PythonLibrary-博客中文翻译-四-
PythonLibrary 博客中文翻译(四)
本周 PyDev:特里斯坦·邦恩
原文:https://www.blog.pythonlibrary.org/2021/04/19/pydev-of-the-week-tristan-bunn/
本周我们欢迎特里斯坦·邦恩成为我们的本周 PyDev!Tristan 是 No Starch 出版社的新书《可视化学习 Python》的作者。你可以在特里斯坦的网站或访问 GitHub 了解更多关于他的事情。
让我们花一些时间来更好地了解特里斯坦!
你能告诉我们一些关于你自己的事情吗(爱好、教育等)。):
十五年前,我开始了网页设计师的职业生涯。我上过平面设计课程,特别喜欢我的互动媒体模块。当我进入这个行业时,我很快就被 Web(和 Flash)所吸引,因为我喜欢在设计和代码的交汇处工作。今天,我在创新技术领域担任讲师和研究员。我现在拥有 BTech 设计学位和理学硕士学位,目前正在攻读计算机科学博士学位,重点是人机交互。至于爱好,我喜欢阅读漫画小说和风筝冲浪。
你为什么开始使用 Python?
在之前的一次讲课中,我一直在寻找一种更好的方法来教我的学生如何编程。有处理和闪存,但出于不同的原因,这些环境并不理想。然后我偶然发现了一个名为 Nodebox 的东西——一个 macOS 应用程序,可以让你使用 Python 代码创建 2D 视觉效果(静态的、动画的或交互式的)。然而,我需要一些跨平台的东西,我找到了 Shoebot(灵感来自 DrawBot 和 Ruby 的鞋子)。这是我第一次尝试 Python 那是一见钟情。
你还知道哪些编程语言,你最喜欢哪一种?
我做了很多前端 web 开发,所以:HTML,CSS,JavaScript。
但是我使用过许多其他语言,举几个例子:PHP、ActionScript & Haxe、Lua 和 C# (Unity)。Python 还是我的最爱。
你现在在做什么项目?
几件事,都在发展初期。我的博士探索了学习分析的数据可视化;我还在和艺术家 Mary Guo 合作一个项目,将漫画和电子游戏结合起来。除了那些项目,我还总是在修修补补。现在,我对遗传算法、Unity 的 ML-Agents 和 WebXR 很感兴趣。
哪些 Python 库是你最喜欢的(核心或第三方)?
任何我可以用来混合代码、交互、界面设计和创造力的东西。我特别热衷于将处理思想引入 Python 的任何东西——像 Processing.py (Processing 的 Python 模式)、p5 (p5py)、pyp5js 和 Shoebot 这样的项目。Blender 的 Python API 模块(bpy)也很棒。
你的书《可视化学习 Python》是如何产生的?
我的工作是在学生学习的第一年教他们编程。这些学生将继续在网页、游戏、VFX、虚拟现实和其他课程中使用不同的语言。Python 是教他们编程的理想语言。任何程序员都会告诉你,一旦你学会了一种语言,学习其他语言就容易多了。我也相信教有创造力和视觉的人编码的最好方法是使用类似处理的东西。《可视化学习 Python》是一本关于使用 Processing.py 将 Python 与处理相结合的书,通过编写生成绘图、模式、动画、数据可视化、用户界面和模拟的代码来学习编程。
创作这本书时,你学到的最重要的三件事是什么?
(1)我想我会休息很久再写下一本书,哈哈!但是,(2)写书真的能帮助你理解一个主题——向初学者解释概念能让你自己更好地理解。(3)平克·弗洛伊德的《月亮的阴暗面》的标志性专辑封面上有一道六种颜色(而不是七种)的彩虹。自己算!
你还有什么想说的吗?
你可以在我的作品集网站上查看我的作品,上面有我博客的链接。
我还想感谢所有帮助我写这本书的人,尤其是没有淀粉出版社的人。
特里斯坦,谢谢你接受采访!
本周 PyDev:泰勒·雷迪
原文:https://www.blog.pythonlibrary.org/2020/01/13/pydev-of-the-week-tyler-reddy/
本周,我们欢迎泰勒·雷迪(@泰勒 _ 雷迪)成为我们本周的 PyDev!泰勒是 T2 Scipy 和 Numpy 的核心开发者。他还开发了 MDAnalysis 库,用于粒子物理模拟分析。如果你有兴趣看看他的一些贡献,你可以看看他的 Github 简介。让我们花些时间来更好地了解泰勒!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在加拿大新斯科舍省的达特茅斯长大,在那里一直呆到 20 多岁。我的学士和博士学位都是生物化学,重点是结构生物学。我确实去过很多地方下国际象棋,在我十几岁的时候赢得了一些著名的比赛,在我十几岁的时候在加拿大获得了大师级的评价。达特茅斯也被称为“湖泊之城”,我在附近的巴努克湖上划船长大。在加拿大寒冷的冬天,湖面会结冰,训练会转为包括长跑在内的常规训练——这是我最大的“爱好”真正开始的地方。我仍然每天清晨跑大约 11 英里。
我在英国牛津做了将近六年的博士后。在我读博士期间,我开始意识到我的技能组合更适合计算工作,而不是实验室工作。从形式上看,我在牛津大学时仍然是一名生物学家,但很明显,我的贡献越来越像应用计算机科学,尤其是计算几何。我被招聘到洛斯阿拉莫斯国家实验室研究病毒(使人而不是计算机生病的那种),但最终我的工作在这里演变成了应用计算机科学家,没有什么比在美丽的新墨西哥州圣达菲进行长跑更好的了。
你为什么开始使用 Python?
我想这是从我在加拿大读博士时开始的。他非常乐意让我探索如何使用编程来提高研究过程的效率,即使在短期内我可能会因为“只做科学”而过得更好。最终,我的好奇心增长到了这样的程度,我把马克·卢茨的《学习 Python》从头到尾读了一遍。在阅读这本书的时候,我很少使用终端来测试东西——我只是不停地狂热地浏览章节——我认为 Python 是非常可读的!当处理新问题/语言时,我仍然更喜欢看书而不是随机试验,尽管我并不总是有时间/奢侈去这样做。我记得我读过彼得·赛贝尔的《工作中的程序员》,并且列出了在那里接受采访的著名程序员谈论的所有书籍。
你还知道哪些编程语言,你最喜欢哪一种?
在洛斯阿拉莫斯的第二个博士后期间,我读了 Stephen Kochan 的《C 语言编程》,为了这本书,我基本上在阅读的时候在终端上做了每一个练习,我发现用 C 语言比用 Python 更有必要让这些想法保持不变。我之前尝试过阅读 K&R 的经典著作《C 编程语言》,发现它很难学。我想我做错了一些事情,因为它在《工作中的程序员》中被描述为一个经典。我现在可能再也不会去读那本书了,但是这些天我确实从我的 C 语言知识中获益良多。
我在加州大学伯克利分校休假,与 stfan van der Walt 和 NumPy 核心团队一起全职工作了一年。NumPy 是用 C 写的,所以我至少能读懂源代码是很重要的。我评论或编写的许多 SciPy 中的算法实现都是用混合的 Cython (C/Python)语言编写的,以加速内部循环等。
我也写了相当多的 tcl,最近在工作中我写了很多 CMake 代码。
Python 轻而易举地成为我最喜欢的语言,但是 C 也不算太落后。我不得不同意《工作中的程序员》中那些高调的作者的观点,他们将 C 语言描述为“美丽的”(或类似的),而 C++则是另外一回事。事实上,NumPy 团队用 C 编写了一种自定义类型模板语言,由 Python 处理,而不是使用 C++。也就是说, Bjarne 在我去加州大学伯克利分校的时候确实去过那里,听起来 C++在未来可能会从 Python 世界吸取更多的想法!
你现在在做什么项目?
我是 SciPy 的发布经理,这是我近年来长期关注的主要开源项目。我一直在努力改进 SciPy 中可用的计算几何算法,既从最近的数学文献中添加新算法,又改进我们现有的算法。
不过,我现在花了很多时间在代码审查上。我不介意——这就是它的工作方式——如果我希望其他核心开发人员和社区审查我的代码并帮助我越过终点线,我应该准备好为他们做同样的事情。事实上,随着一些 OSS 项目的资金开始增加,我们很快意识到仅仅向核心团队/社区倾倒一堆新代码将很快导致问题——审查带宽真的很重要。
在 scipy.spatial 中,我收到了一些拒绝资助计算几何工作的提议,但我会继续努力!我们最近为 SciPy 写了一篇论文,对于这样一个大的组/历史/代码体来说,这是一个很大的工作量,但最终可能是值得的。
我也尝试参与 NumPy 代码审查,尤其是与基础设施相关的变更(轮子、CI 测试等)。)以及我对日期时间代码的一些兴趣。
我的开源之旅是从粒子物理模拟分析的 MDAnalysis 库开始的。我也试着在那里帮忙,但是在大部分空闲时间里,仅仅跟上 3+ OSS 项目的电子邮件/通知是极其困难的。我试着跟踪通知/参与到 OpenBLAS 和 asv 的进展中,尽管感觉我大部分时间都跟不上进度!
哪些 Python 库是你最喜欢的(核心或第三方)?
我认为假设可能被低估了——一些图书馆不愿意将它纳入他们的测试框架,但我认为基于属性的测试具有真正的潜力来捕捉人类很难预测的场景,或者至少需要很长时间来正确规划。我发现假设几乎总是会添加一些有用的测试用例,例如,我没有想到需要特殊的错误处理。
对于显示行覆盖率来说,Coverage.py 非常重要,但是我希望更广泛的 CI 测试生态系统能够有更健壮/多样化的选项来显示覆盖率数据,并从 Python 和编译语言源代码中聚合结果。我参与的许多大型项目都存在 codecov 可靠性的问题。Azure Pipelines 服务有一个初始覆盖范围,我们将看看它是否真的起飞。如果我们能很快将鼠标移到一行测试过的代码上,并看到覆盖它的测试的名称,那将会是一件很棒的事情。我想我在某个地方看到过,这也许很快就会成为可能。
你是怎么和 SciPy 扯上关系的?
我的第一个实质性贡献是在scipy.spatial.SphericalVoronoi中实现了球面 Voronoi 图计算。当时我正在研究球形流感病毒的物理模拟,希望有一种可靠的方法来确定分子占据的表面积。我很幸运,当时我的博士后导师,牛津大学的马克·桑瑟姆·T2,允许我探索我对计算几何算法的兴趣。我在我认为是第二届 PyData 伦敦年会上做了一个关于算法实现的演讲,当时还不完整,并从两位计算几何专家那里收到了一些非常有用的反馈——一位是学者,另一位与 CGAL 团队有松散的联系。
我真的很享受与 SciPy 团队一起工作的过程——我记得第一个审查我的代码的人是 CJ Carey,他是一名计算机科学家,现在在 Google 工作。我很害怕,但他们很热情,当指导委员会主席 Ralf Gommers 邀请我加入核心团队时,我可能有点太激动了。从那以后我就迷上了!
使用 SciPy 有什么好处和坏处?
随着时间的推移,您通常可以依赖 SciPy 拥有一个相当稳定的 API 我们通常非常认真地对待行为的变化。向后兼容性的中断通常需要很长的弃用周期。在 SciPy 中实现的算法的质量/健壮性通常很高,并且该库经过了很好的测试,所以如果其中已经有算法,通常最好使用 SciPy。文档的质量相当高,并且在不断改进,许多常见问题都在 StackOverflow 上得到回答。
如果你想玩实验算法或者倡导行为的快速改变,SciPy 可能不是你的首选。不成熟技术的早期采用通常不太可能发生。稳定性和可靠性是 Python 科学计算生态系统的基础。
未来 SciPy / NumPy 会有怎样的变化?
这两个项目的活动/进展数量非常惊人。官方的回应通常是看一看数字时代和 T2 时代的路线图。
我想到了几件事:改进对使用不同后端来执行 NumPy 和 SciPy 计算的支持(例如,使用 GPU 或分布式基础设施),以及使使用定制 dtypes 更容易。你可能想用 Cython、Numba 或 Pythran 来加速代码,而 NumPy 和 SciPy 可能需要一些思考才能很好地适应其中的每一个。
我想我开始看到二进制轮子最终将适用于 PowerPC 和 ARM 架构的迹象,但我的印象是那里仍然有一些挑战。
我想你将来也可能会看到这两个项目发表更好的论文/引用目标。随着为资助这些项目而进行的所有努力,我认为我们将继续看到有资金支持的开发商更快地推动事情向前发展的时期,正如 UC BIDS 的 NumPy 拨款所发生的那样。
泰勒,谢谢你接受采访!
PyDev of the Week: Tzu-ping Chung
原文:https://www.blog.pythonlibrary.org/2021/11/01/pydev-of-the-week-tzu-ping-chung/
This week we welcome Tzu-ping Chung (@uranusjr) as our PyDev of the Week! Tzu-ping is a member of Python Packaging Authority (PyPA) and a maintainer of pip and pipx. You can see what else Tzu-ping has been contributing to over on GitHub. He also maintains a website.
Let's take some time to get to know Tzu-ping better!
Can you tell us a little about yourself (hobbies, education, etc)
I’m a developer based in Taipei, Taiwan. I am currently employed by Astronomer to work on the open source project Apache Airflow.
Aside from work, I’m a member of the Python Packaging Authority (PyPA) and help maintain multiple Python packaging-related projects such as pip and pipx, and (co-)authored several Python Enhancement Proposals (PEPs) around the area.
I am also involved in events around Taiwan and the APAC area, helping organise community events, and served as Chairperson for PyCon Taiwan during 2017–2018.
Primarily trained as a mechatronic engineer in college, I started my career working with microprocessors and embedded systems. These days I’m no longer involved with hardware anymore, however.
I like to listen to people talk and have been enjoying a lot of the “Virtual” YouTuber (vtuber) talk streams. My favourite streamer is Natori Sana, but many other streamers are much fun as well. I also like trivia and enjoy quiz shows.
Why did you start using Python?
I first picked up Python during graduate school for NumPy and SciPy to replace MATLAB to do simulation for my thesis since my university did not provide free licenses for the Mac version. I was introduced to Django at my first job and began learning web development. Python ended up gradually pulling me more and more toward software development and to where I am right now.
How did you get into contributing to open source?
My first non-trivial open source contribution was fixing an SQL generation bug in the ORM. I never completed the patch (the task was eventually completed by another contributor), but the process of discussing the root cause, tracing implementation, experimenting the fix, writing tests, and the interaction with project maintainers gave me a lot of confidence participating in the community.
Any advice for people who would like to start contributing to FOSS?
Find a project and community you feel comfortable working with. Some projects put a lot of effort in accomodating new contributors; look whether the project has a good contributing guide, or a “good first issue” label on the issue tracker. Many projects participate in conferences and sprints, or even host dedicated contributors’ workshops, which are the best way for newcomers to learn about contributing directly from maintainers.
Interaction with people is an important part since open source is all about communication, and online communication is very prone to
misunderstandings. One good rule of thumb is to treat a project’s maintainers as a group of people whose conversation you want to join. Don’t be shy, but also be polite (always ask yourself would I say this to a stranger in real time?) You can expect some defensiveness, but if the maintainers get hostile, leave the conversation as soon as possible.
Brett Cannon’s blog post The social contract of open source is a very good read I’d recommend to all aspiring FOSS contributors.
What other programming languages do you know & which is your favourite?
My first entry to serious programming was through C and Objective-C when I got my first Mac. Objective-C will always have a special place in my heart since it taught me many programming habits and ideas that are still invaluable to me to this day, and I especially appreciate how it (plus the CoreFoundation framework) gets things done with simplistic but powerful designs.
I also learned C++ during my mechatronics days, but can’t no longer claim to have any efficiency in it anymore. Rust is probably my choice if I am pressed to do system programming now. Its ownership and borrowing concepts are really, really nice—and worthwhile to integrate into projects written in other languages even if they don’t have the same checker features!
What projects are you working on now?
I’ve recently been working on a new Airflow feature called “timetable” that generalises DAG scheduling and allows more customization
possibilities. A new concept called “data interval” will also be introduced to make timetables and DAG scheduling, in general, easier to understand.
On the Python packaging side, I’ve been working on pip’s dependency resolution logic since 2020, which is an ongoing battle to support a myriad of package combinations since Python is used in diversive things (it’s a good problem to have). I’m also working on modernising Python packaging tools to adopt more modern concepts, in the form of PEP 621, PEP 665, and some other ideas still in the works.
Which Python libraries are your favourite (core or 3rd party)?
My favourite has to go to Django, not only for the code, but also how the project is run. I have only the greatest respect to everyone working on the project, seeing how it keeps pace with the ever-changing web landscape and continuously being rock-solid and innovative at the same time for such a long time.
Is there anything else you’d like to say?
Reach out to other Python users, maintainers of tools you use, and even more! Python is a wonderful language to use, but don’t miss out on the community.
Thanks for doing the interview, Tzu-ping!
本周 PyDev:瓦伦丁·海内尔
原文:https://www.blog.pythonlibrary.org/2019/06/10/pydev-of-the-week-valentin-haenel/
本周我们欢迎瓦伦丁·海内尔(@ ESC _ _)成为我们本周的 PyDev!瓦伦丁是 Numba 和其他几个软件包的核心开发者,你可以在他的网站或 Github 上看到。他还在欧洲的各种会议上做了几次演讲。让我们花些时间来更好地了解瓦伦汀吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在爱丁堡大学获得了计算机科学学士学位,在柏林的伯恩斯坦中心获得了计算神经科学硕士学位。如今,我倾向于更传统的计算机科学主题,如压缩算法和编译器。在业余时间,我会和我可爱的妻子格洛丽亚在一起,放风筝,在柏林玩长板。我在 Github 上做 Python 和开源大概有 10 年了。
你为什么开始使用 Python?
我第一次开始使用 Python 是在我的硕士项目中。Python 过去和现在都是计算神经科学中非常流行的,既用于对 EEG 和 fMRI 等传感器数据进行机器学习,也用于模拟神经模型和神经元网络。我以前一直在使用 Java,花了一些时间来适应动态(鸭)打字风格。作为学术工作的一部分,我接触了早期的科学堆栈,当时主要由 Numpy、Scipy、Matplotlib 和命令行 IPython shell 组成。那时我最早的一些 Python 作品仍然存在。我做了一个项目,用一种特定的模型来模拟尖峰神经元:
https://github.com/esc/molif——这是我的第一个 github 回购。
也是从那时起,我的第一个包进入了 Debian,一个到特定类型的硬件光度计的 Python 接口。事实上,我刚刚在这台 Ubuntu 机器上检查过(2019 年 3 月),该包仍然可用:
$ apt search pyoptical
Sorting... Done
Full Text Search... Done
python-pyoptical/bionic,bionic 0.4-1.1 all
python interface to the CRS 'OptiCAL' photometer
😃
你还知道哪些编程语言,你最喜欢哪一种?
我知道一点 C,shell,go 和 Java,但是 Python 是我最喜欢的。我的一个朋友正在从事一个名为“@”的秘密编程语言项目,其目标是...良好的...仅限运行时——非常有趣。
你现在在做什么项目?
我现在正在为 Anaconda Inc .开发 Numba ,除此之外,我还在开发 Blosc(http://blosc.org/),包括 python-blosc 和 Bloscpack 。除此之外,还有几个规模较小但有点受欢迎的项目,是我自己运行的,即 wiki2beamer 、 git-big-picture 、 conda-zsh-complation 和 yadoma 。最近,我对时间追踪越来越感兴趣,并开始使用和贡献freld。
哪些 Python 库是你最喜欢的(核心或第三方)?
我一直对制作命令行界面感兴趣。为了这个任务,我查阅了许多库,如 getopt、optparse、argparse、bup/options.py、miniparser、opster、blargs、plac、begins 和 click(我忘记了吗?!).然而,有一个图书馆是我经常回来的,也是我最推荐的,那就是 docopt:http://docopt.org/。关于把你的命令行界面设计成一个程序概要,然后从中获得一个完全成熟的解析器,有一些东西要说。对我个人来说,这是构造命令行参数解析器最快、最自然、最直观、最方便的方法。如果你还没有意识到,你一定要去看看!
你是如何和 Numba 扯上关系的?
我在 Anaconda Inc .看到一个软件工程职位的空缺,主要在 Numba 上做开源工作。在编译器上做底层工作是我的拿手好戏,也是我很久以来一直想做的事情。我申请了,他们给了我一份工作,剩下的就是历史了。
你能解释一下为什么你会使用 Numba 而不是 PyPy 或 Cython 吗?
Cython 是 Python 的超集,它有额外的语法,允许静态类型,然后编译代码以 C-speed 运行,也就是“cythonize”代码。该代码不能再作为常规 Python 代码运行。Numba 的侵入性比这小得多,但有类似的目标。它提供了@ jit decorator,允许 Numba 使用 LLVM 编译器基础设施执行即时(jit)类型推理和编译。重要的是,它在 Python 字节码上这样做,不需要注释任何类型,代码可以像普通 Python 一样继续运行(一旦注释掉@ jit decorator。)这样做的好处是,您可以将可移植的数字代码作为纯 Python 发布,只有 Numba 作为依赖项,这将大大减少您的打包和分发开销。Cython 和 Numba 传统上都用于科学领域。这是因为它们与现有的生态系统、原生库(Cython 甚至可以与 C++接口,而 Numba 不能)交互良好,并且被设计为对 Numpy 非常敏感。所以这些是你在那个领域工作时会用到的:例如机器学习和广义上的任何科学算法和模拟。另一方面,PyPy 传统上对整个科学堆栈没有很好的支持。现在(2019 年初)稍微好一点,因为 Numpy 和 Pandas 都可以编译,并且已经做了很多工作来使
c-extensions 在 PyPy 中工作。
无论如何,PyPy 的主要目标集中在超越 CPython(Python 解释器的 C 实现)作为 Python 程序的基础,它正在缓慢但肯定地实现。
因此,总而言之:PyPy 是 Python 语言的未来,但它还没有为数据密集型应用做好准备。如果你今天想拥有尽可能高的计算效率,那么 Numba 和 Cython 都是不错的选择。Numba 非常容易试用——只需修饰一下您的瓶颈——众所周知,它可以将代码加速一到两个数量级。
对于想开始帮助开源项目的新人,你有什么建议?
去给自己找个痒处;找到一个你最喜欢的语言的项目,你觉得对你个人有用,然后改进它。然后,把你的改变反馈回来。很有可能,如果它对你有用,对其他人也会有用。此外,因为它对你个人有用,你可能会继续为它做出贡献,因为你最终会在其中获得既得利益。所以很明显,个人工具是寻找这种工具的一个很好的类别。找到对你日常有用的东西,并为此做出贡献。此外,不要害怕公开你的代码,如果你的贡献被拒绝也不要气馁,你才刚刚开始你的旅程,所以继续前进。祝你好运!
你还有什么想说的吗?
非常感谢所有开源/自由软件开发者和贡献者。我很自豪能成为这个奇妙的、鼓舞人心的社区的一员。
瓦伦丁,谢谢你接受采访!
本周 PyDev:Vasudev Ram
原文:https://www.blog.pythonlibrary.org/2015/05/18/pydev-of-the-week-vasudev-ram/
本周我们欢迎 Vasudev Ram ( @vasudevram )成为我们本周的 PyDev。瓦苏德夫是一名自由开发者,他在很多不同的软件主题上写博客,包括 Python 。他是 xtopdf 的创作者,你可以在这里阅读更多关于的内容。让我们花些时间去更好地了解他吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
当然可以。我在印度工作,目前是一名独立的软件顾问,曾在美国和印度的多家公司工作多年。音乐(各种流派,包括西方和印度),徒步旅行是我的一些爱好。
我在大学学的是数学。我在高中 12 年级开始接触计算机,通过许多人都有的途径:在许多品牌的个人计算机上学习。
一天,一个学校的朋友(一个电子爱好者)向我展示了一台卡西欧袖珍电脑,里面有 BASIC 语言的只读存储器。它带有一个手册和示例程序。它甚至有一个 4 线图形液晶显示器。
我对这个新设备很感兴趣,向他借了几天。我用它玩了一圈,写了许多程序——像算术计算、统计、字符串操作、简单的游戏和图形——有数学/物理/逻辑背景的人可能会尝试编程的常见事物。这就是我对编程感兴趣的原因。(后来在许多不同类型的计算机和一些不同的操作系统上工作过——许多 UNIX 版本,包括基于 PC 的和更高端的,还有 Windows——在早期,还有 DOS 和 Netware。)
然后在我的大学时代,我参加了许多计算机课程,关于编程语言和其他主题;还在我感兴趣的各个领域做了很多编程,包括数学、图形、声音等。
大学毕业后开始做程序员。实际上,一开始我是一名自由职业者,参与了几个小而有趣的项目,使用 dBASE III 和 Turbo Pascal(这两种工具在当时都非常流行,也是相当强大的工具。)然后加入了一个小软件之家做程序员。(后来成长为系统分析师、项目经理等角色。在印度和美国的大公司,这些年来参与了各种各样的项目,并且在各种基础软件主题上得到了很好的培训;我现在又成了一名开发人员,回到了几年前的自由职业咨询公司。)在我职业生涯的早期,在 UNIX 上做过很多 C 编程和 shell 脚本。从中我学到了很多系统层面的东西,这对我的职业生涯很有帮助。此外,我一直对系统级工作以及工具和实用程序的开发感兴趣。在 IBM developerWorks 上发表了一篇主题为“开发 Linux 命令行实用程序”的文章——参见下面的链接一节。
就公司而言,在我的职业生涯中,我曾为各种公司工作或提供咨询,无论是大公司还是小公司、印度公司还是美国公司、企业还是初创公司。由于我工作过的公司种类繁多,角色各异,我接触了许多不同的技术和业务领域。我也做过一些软件产品(相对于咨询项目),包括在一个成功的 C 语言中间件产品中担任团队领导,我的 xtopdf 产品有一些用户。我接触过的行业领域包括:软件和数据库设计、项目管理、配置管理和良好的软件工程实践,以及 UNIX 系统管理。我曾经有一点 UNIX 管理的天赋,作为一名系统工程师在现场工作(随叫随到),除了日常的管理工作之外,还在早期为我的雇主——一家大型 UNIX 供应商的客户解决了许多棘手的问题;在那个阶段获得的系统优势和故障排除技能对我的整个职业生涯都有帮助)
我从所有这些经历中学到了不同的东西,包括什么有效,什么无效,我还在学习🙂
你为什么开始使用 Python?
几年前,在网上看到一些文章后,我开始学习 Python,最初是作为一种爱好。当时我正在专业地研究 Java 和 C 语言。我发现 Python 非常可读和高效,你知道——“可执行伪代码”,当然还有“包括电池”的东西,尽管它现在比我开始时有更多的库,而且版本也更高;我想当时大概是 1.5 左右吧。随着时间的推移,我开始在自由职业者的咨询项目中使用它,也因为它的高级性质,开始使用它来构建一些项目/产品想法的原型,并且它经常证明原型足够好,足以成为最终产品——从某种意义上说,不需要为了性能或其他原因而用另一种语言重写它。
你还知道哪些编程语言,你最喜欢哪一种?
至少在某种程度上,我喜欢我所学习和使用的大多数语言。你可以从你学习的每一种语言中学到一些东西。但是回答你的问题,大致按时间顺序,从早到晚:
Turbo Pascal 非常有趣——在我职业生涯的初期,我经常使用它。这在当时是一个不可思议的环境——一个快得惊人的编译器(就像 Turbo C 和后来的 Delphi)和不到 40KB 的编辑器,是的,K,而不是 m。在工作中做了许多 UNIX C,有些是为了好玩,早期的 Turbo C 也是,也很好玩,用 Turbo C 和 Turbo Pascal 做了许多基本的图形编程;在一段时间内,Borland tools 几乎是终极产品(对我来说);Java,在工作中,更早,也很好;我喜欢 Servlet 的优雅,这是我很早就开始研究的,在 J2EE 出现之前,虽然 JSP——不太喜欢,直到今天,Jason Hunter 的 Java Servlet 编程(第一版)仍然是我最喜欢的编程书籍之一——我认为写得非常好。然后在. com 项目中使用 Ruby(和 Rails ),几年来,在 web 和非 web 工作以及我自己的开源项目中使用了大量 Python。在我的职业生涯中,我几乎一直在使用 SQL(在各种关系数据库中,包括私有的和开源的)和 shell (sh/ksh/bash 以及 sed 和 awk 等朋友)。我也做过一些 Visual Basic,用于现实生活中的项目和小工具,我喜欢它(和 Delphi 一样)是因为它的 GUI 应用程序开发速度,尽管我对 VB 语法不太感兴趣。
我没有一个最喜欢的,但是 Python 可能是第一个——暂时是——因为它的生产力、可读性、社区性、用户友好性和它的大量库(尽管和所有语言和工具一样,它也有它的问题)。我想是 Dennis Ritchie 被问到,如果他被困在一个荒岛上,只有一种编程语言,他会想要哪一种,他说 C。我可能会想要 Python 和 C。我最喜欢的其他语言是 C (evergreen)和 Delphi(尽管 Delphi 更像是一个完整的开发环境,而不仅仅是一种语言)。我之前在里面写过几个小工具。虽然不是这方面的专家。
Ruby 也很有趣。我是 Ruby 的早期用户,我喜欢它比 Python 更注重面向对象,但我不是语言律师,所以不要引用我的话:)。最近没怎么用,虽然前一段时间很擅长。我也偶尔涉猎其他语言,在空闲时间,出于兴趣和学习其他做事方式。通过 Franz 的 Allegro CL 和 LispWorks 的工具,我尝试了一下 Lisp(也叫 Scheme ),阅读了 Peter Seibel 的一些实用的 Common Lisp 和一些其他 Lisp 书籍,并且喜欢上了这门语言。对于任何对新/旧/另类语言感兴趣的人来说,我在过去检查过的一些语言包括 Pike、Elastic、Icon 等等。
你现在在做什么项目?
除了经常涉及 Python、Linux 和数据库(针对 web 或非 web 应用程序)的专业咨询工作,我一直致力于 xtopdf(参见:http://slides.com/vasudevram/xtopdf)和其他一些产品创意。我在我的博客上宣布我的新产品发布/版本:http://jugad2.blogspot.com
任何感兴趣的人都可以随意订阅它的提要,或者由 Python 帖子组成的子集。
哪些 Python 库是你最喜欢的(核心或第三方)?
就像语言一样,有许多种。xtopdf 是我自己的用于 pdf 创建的 Python 库。它建立在 ReportLab 的基础上,为 ReportLab 的功能子集提供了一些更高级别的抽象。这是我喜欢做的一件事。不知何故,我一直在为它寻找新的应用/用途。
我认为这与我最初开发它时应用了一些约束有关,从某种意义上说,我没有试图成为每个人的一切,或者有太多的功能(至少一开始是这样)。也许结果是,我发现它与许多其他库是正交的(我喜欢这个词和概念),并且可以很好地与许多其他库一起使用——就像 UNIX 哲学(创建小工具,做好一件事),这可能影响了我,因为我在 UNIX 上工作了很多。这里不得不提的是,ReportLab 的工作人员做得非常出色。在其他库中,我喜欢 XML-RPC(轻量级分布式计算)的简单性,Python 中有针对它的客户端和服务器库,我还研究了同一领域的其他一些技术,如 PYRO 和 RPyC。DB API,当然是面包和黄油之类的东西。SQLAlchemy。喜欢 PyDAL,最近发现的。它就像 SQLAlchemy 核心 ORM 本身下面的一层。wxPython,requests,json,一些 XML 库。csv,tablib(最近看到的)-作为一个喜欢数据管理的人。我喜欢时不时地去看看与互联网、网络和多媒体相关的图书馆。我继续探索新的库——事实上,我博客上的许多帖子都是关于我遇到的新 Python 库,然后编写演示程序来展示/探索如何使用它们;参见:
http://jugad2.blogspot.com/search/label/python
你还有什么事吗?我想说什么?
是的。感谢邀请我参加这个系列!我一直在阅读该系列的其他帖子;它们很有趣。我想提一下,我是你博客的读者,在那里发现了许多好文章。最后,我发现你是经常在 IRC 频道#wxpython(昵称 driscollis)上闲逛的人,很多人,包括我,都发现你在上面的回答很有帮助。谢谢!
非常感谢!
一周的最后 10 个 PyDevs
- 朱利安·丹朱
- 马特·哈里森
- 阿迪娜·豪
- 诺亚礼物
- 道格拉斯·斯塔内斯
- 可降解的脊椎动物
- 迈克·弗莱彻
- 丹尼尔·格林菲尔德
- 伊莱·本德斯基
- Ned Batchelder
本周 PyDev:维罗妮卡·哈努斯
原文:https://www.blog.pythonlibrary.org/2019/09/16/pydev-of-the-week-veronica-hanus/
本周我们欢迎维罗妮卡·哈努斯(@维罗妮卡 _ 哈努斯)成为我们本周的 PyDev!Veronica 经常在 Python 和其他技术会议上发表技术演讲。你可以在她的网站上看到她的一些演讲和日程安排。在过去的几年里,她一直活跃在 Python 社区中。让我们花一些时间来更好地了解她!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我喜欢写作和拍照。对我来说,挑战是帮助别人感受我当时的感受,当我决定那个时刻值得拍照或讲故事时,两者都需要结合你可以学习的技能和我觉得非常有益的普通老人关怀。拍照远足是我最喜欢的与朋友共度时光的方式之一,因为这是“安静、沉思的并排活动”和“让我们出去做点什么吧”的完美结合!
我曾经抽出时间和一个新的会议朋友在会场一个有趣的颠倒的房间里拍傻乎乎的照片。在我第一次会议演讲的压力之后,被人大惊小怪的感觉真好,这让我感到惊讶。随着我说得越来越多,我开始主动为与会者拍照,许多人都有同样的感受。许多人觉得会议让人应接不暇,花几分钟放松一下,交个新朋友,也许带着新的头像回家也不错。
我的教育经常让人们感到惊讶,因为它违背了许多人的期望:我没有计算机学位,也没有参加过训练营。在大学里,我学习地质学,结合了地球化学和行星科学。自从进入软件行业以来,我已经无数次听到“地质学!?这一定是一个很大的变化。即使在今天,这样的评论仍然让人觉得具有挑战性和排斥性,在我职业转变的早期,这种感觉很糟糕。我们一次又一次地听到来自不同背景的人有助于团队创新,但是当遇到不符合我们期望的人时,我们大多数人仍然会犹豫不决。如果我是一个白人,一个吹嘘学位的前科学家,想象一下当我们表达我们的惊讶时,有更多偏见的群体中的人会遇到的不舒服的反应!
事实证明,我曲折的编程之路让我做出了一些最有用的贡献。我们没有足够地谈论它,但是许多人使用编程技能,即使他们没有写过一行代码。如果你正在考虑发展,但不知道如何适应,我鼓励你去看看社区,比如写文档(他们的 Slack ),#CodeNewbie(他们的 Twitter ),或者通过我的 Twitter 或电子邮件向我问好。
你的科学背景对你的编程生涯有什么影响?
直到我在 JPL 做研究时,我才开始理解什么是编程。这需要相当大的勇气:我需要在实习的前一个学期学习 MATLAB,所以我找到了一位教授,他的研究依赖于 MATLAB,并和他一起建立了一项独立的研究。获得许可的计算机在校园对面一栋建筑的地下室里。他允许我在他的办公时间练习,所以我每周去那里两次,尽可能多地学习 MATLAB。当我的暑期研究导师来自一所重代码的技术学校时,当他看到我磕磕绊绊时,他评论道,“我以为你去了一所好学校。â€
那年夏天我没有学习编程,但我开始在我们团队的开发人员和其他手动测试他的程序的实习生之间充当联络人。在那些会议中,我们打破了我的许多个人编程神话。例如,到那时为止,我一直相信熟练的程序员会像我给朋友写信一样写程序,通常是从上到下(可能会因为一两个拼写错误而退回去)。程序可以由现有代码库和一些“胶水”组成,这让我大吃一惊。我开始阅读我们的程序,并很快指出和建议修改。我开始将我们程序中的模块与我们可能在我习惯的实验室环境中运行的过程进行比较。在与编程相关的领域工作使编程变得更加容易,即使我需要一路乞讨才能进入某人的地下实验室!

你为什么开始使用 Python?
有两件事吸引我来到 Python 社区:Python 与众多科学领域的接近(有如此多为特定应用开发的库)和他们热情的社区。
当我决定探索编程的时候,和我交谈过的每个人都强调了友好社区的重要性,并推荐我从 Python 开始。Python 给自己找了一个新的“终身监禁者”。虽然我发现许多普通的“编程”社区让人应接不暇(我可能永远也不会在 Stack Overflow 上为自己开拓一席之地),但我很快在 Boston Python 上找到了自己的位置(他们有长达一个周末的教程,我都参加了,并和他们一起学习)。哈佛天文小组的电子邮件列表,其研究问题有时与我的兴趣重叠,成为我潜伏的地方,并观察那些依赖 Python 的人如何使用该语言解决他们的问题。有很多不同的学习方法!
人们对 Python 的兴趣越来越大,有很多方法可以参与社区活动。我鼓励你找到最适合你学习和社交风格的方式。我们不都是聚会/会议的人!
在线社区/论坛 : 代码新手和开发者到是我最喜欢的两个!他们有推特签到,播客,博客帖子。我也是 Recurse Center 的成员,该中心被亲切地称为“世界上最好的编程社区,为期三个月的入职培训”,我会时不时地加入他们的聊天。
Meetup:因城市而异,但我最喜欢那些轮换主题、宣传&支持其他 Meetup 社区、努力记录资源的 Meetup。有些有活跃的 Slack 社区,允许人们在会议间隙轻松交流!
会议很精彩(对我来说),每个会议都有自己的文化。我发现那些有意进行文化建设的人给与会者和演讲者最好的体验(如果他们致力于阐明与会者的需求或解释吃豆人规则,我加入!)
非正式资源:有几个你可以去寻求建议的人是非常宝贵的。找出那些人,培养他们的关系。
有很多方法可以找到支持,但找到你可以成长的空间需要时间。实验!
你还知道哪些编程语言,你最喜欢哪一种?
我对 HTML/CSS/JS、Django 和 LaTeX 相当熟悉。Python 和 LaTeX 是我的初恋,可能永远是我的最爱。很少有人知道 LaTeX,所以我将在这里分享我的故事。
LaTeX 是由 Donald Knuth 创建的一种排版语言,除了他在算法复杂性分析方面的开创性工作之外,他还手工测量了字距调整和行距,以找到视觉上最吸引人的组合,结果非常棒。LaTeX 被数学和数学密集型学科(如物理)的学者广泛使用,并受到其他一些排版爱好者的青睐。我举办过关于乳胶的研讨会,希望能引起工业界人士使用它的兴趣。唉,LaTeX 仍然等待着在计算机科学和科学之外流行起来。目前,它仍然是主要保留用于学术用途的珍品。
我投身 LaTeX 是因为在我大学期间的实习和毕业后的第一份工作中(分别在加州理工学院和麻省理工学院),我看到人们在打作业、论文和笔记(我听说有些人甚至能熟练地排版他们的课堂笔记!)结果很漂亮!我来自一所文科学校,以前从未见过这种情况——数学变得像艺术一样美丽!我决定,如果我把我需要的时间放入我的数学集,我也可以让它们看起来像一个艺术家在纸上安排的单词/符号!我开始为所有的东西排版,这是由美丽和融入的愿望所驱动的,直到今天,看到我的简历(由我设计和排版)时,我的脸上会带着微笑。学习 LaTeX 是我第一次感受到编程的兴奋、喜悦和精通。
你现在在做什么项目?
我现在最喜欢的项目是分析一个 200 人的关于开发者使用代码内注释的调查结果。在我看到如此多的新程序员被鼓励避免注释之后,我有动力学习更多关于注释实践的知识,尽管它们在许多情况下似乎是有用的。我已经从开始谈论结果,并将从回答中创建一个开放数据集。
你对那些想在会议上发言的人有什么建议?
多年来,我一直觉得自己不适合做演讲,尽管我很想做(我并不孤单!75%的人避免公开演讲),所以我满脑子都是建议!
和朋友一起头脑风暴,快速开始!每个人都有自己最喜欢的把想法写在纸上的方法,做任何能帮助你关掉自我怀疑过滤器的事情。我发现召集一些人进行头脑风暴特别有效,在草拟了一个大类列表后(例如“你遇到过什么有趣的 bug?),每个人在自己的纸上写下自己的答案(1 分钟内你能想到多少就写多少!).小组成员交换论文,并标记他们想进一步了解的每个想法。你不仅会很快发现你的想法有多有趣,还会听到一些有用的建议。
拥抱脆弱,不要屈服于低价出售你的想法的诱惑,无论是对自己还是对他人!当寻求帮助时,人们通常会分享他们的想法(通常是很棒的),然后立即用“哦,但是我不确定这是否可行”、“很抱歉打扰你”等等来搪塞。相反,尽你所能做好谈话准备——人们更愿意(也更有能力!)在你能为他们提供反馈材料时提供帮助。
给自己找个审查小组。我有五个经常给我写信的人和他们的评论(甚至只是“我喜欢!)在我挣扎的时候,给我前进的力量。
直到我无意中听到一位经验丰富的演讲者(他似乎在我参加的每个会议上都发言!)说他通常会向每个会议提交至少五个提案,我意识到提案的选择比演讲质量重要得多!组织者努力策划一个演讲阵容,为每个与会者提供一些东西。如果你提交的是一个热门的新技术,它可能会被比作几个(或几十个!)的其他探索该技术的提交。创建多个你感觉良好的提案可能需要一段时间,但希望知道即使是我们中最有经验的人采取这种预防措施也会帮助你向前推进,不管你第一次提交的结果如何!
加入一个评审委员会!大多数会议都在 Twitter 上征集评论者。通过回顾,阅读足够多的提案,你会认识到最常见的错误(例如,当作者遗漏重要信息时),并看到你想要在自己的提案中模仿的风格。你还将为你最喜欢的会议提供支持,并接触到该领域的新领域或新语言。
记住这个秘密:很少有“糟糕的谈话想法”,创造一个成功的谈话更多地依赖于你持续的兴趣和意愿去研究、接受反馈和修改,而不是你的想法。当你需要把你最糟糕的“怪异”想法公之于众时,提醒自己这一点,看看你能从中得到什么。
你还有什么想说的吗?
经历了“什么,你是地质学家?作为我编程转型的一部分和“也许演讲是为了其他人”的一部分,我已经亲眼看到了谁在演讲有多重要。通过演讲,我们不仅分享了我们的编程冒险,而且有机会分享我们的错误冒险,并且听到旅程中困难的部分可能是强大的——对每个人来说,尤其是对与我们相关的人来说,因为共同的经历或身份。没有人能像你一样讲述你的故事。
谢谢你接受采访,维罗妮卡!
本周 PyDev:维克多·斯坦纳
原文:https://www.blog.pythonlibrary.org/2017/02/27/pydev-of-the-week-victor-stinner/
本周我们欢迎维克多·斯坦纳成为我们的本周 PyDev!Victor 在 Python 社区非常活跃,是一名核心 Python 开发人员。你可以在这里看到他的一些贡献。他是八个公认的 pep 的作者,你也可以在前面的链接中读到。如果你有兴趣看看 Victor 还做了什么,那么我强烈推荐你去看看 Github 和 ReadTheDocs 。Victor 还为 CPython 和 FASTCALL 优化收集了一些有趣的基准测试。您可能还想在这里查看他关于 Python 基准的最新演讲:https://fosdem . org/2017/schedule/event/Python _ stable _ benchmark/
现在,让我们花些时间来更好地了解 Victor!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
大家好,我叫 Victor Stinner,我在 OpenStack 上为 Red Hat 工作,从 2010 年开始就是一名 CPython 核心开发人员。
我是一名来自法国贝尔福-蒙彼利亚德大学(UTBM)工程学院的工程师。当我不黑 CPython 的时候,我就和我的两个可爱的小女儿一起玩🙂
你还知道哪些编程语言,你最喜欢哪一种?
我一直在编程。我尝试了各种编程语言,从最低级别的 Intel x86 汇编程序到高级语言,如 Javascript 和 BASIC。即使我现在真的喜欢编写 C 代码以获得最佳性能,Python 更适合我的日常工作需求。由于编写 Python 代码很容易,而且我也不讨厌内存管理或分析崩溃,所以我利用“空闲”时间编写更多的单元测试,关注编码风格
,以及所有使软件成为“好软件”的微小事情。
经过 10 年的专业编程,我现在可以说,我花在阅读“旧”代码和修复旧的复杂问题上的时间比从头开始编写新代码的时间还多。拥有一个可扩展的测试套件让我更酷。不得不在没有束缚的压力下工作很可能会导致精疲力竭,或者更简单地说,辞职。
你现在在做什么项目?
在红帽,我有一个把 OpenStack 移植到 Python 3 的大项目。OpenStack 由 300 多万条 Python 代码组成,并且每天都在增长!超过 90%的单元测试已经在 Python 3 上通过,我们现在正致力于解决功能和
集成测试的最后问题。
在 CPython 上,我在 Python 3 的童年花了很多时间修复 Unicode。如今,我正在从事多个项目,以使 CPython 更快。非常好的消息是,在大多数基准测试中,CPython 3.6 现在比 2.7 快,CPython 3.7 已经比 CPython 3.6 快了!总之 Python 3 终于比 Python 2 快了!
去年,我花了很多时间进行“FASTCALL”优化,避免创建临时元组来传递位置参数,创建临时字典来传递关键字参数。我现在 3/4 以上的 FASTCALL 工作都合并到 CPython 里了。当一个函数被转换为 FASTCALL 时,它通常会快 20%,而且转换非常简单。
在进行 FASTCALL 和其他优化时,我被不可靠的基准测试阻塞了。你可以看到我刚刚在 FOSDEM(比利时布鲁塞尔)上发表的“如何运行稳定的基准测试”演讲,其中列出了我的所有发现,并解释了如何获得可重复且可靠的结果:https://FOSDEM . org/2017/schedule/event/python _ stable _ benchmark/
另请参见我为使基准测试更加可靠而创建的 perf 项目。这是一个用两行代码编写基准的 Python 模块。该模块提供了许多工具来检查一个基准是否可靠,比较两个基准和检查一个优化是否重要,等等。
哪些 Python 库是你最喜欢的(核心或第三方)?
在 Python 标准库中,我喜欢 asyncio、argparse 和 datetime 模块。
日期时间做一件事,而且做得很好。它最近得到了增强,以支持夏令时(DST):https://www.python.org/dev/peps/pep-0495/
argparse 模块非常完整,它允许构建高级命令行界面。我在我的 perf 模块中使用它来获得子命令,如“python3 -m perf timeit stmt”、“python 3-m perf show-metadata file . JSON”,...
asyncio 很好地集成了一些很酷的东西:网络服务器的高效事件循环和 Python 3 新的 async/await 关键字。不仅 asyncio 有很好的 API(不再有回调地狱!),但它也有很好的实现。例如,很少有事件循环库支持子进程,尤其是在 Windows IOCP 上(在 Windows 上进行异步编程的最有效方式)。
作为一名核心开发人员,我最关心的是标准库的模块,但事实上最好的库都在 PyPI 上!仅举几个例子:pip,jinja2,django 等。抱歉,列表太长,这里放不下🙂
作为一门编程语言,你认为 Python 将何去何从?
我希望 Python 停止进化,我说的是语言本身。在花了几年时间缓慢过渡到 Python 3 的过程中,我意识到有多少像 Python 2.7 这样的用户停止了进化。与快速移动的库甚至编程语言相比,不必接触他们的代码被视为一种优势。
由于打包现在可以用 pip 流畅地运行,拥有外部依赖变得很容易。外部代码的优势在于它可以比 Python 标准库移动得更快,Python 标准库基本上每两年更新一次主要的 Python 版本。
即使我不喜欢进化,我也不得不承认这种语言最近增加的功能真的很酷:通用解包、async/await 关键字、f-string、允许数字中有下划线等等。
你还有什么想说的吗?
我听 Twitter 的时候,Go,Rust,Javascript,Elm 等。似乎比其他任何语言都要活跃得多。
同时,我总是对每个 Python 版本中所做的工作印象深刻。甚至 Python 语言也在不断发展。脸书决定只使用 Python 3.5 来获得新的 async 和 await 关键字和 asyncio!Python 3.6 增加了更多东西:f-string (PEP 498)、变量注释语法(PEP 526)和数字文字中的下划线(PEP 515)。
顺便说一下,许多人抱怨类型暗示。有些人认为它们是“非 pythonic 式的”。其他人担心 Python 会变成一种乏味的类似 Java 的语言。我也知道类型提示已经在像 Dropbox 和脸书这样的大公司的 Python 中使用了,它们对于非常大的代码库非常有帮助。
Python 很酷的一点是它不强制任何东西。例如,您可以不使用对象来设计整个应用程序。你也可以完全忽略类型提示,它们是完全可选的。那可是巨蟒的一个实力!
非常感谢你接受采访!
本周 PyDev:Vinay Sajip
原文:https://www.blog.pythonlibrary.org/2022/10/31/pydev-of-the-week-vinay-sajip/
本周我们欢迎 Vinay Sajip 成为我们本周的 PyDev!Vinay 是 Python 语言的核心开发者。Vinay 还是 python-gnupg、GNU Privacy Guard 的 Python API 以及其他优秀软件包的核心贡献者。
如果你需要 Python 或者工程方面的咨询,可以查看 Vinay 的网站。你可以通过访问 Vinay 的 GitHub 简介来了解 Vinay 最近在做什么。
让我们花一些时间来更好地了解 Vinay!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在大学学的是化学工程,在一家建造化工厂的公司找到了一份过程系统工程师的工作。几年后,该行业产能过剩,新工厂建设不多,我感到厌倦,加入了一家制作 CAD 软件的小公司,用定制的操纵杆开发 Apple II。这个软件是用 6502 汇编语言编写的,我学到了很多关于接近金属编程的知识。编程是我的一种爱好,我基本上是自学的——所以拥有一份基于爱好的工作对我来说是最理想的!我没有回头,很快就进入了咨询——做软件开发,项目管理,对别人的软件质量提出建议。
我的其他爱好是阅读、电影和戏剧,我偶尔玩电子游戏。为了锻炼,我步行和远足。
你为什么开始使用 Python?
1999 年左右,我在当地图书馆浏览时,偶然发现了马克·卢茨的《编程 Python》。作为一个对编程语言有点痴迷的人,我对这种语言非常着迷,并且看到了它如何在使用起来很有趣的同时极大地提高了我的工作效率。尽管当时 Python 鲜为人知,我的大多数客户都使用 Java 或 C/C++,但我能够开发出让我非常高效的工具,而且(因为我通常从事固定价格的项目),使用 Python 有助于我的咨询底线。
你还知道哪些编程语言,你最喜欢哪一种?
我对相当多的语言非常了解,足以用它们进行生产。Python 是我最喜欢的,但是我不确定我能从其他语言中找到我最喜欢的——它们在不同的场景中有不同的优势和适用性。我相当擅长使用 C/C++、JavaScript/TypeScript、Java、Kotlin、C#、Rust、Go、Dart、Ruby、D、Elixir、Pascal/Delphi 和 Nim。当然,内存管理语言比其他语言更容易使用。
你现在在做什么项目?
我目前正在开发一个解析器生成器,它用 Python 生成词法分析器和递归下降解析器,没有外部依赖性。它仍然是一个进行中的工作,还没有准备好发布。除此之外,我还有许多项目处于维护模式,但我认为自己仍在从事这些项目,因为我偶尔会收到错误报告和功能请求:
-
我维护的 Python 部分——日志、venv 和用于 Windows 的 Python 启动器。
-
Python-gnupg——GNU 隐私保护(GnuPG)的 Python API
-
page sign——age 和 minisign 的 Python 包装器,是 GnuPG 更现代的等价物
-
dist lib——实现一些 Python 打包标准(PEPs)的库,由 pip 使用
-
CFG——一种分层的配置格式,是 JSON 的超集,在 Python、JVM。NET,Go,Rust,D,JavaScript,Ruby,Elixir,Dart 和 Nim
-
simple _ launcher——一个用于 Windows 的可执行启动器,可以用来部署用 Python 和其他语言编写的应用程序。它由 pip 通过 distlib 使用
-
sarge——提供命令管道功能的子进程包装器
哪些 Python 库是你最喜欢的(核心或第三方)?
我喜欢 Django,也喜欢 Bottle web framework(非常被低估),Trio for async,BeautifulSoup for parsing HTML,Whoosh for the full-text search and requests for HTTP client work。我也使用 Supervisor 进行流程管理,尽管这更多的是应用程序而不是库。
你是如何入门 python-gnupg 的?
我需要一个客户项目的加密/解密和签名/验证功能,该项目涉及核对信用卡交易和与银行系统接口。我意识到 GnuPG 符合要求,但是没有可用的可编程接口。所以我建了一个(虽然是用 C#,不是用 Python——客户端是微软商店)。它工作得很好,所以我在 Python 中寻找一个类似的库,并修改了我找到的一个库——以便与 stdlib 子进程一起工作,并具有扩展的功能。我发布了 python-gnupg。
作为开源软件的创造者或维护者,你学到了什么?
喜欢你的开源软件的人有时会发来感谢的信息——当我做了大量工作将 Django 移植到 Python 3 时(这样它可以在 2.x 和 3.x 上用一个代码库工作),我甚至收到了小礼物作为感谢。但是很少有人会特意公开表示感谢(尽管人们有时会这样做,例如,关于 requests 库或 Flask)。另一方面,不喜欢你的软件的人(不管出于什么原因)会公开指责它,谈论他们如何“讨厌它”,但不会给出任何深思熟虑的理由。您会发现这种情绪经常与 Python 的日志记录有关。负面反馈往往会被放大,我已经学会不理会任何情绪化的、没有具体例子和理由来解释为什么会有问题的东西。
我还发现,人们经常不先讨论问题/功能就直接创建 pr。有时他们会错过目标,导致他们和维护人员浪费时间。我通常认为在制作公关之前提出一个潜在的问题进行讨论更有用。
你还有什么想说的吗?
我希望 Python 打包在一个更好的地方。在这个领域,每个人都有自己的观点,很难在重要的事情上达成共识,所以这可能是一个费力不讨好的领域。但是我喜欢更广泛的 Python 社区和 Python 核心开发社区,因为他们非常友好和乐于助人。
Vinay,谢谢你接受采访!
本周 PyDev:Vuyisile Ndlovu
原文:https://www.blog.pythonlibrary.org/2019/11/11/pydev-of-the-week-vuyisile-ndlovu/
本周我们欢迎 Vuyisile Ndlovu(@ terrameijar)成为我们的本周 PyDev!Vuyisile 是真实 Python 的贡献者,也是他自己的网站的 Python 博主。他还活跃在非洲的 Python 社区。你可以在 Vuyisile 的网站上找到更多关于他的信息,或者查看他的 Github 简介。让我们花些时间去更好地了解他!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是来自津巴布韦布拉瓦约的开发人员。我一直对计算机很着迷,所以高中毕业后,我在当地一所社区大学注册了一个信息技术文凭项目,该项目将编程作为课程的一部分。可惜我的情况变了,最后没能毕业。我转而通过在线课程和书籍自学计算机科学主题和编程。
当我不写代码时,我喜欢在后院做木工项目,带着我的狗定期散步。这样做可以让我从技术中解脱出来,以不同的方式发挥创造力,还可以得到一些锻炼。
你为什么开始使用 Python?
几年来,我一直是 Mozilla 项目的核心贡献者,和我一起工作的一个团队广泛使用 Python 来自动化他们的工作。我喜欢 Python 看起来简单直观,所以我开始学习它。与我所习惯的 C++相比,Python 语法更容易理解,我喜欢它可以用于 Web 开发,这是我感兴趣的一个领域。随着我对这种语言了解的越来越多,我意识到它有一个令人惊叹的社区,从那时起,作为 Python 社区的一员,我交了很多朋友,这也是我坚持使用 Python 的原因之一。
你还知道哪些编程语言,你最喜欢哪一种?
我还没有最喜欢的语言,因为我没有编程很长时间,我知道不同的语言适合不同的事情。我正在学习 JavaScript,在大学的时候,我上过 C++和 Visual Basic 课程。我在一所高中用 VB.Net 教编程课,因为我发现使用 Visual Basic 可以使在 Windows 环境下构建 GUI 变得容易,而且这种语言对初学者来说也相对简单。
我从事的工作项目是 web 项目,我喜欢使用 Python 和 Django 来构建这些项目。
你现在在做什么项目?
我正在为一家婚礼和活动公司开发一个由 REST API 支持的 Django 客户门户。
另一方面,我正在进行一个项目,该项目将使用负担得起的硬件来制作有用的网站和服务,如 PyPI(https://pypi.org/)、维基百科和 Stack Overflow,供离线使用,因为非洲的互联网接入非常昂贵,在一些地方并不总是可用。我还不太清楚我将如何实现这一点,但它肯定是在管道中。
哪些 Python 库是你最喜欢的(核心或第三方)?
我喜欢的一个内置是 Pathlib,它使文件系统的工作变得简单。
我喜欢的第三方库是 pytest,尤其是它的测试参数化特性。
你是如何成为一名博客写手的?
当我开始在我的个人网站上写博客时,我这样做是为了让其他人知道在开源中工作是多么有趣,并分享我正在做的事情。现在我这样做是为了与世界分享我的知识,也是为了记录我自己的学习。
我发现你是真正的 Python 团队的一员。这种体验如何?
为真正的 Python 写博客真是太棒了,不仅我为他们写的文章获得了报酬,我作为一名作家也变得更好了,因为他们有非常高的质量标准,我发现这些标准在真正的 Python 之外影响着我的写作。它不仅仅是一个博客网站,真正的 Python 是一个由非常聪明的人组成的紧密结合的社区,我喜欢和他们一起工作。
Python 在非洲发生了哪些令人兴奋的事情?
软件开发行业正在快速增长,我们的商业之都拥有金融科技公司、初创公司和一些大公司,如微软、谷歌和亚马逊,它们在当地招聘员工。我们最近在加纳举办了第一届PyCon,取得了巨大的成功。我们的社区成员支持在他们的公司、学校和大学中使用 Python。例如,在我的国家,有一个完整的网络安全学位是用 Python 教授的,这是你每天都不会看到的。
一些社区有令人印象深刻的统计数据,一个很好的例子是 PyCon Namibia 2018 ,其中男性和女性各占 50%。我们也有致力于塑造 Python 和流行 Python 项目(如 Django)方向的开发人员。我能想到的名字有 Joannah Nanjekye ,她是一名作家和 Python 核心团队的成员, Marlene Mhangami ,她是 Python 软件基金会的董事,还有 Anna Makarudze ,她是 Django 软件基金会的副主席
你还有什么想说的吗?
是的,如果你正在读这封信,而你的团队正在招人,我很想和你聊聊🙂你可以在我的网站上找到我的联系方式。
谢谢你接受采访,Vuyisile!
本周 PyDev:沃纳·布鲁欣
原文:https://www.blog.pythonlibrary.org/2014/10/27/pydev-of-the-week-werner-bruhin/
本周,我们的本周 PyDev 是 Werner Bruhin!他在 wxPython Google 小组非常忙碌,帮助人们进入 wxPython,并为 wxPython 工具包创建补丁。让我们更多地了解我们的 Python 程序员伙伴吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在瑞士完成了所有的教育,并在卢塞恩的酒店贸易学校完成了学业。在多家国际酒店不同岗位工作过。早期,我进入 IT 部门,专门为酒店公司和专门从事酒店软件开发的软件公司从事酒店软件安装和酒店 IT 项目管理。我的爱好是滑雪,虽然我最近不怎么滑雪了,在周围的山上散步,吃美食和美酒,最后但同样重要的是做一点编程。
你为什么开始使用 Python?
我在 2002 年左右开始使用 Python。我通过对葡萄酒的兴趣找到了它,想找一个酒窖管理软件。我对我当时使用的那个不满意,认为我可以做得更好🙂我想这也可能是一个有趣的爱好。我四处查看了不同的软件工具(Delphi 等),偶然发现了一篇关于 Python 的文章,感到好奇并尝试了一下,尤其是 wxWidgets 的 Python 包装器-wxPython(http://wxpython.org)。我真的被一个人可以如此迅速地使用它所打动,并且对这个社区以及他们如何帮助/支持每个人——尤其是像我这样的新来者——印象更加深刻。
你还知道哪些编程语言,你最喜欢哪一种?
我们当时使用的酒店软件是用 RPG II(一种运行在 S/34 和 S/36 等系统上的 IBM 语言)编写的,我最终用它做了一点编程,这是我在学习 Python 之前接触的唯一一种编程语言,我是从网上的不同教程和一些 Python 和 wxPython 书籍中接触到的(http://wiki.wxpython.org/wxPythonInAction,https://www . packtpub . com/application-development/wxPython-28-application-development-cookbook和【微软】
你现在在做什么项目?
我的主要项目是酒窖管理共享软件(http://thewinecellarbook.com/),然后我还参与了 vinoXML 项目(一个交换葡萄酒信息的 XML 模式-http://www.vinoxml.org/。在过去的几年里,我也试图对我使用的开源项目有所回报,尤其是 wxPython 和达波(我使用他们的报告作家http://dabodev.com/)。我以回答问题的形式做这件事,但如果可能的话,当我找到问题的解决方案时,我也会尝试创建 PR(拉请求)和补丁,其中很多都与 wxPython Phoenix 项目有关——wxPython 的重写(http://wxpython.org/Phoenix/docs/html/main.html)。
哪些 Python 库是你最喜欢的(核心或第三方)?
wxPython 肯定是第一位,但紧随其后的是 SQLAlchemy ,然后我还喜欢 XML 处理的 Amara 和 matplotlib 。
你还有什么想说的吗?
当时我犹豫是否使用 Python/wxPython 等,因为它们都是开源项目,对我来说是新的。我很快就确信这是一个好的选择,因为我对这些项目的出色完成和社区支持的效果印象深刻。社区是成功的关键,我觉得今天的一些适配器/用户没有意识到这一点。如果你开始使用一个开源项目,请考虑回报它一些东西。迈克的博客是一个回馈社区的完美例子,我相信还有很多其他的方式!
前一周的 PyDevs
- 浸信会二次方阵
- 本·劳什
本周 PyDev:Wesley Chun
原文:https://www.blog.pythonlibrary.org/2016/05/23/pydev-of-the-week-wesley-chun/
This week we welcome Wesley Chun as our PyDev of the Week! Wesley Chun, MSCS, is author of Prentice Hall's bestselling "Core Python" series (corepython.com), the "Python Fundamentals" companion videos, co-author of "Python Web Development with Django" (withdjango.com), and has written for Linux Journal, CNET, and InformIT. In addition to being an engineer at Google, he runs CyberWeb (cyberwebconsulting.com), a consultancy specializing in Python training. Wesley has over 25 years of programming, teaching, and writing experience, including more than a decade of Python. While at Yahoo!, helped create Yahoo!Mail using Python. Wesley holds degrees in Computer Science, Mathematics, and Music from the University of California. He is based in Silicon Valley and can be reached on Twitter (twitter.com/wescpy) or Google+ (google.com/+WesleyChun). Let's spend a few minutes getting to know him better! Can you tell us a little about yourself (hobbies, education, etc):I've been a software engineer by profession, coding in Python, JavaScript, and a few others, at big companies as well as startups. I'm currently at Google, a nice blend of both worlds. I enjoy helping the next generation of developers get up-to-speed on the latest technologies and best practices with the least amount of friction, meaning that in addition to coding, I also teach technology, publish books & blogposts, and give talks at conferences. Stuff I like to do away from the keyboard include family time, piano, personal finance, world travel, physical fitness (cycling, yoga, biking, basketball), poker, and learning a few words in as many languages as I can.Why did you start using Python?After leaving Sun Microsystems in the mid-90s with C and a few scripting languages under my belt, I went to a startup where our small team of ~10 engineers built what was eventually to become Yahoo!Mail using Python at a time when very few people had ever heard of it. It was amazing how fast we could create our own web framework and build the mail service with. It was like a breath of fresh air, and learning Python at that job changed the course of the rest of my career. Because of its uniqueness at encouraging group collaboration and being both powerful and expressive, I really didn't want to work in any other language ever again. As a result, I've quite a challenging and rewarding career as a senior engineer working at companies where Python is a primary development tool.What other programming languages do you know and which is your favorite?In high school, I was exposed to programming in (Commodore) BASIC, FORTRAN, 6502 assembly, and Pascal. I added Logo and C to that collection in college. These days, I mostly tinker in Unix shell, Python, and JavaScript, with some Java, C++, Dart, and Go thrown in there. This is my 20th year coding in Python, so I'll stick with that for a little while longer.What projects are you working on now?I've officially started work on the 3rd edition of my well-received, "Core Python Programming" book. The 2nd edition (ISBN 0132269937) is still doing quite well, and with all the new material going into it, the publishers and I have split that original book of two parts into two volumes. The 3rd edition of part 2 has already published as "Core Python: Applications Programming" (ISBN 0132678209), so now I need to complete the 3rd ed. of part 1 (tentatively called, "Core Python: Language Fundamentals". It will feature both Python 2 and 3 prominently. We're at the crossroads whereby adoption of 3.x has picked up, so while much legacy code still runs 2.x, there's no reason why a new book should focus solely on either version, but can serve the community better as a bridge between both worlds.At work, I'm currently bringing the goodness of Google developer tools, APIs, and platforms to the global community. I advocate for our devtools to engineers in industry as well as the next generation in the classroom, building sample code, writing about best practices, making product announcements, and creating Python or JavaScript-flavored developer videos (http://goo.gl/kFMUa6) that help on-board developers with integrating Google techologies into the web, mobile, and server-side apps they're building. If it's Python, then there's a high likelihood that a deeper dive into the code covered in the video will be featured on my Python blog (wescpy.blogspot.com).Which Python libraries are your favorite (core or 3rd party)?I don't really have one particular favorite. I think everyone should learn unittest. I thought doctest was pretty awesome the first time I heard of it. I feel that csv, json, and the xml and email packages are "must-have"s in every Python developers toolbox. I also think large tools like pip, ipython, Jupyter (formerly "IPython Notebook"), Django, Pyramid, and Sphinx are pretty awesome. Finally, I think that the Google APIs Client Library for Python is also great because it gives Python developers access to integrating the use of Google APIs into any Python script.Where do you see Python going as a programming language?Since I started learning Python way back in 1997 with 1.4(!), it has taken off like a weed. Back then, Python appeared on NO job listings whatsoever. In fact, at the startup where I learned Python, they had no expectations that anyone knew any Python. Today, it's fairly clear that Python is everywhere and continues to grow in mindshare. Now developers can have an entire career writing Python code, and better yet, the next generation will also be familiar with it as it's being taught in primary and secondary schools in addition to many colleges and universities worldwide!The next step for Python is the growth of 3.x adoption. Many are skeptical when they hear that "no one" has been using it since it came out at the end of 2008 which isn't true. It's just that the term "backwards-incompatible" tends to scare the timid away and requires porting of dependencies before considering migration. Fortunately most experienced Python developers recognize that while it is a big deal, the core language itself isn't changing in a way that 2.x developers would be completely lost. It's not being rewritten from scratch. Much progress has already been made on the porting front, and it represents a good opportunity to continue Python's growth and evolution as all new features are only going into the 3.x branch. When it first came out, I called for adoption to take a decade because it was backwards-incompatible -- I have about two years left on this prediction, so I'm curious how things will turn out.What is your take on the current market for Python programmers?It can't be a more exciting time for Python developers. With the growing mindshare and number of libraries and jobs available in all industries, the future for Python developers has never been brighter. I will continue to support the community with books, talks, volunteering, and general advocacy. I hope to continue bringing new engineers into the Python community, which while not a language feature, is one of the best things about Python itself.Is there anything else you’d like to say?Hope to see you all at PyCon next week or in one of my future courses!!Thanks for doing the interview!
Can you tell us a little about yourself (hobbies, education, etc):I've been a software engineer by profession, coding in Python, JavaScript, and a few others, at big companies as well as startups. I'm currently at Google, a nice blend of both worlds. I enjoy helping the next generation of developers get up-to-speed on the latest technologies and best practices with the least amount of friction, meaning that in addition to coding, I also teach technology, publish books & blogposts, and give talks at conferences. Stuff I like to do away from the keyboard include family time, piano, personal finance, world travel, physical fitness (cycling, yoga, biking, basketball), poker, and learning a few words in as many languages as I can.Why did you start using Python?After leaving Sun Microsystems in the mid-90s with C and a few scripting languages under my belt, I went to a startup where our small team of ~10 engineers built what was eventually to become Yahoo!Mail using Python at a time when very few people had ever heard of it. It was amazing how fast we could create our own web framework and build the mail service with. It was like a breath of fresh air, and learning Python at that job changed the course of the rest of my career. Because of its uniqueness at encouraging group collaboration and being both powerful and expressive, I really didn't want to work in any other language ever again. As a result, I've quite a challenging and rewarding career as a senior engineer working at companies where Python is a primary development tool.What other programming languages do you know and which is your favorite?In high school, I was exposed to programming in (Commodore) BASIC, FORTRAN, 6502 assembly, and Pascal. I added Logo and C to that collection in college. These days, I mostly tinker in Unix shell, Python, and JavaScript, with some Java, C++, Dart, and Go thrown in there. This is my 20th year coding in Python, so I'll stick with that for a little while longer.What projects are you working on now?I've officially started work on the 3rd edition of my well-received, "Core Python Programming" book. The 2nd edition (ISBN 0132269937) is still doing quite well, and with all the new material going into it, the publishers and I have split that original book of two parts into two volumes. The 3rd edition of part 2 has already published as "Core Python: Applications Programming" (ISBN 0132678209), so now I need to complete the 3rd ed. of part 1 (tentatively called, "Core Python: Language Fundamentals". It will feature both Python 2 and 3 prominently. We're at the crossroads whereby adoption of 3.x has picked up, so while much legacy code still runs 2.x, there's no reason why a new book should focus solely on either version, but can serve the community better as a bridge between both worlds.At work, I'm currently bringing the goodness of Google developer tools, APIs, and platforms to the global community. I advocate for our devtools to engineers in industry as well as the next generation in the classroom, building sample code, writing about best practices, making product announcements, and creating Python or JavaScript-flavored developer videos (http://goo.gl/kFMUa6) that help on-board developers with integrating Google techologies into the web, mobile, and server-side apps they're building. If it's Python, then there's a high likelihood that a deeper dive into the code covered in the video will be featured on my Python blog (wescpy.blogspot.com).Which Python libraries are your favorite (core or 3rd party)?I don't really have one particular favorite. I think everyone should learn unittest. I thought doctest was pretty awesome the first time I heard of it. I feel that csv, json, and the xml and email packages are "must-have"s in every Python developers toolbox. I also think large tools like pip, ipython, Jupyter (formerly "IPython Notebook"), Django, Pyramid, and Sphinx are pretty awesome. Finally, I think that the Google APIs Client Library for Python is also great because it gives Python developers access to integrating the use of Google APIs into any Python script.Where do you see Python going as a programming language?Since I started learning Python way back in 1997 with 1.4(!), it has taken off like a weed. Back then, Python appeared on NO job listings whatsoever. In fact, at the startup where I learned Python, they had no expectations that anyone knew any Python. Today, it's fairly clear that Python is everywhere and continues to grow in mindshare. Now developers can have an entire career writing Python code, and better yet, the next generation will also be familiar with it as it's being taught in primary and secondary schools in addition to many colleges and universities worldwide!The next step for Python is the growth of 3.x adoption. Many are skeptical when they hear that "no one" has been using it since it came out at the end of 2008 which isn't true. It's just that the term "backwards-incompatible" tends to scare the timid away and requires porting of dependencies before considering migration. Fortunately most experienced Python developers recognize that while it is a big deal, the core language itself isn't changing in a way that 2.x developers would be completely lost. It's not being rewritten from scratch. Much progress has already been made on the porting front, and it represents a good opportunity to continue Python's growth and evolution as all new features are only going into the 3.x branch. When it first came out, I called for adoption to take a decade because it was backwards-incompatible -- I have about two years left on this prediction, so I'm curious how things will turn out.What is your take on the current market for Python programmers?It can't be a more exciting time for Python developers. With the growing mindshare and number of libraries and jobs available in all industries, the future for Python developers has never been brighter. I will continue to support the community with books, talks, volunteering, and general advocacy. I hope to continue bringing new engineers into the Python community, which while not a language feature, is one of the best things about Python itself.Is there anything else you’d like to say?Hope to see you all at PyCon next week or in one of my future courses!!Thanks for doing the interview!
本周 PyDev:威尔·麦古根
原文:https://www.blog.pythonlibrary.org/2021/04/12/pydev-of-the-week-will-mcgugan/
本周我们欢迎威尔·麦古根(@威尔·麦古根)成为我们本周的 PyDev!Will 是富包的作者,该包用于终端中的富文本和漂亮的格式。如果你有时间,你应该看看威尔的博客。Will 也是《用 Python 和 Pygame 开始游戏开发的作者。你可以在 GitHub 上看到他还参与了哪些项目。
让我们花些时间更好地了解威尔吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在苏格兰东北部的一个小镇长大。我的职业生涯让我走遍了英国,包括在牛津和伦敦的几年。从那以后,我和妻子回到了苏格兰,住在爱丁堡。很幸运的是,早在疫情开始之前,我就已经作为一名自由软件开发员在家工作了。
我大部分时间都是自学的,从大学辍学,从事电子游戏工作。尽管我认为当你到了我这个年龄时,所有的开发者都是自学成才的。在这样一个快速发展的行业中,在职学习是必须的。
我在软件开发之外的主要爱好是摄影——尤其是野生动物摄影。我曾经花了一个晚上在芬兰的森林里拍摄野生欧亚熊。那真是一次不寻常的经历!一旦世界恢复正常,我计划做更多的旅行和摄影。
我在我的博客上贴了很多照片,如果你提醒我,我会详细谈谈焦距和散景。
你为什么开始使用 Python?
早在 21 世纪初,当我从事视频游戏工作时,我就发现了 Python。我在寻找一种脚本语言,可以编译到游戏引擎中来管理游戏机制,而 C++则处理繁重的工作和图形。我考虑了 Python、Ruby 和 Lua。经过一些研究和实验,我决定不使用 Python,而使用 Lua。
Lua 可能是这个任务的最佳选择,但是我发现自己转向 Python 来获得脚本和工具。我当时认为 Python 更像是 Windows 批处理文件的升级,而不是真正的编程语言。只有当我编写的脚本变得更加复杂时,我才开始欣赏 Python 的表现力和包含电池的方法。与 C++相比,这是一个令人耳目一新的变化,在 c++中,很多东西都必须从头开始编写。
几年后,我转而全职使用 Python,为互联网象棋俱乐部编写象棋界面。从那以后,Python 一直是我职业生涯的焦点,即使我花了几年时间学习 C++,我也不后悔这一转变!
你还知道哪些编程语言,你最喜欢哪一种?
我日常使用的其他主要语言是 Javascript 和 Typescript(如果这也算另一种语言的话),通常是在后端用 Python 编写的 web 应用程序的上下文中。
已经有一段时间了,但是以前用 C 和 C++做了很多工作。我还写了相当多的 80x86 汇编语言,在那个时候手动调整指令是一件明智的事情。
我最喜欢的语言当然是 Python。我热爱语言本身以及围绕它发展起来的生态系统。
你现在在做什么项目?
我的副业项目目前是 Rich,一个用于花式终端渲染的库。稍后我会详细介绍这一点。
我的日常工作是为 dataplicity.com 构建技术,这是一个针对 Raspberry Pi 单板计算机的远程管理工具(但适用于任何 Linux)。除了前端,堆栈完全运行在 Python 上。
哪些 Python 库是你最喜欢的(核心或第三方)?
我是 asyncio 的超级粉丝,因为我做的很多工作都需要某种形式的并发。我过去曾用 Twisted 和 Tornado 做过非常类似的事情,但 asyncio 和 async 和 await 关键字带来了更愉快的体验。与之相关的是 aiohttp,它是一个基于 asyncio 的 web 框架,我在日常工作中使用它来构建一个高度可伸缩的 websocket 服务器。
我现在喜欢的两个库是 PyDantic 和 Typer。我真的很喜欢他们使用类型创建对象的方式,这些对象可以用 Mypy 和相关工具进行静态检查。作者是先驱,我希望在未来看到更多的这种方法!
有钱包是怎么来的?
不久前,我的副业是一个名为 Moya 的 web 应用框架。在为 Moya 构建命令行界面时,我创建了一个“控制台”类,这就是 Rich 的原型版本。Moya 控制台类没有经过深思熟虑,很难从主项目中分离出来,但那里有一些非常好的想法,我一直认为我应该构建它的独立版本。
每当我艰难地阅读一些难看的、格式糟糕的终端输出(通常由我自己实现)时,我都会在脑海中重温这个想法。我希望我在脑海中构想的这个优步控制台已经完全成熟并被记录在案,但它不会自己写出来。2019 年底的某个时候,我开始着手这项工作。
核心功能很快组合在一起。顺便提一下,就在疫情飓风来袭的几周前,我在中国武汉,当时第一个丰富的输出产生了(自然是一个醒目的洋红色下划线闪烁着“你好,世界!”).
第一个核心特性是富文本,它是包名的来源。我可以将样式与字符串中的一系列字符关联起来,就像在 HTML 中标记文本一样。然后可以在保留样式的同时进一步操作该标记字符串。这一特性使得许多其他特性成为可能,比如语法高亮和降价呈现。
v1.0.0 版本于 2020 年 5 月发布,它真的起飞了,远远超过了我的预期。当然也有一些错误和大量的反馈。我本来打算把它留在那里,也许只是维护一段时间,但有这么多好的功能建议,我继续工作。目前,我正在考虑开发更多的 TUI(文本用户界面)功能来开发基于终端的应用程序。
Rich 的优势和劣势是什么?
主要优势可能是可呈现的可组合性(可呈现是我对在终端中生成输出的任何事物的描述)。例如,一个表格单元可能包含一个面板(或任何其他可呈现的),该面板本身可能包含另一个表格,无限地继续下去,或者至少直到用完所有的字符。这个模型允许你在终端中快速创建优雅的格式,更像一个网页而不是一串字符。一个用户甚至用 Rich 写了他的简历,看起来棒极了!
一个弱点可能是表情符号支持。大家都爱终端输出的表情符号。但许多人没有意识到的是,终端对表情符号的支持参差不齐。并非所有的终端都以相同的宽度显示表情符号,因此相同的输出在一个终端上可能看起来很整齐,但在另一个终端上却不对齐,更糟糕的是,Rich 没有办法检测表情符号是如何呈现的。
你还有什么想说的吗?
我不时在我的博客(https://www.willmcgugan.com)上发布 Python 相关的文章。我是推特上的 @willmcgugan 。
谢谢你接受采访,威尔!
本周 PyDev:威廉·考克斯
原文:https://www.blog.pythonlibrary.org/2020/09/28/pydev-of-the-week-william-cox/
本周,我们欢迎威廉·考克斯成为本周的 PyDev。William 是一名数据科学家,曾在几次 Python 会议上发言。他有一个博客,你可以在那里了解他的最新动态
让我们花一些时间来更好地了解威廉!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我一直喜欢建造东西。我高中的大部分时间都在制作机器人和运营一个关于机器人的博客。由于这个原因,我获得了电子工程学位,然后又获得了信号处理和数字通信博士学位。工作之外,我喜欢木材和金属加工以及户外活动。不过,最重要的是,我是一个全职家长。
你为什么开始使用 Python?
我第一次使用 Python 是在研究生院,当时我需要从连接到我们的一个传感器的串行输入设备自动读取数据。那时我已经编程很长时间了,Python 是从 Perl 的一个非常简单的跳跃。我的计算机科学朋友告诉我 Python 很棒,所以我将它视为再次拓展业务的机会。
你还知道哪些编程语言,你最喜欢哪一种?
当我 12 岁的时候,我爸爸把“21 天自学 Perl”放在我的桌子上,说:“你应该学学这个。”我花了比 21 天更长的时间,但我很高兴他这么做了。我涉猎了几种语言(PHP、Java、C ),但由于其强大的绘图和数据分析能力,我在研究生院花了多年时间磨练我的 MATLAB 技能。我的第一份工作是在一家军事承包商,他们都用 MATLAB。这是 10 年代初,Python 作为科学计算的语言真正起飞了,所以我能够说服我的老板,这是我应该学习的东西——他特别被他们可以节省的大量 MATLAB 费用所吸引。凭借令人印象深刻的 iPython 笔记本技能,我找到了第二份工作!然而,直到我开始我的第二份工作,我才终于开始了解和团队一起写软件意味着什么。这和自己涉猎有很大的不同。
你现在在做什么项目?
在疫情开始的时候,我拒绝了 www.makeamaze.com,它是基于 Python 的,托管在 Heroku 上。最近我花了更多的时间在 http://www.remotedatascience.com/的上,这是一份关于远程数据科学和机器学习工作的时事通讯。促进远程工作是我最喜欢的爱好,我已经完全远程工作了很多年。我对每个人新发现的对遥控器的热爱既高兴又怀疑!我还为那些想从工程工作转型到数据科学/ML 职位的人做了一些一对一的辅导。教这个特别有意义。在我的日常工作中,我编写机器学习工作来预测雇主的需求。这也是基于 Python 的。
哪些 Python 库是你最喜欢的(核心或第三方)?
我是一家大型食品订购和配送公司的机器学习工程师,每天都使用熊猫。黑色'、 isort '和` flake8 '使我的工作更容易。我们用 Dask 和它的软件包家族分发我们所有的机器学习工作。我真的很喜欢 Dask 社区正在做的事情,去年我在科罗拉多做了一个关于我们如何使用它的演讲。
你能描述一下你从电气工程到数据科学家的历程吗?
数据科学是一个相当新的领域,因此这个职业没有太多既定的道路。我来的时候肯定没有。我在大学时遇到并避开了机器视觉和所谓的人工智能课程,认为它们太深奥,在现实世界中没有用。直到我完成了博士学位,为了好玩选修了巴斯蒂安·特龙的“建造一辆自动驾驶汽车”MOOC,我才意识到我以前在我的电气工程课程中见过他的所有方程,只是名称或应用不同。我还同时上了吴恩达的机器学习课,第一次体验了构建预测模型。随后,在我的第一份工作中,我有一位出色的导师,他鼓励我探索所有围绕机器学习和深度学习的新主题。我也有大量涉足计算机、运行网站、管理 Linux 机器等方面的经验。在高中和大学的时候(我没有派对!).所有这些结合在一起,让我说服一位首席执行官聘请我在一家初创公司担任数据科学家。活跃在 Twitter 上,定期在会议上发言,并寻找志同道合的机器学习实践者,这些都大大加快了我的职业生涯。
对于那些想从其他学科进入数据科学的人,你有什么建议吗?
首先,草并不总是更绿。数据科学是一项艰苦的工作——就像大多数工作一样——只有一小部分是有趣和令人兴奋的数据分析或训练 ML 模型。值得注意的是,我首先会专注于成为一名优秀的软件工程师,其次才是数据科学家。工作的 SWE 方面——与计算机打交道、编写测试、预测故障模式以及编写可重复的分析——是不花时间就很难学会的部分。它们也不是很好的博客文章,所以除了一些花哨的分析之外,关于它们的文章很少。综上所述,最好的前进方式是找到一个可以指导你学习的导师,让你不会偏离轨道太多。https://www.sharpestminds.com/是一个可以找到这样一个人的地方。加入一些 Slack/Reddit/Twitter 社区,明确要求一位导师将是另一条途径。开始进行信息面试(我的朋友马特有一个关于这个主题的很好的播客:信息面试——学习很酷的东西,遇到很棒的人,并积累对你有利的信息——生活遇到金钱)以确定你是否真的想成为一名数据科学家,然后缩小你想工作的商业领域。制定一个计划,并在你学习的时候写下来。记录你的学习有助于巩固你头脑中的概念,并成为向潜在雇主和你未来将指导的人展示的良好资源。最后,正如我上面提到的,不要忘记职业生涯是漫长的事情。要善良,不要被烧坏了!
你还有什么想说的吗?
善待你的同事!职业生涯很长。
谢谢你接受采访,威廉
本周 PyDev:威廉·潘趣
原文:https://www.blog.pythonlibrary.org/2018/07/30/pydev-of-the-week-william-f-punch/
本周我们欢迎威廉·潘趣成为本周的 PyDev。Punch 先生是《使用 Python 进行计算的实践》一书的合著者,他是密歇根州立大学计算机科学的助理教授。让我们花一些时间来更好地了解他!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是俄亥俄州立大学的毕业生。我读大学时学的是有机/生物化学,并在一个医学研究实验室工作过一段时间。我发现我不像在大学时那样喜欢这份工作,所以我寻找其他工作。幸运的是,我工作的地方提供继续教育,所以我开始在辛辛那提大学上夜校,学习化学工程。鉴于我的背景,我想我可以很快度过难关。我上的第一门课是计算机科学课,我完全被它们迷住了。我转了 CS,最终回到 OSU,拿到了博士学位
作为一名化学家,我总是对玻璃制品着迷,所以当我有时间的时候,我就在我的镇上吹玻璃。
你为什么开始使用 Python?
我的同事 Rich Enbody 和我开始重新设计我们的 C++编程入门课程。我们知道这不是介绍性语言的好选择,但是不确定用什么来代替。最幸运的是,我们有了一个新的教员 MSU,Titus Brown(现在在加州大学戴维斯分校),他是一个 Python 爱好者。他的热情很有感染力,所以我们研究了 Python,并立即确信这是一种很棒的入门编程语言。
我们用 Python 重新编写了课程,但找不到一本好书来支持它,所以我们写了自己的书(使用 Python 进行计算的实践,现在是第三版)
你还知道哪些编程语言,你最喜欢哪一种?
我非常精通 Lisp,尤其是在我攻读人工智能博士学位的早期。我仍然喜欢 Lisp,但事实证明其他语言更“耐用”,所以我主要用 Python 或 C++(我认为编程语言的阿尔法和欧米茄,至少在难度方面)编程
你现在在做什么项目?
我认为我使用 Python 的经历激励我重新思考 C++的教学方式(在 MSU,我们把 C++作为第二语言来教)。考虑到 C++11 到 17 的变化以及 STL 的发展,你可以用 C++编写非常类似 Python 的代码,并且非常有效。我正在修改这门课程,并准备出一本与之配套的书。
哪些 Python 库是你最喜欢的(核心或第三方)?
我最喜欢的库无疑是 matplotlib。Python 书籍的重点是数据分析和可视化,matplotlib 是可视化工具。如此易于使用,但也如此灵活。我喜欢他们的说法:“让简单的事情变得简单,让困难的事情变得可能”。我用 numpy(谁不用?)和 pandas(考虑到数据分析的重点),但也喜欢更具计算性的东西,如 pycuda 和 pytorch。我的一个博士生用 pypy 做了很多他的 Python 原型来加速,这对我们解决他论文的一些细节帮助很大。
最后,我使用 ipython 作为我的控制台,我认为这也是这些天来的既定事实。Fernando Gomez 在启动整个 ipython/notebook/jupyter 系统时所做的事情是一个了不起的故事,讲述了一个小创意如何能够起飞并产生非常大的影响。
你从写《使用 Python 进行计算的实践》这本书中学到了什么?
我学到的可能不是大多数人想的那样。我了解到写一本书是困难的。不仅仅是磨平书页的艰苦工作,而是以一种对可能阅读它的学生有用的方式写作。简单明了地解释想法既不容易,也不容易。我最喜欢的一句话(可能应该归功于布莱士·帕斯卡)被翻译成这样
“我把它做得比平时长,因为我没有时间把它改短。(参见https://quoteinvestigator.com/2012/04/28/shorter-letter/)
如果让你重写,你会有什么不同的做法?
我是整个 notebook/jupyter 生态系统的超级粉丝,我很遗憾我们的工作是在一个开发良好的系统出现之前完成的。我认为编写教科书的未来将会因为笔记本而改变,学生们也会因为这项工作而变得更好。
感谢您接受采访!
本周 PyDev:威廉姆·霍顿
原文:https://www.blog.pythonlibrary.org/2020/10/26/pydev-of-the-week-william-horton/
本周,我们欢迎威廉姆·霍顿( @hortonhearsafoo )成为我们本周的 PyDev!William 是 Compass 的一名高级软件工程师,曾在多个本地 Python 会议上发言。他是 PyTorch 和 fastai 的撰稿人。
让我们花些时间更好地了解威廉!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
关于我自己:人们可能会对我的教育背景感到惊讶——我没有学习计算机科学。我有社会科学学士学位。所以当我本科毕业时,我做的最多的编程工作可能就是在 Stata 中做回归分析来完成我的论文。我决定不去读研,而是报名参加了纽约的一个编程训练营(App Academy)。我写这篇文章的那天,9 月 28 日,实际上是我进入 App Academy 的第五年。
从那以后,我在纽约的几家不同行业的初创公司工作过:先是投资银行,然后是网上药店,现在是房地产。我目前是 Compass 人工智能服务团队的高级工程师,致力于为我们的房地产代理商和消费者提供机器学习解决方案。
我喜欢把空闲时间花在一些不同的爱好上。我是一个有竞争力的举重运动员,所以我喜欢一周去几次健身房(尽管在纽约的疫情,我有六个月左右没有举重)。实际上,我发现力量举是软件工程师中非常普遍的爱好。每次有新人加入我的健身房,他们似乎来自不同的创业公司。我喜欢打篮球。我对音乐充满热情:我几乎一生都是歌手,最近在纽约与一个无伴奏合唱团一起表演。去年,我拿起了吉他,从十几岁开始我就没有碰过它,这让我很有成就感。
你为什么开始使用 Python?
我肯定不是从 Python 开发开始的——我的编码训练营专注于 Ruby 和 Rails,他们也教我们 JavaScript 和 React。我得到了我的第一份工作,主要是因为我知道反应,当时它是相当新的。但是我加入的公司也有一个用 Python 编写的相当大的数据处理组件,而且只有几个工程师,所以最终我也加入了那个部分。当我找第二份工作时,我知道我想做更多的 Python,所以我找到了一个全栈角色,即 React 前端和 Python 后端(在 Flask 中)。
但我觉得对我来说真正的转折点是在 2017 年秋天我发现了 fast.ai 课程。我在网上上过一些机器学习课程,包括吴恩达的 Coursera 课程,这是一个我觉得有趣的话题。但是 fast.ai 课程真的吸引了我——杰瑞米·霍华德展示材料的方式以某种方式抓住了我,让我想了解更多。我喜欢他的观点:如果你懂一些 Python,并且你有高中水平的数学,你就可以实践机器学习,并开始提高你的技能。
所以到了 2018 年找工作的时候,我知道我想做的是更接近数据和机器学习的工作。我加入 Compass 担任后端数据角色,在一个不断发展的团队中处理我们从不同来源获得的所有房地产列表数据。这给了我学习一些重要工具的机会:我在 Compass 上设置了第一个 Airflow 实例,并致力于我们的 PySpark 代码。当机器学习团队成立时,我能够为第一个项目做出贡献,并最终全职加入这个团队。
你还知道哪些编程语言,你最喜欢哪一种?
我从我的编码训练营了解 Ruby,从我之前的两份工作中了解 JavaScript,我也在 Go 中做过少量的编程工作。其中,我可能会说 JavaScript 是我最喜欢的。
你现在在做什么项目?
我现在的主要项目是在 Compass 上销售推荐。我们使用历史数据来学习哪些物业可能会出售的模型,然后将它与代理放入 Compass CRM 联系人列表中的地址联系起来。这是一个完全基于 Python 的项目:模型是 scikit-learn,我们使用 PySpark 处理数据,API 是 Python GRPC 服务。如果人们有兴趣了解更多信息,我们在 Compass Medium 页面上有一个博客帖子。
另一个让我非常兴奋的项目是我们的机器学习管道项目,我们正在开源平台 Kubeflow 的基础上构建这个项目。这是一种在 Kubernetes 之上定义和运行机器学习工作流的方法,它允许您在利用分布式计算、并行化和资源管理方面获得一些巨大的好处。我们已经在我上面提到的可能出售的项目中使用它,它允许我们更快地迭代和实验。我有机会在 SciPy 2020 上展示了一张关于 Kubeflow 管道的海报,我还在 SciPy Japan(10 月 30 日至 11 月 2 日)上做了一个关于这个主题的(虚拟)演讲
哪些 Python 库是你最喜欢的(核心或第三方)?
很难选择,外面有很多很棒的图书馆!但仅举几个例子:对于我专业从事的工作,我认为 Jupyter 笔记本、熊猫和 scikit-learn 是必不可少的。真正伟大的图书馆已经存在了一段时间,并且经受住了时间的考验。我还必须对 pytorch 和 fastai 表示感谢,感谢他们培养了我对深度学习和机器学习的兴趣,这也是我走上目前职位的原因。
你是如何在 Python 大会上发表演讲的?
我想说几件事促成了它:我自己的好奇心,社区的支持,当然,还有运气。这一切都是因为我注册了一个 meetup,这是一个在纽约 Dropbox 上举办的 PyGotham talk 头脑风暴会议。他们带我们做了一些练习,我们都分享了一些想法,我拿了我最好的一个提交给了 PyGotham 2018 CFP。但是我被拒绝了。

然而,PyOhio CFP 大约在同一时间,我看到一条推文鼓励人们也提交给那个,所以我向 PyOhio 发送了相同的建议。我被录取了!我对这次旅行非常兴奋,但做演讲时也非常紧张。PyOhio 确实为第一次演讲的人提供了演讲指导,所以我很感谢他们。最后,我在演讲中度过了一段美好的时光,并享受了与一些人见面和观看其他演讲的机会。所以我决定再做一次。

