(input_pdf='w9.pdf',
output_pdf='watermarked_w9.pdf',
watermark_pdf='watermark.pdf')
我们在这里做的第一件事是从 PDF 中提取水印页面。然后,我们打开要应用水印的 PDF。我们使用一个 for 循环来遍历它的每个页面,并调用页面对象的 mergePage 方法来应用水印。接下来,我们将水印页面添加到 PDF writer 对象中。一旦循环结束,我们就把新的水印版本写到磁盘上。
这是第一页的样子:

这很简单。
PDF 加密
PyPDF2 包还支持向现有 PDF 添加密码和加密。你可能还记得第 10 章,pdf 支持用户密码和所有者密码。用户密码仅允许用户打开和阅读 PDF,但可能会对 PDF 应用一些限制,例如,可能会阻止用户打印。据我所知,您实际上不能使用 PyPDF2 应用任何限制,或者它只是没有被很好地记录。
以下是如何使用 PyPDF2 向 PDF 添加密码:
# pdf_encryption.py
from PyPDF2 import PdfFileWriter, PdfFileReader
def encrypt(input_pdf, output_pdf, password):
pdf_writer = PdfFileWriter()
pdf_reader = PdfFileReader(input_pdf)
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
pdf_writer.encrypt(user_pwd=password, owner_pwd=None,
use_128bit=True)
with open(output_pdf, 'wb') as fh:
pdf_writer.write(fh)
if __name__ == '__main__':
encrypt(input_pdf='reportlab-sample.pdf',
output_pdf='encrypted.pdf',
password='blowfish')
我们在这里所做的只是创建了一组 PDF 阅读器,编写对象并用阅读器阅读所有页面。然后,我们将这些页面添加到指定的 writer 对象中,并添加了指定的密码。如果只设置用户密码,则所有者密码会自动设置为用户密码。无论何时添加密码,默认情况下都会应用 128 位加密。如果您将该参数设置为 False,则 PDF 将以 40 位加密进行加密。
包扎
在本文中,我们涵盖了许多有用的信息。您学习了如何从 pdf 中提取元数据和文本。我们发现了如何分割和合并 pdf。您还学习了如何在 PDF 中旋转页面和应用水印。最后,我们发现 PyPDF2 可以为我们的 PDF 添加加密和密码。
相关阅读
- PyPDF2 文档
- PyPDF2 Github page
- 自动化枯燥的东西- 第 13 章:使用 PDF 和 Word 文档
Python 属性介绍(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/20/an-intro-to-python-properties-video/
在本视频教程中,您将与 Mike Driscoll 一起学习 Python 属性的基础知识。
您将了解到:
- Python 属性
- Setters 和 Getters
- 删除者
https://www.youtube.com/embed/3c0k-idqDjU?feature=oembed
Python 虚拟环境简介
原文:https://www.blog.pythonlibrary.org/2021/01/27/an-intro-to-python-virtual-environments/
Python 语言内置了虚拟环境的概念。Python 虚拟环境是一个可以安装第三方包进行测试而不影响系统 Python 安装的环境。每个虚拟环境都有自己的一组安装包,并且根据虚拟环境及其设置方式,可能还有自己的 Python 二进制和标准库副本。
有几种不同的方法来创建 Python 虚拟环境。您将关注以下两种方法:
- 内置
venv模块 virtualenv套餐
您还可以使用其他工具来创建虚拟 Python 环境。在本章的最后一节,你会学到一些关于它们的知识。
现在,让我们从查看venv库开始吧!
Python 的venv库
Python 在 3.3 版本中增加了venv模块。你可以在这里阅读所有相关内容:
要使用venv,您可以使用-m标志运行 Python。-m标志告诉 Python 运行跟在-m后面的指定模块。
让我们试一试。在 Windows 上打开一个cmd.exe或者在 Mac 或 Linux 上打开一个终端。然后键入以下内容:
python -m venv test
这将在终端会话中打开的任何目录下创建一个名为 test 的文件夹。
要激活虚拟环境,您需要将目录切换到 test 文件夹,并在 Linux/Mac 上运行:
source bin/activate
如果你是 Windows 用户,你可以通过运行脚本子文件夹中的 bat 文件来激活它,你可以在你的测试文件夹中找到这个子文件夹。
现在,您应该会看到类似这样的内容:

请注意,提示的名称现在是“test”。这表明虚拟环境已经被激活,可以使用了。
您现在可以安装新的包,它们将安装到您的虚拟环境中,而不是您的系统 Python 中。
完成后,您可以通过在终端或命令提示符下运行 deactivate 来停用虚拟环境。deactivate的确切性质是依赖于实现的:它可能是一个脚本或批处理文件或其他东西。
PyCharm、WingIDE 和 VS 代码都支持使用 Python 虚拟环境。事实上,您通常可以在 IDE 中创建和激活它们,而不是在命令行中。
virtualenv套餐
virtualenv包是创建 Python 虚拟环境的原始方法。你可以在这里阅读virtualenv包的文档:
virtualenv的一个子集最终被集成到 Python 自己的venv模块中。实际的virtualenv包在以下几个方面比venv好:
- 这样更快
- 更易于扩展
- 可以为多个 Python 版本创建虚拟环境
- 可以通过
pip升级 - 拥有丰富的编程 API
您可以使用pip安装virtualenv:
pip install virtualenv
安装后,您可以使用您的终端或cmd.exe创建一个虚拟环境,如下所示:
virtualenv FOLDER_NAME
激活和停用虚拟环境的工作方式与您使用 Python 的venv模块创建虚拟环境时完全一样。
有相当多的命令行参数可以和virtualenv一起使用。你可以在这里阅读完整的列表:
https://virtualenv.pypa.io/en/latest/cli_interface.html
大多数情况下,您可以使用默认值。但是有时候配置您的虚拟环境来使用其他的pip版本,或者让它访问您系统的 site-packages 文件夹也是不错的。点击上面的链接,看看你能用virtualenv做些什么。
其他工具
您还可以使用其他工具来处理 Python 虚拟环境。以下是几个例子:
- 蟒蛇-https://www.anaconda.com/
- https://pypi.org/project/pipx/
- pipenv-https://github . com/pypa/pipenv
Anaconda 有自己的创建虚拟环境的工具。
另外两个是用于创建和管理虚拟环境的流行包。pipx和pipenv都挺受欢迎的。您应该仔细阅读它们,并确定它们是否对您自己的项目有用。
总结
Python 虚拟环境是隔离您的系统 Python 的好方法,同时允许您测试新的包。您可以通过使用多个虚拟环境来测试一个包的多个版本。完成后,您只需删除虚拟环境的文件夹。
这允许快速迭代以验证您的包装堆中没有任何东西导致破损。标准的实践是,每当您测试一个新的包时,总是使用虚拟 Python 环境。
去试一试吧。你很快就会发现这已经成为你的第二天性,而且超级有用!
Introduction to Python Web Framework (Video)
原文: https://www。博客。python 库。org/2022/06/09/an-intro-to-python-we b-frameworks-video/
In this video, you can learn about some Python web frameworks.
https://www.youtube.com/embed/YD1dFh23Y4s?feature=oembed
The network framework mentioned in the video
- 姜戈——https://www.djangoproject.com/
- 烧瓶——https://flask.palletsprojects.com/en/2.1.x/
- 金字塔——https://trypyramid.com/
- FastAPI-https://fastapi.tiangolo.com/
- CherryPy-https://docs.cherrypy.dev/en/latest/
- 涡轮齿轮-https://turbogears.org/
- web2py-http://www.web2py.com/
- 瓶子-https://bottlepy.org/docs/dev/
Python content management system
- plone-https://plone.org/
- 姜戈 CMS-https://www.django-cms.org/en/
- 鹡鸰 CMS-https://wagtail.org/
Python 内置函数介绍
原文:https://www.blog.pythonlibrary.org/2021/02/17/an-intro-to-pythons-built-in-functions/
内置是 Python 中有点被忽视的部分。你每天都在使用它们,但是有一些被忽视了,或者只是没有充分发挥它们的潜力。本文不会涵盖 Python 中的所有内置功能,而是将重点放在那些您可能不会每天使用的功能上。
任何()
内置的 any() 接受一个 iterable,如果 iterable 中的任何元素为 True,将返回 True。让我们来看一个例子:
>>> any([0,0,0,1])
True
在这种情况下,您传递给 any() 一个由 0 和 1 组成的列表。因为那里有一个,它返回 True。你可能想知道你什么时候会用到这个内置的。一开始我也是。在我的一份工作中出现的一个例子涉及到一个非常复杂的用户界面,我必须在那里测试各种功能。我需要测试的一个项目是,某个小部件列表是否在不应该显示或启用的时候显示或启用了。内置的 any() 对此非常有用。
这里有一个例子可以说明我所说的内容,尽管这不是我实际使用的代码:
>>> widget_one = ''
>>> widget_two = ''
>>> widget_three = 'button'
>>> widgets_exist = any([widget_one, widget_two, widget_three])
>>> widgets_exist
True
在本例中,您将查询用户界面,询问是否存在部件 1 到部件 3,并将响应放入一个列表中。如果它们中的任何一个返回 True,那么就会产生一个错误。
您可能想要检查 Python 的所有内置功能,因为它具有类似的功能,除了只有当 iterable 中的每一项都为 True 时,它才会返回 True。
枚举()
你是否曾经需要遍历一个列表,并且需要知道你在列表中的位置?您可以添加一个在循环时递增的计数器,或者使用 Python 内置的 enumerate() 函数!让我们用绳子试一下!
>>> my_string = 'abcdefg'
>>> for pos, letter in enumerate(my_string):
... print (pos, letter)
...
0 a
1 b
2 c
3 d
4 e
5 f
6 g
在本例中,您有一个 6 个字母的字符串。在循环中,将字符串包装在枚举调用中。这将返回 iterable 中每一项的位置以及值。你把它们都打印出来,这样你就能看到发生了什么。我个人发现了很多 enumerate() 的用例。我相信你也会的。
eval()
内置的 eval() 在 Python 社区中颇具争议。原因是 eval 接受字符串并运行它们。如果您允许用户输入任何要被 eval 解析和评估的字符串,那么您就犯了一个严重的安全漏洞。但是,如果使用 eval 的代码不能被用户交互,只能被开发人员交互,那么就可以使用。有些人会认为它仍然不安全,但是如果你有一个流氓开发人员,他们做其他事情会比使用 eval 造成更多的伤害。
让我们看一个简单的例子:
>>> var = 10
>>> source = 'var * 2'
>>> eval(source)
20
这里,您创建了两个变量。第一个被赋予整数 10。第二个有一个字符串,和你刚刚定义的变量有相同的字母,看起来你要把它乘以 2。然而,它只是一个字符串,所以它不做任何事情。但是有了 eval() ,就可以让它做点什么了!你可以在下一行看到它的运行,你把字符串传递给 eval,得到一个结果。这就是为什么人们认为 eval 可能是危险的。
还有一个内置函数叫做 exec() ,支持 Python 代码的动态执行。这也是一个有点“危险”的内置,但它没有 eval() 的坏名声。这是一个简洁的小工具,但要小心使用。
过滤器()
filter() 内置函数将接受一个函数和一个 iterable,并为 iterable 中那些传入函数返回 True 的元素返回一个迭代器。这句话听起来有点令人费解,所以让我们来看一个例子:
>>> def less_than_ten(x):
... return x < 10
...
>>> my_list = [1, 2, 3, 10, 11, 12]
>>> for item in filter(less_than_ten, my_list):
... print(item)
...
1
2
3
这里您创建了一个简单的函数来测试您传递给它的整数是否小于 10。如果是,则返回真;否则,返回假。接下来,创建一个包含 6 个整数的列表,其中一半小于 10。最后,使用 filter() 过滤掉大于 10 的整数,只打印小于 10 的整数。
你可能还记得 itertools 模块有一个类似于这个叫做 filterfalse 的功能。那个函数与这个函数相反,只在函数返回 False 时返回 iterable 的元素。
地图()
内置的 map() 也接受一个函数和一个 iterable,并返回一个迭代器,迭代器将函数应用于 iterable 中的每一项。让我们看一个简单的例子:
>>> def doubler(x):
... return x * 2
...
>>> my_list = [1, 2, 3, 4, 5]
>>> for item in map(doubler, my_list):
... print(item)
...
2
4
6
8
10
你定义的第一件事是一个函数,无论传递给它什么,它都会加倍。接下来,你有一个整数列表,1-5。最后,为创建一个循环,该循环遍历用我们的函数和列表调用 map 时返回的迭代器。循环中的代码将打印出结果。
map 和 filter 函数基本上复制了 Python 3 中生成器表达式的特性。在 Python 2 中,它们复制了列表理解的功能。您可以将上面的代码缩短一点,让它返回一个列表,如下所示:
>>> list(map(doubler, my_list))
[2, 4, 6, 8, 10]
但是你可以用列表理解做同样的事情:
>>> [doubler(x) for x in my_list]
[2, 4, 6, 8, 10]
所以你想用哪个真的取决于你。
zip()
内置的 zip()接受一系列 iterables,并从每个 iterables 中聚合元素。让我们看看这意味着什么:
>>> keys = ['x', 'y', 'z']
>>> values = [5, 6, 7]
>>> zip(keys, values)
<zip object at 0x7fc76575a548>
>>> list(zip(keys, values))
[('x', 5), ('y', 6), ('z', 7)]
在本例中,您有两个大小相同的列表。接下来,使用 zip 函数将它们压缩在一起。这只是返回一个 zip 对象,所以您将它包装在对内置 list 的调用中,以查看结果。你最终会得到一个元组列表。您可以在这里看到,zip 按照位置匹配每个列表中的条目,并将它们放入元组中。
zip()最流行的一个用例是获取两个列表,并将它们转换成一个字典:
>>> keys = ['x', 'y', 'z']
>>> values = [5, 6, 7]
>>> my_dict = dict(zip(keys, values))
>>> my_dict
{'x': 5, 'y': 6, 'z': 7}
当你将一系列元组传递给 Python 的 dict() 内置时,它会创建一个字典,如上图所示。我在自己的代码中经常使用这种技术。
包扎
虽然这是一个简短的旅程,但我希望它能让您很好地了解 Python 的内置功能给了您多大的力量。还有很多其他你每天都在用的,比如 list,dict 和 dir。你在本章中学到的内置函数可能不会每天都用到,但在某些情况下会非常有用。实际上,我用了整整一章来介绍一种叫做 super 的特殊内置功能,你可以在本书的后面读到。享受这些乐趣,并确保查找文档,看看还有什么其他的珠宝存在。
相关阅读
Introduction of difflib module in Python (video)
原文: https://www。博客。python 库。org/2022/07/05/an-intro-to-python-difflib-module-video/
In this latest tutorial written by Mike Driscoll, learn the basic knowledge of Python's difflib module.
What will you learn?
- Get a close match
- Use different
- Get unified difference
- 获取 HTML 差异
https://www.youtube.com/embed/FxdXEufiZoI?feature=oembed
Python 的命名元组介绍(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/06/an-intro-to-pythons-namedtuple-video/
在 Mike Driscoll 的视频教程中学习 Python 的基础知识
您将学到的内容:
- 常规元组
- 什么是
namedtuple? - 创建一个
namedtuple - 将一个
dict转换成一个namedtuple - 键入一个
namedtuple
https://www.youtube.com/embed/tzX8Pjn2mhI?feature=oembed
Python 的包安装程序简介:pip(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/02/an-intro-to-pythons-package-installer-pip-video/
在本教程中,您将了解 Python 的包安装程序 pip。
您将发现如何执行以下操作:
- 安装软件包
- 探索命令行选项
- 使用 requirements.txt 安装
- Upgrading a Package
- Checking What's Installed
- Uninstalling Packages
https://www.youtube.com/embed/UKOCoUvQXRU?feature=oembed
rst2pdf 简介——用 Python 将重构的文本转换成 pdf
用 Python 创建 pdf 有几种很酷的方法。在本文中,我们将关注一个叫做 rst2pdf 的很酷的小工具,它获取一个包含重构文本的文本文件,并将其转换为 pdf。这个 rst2pd f 包需要 Reportlab 才能运行。这不会是一个关于重构文本的教程,尽管我们将不得不在某种程度上讨论它,只是为了理解发生了什么。
入门指南
首先,我们需要创建一个带有所需标记的文档。让我们先做那件事。这里有一些简单的重组文本,混合了一些指令。我们将在你有机会阅读代码后解释一切:
.. header:: Python Rules! - page ###Page###
=====
Title
这是一些废话
.. raw:: pdf
一列分页
新章节
或者说
..代码块::python
import urllib
import urllib2
import webbrowser
URL = " http://duck duck go . com/html "
data = urllib . urlencode({ ' q ':' Python ' })
results = urllib 2 . urlopen(URL,data)
with open(" results . html "," w ")as f:
f . write(results . read())
webbrowser . open(" results . html ")
前几行定义了每页的标题。在这种情况下,我们将有“Python 规则!”打印在每一页的顶部,并附有页码。还有其他几种特殊的散列标记插入指令可用。你应该查看官方文档以获得更多相关信息。然后我们有了一个称号。请注意,它的前面和后面有一串等号,与文本的长度相同。这告诉我们,这个文本将被样式化和居中。下面这一行只是出于演示目的的蹩脚句子。接下来是另一个特殊的指令,它告诉 rst2pdf 插入一个分页符。第二页包含一个章节标题、一个蹩脚的句子和一个用颜色标记的代码示例。
要生成 PDF,您需要在命令行上执行如下操作:
rst2pdf test.rst -o out.pdf
您还可以对配置文件运行 rst2pdf 来控制一些特殊的 pdf 指令,如页眉和页脚等。关于如何读取配置文件的信息有点令人困惑。听起来好像必须将文件放在一个特定的位置:/etc/rst2pdf.conf 和~/.rst2pdf/config。也有一个- config 标志可以传递,但我在网上发现了各种报告,这不起作用,所以您的里程可能会有所不同。在项目的 repo 中有一个示例配置文件,您会发现它很有指导意义。
包扎
我希望 rst2pdf 能够提供一种简单的方法来指定绝对位置并创建行和框,这样我就可以用更简单的东西来替换我正在处理的 XSL / XML 项目。唉,在撰写本文时,rst2pdf 只是不支持 reportlab 本身所支持的行和框。然而,如果你需要一些易于使用的东西来创建你的文档,并且你已经知道重构的文本,我认为这是一个非常好的方法。您还可以将您重新构建的文本技能用于 Sphinx 文档项目。
进一步阅读
StaticBox 和 StaticBoxSizers 简介
原文:https://www.blog.pythonlibrary.org/2019/05/09/an-intro-to-staticbox-and-staticboxsizers/
wxPython GUI 工具包中包含了许多小部件。其中之一是一个相当方便的叫做 wx 的小部件。静态箱。这个小部件接受一个字符串,然后用这个字符串在盒子的左上角画一个盒子。然而,这只有在你和 wx 一起使用时才有效。StaticBoxSizer 。
下面是一个可能的例子:

现在让我们继续编写您将用来创建上述示例的代码:
import wx
class MyPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
box = wx.StaticBox(self, -1, "This is a wx.StaticBox")
bsizer = wx.StaticBoxSizer(box, wx.VERTICAL)
t = wx.StaticText(self, -1, "Controls placed \"inside\" the box are really its siblings")
bsizer.Add(t, 0, wx.TOP|wx.LEFT, 10)
border = wx.BoxSizer()
border.Add(bsizer, 1, wx.EXPAND|wx.ALL, 25)
self.SetSizer(border)
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Test')
panel = MyPanel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(False)
frame = MyFrame()
app.MainLoop()
这段代码基于 wx。来自 wxPython 的演示应用的 StaticBox 演示代码。基本上你创建了 wx。StaticBox ,将其添加到 wx 的一个实例中。StaticBoxSizer ,然后将其添加到一个 wx 中。BoxSizer 就大功告成了。
但是如果你想要一个更复杂的盒子布局呢?
接下来让我们看看这个用例!
在 wx 中嵌套 Sizers。静态框尺寸仪
通常情况下,您会希望在您的 box 小部件中包含不止一个小部件。当这种情况发生时,你将需要在你的 wx 里面使用 sizers。StaticBoxSizer 。
这里有一个例子:

让我们来看看这个例子的代码:
import wx
class MyPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
box = wx.StaticBox(self, -1, "Group Name")
bsizer = wx.StaticBoxSizer(box, wx.VERTICAL)
hsizer = wx.BoxSizer()
vsizer = wx.BoxSizer(wx.VERTICAL)
lbl = wx.StaticText(self, label='label 1')
vsizer.Add(lbl)
cbo = wx.ComboBox(self, value='Python', choices=['Python', 'Ruby'],
size=(75, -1))
vsizer.Add(cbo)
hsizer.Add(vsizer)
hsizer.AddSpacer(80)
vsizer = wx.BoxSizer(wx.VERTICAL)
lbl = wx.StaticText(self, label='label 2')
vsizer.Add(lbl)
cbo = wx.ComboBox(self, value='Ford', choices=['Ford', 'Chevrolet'],
size=(75, -1))
vsizer.Add(cbo)
hsizer.Add(vsizer)
bsizer.Add(hsizer, 0, wx.CENTER)
main_sizer = wx.BoxSizer()
main_sizer.Add(bsizer, 1, wx.EXPAND | wx.ALL, 10)
self.SetSizer(main_sizer)
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Test')
panel = MyPanel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(False)
frame = MyFrame()
app.MainLoop()
在这种情况下,你需要创建两个垂直定向的 wx。box sizer将四个小部件放在两列中。你将这些尺寸添加到水平定向的 wx 中。BoxSizer 也是如此。如果你想简化一点,你可以使用一个 wx。GridSizer 而不是这些 BoxSizers。
不管采用哪种方法,您最终都会得到一个布局良好的应用程序。
包扎
使用 wx。StaticBox 小部件总体上非常简单。我认为如果将 widget 和 sizer 合并到一个类中会更简单。无论如何,如果你想了解更多关于这个小部件的信息,你应该看看文档。开心快乐编码!
Python 中的 contextlib 模块介绍(视频)
原文:https://www.blog.pythonlibrary.org/2022/06/08/an-intro-to-the-contextlib-module-in-python-video/
了解如何使用 Python 的 contextlib 模块创建不同类型的上下文管理器!
您可以在 contextlib 文档中了解更多信息。
https://www.youtube.com/embed/e7oGj_fa-J8?feature=oembed
相关文章
- 带语句和上下文管理器的 Python
- Python 3.10 - 带括号的上下文管理器
- wxPython 的上下文管理器
- Python 201 - 上下文管理器简介
Python 图像库/ Pillow 简介
原文:https://www.blog.pythonlibrary.org/2016/10/07/an-intro-to-the-python-imaging-library-pillow/
Python 图像库或 PIL 允许您用 Python 进行图像处理。最初的作者 Fredrik Lundh 在我刚开始学习 Python 时写了我最喜欢的 Python 博客之一。然而,PIL 最后一次发布是在 2009 年,博客也停止更新。幸运的是,有其他一些 Python 爱好者来了,他们分叉了 PIL,并把他们的项目叫做 Pillow。Pillow 项目是 PIL 的替代项目,它也支持 Python 3,这是 PIL 从来没有做过的事情。
请注意,您不能同时安装 PIL 和枕头。在他们的文档中有一些警告,列出了 PIL 和 Pillow 之间的一些差异,这些差异会不时更新,所以我只是将您引导到那里,而不是在这里重复它们,因为它们可能会过时。
安装枕头
您可以使用 pip 或 easy_install 安装 Pillow。下面是一个使用画中画的例子:
pip install Pillow
注意,如果您在 Linux 或 Mac 上,您可能需要使用 sudo 运行该命令。
打开图像

Pillow 使打开和显示图像文件变得很容易。让我们来看看:
from PIL import Image
image = Image.open('/path/to/photos/jelly.jpg')
image.show()
在这里,我们只是导入图像模块,并要求它打开我们的文件。如果您去阅读源代码,您会看到在 Unix 上, open 方法将图像保存到一个临时的 PPM 文件中,并用 xv 实用程序打开它。例如,在我的 Linux 机器上,它用 ImageMagick 打开了它。在 Windows 上,它会将图像保存为一个临时 BMP,并在类似画图的东西中打开它。
获取图像信息
使用 Pillow,您也可以获得关于图像的大量信息。让我们看几个小例子,看看我们能从中提取什么:
>>> from PIL import Image
>>> image = Image.open('/path/to/photos/jelly.jpg')
>>> r, g, b = image.split()
>>> histogram = image.histogram()
[384761, 489777, 557209, 405004, 220701, 154786, 55807, 35806, 21901, 16242]
>>> exif = image._getexif()
exif
{256: 1935,
257: 3411,
271: u'Panasonic',
272: u'DMC-LX7',
274: 1,
282: (180, 1),
283: (180, 1),
296: 2,
305: u'PaintShop Pro 14.00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00',
306: u'2016:08:21 07:54:57',
36867: u'2016:08:21 07:54:57',
36868: u'2016:08:21 07:54:57',
37121: '\x01\x02\x03\x00',
37122: (4, 1),
37381: (124, 128),
37383: 5,
37384: 0,
37385: 16,
37386: (47, 10),
40960: '0100',
40961: 1,
40962: 3968,
40963: 2232,
41495: 2,
41728: '\x03',
41729: '\x01',
41985: 0,
41986: 0,
41987: 0,
41988: (0, 10),
41989: 24,
41990: 0,
41991: 0,
41992: 0,
41993: 0,
41994: 0}
在这个例子中,我们展示了如何从图像中提取 RGB(红、绿、蓝)值。我们还学习了如何从图像中获取历史程序。请注意,由于直方图的输出要大得多,我对输出进行了一点截断。您可以使用另一个 Python 包(如 matplotlib)来绘制历史程序。最后,上面的例子演示了如何从图像中提取 EXIF 信息。同样,我稍微缩短了这个方法的输出,因为它包含的信息对于本文来说太多了。
裁剪图像
您也可以用 Pillow 裁剪图像。这实际上很容易,尽管你可能需要一点尝试和错误才能弄明白。让我们尝试裁剪我们的水母照片:
>>> from PIL import Image
>>> image = Image.open('/path/to/photos/jelly.jpg')
>>> cropped = image.crop((0, 80, 200, 400))
>>> cropped.save('/path/to/photos/cropped_jelly.png')
你会注意到我们需要做的就是打开图像,然后调用它的 crop 方法。您还需要传入想要裁剪的 x/y 坐标,即(x1,y1,x2,y2)。在 Pillow 中,0 像素是左上角的像素。随着 x 值的增加,它会向右移动。随着 y 值的增加,图像向下移动。当您运行上面的代码时,您将得到下图:

那是一种相当无聊的作物。我想把水母的“头”剪掉。为了快速获得正确的坐标,我使用 Gimp 来帮助我确定下一次裁剪使用什么坐标。
>>> from PIL import Image
>>> image = Image.open('/path/to/photos/jelly.jpg')
>>> cropped = image.crop((177, 882, 1179, 1707))
>>> cropped.save('/path/to/photos/cropped_jelly2.png')
如果我们运行这段代码,我们将得到如下裁剪后的版本:

那就好多了!
使用过滤器
原始水母
在 Pillow 中,您可以使用各种滤镜来应用到您的图像。它们包含在图像过滤器模块中。让我们来看看其中的几个:
>>> from PIL import ImageFilter
>>> from PIL import Image
>>> image = Image.open('/path/to/photos/jelly.jpg')
>>> blurred_jelly = image.filter(ImageFilter.BLUR)
>>> blurred_jelly.save('/path/to/photos/blurry_jelly.png')
这将使水母照片稍微模糊。这是我得到的结果:

模糊的水母
当然,大多数人喜欢他们的图像更清晰而不是更模糊。枕头支持你。以下是锐化图像的一种方法:
>>> from PIL import ImageFilter
>>> from PIL import Image
>>> image = Image.open('/path/to/photos/jelly.jpg')
>>> blurred_jelly = image.filter(ImageFilter.SHARPEN)
>>> blurred_jelly.save('/path/to/photos/sharper_jelly.png')
当您运行这段代码时,您将得到以下结果:

更锋利的水母
您还可以使用 ImageEnhance 模块来锐化照片等。
还有其他过滤器,你可以应用,如细节,边缘增强,浮雕,平滑等。您也可以用这样的方式编写代码,将多个滤镜应用于您的图像。
您可能需要下载上面的图像,以便真正能够比较过滤器的差异。
包扎
除了这篇短文中介绍的内容之外,您还可以使用枕头套装做更多的事情。Pillow 支持图像转换、处理带、图像增强、打印图像的能力等等。我强烈推荐阅读枕头文档,以便很好地掌握你能做的一切。
相关阅读
winshell 简介
原文:https://www.blog.pythonlibrary.org/2014/11/25/an-intro-to-winshell/
今天我们将看看 Tim Golden 的便捷软件包 winshell 。winshell 软件包允许您在 Windows 上查找特殊文件夹,轻松创建快捷方式,通过“结构化存储”处理元数据,使用 Windows shell 完成文件操作,以及使用 Windows 回收站。
在本文中,我们将重点介绍 winshell 的特殊文件夹、快捷方式和回收站功能。
入门指南
winshell 包依赖于安装了 PyWin32 。确保你已经安装了。完成后,您可以使用 pip 安装 winshell:
pip install winshell
现在您已经安装了 winshell,我们可以继续了。
访问特殊文件夹
winshell 包公开了对 Windows 中特殊文件夹路径的访问。暴露的路径有:
- 应用程序 _ 数据
- 收藏
- 书签(收藏夹的别名)
- 开始菜单
- 程序
- 启动
- 个人 _ 文件夹
- 我的文档(个人文件夹的别名)
- 最近的
- sendto
让我们看几个例子:
>>> import winshell
>>> winshell.application_data()
'C:\\Users\\mdriscoll\\AppData\\Roaming'
>>> winshell.desktop()
'C:\\Users\\mdriscoll\\Desktop'
>>> winshell.start_menu()
'C:\\Users\\mdriscoll\\AppData\\Roaming\\Microsoft\\Windows\\Start Menu'
这是不言自明的。让我们看看另一个相关的方法,叫做文件夹。根据文档,它使用CSIDL 数值常量或相应的名称,例如“appdata”代表 CSIDL_APPDATA,或者“desktop”代表 CSIDL _ 桌面。让我们看一个简单的例子:
>>> import winshell
>>> winshell.folder("desktop")
'C:\\Users\\mdriscoll\\Desktop'
这使用了一些我从未听说过的 Windows 内部机制。您可能需要在 MSDN 上查找 CSIDL 数值常量,以便有效地使用 winshell 的这一部分。否则,我会建议坚持使用前面提到的功能。
使用快捷方式
您可以使用 winshell 来获取有关快捷方式的信息。让我们来看一个例子,看看谷歌浏览器的快捷方式:
>>> import winshell
>>> import os
>>> link_path = os.path.join(winshell.desktop(), "Google Chrome.lnk")
>>> sh = winshell.shortcut(link_path)
>>> sh.path
'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe'
>>> sh.description
'Access the Internet'
>>> sh.arguments
''
这让我们了解一下快捷方式的属性。我们还可以调用很多其他的方法。我建议阅读完整的文档,看看还能做些什么。现在让我们尝试使用 winshell 创建一个快捷方式:
>>> winshell.CreateShortcut(
Path=os.path.join(winshell.desktop(), "Custom Python.lnk"),
Target=r"c:\python34\python.exe",
Icon=(r"c:\python34\python.exe", 0),
Description="The Python Interpreter")
如果你是这个博客的长期读者,你可能还记得几年前我曾经写过关于用 winshell 创建快捷方式的文章。这里的功能与以前并没有什么不同,而且是不言自明的。您可能想看看那篇旧文章,因为它也展示了如何使用 PyWin32 创建快捷方式。
winshell 和回收站
您还可以使用 winshell 来访问 Windows 回收站。让我们看看你能做什么:
>>> import winshell
>>> recycle_bin = winshell.recycle_bin()
>>>
>>> # undelete a file
>>> recycle_bin.undelete(filepath)
>>>
>>> # empty the recycle bin
>>> recycle_bin.empty(confirm=False)
如果您在同一路径上多次调用 undelete 方法,您将会取消删除文件的先前版本,如果适用的话。您也可以通过清空方法清空回收箱。还有一些未记录的方法,如条目或文件夹,它们似乎返回一个生成器对象,我假设您可以迭代该对象以发现当前回收站中的所有内容。
包扎
至此,您应该能够很好地使用 winshell 包了。您刚刚学习了如何使用回收站、读写快捷方式以及获取 Windows 上的特殊文件夹。我希望你喜欢这篇教程,并能很快在你自己的代码中使用它。
使用 Python 和 Pillow 进行图像处理概述(视频)
了解如何使用 Pillow 和 Python 编程语言编辑和增强照片。
您将在本视频中学到什么:
- 打开图像
- 提取图像信息(EXIF)
- 种植
- 轮流
- 图像增强
- 图画
- 添加 GUI
- 还有更多!
https://www.youtube.com/embed/_T-h1X2-Q1M?feature=oembed
Jupyter 笔记本概述(视频)
原文:https://www.blog.pythonlibrary.org/2020/06/28/an-overview-of-jupyter-notebook-video/
在本视频中,您将了解 Jupyter 笔记本的基本使用方法。如何改变单元格,编辑单元格,运行单元格,等等!
https://www.youtube.com/embed/U4nobvlS_r0?feature=oembed
JupyterLab 概述(视频)
原文:https://www.blog.pythonlibrary.org/2020/07/14/an-overview-of-jupyterlab-video/
在我最新的视频教程中,学习使用 JupyterLab 的基本知识,它是 Jupyter 笔记本的替代品。
https://www.youtube.com/embed/_omZFAgT0TQ?feature=oembed
买书:https://leanpub.com/jupyternotebook101/
Python 的分析工具概述
原文:https://www.blog.pythonlibrary.org/2020/04/14/an-overview-of-profiling-tools-for-python/
剖析一个人的代码意味着什么?基准测试或分析背后的主要思想是计算出代码执行的速度以及瓶颈在哪里。做这种事情的主要原因是为了优化。您会遇到这样的情况,由于业务需求发生了变化,您需要代码运行得更快。当这种情况发生时,您将需要找出代码的哪些部分降低了速度。
本文将只讨论如何使用各种工具来分析您的代码。它不会实际优化你的代码。我们开始吧!
使用 timeit
Python 附带了一个名为 timeit 的模块。你可以用它来计时小代码片段。 timeit 模块使用特定于平台的时间函数,因此您将获得尽可能精确的计时。
timeit 模块有一个命令行界面,但是也可以导入。我们将从如何从命令行使用 timeit 开始。打开终端,尝试以下示例:
python -m timeit -s "[ord(x) for x in 'abcdfghi']"
100000000 loops, best of 3: 0.0115 usec per loop
python -m timeit -s "[chr(int(x)) for x in '123456789']"
100000000 loops, best of 3: 0.0119 usec per loop
这是怎么回事?当你在命令行上调用 Python 并给它传递“-m”选项时,你是在告诉它查找一个模块并把它作为主程序使用。“-s”告诉 timeit 模块运行一次安装程序。然后,它将代码运行 n 次循环,并返回 3 次运行的最佳平均值。对于这些愚蠢的例子,你不会看到太大的区别。
您的输出可能会略有不同,因为它取决于您的计算机的规格。
让我们编写一个简单的函数,看看您是否可以从命令行计时:
# simple_func.py
def my_function():
try:
1 / 0
except ZeroDivisionError:
pass
这个函数所做的就是产生一个错误,这个错误很快就会被忽略。是的,又是一个很傻的例子。要让 timeit 在命令行上运行这段代码,您需要将代码导入到它的名称空间中,因此要确保您已经将当前的工作目录更改到了这个脚本所在的文件夹中。然后运行以下命令:
python -m timeit "import simple_func; simple_func.my_function()"
1000000 loops, best of 3: 1.77 usec per loop
在这里,您导入函数,然后调用它。注意,我们用分号分隔导入和函数调用,Python 代码用引号括起来。现在我们准备学习如何在实际的 Python 脚本中使用 timeit。
导入 timeit 进行测试
在代码中使用 timeit 模块也很容易。您将使用之前相同的愚蠢脚本,并在下面向您展示如何操作:
# simple_func2.py
def my_function():
try:
1 / 0
except ZeroDivisionError:
pass
if __name__ == "__main__":
import timeit
setup = "from __main__ import my_function"
print(timeit.timeit("my_function()", setup=setup))
在这里,您可以检查脚本是否正在直接运行(即没有导入)。如果是,那么您导入 timeit ,创建一个设置字符串以将函数导入 timeit 的名称空间,然后我们调用 timeit.timeit 。您会注意到,我们用引号将对函数的调用传递出去,然后是设置字符串。这真的就是全部了!现在让我们学习如何编写我们自己的计时器装饰器。
使用室内装饰
编写自己的定时器也很有趣,尽管它可能没有使用 timeit 精确,这取决于用例。不管怎样,您将编写自己的自定义函数计时装饰器!
代码如下:
import random
import time
def timerfunc(func):
"""
A timer decorator
"""
def function_timer(*args, **kwargs):
"""
A nested function for timing other functions
"""
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "The runtime for {func} took {time} seconds to complete"
print(msg.format(func=func.__name__,
time=runtime))
return value
return function_timer
@timerfunc
def long_runner():
for x in range(5):
sleep_time = random.choice(range(1,5))
time.sleep(sleep_time)
if __name__ == '__main__':
long_runner()
对于这个例子,您从 Python 的标准库中导入了随机和时间模块。然后创建我们的装饰函数。你会注意到它接受一个函数,并且在它里面有另一个函数。嵌套函数会在调用传入函数之前抢占时间。然后等待函数返回,并获取结束时间。现在你知道这个函数运行了多长时间,所以你把它打印出来。当然,装饰器还需要返回函数调用的结果和函数本身,所以这就是最后两条语句的意义所在。
下一个函数是用我们的计时装饰器来装饰的。你会注意到它使用 random 来“随机”睡眠几秒钟。这只是为了演示一个长时间运行的程序。实际上,您可能希望对连接到数据库(或运行大型查询)、网站、运行线程或做其他需要一段时间才能完成的事情的功能进行计时。
每次运行这段代码,结果都会略有不同。试试看,自己看吧!
创建计时上下文管理器
一些程序员喜欢使用上下文管理器来为小代码片段计时。所以让我们创建自己的定时器上下文管理器类!
import random
import time
class MyTimer():
def __init__(self):
self.start = time.time()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
end = time.time()
runtime = end - self.start
msg = 'The function took {time} seconds to complete'
print(msg.format(time=runtime))
def long_runner():
for x in range(5):
sleep_time = random.choice(range(1,5))
time.sleep(sleep_time)
if __name__ == '__main__':
with MyTimer():
long_runner()
在这个例子中,我们使用类的 init 方法来启动我们的计时器。 enter 方法除了返回自身之外不需要做任何其他事情。最后, exit 方法包含了所有有趣的部分。这里我们获取结束时间,计算总运行时间并打印出来。
代码的结尾实际上展示了一个使用我们的上下文管理器的例子,其中我们在自定义上下文管理器中包装了上一个例子中的函数。
使用配置文件
Python 自带内置的代码分析器。有 profile 模块和 cProfile 模块。profile 模块是纯 Python 的,但是它会给你分析的任何东西增加很多开销,所以通常推荐你使用 cProfile,它有一个相似的接口,但是要快得多。
在本文中,我们不会深入讨论这个模块的很多细节,但是让我们来看几个有趣的例子,这样您就可以了解它能做什么。
>>> import cProfile
>>> cProfile.run("[x for x in range(1500)]")
4 function calls in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<listcomp>)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.001 0.001 0.001 0.001 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
让我们把它分解一下。第一行显示有 4 个函数调用。下一行告诉我们结果是如何排序的。根据文档,标准名称是指最右边的列。这里有许多列。
- ncalls 是发出的呼叫数。
- tottime 是给定函数花费的总时间。
- percall 指总时间除以 ncalls 的商
- 累计时间是在该功能和所有子功能中花费的累计时间。甚至对递归函数也很准确!
- 第二个 percall 列是累计时间除以原始调用的商
- filename:line no(function)提供每个函数各自的数据
您可以在命令行上调用 cProfile,方式与我们使用 timeit 模块的方式非常相似。主要的区别在于,您将向它传递一个 Python 脚本,而不仅仅是传递一个代码片段。下面是一个调用示例:
python -m cProfile test.py
在您自己的一个模块上尝试一下,或者在 Python 的一个模块上尝试一下,看看效果如何。
线条轮廓图
有一个很棒的第三方项目叫做 line_profiler ,它被设计用来分析每一行执行所花费的时间。它还包括一个名为 kernprof 的脚本,用于使用 line_profiler 分析 Python 应用程序和脚本。只需使用 pip 安装包即可。方法如下:
pip install line_profiler
为了实际使用 line_profiler ,我们需要一些代码来进行分析。但首先,我需要解释当你在命令行调用 line_profiler 时,它是如何工作的。您实际上将通过调用 kernprof 脚本来调用 line_profiler。我第一次使用它的时候觉得有点混乱,但这就是它的工作方式。
下面是使用它的正常方法:
kernprof -l silly_functions.py
这将在完成时打印出以下消息:将概要结果写入 silly_functions.py.lprof 。这是一个不能直接查看的二进制文件。当您运行 kernprof 时,它实际上会将 LineProfiler 的一个实例注入到您的脚本的 builtins 名称空间中。该实例将被命名为 profile ,并被用作装饰器。
考虑到这一点,您可以实际编写您的脚本:
# silly_functions.py
import time
@profile
def fast_function():
print("I'm a fast function!")
@profile
def slow_function():
time.sleep(2)
print("I'm a slow function")
if __name__ == '__main__':
fast_function()
slow_function()
所以现在你有两个修饰函数,它们是用没有导入的东西修饰的。如果您真的试图运行这个脚本,您将得到一个 NameError ,因为“profile”没有被定义。所以在你分析完你的代码之后,一定要记得移除你的装饰者!
让我们后退一步,学习如何实际查看我们的分析器的结果。有两种方法我们可以使用。第一种是使用 line_profiler 模块读取我们的结果文件:
python -m line_profiler silly_functions.py.lprof
另一种方法是在详细模式下通过传递 is -v 来使用 kernprof:
kernprof -l -v silly_functions.py
无论您使用哪种方法,您最终都会看到类似以下内容打印到您的屏幕上:
I'm a fast function!
I'm a slow function
Wrote profile results to silly_functions.py.lprof
Timer unit: 1e-06 s
Total time: 3.4e-05 s
File: silly_functions.py
Function: fast_function at line 3
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 @profile
4 def fast_function():
5 1 34 34.0 100.0 print("I'm a fast function!")
Total time: 2.001 s
File: silly_functions.py
Function: slow_function at line 7
Line # Hits Time Per Hit % Time Line Contents
==============================================================
7 @profile
8 def slow_function():
9 1 2000942 2000942.0 100.0 time.sleep(2)
10 1 59 59.0 0.0 print("I'm a slow function")
源代码被打印出来,每一行都有计时信息。这里有六列信息。让我们来看看每一个是什么意思。
- 行号 -被分析的代码的行号
- 命中——特定行被执行的次数
- Time -执行该行所花费的总时间(以计时器为单位)。在输出的开头可以看到计时器单元
- 每次点击——一行代码执行的平均时间(以计时器为单位)
- %
- 行内容 -实际执行的源代码
如果您碰巧是 IPython 用户,那么您可能想知道 IPython 有一个神奇的命令( %lprun ),它允许您指定要分析的函数,甚至是要执行的语句。
内存分析器
另一个很棒的第三方剖析包是 内存剖析 。 memory_profiler 模块可用于监控进程中的内存消耗,或者您可以使用它对代码的内存消耗进行逐行分析。因为 Python 中没有包含它,所以您必须安装它。为此,您可以使用 pip :
pip install memory_profiler
一旦安装完毕,我们需要一些代码来运行它。 memory_profiler 实际上与 line_profiler 的工作方式非常相似,当您运行它时, memory_profiler 会将它自己的一个实例注入到 builtins 命名的 profile 中,您应该将它用作您正在分析的函数的装饰器。
这里有一个简单的例子:
# memo_prof.py
@profile
def mem_func():
lots_of_numbers = list(range(1500))
x = ['letters'] * (5 ** 10)
del lots_of_numbers
return None
if __name__ == '__main__':
mem_func()
在本例中,您创建了一个包含 1500 个整数的列表。然后创建一个包含 9765625 (5 的 10 次方)个字符串实例的列表。最后,您删除第一个列表并返回。与 line_profiler 不同的是, memory_profiler 不需要运行另一个脚本来进行实际的分析。相反,您可以运行 Python 并在命令行上使用它的 -m 参数来加载模块并根据我们的脚本运行它:
python -m memory_profiler memo_prof.py
Filename: memo_prof.py
Line # Mem usage Increment Line Contents
================================================
1 16.672 MiB 0.000 MiB @profile
2 def mem_func():
3 16.707 MiB 0.035 MiB lots_of_numbers = list(range(1500))
4 91.215 MiB 74.508 MiB x = ['letters'] * (5 ** 10)
5 91.215 MiB 0.000 MiB del lots_of_numbers
6 91.215 MiB 0.000 MiB return None
这一次,这些列非常简单明了。我们有自己的行号,然后是执行该行后使用的内存量。接下来我们有一个增量字段,它告诉我们当前行与前一行的内存差异。最后一列是代码本身。
memory_profiler 还包括 mprof ,它可以用来创建完整的随时间变化的内存使用报告,而不是逐行创建。它非常容易使用;看一看:
$ mprof run memo_prof.py
mprof: Sampling memory every 0.1s
running as a Python program...
mprof 还可以创建一个图表,显示应用程序如何随时间消耗内存。要得到图表,你需要做的就是:
$ mprof plot
对于我们之前创建的愚蠢示例,我得到了下面的图表:

你应该试着自己运行一个更复杂的例子,看看更有趣的情节。
个人资料查看
本文中您将看到的最后一个第三方包叫做 profilehooks 。它是一个装饰器的集合,专门为剖析函数而设计。要安装配置文件,只需执行以下操作:
pip install profilehooks
现在我们已经安装好了,让我们重新使用上一节中的例子,并稍微修改一下以使用 profilehooks :
# profhooks.py
from profilehooks import profile
@profile
def mem_func():
lots_of_numbers = list(range(1500))
x = ['letters'] * (5 ** 10)
del lots_of_numbers
return None
if __name__ == '__main__':
mem_func()
使用 profilehooks 所要做的就是导入它,然后修饰你想要分析的函数。如果您运行上面的代码,您将得到类似于以下发送到 stdout 的输出:

这个包的输出似乎遵循 Python 标准库中的 cProfile 模块的输出。您可以参考本章前面对这些列的描述来了解它们的含义。 profilehooks 包还有两个装饰器。我们要看的第一个叫做时间呼叫。它给出了函数的过程运行时间:
# profhooks2.py
from profilehooks import timecall
@timecall
def mem_func():
lots_of_numbers = list(range(1500))
x = ['letters'] * (5 ** 10)
del lots_of_numbers
return None
if __name__ == '__main__':
mem_func()
当您运行这段代码时,您将看到类似于以下输出的内容:
mem_func (c:\path_to_script\profhooks2.py:3):
0.141 seconds
decorator 所做的只是计算函数的执行时间,但没有分析的开销。这有点像使用 timeit 。
profilehooks 提供的最后一个装饰器被称为覆盖率。它应该打印出单个函数的行覆盖。我自己并不觉得这个很有用,但是欢迎你自己尝试一下。
最后我想提一下,你也可以在命令行上使用 Python 的 -m 标志运行 profilehooks :
python -m profilehooks mymodule.py
profilehooks 包很酷,有很大的潜力。
包扎
您在这篇文章中涵盖了很多信息。您学习了如何使用 Python 的内置模块, timeit 和 cProfile 来分别计时和分析您的代码。您还学习了如何编写自己的计时代码,并将其用作装饰器或上下文管理器。然后我们继续前进,看了一些第三方软件包;即 line_profiler 、memory _ profiler*和 profilehooks 。此时,您应该已经开始对自己的代码进行基准测试了。试一试,看看是否能找到自己的瓶颈。
Anaconda 和微软机器学习合作伙伴
原文:https://www.blog.pythonlibrary.org/2017/09/29/anaconda-and-microsoft-partner-for-machine-learning/
Anaconda 发布了一份声明,称他们正在与微软合作“提供 Python 驱动的机器学习”。Anaconda 是 Python 编程语言的数据科学发行版。如果你去看看声明,你会发现微软正在专门计划“将 Anaconda 嵌入 Azure 机器学习、Visual Studio 和 SQL Server”。
我曾经在 Windows 桌面和服务器上使用 Python 进行系统管理,这听起来让我很兴奋。我喜欢 PyWin32 包,但是如果我在 SQL Server 中有一个原生 Python 实现,那就太棒了!
Python Reddit 社区似乎对这一合作持谨慎乐观态度。
总的来说,我相信这对 Python 整体来说是一件好事,尤其是对数据科学社区来说。
Anaconda 数据科学调查结果
原文:https://www.blog.pythonlibrary.org/2018/06/13/anaconda-data-science-survey-results/
Anaconda 今天宣布了他们第一次“数据科学状态”调查的结果。在 4,218 份回复中,26%来自学生,16%来自数据科学家,15%来自学者,15%来自软件开发人员。

根据 Anaconda,关键要点如下:
- 99%的受访者将 Anaconda 用于 Python
- Docker 和 Kubernetes 正在击败 Hadoop / Spark。
- 谷歌云数据服务击败了亚马逊网络服务和微软的 Azure
- Matplotlib 仍然是可视化的顶级包。然而,“Plotly、Tableau、微软 Power BI 和 Tibco Spotfire 都是 Matplotlib 和其他开源项目(如 ggplot、Bokeh、D3 和 Altair)的强大商业竞争对手。”
- 14%的受访者使用 Anaconda 进行机器学习
- Anaconda 是免费的这一事实被列为其最重要的属性,而它拥有开源许可的事实则是倒数第二。
最后一点有点困扰我,但是我想学生们不理解开源的重要性。不管怎样,这是一个关于 Python 发行版的顶级替代版本的非常有趣的调查。你可以在这里阅读完整的公告。
Anaconda 首次推出数据科学认证计划
原文:https://www.blog.pythonlibrary.org/2018/04/09/anaconda-debuts-data-science-certification-program/
阿纳康达今天早上发布了一份新闻稿,声明如下:
最受欢迎的 Python 数据科学平台提供商 Anaconda 今天推出了 Anaconda 数据科学认证,为数据科学家提供了一种验证其熟练程度的方法,并为组织提供了一种独立的标准来鉴定当前和未来的数据科学专家。"
Anaconda 与 Datacamp 建立了非独家合作关系,以使该程序可用。Datacamp 是用 Python 和 R 编程语言学习数据科学的最大网站之一。
根据新闻稿,获得 Anaconda 认证专家(ACP) -数据科学家称号所需的方法是,个人必须通过七个模块的考试,并完成一项全面的考试。这些模块包括:
- 数据导入和导出
- 数据处理和分析
- 形象化
- 统计分析和推断
- 机器学习
- 大规模数据科学
我知道会有企业对认证表示赞赏。然而,我个人并没有发现获得认证对我有那么大的帮助。这可能有用,但也可能没用。听取通过认证程序的人的意见,看看他们对此有何看法,以及他们是否认为值得花费时间和金钱,这将是一件有趣的事情。
要了解更多关于 Anaconda 的新认证计划,请查看以下链接:
安:树蛇 XML
原文:https://www.blog.pythonlibrary.org/2017/06/12/ann-boomslang-xml/
最近,我决定开始使用 Python 编写一些有趣的桌面应用程序示例。我一直使用 wxPython 来创建跨平台的应用程序。我的第一个叫做 Boomslang XML ,是一个基本的 XML 编辑器。

Boomslang 这个名字来自一种巨大的毒蛇。它的名字基本上是“树蛇”的意思,我认为这很恰当,因为用户界面使用一个树部件来表示 XML 文档的结构。
Boomslang 的当前功能包括:
- 打开/编辑多个 XML 文件
- 编辑 XML 时自动保存
- 最近文件支持
- 一些键盘快捷键(加速器)
- 添加新的 XML 节点或属性
- 编辑节点和属性
- 删除节点
目前这是相当测试,但我想其他人可能会觉得有趣。我知道它目前有几个问题,比如不能删除属性或者不能添加包含空格的 XML 节点,但是我会尽快解决这些问题。与此同时,你可以随时在 Github 上查看这个项目。
注意:这个项目已经在 Python 2 和 3、wxPython 2.9、3.0 和 4.0 上使用 lxml 包在 Windows 7、Xubuntu 16.04 和 Mac OSX Sierra 上进行了测试。
安:朱庇特笔记本 101 Kickstarter
原文:https://www.blog.pythonlibrary.org/2018/07/16/ann-jupyter-notebook-101-kickstarter/
我很高兴地宣布我最新的 Kickstarter 是筹集资金在 Jupyter 笔记本上创作一本书!
Jupyter Notebook 101 将教你有效创建和使用笔记本所需的所有知识。您可以使用 Jupyter Notebook 来帮助您学习编码、创建演示文稿、制作精美的文档等等!

Jupyter 笔记本也被科学界用来以一种易于复制的方式展示研究。
你将在 Jupyter 笔记本 101 中学到以下内容:
- 如何创建和编辑笔记本
- 如何添加样式、图像、图表等
- 如何配置笔记本
- 如何将您的笔记本导出为其他格式
- 笔记本扩展
- 使用笔记本进行演示
- 还有更多!
出厂日期
我计划在 2018 年 11 月日发行这本书
可以在 Kickstarter 上了解更多!
安:Media locker——一个 wxPython 应用程序来跟踪你的媒体
原文:https://www.blog.pythonlibrary.org/2011/12/09/ann-medialocker-–-a-wxpython-app-to-track-your-media/

背景
= = = = = = = = = = = = = = = = =
这是我参与的真实项目的第一次发布。上个月我写了一篇文章,这篇文章启发了 Werner Bruhin,他想把它变成一个演示程序,让 wxPython 的新程序员了解如何在与数据库交互的同时进行 MVC 和 CRUD。于是,MediaLocker 诞生了。我们希望你喜欢它。
描述
= = = = = = = = = = = = = = = = =
一个 wxPython 数据库应用程序,可以帮助您跟踪您的媒体。目前,它只跟踪你的图书图书馆。您可以在以下两篇文章中了解有关该项目的更多信息:
需求
= = = = = = = = = = = = = = = = =
-Python 2.6+
-wxPython 2 . 8 . 11+带新的 pubsub(此处下载)或 wxPython 2 . 9 . 3
-SQLAlchemy0 . 7 . 3+
-object listview1.2
配置
= = = = = = = = = = = = = = = = =
下载完源代码后,在尝试运行“mediaLocker.py”之前,运行主文件夹中的“python setup_lib.py develop”。如果您使用的是 wxPython 2.8,请下载 pubsub 路径(如上),并将其解压缩到“C:\ python 27 \ Lib \ site-packages \ wx-2 . 9 . 2-MSW \ wx \ Lib”(或安装 wxPython 的任何位置)。
来源
= = = = = = = = = = = = = = = = =
可以从 Github 下载源码:https://github.com/driscollis/MediaLocker
你也可以在这里下载当前文件的快照(上传于 2011.12.09 @ 1138 hrs CST):
- 介质阻挡子. zip
- 介质阻挡器。取
- 或者直接从 Github 上的提示下载
你能如何帮助
下载软件,在 Github 上报告 bug。我们也很乐意接受功能请求,尤其是如果它们包含补丁或代码。
注意:这仅在 Windows XP 和 7 上测试过
安:Python 101 -那本书!
原文:https://www.blog.pythonlibrary.org/2014/02/19/ann-python-101-the-book/

几年来,我的读者一直要求我写一本书,现在我终于决定硬着头皮试一试。对于我的第一本书,我决定为初学者和中级程序员写一些东西。这本书将有四个部分,第一部分直接面向初学程序员。接下来的 3 个部分将遵循更像烹饪书的风格,因为它们将包含大量的教程。我会把我博客上的一些文章放进书里,如果合适的话会更新它们,但是会有很多新的内容。
为了让事情继续下去,我正在 Kickstarter 上运行一个活动。筹集一些资金来帮助这本书的发展。如果你觉得这个博客有用,请考虑资助我的书。
为了您的方便,我在这里复制了 Kickstarter 活动的大部分文本:
第一部分
第一部分是初学者部分。在这里你将学到 Python 的所有基础知识。从 Python 类型(字符串、列表、字典)到条件语句再到循环。你还将学习理解、函数和类以及它们之间的一切!注: 本节已完成,正处于编辑阶段。
第二部分
这一部分将是 Python 标准库的一次策划之旅。其目的并不是涵盖其中的所有内容,而是向读者展示开箱即用的 Python 可以做很多事情。我们将讨论我认为在日常编程任务中最有用的模块,比如 os、sys、日志、线程等等。
第三部分
现在事情变得非常有趣!在第三部分,我们将学习如何从 Python 包索引和其他位置安装第三方库(即包)。我们将介绍简易安装和 pip。这一节也将是一系列的教程,在这里你将学习如何使用你下载的软件包。例如,您将学习如何下载文件、解析 XML、使用对象关系映射器处理数据库等。
第四部分
这本书的最后一部分将介绍如何与你的朋友和全世界分享你的代码!您将了解如何将其打包并在 Python 包索引上共享(例如,如何创建一个鸡蛋或轮子)。您还将学习如何使用 py2exe、bb_freeze、cx_freeze 和 PyInstaller 创建可执行文件。最后,您将学习如何使用 Inno Setup 创建安装程序。
写作风格
这本书将使用我最初的博客风格来写。这意味着章节会比你通常的编程教科书要短。大多数章节将很可能少于 10 页!这里的想法是让读者快速了解这个主题,而不是用它来打击他们。谁应该读这本书?
这本书是给初学者看的,但我相信有中级技能的人也会觉得它的内容很有价值。
这些钱是干什么用的?
我需要为这本书的每个版本购买一个 ISBN,所以如果我有不同的电子书格式,钱就开始增加了。我有一个志愿编辑,我想支付。我还打算雇一个插图画家给这本书添加一些插图。我期待着与我的支持者合作,尽可能做出最好的 Python 书籍!
安:Python 101 网站
原文:https://www.blog.pythonlibrary.org/2017/08/03/ann-python-101-website/
在我的第一本书《Python 101》免费发布后,我一直在研究让它的内容也能在网上发布的最佳方式。因为我所有的书都是用 RestructuredText 写的,所以我有几个选择。目前我最终选择了 Sphinx,但是将来我可能会选择其他的。
Sphinx 是 Python 语言使用的文档工具,也是 Read the Docs 的主干,Read the Docs 是第三方 Python 包的文档网站。我尝试了默认的斯芬克斯主题雪花石膏,但它没有我最想要的两个功能:
- 移动友好
- 下一页/上一页按钮,方便章节导航
或者至少它看起来不容易修改以使这些特性可用。所以我最终切换到阅读文档主题,因为它同时具备这两个功能。你可以在以下网址查阅这本书:
http://python101.pythonlibrary.org
安:Python 201 Book Kickstarter
原文:https://www.blog.pythonlibrary.org/2016/03/09/ann-python-201book-kickstarter/
我很高兴地宣布我的最新项目,这是我的 Python 101 书的续集:Python 201 -中级 Python。我正在 Kickstarter 上发起一项活动来资助它的出版,所以如果你有兴趣支持,你可以在这里这样做:https://www . Kickstarter . com/projects/34257246/python-201-intermediate-python
如果你已经知道了 Python 的基础知识,现在你想更上一层楼,那么这本书就是为你准备的!本书仅面向中级 Python 程序员。这里不会有什么入门章节。
注意:这本书将涵盖 Python 3
以下是所涉及的一些主题:
- 生成器/迭代器
- 功能性习惯用法(映射、过滤、减少)。
- 编写自己的上下文管理器。
- 命令行参数处理
- 收集
- itertools
- functools
- 函数重载
- 正则表达式的基础
- httplib / urllib(客户端/服务器)
- 网页抓取
- Unicode 基础知识(编码和编解码器)
- 时间代码(基准测试)
- 测试(单元测试、文档测试、模拟、覆盖)
ANN:用 Python Kickstarter 处理 ReportLab PDF
原文:https://www.blog.pythonlibrary.org/2018/01/29/ann-reportlab-pdf-processing-with-python-kickstarter/
您是否曾经想过如何以编程方式创建 PDF 报告?如果是这样,那么这本书就是给你的!在 ReportLab:用 Python 进行 PDF 处理中,您将学习如何使用流行的 Python 编程语言生成 PDF。本书中的代码将在所有 3 个主要平台上运行:
- Windows 操作系统
- 苹果个人计算机
- Linux 操作系统
ReportLab 被维基百科、 NASA 、 Fidelity 、惠普和许多其他大大小小的组织使用。
ReportLab 快速可靠。在过去的 10 多年里,我一直在专业地使用它。也挺好学的。在这本书里,你将学到所有你需要知道的生成你自己的 pdf。
以下是您将要学习的一些内容的示例:
- 如何嵌入字体
- 生成多页文档
- 添加表格
- 插入照片
- 向您的 PDF 添加图表
- 将条形码添加到 PDF
- 绘制形状
- 生成多栏页面
- 关于生成特定复杂示例的教程
这本书将分为两个主要部分。第一部分将包含对 ReportLab 各个部分的全面介绍。第二部分是一个简短的系列章节,讲述如何用 ReportLab 创建各种布局。
我还计划在本书的一个章节(或一系列附录)中向您介绍其他 Python PDF 包,如 PyPDF2 和 rst2pdf,以及您可能如何使用它们。
如果你想成为这个项目的一部分,现在就来看看我的 Kickstarter !
安:我的课程中的 Python 实例
原文:https://www.blog.pythonlibrary.org/2016/07/12/ann-the-python-by-example-udemy-course/
我很高兴地宣布我的第一个关于 Python 编程语言的 Udemy 课程。它被称为 Python 的例子,是我的 Python 101 Screencast 系列的重新命名。我原本希望在 Udemy 上保留 Python 101 这个名字,但是当我在 Udemy 上开始我的课程时,已经有人取了这个名字。不管怎样,这门课程是用 Python 101 截屏的前 35 个视频制作的。我计划在今年晚些时候添加其余的。

你有什么
写作时,你会收到 35 节课或 6.5 小时的内容。我还包括了 Python 101 中与每个讲座相对应的章节。
如何购买
购买 Python 的例子,只需进入以下链接:https://www.udemy.com/python-by-example/?couponCode=py25。优惠券代码会给你 25%的折扣。
wxPython 烹饪书 Kickstarter
原文:https://www.blog.pythonlibrary.org/2016/08/22/ann-the-wxpython-cookbook-kickstarter/
几年前,这个博客的读者要求我把我的一些文章变成一本关于 wxPython 的食谱。我终于决定这么做了。我收录了 50 多个食谱,我目前正在编辑它们以使它们更加一致,并更新它们以兼容 wxPython 的最新版本。我目前有将近 300 页的内容!
为了资助这本书的最初制作,我正在为这个项目做一个有趣的小活动。筹集的资金将用于该活动中提供的独特津贴以及与该书相关的各种制作成本,如 ISBN 采购、插图、软件费用、广告等。
如果您不知道 wxPython 是什么,那么, wxPython 包是一个用于创建跨平台桌面用户界面的流行工具包。它可以在 Windows、Mac 和 Linux 上运行,几乎不需要修改你的代码。
我书中的例子将同时适用于 wxPython 3.0.2 Classic 和 wxPython Phoenix,,后者是支持 Python 3 的 wxPython 的前沿技术。如果我发现任何不适合凤凰城的食谱,它们会被清楚地标记出来,或者会有一个可行的替代例子。
以下是当前食谱的列表,排名不分先后:
- 动态添加/移除小部件
- 如何在面板上放置背景图像
- 将多个小部件绑定到同一个处理程序
- 从任何地方捕捉异常
- wxPython 的上下文管理器
- 转换 wx。日期时间到 Python 日期时间
- 创建“关于”框
- 如何创建登录对话框
- 如何创建“黑暗模式”
- 从配置文件生成对话框
- 如何禁用向导的“下一步”按钮
- 如何使用拖放
- 如何将文件从应用程序拖放到操作系统
- 如何使用 reload()交互式编辑您的 GUI
- 如何在标题栏中嵌入图像
- 从 RichTextCtrl 中提取 XML
- 如何淡入一个框架/对话框
- 如何触发多个事件处理程序
- 使您的框架最大化或全屏
- 使用 wx。框架样式
- 获取事件名称而不是整数
- 如何从 Sizer 中获取子部件
- 如何使用剪贴板
- 捕捉按键和字符事件
- 了解 wxPython 中焦点的工作方式
- 让您的文本闪烁
- 最小化到系统托盘
- 使用 ObjectListView 而不是 ListCtrl
- 让面板自毁
- 如何在面板之间切换
- wxPython:使用 PyDispatcher 而不是 Pubsub
- 使用 PyPlot 创建图表
- 将 Python 的日志模块重定向到 TextCtrl
- 重定向标准输出/标准错误
- 重置背景颜色
- 将数据保存到配置文件
- 如何截图并打印你的 wxPython 应用程序
- 创建一个简单的笔记本
- 确保每帧只有一个实例
- 在组合框或列表框小工具中存储对象
- 同步两个网格之间的滚动
- 创建任务栏图标
- 一个 wx。定时器教程
- 如何从线程更新进度条
- 用 Esky 更新应用程序
- 创建 URL 缩写
- 在 wxPython 中使用线程
- 如何在 XRC 创建网格
- XRC 简介
注:配方名称和顺序可能会改变

宣布:用 Python Kickstarter 自动化 Excel
原文:https://www.blog.pythonlibrary.org/2021/07/12/announcing-automating-excel-with-python-kickstarter/
Automating Excel with Python will be Michael Driscoll's 10th Python book! This book's primary goal is to help you automate the creation, editing, and reading of Excel spreadsheets using the Python programming language.You can purchase early access to the book on Kickstarter as well as get exclusive perks there such as T-shirts, signed copies of the paperback, and discounted copies of one or more of my other books. Feel free to make requests for new perks to be added to the Kickstarter too!  In Automating Excel with Python, you will learn how to use Python to do the following:
In Automating Excel with Python, you will learn how to use Python to do the following:
- 创建 Excel 电子表格
- 读取 Excel 电子表格
- 创建不同的细胞类型
- 添加和删除工作表
- 将 Excel 电子表格转换成其他文件类型
- 单元格样式(改变字体、插入图像、背景颜色等)
- 条件格式
- 添加图表
- 还有更多!
这本书主要关注于 OpenPyXL 包。OpenPyXL 可以跨平台工作,不需要安装 Microsoft Excel 就可以创建、编辑或编写 Excel 电子表格。您将学到使用 OpenPyXL 高效处理 Microsoft Excel 电子表格所需的一切。
现在查看 Kickstarter 来支持这本书。平装本将于 2022 年 1 月在所有主要平台上出版,但你现在可以提前获得!
宣布:使用 Python Kickstarter 进行图像处理
原文:https://www.blog.pythonlibrary.org/2021/01/04/announcing-image-processing-with-python-kickstarter/
我很高兴地宣布我的最新图书项目, Pillow:用 Python 进行图像处理。这本书将教你如何使用枕头、 Python 影像库(PIL) 的“友好”叉子。你可以在 Kickstarter 上提前购买这本书,还可以在那里获得额外的优惠,比如 t 恤、签名的平装本,以及我其他一些书的打折本。

Pillow:使用 Python 进行图像处理将涵盖以下主题:
- 访问图像元数据
- 使用图像颜色
- 使用 Python 打开/查看图像
- 将滤镜应用于图像
- 裁剪、旋转和调整照片大小
- 使用 Python 增强照片
- 组合图像
- 还有更多!
本书重点介绍枕包。您在这里不会学到图像识别,因为那是其他 Python 包的领域,如 OpenCV 或 Scikit-image。相反,您将学习如何使用 Pillow 通过小代码示例进行许多不同类型的图像操作。这些可以用来批量处理您的图像。
您还将学习如何使用 Python 创建小型的跨平台 GUI,让您可以在图像上实时试用 Pillow。
现在查看 Kickstarter 来支持这本书。将于 2021 年 4 月在各大平台发布,不过现在就可以提前获取啦!
宣布:教我 Python
原文:https://www.blog.pythonlibrary.org/2022/09/12/announcing-teach-me-python/
教我 Python 是一个关于 Python 编程语言的全新网站。“教我 Python”是一项基于订阅的服务,它将使用课程、电子书、教程和视频来教你 Python。教程和课程将包括现场代码的例子,如果可能的话,你可以在你的浏览器中运行。
课程会跟踪你的进度,这样你就可以知道你在学习过程中走了多远。

你有什么
购买“教我 Python”订阅后,您将收到以下内容:
- 访问所有迈克·德里斯科尔自助出版的电子书
- 访问 Mike Driscoll 的所有视频课程
- 访问专门用于教授我 Python 的额外 Python 课程
- 订阅期间出版的任何新 Python 书籍
- 提前获得新的 Python 教程,这些教程可能会也可能不会出现在 Mouse vs Python 上
当您终止订阅时,您将能够保留您订阅时可用的任何电子书和视频课程。但是,“教我 Python”独家课程仅面向订户。
未来课程
教我 Python 根据迈克·德里斯科尔的畅销书 Python 101 -第二版推出了两个初学者课程。本月晚些时候或 2022 年 10 月初将增加第三个中级课程。
Python 测验课程也将在 10 月或 11 月初发布,然后用新测验更新,直到完成。最终也会有配套的书出售。
其他额外的中级课程正在规划阶段。
订阅类型
教我 Python 有三种订阅类型:
- 每月 10 美元
- 每年 99 美元
- 终身-250 美元(一次性付款)
查看网站
通过观看此视频,您可以了解该网站提供了哪些服务:
https://www.youtube.com/embed/lUR-fZR67-A?feature=oembed
今天就开始学习 Python 编程语言吧!
宣布:Python 101 视频课程
原文:https://www.blog.pythonlibrary.org/2022/05/03/announcing-the-python-101-video-course/
我很高兴地宣布,我正在创建一个 Python 101 视频课程,它基于 Python 101:第二版。
这门课程最终将包括涵盖书中章节的视频。它将与运行 168 分钟以上的 13 个视频一起发布!
以下链接将给您 10 美元的折扣!
立即购买

你有什么
- 13 个视频(还有更多)
- 同伴 Jupyter 笔记本文件
- Python 101:第二版(PDF,epub,mobi)
立即购买
另一个 GUI2Exe 教程——构建二进制系列!
原文:https://www.blog.pythonlibrary.org/2010/08/31/another-gui2exe-tutorial-build-a-binary-series/
这是我的“构建二进制系列”的最后一篇文章。如果你还没有这样做,一定要看看其他的。最后,我们来看看 Andrea Gavana 的基于 wxPython 的 GUI2Exe,这是一个很好的 py2exe、bbfreeze、cx_Freeze、PyInstaller 和 py2app 的图形用户界面。GUI2Exe 的最新版本是 0.5.0,虽然源代码可能稍新。也可以从顶端自由运行。我们将使用前几篇文章中使用的示例脚本:一个控制台和一个 GUI 脚本,这两个脚本都没做什么。
GUI2Exe 入门

很久以前,我写了另一篇关于这个很酷的工具的文章。然而,应用程序的外观已经发生了很大的变化,所以我觉得我应该在本系列的背景下重新编写那篇文章。要继续阅读这篇文章,你需要点击 Google Code 来查找出处。我们开始吧,好吗?以下是通过 GUI2Exe 使用 py2exe 制作控制台脚本的一些分步指导:
- 下载源代码并在一个方便的位置解压缩
- 运行“GUI2Exe.py”文件(您可以使用您最喜欢的编辑器,通过命令行或其他方式打开它)
- 转到文件,新建项目。将出现一个对话框,要求您命名项目。给它起个好名字!然后点击确定。
- 单击“Exe 种类”列,将其更改为“控制台”
- 点击“Python 主脚本”栏,你会看到一个按钮出现。
- 按下按钮,使用文件对话框找到您的主脚本
- 随意填写其他可选字段
- 点击右下角的编译按钮
- 试试结果,看看有没有效果!