在 PyColordao 建立
然后来了...更多的拒绝。我想我在 2018 年底又向两个会议发送了同样的讲话,并被拒绝。我决定在 2019 年推出一些新鲜的材料,我会说 PyTexas 2019 是我真正实现飞跃的时候。我做了一个演讲,我真的为“你的 Python 中的 CUDA”)感到骄傲,但我也开始在社区中认识更多的人,这真的为我的会议经历做出了很大贡献。
对于想做技术演讲的人,你有什么建议吗?
我要说的第一件事是:把你自己放出去。我天生是一个完美主义者,所以对我来说真的很难在 CFP 上点击提交按钮(即使现在,当我已经接受了谈话)。但是到最后,有些评论家会喜欢你的提议,有些不会,所以如果你想发表演讲,你只需要玩数字游戏,服从几个地方,然后抱最好的希望。
我要强调的另一件事是,你不必成为某方面的世界专家来谈论它。当你看到演讲者是图书馆的作者,或者比你多 10 年的经验,或者在大公司工作时,你可能会感到害怕。但我会告诉刚开始的人:你所要做的就是创造一个 25 分钟的体验,让人们享受演示,并从中学习一些他们以前不知道的东西。许多参加会议的人,尤其是地区 Python 会议的人,都处于学习过程的早期,所以仅仅介绍一下自己对一些入门材料的看法就很有价值。
威廉,谢谢你接受采访!
本周 PyDev:威廉·文森特
原文:https://www.blog.pythonlibrary.org/2018/12/24/pydev-of-the-week-william-vincent/
本周我们欢迎威廉·文森特( @wsv3000 )成为我们本周的 PyDev!威廉是 Django web 框架上的 3 本书的作者,包括 Django for 初学者。你可以在他的网站上找到更多关于 William 正在做什么的信息,在那里他写了关于 Python、Django 等的文章。让我们花一些时间来更好地了解他!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我有一个“非传统”的背景,因为我的职业生涯始于图书编辑,过渡到商业方面的初创公司,最终在 30 多岁时学会了如何编码,现在是一名软件工程师和教师。我基本上是把自己关在一个房间里两年,学习如何编码,创办了我的第一家创业公司,一路上经历了很多风风雨雨。我不一定推荐这种方法,但它当时对我的家庭有效。我也是两个小女孩的父母,所以这些天我几乎都在检查我的“爱好”框。
你为什么开始使用 Python?
早在 2012 年,当我住在旧金山并在 Quizlet 工作时,我就开始认真地编程了。当时,在我所知道的其他创业公司中,要么选择 Ruby on Rails,要么选择 Python/Django。我选择 Python 是因为我需要挑选一些东西,而且我喜欢 Python 不像 Ruby 那样可以广泛应用于 web 开发之外的想法。事后看来,Rails 可能是一个更容易的选择,因为社区为初学者提供了更好的资源,而且 Rails 有更多的魔力,所以在获得第一个 CRUD/auth 应用程序方面的学习曲线要快得多。但是我知道我一开始只能致力于一种语言,而且我很固执,所以我选择了 Python。
你还知道哪些编程语言,你最喜欢哪一种?
我总是觉得尝试其他语言很有趣。Lisp 尤其令人兴奋。但是日常我主要使用 JavaScript 作为我选择的另一种语言。它有一些缺点,但我真的很喜欢使用它,一点也不觉得它令人不快。它变得更加 Pythonic 化,具有 ES6 特性。
你现在在做什么项目?
我主要关注的是我的书;今年我会出三部,感觉很多,但事实上第一部是两年前制作的。在过去的几个月里,我还与 Michael Herman 和 Jason Parent 一起开发了一个基于文本的 LMS,它将很快公开发布(可能会在 12 月份在 TestDriven.io 上发布)。
哪些 Python 库是你最喜欢的(核心或第三方)?
我认为 requests 是一个优雅的、文档齐全的第三方包的标准答案。这些天我使用的大部分都是 Django 相关的,所以一个简短的列表包括 django-environ(环境变量)、Django REST Framework、django-allauth(用户和社会注册)和 django-rest-auth(开箱即用的用户端点)。
你是如何开始写关于 Django 的书的?
Django for 初学者始于我个人关于 web 开发的笔记。我记得当我弄清楚 Django 的基本功能后,我几乎感到愤怒;就像,真的,这就是全部代码?为什么网上没有完整的例子?为什么我花了几天时间才想明白?
我开始djangoforbeginners.com的时候有一个模糊的想法,也许有一天它会成为一本书,但直到 2016 年底,我所在的一家初创公司被收购后,我才开始认真对待它。在线写作和看到读者评论激励我继续下去,也极大地改善了内容。我也开始在我的个人网站上写作,wsvincent.com,我的想法是,它将会是一些简短的代码示例,我以后可以对其进行扩展。在过去的 6 个月里,这个网站的流量增加了很多。
你从写书中学到了什么?如果可以重来,你会做些什么不同的事情?
我在撰写技术书籍的过程中写下了一些详细的想法。基本上这是一大堆的工作,而自助出版是另一轮额外的工作。我非常理解为什么现在几乎没有最新的 Django 资源。当框架每年更新时,你永远不会“完成”一本书,它需要不断的维护。
要成为一名优秀的技术作者,你必须身兼三职:开发人员、作家和营销人员。很难恰当地平衡这三者,尤其是当你喜欢编码并且可以从中赚很多钱的时候,市场营销方面的事情通常根本不会发生。在这方面,它就像开源软件;如果你不花时间和精力去传播消息,写可靠的文档等等,质量是没有意义的。
你对其他有抱负的作者有什么建议吗?
每个人都应该写。这有助于你自己的学习,也有助于社区,因为我们都以不同的方式看待世界。不要浪费时间为你的博客设计花哨的布局;只需写下并留下评论的空间或你的电子邮件地址,这样读者就可以联系你了。是个人的接触让它保持动力;而不是浏览量旁边的零的数量。
对于书籍,认真思考你想从中获得什么。大多数人都有写一本书的模糊愿望和/或想要相关的声望。对他们来说,走传统的图书出版路线可能是有意义的。一路上你会有一群人帮助你,最大的风险是你根本无法读完这本书。这比任何一个刚开始读书的人所能想象的要多得多的时间来完成一本书。如果你想从这本书里赚到有意义的钱,考虑自助出版,并意识到你需要推销自己。
你还有什么想说的吗?
编程是为每个人准备的。我坚信,学习编程之所以困难,是因为缺乏好的、最新的教育资源。我希望想教书的开发者能更容易找到一种可持续的方法。我希望学生们有一个正式的方法来学习这些东西,而不是先坐着听关于离散数学和数据结构的抽象讲座,而没有任何关于如何创造和交互代码的更大背景。
如果你在网上读到了某个帮助你的人的博客,请花点时间给他们写一封感谢信。这有很大的不同。如果你读了一本关于编程的书,在亚马逊上为作者写一篇评论!
感谢您接受采访!
本周 PyDev:Wolf Vollprecht
原文:https://www.blog.pythonlibrary.org/2022/08/08/pydev-of-the-week-wolf-vollprecht/
本周我们欢迎 Wolf Vollprecht(@ woulf)成为我们本周的 PyDev!Wolf 是快速跨平台软件包管理器 mamba 以及用于多维数组表达式数值分析的 C++库 xtensor 的核心维护者。
你可以在 GitHub 上看到一些 Wolf 正在做的事情。让我们花一些时间来更好地了解 Wolf!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是 Wolf,目前是 QuantStack 的 CTO。我在一台 TI 83-Plus 上开始编程,用的是 Basic,然后继续学习 PHP 去一家网络代理公司工作。上大学的时候,我参加了 Ubuntu App 挑战赛(那是 2012 年的事了)。为此,我开发了一个基于 GTK 的 Markdown 编辑器(叫做 Uberwriter,现在是撇号),那是我第一次认真使用 Python。后来,我研究了一个叫做 Beachbot 的小机器人,它可以在沙子上画画,然后我攻读了机器人学硕士学位。我有一个为开源公司工作的愿景,也为 xtensor 做出了贡献,这是一个具有 Python 绑定的 C++库,也是首批 QuantStack 项目之一。这让我在 5 年前加入了 QuantStack。
你为什么开始使用 Python?
我开始用 Python 做 Uberwriter!我非常喜欢语言和强大的表现力。在 Uberwriter 之后,我涉足了其他一些个人项目,例如“SilverFlask”,这是一个基于 Flask 和 SQLAlchemy 的 CMS,它的灵感很大程度上来自于 PHPs SilverStripe。SilverFlask 从未去过任何地方,但我学到了很多关于 Python 中抽象基类和元类的知识,这些知识至今仍在帮助我。后来,我基于表达式图开发了一个名为 PyJet 的 Python 到 C++的编译器,它也教会了我很多关于 Python 的知识,以及捕捉这种语言的动态本质有多难。
你还知道哪些编程语言,你最喜欢哪一种?
我经常使用 C++,但是我不太喜欢它。它非常冗长,是一种非常古老的学校语言(尽管人们可以用它做非常快速和复杂的事情)。尤其是当涉及到模板时,错误消息并不重要!我也非常了解 Javascript,但也不太喜欢它。它不是一种非常“深思熟虑”的语言,也不支持运算符重载。我喜欢 Javascript 的一点是它有非常强大的实时编译引擎。有一些新兴的编程语言看起来像是“编译”语言& Python 的有趣交叉——例如 Nim 和 Zig。我梦想中的语言是可编译的,但也是可解释的(这样人们可以在编译时用语言本身运行宏)。我想齐格已经接近了。还有一个新的领先于时代的 Python 编译器 LPython,看起来很有前途(但仍然很早!).
你现在在做什么项目?
我目前正在开发跨所有平台的最终包管理解决方案。这个项目叫做“mamba”,是一个使用“conda”包的包管理器。Mamba 可以在所有平台上运行(Windows、macOS 和 Linux)。我也是提供这些包的最大社区 conda-forge 社区的一员。我们很自豪有超过 4000 名个人贡献者为 6 个不同的平台提供软件包:Windows,3 个 Linux 版本(英特尔,Arm 和 PowerPC),以及 macOS(英特尔和苹果芯片)。大多数 conda-forge 包都与 Python 和数据科学相关。然而,我们也有大量的 R 编程语言的包,以及许多 C 和 C++,Go 和 Rust 的包。我们真的试图把每个人都集中在一个单一的包管理系统!
我也在“mamba-生态系统”中做两个包:一个是 boa,一个包构建器,另一个是 quetz,一个包服务器。两者都是纯 Python 包。Quetz 正在使用 FastAPI,这对我们来说非常有用。
哪些 Python 库是你最喜欢的(核心或第三方)?
非常好的问题。我可以利用这个机会宣传我们在 QuantStack 工作的一些 Python 库:ipywidgets、ipycanvas、ipyleaflet、bq plot——所有这些都有助于在 Jupyter 笔记本中制作强大的用户界面。JupyterLab 和 Voila 当然也很棒!
总的来说,我真的很喜欢我们在 boa 中使用的“rich”和“prompt_toolkit ”,它对漂亮的终端用户界面帮助很大。有许多经过深思熟虑的 Python 库!
你是如何结束曼巴的工作的?
回到过去,conda 真的很慢(那是在他们添加一些有帮助的优化之前)。康达锻造厂发展得越来越快。我有一个疯狂的想法来构建 ROS 生态系统的所有机器人包(这仍在 robostack 项目中进行)。在任何给定的环境中都有许多 ROS 包,在 conda 的限制下让它工作似乎是不可行的。
因此,我开始摆弄 libsolv,看看它是否会更快(作为另一种 SAT 求解器实现,因为那是真正慢的部分。openSUSE 的 Michael schroder 在 libsolv 中实现了大部分必要的部分,剩下的就是历史了!
你认为 Python 在数据科学领域最擅长什么?
我认为 Python 之所以强大,不仅是因为它是高级动态代码(Python)和低级 FORTRAn、C 或 C++代码之间的一种伟大的粘合语言。使用 pybind11 用 C++或者使用 pyo3 用 Rust 编写自己的高速 Python 扩展非常简单。这使得许多流行的数据科学库成为可能,如 NumPy、Pandas、scikit-learn 和 scikit-image 库、Tensorflow、PyTorch 等
你还有什么想说的吗?
我们最近开始认真考虑 Webassembly!我们开发了 JupyterLite(一个在浏览器中运行 Python 的非常棒的工具,例如用于交互式文档!).此外,我们正在尝试为 Webassembly 包准备 conda-forge。这确实是一项令人兴奋的工作,正在 Github 上的“emscripten-forge”组织中进行。
谢谢你接受采访,Wolf!
本周 PyDev:yaso ob Khalid
原文:https://www.blog.pythonlibrary.org/2015/07/20/pydev-of-the-week-yasoob-khalid/
本周,我们欢迎 Yasoob Khalid(@ yasoobkhalid)成为我们本周的 PyDev。他是免费 Python 技巧博客的作者。让我们花些时间更好地了解他。

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
你好!我来自巴基斯坦。我的爱好包括足球、电影和编程。关于我的教育,我在上大学。我学习编程大多是通过书籍、网络论坛和唠叨的专业程序员。我对博客和公开演讲很感兴趣。去年(2014 年),我有机会在欧洲最大的 Python 大会欧洲 Python 大会上发言。我是那边最年轻的演讲者!我自己在那里学到了很多东西。
你为什么开始使用 Python?
有一天,我正在使用 Visual Basic,每当我在 Visual Basic 中搜索教程时,这些 Python 教程就会不断出现。这种语言的名字让我觉得它是一种玩具语言。谁给一种语言命名为“Python”?不管怎样,我决定试一试。从那天以后,我再也没有回头看过任何其他语言。
你还知道哪些编程语言,你最喜欢哪一种?
我知道 Java,一些 C++,Visual Basic 和 C#。你可能已经猜到了,我最喜欢的语言是 Python。
你现在在做什么项目?
我大部分时间都在做开源贡献。我也在写一本关于中级 Python 的书。它基本上是一本最佳实践的书,教你一些隐藏的和经常被忽视的 Python 特性,这些特性可以极大地提高你的工作效率。
哪些 Python 库是你最喜欢的(核心或第三方)?
这个是可变的。我的兴趣随着时间而改变。现在我最喜欢的是 Scrapy 和 Flask。
你为什么决定写一篇关于 Python 的博客?
我曾经听别人说过,学习一件事的最好方法是像你要教给别人一样去学习它。我只是应用了这句口头禅,决定开个博客。主要是记录我每天的学习,其次是教别人我学到的东西。我很高兴我开始写博客。
现在我正在向前迈出这一步,写一本书。它将于今年问世。
作为一门编程语言,你认为 Python 将何去何从?
Python 真的很强大。Django 和 Flask 促进了它在 web 开发中的使用,SciPy、NumPy、Pandas 等图书馆鼓励科学家和数据分析师采用它。它已经成为许多人日常工作中不可或缺的一部分。我不认为它会很快过时。
你还有什么想说的吗?
没什么。但是我想说一件事。如果有哪个年轻人正在读这篇文章,那么我想让他/她知道,你的年龄不应该阻止你学习一些东西。现在有像“一小时代码”这样的项目,但是当我开始学习编程的时候,还没有这样的项目。当我请几个人教我的时候,他们让我泄气了。他们说我太小了,不能学习编码,对我来说真的很难!我继续努力工作。我决定不依赖任何老师,而是通过谷歌和电子书来学习。我想证明他们是错的,现在我可以说我成功了。然而,有一个人对我的帮助最大。他叫菲利普。他是德国人,他总是支持我。在我编程的早期,我经常问很多问题。我曾经给几个杰出的程序员发电子邮件。除了菲利普,没有人回答。他回答了我的每一个问题,并鼓励我前进。没有他,我不会走到这一步。如果你们中的任何人有任何关于编程、Python 或我的问题,请给我发电子邮件,我非常乐意帮助你们。
谢谢!
一周的最后 10 个 PyDevs
本周 PyDev:耶雷·迪亚兹
原文:https://www.blog.pythonlibrary.org/2022/11/28/pydev-of-the-week-yeray-diaz/
本周我们欢迎耶雷·迪亚兹(@耶拉 _ee )成为我们的本周 PyDev!耶雷是 PyPI.org电视台的主持人。Yeray 还写了一个博客,并且在他的 GitHub 个人资料上有几个项目。
让我们花点时间来更好地了解一下 Yeray!
你能告诉我们一些关于你自己的情况吗(爱好、教育等):
我在加那利群岛长大,那里远离摩洛哥海岸,但却是西班牙的一部分。我总是着迷于电子游戏,因为我是一个多病的孩子,大部分时间都呆在家里。我父亲不喜欢视频游戏机,但他买了一台 Amstrad PC 1512(是的,我有那么老)用于工作。如果我想玩电子游戏,那就迫使我去学电脑。随着计算机变得越来越强大和复杂,它们不断要求更多的技能,直到我成为家庭中的常驻计算机专家,并最终在当地的大学学习计算机科学。
你为什么开始使用 Python?
我记得一个大学朋友向我简单介绍了 Python,他刚刚启动了 REPL,输入了 2 + 2 之类的东西,并向我展示了 python.org 的网站。我试图在我的一个班级项目中使用它,但我没有时间完成它,当我重新上课时,我选择了 PHP,因为它在当时非常流行。我最终毕业了,并作为一名开发人员工作了一段时间,但进入了一个叛逆的阶段,并决定成为一名 CG 动画师。
当我在英国一家名为 Frontier Developments 的游戏公司工作时,他们从 3D Studio Max 转到了 Maya。Maya 刚刚添加了一个 Python API 来与它交互,我的部分工作是编写脚本来帮助完成动画任务,所以我通读了 Python 教程,并非常喜欢它作为一种语言,特别是与 PHP 以及 Maya 和 3D Studio Max 中嵌入的语言相比。
大约在同一时间,有人离开了 Frontier Developments,并赠送了一本 Python 书籍,我不记得是哪本了,但它很厚,封面部分是中文,尽管文本完全是英文。我读了整本书,并开始做一些更高级的东西,最终我发现了 Django,我认为它正变得越来越受欢迎,并决定将职业生涯转回专注于 Python 的全职开发。
你还知道哪些编程语言,你最喜欢哪一种?
我曾经专业地使用过 Ruby、Objective-C、JavaScript 和 Typescript,所有这些都有我喜欢的东西,但没有一个足以让我说我喜欢使用它们。然而,几年前我发现了长生不老药,它真的很适合我。我真的很喜欢它的实用和直接,这是我真正喜欢 Python 的地方,也是底层 Erlang VM 提供的强大并发模型。我写了一篇文章关于他们的异同,以防有人感兴趣。
你现在在做什么项目?
不幸的是,这些天我没有太多时间研究开源,尽管我的最新项目是 Sublime REST Client ,Sublime Text 4 的一个插件,允许你通过键入 HTTP 动词和有效载荷直接从它发送 HTTP 请求。
除此之外,我还维护了几个库 lunr.py 和 futureproof ,尽管没有我希望的那么活跃。
哪些 Python 库是你最喜欢的(核心或第三方)?
我想说 asyncio 是我最喜欢的核心库,它给这门语言注入了大量的新鲜空气,并产生了许多新的框架和思想。当它第一次出现时,我写了一系列关于它的介绍性文章,你可以在我的媒体页面上找到。
我最喜欢的第三方库很难选择。这可能是 urllib3,pandas 和 attrs 之间的三方合作。这些年来,我一直在努力达到这些目标,在表现和行为方面,我一直都是有用的和可靠的。
你是如何成为 PyPI 的版主的?
在代号为 Warehouse 的 pypi.org 的开发过程中,我读到了 Warehouse 的常驻设计师 Nicole Harris 对希望在 Javascript 方面有所贡献的开发人员的请求。有了工作和一些空闲时间,我开始做贡献,慢慢地开始参与 PyPA。
一旦大的转变发生,我们开始遇到与仓库代码无关的问题,更多的是与通常留给管理员的任务有关的问题。于是主持人的角色被引入,达斯汀·英格拉姆问我是否愿意成为一名主持人,于是我接受了。
你还有什么想说的吗?
不久前,我意识到学习 Python 改变了我的生活。听起来有点戏剧性,但这是真的。
我学习 Python 是因为它越来越受欢迎,它允许我改变职业生涯,并在英国得到了我的第一份开发工作,作为一名在 Django 上工作的 Python 程序员,并由于 Python 的生态系统和可扩展性而慢慢扩展到其他开发领域。丰富的生态系统和社区吸引着我,并允许我通过为开源做贡献来进一步进步,这为我开辟了更多的途径。
我将永远与 Python 有一种特殊的联系。
谢谢你接受采访,耶雷!
本周 PyDev:young gun Kim
原文:https://www.blog.pythonlibrary.org/2018/09/17/pydev-of-the-week-younggun-kim/
本周我们欢迎金英君(@ scari_net )成为我们本周的 PyDev!Younggun 是 Python 软件基金会的董事会成员,也是韩国 PyCon 的创始人。他已经把几本编程书翻译成了韩语。你可以在他的网站上获得完整的名单。你也可以查看他的 Github 来看看他参与的一些项目。现在,让我们花一些时间来更好地了解他!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是一名住在韩国首尔的 Pythonista,在一家视频流公司领导工程部。我还积极参与我们的社区,尤其是在东亚地区。我在 2016/17 年任期内担任 PSF 的董事会董事,由 Carol Willing 提名。2014 年,我和几个当地社区成员第一次创办了韩国 PyCon。我一年中带着一个漂亮的 PSF 会议包去 5 或 6 个 PyCons 旅行。我现在是 PSF 赠款工作组的成员。

你为什么开始使用 Python?
我在 8 岁的时候开始学习如何编程。在学习编程之前,我必须先学习字母表,因为我是一个不会说英语的孩子,在我 8 年的生命中从未见过字母表。事实上,我从键盘上学会了字母表,并学会了几个英语单词,如 PRINT,GOTO,RUN 等。在我正式从学校学习英语之前。
从那以后,我迷上了学习编程语言。当我在 21 世纪初第一次从 IRC 渠道听说 Python 这种新语言时,我对它感兴趣并不奇怪。频道的 Hyeshik 是一个 Python 爱好者,经过几年的贡献,他成为了 CPython 的提交者。他介绍了很多关于 Python 的趣事,见证这种快节奏语言的历史是一种极大的乐趣。
你还知道哪些编程语言,你最喜欢哪一种?
我知道很多编程语言,从古老的到深奥的。c 是我最喜欢的语言,因为它是我使用时间最长的语言。我想说 Python 是我现在最喜欢的。我经常把 C lang 比作驾驶手动挡汽车。从某种意义上来说这很有趣,但是为什么要每天在交通堵塞的时候用手动挡汽车呢?
你现在在做什么项目?
我现在不怎么写代码了,尤其是在工作中。过去我确实为 pandas 做了一些贡献,但最近,我更喜欢组织开发冲刺,并喜欢帮助他人为开源做贡献。当我写代码时,只有当我需要为决策快速建立原型或自动化单调乏味的工作时。我不能说太多,但我正在用 Python 编写一个可以检测实时视频流中特定内容的系统原型。
哪些 Python 库是你最喜欢的(核心或第三方)?
拼写错误。不是玩笑。😉拼写错误是一个库,用于检查源代码中拼写错误的单词。我没有亲自使用它,而是在一次关于开源贡献的演讲中介绍了它。我在我的演讲中强调的是,不仅仅是解决难题的英雄行为,报告错误、修正错误、文档和捐赠也是有价值的贡献。我引入拼写错误是为了让人们第一次投稿时更容易。我相信一旦他们开始,他们会继续尝试,没有人知道未来会有多美好。
你还有什么想说的吗?
在我们的社区中,我们感受到了与他人的友谊,因为我们有着共同的兴趣,对他人表现出尊重和礼貌,没有任何歧视。事实上,这让我们的社区变得更好。
如你所知,朝鲜半岛的和平指日可待。这是朝鲜人民的热切梦想。然而,由于朝鲜半岛长达 70 年的分裂,南北方在生活方式、财富、政治信仰和其他问题上的巨大差异可能会让我们每天都在挣扎。
我希望南方和北方的 Pythonistas 们有一天能聚在一起,用我们从社区中学到的东西超越彼此之间的差异,这样我们就能为和平做出一点贡献。
如果这个博客的读者认识朝鲜的一个皮托尼斯塔,你能告诉他们当和平到来的时候我会去看他们,请等我到那时吗?
感谢您接受采访!
PyDev of the Week: Yury Selivanov
原文:https://www.blog.pythonlibrary.org/2021/10/25/pydev-of-the-week-yury-selivanov/
This week we welcome Yury Selivanov (@1st1) as our PyDev of the Week! Yury is the founder of CEO of EdgeDB. Yury is also a core developer of the Python programming language. One of his most well known recent contributions is adding async to Python in PEP 492. You can see what else he has been working on in Python on GitHub.
Let's spend some time getting to know Yury better!
Can you tell us a little about yourself (hobbies, education, etc):
Hi there! My name is Yury and I’m a software engineer, also wearing a hat of co-founder and CEO of EdgeDB.
I graduated from Moscow State Technical University named after Bauman with a Bachelor degree in Computer Science in 2006. Shortly after that, I moved to Toronto, Canada, where I lived until relocating to San Francisco in 2020.
My hobbies include photography, UI design, and most recently I’ve been trying to teach myself guitar. Last but not least, somehow programming still feels like a hobby to me after all these years.
Why did you start using Python?
In summer 2008 I co-founded MagicStack. My co-founder Elvis and I did not have a clear business plan back then, but we did have a clear vision of how we want to write software. We were obsessed with metaprogramming, data modeling, and domain-specific languages and wanted to push the limits of what was possible in web frameworks back in the day. We spent weeks, if not months, researching the state of the art and ultimately decided to start from a clean state and build the foundation for our future projects ourselves.
We looked around for a programming language that was aligned with our vision and philosophy and Python was the best match. To make our life more challenging we started with Python 3.0 alpha 6.
What other programming languages do you know and which is your favorite?
I’m very comfortable with TypeScript/JavaScript and C. I used to know C#, C++, Java, and dabbled with many other languages, like Erlang and Go. Recently I’ve been playing with Rust a little bit.
Out of all programming languages I know, Python is my most favorite simply because I know its ins and outs.
What projects are you working on now?
EdgeDB.
EdgeDB is the project that underpins my entire career. It drived pretty much all of my contributions to Python. Some examples:
- When I saw a demo of Google Wave I was completely blown away. Turned out they used non-blocking IO to make it, so naturally, we had to start using it too! Years later I’ve acquired some knowledge and started to help Guido with asyncio.
- At some point we used asyncio heavily but Python lacked an asynchronous “with” block and “yield from” felt weird to me. So I proposed to add async/await to Python.
- I knew that IO performance would be a bottleneck eventually so I looked into ways of improving the performance; that’s how uvloop was born.
- We needed an async driver to talk to PostgreSQL, which led us to create asyncpg.
- Later we needed an equivalent of thread local storage for async/await, that’s how we ended up proposing and implementing Python’s contextvars.
The story continues to this day. I have a unique luxury of being able to build an open source project I love day by day and contribute to Python anytime we need to push it a little further. And I’m very grateful for this opportunity.
Which Python libraries are your favorite (core or 3rd party)?
Core: asyncio. I use it every day and I’m one of the maintainers (even though not a very active one lately).
3rd party: click. mypy. Even though mypy isn’t exactly a library it is the tool that has impacted my workflow a lot, so it deserves to be mentioned.
How did you become a core developer of the Python programming language?
Around 2012 Brett Cannon asked on the python-dev mailing list if someone wants to help with PEP 362. And it just happened that I looked at that PEP a year before that and implemented its API for myself, making some changes along the way. I offered help and started working on it. In a few months, Larry Hastings, Brett, and I made progress, and got the PEP accepted. A year later, I noticed that the API needed some updates for the upcoming Python release and I submitted a few PRs. That’s when I was promoted to a core developer.
If you have some spare time and love Python: consider contributing! Becoming a core developer isn’t that hard but it would help the project, benefit the community, and open many doors for you.
Is there anything else you’d like to say?
If you follow my work or use uvloop or asyncpg, please give EdgeDB a try and share some feedback at https://github.com/edgedb/edgedb.
EdgeDB is our attempt to rethink what a relational database is. How can we streamline them? How can we make developers fall in love with databases?
To answer those questions we had to start with the very fundamentals. EdgeDB has a high-level data model with object types that map naturally to Python and JavaScript. It has a pretty cool querying language -- EdgeQL -- that aims to surpass SQL in power, composability, and expressiveness. It’s high performance, supports GraphQL, and has amazing client libraries. We have been working hard to ensure that EdgeDB is a joy to use. Follow EdgeDB on Twitter to stay tuned!
Thanks for doing the interview, Yury!
本周 PyDev:Yusuke Tsutsumi
原文:https://www.blog.pythonlibrary.org/2018/03/26/pydev-of-the-week-yusuke-tsutsumi/
本周我们欢迎 Yusuke Tsutsumi 成为我们的本周 PyDev!Yusuke 是 Zillow 的 web 开发人员,从事开源项目已经有几年了。他有一个博客——在那里你可以了解更多关于他以及各种编程语言的信息。你也可以在 Github 上查看他参与了哪些项目。让我们花些时间去更好地了解他!

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在西雅图长大,热爱西北太平洋。在高中涉猎了一点音乐之后,我在大学里选择了电子工程。我研究模拟和生物医学系统(心电图仍然是我所知道的最酷的设备之一)。我还最终了解了嵌入式系统,加上在大学期间帮助改进内容管理系统的一些经验,帮助我在 Zillow 获得了一个职位,也就是我今天工作的地方。
在工作中,我为用于持续交付、测试和监控的工具和基础设施做出贡献,这当然是我的热情所在。在家里,我喜欢阅读、远足和在城市里骑自行车。
你为什么开始使用 Python?
Python 不是一个有意的选择:我加入了华盛顿大学的一个开发团队,他们主要在 Plone 上工作,Plone 是用 Python 编写的。我记得我的第一个项目是写一个 Plone 插件,只上了几门 CS 课程。我不知道我在做什么!在那之后,我得到了一份实习工作,在那里我可以自由地使用任何我想要的工具,我选择了 Python。令人敬畏的社区和语言库帮助我解决了所有抛给我的问题。从自动化部署过程到构建分布式 web 服务,Python 一直是一个很好的工具。
你还知道哪些编程语言,你最喜欢哪一种?
我已经涉猎了一些。我用 C#和 Java 开发过游戏,用 Javascript 做过前端工作,在我黑我的 Emacs 系统的时候还学过一点 lisp。我一直在 Rust 做一些副业,我真的很喜欢。很难找到一种具有强大社区、开发人员友好的设计原则和出色性能的语言。结合 CFFI,Rust 也可以与 Python 集成。我认为这两个系统是彼此强大的补充:使用 Python 实现富于表现力的语法和快速原型,使用 Rust 处理高性能是关键的情况。
你现在在做什么项目?
在 Python 中,我主要改进了嬗变核心。readthedocs.io/en/latest/
去年,我决定停止使用 Emacs,而选择 Atom ( atom.io )作为我的文本编辑器。构建一个文本编辑器,结合 VIM 的模态编辑能力、Emacs 的可扩展性,并专注于消除使用鼠标,这一直是我的梦想。我一直在构建一个名为 chimera(https://atom.io/packages/
哪些 Python 库是你最喜欢的(核心或第三方)?
在标准图书馆,我是 asyncio 的超级粉丝。事件驱动的编程范式与受 GIL 约束的 Python 解释器配合得很好,能够显著提高内存利用率,并且在面对长网络连接时也能很好地扩展。我做了一些基准测试来说明它也有显著的性能提升(http://y.tsutsumi.io/aiohttp-
第三方,我对面料很欣赏(http://www.fabfile.org/)。界面设计得很好,实现稳定的 SSH 连接和命令执行的技术复杂性是巨大的。我喜欢能帮助你解决大问题的库,fabric 使用 Python 的力量实现了大规模编排的执行。
Is there anything else you’d like to say?
A little random, but as you know, I was not a computer science major. I really respect those who have a degree in the field: it's tough, and requires a lot of hard work and dedication. I played a lot of catch up my first few years to match my peers.If you are interested in software and do not have a degree, sometimes the job market can be tough. If you find it difficult to land your first job, don't lose hope. In my experience, the way to getting into the industry is to get really involved. Go to local meetups, blog like crazy, and write code and contribute to open source constantly. Coding is one of the few professions where ability is really the only requirement. So if you have the skills, the next step is to get yourself out there.
感谢您接受采访!
本周人物:刘禹锡(海登)
原文:https://www.blog.pythonlibrary.org/2021/03/29/pydev-of-the-week-yuxi-hayden-liu/
这一周,我们欢迎刘禹锡(海登)作为我们的周 PyDev!海登是《Python 机器学习示例》和《T2 其他书籍》的作者。你可以在 LinkedIn 上联系海登。
现在让我们花些时间来更好地了解海登!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我目前是一名软件工程师,在谷歌从事机器学习。之前,我作为一名机器学习科学家在各种数据驱动的领域工作,并将我的 ML 专业知识应用于计算广告、营销和网络安全。我是一个机器学习系列书籍的作者,也是一个教育爱好者。我的第一本书《Python Machine Learning by Example》在 2017 年和 2018 年位列亚马逊畅销书排行榜第一,并被翻译成多种不同的语言。我在多伦多大学获得了学位。
我非常喜欢徒步旅行,所以我很感激旧金山湾区有许多徒步旅行路线,加上持续晴朗的天气。
你为什么开始使用 Python?
2008 年我读大学的时候。
你还知道哪些编程语言,你最喜欢哪一种?
C++、Java、Go 等。当然 Python 一直是我的最爱。
你现在在做什么项目?
我现在正在开发和改进世界上最大的搜索引擎上广告优化的机器学习模型和系统。
哪些 Python 库是你最喜欢的(核心或第三方)?
这么多,Numpy,Scipy,Pandas,TensorFlow,PyTorch,matplotlib,gensim,scikit-learn,XGBoost
你的书《Python 机器学习示例》是如何产生的?
当我回顾我多年的研究和行业经验时,我总是发现通过实例学习是掌握新技术的最快方法。我相信大多数读者都会和我产生共鸣。例如,当你学习如何用 Python 编码时,你不会从一本 800 页的 Python 语法书开始。相反,你应该从打印出“Hello World”开始。如果你想了解强化学习,你首先要看看它在真实例子中是如何使用的,而不是一头扎进它的数学基础。学习 ML 是没有区别的。在我看来,以身作则是最有效和最有趣的方法。我的目标是写一本范例厚重的书,它可以成为进入实用机器学习世界的最全面的门户。
你还有什么想说的吗?
如果你爱聊 ML,data,Python,欢迎随时联系我 LinkedIn 。这里是我的亚马逊作者页面。如果你有任何你想让我写的话题,请随时告诉我。
海登,谢谢你接受采访!
本周 PyDev:安·安德勒
原文:https://www.blog.pythonlibrary.org/2021/03/15/pydev-of-the-week-zan-anderle/
本周我们欢迎安·安德勒(@ z _ 安德勒)成为我们本周的 PyDev!安是一名自由软件开发人员。你可以查看他的博客或者查看他的 Github 简介你想知道他在做什么。
让我们花些时间去更好地了解 an!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我的名字是安,我是一个在斯洛文尼亚的顾问/软件开发人员。在过去的 7 年里,我一直从事软件开发工作。最初,我想我会从事机械工程,但是当我在读机械工程的本科课程时,我意识到两件事:1)我不认为自己在从事机械工程 2)软件开发似乎真的很有趣。所以我继续攻读计算机科学硕士学位。从那以后我一直从事软件开发。
当然,这只是我职业的一部分。除此之外,我还是一个丈夫和父亲。说到爱好,我非常喜欢桌游和音乐(尤其是爵士乐)。问我关于路易斯·阿姆斯特朗的事,我几个小时都不会闭嘴。如果你在会议上遇到我,我会一直玩一个很酷的棋盘游戏。
你为什么开始使用 Python?
当我还是一名机械工程本科生时,在我意识到这不是我想做的事情后,我想探索计算机科学是否是我想要的。所以我去了 Coursera,在那里上了一堆课。其中一个是编程入门,他们用的是 Python。我从一开始就喜欢用它。过了一段时间,我得到了我的第一份开发(兼职)工作,他们正在使用 Python 和 Django。所以从我职业生涯的一开始,Python 就一直伴随着我。
你还知道哪些编程语言,你最喜欢哪一种?
除了 Python,我使用(和知道)最多的语言是 JavaScript(和 TypeScript),HTML 和 CSS。除此之外,我用过的唯一能说我知道它们的语言是 MatLab/Octave,还有以前的 LabVIEW。
我最喜欢的肯定是 Python,其次是 JavaScript。
你现在在做什么项目?
除了做客户端工作(主要是使用 Django 和 frontend 框架的全栈开发),我目前正在为 Python 开发人员开发一门现代 JavaScript 课程,我对此非常兴奋,我认为它会非常好。我还在做一个名为让我们玩桌游的兼职项目,这将是一个更好更容易组织桌游之夜的网络应用程序。有时候我希望这是我唯一在做的项目,但遗憾的是事实并非如此。也许有一天。
我很幸运在 12 月加入 Django 软件基金会,成为董事会成员。
哪些 Python 库是你最喜欢的(核心或第三方)?
这么多可以选择!单看 core,真的很喜欢收藏。虽然是第三方,嗯…可能是 Django,DRF,httpx 和 scikit-learn。
你对想从事自由职业的人有什么建议吗?
不仅在技术方面(你可能已经有足够的知识对你的客户来说是有价值的),还要在商业方面进行自我教育。就我个人而言,我喜欢阅读书籍和听不同“商业”话题的播客。这对我非常有帮助,可能比我的技术知识对我的业务影响更大。
你还有什么想说的吗?
谢谢你接受这些采访,也谢谢你邀请我!
谢谢你接受采访,安!
本周 PyDev:阿伦·拉文德兰
原文:https://www . blog . python library . org/2015/11/23/pydev-of-week-arun-ravindran/
本周我们欢迎 Arun Ravindran ( @arocks )成为我们的本周 PyDev!阿伦有一个有趣的 Python 博客,值得一试。他也是 Django 设计模式和最佳实践的作者。让我们花些时间来了解阿伦。

你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我在印度绿色葱茏的喀拉拉邦一个名为 Thrissur 的小镇长大。我上中学的时候,个人电脑革命刚刚开始。我们是一群睁大眼睛的孩子,玩着波斯王子或危险的戴夫,学习用 BASIC 语言创建单色云纹图案来编程。
现在,我是一名产品经理、丈夫和两个可爱孩子的父亲。几个月前,我的第一本书《Django 设计模式和最佳实践》出版了。我把空闲时间花在开源项目、玩复古视频游戏和旅游上。
你为什么开始使用 Python?
当我在政府部门学习计算机科学时,我从官方教程(标题为“激起你的食欲”,我记得我认为这个标题看起来很有趣)中学到了 Python。工程学院,1998 年成立。那是开源运动的早期。
我喜欢 Python 中的许多语言决策,比如基于缩进的语法和非常丰富的内置标准库。我发现自己同意《Python 之禅》中的大部分建议。最终,我关于图像压缩的最后一年项目的用户界面完全是用 Python 编写的。
你还知道哪些编程语言,你最喜欢哪一种?
我是一个编程语言爱好者。我总是在学习新的甚至深奥的语言。所以当我掌握了大约 20 种语言后,我就不再数数了。我更喜欢学习引入新思想并且对日常使用实用的语言。
我喜欢像 OCaml、Haskell 或 Haxe 这样有强大类型推理机制的语言。但是对于我的大多数需求,我最终使用 Python。你可以说 Python 是我的首选语言(不是双关语),但我最喜欢的语言一直在变。目前是 OCaml 和酏剂。
你现在在做什么项目?
我很擅长开始项目,但却发现很难完成它们。因此,在任何给定的时间点,我都会从事数量惊人的项目。其中最让我兴奋的是 Django Edge,一个解决了很多 Django 初学者常见需求的项目模板。
我还在与 Anand 合著我的下一本书,这是一本关于 Emacs 初学者的书。其他项目包括基于地理的搜索引擎和儿童友好的编程语言,主要用于创建游戏。
哪些 Python 库是你最喜欢的(核心或第三方)?
从标准库中,我发现 itertools 非常酷,因为它是用于迭代器的功能工具的简洁集合。在第三方库中,我发现 Pandas(和 Jupyter Notebook)对于数据分析非常有用。
就拥有最多 Pythonic API 的库而言,我会投票支持请求。当然,我最喜欢的框架是 Django。
作为一门编程语言,你认为 Python 将何去何从?
作为一门初学者友好的编程语言,Python 非常成功。它的影响可以在一些现代语言中看到,如 Julia 或 Swift。
这门语言的未来是 Python 3。尽管早期有所怀疑,但现在 Python 3 已经被广泛采用。我将我的书基于 Python 3,因为我相信我们需要尽快停止使用许多过时的结构,如“unicode”和“xrange”。
我对 Python 的其他实现很感兴趣,比如 PyPy 和 MicroPython。PyPy 越来越适合生产。它已经是最快的 Python 实现之一。MicroPython 是 Python 3 的缩小版实现,甚至可以在微控制器中工作。想象一下能够用 Python 对你的洗衣机或汽车进行(重新)编程!
你还有什么想说的吗?
尽管 Python 比 Java 更古老,但它现在仍然让人兴奋不已。有些人不明白它有什么了不起的。我相信是社区。这些年来,我很少发现有一群人对外界的反馈如此开放,不管是建议还是批评,并努力提高语言水平。所以,我对它的未来相当乐观。
万分感谢!
一周的最后 10 个 PyDevs
PyDev 在 Indiegogo 上发起众包运动
原文:https://www.blog.pythonlibrary.org/2013/03/25/pydev-starts-a-crowdsoursing-campaign-on-indiegogo/
PyDev 的主要开发者 Fabio Zadrozny 在 Indiegogo 上发起了一项活动,为 PyDev 的持续开发提供资金。如果您是 Python 开发的新手, PyDev 是 Eclipse 的一个插件,它在 Eclipse 环境中为 Python、Jython 和 IronPython 提供了一个很好的集成开发环境(IDE)。
你可以在他的博客上了解为什么法比奥决定走 Indiegogo 的融资路线。虽然我个人不使用 PyDev,但我的几个同事非常喜欢它。我认为支持我们的 Python 开发者伙伴是一件好事,所以如果你有多余的钱来支持一个非常棒的开源项目,那么你可能会想要支持这个活动。
本周 PyDevs:费利克斯·朱姆斯坦和埃里克·雷诺兹
原文:https://www.blog.pythonlibrary.org/2016/01/25/pydevs-of-the-week-felix-zumstein-eric-reynolds/
本周我们要做一些不同的事情。我采访的不仅仅是一个开发者,而是 xlwings 背后的主要开发者:菲利克斯·朱姆斯坦&埃里克·雷诺兹。让我们花些时间来了解一下我们的 python 同胞吧!
你能告诉我们一些关于你自己的情况吗(爱好、教育等)
我是 Zoomer Analytics 的创始人,这是一家开发定制分析软件系统的咨询公司。我没有正式的计算机科学背景,但通过之前在金融建模团队的工作进入了应用程序开发领域。在我进入 Matlab 之前,我的第一步是在 VBA,Matlab 是我的团队中使用的主要建模语言。
Eric : 我是 Zoomer Analytics 的合伙人,加入 Felix 之前,我们发现我们对开源工具有一个共同的愿景,使您能够在 Excel 主导的业务环境中利用 Python 的力量。我学的是数学和计算机科学,我职业生涯的大部分时间都是在交易大厅里从事量化和交易工作。编程一直是我从小的爱好。
你为什么开始使用 Python?
菲利克斯 : 我对 Matlab 在部署、许可管理和集成到其他系统方面的笨拙感到沮丧。除了价格昂贵之外,当 Matlab 被集成到更大的系统如 web 应用程序中时,它通常被视为黑盒。我在寻找一种开源的替代语言,它是一种带有科学包的通用语言,而不是一种特定领域的语言,我发现 Python 是最好的选择。
Eric : 我的一个同事在使用 Python 时感染了它(并从此传播了这种疾病)。Python 是非常独特的,它介于对初学者来说是容易的、逻辑结构化的、非领域特定的和由大量库支持之间。大多数语言只勾选了一两个选项。在实践中,我越来越多地使用 Python,因为用 Python 脚本快速完成实际任务是如此容易,而不必在有趣的语言怪癖上妥协(我想到了 VBA),也不必绑定到某个特定的供应商(比如 Matlab)。
你还知道哪些编程语言,你最喜欢哪一种?
除了 VBA 和 Matlab,我还在学习 JavaScript。
Eric : VBA,JavaScript,C++和我目前最喜欢的 C#。
你现在在做什么项目?
我们的主要客户项目是一个基于网络的交易平台,具有实时和协作功能,在交互式经纪人的基础上获取市场数据并执行交易。
我们主要的免费开源项目是 xlwings,它为用 Python 而不是 VBA 编程 Excel 提供了一个强大的替代方案。与我们的商业竞争对手不同,我们从单个 Python 包中提供简单的自动化和基于阵列的用户定义函数(UDF)。此外,xlwings 还完全跨平台(Windows、Mac),但 UDF 除外(目前仅在 Windows 上受支持)。
哪些 Python 库是你最喜欢的(核心或第三方)?
费利克斯 : 我非常喜欢熊猫和 reportlab,因为它们与 xlwings 结合得很好。
Eric : SQLAlchemy 是一个如何出色地编写库的例子。
作为一门编程语言,你认为 Python 将何去何从?
Felix : 我喜欢 Python 作为服务器端 web 技术和数据科学语言,这些领域也是我认为未来增长最大的领域。
Eric : 我认为对 Python 最大的威胁是 JavaScript。Python 在语言质量和可用库(尤其是科学计算)方面仍有显著优势,但这两方面的差距正在缩小,JavaScript 有一个致命的特性,那就是它可以在浏览器中运行。如果能看到将 Python 作为一种客户端语言的进展,那将是非常好的。
创建 xlwings 的动机是什么?
菲利克斯 : 我的第一个客户想要从 Excel 访问 Python 脚本,我为他构建了一个投资组合优化工具。那时,只有商业图书馆能提供我想要的东西。试图说服远离 Matlab 的人使用 Python 是错误的,如果他们仅仅为了通过 Excel 作为用户界面访问 Python 的简单任务而回到许可/部署地狱。
Eric : 我对 xlwings 的贡献是 ExcelPython 项目,该项目现已被并入。我最初的动机是个人使用。工作时被 Excel 电子表格包围,自动化一些无聊任务的唯一可行方法是使用 VBA,这是一种古怪的语言。在某个时候,我考虑用 Python 代替它,但是没有一个可用的库说服了我——部分原因是它们不是开源的。然后,将它作为开源库提供是一个自然的结果,这导致了与 Felix 的联系,并最终联手。
非常感谢!
py flakes——Python 程序的被动检查器
原文:https://www.blog.pythonlibrary.org/2012/06/13/pyflakes-the-passive-checker-of-python-programs/
Python 有几个代码分析工具。最著名的是 pylint。接下来是 pychecker,现在我们开始讨论 pyflakes。pyflakes 项目是 Divmod 项目的一部分。与 pychecker 不同,Pyflakes 实际上并不执行它检查的代码。当然,pylint 也不执行代码。不管怎样,我们将快速浏览一下,看看 pyflakes 是如何工作的,以及它是否比竞争对手更好。
入门指南
正如您可能已经猜到的,pyflakes 不是 Python 发行版的一部分。你需要从 PyPI 或者从项目的启动页面下载它。一旦你安装了它,你就可以在你自己的代码上运行它。或者您可以跟随我们的测试脚本,看看它是如何工作的。
运行 pyflakes
我们将使用一个超级简单且相当愚蠢的示例脚本。事实上,它与我们在 pylint 和 pychecker 文章中使用的是同一个。这又是为了你的观赏乐趣:
import sys
########################################################################
class CarClass:
""""""
#----------------------------------------------------------------------
def __init__(self, color, make, model, year):
"""Constructor"""
self.color = color
self.make = make
self.model = model
self.year = year
if "Windows" in platform.platform():
print "You're using Windows!"
self.weight = self.getWeight(1, 2, 3)
#----------------------------------------------------------------------
def getWeight(this):
""""""
return "2000 lbs"
正如在其他文章中提到的,这段愚蠢的代码有 4 个问题,其中 3 个会使程序停止运行。让我们看看 pyflakes 能找到什么!尝试运行以下命令,您将看到以下输出:
C:\Users\mdriscoll\Desktop>pyflakes crummy_code.py crummy_code.py:1: 'sys' imported but unused crummy_code.py:15: undefined name 'platform'
虽然 pyflakes 返回这个输出的速度非常快,但是它没有找到所有的错误。getWeight 方法调用传递了太多参数,getWeight 方法本身的定义不正确,因为它没有“self”参数。实际上,你可以把第一个论点称为任何你想要的东西,但是按照惯例,它通常被称为“自我”。如果你按照 pyflakes 告诉你的去修改你的代码,你的代码仍然不会工作。
包扎
pyflakes 网站声称 pyflakes 比 pychecker 和 pylint 更快。我没有对此进行测试,但是任何想要这样做的人都可以很容易地对一些大文件进行测试。也许可以获取 BeautifulSoup 文件,或者将它(以及其他文件)与 PySide 或 SQLAlchemy 等复杂的文件进行比较,看看它们之间的差别。我个人感到失望的是,它没有抓住我所寻找的所有问题。我想出于我的目的,我会坚持使用 pylint。这可能是一个方便的工具,用于快速和肮脏的测试,或者只是在 pylint 扫描的结果特别差之后让你感觉好一些。
进一步阅读
- 我在 PyChecker 上的文章
- PyChecker 官方网站(类似 pyflakes 的项目)
- 来自 Python 杂志的 Doug Hellman 对 Python 静态代码分析器的评论
Pyhon 101 图书写作更新#2
原文:https://www.blog.pythonlibrary.org/2014/03/19/pyhon-101-book-writing-update-2/
图书战役还剩不到 2 天!我认为这很令人兴奋。我希望你也是!
最近一直忙着写新的第三部。在它完成之前我只剩下两章了。我希望第三部分能在周末完成。
我还想出了一个有趣的小脚本,可以为我把我的书放在一起。今天,我突然意识到,这个小程序可以很好地向我的读者展示如何处理一个项目,并将其分成更容易管理的部分。所以我会在书中的某个地方增加一两章,因为我的一些支持者已经提到他们想知道如何做这种事情。
感谢您的支持!
py installer——如何将你的 Python 代码转换成 Windows 上的 Exe 文件
您刚刚创建了一个非常棒的新应用程序。可能是游戏,也可能是图像查看器。无论您的应用程序是什么,您都希望与您的朋友或家人分享。然而,你知道他们不知道如何安装 Python 或任何依赖项。你是做什么的?你需要将你的代码转换成可执行文件的东西!
Python 有许多不同的工具可以用来将 Python 代码转换成 Windows 可执行文件。以下是一些您可以使用的不同工具:
- PyInstaller(安装程序)
- py2exe
- cx _ 冻结
- 努特卡
- 公文包
这些不同的工具都可以用来为 Windows 创建可执行文件。它们的工作方式略有不同,但最终结果是您将拥有一个可执行文件,也许还有一些您需要分发的其他文件。
PyInstaller 和公文包可用于创建 Windows 和 MacOS 可执行文件。Nuitka 有一点不同,它在将 Python 代码转换成可执行文件之前,先将其转换成 C 代码。这意味着结果比 PyInstaller 的可执行文件小得多。
然而,对于本文,您将关注于 PyInstaller 。为此,它是最受欢迎的包之一,并得到了很多支持。PyInstaller 也有很好的文档,并且有许多教程可供使用。
在本文中,您将了解到:
- 安装 PyInstaller
- 为命令行应用程序创建可执行文件
- 为 GUI 创建可执行文件
让我们将一些代码转换成 Windows 可执行文件!
安装 PyInstaller
要开始,您需要安装 PyInstaller。幸运的是,PyInstaller 是一个 Python 包,可以使用pip轻松安装:
python -m pip install pyinstaller
该命令将在您的计算机上安装 PyInstaller 及其所需的任何依赖项。现在,您应该准备好使用 PyInstaller 创建可执行文件了!
为命令行应用程序创建可执行文件
下一步是选择一些你想转换成可执行文件的代码。你可以使用我的书 Python 101: 2nd Edition 的第 32 章 中的 PySearch 实用程序,把它变成二进制。代码如下:
# pysearch.py
import argparse
import pathlib
def search_folder(path, extension, file_size=None):
"""
Search folder for files
"""
folder = pathlib.Path(path)
files = list(folder.rglob(f'*.{extension}'))
if not files:
print(f'No files found with {extension=}')
return
if file_size is not None:
files = [f for f in files
if f.stat().st_size > file_size]
print(f'{len(files)} *.{extension} files found:')
for file_path in files:
print(file_path)
def main():
parser = argparse.ArgumentParser(
'PySearch',
description='PySearch - The Python Powered File Searcher')
parser.add_argument('-p', '--path',
help='The path to search for files',
required=True,
dest='path')
parser.add_argument('-e', '--ext',
help='The extension to search for',
required=True,
dest='extension')
parser.add_argument('-s', '--size',
help='The file size to filter on in bytes',
type=int,
dest='size',
default=None)
args = parser.parse_args()
search_folder(args.path, args.extension, args.size)
if __name__ == '__main__':
main()
接下来,在 Windows 中打开命令提示符(cmd.exe ),导航到包含您的pysearch.py文件的文件夹。要将 Python 代码转换为二进制可执行文件,您需要运行以下命令:
pyinstaller pysearch.py
如果 Python 不在您的 Windows 路径上,您可能需要键入到pyinstaller的完整路径来运行它。它将位于一个脚本文件夹中,无论你的 Python 安装在系统的哪个位置。
当您运行该命令时,您将看到类似于以下内容的一些输出:
6531 INFO: PyInstaller: 3.6
6576 INFO: Python: 3.8.2
6707 INFO: Platform: Windows-10-10.0.10586-SP0
6828 INFO: wrote C:\Users\mike\AppData\Local\Programs\Python\Python38-32\pysearch.spec
6880 INFO: UPX is not available.
7110 INFO: Extending PYTHONPATH with paths
['C:\\Users\\mike\\AppData\\Local\\Programs\\Python\\Python38-32',
'C:\\Users\\mike\\AppData\\Local\\Programs\\Python\\Python38-32']
7120 INFO: checking Analysis
7124 INFO: Building Analysis because Analysis-00.toc is non existent
7128 INFO: Initializing module dependency graph...
7153 INFO: Caching module graph hooks...
7172 INFO: Analyzing base_library.zip ...
PyInstaller 非常冗长,会打印出大量输出。完成后,你将有一个dist文件夹,里面有一个pysearch文件夹。在pysearch文件夹中有许多其他文件,包括一个名为pysearch.exe的文件。您可以尝试在命令提示符下导航到pysearch文件夹,然后运行pysearch.exe:
C:\Users\mike\AppData\Local\Programs\Python\Python38-32\dist\pysearch>pysearch.exe
usage: PySearch [-h] -p PATH -e EXTENSION [-s SIZE]
PySearch: error: the following arguments are required: -p/--path, -e/--ext
这看起来是一个非常成功的构建!然而,如果你想把可执行文件给你的朋友,你必须给他们整个pysearch文件夹,因为那里的所有其他文件也是必需的。
您可以通过传递--onefile标志来解决这个问题,如下所示:
pyinstaller pysearch.py --onefile
该命令的输出类似于第一个命令。这次当你进入dist文件夹时,你会发现一个名为pysearch.exe的文件,而不是一个装满文件的文件夹。
为 GUI 创建可执行文件
为 GUI 创建可执行文件与为命令行应用程序创建略有不同。原因是 GUI 是主界面,PyInstaller 的默认界面是用户将使用命令提示符或控制台窗口。如果您运行在上一节中学习的 PyInstaller 命令,它将成功创建您的可执行文件。但是,当您使用可执行文件时,除了 GUI 之外,您还会看到一个命令提示符。
你通常不想这样。要抑制命令提示符,您需要使用--noconsole标志。
为了测试这是如何工作的,从 Python 101:第二版的第 42 章中获取用 wxPython 创建的图像查看器的代码。为了方便起见,下面是代码:
# image_viewer.py
import wx
class ImagePanel(wx.Panel):
def __init__(self, parent, image_size):
super().__init__(parent)
self.max_size = 240
img = wx.Image(*image_size)
self.image_ctrl = wx.StaticBitmap(self,
bitmap=wx.Bitmap(img))
browse_btn = wx.Button(self, label='Browse')
browse_btn.Bind(wx.EVT_BUTTON, self.on_browse)
self.photo_txt = wx.TextCtrl(self, size=(200, -1))
main_sizer = wx.BoxSizer(wx.VERTICAL)
hsizer = wx.BoxSizer(wx.HORIZONTAL)
main_sizer.Add(self.image_ctrl, 0, wx.ALL, 5)
hsizer.Add(browse_btn, 0, wx.ALL, 5)
hsizer.Add(self.photo_txt, 0, wx.ALL, 5)
main_sizer.Add(hsizer, 0, wx.ALL, 5)
self.SetSizer(main_sizer)
main_sizer.Fit(parent)
self.Layout()
def on_browse(self, event):
"""
Browse for an image file
@param event: The event object
"""
wildcard = "JPEG files (*.jpg)|*.jpg"
with wx.FileDialog(None, "Choose a file",
wildcard=wildcard,
style=wx.ID_OPEN) as dialog:
if dialog.ShowModal() == wx.ID_OK:
self.photo_txt.SetValue(dialog.GetPath())
self.load_image()
def load_image(self):
"""
Load the image and display it to the user
"""
filepath = self.photo_txt.GetValue()
img = wx.Image(filepath, wx.BITMAP_TYPE_ANY)
# scale the image, preserving the aspect ratio
W = img.GetWidth()
H = img.GetHeight()
if W > H:
NewW = self.max_size
NewH = self.max_size * H / W
else:
NewH = self.max_size
NewW = self.max_size * W / H
img = img.Scale(NewW,NewH)
self.image_ctrl.SetBitmap(wx.Bitmap(img))
self.Refresh()
class MainFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='Image Viewer')
panel = ImagePanel(self, image_size=(240,240))
self.Show()
if __name__ == '__main__':
app = wx.App(redirect=False)
frame = MainFrame()
app.MainLoop()
要将其转换为可执行文件,您可以运行以下 PyInstaller 命令:
pyinstaller.exe image_viewer.py --noconsole
请注意,在这里使用--onefile标志的是而不是。Windows Defender 会将使用--onefile创建的 GUI 标记为恶意软件并将其删除。您可以通过不使用--onefile标志或对可执行文件进行数字签名来解决这个问题。从 Windows 10 开始,所有 GUI 应用程序都需要签名,否则将被视为恶意软件。
微软有一个签名工具你可以使用,但是你需要购买一个数字证书或者用 Makecert 、一个. NET 工具或者类似的东西创建一个自签名证书。
包扎
用 Python 创建可执行文件有很多不同的方法。在本文中,您使用了 PyInstaller。您了解了以下主题:
- 安装 PyInstaller
- 为命令行应用程序创建可执行文件
- 为 GUI 创建可执行文件
PyInstaller 有许多其他标志,您可以使用它们在生成可执行文件时修改其行为。如果你在 PyInstaller 上遇到问题,有一个邮件列表可以帮助你。或者你可以在谷歌和 StackOverflow 上搜索。出现的大多数常见问题都包含在 PyInstaller 文档中,或者很容易通过在线搜索发现。
|  | 您想了解更多关于 Python 的知识吗?
| 您想了解更多关于 Python 的知识吗?
Python 101 -第二版
立即在 Leanpub 或亚马逊 购买
|
PyLint:分析 Python 代码
原文:https://www.blog.pythonlibrary.org/2012/06/12/pylint-analyzing-python-code/
Python 代码分析可能是一个沉重的主题,但它对改进您的程序非常有帮助。有几个 Python 代码分析器可以用来检查您的代码,看看它们是否符合标准。pylint 可能是最受欢迎的。它的可配置性、可定制性和可插拔性都很强。它还检查你的代码是否符合 Python Core 的官方风格指南 PEP8 ,并且它还寻找编程错误。我们将花几分钟时间来看看您可以用这个方便的工具做些什么。
入门指南
遗憾的是,pylint 没有包含在 Python 中,所以你需要从 Logilab 或 PyPI 下载。如果您安装了 pip,那么您可以像这样安装它:
pip install pylint
现在您应该已经安装了 pylint 及其所有依赖项。现在我们准备好出发了!
分析你的代码
撰写本文时的最新版本是 0.25.1。一旦安装了 pylint,您就可以在命令行上不带任何参数地运行它,以查看它接受哪些选项。现在我们需要一些代码来测试。由于我去年为我的 PyChecker 文章写了一些糟糕的代码,我们将在这里重用它们,看看 pylint 是否会发现同样的问题。应该有四个问题。代码如下:
import sys
########################################################################
class CarClass:
""""""
#----------------------------------------------------------------------
def __init__(self, color, make, model, year):
"""Constructor"""
self.color = color
self.make = make
self.model = model
self.year = year
if "Windows" in platform.platform():
print "You're using Windows!"
self.weight = self.getWeight(1, 2, 3)
#----------------------------------------------------------------------
def getWeight(this):
""""""
return "2000 lbs"
现在让我们对这段代码运行 pylint,看看它会发现什么。您应该会得到如下所示的内容:
C:\Users\mdriscoll\Desktop>pylint crummy_code.py No config file found, using default configuration ************* Module crummy_code C: 1,0: Missing docstring C: 4,0:CarClass: Empty docstring E: 15,24:CarClass.__init__: Undefined variable 'platform' E: 18,22:CarClass.__init__: Too many positional arguments for function call E: 21,4:CarClass.getWeight: Method should have "self" as first argument C: 21,4:CarClass.getWeight: Invalid name "getWeight" (should match [a-z_][a-z0-9 _]{2,30}$) C: 21,4:CarClass.getWeight: Empty docstring R: 21,4:CarClass.getWeight: Method could be a function R: 4,0:CarClass: Too few public methods (1/2) W: 1,0: Unused import sys
报告
= = = = =
分析了 13 个报表。
按类别分类的消息
+---+--+
| type | number | previous | difference |
+= = = = = = = = = = = = = = = = =+= = = = = = = = = = = = = = = = = =+
|约定| 4 | NC | NC |
+---+----+
|重构| 2 | NC | NC |
+----+
|警告| 1 | NC | NC |
+-----+--+--+
消息
+--+
|消息 id |出现次数|
+= = = = = = = = = = = = = = = = = = = = =+
| c 0112 | 2 |
+---+
| w 0611 | 1 |
+--+
+--+
| 1 |+-+
| r 0201 | 1 |
+-+-+
| e 1121 | 1 |
。
+--+
| c 0111 | 1 |
+--+
| c 0103 | 1 |
+-+-+
全局评估
您的代码被评为-6.92/10
按类型统计
+--+--+---+--+
|类型|编号|旧编号|差异| %已记录| % bad name |
+= = = = = = = = = = = = = = = =+= = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = =+= = = = = = = = = = = =+
|模块| 1 | NC | NC | NC | 0.00 | 0.00 |
+---+----+--+----+-+-+
|类| 1 | NC | NC | NC | 0
+-+-+-+-+-+
|函数| 0 | NC | NC | 0 |
+-+-+-+-+-+
原始指标
+---+--+--+
| type | number | % | previous | difference |
+= = = = = = = = = =+= = = = = = = = = = = = = = = = = = = = = = =+= = = = = = =+
| code | 12 | 63.16 | NC | NC |
+---+-+--+
| docstring | 4 | 21.05 | NC |
+-----+---+---+--+--+--+-+-+
。
重复
+--+--+--+
| |现在|以前|差别|
+= = = = = = = = = = = = = = = = = = = = = =+= = = = = = = = = = = =+= = = = = = = =+
| nb 重复行| 0 | NC | NC |
+---+--+-+
|百分比重复行| 0.000 | NC | NC |
+-------+--+
如果您想知道 Messages 部分中的这些项目的含义,您可以通过在命令行上执行以下操作让 pylint 告诉您:
pylint --help-msg=C0112
然而,我们实际上只关心报告的第一部分,因为其余部分基本上只是以更模糊的方式显示相同信息的表格。让我们更仔细地看看这一部分:
C: 1,0: Missing docstring C: 4,0:CarClass: Empty docstring E: 15,24:CarClass.__init__: Undefined variable 'platform' E: 18,22:CarClass.__init__: Too many positional arguments for function call E: 21,4:CarClass.getWeight: Method should have "self" as first argument C: 21,4:CarClass.getWeight: Invalid name "getWeight" (should match [a-z_][a-z0-9 _]{2,30}$) C: 21,4:CarClass.getWeight: Empty docstring R: 21,4:CarClass.getWeight: Method could be a function R: 4,0:CarClass: Too few public methods (1/2) W: 1,0: Unused import sys
首先我们需要弄清楚字母代表什么:C 代表约定,R 代表重构,W 代表警告,E 代表错误。pylint 发现了 3 个错误、4 个约定问题、2 行值得重构的代码和 1 个警告。这 3 个错误加上警告正是我想要的。我们应该努力让这个糟糕的代码变得更好,减少问题的数量。我们将修复导入并将 getWeight 函数改为 get_weight,因为 camelCase 不允许用于方法名。我们还需要修复对 get_weight 的调用,以便它传递正确数量的参数,并修复它,以便它将“self”作为第一个参数。下面是新代码:
# crummy_code_fixed.py
import platform
########################################################################
class CarClass:
""""""
#----------------------------------------------------------------------
def __init__(self, color, make, model, year):
"""Constructor"""
self.color = color
self.make = make
self.model = model
self.year = year
if "Windows" in platform.platform():
print "You're using Windows!"
self.weight = self.get_weight(3)
#----------------------------------------------------------------------
def get_weight(self, this):
""""""
return "2000 lbs"
让我们对 pylint 运行一下,看看我们对结果的改进有多大。为简洁起见,我们只展示下面的第一部分:
C:\Users\mdriscoll\Desktop>pylint crummy_code_fixed.py No config file found, using default configuration ************* Module crummy_code_fixed C: 1,0: Missing docstring C: 4,0:CarClass: Empty docstring C: 21,4:CarClass.get_weight: Empty docstring W: 21,25:CarClass.get_weight: Unused argument 'this' R: 21,4:CarClass.get_weight: Method could be a function R: 4,0:CarClass: Too few public methods (1/2)
那帮了大忙!如果我们添加 docstrings,我们可以将问题的数量减半。
包扎
下一步将是尝试对您自己的一些代码或像 SQLAlchemy 这样的 Python 包运行 pylint,看看会得到什么输出。使用这个工具,您可以学到很多关于您自己的代码的知识。如果你有 Wingware 的 Python IDE,你可以安装 pylint 作为一个工具,只需点击几下鼠标就可以运行。你可能会发现有些警告很烦人,甚至不太适用。有一些方法可以通过命令行选项来抑制诸如不推荐使用警告这样的事情。或者您可以使用 - generate-rcfile 来创建一个示例配置文件,帮助您控制 pylint。注意,pylint 不会导入您的代码,所以您不必担心不良副作用。
此时,您应该准备好开始改进您自己的代码库。向前迈进,让您的代码令人惊叹!
进一步阅读
- PyLint 官网
- 我在 PyChecker 上的文章
- PyChecker 官方网站(与 PyLint 类似的项目)
- 另一个类似的项目
- 来自 Python 杂志的 Doug Hellman 对 Python 静态代码分析器的评论
py OWA-2010 年 7 月总结
原文:https://www.blog.pythonlibrary.org/2010/07/03/pyowa-july-2010-wrapup/
七月一日星期四,我们举行了七月派瓦会议。它是由马特·莫瑞森在 T2 IMT T3 集团位于爱荷华州得梅因的大楼里举办的。我们有史以来最大的出席人数,共有 15 人出席。酒馆披萨和汽水被端上来,这也是第一次...我们以前吃过汽水,但不是食物!
我们有两个演示。第一篇大约 70 分钟,介绍了关于用 Python 编写的全栈 web 框架 Django 的介绍材料。它是由我们的主持人提供的,他还讲述了他的公司如何使用 Django 以及给他带来了哪些挑战的趣闻。接下来,我们简单谈了一下另一个 web 框架 TurboGears 。TurboGears 实际上是拼凑起来的各种 Python 模块的集合,这使得它比 Django 模块化得多。然而,Django 背后有更多的用户,内置所有东西肯定有一些好处。无论如何,TurboGears 演示涵盖了演示者创建的一组不同的网站(或 web 应用程序)。比较和对比这两个框架,看看它们是如何不同还是相同,这很有意思。
我们目前正在为我们 8 月和 9 月的会议寻找演示者,所以如果你想谈谈你现在、过去是如何使用 Python 的,或者你将来打算用它做什么,请给我发电子邮件或在评论中告诉我!
Pyowa 会议(2017 年 2 月)
原文:https://www.blog.pythonlibrary.org/2017/02/08/pyowa-meeting-feb-2017/
当地的 Python 用户组 Pyowa 在经历了一年半的冬眠之后,于昨晚重新启动。我已经有几年没去参加他们的会议了,但我在 2016 年底决定让它重新开始。一旦开始,我们就收到了会议的多个赞助提议,并最终选择了 Pillar Technology 作为我们 2017 年第一次会议的赞助商。他们称他们的空间为铁匠铺,并提供披萨和点心。它们位于得梅因市中心。
包括 Pillar 的工作人员在内,大约有 23 人到场。我们的演讲者是来自先锋公司的杰西·霍恩,他谈到了 Chalice ,一个用于 AWS(亚马逊网络服务)的 Python 无服务器微框架。圣杯是一种轻量的瓶子。Jesse 最终编写了一个非常基本的图书数据库 web 应用程序。虽然有一些技术问题,但观众非常支持和帮助,我认为会议进行得相当顺利。甚至有一个机器人四处游荡,由 Pillar 的一名员工远程控制。
下一次会议目前安排在 3 月 7 日@先锋。关注 Pyowa 网站的更新,获取最新信息。
2009 年 2 月的 Pyowa 会议
原文:https://www.blog.pythonlibrary.org/2009/01/31/pyowa-meeting-for-february-2009/
在上次的爱荷华 Python 用户组会议上,我们决定发起一项调查,看看我们能做些什么来吸引更多的人加入我们的小组。这些回答让我们决定尝试一个不同的时间表。我们将试着每隔一个月,在一周的不同时间,在不同地点会面。
因此,我们的下一次会议将于 2 月 5 日星期四在爱荷华州的埃姆斯举行。完整的细节在我们上面链接的网站上。从我们目前收到的电子邮件来看,似乎会有比以往更多的消息。我们在会议上的主要焦点将是团队合作解决各种常见的计算机科学问题,例如转换数值、I/O、输出格式等。
如果你打算参加我们的会议,请让我知道,因为我们的空间有限。我希望在那里见到你。
py OWA-2009 年 10 月会议总结
原文:https://www.blog.pythonlibrary.org/2009/10/02/pyowa-october-2009-meeting-wrap-up/
昨晚我们举行了十月派瓦会议,我认为这很有趣。我们请到了一家名为 Priority5 的当地技术公司的高管,他告诉我们他是如何开始使用 Python 的,以及他们如何在他目前的雇主那里使用 Python。我们还讨论了 Optparse、ConfigParser 和 ConfigObj。
这位 Priority5 的代表使用了一个看起来像 Touchsmart 的惠普触摸屏(类似于这个)来演示他公司最酷的项目之一。不幸的是,这是一个用于国防的产品,所以我们不能记录演示。总之,他说这个产品(它看起来像一个地球仪,你可以用它缩小到街道的高度)是用 C++做底层,用 Python 做高层。
GUI 是用 pyQT 创建的,而互联网连接是用 Twisted 完成的。他们使用 SqlAlchemy 作为他们的 ORM。他告诉我们他们如何使用 pySerial 对其中一个触摸屏上的串行端口进行逆向工程。他还提到了他的组织如何通过贡献补丁来帮助 pyQT & Twisted,以及他们如何帮助开发 Py++ 。他们还使用 SCons 进行构建,使用 Trac 进行 bug 跟踪(最后一个可能是他在以前的组织中使用的)...在那一点上他不是很清楚)。
看着他在华盛顿 DC 的街道上拉近镜头,看着摄像机的实时画面,真是有趣。当演讲者开始阐述该系统如何在总统就职典礼或其他重要活动中使用,或者只是听听他们的程序如何模拟工作时,演讲也非常有趣。
接下来的演示是关于 Python 的标准库加上第三方包,即 Optparse 、 ConfigParser 和 ConfigObj 。虽然这次谈话本身很好,但与第一次相比就相形见绌了。我们应该颠倒会谈的顺序。无论如何,他使用了爱荷华州的地理信息系统库来说明这个例子。
虽然我们只有 6 个人参加这个会议,但我想我们都有所收获。希望下次会有更多。说到这里,下一次会议将于 2009 年 11 月 2 日星期一下午 7-9 点在马歇尔郡治安官办公室举行。详情请访问 Pyowa 官方网站了解!
py OWA-2010 年 9 月总结
原文:https://www.blog.pythonlibrary.org/2010/09/03/pyowa-september-2010-wrap-up/
这是写给所有错过我们聚会的 Pyowa 家男孩的。我们不知道你们这些居家男人为什么不来和我们一起逛逛,聊聊生意,但我们认为你们真的错过了我们的聚会。我们有大约 10 个真正的朋友来听 jibber jabber 谈论 South,一个 Django 数据迁移工具。我们应该也听说过 SWIG,但是最后我们喝了汽水(或者你们南方人喝的汽水),吃了免费的披萨。
下一次,我们将在埃姆斯公共图书馆预定它(你猜对了!)10 月 7 日,星期四,爱荷华州埃姆斯。如果你认为你有能力谈论 Python,给我写封短信,我会帮你联系的。
Pyowa:爱荷华 Python 用户组
原文:https://www.blog.pythonlibrary.org/2010/05/05/pyowa-the-iowa-python-users-group/
自从我写了关于我创建的爱荷华 Python 用户组 Pyowa 已经有一段时间了。我们的第一次会面是在 2008 年 9 月 24 日,我对这个团队寄予厚望。但是,差不多两年了,根本没怎么长。出于某种原因,我们的会议安排到今年 7 月。我们的会议上有 3-10 个人,平均 4-5 个人。我们的下一次会议是明天,5 月 6 日,在爱荷华州的埃姆斯。我们将于晚上 7-8:45 在埃姆斯公共图书馆会面。以下是我们将要报道的内容:
如果你认为你能来,请在评论中告诉我或者发邮件给我。如果你有办法让更多的人出现,请告诉我。我可以用一些更好的主意。我希望在那里见到你!
PyPdf:如何将 Pdf 写入内存
原文:https://www.blog.pythonlibrary.org/2013/07/16/pypdf-how-to-write-a-pdf-to-memory/
在我的工作中,我们有时需要将 PDF 写入内存而不是磁盘,因为我们需要将一个覆盖图合并到它上面。通过写入内存,我们可以加快这个过程,因为我们没有额外的步骤将文件写入磁盘,然后再将它读回内存。遗憾的是,pyPdf 的 PdfFileWriter()类不支持提取二进制字符串,所以我们只能用 StringIO 来代替。这里有一个例子,我将两个 pdf 合并到内存中:
import pyPdf
from StringIO import StringIO
#----------------------------------------------------------------------
def mergePDFs(pdfOne, pdfTwo):
"""
Merge PDFs
"""
tmp = StringIO()
output = pyPdf.PdfFileWriter()
pdfOne = pyPdf.PdfFileReader(file(pdfOne, "rb"))
for page in range(pdfOne.getNumPages()):
output.addPage(pdfOne.getPage(page))
pdfTwo = pyPdf.PdfFileReader(file(pdfTwo, "rb"))
for page in range(pdfTwo.getNumPages()):
output.addPage(pdfTwo.getPage(page))
output.write(tmp)
return tmp.getvalue()
if __name__ == "__main__":
pdfOne = '/path/to/pdf/one'
pdfTwo = '/path/to/pdf/two'
pdfObj = mergePDFs(pdfOne, pdfTwo)
如您所见,您需要做的就是创建一个 StringIO ()对象,向 PdfFileWriter ()对象添加一些页面,然后将数据写入 StringIO 对象。然后要提取二进制字符串,就得调用 StringIO 的 getvalue ()方法。简单吧?现在你在内存中有了一个类似文件的对象,你可以用它来添加更多的页面或者覆盖 OMR 标记等等。
相关文章
- 用 Python 和 pyPdf 操作 Pdf
- pyPdf 2:pyPdf 的新分支
pyPdf 2:pyPdf 的新分支
原文:https://www.blog.pythonlibrary.org/2012/07/11/pypdf2-the-new-fork-of-pypdf/
今天我得知 pyPDF 项目并没有像我最初认为的那样死去。事实上,它已经被分为 PyPDF2(注意拼写略有不同)。也有可能其他人已经接管了最初的 pyPDF 项目并正在积极地工作。如果你愿意,你可以在 reddit 上关注这些。与此同时,我决定试一试 PyPDF2,看看它与原版有什么不同。如果你有一两个空闲时间,请随意跟随。
PyPDF2 简介
我最初在两年前写了关于 pyPDF 的文章,最近我一直在深入研究各种 Python PDF 相关的库,所以偶然发现 pyPDF 的一个新分支是非常令人兴奋的。我们将采用我的一些旧示例,并在新的 PyPDF2 中运行它们,看看它们是否以相同的方式工作。
# Merge two PDFs
from PyPDF2 import PdfFileReader, PdfFileWriter
output = PdfFileWriter()
pdfOne = PdfFileReader(file( "some\path\to\a\PDf", "rb"))
pdfTwo = PdfFileReader(file("some\other\path\to\a\PDf", "rb"))
output.addPage(pdfOne.getPage(0))
output.addPage(pdfTwo.getPage(0))
outputStream = file(r"output.pdf", "wb")
output.write(outputStream)
outputStream.close()
这在我的 Windows 7 机器上运行得非常好。正如您可能已经猜到的,代码所做的只是创建 PdfFileReader 对象,并读取每个对象的第一页。接下来,它将这两个页面添加到我们的 PdfFileWriter 中。最后,我们打开一个新文件,写出我们的 PDF 页面。就是这样!您刚刚从两个单独的 pdf 创建了一个新文档!
现在让我们试试我的另一篇文章中的页面旋转脚本:
from PyPDF2 import PdfFileWriter, PdfFileReader
output = PdfFileWriter()
input1 = PdfFileReader(file("document1.pdf", "rb"))
output.addPage(input1.getPage(1).rotateClockwise(90))
# output.addPage(input1.getPage(2).rotateCounterClockwise(90))
outputStream = file("output.pdf", "wb")
output.write(outputStream)
outputStream.close()
那也在我的机器上工作。到目前为止一切顺利。我对奇偶校验的最后一个测试是看它是否能提取与原始 pyPdf 相同的数据。我们将尝试从最新的 Reportlab 用户手册中读取元数据:
>>> from PyPDF2 import PdfFileReader
>>> p = r'C:\Users\mdriscoll\Documents\reportlab-userguide.pdf'
>>> pdf = PdfFileReader(open(p, 'rb'))
>>> pdf.documentInfo
{'/ModDate': u'D:20120629155504', '/CreationDate': u'D:20120629155504', '/Producer': u'GPL Ghostscript 8.15', '/Title': u'reportlab-userguide.pdf', '/Creator': u'Adobe Acrobat 10.1.3', '/Author': u'mdriscoll'}
>>> pdf.getNumPages()
120
>>> info = pdf.getDocumentInfo()
>>> info.author
u'mdriscoll'
>>> info.creator
u'Adobe Acrobat 10.1.3'
>>> info.producer
u'GPL Ghostscript 8.15'
>>> info.title
u'reportlab-userguide.pdf'
这一切看起来都很好,除了作者那一点。我当然不是那份文件的作者,我也不知道为什么它认为我是。否则,它看起来工作正常。现在让我们来看看有什么新内容!
PyPDF2 中的新增功能
在查看 PyPDF2 的源代码时,我注意到的第一件事是它为 PdfFileReader 和 PdfFileWriter 添加了一些新方法。我还注意到有一个全新的模块叫做 merger.py ,它包含了类:PdfFileMerger。因为在撰写本文时没有真正的文档,所以让我们看一看幕后的情况。添加到阅读器中的唯一新方法是 getOutlines ,它检索文档大纲(如果存在的话)。在 writer 中,支持添加书签和命名目的地。不多,但是要饭的不能挑肥拣瘦。我认为我最兴奋的部分是新的 PdfFileMerger 类,它让我想起了死去的订书机项目。PDF merger 允许程序员通过连接、切片、插入或三者的任意组合将多个 PDF 合并成一个 PDF。
让我们用几个示例脚本来尝试一下,好吗?
import PyPDF2
path = open('path/to/hello.pdf', 'rb')
path2 = open('path/to/another.pdf', 'rb')
merger = PyPDF2.PdfFileMerger()
merger.merge(position=0, fileobj=path2)
merger.merge(position=2, fileobj=path)
merger.write(open("test_out.pdf", 'wb'))
这是将两个文件合并在一起。第一个将从第 3 页开始插入第二个文件(注意逐个插入),并在插入后继续。这比遍历两个文档的页面并将它们放在一起要容易得多。 merge 命令有以下签名和文档字符串,这很好地概括了它:
>>> merge(position, file, bookmark=None, pages=None, import_bookmarks=True)
Merges the pages from the source document specified by "file" into the output
file at the page number specified by "position".
Optionally, you may specify a bookmark to be applied at the beginning of the
included file by supplying the text of the bookmark in the "bookmark" parameter.
You may prevent the source document's bookmarks from being imported by
specifying "import_bookmarks" as False.
You may also use the "pages" parameter to merge only the specified range of
pages from the source document into the output document.
还有一个 append 方法,它与 merge 命令相同,只是它假设您想要将所有页面追加到 PDF 的末尾。为了完整起见,这里有一个示例脚本:
import PyPDF2
path = open('path/to/hello.pdf', 'rb')
path2 = open('path/to/another.pdf', 'rb')
merger = PyPDF2.PdfFileMerger()
merger.append(fileobj=path2)
merger.append(fileobj=path)
merger.write(open("test_out2.pdf", 'wb'))
这是相当无痛的,也非常好!
包扎
我想我已经为 PDF 黑客找到了一个很好的替代方案。我可以用 PyPDF2 合并和拆分 PDF,比使用原始 PyPDF 更容易。我也希望 PyPDF 能坚持下去,因为它有一个赞助者付钱给人们来开发它。根据 reddit 的帖子,最初的 pyPdf 有可能会复活,这两个项目可能会一起工作。不管发生什么,我只是很高兴它又回到了开发阶段,并希望能保持一段时间。让我知道你对这个话题的想法。
进一步阅读
- github 上的 PyPDF2 源代码库
- PyPDF2 网站也在 github 上
- 我看到的关于 PyPDF2 的两个 reddit 线程:线程一和线程二
- 用 Python 和 pyPdf 操作 Pdf
用单个文件运行 Python
原文:https://www.blog.pythonlibrary.org/2014/06/19/pyrun-running-python-with-a-single-file/
eGenix 本周宣布,他们将发布一个“开源、一个文件、无安装版本的 Python”。你可以在这里阅读他们的新闻稿中的全部声明。如果你想看看实际的产品,你可以在以下网址得到它:【http://www.egenix.com/products/python/PyRun/。
这是一个基于 Unix 的 Python,他们声明他们只提供 Linux,FreeBSD 和 Mac OS X,作为 32 位和 64 位版本,所以如果你是一个 Windows 的家伙,你就不走运了。我认为这个工具最酷的一个方面是 Python 2 的 11MB 和 Python 3 的 13MB,但它仍然支持大多数 Python 应用程序和您编写的代码。如果你写了很多依赖于第三方工具的代码,那么我不认为 PyRun 会对你有很大帮助。但是如果你主要依赖 Python 的标准库,那么我认为这是一个非常方便的工具。
PyRun 的一个替代方案是 Portable Python ,它提供了大量的第三方库,这些库与标准库结合在一起。我已经在我自己的几个应用程序中使用了 Portable Python,在这些应用程序中我不想安装 Python 本身。无论如何,我希望这些信息对你自己的努力有用。
PySide:将多个小部件连接到同一个插槽
原文:https://www.blog.pythonlibrary.org/2013/04/10/pyside-connecting-multiple-widgets-to-the-same-slot/
当我学习 PyQt 和 PySide 时,我正在写一些教程来帮助我的同路人。今天我们将看看如何将多个小部件连接到同一个插槽。换句话说,我们将把窗口小部件信号(基本上是事件)绑定到插槽(也就是像函数、方法这样的可调用程序),它们更好地被称为“事件处理程序”。是的,我知道在皮赛德郡你不这么叫它。这是一个插槽,而不是一个事件处理程序。但是我跑题了。无论如何,有两种方法可以解决这个问题。一种是使用 functools 及其分部类来传递参数,或者使用 PySide 的内省功能从执行调用的小部件中获取信息。实际上至少还有一种方法与 functools.partial 非常相似,那就是使用臭名昭著的匿名函数实用程序 lambda。我们来看看这些方法都是怎么做到的!
入门指南
如果你还没有 PySide,那就出去买吧。如果您想在 PyQt 上尝试,请确保您的 PyQt 版本是 4.3 或更高版本,因为下面示例应用程序中的第一个 partial 示例在以前版本的 PyQt 上无法工作。你可以在这里得到 py side。一旦你做好了一切准备,继续阅读下面的代码:
from functools import partial
from PySide.QtCore import SIGNAL
from PySide.QtGui import QApplication, QLabel, QWidget
from PySide.QtGui import QPushButton, QVBoxLayout
########################################################################
class MultiButtonDemo(QWidget):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
super(MultiButtonDemo, self).__init__()
layout = QVBoxLayout()
self.label = QLabel("You haven't pressed a button!")
# use a normal signal / slot mechanic
button1 = QPushButton("One")
self.connect(button1, SIGNAL("clicked()"), self.one)
# now let's use partial functions
button2 = QPushButton("Two")
self.connect(button2, SIGNAL("clicked()"),
partial(self.onButton, "Two"))
button3 = QPushButton("Three")
self.btn3Callback = partial(self.onButton, "Three")
button3.clicked.connect(self.btn3Callback)
# now let's try using a lambda function
button4 = QPushButton("Four")
button4.clicked.connect(lambda name="Four": self.onButton(name))
layout.addWidget(self.label)
layout.addWidget(button1)
layout.addWidget(button2)
layout.addWidget(button3)
layout.addWidget(button4)
self.setLayout(layout)
self.setWindowTitle("PySide Demo")
#----------------------------------------------------------------------
def one(self):
""""""
self.label.setText("You pressed One!")
#----------------------------------------------------------------------
def onButton(self, lbl):
"""Change the label to the text (lbl) passed in"""
self.label.setText("You pressed %s!" % lbl)
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QApplication([])
form = MultiButtonDemo()
form.show()
app.exec_()
让我们花点时间来分析一下。我们子类化 QWidget 来创建我们的窗口。然后,我们使用 QVBoxLayout 在垂直行中布局我们的小部件。接下来,我们创建一个标签和四个按钮。我们挂接到事件处理程序的第一个按钮是以正常方式完成的。在 one 处理程序中,它只是更新标签说“你按了一个!”。您可以对其他 3 个按钮这样做,但这不是本文的重点。相反,我们使用 Python 的 functools 库,它有一个非常方便的分部类。partial 类允许开发人员创建一个可调用的,你可以给你的 PySide 信号。第一个示例创建了一个其他任何对象都无法访问的分部可调用对象。partial 的第二个例子(按钮 3)被分配给一个类变量, self.btn3Callback ,然后你可以把它赋予你的信号。最后一个例子(按钮 4)展示了如何做与 partial 相同的事情,但是使用 Python 的 lambda。最后一种方法在 Tkinter GUI 工具包中特别流行。
现在我们准备了解如何让 PySide 本身告诉我们哪个按钮向插槽发送信号。
如何让 PySide 说出一切
实际上,我们将对代码进行一点重构,以使代码更短,并向您展示布局小部件的另一种方式。这一次,我们还将所有按钮连接到一个插槽(即事件处理程序/可调用程序)。代码如下:
from PySide.QtCore import SIGNAL
from PySide.QtGui import QApplication, QLabel, QWidget
from PySide.QtGui import QPushButton, QVBoxLayout
########################################################################
class MultiButtonDemo(QWidget):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
super(MultiButtonDemo, self).__init__()
layout = QVBoxLayout()
self.label = QLabel("You haven't pressed a button!")
layout.addWidget(self.label)
labels = ["One", "Two", "Three", "Four"]
for label in labels:
btn = QPushButton(label)
btn.clicked.connect(self.clicked)
layout.addWidget(btn)
self.setLayout(layout)
self.setWindowTitle("PySide Signals / Slots Demo")
#----------------------------------------------------------------------
def clicked(self):
"""
Change label based on what button was pressed
"""
button = self.sender()
if isinstance(button, QPushButton):
self.label.setText("You pressed %s!" % button.text())
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QApplication([])
form = MultiButtonDemo()
form.show()
app.exec_()
好了,现在导入稍微短了一点,因为我们不再需要 functools 了。在下面的 init 中,我们创建了一个按钮标签列表,然后遍历它们来创建四个按钮。在循环中,我们还将按钮连接到 callable(或将信号连接到 slot ),并将小部件添加到布局管理器。根据《用 Python 和 PyQt 进行快速 GUI 编程》的作者马克·萨默菲尔德在他的书中所说,callable (slot)应该和 signal 一样命名,因为这是 PyQt 的惯例。我猜这也是皮赛德的惯例,所以我们会坚持下去。
在我们的 clicked 方法/signal/callable/whatever 中,我们使用 self.sender() 从调用该方法的任何对象中获取按钮对象。然后,为了安全起见,我们确保发送者是 QPushButton 的一个实例,如果是,那么我们通过它的 text() 调用获取按钮的标签,并适当地设置标签。就是这样!又短又甜!
包扎
现在,您知道了几种向插槽/处理程序传递参数的方法。您还学习了如何询问 PySide 哪个小部件调用了 callable。现在你可以出去自己写一些很酷的东西了。
附加阅读
- Python 关于 functools.partial 的文档
- Python Lambda
- wxPython: 将多个小部件绑定到同一个处理程序
- wxPython wiki - 向回调传递参数
下载源代码
PySide:创建货币转换器
原文:https://www.blog.pythonlibrary.org/2013/04/09/pyside-creating-a-currency-converter/
我目前正在通读 Mark Summerfield 关于 PyQt 的书,用 Python 和 Qt 进行快速 GUI 编程,我认为将其中的一些示例应用程序转换成 PySide 会很有趣。因此,我将撰写一系列文章,展示书中的原始 PyQt 示例,然后将它们转换成 PySide,并可能在代码中添加一些我自己的东西。直到第 4 章作者创建了一个有趣的小货币转换器,这本书才真正开始 Qt GUI 编码。一起来享受乐趣吧!
以下是大部分原始代码:
import sys
import urllib2
from PyQt4.QtCore import SIGNAL
from PyQt4.QtGui import QComboBox, QDialog, QDoubleSpinBox, QLabel
from PyQt4.QtGui import QApplication, QGridLayout
########################################################################
class CurrencyDlg(QDialog):
""""""
#----------------------------------------------------------------------
def __init__(self, parent=None):
"""Constructor"""
super(CurrencyDlg, self).__init__(parent)
date = self.getdata()
rates = sorted(self.rates.keys())
dateLabel = QLabel(date)
self.fromComboBox = QComboBox()
self.fromComboBox.addItems(rates)
self.fromSpinBox = QDoubleSpinBox()
self.fromSpinBox.setRange(0.01, 10000000.00)
self.fromSpinBox.setValue(1.00)
self.toComboBox = QComboBox()
self.toComboBox.addItems(rates)
self.toLabel = QLabel("1.00")
# layout the controls
grid = QGridLayout()
grid.addWidget(dateLabel, 0, 0)
grid.addWidget(self.fromComboBox, 1, 0)
grid.addWidget(self.fromSpinBox, 1, 1)
grid.addWidget(self.toComboBox, 2, 0)
grid.addWidget(self.toLabel, 2, 1)
self.setLayout(grid)
# set up the event handlers
self.connect(self.fromComboBox, SIGNAL("currentIndexChanged(int)"),
self.updateUi)
self.connect(self.toComboBox, SIGNAL("currentIndexChanged(int)"),
self.updateUi)
self.connect(self.fromSpinBox, SIGNAL("valueChanged(double)"),
self.updateUi)
self.setWindowTitle("Currency")
#----------------------------------------------------------------------
def getdata(self):
"""
"""
self.rates = {}
url = "http://www.bankofcanada.ca/en/markets/csv/exchange_eng.csv"
try:
date = None
fh = urllib2.urlopen(url)
for line in fh:
line = line.rstrip()
if not line or line.startswith(("#", "Closing ")):
continue
fields = line.split(",")
if line.startswith("Date "):
date = fields[-1]
else:
try:
value = float(fields[-1])
self.rates[unicode(fields[0])] = value
except ValueError:
pass
return "Exchange Rates Date: " + date
except Exception, e:
return "Failed to download: \n%s" % e
#----------------------------------------------------------------------
def updateUi(self):
"""
Update the user interface
"""
to = unicode(self.toComboBox.currentText())
frum = unicode(self.fromComboBox.currentText())
amount = ( self.rates[frum] / self.rates[to] )
amount *= self.fromSpinBox.value()
self.toLabel.setText("%0.2f" % amount)
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QApplication(sys.argv)
form = CurrencyDlg()
form.show()
app.exec_()
如果你真的想知道这些代码是如何工作的,我推荐你去阅读前面提到的书或者研究这些代码。毕竟是 Python。
移植到 PySide
现在我们需要将它“移植”到 PySide ,Python 的 QT 绑定的 LGPL 版本。幸运的是,在这个例子中这是非常容易的。您所要做的就是更改以下导入
from PyQt4.QtCore import SIGNAL
from PyQt4.QtGui import QComboBox, QDialog, QDoubleSpinBox, QLabel
from PyQt4.QtGui import QApplication, QGridLayout
到
from PySide.QtCore import SIGNAL
from PySide.QtGui import QComboBox, QDialog, QDoubleSpinBox
from PySide.QtGui import QApplication, QGridLayout, QLabel
如果您这样做并保存它,您就完成了移植,代码现在可以在 PySide land 中工作了。然而,我认为我们需要更进一步,让这些代码更智能一些。您会注意到,在最初的版本中,每次运行该应用程序时,它都会上线并下载汇率数据。这似乎有点矫枉过正,所以让我们添加一个检查,看看它是否已经下载并且不到一天。只有超过一天,我们才会想下载新的副本。我们不使用 urllib2,而是使用新的请求库。
下面是新代码:
import datetime
import os
import PySide
import requests
import sys
from PySide.QtCore import SIGNAL
from PySide.QtGui import QComboBox, QDialog, QDoubleSpinBox
from PySide.QtGui import QApplication, QGridLayout, QLabel
########################################################################
class CurrencyDlg(QDialog):
""""""
#----------------------------------------------------------------------
def __init__(self, parent=None):
"""Constructor"""
super(CurrencyDlg, self).__init__(parent)
date = self.getdata()
rates = sorted(self.rates.keys())
dateLabel = QLabel(date)
self.fromComboBox = QComboBox()
self.fromComboBox.addItems(rates)
self.fromSpinBox = QDoubleSpinBox()
self.fromSpinBox.setRange(0.01, 10000000.00)
self.fromSpinBox.setValue(1.00)
self.toComboBox = QComboBox()
self.toComboBox.addItems(rates)
self.toLabel = QLabel("1.00")
# layout the controls
grid = QGridLayout()
grid.addWidget(dateLabel, 0, 0)
grid.addWidget(self.fromComboBox, 1, 0)
grid.addWidget(self.fromSpinBox, 1, 1)
grid.addWidget(self.toComboBox, 2, 0)
grid.addWidget(self.toLabel, 2, 1)
self.setLayout(grid)
# set up the event handlers
self.connect(self.fromComboBox, SIGNAL("currentIndexChanged(int)"),
self.updateUi)
self.connect(self.toComboBox, SIGNAL("currentIndexChanged(int)"),
self.updateUi)
self.connect(self.fromSpinBox, SIGNAL("valueChanged(double)"),
self.updateUi)
self.setWindowTitle("Currency - by PySide %s" % PySide.__version__)
#----------------------------------------------------------------------
def downloadFile(self, rate_file):
"""
Download the file
"""
url = "http://www.bankofcanada.ca/en/markets/csv/exchange_eng.csv"
r = requests.get(url)
try:
with open(rate_file, "wb") as f_handler:
f_handler.write(r.content)
except IOError:
print "ERROR: Unable to download file to %s" % rate_file
#----------------------------------------------------------------------
def getdata(self):
"""
"""
base_path = os.path.dirname(os.path.abspath(__file__))
rate_file = os.path.join(base_path, "exchange_eng.csv")
today = datetime.datetime.today()
self.rates = {}
if not os.path.exists(rate_file):
self.downloadFile(rate_file)
else:
# get last modified date:
ts = os.path.getmtime(rate_file)
last_modified = datetime.datetime.fromtimestamp(ts)
if today.day != last_modified.day:
self.downloadFile(rate_file)
try:
date = None
with open(rate_file) as fh:
for line in fh:
result = self.processLine(line)
if result != None:
date = result
return "Exchange Rates Date: " + date
except Exception, e:
return "Failed to download: \n%s" % e
#----------------------------------------------------------------------
def processLine(self, line):
"""
Processes each line and updates the "rates" dictionary
"""
line = line.rstrip()
if not line or line.startswith(("#", "Closing ")):
return
fields = line.split(",")
if line.startswith("Date "):
date = fields[-1]
return date
else:
try:
value = float(fields[-1])
self.rates[unicode(fields[0])] = value
except ValueError:
pass
return None
#----------------------------------------------------------------------
def updateUi(self):
"""
Update the user interface
"""
to = unicode(self.toComboBox.currentText())
frum = unicode(self.fromComboBox.currentText())
amount = ( self.rates[frum] / self.rates[to] )
amount *= self.fromSpinBox.value()
self.toLabel.setText("%0.2f" % amount)
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QApplication(sys.argv)
form = CurrencyDlg()
form.show()
app.exec_()
好了,让我们花点时间看看代码。我们不会解释所有的事情,但是我们会回顾一下发生了什么变化。首先,我们导入了更多的模块:日期时间、操作系统、请求和系统。我们还导入了 PySide 本身,这样我们就可以很容易地将其版本信息添加到对话框的标题栏中。接下来我们添加了几个新方法: downloadFile 和 processLine 。但是首先我们需要看看在 getdata 中发生了什么变化。在这里,我们获取脚本运行的路径,并使用它来创建 rates 文件的完全限定路径。然后我们检查它是否已经存在。如果它不存在,我们调用 downloadFile 方法,该方法使用请求库来下载文件。我们还使用 Python 的和上下文管理器构造,当我们完成写入时,它会自动关闭文件。
如果文件确实存在,那么我们进入语句的 else 部分,检查文件的最后修改日期是否早于今天的日期。如果是,那么我们下载文件并覆盖原始文件。然后我们继续处理文件。为了进行处理,我们将大部分代码转移到一个名为 processLine 的独立方法中。这样做的主要原因是,如果我们不这样做,我们最终会得到一个非常复杂的嵌套结构,很难理解。我们还添加了一个检查来查看日期是否已经从 processLine 返回,如果是,我们设置日期变量。其余的代码保持不变。
包扎
至此,您应该知道如何创建一个非常简单的 PySide 应用程序,它实际上可以做一些有用的事情。不仅如此,您还对如何将您的 PyQt 代码移植到 PySide 有一个非常一般的想法。您还接触过两种从网上下载文件的不同方式。我希望这已经让您看到了 Python 的强大和编程的乐趣。
注意:本文中的代码是在使用 Python 2.6.6、PySide 1.2.2 和 PyQt4 的 Windows 7 Professional 上测试的
相关链接
下载源代码
PySide:标准对话框和消息框
原文:https://www.blog.pythonlibrary.org/2013/04/16/pyside-standard-dialogs-and-message-boxes/
PySide GUI toolkit for Python 有几个标准对话框和消息框,您可以按原样使用。您也可以创建自定义对话框,但是我们将把它留到以后的文章中。在本帖中,我们将讨论以下对话:
- 颜色对话框
- 文件对话框
- 字体对话框
- 输入对话框
- 打印和打印预览对话框
我们还将介绍 PySide 的信息盒。本文中的所有代码都是在使用 PySide 1.2.2 和 Python 2.6.6 的 Windows 7 Professional 上测试的。现在让我们开始吧!
用标准对话框获取信息
我们将从显示上面列出的前四个对话框的代码开始。另外两个比较复杂,有自己专门的演示代码。在代码之后,我们将单独看一下每个对话框的代码以帮助理解它。
# stdDialogDemo_pyside.py
from PySide import QtCore, QtGui
########################################################################
class DialogDemo(QtGui.QWidget):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
# super(DialogDemo, self).__init__()
QtGui.QWidget.__init__(self)
self.label = QtGui.QLabel("Python rules!")
# create the buttons
colorDialogBtn = QtGui.QPushButton("Open Color Dialog")
fileDialogBtn = QtGui.QPushButton("Open File Dialog")
self.fontDialogBtn = QtGui.QPushButton("Open Font Dialog")
inputDlgBtn = QtGui.QPushButton("Open Input Dialog")
# connect the buttons to the functions (signals to slots)
colorDialogBtn.clicked.connect(self.openColorDialog)
fileDialogBtn.clicked.connect(self.openFileDialog)
self.fontDialogBtn.clicked.connect(self.openFontDialog)
self.connect(inputDlgBtn, QtCore.SIGNAL("clicked()"), self.openInputDialog)
# layout widgets
layout = QtGui.QVBoxLayout()
layout.addWidget(self.label)
layout.addWidget(colorDialogBtn)
layout.addWidget(fileDialogBtn)
layout.addWidget(self.fontDialogBtn)
layout.addWidget(inputDlgBtn)
self.setLayout(layout)
# set the position and size of the window
self.setGeometry(100, 100, 400, 100)
self.setWindowTitle("Dialog Demo")
#----------------------------------------------------------------------
def openColorDialog(self):
"""
Opens the color dialog
"""
color = QtGui.QColorDialog.getColor()
if color.isValid():
print color.name()
btn = self.sender()
pal = btn.palette()
pal.setColor(QtGui.QPalette.Button, color)
btn.setPalette(pal)
btn.setAutoFillBackground(True)
#btn.setStyleSheet("QPushButton {background-color: %s}" % color)
#----------------------------------------------------------------------
def openFileDialog(self):
"""
Opens a file dialog and sets the label to the chosen path
"""
import os
path, _ = QtGui.QFileDialog.getOpenFileName(self, "Open File", os.getcwd())
self.label.setText(path)
#----------------------------------------------------------------------
def openDirectoryDialog(self):
"""
Opens a dialog to allow user to choose a directory
"""
flags = QtGui.QFileDialog.DontResolveSymlinks | QtGui.QFileDialog.ShowDirsOnly
d = directory = QtGui.QFileDialog.getExistingDirectory(self,
"Open Directory",
os.getcwd(),
flags)
self.label.setText(d)
#----------------------------------------------------------------------
def openFontDialog(self):
"""
Open the QFontDialog and set the label's font
"""
font, ok = QtGui.QFontDialog.getFont()
if ok:
self.label.setFont(font)
#----------------------------------------------------------------------
def openInputDialog(self):
"""
Opens the text version of the input dialog
"""
text, result = QtGui.QInputDialog.getText(self, "I'm a text Input Dialog!",
"What is your favorite programming language?")
if result:
print "You love %s!" % text
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QtGui.QApplication([])
form = DialogDemo()
form.show()
app.exec_()
这看起来很简单明了。让我们把它分解一下。您可以在 init 方法的开头看到,我注释掉了使用 Python 的 super 初始化 QWidget 的另一种方法。你可以选择任何一种方式,你的程序都会运行良好。我只想告诉你两种方法。您还会注意到,这段代码只显示了一个 QLabel 和四个 QPushButton 小部件。我们使用两种不同的方法将来自按钮的信号(即事件)连接到插槽(即事件处理程序)。第一种更“Pythonic 化”,因为它使用了点符号:
colorDialogBtn.clicked.connect(self.openColorDialog)
第二种方法(我们曾经使用过一次)可能是最常见的方法,但是如果您只是习惯于 Python 代码,那么理解起来会有点困难:
self.connect(inputDlgBtn, QtCore.SIGNAL("clicked()"), self.openInputDialog)
将信号连接到插槽的两种方式都有效。注意,我们正在绑定 clicked 事件。这意味着当用户单击按钮时,它调用连接的方法。现在我们将依次看一下每个对话框。
PySide 颜色对话框
PySide 颜色对话框是一个非常标准的颜色对话框,你可以在大多数简单的绘图程序中看到,比如 Windows Paint。为了创建它,我们执行以下操作:
#----------------------------------------------------------------------
def openColorDialog(self):
"""
Opens the color dialog
"""
color = QtGui.QColorDialog.getColor()
if color.isValid():
print color.name()
btn = self.sender()
pal = btn.palette()
pal.setColor(QtGui.QPalette.Button, color)
btn.setPalette(pal)
btn.setAutoFillBackground(True)
#btn.setStyleSheet("QPushButton {background-color: %s}" % color)
这里我们称之为 QtGui。QColorDialog.getColor() 返回用户选择的颜色,并实例化对话框。如果选择的颜色有效,我们将它应用到我们的 QPushButton。你会注意到在这个方法的末尾有一行注释掉了。有人告诉我你可以使用一种 PySide CSS 来改变按钮的背景颜色,但是我不知道正确的方法。PySide IRC 频道上的一些人说评论行应该管用。别人说应该只是背景而不是背景色,但那对我也没用。即使使用这里显示的调色板方法,背景色仍然没有改变。相反,您只会注意到按钮轮廓颜色的细微变化。
PySide 文件对话框
PySide 文件对话框应该为大多数人所熟悉,因为它与本机文件对话框非常相似(至少在 Windows 上)。下面是实例化它的代码:
#----------------------------------------------------------------------
def openFileDialog(self):
"""
Opens a file dialog and sets the label to the chosen path
"""
import os
path, _ = QtGui.QFileDialog.getOpenFileName(self, "Open File", os.getcwd())
self.label.setText(path)
我们使用 getOpenFileName 返回一个元组中的文件路径,该元组还包括文件类型,在本例中是所有文件(。) 。我们还将 QLabel 设置为返回的路径。在我们的主代码中还有一个名为 openDirectoryDialog 的方法,它使用相同的调用签名,但是我们使用 getExistingDirectory 而不是 getOpenFileName。请参见下面的示例:
#----------------------------------------------------------------------
def openDirectoryDialog(self):
"""
Opens a dialog to allow user to choose a directory
"""
flags = QtGui.QFileDialog.DontResolveSymlinks | QtGui.QFileDialog.ShowDirsOnly
d = directory = QtGui.QFileDialog.getExistingDirectory(self,
"Open Directory",
os.getcwd(),
flags)
self.label.setText(d)
正如你所看到的,我们必须向这个对话框传递几个标志,告诉它不要解析符号链接,只显示目录。最后,QFileDialog 还有一个 getOpenFileNames 方法,允许用户从对话框中选择多个文件并返回所有选择的文件。这个没有显示,但操作类似。
PySide 字体对话框
PySide 字体对话框与您在 Microsoft Office 产品的旧版本中看到的非常相似。创建对话框非常简单:
#----------------------------------------------------------------------
def openFontDialog(self):
"""
Open the QFontDialog and set the label's font
"""
font, ok = QtGui.QFontDialog.getFont()
if ok:
self.label.setFont(font)
如您所见,您只需创建对话框并调用它的 getFont() 方法。这将返回所选择的字体以及是否按下了 OK 按钮。如果是,我们用新字体重置 QLabel 小部件。
PySide 输入对话框
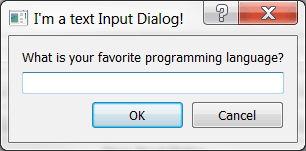
PySide 输入对话框也非常简单。但是,有四个变种:文本、整数、双精度和项目。显而易见,这些函数返回文本、整数、双精度数(即浮点数)和项目,允许用户从 combobox 的项目列表中进行选择。这里我们展示了如何创建文本版本:
#----------------------------------------------------------------------
def openInputDialog(self):
"""
Opens the text version of the input dialog
"""
text, result = QtGui.QInputDialog.getText(self, "I'm a text Input Dialog!",
"What is your favorite programming language?")
if result:
print "You love %s!" % text
如果你想看看其他类型的输入对话框的例子,我推荐你看看 git 上的 pyside-examples 文件夹,特别是 standarddialogs.py 脚本。你也可以在这里看到这四个小工具的截图。
至此,我们已经准备好学习两种类型的打印对话框。
PySide 的打印对话框
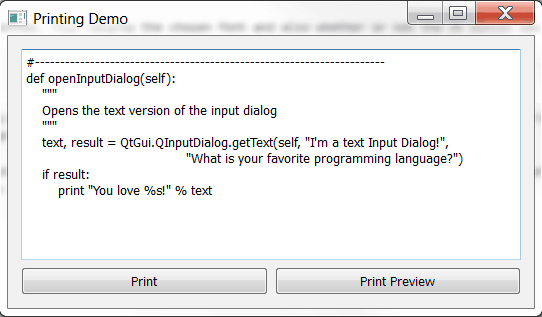
对于这个演示,我们创建了一个简单的小窗口,带有一个 QTextEdit 来保存一些示例文本和两个按钮。我们将把上一节中的代码示例复制并粘贴到这个演示应用程序中,然后点击打印按钮。下面是演示代码:
# printDlgDemo.py
from PySide import QtGui, QtCore
########################################################################
class PrinterWindow(QtGui.QWidget):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
QtGui.QWidget.__init__(self)
self.setWindowTitle("Printing Demo")
self.text_editor = QtGui.QTextEdit(self)
printButton = QtGui.QPushButton('Print')
printButton.clicked.connect(self.onPrint)
printPreviewButton = QtGui.QPushButton('Print Preview')
printPreviewButton.clicked.connect(self.onPrintPreview)
btnLayout = QtGui.QHBoxLayout()
mainLayout = QtGui.QVBoxLayout()
btnLayout.addWidget(printButton)
btnLayout.addWidget(printPreviewButton)
mainLayout.addWidget(self.text_editor)
mainLayout.addLayout(btnLayout)
self.setLayout(mainLayout)
#----------------------------------------------------------------------
def onPrint(self):
"""
Create and show the print dialog
"""
dialog = QtGui.QPrintDialog()
if dialog.exec_() == QtGui.QDialog.Accepted:
doc = self.text_editor.document()
doc.print_(dialog.printer())
#----------------------------------------------------------------------
def onPrintPreview(self):
"""
Create and show a print preview window
"""
dialog = QtGui.QPrintPreviewDialog()
dialog.paintRequested.connect(self.text_editor.print_)
dialog.exec_()
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QtGui.QApplication([])
form = PrinterWindow()
form.show()
app.exec_()
如果你点击打印按钮,你应该会看到一个类似下面的对话框(如果你在 Windows 7 上):
让我们来看看这个对话框背后的代码:
#----------------------------------------------------------------------
def onPrint(self):
"""
Create and show the print dialog
"""
dialog = QtGui.QPrintDialog()
if dialog.exec_() == QtGui.QDialog.Accepted:
doc = self.text_editor.document()
doc.print_(dialog.printer())
这里我们实例化了 QPrintDialog ,并通过调用它的 exec_() 方法来展示它。如果用户真的点击了打印按钮,我们将从 QTextEdit 控件中提取一个 QTextDocument ,然后通过将它传递给打印机对话框来调用它的 print_() 方法。
现在让我们做打印预览对话框!这是前面提到的演示中的代码:
#----------------------------------------------------------------------
def onPrintPreview(self):
"""
Create and show a print preview window
"""
dialog = QtGui.QPrintPreviewDialog()
dialog.paintRequested.connect(self.text_editor.print_)
dialog.exec_()
这段代码比创建 QPrintDialog 简单一点。这里我们只是实例化了一个 QPrintPreviewDialog 的实例,告诉它我们想要将 paintRequested 信号连接到文本控件的 print_ 方法。最后,我们显示对话框。PySide 完成了剩下的工作,并最终创建了一个如下所示的对话框:
您现在知道如何创建这两种类型的 PySide 打印对话框了!至此,我们已经准备好进入消息框了!
PySide 的消息框
PySide 有四个基于 QMessageBox 小部件的消息框:关键、信息、问题和警告。我们将看一看所有四个。我们将从一个完整的代码示例开始,这是一个可以启动 4 个消息框中任何一个的演示,然后我们将像在上一节中一样查看每个部分。下面是主程序的源代码:
from PySide import QtCore, QtGui
########################################################################
class MessageBoxDemo(QtGui.QWidget):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
# super(DialogDemo, self).__init__()
QtGui.QWidget.__init__(self)
self.setWindowTitle("MessageBox Demo")
# create buttons
criticalMsgBtn = QtGui.QPushButton("Show Critical Message")
criticalMsgBtn.clicked.connect(self.onShowCriticalMessage)
infoMsgBtn = QtGui.QPushButton("Show Informational Message")
infoMsgBtn.clicked.connect(self.onShowInformation)
questionMsgBtn = QtGui.QPushButton("Show Question Message")
questionMsgBtn.clicked.connect(self.onShowQuestion)
warningMsgBtn = QtGui.QPushButton("Show Warning Message")
warningMsgBtn.clicked.connect(self.onShowWarning)
# layout widgets
layout = QtGui.QVBoxLayout()
layout.addWidget(criticalMsgBtn)
layout.addWidget(infoMsgBtn)
layout.addWidget(questionMsgBtn)
layout.addWidget(warningMsgBtn)
self.setLayout(layout)
self.setGeometry(100,100,300,100)
#----------------------------------------------------------------------
def onShowCriticalMessage(self):
"""
Show the critical message
"""
flags = QtGui.QMessageBox.Abort
flags |= QtGui.QMessageBox.StandardButton.Retry
flags |= QtGui.QMessageBox.StandardButton.Ignore
result = QtGui.QMessageBox.critical(self, "CRITICAL ERROR",
"You're trying Perl aren't you?",
flags)
if result == QtGui.QMessageBox.Abort:
print "Aborted!"
elif result == QtGui.QMessageBox.Retry:
print "Retrying!"
elif result == QtGui.QMessageBox.Ignore:
print "Ignoring!"
#----------------------------------------------------------------------
def onShowInformation(self):
"""
Show the information message
"""
QtGui.QMessageBox.information(self, "Information", "Python rocks!")
#----------------------------------------------------------------------
def onShowQuestion(self):
"""
Show the question message
"""
flags = QtGui.QMessageBox.StandardButton.Yes
flags |= QtGui.QMessageBox.StandardButton.No
question = "Do you really want to work right now?"
response = QtGui.QMessageBox.question(self, "Question",
question,
flags)
if response == QtGui.QMessageBox.Yes:
print "You're very dedicated!"
elif QtGui.QMessageBox.No:
print "You're fired!"
else:
print "You chose wisely!"
#----------------------------------------------------------------------
def onShowWarning(self):
"""
Show a warning message
"""
flags = QtGui.QMessageBox.StandardButton.Ok
flags |= QtGui.QMessageBox.StandardButton.Discard
msg = "This message will self-destruct in 30 seconds!"
response = QtGui.QMessageBox.warning(self, "Warning!",
msg, flags)
if response == 0:
print "BOOM!"
else:
print "MessageBox disarmed!"
#----------------------------------------------------------------------
if __name__ == "__main__":
app = QtGui.QApplication([])
form = MessageBoxDemo()
form.show()
app.exec_()
现在让我们依次看看每个消息框。我们要看的第一个是关键消息框。
关键消息框

使用以下方法从我们的演示程序中启动关键消息框:
#----------------------------------------------------------------------
def onShowCriticalMessage(self):
"""
Show the critical message
"""
flags = QtGui.QMessageBox.Abort
flags |= QtGui.QMessageBox.StandardButton.Retry
flags |= QtGui.QMessageBox.StandardButton.Ignore
result = QtGui.QMessageBox.critical(self, "CRITICAL ERROR",
"You're trying Perl aren't you?",
flags)
if result == QtGui.QMessageBox.Abort:
print "Aborted!"
elif result == QtGui.QMessageBox.Retry:
print "Retrying!"
elif result == QtGui.QMessageBox.Ignore:
print "Ignoring!"
所有消息框都遵循相同的基本公式。它们有一个标题(“严重错误”),一条消息(“您正在尝试 Perl,是吗?”)和一些控制显示什么按钮的标志。在本例中,我们显示了一个中止、一个重试和一个忽略按钮。我们向 stdout 输出一条特殊的消息,这取决于按下了哪个按钮。
信息消息框
信息消息框可能是所有消息框中最简单的一个:
#----------------------------------------------------------------------
def onShowInformation(self):
"""
Show the information message
"""
QtGui.QMessageBox.information(self, "Information", "Python rocks!")
如您所见,我们甚至不需要为此指定任何按钮。它自己添加了一个 OK 按钮。
问题消息框
问题消息框也非常简单。代码如下:
#----------------------------------------------------------------------
def onShowQuestion(self):
"""
Show the question message
"""
flags = QtGui.QMessageBox.StandardButton.Yes
flags |= QtGui.QMessageBox.StandardButton.No
question = "Do you really want to work right now?"
response = QtGui.QMessageBox.question(self, "Question",
question,
flags)
if response == QtGui.QMessageBox.Yes:
print "You're very dedicated!"
elif QtGui.QMessageBox.No:
print "You're fired!"
else:
print "You chose wisely!"
对于这个消息框,我们需要两个按钮:是和否。我们还检查用户按了哪个按钮,并根据他们的选择打印出特殊的消息。您会注意到,没有办法执行最后一条 print 语句。
警告消息框

警告消息框也非常简单,与问题框非常相似。
#----------------------------------------------------------------------
def onShowWarning(self):
"""
Show a warning message
"""
flags = QtGui.QMessageBox.StandardButton.Ok
flags |= QtGui.QMessageBox.StandardButton.Discard
msg = "This message will self-destruct in 30 seconds!"
response = QtGui.QMessageBox.warning(self, "Warning!",
msg, flags)
if response == 0:
print "BOOM!"
else:
print "MessageBox disarmed!"
这里我们有两个按钮:一个确定按钮和一个放弃按钮。我们再次检查哪个按钮被按下,并相应地采取行动。
包扎
现在您知道了如何创建 PySide 提供的各种标准对话框和消息框。当你需要提醒用户你的程序有问题或者需要获取一些小信息的时候,这些是非常方便的。现在向前迈进,开始明智地使用你新发现的知识吧!
参考
- Zetcode 的 PySide 对话框教程
- git 上的 PySide repo 显示了标准对话框和消息框示例
- StackOverflow - 使用 PyQt4 通过打印机打印文本
下载源代码
PySimpleGUI——元素布局介绍
原文:https://www.blog.pythonlibrary.org/2022/01/25/pysimplegui-an-intro-to-laying-out-elements/
PySimpleGUI 是一个 Python GUI,它包装了其他 Python GUI 工具包(Tkinter、PySide、wxPython)。通过将其他 GUI 的复杂性抽象成一个公共 API,您可以快速编写代码,只需更改程序顶部的导入,就可以使用任何其他工具包来呈现这些代码。
如果您使用 wxPython,并且想要布局您的小部件,您将使用 wx.Sizer。Tkinter 使用几何图形管理器。一般概念是一样的。当您使用这些工具时,GUI 工具包使用小部件的相对位置在屏幕上排列它们。
在 PySimpleGUI 中,使用嵌套列表做同样的事情。在本教程中,您将看到几个不同的示例,这些示例将让您大致了解这一切是如何工作的。
创建水平布局
用 PySimpleGUI 中的一个小列表创建一系列水平方向(从左到右)的元素。

打开 Python 编辑器,添加以下代码:
import PySimpleGUI as sg
# Horizontal layout
layout = [[sg.Button(f"OK {num}") for num in range(1, 6)]]
# Create the window
window = sg.Window("Demo", layout)
# Create an event loop
while True:
event, values = window.read()
# End program if user closes window or
# presses the OK button
if event == "OK" or event == sg.WIN_CLOSED:
break
window.close()
这里您使用 Python list comprehension 创建一个嵌套列表,其中包含五个按钮对象。当您运行这段代码时,您将看到按钮水平对齐,从左到右一个挨着一个。
现在,您可以看到如何重写代码来创建垂直布局了!
创建垂直布局
要用 PySimpleGUI 创建垂直方向的布局,需要让布局包含一系列嵌套列表,每个列表包含一个或多个元素。

Create a new Python file and add this code to it:
import PySimpleGUI as sg
layout = [[sg.Button("OK")],
[sg.Button("OK 2")],
[sg.Button("OK 3")],
[sg.Button("OK 4")],
[sg.Button("OK 5")]]
# Create the window
window = sg.Window("Demo", layout)
# Create an event loop
while True:
event, values = window.read()
# End program if user closes window or
# presses the OK button
if event == "OK" or event == sg.WIN_CLOSED:
break
window.close()
When you run this code, the Button Elements will be stacked from top to bottom vertically, instead of horizontally.
Using Columns for Complex Layouts
If you need to add two or more columns of Elements next to each other in PySimpleGUI, you can use a sg.Column Element. It is a type of container Element specifically made for creating stacked sets of Elements!

Create another Python file and add the following code:
import PySimpleGUI as sg
import os.path
# First the window layout in 2 columns
file_list_column = [
[sg.Text("Image Folder"),
sg.In(size=(25, 1), enable_events=True, key="-FOLDER-"),
sg.FolderBrowse(),],
[sg.Listbox(values=[], enable_events=True, size=(40, 20), key="-FILE LIST-")],
]
# For now will only show the name of the file that was chosen
image_viewer_column = [
[sg.Text("Choose an image from list on left:")],
[sg.Text(size=(40, 1), key="-TEXT-")],
[sg.Image(key="-IMAGE-")],
]
# ----- Full layout -----
layout = [
[sg.Column(file_list_column),
sg.VSeperator(),
sg.Column(image_viewer_column),]
]
window = sg.Window("Column Demo", layout)
# Run the Event Loop
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
# Folder name was filled in, make a list of files in the folder
if event == "-FOLDER-":
folder = values["-FOLDER-"]
try:
# Get list of files in folder
file_list = os.listdir(folder)
except:
file_list = []
fnames = [
f
for f in file_list
if os.path.isfile(os.path.join(folder, f))
and f.lower().endswith((".png", ".gif"))
]
window["-FILE LIST-"].update(fnames)
elif event == "-FILE LIST-": # A file was chosen from the listbox
try:
filename = os.path.join(values["-FOLDER-"], values["-FILE LIST-"][0])
window["-TEXT-"].update(filename)
window["-IMAGE-"].update(filename=filename)
except:
pass
window.close()
In this example, you create two layouts! The first layout is called file_list_column and contains four Elements in it. The second layout is called image_viewer_column and contains three Elements. Then you put these layouts inside of Columns that are themselves inside a layout. As you can see, PySimpleGUI layouts are lists inside of lists all the way down!
Wrapping Up
PySimpleGUI removes some of the complexity of creating layouts by using Python lists. The PyQt / PySide and wxPython GUI toolkits use an object-oriented approach which includes a significant amount of boilerplate and flags to do much the same thing. They each have their tradeoffs, but PySimpleGUI's learning curve is that much flatter because of their design choice.
Related Reading
PySimpleGUI:用 Python GUI 在图像上绘制文本
原文:https://www.blog.pythonlibrary.org/2021/02/03/pysimplegui-drawing-text-on-images-with-a-python-gui/
Pillow 包让你使用 Python 在图像上绘制文本。这包括使用 TrueType 和 OpenType 字体。当你在图片中添加这些文字时,你有很大的灵活性。如果你想知道更多,你应该看看用 Pillow 和 Python 在图像上绘制文本。
注:本教程使用的代码和字体可以在 Github repo for my book,Pillow:Image Processing with Python(第九章) 中找到
当然,如果你能实时看到你的结果,那就更好了。您可以通过编写图形用户界面(GUI)来实现这一点,该界面允许您应用不同的字体并调整它们的设置。您创建的 GUI 将允许您的用户修改其文本的以下属性:
- 字体类型
- Font color
- 字体大小
- 文本位置
当您的 GUI 完成时,它将看起来像这样:

让我们开始写一些代码吧!
创建 GUI
对于本教程,您将使用 PySimpleGUI 。你可以用 pip 来安装。一旦完成 PySimpleGUI 的安装,就可以开始了!
现在是您编写 GUI 代码的时候了。打开 Python 编辑器,创建一个新文件。然后将其命名为text_gui.py,并输入以下代码:
# text_gui.py
import glob
import os
import PySimpleGUI as sg
import shutil
import tempfile
from PIL import Image
from PIL import ImageColor
from PIL import ImageDraw
from PIL import ImageFont
from PIL import ImageTk
file_types = [("JPEG (*.jpg)", "*.jpg"), ("All files (*.*)", "*.*")]
tmp_file = tempfile.NamedTemporaryFile(suffix=".jpg").name
def get_value(key, values):
value = values[key]
if value:
return int(value)
return 0
def apply_text(values, window):
image_file = values["filename"]
font_name = values["ttf"]
font_size = get_value("font_size", values)
color = values["colors"]
x, y = get_value("text-x", values), get_value("text-y", values)
text = values["text"]
if image_file and os.path.exists(image_file):
shutil.copy(image_file, tmp_file)
image = Image.open(tmp_file)
image.thumbnail((400, 400))
if text:
draw = ImageDraw.Draw(image)
if font_name == "Default Font":
font = None
else:
font = ImageFont.truetype(font_name, size=font_size)
draw.text((x, y), text=text, font=font, fill=color)
image.save(tmp_file)
photo_img = ImageTk.PhotoImage(image)
window["image"].update(data=photo_img)
def create_row(label, key, file_types):
return [
sg.Text(label),
sg.Input(size=(25, 1), enable_events=True, key=key),
sg.FileBrowse(file_types=file_types),
]
def get_ttf_files(directory=None):
if directory is not None:
ttf_files = glob.glob(directory + "/*.ttf")
else:
ttf_files = glob.glob("*.ttf")
if not ttf_files:
return {"Default Font": None}
ttf_dict = {}
for ttf in ttf_files:
ttf_dict[os.path.basename(ttf)] = ttf
return ttf_dict
def save_image(values):
save_filename = sg.popup_get_file(
"File", file_types=file_types, save_as=True, no_window=True
)
if save_filename == values["filename"]:
sg.popup_error(
"You are not allowed to overwrite the original image!")
else:
if save_filename:
shutil.copy(tmp_file, save_filename)
sg.popup(f"Saved: {save_filename}")
def update_ttf_values(window):
directory = sg.popup_get_folder("Get TTF Directory")
if directory is not None:
ttf_files = get_ttf_files(directory)
new_values = list(ttf_files.keys())
window["ttf"].update(values=new_values,
value=new_values[0])
def main():
colors = list(ImageColor.colormap.keys())
ttf_files = get_ttf_files()
ttf_filenames = list(ttf_files.keys())
menu_items = [["File", ["Open Font Directory"]]]
elements = [
[sg.Menu(menu_items)],
[sg.Image(key="image")],
create_row("Image File:", "filename", file_types),
[sg.Text("Text:"), sg.Input(key="text", enable_events=True)],
[
sg.Text("Text Position"),
sg.Text("X:"),
sg.Input("10", size=(5, 1), enable_events=True,
key="text-x"),
sg.Text("Y:"),
sg.Input("10", size=(5, 1), enable_events=True,
key="text-y"),
],
[
sg.Combo(colors, default_value=colors[0], key='colors',
enable_events=True),
sg.Combo(ttf_filenames, default_value=ttf_filenames[0], key='ttf',
enable_events=True),
sg.Text("Font Size:"),
sg.Input("12", size=(5, 1), key="font_size", enable_events=True),
],
[sg.Button("Save Image", enable_events=True,
key="save")],
]
window = sg.Window("Draw Text GUI", elements)
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event in ["filename", "colors", "ttf", "font_size",
"text-x", "text-y", "text"]:
apply_text(values, window)
if event == "save" and values["filename"]:
save_image(values)
if event == "Open Font Directory":
update_ttf_values(window)
window.close()
if __name__ == "__main__":
main()
这个 GUI 中有超过 100 行代码!为了更容易理解发生了什么,您将把代码分成更小的块。
下面是前几行代码:
# text_gui.py
import glob
import os
import PySimpleGUI as sg
import shutil
import tempfile
from PIL import Image
from PIL import ImageColor
from PIL import ImageDraw
from PIL import ImageFont
from PIL import ImageTk
file_types = [("JPEG (*.jpg)", "*.jpg"), ("All files (*.*)", "*.*")]
tmp_file = tempfile.NamedTemporaryFile(suffix=".jpg").name
这是代码的导入部分。您需要导入所有必要的模块和包来使您的代码工作。最后你还设置了几个变量。file_types定义了用户界面可以加载的文件类型。tmp_file是一个临时文件,您可以创建它来保存您的图像更改,直到用户准备好将文件保存到他们想要的位置。
代码中的第一个函数叫做get_value()。下面是它的代码:
def get_value(key, values):
value = values[key]
if value:
return int(value)
return 0
这个函数的工作是将字符串转换成整数,如果用户清空了一个需要值的控件,则返回零。
现在,您可以继续了解apply_text():
def apply_text(values, window):
image_file = values["filename"]
font_name = values["ttf"]
font_size = get_value("font_size", values)
color = values["colors"]
x, y = get_value("text-x", values), get_value("text-y", values)
text = values["text"]
if image_file and os.path.exists(image_file):
shutil.copy(image_file, tmp_file)
image = Image.open(tmp_file)
image.thumbnail((400, 400))
if text:
draw = ImageDraw.Draw(image)
font = ImageFont.truetype(font_name, size=font_size)
draw.text((x, y), text=text, font=font, fill=color)
image.save(tmp_file)
photo_img = ImageTk.PhotoImage(image)
window["image"].update(data=photo_img)
这就是奇迹发生的地方。每当用户打开新图像、更改字体、更改字体大小、更改字体颜色、更改文本本身或修改文本位置时,此代码都会运行。如果用户没有输入任何文本,但他们选择了一个图像,只有图像会改变。如果用户输入了文本,那么其他的改变也会被更新。
注意:保存图像时,它会保存为缩略图版本。因此,您将保存一个较小版本的图像,但上面有文字。
您将看到的下一个函数叫做create_row():
def create_row(label, key, file_types):
return [
sg.Text(label),
sg.Input(size=(25, 1), enable_events=True, key=key),
sg.FileBrowse(file_types=file_types),
]
你以前见过这个函数。它用于创建三个元素:
- 一个标签(
sg.Text) - 一个文本框 _
sg.Input) - 一个文件浏览按钮(
sg.FileBrowse)
这些元素在 Python 列表中返回。这将在用户界面中创建一个水平的元素行。
下一个要学习的功能是get_ttf_files():
def get_ttf_files(directory=None):
if directory is not None:
ttf_files = glob.glob(directory + "/*.ttf")
else:
ttf_files = glob.glob("*.ttf")
if not ttf_files:
return {"Default Font": None}
ttf_dict = {}
for ttf in ttf_files:
ttf_dict[os.path.basename(ttf)] = ttf
return ttf_dict
这段代码使用 Python 的glob模块来查找 GUI 文件所在目录中的所有 TrueType 字体文件,或者通过搜索传入的directory来查找。如果 GUI 没有找到任何 TTF 文件,它将加载 Pillow 的默认字体。
不管发生什么,你的代码将返回一个 Python 字典,它将字体的名称映射到字体文件的绝对路径。如果您的代码没有找到任何 TTF 文件,它会将“默认字体”映射到None以向您的代码表明没有找到字体,因此您将使用 Pillow 的默认字体。
下一个函数定义了如何保存编辑过的图像:
def save_image(values):
save_filename = sg.popup_get_file(
"File", file_types=file_types, save_as=True, no_window=True
)
if save_filename == values["filename"]:
sg.popup_error(
"You are not allowed to overwrite the original image!")
else:
if save_filename:
shutil.copy(tmp_file, save_filename)
sg.popup(f"Saved: {save_filename}")
这段代码使用弹出对话框询问用户新图像的名称。然后,它检查以确保用户不会覆盖他们的原始图像。事实上,如果他们试图这样做,您可以通过向他们显示错误消息来防止这种情况发生。
否则,通过将临时文件复制到用户选择的新位置来保存文件。
现在您已经准备好学习update_ttf_values()功能了:
def update_ttf_values(window):
directory = sg.popup_get_folder("Get TTF Directory")
if directory is not None:
ttf_files = get_ttf_files(directory)
new_values = list(ttf_files.keys())
window["ttf"].update(values=new_values,
value=new_values[0])
该功能从用户界面的文件菜单中调用。当它被调用时,它会显示一个对话框,询问用户他们的 TTF 文件在哪里。如果用户按取消,则不返回目录。但是如果用户选择了一个目录并接受了对话框,那么你调用gett_ttf_files(),它将搜索文件夹中的所有 TTF 文件。
然后它会更新你的 TTF 组合框的内容,这样你就可以选择一种 TTF 字体来应用到你的文本中。
您需要回顾的最后一个函数是main()函数:
def main():
colors = list(ImageColor.colormap.keys())
ttf_files = get_ttf_files()
ttf_filenames = list(ttf_files.keys())
menu_items = [["File", ["Open Font Directory"]]]
elements = [
[sg.Menu(menu_items)],
[sg.Image(key="image")],
create_row("Image File:", "filename", file_types),
[sg.Text("Text:"), sg.Input(key="text", enable_events=True)],
[
sg.Text("Text Position"),
sg.Text("X:"),
sg.Input("10", size=(5, 1), enable_events=True,
key="text-x"),
sg.Text("Y:"),
sg.Input("10", size=(5, 1), enable_events=True,
key="text-y"),
],
[
sg.Combo(colors, default_value=colors[0], key='colors',
enable_events=True),
sg.Combo(ttf_filenames, default_value=ttf_filenames[0], key='ttf',
enable_events=True),
sg.Text("Font Size:"),
sg.Input("12", size=(5, 1), key="font_size", enable_events=True),
],
[sg.Button("Save Image", enable_events=True,
key="save")],
]
window = sg.Window("Draw Text GUI", elements)
这个函数的前三行创建了一个 Python 列表colors和一个列表ttf_filenames。接下来,创建一个嵌套列表,表示用户界面的菜单。然后创建一个elements列表,用于布局所有用于创建用户界面的元素。一旦你有了它,你就可以把它传递给你的sg.Window,它将布局你的元素并显示给用户。
最后一段代码是用户界面的事件处理程序:
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event in ["filename", "colors", "ttf", "font_size",
"text-x", "text-y", "text"]:
apply_text(values, window)
if event == "save" and values["filename"]:
save_image(values)
if event == "Open Font Directory":
update_ttf_values(window)
window.close()
if __name__ == "__main__":
main()
在这里你检查用户是否关闭了窗口。如果是,那么你退出循环并结束程序。
下一个条件语句检查除“保存”和菜单事件之外的所有其他事件。如果任何其他启用了事件的元素被触发,那么您将运行apply_text()。这将根据您更改的设置更新图像。
下一个条件在您完成编辑后保存图像。它将调用save_image(),询问用户他们想在哪里保存图像。
最后一个条件是针对你的文件的菜单事件。如果用户选择“打开字体目录”选项,它将调用update_ttf_values(),让你选择一个新的 TTF 文件夹进行搜索。
包扎
您已经创建了一个不错的 GUI,可以用来学习如何在自己的图像上绘制文本。这段代码教你如何有效地使用 Pillow 来绘制文本。它还教您如何使用 PySimpleGUI 创建一个功能性的图形用户界面。这个 GUI 可以在 Windows、Mac 和 Linux 上运行。尝试一下,添加一些很酷的新功能,让它成为你自己的。
如何用图形用户界面在图像上绘制形状
原文:https://www.blog.pythonlibrary.org/2021/02/24/pysimplegui-how-to-draw-shapes-on-an-image-with-a-gui/
在图像上画出形状是很整洁的。但是如果你能交互地画出形状,那不是很好吗?这就是本教程的要点。您将使用 PySimpleGUI 创建一个用户界面,允许您在图像上绘制形状!
这个用户界面的目的是向您展示如何创建一个 GUI 来包装 Pillow 支持的一些形状。尽管 GUI 并不支持所有这些。事实上,该 GUI 仅支持以下内容:
- 椭圆
- 矩形
原因是这两种形状采用相同的参数。您可以自己接受挑战,将其他形状添加到 GUI 中!
当您的 GUI 完成时,它将看起来像这样:

PySimpleGUI Image Shape GUI
入门指南
您将需要 PySimpleGUI 和 Pillow 来跟随本教程。下面是如何用 pip 安装它们:
python3 -m pip install PySimpleGUI pillow
现在您已经准备好创建您的 GUI 了!
创建 GUI
现在打开 Python 编辑器,创建一个名为drawing_gui.py的新文件。然后将这段代码添加到新文件中:
# drawing_gui.py
import io
import os
import PySimpleGUI as sg
import shutil
import tempfile
from PIL import Image, ImageColor, ImageDraw
file_types = [("JPEG (*.jpg)", "*.jpg"), ("All files (*.*)", "*.*")]
tmp_file = tempfile.NamedTemporaryFile(suffix=".jpg").name
def get_value(key, values):
value = values[key]
if value.isdigit():
return int(value)
return 0
def apply_drawing(values, window):
image_file = values["-FILENAME-"]
shape = values["-SHAPES-"]
begin_x = get_value("-BEGIN_X-", values)
begin_y = get_value("-BEGIN_Y-", values)
end_x = get_value("-END_X-", values)
end_y = get_value("-END_Y-", values)
width = get_value("-WIDTH-", values)
fill_color = values["-FILL_COLOR-"]
outline_color = values["-OUTLINE_COLOR-"]
if os.path.exists(image_file):
shutil.copy(image_file, tmp_file)
image = Image.open(tmp_file)
image.thumbnail((400, 400))
draw = ImageDraw.Draw(image)
if shape == "Ellipse":
draw.ellipse(
(begin_x, begin_y, end_x, end_y),
fill=fill_color,
width=width,
outline=outline_color,
)
elif shape == "Rectangle":
draw.rectangle(
(begin_x, begin_y, end_x, end_y),
fill=fill_color,
width=width,
outline=outline_color,
)
image.save(tmp_file)
bio = io.BytesIO()
image.save(bio, format="PNG")
window["-IMAGE-"].update(data=bio.getvalue())
def create_coords_elements(label, begin_x, begin_y, key1, key2):
return [
sg.Text(label),
sg.Input(begin_x, size=(5, 1), key=key1, enable_events=True),
sg.Input(begin_y, size=(5, 1), key=key2, enable_events=True),
]
def save_image(values):
save_filename = sg.popup_get_file(
"File", file_types=file_types, save_as=True, no_window=True
)
if save_filename == values["-FILENAME-"]:
sg.popup_error(
"You are not allowed to overwrite the original image!")
else:
if save_filename:
shutil.copy(tmp_file, save_filename)
sg.popup(f"Saved: {save_filename}")
def main():
colors = list(ImageColor.colormap.keys())
layout = [
[sg.Image(key="-IMAGE-")],
[
sg.Text("Image File"),
sg.Input(
size=(25, 1), key="-FILENAME-"
),
sg.FileBrowse(file_types=file_types),
sg.Button("Load Image"),
],
[
sg.Text("Shapes"),
sg.Combo(
["Ellipse", "Rectangle"],
default_value="Ellipse",
key="-SHAPES-",
enable_events=True,
readonly=True,
),
],
[
*create_coords_elements(
"Begin Coords", "10", "10", "-BEGIN_X-", "-BEGIN_Y-"
),
*create_coords_elements(
"End Coords", "100", "100", "-END_X-", "-END_Y-"
),
],
[
sg.Text("Fill"),
sg.Combo(
colors,
default_value=colors[0],
key="-FILL_COLOR-",
enable_events=True,
readonly=True
),
sg.Text("Outline"),
sg.Combo(
colors,
default_value=colors[0],
key="-OUTLINE_COLOR-",
enable_events=True,
readonly=True
),
sg.Text("Width"),
sg.Input("3", size=(5, 1), key="-WIDTH-", enable_events=True),
],
[sg.Button("Save")],
]
window = sg.Window("Drawing GUI", layout, size=(450, 500))
events = [
"Load Image",
"-BEGIN_X-",
"-BEGIN_Y-",
"-END_X-",
"-END_Y-",
"-FILL_COLOR-",
"-OUTLINE_COLOR-",
"-WIDTH-",
"-SHAPES-",
]
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event in events:
apply_drawing(values, window)
if event == "Save" and values["-FILENAME-"]:
save_image(values)
window.close()
if __name__ == "__main__":
main()
那是一堆代码!为了使事情变得简单,您将把这段代码分成更小的块。
第一部分是文件顶部的代码:
# drawing_gui.py
import io
import os
import PySimpleGUI as sg
import shutil
import tempfile
from PIL import Image, ImageColor, ImageDraw
file_types = [("JPEG (*.jpg)", "*.jpg"), ("All files (*.*)", "*.*")]
tmp_file = tempfile.NamedTemporaryFile(suffix=".jpg").name
这些代码行定义了您需要的包和模块的导入。它还设置了两个变量:
file_types-用于浏览和保存图像tmp_file-为保存中间图像文件而创建的临时文件
现在你可以看看你的第一个函数:
def get_value(key, values):
value = values[key]
if value.is_digit():
return int(value)
return 0
这个函数用于将字符串转换成整数。如果输入字母字符或特殊字符,将导致代码抛出错误。您可以在这里随意捕捉这些内容,或者实现一个过滤器来防止用户输入除整数之外的任何内容。
如果用户清空了元素的内容,你就强制它返回一个零。这允许用户界面继续工作。您可以在这里添加的另一个改进是考虑图像边界。您可以让用户不能输入负数或大于图像的数字。
下一个功能很重要:
def apply_drawing(values, window):
image_file = values["-FILENAME-"]
shape = values["-SHAPES-"]
begin_x = get_value("-BEGIN_X-", values)
begin_y = get_value("-BEGIN_Y-", values)
end_x = get_value("-END_X-", values)
end_y = get_value("-END_Y-", values)
width = get_value("-WIDTH-", values)
fill_color = values["-FILL_COLOR-"]
outline_color = values["-OUTLINE_COLOR-"]
if image_file and os.path.exists(image_file):
shutil.copy(image_file, tmp_file)
image = Image.open(tmp_file)
image.thumbnail((400, 400))
draw = ImageDraw.Draw(image)
if shape == "Ellipse":
draw.ellipse(
(begin_x, begin_y, end_x, end_y),
fill=fill_color,
width=width,
outline=outline_color,
)
elif shape == "Rectangle":
draw.rectangle(
(begin_x, begin_y, end_x, end_y),
fill=fill_color,
width=width,
outline=outline_color,
)
image.save(tmp_file)
bio = io.BytesIO()
image.save(bio, format="PNG")
window["-IMAGE-"].update(data=bio.getvalue())
这段代码用于创建您想要在图像上绘制的两个形状。它获得了创建椭圆或矩形所需的各种设置。您可以更改的设置有:
- 图像文件名
- 形状组合框
- 起始坐标(
-BEGIN_X-,-BEGIN_Y-) - 终点坐标(
-END_X-,-END_Y-) - 轮廓的宽度
- 要使用的填充颜色(使用颜色名称)
- 轮廓颜色(使用颜色名称)
如果用户打开了一个图像,那么您的代码将使用默认设置自动绘制一个形状。当您编辑这些设置中的任何一个时,这个函数将被调用,图像将更新。
注意:绘图应用于图像的缩略图版本,而不是图像的副本。这样做是为了保持图像在 GUI 中可见。许多照片的分辨率比普通显示器显示的分辨率要高。
下一个函数叫做create_coords_elements():
def create_coords_elements(label, begin_x, begin_y, key1, key2):
return [
sg.Text(label),
sg.Input(begin_x, size=(5, 1), key=key1, enable_events=True),
sg.Input(begin_y, size=(5, 1), key=key2, enable_events=True),
]
这个函数返回一个包含三个元素的 Python 列表。一个标签(sg.Text)和两个文本框(sg.Input)。因为这些元素在单个列表中,所以它们将作为水平行添加到您的用户界面中。
现在,您已经准备好继续执行save_image()功能:
def save_image(values):
save_filename = sg.popup_get_file(
"File", file_types=file_types, save_as=True, no_window=True
)
if save_filename == values["-FILENAME-"]:
sg.popup_error(
"You are not allowed to overwrite the original image!")
else:
if save_filename:
shutil.copy(tmp_file, save_filename)
sg.popup(f"Saved: {save_filename}")
这个函数询问用户在哪里保存你的文件。这也将防止用户试图覆盖原始图像。
最后一个功能是你的main()功能:
def main():
colors = list(ImageColor.colormap.keys())
layout = [
[sg.Image(key="-IMAGE-")],
[
sg.Text("Image File"),
sg.Input(
size=(25, 1), key="-FILENAME-"
),
sg.FileBrowse(file_types=file_types),
sg.Button("Load Image"),
],
[
sg.Text("Shapes"),
sg.Combo(
["Ellipse", "Rectangle"],
default_value="Ellipse",
key="-SHAPES-",
enable_events=True,
readonly=True,
),
],
[
*create_coords_elements(
"Begin Coords", "10", "10", "-BEGIN_X-", "-BEGIN_Y-"
),
*create_coords_elements(
"End Coords", "100", "100", "-END_X-", "-END_Y-"
),
],
[
sg.Text("Fill"),
sg.Combo(
colors,
default_value=colors[0],
key="-FILL_COLOR-",
enable_events=True,
readonly=True
),
sg.Text("Outline"),
sg.Combo(
colors,
default_value=colors[0],
key="-OUTLINE_COLOR-",
enable_events=True,
readonly=True
),
sg.Text("Width"),
sg.Input("3", size=(5, 1), key="-WIDTH-", enable_events=True),
],
[sg.Button("Save")],
]
window = sg.Window("Drawing GUI", layout, size=(450, 500))
这是你编写的最复杂的用户界面之一。它在行中添加了许多元素。您还可以看到,您正在使用一种特殊的语法从列表中提取项目:
*create_coords_elements()
当你调用create_coords_elements()时,它返回一个列表。但是您希望起点和终点坐标在同一条线上。所以你从列表中提取元素。
这个小代码示例说明了正在发生的情况:
>>> def get_elements():
... return ["element_one", "element_two"]
...
>>> [*get_elements()]
['element_one', 'element_two']
如果你不使用星号,你将得到一个嵌套的列表,而不是一个包含三个元素的列表。
下面是main()函数的最后几行代码:
events = [
"Load Image",
"-BEGIN_X-",
"-BEGIN_Y-",
"-END_X-",
"-END_Y-",
"-FILL_COLOR-",
"-OUTLINE_COLOR-",
"-WIDTH-",
"-SHAPES-",
]
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event in events:
apply_drawing(values, window)
if event == "Save" and values["-FILENAME-"]:
save_image(values)
window.close()
if __name__ == "__main__":
main()
第一行定义了用于了解何时更新绘图的事件。最后一个条件将在用户选择的地方保存图像。试试你的新阿桂。然后你可以开始计划你将如何改善它!
包扎
现在你有了一个方便的工具来测试 Pillow 的绘图功能。您可以通过添加 Pillow 的其他形状来使这个 GUI 变得更好。例如,您可以通过在不同的选项卡下添加不同选项的选项卡式界面来实现这一点。
试一试,看看你能想出什么!
相关阅读
|  |
|
枕头:使用 Python 进行图像处理
在LeanpubT3 上立即购买
|
PySimpleGUI:使用图像作为按钮
原文:https://www.blog.pythonlibrary.org/2021/09/05/pysimplegui-using-an-image-as-a-button/
当你为你的令人惊奇的程序创建一个图形用户界面时,你想在应用程序中加入一点你自己的东西。一种方法是使用图像作为按钮。虽然有些人觉得这些类型的按钮不直观,因为它们看起来不像按钮,但这是一种合法的方式来区分您的应用程序和竞争对手。
PySimpleGUI 在他们的食谱中为这个过程提供了一个四步过程:
- 查找您的图像(PNG 或 GIF)
- 将您的图像转换成 Base64 字节字符串
- 将 Base64 字节字符串添加到代码中
- 指定 Base64 字节字符串作为创建按钮时使用的图像
在本教程中,您将遵循这一过程。如果您没有安装 PySimpleGUI,那么您需要发出以下命令:
python -m pip install PySimpleGUI
现在您已经有了 PySimpleGUI,下一步是为您的按钮找到一个图像!
寻找图像
你可以在很多不同的地方找到图像。你可能在电脑上有自己的收藏。你可以去网上购买图标集。或者你可以在网上搜索图片,试着找到开源或者其他免费的图标。你不应该使用受版权保护的图片,因为这会给你带来法律上的麻烦。
对于这个例子,你可以使用你最喜欢的搜索引擎进行搜索。出于本教程的目的,使用了以下搜索字符串:“紫花图标”,它在 freeiconspng.com 的上找到了以下图像:

现在您有了一个可以使用的图像,您需要将它转换成一个字符串!
将您的图像转换成 Base64 字节字符串
现在您需要将图像转换成 base64 字节的字符串。PySimpleGUI 有两个演示可以用于这个目的:
- Demo _ Base64 _ Single _ Image _ encoder . py-转换单个输入文件并将字符串保存到剪贴板
- Demo _ Base64 _ Image _ encoder . py——将整个文件夹的图像转换成字符串,并保存到
output.py
这两个程序都行得通。因为这个例子只有一个图像,所以第一个演示可能最有意义。
一旦您对花卉照片运行了该演示,您的计算机剪贴板中就会有 base64 编码的字符串。
将 Base64 字节字符串添加到代码中
您可以从剪贴板中取出 base64 编码的字符串,并将其粘贴到您的代码中。您需要将该字符串赋给一个变量,以便可以在 GUI 代码中引用它。
下面是您将用来显示自定义按钮的代码:
import PySimpleGUI as sg
flower_base64 = b'paste your base64 encoded string here'
layout = [ [sg.Text('Base64 Button Demo')],
[sg.Button('', image_data=flower_base64,
button_color=(sg.theme_background_color(),sg.theme_background_color()),border_width=0, key='Exit')] ]
window = sg.Window('Flowers!', layout, no_titlebar=True)
while True: # Event Loop
event, values = window.read()
print(event, values)
if event in (sg.WIN_CLOSED, 'Exit'):
break
window.close()
这段代码基于 PySimpleGUI 食谱中的例子。您需要将 base64 编码的字符串粘贴到这段代码中。它太长了,不能包含在这里。
当您运行这段代码时,您会看到一个如下所示的 GUI:

那看起来不是很好吗?当你点击花按钮,它关闭应用程序。
包扎
PySimpleGUI 使创建定制按钮变得简单。你制作纽扣的能力只受到你想象力的限制。
相关阅读
想了解更多关于 PySimpleGUI 的信息,请查阅以下资源:
- PySimpleGUI–如何使用 GUI 在图像上绘制形状
- 使用 PySimpleGUI 创建图像查看器
- 用 PySimpleGUI 创建一个 Exif 查看器
- 【PySimpleGUI 的演示
PySimpleGUI:使用多个窗口
原文:https://www.blog.pythonlibrary.org/2021/01/20/pysimplegui-working-with-multiple-windows/
当你创建图形用户界面(GUI)时,你经常会发现你需要创建不止一个窗口。在本教程中,您将学习如何使用 PySimpleGUI 创建两个窗口。
PySimpleGUI 是最容易上手的 Python GUIs 之一。它包装了其他 Python GUIs,并为它们提供了一个公共接口。你可以在我的PySimpleGUI 简介或者我的文章《真正的 Python, PySimpleGUI:用 Python 创建 GUI 的简单方法中读到更多。
入门指南
您需要安装 PySimpleGUI 来开始使用它。您可以使用画中画来做到这一点:
python -m pip install pysimplegui
使窗口模式化
PySimpleGUI 提供了一个窗口元素,用于显示其他元素,比如按钮、文本、图像等等。这些窗口可以是模态的。模式窗口不允许你与程序中的其他窗口交互,直到你退出它。当你想强迫用户读一些东西或者问用户一个问题时,这是很有用的。例如,一个模态对话框可以用来询问用户是否真的想退出你的程序,或者显示一个最终用户协议(EULA)对话框。
您可以创建两个窗口,并在 PySimpleGUI 中同时显示它们,如下所示:
import PySimpleGUI as sg
def open_window():
layout = [[sg.Text("New Window", key="new")]]
window = sg.Window("Second Window", layout, modal=True)
choice = None
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
window.close()
def main():
layout = [[sg.Button("Open Window", key="open")]]
window = sg.Window("Main Window", layout)
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "open":
open_window()
window.close()
if __name__ == "__main__":
main()
当您运行这段代码时,您会看到一个小的主窗口,如下所示:

如果你点击“打开窗口”按钮,你会得到一个新的窗口,看起来像这样:

第二个窗口中有一个名为模态的参数,它被设置为真。这意味着在关闭第二个窗口之前,您无法与第一个窗口进行交互。
现在让我们来看一种方法,如果你正在创建一个像上面这样的简单窗口,你可以缩短你的代码。
创建内嵌的新窗口
你不必为你的第二窗口写一个完全独立的函数。如果你不想在第二个窗口中有很多小部件,那么你可以创建一个一行或两行的窗口。
有一种方法可以做到:
import PySimpleGUI as sg
def main():
layout = [[sg.Button("Open Window", key="open")]]
window = sg.Window("Main Window", layout)
while True:
event, values = window.read()
if event == "Exit" or event == sg.WIN_CLOSED:
break
if event == "open":
if sg.Window("Other Window", [[sg.Text("Try Again?")],
[sg.Yes(), sg.No()]]).read(close=True)[0] == "Yes":
print("User chose yes!")
else:
print("User chose no!")
window.close()
if __name__ == "__main__":
main()
在本例中,当您单击“打开窗口”按钮时,它会在条件语句中创建第二个窗口。该窗口直接调用 read() ,当用户选择“是”、“否”或退出窗口时关闭。根据用户的选择,条件将打印出不同的内容。
传统的多窗口设计模式
PySimpleGUI 有一个推荐的方法来处理多个窗口。在他们的食谱和 Github 上的演示中提到了这一点。这里有一个来自的例子 Demo _ Design _ Pattern _ Multiple _ windows . py:
import PySimpleGUI as sg
"""
Demo - 2 simultaneous windows using read_all_window
Window 1 launches window 2
BOTH remain active in parallel
Both windows have buttons to launch popups. The popups are "modal" and thus no other windows will be active
Copyright 2020 PySimpleGUI.org
"""
def make_win1():
layout = [[sg.Text('This is the FIRST WINDOW'), sg.Text(' ', k='-OUTPUT-')],
[sg.Text('Click Popup anytime to see a modal popup')],
[sg.Button('Launch 2nd Window'), sg.Button('Popup'), sg.Button('Exit')]]
return sg.Window('Window Title', layout, location=(800,600), finalize=True)
def make_win2():
layout = [[sg.Text('The second window')],
[sg.Input(key='-IN-', enable_events=True)],
[sg.Text(size=(25,1), k='-OUTPUT-')],
[sg.Button('Erase'), sg.Button('Popup'), sg.Button('Exit')]]
return sg.Window('Second Window', layout, finalize=True)
window1, window2 = make_win1(), None # start off with 1 window open
while True: # Event Loop
window, event, values = sg.read_all_windows()
if event == sg.WIN_CLOSED or event == 'Exit':
window.close()
if window == window2: # if closing win 2, mark as closed
window2 = None
elif window == window1: # if closing win 1, exit program
break
elif event == 'Popup':
sg.popup('This is a BLOCKING popup','all windows remain inactive while popup active')
elif event == 'Launch 2nd Window' and not window2:
window2 = make_win2()
elif event == '-IN-':
window['-OUTPUT-'].update(f'You enetered {values["-IN-"]}')
elif event == 'Erase':
window['-OUTPUT-'].update('')
window['-IN-'].update('')
window.close()
当您运行这段代码时,您可以打开几个不同的窗口,如下所示:

你会想尝试使用这两种方法,看看哪种最适合你。这个方法的好处是只有一个事件循环,这简化了事情。
包扎
PySimpleGUI 允许您创建简单和复杂的用户界面。虽然这里没有涉及,但是您也可以使用 sg.popup() 向用户显示一个更简单的对话框。这些对话框也可以是模态的,但不像常规窗口那样可以完全自定义。
试试 PySimpleGUI,看看你的想法。
相关阅读
- PySimpleGUI 简介
- 【PySimpleGUI 的演示
- 真正的 Python - PySimpleGUI:用 Python 创建 GUI 的简单方法
Python 101:Python 调试器介绍
原文:https://www.blog.pythonlibrary.org/2014/03/19/pytho-101-an-introduction-to-pythons-debugger/
Python 自带了名为 pdb 的调试器模块。该模块为您的 Python 程序提供了一个交互式源代码调试器。你可以设置断点,单步调试你的代码,检查堆栈帧等等。我们将了解本模块的以下方面:
- 如何启动调试器
- 单步执行您的代码
- 设置断点
让我们从创建一段快速代码来尝试调试开始。这里有一个愚蠢的例子:
# debug_test.py
#----------------------------------------------------------------------
def doubler(a):
""""""
result = a*2
print(result)
return result
#----------------------------------------------------------------------
def main():
""""""
for i in range(1,10):
doubler(i)
if __name__ == "__main__":
main()
现在让我们学习如何针对这段代码运行调试器。
如何启动调试器
您可以通过三种不同的方式启动调试器。第一种方法是导入它并将pdb.set_trace()插入到您的代码中以启动调试器。您可以在空闲状态下导入调试器,并让它运行您的模块。或者您可以在命令行上调用调试器。在本节中,我们将重点讨论最后两种方法。我们将从在解释器(空闲)中使用它开始。打开一个终端(命令行窗口)并导航到保存上述代码示例的位置。然后启动 Python。现在执行以下操作:
>>> import debug_test
>>> import pdb
>>> pdb.run('debug_test.main()')
> (1)<module>()
(Pdb) continue
2
4
6
8
10
12
14
16
18
>>>
在这里,我们导入我们的模块和 pdb。然后我们执行 pdb 的 run 方法,并告诉它调用我们模块的 main 方法。这将打开调试器的提示。在这里,我们键入继续来告诉它继续运行脚本。您也可以键入字母 c 作为继续的快捷键。当您继续时,调试器将继续执行,直到到达断点或脚本结束。
启动调试器的另一种方法是通过终端会话执行以下命令:
python -m pdb debug_test.py
如果您以这种方式运行,您将看到略有不同的结果:
-> def doubler(a):
(Pdb) c
2
4
6
8
10
12
14
16
18
The program finished and will be restarted
你会注意到在这个例子中我们使用了 c 而不是继续。您还会注意到调试器会在最后重新启动。这保留了调试器的状态(如断点),比让调试器停止更有用。有时候,你需要反复检查代码几次,才能明白哪里出了问题。
让我们再深入一点,学习如何单步执行代码。
单步执行代码
如果您想一次单步执行一行代码,那么您可以使用 step (或者简称为“s”)命令。这里有一个片段供你观赏:
C:\Users\mike>cd c:\py101
c:\py101>python -m pdb debug_test.py
> c:\py101\debug_test.py(4)()
-> def doubler(a):
(Pdb) step
> c:\py101\debug_test.py(11)<module>()
-> def main():
(Pdb) s
> c:\py101\debug_test.py(16)<module>()
-> if __name__ == "__main__":
(Pdb) s
> c:\py101\debug_test.py(17)<module>()
-> main()
(Pdb) s
--Call--
> c:\py101\debug_test.py(11)main()
-> def main():
(Pdb) next
> c:\py101\debug_test.py(13)main()
-> for i in range(1,10):
(Pdb) s
> c:\py101\debug_test.py(14)main()
-> doubler(i)
(Pdb)
这里我们启动调试器,并告诉它进入代码。它从顶部开始,遍历前两个函数定义。然后,它到达条件,发现它应该执行 main 函数。我们进入主函数,然后使用 next 命令。下一个命令将执行一个被调用的函数,如果它遇到该函数而没有进入该函数。如果你想进入被调用的函数,那么你只需要使用 step 命令。
当你看到类似于>c:\ py 101 \ debug _ test . py(13)main()这样的一行时,你会想要注意圆括号中的数字。这个数字是代码中的当前行号。
您可以使用 args (或 a )将当前参数列表打印到屏幕上。另一个方便的命令是跳转(或 j ),后跟一个空格和您想要“跳转”到的行号。这让你能够跳过一堆单调的步进,到达你想要到达的那一行。这就引导我们学习断点!
设置断点
断点是代码中要暂停执行的一行。您可以通过调用break(或b)命令,后跟一个空格和要中断的行号来设置断点。还可以在行号前加上文件名和冒号,以在不同的文件中指定断点。break 命令还允许您使用function参数设置断点。还有一个tbreak命令,该命令将设置一个临时断点,当遇到断点时会自动删除。
这里有一个例子:
c:\py101>python -m pdb debug_test.py
> c:\py101\debug_test.py(4)()
-> def doubler(a):
(Pdb) break 6
Breakpoint 1 at c:\py101\debug_test.py:6
(Pdb) c
> c:\py101\debug_test.py(6)doubler()
-> result = a*2
我们启动调试器,然后告诉它在第 6 行设置一个断点。然后我们继续,它在第 6 行停止,就像它应该的那样。现在是检查参数列表的好时机,看看它是否是你所期望的。现在输入 args 试试看。然后做另一个继续和另一个 args 来看看它是如何变化的。
包扎
您可以在调试器中使用许多其他命令。我建议阅读文档来了解其他的。但是,此时您应该能够有效地使用调试器来调试您自己的代码。
附加阅读
Python 101 第二版完全资助+扩展目标
原文:https://www.blog.pythonlibrary.org/2020/02/19/python-101-2nd-edition-fully-funded-stretch-goals/
我的书《Python 101》的第二版已经在 Kickstarter 上成功融资。按照传统,我增加了几个扩展目标,为这本已经很厚的书增加更多内容。

目标如下:
1) $5000 -获得 4 个奖励章节
这些章节将涵盖以下主题:
- 赋值表达式
- 如何创建图形用户界面
- 如何创建图表
- 如何在 Python 中处理图像
2) $7500 -添加章节复习题
额外的章节让我非常兴奋,因为它们是用 Python 做的有趣的事情,同时也很有用。赋值表达式一章也是 Python 中的新内容,可能很快就会对您有用。
添加章节回顾问题是我一直想用 Python 101 做的事情。希望你也会发现这个想法很有趣。
如果你有兴趣得到这本书或者支持这个网站,你现在可以去 Kickstarter 了。我的其他一些书在那里也有很好的交易!
Python 101:第二版对 PyCon 2021 是免费的!
原文:https://www.blog.pythonlibrary.org/2021/05/13/python-101-2nd-edition-is-free-for-pycon-2021/
我将在 PyCon 2021 期间免费发布 Python 101:第二版。本次销售将于 2021 年 5 月 17 日星期一结束。您可以通过以下链接免费获得这本书:
- https://leanpub.com/py101/c/pycon
- gum road-https://gumroad.com/l/pypy101/pycon
- 或者使用此链接支付你想要的东西起价 5 美元:【https://gumroad.com/l/pypy101】T2
如果你喜欢电子书,并且想要平装本,你可以在亚马逊上买到。

第二版 Python 101 完全从头重写。在本书中,您将学习 Python 编程语言以及更多内容。
这本书分为四个部分:
- Python 语言
- 中级主题
- 创建示例应用程序
- 分发您的代码
Python 101 第二版 Kickstarter 两天后结束
原文:https://www.blog.pythonlibrary.org/2020/03/16/python-101-2nd-edition-kickstarter-ending-in-two-days/
我的 Python 101 第二版 Kickstarter 还有不到两天就要结束了。如果你想要一本签名的书或者打折购买我的其他书,你应该去 Kickstarter 看看,因为我在那里有很多好的交易。
另外,请注意 Python 101 的第二版是完全重写的。这本书将有全新的内容,有望成为我最长的书之一。我想如果你是一个初学 Python 的人或者一直在使用 Python 但想提高到下一个水平的人,你会真的喜欢它。
Python 101 第二版 Kickstarter 上线了!
原文:https://www.blog.pythonlibrary.org/2020/02/17/python-101-2nd-edition-kickstarter-is-live/
我很兴奋地宣布,我的新书《Python 101,第二版》今天将在 Kickstarter 上发布!
点击照片跳转到 Kickstarter
Python 101 在我心中有着特殊的地位,因为它是我写的第一本书。坦率地说,如果不是这个博客的读者鼓励我这么做,我想我甚至不会写一本书。
新版的 Python 101 将是一本全新的、从头重写的书。虽然我将会涵盖与原著相同的大部分内容,但我对这本书进行了大量的重新组织,并加入了所有新的内容。我还删除了不再相关的旧内容。
我希望你能和我一起支持这本书,并在我写这本书的时候给我反馈,这样我就能为你提供一个非常棒的学习资源!
Python 101 第二版 Kickstarter 预览版
原文:https://www.blog.pythonlibrary.org/2020/02/10/python-101-2nd-edition-kickstarter-preview/
一年多来,我一直在考虑更新我的第一本书《Python 101》。在做了大量的计划和大纲之后,我准备宣布我已经开始写这本书了。
新的 Python 101 第二版将是一本全新的书,而不像许多出版商喜欢做的那样只是一本更新的书。我觉得更新一两章对我的读者是一种伤害。这本新书将涵盖原著中的大部分内容。然而,我放弃了对标准库的参观,取而代之的是一个“如何做”的部分,因为我认为看到真实的、工作的代码比谈论语法更好。
如果你愿意,现在可以关注我的 Kickstarter。Kickstarter 将于 2 月 17 日美国中部时间上午 8 点左右在上线,运行 30 天。
Python 101 第二版发布!
原文:https://www.blog.pythonlibrary.org/2020/09/14/python-101-2nd-edition-released/
我最新的一本书, Python 101(第二版),现在已经在 Leanpub (PDF,epub,mobi) 和亚马逊(平装/ Kindle) 上架。
我几乎完全从零开始重写了 Python 101。我用原著作为指南,但这本书完全是新的。它基于 Python 3.8,涵盖了大量初级和中级主题。
Python 101 有 4 段:
- 第一部分 Python 语言
- 第二部分-超越基础(中间材料)
- 第三部分-实用 Python(示例应用程序等)
- 第四部分-分发您的代码(PyPI、Windows 和 Mac 可执行文件)
著名的 Python 书籍作者 Steven Lott 在他的博客上写了一篇关于 Python 101 的书评。看看他的观点。
Python 101 第二版示例章节
原文:https://www.blog.pythonlibrary.org/2020/02/23/python-101-2nd-edition-sample-chapters/
我为 Python 101 第二版收集了一些样本章节,该版本将于今年晚些时候发布。你可以在这里下载这些样本章节的 PDF 版本。请注意,这些章节可能有轻微的错别字。如果你发现任何错误,请随时告诉我。
如果你有兴趣得到这本书的副本,你可以在 Kickstarter 上完成。
Python 101 五折优惠
原文:https://www.blog.pythonlibrary.org/2015/03/11/python-101-50-off/
在三月的剩余时间里,如果你使用下面的代码,你可以以 50%的价格得到我的书,Python 101:3 月 15 日
从头到尾学习如何用 Python 编程。我的书主要是为初学者写的。但是,至少有三分之二是针对中级程序员的。你可能想知道这是怎么回事。这本书将分成四部分。
第一部分
第一部分是初学者部分。在这里你将学到 Python 的所有基础知识。从 Python 类型(字符串、列表、字典)到条件语句再到循环。你还将学习理解、函数和类以及它们之间的一切!注:本节已经完成,正处于编辑阶段。
第二部分
这一部分将是 Python 标准库的一次策划之旅。其目的并不是涵盖其中的所有内容,而是向读者展示开箱即用的 Python 可以做很多事情。我们将讨论我认为在日常编程任务中最有用的模块,比如 os、sys、日志、线程等等。
第三部分
这部分都是中级材料。它包括以下内容:
- 希腊字母的第 11 个
- 装修工
- 性能
- 排除故障
- 测试
- 压型
第四部分
现在事情变得非常有趣!在第四部分,我们将学习如何从 Python 包索引和其他位置安装第三方库(即包)。我们将介绍简易安装和 pip。这一节也将是一系列的教程,在这里你将学习如何使用你下载的软件包。例如,您将学习如何下载文件、解析 XML、使用对象关系映射器处理数据库等。
第五部分
这本书的最后一部分将介绍如何与你的朋友和全世界分享你的代码!您将了解如何将其打包并在 Python 包索引上共享(例如,如何创建一个鸡蛋或轮子)。您还将学习如何使用 py2exe、bb_freeze、cx_freeze 和 PyInstaller 创建可执行文件。最后,您将学习如何使用 Inno Setup 创建安装程序。
Python 101:关于字典的一切
原文:https://www.blog.pythonlibrary.org/2017/03/15/python-101-all-about-dictionaries/
Python 编程语言支持几种内置类型。我最喜欢的东西之一是字典。字典是一个映射对象,它将散列值映射到任意对象。其他语言称字典为“哈希表”。与元组不同,它们是可以随时更改的可变对象。字典的键必须是可散列的或不可变的,这意味着不能使用列表或另一个字典作为键。注意 Python 3.6 之前的词典是不排序的。在 Python 3.7 中,他们改变了 dict 的实现,所以它现在是有序的。
在这篇文章中,我们将花一些时间来了解一些你可以用字典做的事情。
创建词典
字典是一个键:值对。在 Python 中,这些键:值对用大括号括起来,每对之间用逗号隔开。用 Python 创建字典真的很容易。以下是创建词典的三种方法:
>>> my_dict = {}
>>> my_other_dict = dict()
>>> my_other_other_dict = {1: 'one', 2: 'two', 3: 'three'}
在第一个例子中,我们通过将变量赋给一对空花括号来创建一个空字典。还可以通过调用 Python 内置的 dict() 关键字来创建 dictionary 对象。我看到有人提到调用 dict()比只做赋值操作符要稍微慢一点。最后一个例子展示了如何用一些预定义的键:值对创建一个字典。您可以拥有包含各种类型映射的字典,包括到函数或对象的映射。你也可以在你的字典中嵌套字典和列表!
访问字典值
访问保存在字典中的值非常简单。你所需要做的就是把一个键传递给你的字典,放在方括号内。让我们来看一个例子:
>>> my_other_other_dict = {1: 'one', 2: 'two', 3: 'three'}
>>> my_other_other_dict[1]
'one'
如果你在字典里找一个不存在的键会怎么样?你会收到一个键错误,就像这样:
>>> my_other_other_dict[4]
Traceback (most recent call last):
Python Shell, prompt 5, line 1
KeyError: 4
这个错误告诉我们,字典中没有名为“4”的键。如果你想避免这个错误,你可以使用 dict 的 get() 方法:
>>> my_other_other_dict.get(4, None)
None
get()方法将询问字典是否包含指定的键(即 4),如果不包含,您可以指定返回什么值。在这个例子中,如果键不存在,我们返回 None 类型。
您还可以在操作符中使用 Python 的来检查字典是否也包含一个键:
>>> key = 4
>>> if key in my_other_other_dict:
print('Key ({}) found'.format(key))
else:
print('Key ({}) NOT found!'.format(key))
Key (4) NOT found!
这将检查键 4 是否在字典中,并打印适当的响应。在 Python 2 中,字典还有一个 has_key() 方法,除了使用 In 操作符之外,还可以使用这个方法。但是,在 Python 3 中移除了 has_key()。
更新密钥
您可能已经猜到,更新一个键所指向的值是非常容易的。方法如下:
>>> my_dict = {}
>>> my_dict[1] = 'one'
>>> my_dict[1]
'one'
>>> my_dict[1] = 'something else'
>>> my_dict[1]
'something else'
这里我们创建一个空的字典实例,然后向字典中添加一个元素。然后,我们将这个键(在本例中是整数 1)指向另一个字符串值。
拆卸钥匙
有两种方法可以从字典中删除键:值对。我们将涉及第一件事是字典的 pop() 方法。Pop 将检查该键是否在字典中,如果在,就删除它。如果密钥不在那里,您将收到一个密钥错误。实际上,您可以通过传入第二个参数(这是默认的返回值)来抑制 KeyError。
让我们来看几个例子:
>>> my_dict = {}
>>> my_dict[1] = 'something else'
>>> my_dict.pop(1, None)
'something else'
>>> my_dict.pop(2)
Traceback (most recent call last):
Python Shell, prompt 15, line 1
KeyError: 2
这里我们创建一个字典并添加一个条目。然后,我们使用 pop()方法删除相同的条目。您会注意到,我们还将缺省值设置为 None,这样,如果键不存在,pop 方法将返回 None。在第一种情况下,键确实存在,所以它返回它移除或弹出的项的值。
第二个例子演示了当您试图对字典中没有的键调用 pop()时会发生什么。
从字典中删除条目的另一种方法是使用 Python 的内置 del:
>>> my_dict = {1: 'one', 2: 'two', 3: 'three'}
>>> del my_dict[1]
>>> my_dict
>>> {2: 'two', 3: 'three'}
这将从字典中删除指定的键:值对。如果这个键不在字典中,您将收到一个 KeyError 。这就是为什么我实际上推荐 pop()方法,因为只要你提供一个默认值,你就不需要 try/except 包装 pop()。
重复
Python 字典允许程序员使用简单的 for 循环来迭代它的键。让我们来看看:
>>> my_dict = {1: 'one', 2: 'two', 3: 'three'}
>>> for key in my_dict:
print(key)
1
2
3
简单提醒一下:Python 字典是无序的,所以当您运行这段代码时,可能不会得到相同的结果。我认为在这一点上需要提及的一件事是,Python 3 在字典方面做了一些改变。在 Python 2 中,您可以调用字典的 keys()和 values()方法来分别返回键和值的 Python 列表:
# Python 2
>>> my_dict = {1: 'one', 2: 'two', 3: 'three'}
>>> my_dict.keys()
[1, 2, 3]
>>> my_dict.values()
['one', 'two', 'three']
>>> my_dict.items()
[(1, 'one'), (2, 'two'), (3, 'three')]
但是在 Python 3 中,您将获得返回的视图:
# Python 3
>>> my_dict = {1: 'one', 2: 'two', 3: 'three'}
>>> my_dict.keys()
>>> dict_keys([1, 2, 3])
>>> my_dict.values()
>>> dict_values(['one', 'two', 'three'])
>>> my_dict.items()
dict_items([(1, 'one'), (2, 'two'), (3, 'three')])
在任一 Python 版本中,您仍然可以迭代结果:
for item in my_dict.values():
print(item)
one
two
three
原因是列表和视图都是可迭代的。请记住,视图是不可索引的,因此在 Python 3:
>>> my_dict.values()[1]
这将引发一个类型错误。
Python 有一个可爱的库,叫做 collections ,其中包含了字典的一些简洁的子类。我们将在接下来的两节中讨论 defaultdict 和 OrderDict。
默认词典
有一个非常方便的名为 collections 的库,里面有一个 defaultdict 模块。defaultdict 将接受一个类型作为它的第一个参数,或者默认为 None。我们传入的参数成为一个工厂,用于创建字典的值。让我们看一个简单的例子:
from collections import defaultdict
sentence = "The red for jumped over the fence and ran to the zoo"
words = sentence.split(' ')
d = defaultdict(int)
for word in words:
d[word] += 1
print(d)
在这段代码中,我们向 defaultdict 传递一个 int。这允许我们在这种情况下计算一个句子的字数。下面是上面代码的输出:
defaultdict(,
{'and': 1,
'fence': 1,
'for': 1,
'ran': 1,
'jumped': 1,
'over': 1,
'zoo': 1,
'to': 1,
'The': 1,
'the': 2,
'red': 1})
如您所见,除了字符串“the”之外,每个单词都只出现一次。您会注意到它是区分大小写的,因为“The”只出现过一次。如果我们将字符串的大小写改为小写,我们可能会使代码变得更好。
有序词典
“收藏库”还允许您创建记住插入顺序的词典。这就是所谓的有序直接。让我们来看看我以前的文章中的一个例子:
>>> from collections import OrderedDict
>>> d = {'banana': 3, 'apple':4, 'pear': 1, 'orange': 2}
>>> new_d = OrderedDict(sorted(d.items()))
>>> new_d
OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)])
>>> for key in new_d:
... print (key, new_d[key])
...
apple 4
banana 3
orange 2
pear 1
在这里,我们创建一个常规字典,对其进行排序,并将其传递给我们的 OrderedDict。然后我们迭代 OrderedDict 并打印出来。你会注意到它是按字母顺序打印出来的,因为这是我们插入数据的方式。如果只是迭代原始字典,您可能看不到这一点。
在 collections 模块中还有一个叫做 Counter 的字典子类,我们不会在这里讨论。我鼓励你自己去看看。
包扎
在这篇文章中,我们已经讨论了很多内容。现在,您应该已经基本了解了在 Python 中使用字典的所有知识。您已经学习了几种创建字典、添加字典、更新字典值、删除关键字甚至字典的一些可选子类的方法。我希望您发现这很有用,并且您很快会在自己的代码中发现字典的许多重要用途!
相关阅读
- Python 字典文档
- 收藏模块文档
- Python 201: OrderedDict
- Python 201 便捷的默认规则
Python 101:关于导入的一切
原文:https://www.blog.pythonlibrary.org/2016/03/01/python-101-all-about-imports/
作为一名初学 Python 的程序员,您首先要学习的一件事就是如何导入其他模块或包。但是,我注意到,即使是随便使用 Python 多年的人,也不总是知道 Python 的导入基础设施有多灵活。在本文中,我们将探讨以下主题:
- 常规进口
- 使用来自
- 相对进口
- 可选进口
- 本地进口
- 进口陷阱
常规进口
一个常规的导入,很可能是最流行的导入是这样的:
import sys
您所需要做的就是使用单词“import ”,然后指定您想要实际导入的模块或包。不过,import 的好处是它还可以一次导入多个包:
import os, sys, time
虽然这样可以节省空间,但这违背了 Python 风格指南的建议,即把每个导入放在自己的行上。
有时当您导入一个模块时,您想要重命名它。Python 很容易支持这一点:
import sys as system
print(system.platform)
这段代码只是将我们的导入重命名为“system”。我们可以像以前一样调用所有的模块方法,但是使用新的名称。还有一些必须使用点符号导入的子模块:
import urllib.error
你不会经常看到这些,但了解它们是有好处的。
使用从模块导入内容
很多时候你只想导入模块或库的一部分。让我们看看 Python 是如何做到这一点的:
from functools import lru_cache
上面的代码允许你直接调用 lru_cache 。如果您以正常方式只导入了 functools ,那么您将不得不像这样调用 lru_cache:
functools.lru_cache(*args)
根据你正在做的事情,以上事实上可能是一件好事。在复杂的代码库中,知道某些东西是从哪里导入的非常好。然而,如果你的代码被很好地维护和模块化,从模块中导入一部分代码会非常方便和简洁。
当然你也可以使用中的方法来导入所有内容,就像这样:
from os import *
这在极少数情况下很方便,但也可能会搞乱名称空间。问题是你可能定义了你自己的函数或一个顶级变量,它与你导入的一个项目同名,如果你试图使用来自 os 模块的那个,它将使用你的。所以你最终会得到一个相当混乱的逻辑错误。Tkinter 模块真的是我见过的标准库中唯一推荐全部导入的。
如果你碰巧编写了自己的模块或包,有些人建议把所有东西都导入到你的 init。py 让你的模块或者包更容易使用。我个人更喜欢显性的,而不是隐性的,而是各取所需。
您也可以通过从一个包中导入多个项目来折中:
from os import path, walk, unlink
from os import uname, remove
在上面的代码中,我们从 os 模块导入了五个函数。您还会注意到,我们可以通过多次从同一个模块导入来实现这一点。如果您愿意,也可以使用括号来导入大量项目:
from os import (path, walk, unlink, uname,
remove, rename)
这是一种有用的技术,但是您也可以用另一种方式来实现:
from os import path, walk, unlink, uname, \
remove, rename
上面看到的反斜杠是 Python 的行继续符,它告诉 Python 这行代码在下一行继续。
相对进口
PEP 328 描述了相对导入是如何产生的,以及选择了什么特定的语法。其背后的想法是使用句点来确定如何相对导入其他包/模块。原因是为了防止标准库模块的意外隐藏。让我们使用 PEP 328 建议的示例文件夹结构,看看我们是否能让它工作:
my_package/
__init__.py
subpackage1/
__init__.py
module_x.py
module_y.py
subpackage2/
__init__.py
module_z.py
module_a.py
在硬盘上的某个地方创建上面的文件和文件夹。在顶层 init。py ,将以下代码放在适当的位置:
from . import subpackage1
from . import subpackage2
接下来在子包 1 中向下导航,并编辑它的 init。py 要有以下内容:
from . import module_x
from . import module_y
现在编辑 module_x.py ,使其具有以下代码:
from .module_y import spam as ham
def main():
ham()
最后编辑 module_y.py 来匹配这个:
def spam():
print('spam ' * 3)
打开一个终端,将 cd 放到有 my_package 的文件夹中,但不要放到 my_package 中。运行该文件夹中的 Python 解释器。我使用下面的 iPython 主要是因为它的自动完成非常方便:
In [1]: import my_package
In [2]: my_package.subpackage1.module_x
Out[2]: In [3]: my_package.subpackage1.module_x.main()
spam spam spam
相对导入对于创建您可以转换成包的代码非常有用。如果您已经创建了许多相关的代码,那么这可能是一条可行之路。你会发现在 Python 包索引(PyPI)上很多流行的包中都使用了相对导入。另请注意,如果您需要进入多个级别,您可以只使用额外的期间。但是,根据 PEP 328,你真的不应该超过两个。
还要注意的是,如果您要向 module_x.py 添加一个“ if name == 'main' ”部分并试图运行它,您将会以一个相当令人困惑的错误结束。让我们编辑文件并尝试一下吧!
from . module_y import spam as ham
def main():
ham()
if __name__ == '__main__':
# This won't work!
main()
现在导航到终端中的 subpackage1 文件夹,并运行以下命令:
python module_x.py
对于 Python 2,您应该会在屏幕上看到以下错误:
Traceback (most recent call last):
File "module_x.py", line 1, in from . module_y import spam as ham
ValueError: Attempted relative import in non-package
如果你试着用 Python 3 运行它,你会得到这个:
Traceback (most recent call last):
File "module_x.py", line 1, in from . module_y import spam as ham
SystemError: Parent module '' not loaded, cannot perform relative import
这意味着 module_x.py 是包内的一个模块,你试图将它作为脚本运行,这与相对导入不兼容。
如果您想在代码中使用这个模块,您必须将它添加到 Python 的导入搜索路径中。最简单的方法如下:
import sys
sys.path.append('/path/to/folder/containing/my_package')
import my_package
请注意,您想要的是位于 my_package 正上方的文件夹的路径(例如。subpackage1),而不是 my_package 本身。原因是 my_package 是这个包,所以如果你添加了它,你在使用这个包的时候会有问题。让我们转到可选导入!
可选进口
当您有一个想要使用的首选模块或包,但是您还想在它不存在的情况下有一个后备时,可以使用可选导入。例如,您可以使用可选导入来支持软件的多个版本或加速。这里有一个来自包 github2 的例子,演示了如何使用可选的导入来支持不同版本的 Python:
try:
# For Python 3
from http.client import responses
except ImportError: # For Python 2.5-2.7
try:
from httplib import responses # NOQA
except ImportError: # For Python 2.4
from BaseHTTPServer import BaseHTTPRequestHandler as _BHRH
responses = dict([(k, v[0]) for k, v in _BHRH.responses.items()])
lxml 包也使用可选的导入:
try:
from urlparse import urljoin
from urllib2 import urlopen
except ImportError:
# Python 3
from urllib.parse import urljoin
from urllib.request import urlopen
正如你所看到的,它一直被用来产生巨大的效果,是一个方便的工具来增加你的曲目。
本地进口
局部导入是指将模块导入局部范围。当您在 Python 脚本文件的顶部进行导入时,也就是将模块导入到全局范围内,这意味着后面的任何函数或方法都可以使用它。让我们看看导入到本地范围是如何工作的:
import sys # global scope
def square_root(a):
# This import is into the square_root functions local scope
import math
return math.sqrt(a)
def my_pow(base_num, power):
return math.pow(base_num, power)
if __name__ == '__main__':
print(square_root(49))
print(my_pow(2, 3))
这里我们将 sys 模块导入到全局作用域中,但是我们实际上并没有使用它。然后在平方根函数中,我们将 Python 的数学模块导入到函数的局部范围内,这意味着数学模块只能在平方根函数内部使用。如果我们试图在 my_pow 函数中使用它,我们将会收到一个 NameError 。继续尝试运行代码,看看这是怎么回事!
使用局部作用域的好处之一是,您可能会使用一个需要很长时间才能加载的模块。如果是这样,将它放入一个很少被调用的函数而不是模块的全局作用域中可能是有意义的。这真的取决于你想做什么。坦白地说,我几乎从未在局部范围内使用导入,主要是因为如果导入分散在整个模块中,很难判断会发生什么。按照惯例,所有的导入都应该在模块的顶部。
进口陷阱
程序员会陷入一些非常常见的导入陷阱。我们将在这里讨论两个最常见的问题:
- 循环进口
- 隐藏的导入
让我们从循环导入开始
循环进口
当您创建两个相互导入的模块时,就会发生循环导入。让我们看一个例子,因为这将使我所指的非常清楚。将以下代码放入名为 a.py 的模块中
# a.py
import b
def a_test():
print("in a_test")
b.b_test()
a_test()
然后在与上面相同的文件夹中创建另一个模块,并将其命名为 b.py
import a
def b_test():
print('In test_b"')
a.a_test()
b_test()
如果您运行这些模块中的任何一个,您应该会收到一个 AttributeError 。发生这种情况是因为两个模块都试图相互导入。基本上,这里发生的是模块 a 试图导入模块 b,但是它不能这样做,因为模块 b 试图导入已经在执行的模块 a。我读过一些黑客的解决方法,但是一般来说,你应该重构你的代码来防止这种事情发生
隐藏的导入
当程序员创建一个与 Python 模块同名的模块时,就会发生影子导入(又名名称屏蔽)。让我们创造一个人为的例子!在这种情况下,创建一个名为 math.py 的文件,并将以下代码放入其中:
import math
def square_root(number):
return math.sqrt(number)
square_root(72)
现在打开一个终端,试着运行这段代码。当我尝试这样做时,我得到了以下回溯:
Traceback (most recent call last):
File "math.py", line 1, in import math
File "/Users/michael/Desktop/math.py", line 6, in <module>square_root(72)
File "/Users/michael/Desktop/math.py", line 4, in square_root
return math.sqrt(number)
AttributeError: module 'math' has no attribute 'sqrt'
这里发生了什么?当你运行这段代码时,Python 首先会在当前运行脚本的文件夹中寻找一个名为“math”的模块。在这种情况下,它会找到我们正在运行的模块并尝试使用它。但是我们的模块没有一个名为 sqrt 的函数或属性,所以产生了一个 AttributeError 。
包扎
我们已经在本文中介绍了很多内容,关于 Python 的导入系统还有很多需要学习的地方。有 PEP 302 涵盖了导入挂钩,允许你做一些非常酷的事情,比如直接从 github 导入。还有 Python 的 importlib ,非常值得一看。走出去,开始挖掘源代码,了解更多巧妙的技巧。编码快乐!
相关阅读
- 导入陷阱
- Python 2 和 Python 3 中的循环导入
- Stackoverflow - Python 第十亿次相对导入
Python 101:代码基准测试简介
原文:https://www.blog.pythonlibrary.org/2016/05/24/python-101-an-intro-to-benchmarking-your-code/
对一个人的代码进行基准测试意味着什么?基准测试或分析背后的主要思想是计算出代码执行的速度以及瓶颈在哪里。做这种事情的主要原因是为了优化。您会遇到这样的情况,由于业务需求发生了变化,您需要代码运行得更快。当这种情况发生时,您将需要找出代码的哪些部分降低了速度。
本章将只讲述如何使用各种工具来分析你的代码。它不会实际优化你的代码。我们开始吧!
时间
Python 附带了一个名为 timeit 的模块。你可以用它来计时小代码片段。timeit 模块使用特定于平台的时间函数,因此您可以获得尽可能精确的计时。
timeit 模块有一个命令行界面,但是也可以导入。我们将从如何从命令行使用 timeit 开始。打开终端,尝试以下示例:
python -m timeit -s "[ord(x) for x in 'abcdfghi']"
100000000 loops, best of 3: 0.0115 usec per loop
python -m timeit -s "[chr(int(x)) for x in '123456789']"
100000000 loops, best of 3: 0.0119 usec per loop
这是怎么回事?嗯,当你在命令行上调用 Python 并给它传递“-m”选项时,你是在告诉它查找一个模块并把它作为主程序使用。“-s”告诉 timeit 模块运行一次安装程序。然后,它将代码运行 n 次循环,并返回 3 次运行的最佳平均值。对于这些愚蠢的例子,你不会看到太大的区别。
您的输出可能会略有不同,因为它取决于您的计算机的规格。
让我们写一个简单的函数,看看我们能否从命令行计时:
# simple_func.py
def my_function():
try:
1 / 0
except ZeroDivisionError:
pass
这个函数所做的就是产生一个错误,这个错误很快就会被忽略。是的,又是一个很傻的例子。为了让 timeit 在命令行上运行这段代码,我们需要将代码导入到它的名称空间中,所以要确保您已经将当前的工作目录更改到了这个脚本所在的文件夹中。然后运行以下命令:
python -m timeit "import simple_func; simple_func.my_function()"
1000000 loops, best of 3: 1.77 usec per loop
这里我们导入函数,然后调用它。注意,我们用分号分隔导入和函数调用,Python 代码用引号括起来。现在我们准备学习如何在实际的 Python 脚本中使用 timeit。
导入 timeit 进行测试
在代码中使用 timeit 模块也很容易。我们将使用之前相同的愚蠢脚本,并在下面向您展示如何操作:
def my_function():
try:
1 / 0
except ZeroDivisionError:
pass
if __name__ == "__main__":
import timeit
setup = "from __main__ import my_function"
print timeit.timeit("my_function()", setup=setup)
在这里,我们检查脚本是否正在直接运行(即没有导入)。如果是,那么我们导入 timeit,创建一个设置字符串将函数导入 timeit 的名称空间,然后我们调用 timeit.timeit。您会注意到,我们用引号将对函数的调用,然后是设置字符串。这就是真正的全部内容!现在让我们学习如何编写我们自己的计时器装饰器。
使用室内装饰
编写自己的定时器也很有趣,尽管它可能没有使用 timeit 精确,这取决于用例。不管怎样,我们将编写自己的自定义函数计时装饰器!代码如下:
import random
import time
def timerfunc(func):
"""
A timer decorator
"""
def function_timer(*args, **kwargs):
"""
A nested function for timing other functions
"""
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "The runtime for {func} took {time} seconds to complete"
print(msg.format(func=func.__name__,
time=runtime))
return value
return function_timer
@timerfunc
def long_runner():
for x in range(5):
sleep_time = random.choice(range(1,5))
time.sleep(sleep_time)
if __name__ == '__main__':
long_runner()
对于这个例子,我们从 Python 的标准库中导入random和time模块。然后我们创建装饰函数。你会注意到它接受一个函数,并且在它里面有另一个函数。嵌套函数会在调用传入函数之前抢占时间。然后等待函数返回,并获取结束时间。现在我们知道这个函数运行了多长时间,所以我们把它打印出来。当然,装饰器还需要返回函数调用的结果和函数本身,所以这就是最后两条语句的意义所在。
下一个函数是用我们的计时装饰器来装饰的。你会注意到它使用 random 来“随机”睡眠几秒钟。这只是为了演示一个长时间运行的程序。实际上,您可能希望对连接到数据库(或运行大型查询)、网站、运行线程或做其他需要一段时间才能完成的事情的功能进行计时。
每次运行这段代码,结果都会略有不同。试试看,自己看吧!
创建计时上下文管理器
一些程序员喜欢使用上下文管理器来为小代码片段计时。所以让我们创建自己的定时器上下文管理器类!
import random
import time
class MyTimer():
def __init__(self):
self.start = time.time()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
end = time.time()
runtime = end - self.start
msg = 'The function took {time} seconds to complete'
print(msg.format(time=runtime))
def long_runner():
for x in range(5):
sleep_time = random.choice(range(1,5))
time.sleep(sleep_time)
if __name__ == '__main__':
with MyTimer():
long_runner()
在这个例子中,我们使用类的 init 方法来启动我们的计时器。 enter 方法除了返回自身之外不需要做任何其他事情。最后, exit 方法包含了所有有趣的部分。这里我们获取结束时间,计算总运行时间并打印出来。
代码的结尾实际上展示了一个使用我们的上下文管理器的例子,其中我们在自定义上下文管理器中包装了上一个例子中的函数。
轮廓
ython 自带内置的代码分析器。有 profile 模块和 cProfile 模块。profile 模块是纯 Python 的,但是它会给你分析的任何东西增加很多开销,所以通常推荐你使用 cProfile,它有一个相似的接口,但是要快得多。
在这一章中,我们不打算详细讨论这个模块,但是让我们来看几个有趣的例子,这样你就能体会到它能做什么。
>>> import cProfile
>>> cProfile.run("[x for x in range(1500)]")
4 function calls in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :1(<listcomp>)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.001 0.001 0.001 0.001 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}</string></listcomp>
让我们把它分解一下。第一行显示有 4 个函数调用。下一行告诉我们结果是如何排序的。根据文档,标准名称是指最右边的列。这里有许多列。
- ncalls 是发出的呼叫数。
- tottime 是给定函数花费的总时间。
- percall 指总时间除以 ncalls 的商
- 累计时间是在该功能和所有子功能中花费的累计时间。甚至对递归函数也很准确!
- 第二个 percall 列是累计时间除以原始调用的商
- filename:line no(function)提供每个函数各自的数据
您可以在命令行上调用 cProfile,方式与我们使用 timeit 模块的方式非常相似。主要的区别在于,您将向它传递一个 Python 脚本,而不仅仅是传递一个代码片段。下面是一个调用示例:
python -m cProfile test.py
在您自己的一个模块上尝试一下,或者在 Python 的一个模块上尝试一下,看看效果如何。
线条轮廓图
有一个很棒的第三方项目叫做 line_profiler ,它被设计用来分析每一行执行所花费的时间。它还包括一个名为 kernprof 的脚本,用于使用 line_profiler 分析 Python 应用程序和脚本。只需使用 pip 来安装软件包。方法如下:
pip install line_profiler
为了实际使用 line_profiler,我们需要一些代码来进行分析。但首先,我需要解释当你在命令行调用 line_profiler 时,它是如何工作的。您实际上将通过调用 kernprof 脚本来调用 line_profiler。我第一次使用它的时候觉得有点混乱,但这就是它的工作方式。下面是使用它的正常方法:
kernprof -l silly_functions.py
这将在完成时打印出以下消息:将概要结果写入 silly_functions.py.lprof 。这是一个我们无法直接查看的二进制文件。但是当我们运行 kernprof 时,它实际上会将一个 LineProfiler 的实例注入到脚本的 builtins 名称空间中。该实例将被命名为 profile 并被用作装饰器。考虑到这一点,我们实际上可以编写我们的脚本:
# silly_functions.py
import time
@profile
def fast_function():
print("I'm a fast function!")
@profile
def slow_function():
time.sleep(2)
print("I'm a slow function")
if __name__ == '__main__':
fast_function()
slow_function()
所以现在我们有两个修饰函数,它们是用没有导入的东西修饰的。如果您真的试图运行这个脚本,您将得到一个 NameError ,因为“profile”没有被定义。所以在你分析完你的代码之后,一定要记得移除你的装饰者!
让我们后退一步,学习如何实际查看我们的分析器的结果。有两种方法我们可以使用。第一种是使用 line_profiler 模块读取我们的结果文件:
python -m line_profiler silly_functions.py.lprof
另一种方法是在详细模式下通过传递 is -v 来使用 kernprof:
kernprof -l -v silly_functions.py
无论您使用哪种方法,您最终都会看到类似以下内容打印到您的屏幕上:
I'm a fast function!
I'm a slow function
Wrote profile results to silly_functions.py.lprof
Timer unit: 1e-06 s
Total time: 3.4e-05 s
File: silly_functions.py
Function: fast_function at line 3
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 @profile
4 def fast_function():
5 1 34 34.0 100.0 print("I'm a fast function!")
Total time: 2.001 s
File: silly_functions.py
Function: slow_function at line 7
Line # Hits Time Per Hit % Time Line Contents
==============================================================
7 @profile
8 def slow_function():
9 1 2000942 2000942.0 100.0 time.sleep(2)
10 1 59 59.0 0.0 print("I'm a slow function")
您会注意到源代码被打印出来,每一行都有计时信息。这里有六列信息。让我们来看看每一个是什么意思。
- 行号 -被分析的代码的行号
- 命中——特定行被执行的次数
- Time -执行该行所花费的总时间(以计时器为单位)。在输出的开头可以看到计时器单元
- 每次点击——一行代码执行的平均时间(以计时器为单位)
- %
- 行内容——实际执行的源代码
如果您碰巧是 IPython 用户,那么您可能想知道 IPython 有一个神奇的命令(%lprun),它允许您指定要分析的函数,甚至是要执行的语句。
内存分析器
另一个很棒的第三方评测包是 memory_profiler 。memory_profiler 模块可用于监视进程中的内存消耗,也可以用于逐行分析代码的内存消耗。因为 Python 中没有包含它,所以我们必须安装它。您可以为此使用画中画:
pip install memory_profiler
一旦安装完毕,我们需要一些代码来运行它。memory_profiler 实际上与 line_profiler 的工作方式非常相似,因为当您运行它时,memory_profiler 会将它自己的一个实例注入 builtins named profile 中,您应该将它用作正在分析的函数的装饰器。这里有一个简单的例子:
# memo_prof.py
@profile
def mem_func():
lots_of_numbers = list(range(1500))
x = ['letters'] * (5 ** 10)
del lots_of_numbers
return None
if __name__ == '__main__':
mem_func()
在这个例子中,我们创建了一个包含 1500 个整数的列表。然后我们创建一个包含 9765625 (5 的 10 次方)个字符串实例的列表。最后,我们删除第一个列表并返回。memory_profiler 不像 line_profiler 那样需要运行另一个脚本来进行实际的分析。相反,您可以运行 Python 并在命令行上使用它的-m参数来加载模块并根据我们的脚本运行它:
python -m memory_profiler memo_prof.py
Filename: memo_prof.py
Line # Mem usage Increment Line Contents
================================================
1 16.672 MiB 0.000 MiB @profile
2 def mem_func():
3 16.707 MiB 0.035 MiB lots_of_numbers = list(range(1500))
4 91.215 MiB 74.508 MiB x = ['letters'] * (5 ** 10)
5 91.215 MiB 0.000 MiB del lots_of_numbers
6 91.215 MiB 0.000 MiB return None
这一次,这些列非常简单明了。我们有自己的行号,然后是执行该行后使用的内存量。接下来我们有一个增量字段,它告诉我们当前行与前一行的内存差异。最后一列是代码本身。
memory_profiler 还包括 mprof ,它可以用来创建一段时间内的完整内存使用报告,而不是逐行创建。它非常容易使用;看一看:
$ mprof run memo_prof.py
mprof: Sampling memory every 0.1s
running as a Python program...
mprof 还可以创建一个图表,显示应用程序如何随时间消耗内存。要得到图表,你需要做的就是:
$ mprof plot
对于我们之前创建的愚蠢示例,我得到了下面的图表:

你应该试着自己运行一个更复杂的例子,看看更有趣的情节。
个人资料查看
本章中我们要看的最后一个第三方包叫做 profilehooks 。它是一个装饰器的集合,专门为剖析函数而设计。要安装 profilehooks,只需执行以下操作:
pip install profilehooks
现在我们已经安装了它,让我们重新使用上一节中的示例,并稍微修改它以使用 profilehooks:
# profhooks.py
from profilehooks import profile
@profile
def mem_func():
lots_of_numbers = list(range(1500))
x = ['letters'] * (5 ** 10)
del lots_of_numbers
return None
if __name__ == '__main__':
mem_func()
要使用 profilehooks,您只需导入它,然后修饰您想要分析的函数。如果您运行上面的代码,您将得到类似于以下发送到 stdout 的输出:
*** PROFILER RESULTS ***
mem_func (c:\Users\mike\Dropbox\Scripts\py3\profhooks.py:3)
function called 1 times
3 function calls in 0.096 seconds
Ordered by: cumulative time, internal time, call count
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.096 0.096 0.096 0.096 profhooks.py:3(mem_func)
1 0.000 0.000 0.000 0.000 {range}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
0 0.000 0.000 profile:0(profiler)
这个包的输出似乎遵循 Python 标准库中的 cProfile 模块的输出。您可以参考本章前面对这些列的描述来了解它们的含义。profilehooks 包还有两个装饰器。我们要看的第一个叫做 timecall 。它给出了函数的过程运行时间:
# profhooks2.py
from profilehooks import timecall
@timecall
def mem_func():
lots_of_numbers = list(range(1500))
x = ['letters'] * (5 ** 10)
del lots_of_numbers
return None
if __name__ == '__main__':
mem_func()
如果您运行这段代码,您将看到如下输出:
mem_func (c:\path_to_script\profhooks2.py:3):
0.141 seconds
decorator 所做的只是计算函数的执行时间,但没有分析的开销。有点像用timeit。
profhooks 提供的最后一个装饰器叫做**覆盖率* *。它应该打印出单个函数的行覆盖。我自己并不觉得这个很有用,但是欢迎你自己尝试一下。
最后,我只想提一下,您也可以在命令行上使用 Python 的-m 标志运行 profilehooks:
python -m profilehooks mymodule.py
profilehooks 包相当新,但我认为它有一些潜力。
包扎
我们在这一章中介绍了很多信息。您了解了如何分别使用 Python 的内置模块 timeit 和 cProfile 来计时和分析代码。您还学习了如何编写自己的计时代码,并将其用作装饰器或上下文管理器。然后我们继续前进,看了一些第三方软件包;即 line_profiler、memory_profiler 和 profilehooks。此时,您应该已经开始对自己的代码进行基准测试了。试一试,看看是否能找到自己的瓶颈。
相关阅读
Python 101 -类介绍(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/01/python-101-an-intro-to-classes-video/
在本教程中,学习类的基础知识,并初步体验 Python 中的面向对象编程
您将了解到:
- 班级创建
- 自我 -这意味着什么
- 子类创建
- 多态性
https://www.youtube.com/embed/wtGkI-6ZuZ4?feature=oembed
想了解更多?
买我的书, Python 101 -第二版:
python 101:config parser 简介
原文:https://www.blog.pythonlibrary.org/2013/10/25/python-101-an-intro-to-configparser/
用户和程序员都使用配置文件。它们通常用于存储应用程序的设置,甚至是操作系统的设置。Python 的核心库包括一个名为 ConfigParser 的模块,您可以使用它来创建配置文件并与之交互。在本文中,我们将花几分钟时间了解它是如何工作的。
注意:本文中的例子使用的是 Python 2。在 Python 3 中,ConfigParser 被重命名为 configparser。
创建配置文件
用 ConfigParser 创建配置文件非常简单。让我们创建一些代码来演示:
import ConfigParser
#----------------------------------------------------------------------
def createConfig(path):
"""
Create a config file
"""
config = ConfigParser.ConfigParser()
config.add_section("Settings")
config.set("Settings", "font", "Courier")
config.set("Settings", "font_size", "10")
config.set("Settings", "font_style", "Normal")
config.set("Settings", "font_info",
"You are using %(font)s at %(font_size)s pt")
with open(path, "wb") as config_file:
config.write(config_file)
#----------------------------------------------------------------------
if __name__ == "__main__":
path = "settings.ini"
createConfig(path)
上面的代码将创建一个配置文件,其中一个部分标记为 Settings ,包含四个选项:font、font_size、font_style 和 font_info。还要注意,当我们将配置写入磁盘时,我们使用“wb”标志以二进制模式写入。这不是必需的,但是官方文档示例就是这样做的。您也可以使用普通的“w”标志,它仍然可以工作。我在文档中找不到任何东西来解释其中的原因。
如何读取、更新和删除选项
现在我们正在阅读学习如何阅读配置文件,更新它的选项,甚至如何删除选项。在这种情况下,通过实际编写一些代码来学习更容易!只需将下面的函数添加到您上面编写的代码中。
import ConfigParser
import os
#----------------------------------------------------------------------
def crudConfig(path):
"""
Create, read, update, delete config
"""
if not os.path.exists(path):
createConfig(path)
config = ConfigParser.ConfigParser()
config.read(path)
# read some values from the config
font = config.get("Settings", "font")
font_size = config.get("Settings", "font_size")
# change a value in the config
config.set("Settings", "font_size", "12")
# delete a value from the config
config.remove_option("Settings", "font_style")
# write changes back to the config file
with open(path, "wb") as config_file:
config.write(config_file)
#----------------------------------------------------------------------
if __name__ == "__main__":
path = "settings.ini"
crudConfig(path)
这段代码首先检查配置文件的路径是否存在。如果没有,那么它使用我们之前创建的 createConfig 函数来创建它。接下来,我们创建一个 ConfigParser 对象,并向其传递要读取的配置文件路径。为了读取配置文件中的选项,我们调用我们的 ConfigParser 对象的 get 方法,向它传递节名和选项名。这将返回选项的值。如果你想改变一个选项的值,那么你可以使用 set 方法,在这里你传递节名、选项名和新值。最后,您可以使用 remove_option 方法来删除一个选项。
在我们的示例代码中,我们将 font_size 的值更改为“12 ”,并完全删除了 font_style 选项。然后,我们将更改写回磁盘。
虽然这不是一个很好的例子,但是你不应该有一个函数像这个函数一样做所有的事情。所以让我们把它分成一系列的功能:
import ConfigParser
import os
def create_config(path):
"""
Create a config file
"""
config = ConfigParser.ConfigParser()
config.add_section("Settings")
config.set("Settings", "font", "Courier")
config.set("Settings", "font_size", "10")
config.set("Settings", "font_style", "Normal")
config.set("Settings", "font_info",
"You are using %(font)s at %(font_size)s pt")
with open(path, "wb") as config_file:
config.write(config_file)
def get_config(path):
"""
Returns the config object
"""
if not os.path.exists(path):
create_config(path)
config = ConfigParser.ConfigParser()
config.read(path)
return config
def get_setting(path, section, setting):
"""
Print out a setting
"""
config = get_config(path)
value = config.get(section, setting)
print "{section} {setting} is {value}".format(
section=section, setting=setting, value=value)
return value
def update_setting(path, section, setting, value):
"""
Update a setting
"""
config = get_config(path)
config.set(section, setting, value)
with open(path, "wb") as config_file:
config.write(config_file)
def delete_setting(path, section, setting):
"""
Delete a setting
"""
config = get_config(path)
config.remove_option(section, setting)
with open(path, "wb") as config_file:
config.write(config_file)
#----------------------------------------------------------------------
if __name__ == "__main__":
path = "settings.ini"
font = get_setting(path, 'Settings', 'font')
font_size = get_setting(path, 'Settings', 'font_size')
update_setting(path, "Settings", "font_size", "12")
delete_setting(path, "Settings", "font_style")
与第一个例子相比,这个例子进行了大量的重构。我甚至用 PEP8 来命名函数。每个函数都应该是自解释和自包含的。我们没有将所有的逻辑放入一个函数中,而是将它分成多个函数,然后在底层的 if 语句中演示它们的功能。现在您可以导入该模块并自己使用它。
请注意,本例中的部分是硬编码的,因此您需要进一步更新本例,使其完全通用。
如何使用插值
ConfigParser 模块还允许插值,这意味着您实际上可以使用一些选项来构建另一个选项。我们实际上是用 font_info 选项来实现的,因为它的值是基于 font 和 font_size 选项的。我们实际上可以使用 Python 字典来更改插值。让我们花点时间来证明这两个事实。
import ConfigParser
#----------------------------------------------------------------------
def interpolationDemo(path):
""""""
if not os.path.exists(path):
createConfig(path)
config = ConfigParser.ConfigParser()
config.read(path)
print config.get("Settings", "font_info")
print config.get("Settings", "font_info", 0,
{"font": "Arial", "font_size": "100"})
#----------------------------------------------------------------------
if __name__ == "__main__":
path = "settings.ini"
interpolationDemo(path)
如果运行此代码,您应该会看到类似如下的输出:
You are using Courier at 12 pt
You are using Arial at 100 pt
包扎
至此,您应该对 ConfigParser 的功能有了足够的了解,可以在自己的项目中使用它。还有另一个名为 ConfigObj 的项目,它不是 Python 的一部分,您可能也想看看。ConfigObj 比 ConfigParser 更灵活,功能更多。但是如果您有困难或者您的组织不允许第三方软件包,那么 ConfigParser 可能会满足您的要求。
附加阅读
- 官方 ConfigParser 文档
- 简要的 ConfigObj 教程
- ConfigObj + wxPython =极客快乐
python 101:ftplib 简介
原文:https://www.blog.pythonlibrary.org/2016/06/23/python-101-an-intro-to-ftplib/
许多公司和组织使用文件传输协议(FTP)来共享数据。Python 在其标准库中提供了一个名为 ftplib 的文件传输协议模块,实现 FTP 协议的客户端。您可以通过阅读互联网上的 RFC 959 文档来了解文件传输协议的所有内容。然而,完整的规范超出了本文的范围。相反,我们将关注以下主题:
- 连接到 FTP 服务器
- 浏览它的结构
- 从 FTP 服务器下载文件
- 将文件上传到 FTP 服务器
我们开始吧!
连接到 FTP 服务器
我们需要做的第一件事是找到一个要连接的 FTP 服务器。有很多免费的可以用。例如,大多数 Linux 发行版都有可以公开访问的 FTP 镜像。如果你去 Fedora 的网站(https://admin.fedoraproject.org/mirrormanager/)你会发现一长串你可以使用的镜子。但是它们不仅仅是 FTP,所以请确保您选择了正确的协议,否则您将会收到连接错误。
对于这个例子,我们将使用ftp.cse.buffalo.edu。官方的 Python 文档使用 ftp.debian.org 的 T2,所以也可以随意尝试一下。现在让我们尝试连接到服务器。在您的终端中打开 Python 解释器或使用 IDLE 跟随:
>>> from ftplib import FTP
>>> ftp = FTP('ftp.cse.buffalo.edu')
>>> ftp.login()
'230 Guest login ok, access restrictions apply.'
让我们把它分解一下。这里我们从 ftplib 导入FTP类。然后,我们创建一个类的实例,将它传递给我们想要连接的主机。因为我们没有传递用户名或密码,Python 假设我们想要匿名登录。如果您碰巧需要使用非标准端口连接到 FTP 服务器,那么您可以使用 connect 方法。方法如下:
>>> from ftplib import FTP
>>> ftp = FTP()
>>> HOST = 'ftp.cse.buffalo.edu'
>>> PORT = 12345
>>> ftp.connect(HOST, PORT)
这段代码将会失败,因为这个例子中的 FTP 服务器没有为我们打开端口 12345。然而,这个想法是传达如何连接到一个不同于默认的端口。
如果你正在连接的 FTP 服务器需要 TLS 安全性,那么你将需要导入 FTP_TLS 类,而不是 FTP 类。 FTP_TLS 类支持密钥文件和证书文件。如果您想要保护您的连接,那么您将需要调用 prot_p 来这样做。
使用 ftplib 导航目录
让我们来学习如何查看 FTP 服务器上的内容并更改目录!下面是一些代码,演示了这样做的正常方法:
>>> from ftplib import FTP
>>> ftp = FTP()
>>> ftp.login()
>>> ftp.retrlines('LIST')
total 28
drwxrwxrwx 2 0 0 4096 Sep 6 2015 .snapshot
drwxr-xr-x 2 202019 5564 4096 Sep 6 2015 CSE421
drwxr-xr-x 2 0 0 4096 Jul 23 2008 bin
drwxr-xr-x 2 0 0 4096 Mar 15 2007 etc
drwxr-xr-x 6 89987 546 4096 Sep 6 2015 mirror
drwxrwxr-x 7 6980 546 4096 Jul 3 2014 pub
drwxr-xr-x 26 0 11 4096 Apr 29 20:31 users
'226 Transfer complete.'
>>> ftp.cwd('mirror')
'250 CWD command successful.'
>>> ftp.retrlines('LIST')
total 16
drwxr-xr-x 3 89987 546 4096 Sep 6 2015 BSD
drwxr-xr-x 5 89987 546 4096 Sep 6 2015 Linux
drwxr-xr-x 4 89987 546 4096 Sep 6 2015 Network
drwxr-xr-x 4 89987 546 4096 Sep 6 2015 X11
'226 Transfer complete.'
我们在这里登录,然后向 FTP 服务器发送 LIST 命令。这是通过调用我们的 ftp 对象的 retrlines 方法来完成的。 retrlines 方法打印出我们调用的命令的结果。在这个例子中,我们调用 LIST 来检索文件和/或文件夹的列表以及它们各自的信息并打印出来。然后我们使用 cwd 命令将我们的工作目录更改到一个不同的文件夹,然后重新运行 LIST 命令来查看其中的内容。您也可以使用 ftp 对象的 dir 函数来获取当前文件夹的列表。
通过 FTP 下载文件
仅仅查看 FTP 服务器上的内容并没有那么有用。您几乎总是想从服务器下载文件。让我们看看如何下载单个文件:
>>> from ftplib import FTP
>>> ftp = FTP('ftp.debian.org')
>>> ftp.login()
'230 Login successful.'
>>> ftp.cwd('debian')
'250 Directory successfully changed.'
>>> out = '/home/mike/Desktop/README'
>>> with open(out, 'wb') as f:
... ftp.retrbinary('RETR ' + 'README.html', f.write)
在这个例子中,我们登录到 Debian Linux FTP 并切换到 Debian 文件夹。然后,我们创建想要保存的文件的名称,并以写二进制模式打开它。最后,我们使用 ftp 对象的 retrbinary 调用 RETR 来检索文件并将其写入本地磁盘。如果你想下载所有的文件,那么我们需要一个文件列表。
import ftplib
import os
ftp = ftplib.FTP('ftp.debian.org')
ftp.login()
ftp.cwd('debian')
filenames = ftp.nlst()
for filename in filenames:
host_file = os.path.join(
'/home/mike/Desktop/ftp_test', filename)
try:
with open(host_file, 'wb') as local_file:
ftp.retrbinary('RETR ' + filename, local_file.write)
except ftplib.error_perm:
pass
ftp.quit()
这个例子和上一个很相似。不过,您需要修改它以匹配您自己的首选下载位置。代码的第一部分非常相似,但是你会注意到我们调用了 nlst ,它给出了文件名和目录的列表。你可以给它一个目录列表,或者直接调用它,它会假设你想要一个当前目录的列表。注意,nlst 命令没有告诉我们如何从结果中区分文件和目录。但是对于这个例子,我们根本不关心。这更像是一个暴力脚本。所以它将遍历返回的列表并尝试下载它们。如果“文件”实际上是一个目录,那么我们将在本地磁盘上创建一个与 FTP 服务器上的目录同名的空文件。
有一个 MLSD 命令可以通过 mlsd 方法调用,但是并不是所有的 FTP 服务器都支持这个命令。如果是这样,那么你也许能够区分这两者。
将文件上传到 FTP 服务器
FTP 服务器的另一个主要任务是向它上传文件。Python 也可以处理这个问题。实际上有两种方法可以用来上传文件:
- storlines -用于上传文本文件(TXT,HTML,RST)
- storbinary -用于上传二进制文件(PDF,XLS 等)
让我们来看一个如何实现这一点的示例:
import ftplib
def ftp_upload(ftp_obj, path, ftype='TXT'):
"""
A function for uploading files to an FTP server
@param ftp_obj: The file transfer protocol object
@param path: The path to the file to upload
"""
if ftype == 'TXT':
with open(path) as fobj:
ftp.storlines('STOR ' + path, fobj)
else:
with open(path, 'rb') as fobj:
ftp.storbinary('STOR ' + path, fobj, 1024)
if __name__ == '__main__':
ftp = ftplib.FTP('host, 'username', 'password')
ftp.login()
path = '/path/to/something.txt'
ftp_upload(ftp, path)
pdf_path = '/path/to/something.pdf'
ftp_upload(ftp, pdf_path, ftype='PDF')
ftp.quit()
在这个例子中,我们创建了一个上传文件的函数。它接受一个 ftp 对象、我们想要上传的文件的路径和文件的类型。然后,我们对文件类型进行快速检查,以确定我们是否应该使用 storlines 或 storbinary 进行上传。最后,在底部的条件语句中,我们连接到 FTP 服务器,登录并上传一个文本文件和一个 PDF 文件。一个简单的增强功能是在我们登录后切换到一个特定的目录,因为我们可能不希望只是将文件上传到根目录。
包扎
至此,您应该对 Python 的 ftplib 有了足够的了解,可以开始使用了。它还有很多其他方法,值得在 Python 的文档中查看。但是您现在已经知道了列出目录、浏览文件夹结构以及下载和上传文件的基本知识。
相关阅读
Python 101 -函数介绍
原文:https://www.blog.pythonlibrary.org/2022/06/28/python-101-an-intro-to-functions/
函数是可重用的代码片段。任何时候你发现自己写了两次相同的代码,这些代码应该放在一个函数中。
比如 Python 有很多内置函数,比如dir()和sum()。您还导入了math模块,并使用了它的平方根函数sqrt()。
在本教程中,您将了解:
- 创建函数
- 调用函数
- 传递参数
- 键入暗示你的论点
- 传递关键字参数
- 必需和默认参数
*args和**kwargs- 仅位置参数
- 范围
我们开始吧!
创建函数
函数以关键字def开头,后跟函数名、两个括号,然后是一个冒号。接下来,在函数下缩进一行或多行代码,形成函数“块”。
下面是一个空函数:
def my_function():
pass
当你创建一个函数时,通常建议函数名全部小写,并用下划线隔开。这叫做蛇案。
pass是 Python 中的一个关键字,Python 知道可以忽略它。您也可以像这样定义一个空函数:
def my_function():
...
在本例中,函数除了省略号之外没有任何内容。
接下来让我们学习如何使用一个函数!
调用函数
现在你有了一个函数,你需要让它做一些事情。让我们先这样做:
def my_function():
print('Hello from my_function')
现在不用省略号或关键字pass,而是用一个函数打印出一条消息。
要调用一个函数,你需要写出它的名字,后跟括号:
>>> def my_function():
... print('Hello from my_function')
...
>>> my_function()
Hello from my_function
很好,很简单!
现在让我们来学习如何向函数传递参数。
传递参数
大多数函数允许你传递参数给它们。这样做的原因是,您通常希望向函数传递一个或多个位置参数,以便函数可以对它们做一些事情。
让我们创建一个函数,它接受一个名为name的参数,然后打印出一条欢迎消息:
>>> def welcome(name):
... print(f'Welcome {name}')
...
>>> welcome('Mike')
Welcome Mike
如果您使用过其他编程语言,您可能知道其中一些语言需要函数来返回某些内容。如果不指定返回值,Python 会自动返回None。
让我们试着调用这个函数,并将其结果赋给一个名为return_value的变量:
>>> def welcome(name):
... print(f'Welcome {name}')
...
>>> return_value = welcome('Mike')
Welcome Mike
>>> print(return_value)
None
当你打印出return_value的时候,你可以看到它是None。
键入暗示你的论点
有些编程语言使用静态类型,因此当您编译代码时,编译器会警告您与类型相关的错误。Python 是一种动态类型的语言,所以直到运行时才会发生这种情况
然而,在 Python 3.5 中,typing模块被添加到 Python 中,以允许开发人员将类型提示添加到他们的代码中。这允许你在代码中指定参数和返回值的类型,但是没有强制执行它。你可以使用外部工具,比如mypy(http://mypy-lang.org/)来检查你的代码库是否遵循了你设置的类型提示。
Python 中不需要类型提示,这种语言也没有强制要求,但是当与开发团队一起工作时,尤其是当团队由不熟悉 Python 的人组成时,类型提示非常有用。
让我们重写最后一个例子,使它使用类型提示:
>>> def welcome(name: str) -> None:
... print(f'Welcome {name}')
...
>>> return_value = welcome('Mike')
Welcome Mike
>>> print(return_value)
None
这一次,当您放入name参数时,您用冒号(:)结尾,后跟您期望的类型。在这种情况下,您希望传入一个字符串类型。之后你会注意到代码的-> None:位。->是一种特殊的语法,用来表示预期的返回值。对于这个代码,返回值是None。
如果您想显式返回值,那么您可以使用return关键字,后跟您希望返回的内容。
当您运行代码时,它的执行方式与之前完全相同。
为了证明类型提示不是强制的,您可以使用return关键字告诉 Python 返回一个整数:
>>> def welcome(name: str) -> None:
... print(f'Welcome {name}')
... return 5
...
>>> return_value = welcome('Mike')
Welcome Mike
>>> print(return_value)
5
当您运行这段代码时,您可以看到类型提示说返回值应该是None,但是您对它进行了编码,使它返回整数5。Python 不会抛出异常。
您可以对这段代码使用 mypy 工具来验证它是否遵循了类型提示。如果你这样做了,你会发现这确实说明了一个问题。你将在本书的第二部分学习如何使用 mypy 。
这里的要点是 Python 支持类型提示。但是 Python 并不强制类型。然而,一些 Python 编辑器可以在内部使用类型提示来警告您与类型相关的问题,或者您可以手动使用 mypy 来查找问题。
现在让我们学习你还可以传递给函数什么。
传递关键字参数
Python 还允许你传入关键字参数。关键字参数是通过传入一个命名参数来指定的,例如您可以传入age=10。
让我们创建一个显示常规参数和单个关键字参数的新示例:
>>> def welcome(name: str, age: int=15) -> None:
... print(f'Welcome {name}. You are {age} years old.')
...
>>> welcome('Mike')
Welcome Mike. You are 15 years old.
这个例子有一个常规参数name和一个关键字参数age,默认为15。当您在没有指定age的情况下调用这个代码时,您会看到它默认为 15。
为了让事情更加清楚,你可以用另一种方式来称呼它:
>>> def welcome(name: str, age: int) -> None:
... print(f'Welcome {name}. You are {age} years old.')
...
>>> welcome(age=12, name='Mike')
Welcome Mike. You are 12 years old.
在这个例子中,您指定了age和name两个参数。当您这样做时,您可以以任何顺序指定它们。例如,这里您以相反的顺序指定了它们,Python 仍然理解您的意思,因为您指定了这两个值。
让我们看看不使用关键字参数时会发生什么:
>>> def welcome(name: str, age: int) -> None:
... print(f'Welcome {name}. You are {age} years old.')
...
>>> welcome(12, 'Mike')
Welcome 12\. You are Mike years old.
当您在没有指定它们应该去哪里的情况下传递值时,它们将按顺序传递。于是name变成了12,age变成了'Mike'。
必需和默认参数
默认参数是一种简便的方法,可以用更少的参数调用你的函数,而必需参数是那些你必须传递给函数来执行函数的参数。
让我们看一个有一个必需参数和一个默认参数的例子:
>>> def multiply(x: int, y: int=5) -> int:
... return x * y
...
>>> multiply(5)
25
第一个参数x是必需的。如果您不带任何参数调用multiply(),您将收到一个错误:
>>> multiply()
Traceback (most recent call last):
Python Shell, prompt 25, line 1
builtins.TypeError: multiply() missing 1 required positional argument: 'x'
第二个参数y,不是必需的。换句话说,它是一个默认参数,默认值为5。这允许你只用一个参数调用multiply()!
什么是*args和**kwargs?
大多数情况下,您会希望您的函数只接受少量的参数、关键字参数或两者都接受。你通常不希望有太多的参数,因为以后改变你的函数会变得更加复杂。
然而 Python 确实支持任意数量的参数或关键字参数的概念。
您可以在函数中使用以下特殊语法:
*args-任意数量的参数**kwargs-任意数量的关键字参数
你需要注意的是*和**。名字,arg或者kwarg可以是任何东西,但是习惯上把它们命名为args和kwargs。换句话说,大多数 Python 开发者称它们为*args或**kwargs。虽然您没有被强制这样做,但您可能应该这样做,以便代码易于识别和理解。
让我们看一个例子:
>>> def any_args(*args):
... print(args)
...
>>> any_args(1, 2, 3)
(1, 2, 3)
>>> any_args(1, 2, 'Mike', 4)
(1, 2, 'Mike', 4)
这里您创建了any_args(),它接受任意数量的参数(包括零)并打印出来。
您实际上可以创建一个函数,它有一个必需的参数和任意数量的附加参数:
>>> def one_required_arg(required, *args):
... print(f'{required=}')
... print(args)
...
>>> one_required_arg('Mike', 1, 2)
required='Mike'
(1, 2)
所以在这个例子中,函数的第一个参数是必需的。如果你在没有任何参数的情况下调用one_required_arg(),你将得到一个错误。
现在让我们尝试添加关键字参数:
>>> def any_keyword_args(**kwargs):
... print(kwargs)
...
>>> any_keyword_args(1, 2, 3)
Traceback (most recent call last):
Python Shell, prompt 7, line 1
builtins.TypeError: any_keyword_args() takes 0 positional arguments but 3 were given
哎呀!您创建了接受关键字参数的函数,但只传入普通参数。这导致抛出了一个TypeError。
让我们尝试传入与关键字参数相同的值:
>>> def any_keyword_args(**kwargs):
... print(kwargs)
...
>>> any_keyword_args(one=1, two=2, three=3)
{'one': 1, 'two': 2, 'three': 3}
这一次,它以你期望的方式工作。
现在让我们检查一下我们的*args和**kwargs,看看它们是什么:
>>> def arg_inspector(*args, **kwargs):
... print(f'args are of type {type(args)}')
... print(f'kwargs are of type {type(kwargs)}')
...
>>> arg_inspector(1, 2, 3, x='test', y=5)
args are of type <class 'tuple'>
kwargs are of type <class 'dict'>
这意味着args是一个tuple,而kwargs是一个dict。
让我们看看是否可以为*args和**kwargs传递函数 a tuple和dict:
>>> my_tuple = (1, 2, 3)
>>> my_dict = {'one': 1, 'two': 2}
>>> def output(*args, **kwargs):
... print(f'{args=}')
... print(f'{kwargs=}')
...
>>> output(my_tuple)
args=((1, 2, 3),)
kwargs={}
>>> output(my_tuple, my_dict)
args=((1, 2, 3), {'one': 1, 'two': 2})
kwargs={}
好吧,那不太对劲。tuple和dict都在*args结束。不仅如此,tuple还停留在了一个元组,而不是变成了三个实参。
如果您使用特殊的语法,您可以做到这一点:
>>> def output(*args, **kwargs):
... print(f'{args=}')
... print(f'{kwargs=}')
...
>>> output(*my_tuple)
args=(1, 2, 3)
kwargs={}
>>> output(**my_dict)
args=()
kwargs={'one': 1, 'two': 2}
>>> output(*my_tuple, **my_dict)
args=(1, 2, 3)
kwargs={'one': 1, 'two': 2}
在这个例子中,你用*my_tuple调用output()。Python 将提取tuple中的单个值,并将它们作为参数传入。接下来传入**my_dict,它告诉 Python 将每个键/值对作为关键字参数传入。
最后一个例子同时传入了tuple和dict。
相当整洁!
仅位置参数
Python 3.8 为函数增加了一个新特性,称为仅位置参数。它们使用一种特殊的语法告诉 Python,一些参数必须是位置参数,一些参数必须是关键字参数。
让我们看一个例子:
>>> def positional(name, age, /, a, b, *, key):
... print(name, age, a, b, key)
...
>>> positional(name='Mike')
Traceback (most recent call last):
Python Shell, prompt 21, line 1
builtins.TypeError: positional() got some positional-only arguments passed as
keyword arguments: 'name'
前两个参数name和age仅是位置性的。它们不能作为关键字参数传入,这就是你看到上面的TypeError的原因。参数,a和b可以是位置参数,也可以是关键字。最后,key,仅关键字。
正斜杠/向 Python 表明,正斜杠之前的所有参数都是仅限位置的参数。任何跟在正斜杠后面的都是位置或关键字参数,直到 th *。星号表示其后的所有内容都是仅关键字参数。
以下是调用该函数的有效方法:
>>> positional('Mike', 17, 2, b=3, keyword='test')
Mike 17 2 3 test
但是,如果试图只传入位置参数,将会出现错误:
>>> positional('Mike', 17, 2, 3, 'test')
Traceback (most recent call last):
Python Shell, prompt 25, line 1
builtins.TypeError: positional() takes 4 positional arguments but 5 were given
positional()函数期望最后一个参数是关键字参数。
主要思想是,仅位置参数允许在不破坏客户端代码的情况下更改参数名。
您也可以对仅位置参数和**kwargs使用相同的名称:
>>> def positional(name, age, /, **kwargs):
... print(f'{name=}')
... print(f'{age=}')
... print(f'{kwargs=}')
...
>>> positional('Mike', 17, name='Mack')
name='Mike'
age=17
kwargs={'name': 'Mack'}
您可以在此阅读语法背后的完整实现和推理:
让我们继续,了解一点关于作用域的话题!
范围
所有的编程语言都有范围的概念。作用域告诉编程语言哪些变量或函数对它们可用。
让我们看一个例子:
>>> name = 'Mike'
>>> def welcome(name):
... print(f'Welcome {name}')
...
>>> welcome()
Traceback (most recent call last):
Python Shell, prompt 34, line 1
builtins.TypeError: welcome() missing 1 required positional argument: 'name'
>>> welcome('Nick')
Welcome Nick
>>> name
'Mike'
变量name在welcome()函数之外定义。如果你试图调用welcome()而不给它传递一个参数,即使参数与变量name匹配,它也会抛出一个错误。如果你给welcome()传递一个值,这个变量只在welcome()函数内部被改变。您在函数外部定义的name保持不变。
让我们看一个在函数内部定义变量的例子:
>>> def add():
... a = 2
... b = 4
... return a + b
...
>>> def subtract():
... a = 3
... return a - b
...
>>> add()
6
>>> subtract()
Traceback (most recent call last):
Python Shell, prompt 40, line 1
Python Shell, prompt 38, line 3
builtins.NameError: name 'b' is not defined
在add()中,你定义a和b并将它们加在一起。变量a和b具有局部范围。这意味着它们只能在add()功能中使用。
在subtract()中,你只定义了a却试图使用b。Python 直到运行时才检查subtract()函数中是否存在b。
这意味着 Python 不会警告你这里缺少了什么,直到你真正调用了subtract()函数。这就是为什么直到最后你才看到任何错误。
Python 有一个特殊的global关键字,您可以使用它来允许跨函数使用变量。
让我们更新代码,看看它是如何工作的:
>>> def add():
... global b
... a = 2
... b = 4
... return a + b
...
>>> def subtract():
... a = 3
... return a - b
...
>>> add()
6
>>> subtract()
-1
这次您在add()函数的开头将b定义为global。这允许你在subtract()中使用b,即使你没有在那里定义它。
通常不建议使用全局变量。在大型代码文件中很容易忽略它们,这使得跟踪细微的错误变得困难——例如,如果你在调用add()之前调用了subtract(),你仍然会得到错误,因为即使b是global,它也不存在,直到add()被运行。
在大多数情况下,如果你想使用global,你可以使用class来代替。
只要你明白你在做什么,使用全局变量没有错。他们有时会很有帮助。但是你应该小心使用它们。
包扎
函数是重用代码的一种非常有用的方式。它们可以被反复调用。函数也允许您传递和接收数据。
在本教程中,您学习了以下主题:
- 创建函数
- 调用函数
- 传递参数
- 键入暗示你的论点
- 传递关键字参数
- 必需和默认参数
*args和**kwargs- 仅位置参数
- 范围
您可以使用函数来保持代码的整洁和有用。一个好的函数是独立的,可以被其他函数轻松使用。虽然本教程没有涉及到,但是您可以将函数嵌套在一起。
相关文章
-
Python 101 - 了解所有函数(视频)
-
Python 的内置函数简介
Python 101 -空闲介绍
原文:https://www.blog.pythonlibrary.org/2017/03/18/python-101-an-intro-to-idle/
Python 自带代码编辑器: IDLE (集成开发学习环境)。有一些传说认为“游手好闲”这个名字来自《T2》中的演员埃里克·艾多尔。IDE 是一个面向程序员的编辑器,它提供了语言中关键词的颜色高亮、自动完成、一个“实验性”调试器和许多其他有趣的东西。您可以找到大多数流行语言的 IDE,许多 IDE 可以支持多种语言。IDLE 是一个 lite IDE,但是它确实有上面提到的所有项目。它允许程序员非常容易地编写 Python 和调试他们的代码。我称之为“精简版”的原因是调试器非常简单,而且它缺少其他功能,而那些有使用像 Visual Studio 这样的产品背景的程序员将会缺少这些功能。您可能还想知道 IDLE 是使用 Tkinter 创建的,Tkinter 是 Python 自带的一个 Python GUI 工具包。
要打开 IDLE,您需要找到它,然后您会看到类似这样的内容:

是的,这是一个 Python shell,您可以在其中键入简短的脚本,并立即看到它们的输出,甚至可以实时与代码进行交互。因为 Python 是一种解释性语言,并且在 Python 解释器中运行,所以不需要编译代码。现在让我们写你的第一个程序。在空闲状态下,在命令提示符(>>>)后键入以下内容:
print("Hello from Python!")
你刚刚写了你的第一个程序!你的程序所做的只是在屏幕上写一个字符串,但是你会发现这在以后会很有帮助。请注意,在 Python 3.x 中,print语句已经更改。在 Python 2.x 中,您应该这样编写上面的语句:
print "Hello from Python!"
在 Python 3 中,打印语句变成了打印函数,这就是为什么需要括号的原因。你会在第 10 章学到什么功能。
如果要将代码保存到文件中,请转到“文件”菜单,选择“新建窗口”(或按 CTRL+N)。现在你可以输入你的程序并保存在这里。使用 Python shell 的主要好处是,在将代码放入真正的程序之前,您可以用小代码片段进行试验,看看您的代码将如何运行。代码编辑器屏幕看起来与上面的空闲屏幕截图有些不同:

现在我们将花一点时间来看看 IDLE 的其他有用功能。
Python 附带了许多模块和包,您可以导入它们来添加新特性。例如,您可以为各种好的数学函数导入 math 模块,比如平方根、余弦等。在文件菜单中,你会发现一个路径浏览器,这对于弄清楚 Python 在哪里寻找模块导入非常有用。您可以看到,Python 首先在正在运行的脚本所在的目录中查找,看它需要导入的文件是否在那里。然后,它检查其他位置的预定义列表。您实际上也可以添加和删除位置。如果您导入了任何文件,路径浏览器会显示这些文件在硬盘上的位置。我的路径浏览器看起来像这样:

接下来是一个类浏览器,它将帮助你导航你的代码。坦白地说,如果这个菜单选项被称为“模块浏览器”会更有意义,因为这更接近你实际要做的事情。这其实是现在对你不会很有用,但将来会很有用的东西。当你在一个文件中有很多行代码时,你会发现它很有帮助,因为它会给你一个“树状”的代码界面。请注意,除非您实际保存了程序,否则您将无法加载类浏览器。
编辑菜单具有您的典型功能,如复制、剪切、粘贴、撤销、重做和全选。它还包含各种方法来搜索您的代码,并进行搜索和替换。最后,Edit 菜单有一些菜单项可以显示各种内容,比如突出显示括号或显示自动完成列表。
格式菜单有很多有用的功能。它有一些对缩进和去缩进你的代码以及注释掉你的代码很有帮助的项目。当我测试我的代码时,我发现这很有帮助。注释掉您的代码会非常有帮助。一种有用的方法是当你有很多代码,你需要找出为什么它不能正常工作。注释掉部分内容并重新运行脚本可以帮助您找出哪里出错了。你只是慢慢地取消注释,直到你碰到你的 bug。这提醒了我。你可能已经注意到主空闲屏幕有一个调试器菜单。
这对于调试来说很好,但只是在 Shell 窗口中。遗憾的是,你不能在主编辑菜单中使用调试器。但是,您可以在打开调试的情况下运行模块,以便能够与程序的对象进行交互。例如,这在您试图确定循环内某项的当前值的循环中非常有用。如果您碰巧正在使用 tkinter 创建用户界面(UI),那么您实际上可以关闭 mainloop() 调用(这会阻塞 UI),以便调试您的用户界面。最后,当调试器运行时引发异常,可以双击该异常直接跳转到发生异常的代码。
如果你需要一个更通用的调试器,你应该找一个不同的 IDE 或者尝试 Python 的调试器,可以在 pdb 库中找到。
运行菜单有几个方便的选项。您可以使用它来打开 Python Shell、检查代码错误或运行代码。选项菜单没有太多的项目。它有一个配置选项,允许您更改代码高亮颜色、字体和快捷键。除此之外,您还可以获得一个代码上下文选项,这很有帮助,因为它在编辑窗口中放置了一个覆盖图,显示您当前所在的类或函数。您会发现,每当您在一个函数中有很多代码,并且名称已经滚出屏幕顶部时,这个特性就非常有用。启用此选项后,这种情况不会发生。当然,如果功能太大,无法在一个屏幕上显示,那么它可能会变得太长,可能需要将该功能分解为多个功能。在设置对话框中的另一个整洁的项目是在常规选项卡下,在那里你可以添加其他文档。这意味着你可以添加第三方文档的 URL,比如 SQLAlchemy 或者 pillow,并让它进入空闲状态。要访问新文档,只需跳转到帮助菜单。
窗口菜单向您显示当前打开的窗口列表,并允许您在它们之间切换。
最后但同样重要的是 Help 菜单,在这里你可以了解 IDLE,获得 IDLE 本身的帮助或者加载 Python 文档的本地副本。该文档将解释 Python 的每一部分是如何工作的,并且在覆盖面上相当详尽。帮助菜单可能是最有用的,因为即使你没有连接到互联网,你也可以访问文档。您可以搜索文档,找到 HOWTOs,阅读任何内置的库,了解如此多的内容,您可能会感到头晕。
包扎
在本文中,我们学习了如何使用 Python 的集成开发环境 IDLE。此时,您应该对 IDLE 足够熟悉,可以自己使用它了。Python 还有许多其他的集成开发环境(ide)。有像 PyDev 和 Editra 这样的免费软件,也有一些你需要付费的软件,比如 WingWare 和 PyCharm,尽管它们都有免费版本。还有用于常规文本编辑器的插件,允许您也用 Python 编码。我认为 IDLE 是一个很好的起点,但是如果你已经有了一个最喜欢的编辑器,请继续使用它。
如果你碰巧是视觉学习者,我也创建了这个教程的截屏版本:
https://www.youtube.com/embed/yEusyqoxNQI?feature=oembed
这来自我的 Python 101 截屏
python 101-Jupyter 笔记本简介
原文:https://www.blog.pythonlibrary.org/2021/09/19/python-101-an-intro-to-jupyter-notebook/
Jupyter Notebook 是一个开源的网络应用程序,它允许你创建和共享包含代码、公式、可视化和格式化文本的文档。默认情况下,Jupyter Notebook 开箱即可运行 Python。此外,Jupyter Notebook 通过扩展支持许多其他编程语言。您可以使用 Jupyter 笔记本进行数据清理和转换、数值模拟、统计建模、数据可视化、机器学习等等!
在本章中,您将了解以下内容:
- 安装 Jupyter 笔记本电脑
- 创建笔记本
- 添加内容
- 添加降价内容
- 添加扩展
- 将笔记本导出为其他格式
本章并不是 Jupyter 笔记本的全面教程。相反,它将向您展示如何使用笔记本的基本知识,以及为什么它可能有用。如果你对这项技术感兴趣,你可能想看看我写的关于这个主题的书,Jupyter 笔记本 101。
我们开始吧!
安装 Jupyter 笔记本电脑
Jupyter Notebook 没有附带 Python。您需要使用pip来安装它。如果你用的是 Anaconda 而不是官方的 Python,那么 Jupyter Notebook 预装了 Anaconda。
以下是如何用pip安装 Jupyter 笔记本电脑:
python3 -m pip install jupyter
当你安装 Jupyter Notebook 的时候,它会安装很多其他的依赖项。您可能希望将 Jupyter Notebook 安装到 Python 虚拟环境中。更多信息见第 21 章。
安装完成后,您就可以创建 Jupyter 笔记本了!
创建笔记本
创建笔记本是一个基本概念。Jupyter Notebook 通过自己的服务器运行,该服务器包含在您的安装中。为了能够使用 Jupyter 做任何事情,您必须首先通过运行以下命令启动这个 Jupyter 笔记本服务器:
jupyter notebook
该命令将启动您的默认浏览器或打开一个新的选项卡,这取决于您的浏览器是否已经运行。在这两种情况下,您将很快看到一个指向以下 URL 的新选项卡:http://localhost:8888/tree。您的浏览器应该会加载如下所示的页面:

Jupyter 服务器
在这里,您可以通过点击右侧的新建按钮来创建笔记本:

创建 Jupyter 笔记本
您可以使用此菜单以及文本文件、文件夹和浏览器内终端会话来创建笔记本。现在,你应该选择 Python 3 选项。
完成后,将会打开一个新的选项卡,其中会加载您的新笔记本:

一个新笔记本
现在,让我们了解一下如何与笔记本互动!
命名您的笔记本
笔记本上面写着无标题。要解决这个问题,你需要做的就是点击单词无标题,一个浏览器内对话框就会出现:

重命名笔记本
重命名笔记本时,它还会重命名保存该笔记本的文件,以便与您为其指定的名称相匹配。你可以把这个笔记本命名为“Hello World”。
运行单元
Jupyter 笔记本电池是奇迹发生的地方。这是您可以创建内容和交互式代码的地方。默认情况下,笔记本将在代码模式下创建单元格。这意味着它将允许您在创建笔记本时选择的任何内核中编写代码。内核指的是你在创建 Jupyter 笔记本时选择的编程语言。您在创建这个笔记本时选择了 Python 3,因此您可以在单元格中编写 Python 3 代码。
现在单元格是空的,所以它什么也不做。让我们添加一些代码来改变这种情况:
print('Hello from Python!')
要执行一个单元格的内容,你需要运行那个单元格。选择单元后,有三种运行方式:
- 点击顶部按钮行中的运行按钮
- 从笔记本菜单导航至
Cell -> Run Cells - 使用键盘快捷键: Shift+Enter
运行该单元格时,输出应该如下所示:

运行 Jupyter 笔记本电池
Jupyter 笔记本细胞记得他们运行的顺序。如果您没有按顺序运行单元格,您可能会因为没有按正确的顺序导入内容而导致错误。然而,当您按顺序运行单元格时,您可以在一个单元格中写入导入,并在后面的单元格中使用这些导入。笔记本使得将代码的逻辑片段放在一起变得简单。事实上,您可以在代码单元之间放置解释单元、图表等,而代码单元仍将彼此共享。
当您运行一个单元格时,单元格旁边会有一些括号,这些括号中会填入一个数字。这表示单元运行的顺序。在本例中,当运行第一个单元格时,括号中填入了数字 1。因为笔记本中的所有代码单元都在同一个全局名称空间上操作,所以能够跟踪代码单元的执行顺序非常重要。
了解菜单
Jupyter 笔记本中有一个菜单,您可以使用它来处理您的笔记本。菜单在笔记本的顶部。以下是您的菜单选项:
- 文件
- 编辑
- 视角
- 插入
- 细胞
- 核心
- 小工具
- 帮助
让我们看一下这些菜单。开始使用 Jupyter 时,您不需要了解这些菜单中的每个选项,因此这将是一个高层次的概述。
文件菜单用于打开笔记本或创建新的笔记本。您也可以在此重命名笔记本。笔记本的一个很好的特性是你可以创建检查点。检查点允许您回滚到以前的状态。要创建检查点,进入文件菜单,选择保存和检查点选项。
编辑菜单包含常规的剪切、复制和粘贴命令,您可以在单元格级别使用这些命令。您还可以从这里删除、拆分或合并单元格。最后,您可以使用此菜单对单元格重新排序。
你会发现这里的一些选项是灰色的。项目呈灰色的原因是因为该选项不适用于笔记本中当前选定的单元格。例如,如果您选择了一个代码单元格,您将无法插入图像。尝试将单元格类型更改为 Markdown,以查看选项如何变化。
视图菜单用于切换页眉和工具栏的可见性。这也是你打开或关闭线号的地方。
插入菜单用于在当前选中单元格的上方或下方插入单元格。
单元格菜单对于运行一个单元格、一组单元格或笔记本中的任何内容都很有用!您可以在这里更改单元格类型,但您可能会发现工具栏比菜单更直观。
单元格菜单的另一个有用的特性是,你可以用它来清除单元格的输出。许多人与他人分享他们的笔记本。如果你想这样做,清除细胞的输出是有用的,这样你的朋友或同事就可以自己运行细胞并发现它们是如何工作的。
内核菜单用于操作内核本身。内核指的是编程语言插件。您偶尔需要重启、重新连接或关闭您的内核。您还可以更改笔记本中运行的内核。
你不会经常使用内核菜单。然而,当您需要在 Jupyter Notebook 中进行一些调试时,重启内核比重启整个服务器更方便。
微件菜单用于清除和保存微件状态。小部件是向笔记本添加动态内容的一种方式,如按钮或滑块。这些是在幕后用 JavaScript 编写的。
最后一个菜单是帮助菜单。您可以在这里了解笔记本电脑的特殊快捷键。它还提供了用户界面浏览和大量参考资料,您可以使用它们来学习如何更好地与您的笔记本进行交互。
现在让我们学习如何在笔记本中创建内容!
添加内容
您可以为笔记本电脑选择两种主要的内容类型:
- 密码
- 降价
从技术上讲,还有两种细胞类型可供选择。一个是 Raw NBConvert ,仅用于使用nbconvert命令行工具时的特殊用例。此工具用于将您的笔记本转换为其他格式,如 PDF。
另一种是标题,实际上已经不用了。如果您选择这种单元格类型,您将收到以下对话框:

标题类型
您已经看到了如何使用默认的单元格类型,代码。所以下一节将关注降价。
创建降价内容
Markdown 单元格类型允许您设置文本格式。您可以创建标题,添加图像和链接,以及用斜体、粗体等格式设置您的文本。
这一章不会涵盖你可以用 Markdown 做的所有事情,但是它会教你一些基础知识。让我们来看看如何做几件不同的事情!
格式化您的文本
如果你想在文本中添加斜体,你可以使用单下划线或单星号。如果你想加粗你的文本,那么你可以将星号或下划线的数量增加一倍。
这里有几个例子:
You can italicize like *this* or _this_
Or bold like **this** or __this__
尝试将您的笔记本单元格设置为 Markdown,并将上面的文本添加到其中。然后,您会看到笔记本会自动为您设置文本格式:

格式化文本
当您运行单元格时,它会很好地格式化文本:

格式化文本(运行后)
如果您需要再次编辑该单元格,您可以双击该单元格,它将返回到编辑模式。
现在让我们来看看如何添加标题级别!
使用标题
标题非常适合在笔记本中创建分区,就像在 Microsoft Word 中创建网页或文档一样。要在 Markdown 中创建标题,您可以使用一个或多个#符号。
以下是一些例子:
# Heading 1
## Heading 2
### Heading 3
#### Heading 4
如果您将上面的代码添加到笔记本中的一个 Markdown 单元格中,它将如下所示:

降价标题
您可以看到,笔记本已经为您生成了一种预览,方法是稍微收缩每个标题级别的文本。
当您运行该单元时,您将看到如下内容:

降价标题(运行后)
正如你所看到的,Jupyter 很好地将你的文本格式化为不同层次的标题,这有助于你的文本结构。
添加列表
在 Markdown 中,创建一个列表或项目符号非常简单。要创建一个列表,需要在行首添加一个星号(*)或破折号(-)。
这里有一个例子:
* List item 1
* sub item 1
* sub item 2
* List item 2
* List item 3
让我们将此代码添加到您的笔记本中:

在 Markdown 中添加列表
这一次,您实际上没有得到列表的预览,所以让我们运行单元格来看看您得到了什么:

Markdown 中的列表(运行后)
看起来不错!现在让我们来看看如何让你的代码语法高亮!
突出显示代码语法
笔记本已经允许你显示和运行代码,它们甚至显示语法高亮。然而,这只适用于 Jupyter Notebook 中安装的内核或语言。
如果您想显示未安装的另一种语言的代码,或者如果您想突出显示语法,而不允许用户运行代码,那么您可以使用 Markdown。
要在 Markdown 中创建一个代码块,您需要使用 3 个反勾号,后跟您想要显示的语言。如果您想要突出显示内联代码,请用单个反勾号将代码段括起来。但是,请记住,内联代码不支持语法突出显示。
笔记本里有两个例子:

降价中的语法突出显示
当您运行单元格时,笔记本会将降价转换为以下内容:

语法突出显示(运行后)
这里您可以看到代码现在是如何突出显示语法的。
现在让我们学习如何生成一个超链接!
创建超链接
在 Markdown 中创建超链接非常容易。语法如下:
[text](URL)
所以如果你想链接到谷歌,你可以这样做:
[Google](https://www.google.com)
下面是笔记本中的代码:

超链接降价
当您运行单元格时,您会看到降价变成了一个常规的超链接:

超链接降价(运行后)
正如你所看到的,减价已经变成了一个传统的超链接。
接下来让我们来了解一下 Jupyter extensions!
添加扩展
Jupyter 笔记本开箱即可拥有大量功能。如果你需要更多的东西,你也可以从一个大的扩展生态系统中通过扩展添加新的特性。有四种不同类型的扩展可用:
- 核心
- IPython 内核
- 笔记本
- 笔记本服务器
大多数时候,你会想安装一个笔记本扩展。
Jupyter Notebook 的扩展在技术上是一个 JavaScript 模块,它将被加载到笔记本的前端,以添加新的功能或使笔记本看起来不同。如果你懂 JavaScript,你可以自己写扩展!
如果你需要给 Jupyter Notebook 添加一些新的东西,你应该使用谷歌看看是否有人写了一些对你有用的东西。最流行的扩展实际上是一个名为jupyter _ contrib _ nb extensions的大型扩展集,您可以从这里获得:
大多数好的扩展可以使用pip来安装。例如,要安装上面提到的那个,您可以运行以下命令:
$ pip install jupyter_contrib_nbextensions
有几个和pip不兼容。在这些情况下,您可以使用 Jupyter 本身来安装扩展:
$ jupyter nbextension install NAME_OF_EXTENSION
虽然这安装了扩展供 Jupyter 使用,但它并没有激活扩展。如果您使用此方法安装扩展,则需要先启用它,然后才能使用它。
要启用扩展,您需要运行以下命令:
$ jupyter nbextension enable NAME_OF_EXTENSION
如果您在运行 Jupyter Notebook 时安装了扩展,您可能需要重新启动内核或整个服务器才能使用新的扩展。
您可能希望获得Jupyter nb extensions Configurator扩展来帮助您管理您的扩展。这是一个简洁的扩展,用于在笔记本用户界面中启用和禁用其他扩展。它还显示您当前已经安装的扩展。
将笔记本导出为其他格式
在您创建了一个令人惊叹的笔记本后,您可能想与其他不像您这样精通计算机的人分享它。Jupyter Notebook 支持将笔记本转换为其他格式:
- 超文本标记语言
- 乳液
- 便携文档格式
- RevealJS
- 降价
- 重组后的文本
- 可执行脚本
您可以使用最初安装 Jupyter Notebook 时安装的nbconvert工具转换笔记本。要使用nbconvert,您可以执行以下操作:
$ jupyter nbconvert <notebook file> --to <output format>
假设您想将笔记本转换为 PDF 格式。为此,您应该这样做:
$ jupyter nbconvert my_notebook.ipynb --to pdf
当它将笔记本转换成 PDF 时,您会看到一些输出。nbconvert工具还会显示转换过程中遇到的任何警告或错误。如果该过程成功完成,您将在笔记本文件所在的文件夹中拥有一个my_notebook.pdf文件
Jupyter 笔记本也提供了一种更简单的方式来转换您的笔记本。你可以从笔记本本身的文件菜单中选择。您可以选择Download as选项进行转换。
根据您所在的平台,您可能需要安装 LaTeX 或其他依赖项,以使某些导出格式正常工作。
包扎
Jupyter 笔记本是一种学习如何使用 Python 或机器学习的有趣方式。这是一种很好的组织数据的方式,这样你就可以和别人分享了。您可以使用它来创建演示文稿、展示您的作品以及运行您的代码。
在本文中,您了解了以下内容:
- 安装 Jupyter 笔记本电脑
- 创建笔记本
- 添加内容
- 添加降价内容
- 添加扩展
- 将笔记本导出为其他格式
你应该试试 Jupyter 笔记本。这是一个有用的编码环境,非常值得您花费时间。
相关文章
在以下文章中了解更多关于 Jupyter 笔记本的功能:
Python 101:日志介绍
原文:https://www.blog.pythonlibrary.org/2012/08/02/python-101-an-intro-to-logging/
Python 在其标准库中提供了一个非常强大的日志库。很多程序员使用 print 语句进行调试(包括我自己),但是你也可以使用日志来做这件事。使用日志记录实际上更干净,因为您不必遍历所有代码来删除 print 语句。在本教程中,我们将讨论以下主题:
- 创建简单的记录器
- 如何从多个模块登录
- 日志格式
- 日志配置
在本教程结束时,您应该能够自信地为您的应用程序创建自己的日志。我们开始吧!
创建简单的记录器
使用日志模块创建日志既简单又直接。最简单的方法是看一段代码,然后解释它,所以这里有一些代码供你阅读:
import logging
# add filemode="w" to overwrite
logging.basicConfig(filename="sample.log", level=logging.INFO)
logging.debug("This is a debug message")
logging.info("Informational message")
logging.error("An error has happened!")
如您所料,要访问日志模块,您必须首先导入它。创建日志最简单的方法是使用日志模块的 basicConfig 函数,并向它传递一些关键字参数。它接受以下内容:文件名、文件模式、格式、日期、级别和流。在我们的示例中,我们传递给它一个文件名和日志级别,我们将日志级别设置为 INFO。日志记录有五个级别(按升序排列):调试、信息、警告、错误和严重。默认情况下,如果您多次运行此代码,它将追加到日志中(如果它已经存在)。如果您想让日志记录器覆盖日志,那么就像代码注释中提到的那样传入一个 filemode="w" 。说到运行代码,如果您运行了一次,应该会得到以下结果:
INFO:root:Informational message
ERROR:root:An error has happened!
请注意,调试消息不在输出中。这是因为我们将级别设置为 INFO,所以我们的日志记录程序只会记录 INFO、警告、错误或关键消息。根部分仅仅意味着这个日志消息来自根日志记录器或主日志记录器。我们将在下一节中探讨如何改变这一点,以便更好地描述。如果不使用 basicConfig ,那么日志模块将输出到 console / stdout。
日志模块还可以将一些异常记录到文件中,或者记录到您配置的任何地方。这里有一个例子:
import logging
logging.basicConfig(filename="sample.log", level=logging.INFO)
log = logging.getLogger("ex")
try:
raise RuntimeError
except Exception, err:
log.exception("Error!")
这将把整个回溯记录到文件中,这在调试时非常方便。
如何从多个模块登录(以及格式化!)
您编写的代码越多,您就越有可能创建一组共同工作的定制模块。如果您希望它们都登录到同一个位置,那么您来对地方了。我们将看一下简单的方法,然后展示一个更复杂的方法,它也更具可定制性。这里有一个简单的方法:
import logging
import otherMod
#----------------------------------------------------------------------
def main():
"""
The main entry point of the application
"""
logging.basicConfig(filename="mySnake.log", level=logging.INFO)
logging.info("Program started")
result = otherMod.add(7, 8)
logging.info("Done!")
if __name__ == "__main__":
main()
在这里,我们导入日志记录和我们自己创建的一个模块(“otherMod”)。然后我们像以前一样创建日志文件。另一个模块如下所示:
# otherMod.py
import logging
#----------------------------------------------------------------------
def add(x, y):
""""""
logging.info("added %s and %s to get %s" % (x, y, x+y))
return x+y
如果您运行主代码,您应该得到一个包含以下内容的日志:
INFO:root:Program started
INFO:root:added 7 and 8 to get 15
INFO:root:Done!
你看这样做有什么问题吗?您真的不能很容易地判断日志消息来自哪里。写这个日志的模块越多,只会越混乱。所以我们需要解决这个问题。这让我们想到了创建记录器的复杂方式。让我们来看一个不同的实现:
import logging
import otherMod2
#----------------------------------------------------------------------
def main():
"""
The main entry point of the application
"""
logger = logging.getLogger("exampleApp")
logger.setLevel(logging.INFO)
# create the logging file handler
fh = logging.FileHandler("new_snake.log")
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
# add handler to logger object
logger.addHandler(fh)
logger.info("Program started")
result = otherMod2.add(7, 8)
logger.info("Done!")
if __name__ == "__main__":
main()
在这里,我们创建一个名为“exampleApp”的记录器实例。我们设置它的日志级别,创建一个日志文件处理程序对象和一个日志格式化程序对象。文件处理程序必须将 formatter 对象设置为其格式化程序,然后文件处理程序必须添加到 logger 实例中。主中的其余代码大部分都是一样的。请注意,它不是“logging.info ”,而是“logger.info”或任何您称之为 logger 变量的东西。以下是更新后的 otherMod2 代码:
# otherMod2.py
import logging
module_logger = logging.getLogger("exampleApp.otherMod2")
#----------------------------------------------------------------------
def add(x, y):
""""""
logger = logging.getLogger("exampleApp.otherMod2.add")
logger.info("added %s and %s to get %s" % (x, y, x+y))
return x+y
注意,这里我们定义了两个记录器。在这种情况下,我们不用模块记录器做任何事情,但是我们使用另一个。如果运行主脚本,您应该会在文件中看到以下输出:
2012-08-02 15:37:40,592 - exampleApp - INFO - Program started
2012-08-02 15:37:40,592 - exampleApp.otherMod2.add - INFO - added 7 and 8 to get 15
2012-08-02 15:37:40,592 - exampleApp - INFO - Done!
你会注意到,我们不再有任何参考根已被删除。相反,它使用我们的 Formatter 对象,该对象表示我们应该获得人类可读的时间、记录器名称、日志记录级别,然后是消息。这些实际上被称为日志记录属性。关于日志记录属性的完整列表,请参见文档,因为这里列出的太多了。
为工作和娱乐配置日志
日志模块可以通过 3 种不同的方式进行配置。您可以像我们在本文前面所做的那样,使用方法(记录器、格式化器、处理程序)来配置它;您可以使用一个配置文件,并将其传递给 file config();或者您可以创建一个配置信息字典,并将其传递给 dictConfig()函数。让我们先创建一个配置文件,然后看看如何用 Python 执行它。下面是一个配置文件示例:
[loggers]
keys=root,exampleApp
[handlers]
keys=fileHandler, consoleHandler
[formatters]
keys=myFormatter
[logger_root]
level=CRITICAL
handlers=consoleHandler
[logger_exampleApp]
level=INFO
handlers=fileHandler
qualname=exampleApp
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=myFormatter
args=(sys.stdout,)
[handler_fileHandler]
class=FileHandler
formatter=myFormatter
args=("config.log",)
[formatter_myFormatter]
format=%(asctime)s - %(name)s - %(levelname)s - %(message)s
datefmt=
您会注意到我们指定了两个记录器:root 和 exampleApp。无论什么原因,都需要“root”。如果不包含它,Python 会从 config.py 的 _install_loggers 函数中抛出一个 ValueError,该函数是日志模块的一部分。如果您将 root 的处理程序设置为 fileHandler ,那么您将导致日志输出加倍,因此为了防止这种情况发生,我们将它发送到控制台。仔细研究这个例子。前三个部分中的每个键都需要一个部分。现在让我们看看如何在代码中加载它:
# log_with_config.py
import logging
import logging.config
import otherMod2
#----------------------------------------------------------------------
def main():
"""
Based on http://docs.python.org/howto/logging.html#configuring-logging
"""
logging.config.fileConfig('logging.conf')
logger = logging.getLogger("exampleApp")
logger.info("Program started")
result = otherMod2.add(7, 8)
logger.info("Done!")
if __name__ == "__main__":
main()
如您所见,您需要做的就是将配置文件路径传递给logging . config . file config。您还会注意到,我们不再需要所有的设置代码,因为它们都在配置文件中。我们也可以直接导入 otherMod2 模块,不做任何改动。无论如何,如果您运行以上内容,您的日志文件中应该会出现以下内容:
2012-08-02 18:23:33,338 - exampleApp - INFO - Program started
2012-08-02 18:23:33,338 - exampleApp.otherMod2.add - INFO - added 7 and 8 to get 15
2012-08-02 18:23:33,338 - exampleApp - INFO - Done!
您可能已经猜到了,它与另一个示例非常相似。现在我们将转到另一个配置方法。直到 Python 2.7 才添加了字典配置方法(dictConfig ),所以请确保您拥有该方法或更好的方法,否则您将无法跟上。没有很好地记录这是如何工作的。事实上,出于某种原因,文档中的示例显示了 YAML。无论如何,这里有一些工作代码供您查看:
# log_with_config.py
import logging
import logging.config
import otherMod2
#----------------------------------------------------------------------
def main():
"""
Based on http://docs.python.org/howto/logging.html#configuring-logging
"""
dictLogConfig = {
"version":1,
"handlers":{
"fileHandler":{
"class":"logging.FileHandler",
"formatter":"myFormatter",
"filename":"config2.log"
}
},
"loggers":{
"exampleApp":{
"handlers":["fileHandler"],
"level":"INFO",
}
},
"formatters":{
"myFormatter":{
"format":"%(asctime)s - %(name)s - %(levelname)s - %(message)s"
}
}
}
logging.config.dictConfig(dictLogConfig)
logger = logging.getLogger("exampleApp")
logger.info("Program started")
result = otherMod2.add(7, 8)
logger.info("Done!")
if __name__ == "__main__":
main()
如果您运行这段代码,您将得到与前一个方法相同的输出。注意,当您使用字典配置时,您不需要“根”记录器。
包扎
至此,您应该知道如何开始使用记录器,以及如何以几种不同的方式配置它们。您还应该已经了解了如何使用 Formatter 对象修改输出。如果你真的想了解输出,我建议你查看下面的一些链接。
附加阅读
- 记录模块文档
- 记录如何操作
- 日志食谱
- 日志 _ 树包
- 水管工杰克的 Python 日志 101
- 停止使用 print 进行调试:Python 日志模块的 5 分钟快速入门指南
- Hellman 的 PyMOTW 日志页面
源代码
python 101:Pickle 对象序列化简介
Python 的“包含电池”理念甚至包括一个对象序列化模块。他们称之为泡菜模块。有些人用其他名字来称呼序列化,比如编组或扁平化。在 Python 中,它被称为“酸洗”。Pickle 模块还有一个优化的基于 C 的版本,称为 cPickle,运行速度比普通 pickle 快 1000 倍。该文档确实带有警告,但这很重要,所以转载如下:
警告:pickle 模块并不旨在防止错误或恶意构建的数据。不要从不受信任或未经验证的来源提取数据。
现在我们已经解决了这个问题,我们可以开始学习如何使用泡菜了!到这篇帖子结束的时候,你可能已经饿了!
编写简单的 Pickle 脚本
我们将从编写一个简单的脚本开始,演示如何处理 Python 列表。代码如下:
import pickle
#----------------------------------------------------------------------
def serialize(obj, path):
"""
Pickle a Python object
"""
with open(path, "wb") as pfile:
pickle.dump(obj, pfile)
#----------------------------------------------------------------------
def deserialize(path):
"""
Extracts a pickled Python object and returns it
"""
with open(path, "rb") as pfile:
data = pickle.load(pfile)
return data
#----------------------------------------------------------------------
if __name__ == "__main__":
my_list = [i for i in range(10)]
pkl_path = "data.pkl"
serialize(my_list, pkl_path)
saved_list = deserialize(pkl_path)
print saved_list
让我们花几分钟来研究一下这段代码。我们有两个函数,第一个函数用于保存(或酸洗)Python 对象。第二个是用于反序列化(或反挑选)对象。要进行序列化,只需调用 pickle 的 dump 方法,并向其传递要 pickle 的对象和一个打开的文件句柄。要反序列化对象,只需调用 pickle 的 load 方法。您可以将多个对象 pickle 到一个文件中,但是 pickle 的工作方式类似于 FIFO(先进先出)堆栈。所以你要按照你放东西的顺序把它们拿出来。让我们修改上面的代码来演示这个概念!
import pickle
#----------------------------------------------------------------------
def serialize(objects, path):
"""
Pickle a Python object
"""
with open(path, "wb") as pfile:
for obj in objects:
pickle.dump(obj, pfile)
#----------------------------------------------------------------------
def deserialize(path):
"""
Extracts a pickled Python object and returns it
"""
with open(path, "rb") as pfile:
lst = pickle.load(pfile)
dic = pickle.load(pfile)
string = pickle.load(pfile)
return lst, dic, string
#----------------------------------------------------------------------
if __name__ == "__main__":
my_list = [i for i in range(10)]
my_dict = {"a":1, "b":2}
my_string = "I'm a string!"
pkl_path = "data.pkl"
serialize([my_list, my_dict, my_string], pkl_path)
data = deserialize(pkl_path)
print data
在这段代码中,我们传入一个包含 3 个 Python 对象的列表:一个列表、一个字典和一个字符串。注意,我们必须调用 pickle 的 dump 方法来存储这些对象。当您反序列化时,您需要调用 pickle 的 load 方法相同的次数。
关于酸洗的其他注意事项
你不能腌制所有的东西。例如,您不能处理与 C/C++有关联的 Python 对象,比如 wxPython。如果你试图这样做,你会收到一个 PicklingError。根据文档,可以对以下类型进行酸洗:
- 无、真和假
- 整数、长整数、浮点数、复数
- 普通字符串和 Unicode 字符串
- 仅包含可选择对象的元组、列表、集合和字典
- 在模块顶层定义的函数
- 在模块顶层定义的内置函数
- 在模块顶层定义的类
- 这些类的实例,它们的 dict 或调用 getstate()的结果是可 pickle 的(有关详细信息,请参见 pickle 协议一节)。
还要注意,如果您碰巧使用 cPickle 模块来加速处理时间,那么您不能对它进行子类化。cPickle 模块不支持 Pickler()和 Unpickler()的子类化,因为它们实际上是 cPickle 中的函数。你需要知道这是一个相当狡猾的家伙。
最后,pickle 的输出数据格式使用可打印的 ASCII 表示。让我们看看第二个脚本的输出,只是为了好玩:
(lp0
I0
aI1
aI2
aI3
aI4
aI5
aI6
aI7
aI8
aI9
a.(dp0
S'a'
p1
I1
sS'b'
p2
I2
s.S"I'm a string!"
p0
.
现在,我不是这种格式的专家,但你可以看到发生了什么。然而,我不确定如何判断一个部分的结尾是什么。还要注意,默认情况下,pickle 模块使用协议版本 0。有 2 号和 3 号协议。您可以通过将它作为第三个参数传递给 pickle 的 dump 方法来指定您想要的协议。
最后,Richard Saunders 在 PyCon 2011 上发布了一个关于 pickle 模块的非常酷的视频。
包扎
至此,您应该能够使用 pickle 满足自己的数据序列化需求了。玩得开心!
python 101:Pony ORM 简介
原文:https://www.blog.pythonlibrary.org/2014/07/21/python-101-an-intro-to-pony-orm/
Pony ORM 项目是 Python 的另一个对象关系映射器包。它们允许您使用生成器查询数据库。他们还有一个在线的 ER 图编辑器,可以帮助你创建一个模型。当我第一次开始使用 PonyORM 时,它们是我见过的唯一一个带有多许可方案的 Python 包,在这种方案中,您可以使用 GNU 许可证进行开发,或者购买非开源作品的许可证。但是,截至 2016 年 10 月,PonyORM 包处于 Apache 2.0 许可之下。
在本文中,我们将花一些时间学习这个包的基础知识。
入门指南
因为这个项目不包含在 Python 中,所以您需要下载并安装它。如果你有 pip,你可以这样做:
pip install pony
否则你将不得不下载源代码并通过它的 setup.py 脚本安装它。
创建数据库
我们将首先创建一个数据库来保存一些音乐。我们将需要两个表:艺术家和专辑。我们开始吧!
import datetime
import pony.orm as pny
database = pny.Database("sqlite",
"music.sqlite",
create_db=True)
########################################################################
class Artist(database.Entity):
"""
Pony ORM model of the Artist table
"""
name = pny.Required(unicode)
albums = pny.Set("Album")
########################################################################
class Album(database.Entity):
"""
Pony ORM model of album table
"""
artist = pny.Required(Artist)
title = pny.Required(unicode)
release_date = pny.Required(datetime.date)
publisher = pny.Required(unicode)
media_type = pny.Required(unicode)
# turn on debug mode
pny.sql_debug(True)
# map the models to the database
# and create the tables, if they don't exist
database.generate_mapping(create_tables=True)
如果我们不指定主键,Pony ORM 会自动为我们创建主键。要创建外键,您只需将 model 类传递到另一个表中,就像我们在 Album 类中所做的那样。每个必填字段都采用 Python 类型。我们的大多数字段都是 unicode 的,其中一个是 datatime 对象。接下来我们打开调试模式,它将输出 Pony 在最后一条语句中创建表时生成的 SQL。注意,如果多次运行这段代码,将不会重新创建表。Pony 将在创建表之前检查它们是否存在。
如果您运行上面的代码,您应该会看到这样的输出:
GET CONNECTION FROM THE LOCAL POOL
PRAGMA foreign_keys = false
BEGIN IMMEDIATE TRANSACTION
CREATE TABLE "Artist" (
"id" INTEGER PRIMARY KEY AUTOINCREMENT,
"name" TEXT NOT NULL
)
CREATE TABLE "Album" (
"id" INTEGER PRIMARY KEY AUTOINCREMENT,
"artist" INTEGER NOT NULL REFERENCES "Artist" ("id"),
"title" TEXT NOT NULL,
"release_date" DATE NOT NULL,
"publisher" TEXT NOT NULL,
"media_type" TEXT NOT NULL
)
CREATE INDEX "idx_album__artist" ON "Album" ("artist")
SELECT "Album"."id", "Album"."artist", "Album"."title", "Album"."release_date", "Album"."publisher", "Album"."media_type"
FROM "Album" "Album"
WHERE 0 = 1
SELECT "Artist"."id", "Artist"."name"
FROM "Artist" "Artist"
WHERE 0 = 1
COMMIT
PRAGMA foreign_keys = true
CLOSE CONNECTION
是不是很棒?现在我们准备学习如何向数据库添加数据。
如何向表格中插入/添加数据
Pony 使得向表中添加数据变得相当容易。让我们来看看有多简单:
import datetime
import pony.orm as pny
from models import Album, Artist
#----------------------------------------------------------------------
@pny.db_session
def add_data():
""""""
new_artist = Artist(name=u"Newsboys")
bands = [u"MXPX", u"Kutless", u"Thousand Foot Krutch"]
for band in bands:
artist = Artist(name=band)
album = Album(artist=new_artist,
title=u"Read All About It",
release_date=datetime.date(1988,12,01),
publisher=u"Refuge",
media_type=u"CD")
albums = [{"artist": new_artist,
"title": "Hell is for Wimps",
"release_date": datetime.date(1990,07,31),
"publisher": "Sparrow",
"media_type": "CD"
},
{"artist": new_artist,
"title": "Love Liberty Disco",
"release_date": datetime.date(1999,11,16),
"publisher": "Sparrow",
"media_type": "CD"
},
{"artist": new_artist,
"title": "Thrive",
"release_date": datetime.date(2002,03,26),
"publisher": "Sparrow",
"media_type": "CD"}
]
for album in albums:
a = Album(**album)
if __name__ == "__main__":
add_data()
# use db_session as a context manager
with pny.db_session:
a = Artist(name="Skillet")
您会注意到,我们需要使用一个名为 db_session 的装饰器来处理数据库。它负责打开连接、提交数据和关闭连接。您还可以将它用作上下文管理器,这段代码的最后演示了这一点。
使用基本查询修改记录
在本节中,我们将学习如何进行一些基本的查询并修改数据库中的一些条目。
import pony.orm as pny
from models import Artist, Album
with pny.db_session:
band = Artist.get(name="Newsboys")
print band.name
for record in band.albums:
print record.title
# update a record
band_name = Artist.get(name="Kutless")
band_name.name = "Beach Boys"
这里我们使用 db_session 作为上下文管理器。我们通过查询从数据库中获取一个 artist 对象并打印其名称。然后我们遍历返回对象中包含的艺术家的专辑。最后,我们更改一个艺术家的名字。
让我们尝试使用生成器查询数据库:
result = pny.select(i.name for i in Artist)
result.show()
如果您运行这段代码,您应该会看到如下内容:
i.name
--------------------
Newsboys
MXPX
Beach Boys
Thousand Foot Krutch
文档中有几个值得一试的例子。注意,Pony 还通过其 select_by_sql 和 get_by_sql 方法支持使用 SQL 本身。
如何在表格中删除记录
用 Pony 删除记录也很容易。让我们从数据库中删除一个波段:
import pony.orm as pny
from models import Artist
with pny.db_session:
band = Artist.get(name="MXPX")
band.delete()
我们再次使用 db_session 来访问数据库并提交我们的更改。我们使用 band 对象的 delete 方法来删除记录。你将需要挖掘,找出是否 Pony 支持级联删除,如果你删除艺术家,它也将删除所有专辑连接到它。根据文件,如果该字段为必填,则级联被启用。
包扎
现在您知道了使用 Pony ORM 包的基本知识。我个人认为文档需要一点工作,因为你必须挖掘很多才能找到一些我认为应该在教程中的功能。尽管总的来说,文档仍然比大多数项目要好得多。试试看,看看你有什么想法!
额外资源
- 小马奥姆的网站
- 小马文档
- SQLAlchemy 教程
- peewee 的简介
python 101:URL lib 简介
原文:https://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/
Python 3 中的 urllib 模块是一个模块集合,可以用来处理 URL。如果你来自 Python 2 背景,你会注意到在 Python 2 中你有 urllib 和 urllib2。这些现在是 Python 3 中 urllib 包的一部分。urllib 的当前版本由以下模块组成:
- urllib.request
- urllib.error
- urllib.parse
- urllib.rebotparser
除了 urllib.error 之外,我们将分别讨论每个部分。官方文档实际上建议您可能想要查看第三方库,请求,以获得更高级别的 HTTP 客户端接口。然而,我相信知道如何打开 URL 并与它们交互而不使用第三方是有用的,它也可以帮助你理解为什么请求包如此受欢迎。
urllib.request
urllib.request 模块主要用于打开和获取 URL。让我们来看看您可以使用 urlopen 函数做的一些事情:
>>> import urllib.request
>>> url = urllib.request.urlopen('https://www.google.com/')
>>> url.geturl()
'https://www.google.com/'
>>> url.info()
>>> header = url.info()
>>> header.as_string()
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
'Expires: -1\n'
'Cache-Control: private, max-age=0\n'
'Content-Type: text/html; charset=ISO-8859-1\n'
'P3P: CP="This is not a P3P policy! See '
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
'Server: gws\n'
'X-XSS-Protection: 1; mode=block\n'
'X-Frame-Options: SAMEORIGIN\n'
'Set-Cookie: '
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
'Alternate-Protocol: 443:quic\n'
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
'Accept-Ranges: none\n'
'Vary: Accept-Encoding\n'
'Connection: close\n'
'\n')
>>> url.getcode()
200
在这里,我们导入我们的模块,并要求它打开谷歌的网址。现在我们有了一个可以与之交互的 HTTPResponse 对象。我们做的第一件事是调用 geturl 方法,该方法将返回检索到的资源的 url。这有助于发现我们是否遵循了重定向。
接下来我们调用 info ,它将返回关于页面的元数据,比如标题。因此,我们将结果赋给我们的 headers 变量,然后调用它的 as_string 方法。这将打印出我们从 Google 收到的标题。您还可以通过调用 getcode 来获取 HTTP 响应代码,在本例中是 200,这意味着它成功地工作了。
如果您想查看页面的 HTML,您可以在我们创建的 url 变量上调用 read 方法。我不会在这里重复,因为输出会很长。
请注意,请求对象默认为 GET 请求,除非您指定了数据参数。如果您传入数据参数,那么请求对象将发出 POST 请求。
下载文件
urllib 包的一个典型用例是下载文件。让我们找出完成这项任务的几种方法:
>>> import urllib.request
>>> url = 'https://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
>>> response = urllib.request.urlopen(url)
>>> data = response.read()
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
... fobj.write(data)
...
在这里,我们只需打开一个 URL,它会将我们带到存储在我的博客上的一个 zip 文件。然后我们读取数据并把它写到磁盘上。实现这一点的另一种方法是使用 urlretrieve :
>>> import urllib.request
>>> url = 'https://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
>>> tmp_file, header = urllib.request.urlretrieve(url)
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
... with open(tmp_file, 'rb') as tmp:
... fobj.write(tmp.read())
urlretrieve 方法将网络对象复制到本地文件。它复制到的文件是随机命名的,并放在 temp 目录中,除非您使用 urlretrieve 的第二个参数,在那里您可以实际指定您想要保存文件的位置。这将为您节省一个步骤,并使您的代码更加简单:
>>> import urllib.request
>>> url = 'https://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
('/home/mike/Desktop/blog.zip',
)
如您所见,它从请求中返回保存文件的位置和头信息。
指定您的用户代理
当你用浏览器访问一个网站时,浏览器会告诉网站它是谁。这被称为用户代理字符串。Python 的 urllib 将自己标识为 Python-urllib/x.y ,其中 x 和 y 是 Python 的主版本号和次版本号。一些网站不会识别这个用户代理字符串,并且会以奇怪的方式运行或根本不工作。幸运的是,您很容易设置自己的自定义用户代理字符串:
>>> import urllib.request
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
>>> url = 'http://www.whatsmyua.com/'
>>> headers = {'User-Agent': user_agent}
>>> request = urllib.request.Request(url, headers=headers)
>>> with urllib.request.urlopen(request) as response:
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
... out.write(response.read())
这里我们设置了 Mozilla FireFox 的用户代理,我们设置了 http://www.whatsmyua.com/的 URL,它会告诉我们它认为我们的用户代理字符串是什么。然后,我们使用我们的 url 和头创建一个请求实例,并将其传递给 urlopen 。最后我们保存结果。如果您打开结果文件,您将看到我们成功地更改了用户代理字符串。您可以用这段代码尝试一些不同的字符串,看看它会有什么变化。
urllib.parse
urllib.parse 库是分解 URL 字符串并将它们组合在一起的标准接口。例如,您可以使用它将相对 URL 转换为绝对 URL。让我们尝试使用它来解析包含查询的 URL:
>>> from urllib.parse import urlparse
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
>>> result
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
>>> result.netloc
'duckduckgo.com'
>>> result.geturl()
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
>>> result.port
None
这里,我们导入了 urlparse 函数,并向它传递一个包含对 duckduckgo 网站的搜索查询的 URL。我的查询是查找关于“python stubbing”的文章。如您所见,它返回了一个 ParseResult 对象,您可以用它来了解更多关于 URL 的信息。例如,您可以获得端口信息(本例中没有)、网络位置、路径等等。
提交 Web 表单
这个模块还保存了 urlencode 方法,这对于向 URL 传递数据非常有用。urllib.parse 库的一个典型用例是提交 web 表单。让我们通过让 duckduckgo 搜索引擎查找 Python 来了解如何做到这一点:
>>> import urllib.request
>>> import urllib.parse
>>> data = urllib.parse.urlencode({'q': 'Python'})
>>> data
'q=Python'
>>> url = 'http://duckduckgo.com/html/'
>>> full_url = url + '?' + data
>>> response = urllib.request.urlopen(full_url)
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
... f.write(response.read())
这很简单。基本上,我们希望自己使用 Python 而不是浏览器向 duckduckgo 提交一个查询。为此,我们需要使用 urlencode 来构造查询字符串。然后我们将它们放在一起创建一个完全合格的 URL,并使用 urllib.request 提交表单。然后我们获取结果并保存到磁盘上。
URL lib robotparser
robotparser 模块由一个类 RobotFileParser 组成。这个类将回答关于一个特定的用户代理是否可以获取一个已经发布了 robot.txt 文件的 URL 的问题。robots.txt 文件将告诉 web scraper 或 robot 服务器的哪些部分不应该被访问。让我们用 ArsTechnica 的网站看一个简单的例子:
>>> import urllib.robotparser
>>> robot = urllib.robotparser.RobotFileParser()
>>> robot.set_url('http://arstechnica.com/robots.txt')
None
>>> robot.read()
None
>>> robot.can_fetch('*', 'http://arstechnica.com/')
True
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
False
这里我们导入 robot parser 类并创建它的一个实例。然后我们传递给它一个 URL,指定网站的 robots.txt 文件所在的位置。接下来,我们告诉解析器读取文件。现在已经完成了,我们给它几个不同的 URL 来找出哪些我们可以抓取,哪些不可以。我们很快发现我们可以访问主站点,但不能访问 cgi-bin。
包扎
您已经达到了应该能够胜任使用 Python 的 urllib 包的程度。在本章中,我们学习了如何下载文件、提交 web 表单、更改用户代理以及访问 robots.txt 文件。urllib 有很多额外的功能没有在这里讨论,比如网站认证。然而,在尝试使用 urllib 进行身份验证之前,您可能需要考虑切换到 requests 库,因为 requests 实现更容易理解和调试。我还想指出的是,Python 通过其 http.Cookiess 模块支持 cookie,尽管这也很好地包装在 requests 包中。你也许应该考虑两者都尝试一下,看看哪一个对你最有意义。
python 101:JSON 使用简介
原文:https://www.blog.pythonlibrary.org/2020/09/15/python-101-an-intro-to-working-with-json/
JavaScript Object Notation,通常被称为 JSON,是一种受 JavaScript object literal 语法启发的轻量级数据交换格式。JSON 对于人类来说很容易读写。也便于计算机解析生成。JSON 用于存储和交换数据,与 XML 的使用方式非常相似。
Python 有一个名为json的内置库,可以用来创建、编辑和解析 JSON。您可以在此阅读关于该图书馆的所有信息:
了解 JSON 的样子可能会有所帮助。这里有一个来自 https://json.org 的 JSON 的例子:
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
从 Python 的角度来看,这个 JSON 是一个嵌套的 Python 字典。你会发现 JSON 总是被翻译成某种原生 Python 数据类型。在本文中,您将了解以下内容:
- 编码 JSON 字符串
- 解码 JSON 字符串
- 将 JSON 保存到磁盘
- 从磁盘加载 JSON
- 使用
json.tool验证 JSON
JSON 是一种非常流行的格式,经常在 web 应用程序中使用。您会发现,知道如何使用 Python 与 JSON 交互在您自己的工作中很有用。
我们开始吧!
编码 JSON 字符串
Python 的json模块使用dumps()将对象序列化为字符串。dumps()中的“s”代表“弦”。通过在一些代码中使用json模块,可以更容易地看出这是如何工作的:
>>> import json
>>> j = {"menu": {
... "id": "file",
... "value": "File",
... "popup": {
... "menuitem": [
... {"value": "New", "onclick": "CreateNewDoc()"},
... {"value": "Open", "onclick": "OpenDoc()"},
... {"value": "Close", "onclick": "CloseDoc()"}
... ]
... }
... }}
>>> json.dumps(j)
'{"menu": {"id": "file", "value": "File", "popup": {"menuitem": [{"value": "New", '
'"onclick": "CreateNewDoc()"}, {"value": "Open", "onclick": "OpenDoc()"}, '
'{"value": "Close", "onclick": "CloseDoc()"}]}}}'
这里使用了json.dumps(),它将 Python 字典转换成 JSON 字符串。该示例的输出被修改为换行打印。否则字符串将全部在一行上。
现在您已经准备好学习如何将一个对象写入磁盘了!
将 JSON 保存到磁盘
Python 的json模块使用dump()函数将对象序列化或编码为 JSON 格式的流,成为类似文件的对象。Python 中的类文件对象是指使用 Python 的io模块创建的文件处理程序或对象。
继续创建一个名为create_json_file.py的文件,并向其中添加以下代码:
# create_json_file.py
import json
def create_json_file(path, obj):
with open(path, 'w') as fh:
json.dump(obj, fh)
if __name__ == '__main__':
j = {"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
create_json_file('test.json', j)
在本例中,您使用了json.dump(),它用于写入文件或类似文件的对象。它将写入文件处理程序fh。
现在您可以学习如何解码 JSON 字符串了!
解码 JSON 字符串
JSON 字符串的解码或反序列化是通过loads()方法完成的。loads()是dumps()的配套功能。下面是它的用法示例:
>>> import json
>>> j_str = """{"menu": {
... "id": "file",
... "value": "File",
... "popup": {
... "menuitem": [
... {"value": "New", "onclick": "CreateNewDoc()"},
... {"value": "Open", "onclick": "OpenDoc()"},
... {"value": "Close", "onclick": "CloseDoc()"}
... ]
... }
... }}
... """
>>> j_obj = json.loads(j_str)
>>> type(j_obj)
<class 'dict'>
这里,您将前面的 JSON 代码重新创建为 Python 多行字符串。然后使用json.loads()加载 JSON 字符串,将它转换成 Python 对象。在这种情况下,它将 JSON 转换为 Python 字典。
现在您已经准备好学习如何从文件加载 JSON 了!
从磁盘加载 JSON
使用json.load()从文件加载 JSON。这里有一个例子:
# load_json_file.py
import json
def load_json_file(path):
with open(path) as fh:
j_obj = json.load(fh)
print(type(j_obj))
if __name__ == '__main__':
load_json_file('example.json')
在这段代码中,您像以前看到的那样打开传入的文件。然后您将文件处理程序fh传递给json.load(),这将把 JSON 转换成 Python 对象。
还可以使用 Python 的json模块来验证 JSON。接下来你会知道如何去做。
使用json.tool验证 JSON
Python 的json模块提供了一个工具,您可以在命令行上运行该工具来检查 JSON 是否具有正确的语法。这里有几个例子:
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
$ echo '{"1.2":3.4}' | python -m json.tool
{
"1.2": 3.4
}
第一个调用将字符串'{1.2:3.4}'传递给json.tool,这告诉您 JSON 代码有问题。第二个示例向您展示了如何解决这个问题。当固定字符串被传递给json.tool时,它会“漂亮地打印”出 JSON,而不是发出一个错误。
包扎
在处理 web APIs 和 web 框架时,经常使用 JSON 格式。Python 语言为您提供了一个很好的工具,可以用来将 JSON 转换成 Python 对象,然后在json库中再转换回来。
在本章中,您学习了以下内容:
- 编码 JSON 字符串
- 解码 JSON 字符串
- 将 JSON 保存到磁盘
- 从磁盘加载 JSON
- 使用
json.tool验证 JSON
现在,您有了另一个可以使用 Python 的有用工具。只要稍加练习,您很快就能使用 JSON 了!
Python 101 -赋值表达式
原文:https://www.blog.pythonlibrary.org/2021/09/24/python-101-assignment-expressions-2/
Python 在版本 3.8 中增加了赋值表达式。一般的想法是,赋值表达式允许你在表达式中给变量赋值。
这样做的语法是:
NAME := expr
这个操作符被称为“walrus 操作符”,尽管它们的真名是“赋值表达式”。有趣的是,CPython 内部也将它们称为“命名表达式”。
你可以在 PEP 572 中阅读所有关于赋值表达式的内容。让我们来看看如何使用赋值表达式!
使用赋值表达式
赋值表达式还是比较少见的。但是,您需要了解赋值表达式,因为您可能会不时地遇到它们。PEP 572 有一些很好的赋值表达式的例子。
# Handle a matched regex
if (match := pattern.search(data)) is not None:
...
# A more explicit alternative to the 2-arg form of iter() invocation
while (value := read_next_item()) is not None:
...
# Share a subexpression between a comprehension filter clause and its output
filtered_data = [y for x in data if (y := f(x)) is not None]
在这 3 个例子中,您在表达式语句本身中创建了一个变量。第一个示例通过将 regex 模式搜索的结果赋给变量match来创建变量。第二个例子将变量value赋给在while循环表达式中调用函数的结果。最后,将调用f(x)的结果赋给列表理解中的变量y。
看看不使用赋值表达式的代码和使用赋值表达式的代码之间的区别可能会有所帮助。下面是一个分块读取文件的示例:
with open(some_file) as file_obj:
while True:
chunk_size = 1024
data = file_obj.read(chunk_size)
if not data:
break
if 'something' in data:
# process the data somehow here
这段代码将打开一个大小不确定的文件,一次处理 1024 个字节。您会发现这在处理非常大的文件时非常有用,因为它可以防止您将整个文件加载到内存中。如果这样做,可能会耗尽内存,导致应用程序甚至计算机崩溃。
您可以使用赋值表达式将这段代码缩短一点:
with open(some_file) as file_obj:
chunk_size = 1024
while data := file_obj.read(chunk_size):
if 'something' in data:
# process the data somehow here
在这里,你在while循环的表达式中将read()的结果赋值给data。这允许您在while循环的代码块中使用该变量。它还检查是否返回了一些数据,这样就不必使用if not data: break节了。
PEP 572 中提到的另一个好例子取自 Python 自己的site.py。代码最初是这样的:
env_base = os.environ.get("PYTHONUSERBASE", None)
if env_base:
return env_base
这就是如何通过使用赋值表达式来简化它:
if env_base := os.environ.get("PYTHONUSERBASE", None):
return env_base
您将赋值移动到conditional语句的表达式中,这很好地缩短了代码。
现在让我们发现一些不能使用赋值表达式的情况。
你不能用赋值表达式做什么
有几种情况不能使用赋值表达式。
赋值表达式最有趣的特性之一是它们可以用在赋值语句不能用的上下文中,比如在lambda或前面提到的理解中。但是,它们不支持赋值语句可以做的一些事情。例如,您不能执行多个目标分配:
x = y = z = 0 # Equivalent, but non-working: (x := (y := (z := 0)))
另一个被禁止的用例是在表达式语句的顶层使用赋值表达式。这里有一个来自 PEP 572 的例子:
y := f(x) # INVALID
(y := f(x)) # Valid, though not recommended
PEP 中有一个详细的列表,列出了禁止或不鼓励使用赋值表达式的其他情况。如果您计划经常使用赋值表达式,那么您应该查阅该文档。
包扎
赋值表达式是清理代码某些部分的一种优雅方式。该特性的语法有点类似于类型提示变量。一旦你掌握了其中的一个,另一个也会变得更容易。
在本文中,您看到了一些使用“walrus 操作符”的真实例子。您还了解了什么时候不应该使用赋值表达式。该语法仅在 Python 3.8 或更新版本中可用,因此如果您碰巧被迫使用 Python 的旧版本,该功能对您来说不会有太大用处。
相关阅读
这篇文章基于 Python 101 第二版中的一章,你可以在 Leanpub 或亚马逊上购买。
如果你想学习更多的 Python,那么看看这些教程:
-
python 101—如何处理图像
-
python 101-记录你的代码
-
Python 101: 使用 JSON 的介绍
-
python 101-创建多个流程
Python 3 -赋值表达式
原文:https://www.blog.pythonlibrary.org/2018/06/12/python-101-assignment-expressions/
我最近偶然发现了 PEP 572 ,这是克里斯·安吉利科、蒂姆·皮特斯和吉多·范·罗苏姆本人提出的在 Python 3.8 中加入赋值表达式的建议!我决定检查一下,看看什么是赋值表达式。这个想法其实很简单。Python 核心开发人员想要一种使用以下符号在表达式中分配变量的方法:
NAME := expr
这个话题已经有了很多争论,如果你愿意,你可以阅读关于 Python-Dev Google group 的详细内容。我个人发现通读 Python 核心开发社区提出的各种利弊是非常有见地的。
不管怎样,让我们看看 PEP 572 中的一些例子,看看我们是否能弄清楚如何使用赋值表达式。
# Handle a matched regex
if (match := pattern.search(data)) is not None:
...
# A more explicit alternative to the 2-arg form of iter() invocation
while (value := read_next_item()) is not None:
...
# Share a subexpression between a comprehension filter clause and its output
filtered_data = [y for x in data if (y := f(x)) is not None]
在这 3 个例子中,我们在表达式语句本身中创建了一个变量。第一个示例通过将 regex 模式搜索的结果赋给变量 match 来创建变量。第二个示例将变量的值赋给在 while 循环表达式中调用函数的结果。最后,我们将调用 f(x)的结果赋给列表理解中的变量 y 。
赋值表达式最有趣的特性之一(至少对我来说)是它们可以用在赋值语句不能用的上下文中,比如 lambda 或前面提到的 comprehension。然而,它们也不支持赋值语句可以做的一些事情。例如,你不能给多个目标赋值:
x = y = z = 0 # Equivalent: (x := (y := (z := 0)))
您可以在 PEP 中看到完整的差异列表
PEP 中有更多的信息,包括其他几个例子,讨论被拒绝的备选方案和范围。
相关阅读
Python 101 返校特卖
原文:https://www.blog.pythonlibrary.org/2015/08/12/python-101-back-to-school-sale/
我将在返校时出售我的 Python 101 课程。现在使用以下优惠码即可五折获得 Python 101 书:2015 年秋季。此报价有效期至 2015 年 9 月 15 日。
您还可以以 50%的价格获得我的 Python 101 Screencast (即 25 美元,无需提供代码)。其中包括了这本书,但需要注意的是,这本书要到 2015 年 12 月才能完成。此时完成了 15 个视频。前 11 个可以在 Youtube 上免费获得,所以你可以在购买前尝试一下。
Python 101 书籍:幕后-封面
原文:https://www.blog.pythonlibrary.org/2014/02/26/python-101-book-behind-the-scenes-the-cover/
我对 Python 101 的封面有很多想法。我的第一个想法是去动物园拍一些蟒蛇的照片,然后挑一张合适的贴在封面上。我有很多照片编辑软件,所以我也考虑过把照片拍下来,然后把它修改成素描或油画的样子。然后我开始思考我的博客,以及我的读者是如何首先鼓励我写这本书的。所以我最终选择了我的另一个想法,那就是继续鼠标 Vs Python 的主题。
最后,我雇了一个我认识的艺术家,他设计了我最初的博客标识。他的名字叫泰勒,他拥有并经营着 Killustration 工作室。你可以看到他在 deviantArt 上的一些作品。无论如何,我告诉他我对这本书封面的想法,我想我会分享封面的各种版本。
第一个粗糙的封面
下图是封面的第一个版本。这很粗糙,但我可以看到我的愿景正在成形:

第二场比赛
下一个粗略的封面图片稍微好一点,有更多的细节:

铅笔版本
在批准这项工作后,泰勒创作了铅笔版的封面:

我喜欢这个版本,我们继续。
着墨的封面
接下来是给封面上色。我没想到会有这么多台阶!