如果您按照上面的说明做了,现在您应该在主脚本位置的“dist”文件夹中有一个可执行文件(和一些依赖项)。正如您在上面的截图中看到的,在 setup.py 文件中有您可以设置的所有典型选项。您可以设置您的排除列表,包括,优化和压缩设置,是否包括一个 zip,包和更多!当你准备好看到结果时,你可以调整你的心的内容并点击“编译”按钮。如果我在做实验,我通常会更改输出目录的名称,这样我就可以比较结果,看看哪个是最紧凑的。
如果你想使用 bbfreeze、cx_freeze、PyInstaller 或 py2app,只需点击右边栏中各自的名称。这将导致屏幕的中间部分根据您的选择而改变,并显示所述选择的相应选项。让我们来一个快速的视觉游览!
图片中的 GUI2Exe!
以下是 py2app 选项的快照:

接下来是 cx_Freeze 选项的一个镜头:

下面是 PyInstaller 的设置:

最后,我们有 bbfreeze 的选项:

还有一个 VendorId 屏幕,但我不太了解那个,所以我们将跳过它。
GUI2Exe 的菜单选项
正如您可能猜到的那样,所有这些选项的工作方式都与您自己用代码完成时一样。如果你需要检查 GUI2Exe 为你制作的 setup.py 文件,只需进入 Builds 菜单并选择 View Setup Script 。如果您想查看它输出的文件列表以及输出文件的位置,请转到 Build,Explorer,您应该会看到类似下面的截图:

构建菜单中的其他便利选项包括任务模块和二进制依赖菜单项。这些向你展示了在分发你的杰作时,你可能需要包括的 dist 文件夹中可能缺少的东西。
Options 菜单控制 GUI2Exe 本身的选项和构建过程的一些自定义项目,如设置 Python 版本、删除构建和/或 dist 文件夹、设置 PyInstaller 路径等等。其他菜单非常简单明了,我把它们留给喜欢冒险的读者。
包扎
如果您已经阅读了我在“构建二进制系列”中的其他教程,那么您应该能够掌握这些知识,并将其有效地用于 GUI2Exe。当我构建可执行文件时,我发现 GUI2Exe 非常有用,我用它来帮助我找出本系列中其他二进制构建器的选项。我希望您喜欢这个系列,并发现它很有帮助。下次见!
进一步阅读
另一个循序渐进的 SqlAlchemy 教程(第 1 部分,共 2 部分)
原文:https://www.blog.pythonlibrary.org/2010/02/03/another-step-by-step-sqlalchemy-tutorial-part-1-of-2/
很久以前(大约 2007 年,如果谷歌没看错的话),有一个叫 Robin Munn 的 Python 程序员写了一篇非常好的关于 SqlAlchemy 的教程。它最初基于 0.1 版本,但针对较新的 0.2 版本进行了更新。然后,Munn 先生就这么消失了,教程再也没更新过。很长一段时间以来,我一直在考虑发布我自己版本的教程,最终决定就这么做。我希望你会发现这篇文章有帮助,因为我发现原来是。
入门指南
SqlAlchemy 通常被称为对象关系映射器(ORM ),尽管它比我使用过的任何其他 Python ORMs(如 SqlObject 或内置于 Django 的 ORM)功能都更加全面。SqlAlchemy 是由一个叫迈克尔·拜尔的人创立的。我也经常看到 Jonathan Ellis 的名字出现在项目中,尤其是在 PyCon 上。
本教程将基于最新发布的 SqlAlchemy 版本:0.5.8。您可以通过执行以下操作来检查您的版本:
import sqlalchemy
print sqlalchemy.__version__
注意:我也将在 Windows 上使用 Python 2.5 进行测试。然而,这段代码在 Mac 和 Linux 上应该同样适用。如果您需要 SqlAlchemy 在 Python 3 上工作,那么您将需要 0.6 的 SVN 版本。该网站给出了如何获取代码的说明。
如果你没有 SqlAlchemy,你可以从他们的网站下载或者使用 easy_install,如果你已经安装了 setuptools 。让我们看看如何:
在下载源代码的情况下,您需要提取它,然后打开一个控制台窗口(在 Windows 上,转到开始,运行并键入“cmd”,不带引号)。然后改变目录,直到你在解压缩的文件夹。
要安装 SQLAlchemy,您可以使用 pip:
pip install sqlalchemy
这也假设您的路径上有 pip。如果没有,那么使用完整路径来使用它(即 c:\python38\scripts\pip.exe 或其他)。
创建第一个脚本
现在我们开始使用 SqlAlchemy 创建我们的第一个示例。我们将创建一个简单的表来存储用户名、年龄和密码。
from sqlalchemy import create_engine
from sqlalchemy import MetaData, Column, Table, ForeignKey
from sqlalchemy import Integer, String
engine = create_engine('sqlite:///tutorial.db',
echo=True)
metadata = MetaData(bind=engine)
users_table = Table('users', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(40)),
Column('age', Integer),
Column('password', String),
)
addresses_table = Table('addresses', metadata,
Column('id', Integer, primary_key=True),
Column('user_id', None, ForeignKey('users.id')),
Column('email_address', String, nullable=False)
)
# create tables in database
metadata.create_all()
看得更深
正如您所看到的,我们需要从 sqlalchemy 包中导入各种各样的东西,即 create_engine、元数据、列、表、整数和字符串。然后,我们创建一个“引擎”,它基本上是一个知道如何使用您提供的凭证与所提供的数据库进行通信的对象。在这种情况下,我们使用不需要凭证的 Sqlite 数据库。仅在这个主题上就有篇深入的文档,你可以在那里阅读你最喜欢的数据库风格。还要注意,我们将 echo 设置为 True。这意味着 SqlAlchemy 将把它正在执行的所有 SQL 命令输出到 stdout。这对于调试很方便,但是当您准备将代码投入生产时,应该将其设置为 False。
接下来,我们创建一个元数据对象。这个来自 SqlAlchemy 团队的很酷的创造保存了所有的数据库元数据。它由 Python 对象组成,这些对象包含数据库的表和其他模式级对象的描述。我们可以在这里或者在代码末尾附近的 create_all 语句中将元数据对象绑定到我们的数据库。
最后一部分是我们如何以编程方式创建表。这是通过使用 SqlAlchemy 的表和列对象来实现的。注意,我们有各种可用的字段类型,比如 String 和 Integer。还有很多其他的。对于这个例子,我们创建一个数据库并将其命名为“users”,然后传入我们的元数据对象。接下来,我们将它放入列中。“id”列被设置为我们的主键。当我们向数据库中添加用户时,SqlAlchemy 会神奇地为我们增加这个值。“name”列是字符串类型,长度不超过 40 个字符。“年龄”列只是一个简单的整数,“密码”列只是设置为字符串。我们没有设置它的长度,但我们可能应该设置。 addresses_table 中唯一的主要区别是我们如何设置连接两个表的外键属性。基本上,我们通过将字符串中正确的字段名传递给 ForeignKey 对象来指向另一个表。
这个代码片段的最后一行实际上创建了数据库和表。您可以随时调用它,因为它会在尝试创建表之前检查指定表是否存在。这意味着您可以创建额外的表并调用 create_all,SqlAlchemy 将只创建新表。
SqlAlchemy 还提供了一种加载以前创建的表的方法:
someTable = Table("users", metadata, autoload=True, schema="schemaName")
我注意到,在这个版本中,SqlAlchemy 对于在自动加载数据库时指定数据库模式变得非常挑剔。如果您遇到这个问题,您需要将以下内容添加到您的表定义中:schema="some schema "。更多信息,请参见文档。
插入
有几种方法可以从数据库中添加和提取信息。我们将首先查看底层方式,然后在本系列的另一部分中,我们将进入会话和声明式风格,它们往往更抽象一些。让我们看看将数据插入数据库的不同方法:
# create an Insert object
ins = users_table.insert()
# add values to the Insert object
new_user = ins.values(name="Joe", age=20, password="pass")
# create a database connection
conn = engine.connect()
# add user to database by executing SQL
conn.execute(new_user)
上面的代码显示了如何使用一个连接对象来执行插入。首先,您需要通过调用表的 insert 方法来创建插入对象。然后,您可以使用插入的值方法来添加该行所需的值。接下来,我们通过引擎的连接方法创建连接对象。最后,我们在插入对象上调用连接对象的执行方法。这听起来有点复杂,但实际上很简单。
下面的代码片段展示了在没有连接对象的情况下进行插入的几种方法:
# a connectionless way to Insert a user
ins = users_table.insert()
result = engine.execute(ins, name="Shinji", age=15, password="nihongo")
# another connectionless Insert
result = users_table.insert().execute(name="Martha", age=45, password="dingbat")
在这两种情况下,你都需要调用 table 对象的 insert 方法。基本上,在第二种情况下,你只需将引擎从画面中移除。我们要看的最后一个插入方法是如何插入多行:
conn.execute(users_table.insert(), [
{"name": "Ted", "age":10, "password":"dink"},
{"name": "Asahina", "age":25, "password":"nippon"},
{"name": "Evan", "age":40, "password":"macaca"}
])
这是不言自明的,但是要点是您需要使用前面的 Connection 对象并传递给它两个参数:表的 Insert 对象和包含列名和值对的字典列表。请注意,在这些示例中,通过使用 execute 方法,数据被提交到数据库。
现在让我们继续做选择。
选择
SqlAlchemy 提供了一组健壮的方法来完成选择。这里我们将重点介绍简单的方法。对于高级的东西,我推荐他们的官方文档和邮件列表。一个最常见的例子是进行全选,让我们从这个例子开始:
from sqlalchemy.sql import select
s = select([users_table])
result = s.execute()
for row in result:
print row
首先我们必须从 sqlalchemy.sql 导入 select 方法,然后我们将表作为一个元素列表传递给它。最后,我们调用选择对象的执行方法,并将返回的数据存储在结果变量中。现在我们已经有了所有的结果,我们也许应该看看我们是否得到了我们所期望的。因此,我们为循环创建一个来迭代结果。
如果你需要元组列表中的所有结果而不是行对象,你可以执行以下操作:
# get all the results in a list of tuples
conn = engine.connect()
res = conn.execute(s)
rows = res.fetchall()
如果您只需要返回第一个结果,那么您可以使用 fetchone()而不是 fetchall():
res = conn.execute(s)
row = res.fetchone()
现在,让我们假设我们需要在我们的结果中得到更多一点的粒度。在下一个示例中,我们只想返回用户的姓名和年龄,而忽略他们的密码。
s = select([users_table.c.name, users_table.c.age])
result = conn.execute(s)
for row in result:
print row
嗯,那很简单。我们所要做的就是在 select 语句中指定列名。小“c”基本上意味着“列”,所以我们选择列名和列年龄。如果有多个表,那么 select 语句应该是这样的:
选择([表一,表二])
当然,这很可能会返回重复的结果,所以您需要做一些类似的事情来缓解这个问题:
s = select([tableOne,tableTwo],table one . c . id = = table two . c . user _ id)
SqlAlchemy 文档将第一个结果称为笛卡尔积,因为它导致第一个表中的每一行都是针对第二个表中的每一行生成的。上面的第二个陈述消除了这种烦恼。怎么会?这是使用这种形式的 select 来执行 WHERE 子句的方法。在本系列的下一部分中,我将展示一种不同的方式来进行会话的选择和 where。
这里还有几个例子,在评论中有解释:
from sqlalchemy.sql import and_
# The following is the equivalent to
# SELECT * FROM users WHERE id > 3
s = select([users_table], users_table.c.id > 3)
# You can use the "and_" module to AND multiple fields together
s = select(and_(users_table.c.name=="Martha", users_table.c.age < 25))
上面的代码说明了 SqlAlchemy 也可以在查询中使用操作符和连接词。我推荐阅读他们的文档以了解全部细节这里。
包扎
我想这是我们停下来的好地方。我们现在已经学习了如何创建数据库、添加行以及从数据库中选择数据。在我们系列的下一部分,我们将学习使用对象关系方法来做这件事的更流行的方法。我们还将了解一些其他关键主题,例如 SqlAlchemy 会话。我们还将了解 SqlAlchemy 中的连接是如何工作的。到时候见!
延伸阅读
下载量
另一个循序渐进的 SqlAlchemy 教程(第 2 部分,共 2 部分)
原文:https://www.blog.pythonlibrary.org/2010/02/03/another-step-by-step-sqlalchemy-tutorial-part-2-of-2/
在本系列的第一部分中,我们回顾了使用 SqlAlchemy 与数据库交互的“SQL 表达式”方法。这背后的理论是,我们应该在学习更高层次(和更抽象)的方法之前,学习不太抽象的做事方法。这在许多数学课中都是真实的,比如微积分,在你学习捷径之前,你需要学习很长的路去寻找一些计算的标准偏差。
对于后半部分,我们将做一些可能被认为是使用 SqlAlchemy 的简单方法。它被称为“对象关系”方法,官方文档实际上就是从它开始的。这种方法最初需要花费较长的时间来建立,但在许多方面,它也更容易遵循。
习惯数据映射
Robin Munn 的老学校 SqlAlchemy 教程称这个部分为“数据映射”,因为我们将把数据库中的数据映射到 Python 类。我们开始吧!
from sqlalchemy import create_engine
from sqlalchemy import Column, MetaData, Table
from sqlalchemy import Integer, String, ForeignKey
from sqlalchemy.orm import mapper, sessionmaker
####################################################
class User(object):
""""""
#----------------------------------------------------------------------
def __init__(self, name, fullname, password):
"""Constructor"""
self.name = name
self.fullname = fullname
self.password = password
def __repr__(self):
return "" % (self.name, self.fullname, self.password)
# create a connection to a sqlite database
# turn echo on to see the auto-generated SQL
engine = create_engine("sqlite:///tutorial.db", echo=True)
# this is used to keep track of tables and their attributes
metadata = MetaData()
users_table = Table('users', metadata,
Column('user_id', Integer, primary_key=True),
Column('name', String),
Column('fullname', String),
Column('password', String)
)
email_table = Table('email', metadata,
Column('email_id', Integer, primary_key=True),
Column('email_address', String),
Column('user_id', Integer, ForeignKey('users.user_id'))
)
# create the table and tell it to create it in the
# database engine that is passed
metadata.create_all(engine)
# create a mapping between the users_table and the User class
mapper(User, users_table)
与前面的例子相比,要注意的第一个区别是用户类。我们对我们的原始示例(参见第一部分)做了一点修改,以匹配官方文档中的内容,即参数现在是 name、full name 和 password。剩下的看起来应该是一样的,直到我们看到映射器语句。这个方便的方法允许 SqlAlchemy 将 User 类映射到 users_table。这看起来没什么大不了的,但是这种方法使得向数据库添加用户变得更加简单。
然而,在此之前,我们需要讨论一下声明性配置风格。虽然上面的样式给了我们对表、映射器和类的细粒度控制,但在大多数情况下,我们不需要它那么复杂。这就是声明式风格的由来。这使得配置一切变得更加容易。我所知道的第一种声明式风格是 SqlAlchemy 的一个插件,名为药剂。这种内置的声明式风格不像 Elixir 那样功能齐全,但是更方便,因为您没有额外的依赖性。让我们看看声明性有什么不同:
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import backref, mapper, relation, sessionmaker
Base = declarative_base()
########################################################################
class User(Base):
""""""
__tablename__ = "users"
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
password = Column(String)
#----------------------------------------------------------------------
def __init__(self, name, fullname, password):
"""Constructor"""
self.name = name
self.fullname = fullname
self.password = password
def __repr__(self):
return "" % (self.name, self.fullname, self.password)
########################################################################
class Address(Base):
"""
Address Class
Create some class properties before initilization
"""
__tablename__ = "addresses"
id = Column(Integer, primary_key=True)
email_address = Column(String, nullable=False)
user_id = Column(Integer, ForeignKey('users.id'))
# creates a bidirectional relationship
# from Address to User it's Many-to-One
# from User to Address it's One-to-Many
user = relation(User, backref=backref('addresses', order_by=id))
#----------------------------------------------------------------------
def __init__(self, email_address):
"""Constructor"""
self.email_address = email_address
def __repr__(self):
return "
<address>" % self.email_address
# create a connection to a sqlite database
# turn echo on to see the auto-generated SQL
engine = create_engine("sqlite:///tutorial.db", echo=True)
# get a handle on the table object
users_table = User.__table__
# get a handle on the metadata
metadata = Base.metadata
metadata.create_all(engine)
如你所见,现在几乎所有的东西都是在类中创建的。我们创建类属性(类似于类的全局变量)来标识表的列。然后,我们创建与上面的原始类示例中相同的 init。同样,我们子类化 declarative_base 而不是基本的对象。如果我们需要一个表对象,我们必须调用下面的魔法方法 User。__ 表 _ _;为了获取元数据,我们需要调用 Base.metadata 。涵盖了我们所关心的差异。现在我们可以看看如何向数据库添加数据。
课程现在开始
使用对象关系方法与我们的数据库进行交互的好处可以在几个简短的代码片段中展示出来。让我们看看如何创建一行:
mike_user = User("mike", "Mike Driscoll", "password")
print "User name: %s, fullname: %s, password: %s" % (mike_user.name,
mike_user.fullname,
mike_user.password)
如您所见,我们可以用 User 类创建用户。我们可以使用点符号来访问属性,就像在任何其他 Python 类中一样。我们甚至可以用它们来更新行。例如,如果我们需要更改上面的用户对象,我们将执行以下操作:
# this is how you would change the name field
mike_user.fullname = "Mike Dryskull"
请注意,所有这些都不会像我们在第一篇文章中看到的那些插入方法那样自动将行添加到数据库中。相反,我们需要一个会话对象来完成这项工作。让我们浏览一下使用会话的一些基础知识:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
mike_user = User("mike", "Mike Driscoll", "password")
session.add(mike_user)
我们在这里暂停一下,解释一下是怎么回事。首先,我们需要从 sqlalchemy.orm 中导入 sessionmaker ,并将其绑定到引擎(从技术上讲,您可以在不绑定的情况下创建会话,但要做任何有用的事情,您最终需要绑定它)。接下来,我们创建一个会话实例。然后我们实例化一个用户对象,并将其添加到会话中。此时,还没有运行任何 SQL 代码,事务只是挂起。为了持久化这一行,我们需要调用 session.commit() 或者运行一个查询。
如果需要添加多个用户,请执行以下操作:
session.add_all([
User('Mary', 'Mary Wonka', 'foobar'),
User('Sue', 'Sue Lawhead', 'xxg527'),
User('Fay', 'Fay Ray', 'blah')])
如果您在将用户的属性提交到数据库后碰巧更改了其中一个属性,您可以使用 session.dirty 来检查哪个属性被修改了。如果您只需要知道哪些行是未决的,就调用 session.new 。最后,我们可以使用 session.rollback() 回滚一个事务。
现在让我们来看一些示例查询:
# do a Select all
all_users = session.query(User).all()
# Select just one user by the name of "mike"
our_user = session.query(User).filter_by(name='mike').first()
print our_user
# select users that match "Mary" or "Fay"
users = session.query(User).filter(User.name.in_(['Mary', 'Fay'])).all()
print users
# select all and print out all the results sorted by id
for instance in session.query(User).order_by(User.id):
print instance.name, instance.fullname
我们不需要逐一讨论,因为它们在评论中都有解释。相反,我们将继续讨论连接的主题。
来凑热闹
有些连接使用了 SQL 表达式语法,我不会在这里介绍。相反,我们将使用对象关系方法。如果您回头看一下创建表的开始示例,您会注意到我们已经设置了与外键对象的连接。声明格式如下所示:
user_id = Column(Integer, ForeignKey('users.id'))
# creates a bidirectional relationship
# from Address to User it's Many-to-One
# from User to Address it's One-to-Many
user = relation(User, backref=backref('addresses', order_by=id))
让我们通过创建一个新用户来看看这是如何工作的:
prof = User("Prof", "Prof. Xavier", "fudge")
prof.addresses
由于外键和 backref 命令,用户对象具有地址属性。如果您运行该代码,您将看到它是空的。让我们添加一些地址!(注意:一定要将 prof 用户添加到 session: session.add(prof))
prof.addresses = [Address(email_address='profx@dc.com'),
Address(email_address='xavier@yahoo.com')]
看到这有多简单了吗?甚至很容易把信息弄回来。例如,如果您只想访问第一个地址,您只需调用 prof.addresses[0] 。现在,假设您需要更改其中一个地址(即进行更新)。这很容易:
# change the first address
prof.addresses[0].email_address = "profx@marvel.com"
现在让我们继续对连接进行查询:
for u, a in session.query(User, Address).filter(User.id==Address.user_id).filter(Address.email_address=='xavier@yahoo.com').all():
print u, a
这是一个很长的查询!我发现自己很难做到这些,所以我通常会做以下事情来让我的大脑更容易理解:
sql = session.query(User, Address)
sql = sql.filter(User.id==Address.user_id)
sql = sql.filter(Address.email_address=='xavier@yahoo.com')
for u, a in sql.all():
print u, a
现在,对于那些喜欢一行程序的人来说,第一个例子没有任何问题。它会产生完全相同的结果。我只是碰巧发现更长的版本更容易调试。最后,我们还可以使用一个真正的连接:
from sqlalchemy.orm import join
session.query(User).select_from(join(User, Address)).filter(Address.email_address=='xavier@yahoo.com').all()
这也与前两个例子一样,但是以更明确的方式。关于使用对象关系语法连接的更多信息,我推荐使用官方文档。
包扎
此时,您应该能够用表创建数据库,用数据填充表,以及使用 SqlAlchemy 选择、更新和提交事务到数据库。我希望这篇教程有助于你理解这项神奇的技术。
注意:本教程是在使用 Python 2.5 和 SqlAlchemy 0.5.8 的 Windows 上测试的。
延伸阅读
箭头 Python 的一个新的日期/时间包
原文:https://www.blog.pythonlibrary.org/2014/08/05/arrow-a-new-date-time-package-for-python/
arrow 项目试图将 Python 的时间和日期时间模块封装到一个 API 中。它还声称要填补这些模块中的功能空白,如时间跨度、ISO-8601 和人性化。你可以把 arrow 看作 Python 的 datetime 和 time 模块的替代物,就像可以用 requests 项目代替 Python 的 urllib 一样。在撰写本文时,Arrow 支持 Python 2.6、2.7 和 3.3。
安装箭头
要开始使用 arrow,只需点击安装即可:
pip install arrow
使用箭头
arrow 包使用起来非常简单。让我们看几个常见的例子:
>>> import arrow
>>> arrow.now()
>>> now = arrow.now()
>>> now.ctime()
'Fri Jul 25 15:41:30 2014'
>>> pacific = now.to("US/Pacific")
>>> pacific
>>> pacific.timestamp
1406320954
这里我们得到了当天的日期和时间。然后,我们将它存储在一个变量中,并将时区更改为太平洋标准时间。我们还可以获得时间戳值,即从 epoch 开始的秒数。让我们再看几个例子:
>>> day = arrow.get("2014-07-13")
>>> day.format("MM-DD-YYYY")
'07-13-2014'
>>> day.humanize()
u'12 days ago'
我们在这里选择一个日期,然后重新格式化它的显示方式。如果您调用 arrow 的人源化()方法,它会告诉您是多少天前的事了。如果你通过【T2 现在】()方法得到现在的时间,然后叫做人性化,你会得到不同的信息。
包扎
我最喜欢这个包的地方是它很好地包装了 Python 的日期和时间模块。能够通过一个公共界面访问他们的每一个功能是很好的。作者已经使日期和时间操作更容易使用。我认为值得你花时间试一试。开心快乐编码!
八月平壤会议总结
原文:https://www.blog.pythonlibrary.org/2010/08/06/august-pyowa-meeting-wrapup/
我们昨晚在埃姆斯公共图书馆举行了 2010 年 8 月的 Pyowa 会议。七个人参加了会议,其中大多数是常客。我想我们有了一个新人或者他只去过一个。总之,斯科特在 SqlAlchemy 上发表了。他用一个电影的例子向我们介绍了基本知识,我想这个例子可以在 Jonathan Ellis 的网站上找到。他还谈到了 SqlSoup、Migrate、其他几个扩展以及 SqlAlchemy 的 TurboGears 2 集成。事实上,他还演示了几个涡轮齿轮的应用。
我们的下一次会议将在得梅因的 IMT 集团大楼举行。我们目前正在确定所有的细节,所以一定要查看 Pyowa 网站的更新或者加入我们的邮件列表!
在产品搜索上使用计算机编程语言自动化擅长
原文:https://www.blog.pythonlibrary.org/2022/02/10/automating-excel-with-python-now-on-producthunt/
My latest Python book "Automating Excel with Python" is now on Product Hunt
If you have a ProductHunt account, I would appreciate it if you voted to recommend this book.
This book is currently available for purchase on Leanpub or Gumroad in T2 or Amazon in T4.
自动化 Excel 与 Python 平装现已上市!
原文:https://www.blog.pythonlibrary.org/2022/01/03/automating-excel-with-python-paperback-now-available/
我的第十本 Python 书,用 Python 自动化 Excel】现在在亚马逊上有平装本和 Kindle 版本。
在本书中,您将学习如何使用 Python 来完成以下任务:
- Create Excel spreadsheets
- Read Excel spreadsheets
- Create different cell types
- Add and remove sheets
- Convert Excel spreadsheets into other file types
- Cell styling (changing fonts, inserting images, background colors, etc)
- Conditional formattings
- Adding charts
- and much more!
如果你喜欢这本书的 PDF 或 epub 版本,我可以在 Leanpub 和 Gumroad 上找到。
Video Overview of Excel Automation Using Python
原文: https://www。博客。python 库。org/2022/03/29/automating-excel-with-python-video-overview/
In this tutorial, I will give you an overview of how to use OpenPyXL and Python to read and write Excel documents. You will also learn how to:
- Style cell
- Change font
- Create a named style
- Use panda in Excel
- Combine panda with OpenPyXL
- The basics of using XslxWriter
The code in this tutorial is based on the code in my book, and Excel is automated with Python:
- 口香糖路(电子书)
- Leanpub (e-book)
- 亚马逊(平装)
https://www.youtube.com/embed/xjO5ns0nj2c?feature=oembed
返校 Python 售书 2017
原文:https://www.blog.pythonlibrary.org/2017/08/28/back-to-school-python-book-sale-2017/
现在是上学和回到大学的时候了,所以我正在为我的 Python 书籍举办一次“返校”销售活动。你现在可以在 Leanpub 上以 50%的价格购买我的第二和第三本书。
如果你需要我写作风格的样本,你可以在http://python101.pythonlibrary.org/查阅我的第一本书《Python 101》。Leanpub 也有这两本书的样本,你可以下载成 PDF 格式。
欢迎在评论中提问或通过联系方式联系我。
最佳编程/脚本语言?计算机编程语言
原文:https://www.blog.pythonlibrary.org/2010/12/22/best-programming-scripting-language-python/
至少, Linux Journal 的读者是这么认为的。我同意。你们这些了不起的小伙子和姑娘认为什么是最好的?
向史蒂夫·霍尔登致敬
2020 年黑色星期五/网络星期一提前到来
原文:https://www.blog.pythonlibrary.org/2020/11/25/black-friday-cyber-monday-comes-early-in-2020/
今年早些时候,黑色星期五/网络星期一交易开始了。从现在起到 12 月 1 日,我所有的书都在 Leanpub 上出售,使用下面的特殊链接。今天就来看看它们,学习一些新的 Python 知识吧!

- Python 101:第二版- 在 Leanpub 上享受 25%的折扣
- Python 201:中级 Python-Leanpub 上的 30%折扣
- Jupyter 笔记本 101 - 在 Leanpub 享受 34%的折扣
- ReportLab:使用 Python 处理 PDF-在 Leanpub 上享受 25%的折扣
- 使用 wxPython 创建 GUI 应用程序- 在 Leanpub 上享受 25%的折扣
我所有的书在 Leanpub 上都有免费的样本,所以你可以在购买之前下载一些样本章节,看看它们是什么样的。
2018 年黑色星期五/网络星期一特卖
原文:https://www.blog.pythonlibrary.org/2018/11/21/black-friday-cyber-monday-sale-2018/
本周,我将从今天开始发售我最近的两本自助出版的书,时间是从 11 月 26 日到 11 月 26 日。
使用 Python 处理 ReportLab - PDF 的价格为 9.99 美元:

JupyterLab 101 售价 9.99 美元:

你也可以用下面的优惠券代码,在限定时间内以 7 美元的价格从 Apress 获得我的书wxPython Recipes:cyber week 18。

Python 访谈现在也是 10 美元!
Python 书籍的黑色星期五交易
原文:https://www.blog.pythonlibrary.org/2019/11/26/black-friday-deals-on-python-books/
对学习 Python 感兴趣?好吧,你会很高兴地知道,我正在运行一个黑色星期五/网络星期一销售我的 Python 书籍。但是我会提前开始销售,这样你就有足够的时间来决定是否要买我的书。下面就来看看吧!
注意 Python 101 是免费的。如果你想要一份免费的拷贝,你可以把支付的金额一路降到 0 美元。
也请注意,我所有的书都有免费的样本章节,所以你可以在购买前检查一下。
用 wxPython 创建 GUI 应用程序

用 wxPython 创建 GUI 应用程序是我最近的一本书。在这篇文章中,您将学习如何使用 wxPython 创建跨平台的桌面应用程序。使用此链接或点击上面的图片获得折扣。
Jupyter 笔记型电脑 101
Jupyter Notebook 是一个很好的教学工具,也是使用和学习 Python 和数据科学的有趣方式。我写了一本关于这个主题的很好的入门书,叫做《Jupyter 笔记本 101 。
使用 Python 处理 ReportLab - PDF
用 Python 创建和操作 pdf 很有趣!在使用 Python 的 ReportLab - PDF 处理中,您将了解如何使用 ReportLab 包创建 PDF。您还将学习如何使用 PyPDF2 和 pdfrw 以及其他一些方便的 PDF 相关 Python 包来操作预先存在的 PDF。
Python 201:中级 Python

Python 201:中级 Python 是我的第一本书 Python 101 的续集,向读者讲授 Python 中的中级到高级主题。
黑莓发布了一款用 Python 编写的反恶意软件工具
如果你错过了这个月早些时候的,黑莓发布了他们的一个工具,他们用它来逆向工程恶意软件。这个工具叫做 PE 树,是开源的,用 Python 编写。
Blackberry 使用流行的 PyQt5 GUI 工具包来编写显示可移植可执行文件的树形视图,这使得更容易转储和重建内存中的恶意软件。
公关树工具适用于视窗、苹果和 Linux。它可以作为一个独立的应用程序运行,也可以作为一个插件运行,这本身就是一个反汇编器的插件。
这听起来像是一个非常好的工具。如果没有别的,它将是学习如何用 Python 创建真实世界 GUI 的一个很好的应用程序。
图书竞赛:用 wxPython 创建 GUI 应用程序
原文:https://www.blog.pythonlibrary.org/2019/06/19/book-contest-creating-gui-applications-with-wxpython/
上个月,我发布了一本名为用 wxPython 创建 GUI 应用程序的新书。为了庆祝一次成功的发射,我决定做一个小竞赛。

规则
- 发关于比赛的微博,并附上我的名字: @driscollis
- 在 Twitter 上或通过我的联系表格给我发送一条直接消息,并附上你的推文链接
- 如果你没有 Twitter,请随时通过网站给我发消息,我会帮你报名的
比赛将从现在开始持续到 6 月 21 日星期五晚上 11:59 分。
亚军将获得一本免费的电子书。大奖将是签名平装本+电子书版本!
图书竞赛:ReportLab:用 Python 处理 PDF
原文:https://www.blog.pythonlibrary.org/2018/08/14/book-contest-reportlab-pdf-processing-with-python/
我最近发布了一本名为 ReportLab:用 Python 处理 PDF的新书。为了庆祝一次成功的发射,我决定做一个小竞赛。
规则
- 发表评论,告诉我你为什么想要一本
- 最聪明或最真诚的评论者将由我选出
比赛将从现在开始持续到 8 月 17 日星期五晚上 11:59 分。
亚军将获得一本免费的电子书。大奖将是签名平装本+电子书版本!
图书竞赛:赢得一本 Python 101
原文:https://www.blog.pythonlibrary.org/2014/06/20/book-contest-win-a-copy-of-python-101/
这场比赛现在结束了
我已经决定赞助我的第一本书《Python 101》的竞赛。我将送出 3 本电子书包(PDF、EPUB 和 MOBI)和 1 本平装本,我将把它们运往世界各地。如果你没听说过我的书,你可能想看看这篇其他帖子。
你如何能赢
要赢得这本书,你需要做的就是在下面提出评论,强调“你为什么想赢得这本书”的原因。
竞赛持续时间和获胜者的选择
比赛有效期为两周,对所有人开放。获胜者将根据他们发表的评论选出。比赛将于 2014 年 4 月 7 日上午 9 点(美国中部时间)结束。

图书竞赛:赢得一本 Python 201
原文:https://www.blog.pythonlibrary.org/2016/09/12/book-contest-win-a-copy-of-python-201/
我已经决定为我的第二本书 Python 201:中级 Python 赞助一个竞赛。我将送出 3 本电子书包(PDF、EPUB 和 MOBI)和 2 本平装本,我将把它们发往世界各地。如果你没听说过我的书,你可能想在这里读到它。
你如何能赢
要赢得这本书,您只需在下面发表评论,强调“您为什么想赢得这本书”的原因。
竞赛持续时间和获胜者的选择
竞赛有效期至 9 月 16 日星期五美国中部时间晚上 11:59,对所有人开放。获胜者将根据他们发表的评论选出。比赛将于 2016 年 9 月 17 日美国中部时间上午 12 点结束。

图书预览:用 Python 构建机器学习系统

今年早些时候,Packt Publishing 邀请我担任他们即将出版的新书《用 Python 构建机器学习系统》的技术评论员,该书作者是威利·里歇特和路易斯·佩德罗·科埃略。现在这本书可以买到了,他们让我写一点关于它的东西。我自己没有通读过成品,所以我不知道作者是否采纳了我的任何建议,但我应该注意到,英语似乎是他们的第二语言,所以这本书可能会有点粗糙。
然而,内容很有趣,我认为它相当全面。他们似乎知道他们在谈论什么。这本书的很多内容都超出了我的理解范围,因为我不是这本书所涉及主题的科学家或工程师。基本上,这本书是关于使用 scikit-learn、mahotas 和 jug 进行数据挖掘的。你将学习诸如计算机视觉、篮子分析、如何分类数据等令人兴奋的话题。
更新(2013-08-22) -其中一位作者在这篇文章上发表了评论,让我知道他们已经清理了文字。
图书预览:Numpy 1.5 初学者指南
原文:https://www.blog.pythonlibrary.org/2011/11/23/book-preview-numpy-1-5-beginners-guide/
最近,我被链接到了 Python 论坛上,因为我在 wxPython IRC 频道上的一个朋友说,Packt 正在为他们的新书寻找评论者,这本书是伊凡·伊德里斯的 Numpy 1.5 初学者指南。不过,我怀疑他们会在那个网站上找到很多人。我当然从未听说过它。无论如何,Packt 给了我一本电子书,所以我将在接下来的几周内阅读它,这样我就可以在这个网站上回顾它。
我以前没有使用过 NumPy,但是我在 wxPython 邮件列表中时不时地听说过它,我认为它听起来很有趣。所以我很高兴有一本关于这个主题的新的初学者书籍。我希望它是一个好的。与此同时,Packt 给了我一个第三章的链接,所以你可以在等待我的评论时阅读。看起来道格·芬克也会对这本书进行评论,所以你可能想关注一下他的博客,看看他也有什么想法。
|  |
|
Numpy 1.5 初学者指南
图书预览:Python 3 面向对象编程
原文:https://www.blog.pythonlibrary.org/2010/05/20/book-preview-python-3-object-oriented-programming/
12 月下旬,Packt Publishing 找到我,要我写一本关于 wxPython 的书。我拒绝了他们,因为我和编辑对这本书的看法不一致。无论如何,我最终接受了他们即将出版的一本书的技术编辑的工作:达斯丁·菲利普斯的《Python 3 面向对象编程》 。我从 2010 年 1 月开始这样做。“报酬”是这本书的副本加上我从 Packt 的目录中选择的另一本书。就是这样。在这本书出版之前,我不会得到任何一本书,这本书应该在今年八月出版。这篇文章是这本书的预演。
直到开始评论这本书的几个月后,我才知道作者的名字。出于某种原因,帕克特不给我这些信息。幸运的是,达斯丁·菲利普斯最终在书的正文中透露了自己的名字。找到他的网站有点困难,但在这里:http://archlinux.me/dusty/。看起来他也在书上写了一小段。
无论如何,关于这本书的预览。
这不是你的典型的 Python 书籍。第一章不是简单的语言介绍。事实上,第一章甚至没有任何代码。相反,你会得到大量的 UML 图和关于面向对象编程(OOP)的理论。奇怪的是,这仍然是一个有趣的章节,有点令人耳目一新,因为它偏离了常规。
第一章之后还有十一章。接下来的四章将深入探讨 Python 如何将面向对象编程融入到语言中。在第 2 章中,您将学习如何创建类、添加属性以及创建模块和包。第 3 章带读者了解继承、多态性和鸭子分型。对于第 4 章,作者带我们进入异常处理的世界,包括如何创建你自己的定制异常。在大多数章节中,你还会得到一个案例研究或一些练习,有时你会两者兼得。
这是这本书接下来三分之一的简要介绍:
- 第五章是关于什么时候在 Python 中使用 OOP,重构和 DRY 原则
- 第 6 章涵盖了基本的 Python 数据结构(即列表、字典、集合等)
- 在第七章中,我们将介绍一些内置函数;列表、字典和集合理解、生成器和重载
- 最后,在第八章我们开始学习设计模式,比如观察者模式或者策略模式
我个人认为设计模式章节是最有趣的。作者实际上也将这一部分扩展到了第 9 章。无论如何,我认为我从这本书的这一部分学到了很多,我希望能够在我自己的工作中使用这些模式。
后三章是关于字符串和文件的(第 10 章);用 Python 进行测试,有单元测试、nose、py.test 等等;快速浏览一些流行的第三方模块/包,如 PyQT、CherryPy 和 SqlAlchemy。
我看到的大部分章节还是初稿或二稿,所以有点粗糙。然而,大多数信息看起来真的很好,我认为这实际上将是迄今为止 Packt 最好的发行之一。我拥有他们的其他几本 Python 书籍,但没有一本是这种质量的(假设作者确实认真对待了编辑的建议)。我并不羞于批评写得不好的书或电影,我的朋友可以证明这一点。如果你想学习更多关于如何以面向对象的方式使用 Python,我想这本书会很好地为你服务。你可以从 Packt 预订这本书(唉,我没有任何回扣...所以你可以随意从亚马逊或者你最喜欢的书店订购...我这里只链接一下,因为最简单)。
图书预览:Python 图形烹饪书
原文:https://www.blog.pythonlibrary.org/2010/09/22/book-preview-python-graphics-cookbook/
本周,我完成了为 Packt 出版社编辑的另一本书。这本书的名字叫 Python 图形烹饪书作者是 Mike Ohlson de Fine(我想)。你可能会奇怪为什么我不知道德·法恩是不是作者?Packt 认为它的技术编辑不应该知道这些信息。事实上,Packt 非常谨慎(而且愚蠢),他们会给我们表格让我们填写,问我们要我们正在评论的书的 ISBN,但拒绝给我们 ISBN。
让大家知道,Packt Publishing 的技术审查人员完全没有报酬。我们得到的唯一报酬是我们评论的书的副本,加上我们选择的另一本书,我们的名字/简历出现在我们评论的书中。就是这样。如果帕克特接近你,让这成为对你的警告。
现在,也不全是坏事。你可以在几乎所有人之前阅读一本书,你甚至可以帮助塑造这本书!那真的很酷!然而,如果你不快速阅读,那么这份工作不适合你。你通常只有 3 到 4 天的时间来复习一章。但是我的抱怨已经够多了,让我们开始预览吧!
可悲的是,我收到的这本书的前四章都很糟糕。所有四章都是第三或第四稿,然而,它们仍然错误百出。这些问题从拼写错误这样简单的事情(Open Office 的拼写检查真的这么糟糕吗?),糟糕的语法和糟糕的句子结构导致代码由于明显的语法错误或不完整的代码而无法运行。还有许多复制和粘贴的错误(通常在代码中)。我可以继续说很长一段时间,但我同情作者,所以我不会。
不管怎样,作者在那之后确实变好了。这些章节不是很好,但总体平均误差略有下降。主要的问题(我认为)是,英语不是作者的第一语言,这使得文本看起来不自然。总共有十一章。
该书涵盖以下主题:
- 如何用 Tkinter 绘制形状
- 带 Tkinter 的文本
- 带 Tkinter 的简单动画
- 使用 Python 图像库处理图片
- 组合光栅和矢量图片(也用 Tkinter)
- Python I/O 和鼠标事件
- Inkscape 和 Tkinter
- 使用 Tkinter 的通用 GUI 构造
我发现一些题材相当有趣,比如动画和它背后的三角学。书中有一个 Inkscape 教程有点奇怪,但也很有趣。作者肯定知道他的东西,并且确实用他的一些图片例子和后来的动画例子发光。我真心希望普通的 Packt 编辑团队可以帮助他润色这本书,以便发行。不过,这本书结尾的通用图形用户界面在一本图形食谱中并不合适...
唉,我们技术编辑只能看到这一章的一个版本,所以在这本书出版之前,我们永远看不到作者做了什么(如果有的话)来解决我们发现的问题。我希望他们有某种技术编辑,在新草稿完成后检查每一章。
虽然我不像为 Packt 写的上一本书那样喜欢这本书,但也不全是坏事。我学到了一些新的技巧,并对我在这里和另一本书上找到的 PIL 信息有了一些很酷的想法。我现在的主要警告是,你应该在买这本书之前先预习一下。我不知道这本书什么时候会发行,但是当我拿到我的那本书的时候,我会试着再读一遍,这样我就可以告诉你它有多好或者多差。
图书预览:Python 测试-初学者指南
原文:https://www.blog.pythonlibrary.org/2010/02/17/book-preview-python-testing-beginners-guide/
本周有人联系我,让我评论一本来自 Packt Publishing 的新书,书名是《Python 测试:初学者指南》,作者是 Daniel Arbuckle(据我所知,与 Garfield 的主人没有任何关系)。我还没有收到这本书,但是你可以在他们的网站上看到。我还在亚马逊上找到了这本书。唉,如果你点击这些链接中的任何一个,我都不会得到报酬,所以请随意点击而不受惩罚。
有兴趣可以免费看第五章。注意:该链接指向一个 PDF。
我期待着评论这本书,因为我已经很久没有写书评了。我保证完全诚实。如果这本书很烂,我一定会让你知道。
书评:Django 1.0 网站开发
原文:https://www.blog.pythonlibrary.org/2009/06/07/book-review-django-10-web-site-development/
几周前,我从 Packt 出版社收到了艾曼·霍利的《Django 1.0 网站开发 》供我审阅。我曾经和 Django 一起工作过,当时我翻阅了另一本关于 Python web 框架的书以及他们的一个官方教程。我对这本书有所怀疑,因为它只有 257 页,我不认为它能在这么少的几页里教会我很多东西。
然而,我对它的可读性和代码示例的质量感到惊喜。我阅读了很多 Python 书籍和其他编程文本,并且通常情况下,这些例子在某种程度上是欠缺的。有些书有彻头彻尾的坏例子。Hourieh 在解释他的代码方面做得非常好,他一行一行地检查了他写的所有东西。虽然过一段时间后可能会有点单调,但他的一丝不苟确实让读者明白了正在发生的事情。
这本书的主旨是教读者如何构建一个社会化书签应用程序。事实上,这是整本书中你唯一会创造的东西。最后两章是关于在 web 服务器上部署应用程序,以及通过缓存和安全性增强来改进应用程序。
我读了这本书的核心。我并不真的需要知道如何安装 Django,因为我以前已经安装过了,而且我也没有去部署它,因为我现在还没有一个用于 web 服务器的开发盒。我读的真的很好。
这本书从头到尾教你在 Django 中创建 web 应用程序所需的所有基础知识。有几个小的句子结构的失误和一些轻松愉快,似乎有点不合适,但除此之外,这是一个非常坚实的书。您将了解 Django 的用户管理模型是如何工作的,如何使用 jQuery 实现 AJAX,将投票和评论添加到书签应用程序中,使用 Django 的内置工具创建一个管理界面,添加一些基本的搜索功能,并构建一个可以邀请朋友的社交网络。如果你曾经想知道像脸书这样的网站的内部情况,这本书会让你有所体会。我应该注意的是,封面暗示它讲述了如何构建 web 应用程序,而正文只是向读者展示了如何创建一个应用程序。创建其他应用程序的概念是存在的,但我认为这种说法有点误导。
总的来说,我推荐这本书。如果你也有机会阅读,请告诉我你的想法。
书评:掌握面向对象的 Python
原文:https://www.blog.pythonlibrary.org/2014/05/02/book-review-mastering-object-oriented-python/
Packt Publishing 邀请我担任他们最新的 Python 书籍之一的技术评论员,Steven Lott 的《掌握面向对象的 Python》。这本书是他们 2010 年版本的续篇,由 Dusty Phillips 写的 Python 3 面向对象编程,我在这里评论了。
注意:这本书显然是给 Python 3 开发者看的,而而根本没怎么谈论 Python 2。
快速回顾
- 我选择它的原因:出版商邀请我参与编辑这本书,但这正是我喜欢读的书
- 我完成它的原因:它写得很好,你可以学到很多关于类内部是如何工作的
- 我想把它给:一个想学习新事物的中级 Python 程序员
图书格式
你可以得到这本书的平装本、epub、mobi 或 PDF。
书籍内容
这本书分成 3 部分或 18 章。
全面审查
这是 Packt 最好的书之一,也是我读过的最好的高级 Python 书籍之一。让我们花点时间来讨论一下这些章节。这本书是基于赌场 21 点的概念,这是一个奇怪的编程书籍的主题。无论如何,作者使用它和其他几个例子来帮助演示 Python 中一些相当高级的主题。第一章都是关于 Python init() 方法。它向读者展示了如何在超类和工厂函数中使用 init。第二章跳转到 Python 的所有基本的特殊方法,比如 repr,format,hash,等等。在前几章中,你会学到很多关于元编程的知识。
第 3 章深入探讨了属性、特性和描述符。您将学习如何使用 slots,创建不可变的对象,以及使用“热切的计算机属性”。第 4-6 章是关于创建和使用可调用、上下文和容器的。有关于内存化、创建自定义可调用程序、如何使用 enter / exit、使用集合模块(deque、ChainMap、OrderedDict 等)的信息,还有更多!第 7 章谈到创建你自己的号码,这是我从未考虑过的事情。作者承认你通常也不会这样做,但是他确实教了读者一些有趣的概念(数字散列和就地操作符)。第 8 章以装饰者和混合者的信息结束了第 1 部分。
第 2 部分是关于持久性和序列化的。第九章重点介绍 JSON、YAML 和 Pickle。作者倾向于 YAML,所以在这一节你会看到很多使用它的例子。第 10 章深入探讨了使用 Python shelve 对象和使用与复杂对象相关的 CRUD 操作。第 11 章是关于 SQLite 的。第 12 章将详细介绍如何使用 Python 创建 REST 服务器和 WSGI 应用程序。第 13 章涵盖了使用 Python、JSON、YAML 和 PLIST 的配置文件,从而完成了第 2 部分。
本书的最后一部分涵盖了测试、调试、部署和维护。它直接跳到了第 14 章关于日志和警告模块的主题。第 15 章详细介绍了如何用 Python 创建单元测试和文档测试。第 16 章讲述了通过 argparse 使用命令行选项和创建 main()函数。在第 17 章,我们学习如何设计模块和包。这本书的最后一章讲述了质量保证和文档。您将学习一些关于 RST 标记语言和 Sphinx 的知识,用于创建文档。
我发现第一部分是这本书最有趣的部分。我学到了很多关于类如何工作、元编程技术以及可调用函数和函数之间的区别的知识。我认为这本书就这一部分而言值得购买!第 2 部分也有很多有趣的内容,尽管我质疑作者坚持使用 YAML 而不是 JSON。我也不明白为什么 PLIST 会被包含在配置文件类型中。第三部分对我来说有点仓促。章节不够详细,例子也不够有趣。另一方面,我可能有点厌倦了,因为这部分主要是我已经知道的材料。总的来说,我发现这是我在过去几年中读过的最好的 Python 书籍之一。我肯定会把它推荐给任何想了解 Python 内部,尤其是 Python 的“神奇方法”的人。
|  |
|
掌握面向对象的 Python
史蒂文·f·洛特[亚马逊](http://www.amazon.com/gp/product/1783280972/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=1783280972&linkCode=as2&tag=thmovsthpy-20&linkId=C535EKMPDQIEEOS4 target=)打包发布 |
其他书评
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:掌握 Python 高性能
原文:https://www.blog.pythonlibrary.org/2015/10/15/book-review-mastering-python-high-performance/
Packt Publishing 最近发给我一本 Fernando Doglio 的《掌握 Python 高性能》。他们还让我在这本书出版前担任技术审查。无论如何,让我们做一个快速回顾,如果你认为这听起来很有趣,你也可以看看我的完整评论!
快速回顾
- 拿起它的原因:我是免费得到的,但我确实觉得这个标题耐人寻味。
- 为什么读完:作为这本书的技术审稿人,我必须从头到尾读完。然而,它有许多有趣的概念,而且很短。
- 我想把它给:需要学习如何提高 Python 代码效率的人。
图书格式
你可以得到一个电子书(PDF、EPUB 或 MOBI)版本或一个软封面。
书籍内容
这本书分为 8 章 235 页。
全面审查
当我最初读这本书的时候,我对作者如何加速他们的代码很感兴趣。他涵盖了各种各样的主题,这很好,但这也妨碍了这本书,因为没有一个主题是深入的。他使用了许多小例子,并展示了如何在继续优化它们之前进行概要分析。让我们把每一章都过一遍,这样你就能对这本书的内容有所了解。
第一章是关于剖析你的代码。它涵盖了统计分析和基于事件的分析之间的区别,什么是分析,为什么它很重要,瓶颈和内存泄漏。它还介绍了运行时间复杂性(线性、阶乘、二次等)和最佳实践分析。
然后我们顺理成章地进入第二章,在那里我们学习一些可以和 Python 一起使用的分析器。这两个工具是 cProfile(包含在 Python 中)和 line_profiler 。作者演示了使用 cProfile 测量代码的各种方法,以及如何使用 Python 的 pstats 模块,该模块用于分析从 cProfile 收到的结果。然后作者继续使用 line_profiler 和 kernprof 来分析与 cProfile 相同(或相似)的例子。我认为这是书中最平衡的章节之一,本身就非常有趣。
第三章介绍了如何使用可视化工具来帮助您理解分析器的输出。在本章中,您将了解 KCacheGrind / pyprof2calltree 和 RunSnakeRun。在大多数情况下,您只需学习如何使用这些工具来弄清楚您的数据意味着什么。
在第四章,我们学习优化你的代码。涵盖的主题有记忆化、列表理解、生成器、类型、加载自己的自定义 C 库,以及其他一些技巧和窍门。虽然这一章很短,但它有一些好的想法,值得一读或至少略读。
第五章深入探讨多线程和多重处理。你会了解到每种方法的优缺点。您还将了解全局解释器锁,以及当您选择其中一种技术时,它会如何影响您。
第六章介绍了 PyPy 和 Cython 的使用,以及它们如何对你的代码进行额外的优化。我很喜欢这一章,虽然我觉得 PyPy 没有 Cython 得到那么多的关注。也没有太多的编码例子。
如果你喜欢数字运算,那么第七章适合你。它讲述了如何使用 Numba,鹦鹉和熊猫。坦白地说,在这三个图书馆中,我只听说过熊猫。就我个人而言,在我的工作中不需要做大量的数字运算,但是看看每个库是如何工作的并大致了解它们的用途是很有趣的。
最后,在第八章,作者试图把这一切联系起来。这一章可能应该有两倍的长度,这样他就可以涵盖所有的内容。但是最后,它仅仅覆盖了很少的内容,你可以看到一个完整的例子从头到尾都得到了优化。
总的来说,我喜欢这本书。我将把它推荐给任何需要优化 Python 代码的想法或者只是学习概要分析的人。
|  |
|
掌握 Python 高性能
费尔南多·多利奥亚马逊 |
其他书评
- 中级蟒蛇皮作者:Muhammad Yasoob Ullah Khalid
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:任务 Python
原文:https://www.blog.pythonlibrary.org/2019/03/20/book-review-mission-python/
几个月前,No Starch 出版社问我是否有兴趣阅读他们的新书《任务 Python:编码太空冒险游戏》!肖恩·麦克马纳斯。我喜欢阅读新的科技书籍,但当我过去一年如此忙碌时,很难将它们融入进去。然而,我 2019 年的一个决议是通读我积压的技术书籍,所以我决定接下来处理这本书!
快速回顾
- 为什么我会选择这本书:最初,出版商让我看看这本书,但我也很感兴趣,因为我认为游戏编程很有趣
- 我为什么要完成它:我基本上浏览了这本书,但它绝对值得一读,看看如何把一个游戏放在一起
- 我想把它给:想了解用 Python 写一个 2D 游戏有多简单快捷的开发人员
图书格式
你可以得到这本书的平装本、PDF、Mobi 或 ePub。
书籍内容
这本书包含 12 章和 3 个附录,共 280 页。本书中的代码是针对 Windows 或 Raspberry Pi 的。这本书还需要 Python 3,因为它使用 PyGame Zero,而 PyGame Zero 需要 Python 3。
全面审查
任务 Python 试图教你 Python 编程语言,同时也用 PyGame Zero 构建一个 2D 视频游戏。简介很有帮助地解释了如何在 Windows 和 Raspberry Pi 上安装 Python 和游戏所需的依赖项。如果你碰巧在 Linux 或 Mac 上,你将不得不弄清楚如何自己安装它。
这本书的第一章指导读者使用 Python 的空闲应用程序来开发代码。这一章的其余部分将向你介绍如何编写游戏的一些内容。基本上,你创建游戏的背景,并了解 blitting。您还将学习如何使用键盘移动游戏中的角色。
第 2 章深入探讨了 Python 列表以及如何在游戏中使用它们。作者使用列表构建和访问列表中的元素来帮助读者创建与空间相关的清单,并最终创建排序图。这是一个相当有创意的方式来同时整合 Python 列表和视频游戏。
读者旅程的下一步是在第 3 章学习 Python 循环。循环用于将“地图”打印到屏幕上。地图基本上是一个数字矩阵。在描述了如何进行嵌套循环之后,作者使用新发现的知识来帮助用户使用 PyGame Zero 的绘图能力创建一个房间图像。
对于第四章,作者教读者如何创建地图和自动地图生成器。在这里,您将学习如何使用 PyGame Zero 在屏幕上绘制地图,并在不可避免地遇到问题时调试代码。

第 5 章和第 6 章是关于空间站的设备,重点是 Python 字典。在这里,读者将学习如何在 Python 中混合数据类型,比如向字典中添加列表。你还将学习如何在游戏中加载场景到房间里。
第七章的目的是教你如何在游戏中移动精灵。在这个任务中,读者将学习如何将键盘连接到游戏中,以及如何使用不同版本的精灵来让动作看起来自然。
本书的其余部分构建了游戏本身的各个部分。你会学到如何使用函数,整本书都有练习。本书的其余部分主要关注 PyGame 特定的函数和方法,以及如何有效地使用它们。
这本书似乎组织得很好,写得也很好。我个人觉得章节的标题有点混乱,因为你不能仅仅从标题上判断出这一章实际上是关于什么的。章节名有时也写得很笨拙。然而,这本书的内容很有趣,学习如何用 Python 写游戏也很有趣。我会把这本书给那些想学习用 Python 写游戏的所有活动部分的人。你不会学习游戏理论,但它仍然是一个很好的游戏开发入门,代码很少。
你可以访问作者的网站获得这本书的免费样本,并了解更多相关信息。
|  |
|
任务 Python
其他书评
- Julien Danjou 的《严肃的 Python:关于部署、可伸缩性、测试等的黑带建议》
- Brian Okken 的 pytestPython 测试
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
书评:现代 Python 食谱
原文:https://www.blog.pythonlibrary.org/2020/09/03/book-review-modern-python-cookbook/
Packt Publishing 最近发布了一本新书,书名为现代 Python 食谱,作者是 Steven Lott。它的副标题是“在 Python 3.8 第二版中开发完美且富于表现力的程序的 133 种方法”,这可能会给你一些暗示,这是一本大书。事实上,它长达 822 页!