全彩封面!
下一步是给封面添加颜色。我认为这个结果很好:

最终封面
最后一次修改是在标题上加上我的名字。

我已经重新雇用了我的艺术家,为这本书添加一些更有趣的艺术。如果你想支持图书项目,请查看 Kickstarter 活动页面
Python 101 书战役结束了!
原文:https://www.blog.pythonlibrary.org/2014/03/21/python-101-book-campaign-is-finished/
Python 101 book 活动今天结束。我现在有足够的资金来创作这本书,并完成所有的艺术作品。我想我也可以试着得到额外的插图。虽然我们没有达到下一个延伸目标,但我计划继续进行截屏工作。正如我之前提到的,在我写完这本书之前,我很可能不会开始写这些。到目前为止,我已经收到了很多关于这本书的正面评论,我希望推出一款对你有用的产品。
在 Kickstarter 转移资金后,我将尽快发送第一部分。您将收到一份要求您提供电子邮件地址的调查。我可能会向那些购买 t 恤和类似物品的人发送一份调查。
非常感谢你的支持。我非常感激。
Python 101 书籍可供预购
原文:https://www.blog.pythonlibrary.org/2014/03/31/python-101-book-is-available-for-pre-order/
我只是想快速说明一下,Python 101 书籍现在可以在这里预订。目前,你将会收到这本书的草稿版本,因为它们已经可以使用了。现在,第一部分和第二部分已被释放,这相当于约。115 页内容。

你可以在下面阅读更多关于这本书的内容:
Python 101
从头到尾学习如何用 Python 编程。我的书主要是为初学者写的。但是,至少有三分之二是针对中级程序员的。你可能想知道这是怎么回事。这本书将分成四部分。
第一部分
第一部分是初学者部分。在这里你将学到 Python 的所有基础知识。从 Python 类型(字符串、列表、字典)到条件语句再到循环。你还将学习理解、函数和类以及它们之间的一切!注:本节已经完成,正处于编辑阶段。
第二部分
这一部分将是 Python 标准库的一次策划之旅。其目的并不是涵盖其中的所有内容,而是向读者展示开箱即用的 Python 可以做很多事情。我们将讨论我认为在日常编程任务中最有用的模块,比如 os、sys、日志、线程等等。
第三部分
这部分都是中级材料。它包括以下内容:
- 希腊字母的第 11 个
- 装修工
- 性能
- 排除故障
- 测试
- 压型
第四部分
现在事情变得非常有趣!在第四部分,我们将学习如何从 Python 包索引和其他位置安装第三方库(即包)。我们将介绍简易安装和 pip。这一节也将是一系列的教程,在这里你将学习如何使用你下载的软件包。例如,您将学习如何下载文件、解析 XML、使用对象关系映射器处理数据库等。
第五部分
这本书的最后一部分将介绍如何与你的朋友和全世界分享你的代码!您将了解如何将其打包并在 Python 包索引上共享(例如,如何创建一个鸡蛋或轮子)。您还将学习如何使用 py2exe、bb_freeze、cx_freeze 和 PyInstaller 创建可执行文件。最后,您将学习如何使用 Inno Setup 创建安装程序。
写作风格
这本书将使用我最初的博客风格来写。这意味着章节会比你通常的编程教科书要短。大多数章节将很可能少于 10 页!这里的想法是让读者快速了解这个主题,而不是用它来打击他们。
你可以在这里预购 Python 101
Python 101:书籍大纲
原文:https://www.blog.pythonlibrary.org/2014/02/21/python-101-book-outline/
我确信你们中的一些人一直在想,我是否有一个更具体的关于我正在写的书的大纲。事实上,我有。以下是我目前掌握的情况:
第一部分:学习基础知识
- 第 1 章-闲置
- 第 2 章-字符串
- 第 3 章-列表、元组和字典
- 第 4 章- if/elif/else 语句
- 第 5 章-循环
- 第六章-理解
- 第 7 章-异常处理
- 第 8 章-使用文件
- 第 9 章-导入
- 第 10 章-功能
- 第 11 章-课程
注:第一部分已经完成,并处于编辑阶段
第二部分:标准库
- 反省
- ConfigParser
- 记录
- 操作系统(Operating System)
- smtplib /电子邮件
- 子过程
- [计]系统复制命令(system 的简写)
- 线程/队列
- time / datetime
- xml 解析
第三部分:提示、技巧和教程
- pip 和简易安装
- configobj
- lxml
- 要求
- virtualenv(虚拟环境)
- pylin/pychecker
- sqllcemy(SQL 语法)
第四部分:包装和配送
- 如何创建自己的模块和包
- 如何将它们添加到 Python 打包索引中
- 鸡蛋创造
- 车轮创建
- cx _ 冻结
- bb _ 冻结
- py2exe
- pyInstaller(安装程序)
- 创建安装程序(NSIS 或 InnoSetup 或两者)
当我看到这个的时候,我能想到很多值得添加的额外章节,但是我想得到一些关于你的想法的反馈。是不是少了什么?如果是这样(而且兴趣足够大),我会考虑加进去。请注意,我不能在添加每个人的想法的同时仍然及时完成项目。
如果你愿意,你可以在这里支持这本书的 Kickstarter 活动。
Python 101 书今天出版!
原文:https://www.blog.pythonlibrary.org/2014/06/03/python-101-book-published-today/
我的第一本书《Python 101》今天出版了。你可以直接从我的博客购买,那里会有这本书的 PDF、EPUB 和 MOBI 版本。你也可以通过露露购买这本书的精装版。最后,我把电子书发布到了亚马逊。
如果你碰巧开了一个 Python 或技术博客,并且对阅读我的书《Python 101》感兴趣,请随时用你的博客信息联系我。我想找几个好的博客写手来评论这本书。
现在订购
Python 101 -图书样本
原文:https://www.blog.pythonlibrary.org/2014/03/15/python-101-book-sample/
在战役结束之前,我们只有五天多的时间,所以我想分享这本书的几个章节会很不错。你可以在这里下载第一章和第二章的简介。
我一直在做这本书的新部分,因为现在是新的第三部分。进展得相当顺利。我的插图画家正忙着为这本书创作一些新的艺术作品。我很快就会和大家分享。
非常感谢你的支持,祝你周末愉快!
Python 101 图书网站上线
原文:https://www.blog.pythonlibrary.org/2014/03/17/python-101-book-website-launched/
周末,我为我即将出版的书《Python 101》建立了一个网站。我发现 www.python101.com 属于擅自占地者,所以我选择了 www.python101.org。它将重定向到 http://python101.pythonlibrary.org 的 T2,因为我认为这本书应该是 Python 库的一部分,同时保持其独立性。
网站上还没有太多的内容,但我希望随着这本书上市日期的临近,能增加更多内容。对于那些感兴趣的人来说, Kickstarter 活动还有 3 天就要开始了,所以如果你想投稿,你需要抓紧时间!
Python 101 书籍写作更新
原文:https://www.blog.pythonlibrary.org/2014/05/13/python-101-book-writing-update/

Python 101,我正在创作的这本书快完成了。我有几份由 Lulu 制作的“证明”副本,用来验证事情的安排是否正确,并帮助我发现错误。在印刷品上看到它很酷。这也让一些疏漏变得相当明显,尽管它们本质上都是装饰性的。
不管怎样,现在我正在浏览这本书,做一些最后的编辑。我还有一个附录要添加,我目前正在等待两个以上的插图完成。这本书仍然计划在 2014 年 6 月推出。你现在就可以预订电子书。当准备好购买的时候,我会添加一个链接到封面,大概是在六月的第一周。
这里有一个有趣的下一件艺术品的预览:

Python 101 -布尔运算符和无(视频)
原文:https://www.blog.pythonlibrary.org/2020/08/21/python-101-boolean-operators-and-none-video/
在本视频教程中,您将了解 Python 的布尔运算符是如何工作的。您还将了解 Python 的 None 关键字
https://www.youtube.com/embed/4cX-nC61BTU?feature=oembed
你喜欢这个视频吗?查看它所基于的书: Python 101 -第二版。
Python 101 圣诞特卖
原文:https://www.blog.pythonlibrary.org/2015/12/07/python-101-christmas-sale/
我将在 12 月的剩余时间里发售我的书《Python 101(T1)》。你现在可以通过使用以下优惠代码获得电子书的 50%折扣: xmas2015
这段代码也适用于预先订购 Python 101 截屏,这是一系列基于 Python 101 书籍的视频。目前 44 个视频中有 29 个已经完成,但在本周末会有更多。尽情享受吧!
Python 101 -条件语句(视频)
原文:https://www.blog.pythonlibrary.org/2020/09/01/python-101-conditional-statements-video/
在本视频中,您将学习如何使用 Python 编程语言创建条件语句。
具体来说,您将了解以下主题:
- 比较运算符
- 创建简单的条件
- 分支条件语句
- 嵌套条件句
- 逻辑运算符
- 特殊操作员
https://www.youtube.com/embed/T_ha-KFqZMA?feature=oembed
Python 101:条件语句
原文:https://www.blog.pythonlibrary.org/2020/04/29/python-101-conditional-statements/
开发人员不得不一直做决策。你如何处理这个问题?你用 X 技术还是 Y 技术?您可以使用哪种编程语言来解决这个问题?您的代码有时也需要做出决定。
以下是代码每天都要检查的一些常见问题:
- 你被授权做那件事吗?
- 这是有效的电子邮件地址吗
- 该值在该字段中有效吗?
这类事情通过使用条件语句来控制。这个题目通常叫做控制流。在 Python 中,你可以使用if、elif和else语句来控制程序的流程。您还可以使用异常处理来实现一种简单的控制流,尽管通常不建议这样做。
有些编程语言也有switch或case语句,可以用于控制流。Python 没有这些。
在本章中,您将了解以下内容:
- 比较运算符
- 创建简单的条件
- 分支条件语句
- 嵌套条件句
- 逻辑运算符
- 特殊操作员
让我们从学习比较运算符开始吧!
| | 你想了解更多关于 Python 的知识吗?
Python 101 -第二版
在 Leanpub 上立即购买 |
比较运算符
在开始使用条件语句之前,了解一下比较运算符是很有用的。比较运算符允许您询问某物是否等于另一物,或者它们是否大于或小于某个值,等等。
下表显示了 Python 的比较运算符:
| 操作员 | 意义 |
|---|---|
| > | 大于——这是True是左操作数大于右操作数 |
| < | 小于-这是True左操作数小于右操作数 |
| == | 等于-只有当两个操作数相等时,这才是True |
| != | 不等于-如果操作数不相等,这是True |
| >= | 大于或等于-当左操作数大于或等于右操作数时,这是True |
| <= | 小于或等于-当左操作数小于或等于右操作数时,这是True |
现在您已经知道 Python 中有哪些比较运算符,您可以开始使用它们了!
以下是一些例子:
>>> a = 2
>>> b = 3
>>> a == b
False
>>> a > b
False
>>> a < b
True
>>> a >= b
False
>>> a <= b
True
>>> a != b
True
继续,在 Python REPL 中自己使用比较运算符。尝试一下是有好处的,这样你就能完全理解发生了什么。
现在让我们学习如何创建一个条件语句。
创建简单的条件
创建条件语句允许您的代码分支到两个或更多不同的路径。我们以认证为例。如果您在新电脑上使用您的网络邮件帐户,您需要登录才能查看您的电子邮件。主页的代码要么会在你进入时加载你的邮箱,要么会提示你登录。
你可以很有把握地打赌,代码正在使用一个条件语句来检查和查看你是否已经验证/授权查看该电子邮件。如果是,它会加载你的电子邮件。如果不是,它会加载登录屏幕。
让我们创建一个假想的身份验证示例:
>>> authenticated = True
>>> if authenticated:
... print('You are logged in')
...
You are logged in
在本例中,您创建了一个名为authenticated的变量,并将其设置为True。然后使用 Python 的if关键字创建一个条件语句。Python 中的条件语句采用以下形式:
if <expression>:
# do something here
要创建一个条件,您可以以单词if开始,后面跟着一个表达式,然后以冒号结束。当该表达式的计算结果为True时,执行条件下的代码。
如果authenticated被设置为False,那么什么都不会被打印出来。
在 Python 中缩进很重要
Python 关心缩进。代码块是一系列统一缩进的代码行。Python 通过缩进来确定代码块的开始和结束位置。
其他语言使用括号或分号来标记代码块的开始或结束。
Python 要求统一缩进代码。如果没有正确地做到这一点,您的代码可能很难诊断问题。
另外一个警告。不要混用制表符和空格。如果你这样做,IDLE 会抱怨,你的代码可能有难以诊断的问题。Python 风格指南(PEP8)建议使用 4 个空格来缩进代码块。只要代码一致,您可以缩进任意数量的空格。但是,通常建议使用 4 个空格。
如果您处理了这两种情况,这段代码会更好。让我们看看接下来该怎么做!
分支条件语句
根据问题的答案,您通常需要做不同的事情。因此,对于这种假设的情况,您希望让用户知道他们何时还没有进行身份验证,以便他们能够登录。
要实现这一点,您可以使用关键字else:
>>> authenticated = False
>>> if authenticated:
... print('You are logged in')
... else:
... print('Please login')
...
Please login
这段代码所做的是,如果你是authenticated,它会打印“你已登录”,如果不是,它会打印“请登录”。在一个真正的程序中,你不仅仅会有一个print()语句。您可能有代码将用户重定向到登录页面,或者如果他们通过了身份验证,它将运行代码来加载他们的收件箱。
让我们看一个新的场景。在下面的代码片段中,您将创建一个条件语句,该语句将检查您的年龄,并允许您根据该因素购买不同的商品:
>>> age = 10
>>> if age < 18:
... print('You can buy candy')
... elif age < 21:
... print('You can purchase tobacco and candy, but not alcohol')
... elif age >= 21:
... print('You can buy anything!')
...
You can buy candy
在这个例子中,您使用了if和elif。关键词,elif是“else if”的简称。因此,您在这里所做的是对照不同的硬编码值检查年龄。如果年龄小于 18 岁,那么买家只能买糖果。
如果他们大于 18 岁但小于 21 岁,他们可以购买烟草。当然,你不应该这样做,因为烟草对你不好,但它在大多数地方都有年龄限制。接下来你要检查买家的年龄是否大于或等于 21 岁。然后他们可以买任何他们想要的东西。
如果你想的话,你可以把最后一个elif改成一个简单的else子句,但是 Python 鼓励开发者在他们的代码中显式表达,在这种情况下使用elif会更容易理解。
您可以根据需要使用任意多的elif语句,尽管通常建议当您看到一个长的if/elif语句时,该代码可能需要重新编写。
嵌套条件句
您可以将一个if语句放在另一个if语句中。这就是所谓的嵌套。
让我们看一个愚蠢的例子:
>>> age = 21
>>> car = 'Ford'
>>> if age >= 21:
... if car in ['Honda', 'Toyota']:
... print('You buy foreign cars')
... elif car in ['Ford', 'Chevrolet']:
... print('You buy American')
... else:
... print('You are too young!')
...
You buy American
这段代码有多条路径,因为它依赖于两个变量:age和car。如果年龄大于某个值,那么它将落入该代码块,并将执行嵌套的if语句,该语句检查car类型。如果age小于一个任意值,那么它将简单地打印出一条消息。
理论上,你可以任意多次嵌套条件语句。但是,嵌套做得越多,后期调试就越复杂。在大多数情况下,您应该将嵌套保持在一两层深度。
幸运的是,逻辑运算符可以帮助缓解这个问题!
逻辑运算符
逻辑运算符允许您使用特殊的关键字将多个表达式链接在一起。
以下是 Python 支持的三种逻辑运算符:
and——如果两个操作数都为真,则只有Trueor-True如果任一操作数为真not-True如果操作数为假
让我们在上一节的示例中尝试使用逻辑运算符and来简化条件语句:
>>> age = 21
>>> car = 'Ford'
>>> if age >= 21 and car in ['Honda', 'Toyota']:
... print('You buy foreign cars')
... elif age >= 21 and car in ['Ford', 'Chevrolet']:
... print('You buy American')
... else:
... print('You are too young!')
...
You buy American
当您使用and时,两个表达式的计算结果都必须是True才能执行下面的代码。所以第一个条件检查年龄是否大于或等于 21,并且该车是否在日系车列表中。因为不是这两种情况,所以您下降到elif并检查这些条件。这次两个条件都是True,所以它打印出你的用车偏好。
让我们看看如果将and改为or会发生什么:
>>> age = 21
>>> car = 'Ford'
>>> if age >= 21 or car in ['Honda', 'Toyota']:
... print('You buy foreign cars')
... elif age >= 21 or car in ['Ford', 'Chevrolet']:
... print('You buy American')
... else:
... print('You are too young!')
...
You buy foreign cars
等一下!你说你的车是“福特”,但这个代码是说你买外国车!这是怎么回事?
当你使用一个逻辑or时,这意味着如果任何一个语句为True,代码块中的代码将会执行。
让我们把它分解一下。if age >= 21 or car in ['Honda', 'Toyota']中有两个表达式。第一个是age >= 21。那就评估为True。Python 一看到or并且第一条语句是True,它就将整个事件评估为True。要么你的年龄大于等于 21 要么你的车是福特。无论哪种方式,它都是真的,代码被执行。
使用not有点不同。它根本不适合这个例子,所以你得写点别的。
这里有一种使用not的方法:
>>> my_list = [1, 2, 3, 4]
>>> 5 not in my_list
True
在这种情况下,您要检查一个整数是否在一个list中。
让我们用另一个认证例子来演示如何使用not:
>>> ids = [1234, 5678]
>>> my_id = 1001
>>> if my_id not in ids:
... print('You are not authorized!')
...
You are not authorized!
这里有一组已知的 id。这些 id 可以是数字,就像这里一样,也可以是电子邮件地址或其他东西。无论如何,您需要检查给定的 id,my_id是否在您的已知 id 列表中。如果不是,那么您可以让用户知道他们无权继续。
您也可以在条件语句中组合逻辑运算符。这里有一个例子:
>>> hair = 'brown'
>>> age = 21
>>> if age >= 21 and (hair == 'brown' or hair == 'blue'):
... print(f'You are {age} years old with {hair} hair')
... else:
... print(f'You are too young at {age} years old')
...
You are 21 years old with brown hair
这一次,如果年龄大于或等于 21 岁,头发颜色是棕色或蓝色,您将运行if语句前半部分的代码。为了便于阅读,您在第二个和第三个表达式两边放了括号。
特殊操作员
您可以在条件表达式中使用一些特殊的运算符。事实上,在上一节中您已经使用了其中的一个。
你记得你刚刚用的是哪一个吗?
is-True当操作数相同时(即具有相同的 id)is not-True当操作数不相同时in-True当值在序列中时not in-True当值不在序列中时
您使用最后一个选项not in来确定一个 id 是否不在授权访问列表中。
前两个用于测试身份。您想知道一个项目是否引用相同的对象(或 id)。最后两个用于检查成员资格,这意味着您想知道一个项目是否在一个序列中。
让我们看看身份是如何工作的:
>>> x = 'hi'
>>> y = 'hi'
>>> x is y
True
>>> id(x)
140328219549744
>>> id(y)
140328219549744
当您将同一个字符串赋给两个不同的变量时,它们的身份是相同的,因为 Python 将x和y指向内存中相同的 ID 或位置。
让我们看看在创建列表时是否会发生同样的事情:
>>> x = [1, 2, 3]
>>> y = [1, 2, 3]
>>> x is y
False
>>> id(x)
140328193994832
>>> id(y)
140328193887760
>>> x == y
True
Python 列表的工作方式略有不同。每个列表都有自己的 id,所以当您在这里测试身份时,它会返回False。请注意,当您在最后测试相等性时,这两个列表确实彼此相等。
你可以使用in和not in来测试一个东西是否在一个序列中。Python 中的序列指的是列表、字符串、元组等。
有一种方法可以让你利用这些知识:
>>> valid_chars = 'yn'
>>> char = 'x'
>>> if char in valid_chars:
... print(f'{char} is a valid character')
... else:
... print(f'{char} is not in {valid_chars}')
...
x is not in yn
这里你检查一下char是否在valid_chars的字符串中。如果不是,它将打印出有效的字母。
尝试将char改为一个有效的字符,比如小写的“y”或小写的“n ”,然后重新运行代码。
包扎
条件语句在编程中非常有用。您将经常使用它们来根据用户的选择做出决策。你也可以使用基于数据库、网站和任何你的程序输入来源的响应的条件语句。
创建一个真正好的条件语句可能需要一些技巧,但是如果你在代码中投入足够的思想和精力,你就能做到!
Python 101 -创建多个流程
原文:https://www.blog.pythonlibrary.org/2020/07/15/python-101-creating-multiple-processes/
现在大部分 CPU 厂商都在打造多核 CPU。连手机都是多核的!由于全局解释器锁,Python 线程不能使用这些内核。从 Python 2.6 开始,添加了multiprocessing模块,让您可以充分利用机器上的所有内核。
在本文中,您将了解以下主题:
- 使用流程的优点
- 使用过程的缺点
- 使用
multiprocessing创建流程 - 子类化
Process - 创建进程池
本文并不是对多重处理的全面概述。一般来说,多处理和并发的主题更适合写在自己的书里。如果需要,您可以点击此处查看multiprocessing模块的文档:
现在,让我们开始吧!
使用流程的优点
使用流程有几个好处:
- 进程使用单独的内存空间
- 与线程相比,代码可以更加直接
- 使用多个 CPUs 内核
- 避免全局解释器锁(GIL)
- 子进程可以被杀死(不像线程)
multiprocessing模块有一个类似于threading.Thread的界面- 适用于 CPU 密集型处理(加密、二分搜索法、矩阵乘法)
现在让我们来看看流程的一些缺点!
使用过程的缺点
使用流程也有一些缺点:
- 进程间通信更加复杂
- 内存占用大于线程
现在让我们学习如何用 Python 创建一个流程!
使用multiprocessing创建流程
multiprocessing模块被设计成模仿threading.Thread类的工作方式。
下面是一个使用multiprocessing模块的例子:
import multiprocessing
import random
import time
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
processes = []
for i in range(5):
process = multiprocessing.Process(target=worker,
args=(f'computer_{i}',))
processes.append(process)
process.start()
for proc in processes:
proc.join()
第一步是导入multiprocessing模块。另外两个导入分别用于random和time模块。
然后你有愚蠢的worker()函数假装做一些工作。它接受一个name并且不返回任何东西。在worker()函数中,它将打印出工作者的name,然后它将使用time.sleep()来模拟做一些长时间运行的过程。最后,它会打印出它已经完成。
代码片段的最后一部分是创建 5 个工作进程的地方。你使用multiprocessing.Process(),它的工作方式和threading.Thread()差不多。你告诉Process使用什么目标函数,传递什么参数给它。主要区别在于,这次您创建了一个list流程。对于每个流程,您调用它的start()方法来启动流程。
最后,循环遍历进程列表并调用它的join()方法,该方法告诉 Python 等待进程终止。
运行此代码时,您将看到类似于以下内容的输出:
Started worker computer_2
computer_2 worker finished in 2 seconds
Started worker computer_1
computer_1 worker finished in 3 seconds
Started worker computer_3
computer_3 worker finished in 3 seconds
Started worker computer_0
computer_0 worker finished in 4 seconds
Started worker computer_4
computer_4 worker finished in 4 seconds
每次运行脚本时,由于使用了random模块,输出会有一些不同。试试看,自己看吧!
子类化Process
来自multiprocessing模块的Process类也可以被子类化。它的工作方式与threading.Thread类非常相似。
让我们来看看:
# worker_thread_subclass.py
import random
import multiprocessing
import time
class WorkerProcess(multiprocessing.Process):
def __init__(self, name):
multiprocessing.Process.__init__(self)
self.name = name
def run(self):
"""
Run the thread
"""
worker(self.name)
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
processes = []
for i in range(5):
process = WorkerProcess(name=f'computer_{i}')
processes.append(process)
process.start()
for process in processes:
process.join()
这里您子类化了multiprocess.Process()并覆盖了它的run()方法。
接下来,在代码末尾的循环中创建进程,并将其添加到进程列表中。然后,为了让进程正常工作,您需要遍历进程列表,并对每个进程调用join()。这与上一节中的流程示例完全一样。
这个类的输出应该与上一节的输出非常相似。
创建进程池
如果您有许多进程要运行,有时您会希望限制可以同时运行的进程的数量。例如,假设您需要运行 20 个进程,但您的处理器只有 4 个内核。您可以使用multiprocessing模块创建一个进程池,将一次运行的进程数量限制为 4 个。
你可以这样做:
import random
import time
from multiprocessing import Pool
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
process_names = [f'computer_{i}' for i in range(15)]
pool = Pool(processes=5)
pool.map(worker, process_names)
pool.terminate()
在这个例子中,您有相同的worker()函数。代码的真正内容在最后,您使用列表理解创建了 15 个进程名。然后创建一个Pool,并将一次运行的进程总数设置为 5。要使用pool,您需要调用map()方法,并将您希望调用的函数以及要传递给该函数的参数传递给它。
Python 现在将一次运行 5 个(或更少)进程,直到所有进程都完成。您需要在最后调用池中的terminate(),否则您将看到如下消息:
/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/multiprocessing/resource_tracker.py:216:
UserWarning: resource_tracker: There appear to be 6 leaked semaphore objects to clean up at shutdown
现在你知道如何用 Python 创建一个进程Pool!
包扎
您现在已经了解了使用multiprocessing模块的基本知识。您已经了解了以下内容:
- 使用流程的优点
- 使用过程的缺点
- 使用
multiprocessing创建流程 - 子类化
Process - 创建进程池
除了这里介绍的内容,还有很多其他的内容。您可以学习如何使用 Python 的Queue模块从流程中获取输出。还有进程间通信的话题。还有更多。然而,目标是学习如何创建流程,而不是学习multiprocessing模块的每一个细微差别。并发是一个很大的主题,需要比本文更深入的讨论。
Python 101 -创建多线程
原文:https://www.blog.pythonlibrary.org/2022/04/26/python-101-creating-multiple-threads/
并发是编程中的一个大话题。并发的概念是一次运行多段代码。Python 有几个内置于其标准库中的不同解决方案。您可以使用线程或进程。在这一章中,你将学习使用线程。
当您运行自己的代码时,您使用的是单线程。如果想在后台运行别的东西,可以使用 Python 的threading模块。
在本文中,您将了解以下内容:
- Pros of Using Threads
- Cons of Using Threads
- Creating Threads
- Subclassing
Thread - Writing Multiple Files with Threads
注意 : 这一章并不打算全面地介绍线程。但是您将学到足够的知识来开始在您的应用程序中使用线程。
让我们从回顾使用线程的利与弊开始吧!
使用线程的优点
线程在以下方面很有用:
- They have a small memory footprint, which means they are lightweight to use
- Memory is shared between threads - which makes it easy to share state across threads
- Allows you to easily make responsive user interfaces
- Great option for I/O bound applications (such as reading and writing files, databases, etc)
现在让我们来看看缺点!
使用线程的缺点
线程在以下方面不有用:
- Poor option for CPU bound code due to the Global Interpreter Lock (GIL) - see below
- They are not interruptible / able to be killed
- Code with threads is harder to understand and write correctly
- Easy to create race conditions
全局解释器锁是一个保护 Python 对象的互斥锁。这意味着它防止多个线程同时执行 Python 字节码。所以当你使用线程时,它们不会在你机器上的所有 CPU 上运行。
线程非常适合运行 I/O 繁重的应用程序、图像处理和 NumPy 的数字处理,因为它们不使用 GIL 做任何事情。如果您需要跨多个 CPU 运行并发进程,请使用multiprocessing模块。你将在下一章学习multiprocessing模块。
当你有一个计算机程序,它依赖于某个事件发生的顺序来正确执行时,就会发生竞争情况。如果您的线程没有按顺序执行,那么下一个线程可能无法工作,您的应用程序可能会崩溃或以意想不到的方式运行。
创建线程
如果你所做的只是谈论线程,那么线程是令人困惑的。熟悉如何编写实际代码总是好的。对于这一章,您将使用下面使用_thread模块的threading模块。
threading模块的完整文档可在此处找到:
让我们写一个简单的例子,展示如何创建多线程。将以下代码放入名为worker_threads.py的文件中:
# worker_threads.py
import random
import threading
import time
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
for i in range(5):
thread = threading.Thread(
target=worker,
args=(f'computer_{i}',),
)
thread.start()
前三个导入让您可以访问random、threading和time模块。你可以用random生成伪随机数,或者从一个序列中随机选择。threading模块是用来创建线程的,而time模块可以用于许多与时间相关的事情。
在这段代码中,您使用time等待一段随机的时间来模拟您的“工人”代码工作。
接下来,创建一个worker()函数,它接收工人的name。当这个函数被调用时,它将打印出哪个工人已经开始工作。然后它会在 1 到 5 之间选择一个随机数。您使用这个数字来模拟员工使用time.sleep()工作的时间。最后,您打印出一条消息,告诉您一个工人已经完成了工作,以及这项工作用了多长时间。
最后一个代码块创建了 5 个工作线程。要创建一个线程,您需要将您的worker()函数作为线程要调用的target函数来传递。传递给thread的另一个参数是一个参数元组,thread将把它传递给目标函数。然后你调用thread.start()来开始运行那个线程。
当函数停止执行时,Python 会删除你的线程。
尝试运行代码,您将看到输出如下所示:
Started worker computer_0
Started worker computer_1
Started worker computer_2
Started worker computer_3
Started worker computer_4
computer_0 worker finished in 1 seconds
computer_3 worker finished in 1 seconds
computer_4 worker finished in 3 seconds
computer_2 worker finished in 3 seconds
computer_1 worker finished in 4 seconds
你的输出会与上面的不同,因为工人sleep()的时间是随机的。事实上,如果您多次运行该代码,每次调用该脚本可能会有不同的结果。
threading.Thread is a class. Here is its full definition:
threading.Thread(
group=None, target=None, name=None,
args=(), kwargs={},
*,
daemon=None,
)
You could have named the threads when you created the thread rather than inside of the worker() function. The args and kwargs are for the target function. You can also tell Python to make the thread into a daemon. "Daemon threads" have no claim on the Python interpreter, which has two main consequences: 1) if only daemon threads are left, Python will shut down, and 2) when Python shuts down, daemon threads are abruptly stopped with no notification. The group parameter should be left alone as it was added for future extension when a ThreadGroup is added to the Python language.
Subclassing Thread
The Thread class from the threading module can also be subclassed. This allows you more fine-grained control over your thread's creation, execution and eventual deletion. You will encounter subclassed threads often.
Let's rewrite the previous example using a subclass of Thread. Put the following code into a file named worker_thread_subclass.py.
# worker_thread_subclass.py
import random
import threading
import time
class WorkerThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self)
self.name = name
self.id = id(self)
def run(self):
"""
Run the thread
"""
worker(self.name, self.id)
def worker(name: str, instance_id: int) -> None:
print(f'Started worker {name} - {instance_id}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} - {instance_id} worker finished in '
f'{worker_time} seconds')
if __name__ == '__main__':
for i in range(5):
thread = WorkerThread(name=f'computer_{i}')
thread.start()
In this example, you create the WorkerThread class. The constructor of the class, __init__(), accepts a single argument, the name to be given to thread. This is stored off in an instance attribute, self.name. Then you override the run() method.
The run() method is already defined in the Thread class. It controls how the thread will run. It will call or invoke the function that you passed into the class when you created it. When you create your own run() method in your subclass, it is known as overriding the original. This allows you to add custom behavior such as logging to your thread that isn't there if you were to use the base class's run() method.
You call the worker() function in the run() method of your WorkerThread. The worker() function itself has a minor change in that it now accepts the instance_id argument which represents the class instance's unique id. You also need to update the print() functions so that they print out the instance_id.
The other change you need to do is in the __main__ conditional statement where you call WorkerThread and pass in the name rather than calling threading.Thread() directly as you did in the previous section.
When you call start() in the last line of the code snippet, it will call run() for you itself. The start() method is a method that is a part of the threading.Thread class and you did not override it in your code.
The output when you run this code should be similar to the original version of the code, except that now you are also including the instance id in the output. Give it a try and see for yourself!
Writing Multiple Files with Threads
There are several common use cases for using threads. One of those use cases is writing multiple files at once. It's always nice to see how you would approach a real-world problem, so that's what you will be doing here.
To get started, you can create a file named writing_thread.py. Then add the following code to your file:
# writing_thread.py
import random
import time
from threading import Thread
class WritingThread(Thread):
def __init__(self,
filename: str,
number_of_lines: int,
work_time: int = 1) -> None:
Thread.__init__(self)
self.filename = filename
self.number_of_lines = number_of_lines
self.work_time = work_time
def run(self) -> None:
"""
Run the thread
"""
print(f'Writing {self.number_of_lines} lines of text to '
f'{self.filename}')
with open(self.filename, 'w') as f:
for line in range(self.number_of_lines):
text = f'This is line {line+1}\n'
f.write(text)
time.sleep(self.work_time)
print(f'Finished writing {self.filename}')
if __name__ == '__main__':
files = [f'test{x}.txt' for x in range(1, 6)]
for filename in files:
work_time = random.choice(range(1, 3))
number_of_lines = random.choice(range(5, 20))
thread = WritingThread(filename, number_of_lines, work_time)
thread.start()
Let's break this down a little and go over each part of the code individually:
import random
import time
from threading import Thread
class WritingThread(Thread):
def __init__(self,
filename: str,
number_of_lines: int,
work_time: int = 1) -> None:
Thread.__init__(self)
self.filename = filename
self.number_of_lines = number_of_lines
self.work_time = work_time
Here you created the WritingThread class. It accepts a filename, a number_of_lines and a work_time. This allows you to create a text file with a specific number of lines. The work_time is for sleeping between writing each line to simulate writing a large or small file.
Let's look at what goes in run():
def run(self) -> None:
"""
Run the thread
"""
print(f'Writing {self.number_of_lines} lines of text to '
f'{self.filename}')
with open(self.filename, 'w') as f:
for line in range(self.number_of_lines):
text = f'This is line {line+1}\n'
f.write(text)
time.sleep(self.work_time)
print(f'Finished writing {self.filename}')
This code is where all the magic happens. You print out how many lines of text you will be writing to a file. Then you do the deed and create the file and add the text. During the process, you sleep() to add some artificial time to writing the files to disk.
The last piece of code to look at is as follows:
if __name__ == '__main__':
files = [f'test{x}.txt' for x in range(1, 6)]
for filename in files:
work_time = random.choice(range(1, 3))
number_of_lines = random.choice(range(5, 20))
thread = WritingThread(filename, number_of_lines, work_time)
thread.start()
In this final code snippet, you use a list comprehension to create 5 file names. Then you loop over the files and create them. You use Python's random module to choose a random work_time amount and a random number_of_lines to write to the file. Finally you create the WritingThread and start() it.
When you run this code, you will see something like this get output:
Writing 5 lines of text to test1.txt
Writing 18 lines of text to test2.txt
Writing 7 lines of text to test3.txt
Writing 11 lines of text to test4.txt
Writing 11 lines of text to test5.txt
Finished writing test1.txt
Finished writing test3.txt
Finished writing test4.txtFinished writing test5.txt
Finished writing test2.txt
You may notice some odd output like the line a couple of lines from the bottom. This happened because multiple threads happened to write to stdout at once.
You can use this code along with Python's urllib.request to create an application for downloading files from the Internet. Try that project out on your own.
Wrapping Up
You have learned the basics of threading in Python. In this chapter, you learned about the following:
- Pros of Using Threads
- Cons of Using Threads
- Creating Threads
- Subclassing
Thread - Writing Multiple Files with Threads
There is a lot more to threads and concurrency than what is covered here. You didn't learn about thread communication, thread pools, or locks for example. However you do know the basics of creating threads and you will be able to use them successfully. In the next chapter, you will continue to learn about concurrency in Python through discovering how multiprocessing works in Python!
Related Articles
-
Python 101 - Creating Multiple Processes
-
Python 201: A Tutorial on Threads
This article is based on a chapter from Python 101: 2nd Edition. You can purchase Python 101 on Amazon or Leanpub.
Python 101 - Debugging Your Code with pdb (Video)
原文:https://www.blog.pythonlibrary.org/2022/08/19/python-101-debugging-your-code-with-pdb-video/
Learn how to debug your Python programs using Python's built-in debugger, pdb with Mike Driscoll
In this tutorial, you will learn the following:
- Starting pdb in the REPL
- Starting pdb on the Command Line
- Stepping Through Code
- Adding Breakpoints in pdb
- Creating a Breakpoint with set_trace()
- Using the built-in breakpoint() Function - Getting Help
https://www.youtube.com/embed/PY4TKPzR9j8?feature=oembed
This video is based on a chapter from the book, Python 101 by Mike Driscoll
Related Articles
Python 101 -用 pdb 调试代码
原文:https://www.blog.pythonlibrary.org/2020/07/07/python-101-debugging-your-code-with-pdb/
代码中的错误被称为“bug”。你会犯错误。你会犯很多错误,这完全没关系。很多时候会是错别字之类的简单错误。但是由于计算机是非常字面化的,即使是错别字也会阻止你的代码按预期工作。所以它们需要被修复。修复编程错误的过程被称为调试。
Python 编程语言自带名为pdb的内置调试器。可以在命令行使用pdb或者作为模块导入。pdb这个名字是“Python 调试器”的简称。
以下是pdb完整文档的链接:
在本文中,您将熟悉使用pdb的基础知识。具体来说,您将学习以下内容:
- 从 REPL 出发
- 在命令行上启动
pdb - 逐句通过代码
- 在
pdb中添加断点 - 用
set_trace()创建断点 - 使用内置的
breakpoint()功能 - 获得帮助
虽然pdb很方便,但是大多数 Python 编辑器都有更多特性的调试器。您会发现 PyCharm 或 WingIDE 中的调试器有更多的特性,比如自动完成、语法突出显示和图形化调用堆栈。
调试器将使用调用堆栈来跟踪函数和方法调用。如果可能,您应该使用 Python IDE 附带的调试器,因为它更容易理解。
然而,有时您可能没有 Python IDE,例如当您在服务器上远程调试时。正是在这些时候,你会发现pdb特别有用。
我们开始吧!
从 REPL 出发
最好的开始方式是准备一些你想运行的代码。请随意使用您自己的代码或本博客上另一篇文章中的代码示例。
或者您可以在名为debug_code.py的文件中创建以下代码:
# debug_code.py
def log(number):
print(f'Processing {number}')
print(f'Adding 2 to number: {number + 2}')
def looper(number):
for i in range(number):
log(i)
if __name__ == '__main__':
looper(5)
有几种方法可以启动pdb并在你的代码中使用它。对于这个例子,您需要打开一个终端(如果您是 Windows 用户,则需要打开cmd.exe)。然后导航到保存代码的文件夹。
现在在您的终端中启动 Python。这将为您提供 Python REPL,您可以在其中导入代码并运行调试器。方法如下:
>>> import debug_code
>>> import pdb
>>> pdb.run('debug_code.looper(5)')
> <string>(1)<module>()
(Pdb) continue
Processing 0
Adding 2 to number: 2
Processing 1
Adding 2 to number: 3
Processing 2
Adding 2 to number: 4
Processing 3
Adding 2 to number: 5
Processing 4
Adding 2 to number: 6
前两行代码导入您的代码和pdb。为了对你的代码运行pdb,你需要使用pdb.run()并告诉它做什么。在本例中,您将debug_code.looper(5)作为一个字符串传入。当你这样做的时候,pdb模块会将字符串转换成一个实际的函数调用debug_code.looper(5)。
下一行以(Pdb)为前缀。这意味着您现在处于调试器中。成功!
要在调试器中运行您的代码,键入continue或简称c。这将运行您的代码,直到发生以下情况之一:
- 代码引发了一个异常
- 您会到达一个断点(本文稍后会解释)
- 代码结束
在这种情况下,没有设置异常或断点,所以代码运行良好并完成了执行!
在命令行上启动pdb
启动pdb的另一种方法是通过命令行。以这种方式启动pdb的过程与前面的方法类似。您仍然需要打开终端并导航到保存代码的文件夹。
但是您将运行以下命令,而不是打开 Python:
python -m pdb debug_code.py
当您以这种方式运行pdb时,输出会略有不同:
> /python101code/chapter26_debugging/debug_code.py(1)<module>()
-> def log(number):
(Pdb) continue
Processing 0
Adding 2 to number: 2
Processing 1
Adding 2 to number: 3
Processing 2
Adding 2 to number: 4
Processing 3
Adding 2 to number: 5
Processing 4
Adding 2 to number: 6
The program finished and will be restarted
> /python101code/chapter26_debugging/debug_code.py(1)<module>()
-> def log(number):
(Pdb) exit
上面的第三行输出具有与您在上一节中看到的相同的 (Pdb) 提示。当您看到该提示时,您知道您现在正在调试器中运行。要开始调试,输入continue命令。
代码将像以前一样成功运行,但是您将看到一条新消息:
The program finished and will be restarted
调试器运行完你所有的代码,然后又从头开始!这对于多次运行您的代码非常方便!如果不希望再次运行代码,可以键入exit退出调试器。
逐句通过代码
单步执行代码是指使用调试器一次运行一行代码。通过使用step命令,或者简称为s,你可以使用pdb来单步调试你的代码。
如果您使用pdb单步执行代码,您将看到以下几行输出:
$ python -m pdb debug_code.py
> /python101code/chapter26_debugging/debug_code.py(3)<module>()
-> def log(number):
(Pdb) step
> /python101code/chapter26_debugging/debug_code.py(8)<module>()
-> def looper(number):
(Pdb) s
> /python101code/chapter26_debugging/debug_code.py(12)<module>()
-> if __name__ == '__main__':
(Pdb) s
> /python101code/chapter26_debugging/debug_code.py(13)<module>()
-> looper(5)
(Pdb)
你传递给pdb的第一个命令是step。然后使用s来遍历下面两行。您可以看到这两个命令的作用完全相同,因为“s”是“step”的快捷方式或别名。
您可以使用next(或n)命令继续执行,直到函数中的下一行。如果你的函数中有函数调用,next会跳过。这意味着它将调用函数,执行其内容,然后继续到当前函数中的下一个行。实际上,这就跳过了函数。
您可以使用step和next来导航您的代码并高效地运行各部分。
如果要进入looper()功能,继续使用step。另一方面,如果您不想运行looper()函数中的每一行代码,那么您可以使用next来代替。
您应该通过呼叫step继续您在pdb的会话,以便进入looper():
(Pdb) s
--Call--
> /python101code/chapter26_debugging/debug_code.py(8)looper()
-> def looper(number):
(Pdb) args
number = 5
当你进入looper(),pdb会打印出--Call--让你知道你调用了这个函数。接下来,使用args命令打印出名称空间中的所有当前参数。在这种情况下,looper()有一个参数number,它显示在上面输出的最后一行。可以用更短的a代替args。
您应该知道的最后一个命令是jump或j。您可以使用该命令跳转到代码中的特定行号,方法是键入jump,后跟一个空格,然后是您希望跳转到的行号。
现在让我们来学习如何添加断点!
在pdb中添加断点
断点是代码中您希望调试器停止的位置,以便您可以检查变量状态。这允许你做的是检查调用栈,这是一个时髦的术语,指当前在内存中的所有变量和函数参数。
如果你有 PyCharm 或者 WingIDE,那么他们会有一个图形化的方式让你检查调用栈。您可能能够将鼠标悬停在变量上,以查看它们当前的设置。或者他们可能有一个工具,可以在侧边栏中列出所有变量。
让我们在looper()函数的最后一行添加一个断点,即第 10 行。
下面是您的代码:
# debug_code.py
def log(number):
print(f'Processing {number}')
print(f'Adding 2 to number: {number + 2}')
def looper(number):
for i in range(number):
log(i)
if __name__ == '__main__':
looper(5)
要在pdb调试器中设置断点,您可以使用break或b命令,后跟您希望中断的行号:
$ python3.8 -m pdb debug_code.py
> /python101code/chapter26_debugging/debug_code.py(3)<module>()
-> def log(number):
(Pdb) break 10
Breakpoint 1 at /python101code/chapter26_debugging/debug_code.py:10
(Pdb) continue
> /python101code/chapter26_debugging/debug_code.py(10)looper()
-> log(i)
(Pdb)
现在您可以在这里使用args命令来找出当前的参数设置为什么。您也可以使用print(或简称p)命令打印出变量值,如i的值:
(Pdb) print(i)
0
现在让我们看看如何在代码中添加断点!
用set_trace()创建断点
Python 调试器允许您导入pbd模块并直接在代码中添加断点,如下所示:
# debug_code_with_settrace.py
def log(number):
print(f'Processing {number}')
print(f'Adding 2 to number: {number + 2}')
def looper(number):
for i in range(number):
import pdb; pdb.set_trace()
log(i)
if __name__ == '__main__':
looper(5)
现在,当您在终端中运行这段代码时,它会在到达set_trace()函数调用时自动启动进入pdb:
$ python3.8 debug_code_with_settrace.py
> /python101code/chapter26_debugging/debug_code_with_settrace.py(12)looper()
-> log(i)
(Pdb)
这需要您添加大量额外的代码,稍后您需要删除这些代码。如果您忘记在导入和pdb.set_trace()调用之间添加分号,您也会遇到问题。
为了让事情变得更简单,Python 核心开发人员添加了breakpoint(),这相当于编写import pdb; pdb.set_trace()。
接下来让我们来看看如何使用它!
使用内置的breakpoint()功能
从 Python 3.7 开始,breakpoint()函数已经被添加到语言中,以使调试更容易。你可以在这里阅读所有关于变化的信息:
继续更新上一节的代码,改为使用breakpoint():
# debug_code_with_breakpoint.py
def log(number):
print(f'Processing {number}')
print(f'Adding 2 to number: {number + 2}')
def looper(number):
for i in range(number):
breakpoint()
log(i)
if __name__ == '__main__':
looper(5)
现在,当您在终端中运行这个程序时,Pdb 将像以前一样启动。
使用breakpoint()的另一个好处是许多 Python IDEs 会识别该函数并自动暂停执行。这意味着您可以在此时使用 IDE 的内置调试器来进行调试。如果您使用旧的set_trace()方法,情况就不一样了。
获得帮助
本章并没有涵盖pdb中所有可用的命令。因此,要了解如何使用调试器的更多信息,您可以在pdb中使用help命令。它将打印出以下内容:
(Pdb) help
Documented commands (type help <topic>):
========================================
EOF c d h list q rv undisplay
a cl debug help ll quit s unt
alias clear disable ignore longlist r source until
args commands display interact n restart step up
b condition down j next return tbreak w
break cont enable jump p retval u whatis
bt continue exit l pp run unalias where
Miscellaneous help topics:
==========================
exec pdb
如果你想知道一个特定的命令是做什么的,你可以在命令后面输入help。
这里有一个例子:
(Pdb) help where
w(here)
Print a stack trace, with the most recent frame at the bottom.
An arrow indicates the "current frame", which determines the
context of most commands. 'bt' is an alias for this command.
自己去试试吧!
包扎
成功调试代码需要练习。Python 为您提供了一种无需安装任何其他东西就能调试代码的方法,这很棒。您会发现在 IDE 中使用breakpoint()来启用断点也非常方便。
在本文中,您了解了以下内容:
- 从 REPL 出发
- 在命令行上启动
pdb - 逐句通过代码
- 用
set_trace()创建断点 - 在
pdb中添加断点 - 使用内置的
breakpoint()功能 - 获得帮助
您应该去尝试在自己的代码中使用您在这里学到的知识。将故意的错误添加到代码中,然后通过调试器运行它们,这是了解事情如何工作的好方法!
Python 101:使用 ftplib 下载文件
原文:https://www.blog.pythonlibrary.org/2012/07/19/python-101-downloading-a-file-with-ftplib/
使用 Python 从互联网下载文件有很多不同的方法。一种流行的方法是连接到 FTP 服务器,并通过这种方式下载文件。这就是我们将在本文中探讨的内容。您所需要的只是 Python 的标准安装。它包括一个名为 ftplib 的库,其中包含了我们完成这项任务所需的所有信息。
下载吧!
下载文件其实很容易。下面是一个简单的例子来说明如何做到这一点:
# ftp-ex.py
import os
from ftplib import FTP
ftp = FTP("www.myWebsite.com", "USERNAME", "PASSWORD")
ftp.login()
ftp.retrlines("LIST")
ftp.cwd("folderOne")
ftp.cwd("subFolder") # or ftp.cwd("folderOne/subFolder")
listing = []
ftp.retrlines("LIST", listing.append)
words = listing[0].split(None, 8)
filename = words[-1].lstrip()
# download the file
local_filename = os.path.join(r"c:\myfolder", filename)
lf = open(local_filename, "wb")
ftp.retrbinary("RETR " + filename, lf.write, 8*1024)
lf.close()
让我们把它分解一下。首先,我们需要登录到 FTP 服务器,所以您将传递 URL 以及您的凭证,或者如果它是那些匿名 FTP 服务器之一,您可以跳过它。retrlines("LIST") 命令将给出一个目录列表。 cwd 命令代表“更改工作目录”,所以如果当前目录没有你要找的,你需要使用 cwd 来更改到有你要找的目录。下一节将展示如何以一种相当愚蠢的方式获取文件名。在大多数情况下,你也可以使用 os.path.basename 得到同样的结果。最后一节展示了如何实际下载文件。注意,我们必须打开带有“wb”(写二进制)标志的文件处理程序,这样我们才能正确下载文件。“8*1024”位是下载的块大小,尽管 Python 很聪明地选择了一个合理的默认值。
注意:本文基于 ftplib 模块的 Python 文档,以及您的默认 Python 安装文件夹中的以下脚本:Tools/scripts/ftpmirror.py.
进一步阅读
Python 101: easy_install 或如何创建 eggs
原文:https://www.blog.pythonlibrary.org/2012/07/12/python-101-easy_install-or-how-to-create-eggs/
今天我们将看看有争议的安装 Python 模块和包的 easy_install 方法。我们还将学习如何创建我们自己的*。鸡蛋文件。你需要去拿 SetupTools 包来跟进。这个包不支持 Python 3.x,所以如果你需要,请查看 pip 或 distribute 。将来会有关于这些项目的文章。现在,我们将从 SetupTools 和 easy_install 开始。
为什么会有争议?我不完全确定,但人们不喜欢它部分安装软件包的方式,因为它不会等待下载完成。我还听说作者对更新它不太感兴趣,但也不允许任何人更新它。参见本文末尾的 Ziade 文章。
SetupTools 是通过命令行从 PyPI 和其他来源下载和安装 Python 包的原始主流方法,有点像 Python 的 apt-get。当您安装 SetupTools 时,它会安装一个名为 easy_install 的脚本或 exe,您可以在命令行上调用它来安装或升级软件包。它还提供了一种创建 Python 蛋的方法。让我们花一点时间来了解这个实用程序。
使用 easy_install 安装软件包
一旦安装了 SetupTools,您的路径上应该有 easy_install。这意味着您可以打开终端(Linux)或命令行(Windows ),然后简单地运行 easy_install。下面是一个调用示例:
easy_install sqlalchemy
这将发送到 PyPI,并尝试从那里或者从 PyPI 包页面指向的任何位置下载最新的 SQLAlchemy。easy_install 脚本也将安装它。easy_install 出错的一个常见问题是,它会在下载完软件包之前尝试开始安装,这可能会导致错误的安装。easy_install 很酷的一点是,如果你正确设置了 setup.py 文件,它也可以下载并安装依赖项。所以如果你安装一些复杂的东西,比如 TurboGears,你会看到它安装了很多包。这就是为什么你想使用 virtualenv 的一个原因,因为你可以确定你喜欢新的软件包,并且它们可以正常工作。如果没有,你就删除 virtualenv 文件夹。否则,你将不得不进入你的 Python 文件夹,并尝试自己“卸载”(即删除文件夹)。easy_install 在安装 egg 时做的另一件事是,它将 egg 添加到 site-packages 中的一个 easy-install.pth 文件中,所以当你卸载它时,你也需要编辑它。幸运的是,如果你不喜欢自己动手,你可以用 pip 卸载它。有一个-uninstall (-u)命令,但是我听到了关于它如何工作的混合报告。
您可以通过将 url 直接传递给 easy_install 来安装软件包。另一个有趣的功能是,你可以告诉 easy_install 你想要哪个版本,它会尝试安装它。最后,easy_install 可以从源文件或 eggs 安装。要获得完整的命令列表,您应该阅读文档
创造一个卵子
egg 文件是 Python 包的分发格式。它只是一个源代码发行版或 Windows 可执行文件的替代品,但需要注意的是,对于纯 Python 来说,egg 文件是完全跨平台的。我们将看看如何使用我们在之前的教程中创建的包来创建我们自己的蛋。创建一个新文件夹,并将 mymath 文件夹放入其中。然后在 mymath 的父目录中创建一个 setup.py 文件,内容如下:
from setuptools import setup, find_packages
setup(
name = "mymath",
version = "0.1",
packages = find_packages()
)
注意,我们没有使用 Python 的 distutils 的 setup 函数,而是使用 setuptools 的 setup。我们还使用 setuptools 的 find_packages 函数,该函数将自动查找当前目录中的任何包,并将它们添加到 egg 中。要创建上述 egg,您需要从命令行执行以下操作:
python setup.py bdist_egg
这将生成大量输出,但是当它完成时,您将看到有三个新文件夹:build、dist 和 mymath.egg-info。我们唯一关心的是 dist 文件夹,在这个文件夹中您可以填充并找到您的 egg 文件, mymath-0.1-py2.6.egg 。请注意,在我的机器上,它选择了我的默认 Python,即 2.6 版本,并针对该版本的 Python 创建了 egg。egg 文件本身基本上是一个 zip 文件。如果您将扩展名改为“zip ”,您可以看到它有两个文件夹:mymath 和 EGG-INFO。此时,您应该能够将 easy_install 指向文件系统上的 egg,并让它安装您的包。
如果您愿意,还可以使用 easy_install 将您的 egg 或源代码直接上传到 Python 包索引(PyPI),方法是使用以下命令(从 docs 复制):
setup.py bdist_egg upload # create an egg and upload it
setup.py sdist upload # create a source distro and upload it
setup.py sdist bdist_egg upload # create and upload both
包扎
此时,您应该能够使用 easy_install,或者对尝试其中一种替代方法有足够的了解。就我个人而言,我很少使用它,也不介意使用它。然而,我们将会关注 pip 并很快发布,因此在接下来的一两篇文章中,您将能够学习如何使用它们。与此同时,试试 easy_install 吧,看看你有什么想法,或者在评论中说出你的恐怖故事!
进一步阅读
- 设置工具文档
- EasyInstall 文档
- 搭便车的包装指南
- Python 在 Windows 上的开发【第二部分】:安装 easy_install...可能更容易
- 如何安装 Python Easy_install 来配合 Siri 服务器使用( youtube )
- 包装的奇异世界 Tarek Ziade 的分叉设置工具
Python 101:第 10 集-函数
原文:https://www.blog.pythonlibrary.org/2015/07/14/python-101-episode-10-functions/
我最近完成了 Python 101 的第 10 集。是关于函数的基础知识。希望你喜欢!
https://www.youtube.com/embed/n_DX6n2TSOg?feature=oembed
Python 101:第 11 集-类
原文:https://www.blog.pythonlibrary.org/2015/07/30/python-101-episode-11-classes/
我本想早点把这个贴出来,但是我的笔记本电脑出了点问题。无论如何,这是我的 Python 101 截屏系列的最后一个免费视频。在这一集中,您将学习在 Python 3 中使用类的基础知识。我希望你喜欢它!
https://www.youtube.com/embed/tIsmzPFPLlg?feature=oembed
Python 101:第 16 集-操作系统模块
原文:https://www.blog.pythonlibrary.org/2018/07/21/python-101-episode-16-the-os-module/
https://www.youtube.com/embed/16PRrtwPKX0?feature=oembed
在这一集里,你将学习 Python 的操作系统模块。这一集是根据我的书《Python 101》改编的,你可以在 Leanpub 这里https://leanpub.com/python_101或者在 http://python101.pythonlibrary.org/在线阅读
Python 101:第 17 集——电子邮件和 smtp 模块
原文:https://www.blog.pythonlibrary.org/2018/07/25/python-101-episode-17-the-email-and-smtp-modules/
https://www.youtube.com/embed/0Cf957owkSQ?feature=oembed
在这个视频中学习如何使用 Python 的电子邮件和 smtp 模块。你也可以在这里阅读这个视频的书面版本:http://python101.pythonlibrary.org/或者在这里得到书:https://leanpub.com/python_101
Python 101:第 18 集 sqlite 模块
原文:https://www.blog.pythonlibrary.org/2018/08/02/python-101-episode-18-the-sqlite-module/
https://www.youtube.com/embed/vXrRextJjfs?feature=oembed
在这个截屏中,我们将学习 Python 的内置 sqlite 模块。这一集是根据 Python 101 的第 18 章改编的,你可以在这里读到:【http://python101.pythonlibrary.org/T2
Python 101:第 20 集 sys 模块
原文:https://www.blog.pythonlibrary.org/2018/08/14/python-101-episode-20-the-sys-module/
https://www.youtube.com/embed/vcJiGIbpcMI?feature=oembed
在这个截屏中,您将从标准库中学习 Python 的 sys 模块的基础知识。你也可以在这里或者 Leanpub 阅读这个截屏所基于的章节
查看完整的 Python 101 截屏播放列表
Python 101:第 21 集——使用线程
原文:https://www.blog.pythonlibrary.org/2018/08/22/python-101-episode-21-using-threads/
https://www.youtube.com/embed/SDhuifkMmAw?feature=oembed
在这个截屏中,您将学习使用 Python 线程模块的基础知识。如果你更喜欢阅读,那就去 http://python101.pythonlibrary.org/或 https://leanpub.com/python_101的看看这本书的基础章节
Python 101:第 22 集——日期时间/时间模块
原文:https://www.blog.pythonlibrary.org/2018/08/30/python-101-episode-22-the-datetime-time-modules/
https://www.youtube.com/embed/x2quUrQE3MA?feature=oembed
在这个截屏中,你将学习 Python 的日期时间和时间模块的基础知识。如果你更喜欢阅读,那就去 http://python101.pythonlibrary.org/的看看这一章,或者去 https://leanpub.com/python_101的看看这本书
Python 101:第 23 集——使用 XML
原文:https://www.blog.pythonlibrary.org/2018/09/06/python-101-episode-23-working-with-xml/
https://www.youtube.com/embed/JNU6_dE9aws?feature=oembed
了解 Python 内置 XML 模块 minidom 和 ElementTree 的基础知识。你可以在这里阅读这本书的基础章节:http://python101.pythonlibrary.org/chapter23_xml.html或者从 Leanpub:https://leanpub.com/python_101得到这本书
Python 101:第 24 集——用 pdb 调试
原文:https://www.blog.pythonlibrary.org/2018/09/11/python-101-episode-24-debugging-with-pdb/
https://www.youtube.com/embed/iYPkSbdjJbg?feature=oembed
了解使用 Python 内置调试器 pdb 的基础知识。请注意,这个截屏是在 Python 3.6 和 3.7 之前录制的,因此它没有涵盖调试器中的一些新增强。
你可以在这里阅读这个截屏所基于的章节:http://python101.pythonlibrary.org/chapter24_debugging.html
Python 101:第 25 集-装饰者
原文:https://www.blog.pythonlibrary.org/2018/09/20/python-101-episode-25-decorators/
https://www.youtube.com/embed/9uL7V2PZ0SY?feature=oembed
在这一集中,您将学习 Python decorators 的基础知识以及它们的优势。
你可以在这里阅读这个截屏所基于的章节:http://python101.pythonlibrary.org/或者在 Leanpub 上购买这本书
你也可以在我博客的其他几篇文章中读到关于装饰者的内容:
Python 101:第 26 集-兰达斯
原文:https://www.blog.pythonlibrary.org/2018/09/26/python-101-episode-26-lambdas/
https://www.youtube.com/embed/LJQgwL0IrJE?feature=oembed
在这个截屏中,你将学习如何在 Python 中使用 lambdas。
你可以在这里阅读这个截屏所基于的章节:http://python101.pythonlibrary.org/或者在 Leanpub 上购买这本书
相关文章
- Python 101: Lambda 基础知识
- 巨蟒λ
Python 101 -第 27 集:剖析 Python 代码
原文:https://www.blog.pythonlibrary.org/2018/10/03/python-101-episode-27-profiling-python-code/
https://www.youtube.com/embed/h1NwqPX9TX4?feature=oembed
在这个截屏中,您将学习使用 Python 内置的 cProfile 模块分析代码的基础知识。
你可以在这里-http://python101.pythonlibrary.org/或者在 Leanpub 上找到这本书的副本。
Python 101:第 28 集——测试介绍
原文:https://www.blog.pythonlibrary.org/2018/10/10/python-101-episode-28-an-intro-to-testing/
https://www.youtube.com/embed/xNDMdrydX5k?feature=oembed
在这一集中,你将学习使用 Python 的 doctest 和 unittest 模块的基础知识。
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书

相关文章
- Python 3 测试:单元测试简介
- python 102:TDD 和单元测试简介
Python 101:第 29 集——安装包
原文:https://www.blog.pythonlibrary.org/2018/10/18/python-101-episode-29-installing-packages/
https://www.youtube.com/embed/9T6kI8KUGvk?feature=oembed
在这个截屏视频中,我们将学习如何使用 easy_install、pip 和 from source 安装第三方模块和软件包。
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101:第 30 集 configobj 包
原文:https://www.blog.pythonlibrary.org/2018/10/24/python-101-episode-30-the-configobj-package/
在这一集里,你将学习如何使用 configobj 包。这是一个第三方包,我认为它比 Python 内置的 configparser 模块更好用,也更容易使用。
https://www.youtube.com/embed/CvtKvxspJmo?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
相关阅读
Python 101:第 31 集——用 lxml 包解析 XML
在这个截屏中,您将学习使用流行的 lxml(https://lxml.de/)包解析 xml 的基础知识。
https://www.youtube.com/embed/h8FsjpEzAp4?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101:第 32 集——静态代码分析
原文:https://www.blog.pythonlibrary.org/2018/11/07/python-101-episode-32-static-code-analysis/
在这一集里,我们将学习如何使用 PyLine 和 PyFlakes 来检查代码中的问题。当然,自从这个视频制作完成后,Flake8 和 Python Black 变得非常流行,所以你可能也想看看这些。
https://www.youtube.com/embed/O-3s_YnjNb8?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101:第 33 集——请求包
原文:https://www.blog.pythonlibrary.org/2018/11/14/python-101-episode-33-the-requests-package/
在这个截屏中,我介绍了流行的请求包,它是 Python 的 urllib 的替代品。
https://www.youtube.com/embed/GKYt99Iq0U4?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101:第 34 集 SQLAlchemy 包
原文:https://www.blog.pythonlibrary.org/2018/11/20/python-101-episode-34-the-sqlalchemy-package/
在这个截屏中,我们了解了流行的 SQLAlchemy 包。SQLAlchemy 是 Python 的一个对象关系映射器,它允许你以一种“Python 式”的方式与数据库交互。
https://www.youtube.com/embed/xMT3ckHOrx0?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
注意:这个视频是几年前录制的,所以 SQLAlchemy 中可能会有一些小的 API 变化。
Python 101:第 35 集-虚拟包
原文:https://www.blog.pythonlibrary.org/2018/11/27/python-101-episode-35-the-virtualenv-package/
在这个截屏中,我们将学习使用流行的 virtualenv 包创建 Python 虚拟环境。
https://www.youtube.com/embed/UP38fzVyoiE?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
前几集
- Python 101:第 34 集-SQLAlchemy 包
- Python 101 第 33 集:请求包
- Python 101:第 32 集——静态代码分析
Python 101:第 36 集——创建模块和包
原文:https://www.blog.pythonlibrary.org/2018/12/04/python-101-episode-36-creating-modules-and-packages/
在这个截屏中,我们将学习如何创建我们自己的模块或包的基础知识。
https://www.youtube.com/embed/8ILj4VJQrwU?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
前几集
- Python 101:第 35 集- 虚拟包
- Python 101:第 34 集-SQLAlchemy 包
- Python 101 第 33 集:请求包
- Python 101:第 32 集——静态代码分析
Python 101:第 37 集——如何将代码添加到 PyPI 中
原文:https://www.blog.pythonlibrary.org/2018/12/11/python-101-episode-37-how-to-add-your-code-to-pypi/
在这一集里,你将学习添加代码到 Python 打包索引的老方法。请注意,虽然这个视频的一些内容仍然相关,但是您现在应该使用 twine 包来上传到 PyPI。更多信息见 https://packaging.python.org/guides/using-testpypi/的。
https://www.youtube.com/embed/dA48rPPIn3M?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
前几集
- Python 101:第 35 集- 虚拟包
- Python 101:第 34 集-SQLAlchemy 包
- Python 101 第 33 集:请求包
- Python 101:第 32 集——静态代码分析
蟒蛇 101:第 38 集-蟒蛇蛋
原文:https://www.blog.pythonlibrary.org/2018/12/12/python-101-episode-38-the-python-egg/
在这个截屏中,我们了解了 Python egg,这是 Python 发布代码的旧格式之一。在现代 Python 中,我们现在使用轮子。
https://www.youtube.com/embed/ncTdIy5Oleo?feature=oembed
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
前几集
- Python 101:第 35 集- 虚拟包
- Python 101:第 34 集-SQLAlchemy 包
- Python 101 第 33 集:请求包
- Python 101:第 32 集——静态代码分析
Python 101:第 39 集——Python 轮子
原文:https://www.blog.pythonlibrary.org/2018/12/20/python-101-episode-39-python-wheels/
在这个视频中,你将了解 Python 轮子以及如何制作自己的轮子。Python wheel 是一种打包格式,允许安装一个包,而无需编译或构建。
https://www.youtube.com/embed/tDwOhlJAV2s
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101
Python 101:第 4 集-if 语句
原文:https://www.blog.pythonlibrary.org/2015/06/02/python-101-episode-4-the-if-statement/
正如你们许多人所知,我重新启动了我的众筹活动,将我的书《Python 101》改编成一系列的电影。周末的时候我把第四集放在了一起。是关于 Python 的 if 语句。结束的时间比我预期的要长一点,但我觉得总体来说还不错:
https://www.youtube.com/embed/LgK-YAg68bY?feature=oembed
Python 101:第 40 集——用 bbfreeze 创建可执行文件
In this screencast, we will learn how to turn your Python code into a Windows executable file using the bbfreeze project. https://www.youtube.com/embed/BQqfvYF5G_4
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101
相关阅读
- bb freeze 教程构建二进制序列!
Python 101:第 40 集——用 py2exe 创建可执行文件
在这个截屏中,我们将学习如何使用 py2exe 将 Python 代码转换成 Windows 可执行文件。
https://www.youtube.com/embed/LjWkpIG1jjY
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101
Python 101:第 42 集——用 cx_Freeze 创建可执行文件
In this screencast, we will learn how to turn your Python code into a Windows executable file using the cx_Freeze project. https://www.youtube.com/embed/9M0xHgX3-Ak
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101
Python 101:第 43 集使用 PyInstaller 创建可执行文件
In this screencast, we will learn how to turn your Python code into a Windows executable file using the PyInstaller project. https://www.youtube.com/embed/j8tDywvrnJU
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101
Python 101:第 44 集——用 Inno Setup 创建安装程序
In this screencast, we will learn how to turn your Python application into a Windows installer using Inno Setup. https://www.youtube.com/embed/jPnl5-bQGHI
你也可以在这里阅读本视频所依据的章节,或者在 Leanpub 上找到这本书
Python 101
Python 101:第 5 集-循环
原文:https://www.blog.pythonlibrary.org/2015/06/13/python-101-episode-5-loops/
我今天录制了我的 Python 101 截屏的下一集。可以在这里支持我的众筹活动。
视频是关于 Python 的循环结构的。您还将学习如何在循环中使用 else 构造。这是视频:
https://www.youtube.com/embed/ePBlu_4kHi8?feature=oembed
Python 101:第 6 集-理解
原文:https://www.blog.pythonlibrary.org/2015/06/16/python-101-episode-6-comprehensions/
我完成了 Python 101 的另一集。这是关于 Python 的理解结构。在这个视频中,我涵盖了列表,字典和集合理解。我希望你喜欢它:
https://www.youtube.com/embed/AZDhV6i-gkY?feature=oembed
你可以通过我的 IndieGogo 众筹活动支持我的 Python 101 视频项目,该活动将于本周结束。
Python 101:第 7 集——异常处理
原文:https://www.blog.pythonlibrary.org/2015/06/29/python-101-episode-7-exception-handling/
最近录了 Python 101 的下集。这个是关于异常处理的。我希望你喜欢它:
https://www.youtube.com/embed/95ubQZoBnks?feature=oembed
Python 101:第 9 集-导入
原文:https://www.blog.pythonlibrary.org/2015/07/08/python-101-episode-9-imports/
看看我最新一集的 Python 101。这篇文章讲述了 Python 中导入的工作原理。您将了解导入的以下方面:
- 进口
- 从模块导入子模块
- 从模块导入*
尽情享受吧!
https://www.youtube.com/embed/80qC1ckBzFw?feature=oembed
Python 101:平等 vs 身份
原文:https://www.blog.pythonlibrary.org/2017/02/28/python-101-equality-vs-identity/
刚接触 Python 编程语言的人可能会对 "==" (相等)和 Python 的关键字"是"(身份)之间的区别感到有点困惑。我甚至见过一些有经验的程序员,他们会发现这种差别非常微妙,以至于他们会在代码中引入逻辑错误,从而造成两者之间的误解。在这篇文章中,我们将看看这个有趣的话题。
Python 中的等式
许多编程语言都有相等的概念,一些语言使用双等号(“==”)来表示这个概念。让;让我们来看看行动中的平等:
>>> num = 1
>>> num_two = num
>>> num == num_two
True
这里我们创建了一个名为 num 的变量,并将它赋给整数 1。接下来,我们创建第二个变量 num_two ,并将其赋值给 num 的值。最后我们问 Python num 和 num_two 是否相等。在这种情况下,Python 告诉我们这个表达式是真。
另一种思考等式的方式是,我们询问 Python 两个变量是否包含相同的东西。在上面的例子中,它们都包含整数 1。让我们看看当我们创建两个具有相同值的列表时会发生什么:
>>> list_one = [1, 2, 3]
>>> list_two = [1, 2, 3]
>>> list_one == list_two
True
这正如我们所料。
现在让我们看看如果我们询问 Python 他们的身份会发生什么:
>>> num is num_two
True
>>> list_one is list_two
False
这里发生了什么?第一个示例返回 True,但第二个返回 False!我们将在下一节研究这个问题。
Python 中的身份
当你问 Python 一个对象是否与另一个对象相同时,你是在问它们是否有相同的身份。它们实际上是同一个对象吗?在 num 和 num_two 的情况下,答案是肯定的。Python 通过其内置的 id() 函数提供了一种简单的证明方法:
>>> id(num)
10914368
>>> id(num_two)
10914368
这两个变量共享相同标识的原因是,当我们将 num 赋值给 num_two(即 num_two = num)时,我们告诉 Python 它们应该返回。如果你来自 C 或 C++,你可以把标识看作一个指针,其中 num 和 num_two 都指向内存中的同一个位置。如果您在两个列表对象上使用 Python 的 id()函数,您会很快发现它们具有不同的身份:
>>> id(list_one)
140401050827592
>>> id(list_two)
140401050827976
因此,当你问 Python“list _ one 是 list_two”这个问题时,你会得到 False。请注意,您也可以询问 Python 一个对象是否不是另一个对象:
>>> list_one = [1, 2, 3]
>>> list_two = [1, 2, 3]
>>> list_one is not list_two
True
让我们花一点时间来看看当你混淆平等和身份时会发生什么。
混合起来
我知道当我开始做 Python 程序员时,这类事情会导致愚蠢的错误。原因是我会看到这样的推荐语句:
if obj is None:
# do something
call_function()
所以我会天真地认为你可以这样做:
>>> def func():
return [1, 2, 3]
>>> list_one = [1, 2, 3]
>>> list_two = func()
>>> list_one is list_two
False
当然,这不起作用,因为我现在有两个不同的对象,它们有不同的身份。我想做的是:
>>> list_one == list_two
True
与这个问题无关的另一个问题是,当您创建指向同一个对象的两个变量时,您认为您可以独立地处理它们:
>>> list_one = list_two = [1, 2, 3]
>>> list_one == list_two
True
>>> list_one is list_two
True
>>> list_two.append(5)
>>> list_one
[1, 2, 3, 5]
在这个例子中,我创建了两个指向一个对象的变量。然后我试着添加一个元素到两个列表中。很多初学者没有意识到的是,他们刚刚把那个元素也添加到了列表中。原因是 list_one 和 list_two 都指向完全相同的对象。这一点在我们问 Python 是 list_one 是 list_two 时得到了证明,它返回了 True 。
包扎
希望现在您已经理解了 Python 中等式(==)和等式(is)之间的区别。相等基本上就是询问两个对象的内容是否相同,在列表的情况下,也需要相同的顺序。Python 中的身份指的是你所指的对象。在 Python 中,对象的标识是一个惟一的常量整数(或长整数),它在对象的生命周期中一直存在。
附加阅读
- Python 文档中关于 id()函数
- 的 Python 文档是
- StackOverflow: 理解 Python 的“is”操作符
Python 101 -异常处理
原文:https://www.blog.pythonlibrary.org/2020/06/17/python-101-exception-handling-2/
开发软件是一项艰苦的工作。为了让你的软件变得更好,你的应用程序需要保持工作,即使发生了意想不到的事情。例如,假设您的应用程序需要从互联网上下载信息。如果使用您的应用程序的人失去了互联网连接,会发生什么?
另一个常见的问题是,如果用户输入了无效的输入,该怎么办。或者试图打开应用程序不支持的文件。
所有这些情况都可以使用 Python 内置的异常处理功能来处理,这些功能通常被称为try和except语句。
在本文中,您将了解到:
- 常见例外
- 处理异常
- 引发异常
- 检查异常对象
- 使用
finally语句 - 使用
else语句
让我们从了解一些最常见的异常开始。
最常见的例外
Python 支持许多不同的异常。当你第一次开始使用这种语言时,你可能会看到下面的一些:
- 所有其他异常所基于的基础异常
AttributeError-当属性引用或赋值失败时引发。ImportError-当导入语句找不到模块定义或当...导入找不到要导入的名称。ModuleNotFoundError-import error 的一个子类,当模块无法定位时,由 import 引发IndexError-当序列下标超出范围时引发。KeyError-在现有键集中找不到映射(字典)键时引发。KeyboardInterrupt-当用户点击中断键时触发(通常为Control-C或Delete)。NameError-找不到本地或全局名称时引发。OSError-当函数返回与系统相关的错误时引发。RuntimeError-当检测到不属于任何其他类别的错误时引发。SyntaxError-当解析器遇到语法错误时引发。TypeError-当一个操作或函数被应用到一个不合适类型的对象时引发。关联的值是一个字符串,给出关于类型不匹配的详细信息。ValueError-当内置操作或函数接收到类型正确但值不正确的参数,并且这种情况没有通过更精确的异常(如 IndexError)来描述时引发。ZeroDivisionError—当除法或模运算的第二个参数为零时引发。
有关内置异常的完整列表,您可以在此处查看 Python 文档:
现在让我们来看看当一个异常发生时,实际上如何处理它。
处理异常
Python 提供了一种特殊的语法,可以用来捕捉异常。它被称为try/except语句。
这是您将用于捕捉异常的基本形式:
try:
# Code that may raise an exception goes here
except ImportError:
# Code that is executed when an exception occurs
您将您认为可能有问题的代码放在try块中。这可能是打开文件的代码,也可能是从用户那里获得输入的代码。第二个模块被称为except模块。这段代码只有在出现ImportError时才会被执行。
当你在没有指定异常类型的情况下编写except时,它被称为裸异常。不建议使用这些方法:
try:
with open('example.txt') as file_handler:
for line in file_handler:
print(line)
except:
print('An error occurred')
创建一个空的异常是不好的做法,因为你不知道你正在捕捉什么类型的异常。这使得找出你做错了什么变得更加困难。如果您将异常类型缩小到您期望的类型,那么意外的类型实际上会使您的应用程序崩溃,并显示有用的消息。
此时,您可以决定是否要捕捉其他条件。
假设您想要捕获多个异常。有一种方法可以做到:
try:
with open('example.txt') as file_handler:
for line in file_handler:
print(line)
import something
except OSError:
print('An error occurred')
except ImportError:
print('Unknown import!')
这个异常处理程序将捕获两种类型的异常:OSError和ImportError。如果发生另一种类型的异常,这个处理程序将不会捕捉到它,您的代码将会停止。
通过这样做,您可以将上面的代码重写得简单一点:
try:
with open('example.txt') as file_handler:
for line in file_handler:
print(line)
import something
except (OSError, ImportError):
print('An error occurred')
当然,通过创建异常元组,这将混淆哪个异常已经发生。换句话说,这段代码使得知道发生了哪个异常变得更加困难。
引发异常
在你捕捉到一个异常后你会怎么做?你有几个选择。您可以像前面的例子一样打印出一条消息。您还可以将消息记录到日志文件中。或者,如果您知道该异常需要停止应用程序的执行,您可以重新引发该异常。
引发异常是强制异常发生的过程。你在特殊情况下提出例外。例如,如果应用程序进入不良状态,您可能会引发一个异常。在已经处理了异常之后,您还会倾向于引发异常。
您可以使用 Python 的内置raise语句来引发异常:
try:
raise ImportError
except ImportError:
print('Caught an ImportError')
当您引发异常时,您可以让它打印出一条自定义消息:
>>> raise Exception('Something bad happened!')
Traceback (most recent call last):
Python Shell, prompt 1, line 1
builtins.Exception: Something bad happened!
如果不提供消息,则异常如下所示:
>>> raise Exception
Traceback (most recent call last):
Python Shell, prompt 2, line 1
builtins.Exception:
现在让我们来了解一下异常对象!
检查异常对象
当异常发生时,Python 会创建一个异常对象。您可以通过使用as语句将异常对象赋给一个变量来检查它:
>>> try:
... raise ImportError('Bad import')
... except ImportError as error:
... print(type(error))
... print(error.args)
... print(error)
...
<class 'ImportError'>
('Bad import',)
Bad import
在本例中,您将ImportError对象分配给了error。现在您可以使用 Python 的type()函数来了解它是哪种异常。这将允许您解决本文前面提到的问题,当您有一个异常元组,但您不能立即知道您捕获了哪个异常。
如果您想更深入地调试异常,您应该查找 Python 的traceback模块。
使用finally语句
除了try和except,还有更多关于try/except的陈述。您也可以向它添加一个finally语句。finally语句是一个代码块,即使在try语句中出现异常,它也会一直运行。
您可以使用finally语句进行清理。例如,您可能需要关闭数据库连接或文件句柄。为此,您可以将代码包装在一个try/except/finally语句中。
让我们看一个人为的例子:
>>> try:
... 1 / 0
... except ZeroDivisionError:
... print('You can not divide by zero!')
... finally:
... print('Cleaning up')
...
You can not divide by zero!
Cleaning up
这个例子演示了如何处理ZeroDivisionError异常以及添加清理代码。
但是您也可以完全跳过except语句,而是创建一个try/finally:
>>> try:
... 1/0
... finally:
... print('Cleaning up')
...
Cleaning upTraceback (most recent call last):
Python Shell, prompt 6, line 2
builtins.ZeroDivisionError: division by zero
这次您不处理ZeroDivisionError异常,但是finally语句的代码块仍然运行。
使用else语句
还有一个语句可以用于 Python 的异常处理,那就是else语句。当没有异常时,可以使用else语句来执行代码。
这里有一个例子:
>>> try:
... print('This is the try block')
... except IOError:
... print('An IOError has occurred')
... else:
... print('This is the else block')
...
This is the try block
This is the else block
在这段代码中,没有发生异常,所以try块和else块都运行。
让我们试着提高一个IOError,看看会发生什么:
>>> try:
... raise IOError
... print('This is the try block')
... except IOError:
... print('An IOError has occurred')
... else:
... print('This is the else block')
...
An IOError has occurred
由于出现异常,只有try和except模块运行。注意,try块在raise语句处停止运行。它根本没有到达print()函数。一旦出现异常,下面的所有代码都会被跳过,直接进入异常处理代码。
包扎
现在您知道了使用 Python 内置异常处理的基本知识。在本文中,您了解了以下主题:
- 常见例外
- 处理异常
- 引发异常
- 检查异常对象
- 使用
finally语句 - 使用
else语句
学习如何有效地捕捉异常需要练习。一旦你学会了如何捕捉异常,你将能够强化你的代码,使它以一种更好的方式工作,即使发生了意想不到的事情。
相关阅读
Python 101:异常处理
原文:https://www.blog.pythonlibrary.org/2012/09/12/python-101-exception-handling/
Python 提供了强大的异常处理功能,并将其融入到语言中。异常处理是每个程序员都需要学习的东西。它允许程序员继续他们的程序,或者在异常发生后优雅地终止应用程序。Python 使用 try/except/finally 约定。我们将花一些时间了解标准异常,如何创建自定义异常,以及如何在调试时获取异常信息。
基本异常处理
首先,必须说明的是,通常不建议使用裸露的异常!你会看到它们被使用,我自己也不时地使用它们。一只光秃秃的除了看起来像这样:
try:
print monkey
except:
print "This is an error message!"
如您所见,这将捕获所有异常,但是您并不真正了解异常的任何信息,这使得处理异常非常棘手。因为您不知道捕获了什么异常,所以您也不能打印出与用户非常相关的消息。另一方面,有时候我认为使用一个简单的 except 更容易。我的一位读者就此与我联系,他说数据库交互是一个很好的例子。我注意到,在处理数据库时,我似乎也遇到了大量的异常,所以我同意这一点。我认为当你在一行中遇到 3 或 4 个以上的异常处理程序时,最好使用一个空的 except,如果你需要回溯,有很多方法可以得到它(见最后一节)。
让我们来看几个常见的异常处理的例子。
try:
import spam
except ImportError:
print "Spam for eating, not importing!"
try:
print python
except NameError, e:
print e
try:
1 / 0
except ZeroDivisionError:
print "You can't divide by zero!"
第一个例子捕获了一个 ImportError,它只在您导入 Python 找不到的内容时发生。如果您试图在没有实际安装 SQLAlchemy 的情况下导入它,或者拼错了模块或包名,您就会看到这种情况。捕捉 ImportErrors 的一个很好的用途是当您想要导入一个替代模块时。取 md5 模块。Python 2.5 中的已被弃用,因此如果您正在编写支持 2.5-3.x 的代码,那么您可能希望尝试导入 md5 模块,然后在导入失败时退回到较新的(也是推荐的)hashlib 模块。
下一个异常是 NameError。当一个变量还没有被定义时,你会得到这个。您还会注意到,我们在异常部分添加了一个逗号“e”。这让我们不仅可以捕捉到错误,还可以打印出它的信息部分,在本例中是:name‘python’没有定义。
第三个也是最后一个异常是一个如何捕捉零除法异常的例子。是的,用户仍然试图被零除,不管你告诉他们多少次不要这样做。所有这些异常,我们已经查看了我们的子类 Exception ,所以如果你要写一个Exception子句,你实际上是在写一个捕捉所有异常的 bare Exception。
现在,如果您想捕获多个错误,但不是所有错误,您会怎么做?还是不管发生了什么都做点什么?让我们来了解一下!
try:
5 + "python"
except TypeError:
print "You can't add strings and integers!"
except WindowsError:
print "A Windows error has occurred. Good luck figuring it out!"
finally:
print "The finally section ALWAYS runs!"
在上面的代码中,你会看到在一个 try 下有两个 except 语句。您可以根据需要添加任意多的例外,并对每个例外做不同的处理。在 Python 2.5 及更新版本中,你实际上可以这样把异常串在一起: except TypeError,WindowsError: 或 except (TypeError,WindowsError) 。您还会注意到,我们有一个可选的 finally 子句,无论是否有异常,该子句都会运行。它有利于清理动作,比如关闭文件或数据库连接。你也可以做一个 try/except/else/finally 或者 try/except/else,但是 else 在实践中有点混乱,老实说,我从来没有见过它被使用。基本上,else 子句只在 except 没有执行时执行。如果您不想将一堆代码放在 try 部分,这可能会引发其他错误,那么这是非常方便的。更多信息参见文档。
获取整个堆栈回溯
如果您想获得异常的完整回溯,该怎么办?Python 为此提供了一个模块。从逻辑上来说,这叫做回溯。这里有一个快速和肮脏的小例子:
import traceback
try:
with open("C:/path/to/py.log") as f:
for line in f:
print line
except IOError, exception:
print exception
print
print traceback.print_exc()
上面的代码将打印出异常文本,打印一个空行,然后使用回溯模块的 print_exc 方法打印整个回溯。traceback 模块中有许多其他方法,允许您格式化输出或获取堆栈跟踪的各个部分,而不是完整的部分。你应该查看一下文档以获得更多的细节和例子。
还有另一种方法可以不使用回溯模块,至少不直接获得整个回溯。你可以使用 Python 的日志模块。这里有一个简单的例子:
import logging
logging.basicConfig(filename="sample.log", level=logging.INFO)
log = logging.getLogger("ex")
try:
raise RuntimeError
except RuntimeError, err:
log.exception("RuntimeError!")
这将在运行脚本的同一目录下创建一个日志文件,包含以下内容:
ERROR:ex:RuntimeError!
Traceback (most recent call last):
File "C:\Users\mdriscoll\Desktop\exceptionLogger.py", line 7, in raise RuntimeError
RuntimeError
如您所见,它将记录正在记录的级别(错误)、记录器名称(ex)和我们传递给它的消息(RuntimeError!)以及完整的追溯。您可能会发现这比使用回溯模块更方便。
创建自定义异常
当您编写复杂的程序时,您可能会发现需要创建自己的异常。幸运的是,Python 使得编写新异常的过程变得非常容易。这里有一个非常简单的例子:
########################################################################
class ExampleException(Exception):
pass
try:
raise ExampleException("There are no droids here")
except ExampleException, e:
print e
我们在这里所做的就是用一个空白的主体子类化异常类型。然后,我们通过在 try/except 子句中引发错误来测试它,并打印出我们传递给它的自定义错误消息。实际上,您可以通过引发任何异常来做到这一点: raise NameError("这是一个不正确的名称!")。与此相关,参见 pydanny 的文章中关于将自定义异常附加到函数和类的内容。它非常好,展示了一些巧妙的技巧,使得使用您的自定义异常更加容易,而不必导入它们太多。
包扎
现在你应该知道如何成功地捕捉异常,获取回溯,甚至创建你自己的定制异常。您有工具让您的脚本继续运行,即使发生了不好的事情!当然,如果停电了,他们也不会帮忙,但你可以覆盖大多数情况。享受针对用户和他们使你的程序崩溃的各种方法强化你的代码的乐趣。
附加阅读
- 官方异常教程
- Python 的回溯模块文档
- StackOverflow: 在一行中捕获多个异常,除了
Python 101:如何将字典变成类
原文:https://www.blog.pythonlibrary.org/2014/02/14/python-101-how-to-change-a-dict-into-a-class/
我在工作中接触了很多字典。有时字典会变得非常复杂,因为其中嵌入了许多嵌套的数据结构。最近,我有点厌倦了试图记住我的字典中的所有键,所以我决定将我的一个字典改为一个类,这样我就可以将键作为实例变量/属性来访问。如果你曾经生病
这里有一个简单的方法:
########################################################################
class Dict2Obj(object):
"""
Turns a dictionary into a class
"""
#----------------------------------------------------------------------
def __init__(self, dictionary):
"""Constructor"""
for key in dictionary:
setattr(self, key, dictionary[key])
#----------------------------------------------------------------------
if __name__ == "__main__":
ball_dict = {"color":"blue",
"size":"8 inches",
"material":"rubber"}
ball = Dict2Obj(ball_dict)
这段代码使用 setattr 将每个键作为属性添加到类中。下面显示了它如何工作的一些例子:
>>> ball.color
'blue'
>>> ball.size
'8 inches'
>>> print ball
<__main__.dict2obj object="" at="">
当我们打印球对象时,我们从类中得到一个无用的字符串。让我们覆盖我们类的 repr 方法,让它打印出更有用的东西:
########################################################################
class Dict2Obj(object):
"""
Turns a dictionary into a class
"""
#----------------------------------------------------------------------
def __init__(self, dictionary):
"""Constructor"""
for key in dictionary:
setattr(self, key, dictionary[key])
#----------------------------------------------------------------------
def __repr__(self):
""""""
return "" % self.__dict__
#----------------------------------------------------------------------
if __name__ == "__main__":
ball_dict = {"color":"blue",
"size":"8 inches",
"material":"rubber"}
ball = Dict2Obj(ball_dict)
现在,如果我们打印出球对象,我们会得到以下结果:
>>> print ball
这有点不直观,因为它使用类的内部 dict 打印出一个字典,而不仅仅是属性名。这与其说是一个问题,不如说是一个品味问题,但是让我们试着只得到方法名:
########################################################################
class Dict2Obj(object):
"""
Turns a dictionary into a class
"""
#----------------------------------------------------------------------
def __init__(self, dictionary):
"""Constructor"""
for key in dictionary:
setattr(self, key, dictionary[key])
#----------------------------------------------------------------------
def __repr__(self):
""""""
attrs = str([x for x in self.__dict__])
return "" % attrs
#----------------------------------------------------------------------
if __name__ == "__main__":
ball_dict = {"color":"blue",
"size":"8 inches",
"material":"rubber"}
ball = Dict2Obj(ball_dict)
在这里,我们只是循环遍历 dict 的内容,并返回一个只包含与属性名称匹配的键列表的字符串。你也可以这样做:
attrs = str([x for x in dir(self) if "__" not in x])
我相信还有很多其他的方法来完成这类事情。不管怎样,我发现这段代码对我的一些工作很有帮助。希望你也会发现它很有用。
Python 101 -如何创建 Python 包
原文:https://www.blog.pythonlibrary.org/2021/09/23/python-101-how-to-create-a-python-package/
当您创建一个 Python 文件时,您正在创建一个 Python 模块。您创建的任何 Python 文件都可以由另一个 Python 脚本导入。因此,根据定义,它也是一个 Python 模块。如果您有两个或更多相关的 Python 文件,那么您可能有一个 Python 包。
一些组织将他们所有的代码留给自己。这就是所谓的闭源。Python 是一种开源语言,你可以从 Python 包索引(PyPI) 获得的大部分 Python 模块和包也都是免费和开源的。共享您的包或模块的最快方法之一是将它上传到 Python 包索引或 Github 或两者。
在本文中,您将了解以下主题:
- 创建模块
- 创建包
- 为 PyPI 打包项目
- 创建项目文件
- 正在创建
setup.py - 上传到 PyPI
这个过程的第一步是理解创建一个可重用模块是什么样子的。我们开始吧!
创建模块
您创建的任何 Python 文件都是可以导入的模块。您可以通过向任何文章的代码文件夹中添加一个新文件,并尝试在其中导入一个模块,用本书中的一些示例来尝试一下。例如,如果您有一个名为a.py的 Python 文件,然后创建一个名为b.py的新文件,您可以通过使用import a将a导入到b中。
当然,这是一个愚蠢的例子。相反,您将创建一个简单的模块,其中包含一些基本的算术函数。您可以将文件命名为arithmetic.py,并将以下代码添加到其中:
# arithmetic.py
def add(x, y):
return x + y
def divide(x, y):
return x / y
def multiply(x, y):
return x * y
def subtract(x, y):
return x - y
这段代码很幼稚。例如,您根本没有错误处理。这意味着你可以除以零,并引发一个异常。您还可以向这些函数传递不兼容的类型,比如字符串和整数——这将导致引发不同类型的异常。
但是,出于学习的目的,这段代码已经足够了。您可以通过创建一个测试文件来证明它是可导入的。创建一个名为test_arithmetic.py的新文件,并将以下代码添加到其中:
# test_arithmetic.py
import arithmetic
import unittest
class TestArithmetic(unittest.TestCase):
def test_addition(self):
self.assertEqual(arithmetic.add(1, 2), 3)
def test_subtraction(self):
self.assertEqual(arithmetic.subtract(2, 1), 1)
def test_multiplication(self):
self.assertEqual(arithmetic.multiply(5, 5), 25)
def test_division(self):
self.assertEqual(arithmetic.divide(8, 2), 4)
if __name__ == '__main__':
unittest.main()
将测试保存在与模块相同的文件夹中。现在,您可以使用以下命令运行这段代码:
$ python3 test_arithmetic.py
....
----------------------------------------------------------------------
Ran 4 tests in 0.000s
OK
这表明您可以将arithmetic.py作为一个模块导入。这些测试还显示了代码工作的基本功能。您可以通过测试被零除以及混合字符串和整数来增强这些测试。这些类型的测试目前会失败。一旦您有一个失败的测试,您可以遵循测试驱动的开发方法来修复问题。
现在让我们来看看如何制作一个 Python 包!
创建包
Python 包是您计划与其他人共享的一个或多个文件,通常通过将其上传到 Python 包索引(PyPI)来实现。包通常是通过命名文件目录而不是文件本身来制作的。然后,在该目录中,您将有一个特殊的__init__.py文件。当 Python 看到__init__.py文件时,它知道这个文件夹可以作为一个包导入。
有几种方法可以将arithmetic.py转换成一个包。最简单的方法是将代码从arithmetic.py移到arithmetic/__init__.py:
- 创建文件夹
arithmetic - 将
arithmetic.py移动/复制到arithmetic/__init__.py - 如果在上一步中使用了“复制”,则删除
arithmetic.py - 运行
test_arithmetic.py
最后一步非常重要!如果您的测试仍然通过,那么您就知道从模块到包的转换成功了。要测试你的包,如果你在 Windows 上打开一个命令提示符,如果你在 Mac 或 Linux 上打开一个终端。然后导航到包含arithmetic文件夹的文件夹,但不在其中。现在你应该和你的test_arithmetic.py文件在同一个文件夹中。此时你可以运行python test_arithmetic.py,看看你的努力是否成功。
简单地将所有代码放在一个__init__.py文件中似乎很愚蠢,但是对于长达几千行的文件来说,这确实很好。
将arithmetic.py转换成一个包的第二种方式与第一种类似,但是涉及到使用比__init__.py更多的文件。在实代码中,函数/类等。在中,每个文件都会以某种方式分组——可能一个文件用于所有的定制异常,一个文件用于公共工具,一个文件用于主要功能。
对于我们的例子,您只需将arithmetic.py中的四个函数拆分到它们自己的文件中。继续将每个函数从__init__.py移到它自己的文件中。您的文件夹结构应该如下所示:
arithmetic/
__init__.py
add.py
subtract.py
multiply.py
divide.py
对于__init__.py文件,您可以添加以下代码:
# __init__.py
from .add import add
from .subtract import subtract
from .multiply import multiply
from .divide import divide
现在你已经做了这些改变,你的下一步应该是什么?希望你说,“运行我的测试!”如果您的测试仍然通过,那么您没有破坏您的 API。
现在,如果你碰巧和你的test_arithmetic.py文件在同一个文件夹中,你的arithmetic包只对你的其他 Python 代码可用。要使它在 Python 会话或其他 Python 代码中可用,您可以使用 Python 的sys模块将您的包添加到 Python 搜索路径。当您使用import关键字时,Python 使用搜索路径来查找模块。通过打印出sys.path,你可以看到 Python 搜索了哪些路径。
假设你的arithmetic文件夹在这个位置:/Users/michael/packages/arithmetic。要将它添加到 Python 的搜索路径中,您可以这样做:
import sys
sys.path.append("/Users/michael/packages/arithmetic")
import arithmetic
print(arithmetic.add(1, 2))
这将把arithmetic添加到 Python 的路径中,这样你就可以导入它,然后在你的代码中使用这个包。然而,那真的很尴尬。如果你能使用pip来安装你的软件包就好了,这样你就不用一直摆弄路径了。
让我们看看接下来该怎么做!
为 PyPI 打包项目
在为 Python 包索引(PyPI)创建包时,您将需要一些附加文件。这里有一个很好的教程,介绍了创建包并上传到 PyPI 的过程:
官方包装说明建议您建立如下目录结构:
my_package/
LICENSE
README.md
arithmetic/
__init__.py
add.py
subtract.py
multiply.py
divide.py
setup.py
tests/
tests文件夹可以是空的。这是您将包含包测试的文件夹。大多数开发人员使用 Python 的unittest或pytest框架进行测试。对于本例,您可以将文件夹留空。
让我们继续,在下一节中学习您需要创建的其他文件!
创建项目文件
在许可证文件中,您可以提到您的软件包拥有什么许可证。这告诉软件包的用户他们能做什么,不能做什么。您可以使用许多不同的许可证。GPL 和 MIT 许可证只是两个流行的例子。
README.md 文件是对你的项目的描述,用 Markdown 编写。您将希望在这个文件中写下您的项目,并包括它可能需要的关于依赖项的任何信息。您可以给出安装说明以及软件包的示例用法。Markdown 是相当多才多艺的,甚至让你做语法突出!
你需要提供的另一个文件是setup.py。该文件更复杂,因此您将在下一节中了解这一点。
正在创建setup.py
有一个名为setup.py的特殊文件,用作 Python 发行版的构建脚本。它由setuptools使用,它为您进行实际的构建。如果你想了解更多关于setuptools的信息,那么你应该看看以下内容:
你可以使用setup.py来创建一个 Python 轮子。wheel 是一个 ZIP 格式的存档文件,有一个特殊格式的名称和一个.whl扩展名。它包含安装软件包所需的一切。你可以把它想象成你的代码的压缩版本,pip可以帮你解压并安装。车轮遵循 PEP 376,您可以在这里阅读:
一旦你读完了所有的文档(如果你想的话),你就可以创建你的setup.py并把这段代码添加进去:
import setuptools
with open("README.md", "r") as fh:
long_description = fh.read()
setuptools.setup(
name="arithmetic-YOUR-USERNAME-HERE", # Replace with your own username
version="0.0.1",
author="Mike Driscoll",
author_email="driscoll@example.com",
description="A simple arithmetic package",
long_description=long_description,
long_description_content_type="text/markdown",
url="https://github.com/driscollis/arithmetic",
packages=setuptools.find_packages(),
classifiers=[
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
],
python_requires='>=3.6',
)
这段代码的第一步是导入setuptools。然后,将您的README.md文件读入一个您很快就会用到的变量。最后一位是大部分代码。这里你调用setuptools.setup(),它可以接受很多不同的参数。上面的例子只是你可以传递给这个函数的一个例子。要查看完整列表,您需要访问此处:
大多数论点都是不言自明的。让我们把注意力集中在更迟钝的人身上。packages参数是您的包所需的包的列表。在这种情况下,您使用find_packages()自动为您找到必要的包。classifiers参数用于向pip传递额外的元数据。例如,这段代码告诉pip这个包是 Python 3 兼容的。
现在你已经有了一个setup.py,你已经准备好创建一个 Python 轮子了!
生成 Python 轮子
setup.py用于创建 Python 轮子。确保你已经安装了最新版本的setuptools和wheel总是一个好主意,所以在你创建你自己的轮子之前,你应该运行下面的命令:
python3 -m pip install --user --upgrade setuptools wheel
如果有比您当前安装的版本更新的版本,这将更新软件包。现在你已经准备好自己创建一个轮子了。打开命令提示符或终端应用程序,导航到包含您的setup.py文件的文件夹。然后运行以下命令:
python3 setup.py sdist bdist_wheel
该命令将输出大量文本,但一旦完成,您会发现一个名为dist的新文件夹,其中包含以下两个文件:
arithmetic_YOUR_USERNAME_HERE-0.0.1-py3-none-any.whlarithmetic-YOUR-USERNAME-HERE-0.0.1.tar.gz
tar.gz是一个源文件,这意味着它包含了您的包的 Python 源代码。如果需要,您的用户可以使用源归档文件在他们自己的机器上构建包。whl格式是一个归档文件,由pip用来在用户的机器上安装你的软件包。
如果需要,您可以使用pip直接安装车轮:
python3 -m pip install arithmetic_YOUR_USERNAME_HERE-0.0.1-py3-none-any.whl
但是通常的方法是将您的包上传到 Python 包索引(PyPI ),然后安装它。接下来,让我们来看看如何在 PyPI 上获得您的惊喜套餐吧!
上传到 PyPI
将包上传到 PyPI 的第一步是在 Test PyPI 上创建一个帐户。这允许您测试您的包是否可以上传到测试服务器上,并从该测试服务器安装。要创建帐户,请转到以下 URL 并按照该页面上的步骤操作:
现在您需要创建一个 PyPI API 令牌。这将允许您安全地上传软件包。要获得 API 令牌,您需要转到这里:
您可以限制令牌的范围。但是,您不需要为这个令牌这样做,因为您正在为一个新项目创建它。确保在关闭页面之前复制令牌并将其保存在某个地方。一旦页面关闭,您将无法再次检索令牌。您将需要创建一个新的令牌。
现在您已经注册并拥有了 API 令牌,您将需要获得twine包。您将使用twine将您的包上传到 PyPI。要安装twine,可以这样使用pip:
python3 -m pip install --user --upgrade twine
安装完成后,您可以使用以下命令将您的包上传到测试 PyPI:
python3 -m twine upload --repository testpypi dist/*
注意,您需要从包含setup.py文件的文件夹中运行这个命令,因为它正在复制dist文件夹中的所有文件来测试 PyPI。当您运行这个命令时,它会提示您输入用户名和密码。对于用户名,您需要使用__token__。密码是以pypi-为前缀的令牌值。
当此命令运行时,您应该会看到类似如下的输出:
Uploading distributions to https://test.pypi.org/legacy/
Enter your username: [your username]
Enter your password:
Uploading arithmetic_YOUR_USERNAME_HERE-0.0.1-py3-none-any.whl
100%|?????????????????????| 4.65k/4.65k [00:01<00:00, 2.88kB/s]
Uploading arithmetic_YOUR_USERNAME_HERE-0.0.1.tar.gz
100%|?????????????????????| 4.25k/4.25k [00:01<00:00, 3.05kB/s]
至此,您应该能够在 Test PyPI 上查看您的包,网址如下:
现在您可以使用下面的命令从 Test PyPI 测试安装您的包:
python3 -m pip install --index-url https://test.pypi.org/simple/ --no-deps arithmetic-YOUR-USERNAME-HERE
如果一切正常,您现在应该已经在系统上安装了arithmetic包。当然,本教程向您展示了如何打包测试 PyPI。一旦您验证了它可以工作,那么您将需要执行以下操作来安装到真正的 PyPI:
- 为包装选择一个容易记忆且独特的名称
- 在https://pypi.org注册账户
- 使用
twine upload dist/*上传您的包裹,并输入您在 real PyPI 上注册的帐户的凭证。当上传到真正的 PyPI 时,您不需要使用--repository标志,因为该服务器是默认的 - 使用
pip install your_unique_package_name从真实的 PyPI 安装你的包
现在您知道如何在 Python 包索引上分发您自己创建的包了!
包扎
Python 模块和包是您在程序中导入的内容。从很多方面来说,它们是你的程序的组成部分。在本文中,您了解了以下内容:
- 创建模块
- 创建包
- 为 PyPI 打包项目
- 创建项目文件
- 正在创建
setup.py - 上传到 PyPI
至此,您不仅知道了什么是模块和包,还知道了如何通过 Python 包索引来分发它们。现在,您和任何其他 Python 开发人员都可以下载并安装您的包。恭喜你!你现在是一个包维护者了!
相关阅读
这篇文章基于 Python 101 第二版中的一章,你可以在 Leanpub 或亚马逊上购买。
如果你想学习更多的 Python,那么看看这些教程:
-
python 101—如何处理图像
-
python 101-记录你的代码
-
Python 101: 使用 JSON 的介绍
-
python 101-创建多个流程
Python 101 -如何裁剪照片(视频)
原文:https://www.blog.pythonlibrary.org/2020/09/10/python-101-how-to-crop-a-photo-video/
在本教程中,您将学习如何使用 Python 来裁剪使用 Pillow 的照片,Pillow 是 Python 图像库的友好分支。
https://www.youtube.com/embed/gE6Irl13jUY?feature=oembed
| | 你想了解更多关于 Python 的知识吗?
Python 101 -第二版
在 Leanpub 上立即购买 |
Python 101:如何下载文件
原文:https://www.blog.pythonlibrary.org/2012/06/07/python-101-how-to-download-a-file/
从互联网上下载文件是几乎每个程序员都必须做的事情。Python 在其标准库中提供了几种方法来实现这一点。下载文件最流行的方式可能是使用 urllib 或 urllib2 模块通过 HTTP。Python 还附带了 FTP 下载的 ftplib。最后,有一个新的第三方模块得到了很多关注,称为请求。对于本文,我们将重点关注两个 urllib 模块和请求。
由于这是一个非常简单的任务,我们将只展示一个快速而肮脏的脚本,该脚本下载每个库的相同文件,并将结果命名为稍微不同的名称。我们将从这个博客下载一个压缩文件作为我们的示例脚本。让我们来看看:
# Python 2 code
import urllib
import urllib2
import requests
url = 'https://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
print "downloading with urllib"
urllib.urlretrieve(url, "code.zip")
print "downloading with urllib2"
f = urllib2.urlopen(url)
data = f.read()
with open("code2.zip", "wb") as code:
code.write(data)
print "downloading with requests"
r = requests.get(url)
with open("code3.zip", "wb") as code:
code.write(r.content)
如您所见, urllib 只是一行代码。它的简单性使得它非常容易使用。另一方面,其他两个库也非常简单。对于 urllib2 ,你只需要打开网址,然后读取并写出数据。事实上,您可以通过执行以下操作将这部分脚本减少一行:
f = urllib2.urlopen(url)
with open("code2.zip", "wb") as code:
code.write(f.read())
无论哪种方式,它都非常有效。请求库方法是获取,对应 HTTP 获取。然后,您只需获取请求对象并调用其内容属性来获取您想要写入的数据。我们将与语句一起使用,因为它会自动关闭文件并简化代码。注意,如果文件很大,只使用“read()”可能会有危险。通过传递 read a 大小,会更好的阅读。
更新(2012 年 6 月 8 日)
正如我的一位读者所指出的,如果你通过 2to3.py 运行 urllib,它的内容会发生很大的变化,因此它是 Python 3 格式的。为了完整起见,下面是代码的样子:
# Python 3 code
import urllib.request
url = 'https://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
print("downloading with urllib")
urllib.request.urlretrieve(url, "code.zip")
print("downloading with urllib2")
f = urllib.request.urlopen(url)
data = f.read()
with open("code2.zip", "wb") as code:
code.write(data)
你会注意到 urllib2 不再存在,并且 urllib.urlretrieve 和 urllib2.urlopen 分别变成了URL lib . request . URL retrieve和 urllib.request.urlopen 。其余都一样。为了简洁起见,我删除了请求部分。
所以你有它!现在你也可以开始使用 Python 2 或 3 下载文件了!
进一步阅读
- 如何使用 Python 通过 HTTP 下载文件?
- 通过网络下载文件食谱
Python 101:如何找到运行脚本的路径
原文:https://www.blog.pythonlibrary.org/2013/10/29/python-101-how-to-find-the-path-of-a-running-script/
这个话题实际上比它第一次出现时更复杂。在这篇文章中,我们将花一点时间来看看这个问题和一些解决方案。
几年前,我在 wxPython 用户邮件列表中的一个朋友告诉我,他使用了以下方法:
import os
script_path = os.path.dirname(os.path.abspath( __file__ ))
这对我很有效,也是我目前使用的方法。顺便说一下,上面的代码返回了绝对路径。根据文档,它相当于
import os
os.path.normpath(join(os.getcwd(), path))
我也看到有人推荐以下类似的解决方案:
import os
os.path.dirname(os.path.realpath(__file__))
文档声明 realpath 将返回指定文件名的规范路径,消除路径中遇到的任何符号链接,这听起来可能比我一直使用的解决方案更好。
不管怎样,正如一些人可能指出的,你不能在 IDLE /解释器中使用 file 。如果这样做,您将得到以下错误:
Traceback (most recent call last):
File "", line 1, in <module>__file__
NameError: name '__file__' is not defined
如果您碰巧通过创建一个类似 py2exe 的可执行文件来“冻结”您的应用程序,您将会得到同样的错误。对于这种情况,有些人会推荐以下替代方案:
import os
os.path.dirname(sys.argv[0])
现在,如果您碰巧从另一个脚本调用您的脚本,这将不起作用。我也很确定,当我用一个冻结的应用程序尝试这样做并从一个快捷方式调用可执行文件时,它返回的是快捷方式的路径,而不是可执行文件的路径。然而,我可能会和 os.getcwd()混淆,后者肯定不会可靠地工作。
我用 py2exe 创建的可执行文件的最终解决方案是这样的:
import os, sys
os.path.abspath(os.path.dirname(sys.argv[0]))
我很确定 wxPython 的一个核心开发人员推荐过使用它,但是我不能确定,因为我好像已经没有那封邮件了。不管怎样,《深入 Python 的作者 Mark Pilgrim 也推荐使用 os.path.abspath。
现在,我想我将继续使用 os.path.abspath 或 os.path.realpath 来编写脚本,并为我冻结的 Windows 应用程序使用上面的变体。不过,我很想听听你的解决方案。让我知道你是否发现了任何跨平台和/或用于冻结脚本的东西。
进一步阅读
- Python: [如何找到脚本的目录](http://stackoverflow.com/questions/4934806/python-how-to-find-scripts-directory
- Python 的 os.path 文档
- python,脚本路径
- 深入 Python: 寻找路径
)
Python 101 - How to Generate a PDF
原文:https://www.blog.pythonlibrary.org/2021/09/28/python-101-how-to-generate-a-pdf/
The Portable Document Format (PDF) is a very popular way to share documents across multiple platforms. The goal of the PDF is to create a document that will look the same on multiple platforms and that will print the same (or very similar) on various printers. The format was originally developed by Adobe but has been made open-source.
Python has multiple libraries that you can use to create new PDFs or export portions of pre-existing PDFs. There are currently no Python libraries available for editing a PDF in-place. Here are a few of the packages you can use:
- ReportLab - used for creating PDFs
- pdfrw - used for splitting, merging, watermarking and rotating a PDF
- PyPDF2 / PyPDF4 - used for splitting, merging, watermarking and rotating a PDF
- PDFMiner - used for extracting text from PDFs
There are many other PDF packages for Python. In this article, you will learn how to create a PDF using ReportLab. The ReportLab package has been around since the year 2000. It has an open-source version as well as a paid commercial version which has some extra features in it. You will be learning about the open-source version here.
In this article, you will learn about the following:
- Installing ReportLab
- Creating a Simple PDF with the Canvas
- Creating Drawings and Adding Images Using the Canvas
- Creating Multi-page Documents with PLATYPUS
- Creating a Table
ReportLab can generate almost any kind of report you can imagine. This article will not cover every feature that ReportLab has to offer, but you will learn enough about it to see how useful ReportLab can be.
Let's get started!
Installing ReportLab
You can install ReportLab using pip:
python3 -m pip install reportlab
ReportLab depends on the Pillow package, which is an image manipulation library for Python. It will be installed as well if you do not already have it on your system. Now that you have ReportLab installed, you are ready to learn how to create a simple PDF!
Creating a Simple PDF with the Canvas
There are two ways to create PDFs using the ReportLab package. The low-level method is drawing on the "canvas". This allows you to draw at specific locations on the page. PDFs measure their size in points internally. There are 72 points per inch. A letter-size page is 612 x 792 points. However, the default page size is A4. There are several default page sizes that you can set or you can create your own page size.
It's always easier to see some code so that you can understand how this will work. Create a new file named hello_reportlab.py and add this code:
# hello_reportlab.py
from reportlab.pdfgen import canvas
my_canvas = canvas.Canvas("hello.pdf")
my_canvas.drawString(100, 750, "Welcome to Reportlab!")
my_canvas.save()
This will create a PDF that is A4-sized. You create a Canvas() object that takes in the path to the PDF that you want to create. To add some text to the PDF, you use drawString(). This code tells ReportLab to start drawing the text 100 points from the left and 750 from the bottom of the page. If you were to start drawing at (0, 0), your text would appear at the bottom left of the page. You can change the location you start drawing by setting the bottomup canvas argument to 0.
The last line saves the PDF to disk. Don't forget to do that or you won't get to see your new creation!
The PDF should look something like this when you open it:

Hello World on ReportLab Canvas
While this demonstrates how easy it is to create a PDF with ReportLab, it's kind of a boring example. You can use the canvas to draw lines, shapes and different fonts too. To learn how, create a new file named canvas_form.py and enter this code in it:
# canvas_form.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def form(path):
my_canvas = canvas.Canvas(path, pagesize=letter)
my_canvas.setLineWidth(.3)
my_canvas.setFont('Helvetica', 12)
my_canvas.drawString(30, 750, 'OFFICIAL COMMUNIQUE')
my_canvas.drawString(30, 735, 'OF ACME INDUSTRIES')
my_canvas.drawString(500, 750, "12/12/2010")
my_canvas.line(480, 747, 580, 747)
my_canvas.drawString(275, 725, 'AMOUNT OWED:')
my_canvas.drawString(500, 725, "$1,000.00")
my_canvas.line(378, 723, 580, 723)
my_canvas.drawString(30, 703, 'RECEIVED BY:')
my_canvas.line(120, 700, 580, 700)
my_canvas.drawString(120, 703, "JOHN DOE")
my_canvas.save()
if __name__ == '__main__':
form('canvas_form.pdf')
Here you import the letter size from reportlab.lib.pagesizes which has several other sizes you could use. Then in the form() function, you set the pagesize when you instantiate Canvas(). Next, you use setLineWidth() to set the line width, which is used when you draw lines. Then you change the font to Helvetica with the font size at 12 points.
The rest of the code is a series of drawing strings at various locations with lines being drawn here and there. When you draw a line(), you pass in the starting coordinate (x/y positions) and the end coordinate (x/y position) and ReportLab will draw the line for you using the line width you set.
When you open the PDF, you will see the following:

A Form Created with ReportLab Canvas
That looks pretty good. But what if you wanted to draw something or add a logo or some other photo to your report? Let's find out how to do that next!
Creating Drawings and Adding Images Using the Canvas
The ReportLab Canvas() is very flexible. It allows you to draw different shapes, use different colors, change the line widths, and more. To demonstrate some of these features, create a new file named drawing_polygons.py and add this code to it:
# drawing_polygons.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def draw_shapes():
my_canvas = canvas.Canvas("drawing_polygons.pdf")
my_canvas.setStrokeColorRGB(0.2, 0.5, 0.3)
my_canvas.rect(10, 740, 100, 80, stroke=1, fill=0)
my_canvas.ellipse(10, 680, 100, 630, stroke=1, fill=1)
my_canvas.wedge(10, 600, 100, 550, 45, 90, stroke=1, fill=0)
my_canvas.circle(300, 600, 50)
my_canvas.save()
if __name__ == '__main__':
draw_shapes()
Here you create a Canvas() object as you have before. You can use setStrokeColorRGB() to change the border color using RGB values between zero and one. The next few lines of code create different shapes. For the rect() function, you specify the x and y start position which is the lower left-hand coordinate of the rectangle. Then you specify the width and height of the shape.
The stroke parameter tells ReportLab whether or not to draw the border while the fill parameter tells ReportLab whether or not to fill the shape with a color. All of the shapes support these two parameters.
According to the documentation for the ellipse(), it takes in the starting (x,y) and ending (x,y) coordinates for the enclosing rectangle for the ellipse shape.
The wedge() shape is similar in that you are once again specifying a series of points for an invisible rectangle that encloses the wedge shape. What you need to do is imagine that there is a circle inside of a rectangle and you are describing the size of the rectangle. The 5th argument is startAng, which is the starting angle of the wedge. The 6th argument is for the extent, which tells the wedge how far out the arc can extend.
Lastly, you create a circle(), which takes in the (x,y) coordinates of its center and then its radius. You skip setting the stroke and fill parameters.
When you run this code, you will end up with a PDF that looks like this:

Creating Polygons with ReportLab
That looks pretty nice. You can play around with the values on your own and see if you can figure out how to change the shapes in different ways.
While these shapes you drew look fun, they wouldn't really look great on any professional company document. What if you want to add a company logo to your PDF report? You can do this with ReportLab by adding an image to your document. To discover how to do that, create a file named image_on_canvas.py and add this code to it:
# image_on_canvas.py
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
def add_image(image_path):
my_canvas = canvas.Canvas("canvas_image.pdf", pagesize=letter)
my_canvas.drawImage(image_path, 30, 600, width=100, height=100)
my_canvas.save()
if __name__ == '__main__':
image_path = 'snakehead.jpg'
add_image(image_path)
To draw an image on your canvas, you use the drawImage() method. It takes in the image path, the x and y starting positions, and the width and height you want to use for the image. This method does not maintain the aspect ratio of the image you pass in. If you set the width and height incorrectly, the image will be stretched.
When you run this code, you will end up with a PDF that looks something like this:

Adding an Image to a PDF
The Canvas() class is quite powerful. However, you need to keep track of where you are at on a page and tell the canvas when to create a new page. This can be difficult to do without making the code quite complex. Fortunately, there is a better way and you'll find out what that is in the next section!
Creating Multi-page Documents with PLATYPUS
ReportLab has a neat concept that they call PLATYPUS, which stands for “Page Layout and Typography Using Scripts”. It is a high-level layout library that ReportLab provides that makes it easier to programmatically create complex layouts with a minimum of code. PLATYPUS basically takes care of page breaking, layout, and styling for you.
There are several classes that you can use within PLATYPUS. These classes are known as Flowables. A Flowable has the ability to be added to a document and can break itself intelligently over multiple pages. The Flowables that you will use the most are:
Paragraph()- for adding textgetSampleStyleSheet()- for applying styles to ParagraphsTable()- for tabular dataSimpleDocTemplate()- a document template used to hold other flowables
To see how these classes can be used, create a file named hello_platypus.py and add the following code:
# hello_platypus.py
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Paragraph
from reportlab.lib.styles import getSampleStyleSheet
def hello():
doc = SimpleDocTemplate(
"hello_platypus.pdf",
pagesize=letter,
rightMargin=72, leftMargin=72,
topMargin=72, bottomMargin=18,
)
styles = getSampleStyleSheet()
flowables = []
text = "Hello, I'm a Paragraph"
para = Paragraph(text, style=styles["Normal"])
flowables.append(para)
doc.build(flowables)
if __name__ == '__main__':
hello()
In this code, you import two new classes from reportlab.platypus: SimpleDocTemplate() and Paragraph(). You also import getSampleStyleSheet() from reportlab.lib.styles. Then in the hello() function, you create a document template object. This is where you pass the file path to the PDF that you want to create. It is analogous to the Canvas() class, but for PLATYPUS. You set the pagesize here as well and you also specify the margins. You aren't required to set up the margins, but you should know that you can, which is why it is shown here.
Then you get the sample style sheet. The styles variable is a reportlab.lib.styles.StyleSheet1 object type. You can access several different styles in that stylesheet. For the purposes of this example, you use the Normal stylesheet.
This code creates a single Flowable using Paragraph(). The Paragraph() can take several different arguments. In this case, you pass in some text and what style you want to apply to the text. If you look at the code for the stylesheet, you see that you can apply various "Heading" styles to the text as well as a "Code" style and an "Italic" style, among others.
To make the document generate properly, you keep a Python list of the Flowables. In this example, you have a list with only one element in it: a Paragraph(). Instead of calling save() to create the PDF, you call build() and pass in the list of Flowables.
The PDF is now generated. It will look like this:

Creating a Paragraph in ReportLab
That's neat! But it's still kind of boring since it only has one element in it.
To see how useful using the PLATYPUS framework is, you will create a document with dozens of Flowables. Go ahead and create a new file named platypus_multipage.py and add this code:
# platypus_multipage.py
from reportlab.lib.pagesizes import letter
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib.units import inch
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer
def create_document():
doc = SimpleDocTemplate(
"platypus_multipage.pdf",
pagesize=letter,
)
styles = getSampleStyleSheet()
flowables = []
spacer = Spacer(1, 0.25*inch)
# Create a lot of content to make a multipage PDF
for i in range(50):
text = 'Paragraph #{}'.format(i)
para = Paragraph(text, styles["Normal"])
flowables.append(para)
flowables.append(spacer)
doc.build(flowables)
if __name__ == '__main__':
create_document()
In this example, you create 50 Paragraph() objects. You also create a Spacer(), which you use to add space between the flowables. When you create a Paragraph(), you add it and a Spacer() to the list of flowables. You end up with 100 flowables in the list.
When you run this code, you will generate a 3-page document. The first page will begin like the following screenshot:

Creating a Multipage PDF
That wasn't too hard! Now let's find out how you might add a table to your PDF!
Creating a Table
One of the most complex Flowables in ReportLab is the Table(). It allows you to show tabular data with columns and rows. Tables allow you to put other Flowable types in each cell of the table. This allows you to create complex documents.
To get started, create a new file named simple_table.py and add this code to it:
# simple_table.py
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Table
def simple_table():
doc = SimpleDocTemplate("simple_table.pdf", pagesize=letter)
flowables = []
data = [
['col_{}'.format(x) for x in range(1, 6)],
[str(x) for x in range(1, 6)],
['a', 'b', 'c', 'd', 'e'],
]
tbl = Table(data)
flowables.append(tbl)
doc.build(flowables)
if __name__ == '__main__':
simple_table()
This time you import Table() instead of Paragraph(). The rest of the imports should look familiar. To add some data to the table, you need to have a Python list of lists. The items inside the lists must be strings or Flowables. For this example, you create three rows of strings. The first row is the column row, which labels what will be in the following rows.
Next, you create the Table() and pass in the data, which is your list of lists. Finally, you build() the document as you did before. Your PDF should now have a table in it that looks like this:

Creating a Simpe Table in ReportLab
A Table() does not have a border or a cell border turned on by default. This Table() has no styling applied to it at all.
Tables can have styles applied to them using a TableStyle(). Table styles are kind of like the stylesheets you can apply to a Paragraph(). To see how they work, you need to create a new file named simple_table_with_style.py and add the following code to it:
# simple_table_with_style.py
from reportlab.lib import colors
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Table, TableStyle
def simple_table_with_style():
doc = SimpleDocTemplate(
"simple_table_with_style.pdf",
pagesize=letter,
)
flowables = []
data = [
['col_{}'.format(x) for x in range(1, 6)],
[str(x) for x in range(1, 6)],
['a', 'b', 'c', 'd', 'e'],
]
tblstyle = TableStyle([
('BACKGROUND', (0, 0), (-1, 0), colors.red),
('TEXTCOLOR', (0, 1), (-1, 1), colors.blue),
])
tbl = Table(data)
tbl.setStyle(tblstyle)
flowables.append(tbl)
doc.build(flowables)
if __name__ == '__main__':
simple_table_with_style()
This time you add a TableStyle(), which is a Python list of tuples. The tuples contain the type of styling you wish to apply and which cells to apply the styling to. The first tuple states that you want to apply a red background color starting on column 0, row 0. This style should be applied through to the last column, which is specified as -1.
The second tuple applies blue color to the text, starting in column 0, row 1 though all the columns on row 1. To add the style to the table, you call setStyle() and pass it the TableStyle() instance that you created.
Note that you needed to import colors from reportlab.lib to get the two colors that you applied.
When you run this code, you will end up with the following table:

ReportLab Table with Style
If you want to apply a border to the table and cells, you would add a tuple using "GRID" as the style command and then tell it which cells to apply it to.
Wrapping Up
ReportLab is the most comprehensive package available for creating PDFs with Python. In this article, you learned about the following topics:
- Installing ReportLab
- Creating a Simple PDF with the Canvas
- Creating Drawings and Adding Images Using the Canvas
- Creating Multi-page Documents with PLATYPUS
- Creating a Table
This article only scratched the surface of what you can do with ReportLab. You can use ReportLab with different types of fonts, add headers and footers, insert barcodes and much, much more. You can learn about these topics as well as other Python PDF packages in my book, ReportLab: PDF Processing with Python
Related Articles
You can do a lot more with ReportLab than what is contained in this article. Check out some of these other tutorials to learn more:
Python 101:如何从 RottenTomatoes 获取数据
原文:https://www.blog.pythonlibrary.org/2013/11/06/python-101-how-to-grab-data-from-rottentomatoes/
今天我们将学习如何从流行电影网站烂番茄获取数据。接下来,你需要在这里注册一个 API 密匙。当你拿到钥匙时,记下你的使用限制,如果有的话。你不希望对他们的 API 做太多的调用,否则你的密钥可能会被撤销。最后,阅读您将使用的 API 的文档总是一个非常好的主意。这里有几个链接:
一旦你仔细阅读或决定留着以后看,我们将继续我们的旅程。
开始表演
烂番茄的 API 提供了一组 json 提要,我们可以从中提取数据。我们将使用请求和 simplejson 来提取数据并进行处理。让我们写一个小脚本来获取当前正在播放的电影。
import requests
import simplejson
#----------------------------------------------------------------------
def getInTheaterMovies():
"""
Get a list of movies in theaters.
"""
key = "YOUR API KEY"
url = "http://api.rottentomatoes.com/api/public/v1.0/lists/movies/in_theaters.json?apikey=%s"
res = requests.get(url % key)
data = res.content
js = simplejson.loads(data)
movies = js["movies"]
for movie in movies:
print movie["title"]
#----------------------------------------------------------------------
if __name__ == "__main__":
getInTheaterMovies()
如果您运行这个代码,您将看到一个打印到 stdout 的电影列表。在撰写本文时运行该脚本,我得到了以下输出:
Free Birds
Gravity
Ender's Game
Jackass Presents: Bad Grandpa
Last Vegas
The Counselor
Cloudy with a Chance of Meatballs 2
Captain Phillips
Carrie
Escape Plan
Enough Said
Insidious: Chapter 2
12 Years a Slave
We're The Millers
Prisoners
Baggage Claim
在上面的代码中,我们使用 API 键构建了一个 URL,并使用请求来下载提要。然后,我们将数据加载到 simplejson 中,返回一个嵌套的 Python 字典。接下来,我们遍历电影字典并打印出每部电影的标题。现在,我们准备创建一个函数,从烂番茄提取每部电影的附加信息。
import requests
import simplejson
import urllib
#----------------------------------------------------------------------
def getMovieDetails(key, title):
"""
Get additional movie details
"""
if " " in title:
parts = title.split(" ")
title = "+".join(parts)
link = "http://api.rottentomatoes.com/api/public/v1.0/movies.json"
url = "%s?apikey=%s&q=%s&page_limit=1"
url = url % (link, key, title)
res = requests.get(url)
js = simplejson.loads(res.content)
for movie in js["movies"]:
print "rated: %s" % movie["mpaa_rating"]
print "movie synopsis: " + movie["synopsis"]
print "critics_consensus: " + movie["critics_consensus"]
print "Major cast:"
for actor in movie["abridged_cast"]:
print "%s as %s" % (actor["name"], actor["characters"][0])
ratings = movie["ratings"]
print "runtime: %s" % movie["runtime"]
print "critics score: %s" % ratings["critics_score"]
print "audience score: %s" % ratings["audience_score"]
print "for more information: %s" % movie["links"]["alternate"]
print "-" * 40
print
#----------------------------------------------------------------------
def getInTheaterMovies():
"""
Get a list of movies in theaters.
"""
key = "YOUR API CODE"
url = "http://api.rottentomatoes.com/api/public/v1.0/lists/movies/in_theaters.json?apikey=%s"
res = requests.get(url % key)
data = res.content
js = simplejson.loads(data)
movies = js["movies"]
for movie in movies:
print movie["title"]
getMovieDetails(key, movie["title"])
print
#----------------------------------------------------------------------
if __name__ == "__main__":
getInTheaterMovies()
这个新代码提取了关于每部电影的大量数据,但是 json 提要包含了更多的数据,这些数据在这个例子中没有显示。您可以通过将 js 字典打印到 stdout 来查看您错过了什么,或者您可以在烂番茄文档页面上查看 json 提要示例。如果你一直密切关注,你会注意到烂番茄 API 并没有覆盖他们网站上的很多数据。比如演员信息本身就没有办法拉。例如,如果我们想知道金凯瑞演了什么电影,没有 URL 端点可以查询。你也不能查找演员中的其他人,比如导演或制片人。信息在网站上,但是没有被 API 公开。为此,我们必须求助于互联网电影数据库(IMDB),但这将是另一篇文章的主题。
让我们花些时间来改进这个例子。一个简单的改进是将 API 键放在一个配置文件中。另一种方法是将我们下载的信息存储到数据库中。第三个改进将是添加一些代码来检查我们是否已经下载了今天的最新电影,因为确实没有一个好的理由来一天下载今天的电影超过一次。让我们添加那些功能!
添加配置文件
我更喜欢和推荐 ConfigObj 来处理配置文件。让我们用以下内容创建一个简单的“config.ini”文件:
[Settings]
api_key = API KEY
last_downloaded =
现在,让我们更改代码以导入 ConfigObj,并更改 getInTheaterMovies 函数以使用它:
import requests
import simplejson
import urllib
from configobj import ConfigObj
#----------------------------------------------------------------------
def getInTheaterMovies():
"""
Get a list of movies in theaters.
"""
config = ConfigObj("config.ini")
key = config["Settings"]["api_key"]
url = "http://api.rottentomatoes.com/api/public/v1.0/lists/movies/in_theaters.json?apikey=%s"
res = requests.get(url % key)
data = res.content
js = simplejson.loads(data)
movies = js["movies"]
for movie in movies:
print movie["title"]
getMovieDetails(key, movie["title"])
print
#----------------------------------------------------------------------
if __name__ == "__main__":
getInTheaterMovies()
如您所见,我们导入 configobj 并向其传递我们的文件名。您也可以将完全限定路径传递给它。接下来我们取出 api_key 的值,并在我们的 URL 中使用它。由于我们的配置中有一个 last_downloaded 值,我们应该继续将它添加到我们的代码中,这样我们就可以避免一天多次下载数据。
import datetime
import requests
import simplejson
import urllib
from configobj import ConfigObj
#----------------------------------------------------------------------
def getInTheaterMovies():
"""
Get a list of movies in theaters.
"""
today = datetime.datetime.today().strftime("%Y%m%d")
config = ConfigObj("config.ini")
if today != config["Settings"]["last_downloaded"]:
config["Settings"]["last_downloaded"] = today
try:
with open("config.ini", "w") as cfg:
config.write(cfg)
except IOError:
print "Error writing file!"
return
key = config["Settings"]["api_key"]
url = "http://api.rottentomatoes.com/api/public/v1.0/lists/movies/in_theaters.json?apikey=%s"
res = requests.get(url % key)
data = res.content
js = simplejson.loads(data)
movies = js["movies"]
for movie in movies:
print movie["title"]
getMovieDetails(key, movie["title"])
print
#----------------------------------------------------------------------
if __name__ == "__main__":
getInTheaterMovies()
这里我们导入 Python 的 datetime 模块,用它来获取今天的日期,格式如下:YYYYMMDD。接下来,我们检查配置文件的最后下载的值是否等于今天的日期。如果发生了,我们什么也不做。然而,如果它们不匹配,我们将最后下载的设置为今天的日期,然后我们下载电影数据。现在我们准备学习如何将数据保存到数据库中。
用 SQLite 保存数据
Python 从 2.5 版本开始就支持 SQLite,所以除非您使用的是非常旧的 Python 版本,否则您应该能够毫无问题地理解本文的这一部分。基本上,我们只需要添加一个功能,可以创建一个数据库,并将我们的数据保存到其中。下面是函数:
#----------------------------------------------------------------------
def saveData(movie):
"""
Save the data to a SQLite database
"""
if not os.path.exists("movies.db"):
# create the database
conn = sqlite3.connect("movies.db")
cursor = conn.cursor()
cursor.execute("""CREATE TABLE movies
(title text, rated text, movie_synopsis text,
critics_consensus text, runtime integer,
critics_score integer, audience_score integer)""")
cursor.execute("""
CREATE TABLE cast
(actor text,
character text)
""")
cursor.execute("""
CREATE TABLE movie_cast
(movie_id integer,
cast_id integer,
FOREIGN KEY(movie_id) REFERENCES movie(id),
FOREIGN KEY(cast_id) REFERENCES cast(id)
)
""")
else:
conn = sqlite3.connect("movies.db")
cursor = conn.cursor()
# insert the data
print
sql = "INSERT INTO movies VALUES(?, ?, ?, ?, ?, ?, ?)"
cursor.execute(sql, (movie["title"],
movie["mpaa_rating"],
movie["synopsis"],
movie["critics_consensus"],
movie["runtime"],
movie["ratings"]["critics_score"],
movie["ratings"]["audience_score"]
)
)
movie_id = cursor.lastrowid
for actor in movie["abridged_cast"]:
print "%s as %s" % (actor["name"], actor["characters"][0])
sql = "INSERT INTO cast VALUES(?, ?)"
cursor.execute(sql, (actor["name"],
actor["characters"][0]
)
)
cast_id = cursor.lastrowid
sql = "INSERT INTO movie_cast VALUES(?, ?)"
cursor.execute(sql, (movie_id, cast_id) )
conn.commit()
conn.close()
这段代码首先检查数据库文件是否已经存在。如果没有,那么它将创建数据库和 3 个表。否则, saveData 函数将创建一个连接和一个光标对象。接下来,它将使用传递给它的电影字典插入数据。我们将调用这个函数,并从 getMovieDetails 函数传递电影字典。最后,我们将数据提交到数据库并关闭连接。
您可能想知道完整的代码是什么样子的。嗯,这就是:
import datetime
import os
import requests
import simplejson
import sqlite3
import urllib
from configobj import ConfigObj
#----------------------------------------------------------------------
def getMovieDetails(key, title):
"""
Get additional movie details
"""
if " " in title:
parts = title.split(" ")
title = "+".join(parts)
link = "http://api.rottentomatoes.com/api/public/v1.0/movies.json"
url = "%s?apikey=%s&q=%s&page_limit=1"
url = url % (link, key, title)
res = requests.get(url)
js = simplejson.loads(res.content)
for movie in js["movies"]:
print "rated: %s" % movie["mpaa_rating"]
print "movie synopsis: " + movie["synopsis"]
print "critics_consensus: " + movie["critics_consensus"]
print "Major cast:"
for actor in movie["abridged_cast"]:
print "%s as %s" % (actor["name"], actor["characters"][0])
ratings = movie["ratings"]
print "runtime: %s" % movie["runtime"]
print "critics score: %s" % ratings["critics_score"]
print "audience score: %s" % ratings["audience_score"]
print "for more information: %s" % movie["links"]["alternate"]
saveData(movie)
print "-" * 40
print
#----------------------------------------------------------------------
def getInTheaterMovies():
"""
Get a list of movies in theaters.
"""
today = datetime.datetime.today().strftime("%Y%m%d")
config = ConfigObj("config.ini")
if today != config["Settings"]["last_downloaded"]:
config["Settings"]["last_downloaded"] = today
try:
with open("config.ini", "w") as cfg:
config.write(cfg)
except IOError:
print "Error writing file!"
return
key = config["Settings"]["api_key"]
url = "http://api.rottentomatoes.com/api/public/v1.0/lists/movies/in_theaters.json?apikey=%s"
res = requests.get(url % key)
data = res.content
js = simplejson.loads(data)
movies = js["movies"]
for movie in movies:
print movie["title"]
getMovieDetails(key, movie["title"])
print
#----------------------------------------------------------------------
def saveData(movie):
"""
Save the data to a SQLite database
"""
if not os.path.exists("movies.db"):
# create the database
conn = sqlite3.connect("movies.db")
cursor = conn.cursor()
cursor.execute("""CREATE TABLE movies
(title text, rated text, movie_synopsis text,
critics_consensus text, runtime integer,
critics_score integer, audience_score integer)""")
cursor.execute("""
CREATE TABLE cast
(actor text,
character text)
""")
cursor.execute("""
CREATE TABLE movie_cast
(movie_id integer,
cast_id integer,
FOREIGN KEY(movie_id) REFERENCES movie(id),
FOREIGN KEY(cast_id) REFERENCES cast(id)
)
""")
else:
conn = sqlite3.connect("movies.db")
cursor = conn.cursor()
# insert the data
print
sql = "INSERT INTO movies VALUES(?, ?, ?, ?, ?, ?, ?)"
cursor.execute(sql, (movie["title"],
movie["mpaa_rating"],
movie["synopsis"],
movie["critics_consensus"],
movie["runtime"],
movie["ratings"]["critics_score"],
movie["ratings"]["audience_score"]
)
)
movie_id = cursor.lastrowid
for actor in movie["abridged_cast"]:
print "%s as %s" % (actor["name"], actor["characters"][0])
sql = "INSERT INTO cast VALUES(?, ?)"
cursor.execute(sql, (actor["name"],
actor["characters"][0]
)
)
cast_id = cursor.lastrowid
sql = "INSERT INTO movie_cast VALUES(?, ?)"
cursor.execute(sql, (movie_id, cast_id) )
conn.commit()
conn.close()
#----------------------------------------------------------------------
if __name__ == "__main__":
getInTheaterMovies()
如果你使用 Firefox,有一个有趣的插件叫做 SQLite Manager ,你可以用它来可视化我们创建的数据库。以下是撰写本文时制作的截图:
包扎
还有很多东西需要补充。例如,我们需要在 getInTheaterMovies 函数中的一些代码,如果我们已经获得了当前数据,它将从数据库中加载详细信息。我们还需要向数据库添加一些逻辑,以防止我们多次添加同一个演员或电影。如果我们也有某种图形用户界面或网络界面就好了。这些都是你可以添加的有趣的小练习。
顺便说一下,这篇文章的灵感来自迈克尔·赫尔曼的《面向 Web 的真正 Python》。里面有很多巧妙的想法和例子。你可以在这里查看。
相关阅读
- Python: 一个简单的逐步 SQLite 教程
- wxPython 和 SQLAlchemy: 加载随机 SQLite 数据库以供查看
- StackOverflow: SQLite 外键示例
- Python 关于 sqlite3 模块的官方文档
Python 101:如何在服务器之间移动文件
原文:https://www.blog.pythonlibrary.org/2012/10/26/python-101-how-to-move-files-between-servers/
如果您做过大量的系统管理工作,那么您会知道有时您必须编写脚本来在服务器之间移动文件。我并不是一个真正的系统管理员,但是无论如何我必须在我的一些程序中做这样的事情。Python 有几个提供这种能力的第三方包。我们将看看如何用依赖于 PyCrypto 的 paramiko 来做这件事(或者从 PyPI 下载 PyCrypto)。
编写代码
假设你有前面提到的所有第三方包,我们就可以开始编码了。为了使事情超级简单,我们将只使用 paramiko 作为我们的第一个例子。以下代码大致基于我在工作中使用的一些代码。我们来看看吧!
import paramiko
########################################################################
class SSHConnection(object):
""""""
#----------------------------------------------------------------------
def __init__(self, host, username, password, port=22):
"""Initialize and setup connection"""
self.sftp = None
self.sftp_open = False
# open SSH Transport stream
self.transport = paramiko.Transport((host, port))
self.transport.connect(username=username, password=password)
#----------------------------------------------------------------------
def _openSFTPConnection(self):
"""
Opens an SFTP connection if not already open
"""
if not self.sftp_open:
self.sftp = paramiko.SFTPClient.from_transport(self.transport)
self.sftp_open = True
#----------------------------------------------------------------------
def get(self, remote_path, local_path=None):
"""
Copies a file from the remote host to the local host.
"""
self._openSFTPConnection()
self.sftp.get(remote_path, local_path)
#----------------------------------------------------------------------
def put(self, local_path, remote_path=None):
"""
Copies a file from the local host to the remote host
"""
self._openSFTPConnection()
self.sftp.put(local_path, remote_path)
#----------------------------------------------------------------------
def close(self):
"""
Close SFTP connection and ssh connection
"""
if self.sftp_open:
self.sftp.close()
self.sftp_open = False
self.transport.close()
if __name__ == "__main__":
host = "myserver"
username = "mike"
pw = "dingbat!"
origin = '/home/mld/projects/ssh/random_file.txt'
dst = '/home/mdriscoll/random_file.txt'
ssh = SSHConnection(host, username, pw)
ssh.put(origin, dst)
ssh.close()
让我们花点时间来分解一下。在我们类的 init 中,我们至少需要传入参数。在这个例子中,我们传递给它我们的主机,用户名和密码。然后我们打开一个 SSH 传输流对象。接下来,我们调用我们的 put 方法将文件从我们的机器发送到服务器。如果你想下载一个文件,参见获取方法。最后,我们调用我们的 close 方法来关闭我们的连接。您会注意到,在 put 和 get 方法中,我们让它们调用一个半私有的方法来检查我们的 SFTPClient 是否已初始化,如果没有,它将继续创建它。
包扎
Paramiko 让这一切变得简单。我强烈推荐阅读 Jesse 关于这个主题的旧文章(链接如下),因为他有更多的细节。我很好奇其他人用什么包来实现 ssh 和 scp,所以请在评论中给我留下一些建议。我听到了一些关于布料的好消息。
进一步阅读
- Jesse Noller 的使用 Paramiko 的 SSH 编程
Python 101:如何打开文件或程序
原文:https://www.blog.pythonlibrary.org/2010/09/04/python-101-how-to-open-a-file-or-program/
当我开始学习 Python 时,我需要知道的第一件事就是打开一个文件。现在,术语“打开文件”可以根据上下文有不同的含义。有时这意味着用 Python 打开文件并从中读取,就像读取文本文件一样。其他时候,它意味着“在默认程序中打开文件”;有时它意味着,“在我指定的程序中打开文件”。所以,当你在寻找如何做到后两者时,你需要知道如何问谷歌正确的问题,否则你最终只能学会如何打开和阅读一个文本文件。
在这篇文章中,我们将涵盖所有三个,我们还将展示如何打开(或运行)程序,已经安装在您的电脑上。为什么?因为这个话题也是我首先需要学习的东西之一,它使用了一些相同的技术。
如何打开文本文件
让我们从学习如何用 Python 打开文件开始。在这种情况下,我们的意思是实际使用 Python 打开它,而不是其他程序。为此,我们有两个选择(在 Python 2.x 中):打开或文件。我们来看看,看看是怎么做到的!
# the open keyword opens a file in read-only mode by default
f = open("path/to/file.txt")
# read all the lines in the file and return them in a list
lines = f.readlines()
f.close()
如你所见,打开和阅读一个文本文件真的很容易。你可以用“文件”关键字替换“打开”关键字,效果是一样的。如果您想更加明确,您可以这样写 open 命令:
f = open("path/to/file.txt", mode="r")
“r”表示只读取文件。也可以用“rb”(读二进制)、“w”(写)、“a”(追加)或“wb”(写二进制)打开文件。请注意,如果您使用“w”或“WB ”, Python 将覆盖该文件(如果它已经存在),或者创建它(如果该文件不存在)。
如果要读取文件,可以使用以下方法:
- 读取整个文件并以字符串的形式返回整个文件
- readline -读取文件的第一行,并将其作为字符串返回
- 读取整个文件并以字符串列表的形式返回
您也可以使用循环读取文件,如下所示:
f = open("path/to/file.txt")
for line in f:
print line
f.close()
很酷吧。巨蟒摇滚!现在是时候看看如何用另一个程序打开一个文件了。
用自己的程序打开文件
Python 有一个用默认程序打开文件的简单方法。事情是这样的:
import os
os.startfile(path)
是的,很简单,如果你用的是 Windows。如果你在 Unix 或 Mac 上,你将需要子进程模块或“os.system”。当然,如果你是一个真正的极客,那么你可能有多个程序可以用来打开一个特定的文件。例如,我可能想用 Picasa、Paint Shop Pro、Lightroom、Paint 或许多其他程序编辑我的 JPEG 文件,但我不想更改我的默认 JPEG 编辑程序。我们如何用 Python 解决这个问题?我们用的是 Python 的子流程模块!注意:如果你想走老路,你也可以使用 os.popen*或 os.system,但是子进程应该取代它们。
导入子流程
import subprocess
pdf = "path/to/pdf"
acrobat_path = r'C:\Program Files\Adobe\Reader 9.0\Reader\AcroRd32.exe'
subprocess.Popen(f"{acrobat_path} {pdf}")
也可以这样写最后一行:子流程。Popen([acrobatPath,pdf]) 。可以说,使用子流程模块也是轻而易举的事情。使用子流程模块还有许多其他方式,但这是它的主要任务之一。我通常用它来打开一个特定的文件(如上)或打开一个应用了特定参数的程序。我还使用 subprocess 的“call”方法,该方法使 Python 脚本在继续之前等待“被调用”的应用程序完成。如果您知道如何操作,您还可以与子流程启动的流程进行交流。
包扎
像往常一样,Python 提供了完成任务的简单方法。我发现 Python 很少不能以一种易于理解的方式雄辩地处理。我希望当你刚开始需要知道如何打开一个文件或程序时,这能对你有所帮助。
进一步阅读
Python 101:如何用 Twilio 发送短信/彩信
原文:https://www.blog.pythonlibrary.org/2014/09/23/python-101-how-to-send-smsmms-with-twilio/
我一直听到一些关于一种叫做 Twilio 的新型网络服务的传言,这种服务可以让你发送短信和彩信等。他们的 REST API 也有一个方便的 Python 包装器。如果你注册了 Twilio,他们会给你一个试用账户,甚至不需要你提供信用卡,我很感激。您将收到一个 Twilio 号码,可用于发送您的信息。因为您使用的是试用帐户,所以在实际发送消息之前,您必须授权您想要发送消息的任何电话号码。让我们花点时间了解一下这是如何工作的!
入门指南
首先,你需要注册 Twilio,还需要安装 Python twilio 包装器。要安装后者,只需执行以下操作:
pip install twilio
一旦安装完成并且你注册了,我们就可以继续了。
使用 Twilio 发送短信
通过 Twilio 发送短信非常简单。您需要查看您的 twilio 帐户,以获得 sid 和认证令牌以及您的 Twilio 号码。一旦你有了这三条关键信息,你就可以发送短信了。让我们看看如何:
from twilio.rest import TwilioRestClient
#----------------------------------------------------------------------
def send_sms(msg, to):
""""""
sid = "text-random"
auth_token = "youAreAuthed"
twilio_number = "123-456-7890"
client = TwilioRestClient(sid, auth_token)
message = client.messages.create(body=msg,
from_=twilio_number,
to=to,
)
if __name__ == "__main__":
msg = "Hello from Python!"
to = "111-111-1111"
send_sms(msg, to)
当您运行上面的代码时,您将在手机上收到一条消息,内容如下:从您的 Twilio 试用帐户发送——来自 Python 的 Hello!。如你所见,这真的很简单。您所需要做的就是创建一个 TwilioRestClient 的实例,然后创建一条消息。剩下的交给提里奥。发送彩信几乎同样简单。让我们在下一个例子中看看!
发送彩信
大多数情况下,您实际上并不想将您的 sid、身份验证令牌或 Twilio 电话号码放在代码本身中。相反,它通常存储在数据库或配置文件中。因此,在本例中,我们将把这些信息放入一个配置文件,并使用 ConfigObj 提取它们。下面是我的配置文件的内容:
[twilio]
sid = "random-text"
auth_token = "youAreAuthed!"
twilio_number = "123-456-7890"
现在,让我们编写一些代码来提取这些信息并发送一条彩信:
import configobj
from twilio.rest import TwilioRestClient
#----------------------------------------------------------------------
def send_mms(msg, to, img):
""""""
cfg = configobj.ConfigObj("/path/to/config.ini")
sid = cfg["twilio"]["sid"]
auth_token = cfg["twilio"]["auth_token"]
twilio_number = cfg["twilio"]["twilio_number"]
client = TwilioRestClient(sid, auth_token)
message = client.messages.create(body=msg,
from_=twilio_number,
to=to,
MediaUrl=img
)
if __name__ == "__main__":
msg = "Hello from Python!"
to = "111-111-1111"
img = "http://www.website.com/example.jpg"
send_mms(msg, to=to, img=img)
这段代码生成与上一段代码相同的消息,但它也发送一幅图像。您会注意到,Trilio 要求您使用 HTTP 或 HTTPS URL 将照片附加到您的彩信中。否则,这也很容易做到!
包扎
在现实世界中你能用它做什么?我敢肯定,企业会想用它来发送优惠券或提供新产品代码。这听起来也像是一个乐队或政治家用来向他们的粉丝、拥护者等传递信息的东西。我看到一篇文章,有人用它自动给自己发送体育比分。我发现这项服务很容易使用。我不知道他们的定价是否有竞争力,但试用帐户肯定足以进行测试,当然值得一试。
附加阅读
- Twilio Python 文档
- 使用 Python 来保存分数
- 星期五的乐趣:创建你自己的简单得令人讨厌的消息应用程序,就像你一样
Python 101:如何提交 web 表单
原文:https://www.blog.pythonlibrary.org/2012/06/08/python-101-how-to-submit-a-web-form/
今天我们将花一些时间来看看让 Python 提交 web 表单的三种不同方式。在这种情况下,我们将使用duckduckgo.com对术语“python”进行网络搜索,并将结果保存为 HTML 文件。我们将使用 Python 包含的 urllib 模块和两个第三方包:请求和机械化。我们有三个小脚本要讲,所以让我们开始吧!
使用 urllib 提交 web 表单
我们将从 urllib 和 urllib2 开始,因为它们包含在 Python 的标准库中。我们还将导入网络浏览器来打开搜索结果进行查看。代码如下:
import urllib
import urllib2
import webbrowser
data = urllib.urlencode({'q': 'Python'})
url = 'http://duckduckgo.com/html/'
full_url = url + '?' + data
response = urllib2.urlopen(full_url)
with open("results.html", "w") as f:
f.write(response.read())
webbrowser.open("results.html")
当你想提交一个网络表单时,你要做的第一件事就是弄清楚这个表单叫什么,以及你要发布的 url 是什么。如果你去 duckduckgo 的网站查看源代码,你会注意到它的动作指向一个相对链接,“/html”。所以我们的网址是“http://duckduckgo.com/html”。输入字段被命名为“q ”,因此要向 duckduckgo 传递一个搜索项,我们必须将 url 连接到“q”字段。结果被读取并写入磁盘。最后,我们使用 webbrowser 模块打开保存的结果。现在让我们看看在使用请求包时这个过程有什么不同。
提交带有请求的 web 表单
requests 包确实使提交的形式更优雅了一点。让我们来看看:
# Python 2.x example
import requests
url = 'https://duckduckgo.com/html/'
payload = {'q':'python'}
r = requests.get(url, params=payload)
with open("requests_results.html", "w") as f:
f.write(r.content)
对于请求,您只需要创建一个字典,将字段名作为键,将搜索词作为值。然后使用 requests.get 进行搜索。最后,使用产生的请求对象“r”,并访问保存到磁盘的其内容属性。为了简洁起见,我们跳过了这个例子(以及下一个例子)中的 webbrowser 部分。
在 Python 3 中,需要注意的是 r.content 现在返回字节而不是字符串。如果我们试图把它写到磁盘上,这将导致一个类型的错误被引发。要修复它,我们需要做的就是将文件标志从“w”更改为“wb”,就像这样:
with open("requests_results.html", "wb") as f:
f.write(r.content)
现在我们应该准备好看看机械化如何完成它的工作。
用 mechanize 提交 web 表单
mechanize 模块有很多有趣的特性,可以用 Python 浏览互联网。遗憾的是,它不支持 javascript。不管怎样,让我们继续表演吧!
import mechanize
url = "http://duckduckgo.com/html"
br = mechanize.Browser()
br.set_handle_robots(False) # ignore robots
br.open(url)
br.select_form(name="x")
br["q"] = "python"
res = br.submit()
content = res.read()
with open("mechanize_results.html", "w") as f:
f.write(content)
正如您所看到的,mechanize 比其他两种方法更加冗长。我们还需要告诉它忽略 robots.txt 指令,否则它会失败。当然,如果你想成为一个好网民,那么你就不应该忽视它。无论如何,首先,您需要一个浏览器对象。然后打开 url,选择表单(在本例中是“x”),像以前一样用搜索参数设置一个字典。请注意,在每种方法中,dict 设置都略有不同。接下来,您提交查询并阅读结果。最后,你把结果保存到磁盘,你就完成了!
包扎
在这三者中,requests 可能是最简单的,紧接着是 urllib。尽管 Mechanize 比其他两个做得更多。它是为屏幕抓取和网站测试而设计的,所以有点冗长也就不足为奇了。你也可以用 selenium 提交表单,但是你可以在这个博客的档案中读到。我希望你觉得这篇文章很有趣,也许会有启发。下次见!
进一步阅读
源代码
Python 101:如何使子流程超时
原文:https://www.blog.pythonlibrary.org/2016/05/17/python-101-how-to-timeout-a-subprocess/
有一天,我遇到了一个用例,我需要与一个已经启动的子流程进行通信,但是我需要它超时。不幸的是,Python 2 没有办法让 communicate 方法调用超时,所以它只是阻塞,直到它返回或者进程本身关闭。我在 StackOverflow 上发现了许多不同的方法,但我认为我最喜欢的是使用 Python 的线程模块的 Timer 类:
import subprocess
from threading import Timer
kill = lambda process: process.kill()
cmd = ['ping', 'www.google.com']
ping = subprocess.Popen(
cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
my_timer = Timer(5, kill, [ping])
try:
my_timer.start()
stdout, stderr = ping.communicate()
finally:
my_timer.cancel()
这个特殊的例子并不完全符合我遇到的用例,但是很接近。基本上,我们这里有一个长期运行的流程,我们希望与之进行交互。在 Linux 上,如果您调用 ping,它将无限期运行。所以这是一个很好的例子。在这种情况下,我们编写 killing lambda 来调用进程的 kill 方法。然后,我们启动 ping 命令,将它放入一个计时器中,该计时器设置为 5 秒后到期,然后启动计时器。当进程运行时,我们收集它的 stdout 和 stderr,然后进程终止。最后,我们通过停止计时器来清理。
Python 3.5 增加了接受超时参数的 run 函数。根据文档,它将被传递给子流程的 communicate 方法,如果流程超时,将引发 TimeoutExpired 异常。让我们来试试:
>>> import subprocess
>>> cmd = ['ping', 'www.google.com']
>>> subprocess.run(cmd, timeout=5)
PING www.google.com (216.58.216.196) 56(84) bytes of data.
64 bytes from ord31s21-in-f4.1e100.net (216.58.216.196): icmp_seq=1 ttl=55 time=16.3 ms
64 bytes from ord31s21-in-f4.1e100.net (216.58.216.196): icmp_seq=2 ttl=55 time=19.4 ms
64 bytes from ord31s21-in-f4.1e100.net (216.58.216.196): icmp_seq=3 ttl=55 time=20.0 ms
64 bytes from ord31s21-in-f4.1e100.net (216.58.216.196): icmp_seq=4 ttl=55 time=19.4 ms
64 bytes from ord31s21-in-f4.1e100.net (216.58.216.196): icmp_seq=5 ttl=55 time=17.0 ms
Traceback (most recent call last):
Python Shell, prompt 3, line 1
File "/usr/local/lib/python3.5/subprocess.py", line 711, in run
stderr=stderr)
subprocess.TimeoutExpired: Command '['ping', 'www.google.com']' timed out after 5 seconds
很明显它是按照记载的方式工作的。为了真正有用,我们可能希望将子流程调用包装在一个异常处理程序中:
>>> try:
... subprocess.run(cmd, timeout=5)
... except subprocess.TimeoutExpired:
... print('process ran too long')
...
PING www.google.com (216.58.216.196) 56(84) bytes of data.
64 bytes from ord31s21-in-f196.1e100.net (216.58.216.196): icmp_seq=1 ttl=55 time=18.3 ms
64 bytes from ord31s21-in-f196.1e100.net (216.58.216.196): icmp_seq=2 ttl=55 time=21.1 ms
64 bytes from ord31s21-in-f196.1e100.net (216.58.216.196): icmp_seq=3 ttl=55 time=22.7 ms
64 bytes from ord31s21-in-f196.1e100.net (216.58.216.196): icmp_seq=4 ttl=55 time=20.3 ms
64 bytes from ord31s21-in-f196.1e100.net (216.58.216.196): icmp_seq=5 ttl=55 time=16.8 ms
process ran too long
既然我们可以捕捉异常,我们可以继续做其他事情或保存错误异常。有趣的是,在 Python 3.3 中,超时参数被添加到了子流程模块中。您可以在 subprocess.call、check_output 和 check_call 中使用它。在 Popen.wait()中也有。
Python 101:如何遍历目录
原文:https://www.blog.pythonlibrary.org/2016/01/26/python-101-how-to-traverse-a-directory/
您经常会发现自己需要编写遍历目录的代码。以我的经验来看,它们往往是一次性脚本或运行在 cron 中的清理脚本。总之,Python 提供了一种非常有用的遍历目录结构的方法,被恰当地称为 os.walk 。我通常使用该功能浏览一组文件夹和子文件夹,在这些文件夹和子文件夹中,我需要删除旧文件或将它们移动到归档目录中。让我们花一些时间来学习如何在 Python 中遍历目录!
使用 os.walk
使用 os.walk 需要一点练习才能正确。下面是一个例子,它只打印出您传递给它的路径中的所有文件名:
import os
def pywalker(path):
for root, dirs, files in os.walk(path):
for file_ in files:
print( os.path.join(root, file_) )
if __name__ == '__main__':
pywalker('/path/to/some/folder')
通过连接根和文件 _ 元素,您最终得到了文件的完整路径。如果你想检查文件的创建日期,那么你可以使用 os.stat 。例如,我曾经用它创建了一个清理脚本。
如果您想要做的只是检查指定路径中的文件夹和文件列表,那么您正在寻找 os.listdir 。大多数时候,我通常需要深入到最低的子文件夹,所以 listdir 不够好,我需要使用 os.walk 来代替。
直接使用 os.scandir()
Python 3.5 最近增加了 os.scandir() ,这是一个新的目录迭代函数。你可以在 PEP 471 里读到。在 Python 3.5 中, os.walk 是使用 os.scandir 实现的,根据 Python 3.5 公告“这使得它在 POSIX 系统上快 3 到 5 倍,在 Windows 系统上快 7 到 20 倍”。
让我们直接使用 os.scandir 来尝试一个简单的例子。
import os
folders = []
files = []
for entry in os.scandir('/'):
if entry.is_dir():
folders.append(entry.path)
elif entry.is_file():
files.append(entry.path)
print('Folders:')
print(folders)
Scandir 返回一个由 DirEntry 对象组成的迭代器,这些对象是轻量级的,有方便的方法可以告诉你正在迭代的路径。在上面的例子中,我们检查条目是文件还是目录,并将条目添加到适当的列表中。你还可以通过 DirEntry 的 stat 方法创建一个 stat 对象,这非常简单!
包扎
现在您知道了如何在 Python 中遍历目录结构。如果你想在 than 3.5 之前的版本中获得 os.scandir 的速度提升,你可以在 T2 的 PyPI 上获得 scandir 包。
相关阅读
- Python 3.5 - 新功能
- Python 增强提案 0471 (PEP471)
- PyPI 版本的 scandir
- Webucator 在 os.scandir 上的文章
- Python 101 - 如何编写清理脚本
Python 101 - How to Work with CSV files
原文:https://www.blog.pythonlibrary.org/2022/11/03/python-101-how-to-work-with-csv-files/
There are many common file types that you will need to work with as a software developer. One such format is the CSV file. CSV stands for "Comma-Separated Values" and is a text file format that uses a comma as a delimiter to separate values from one another. Each row is its own record and each value is its own field. Most CSV files have records that are all the same length.
Unfortunately, CSV is not a standardized file format, which makes using them directly more complicated, especially when the data of an individual field itself contains commas or line breaks. Some organizations use quotation marks as an attempt to solve this problem, but then the issue is shifted to what happens when you need quotation marks in that field?
A couple of the benefits of CSV files is that they are human readable, and most spreadsheet software can use them. For example, Microsoft Excel and Libre Office will happily open CSV files for you and format them into rows and columns.
Python has made creating and reading CSV files much easier via its csv library. It works with most CSV files out of the box and allows some customization of its readers and writers. A reader is what the csv module uses to parse the CSV file, while a writer is used to create/update csv files.
In this article, you will learn about the following:
- Reading a CSV File
- Reading a CSV File with
DictReader - Writing a CSV File
- Writing a CSV File with
DictWriter
If you need more information about the csv module, be sure to check out the documentation.
Let's start learning how to work with CSV files!
Reading a CSV File
Reading CSV files with Python is pretty straight-forward once you know how to do so. The first piece of the puzzle is to have a CSV file that you want to read. For the purposes of this section, you can create one named books.csv and copy the following text into it:
book_title,author,publisher,pub_date,isbn
Python 101,Mike Driscoll, Mike Driscoll,2020,123456789
wxPython Recipes,Mike Driscoll,Apress,2018,978-1-4842-3237-8
Python Interviews,Mike Driscoll,Packt Publishing,2018,9781788399081
The first row of data is known as the header record. It explains what each field of data represents. Let's write some code to read this CSV file into Python so you can work with its content. Go ahead and create a file named csv_reader.py and enter the following code into it:
# csv_reader.py
import csv
def process_csv(path):
with open(path) as csvfile:
reader = csv.reader(csvfile)
for row in reader:
print(row)
if __name__ == '__main__':
process_csv('books.csv')
Here you import csv and create a function called process_csv(), which accepts the path to the CSV file as its sole argument. Then you open that file and pass it to csv.reader() to create a reader object. You can then iterate over this object line-by-line and print it out.
Here is the output you will receive when you run the code:
['book_title', 'author', 'publisher', 'pub_date', 'isbn']
['Python 101', 'Mike Driscoll', ' Mike Driscoll', '2020', '123456789']
['wxPython Recipes', 'Mike Driscoll', 'Apress', '2018', '978-1-4842-3237-8']
['Python Interviews', 'Mike Driscoll', 'Packt Publishing', '2018', '9781788399081']
Most of the time, you probably won't need to process the header row. You can skip that row by updating your code like this:
# csv_reader_no_header.py
import csv
def process_csv(path):
with open(path) as csvfile:
reader = csv.reader(csvfile)
# Skip the header
next(reader, None)
for row in reader:
print(row)
if __name__ == '__main__':
process_csv('books.csv')
Python's next() function will take an iterable, such as reader, and return the next item from the iterable. This will, in effect, skip the first row. If you run this code, you will see that the output is now missing the header row:
['Python 101', 'Mike Driscoll', ' Mike Driscoll', '2020', '123456789']
['wxPython Recipes', 'Mike Driscoll', 'Apress', '2018', '978-1-4842-3237-8']
['Python Interviews', 'Mike Driscoll', 'Packt Publishing', '2018', '9781788399081']
The csv.reader() function takes in some other optional arguments that are quite useful. For example, you might have a file that uses a delimiter other than a comma. You can use the delimiter argument to tell the csv module to parse the file based on that information.
Here is an example of how you might parse a file that uses a colon as its delimiter:
reader = csv.reader(csvfile, delimiter=':')
You should try creating a few variations of the original data file and then read them in using the delimiter argument.
Let's learn about another way to read CSV files!
Reading a CSV File with DictReader
The csv module provides a second "reader" object you can use called the DictReader class. The nice thing about the DictReader is that when you iterate over it, each row is returned as a Python dictionary. Go ahead and create a new file named csv_dict_reader.py and enter the following code:
# csv_dict_reader.py
import csv
def process_csv_dict_reader(file_obj):
reader = csv.DictReader(file_obj)
for line in reader:
print(f'{line["book_title"]} by {line["author"]}')
if __name__ == '__main__':
with open('books.csv') as csvfile:
process_csv_dict_reader(csvfile)
In this code you create a process_csv_dict_reader() function that takes in a file object rather than a file path. Then you convert the file object into a Python dictionary using DictReader(). Next, you loop over the reader object and print out a couple fields from each record using Python's dictionary access syntax.
You can see the output from running this code below:
Python 101 by Mike Driscoll
wxPython Recipes by Mike Driscoll
Python Interviews by Mike Driscoll
csv.DictReader() makes accessing fields within records much more intuitive than the regular csv.reader object. Try using it on one of your own CSV files to gain additional practice.
Now, you will learn how to write a CSV file using Python's csv module!
Writing a CSV File
Python's csv module wouldn't be complete without some way to create a CSV file. In fact, Python has two ways. Let's start by looking at the first method below. Go ahead and create a new file named csv_writer.py and enter the following code:
# csv_writer.py
import csv
def csv_writer(path, data):
with open(path, 'w') as csvfile:
writer = csv.writer(csvfile, delimiter=',')
for row in data:
writer.writerow(row)
if __name__ == '__main__':
data = '''book_title,author,publisher,pub_date,isbn
Python 101,Mike Driscoll, Mike Driscoll,2020,123456789
wxPython Recipes,Mike Driscoll,Apress,2018,978-1-4842-3237-8
Python Interviews,Mike Driscoll,Packt Publishing,2018,9781788399081'''
records = []
for line in data.splitlines():
records.append(line.strip().split(','))
csv_writer('output.csv', records)
In this code, you create a csv_writer() function that takes two arguments:
- The
pathto the CSV file that you want to create - The
datathat you want to write to the file
To write data to a file, you need to create a writer() object. You can set the delimiter to something other than commas if you want to, but to keep things consistent, this example explicitly sets it to a comma. When you are ready to write data to the writer(), you will use writerow(), which takes in a list of strings.
The code that is outside of the csv_writer() function takes a multiline string and transforms it into a list of lists for you.
If you would like to write all the rows in the list at once, you can use the writerows() function. Here is an example for that:
# csv_writer_rows.py
import csv
def csv_writer(path, data):
with open(path, 'w') as csvfile:
writer = csv.writer(csvfile, delimiter=',')
writer.writerows(data)
if __name__ == '__main__':
data = '''book_title,author,publisher,pub_date,isbn
Python 101,Mike Driscoll, Mike Driscoll,2020,123456789
wxPython Recipes,Mike Driscoll,Apress,2018,978-1-4842-3237-8
Python Interviews,Mike Driscoll,Packt Publishing,2018,9781788399081'''
records = []
for line in data.splitlines():
records.append(line.strip().split(','))
csv_writer('output2.csv', records)
Instead of looping over the data row by row, you can write the entire list of lists to the file all at once.
This was the first method of creating a CSV file. Now let's learn about the second method: the DictWriter!
Writing a CSV File with DictWriter
The DictWriter is the complement class of the DictReader. It works in a similar manner as well. To learn how to use it, create a file named csv_dict_writer.py and enter the following:
# csv_dict_writer.py
import csv
def csv_dict_writer(path, headers, data):
with open(path, 'w') as csvfile:
writer = csv.DictWriter(
csvfile,
delimiter=',',
fieldnames=headers,
)
writer.writeheader()
for record in data:
writer.writerow(record)
if __name__ == '__main__':
data = '''book_title,author,publisher,pub_date,isbn
Python 101,Mike Driscoll, Mike Driscoll,2020,123456789
wxPython Recipes,Mike Driscoll,Apress,2018,978-1-4842-3237-8
Python Interviews,Mike Driscoll,Packt Publishing,2018,9781788399081'''
records = []
for line in data.splitlines():
records.append(line.strip().split(','))
headers = records.pop(0)
list_of_dicts = []
for row in records:
my_dict = dict(zip(headers, row))
list_of_dicts.append(my_dict)
csv_dict_writer('output_dict.csv', headers, list_of_dicts)
In this example, you pass in three arguments to csv_dict_writer():
- The
pathto the file that you are creating - The header row (a list of strings)
- The
dataargument as a Python list of dictionaries
When you instantiate DictWriter(), you give it a file object, set the delimiter, and, using the headers parameter, tell it what the fieldnames are. Next, you call writeheader() to write that header to the file. Finally, you loop over the data as you did before and use writerow() to write each record to the file. However, the record is now a dictionary instead of a list.
The code outside the csv_dict_writer() function is used to create the pieces you need to feed to the function. Once again, you create a list of lists, but this time you extract the first row and save it off in headers. Then you loop over the rest of the records and turn them into a list of dictionaries.
Wrapping Up
Python's csv module is great! You can read and write CSV files with very few lines of code. In this article you learned how to do that in the following sections:
- Reading a CSV File
- Reading a CSV File with
DictReader - Writing a CSV File
- Writing a CSV File with
DictWriter
There are other ways to work with CSV files in Python. One popular method is to use the pandas package. Pandas is primarily used for data analysis and data science, so using it for working with CSVs seems like using a sledgehammer on a nail. Python's csv module is quite capable all on its own. But you are welcome to check out pandas and see how it might work for this use-case.
If you don't work as a data scientist, you probably won't be using pandas. In that case, Python's csv module works fine. Go ahead and put in some more practice with Python's csv module to see how nice it is to work with!
Related Articles / Videos
Python 101 -如何处理图像
原文:https://www.blog.pythonlibrary.org/2021/09/14/python-101-how-to-work-with-images/
Python 图像库 (PIL)是一个第三方 Python 包,为您的 Python 解释器增加了图像处理能力。它允许你处理照片和做许多常见的图像文件操作。这个软件的当前版本在枕里,是原 PIL 支持 Python 3 的一个分叉。其他几个 Python 包,如 wxPython 和 ReportLab,使用 Pillow 来支持加载许多不同的图像文件类型。您可以在以下几种情况下使用 Pillow:
- 图像处理
- 图像存档
- 成批处理
- 通过 Tkinter 显示图像
在这篇文章中,你将学习如何用枕头做以下事情:
- 打开图像
- 裁剪图像
- 使用过滤器
- 添加边框
- 调整图像大小
如你所见,Pillow 可以用于多种类型的图像处理。本文中使用的图片是作者自己拍摄的一些图片。它们包含在 Github 上的代码示例中。详见简介。
现在让我们开始安装枕头吧!
安装枕头
使用pip可以轻松安装枕头。打开终端或控制台窗口后,您可以这样做:
python -m pip install pillow
现在枕头安装好了,你可以开始使用它了!
打开图像
枕头让你打开和查看许多不同的文件类型。有关 Pillow 支持的图像文件类型的完整列表,请参见以下内容:
您可以使用 Pillow 打开并查看上面链接中“完全支持的格式”部分提到的任何文件类型。查看器是用 Tkinter 制作的,在显示图形时,其工作方式与 Matplotlib 非常相似。
要了解这是如何工作的,创建一个名为open_image.py的新文件,并输入以下代码:
# open_image.py
from PIL import Image
image = Image.open('jellyfish.jpg')
image.show()
在这里,您从PIL包中导入Image。然后你用Image.open()打开一个图像。这将返回一个PIL.JpegImagePlugin.JpegImageFile对象,您可以使用它来了解关于您的图像的更多信息。当您运行此代码时,您将看到一个类似如下的窗口:

这非常方便,因为现在您可以使用 Python 查看图像,而无需编写完整的图形用户界面。您也可以使用 Pillow 来了解更多关于图像的信息。创建一个名为get_image_info.py的新文件,并将以下代码添加到其中:
# get_image_info.py
from PIL import Image
def get_image_info(path):
image = Image.open(path)
print(f'This image is {image.width} x {image.height}')
exif = image._getexif()
print(exif)
if __name__ == '__main__':
get_image_info('ducks.jpg')
这里你使用image对象得到图像的宽度和高度。然后使用_getexif()方法获取关于图像的元数据。EXIF 代表“可交换图像文件格式”,是一种指定数码相机使用的图像、声音和辅助标签格式的标准。输出非常详细,但您可以从数据中了解到,这张特定的照片是用索尼 6300 相机拍摄的,设置如下:“E 18-200mm F3.5-6.3 OSS LE”。照片的时间戳也在 Exif 信息中。
但是,如果您使用照片编辑软件进行裁剪、应用滤镜或进行其他类型的图像处理,Exif 数据可能会被更改。这可以删除部分或全部 Exif 数据。试着在你自己的一些照片上运行这个功能,看看你能提取出什么样的信息!
您可以从图像中提取的另一个有趣信息是直方图数据。图像的直方图是其色调值的图形表示。它将照片的亮度显示为一个数值列表,您可以用图形表示出来。让我们以这张图片为例:

要从该图像中获得直方图,您将使用图像的histogram()方法。然后你会用 Matplotlib 把它画出来。要查看实现这一点的一种方法,创建一个名为get_histrogram.py的新文件,并向其中添加以下代码:
# get_histrogram.py
import matplotlib.pyplot as plt
from PIL import Image
def get_image_histrogram(path):
image = Image.open(path)
histogram = image.histogram()
plt.hist(histogram, bins=len(histogram))
plt.xlabel('Histogram')
plt.show()
if __name__ == '__main__':
get_image_histrogram('butterfly.jpg')
当运行这段代码时,像以前一样打开图像。然后从中提取直方图,并将值列表传递给 Matplotlib 对象,在该对象中调用hist()函数。hist()函数接受值列表以及值范围内的等宽仓的数量。
运行此代码时,您将看到下图:

这个图表显示了之前提到的图像中的色调值。您可以尝试传入 Github 上包含的一些其他图像来查看不同的图表,或者换入一些您自己的图像来查看它们的直方图。
现在让我们来看看如何使用 Pillow 来裁剪图像!
裁剪图像
当你拍照时,照片的主体经常会移动,或者你没有放大足够远。这导致照片中图像的焦点并不在正面中央。要解决此问题,您可以将图像裁剪到您想要突出显示的图像部分。
枕头内置了这种功能。要了解它是如何工作的,创建一个名为cropping.py的文件,并向其中添加以下代码:
# cropping.py
from PIL import Image
def crop_image(path, cropped_path):
image = Image.open(path)
cropped = image.crop((40, 590, 979, 1500))
cropped.save(cropped_path)
if __name__ == '__main__':
crop_image('ducks.jpg', 'ducks_cropped.jpg')
crop_image()函数接受您希望裁剪的文件的路径以及新裁剪文件的路径。然后你像以前一样open()这个文件并打电话给crop()。此方法采用您用来裁剪的起始和结束 x/y 坐标。您正在创建一个用于裁剪的框。
让我们拍摄这张有趣的鸭子照片,并尝试使用上面的代码进行裁剪:

现在,当您对此运行代码时,您将得到以下裁剪后的图像:

您用来裁剪的坐标会因照片而异。事实上,您可能应该更改这段代码,以便它接受裁剪坐标作为参数。你可以自己做一点功课。找出要使用的裁剪边界框需要一些反复试验。你可以使用 Gimp 这样的工具来帮助你,用 Gimp 画一个边界框,并记下它给你的坐标,用 Pillow 试试。
现在让我们继续学习如何将滤镜应用到你的图片中!
使用过滤器
枕头包有几个过滤器,您可以应用到您的图像。以下是当前支持的过滤器:
- 虚化
- 轮廓
- 详述
- 边缘增强
- 边缘 _ 增强 _ 更多
- 装饰
- 查找 _ 边
- 尖锐
- 光滑的
- 平滑 _ 更多
让我们使用之前的蝴蝶图像来测试这些过滤器。以下是您将使用的图像:
现在您已经有了一个可以使用的图像,接下来创建一个名为blur.py的新文件,并将这段代码添加到其中,以试用 Pillow 的BLUR过滤器:
# blur.py
from PIL import Image
from PIL import ImageFilter
def blur(path, modified_photo):
image = Image.open(path)
blurred_image = image.filter(ImageFilter.BLUR)
blurred_image.save(modified_photo)
if __name__ == '__main__':
blur('butterfly.jpg', 'butterfly_blurred.jpg')
要在 Pillow 中实际使用滤镜,需要导入ImageFilter。然后将您想要使用的特定过滤器传递给filter()方法。当你调用filter()时,它会返回一个新的图像对象。然后将文件保存到磁盘。
这是您运行代码时将得到的图像:

这看起来有点模糊,所以你可以认为这是一个成功!如果你想让它更模糊,你可以通过你的脚本第二次运行模糊的照片。
当然,有时候你拍的照片有点模糊,你想把它们锐化一点。枕头包括你可以应用的过滤器。创建一个名为sharpen.py的新文件,并添加以下代码:
# sharpen.py
from PIL import Image
from PIL import ImageFilter
def sharpen(path, modified_photo):
image = Image.open(path)
sharpened_image = image.filter(ImageFilter.SHARPEN)
sharpened_image.save(modified_photo)
if __name__ == '__main__':
sharpen('butterfly.jpg', 'butterfly_sharper.jpg')
在这里,你要拍摄原始的蝴蝶照片,并在保存之前应用SHARPEN滤镜。当您运行此代码时,您的结果将如下所示:

根据您的视力和显示器的质量,您可能会看到也可能看不到太大的差异。不过,你可以放心,它稍微锋利一点。
现在让我们来看看如何给你的图片添加边框!
添加边框
让照片看起来更专业的一个方法是给它们添加边框。Pillow 通过他们的ImageOps模块让这变得非常容易。但是在你做任何边界之前,你需要一个图像。下面是您将使用的一个:

现在您已经有了一个很好的图像,接下来创建一个名为border.py的文件,并将以下代码放入其中:
# border.py
from PIL import Image, ImageOps
def add_border(input_image, output_image, border):
img = Image.open(input_image)
if isinstance(border, int) or isinstance(border, tuple):
bimg = ImageOps.expand(img, border=border)
else:
raise RuntimeError('Border is not an integer or tuple!')
bimg.save(output_image)
if __name__ == '__main__':
in_img = 'butterfly_grey.jpg'
add_border(in_img, output_image='butterfly_border.jpg',
border=100)
add_border()函数接受 3 个参数:
input_image-要添加边框的图像output_image-应用了新边框的图像border-以像素为单位应用的边框数量
在这段代码中,您告诉 Pillow,您想要为传入的照片添加一个 100 像素的边框。当您传入一个整数时,该整数将用于所有四条边的边框。边框的默认颜色是黑色。这里的关键方法是expand(),它接受图像对象和边框量。
当您运行这段代码时,您将得到这个可爱的结果:

您可以传入一组值来使边框具有不同的宽度。例如,如果你传入(10, 50),它会在图片的左右两边添加一个 10 像素的边框,在顶部和底部添加一个 50 像素的边框。试着用上面的代码做这件事,然后重新运行。如果这样做,您将得到以下内容:

这不是很好吗?如果你想变得更漂亮,你可以为图像的四个边传递不同的值。但是可能没有太多有意义的用例。
有一个黑色的边框是很好的,但有时你会想给你的图片添加一点活力。您可以通过将参数fill传递给expand()来更改边框颜色。该参数采用命名颜色或 RGB 颜色。
创建一个名为colored_border.py的新文件,并将以下代码添加到其中:
# colored_border.py
from PIL import Image, ImageOps
def add_border(input_image, output_image, border, color=0):
img = Image.open(input_image)
if isinstance(border, int) or isinstance(
border, tuple):
bimg = ImageOps.expand(img,
border=border,
fill=color)
else:
msg = 'Border is not an integer or tuple!'
raise RuntimeError(msg)
bimg.save(output_image)
if __name__ == '__main__':
in_img = 'butterfly_grey.jpg'
add_border(in_img,
output_image='butterfly_border_red.jpg',
border=100,
color='indianred')
现在你的add_border()函数接受一个color参数,你把它传递给expand()方法。当您运行这段代码时,您会看到这样的结果:

看起来很不错。你可以尝试不同的颜色,或者用自己喜欢的颜色作为边框。
枕头之旅的下一个项目是学习如何调整图像大小!
调整图像大小
使用 Pillow 调整图像大小相当简单。您将使用resize()方法,该方法接受一个整数元组,用于调整图像的大小。为了了解这是如何工作的,你将使用这张可爱的蜥蜴照片:

现在您已经有了一张照片,继续创建一个名为resize_image.py的新文件,并将以下代码放入其中:
# resize_image.py
from PIL import Image
def resize_image(input_image_path, output_image_path, size):
original_image = Image.open(input_image_path)
width, height = original_image.size
print(f'The original image size is {width} wide x {height} '
f'high')
resized_image = original_image.resize(size)
width, height = resized_image.size
print(f'The resized image size is {width} wide x {height} '
f'high')
resized_image.show()
resized_image.save(output_image_path)
if __name__ == '__main__':
resize_image(
input_image_path='lizard.jpg',
output_image_path='lizard_small.jpg',
size=(800, 400),
)
这里,您传入蜥蜴照片,并告诉 Pillow 将其大小调整为 600 x 400。当您运行这段代码时,输出会告诉您原始照片在为您调整大小之前是 1191 x 1141 像素。
运行这段代码的结果如下所示:

嗯,这看起来有点奇怪!Pillow 在调整图像大小时实际上不做任何缩放。相反,枕头会拉伸或扭曲你的图像,以适应你告诉它使用的值。
你要做的是缩放图像。要做到这一点,您需要创建一个名为scale_image.py的新文件,并向其中添加一些新代码。以下是您需要的代码:
# scale_image.py
from PIL import Image
def scale_image(
input_image_path,
output_image_path,
width=None,
height=None
):
original_image = Image.open(input_image_path)
w, h = original_image.size
print(f'The original image size is {w} wide x {h} '
'high')
if width and height:
max_size = (width, height)
elif width:
max_size = (width, h)
elif height:
max_size = (w, height)
else:
# No width or height specified
raise ValueError('Width or height required!')
original_image.thumbnail(max_size, Image.ANTIALIAS)
original_image.save(output_image_path)
scaled_image = Image.open(output_image_path)
width, height = scaled_image.size
print(f'The scaled image size is {width} wide x {height} '
'high')
if __name__ == '__main__':
scale_image(
input_image_path='lizard.jpg',
output_image_path='lizard_scaled.jpg',
width=800,
)
这一次,您让用户指定宽度和高度。如果用户指定了宽度和/或高度,那么条件语句使用这些信息创建一个max_size。一旦计算出了max_size的值,就将它传递给thumbnail()并保存结果。如果用户指定了这两个值,thumbnail()将在调整大小时正确保持纵横比。
当您运行这段代码时,您会发现结果是原始图像的一个较小版本,并且它现在保持了它的纵横比。
包扎
Pillow 对于使用 Python 处理图像非常有用。在本文中,您学习了如何执行以下操作:
- 打开图像
- 裁剪图像
- 使用过滤器
- 添加边框
- 调整图像大小
你可以用枕头做比这里展示的更多的事情。例如,您可以进行各种图像增强,如更改图像的对比度或亮度。或者你可以将多张图片合成在一起。枕头还有许多其他用途。您应该检查一下这个包,并阅读它的文档以了解更多信息。
相关阅读
这篇文章基于 Python 101 第二版中的一章,你可以在 Leanpub 或亚马逊上购买。
如果你想学习更多的 Python,那么看看这些教程:
-
python 101-记录你的代码
-
Python 101: 使用 JSON 的介绍
-
python 101-创建多个流程
Python 101:如何编写清理脚本
原文:https://www.blog.pythonlibrary.org/2013/11/14/python-101-how-to-write-a-cleanup-script/
有一天,有人问我是否可以写一个脚本来清理目录中所有大于或等于 X 天的文件。我最终使用 Python 的核心模块来完成这项任务。我们将花一些时间来看看做这个有用练习的一种方法。
公平警告:本文中的代码旨在删除文件。使用风险自担!
这是我想出的代码:
import os
import sys
import time
#----------------------------------------------------------------------
def remove(path):
"""
Remove the file or directory
"""
if os.path.isdir(path):
try:
os.rmdir(path)
except OSError:
print "Unable to remove folder: %s" % path
else:
try:
if os.path.exists(path):
os.remove(path)
except OSError:
print "Unable to remove file: %s" % path
#----------------------------------------------------------------------
def cleanup(number_of_days, path):
"""
Removes files from the passed in path that are older than or equal
to the number_of_days
"""
time_in_secs = time.time() - (number_of_days * 24 * 60 * 60)
for root, dirs, files in os.walk(path, topdown=False):
for file_ in files:
full_path = os.path.join(root, file_)
stat = os.stat(full_path)
if stat.st_mtime <= time_in_secs:
remove(full_path)
if not os.listdir(root):
remove(root)
#----------------------------------------------------------------------
if __name__ == "__main__":
days, path = int(sys.argv[1]), sys.argv[2]
cleanup(days, path)
让我们花几分钟时间看看这段代码是如何工作的。在清理函数中,我们采用天数参数并将其转换为秒。然后我们从今天的时间中减去这个数量。接下来,我们使用 os 模块的 walk 方法遍历目录。我们将 topdown 设置为 False,告诉 walk 方法从最里面到最外面遍历目录。然后我们遍历最里面的文件夹中的文件,并检查它的最后访问时间。如果该时间小于或等于时间间隔(即 X 天前),则我们尝试移除该文件。当这个循环结束时,我们在 root 上检查它是否有文件(其中 root 是最里面的文件夹)。如果没有,我们就删除这个文件夹。
移除功能非常简单。它所做的只是检查传递的路径是否是一个目录。然后,它会尝试使用适当的方法(即 os.rmdir 或 os.remove)删除该路径。
删除文件夹/文件的其他方法
还有一些其他的方法来修改文件夹和文件,应该提到。如果你知道你有一组嵌套目录都是空的,你可以使用 os.removedirs()将它们全部删除。另一种更极端的方法是使用 Python 的 shutil 模块。它有一个名为 rmtree 的方法,可以删除文件和文件夹!
我在其他脚本中使用这两种方法都取得了很好的效果。我还发现,有时我无法删除 Windows 上的某个特定文件,除非我通过 Windows 资源管理器删除它。为了解决这个问题,我使用 Python 的子进程模块调用 Window 的 del 命令及其 /F 标志来强制删除。你可以在 Linux 上用它的 rm -r 命令做类似的事情。偶尔你会碰到文件被锁定,保护或你只是没有正确的权限,你不能删除它们。
要添加的功能
如果您花了一些时间思考上面的脚本,您可能已经想到了一些改进或添加的特性。这里有一些我认为不错的:
- 添加日志记录,这样你就知道什么被删除了,什么没有被删除(或者两者都有)
- 添加上一节中提到的其他一些删除方法
- 使清理脚本能够接受要删除的日期范围或日期列表
我相信你已经想到了其他有趣的想法或解决方案。欢迎在下面的评论中分享它们。
进一步阅读
- 如何在 Python 中遍历目录树
- Python 的 os 模块官方文档
- Python 的官方文档 shutil
Python 101 -导入模块(视频)
原文:https://www.blog.pythonlibrary.org/2021/09/17/python-101-importing-video/
在这个视频教程中,你将学习如何使用 import 和 from 关键字导入模块
https://www.youtube.com/embed/ff_0hypwIPA?feature=oembed
相关教程
-
Python 101: 关于导入的一切
Python 101 -安装包
原文:https://www.blog.pythonlibrary.org/2014/03/27/python-101-installing-packages/
当您第一次开始成为 Python 程序员时,您不会考虑您可能需要如何安装外部包或模块。但是当这种需求出现时,你会很快想知道如何去做!Python 包在互联网上随处可见。大部分流行的都可以在 Python 包索引(PyPI) 上找到。你还会在 github、bitbucket、Google code 上找到很多 Python 包。在本文中,我们将介绍以下安装 Python 包的方法:
- 从源安装
- 简单安装
- 点
- 安装软件包的其他方式
从源安装
从源代码安装是一项很好的技能。还有更简单的方法,我们将在本文后面讨论。然而,有一些软件包您必须从源代码安装。例如,要使用 easy_install ,您需要首先安装 setuptools 。为此,您需要下载 tar 或 zip 文件,并将其解压缩到系统中的某个位置。然后寻找 setup.py 文件。打开终端会话,将目录切换到包含安装文件的文件夹。然后运行以下命令:
python setup.py install
如果 python 不在您的系统路径上,您将收到一条错误消息,指出“Python”命令未找到或者是一个未知的应用程序。您可以使用 Python 的完整路径来调用此命令。如果你在 Windows 上,你可以这样做:
c:\python34\python.exe setup.py install
如果您安装了多个版本的 Python,并且需要将包安装到不同的版本上,这种方法尤其方便。您所需要做的就是输入正确 Python 版本的完整路径,并根据它安装软件包。
有些软件包包含 C 代码,例如 C 头文件,需要编译这些文件才能正确安装软件包。在 Linux 上,你通常已经安装了一个 C/C++编译器,你可以轻松地安装这个包。在 Windows 上,您需要安装正确版本的 Visual Studio 才能正确编译该包。有些人说你也可以使用 MingW,但是我还没有找到一种方法让它工作。如果软件包中已经预先制作了 Windows installer,请使用它。那你就完全不用乱搞编译了。
使用简易安装
一旦安装了 setuptools,您就可以使用 easy_install 。你可以在你的 Python 安装的脚本文件夹中找到它。请确保将 Scripts 文件夹添加到您的系统路径中,这样您就可以在命令行上调用 easy_install,而无需指定其完整路径。尝试运行以下命令来了解 easy_install 的所有选项:
easy_install -h
当你想用 easy_install 安装包时,你所要做的就是:
easy_install package_name
easy_install 将尝试从 PyPI 下载软件包,编译它(如果需要)并安装它。如果你进入你的 Python 的 site-packages 目录,你会发现一个名为 easy-install.pth 的文件,它将包含所有用 easy_install 安装的包的条目。Python 使用这个文件来帮助导入模块或包。
您还可以告诉 easy_install 从 URL 或您计算机上的路径进行安装。它还可以直接从 tar 文件安装软件包。你可以使用 easy_install 通过使用 - upgrade (或者-U)来升级一个包。最后,您可以使用 easy_install 来安装 Python eggs。您可以在 PyPI 和其他位置找到 egg 文件。egg 基本上是一个特殊的 zip 文件。事实上,如果您将扩展名更改为。zip,可以解压 egg 文件。
以下是一些例子:
easy_install -U SQLAlchemy
easy_install http://example.com/path/to/MyPackage-1.2.3.tgz
easy_install /path/to/downloaded/package
easy_install 存在一些问题。它会在下载完成前尝试安装一个软件包。无法使用 easy_install 卸载软件包。您必须自己删除软件包,并通过删除软件包中的条目来更新 easy-install.pth 文件。出于这些和其他原因,Python 社区中出现了创造不同事物的运动,这导致了 pip 的诞生。
使用画中画
安装 pip 与我们之前讨论的稍有不同。您仍然可以访问 PyPI,但是不是下载包并运行它的 setup.py 脚本,而是要求您下载一个名为 get-pip.py 的脚本。然后,您需要通过执行以下操作来执行它:
python get-pip.py
这将安装 setuptools 或 setuptools 的替代产品 distribute ,如果其中一个尚未安装的话。它还将安装 pip。pip 与 CPython 版本 2.6、2.7、3.1、3.2、3.3、3.4 以及 pypy 一起工作。您可以使用 pip 来安装 easy_install 可以安装的任何东西,但是调用有点不同。要安装软件包,请执行以下操作:
pip install PackageName
要升级软件包,您需要执行以下操作:
pip install -U PackageName
您可能想调用“pip -h”来获得 pip 可以做的所有事情的完整列表。pip 可以安装而 easy_install 不能安装的一个东西是 Python wheel 格式。wheel 是一个 ZIP 格式的归档文件,具有特殊格式的文件名和。whl 分机。您也可以通过自己的命令行实用程序安装轮子。另一方面,pip 不能安装鸡蛋。如果你需要安装一个 egg,你会希望使用 easy_install。
关于依赖性的一个注记
使用 easy_install 和 pip 的众多好处之一是,如果软件包在其 setup.py 脚本中指定了依赖项,easy_install 和 pip 也会尝试下载并安装它们。当您尝试新的软件包时,这可以减轻很多挫折,您没有意识到软件包 A 依赖于软件包 B、C 和 d。
包扎
现在,您应该能够安装您需要的任何包了,假设这个包支持您的 Python 版本。Python 程序员可以使用很多工具。虽然现在 Python 中的打包有点混乱,但是一旦你知道如何使用合适的工具,你通常可以得到你想要安装或打包的东西。
附加阅读
Python 101-Python 和 Matplotlib 绘图简介(视频)
Python 有许多可用的数据可视化包。其中最流行的是 Matplotlib。
在本视频教程中,我们将学习以下主题:
- 用 PyPlot 创建简单的折线图
- 创建条形图
- 创建饼图
- 添加标签
- Adding Titles to Plots
- Creating a Legend
- Showing Multiple Figures
https://www.youtube.com/embed/7dXMSVLK44A?feature=oembed
相关文章
-
Matplotlib - 用 Python 创建图形的介绍
-
wxPython:py plot-Graphs with Python
Python 101-Python 和 unittest 测试简介(视频)
在本教程中,您将学习使用 Python 和内置的 unittest 模块进行测试的基础知识
https://www.youtube.com/embed/OADBcF3zJfs?feature=oembed
你也可以在这里阅读这个视频所基于的文章: Python 3 测试:单元测试简介
Python 101 -用 ElementTree 解析 XML 简介
原文:https://www.blog.pythonlibrary.org/2013/04/30/python-101-intro-to-xml-parsing-with-elementtree/
如果您关注这个博客已经有一段时间了,您可能还记得我们已经介绍了 Python 中包含的几个 XML 解析库。在本文中,我们将通过快速浏览 ElementTree 库来继续这个系列。您将学习如何创建 XML 文件、编辑 XML 和解析 XML。为了便于比较,我们将使用在之前的 minidom 文章中使用的相同 XML 来说明使用 minidom 和 ElementTree 之间的区别。下面是原始的 XML:
<appointment><begin>1181251680</begin>
<uid>040000008200E000</uid>
<alarmtime>1181572063</alarmtime>
<state><location><duration>1800</duration>
<subject>Bring pizza home</subject></location></state></appointment>
现在让我们深入研究一下 Python!
如何用 ElementTree 创建 XML
用 ElementTree 创建 XML 非常简单。在本节中,我们将尝试用 Python 创建上面的 XML。代码如下:
import xml.etree.ElementTree as xml
#----------------------------------------------------------------------
def createXML(filename):
"""
Create an example XML file
"""
root = xml.Element("zAppointments")
appt = xml.Element("appointment")
root.append(appt)
# add appointment children
begin = xml.SubElement(appt, "begin")
begin.text = "1181251680"
uid = xml.SubElement(appt, "uid")
uid.text = "040000008200E000"
alarmTime = xml.SubElement(appt, "alarmTime")
alarmTime.text = "1181572063"
state = xml.SubElement(appt, "state")
location = xml.SubElement(appt, "location")
duration = xml.SubElement(appt, "duration")
duration.text = "1800"
subject = xml.SubElement(appt, "subject")
tree = xml.ElementTree(root)
with open(filename, "w") as fh:
tree.write(fh)
#----------------------------------------------------------------------
if __name__ == "__main__":
createXML("appt.xml")
如果您运行这段代码,您应该会得到如下所示的内容(可能都在一行中):
<appointment><begin>1181251680</begin>
<uid>040000008200E000</uid>
<alarmtime>1181572063</alarmtime>
<state><location><duration>1800</duration></location></state></appointment>
这非常接近原始的 XML,当然也是有效的 XML,但又不完全相同。不过,已经够近了。让我们花点时间回顾一下代码,确保我们理解了它。首先,我们使用 ElementTree 的元素函数创建根元素。然后,我们创建一个约会元素,并将其附加到根元素上。接下来,我们通过将约会元素对象(appt)和一个名称(如“begin ”)传递给子元素来创建子元素。然后,对于每个子元素,我们设置它的文本属性来赋予它一个值。在脚本的最后,我们创建了一个 ElementTree,并用它将 XML 写出到一个文件中。
令人恼火的是,它将 XML 全部写在一行上,而不是以一种易读的格式(即“漂亮的打印”)。Effbot 上有一个秘方,但似乎没有内部实现的方法。你可能还想看看 StackOverflow 上的其他一些解决方案。应该注意的是,lxml 支持开箱即用的“漂亮打印”。
现在我们准备学习如何编辑文件!
如何用 ElementTree 编辑 XML
用 ElementTree 编辑 XML 也很容易。为了让事情变得更有趣,我们将在 XML 中添加另一个约会块:
<appointment><begin>1181251680</begin>
<uid>040000008200E000</uid>
<alarmtime>1181572063</alarmtime>
<state><location><duration>1800</duration>
<subject>Bring pizza home</subject></location></state></appointment>
<appointment><begin>1181253977</begin>
<uid>sdlkjlkadhdakhdfd</uid>
<alarmtime>1181588888</alarmtime>
<state>TX</state>
<location>Dallas</location>
<duration>1800</duration>
<subject>Bring pizza home</subject></appointment>
现在,让我们编写一些代码,将每个 begin 标签的值从 epoch 以来的秒数更改为可读性更好的值。我们将使用 Python 的时间模块来实现这一点:
import time
import xml.etree.cElementTree as ET
#----------------------------------------------------------------------
def editXML(filename):
"""
Edit an example XML file
"""
tree = ET.ElementTree(file=filename)
root = tree.getroot()
for begin_time in root.iter("begin"):
begin_time.text = time.ctime(int(begin_time.text))
tree = ET.ElementTree(root)
with open("updated.xml", "w") as f:
tree.write(f)
#----------------------------------------------------------------------
if __name__ == "__main__":
editXML("original_appt.xml")
这里我们创建了一个 ElementTree 对象(树),并从中提取了根。然后我们使用 ElementTree 的 iter ()方法来查找所有标记为“begin”的标签。注意,iter()方法是在 Python 2.7 中添加的。在我们的 for 循环中,我们通过 time.ctime (),将每一项的 text 属性设置为更易于阅读的时间格式。您会注意到,在将字符串传递给 ctime 时,我们必须将其转换为整数。输出应该如下所示:
<appointment><begin>Thu Jun 07 16:28:00 2007</begin>
<uid>040000008200E000</uid>
<alarmtime>1181572063</alarmtime>
<state><location><duration>1800</duration>
<subject>Bring pizza home</subject></location></state></appointment>
<appointment><begin>Thu Jun 07 17:06:17 2007</begin>
<uid>sdlkjlkadhdakhdfd</uid>
<alarmtime>1181588888</alarmtime>
<state>TX</state>
<location>Dallas</location>
<duration>1800</duration>
<subject>Bring pizza home</subject></appointment>
还可以使用 ElementTree 的 find ()或 findall ()方法在 XML 中搜索特定的标签。find()方法将只查找第一个实例,而 findall()将查找带有指定标签的所有标签。这些对于编辑和解析都很有帮助,这是我们的下一个主题!
如何用 ElementTree 解析 XML
现在我们开始学习如何用 ElementTree 做一些基本的解析。首先,我们将通读代码,然后我们将一点一点地浏览,以便我们能够理解它。注意,这段代码是基于最初的例子,但是它也应该适用于第二个例子。
import xml.etree.cElementTree as ET
#----------------------------------------------------------------------
def parseXML(xml_file):
"""
Parse XML with ElementTree
"""
tree = ET.ElementTree(file=xml_file)
print tree.getroot()
root = tree.getroot()
print "tag=%s, attrib=%s" % (root.tag, root.attrib)
for child in root:
print child.tag, child.attrib
if child.tag == "appointment":
for step_child in child:
print step_child.tag
# iterate over the entire tree
print "-" * 40
print "Iterating using a tree iterator"
print "-" * 40
iter_ = tree.getiterator()
for elem in iter_:
print elem.tag
# get the information via the children!
print "-" * 40
print "Iterating using getchildren()"
print "-" * 40
appointments = root.getchildren()
for appointment in appointments:
appt_children = appointment.getchildren()
for appt_child in appt_children:
print "%s=%s" % (appt_child.tag, appt_child.text)
#----------------------------------------------------------------------
if __name__ == "__main__":
parseXML("appt.xml")
您可能已经注意到了这一点,但是在这个例子和最后一个例子中,我们一直在导入 cElementTree,而不是普通的 ElementTree。两者的主要区别在于 cElementTree 是基于 C 而不是基于 Python 的,所以速度要快得多。无论如何,我们再次创建一个 ElementTree 对象并从中提取根。您会注意到 e 打印出了根以及根的标签和属性。接下来,我们展示几种迭代标签的方法。第一个循环只是一个接一个地遍历 XML。不过这只会打印出顶层的子节点(约会),所以我们添加了一个 if 语句来检查这个子节点,并遍历它的子节点。
接下来,我们从树对象本身获取一个迭代器,并以这种方式遍历它。您将获得相同的信息,但是没有第一个示例中的额外步骤。第三种方法使用根的 getchildren ()函数。这里我们再次需要一个内部循环来获取每个约会标记中的所有子元素。最后一个例子使用根的 iter()方法遍历所有匹配字符串“begin”的标签。
正如上一节所提到的,您还可以使用 find()或 findall()分别帮助您找到特定的标签或标签集。还要注意,每个元素对象都有一个标签和一个文本属性,您可以使用它们来获取准确的信息。
包扎
现在您知道了如何使用 ElementTree 来创建、编辑和解析 XML。您可以将这些信息添加到 XML 解析工具包中,并将其用于娱乐或盈利目的。您可以在下面找到以前关于其他 XML 解析工具的文章的链接,以及关于 ElementTree 本身的其他信息。
来自鼠标 Vs Python 的相关文章
附加阅读
- 元素树的官方 Python 文档
- Effbot 的元素树概述
- 用 elementree 在 Python 中处理 XML
- 查克博士的简单元素树示例
下载源代码
Python 101:内省
原文:https://www.blog.pythonlibrary.org/2010/10/14/python-101-introspection/
无论您是 Python 新手、使用了几年还是专家,了解如何使用 Python 的自省功能都有助于理解您的代码和您刚刚下载的带有蹩脚文档的新包。自省是一个花哨的词,意思是观察自己,思考自己的思想、感觉和欲望。在 Python 世界中,自省实际上有点类似。这种情况下的自省就是用 Python 来搞清楚 Python。在本文中,您可以学习如何使用 Python 来给自己一些关于您正在处理或试图学习的代码的线索。有些人甚至称之为调试的一种形式。
以下是我们将要讲述的内容:
- 类型
- 目录
- 帮助
- [计]系统复制命令(system 的简写)
需要注意的是,这不是一篇有深度的文章。它会给你一些工具,让你开始行动。但废话少说,我们需要继续下去!
Python 类型
您可能不知道这一点,但 Python 可能正是您喜欢的类型。是的,Python 可以告诉你你有什么类型的变量,或者从一个函数返回什么类型。这是一个非常方便的小工具。让我们看几个例子来说明这一点:
>>> x = "test"
>>> y = 7
>>> z = None
>>> type(x)
<type 'str'>
>>> type(y)
<type 'int'>
>>> type(z)
<type 'NoneType'>
如你所见,Python 有一个名为 type 的关键字,可以告诉你什么是什么。在我的实际经验中,我使用 type 来帮助我弄清楚当我的数据库数据损坏或者不是我所期望的时候发生了什么。我只是添加了几行,并打印出每一行的数据及其类型。当我被自己写的一些愚蠢的代码弄糊涂的时候,这给了我很大的帮助。
Python 目录
什么是 dir ?它是当某人说或做一些愚蠢的事情时你说的话吗?不是在这种背景下!不,在 Python 这个星球上, dir 关键字(又名:builtin)是用来告诉程序员传入的对象有什么属性的。如果您忘记传入一个对象,dir 将返回当前范围内的名称列表。和往常一样,这用几个例子就比较好理解了。
>>> dir("test")
['__add__', '__class__', '__contains__', '__delattr__',
'__doc__', '__eq__', '__ge__', '__getattribute__',
'__getitem__', '__getnewargs__', '__getslice__', '__gt__',
'__hash__', '__init__', '__le__', '__len__', '__lt__',
'__mod__', '__mul__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__rmod__', '__rmul__',
'__setattr__', '__str__', 'capitalize', 'center',
'count', 'decode', 'encode', 'endswith', 'expandtabs',
'find', 'index', 'isalnum', 'isalpha', 'isdigit', 'islower',
'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower',
'lstrip', 'replace', 'rfind', 'rindex', 'rjust', 'rsplit',
'rstrip', 'split', 'splitlines', 'startswith', 'strip',
'swapcase', 'title', 'translate', 'upper', 'zfill']
由于 Python 中的一切都是对象,我们可以将一个字符串传递给 dir,并找出它有哪些方法。很整洁,是吧?现在让我们用一个导入的模块来尝试一下:
>>> import sys
>>> dir(sys)
['__displayhook__', '__doc__', '__egginsert', '__excepthook__',
'__name__', '__plen', '__stderr__', '__stdin__', '__stdout__',
'_getframe', 'api_version', 'argv', 'builtin_module_names',
'byteorder', 'call_tracing', 'callstats', 'copyright',
'displayhook', 'dllhandle', 'exc_clear', 'exc_info',
'exc_traceback', 'exc_type', 'exc_value', 'excepthook',
'exec_prefix', 'executable', 'exit', 'exitfunc',
'getcheckinterval', 'getdefaultencoding', 'getfilesystemencoding',
'getrecursionlimit', 'getrefcount', 'getwindowsversion', 'hexversion',
'maxint', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks',
'path_importer_cache', 'platform', 'prefix', 'setcheckinterval',
'setprofile', 'setrecursionlimit', 'settrace', 'stderr', 'stdin',
'stdout', 'version', 'version_info', 'warnoptions', 'winver']
现在,这很方便!如果您还没有弄明白,dir 函数对于那些您已经下载(或即将下载)的几乎没有文档的第三方包来说是非常方便的。在这些情况下,你如何找到可用的方法?嗯,dir 会帮你搞清楚的。当然,有时文档就在代码本身中,这就把我们带到了内置的帮助实用程序中。
Python 救命!
Python 附带了一个方便的帮助工具。只需在 Python shell 中键入“help()”(去掉引号),您将看到以下说明(Python 版本可能有所不同...)
>>> help()
Welcome to Python 2.6! This is the online help utility.
If this is your first time using Python, you should definitely check out
the tutorial on the Internet at http://www.python.org/doc/tut/.
Enter the name of any module, keyword, or topic to get help on writing
Python programs and using Python modules. To quit this help utility and
return to the interpreter, just type "quit".
To get a list of available modules, keywords, or topics, type "modules",
"keywords", or "topics". Each module also comes with a one-line summary
of what it does; to list the modules whose summaries contain a given word
such as "spam", type "modules spam".
help>
请注意,您现在有了一个帮助> 提示,而不是 > > > 。在帮助模式下,您可以探索 Python 中的各种模块、关键字和主题。还要注意,当输入单词模块时,当 Python 搜索其库文件夹以获取列表时,您会看到一个延迟。如果你已经安装了很多第三方模块,这可能需要一段时间,所以准备好在你等待的时候给自己弄杯摩卡吧。一旦完成,只需按照说明进行操作,我想你会掌握要点的。
Python sys 模块
是的,如果你大声读出来,标题听起来像是在嘶嘶作响,但我们在这里谈论的是 Python。无论如何,我们关心 Python 的 sys 模块的主要原因是因为它可以告诉我们关于 Python 环境的所有事情。看看它在我的机器上发现了什么:
>>> import sys
>>> sys.executable
'L:\\Python24\\pythonw.exe'
>>> sys.platform
'win32'
>>> sys.version
'2.4.3 (#69, Mar 29 2006, 17:35:34) [MSC v.1310 32 bit (Intel)]'
>>> sys.argv
['']
>>> sys.path
['L:\\Python24\\Lib\\idlelib', 'L:\\Python24\\lib\\site-packages\\icalendar-1.2-py2.4.egg', 'C:\\WINDOWS\\system32\\python24.zip', 'L:\\Python24', 'L:\\Python24\\DLLs', 'L:\\Python24\\lib', 'L:\\Python24\\lib\\plat-win', 'L:\\Python24\\lib\\lib-tk', 'L:\\Python24\\lib\\site-packages', 'L:\\Python24\\lib\\site-packages\\win32', 'L:\\Python24\\lib\\site-packages\\win32\\lib', 'L:\\Python24\\lib\\site-packages\\Pythonwin', 'L:\\Python24\\lib\\site-packages\\wx-2.8-msw-unicode']
仅供参考:我现在很少使用 Python 2.4。出于某种原因,它只是碰巧是我在写作时手边的 IDLE 版本。无论如何,正如你所看到的,sys 模块对于弄清楚你的机器和 Python 本身是非常方便的。例如,当您通过 sys.path.add()或 sys.path.remove()键入“import”时,可以使用 sys 在 Python 搜索模块的路径列表中添加或移除路径。
包扎
好吧,我希望你能从这篇文章中学到一些东西。几年前,我的老板做了一个关于自省的讲座,我认为这真的很有趣,尽管我知道他在说什么。当我开始写这篇文章时,我决定看看是否有其他人写过关于这个主题的东西,其中最臭名昭著的是帕特里克·奥布莱恩(PyCrust 的作者)2002 年的一篇旧文章。它比这个长得多,但相当有趣。如果你有时间,我也推荐你读一读。
python 101 48 小时免费!
原文:https://www.blog.pythonlibrary.org/2016/11/07/python-101-is-free-for-48-hours/
今天我将发布我的第一本书,48 小时免费。Python 101 是作为对 Python 编程语言的介绍而编写的。虽然它是为初学者设计的,但有些人声称他们需要比这本书提供给他们的更多的手把手。所以我目前推荐它作为寻求学习 Python 的开发人员的入门和中级书籍。
当我最初写这本书的时候,我注意到很少有或者根本没有描述如何创建代码的可执行文件或者如何通过 Python 的包索引(PyPI)分发代码的书籍。Python 101 涵盖了这些主题,并向读者介绍了 Python 的标准库、如何安装第三方包以及一些最流行的 Python 第三方包的介绍,如 SQLAlchemy、requests 和 virtualenv。
Python 101 有 5 节,44 章,295 页。
你可以使用下面的链接在 Leanpub 上免费获得 Python 101:http://leanpub.com/python_101/c/48hours
如果你碰巧有一个 Gumroad 的账户,那么你也可以通过使用下面的优惠代码免费得到这本书:48 小时
你会得到这本书的 PDF,epub 和 mobi 版本。你可以在 Leanpub 网站上看到完整的目录
如果你喜欢我的第一本书,你可以得到它的续集, Python 201:中级 Python 换五折这里:【http://leanpub.com/python201/c/50percent】T4
Python 101 现在是一门教育性的课程
原文:https://www.blog.pythonlibrary.org/2017/01/16/python-101-is-now-a-course-on-educative/
我的第一本书 Python 101 ,已经在教育网站上被做成在线课程。Educative 有点像 Code Academy,你可以运行书中的代码片段,看看它们会产生什么样的输出。您可以编辑可执行的示例,但当前不能保存您的编辑。使用以下优惠券代码可以获得课程的五折优惠: au-pythonlibrary50 (注:此优惠券仅一周有效)
Python 101 主要面向理解编程概念或者已经用另一种语言编程的人。我确实有很多对编程完全陌生的读者,他们也很喜欢这本书。这本书本身分为 5 个不同的部分:
第一部分涵盖了 Python 的基础知识。第二部分开始学习一点 Python 的标准库。在这一节中,我将介绍我发现自己日常使用最多的库。第三部分进入中级领域,涵盖各种主题,如装饰器、调试、代码剖析和测试代码。第四部分向读者介绍了如何安装第三方库,并简要演示了一些流行的库,如 lxml、requests、SQLAlchemy 和 virtualenv。最后一部分是关于分发你的代码。在这里,您将了解如何将您的代码添加到 Python 包索引以及创建 Windows 可执行文件。
想要完整的目录,你可以访问这本书的网页这里。Educative 也有一个非常好的在线课程的内容页面。
Python 101 是 24 小时按需付费
原文:https://www.blog.pythonlibrary.org/2021/04/08/python-101-is-pay-what-you-want-for-24-hours/
For the next 24 hours, Python 101 will be Pay What You Want, $3 minimum (usually $25).
第二版 Python 101 完全从头重写。在本书中,您将学习 Python 编程语言以及更多内容。
这本书分为四个部分:
- Python 语言
- 中级主题
- 创建示例应用程序
- 分发您的代码
Python 101: Lambda 基础
原文:https://www.blog.pythonlibrary.org/2015/10/28/python-101-lambda-basics/
许多编程语言都有 lambda 函数的概念。在 Python 中,lambda 是匿名函数或非绑定函数。它们的语法看起来有点奇怪,但实际上只是将一个简单的函数变成一行程序。让我们从一个常规的简单函数开始:
#----------------------------------------------------------------------
def doubler(x):
return x*2
这个函数所做的就是取一个整数,然后翻倍。从技术上来说,它还会加倍其他东西,因为没有类型检查,但这是它的意图,现在让我们把它变成一个 lambda 函数!
幸运的是,将一行函数转换成 lambda 非常简单。方法如下:
doubler = lambda x: x*2
所以 lambda 的工作方式和函数差不多。我们先说清楚,这里的“x”是你传入的参数。冒号将参数列表与返回值或表达式分开。所以当你到了“x*2”部分,这就是返回的内容。让我们看另一个例子:
>>> poww = lambda i: i**2
>>> poww(2)
4
>>> poww(4)
16
>>> (lambda i: i**2)(6)
36
在这里,我们演示了如何创建一个 lambda,它接受一个输入并对其求平方。Python 社区中有一些关于是否应该给变量赋值 lambda 的争论。原因是当你命名一个 lambda 时,它不再是真正的匿名,你还不如只写一个普通的函数。lambda 的要点是使用一次就扔掉。上面的最后一个例子展示了一种匿名调用 lambda 的方法(即使用一次)。
此外,如果你给 lambda 命名,你可以这样做:
>>> def poww(i): return i**2
>>> poww(2)
4
让我们继续,看看如何在列表理解中使用 lambda!
Lambdas,列表理解和地图
除了在事件回调中使用 lambdass 之外,我总是很难想出 lambda 的好的用法。所以我去找了一些其他的用例。似乎有些人喜欢在列表理解中使用它们。这里有几个例子:
>>> [(lambda x: x*3)(i) for i in range(5)]
[0, 3, 6, 9, 12]
>>> tripler = lambda x: x*3
>>> [tripler(i) for i in range(5)]
[0, 3, 6, 9, 12]
第一个例子有点尴尬。虽然它匿名调用 lambda,但阅读起来也有点困难。下一个例子把 lambda 赋值给一个变量,然后我们这样调用它。有趣的是 Python 有一个内置的方法来调用一个带有 iterable 的函数,这个函数叫做 map 。以下是您通常使用它的方式:
map(function, interable)
这是一个使用我们之前的 lambda 函数的真实例子:
>>> map(tripler, range(5))
[0, 3, 6, 9, 12]
当然,在大多数情况下,lambda 非常简单,在列表中做同样的事情可能更容易理解:
>>> [x*3 for x in range(5)]
[0, 3, 6, 9, 12]
λ的其他用途
我的读者建议了 lambda 的一些其他用途。第一个例子是从函数调用中返回一个 lambda:
>>> def increment(n):
return lambda(x): x + n
>>> i = increment(5)
>>> i(2)
7
这里我们创建了一个函数,无论我们给它什么,它都会递增 5。我的另一个读者建议给 Python 的排序的函数传递一个 lambda:
sorted(list, key=lambda i: i.address)
这里的想法是用属性“地址”对对象列表进行排序。然而,我仍然发现 lambda 的最佳用例仍然是事件回调,所以让我们看看如何使用 Tkinter 来使用它们。
使用 lambda 进行回调
Tkinter 是 Python 内置的一个 GUI 工具包。当你想与你的用户界面交互时,你通常会使用键盘和鼠标。这些交互通过事件工作,这就是 lambda 出现的地方。让我们创建一个简单的用户界面,这样您就可以看到 lambda 是如何在 Tkinter 中使用的!
import Tkinter as tk
########################################################################
class App:
""""""
#----------------------------------------------------------------------
def __init__(self, parent):
"""Constructor"""
frame = tk.Frame(parent)
frame.pack()
print_btn = tk.Button(frame, text='Print',
command=lambda: self.onPrint('Print'))
print_btn.pack(side=tk.LEFT)
close_btn = tk.Button(frame, text='close', command=frame.quit)
close_btn.pack(side=tk.LEFT)
#----------------------------------------------------------------------
def onPrint(self, num):
print "You just printed something"
#----------------------------------------------------------------------
if __name__ == "__main__":
root = tk.Tk()
app = App(root)
root.mainloop()
这里我们有一个简单的用户界面,有两个按钮。一个按钮使用 lambda 调用 onPrint 方法,而另一个按钮使用 Tkinter 方法关闭应用程序。如你所见,Tkinter 对 lambda 的使用符合其初衷。这里的 lambda 用一次就扔掉了。除了按下按钮之外,没有其他方法可以引用它。
包扎
正如我的长期读者可能知道的,五年前我在另一篇文章中写过关于 lambda 的文章。那时,我对兰姆达斯没有太大的用处,坦白地说,现在也没有。它们是这种语言的一个简洁的特性,但是在用 Python 编程 9 年多之后,我几乎没有发现使用它们的需要,尤其是在它们应该被使用的方式上。而是每个人自己的。使用 lambdas 当然没有错,但是我希望这篇文章对于弄清楚您是否真的需要在自己的工作中使用它们是有用的。
相关阅读
- 巨蟒λ
- 又一个 Lambda 教程
- 用 Python lambdas 迭代
- 当操作列表中的元素时,使用列表理解还是使用带有 lambda 函数的 map 更好?- Quora
- 使用 lambda 函数深入 Python-
Python 101 -使用 Python 启动子流程
原文:https://www.blog.pythonlibrary.org/2020/06/30/python-101-launching-subprocesses-with-python/
有时候,当你正在编写一个应用程序,你需要运行另一个应用程序。例如,出于某种原因,您可能需要在 Windows 上打开 Microsoft 记事本。或者如果你在 Linux 上,你可能想运行 grep 。Python 支持通过subprocess模块启动外部应用程序。
从 Python 2.4 开始,subprocess模块就是 Python 的一部分。在此之前,您需要使用os模块。你会发现subprocess模块功能强大,使用简单。
在本文中,您将学习如何使用:
subprocess.run()功能subprocess.Popen()类subprocess.Popen.communicate()功能- 用
stdin和stdout读写
我们开始吧!
subprocess.run()功能
在 Python 3.5 中增加了run()函数。run()功能是使用subprocess的推荐方法。
查看函数的定义通常有助于更好地理解它的工作原理:
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None,
capture_output=False, shell=False, cwd=None, timeout=None, check=False,
encoding=None, errors=None, text=None, env=None, universal_newlines=None)
你不需要知道所有这些参数是如何有效地使用run()的。事实上,大多数时候您可能只需要知道第一个参数是什么以及是否启用shell就可以了。其余的论点对于非常具体的用例是有帮助的。
让我们试着运行一个常见的 Linux / Mac 命令,ls。ls命令用于列出目录中的文件。默认情况下,它会列出您当前所在目录中的文件。
要使用subprocess运行它,您需要执行以下操作:
>>> import subprocess
>>> subprocess.run(['ls'])
filename
CompletedProcess(args=['ls'], returncode=0)
您还可以设置shell=True,它将通过 shell 本身运行命令。大多数情况下,您不需要这样做,但是如果您需要对进程进行更多的控制,并且想要访问 shell 管道和通配符,这可能会很有用。
但是,如果您希望保留命令的输出,以便以后使用,该怎么办呢?让我们看看你接下来会怎么做!
获取输出
通常,您会希望从外部流程获得输出,然后对该数据进行处理。要从run()获得输出,您可以将capture_output参数设置为 True:
>>> subprocess.run(['ls', '-l'], capture_output=True)
CompletedProcess(args=['ls', '-l'], returncode=0,
stdout=b'total 40\n-rw-r--r--@ 1 michael staff 17083 Apr 15 13:17 some_file\n',
stderr=b'')
现在这并没有太大的帮助,因为您没有将返回的输出保存到变量中。继续更新代码,这样你就可以访问stdout。
>>> output = subprocess.run(['ls', '-l'], capture_output=True)
>>> output.stdout
b'total 40\n-rw-r--r--@ 1 michael staff 17083 Apr 15 13:17 some_file\n'
output是一个CompletedProcess类实例,它允许您访问传入的args、returncode以及stdout和stderr。
一会儿你就会了解到returncode。stderr是大多数程序打印错误信息的地方,而stdout是用来显示信息性消息的。
如果您感兴趣,可以研究一下这段代码,看看当前这些属性中有什么:
output = subprocess.run(['ls', '-l'], capture_output=True)
print(output.returncode)
print(output.stdout)
print(out.stderr)
让我们继续,了解下一个Popen。
subprocess.Popen()类
自从添加了subprocess模块之后,subprocess.Popen()类就已经存在了。在 Python 3 中已经更新了几次。如果你有兴趣了解这些变化,你可以在这里阅读:
你可以把Popen看成是run()的低级版本。如果你有一个run()无法处理的异常用例,那么你应该使用Popen来代替。
现在,让我们看看如何使用Popen运行上一节中的命令:
>>> import subprocess
>>> subprocess.Popen(['ls', '-l'])
<subprocess.Popen object at 0x10f88bdf0>
>>> total 40
-rw-r--r--@ 1 michael staff 17083 Apr 15 13:17 some_file
>>>
语法几乎相同,除了您使用的是Popen而不是run()。
以下是从外部进程获取返回代码的方式:
>>> process = subprocess.Popen(['ls', '-l'])
>>> total 40
-rw-r--r--@ 1 michael staff 17083 Apr 15 13:17 some_file
>>> return_code = process.wait()
>>> return_code
0
>>>
0的一个return_code表示程序成功完成。如果你打开一个有用户界面的程序,比如微软记事本,你需要切换回你的 REPL 或者空闲会话来添加process.wait()行。这样做的原因是记事本会出现在程序的顶部。
如果您没有将process.wait()调用添加到您的脚本中,那么您将无法在手动关闭您可能已经通过subprocess启动的任何用户界面程序后捕获返回代码。
您可以使用您的process句柄通过pid属性访问进程 id。您也可以通过调用process.kill()来终止(SIGKILL)进程,或者通过process.terminate()来终止(SIGTERM)进程。
subprocess.Popen.communicate()功能
有时候,您需要与自己创建的进程进行交流。您可以使用Popen.communicate()方法向流程发送数据以及提取数据。
对于本节,您将只使用communicate()来提取数据。让我们使用communicate()来获得使用ifconfig命令的信息,您可以使用它来获得关于 Linux 或 Mac 上的计算机网卡的信息。在 Windows 上,你可以使用ipconfig。请注意,根据您的操作系统,此命令中有一个字母的差异。
代码如下:
>>> import subprocess
>>> cmd = ['ifconfig']
>>> process = subprocess.Popen(cmd,
stdout=subprocess.PIPE,
encoding='utf-8')
>>> data = process.communicate()
>>> print(data[0])
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
options=1203<RXCSUM,TXCSUM,TXSTATUS,SW_TIMESTAMP>
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
nd6 options=201<PERFORMNUD,DAD>
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
XHC20: flags=0<> mtu 0
# -------- truncated --------
这段代码的设置与上一段略有不同。让我们更详细地检查一下每一部分。
首先要注意的是,您将stdout参数设置为一个subprocess.PIPE。这允许您捕获该流程发送给stdout的任何内容。你还设置了encoding为utf-8。这样做的原因是为了使输出更容易阅读,因为默认情况下subprocess.Popen调用返回字节而不是字符串。
下一步是调用communicate(),它将从流程中捕获数据并返回。communicate()方法同时返回stdout和stderr,所以你将得到一个tuple。你在这里没有捕捉到stderr,所以那将是None。
最后,你打印出数据。该字符串相当长,所以输出在这里被截断。
让我们继续学习如何使用subprocess进行读写!
用stdin和stdout读写
让我们假设您今天的任务是编写一个 Python 程序,该程序检查您的 Linux 服务器上当前运行的进程,并打印出使用 Python 运行的进程。
您可以使用ps -ef获得当前正在运行的进程列表。通常情况下,您会使用该命令,并将其“传输”到另一个 Linux 命令行实用程序grep,用于搜索字符串文件。
以下是您可以使用的完整 Linux 命令:
ps -ef | grep python
但是,您希望使用subprocess模块将该命令翻译成 Python。
有一种方法可以做到这一点:
import subprocess
cmd = ['ps', '-ef']
ps = subprocess.Popen(cmd, stdout=subprocess.PIPE)
cmd = ['grep', 'python']
grep = subprocess.Popen(cmd, stdin=ps.stdout, stdout=subprocess.PIPE,
encoding='utf-8')
ps.stdout.close()
output, _ = grep.communicate()
python_processes = output.split('\n')
print(python_processes)
这段代码重新创建了ps -ef命令,并使用subprocess.Popen来调用它。使用subprocess.PIPE捕获命令的输出。然后您还创建了grep命令。
对于grep命令,您将其stdin设置为ps命令的输出。您还捕获了grep命令的stdout,并像以前一样将编码设置为utf-8。
这有效地从ps命令和“管道”中获得输出,或者将其输入到grep命令中。接下来,您close()了ps命令的stdout,并使用grep命令的communicate()方法从grep获得输出。
最后,在新行(\n)上分割输出,得到一个字符串的list,它应该是所有活动 Python 进程的列表。如果您现在没有运行任何活动的 Python 进程,那么输出将是一个空列表。
你总是可以自己运行ps -ef,找到除了python之外的其他东西来搜索,并尝试这样做。
包扎
subprocess模块是非常通用的,它为您提供了一个丰富的接口来处理外部进程。
在本文中,您了解了:
subprocess.run()功能subprocess.Popen()类subprocess.Popen.communicate()功能- 用
stdin和stdout读写
subprocess模块的内容比这里介绍的要多。然而,你现在应该能够正确使用subprocess了。来吧,试一试!
Python 101 -了解所有关于函数的知识(视频)
原文:https://www.blog.pythonlibrary.org/2022/05/07/python-101-learn-all-about-functions-video/
在本视频教程中,您将了解以下内容:
- 创建函数
- 调用函数
- 传递参数
- 键入暗示你的论点
- 传递关键字参数
- 必需和默认参数
*args和**kwargs- 仅位置参数
- 范围
https://www.youtube.com/embed/7SIMQ13x1hw?feature=oembed
相关业务
- Python 101 视频系列
- Python 101 -第二版:
Python 101 -了解理解(视频)
原文:https://www.blog.pythonlibrary.org/2020/09/11/python-101-learning-about-comprehensions-video/
在本教程中,你将学习 Python 的理解,比如流行的列表理解和字典理解。
https://www.youtube.com/embed/DY74inobtfY?feature=oembed
| | 您想了解更多关于 Python 的知识吗?
Python 101 -第二版
立即在 Leanpub 或亚马逊购买
|
Python 101 -了解字典(视频)
原文:https://www.blog.pythonlibrary.org/2020/07/08/python-101-learning-about-dictionaries-video/
在本视频教程中,您将了解以下内容:
- 创建词典
- 访问词典
- 字典方法
- 修改词典
- 从字典中删除
https://www.youtube.com/embed/270RSqgzzPY?feature=oembed
如果你喜欢阅读你的教程,那么你可以看看这个:
- Python 101 - 了解字典
Python 101 -了解字典
原文:https://www.blog.pythonlibrary.org/2020/03/31/python-101-learning-about-dictionaries/
字典是 Python 中的另一种基本数据类型。字典是一个键、值对。一些编程语言将它们称为哈希表。它们被描述为一个映射对象,将散列值映射到任意对象。
字典的键必须是不可变的,也就是说,不能改变。从 Python 3.7 开始,字典是有序的。这意味着当你添加一个新的键,值对到字典时,它会记住它们的添加顺序。在 Python 3.7 之前,情况并非如此,您不能依赖插入顺序。
在本章中,您将学习如何执行以下操作:
- 创建词典
- 访问词典
- 字典方法
- 修改词典
- 从字典中删除
让我们从学习创建字典开始吧!
你可以用几种不同的方法创建字典。最常见的方法是将逗号分隔的列表key: value对放在花括号内。
让我们看一个例子:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict
{'email': 'jdoe@gmail.com', 'first_name': 'James', 'last_name': 'Doe'}
还可以使用 Python 内置的dict()函数来创建字典。dict()将接受一系列关键字参数(即 1= '一',2= '二'等),一个元组列表或另一个字典。
这里有几个例子:
>>> numbers = dict(one=1, two=2, three=3)
>>> numbers
{'one': 1, 'three': 3, 'two': 2}
>>> info_list = [('first_name', 'James'), ('last_name', 'Doe'), ('email', 'jdoes@gmail.com')]
>>> info_dict = dict(info_list)
>>> info_dict
{'email': 'jdoes@gmail.com', 'first_name': 'James', 'last_name': 'Doe'}
第一个例子在一系列关键字参数上使用了dict()。当你学习函数的时候,你会学到更多。您可以将关键字参数看作是一系列关键字,在它们和它们的值之间有等号。
第二个例子展示了如何创建一个包含 3 个元组的列表。然后您将该列表传递给dict()以将其转换为字典。
访问词典
词典因其速度快而出名。您可以通过键访问字典中的任何值。如果没有找到密钥,您将收到一个KeyError。
让我们来看看如何使用字典:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict['first_name']
'James'
要获得first_name的值,必须使用以下语法:dictionary_name[key]
现在让我们试着得到一个不存在的键:
>>> sample_dict['address']
Traceback (most recent call last):
Python Shell, prompt 118, line 1
builtins.KeyError: 'address'
那没用。你要求字典给你一个字典里没有的值!
您可以使用 Python 的in关键字来询问一个键是否在字典中:
>>> 'address' in sample_dict
False
>>> 'first_name' in sample_dict
True
您还可以通过使用 Python 的not关键字来检查字典中的键是否是而不是:
>>> 'first_name' not in sample_dict
False
>>> 'address' not in sample_dict
True
访问字典中的键的另一种方法是使用字典方法之一。现在让我们了解更多关于字典方法的知识吧!
字典方法
与大多数 Python 数据类型一样,字典有您可以使用的特殊方法。让我们来看看字典的一些方法吧!
d.get(键[,默认值])
您可以使用get()方法来获取一个值。get()要求您指定要查找的键。如果找不到键,它允许您返回一个默认值。默认是None。让我们来看看:
>>> print(sample_dict.get('address'))
None
>>> print(sample_dict.get('address', 'Not Found'))
Not Found
第一个例子向您展示了当您试图在不设置get的default的情况下get()一个不存在的键时会发生什么。在这种情况下,它返回None。然后,第二个示例向您展示了如何将默认值设置为字符串“Not Found”。
d .清除()
方法可以用来从字典中删除所有的条目。
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict
{'email': 'jdoe@gmail.com', 'first_name': 'James', 'last_name': 'Doe'}
>>> sample_dict.clear()
>>> sample_dict
{}
d.copy()
如果您需要创建字典的浅层副本,那么copy()方法适合您:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> copied_dict = sample_dict.copy()
>>> copied_dict
{'email': 'jdoe@gmail.com', 'first_name': 'James', 'last_name': 'Doe'}
如果你的字典里面有对象或者字典,那么你可能会因为这个方法而陷入逻辑错误,因为改变一个字典会影响到副本。在这种情况下,您应该使用 Python 的copy模块,它有一个deepcopy函数,可以为您创建一个完全独立的副本。
d .项目()
items()方法将返回字典条目的新视图:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict.items()
dict_items([('first_name', 'James'), ('last_name', 'Doe'), ('email', 'jdoe@gmail.com')])
这个视图对象将随着字典对象本身的改变而改变。
钥匙()
如果您需要查看字典中的键,那么keys()就是适合您的方法。作为一个视图对象,它将为您提供字典键的动态视图。您可以迭代一个视图,也可以检查成员资格视图in关键字:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> keys = sample_dict.keys()
>>> keys
dict_keys(['first_name', 'last_name', 'email'])
>>> 'email' in keys
True
>>> len(keys)
3
d.values()
values()方法也返回一个视图对象,但是在这种情况下,它是字典值的动态视图:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> values = sample_dict.values()
>>> values
dict_values(['James', 'Doe', 'jdoe@gmail.com'])
>>> 'Doe' in values
True
>>> len(values)
3
d.pop(键[,默认])
你需要从字典中删除一个键吗?那么pop()就是适合你的方法。pop()方法接受一个键和一个选项默认字符串。如果不设置默认值,并且没有找到密钥,将会出现一个KeyError。
以下是一些例子:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict.pop('something')
Traceback (most recent call last):
Python Shell, prompt 146, line 1
builtins.KeyError: 'something'
>>> sample_dict.pop('something', 'Not found!')
'Not found!'
>>> sample_dict.pop('first_name')
'James'
>>> sample_dict
{'email': 'jdoe@gmail.com', 'last_name': 'Doe'}
d 波普姆()
popitem()方法用于从字典中移除和返回一个(key, value)对。这些对按照后进先出(LIFO)的顺序返回。如果在一个空字典上被调用,你会收到一个KeyError
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict.popitem()
('email', 'jdoe@gmail.com')
>>> sample_dict
{'first_name': 'James', 'last_name': 'Doe'}
d .更新([其他])
用来自其他的(key, value)对更新字典,覆盖现有的键。返回None。
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict.update([('something', 'else')])
>>> sample_dict
{'email': 'jdoe@gmail.com',
'first_name': 'James',
'last_name': 'Doe',
'something': 'else'}
修改你的字典
你需要不时修改你的字典。假设您需要添加一个新的键,值对:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict['address'] = '123 Dunn St'
>>> sample_dict
{'address': '123 Dunn St',
'email': 'jdoe@gmail.com',
'first_name': 'James',
'last_name': 'Doe'}
要向字典中添加一个新条目,可以使用方括号输入一个新键并将其设置为一个值。
如果需要更新预先存在的密钥,可以执行以下操作:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict['email'] = 'jame@doe.com'
>>> sample_dict
{'email': 'jame@doe.com', 'first_name': 'James', 'last_name': 'Doe'}
在本例中,您将sample_dict['email']设置为jame@doe.com。每当您将预先存在的键设置为新值时,都会覆盖以前的值。
从字典中删除项目
有时你需要从字典中删除一个键。您可以使用 Python 的del关键字来实现:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> del sample_dict['email']
>>> sample_dict
{'first_name': 'James', 'last_name': 'Doe'}
在这种情况下,您告诉 Python 从sample_dict中删除键“email”。
移除键的另一种方法是使用字典的pop()方法,这在上一节中已经提到:
>>> sample_dict = {'first_name': 'James', 'last_name': 'Doe', 'email': 'jdoe@gmail.com'}
>>> sample_dict.pop('email')
'jdoe@gmail.com'
>>> sample_dict
{'first_name': 'James', 'last_name': 'Doe'}
当你使用pop()时,它将返回被删除的值。
包扎
字典数据类型非常有用。你会发现用它来快速查找各种数据很方便。可以将key: value对的值设置为 Python 中的任何对象。因此,您可以将列表、元组或对象作为值存储在字典中。
如果你需要一个字典,当你去获取一个不存在的键时,它可以创建一个默认值,你应该看看 Python 的collections模块。它有一个defaultdict类,就是为这个用例设计的。
相关阅读
Python 101 -了解列表(视频)
原文:https://www.blog.pythonlibrary.org/2020/06/22/python-101-learning-about-lists-video/
在本视频教程中,您将了解 Python 的列表数据类型。
https://www.youtube.com/embed/k0zZcnZHYAo?feature=oembed
如果你不喜欢视频,你可以在这里阅读相同的内容:
- Python 101: 了解列表
Python 101:了解列表
原文:https://www.blog.pythonlibrary.org/2020/03/10/python-101-learning-about-lists/
列表是 Python 编程语言中的一种基本数据类型。一个列表是一个可变序列,通常是同类项目的集合。可变意味着您可以在列表创建后对其进行更改。您会经常看到包含其他列表的列表。这些被称为嵌套列表。您还将看到包含各种其他数据类型的列表,如字典、元组或对象。
让我们来看看如何创建列表!
创建列表
有几种方法可以创建列表。您可以通过以下任何一种方式构建列表:
- 使用一对方括号创建一个空列表: []
- 使用带逗号分隔项的方括号:【1,2,3】
- 使用列表理解:【x for x in iterable】
- 使用 list() 函数:list(iterable)
iterable 是一个序列,一个支持迭代的容器或者一个 iterator 对象。列表本身和字符串一样是序列。
让我们来看几个创建列表的例子,这样你就可以看到它的作用了:
>>> my_list = [1, 2, 3]
>>> my_list
[1, 2, 3]
第一个例子非常简单。在这里,您创建了一个包含 3 个数字的列表。然后打印出来,验证它包含了您认为应该包含的内容。
创建列表的下一种方法是使用 Python 内置的 list() 函数:
>>> list_of_strings = list('abc')
>>> list_of_strings
['a', 'b', 'c']
在本例中,您将三个字母的字符串传递给 list()函数。它自动遍历字符串中的字符,创建一个包含三个字符串的列表,其中每个字符串都是一个字符。
最后一个例子是如何创建空列表:
>>> empty_list = []
>>> empty_list
[]
>>> another_empty_list = list()
>>> another_empty_list
[]
创建空列表的最快方法是使用方括号,而不用在里面放任何东西。第二种最简单的方法是不带任何参数调用 list()。一般来说,使用 list()的好处是可以用它将兼容的数据类型转换为列表,就像前面的例子中使用字符串“abc”一样。
列出方法
Python 列表有几个可以调用的方法。以下是您可以对列表使用的方法列表:
- 追加()
- 清除()
- 复制()
- 计数()
- 扩展()
- 索引()
- 插入()
- 流行()
- 移除()
- 反向()
- 排序()
其中大部分将在下面的章节中介绍。先说具体章节没有涉及到的。
您可以使用 count() 来计算传入的对象的实例数。
这里有一个例子:
>>> my_list = list('abcc')
>>> my_list.count('a')
1
>>> my_list.count('c')
2
这是一个简单的方法来计算列表中一个条目出现的次数。
index() 方法对于查找列表中项目的第一个实例很有用:
>>> my_list = list('abcc')
>>> my_list.index('c')
2
>>> my_list.index('a')
0
Python 列表是零索引的,所以“a”在位置 0,“b”在位置 1,依此类推。
您可以使用 reverse()方法来就地反转列表:
>>> my_list = list('abcc')
>>> my_list.reverse()
>>> my_list
['c', 'c', 'b', 'a']
注意, reverse() 方法返回 None。这意味着,如果你试图将反转列表赋给一个新变量,你可能会得到意想不到的结果:
>>> x = my_list.reverse()
>>> print(x)
None
这里你最终得到的是 None 而不是反向列表。这就是到位的意思。原来的列表是反向的,但是 reverse() 方法本身不返回任何东西。
现在让我们看看你能用其他的列表方法做什么!
添加到列表
有三种列表方法可用于添加到列表中。它们如下:
- 追加()
- 扩展()
- 插入()
append() 方法会将一个项目添加到一个预先存在的列表的末尾:
>>> my_list = list('abcc')
>>> my_list
['a', 'b', 'c', 'c']
>>> my_list.append(1)
>>> my_list
['a', 'b', 'c', 'c', 1]
首先,创建一个由四个单字符字符串组成的列表。然后在列表末尾追加一个整数。现在列表应该有 5 个项目,1 在最后。
您可以使用 Python 的内置 len() 函数来检查列表中的项目数量:
>>> len(my_list)
5
这告诉你,事实上你在列表中有五个条目。但是如果你想在列表末尾之外的地方添加一个元素呢?
为此,您可以使用 insert() :
>>> my_list.insert(0, 'first')
>>> my_list
['first', 'a', 'b', 'c', 'c', 1]
insert() 方法有两个参数:
- 要插入的位置
- 要插入的项目
在上面的代码中,您告诉 Python 您想要将字符串“first”插入到 0 位置,这是列表中的第一个位置。
还有两种方法可以将项目添加到列表中。您可以使用 extend() 将 iterable 添加到列表中:
>>> my_list = [1, 2, 3]
>>> other_list = [4, 5, 6]
>>> my_list.extend(other_list)
>>> my_list
[1, 2, 3, 4, 5, 6]
这里您创建了两个列表。然后使用 my_list 的 extend() 方法将 other_list 中的项目添加到 my_list 中。extend() 将遍历传入列表中的条目,并将它们添加到列表中。
您也可以使用串联来组合列表:
>>> my_list = [1, 2, 3]
>>> other_list = [4, 5, 6]
>>> combined = my_list + other_list
>>> combined
[1, 2, 3, 4, 5, 6]
在这种情况下,您创建两个列表,然后使用 Python 的 + 操作符将它们组合起来。
您还可以在 Python 列表中使用 += :
>>> my_list = [1, 2, 3]
>>> other_list = [4, 5, 6]
>>> my_list += other_list
>>> my_list
[1, 2, 3, 4, 5, 6]
这是合并两个列表的更简单的方法。
现在让我们学习如何访问和改变列表中的元素。
访问和更改列表元素
列表是用来处理的。您将需要学习如何访问单个元素以及如何更改它们。
让我们从学习如何访问一个项目开始:
>>> my_list = [1, 2, 3]
>>> my_list[0]
1
>>> my_list[2]
3
要访问列表中的一个项目,您需要使用方括号,并传入您希望访问的项目的索引。在上面的例子中,您访问第一个和第三个元素。
列表还支持通过使用负值反向访问项目:
>>> my_list[-1]
3
这个例子演示了当你传入 -1 时,你得到的是返回列表中的最后一项。尝试使用其他值,看看是否可以使用负索引获得第一项。
如果您试图使用一个列表中不存在的索引,您将得到一个 IndexError :
>>> my_list[-5]
Traceback (most recent call last):
Python Shell, prompt 41, line 1
builtins.IndexError: list index out of range
现在让我们学习如何移除物品!
从列表中删除
从列表中删除项目非常简单。从列表中删除项目有 4 种主要方法:
- 清除()
- 流行()
- 移除()
- 是吗
您可以使用 clear() 从列表中删除所有内容。让我们看看它是如何工作的:
>>> my_list = [1, 2, 3]
>>> my_list.clear()
>>> my_list
[]
调用 clear() 后,列表现在为空。当您处理完列表中的项目,并且需要从头开始时,这可能会很有用。当然,你也可以这样做来代替【clear()】:
>> my_list = []
这将创建一个新的空列表。如果总是使用同一个对象对你来说很重要,那么使用 clear() 会更好。如果这不重要,那么将其设置为空列表也很好。
如果您想删除单个项目,那么您应该签出 pop()或 remove()。先说 pop() :
>>> my_list = [1, 2, 3]
>>> my_list.pop()
3
>>> my_list
[1, 2]
您可以向 pop() 传递一个索引来移除并返回一个项目。或者可以像上面的例子那样不带参数地调用 pop(),它将默认删除列表中的最后一项并返回它。 pop() 是从列表中删除项目的最灵活的方式。
如果列表是空的或者你传入了一个不存在的索引, pop() 将抛出一个异常:
>>> my_list.pop(10)
Traceback (most recent call last):
Python Shell, prompt 50, line 1
builtins.IndexError: pop index out of range
现在让我们来看看 remove()是如何工作的:
>>> my_list = [1, 2, 3]
>>> my_list.remove(2)
>>> my_list
[1, 3]
remove() 将删除传入项的第一个实例。所以在这种情况下,您告诉列表删除第一次出现的数字 2。
如果您告诉 remove() 删除一个不在列表中的项目,您将收到一个异常:
>>> my_list.remove(4)
Traceback (most recent call last):
Python Shell, prompt 51, line 1
builtins.ValueError: list.remove(x): x not in list
您还可以使用 Python 内置的 del 关键字从列表中删除项目:
>>> my_list = [1, 2, 3]
>>> del my_list[1]
>>> my_list
[1, 3]
如果您尝试删除不存在的索引,将会收到一条错误消息:
>>> my_list = [1, 2, 3]
>>> del my_list[6]
Traceback (most recent call last):
Python Shell, prompt 296, line 1
builtins.IndexError: list assignment index out of range
现在让我们来学习如何对列表进行排序!
对列表进行排序
Python 中的列表可以排序。可以使用内置的 sort() 方法对列表进行就地排序,也可以使用 Python 的 sorted()函数。
让我们创建一个列表并尝试对其进行排序:
>>> my_list = [4, 10, 2, 1, 23, 9]
>>> my_list.sort()
>>> my_list
[1, 2, 4, 9, 10, 23]
这里你创建了一个包含 6 个整数的列表,它们的顺序非常随机。为了对列表进行排序,您调用它的 sort()方法,该方法将对列表进行就地排序。这意味着 sort() 不会返回任何内容。
Python 的一个常见误解是,如果调用 sort() ,可以将结果赋给一个变量,如下所示:
>>> sorted_list = my_list.sort()
>>> print(sorted_list)
None
然而,当你这样做时,你会看到 sort() 实际上并没有返回一个排序后的列表。它总是不返回任何值。
幸运的是,您也可以为此使用 Python 的内置 sorted() 方法:
>>> my_list = [4, 10, 2, 1, 23, 9]
>>> sorted_list = sorted(my_list)
>>> sorted_list
[1, 2, 4, 9, 10, 23]
如果你使用 sorted() ,它将返回一个新的列表,默认情况下是升序排序。sorted()函数也允许你按指定的键排序,你可以通过设置它的反转标志告诉它升序或降序排序。
让我们按降序排列这个列表:
>>> my_list = [4, 10, 2, 1, 23, 9]
>>> sorted_list = sorted(my_list, reverse=True)
>>> sorted_list
[23, 10, 9, 4, 2, 1]
当你有一个更复杂的数据结构时,比如一个嵌套列表或者一个字典,你可以使用 sorted() 以特殊的方式进行排序,比如按键或者按值。
列表切片
Python 列表支持切片的思想。分割列表是通过使用方括号并输入开始和停止值来完成的。例如,如果您有 my_list[1:3],您会说您想要创建一个新的列表,其元素从索引 1 到 3 开始,但不包括索引 3。
这里有一个例子:
>>> my_list = [4, 10, 2, 1, 23, 9]
>>> my_list[1:3]
[10, 2]
这个切片返回索引 1 (10)和索引 2 (2)作为新列表。
您也可以使用负值进行切片:
>>> my_list = [4, 10, 2, 1, 23, 9]
>>> my_list[-2:]
[23, 9]
在本例中,您没有指定结束值。这意味着您希望从列表中的倒数第二个项目 23 开始,并将其移动到列表的末尾。
让我们尝试另一个例子,其中您只指定了结束索引:
>>> my_list = [4, 10, 2, 1, 23, 9]
>>> my_list[:3]
[4, 10, 2]
在本例中,您希望获取从索引 0 开始到索引 3 的所有值,但不包括索引 3。
复制列表
偶尔你会想要复制一个列表。复制列表的一个简单方法是使用 copy 方法:
>>> my_list = [1, 2, 3]
>>> new_list = my_list.copy()
>>> new_list
[1, 2, 3]
这成功地创建了一个新列表,并将其赋给变量 new_list。
但是请注意,当您这样做时,您正在创建所谓的“浅层拷贝”。这意味着,如果你的列表中有对象,它们可以被改变,这将影响两个列表。例如,如果您的列表中有一个词典,而该词典被修改了,则两个列表都会改变,这可能不是您想要的。
您也可以使用以下有趣的语法来复制列表:
>>> my_list = [1, 2, 3]
>>> new_list = my_list[:]
>>> new_list
[1, 2, 3]
这个例子告诉 Python 从 0(第一个)元素到最后一个元素创建一个切片,这实际上是整个列表的副本。
您还可以使用 Python 的 list() 函数来复制一个列表:
>>> my_list = [1, 2, 3]
>>> new_list = list(my_list)
>>> new_list
[1, 2, 3]
但是不管你选择哪种方法,不管是通过[:], copy() 还是 list() ,这三种方法都会进行浅层复制。如果你遇到奇怪的问题,改变一个列表会影响复制的列表,那么你应该使用复制模块中的 deepcopy 方法。
包扎
在本文中,您了解了 Python 美妙的 list 数据类型。当你用 Python 编程时,你将会广泛地使用列表。在这里,您学习了如何创建列表、编辑列表以及从列表中删除项目。你学会了如何完全清除列表。您发现了如何对列表进行排序以及如何对列表进行切片。最后,您了解了关于复制列表的所有内容,以及这样做时可能会遇到的陷阱。*
Python 101 -了解循环(视频)
原文:https://www.blog.pythonlibrary.org/2020/09/04/python-101-learning-about-loops-video/
在本教程中,您将学习如何在 Python 中使用 for 和 while 循环。
具体来说,您将学习如何:
- 创建一个
for循环 - 在字符串上循环
- 循环查阅字典
- 从元组中提取多个值
- 将
enumerate用于循环 - 创建一个
while循环 - 环路中断
- 使用
continue - 将
else用于循环 - 嵌套循环
https://www.youtube.com/embed/2fdhYGmucow?feature=oembed
| | 你想了解更多关于 Python 的知识吗?
Python 101 -第二版
在 Leanpub 上立即购买 |
Python 101 -了解循环
原文:https://www.blog.pythonlibrary.org/2020/05/27/python-101-learning-about-loops/
很多时候,当你写代码的时候,你需要找到一种迭代的方法。也许您需要迭代字符串中的字母或list中的对象。迭代的过程是通过一个循环来完成的。
循环是一种编程结构,它允许你迭代块。这些块可能是字符串中的字母,也可能是文件中的行。
在 Python 中,有两种类型的循环结构:
for循环while循环
除了对序列进行迭代,你还可以使用一个循环多次做同样的事情。一个例子是 web 服务器,它基本上是一个无限循环。服务器等待,监听客户端发送给它的消息。当收到消息时,循环将调用一个函数作为响应。
再比如游戏循环。当你赢了一局或输了一局,游戏通常不会退出。而是会问你要不要再玩一次。这也是通过将整个程序包装在一个循环中来实现的。
在本章中,您将学习如何:
- 创建一个
for循环 - 在字符串上循环
- 循环查阅字典
- 从元组中提取多个值
- 通过循环使用
enumerate - 创建一个
while循环 - 打破循环
- 使用
continue - 循环和
else语句 - 嵌套循环
让我们从看for循环开始吧!
创建 for 循环
for循环是 Python 中最流行的循环结构。使用以下语法创建一个for循环:
for x in iterable:
# do something
现在上面的代码什么也不做。因此,让我们编写一个for循环来遍历一个列表,一次一项:
>>> my_list = [1, 2, 3]
>>> for item in my_list:
... print(item)
...
1
2
3
在这段代码中,您创建了一个包含三个整数的list。接下来,创建一个for循环,表示“对于我列表中的每一项,打印出该项”。
当然,大多数时候你实际上想要对物品做些什么。例如,您可能想要加倍它:
>>> my_list = [1, 2, 3]
>>> for item in my_list:
... print(f'{item * 2}')
...
2
4
6
或者您可能只想打印偶数编号的项目:
>>> my_list = [1, 2, 3]
>>> for item in my_list:
... if item % 2 == 0:
... print(f'{item} is even')
...
2 is even
这里使用模数运算符%来计算该项除以 2 的余数。如果余数是 0,那么你就知道一个项是偶数。
您可以使用循环和条件以及任何其他 Python 构造来创建复杂的代码片段,这些代码片段只受您的想象力的限制。
让我们来学习除了列表之外你还能循环什么。
在字符串上循环
Python 中的for循环与其他编程语言的一个不同之处在于,您可以迭代任何序列。因此可以迭代其他数据类型。
让我们来看看字符串的迭代:
>>> my_str = 'abcdefg'
>>> for letter in my_str:
... print(letter)
...
a
b
c
d
e
f
g
这向您展示了迭代一个字符串是多么容易。
现在让我们尝试迭代另一种常见的数据类型!
在字典上循环
Python 字典也允许循环。默认情况下,当您在字典上循环时,您将在它的键上循环:
>>> users = {'mdriscoll': 'password', 'guido': 'python', 'steve': 'guac'}
>>> for user in users:
... print(user)
...
mdriscoll
guido
steve
如果使用字典的items()方法,可以循环遍历字典的键和值:
>>> users = {'mdriscoll': 'password', 'guido': 'python', 'steve': 'guac'}
>>> for user, password in users.items():
... print(f"{user}'s password is {password}")
...
mdriscoll's password is password
guido's password is python
steve's password is guac
在这个例子中,您指定您想要在每次迭代中提取user和password。您可能还记得,items()方法返回一个格式类似元组列表的视图。因此,您可以从这个视图中提取每个key: value对并打印出来。
这导致我们在元组上循环,并在循环时从元组中取出单个项目!
循环时提取元组中的多个值
有时,您需要循环遍历元组列表,并获取元组中的每一项。这听起来有点奇怪,但是你会发现这是一个相当常见的编程任务。
>>> list_of_tuples = [(1, 'banana'), (2, 'apple'), (3, 'pear')]
>>> for number, fruit in list_of_tuples:
... print(f'{number} - {fruit}')
...
1 - banana
2 - apple
3 - pear
为了实现这一点,您要利用这样一个事实,即您知道每个元组中有两个条目。因为您事先知道元组列表的格式,所以您知道如何提取值。
如果您没有从元组中单独提取项目,您可能会得到这样的输出:
>>> list_of_tuples = [(1, 'banana'), (2, 'apple'), (3, 'pear')]
>>> for item in list_of_tuples:
... print(item)
...
(1, 'banana')
(2, 'apple')
(3, 'pear')
这可能不是你所期望的。您通常希望从tuple中提取一个项目或者多个项目,而不是提取整个tuple。
现在让我们发现另一种有用的循环方式!
通过循环使用enumerate
Python 自带一个名为enumerate的内置函数。这个函数接受一个迭代器或序列,比如一个字符串或列表,并以(position, item)的形式返回一个元组。
这可让您在序列中循环时轻松了解项目在序列中的位置。
这里有一个例子:
>>> my_str = 'abcdefg'
>>> for pos, letter in enumerate(my_str):
... print(f'{pos} - {letter}')
...
0 - a
1 - b
2 - c
3 - d
4 - e
5 - f
6 - g
现在让我们看看 Python 支持的另一种类型的循环!
创建一个while循环
Python 还有另一种类型的循环结构,叫做while循环。用关键字while后跟一个表达式创建一个while循环。换句话说,while循环将一直运行,直到满足特定条件。
让我们来看看这些循环是如何工作的:
>>> count = 0
>>> while count < 10:
... print(count)
... count += 1
这个循环的表述方式与条件语句非常相似。您告诉 Python,只要count小于 10,您就希望循环运行。在循环内部,打印出当前的count,然后将count加 1。
如果您忘记增加count,循环将一直运行,直到您停止或终止 Python 进程。
您可以通过犯这种错误来创建一个无限循环,或者您可以这样做:
由于表达式总是True,这段代码将打印出字符串“程序正在运行”,直到您终止该进程。
打破循环
有时你想提前停止一个循环。例如,您可能想要循环,直到找到特定的内容。一个很好的用例是遍历文本文件中的行,当找到第一个出现的特定字符串时停止。
要提前停止循环,可以使用关键字break:
>>> count = 0
>>> while count < 10:
... if count == 4:
... print(f'{count=}')
... break
... print(count)
... count += 1
...
0
1
2
3
count=4
在本例中,您希望在计数达到 4 时停止循环。为了实现这一点,您添加了一个条件语句来检查count是否等于 4。当它出现时,您打印出计数等于 4,然后使用break语句退出循环。
您也可以在for循环中使用break:
>>> list_of_tuples = [(1, 'banana'), (2, 'apple'), (3, 'pear')]
>>> for number, fruit in list_of_tuples:
... if fruit == 'apple':
... print('Apple found!')
... break
... print(f'{number} - {fruit}')
...
1 - banana
Apple found!
对于这个例子,当你找到一个苹果的时候,你想跳出这个循环。否则你打印出你发现了什么水果。因为苹果在第二个元组中,所以你永远不会得到第三个元组。
当使用break时,循环将只从break语句所在的最内层循环中跳出。
你可以使用break来帮助控制程序的流程。事实上,条件语句和break一起被称为flow control语句。
另一个可以用来控制代码流的语句是 continue 。接下来让我们来看看!
使用continue
continue语句用于继续循环中的下一次迭代。你可以用continue跳过一些东西。
让我们编写一个跳过偶数的循环:
>>> for number in range(2, 12):
... if number % 2 == 0:
... continue
... print(number)
...
3
5
7
9
11
在这段代码中,您对从 2 开始到 11 结束的一系列数字进行循环。对于此范围内的每个数字,使用模数运算符%,得到该数字除以 2 的余数。如果余数是零,它就是一个偶数,您可以使用continue语句继续到序列中的下一个值。这实际上跳过了偶数,所以只打印出奇数。
通过使用continue语句,您可以使用巧妙的条件语句跳过序列中任意数量的内容。
循环和else语句
关于 Python 循环,一个鲜为人知的事实是,您可以像处理if/else语句一样向它们添加一个else语句。else语句只有在没有break语句出现时才会被执行。
从另一个角度来看,else语句只有在循环成功完成时才会执行。
循环中的else语句的主要用例是在序列中搜索一个项目。如果没有找到条目,您可以使用else语句来引发一个异常。
让我们看一个简单的例子:
>>> my_list = [1, 2, 3]
>>> for number in my_list:
... if number == 4:
... print('Found number 4!')
... break
... print(number)
... else:
... print('Number 4 not found')
...
1
2
3
Number 4 not found
这个例子在三个整数的list上循环。它会寻找数字 4,如果找到了,就会跳出循环。如果没有找到那个号码,那么else语句将会执行并通知您。
尝试将数字 4 添加到list中,然后重新运行代码:
>>> my_list = [1, 2, 3, 4]
>>> for number in my_list:
... if number == 4:
... print('Found number 4')
... break
... print(number)
... else:
... print('Number 4 not found')
...
1
2
3
Found number 4
更合适的方法是引发一个异常,而不是打印一条消息。
嵌套循环
循环也可以相互嵌套。嵌套循环有很多原因。最常见的原因之一是解开嵌套的数据结构。
让我们用一个嵌套的list作为例子:
>>> nested = [['mike', 12], ['jan', 15], ['alice', 8]]
>>> for lst in nested:
... print(f'List = {lst}')
... for item in lst:
... print(f'Item -> {item}')
外部循环将提取每个嵌套的list并打印出来。然后在内部循环中,您的代码将提取嵌套列表中的每一项并打印出来。
如果您运行这段代码,您应该会看到如下所示的输出:
List = ['mike', 12]
Item -> mike
Item -> 12
List = ['jan', 15]
Item -> jan
Item -> 15
List = ['alice', 8]
Item -> alice
Item -> 8
当嵌套列表的长度不同时,这种类型的代码特别有用。例如,您可能需要对包含额外数据或数据不足的列表进行额外的处理。
包扎
循环对于迭代数据非常有帮助。在本文中,您了解了 Python 的两个循环结构:
for循环while循环
您还学习了使用break和continue语句进行流控制。最后,你学会了如何在循环中使用else,以及为什么要嵌套循环。
只要稍加练习,你很快就会非常熟练地在自己的代码中使用循环!
Python 101 -了解集合(视频)
原文:https://www.blog.pythonlibrary.org/2020/08/05/python-101-learning-about-sets-video/
在本视频中,您将了解 Python 字典数据类型的基础知识。您将涵盖以下内容:
- 创建词典
- 访问词典
- 字典方法
- 修改词典
- 从字典中删除
https://www.youtube.com/embed/MMX1c-neLAw?feature=oembed
- 买书: Python 101 第二版
- 获取 Github 上的代码
Python 101:学习集合
原文:https://www.blog.pythonlibrary.org/2020/04/28/python-101-learning-about-sets/
根据 Python 3 文档,数据类型被定义为“不同可散列对象的无序集合”。您可以使用set进行成员测试,从序列中删除重复项,并计算数学运算,如交集、并集、差集和对称差集。
由于它们是无序的集合,set不记录元素的位置或插入顺序。因此,它们也不支持索引、切片或其他类似序列的行为,而这些行为你在列表和元组中见过。
Python 语言内置了两种类型的set:
- 可变的
- 这是不可改变的,也是可改变的
本文将重点介绍set。
您将学习如何使用器械包执行以下操作:
- 创建一个
set - 访问
set成员 - 时代的变化
- 添加项目
- 移除项目
- 删除一个
set
让我们从创建一套开始吧!
| | Would you like to learn more about Python?
Python 101 -第二版
在 Leanpub 上立即购买 |
创建集合
创建一个set非常简单。您可以通过在花括号内添加一系列逗号分隔的对象来创建它们,或者您可以将一个序列传递给内置的set()函数。
让我们看一个例子:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set
{'c', 'a', 'b'}
>>> type(my_set)
<class 'set'>
A set使用了你用来创建字典的相同的花括号。请注意,您有一系列值,而不是key: value对。当您打印出set时,您可以看到重复的内容被自动删除了。
现在让我们尝试使用set()创建一个set:
>>> my_list = [1, 2, 3, 4]
>>> my_set = set(my_list)
>>> my_set
{1, 2, 3, 4}
>>> type(my_set)
<class 'set'>
在这个例子中,您创建了一个list,然后使用set()将其转换为一个set。如果list中有任何重复,它们将被删除。
现在让我们继续,看看可以用这种数据类型做些什么。
访问集合成员
您可以使用 Python 的in操作符来检查项目是否在set中:
>>> my_set = {"a", "b", "c", "c"}
>>> "a" in my_set
True
集合不允许你使用切片或类似的方法来访问set的单个成员。相反,您需要迭代一个set。你可以使用一个循环来完成,比如一个while循环或者一个for循环。
在本文中,您不会深入讨论循环,但是下面是使用for循环迭代集合的基本语法:
>>> for item in my_set:
... print(item)
...
c
a
b
这将循环遍历set中的每一项,一次一项,并将其打印出来。
时代的变化
一旦创建了一个set,您就不能更改它的任何项目。
但是,您可以向set添加新项目。让我们来看看是如何做到的!
添加项目
向set添加项目有两种方式:
add()update()
让我们尝试使用add()添加一个项目:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.add('d')
>>> my_set
{'d', 'c', 'a', 'b'}
那很容易!您可以通过将项目传递给add()方法来将它添加到set中。
如果您想一次添加多个项目,那么您应该使用update()来代替:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.update(['d', 'e', 'f'])
>>> my_set
{'a', 'c', 'd', 'e', 'b', 'f'}
注意update()将接受你传递给它的任何 iterable。例如,它可能需要一个list、tuple或另一个set。
移除项目
您可以用几种不同的方式从器械包中移除物品。
您可以使用:
remove()discard()pop()
让我们在接下来的小节中逐一查看!
使用。移除()
remove()方法将尝试从set中移除指定的项目:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.remove('a')
>>> my_set
{'c', 'b'}
如果您碰巧向set到remove()询问一个不存在的项目,您将收到一个错误:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.remove('f')
Traceback (most recent call last):
Python Shell, prompt 208, line 1
builtins.KeyError: 'f'
现在让我们看看密切相关的discard()方法是如何工作的!
使用。丢弃()
discard()方法的工作方式与remove()几乎完全相同,它将从set中删除指定的项目:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.discard('b')
>>> my_set
{'c', 'a'}
与discard()的不同之处在于,如果你试图移除一个不存在的项目,它不会抛出错误:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.discard('d')
>>>
如果您希望能够在尝试移除不存在的项目时捕捉到错误,请使用remove()。如果你不介意,那么discard()可能是更好的选择。
使用。流行()
pop()方法将从set中移除并返回任意一项:
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.pop()
'c'
>>> my_set
{'a', 'b'}
如果您的器械包是空的,并且您试图pop()取出物品,您将收到一条错误消息:
>>> my_set = {"a"}
>>> my_set.pop()
'a'
>>> my_set.pop()
Traceback (most recent call last):
Python Shell, prompt 219, line 1
builtins.KeyError: 'pop from an empty set'
这与pop()处理list数据类型的方式非常相似,除了对于list,它将引发一个IndexError。列表是有序的,而集合是无序的,所以你不能确定你会用pop()删除什么,因为集合是无序的。
清除或删除集合
有时候你会想清空一个set甚至完全移除它。
要清空一个set,可以使用clear():
>>> my_set = {"a", "b", "c", "c"}
>>> my_set.clear()
>>> my_set
set()
如果你想完全删除set,那么你可以使用 Python 的内置del:
>>> my_set = {"a", "b", "c", "c"}
>>> del my_set
>>> my_set
Traceback (most recent call last):
Python Shell, prompt 227, line 1
builtins.NameError: name 'my_set' is not defined
现在,让我们学习一下您还可以用器械包做什么!
集合操作
器械包为您提供了一些常见的操作,例如:
union()-合并两个集合并返回一个新集合intersection()-返回两个集合中相同元素的新集合difference()-返回一个新的set,其元素不在另一个set中
这些操作是您在使用sets时最常用的操作。
union()方法实际上有点像你之前学过的update()方法,因为它将两个或更多的集合组合成一个新的集合。但是,不同之处在于它返回一个新的集合,而不是用新项目更新原始集合:
>>> first_set = {'one', 'two', 'three'}
>>> second_set = {'orange', 'banana', 'peach'}
>>> first_set.union(second_set)
{'two', 'banana', 'three', 'peach', 'orange', 'one'}
>>> first_set
{'two', 'three', 'one'}
在本例中,您创建了两个集合。然后在第一个集合上使用union()来添加第二个集合。然而union并没有更新set。它创建了一个新的set。如果你想保存新的set,那么你应该改为执行以下操作:
>>> united_set = first_set.union(second_set)
>>> united_set
{'two', 'banana', 'three', 'peach', 'orange', 'one'}
intersection()方法接受两个集合并返回一个新的set,它只包含两个集合中相同的项目。
让我们看一个例子:
>>> first_set = {'one', 'two', 'three'}
>>> second_set = {'orange', 'banana', 'peach', 'one'}
>>> first_set.intersection(second_set)
{'one'}
这两个集合只有一个共同点:字符串“one”。因此,当您调用intersection()时,它会返回一个新的set,其中只有一个元素。与union()一样,如果您想要保存这个新的set,那么您会想要做这样的事情:
>>> intersection = first_set.intersection(second_set)
>>> intersection
{'one'}
difference()方法将返回一个新的集合,该集合中的元素是另一个集合中的而不是。这可能有点令人困惑,所以我们来看几个例子:
>>> first_set = {'one', 'two', 'three'}
>>> second_set = {'three', 'four', 'one'}
>>> first_set.difference(second_set)
{'two'}
>>> second_set.difference(first_set)
{'four'}
当您在first_set上调用difference()时,它返回一个以“two”作为其唯一元素的set。这是因为“two”是唯一没有在second_set中找到的字符串。当你在second_set上调用difference()时,它会返回“四”,因为“四”不在first_set中。
还有其他方法可以用于集合,但是它们很少被使用。如果你需要使用这些方法,你应该去查阅文档以获得关于这些方法的全部细节。
包扎
集合是一种很好的数据类型,用于非常特殊的情况。您会发现集合对于删除重复列表或元组最有用,或者通过使用它们来查找多个列表之间的差异。
在本文中,您了解了以下内容:
- 创建一个
set - 访问
set成员 - 时代的变化
- 添加项目
- 移除项目
- 删除一个
set
任何时候你需要使用类似集合的操作,你都应该看看这个数据类型。然而,很有可能,您会更频繁地使用列表、字典和元组。
相关阅读
Python 101 -了解元组(视频)
原文:https://www.blog.pythonlibrary.org/2020/07/01/python-101-learning-about-tuples-video/
在本教程中,您将了解 Python 的元组数据类型:
https://www.youtube.com/embed/Jrhyuiw8XVE?feature=oembed
如果你喜欢阅读而不是观看,那么你应该看看Python 101——学习元组
在 Github 上获取 Jupyter 笔记本
Python 101 -了解元组
原文:https://www.blog.pythonlibrary.org/2020/03/26/python-101-learning-about-tuples/
元组是 Python 中的另一种序列类型。元组由许多用逗号分隔的值组成。元组是不可变的,而列表不是。不可变意味着元组有一个固定的值,不能改变。您不能添加、删除或修改元组中的项目。当您需要一个常量哈希值时,不可变对象非常有用。最流行的例子是 Python 字典的密钥。
在本文中,您将学习如何:
- 创建元组
- 使用元组
- 连接元组
- 特殊情况元组
让我们来看看如何创建元组!
创建元组
可以用几种不同的方式创建元组。让我们来看看:
>>> a_tuple = (4, 5)
>>> type(a_tuple)
<type 'tuple'>
创建一个元组的最简单方法之一是使用普通括号:()。括号中的项目是一系列值。它们可以是整数、列表、字典或任何其他对象。
您还可以使用元组()函数将列表转换为元组:
>>> a_tuple = tuple(['1', '2', '3'])
>>> type(a_tuple)
<type 'tuple'>
这个例子演示了如何将一个 Python 列表转换或造型为一个元组。
这最后一段代码显示了如何隐式创建元组:
>>> a_tuple = 2, 3, 4
>>> type(a_tuple)
<type 'tuple'>
如果你有一个对象序列(整数、字符串等)并将它们赋给一个变量,Python 会自动将它们转换成一个元组。
使用元组
由于元组是不可变的,所以实际上没有很多方法来处理它们。如果您正在运行 dir(tuple()) ,您会发现元组只有两个方法:
- count()
- 索引()
您可以使用 count() 来找出有多少元素与您传入的值相匹配:
>>> a_tuple = (1, 2, 3, 3)
>>> a_tuple.count(3)
2
在这种情况下,您可以找出整数“3”在“元组”中出现了多少次。
您可以使用“index()”来查找一个值的第一个索引:
>>> a_tuple = (1, 2, 3, 3)
>>> a_tuple.index(2)
1
这个例子向您展示了数字 2 位于索引 1 处,这是元组中的第二项。元组是零索引的,这意味着第一个元素从零开始。
您可以使用在前一章中学习的索引方法来访问元组中的元素:
>>> a_tuple = (1, 2, 3, 3)
>>> a_tuple[2]
3
换言之,元组中的第一个“3”位于索引 2 处。
让我们尝试修改您的元组中的一个元素:
>>> a_tuple[0] = 8
Traceback (most recent call last):
Python Shell, prompt 92, line 1
TypeError: 'tuple' object does not support item assignment
这里,您尝试将元组中的第一个元素设置为 8。然而,这导致产生了一个类型错误,因为元组是不可变的,不能被改变。
连接元组
元组可以连接在一起。但是,当您这样做时,您将最终创建一个新的元组:
>>> a_tuple = (1, 2, 3, 3)
>>> id(a_tuple)
140617302751760
>>> a_tuple = a_tuple + (6, 7)
>>> id(a_tuple)
140617282270944
在这里,您将第二个元组连接到第一个tuple。可以使用 Python 的 id() 函数来查看变量 a_tuple 发生了变化。方法返回对象的 id。这相当于在 C++中使用的内存地址。您会注意到在连接第二个元组之后,数字发生了变化。这意味着你有了一个新的对象。
特殊情况元组
有两种特殊情况的元组。一个包含零项的元组和一个包含一项的元组。它们是特例的原因是创建它们的语法有点不同。
要创建空元组,可以执行下列操作之一:
>>> empty = tuple()
>>> len(empty)
0
>>> type(empty)
<type 'tuple'>
>>> also_empty = ()
>>> len(also_empty)
0
您可以通过调用不带参数的 tuple() 函数来创建空元组,或者在使用空括号对时通过赋值来创建空元组。
现在让我们用单个元素创建一个元组:
>>> single = 2,
>>> len(single)
1
>>> type(single)
<type 'tuple'>
要用单个元素创建一个元组,可以用一个逗号来赋值。注意上面例子中 2 后面的逗号。
包扎
元组是 Python 中的基本数据类型。它在语言中经常使用,当然是你应该熟悉的。在这一章中,你学习了如何用三种不同的方法创建一个元组。
您还了解了元组是不可变的。最后,您学习了如何连接元组和创建空元组。现在你已经准备好进入下一章,学习所有关于字典的知识了!
Python 101 现在在 Leanpub 上永久免费
原文:https://www.blog.pythonlibrary.org/2017/01/23/python-101-now-free-on-leanpub-permanently/
几个月前,当我让 Python 101 免费几天(见此处)后,我得到了惊人的反响,我决定让它在 Leanpub (PDF、mobi 和 epub)上永久免费(或付费):
注意:我仍然在亚马逊、Gumroad 和 Lulu 上出售它
现在你可以随时免费检查。如果你碰巧喜欢这本书,如果你能在亚马逊上发表评论或者联系我在 Leanpub 上做读者推荐,我会很感激,因为他们没有自动离开其中一个的方法。
当我最初写这本书的时候,我注意到很少有或者根本没有描述如何创建代码的可执行文件或者如何通过 Python 的包索引(PyPI)分发代码的书籍。Python 101 涵盖了这些主题,并向读者介绍了 Python 的标准库、如何安装第三方包以及一些最流行的 Python 第三方包,如 SQLAlchemy、requests 和 virtualenv。
Python 101 有 5 节,44 章,295 页。
这里有一些我其他书的优惠券,以防有人感兴趣:
- Python 201:中级 Python-http://leanpub.com/python201/c/reddit
- wxPython 食谱-http://leanpub.com/wxpythoncookbook/c/reddit
Python 101 将于 9 月上市
原文:https://www.blog.pythonlibrary.org/2014/09/03/python-101-on-sale-for-september/
我的第一本书《Python 101》这个月发售。你可以在亚马逊美国网站上花 2.99 美元买到它,也可以通过我的 T2 网站打五折买到它。要享受五折优惠,只需在结账时输入以下优惠代码:2014 年秋季
Python 101 在线课程 48 小时免费!
原文:https://www.blog.pythonlibrary.org/2017/03/20/python-101-online-course-is-free-for-48-hours/
在接下来的 48 小时里,我的 Python 101 在线课程将在教育网站上完全免费。一定要去给自己弄一份。
它基于我的 Python 101 书。当你从教育中得到它,它将是你的终身财富。请注意,这是一个互动的在线课程,而不是视频课程。如果你喜欢 Python 101 在线课程,只需使用以下优惠券,你就可以获得我的第二个在线课程, Python 201 的 50%折扣: au-promo-py201 。
链接:
- Python 101 在线课程(48 小时免费)
- Python 201 在线课程(使用 au-promo-py201 优惠券可享受 50%的折扣
您也可以通过以下链接以建议价格的 50%购买我的电子书:
- Python 201: 中级 Python
- wxPython 食谱
python 101:pip——easy _ install 的替代品
原文:https://www.blog.pythonlibrary.org/2012/07/16/python-101-pip-a-replacement-for-easy_install/
Pip 安装 Python 或者说 Pip 是一个安装和管理 Python 包的工具,很多都在 Python 包索引 (PyPI)上。它是 easy_install 的替代品。在本文中,我们将花一点时间试用 pip,看看它是如何工作的,以及它如何帮助我们开发 Python。
装置
你需要出去找分发或设置工具来让 pip 工作。如果您使用的是 Python 3,那么 distribute 是您唯一的选择,因为在撰写本文时 setuptools 还不支持它。在 pip 的网站上有一个安装程序,你可以使用,名为 get-pip.py ,或者你可以直接去 PyPI 下载它作为源代码。
希望你已经知道了这一点,但是要从源代码安装大多数模块,你必须压缩它,然后打开一个终端或命令行窗口。然后将目录(cd)切换到解压后的文件夹,运行“ python setup.py install ”(去掉引号)。请注意,您可能需要提升权限来安装它(即 root 或管理员)。pip 网站建议在 virtualenv 中使用 pip,因为它是自动安装的,并且“不需要 root 访问权限或修改您的系统 Python 安装”。我会让你自己决定。
pip 使用
pip 最常见的用法是安装、升级或卸载软件包。这在 pip 网站上都有涉及,但我们还是在这里看一下。因为我们一直在提到 virtualenv,所以让我们试着用 pip 安装它:
pip install virtualenv
如果您在终端中运行上面的命令,您应该得到类似如下的输出:
Downloading/unpacking virtualenv
Downloading virtualenv-1.7.2.tar.gz (2.2Mb): 2.2Mb downloaded
Running setup.py egg_info for package virtualenv
warning: no previously-included files matching '*' found under directory 'do
cs\_templates'
warning: no previously-included files matching '*' found under directory 'do
cs\_build'
Installing collected packages: virtualenv
Running setup.py install for virtualenv
warning: no previously-included files matching '*' found under directory 'do
cs\_templates'
warning: no previously-included files matching '*' found under directory 'do
cs\_build'
Installing virtualenv-script.py script to C:\Python26\Scripts
Installing virtualenv.exe script to C:\Python26\Scripts
Installing virtualenv.exe.manifest script to C:\Python26\Scripts
Installing virtualenv-2.6-script.py script to C:\Python26\Scripts
Installing virtualenv-2.6.exe script to C:\Python26\Scripts
Installing virtualenv-2.6.exe.manifest script to C:\Python26\Scripts
Successfully installed virtualenv
Cleaning up...
这似乎很有效。请注意,pip 在开始安装之前下载软件包,这是 easy_install 所不做的(关于其他区别,请参见这个比较)。比如说这篇文章写完之后 virtualenv 出了一个新版本,你想升级?皮普掩护你!
pip install --upgrade virtualenv
那不是很容易吗?另一方面,如果你喜欢总是在沙盒安全之外的危险边缘工作,那该怎么办?卸载沙盒和安装沙盒一样简单:
pip uninstall virtualenv
没错。就这么简单。真的!
Pip 还可以从文件路径、URL 和版本控制系统(如 Subversion、Git、Mercurial 和 Bazaar)安装。更多信息参见文档。
其他画中画功能
Pip 还使您能够创建配置文件,这些文件可以保存您通常以类似 INI 文件的格式使用的所有命令行选项。你可以在这里阅读。遗憾的是,看起来 pip 只在一个特定的位置寻找配置,所以您实际上不能将不同的配置传递给 pip。
我想强调的另一个特性是它的需求文件概念。这些文件只是要安装的软件包列表。它们提供了安装软件包和所有依赖项的方法,包括依赖项的特定版本。您甚至可以添加可选库和支持工具的列表。如果你需要知道你当前的安装程序已经安装了什么,你可以像这样把它们“冻结”到一个需求文件中:
pip freeze > myrequirements.txt
这在 virtualenv 中非常有用,因为您可能会在主 Python 套件中安装许多与当前项目没有任何关系的包。这也是为什么与 virtualenv 合作是个好主意的另一个原因。
包扎
现在,您已经了解了足够的知识,可以开始使用 pip 了。这是一个非常方便的工具,可以添加到您的工具包中,并使安装和管理软件包变得轻而易举。玩得开心!
Python 101:读取和写入 CSV 文件
原文:https://www.blog.pythonlibrary.org/2014/02/26/python-101-reading-and-writing-csv-files/
Python 有一个庞大的模块库,包含在它的发行版中。csv 模块为 Python 程序员提供了解析 CSV(逗号分隔值)文件的能力。CSV 文件是人类可读的文本文件,其中每一行都有许多由逗号或其他分隔符分隔的字段。您可以将每行视为一行,将每个字段视为一列。csv 格式没有标准,但是它们非常相似,CSV 模块能够读取绝大多数 CSV 文件。您也可以使用 csv 模块编写 CSV 文件。
读取 CSV 文件
有两种方法可以读取 CSV 文件。你可以使用 csv 模块的 reader 函数或者你可以使用 DictReader 类。我们将研究这两种方法。但是首先,我们需要得到一个 CSV 文件,这样我们就有东西可以解析了。有许多网站以 CSV 格式提供有趣的信息。我们将使用世界卫生组织(世卫组织)的网站下载一些关于结核病的信息。可以去这里领取:【http://www.who.int/tb/country/data/download/en/。一旦你拿到文件,我们就可以开始了。准备好了吗?然后我们来看一些代码!
import csv
#----------------------------------------------------------------------
def csv_reader(file_obj):
"""
Read a csv file
"""
reader = csv.reader(file_obj)
for row in reader:
print(" ".join(row))
#----------------------------------------------------------------------
if __name__ == "__main__":
csv_path = "TB_data_dictionary_2014-02-26.csv"
with open(csv_path, "rb") as f_obj:
csv_reader(f_obj)
让我们花点时间来分解一下。首先,我们必须实际导入 csv 模块。然后我们创建一个非常简单的函数,名为 csv_reader ,它接受一个文件对象。在函数内部,我们将文件对象传递给 csv_reader 函数,该函数返回一个 reader 对象。reader 对象允许迭代,就像常规的 file 对象一样。这让我们遍历 reader 对象中的每一行,并打印出数据行,去掉逗号。这是因为每一行都是一个列表,我们可以将列表中的每个元素连接在一起,形成一个长字符串。
现在让我们创建自己的 CSV 文件,并将其输入到 DictReader 类中。这里有一个非常简单的问题:
first_name,last_name,address,city,state,zip_code
Tyrese,Hirthe,1404 Turner Ville,Strackeport,NY,19106-8813
Jules,Dicki,2410 Estella Cape Suite 061,Lake Nickolasville,ME,00621-7435
Dedric,Medhurst,6912 Dayna Shoal,Stiedemannberg,SC,43259-2273
让我们将它保存在一个名为 data.csv 的文件中。现在我们准备使用 DictReader 类解析文件。让我们试一试:
import csv
#----------------------------------------------------------------------
def csv_dict_reader(file_obj):
"""
Read a CSV file using csv.DictReader
"""
reader = csv.DictReader(file_obj, delimiter=',')
for line in reader:
print(line["first_name"]),
print(line["last_name"])
#----------------------------------------------------------------------
if __name__ == "__main__":
with open("data.csv") as f_obj:
csv_dict_reader(f_obj)
在上面的例子中,我们打开一个文件,并像以前一样将文件对象传递给我们的函数。该函数将文件对象传递给我们的 DictReader 类。我们告诉 DictReader 分隔符是逗号。这实际上并不是必需的,因为没有那个关键字参数,代码仍然可以工作。然而,明确一点是个好主意,这样你就知道这里发生了什么。接下来我们遍历 reader 对象,发现 reader 对象中的每一行都是一个字典。这使得打印出该行的特定部分非常容易。
现在我们准备学习如何将 csv 文件写入磁盘。
编写 CSV 文件
csv 模块也有两种方法可以用来编写 CSV 文件。你可以使用 writer 函数或者 DictWriter 类。我们也将研究这两个问题。我们将从 writer 函数开始。让我们看一个简单的例子:
# Python 2.x version
import csv
#----------------------------------------------------------------------
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "wb") as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
path = "output.csv"
csv_writer(data, path)
在上面的代码中,我们创建了一个接受两个参数的 csv_writer 函数:数据和路径。数据是我们在脚本底部创建的列表列表。我们使用前一个例子中数据的简化版本,并在逗号上分割字符串。这将返回一个列表。所以我们最终得到一个嵌套列表,如下所示:
[['first_name', 'last_name', 'city'],
['Tyrese', 'Hirthe', 'Strackeport'],
['Jules', 'Dicki', 'Lake Nickolasville'],
['Dedric', 'Medhurst', 'Stiedemannberg']]
csv_writer 函数打开我们传入的路径,并创建一个 csv writer 对象。然后我们遍历嵌套列表结构,将每一行写到磁盘上。注意,我们在创建 writer 对象时指定了分隔符应该是什么。如果您希望分隔符不是逗号,那么您可以在这里设置它。
现在如果你想用 Python 3 写一个 csv 文件,语法略有不同。下面是您必须重写该函数的方式:
# Python 3.x version
import csv
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "w", newline='') as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
您会注意到,您需要将写模式更改为仅仅是‘w’,并添加换行符参数。
现在我们准备学习如何使用 DictWriter 类编写 CSV 文件!我们将使用前一个版本的数据,并将其转换成一个字典列表,我们可以将它提供给我们饥渴的 DictWriter。让我们来看看:
# Python 2.x version
import csv
#----------------------------------------------------------------------
def csv_dict_writer(path, fieldnames, data):
"""
Writes a CSV file using DictWriter
"""
with open(path, "wb") as out_file:
writer = csv.DictWriter(out_file, delimiter=',', fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
my_list = []
fieldnames = data[0]
for values in data[1:]:
inner_dict = dict(zip(fieldnames, values))
my_list.append(inner_dict)
path = "dict_output.csv"
csv_dict_writer(path, fieldnames, my_list)
注意:要将这段代码转换成 Python 3 语法,您需要像以前一样用语句修改:用 open(path," w ",newline= ' ')作为 out_file:
我们将首先从第二部分开始。如你所见,我们从之前的嵌套列表结构开始。接下来,我们创建一个空列表和一个包含字段名称的列表,这恰好是嵌套列表中的第一个列表。记住,列表是从零开始的,所以列表中的第一个元素从零开始!接下来,我们遍历嵌套列表结构,从第二个元素开始:
for values in data[1:]:
inner_dict = dict(zip(fieldnames, values))
my_list.append(inner_dict)
在 for 循环中,我们使用 Python 内置函数来创建字典。zip方法将接受两个迭代器(本例中是列表),并将它们转换成元组列表。这里有一个例子:
zip(fieldnames, values)
[('first_name', 'Dedric'), ('last_name', 'Medhurst'), ('city', 'Stiedemannberg')]
现在,当您在dict中包装该调用时,它会将元组列表转换为字典。最后,我们把字典添加到列表中。当for完成时,您将得到如下所示的数据结构:
[{'city': 'Strackeport', 'first_name': 'Tyrese', 'last_name': 'Hirthe'},
{'city': 'Lake Nickolasville', 'first_name': 'Jules', 'last_name': 'Dicki'},
{'city': 'Stiedemannberg', 'first_name': 'Dedric', 'last_name': 'Medhurst'}]
在第二个会话结束时,我们调用我们的 csv_dict_writer 函数,并传入所有需要的参数。在函数内部,我们创建一个 DictWriter 实例,并向它传递一个文件对象、一个分隔符值和我们的字段名列表。接下来,我们将字段名写到磁盘上,一次循环一行数据,将数据写到磁盘上。DictWriter 类也支持 writerows 方法,我们可以用它来代替循环。 csv.writer 函数也支持该功能。
您可能有兴趣知道,您还可以使用 csv 模块创建方言。这允许您以非常明确的方式告诉 csv 模块如何读取或写入文件。如果您因为来自客户端的格式奇怪的文件而需要这种东西,那么您会发现这种功能非常有价值。
包扎
现在您知道了如何使用 csv 模块来读写 CSV 文件。有许多网站以这种格式发布数据,这种格式在商业领域被广泛使用。开心快乐编码!
附加阅读
- Python 文档- 第 13.1 节 csv
- 用 Python DictReader 和 DictWriter 读写 CSV 文件
- 本周 Python 模块: csv
Python 101:递归
原文:https://www.blog.pythonlibrary.org/2017/08/10/python-101-recursion/
递归是数学和计算机科学中的一个话题。在计算机编程语言中,术语“递归”指的是调用自身的函数。另一种说法是函数定义将函数本身包含在其定义中。当我的计算机科学教授谈到递归时,我收到的第一个警告是,您可能会意外地创建一个无限循环,这将使您的应用程序挂起。发生这种情况是因为当你使用递归时,你的函数可能会无限地调用自己。因此,与任何其他潜在的无限循环一样,您需要确保您有办法打破循环。大多数递归函数的思想是将正在进行的过程分解成更小的部分,我们仍然可以用同一个函数来处理。
描述递归的最常用方法通常是通过创建阶乘函数来说明。阶乘通常是这样的: 5!注意数字后面有感叹号。该符号表示它将被视为阶乘。这意味着 5!= 54321 或者 120。
让我们看一个简单的例子。
# factorial.py
def factorial(number):
if number == 0:
return 1
else:
return number * factorial(number-1)
if __name__ == '__main__':
print(factorial(3))
print(factorial(5))
在这段代码中,我们检查传入的数字,看它是否等于零。如果是,我们返回数字 1。否则,我们取这个数,用它乘以调用同一个函数的结果,但是这个数减一。我们可以稍微修改一下这段代码,以获得递归的次数:
def factorial(number, recursed=0):
if number == 0:
return 1
else:
print('Recursed {} time(s)'.format(recursed))
recursed += 1
return number * factorial(number-1, recursed)
if __name__ == '__main__':
print(factorial(3))
每次我们调用 factorial 函数并且这个数大于零时,我们打印出我们递归的次数。您应该看到的最后一个字符串应该是 "Recursed 2 time(s)" ,因为它应该只需要用数字 3 调用 factorial 两次。
Python 的递归极限
在本文的开始,我提到你可以创建一个无限递归循环。在某些语言中可以,但是 Python 实际上有递归限制。您可以通过执行以下操作自行检查:
>>> import sys
>>> sys.getrecursionlimit()
1000
如果您觉得这个限制对您的程序来说太低,您也可以通过 sys 模块的 setrecursionlimit() 函数来设置递归限制。让我们试着创建一个超过这个限制的递归函数,看看会发生什么:
# bad_recursion.py
def recursive():
recursive()
if __name__ == '__main__':
recursive()
如果您运行这段代码,您应该会看到以下抛出的异常: RuntimeError:超过了最大递归深度
Python 阻止你创建一个以永无止境的递归循环结束的函数。
用递归展平列表
除了阶乘,你还可以用递归做其他事情。更实际的例子是创建一个函数来展平嵌套列表,例如:
# flatten.py
def flatten(a_list, flat_list=None):
if flat_list is None:
flat_list = []
for item in a_list:
if isinstance(item, list):
flatten(item, flat_list)
else:
flat_list.append(item)
return flat_list
if __name__ == '__main__':
nested = [1, 2, 3, [4, 5], 6]
x = flatten(nested)
print(x)
当你运行这段代码时,你应该得到一个整数列表,而不是一个整数列表和一个列表。当然,还有许多其他有效的方法来展平嵌套列表,比如使用 Python 的 itertools.chain() 。您可能想要检查 chain()类背后的代码,因为它有一种非常不同的方法来展平列表。
包扎
现在,您应该对递归的工作原理以及如何在 Python 中使用它有了基本的了解。我认为 Python 对递归有一个内置的限制,以防止开发人员创建结构不良的递归函数,这很好。我还想指出,在我多年的开发生涯中,我不认为我真的需要使用递归来解决问题。我肯定有很多问题的解决方案可以在递归函数中实现,但是 Python 有如此多的其他方法来做同样的事情,我从来没有觉得有必要这样做。我想提出的另一个注意事项是,递归可能很难调试,因为很难判断错误发生时你已经达到了什么级别的递归。
不管怎样,我希望这篇文章对你有用。编码快乐!
相关阅读
- 如何像计算机科学家一样思考- 第三章
- StackOverflow - 如何用 python 构建递归函数?
- Python 练习册- 函数式编程
Python 101:重定向标准输出
原文:https://www.blog.pythonlibrary.org/2016/06/16/python-101-redirecting-stdout/
将 stdout 重定向到大多数开发人员在某个时候需要做的事情。将 stdout 重定向到文件或类似文件的对象会很有用。在我的一些桌面 GUI 项目中,我还将 stdout 重定向到一个文本控件。在本文中,我们将了解以下内容:
- 将标准输出重定向到文件(简单)
- 外壳重定向方法
- 使用自定义上下文管理器重定向 stdout
- Python 3's contextlib.redirect_stdout()
- 将 stdout 重定向到 wxPython 文本控件
重定向标准输出
在 Python 中重定向 stdout 最简单的方法就是给它分配一个 open file 对象。让我们看一个简单的例子:
import sys
def redirect_to_file(text):
original = sys.stdout
sys.stdout = open('/path/to/redirect.txt', 'w')
print('This is your redirected text:')
print(text)
sys.stdout = original
print('This string goes to stdout, NOT the file!')
if __name__ == '__main__':Redirecting stdout / stderr
redirect_to_file('Python rocks!')
这里我们只是导入 Python 的 sys 模块并创建一个函数,我们可以传递我们希望重定向到文件的字符串。我们保存了对 sys.stdout 的引用,这样我们可以在函数结束时恢复它。如果您打算将 stdout 用于其他用途,这可能会很有用。在运行这段代码之前,请确保将路径更新为可以在您的系统上运行的路径。当您运行它时,您应该在文件中看到以下内容:
This is your redirected text:
Python rocks!
最后一条 print 语句将被输出到 stdout,而不是文件。
外壳重定向
Shell 重定向也很常见,尤其是在 Linux 中,尽管 Windows 在大多数情况下也以同样的方式工作。让我们创建一个愚蠢的噪声函数示例,我们称之为 noisy.py:
# noisy.py
def noisy(text):
print('The noisy function prints a lot')
print('Here is the string you passed in:')
print('*' * 40)
print(text)
print('*' * 40)
print('Thank you for calling me!')
if __name__ == '__main__':
noisy('This is a test of Python!')
您会注意到,这次我们没有导入 sys 模块。原因是我们不需要它,因为我们将使用 shell 重定向。要进行 shell 重定向,请打开终端(或命令提示符)并导航到保存上面代码的文件夹。然后执行以下命令:
python noisy.py > redirected.txt
大于号(即>)告诉您的操作系统将 stdout 重定向到您指定的文件名。此时,在 Python 脚本所在的文件夹中,应该有一个名为“redirected.txt”的文件。如果打开它,该文件应该包含以下内容:
The noisy function prints a lot
Here is the string you passed in:
****************************************
This is a test of Python!
****************************************
Thank you for calling me!
这不是很酷吗?
用上下文管理器重定向标准输出
重定向 stdout 的另一个有趣的方法是使用上下文管理器。让我们创建一个定制的上下文管理器,它接受一个文件对象来将 stdout 重定向到:
import sys
from contextlib import contextmanager
@contextmanager
def custom_redirection(fileobj):
old = sys.stdout
sys.stdout = fileobj
try:
yield fileobj
finally:
sys.stdout = old
if __name__ == '__main__':
with open('/path/to/custom_redir.txt', 'w') as out:
with custom_redirection(out):
print('This text is redirected to file')
print('So is this string')
print('This text is printed to stdout')
当您运行这段代码时,它会将两行文本写到您的文件中,一行写到 stdout 中。像往常一样,我们在函数结束时重置 stdout。
使用 contextlib.redirect_stdout
Python 3.4 在他们的 contextlib 模块中加入了 redirect_stdout 函数。让我们尝试使用它来创建一个上下文管理器来重定向 stdout:
import sys
from contextlib import redirect_stdout
def redirected(text, path):
with open(path, 'w') as out:
with redirect_stdout(out):
print('Here is the string you passed in:')
print('*' * 40)
print(text)
print('*' * 40)
if __name__ == '__main__':
path = '/path/to/red.txt'
text = 'My test to redirect'
redirected(text, path)
这段代码稍微简单一点,因为内置函数会自动为您完成所有对 stdout 的让步和重置。除此之外,它的工作方式与我们的定制上下文管理器非常相似。
在 wxPython 中重定向 stdout

我已经多次写过关于在 wxPython 中重定向 stdout 的文章。下面这段代码其实来自我 2009 年写的一篇文章,2015 年更新:
import sys
import wx
class MyForm(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None,
title="wxPython Redirect Tutorial")
# Add a panel so it looks the correct on all platforms
panel = wx.Panel(self, wx.ID_ANY)
style = wx.TE_MULTILINE|wx.TE_READONLY|wx.HSCROLL
log = wx.TextCtrl(panel, wx.ID_ANY, size=(300,100),
style=style)
btn = wx.Button(panel, wx.ID_ANY, 'Push me!')
self.Bind(wx.EVT_BUTTON, self.onButton, btn)
# Add widgets to a sizer
sizer = wx.BoxSizer(wx.VERTICAL)
sizer.Add(log, 1, wx.ALL|wx.EXPAND, 5)
sizer.Add(btn, 0, wx.ALL|wx.CENTER, 5)
panel.SetSizer(sizer)
# redirect text here
sys.stdout = log
def onButton(self, event):
print "You pressed the button!"
# Run the program
if __name__ == "__main__":
app = wx.App(False)
frame = MyForm().Show()
app.MainLoop()
这段代码只是创建了一个简单的框架,带有一个包含多行文本控件和一个按钮的面板。无论何时按下按钮,它都会将一些文本打印到 stdout,我们已经将它重定向到文本控件。试一试,看看效果如何!
包扎
现在,您已经知道了几种不同的将 stdout 重定向到文件的方法。有些方法比其他方法更好。就个人而言,我认为 Python 3 现在内置了一个专门用于这个目的的上下文管理器,这很酷。说到这里,Python 3 还有一个重定向 stderr 的功能。所有这些示例都可以稍加修改,以支持重定向 stderr 或同时重定向 stdout 和 stderr。我们最后谈到的是在 wxPython 中将 stdout 重定向到一个文本控件。这对于调试或获取子流程的输出非常有用,尽管在后一种情况下,您需要打印输出以正确重定向。
相关阅读
- StackOverflow: 将标准输出重定向到 Python 中的一个文件
- wxPython – Redirecting stdout / stderr
Python 101 销售
原文:https://www.blog.pythonlibrary.org/2015/05/13/python-101-sale/
我的第一本书《Python 101》这个月发售。你可以在亚马逊美国网站上花 5.99 美元买到它,也可以通过我的 T2 网站打五折买到它。要享受 50%的折扣,只需在结账时输入以下优惠代码:may50
Python 101 截屏可供预购
原文:https://www.blog.pythonlibrary.org/2015/08/04/python-101-screencast-available-for-pre-order/
Python 101 截屏现可预购。如果你预先订购的截屏系列,那么你会收到我目前已经完成(12 个视频+电子书),然后收到我添加新的更新。将有至少 44 个视频。购买后,您可以随时观看或下载视频。
这些截屏是根据我的书《Python 101 》改编的。每个截屏都基于书中的一章。前 11 个视频是免费的,所以你可以先试后买!你可以在 Youtube 这里查看它们。
Python 101 投屏众筹活动重新启动
我终于重启了 Python 101 截屏活动。然而我已经转到 IndieGogo 这里:http://igg.me/p/python-101-screencast/x/2068547
改变的原因是他们有更低的费用,并且他们也允许更多类型的支付。我似乎总是得到无法支持我的项目的支持者,因为 Kickstarter 不支持他们的支付类型(即 Paypal)。
无论如何,我已经增加了一些更高层次的支持和一些有趣的东西。我希望增加一些免费赠品,但我不希望该项目遭受范围蔓延,最终不能按时交付。
我希望你们都能加入我的新活动,帮我全速推进这个项目。再次感谢您的支持!
迈克
Python 101 截屏:第 13 集 csv 模块
原文:https://www.blog.pythonlibrary.org/2017/03/26/python-101-screencast-episode-13-the-csv-module/
https://www.youtube.com/embed/t5LpZDnrYIY?feature=oembed
这个视频教程是关于 Python 的 csv 模块的。来自我的第一本书 Python 101 。你也可以在这里阅读《T2》的一个版本。
Python 101 截屏:第 14 集 configparser 模块
https://www.youtube.com/embed/lpgHI-eJ2Gw?feature=oembed
在这个截屏中,您将学习使用 Python 的 configparser 模块的基础知识
Python 101 截屏:第 15 集-日志模块
原文:https://www.blog.pythonlibrary.org/2018/07/12/python-101-screencast-episode-15-the-logging-module/
https://www.youtube.com/embed/QAiWtpIRuCw?feature=oembed
在这个截屏中,您将学习使用 Python 的日志模块的基础知识。
免费在线查看本视频所依据的书:http://python101.pythonlibrary.org/
Python 101 截屏:第 8 集-文件 I/O
原文:https://www.blog.pythonlibrary.org/2015/07/01/python-101-screencast-episode-8-file-io/
查看我在 Python 101 截屏中的最新视频。在这一集里,我们将学习如何使用 Python 的文件处理功能。您将学习如何读取、写入和追加文件。
https://www.youtube.com/embed/mN-72tOZt0c?feature=oembed
Python 101 截屏:自省
原文:https://www.blog.pythonlibrary.org/2017/03/16/python-101-screencast-introspection/
Python 有一些强大的特性,允许你自省自己的代码或他人的代码。我制作了下面的视频教程来帮助你了解它是如何工作的。
https://www.youtube.com/embed/Hw9N5wXnadM?feature=oembed
本教程来自 Python 101 截屏
相关文章
- Python 101: 自省
Python 101 截屏 Kickstarter 更新
原文:https://www.blog.pythonlibrary.org/2015/03/30/python-101-screencast-kickstarter-update/
周末,我为我的 Python 101 Kickstarter 录制了我的第一个官方截屏。现在基本上是测试质量,但我想得到你的反馈。第一个视频基于第 2 章,涵盖了 Python 字符串。它以 13 分钟多一点结束,这让我有点惊讶。
亲爱的读者,我想从你这里知道:
- 你喜欢/不喜欢什么?
- 少了什么?
- 太长了吗?
完成后,我可以看到许多不同的方法来改善它。首先,我个人认为它太长了。我认为最好把这一章分成 2-4 个视频,让它们更容易理解。这也可以让我更深入地讨论一些子主题,而不会让听众感到厌烦,而且还有一个很好的副作用,那就是将每个视频精简到一个核心元素。
不管怎样,我很期待你要说的话。这是视频:
https://www.youtube.com/embed/PPOXOb3svBk?feature=oembed
Python 101 截屏发布
原文:https://www.blog.pythonlibrary.org/2016/02/09/python-101-screencast-released/
Python 101 的截屏已经完成一个多月了,我现在发布它供大众使用。

Python 101 截屏是根据我的书《Python 101》改编的。我看完了这本书的所有 44 章,并把每一章都变成了独立的截屏。换句话说,截屏覆盖了 44 个视频。你可以在我博客的 youTube 页面上观看前 11 个视频。
你得到了什么:
最少 44 集 +你将收到一份 PDF、MOBI 和 EPUB 版本的 Python 101 书籍。您还将收到一份 A4 大小的 PDF 副本。
第一部分
第一部分是初学者部分。在这里你将学到 Python 的所有基础知识。从 Python 类型(字符串、列表、字典)到条件语句再到循环。你还将学习理解、函数和类以及它们之间的一切!
第二部分
这一节是对 Python 标准库的有组织的参观。其目的并不是涵盖其中的所有内容,而是向读者展示开箱即用的 Python 可以做很多事情。我们将涵盖我认为在日常编程任务中最有用的模块,例如 os、sys、日志、线程等等。
第三部分
一个中间部分,涵盖了 lambda,decorators,properties,debugging,testing 和 profiling 。
第四部分
现在事情变得非常有趣!在第四部分,我们将学习如何从 Python 包索引和其他位置安装第三方库(即包)。我们将介绍简易安装和 pip。这一节也将是一系列的教程,在这里你将学习如何使用你下载的软件包。例如,您将学习如何下载文件、解析 XML、使用对象关系映射器处理数据库等。
第五部分
本系列的最后一部分将介绍如何与你的朋友和全世界分享你的代码!您将了解如何将其打包并在 Python 包索引上共享(例如,如何创建一个鸡蛋或轮子)。您还将学习如何使用 py2exe、bb_freeze、cx_freeze 和 PyInstaller 创建可执行文件。最后,您将学习如何使用 Inno Setup 创建安装程序
立即购买
Python 101 截屏更新-另一个演示视频
原文:https://www.blog.pythonlibrary.org/2015/04/16/python-101-screencast-update-another-demo-of-idle/
昨天我整理了另一个 Python 101 的演示,截屏。这个是基于我的书的第一章,这本书涵盖了 Python 的内置开发环境 IDLE 的基础知识。你可以看看下面的视频:
https://www.youtube.com/embed/yEusyqoxNQI?feature=oembed
截屏系列的 Kickstarter 活动还有一周时间。你可以点击查看 Kickstarter。感谢你的支持!
Python 101:在 Windows 截屏上设置 Python
原文:https://www.blog.pythonlibrary.org/2014/11/30/python-101-setting-up-python-on-windows-screencast/
我根据我写的一篇关于在 Windows 上设置 Python 的旧文章创作了我的第一个截屏。
//www.youtube.com/embed/Ly1CB8jzxzI
Python 101:在 Windows 上设置 Python
原文:https://www.blog.pythonlibrary.org/2011/11/24/python-101-setting-up-python-on-windows/
Python 很容易在 Windows 上安装,但有时你需要做一些额外的调整,以真正获得最大的开发环境。在本文中,我们将尝试涵盖您可能想要做或安装的所有常见事情,以便设置一个理想的 Python Windows 开发工作区。你们中的一些人可能认为你需要做的就是安装 Python,然后你就完成了,但是如果你要做 Windows 开发,那么你将需要一些其他的包来使它更好。
安装和配置 Python
下载 Python 并运行安装程序。确保您获得了想要的版本(即 Python 2.7 或 3.x)。您还需要确保获得您想要的位类型,因为有 32 位和 64 位版本。注意:32 位 Python 可以在 64 位系统上很好地运行,但反之则不然!一旦你安装好,我们将继续前进。
现在,我们将确保 Python 设置正确。打开命令窗口,方法是进入开始>运行,然后键入“cmd”并按回车或回车。尝试在那里输入“python ”(不带引号),然后按回车键。如果您看到 Python shell,那么我们已经成功了一半。它应该是这样的:

如果没有,我们需要修改一些设置。
修改您的路径
在 Windows 上,通过将 Python 路径和脚本文件夹的路径添加到系统路径中,可以很好地修改路径设置。有一种方法可以做到:
-
Right-Click "My Computer" and choose Properties (Windows XP) or you may have to go digging in Control Panel on Windows 7 and do a "Show All Control Panel Items" from the path bar and look for System. You should see something like this:

-
Go to the Advanced tab and press the Environmental Variable button to see something like the following:

-
这里你会看到两种类型的变量。底部是系统变量。向下滚动到标有路径的那一行,并在最后添加下面两行:;c:\ python 26;C:\Python26\Scripts(根据您的 Python 版本及其位置进行必要的调整)请注意,每个条目都由分号分隔,因此请确保您也这样做,否则将不起作用!


现在,您应该能够从命令行运行 Python 了。不仅如此,您还可以运行 Python 脚本文件夹中的特殊脚本。你为什么会在乎?嗯,如果你安装 easy_install / SetupTools 或 pip,他们会在你可以运行的脚本文件夹中安装东西。说到这里,既然您现在已经安装了全新的 Python,那么让我们花点时间向您展示如何安装第三方包。
如何在 Windows 上安装软件包
我们将以 pip 为例。它用于从 Python 包索引(PyPI,不要与 PyPy 混淆)中轻松安装 Python 包。无论如何,你需要去这里下载它。pip 包在页面底部的 tar 和 pip 下载中。你可能需要像 IZArc 或 Filzip 这样的东西来解压它,因为 Windows 本身并不解压 tar 文件。
像以前一样打开一个命令行窗口。现在,您需要使用“cd”命令将目录切换到您解压缩文件的位置。这需要一些练习。在我的机器上,我通常解压到我的桌面,然后放入解压后的包中。一旦你进入了包含有 setup.py 文件的文件夹,你需要做的就是输入以下内容来安装它:
python setup.py install
大多数情况下,这很有效,并且软件包安装正确。偶尔,你会碰到某些抱怨他们需要编译器的包。如果你没有安装(比如 Visual Studio 或 MingW),那么你就不能用这种方式安装这个包。你必须为它找到一个预打包的安装程序。在我的机器上,我通常也会安装 easy_install。出于某种原因,这个包被称为 SetupTools 。无论如何,你过去需要 easy_install 的主要原因是它是安装 Python Eggs 的事实上的标准,你可以在这里或者这里阅读。现在你可以使用 pip 或 distribute 来做同样的事情。这三个软件都可以安装压缩文件中的软件包。通常,使用这些实用程序中的一个来安装一个软件包,您所要做的就是这样:
easy_install PackageName pip install PackageName
请阅读他们各自的文档以获取更多信息。
为 Windows 开发人员提供的其他方便的软件包
如果你是一个需要访问 Windows APIs 的严肃的 Windows 开发者,那么你将需要 PyWin32 包。你也会想熟悉 ctypes ,但是从 2.5 版本开始 Python 就包含了这一点。PyWin32 是一个轻量级的 Windows APIs 包装器。你可以在 MSDN 上找到 API 文档,然后直接翻译成 Python。ctypes 包放在一个更低的层次上,可以用来直接与 dll 交互,等等。
在 Windows 上编程的另一个常见需求是访问窗口管理工具(WMI)。幸运的是,Tim Golden 写了一个很好的 wmi 模块。使用 PyWin32 通常可以获得相同的信息,但是这比仅仅使用 WMI 要复杂得多。Tim Golden 还编写了其他几个实用程序:
- WinSys -面向 Windows 管理员的 Python 工具
- winshell -一个轻松获取 Windows 路径的工具
- 一个活动目录包装器
你也应该看看他那令人敬畏的“How I”系列教程。
最后,Python 包含一个名为 _winreg 的模块,您可以使用它来访问 Windows 注册表。这是一个非常强大的工具,如果您在 Windows 上执行大量管理脚本,它会非常有用。
用于 Windows 的其他 Python 安装
评论部分开始有人提到您可以获得的特殊 Python 安装,这些安装实际上包括 PyWin32 和其他打包在一个安装程序中的包。这也是一种选择。以下是其中的几个例子:
- python xy——这个包包含了大量其他包,包括 PyWin32、SciPy、wxPython、NumPy 和许多其他包。它看起来像一个万事通。我没有用过这个,但是听起来很有趣。
- 这个链接是他们的付费版本,但是也有一个轻量级免费版本。
- ActiveState 的 active python(——它已经存在很长时间了,包括 PyWin32 文档和各种其他工具。
包扎
现在,您应该拥有了成为一名高效的 Python Windows 开发人员所需的所有工具。如果你需要帮助,PyWin32 和 ctypes 邮件列表是活跃的,他们有专家可以回答你想知道的关于这些包的任何问题。
进一步阅读
- 一个 Python 的 Windows 注册表教程
- 另外一些关于 MvP 的文章是关于 Windows 和 Python
- Windows 上的官方 Python 文档
- 另一个关于 Windows 上的 Python 的教程
- 来自 ActiveState 的 PyWin32 文档
python 101-REPL(视频)
原文:https://www.blog.pythonlibrary.org/2022/04/27/python-101-the-repl-video/
在本教程中,您将了解什么是 REPL 以及它为什么有用。在本教程中,我还向您展示了几个可供选择的 REPL 环境,比如 IDLE 和 IPython 。
https://www.youtube.com/embed/ucllf6bDgnw?feature=oembed
相关文章
- Python 编辑器简介
- Python 101 - 空闲介绍
Python 101:三元运算符
原文:https://www.blog.pythonlibrary.org/2012/08/29/python-101-the-ternary-operator/
有很多计算机语言都包含三元(或第三)运算符,这基本上是 Python 中的一行条件表达式。如果你感兴趣,你可以在维基百科上阅读其他语言的各种翻译方式。在这里,我们将花一些时间来看几个不同的例子,以及为什么你可能会在现实生活中使用这个操作符。
我记得在 C++中使用三元运算符时,它是一个问号。我用谷歌查了一下,在 StackOverflow 问答和前面提到的维基百科的例子中找到了一些很好的例子。让我们来看看其中的一些,看看我们是否能解决它们。下面是一个最简单的例子:
x = 5
y = 10
result = True if x > y else False
这基本上是这样的:结果将是真是 x 大于 y,否则结果是假。老实说,这让我想起了我见过的一些 Microsoft Excel 条件语句。有些人反对这种格式,但这就是官方的 Python 文档所使用的格式。下面是如何在普通条件语句中编写它:
x = 5
y = 10
if x > y:
print("True")
else:
print("False")
因此,使用三元运算符可以节省 3 行代码。无论如何,当你在一组文件上循环时,你可能想要使用这个结构,并且你想要过滤掉一些部分或行。在下一个例子中,我们将循环一些数字,检查它们是奇数还是偶数:
for i in range(1, 11):
x = i % 2
result = "Odd" if x else "Even"
print(f"{i} is {result}")
您会惊讶于检查除法语句剩余部分的频率。这是一种快速判断数字是奇数还是偶数的方法。在前面提到的 StackOverflow 链接中,有一段有趣的代码,作为示例展示给那些仍在使用 Python 2.4 或更早版本的人:
# (falseValue, trueValue)[test]
>>> (0, 1)[5>6]
0
>>> (0, 1)[5<6]
1
这是相当丑陋的,但它做的工作。这是索引一个元组,当然是一个黑客,但这是一段有趣的代码。当然,它没有我们之前看到的新方法的短路值,所以两个值都要计算。这样做你甚至会遇到奇怪的错误,其中 True 是 False,反之亦然,所以我不推荐这样做。
用 Python 的 lambda 做三元也有几种方法。这是之前提到的维基百科条目中的一条:
def true():
print("true")
return "truly"
def false():
print("false")
return "falsely"
func = lambda b,a1,a2: a1 if b else a2
func(True, true, false)()
func(False, true, false)()
这是一些古怪的代码,尤其是如果你不理解 lambdas 是如何工作的。基本上,lambda 是一个匿名函数。这里我们创建了两个正常的函数和一个 lambda 函数。然后我们用一个布尔值 True 和一个 False 来调用它。在第一次调用中,如下所示:如果布尔值为真,则调用 true 函数,否则调用 false 函数。第二个稍微有点混乱,因为它似乎是说如果布尔为 false,你应该调用 true 方法,但它实际上是说只有当 b 为布尔 False 时,它才会调用 False 方法。是啊,我也觉得有点困惑。
包扎
在下面的“补充阅读”一节中,还有几个其他的三元运算符的例子,您可以查看一下,但是现在您应该已经很好地掌握了如何使用它以及何时使用它。当我知道我需要创建一个简单的真/假条件,并且我想节省几行代码时,我个人会使用这种方法。然而,我经常倾向于使用显式而不是隐式,因为我知道我必须回来维护这些代码,而且我不喜欢总是不得不弄清楚这种奇怪的东西,所以我可能会直接写下这 4 行代码。当然,选择权在你。
附加阅读
- 表达式中的“条件句”( Python 食谱)
- Python Lambda
- Lambda 代替 if - StackOverflow
- 愚蠢的λ把戏包括一个三元例子
Python 101-Python 中的类型提示(视频)
原文:https://www.blog.pythonlibrary.org/2022/07/21/python-101-type-hinting-in-python-video/
在这篇由 Mike Driscoll 撰写的教程中学习所有关于类型提示(又名类型注释)的知识
你会学到什么
- 类型提示的利与弊
- 内置类型提示/变量注释
- 集合类型提示
- 可能为无的提示值
- 类型提示功能
- 当事情变得复杂时该怎么办
- 班级
- 装修工
- 错认假频伪信号
- 其他类型提示
https://www.youtube.com/embed/fmCQ5XM4igA?feature=oembed
本教程基于迈克尔·德里斯科尔的《Python 101 -第二版》一书中的一章
在此购买图书:
Python 101 -我们的活动已经进行了一半了!
原文:https://www.blog.pythonlibrary.org/2014/03/06/python-101-were-halfway-through-the-campaign/
这是我为支持我的 Python 101 书而举办的 Kickstarter 活动的更新:
我们已经完成了活动的一半,我认为我们将达到的第一阶段目标!说到挑战目标,我想我应该继续宣布几个。
拓展目标 2: 1500 名支持者
如果我们能获得 1500 名支持者,那么我会制作一些配套的视频来配合这本书。这些截屏可能赶不上这本书的发布,也可能不会涵盖每一章,所以我会在夏天发布它们,并根据我收到的反馈来填补空白。我还计划向任何人发布视频,可能会在 Youtube 上发布。
关于许可的话题
我在上一次更新中提到,我正在考虑制作这本书的网站版本,并在其上附加一个知识共享许可。我没有得到太多的反馈,但在为数不多的回复中,似乎有更多的人认为我应该免费赠送这本书。通过把这本书变成一个网站,我怀疑购买这本书的人数会显著下降。因此,我们将把它变成一个特殊的双重延伸目标:
拓展目标 3——25,000 美元或 2500 名支持者
如果我们的资金达到 2.5 万美元,或者有 2500 名支持者,那么我会把这本书作为一个网站发布,但有版权。如果我们的收入明显高于这个数字,那么我会考虑在知识共享下发布网站内容。
同时,我请你告诉你的朋友、同学和同事关于这个 Kickstarter。我们传播的信息越多,我们就越有可能达到延伸目标!
附注:我正在完成第二部最后一章的后半部分。希望第二部分能在今天或明天早些时候完成。
Python 101:使用日期和时间
原文:https://www.blog.pythonlibrary.org/2017/06/15/python-101-working-with-dates-and-time/
Python 为开发人员提供了几个处理日期和时间的工具。在本文中,我们将关注日期时间和时间模块。我们将学习它们是如何工作的,以及它们的一些常见用途。让我们从日期时间模块开始吧!
日期时间模块
我们将从日期时间模块中学习以下课程:
- datetime.date
- datetime.timedelta
- datetime.datetime
这些将涵盖 Python 中需要使用日期和日期时间对象的大多数情况。还有一个用于处理时区的 tzinfo 类,我们将不再介绍。有关该类的更多信息,请随意查看 Python 文档。
datetime.date
Python 可以用几种不同的方式表示日期。我们将首先看一下 datetime.date 格式,因为它恰好是一个比较简单的日期对象。
>>> datetime.date(2012, 13, 14)
Traceback (most recent call last):
File "", line 1, in <fragment>builtins.ValueError: month must be in 1..12
>>> datetime.date(2012, 12, 14)
datetime.date(2012, 12, 14)
这段代码展示了如何创建一个简单的日期对象。date 类接受三个参数:年、月和日。如果你给它传递一个无效的值,你会看到一个 ValueError ,如上图所示。否则你将会看到一个返回的日期时间.日期对象。让我们看另一个例子:
>>> import datetime
>>> d = datetime.date(2012, 12, 14)
>>> d.year
2012
>>> d.day
14
>>> d.month
12
这里我们将日期对象赋给变量 d 。现在我们可以按名称访问各种日期组件,例如 d 年或 d 月。现在让我们找出今天是星期几:
>>> datetime.date.today()
datetime.date(2014, 3, 5)
每当你需要记录今天是哪一天时,这都会很有帮助。或者,您可能需要根据今天进行基于日期的计算。不过这是一个方便的小方法。
datetime.datetime
datetime.datetime 对象包含 datetime.date 加上 datetime.time 对象的所有信息。让我们创建几个例子,以便更好地理解这个对象和 datetime.date 对象之间的区别。
>>> datetime.datetime(2014, 3, 5)
datetime.datetime(2014, 3, 5, 0, 0)
>>> datetime.datetime(2014, 3, 5, 12, 30, 10)
datetime.datetime(2014, 3, 5, 12, 30, 10)
>>> d = datetime.datetime(2014, 3, 5, 12, 30, 10)
>>> d.year
2014
>>> d.second
10
>>> d.hour
12
这里我们可以看到 datetime.datetime 接受几个额外的参数:年、月、日、小时、分钟和秒。它还允许您指定微秒和时区信息。当您使用数据库时,您会发现自己经常使用这些类型的对象。大多数情况下,您需要将 Python 日期或日期时间格式转换为 SQL 日期时间或时间戳格式。您可以使用两种不同的方法通过 datetime.datetime 找出今天是什么日子:
>>> datetime.datetime.today()
datetime.datetime(2014, 3, 5, 17, 56, 10, 737000)
>>> datetime.datetime.now()
datetime.datetime(2014, 3, 5, 17, 56, 15, 418000)
datetime 模块有另一个您应该知道的方法,叫做 strftime 。该方法允许开发人员创建一个字符串,以更易于阅读的格式表示时间。在 Python 文档 8.1.7 节中,有一个完整的格式选项表,您应该去阅读。我们将通过几个例子向您展示这种方法的威力:
>>> datetime.datetime.today().strftime("%Y%m%d")
'20140305'
>>> today = datetime.datetime.today()
>>> today.strftime("%m/%d/%Y")
'03/05/2014'
>>> today.strftime("%Y-%m-%d-%H.%M.%S")
'2014-03-05-17.59.53'
第一个例子有点像黑客。它展示了如何将今天的 datetime 对象转换成符合 YYYYMMDD (年、月、日)格式的字符串。第二个例子更好。这里我们将今天的 datetime 对象赋给一个名为 today 的变量,然后尝试两种不同的字符串格式化操作。第一个在 datetime 元素之间添加了正斜杠,并重新排列,使其成为月、日、年。最后一个例子创建了一个时间戳,它遵循一种非常典型的格式: YYYY-MM-DD。HH.MM.SS 。如果想去两位数的年份,可以把 %Y 换成 %y 。
datetime.timedelta
datetime.timedelta 对象表示持续时间。换句话说,它是两个日期或时间之间的差异。让我们看一个简单的例子:
>>> now = datetime.datetime.now()
>>> now
datetime.datetime(2014, 3, 5, 18, 13, 51, 230000)
>>> then = datetime.datetime(2014, 2, 26)
>>> delta = now - then
>>> type(delta)
>>> delta.days
7
>>> delta.seconds
65631
我们在这里创建两个日期时间对象。一个是今天的,一个是一周前的。然后我们取两者之差。这将返回一个 timedelta 对象,我们可以用它来找出两个日期之间的天数或秒数。如果你需要知道两者之间的小时数或分钟数,你将不得不使用一些数学来计算出来。有一种方法可以做到:
>>> seconds = delta.total_seconds()
>>> hours = seconds // 3600
>>> hours
186.0
>>> minutes = (seconds % 3600) // 60
>>> minutes
13.0
这告诉我们一周有 186 小时 13 分钟。注意,我们使用双正斜杠作为除法运算符。这就是所谓的楼层划分。
现在我们准备好继续学习关于时间模块的知识了!
时间模块
time 模块为 Python 开发者提供了对各种时间相关函数的访问。时间模块是基于所谓的纪元,时间开始的时间点。对于 Unix 系统来说,这个时代是在 1970 年。要找出您系统上的纪元,请尝试运行以下命令:
>>> import time
>>> time.gmtime(0)
time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0,
tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)
我在 Windows 7 上运行这个程序,它似乎也认为时间是从 1970 年开始的。无论如何,在本节中,我们将学习以下与时间相关的函数:
- time.ctime
- 时间.睡眠
- time.strftime
- 时间时间
我们开始吧!
time.ctime
time.ctime 函数将从 epoch 开始以秒为单位的时间转换为表示本地时间的字符串。如果你没有传递任何东西给它,那么返回当前时间。让我们尝试几个例子:
>>> import time
>>> time.ctime()
'Thu Mar 06 07:28:48 2014'
>>> time.ctime(1384112639)
'Sun Nov 10 13:43:59 2013'
这里我们展示了调用 ctime 的结果,没有任何东西,并且从 epoch 开始有一个相当随机的秒数。我见过有人把日期保存为纪元后的秒,然后想把它转换成人类可以理解的东西。将大整数(或长整数)保存到数据库中,然后将其从日期时间对象格式化为数据库接受的任何日期对象,这要简单一些。当然,这也有一个缺点,那就是你需要将整型或浮点型值转换回字符串。
时间.睡眠
time.sleep 函数让开发人员能够在给定的秒数内暂停脚本的执行。这就像给你的程序添加一个暂停。当我需要等待一个文件完成关闭或者一个数据库提交完成时,我发现这非常有用。让我们看一个例子。在空闲状态下打开一个新窗口,并保存以下代码:
import time
for x in range(5):
time.sleep(2)
print("Slept for 2 seconds")
现在在空闲状态下运行代码。你可以进入运行菜单,然后选择运行模块菜单项。当你这样做的时候,你会看到它打印出短语睡眠 2 秒五次,每次打印之间有两秒钟的停顿。真的那么好用!
time.strftime
时间模块有一个 strftime 函数,其工作方式与 datetime 版本非常相似。区别主要在于它接受的输入:一个元组或一个 struct_time 对象,就像调用 time.gmtime() 或 time.localtime() 时返回的那些对象。这里有一个小例子:
>>> time.strftime("%Y-%m-%d-%H.%M.%S",
time.localtime())
'2014-03-06-20.35.56'
这段代码与我们在本章的日期时间部分创建的时间戳代码非常相似。我认为 datetime 方法更直观一些,因为您只需创建一个 datetime.datetime 对象,然后用您想要的格式调用它的 strftime 方法。对于时间模块,必须传递格式和时间元组。哪个对你最有意义,真的是你自己决定的。
时间时间
time.time 函数将以浮点数的形式返回从 epoch 开始的时间(以秒为单位)。让我们来看看:
>>> time.time()
1394199262.318
这很简单。当您想将当前时间保存到数据库中,但又不想麻烦地将其转换为数据库的 datetime 方法时,可以使用这个方法。您可能还记得, ctime 方法接受以秒为单位的时间,因此我们可以使用 time.time 来获取传递给 ctime 的秒数,如下所示:
>>> time.ctime(time.time())
'Fri Mar 07 07:36:38 2014'
如果您在 time 模块的文档中做了一些研究,或者只是做了一点试验,您可能会发现这个函数的一些其他用途。
包扎
至此,您应该知道如何使用 Python 的标准模块处理日期和时间。在处理日期时,Python 为您提供了强大的功能。如果您需要创建一个跟踪约会或需要在特定日期运行的应用程序,您会发现这些模块非常有用。它们在处理数据库时也很有用。
相关阅读
- 关于日期时间模块的 Python 文档
- 关于时间模块的 Python 文档
- 本周 Python 模块:日期时间
- 另一个 Python 日期时间替代:钟摆
- 日期搜索包
- Python 与 Delorean 共度时光
- arrow "Python 的新日期/时间包
Python 101 -使用文件(视频)
原文:https://www.blog.pythonlibrary.org/2021/09/03/python-101-working-with-files-video/
应用程序开发人员总是与文件打交道。每当您编写新的脚本或应用程序时,都会创建它们。你用微软 Word 写报告,保存电子邮件或下载书籍或音乐。文件到处都是。您的网络浏览器会下载大量小文件,让您的浏览体验更快。
当你写程序的时候,你必须与预先存在的文件交互或者自己写出文件。Python 提供了一个名为open()的内置函数,可以帮助您完成这些任务。
在本视频中,您将学习如何:
- 打开文件
- 读取文件
- 写文件
- 附加到文件
我们开始吧!
https://www.youtube.com/embed/Tg0rZkuuB0I?feature=oembed
如果你更喜欢阅读教程而不是观看,那么你可能想看看下面的文章:
- Python 101 - 处理文件
Python 101 -使用文件
原文:https://www.blog.pythonlibrary.org/2020/06/24/python-101-working-with-files/
应用程序开发人员总是与文件打交道。每当您编写新的脚本或应用程序时,都会创建它们。你用微软 Word 写报告,保存电子邮件或下载书籍或音乐。文件到处都是。您的网络浏览器会下载大量小文件,让您的浏览体验更快。
当您编写程序时,您必须与预先存在的文件交互或自己写出文件。Python 提供了一个很好的内置函数open(),可以帮助您完成这些任务。
在本章中,您将学习如何:
- 打开文件
- 读取文件
- 写文件
- 附加到文件
我们开始吧!
open()函数
您可以打开文件进行读取、写入或附加。要打开一个文件,可以使用内置的open()函数。
下面是open()函数的参数和默认值:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None,
closefd=True, opener=None)
当您打开一个文件时,您需要传入一个文件名或文件路径。打开文件的默认方式是以只读模式打开,这就是“r”的意思。
下表介绍了打开文件时可以使用的其他模式:
| 性格;角色;字母 | 意义 |
|---|---|
| r ' | 打开文件进行读取(默认) |
| w ' | 打开进行写入,覆盖现有文件 |
| 一个 | 打开进行写入。如果文件存在,追加到末尾 |
| ' b ' | 二进制 |
| t | 文本模式(默认) |
| '+' | 阅读和写作 |
在这一章中,你将着重于阅读、写作和附加。如果您需要将文件编码成特定的格式,比如 UTF-8,您可以通过encoding参数来设置。有关 Python 支持的编码类型的完整列表,请参见文档。
有两种打开文件的主要方法。你可以这样做:
file_handler = open('example.txt')
# do something with the file
file_handler.close()
在这里你打开文件,然后关闭它。但是,如果在尝试打开文件时出现异常,会发生什么情况呢?例如,假设您试图打开一个不存在的文件。或者您打开了一个文件,但无法写入。这些事情会发生,它们会导致文件句柄处于打开状态而没有正确关闭。
一种解决方案是使用try/finally:
try:
file_handler = open('example.txt')
except:
# ignore the error, print a warning or log the exception
pass
finally:
file_handler.close()
然而,用 Python 打开文件的最好方法是使用 Python 特殊的with语句。with语句激活了所谓的上下文管理器。上下文管理器在你想要设置和拆除某些东西的时候使用。在本例中,您想要打开一个文件,执行一些操作,然后关闭该文件。
Python 的核心开发者把open()做成一个上下文管理器。这意味着您也可以像这样打开文件:
with open('example.txt') as file_handler:
# do something with the handler here
data = file_handler.read()
它所做的是打开文件并将文件对象分配给file_handler。那么缩进到with语句内部的任何代码都被认为是上下文的一部分。这是您与文件处理程序交互的地方,无论是读取还是写入文件。然后当你退出with语句时,它会自动关闭文件。
就像有一个内置的finally语句!
现在你已经知道了如何打开一个文件,让我们继续学习如何用 Python 读取一个文件。
读取文件
用 Python 编程语言读取文件非常简单。事实上,当你打开一个文件并且没有设置mode参数时,默认是以“只读”模式打开文件。
这里有一个例子:
with open('example.txt') as file_handler:
for line in file_handler:
print(line)
这段代码将打开文本文件,然后遍历文件中的每一行并打印出来。是的,file_handler可以使用 Python 的for循环进行迭代,这非常方便。事实上,这实际上是一种推荐的读取文件的方法,因为你是成块读取的,这样你就不会耗尽内存。
另一种循环遍历文件中各行的方法是执行以下操作:
with open('example.txt') as file_handler:
lines = file_handler.readlines()
for line in lines:
print(line)
如果你走这条路,那么你只是把整个文件读入内存。根据你的机器有多少内存,你可能会耗尽内存。这就是推荐第一种方法的原因。
但是,如果您知道文件很小,有另一种方法可以将整个文件读入内存:
with open('example.txt') as file_handler:
file_contents = file_handler.read()
方法会把整个文件读入内存,并把它赋给你的变量。
有时,您可能希望以较小或较大的块读取文件。这可以通过将字节大小指定给read()来实现。您可以为此使用一个while循环:
while True:
with open('example.txt') as file_handler:
data = file_handler.read(1024)
if not data:
break
print(data)
在本例中,您一次读取 1024 个字节。当您调用read()并返回一个空字符串时,那么while循环将停止,因为break语句将被执行。
读取二进制文件
有时你需要读取一个二进制文件。Python 也可以通过将r模式与b结合起来来实现这一点:
with open('example.pdf', 'rb') as file_handler:
file_contents = file_handler.read()
注意open()的第二个参数是rb。这告诉 Python 以只读二进制模式打开文件。如果你要打印出file_contents,你会看到什么是乱码,因为大多数二进制文件是不可读的。
写文件
用 Python 编写一个新文件使用的语法与读取几乎完全相同。但是,对于写入模式,您不是将模式设置为r,而是将其设置为w。如果你需要用二进制模式写,那么你可以用wb模式打开文件。
警告:使用w和wb模式时,如果文件已经存在,最终会被覆盖。Python 不会以任何方式警告你。Python 确实提供了一种通过使用os模块经由os.path.exists()来检查文件是否存在的方法。更多细节参见 Python 的文档。
让我们向文件中写入一行文本:
>>> with open('example.txt', 'w') as file_handler:
... file_handler.write('This is a test')
这将向文件中写入单行文本。如果你写更多的文字,它将被写在前面的文字旁边。因此,如果您需要添加一个新行,那么您将需要使用\n写出一行。
要验证这是否有效,您可以读取该文件并打印出其内容:
>>> with open('example.txt') as file_handler:
... print(file_handler.read())
...
This is a test
如果需要一次写多行,可以使用writelines()方法,该方法接受一系列字符串。例如,你可以使用字符串的list并将它们传递给writelines()。
在文件中查找
文件处理程序还提供了另一个值得一提的方法。这个方法就是seek(),你可以用它来改变文件对象的位置。换句话说,您可以告诉 Python 从文件的哪里开始读取。
seek()方法接受两个参数:
offset-来自whence的字节数whence-参考点
您可以将whence设置为以下三个值:
- 0 -文件的开头(默认)
- 1 -当前文件位置
- 2 -文件的结尾
让我们以您在本章前面写的文件为例:
>>> with open('example.txt') as file_handler:
... file_handler.seek(4)
... chunk = file_handler.read()
... print(chunk)
...
is a test
在这里,您以只读模式打开文件。然后寻找第 4 个字节,将文件的其余部分读入变量chunk。最后,打印出chunk,看到文件的只读部分。
附加到文件
您也可以使用a模式将数据追加到预先存在的文件中,这是一种追加模式。
这里有一个例子:
>>> with open('example.txt', 'a') as file_handler:
... file_handler.write('Here is some more text')
如果文件存在,这将在文件末尾添加一个新字符串。另一方面,如果文件不存在,Python 将创建文件并将数据添加到文件中。
捕捉文件异常
当您处理文件时,有时会遇到错误。例如,您可能没有创建文件或编辑文件的正确权限。在这种情况下,Python 将引发一个OSError。偶尔还会出现其他错误,但这是处理文件时最常见的错误。
您可以使用 Python 的异常处理工具来保持您的程序正常工作:
try:
with open('example.txt') as file_handler:
for line in file_handler:
print(line)
except OSError:
print('An error has occurred')
这段代码将试图打开一个文件并一次打印出一行内容。如果一个OSError被引发,你将用try/except捕捉它并打印出一条消息给用户。
包扎
现在,您已经了解了使用 Python 处理文件的基础知识。在本章中,您学习了如何打开文件。然后你学会了如何读写文件。您还了解了如何在文件中查找、向文件追加内容以及在访问文件时处理异常。在这一点上,你真的只需要实践你所学的。继续尝试你在本章中学到的东西,看看你自己能做什么!
Python 101 -使用字符串(视频)
原文:https://www.blog.pythonlibrary.org/2020/06/16/python-101-working-with-strings-video/
在这个截屏中学习如何使用 Python 中的字符串。
https://www.youtube.com/embed/2mDTBHODJR0?feature=oembed
这个视频基于我的书 Python 101 第二版中的一章。
你可以在这里阅读书面版本:
Python 101 -使用字符串
原文:https://www.blog.pythonlibrary.org/2020/04/07/python-101-working-with-strings/
当你编程的时候,你会经常用到字符串。字符串是由单引号、双引号或三引号括起来的一系列字母。Python 3 将 string 定义为“文本序列类型”。您可以使用内置的str()函数将其他类型转换为字符串。
在本文中,您将学习如何:
- 创建字符串
- 字符串方法
- 字符串格式
- 串并置
- 字符串切片
让我们从学习创建字符串的不同方法开始吧!
创建字符串
以下是创建字符串的一些示例:
name = 'Mike'
first_name = 'Mike'
last_name = "Driscoll"
triple = """multi-line
string"""
当您使用三重引号时,您可以在字符串的开头和结尾使用三个双引号或三个单引号。另外,请注意,使用三重引号允许您创建多行字符串。字符串中的任何空白也将包括在内。
下面是一个将整数转换为字符串的示例:
>>> number = 5
>>> str(number)
'5'
在 Python 中,反斜杠可以用来创建转义序列。这里有几个例子:
\b-退格键\n-换行\r- ASCII 回车\t-标签
如果您阅读 Python 的文档,还可以了解其他几个。
您还可以使用反斜杠来转义引号:
>>> 'This string has a single quote, \', in the middle'
"This string has a single quote, ', in the middle"
如果上面的代码中没有反斜杠,您将收到一个SyntaxError:
>>> 'This string has a single quote, ', in the middle'
Traceback (most recent call last):
Python Shell, prompt 59, line 1
invalid syntax: <string>, line 1, pos 38
这是因为字符串在第二个单引号处结束。通常最好是混合使用双引号和单引号来解决这个问题:
>>> "This string has a single quote, ', in the middle"
"This string has a single quote, ', in the middle"
在这种情况下,您使用双引号创建字符串,并将单引号放入其中。这在处理缩略词时尤其有用,比如“不要”、“不能”等。
现在让我们继续,看看你能用什么方法来处理字符串!
字符串方法
在 Python 中,一切都是对象。当你学习内省的时候,你会在第 18 章学到这是多么有用。现在,只要知道字符串有可以调用的方法(或函数)就行了。
这里有三个例子:
>>> name = 'mike'
>>> name.capitalize()
'Mike'
>>> name.upper()
'MIKE'
>>> 'MIke'.lower()
'mike'
方法名给了你一个线索,让你知道它们是做什么的。例如,.capitalize()会将字符串中的第一个字母改为大写字母。
要获得可以访问的方法和属性的完整列表,可以使用 Python 内置的dir()函数:
>>> dir(name)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize',
'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index',
'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable',
'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace',
'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip',
'swapcase', 'title', 'translate', 'upper', 'zfill']
清单的前三分之一是特殊方法,有时被称为“dunder 方法”(又名双下划线方法)或“魔术方法”。您现在可以忽略这些,因为它们更多地用于中级和高级用例。上面列表中开头没有双下划线的条目可能是您最常用的条目。
您会发现.strip()和.split()方法在解析或操作文本时特别有用。
您可以使用.strip()及其变体、.rstrip()和.lstrip()来去除字符串中的空白,包括制表符和换行符。这在您读取需要解析的文本文件时特别有用。
事实上,您通常会从字符串中去掉行尾字符,然后对结果使用.split()来解析出子字符串。
让我们做一个小练习,学习如何解析字符串中的第二个单词。
首先,这里有一个字符串:
>>> my_string = 'This is a string of words'
'This is a string of words'
现在要得到字符串的各个部分,你可以调用.split(),就像这样:
>>> my_string.split()
['This', 'is', 'a', 'string', 'of', 'words']
结果是字符串的list。现在通常你会把这个结果赋给一个变量,但是为了演示的目的,你可以跳过这部分。
相反,既然您现在知道结果是一个字符串,那么您可以使用列表切片来获得第二个元素:
>>> 'This is a string of words'.split()[1]
'is'
记住,在 Python 中,列表元素从 0(零)开始,所以当你告诉它你想要元素 1(一)时,它是列表中的第二个元素。
当在工作中进行字符串解析时,我个人发现您可以非常有效地使用.strip()和.split()方法来获得几乎任何您需要的数据。偶尔您会发现您可能还需要使用正则表达式(regex),但是大多数时候这两种方法就足够了。
字符串格式
字符串格式化或字符串替换是指将一个字符串插入到另一个字符串中。这在你需要做模板的时候特别有用,比如套用信函。但是您将大量使用字符串替换来调试输出、打印到标准输出等等。
Python 有三种不同的方法来完成字符串格式化:
- 使用%方法
- 使用
.format() - 使用格式化字符串(f 字符串)
这本书将重点放在 f 弦上,也不时使用.format()。但是理解这三者是如何工作的是有好处的。
让我们花一些时间来学习更多关于字符串格式的知识。
使用%s 格式化字符串(printf 样式)
使用%方法是 Python 最古老的字符串格式化方法。它有时被称为“printf 风格的字符串格式化”。如果您过去使用过 C 或 C++,那么您可能已经熟悉了这种类型的字符串替换。为了简洁起见,您将在这里学习使用%的基本知识。
注意:这种格式很难处理,并且会导致常见的错误,比如无法正确显示 Python 元组和字典。在这种情况下,最好使用其他两种方法中的任何一种。
使用%符号最常见的情况是使用%s,这意味着使用str()将任何 Python 对象转换成字符串。
这里有一个例子:
>>> name = 'Mike'
>>> print('My name is %s' % name)
My name is Mike
在这段代码中,使用特殊的%s语法将变量name插入到另一个字符串中。为了让它工作,你需要在字符串外面使用%,后跟你想要插入的字符串或变量。
下面是第二个例子,展示了您可以将一个int传入一个字符串,并让它自动为您转换:
>>> age = 18
>>> print('You must be at least %s to continue' % age)
You must be at least 18 to continue
当你需要转换一个对象但不知道它是什么类型时,这种事情特别有用。
您还可以使用多个变量进行字符串格式化。事实上,有两种方法可以做到这一点。
这是第一个:
>>> name = 'Mike'
>>> age = 18
>>> print('Hello %s. You must be at least %i to continue!' % (name, age))
Hello Mike. You must be at least 18 to continue!
在这个例子中,您创建了两个变量并使用了%s和%i。%i表示你要传递一个整数。要传入多个项,可以使用百分号,后跟要插入的项的元组。
你可以用名字来说明这一点,就像这样:
>>> print('Hello %(name)s. You must be at least %(age)i to continue!' % {'name': name, 'age': age})
Hello Mike. You must be at least 18 to continue!
当%符号右侧的参数是字典(或另一种映射类型)时,字符串中的格式必须引用字典中带括号的键。换句话说,如果你看到%(name)s,那么在%右边的字典一定有一个name键。
如果没有包含所有必需的密钥,您将收到一条错误消息:
>>> print('Hello %(name)s. You must be at least %(age)i to continue!' % {'age': age})
Traceback (most recent call last):
Python Shell, prompt 23, line 1
KeyError: 'name'
有关使用 printf 样式的字符串格式的更多信息,请参见以下链接:
https://docs . python . org/3/library/stdtypes . html # printf-style-string-formatting
现在让我们继续使用.format()方法。
使用格式化字符串。格式()
Python 字符串支持.format()方法已经很久了。虽然这本书将重点关注 f 弦的使用,但你会发现.format()仍然很受欢迎。
有关格式化如何工作的完整详细信息,请参见以下内容:
https://docs.python.org/3/library/string.html#formatstrings
让我们来看几个简短的例子,看看.format()是如何工作的:
>>> age = 18
>>> name = 'Mike'
>>> print('Hello {}. You must be at least {} to continue!'.format(name, age))
Hello Mike. You must be at least 18 to continue!
此示例使用位置参数。Python 寻找{}的两个实例,并相应地插入变量。如果您没有传入足够的参数,您将收到如下错误:
>>> print('Hello {}. You must be at least {} to continue!'.format(age))
Traceback (most recent call last):
Python Shell, prompt 33, line 1
IndexError: tuple index out of range
这个错误表明您在.format()调用中没有足够的项目。
您也可以按照与上一节类似的方式使用命名参数:
>>> age = 18
>>> name = 'Mike'
>>> print('Hello {name}. You must be at least {age} to continue!'.format(name=name, age=age))
Hello Mike. You must be at least 18 to continue!
您可以通过名称传入参数,而不是将字典传递给.format()。事实上,如果您尝试传入一个字典,您将会收到一个错误:
>>> print('Hello {name}. You must be at least {age} to continue!'.format({'name': name, 'age': age}))
Traceback (most recent call last):
Python Shell, prompt 34, line 1
KeyError: 'name'
不过,有一个解决方法:
>>> print('Hello {name}. You must be at least {age} to continue!'.format(**{'name': name, 'age': age}))
Hello Mike. You must be at least 18 to continue!
这看起来有点奇怪,但是在 Python 中,当您看到像这样使用双星号(**)时,这意味着您正在向函数传递命名参数。所以 Python 正在为你把字典转换成name=name, age=age。
您也可以使用.format()在字符串中多次重复一个变量:
>>> name = 'Mike'
>>> print('Hello {name}. Why do they call you {name}?'.format(name=name))
Hello Mike. Why do they call you Mike?
这里你在字符串中引用了两次{name},你可以用.format()来替换它们。
如果需要,您也可以使用数字来插值:
>>> print('Hello {1}. You must be at least {0} to continue!'.format(name, age))
Hello 18\. You must be at least Mike to continue!
因为 Python 中的大多数东西都是从 0(零)开始的,所以在这个例子中,您最终将age传递给了{1},将name传递给了{0}。
使用.format()时,一种常见的编码方式是创建一个格式化字符串,并将其保存到一个变量中以备后用:
>>> age = 18
>>> name = 'Mike'
>>> greetings = 'Hello {name}. You must be at least {age} to continue!'
>>> greetings.format(name=name, age=age)
'Hello Mike. You must be at least 18 to continue!'
这允许你在程序中重用greetings并传递更新后的name和age的值。
您还可以指定字符串宽度和对齐方式:
>>> '{:<20}'.format('left aligned')
'left aligned '
>>> '{:>20}'.format('right aligned')
' right aligned'
>>> '{:^20}'.format('centered')
' centered '
默认为左对齐。冒号(:)告诉 Python 您将应用某种格式。在第一个示例中,您指定字符串左对齐,宽度为 20 个字符。第二个例子也是 20 个字符宽,但它是右对齐的。最后,^告诉 Python 将字符串放在 20 个字符的中间。
如果你想像前面的例子那样传入一个变量,你可以这样做:
>>> '{name:^20}'.format(name='centered')
' centered '
请注意,name必须在{}内的:之前。
至此,您应该非常熟悉.format()的工作方式。
让我们继续前进到 f 弦!
用 f 字符串格式化字符串
格式化的字符串文字或 string 是在开头有一个“f”的字符串,在它们里面有包含表达式的花括号,很像您在上一节中看到的那些。这些表达式告诉 f 字符串需要对插入的字符串进行的任何特殊处理,比如对齐、浮点精度等。
f 字符串是在 Python 3.6 中添加的。你可以通过点击这里查看 PEP 498 来了解更多关于它和它是如何工作的:
https://www.python.org/dev/peps/pep-0498/
f 字符串中包含的表达式在运行时进行计算。如果 f-string 包含一个表达式,那么它就不能作为函数、方法或类的文档字符串。原因是文档字符串是在函数定义时定义的。
让我们来看一个简单的例子:
>>> name = 'Mike'
>>> age = 20
>>> f'Hello {name}. You are {age} years old'
'Hello Mike. You are 20 years old'
在这里,您通过在字符串开头的单引号、双引号或三引号前加上“f”来创建 f 字符串。然后在字符串内部,使用花括号{},将变量插入字符串。
但是,您的花括号必须包含一些内容。如果您创建一个带有空括号的 f 字符串,您将得到一个错误:
>>> f'Hello {}. You are {} years old'
SyntaxError: f-string: empty expression not allowed
f 弦可以做%s和.format()都做不到的事情。因为 f 字符串是在运行时计算的,所以可以在其中放入任何有效的 Python 表达式。
例如,您可以增加age变量:
>>> age = 20
>>> f'{age+2}'
'22'
或者调用一个方法或函数:
>>> name = 'Mike'
>>> f'{name.lower()}'
'mike'
您也可以直接在 f 字符串中访问字典值:
>>> sample_dict = {'name': 'Tom', 'age': 40}
>>> f'Hello {sample_dict["name"]}. You are {sample_dict["age"]} years old'
'Hello Tom. You are 40 years old'
但是,f 字符串表达式中不允许使用反斜杠:
>>> print(f'My name is {name\n}')
SyntaxError: f-string expression part cannot include a backslash
但是您可以在 f 字符串中的表达式之外使用反斜杠:
>>> name = 'Mike'
>>> print(f'My name is {name}\n')
My name is Mike
另一件不能做的事情是在 f 字符串的表达式中添加注释:
>>> f'My name is {name # name of person}'
SyntaxError: f-string expression part cannot include '#'
在 Python 3.8 中,f-strings 增加了对=的支持,这将扩展表达式的文本,以包括表达式的文本加上等号,然后是求值的表达式。这听起来有点复杂,所以让我们看一个例子:
>>> username = 'jdoe'
>>> f'Your {username=}'
"Your username='jdoe'"
这个例子演示了表达式中的文本username=被添加到输出中,后面是引号中的实际值username。
f 弦非常有力,非常有用。如果你明智地使用它们,它们会大大简化你的代码。你绝对应该给他们一个尝试。
让我们看看你还能用绳子做些什么吧!
串并置
字符串还允许连接,这是一个将两个字符串连接成一个字符串的时髦词。
要将字符串连接在一起,可以使用+符号:
>>> first_string = 'My name is'
>>> second_string = 'Mike'
>>> first_string + second_string
'My name isMike'
哎呀!看起来字符串以一种奇怪的方式合并了,因为你忘了在first_string的末尾加一个空格。您可以像这样更改它:
>>> first_string = 'My name is '
>>> second_string = 'Mike'
>>> first_string + second_string
'My name is Mike'
另一种合并字符串的方法是使用.join()方法。.join()方法接受一个可迭代的字符串,比如一个列表,并将它们连接在一起。
>>> first_string = 'My name is '
>>> second_string = 'Mike'
>>> ''.join([first_string, second_string])
'My name is Mike'
这将使字符串紧挨着彼此连接。你可以在要连接的字符串中放一些东西:
>>> '***'.join([first_string, second_string])
'My name is ***Mike'
在这种情况下,它会将第一个字符串连接到***加上第二个字符串。
通常情况下,您可以使用 f 字符串而不是串联或.join(),这样代码会更容易理解。
切串
字符串切片的工作方式与 Python 列表非常相似。让我们以“迈克”为例。字母“M”在位置 0,字母“e”在位置 3。
如果你想抓取字符 0-3,你可以使用这个语法:my_string[0:4]
这意味着您希望子字符串从位置 0 开始,但不包括位置 4。
这里有几个例子:
>>> 'this is a string'[0:4]
'this'
>>> 'this is a string'[:4]
'this'
>>> 'this is a string'[-4:]
'ring'
第一个示例从字符串中获取前四个字母并返回它们。如果你愿意,你可以去掉默认的零,而使用 [:4] ,这就是第二个例子所做的。
您也可以使用负的位置值。所以 [-4:] 的意思是你想从字符串的末尾开始,得到字符串的最后四个字母。
您应该自己尝试切片,看看还能想到什么其他切片。
总结
Python 字符串功能强大,非常有用。可以使用单引号、双引号或三引号来创建它们。字符串是对象,所以有方法。您还了解了字符串连接、字符串切片和三种不同的字符串格式化方法。
最新的字符串格式是 f 字符串。它也是格式化字符串的最强大和当前首选的方法。
相关阅读
Python 101:编写清理脚本
原文:https://www.blog.pythonlibrary.org/2014/01/24/python-101-writing-a-cleanup-script/
编者按:这是 Yasoob Khalid 的客座博文,他是免费 Python 技巧博客 的作者
嗨,伙计们!我希望你一切都好。那么这个帖子里是什么呢?今天我们将编写一个清理脚本。这篇文章的想法来自于 Mike Driscoll,他最近写了一篇关于用 python 写清理脚本的非常有用的文章。那么我的帖子和他的帖子有什么不同呢?在我的帖子里我会用
path.py
。当我使用
path.py
我第一次爱上了它。
正在安装 path.py:
因此,有几种安装 path.py 的方法。Path.py 可以使用 setuptools 或 distribute 或 pip 来安装:
easy_install path.py
最新版本总是更新到 Python 包索引。源代码托管在 Github 上。
查找目录中文件的数量:
所以我们的第一个任务是找到目录中存在的文件数量。在本例中,我们不会遍历子目录,而是只计算顶层目录中的文件数量。这个很简单。以下是我的解决方案:
from path import path
d = path(DIRECTORY)
#Replace DIRECTORY with your required directory
num_files = len(d.files())
print num_files
在这个脚本中,我们首先导入了路径模块。然后我们设置
num_file
变量设置为 0。这个变量将记录我们目录中文件的数量。然后我们用一个目录名调用 path 函数。此外,我们遍历目录根目录中的文件,并增加
num_files
可变。最后,我们打印出
num_files
可变。下面是这个脚本的一个小修改版本,它输出了我们目录的根目录下子目录的数量。
from path import path
d = path(DIRECTORY)
#Replace DIRECTORY with your required directory
num_dirs = len(d.dirs())
print num_dirs
查找目录中递归文件的数量:
那很容易!不是吗?所以现在我们的工作是找到一个目录中递归文件的数量。为了完成这项任务,我们被赋予了
walk()
方法依据
path.py
。这与相同
os.walk()
。因此,让我们编写一个简单的脚本,用 Python 递归地列出一个目录及其子目录中的所有文件。
from path import path
file_count = 0
dir_count = 0
total = 0
d = path(DIRECTORY)
#Replace DIRECTORY with your required directory
for i in d.walk():
if i.isfile():
file_count += 1
elif i.isdir():
dir_count += 1
else:
pass
total += 1
print "Total number of files == {0}".format(file_count)
print "Total number of directories == {0}".format(dir_count)
这也很简单。现在,如果我们想漂亮地打印目录名呢?我知道有一些终端一行程序,但是这里我们只讨论 Python。让我们看看如何实现这一目标。
files_loc = {}
file_count = 0
dir_count = 0
total = 0
for i in d.walk():
if i.isfile():
if i.dirname().basename() in files_loc:
files_loc[i.dirname().basename()].append(i.basename())
else:
files_loc[i.dirname().basename()] = []
files_loc[i.dirname().basename()].append(i.basename())
file_count += 1
elif i.isdir():
dir_count += 1
else:
pass
total += 1
for i in files_loc:
print "|---"+i
for i in files_loc[i]:
print "| |"
print "| `---"+i
print "|"
这里没有什么花哨的东西。在这个脚本中,我们只是打印了一个目录和其中包含的文件。现在让我们继续。
从目录中删除特定文件:
假设我们有一个名为
this_file_sucks.py
。现在我们如何删除它。让我们假设我们不知道它被放在哪个目录中,让这个场景更真实一些。解决这个问题也很简单。只需转到顶层目录并执行以下脚本:
from path import path
d = path(DIRECTORY)
#replace directory with your desired directory
for i in d.walk():
if i.isfile():
if i.name == 'php.py':
i.remove()
在上面的脚本中,我没有实现任何日志记录和错误处理。这是留给读者的练习。
根据扩展名删除文件
假设你想删除所有的。pyc '文件。你将如何着手处理这个问题。这是我在 1999 年提出的一个解决方案
path.py
。
from path import path
d = path(DIRECTORY)
files = d.walkfiles("*.pyc")
for file in files:
file.remove()
print "Removed {} file".format(file)
根据文件大小删除文件:
另一个有趣的场景是。如果我们想删除那些超过 5Mb 的文件怎么办?
注:Mb 和 Mb 是有区别的。我将在这里报道 Mb。
有没有可能
path.py
?是的,它是!这是一个完成这项工作的脚本:
d = path('./')
del_size = 4522420
for i in d.walk():
if i.isfile():
if i.size > del_size:
#4522420 is approximately equal to 4.1Mb
#Change it to your desired size
i.remove()
因此,我们看到了如何根据文件大小删除文件。
根据文件的上次访问时间删除文件
在这一部分中,我们将了解如何根据文件的最后访问时间来删除文件。我写了下面的代码来实现这个目标。把天数改成自己喜欢的就行了。该脚本将删除在
DAYS
可变。
from path import path
import time
#Change the DAYS to your liking
DAYS = 6
removed = 0
d = path(DIRECTORY)
#Replace DIRECTORY with your required directory
time_in_secs = time.time() - (DAYS * 24 * 60 * 60)
for i in d.walk():
if i.isfile():
if i.mtime <= time_in_secs:
i.remove()
removed += 1
print removed
我们还学习了如何根据文件的最后修改时间来删除文件。如果您想根据上次访问时间删除文件,只需更改
i.mtime
到
i.atime
你就可以走了。
再见
原来如此。我希望你喜欢这篇文章。最后,我想公开道歉,我的英语不好,所以你可能会发现一些语法错误。请你把它们发邮件给我,这样我可以提高我的英语水平。如果你喜欢这篇文章,那么别忘了在 twitter 和 facebook 上关注我。一条转发也没坏处!如果你想发给我一个下午,然后使用这个电子邮件。
注:
这是来自 Pytips 博客的官方交叉帖子。如果你想阅读原文,请点击链接。
Python 101 -编写更新
原文:https://www.blog.pythonlibrary.org/2014/03/03/python-101-writing-update/
又到了更新的时候了!我想为没有早点写信道歉,但是我已经好几天没有网络了,我正在用我的手机写这篇文章。我只是想让你们知道,我计划在本周完成第二部分。
有人问我是否打算在知识共享或类似的许可下发行这本书。虽然我对像那样发布电子书本身并不感兴趣,但我正在考虑把这本书的内容变成一个网站,有点像钻研 Python。Â
我可能会把它作为我的下一个延伸目标。请在评论中告诉我你的想法。
如果你想支持这本书,请随意去 Kickstarter 页面
python 102:TDD 和单元测试简介
原文:https://www.blog.pythonlibrary.org/2011/03/09/python-102-an-intro-to-tdd-and-unittest/
Python 代码测试对我来说是新事物。我工作的地方并不要求这样,所以除了读一本关于这个主题的书和读几个博客之外,我没有花太多时间去研究它。然而,我决定是时候来看看这个,看看到底是怎么回事。在本文中,您将使用 Python 的内置 unittest 模块了解 Python 的测试驱动开发(TDD)。这实际上是基于我的一次 TDD 和结对编程的经验(感谢 Matt 和 Aaron!).在这篇文章中,我们将学习如何用 Python 打保龄球!
入门指南
我在网上搜索了如何给保龄球评分。我找到了一本关于 About.com 的有用教程,欢迎你也来读。一旦你知道了规则,就该写一些测试了。如果你不知道,测试驱动开发背后的思想是在你写实际代码之前写测试。在本文中,我们将编写一个测试,然后通过测试的一些代码。我们将在编写测试和代码之间来回迭代,直到完成为止。对于本文,我们将只编写三个测试。我们开始吧!
第一次测试
我们的第一个测试将是测试我们的游戏对象,看看如果我们掷骰子 11 次,每次只打翻一个瓶子,它是否能计算出正确的总数。这应该给我们总共 11 个。
import unittest
########################################################################
class TestBowling(unittest.TestCase):
""""""
#----------------------------------------------------------------------
def test_all_ones(self):
"""Constructor"""
game = Game()
game.roll(11, 1)
self.assertEqual(game.score, 11)
这是一个非常简单的测试。我们创建一个游戏对象,然后调用它的 roll 方法 11 次,每次得分为 1。然后我们使用来自 unittest 模块的 assertEqual 方法来测试游戏对象的分数是否正确(即十一)。下一步是编写您能想到的最简单的代码来通过测试。这里有一个例子:
########################################################################
class Game:
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self.score = 0
#----------------------------------------------------------------------
def roll(self, numOfRolls, pins):
""""""
for roll in numOfRolls:
self.score += pins
为了简单起见,您可以将它复制并粘贴到与您的测试相同的文件中。为了下一次测试,我们将把它们分成两个文件。反正你也看到了,我们的游戏类超级简单。通过测试所需要的只是一个 score 属性和一个可以更新它的 roll 方法。如果你不知道循环的是如何工作的,那么你需要去读一读 Python 教程。
让我们运行测试,看看它是否通过!运行测试最简单的方法是将下面两行代码添加到文件的底部:
if __name__ == '__main__':
unittest.main()
然后,只需通过命令行运行 Python 文件,如果这样做,您应该会得到如下所示的内容:
E
======================================================================
ERROR: test_all_ones (__main__.TestBowling)
Constructor
----------------------------------------------------------------------
Traceback (most recent call last):
File "C:\Users\Mike\Documents\My Dropbox\Scripts\Testing\bowling\test_one.py",
line 27, in test_all_ones
game.roll(11, 1)
File "C:\Users\Mike\Documents\My Dropbox\Scripts\Testing\bowling\test_one.py",
line 15, in roll
for roll in numOfRolls:
TypeError: 'int' object is not iterable
----------------------------------------------------------------------
Ran 1 test in 0.001s
FAILED (errors=1)
哎呀!我们在某个地方弄错了。看起来我们在传递一个整数,然后试图迭代它。那不行!我们需要将我们的游戏对象的 roll 方法更改为下面的方法来使它工作:
#----------------------------------------------------------------------
def roll(self, numOfRolls, pins):
""""""
for roll in range(numOfRolls):
self.score += pins
如果您现在运行测试,您应该得到以下结果:
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK
请注意“.”因为这很重要。那个小点意味着一个测试已经运行并且通过了。结尾的“OK”也暗示了你这个事实。如果您研究原始输出,您会注意到它以“E”开头表示错误,并且没有点!让我们继续测试#2。
第二个测试
对于第二个测试,我们将测试当我们得到一个罢工会发生什么。我们需要改变第一个测试,使用一个列表来显示每一帧中被击倒的球瓶数量,所以我们将在这里查看两个测试。您可能会发现这是一个相当常见的过程,由于您测试的内容发生了根本性的变化,您可能需要编辑几个测试。通常这只会发生在你编码的开始阶段,你会在以后变得更好,这样你就不需要这样做了。因为这是我第一次这么做,所以我想得不够多。无论如何,让我们看看代码:
from game import Game
import unittest
########################################################################
class TestBowling(unittest.TestCase):
""""""
#----------------------------------------------------------------------
def test_all_ones(self):
"""Constructor"""
game = Game()
pins = [1 for i in range(11)]
game.roll(11, pins)
self.assertEqual(game.score, 11)
#----------------------------------------------------------------------
def test_strike(self):
"""
A strike is 10 + the value of the next two rolls. So in this case
the first frame will be 10+5+4 or 19 and the second will be
5+4\. The total score would be 19+9 or 28.
"""
game = Game()
game.roll(11, [10, 5, 4])
self.assertEqual(game.score, 28)
if __name__ == '__main__':
unittest.main()
让我们看看我们的第一个测试,以及它是如何变化的。是的,当谈到 TDD 时,我们在这里打破了一些规则。放心,不要改变第一个测试,看看有什么问题。在 test_all_ones 方法中,我们将 pins 变量设置为等于 list comprehension,它创建了一个包含 11 个 1 的列表。然后我们把它和掷骰数一起传递给我们的游戏对象的掷骰子方法。
在第二个测试中,我们在第一轮投了一个好球,第二轮投了五个好球,第三轮投了四个好球。请注意,我们去了头,告诉它我们通过了 11 卷,但我们只通过了 3 卷。这意味着我们需要将其他八个卷设置为零。最后,我们使用可靠的 assertEqual 方法来检查我们是否得到了正确的总数。最后,注意我们现在正在导入游戏类,而不是在测试中保留它。现在我们需要实现通过这两个测试所必需的代码。让我们来看看一个可能的解决方案:
########################################################################
class Game:
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self.score = 0
self.pins = [0 for i in range(11)]
#----------------------------------------------------------------------
def roll(self, numOfRolls, pins):
""""""
x = 0
for pin in pins:
self.pins[x] = pin
x += 1
x = 0
for roll in range(numOfRolls):
if self.pins[x] == 10:
self.score = self.pins[x] + self.pins[x+1] + self.pins[x+2]
else:
self.score += self.pins[x]
x += 1
print self.score
马上,你会注意到我们有了一个新的类属性叫做 self.pins ,它保存了默认的管脚列表,有十一个零。然后在我们的 roll 方法中,我们在第一个循环中将正确的分数添加到 self.pins 列表中的正确位置。然后在第二个循环中,我们检查被击倒的瓶子是否等于 10。如果是的话,我们把它和接下来的两个分数加起来计分。否则,我们做我们以前做的。在方法的最后,我们打印出分数来检查它是否是我们所期望的。在这一点上,我们已经准备好编码我们的最终测试。
第三个(也是最后一个)测试
我们的最后一个测试将测试正确的分数,如果有人掷出一个备用。测试很容易,解决方法稍微难一点。当我们这样做的时候,我们将对测试代码进行一点重构。和往常一样,我们先来看看测试。
from game_v2 import Game
import unittest
########################################################################
class TestBowling(unittest.TestCase):
""""""
#----------------------------------------------------------------------
def setUp(self):
""""""
self.game = Game()
#----------------------------------------------------------------------
def test_all_ones(self):
"""
If you don't get a strike or a spare, then you just add up the
face value of the frame. In this case, each frame is worth
one point, so the total is eleven.
"""
pins = [1 for i in range(11)]
self.game.roll(11, pins)
self.assertEqual(self.game.score, 11)
#----------------------------------------------------------------------
def test_spare(self):
"""
A spare is worth 10, plus the value of your next roll. So in this
case, the first frame will be 5+5+5 or 15 and the second will be
5+4 or 9\. The total is 15+9, which equals 24,
"""
self.game.roll(11, [5, 5, 5, 4])
self.assertEqual(self.game.score, 24)
#----------------------------------------------------------------------
def test_strike(self):
"""
A strike is 10 + the value of the next two rolls. So in this case
the first frame will be 10+5+4 or 19 and the second will be
5+4\. The total score would be 19+9 or 28.
"""
self.game.roll(11, [10, 5, 4])
self.assertEqual(self.game.score, 28)
if __name__ == '__main__':
unittest.main()
首先,我们添加了一个 setUp 方法,它将为我们的每个测试创建一个 self.game 对象。如果我们访问数据库或类似的东西,我们可能会有一个关闭连接或文件或类似的东西的方法。如果存在的话,它们分别在每个测试的开始和结束时运行。 test_all_ones 和 test_strike 测试除了现在用的是“self.game”之外,基本相同。唯一的新测试是测试 _ 备用。docstring 解释了备件如何工作,代码只有两行。是的,你可以解决这个问题。让我们看看通过这些测试所需的代码:
# game_v2.py
########################################################################
class Game:
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self.score = 0
self.pins = [0 for i in range(11)]
#----------------------------------------------------------------------
def roll(self, numOfRolls, pins):
""""""
x = 0
for pin in pins:
self.pins[x] = pin
x += 1
x = 0
spare_begin = 0
spare_end = 2
for roll in range(numOfRolls):
spare = sum(self.pins[spare_begin:spare_end])
if self.pins[x] == 10:
self.score = self.pins[x] + self.pins[x+1] + self.pins[x+2]
elif spare == 10:
self.score = spare + self.pins[x+2]
x += 1
else:
self.score += self.pins[x]
x += 1
if x == 11:
break
spare_begin += 2
spare_end += 2
print self.score
对于谜题的这一部分,我们在循环中添加了条件语句。为了计算备件的值,我们使用 spare_begin 和 spare_end 列表位置从我们的列表中获得正确的值,然后对它们求和。这就是备用变量的用途。这可能更适合放在 elif 中,但是我将留给读者去试验。严格来说,那只是备用分数的前半部分。后半部分是接下来的两卷,这是你在当前代码的 elif 部分的计算中会发现的。代码的其余部分是相同的。
其他注释
正如您可能已经猜到的那样,unittest 模块的内容远不止于此。有很多其他的断言可以用来测试结果。您可以跳过测试,从命令行运行测试,使用 TestLoader 创建测试套件等等。当你有机会的时候一定要阅读完整的文档,因为本教程仅仅触及了这个库的表面。
包扎
我对测试还不是很了解,但是我从这篇文章中学到了很多,希望没有做得太糟糕。如果有,请告诉我,我会更新帖子。也可以随时让我知道我将来应该涉及的测试的其他方面,我会看一看。除了 mock 和 nose 之外,我还想解决一些我在本教程中没有提到的其他单元测试特性。你有什么建议?
Python 102:如何剖析您的代码
原文:https://www.blog.pythonlibrary.org/2014/03/20/python-102-how-to-profile-your-code/
代码分析是试图在代码中找到瓶颈。剖析应该是为了找出代码的哪些部分耗时最长。一旦你知道了这一点,你就可以看看你的代码,并试图找到优化它的方法。Python 内置了三个分析器: cProfile 、 profile 和 hotshot 。根据 Python 文档, hotshot “不再维护,可能会在 Python 的未来版本中被删除”。 profile 模块是一个纯粹的 Python 模块,但是给被分析的程序增加了很多开销。因此,我们将关注于 cProfile ,它有一个模拟 Profile 模块的接口。
用概要文件分析代码
用 cProfile 分析代码真的很容易。你需要做的就是导入模块并调用它的 run 函数。让我们看一个简单的例子:
>>> import hashlib
>>> import cProfile
>>> cProfile.run("hashlib.md5('abcdefghijkl').digest()")
4 function calls in 0.000 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :1(<module>)
1 0.000 0.000 0.000 0.000 {_hashlib.openssl_md5}
1 0.000 0.000 0.000 0.000 {method 'digest' of '_hashlib.HASH' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
这里我们导入了 hashlib 模块,并使用 cProfile 来分析 MD5 散列的创建。第一行显示有 4 个函数调用。下一行告诉我们结果是如何排序的。根据文献记载,标准名称是指最右边的列。这里有许多列。
- ncalls 是发出的呼叫数。
- tottime 是给定函数花费的总时间。
- percall 指总时间除以 ncalls 的商
- 累计时间是在该功能和所有子功能中花费的累计时间。甚至对递归函数也很准确!
- 第二个 percall 列是累计时间除以原始调用的商
- filename:line no(function)提供每个函数各自的数据
原始调用不是通过递归引起的。
这不是一个非常有趣的例子,因为没有明显的瓶颈。让我们创建一段带有内置瓶颈的代码,看看分析器是否能检测到它们。
import time
#----------------------------------------------------------------------
def fast():
""""""
print("I run fast!")
#----------------------------------------------------------------------
def slow():
""""""
time.sleep(3)
print("I run slow!")
#----------------------------------------------------------------------
def medium():
""""""
time.sleep(0.5)
print("I run a little slowly...")
#----------------------------------------------------------------------
def main():
""""""
fast()
slow()
medium()
if __name__ == '__main__':
main()
在这个例子中,我们创建了四个函数。前三种以不同的速度运行。快速功能将以正常速度运行;中功能大约需要半秒钟运行,慢功能大约需要 3 秒钟运行。主函数调用其他三个。现在让我们对这个愚蠢的小程序运行 cProfile:
>>> import cProfile
>>> import ptest
>>> cProfile.run('ptest.main()')
I run fast!
I run slow!
I run a little slowly...
8 function calls in 3.500 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 3.500 3.500 :1(<module>)
1 0.000 0.000 0.500 0.500 ptest.py:15(medium)
1 0.000 0.000 3.500 3.500 ptest.py:21(main)
1 0.000 0.000 0.000 0.000 ptest.py:4(fast)
1 0.000 0.000 3.000 3.000 ptest.py:9(slow)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
2 3.499 1.750 3.499 1.750 {time.sleep}
这一次,我们看到程序运行了 3.5 秒。如果您检查结果,您将看到 cProfile 已经将慢速函数标识为花费 3 秒来运行。那是继主功能之后的最大瓶颈。通常,当您发现类似这样的瓶颈时,您会试图找到一种更快的方法来执行您的代码,或者可能决定运行时是可以接受的。在这个例子中,我们知道加速这个函数的最好方法是删除 time.sleep 调用或者至少减少睡眠时间。
您也可以在命令行上调用 cProfile,而不是在解释器中使用它。有一种方法可以做到:
python -m cProfile ptest.py
这将按照与我们之前相同的方式对您的脚本运行 cProfile。但是,如果您想保存分析器的输出,该怎么办呢?嗯,使用 cProfile 很简单!你需要做的就是给它传递 -o 命令,后跟输出文件的名称(或路径)。这里有一个例子:
python -m cProfile -o output.txt ptest.py
不幸的是,它输出的文件不完全是人类可读的。如果你想读取这个文件,那么你需要使用 Python 的 pstats 模块。您可以使用 pstats 以各种方式格式化输出。下面是一些代码,展示了如何获得一些类似于我们目前所看到的输出:
>>> import pstats
>>> p = pstats.Stats("output.txt")
>>> p.strip_dirs().sort_stats(-1).print_stats()
Thu Mar 20 18:32:16 2014 output.txt
8 function calls in 3.501 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 3.501 3.501 ptest.py:1()
1 0.001 0.001 0.500 0.500 ptest.py:15(medium)
1 0.000 0.000 3.501 3.501 ptest.py:21(main)
1 0.001 0.001 0.001 0.001 ptest.py:4(fast)
1 0.001 0.001 3.000 3.000 ptest.py:9(slow)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
2 3.499 1.750 3.499 1.750 {time.sleep}
<pstats.stats instance="" at=""></pstats.stats>
strip_dirs 调用将从输出中去除所有到模块的路径,而 sort_stats 调用进行我们习惯看到的排序。在 cProfile 文档中有许多非常有趣的例子,展示了使用 pstats 模块提取信息的不同方法。
包扎
此时,您应该能够使用 cProfile 模块来帮助您诊断代码如此缓慢的原因。您可能还想看看 Python 的 timeit 模块。如果您不想处理复杂的概要分析,它允许您对代码的小部分进行计时。还有其他几个第三方模块也很适合进行概要分析,比如 line_profiler 和 memory_profiler 项目。
相关阅读
- 关于概要模块的 Python 文档
- 如何用 timeit 为小块 Python 代码计时
- Python 性能分析指南
- PyMOTW: profile,cProfile,pstats
Python 102:如何使用 smtplib + email 发送电子邮件
原文:https://www.blog.pythonlibrary.org/2013/06/26/python-102-how-to-send-an-email-using-smtplib-email/
几年前我就这个话题写过一篇文章,但是我觉得现在是我重温的时候了。为什么?嗯,最近我在一个发送电子邮件的程序上做了很多工作,我一直在看我以前的文章,觉得我第一次写它的时候错过了一些东西。因此,在本文中,我们将了解以下内容:
- 电子邮件的基本知识——有点像原始文章的翻版
- 如何使用“收件人”、“抄送”和“密件抄送”行发送电子邮件
- 如何一次发送到多个地址
- 如何使用电子邮件模块添加附件和正文
我们开始吧!
如何使用 Python 和 smtplib 发送电子邮件
我们将从原始文章中稍加修改的代码版本开始。我注意到我忘记了在原来的中设置主机变量,所以这个例子会更完整一点:
import smtplib
import string
HOST = "mySMTP.server.com"
SUBJECT = "Test email from Python"
TO = "mike@someAddress.org"
FROM = "python@mydomain.com"
text = "Python rules them all!"
BODY = string.join((
"From: %s" % FROM,
"To: %s" % TO,
"Subject: %s" % SUBJECT ,
"",
text
), "\r\n")
server = smtplib.SMTP(HOST)
server.sendmail(FROM, [TO], BODY)
server.quit()
您会注意到这段代码中没有用户名或密码。如果您的服务器需要身份验证,那么您需要添加以下代码:
server.login(username, password)
这应该在您创建了服务器对象之后添加。通常,您会希望将这段代码放入一个函数中,并使用其中的一些参数来调用它。您甚至可能希望将这些信息放入配置文件中。让我们接下来做那件事。
#----------------------------------------------------------------------
def send_email(host, subject, to_addr, from_addr, body_text):
"""
Send an email
"""
BODY = string.join((
"From: %s" % from_addr,
"To: %s" % to_addr,
"Subject: %s" % subject ,
"",
body_text
), "\r\n")
server = smtplib.SMTP(host)
server.sendmail(from_addr, [to_addr], BODY)
server.quit()
if __name__ == "__main__":
host = "mySMTP.server.com"
subject = "Test email from Python"
to_addr = "mike@someAddress.org"
from_addr = "python@mydomain.com"
body_text = "Python rules them all!"
send_email(host, subject, to_addr, from_addr, body_text)
现在,您可以通过查看函数本身来了解实际代码有多小。那是 13 行!如果我们不把正文中的每一项都放在自己的行上,我们可以把它变得更短,但是可读性会差一些。现在我们将添加一个配置文件来保存服务器信息和 from 地址。为什么?在我的工作中,我们可能会使用不同的电子邮件服务器来发送电子邮件,或者如果电子邮件服务器升级了,名称改变了,那么我们只需要改变配置文件而不是代码。如果我们的公司被另一家公司收购并合并,同样的事情也适用于发件人地址。我们将使用 configObj 包而不是 Python 的 ConfigParser,因为我发现 configObj 更简单。如果你还没有 Python 包索引 (PyPI)的话,你应该下载一份。
让我们看一下配置文件:
[smtp]
server = some.server.com
from_addr = python@mydomain.com
这是一个非常简单的配置文件。在其中,我们有一个标记为 smtp 的部分,其中有两个项目:server 和 from_addr。我们将使用 configObj 读取该文件,并将其转换为 Python 字典。下面是代码的更新版本:
import os
import smtplib
import string
import sys
from configobj import ConfigObj
#----------------------------------------------------------------------
def send_email(subject, to_addr, body_text):
"""
Send an email
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "config.ini")
if os.path.exists(config_path):
cfg = ConfigObj(config_path)
cfg_dict = cfg.dict()
else:
print "Config not found! Exiting!"
sys.exit(1)
host = cfg_dict["smtp"]["server"]
from_addr = cfg_dict["smtp"]["from_addr"]
BODY = string.join((
"From: %s" % from_addr,
"To: %s" % to_addr,
"Subject: %s" % subject ,
"",
body_text
), "\r\n")
server = smtplib.SMTP(host)
server.sendmail(from_addr, [to_addr], BODY)
server.quit()
if __name__ == "__main__":
subject = "Test email from Python"
to_addr = "mike@someAddress.org"
body_text = "Python rules them all!"
send_email(subject, to_addr, body_text)
我们在这段代码中添加了一个小检查。我们想首先获取脚本本身所在的路径,这就是 base_path 所代表的。接下来,我们将路径和文件名结合起来,得到配置文件的完全限定路径。然后,我们检查该文件是否存在。如果存在,我们创建一个字典,如果不存在,我们打印一条消息并退出脚本。为了安全起见,我们应该在 ConfigObj 调用周围添加一个异常处理程序,尽管该文件可能存在,但可能已损坏,或者我们可能没有权限打开它,这将引发一个异常。这将是一个你可以自己尝试的小项目。不管怎样,假设一切顺利,我们拿到了字典。现在,我们可以使用普通的字典语法提取主机和 from_addr 信息。
现在我们准备学习如何同时发送多封电子邮件!
如何一次发送多封邮件
如果你在网上搜索这个话题,你可能会遇到这个 StackOverflow 问题,在这里我们可以学习如何通过 smtplib 模块发送多封电子邮件。让我们稍微修改一下上一个例子,这样我们就可以发送多封电子邮件了!
import os
import smtplib
import string
import sys
from configobj import ConfigObj
#----------------------------------------------------------------------
def send_email(subject, body_text, emails):
"""
Send an email
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "config.ini")
if os.path.exists(config_path):
cfg = ConfigObj(config_path)
cfg_dict = cfg.dict()
else:
print "Config not found! Exiting!"
sys.exit(1)
host = cfg_dict["smtp"]["server"]
from_addr = cfg_dict["smtp"]["from_addr"]
BODY = string.join((
"From: %s" % from_addr,
"To: %s" % ', '.join(emails),
"Subject: %s" % subject ,
"",
body_text
), "\r\n")
server = smtplib.SMTP(host)
server.sendmail(from_addr, emails, BODY)
server.quit()
if __name__ == "__main__":
emails = ["mike@example.org", "someone@gmail.com"]
subject = "Test email from Python"
body_text = "Python rules them all!"
send_email(subject, body_text, emails)
您会注意到,在这个例子中,我们删除了 to_addr 参数,并添加了一个 emails 参数,这是一个电子邮件地址列表。为此,我们需要在正文的 To: 部分创建一个逗号分隔的字符串,并将电子邮件列表传递给 sendmail 方法。因此,我们做下面的事情来创建一个简单的逗号分隔的字符串:','。加入(邮件)。很简单,是吧?
现在我们只需要弄清楚如何使用“抄送”和“密件抄送”字段发送邮件。让我们创建一个支持该功能的新版本的代码!
import os
import smtplib
import string
import sys
from configobj import ConfigObj
#----------------------------------------------------------------------
def send_email(subject, body_text, to_emails, cc_emails, bcc_emails):
"""
Send an email
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "config.ini")
if os.path.exists(config_path):
cfg = ConfigObj(config_path)
cfg_dict = cfg.dict()
else:
print "Config not found! Exiting!"
sys.exit(1)
host = cfg_dict["smtp"]["server"]
from_addr = cfg_dict["smtp"]["from_addr"]
BODY = string.join((
"From: %s" % from_addr,
"To: %s" % ', '.join(to_emails),
"CC: %s" % ', '.join(cc_emails),
"BCC: %s" % ', '.join(bcc_emails),
"Subject: %s" % subject ,
"",
body_text
), "\r\n")
emails = to_emails + cc_emails + bcc_emails
server = smtplib.SMTP(host)
server.sendmail(from_addr, emails, BODY)
server.quit()
if __name__ == "__main__":
emails = ["mike@somewhere.org"]
cc_emails = ["someone@gmail.com"]
bcc_emails = ["schmuck@newtel.net"]
subject = "Test email from Python"
body_text = "Python rules them all!"
send_email(subject, body_text, emails, cc_emails, bcc_emails)
在这段代码中,我们传入 3 个列表,每个列表都有一个电子邮件地址。我们像以前一样创建 CC 和 BCC 字段,但是我们还需要将 3 个列表合并成一个,这样我们就可以将合并后的列表传递给 sendmail()方法。在 StackOverflow 上有传言说,一些电子邮件客户端可能会以奇怪的方式处理密件抄送字段,从而允许收件人通过电子邮件标题查看密件抄送列表。我无法确认这种行为,但我知道 Gmail 成功地从邮件标题中删除了密件抄送信息。我还没有发现哪个客户不知道,但是如果你知道,请在评论中告诉我们。
现在我们准备好使用 Python 的电子邮件模块了!
使用 Python 发送电子邮件附件
现在,我们将学习上一节的内容,并将其与 Python 电子邮件模块结合起来。电子邮件模块使得添加附件变得极其容易。代码如下:
import os
import smtplib
import string
import sys
from configobj import ConfigObj
from email import Encoders
from email.mime.text import MIMEText
from email.MIMEBase import MIMEBase
from email.MIMEMultipart import MIMEMultipart
from email.Utils import formatdate
#----------------------------------------------------------------------
def send_email_with_attachment(subject, body_text, to_emails,
cc_emails, bcc_emails, file_to_attach):
"""
Send an email with an attachment
"""
base_path = os.path.dirname(os.path.abspath(__file__))
config_path = os.path.join(base_path, "config.ini")
header = 'Content-Disposition', 'attachment; filename="%s"' % file_to_attach
# get the config
if os.path.exists(config_path):
cfg = ConfigObj(config_path)
cfg_dict = cfg.dict()
else:
print "Config not found! Exiting!"
sys.exit(1)
# extract server and from_addr from config
host = cfg_dict["smtp"]["server"]
from_addr = cfg_dict["smtp"]["from_addr"]
# create the message
msg = MIMEMultipart()
msg["From"] = from_addr
msg["Subject"] = subject
msg["Date"] = formatdate(localtime=True)
if body_text:
msg.attach( MIMEText(body_text) )
msg["To"] = ', '.join(to_emails)
msg["cc"] = ', '.join(cc_emails)
attachment = MIMEBase('application', "octet-stream")
try:
with open(file_to_attach, "rb") as fh:
data = fh.read()
attachment.set_payload( data )
Encoders.encode_base64(attachment)
attachment.add_header(*header)
msg.attach(attachment)
except IOError:
msg = "Error opening attachment file %s" % file_to_attach
print msg
sys.exit(1)
emails = to_emails + cc_emails
server = smtplib.SMTP(host)
server.sendmail(from_addr, emails, msg.as_string())
server.quit()
if __name__ == "__main__":
emails = ["mike@somewhere.org", "nedry@jp.net"]
cc_emails = ["someone@gmail.com"]
bcc_emails = ["anonymous@circe.org"]
subject = "Test email with attachment from Python"
body_text = "This email contains an attachment!"
path = "/path/to/some/file"
send_email_with_attachment(subject, body_text, emails,
cc_emails, bcc_emails, path)
在这里,我们重命名了我们的函数,并添加了一个新的参数, file_to_attach 。我们还需要添加一个头并创建一个 MIMEMultipart 对象。在我们添加附件之前,可以随时创建标题。我们向 MIMEMultipart 对象(msg)添加元素,就像我们向字典添加键一样。您会注意到,我们必须使用 email 模块的 formatdate 方法来插入正确格式化的日期。为了添加消息体,我们需要创建一个 MIMEText 的实例。如果你注意的话,你会发现我们没有添加密件抄送信息,但是你可以通过遵循上面代码中的约定很容易地做到这一点。接下来我们添加附件。我们将它包装在一个异常处理程序中,并使用带有语句的来提取文件,并将其放在我们的 MIMEBase 对象中。最后,我们将它添加到 msg 变量中,然后发送出去。注意,我们必须在 sendmail 方法中将 msg 转换成一个字符串。
包扎
现在你知道如何用 Python 发送电子邮件了。对于那些喜欢迷你项目的人来说,您应该返回并在代码的 server.sendmail 部分添加额外的错误处理,以防在这个过程中发生一些奇怪的事情,比如 SMTPAuthenticationError 或 SMTPConnectError。我们还可以在附加文件时加强错误处理,以捕捉其他错误。最后,我们可能希望获得这些不同的电子邮件列表,并创建一个已删除重复的规范化列表。如果我们从一个文件中读取电子邮件地址列表,这一点尤其重要。
还要注意,我们的 from 地址是假的。我们可以使用 Python 和其他编程语言来欺骗电子邮件,但这是非常糟糕的礼仪,而且可能是非法的,这取决于你住在哪里。你已经被警告了!明智地使用你的知识,享受 Python 带来的乐趣和收益!
注意:以上代码中的所有电子邮件地址都是假的。这段代码是在 Windows 7 上使用 Python 2.6.6 测试的。
附加阅读
- smtplib 上的 Python 文档
- 关于电子邮件模块的 Python 文档
- 从向多个收件人发送电子邮件。带 Python smtplib 的 txt 文件
- python:如何用 to、CC、BCC 发送邮件?
- 如何用 Python 发送邮件
下载源代码
Python 103 -实用 Python 课程现已推出
原文:https://www.blog.pythonlibrary.org/2022/09/19/python-103-practical-python-course-now-available/
我刚刚在“教我 Python”上推出了我的第三个课程。这门课叫做Python 103——实用 Python

在这门新课程中,您将了解以下内容:
第一部分——Python 用例
- 第 1 课-如何用
argparse创建命令行应用程序 - 第 2 课——如何解析 XML
- 第 3 课——如何解析 JSON
- 第 4 课-如何抓取网站
- 第 5 课-如何处理 CSV 文件
- 第 6 课-如何使用
sqlite3操作数据库 - 第 7 课-如何创建 Excel 文档
- 第 8 课-如何生成 PDF
- 第 9 课-如何创建图表
- 第 10 课-如何在 Python 中处理图像
- 第 11 课-如何创建图形用户界面
第二部分-分发您的代码
- 第 12 课-如何创建 Python 包
- 第 13 课-如何为 Windows 创建可执行文件
- 第 14 课-如何为 Windows 创建安装程序
- 第 15 课-如何为 Mac 创建一个“exe”
这个课程是基于我的热门书籍 Python 101 -第二版,可以在 Leanpub 或者亚马逊上找到。
Python 201:多重处理教程
原文:https://www.blog.pythonlibrary.org/2016/08/02/python-201-a-multiprocessing-tutorial/
多处理模块是在 2.6 版本中添加到 Python 中的。它最初是由杰西·诺勒和理查德·奥德克尔克在 PEP 371 中定义的。多处理模块允许您以与使用线程模块生成线程几乎相同的方式生成进程。这里的想法是,因为您现在正在生成进程,所以您可以避免全局解释器锁(GIL ),并充分利用一台机器上的多个处理器。
多处理包还包括一些根本不在线程模块中的 API。例如,有一个简单的 Pool 类,您可以使用它来并行执行一个跨多个输入的函数。我们将在后面的部分中讨论 Pool。我们将从多处理模块的进程类开始。
多重处理入门
进程类与线程模块的线程类非常相似。让我们尝试创建一系列调用同一个函数的流程,看看它是如何工作的:
import os
from multiprocessing import Process
def doubler(number):
"""
A doubling function that can be used by a process
"""
result = number * 2
proc = os.getpid()
print('{0} doubled to {1} by process id: {2}'.format(
number, result, proc))
if __name__ == '__main__':
numbers = [5, 10, 15, 20, 25]
procs = []
for index, number in enumerate(numbers):
proc = Process(target=doubler, args=(number,))
procs.append(proc)
proc.start()
for proc in procs:
proc.join()
对于这个例子,我们导入 Process 并创建一个 doubler 函数。在函数内部,我们将传入的数字加倍。我们还使用 Python 的 os 模块来获取当前进程的 ID(或 pid)。这将告诉我们哪个进程正在调用该函数。然后在底部的代码块中,我们创建一系列进程并启动它们。最后一个循环只是在每个进程上调用 join() 方法,告诉 Python 等待进程终止。如果需要停止一个进程,可以调用它的 terminate() 方法。
运行此代码时,您应该会看到类似于以下内容的输出:
5 doubled to 10 by process id: 10468
10 doubled to 20 by process id: 10469
15 doubled to 30 by process id: 10470
20 doubled to 40 by process id: 10471
25 doubled to 50 by process id: 10472
不过,有时为您的过程取一个更容易理解的名字会更好。幸运的是,Process 类确实允许您访问相同的进程。让我们来看看:
import os
from multiprocessing import Process, current_process
def doubler(number):
"""
A doubling function that can be used by a process
"""
result = number * 2
proc_name = current_process().name
print('{0} doubled to {1} by: {2}'.format(
number, result, proc_name))
if __name__ == '__main__':
numbers = [5, 10, 15, 20, 25]
procs = []
proc = Process(target=doubler, args=(5,))
for index, number in enumerate(numbers):
proc = Process(target=doubler, args=(number,))
procs.append(proc)
proc.start()
proc = Process(target=doubler, name='Test', args=(2,))
proc.start()
procs.append(proc)
for proc in procs:
proc.join()
这一次,我们导入了一些额外的东西: current_process。current _ process 和线程模块的 current_thread 基本是一回事。我们用它来获取调用我们函数的线程的名字。您会注意到,对于前五个过程,我们没有设置名称。然后对于第六个,我们将流程名设置为“Test”。让我们看看我们得到了什么输出:
5 doubled to 10 by: Process-2
10 doubled to 20 by: Process-3
15 doubled to 30 by: Process-4
20 doubled to 40 by: Process-5
25 doubled to 50 by: Process-6
2 doubled to 4 by: Test
输出表明,默认情况下,多处理模块为每个进程分配一个数字作为其名称的一部分。当然,当我们指定一个名字时,一个数字不会被加进去。
锁
多处理模块支持锁的方式与线程模块非常相似。你所需要做的就是导入锁,获取它,做一些事情,然后释放它。让我们来看看:
from multiprocessing import Process, Lock
def printer(item, lock):
"""
Prints out the item that was passed in
"""
lock.acquire()
try:
print(item)
finally:
lock.release()
if __name__ == '__main__':
lock = Lock()
items = ['tango', 'foxtrot', 10]
for item in items:
p = Process(target=printer, args=(item, lock))
p.start()
在这里,我们创建了一个简单的打印函数,打印您传递给它的任何内容。为了防止线程相互干扰,我们使用了一个锁对象。这段代码将遍历我们的三项列表,并为每一项创建一个流程。每个进程都将调用我们的函数,并向它传递 iterable 中的一项。因为我们使用了锁,所以队列中的下一个进程将等待锁被释放,然后才能继续。
记录
记录进程与记录线程略有不同。这是因为 Python 的日志包不使用进程共享锁,所以可能会导致来自不同进程的消息混淆。让我们尝试将基本日志添加到前面的示例中。代码如下:
import logging
import multiprocessing
from multiprocessing import Process, Lock
def printer(item, lock):
"""
Prints out the item that was passed in
"""
lock.acquire()
try:
print(item)
finally:
lock.release()
if __name__ == '__main__':
lock = Lock()
items = ['tango', 'foxtrot', 10]
multiprocessing.log_to_stderr()
logger = multiprocessing.get_logger()
logger.setLevel(logging.INFO)
for item in items:
p = Process(target=printer, args=(item, lock))
p.start()
记录日志的最简单方法是将其全部发送到 stderr。我们可以通过调用 log_to_stderr() 函数来实现。然后我们调用 get_logger 函数来访问一个日志记录器,并将其日志记录级别设置为 INFO。代码的其余部分是相同的。我要注意,我在这里没有调用 join() 方法。相反,父线程(即您的脚本)在退出时会隐式调用 join() 。
当您这样做时,您应该得到如下输出:
[INFO/Process-1] child process calling self.run()
tango
[INFO/Process-1] process shutting down
[INFO/Process-1] process exiting with exitcode 0
[INFO/Process-2] child process calling self.run()
[INFO/MainProcess] process shutting down
foxtrot
[INFO/Process-2] process shutting down
[INFO/Process-3] child process calling self.run()
[INFO/Process-2] process exiting with exitcode 0
10
[INFO/MainProcess] calling join() for process Process-3
[INFO/Process-3] process shutting down
[INFO/Process-3] process exiting with exitcode 0
[INFO/MainProcess] calling join() for process Process-2
现在,如果您想将日志保存到磁盘,那么就有点棘手了。你可以在 Python 的日志食谱中读到这个话题。
台球课
Pool 类用于表示一个工作进程池。它有允许你卸载任务到工作进程的方法。让我们看一个非常简单的例子:
from multiprocessing import Pool
def doubler(number):
return number * 2
if __name__ == '__main__':
numbers = [5, 10, 20]
pool = Pool(processes=3)
print(pool.map(doubler, numbers))
基本上,这里发生的事情是,我们创建一个 Pool 实例,并告诉它创建三个工作进程。然后我们使用 map 方法将一个函数和一个 iterable 映射到每个流程。最后我们打印结果,在这个例子中实际上是一个列表:【10,20,40】。
您还可以通过使用 apply_async 方法在池中获得流程的结果:
from multiprocessing import Pool
def doubler(number):
return number * 2
if __name__ == '__main__':
pool = Pool(processes=3)
result = pool.apply_async(doubler, (25,))
print(result.get(timeout=1))
这让我们可以询问过程的结果。这就是 get 函数的意义所在。它试图得到我们的结果。您会注意到,我们还设置了一个超时,以防我们调用的函数发生问题。我们毕竟不希望它无限期地阻塞。
过程通信
谈到进程间的通信,多处理模块有两种主要方法:队列和管道。队列实现实际上是线程和进程安全的。让我们来看一个相当简单的例子,它基于我的一篇线程文章中的队列代码:
from multiprocessing import Process, Queue
sentinel = -1
def creator(data, q):
"""
Creates data to be consumed and waits for the consumer
to finish processing
"""
print('Creating data and putting it on the queue')
for item in data:
q.put(item)
def my_consumer(q):
"""
Consumes some data and works on it
In this case, all it does is double the input
"""
while True:
data = q.get()
print('data found to be processed: {}'.format(data))
processed = data * 2
print(processed)
if data is sentinel:
break
if __name__ == '__main__':
q = Queue()
data = [5, 10, 13, -1]
process_one = Process(target=creator, args=(data, q))
process_two = Process(target=my_consumer, args=(q,))
process_one.start()
process_two.start()
q.close()
q.join_thread()
process_one.join()
process_two.join()
这里我们只需要导入队列和流程。然后我们有两个函数,一个用来创建数据并将其添加到队列中,另一个用来消费和处理数据。向队列添加数据是通过使用队列的 put() 方法完成的,而从队列获取数据是通过 get 方法完成的。最后一段代码只是创建队列对象和几个进程,然后运行它们。您会注意到,我们在流程对象上调用 join() ,而不是队列本身。
包扎
我们这里有很多材料。您已经学习了如何使用多处理模块来定位常规函数、使用队列在进程间通信、命名线程等等。Python 文档中还有很多本文没有涉及到的内容,所以一定要深入研究。同时,您现在知道了如何使用 Python 来利用计算机的所有处理能力!
相关阅读


 浙公网安备 33010602011771号
浙公网安备 33010602011771号