我第一次看 Lott 的掌握面向对象 Python ,这是一本很优秀的书。他是一个优秀的作家,可以很容易地钻研 Python 中任何主题的技术细节。
O'Reilly 是第一家出版 Python 食谱的公司。那本书也不错,几乎和洛特的最新作品一样大。烹饪书不是用来从头到尾读的。但是他们对学习新的信息很有帮助。洛特的书是按食谱分组排列的。有趣的是,Packt 能够让第一本 Python 食谱的作者 Alex Martelli 成为这本书的技术评审之一。
共有 15 章,每一章都有不同数量的食谱。你会惊讶于食谱有多详细。例如,有一个名为“处理大整数和小整数”的食谱,乍一看似乎很琐碎。但是通读之后,你会学到很多关于 Python 如何不同于其他编程语言地表示整数。
它还解释了 sys.maxsize()是如何发挥作用的,这实际上比我预期的要有趣得多。我很欣赏食谱有一个“另见”部分,告诉你下一步去哪里学习书中或 URL 上的相关内容。
我喜欢有解释如何使用 walrus 操作符的方法,强制只使用关键字参数和只使用位置参数。这里有很多关于 Python 最新版本中新特性的精彩报道。
在这本书里,你还会学到类、对象和函数式编程。
令人惊讶的是,作者还涵盖了 web 服务、配置、组合应用程序、统计编程和线性回归。
你应该去看看这本书。这真的很有趣,会是一本很棒的参考书。
书评:用 Python 进行模块化编程
原文:https://www.blog.pythonlibrary.org/2016/06/15/book-review-modular-programming-with-python/
今年早些时候或 2015 年末,Packt Publishing 邀请我担任 Erik Westra 所著的《Python 模块化编程》一书的技术评审。这听起来真的很有趣,最终成为我读过的 Packt 的最好的书之一。请注意,我是这本书的唯一技术评论家。我不知道为什么 Packt 为这本书走这条路,因为他们通常有 2-3 个评论家,但也许他们试图加快他们的写作过程。
快速回顾
- 为什么我要拿起它:主要是因为 Packt 要求我这么做。然而,这确实是一本有趣的书
- 为什么我要完成它:因为这本书很短,写得很好
- 我会把它给:一个需要提高代码组织技能的中级开发人员
图书格式
你可以得到一个电子书(PDF、EPUB 或 MOBI)版本或一个软封面。
书籍内容
这本书只有 9 章,长达 228 页。
全面审查
用 Python 进行模块化编程,读起来其实挺好玩的。它旨在帮助您学习如何使您的代码更加模块化,并提供了一些非常好的示例。第一章从 Python 本身组织其模块和包的方式开始。它继续解释为什么模块化编程是重要的,并且有一个创建你自己的模块的简单例子,这个模块恰好是一个缓存模块。
第二章是关于创建你的第一个模块化程序。它将带你经历以模块化的方式设计程序的各个步骤,然后实际实现它。在设计阶段,作者只是把界面截出来。然后在实现阶段,我们开始实际添加代码。
对于第三章,我们学习模块和包是如何初始化的。作者还介绍了 Python 的导入系统。我们学习进口如何工作,什么是相对进口,控制进口什么,循环进口等等。
第四章是关于创建一个模块化的图表包。我们学习如何使用 pillow 包制作图表,pillow 包是 Python 图像库(PIL)的一个分支。然后作者谈到了项目的需求是如何变化的,以及我们必须如何应对它们。在这个例子中,我们需要一种 pillow 不支持的方法来制作矢量图像。因此,作者展示了如何添加使用 Reportlab 或 pillow 创建图表的功能。这也是真正伟大的一章。
第五章着眼于模块化模式,如封装、包装器等。我认为我发现最有趣的部分是关于动态导入、插件和钩子的章节。
在第六章中,我们学习了可重用模块。作者首先描述了什么是可重用模块,然后给出了一些例子。本章的其余部分将致力于创建一个可重用的模块,它恰好是一个单位转换模块。
第七章深入探讨了 Python 的导入系统。它涵盖了可选导入、本地导入、将包添加到 sys.path、各种导入“陷阱”、处理全局等等。这实际上是我最喜欢的章节之一。
第八章,我们改变了节奏。这都是关于测试和部署我们的模块。本章只给出了单元测试、代码覆盖和测试驱动开发的基础知识。这一章的大部分是关于准备发布到 Github 或 Python 包索引的模块。
最后一章旨在展示模块化编程技术如何使编程过程更加有效。它给出了一个非常简短的例子,结束了这本书。
总的来说,我发现这本书很好地传达了它的信息。代码示例简单易懂。文笔很好。比我通常在 Packt 出版物上看到的好多了。我喜欢阅读简洁或有趣的代码,这本书有几个很好的例子。我确实觉得这本书的结尾有点突然。虽然我不知道应该添加什么,但我只是觉得它可以再有一两章。不管怎样,我向那些在组织代码方面有困难的人推荐这本书。
|  |
|
用 Python 进行模块化编程
埃里克·韦斯特拉亚马逊 |
其他书评
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:穆拉希的 Python 编程
原文:https://www.blog.pythonlibrary.org/2017/02/10/book-review-murachs-python-programming/
我不时为 i-programmer 网站书评,他们最近给了我一本迈克尔·厄本和乔尔·穆拉希写的 T2·穆拉希的 Python 编程。这本书长达近 600 页,对于平装本来说相当昂贵。对于那些注意力持续时间短的人,我给你们快速回顾一下。对于那些想要更深入一点的人来说,你需要点击查看剩下的内容。
快速回顾
- 为什么我拿起它:在这种情况下,因为我-编程要求我
- 我为什么要读完它:因为这本书写得很好,而且相当有趣
- 我会把它给:想学 Python 的人
图书格式
你可以在穆拉希买到 DRM 电子书,或者在你附近的网上商店买到平装本。
书籍内容
这本书有 4 节,18 章,576 页长。
全面审查
穆拉希不是我熟悉的出版商,所以当我开始阅读他们的 Python 编程书籍并发现其质量如此之高时,我感到很惊讶。这本书是迈克尔·厄本和乔尔·穆拉希写的。它基于 Python 3,本质上是一本入门书。这本书分为 4 个部分,共 18 章。让我们花些时间一章一章地看这本书。
第一部分包括 8 章。第 1 章是一个非常基础的介绍性章节,旨在向您展示 Python 和其他语言之间的区别。它还介绍了如何使用 IDLE (Python 包含的 IDE)并运行“Hello,World”类型的程序。作者还解释了 Python 如何在运行之前将源代码“编译”成字节码。最后,本章给出了一些关于如何修复语法和运行时错误的提示。
第 2 章介绍了 Python 中的编码。您将了解注释、使用内置函数、Python 的一些数据类型、算术表达式、字符串连接和许多其他主题。还有两个小程序,作者在这一章的最后用你到目前为止学到的概念实现了它们。
第 3 章深入研究控制语句。在这种情况下,我们将讨论 Python 的 if/elif/else 语句,以及关系和逻辑操作符在 Python 中是如何工作的。本章还介绍了 Python 的循环结构(while 和 for 循环),以及 break 和 continue 语句。我没有看到任何关于在你的循环中使用“else”语句的内容,但是我不确定我以前是否在书上看到过。不管怎样,他们更新了前一章的程序,并用第三章的新概念演示了几个新程序。
第 4 章介绍了功能和模块的定义和使用。这是一个有趣的小章节,你会学到默认值,以及局部和全局变量。您还将创建一个模块,记录它并学习如何导入它。他们还提到了 Python 的标准库,并描述了如何从中导入模块。最后,我们学习如何设计一个程序,然后编写代码。
第 5 章是我们学习如何测试和调试程序的地方。您将了解常见的 Python 错误以及一些测试和调试软件的技术。正如所料,他们使用 IDLE 的调试器以及 print()语句来帮助调试代码。有趣的是,我们直到第 8 章才学到异常处理。
第 6 章是关于 Python 的列表和元组数据类型。在这一章中,你将学习使用列表的基本知识,并且你将在这一章中编写另外三个程序。由于元组是不可变的,所以它们的覆盖面要小得多,但是我认为您学到的足够多,可以正确地使用它们。
第 7 章是关于如何使用 Python 来处理文件。在本章中,你将学习如何打开、创建、读取和写入文件。您还将了解如何处理二进制文件和 CSV 文件。
第 8 章是异常处理章节。它描述了异常如何工作,如何处理单个和多个异常,以及如何从异常对象中提取信息。您还将了解 finally 子句以及如何自己引发异常。这一章结束了第一部分。
第 2 部分被描述为涵盖“其他概念和技能”,只有 5 章长。我会说得很简短:
在第九章,我们学习了数字的一般知识。以下是一些例子:浮点数、格式化数字、使用区域设置模块、舍入和小数模块。
第 10 章是关于字符串的。我们将学习一些关于 Unicode、切片、索引、分割和连接字符串的知识。我们还将创建或增强 4 个程序。最复杂的是一个刽子手游戏,非常值得一读,因为它将游戏的功能分成了多个模块。
第 11 章的主题是使用日期和时间。在本章中,你将学习 Python 的时间和日期时间模块的基础知识,并使用它们创建一些程序。
在第 12 章,我们终于了解了 Python 最重要的数据类型之一:字典(或 dict)。在这里,您将学习如何创建字典以及获取、设置、添加和删除条目。还有一些关于将字典转换成列表以及向字典中添加更复杂的值的信息。像往常一样,在本章中你将创建一些简单的程序。
这一部分将在第 13 章结束,在那里我们将学习递归和算法。这一章大约有一半的篇幅是用来学习递归的工作原理以及它在 Python 中是如何工作的。其余部分涵盖了一些常见的算法,如阶乘,斐波纳契数列和汉诺塔。
第 3 节是关于 Python 中的面向对象编程(OOP)。它只有三章。基本上这三章涵盖了定义和使用你的类,继承和设计方面,当你做面向对象编程时需要用到。在这一章中,你将创建更多有趣的小程序,并学习许多有用的信息,如多态如何工作、重写方法、创建自定义异常等。
最后两章在第四节。第 17 章介绍数据库,然后深入使用 Python 的 SQLite 模块 sqlite3。但是,它没有谈到任何可以用来连接到企业级数据库的第三方模块。学完本章后,你应该知道如何创建数据库,以及如何在 SQL 中使用 SELECT 语句、INSERT 语句、UPDATE 语句和 DELETE 语句。
最后一章是第 18 章。这是使用 tkinter 创建 GUI 程序的介绍。tkinter 模块有基于它的整本书,所以不要期望这一章涵盖所有的内容。你将学到的是如何编写一个简单的未来值计算器应用程序,这很好。但你不会学到比这更多的东西。
总的来说,我认为这本书是经过深思熟虑和执行的。这本书使用了“成对页面”的方法,在右页有语法、指南和例子,在左页有额外的解释信息。我敢肯定这在书的形式下很好,但在他们的电子书版本中有点尴尬。事实上,我真的不能推荐你直接从穆拉希得到的电子书。它使用一个名为 LockLizard Safeguard 的 DRM 应用程序,你必须下载。您将获得一个许可证文件,您需要在打开图书之前运行该文件,该文件为. pdc 格式。该应用程序目前只支持 Windows 和 Mac,所以对于 Linux 来说,你只是运气不好。该应用程序看起来像 Adobe 的 Reader 应用程序,但它非常有限。您不能突出显示或添加注释。我在 Windows 中使用它,发现如果你有书签窗格,那么你只能在其中滚动。您需要在图书窗格中单击后退才能滚动到那里。
无论如何,除了令人讨厌的电子书客户端,这本书其实很好。我觉得它很好地涵盖了主题,并且包括了一些在 Python 入门书籍中不经常看到的内容,比如 CSV、数据库和 GUI 示例。这本书的其余部分对于初学者来说是相当标准的,但是文本清晰,例子有趣。我真的很喜欢你在几乎所有的章节里写小程序,它们除了打印出一个字符串之外,几乎总是做一些事情。我相信对于想要学习 Python 的人来说,这是一本值得一读的书,但如果你已经了解 Python,那么这本书很可能不会有你感兴趣的东西。
|  |
|
穆拉希的 Python 编程
迈克尔·厄本和乔尔·穆拉希亚马逊 |
其他书评
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:Numpy 1.5 初学者指南
原文:https://www.blog.pythonlibrary.org/2011/12/15/book-review-numpy-1-5-beginners-guide/
这是一篇由伊万·伊德里斯撰写的 Numpy 1.5 初学者指南的非正统评论。在我们开始评论之前,我必须说两件事:
- 这本书是直接从 Packt 出版社以电子书和实物形式给我的
- 实际上,我认为我没有足够的数学知识来复习这个
关于第二个问题,我学了大学微积分,但是这本书讲的术语我要么不记得了,要么就是没讲过。我也学过统计学 I 和 II,但是作者更多的是处理矩阵操作和线性代数。我认为我以前的金融和会计课程帮助最大,但那是在书的结尾。
这本书的读者
那么这本书到底是针对谁的呢?我认为它的目标是高水平的数学家、科学家和股票市场的数据分析者。这篇散文相当不错,只是有点枯燥。书的大部分都是由一个小节介绍,一个问题,如何用 NumPy / Matplotlib 解决,以及一些代码示例组成。代码示例是片段,而不是完整的可运行代码,但是您应该能够轻松地拼凑出大部分代码。作者没有花时间导入库或创建奇特的类,所以所有的例子都非常简单,尤其是如果你已经理解了数学方程。注意方程没有解释,所以如果你不知道,你就要自己去挖掘了。
涵盖哪些内容
大量的方程式和数学术语。例如,你将学习如何做各种移动平均线,布林线,趋势线,阶乘,矩阵(很多很多),汉宁,汉明,ufuncs,李萨如曲线,行列式,傅立叶变换,各种对数,矩阵排序等等。所有这些都在 NumPy 的范围内,偶尔会有一些敏感的东西出现。这些例子侧重于股票市场和金融,在这种情况下似乎效果不错。
在这本书的最后,在第 9 章,作者稍微改变了思路,更深入地讨论了 Matplotlib。在前几章中,他已经断断续续地使用过它,但在这一章中,他涵盖了更多的基本功能。然后在第十章也是最后一章,他深入研究了 SciPy,甚至设法提到了 SciKits。
我注意到一些小的语法或句子结构问题,但这是一本写得较好的 Packt 书。
包扎
正如我提到的,由于高水平的数学,我并不真正理解这本书的很多内容。令我难过的是,我要么在高中或大学时没有涉及到这一点,要么我已经设法忘记了这么多。然而,虽然作者没有花太多的时间来解释这些例子,但我认为这种快速的写作方式是有效的。欢迎下载第三章来体验一下。如果你对这类东西感兴趣,或者想学习如何在 Python 中应用这类东西,那么我认为这本书可能正合你的胃口。
| |
Numpy 1.5 初学者指南
书评:实用编程:使用 Python 的计算机科学导论
|  |
|
实用编程:使用 Python 的计算机科学导论
詹妮弗·坎贝尔、保罗·格里斯、杰森·蒙托霍和格雷格·威尔逊亚马逊 |
上个月,我收到了一个家庭成员送给我的礼物,《实用编程:使用 Python 的计算机科学入门》。这本书是由四个作者:詹妮弗坎贝尔,保罗格里斯,贾森蒙托霍和格雷格威尔逊。我对阅读另一本与 Python 相关的教科书感兴趣已经有一段时间了,而这恰好是为数不多的几本之一。我唯一读过的另外一本 Python 教材是约翰·泽尔的 Python 编程:计算机科学导论 。我知道还有一两本书,但这些书超出了我的支付能力。
通常情况下,当我看到需要多个作者的东西时,结果不会很好。然而,这本书在使用 Python 向学生介绍计算机科学方面做得很好。当然,当我在计算机科学课上的时候,我们花了很多时间在理论上。这本书的大部分内容是关于学习 Python 的基础知识,比如如何使用字符串、列表、字典、元组等。因此,如果你希望用 Python 学习算法和数据结构,你在这里找不到太多。其中有一章是关于算法的,涵盖了排序和搜索算法,我认为这是这本书的亮点之一。
另一方面,你将会很好地了解到有史以来最简单、最有趣的编程语言之一。你不仅会得到一个很好的介绍,而且每章都以一系列基于该章内容的练习结束。我喜欢让复习题或要解决的问题让我学到的东西留在脑子里。我主要浏览了练习,因为这些章节是为没有编程经验的大学新生设计的。
这本书在两个地方涵盖了基本测试。它并不全面,但它确实让读者尝到了甜头,我认为它很好地传达了测试背后的推理。在书的结尾,他们对我们有了更多的关注。这本书概述了以下主题:调试、面向对象的哲学(类、继承、多态)、使用 Tkinter 的图形用户界面和数据库(sqlite)。
在读了 Dusty Phillips 关于 Python 面向对象编程的书之后,我发现这本书缺少了一章。但是,它是典型的介绍,所以我不能过多地敲打它。Tkinter 这一章很有趣,因为我一直计划在这个博客的其他文章中重温这一章。作者甚至花了一些时间在模型-查看器-控制器范例上。尽管我不太喜欢他们布置代码的方式,因为很难判断哪个代码适合整个 MVC 模式。数据库部分几乎是使用 Python 2.5 的 sqlite 模块的简单 SQL 代码。虽然这种方法没有什么特别糟糕的地方,但我知道我会被它弄得有点困惑,因为所有的新语法都与我之前在书中学到的不匹配。
有一些奇怪或糟糕的语法实例,但我没有发现任何明显的故意不在那里的编码错误。这本书定价合理,尤其是考虑到它应该是一本大学教材。如果你是计算机科学或 Python 的新手,我想你会发现这本书很有帮助。如果你是一个有经验的程序员,或者你已经上过几门计算机科学的课程,那么你可能会想跳过这本书(除非你想学习 Python)。
书评:实用 Python 和 OpenCV
原文:https://www.blog.pythonlibrary.org/2019/06/06/book-review-practical-python-and-opencv/
几年前,我在一个作者的 Kickstarters 上买了实用的 Python 和 OpenCV。开始看了,然后就忙别的了。在过去的几周里,我决定再试一次这本书,并且完成了它。请注意,我开始读这本书的第三版时并没有意识到还有第四版。完成第三版后,我把它和第四版并列比较,看起来它们几乎是一样的,所以我不认为这有多大关系。
快速回顾
- 我选择它的原因:计算机视觉/机器学习听起来很有趣,作者有一个有趣的博客
- 我完成它的原因:它很短,写作风格很吸引人
- 我想把它送给:任何希望开始使用 Python 中的 OpenCV 的人
图书格式
你可以得到这本书的精装本、PDF 或 Mobi。
书籍内容
这本书包含 11 章,共 169 页。它涵盖了第 4 版中的 Python 3 和 OpenCV 4。
全面审查
实用 Python 和 OpenCV 是一本有趣的书。它比普通的技术书籍要短,但是它涵盖了很多领域。这是一种异常现象,因为许多技术书籍看起来要长得多。不管怎样,让我们把这本书一篇一篇地过一遍。
第一章只是一个介绍。它描述了什么是计算机视觉,并给出了一些例子。然后第二章跳出来,教你如何安装你需要的软件包来有效地使用这本书。我个人认为这两章可以合并在一起,或者安装一章可以作为附录。但是没关系。
第三章是你最终进入代码的地方。在这里,您将学习如何将图像加载到 OpenCV 中并显示给用户。您还将学习如何保存图像。这对于不同图像格式之间的转换很有用,但更重要的是,它有助于在需要时保存数据。
在第四章中,你将从 OpenCV 的角度学习图像的基础知识。您将学习它的坐标系统,以及如何访问和操作图像中的单个像素。
然后在第五章,你会发现如何画直线、矩形和圆形。您可以更改每个形状的宽度、位置和颜色。您也可以将形状堆叠在一起。
第六章讨论了图像处理的主题。在这里,您将学习所有关于图像转换(平移、旋转、调整大小等)、图像算术、位运算、蒙版、分割、合并和色彩空间的重要性(RGB 与 BGR 和 HSV)。
对于第七章,您将学习如何在 OpenCV 中有效地使用直方图。直方图将帮助您确定正在处理的图像的对比度、亮度和强度分布。OpenCV 支持处理灰度和彩色直方图。您还将了解直方图均衡化和遮罩。
第八章解释了 OpenCV 可以实现的不同类型的模糊和平滑。在这里,您将了解高斯模糊、中间模糊和双边模糊。Adrian 没有深入解释这些话题。相反,他选择用小代码片段向读者展示如何完成每一项。
第九章介绍了阈值处理的主题,即图像的二值化。阈值是用于描述聚焦在图像中感兴趣的对象或区域上的术语。阿德里安在本章和书的其余部分使用了一些硬币的照片。你最终使用阈值来找到照片中的硬币。
然后在第十章中,你将学习如何使用渐变和边缘检测来提炼你在第九章中学到的东西。这可以让你找到照片中硬币的边缘。这一章集中在使用拉普拉斯和索贝尔方法的梯度。然后,您将了解如何使用 Canny 边缘检测技术。
为了包装这本书,Adrian 使用 OpenCV 找到硬币的轮廓,以便他可以计算图像中的硬币。他还谈到了在寻找轮廓时 OpenCV 版本之间存在的差异。
这本书很快涵盖了许多不同的主题。在我看来,有些布局上的小问题,因为有时他指的是一张没有很快出现或者在这一章的前面莫名其妙地出现过的图片。也有几次,他在解释一些页面上没有的代码。然而,这些事情不会影响代码示例本身的质量。您还可以获得一个包含更多信息的案例研究 PDF。
总的来说,我认为这是一本相当好的书。这些例子很有趣,节奏很快,在 Python 书籍中看到恐龙总是很有趣。这本书有点贵。
|  |
|
实用 Python 和 OpenCV
阿德里安·罗斯布鲁克博士PyImagesearch |
其他书评
- 肖恩·麦克马纳斯的任务 Python
- Julien Danjou 的《严肃的 Python:关于部署、可伸缩性、测试等的黑带建议》
- Brian Okken 的 pytestPython 测试
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
书评:Python 3 面向对象编程
原文:https://www.blog.pythonlibrary.org/2010/08/22/book-review-python-3-object-oriented-programming/
|  |
|
Python 3 面向对象编程
几个月前,我写了这本书的预览。一周前,我收到了这本书。不过,在我们开始评论之前,我想充分披露:去年 12 月,Packt 联系我成为这本书的“评论者”(阅读:技术编辑)。报酬呢?他们给了我一本书,一本我想要的他们目录中的任何一本书,我的名字出现在书里。如果你认为报酬会使我产生偏见,那就这样吧。每个人都有这样或那样的偏见。不过,我倾向于对我参与的事情更加苛刻。
好吧,我的灵魂暴露得够多了。让我们看看这本书。这本书的作者非常喜欢统一建模语言(UML)类图,所以如果你发现那些对学习有帮助,那么你会喜欢这本书。毕竟,整个第一章是由文本和 UML 图组成的,它简要介绍了面向对象的哲学。第 2 章跳到 Python 对象、模块和包。第 3 章深入探讨了继承(基本的和多重的)和多态。第 4 章是关于 Python 中的异常。第五章试图解释什么时候使用面向对象编程。我认为这是一个有趣的章节,因为在我看来,大学恐吓他们的学生,让他们认为应该对所有事情都使用 OOP。第 6 章和第 7 章通过覆盖元组、列表、字典、集合、各种理解、生成器和函数来深入 Python 标准库。从这些章节中我学到了很多关于理解的东西,这让我希望我能更多地使用 Python 3。第 8 章和第 9 章涵盖了 Python 设计模式。我发现这些章节是这本书的亮点,非常有趣。他涵盖了以下模式:装饰者、观察者、策略、状态、单例、模板、适配器、门面、flyweight、命令、抽象工厂和复合。
第 10 章涵盖了文件和字符串的基础知识;第 11 章介绍了单元测试和 py.test 测试。最后,第 12 章简要介绍了常见的 Python 3 库,如 SqlAlchemy、Tkinter、PyQt、lxml 和 CherryPy。
当我回顾这本书时,第 5 章和第 8 章有一些 Python 图像库的例子。作者注意到 PIL 当时还没有移植到 Python 3,但他认为通过发布会实现。唉,PIL 背后的人仍然没有 Python 3 端口。所以我很好奇作者是如何处理这个难题的。原来他最终用 pygame 代替了 PIL。这是一个有趣的选择,看起来对这些例子都适用。我没有重读这本书(尽管我打算在某个时候重读)。相反,我只是做了一个抽查,看看作者是否遵循了我的任何建议或修复了错误。看来他做到了。
在他解决这本书的问题之前,这本书很好。这里的理论比你通常在 Python 教科书中找到的要多,但我发现例子很有趣,他在章节的结尾有不寻常的练习,应该会让你思考。我敢肯定,如果我买了这本书,我会非常高兴。如果你不熟悉 Python 3,特别是面向对象编程,或者你想学习编程模式,我推荐这本书。如果你想先睹为快,Packt 在他们的网站上有第七章这里。
书评:面向儿童的 Python 有趣的编程入门
No Starch Press 的一名代表找到我,让我评论他们的书,No Starch Press 是面向儿童的 Python 的出版商。他们给我提供了一个免费的枯树拷贝和一个电子书(PDF)版本。这本书似乎与曼宁的
快速回顾
- 我选择它的原因:主要是因为我被出版商要求阅读它。然而,我发现这些极限初学者书籍本身就很有趣。我只是不想花我自己的钱。也是 Python 3 的书!
- 为什么写完:其实我没写完。这本书很好,但它是一本初学者的书,我读了大约一半就草草看完了。但这是一本写得很好的书,有着引人入胜的写作风格。
- 我会把这本书送给:我会把这本书送给那些有孩子的高中生,他们对编程感兴趣,尤其是对 Python 感兴趣。
图书格式
这本书可作为文书教科书或 PDF 电子书。
全面审查
《面向儿童的 Python》的作者是 Jason R. Briggs。这篇文章基于 Python 3,这很酷。我想这是我看过的第一本 Python 3 入门书。文本可读性很强,作者很好地为读者分解了语言,尤其是在书的前半部分。当我们上课的时候,它看起来更像一本普通的入门书,而不一定是给孩子们看的。这些章节简短扼要,并且在每一章的结尾都有练习。作者在一些例子中使用了 turtle 库,试图让事情变得更有趣。我觉得这是一个很有意思的做法,但是他并不是每一章都用,所以有点前后矛盾。
不过有几个奇怪的地方。例如,在第 5 页,作者声明 Python 不使用“复杂的符号,如大括号({})、散列”等,而事实上 Python 确实使用了这些符号。哈希用于注释,大括号用于字典对象。书中还有一些奇怪的命名惯例。他将字符串替换(或插入)描述为“嵌入值”。我从未在任何其他 Python 书籍中看到过这样的描述。这样描述并没有什么特别的错,但是如果你用这些关键词来搜索这个主题,你可能不会得到最好的结果。他还使用了旧的字符串插入方法:
print ("My name is %s" % "Mike")
而我通常看到的与 Python 3 相关的新方式更像这样:
print ("My name is %(name)s" % {"name":"Mike"})
# or
msg = "My name is {0}".format("Mike")
print (msg)
我认为我在阅读的文本中看到的最大问题是在第 39 页,其中描述了一个 Python 地图,作者将其描述为字典的另一个单词。地图命令是一个内置的 Python 函数,它将一个函数应用于 iterable 中的每一项。我认为这一节很差,因为读它的学生会认为 map 和 dict 是同一个东西,它们甚至不接近。如果学生试图通过查找 Python 地图来找到字典的例子,他们会非常困惑!
说够了,让我们快速浏览一下章节,这样你就知道如果你决定购买,你会得到什么:
这本书有三个部分。第一部分由 12 章组成。前 3 章涵盖了变量、元组、列表和“地图”(即字典)。在第四章我们用海龟库画画。然后我们回到基础,第 5 章讨论条件句(if/else ),第 6 章讨论循环。第 7 章和第 8 章用函数、类、模块和对象探讨了面向对象的领域。第 9 章是关于 Python 的一些内置函数,但不是很多。第 10 章似乎只是作者最喜欢的内置模块的概述,如 copy、keyword、random 等。第 11 章回到使用 turtle 模块绘制图形和形状。最后,第 12 章是对 Tkinter 的一个尝试,Tkinter 是大多数 Python 发行版中包含的 GUI 工具包。看起来作者展示了如何用 Tkinter 画图,就像他用 turtle 画图一样,也展示了 Tkinter 的一些其他技巧。
在第二部分中,作者花了一些时间教读者关于使用 Tkinter 的游戏。他用了两个章节用一个弹跳球和一个球拍创造了一个游戏。第三部分也是游戏相关的。这一次作者用 GIMP 中创建的精灵创建了一个游戏,游戏本身是用 Tkinter 构建的。我不确定为什么你会使用 Tkinter 而不是 pyGame,除了 pyGame 没有包含在 Python 中。
结论
总的来说,我觉得这本书很有趣。如果你有一个高中生(或者一个非常聪明的中学生),那么这本书可能是给你的孩子的!我认为这本书也可以作为大学里 Python 的入门教材,或者只是给那些想学习这门语言的人。像往常一样,它有几个粗糙的边缘(地图/字典的东西是我看到的唯一主要的一个),但我认为这些很容易被忽视。
|  |
|
面向儿童的 Python
杰森·布里格斯亚马逊 |
书评:Python 多媒体应用初学者指南
|  |
|
Python 多媒体应用初学者指南
我从 Packt 出版社收到了这本书的电子书格式的书评。我喜欢免费的书,但我不会让这影响我对这本书是否值得你花血汗钱的判断。Packt Publishing 出版了比其他任何出版商更多的小众 Python 书籍,我认为这很酷。不幸的是,他们在出版之前似乎没有花足够的时间润色书籍,所以他们的书往往会被击中或错过。比如他们的 Python 3 书就相当不错。唉,这个更倾向于平庸。
别误会我的意思。这本书的内容启发了我去写这本书所涵盖的一些主题,所以它并不都是平庸的。问题主要在于作者的母语显然不是英语,以及 Packt 的编辑过程没有将“非英语”的散文平滑到有时读起来很痛苦的程度。这里有几个例子:
- 一个简单的 PyGame 应用程序,在表面(窗口)画了一个圆。
右边的图像是在箭头键(第 17 页)的帮助下移动圆的位置
后拍摄的截图 - 如果指定了 4 元组框,则要粘贴的图像的大小必须与区域的大小相同。(第 40 页)
这是一个 Packt 编辑错误:
- box 参数可以是 4 元组错误:未找到引用源或 2 元组。
哎哟...他们在这篇文章中做了两次奇怪的查找和替换错误。
无论如何,我真的不想太多抨击这本书。写书很难(一直写博客也很难!).批评很容易。让我们来看看这本书的八个章节涵盖了什么:
- 第一章——Python 和多媒体:介绍你可以用来播放和编辑音乐、视频和图像文件的各种模块
- 第 2 章——使用图像:Python 图像库(PIL)的快速浏览,展示了如何调整图像的大小、旋转和翻转等
- 第三章-增强图像:更多涉及 PIL 的配方,如如何调整图像的亮度和对比度,交换颜色,混合照片,平滑效果,锐化,模糊,边缘锐化,浮雕等
- 第 4 章-动画的乐趣:皮格莱特 2D 动画介绍
- 第 5 章——处理音频:本章向您展示了如何在 Python 2.6 中使用 GStreamer 来播放音频、在不同格式之间转换音频、录制音频等等。这一章还反复使用“音频”这个词,比如“播放音频”、“提取音频”等等。
- 第 6 章——音频控制和效果:更多的 GStreamer 技巧和窍门,比如如何给你的音频文件添加回声和淡入淡出,混合音频文件和添加一些可视化效果
- 第 7 章——处理视频:如何使用 Python 2.6 + GStreamer 处理视频
- 第 8 章——使用 QT Phonon 的基于 GUI 的媒体播放器:使用 PyQt GUI 框架创建一个媒体播放器
我认为这本书最令人沮丧的部分是第 5-7 章。出于某种原因,GStreamer 的最新 Python 绑定只适用于 Python 2.6!书中的安装说明和书中提供的链接有些混乱,所以我没有尝试。我确实找到了一些 2.4 和 2.5 版本的 GStreamer 绑定,但它们是针对 GStreamer 的一个旧版本的。最新的 GStreamer 版本没有任何绑定(至少,我找不到它们)。因此,虽然这些章节很有用,但是如果你使用的是最前沿的 Python 或者需要使用旧版本,那你就完了。
我没能把最后一章读完,所以我对此没有任何评论。
PIL 分会是我最喜欢的,我计划用它们来做我自己的项目。皮格莱特这一章再次启发了我,让我重新审视这个框架...但我还没那么做。我怀疑 PyQt 声子章在技术层面上会很有趣。
到这个时候,你可能在想:结论是什么?我认为你应该试着找一个免费的章节或者在书店找到这本书,在你买之前读一读。毕竟标价几乎是 45 美元,所以明智地使用你的钱。
更新(2010 年 10 月 15 日)-这里有一个链接到第二章,使用图像
书评:Python Playground——好奇的程序员的极客项目
没有淀粉出版社最近发给我一本由 Mahesh Venkitachalam 撰写的名为Python Playground:Geeky Projects for the Curious Programmer的书,供我评论。我通常不会从那家出版商那里买书,所以我不知道该期待什么,但这本书相当不错。但我不会在这里提供任何剧透,因为我们有一个快速审查要做!
快速回顾
- 我为什么拿起它:我是免费得到的,但是书上的描述让我也想得到它。
- 我完成它的原因:它写得很好,项目也很有趣。
- 我会把它给:一个程序员,他也是一个数学呆子,或者只是想要一个新的有趣的项目的想法。
图书格式
你可以得到一个电子书(PDF、EPUB 或 MOBI)版本或一个软封面。
书籍内容
这本书分为 5 个部分,14 章+ 3 个附录,330 页。
全面审查
Python Playground 是一本非常有趣的书。它有很多有趣的小项目可以学习。写作很吸引人,代码大部分时间都很容易理解。你可能会从这本书得到最多,因为你碰巧喜欢数学,因为很多项目使用 numpy 和各种方程或算法来使它们工作。换句话说,这不是一本初学者的书。让我们复习一下这本书涵盖的内容。
第一部分只有两章,但它们被认为是对未来的热身。第一章从学习如何解析 iTunes 播放列表开始。我忘记了 Python 内置了自己的 plist 解析器库,所以学习起来很有趣。在第二章,我们学习如何使用 Python 的 turtle 库来创建肺活量图。我认为这一章很有趣,尽管这个例子在我的双显示器系统上表现得有点奇怪。这个想法非常酷,非常值得学习。
第三章以康威的人生游戏开始了第二部分。基本上你在创造一个基本的生活模拟器。接下来是第四章,我们学习如何用卡普勒斯-斯特朗算法创造音乐泛音。在本章中,您将使用 numpy、matplotlib 和 pygame。作者很好地解释了算法是如何工作的,所以你不应该迷路(或者不会迷路)。第五章以另一个模拟器结束了第二部分。在这个游戏中,我们学习如何使用所谓的 Boids 模型来模拟一群鸟。我发现这一章非常有趣。
第三部分是关于处理图像的。因此,在第六章中,我们学习了如何使用 Python 从一个常规图像创建 ASCII 艺术。这真是有趣的一章。看到它是如何工作的真的很有趣。然后在第七章中,我们学习如何创建照片拼版,也就是你拍摄数百张不同的照片来重新创建另一张照片。这里可以看到几个例子。本节的最后一章讨论了如何创建自动立体图。我不像前两章那样喜欢这一章的唯一原因是我很难看到自动立体图中隐藏的 3D 图像,所以你的里程可能会随着这一章而变化。
在第四部分,我们学习 3D。所以在第九章中,我们学习如何用 Python 中的 OpenGL 绘制 3D 物体。第十章深入探讨了粒子系统,这是用于动画火,烟和头发。本章在最后一章的基础上继续使用 PyOpenGL 和 numpy。在第十一章中,我们将学习如何使用 Python 进行体绘制。想象一下显示 3D 体积横截面的 2D 图像(即 MRI 或 CT 扫描做到这一点)。本章还使用 PyOpenGL 和 numpy。
最后,我们到了第五部分,它涵盖了硬件黑客。第十二章向我们介绍了 Arduino 以及使用 Python 与 Arduino 交互的基础知识。在第十三章中,你将使用 Arduino 和 Python 创建一个“激光音频显示器”。本书的最后一章详细介绍了如何使用 Python 创建基于 raspberry-pi 的天气监视器。
这本书的最后一部分是三个附录。附录 A 只是讲了 Python 的安装步骤和书中用到的各种包。附录 B 介绍了实用电子学的基础知识(术语、元件、工具等)。最后,附录 C 是树莓 Pi 提示和技巧。
总的来说,我很喜欢这本书。数学有时可能有点难以理解,但作者很擅长解释它的作用和原因,所以我通常不会因此而陷入困境。这些项目都非常有趣,我总是很好奇作者将如何使用 Python 来创造奇迹。我很乐意把这本书推荐给那些想找点不一样的东西来读的人,但是我也必须警告他们,作者不会指导他们学习 Python。如果你想学 Python,还有很多其他的书可以去看看。这本书是为那些已经学习了 Python 并且想要了解 Python 的能力的人或者那些需要让他们的创造力流动起来的人准备的。
|  |
|
python Playground——好奇的程序员的极客项目
马赫什·文基塔查拉姆亚马逊
无淀粉出版社 |
其他书评
- 中级蟒蛇皮作者:Muhammad Yasoob Ullah Khalid
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:面向儿童的 Python 项目
原文:https://www.blog.pythonlibrary.org/2016/06/24/book-review-python-projects-for-kids/
出版商不时要求我对书籍进行评论。上个月,Packt 问我是否愿意评论他们的书,Jessica Ingrassellino 的《Python 儿童项目》。坦白地说,我倾向于避免现在开始读 Python 书籍,因为它们往往非常相似,但我认为这本书可能会很有趣。
快速回顾
- 我选择它的原因:在这种情况下,因为 Packt Publishing 要求我这样做
- 我完成它的原因:主要是因为包装公司的人缠着我这样做
- 我想给:不太确定。有更好、更深入的 Python 初学者书籍
图书格式
你可以得到一个电子书(PDF、EPUB 或 MOBI)版本或一个软封面。
书籍内容
这本书只有 10 章,长达 193 页。
全面审查
首先,我并没有真正读完这本书里的每一个字。我称之为略读复习法。就我个人而言,我更喜欢以自己的节奏阅读一本书,并相应地进行评论,然而我被反复要求完成这篇评论,所以这就是你所得到的。我的第一印象是,这本书将通过创建迷你游戏来教年轻人如何用 Python 编程。然而直到第五章我们才真正进入游戏。直到第八章我们才了解到 pygame。在我真正深入研究之前,让我们先看一下每一章,看看它们是关于什么的
第一章是对 Python 是什么以及如何安装它的基本介绍。作者选择用 Python 2.7 而不是 Python 3 来写这本书。本章的其余部分是关于创建一个“Hello World”应用程序和一个工作文件夹。
第二章是关于变量和函数。这一章非常简短,但我认为它已经足够好地涵盖了主题。它所做的最大的事情是向读者解释如何创建一个函数并将其保存到一个文件中。
在第三章中,我们实际上要创建一个计算器。它只是基于文本的,并不真正处理用户的错误输入。事实上,这本书的一大缺点是它根本没有谈到异常处理。我对这一章也有几个问题。我认为第 34 页显示的是错误的截图,因为附带的文字是关于从一种类型到另一种类型的转换,而截图没有显示任何类型的转换。另一个问题是,在第 41 页,文本声明您可以按照书中所写的运行脚本。然而,我在实际调用任何函数的代码中看不到任何东西,所以如果您运行这段代码,您将不会在终端上得到任何输出。
第四章是关于条件语句和循环的。本章的目的是增强你在前一章中编写的计算器应用程序,使它一直运行,直到用户要求它退出。
在第五章,我们学习如何为我们的游戏创建简单和困难的水平。这个游戏就是“更高或更低”的游戏。您将了解什么是布尔值,如何导入库,以及全局变量。
第六章深入到 Python 的一些更有趣的数据类型,列表和字典。本章的前提是教读者如何存储数据。虽然我同意列表和字典是一种好的格式,但我想知道在这里学习 pickle、json 或 yaml 是否也有好处。诚然,我不认为这本书谈到了文件 I/O,所以那些主题可能被认为超出了范围。
对于第七章,读者学习如何创建一个两人游戏,作者称之为“你的背包里有什么?”本章帮助读者设计一个可以记分、重新开始游戏或停止游戏的游戏。您还将学习如何创建一个球员档案,这是一个字典格式。对我来说,这似乎是一个使用类的好地方,尤其是如果我们将在下一章使用 pygame,但是我意识到目标受众应该是孩子。无论如何,你也可以在虚拟背包中添加物品,这对于学习作者的实现是一种乐趣。
在第八章中我们最终到达了 pygame,在那里你将学习如何安装 pygame。您还将学习如何设置屏幕大小和颜色,以及创建静止和移动的对象。
第九章在第八章的基础上,教读者如何创建一个网球游戏(如 pong)。它向读者介绍了游戏编程的概念,以及如何在编码之前概述你的项目。这一章实际上在这一点之后被分成四个部分。第一部分基本上创建了你需要的游戏的所有部分。第二部分将教你如何移动球拍,第三部分将教你如何移动球。第四部分是关于如何运行游戏和保持分数。
最后一章鼓励读者继续编码!这篇文章告诉读者从这里该何去何从。例如,它谈到他们将如何需要学习类和对象来促进代码重用。还提到可以用 pygame 添加音乐和图形。然后,它谈到重新设计你的游戏或试图创造你自己的经典游戏版本。最后,它谈到了 Python 的其他用途和库,比如 SciPy、iPython 和 MatPlotLib。
当我第一次听说这本书时,我立即想到了杰森·布里格斯的书, Python for Kids 和桑德的书, Hello World!:儿童和其他初学者的计算机编程。这两本书都比“面向儿童的 Python 项目”更长,包含的信息也更多。我个人认为,在这三本书中,我会选择桑德的书,因为它最容易让孩子们进入。布里格斯涵盖了更多有趣的话题,但他可能会根据孩子的情况讲得有点快。至于“面向儿童的 Python 项目”,我觉得有太多的项目没有被涵盖(类、异常、许多 Python 数据构造等)。也感觉 pygame 本身并没有真正覆盖。似乎有一个很大的建设,以达到 pygame,然后就没有太多的内容,当我们终于到了那里。
如果我要为孩子们制定学习 Python 的策略,我会从 Sande 开始,然后如果孩子想学习游戏,我会继续阅读 Sweigart 关于用 Python 创作游戏的书籍(用 Python 发明你自己的电脑游戏和用 Python 制作游戏& Pygame )。然后我可能会转向其他东西,比如《我的世界》的 Python 书籍。
至于这本书,我只是不知道它适合放在哪里。我认为它写得很好,但需要一些额外的润色才能登上榜首。
|  |
|
面向儿童的 Python 项目
杰西卡·英格拉塞利诺亚马逊 |
其他书评
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:用 pytest 测试 Python
原文:https://www.blog.pythonlibrary.org/2017/11/14/book-review-python-testing-with-pytest/
几个月前,Brian Okken 问我是否有兴趣阅读他的书《用 pytest 进行 Python 测试》。我有兴趣了解更多关于 pytest 包的信息已经有一段时间了,所以我同意看一看。我也喜欢出版商是务实的程序员,这一点我在过去有过很好的体验。我们将从快速回顾开始,然后深入到具体操作中。
快速回顾
- 我为什么拿起它:这本书的作者请我读他的书
- 我为什么要完成它:我主要是浏览了一下这本书,看看它是怎么写的,并检查一下例子
- 我想把它给:任何对 Python 测试感兴趣的人,尤其是对 pytest 包感兴趣的人
图书格式
你可以通过 practical Programming 的网站获得这种物理软封面、亚马逊上的 Kindle 或其他各种电子书格式。
书籍内容
这本书有 7 章,5 个附录,长达 222 页。
全面审查
这本书直接从第一章的一个例子开始。实际上,我发现这有点不和谐,因为通常每一章的开头都有一个介绍,说明这一章的内容。但是第一章只是用一个 Python 测试的例子来说明。不是不好,只是不一样。本章解释了如何开始使用 pytest,并介绍了一些可以传递给 pytest 的常见命令行选项。
第二章介绍如何用 pytest 编写测试函数。它还讨论了 pytest 如何使用 Python 的 assert 关键字,而不是像 Python 的 unittest 库那样使用 assert 方法。我发现这是 pytest 的一个吸引人的特性。您还将学习如何跳过测试,如何标记我们预计会失败的测试,以及其他一些事情。
如果你想知道 pytest 中的 fixtures,那么你会很兴奋地知道这本书有两章是关于这个主题的;特别是第三章和第四章。这些章节涵盖了大量的材料,所以我将只提到重点。您将了解如何为安装和拆卸创建夹具,如何跟踪夹具执行、夹具范围、参数化夹具和内置夹具。
第五章是关于如何给 pytest 添加插件。您还将学习如何编写自己的插件,如何安装插件以及如何测试插件。在本章中,您还将获得如何使用 conftest.py 的良好基础。
在第六章中,我们学习了所有关于配置 pytest 的知识。本章涵盖的主要主题涉及 pytest.ini、conftest.py 和 init。py 以及您可能使用 setup.cfg 做什么。这一章还有很多有趣的话题,比如注册标记或改变测试发现位置。我鼓励你看一下这本书的目录来了解更多!
最后,在第 7 章(最后一章),我们将学习 pytest 与其他测试工具的结合使用。在这种情况下,该书涵盖了、pdb、coverage.py、mock、tox、Jenkins 甚至 unittest。
这本书的其余部分由五个附录和一个索引组成。附录包括虚拟环境、pip、插件采样器、打包/分发 Python 项目和 xUnit 设备。
我认为这本书写得很好,很好地抓住了主题。这些例子简明扼要。当我想在自己的代码中使用 pytest 包时,我期待着更深入地阅读这本书。我会向任何对 pytest 软件包感兴趣的人推荐这本书。
|  |
|
用 pytest 进行 Python 测试
其他书评
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:Python 测试
原文:https://www.blog.pythonlibrary.org/2010/03/06/book-review-python-testing/
在 PyCon 之前,Packt Publishing 的一位代表找到我,让我评论他们的一本书。他们想让我读丹尼尔·阿巴克尔的 Python 测试:初学者指南 。我不太喜欢测试框架或测试驱动的开发,我认为这是一个学习方法论的好借口,看看它是否真的有价值或者只是一场炒作。这本书只有 256 页,所以我告诉 Packt 联系人,我可能需要一周左右的时间来审阅。一周后,她似乎有点担心我还没做完。因此,这是一项不全面的审查。我不喜欢被迫快速复习。我希望我的评论是全面的,并且是我能做到的最好的质量。你会看到我完成的章节的详细回顾。如果你想要一个完整的评论,我很确定 Python 星球上的其他人说他们正在做一个。
我读了 1-6 章,然后浏览了 7-10 章。作者以一种引人入胜的方式写作,章节被分成几节,这使得它很容易拿起,做一节,然后放下,而不会失去你的位置。我迟迟不看这本书的主要原因是,它有很多代码示例,需要花相当长的时间来重新输入它们。我讨厌充斥着破损代码的技术书籍,所以我想确保这本书的代码和测试能够正常工作。如果我将来要审查一本有很多代码的书,我会坚持花很多时间或者一本电子书,这样我就可以复制和粘贴代码了。
无论如何,前几章过去了,只有文本本身的小错误。内容很好,但是编辑漏掉了作者用“白色”代替“写”的简单内容。大部分章节都有这样的傻错误。真正的问题直到第 3 章才出现,这是关于用 doctest 创建单元测试的。在第 45 页,有一个代码示例,其中包含以下代码行:
self.integrated_error +q= err * delta
由于作者推荐使用 Python 2.6,我认为“+q=”可能是某种我不知道的新格式。但这只是一个错别字。在第 48-50 页,他修改了本章前面的测试。正文明确说明,所有修改都会明确标注。他们不是,我也找不到所有的修改,使新版本的工作。我不想再次重新输入整个内容,所以我跳过了它,并决定从出版商的网站上下载作者的代码包。
这是我真正走下坡路的地方。得到代码后,我注意到文件和文件夹不是按章节排列的,而是按其他方法排列的。这使得我很难找到我要找的东西。我最终在“tests”文件夹中找到了 chapters 子文件夹(我想)。我计划是在代码和我的代码上做些不同。但是当我打开这本书的代码时,我注意到作者在其中包含了一堆模拟测试。他直到第 4 章才谈到模拟。我本想就此打住,告诉所有我认识的人避开这本书,但既然我免费得到了这本书,我决定继续坚持下去。
第 4 章是关于 Labix 的 Python 模仿器包。这一章很好,我想我从中学到了很多。唯一令人沮丧的是作者提到你可以使用 easy_install 来安装这个模块,这样一来, Nose 就可以运行了。那真是太傻了。除此之外,我认为这是一个很好的章节。
第 5 章向读者介绍了 Python 的 unittest 库。我不记得我是否测试了本章中的所有代码,但是我没有注意到任何错误。我认为这是对 unittest 的一个很好的介绍,尤其是对初学者来说。
第 6 章的主题改为鼻子。正如你可能已经注意到的,从我到目前为止的描述来看,作者是相当循序渐进的。他从 doctests 开始,发展到 mock,然后是 unittests,然后是 Nose,这是一种测试运行器和增强器。当我试着安装它的时候,我的鼻子出现了奇怪的问题。出于某种原因,我最终选择了 0.10.1 版本,该版本并不适用于本书中的所有命令。一旦我得到了当前的版本,一切工作得更好。我应该指出,我无法让 112 页的例子通过 note 测试。我不知道问题是什么,尽管它与 Python Mocker 模块有关。可能是我打错了什么,但是我想不通。
作者简要介绍了 Nose 的配置文件,并回顾了 nosetests 的几个命令行标志。他还介绍了夹具以及如何使用它们来增强您的测试。最后,他展示了如何使用 Nose 的模式匹配能力来运行匹配特定命名约定的测试。很酷的东西!
不过,在这一章之后,我开始认真地略读。在第七步中,他一步一步地描述了如何测试和创建个人日程安排程序。我期待着阅读这一部分,看看这是多么复杂或简单。这一部分当然有大量的代码和大量的测试(或者他可能只是重新打印了一些小部分的例子作为注释)。我不知道它是否有任何功能。
在第八章中,这本书继续讨论 Web 测试。我认为这是一个有趣的选择,因为 Twill 的网站说它已经超过 3 年没有更新了。我测试了本章中的几个例子,它们像宣传的那样工作。这一节的大部分内容都是对 Twill 命令的解释。最后一节据称展示了如何将 Twill 测试与 unittest 测试相结合。不过,我没演那部分。
第 9 章讲述了集成和系统测试。我认为在图中画同心圆来弄清楚如何为测试创建集成单元是一个好主意。这可能会吸引喜欢视觉效果的读者。唉,除了前几页,我真的什么也没读,但是看起来他在这里也使用了他的日程安排例子。
最后一章题为“其他测试工具和技术”。我认为这一章看起来相当有趣,但没有机会阅读它。现在来看文本,它似乎简要地涵盖了以下内容: coverage.py 、版本控制挂钩(Bazaar、Mercurial、Darcs、Subversion)和 buildbot。
还有一个附录是突击测验的答案。
总的来说,我认为我读过的章节包含了很多有用的信息,而且组织得非常好。不幸的是,小的语法或句子结构问题以及偶尔出现的更大的代码/测试失败问题严重破坏了这一优势。如果它只发生一次,那么我认为可能还有其他代码或测试也出现了问题。如果是这种情况,那么我建议买二手的或者等待某种形式的打包出售。另一方面,如果这本书在第六章之后还保持原样...嗯,我想这真的没关系,因为这意味着超过一半的书有问题。
好吧。这里有一个更好的建议:找一家你附近有这本书和免费无线网络的 Borders 或 Barnes & Nobles。去那里,找到那本书,在你买它之前,读一读,看看例子。
评分等级:1(低)- 5(高)
代码评级= 3
编写= 4
组织= 5
平均分= 4(如果破损的代码让你烦恼,就扣一两分)
书评:严肃的 Python
原文:https://www.blog.pythonlibrary.org/2019/03/06/book-review-serious-python/
没有淀粉出版社要求我对他们即将出版的一本书做一个技术评论,这本书是 Julien Danjou 去年写的严肃的 Python:关于部署、可伸缩性、测试等的黑带建议。我以前从未使用过淀粉,但我决定尝试一下,看看它们与 Packt Publishing 有什么不同。我最终喜欢上了他们的过程,这本书读起来也很有趣。需要说明的是,无淀粉没有请我做书评。他们只是想让我在这本书出版前为他们做一个技术审查。
我写这篇评论是因为我认为这本书应该得到更多的关注。另外,几年前我采访了它的作者,所以你可能也想看看。
快速回顾
- 我为什么拿起它:最初,出版商让我做一个技术审查
- 我为什么要完成它:这本书涵盖了中级水平的材料,有着引人入胜的写作风格
- 我想把它给:希望超越仅仅了解 Python 语法的初学者
图书格式
你可以得到这本书的平装本、PDF、Mobi 或 ePub。
书籍内容
这本书包含 13 章,共 240 页。这本书涵盖了 Python 2 和 3。
全面审查
《认真的 Python》是一本有趣的书。让我们从第一章开始,这是关于开始你的项目。这一章涵盖了布局你的代码项目的注意事项。您将了解版本编号和自动检查。每章都以采访 Python 社区中的某个人结束。第一章采访了约书亚·哈洛。
第 2 章深入探讨了模块、库和框架。在这里,您可以大致了解 Python 的导入系统是如何工作的。作者花了几页列出了有用的标准库,也谈到了使用外部库。他甚至提到了从外部资源下载时的安全实践,您将了解到 pip。
对于第 3 章,您将学习如何用 Sphinx 编写好的文档和 API。本章几乎只关注 Sphinx 框架,这是 Python 团队用来记录 Python 本身的。您将在这里学习 Sphinx 模块和编写自己的 Sphinx 扩展。
第 4 章的主题是时间戳和时区。您将学习如何使用 Python 的 datetime 库以及超级酷的 dateutil 模块,它是 Python 的一个外部模块。作者还花了一些时间讨论序列化 datetime 对象和解决不明确的时间。
在第五章中,分发软件的主题是最重要的。在这里,您将了解如何使用 setup.py 、 setup.cfg 和滚轮格式。您还将发现入口点是如何工作的!
在第 6 章中,你将深入研究 Python 的单元测试模块的单元测试。Julien 讨论了常规的单元测试以及模拟,然后深入讨论了如何使用 tox 自动化项目。
如果你对装饰器、静态方法或类方法感兴趣,那么第 7 章适合你。整个章节都致力于这些类型的代码构造,并且还谈到了抽象方法!
在第八章中,Julien 向读者讲述了 Python 对于函数式编程是多么有用。他专注于生成器、列表理解和 Python 的内置,比如 map()、filter()和 enumerate()等等。
抽象语法树是第九章的主题。您将学习如何使用 AST 和 Hy 编写程序,Hy 是嵌入在 Python 中的 Lisp 的一种方言。你可以在这里了解更多关于这个项目的信息。还有一节是关于用 AST 扩展 flake8 的。
对于第 10 章,你将学习性能和优化。这里作者使用 Python 的 cProfile 和 dis 模块来理解你的程序的行为。本章的其余部分涵盖了各种优化技术,如使用内存化、PyPy、缓冲区等。
在第 11 章中,你将学习到伸缩和架构。在我看来,这一章的标题有点晦涩,因为实际的主题是并发性。在这里,您将了解 Python 线程、流程和 asyncio。他也谈了一点关于 ZeroMQ 的内容。
如果你碰巧对学习 Python 如何处理关系数据库感兴趣,那么你会想看看第 12 章。在这里,作者讨论了各种数据库后端,并展示了一个结合 PostgreSQL 使用 Flask 的例子。
最后,在第 13 章中,Julien 介绍了如何使用六个模块来支持为 Python 2 和 3 编写代码。他还在这一章中介绍了单个调度和上下文管理器,然后通过讨论 attrs 包结束了这一章。
虽然其中涉及的一些主题看起来很明显,但实际上我并没有看到很多作者或博客经常谈论它们。例如,我只在极少数情况下听说过伸缩,甚至并发文章也不经常出现。我能想到的唯一真正的错误是,我可能把这些章节的顺序安排得与它们结束的方式略有不同。我会给这本书一个机会,看看它,如果你想了解更多关于上述任何主题!
|  |
|
严肃的 Python:关于部署、可伸缩性、测试等的黑带建议
朱利安·丹茹亚马逊,无淀粉 ,原创正经 Python 网站 |
其他书评
- Brian Okken 的 pytestPython 测试
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
书评:使用 Python 的软件架构
原文:https://www.blog.pythonlibrary.org/2017/06/22/book-review-software-architecture-with-python/
Packt Publishing 找到我,让我担任 Anand Balachandran Pillai 所著的《使用 Python 的软件架构》一书的技术评论员。这听起来很有趣,所以我最终为 Packt 做了评论。他们最终在 2017 年 4 月发布了这本书。
快速回顾
- 我选择它的原因:帕克特出版社让我对这本书做一个技术审查
- 我为什么要完成它:坦白地说,因为这是一本涵盖广泛主题的好书
- 我想把它给:一个正在学习如何组装一个基于 Python 的大型项目或应用程序的人
图书格式
你可以通过 Packt Publishing 的网站获得这本书的物理软封面、亚马逊上的 Kindle 或其他各种电子书格式。
书籍内容
这本书有 10 章,长达 556 页。
全面审查
这本书的重点是教育读者如何用 Python 设计和构建一个高度可伸缩的、健壮的应用程序。第一章首先回顾了作者关于“软件架构原则”的观点以及它们是什么。这一章没有任何代码示例。它基本上都是理论,并基本上建立了本书其余部分将涵盖的内容。
第二章是关于编写易于修改的可读代码。它教授了一些编写可读代码的技巧,并涉及了关于文档、PEP8、重构等方面的建议。它还教授编写可修改代码的基础知识。本章演示的一些技术包括抽象公共服务、使用继承和后期绑定。它还讨论了代码气味的主题。
第三章差不多有 50 页,重点是编写可测试的代码。虽然你不可能只用一章来教授测试,但它确实谈到了诸如单元测试、使用 nose2 和 py.test、代码覆盖率、模仿和文档测试之类的东西。还有一个关于测试驱动开发的部分。
在第四章中,我们学习如何从代码中获得良好的性能。本章是关于 Python 中的计时代码、代码剖析和高性能容器。它涵盖了相当多的模块/包,如 cProfile、line profiler、memory profiler、objgraph 和 Pympler。
对于第五章,我们深入探讨编写可伸缩的应用程序的主题。本章有一些很好的例子,并讨论了并发性、并行性、多线程与多处理以及 Python 新的 asyncio 模块之间的区别。它还讨论了全局解释器锁(GIL)以及它在某些情况下如何影响 Python 的性能。最后,读者将了解 web 的伸缩和队列的使用,比如 Celery。
如果你碰巧对 Python 中的安全性感兴趣,那么第 6 章适合你。它涵盖了软件中各种类型的安全漏洞,然后讨论了作者所认为的 Python 本身的安全问题。它还讨论了帮助开发人员编写安全代码的各种编码策略。
第七章深入探讨了设计模式的主题,长达 70 多页。您将了解到诸如单例、工厂、原型、适配器、门面、代理、迭代器、观察者和状态模式之类的东西。这一章很好地给出了设计模式的概述,但是我认为一本每一种设计模式都有一章的书将会非常有趣,并且真正有助于把重点放在家里。
继续,我们到了第 8 章,它谈到了“架构模式”。在这里,我们学习模型视图控制器(MVC),它在 web 编程领域非常流行。我们还学习了一些使用 twisted、eventlet、greenlet 和 Gevent 的事件驱动编程。当我想到事件驱动编程时,我通常会想到使用 PyQt 或 wxPython 之类的用户界面,但无论哪种方式,概念都是相同的。本章还有一节是关于微服务的。
第九章的重点是部署你的 Python 应用程序。在这里,您将了解如何使用 pip、virtualenv、PyPI 和 PyPA。在本章中,你还会学到一些关于织物和 Ansible 的知识。
最后一章介绍了调试应用程序的技术。他从基本的打印语句开始,然后使用模拟和日志模块。他还谈到了使用 pdb 和类似的工具,如 iPdb 和 pdb++。本章还包括跟踪模块、lptrace 包和 strace 包。
这本书与你通常的 Python 书籍有一点不同,因为它不是真正针对初学者的。相反,我们有拥有近 20 年经验的专业软件开发人员来概述他在大公司创建自己的应用程序时使用的一些技术。虽然这里和那里有一些小的语法问题,但总的来说,我觉得这是一本非常有趣的书。我这么说并不是因为我是这本书的技术评论家。我已经批评了一些我过去作为技术评论家的书。这本书实际上非常好,我想把它推荐给任何想学习更多真实世界软件开发的人。对于想学习并发性或设计模式的人来说,这也是一个好消息。
|  |
|
使用 Python 的软件架构
其他书评
- Erik Westra 的 Python 模块编程
- Python Playground——好奇的程序员的极客项目Mahesh Venkitachalam 著
- L. Felipe Martins 著
- 达斯丁·菲利普斯用 Kivy 语言创建应用程序
- Roberto Ulloa 的 Python 交互式应用
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 达斯丁·菲利普斯的 Python 3 面向对象编程
书评:思考复杂性——复杂性科学和计算建模
艾伦·唐尼的《思考复杂性》是为中级大学水平的学生写的。它有 Python 代码的例子,并谈论了很多算法。就我个人而言,我认为它可能适合作为 300 级或更高的课程,因为所有的数学和科学相关的东西。
作者到处跑,经常参考维基百科。第一章是关于复杂性科学,它似乎倾向于“质疑一切”和“提出问题”的想法,而不是真正关心答案。第二章是关于图形的,但不是常规意义上的图形。相反,作者指的是一个“包含离散的、相互联系的元素的系统”,比如地图。第三章是关于算法的分析,有一些关于搜索算法和哈希表的有趣的小研究。
第四章是关于小世界图的,包含了很多像瓦特、斯特罗加兹和迪克斯特拉这样的科学家的参考资料。第五章讨论无尺度网络及其各种类型的分布。第六章介绍了细胞自动机的概念和史蒂夫·沃尔夫勒姆提出的不同层次。这个话题在第七章以生命观念的游戏继续。正如你所看到的,这些章节在内容上有很大的不同,无论是章节之间还是章节内部。它们也很短,因为大多数都在 10 页左右。第 8-10 章讨论了诸如分形、傅立叶变换和基于主体的模型等令人兴奋的话题。最后四章是案例研究。
这本书里没有很多 Python 代码。它主要是一本旨在让读者思考的“思想”书。不过,一些代码示例很有趣。例如,作者教读者如何非常清楚地用 Python 构造一个抽象类,以及如何设计它,使它不能被实例化,而是必须被子类化和重写。作者也有几个使用 SciPy 或 NumPy 的例子来说明他的一些想法,所以这本书可能对科学 Python 程序员最有吸引力。一个好的补充是,作者确实有一些有趣的练习供学生尝试,尽管他没有在书中提供解决方案。我认为在这本书的网站上可以找到一些解决方法。
如果你正在寻找一本相当随意的带有少量代码的科学书籍(或者你只是想学习一点复杂性科学),那么这本书可能适合你。另一方面,如果您希望了解科学界的实际 Python 代码,那么您不会从这项工作中学到太多东西。我知道这与上一段有点矛盾,但是虽然有一些使用 NumPy 和 SciPy 的方程的小例子,但这本书的大部分都是散文。最后,这本书读起来很有趣,但可能不会给你的编程工具箱增加很多东西。
注:我从出版商那里免费得到了这本书
书评:Tkinter GUI 应用程序开发高手
现有的 Tkinter 书籍并不多,这是我一直觉得有点奇怪的地方,因为它是 Python 中包含的 GUI 工具包。基本上你可以从 2000 年的 Grayson 的 Python 和 Tkinter 编程或者从 2012 年的 Roseman 的现代 Tkinter 为忙碌的 Python 开发者准备的。如果你感兴趣的话,我在这里回顾了后者。还有其他包含 Tkinter 编程的书籍(如 Core Python 或 Programming Python),但这些文本不是以 Tkinter 为中心的书籍。这让我们看到了 Bhaskar Chaudhary 在 2013 年发布的 Tkinter GUI 应用程序开发热点,这是过去 13 年中关于 Tkinter 的第三本书!今天,你可以看看我对这本有趣的书的评论。
充分披露:Packt Publishing 让我担任这本书的技术评审,所以在评审过程结束后,我收到了一份免费的副本。
如果没有太多时间,下面是对你们的快速回顾:
快速回顾
- 我选择它的原因:从技术上来说,我没有把它作为帮助编辑这本书的“报酬”,但我会选择它,只是因为 Tkinter 的书很少,而且我发现 GUI 编程是一门迷人的学科。
- 我为什么要读完它:这本书有很多有趣的全功能应用程序,所以我一直读下去,只是想看看作者接下来会想出什么。
- 我想把它给:想先进入 GUI 应用程序开发的程序员——这本书有很多没有复杂代码的应用程序的好例子!
图书格式
你可以得到这本书的平装本、epub、mobi 或 PDF。
书籍内容
这本书被分成项目而不是章节。共有 7 个项目和两个附录。第一个项目基本上是对 Tkinter 的介绍。第二个是创建一个简单的文本编辑器,比如记事本。项目 3 涵盖了一个可编程鼓机。在项目 4 中,您将学习如何创建一个象棋游戏。对于项目 5,您创建一个音频播放应用程序。Project 6 是一个类似于 Paint 的绘图应用程序。最后一个项目章节实际上涵盖了几个迷你项目,从创建一个屏幕保护程序,到建立一个游戏,到绘图和其他几个有趣的活动。
全面审查
作为这本书的技术评论者,然后从读者的角度来评论这本书是很困难的。Packt 喜欢雇佣国际程序员来写他们的书,结果往往是喜忧参半。一些书最终变得非常好,而另一些则因为语言上的差距而变得摇摇欲坠或彻底失败。在这种情况下,虽然英语显然不是作者的第一语言,但他总体上做得相当不错。这本书通过例子教读者如何使用 Tkinter。这不是一本针对 Python 初学者的书,但对于 Tkinter 初学者和 Tkinter 中级者来说是一本好书。
我个人非常喜欢学习如何制作各种应用程序和游戏。多样性和创造性是显而易见的,我很惊讶这些节目最终变得如此之短。我想我最喜欢鼓机项目,因为它是如此独特,也因为我是电子音乐的忠实粉丝已经很长时间了。象棋游戏在作者如何构建程序和设置逻辑方面也非常有趣。
即使我不是帮助作者完成这本书的人之一,我相信我也会对我的购买感到满意。这里有太多好主意了。当我阅读这几章的时候,我总是在想我会如何在 wxPython 或 PySide 中尝试这个或那个想法,看看他们会如何比较。因此,如果你正在为你的第一个 GUI 项目寻找一些想法,不管你通常使用哪个工具包,我都会推荐这本书。我也会推荐给任何想学 Tkinter 的人。
|  |
|
Tkinter GUI 应用程序开发热点
其他书评
- Ron DuPlain 开发的
- 弗莱彻·海斯勒的《真正的蟒蛇》
- 马特·哈里森著《踩 Python 第二卷:中级 Python》
- 约翰·罗兰的《快速学习 Python》
书评:web2py 应用程序开发指南
原文:https://www.blog.pythonlibrary.org/2012/05/25/book-review-web2py-application-development-cookbook/
我在好几个场合看过关于 web2py 的介绍,但是我自己从来没有用过。几周前, Packt Publishing 的一名代表联系我,询问他们关于 web2py 的新食谱的评论。它由七位作者撰写,即:理查德·戈登、巴勃罗·马丁·穆隆、马里亚诺·莱因加特、布鲁诺·塞扎尔·罗查、马西莫·迪·皮埃罗、米歇尔·科米蒂尼和乔纳森·伦德尔。我不得不承认,我想知道你怎么能有一本有这么多作者的连贯的书,但是因为它是一本烹饪书,所以它做得很好。
快速回顾
- 我选择它的原因:一方面是因为 Packt 给了我一份评论,另一方面是因为我想看看 web2py 与 django 和 TurboGears 有什么不同
- 我完成它的原因:我完成它是出于对出版商和我的读者的责任。烹饪书很难通读,而且有点乏味。
- 我想把它给:希望学习一些 web2py 新技巧的初级到中级开发人员
图书格式
平装本、Kindle (mobi)或 PDF 和 epub(来自 Packt)
书籍内容
第 1 章是关于将 web2py 部署到各种后端。虽然有点枯燥,但我认为这一部分对部署非常有帮助。第二章主要是关于改进 web2py 附带的“支架”应用程序。第 3 章介绍了 web2py 如何与数据库和各种 CSV 操作进行交互。第四个包括高级表单,比如一页上的多个表单。我现在并不觉得 javascript 很有趣,所以第 5 章的 AJAX 主题对我来说没什么用。第 6 章介绍了一些第三方库,比如 Twitter 连接,定制日志等等。在第 7 节中,我们将学习 web 服务,在第 8 节中,我们将讨论认证和授权技术。第 9 章是关于自定义 URL 路由的。对于 10,我们学习创建 PDF 报告的各种方法。最后一章收集了一些食谱,这些食谱并不适合其他地方,而且非常随意。从 PDB 集成到将 web2py 与 wxPython 结合使用,它涵盖了广泛的主题。
回顾
我们将从一些不好的开始,因为我喜欢以好的结束。我发现了许多普通拼写检查程序应该标记的愚蠢问题。写作也不引人注目,但我读过的大多数烹饪书都是这样的。它可能很枯燥,但它很好地解释了大部分食谱。有些解释得比其他的多。这在烹饪书中也是相当标准的。我并不是批评作者糟糕的编辑,因为这不是他们的工作,而且我可以告诉他们,即使不是所有人,也有几个不是以英语为母语的人。我相信他们尽力了。
我最喜欢的是,这本书实际上有食谱,我不仅认为很有趣,而且我可以看到自己实际使用。有整合贝宝支付的方法,创建验证码,建立脸书和 Reddit 的克隆,各种网络服务消费者的方法,最后还有一些调试的东西。我对 PayPal 的东西特别感兴趣,因为我在 Python web 框架世界中还没有看到太多关于支付系统的东西。
PDF 集成也很有趣,因为 web2py 可以使用 reportlab、LaTeX 或 pyfpdf。我从未听说过最后一个,所以它本身就很有趣。真的没有足够的空间来检查所有吸引我的食谱。我将指出,大多数例子是不完整的,可能是因为没有空间。幸运的是,您可以从 Packt 的网站下载完整的源代码。我还应该注意,有些章节的 javascript 似乎比 Python 多。这可能是意料之中的,但我仍然对此感到有点惊讶。因为代码不完整,所以没有尝试从书上运行。无论如何,当它不完全存在时,我并不真的推荐它。
从本书中获益最多的开发人员可能是希望提高技能的初级到中级 web2py 程序员。我认为从这本书里可以学到很多有趣的技巧,我希望在某个时候尝试一下。
PyCon 2019 销售的书籍
原文:https://www.blog.pythonlibrary.org/2019/05/01/books-on-sale-for-pycon-2019/
为了纪念本周开始的 PyCon 2019,我将出售我的三本书。从5 月 6 日到 $9.99 你可以通过点击链接获得以下任何一本书:
对于那些对学习 Python 中级和高级主题感兴趣的人来说,Python 201 是一本有趣的书。
我的 ReportLab 书讲述了如何使用 Python 和 ReportLab 创建 pdf。它还涵盖了许多其他与 pdf 相关的主题,例如分割、合并和叠加 pdf 等。
最后,我的 Jupyter Notebook 101 这本书是你了解 Jupyter 笔记本和它的许多功能的好方法。
将 SQLAlchemy 添加到待办事项列表 Web 应用程序
原文:https://www.blog.pythonlibrary.org/2013/07/23/bottle-adding-sqlalchemy-to-the-todo-list-web-app/
在本文中,我们将从上一篇关于 Bottle 的文章中提取代码,并对其进行修改,使其使用 SQLAlchemy,而不仅仅是普通的 SQLite 代码。这将需要您从 PyPI 下载 bottle-sqlalchemy 包。你也可以使用“pip install bottle-sqlalchemy”来安装它,假设你已经安装了 pip。当然,你还需要瓶本身。一旦你准备好了,我们可以继续。
向瓶中添加 SQLAlchemy
bottle-sqlalchemy 包是 bottle 的一个插件,它使得向 web 应用程序添加 sqlalchemy 变得非常容易。但是首先,让我们实际创建数据库。我们将使用 SQLAlchemy,而不是另一篇文章中的脚本。代码如下:
from sqlalchemy import create_engine, Column, Boolean, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
engine = create_engine("sqlite:///todo.db", echo=True)
########################################################################
class TODO(Base):
"""
TODO database class
"""
__tablename__ = "todo"
id = Column(Integer, primary_key=True)
task = Column(String, nullable=False)
status = Column(Boolean, nullable=False)
#----------------------------------------------------------------------
def __init__(self, task, status):
"""Constructor"""
self.task = task
self.status = status
#----------------------------------------------------------------------
def main():
"""
Create the database and add data to it
"""
Base.metadata.create_all(engine)
create_session = sessionmaker(bind=engine)
session = create_session()
session.add_all([
TODO('Read Google News', 0),
TODO('Visit the Python website', 1),
TODO('See how flask differs from bottle', 1),
TODO('Watch the latest from the Slingshot Channel', 0)
])
session.commit()
if __name__ == "__main__":
main()
如果你了解 SQLAlchemy,那么你就知道这里发生了什么。基本上,您需要创建一个表示数据库的类,并将其映射到一个数据库“引擎”。然后创建一个会话对象来运行查询等。在本例中,我们插入了四条记录。您需要运行该程序来创建 web 应用程序将使用的数据库。
现在我们准备看看项目的核心部分:
from bottle import Bottle, route, run, debug
from bottle import redirect, request, template
from bottle.ext import sqlalchemy
from sqlalchemy import create_engine, Column, Boolean, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# --------------------------------
# Add SQLAlchemy app
# --------------------------------
app = Bottle()
Base = declarative_base()
engine = create_engine("sqlite:///todo.db", echo=True)
create_session = sessionmaker(bind=engine)
plugin = sqlalchemy.Plugin(
engine,
Base.metadata,
keyword='db',
create=True,
commit=True,
use_kwargs=False
)
app.install(plugin)
########################################################################
class TODO(Base):
"""
TODO database class
"""
__tablename__ = "todo"
id = Column(Integer, primary_key=True)
task = Column(String, nullable=False)
status = Column(Boolean, nullable=False)
#----------------------------------------------------------------------
def __init__(self, task, status):
"""Constructor"""
self.task = task
self.status = status
#----------------------------------------------------------------------
def __repr__(self):
""""""
return "', method='GET')
def edit_item(no):
"""
Edit a TODO item
"""
session = create_session()
result = session.query(TODO).filter(TODO.id==no).first()
if request.GET.get('save','').strip():
task = request.GET.get('task','').strip()
status = request.GET.get('status','').strip()
if status == 'open':
status = 1
else:
status = 0
result.task = task
result.status = status
session.commit()
redirect("/")
else:
return template('edit_task', old=result, no=no)
#----------------------------------------------------------------------
@route("/new", method="GET")
def new_item():
"""
Add a new TODO item
"""
if request.GET.get("save", "").strip():
task = request.GET.get("task", "").strip()
status = 1
session = create_session()
new_task = TODO(task, status)
session.add(new_task)
session.commit()
redirect("/")
else:
return template("new_task.tpl")
#----------------------------------------------------------------------
@route("/done")
def show_done():
"""
Show all items that are done
"""
session = create_session()
result = session.query(TODO).filter(TODO.status==0).all()
output = template("show_done", rows=result)
return output
#----------------------------------------------------------------------
@route("/")
@route("/todo")
def todo_list():
"""
Show the main page which is the current TODO list
"""
session = create_session()
result = session.query(TODO).filter(TODO.status==1).all()
myResultList = [(item.id, item.task) for item in result]
output = template("make_table", rows=myResultList)
return output
#----------------------------------------------------------------------
if __name__ == "__main__":
debug(True)
run()
让我们把它分解一下。首先,我们需要一个瓶子对象,这样我们就可以添加一个插件。然后我们创建一个 declarative_base 对象,我们将使用它从数据库的类表示中派生出子类。接下来我们创建 SQLAlchemy 引擎和一个 sessionmaker 对象。最后,我们创建插件并安装它。从第 56 行开始,我们进入实际的瓶子代码(edit_item 函数开始的地方)。如果您运行了最初的版本,您可能会注意到一个关于使用通配符过滤器的反对警告。在本文中,我们通过将 edit_item 函数的路由构造从 @route('/edit/:no ',method='GET') 更改为 @route('/edit/ 【T11 ' ',method='GET') ,解决了这个问题。这也允许我们移除@validation 装饰器。
您会注意到,在每个函数中,我们都创建了一个会话对象来运行页面的查询。看一下主函数, todo_list 。从 out 查询返回的结果是一个对象列表。模板需要一个元组列表或一个列表列表,所以我们使用列表理解来创建一个元组列表。但是如果想要改变模板本身呢?我们用另外两个模板来做。我们来看看 show_done.tpl 代码:
%#template to generate a HTML table from a list of tuples (or list of lists, or tuple of tuples or ...)
您已完成的待办事项:
%for row in rows: %end
| {{row.id}} | {{row.task}} | 编辑 |
创建新的项目
这段代码与主模板 make_table.tpl 中的代码几乎完全相同。由于 Bottle 的模板代码几乎是 Python 代码,因此我们可以使用点符号来访问 row 对象的属性。这使我们能够大量清理代码,并非常容易地获得 row.id 和 row.task。您还会注意到,查询本身的代码更短,因为在使用 SQLAlchemy 时,我们没有额外的连接设置和拆除工作要处理。除此之外,应用程序保持不变。
现在,您应该能够创建自己的包含 SQLAlchemy 的瓶子应用程序了。
下载源代码
瓶子-创建 Python 待办事项列表 Web 应用程序
原文:https://www.blog.pythonlibrary.org/2013/07/22/bottle-creating-a-python-todo-list-web-app/
Python 有很多 web 框架。Bottle 就是其中之一,被认为是一个 WSGI 框架。它有时也被称为“微框架”,可能是因为 Bottle 只包含一个 Python 文件,除了 Python 本身之外没有任何依赖关系。我一直在努力学习它,并且在他们的网站上使用官方的待办事项教程。在本文中,我们将检查这个应用程序,并对 UI 做一点改进。然后在另一篇后续文章中,我们将更改应用程序以使用 SQLAlchemy,而不是直接的 sqlite。如果你想跟着去,你可能会想去安装瓶。
入门指南
您总是需要从某个地方开始,因此对于这个应用程序,我们将从创建数据库的代码开始。我们将从一开始就导入所有内容,而不是一点一点地添加额外的导入内容。与原始代码相比,我们还将对代码进行一些编辑。让我们开始吧:
import sqlite3
con = sqlite3.connect('todo.db') # Warning: This file is created in the current directory
con.execute("CREATE TABLE todo (id INTEGER PRIMARY KEY, task char(100) NOT NULL, status bool NOT NULL)")
con.execute("INSERT INTO todo (task,status) VALUES ('Read Google News',0)")
con.execute("INSERT INTO todo (task,status) VALUES ('Visit the Python website',1)")
con.execute("INSERT INTO todo (task,status) VALUES ('See how flask differs from bottle',1)")
con.execute("INSERT INTO todo (task,status) VALUES ('Watch the latest from the Slingshot Channel',0)")
con.commit()
这段代码将创建一个有 4 个条目的小数据库。被设置为 0 的项目是“完成的”,而被设置为 1 的项目仍然是待办事项。在继续之前,请确保首先运行该程序,以便在我们对该数据库进行查询时,其余的代码能够正常工作。现在我们准备看看主页的代码。
创建主页
import sqlite3
from bottle import route, run, debug
from bottle import redirect, request, template, validate
#----------------------------------------------------------------------
@route("/")
@route("/todo")
def todo_list():
"""
Show the main page which is the current TODO list
"""
conn = sqlite3.connect("todo.db")
c = conn.cursor()
c.execute("SELECT id, task FROM todo WHERE status LIKE '1'")
result = c.fetchall()
c.close()
output = template("make_table", rows=result)
return output
if __name__ == "__main__":
debug(True)
run()
在这里,我们导入整个应用程序的所有必要部分。接下来,我们创建一些routedecorator。瓶中的路由是对函数调用映射的请求。看看上面的代码,看看这是什么意思。第一条路线将主页面“/”映射到 todo_list 函数。请注意,我们还有第二条路线。这个函数将“/todo”页面映射到同一个函数。是的,Bottle 支持多路径映射。如果您要运行这段代码,您可以访问 http://127.0.0.1:8080/todo,或者只访问 http://127.0.0.1:8080/该页面上的 SQL 命令只是从数据库中获取所有仍需完成的项目。我们将该结果集(元组列表)传递给 Bottle 的模板函数。如您所见,它接受模板的名称和结果。最后,我们返回呈现的模板。
请注意,我们已经打开了调试。这将返回一个完整的 stacktrace 来帮助调试问题。如果将它放在您的生产服务器上,您不会希望让它保持启用状态。
现在,让我们来看看模板代码:
%#template to generate a HTML table from a list of tuples (or list of lists, or tuple of tuples or ...)
您的待办事项:
%for row in rows: %id, title = row %for col in row: %end %end
| {{col}} | 编辑 |
创建新的项目
显示已完成的项目
现在瓶中的模板以。tpl 扩展,所以这个应该保存为 make_table.tpl 任何以百分号(%)开头的都是 Python。剩下的就是 HTML 了。在这段代码中,我们创建了一个表,在第一列和第二列中包含行的 id 字段和任务。我们还添加了第三列,以允许编辑。最后,我们添加一个链接来添加一个新项目和另一个链接,以便显示所有“完成”或完成的项目。
现在我们准备继续编辑我们的待办事项!
编辑我们的项目
使用 Bottle 时,编辑待办事项非常容易。但是,这里涉及的代码比主脚本多,因为它显示要编辑的项目,还处理保存更改请求。这段代码与原始代码基本相同:
#----------------------------------------------------------------------
@route('/edit/:no', method='GET')
@validate(no=int)
def edit_item(no):
"""
Edit a TODO item
"""
if request.GET.get('save','').strip():
edit = request.GET.get('task','').strip()
status = request.GET.get('status','').strip()
if status == 'open':
status = 1
else:
status = 0
conn = sqlite3.connect('todo.db')
c = conn.cursor()
c.execute("UPDATE todo SET task = ?, status = ? WHERE id LIKE ?", (edit, status, no))
conn.commit()
redirect("/")
else:
conn = sqlite3.connect('todo.db')
c = conn.cursor()
c.execute("SELECT task FROM todo WHERE id LIKE ?", (str(no)))
cur_data = c.fetchone()
return template('edit_task', old=cur_data, no=no)
您会注意到第一个 route decorator 的格式与我们之前看到的不同。“:no”部分意味着我们将向这个路由映射到的方法传递一个值。在这种情况下,我们将传递要编辑的条目的编号(id)。我们还设置了方法来使编辑表单正确工作。如果您想执行该操作,也可以将其设置为 POST。如果用户按下保存按钮,那么 If 语句的第一部分将执行;否则,如果用户只是加载编辑页面,语句的第二部分将加载并预填充表单。还有第二个装饰器叫做 validate ,我们可以用它来验证 URL 中传递的数据。在这种情况下,我们检查该值是否是一个整数。您还会注意到,一旦我们保存了更改,我们会使用重定向将用户返回到主网页。
现在,让我们花点时间看看模板代码:
%#template for editing a task
%#the template expects to receive a value for "no" as well a "old", the text of the selected ToDo item
编辑 ID 为{{no}}的任务
如您所见,这创建了一个简单的输入控件来编辑文本和一个组合框来更改状态。你应该将这段代码保存为 edit_task.tpl 。下一部分也是最后一部分,我们将讨论如何为我们的待办事项列表创建一个新项目。
创建新的待办事项列表项
正如您到目前为止所看到的,Bottle 非常容易使用。向我们的待办事项列表添加一个新项目也非常简单。让我们看一下代码:
#----------------------------------------------------------------------
@route("/new", method="GET")
def new_item():
"""
Add a new TODO item
"""
if request.GET.get("save", "").strip():
new = request.GET.get("task", "").strip()
conn = sqlite3.connect("todo.db")
c = conn.cursor()
c.execute("INSERT INTO todo (task,status) VALUES (?,?)", (new,1))
new_id = c.lastrowid
conn.commit()
c.close()
redirect("/")
else:
return template("new_task.tpl")
这段代码还在其路由定义中使用了 GET 请求,我们在这里使用了与编辑函数相同的思想,即当页面加载时,我们在 if 语句的 else 部分中执行代码,如果我们保存表单,我们将 todo 项保存到数据库并重定向到主页,主页已被适当更新。为了完整起见,我们将快速查看一下 new_task.tpl 模板:
向待办事项列表添加新任务:
包扎
至此,您应该知道如何创建一个全功能的 todo 应用程序。如果您下载了源代码,您会看到它包含了几个其他函数,用于显示单个项目或显示“完成”(或已完成)项目的表格。这段代码可能应该添加额外的错误处理,它可以使用一个好的网页设计师用一些 CSS 或图像来美化它。如果你觉得有启发,我们会把这些项目留给读者去做。
下载源代码
Python 3.10 中的案例/开关
原文:https://www.blog.pythonlibrary.org/2021/09/16/case-switch-comes-to-python-in-3-10/
Python 3.10 正在增加一个叫做结构模式匹配的新特性,这个特性在 PEP 634 中有定义,在 PEP 636 中有关于这个主题的教程。结构化模式匹配为 Python 带来了 case / switch 语句。新语法超越了某些语言用于 case 语句的语法。
本教程的目的是让你熟悉 Python 3.10 中可以使用的新语法。但是在您深入了解 Python 的最新版本之前,让我们回顾一下在 3.10 发布之前您可以使用什么
3.10 之前的 Python
Python 一直有几种解决方案,可以用来代替 case 或 switch 语句。一个通俗的例子就是用 Python 的if - elif - else就像这个 StackOverflow 回答中提到的。在该答案中,它显示了以下示例:
if x == 'a':
# Do the thing
elif x == 'b':
# Do the other thing
if x in 'bc':
# Fall-through by not using elif, but now the default case includes case 'a'!
elif x in 'xyz':
# Do yet another thing
else:
# Do the default
这是使用 case 语句的一个非常合理的替代方法。
你会在 StackOverflow 和其他网站上找到的另一个常见解决方案是使用 Python 的字典来做这样的事情:
choices = {'a': 1, 'b': 2}
result = choices.get(key, 'default')
还有其他解决方案在字典内部使用 lambdas 或者在字典内部使用函数。这些也是有效的解决方案。
在 Python 3.10 发布之前,使用if - elif - else很可能是最常见的,也通常是最可读的解决方案。
结构模式匹配入门
Python 新的结构模式匹配使用了两个新的关键字:
- 匹配(不是开关!)
- 案例
要了解如何使用这段代码,请看下面基于 Guido 的教程的例子:
>>> status_code = 400
>>> match status_code:
... case 400:
... print("bad request")
... case 200:
... print("good")
... case _:
print("Something else bad happened")
bad request
这段代码接受 status_code,并告诉 Python 将其与其中一种情况进行匹配。如果大小写是 _(下划线),则没有找到大小写,这是默认大小写。最后一个 case 语句有时被称为“失败”情况。
组合文字
通过组合要比较的文字,可以稍微简化 case 语句。例如,您可能想要检查模式 status_code 是否匹配多个文字。为此,您可以像这样修改代码:case 400|401|403
这里有一个完整的例子:
>>> status_code = 400
>>> match status_code:
... case 400|401|403 :
... print("bad request")
... case 200:
... print("good")
... case _:
print("Something else bad happened") bad request
bad request
是不是很酷?
包扎
结构模式匹配是一个激动人心的新特性,仅在 Python 3.10 和更新版本中可用。这是一个强大的新功能,有很多有趣的用途。这些用例可以用 Python 现有的特性来解决吗?可能吧,但这让事情变得更简单了!
相关文章
- Guido 的模式匹配教程
- 当模式匹配被添加到 Python 3.10 中时,堆栈溢出用户欢欣鼓舞
中央 Python 活动日历宣布
原文:https://www.blog.pythonlibrary.org/2012/10/25/central-python-events-calendar-announced/
Python 软件基金会最近发布了一个关于中央 Python 事件日历的公告。我认为这真的很酷,所以我在这里复制他们的声明。把话传出去!
【宣布】宣布
中央 Python 事件日历
由 Python 软件基金会(PSF)
和一群志愿者维护
简介
PSF 组建了一个志愿者团队,他们维护着一个
中央 Python 事件日历。我们目前有两个日历
:
-
Python 事件日历——旨在用于关注 Python 或相关技术(全部或部分)的会议和大型聚会
-
Python 用户组日历——用于用户组活动和其他
较小的本地活动
日历显示在http://pycon.org/上,在http://python.org/网站的侧边栏中以较小的
版本显示(目前
那里只显示主要赛事日历)。
添加事件
如果您想将条目添加到这些日历中,请写信
给 events@pycon.org,并附上以下信息:
*活动名称
*活动类型(会议、酒吧营地、用户群等)
*关注 Python
- URL
*地点和国家
*日期和时间(如果相关)
对于重复发生的事件,也请以谷歌
日历兼容和支持的方式包括对
重复发生的描述。
更多信息
关于日历、URL、提要链接、id、嵌入、
等的更多信息。可在维基上找到:
http://wiki.python.org/moin/PythonEventsCalendar
coding 游牧民技术讲座系列!
原文:https://www.blog.pythonlibrary.org/2020/09/24/codingnomads-tech-talk-series/
最近,coding 游牧民邀请我参加他们的技术讲座系列。code 游牧民做 Python 和 Java 的在线代码营。
技术讲座是一系列教授或谈论技术的视频。就我而言,我要谈谈我最喜欢的编程语言,Python!
我做的第一个演讲是在 wxPython 上。在本视频中,我将展示如何创建一个简单的图像查看器:
https://www.youtube.com/embed/OYD7geVMde8?feature=oembed
令人惊讶的是,我被邀请做第二次演讲。这一次,我觉得介绍 Jupyter 笔记本会很有趣。
https://www.youtube.com/embed/P_wPlxI9fig?feature=oembed
CodingNomads 不是 Mouse vs Python 的赞助商。他们是一个整洁的团体,在我志愿花一些时间在夏天为他们指导人们之后,他们友好地邀请我成为他们系列的一部分。
ConfigObj + wxPython =极客快乐
原文:https://www.blog.pythonlibrary.org/2010/01/17/configobj-wxpython-geek-happiness/
我最近开始在工作中使用 Michael Foord 的 ConfigObj 用于我们内部的 wxPython 应用程序。当我写我的另一个 ConfigObj 教程时,我想向你展示我是如何在我的首选项对话框中使用 ConfigObj 的,但我不希望我所有的帖子都包含 wx。在本文中,我将向您展示在 ConfigObj 中添加一个新的首选项设置而不删除原来的设置是多么容易,以及如何用 wxPython 对话框加载和保存它们。现在,让我们开始吧!
首先,我们将创建一个简单的控制器,用于使用 ConfigObj 创建和访问配置文件:
import configobj
import os
import sys
import wx
from wx.lib.buttons import GenBitmapTextButton
appPath = os.path.abspath(os.path.dirname(os.path.join(sys.argv[0])))
inifile = os.path.join(appPath, "example.ini")
########################################################################
class CloseBtn(GenBitmapTextButton):
"""
Creates a reusuable close button with a bitmap
"""
#----------------------------------------------------------------------
def __init__(self, parent, label="Close"):
"""Constructor"""
font = wx.Font(16, wx.SWISS, wx.NORMAL, wx.BOLD)
img = wx.Bitmap(r"%s\images\cancel.png" % appPath)
GenBitmapTextButton.__init__(self, parent, wx.ID_CLOSE, img,
label=label, size=(110, 50))
self.SetFont(font)
#----------------------------------------------------------------------
def createConfig():
"""
Create the configuration file
"""
config = configobj.ConfigObj()
config.filename = inifile
config['update server'] = "http://www.someCoolWebsite/hackery.php"
config['username'] = ""
config['password'] = ""
config['update interval'] = 2
config['agency filter'] = 'include'
config['filters'] = ""
config.write()
#----------------------------------------------------------------------
def getConfig():
"""
Open the config file and return a configobj
"""
if not os.path.exists(inifile):
createConfig()
return configobj.ConfigObj(inifile)
这段代码非常简单。在 createConfig 函数中,它在运行该脚本的目录中创建一个“example.ini”文件。配置文件有六个字段,但没有节。在 getConfig 函数中,代码检查配置文件是否存在,如果不存在就创建它。无论如何,该函数都会向调用者返回一个 ConfigObj 对象。我们将把这个脚本放到“controller.py”中。现在我们将 wx 子类化。对话框类来创建首选项对话框。
# -----------------------------------------------------------
# preferencesDlg.py
#
# Created 10/20/2009 by mld
# -----------------------------------------------------------
import controller
import wx
from wx.lib.buttons import GenBitmapTextButton
########################################################################
class PreferencesDialog(wx.Dialog):
"""
Creates and displays a preferences dialog that allows the user to
change some settings.
"""
#----------------------------------------------------------------------
def __init__(self):
"""
"""
wx.Dialog.__init__(self, None, wx.ID_ANY, 'Preferences', size=(550,300))
appPath = controller.appPath
# ---------------------------------------------------------------------
# Create widgets
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.BOLD)
serverLbl = wx.StaticText(self, wx.ID_ANY, "Update Server:")
self.serverTxt = wx.TextCtrl(self, wx.ID_ANY, "")
self.serverTxt.Disable()
usernameLbl = wx.StaticText(self, wx.ID_ANY, "Username:")
self.usernameTxt = wx.TextCtrl(self, wx.ID_ANY, "")
self.usernameTxt.Disable()
passwordLbl = wx.StaticText(self, wx.ID_ANY, "Password:")
self.passwordTxt = wx.TextCtrl(self, wx.ID_ANY, "", style=wx.TE_PASSWORD)
self.passwordTxt.Disable()
updateLbl = wx.StaticText(self, wx.ID_ANY, "Update Interval:")
self.updateTxt = wx.TextCtrl(self, wx.ID_ANY, "")
minutesLbl = wx.StaticText(self, wx.ID_ANY, "minutes")
agencyLbl = wx.StaticText(self, wx.ID_ANY, "Agency Filter:")
choices = ["Include all agencies except", "Exclude all agencies except"]
self.agencyCbo = wx.ComboBox(self, wx.ID_ANY, "Include all agencies except",
None, wx.DefaultSize, choices, wx.CB_DROPDOWN|wx.CB_READONLY)
self.agencyCbo.SetFont(font)
self.filterTxt = wx.TextCtrl(self, wx.ID_ANY, "")
img = wx.Bitmap(r"img/filesave.png" % appPath)
saveBtn = GenBitmapTextButton(self, wx.ID_ANY, img, "Save", size=(110, 50))
saveBtn.Bind(wx.EVT_BUTTON, self.savePreferences)
cancelBtn = controller.CloseBtn(self, label="Cancel")
cancelBtn.Bind(wx.EVT_BUTTON, self.onCancel)
widgets = [serverLbl, usernameLbl, passwordLbl, updateLbl, agencyLbl, minutesLbl,
self.serverTxt, self.usernameTxt, self.passwordTxt, self.updateTxt,
self.agencyCbo, self.filterTxt, saveBtn, cancelBtn]
for widget in widgets:
widget.SetFont(font)
# ---------------------------------------------------------------------
# layout widgets
mainSizer = wx.BoxSizer(wx.VERTICAL)
updateSizer = wx.BoxSizer(wx.HORIZONTAL)
btnSizer = wx.BoxSizer(wx.HORIZONTAL)
prefSizer = wx.FlexGridSizer(cols=2, hgap=5, vgap=5)
prefSizer.AddGrowableCol(1)
prefSizer.Add(serverLbl, 0, wx.ALIGN_LEFT | wx.ALIGN_CENTER_VERTICAL)
prefSizer.Add(self.serverTxt, 0, wx.EXPAND)
prefSizer.Add(usernameLbl, 0, wx.ALIGN_LEFT | wx.ALIGN_CENTER_VERTICAL)
prefSizer.Add(self.usernameTxt, 0, wx.EXPAND)
prefSizer.Add(passwordLbl, 0, wx.ALIGN_LEFT | wx.ALIGN_CENTER_VERTICAL)
prefSizer.Add(self.passwordTxt, 0, wx.EXPAND)
prefSizer.Add(updateLbl, 0, wx.ALIGN_LEFT | wx.ALIGN_CENTER_VERTICAL)
updateSizer.Add(self.updateTxt, 0, wx.RIGHT, 5)
updateSizer.Add(minutesLbl, 0, wx.ALIGN_LEFT | wx.ALIGN_CENTER_VERTICAL)
prefSizer.Add(updateSizer)
prefSizer.Add(agencyLbl, 0, wx.ALIGN_LEFT | wx.ALIGN_CENTER_VERTICAL)
prefSizer.Add(self.agencyCbo, 0, wx.EXPAND)
prefSizer.Add((20,20))
prefSizer.Add(self.filterTxt, 0, wx.EXPAND)
mainSizer.Add(prefSizer, 0, wx.EXPAND|wx.ALL, 5)
btnSizer.Add(saveBtn, 0, wx.ALL, 5)
btnSizer.Add(cancelBtn, 0, wx.ALL, 5)
mainSizer.Add(btnSizer, 0, wx.ALL | wx.ALIGN_RIGHT, 10)
self.SetSizer(mainSizer)
# ---------------------------------------------------------------------
# load preferences
self.loadPreferences()
#----------------------------------------------------------------------
def loadPreferences(self):
"""
Load the preferences and fill the text controls
"""
config = controller.getConfig()
updateServer = config['update server']
username = config['username']
password = config['password']
interval = config['update interval']
agencyFilter = config['agency filter']
filters = config['filters']
self.serverTxt.SetValue(updateServer)
self.usernameTxt.SetValue(username)
self.passwordTxt.SetValue(password)
self.updateTxt.SetValue(interval)
self.agencyCbo.SetValue(agencyFilter)
self.filterTxt.SetValue(filters)
#----------------------------------------------------------------------
def onCancel(self, event):
"""
Closes the dialog
"""
self.EndModal(0)
#----------------------------------------------------------------------
def savePreferences(self, event):
"""
Save the preferences
"""
config = controller.getConfig()
config['update interval'] = self.updateTxt.GetValue()
config['agency filter'] = str(self.agencyCbo.GetValue())
data = self.filterTxt.GetValue()
if "," in data:
filters = [i.strip() for i in data.split(',')]
elif " " in data:
filters = [i.strip() for i in data.split(' ')]
else:
filters = [data]
text = ""
for f in filters:
text += " " + f
text = text.strip()
config['filters'] = text
config.write()
dlg = wx.MessageDialog(self, "Preferences Saved!", 'Information',
wx.OK|wx.ICON_INFORMATION)
dlg.ShowModal()
self.EndModal(0)
if __name__ == "__main__":
app = wx.PySimpleApp()
dlg = PreferencesDialog()
dlg.ShowModal()
dlg.Destroy()
上面的代码创建了一个基本的首选项对话框,并使用 ConfigObj 从一个文件中加载它的配置。您可以通过阅读 loadPreferences 方法中的代码来了解其工作原理。我们关心的另一件事是,当用户更改参数时,代码如何保存它们。为此,我们需要看看 savePreferences 方法。这是一个非常简单的方法,因为它所做的就是使用 wx 的特定 getter 函数从小部件中获取各种值。还有一个条件,对筛选字段做一些小的检查。主要原因是,在我的原始程序中,我使用空格作为分隔符,程序需要将逗号等转换为空格。这个代码仍然是一个正在进行的工作,虽然它没有涵盖用户可以输入的所有情况。
无论如何,一旦我们在 ConfigObj 的类似 dict 的接口中有了值,我们就把 ConfigObj 实例的数据写到文件中。然后程序显示一个简单的对话框让用户知道已经保存了。
现在,假设我们的程序规范发生了变化,我们需要添加或删除一个偏好。这样做所需要的只是在配置文件中添加或删除它。ConfigObj 将获取更改,我们只需要记住在 GUI 中添加或删除适当的小部件。ConfigObj 最好的一点是,它不会重置文件中的数据,它只会在适当的时候添加更改。试一试,发现它是多么简单!
注意:所有代码都是在 Windows XP 上用 Python 2.5、ConfigObj 4.6.0 和 Validate 1.0.0 测试的。
下载量
使用 Python 连接到 Dropbox
原文:https://www.blog.pythonlibrary.org/2013/07/17/connecting-to-dropbox-with-python/
昨天偶然发现了 Dropbox 的 Python API 。我最终使用他们的教程设计了一个简单的类来访问我的 Dropbox。你需要下载他们的 dropbox 模块,或者使用“pip install dropbox”来安装。您还需要注册一个密钥和密码。一旦有了这些,您就需要命名您的应用程序并选择您的访问级别。那你应该可以走了!
现在我们准备开始写一些代码。这是我想到的:
import dropbox
import os
import sys
import webbrowser
from configobj import ConfigObj
########################################################################
class DropObj(object):
"""
Dropbox object that can access your dropbox folder,
as well as download and upload files to dropbox
"""
#----------------------------------------------------------------------
def __init__(self, filename=None, path='/'):
"""Constructor"""
self.base_path = os.path.dirname(os.path.abspath(__file__))
self.filename = filename
self.path = path
self.client = None
config_path = os.path.join(self.base_path, "config.ini")
if os.path.exists(config_path):
try:
cfg = ConfigObj(config_path)
except IOError:
print "ERROR opening config file!"
sys.exit(1)
self.cfg_dict = cfg.dict()
else:
print "ERROR: config.ini not found! Exiting!"
sys.exit(1)
self.connect()
#----------------------------------------------------------------------
def connect(self):
"""
Connect and authenticate with dropbox
"""
app_key = self.cfg_dict["key"]
app_secret = self.cfg_dict["secret"]
access_type = "dropbox"
session = dropbox.session.DropboxSession(app_key,
app_secret,
access_type)
request_token = session.obtain_request_token()
url = session.build_authorize_url(request_token)
msg = "Opening %s. Please make sure this application is allowed before continuing."
print msg % url
webbrowser.open(url)
raw_input("Press enter to continue")
access_token = session.obtain_access_token(request_token)
self.client = dropbox.client.DropboxClient(session)
#----------------------------------------------------------------------
def download_file(self, filename=None, outDir=None):
"""
Download either the file passed to the class or the file passed
to the method
"""
if filename:
fname = filename
f, metadata = self.client.get_file_and_metadata("/" + fname)
else:
fname = self.filename
f, metadata = self.client.get_file_and_metadata("/" + fname)
if outDir:
dst = os.path.join(outDir, fname)
else:
dst = fname
with open(fname, "w") as fh:
fh.write(f.read())
return dst, metadata
#----------------------------------------------------------------------
def get_account_info(self):
"""
Returns the account information, such as user's display name,
quota, email address, etc
"""
return self.client.account_info()
#----------------------------------------------------------------------
def list_folder(self, folder=None):
"""
Return a dictionary of information about a folder
"""
if folder:
folder_metadata = self.client.metadata(folder)
else:
folder_metadata = self.client.metadata("/")
return folder_metadata
#----------------------------------------------------------------------
def upload_file(self):
"""
Upload a file to dropbox, returns file info dict
"""
try:
with open(self.filename) as fh:
path = os.path.join(self.path, self.filename)
res = self.client.put_file(path, fh)
print "uploaded: ", res
except Exception, e:
print "ERROR: ", e
return res
if __name__ == "__main__":
drop = DropObj("somefile.txt")
我把我的密钥和秘密放在一个配置文件中,如下所示:
key = someKey
secret = secret
然后我使用 configobj 将这些信息提取到一个 Python 字典中。我试图找到一种方法来缓存请求令牌,但我总是得到一个关于我的令牌过期的错误,所以这个脚本总是会弹出一个浏览器窗口,要求您“允许”您的应用程序访问您的 Dropbox。一旦你连接上了,客户端就被实例化了,你可以提取关于你的 Dropbox 的各种信息。例如,你可以在你的 Dropbox 中获得你的账户信息或者任何文件夹的元数据。我还创建了和 upload_file 方法来允许轻松上传文件。我可能应该这样做,这样你也可以传递一个文件给这个方法,但是那要等到版本 2。 download_file 方法遵循 Dropbox 支持的官方方法,然而我下载的每个文件最终都被破坏了。
无论如何,我认为这是一个有趣的 API,希望你会发现这个小脚本也很有帮助。
竞赛:为我的博客创建一个标志!
原文:https://www.blog.pythonlibrary.org/2010/09/22/contest-create-a-logo-for-my-blog/
我一直在想,如果这个网站有一个很酷的标志或某种艺术品,它会摇滚。所以我想我应该举办一场比赛,让我才华横溢的读者们有机会帮助我。这是我想要的:
- 某种横幅或背景图片
- 一只老鼠(毛茸茸的那种,电脑鼠标,机甲什么的)对抗一条蟒蛇(或者其他很酷的蛇)。它可以是现实的、卡通的、超现实的等等。
这些艺术作品会被用在我的博客上,我会把它放在衬衫和 Zazzle 类型的账户上的其他项目上,与我的博客交叉链接。这种艺术将被归入知识共享署名-相似分享 3.0 无版权许可。
以下是幸运赢家获得的奖励:
一等奖
- 价值 100 美元的亚马逊礼券
- 实用编程:使用 Python 的计算机科学导论
- 我的博客上的署名和艺术家网站的链接
二等奖
- 价值 50 美元的亚马逊礼券
- 我的博客上的署名和艺术家网站的链接
是的,我知道这不多,但这是我自己掏腰包,我不是公司的大人物。对于那些对统计感兴趣的人来说,这个博客每月产生大约 21000 的页面浏览量。12-14000 名访客。
通过电子邮件将您的投稿发送给 contest@pythonlibrary.org。提交的内容不得超过 10 MB。比赛将于中部标准时间 2010 年 10 月 31 日晚上 11:59 结束。我是唯一的评委,将选择我最喜欢的两个意见书。
竞赛:赢得一份即时烧瓶网络开发
原文:https://www.blog.pythonlibrary.org/2013/11/08/contest-win-a-copy-of-instant-flask-web-development/
这场比赛现在结束了!
Packt Publishing 让我为他们举办一场竞赛,分发他们的新书:Ron DuPlain 的《即时烧瓶网络开发》。它在亚马逊上受到好评,我计划很快发布这本书的评论。
我有这本书的 3 本电子版要赠送。这里有一些关于这本书内容的信息:

- 使用 virtualenv 管理项目依赖关系
- 了解 Flask 如何提供 URL 路由和 web 请求处理
- 了解 Flask 如何在磁盘上提供静态文件
- 了解如何使用 SQLAlchemy 建模、存储和查询数据
- 呈现 HTML 表单并用 WTForms 验证输入
- 使用一个基本的 Jinja 模板,用 Twitter Bootstrap 构建一个页面布局
- 创建、调用、更新、删除和列出数据库记录
- 在 Jinja 中构建自定义模板过滤器来格式化数据
- 验证用户身份并维护会话
如何进入?
你所需要做的就是前往书的页面,浏览这本书的产品描述,并在这篇文章下面的评论中留言,让我们知道你对这本书最感兴趣的是什么。就这么简单。
获胜者将获得该书的电子版。
最后期限
比赛将于 2013 年 11 月 15 日美国中部时间下午 12:01 结束。获奖者将通过他们在评论时使用的电子邮件联系!别担心,我是这个博客上唯一能看到你的电子邮件地址的人。
用 Python 将照片转换成黑白
原文:https://www.blog.pythonlibrary.org/2017/10/11/convert-a-photo-to-black-and-white-in-python/
黑白图像并不适合所有人。我个人喜欢和他们一起玩,因为你有时可以拍一张无聊的照片,然后把它变成一些戏剧性的东西。我还拯救了一张单调的照片,把它变成黑白的。如果您想通过编程将自己拍摄的照片转换成黑白照片,枕头套装可以满足您的需求。在这篇文章中,我们将看看两个简单的方法来转换成黑白照片,然后我们也将学习如何制作一张棕褐色调的照片。
让它变成黑色和白色
第一个障碍是找到一张你想编辑的照片。对于这个例子,我们将使用下面的模糊毛虫:

现在我们只需要创建一个简单的函数,可以将我们的彩色照片转换成黑白照片:
from PIL import Image
def black_and_white(input_image_path,
output_image_path):
color_image = Image.open(input_image_path)
bw = color_image.convert('L')
bw.save(output_image_path)
if __name__ == '__main__':
black_and_white('caterpillar.jpg',
'bw_caterpillar.jpg')
上面的函数有两个参数:输入图像的文件路径和我们想要保存输出的路径。在这个脚本中,我们真正关心的是这个函数。它包含一个打开图像的调用,该调用将返回一个图像对象。然后,我们使用该对象的转换方法,通过向其传递字符串‘L’,将图像转换为黑白。这可能看起来有点奇怪,所以让我们看看文档。
这里您会发现 convert()方法的第一个参数是模式。枕头支持多种模式,包括:“P”、“L”和“1”。我们目前关心的模式是‘L’。文档说明“当将彩色图像转换为黑白图像时(模式 L ),库使用 ITU-R 601-2 亮度变换:L = R * 299/1000+G * 587/1000+B * 114/1000”其中 RGB 映射为红色、绿色和蓝色。让我们看看我们的代码生成了什么样的输出:

如果我自己这么说,那看起来很不错。Pillow 项目还支持创建带有抖动的黑白图像,这基本上是给图像添加噪声。让我们看看这是如何改变代码的:
from PIL import Image
def black_and_white_dithering(input_image_path,
output_image_path,
dithering=True):
color_image = Image.open(input_image_path)
if dithering:
bw = color_image.convert('1')
else:
bw = color_image.convert('1', dither=Image.NONE)
bw.save(output_image_path)
if __name__ == '__main__':
black_and_white_dithering(
'caterpillar.jpg',
'bw_caterpillar_dithering.jpg')
这个函数与前一个函数的唯一区别是,我们添加了一个抖动参数,并且我们还使用“1”(one)而不是“L”来调用 convert()方法。你可以用“L”模式做抖动,但是我想展示一下当你用“1”时会发生什么。让我们来看看输出:

当你有完整尺寸的图像时,这张看起来很不一样,因为你可以更容易地看到白噪音。然而,由于我在这里使用的是一个小版本,变化是相当微妙的。
现在让我们调用抖动设置为 False 的函数。如果这样做,您将看到下图:

这个看起来有点抽象,但也有点意思。这几乎是一个墨迹!正如你所看到的,在创建黑白图像时,“L”可能是你想要关注的模式。
创建棕褐色调图像
既然我们已经学会了如何使我们的图像黑白化,我想谈谈如何给你的图像添加棕褐色调色。深褐色调的图像非常受欢迎,让你的图像看起来像老式的黄色。我在网上搜索了一下,在 Fredrik Lundh 的网站上找到了一篇关于如何做到这一点的文章。
让我们看一下代码:
from PIL import Image
def make_sepia_palette(color):
palette = []
r, g, b = color
for i in range(255):
palette.extend((r*i/255, g*i/255, b*i/255))
return palette
def create_sepia(input_image_path,
output_image_path):
whitish = (255, 240, 192)
sepia = make_sepia_palette(whitish)
color_image = Image.open(input_image_path)
# convert our image to gray scale
bw = color_image.convert('L')
# add the sepia toning
bw.putpalette(sepia)
# convert to RGB for easier saving
sepia_image = bw.convert('RGB')
sepia_image.save(output_image_path)
if __name__ == '__main__':
create_sepia('caterpillar.jpg',
'sepia_caterpillar.jpg')
这里我们创建了两个函数。一个用于创建棕褐色调色板,另一个用于应用它。为了创建调色板,我们需要创建一个灰白色,所以我们通过迭代一个灰白色的元组,然后迭代 RGB 色谱的所有 255 种变化来实现。这就创建了一个大小合适的代表棕褐色调色板的各种 RGB 值的元组。
接下来,我们将图像转换成黑白(或者灰度,取决于你怎么看)。然后我们使用 image 对象的 putpalette() 方法应用我们的棕褐色调色板。最后,我们将图像转换回“RGB ”,根据 Lundh 的说法,这允许我们将图像保存为 Jpeg。我没有做任何挖掘,看看这是否仍然需要在枕头或没有。最后,我们保存图像,这是我得到的:

相当整洁,代码运行速度也相当快!
包扎
现在你知道如何使用枕头包来创建黑白照片的几种变化。您还发现了将调色板应用到黑白图像来添加棕褐色色调是多么容易。你可以尝试其他颜色,让你的黑白照片看起来有很大的变化。开心快乐编码!
相关阅读
- PIL 和棕褐色
- 自动化无聊的东西的章
- 如何用 Python 旋转/镜像照片
- 如何用 Python 裁剪照片
用 Python 将图像转换成 ASCII 码
原文:https://www.blog.pythonlibrary.org/2021/05/11/converting-an-image-to-ascii-with-python/
有很多有趣的 Python 片段可以用来将你的照片转换成 ASCII 艺术。Anthony Shaw 是 Real Python 的作者和撰稿人,他在 GitHub 上有自己的片段。这些小程序大多使用枕包。
这些程序最适合处理简单的图像,尤其是没有背景的图像。Shaw 的程序使用 ansicolors 包为你的 ASCII 艺术增添一些色彩。
以下是肖的完整计划:
"""
image2ansi.py
usage: image2ansi.py [-h] [--no-color] [--width WIDTH] path
Display an image in ASCII with ANSI colors
positional arguments:
path the path to the image file
optional arguments:
-h, --help show this help message and exit
--no-color no ANSI colors
--width WIDTH output width in characters (Default 120)
Features:
- Converts ALPHA channel to whitespace (transparency)
- Uses a sharpness filter to improve the output
Requires:
- Python 3
- Pillow
- ansicolors
Install:
- pip3 install pillow ansicolors
"""
import argparse
from PIL import Image, ImageEnhance
from colors import color
def render(image_file, width=120, height_scale=0.55, colorize=True):
img = Image.open(image_file)
org_width, orig_height = img.size
aspect_ratio = orig_height / org_width
new_height = aspect_ratio * width * height_scale
img = img.resize((width, int(new_height)))
img = img.convert('RGBA')
img = ImageEnhance.Sharpness(img).enhance(2.0)
pixels = img.getdata()
def mapto(r, g, b, alpha):
if alpha == 0.:
return ' '
chars = ["B", "S", "#", "&", "@", "$", "%", "*", "!", ".", " "]
pixel = (r * 19595 + g * 38470 + b * 7471 + 0x8000) >> 16
if colorize:
return color(chars[pixel // 25], (r, g, b))
else:
return chars[pixel // 25]
new_pixels = [mapto(r, g, b, alpha) for r, g, b, alpha in pixels]
new_pixels_count = len(new_pixels)
ascii_image = [''.join(new_pixels[index:index + width]) for index in range(0, new_pixels_count, width)]
ascii_image = "\n".join(ascii_image)
return ascii_image
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Display an image in ASCII with ANSI colors')
parser.add_argument('path',
metavar='path',
type=str,
help='the path to the image file ')
parser.add_argument('--no-color',
action='store_true',
help='no ANSI colors')
parser.add_argument('--width',
action='store',
type=int,
default=120,
help='output width in characters (Default 120)')
parser.add_argument('--height-scale',
action='store',
default=.55,
type=float,
help='scale ratio for height (default .55')
args = parser.parse_args()
print(render(
args.path,
args.width,
height_scale=args.height_scale,
colorize=not args.no_color))
你可以在你拥有的任何图像上使用这个程序。要了解如何使用该程序,您可以使用本文作者的这张照片:

迈克尔·德里斯科尔
要运行该程序,您需要打开一个终端并更改目录,直到您进入保存该程序的同一文件夹。然后,您将运行以下命令:
python3 image2ansi.py my_photo.jpg
当您对上图运行这个程序时,您将得到以下输出:

您可以看到,转换删除了图像的许多细节,这是意料之中的。
现在让我们用一个更简单的图像来试试这个程序,比如企鹅 Tux:

当您对此映像运行 image2ansi.py 时,您的输出将如下所示:
与之前的转换相比,这次转换看起来更像原始图像。
像 image2ansi.py 这样的程序玩起来很有趣。去试试吧,或者看看你能不能想出一个更好的。开心快乐编码!
用 Python 将 CSV 转换为 Excel
原文:https://www.blog.pythonlibrary.org/2021/09/25/converting-csv-to-excel-with-python/
作为软件开发人员,您需要使用许多常见的文件类型。CSV 文件就是这样一种格式。CSV 代表“逗号分隔值”,是一种文本文件格式,使用逗号作为分隔符来分隔值。每行是它自己的记录,每个值是它自己的字段。大多数 CSV 文件都有相同长度的记录。
Microsoft Excel 打开 CSV 文件没有问题。可以自己用 Excel 打开一个,然后自己保存成 Excel 格式。这篇文章的目的是教你以下概念:
- 将 CSV 文件转换为 Excel
- 将 Excel 电子表格转换为 CSV
您将使用 Python 和 OpenPyXL 来完成从一种文件类型到另一种文件类型的转换。
入门指南
您需要安装 OpenPyXL 才能使用本文中的示例。您可以使用 pip 来安装 OpenPyXL:
python3 -m pip install openpyxl
现在您已经有了 OpenPyXL,您已经准备好学习如何将 CSV 文件转换成 Excel 电子表格了!
将 CSV 文件转换为 Excel
您很快就会发现,将 CSV 文件转换为 Excel 电子表格并不需要太多代码。但是,您需要有一个 CSV 文件才能开始。记住这一点,打开您最喜欢的文本编辑器(记事本、SublimeText 或其他东西)并添加以下内容:
book_title,author,publisher,pub_date,isbn
Python 101,Mike Driscoll, Mike Driscoll,2020,123456789
wxPython Recipes,Mike Driscoll,Apress,2018,978-1-4842-3237-8
Python Interviews,Mike Driscoll,Packt Publishing,2018,9781788399081
将此文件另存为 books.txt 。你也可以从这本书的 GitHub 代码库下载 CSV 文件。
现在您已经有了 CSV 文件,您还需要创建一个新的 Python 文件。打开 Python IDE 并创建一个名为csv_to_excel.py的新文件。然后输入以下代码:
# csv_to_excel.py
import csv
import openpyxl
def csv_to_excel(csv_file, excel_file):
csv_data = []
with open(csv_file) as file_obj:
reader = csv.reader(file_obj)
for row in reader:
csv_data.append(row)
workbook = openpyxl.Workbook()
sheet = workbook.active
for row in csv_data:
sheet.append(row)
workbook.save(excel_file)
if __name__ == "__main__":
csv_to_excel("books.csv", "books.xlsx")
除了 OpenPyXL,您的代码还使用了 Python 的csv模块。您创建一个函数csv_to_excel(),然后接受两个参数:
csv_file-输入 CSV 文件的路径excel_file-您想要创建的 Excel 文件的路径
您希望从 CSV 中提取每一行数据。为了提取数据,您创建一个csv.reader()对象,然后一次迭代一行。对于每次迭代,您将该行追加到csv_data。一个row是一个字符串列表。
流程的下一步是创建 Excel 电子表格。要将数据添加到您的Workbook中,您需要迭代csv_data中的每一行,并将它们append()到您的工作表中。最后,保存 Excel 电子表格。
当您运行这段代码时,您将得到一个如下所示的 Excel 电子表格:

CSV 到 Excel 电子表格
现在,您可以用不到 25 行代码将 CSV 文件转换为 Excel 电子表格!
现在您已经准备好学习如何将 Excel 电子表格转换为 CSV 文件了!
将 Excel 电子表格转换为 CSV
如果您需要其他过程来使用数据,将 Excel 电子表格转换为 CSV 文件会很有用。CSV 文件的另一个潜在需求是当您需要与没有电子表格程序打开它的人共享您的 Excel 电子表格时。虽然很少,但这种情况可能会发生。
您可以使用 Python 将 Excel 电子表格转换为 CSV 文件。创建一个名为excel_to_csv.py的新文件,并添加以下代码:
# excel_to_csv.py
import csv
import openpyxl
from openpyxl import load_workbook
def excel_to_csv(excel_file, csv_file):
workbook = load_workbook(filename=excel_file)
sheet = workbook.active
csv_data = []
# Read data from Excel
for value in sheet.iter_rows(values_only=True):
csv_data.append(list(value))
# Write to CSV
with open(csv_file, 'w') as csv_file_obj:
writer = csv.writer(csv_file_obj, delimiter=',')
for line in csv_data:
writer.writerow(line)
if __name__ == "__main__":
excel_to_csv("books.xlsx", "new_books.csv")
同样,您只需要csv和openpyxl模块来进行转换。这一次,首先加载 Excel 电子表格,并使用iter_rows方法迭代工作表。在iter_tools的每次迭代中,您收到的value是一个字符串列表。您将字符串列表附加到csv_data。
下一步是创建一个csv.writer()。然后遍历csv_data中的每个字符串列表,并调用writerow()将其添加到您的 CSV 文件中。
一旦你的代码完成,你将有一个全新的 CSV 文件!
包扎
使用 Python 很容易将 CSV 文件转换成 Excel 电子表格。这是一个有用的工具,您可以用它从客户或其他数据源获取数据,并将其转换为您可以向公司展示的内容。
您也可以在将数据写入工作表时对其应用单元格样式。通过应用单元格样式,您可以用不同的字体或背景行颜色突出您的数据。
在您自己的 Excel 或 CSV 文件上尝试这段代码,看看您能做些什么。
相关阅读
您想了解有关使用 Python 处理 Excel 电子表格的更多信息吗?然后查看这些教程:
-
OpenPyXL–使用 Python 使用 Microsoft Excel】
用 Python 将 MP4 转换成动画 gif
原文:https://www.blog.pythonlibrary.org/2021/06/29/converting-mp4-to-animated-gifs-with-python/
Python 可以用来读取常见的 MP4 视频格式,并将其转换为动画 GIF。当然,如果你愿意的话,你可以使用一个预建的软件,但是自己动手也很有趣(也是一个很好的学习体验)。
在本教程中,您将学习以下内容:
- 如何从 MP4 视频中提取帧
- 将帧转换成 GIF
- 创建一个 MP4 到 GIF 的图形用户界面
我们开始吧!
你需要什么
您需要为 Python 安装 OpenCV 绑定来读取 MP4 文件,并将视频中的每一帧转换为 JPG 文件。您可以使用 pip 进行安装,如下所示:
python3 -m pip install opencv-python
你还需要 Pillow 来从视频中提取的 jpg 创建动画 GIF。它也可以与 pip 一起安装:
python3 -m pip install Pillow
要创建一个 GUI,您将使用 PySimpleGUI 。要安装该软件包,请使用以下命令:
python3 -m pip install PySimpleGUI
如果你使用的是 Anaconda,opencv-python 和 Pillow 都包括在内。您只需要单独安装 PySimpleGUI。
如何从 MP4 视频中提取帧
从 MP4 视频中提取帧的第一步是找到您想要转换为 GIF 的视频。对于这个例子,您将使用这个简短的视频来演示如何使用 Python 安装 Flask web 框架:
https://www.blog.pythonlibrary.org/wp-content/uploads/2021/06/flask_demo.mp4
为了从上面的视频中提取单独的帧,你需要写一些 Python。创建一个新文件,命名为 mp4_converter.py 。然后输入以下代码:
import cv2
def convert_mp4_to_jpgs(path):
video_capture = cv2.VideoCapture(path)
still_reading, image = video_capture.read()
frame_count = 0
while still_reading:
cv2.imwrite(f"output/frame_{frame_count:03d}.jpg", image)
# read next image
still_reading, image = video_capture.read()
frame_count += 1
if __name__ == "__main__":
convert_mp4_to_jpgs("flask_demo.mp4")
这段代码获取一个 MP4 视频文件的路径。然后它使用 cv2 打开视频。视频捕捉(路径)。您可以使用此方法通读整个视频并提取每一帧。当你提取一个帧时,你可以使用 cv2.imwrite() 把它写出来。
当你运行这段代码时,你会发现这段 7 秒的视频产生了 235 帧!
现在,您已经准备好将这些帧转换成动画 GIF。
将帧转换成 GIF
该过程的下一步是将使用 OpenCV 从 MP4 文件中提取的帧转换成动画 GIF。
这就是枕头包装的由来。你可以用它来获取一个图像文件夹,并创建你的 GIF。打开一个新文件,命名为 gif_maker.py 。然后输入以下代码:
import glob
from PIL import Image
def make_gif(frame_folder):
images = glob.glob(f"{frame_folder}/*.jpg")
images.sort()
frames = [Image.open(image) for image in images]
frame_one = frames[0]
frame_one.save("flask_demo.gif", format="GIF", append_images=frames,
save_all=True, duration=50, loop=0)
if __name__ == "__main__":
make_gif("output")
这里您使用 Python 的 glob 模块在输出文件夹中搜索 JPG 文件。然后,您对这些帧进行排序,使它们处于正确的顺序。最后,你将它们保存为 GIF 格式。如果你有兴趣了解更多关于 Pillow 如何保存 GIF 的信息,你应该看看下面的文章:用 Python 制作动画 GIF。
现在,您已经准备好创建一个 GUI 来简化将 MP4 转换为 GIF 的过程。
创建一个 MP4 到 GIF 的图形用户界面
PySimpleGUI 是一个跨平台的 GUI 框架,可以在 Linux、Mac 和 Windows 上运行。它包装了 Tkinter、wxPython、PyQt 和其他几个 GUI 工具包,为它们提供了一个公共接口。
当您在本文前面安装 PySimpleGUI 时,您安装了包装 Tkinter 的默认版本。
打开一个新的 Python 文件,将其命名为 mp4_converter_gui.py. 然后将以下代码添加到您的文件中:
# mp4_converter_gui.py
import cv2
import glob
import os
import shutil
import PySimpleGUI as sg
from PIL import Image
file_types = [("MP4 (*.mp4)", "*.mp4"), ("All files (*.*)", "*.*")]
def convert_mp4_to_jpgs(path):
video_capture = cv2.VideoCapture(path)
still_reading, image = video_capture.read()
frame_count = 0
if os.path.exists("output"):
# remove previous GIF frame files
shutil.rmtree("output")
try:
os.mkdir("output")
except IOError:
sg.popup("Error occurred creating output folder")
return
while still_reading:
cv2.imwrite(f"output/frame_{frame_count:05d}.jpg", image)
# read next image
still_reading, image = video_capture.read()
frame_count += 1
def make_gif(gif_path, frame_folder="output"):
images = glob.glob(f"{frame_folder}/*.jpg")
images.sort()
frames = [Image.open(image) for image in images]
frame_one = frames[0]
frame_one.save(gif_path, format="GIF", append_images=frames,
save_all=True, duration=50, loop=0)
def main():
layout = [
[
sg.Text("MP4 File"),
sg.Input(size=(25, 1), key="-FILENAME-", disabled=True),
sg.FileBrowse(file_types=file_types),
],
[
sg.Text("GIF File Save Location"),
sg.Input(size=(25, 1), key="-OUTPUTFILE-", disabled=True),
sg.SaveAs(file_types=file_types),
],
[sg.Button("Convert to GIF")],
]
window = sg.Window("MP4 to GIF Converter", layout)
while True:
event, values = window.read()
mp4_path = values["-FILENAME-"]
gif_path = values["-OUTPUTFILE-"]
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event in ["Convert to GIF"]:
if mp4_path and gif_path:
convert_mp4_to_jpgs(mp4_path)
make_gif(gif_path)
sg.popup(f"GIF created: {gif_path}")
window.close()
if __name__ == "__main__":
main()
这是一段相当长的代码。为了使事情变得简单,您将单独了解每个块。
首先,看一下导入部分:
# mp4_converter_gui.py
import cv2
import glob
import os
import shutil
import PySimpleGUI as sg
from PIL import Image
file_types = [("MP4 (*.mp4)", "*.mp4"), ("All files (*.*)", "*.*")]
在这里,您可以导入创建 GUI 应用程序所需的所有模块和包。这包括 OpenCV (cv2)、Pillow 的 Image clas 和 PySimpleGUI,以及许多 Python 自己的模块。
您还可以创建一个变量来保存可以加载到 GUI 中的文件类型。这是一个元组列表。
现在是时候将注意力转向程序中的第一个函数了:
def convert_mp4_to_jpgs(path):
video_capture = cv2.VideoCapture(path)
still_reading, image = video_capture.read()
frame_count = 0
if os.path.exists("output"):
# remove previous GIF frame files
shutil.rmtree("output")
try:
os.mkdir("output")
except IOError:
sg.popup("Error occurred creating output folder")
return
while still_reading:
cv2.imwrite(f"output/frame_{frame_count:05d}.jpg", image)
# read next image
still_reading, image = video_capture.read()
frame_count += 1
这是您之前创建的 MP4 转换器代码的修改版本。在这个版本中,你仍然使用 VideoCapture() 来读取 MP4 文件,并将其转换为单独的帧。
但是,您还添加了一些额外的代码来删除“输出”文件夹(如果它存在的话)。这可以防止您意外地将两个 MP4 文件合并在一个输出文件中,这将导致混乱的 GIF。
您还添加了一些代码,试图在删除“output”文件夹后创建它。如果创建文件夹时出现错误,将显示一个错误对话框。
剩下的代码和以前一样。
现在,您已经准备好检查下一个函数了:
def make_gif(gif_path, frame_folder="output"):
images = glob.glob(f"{frame_folder}/*.jpg")
images.sort()
frames = [Image.open(image) for image in images]
frame_one = frames[0]
frame_one.save(gif_path, format="GIF", append_images=frames,
save_all=True, duration=50, loop=0)
您使用 make_gif() 将您的框架文件夹转换为 gif 文件。这段代码与原始代码几乎相同,只是您传递了 GIF 文件的路径,这样它就可以是惟一的。
最后一段代码是您的 GUI 代码:
def main():
layout = [
[
sg.Text("MP4 File"),
sg.Input(size=(25, 1), key="-FILENAME-", disabled=True),
sg.FileBrowse(file_types=file_types),
],
[
sg.Text("GIF File Save Location"),
sg.Input(size=(25, 1), key="-OUTPUTFILE-", disabled=True),
sg.SaveAs(file_types=file_types),
],
[sg.Button("Convert to GIF")],
]
window = sg.Window("MP4 to GIF Converter", layout)
while True:
event, values = window.read()
mp4_path = values["-FILENAME-"]
gif_path = values["-OUTPUTFILE-"]
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event in ["Convert to GIF"]:
if mp4_path and gif_path:
convert_mp4_to_jpgs(mp4_path)
make_gif(gif_path)
sg.popup(f"GIF created: {gif_path}")
window.close()
if __name__ == "__main__":
main()
在 PySimpleGUI 中,当您想要“布局”用户界面中的元素时,您可以将项目添加到 Python 列表中。对于此示例,您将添加以下元素:
- sg。text——这个元素有两个实例。它们被用作输入(文本框)的标签
- sg。input——这个元素有两个实例,是一个文本框类型的元素。一个用来保存 MP4 文件的位置,另一个用来保存 GIF 文件
- sg。文件浏览-打开文件浏览对话框的按钮
- sg。另存为-打开文件另存为对话框的按钮
- sg。按钮-一个可以做任何你想让它做的事情的按钮
接下来,获取元素列表并将其传递给 sg。窗口,它代表包含所有其他元素的窗口。您的窗口还有一个退出按钮、一个最小化按钮和一个标题栏。
要启动 GUI 的事件循环,您需要创建一个 while 循环并从 Window 对象中读取。这允许您提取两个 sg 的值。Input() 对象,包含 MP4 和 GIF 文件的路径。
当用户按下标记为“Convert to GIF”的按钮时,您捕捉到该事件并调用 convert_mp4_to_jpgs() ,然后调用 make_gif() 。如果一切顺利,视频将被转换,您将看到一个弹出对话框,说明新创建的 GIF 保存在哪里。
尝试运行这段代码。您应该会看到类似这样的内容:

很漂亮,是吧?
包扎
现在你已经有了将 MP4 视频文件转换成 gif 文件所需的所有部分。有几种不同的方法可以让你的代码变得更好。例如,您可以在代码中添加更多的错误处理,这样就不会意外地覆盖 gif 文件。
您还可以添加一些新的 UI 元素,告诉您的代码向下调整单个框架的大小,以帮助 gif 变得更小。你可以在如何用 Python 调整照片大小中读到。另一个选择是改变每个单独 JPG 的压缩,这也将减少 GIF 的大小。
还有很多其他有趣的方法可以让代码变得更好。想想看,你一定会自己想出一些新功能!
核心 Python 开发:如何提交补丁
原文:https://www.blog.pythonlibrary.org/2012/05/22/core-python-development-how-to-submit-a-patch/
正如我在上一篇文章中提到的,我想我应该试着找到一些可以用 Python 修补的东西并提交。在写另一篇文章时,我在 Python devguide 的 Windows 部分中发现了一个小错误。虽然修补一个文档远没有我想象的修补 Python 那么酷,但我认为它对我来说相当合适,因为我最近倾向于贡献更多的文档。所以我将解释我发现的过程。
入门指南
首先,你需要用 Python 的 Bug 追踪器获得一个账户。如果您希望成为核心开发人员,那么您需要确保您的用户名遵循他们的指导原则,这非常简单:
firstname.lastname
一旦你有了这些,你就可以开始寻找修补的东西了。有一个链接写着“简单问题”,这是一个很好的起点。你也可以搜索一个你能胜任使用的组件,看看是否有你认为可以修复的 bug。一旦你发现了什么,你需要确保更新你的本地回购,然后阅读 devguide 的补丁页面。
创建补丁
假设您已经在本地机器上签出了必要的存储库,那么您需要做的就是编辑适当的文件。在我的例子中,我必须检查 devguide(你可以在这里阅读)并编辑 setup.rst 文件。如果你正在编辑 Python 代码,那么你必须遵守 PEP8。编辑完文件后,我保存了我的更改,然后必须使用 Mercurial 来创建补丁。这是我根据 Python 补丁指令使用的命令。
hg diff > setup.patch
下面是该补丁文件的内容:
diff -r b1c1d15271c0 setup.rst --- a/setup.rst Tue May 22 00:33:42 2012 +0200 +++ b/setup.rst Tue May 22 13:55:09 2012 -0500 @@ -173,7 +173,7 @@ To build from the Visual Studio GUI, open pcbuild.sln to load the project files and choose the Build Solution option from the Build menu, often associated with the F7 key. Make sure you have chosen the "Debug" option from -the build configuration drop-down first. +the configuration toolbar drop-down first.
构建完成后,您可能希望将 Python 设置为一个启动项目。在
Visual Studio 中按 F5,或者从调试菜单中选择开始调试,将启动
现在我们有了一个补丁,我们需要提交它!
提交补丁
举起你的盾牌,我们要进去了!提交补丁有点令人生畏。别人会怎么看你?我怀疑如果你打算做一些重大的事情,那么你最好开始厚脸皮。在我的情况下,我将提交一个非常简单的错别字修复,所以我希望这种事情不值得大动干戈。话说回来,这是我的第一个补丁,所以我可能会以一种完全错误的方式提交它。因为我的补丁将会是新的,所以我做了一个快速搜索以确保它没有被报道过。什么也没看到,我战战兢兢地点击了“Create New”链接,并选择“devguide”作为我的组件。我也选择了最新版本的 Python。我在 devguide 中没有看到任何说它只适用于一组 Python 版本的内容,所以我打算就此打住。我没有真正看到适合 devguide 编辑“类型”,所以我把空白留给我的上级来修复。最后,我把我的补丁文件附在了 bug 单上。如果你愿意,你可以在这里看到我的虫票。
向 Python 贡献一个补丁时,你应该填写一份贡献者协议表,它允许 Python 软件基金会许可你的代码与 Python 一起使用,而你可以保留版权。是的,你也可以因为写 Python 代码而出名!假设人们阅读了源代码或那些确认页。
包扎
我不知道我那相当蹩脚的贡献会怎么样。也许会被接受,也许不会。但是我想我会花一些时间尝试找出一些其他的 bug,看看我能做些什么来帮助 Python 社区。欢迎加入我的冒险之旅!
圣诞销售倒计时+赠品
原文:https://www.blog.pythonlibrary.org/2022/12/16/countdown-to-christmas-sale-giveaway/
圣诞节是给予的时刻,至少在我家是这样。我写了很多 Python 书籍,最近开始了教我 Python ,除了网站上现有的基于文本的课程之外,我计划开始主持关于 Python 编程语言的视频课程。
在接下来的九天里,我将分发超过一千本电子书!
首先,Python 101 -第二版将从今天开始免费,到圣诞节结束。您可以通过以下链接在 Leanpub 或 Gumroad 上免费获得该电子书:
其他书籍将在一天的不同时间在推特上分批分发,每批 50 本。例如,我将在明天(12 月 17 日)通过发布一个特别的链接来分发两次 Python 201 -中级 Python ,每次最多可获得该书的 50 份。但是你必须在推特上关注我才能得到这笔交易。
如果你错过了 Twitter 上的所有赠品,你可以使用以下优惠券代码在 Gumroad 上的任何一本书上减去 $10:
https://www.blog.pythonlibrary.org/wp-content/uploads/2022/12/Get-10-off-Coupon-christmas22.mp4
使用 Winshell 或 PyWin32 在 Windows 中创建快捷方式
在过去的几天里,我需要一种方法在登录过程中在用户的桌面上创建快捷方式。我有一个适用于大多数捷径的方法,但是我就是不知道如何去做这个。
设置如下:我需要一种方法来创建一个快捷方式,使用特定的 web 浏览器访问特定的网站。我的第一次尝试如下:
import win32com.client
import winshell
userDesktop = winshell.desktop()
shell = win32com.client.Dispatch('WScript.Shell')
shortcut = shell.CreateShortCut(userDesktop + '\\Zimbra Webmail.lnk')
shortcut.Targetpath = r'C:\Program Files\Mozilla Firefox\firefox.exe'
shortcut.Arguments = 'http://mysite.com/auth/preauth.php'
shortcut.WorkingDirectory = r'C:\Program Files\Mozilla Firefox'
shortcut.save()
这段代码的问题在于它创建了以下内容作为快捷方式的目标路径:
" C:\ " C:\ Program Files \ Mozilla Firefox \ Firefox . exe " http://mysite.com/auth/preauth.php
我们一会儿将回到解决方案,但是首先我猜想你们中的一些人可能想知道我怎么知道 Mozilla 会在哪里。嗯,在我工作的地方,我们将 Mozilla 放在硬盘上的一个特定位置,如果我的一个登录脚本没有检测到该位置,那么该脚本将自动重新安装该程序。在与 pywin32 邮件列表上的知识渊博的人谈论这个话题时,他们提醒我应该通过注册表获取位置。
蒂姆·罗伯茨指出了这种发现方法:
import _winreg
ffkey = _winreg.OpenKey( _winreg.HKEY_LOCAL_MACHINE, 'SOFTWARE\\Mozilla\\Mozilla Firefox')
ffver = _winreg.QueryValueEx( ffkey, 'CurrentVersion' )[0]
print ffver
ffmainkey = _winreg.OpenKey( ffkey, sub + "\\Main" )
ffpath = _winreg.QueryValueEx( ffmainkey, 'PathToExe' )[0]
_winreg.CloseKey( ffkey )
_winreg.CloseKey( ffmainkey )
而邓肯·布斯在 c.l.py 上指出了这种方法:
import _winreg
print _winreg.QueryValue(_winreg.HKEY_CLASSES_ROOT,
'FirefoxURL\shell\open\command')
事实证明,有三种方法可以做到这一点,所有这些方法都是相关的。
- 你可以用这个食谱,它是加布里埃尔·吉纳林娜在 c.l.py 上和我分享的
- 您可以添加“更改我的代码”以包含参数或
- 你可以使用 Tim Golden 的 winshell 模块来完成这一切。
我们来看看最后两个。首先,我们将修改我的代码。c.l.py 的 Chris 和 pywin32 列表上的 Roger Upole 向我指出了这种添加“Arguments”参数的方法。见下文:
import win32com.client
import winshell
shortcut = shell.CreateShortCut(userDesktop + '\\MyShortcut.lnk')
shortcut.TargetPath = r'Program Files\Mozilla Firefox\firefox.exe'
shortcut.Arguments = r'http://mysite.com/auth/preauth.php'
shortcut.WorkingDirectory = r'C:\Program Files\Mozilla Firefox'
shortcut.save()
最后,Tim Golden 指出他的 winshell 模块可以做我想做的事情。他告诉我 winshell 在 pywin32 列表上包装了“IShellLink
功能”。您可以在下面看到结果:
import os
import winshell
winshell.CreateShortcut (
Path=os.path.join (winshell.desktop (), "Zimbra Monkeys.lnk"),
Target=r"c:\Program Files\Mozilla Firefox\firefox.exe",
Arguments="http://mysite.com/auth/preauth.php",
Description="Open http://localhost with Firefox",
StartIn=r'C:\Program Files\Mozilla Firefox'
)
现在,您也有一些新工具可以在项目中使用了。
附加资源:
- 蒂姆·戈登的网站
- PyWin32 文档
用 PySimpleGUI 创建 Exif 查看器
原文:https://www.blog.pythonlibrary.org/2021/01/26/create-an-exif-viewer-with-pysimplegui/
Pillow package 让你能够从图像中提取 Exif(可交换图像文件格式)元数据。你可以通过 Exif 数据获得很多关于你的图片的信息。然而,有一些关键数据点比其他数据点更有用。
对于这些数据,最好创建一个 GUI,以便您可以轻松查看。对于本教程,您将使用 PySimpleGUI 。
入门指南
Pillow 和 PySimpleGUI 都需要安装,以便能够遵循本教程。您可以使用 pip 安装它们:
python -m pip install pillow PySimpleGUI
您可能希望在 Python 虚拟环境中安装这些包。可以使用 virtualenv 或者 Python 内置的 venv 模块。
无论您最终选择哪种方式,您现在都已经准备好编写 GUI 代码了!
创建简单的 Exif 查看器
第一步是找到一个包含 Exif 数据的图像。如果你愿意,你可以用这个:

当您写完代码后,您的 Exif 查看器将如下所示:

首先,创建一个名为 exif_viewer.py 的新文件,并添加以下代码:
# exif_viewer.py
import PySimpleGUI as sg
from pathlib import Path
from PIL import Image
from PIL.ExifTags import TAGS
file_types = [("(JPEG (*.jpg)", "*.jpg"),
("All files (*.*)", "*.*")]
fields = {
"File name": "File name",
"File size": "File size",
"Model": "Camera Model",
"ExifImageWidth": "Width",
"ExifImageHeight": "Height",
"DateTime": "Creation Date",
"static_line": "*",
"MaxApertureValue": "Aperture",
"ExposureTime": "Exposure",
"FNumber": "F-Stop",
"Flash": "Flash",
"FocalLength": "Focal Length",
"ISOSpeedRatings": "ISO",
"ShutterSpeedValue": "Shutter Speed",
}
def get_exif_data(path):
"""
Extracts the Exif information from the provided photo
"""
exif_data = {}
try:
image = Image.open(path)
info = image._getexif()
except OSError:
info = {}
if info is None:
info = {}
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
exif_data[decoded] = value
return exif_data
def main():
elements = [
[
sg.FileBrowse(
"Load image data", file_types=file_types, key="load",
enable_events=True
)
]
]
for field in fields:
elements += [
[sg.Text(fields[field], size=(10, 1)),
sg.Text("", size=(25, 1), key=field)]
]
window = sg.Window("Image information", elements)
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "load":
image_path = Path(values["load"])
exif_data = get_exif_data(image_path.absolute())
for field in fields:
if field == "File name":
window[field].update(image_path.name)
elif field == "File size":
window[field].update(image_path.stat().st_size)
else:
window[field].update(exif_data.get(field, "No data"))
if __name__ == "__main__":
main()
这是一大段代码!试图一次解释所有内容会令人困惑,所以为了使事情变得简单,你将一段一段地检查代码。
下面是前几行代码:
# exif_viewer.py
import PySimpleGUI as sg
from pathlib import Path
from PIL import Image
from PIL.ExifTags import TAGS
file_types = [("(JPEG (*.jpg)", "*.jpg"),
("All files (*.*)", "*.*")]
fields = {
"File name": "File name",
"File size": "File size",
"Model": "Camera Model",
"ExifImageWidth": "Width",
"ExifImageHeight": "Height",
"DateTime": "Creation Date",
"static_line": "*",
"MaxApertureValue": "Aperture",
"ExposureTime": "Exposure",
"FNumber": "F-Stop",
"Flash": "Flash",
"FocalLength": "Focal Length",
"ISOSpeedRatings": "ISO",
"ShutterSpeedValue": "Shutter Speed",
}
这段代码的前半部分是使应用程序正常运行所需的导入。接下来,创建一个file_types变量。这在您稍后将创建的文件对话框中使用,以允许用户选择要加载的图像。
然后创建一个 Python 字典,保存所有想要显示的 Exif 字段。这个字典将 Exif 名称映射到一个更易读的名称。
现在您已经准备好学习get_exif_data()功能了:
def get_exif_data(path):
"""
Extracts the EXIF information from the provided photo
"""
exif_data = {}
try:
image = Image.open(path)
info = image._getexif()
except OSError:
info = {}
if info is None:
info = {}
for tag, value in info.items():
decoded = TAGS.get(tag, tag)
exif_data[decoded] = value
return exif_data
这个函数接收图像路径,并试图从中提取 Exif 数据。如果失败,它将info设置为一个空字典。如果_getexif()返回None,那么你也将info设置为一个空字典。如果填充了info,那么在返回之前,循环遍历它,解码 Exif 数据并填充您的exif_data字典。
接下来您可以进入main()功能:
def main():
elements = [
[
sg.FileBrowse(
"Load image data", file_types=file_types, key="load",
enable_events=True
)
]
]
for field in fields:
elements += [
[sg.Text(fields[field], size=(10, 1)),
sg.Text("", size=(25, 1), key=field)]
]
window = sg.Window("Image information", elements)
在这里,您可以创建创建用户界面所需的所有元素。循环遍历在程序开始时定义的字段字典,并添加几个文本控件,这些控件将显示从图像中提取的 Exif 数据。
PySimpleGUI 使这变得很容易,因为您可以将新元素连接到您的elements列表中。
一旦这些都完成了,你就把elements加到你的Window上。
接下来是拼图的最后一块:
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "load":
image_path = Path(values["load"])
exif_data = get_exif_data(image_path.absolute())
for field in fields:
if field == "File name":
window[field].update(image_path.name)
elif field == "File size":
window[field].update(image_path.stat().st_size)
else:
window[field].update(exif_data.get(field, "No data"))
if __name__ == "__main__":
main()
这是您的事件循环。当用户按下“加载图像数据”按钮时,事件被设置为“加载”。在这里,您将选择的图像路径加载到 Python 的pathlib中。这允许您使用Path对象的功能和属性提取文件名、绝对路径和文件大小。
您使用字典的get()方法来获取字段。如果该字段不在字典中,则显示该字段“无数据”。
如果您想要一个小的挑战,尝试在这个 GUI 中添加一个sg.Image()元素,这样您就可以查看照片及其元数据了!
包扎
现在你知道如何从图像中解析出 EXIF 标签了。您还学习了如何使用 PySimpleGUI 创建一个简单的 GUI。这个 GUI 的总行数只有 84 行!您可以创建功能性 GUI,而无需编写数百行代码。
Pillow 能做的不仅仅是提取 EXIF 数据。检查一下,看看你还能做什么!
相关阅读
- 使用 Python 获取 GPS Exif 数据
- 使用 Python 获取照片元数据(EXIF)
Python 101 - How to Create a Graphical User Interface
原文:https://www.blog.pythonlibrary.org/2021/09/29/create-gui/
When you first get started as a programmer or software developer, you usually start by writing code that prints to your console or standard out. A lot of students are also starting out by writing front-end programs, which are typically websites written with HTML, JavaScript and CSS. However, most beginners do not learn how to create a graphical user interface until much later in their classwork.
Graphical user interfaces (GUI) are programs that are usually defined as created for the desktop. The desktop refers to Windows, Linux and MacOS. It could be argued that GUIs are also created for mobile and web as well though. For the purposes of this article, you will learn about creating desktop GUIs. The concepts you learn in this article can be applied to mobile and web development to some degree as well.
A graphical user interface is made up of some kind of window that the user interacts with. The window holds other shapes inside it. These consist of buttons, text, pictures, tables, and more. Collectively, these items are known as "widgets".
There are many different GUI toolkits for Python. Here is a list of some of the most popular:
- Tkinter
- wxPython
- PyQt
- Kivy
You will be learning about wxPython in this article. The reason that wxPython was chosen is that the author has more experience with it than any other and wxPython has a very friendly and helpful community.
In this article, you will be learning:
- Learning About Event Loops
- How to Create Widgets
- How to Lay Out Your Application
- How to Add Events
- How to Create an Application
This article does not attempt to cover everything there is to know about wxPython. However, you will learn enough to see the power of wxPython as well as discover how much fun it is to create a desktop GUI of your very own.
Note: Some of the examples in this chapter come from my book, Creating GUI Applications with wxPython.
Let's get started!
Installing wxPython
Installing wxPython is usually done with pip. If you are installing on Linux, you may need to install some prerequisites before installing wxPython. You can see the most up-to-date set of requirements on the wxPython Github page.
On Mac OSX, you may need the XCode compiler to install wxPython.
Here is the command you would use to install wxPython using pip:
python3 -m pip install wxpython
Assuming everything worked, you should now be able to use wxPython!
Learning About Event Loops
Before you get started, there is one other item that you need to know about. In the introduction, you learned what widgets are. But when it comes to creating GUI programs, you need to understand that they use events to tell the GUI what to do. Unlike a command-line application, a GUI is basically an infinite loop, waiting for the user to do something, like click a button or press a key on the keyboard.
When the user does something like that, the GUI receives an event. Button events are usually connected to wx.EVT_BUTTON, for example. Some books call this event-driven programming. The overarching process is called the event loop.
You can think of it like this:
- The GUI waits for the user to do something
- The user does something (clicks a button, etc)
- The GUI responds somehow
- Go back to step 1
The user can stop the event loop by exiting the program.
Now that you have a basic understanding of event loops, it's time to learn how to write a simple prototype application!
How to Create Widgets
Widgets are the building blocks of your application. You start out with top-level widgets, such as a wx.Frame or a wx.Dialog. These widgets can contain other widgets, like buttons and labels. When you create a frame or dialog, it includes a title bar and the minimize, maximize, and exit buttons. Note that when using wxPython, most widgets and attributes are pre-fixed with wx.
To see how this all works, you should create a little "Hello World" application. Go ahead and create a new file named hello_wx.py and add this code to it:
# hello_wx.py
import wx
app = wx.App(False)
frame = wx.Frame(parent=None, title='Hello World')
frame.Show()
app.MainLoop()
Here you import wx, which is how you access wxPython in your code. Then you create an instance of wx.App(), which is your Application object. There can only be one of these in your application. It creates and manages your event loop for you. You pass in False to tell it not to redirect standard out. If you set that to True, then standard out is redirected to a new window. This can be useful when debugging, but should be disabled in production applications.
Next, you create a wx.Frame() where you set its parent to None. This tells wxPython that this frame is a top-level window. If you create all your frames without a parent, then you will need to close all the frames to end the program. The other parameter that you set is the title, which will appear along the top of your application's window.
The next step is to Show() the frame, which makes it visible to the user. Finally, you call MainLoop() which starts the event loop and makes your application work. When you run this code, you should see something like this:

Hello World in wxPython
When working with wxPython, you will actually be sub-classing wx.Frame and quite a few of the other widgets. Create a new file named hello_wx_class.py and put this code into it:
# hello_wx_class.py
import wx
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Hello World')
self.Show()
if __name__ == '__main__':
app = wx.App(False)
frame = MyFrame()
frame.Show()
app.MainLoop()
This code does the same thing as the previous example, but this time you are creating your own version of the wx.Frame class.
When you create an application with multiple widgets in it, you will almost always have a wx.Panel as the sole child widget of the wx.Frame. Then the wx.Panel widget is used to contain the other widgets. The reason for this is that wx.Panel provides the ability to tab between the widgets, which is something that does not work if you make all the widget children of wx.Frame.
So, for a final "Hello World" example, you can add a wx.Panel to the mix. Create a file named hello_with_panel.py and add this code:
# hello_with_panel.py
import wx
class MyPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
button = wx.Button(self, label='Press Me')
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Hello World')
panel = MyPanel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MyFrame()
app.MainLoop()
In this code, you create two classes. One sub-classes wx.Panel and adds a button to it using wx.Button. The MyFrame() class is almost the same as the previous example except that you now create an instance of MyPanel() in it. Note that you are passing self to MyPanel(), which is telling wxPython that the frame is now the parent of the panel widget.
When you run this code, you will see the following application appear:

Hello World with a wxPython Panel
This example shows that when you add a child widget, like a button, it will automatically appear at the top left of the application. The wx.Panel is an exception when it is the only child widget of a wx.Frame. In that case, the wx.Panel will automatically expand to fill the wx.Frame.
What do you think happens if you add multiple widgets to the panel though? Let's find out! Create a new file named stacked_buttons.py and add this code:
# stacked_buttons.py
import wx
class MyPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
button = wx.Button(self, label='Press Me')
button2 = wx.Button(self, label='Press Me too')
button3 = wx.Button(self, label='Another button')
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Hello World')
panel = MyPanel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MyFrame()
app.MainLoop()
Now you have three buttons as children of the panel. Try running this code to see what happens:

Oops! You only see one button, which happens to be the last one you created. What happened here? You didn't tell the buttons where to go, so they all went to the default location, which is the upper left corner of the widget. In essence, the widgets are now stacked on top of each other.
Let's find out how you can fix that issue in the next section!
How to Lay Out Your Application
You have two options when it comes to laying out your application:
- Absolute positioning
- Sizers
In almost all cases, you will want to use Sizers. If you want to use absolute positioning, you can use the widget's pos parameter and give it a tuple that specifies the x and y coordinate in which to place the widget. Absolute positioning can be useful when you need pixel perfect positioning of widgets. However, when you use absolute positioning, your widgets cannot resize or move when the window they are in is resized. They are static at that point.
The solution to those issues is to use Sizers. They can handle how your widgets should resize and adjust when the application size is changed. There are several different sizers that you can use, such as wx.BoxSizer, wx.GridSizer, and more.
The wxPython documentation explains how sizers work in detail. Check it out when you have a chance.
Let's take that code from before and reduce it down to two buttons and add a Sizer. Create a new file named sizer_with_two_widgets.py and put this code into it:
# sizer_with_two_widgets.py
import wx
class MyPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
button = wx.Button(self, label='Press Me')
button2 = wx.Button(self, label='Second button')
main_sizer = wx.BoxSizer(wx.HORIZONTAL)
main_sizer.Add(button, proportion=1,
flag=wx.ALL | wx.CENTER | wx.EXPAND,
border=5)
main_sizer.Add(button2, 0, wx.ALL, 5)
self.SetSizer(main_sizer)
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Hello World')
panel = MyPanel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MyFrame()
app.MainLoop()
In this example, you create a wx.BoxSizer. A wx.BoxSizer can be set to add widgets horizontally (left-to-right) or vertically (top-to-bottom). For your code, you set the sizer to add widgets horizontally by using the wx.HORIZONTAL constant. To add a widget to a sizer, you use the Add() method.
The Add() method takes up to five arguments:
window- the widget to addproportion- tells wxPython if the widget can change its size in the same orientation as the sizerflag- one or more flags that affect the sizer's behaviorborder- the border width, in pixelsuserData- allows adding an extra object to the sizer item, which is used for subclasses of sizers.
The first button that you add to the sizer is set to a proportion of 1, which will make it expand to fill as much space in the sizer as it can. You also give it three flags:
wx.ALL- add a border on all sideswx.CENTER- center the widget within the sizerwx.EXPAND- the item will be expanded as much as possible while also maintaining its aspect ratio
Finally, you add a border of five pixels. These pixels are added to the top, bottom, left, and right of the widget because you set the wx.ALL flag.
The second button has a proportion of 0, which means it wont expand at all. Then you tell it to add a five pixel border all around it as well. To apply the sizer to the panel, you need to call the panel's SetSizer() method.
When you run this code, you will see the following applications:

Buttons in Sizers
You can see how the various flags have affected the appearance of the buttons. Note that on MacOS, wx.Button cannot be stretched, so if you want to do that on a Mac, you would need to use a generic button from wx.lib.buttons instead. Generic buttons are usually made with Python and do not wrap the native widget.
Now let's move on and learn how events work!
How to Add Events
So far you have created a couple of neat little applications with buttons, but the buttons don't do anything when you click on them. Why is that? Well, when you are writing a GUI application, you need to tell it what to do when something happens. That "something" that happens is known as an event.
To hook an event to a widget, you will need to use the Bind() method. Some widgets have multiple events that can be bound to them while others have only one or two. The wx.Button can be bound to wx.EVT_BUTTON only.
Let's copy the code from the previous example and paste it into a new file named button_events.py. Then update it to add events like this:
# button_events.py
import wx
class MyPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
button = wx.Button(self, label='Press Me')
button.Bind(wx.EVT_BUTTON, self.on_button1)
button2 = wx.Button(self, label='Second button')
button2.Bind(wx.EVT_BUTTON, self.on_button2)
main_sizer = wx.BoxSizer(wx.HORIZONTAL)
main_sizer.Add(button, proportion=1,
flag=wx.ALL | wx.CENTER | wx.EXPAND,
border=5)
main_sizer.Add(button2, 0, wx.ALL, 5)
self.SetSizer(main_sizer)
def on_button1(self, event):
print('You clicked the first button')
def on_button2(self, event):
print('You clicked the second button')
class MyFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Hello World')
panel = MyPanel(self)
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MyFrame()
app.MainLoop()
Here you call Bind() for each of the buttons in turn. You bind the button to wx.EVT_BUTTON, which will fire when the user presses a button. The second argument to Bind() is the method that should be called when you click the button.
If you run this code, the GUI will still look the same. However, when you press the buttons, you should see different messages printed to stdout (i.e. your terminal or console window). Give it a try and see how it works.
Now let's go ahead and write a simple application!
How to Create an Application
The first step in creating an application is to come up with an idea. You could try to copy something simple like Microsoft Paint or Notepad. You will quickly find that they aren't so easy to emulate as you would think, though! So instead, you will create a simple application that can load and display a photo.
When it comes to creating a GUI application, it is a good idea to think about what it will look like. If you enjoy working with pencil and paper, you could draw a sketch of what your application will look like. There are many software applications you can use to draw with or create simple mock-ups. To simulate a Sizer, you can draw a box.
Here is a mockup of what the finished application should look like:

Image Viewer Mockup
Now you have a goal in mind. This allows you to think about how you might lay out the widgets. Go ahead and create a new file named image_viewer.py and add the following code to it:
# image_viewer.py
import wx
class ImagePanel(wx.Panel):
def __init__(self, parent, image_size):
super().__init__(parent)
img = wx.Image(*image_size)
self.image_ctrl = wx.StaticBitmap(self,
bitmap=wx.Bitmap(img))
browse_btn = wx.Button(self, label='Browse')
main_sizer = wx.BoxSizer(wx.VERTICAL)
main_sizer.Add(self.image_ctrl, 0, wx.ALL, 5)
main_sizer.Add(browse_btn)
self.SetSizer(main_sizer)
main_sizer.Fit(parent)
self.Layout()
class MainFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Image Viewer')
panel = ImagePanel(self, image_size=(240,240))
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MainFrame()
app.MainLoop()
Here you create a new class named ImagePanel() that will hold all your widgets. Inside it, you have a wx.Image, which you will use to hold the photo in memory in an object that wxPython can work with. To display that photo to the user, you use wx.StaticBitmap. The other widget you need is the familiar wx.Button, which you will use to browse to the photo to load.
The rest of the code lays out the widgets using a vertically oriented wx.BoxSizer. You use the sizer's Fit() method to try to make the frame "fit" the widgets. What that means is that you want the application to not have a lot of white space around the widgets.
When you run this code, you will end up with the following user interface:

Initial Image Viewer GUI
That looks almost right. It looks like you forgot to add the text entry widget to the right of the browse button, but that's okay. The objective was to try and get a close approximation to what the application would look like in the end, and this looks pretty good. Of course, none of the widgets actually do anything yet.
Your next step is to update the code so it works. Copy the code from the previous example and make a new file named image_viewer_working.py. There will be significant updates to the code, which you will learn about soon. But first, here is the full change in its entirety:
# image_viewer_working.py
import wx
class ImagePanel(wx.Panel):
def __init__(self, parent, image_size):
super().__init__(parent)
self.max_size = 240
img = wx.Image(*image_size)
self.image_ctrl = wx.StaticBitmap(self,
bitmap=wx.Bitmap(img))
browse_btn = wx.Button(self, label='Browse')
browse_btn.Bind(wx.EVT_BUTTON, self.on_browse)
self.photo_txt = wx.TextCtrl(self, size=(200, -1))
main_sizer = wx.BoxSizer(wx.VERTICAL)
hsizer = wx.BoxSizer(wx.HORIZONTAL)
main_sizer.Add(self.image_ctrl, 0, wx.ALL, 5)
hsizer.Add(browse_btn, 0, wx.ALL, 5)
hsizer.Add(self.photo_txt, 0, wx.ALL, 5)
main_sizer.Add(hsizer, 0, wx.ALL, 5)
self.SetSizer(main_sizer)
main_sizer.Fit(parent)
self.Layout()
def on_browse(self, event):
"""
Browse for an image file
@param event: The event object
"""
wildcard = "JPEG files (*.jpg)|*.jpg"
with wx.FileDialog(None, "Choose a file",
wildcard=wildcard,
style=wx.ID_OPEN) as dialog:
if dialog.ShowModal() == wx.ID_OK:
self.photo_txt.SetValue(dialog.GetPath())
self.load_image()
def load_image(self):
"""
Load the image and display it to the user
"""
filepath = self.photo_txt.GetValue()
img = wx.Image(filepath, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.max_size
NewH = self.max_size * H / W
else:
NewH = self.max_size
NewW = self.max_size * W / H
img = img.Scale(NewW,NewH)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
class MainFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Image Viewer')
panel = ImagePanel(self, image_size=(240,240))
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MainFrame()
app.MainLoop()
This change is pretty long. To make things easier, you will go over each change in its own little chunk. The changes all occurred in the ImagePanel class, so you will go over the changes in each of the methods in turn, starting with the constructor below:
def __init__(self, parent, image_size):
super().__init__(parent)
self.max_size = 240
img = wx.Image(*image_size)
self.image_ctrl = wx.StaticBitmap(self,
bitmap=wx.Bitmap(img))
browse_btn = wx.Button(self, label='Browse')
browse_btn.Bind(wx.EVT_BUTTON, self.on_browse)
self.photo_txt = wx.TextCtrl(self, size=(200, -1))
main_sizer = wx.BoxSizer(wx.VERTICAL)
hsizer = wx.BoxSizer(wx.HORIZONTAL)
main_sizer.Add(self.image_ctrl, 0, wx.ALL, 5)
hsizer.Add(browse_btn, 0, wx.ALL, 5)
hsizer.Add(self.photo_txt, 0, wx.ALL, 5)
main_sizer.Add(hsizer, 0, wx.ALL, 5)
self.SetSizer(main_sizer)
main_sizer.Fit(parent)
self.Layout()
There are a few minor changes here. The first one is that you added a max_size for the image. Then you hooked up an event to the the browse button. This button will now call on_browse() when it is clicked.
The next change is that you added a new widget, a wx.TextCtrl to be precise. You stored a reference to that widget in self.photo_txt, which will allow you to extract the path to the photo later.
The final change is that you now have two sizers. One is horizontal and the other remains vertical. The horizontal sizer is for holding the browse button and your new text control widgets. This allows your to place them next to each other, left-to-right. Then you add the horizontal sizer itself to the vertical main_sizer.
Now let's see how on_browse() works:
def on_browse(self, event):
"""
Browse for an image file
@param event: The event object
"""
wildcard = "JPEG files (*.jpg)|*.jpg"
with wx.FileDialog(None, "Choose a file",
wildcard=wildcard,
style=wx.ID_OPEN) as dialog:
if dialog.ShowModal() == wx.ID_OK:
self.photo_txt.SetValue(dialog.GetPath())
self.load_image()
Here you create a wildcard which is used by the wx.FileDialog to filter out all the other files types except the JPEG format. Next, you create the wx.FileDialog. When you do that, you set its parent to None and give it a simple title. You also set the wildcard and the style. style is an open file dialog instead of a save file dialog.
Then you show your dialog modally. What that means is that the dialog will appear over your main application and prevent you from interacting with the main application until you have accepted or dismissed the file dialog. If the user presses the OK button, then you will use GetPath() to get the path of the selected file and set the text control to that path. This effectively saves off the photo's path so you can use it later.
Lastly, you call load_image() which will load the image into wxPython and attempt to show it. You can find out how by reading the following code:
def load_image(self):
"""
Load the image and display it to the user
"""
filepath = self.photo_txt.GetValue()
img = wx.Image(filepath, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.max_size
NewH = self.max_size * H / W
else:
NewH = self.max_size
NewW = self.max_size * W / H
img = img.Scale(NewW,NewH)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
The first step in this method is to extract the filepath from the text control widget. Then you pass that path along to a new instance of wx.Image. This will load the image into wxPython for you. Next, you get the width and height from the wx.Image object and use the max_size value to resize the image while maintaining its aspect ratio. You do this for two reasons. The first is because if you don't, the image will get stretched out or warped. The second is that most images at full resolution won't fit on-screen, so they need to be resized.
Once you have the new width and height, you Scale() the image down appropriately. Then you call your wx.StaticBitmap control's SetBitmap() method to update it to the new image that you loaded. Finally, you call Refresh(), which will force the bitmap widget to redraw with the new image in it.
Here it is with a butterfly photo loaded in it:

Viewing an Image in wxPython
Now you have a fully-functional application that can load JPEG photos. You can update the application to load other image types if you'd like. The wxPython toolkit uses Pillow, so it will load the same types of image file types that Pillow itself can load.
Wrapping Up
The wxPython toolkit is extremely versatile. It comes with many, many widgets built-in and also includes a wonderful demo package. The demo package will help you learn how to use the widgets in your own code. You are only limited by your imagination.
In this chapter, you learned about the following topics:
- Learning About Event Loops
- How to Create Widgets
- How to Lay Out Your Application
- How to Add Events
- How to Create an Application
You can take the code and the concepts in this code and add new features or create brand new applications. If you need ideas, you can check out some of the applications on your own computer or phone. You can also check out my book, Creating GUI Applications with wxPython, which has lots of fun little applications you can create and expand upon.
用 wxPython 创建计算器
原文:https://www.blog.pythonlibrary.org/2019/02/12/creating-a-calculator-with-wxpython/
很多初学者教程都是从“Hello World”的例子开始的。有很多网站将计算器应用程序作为 GUI 初学者的一种“Hello World”。计算器是一个很好的学习方法,因为它有一组你需要有序排列的部件。它们还需要一定的逻辑才能正常工作。对于该计算器,让我们关注能够做到以下几点:
- 添加
- 减法
- 增加
- 分开
我认为支持这四个功能是一个很好的起点,也给你足够的空间来增强你自己的应用程序。
弄清楚逻辑
你需要解决的第一件事就是如何实际执行你建立的方程。例如,假设您有以下等式:
1 + 2 * 5
解决方法是什么?如果你从左向右读,答案似乎是 3 * 5 或 15。但是乘法的优先级高于加法,所以它实际上是 10 + 1 或 11。你如何在代码中找出优先级?你可以花很多时间创建一个字符串解析器,通过操作数对数字进行分组,或者你可以使用 Python 的内置“eval”函数。 eval() 函数是 evaluate 的缩写,它将计算一个字符串,就像它是 Python 代码一样。
许多 Python 程序员实际上不鼓励使用 eval()。让我们找出原因。
eval()邪恶吗?
eval() 函数在过去被称为“邪恶的”,因为它允许你将字符串作为代码运行,这可能会将你的应用程序暴露给邪恶的作恶者。你可能听说过 SQL 注入的一些网站没有正确地对字符串进行转义,并意外地允许不诚实的人通过字符串运行 SQL 命令来编辑他们的数据库表。使用 eval()函数时,Python 中也会出现同样的概念。eval 如何被用于邪恶的一个常见示例如下:
eval("__import__('os').remove('file')")
这段代码将导入 Python 的 os 模块,并调用其 remove() 函数,这将允许您的用户删除您可能不想让他们删除的文件。有几种方法可以避免这个问题:
- 不要使用 eval()
- 控制允许哪些字符进入 eval()
因为您将为这个应用程序创建用户界面,所以您还将完全控制用户如何输入字符。这实际上可以以一种直截了当的方式保护您免受 eval 的阴险。您将学习使用 wxPython 来控制传递给 eval()的内容的两种方法,然后在本文的最后,您将学习如何创建一个定制的 eval()函数。
设计计算器
让我们花一点时间,尝试使用本章开头提到的约束条件来设计一个计算器。这是我想出的草图:

计算器模型
注意,这里只关心基本的算术。你不必创建一个科学计算器,尽管这可能是挑战自我的一个有趣的增强。相反,您将创建一个漂亮的基本计算器。
我们开始吧!
创建初始计算器
每当你创建一个新的应用程序时,你都必须考虑代码的去向。它在 wx 里吗?架级, wx 级。面板类,其他类还是什么?谈到 wxPython,几乎总是不同类的混合。与大多数 wxPython 应用程序一样,您可能希望从为应用程序起一个名字开始。为了简单起见,我们暂时称它为 wxcalculator.py 。
第一步是添加一些导入,并子类化框架小部件。让我们来看看:
import wx
class CalcFrame(wx.Frame):
def __init__(self):
super().__init__(
None, title="wxCalculator",
size=(350, 375))
panel = CalcPanel(self)
self.SetSizeHints(350, 375, 350, 375)
self.Show()
if __name__ == '__main__':
app = wx.App(False)
frame = CalcFrame()
app.MainLoop()
这段代码与您过去看到的非常相似。你子类化 wx。框架并给它一个标题和初始大小。然后实例化面板类, CalcPanel (未显示)并调用 SetSizeHints() 方法。该方法取框架允许的最小(宽度,高度)和最大(宽度,高度)。你可以用这个来控制你的框架可以调整多少大小,或者在这种情况下,防止任何大小调整。您还可以修改框架的样式标志,使其无法调整大小。
方法如下:
class CalcFrame(wx.Frame):
def __init__(self):
no_resize = wx.DEFAULT_FRAME_STYLE & ~ (wx.RESIZE_BORDER |
wx.MAXIMIZE_BOX)
super().__init__(
None, title="wxCalculator",
size=(350, 375), style=no_resize)
panel = CalcPanel(self)
self.Show()
看一下 no_resize 变量。它正在创造一个 wx。DEFAULT_FRAME_STYLE 然后使用按位运算符从框架中移除可调整大小的边框和最大化按钮。
让我们继续创建 CalcPanel :
class CalcPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.last_button_pressed = None
self.create_ui()
我在前面一章中提到过这一点,但我认为这里值得重复一遍。您不需要将所有的接口创建代码放在 init 方法中。这是这个概念的一个例子。在这里实例化该类,将 last_button_pressed 属性设置为 None ,然后调用 create_ui() 。这就是你在这里需要做的一切。
当然,这引出了一个问题。create_ui()方法中有什么?好吧,让我们来看看!
def create_ui(self):
main_sizer = wx.BoxSizer(wx.VERTICAL)
font = wx.Font(12, wx.MODERN, wx.NORMAL, wx.NORMAL)
self.solution = wx.TextCtrl(self, style=wx.TE_RIGHT)
self.solution.SetFont(font)
self.solution.Disable()
main_sizer.Add(self.solution, 0, wx.EXPAND|wx.ALL, 5)
self.running_total = wx.StaticText(self)
main_sizer.Add(self.running_total, 0, wx.ALIGN_RIGHT)
buttons = [['7', '8', '9', '/'],
['4', '5', '6', '*'],
['1', '2', '3', '-'],
['.', '0', '', '+']]
for label_list in buttons:
btn_sizer = wx.BoxSizer()
for label in label_list:
button = wx.Button(self, label=label)
btn_sizer.Add(button, 1, wx.ALIGN_CENTER|wx.EXPAND, 0)
button.Bind(wx.EVT_BUTTON, self.update_equation)
main_sizer.Add(btn_sizer, 1, wx.ALIGN_CENTER|wx.EXPAND)
equals_btn = wx.Button(self, label='=')
equals_btn.Bind(wx.EVT_BUTTON, self.on_total)
main_sizer.Add(equals_btn, 0, wx.EXPAND|wx.ALL, 3)
clear_btn = wx.Button(self, label='Clear')
clear_btn.Bind(wx.EVT_BUTTON, self.on_clear)
main_sizer.Add(clear_btn, 0, wx.EXPAND|wx.ALL, 3)
self.SetSizer(main_sizer)
这是一大段相当不错的代码,所以让我们把它分解一下:
def create_ui(self):
main_sizer = wx.BoxSizer(wx.VERTICAL)
font = wx.Font(12, wx.MODERN, wx.NORMAL, wx.NORMAL)
在这里,您可以创建帮助组织用户界面所需的 sizer。您还将创建一个 wx。字体对象,用于修改 wx 等小工具的默认字体。文本控制或 wx。静态文本。当你想要一个更大的字体或者一个不同于默认字体的字体时,这是很有用的。
self.solution = wx.TextCtrl(self, style=wx.TE_RIGHT)
self.solution.SetFont(font)
self.solution.Disable()
main_sizer.Add(self.solution, 0, wx.EXPAND|wx.ALL, 5)
接下来的三行创建了 wx。TextCtrl ,设置为右对齐(wx。TE_RIGHT),设置字体并 Disable()小工具。您想要禁用小部件的原因是因为您不希望用户能够在控件中键入任何文本字符串。
您可能还记得,您将使用 eval() 来评估小部件中的字符串,因此您不能允许用户滥用它。相反,您希望对用户可以输入到该小部件中的内容进行细粒度控制。
self.running_total = wx.StaticText(self)
main_sizer.Add(self.running_total, 0, wx.ALIGN_RIGHT)
一些计算器应用程序在实际的“显示”下面有一个运行总数小部件。添加这个小部件的一个简单方法是通过 wx。StaticText 小部件。
现在让我们添加有效使用计算器所需的主要按钮:
buttons = [['7', '8', '9', '/'],
['4', '5', '6', '*'],
['1', '2', '3', '-'],
['.', '0', '', '+']]
for label_list in buttons:
btn_sizer = wx.BoxSizer()
for label in label_list:
button = wx.Button(self, label=label)
btn_sizer.Add(button, 1, wx.ALIGN_CENTER|wx.EXPAND, 0)
button.Bind(wx.EVT_BUTTON, self.update_equation)
main_sizer.Add(btn_sizer, 1, wx.ALIGN_CENTER|wx.EXPAND)
在这里你创建了一个列表列表。在这个数据结构中,有计算器使用的主要按钮。你会注意到在最后一个列表中有一个空白字符串,它将被用来创建一个按钮,这个按钮不做任何事情。这是为了保持布局正确。理论上,你可以更新这个计算器,这样这个按钮就可以是百分比或者其他功能。
下一步是创建一个按钮,可以通过遍历列表来完成。每个嵌套列表代表一行按钮。因此,对于每一行按钮,您将创建一个水平方向的 wx。BoxSizer ,然后遍历一行小部件,将它们添加到那个 Sizer 中。一旦每个按钮被添加到行尺寸,您将添加到您的主尺寸。请注意,这些按钮中的每一个都绑定到“update_equation”事件处理程序。
现在您需要添加等号按钮和可以用来清空计算器的按钮:
equals_btn = wx.Button(self, label='=')
equals_btn.Bind(wx.EVT_BUTTON, self.on_total)
main_sizer.Add(equals_btn, 0, wx.EXPAND|wx.ALL, 3)
clear_btn = wx.Button(self, label='Clear')
clear_btn.Bind(wx.EVT_BUTTON, self.on_clear)
main_sizer.Add(clear_btn, 0, wx.EXPAND|wx.ALL, 3)
self.SetSizer(main_sizer)
在这段代码中,您创建了“equals”按钮,然后将它绑定到 on_total 事件处理程序方法。您还创建了“清除”按钮,用于清除计算器并重新开始。最后一行设置面板的 sizer。
让我们继续,了解一下您的计算器中的大多数按钮都绑定了什么:
def update_equation(self, event):
operators = ['/', '*', '-', '+']
btn = event.GetEventObject()
label = btn.GetLabel()
current_equation = self.solution.GetValue()
if label not in operators:
if self.last_button_pressed in operators:
self.solution.SetValue(current_equation + ' ' + label)
else:
self.solution.SetValue(current_equation + label)
elif label in operators and current_equation is not '' \
and self.last_button_pressed not in operators:
self.solution.SetValue(current_equation + ' ' + label)
self.last_button_pressed = label
for item in operators:
if item in self.solution.GetValue():
self.update_solution()
break
这是一个将多个小部件绑定到同一个事件处理程序的例子。要获得哪个小部件调用了事件处理程序的信息,可以调用event对象的 GetEventObject() 方法。这将返回调用事件处理程序的小部件。在这种情况下,你知道你用 wx 调用它。按钮实例,所以你知道 wx。按钮有一个“GetLabel()”方法,该方法将返回按钮上的标签。然后,您将获得解决方案文本控件的当前值。
接下来,您要检查按钮的标签是否是一个操作符(例如/、*、-、+)。如果是,您将把文本控件的值更改为当前文本控件中的值加上标签。另一方面,如果标签是而不是操作符,那么你需要在当前文本框和新标签之间放置一个空格。这是为了演示的目的。如果你愿意,技术上可以跳过字符串格式。
最后一步是循环操作数,并检查它们中是否有任何一个当前在方程式字符串中。如果是,那么您将调用 update_solution() 方法并退出循环。
现在您需要编写 update_solution() 方法:
def update_solution(self):
try:
current_solution = str(eval(self.solution.GetValue()))
self.running_total.SetLabel(current_solution)
self.Layout()
return current_solution
except ZeroDivisionError:
self.solution.SetValue('ZeroDivisionError')
except:
pass
这里是“邪恶” eval() 出现的地方。您将从文本控件中提取方程的当前值,并将该字符串传递给 eval() 。然后将结果转换回字符串,这样就可以将文本控件设置为新计算的解。你想用一个 try/except 语句来捕捉错误,比如zerodisdivisionerror。最后一个 except 语句被称为 bare except 语句,在大多数情况下应该避免使用。为了简单起见,我把它放在那里,但是如果最后两行冒犯了你,请随意删除。
下一个您想要了解的方法是 on_clear() 方法:
def on_clear(self, event):
self.solution.Clear()
self.running_total.SetLabel('')
这段代码非常简单。你需要做的就是调用你的解决方案文本控件的 Clear() 方法来清空它。您还需要清除“running_total”小部件,它是 wx 的一个实例。静态文本。该小部件没有 Clear() 方法,因此您将调用 SetLabel() 并传入一个空字符串。
您需要创建的最后一个方法是 on_total() 事件处理程序,它将计算总数并清除您的运行总数小部件:
def on_total(self, event):
solution = self.update_solution()
if solution:
self.running_total.SetLabel('')
这里可以调用 update_solution() 方法,得到结果。假设一切顺利,解决方案将出现在主文本区,运行总数将被清空。
下面是我在 Mac 上运行计算器时的样子:

Mac OS 上的 wxPython 计算器
这是计算器在 Windows 10 上的样子:

Windows 10 上的 wxPython 计算器
让我们继续学习如何让用户除了使用小部件之外还可以使用键盘来输入公式。
使用角色事件
大多数计算器允许用户在输入数值时使用键盘。在这一节中,我将向您展示如何开始将这种能力添加到您的代码中。最简单的方法是绑定 wx。文本 Ctrl 到 wx。EVT _ 正文事件。我将在这个例子中使用这个方法。然而,你可以这样做的另一种方式是抓住 wx。EVT _ 按键 _ 按下然后分析键码。不过这种方法有点复杂。
我们需要更改的第一项是我们的 CalcPanel 的构造函数:
# wxcalculator_key_events.py
import wx
class CalcPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.last_button_pressed = None
self.whitelist = ['0', '1', '2', '3', '4',
'5', '6', '7', '8', '9',
'-', '+', '/', '*', '.']
self.on_key_called = False
self.empty = True
self.create_ui()
这里您添加了一个白名单属性和几个简单的标志, self.on_key_called 和 self.empty 。白名单是您允许用户在您的文本控件中键入的唯一字符。当我们实际到达使用这些标志的代码时,您将会了解到这些标志。
但是首先,您需要修改 panel 类的 create_ui() 方法。为了简洁起见,我将只复制这个方法的前几行:
def create_ui(self):
main_sizer = wx.BoxSizer(wx.VERTICAL)
font = wx.Font(12, wx.MODERN, wx.NORMAL, wx.NORMAL)
self.solution = wx.TextCtrl(self, style=wx.TE_RIGHT)
self.solution.SetFont(font)
self.solution.Bind(wx.EVT_TEXT, self.on_key)
main_sizer.Add(self.solution, 0, wx.EXPAND|wx.ALL, 5)
self.running_total = wx.StaticText(self)
main_sizer.Add(self.running_total, 0, wx.ALIGN_RIGHT)
请随意从 Github 下载完整的源代码,或者参考上一节中的代码。这里关于文本控件的主要区别是你不再禁用它,而是将它绑定到一个事件: wx。EVT _ 正文。
让我们继续编写 on_key() 方法:
def on_key(self, event):
if self.on_key_called:
self.on_key_called = False
return
key = event.GetString()
self.on_key_called = True
if key in self.whitelist:
self.update_equation(key)
这里你检查一下 self.on_key_called 标志是否为真。如果是,我们将其设置回 False 并提前“返回”。这样做的原因是当你用鼠标点击一个按钮时,它会导致 EVT_TEXT 开火。“update_equation()”方法将获取文本控件的内容,这将是我们刚刚按下的键,并将该键添加回自身,从而产生一个双精度值。这是解决该问题的一种方法。
您还会注意到,要获得被按下的键,您可以调用事件对象的 GetString() 方法。然后,您将检查该键是否在白名单中。如果是,您将更新等式。
您需要更新的下一个方法是 update_equation() :
def update_equation(self, text):
operators = ['/', '*', '-', '+']
current_equation = self.solution.GetValue()
if text not in operators:
if self.last_button_pressed in operators:
self.solution.SetValue(current_equation + ' ' + text)
elif self.empty and current_equation:
# The solution is not empty
self.empty = False
else:
self.solution.SetValue(current_equation + text)
elif text in operators and current_equation is not '' \
and self.last_button_pressed not in operators:
self.solution.SetValue(current_equation + ' ' + text)
self.last_button_pressed = text
self.solution.SetInsertionPoint(-1)
for item in operators:
if item in self.solution.GetValue():
self.update_solution()
break
这里你添加一个新的 elif 来检查 self.empty 标志是否被置位,以及 current_equation 中是否有任何内容。换句话说,如果它应该是空的,而不是空的,那么我们将标志设置为 False ,因为它不是空的。这可以防止按下键盘键时出现重复值。所以基本上你需要两个标志来处理因为你决定允许用户使用他们的键盘而导致的重复值。
该方法的另一个变化是在文本控件上添加对 SetInsertionPoint() 的调用,这将在每次更新后将插入点放在文本控件的末尾。
对 panel 类的最后一个必需的更改发生在 on_clear() 方法中:
def on_clear(self, event):
self.solution.Clear()
self.running_total.SetLabel('')
self.empty = True
self.solution.SetFocus()
这种改变是通过在方法的末尾添加两行新行来完成的。首先是将 self.empty 复位为 True 。第二个是调用文本控件的 SetFocus() 方法,以便在文本控件被清除后,焦点被重置到文本控件。
您还可以将这个 SetFocus() 调用添加到 on_calculate() 和 on_total() 方法的末尾。这将使文本控件始终保持焦点。你可以自己随意摆弄它。
创建更好的评估()
既然您已经了解了控制“邪恶”eval() 的几种不同方法,那么让我们花一些时间来学习如何自己创建一个定制版本的 eval() 。Python 附带了几个方便的内置模块,称为 ast 和操作符。根据文档, ast 模块是代表“抽象语法树”的首字母缩写,用于“处理 Python 抽象语法语法的树”。你可以把它想象成一个代表代码的数据结构。您可以使用 ast 模块在 Python 中创建一个编译器。
操作符模块是一组与 Python 的操作符相对应的函数。一个很好的例子就是运算符。add(x,y) 等价于表达式 x+y 。您可以将此模块与' ast '模块一起使用,创建一个受限版本的 eval() 。
让我们来看看如何实现:
import ast
import operator
allowed_operators = {ast.Add: operator.add, ast.Sub: operator.sub,
ast.Mult: operator.mul, ast.Div: operator.truediv}
def noeval(expression):
if isinstance(expression, ast.Num):
return expression.n
elif isinstance(expression, ast.BinOp):
print('Operator: {}'.format(expression.op))
print('Left operand: {}'.format(expression.left))
print('Right operand: {}'.format(expression.right))
op = allowed_operators.get(type(expression.op))
if op:
return op(noeval(expression.left),
noeval(expression.right))
else:
print('This statement will be ignored')
if __name__ == '__main__':
print(ast.parse('1+4', mode='eval').body)
print(noeval(ast.parse('1+4', mode='eval').body))
print(noeval(ast.parse('1**4', mode='eval').body))
print(noeval(ast.parse("__import__('os').remove('path/to/file')", mode='eval').body))
在这里,您创建了一个允许操作符的字典。你映射 ast。添加到操作符,添加等等。然后创建一个名为“noeval”的函数,它接受一个“ast”对象。如果表达式只是一个数字,就返回它。然而,如果它是一个 BinOp 实例,那么你打印出表达式的片段。一个 BinOp 由三部分组成:
- 表达式的左边部分
- 接线员
- 表达式的右边
当这段代码找到一个 BinOp 对象时,它会尝试获取 ast 操作的类型。如果它在我们的 allowed_operators 字典中,那么用表达式的左右部分调用映射的函数并返回结果。
最后,如果表达式不是一个数字或者一个被认可的操作符,那么你可以忽略它。试着用不同的字符串和表达式来试验一下这个例子,看看它是如何工作的。
一旦你玩完了这个例子,让我们把它集成到你的计算器代码中。对于这个版本的代码,可以调用 Python 脚本 wxcalculator_no_eval.py 。新文件的顶部应该如下所示:
# wxcalculator_no_eval.py
import ast
import operator
import wx
class CalcPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.last_button_pressed = None
self.create_ui()
self.allowed_operators = {
ast.Add: operator.add, ast.Sub: operator.sub,
ast.Mult: operator.mul, ast.Div: operator.truediv}
这里的主要区别在于,您现在有了几个新的导入(即 ast 和 operator),您需要添加一个名为 self.allowed_operators 的 Python 字典。接下来,您将想要创建一个名为 noeval() 的新方法:
def noeval(self, expression):
if isinstance(expression, ast.Num):
return expression.n
elif isinstance(expression, ast.BinOp):
return self.allowed_operators[
type(expression.op)](self.noeval(expression.left),
self.noeval(expression.right))
return ''
这个方法与您在另一个脚本中创建的函数几乎完全相同。不过,它已被稍微修改以调用正确的类方法和属性。您需要做的另一个更改是在 update_solution() 方法中:
def update_solution(self):
try:
expression = ast.parse(self.solution.GetValue(),
mode='eval').body
current_solution = str(self.noeval(expression))
self.running_total.SetLabel(current_solution)
self.Layout()
return current_solution
except ZeroDivisionError:
self.solution.SetValue('ZeroDivisionError')
except:
pass
现在,计算器代码将使用您自定义的 eval() 方法,并保护您免受 eval() 的潜在危害。Github 中的代码具有额外的保护,只允许用户使用屏幕 UI 来修改文本控件的内容。然而,你可以很容易地改变它来启用文本控制,并尝试这段代码,而不用担心 eval() 会对你造成任何伤害。
包扎
在本章中,你学习了几种使用 wxPython 创建计算器的不同方法。您还了解了使用 Python 内置的 eval() 函数的优缺点。最后,您了解到可以使用 Python 的 ast 和 operator 模块来创建一个细粒度版本的 eval() 供您安全使用。当然,因为您正在控制所有进入 eval() 的输入,所以您也可以通过您用 wxPython 生成的 UI 很容易地控制真正的版本。
花些时间,用这篇文章中的例子做些试验。有许多改进可以使这个应用程序变得更好。当你发现错误或缺失的特性时,挑战自己,尝试修复或添加它们。
下载源代码
本文的源代码可以在 Github 上找到。本文基于我的书《用 wxPython 创建 GUI 应用程序》中的一章。
使用 wxPython 创建跨平台图像查看器(视频)
了解如何使用 wxPython 和 Python 创建基本的跨平台图像查看器
https://www.youtube.com/embed/2WJnM6WiZMo?feature=oembed
这个视频是基于我的书《用 wxPython 创建 GUI 应用程序》中的一个例子,你可以在下面的网址购买:
这个例子的代码可以在本书的第二章以及 Github 上找到。
用 wxPython 创建文件搜索 GUI
原文:https://www.blog.pythonlibrary.org/2021/09/02/creating-a-file-search-gui-with-wxpython/
你曾经需要在你的计算机上搜索一个文件吗?大多数操作系统都有办法做到这一点。Windows 资源管理器有搜索功能,现在开始菜单中也有内置的搜索功能。其他操作系统如 Mac 和 Linux 也类似。你也可以下载一些应用程序,它们搜索硬盘的速度有时比内置的要快。
在本文中,您将使用 wxPython 创建一个简单的文件搜索实用程序。
您需要支持文件搜索工具的以下任务:
- 按文件类型搜索
- 区分大小写的搜索
- 在子目录中搜索
你可以在 GitHub 上下载这篇文章的源代码。
我们开始吧!
设计您的文件搜索工具
尝试再造一个你自己使用的工具总是很有趣的。然而,在这种情况下,您只需利用上面提到的特性,创建一个简单明了的用户界面。您可以使用wx.SearchCtrl来搜索文件,使用ObjectListView来显示结果。对于这个特定的实用程序,一两个wx.CheckBox将很好地告诉您的应用程序在子目录中搜索,或者搜索项是否区分大小写。
以下是应用程序最终外观的模型:

文件搜索模型
既然你心中有了目标,那就让我们开始编码吧!
创建文件搜索实用程序
您的搜索工具将需要两个模块。第一个模块将被称为 main ,它将保存你的用户界面和应用程序的大部分逻辑。第二个模块被命名为 search_threads ,它将包含使用 Python 的threading模块搜索文件系统所需的逻辑。找到结果后,您将使用pubsub更新主模块。
主脚本
主模块拥有您的应用程序的大部分代码。如果您继续并增强这个应用程序,代码的搜索部分可能最终拥有大部分代码,因为这可能是您的代码应该进行大量改进的地方。
不管怎样,这里是主的开始:
# main.py
import os
import sys
import subprocess
import time
import wx
from ObjectListView import ObjectListView, ColumnDefn
from pubsub import pub
from search_threads import SearchFolderThread, SearchSubdirectoriesThread
这一次,您将使用更多的内置 Python 模块,比如os、sys、subprocess和time。其他的导入都很正常,最后一个是几个类,你将从threading模块中基于 Python 的Thread类创建。
不过现在,让我们只关注主模块。
下面是您需要创建的第一个类:
class SearchResult:
def __init__(self, path, modified_time):
self.path = path
self.modified = time.strftime('%D %H:%M:%S',
time.gmtime(modified_time))
SearchResult类用于保存搜索结果的相关信息。它也由ObjectListView小部件使用。目前,您将使用它来保存搜索结果的完整路径以及文件的修改时间。您可以很容易地增强它,使其包括文件大小、创建时间等。
现在让我们创建包含大部分 UI 代码的MainPanel:
class MainPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.search_results = []
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
self.create_ui()
self.SetSizer(self.main_sizer)
pub.subscribe(self.update_search_results, 'update')
__init__()方法设置好了一切。这里您创建了main_sizer,一个空的search_results列表和一个使用pubsub的监听器或订阅。您还可以调用create_ui()将用户界面小部件添加到面板中。
让我们看看现在有什么:
def create_ui(self):
# Create the widgets for the search path
row_sizer = wx.BoxSizer()
lbl = wx.StaticText(self, label='Location:')
row_sizer.Add(lbl, 0, wx.ALL | wx.CENTER, 5)
self.directory = wx.TextCtrl(self, style=wx.TE_READONLY)
row_sizer.Add(self.directory, 1, wx.ALL | wx.EXPAND, 5)
open_dir_btn = wx.Button(self, label='Choose Folder')
open_dir_btn.Bind(wx.EVT_BUTTON, self.on_choose_folder)
row_sizer.Add(open_dir_btn, 0, wx.ALL, 5)
self.main_sizer.Add(row_sizer, 0, wx.EXPAND)
有很多小部件可以添加到这个用户界面中。首先,添加一行由标签、文本控件和按钮组成的小部件。这一系列小部件允许用户使用按钮选择他们想要搜索的目录。文本控件将保存他们的选择。
现在让我们添加另一行小部件:
# Create search filter widgets
row_sizer = wx.BoxSizer()
lbl = wx.StaticText(self, label='Limit search to filetype:')
row_sizer.Add(lbl, 0, wx.ALL|wx.CENTER, 5)
self.file_type = wx.TextCtrl(self)
row_sizer.Add(self.file_type, 0, wx.ALL, 5)
self.sub_directories = wx.CheckBox(self, label='Sub-directories')
row_sizer.Add(self.sub_directories, 0, wx.ALL | wx.CENTER, 5)
self.case_sensitive = wx.CheckBox(self, label='Case-sensitive')
row_sizer.Add(self.case_sensitive, 0, wx.ALL | wx.CENTER, 5)
self.main_sizer.Add(row_sizer)
这一行小部件包含另一个标签、一个文本控件和两个wx.Checkbox实例。这些是过滤器部件,控制你要搜索的内容。您可以根据以下任何一项进行筛选:
- 文件类型
- 搜索子目录(选中时)或只搜索选定的目录
- 搜索词区分大小写
后两个选项通过使用wx.Checkbox小部件来表示。
接下来让我们添加搜索控件:
# Add search bar
self.search_ctrl = wx.SearchCtrl(
self, style=wx.TE_PROCESS_ENTER, size=(-1, 25))
self.search_ctrl.Bind(wx.EVT_SEARCHCTRL_SEARCH_BTN, self.on_search)
self.search_ctrl.Bind(wx.EVT_TEXT_ENTER, self.on_search)
self.main_sizer.Add(self.search_ctrl, 0, wx.ALL | wx.EXPAND, 5)
wx.SearchCtrl是用于搜索的小部件。不过你可以很容易地使用一个wx.TextCtrl来代替。无论如何,在这种情况下,您绑定到 Enter 键的按下和控件内的放大类的鼠标单击。如果你做了这些动作中的任何一个,你将呼叫search()。
现在让我们添加最后两个小部件,您将完成create_ui()的代码:
# Search results widget
self.search_results_olv = ObjectListView(
self, style=wx.LC_REPORT | wx.SUNKEN_BORDER)
self.search_results_olv.SetEmptyListMsg("No Results Found")
self.main_sizer.Add(self.search_results_olv, 1, wx.ALL | wx.EXPAND, 5)
self.update_ui()
show_result_btn = wx.Button(self, label='Open Containing Folder')
show_result_btn.Bind(wx.EVT_BUTTON, self.on_show_result)
self.main_sizer.Add(show_result_btn, 0, wx.ALL | wx.CENTER, 5)
您的搜索结果将出现在您的ObjectListView小工具中。您还需要添加一个按钮,尝试在包含文件夹中显示结果,有点像 Mozilla Firefox 有一个名为“打开包含文件夹”的右键菜单,用于打开下载的文件。
下一个要创建的方法是on_choose_folder():
def on_choose_folder(self, event):
with wx.DirDialog(self, "Choose a directory:",
style=wx.DD_DEFAULT_STYLE,
) as dlg:
if dlg.ShowModal() == wx.ID_OK:
self.directory.SetValue(dlg.GetPath())
您需要允许用户选择您想要在其中进行搜索的文件夹。您可以让用户输入路径,但是这很容易出错,并且您可能需要添加特殊的错误检查。相反,您选择使用一个wx.DirDialog,它可以防止用户输入一个不存在的路径。用户可以选择文件夹,然后在执行搜索之前删除文件夹,但这种情况不太可能发生。
现在您需要一种用 Python 打开文件夹的方法:
def on_show_result(self, event):
"""
Attempt to open the folder that the result was found in
"""
result = self.search_results_olv.GetSelectedObject()
if result:
path = os.path.dirname(result.path)
try:
if sys.platform == 'darwin':
subprocess.check_call(['open', '--', path])
elif 'linux' in sys.platform:
subprocess.check_call(['xdg-open', path])
elif sys.platform == 'win32':
subprocess.check_call(['explorer', path])
except:
if sys.platform == 'win32':
# Ignore error on Windows as there seems to be
# a weird return code on Windows
return
message = f'Unable to open file manager to {path}'
with wx.MessageDialog(None, message=message,
caption='Error',
style= wx.ICON_ERROR) as dlg:
dlg.ShowModal()
on_show_result()方法将检查代码在什么平台下运行,然后尝试启动该平台的文件管理器。Windows 用 Explorer 而 Linux 用 xdg-open 比如。
在测试过程中,我们注意到在 Windows 上,即使 Explorer 成功打开,它也会返回一个非零结果,所以在这种情况下,您可以忽略该错误。但是在其他平台上,您可以向用户显示一条消息,说明您无法打开该文件夹。
您需要编写的下一段代码是on_search()事件处理程序:
def on_search(self, event):
search_term = self.search_ctrl.GetValue()
file_type = self.file_type.GetValue()
file_type = file_type.lower()
if '.' not in file_type:
file_type = f'.{file_type}'
if not self.sub_directories.GetValue():
# Do not search sub-directories
self.search_current_folder_only(search_term, file_type)
else:
self.search(search_term, file_type)
当你点击“搜索”按钮时,你希望它做一些有用的事情。这就是上面的代码发挥作用的地方。这里你得到了search_term和file_type。为了防止出现问题,您将文件类型设置为小写,并在搜索过程中执行同样的操作。
接下来,检查是否勾选了sub_directories复选框。如果sub_directories没有勾选,那么你调用search_current_folder_only();不然你叫search()。
让我们先看看search()里有什么:
def search(self, search_term, file_type):
"""
Search for the specified term in the directory and its
sub-directories
"""
folder = self.directory.GetValue()
if folder:
self.search_results = []
SearchSubdirectoriesThread(folder, search_term, file_type,
self.case_sensitive.GetValue())
在这里,您获取用户选择的文件夹。如果用户没有选择文件夹,搜索按钮将不起任何作用。但是如果他们已经选择了什么,那么你就用合适的参数调用SearchSubdirectoriesThread线程。您将在后面的部分看到该类中的代码。
但是首先,您需要创建search_current_folder_only()方法:
def search_current_folder_only(self, search_term, file_type):
"""
Search for the specified term in the directory only. Do
not search sub-directories
"""
folder = self.directory.GetValue()
if folder:
self.search_results = []
SearchFolderThread(folder, search_term, file_type,
self.case_sensitive.GetValue())
这段代码与前面的函数非常相似。它唯一的区别是执行
SearchFolderThread而不是SearchSubdirectoriesThread。
下一个要创建的函数是update_search_results():
def update_search_results(self, result):
"""
Called by pubsub from thread
"""
if result:
path, modified_time = result
self.search_results.append(SearchResult(path, modified_time))
self.update_ui()
当找到一个搜索结果时,线程将使用线程安全的方法和pubsub把结果发送回主应用程序。假设主题与您在__init__()中创建的订阅相匹配,这个方法将被调用。一旦被调用,这个方法将把结果追加到search_results中,然后调用update_ui()。
说到这里,你现在可以编码了:
def update_ui(self):
self.search_results_olv.SetColumns([
ColumnDefn("File Path", "left", 300, "path"),
ColumnDefn("Modified Time", "left", 150, "modified")
])
self.search_results_olv.SetObjects(self.search_results)
update_ui()方法定义了在ObjectListView小部件中显示的列。它还调用SetObjects(),这将更新小部件的内容,并向用户显示您的搜索结果。
为了包装主模块,您需要编写Search类:
class Search(wx.Frame):
def __init__(self):
super().__init__(None, title='Search Utility',
size=(600, 600))
pub.subscribe(self.update_status, 'status')
panel = MainPanel(self)
self.statusbar = self.CreateStatusBar(1)
self.Show()
def update_status(self, search_time):
msg = f'Search finished in {search_time:5.4} seconds'
self.SetStatusText(msg)
if __name__ == '__main__':
app = wx.App(False)
frame = Search()
app.MainLoop()
这个类创建了MainPanel,它保存了用户将会看到并与之交互的大多数小部件。它还设置应用程序的初始大小及其标题。还有一个状态栏,用于通知用户搜索何时完成,以及搜索完成需要多长时间。
下面是该应用程序的外观:

现在让我们继续创建保存搜索线程的模块。
搜索线程模块
search_threads 模块包含两个用于搜索文件系统的Thread类。线程类实际上在形式和功能上非常相似。
让我们开始吧:
# search_threads.py
import os
import time
import wx
from pubsub import pub
from threading import Thread
这些是使代码工作所需的模块。您将使用os模块来检查路径、遍历文件系统并从文件中获取统计数据。当您的搜索返回结果时,您将使用pubsub与您的应用程序通信。
下面是第一节课:
class SearchFolderThread(Thread):
def __init__(self, folder, search_term, file_type, case_sensitive):
super().__init__()
self.folder = folder
self.search_term = search_term
self.file_type = file_type
self.case_sensitive = case_sensitive
self.start()
这个线程接受要搜索的folder、要查找的search_term、一个file_type过滤器以及搜索词是否为case_sensitive。您接受这些变量,并将它们赋给同名的实例变量。这个线程的目的只是搜索传入的文件夹的内容,而不是它的子目录。
您还需要覆盖线程的run()方法:
def run(self):
start = time.time()
for entry in os.scandir(self.folder):
if entry.is_file():
if self.case_sensitive:
path = entry.name
else:
path = entry.name.lower()
if self.search_term in path:
_, ext = os.path.splitext(entry.path)
data = (entry.path, entry.stat().st_mtime)
wx.CallAfter(pub.sendMessage, 'update', result=data)
end = time.time()
# Always update at the end even if there were no results
wx.CallAfter(pub.sendMessage, 'update', result=[])
wx.CallAfter(pub.sendMessage, 'status', search_time=end-start)
这里你收集线程的开始时间。然后使用os.scandir()循环遍历folder的内容。如果路径是一个文件,您将检查search_term是否在路径中,以及是否有正确的file_type。如果这两个函数都返回True,那么您将获得必要的数据,并使用wx.CallAfter()将其发送到您的应用程序,这是一个线程安全的方法。
最后,您获取end_time并使用它来计算搜索的总运行时间,然后将其发送回应用程序。然后,应用程序会用搜索时间更新状态栏。
现在让我们看看另一个类:
class SearchSubdirectoriesThread(Thread):
def __init__(self, folder, search_term, file_type, case_sensitive):
super().__init__()
self.folder = folder
self.search_term = search_term
self.file_type = file_type
self.case_sensitive = case_sensitive
self.start()
SearchSubdirectoriesThread线程不仅用于搜索传入的folder,还用于搜索它的子目录。它接受与前一个类相同的参数。
下面是您需要放入它的run()方法中的内容:
def run(self):
start = time.time()
for root, dirs, files in os.walk(self.folder):
for f in files:
full_path = os.path.join(root, f)
if not self.case_sensitive:
full_path = full_path.lower()
if self.search_term in full_path and os.path.exists(full_path):
_, ext = os.path.splitext(full_path)
data = (full_path, os.stat(full_path).st_mtime)
wx.CallAfter(pub.sendMessage, 'update', result=data)
end = time.time()
# Always update at the end even if there were no results
wx.CallAfter(pub.sendMessage, 'update', result=[])
wx.CallAfter(pub.sendMessage, 'status', search_time=end-start)
对于这个线程,需要使用os.walk()来搜索传入的folder及其子目录。除此之外,条件语句实际上与前面的课程相同。
包扎
创建搜索工具并不特别困难,但是很耗时。在创建软件时,找出边缘情况以及如何考虑它们通常是最耗时的事情。在本文中,您了解了如何创建一个实用程序来搜索计算机上的文件。
以下是您可以添加到该程序中的一些增强功能:
- 添加停止搜索的功能
- 防止多个搜索同时发生
- 添加其他过滤器
相关阅读
想学习如何用 wxPython 创建更多的 GUI 应用程序吗?然后查看以下资源:
用 wxPython 为 NASA 的 API 创建 GUI 应用程序
从小到大,我一直觉得宇宙和太空总的来说是令人兴奋的。梦想什么样的世界尚未被探索是很有趣的。我也喜欢看来自其他世界的照片或思考浩瀚的太空。但是这和 Python 有什么关系呢?嗯,美国国家航空航天局(NASA)有一个 web API,允许你搜索他们的图像库。
你可以在他们的网站上看到所有的信息。
美国宇航局网站建议获取一个应用编程接口(API)密钥。如果你去那个网站,你要填写的表格又好又短。
从技术上讲,你不需要一个 API 键来请求 NASA 的服务。然而,他们对没有 API 密匙访问他们网站的开发者有限制。即使有一个键,默认情况下每小时也只能处理 1000 个请求。如果您检查了您的分配,您将被暂时禁止提出请求。不过,你可以联系美国宇航局要求更高的速率限制。
有趣的是,文档并没有真正说明在没有 API 键的情况下可以发出多少个请求。
API 文档与 NASA 的图像 API 文档不一致,这使得他们的网站有点混乱。
例如,您会看到 API 文档中谈到了这个 URL:
但是在图像 API 文档中,API 根是:
出于本教程的目的,您将使用后者。
|  | 这篇文章改编自我的书:
| 这篇文章改编自我的书:
用 wxPython 创建 GUI 应用程序
在 Leanpub 上立即购买 |
使用美国宇航局的 API
当您开始使用一个不熟悉的 API 时,最好从阅读该接口的文档开始。另一种方法是在互联网上快速搜索,看看是否有包装了目标 API 的 Python 包。不幸的是,似乎没有任何维护 Python 的 NASA 库。当这种情况发生时,你可以创造你自己的。
要开始,请尝试阅读 NASA 图像 API 文档。
他们的 API 文档不是很长,所以阅读或至少浏览它不会花费你很长时间。
下一步是获取这些信息并尝试使用他们的 API。
下面是访问他们的 API 的实验的前几行:
# simple_api_request.py
import requests
from urllib.parse import urlencode, quote_plus
base_url = 'https://images-api.nasa.gov/search'
search_term = 'apollo 11'
desc = 'moon landing'
media = 'image'
query = {'q': search_term, 'description': desc, 'media_type': media}
full_url = base_url + '?' + urlencode(query, quote_via=quote_plus)
r = requests.get(full_url)
data = r.json()
如果在调试器中运行,可以打印出返回的 JSON。
以下是返回内容的一个片段:
'items': [{'data':
[{'center': 'HQ',
'date_created': '2009-07-18T00:00:00Z',
'description': 'On the eve of the '
'fortieth anniversary of '
"Apollo 11's first human "
'landing on the Moon, '
'Apollo 11 crew member, '
'Buzz Aldrin speaks during '
'a lecture in honor of '
'Apollo 11 at the National '
'Air and Space Museum in '
'Washington, Sunday, July '
'19, 2009\. Guest speakers '
'included Former NASA '
'Astronaut and U.S. '
'Senator John Glenn, NASA '
'Mission Control creator '
'and former NASA Johnson '
'Space Center director '
'Chris Kraft and the crew '
'of Apollo 11\. Photo '
'Credit: (NASA/Bill '
'Ingalls)',
'keywords': ['Apollo 11',
'Apollo 40th Anniversary',
'Buzz Aldrin',
'National Air and Space '
'Museum (NASM)',
'Washington, DC'],
'location': 'National Air and Space '
'Museum',
'media_type': 'image',
'nasa_id': '200907190008HQ',
'photographer': 'NASA/Bill Ingalls',
'title': 'Glenn Lecture With Crew of '
'Apollo 11'}],
'href': 'https://images-assets.nasa.gov/image/200907190008HQ/collection.json',
'links': [{'href': 'https://images-assets.nasa.gov/image/200907190008HQ/200907190008HQ~thumb.jpg',
'rel': 'preview',
'render': 'image'}]}
现在您已经知道了 JSON 的格式,您可以试着对它进行一点解析。
让我们将以下代码行添加到您的 Python 脚本中:
item = data['collection']['items'][0]
nasa_id = item['data'][0]['nasa_id']
asset_url = 'https://images-api.nasa.gov/asset/' + nasa_id
image_request = requests.get(asset_url)
image_json = image_request.json()
image_urls = [url['href'] for url in image_json['collection']['items']]
print(image_urls)
这将从 JSON 响应中提取出列表中第一个条目。然后您可以提取 nasa_id ,这是获取与这个特定结果相关的所有图像所必需的。现在,您可以将那个 nasa_id 添加到一个新的 URL 端点,并提出一个新的请求。
对图像 JSON 的请求返回如下内容:
{'collection': {'href': 'https://images-api.nasa.gov/asset/200907190008HQ',
'items': [{'href': 'http://images-assets.nasa.gov/image/200907190008HQ/200907190008HQ~orig.tif'},
{'href': 'http://images-assets.nasa.gov/image/200907190008HQ/200907190008HQ~large.jpg'},
{'href': 'http://images-assets.nasa.gov/image/200907190008HQ/200907190008HQ~medium.jpg'},
{'href': 'http://images-assets.nasa.gov/image/200907190008HQ/200907190008HQ~small.jpg'},
{'href': 'http://images-assets.nasa.gov/image/200907190008HQ/200907190008HQ~thumb.jpg'},
{'href': 'http://images-assets.nasa.gov/image/200907190008HQ/metadata.json'}],
'version': '1.0'}}
Python 代码中的最后两行将从 JSON 中提取 URL。现在你已经拥有了编写一个基本用户界面所需的所有部分!
设计用户界面
有许多不同的方法可以设计你的图像下载应用程序。您将做最简单的事情,因为这几乎总是创建原型的最快方法。原型设计的好处在于,您最终获得了创建有用应用程序所需的所有部分。然后你可以利用你的知识,或者增强原型,或者用你获得的知识创造新的东西。
这里有一个你将尝试创建的模型:

美国宇航局图像搜索模型
如您所见,您希望应用程序具有以下特性:
- 搜索栏
- 保存搜索结果的小部件
- 选择结果时显示图像的方式
- 下载图像的能力
现在让我们来学习如何创建这个用户界面!
创建 NASA 搜索应用程序
快速原型是一种想法,在这种想法中,您将尽可能快地创建一个小的、可运行的应用程序。让我们在应用程序中从上到下添加小部件,而不是花费大量时间来布置所有的小部件。这将比创建一系列嵌套的 sizers 更快地为您提供一些工作。
让我们首先创建一个名为 nasa_search_ui.py 的脚本:
# nasa_search_ui.py
import os
import requests
import wx
from download_dialog import DownloadDialog
from ObjectListView import ObjectListView, ColumnDefn
from urllib.parse import urlencode, quote_plus
在这里,您导入了一些您尚未看到的新项目。第一个是请求包。这是一个用 Python 在互联网上下载文件和做事情的便利包。很多开发者觉得比 Python 自己的 urllib 要好。你需要安装它来使用它。您还需要安装 ObjectListView。
下面是你如何用 pip 来做这件事:
pip install requests ObjectListView
另一个新的部分是从 urllib.parse 的导入。您将使用这个模块对 URL 参数进行编码。最后, DownloadDialog 是一个小对话框的类,您将创建它来下载 NASA 的图像。
因为您将在这个应用程序中使用 ObjectListView,所以您需要一个类来表示该小部件中的对象:
class Result:
def __init__(self, item):
data = item['data'][0]
self.title = data['title']
self.location = data.get('location', '')
self.nasa_id = data['nasa_id']
self.description = data['description']
self.photographer = data.get('photographer', '')
self.date_created = data['date_created']
self.item = item
if item.get('links'):
try:
self.thumbnail = item['links'][0]['href']
except:
self.thumbnail = ''
结果类是您将用来保存构成您的对象列表视图中每一行的数据。项参数是 JSON 的一部分,它是 NASA 对您的查询的回应。在这堂课上,你需要分析出你所需要的信息。
在这种情况下,您需要以下字段:
- 标题
- 图像的位置
- NASA 的内部 ID
- 照片的描述
- 摄影师的名字
- 图像的创建日期
- 缩略图 URL
其中一些条目并不总是包含在 JSON 响应中,所以在这些情况下,您将使用字典的 get() 方法返回一个空字符串。
现在让我们开始研究用户界面:
class MainPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.search_results = []
self.max_size = 300
self.paths = wx.StandardPaths.Get()
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.NORMAL)
main_sizer = wx.BoxSizer(wx.VERTICAL)
主面板是你的大部分代码所在的地方。这里你做一些内务处理,创建一个 search_results 来保存用户搜索时的 Result 对象列表。你也可以设置缩略图的最大尺寸,使用的字体,尺寸,你也可以得到一些标准路径。
现在让我们将下面的代码添加到 init() 中:
txt = 'Search for images on NASA'
label = wx.StaticText(self, label=txt)
main_sizer.Add(label, 0, wx.ALL, 5)
self.search = wx.SearchCtrl(
self, style=wx.TE_PROCESS_ENTER, size=(-1, 25))
self.search.Bind(wx.EVT_SEARCHCTRL_SEARCH_BTN, self.on_search)
self.search.Bind(wx.EVT_TEXT_ENTER, self.on_search)
main_sizer.Add(self.search, 0, wx.EXPAND)
这里您使用 wx 为应用程序创建一个标题标签。静态文本。然后你加一个 wx。SearchCtrl ,非常类似于一个 wx。除了它内置了特殊的按钮。您还可以将搜索按钮的点击事件(【TEXT _ 搜索 ctrl _ 搜索 _BTN 和【TEXT _ 文本 _ 输入绑定到一个与搜索相关的事件处理程序(开 _ 搜索)。
接下来的几行添加了搜索结果小部件:
self.search_results_olv = ObjectListView(
self, style=wx.LC_REPORT | wx.SUNKEN_BORDER)
self.search_results_olv.SetEmptyListMsg("No Results Found")
self.search_results_olv.Bind(wx.EVT_LIST_ITEM_SELECTED,
self.on_selection)
main_sizer.Add(self.search_results_olv, 1, wx.EXPAND)
self.update_search_results()
这段代码设置了 ObjectListView ,与我的其他文章使用它的方式非常相似。您可以通过调用 SetEmptyListMsg() 来定制空消息,还可以将小部件绑定到EVT _ 列表 _ 项目 _ 选定的,以便在用户选择搜索结果时执行操作。
现在让我们将剩余的代码添加到 init() 方法中:
main_sizer.AddSpacer(30)
self.title = wx.TextCtrl(self, style=wx.TE_READONLY)
self.title.SetFont(font)
main_sizer.Add(self.title, 0, wx.ALL|wx.EXPAND, 5)
img = wx.Image(240, 240)
self.image_ctrl = wx.StaticBitmap(self,
bitmap=wx.Bitmap(img))
main_sizer.Add(self.image_ctrl, 0, wx.CENTER|wx.ALL, 5
)
download_btn = wx.Button(self, label='Download Image')
download_btn.Bind(wx.EVT_BUTTON, self.on_download)
main_sizer.Add(download_btn, 0, wx.ALL|wx.CENTER, 5)
self.SetSizer(main_sizer)
最后几行代码添加了一个标题文本控件和一个图像小部件,当结果被选中时,它将会更新。您还添加了一个下载按钮,允许用户选择他们想要下载的图像大小。NASA 通常会给出几个不同版本的图像,从缩略图一直到原始的 TIFF 图像。
要查看的第一个事件处理程序是 on_download() :
def on_download(self, event):
selection = self.search_results_olv.GetSelectedObject()
if selection:
with DownloadDialog(selection) as dlg:
dlg.ShowModal()
这里调用 GetSelectedObject() 来获取用户的选择。如果用户没有选择任何东西,那么这个方法退出。另一方面,如果用户选择了一个项目,那么你实例化 DownloadDialog 并显示给用户以允许他们下载一些东西。
现在我们来学习如何进行搜索:
def on_search(self, event):
search_term = event.GetString()
if search_term:
query = {'q': search_term, 'media_type': 'image'}
full_url = base_url + '?' + urlencode(query, quote_via=quote_plus)
r = requests.get(full_url)
data = r.json()
self.search_results = []
for item in data['collection']['items']:
if item.get('data') and len(item.get('data')) > 0:
data = item['data'][0]
if data['title'].strip() == '':
# Skip results with blank titles
continue
result = Result(item)
self.search_results.append(result)
self.update_search_results()
on_search() 事件处理程序将获取用户输入到搜索控件中的字符串,或者返回一个空字符串。假设用户实际输入了要搜索的东西,您使用 NASA 的通用搜索查询, q 并将 media_type 硬编码为图像。然后,将查询编码成格式正确的 URL,并使用 requests.get() 请求 JSON 响应。
接下来,您尝试循环搜索结果。请注意,如果没有数据返回,此代码将失败并引发异常。但是如果您确实获得了数据,那么您将需要解析它以获得您需要的片段。
您将跳过未设置标题字段的项目。否则,您将创建一个结果对象,并将其添加到 search_results 列表中。在方法的最后,您告诉您的 UI 更新搜索结果。
在我们开始这个函数之前,您需要创建 on_selection() :
def on_selection(self, event):
selection = self.search_results_olv.GetSelectedObject()
self.title.SetValue(f'{selection.title}')
if selection.thumbnail:
self.update_image(selection.thumbnail)
else:
img = wx.Image(240, 240)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
self.Layout()
您再次获得选定的项目,但这一次您接受该选择,并用该选择的标题文本更新标题文本控件。然后检查是否有缩略图,如果有,就相应地更新它。当没有缩略图时,您可以将其设置回空图像,因为您不希望它一直显示以前选择的图像。
下一个要创建的方法是 update_image() :
def update_image(self, url):
filename = url.split('/')[-1]
tmp_location = os.path.join(self.paths.GetTempDir(), filename)
r = requests.get(url)
with open(tmp_location, "wb") as thumbnail:
thumbnail.write(r.content)
if os.path.exists(tmp_location):
img = wx.Image(tmp_location, wx.BITMAP_TYPE_ANY)
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.max_size
NewH = self.max_size * H / W
else:
NewH = self.max_size
NewW = self.max_size * W / H
img = img.Scale(NewW,NewH)
else:
img = wx.Image(240, 240)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
self.Layout()
update_image() 接受一个 URL 作为它的唯一参数。它获取这个 URL 并分离出文件名。然后,它会创建一个新的下载位置,即计算机的临时目录。然后,您的代码下载图像并检查以确保文件保存正确。如果是,那么缩略图使用您设置的 max_size 加载;否则,您可以将其设置为使用空白图像。
最后几行刷新()和布局()面板,以便小部件正确显示。
最后,您需要创建最后一个方法:
def update_search_results(self):
self.search_results_olv.SetColumns([
ColumnDefn("Title", "left", 250, "title"),
ColumnDefn("Description", "left", 350, "description"),
ColumnDefn("Photographer", "left", 100, "photographer"),
ColumnDefn("Date Created", "left", 150, "date_created")
])
self.search_results_olv.SetObjects(self.search_results)
在这里,您创建框架,设置标题和初始大小,并添加面板。然后你展示框架。
这是主用户界面的样子:

美国宇航局图像搜索主应用程序
现在让我们来学习如何制作一个下载对话框!
下载对话框
下载对话框将允许用户下载他们选择的一个或多个图像。几乎总是有至少两个版本的每张图片,有时五个或六个。
要学习的第一段代码是前几行:
# download_dialog.py
import requests
import wx
wildcard = "All files (*.*)|*.*"
这里您再次导入请求并设置一个通配符,您将在保存图像时使用它。
现在让我们创建对话框的 init() :
class DownloadDialog(wx.Dialog):
def __init__(self, selection):
super().__init__(None, title='Download images')
self.paths = wx.StandardPaths.Get()
main_sizer = wx.BoxSizer(wx.VERTICAL)
self.list_box = wx.ListBox(self, choices=[], size=wx.DefaultSize)
urls = self.get_image_urls(selection)
if urls:
choices = {url.split('/')[-1]: url for url in urls if 'jpg' in url}
for choice in choices:
self.list_box.Append(choice, choices[choice])
main_sizer.Add(self.list_box, 1, wx.EXPAND|wx.ALL, 5)
save_btn = wx.Button(self, label='Save')
save_btn.Bind(wx.EVT_BUTTON, self.on_save)
main_sizer.Add(save_btn, 0, wx.ALL|wx.CENTER, 5)
self.SetSizer(main_sizer)
在本例中,您创建了一个对标准路径的新引用,并添加了一个 wx。列表框。列表框将包含您可以下载的照片的变体。它还会自动添加一个滚动条,如果有太多的结果,以适应屏幕上一次。你用传入的选择对象调用 get_image_urls 来获得一个URL的列表。然后循环遍历URL并提取名称中包含 jpg 的 URL。这确实会导致您错过其他图像文件类型,如 PNG 或 TIFF。
这给了你一个增强和改进代码的机会。您过滤 URL 的原因是,结果中通常包含非图像 URL,您可能不想将这些 URL 显示为潜在的可下载 URL,因为这会使用户感到困惑。
最后要添加的小部件是“保存”按钮。你也可以添加一个“取消”按钮,但是对话框顶部有一个退出按钮,所以不需要。
现在是时候了解一下 get_image_urls() 的功能了:
def get_image_urls(self, item):
asset_url = f'https://images-api.nasa.gov/asset/{item.nasa_id}'
image_request = requests.get(asset_url)
image_json = image_request.json()
try:
image_urls = [url['href'] for url in image_json['collection']['items']]
except:
image_urls = []
return image_urls
当用户按下“保存”按钮时,该事件处理程序被激活。当用户试图在不选择列表框中的项目的情况下保存某些内容时,它将返回-1。如果发生这种情况,你向他们显示一个 MessageDialog 来告诉他们可能想要选择某样东西。当他们选择某样东西时,你会给他们看一个 wx。FileDialog 允许他们选择文件的保存位置和命名方式。
事件处理程序调用 save() 方法,这就是您的下一个项目:
def save(self, path):
selection = self.list_box.GetSelection()
r = requests.get(
self.list_box.GetClientData(selection))
try:
with open(path, "wb") as image:
image.write(r.content)
message = 'File saved successfully'
with wx.MessageDialog(None, message=message,
caption='Save Successful',
style=wx.ICON_INFORMATION) as dlg:
dlg.ShowModal()
except:
message = 'File failed to save!'
with wx.MessageDialog(None, message=message,
caption='Save Failed',
style=wx.ICON_ERROR) as dlg:
dlg.ShowModal()
这里您再次获得选择,并使用请求包下载图像。注意,没有检查来确保用户已经添加了扩展,更不用说正确的扩展了。有机会可以自己补充一下。
无论如何,当文件下载完成时,你将向用户显示一条消息让他们知道。
如果出现异常,你可以显示一个对话框让他们知道!
下载对话框如下所示:

NASA 图像下载对话框
现在让我们添加一些新的功能!
添加高级搜索
您可以使用几个字段来帮助缩小搜索范围。然而,除非用户真的想使用这些过滤器,否则你不会想让你的用户界面变得杂乱。为此,您可以添加一个“高级搜索”选项。
添加这个选项需要您稍微重新安排一下代码,所以让我们将您的 nasa_search_ui.py 文件和您的 download_dialog.py 模块复制到一个名为 version_2 的新文件夹中。
现在将重新命名为main . pyNASA _ search _ ui . py,这样可以更明显地看出哪个脚本是你的程序的主入口点。为了使事情更加模块化,您将把您的搜索结果提取到它自己的类中,并在一个单独的类中进行高级搜索。这意味着您最终将拥有三个面板:
- 主面板
- 搜索结果面板
- 高级搜索面板
以下是完成后主对话框的样子:

带有高级搜索选项的 NASA 图像搜索
让我们分别检查一下这些。
main.py 脚本
main 模块是应用程序的主要入口点。入口点是用户将运行来启动应用程序的代码。如果要将应用程序捆绑到可执行文件中,也可以使用这个脚本。
让我们来看看您的主模块是如何启动的:
# main.py
import wx
from advanced_search import RegularSearch
from regular_search import SearchResults
from pubsub import pub
class MainPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
pub.subscribe(self.update_ui, 'update_ui')
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
search_sizer = wx.BoxSizer()
此示例导入两个与搜索相关的面板:
- 高级搜索
- 常规搜索
它还使用 pubsub 来订阅更新主题。
让我们看看 init() 中还有什么:
txt = 'Search for images on NASA'
label = wx.StaticText(self, label=txt)
self.main_sizer.Add(label, 0, wx.ALL, 5)
self.search = wx.SearchCtrl(
self, style=wx.TE_PROCESS_ENTER, size=(-1, 25))
self.search.Bind(wx.EVT_SEARCHCTRL_SEARCH_BTN, self.on_search)
self.search.Bind(wx.EVT_TEXT_ENTER, self.on_search)
search_sizer.Add(self.search, 1, wx.EXPAND)
self.advanced_search_btn = wx.Button(self, label='Advanced Search',
size=(-1, 25))
self.advanced_search_btn.Bind(wx.EVT_BUTTON, self.on_advanced_search)
search_sizer.Add(self.advanced_search_btn, 0, wx.ALL, 5)
self.main_sizer.Add(search_sizer, 0, wx.EXPAND)
在这里,您可以像以前一样添加页面标题和搜索控件。您还添加了新的高级搜索按钮,并使用新的 sizer 来包含搜索小部件和按钮。然后将该筛选器添加到主筛选器中。
现在让我们添加面板:
self.search_panel = RegularSearch(self)
self.advanced_search_panel = AdvancedSearch(self)
self.advanced_search_panel.Hide()
self.main_sizer.Add(self.search_panel, 1, wx.EXPAND)
self.main_sizer.Add(self.advanced_search_panel, 1, wx.EXPAND)
在这个例子中,您实例化了常规搜索和高级搜索面板。因为常规搜索是默认的,所以你在启动时对用户隐藏了高级搜索。
现在我们来更新一下 on_search() :
def on_search(self, event):
search_results = []
search_term = event.GetString()
if search_term:
query = {'q': search_term, 'media_type': 'image'}
pub.sendMessage('search_results', query=query)
当用户按下键盘上的“Enter / Return”键或者当他们按下搜索控件中的搜索按钮图标时,就会调用 on_search() 方法。如果用户在搜索控件中输入了一个搜索字符串,搜索查询将被构建,然后使用 pubsub 发送出去。
让我们看看当用户按下高级搜索按钮时会发生什么:
def on_advanced_search(self, event):
self.search.Hide()
self.search_panel.Hide()
self.advanced_search_btn.Hide()
self.advanced_search_panel.Show()
self.main_sizer.Layout()
当 on_advanced_search() 触发时,它会隐藏搜索小工具、常规搜索面板和高级搜索按钮。接下来,它显示高级搜索面板并调用 main_sizer 上的 Layout() 。这将导致面板向外切换并调整大小以适合框架。
最后创建的方法是 update_ui() :
def update_ui(self):
"""
Hide advanced search and re-show original screen
Called by pubsub when advanced search is invoked
"""
self.advanced_search_panel.Hide()
self.search.Show()
self.search_panel.Show()
self.advanced_search_btn.Show()
self.main_sizer.Layout()
当用户进行高级搜索时,调用 update_ui() 方法。该方法由发布订阅调用。它将在 _advanced_search() 上执行与相反的操作,取消隐藏高级搜索面板显示时隐藏的所有小部件。它还会隐藏高级搜索面板。
帧代码和之前一样,所以这里不显示。
让我们继续学习如何创建常规搜索面板!
正则 _ 搜索. py 脚本
regular_search 模块是您重构的模块,它包含将显示您的搜索结果的对象列表视图。它上面还有下载按钮。
下面的方法/类将不被涵盖,因为它们与前一个迭代中的相同:
- 下载时()
- on_selection()
- 更新图像()
- 更新搜索结果()
- 结果类
让我们先看看模块中的前几行是如何布局的:
# regular_search.py
import os
import requests
import wx
from download_dialog import DownloadDialog
from ObjectListView import ObjectListView, ColumnDefn
from pubsub import pub
from urllib.parse import urlencode, quote_plus
base_url = 'https://images-api.nasa.gov/search'
在这里,你拥有了来自版本 1 的原始 nasa_search_ui.py 脚本中的所有导入。您还需要向 NASA 的图像 API 发出请求的 base_url 。唯一的新导入是针对 pubsub 的。
让我们继续创建 RegularSearch 类:
class RegularSearch(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.search_results = []
self.max_size = 300
font = wx.Font(12, wx.SWISS, wx.NORMAL, wx.NORMAL)
main_sizer = wx.BoxSizer(wx.VERTICAL)
self.paths = wx.StandardPaths.Get()
pub.subscribe(self.load_search_results, 'search_results')
self.search_results_olv = ObjectListView(
self, style=wx.LC_REPORT | wx.SUNKEN_BORDER)
self.search_results_olv.SetEmptyListMsg("No Results Found")
self.search_results_olv.Bind(wx.EVT_LIST_ITEM_SELECTED,
self.on_selection)
main_sizer.Add(self.search_results_olv, 1, wx.EXPAND)
self.update_search_results()
这段代码将把 search_results 列表初始化为空列表,并设置图像的 max_size 。它还设置了一个 sizer 和用于向用户显示搜索结果的 ObjectListView 小部件。该代码实际上非常类似于所有类被组合时的第一次代码迭代。
下面是 init() 的其余代码:
main_sizer.AddSpacer(30)
self.title = wx.TextCtrl(self, style=wx.TE_READONLY)
self.title.SetFont(font)
main_sizer.Add(self.title, 0, wx.ALL|wx.EXPAND, 5)
img = wx.Image(240, 240)
self.image_ctrl = wx.StaticBitmap(self,
bitmap=wx.Bitmap(img))
main_sizer.Add(self.image_ctrl, 0, wx.CENTER|wx.ALL, 5
)
download_btn = wx.Button(self, label='Download Image')
download_btn.Bind(wx.EVT_BUTTON, self.on_download)
main_sizer.Add(download_btn, 0, wx.ALL|wx.CENTER, 5)
self.SetSizer(main_sizer)
这里的第一项是给 main_sizer 添加一个垫片。然后添加与标题和 img 相关的小部件。最后添加的小部件仍然是下载按钮。
接下来,您需要编写一个新方法:
def reset_image(self):
img = wx.Image(240, 240)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
reset_image() 方法用于复位 wx。StaticBitmap 回一个空图像。当用户首先使用常规搜索,选择一个项目,然后决定进行高级搜索时,就会发生这种情况。重置图像可以防止用户看到之前选择的项目,并可能使用户感到困惑。
您需要添加的最后一个方法是 load_search_results() :
def load_search_results(self, query):
full_url = base_url + '?' + urlencode(query, quote_via=quote_plus)
r = requests.get(full_url)
data = r.json()
self.search_results = []
for item in data['collection']['items']:
if item.get('data') and len(item.get('data')) > 0:
data = item['data'][0]
if data['title'].strip() == '':
# Skip results with blank titles
continue
result = Result(item)
self.search_results.append(result)
self.update_search_results()
self.reset_image()
使用 pubsub 调用 load_search_results() 方法。 main 和 advanced_search 模块都通过传入查询字典来调用它。然后将字典编码成格式化的 URL。接下来,使用请求发送一个 JSON 请求,然后提取结果。这也是您调用 reset_image() 的地方,这样当加载一组新的结果时,就不会有结果被选中。
现在您已经准备好创建高级搜索了!
高级 _ 搜索. py 脚本
高级搜索模块是一个 wx。面板有你需要的所有小部件来对 NASA 的 API 进行高级搜索。如果你阅读他们的文档,你会发现大约有十几个过滤器可以应用于搜索。
让我们从顶部开始:
class AdvancedSearch(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
self.free_text = wx.TextCtrl(self)
self.ui_helper('Free text search:', self.free_text)
self.nasa_center = wx.TextCtrl(self)
self.ui_helper('NASA Center:', self.nasa_center)
self.description = wx.TextCtrl(self)
self.ui_helper('Description:', self.description)
self.description_508 = wx.TextCtrl(self)
self.ui_helper('Description 508:', self.description_508)
self.keywords = wx.TextCtrl(self)
self.ui_helper('Keywords (separate with commas):',
self.keywords)
设置各种过滤器的代码都非常相似。您为过滤器创建一个文本控件,然后将它和一个字符串一起传递给 ui_helper() ,该字符串是文本控件小部件的标签。重复,直到你有所有的过滤器到位。
以下是其余的过滤器:
self.location = wx.TextCtrl(self)
self.ui_helper('Location:', self.location)
self.nasa_id = wx.TextCtrl(self)
self.ui_helper('NASA ID:', self.nasa_id)
self.photographer = wx.TextCtrl(self)
self.ui_helper('Photographer:', self.photographer)
self.secondary_creator = wx.TextCtrl(self)
self.ui_helper('Secondary photographer:', self.secondary_creator)
self.title = wx.TextCtrl(self)
self.ui_helper('Title:', self.title)
search = wx.Button(self, label='Search')
search.Bind(wx.EVT_BUTTON, self.on_search)
self.main_sizer.Add(search, 0, wx.ALL | wx.CENTER, 5)
self.SetSizer(self.main_sizer)
最后,将 sizer 设置为 main_sizer 。请注意,并非 NASA API 中的所有过滤器都在这段代码中实现。例如,我没有添加 media_type ,因为这个应用程序将被硬编码为只查找图像。然而,如果你想要音频或视频,你可以更新这个应用程序。我也没有包括年初和年末过滤器。如果你愿意,可以随意添加。
现在让我们继续创建 ui_helper() 方法:
def ui_helper(self, label, textctrl):
sizer = wx.BoxSizer()
lbl = wx.StaticText(self, label=label, size=(150, -1))
sizer.Add(lbl, 0, wx.ALL, 5)
sizer.Add(textctrl, 1, wx.ALL | wx.EXPAND, 5)
self.main_sizer.Add(sizer, 0, wx.EXPAND)
ui_helper() 接受标签文本和文本控件小部件。然后它创建一个 wx。BoxSizer 和一个 wx。静态文本。 wx。StaticText 被添加到 sizer 中,传入的文本控件也是如此。最后,新的 sizer 被添加到 main_sizer 中,然后就完成了。这是减少重复代码的好方法。
这个类中最后创建的项目是 on_search() :
def on_search(self, event):
query = {'q': self.free_text.GetValue(),
'media_type': 'image',
'center': self.nasa_center.GetValue(),
'description': self.description.GetValue(),
'description_508': self.description_508.GetValue(),
'keywords': self.keywords.GetValue(),
'location': self.location.GetValue(),
'nasa_id': self.nasa_id.GetValue(),
'photographer': self.photographer.GetValue(),
'secondary_creator': self.secondary_creator.GetValue(),
'title': self.title.GetValue()}
pub.sendMessage('update_ui')
pub.sendMessage('search_results', query=query)
当用户按下搜索按钮时,这个事件处理程序被调用。它根据用户在每个字段中输入的内容创建搜索查询。然后,处理程序将使用 pubsub 发出两条消息。第一条消息将更新 UI,以便隐藏高级搜索并显示搜索结果。第二条消息将根据 NASA 的 API 执行搜索。
以下是高级搜索页面的外观:

美国宇航局图像搜索与高级搜索页面
现在让我们更新下载对话框。
下载 _ 对话框. py 脚本
下载对话框有几处小改动。基本上你需要添加一个 Python 的 os 模块的导入,然后更新 save() 函数。
将以下几行添加到函数的开头:
def save(self, path):
_, ext = os.path.splitext(path)
if ext.lower() != '.jpg':
path = f'{path}.jpg'
添加此代码是为了解决用户没有在保存的文件名中指定图像扩展名的情况。
包扎
这篇文章涵盖了许多有趣的新信息。您了解了一种使用开放 API 的方法,该 API 周围没有 Python 包装器。您发现了阅读 API 文档的重要性,然后为该 API 添加了一个用户界面。然后您学习了如何解析 JSON 和从互联网下载图像。
虽然这里没有涉及,但是 Python 有一个 json 模块,您也可以使用。
以下是增强该应用程序的一些想法:
- 缓存搜索结果
- 在后台下载缩略图
- 在后台下载链接
您可以使用线程下载缩略图和较大的图像,以及进行一般的 web 请求。这将提高应用程序的性能。您可能已经注意到,根据您的互联网连接,应用程序变得稍微没有响应。这是因为当它执行 web 请求或下载文件时,它会阻塞 UI 的主循环。如果你觉得这种事情很麻烦,你应该试试线程。
下载代码
- 源代码作为一个 tarball
相关阅读
- 用 wxPython 创建一个计算器
- 如何分发一个 wxPython 应用
使用 wxPython 创建照片幻灯片应用程序(视频)
原文:https://www.blog.pythonlibrary.org/2020/06/25/creating-a-photo-slideshow-application-with-wxpython/
在本教程中,您将学习如何改进您在之前的视频教程中创建的图像查看器应用程序,使其加载一个图像文件夹。
然后,您将添加一些按钮,以便用户可以在图像中前进和后退,或者播放图像的幻灯片。
https://www.youtube.com/embed/_OskysylW6c?feature=oembed
相关阅读
使用 Jupyter 笔记本和 RISE 创建演示文稿(视频)
在本教程中,您将学习如何使用 Jupyter 笔记本来创建幻灯片演示文稿。这允许您在幻灯片中运行和编辑实时代码。
https://www.youtube.com/embed/T7rVvK4Vc0M?feature=oembed
想了解更多关于 Jupyter 笔记本的信息?然后看看我的书,Jupyter Notebook 101 T1,可以在 T2 Leanpub T3,T4 亚马逊 T5 和 gum road T7 找到
用 wxPython 创建简单的照片查看器
原文:https://www.blog.pythonlibrary.org/2010/03/26/creating-a-simple-photo-viewer-with-wxpython/
有一天,我在 wxPython IRC 频道上和一些 wxPython 新手聊天,其中一个人想知道如何在 wx 中显示图像。有很多不同的方法可以做到这一点,但我有一个预制的解决方案,这是我几年前为了工作拼凑起来的。由于这是一个相当热门的话题,亲爱的读者,我认为让你知道这个秘密是明智的。
图像浏览器拿一个

在 wxPython 中显示图像的最简单的方法之一是使用 wx。StaticBitmap 来做你的脏活。在这个例子中,我们想要一个图像的占位符,所以我们将使用 wx。空白图片。最后,如果图像对于我们的分辨率或应用程序来说太大,我们需要一种方法来缩小图像。为此,我们将使用我从杰出的安德里亚·加瓦那(AGW 图书馆的创建者)那里得到的一个提示。介绍到此为止,让我们看看代码:
import os
import wx
class PhotoCtrl(wx.App):
def __init__(self, redirect=False, filename=None):
wx.App.__init__(self, redirect, filename)
self.frame = wx.Frame(None, title='Photo Control')
self.panel = wx.Panel(self.frame)
self.PhotoMaxSize = 240
self.createWidgets()
self.frame.Show()
def createWidgets(self):
instructions = 'Browse for an image'
img = wx.EmptyImage(240,240)
self.imageCtrl = wx.StaticBitmap(self.panel, wx.ID_ANY,
wx.BitmapFromImage(img))
instructLbl = wx.StaticText(self.panel, label=instructions)
self.photoTxt = wx.TextCtrl(self.panel, size=(200,-1))
browseBtn = wx.Button(self.panel, label='Browse')
browseBtn.Bind(wx.EVT_BUTTON, self.onBrowse)
self.mainSizer = wx.BoxSizer(wx.VERTICAL)
self.sizer = wx.BoxSizer(wx.HORIZONTAL)
self.mainSizer.Add(wx.StaticLine(self.panel, wx.ID_ANY),
0, wx.ALL|wx.EXPAND, 5)
self.mainSizer.Add(instructLbl, 0, wx.ALL, 5)
self.mainSizer.Add(self.imageCtrl, 0, wx.ALL, 5)
self.sizer.Add(self.photoTxt, 0, wx.ALL, 5)
self.sizer.Add(browseBtn, 0, wx.ALL, 5)
self.mainSizer.Add(self.sizer, 0, wx.ALL, 5)
self.panel.SetSizer(self.mainSizer)
self.mainSizer.Fit(self.frame)
self.panel.Layout()
def onBrowse(self, event):
"""
Browse for file
"""
wildcard = "JPEG files (*.jpg)|*.jpg"
dialog = wx.FileDialog(None, "Choose a file",
wildcard=wildcard,
style=wx.OPEN)
if dialog.ShowModal() == wx.ID_OK:
self.photoTxt.SetValue(dialog.GetPath())
dialog.Destroy()
self.onView()
def onView(self):
filepath = self.photoTxt.GetValue()
img = wx.Image(filepath, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.PhotoMaxSize
NewH = self.PhotoMaxSize * H / W
else:
NewH = self.PhotoMaxSize
NewW = self.PhotoMaxSize * W / H
img = img.Scale(NewW,NewH)
self.imageCtrl.SetBitmap(wx.BitmapFromImage(img))
self.panel.Refresh()
if __name__ == '__main__':
app = PhotoCtrl()
app.MainLoop()
你可能认为这个例子有点复杂。嗯,实际上并没有那么糟糕,因为代码只有 76 行长!让我们检查一下各种方法,看看发生了什么。
def __init__(self, redirect=False, filename=None):
wx.App.__init__(self, redirect, filename)
self.frame = wx.Frame(None, title='Photo Control')
self.panel = wx.Panel(self.frame)
self.PhotoMaxSize = 500
self.createWidgets()
self.frame.Show()
init 初始化 wx。App 对象,实例化一个框架并添加一个面板作为该框架的唯一子级。我们将照片的最大尺寸设置为 500 像素,以便于查看,但不会对我们的显示器太大。然后我们调用我们的 createWidgets 方法,最后通过调用 Show()显示该帧。因为我们之前已经讨论过 EmptyImage 小部件,所以我认为跳过 createWidgets 方法是安全的,并且继续讨论一个警告。注意来自 createWidgets 的最后三行:
self.panel.SetSizer(self.mainSizer)
self.mainSizer.Fit(self.frame)
self.panel.Layout()
这将设置面板的 sizer,然后使框架适合 sizer 中包含的小部件。这将保持应用程序看起来整洁,因为我们不会有一堆额外的像素价值的面板突出在奇怪的地方。试试没有这些线,看看如果你不能想象会发生什么!
接下来是我们的 onBrowse 方法:
def onBrowse(self, event):
"""
Browse for file
"""
wildcard = "JPEG files (*.jpg)|*.jpg"
dialog = wx.FileDialog(None, "Choose a file",
wildcard=wildcard,
style=wx.OPEN)
if dialog.ShowModal() == wx.ID_OK:
self.photoTxt.SetValue(dialog.GetPath())
dialog.Destroy()
self.onView()
首先,我们创建一个仅指定 JPEG 文件的通配符,然后将它传递给我们的 wx。FileDialog 构造函数。这将限制对话框,使其只显示 JPEG 文件。如果用户按下 OK(或 Open)按钮,那么我们将photo XT控件的值设置为所选文件的路径。我们可能应该添加一些错误检查,以确保该文件是一个有效的 JPEG 文件,但我们将把它作为读者的练习。设置好值后,对话框被破坏,调用 onView ,将显示图片。让我们看看它是如何工作的:
def onView(self):
filepath = self.photoTxt.GetValue()
img = wx.Image(filepath, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.PhotoMaxSize
NewH = self.PhotoMaxSize * H / W
else:
NewH = self.PhotoMaxSize
NewW = self.PhotoMaxSize * W / H
img = img.Scale(NewW,NewH)
self.imageCtrl.SetBitmap(wx.BitmapFromImage(img))
self.panel.Refresh()
self.mainSizer.Fit(self.frame)
首先,我们从 photo text 控件中获取图像的路径,并创建一个 wx 实例。使用该信息成像。接下来,我们获取文件的宽度和高度,并使用简单的计算将图片缩小到我们在开始时指定的大小。然后我们调用 StaticBitmap 的 SetBitmap()方法来显示图像。最后,我们刷新面板,以便重新绘制所有内容,我们调用 sizer 的 Fit 方法,以便调整框架大小,以适当的方式适应新照片。现在我们有一个全功能的图像浏览器!
打造更好的照片浏览器

如果你是我的一个敏锐的读者,你会注意到每次你想在你的图片文件夹中查看一张新图片,你需要浏览它。这不是一个好的用户体验,是吗?让我们尝试扩展我们的控制,这样我们可以做到以下几点:
- 添加“上一页”和“下一页”按钮,在图片上向前和向后移动
- 创建一个可以“播放”照片的按钮(即经常更换照片)
- 让“上一个”和“下一个”按钮足够“智能”,当它们到达文件列表的末尾时可以重新开始
对于我们的第一个技巧,我们将把框架和面板放入单独的类中,并且只使用 PySimpleApp 而不是 App。这使得我们的代码更加有序,尽管它也有一些缺点(比如框架和面板之间的通信)。面板将容纳我们的大部分小部件,所以让我们先看看 frame 类,因为它简单得多:
import glob
import wx
from wx.lib.pubsub import Publisher
########################################################################
class ViewerFrame(wx.Frame):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, title="Image Viewer")
panel = ViewerPanel(self)
self.folderPath = ""
Publisher().subscribe(self.resizeFrame, ("resize"))
self.initToolbar()
self.sizer = wx.BoxSizer(wx.VERTICAL)
self.sizer.Add(panel, 1, wx.EXPAND)
self.SetSizer(self.sizer)
self.Show()
self.sizer.Fit(self)
self.Center()
#----------------------------------------------------------------------
def initToolbar(self):
"""
Initialize the toolbar
"""
self.toolbar = self.CreateToolBar()
self.toolbar.SetToolBitmapSize((16,16))
open_ico = wx.ArtProvider.GetBitmap(wx.ART_FILE_OPEN, wx.ART_TOOLBAR, (16,16))
openTool = self.toolbar.AddSimpleTool(wx.ID_ANY, open_ico, "Open", "Open an Image Directory")
self.Bind(wx.EVT_MENU, self.onOpenDirectory, openTool)
self.toolbar.Realize()
#----------------------------------------------------------------------
def onOpenDirectory(self, event):
"""
Opens a DirDialog to allow the user to open a folder with pictures
"""
dlg = wx.DirDialog(self, "Choose a directory",
style=wx.DD_DEFAULT_STYLE)
if dlg.ShowModal() == wx.ID_OK:
self.folderPath = dlg.GetPath()
print self.folderPath
picPaths = glob.glob(self.folderPath + "\\*.jpg")
print picPaths
Publisher().sendMessage("update images", picPaths)
#----------------------------------------------------------------------
def resizeFrame(self, msg):
""""""
self.sizer.Fit(self)
如果你读过很多 wxPython 代码,那么上面的代码对你来说应该很熟悉。我们像往常一样构造框架,然后创建我们的 ViewerPanel 的一个实例,并将其传递给 self ,这样面板将有一个对框架的引用。下一个要点是创建我们的 Pubsub 监听器 singleton。这将调用框架的 resizeFrame 方法,该方法仅在我们显示新图片时被调用。下一个重要的部分是对 initToolbar 的调用,它在我们的框架上创建了一个工具栏。框架的另一个方法是 onOpenDirectory ,它与我们第一个应用程序中的浏览功能非常相似。在这种情况下,我们希望选择整个文件夹,并且只从中提取 JPEG 文件的路径。因此,我们使用 Python 的 glob 文件来完成这项工作。完成后,它会向面板发送一条 pubsub 消息,以及图片路径列表。
现在我们可以看看最重要的一段代码:ViewerPanel。
import wx
from wx.lib.pubsub import Publisher
########################################################################
class ViewerPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent)
width, height = wx.DisplaySize()
self.picPaths = []
self.currentPicture = 0
self.totalPictures = 0
self.photoMaxSize = height - 200
Publisher().subscribe(self.updateImages, ("update images"))
self.slideTimer = wx.Timer(None)
self.slideTimer.Bind(wx.EVT_TIMER, self.update)
self.layout()
#----------------------------------------------------------------------
def layout(self):
"""
Layout the widgets on the panel
"""
self.mainSizer = wx.BoxSizer(wx.VERTICAL)
btnSizer = wx.BoxSizer(wx.HORIZONTAL)
img = wx.EmptyImage(self.photoMaxSize,self.photoMaxSize)
self.imageCtrl = wx.StaticBitmap(self, wx.ID_ANY,
wx.BitmapFromImage(img))
self.mainSizer.Add(self.imageCtrl, 0, wx.ALL|wx.CENTER, 5)
self.imageLabel = wx.StaticText(self, label="")
self.mainSizer.Add(self.imageLabel, 0, wx.ALL|wx.CENTER, 5)
btnData = [("Previous", btnSizer, self.onPrevious),
("Slide Show", btnSizer, self.onSlideShow),
("Next", btnSizer, self.onNext)]
for data in btnData:
label, sizer, handler = data
self.btnBuilder(label, sizer, handler)
self.mainSizer.Add(btnSizer, 0, wx.CENTER)
self.SetSizer(self.mainSizer)
#----------------------------------------------------------------------
def btnBuilder(self, label, sizer, handler):
"""
Builds a button, binds it to an event handler and adds it to a sizer
"""
btn = wx.Button(self, label=label)
btn.Bind(wx.EVT_BUTTON, handler)
sizer.Add(btn, 0, wx.ALL|wx.CENTER, 5)
#----------------------------------------------------------------------
def loadImage(self, image):
""""""
image_name = os.path.basename(image)
img = wx.Image(image, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.photoMaxSize
NewH = self.photoMaxSize * H / W
else:
NewH = self.photoMaxSize
NewW = self.photoMaxSize * W / H
img = img.Scale(NewW,NewH)
self.imageCtrl.SetBitmap(wx.BitmapFromImage(img))
self.imageLabel.SetLabel(image_name)
self.Refresh()
Publisher().sendMessage("resize", "")
#----------------------------------------------------------------------
def nextPicture(self):
"""
Loads the next picture in the directory
"""
if self.currentPicture == self.totalPictures-1:
self.currentPicture = 0
else:
self.currentPicture += 1
self.loadImage(self.picPaths[self.currentPicture])
#----------------------------------------------------------------------
def previousPicture(self):
"""
Displays the previous picture in the directory
"""
if self.currentPicture == 0:
self.currentPicture = self.totalPictures - 1
else:
self.currentPicture -= 1
self.loadImage(self.picPaths[self.currentPicture])
#----------------------------------------------------------------------
def update(self, event):
"""
Called when the slideTimer's timer event fires. Loads the next
picture from the folder by calling th nextPicture method
"""
self.nextPicture()
#----------------------------------------------------------------------
def updateImages(self, msg):
"""
Updates the picPaths list to contain the current folder's images
"""
self.picPaths = msg.data
self.totalPictures = len(self.picPaths)
self.loadImage(self.picPaths[0])
#----------------------------------------------------------------------
def onNext(self, event):
"""
Calls the nextPicture method
"""
self.nextPicture()
#----------------------------------------------------------------------
def onPrevious(self, event):
"""
Calls the previousPicture method
"""
self.previousPicture()
#----------------------------------------------------------------------
def onSlideShow(self, event):
"""
Starts and stops the slideshow
"""
btn = event.GetEventObject()
label = btn.GetLabel()
if label == "Slide Show":
self.slideTimer.Start(3000)
btn.SetLabel("Stop")
else:
self.slideTimer.Stop()
btn.SetLabel("Slide Show")
我们不打算在这堂课中复习每一个方法,我们只是浏览一下重点。放心吧!我们跳过的方法非常容易掌握,如果你不明白,请随意评论这篇文章或者在 wxPython 邮件列表上提问。我们的第一项任务是查看 init。在很大程度上,这是一个非常正常的初始化,但是我们也有一些愚蠢的行:
width, height = wx.DisplaySize()
self.photoMaxSize = height - 200
这是怎么回事?这里的想法是获得用户的显示器分辨率,然后将应用程序调整到合适的高度。我们希望它位于任务栏的上方和屏幕顶部的下方。这就是我们在这里做的一切。请注意,这是在 Windows 7 上测试的,因此您可能需要根据您选择的操作系统进行相应的调整。 loadImage 与我们在第一个例子中看到的几乎完全相同。唯一不同的是,我们使用 pubsub 来告诉框架调整大小。从技术上讲,你也可以这样做:self . frame . sizer . fit(self . frame)。这就是所谓的坏代码。请改用 pubsub 方法。
下一张图片和前一张图片的方法非常相似,可能应该合并,但现在我们将让它们保持原样。在这两种方法中,我们使用 currentPicture 属性,并根据需要增加或减少,以转到下一张或上一张图片。我们还检查是否达到了上限或下限(即零或总图片数),并相应地重置 currentPicture。这允许我们永远循环所有的照片。既然我们已经讨论了自行车,我们需要想出如何做一个幻灯片。这其实很简单。
首先,我们创建一个 wx。Timer 对象,并将其绑定到 update 方法。当按下“幻灯片放映”按钮时,计时器启动或停止。如果它被启动,那么计时器将每 3 秒触发一次(1000 = 1 秒),这将调用更新方法,该方法调用下一张图片方法。如您所见,Python 使得一切都变得非常简单。其余的方法都是简单的实用方法,由其他方法调用。
包扎
我希望你觉得这很有趣。我将努力把这个例子扩展成更酷的东西,我一定会在这里分享我想到的任何东西。就在几天前,wxPython IRC 频道上有人认为,如果有一系列关于简单工作的 wxPython 应用程序的文章,那会很酷。把这当成第一次(或者第二次,如果你算上 wxPyMail )。希望我能想出一些其他有趣的。
注意:这段代码已经在 Windows 7 家庭版(32 位)、wxPython 2.8.10.1、Python 2.6 上测试过
下载
使用 wxPython 创建简单的向导(视频)
原文:https://www.blog.pythonlibrary.org/2021/09/10/creating-a-simple-wizard-with-wxpython-video/
在本视频教程中,您将学习如何使用 wxPython GUI 工具包创建向导:
https://www.youtube.com/embed/dwe0jUnSrXo?feature=oembed
相关教程
用 wxPython 创建文本搜索 GUI
原文:https://www.blog.pythonlibrary.org/2021/09/04/creating-a-text-search-gui-with-wxpython/
在前面的教程中,您学习了如何使用 wxPython 创建文件搜索 GUI。在本文中,您将学习如何使用 wxPython 创建一个文本搜索实用程序。
如果你想了解更多关于创建 GUI 应用程序的知识,你应该看看我的书用 wxPython 在 Leanpub 、 Gumroad 或 Amazon 上创建 GUI 应用程序。
你可以在 GitHub 上下载这篇文章的源代码。注意:本文依赖于来自的用 wxPython 创建文件搜索 GUI 的一些代码。
现在,让我们开始吧!
文本搜索实用程序
文本搜索工具是一种可以在其他文件中搜索单词或短语的工具,比如流行的 GNU grep 工具。有一些工具也可以搜索 Microsoft Word、PDF 文件内容等等。您将只专注于搜索文本文件。除了常规文本文件之外,这些文件还包括 XML、HTML、Python 文件和其他代码文件。
有一个很好的 Python 包为我们做文本搜索,名为grin。因为这本书使用的是 Python 3,你会想要使用grin3,因为这是与 Python 3 兼容的grin的版本。
您可以在此阅读关于该套餐的所有信息:
您将在这个包的顶部添加一个轻量级用户界面,允许您使用它来搜索文本文件。
安装依赖项
您可以使用pip安装grin3:
pip install grin3
一旦安装完毕,你将能够在 Mac 或 Linux 上从命令行运行grin或grind。如果您在 Windows 上,您可能需要将它添加到您的路径中。
警告:grin3之前的版本是grin。如果你把它安装到 Python 3 中并试图运行它,你会看到错误,因为grin与Python 3 不兼容。你需要卸载grin,然后安装grin3。
现在你可以设计你的用户界面了!
设计文本搜索工具
您可以从本章前面的文件搜索实用程序中获取代码,并修改用户界面以用于文本搜索。您现在不关心搜索词是否区分大小写,所以您可以删除这个小部件。你也可以去掉子目录复选框,因为默认情况下grin会搜索子目录,这也是你想要的。
您仍然可以按文件类型过滤,但是为了简单起见,让我们也删除它。但是,您需要一种方法来显示找到的文件以及包含找到的文本的行。为此,除了ObjectListView小部件之外,您还需要添加一个多行文本控件。
记住所有这些,这里是模型:

是时候开始编码了!
创建文本搜索实用程序
新的文本搜索工具将分为三个模块:
- 主模块
- 搜索线程模块
- 偏好模块
主模块将包含主用户界面的代码。 search_thread 模块将包含使用grin搜索文本的逻辑。最后,首选项将用于创建一个对话框,您可以用它来保存grin可执行文件的位置。
现在您可以开始创建主模块。
主模块
主模块不仅保存用户界面,它还会检查以确保你已经安装了grin以便它能够工作。它还将启动首选项对话框,并向用户显示搜索结果(如果有)。
下面是前几行代码:
# main.py
import os
import sys
import subprocess
import time
import wx
from configparser import ConfigParser, NoSectionError
from ObjectListView import ObjectListView, ColumnDefn
from preferences import PreferencesDialog
from pubsub import pub
from search_thread import SearchThread
这个主模块与之前版本的主模块有许多相同的导入。然而在这一个中,你将使用 Python 的configparser模块以及创建一个PreferencesDialog和一个SearchThread。其余的导入应该是不言自明的。
您需要复制SearchResult类,并像这样修改它:
class SearchResult:
def __init__(self, path, modified_time, data):
self.path = path
self.modified = time.strftime('%D %H:%M:%S',
time.gmtime(modified_time))
self.data = data
该类现在接受一个新的参数data,它保存一个字符串,该字符串包含在文件中找到搜索词的所有位置的引用。当用户选择一个搜索结果时,您将向用户显示该信息。
但是首先,您需要创建 UI:
class MainPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.search_results = []
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
self.create_ui()
self.SetSizer(self.main_sizer)
pub.subscribe(self.update_search_results, 'update')
module_path = os.path.dirname(os.path.abspath( __file__ ))
self.config = os.path.join(module_path, 'config.ini')
if not os.path.exists(self.config):
message = 'Unable to find grin3 for text searches. ' \
'Install grin3 and open preferences to ' \
'configure it: pip install grin3'
self.show_error(message)
像以前一样,MainPanel建立一个空的search_results列表。它还通过调用create_ui()创建了 UI,并添加了一个pubsub订阅。但是添加了一些新代码来获取脚本的路径并检查配置文件。如果配置文件不存在,你向用户显示一条消息,告诉他们需要安装grin3并使用首选项菜单配置应用程序。
现在让我们看看用户界面代码是如何变化的:
def create_ui(self):
# Create a widgets for the search path
row_sizer = wx.BoxSizer()
lbl = wx.StaticText(self, label='Location:')
row_sizer.Add(lbl, 0, wx.ALL | wx.CENTER, 5)
self.directory = wx.TextCtrl(self, style=wx.TE_READONLY)
row_sizer.Add(self.directory, 1, wx.ALL | wx.EXPAND, 5)
open_dir_btn = wx.Button(self, label='Choose Folder')
open_dir_btn.Bind(wx.EVT_BUTTON, self.on_choose_folder)
row_sizer.Add(open_dir_btn, 0, wx.ALL, 5)
self.main_sizer.Add(row_sizer, 0, wx.EXPAND)
这段代码将创建一个水平的row_sizer并添加三个小部件:一个标签、一个保存要搜索的文件夹的文本控件和一个选择该文件夹的按钮。这一系列小部件与其他代码示例中的小部件相同。
事实上,下面的搜索控制代码也是如此:
# Add search bar
self.search_ctrl = wx.SearchCtrl(
self, style=wx.TE_PROCESS_ENTER, size=(-1, 25))
self.search_ctrl.Bind(wx.EVT_SEARCHCTRL_SEARCH_BTN, self.on_search)
self.search_ctrl.Bind(wx.EVT_TEXT_ENTER, self.on_search)
self.main_sizer.Add(self.search_ctrl, 0, wx.ALL | wx.EXPAND, 5)
同样,您创建了一个wx.SearchCtrl实例,并将其绑定到相同的事件和相同的事件处理程序。事件处理程序的代码会有所不同,但是您很快就会看到变化。
让我们先完成小部件代码:
# Search results widget
self.search_results_olv = ObjectListView(
self, style=wx.LC_REPORT | wx.SUNKEN_BORDER)
self.search_results_olv.SetEmptyListMsg("No Results Found")
self.search_results_olv.Bind(wx.EVT_LIST_ITEM_SELECTED,
self.on_selection)
self.main_sizer.Add(self.search_results_olv, 1, wx.ALL | wx.EXPAND, 5)
self.update_ui()
self.results_txt = wx.TextCtrl(
self, style=wx.TE_MULTILINE | wx.TE_READONLY)
self.main_sizer.Add(self.results_txt, 1, wx.ALL | wx.EXPAND, 5)
show_result_btn = wx.Button(self, label='Open Containing Folder')
show_result_btn.Bind(wx.EVT_BUTTON, self.on_show_result)
self.main_sizer.Add(show_result_btn, 0, wx.ALL | wx.CENTER, 5)
当用户在ObjectListView小部件中选择一个搜索结果时,触发on_selection事件处理程序。您获取选择,然后将文本控件值设置为data属性。data属性是字符串的list,因此您需要使用字符串的join()方法,通过换行符\n将所有这些行连接在一起。您希望每一行都在自己的行上,以便于阅读结果。
您可以将文件搜索实用程序中的on_show_result()方法复制到这个程序中,因为该方法不需要任何更改。
下一个要写的新代码是on_search()方法:
def on_search(self, event):
search_term = self.search_ctrl.GetValue()
self.search(search_term)
这次的on_search()方法要简单得多,因为您只需要获取search_term。在这个版本的应用程序中没有任何过滤器,这无疑减少了代码混乱。一旦你有了要搜索的术语,你就打电话给search()。
说到这里,这是下一个要创建的方法:
def search(self, search_term):
"""
Search for the specified term in the directory and its
sub-directories
"""
folder = self.directory.GetValue()
config = ConfigParser()
config.read(self.config)
try:
grin = config.get("Settings", "grin")
except NoSectionError:
self.show_error('Settings or grin section not found')
return
if not os.path.exists(grin):
self.show_error(f'Grin location does not exist {grin}')
return
if folder:
self.search_results = []
SearchThread(folder, search_term)
search()代码将获得folder路径并创建一个config对象。然后,它将尝试打开配置文件。如果配置文件不存在或无法读取“设置”部分,您将显示一条错误消息。如果“Settings”部分存在,但grin可执行文件的路径不存在,您将显示不同的错误消息。但是如果你通过了这两个关卡,文件夹本身也设置好了,那么你就可以开始SearchThread了。该代码保存在另一个模块中,所以您必须等待了解这一点。
现在,让我们看看show_error()方法中发生了什么:
def show_error(self, message):
with wx.MessageDialog(None, message=message,
caption='Error',
style= wx.ICON_ERROR) as dlg:
dlg.ShowModal()
这个方法将创建一个wx.MessageDialog并向用户显示一个错误,并向用户传递一个message。该函数对于显示错误非常方便。如果你想显示其他类型的消息,你可以稍微更新一下。
当搜索完成时,它将发出一条pubsub消息,这将导致以下代码执行:
def update_search_results(self, results):
"""
Called by pubsub from thread
"""
for key in results:
if os.path.exists(key):
stat = os.stat(key)
modified_time = stat.st_mtime
result = SearchResult(key, modified_time, results[key])
self.search_results.append(result)
if results:
self.update_ui()
else:
search_term = self.search_ctrl.GetValue()
self.search_results_olv.ClearAll()
msg = f'No Results Found for: "{search_term}"'
self.search_results_olv.SetEmptyListMsg(msg)
这个方法接受一个dict搜索结果。然后,它遍历dict中的键,并验证路径是否存在。如果是的话,那么您使用os.stat()来获取关于文件的信息并创建一个SearchResult对象,然后将它append()到您的search_results。
当搜索没有返回结果时,您将希望清除搜索结果小部件,并通知用户他们的搜索没有找到任何结果。
update_ui()代码与前面的代码几乎完全相同:
def update_ui(self):
self.search_results_olv.SetColumns([
ColumnDefn("File Path", "left", 800, "path"),
ColumnDefn("Modified Time", "left", 150, "modified")
])
self.search_results_olv.SetObjects(self.search_results)
这里唯一的区别是列比文件搜索工具中的要宽一些。这是因为在测试过程中发现的许多结果往往是相当长的字符串。
wx.Frame的代码也发生了变化,因为您现在可以添加一个菜单:
class Search(wx.Frame):
def __init__(self):
super().__init__(None, title='Text Search Utility',
size=(1200, 800))
pub.subscribe(self.update_status, 'status')
panel = MainPanel(self)
self.create_menu()
self.statusbar = self.CreateStatusBar(1)
self.Show()
def update_status(self, search_time):
msg = f'Search finished in {search_time:5.4} seconds'
self.SetStatusText(msg)
这里你创建了一个Search框架,并设置了一个比其他工具更宽的尺寸。您还将创建面板、订户和菜单。update_status()方法和上次一样。
真正新的一点是对create_menu()的调用,这也是接下来要做的:
def create_menu(self):
menu_bar = wx.MenuBar()
# Create file menu
file_menu = wx.Menu()
preferences = file_menu.Append(
wx.ID_ANY, "Preferences",
"Open Preferences Dialog")
self.Bind(wx.EVT_MENU, self.on_preferences,
preferences)
exit_menu_item = file_menu.Append(
wx.ID_ANY, "Exit",
"Exit the application")
menu_bar.Append(file_menu, '&File')
self.Bind(wx.EVT_MENU, self.on_exit,
exit_menu_item)
self.SetMenuBar(menu_bar)
在这段代码中,您创建了MenuBar并添加了一个file_menu。在该菜单中,添加两个菜单项;一个用于preferences,一个用于退出应用程序。
您可以首先创建退出代码:
def on_exit(self, event):
self.Close()
如果用户进入文件菜单并选择“退出”,该代码将会执行。当他们这样做时,你的应用程序将Close()。由于框架是最顶层的窗口,当它关闭时,它也会自我毁灭。
该类中的最后一段代码用于创建首选项对话框:
def on_preferences(self, event):
with PreferencesDialog() as dlg:
dlg.ShowModal()
在这里,您实例化了PreferencesDialog并显示给用户。当用户关闭对话框时,它将被自动销毁。
您需要将以下代码添加到文件的末尾,以便代码能够运行:
if __name__ == '__main__':
app = wx.App(False)
frame = Search()
app.MainLoop()
当您完成了该应用程序的其余部分的编码后,它将如下所示:

注意,当您进行搜索时,grin允许正则表达式,所以您也可以在 GUI 中输入它们。
下一步是创建线程代码!
搜索线程模块
search_thread 模块包含使用grin3可执行文件在文件中搜索文本的逻辑。在这个模块中,您只需要一个Thread的子类,因为您将总是搜索子目录。
第一步是创建导入:
# search_thread.py
import os
import subprocess
import time
import wx
from configparser import ConfigParser
from pubsub import pub
from threading import Thread
对于搜索线程模块,您需要访问os、subprocess和time模块。新的模块是subprocess模块,因为您将启动一个外部应用程序。这里的另一个新增功能是ConfigParser,它用于从配置文件中获取可执行文件的路径。
让我们继续创建SearchThread本身:
class SearchThread(Thread):
def __init__(self, folder, search_term):
super().__init__()
self.folder = folder
self.search_term = search_term
module_path = os.path.dirname(os.path.abspath( __file__ ))
self.config = os.path.join(module_path, 'config.ini')
self.start()
__init__()方法接受目标folder和search_term来寻找。它还重新创建了module_path来导出config文件的位置。
最后一步是start()线程。当这个方法被调用时,它调用了run()方法。
让我们忽略下一个:
def run(self):
start = time.time()
config = ConfigParser()
config.read(self.config)
grin = config.get("Settings", "grin")
cmd = [grin, self.search_term, self.folder]
output = subprocess.check_output(cmd, encoding='UTF-8')
current_key = ''
results = {}
for line in output.split('\n'):
if self.folder in line:
# Remove the colon off the end of the line
current_key = line[:-1]
results[current_key] = []
elif not current_key:
# key not set, so skip it
continue
else:
results[current_key].append(line)
end = time.time()
wx.CallAfter(pub.sendMessage,
'update',
results=results)
wx.CallAfter(pub.sendMessage, 'status', search_time=end-start)
在这里,您添加一个start时间,并获得应该在此时创建的config。接下来,您创建一个命令的list。grin实用程序将搜索词和要搜索的目录作为其主要参数。实际上,您可以添加其他参数来使搜索更有针对性,但这需要额外的 UI 元素,并且您的目标是保持该应用程序美观简单。
下一步是调用获取命令列表的subprocess.check_output()。你还把encoding设置为 UTF-8。这告诉subprocess模块返回一个字符串,而不是字节串,它还验证返回值是否为零。
现在需要对返回的结果进行解析。您可以通过在换行符上拆分来循环遍历每一行。每个文件路径应该是唯一的,所以它们将成为您的results字典的关键字。请注意,您需要删除该行的最后一个字符,因为键的末尾有一个冒号。这会使路径无效,所以删除它是个好主意。然后,对于路径后面的每一行数据,将它附加到字典中特定键的值上。
完成后,您通过pubsub发送两条消息来更新 UI 和状态栏。
现在是时候创建最后一个模块了!
首选项模块
首选项模块包含创建PreferencesDialog所需的代码,这将允许您配置grin可执行文件在您机器上的位置。
让我们从进口开始:
# preferences.py
import os
import wx
from configparser import ConfigParser
幸运的是,模块的导入部分很短。你只需要os、wx和configparser模块就能完成这项工作。
既然你已经弄清楚了那部分,你可以通过进入文件- >首选项菜单来创建对话框本身:
class PreferencesDialog(wx.Dialog):
def __init__(self):
super().__init__(None, title='Preferences')
module_path = os.path.dirname(os.path.abspath( __file__ ))
self.config = os.path.join(module_path, 'config.ini')
if not os.path.exists(self.config):
self.create_config()
config = ConfigParser()
config.read(self.config)
self.grin = config.get("Settings", "grin")
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
self.create_ui()
self.SetSizer(self.main_sizer)
在这里,您创建了__init__()方法并获得了module_path,这样您就可以找到config。然后验证config是否存在。如果没有,那么创建配置文件,但是不要设置可执行文件的位置。
您确实试图通过config.get()获得它的位置,但是如果它在文件中是空白的,那么您将得到一个空字符串。
最后三行设置了一个 sizer 并调用create_ui()。
接下来您应该编写最后一个方法:
def create_ui(self):
row_sizer = wx.BoxSizer()
lbl = wx.StaticText(self, label='Grin3 Location:')
row_sizer.Add(lbl, 0, wx.ALL | wx.CENTER, 5)
self.grin_location = wx.TextCtrl(self, value=self.grin)
row_sizer.Add(self.grin_location, 1, wx.ALL | wx.EXPAND, 5)
browse_button = wx.Button(self, label='Browse')
browse_button.Bind(wx.EVT_BUTTON, self.on_browse)
row_sizer.Add(browse_button, 0, wx.ALL, 5)
self.main_sizer.Add(row_sizer, 0, wx.EXPAND)
save_btn = wx.Button(self, label='Save')
save_btn.Bind(wx.EVT_BUTTON, self.save)
self.main_sizer.Add(save_btn, 0, wx.ALL | wx.CENTER, 5)
在这段代码中,您创建了一行小部件。一个标签、一个保存可执行文件路径的文本控件和一个浏览该路径的按钮。您将所有这些添加到 sizer 中,然后 sizer 嵌套在main_sizer中。然后在对话框底部添加一个“保存”按钮。
下面是从头开始创建配置的代码:
def create_config(self):
config = ConfigParser()
config.add_section("Settings")
config.set("Settings", 'grin', '')
with open(self.config, 'w') as config_file:
config.write(config_file)
当配置不存在时,将调用该代码。它实例化一个ConfigParser对象,然后向其添加适当的部分和设置。然后将它写到磁盘的适当位置。
save()方法可能是下一段最重要的代码:
def save(self, event):
grin_location = self.grin_location.GetValue()
if not grin_location:
self.show_error('Grin location not set!')
return
if not os.path.exists(grin_location):
self.show_error(f'Grin location does not exist {grin_location}')
return
config = ConfigParser()
config.read(self.config)
config.set("Settings", "grin", grin_location)
with open(self.config, 'w') as config_file:
config.write(config_file)
self.Close()
在这里,您从文本控件中获得了grin应用程序的位置,如果没有设置,就会显示一个错误。如果该位置不存在,也会显示错误。但是,如果设置了它并且它确实存在,那么您打开配置文件备份并保存配置文件的路径,供主应用程序使用。一旦保存完成,你Close()对话框。
最后一个常规方法用于显示错误:
def show_error(self, message):
with wx.MessageDialog(None, message=message,
caption='Error',
style= wx.ICON_ERROR) as dlg:
dlg.ShowModal()
这段代码实际上和你在主模块中的show_error()方法完全一样。每当你在代码中看到这样的事情,你知道你应该重构它。这个方法可能应该进入它自己的模块,然后导入到主和首选项模块。不过你可以自己想办法做到这一点。
最后,您需要为这个类创建唯一的事件处理程序:
def on_browse(self, event):
"""
Browse for the grin file
"""
wildcard = "All files (*.*)|*.*"
with wx.FileDialog(None, "Choose a file",
wildcard=wildcard,
style=wx.ID_OPEN) as dialog:
if dialog.ShowModal() == wx.ID_OK:
self.grin_location.SetValue(dialog.GetPath())
当用户按下“浏览”按钮去寻找可执行文件 grin 时,这个事件处理器被调用。当他们找到文件时,他们可以选择它,文本控件将被设置到它的位置。
现在你已经把对话框全部编码好了,下面是它的样子:

包扎
现在您知道了如何使用 Python 和 wxPython GUI 工具包创建文本搜索实用程序。
以下是您可以添加的一些增强功能:
- 添加停止搜索的功能
- 防止多个搜索同时发生
- 添加其他过滤器
您还可以通过添加对更多 grin 命令行选项的支持来增强它。查看 grin 的文档以获得关于该主题的更多信息。
用 Python 和 PySimpleGUI 创建井字游戏(视频)
在本教程中,您将学习如何使用 PySimpleGUI 和 Python 创建井字游戏。
https://www.youtube.com/embed/AsNbI83uwTs?feature=oembed
下载代码
用枕头和蟒蛇皮创作沃霍尔三联画
安迪·沃霍尔是一位著名的艺术家,他创造了一幅著名的图像,其中有同一张脸的多个副本,但背景颜色不同。
你可以用 Python 和 Pillow package 的软件做类似的事情。您还需要安装 NumPy 来完成这项工作。
让我们来看看这一切是如何运作的!
入门指南
你需要做的第一件事是确保你有枕头和 NumPy 安装。如果您使用 pip,可以尝试运行以下命令:
python3 -m pip install numpy Pillow
如果您还没有安装 NumPy 和 Pillow,这将安装它们。
如果您运行的是 Anaconda,那么这两个包应该已经安装好了。
现在你已经准备好创作一些艺术品了!
创作三联画
用 Python 创建三联画并不需要很多代码。你所需要的只是一点知识和一些实验。第一步是了解你为什么需要 NumPy。
NumPy 与其说是枕头的替代品,不如说是增强枕头功能的一种方式。您可以使用 NumPy 来做 Pillow 本身做的一些事情。对于本节中的示例,您将使用作者的这张照片:
迈克尔·德里斯科尔
为了体验如何在 Pillow 中使用 NumPy,您将创建一个 Python 程序,将几个图像连接在一起。这将创建您的三联图像!打开 Python 编辑器,创建一个名为concatenating.py的新文件。然后在其中输入以下代码:
# concatenating.py
import numpy as np
from PIL import Image
def concatenate(input_image_path, output_path):
image = np.array(Image.open(input_image_path))
red = image.copy()
red[:, :, (1, 2)] = 0
green = image.copy()
green[:, :, (0, 2)] = 0
blue = image.copy()
blue[:, :, (0, 1)] = 0
rgb = np.concatenate((red, green, blue), axis=1)
output = Image.fromarray(rgb)
output.save(output_path)
if __name__ == "__main__":
concatenate("author.jpg", "stacked.jpg")
这段代码将使用 Pillow 打开图像。然而,不是将图像保存为一个Image对象,而是将该对象传递到一个 Numpy array()中。然后创建数组的三个副本,并使用一些矩阵数学将其他颜色通道清零。例如,对于red,你将绿色和蓝色通道归零,只留下红色通道。
当你这样做时,它将创建原始图像的三个着色版本。你现在会有一个红色,绿色和蓝色版本的照片。然后使用 NumPy 将三幅图像连接成一幅。
为了保存这个新图像,您使用 Pillow 的Image.fromarray()方法将 NumPy 数组转换回 Pillow Image对象。
运行此代码后,您将看到以下结果:

这是一个整洁的效果!
NumPy 可以做 Pillow 不容易做的其他事情,比如二值化或者去噪。当您将 NumPy 与其他科学 Python 包(如 SciPy 或 Pandas)结合使用时,您可以做得更多。
包扎
Python 功能强大。你可以用 Python,Pillow 和 NumPy 做很多事情。你应该试着用你自己的图像做这件事,看看你能想出什么。例如,您可以创建四个图像并将它们放在一个正方形中,而不是从左到右排列图像!
相关阅读
- 如何使用 Python 改变图像的颜色?
- StackOverflow: Python PIL 图像分割成 RGB
- 枕头:用 Python 进行图像处理
用 Python 制作动画 GIF
原文:https://www.blog.pythonlibrary.org/2021/06/23/creating-an-animated-gif-with-python/
动画 gif 是一种图像类型,包含多幅略有不同的图像。然后这些像卡通一样被回放。你甚至可以把它想象成一本翻页的书,每一页都有一个小棍。当你翻书的时候,图像似乎在移动。
您可以使用 Python 编程语言和 Pillow 包创建自己的动画 gif。
我们开始吧!
你需要什么
你需要在你的机器上安装 Python。你可以从 Python 网站安装或者使用 Anaconda 。你还需要有枕头。如果您使用的是 Anaconda,Pillow 已经安装了。
否则,您将需要安装枕头。下面是如何使用画中画:
python3 -m pip install Pillow
一旦 Pillow 安装完毕,你就可以创建 GIF 了!
创建动画
你需要有多个动画帧来创建一个动画 GIF。如果你有一个好的傻瓜相机或 DSLR 相机,你通常可以使用它们的高速设置来快速拍摄一系列照片。
如果你想让你的 GIF 看起来漂亮,你应该在拍照前使用三脚架或将相机放在坚固的表面上。
您还可以使用 Pillow 绘制一系列图像,并将该系列图像转换为 GIF。在本文中,您将学习如何使用这两种方法来创建动画 GIF。
您将学习的第一种方法是如何拍摄一系列图像(jpg)并将它们转换成动画 GIF。创建一个新文件,命名为 gif_maker.py 。然后输入以下代码:
import glob
from PIL import Image
def make_gif(frame_folder):
frames = [Image.open(image) for image in glob.glob(f"{frame_folder}/*.JPG")]
frame_one = frames[0]
frame_one.save("my_awesome.gif", format="GIF", append_images=frames,
save_all=True, duration=100, loop=0)
if __name__ == "__main__":
make_gif("/path/to/images")
这里你导入 Python 的 glob 模块和 Pillow 的 Image 类。使用 glob 在传递给函数 make_gif() 的路径中搜索 JPG 文件。
注意:你需要传入一个真实的路径,而不是使用上面代码中的占位符
下一步是创建一个包含图像对象的 Python 列表。如果你的图片很大,你可能需要添加一个步骤来调整它们的大小,这样 GIF 本身就不会很大!如果你不这样做,你实际上是在接受所有这些图像,并把它们变成一个巨大的文件。查看如何用枕头调整照片大小了解更多信息!
一旦你有了你的 Python 图像列表,你告诉 Pillow 使用你的 Python 列表中的第一个图像将它保存()为 GIF。为了实现这一点,你需要明确地告诉 Pillow,格式被设置为“GIF”。您还可以将动画帧传递给 append_images 参数。您还必须将 save_all 参数设置为 True。
可以以毫秒为单位设置每帧的时长。在这个例子中,你将它设置为 100 毫秒。最后,你将循环设置为 0(零),这意味着你希望 GIF 永远循环。如果你把它设置为一个大于零的数字,它会循环很多次,然后停止。
如果你想在某些东西上测试这个代码,你可以使用这个压缩的蜂鸟图片档案。当你对这个解压后的文件夹运行这段代码时,你的 GIF 看起来会像这样:

这张 GIF 不太流畅的原因是这些照片是在没有三脚架的情况下拍摄的。尝试使用三脚架拍摄一些移动的东西,然后重新运行这段代码,它会平滑得多。
现在你已经准备好学习如何用枕头来制作动画了!
用枕头画动画
枕头可以让你画各种形状的图像对象。你可以用它来制作你自己的动画!如果您想了解更多关于使用 Pillow 可以创建哪些类型的绘图,那么您可能会喜欢这篇文章:使用 Python 和 Pillow 在图像上绘制形状。
对于本例,您将使用 Pillow 的椭圆形状绘制圆形。你也可以画弧线,直线,矩形,多边形,直线等等。
首先,创建一个新文件并添加以下代码:
from PIL import Image, ImageDraw
def ellipse(x, y, offset):
image = Image.new("RGB", (400, 400), "blue")
draw = ImageDraw.Draw(image)
draw.ellipse((x, y, x+offset, y+offset), fill="red")
return image
def make_gif():
frames = []
x = 0
y = 0
offset = 50
for number in range(20):
frames.append(ellipse(x, y, offset))
x += 35
y += 35
frame_one = frames[0]
frame_one.save("circle.gif", format="GIF", append_images=frames,
save_all=True, duration=100, loop=0)
if __name__ == "__main__":
make_gif()
make_gif() 函数中的代码与前面的例子几乎相同。主要区别在于如何构建 Python 框架列表。在本例中,您创建了一个循环,该循环创建了 20 幅图像并将它们附加到帧列表中。
要创建您的圆,您可以调用 ellipse() 函数。它接受要绘制椭圆的 x 和 y 位置。它还包括一个偏移值。偏移量用于确定图像的绘制大小。Pillow 的 ellipse() 方法接受椭圆半径的起始 x/y 坐标和半径的结束 x/y 坐标。然后它画椭圆。
绘制椭圆时,它会添加到一个 400 x 400 像素的新图像中。这张图片背景是蓝色的。圆形(或椭圆形)有蓝色背景。
继续运行您的代码。输出将如下所示:

这不是很好吗?尝试更改您绘制的形状。或者编辑您的代码以使用不同的颜色。你也可以在你的动画中添加多个球!
包扎
枕头套装能让你收获更多。您可以编辑照片、应用效果、更改图像对比度等等。尽情了解 Pillow 和 Python 吧!太棒了。
使用 PySimpleGUI 创建图像查看器
原文:https://www.blog.pythonlibrary.org/2021/02/16/creating-an-image-viewer-with-pysimplegui/
PySimpleGUI 使创建应用程序变得容易。在本教程中,您将学习如何使用 PySimpleGUI 创建一个简单的图像查看器。您将使用包装了 Tkinter 的 PySimpleGUI 的常规版本,而不是它的 wxPython 或 PyQt 变体。
我们开始吧!
入门指南
您需要安装 PySimpleGUI,因为它不包含在 Python 中。您还需要 Pillow,因为 Tkinter 只支持 GIF 和 PGM/PPM 图像类型。
幸运的是,您可以使用 pip 轻松安装这两个软件包:
python3 -m pip install PySimpleGUI Pillow
现在您已经安装了您的依赖项,您可以创建一个全新的应用程序了!
创建图像查看器
PySimpleGUI 允许您用不到 50 行代码创建一个简单的图像查看器。要了解如何操作,请创建一个新文件并将其命名为 image_viewer.py 。然后将以下代码添加到文件中:
# image_viewer.py
import io
import os
import PySimpleGUI as sg
from PIL import Image
file_types = [("JPEG (*.jpg)", "*.jpg"),
("All files (*.*)", "*.*")]
def main():
layout = [
[sg.Image(key="-IMAGE-")],
[
sg.Text("Image File"),
sg.Input(size=(25, 1), key="-FILE-"),
sg.FileBrowse(file_types=file_types),
sg.Button("Load Image"),
],
]
window = sg.Window("Image Viewer", layout)
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "Load Image":
filename = values["-FILE-"]
if os.path.exists(filename):
image = Image.open(values["-FILE-"])
image.thumbnail((400, 400))
bio = io.BytesIO()
image.save(bio, format="PNG")
window["-IMAGE-"].update(data=bio.getvalue())
window.close()
if __name__ == "__main__":
main()
这是一段相当不错的代码。让我们把它分成几个小部分:
# image_viewer.py
import io
import os
import PySimpleGUI as sg
from PIL import Image
file_types = [("JPEG (*.jpg)", "*.jpg"),
("All files (*.*)", "*.*")]
这是您的初始设置代码。您从 PIL 导入 PySimpleGUI 和您需要的模块,并将 file_types 设置为表单中浏览按钮的文件选择选项,默认为 JPEG。
现在您已经准备好学习 main() 函数了:
def main():
elements = [
[sg.Image(key="-IMAGE-")],
[
sg.Text("Image File"),
sg.Input(size=(25, 1), enable_events=True, key="-FILE-"),
sg.FileBrowse(file_types=file_types),
],
]
window = sg.Window("Image Viewer", elements)
这是你的main()功能。这 11 行代码定义了元素的布局。PySimpleGUI 使用 Python 列表来布局用户界面。在这种情况下,您告诉它您想要在您的Window顶部创建一个Image小部件。然后,您想在它下面再添加三个小部件。这三个小部件以从左到右的形式水平排列。它们水平排列的原因是因为它们在嵌套列表中。
这三个小部件如下:
Text-一个标签元素Input-文本输入元素FileBrowse-打开文件浏览器对话框的按钮
要为一个元素启用事件,可以将enable_events参数设置为True——这将在元素发生变化时提交一个事件。您禁用了 Input 元素,使其成为只读的,并防止向其中键入内容——每一次按键都是一个单独的事件,您的循环没有为此做好准备。以后需要访问的任何元素都应该有一个名字,这就是key参数。这些必须是独一无二的。
要覆盖的最后一段代码是这几行:
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "Load Image":
filename = values["-FILE-"]
if os.path.exists(filename):
image = Image.open(values["-FILE-"])
image.thumbnail((400, 400))
bio = io.BytesIO()
image.save(bio, format="PNG")
window["-IMAGE-"].update(data=bio.getvalue())
window.close()
if __name__ == "__main__":
main()
这就是在 PySimpleGUI 中创建事件循环的方法。你read()的window对象为事件和值。您检查Exit事件,它在您关闭应用程序时发生。您还要检查file事件。这是您之前为Input元素定义的key名称。当该元素发生事件时,将使用该元素的key或名称将其添加到window中。
这是该计划的核心所在。当触发file事件时,您将通过使用values字典上的键进行查找来获取所选择的图像。现在你有了通向图像的路径!你可以用枕头打开图像,然后用thumbnail()调整大小。要显示图像,您可以使用io.BytesIO将文件转换成字节流,这允许您将图像保存在内存中。然后从内存文件中取出字节数据,并在最后将其传递给window.update()方法中的sg.Image对象。
最后,通过调用Image小部件上的update()并传入PhotoImage对象来显示图像。你可以通过使用包含在window对象中的image键来实现。
当您运行这段代码时,您将得到类似这样的结果:

这是图像浏览器在图像未加载时的样子。如果你加载一个图像,它看起来会像这样:

那看起来不是很好吗?在你的电脑上打开一张照片试试吧!
创建图像浏览器
您的应用程序让您通过一次浏览一个文件来不断打开新图像。如果你能让浏览器加载一个图片目录并循环浏览它们,那就太好了。
将您在上一节中学到的内容重写到一个名为 image_browser.py: 的新文件中
# image_browser.py
import glob
import PySimpleGUI as sg
from PIL import Image, ImageTk
def parse_folder(path):
images = glob.glob(f'{path}/*.jpg') + glob.glob(f'{path}/*.png')
return images
def load_image(path, window):
try:
image = Image.open(path)
image.thumbnail((400, 400))
photo_img = ImageTk.PhotoImage(image)
window["image"].update(data=photo_img)
except:
print(f"Unable to open {path}!")
def main():
elements = [
[sg.Image(key="image")],
[
sg.Text("Image File"),
sg.Input(size=(25, 1), enable_events=True, key="file"),
sg.FolderBrowse(),
],
[
sg.Button("Prev"),
sg.Button("Next")
]
]
window = sg.Window("Image Viewer", elements, size=(475, 475))
images = []
location = 0
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "file":
images = parse_folder(values["file"])
if images:
load_image(images[0], window)
if event == "Next" and images:
if location == len(images) - 1:
location = 0
else:
location += 1
load_image(images[location], window)
if event == "Prev" and images:
if location == 0:
location = len(images) - 1
else:
location -= 1
load_image(images[location], window)
window.close()
if __name__ == "__main__":
main()
用户选择一个文件夹后,通过使用 Python 的 glob 模块在文件夹中搜索 JPG 和 PNG 文件来加载图像。接下来,检查用户是否按下了“下一页”或“上一页”,图像是否已经加载。如果是,那么在加载下一个图像之前,检查您在路径列表中的位置并相应地更新它。
当您运行这段代码时,您的应用程序将如下所示:

现在,您可以使用 PySimpleGUI 轻松浏览整个文件夹。
包扎
PySimpleGUI 使得创建图像应用程序变得非常简单。你可以用很少的代码写一个非常漂亮的小图像浏览器。只要稍加润色,您就可以让这个应用程序变得更加有用。尝试添加菜单栏或工具栏,使打开文件/文件夹更简单。您还可以创建一个支持打开文件和文件夹的应用程序。你还可以添加许多其他功能,但这些都是简单的功能,可以激发你的创造力。开心快乐编码!
用 wxPython 创建 MP3 标记器 GUI
原文:https://www.blog.pythonlibrary.org/2021/09/22/creating-an-mp3-tagger-gui-with-wxpython/
我不知道你怎么样,但是我喜欢听音乐。作为一个狂热的音乐迷,我也喜欢把我的 CD 翻成 MP3,这样我就可以在旅途中更轻松地听音乐了。仍有许多音乐无法通过数字方式购买。不幸的是,当你翻录大量音乐时,你有时会在 MP3 标签中出现错误。通常,标题中会有拼写错误,或者一首歌没有正确的艺术家标签。虽然您可以使用许多开源和付费程序来标记 MP3 文件,但编写自己的程序也很有趣。
这就是本文的主题。在本文中,您将编写一个简单的 MP3 标签应用程序。此应用程序将允许您查看 MP3 文件的当前标签,并编辑以下标签:
- 艺术家
- 唱片
- 轨道名称
- 曲目编号
冒险的第一步是找到适合这项工作的 Python 包!
寻找 MP3 包
有几个 Python 包可以用来编辑 MP3 标签。以下是我在谷歌搜索时发现的一些例子:
- 眼睛 3
- 诱导有机体突变的物质
- mp3 标签
- pytaglib
在本章中,你将使用 eyeD3 。它有一个非常简单的 API。坦率地说,我发现这些包的大多数 API 都很简短,并不那么有用。然而,eyeD3 的工作方式似乎比我尝试的其他产品更自然一些,这也是它被选中的原因。
对了,包名 eyeD3 指的是 MP3 文件相关元数据的 ID3 规范。
然而,诱变剂包绝对是一个很好的后备选择,因为它支持许多其他类型的音频元数据。如果你碰巧在处理 MP3 之外的其他音频文件类型,那么你绝对应该尝试一下诱变剂。
安装孔眼 3
eyeD3 包可以和 pip 一起安装。如果你已经为这本书使用了一个虚拟环境(venv或virtualenv),确保你在安装 eyeD3:
python3 -m pip install eyeD3
一旦你安装了 eyeD3,你可能想看看它的文档:
现在让我们开始制作一个整洁的应用程序吧!
设计 MP3 标签
你的第一步是弄清楚你想要的用户界面是什么样子的。要制作一个有用的应用程序,您将需要以下特性:
- 导入 MP3 的一些方法
- 显示文件的一些元数据的方法
- 一种编辑元数据的方法
下面是主界面的一个简单模型:

MP3 标签图形用户界面模型
这个用户界面没有显示如何实际编辑 MP3,但它暗示用户需要按下底部的按钮来开始编辑。这似乎是一个合理的开始方式。
先给主界面编码吧!
创建主应用程序
现在有趣的部分来了,就是编写实际的应用程序。在这个例子中,您将再次使用ObjectListView来显示 MP3 的元数据。从技术上讲,你可以使用 wxPython 的列表控件。如果你想要一个挑战,你应该试着把本章的代码改成使用其中的一个。
注意:本文的代码可以在 GitHub 上下载
无论如何,您可以首先创建一个名为 main.py 的文件,并输入以下内容:
# main.py
import eyed3
import editor
import glob
import wx
from ObjectListView import ObjectListView, ColumnDefn
class Mp3:
def __init__(self, id3):
self.artist = ''
self.album = ''
self.title = ''
self.year = ''
# Attempt to extract MP3 tags
if not isinstance(id3.tag, type(None)):
id3.tag.artist = self.normalize_mp3(
id3.tag.artist)
self.artist = id3.tag.artist
id3.tag.album = self.normalize_mp3(
id3.tag.album)
self.album = id3.tag.album
id3.tag.title = self.normalize_mp3(
id3.tag.title)
self.title = id3.tag.title
if hasattr(id3.tag, 'best_release_date'):
if not isinstance(
id3.tag.best_release_date, type(None)):
self.year = self.normalize_mp3(
id3.tag.best_release_date.year)
else:
id3.tag.release_date = 2019
self.year = self.normalize_mp3(
id3.tag.best_release_date.year)
else:
tag = id3.initTag()
tag.release_date = 2019
tag.artist = 'Unknown'
tag.album = 'Unknown'
tag.title = 'Unknown'
self.id3 = id3
self.update()
这里有你需要的进口货。您还创建了一个名为Mp3的类,它将由ObjectListView小部件使用。该类中的前四个实例属性是将在应用程序中显示的元数据,默认为字符串。最后一个实例属性id3,将是当你加载一个 MP3 文件时从eyed3返回的对象。
并非所有的 MP3 都是一样的。有些没有任何标签,有些可能只有部分标签。由于这些问题,您将检查id3.tag是否存在。如果没有,那么 MP3 没有标签,您需要调用id3.initTag()来添加空白标签。如果id3.tag确实存在,那么你需要确保你感兴趣的标签也存在。这就是if语句的第一部分在调用normalize_mp3()函数时试图做的事情。
这里的另一项是,如果没有设置日期,那么best_release_date属性将返回None。所以你需要检查一下,如果碰巧是None,就把它设置成默认值。
现在让我们继续创建normalize_mp3()方法:
def normalize_mp3(self, tag):
try:
if tag:
return tag
else:
return 'Unknown'
except:
return 'Unknown'
这将检查指定的标签是否存在。如果是的话,它只是返回标签的值。如果没有,则返回字符串:“未知”
您需要在Mp3类中实现的最后一个方法是update():
def update(self):
self.artist = self.id3.tag.artist
self.album = self.id3.tag.album
self.title = self.id3.tag.title
self.year = self.id3.tag.best_release_date.year
这个方法在类的__init__()方法中的外层else的末尾被调用。它用于在初始化 MP3 文件的标签后更新实例属性。
这种方法和__init__()方法可能会捕捉不到一些边缘情况。我们鼓励您自己增强这些代码,看看是否能够解决这些问题。
现在让我们继续创建一个名为TaggerPanel的wx.Panel的子类:
class TaggerPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.mp3s = []
main_sizer = wx.BoxSizer(wx.VERTICAL)
self.mp3_olv = ObjectListView(
self, style=wx.LC_REPORT | wx.SUNKEN_BORDER)
self.mp3_olv.SetEmptyListMsg("No Mp3s Found")
self.update_mp3_info()
main_sizer.Add(self.mp3_olv, 1, wx.ALL | wx.EXPAND, 5)
edit_btn = wx.Button(self, label='Edit Mp3')
edit_btn.Bind(wx.EVT_BUTTON, self.edit_mp3)
main_sizer.Add(edit_btn, 0, wx.ALL | wx.CENTER, 5)
self.SetSizer(main_sizer)
TaggerPanel又好看又短。这里您设置了一个名为mp3s的实例属性,它被初始化为一个空列表。这个列表将最终保存你的Mp3类的实例列表。您还可以在这里创建您的ObjectListView实例,并添加一个用于编辑 MP3 文件的按钮。
说到编辑,让我们创建用于编辑 MP3 的事件处理程序:
def edit_mp3(self, event):
selection = self.mp3_olv.GetSelectedObject()
if selection:
with editor.Mp3TagEditorDialog(selection) as dlg:
dlg.ShowModal()
self.update_mp3_info()
在这里,您将使用ObjectListView小部件中的GetSelectedObject()方法来获取您要编辑的选定 MP3。然后你要确保你得到了一个有效的选择,并打开一个编辑器对话框,这个对话框包含在你即将编写的editor模块中。该对话框接受一个参数,即eyed3对象,您在这里称其为selection。
请注意,您需要调用update_mp3_info()来应用您在编辑器对话框中对 MP3 标签所做的任何更新。
现在让我们学习如何加载包含 MP3 文件的文件夹:
def load_mp3s(self, path):
if self.mp3s:
# clear the current contents
self.mp3s = []
mp3_paths = glob.glob(path + '/*.mp3')
for mp3_path in mp3_paths:
id3 = eyed3.load(mp3_path)
mp3_obj = Mp3(id3)
self.mp3s.append(mp3_obj)
self.update_mp3_info()
在这个例子中,您接受一个文件夹路径,并使用 Python 的glob模块来搜索 MP3 文件。假设您找到了这些文件,那么您将循环遍历结果并将它们加载到eyed3中。然后创建一个Mp3类的实例,这样就可以向用户显示 MP3 的元数据。为此,您调用了update_mp3_info()方法。方法开头的if语句是用来清除mp3s列表的,这样你就不会无限期地追加列表。
现在让我们继续创建update_mp3_info()方法:
def update_mp3_info(self):
self.mp3_olv.SetColumns([
ColumnDefn("Artist", "left", 100, "artist"),
ColumnDefn("Album", "left", 100, "album"),
ColumnDefn("Title", "left", 150, "title"),
ColumnDefn("Year", "left", 100, "year")
])
self.mp3_olv.SetObjects(self.mp3s)
update_mp3_info()方法用于向用户显示 MP3 元数据。在这种情况下,您将向用户显示艺术家、专辑名称、曲目名称(标题)以及歌曲发行的年份。为了实际更新小部件,您在最后调用了SetObjects()方法。
现在让我们继续创建TaggerFrame类:
class TaggerFrame(wx.Frame):
def __init__(self):
super().__init__(
None, title="Serpent - MP3 Editor")
self.panel = TaggerPanel(self)
self.create_menu()
self.Show()
在这里,您创建了前面提到的TaggerPanel类的一个实例,创建了一个菜单并向用户显示了框架。这也是您设置应用程序初始大小和应用程序标题的地方。只是为了好玩,我称它为蛇,但是你可以随意命名这个应用程序。
接下来让我们学习如何创建菜单:
def create_menu(self):
menu_bar = wx.MenuBar()
file_menu = wx.Menu()
open_folder_menu_item = file_menu.Append(
wx.ID_ANY, 'Open Mp3 Folder', 'Open a folder with MP3s'
)
menu_bar.Append(file_menu, '&File')
self.Bind(wx.EVT_MENU, self.on_open_folder,
open_folder_menu_item)
self.SetMenuBar(menu_bar)
在这段代码中,您创建了一个 menubar 对象。然后,创建带有单个菜单项的文件菜单,用于打开计算机上的文件夹。这个菜单项被绑定到一个名为on_open_folder()的事件处理程序。为了向用户显示菜单,您需要调用框架的SetMenuBar()方法。
拼图的最后一块是创建on_open_folder()事件处理程序:
def on_open_folder(self, event):
with wx.DirDialog(self, "Choose a directory:",
style=wx.DD_DEFAULT_STYLE,
) as dlg:
if dlg.ShowModal() == wx.ID_OK:
self.panel.load_mp3s(dlg.GetPath())
您将希望在这里使用 Python 的with语句打开一个wx.DirDialog,并有模式地向用户显示它。这可以防止用户在选择文件夹时与您的应用程序进行交互。如果用户按下 OK 按钮,您将使用他们选择的路径调用面板实例的load_mp3s()方法。
为了完整起见,下面是您将如何运行该应用程序:
if __name__ == '__main__':
app = wx.App(False)
frame = TaggerFrame()
app.MainLoop()
您总是需要创建一个wx.App实例,以便您的应用程序能够响应事件。
您的应用程序还不会运行,因为您还没有创建editor模块。
接下来让我们学习如何做!
编辑 MP3
编辑 MP3 是这个应用程序的重点,所以你肯定需要有一个方法来完成它。您可以修改ObjectListView小部件,这样您就可以在那里编辑数据,或者您可以打开一个带有可编辑字段的对话框。两者都是有效的方法。对于这个版本的应用程序,您将执行后者。
让我们从创建Mp3TagEditorDialog类开始:
# editor.py
import wx
class Mp3TagEditorDialog(wx.Dialog):
def __init__(self, mp3):
title = f'Editing "{mp3.id3.tag.title}"'
super().__init__(parent=None, title=title)
self.mp3 = mp3
self.create_ui()
在这里,您实例化您的类,并从它的标签中获取 MP3 的标题,使对话框的标题引用您正在编辑的 MP3。然后设置一个实例属性并调用create_ui()方法来创建对话框的用户界面。
现在让我们创建对话框的用户界面:
def create_ui(self):
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
size = (200, -1)
track_num = str(self.mp3.id3.tag.track_num[0])
year = str(self.mp3.id3.tag.best_release_date.year)
self.track_number = wx.TextCtrl(
self, value=track_num, size=size)
self.create_row('Track Number', self.track_number)
self.artist = wx.TextCtrl(self, value=self.mp3.id3.tag.artist,
size=size)
self.create_row('Artist', self.artist)
self.album = wx.TextCtrl(self, value=self.mp3.id3.tag.album,
size=size)
self.create_row('Album', self.album)
self.title = wx.TextCtrl(self, value=self.mp3.id3.tag.title,
size=size)
self.create_row('Title', self.title)
btn_sizer = wx.BoxSizer()
save_btn = wx.Button(self, label="Save")
save_btn.Bind(wx.EVT_BUTTON, self.save)
btn_sizer.Add(save_btn, 0, wx.ALL, 5)
btn_sizer.Add(wx.Button(self, id=wx.ID_CANCEL), 0, wx.ALL, 5)
self.main_sizer.Add(btn_sizer, 0, wx.CENTER)
self.SetSizerAndFit(self.main_sizer)
这里您创建了一系列的wx.TextCtrl小部件,并将其传递给一个名为create_row()的函数。您还可以在末尾添加“保存”按钮,并将其绑定到save()事件处理程序。最后,添加一个“取消”按钮。创建取消按钮的方式有点独特。你需要做的就是给wx.Button一个特殊的 id: wx.ID_CANCEL。这将为按钮添加正确的标签,并自动让它为您关闭对话框,而无需将其绑定到函数。
这是内置于 wxPython 工具包中的便利函数之一。只要不需要做什么特别的事情,这个功能就很棒。
现在让我们来学习将什么放入create_row()方法:
def create_row(self, label, text):
sizer = wx.BoxSizer(wx.HORIZONTAL)
row_label = wx.StaticText(self, label=label, size=(50, -1))
widgets = [(row_label, 0, wx.ALL, 5),
(text, 0, wx.ALL, 5)]
sizer.AddMany(widgets)
self.main_sizer.Add(sizer)
在本例中,您创建了一个水平 sizer 和一个带有传入标签的wx.StaticText实例。然后将这两个小部件添加到一个元组列表中,其中每个元组都包含需要传递给主 sizer 的参数。这允许您通过AddMany()方法一次向 sizer 添加多个小部件。
您需要创建的最后一段代码是save()事件处理程序:
def save(self, event):
current_track_num = self.mp3.id3.tag.track_num
if current_track_num:
new_track_num = (int(self.track_number.GetValue()),
current_track_num[1])
else:
new_track_num = (int(self.track_number.GetValue()), 0)
artist = self.artist.GetValue()
album = self.album.GetValue()
title = self.title.GetValue()
self.mp3.id3.tag.artist = artist if artist else 'Unknown'
self.mp3.id3.tag.album = album if album else 'Unknown'
self.mp3.id3.tag.title = title if title else 'Unknown'
self.mp3.id3.tag.track_num = new_track_num
self.mp3.id3.tag.save()
self.mp3.update()
self.Close()
在这里,您可以检查 MP3 的标签中是否设置了音轨编号。如果是,那么就将其更新为您设置的新值。另一方面,如果没有设置轨道号,那么您需要自己创建元组。元组中的第一个数字是曲目号,第二个数字是专辑中曲目的总数。如果没有设置轨道号,那么您就不能通过编程方式可靠地知道轨道的总数,所以您只需在默认情况下将其设置为零。
剩下的功能是将各种 MP3 对象的标签属性设置为对话框的文本控件中的内容。一旦所有的属性都设置好了,你就可以调用eyed3 MP3 对象上的save()方法,告诉Mp3类实例更新自己并关闭对话框。请注意,如果您试图为artist、album或title传入一个空值,它将被替换为字符串Unknown。
现在你已经有了所有你需要的部分,你应该可以运行程序了。
下面是主应用程序在我的机器上的样子:

MP3 标记图形用户界面
这是编辑器对话框的样子:

MP3 编辑器对话框
现在让我们学习如何给你的程序增加一些增强功能!
添加新功能
这种类型的大多数应用程序都允许用户将文件或文件夹拖放到上面。除了菜单之外,它们通常还有一个打开文件夹的工具栏。在前一章中,您已经学习了如何做到这两点。现在,您也要将这些特性添加到这个程序中。
让我们从创建我们的DropTarget类到 main.py 开始:
import os
class DropTarget(wx.FileDropTarget):
def __init__(self, window):
super().__init__()
self.window = window
def OnDropFiles(self, x, y, filenames):
self.window.update_on_drop(filenames)
return True
添加拖放功能需要您子类化wx.FileDropTarget。您还需要传入将成为拖放目标的小部件。在这种情况下,您希望将wx.Panel作为放置目标。然后你覆盖OnDropFiles以便它调用update_on_drop()方法。这是一个新方法,您将很快添加它。
但是在这之前,您需要更新您的TaggerPanel类的开头:
class TaggerPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.mp3s = []
drop_target = DropTarget(self)
self.SetDropTarget(drop_target)
main_sizer = wx.BoxSizer(wx.VERTICAL)
这里您创建了一个DropTarget的实例,然后通过SetDropTarget()方法将面板设置为放置目标。这样做的好处是,现在你可以拖放文件或文件夹在你的应用程序的任何地方,它会工作。
请注意,上面的代码并不是__init__()方法的完整代码,只是显示了上下文中的变化。完整版见 Github 上的源代码。
第一个要研究的新方法是add_mp3():
def add_mp3(self, path):
id3 = eyed3.load(path)
mp3_obj = Mp3(id3)
self.mp3s.append(mp3_obj)
在这里,您可以传递想要添加到用户界面的 MP3 文件的路径。它将采用该路径并加载eyed3并将它添加到您的mp3s列表中。
这个版本的应用程序没有改变edit_mp3()方法,所以这里不再赘述。
现在让我们继续创建另一个新方法find_mp3s():
def find_mp3s(self, folder):
mp3_paths = glob.glob(folder + '/*.mp3')
for mp3_path in mp3_paths:
self.add_mp3(mp3_path)
这段代码和add_mp3s()方法中的代码对您来说可能有点熟悉。它最初来自您之前创建的load_mp3()方法。您正在将这段代码移动到它自己的函数中。这就是所谓的重构你的代码。重构代码有很多原因。在这种情况下,您这样做是因为您需要从多个地方调用这个函数。与其将这段代码复制到多个函数中,不如将它分离到自己可以调用的函数中。
现在让我们更新load_mp3s()方法,以便它调用上面的新方法:
def load_mp3s(self, path):
if self.mp3s:
# clear the current contents
self.mp3s = []
self.find_mp3s(path)
self.update_mp3_info()
这个方法已经减少到两行代码。第一个调用您刚刚编写的find_mp3s()方法,而第二个调用update_mp3_info(),这将更新用户界面(即ObjectListView小部件)。
DropTarget类正在调用update_on_drop()方法,所以现在让我们这样写:
def update_on_drop(self, paths):
for path in paths:
if os.path.isdir(path):
self.load_mp3s(path)
elif os.path.isfile(path):
self.add_mp3(path)
self.update_mp3_info()
update_on_drop()方法是您之前进行重构的原因。它还需要调用load_mp3s(),但是只有当传入的路径被确定为目录时。否则,检查路径是否是一个文件并加载它。
但是等等!上面的代码有问题。你能说出这是什么吗?
问题是当路径是一个文件时,你不会检查它是否是一个 MP3。如果按原样运行这段代码,将会引发一个异常,因为eyed3包无法将所有文件类型转换成 Mp3 对象。
让我们来解决这个问题:
def update_on_drop(self, paths):
for path in paths:
_, ext = os.path.splitext(path)
if os.path.isdir(path):
self.load_mp3s(path)
elif os.path.isfile(path) and ext.lower() == '.mp3':
self.add_mp3(path)
self.update_mp3_info()
您可以使用 Python 的os模块通过splitext()函数获得文件的扩展名。它将返回一个包含两项的元组:文件的路径和扩展名。
现在您已经有了扩展,您可以检查它是否是.mp3,如果是,只更新 UI。顺便说一下,当您向函数传递一个目录路径时,splitext()函数会返回一个空字符串。
您需要更新的下一段代码是TaggerFrame类,以便您可以添加一个工具栏:
class TaggerFrame(wx.Frame):
def __init__(self):
super().__init__(
None, title="Serpent - MP3 Editor")
self.panel = TaggerPanel(self)
self.create_menu()
self.create_tool_bar()
self.Show()
上面代码的唯一变化是添加了对create_tool_bar()方法的调用。您几乎总是希望用单独的方法创建工具栏,因为通常每个工具栏按钮都有几行代码。对于工具栏中有许多按钮的应用程序,您可能应该将这些代码分离出来,放到一个单独的类或模块中。
让我们继续编写这个方法:
def create_tool_bar(self):
self.toolbar = self.CreateToolBar()
add_folder_ico = wx.ArtProvider.GetBitmap(
wx.ART_FOLDER_OPEN, wx.ART_TOOLBAR, (16, 16))
add_folder_tool = self.toolbar.AddTool(
wx.ID_ANY, 'Add Folder', add_folder_ico,
'Add a folder to be archived')
self.Bind(wx.EVT_MENU, self.on_open_folder,
add_folder_tool)
self.toolbar.Realize()
为了简单起见,您添加了一个工具栏按钮,它将通过on_open_folder()方法打开一个目录对话框。
当您运行这段代码时,更新后的应用程序应该如下所示:

MP3 标记图形用户界面(空)
随意添加更多的工具栏按钮,菜单项,状态栏或其他有趣的增强功能。
包扎
本文向您介绍了一些 Python 的 MP3 相关包,您可以用它们来编辑 MP3 标签以及其他音乐文件格式的标签。您了解了如何创建一个漂亮的主应用程序来打开编辑对话框。主应用程序可用于向用户显示相关的 MP3 元数据。如果用户决定编辑一个或多个标签,它还可以向用户显示他们的更新。
wxPython tookit 支持播放某些类型的音频文件格式,包括 MP3。您可以使用这些功能创建一个 MP3 播放器,并使该应用程序成为其中的一部分。
下载源代码
您可以在 GitHub 上下载本文中示例的源代码
相关文章
想了解更多关于 wxPython 的内容吗?查看以下文章:
使用 pdfrw 创建和操作 pdf
原文:https://www.blog.pythonlibrary.org/2018/06/06/creating-and-manipulating-pdfs-with-pdfrw/
帕特里克·莫平创建了一个他称之为 pdfrw 的包,并于 2012 年发布。pdfrw 包是一个纯 Python 库,可以用来读写 PDF 文件。在撰写本文时,pdfrw 的版本是 0.4。在该版本中,它支持在 pdf 中设置子集、合并、旋转和修改数据。自 2010 年以来,pdfrw 包一直被 rst2pdf 包(见第 18 章)使用,因为 pdfrw 可以“忠实地再现矢量格式,而无需光栅化”。您还可以将 pdfrw 与 ReportLab 结合使用,以便在您使用 ReportLab 创建的新 pdf 中重用现有 pdf 的某些部分。
在本文中,我们将学习如何执行以下操作:
- 从 PDF 中提取某些类型的信息
- 分割 pdf
- 合并/连接 pdf
- 旋转页面
- 创建覆盖或水印
- 缩放页面
- 结合使用 pdfrw 和 ReportLab
我们开始吧!
注:本文基于我的书, ReportLab:用 Python 处理 PDF。代码可以在 GitHub 上找到。
装置
如您所料,您可以使用 pip 安装 pdfrw。让我们完成这项工作,然后开始使用 pdfrw:
python -m pip install pdfrw
现在我们已经安装了 pdfrw,让我们学习如何从我们的 pdf 中提取一些信息。
从 PDF 中提取信息
pdfrw 包提取数据的方式与 PyPDF2 不同。如果您过去使用过 PyPDF2,那么您可能还记得 PyPDF2 让您提取一个文档信息对象,您可以用它来提取诸如作者、标题等信息。虽然 pdfrw 允许您获取 Info 对象,但它以一种不太友好的方式显示它。让我们来看看:
注意:我在这个例子中使用了美国国税局的标准 W9 表格。
# reader.py
from pdfrw import PdfReader
def get_pdf_info(path):
pdf = PdfReader(path)
print(pdf.keys())
print(pdf.Info)
print(pdf.Root.keys())
print('PDF has {} pages'.format(len(pdf.pages)))
if __name__ == '__main__':
get_pdf_info('w9.pdf')
这里我们导入 pdfrw 的 PdfReader 类,并通过传入我们想要读取的 PDF 文件的路径来实例化它。然后我们提取 PDF 对象的键、信息对象和根。我们还获取文档中有多少页。运行这段代码的结果如下:
['/ID', '/Root', '/Info', '/Size']
{'/Author': '(SE:W:CAR:MP)',
'/CreationDate': "(D:20171109144422-05'00')",
'/Creator': '(Adobe LiveCycle Designer ES 9.0)',
'/Keywords': '(Fillable)',
'/ModDate': "(D:20171109144521-05'00')",
'/Producer': '(Adobe LiveCycle Designer ES 9.0)',
'/SPDF': '(1112)',
'/Subject': '(Request for Taxpayer Identification Number and Certification)',
'/Title': '(Form W-9 \\(Rev. November 2017\\))'}
['/Pages', '/Perms', '/MarkInfo', '/Extensions', '/AcroForm', '/Metadata', '/Type', '/Names', '/StructTreeRoot']
PDF has 6 pages
如果您对我在这篇文章的源代码中包含的reportlab-sample.pdf文件运行这个命令,您会发现返回的作者名是“”,而不是“迈克尔·德里斯科尔”。我还没有弄清楚这到底是为什么,但是我假设 PyPDF2 对 PDF 预告片信息做了一些额外的数据处理,而 pdfrw 目前没有这样做。
剧烈的
您也可以使用 PDF wr 来分割 PDF。例如,您可能出于某种原因想要拿掉一本书的封面,或者您只想将一本书的章节提取到多个 pdf 中,而不是将它们存储在一个文件中。这对于 pdfrw 来说相当简单。对于这个例子,我们将使用我的 ReportLab 书的样本章节 PDF,你可以在 Leanpub 上下载。
# splitter.py
from pdfrw import PdfReader, PdfWriter
def split(path, number_of_pages, output):
pdf_obj = PdfReader(path)
total_pages = len(pdf_obj.pages)
writer = PdfWriter()
for page in range(number_of_pages):
if page <= total_pages:
writer.addpage(pdf_obj.pages[page])
writer.write(output)
if __name__ == '__main__':
split('reportlab-sample.pdf', 10, 'subset.pdf')
这里我们创建一个名为 split 的函数,它接受一个输入 PDF 文件路径、您想要提取的页数和输出路径。然后我们使用 pdfrw 的 PdfReader 类打开文件,并从输入的 PDF 中获取总页数。然后我们创建一个 PdfWriter 对象,并在我们传入的页面范围内循环。在每次迭代中,我们试图从输入 PDF 中提取一个页面,并将该页面添加到我们的 writer 对象中。最后,我们将提取的页面写入磁盘。
合并/连接
pdfrw 包使得合并多个 pdf 文件变得非常容易。让我们写一个简单的例子来演示如何做:
# concatenator.py
from pdfrw import PdfReader, PdfWriter, IndirectPdfDict
def concatenate(paths, output):
writer = PdfWriter()
for path in paths:
reader = PdfReader(path)
writer.addpages(reader.pages)
writer.trailer.Info = IndirectPdfDict(
Title='Combined PDF Title',
Author='Michael Driscoll',
Subject='PDF Combinations',
Creator='The Concatenator'
)
writer.write(output)
if __name__ == '__main__':
paths = ['reportlab-sample.pdf', 'w9.pdf']
concatenate(paths, 'concatenate.pdf')
在这个例子中,我们创建了一个名为 concatenate 的函数,它接受我们想要连接在一起的 pdf 的路径列表和输出路径。然后遍历这些路径,打开文件,通过 writer 的 addpages 方法将所有页面添加到 writer 对象中。只是为了好玩,我们还导入了 IndirectPdfDict ,这允许我们向 PDF 添加一些预告片信息。在这种情况下,我们向 PDF 添加标题、作者、主题和创建者脚本信息。然后,我们将连接的 PDF 写到磁盘上。
轮流
pdfrw 包也支持旋转 PDF 的页面。因此,如果您碰巧有一个以奇怪的方式保存的 PDF,或者一个实习生颠倒地扫描了一些文档,那么您可以使用 pdfrw(或 PyPDF2)来修复 PDF。请注意,在 pdfrw 中,您必须以可被 90 度整除的增量顺时针旋转。
对于这个例子,我创建了一个函数,它将从输入 PDF 中提取所有奇数页,并将它们旋转 90 度:
# rotator.py
from pdfrw import PdfReader, PdfWriter, IndirectPdfDict
def rotate_odd(path, output):
reader = PdfReader(path)
writer = PdfWriter()
pages = reader.pages
for page in range(len(pages)):
if page % 2:
pages[page].Rotate = 90
writer.addpage(pages[page])
writer.write(output)
if __name__ == '__main__':
rotate_odd('reportlab-sample.pdf', 'rotate_odd.pdf')
在这里,我们只需打开目标 PDF 并创建一个 writer 对象。然后我们抓取所有的页面,并对它们进行迭代。如果页面是奇数页,我们旋转它,然后将该页面添加到 writer 对象中。这段代码在我的机器上运行得相当快,输出结果如您所料。
覆盖/水印页面
您可以使用 pdfrw 为您的 PDF 添加某种信息的水印。例如,您可能希望在 PDF 中添加买家的电子邮件地址或您的徽标。您也可以将一个 PDF 覆盖在另一个 PDF 上。实际上,我们将在第 17 章中使用覆盖技术来填写 PDF 表单。
让我们创建一个简单的 watermarker 脚本来演示如何使用 pdfrw 将一个 PDF 叠加到另一个之上。
# watermarker.py
from pdfrw import PdfReader, PdfWriter, PageMerge
def watermarker(path, watermark, output):
base_pdf = PdfReader(path)
watermark_pdf = PdfReader(watermark)
mark = watermark_pdf.pages[0]
for page in range(len(base_pdf.pages)):
merger = PageMerge(base_pdf.pages[page])
merger.add(mark).render()
writer = PdfWriter()
writer.write(output, base_pdf)
if __name__ == '__main__':
watermarker('reportlab-sample.pdf',
'watermark.pdf',
'watermarked-test.pdf')
这里我们创建一个简单的 watermarker 函数,它接受一个输入 PDF 路径、包含水印的 PDF 和最终结果的输出路径。然后我们打开基础 PDF 和水印 PDF。我们提取水印页面,然后迭代基本 PDF 中的页面。在每次迭代中,我们使用当前的基本 PDF 页面创建一个页面合并对象。然后,我们将水印覆盖在该页面的顶部,并渲染它。循环完成后,我们创建一个 PdfWriter 对象,并将合并的 PDF 写入磁盘。
缩放比例
pdfrw 包也可以在内存中操作 pdf。事实上,它将允许您创建 XObjects 的表单。这些对象可以代表 PDF 中的任何页面或矩形。这意味着一旦你创建了这些对象中的一个,你就可以缩放、旋转和定位页面或子页面。pdfrw Github 页面上有一个有趣的例子,叫做 4up.py ,它从 PDF 中提取页面,将其缩小到原来大小的四分之一,并将四页放在一页中。
以下是我的版本:
# scaler.py
from pdfrw import PdfReader, PdfWriter, PageMerge
def get4(srcpages):
scale = 0.5
srcpages = PageMerge() + srcpages
x_increment, y_increment = (scale * i for i in srcpages.xobj_box[2:])
for i, page in enumerate(srcpages):
page.scale(scale)
page.x = x_increment if i & 1 else 0
page.y = 0 if i & 2 else y_increment
return srcpages.render()
def scale_pdf(path, output):
pages = PdfReader(path).pages
writer = PdfWriter(output)
scaled_pages = 4
for i in range(0, len(pages), scaled_pages):
four_pages = get4(pages[i: i + 4])
writer.addpage(four_pages)
writer.write()
if __name__ == '__main__':
scale_pdf('reportlab-sample.pdf', 'four-page.pdf')
get4 函数来自 4up.py 脚本。该函数获取一系列页面,并使用 pdfrw 的 PageMerge 类将这些页面合并在一起。我们基本上是在传入的页面上循环,将它们缩小一点,然后将它们放置在页面上,并在一个页面上呈现页面系列。
下一个函数是 scale_pdf ,它接受输入 pdf 和输出路径。然后,我们从输入文件中提取页面并创建一个 writer 对象。接下来,我们一次遍历输入文档 4 的页面,并将它们传递给get4函数。然后,我们将该函数的结果添加到我们的 writer 对象中。
最后,我们将文档写到磁盘上。下面是一个截图,显示了它的样子:
现在让我们学习如何将 pdfrw 与 ReportLab 结合起来!
结合 pdfrw 和 ReportLab
pdfrw 的一个优秀特性是它能够与 ReportLab 工具包集成。pdfrw Github 页面上有几个例子,展示了两个包一起使用的不同方式。pdfrw 的创建者认为您可以模拟 ReportLab 的一些 pagecatcher 功能,这是 ReportLab 付费产品的一部分。不知道有没有,但是你绝对可以用 pdfrw 和 ReportLab 做一些好玩的事情。
例如,您可以使用 pdfrw 从预先存在的 PDF 中读入页面,并将它们转换为可以在 ReportLab 中写出的对象。让我们编写一个脚本,使用 pdfrw 和 ReportLab 创建 PDF 的子集。以下示例基于 pdfrw 项目中的一个示例:
# split_with_rl.py
from pdfrw import PdfReader
from pdfrw.buildxobj import pagexobj
from pdfrw.toreportlab import makerl
from reportlab.pdfgen.canvas import Canvas
def split(path, number_of_pages, output):
pdf_obj = PdfReader(path)
my_canvas = Canvas(output)
# create page objects
pages = pdf_obj.pages[0: number_of_pages]
pages = [pagexobj(page) for page in pages]
for page in pages:
my_canvas.setPageSize((page.BBox[2], page.BBox[3]))
my_canvas.doForm(makerl(my_canvas, page))
my_canvas.showPage()
# write the new PDF to disk
my_canvas.save()
if __name__ == '__main__':
split('reportlab-sample.pdf', 10, 'subset-rl.pdf')
这里我们引入了一些新的功能。首先我们导入 pagexobj ,它将从你给它的视图中创建一个表单 XObject】。视图默认为整个页面,但是您可以告诉 pdfrw 只提取页面的一部分。接下来,我们导入 makerl 函数,该函数将获取一个 ReportLab 画布对象和一个 pdfrw Form XObject,并将其转换为 ReportLab 可以添加到其画布对象的表单。
所以让我们稍微检查一下这段代码,看看它是如何工作的。这里我们创建了一个 reader 对象和一个 canvas 对象。然后我们创建一个表单 XForm 对象列表,从指定的第一页到最后一页。请注意,我们不会检查我们是否要求了太多的页面,所以我们可以做一些事情来增强这个脚本,使它不太可能失败。
接下来,我们迭代刚刚创建的页面,并将它们添加到 ReportLab 画布中。您会注意到,我们使用 pdfrw 的 BBox 属性提取的宽度和高度来设置页面大小。然后,我们将表单 XObjects 添加到画布中。对showPage的调用告诉 ReportLab 您已经完成了一个页面的创建,并开始创建一个新页面。最后,我们将新的 PDF 保存到磁盘。
pdfrw 的网站上还有一些其他的例子,您应该看看。例如,有一段简洁的代码显示了如何从预先存在的 PDF 中提取一个页面,并将其用作在 ReportLab 中创建的新 PDF 的背景。还有一个非常有趣的缩放示例,您可以使用 pdfrw 和 ReportLab 来缩小页面,就像我们单独使用 pdfrw 一样。
包扎
pdfrw 包实际上非常强大,具有 PyPDF2 所没有的特性。它与 ReportLab 集成的能力是我认为非常有趣的一个特性,可以用来创造一些原创的东西。您还可以使用 PDFrw 做许多我们可以用 PyPDF2 做的事情,例如分割、合并、旋转和连接 pdf。实际上,我认为 PDFrw 在生成可行的 pdf 方面比 PyPDF2 更健壮,但是我没有进行大量的测试来证实这一点。
无论如何,我相信 pdfrw 值得添加到您的工具包中。
相关阅读
- pdfrw 的 Github 页面
- pdfrw 简介
- Pdfrw 和 PDF 表单:使用 Python 填充它们
使用 Python 和 GooPyCharts 创建图表
原文:https://www.blog.pythonlibrary.org/2016/10/26/creating-graphs-with-python-and-goopycharts/
整个夏天,我遇到了一个有趣的绘图库,名为 GooPyCharts ,它是 Google Charts API 的 Python 包装器。在本文中,我们将花几分钟时间学习如何使用这个有趣的包。GooPyCharts 遵循类似于 MATLAB 的语法,实际上是 matplotlib 的替代方案。
要安装 GooPyCharts,您需要做的就是像这样使用 pip:
pip install gpcharts
现在我们已经安装好了,我们可以试一试了!
我们的第一张图表
使用 GooPyCharts 创建图表或图形非常容易。事实上,您可以用 3 行代码创建一个简单的图形:
>>> from gpcharts import figure
>>> my_plot = figure(title='Demo')
>>> my_plot.plot([1, 2, 10, 15, 12, 23])
如果运行此代码,您应该会看到默认浏览器弹出窗口,显示如下图像:

您会注意到,您可以下载 PNG 格式的图表,也可以将制作图表的数据保存为 CSV 文件。GooPyCharts 还集成了 Jupyter 笔记本。
创建条形图
GooPyCharts 包有一个很好的 testGraph.py 脚本来帮助你学习如何使用这个包。不幸的是,它实际上并没有展示不同类型的图表。所以我从那里拿了一个例子,并修改它来创建一个条形图:
from gpcharts import figure
fig3 = figure()
xVals = ['Temps','2016-03-20','2016-03-21','2016-03-25','2016-04-01']
yVals = [['Shakuras','Korhal','Aiur'],[10,30,40],[12,28,41],[15,34,38],[8,33,47]]
fig3.title = 'Weather over Days'
fig3.ylabel = 'Dates'
fig3.bar(xVals, yVals)
您会注意到,在这个例子中,我们使用 figure 实例的 title 属性来创建标题。我们也以同样的方式设置了 ylabel 。您还可以看到如何定义图表的日期,以及如何使用嵌套列表设置自动图例。最后你可以看到,我们需要调用条形图来生成条形图,而不是调用图。结果如下:

创建其他类型的图表
让我们再修改一下代码,看看能否创建其他类型的图形。我们将从散点图开始:
from gpcharts import figure
my_fig = figure()
xVals = ['Dates','2016-03-20','2016-03-21','2016-03-25','2016-04-01']
yVals = [['Shakuras','Korhal','Aiur'],[10,30,40],[12,28,41],[15,34,38],[8,33,47]]
my_fig.title = 'Scatter Plot'
my_fig.ylabel = 'Temps'
my_fig.scatter(xVals, yVals)
在这里,我们可以使用上一个示例中使用的大部分数据。我们只需要修改一些值来使 X 和 Y 标签正确工作,我们需要用一些有意义的东西来给图表命名。当您运行这段代码时,您应该会看到类似这样的内容:

这很简单。让我们试着创建一个快速而肮脏的直方图:
from gpcharts import figure
my_fig = figure()
my_fig.title = 'Random Histrogram'
my_fig.xlabel = 'Random Values'
vals = [10, 40, 30, 50, 80, 100, 65]
my_fig.hist(vals)
直方图比我们创建的最后两个图表简单得多,因为它只需要一个值列表就可以成功创建。这是我运行代码时得到的结果:

这是一个看起来很无聊的直方图,但是修改它并添加一组更真实的数据是非常容易的。
包扎
虽然这只是对一些 GooPyCharts 功能的快速浏览,但我认为我们已经对这个图表包的功能有了很好的了解。它真的很容易使用,但只有一个小的图表集工作。PyGal 、Bokeh 和 matplotlib 有许多他们可以创建的其他类型的图表。然而,如果你正在寻找一个超级容易安装和使用的东西,并且你不介意它支持的小图表集,那么 GooPyCharts 可能就是适合你的软件包!
相关阅读
- Python: 用散景可视化
- 使用烧瓶中的 pyGal 图
- wxPython: PyPlot - 用 Python 绘制的图形
使用 wxPython Kickstarter 创建 GUI 应用程序
原文:https://www.blog.pythonlibrary.org/2019/01/14/creating-gui-applications-with-wxpython-kickstarter/
我很高兴地宣布我最新的图书项目,用 wxPython 创建 GUI 应用程序,我正在为它在 Kickstarter 上开展活动。
用 wxPython 创建 GUI 应用程序是一本教你如何使用 wxPython 通过实际创建几个小程序来创建应用程序的书。我发现,虽然学习 wxPython 中各种小部件的工作方式是有价值的,但通过创建一个简单的应用程序来学习更好。
本书中的代码将只针对使用 wxPython 4 的 Python 3。

更多信息,请查看 Kickstarter 。
现在可用 wxPython 创建 GUI 应用程序
原文:https://www.blog.pythonlibrary.org/2019/05/08/creating-gui-applications-with-wxpython-now-available/
我的新书《用 wxPython 创建 GUI 应用程序》现在已经可以购买了。

用 wxPython 创建 GUI 应用程序是一本教你如何使用 wxPython 通过实际创建几个小程序来创建应用程序的书。我发现,虽然学习 wxPython 中各种小部件的工作方式是有价值的,但通过创建一个简单的应用程序来学习更好。
在本书中,您将创建以下应用程序:
- 一个简单的图像浏览器
- 数据库查看器
- 数据库编辑器
- 计算器
- 归档应用程序(tar)
- PDF 合并应用程序
- XML 编辑器
- 文件搜索实用程序
- 简单的 FTP 应用
- NASA 影像下载程式
随着您学习如何创建这些应用程序,您也将学习 wxPython 是如何工作的。您将了解 wxPython 的事件系统是如何工作的,如何在 wxPython 中使用线程,如何使用 sizers 等等!
电子书版本在 Leanpub 上以 14.99 美元的价格出售,直到 5 月 15 日。你也可以在 Gumroad 上购买这本书,或者在亚马逊上获得平装本或 Kindle 版本。
用 PySimpleGUI 和 Python 创建图形用户界面(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/19/creating-guis-with-pysimplegui-and-python-video/
在本入门教程中,学习如何用 Python 和 PySimpleGUI 创建简单的图形用户界面(GUI)。
您将学习如何布局元素(即小部件),使用 Matplotlib 添加图形,以及其他 PySimpleGUI 基础知识
https://www.youtube.com/embed/a57DYkbzvz0?feature=oembed
用 PySimpleGUI 创建图形用户界面(视频)
原文:https://www.blog.pythonlibrary.org/2022/02/15/creating-guis-with-pysimplegui-video/
我的演讲,用 PySimpleGUI 创建 GUI,在 YouTube 上。我在 2022 年 1 月给 SFPython / PyBay 小组做了这个演讲。
我用朱庇特笔记本做了这次演讲的幻灯片。所有的幻灯片和示例代码都可以在我的 GitHub Talks repo 中找到。
https://www.youtube.com/embed/rGhCgONDVzc?feature=oembed
您可以在以下文章中了解关于 PySimpleGUI 的更多信息:
-
如何用 GUI 在图像上绘制形状
使用 Python 在 ReportLab 中创建交互式 PDF 表单
ReportLab 工具包允许您创建交互式可填充表单。PDF 标准实际上有相当丰富的交互元素。ReportLab 并不支持所有这些元素,但它涵盖了其中的大部分。在本节中,我们将了解以下小部件:
- 检验盒
- 收音机
- 选择
- 列表框
- 文本字段
所有这些小部件都是通过调用 canvas.acroform 属性上的各种方法创建的。请注意,每个文档只能有一个表单。让我们来看看 ReportLab 支持的小部件!
检验盒
复选框小部件就像它听起来的那样。这是一个你可以检查的小盒子。尽管 ReportLab 支持几种不同的“检查”样式,所以当复选框被选中时,根据您设置的样式,它看起来会有所不同。
现在让我们写一个简单的例子来演示这些参数是如何工作的:
# simple_checkboxes.py
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfform
from reportlab.lib.colors import magenta, pink, blue, green
def create_simple_checkboxes():
c = canvas.Canvas('simple_checkboxes.pdf')
c.setFont("Courier", 20)
c.drawCentredString(300, 700, 'Pets')
c.setFont("Courier", 14)
form = c.acroForm
c.drawString(10, 650, 'Dog:')
form.checkbox(name='cb1', tooltip='Field cb1',
x=110, y=645, buttonStyle='check',
borderColor=magenta, fillColor=pink,
textColor=blue, forceBorder=True)
c.drawString(10, 600, 'Cat:')
form.checkbox(name='cb2', tooltip='Field cb2',
x=110, y=595, buttonStyle='cross',
borderWidth=2, forceBorder=True)
c.drawString(10, 550, 'Pony:')
form.checkbox(name='cb3', tooltip='Field cb3',
x=110, y=545, buttonStyle='star',
borderWidth=1, forceBorder=True)
c.drawString(10, 500, 'Python:')
form.checkbox(name='cb4', tooltip='Field cb4',
x=110, y=495, buttonStyle='circle',
borderWidth=3, forceBorder=True)
c.drawString(10, 450, 'Hamster:')
form.checkbox(name='cb5', tooltip='Field cb5',
x=110, y=445, buttonStyle='diamond',
borderWidth=None,
checked=True,
forceBorder=True)
c.save()
if __name__ == '__main__':
create_simple_checkboxes()
如您所见,我们设置了名称并设置了工具提示,以基本上匹配小部件的名称。然后我们设置它的位置和其他一些东西。您可以调整复选框边框的宽度,或者关闭边框。如果你关闭它,复选框可能会变得不可见,所以你可能想通过 fillColor 设置它的背景颜色。我为每个复选框设置了不同的 buttonStyle。下面是我运行代码时得到的结果:

如果您打开文档并选中所有复选框,您将看到它们如下所示:

现在让我们来了解一下 radio 小部件!
收音机
单选按钮小部件有点像复选框,只是通常你把单选按钮放在一个组中,在这个组中只能选择一个单选按钮。复选框很少被限制为每个组只允许一个复选框。ReportLab 似乎没有办法明确地将一组单选按钮组合在一起。这似乎只是隐性的。换句话说,如果您一个接一个地创建一系列收音机,它们将被组合在一起。
现在,让我们花点时间来创建一个简单的 radio 小部件演示:
# simple_radios.py
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfform
from reportlab.lib.colors import magenta, pink, blue, green
def create_simple_radios():
c = canvas.Canvas('simple_radios.pdf')
c.setFont("Courier", 20)
c.drawCentredString(300, 700, 'Radio demo')
c.setFont("Courier", 14)
form = c.acroForm
c.drawString(10, 650, 'Dog:')
form.radio(name='radio1', tooltip='Field radio1',
value='value1', selected=False,
x=110, y=645, buttonStyle='check',
borderStyle='solid', shape='square',
borderColor=magenta, fillColor=pink,
textColor=blue, forceBorder=True)
form.radio(name='radio1', tooltip='Field radio1',
value='value2', selected=True,
x=110, y=645, buttonStyle='check',
borderStyle='solid', shape='square',
borderColor=magenta, fillColor=pink,
textColor=blue, forceBorder=True)
c.drawString(10, 600, 'Cat:')
form.radio(name='radio2', tooltip='Field radio2',
value='value1', selected=True,
x=110, y=595, buttonStyle='cross',
borderStyle='solid', shape='circle',
borderColor=green, fillColor=blue,
borderWidth=2,
textColor=pink, forceBorder=True)
form.radio(name='radio2', tooltip='Field radio2',
value='value2', selected=False,
x=110, y=595, buttonStyle='cross',
borderStyle='solid', shape='circle',
borderColor=green, fillColor=blue,
borderWidth=2,
textColor=pink, forceBorder=True)
c.drawString(10, 550, 'Pony:')
form.radio(name='radio3', tooltip='Field radio3',
value='value1', selected=False,
x=110, y=545, buttonStyle='star',
borderStyle='bevelled', shape='square',
borderColor=blue, fillColor=green,
borderWidth=2,
textColor=magenta, forceBorder=False)
form.radio(name='radio3', tooltip='Field radio3',
value='value2', selected=True,
x=110, y=545, buttonStyle='star',
borderStyle='bevelled', shape='circle',
borderColor=blue, fillColor=green,
borderWidth=2,
textColor=magenta, forceBorder=True)
c.save()
if __name__ == '__main__':
create_simple_radios()
当您运行这个代码时,您会注意到您只得到 3 个收音机。这是因为您需要为每个单选按钮创建两个同名的实例,但是具有不同的值和部分。文档没有说明原因,但我认为这样做是为了帮助 ReportLab 跟踪小部件的“选中”状态。这也允许您在选择或取消选择收音机时更改其外观。

现在让我们来看看如何创建一个选择小部件!
选择
choice 小部件基本上是一个组合框,当用户点击它时会显示一个下拉列表。这允许用户根据您设置的字段标志从下拉列表中选择一个或多个选项。如果将编辑添加到字段标志中,那么用户可以编辑 choice 小部件中的项目。
让我们花点时间在 PDF 文档中创建几个选择小部件:
# simple_choices.py
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfform
from reportlab.lib.colors import magenta, pink, blue, green, red
def create_simple_choices():
c = canvas.Canvas('simple_choices.pdf')
c.setFont("Courier", 20)
c.drawCentredString(300, 700, 'Choices')
c.setFont("Courier", 14)
form = c.acroForm
c.drawString(10, 650, 'Choose a letter:')
options = [('A','Av'),'B',('C','Cv'),('D','Dv'),'E',('F',),('G','Gv')]
form.choice(name='choice1', tooltip='Field choice1',
value='A',
x=165, y=645, width=72, height=20,
borderColor=magenta, fillColor=pink,
textColor=blue, forceBorder=True, options=options)
c.drawString(10, 600, 'Choose an animal:')
options = [('Cat', 'cat'), ('Dog', 'dog'), ('Pig', 'pig')]
form.choice(name='choice2', tooltip='Field choice2',
value='Cat',
options=options,
x=165, y=595, width=72, height=20,
borderStyle='solid', borderWidth=1,
forceBorder=True)
c.save()
if __name__ == '__main__':
create_simple_choices()
在这个例子中,我们创建了两个应用了稍微不同样式的 choice 小部件。虽然我在文档中找不到它,但是值参数似乎是必需的。如果你不包括它,你会得到一个相当奇怪的错误,它没有说任何关于参数丢失的事情。无论如何,当你运行这段代码时,你会发现它会生成这样的东西:

现在让我们来学习列表框!
列表框
除了列表框是一个可滚动的框而不是组合框之外,列表框小部件有点像选择小部件。您可以使用 fieldFlags 参数来允许用户从列表框中选择一个或多个项目。
现在,让我们编写一个快速演示,看看如何创建这些小部件之一:
# simple_listboxes.py
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfform
from reportlab.lib.colors import magenta, pink, blue, green, red
def create_simple_listboxes():
c = canvas.Canvas('simple_listboxes.pdf')
c.setFont("Courier", 20)
c.drawCentredString(300, 700, 'Listboxes')
c.setFont("Courier", 14)
form = c.acroForm
c.drawString(10, 650, 'Choose a letter:')
options = [('A','Av'),'B',('C','Cv'),('D','Dv'),'E',('F',),('G','Gv')]
form.listbox(name='listbox1', value='A',
x=165, y=590, width=72, height=72,
borderColor=magenta, fillColor=pink,
textColor=blue, forceBorder=True, options=options,
fieldFlags='multiSelect')
c.drawString(10, 500, 'Choose an animal:')
options = [('Cat', 'cat'), ('Dog', 'dog'), ('Pig', 'pig')]
form.listbox(name='choice2', tooltip='Field choice2',
value='Cat',
options=options,
x=165, y=440, width=72, height=72,
borderStyle='solid', borderWidth=1,
forceBorder=True)
c.save()
if __name__ == '__main__':
create_simple_listboxes()
这个例子实际上非常类似于我们创建了选择小部件的上一个例子。这里的主要区别是 listbox 小部件和 choice 小部件的外观。除此之外,它们几乎是一样的。以下是此代码生成内容的屏幕截图:

现在让我们了解一下 textfield 小部件!
文本字段
文本字段是一个文本输入小工具。你会在输入你的姓名和地址的表格中看到这些。文本字段的大多数参数与您在前面的小部件中看到的参数相同。
# simple_form.py
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfform
from reportlab.lib.colors import magenta, pink, blue, green
def create_simple_form():
c = canvas.Canvas('simple_form.pdf')
c.setFont("Courier", 20)
c.drawCentredString(300, 700, 'Employment Form')
c.setFont("Courier", 14)
form = c.acroForm
c.drawString(10, 650, 'First Name:')
form.textfield(name='fname', tooltip='First Name',
x=110, y=635, borderStyle='inset',
borderColor=magenta, fillColor=pink,
width=300,
textColor=blue, forceBorder=True)
c.drawString(10, 600, 'Last Name:')
form.textfield(name='lname', tooltip='Last Name',
x=110, y=585, borderStyle='inset',
borderColor=green, fillColor=magenta,
width=300,
textColor=blue, forceBorder=True)
c.drawString(10, 550, 'Address:')
form.textfield(name='address', tooltip='Address',
x=110, y=535, borderStyle='inset',
width=400, forceBorder=True)
c.drawString(10, 500, 'City:')
form.textfield(name='city', tooltip='City',
x=110, y=485, borderStyle='inset',
forceBorder=True)
c.drawString(250, 500, 'State:')
form.textfield(name='state', tooltip='State',
x=350, y=485, borderStyle='inset',
forceBorder=True)
c.drawString(10, 450, 'Zip Code:')
form.textfield(name='zip_code', tooltip='Zip Code',
x=110, y=435, borderStyle='inset',
forceBorder=True)
c.save()
if __name__ == '__main__':
create_simple_form()
这里我们创建了一系列应用了不同设置的文本字段。如您所见,我们更改了几个字段的边框和背景色。然后我们只是添加了一些相当标准的。我们还使用了 width 参数来改变文本字段的宽度。
下面是这段代码最终为我生成的结果:

包扎
在本文中,我们学习了如何创建 ReportLab 支持的用于创建交互式 PDF 表单的各种小部件。您可能想要获取一份 ReportLab 用户指南,以了解小部件支持的各种小部件形状、边框类型、字段标志和注释标志,但这在这里不容易再现。如您所见,ReportLab 确实提供了创建相当健壮的表单所需的一切。
相关阅读
使用 interact 创建 Jupyter 笔记本小部件
原文:https://www.blog.pythonlibrary.org/2018/10/23/creating-jupyter-notebook-widgets-with-interact/
Jupyter 笔记本有一个被称为 widgets 的功能。如果您曾经创建过桌面用户界面,您可能已经知道并理解了小部件的概念。它们基本上是构成用户界面的控件。在你的 Jupyter 笔记本中,你可以创建滑块、按钮、文本框等等。
在本章中,我们将学习创建窗口小部件的基础知识。如果你想看一些预制的部件,你可以去下面的网址:
这些小部件是笔记本扩展,可以按照我在 Jupyter extensions 文章中了解到的相同方式安装。如果你想通过查看它们的源代码来研究更复杂的小部件是如何工作的,它们真的很有趣,非常值得你花时间去研究。
入门指南
要创建自己的小部件,您需要安装 ipywidgets 扩展。
使用 pip 安装
下面是如何使用 pip 安装小部件扩展的方法:
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension
如果您正在使用 virtualenv,您可能需要使用--sys-prefix option to keep your environment isolated.
使用 conda 安装
下面是如何用 conda 安装 widgets 扩展:
conda install -c conda-forge ipywidgets
请注意,当安装 conda 时,扩展将自动启用。
学习如何互动
在 Jupyter Notebook 中创建小部件有多种方法。第一种也是最简单的方法是使用来自 ipywidgets.interact 的 interact 函数,它将自动生成用户界面控件(或小部件),然后您可以使用这些控件来探索您的代码并与数据进行交互。
让我们从创建一个简单的滑块开始。启动一个新的 Jupyter 笔记本,并在第一个单元格中输入以下代码:
from ipywidgets import interact
def my_function(x):
return x
# create a slider
interact(my_function, x=20)
这里我们从 ipywidgets 导入 interact 类。然后我们创建一个名为 my_function 的简单函数,它接受一个参数,然后返回它。最后,我们通过传递一个函数以及我们希望 interact 传递给它的值来实例化 interact 。由于我们传入了一个整数(即 20),interact 类将自动创建一个滑块。
尝试运行包含上述代码的单元格,您应该会得到类似如下的结果:

那真是太棒了!尝试用鼠标移动滑块。如果这样做,您将看到滑块以交互方式更新,并且函数的输出也自动更新。
您还可以通过传递浮点数而不是整数来创建一个 FloatSlider 。试试看它是如何改变滑块的。
复选框
一旦你玩完了滑块,让我们来看看我们还能用 interact 做些什么。使用以下代码在同一个 Jupyter 笔记本中添加一个新单元格:
interact(my_function, x=True)
当您运行这段代码时,您会发现 interact 已经为您创建了一个复选框。因为您将“x”设置为True,所以复选框处于选中状态。这是它在我的机器上的样子:

您也可以通过选中和取消选中复选框来使用这个小部件。您将看到它的状态发生了变化,并且函数调用的输出也将打印在屏幕上。
文本框
让我们稍微改变一下,尝试向我们的函数传递一个字符串。创建一个新单元格,并输入以下代码:
interact(my_function, x='Jupyter Notebook!')
当您运行这段代码时,您会发现 interact 生成了一个 textbox,它的值是我们传入的字符串:

尝试编辑文本框的值。当我尝试这样做时,我发现输出文本也发生了变化。
组合框/下拉框
您还可以通过向 interact 中的函数传递列表或字典来创建组合框或下拉小部件。让我们试着传入一个元组列表,看看它的表现如何。回到笔记本,在新的单元格中输入以下代码:
languages = [('Python', 'Rocks!'), ('C++', 'is hard!')]
interact(my_function, x=languages)
当您运行这段代码时,您应该看到“Python”和“C++”作为组合框中的项目。如果您选择了一个,笔记本会将元组的第二个元素显示到屏幕上。下面是我运行这个例子时我的矿是如何渲染的:

如果你想试试字典而不是列表,这里有一个例子:
languages = {'Python': 'Rocks!', 'C++': 'is hard!'}
interact(my_function, x=languages)
运行这个单元的输出与前面的例子非常相似。
关于滑块的更多信息
让我们倒回去一分钟,这样我们就可以更多地讨论滑块。实际上,我们可以利用它们做得比我最初透露的多一点。当你第一次创建滑块的时候,你需要做的就是给我们的函数传递一个整数。下面是再次复习的代码:
from ipywidgets import interact
def my_function(x):
return x
# create a slider
interact(my_function, x=20)
这里的值 20 在技术上是创建整数值滑块的缩写。代码:
interact(my_function, x=20)
实际上相当于以下内容:
interact(my_function, x=widgets.IntSlider(value=20))
从技术上讲,Bools 是复选框的缩写,list/dicts 是 Comboboxes 的缩写,等等。
无论如何,回到滑块。实际上还有另外两种创建整数值滑块的方法。您也可以传入两个或三个项目的元组:
- (最小值,最大值)
- (最小、最大、步长)
这使我们能够使滑块更有用,因为现在我们可以控制滑块的最小值和最大值,以及设置步长。步长是我们改变滑块时滑块的变化量。如果您想设置一个初始值,那么您需要像这样更改您的代码:
def my_function(x=5):
return x
interact(my_function, x=(0, 20, 5))
函数中的 x=5 就是设置初始值的部分。我个人发现有点反直觉,因为 IntSlider 本身似乎被定义为这样工作:
IntSlider(min, max, step, value)
interact 类不会像您自己创建 IntSlider 那样实例化它。
请注意,如果您想要创建一个 FloatSlider,您所需要做的就是将一个 float 传递给三个参数中的任何一个:min、max 或 step。将函数的参数设置为 float 不会将滑块更改为 FloatSlider。
使用 interact 作为装饰器
interact 类也可以用作 Python 装饰器。对于这个例子,我们还将在函数中添加第二个参数。回到正在运行的笔记本,使用以下代码添加一个新单元格:
from ipywidgets import interact
@interact(x=5, y='Python')
def my_function(x, y):
return (x, y)
你会注意到,在这个例子中,我们不需要显式地传递函数名。事实上,如果您这样做,您会看到一个错误。装饰者隐式调用函数。这里需要注意的另一点是,我们传入了两个参数,而不是一个:一个整数和一个字符串。您可能已经猜到,这将分别创建一个滑块和一个文本框:

与前面的所有示例一样,您可以在浏览器中与这些小部件进行交互,并查看它们的输出。
固定参数
很多时候,您会希望将其中一个参数设置为固定值,而不是允许通过小部件来操作它。Jupyter 笔记本 ipywidgets 包通过固定函数支持这一点。让我们来看看如何使用它:
from ipywidgets import interact, fixed
@interact(x=5, y=fixed('Python'))
def my_function(x, y):
return (x, y)
这里我们从 ipywidgets 导入固定函数。然后在我们的 interact 装饰器中,我们将第二个参数设置为“fixed”。当您运行这段代码时,您会发现它只创建了一个小部件:一个滑块。这是因为我们不希望或不需要一个小部件来操纵第二个参数。

在这个截图中,你可以看到我们只有一个滑块,输出是一个元组。如果您更改滑块的值,您将只看到元组中的第一个值发生变化。
互动功能
本章中还有第二个值得讨论的功能,叫做交互。当您想要重用小部件或访问绑定到所述小部件的数据时,这个函数非常有用。互动和互动的最大区别在于,有了互动,小工具不会自动显示在屏幕上。如果您希望显示小部件,那么您需要明确地这样做。
让我们看一个简单的例子。在 Jupyter 笔记本中打开一个新单元格,输入以下代码:
from ipywidgets import interactive
def my_function(x):
return x
widget = interactive(my_function, x=5)
type(widget)
运行此代码时,您应该会看到以下输出:
ipywidgets.widgets.interaction.interactive
但是你不会像使用交互功能时那样看到一个滑块部件。为了演示,下面是我运行该单元时得到的截图:

如果您想要显示小部件,您需要导入 display 函数。让我们将单元格中的代码更新如下:
from ipywidgets import interactive
from IPython.display import display
def my_function(x):
return x
widget = interactive(my_function, x=5)
display(widget)
这里我们从 IPython.display 导入 display 函数,然后在代码的最后调用它。当我运行这个单元格时,我得到了滑块小部件:

为什么这很有帮助?为什么不直接使用 interact 而不是通过额外的关卡呢?答案是交互功能给了你交互所没有的额外信息。您可以访问小部件的关键字参数及其结果。将以下两行添加到您刚刚编辑的单元格的末尾:
print(widget.kwargs)
print(widget.result)
现在,当您运行单元格时,它将打印出传递给函数的参数和调用函数的返回值(即结果)。
包扎
在本章中,我们学习了很多关于 Jupyter 笔记本小部件的知识。我们讨论了使用“交互”功能和“互动”功能的基础知识。然而,通过查看文档,你可以了解更多关于这些函数的信息。
即便如此,这也只是你在 Jupyter 中使用小部件所能做事情的皮毛。在下一章中,我们将深入研究除了使用我们在本章中学到的交互/互动功能之外,如何手工创建小部件。我们将了解更多关于小工具的工作原理,以及如何使用它们让你的笔记本变得更有趣、功能更强大。
相关阅读
- Jupyter 笔记本扩展基础知识
- 使用 Jupyter 笔记本创建演示文稿
用 Python 和 xlwt 创建 Microsoft Excel 电子表格
用 Python 创建 Microsoft Excel 电子表格有几种方法。你可以使用 PyWin32 的 win32com.client 方法,这在几年前的一篇旧的文章中讨论过,或者你可以使用 xlwt 包。在本文中,我们将着眼于后者。您将学习如何创建包含多个工作表的 Excel 电子表格,以及如何创建样式化的单元格。我们开始吧!
获取 xlwt
您会想去下载 xlwt,这样您就可以跟着做了。它在 PyPI 上可用。如果你已经安装了 pip ,那么你也可以这样安装。一旦你有了模块,我们将准备继续。
使用 xlwt
xlwt 包非常容易使用,尽管文档有点少。从好的方面来看,xlwt Github 资源库有很多例子。让我们用一张工作表创建一个简单的 Excel 电子表格:
import xlwt
#----------------------------------------------------------------------
def main():
""""""
book = xlwt.Workbook()
sheet1 = book.add_sheet("PySheet1")
cols = ["A", "B", "C", "D", "E"]
txt = "Row %s, Col %s"
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt % (num+1, col)
row.write(index, value)
book.save("test.xls")
#----------------------------------------------------------------------
if __name__ == "__main__":
main()
让我们把它分解一下。首先,我们导入 xlwt 模块并创建一个名为 main 的函数。在 main 函数中,我们创建了一个 xlwt 的实例。工作簿并通过 add_sheet 方法添加一个工作表。我们用文本“PySheet1”标记工作表。然后我们创建一个嵌套循环来创建 5 行 5 列的内容。基本上,我们将行/列信息写入每个单元格。然后我们保存文件,我们就完成了!
创建样式化单元格

现在让我们以这样一种方式重构代码,即我们可以通过使用函数来添加工作表。我们还将创建另一个函数,该函数可以创建带有样式化单元格的工作表:
import xlwt
#----------------------------------------------------------------------
def add_sheet(book, name):
"""
Add a sheet with one line of data
"""
value = "This sheet is named: %s" % name
sheet = book.add_sheet(name)
sheet.write(0,0, value)
#----------------------------------------------------------------------
def add_styled_sheet(book, name):
"""
Add a sheet with styles
"""
value = "This is a styled sheet!"
sheet = book.add_sheet(name)
style = 'pattern: pattern solid, fore_colour blue;'
sheet.row(0).write(0, value, xlwt.Style.easyxf(style))
#----------------------------------------------------------------------
def main():
""""""
book = xlwt.Workbook()
sheet1 = book.add_sheet("PySheet1")
cols = ["A", "B", "C", "D", "E"]
txt = "Row %s, Col %s"
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt % (num+1, col)
row.write(index, value)
add_sheet(book, "PySheet2")
add_styled_sheet(book, "StyledSheet")
book.save("test2.xls")
#----------------------------------------------------------------------
if __name__ == "__main__":
main()
这里我们创建一个 add_sheet 方法,它接受一个工作簿实例和工作表的名称。它将向图书中添加一个工作表,并带有一个标识工作表名称的单元格。 add_styled_sheet 的工作方式基本相同,只是它创建了一个带有消息的样式化单元格。
创建更复杂样式的单元格
在本例中,我们将使用原始代码创建相同的 5x5 单元格集。然后,我们还将创建一个具有红色背景、边框和特定日期格式的单元格:
from datetime import date
import xlwt
#----------------------------------------------------------------------
def main():
""""""
book = xlwt.Workbook()
sheet1 = book.add_sheet("PySheet1")
cols = ["A", "B", "C", "D", "E"]
txt = "Row %s, Col %s"
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt % (num+1, col)
row.write(index, value)
value = date(2009,3,18)
fmt = xlwt.Style.easyxf("""
font: name Arial;
borders: left thick, right thick, top thick, bottom thick;
pattern: pattern solid, fore_colour red;
""", num_format_str='YYYY-MM-DD')
sheet1.write(6,1,value, fmt)
book.save("test3.xls")
#----------------------------------------------------------------------
if __name__ == "__main__":
main()
这里,我们使用一个大字符串来指定 xlwt,我们希望应用一个使用 Arial 字体的样式,单元格的四边都有边框,fore_color 是红色。当你执行代码的时候,你会发现 fore_color 其实就是背景色的意思。总之,这种语法使得对单元格的内容进行样式化变得非常容易。Python Excel 网站发布的这个 PDF 中有很多很好的例子。
包扎
现在您知道了如何使用 xlwt 包创建简单的 Microsoft Excel 电子表格。您会注意到它使用旧的 *创建电子表格。xls 格式。xlwt 模块目前不支持 *。xlsx 格式。为此,你可能不得不使用 PyWin32 或者 openpyxl 项目或者 XlsxWriter 。祝你好运,编码快乐!
相关阅读
- PyPI 上的 xlwt
- Python-Excel 网站
- an〔t0〕xlwt/xlrd 用户指南(pdf)〔t1〕
- Python 和微软 Office 使用 PyWin32
使用 fpdf2 和 Python 创建 pdf
原文:https://www.blog.pythonlibrary.org/2018/06/05/creating-pdfs-with-pyfpdf-and-python/
ReportLab 是我用来从头开始生成 pdf 的主要工具包。不过我发现还有一个叫 fpdf2 。fpdf2 包实际上是用 PHP 编写的“免费”pdf 包的一个端口。
注:PyFPDF 现已死亡。本文最初就是考虑到这个包而写的。已经换成了fpdf 2
本文对 fpdf2 封装的介绍并不详尽。然而,它将涵盖足够多的,让你开始有效地使用它。请注意,如果您想了解更多关于这个库的信息,而不是本章或包的文档中所涵盖的内容,那么在 Leanpub 上有一本关于 PyFPDF 的短文,书名是“Python does PDF: pyFPDF ”,作者是 Edwood Ocasio。
装置
安装 fpdf2 很容易,因为它是为 pip 设计的。方法如下:
python -m pip install fpdf2
当你安装这个包时,你会发现它没有依赖项,这很好。
| | Want to learn more about working with PDFs in Python? Then check out my book:
ReportLab:使用 Python 处理 PDF
在 Leanpub 上立即购买 |
基本用法
现在您已经安装了 fpdf2,让我们试着用它来创建一个简单的 pdf。打开 Python 编辑器,创建一个名为 simple_demo.py 的新文件。然后在其中输入以下代码:
# simple_demo.py
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.cell(200, 10, txt="Welcome to Python!", ln=1, align="C")
pdf.output("simple_demo.pdf")
我们需要谈的第一项是进口。这里我们从 fpdf 包中导入 FPDF 类。此类别的默认设置是以纵向模式创建 PDF,使用毫米作为度量单位,并使用 A4 页面大小。如果您想要更明确,您可以像这样编写实例化行:
pdf = FPDF(orientation='P', unit='mm', format='A4')
我不喜欢用字母“P”来告诉同学们它的方向。如果你喜欢横向多于纵向,你也可以用 L。
fpdf2 封装支持“pt”、“cm”和“in”作为替代测量单位。
如果深入研究源代码,您会发现 fpdf2 包仅支持以下页面大小:
- A3 号
- A4 号
- A5 号
- 信
- 合法的
与 ReportLab 相比,这是一个小小的限制,在 ReportLab 中,您可以支持多种额外的大小,并且您还可以将页面大小设置为自定义大小。
无论如何,下一步是使用 add_page 方法创建一个页面。然后我们通过 set_font 方法设置页面的字体。你会注意到我们传入了字体的族名和我们想要的大小。您也可以使用样式参数设置字体的样式。如果您想这样做,请注意,它需要一个字符串,如' B '表示粗体,或' BI '表示粗体斜体。
接下来,我们创建一个 200 毫米宽、10 毫米高的单元格。单元格基本上是一个容纳文本的可流动体,可以启用边框。如果启用了自动分页符,并且单元格超出了页面的大小限制,它将自动拆分。 txt 参数是您想要在 PDF 中打印的文本。 ln 参数告诉 PyFPDF 如果设置为 1,就添加一个换行符,这就是我们在这里所做的。最后,我们可以将文本的对齐方式设置为对齐(默认)或居中(C)。我们在这里选择了后者。
最后,我们通过使用我们想要保存的文件的路径调用 output 方法将文档保存到磁盘。
当我运行这段代码时,我得到了一个如下所示的 PDF:

现在让我们了解一点 fpdf2 如何使用字体。
使用字体
fpdf2 有一组硬编码到其 fpdf 类中的核心字体:
self.core_fonts={'courier': 'Courier',
'courierB': 'Courier-Bold',
'courierBI': 'Courier-BoldOblique',
'courierI': 'Courier-Oblique',
'helvetica': 'Helvetica',
'helveticaB': 'Helvetica-Bold',
'helveticaBI': 'Helvetica-BoldOblique',
'helveticaI': 'Helvetica-Oblique',
'symbol': 'Symbol',
'times': 'Times-Roman',
'timesB': 'Times-Bold',
'timesBI': 'Times-BoldItalic',
'timesI': 'Times-Italic',
'zapfdingbats': 'ZapfDingbats'}
您会注意到,尽管我们在前面的示例中使用了 Arial,但它并没有在这里列出。Arial 在实际的源代码中被重新映射到 Helvetica,所以你根本没有真正使用 Arial。无论如何,让我们学习如何使用 fpdf2 改变字体:
# change_fonts.py
from fpdf import FPDF
def change_fonts():
pdf = FPDF()
pdf.add_page()
font_size = 8
for font in pdf.core_fonts:
if any([letter for letter in font if letter.isupper()]):
# skip this font
continue
pdf.set_font(font, size=font_size)
txt = "Font name: {} - {} pts".format(font, font_size)
pdf.cell(0, 10, txt=txt, ln=1, align="C")
font_size += 2
pdf.output("change_fonts.pdf")
if __name__ == '__main__':
change_fonts()
这里我们创建了一个简单的函数叫做 change_fonts ,然后我们创建了一个 FPDF 类的实例。下一步是创建一个页面,然后遍历核心字体。当我尝试这样做时,我发现 fpdf2 不认为其核心字体的变体名称是有效的字体(例如 helveticaB、helveticaBI 等)。所以为了跳过这些变体,我们创建一个列表理解并检查字体名称中的任何大写字符。如果有,我们跳过这个字体。否则,我们设置字体和字体大小,并把它写出来。我们还通过循环每次增加两个点的字体大小。如果你想改变字体的颜色,那么你可以调用 set_text_color 并传入你需要的 RGB 值。
运行这段代码的结果如下所示:

我喜欢在 fpdf2 中改变字体是如此容易。然而,核心字体的数量非常少。您可以通过 add_font 方法使用 fpdf2 添加 TrueType、OpenType 或 Type1 字体。此方法采用以下参数:
- 系列(字体系列)
- 样式(字体样式)
- fname(字体文件名或字体文件的完整路径)
- uni (TTF Unicode 标志)
fpdf2 文档使用的示例如下:
pdf.add_font('DejaVu', '', 'DejaVuSansCondensed.ttf', uni=True)
在试图通过 set_font 方法使用它之前,您将调用 add_font 。我在 Windows 上试了一下,发现了一个错误,因为 Windows 找不到这种字体,这是我预料中的。这是添加字体的一个非常简单的方法,而且可能会奏效。请注意,它使用以下搜索路径:
- FPDF_FONTPATH
- 系统 _ 字体
这些似乎是在您的环境或 PyFPDF 包本身中定义的常量。文档没有解释如何设置或修改它们。相反,你应该使用 set_global() 和你想要使用的字体的路径。:
import fpdf
fpdf_mod.set_global("SYSTEM_TTFONTS", os.path.join(os.path.dirname(__file__),'fonts'))
否则 SYSTEM_TTFONTS 默认设置为 None 。
图画
fpdf2 封装对绘图的支持有限。你可以画直线、椭圆和矩形。我们先来看看如何画线:
# draw_lines.py
from fpdf import FPDF
def draw_lines():
pdf = FPDF()
pdf.add_page()
pdf.line(10, 10, 10, 100)
pdf.set_line_width(1)
pdf.set_draw_color(255, 0, 0)
pdf.line(20, 20, 100, 20)
pdf.output('draw_lines.pdf')
if __name__ == '__main__':
draw_lines()
这里我们调用 line 方法,并传递给它两对 x/y 坐标。线宽默认为 0.2 毫米,所以我们通过调用 set_line_width 方法将第二行的线宽增加到 1 毫米。我们还通过调用 set_draw_color 将第二行的颜色设置为等同于红色的 RGB 值。输出如下所示:

现在我们可以继续画几个形状:
# draw_shapes.py
from fpdf import FPDF
def draw_shapes():
pdf = FPDF()
pdf.add_page()
pdf.set_fill_color(255, 0, 0)
pdf.ellipse(10, 10, 10, 100, 'F')
pdf.set_line_width(1)
pdf.set_fill_color(0, 255, 0)
pdf.rect(20, 20, 100, 50)
pdf.output('draw_shapes.pdf')
if __name__ == '__main__':
draw_shapes()
当你画一个类似于椭圆或矩形的形状时,你将需要传入代表绘图左上角的 x 和 y 坐标。然后,您将需要传入形状的宽度和高度。您可以传入的最后一个参数是用于样式的,它可以是“D”或空字符串(默认)、“F”用于填充或“DF”用于绘制和填充。在这个例子中,我们填充椭圆并使用默认的矩形。结果看起来像这样:

现在让我们了解一下图像支持。
添加图像
fpdf2 软件包支持将 JPEG、PNG 和 GIF 格式添加到您的 pdf 中。如果您碰巧尝试使用动画 GIF,则只使用第一帧。同样值得注意的是,如果您多次向文档中添加相同的图像,fpdf2 足够智能,可以只嵌入图像的一个实际副本。下面是一个使用 fpdf2 向 PDF 添加图像的非常简单的示例:
# add_image.py
from fpdf import FPDF
def add_image(image_path):
pdf = FPDF()
pdf.add_page()
pdf.image(image_path, x=10, y=8, w=100)
pdf.set_font("Arial", size=12)
pdf.ln(85) # move 85 down
pdf.cell(200, 10, txt="{}".format(image_path), ln=1)
pdf.output("add_image.pdf")
if __name__ == '__main__':
add_image('snakehead.jpg')
这里的新代码是对 image 方法的调用。它的签名看起来像这样:
image(name, x = None, y = None, w = 0, h = 0, type = '', link = '')
您可以指定图像文件路径、x 和 y 坐标以及宽度和高度。如果您只指定宽度或高度,另一个会自动计算,并尝试保持图像的原始比例。也可以显式指定文件类型,否则是根据文件名猜测的。最后,您可以在添加图像时添加链接/ URL。
当您运行这段代码时,您应该会看到如下所示的内容:

现在让我们了解 fpdf2 如何支持多页文档。
多页文档
fpdf2 默认启用多页支持。如果您在页面中添加了足够多的单元格,它会自动创建一个新页面,并继续将您的新文本添加到下一页。这里有一个简单的例子:
# multipage_simple.py
from fpdf import FPDF
def multipage_simple():
pdf = FPDF()
pdf.set_font("Arial", size=12)
pdf.add_page()
line_no = 1
for i in range(100):
pdf.cell(0, 10, txt="Line #{}".format(line_no), ln=1)
line_no += 1
pdf.output("multipage_simple.pdf")
if __name__ == '__main__':
multipage_simple()
这只是创建了 100 行文本。当我运行这段代码时,我得到了一个包含 4 页文本的 PDF 文件。
页眉和页脚
fpdf2 软件包内置了对添加页眉、页脚和页码的支持。FPDF 的类只需要被子类化,而页眉和页脚的方法被覆盖以使它们工作。让我们来看看:
# header_footer.py
from fpdf import FPDF
class CustomPDF(FPDF):
def header(self):
# Set up a logo
self.image('snakehead.jpg', 10, 8, 33)
self.set_font('Arial', 'B', 15)
# Add an address
self.cell(100)
self.cell(0, 5, 'Mike Driscoll', ln=1)
self.cell(100)
self.cell(0, 5, '123 American Way', ln=1)
self.cell(100)
self.cell(0, 5, 'Any Town, USA', ln=1)
# Line break
self.ln(20)
def footer(self):
self.set_y(-10)
self.set_font('Arial', 'I', 8)
# Add a page number
page = 'Page ' + str(self.page_no()) + '/{nb}'
self.cell(0, 10, page, 0, 0, 'C')
def create_pdf(pdf_path):
pdf = CustomPDF()
# Create the special value {nb}
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Times', '', 12)
line_no = 1
for i in range(50):
pdf.cell(0, 10, txt="Line #{}".format(line_no), ln=1)
line_no += 1
pdf.output(pdf_path)
if __name__ == '__main__':
create_pdf('header_footer.pdf')
因为这是一段相当长的代码,所以让我们一段一段地看。我们想看的第一部分是头方法:
def header(self):
# Set up a logo
self.image('snakehead.jpg', 10, 8, 33)
self.set_font('Arial', 'B', 15)
# Add an address
self.cell(100)
self.cell(0, 5, 'Mike Driscoll', ln=1)
self.cell(100)
self.cell(0, 5, '123 American Way', ln=1)
self.cell(100)
self.cell(0, 5, 'Any Town, USA', ln=1)
# Line break
self.ln(20)
在这里,我们只是硬编码的标志图像,我们想使用,然后我们设置字体,我们将在我们的标题中使用。接下来,我们添加一个地址,并将该地址放在图像的右侧。您会注意到,当您使用 fpdf2 时,原点在页面的左上角。因此,如果我们想将我们的文本向右移动,那么我们需要创建一个具有多个度量单位的单元格。在这种情况下,我们通过添加一个 100 mm 的单元格,将接下来的三行向右移动。然后,我们在末尾添加一个换行符,这将增加 20 mm 的垂直空间。
接下来,我们想要覆盖页脚方法:
def footer(self):
self.set_y(-10)
self.set_font('Arial', 'I', 8)
# Add a page number
page = 'Page ' + str(self.page_no()) + '/{nb}'
self.cell(0, 10, page, 0, 0, 'C')
我们在这里做的第一件事是将页面上原点的 y 位置设置为-10 mm 或-1 cm。这将页脚的原点放在页面底部的正上方。然后我们为页脚设置字体。最后,我们创建页码文本。你会注意到对 {nb} 的引用。这是 fpdf2 中的一个特殊值,在您调用 alias_nb_pages 时插入,表示文档中的总页数。页脚的最后一步是在页面上书写页面文本并居中。
最后一段代码在 create_pdf 函数中:
def create_pdf(pdf_path):
pdf = CustomPDF()
# Create the special value {nb}
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Times', '', 12)
line_no = 1
for i in range(50):
pdf.cell(0, 10, txt="Line #{}".format(line_no), ln=1)
line_no += 1
pdf.output(pdf_path)
这就是我们调用有点神奇的 alias_nb_pages 方法的地方,该方法将帮助我们获得总页数。我们还为页面中没有被页眉或页脚占据的部分设置了字体。然后,我们向文档中写入 50 行文本,使其创建一个多页 PDF。
当您运行这段代码时,您应该会看到一个如下所示的页面:

现在让我们看看如何用 PyFPDF 创建表。
桌子
fpdf2 包没有表格控件。相反,您必须使用单元格或 HTML 来构建表格。让我们先来看看如何使用单元格创建表格:
# simple_table.py
from fpdf import FPDF
def simple_table(spacing=1):
data = [['First Name', 'Last Name', 'email', 'zip'],
['Mike', 'Driscoll', 'mike@somewhere.com', '55555'],
['John', 'Doe', 'jdoe@doe.com', '12345'],
['Nina', 'Ma', 'inane@where.com', '54321']
]
pdf = FPDF()
pdf.set_font("Arial", size=12)
pdf.add_page()
col_width = pdf.w / 4.5
row_height = pdf.font_size
for row in data:
for item in row:
pdf.cell(col_width, row_height*spacing,
txt=item, border=1)
pdf.ln(row_height*spacing)
pdf.output('simple_table.pdf')
if __name__ == '__main__':
simple_table()
这里我们只是创建一个简单的列表列表,然后循环遍历它。对于列表中的每一行和嵌套行中的每个元素,我们向 PDF 对象添加一个单元格。请注意,我们打开了这些单元格的边框。当我们完成一行的迭代后,我们添加一个换行符。如果您希望单元格中有更多的空间,那么您可以传入一个间距值。当我运行这个脚本时,我得到了一个如下所示的表:

尽管这是一种非常粗糙的创建表格的方法。我个人更喜欢 ReportLab 在这里的方法论。
另一种方法是使用 HTML 创建表格:
# simple_table_html.py
from fpdf import FPDF, HTMLMixin
class HTML2PDF(FPDF, HTMLMixin):
pass
def simple_table_html():
pdf = HTML2PDF()
table = """
| 标题 1 | 标题 2 |
|---|---|
| 单元格 1 | 细胞 2 |
| 细胞 2 | 3 号牢房 |
" " " pdf . add _ page()pdf . write _ html(table)pdf . output(' simple _ table _ html . pdf ')if _ _ name _ _ = ' _ _ main _ _ ':simple _ table _ html()
这里我们使用 fpdf2 的 HTMLMixin 类来允许它接受 HTML 作为输入并将其转换成 pdf。当您运行此示例时,您将得到以下结果:

网站上有一些使用 Web2Py 框架和 PyFPDF 创建更好看的表格的例子,但是代码不完整,所以我在这里不做演示。
将 HTML 转换为 PDF
fpdf2 包对 HTML 标签有一些有限的支持。您可以使用 HTML 创建标题、段落和基本文本样式。您还可以添加超链接、图像、列表和表格。有关受支持的标签和属性的完整列表,请查看文档。然后,您可以使用我们在上一节创建表格时看到的 HTMLMixin 将基本 HTML 转换成 PDF。
# html2fpdf.py
from fpdf import FPDF, HTMLMixin
class HTML2PDF(FPDF, HTMLMixin):
pass
def html2pdf():
html = '''
fpdf2 HTML 演示
这是常规文本
也可以粗体、斜体或下划线' ' ' pdf = html 2 pdf()pdf . add _ page()pdf . write _ html(html)pdf . output(' html 2 pdf ')if _ _ name _ _ = ' _ _ main _ _ ':html 2 pdf()
在这里,我们只是使用非常标准的 HTML 标记来设计 PDF。当您运行这段代码时,它实际上看起来相当不错:

Web2Py
Web2Py 框架包括 fpdf2 包,使在框架中创建报告变得更加容易。这允许您在 Web2Py 中创建 PDF 模板。关于这个主题的文档有点少,所以我不会在本书中涉及这个主题。然而,看起来您确实可以通过这种方式使用 Web2Py 做一些不太好的报告。
模板
您也可以使用 fpdf2 创建模板。这个包甚至包括一个设计器脚本,它使用 wxPython 作为它的用户界面。您可以创建的模板将是您想要指定每个元素在页面上出现的位置、它的样式(字体、大小等)以及要使用的默认文本。模板系统支持使用 CSV 文件或数据库。然而,在关于这个主题的文档中只有一个例子,这有点令人失望。虽然我确实认为这个库的这一部分很有前途,但是由于缺乏文档,我不太愿意大范围地写它。
包扎
fpdf2 包是一个相当不错的项目,可以让您进行基本的 pdf 生成。他们在 FAQ 中指出,他们不支持图表或小部件,也不支持像 ReportLab 这样的“灵活的页面布局系统”。它们也不支持 PDF 文本提取或转换,如 PDFMiner 或 PyPDF2。然而,如果您需要的只是生成 PDF 的基本框架,那么这个库可能适合您。我认为它的学习曲线比 ReportLab 的要简单。然而,fpdf2 的功能远不如 ReportLab 丰富,我觉得在页面上放置元素时,你没有相同的控制粒度。
相关阅读
- 使用 Python 在 ReportLab 中创建交互式 PDF 表单
- 用 Python 填充 PDF 表单
- 使用 Python 从 pdf 中导出数据
源代码
使用 Jupyter 笔记本创建演示文稿
原文:https://www.blog.pythonlibrary.org/2018/09/25/creating-presentations-with-jupyter-notebook/
Jupyter Notebook 可以变成幻灯片演示,有点像使用 Microsoft Powerpoint,只是您可以实时运行幻灯片的代码!它真的很好用。在我的书中,唯一的缺点是没有太多的主题可以应用到你的幻灯片上,所以它们最终看起来有点简单。
在这篇文章中,我们将看看用你的 Jupyter 笔记本制作幻灯片的两种方法。第一种方法是使用 Jupyter Notebook 内置的幻灯片放映功能。第二种是通过使用一个名为 RISE 的插件。
我们开始吧!
注意:本文假设你已经安装了 Jupyter 笔记本。如果你没有,那么你可能想去他们的网站学习如何这样做。
我们需要做的第一件事是创建一个新的笔记本。完成并运行后,让我们创建三个单元格,这样我们就可以有三张幻灯片。您的笔记本现在应该如下所示:

有 3 个单元格的空笔记本
现在让我们打开“幻灯片放映”工具。进入视图菜单,然后点击单元格工具栏菜单选项。你会在那里找到一个叫做幻灯片的子菜单。选择那个。现在,您笔记本的单元格应该是这样的:

一张空幻灯片
现在每个单元格的右上角都有了小的组合框。这些小部件为您提供了以下选项:
- 幻灯片
- 子幻灯片
- 碎片
- 跳跃
- 笔记
如果你喜欢,你可以创建一系列幻灯片,但是你可以通过添加子幻灯片和片段来使幻灯片更有趣。子幻灯片是前一张幻灯片下面的幻灯片,而片段基本上是前一张幻灯片中的片段。顺便说一句,我自己实际上从未使用过片段。无论如何,你也可以设置一张幻灯片跳过,这只是让你跳过一张幻灯片或笔记,这只是发言者的笔记。
让我们给第一个单元格添加一些文本。我们将向它添加文本“# Hello Slideshow ”,并将单元格类型设置为 Markdown。请注意文本开头的英镑符号。这将使文本成为标题。
在单元格二中,我们可以添加一个简单的函数。让我们使用下面的代码:
def double(x):
print(x * 2)
double(4)
对于最后一个单元格,我们将添加以下文本:
# The end
请确保将该单元格也设置为减价单元格。这是我完成后我的细胞看起来的样子:

准备好幻灯片
为了简单起见,只需将每个单元格的单独组合框设置为 Slide 。
现在我们只需要把它变成一个真正的幻灯片。为此,您需要保存您的笔记本并关闭 Jupyter 笔记本服务器。接下来,您需要运行以下命令:
jupyter nbconvert slideshow.ipynb --to slides --post serve

运行幻灯片
要浏览幻灯片,您可以使用左右箭头键,或者使用空格键前进,shift _ 空格键后退。这创建了一个非常漂亮简单的幻灯片,但是它不允许你运行单元格。为此,我们需要使用 RISE 插件!
RISE 入门
reveal . js-Jupyter/IPython slide show Extension(RISE)是一个插件,它使用reveal.js使幻灯片实时运行。这意味着您现在可以在幻灯片中运行您的代码,而无需退出幻灯片。我们需要了解的第一件事是如何安装 RISE。
安装带 conda 的 rise
如果您碰巧是 Anaconda 用户,那么您可以使用以下方法来安装 RISE:
conda install -c conda-forge rise
这是安装 RISE 最简单的方法。然而大多数人仍然使用常规的 CPython,所以接下来我们将学习如何使用 pip!
安装带 pip 的 rise
您可以使用 Python 的 pip 安装工具来安装 RISE,如下所示:
pip install RISE
你也可以做‘python-m pip install rise’如果你想的话。一旦安装了这个包,第二步就是在适当的位置安装 JS 和 CSS,这需要您运行下面的命令:
jupyter-nbextension install rise --py --sys-prefix
如果你得到了一个比 5.3.0 更老的 RISE 版本,那么你还需要在 Jupyter 中启用 RISE 扩展。然而,我建议使用最新版本,这样你就不用担心了。
将 RISE 用于幻灯片显示
现在我们已经安装并启用了 RISE,让我们重新打开之前创建的 Jupyter 笔记本。您的笔记本现在应该看起来像这样:

添加上升
你会注意到我在你的笔记本上圈出了一个由 RISE 添加的新按钮。如果你把鼠标放在那个按钮上,你会看到它有一个工具提示显示“进入/退出上升幻灯片”。点击它,你应该会看到一个幻灯片,看起来很像前一个。这里的区别是,你可以在幻灯片中编辑和运行所有的单元格。只需双击第一张幻灯片,您应该会看到它转换为以下内容:

带着上升奔跑
完成编辑后,按 SHIFT+ENTER 运行单元格。以下是有效播放幻灯片所需的主要快捷方式:
- 空格键-在幻灯片放映中前进一张幻灯片
- SHIFT+空格键-在幻灯片放映中后退一张幻灯片
- SHIFT+ENTER -运行当前幻灯片上的单元格
- 双击-可编辑降价单元格
不在幻灯片模式时,进入帮助菜单,点击键盘快捷键选项,即可查看所有键盘快捷键。这些快捷方式中的大部分(如果不是全部的话)应该可以在 RISE 幻灯片中使用。
如果您想在特定单元格上开始放映幻灯片,只需选择该单元格,然后按下 Enter Slideshow 按钮。
RISE 还支持笔记本小部件。尝试使用以下代码创建一个新单元格:
from ipywidgets import interact
def my_function(x):
return x
# create a slider
interact(my_function, x=20)
现在,在该单元格上开始放映幻灯片,并尝试运行该单元格(SHIFT+ENTER)。您应该会看到类似这样的内容:

在 RISE 中使用 widget
您可以使用 RISE 将整洁的小部件、图形和其他交互式元素添加到您的幻灯片中,您可以实时编辑这些元素,以便向您的与会者演示概念。这真的很有趣,我曾亲自用 RISE 向工程师展示 Python 中的中级材料。
RISE 也有几个不同的主题,你可以应用它们作为幻灯片切换的最小支持。参见文档了解全部信息。
包扎
在这一章中,我们学习了用 Jupyter 笔记本制作演示文稿的两种好方法。您可以通过 Jupyter 的 nbconvert 工具直接使用 Jupyter,从您笔记本中的单元格生成幻灯片。这是很好的,但我个人更喜欢上升。这使得演示更加互动和有趣。我强烈推荐。你会发现使用 Jupyter Notebook 做演示会让幻灯片更吸引人,而且在演示过程中还可以修改幻灯片,这真是太好了!
相关阅读
- 使用 Jupyter 笔记本展示代码
- 崛起 Github 页面
- Jupyter nbconvert 用法
- 如何使用 Jupyter Notebook 创建交互式演示文稿并显示 JS
用 Python 创建二维码
原文:https://www.blog.pythonlibrary.org/2012/05/18/creating-qr-codes-with-python/
前几天,我觉得用 wxPython 创建一个可以生成二维码并显示在屏幕上的小程序会很有趣。当然,我想用 Python 来完成这一切,所以稍微看了一下,我遇到了 3 个候选人:
- python-qrdon github
- sourceforge 上的 pyqrcode 和
- 谷歌代码上的 pyqrnative
我尝试了 python-qrcode 和 pyqrnative,因为它们既能在 Windows 上运行,也能在 Mac 和 Linux 上运行。他们也不需要任何东西,除了 Python 图像库。pyqrcode 项目需要其他几个先决条件,并且不能在 Windows 上工作,所以我不想弄乱它。我最终基于我的照片浏览器应用程序获取了一些旧代码,并对其稍作修改,使其成为一个二维码浏览器。如果我激起了你的兴趣,那就继续读下去吧!
入门指南
正如我在开始时提到的,您将需要 Python 图像库。我们将使用 wxPython 作为 GUI 部分,所以你也需要它。你会想下载 python-qrcode 和 pyqrnative。我发现的主要区别是 python-qrcode 在生成图像方面要快得多,并且它生成的图像类型可能是你见过最多的。出于某种原因,pyqrnative 运行时间要长得多,它创建了一个看起来更密集的二维码。这两个项目可能都有选项允许您生成不同种类的代码,但是这两个项目的文档都很糟糕。我最终更多地使用源代码和 Wingware 的 IDE 来遍历代码。
生成二维码
无论如何,一旦你具备了所有的先决条件,你就可以运行下面的代码,看看 Python 能做什么:
import os
import wx
try:
import qrcode
except ImportError:
qrcode = None
try:
import PyQRNative
except ImportError:
PyQRNative = None
########################################################################
class QRPanel(wx.Panel):
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
wx.Panel.__init__(self, parent=parent)
self.photo_max_size = 240
sp = wx.StandardPaths.Get()
self.defaultLocation = sp.GetDocumentsDir()
img = wx.EmptyImage(240,240)
self.imageCtrl = wx.StaticBitmap(self, wx.ID_ANY,
wx.BitmapFromImage(img))
qrDataLbl = wx.StaticText(self, label="Text to turn into QR Code:")
self.qrDataTxt = wx.TextCtrl(self, value="http://www.mousevspython.com", size=(200,-1))
instructions = "Name QR image file"
instructLbl = wx.StaticText(self, label=instructions)
self.qrPhotoTxt = wx.TextCtrl(self, size=(200,-1))
browseBtn = wx.Button(self, label='Change Save Location')
browseBtn.Bind(wx.EVT_BUTTON, self.onBrowse)
defLbl = "Default save location: " + self.defaultLocation
self.defaultLocationLbl = wx.StaticText(self, label=defLbl)
qrcodeBtn = wx.Button(self, label="Create QR with qrcode")
qrcodeBtn.Bind(wx.EVT_BUTTON, self.onUseQrcode)
pyQRNativeBtn = wx.Button(self, label="Create QR with PyQRNative")
pyQRNativeBtn.Bind(wx.EVT_BUTTON, self.onUsePyQR)
# Create sizer
self.mainSizer = wx.BoxSizer(wx.VERTICAL)
qrDataSizer = wx.BoxSizer(wx.HORIZONTAL)
locationSizer = wx.BoxSizer(wx.HORIZONTAL)
qrBtnSizer = wx.BoxSizer(wx.VERTICAL)
qrDataSizer.Add(qrDataLbl, 0, wx.ALL, 5)
qrDataSizer.Add(self.qrDataTxt, 1, wx.ALL|wx.EXPAND, 5)
self.mainSizer.Add(wx.StaticLine(self, wx.ID_ANY),
0, wx.ALL|wx.EXPAND, 5)
self.mainSizer.Add(qrDataSizer, 0, wx.EXPAND)
self.mainSizer.Add(self.imageCtrl, 0, wx.ALL, 5)
locationSizer.Add(instructLbl, 0, wx.ALL, 5)
locationSizer.Add(self.qrPhotoTxt, 0, wx.ALL, 5)
locationSizer.Add(browseBtn, 0, wx.ALL, 5)
self.mainSizer.Add(locationSizer, 0, wx.ALL, 5)
self.mainSizer.Add(self.defaultLocationLbl, 0, wx.ALL, 5)
qrBtnSizer.Add(qrcodeBtn, 0, wx.ALL, 5)
qrBtnSizer.Add(pyQRNativeBtn, 0, wx.ALL, 5)
self.mainSizer.Add(qrBtnSizer, 0, wx.ALL|wx.CENTER, 10)
self.SetSizer(self.mainSizer)
self.Layout()
#----------------------------------------------------------------------
def onBrowse(self, event):
""""""
dlg = wx.DirDialog(self, "Choose a directory:",
style=wx.DD_DEFAULT_STYLE)
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
self.defaultLocation = path
self.defaultLocationLbl.SetLabel("Save location: %s" % path)
dlg.Destroy()
#----------------------------------------------------------------------
def onUseQrcode(self, event):
"""
https://github.com/lincolnloop/python-qrcode
"""
qr = qrcode.QRCode(version=1, box_size=10, border=4)
qr.add_data(self.qrDataTxt.GetValue())
qr.make(fit=True)
x = qr.make_image()
qr_file = os.path.join(self.defaultLocation, self.qrPhotoTxt.GetValue() + ".jpg")
img_file = open(qr_file, 'wb')
x.save(img_file, 'JPEG')
img_file.close()
self.showQRCode(qr_file)
#----------------------------------------------------------------------
def onUsePyQR(self, event):
"""
http://code.google.com/p/pyqrnative/
"""
qr = PyQRNative.QRCode(20, PyQRNative.QRErrorCorrectLevel.L)
qr.addData(self.qrDataTxt.GetValue())
qr.make()
im = qr.makeImage()
qr_file = os.path.join(self.defaultLocation, self.qrPhotoTxt.GetValue() + ".jpg")
img_file = open(qr_file, 'wb')
im.save(img_file, 'JPEG')
img_file.close()
self.showQRCode(qr_file)
#----------------------------------------------------------------------
def showQRCode(self, filepath):
""""""
img = wx.Image(filepath, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.photo_max_size
NewH = self.photo_max_size * H / W
else:
NewH = self.photo_max_size
NewW = self.photo_max_size * W / H
img = img.Scale(NewW,NewH)
self.imageCtrl.SetBitmap(wx.BitmapFromImage(img))
self.Refresh()
########################################################################
class QRFrame(wx.Frame):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
wx.Frame.__init__(self, None, title="QR Code Viewer", size=(550,500))
panel = QRPanel(self)
if __name__ == "__main__":
app = wx.App(False)
frame = QRFrame()
frame.Show()
app.MainLoop()
改变和显示图片的代码在我写的上一篇文章中解释过(并链接到上面),所以你可能关心的只是生成二维码的两种方法: onUseQrcode 和 onUsePyQR 。我只是从他们各自的网站上取了一些例子,稍微修改了一下,就制作出了二维码图片。它们非常直截了当,但没有很好地记录,所以我真的不能告诉你发生了什么。遗憾的是,在撰写本文时,这些项目的代码严重缺乏 docstrings,到处都是。不过,我还是生成了一些不错的二维码。以下是使用 python-qrcode 完成的:

如您所见,这是一个非常标准的代码。下一个是用 PyQRNative 创建的,看起来更密集:

我试着用我的 Android 手机的条形码扫描应用程序扫描两张图片,两张二维码都被它正确地读取了。因此,如果你需要为你的项目生成二维码图像,我希望其中一个项目能够满足你的需求!
2012 年 5 月 21 日更新
我的一个读者(Mike Farmer)最近联系了我关于他的 PyQRNative 实验,告诉我“第一个参数是容器大小,第二个参数是冗余/错误
纠正”。我大概猜到了第二个是什么,但我不知道纠错级别是什么。幸运的是,法默先生向我解释道:如果纠错能力很低,它将无法容忍标签被涂污或撕破而无法读取。但是,如果你提高错误等级,显然会得到更大的二维码,但你所做的是在标签内创建重复的数据。因此,如果标签被弄脏或撕破,它仍然可以读取和恢复剩余的数据。因此,如果你的应用程序正在创建可能被破坏的标签,明智的做法是加快错误纠正。你还可以做一些很酷的事情,比如在标签上叠加图片或文本,通过启动纠错功能,使数据冗余,然后它可以容忍“损坏”。无论如何,如果你改变第一个数字,你可以放大或缩小二维码图像的大小。你为什么要这么做?你需要在图像中存储的信息越多,图像就需要越大。法默先生想出了一些有趣的测试代码,以帮助他准确地计算出二维码的最小尺寸。我复制下面的代码:
import PyQRNative
def makeQR(data_string,path,level=1):
quality={1: PyQRNative.QRErrorCorrectLevel.L,
2: PyQRNative.QRErrorCorrectLevel.M,
3: PyQRNative.QRErrorCorrectLevel.Q,
4: PyQRNative.QRErrorCorrectLevel.H}
size=3
while 1:
try:
q = PyQRNative.QRCode(size,quality[level])
q.addData(data_string)
q.make()
im=q.makeImage()
im.save(path,format="png")
break
except TypeError:
size+=1
源代码
用 OpenPyXL 和 Python 创建电子表格
原文:https://www.blog.pythonlibrary.org/2021/07/27/creating-spreadsheets-with-openpyxl-and-python/
阅读 Excel 电子表格当然很好。但是,您还需要能够创建或编辑电子表格。本章的重点将是学习如何做到这一点!OpenPyXL 让您可以轻松创建 Microsoft Excel 电子表格。
使用 Python 创建 Excel 电子表格允许您生成用户将使用的新型报告。例如,您可能以 JSON 或 XML 的形式从客户端接收数据。这些数据格式不是大多数会计师或商务人士习惯阅读的。
一旦您学会了如何使用 Python 创建 Excel 电子表格,您就可以利用这些知识将其他数据转换成 Excel 电子表格。这些知识还允许您反过来做,接受一个 Excel 电子表格并输出一种不同的格式,比如 JSON 或 XML。
在本文中,您将学习如何使用 OpenPyXL 完成以下任务:
- 创建电子表格
- 写入电子表格
- 添加和移除工作表
- 插入和删除行和列
- 编辑单元格数据
- 创建合并单元格
- 折叠行和列
让我们开始创建一个全新的电子表格吧!
编者按:本文基于《用 Python 自动化 Excel》一书中的一章。你可以在 Gumroad 或者 Kickstarter 上订购一份。
创建电子表格
使用 OpenPyXL 创建一个空的电子表格不需要太多代码。打开 Python 编辑器,创建一个新文件。命名为creating_spreadsheet.py。
现在将以下代码添加到您的文件中:
# creating_spreadsheet.py
from openpyxl import Workbook
def create_workbook(path):
workbook = Workbook()
workbook.save(path)
if __name__ == "__main__":
create_workbook("hello.xlsx")
这里的关键部分是您需要导入Workbook类。这个类允许您实例化一个workbook对象,然后您可以保存它。这些代码所做的就是创建您传递给它的文件并保存它。
您的新电子表格将如下所示:

现在,您已经准备好学习如何将一些数据添加到电子表格的单元格中。
写入电子表格
当在电子表格中写入数据时,您需要获得“sheet”对象。在上一章中,您已经学习了如何使用workbook.active来实现这一点,这将为您提供活动的或当前可见的工作表。您还可以通过向 OpenPyXL 传递一个工作表标题来明确地告诉它您想要访问哪个工作表。
对于本示例,您将创建另一个新程序,然后使用活动工作表。打开一个新文件,命名为adding_data.py。现在将这段代码添加到您的文件中:
# adding_data.py
from openpyxl import Workbook
def create_workbook(path):
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "Hello"
sheet["A2"] = "from"
sheet["A3"] = "OpenPyXL"
workbook.save(path)
if __name__ == "__main__":
create_workbook("hello.xlsx")
这段代码将覆盖前面示例的 Excel 电子表格。在创建了Workbook()对象之后,您获取了活动工作表。然后向单元格添加文本字符串:A1、A2 和 A3。最后一步是保存新的电子表格。
当您运行这段代码时,您的新电子表格将如下所示:

您可以使用这种技术将数据写入电子表格中的任何单元格。
现在让我们看看如何添加和删除工作表!
添加和移除工作表
创建新工作簿时,会自动向工作簿添加工作表。默认情况下,工作表将被命名为“sheet”。如果需要,您可以自己设置工作表的名称。
要了解这是如何工作的,创建一个名为creating_sheet_title.py的新文件,并添加以下代码:
# creating_sheet_title.py
from openpyxl import Workbook
def create_sheets(path):
workbook = Workbook()
sheet = workbook.active
sheet.title = "Hello"
sheet2 = workbook.create_sheet(title="World")
workbook.save(path)
if __name__ == "__main__":
create_sheets("hello_sheets.xlsx")
这里您创建了Workbook,然后获取活动工作表。然后,您可以使用title属性设置工作表的标题。下面一行代码通过调用create_sheet()向工作簿添加一个新工作表。
create_sheet()方法有两个参数:title和index。title属性给工作表一个标题。index告诉Workbook从左到右在哪里插入工作表。如果您指定零,您的工作表将从开始处插入。
如果您运行此代码,您的新电子表格将如下所示:

有时您需要删除工作表。也许该工作表不再包含有效信息,或者它是意外创建的。
要查看如何删除工作表,创建另一个新文件并将其命名为delete_sheets.py。然后添加以下代码:
# delete_sheets.py
import openpyxl
def create_worksheets(path):
workbook = openpyxl.Workbook()
workbook.create_sheet()
print(workbook.sheetnames)
# Insert a worksheet
workbook.create_sheet(index=1, title="Second sheet")
print(workbook.sheetnames)
del workbook["Second sheet"]
print(workbook.sheetnames)
workbook.save(path)
if __name__ == "__main__":
create_worksheets("del_sheets.xlsx")
在本例中,您将创建两个新工作表。第一个工作表没有指定标题,因此默认为“Sheet1”。您为第二个工作表提供一个标题,然后打印出所有当前工作表的标题。
接下来,使用 Python 的del关键字从工作簿中删除工作表的名称,这将删除工作表。然后再次打印出当前的工作表标题。
以下是运行代码的输出:
['Sheet', 'Sheet1']
['Sheet', 'Second sheet', 'Sheet1']
['Sheet', 'Sheet1']
当实例化Workbook时,第一个工作表会自动创建。该工作表名为“sheet”。然后,您制作“Sheet1”。最后,您创建了“第二张工作表”,但是您将它插入到位置 1,这告诉工作簿将“Sheet1”向右移动一个位置。
从上面的输出可以看出,在添加和删除“第二个工作表”之前和之后,工作表是如何排序的。
现在让我们学习插入和删除行和列!
插入和删除行和列
OpenPyXL 包为您提供了几种方法,您可以使用它们来插入或删除行和列。这些方法是Worksheet对象的一部分。
您将了解以下四种方法:
.insert_rows().delete_rows().insert_cols().delete_cols()
这些方法中的每一个都可以接受这两个参数:
idx–要插入(或删除)的索引amount–要添加(或删除)的行数或列数
您可以使用 insert 方法在指定的索引处插入行或列。
打开一个新文件,命名为insert_demo.py。然后在新文件中输入以下代码:
# insert_demo.py
from openpyxl import Workbook
def inserting_cols_rows(path):
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "Hello"
sheet["A2"] = "from"
sheet["A3"] = "OpenPyXL"
# insert a column before A
sheet.insert_cols(idx=1)
# insert 2 rows starting on the second row
sheet.insert_rows(idx=2, amount=2)
workbook.save(path)
if __name__ == "__main__":
inserting_cols_rows("inserting.xlsx")
在这里,您创建另一个新的电子表格。在这种情况下,您将文本添加到“A”列的前三个单元格中。然后在索引一处插入一列。这意味着您在“A”之前插入了一个单独的列,这将导致“A”列中的单元格移动到“B”列。
接下来,从索引 2 开始插入两个新行。这段代码将在第一行和第二行之间插入两行。
通过下面的截图,您可以看到这是如何改变事情的:

尝试更改索引或要插入的行数和列数,看看效果如何。
您还需要不时地删除列和行。为此,您将使用.delete_rows()和.delete_cols()。
打开一个新文件,命名为delete_demo.py。然后添加以下代码:
# delete_demo.py
from openpyxl import Workbook
def deleting_cols_rows(path):
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "Hello"
sheet["B1"] = "from"
sheet["C1"] = "OpenPyXL"
sheet["A2"] = "row 2"
sheet["A3"] = "row 3"
sheet["A4"] = "row 4"
# Delete column A
sheet.delete_cols(idx=1)
# delete 2 rows starting on the second row
sheet.delete_rows(idx=2, amount=2)
workbook.save(path)
if __name__ == "__main__":
deleting_cols_rows("deleting.xlsx")
在本例中,您将文本添加到六个不同的单元格中。其中四个单元格位于“A”列。然后你用delete_cols()删除列“A”!这意味着你去掉了四个值。接下来,删除两行,从第二行开始。
当您运行这段代码时,您的结果应该如下所示:

尝试编辑索引或数量值,以熟悉删除行和列。
现在您已经准备好学习如何编辑电子表格的值了!
编辑单元格数据
您可以使用 OpenPyXL 来更改预先存在的 Excel 电子表格中的值。您可以通过指定要更改的单元格,然后将其设置为新值来实现。
对于这个例子,您将使用您在上一节中创建的inserting.xlsx文件。现在创建一个名为editing_demo.py的新 Python 文件。然后添加以下代码:
# editing_demo.py
from openpyxl import load_workbook
def edit(path, data):
workbook = load_workbook(filename=path)
sheet = workbook.active
for cell in data:
current_value = sheet[cell].value
sheet[cell] = data[cell]
print(f'Changing {cell} from {current_value} to {data[cell]}')
workbook.save(path)
if __name__ == "__main__":
data = {"B1": "Hi", "B5": "Python"}
edit("inserting.xlsx", data)
这段代码加载您在上一节中创建的 Excel 文件。然后,它对传递给edit()函数的data字典中的每个值进行循环。使用字典中的一个键可以获得单元格的当前值。然后,更改该单元格的值以匹配字典中的值。
为了更清楚地说明发生了什么,您打印出了单元格的新旧值。
当您运行此代码时,您将看到以下输出:
Changing B1 from Hello to Hi
Changing B5 from OpenPyXL to Python
打开新版本的inserting.xlsx文件,它应该看起来像这样:

在这里,您可以看到单元格值是如何变化的,以匹配在data字典中指定的值。
现在,您可以继续学习如何创建合并单元格了!
创建合并单元格
合并单元格是指两个或多个单元格合并成一个。要设置 MergedCell 的值,必须使用最左上角的单元格。例如,如果您合并“A2:E2”,您将为合并的单元格设置单元格“A2”的值。
要了解这在实践中是如何工作的,创建一个名为merged_cells.py的文件,并向其中添加以下代码:
# merged_cells.py
from openpyxl import Workbook
from openpyxl.styles import Alignment
def create_merged_cells(path, value):
workbook = Workbook()
sheet = workbook.active
sheet.merge_cells("A2:E2")
top_left_cell = sheet["A2"]
top_left_cell.alignment = Alignment(horizontal="center",
vertical="center")
sheet["A2"] = value
workbook.save(path)
if __name__ == "__main__":
create_merged_cells("merged.xlsx", "Hello World")
OpenPyXL 有很多方法来样式化单元格。在这个例子中,您从openpyxl.styles导入Alignment。在后面的章节中,你会学到更多关于单元格样式和格式的知识。
在这里,您合并单元格“A2:E2 ”,并将对齐方式设置为单元格的中心。然后将“A2”的值设置为传递给create_merged_cells()函数的字符串。
运行此示例时,新的 Excel 电子表格将如下所示:

要获得一些实践经验,请更改要合并的单元格范围,并在有和没有对齐设置的情况下进行尝试。
现在您已经准备好学习折叠列或行了!
折叠行和列
Microsoft Excel 支持行和列的折叠。术语“折叠”也称为“隐藏”或创建“轮廓”。折叠的行或列可以展开(或展开)以使它们再次可见。您可以使用该功能使电子表格更加简洁。例如,您可能希望只显示小计或公式的结果,而不是一次显示所有数据。
OpenPyXL 也支持折叠。要了解这是如何工作的,创建一个名为folding.py的新文件,并输入以下代码:
# folding.py
import openpyxl
def folding(path, rows=None, cols=None, hidden=True):
workbook = openpyxl.Workbook()
sheet = workbook.active
if rows:
begin_row, end_row = rows
sheet.row_dimensions.group(begin_row, end_row, hidden=hidden)
if cols:
begin_col, end_col = cols
sheet.column_dimensions.group(begin_col, end_col, hidden=hidden)
workbook.save(path)
if __name__ == "__main__":
folding("folded.xlsx", rows=(1, 5), cols=("C", "F"))
您的folding()函数接受行或列或者两者的元组。您可以告诉 OpenPyXL 是否希望隐藏或折叠这些行和列。在这个例子中,您折叠第 1-5 行和第 C-F 列。
当您运行这段代码时,您的电子表格将如下所示:

您可以在该电子表格中看到一些行和列被折叠或隐藏。第 6 行旁边有一个“+”符号,第“G”列上方有另一个“+”符号。如果您单击这些按钮中的任何一个,它将展开折叠的行或列。
试一试这段代码。您还可以尝试不同的行或列范围。
现在你已经准备好学习如何冻结一个窗格!
冻结窗格
Microsoft Excel 允许您冻结窗格。这意味着您可以冻结一个或多个列或行。一个流行的用例是冻结一行标题,这样在滚动大量数据时标题总是可见的。
OpenPyXL 在工作表对象上提供了一个可以设置的freeze_panes属性。您需要在要冻结的列的右下方选择一个单元格。例如,如果您想要冻结电子表格中的第一行,那么您可以选择“A2”处的单元格来冻结该行。
您可以通过编写一些代码来了解这是如何工作的。打开一个新文件,命名为freezing_panes.py。然后在其中输入以下内容:
# freezing_panes.py
from openpyxl import Workbook
def freeze(path, row_to_freeze):
workbook = Workbook()
sheet = workbook.active
sheet.title = "Freeze"
sheet.freeze_panes = row_to_freeze
headers = ["Name", "Address", "State", "Zip"]
sheet["A1"] = headers[0]
sheet["B1"] = headers[1]
sheet["C1"] = headers[2]
sheet["D1"] = headers[3]
data = [dict(zip(headers, ("Mike", "123 Storm Dr", "IA", "50000"))),
dict(zip(headers, ("Ted", "555 Tornado Alley", "OK", "90000")))]
row = 2
for d in data:
sheet[f'A{row}'] = d["Name"]
sheet[f'B{row}'] = d["Address"]
sheet[f'C{row}'] = d["State"]
sheet[f'D{row}'] = d["Zip"]
row += 1
workbook.save(path)
if __name__ == "__main__":
freeze("freeze.xlsx", row_to_freeze="A2")
在这里创建一个新的Workbook,并将当前工作表的标题设置为“冻结”。然后将freeze_panes属性设置为“A2”。函数中的其余代码向工作表添加了几行数据。
运行此代码时,您创建的电子表格将如下所示:

尝试向下滚动电子表格中的一些行。最上面一行应该始终可见,因为它已经被“冻结”了。
包扎
您不仅可以使用 OpenPyXL 创建 Excel 电子表格,还可以修改预先存在的电子表格。在本章中,您学习了如何执行以下操作:
- 创建电子表格
- 写入电子表格
- 添加和移除工作表
- 插入和删除行和列
- 编辑单元格数据
- 创建合并单元格
- 冻结窗格
试一试本章中的例子。然后稍微修改一下,看看自己还能做些什么。
用 Python 创建 Windows 快捷方式(第二部分)
原文:https://www.blog.pythonlibrary.org/2010/02/25/creating-windows-shortcuts-with-python-part-ii/
当我上个月第一次写关于用 Python 创建快捷方式的时候,我一直在想我有第三种方法。今天,我不得不维护我的一些快捷方式代码,我又一次偶然发现了它。我还注意到我的帖子收到了 Tim Golden 关于创建快捷方式的另一种方法的评论,所以我也将把它写在这篇帖子里。
奇怪的是,我的另一个方法碰巧使用了蒂姆·戈尔登的一些东西;也就是他的 winshell 模块。请查看以下内容:
import os
import winshell
program_files = winshell.programs()
winshell.CreateShortcut (
Path=os.path.join (program_files, 'My Shortcut.lnk'),
Target=r'C:\Program Files\SomeCoolProgram\prog.exe')
让我们把这个打开,这样你就知道发生了什么。首先,我们使用 winshell 找到用户的“程序”文件夹,这是用户的“启动”文件夹的子文件夹。然后我们使用 winshell 的 CreateShortcut 方法来实际创建快捷方式。如果您查看 CreateShortcut 的 docstring,您会发现它还可以接受以下关键字参数:arguments、StartIn、Icon 和 Description。
奇怪的是,这不是戈尔登在他的评论中建议的方法。他还有另一个更复杂的想法。让我们快速看一下:
import os, sys
import pythoncom
from win32com.shell import shell, shellcon
shortcut = pythoncom.CoCreateInstance (
shell.CLSID_ShellLink,
None,
pythoncom.CLSCTX_INPROC_SERVER,
shell.IID_IShellLink
)
program_location = r'C:\Program Files\SomeCoolProgram\prog.exe'
shortcut.SetPath (program_location)
shortcut.SetDescription ("My Program Does Something Really Cool!")
shortcut.SetIconLocation (program_location, 0)
desktop_path = shell.SHGetFolderPath (0, shellcon.CSIDL_DESKTOP, 0, 0)
persist_file = shortcut.QueryInterface (pythoncom.IID_IPersistFile)
persist_file.Save (os.path.join (desktop_path, "My Shortcut.lnk"), 0)
在我看来,这对于我的口味来说有点太低级了。然而,这样做也很酷。如果你看看 Tim Golden 的链接页面,你会发现这个例子实际上只是一个复制粘贴的工作。我认为 winshell 的桌面方法和“shell”做了同样的事情。SHGetFolderPath (0,shellcon。CSIDL _ 桌面,0,0)”而且更容易阅读。不管怎样,上面的代码做的和前面的代码一样,只是它把快捷方式放在了用户的桌面上。我真的不明白戈尔登在“pythoncom”里干什么。CoCreateInstance”部分,而不是创建一个我们可以用来创建快捷方式的对象。
还要注意的是,Tim Golden 谈到使用与上面详述的方法非常相似的方法来创建 URL 快捷方式。你可以去他的网站了解所有有趣的细节。
无论如何,我觉得要完整,我最好写下这另外两个在 Windows 中创建快捷方式的方法。希望你觉得这很有趣,甚至有教育意义。
Python 中的数据科学包(视频)
原文:https://www.blog.pythonlibrary.org/2022/06/14/data-science-packages-in-python-video/
在本教程中,我将讨论一些可以在 Python 中使用的不同的数据科学包。
提到的包:pandas,matplotlib,numpy,scipy,mahotas,OpenCV,Keras,PyTorch,Tensorflow,Theano,Bokeh,Plotly,Scikit-learn,Scikit-image
https://www.youtube.com/embed/LgaQYgOGrDg?feature=oembed
在 Python 中确定列表中的所有元素是否都相同
编者按:本周我们有一篇来自亚历克斯的客座博文,他是check ioT3 的首席执行官
在生活中,我们总是有选择,不管我们是否知道。编码也是一样。我们可以用许多不同的方法来完成一项特定的任务。我们可能没有考虑过这些方式,或者对它们一无所知,但是它们确实存在。成为一名程序员不仅仅是了解语言和编写代码的过程。通常,成为一名程序员意味着成为你自己最有创造力的版本,考虑你以前从未考虑过的事情。因此,我想介绍一下我自己。嗨!我叫 Alex,是 CheckiO 的首席执行官,我已经处理这个项目的创意方面有一段时间了。
我们的用户有不同的编码知识水平和经验,这就是为什么我经常看到标准的和更明显的任务解决方法。但我不时会遇到这样独特而不寻常的解决方案,让我再次学习这门语言的新的微妙之处。
在这篇文章中,我想回顾一下一个非常简单的任务的一些解决方案,在我看来,这些方案是最有趣的。这个任务要求你写一个函数来决定是否所有的数组元素都有相同的值。
1。首先想到的解决方案之一是比较输入元素列表的长度和第一个元素进入列表的次数。如果这些值相等,则列表包含相同的元素。还需要检查列表是否为空,因为在这种情况下也需要返回 True。
def all_the_same(elements):
if len(elements) < 1:
return True
return len(elements) == elements.count(elements[0])
或者更简短的版本:
def all_the_same(elements):
return len(elements) < 1 or len(elements) ==
elements.count(elements[0])
2。在这个解决方案中,使用了一个有用的 Python 特性——只使用比较操作符来比较列表的能力——= =(不像其他一些编程语言那样简单)。让我们看看这是如何工作的:
>>>[1, 1, 1] == [1, 1, 1]
True
>>> [1, 1, 0] == [0, 1, 1]
False
这种语言还有另一个很棒的特性——它提供了将列表乘以一个数字的能力,在这个操作的结果中,我们将得到一个列表,其中所有的元素都被复制了指定的次数。让我给你看一些例子:
>>> [1] * 3
[1, 1, 1]
>>> [1] * 5
[1, 1, 1, 1, 1]
>>> [1] * 0
[]
>>> [1, 2] * 3
[1, 2, 1, 2, 1, 2]
因此,您可以提出一个简单的解决方案——如果您将一个包含一个元素的数组(即输入数组的第一个元素)乘以该输入数组的长度,那么在结果中您应该再次返回该输入数组,如果该数组的所有元素确实相同的话。
def all_the_same(elements):
if not elements:
return True
return [elements[0]] * len(elements) == elements
这里,解决方案也可以简化为:
def all_the_same(elements):
return not elements or [elements[0]] * len(elements) == elements
3。在这个解决方案中使用了标准的 set()函数。这个函数将一个对象转换成一个集合,根据定义,这个集合中的所有元素必须是唯一的。看起来是这样的:
>>> elements = [1, 2, 5, 1, 5, 3, 2]
>>> set(elements)
{1, 2, 3, 5}
如果结果集包含 1 个或 0 个元素,那么输入列表包含所有相同的元素或者为空。解决方案可能是这样的:
def all_the_same(elements):
return len(set(elements)) in (0, 1)
或者像这样:
def all_the_same(elements):
return len(set(elements)) <= 1
这种方法可以与 NumPy 模块一起使用,该模块有一个 unique()函数,其工作方式如下:
>>> from numpy import unique
>>> a = [1, 2, 1, 2, 3, 1, 1, 1, 1]
>>> unique(a)
[1 2 3]
正如您所看到的,它的工作与 set()函数非常相似,唯一的区别是在这种情况下对象类型不变——list 仍然是 list。此函数的解决方案如下所示:
from numpy import unique
def all_the_same(elements):
return len(unique(elements)) <= 1
4。下面是一个非常有创意的解决方案的例子,其中使用的 Python 的标准 all()函数就是这个任务名称上的玩法。如果传输列表的所有元素都为真,函数 all()将返回真。例如:
>>> all([1, 2, 0, True])
False
#(0 isn't true)
>>> all([1, 2, None, True])
False
#(None isn't true)
>>> all([1, 2, False, True])
False
>>> all([1, 2, 0.1, True])
True
首先,变量 first 被赋予列表中第一个元素的值,其余的是除第一个元素之外的所有其他元素的列表。然后,根据剩余列表的下一个元素是否等于输入列表的第一个元素,将 True 或 False 值添加到 _same 元组。之后,如果 _same 元组只包含“真”元素,则 all()函数将返回 True,如果元组中至少有一个“假”元素,则返回 False。
def all_the_same(elements):
try:
first, *rest = elements
except ValueError:
return True
the_same = (x == first for x in rest)
return all(the_same)
只有当数组为空时,才会引发 ValueError 异常。但是我们可以进行一个更熟悉的测试:
def all_the_same(elements):
if not elements:
return True
first, *rest = elements
the_same = (x == first for x in rest)
return all(the_same)
5。下一个解决方案与上一个非常相似。只有一个小的修改——输入列表的第一个元素和其余的元素被一个迭代器分隔开。 iter()函数从传递的列表中创建一个迭代器, next()函数从中获取下一个元素(即第一个元素——在第一次调用时)。如果打印 el 和 first 中列出的元素,您将看到以下内容:
>>> el = iter([1, 2, 3])
>>> first = next(el, None)
>>> print(first)
1
>>> for i in el:
>>> print(i)
2
3
除此之外,这个解决方案与前一个类似,只是我们不需要检查列表是否为空。
def all_the_same(elements):
el = iter(elements)
first = next(el, None)
return all(element == first for element in el)
6。解决这一任务的创造性方法之一是重新排列元素。我们改变元素的位置,并检查列表是否因此而改变。它告诉我们列表中的所有元素都是相同的。以下是这种方法的几个例子:
def all_the_same(elements):
return elements[1:] == elements[:-1]
或者
def all_the_same(elements):
return elements == elements[1:] + elements[:1]
还必须承认,数组的比较可以使用 zip()函数逐个元素地进行。让我们考虑以下解决方案。
7。zip()函数将一个对象的第 I 个元素与其余对象的第 I 个元素组合,直到最短的对象结束。
>>> x = [1, 2, 3]
>>> y = [10, 11]
>>> list(zip(x, y))
[(1, 10), (2, 11)]
如您所见,尽管 x 由三个元素组成,但只使用了两个元素,因为最短的对象(在本例中为 y)只包含两个元素。
下面的解决方案是这样工作的:首先,创建第二个列表(elements [1:]),它等于输入列表,但是没有第一个元素。然后依次比较这两个列表中的元素,作为每次比较的结果,我们得到 True 或 False。之后,all()函数返回这个 True 和 False 集合的处理结果。
def all_the_same(elements):
return all(x == y for x, y in zip(elements, elements[1:]))
假设我们的输入列表是 elements = [2,2,2,3]。然后使用 zip(),我们将完整列表([2,2,2,3])和没有第一个元素的列表([2,2,3])组合如下:[(2,2),(2,2),(2,3)]。元素之间的比较将集合[True,True,False]传递给 all()函数,结果我们得到 False,这是正确的答案,因为输入列表中的所有元素并不相同。
8。下面这个使用了 groupby()迭代器的解决方案非常有趣。groupby()迭代器的工作方式是这样的:它将第 I 个元素与第(i-1)个元素进行比较,如果元素相等,则继续移动,如果不相等,则在摘要列表中保留第(i-1)个元素,并继续与下一个元素进行比较。实际上,它看起来像这样:
>>> from itertools import groupby
>>> elements = [1, 1, 1, 2, 1, 1, 1, 2]
>>> for key, group in groupby(elements):
>>> print(key)
1
2
1
2
如您所见,只有那些与下一个位置的元素不同的元素保留了下来(元素[0]、元素[1]、元素[4]和元素[5]被排除在外)。
在这个解决方案中,函数在 groupby()迭代器的帮助下,每当输入列表的下一项与前一项不同时,就在列表中加 1。因此,如果输入列表包含 0 个元素或所有元素都相等,则 sum(sum(1 for _ in group by(elements)))将是 0 或 1,这在任何情况下都小于 2,如解决方案中所指定的。
from itertools import groupby
def all_the_same(elements):
return sum(1 for _ in groupby(elements)) < 2
9。另一个创造性的解决方案,其中一个标准的 Python 模块——集合——已经使用。计数器创建一个字典,其中存储了输入列表中每个元素的数量信息。让我们看看它是如何工作的:
>>> from collections import Counter
>>> a = [1, 1, 1, 2, 2, 3]
>>> Counter(a)
Counter({1: 3, 2: 2, 3: 1})
因此,如果这个字典的长度为 2 或更多,那么在输入列表中至少有 2 个不同的元素,并且它们并不都是相同的。
def all_the_same(elements):
from collections import Counter
return not len(list(Counter(elements))) > 1
10。这个解决方案建立在与 7 号解决方案相同的逻辑上,但是使用的函数是 eq() 和 starmap() 。让我们弄清楚它们是如何工作的:
>>> from operator import eq
>>> eq(1, 2)
False
基本上,eq()函数的作用与“==”相同——比较两个对象,如果相等则返回 True,否则返回 False(eq 代表等价)。但是,请注意,函数是一个对象,例如,它可以作为一个参数传递给另一个函数,这在进一步描述的解决方案中已经完成。
函数创建一个迭代器,将另一个函数应用于对象列表。当对象已经分组为元组时使用。例如:
>>> import math
>>> from itertools import starmap
>>> list(starmap(math.pow, [(1, 2), (3, 4)]))
[1.0, 81.0]
正如您所看到的,math.pow()函数由于 starmap()函数而被指定了两次——应用于两组对象(12 = 1.0,34 = 81.0)。
更简单地说,本例中的 starmap()函数可以表示为一个循环:
import math
elements = [(1, 2), (3, 4)]
result = []
for i in elements:
result.append(math.pow(i[0], i[1]))
使用上述函数的解决方案如下所示:
from operator import eq
from itertools import starmap
def all_the_same(elements):
return all(starmap(eq, zip(elements, elements[1:])))
结论
所以,在这里我们讨论了一些创造性的解决方案,它们都与一个最简单的编码难题有关。我甚至无法开始描述我们的用户由于处理其他有趣和更复杂的挑战而分享的独特方法的数量。我希望你喜欢读这篇文章,就像我喜欢写它一样。我期待你的反馈。请告诉我。这对你有用吗?你会如何解决这个任务?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号